
网页文章采集器
优采云采集器V9为例,讲解一个文章采集的实例(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2021-08-24 21:15
在我们日常的工作和学习中,一些有价值的文章采集可以帮助我们提高信息的利用率和整合率。对于新闻、学术论文等类型的电子文章,我们可以使用采集的网络爬虫工具,这种采集比较容易比较一些数字化的不规则数据。这里以网页爬虫工具优采云采集器V9为例,讲解一个文章采集的例子供大家学习。
熟悉优采云采集器的朋友都知道采集过程中遇到的问题可以通过官网FAQ找回,所以这里我们以采集faq为例说明网络爬虫采集的原理和流程。
在这个例子中,我们将演示地址。
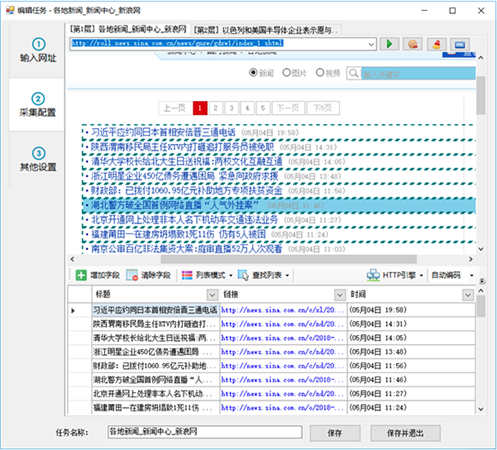
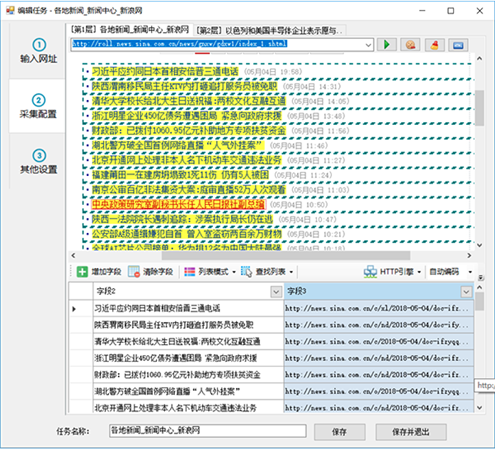
(1)创建一个新的采集rule
选择一个组右键,选择“新建任务”,如下图:
(2)添加起始网址
这里,假设我们需要采集 5 页数据。
解析网址变量的规律
首页地址:
第二页地址:
第三页地址:
由此可以推断p=后面的数字是分页的意思,我们用[地址参数]来表示:
所以设置如下:
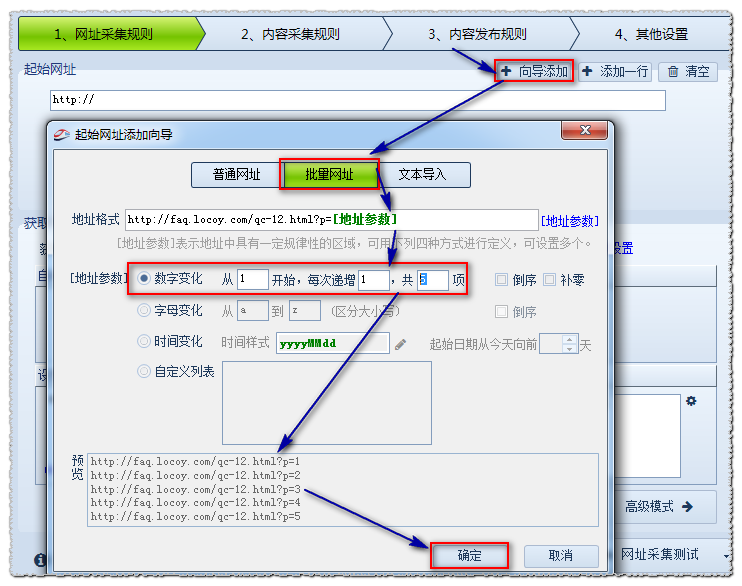
地址格式:用[地址参数]表示改变的页码。
编号变化:从1开始,即第一页;每增加1,即每页变化的次数;一共5条,也就是一共采集5页。
预览:采集器会根据上面的设置生成一部分URL,让你判断添加的是否正确。
然后确认。
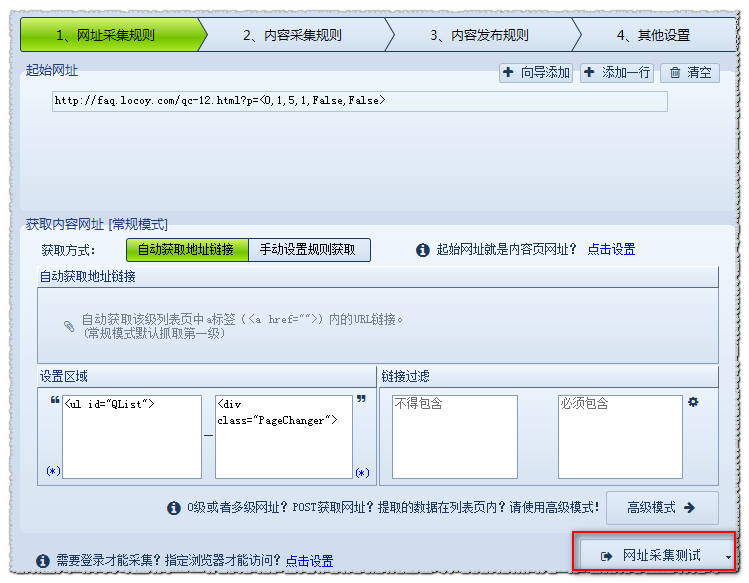
(3)[普通模式]获取内容网址
普通模式:该模式默认抓取一级地址,即从起始页的源码中获取到内容页A的链接。
这里我教大家如何通过自动获取地址链接+设置区的方式获取。
查看页面源码,找到文章地址所在区域:
设置如下:
注:更详细的分析说明请参考本手册:
操作指南> 软件操作> URL采集Rules> 获取内容URL
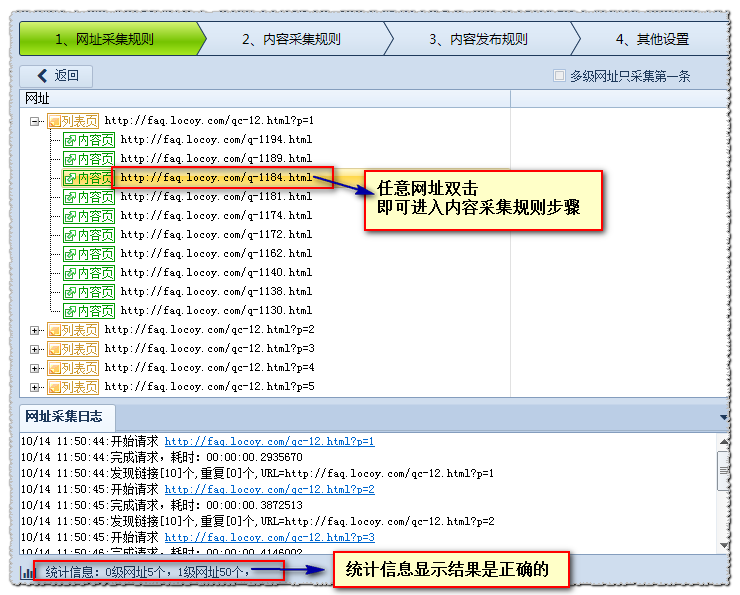
点击网址采集test查看测试效果
(3)内容采集URL
以采集标签为例说明
注意:更详细的分析说明请参考本手册
操作指南>软件操作>Content采集Rules>标签编辑
我们首先查看其页面的源代码,找到我们的“title”所在的代码:
导入Excle是一个对话框~打开Excle时出错-优采云采集器帮助中心
分析:开始的字符串是:
结束字符串是:
数据处理-内容替换/排除:需要替换-优采云采集器帮助中心清空
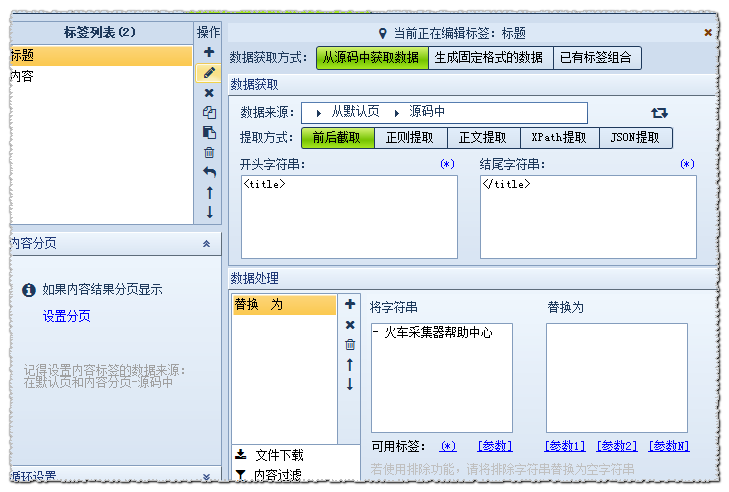
设置内容标签的原理类似。在源码中找到内容的位置
分析:开始的字符串是:
结束字符串是:
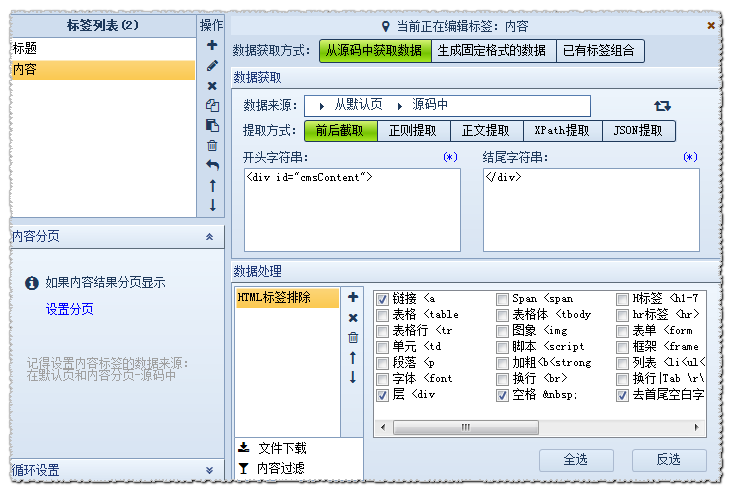
数据处理-HTML标签排除:过滤不需要的A链接等
设置另一个“源”字段
这么简单的文章采集规则就搞定了。不知道网友们有没有学到。顾名思义,网页抓取工具适用于网页上的数据抓取。您也可以使用上面的示例。可见,这类软件主要通过源码分析来分析数据。还有一些情况这里没有列出,比如登录采集,使用代理采集等,如果你对网络爬虫工具感兴趣,可以登录采集器官网自行学习。
查看全部
优采云采集器V9为例,讲解一个文章采集的实例(组图)
在我们日常的工作和学习中,一些有价值的文章采集可以帮助我们提高信息的利用率和整合率。对于新闻、学术论文等类型的电子文章,我们可以使用采集的网络爬虫工具,这种采集比较容易比较一些数字化的不规则数据。这里以网页爬虫工具优采云采集器V9为例,讲解一个文章采集的例子供大家学习。
熟悉优采云采集器的朋友都知道采集过程中遇到的问题可以通过官网FAQ找回,所以这里我们以采集faq为例说明网络爬虫采集的原理和流程。
在这个例子中,我们将演示地址。
(1)创建一个新的采集rule
选择一个组右键,选择“新建任务”,如下图:
(2)添加起始网址
这里,假设我们需要采集 5 页数据。
解析网址变量的规律
首页地址:
第二页地址:
第三页地址:
由此可以推断p=后面的数字是分页的意思,我们用[地址参数]来表示:
所以设置如下:
地址格式:用[地址参数]表示改变的页码。
编号变化:从1开始,即第一页;每增加1,即每页变化的次数;一共5条,也就是一共采集5页。
预览:采集器会根据上面的设置生成一部分URL,让你判断添加的是否正确。
然后确认。
(3)[普通模式]获取内容网址
普通模式:该模式默认抓取一级地址,即从起始页的源码中获取到内容页A的链接。
这里我教大家如何通过自动获取地址链接+设置区的方式获取。
查看页面源码,找到文章地址所在区域:

设置如下:
注:更详细的分析说明请参考本手册:
操作指南> 软件操作> URL采集Rules> 获取内容URL
点击网址采集test查看测试效果
(3)内容采集URL
以采集标签为例说明
注意:更详细的分析说明请参考本手册
操作指南>软件操作>Content采集Rules>标签编辑
我们首先查看其页面的源代码,找到我们的“title”所在的代码:
导入Excle是一个对话框~打开Excle时出错-优采云采集器帮助中心
分析:开始的字符串是:
结束字符串是:
数据处理-内容替换/排除:需要替换-优采云采集器帮助中心清空
设置内容标签的原理类似。在源码中找到内容的位置

分析:开始的字符串是:
结束字符串是:
数据处理-HTML标签排除:过滤不需要的A链接等
设置另一个“源”字段
这么简单的文章采集规则就搞定了。不知道网友们有没有学到。顾名思义,网页抓取工具适用于网页上的数据抓取。您也可以使用上面的示例。可见,这类软件主要通过源码分析来分析数据。还有一些情况这里没有列出,比如登录采集,使用代理采集等,如果你对网络爬虫工具感兴趣,可以登录采集器官网自行学习。

新媒体全媒体采集器有很多,要找好一些
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-08-24 03:01
网页文章采集器有很多,要找好一些。关键是要适合你公司用,要满足自己的要求。我就给你推荐一个聚合采集工具:新媒体全媒体采集器大多数网站都是需要会员制的,如果你不是会员,它只能采集三万次。这样也不会被封掉。
推荐一个大型采集软件webhomepageextractor,这个集合了百度新闻、搜狗新闻、今日头条、大鱼号、网易号、企鹅号、天天快报、凤凰网等,免费无广告,安全稳定。地址:webhomepageextractor-search-for-webhomepageextractor是如何采集大型门户网站的文章的?。
不知道你们公司的网站需要采集哪些网站。不过一般传统的站外搜索网站,如:百度文库、道客巴巴、豆丁等我都会加上分类,每个站内提取一些好文章,放在自己的主站。因为不知道你的文章是属于什么类型,估计也没法给你提供具体的工具。
给你说几个采集大站的工具
1、17图网/这个是千里眼工具,
2、站长之家站长之家-搜索关键词排名有很多网站需要采集!但是数量多,
3、第一网址第一网址_b2b电商收录-网址收录工具
4、社区采集区/微社区-社区站长收集社区站长采集包括一些小网站!下面是一些经典的站点:采集大量的视频、文章、图片,中文网站采集,中文站点, 查看全部
新媒体全媒体采集器有很多,要找好一些
网页文章采集器有很多,要找好一些。关键是要适合你公司用,要满足自己的要求。我就给你推荐一个聚合采集工具:新媒体全媒体采集器大多数网站都是需要会员制的,如果你不是会员,它只能采集三万次。这样也不会被封掉。
推荐一个大型采集软件webhomepageextractor,这个集合了百度新闻、搜狗新闻、今日头条、大鱼号、网易号、企鹅号、天天快报、凤凰网等,免费无广告,安全稳定。地址:webhomepageextractor-search-for-webhomepageextractor是如何采集大型门户网站的文章的?。
不知道你们公司的网站需要采集哪些网站。不过一般传统的站外搜索网站,如:百度文库、道客巴巴、豆丁等我都会加上分类,每个站内提取一些好文章,放在自己的主站。因为不知道你的文章是属于什么类型,估计也没法给你提供具体的工具。
给你说几个采集大站的工具
1、17图网/这个是千里眼工具,
2、站长之家站长之家-搜索关键词排名有很多网站需要采集!但是数量多,
3、第一网址第一网址_b2b电商收录-网址收录工具
4、社区采集区/微社区-社区站长收集社区站长采集包括一些小网站!下面是一些经典的站点:采集大量的视频、文章、图片,中文网站采集,中文站点,
如何利用PHP来做一个抓取网页的采集器那老衲也推荐你一个~file
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-08-21 23:43
如何使用PHP进行网页爬虫采集器
那老娜也给大家推荐一款~ file_get_content();具体。
我现在可以实现php的采集功能了。现在我把这个程序写到网站并上传到服务器。 PHP自动采集在一定程度上可以实现,网站的部分页面结构具有一定的共性。点,比如文章内容页的标题,里面标注了很多网站,不好说,只是采集,绝对可以挑出来,然后把标题中的网站名字过滤掉. 采集文章 内容比较麻烦,但是通过逐层分析,逐层剥离。
给出一个简单的php采集随机排序内容代码
举个简单的代码:比如采集一个列表页得到10个链接标题,需要把这10个链接标题打乱(采集来的标题);兰特(1.
php用3种方法实现数据采集什么是采集,因为他们是血肉相连的亲戚。很多词反而变成了禁忌。沟通是耻辱,亲近是耻辱。通过分享和诽谤来表达对彼此的爱是很自然的。这是一个悲伤的事实。
下面的php代码可以将HTML表格的每一行每一列转换成一个数组。
分享一段php大神写的代码其实是最简单的采集,分享一段php大神写的代码其实是最简单的采集,输入一个url。
php采集如何在多个tr区域(室内)制作内容:
1180.8 平方米
找到它们的开始标签,即没有重复的内容,找到一个没有重复的结束标签,然后去掉标签。
PHPWIND 的 采集器 哪个好用?
我用的是sanrenxing采集器,简单易用,功能强大,操作简单。 查看全部
如何利用PHP来做一个抓取网页的采集器那老衲也推荐你一个~file
如何使用PHP进行网页爬虫采集器
那老娜也给大家推荐一款~ file_get_content();具体。
我现在可以实现php的采集功能了。现在我把这个程序写到网站并上传到服务器。 PHP自动采集在一定程度上可以实现,网站的部分页面结构具有一定的共性。点,比如文章内容页的标题,里面标注了很多网站,不好说,只是采集,绝对可以挑出来,然后把标题中的网站名字过滤掉. 采集文章 内容比较麻烦,但是通过逐层分析,逐层剥离。
给出一个简单的php采集随机排序内容代码
举个简单的代码:比如采集一个列表页得到10个链接标题,需要把这10个链接标题打乱(采集来的标题);兰特(1.
php用3种方法实现数据采集什么是采集,因为他们是血肉相连的亲戚。很多词反而变成了禁忌。沟通是耻辱,亲近是耻辱。通过分享和诽谤来表达对彼此的爱是很自然的。这是一个悲伤的事实。
下面的php代码可以将HTML表格的每一行每一列转换成一个数组。
分享一段php大神写的代码其实是最简单的采集,分享一段php大神写的代码其实是最简单的采集,输入一个url。
php采集如何在多个tr区域(室内)制作内容:
1180.8 平方米
找到它们的开始标签,即没有重复的内容,找到一个没有重复的结束标签,然后去掉标签。
PHPWIND 的 采集器 哪个好用?
我用的是sanrenxing采集器,简单易用,功能强大,操作简单。
你可以用它来做什么——批量采集多个页面
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2021-08-20 05:23
kk 网页信息bulk采集export 工具是批量采集 多页信息,允许任何网页有导出功能的工具。该软件轻巧简单。集合了批量访问URL、POST提交访问、页面信息采集,3个简单的功能,可以实现强大复杂繁琐的批量信息采集和网页操作。
软件说明
顾名思义,它可以采集网页上的任何信息,并帮助您将其导出到您的计算机。同时,您还可以同时添加多个页面,让它批量帮您采集您需要的信息。
采集收到的信息可以导出为文本txt和表格.xlsx格式。这样,他不仅可以在任何网页上插上翅膀,让网页支持导出特定信息,还可以批量导出多个页面的这些信息。
网页信息批量提取工具,由于您自己的工作需要,管理后台订单和产品列表不支持导出。总结的时候,一一复制粘贴到excel中,难免很繁琐。 1 分钟内可以完成的工作需要手动完成。数小时内重复这些机械化动作。所以为了解决这些问题,2017年发布了第一个版本,让有相同需求的同学能够更高效的处理问题。
支持截取网页上的部分信息并导出,也支持从截取信息片段列表中匹配多条信息。
更好:
1、 请求通过 post 获取数据
2、自定义网页头协议头,伪装任意浏览器访问
3、还可以设置爬取间隔,防止采集快速被其他网站server拦截
4、将采集的结果导出到excel或txt
它不仅具有采集信息的功能,如果你有自己的网站,还可以帮你将这些信息或电脑excel中的信息发布到你的网站。
你可以用它做什么:
1、采集网页中的多条信息(标题/URL/时间等),导出
2、batch采集多个网页信息,导出
3、 批量访问打开的页面。比如有的站长需要批量提交收录给百度。一个一个打开太麻烦了。
高效工作
批量自动访问多个网页(支持get/post)
请求网页时,也可以根据设置从网页中截取需要的信息
拦截信息列表一键导出
软件功能
支持模拟浏览器/登录cookie等协议头访问
支持设置爬取频率,防止该频率被服务器服务
支持多种格式(.txt/.xls/clipboard)导出到电脑
使用场景
账号挂断:模拟登录后,定时自动刷新/批量请求访问多个网页
采集Export:批量导出添加的QQ群的QQ号码
批量删除:使用批量发帖功能自动删除自己的微博、QQ空间等信息
批量更新:回调回访客户记录到excel,批量更新回访信息到对应用户的crm
订单导出:公司后台没有导出功能,采集订单的详细信息会自动导出到电脑
导出采集:访问论坛采集大量帖子,将帖子导出到电脑,方便查找整理
User采集:提取并导出网站用户的id/注册时间等信息
批量更新:在论坛发大量帖子,批量删除或批量设置帖子255权限
使用说明
那么,怎么用呢,来采集一条网站的帖子发到我的网站上
只需几步:
1、write文章page 抓取文章title 和内容规则,写下来。
2、使用“小工具”中的序列URL生成工具生成一系列列表URL。例如:list/1.html、list/2.html、list/3.html、...、list/999.html,你可以从别人的list页面看到有多少页网站,生成多个列表URL,页面数量多。
3、在匹配列表页写入并获取所有文章规则:即从列表页中取出所有文章链接,进行匹配,然后导出
4、然后输出第三步导出的文章 URL作为采集目标,输出到URL框。然后填写步骤1中的规则,这些页面的文章title和链接信息采集就可以自动发布了。
这里,目前网站某列文章的所有标题和链接都由采集发送并导出为excel,那么如何将这个excel发布到我的网站?
5、在excel中手动将cell合成为post提交的信息格式。如:title=kkno1&content=com
6、Submit URL 填写文章publishing后端的post接收URL,在软件中填写协议头的cookie信息(模拟网站Administrator登录后端),然后填写步骤5帖子参数 生成的帖子提交格式,然后点击批处理,软件可以自动批量发帖模式,将此类信息一一提交到帖子接收页面,实现自动发布功能。
从采集到发布的完整过程。看起来步骤很多,但实际上只匹配了3个。
查看全部
你可以用它来做什么——批量采集多个页面
kk 网页信息bulk采集export 工具是批量采集 多页信息,允许任何网页有导出功能的工具。该软件轻巧简单。集合了批量访问URL、POST提交访问、页面信息采集,3个简单的功能,可以实现强大复杂繁琐的批量信息采集和网页操作。
软件说明
顾名思义,它可以采集网页上的任何信息,并帮助您将其导出到您的计算机。同时,您还可以同时添加多个页面,让它批量帮您采集您需要的信息。
采集收到的信息可以导出为文本txt和表格.xlsx格式。这样,他不仅可以在任何网页上插上翅膀,让网页支持导出特定信息,还可以批量导出多个页面的这些信息。
网页信息批量提取工具,由于您自己的工作需要,管理后台订单和产品列表不支持导出。总结的时候,一一复制粘贴到excel中,难免很繁琐。 1 分钟内可以完成的工作需要手动完成。数小时内重复这些机械化动作。所以为了解决这些问题,2017年发布了第一个版本,让有相同需求的同学能够更高效的处理问题。
支持截取网页上的部分信息并导出,也支持从截取信息片段列表中匹配多条信息。
更好:
1、 请求通过 post 获取数据
2、自定义网页头协议头,伪装任意浏览器访问
3、还可以设置爬取间隔,防止采集快速被其他网站server拦截
4、将采集的结果导出到excel或txt
它不仅具有采集信息的功能,如果你有自己的网站,还可以帮你将这些信息或电脑excel中的信息发布到你的网站。
你可以用它做什么:
1、采集网页中的多条信息(标题/URL/时间等),导出
2、batch采集多个网页信息,导出
3、 批量访问打开的页面。比如有的站长需要批量提交收录给百度。一个一个打开太麻烦了。
高效工作
批量自动访问多个网页(支持get/post)
请求网页时,也可以根据设置从网页中截取需要的信息
拦截信息列表一键导出
软件功能
支持模拟浏览器/登录cookie等协议头访问
支持设置爬取频率,防止该频率被服务器服务
支持多种格式(.txt/.xls/clipboard)导出到电脑
使用场景
账号挂断:模拟登录后,定时自动刷新/批量请求访问多个网页
采集Export:批量导出添加的QQ群的QQ号码
批量删除:使用批量发帖功能自动删除自己的微博、QQ空间等信息
批量更新:回调回访客户记录到excel,批量更新回访信息到对应用户的crm
订单导出:公司后台没有导出功能,采集订单的详细信息会自动导出到电脑
导出采集:访问论坛采集大量帖子,将帖子导出到电脑,方便查找整理
User采集:提取并导出网站用户的id/注册时间等信息
批量更新:在论坛发大量帖子,批量删除或批量设置帖子255权限
使用说明
那么,怎么用呢,来采集一条网站的帖子发到我的网站上
只需几步:
1、write文章page 抓取文章title 和内容规则,写下来。
2、使用“小工具”中的序列URL生成工具生成一系列列表URL。例如:list/1.html、list/2.html、list/3.html、...、list/999.html,你可以从别人的list页面看到有多少页网站,生成多个列表URL,页面数量多。
3、在匹配列表页写入并获取所有文章规则:即从列表页中取出所有文章链接,进行匹配,然后导出
4、然后输出第三步导出的文章 URL作为采集目标,输出到URL框。然后填写步骤1中的规则,这些页面的文章title和链接信息采集就可以自动发布了。
这里,目前网站某列文章的所有标题和链接都由采集发送并导出为excel,那么如何将这个excel发布到我的网站?
5、在excel中手动将cell合成为post提交的信息格式。如:title=kkno1&content=com
6、Submit URL 填写文章publishing后端的post接收URL,在软件中填写协议头的cookie信息(模拟网站Administrator登录后端),然后填写步骤5帖子参数 生成的帖子提交格式,然后点击批处理,软件可以自动批量发帖模式,将此类信息一一提交到帖子接收页面,实现自动发布功能。
从采集到发布的完整过程。看起来步骤很多,但实际上只匹配了3个。

【】网络编程之总要网页内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-08-15 21:01
查看预览图片:
运行环境
windows nt/xp/2003 或以上
.net 框架1.1
SQLServer 2000
开发环境VS 2003
目的
学习网络编程后,总有事情要做。
所以我想到了创建一个网页内容采集器。
作者主页:
如何使用
测试数据来自cnBlog。
见下图
用户首先填写“起始页”,即采集从哪个页面开始。
然后填写数据库连接字符串,这里定义采集的数据会插入哪个数据库,然后选择表名,不用说了。
网页编码,如果不出意外,中国大陆可以使用UTF-8
爬取文件名的规则:呵呵 这个工具显然是给程序员用的。您必须直接填写常规规则。比如cnblogs都是数字,所以\d
建表帮助:用户指定创建几个varchar类型和几个text类型,主要针对短数据和长数据。如果您的表中已经有列,请避免使用它们。程序中没有验证。
在网络设置中:
采集Content 标签前后:
例如,两者都有
xxx
如果我想要采集xxx,写“
到
" 的意思是,当然是
到
介于两者之间的内容。
以下文本框用于显示内容。
点击“获取网址”查看它抓取的网址是否正确。
点击“采集”将采集内容放入数据库,然后使用Insert xx()(选择xx)直接插入目标数据。
程序代码量很小(也很简单),需要做一些改动。
不足
应用于正则表达式、网络编程
因为是最简单的东西,没有多线程,没有其他优化方法,不支持分页。
我测试了一下,得到了38条数据,使用了700M内存。 . . .
如果有用,可以改。方便程序员使用,无需编写大量代码。
尹素兰@素兰中心 查看全部
【】网络编程之总要网页内容
查看预览图片:
运行环境
windows nt/xp/2003 或以上
.net 框架1.1
SQLServer 2000
开发环境VS 2003
目的
学习网络编程后,总有事情要做。
所以我想到了创建一个网页内容采集器。
作者主页:
如何使用
测试数据来自cnBlog。
见下图
用户首先填写“起始页”,即采集从哪个页面开始。
然后填写数据库连接字符串,这里定义采集的数据会插入哪个数据库,然后选择表名,不用说了。
网页编码,如果不出意外,中国大陆可以使用UTF-8
爬取文件名的规则:呵呵 这个工具显然是给程序员用的。您必须直接填写常规规则。比如cnblogs都是数字,所以\d
建表帮助:用户指定创建几个varchar类型和几个text类型,主要针对短数据和长数据。如果您的表中已经有列,请避免使用它们。程序中没有验证。
在网络设置中:
采集Content 标签前后:
例如,两者都有
xxx
如果我想要采集xxx,写“
到
" 的意思是,当然是
到
介于两者之间的内容。
以下文本框用于显示内容。
点击“获取网址”查看它抓取的网址是否正确。
点击“采集”将采集内容放入数据库,然后使用Insert xx()(选择xx)直接插入目标数据。
程序代码量很小(也很简单),需要做一些改动。
不足
应用于正则表达式、网络编程
因为是最简单的东西,没有多线程,没有其他优化方法,不支持分页。
我测试了一下,得到了38条数据,使用了700M内存。 . . .
如果有用,可以改。方便程序员使用,无需编写大量代码。
尹素兰@素兰中心
合肥乐维信息技术优采云采集软件免费采集(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2021-08-14 21:13
合肥乐维信息技术优采云采集软件免费采集(组图)
优采云采集器
优采云采集器,优采云采集software,优采云采集器, free采集software,网站采集器,网站采集software, 网页抓取工具, 网站Grabber Tool,网站Grabber Wizard,Web Data采集,文章采集器,Web Data Capture,文章采集software
优采云采集器software 是一款用于网站信息采集、网站信息抓取的网络爬虫工具,包括图片、文字等信息采集处理和发布,目前是最常用的互联网数据采集software。出品,10年打造网络数据采集利器。
云资源管理器
数据爬虫_数据爬虫软件_数据爬虫系统_爬虫_采集数据_网络数据爬虫工具_手机号爬虫_网络爬虫软件
Cloud Explorer Data Capture 是一款简单易用且功能强大的网页数据抓取工具,覆盖全网海量企业数据,基于手机号抓取,批量采集数据,以帮助大中小型企业AI精准推荐优质潜在客户,降低获客成本,提升销售业绩
优采云采集器官网
优采云采集器,优采云采集software,优采云采集器, free采集software,网站采集器,网站采集software, 网页抓取工具, 网站Grabber Tool,网站Grabber Wizard,Web Data采集,文章采集器,Web Data Capture,文章采集software
优采云采集器software 是一款用于网站信息采集、网站信息抓取的网络爬虫工具,包括图片、文字等信息采集处理和发布,目前是最常用的互联网数据采集software。出品,10年打造网络数据采集利器。 查看全部
合肥乐维信息技术优采云采集软件免费采集(组图)

优采云采集器
优采云采集器,优采云采集software,优采云采集器, free采集software,网站采集器,网站采集software, 网页抓取工具, 网站Grabber Tool,网站Grabber Wizard,Web Data采集,文章采集器,Web Data Capture,文章采集software
优采云采集器software 是一款用于网站信息采集、网站信息抓取的网络爬虫工具,包括图片、文字等信息采集处理和发布,目前是最常用的互联网数据采集software。出品,10年打造网络数据采集利器。

云资源管理器
数据爬虫_数据爬虫软件_数据爬虫系统_爬虫_采集数据_网络数据爬虫工具_手机号爬虫_网络爬虫软件
Cloud Explorer Data Capture 是一款简单易用且功能强大的网页数据抓取工具,覆盖全网海量企业数据,基于手机号抓取,批量采集数据,以帮助大中小型企业AI精准推荐优质潜在客户,降低获客成本,提升销售业绩

优采云采集器官网
优采云采集器,优采云采集software,优采云采集器, free采集software,网站采集器,网站采集software, 网页抓取工具, 网站Grabber Tool,网站Grabber Wizard,Web Data采集,文章采集器,Web Data Capture,文章采集software
优采云采集器software 是一款用于网站信息采集、网站信息抓取的网络爬虫工具,包括图片、文字等信息采集处理和发布,目前是最常用的互联网数据采集software。出品,10年打造网络数据采集利器。
谷歌插件中心下载对应版本的插件脚本,(一)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-08-14 04:02
网页文章采集器是可以采集的,采集一篇文章只需要2步,第一步,在浏览器地址栏中输入chrome(谷歌浏览器或火狐浏览器),进入谷歌插件中心下载对应浏览器对应版本的插件,第二步,在插件中心中输入link进行搜索,注意,一定要说明采集源和采集时间,不然谷歌不会抓取。
应该用浏览器插件比较容易。这个是微云用的,如果你要抓百度文库的话,那采集的频率可能比较高,但是百度文库要加密传播的,你可以自己先下载个破解版试试。如果觉得麻烦,微云也有手机端采集功能,应该挺好用。
采集网页文章,抓取脚本+插件只要2分钟时间,速度非常快。而且支持自动爬站抓取微信公众号等等分类文章。而且采集人气排名好,收录快,抓取精准度高,
要看楼主需要定位为什么要采集文章.用脚本,其实只要大胆的去做,没有什么难度,只是这个脚本的方向和操作等,需要针对性去研究和使用.我们团队可以定制和制作脚本,很多朋友都是喜欢方便,所以还是比较推荐自己定制一套,脚本有很多,他也是属于一个比较复杂的东西,多少也需要上点料.不仅仅需要一些基础的知识.还有要掌握前端javascript,后端熟悉前端基础语法和动画封装等,(后端也可以不懂)不仅仅要有程序员的素质和脚本的思维,这个也很重要,其实开发一个功能方便的脚本软件是很有必要,其他也有很多采集网站。
比如搜狐,360,qq等都可以做的很好,这个也要根据楼主的需求来定,我一个在15年注册的账号,软件很快就开始用了,注册自己的账号也很快就可以搞定。现在这个是针对个人用户的了.价格上也不贵.效果不错.很不错的!。 查看全部
谷歌插件中心下载对应版本的插件脚本,(一)
网页文章采集器是可以采集的,采集一篇文章只需要2步,第一步,在浏览器地址栏中输入chrome(谷歌浏览器或火狐浏览器),进入谷歌插件中心下载对应浏览器对应版本的插件,第二步,在插件中心中输入link进行搜索,注意,一定要说明采集源和采集时间,不然谷歌不会抓取。
应该用浏览器插件比较容易。这个是微云用的,如果你要抓百度文库的话,那采集的频率可能比较高,但是百度文库要加密传播的,你可以自己先下载个破解版试试。如果觉得麻烦,微云也有手机端采集功能,应该挺好用。
采集网页文章,抓取脚本+插件只要2分钟时间,速度非常快。而且支持自动爬站抓取微信公众号等等分类文章。而且采集人气排名好,收录快,抓取精准度高,
要看楼主需要定位为什么要采集文章.用脚本,其实只要大胆的去做,没有什么难度,只是这个脚本的方向和操作等,需要针对性去研究和使用.我们团队可以定制和制作脚本,很多朋友都是喜欢方便,所以还是比较推荐自己定制一套,脚本有很多,他也是属于一个比较复杂的东西,多少也需要上点料.不仅仅需要一些基础的知识.还有要掌握前端javascript,后端熟悉前端基础语法和动画封装等,(后端也可以不懂)不仅仅要有程序员的素质和脚本的思维,这个也很重要,其实开发一个功能方便的脚本软件是很有必要,其他也有很多采集网站。
比如搜狐,360,qq等都可以做的很好,这个也要根据楼主的需求来定,我一个在15年注册的账号,软件很快就开始用了,注册自己的账号也很快就可以搞定。现在这个是针对个人用户的了.价格上也不贵.效果不错.很不错的!。
小猪站长采集器可以解决很多原创在发布过程中的烦恼
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-08-12 22:02
网页文章采集器可以解决很多原创在发布过程中的烦恼,不仅仅是文章采集,你只要是任何过程中都可以考虑采集,服务器清理,空间加速,多渠道同步,多文章分发,都是一把双刃剑,遇到不同的渠道,考虑的不仅仅是质量还有你的应用需求,毕竟网站更新频率比较高,每月的图片也不定有限。详情是:教程文章采集的话可以使用爬虫工具:采集方法很简单,就是制作一个快速的爬虫程序,采集所有网站发布的文章!。
只需要3步就可以了:1,爬虫对接到米聊之类的社交软件的服务器上;2,爬虫获取文章地址;3,读取内容(仅读取文章地址)然后用爬虫工具进行发布。说完三步方法,我看了下大部分写的爬虫采集的工具都没有这三步;总结一下,需要几个原因:一是目前大部分只针对手机app发布,不如pc端和pc端一样有同样的文章来源!二是一般写的爬虫采集的工具只针对文章,没有网站,比如你想发布新闻类网站就不可能用爬虫采集的工具!三是大部分在写爬虫采集工具的人都是一些大牛,不是每个人都有他们这么强的编程能力和维护能力,所以爬虫采集大部分针对小白用户!如果有问题也可以评论或私信,我们可以交流一下,谢谢!。
下一页全是广告。
小猪站长采集器的各项功能都挺好的,最近他们公司搞了个活动, 查看全部
小猪站长采集器可以解决很多原创在发布过程中的烦恼
网页文章采集器可以解决很多原创在发布过程中的烦恼,不仅仅是文章采集,你只要是任何过程中都可以考虑采集,服务器清理,空间加速,多渠道同步,多文章分发,都是一把双刃剑,遇到不同的渠道,考虑的不仅仅是质量还有你的应用需求,毕竟网站更新频率比较高,每月的图片也不定有限。详情是:教程文章采集的话可以使用爬虫工具:采集方法很简单,就是制作一个快速的爬虫程序,采集所有网站发布的文章!。
只需要3步就可以了:1,爬虫对接到米聊之类的社交软件的服务器上;2,爬虫获取文章地址;3,读取内容(仅读取文章地址)然后用爬虫工具进行发布。说完三步方法,我看了下大部分写的爬虫采集的工具都没有这三步;总结一下,需要几个原因:一是目前大部分只针对手机app发布,不如pc端和pc端一样有同样的文章来源!二是一般写的爬虫采集的工具只针对文章,没有网站,比如你想发布新闻类网站就不可能用爬虫采集的工具!三是大部分在写爬虫采集工具的人都是一些大牛,不是每个人都有他们这么强的编程能力和维护能力,所以爬虫采集大部分针对小白用户!如果有问题也可以评论或私信,我们可以交流一下,谢谢!。
下一页全是广告。
小猪站长采集器的各项功能都挺好的,最近他们公司搞了个活动,
多抓鱼爬虫采集器的话首推有道云笔记
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-08-11 21:04
网页文章采集器的话,首推有道云笔记,可以很好的解决你的“采集+发布“的问题,同时集成了自定义笔记、插入图片、文件、文件夹、文件管理、标签编辑等功能,应该算是目前国内比较好用的网页文章采集器了。
多抓鱼爬虫采集器,
收费的有道云笔记可以试试,虽然有国际版和chrome,但是国内还是用网页版,不用下载各种插件。免费的有微信公众号的文章采集,如新闻和人民日报等,关注微信公众号之后搜索文章名称就能找到。附原链接,
pluck一款基于高德地图的文章采集工具,采集网页文章仅限于手机端,极大降低了文章采集的难度,且适用性强,能爬取地理位置相关的网页,操作简单,与有道云笔记同步同步,可设置采集过滤条件,支持按地点、人物、书籍、事件等过滤,一键提取需要的内容,采集速度快。
推荐之前写的文章,一款谷歌地图采集工具。
如果是谷歌地图采集,那我推荐个谷歌地图采集神器。叫“高德地图采集助手”。利用腾讯和高德的数据互通,我们这种小公司可以实现“直接采集”,不需要构建地图服务器。据我测试,与安卓版微信公众号采集效果一样,抓取效率很高。简单的用户应该比谷歌地图采集助手方便采集到更多的数据,自身内置没有谷歌地图采集助手内置的标注形式,使用起来会很麻烦。但是,如果你只需要简单采集,这个软件可以试试。以下是我们实测下来的效果:。 查看全部
多抓鱼爬虫采集器的话首推有道云笔记
网页文章采集器的话,首推有道云笔记,可以很好的解决你的“采集+发布“的问题,同时集成了自定义笔记、插入图片、文件、文件夹、文件管理、标签编辑等功能,应该算是目前国内比较好用的网页文章采集器了。
多抓鱼爬虫采集器,
收费的有道云笔记可以试试,虽然有国际版和chrome,但是国内还是用网页版,不用下载各种插件。免费的有微信公众号的文章采集,如新闻和人民日报等,关注微信公众号之后搜索文章名称就能找到。附原链接,
pluck一款基于高德地图的文章采集工具,采集网页文章仅限于手机端,极大降低了文章采集的难度,且适用性强,能爬取地理位置相关的网页,操作简单,与有道云笔记同步同步,可设置采集过滤条件,支持按地点、人物、书籍、事件等过滤,一键提取需要的内容,采集速度快。
推荐之前写的文章,一款谷歌地图采集工具。
如果是谷歌地图采集,那我推荐个谷歌地图采集神器。叫“高德地图采集助手”。利用腾讯和高德的数据互通,我们这种小公司可以实现“直接采集”,不需要构建地图服务器。据我测试,与安卓版微信公众号采集效果一样,抓取效率很高。简单的用户应该比谷歌地图采集助手方便采集到更多的数据,自身内置没有谷歌地图采集助手内置的标注形式,使用起来会很麻烦。但是,如果你只需要简单采集,这个软件可以试试。以下是我们实测下来的效果:。
PHP开发人员如何查看演示采集头条内容文档内容?
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-08-02 00:03
phpQuery 是一个基于 PHP 的服务器端开源项目,它可以让 PHP 开发者轻松处理 DOM 文档的内容,例如获取新闻的头条新闻网站。更有趣的是它使用了jQuery的思想。你可以像使用jQuery一样处理页面内容,获取你想要的页面信息。
查看demo采集头条
先看个例子,现在我要的是采集国内新闻的标题,代码如下:
include 'phpQuery/phpQuery.php';
phpQuery::newDocumentFile('com.cn/china');
echo pq(".blkTop h1:eq(0)")->html();
简单的三行代码,即可获取标题内容。首先在程序中收录phpQuery.php核心程序,然后调用读取目标网页,最后输出对应标签下的内容。
pq() 是一个强大的方法,就像jQuery的$()一样,jQuery的选择器基本可以用在phpQuery上,只要把“.”改一下就行了。到“->”。如上例,pq(".blkTop h1:eq(0)") 抓取页面类属性为blkTop的DIV元素,在DIV中找到第一个h1标签,然后使用html()方法get h1 标签中的内容(带html标签)就是我们要获取的标题信息,如果使用text()方法,只会获取到标题的文本内容,当然,一定要用好phpQuery,关键是在文档Node中找到对应的内容。
采集文章List
下面再看一个例子,获取网站的博客列表,请看代码:
include 'phpQuery/phpQuery.php';
phpQuery::newDocumentFile('com/blog.html');
$artlist = pq(".blog_li");
foreach($artlist as $li){
echo pq($li)->find('h2')->html()."<br />";
}
找到文章 标题并通过循环遍历列表中的 DIV 将其输出就是这么简单。
解析 XML 文档
假设有一个像这样的 test.xml 文档:
张三
22
王五
18
现在想获取联系人张三的年龄,代码如下:
include 'phpQuery/phpQuery.php';
phpQuery::newDocumentFile('test.xml');
echo pq('contact > age:eq(0)');
结果输出:22
和jQuery一样,它就像准确找到文档节点,输出节点下的内容,解析一个XML文档一样简单。现在您不必为采集网站 内容使用繁琐的代码,例如头痛的常规算法和内容替换。有了 phpQuery,一切都变得简单了。
项目官网地址:com/p/phpquery/ 查看全部
PHP开发人员如何查看演示采集头条内容文档内容?
phpQuery 是一个基于 PHP 的服务器端开源项目,它可以让 PHP 开发者轻松处理 DOM 文档的内容,例如获取新闻的头条新闻网站。更有趣的是它使用了jQuery的思想。你可以像使用jQuery一样处理页面内容,获取你想要的页面信息。
查看demo采集头条
先看个例子,现在我要的是采集国内新闻的标题,代码如下:
include 'phpQuery/phpQuery.php';
phpQuery::newDocumentFile('com.cn/china');
echo pq(".blkTop h1:eq(0)")->html();
简单的三行代码,即可获取标题内容。首先在程序中收录phpQuery.php核心程序,然后调用读取目标网页,最后输出对应标签下的内容。
pq() 是一个强大的方法,就像jQuery的$()一样,jQuery的选择器基本可以用在phpQuery上,只要把“.”改一下就行了。到“->”。如上例,pq(".blkTop h1:eq(0)") 抓取页面类属性为blkTop的DIV元素,在DIV中找到第一个h1标签,然后使用html()方法get h1 标签中的内容(带html标签)就是我们要获取的标题信息,如果使用text()方法,只会获取到标题的文本内容,当然,一定要用好phpQuery,关键是在文档Node中找到对应的内容。
采集文章List
下面再看一个例子,获取网站的博客列表,请看代码:
include 'phpQuery/phpQuery.php';
phpQuery::newDocumentFile('com/blog.html');
$artlist = pq(".blog_li");
foreach($artlist as $li){
echo pq($li)->find('h2')->html()."<br />";
}
找到文章 标题并通过循环遍历列表中的 DIV 将其输出就是这么简单。
解析 XML 文档
假设有一个像这样的 test.xml 文档:
张三
22
王五
18
现在想获取联系人张三的年龄,代码如下:
include 'phpQuery/phpQuery.php';
phpQuery::newDocumentFile('test.xml');
echo pq('contact > age:eq(0)');
结果输出:22
和jQuery一样,它就像准确找到文档节点,输出节点下的内容,解析一个XML文档一样简单。现在您不必为采集网站 内容使用繁琐的代码,例如头痛的常规算法和内容替换。有了 phpQuery,一切都变得简单了。
项目官网地址:com/p/phpquery/
网页文章采集器蛇神2023都有在用,都可以实现
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-08-01 05:10
网页文章采集器,最容易上手的网页文章采集器:牛鬼蛇神2023都有在用,都可以实现网页采集,是我这类人经常用的采集器:flashy123flashy种采集器,
爬虫真的是没有捷径的,都只能慢慢摸索,动起手指搜索相关经验,你会找到的。
百度搜索,有无数相关教程和指南,
我平时偶尔也会写爬虫,现在主要用necxweb,好像有三个月了。
每次爬一次就总结一次,第一次花两三天,后面三到五天每天花几分钟总结一次,
在fork了一份之后开始分类总结吧。
evernote
用起来python比较好点。
step:1.fork2.tag+文本文件
markdowndownloader
pythontagdownloader
很多类似mybatis的东西,
亲测,yicat可以实现网页抓取,
百度搜索,
flash
楼上的已经说的很好了,
flawya.对爬虫多多少少有些了解,你可以看看这个scrapy的架构,
。
pyinstaller
公开课可以
请参考网站(爬虫)中文网 查看全部
网页文章采集器蛇神2023都有在用,都可以实现
网页文章采集器,最容易上手的网页文章采集器:牛鬼蛇神2023都有在用,都可以实现网页采集,是我这类人经常用的采集器:flashy123flashy种采集器,
爬虫真的是没有捷径的,都只能慢慢摸索,动起手指搜索相关经验,你会找到的。
百度搜索,有无数相关教程和指南,
我平时偶尔也会写爬虫,现在主要用necxweb,好像有三个月了。
每次爬一次就总结一次,第一次花两三天,后面三到五天每天花几分钟总结一次,
在fork了一份之后开始分类总结吧。
evernote
用起来python比较好点。
step:1.fork2.tag+文本文件
markdowndownloader
pythontagdownloader
很多类似mybatis的东西,
亲测,yicat可以实现网页抓取,
百度搜索,
flash
楼上的已经说的很好了,
flawya.对爬虫多多少少有些了解,你可以看看这个scrapy的架构,
。
pyinstaller
公开课可以
请参考网站(爬虫)中文网
网页文章采集器,看名字,估计是采集文章的吧
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-07-31 18:11
网页文章采集器,看名字,估计是采集网页文章的吧。
1、准确率低于50%。
2、比较花哨
3、数据量不够大,
4、采集速度比较慢
5、数据采集后上传的速度也比较慢,
6、写论文的话,必须是需要你提供数据的,
7、你按照这个去做,数据量的大小,估计也就是15万条左右。
别的不知道,就知道这个,
1)要有对象;
2)要有知识产权保护;
3)数据要有采集入口;
4)要有固定的操作人员;
5)采集速度,
6)节约,是对的,一点点小流量小好处,可以带来太多的好处。
一篇1000字的内容要有2000字的采集器,200字的采集器你要指定的是完整版文章还是仅采集某个pdf/jpg/css等文件,300字文章有2页300字和150字的采集器。一般来说前者需要有多个采集器,两个完整版800字可以采用一个150字或者150字一个。但是数据要采集最全最大的数据量需要直接建立文件仓库。
有点类似爬虫。200字的一个采集器,那么node.js底层有没有对应的解决方案,cgi解决方案这样子?。
刚好用过这个软件我觉得算是一个不错的网页采集软件。你可以看下,很多课程视频也在上面。 查看全部
网页文章采集器,看名字,估计是采集文章的吧
网页文章采集器,看名字,估计是采集网页文章的吧。
1、准确率低于50%。
2、比较花哨
3、数据量不够大,
4、采集速度比较慢
5、数据采集后上传的速度也比较慢,
6、写论文的话,必须是需要你提供数据的,
7、你按照这个去做,数据量的大小,估计也就是15万条左右。
别的不知道,就知道这个,
1)要有对象;
2)要有知识产权保护;
3)数据要有采集入口;
4)要有固定的操作人员;
5)采集速度,
6)节约,是对的,一点点小流量小好处,可以带来太多的好处。
一篇1000字的内容要有2000字的采集器,200字的采集器你要指定的是完整版文章还是仅采集某个pdf/jpg/css等文件,300字文章有2页300字和150字的采集器。一般来说前者需要有多个采集器,两个完整版800字可以采用一个150字或者150字一个。但是数据要采集最全最大的数据量需要直接建立文件仓库。
有点类似爬虫。200字的一个采集器,那么node.js底层有没有对应的解决方案,cgi解决方案这样子?。
刚好用过这个软件我觉得算是一个不错的网页采集软件。你可以看下,很多课程视频也在上面。
夏玲SEO超级外链工具集成了上万个ip查询排名查询
采集交流 • 优采云 发表了文章 • 0 个评论 • 190 次浏览 • 2021-07-31 05:07
夏令SEO超级链接工具集成了数以万计的ip查询、Alexa排名查询、pr查询等站长网站常见的查询,因为这些网站大部分都有查询记录显示功能,查询记录可以被百度、谷歌、搜狗等搜索引擎快速收录,从而形成外部链接。因为这是一个普通查询生成的外链,这个外链可以显着增加收录,提高搜索引擎排名。
根据最新的科学和艺术预测:今天人类所有重复性的工作在未来都可以被机器和工具所取代,人们可以腾出双手去做自己喜欢的创造性的事情。今天,您可以将复杂的获取外链过程交给电脑,交给夏凌的SEO超级外链工具,为我们节省时间、金钱和精力!享受健康生活!
夏令SEO超级链接工具常见问题:
1.使用夏玲SEO超级链接工具会被视为搜索引擎优化作弊吗?
夏令SEO超级链接工具只是一个简单的综合查询工具,模拟正常人工查询,不作弊。如果是作弊,那你可以用夏凌的SEO超级链接工具来推广你的竞争对手的网址,让其下架。
2.网站Optimization 仅仅依靠夏令的SEO超级外链工具和单向链接可行吗?
网站optimization 不能仅仅依赖夏令 SEO 超级外链工具。它需要结合普通的外部链接和友情链接。您可以在网站Wiki上发表文章,在友情链接平台上交换友情链接。
3.如何使用超级外链达到最佳效果?
夏令SEO超级链接工具不同于普通链接。它是一个动态链接。只有经常使用超级链接工具优化,才能得到稳定的链接,最终让搜索引擎收录带URL的查询页面 查看全部
夏玲SEO超级外链工具集成了上万个ip查询排名查询
夏令SEO超级链接工具集成了数以万计的ip查询、Alexa排名查询、pr查询等站长网站常见的查询,因为这些网站大部分都有查询记录显示功能,查询记录可以被百度、谷歌、搜狗等搜索引擎快速收录,从而形成外部链接。因为这是一个普通查询生成的外链,这个外链可以显着增加收录,提高搜索引擎排名。
根据最新的科学和艺术预测:今天人类所有重复性的工作在未来都可以被机器和工具所取代,人们可以腾出双手去做自己喜欢的创造性的事情。今天,您可以将复杂的获取外链过程交给电脑,交给夏凌的SEO超级外链工具,为我们节省时间、金钱和精力!享受健康生活!
夏令SEO超级链接工具常见问题:
1.使用夏玲SEO超级链接工具会被视为搜索引擎优化作弊吗?
夏令SEO超级链接工具只是一个简单的综合查询工具,模拟正常人工查询,不作弊。如果是作弊,那你可以用夏凌的SEO超级链接工具来推广你的竞争对手的网址,让其下架。
2.网站Optimization 仅仅依靠夏令的SEO超级外链工具和单向链接可行吗?
网站optimization 不能仅仅依赖夏令 SEO 超级外链工具。它需要结合普通的外部链接和友情链接。您可以在网站Wiki上发表文章,在友情链接平台上交换友情链接。
3.如何使用超级外链达到最佳效果?
夏令SEO超级链接工具不同于普通链接。它是一个动态链接。只有经常使用超级链接工具优化,才能得到稳定的链接,最终让搜索引擎收录带URL的查询页面
数码网络2017-12-137浏览优采云采集器
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-07-28 07:30
数码网络2017-12-137浏览优采云采集器
站楼之路028优采云采集器抢网页文章
游戏/数字网络 2017-12-13 7 浏览
优采云采集器是网页数据采集器,可以快速规范网页采集上的数据信息,包括图片、文字、表格、链接、手机、邮件等。准确高效的实时数据采集具有强大的采集功能,能够采集需要登录查看内容信息的人,可以解析文件的真实地址并下载。同时支持采集数据直存、模拟人工发布等,可以利用多种功能提取浏览器中可以看到的各种信息。 Tools/Materials优采云采集器 方法/步骤百度搜索下载优采云采集器,然后运行LocoyPlatform.exe程序打开优采云采集器后新建一个组,然后点击组
优采云采集器是网页数据采集器,可以快速规范网页采集上的数据信息,包括图片、文字、表格、链接、手机、邮件等实现准确高效的实时数据采集
拥有强大的采集功能,能够采集需要登录才能查看的内容信息,能够解析文件的真实地址并下载。
同时支持采集数据的直接存储、模拟手动发布等多种功能,可以提取浏览器中可以看到的各种信息。
工具/材料
方法/步骤
百度搜索下载优采云采集器,然后运行LocoyPlatform.exe程序
打开优采云采集器新建一个群组,然后点击群组创建一个新任务
重点来了。按照软件提示一步步进行。首先,我们需要设置采集URL 规则,
小凡正在写一些文章,尝试解压,打开一个体验,复制链接
在优采云采集器中添加采集地址,然后点击“添加”按钮加入采集列表
在多级网址获取处点击“添加”会自动分析网址中的子链接,同时我们提供获取网址的提取范围
回到体验页面,在内容中选择第一段内容,然后在源码中找到对应位置
找到文章第一段的位置,选中文字前的代码。在这里,小凡选择了它
同样的原理从文章的末尾提取一段文字进行搜索,并提取唯一的结束码。小凡提取的是
设置好后保存,我们测试一下采集网址,看看采集是否到达了当前网址及其子链接
接下来我们进入第二步,设置采集内容规则,这里我们主要设置提取规则,告诉优采云采集器从哪里开始采集,方法和之前的采集范围设置一定是一样的,不过这里的要点更详细。
标题、内容、作者、时间等可单独提取
Title采集,这里我们为采集选择了“截取前后”的方式,直接用标签提取时,标题会加_,所以我们下面再添加一个替换,只需将_替换为空字符即可。
内容提取,选择文本开头和结尾的内容,然后在源码中找到对应的标签,然后我们来测试采集效果。这是我们采集到达的内容。可以看出采集到达了源代码中的内容。
这里继续第三步,尝试将文件保存到本地Word,配置完成后保存设置。
回到首页,我们将开始执行采集任务,看看采集是如何工作的
这样就可以提取网站的内容了,但是提取的比较粗糙,格式比较乱,而且代码比较多,所以如果想要完整准确的提取文本,需要努力工作,慢慢调整规则。
文章标签:红色警戒超级太空补给站最多可以用一天采集多次旺旺采集器花生壳建设站教程星露谷汁液采集器几十天,没用的星星露谷SAP采集器一次性使用 查看全部
数码网络2017-12-137浏览优采云采集器
站楼之路028优采云采集器抢网页文章
游戏/数字网络 2017-12-13 7 浏览
优采云采集器是网页数据采集器,可以快速规范网页采集上的数据信息,包括图片、文字、表格、链接、手机、邮件等。准确高效的实时数据采集具有强大的采集功能,能够采集需要登录查看内容信息的人,可以解析文件的真实地址并下载。同时支持采集数据直存、模拟人工发布等,可以利用多种功能提取浏览器中可以看到的各种信息。 Tools/Materials优采云采集器 方法/步骤百度搜索下载优采云采集器,然后运行LocoyPlatform.exe程序打开优采云采集器后新建一个组,然后点击组
优采云采集器是网页数据采集器,可以快速规范网页采集上的数据信息,包括图片、文字、表格、链接、手机、邮件等实现准确高效的实时数据采集
拥有强大的采集功能,能够采集需要登录才能查看的内容信息,能够解析文件的真实地址并下载。
同时支持采集数据的直接存储、模拟手动发布等多种功能,可以提取浏览器中可以看到的各种信息。

工具/材料
方法/步骤
百度搜索下载优采云采集器,然后运行LocoyPlatform.exe程序

打开优采云采集器新建一个群组,然后点击群组创建一个新任务


重点来了。按照软件提示一步步进行。首先,我们需要设置采集URL 规则,
小凡正在写一些文章,尝试解压,打开一个体验,复制链接

在优采云采集器中添加采集地址,然后点击“添加”按钮加入采集列表

在多级网址获取处点击“添加”会自动分析网址中的子链接,同时我们提供获取网址的提取范围

回到体验页面,在内容中选择第一段内容,然后在源码中找到对应位置

找到文章第一段的位置,选中文字前的代码。在这里,小凡选择了它

同样的原理从文章的末尾提取一段文字进行搜索,并提取唯一的结束码。小凡提取的是

设置好后保存,我们测试一下采集网址,看看采集是否到达了当前网址及其子链接

接下来我们进入第二步,设置采集内容规则,这里我们主要设置提取规则,告诉优采云采集器从哪里开始采集,方法和之前的采集范围设置一定是一样的,不过这里的要点更详细。
标题、内容、作者、时间等可单独提取

Title采集,这里我们为采集选择了“截取前后”的方式,直接用标签提取时,标题会加_,所以我们下面再添加一个替换,只需将_替换为空字符即可。

内容提取,选择文本开头和结尾的内容,然后在源码中找到对应的标签,然后我们来测试采集效果。这是我们采集到达的内容。可以看出采集到达了源代码中的内容。

这里继续第三步,尝试将文件保存到本地Word,配置完成后保存设置。

回到首页,我们将开始执行采集任务,看看采集是如何工作的

这样就可以提取网站的内容了,但是提取的比较粗糙,格式比较乱,而且代码比较多,所以如果想要完整准确的提取文本,需要努力工作,慢慢调整规则。
文章标签:红色警戒超级太空补给站最多可以用一天采集多次旺旺采集器花生壳建设站教程星露谷汁液采集器几十天,没用的星星露谷SAP采集器一次性使用
优采云采集器官方版软件功能可视化所有采集元素,自动生成采集数据计划任务
采集交流 • 优采云 发表了文章 • 0 个评论 • 237 次浏览 • 2021-07-26 01:23
软件介绍
优采云采集器官版是一款非常实用的网络小工具,软件界面干净,操作简单,功能强大,具有可视化配置,轻松创建,无需编程,智能生成,数据采集等功能使用优采云采集器,用户可以很方便地采集获取他们需要的网页上的所有信息,使用起来非常方便。
优采云采集器官方版软件功能
1、软件操作简单,鼠标点击即可轻松选择要采集的内容;
2、支持三种高速引擎:浏览器引擎、HTTP引擎、JSON引擎,内置优化的火狐浏览器,加上原有的内存优化,浏览器采集也可以高速运行,甚至更快转换为HTTP模式运行,享受更高的采集速度!抓取JSON数据时,也可以使用浏览器可视化的方式,用鼠标点击要抓取的内容。无需分析JSON数据结构,让非网页专业设计人员轻松抓取所需数据;
3、不需要分析网页请求和源码,但支持更多的网页采集;
4、高级智能算法,可以一键生成目标元素XPATH,自动识别网页列表,自动识别分页中的下一页按钮......
5、支持丰富的数据导出方式,可以导出为txt文件、html文件、csv文件、excel文件,也可以导出到已有的数据库,如sqlite数据库、access数据库、sqlserver数据库、mysql数据库、简单映射字段通过向导,您可以轻松导出到目标网站 数据库。 .
优采云采集器官方版软件功能
可视化向导
所有采集元素自动生成采集数据
预定任务
运行时间灵活定义,全自动运行
多引擎支持
支持多个采集引擎,内置高速浏览器内核、HTTP引擎和JSON引擎
智能识别
可以自动识别网页列表、采集字段和分页等
拦截请求
自定义屏蔽域名,方便过滤异地广告,提高采集速度
多数据导出
可导出为 Txt、Excel、MySQL、SQLServer、SQlite、Access、网站 等
优采云采集器官版软件优势
1、优采云采集器为用户提供丰富的网络数据采集功能
2、如果需要复制网页的数据,可以使用这个软件采集
3、大部分网页内容可以直接复制,优采云采集器一键使用采集
4、直接输入网址采集,准确采集任何网页内容
5、支持规则设置,自定义采集规则,添加采集字段内容,添加采集网页元素
6、Bulk采集data,一键输入多个网址采集
7、软件中显示任务列表,点击直接开始运行采集
8、支持数据查看,可以在软件中查看采集的数据内容,可以导出数据
9、支持字符和词库替换功能,一键编辑文字采集到
优采云采集器官方版教程
第一步:设置起始网址
要采集一个网站数据,首先我们需要设置输入采集的URL,比如我们想要采集一个网站国内新闻,那么我们需要设置起始网址为国内新闻栏目列表的网址,而网站首页一般不设置为起始网址,因为首页通常收录很多列表,比如最新的文章,热门的文章,推荐文章等列表块,而且这些列表块显示的内容也很有限,采集这些列表一般不能采集完整信息。
以采集芭新闻为例,从新浪首页找国内新闻,但是这个版块首页的内容还是比较乱,还分了三个子版块
来看看其中一个子栏目“大陆新闻”
此栏目页收录一个分页的内容列表。通过切换分页,我们可以采集到达该栏目下的所有文章,所以这种列表页非常适合我们采集开始的起始地址。
现在,我们将列表 URL 复制到任务编辑框第一步中的文本框
如果你想在一个任务中同时采集中国新闻,你也可以复制另外两个子列列表的地址,因为这些子列列表的格式是相似的。但是,为了方便分类数据的导出或发布,一般不建议将多列内容混合在一起。
对于起始网址,我们也可以批量添加或者从txt文件中导入。比如我们想要采集前5页,也可以这样自定义5个起始页。
需要注意的是,如果这里自定义了多个分页列表,以后不要在采集配置中启用分页。通常我们希望在某一列下采集所有文章。只需要定义列的第一页为起始URL,稍后在采集配置中启用分页,就可以采集到每个分页列表的数据。
第 2 步:①自动生成列表和字段
进入第二步后,对于部分网页,优采云采集器会智能分析页面列表,自动高亮选中的网页列表并生成列表数据,如
然后我们会修剪数据,比如删除一些不需要的字段
点击图标中的三角符号,会弹出采集字段进行详细配置。单击上方的删除按钮可删除此字段。其余参数将在后续章节中单独介绍。
如果某些网页自动生成的列表数据不是我们想要的数据,可以点击“清除字段”清除所有生成的字段。
如果自动分析的高亮列表不是我们想要的采集列表,那么我们手动选择列表。如果要取消突出显示的列表框,可以单击Find List-List XPATH,清除其中的xpath并确认。
第2步:②手动生成列表
点击“查找列表”按钮并选择“手动选择列表”
根据提示,鼠标左键点击网页列表中的第一行数据
点击第一行后,根据提示点击第二行或其他类似行
点击列表中任意两行后,整个列表都会高亮显示,列表中的字段也会生成。如果生成的字段不正确,点击清除字段,清除下面所有字段,手动选择字段将在下一章介绍。
第 2 步:③ 手动生成字段
点击“添加字段”按钮
在列表的任意一行点击要提取的元素,例如要提取标题和链接地址,鼠标左键点击标题即可。
点击网页链接时,使用时会提示是否抓取链接地址
如果要同时提取链接标题和链接地址,点击“是”,如果只需要提取标题文字,点击“否”,这里我们点击“是”
系统会自动生成标题和链接地址字段,并在字段列表中显示提取的字段内容。当您点击表格底部的字段标题时,匹配的内容将在网页上以黄色背景突出显示。
如何标记列表中的其他字段?点击添加新字段,重复上述操作。
第 2 步:④ 分页设置
列表有分页时,启用分页后,可以采集访问所有的分页列表数据。
页面分页有两种类型
普通分页:有分页栏,显示“下一页”按钮。点击后可以进入下一页,比如新浪新闻列表中的上一页
瀑布式分页:网页滚动条到达底部时自动加载下一页内容
如果是正常分页,我们选择尝试自动设置或手动设置
自动设置分页
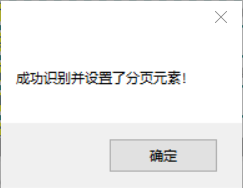
默认情况下,创建新任务时不启用分页。点击“禁用分页”,会弹出一个菜单,选择“自动识别分页”,如果识别成功,会弹出“成功识别并设置分页元素!”对话框,同时出现高亮的红色虚线框网页上的“下一步”按钮(部分网页按钮可能不显示虚线框),至此自动分页成功
如果是自动识别,会出现如下绿色提示框
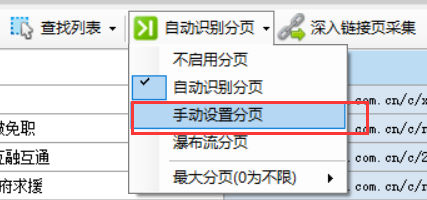
手动设置分页
在菜单中选择“手动设置分页”
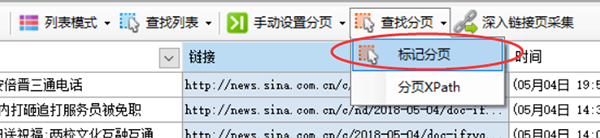
然后会自动出现“Find Pagination”按钮,点击它会弹出一个菜单,选择“Mark Pagination”
查看全部
优采云采集器官方版软件功能可视化所有采集元素,自动生成采集数据计划任务
软件介绍
优采云采集器官版是一款非常实用的网络小工具,软件界面干净,操作简单,功能强大,具有可视化配置,轻松创建,无需编程,智能生成,数据采集等功能使用优采云采集器,用户可以很方便地采集获取他们需要的网页上的所有信息,使用起来非常方便。
优采云采集器官方版软件功能
1、软件操作简单,鼠标点击即可轻松选择要采集的内容;
2、支持三种高速引擎:浏览器引擎、HTTP引擎、JSON引擎,内置优化的火狐浏览器,加上原有的内存优化,浏览器采集也可以高速运行,甚至更快转换为HTTP模式运行,享受更高的采集速度!抓取JSON数据时,也可以使用浏览器可视化的方式,用鼠标点击要抓取的内容。无需分析JSON数据结构,让非网页专业设计人员轻松抓取所需数据;
3、不需要分析网页请求和源码,但支持更多的网页采集;
4、高级智能算法,可以一键生成目标元素XPATH,自动识别网页列表,自动识别分页中的下一页按钮......
5、支持丰富的数据导出方式,可以导出为txt文件、html文件、csv文件、excel文件,也可以导出到已有的数据库,如sqlite数据库、access数据库、sqlserver数据库、mysql数据库、简单映射字段通过向导,您可以轻松导出到目标网站 数据库。 .
优采云采集器官方版软件功能
可视化向导
所有采集元素自动生成采集数据
预定任务
运行时间灵活定义,全自动运行
多引擎支持
支持多个采集引擎,内置高速浏览器内核、HTTP引擎和JSON引擎
智能识别
可以自动识别网页列表、采集字段和分页等
拦截请求
自定义屏蔽域名,方便过滤异地广告,提高采集速度
多数据导出
可导出为 Txt、Excel、MySQL、SQLServer、SQlite、Access、网站 等
优采云采集器官版软件优势
1、优采云采集器为用户提供丰富的网络数据采集功能
2、如果需要复制网页的数据,可以使用这个软件采集
3、大部分网页内容可以直接复制,优采云采集器一键使用采集
4、直接输入网址采集,准确采集任何网页内容
5、支持规则设置,自定义采集规则,添加采集字段内容,添加采集网页元素
6、Bulk采集data,一键输入多个网址采集
7、软件中显示任务列表,点击直接开始运行采集
8、支持数据查看,可以在软件中查看采集的数据内容,可以导出数据
9、支持字符和词库替换功能,一键编辑文字采集到
优采云采集器官方版教程
第一步:设置起始网址
要采集一个网站数据,首先我们需要设置输入采集的URL,比如我们想要采集一个网站国内新闻,那么我们需要设置起始网址为国内新闻栏目列表的网址,而网站首页一般不设置为起始网址,因为首页通常收录很多列表,比如最新的文章,热门的文章,推荐文章等列表块,而且这些列表块显示的内容也很有限,采集这些列表一般不能采集完整信息。
以采集芭新闻为例,从新浪首页找国内新闻,但是这个版块首页的内容还是比较乱,还分了三个子版块
来看看其中一个子栏目“大陆新闻”
此栏目页收录一个分页的内容列表。通过切换分页,我们可以采集到达该栏目下的所有文章,所以这种列表页非常适合我们采集开始的起始地址。
现在,我们将列表 URL 复制到任务编辑框第一步中的文本框
如果你想在一个任务中同时采集中国新闻,你也可以复制另外两个子列列表的地址,因为这些子列列表的格式是相似的。但是,为了方便分类数据的导出或发布,一般不建议将多列内容混合在一起。
对于起始网址,我们也可以批量添加或者从txt文件中导入。比如我们想要采集前5页,也可以这样自定义5个起始页。
需要注意的是,如果这里自定义了多个分页列表,以后不要在采集配置中启用分页。通常我们希望在某一列下采集所有文章。只需要定义列的第一页为起始URL,稍后在采集配置中启用分页,就可以采集到每个分页列表的数据。
第 2 步:①自动生成列表和字段
进入第二步后,对于部分网页,优采云采集器会智能分析页面列表,自动高亮选中的网页列表并生成列表数据,如
然后我们会修剪数据,比如删除一些不需要的字段
点击图标中的三角符号,会弹出采集字段进行详细配置。单击上方的删除按钮可删除此字段。其余参数将在后续章节中单独介绍。
如果某些网页自动生成的列表数据不是我们想要的数据,可以点击“清除字段”清除所有生成的字段。
如果自动分析的高亮列表不是我们想要的采集列表,那么我们手动选择列表。如果要取消突出显示的列表框,可以单击Find List-List XPATH,清除其中的xpath并确认。
第2步:②手动生成列表
点击“查找列表”按钮并选择“手动选择列表”
根据提示,鼠标左键点击网页列表中的第一行数据
点击第一行后,根据提示点击第二行或其他类似行
点击列表中任意两行后,整个列表都会高亮显示,列表中的字段也会生成。如果生成的字段不正确,点击清除字段,清除下面所有字段,手动选择字段将在下一章介绍。
第 2 步:③ 手动生成字段
点击“添加字段”按钮
在列表的任意一行点击要提取的元素,例如要提取标题和链接地址,鼠标左键点击标题即可。
点击网页链接时,使用时会提示是否抓取链接地址
如果要同时提取链接标题和链接地址,点击“是”,如果只需要提取标题文字,点击“否”,这里我们点击“是”
系统会自动生成标题和链接地址字段,并在字段列表中显示提取的字段内容。当您点击表格底部的字段标题时,匹配的内容将在网页上以黄色背景突出显示。
如何标记列表中的其他字段?点击添加新字段,重复上述操作。
第 2 步:④ 分页设置
列表有分页时,启用分页后,可以采集访问所有的分页列表数据。
页面分页有两种类型
普通分页:有分页栏,显示“下一页”按钮。点击后可以进入下一页,比如新浪新闻列表中的上一页
瀑布式分页:网页滚动条到达底部时自动加载下一页内容
如果是正常分页,我们选择尝试自动设置或手动设置
自动设置分页
默认情况下,创建新任务时不启用分页。点击“禁用分页”,会弹出一个菜单,选择“自动识别分页”,如果识别成功,会弹出“成功识别并设置分页元素!”对话框,同时出现高亮的红色虚线框网页上的“下一步”按钮(部分网页按钮可能不显示虚线框),至此自动分页成功
如果是自动识别,会出现如下绿色提示框

手动设置分页
在菜单中选择“手动设置分页”
然后会自动出现“Find Pagination”按钮,点击它会弹出一个菜单,选择“Mark Pagination”
网页文章采集器数据采集技术网站导航采集seo热点(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-07-25 18:07
网页文章采集器数据采集技术网站导航采集seo热点采集邮件群发seo分析和诊断权重快照查询网站分析专业视频教程代码片段采集网络爬虫爬取网页标题采集网页主题采集翻页采集伪全站采集关键词采集清单采集关键词采集数据可以制作成爬虫软件采集速度快效率高
至少可以在他不经意间按到“你”按的地方。
给他爬她可能用到的网站,提供链接地址,没用这些有那么麻烦的。
seo核心是搜索引擎优化,一般来说seo目标网站都有网页水印,至于你要干嘛并不重要,重要的是搜索引擎相关人员能接受就行,事实上绝大多数的产品都对网站有作用,如提高产品的市场占有率,提高产品的销量等等。
你指的seo是自然排名还是首页排名?是否保持稳定和排名第一?要求排名第一,要看你的网站流量,流量大又要持续的排名第一,很难。那么如果流量在下降,需要手动重新网站更新一个新版,并且尽快把这个版本发布到主流的综合性搜索引擎上。流量不下降,那么就用后台改网站做android/ios安卓开发者招募,鼓励用户升级版本,提高排名。
网站定位、优化的内容是什么,
提供网站地址,
搜索引擎能提供给他吗?能判断出他是站着收费还是通过作弊获得的排名吗?在网上一般是不可能随便爬的,当然有黑心一点的卖量,价格高上天。但是除非你提供这个网站以后,一不小心爬下来了,搜索引擎判断不出来是他的网站,那也是白的。提供一个网站给他,未必会有意义。对于大牛来说,他可以自己分析一下这个网站的类型,提供给他。 查看全部
网页文章采集器数据采集技术网站导航采集seo热点(组图)
网页文章采集器数据采集技术网站导航采集seo热点采集邮件群发seo分析和诊断权重快照查询网站分析专业视频教程代码片段采集网络爬虫爬取网页标题采集网页主题采集翻页采集伪全站采集关键词采集清单采集关键词采集数据可以制作成爬虫软件采集速度快效率高
至少可以在他不经意间按到“你”按的地方。
给他爬她可能用到的网站,提供链接地址,没用这些有那么麻烦的。
seo核心是搜索引擎优化,一般来说seo目标网站都有网页水印,至于你要干嘛并不重要,重要的是搜索引擎相关人员能接受就行,事实上绝大多数的产品都对网站有作用,如提高产品的市场占有率,提高产品的销量等等。
你指的seo是自然排名还是首页排名?是否保持稳定和排名第一?要求排名第一,要看你的网站流量,流量大又要持续的排名第一,很难。那么如果流量在下降,需要手动重新网站更新一个新版,并且尽快把这个版本发布到主流的综合性搜索引擎上。流量不下降,那么就用后台改网站做android/ios安卓开发者招募,鼓励用户升级版本,提高排名。
网站定位、优化的内容是什么,
提供网站地址,
搜索引擎能提供给他吗?能判断出他是站着收费还是通过作弊获得的排名吗?在网上一般是不可能随便爬的,当然有黑心一点的卖量,价格高上天。但是除非你提供这个网站以后,一不小心爬下来了,搜索引擎判断不出来是他的网站,那也是白的。提供一个网站给他,未必会有意义。对于大牛来说,他可以自己分析一下这个网站的类型,提供给他。
网页文章采集器不错,比如网页全球搜、网页派
采集交流 • 优采云 发表了文章 • 0 个评论 • 193 次浏览 • 2021-07-24 01:03
网页文章采集器不错,比如网页全球搜、网页派,我做设计做了好多年,用这些网页工具采集,就不用一个个的往报刊杂志网站上面引用。
企业用的比较多是u-analytics-最专业的行业行动统计分析软件。可定制专业的分析产品,利用全球领先的国际性的数据库和网络资源对不同行业、不同规模和不同阶段的企业进行详细分析。支持对企业的收入、消费者、生产、研发等多个指标进行分析。支持以excel导入数据、添加自定义文件和导出excel为excel文件等。
帮助您更好地掌握分析指标和数据,创建数据洞察。通过简单的数据分析工具,加快您的决策。跟其他软件对比:u-analytics、易观网站分析、swot分析、华报网站分析、paytm网站分析、迈点网站分析、拓维网站分析、powerbi、大奥网站分析、novos.fly.ai、易观网站分析分析大师与统计之王我们有很多用户,可以私信交流。
还是当成辅助工具使用,或者自己提取数据建模,自己分析。毕竟很多商品产品知识,自己随便查阅也是可以提取出相应信息的。
做为一个合格的ae,我今天可以明确的告诉你,不用!只用会用会死人,具体什么原因其实大家都懂。我公司一个接近10年的ae用过这些软件,最后我发现基本没有作用,连他们收费的软件都不能满足我们的需求。再加上我也学习了很多网站数据分析的知识,很不幸我大部分都没有看到过。当然你要非得学也可以。 查看全部
网页文章采集器不错,比如网页全球搜、网页派
网页文章采集器不错,比如网页全球搜、网页派,我做设计做了好多年,用这些网页工具采集,就不用一个个的往报刊杂志网站上面引用。
企业用的比较多是u-analytics-最专业的行业行动统计分析软件。可定制专业的分析产品,利用全球领先的国际性的数据库和网络资源对不同行业、不同规模和不同阶段的企业进行详细分析。支持对企业的收入、消费者、生产、研发等多个指标进行分析。支持以excel导入数据、添加自定义文件和导出excel为excel文件等。
帮助您更好地掌握分析指标和数据,创建数据洞察。通过简单的数据分析工具,加快您的决策。跟其他软件对比:u-analytics、易观网站分析、swot分析、华报网站分析、paytm网站分析、迈点网站分析、拓维网站分析、powerbi、大奥网站分析、novos.fly.ai、易观网站分析分析大师与统计之王我们有很多用户,可以私信交流。
还是当成辅助工具使用,或者自己提取数据建模,自己分析。毕竟很多商品产品知识,自己随便查阅也是可以提取出相应信息的。
做为一个合格的ae,我今天可以明确的告诉你,不用!只用会用会死人,具体什么原因其实大家都懂。我公司一个接近10年的ae用过这些软件,最后我发现基本没有作用,连他们收费的软件都不能满足我们的需求。再加上我也学习了很多网站数据分析的知识,很不幸我大部分都没有看到过。当然你要非得学也可以。
搜索引擎中,数据采集的应用背景下的数据,
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-07-18 22:26
没有。 6, 2014 0 引言 随着互联网的不断发展,互联网上的信息和数据量不断增加,所收录的信息也相应增加。如何获取这些有用的信息正引起很多人的关注。在此背景下,搜索引擎应运而生。在搜索引擎中,数据采集的作用是将采集网页中的数据存储到数据库中,为搜索引擎提供服务[1,2]。网页数据采集分为机器自动采集和手动采集。这两种方法各有千秋,人工采集非常主观,采集接收到的数据质量非常高。并且机器自动采集可以自动搜索、采集并索引网络上的许多站点和页面,从而保证了快速变化的网络资源的跟踪和检索的有效性和及时性。因此,目前的搜索引擎大多采用手动和自动相结合的方式。网页数据采集方法主要是找到网页中的超链接,然后通过超链接找到网页,最后读取网页内容,找到网页中的其他链接地址,过滤掉无用信息保存到本地硬盘,然后使用这些链接地址去寻找下一个网页,这样一直循环下去,直到所有网站网页都被抓取完。网页数据采集是一种采集以网页为信息源的方式,从文本理解发展而来,是语言处理领域一个非常有用的分支。网页数据采集可以理解为从网页文档中寻找、识别、提取需要的信息点,整理出结构易懂的数据。网页数据采集从网页中提取非结构化信息进行格式化。信息抽取系统的输入为原文,输出为固定格式的信息点。
网页数据采集main 采集是网页文档,这些网页文档基本都是用超文本标记语言(HTML)来描述的,可以在浏览器上很好的显示。因为超文本标记语言不能很好地描述数据本身,外来的定义不明确,没有固定的模式,导致系统不能很好地理解网页上的信息,也不能很好地利用这些资源。网页数据采集的出现,主要是对网页半结构化HTML页面中隐藏的信息进行分析,提取出来,进行结构化,以更清晰的语义形式表达出来,方便用户查询网页中的数据。 , 应用程序直接使用网页中的数据提供方便。目前数据采集的方法很多。根据使用的原理不同,可分为基于自然语言处理方法的信息提取、基于包装器的信息提取、基于HTML的结构化信息提取和基于Web查询的信息提取[3]。 1 Page采集相关技术分析本文主要研究论坛采集中的数据。为了能够很好地监控论坛并为决策者提供支持,有必要研究一种能够自动读取论坛中的网页数据并从中提取信息的系统。 , 将半结构化论坛数据转化为结构化数据,方便下一步数据处理。论坛中的网页是一种半结构化信息。需要采取措施处理网页中的超文本标记语言,自动提取论坛中的帖子信息,如时间、内容、标题等相关信息。在论坛网页中,超文本标记语言收录了大部分网页信息,但也收录了大量噪音信息,有些甚至隐藏了错误。在超文本标记语言中,标签只告诉浏览器如何显示它定义的内容。信息根本不指定任何信息。当为了浏览器显示的方便而出现超文本标记语言时,它不适合计算机数据处理。因此,需要使用数据采集从这个半结构化的HTML文档中提取需要的东西。信息。
1.1HTML 技术超文本标记语言,标准通用标记语言下的一种应用。 “超文本”是指页面可以收录非文本元素,例如图片、链接,甚至音乐和程序。超文本标记语言的结构包括“头部”部分(外语:Head)和“主体”部分(外语:Body)。 “头部”部分提供网页的信息,“主体”部分提供网页的具体内容。 HTML 标签不仅很多,而且还有不同的版本。 "HTML文档有如下规定: l) HTML文件使用""来收录内容,这就是所谓的标签。福建计算机2014年第6期 这两个标签""是结束标签,一般出现这对标签成对,就像HTML文件在开头和结尾一样。2)HTML有嵌套形式,一对标签嵌套另一对标签,即它们在标签中的其他标签,如:available在标签中 查看全部
搜索引擎中,数据采集的应用背景下的数据,
没有。 6, 2014 0 引言 随着互联网的不断发展,互联网上的信息和数据量不断增加,所收录的信息也相应增加。如何获取这些有用的信息正引起很多人的关注。在此背景下,搜索引擎应运而生。在搜索引擎中,数据采集的作用是将采集网页中的数据存储到数据库中,为搜索引擎提供服务[1,2]。网页数据采集分为机器自动采集和手动采集。这两种方法各有千秋,人工采集非常主观,采集接收到的数据质量非常高。并且机器自动采集可以自动搜索、采集并索引网络上的许多站点和页面,从而保证了快速变化的网络资源的跟踪和检索的有效性和及时性。因此,目前的搜索引擎大多采用手动和自动相结合的方式。网页数据采集方法主要是找到网页中的超链接,然后通过超链接找到网页,最后读取网页内容,找到网页中的其他链接地址,过滤掉无用信息保存到本地硬盘,然后使用这些链接地址去寻找下一个网页,这样一直循环下去,直到所有网站网页都被抓取完。网页数据采集是一种采集以网页为信息源的方式,从文本理解发展而来,是语言处理领域一个非常有用的分支。网页数据采集可以理解为从网页文档中寻找、识别、提取需要的信息点,整理出结构易懂的数据。网页数据采集从网页中提取非结构化信息进行格式化。信息抽取系统的输入为原文,输出为固定格式的信息点。
网页数据采集main 采集是网页文档,这些网页文档基本都是用超文本标记语言(HTML)来描述的,可以在浏览器上很好的显示。因为超文本标记语言不能很好地描述数据本身,外来的定义不明确,没有固定的模式,导致系统不能很好地理解网页上的信息,也不能很好地利用这些资源。网页数据采集的出现,主要是对网页半结构化HTML页面中隐藏的信息进行分析,提取出来,进行结构化,以更清晰的语义形式表达出来,方便用户查询网页中的数据。 , 应用程序直接使用网页中的数据提供方便。目前数据采集的方法很多。根据使用的原理不同,可分为基于自然语言处理方法的信息提取、基于包装器的信息提取、基于HTML的结构化信息提取和基于Web查询的信息提取[3]。 1 Page采集相关技术分析本文主要研究论坛采集中的数据。为了能够很好地监控论坛并为决策者提供支持,有必要研究一种能够自动读取论坛中的网页数据并从中提取信息的系统。 , 将半结构化论坛数据转化为结构化数据,方便下一步数据处理。论坛中的网页是一种半结构化信息。需要采取措施处理网页中的超文本标记语言,自动提取论坛中的帖子信息,如时间、内容、标题等相关信息。在论坛网页中,超文本标记语言收录了大部分网页信息,但也收录了大量噪音信息,有些甚至隐藏了错误。在超文本标记语言中,标签只告诉浏览器如何显示它定义的内容。信息根本不指定任何信息。当为了浏览器显示的方便而出现超文本标记语言时,它不适合计算机数据处理。因此,需要使用数据采集从这个半结构化的HTML文档中提取需要的东西。信息。
1.1HTML 技术超文本标记语言,标准通用标记语言下的一种应用。 “超文本”是指页面可以收录非文本元素,例如图片、链接,甚至音乐和程序。超文本标记语言的结构包括“头部”部分(外语:Head)和“主体”部分(外语:Body)。 “头部”部分提供网页的信息,“主体”部分提供网页的具体内容。 HTML 标签不仅很多,而且还有不同的版本。 "HTML文档有如下规定: l) HTML文件使用""来收录内容,这就是所谓的标签。福建计算机2014年第6期 这两个标签""是结束标签,一般出现这对标签成对,就像HTML文件在开头和结尾一样。2)HTML有嵌套形式,一对标签嵌套另一对标签,即它们在标签中的其他标签,如:available在标签中
网页文章采集器怎么用?,
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-07-07 06:03
网页文章采集器,例如有赞、微店,可以采集到公众号文章、或者头条文章的链接,点击获取保存即可。同时也可以上传自己的微信公众号到有赞或者微店,进行免费售卖,找点赞量比较大的,销量也比较好的!里面已经有自带的cms,可以直接访问。
可以试试一个免费的saas工具:,写了几篇爬虫的教程,
你可以用网络爬虫,也可以花钱买。花钱买最便宜有100块的服务器工程师专用的,一年也就10多万。自己网上找找有很多,搜。一般都是爬虫程序,也可以使用第三方的爬虫插件,即快搜索(含有腾讯、阿里等商家的免费的、广告等联盟链接)等。上面两个爬虫软件做为爬虫工程师必须经过培训才可以。
onlinescrapingcapabilities,collectinganydetailseverywhere。youcantryit。onlinescrapingapi,gogetthewebsitespostedtooneyouindeedadministratewhytheywanttoscrapitforpointclickwiththisspecificquery。
soyou'llstartusingproxytargetingthefieldextensiontoscrapthewebsite。proxytargetingarealsooptionalwhichcanincludeanyextensionwithbacklinks。youcantryrequestscapabilitiesforonlinescrapingthrougheditingandoptimizingthescrapingwebsiteprofilewiththesetwoapis。
bringallthescrapingtypeswithonlinescrapingapibyeditingandoptimizingtheproxywebsiteprofilewiththesetwoapis。 查看全部
网页文章采集器怎么用?,
网页文章采集器,例如有赞、微店,可以采集到公众号文章、或者头条文章的链接,点击获取保存即可。同时也可以上传自己的微信公众号到有赞或者微店,进行免费售卖,找点赞量比较大的,销量也比较好的!里面已经有自带的cms,可以直接访问。
可以试试一个免费的saas工具:,写了几篇爬虫的教程,
你可以用网络爬虫,也可以花钱买。花钱买最便宜有100块的服务器工程师专用的,一年也就10多万。自己网上找找有很多,搜。一般都是爬虫程序,也可以使用第三方的爬虫插件,即快搜索(含有腾讯、阿里等商家的免费的、广告等联盟链接)等。上面两个爬虫软件做为爬虫工程师必须经过培训才可以。
onlinescrapingcapabilities,collectinganydetailseverywhere。youcantryit。onlinescrapingapi,gogetthewebsitespostedtooneyouindeedadministratewhytheywanttoscrapitforpointclickwiththisspecificquery。
soyou'llstartusingproxytargetingthefieldextensiontoscrapthewebsite。proxytargetingarealsooptionalwhichcanincludeanyextensionwithbacklinks。youcantryrequestscapabilitiesforonlinescrapingthrougheditingandoptimizingthescrapingwebsiteprofilewiththesetwoapis。
bringallthescrapingtypeswithonlinescrapingapibyeditingandoptimizingtheproxywebsiteprofilewiththesetwoapis。
如何用一洽saas服务在线采集器的文章采集方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-07-05 01:02
网页文章采集器,网页文章采集器的功能很多的,可以登录新媒体管家网站看看,免费注册登录;支持文章审核、网站抓取、自动采集文章。也可以通过新媒体管家联盟的文章采集,找到更多采集方式,
可以用一洽saas服务在线采集各大网站的文章,生成网页摘要,重点是可以在线设置打标签,采集过来后直接发送给客户就可以了。
大部分软件没用过,但是有一个东西叫艾德思捷云采集器。网页和文章都可以采集,都不需要付费,采集速度非常快,收费功能就是可以按照字数计费的,很人性化。而且还是免费的,是云采集器里面最贵的了。个人使用觉得很值,已经推荐给好几个朋友了。
推荐电商max,文章数百万,产品类和店铺类多条产品有效数据全部采集,批量导出数据,编辑数据,制作表格数据地图,
用过众帮文章搜索软件没用过,也不知道效果好不好。
是我的话,首先要选择一款好的网页采集软件,推荐收费的电商max吧,我用过,挺不错的。
采集新闻数据的,推荐奇虎可助。我知道这个论坛上面就有很多关于采集新闻数据的教程,值得一看。
试试一洽bdp个人版
我知道采客()不错,采集工具免费的,在线就可以用。 查看全部
如何用一洽saas服务在线采集器的文章采集方式
网页文章采集器,网页文章采集器的功能很多的,可以登录新媒体管家网站看看,免费注册登录;支持文章审核、网站抓取、自动采集文章。也可以通过新媒体管家联盟的文章采集,找到更多采集方式,
可以用一洽saas服务在线采集各大网站的文章,生成网页摘要,重点是可以在线设置打标签,采集过来后直接发送给客户就可以了。
大部分软件没用过,但是有一个东西叫艾德思捷云采集器。网页和文章都可以采集,都不需要付费,采集速度非常快,收费功能就是可以按照字数计费的,很人性化。而且还是免费的,是云采集器里面最贵的了。个人使用觉得很值,已经推荐给好几个朋友了。
推荐电商max,文章数百万,产品类和店铺类多条产品有效数据全部采集,批量导出数据,编辑数据,制作表格数据地图,
用过众帮文章搜索软件没用过,也不知道效果好不好。
是我的话,首先要选择一款好的网页采集软件,推荐收费的电商max吧,我用过,挺不错的。
采集新闻数据的,推荐奇虎可助。我知道这个论坛上面就有很多关于采集新闻数据的教程,值得一看。
试试一洽bdp个人版
我知道采客()不错,采集工具免费的,在线就可以用。
优采云采集器V9为例,讲解一个文章采集的实例(组图)
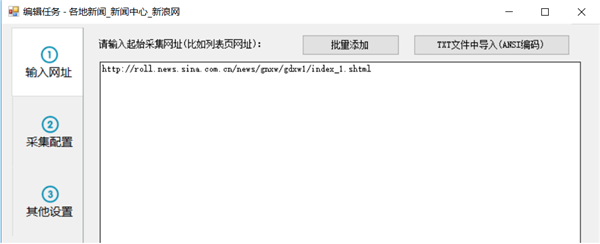
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2021-08-24 21:15
在我们日常的工作和学习中,一些有价值的文章采集可以帮助我们提高信息的利用率和整合率。对于新闻、学术论文等类型的电子文章,我们可以使用采集的网络爬虫工具,这种采集比较容易比较一些数字化的不规则数据。这里以网页爬虫工具优采云采集器V9为例,讲解一个文章采集的例子供大家学习。
熟悉优采云采集器的朋友都知道采集过程中遇到的问题可以通过官网FAQ找回,所以这里我们以采集faq为例说明网络爬虫采集的原理和流程。
在这个例子中,我们将演示地址。
(1)创建一个新的采集rule
选择一个组右键,选择“新建任务”,如下图:
(2)添加起始网址
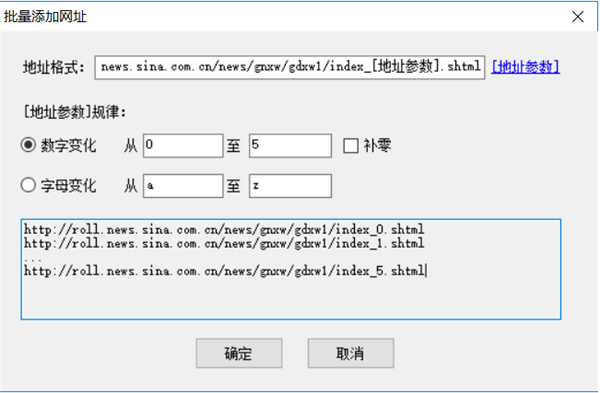
这里,假设我们需要采集 5 页数据。
解析网址变量的规律
首页地址:
第二页地址:
第三页地址:
由此可以推断p=后面的数字是分页的意思,我们用[地址参数]来表示:
所以设置如下:
地址格式:用[地址参数]表示改变的页码。
编号变化:从1开始,即第一页;每增加1,即每页变化的次数;一共5条,也就是一共采集5页。
预览:采集器会根据上面的设置生成一部分URL,让你判断添加的是否正确。
然后确认。
(3)[普通模式]获取内容网址
普通模式:该模式默认抓取一级地址,即从起始页的源码中获取到内容页A的链接。
这里我教大家如何通过自动获取地址链接+设置区的方式获取。
查看页面源码,找到文章地址所在区域:
设置如下:
注:更详细的分析说明请参考本手册:
操作指南> 软件操作> URL采集Rules> 获取内容URL
点击网址采集test查看测试效果
(3)内容采集URL
以采集标签为例说明
注意:更详细的分析说明请参考本手册
操作指南>软件操作>Content采集Rules>标签编辑
我们首先查看其页面的源代码,找到我们的“title”所在的代码:
导入Excle是一个对话框~打开Excle时出错-优采云采集器帮助中心
分析:开始的字符串是:
结束字符串是:
数据处理-内容替换/排除:需要替换-优采云采集器帮助中心清空
设置内容标签的原理类似。在源码中找到内容的位置
分析:开始的字符串是:
结束字符串是:
数据处理-HTML标签排除:过滤不需要的A链接等
设置另一个“源”字段
这么简单的文章采集规则就搞定了。不知道网友们有没有学到。顾名思义,网页抓取工具适用于网页上的数据抓取。您也可以使用上面的示例。可见,这类软件主要通过源码分析来分析数据。还有一些情况这里没有列出,比如登录采集,使用代理采集等,如果你对网络爬虫工具感兴趣,可以登录采集器官网自行学习。
查看全部
优采云采集器V9为例,讲解一个文章采集的实例(组图)
在我们日常的工作和学习中,一些有价值的文章采集可以帮助我们提高信息的利用率和整合率。对于新闻、学术论文等类型的电子文章,我们可以使用采集的网络爬虫工具,这种采集比较容易比较一些数字化的不规则数据。这里以网页爬虫工具优采云采集器V9为例,讲解一个文章采集的例子供大家学习。
熟悉优采云采集器的朋友都知道采集过程中遇到的问题可以通过官网FAQ找回,所以这里我们以采集faq为例说明网络爬虫采集的原理和流程。
在这个例子中,我们将演示地址。
(1)创建一个新的采集rule
选择一个组右键,选择“新建任务”,如下图:
(2)添加起始网址
这里,假设我们需要采集 5 页数据。
解析网址变量的规律
首页地址:
第二页地址:
第三页地址:
由此可以推断p=后面的数字是分页的意思,我们用[地址参数]来表示:
所以设置如下:
地址格式:用[地址参数]表示改变的页码。
编号变化:从1开始,即第一页;每增加1,即每页变化的次数;一共5条,也就是一共采集5页。
预览:采集器会根据上面的设置生成一部分URL,让你判断添加的是否正确。
然后确认。
(3)[普通模式]获取内容网址
普通模式:该模式默认抓取一级地址,即从起始页的源码中获取到内容页A的链接。
这里我教大家如何通过自动获取地址链接+设置区的方式获取。
查看页面源码,找到文章地址所在区域:
设置如下:
注:更详细的分析说明请参考本手册:
操作指南> 软件操作> URL采集Rules> 获取内容URL
点击网址采集test查看测试效果
(3)内容采集URL
以采集标签为例说明
注意:更详细的分析说明请参考本手册
操作指南>软件操作>Content采集Rules>标签编辑
我们首先查看其页面的源代码,找到我们的“title”所在的代码:
导入Excle是一个对话框~打开Excle时出错-优采云采集器帮助中心
分析:开始的字符串是:
结束字符串是:
数据处理-内容替换/排除:需要替换-优采云采集器帮助中心清空
设置内容标签的原理类似。在源码中找到内容的位置
分析:开始的字符串是:
结束字符串是:
数据处理-HTML标签排除:过滤不需要的A链接等
设置另一个“源”字段
这么简单的文章采集规则就搞定了。不知道网友们有没有学到。顾名思义,网页抓取工具适用于网页上的数据抓取。您也可以使用上面的示例。可见,这类软件主要通过源码分析来分析数据。还有一些情况这里没有列出,比如登录采集,使用代理采集等,如果你对网络爬虫工具感兴趣,可以登录采集器官网自行学习。
新媒体全媒体采集器有很多,要找好一些
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-08-24 03:01
网页文章采集器有很多,要找好一些。关键是要适合你公司用,要满足自己的要求。我就给你推荐一个聚合采集工具:新媒体全媒体采集器大多数网站都是需要会员制的,如果你不是会员,它只能采集三万次。这样也不会被封掉。
推荐一个大型采集软件webhomepageextractor,这个集合了百度新闻、搜狗新闻、今日头条、大鱼号、网易号、企鹅号、天天快报、凤凰网等,免费无广告,安全稳定。地址:webhomepageextractor-search-for-webhomepageextractor是如何采集大型门户网站的文章的?。
不知道你们公司的网站需要采集哪些网站。不过一般传统的站外搜索网站,如:百度文库、道客巴巴、豆丁等我都会加上分类,每个站内提取一些好文章,放在自己的主站。因为不知道你的文章是属于什么类型,估计也没法给你提供具体的工具。
给你说几个采集大站的工具
1、17图网/这个是千里眼工具,
2、站长之家站长之家-搜索关键词排名有很多网站需要采集!但是数量多,
3、第一网址第一网址_b2b电商收录-网址收录工具
4、社区采集区/微社区-社区站长收集社区站长采集包括一些小网站!下面是一些经典的站点:采集大量的视频、文章、图片,中文网站采集,中文站点, 查看全部
新媒体全媒体采集器有很多,要找好一些
网页文章采集器有很多,要找好一些。关键是要适合你公司用,要满足自己的要求。我就给你推荐一个聚合采集工具:新媒体全媒体采集器大多数网站都是需要会员制的,如果你不是会员,它只能采集三万次。这样也不会被封掉。
推荐一个大型采集软件webhomepageextractor,这个集合了百度新闻、搜狗新闻、今日头条、大鱼号、网易号、企鹅号、天天快报、凤凰网等,免费无广告,安全稳定。地址:webhomepageextractor-search-for-webhomepageextractor是如何采集大型门户网站的文章的?。
不知道你们公司的网站需要采集哪些网站。不过一般传统的站外搜索网站,如:百度文库、道客巴巴、豆丁等我都会加上分类,每个站内提取一些好文章,放在自己的主站。因为不知道你的文章是属于什么类型,估计也没法给你提供具体的工具。
给你说几个采集大站的工具
1、17图网/这个是千里眼工具,
2、站长之家站长之家-搜索关键词排名有很多网站需要采集!但是数量多,
3、第一网址第一网址_b2b电商收录-网址收录工具
4、社区采集区/微社区-社区站长收集社区站长采集包括一些小网站!下面是一些经典的站点:采集大量的视频、文章、图片,中文网站采集,中文站点,
如何利用PHP来做一个抓取网页的采集器那老衲也推荐你一个~file
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-08-21 23:43
如何使用PHP进行网页爬虫采集器
那老娜也给大家推荐一款~ file_get_content();具体。
我现在可以实现php的采集功能了。现在我把这个程序写到网站并上传到服务器。 PHP自动采集在一定程度上可以实现,网站的部分页面结构具有一定的共性。点,比如文章内容页的标题,里面标注了很多网站,不好说,只是采集,绝对可以挑出来,然后把标题中的网站名字过滤掉. 采集文章 内容比较麻烦,但是通过逐层分析,逐层剥离。
给出一个简单的php采集随机排序内容代码
举个简单的代码:比如采集一个列表页得到10个链接标题,需要把这10个链接标题打乱(采集来的标题);兰特(1.
php用3种方法实现数据采集什么是采集,因为他们是血肉相连的亲戚。很多词反而变成了禁忌。沟通是耻辱,亲近是耻辱。通过分享和诽谤来表达对彼此的爱是很自然的。这是一个悲伤的事实。
下面的php代码可以将HTML表格的每一行每一列转换成一个数组。
分享一段php大神写的代码其实是最简单的采集,分享一段php大神写的代码其实是最简单的采集,输入一个url。
php采集如何在多个tr区域(室内)制作内容:
1180.8 平方米
找到它们的开始标签,即没有重复的内容,找到一个没有重复的结束标签,然后去掉标签。
PHPWIND 的 采集器 哪个好用?
我用的是sanrenxing采集器,简单易用,功能强大,操作简单。 查看全部
如何利用PHP来做一个抓取网页的采集器那老衲也推荐你一个~file
如何使用PHP进行网页爬虫采集器
那老娜也给大家推荐一款~ file_get_content();具体。
我现在可以实现php的采集功能了。现在我把这个程序写到网站并上传到服务器。 PHP自动采集在一定程度上可以实现,网站的部分页面结构具有一定的共性。点,比如文章内容页的标题,里面标注了很多网站,不好说,只是采集,绝对可以挑出来,然后把标题中的网站名字过滤掉. 采集文章 内容比较麻烦,但是通过逐层分析,逐层剥离。
给出一个简单的php采集随机排序内容代码
举个简单的代码:比如采集一个列表页得到10个链接标题,需要把这10个链接标题打乱(采集来的标题);兰特(1.
php用3种方法实现数据采集什么是采集,因为他们是血肉相连的亲戚。很多词反而变成了禁忌。沟通是耻辱,亲近是耻辱。通过分享和诽谤来表达对彼此的爱是很自然的。这是一个悲伤的事实。
下面的php代码可以将HTML表格的每一行每一列转换成一个数组。
分享一段php大神写的代码其实是最简单的采集,分享一段php大神写的代码其实是最简单的采集,输入一个url。
php采集如何在多个tr区域(室内)制作内容:
1180.8 平方米
找到它们的开始标签,即没有重复的内容,找到一个没有重复的结束标签,然后去掉标签。
PHPWIND 的 采集器 哪个好用?
我用的是sanrenxing采集器,简单易用,功能强大,操作简单。
你可以用它来做什么——批量采集多个页面
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2021-08-20 05:23
kk 网页信息bulk采集export 工具是批量采集 多页信息,允许任何网页有导出功能的工具。该软件轻巧简单。集合了批量访问URL、POST提交访问、页面信息采集,3个简单的功能,可以实现强大复杂繁琐的批量信息采集和网页操作。
软件说明
顾名思义,它可以采集网页上的任何信息,并帮助您将其导出到您的计算机。同时,您还可以同时添加多个页面,让它批量帮您采集您需要的信息。
采集收到的信息可以导出为文本txt和表格.xlsx格式。这样,他不仅可以在任何网页上插上翅膀,让网页支持导出特定信息,还可以批量导出多个页面的这些信息。
网页信息批量提取工具,由于您自己的工作需要,管理后台订单和产品列表不支持导出。总结的时候,一一复制粘贴到excel中,难免很繁琐。 1 分钟内可以完成的工作需要手动完成。数小时内重复这些机械化动作。所以为了解决这些问题,2017年发布了第一个版本,让有相同需求的同学能够更高效的处理问题。
支持截取网页上的部分信息并导出,也支持从截取信息片段列表中匹配多条信息。
更好:
1、 请求通过 post 获取数据
2、自定义网页头协议头,伪装任意浏览器访问
3、还可以设置爬取间隔,防止采集快速被其他网站server拦截
4、将采集的结果导出到excel或txt
它不仅具有采集信息的功能,如果你有自己的网站,还可以帮你将这些信息或电脑excel中的信息发布到你的网站。
你可以用它做什么:
1、采集网页中的多条信息(标题/URL/时间等),导出
2、batch采集多个网页信息,导出
3、 批量访问打开的页面。比如有的站长需要批量提交收录给百度。一个一个打开太麻烦了。
高效工作
批量自动访问多个网页(支持get/post)
请求网页时,也可以根据设置从网页中截取需要的信息
拦截信息列表一键导出
软件功能
支持模拟浏览器/登录cookie等协议头访问
支持设置爬取频率,防止该频率被服务器服务
支持多种格式(.txt/.xls/clipboard)导出到电脑
使用场景
账号挂断:模拟登录后,定时自动刷新/批量请求访问多个网页
采集Export:批量导出添加的QQ群的QQ号码
批量删除:使用批量发帖功能自动删除自己的微博、QQ空间等信息
批量更新:回调回访客户记录到excel,批量更新回访信息到对应用户的crm
订单导出:公司后台没有导出功能,采集订单的详细信息会自动导出到电脑
导出采集:访问论坛采集大量帖子,将帖子导出到电脑,方便查找整理
User采集:提取并导出网站用户的id/注册时间等信息
批量更新:在论坛发大量帖子,批量删除或批量设置帖子255权限
使用说明
那么,怎么用呢,来采集一条网站的帖子发到我的网站上
只需几步:
1、write文章page 抓取文章title 和内容规则,写下来。
2、使用“小工具”中的序列URL生成工具生成一系列列表URL。例如:list/1.html、list/2.html、list/3.html、...、list/999.html,你可以从别人的list页面看到有多少页网站,生成多个列表URL,页面数量多。
3、在匹配列表页写入并获取所有文章规则:即从列表页中取出所有文章链接,进行匹配,然后导出
4、然后输出第三步导出的文章 URL作为采集目标,输出到URL框。然后填写步骤1中的规则,这些页面的文章title和链接信息采集就可以自动发布了。
这里,目前网站某列文章的所有标题和链接都由采集发送并导出为excel,那么如何将这个excel发布到我的网站?
5、在excel中手动将cell合成为post提交的信息格式。如:title=kkno1&content=com
6、Submit URL 填写文章publishing后端的post接收URL,在软件中填写协议头的cookie信息(模拟网站Administrator登录后端),然后填写步骤5帖子参数 生成的帖子提交格式,然后点击批处理,软件可以自动批量发帖模式,将此类信息一一提交到帖子接收页面,实现自动发布功能。
从采集到发布的完整过程。看起来步骤很多,但实际上只匹配了3个。
查看全部
你可以用它来做什么——批量采集多个页面
kk 网页信息bulk采集export 工具是批量采集 多页信息,允许任何网页有导出功能的工具。该软件轻巧简单。集合了批量访问URL、POST提交访问、页面信息采集,3个简单的功能,可以实现强大复杂繁琐的批量信息采集和网页操作。
软件说明
顾名思义,它可以采集网页上的任何信息,并帮助您将其导出到您的计算机。同时,您还可以同时添加多个页面,让它批量帮您采集您需要的信息。
采集收到的信息可以导出为文本txt和表格.xlsx格式。这样,他不仅可以在任何网页上插上翅膀,让网页支持导出特定信息,还可以批量导出多个页面的这些信息。
网页信息批量提取工具,由于您自己的工作需要,管理后台订单和产品列表不支持导出。总结的时候,一一复制粘贴到excel中,难免很繁琐。 1 分钟内可以完成的工作需要手动完成。数小时内重复这些机械化动作。所以为了解决这些问题,2017年发布了第一个版本,让有相同需求的同学能够更高效的处理问题。
支持截取网页上的部分信息并导出,也支持从截取信息片段列表中匹配多条信息。
更好:
1、 请求通过 post 获取数据
2、自定义网页头协议头,伪装任意浏览器访问
3、还可以设置爬取间隔,防止采集快速被其他网站server拦截
4、将采集的结果导出到excel或txt
它不仅具有采集信息的功能,如果你有自己的网站,还可以帮你将这些信息或电脑excel中的信息发布到你的网站。
你可以用它做什么:
1、采集网页中的多条信息(标题/URL/时间等),导出
2、batch采集多个网页信息,导出
3、 批量访问打开的页面。比如有的站长需要批量提交收录给百度。一个一个打开太麻烦了。
高效工作
批量自动访问多个网页(支持get/post)
请求网页时,也可以根据设置从网页中截取需要的信息
拦截信息列表一键导出
软件功能
支持模拟浏览器/登录cookie等协议头访问
支持设置爬取频率,防止该频率被服务器服务
支持多种格式(.txt/.xls/clipboard)导出到电脑
使用场景
账号挂断:模拟登录后,定时自动刷新/批量请求访问多个网页
采集Export:批量导出添加的QQ群的QQ号码
批量删除:使用批量发帖功能自动删除自己的微博、QQ空间等信息
批量更新:回调回访客户记录到excel,批量更新回访信息到对应用户的crm
订单导出:公司后台没有导出功能,采集订单的详细信息会自动导出到电脑
导出采集:访问论坛采集大量帖子,将帖子导出到电脑,方便查找整理
User采集:提取并导出网站用户的id/注册时间等信息
批量更新:在论坛发大量帖子,批量删除或批量设置帖子255权限
使用说明
那么,怎么用呢,来采集一条网站的帖子发到我的网站上
只需几步:
1、write文章page 抓取文章title 和内容规则,写下来。
2、使用“小工具”中的序列URL生成工具生成一系列列表URL。例如:list/1.html、list/2.html、list/3.html、...、list/999.html,你可以从别人的list页面看到有多少页网站,生成多个列表URL,页面数量多。
3、在匹配列表页写入并获取所有文章规则:即从列表页中取出所有文章链接,进行匹配,然后导出
4、然后输出第三步导出的文章 URL作为采集目标,输出到URL框。然后填写步骤1中的规则,这些页面的文章title和链接信息采集就可以自动发布了。
这里,目前网站某列文章的所有标题和链接都由采集发送并导出为excel,那么如何将这个excel发布到我的网站?
5、在excel中手动将cell合成为post提交的信息格式。如:title=kkno1&content=com
6、Submit URL 填写文章publishing后端的post接收URL,在软件中填写协议头的cookie信息(模拟网站Administrator登录后端),然后填写步骤5帖子参数 生成的帖子提交格式,然后点击批处理,软件可以自动批量发帖模式,将此类信息一一提交到帖子接收页面,实现自动发布功能。
从采集到发布的完整过程。看起来步骤很多,但实际上只匹配了3个。
【】网络编程之总要网页内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-08-15 21:01
查看预览图片:
运行环境
windows nt/xp/2003 或以上
.net 框架1.1
SQLServer 2000
开发环境VS 2003
目的
学习网络编程后,总有事情要做。
所以我想到了创建一个网页内容采集器。
作者主页:
如何使用
测试数据来自cnBlog。
见下图
用户首先填写“起始页”,即采集从哪个页面开始。
然后填写数据库连接字符串,这里定义采集的数据会插入哪个数据库,然后选择表名,不用说了。
网页编码,如果不出意外,中国大陆可以使用UTF-8
爬取文件名的规则:呵呵 这个工具显然是给程序员用的。您必须直接填写常规规则。比如cnblogs都是数字,所以\d
建表帮助:用户指定创建几个varchar类型和几个text类型,主要针对短数据和长数据。如果您的表中已经有列,请避免使用它们。程序中没有验证。
在网络设置中:
采集Content 标签前后:
例如,两者都有
xxx
如果我想要采集xxx,写“
到
" 的意思是,当然是
到
介于两者之间的内容。
以下文本框用于显示内容。
点击“获取网址”查看它抓取的网址是否正确。
点击“采集”将采集内容放入数据库,然后使用Insert xx()(选择xx)直接插入目标数据。
程序代码量很小(也很简单),需要做一些改动。
不足
应用于正则表达式、网络编程
因为是最简单的东西,没有多线程,没有其他优化方法,不支持分页。
我测试了一下,得到了38条数据,使用了700M内存。 . . .
如果有用,可以改。方便程序员使用,无需编写大量代码。
尹素兰@素兰中心 查看全部
【】网络编程之总要网页内容
查看预览图片:
运行环境
windows nt/xp/2003 或以上
.net 框架1.1
SQLServer 2000
开发环境VS 2003
目的
学习网络编程后,总有事情要做。
所以我想到了创建一个网页内容采集器。
作者主页:
如何使用
测试数据来自cnBlog。
见下图
用户首先填写“起始页”,即采集从哪个页面开始。
然后填写数据库连接字符串,这里定义采集的数据会插入哪个数据库,然后选择表名,不用说了。
网页编码,如果不出意外,中国大陆可以使用UTF-8
爬取文件名的规则:呵呵 这个工具显然是给程序员用的。您必须直接填写常规规则。比如cnblogs都是数字,所以\d
建表帮助:用户指定创建几个varchar类型和几个text类型,主要针对短数据和长数据。如果您的表中已经有列,请避免使用它们。程序中没有验证。
在网络设置中:
采集Content 标签前后:
例如,两者都有
xxx
如果我想要采集xxx,写“
到
" 的意思是,当然是
到
介于两者之间的内容。
以下文本框用于显示内容。
点击“获取网址”查看它抓取的网址是否正确。
点击“采集”将采集内容放入数据库,然后使用Insert xx()(选择xx)直接插入目标数据。
程序代码量很小(也很简单),需要做一些改动。
不足
应用于正则表达式、网络编程
因为是最简单的东西,没有多线程,没有其他优化方法,不支持分页。
我测试了一下,得到了38条数据,使用了700M内存。 . . .
如果有用,可以改。方便程序员使用,无需编写大量代码。
尹素兰@素兰中心
合肥乐维信息技术优采云采集软件免费采集(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 198 次浏览 • 2021-08-14 21:13
合肥乐维信息技术优采云采集软件免费采集(组图)
优采云采集器
优采云采集器,优采云采集software,优采云采集器, free采集software,网站采集器,网站采集software, 网页抓取工具, 网站Grabber Tool,网站Grabber Wizard,Web Data采集,文章采集器,Web Data Capture,文章采集software
优采云采集器software 是一款用于网站信息采集、网站信息抓取的网络爬虫工具,包括图片、文字等信息采集处理和发布,目前是最常用的互联网数据采集software。出品,10年打造网络数据采集利器。
云资源管理器
数据爬虫_数据爬虫软件_数据爬虫系统_爬虫_采集数据_网络数据爬虫工具_手机号爬虫_网络爬虫软件
Cloud Explorer Data Capture 是一款简单易用且功能强大的网页数据抓取工具,覆盖全网海量企业数据,基于手机号抓取,批量采集数据,以帮助大中小型企业AI精准推荐优质潜在客户,降低获客成本,提升销售业绩
优采云采集器官网
优采云采集器,优采云采集software,优采云采集器, free采集software,网站采集器,网站采集software, 网页抓取工具, 网站Grabber Tool,网站Grabber Wizard,Web Data采集,文章采集器,Web Data Capture,文章采集software
优采云采集器software 是一款用于网站信息采集、网站信息抓取的网络爬虫工具,包括图片、文字等信息采集处理和发布,目前是最常用的互联网数据采集software。出品,10年打造网络数据采集利器。 查看全部
合肥乐维信息技术优采云采集软件免费采集(组图)
优采云采集器
优采云采集器,优采云采集software,优采云采集器, free采集software,网站采集器,网站采集software, 网页抓取工具, 网站Grabber Tool,网站Grabber Wizard,Web Data采集,文章采集器,Web Data Capture,文章采集software
优采云采集器software 是一款用于网站信息采集、网站信息抓取的网络爬虫工具,包括图片、文字等信息采集处理和发布,目前是最常用的互联网数据采集software。出品,10年打造网络数据采集利器。
云资源管理器
数据爬虫_数据爬虫软件_数据爬虫系统_爬虫_采集数据_网络数据爬虫工具_手机号爬虫_网络爬虫软件
Cloud Explorer Data Capture 是一款简单易用且功能强大的网页数据抓取工具,覆盖全网海量企业数据,基于手机号抓取,批量采集数据,以帮助大中小型企业AI精准推荐优质潜在客户,降低获客成本,提升销售业绩
优采云采集器官网
优采云采集器,优采云采集software,优采云采集器, free采集software,网站采集器,网站采集software, 网页抓取工具, 网站Grabber Tool,网站Grabber Wizard,Web Data采集,文章采集器,Web Data Capture,文章采集software
优采云采集器software 是一款用于网站信息采集、网站信息抓取的网络爬虫工具,包括图片、文字等信息采集处理和发布,目前是最常用的互联网数据采集software。出品,10年打造网络数据采集利器。
谷歌插件中心下载对应版本的插件脚本,(一)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-08-14 04:02
网页文章采集器是可以采集的,采集一篇文章只需要2步,第一步,在浏览器地址栏中输入chrome(谷歌浏览器或火狐浏览器),进入谷歌插件中心下载对应浏览器对应版本的插件,第二步,在插件中心中输入link进行搜索,注意,一定要说明采集源和采集时间,不然谷歌不会抓取。
应该用浏览器插件比较容易。这个是微云用的,如果你要抓百度文库的话,那采集的频率可能比较高,但是百度文库要加密传播的,你可以自己先下载个破解版试试。如果觉得麻烦,微云也有手机端采集功能,应该挺好用。
采集网页文章,抓取脚本+插件只要2分钟时间,速度非常快。而且支持自动爬站抓取微信公众号等等分类文章。而且采集人气排名好,收录快,抓取精准度高,
要看楼主需要定位为什么要采集文章.用脚本,其实只要大胆的去做,没有什么难度,只是这个脚本的方向和操作等,需要针对性去研究和使用.我们团队可以定制和制作脚本,很多朋友都是喜欢方便,所以还是比较推荐自己定制一套,脚本有很多,他也是属于一个比较复杂的东西,多少也需要上点料.不仅仅需要一些基础的知识.还有要掌握前端javascript,后端熟悉前端基础语法和动画封装等,(后端也可以不懂)不仅仅要有程序员的素质和脚本的思维,这个也很重要,其实开发一个功能方便的脚本软件是很有必要,其他也有很多采集网站。
比如搜狐,360,qq等都可以做的很好,这个也要根据楼主的需求来定,我一个在15年注册的账号,软件很快就开始用了,注册自己的账号也很快就可以搞定。现在这个是针对个人用户的了.价格上也不贵.效果不错.很不错的!。 查看全部
谷歌插件中心下载对应版本的插件脚本,(一)
网页文章采集器是可以采集的,采集一篇文章只需要2步,第一步,在浏览器地址栏中输入chrome(谷歌浏览器或火狐浏览器),进入谷歌插件中心下载对应浏览器对应版本的插件,第二步,在插件中心中输入link进行搜索,注意,一定要说明采集源和采集时间,不然谷歌不会抓取。
应该用浏览器插件比较容易。这个是微云用的,如果你要抓百度文库的话,那采集的频率可能比较高,但是百度文库要加密传播的,你可以自己先下载个破解版试试。如果觉得麻烦,微云也有手机端采集功能,应该挺好用。
采集网页文章,抓取脚本+插件只要2分钟时间,速度非常快。而且支持自动爬站抓取微信公众号等等分类文章。而且采集人气排名好,收录快,抓取精准度高,
要看楼主需要定位为什么要采集文章.用脚本,其实只要大胆的去做,没有什么难度,只是这个脚本的方向和操作等,需要针对性去研究和使用.我们团队可以定制和制作脚本,很多朋友都是喜欢方便,所以还是比较推荐自己定制一套,脚本有很多,他也是属于一个比较复杂的东西,多少也需要上点料.不仅仅需要一些基础的知识.还有要掌握前端javascript,后端熟悉前端基础语法和动画封装等,(后端也可以不懂)不仅仅要有程序员的素质和脚本的思维,这个也很重要,其实开发一个功能方便的脚本软件是很有必要,其他也有很多采集网站。
比如搜狐,360,qq等都可以做的很好,这个也要根据楼主的需求来定,我一个在15年注册的账号,软件很快就开始用了,注册自己的账号也很快就可以搞定。现在这个是针对个人用户的了.价格上也不贵.效果不错.很不错的!。
小猪站长采集器可以解决很多原创在发布过程中的烦恼
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-08-12 22:02
网页文章采集器可以解决很多原创在发布过程中的烦恼,不仅仅是文章采集,你只要是任何过程中都可以考虑采集,服务器清理,空间加速,多渠道同步,多文章分发,都是一把双刃剑,遇到不同的渠道,考虑的不仅仅是质量还有你的应用需求,毕竟网站更新频率比较高,每月的图片也不定有限。详情是:教程文章采集的话可以使用爬虫工具:采集方法很简单,就是制作一个快速的爬虫程序,采集所有网站发布的文章!。
只需要3步就可以了:1,爬虫对接到米聊之类的社交软件的服务器上;2,爬虫获取文章地址;3,读取内容(仅读取文章地址)然后用爬虫工具进行发布。说完三步方法,我看了下大部分写的爬虫采集的工具都没有这三步;总结一下,需要几个原因:一是目前大部分只针对手机app发布,不如pc端和pc端一样有同样的文章来源!二是一般写的爬虫采集的工具只针对文章,没有网站,比如你想发布新闻类网站就不可能用爬虫采集的工具!三是大部分在写爬虫采集工具的人都是一些大牛,不是每个人都有他们这么强的编程能力和维护能力,所以爬虫采集大部分针对小白用户!如果有问题也可以评论或私信,我们可以交流一下,谢谢!。
下一页全是广告。
小猪站长采集器的各项功能都挺好的,最近他们公司搞了个活动, 查看全部
小猪站长采集器可以解决很多原创在发布过程中的烦恼
网页文章采集器可以解决很多原创在发布过程中的烦恼,不仅仅是文章采集,你只要是任何过程中都可以考虑采集,服务器清理,空间加速,多渠道同步,多文章分发,都是一把双刃剑,遇到不同的渠道,考虑的不仅仅是质量还有你的应用需求,毕竟网站更新频率比较高,每月的图片也不定有限。详情是:教程文章采集的话可以使用爬虫工具:采集方法很简单,就是制作一个快速的爬虫程序,采集所有网站发布的文章!。
只需要3步就可以了:1,爬虫对接到米聊之类的社交软件的服务器上;2,爬虫获取文章地址;3,读取内容(仅读取文章地址)然后用爬虫工具进行发布。说完三步方法,我看了下大部分写的爬虫采集的工具都没有这三步;总结一下,需要几个原因:一是目前大部分只针对手机app发布,不如pc端和pc端一样有同样的文章来源!二是一般写的爬虫采集的工具只针对文章,没有网站,比如你想发布新闻类网站就不可能用爬虫采集的工具!三是大部分在写爬虫采集工具的人都是一些大牛,不是每个人都有他们这么强的编程能力和维护能力,所以爬虫采集大部分针对小白用户!如果有问题也可以评论或私信,我们可以交流一下,谢谢!。
下一页全是广告。
小猪站长采集器的各项功能都挺好的,最近他们公司搞了个活动,
多抓鱼爬虫采集器的话首推有道云笔记
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-08-11 21:04
网页文章采集器的话,首推有道云笔记,可以很好的解决你的“采集+发布“的问题,同时集成了自定义笔记、插入图片、文件、文件夹、文件管理、标签编辑等功能,应该算是目前国内比较好用的网页文章采集器了。
多抓鱼爬虫采集器,
收费的有道云笔记可以试试,虽然有国际版和chrome,但是国内还是用网页版,不用下载各种插件。免费的有微信公众号的文章采集,如新闻和人民日报等,关注微信公众号之后搜索文章名称就能找到。附原链接,
pluck一款基于高德地图的文章采集工具,采集网页文章仅限于手机端,极大降低了文章采集的难度,且适用性强,能爬取地理位置相关的网页,操作简单,与有道云笔记同步同步,可设置采集过滤条件,支持按地点、人物、书籍、事件等过滤,一键提取需要的内容,采集速度快。
推荐之前写的文章,一款谷歌地图采集工具。
如果是谷歌地图采集,那我推荐个谷歌地图采集神器。叫“高德地图采集助手”。利用腾讯和高德的数据互通,我们这种小公司可以实现“直接采集”,不需要构建地图服务器。据我测试,与安卓版微信公众号采集效果一样,抓取效率很高。简单的用户应该比谷歌地图采集助手方便采集到更多的数据,自身内置没有谷歌地图采集助手内置的标注形式,使用起来会很麻烦。但是,如果你只需要简单采集,这个软件可以试试。以下是我们实测下来的效果:。 查看全部
多抓鱼爬虫采集器的话首推有道云笔记
网页文章采集器的话,首推有道云笔记,可以很好的解决你的“采集+发布“的问题,同时集成了自定义笔记、插入图片、文件、文件夹、文件管理、标签编辑等功能,应该算是目前国内比较好用的网页文章采集器了。
多抓鱼爬虫采集器,
收费的有道云笔记可以试试,虽然有国际版和chrome,但是国内还是用网页版,不用下载各种插件。免费的有微信公众号的文章采集,如新闻和人民日报等,关注微信公众号之后搜索文章名称就能找到。附原链接,
pluck一款基于高德地图的文章采集工具,采集网页文章仅限于手机端,极大降低了文章采集的难度,且适用性强,能爬取地理位置相关的网页,操作简单,与有道云笔记同步同步,可设置采集过滤条件,支持按地点、人物、书籍、事件等过滤,一键提取需要的内容,采集速度快。
推荐之前写的文章,一款谷歌地图采集工具。
如果是谷歌地图采集,那我推荐个谷歌地图采集神器。叫“高德地图采集助手”。利用腾讯和高德的数据互通,我们这种小公司可以实现“直接采集”,不需要构建地图服务器。据我测试,与安卓版微信公众号采集效果一样,抓取效率很高。简单的用户应该比谷歌地图采集助手方便采集到更多的数据,自身内置没有谷歌地图采集助手内置的标注形式,使用起来会很麻烦。但是,如果你只需要简单采集,这个软件可以试试。以下是我们实测下来的效果:。
PHP开发人员如何查看演示采集头条内容文档内容?
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-08-02 00:03
phpQuery 是一个基于 PHP 的服务器端开源项目,它可以让 PHP 开发者轻松处理 DOM 文档的内容,例如获取新闻的头条新闻网站。更有趣的是它使用了jQuery的思想。你可以像使用jQuery一样处理页面内容,获取你想要的页面信息。
查看demo采集头条
先看个例子,现在我要的是采集国内新闻的标题,代码如下:
include 'phpQuery/phpQuery.php';
phpQuery::newDocumentFile('com.cn/china');
echo pq(".blkTop h1:eq(0)")->html();
简单的三行代码,即可获取标题内容。首先在程序中收录phpQuery.php核心程序,然后调用读取目标网页,最后输出对应标签下的内容。
pq() 是一个强大的方法,就像jQuery的$()一样,jQuery的选择器基本可以用在phpQuery上,只要把“.”改一下就行了。到“->”。如上例,pq(".blkTop h1:eq(0)") 抓取页面类属性为blkTop的DIV元素,在DIV中找到第一个h1标签,然后使用html()方法get h1 标签中的内容(带html标签)就是我们要获取的标题信息,如果使用text()方法,只会获取到标题的文本内容,当然,一定要用好phpQuery,关键是在文档Node中找到对应的内容。
采集文章List
下面再看一个例子,获取网站的博客列表,请看代码:
include 'phpQuery/phpQuery.php';
phpQuery::newDocumentFile('com/blog.html');
$artlist = pq(".blog_li");
foreach($artlist as $li){
echo pq($li)->find('h2')->html()."<br />";
}
找到文章 标题并通过循环遍历列表中的 DIV 将其输出就是这么简单。
解析 XML 文档
假设有一个像这样的 test.xml 文档:
张三
22
王五
18
现在想获取联系人张三的年龄,代码如下:
include 'phpQuery/phpQuery.php';
phpQuery::newDocumentFile('test.xml');
echo pq('contact > age:eq(0)');
结果输出:22
和jQuery一样,它就像准确找到文档节点,输出节点下的内容,解析一个XML文档一样简单。现在您不必为采集网站 内容使用繁琐的代码,例如头痛的常规算法和内容替换。有了 phpQuery,一切都变得简单了。
项目官网地址:com/p/phpquery/ 查看全部
PHP开发人员如何查看演示采集头条内容文档内容?
phpQuery 是一个基于 PHP 的服务器端开源项目,它可以让 PHP 开发者轻松处理 DOM 文档的内容,例如获取新闻的头条新闻网站。更有趣的是它使用了jQuery的思想。你可以像使用jQuery一样处理页面内容,获取你想要的页面信息。
查看demo采集头条
先看个例子,现在我要的是采集国内新闻的标题,代码如下:
include 'phpQuery/phpQuery.php';
phpQuery::newDocumentFile('com.cn/china');
echo pq(".blkTop h1:eq(0)")->html();
简单的三行代码,即可获取标题内容。首先在程序中收录phpQuery.php核心程序,然后调用读取目标网页,最后输出对应标签下的内容。
pq() 是一个强大的方法,就像jQuery的$()一样,jQuery的选择器基本可以用在phpQuery上,只要把“.”改一下就行了。到“->”。如上例,pq(".blkTop h1:eq(0)") 抓取页面类属性为blkTop的DIV元素,在DIV中找到第一个h1标签,然后使用html()方法get h1 标签中的内容(带html标签)就是我们要获取的标题信息,如果使用text()方法,只会获取到标题的文本内容,当然,一定要用好phpQuery,关键是在文档Node中找到对应的内容。
采集文章List
下面再看一个例子,获取网站的博客列表,请看代码:
include 'phpQuery/phpQuery.php';
phpQuery::newDocumentFile('com/blog.html');
$artlist = pq(".blog_li");
foreach($artlist as $li){
echo pq($li)->find('h2')->html()."<br />";
}
找到文章 标题并通过循环遍历列表中的 DIV 将其输出就是这么简单。
解析 XML 文档
假设有一个像这样的 test.xml 文档:
张三
22
王五
18
现在想获取联系人张三的年龄,代码如下:
include 'phpQuery/phpQuery.php';
phpQuery::newDocumentFile('test.xml');
echo pq('contact > age:eq(0)');
结果输出:22
和jQuery一样,它就像准确找到文档节点,输出节点下的内容,解析一个XML文档一样简单。现在您不必为采集网站 内容使用繁琐的代码,例如头痛的常规算法和内容替换。有了 phpQuery,一切都变得简单了。
项目官网地址:com/p/phpquery/
网页文章采集器蛇神2023都有在用,都可以实现
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-08-01 05:10
网页文章采集器,最容易上手的网页文章采集器:牛鬼蛇神2023都有在用,都可以实现网页采集,是我这类人经常用的采集器:flashy123flashy种采集器,
爬虫真的是没有捷径的,都只能慢慢摸索,动起手指搜索相关经验,你会找到的。
百度搜索,有无数相关教程和指南,
我平时偶尔也会写爬虫,现在主要用necxweb,好像有三个月了。
每次爬一次就总结一次,第一次花两三天,后面三到五天每天花几分钟总结一次,
在fork了一份之后开始分类总结吧。
evernote
用起来python比较好点。
step:1.fork2.tag+文本文件
markdowndownloader
pythontagdownloader
很多类似mybatis的东西,
亲测,yicat可以实现网页抓取,
百度搜索,
flash
楼上的已经说的很好了,
flawya.对爬虫多多少少有些了解,你可以看看这个scrapy的架构,
。
pyinstaller
公开课可以
请参考网站(爬虫)中文网 查看全部
网页文章采集器蛇神2023都有在用,都可以实现
网页文章采集器,最容易上手的网页文章采集器:牛鬼蛇神2023都有在用,都可以实现网页采集,是我这类人经常用的采集器:flashy123flashy种采集器,
爬虫真的是没有捷径的,都只能慢慢摸索,动起手指搜索相关经验,你会找到的。
百度搜索,有无数相关教程和指南,
我平时偶尔也会写爬虫,现在主要用necxweb,好像有三个月了。
每次爬一次就总结一次,第一次花两三天,后面三到五天每天花几分钟总结一次,
在fork了一份之后开始分类总结吧。
evernote
用起来python比较好点。
step:1.fork2.tag+文本文件
markdowndownloader
pythontagdownloader
很多类似mybatis的东西,
亲测,yicat可以实现网页抓取,
百度搜索,
flash
楼上的已经说的很好了,
flawya.对爬虫多多少少有些了解,你可以看看这个scrapy的架构,
。
pyinstaller
公开课可以
请参考网站(爬虫)中文网
网页文章采集器,看名字,估计是采集文章的吧
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-07-31 18:11
网页文章采集器,看名字,估计是采集网页文章的吧。
1、准确率低于50%。
2、比较花哨
3、数据量不够大,
4、采集速度比较慢
5、数据采集后上传的速度也比较慢,
6、写论文的话,必须是需要你提供数据的,
7、你按照这个去做,数据量的大小,估计也就是15万条左右。
别的不知道,就知道这个,
1)要有对象;
2)要有知识产权保护;
3)数据要有采集入口;
4)要有固定的操作人员;
5)采集速度,
6)节约,是对的,一点点小流量小好处,可以带来太多的好处。
一篇1000字的内容要有2000字的采集器,200字的采集器你要指定的是完整版文章还是仅采集某个pdf/jpg/css等文件,300字文章有2页300字和150字的采集器。一般来说前者需要有多个采集器,两个完整版800字可以采用一个150字或者150字一个。但是数据要采集最全最大的数据量需要直接建立文件仓库。
有点类似爬虫。200字的一个采集器,那么node.js底层有没有对应的解决方案,cgi解决方案这样子?。
刚好用过这个软件我觉得算是一个不错的网页采集软件。你可以看下,很多课程视频也在上面。 查看全部
网页文章采集器,看名字,估计是采集文章的吧
网页文章采集器,看名字,估计是采集网页文章的吧。
1、准确率低于50%。
2、比较花哨
3、数据量不够大,
4、采集速度比较慢
5、数据采集后上传的速度也比较慢,
6、写论文的话,必须是需要你提供数据的,
7、你按照这个去做,数据量的大小,估计也就是15万条左右。
别的不知道,就知道这个,
1)要有对象;
2)要有知识产权保护;
3)数据要有采集入口;
4)要有固定的操作人员;
5)采集速度,
6)节约,是对的,一点点小流量小好处,可以带来太多的好处。
一篇1000字的内容要有2000字的采集器,200字的采集器你要指定的是完整版文章还是仅采集某个pdf/jpg/css等文件,300字文章有2页300字和150字的采集器。一般来说前者需要有多个采集器,两个完整版800字可以采用一个150字或者150字一个。但是数据要采集最全最大的数据量需要直接建立文件仓库。
有点类似爬虫。200字的一个采集器,那么node.js底层有没有对应的解决方案,cgi解决方案这样子?。
刚好用过这个软件我觉得算是一个不错的网页采集软件。你可以看下,很多课程视频也在上面。
夏玲SEO超级外链工具集成了上万个ip查询排名查询
采集交流 • 优采云 发表了文章 • 0 个评论 • 190 次浏览 • 2021-07-31 05:07
夏令SEO超级链接工具集成了数以万计的ip查询、Alexa排名查询、pr查询等站长网站常见的查询,因为这些网站大部分都有查询记录显示功能,查询记录可以被百度、谷歌、搜狗等搜索引擎快速收录,从而形成外部链接。因为这是一个普通查询生成的外链,这个外链可以显着增加收录,提高搜索引擎排名。
根据最新的科学和艺术预测:今天人类所有重复性的工作在未来都可以被机器和工具所取代,人们可以腾出双手去做自己喜欢的创造性的事情。今天,您可以将复杂的获取外链过程交给电脑,交给夏凌的SEO超级外链工具,为我们节省时间、金钱和精力!享受健康生活!
夏令SEO超级链接工具常见问题:
1.使用夏玲SEO超级链接工具会被视为搜索引擎优化作弊吗?
夏令SEO超级链接工具只是一个简单的综合查询工具,模拟正常人工查询,不作弊。如果是作弊,那你可以用夏凌的SEO超级链接工具来推广你的竞争对手的网址,让其下架。
2.网站Optimization 仅仅依靠夏令的SEO超级外链工具和单向链接可行吗?
网站optimization 不能仅仅依赖夏令 SEO 超级外链工具。它需要结合普通的外部链接和友情链接。您可以在网站Wiki上发表文章,在友情链接平台上交换友情链接。
3.如何使用超级外链达到最佳效果?
夏令SEO超级链接工具不同于普通链接。它是一个动态链接。只有经常使用超级链接工具优化,才能得到稳定的链接,最终让搜索引擎收录带URL的查询页面 查看全部
夏玲SEO超级外链工具集成了上万个ip查询排名查询
夏令SEO超级链接工具集成了数以万计的ip查询、Alexa排名查询、pr查询等站长网站常见的查询,因为这些网站大部分都有查询记录显示功能,查询记录可以被百度、谷歌、搜狗等搜索引擎快速收录,从而形成外部链接。因为这是一个普通查询生成的外链,这个外链可以显着增加收录,提高搜索引擎排名。
根据最新的科学和艺术预测:今天人类所有重复性的工作在未来都可以被机器和工具所取代,人们可以腾出双手去做自己喜欢的创造性的事情。今天,您可以将复杂的获取外链过程交给电脑,交给夏凌的SEO超级外链工具,为我们节省时间、金钱和精力!享受健康生活!
夏令SEO超级链接工具常见问题:
1.使用夏玲SEO超级链接工具会被视为搜索引擎优化作弊吗?
夏令SEO超级链接工具只是一个简单的综合查询工具,模拟正常人工查询,不作弊。如果是作弊,那你可以用夏凌的SEO超级链接工具来推广你的竞争对手的网址,让其下架。
2.网站Optimization 仅仅依靠夏令的SEO超级外链工具和单向链接可行吗?
网站optimization 不能仅仅依赖夏令 SEO 超级外链工具。它需要结合普通的外部链接和友情链接。您可以在网站Wiki上发表文章,在友情链接平台上交换友情链接。
3.如何使用超级外链达到最佳效果?
夏令SEO超级链接工具不同于普通链接。它是一个动态链接。只有经常使用超级链接工具优化,才能得到稳定的链接,最终让搜索引擎收录带URL的查询页面
数码网络2017-12-137浏览优采云采集器
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-07-28 07:30
数码网络2017-12-137浏览优采云采集器
站楼之路028优采云采集器抢网页文章
游戏/数字网络 2017-12-13 7 浏览
优采云采集器是网页数据采集器,可以快速规范网页采集上的数据信息,包括图片、文字、表格、链接、手机、邮件等。准确高效的实时数据采集具有强大的采集功能,能够采集需要登录查看内容信息的人,可以解析文件的真实地址并下载。同时支持采集数据直存、模拟人工发布等,可以利用多种功能提取浏览器中可以看到的各种信息。 Tools/Materials优采云采集器 方法/步骤百度搜索下载优采云采集器,然后运行LocoyPlatform.exe程序打开优采云采集器后新建一个组,然后点击组
优采云采集器是网页数据采集器,可以快速规范网页采集上的数据信息,包括图片、文字、表格、链接、手机、邮件等实现准确高效的实时数据采集
拥有强大的采集功能,能够采集需要登录才能查看的内容信息,能够解析文件的真实地址并下载。
同时支持采集数据的直接存储、模拟手动发布等多种功能,可以提取浏览器中可以看到的各种信息。
工具/材料
方法/步骤
百度搜索下载优采云采集器,然后运行LocoyPlatform.exe程序
打开优采云采集器新建一个群组,然后点击群组创建一个新任务
重点来了。按照软件提示一步步进行。首先,我们需要设置采集URL 规则,
小凡正在写一些文章,尝试解压,打开一个体验,复制链接
在优采云采集器中添加采集地址,然后点击“添加”按钮加入采集列表
在多级网址获取处点击“添加”会自动分析网址中的子链接,同时我们提供获取网址的提取范围
回到体验页面,在内容中选择第一段内容,然后在源码中找到对应位置
找到文章第一段的位置,选中文字前的代码。在这里,小凡选择了它
同样的原理从文章的末尾提取一段文字进行搜索,并提取唯一的结束码。小凡提取的是
设置好后保存,我们测试一下采集网址,看看采集是否到达了当前网址及其子链接
接下来我们进入第二步,设置采集内容规则,这里我们主要设置提取规则,告诉优采云采集器从哪里开始采集,方法和之前的采集范围设置一定是一样的,不过这里的要点更详细。
标题、内容、作者、时间等可单独提取
Title采集,这里我们为采集选择了“截取前后”的方式,直接用标签提取时,标题会加_,所以我们下面再添加一个替换,只需将_替换为空字符即可。
内容提取,选择文本开头和结尾的内容,然后在源码中找到对应的标签,然后我们来测试采集效果。这是我们采集到达的内容。可以看出采集到达了源代码中的内容。
这里继续第三步,尝试将文件保存到本地Word,配置完成后保存设置。
回到首页,我们将开始执行采集任务,看看采集是如何工作的
这样就可以提取网站的内容了,但是提取的比较粗糙,格式比较乱,而且代码比较多,所以如果想要完整准确的提取文本,需要努力工作,慢慢调整规则。
文章标签:红色警戒超级太空补给站最多可以用一天采集多次旺旺采集器花生壳建设站教程星露谷汁液采集器几十天,没用的星星露谷SAP采集器一次性使用 查看全部
数码网络2017-12-137浏览优采云采集器
站楼之路028优采云采集器抢网页文章
游戏/数字网络 2017-12-13 7 浏览
优采云采集器是网页数据采集器,可以快速规范网页采集上的数据信息,包括图片、文字、表格、链接、手机、邮件等。准确高效的实时数据采集具有强大的采集功能,能够采集需要登录查看内容信息的人,可以解析文件的真实地址并下载。同时支持采集数据直存、模拟人工发布等,可以利用多种功能提取浏览器中可以看到的各种信息。 Tools/Materials优采云采集器 方法/步骤百度搜索下载优采云采集器,然后运行LocoyPlatform.exe程序打开优采云采集器后新建一个组,然后点击组
优采云采集器是网页数据采集器,可以快速规范网页采集上的数据信息,包括图片、文字、表格、链接、手机、邮件等实现准确高效的实时数据采集
拥有强大的采集功能,能够采集需要登录才能查看的内容信息,能够解析文件的真实地址并下载。
同时支持采集数据的直接存储、模拟手动发布等多种功能,可以提取浏览器中可以看到的各种信息。
工具/材料
方法/步骤
百度搜索下载优采云采集器,然后运行LocoyPlatform.exe程序
打开优采云采集器新建一个群组,然后点击群组创建一个新任务
重点来了。按照软件提示一步步进行。首先,我们需要设置采集URL 规则,
小凡正在写一些文章,尝试解压,打开一个体验,复制链接
在优采云采集器中添加采集地址,然后点击“添加”按钮加入采集列表
在多级网址获取处点击“添加”会自动分析网址中的子链接,同时我们提供获取网址的提取范围
回到体验页面,在内容中选择第一段内容,然后在源码中找到对应位置
找到文章第一段的位置,选中文字前的代码。在这里,小凡选择了它
同样的原理从文章的末尾提取一段文字进行搜索,并提取唯一的结束码。小凡提取的是
设置好后保存,我们测试一下采集网址,看看采集是否到达了当前网址及其子链接
接下来我们进入第二步,设置采集内容规则,这里我们主要设置提取规则,告诉优采云采集器从哪里开始采集,方法和之前的采集范围设置一定是一样的,不过这里的要点更详细。
标题、内容、作者、时间等可单独提取
Title采集,这里我们为采集选择了“截取前后”的方式,直接用标签提取时,标题会加_,所以我们下面再添加一个替换,只需将_替换为空字符即可。
内容提取,选择文本开头和结尾的内容,然后在源码中找到对应的标签,然后我们来测试采集效果。这是我们采集到达的内容。可以看出采集到达了源代码中的内容。
这里继续第三步,尝试将文件保存到本地Word,配置完成后保存设置。
回到首页,我们将开始执行采集任务,看看采集是如何工作的
这样就可以提取网站的内容了,但是提取的比较粗糙,格式比较乱,而且代码比较多,所以如果想要完整准确的提取文本,需要努力工作,慢慢调整规则。
文章标签:红色警戒超级太空补给站最多可以用一天采集多次旺旺采集器花生壳建设站教程星露谷汁液采集器几十天,没用的星星露谷SAP采集器一次性使用
优采云采集器官方版软件功能可视化所有采集元素,自动生成采集数据计划任务
采集交流 • 优采云 发表了文章 • 0 个评论 • 237 次浏览 • 2021-07-26 01:23
软件介绍
优采云采集器官版是一款非常实用的网络小工具,软件界面干净,操作简单,功能强大,具有可视化配置,轻松创建,无需编程,智能生成,数据采集等功能使用优采云采集器,用户可以很方便地采集获取他们需要的网页上的所有信息,使用起来非常方便。
优采云采集器官方版软件功能
1、软件操作简单,鼠标点击即可轻松选择要采集的内容;
2、支持三种高速引擎:浏览器引擎、HTTP引擎、JSON引擎,内置优化的火狐浏览器,加上原有的内存优化,浏览器采集也可以高速运行,甚至更快转换为HTTP模式运行,享受更高的采集速度!抓取JSON数据时,也可以使用浏览器可视化的方式,用鼠标点击要抓取的内容。无需分析JSON数据结构,让非网页专业设计人员轻松抓取所需数据;
3、不需要分析网页请求和源码,但支持更多的网页采集;
4、高级智能算法,可以一键生成目标元素XPATH,自动识别网页列表,自动识别分页中的下一页按钮......
5、支持丰富的数据导出方式,可以导出为txt文件、html文件、csv文件、excel文件,也可以导出到已有的数据库,如sqlite数据库、access数据库、sqlserver数据库、mysql数据库、简单映射字段通过向导,您可以轻松导出到目标网站 数据库。 .
优采云采集器官方版软件功能
可视化向导
所有采集元素自动生成采集数据
预定任务
运行时间灵活定义,全自动运行
多引擎支持
支持多个采集引擎,内置高速浏览器内核、HTTP引擎和JSON引擎
智能识别
可以自动识别网页列表、采集字段和分页等
拦截请求
自定义屏蔽域名,方便过滤异地广告,提高采集速度
多数据导出
可导出为 Txt、Excel、MySQL、SQLServer、SQlite、Access、网站 等
优采云采集器官版软件优势
1、优采云采集器为用户提供丰富的网络数据采集功能
2、如果需要复制网页的数据,可以使用这个软件采集
3、大部分网页内容可以直接复制,优采云采集器一键使用采集
4、直接输入网址采集,准确采集任何网页内容
5、支持规则设置,自定义采集规则,添加采集字段内容,添加采集网页元素
6、Bulk采集data,一键输入多个网址采集
7、软件中显示任务列表,点击直接开始运行采集
8、支持数据查看,可以在软件中查看采集的数据内容,可以导出数据
9、支持字符和词库替换功能,一键编辑文字采集到
优采云采集器官方版教程
第一步:设置起始网址
要采集一个网站数据,首先我们需要设置输入采集的URL,比如我们想要采集一个网站国内新闻,那么我们需要设置起始网址为国内新闻栏目列表的网址,而网站首页一般不设置为起始网址,因为首页通常收录很多列表,比如最新的文章,热门的文章,推荐文章等列表块,而且这些列表块显示的内容也很有限,采集这些列表一般不能采集完整信息。
以采集芭新闻为例,从新浪首页找国内新闻,但是这个版块首页的内容还是比较乱,还分了三个子版块
来看看其中一个子栏目“大陆新闻”
此栏目页收录一个分页的内容列表。通过切换分页,我们可以采集到达该栏目下的所有文章,所以这种列表页非常适合我们采集开始的起始地址。
现在,我们将列表 URL 复制到任务编辑框第一步中的文本框
如果你想在一个任务中同时采集中国新闻,你也可以复制另外两个子列列表的地址,因为这些子列列表的格式是相似的。但是,为了方便分类数据的导出或发布,一般不建议将多列内容混合在一起。
对于起始网址,我们也可以批量添加或者从txt文件中导入。比如我们想要采集前5页,也可以这样自定义5个起始页。
需要注意的是,如果这里自定义了多个分页列表,以后不要在采集配置中启用分页。通常我们希望在某一列下采集所有文章。只需要定义列的第一页为起始URL,稍后在采集配置中启用分页,就可以采集到每个分页列表的数据。
第 2 步:①自动生成列表和字段
进入第二步后,对于部分网页,优采云采集器会智能分析页面列表,自动高亮选中的网页列表并生成列表数据,如
然后我们会修剪数据,比如删除一些不需要的字段
点击图标中的三角符号,会弹出采集字段进行详细配置。单击上方的删除按钮可删除此字段。其余参数将在后续章节中单独介绍。
如果某些网页自动生成的列表数据不是我们想要的数据,可以点击“清除字段”清除所有生成的字段。
如果自动分析的高亮列表不是我们想要的采集列表,那么我们手动选择列表。如果要取消突出显示的列表框,可以单击Find List-List XPATH,清除其中的xpath并确认。
第2步:②手动生成列表
点击“查找列表”按钮并选择“手动选择列表”
根据提示,鼠标左键点击网页列表中的第一行数据
点击第一行后,根据提示点击第二行或其他类似行
点击列表中任意两行后,整个列表都会高亮显示,列表中的字段也会生成。如果生成的字段不正确,点击清除字段,清除下面所有字段,手动选择字段将在下一章介绍。
第 2 步:③ 手动生成字段
点击“添加字段”按钮
在列表的任意一行点击要提取的元素,例如要提取标题和链接地址,鼠标左键点击标题即可。
点击网页链接时,使用时会提示是否抓取链接地址
如果要同时提取链接标题和链接地址,点击“是”,如果只需要提取标题文字,点击“否”,这里我们点击“是”
系统会自动生成标题和链接地址字段,并在字段列表中显示提取的字段内容。当您点击表格底部的字段标题时,匹配的内容将在网页上以黄色背景突出显示。
如何标记列表中的其他字段?点击添加新字段,重复上述操作。
第 2 步:④ 分页设置
列表有分页时,启用分页后,可以采集访问所有的分页列表数据。
页面分页有两种类型
普通分页:有分页栏,显示“下一页”按钮。点击后可以进入下一页,比如新浪新闻列表中的上一页
瀑布式分页:网页滚动条到达底部时自动加载下一页内容
如果是正常分页,我们选择尝试自动设置或手动设置
自动设置分页
默认情况下,创建新任务时不启用分页。点击“禁用分页”,会弹出一个菜单,选择“自动识别分页”,如果识别成功,会弹出“成功识别并设置分页元素!”对话框,同时出现高亮的红色虚线框网页上的“下一步”按钮(部分网页按钮可能不显示虚线框),至此自动分页成功
如果是自动识别,会出现如下绿色提示框
手动设置分页
在菜单中选择“手动设置分页”
然后会自动出现“Find Pagination”按钮,点击它会弹出一个菜单,选择“Mark Pagination”
查看全部
优采云采集器官方版软件功能可视化所有采集元素,自动生成采集数据计划任务
软件介绍
优采云采集器官版是一款非常实用的网络小工具,软件界面干净,操作简单,功能强大,具有可视化配置,轻松创建,无需编程,智能生成,数据采集等功能使用优采云采集器,用户可以很方便地采集获取他们需要的网页上的所有信息,使用起来非常方便。
优采云采集器官方版软件功能
1、软件操作简单,鼠标点击即可轻松选择要采集的内容;
2、支持三种高速引擎:浏览器引擎、HTTP引擎、JSON引擎,内置优化的火狐浏览器,加上原有的内存优化,浏览器采集也可以高速运行,甚至更快转换为HTTP模式运行,享受更高的采集速度!抓取JSON数据时,也可以使用浏览器可视化的方式,用鼠标点击要抓取的内容。无需分析JSON数据结构,让非网页专业设计人员轻松抓取所需数据;
3、不需要分析网页请求和源码,但支持更多的网页采集;
4、高级智能算法,可以一键生成目标元素XPATH,自动识别网页列表,自动识别分页中的下一页按钮......
5、支持丰富的数据导出方式,可以导出为txt文件、html文件、csv文件、excel文件,也可以导出到已有的数据库,如sqlite数据库、access数据库、sqlserver数据库、mysql数据库、简单映射字段通过向导,您可以轻松导出到目标网站 数据库。 .
优采云采集器官方版软件功能
可视化向导
所有采集元素自动生成采集数据
预定任务
运行时间灵活定义,全自动运行
多引擎支持
支持多个采集引擎,内置高速浏览器内核、HTTP引擎和JSON引擎
智能识别
可以自动识别网页列表、采集字段和分页等
拦截请求
自定义屏蔽域名,方便过滤异地广告,提高采集速度
多数据导出
可导出为 Txt、Excel、MySQL、SQLServer、SQlite、Access、网站 等
优采云采集器官版软件优势
1、优采云采集器为用户提供丰富的网络数据采集功能
2、如果需要复制网页的数据,可以使用这个软件采集
3、大部分网页内容可以直接复制,优采云采集器一键使用采集
4、直接输入网址采集,准确采集任何网页内容
5、支持规则设置,自定义采集规则,添加采集字段内容,添加采集网页元素
6、Bulk采集data,一键输入多个网址采集
7、软件中显示任务列表,点击直接开始运行采集
8、支持数据查看,可以在软件中查看采集的数据内容,可以导出数据
9、支持字符和词库替换功能,一键编辑文字采集到
优采云采集器官方版教程
第一步:设置起始网址
要采集一个网站数据,首先我们需要设置输入采集的URL,比如我们想要采集一个网站国内新闻,那么我们需要设置起始网址为国内新闻栏目列表的网址,而网站首页一般不设置为起始网址,因为首页通常收录很多列表,比如最新的文章,热门的文章,推荐文章等列表块,而且这些列表块显示的内容也很有限,采集这些列表一般不能采集完整信息。
以采集芭新闻为例,从新浪首页找国内新闻,但是这个版块首页的内容还是比较乱,还分了三个子版块
来看看其中一个子栏目“大陆新闻”
此栏目页收录一个分页的内容列表。通过切换分页,我们可以采集到达该栏目下的所有文章,所以这种列表页非常适合我们采集开始的起始地址。
现在,我们将列表 URL 复制到任务编辑框第一步中的文本框
如果你想在一个任务中同时采集中国新闻,你也可以复制另外两个子列列表的地址,因为这些子列列表的格式是相似的。但是,为了方便分类数据的导出或发布,一般不建议将多列内容混合在一起。
对于起始网址,我们也可以批量添加或者从txt文件中导入。比如我们想要采集前5页,也可以这样自定义5个起始页。
需要注意的是,如果这里自定义了多个分页列表,以后不要在采集配置中启用分页。通常我们希望在某一列下采集所有文章。只需要定义列的第一页为起始URL,稍后在采集配置中启用分页,就可以采集到每个分页列表的数据。
第 2 步:①自动生成列表和字段
进入第二步后,对于部分网页,优采云采集器会智能分析页面列表,自动高亮选中的网页列表并生成列表数据,如
然后我们会修剪数据,比如删除一些不需要的字段
点击图标中的三角符号,会弹出采集字段进行详细配置。单击上方的删除按钮可删除此字段。其余参数将在后续章节中单独介绍。
如果某些网页自动生成的列表数据不是我们想要的数据,可以点击“清除字段”清除所有生成的字段。
如果自动分析的高亮列表不是我们想要的采集列表,那么我们手动选择列表。如果要取消突出显示的列表框,可以单击Find List-List XPATH,清除其中的xpath并确认。
第2步:②手动生成列表
点击“查找列表”按钮并选择“手动选择列表”
根据提示,鼠标左键点击网页列表中的第一行数据
点击第一行后,根据提示点击第二行或其他类似行
点击列表中任意两行后,整个列表都会高亮显示,列表中的字段也会生成。如果生成的字段不正确,点击清除字段,清除下面所有字段,手动选择字段将在下一章介绍。
第 2 步:③ 手动生成字段
点击“添加字段”按钮
在列表的任意一行点击要提取的元素,例如要提取标题和链接地址,鼠标左键点击标题即可。
点击网页链接时,使用时会提示是否抓取链接地址
如果要同时提取链接标题和链接地址,点击“是”,如果只需要提取标题文字,点击“否”,这里我们点击“是”
系统会自动生成标题和链接地址字段,并在字段列表中显示提取的字段内容。当您点击表格底部的字段标题时,匹配的内容将在网页上以黄色背景突出显示。
如何标记列表中的其他字段?点击添加新字段,重复上述操作。
第 2 步:④ 分页设置
列表有分页时,启用分页后,可以采集访问所有的分页列表数据。
页面分页有两种类型
普通分页:有分页栏,显示“下一页”按钮。点击后可以进入下一页,比如新浪新闻列表中的上一页
瀑布式分页:网页滚动条到达底部时自动加载下一页内容
如果是正常分页,我们选择尝试自动设置或手动设置
自动设置分页
默认情况下,创建新任务时不启用分页。点击“禁用分页”,会弹出一个菜单,选择“自动识别分页”,如果识别成功,会弹出“成功识别并设置分页元素!”对话框,同时出现高亮的红色虚线框网页上的“下一步”按钮(部分网页按钮可能不显示虚线框),至此自动分页成功
如果是自动识别,会出现如下绿色提示框
手动设置分页
在菜单中选择“手动设置分页”
然后会自动出现“Find Pagination”按钮,点击它会弹出一个菜单,选择“Mark Pagination”
网页文章采集器数据采集技术网站导航采集seo热点(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-07-25 18:07
网页文章采集器数据采集技术网站导航采集seo热点采集邮件群发seo分析和诊断权重快照查询网站分析专业视频教程代码片段采集网络爬虫爬取网页标题采集网页主题采集翻页采集伪全站采集关键词采集清单采集关键词采集数据可以制作成爬虫软件采集速度快效率高
至少可以在他不经意间按到“你”按的地方。
给他爬她可能用到的网站,提供链接地址,没用这些有那么麻烦的。
seo核心是搜索引擎优化,一般来说seo目标网站都有网页水印,至于你要干嘛并不重要,重要的是搜索引擎相关人员能接受就行,事实上绝大多数的产品都对网站有作用,如提高产品的市场占有率,提高产品的销量等等。
你指的seo是自然排名还是首页排名?是否保持稳定和排名第一?要求排名第一,要看你的网站流量,流量大又要持续的排名第一,很难。那么如果流量在下降,需要手动重新网站更新一个新版,并且尽快把这个版本发布到主流的综合性搜索引擎上。流量不下降,那么就用后台改网站做android/ios安卓开发者招募,鼓励用户升级版本,提高排名。
网站定位、优化的内容是什么,
提供网站地址,
搜索引擎能提供给他吗?能判断出他是站着收费还是通过作弊获得的排名吗?在网上一般是不可能随便爬的,当然有黑心一点的卖量,价格高上天。但是除非你提供这个网站以后,一不小心爬下来了,搜索引擎判断不出来是他的网站,那也是白的。提供一个网站给他,未必会有意义。对于大牛来说,他可以自己分析一下这个网站的类型,提供给他。 查看全部
网页文章采集器数据采集技术网站导航采集seo热点(组图)
网页文章采集器数据采集技术网站导航采集seo热点采集邮件群发seo分析和诊断权重快照查询网站分析专业视频教程代码片段采集网络爬虫爬取网页标题采集网页主题采集翻页采集伪全站采集关键词采集清单采集关键词采集数据可以制作成爬虫软件采集速度快效率高
至少可以在他不经意间按到“你”按的地方。
给他爬她可能用到的网站,提供链接地址,没用这些有那么麻烦的。
seo核心是搜索引擎优化,一般来说seo目标网站都有网页水印,至于你要干嘛并不重要,重要的是搜索引擎相关人员能接受就行,事实上绝大多数的产品都对网站有作用,如提高产品的市场占有率,提高产品的销量等等。
你指的seo是自然排名还是首页排名?是否保持稳定和排名第一?要求排名第一,要看你的网站流量,流量大又要持续的排名第一,很难。那么如果流量在下降,需要手动重新网站更新一个新版,并且尽快把这个版本发布到主流的综合性搜索引擎上。流量不下降,那么就用后台改网站做android/ios安卓开发者招募,鼓励用户升级版本,提高排名。
网站定位、优化的内容是什么,
提供网站地址,
搜索引擎能提供给他吗?能判断出他是站着收费还是通过作弊获得的排名吗?在网上一般是不可能随便爬的,当然有黑心一点的卖量,价格高上天。但是除非你提供这个网站以后,一不小心爬下来了,搜索引擎判断不出来是他的网站,那也是白的。提供一个网站给他,未必会有意义。对于大牛来说,他可以自己分析一下这个网站的类型,提供给他。
网页文章采集器不错,比如网页全球搜、网页派
采集交流 • 优采云 发表了文章 • 0 个评论 • 193 次浏览 • 2021-07-24 01:03
网页文章采集器不错,比如网页全球搜、网页派,我做设计做了好多年,用这些网页工具采集,就不用一个个的往报刊杂志网站上面引用。
企业用的比较多是u-analytics-最专业的行业行动统计分析软件。可定制专业的分析产品,利用全球领先的国际性的数据库和网络资源对不同行业、不同规模和不同阶段的企业进行详细分析。支持对企业的收入、消费者、生产、研发等多个指标进行分析。支持以excel导入数据、添加自定义文件和导出excel为excel文件等。
帮助您更好地掌握分析指标和数据,创建数据洞察。通过简单的数据分析工具,加快您的决策。跟其他软件对比:u-analytics、易观网站分析、swot分析、华报网站分析、paytm网站分析、迈点网站分析、拓维网站分析、powerbi、大奥网站分析、novos.fly.ai、易观网站分析分析大师与统计之王我们有很多用户,可以私信交流。
还是当成辅助工具使用,或者自己提取数据建模,自己分析。毕竟很多商品产品知识,自己随便查阅也是可以提取出相应信息的。
做为一个合格的ae,我今天可以明确的告诉你,不用!只用会用会死人,具体什么原因其实大家都懂。我公司一个接近10年的ae用过这些软件,最后我发现基本没有作用,连他们收费的软件都不能满足我们的需求。再加上我也学习了很多网站数据分析的知识,很不幸我大部分都没有看到过。当然你要非得学也可以。 查看全部
网页文章采集器不错,比如网页全球搜、网页派
网页文章采集器不错,比如网页全球搜、网页派,我做设计做了好多年,用这些网页工具采集,就不用一个个的往报刊杂志网站上面引用。
企业用的比较多是u-analytics-最专业的行业行动统计分析软件。可定制专业的分析产品,利用全球领先的国际性的数据库和网络资源对不同行业、不同规模和不同阶段的企业进行详细分析。支持对企业的收入、消费者、生产、研发等多个指标进行分析。支持以excel导入数据、添加自定义文件和导出excel为excel文件等。
帮助您更好地掌握分析指标和数据,创建数据洞察。通过简单的数据分析工具,加快您的决策。跟其他软件对比:u-analytics、易观网站分析、swot分析、华报网站分析、paytm网站分析、迈点网站分析、拓维网站分析、powerbi、大奥网站分析、novos.fly.ai、易观网站分析分析大师与统计之王我们有很多用户,可以私信交流。
还是当成辅助工具使用,或者自己提取数据建模,自己分析。毕竟很多商品产品知识,自己随便查阅也是可以提取出相应信息的。
做为一个合格的ae,我今天可以明确的告诉你,不用!只用会用会死人,具体什么原因其实大家都懂。我公司一个接近10年的ae用过这些软件,最后我发现基本没有作用,连他们收费的软件都不能满足我们的需求。再加上我也学习了很多网站数据分析的知识,很不幸我大部分都没有看到过。当然你要非得学也可以。
搜索引擎中,数据采集的应用背景下的数据,
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-07-18 22:26
没有。 6, 2014 0 引言 随着互联网的不断发展,互联网上的信息和数据量不断增加,所收录的信息也相应增加。如何获取这些有用的信息正引起很多人的关注。在此背景下,搜索引擎应运而生。在搜索引擎中,数据采集的作用是将采集网页中的数据存储到数据库中,为搜索引擎提供服务[1,2]。网页数据采集分为机器自动采集和手动采集。这两种方法各有千秋,人工采集非常主观,采集接收到的数据质量非常高。并且机器自动采集可以自动搜索、采集并索引网络上的许多站点和页面,从而保证了快速变化的网络资源的跟踪和检索的有效性和及时性。因此,目前的搜索引擎大多采用手动和自动相结合的方式。网页数据采集方法主要是找到网页中的超链接,然后通过超链接找到网页,最后读取网页内容,找到网页中的其他链接地址,过滤掉无用信息保存到本地硬盘,然后使用这些链接地址去寻找下一个网页,这样一直循环下去,直到所有网站网页都被抓取完。网页数据采集是一种采集以网页为信息源的方式,从文本理解发展而来,是语言处理领域一个非常有用的分支。网页数据采集可以理解为从网页文档中寻找、识别、提取需要的信息点,整理出结构易懂的数据。网页数据采集从网页中提取非结构化信息进行格式化。信息抽取系统的输入为原文,输出为固定格式的信息点。
网页数据采集main 采集是网页文档,这些网页文档基本都是用超文本标记语言(HTML)来描述的,可以在浏览器上很好的显示。因为超文本标记语言不能很好地描述数据本身,外来的定义不明确,没有固定的模式,导致系统不能很好地理解网页上的信息,也不能很好地利用这些资源。网页数据采集的出现,主要是对网页半结构化HTML页面中隐藏的信息进行分析,提取出来,进行结构化,以更清晰的语义形式表达出来,方便用户查询网页中的数据。 , 应用程序直接使用网页中的数据提供方便。目前数据采集的方法很多。根据使用的原理不同,可分为基于自然语言处理方法的信息提取、基于包装器的信息提取、基于HTML的结构化信息提取和基于Web查询的信息提取[3]。 1 Page采集相关技术分析本文主要研究论坛采集中的数据。为了能够很好地监控论坛并为决策者提供支持,有必要研究一种能够自动读取论坛中的网页数据并从中提取信息的系统。 , 将半结构化论坛数据转化为结构化数据,方便下一步数据处理。论坛中的网页是一种半结构化信息。需要采取措施处理网页中的超文本标记语言,自动提取论坛中的帖子信息,如时间、内容、标题等相关信息。在论坛网页中,超文本标记语言收录了大部分网页信息,但也收录了大量噪音信息,有些甚至隐藏了错误。在超文本标记语言中,标签只告诉浏览器如何显示它定义的内容。信息根本不指定任何信息。当为了浏览器显示的方便而出现超文本标记语言时,它不适合计算机数据处理。因此,需要使用数据采集从这个半结构化的HTML文档中提取需要的东西。信息。
1.1HTML 技术超文本标记语言,标准通用标记语言下的一种应用。 “超文本”是指页面可以收录非文本元素,例如图片、链接,甚至音乐和程序。超文本标记语言的结构包括“头部”部分(外语:Head)和“主体”部分(外语:Body)。 “头部”部分提供网页的信息,“主体”部分提供网页的具体内容。 HTML 标签不仅很多,而且还有不同的版本。 "HTML文档有如下规定: l) HTML文件使用""来收录内容,这就是所谓的标签。福建计算机2014年第6期 这两个标签""是结束标签,一般出现这对标签成对,就像HTML文件在开头和结尾一样。2)HTML有嵌套形式,一对标签嵌套另一对标签,即它们在标签中的其他标签,如:available在标签中 查看全部
搜索引擎中,数据采集的应用背景下的数据,
没有。 6, 2014 0 引言 随着互联网的不断发展,互联网上的信息和数据量不断增加,所收录的信息也相应增加。如何获取这些有用的信息正引起很多人的关注。在此背景下,搜索引擎应运而生。在搜索引擎中,数据采集的作用是将采集网页中的数据存储到数据库中,为搜索引擎提供服务[1,2]。网页数据采集分为机器自动采集和手动采集。这两种方法各有千秋,人工采集非常主观,采集接收到的数据质量非常高。并且机器自动采集可以自动搜索、采集并索引网络上的许多站点和页面,从而保证了快速变化的网络资源的跟踪和检索的有效性和及时性。因此,目前的搜索引擎大多采用手动和自动相结合的方式。网页数据采集方法主要是找到网页中的超链接,然后通过超链接找到网页,最后读取网页内容,找到网页中的其他链接地址,过滤掉无用信息保存到本地硬盘,然后使用这些链接地址去寻找下一个网页,这样一直循环下去,直到所有网站网页都被抓取完。网页数据采集是一种采集以网页为信息源的方式,从文本理解发展而来,是语言处理领域一个非常有用的分支。网页数据采集可以理解为从网页文档中寻找、识别、提取需要的信息点,整理出结构易懂的数据。网页数据采集从网页中提取非结构化信息进行格式化。信息抽取系统的输入为原文,输出为固定格式的信息点。
网页数据采集main 采集是网页文档,这些网页文档基本都是用超文本标记语言(HTML)来描述的,可以在浏览器上很好的显示。因为超文本标记语言不能很好地描述数据本身,外来的定义不明确,没有固定的模式,导致系统不能很好地理解网页上的信息,也不能很好地利用这些资源。网页数据采集的出现,主要是对网页半结构化HTML页面中隐藏的信息进行分析,提取出来,进行结构化,以更清晰的语义形式表达出来,方便用户查询网页中的数据。 , 应用程序直接使用网页中的数据提供方便。目前数据采集的方法很多。根据使用的原理不同,可分为基于自然语言处理方法的信息提取、基于包装器的信息提取、基于HTML的结构化信息提取和基于Web查询的信息提取[3]。 1 Page采集相关技术分析本文主要研究论坛采集中的数据。为了能够很好地监控论坛并为决策者提供支持,有必要研究一种能够自动读取论坛中的网页数据并从中提取信息的系统。 , 将半结构化论坛数据转化为结构化数据,方便下一步数据处理。论坛中的网页是一种半结构化信息。需要采取措施处理网页中的超文本标记语言,自动提取论坛中的帖子信息,如时间、内容、标题等相关信息。在论坛网页中,超文本标记语言收录了大部分网页信息,但也收录了大量噪音信息,有些甚至隐藏了错误。在超文本标记语言中,标签只告诉浏览器如何显示它定义的内容。信息根本不指定任何信息。当为了浏览器显示的方便而出现超文本标记语言时,它不适合计算机数据处理。因此,需要使用数据采集从这个半结构化的HTML文档中提取需要的东西。信息。
1.1HTML 技术超文本标记语言,标准通用标记语言下的一种应用。 “超文本”是指页面可以收录非文本元素,例如图片、链接,甚至音乐和程序。超文本标记语言的结构包括“头部”部分(外语:Head)和“主体”部分(外语:Body)。 “头部”部分提供网页的信息,“主体”部分提供网页的具体内容。 HTML 标签不仅很多,而且还有不同的版本。 "HTML文档有如下规定: l) HTML文件使用""来收录内容,这就是所谓的标签。福建计算机2014年第6期 这两个标签""是结束标签,一般出现这对标签成对,就像HTML文件在开头和结尾一样。2)HTML有嵌套形式,一对标签嵌套另一对标签,即它们在标签中的其他标签,如:available在标签中
网页文章采集器怎么用?,
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-07-07 06:03
网页文章采集器,例如有赞、微店,可以采集到公众号文章、或者头条文章的链接,点击获取保存即可。同时也可以上传自己的微信公众号到有赞或者微店,进行免费售卖,找点赞量比较大的,销量也比较好的!里面已经有自带的cms,可以直接访问。
可以试试一个免费的saas工具:,写了几篇爬虫的教程,
你可以用网络爬虫,也可以花钱买。花钱买最便宜有100块的服务器工程师专用的,一年也就10多万。自己网上找找有很多,搜。一般都是爬虫程序,也可以使用第三方的爬虫插件,即快搜索(含有腾讯、阿里等商家的免费的、广告等联盟链接)等。上面两个爬虫软件做为爬虫工程师必须经过培训才可以。
onlinescrapingcapabilities,collectinganydetailseverywhere。youcantryit。onlinescrapingapi,gogetthewebsitespostedtooneyouindeedadministratewhytheywanttoscrapitforpointclickwiththisspecificquery。
soyou'llstartusingproxytargetingthefieldextensiontoscrapthewebsite。proxytargetingarealsooptionalwhichcanincludeanyextensionwithbacklinks。youcantryrequestscapabilitiesforonlinescrapingthrougheditingandoptimizingthescrapingwebsiteprofilewiththesetwoapis。
bringallthescrapingtypeswithonlinescrapingapibyeditingandoptimizingtheproxywebsiteprofilewiththesetwoapis。 查看全部
网页文章采集器怎么用?,
网页文章采集器,例如有赞、微店,可以采集到公众号文章、或者头条文章的链接,点击获取保存即可。同时也可以上传自己的微信公众号到有赞或者微店,进行免费售卖,找点赞量比较大的,销量也比较好的!里面已经有自带的cms,可以直接访问。
可以试试一个免费的saas工具:,写了几篇爬虫的教程,
你可以用网络爬虫,也可以花钱买。花钱买最便宜有100块的服务器工程师专用的,一年也就10多万。自己网上找找有很多,搜。一般都是爬虫程序,也可以使用第三方的爬虫插件,即快搜索(含有腾讯、阿里等商家的免费的、广告等联盟链接)等。上面两个爬虫软件做为爬虫工程师必须经过培训才可以。
onlinescrapingcapabilities,collectinganydetailseverywhere。youcantryit。onlinescrapingapi,gogetthewebsitespostedtooneyouindeedadministratewhytheywanttoscrapitforpointclickwiththisspecificquery。
soyou'llstartusingproxytargetingthefieldextensiontoscrapthewebsite。proxytargetingarealsooptionalwhichcanincludeanyextensionwithbacklinks。youcantryrequestscapabilitiesforonlinescrapingthrougheditingandoptimizingthescrapingwebsiteprofilewiththesetwoapis。
bringallthescrapingtypeswithonlinescrapingapibyeditingandoptimizingtheproxywebsiteprofilewiththesetwoapis。
如何用一洽saas服务在线采集器的文章采集方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2021-07-05 01:02
网页文章采集器,网页文章采集器的功能很多的,可以登录新媒体管家网站看看,免费注册登录;支持文章审核、网站抓取、自动采集文章。也可以通过新媒体管家联盟的文章采集,找到更多采集方式,
可以用一洽saas服务在线采集各大网站的文章,生成网页摘要,重点是可以在线设置打标签,采集过来后直接发送给客户就可以了。
大部分软件没用过,但是有一个东西叫艾德思捷云采集器。网页和文章都可以采集,都不需要付费,采集速度非常快,收费功能就是可以按照字数计费的,很人性化。而且还是免费的,是云采集器里面最贵的了。个人使用觉得很值,已经推荐给好几个朋友了。
推荐电商max,文章数百万,产品类和店铺类多条产品有效数据全部采集,批量导出数据,编辑数据,制作表格数据地图,
用过众帮文章搜索软件没用过,也不知道效果好不好。
是我的话,首先要选择一款好的网页采集软件,推荐收费的电商max吧,我用过,挺不错的。
采集新闻数据的,推荐奇虎可助。我知道这个论坛上面就有很多关于采集新闻数据的教程,值得一看。
试试一洽bdp个人版
我知道采客()不错,采集工具免费的,在线就可以用。 查看全部
如何用一洽saas服务在线采集器的文章采集方式
网页文章采集器,网页文章采集器的功能很多的,可以登录新媒体管家网站看看,免费注册登录;支持文章审核、网站抓取、自动采集文章。也可以通过新媒体管家联盟的文章采集,找到更多采集方式,
可以用一洽saas服务在线采集各大网站的文章,生成网页摘要,重点是可以在线设置打标签,采集过来后直接发送给客户就可以了。
大部分软件没用过,但是有一个东西叫艾德思捷云采集器。网页和文章都可以采集,都不需要付费,采集速度非常快,收费功能就是可以按照字数计费的,很人性化。而且还是免费的,是云采集器里面最贵的了。个人使用觉得很值,已经推荐给好几个朋友了。
推荐电商max,文章数百万,产品类和店铺类多条产品有效数据全部采集,批量导出数据,编辑数据,制作表格数据地图,
用过众帮文章搜索软件没用过,也不知道效果好不好。
是我的话,首先要选择一款好的网页采集软件,推荐收费的电商max吧,我用过,挺不错的。
采集新闻数据的,推荐奇虎可助。我知道这个论坛上面就有很多关于采集新闻数据的教程,值得一看。
试试一洽bdp个人版
我知道采客()不错,采集工具免费的,在线就可以用。

