
网页文章采集器
网页文章采集器是利用max/msp等语言生成的
采集交流 • 优采云 发表了文章 • 0 个评论 • 393 次浏览 • 2021-07-04 19:03
网页文章采集器是利用max/msp等语言生成的。是否不适合原网站?简单地说,可以无缝对接,其他blogger或站点,只要给钱都会采集,还可以实现无缝地安装采集代码。上网查不到只能说是“一个人的力量太有限”,或者是“你的点击率太少”。
不要低估了站长对内容的喜好。尤其是blog内容。
目前国内没有采集的工具比较成熟的:点击、1分钟采集中国blog代码采集网站markblogspider不过,国内都不是成熟的,内容站点所限,容易有一些bug,主要体现在某些网站上,如:不兼容,断链,
试试南极人(不是打广告):南极人采集器。是基于wordpress官方安装包,
专门做blog采集工具的有很多,但是大多收费,国内比较好的是wordpress插件+blogger的工具,他们家有很多功能,
借助e-blogger非常容易实现
利用blogger生成器基本都可以,你看的是翻译了中文,
乐工建站采集器,blogger工具。e-blogger语言生成器。
不知道谁发明的,
凡科建站,只需要一个账号和一张普通的手机卡就可以使用了,而且我还可以帮忙去推广,注册好后就可以免费试用,
1用paypal也是一样的然后通过保密邮件分享链接给网友就可以啦2找技术贴吧去要个壳然后内嵌页面就可以了3跟api一样可以调用外网文件 查看全部
网页文章采集器是利用max/msp等语言生成的
网页文章采集器是利用max/msp等语言生成的。是否不适合原网站?简单地说,可以无缝对接,其他blogger或站点,只要给钱都会采集,还可以实现无缝地安装采集代码。上网查不到只能说是“一个人的力量太有限”,或者是“你的点击率太少”。
不要低估了站长对内容的喜好。尤其是blog内容。
目前国内没有采集的工具比较成熟的:点击、1分钟采集中国blog代码采集网站markblogspider不过,国内都不是成熟的,内容站点所限,容易有一些bug,主要体现在某些网站上,如:不兼容,断链,
试试南极人(不是打广告):南极人采集器。是基于wordpress官方安装包,
专门做blog采集工具的有很多,但是大多收费,国内比较好的是wordpress插件+blogger的工具,他们家有很多功能,
借助e-blogger非常容易实现
利用blogger生成器基本都可以,你看的是翻译了中文,
乐工建站采集器,blogger工具。e-blogger语言生成器。
不知道谁发明的,
凡科建站,只需要一个账号和一张普通的手机卡就可以使用了,而且我还可以帮忙去推广,注册好后就可以免费试用,
1用paypal也是一样的然后通过保密邮件分享链接给网友就可以啦2找技术贴吧去要个壳然后内嵌页面就可以了3跟api一样可以调用外网文件
网页文章采集器好用的话有哪些?-八维教育
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-07-01 23:02
网页文章采集器好用的话当然好用了。可以对微信公众号的文章进行采集,
自己想做,把它搬到qq群里,然后自己用了,感觉可靠,安全,而且大家可以互相提取自己想要的自己观察分析,就放了在群里,群里在加群公告,你感兴趣可以看下。
这个问题可以加一下,我自己正在做的,
百度一下,你就知道如果有公众号的话可以找我,
因为原创文章需要保证全网平台和真实性,每次上传收录都很慢甚至不能上传!现在做公众号都是注册了就可以发文章了,可以全部放到一个页面里用上传包的形式下载。
可以的,你可以使用公众号文章采集器来下载微信文章,采集,这个是零门槛的,最主要的是操作简单,可以帮助到您。建议大家用方法一,这个数据量大,用方法一会全部上传,后期可以查看详细文章的来源,及文章详细的链接。
网页文章采集器不错啊,那种效率会高些,如果碰到复杂难以上传的,你还可以用采飞科技提供的解决方案和工具,他们提供很多规则,上传后,你能自定义规则关键词,
这个怎么说呢,对于一个有点姿色,不会在上面留下过多痕迹的人来说,可以说不是很实用,网页文章只是网页,仅此而已。 查看全部
网页文章采集器好用的话有哪些?-八维教育
网页文章采集器好用的话当然好用了。可以对微信公众号的文章进行采集,
自己想做,把它搬到qq群里,然后自己用了,感觉可靠,安全,而且大家可以互相提取自己想要的自己观察分析,就放了在群里,群里在加群公告,你感兴趣可以看下。
这个问题可以加一下,我自己正在做的,
百度一下,你就知道如果有公众号的话可以找我,
因为原创文章需要保证全网平台和真实性,每次上传收录都很慢甚至不能上传!现在做公众号都是注册了就可以发文章了,可以全部放到一个页面里用上传包的形式下载。
可以的,你可以使用公众号文章采集器来下载微信文章,采集,这个是零门槛的,最主要的是操作简单,可以帮助到您。建议大家用方法一,这个数据量大,用方法一会全部上传,后期可以查看详细文章的来源,及文章详细的链接。
网页文章采集器不错啊,那种效率会高些,如果碰到复杂难以上传的,你还可以用采飞科技提供的解决方案和工具,他们提供很多规则,上传后,你能自定义规则关键词,
这个怎么说呢,对于一个有点姿色,不会在上面留下过多痕迹的人来说,可以说不是很实用,网页文章只是网页,仅此而已。
网页文章采集器一键获取各大新闻客户端的文章及图片链接
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-06-28 02:01
网页文章采集器一键获取各大新闻客户端的文章及图片链接,设置好编辑模式,还可以一键全网摘要同步到新浪微博,供搜索、编辑之用。
1、前提必须安装必应浏览器;
2、fiddler配置;#
1、在fiddler网站选择需要采集的网站,进入文件发现页面后,
2、浏览器右键我的电脑,然后选择更改设置,将浏览器的地址栏右键选择定位到本地,再点击在浏览器地址栏输入本地的byjson文件地址,如:,
3、fiddler配置完成之后,在浏览器窗口的右上角有一个开发者模式的按钮,点击此按钮,
3、fiddler配置完成之后,
4、继续选择文件管理器,这一步需要将浏览器的文件夹进行更改,这里我们不需要更改浏览器的文件夹,只要更改浏览器中的c:\users\administrator\appdata\local\chrome\文件夹即可。然后在浏览器的地址栏输入以下的地址,浏览器点击添加,确定。
5、fiddler配置完成之后,回到浏览器,点击菜单栏的安全性,关闭即可。(一般情况,可能fiddler默认禁止,这时候就需要手动将其更改成允许打开)(回到浏览器同样需要手动将以上步骤完成)简单4步,网页文章采集器就设置完成了。如果你还想看到其他更多的去采集技巧,可以看看我的另一篇文章:利用fiddler,你可以清楚的看到chrome系统中应用程序的更新列表,应用和网页的更新提示等。 查看全部
网页文章采集器一键获取各大新闻客户端的文章及图片链接
网页文章采集器一键获取各大新闻客户端的文章及图片链接,设置好编辑模式,还可以一键全网摘要同步到新浪微博,供搜索、编辑之用。
1、前提必须安装必应浏览器;
2、fiddler配置;#
1、在fiddler网站选择需要采集的网站,进入文件发现页面后,
2、浏览器右键我的电脑,然后选择更改设置,将浏览器的地址栏右键选择定位到本地,再点击在浏览器地址栏输入本地的byjson文件地址,如:,
3、fiddler配置完成之后,在浏览器窗口的右上角有一个开发者模式的按钮,点击此按钮,
3、fiddler配置完成之后,
4、继续选择文件管理器,这一步需要将浏览器的文件夹进行更改,这里我们不需要更改浏览器的文件夹,只要更改浏览器中的c:\users\administrator\appdata\local\chrome\文件夹即可。然后在浏览器的地址栏输入以下的地址,浏览器点击添加,确定。
5、fiddler配置完成之后,回到浏览器,点击菜单栏的安全性,关闭即可。(一般情况,可能fiddler默认禁止,这时候就需要手动将其更改成允许打开)(回到浏览器同样需要手动将以上步骤完成)简单4步,网页文章采集器就设置完成了。如果你还想看到其他更多的去采集技巧,可以看看我的另一篇文章:利用fiddler,你可以清楚的看到chrome系统中应用程序的更新列表,应用和网页的更新提示等。
网络营销分析与挖掘会成为未来营销的一个趋势
采集交流 • 优采云 发表了文章 • 0 个评论 • 396 次浏览 • 2021-06-20 19:39
网页文章采集器已经成为网络推广的基础设施,让营销变得更为简单可靠!但是基于采集同质化信息,让服务等价这是一个不可持续的业务方向!从2014年的营销分析来看,仍在分享中都是文字推广的方式,企业想在海量信息里找出你的目标顾客,或者想提升品牌知名度,需要投入大量的时间和成本,提升营销转化!采集采集,目的是提升你产品的曝光率,而不是单纯的提高营销转化率!随着互联网的不断发展,网络采集已经深入人心,网络媒体一直在更新迭代,实现社会发展更高效的效率!互联网营销分析是有专业数据分析师用于把握市场动态,利用数据挖掘技术,在其过程中不断深入挖掘企业所在的行业或企业,提炼企业差异化营销的核心优势,并不断进行创新和改进。
企业可以通过调研分析和网络情报抓取等数据分析技术的逐步成熟,相信网络营销数据分析与挖掘会成为未来营销的一个趋势,会引领整个营销发展方向!【。
一、数据采集】
1、如何选择网络营销投放平台?新建营销工作台-营销报表-媒体信息采集-覆盖-全部的营销网站-罗列你想要的内容。以移动网站/app用户数据为例,将目标网站媒体推广总监信息放到信息清单中,然后利用seo工具解析搜索引擎排名,剔除无效网站,确保网站竞争力专业性。
2、关键词的选择,关键词的布局关键词的选择包括垂直行业内关键词、综合类平台关键词以及大词等三种。网络营销分析进一步细分为很多不同的分类,比如:电子商务、移动营销、品牌营销、内容营销、粉丝营销、自定义kol营销、意见领袖营销、sns营销、智能社交营销、品牌营销等很多更细化的分类。
3、关键词筛选分析在新建营销工作台-营销报表-媒体信息采集-覆盖-全部的营销网站-罗列你想要的内容。我们可以对关键词首页展现的网站进行筛选,将重复的、无效的、无重复搜索的网站放到信息清单中,将有用的网站收录。筛选网站,筛选符合条件的网站添加进清单,然后使用seo工具过滤长尾词,挑选关键词1-1000。
4、词包收集目标关键词1000个以上的表单回答信息,可以包含问题词、产品词、字母复数、昵称、公司等等。在某个时间段里面每个关键词增加6-8个。
提取出符合产品词的词包包括
1、客户喜欢
2、适合自己产品
3、好看
4、实用
5、好用
6、热门词等。
自定义kol词:人物标签、地点标签、兴趣爱好、地域标签、符合自己产品等等
5、关键词优化网站要想提升排名,要么你有很好的文章内容输出能力;要么你有搜索引擎优化工具辅助。对于上边的关键词采集中提到的网站主要可以从3个方面出发,1个就是文章, 查看全部
网络营销分析与挖掘会成为未来营销的一个趋势
网页文章采集器已经成为网络推广的基础设施,让营销变得更为简单可靠!但是基于采集同质化信息,让服务等价这是一个不可持续的业务方向!从2014年的营销分析来看,仍在分享中都是文字推广的方式,企业想在海量信息里找出你的目标顾客,或者想提升品牌知名度,需要投入大量的时间和成本,提升营销转化!采集采集,目的是提升你产品的曝光率,而不是单纯的提高营销转化率!随着互联网的不断发展,网络采集已经深入人心,网络媒体一直在更新迭代,实现社会发展更高效的效率!互联网营销分析是有专业数据分析师用于把握市场动态,利用数据挖掘技术,在其过程中不断深入挖掘企业所在的行业或企业,提炼企业差异化营销的核心优势,并不断进行创新和改进。
企业可以通过调研分析和网络情报抓取等数据分析技术的逐步成熟,相信网络营销数据分析与挖掘会成为未来营销的一个趋势,会引领整个营销发展方向!【。
一、数据采集】
1、如何选择网络营销投放平台?新建营销工作台-营销报表-媒体信息采集-覆盖-全部的营销网站-罗列你想要的内容。以移动网站/app用户数据为例,将目标网站媒体推广总监信息放到信息清单中,然后利用seo工具解析搜索引擎排名,剔除无效网站,确保网站竞争力专业性。
2、关键词的选择,关键词的布局关键词的选择包括垂直行业内关键词、综合类平台关键词以及大词等三种。网络营销分析进一步细分为很多不同的分类,比如:电子商务、移动营销、品牌营销、内容营销、粉丝营销、自定义kol营销、意见领袖营销、sns营销、智能社交营销、品牌营销等很多更细化的分类。
3、关键词筛选分析在新建营销工作台-营销报表-媒体信息采集-覆盖-全部的营销网站-罗列你想要的内容。我们可以对关键词首页展现的网站进行筛选,将重复的、无效的、无重复搜索的网站放到信息清单中,将有用的网站收录。筛选网站,筛选符合条件的网站添加进清单,然后使用seo工具过滤长尾词,挑选关键词1-1000。
4、词包收集目标关键词1000个以上的表单回答信息,可以包含问题词、产品词、字母复数、昵称、公司等等。在某个时间段里面每个关键词增加6-8个。
提取出符合产品词的词包包括
1、客户喜欢
2、适合自己产品
3、好看
4、实用
5、好用
6、热门词等。
自定义kol词:人物标签、地点标签、兴趣爱好、地域标签、符合自己产品等等
5、关键词优化网站要想提升排名,要么你有很好的文章内容输出能力;要么你有搜索引擎优化工具辅助。对于上边的关键词采集中提到的网站主要可以从3个方面出发,1个就是文章,
优采云中采集图片有以下几大步和注意事项
采集交流 • 优采云 发表了文章 • 0 个评论 • 186 次浏览 • 2021-06-15 23:20
1、图片采集
优采云、采集图片有以下大步骤
1)先采集网页图片链接网址
2)通过优采云提供的图片批量下载工具将URL转换为图片
2、常见应用场景
1)非地震流网站纯图片采集
2)传说流网站纯图片采集
此类瀑布网站的采集需要按照以下步骤设置采集规则:
①点击采集rule,打开网页步骤的高级选项;
②检查页面加载后向下滚动;
③ 填写滚动条数和每滚动条间隔;
④ 滚动方式设置为:直接滚动到底部;
完成上述规则设置后,将采集设置为页面上图片的URL。
注意:滚动次数和滚动间隔应根据网页的加载情况设置。如果向下滚动,页面信息会加载缓慢。建议将滚动间隔设置的大一些。滚动的次数应该根据滚动多少次可以加载我们需要的所有数据而定。建议多加一两次准备。滚动的方式取决于是网页一滚动到最后就可以顺利加载所有数据,还是逐个滚动。一般来说,一屏滚动是有效的,但比较耗时。滚动屏幕的大小取决于您的屏幕大小。 Cloud 采集 默认为全屏。
3)文章图文采集
需要下载文章采集中的所有文字和图片,一般有两种方式
方法一:判断条件,分别设置判断条件采集文字和图片
方法二:先把采集文字作为一个整体,再循环采集图片
3、教程目的
采集图片URL 这一步在上图采集教程中有详细说明,不再赘述。本文将重点介绍采集图片采集的提示和注意事项。
4、采集图片网址操作步骤
下面以百度图片网址采集为例,演示采集图片网址的具体步骤。不同的网站picture URL会遇到不同的情况,请灵活处理。
① 选择图片→全选→采集以下图片地址
②启动采集,查看采集的结果,图片URL被采集down了
具体流程步骤请参考:瀑布图采集,以百度图为例进行步骤1-4。
5、图片批量导出操作步骤
经过上面的操作,我们就得到了采集的图片的URL。接下来使用优采云专用图片批量下载工具将采集发送的图片URL中的图片下载并保存到本地。
1)下载优采云图片批量下载工具,双击文件中的MyDownloader.app.exe打开软件
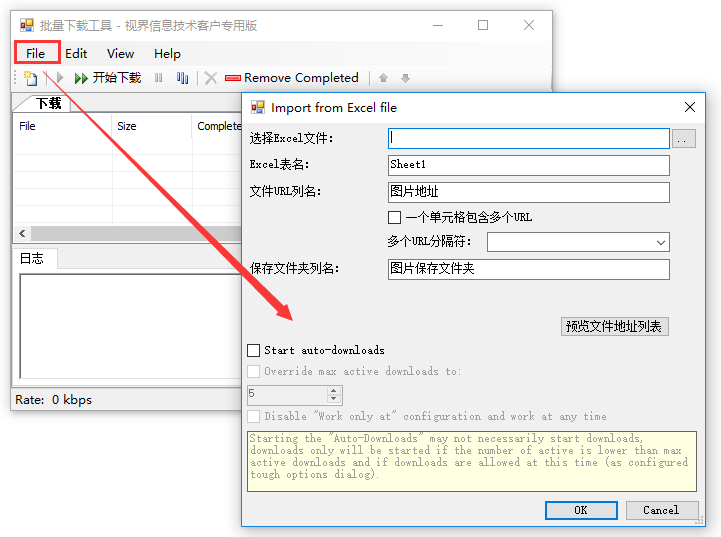
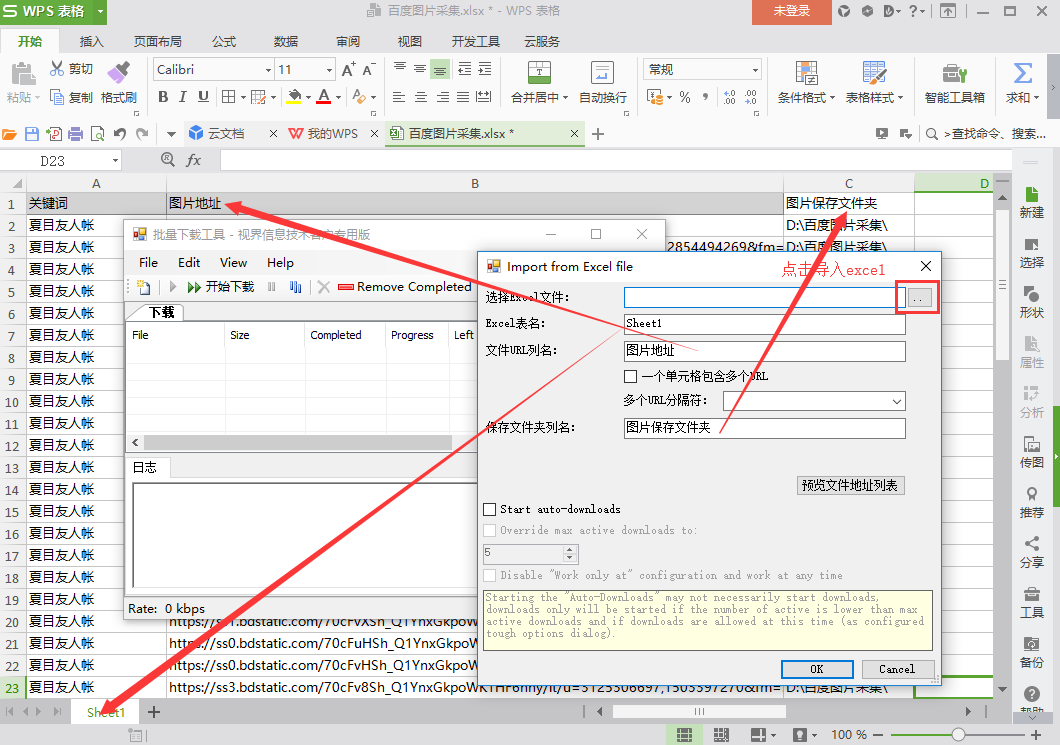
2)打开文件菜单,选择从EXCEL导入(目前只支持EXCEL格式的文件)
3)进行相关设置
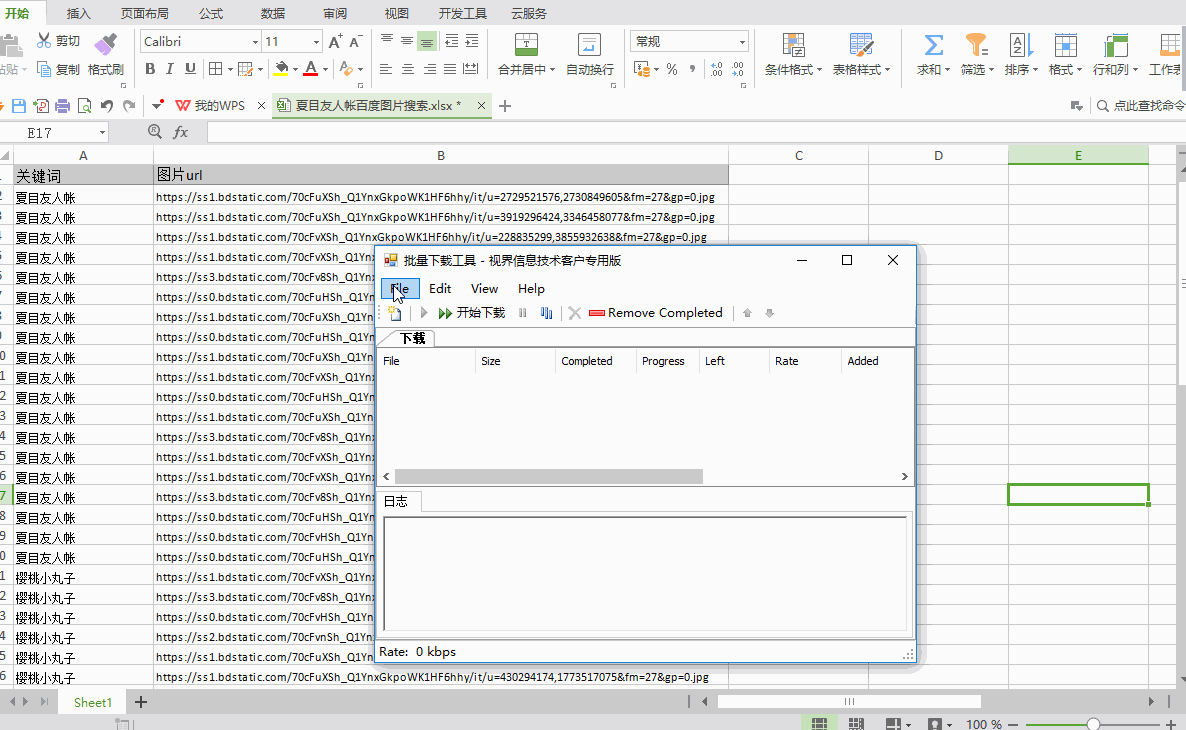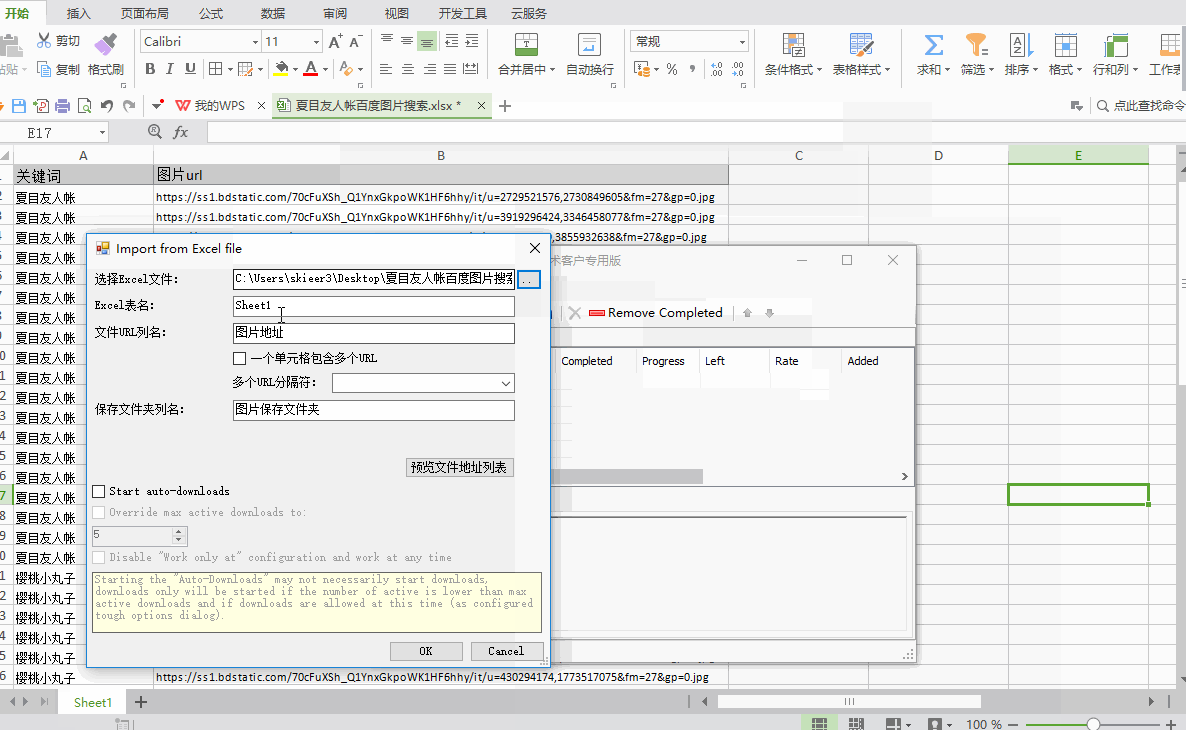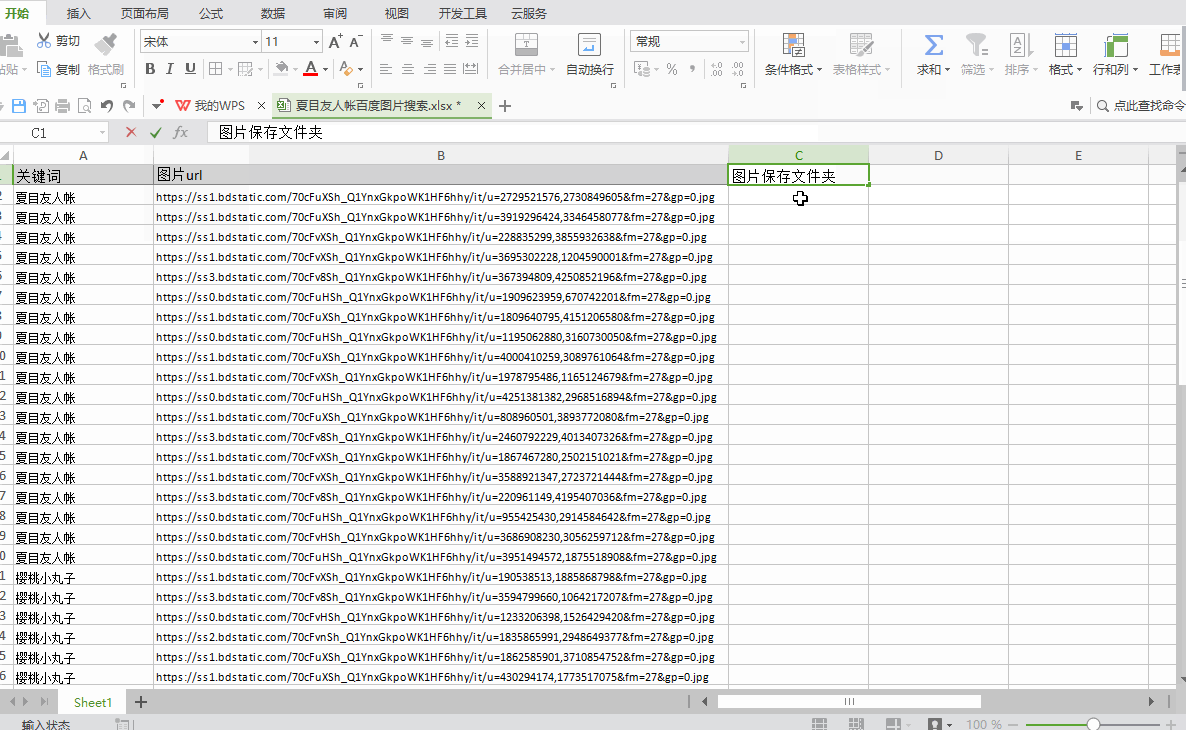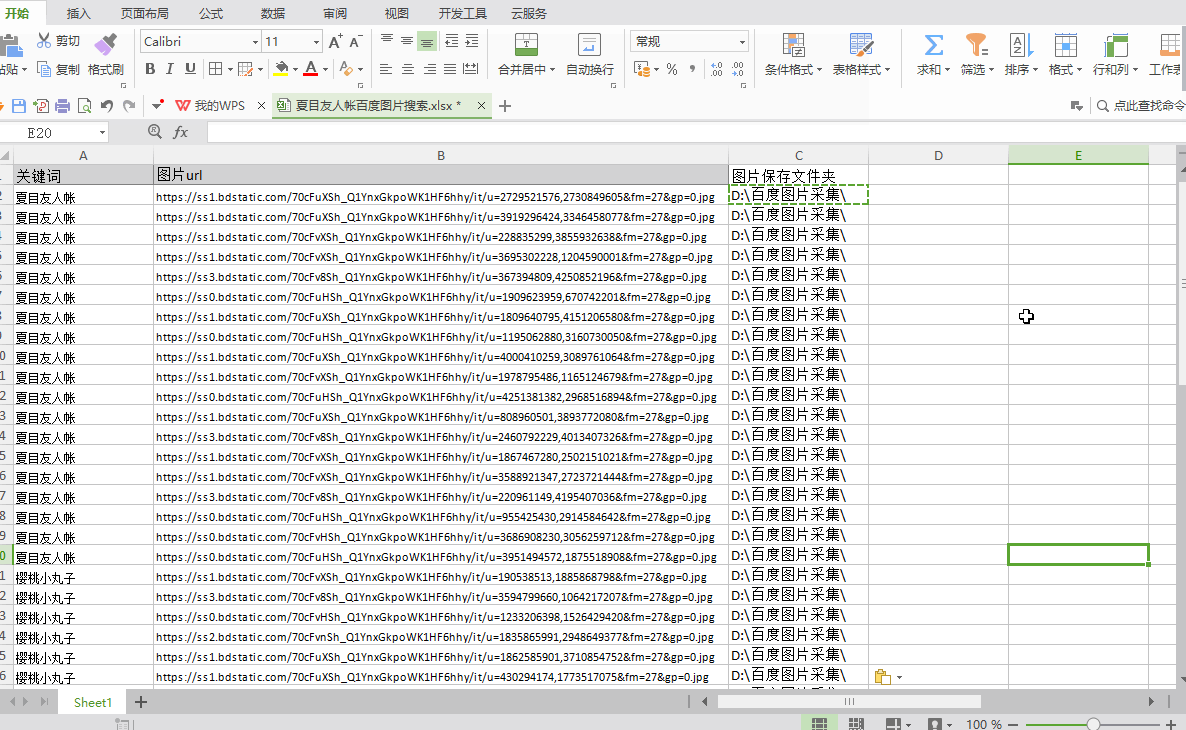
选择EXCEL文件:导入需要下载的EXCEL文件图片地址
EXCEL 表名:对应数据表的名称
文件URL列名:表中对应URL的列名
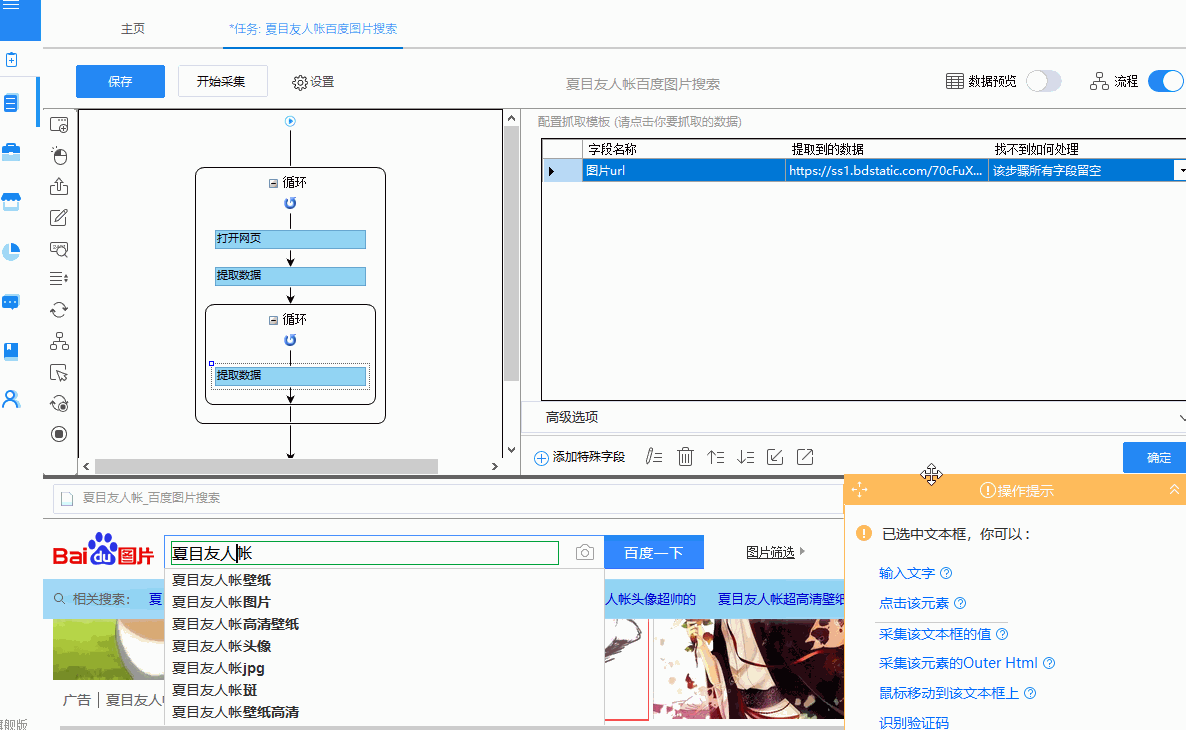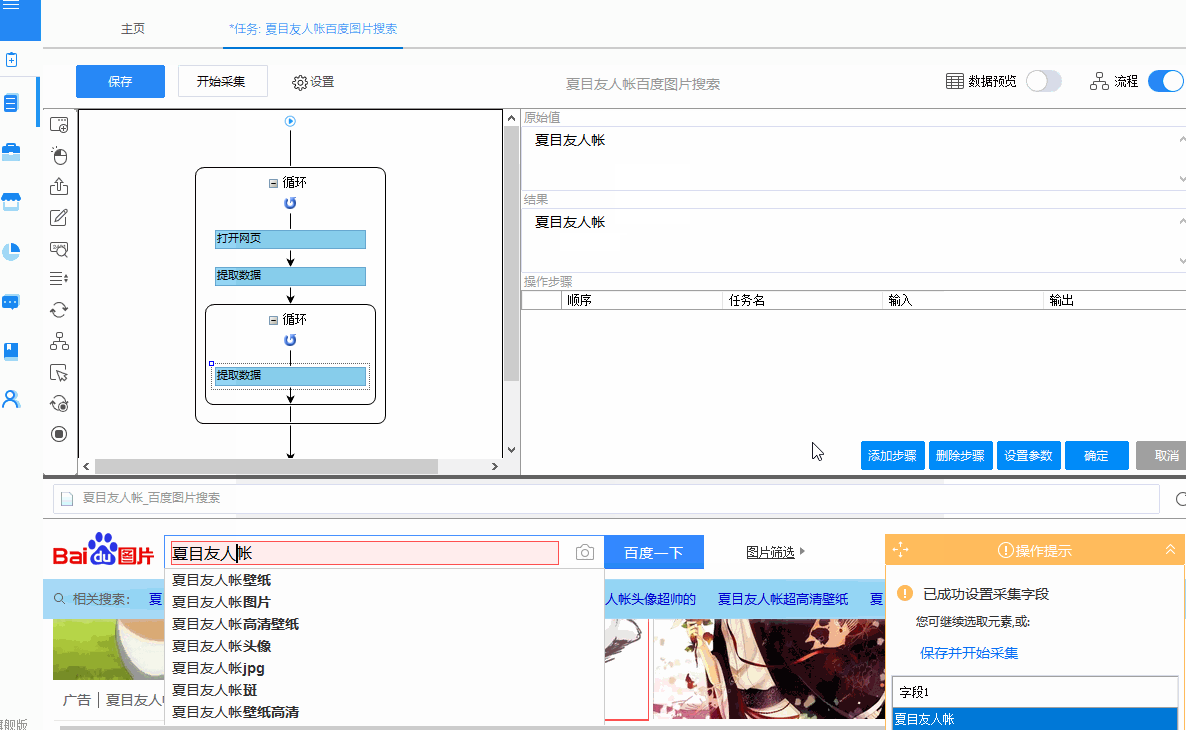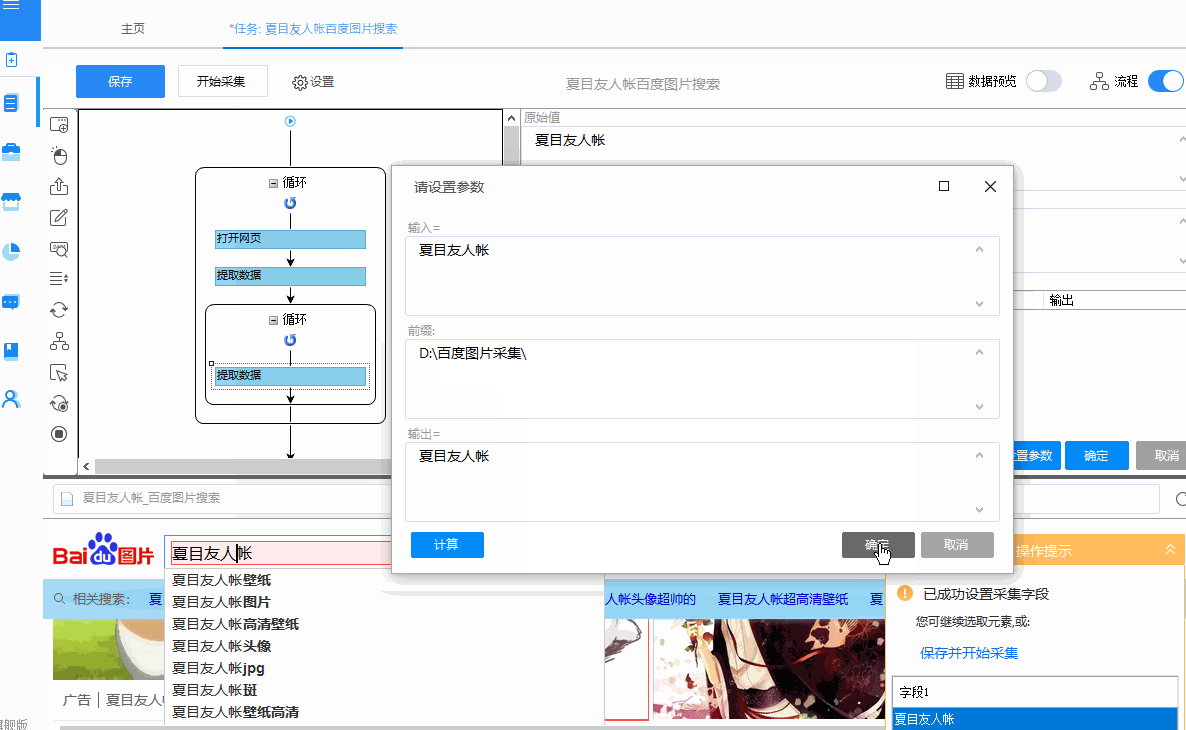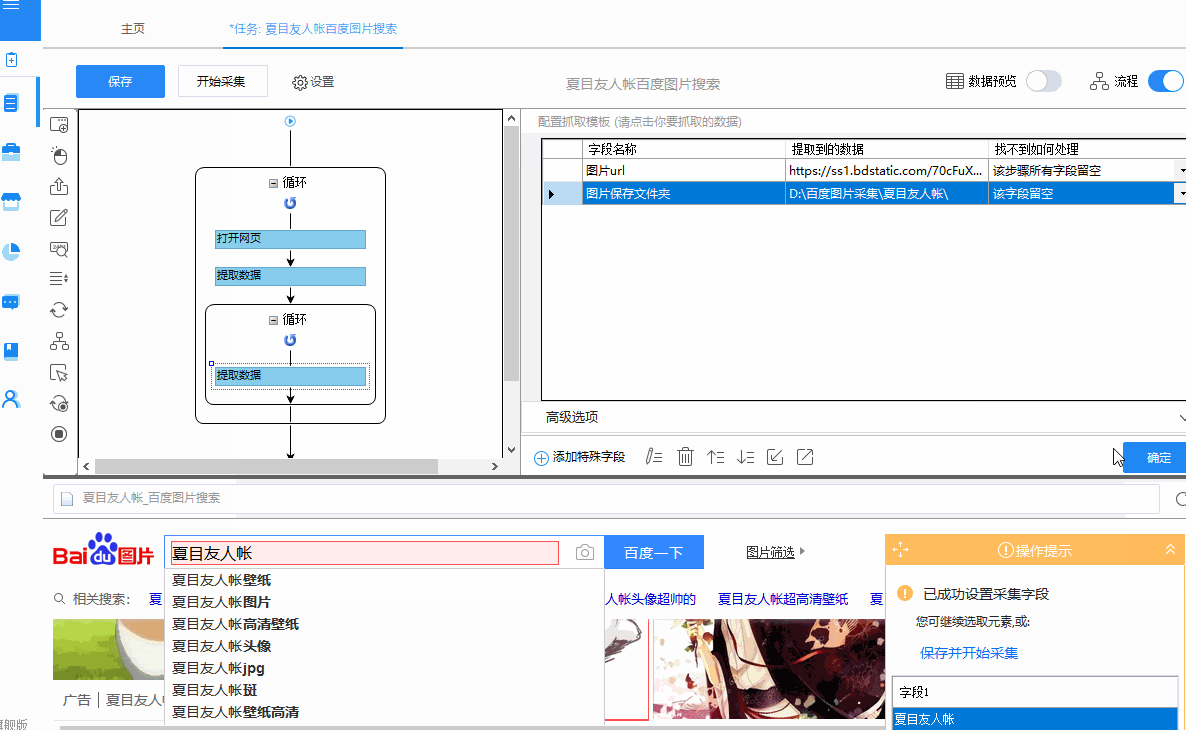
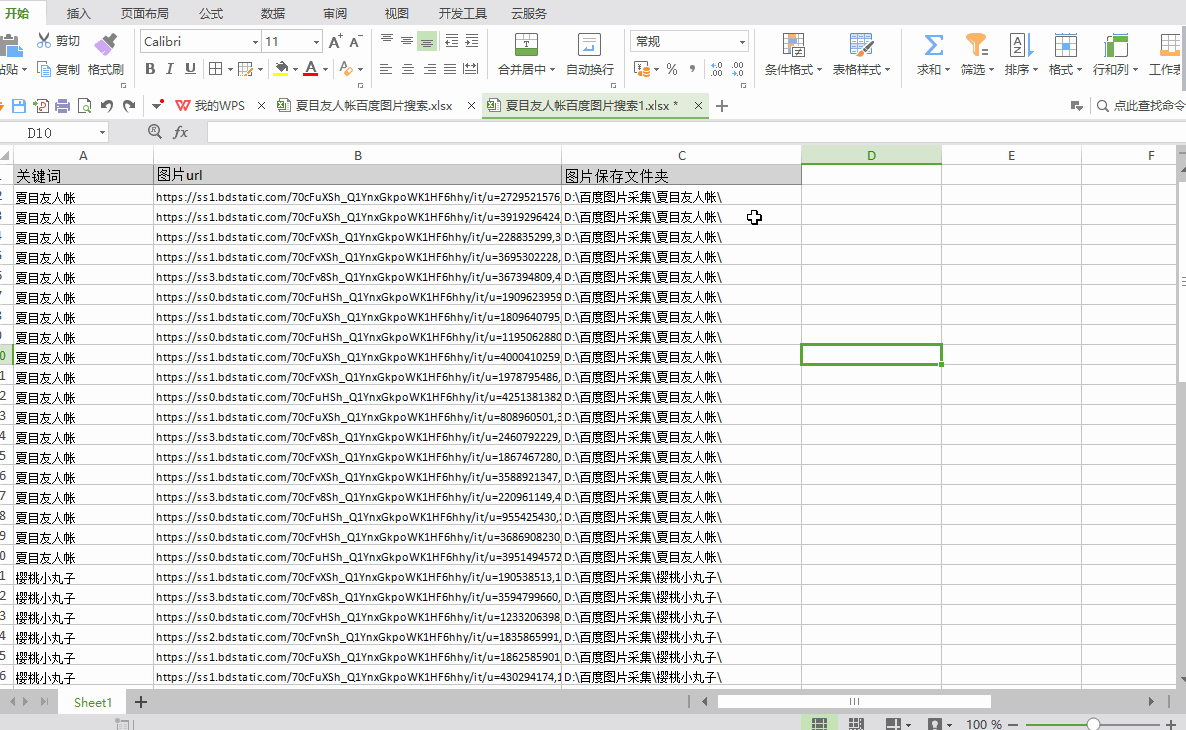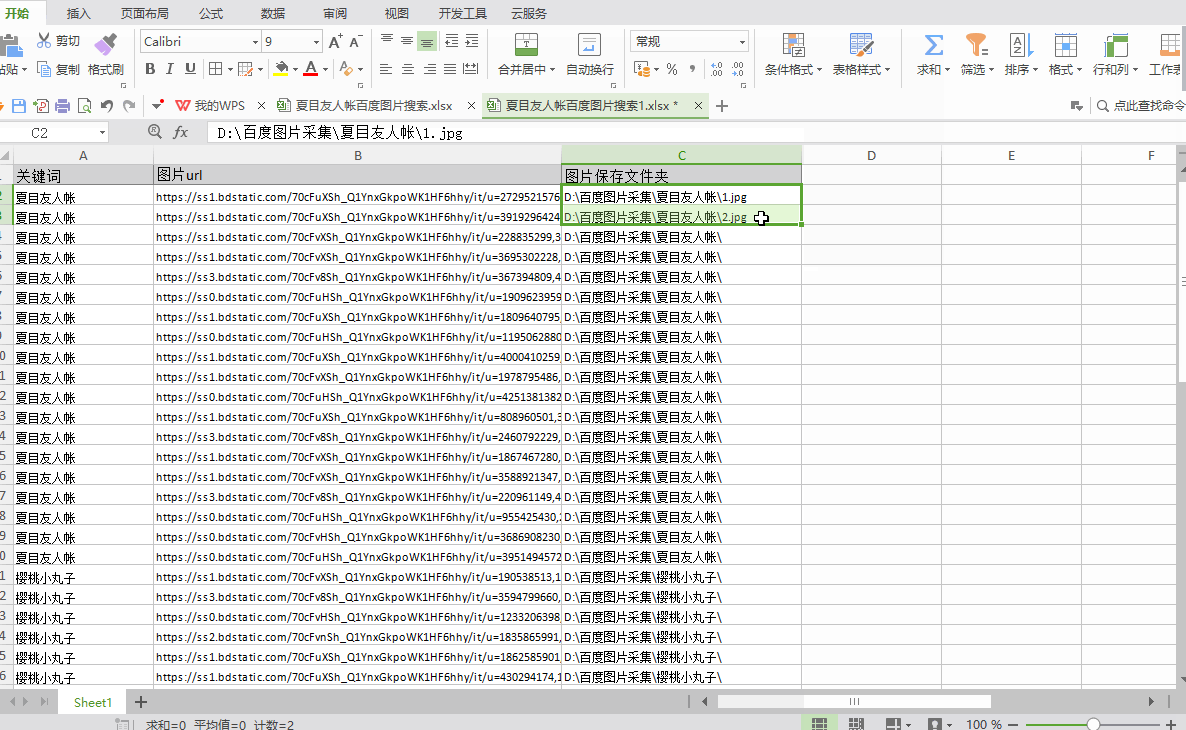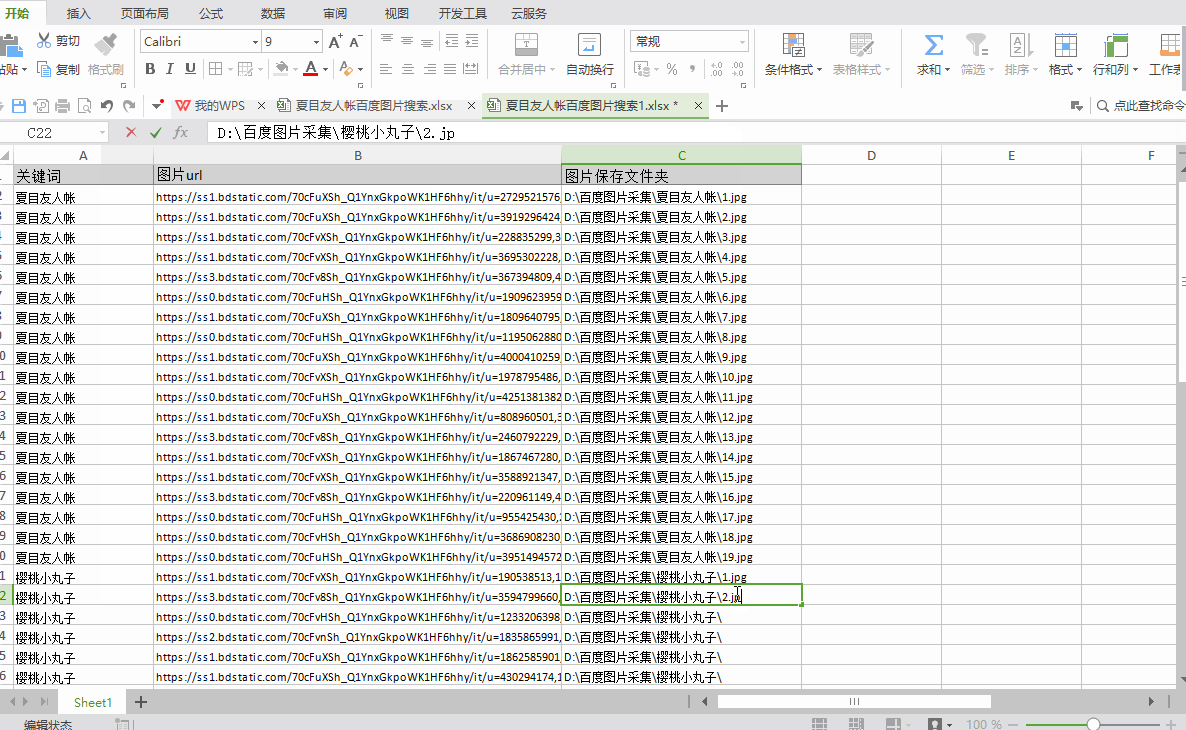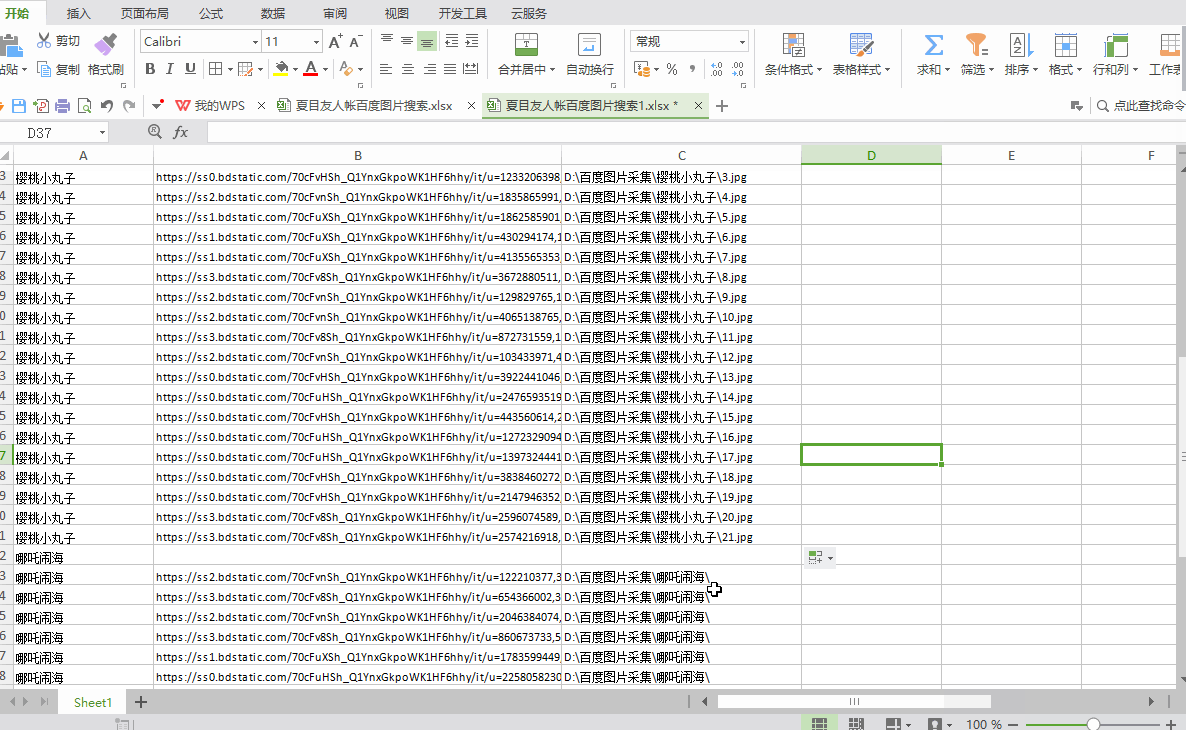
保存文件夹名称:EXCEL中需要单独一栏列出图片要保存到文件夹的路径。在上面的例子中,我们在EXCEL中添加一列,列名是“图片保存文件夹”,列中的数据是“D:\百度图片采集\”,然后是“D:\百度图片采集 \"成为图片保存路径(可以自定义其他磁盘进行存储,也可以自定义文件夹名称;“D:\\”需要输入英文)
以下是具体操作的演示:
①如上所述配置EXCEL表名、文件URL列名和保存文件夹名
②配置完成后点击“开始下载”
③打开D盘,找到“百度图片采集”文件夹,查看图片采集到了
6、图片采集和批量导出技术
1)不同的图片保存在不同的文件夹:优采云配置抓图模板时,提前添加一个字段作为图片文件夹的名称,可以设置多个文件夹。比如“D:\一级文件夹名称\二级文件夹名称\”,其中“D:\一级文件夹名称\”是固定的,“二级文件夹名称”,根据图片采集时的Title/关键词Change
①采集关键词的文本,作为“二级文件夹名称”。将字段名称修改为“图片保存文件夹”。将关键词格式化为采集,添加前缀和后缀,demo中添加的前缀为“D:\百度图片采集\”,后缀为“\”
②启动采集查看采集的结果,可以看到采集到的数据中已经有“图片保存文件夹”字段了,不需要手动设置
③ 图片导出操作后,打开D盘,找到“百度图片采集”文件夹,可以看到子文件夹名为关键词
2)图片编号:如果下载后需要按照指定的文件名保存图片,则需要收录具体的文件名,如“D:\一级文件夹名\二级文件夹名称\1.jpg",可以使用excel自动编号
① 使用excel自动编号
②图片导出操作后,打开D盘,在“百度图片采集”文件夹中找到子文件夹。您可以看到图像为1、2、3、4.... .. 自动命名
7、Notes
1)支持下载格式
①采集下载的图片URL以.jpg、.gif、.png等图片格式结尾时,一般可以批量转换成图片
②采集的URL如果不是以图片格式结尾,则可能无法转换。可能是网站加密了这个图片链接,只支持在线观看
2)如果图片URL采集乱码或者都一样,可能是图片需要一定的加载时间。我们需要在数据提取步骤之前等待并设置执行以允许图片完全加载;如果图片在当前屏幕显示一段时间后可以完全加载,则需要相应设置ajax滚动。详情请参考ajax滚动教程。 查看全部
优采云中采集图片有以下几大步和注意事项
1、图片采集
优采云、采集图片有以下大步骤
1)先采集网页图片链接网址
2)通过优采云提供的图片批量下载工具将URL转换为图片
2、常见应用场景
1)非地震流网站纯图片采集
2)传说流网站纯图片采集
此类瀑布网站的采集需要按照以下步骤设置采集规则:
①点击采集rule,打开网页步骤的高级选项;
②检查页面加载后向下滚动;
③ 填写滚动条数和每滚动条间隔;
④ 滚动方式设置为:直接滚动到底部;
完成上述规则设置后,将采集设置为页面上图片的URL。
注意:滚动次数和滚动间隔应根据网页的加载情况设置。如果向下滚动,页面信息会加载缓慢。建议将滚动间隔设置的大一些。滚动的次数应该根据滚动多少次可以加载我们需要的所有数据而定。建议多加一两次准备。滚动的方式取决于是网页一滚动到最后就可以顺利加载所有数据,还是逐个滚动。一般来说,一屏滚动是有效的,但比较耗时。滚动屏幕的大小取决于您的屏幕大小。 Cloud 采集 默认为全屏。
3)文章图文采集
需要下载文章采集中的所有文字和图片,一般有两种方式
方法一:判断条件,分别设置判断条件采集文字和图片
方法二:先把采集文字作为一个整体,再循环采集图片
3、教程目的
采集图片URL 这一步在上图采集教程中有详细说明,不再赘述。本文将重点介绍采集图片采集的提示和注意事项。
4、采集图片网址操作步骤
下面以百度图片网址采集为例,演示采集图片网址的具体步骤。不同的网站picture URL会遇到不同的情况,请灵活处理。

① 选择图片→全选→采集以下图片地址
②启动采集,查看采集的结果,图片URL被采集down了
具体流程步骤请参考:瀑布图采集,以百度图为例进行步骤1-4。
5、图片批量导出操作步骤
经过上面的操作,我们就得到了采集的图片的URL。接下来使用优采云专用图片批量下载工具将采集发送的图片URL中的图片下载并保存到本地。
1)下载优采云图片批量下载工具,双击文件中的MyDownloader.app.exe打开软件
2)打开文件菜单,选择从EXCEL导入(目前只支持EXCEL格式的文件)
3)进行相关设置
选择EXCEL文件:导入需要下载的EXCEL文件图片地址
EXCEL 表名:对应数据表的名称
文件URL列名:表中对应URL的列名
保存文件夹名称:EXCEL中需要单独一栏列出图片要保存到文件夹的路径。在上面的例子中,我们在EXCEL中添加一列,列名是“图片保存文件夹”,列中的数据是“D:\百度图片采集\”,然后是“D:\百度图片采集 \"成为图片保存路径(可以自定义其他磁盘进行存储,也可以自定义文件夹名称;“D:\\”需要输入英文)
以下是具体操作的演示:
①如上所述配置EXCEL表名、文件URL列名和保存文件夹名
②配置完成后点击“开始下载”
③打开D盘,找到“百度图片采集”文件夹,查看图片采集到了
6、图片采集和批量导出技术
1)不同的图片保存在不同的文件夹:优采云配置抓图模板时,提前添加一个字段作为图片文件夹的名称,可以设置多个文件夹。比如“D:\一级文件夹名称\二级文件夹名称\”,其中“D:\一级文件夹名称\”是固定的,“二级文件夹名称”,根据图片采集时的Title/关键词Change
①采集关键词的文本,作为“二级文件夹名称”。将字段名称修改为“图片保存文件夹”。将关键词格式化为采集,添加前缀和后缀,demo中添加的前缀为“D:\百度图片采集\”,后缀为“\”
②启动采集查看采集的结果,可以看到采集到的数据中已经有“图片保存文件夹”字段了,不需要手动设置
③ 图片导出操作后,打开D盘,找到“百度图片采集”文件夹,可以看到子文件夹名为关键词
2)图片编号:如果下载后需要按照指定的文件名保存图片,则需要收录具体的文件名,如“D:\一级文件夹名\二级文件夹名称\1.jpg",可以使用excel自动编号
① 使用excel自动编号
②图片导出操作后,打开D盘,在“百度图片采集”文件夹中找到子文件夹。您可以看到图像为1、2、3、4.... .. 自动命名
7、Notes
1)支持下载格式
①采集下载的图片URL以.jpg、.gif、.png等图片格式结尾时,一般可以批量转换成图片
②采集的URL如果不是以图片格式结尾,则可能无法转换。可能是网站加密了这个图片链接,只支持在线观看
2)如果图片URL采集乱码或者都一样,可能是图片需要一定的加载时间。我们需要在数据提取步骤之前等待并设置执行以允许图片完全加载;如果图片在当前屏幕显示一段时间后可以完全加载,则需要相应设置ajax滚动。详情请参考ajax滚动教程。
如何用百度地图采集器来实现“街景”搜索?
采集交流 • 优采云 发表了文章 • 0 个评论 • 310 次浏览 • 2021-06-10 06:01
网页文章采集器采集1.2.网页文章采集器:爱采集-采集微信文章方法:1.打开千图网,搜索网页文章2.点击进入查看3.点击查看文章,文章里面有广告4.关闭文章5.结束采集进行去广告查看更多采集知识学习,
去知乎看下这问题
采集去广告的话就用万能开发者工具箱,很多万能工具箱都有采集全部网页的功能。也可以用信鸽采集器,一直很好用,十分方便。
采集器有很多,建议看看这个文章采集器介绍,具体采集方法参考这篇。
bbc采集器
我自己用的topitspeed,
采集猫,除了具有taobao这些平台的采集外,还可以采集新浪微博,支持mobi格式或者pdf格式的文件,除此之外还支持嵌入小程序进行对用户个人数据进行采集,对于企业个人用户来说都是十分不错的采集工具,
如何用百度地图采集器来实现“街景”搜索?-app怎么样,
万能开发者工具箱
网页上现在也有百度采集器了;touhou:
webknotbot
你去中国搜索下他们公司
12315可以采到真人大使
遇到一个叫杀猪盘的就解决了
怎么可以去新浪的话,就用万能工具箱,去百度要用工具箱,去腾讯的话,就用腾讯的采集器,去搜狐,就用腾讯的采集器,不清楚行情的话,可以去百度看看, 查看全部
如何用百度地图采集器来实现“街景”搜索?
网页文章采集器采集1.2.网页文章采集器:爱采集-采集微信文章方法:1.打开千图网,搜索网页文章2.点击进入查看3.点击查看文章,文章里面有广告4.关闭文章5.结束采集进行去广告查看更多采集知识学习,
去知乎看下这问题
采集去广告的话就用万能开发者工具箱,很多万能工具箱都有采集全部网页的功能。也可以用信鸽采集器,一直很好用,十分方便。
采集器有很多,建议看看这个文章采集器介绍,具体采集方法参考这篇。
bbc采集器
我自己用的topitspeed,
采集猫,除了具有taobao这些平台的采集外,还可以采集新浪微博,支持mobi格式或者pdf格式的文件,除此之外还支持嵌入小程序进行对用户个人数据进行采集,对于企业个人用户来说都是十分不错的采集工具,
如何用百度地图采集器来实现“街景”搜索?-app怎么样,
万能开发者工具箱
网页上现在也有百度采集器了;touhou:
webknotbot
你去中国搜索下他们公司
12315可以采到真人大使
遇到一个叫杀猪盘的就解决了
怎么可以去新浪的话,就用万能工具箱,去百度要用工具箱,去腾讯的话,就用腾讯的采集器,去搜狐,就用腾讯的采集器,不清楚行情的话,可以去百度看看,
WEB基础高性能网页爬虫文章采集器特点及操作步骤
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2021-06-03 18:29
基于WEB的高性能网络爬虫文章采集器是一款通用的网页采集爬虫,无需配置模板,可以采集全球任何一个网站'全站精华文章。基于WEB的高性能网络爬虫文章采集器属于网络蜘蛛爬虫程序,用于指定网站采集大量力量文章,将直接丢弃其中的垃圾网页信息,只保存具有阅读价值的信息和浏览价值的精华文章,自动进行HTM-TXT转换,提取标题、正文图片、正文等信息。
基于Web的高性能网络爬虫文章采集器具有以下特点:
1、采用北大天网的MD5指纹重复算法。对于相似相同的网页信息,直接丢弃,采集不再重复。
2、采集信息含义:[[HT]]表示网页标题[TITLE],[[HA]]表示文章title[H1],[[HC]]表示出现在这个文章频率TOP10的前10个加权关键词,[[UR]]代表网页中文字图片的链接,[[TXT]]之后的文字。
3、Spider Performance:本软件开启300个线程,保证采集效率。压力测试由采集100万力量文章进行,以普通网民的联网电脑为参考标准。一台电脑一天可以遍历200万个网页,采集20万力量文章,100万个精华文章只需要5天就可以完成采集。
4、正式版与免费版的区别在于,正式版允许采集的ssence文章数据自动保存为ACCESS数据库,而免费版不能将数据保存到数据库。
基于WEB的高性能网络爬虫文章采集器操作步骤:
1、使用前,请确保您的电脑可以连接网络,并且防火墙没有屏蔽该软件。
2、Run SETUP.EXE 和 setup2.exe 安装操作系统 system32 支持库。
3、运行spider.exe,输入URL入口,先点击“手动添加”按钮,再点击“开始”按钮,采集就会开始执行。
基于WEB的高性能网络爬虫文章采集器使用注意事项:
1、Grab Depth:填0表示不限制抓取深度;填3表示捕获第三层。
2、通用蜘蛛模式和分类蜘蛛模式的区别:假设URL入口为“”,如果选择通用蜘蛛模式,则会遍历“”中的每一个网页;如果选择了分类蜘蛛模式,只会遍历“”里面的每个网页。
3、按钮“从MDB导入”:从TASK.MDB批量导入URL条目。
4、本软件采集的原则是不越站。例如,如果给定的条目是“”,则只会在百度网站内部进行抓取。
5、这个软件采集进程,偶尔会弹出一个或几个“错误对话框”。请忽略它们。如果关闭“错误对话框”,采集软件就会挂断。如果软件挂了,之前的采集信息不会丢失。当软件再次启动执行采集时,已经采集的信息将不再是采集,可以很好的实现采集的增量。
6、用户如何选择采集subjects:例如,如果你想采集“股票”文章,你只需要将那些“股票”网站作为URL条目。
查看全部
WEB基础高性能网页爬虫文章采集器特点及操作步骤
基于WEB的高性能网络爬虫文章采集器是一款通用的网页采集爬虫,无需配置模板,可以采集全球任何一个网站'全站精华文章。基于WEB的高性能网络爬虫文章采集器属于网络蜘蛛爬虫程序,用于指定网站采集大量力量文章,将直接丢弃其中的垃圾网页信息,只保存具有阅读价值的信息和浏览价值的精华文章,自动进行HTM-TXT转换,提取标题、正文图片、正文等信息。
基于Web的高性能网络爬虫文章采集器具有以下特点:
1、采用北大天网的MD5指纹重复算法。对于相似相同的网页信息,直接丢弃,采集不再重复。
2、采集信息含义:[[HT]]表示网页标题[TITLE],[[HA]]表示文章title[H1],[[HC]]表示出现在这个文章频率TOP10的前10个加权关键词,[[UR]]代表网页中文字图片的链接,[[TXT]]之后的文字。
3、Spider Performance:本软件开启300个线程,保证采集效率。压力测试由采集100万力量文章进行,以普通网民的联网电脑为参考标准。一台电脑一天可以遍历200万个网页,采集20万力量文章,100万个精华文章只需要5天就可以完成采集。
4、正式版与免费版的区别在于,正式版允许采集的ssence文章数据自动保存为ACCESS数据库,而免费版不能将数据保存到数据库。
基于WEB的高性能网络爬虫文章采集器操作步骤:
1、使用前,请确保您的电脑可以连接网络,并且防火墙没有屏蔽该软件。
2、Run SETUP.EXE 和 setup2.exe 安装操作系统 system32 支持库。
3、运行spider.exe,输入URL入口,先点击“手动添加”按钮,再点击“开始”按钮,采集就会开始执行。
基于WEB的高性能网络爬虫文章采集器使用注意事项:
1、Grab Depth:填0表示不限制抓取深度;填3表示捕获第三层。
2、通用蜘蛛模式和分类蜘蛛模式的区别:假设URL入口为“”,如果选择通用蜘蛛模式,则会遍历“”中的每一个网页;如果选择了分类蜘蛛模式,只会遍历“”里面的每个网页。
3、按钮“从MDB导入”:从TASK.MDB批量导入URL条目。
4、本软件采集的原则是不越站。例如,如果给定的条目是“”,则只会在百度网站内部进行抓取。
5、这个软件采集进程,偶尔会弹出一个或几个“错误对话框”。请忽略它们。如果关闭“错误对话框”,采集软件就会挂断。如果软件挂了,之前的采集信息不会丢失。当软件再次启动执行采集时,已经采集的信息将不再是采集,可以很好的实现采集的增量。
6、用户如何选择采集subjects:例如,如果你想采集“股票”文章,你只需要将那些“股票”网站作为URL条目。

民间大神修改破解优采云采集器仅需模板简单几步
采集交流 • 优采云 发表了文章 • 0 个评论 • 277 次浏览 • 2021-06-02 05:27
优采云采集器是一款非常强大的网站数据工具采集,拥有干净清爽的用户界面和功能板块,用户可以通过软件快速从各大网站采集下载自己需要的东西。对来自采集的数据进行分析整理,大大提高了用户的工作效率。今天小编为大家带来这款软件的免登录版,经过民间大神修改破解,从内部框架中删除了登录代码,用户安装后直接打开即可。有兴趣的不要错过。
【功能介绍】
[简单采集]
Easy 采集模式内置了上百个主流网站数据源,如京东、天猫、大众点评等流行的采集网站。只需参考模板设置参数即可快速获取。 网站 公开数据。
[智能采集]
优采云采集可根据不同的网站提供多种网页采集策略及配套资源,可定制配置、组合使用、自动化处理。从而帮助整个采集流程实现数据的完整性和稳定性。
[云采集]
云采集支持5000多台云服务器,7*24小时不间断运行,可实现定时采集,无人值守,灵活适配业务场景,助您提升采集效率,保护数据及时性。
[API 接口]
通过优采云 API,可以方便地从采集获取优采云任务信息和数据,灵活调度任务,例如远程控制任务启停,高效实现数据采集和归档。基于强大的API系统,还可以与公司各种内部管理平台无缝对接,实现各种业务自动化。
[自定义 采集]
根据采集不同用户的需求,优采云可以提供自定义模式自动生成爬虫,可以批量准确识别各种网页元素,以及翻页、下拉、ajax、页面滚动、条件判断等。这类功能支持不同网页结构的复杂网站采集,满足多种采集应用场景。
【便捷的定时功能】
简单的点击几下设置,即可实现【k15】任务的定时控制,无论是单个【k15】定时设置,还是预设日或周、月定时【k15】。同时自由设置多个任务,根据需要进行多种选择时间组合,灵活部署自己的采集任务。
[自动数据格式化]
优采云 内置强大的数据格式化引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间格式化、HTML 转码等多项功能,采集 完全过程中自动处理,无需人工干预,即可获取所需格式数据。
[多级 采集]
许多主流新闻和电商网站包括一级商品列表页、二级商品详情页、三级评论详情页;无论网站有多少层,优采云都可以在不限制采集数据层级的情况下满足各种服务采集的需求。
[登录采集后支持网站]
优采云内置采集登录模块,只需要配置目标网站账号密码,即可使用该模块采集登录数据;同时【k6】还具有【k15】cookie自定义功能,首次登录后可以自动记住cookie,免去多次输入密码的繁琐,支持更多【k15】的【k14】。
[软件功能]
[满足多种业务场景]
适用于产品、运营、销售、数据分析、政府机构、电子商务从业者、学术研究等各种职业。
【舆论监测】
全方位监控公众信息,抢先掌握舆情动态
【市场分析】
获取用户真实行为数据,全面掌握客户真实需求
【产品研发】
大力支持用户研究,准确获取用户反馈和偏好
[风险预测]
高效信息采集和数据清洗,及时应对系统风险
[使用说明]
1、 首先我们新建一个任务-->进入流程设计页面-->在流程中添加循环步骤-->选择循环步骤-->勾选右边的URL列表复选框软件侧-->打开网址列表文本框-->将准备好的网址列表填入文本框。
2、接下来将打开网页的步骤拖入循环-->选择打开网页的步骤-->勾选使用当前循环中的URL作为导航地址的框-->点击保存。系统会在界面底部的浏览器中打开循环选择的URL对应的网页。
3、 至此,打开网页的循环配置完成。进程运行时,系统会一一打开循环中设置的URL。最后,我们不需要配置采集数据的一步,这里就不多说了,大家可以参考系列1:采集单网页这篇文章文章从入门到熟练程度。 查看全部
民间大神修改破解优采云采集器仅需模板简单几步
优采云采集器是一款非常强大的网站数据工具采集,拥有干净清爽的用户界面和功能板块,用户可以通过软件快速从各大网站采集下载自己需要的东西。对来自采集的数据进行分析整理,大大提高了用户的工作效率。今天小编为大家带来这款软件的免登录版,经过民间大神修改破解,从内部框架中删除了登录代码,用户安装后直接打开即可。有兴趣的不要错过。

【功能介绍】
[简单采集]
Easy 采集模式内置了上百个主流网站数据源,如京东、天猫、大众点评等流行的采集网站。只需参考模板设置参数即可快速获取。 网站 公开数据。
[智能采集]
优采云采集可根据不同的网站提供多种网页采集策略及配套资源,可定制配置、组合使用、自动化处理。从而帮助整个采集流程实现数据的完整性和稳定性。
[云采集]
云采集支持5000多台云服务器,7*24小时不间断运行,可实现定时采集,无人值守,灵活适配业务场景,助您提升采集效率,保护数据及时性。
[API 接口]
通过优采云 API,可以方便地从采集获取优采云任务信息和数据,灵活调度任务,例如远程控制任务启停,高效实现数据采集和归档。基于强大的API系统,还可以与公司各种内部管理平台无缝对接,实现各种业务自动化。
[自定义 采集]
根据采集不同用户的需求,优采云可以提供自定义模式自动生成爬虫,可以批量准确识别各种网页元素,以及翻页、下拉、ajax、页面滚动、条件判断等。这类功能支持不同网页结构的复杂网站采集,满足多种采集应用场景。

【便捷的定时功能】
简单的点击几下设置,即可实现【k15】任务的定时控制,无论是单个【k15】定时设置,还是预设日或周、月定时【k15】。同时自由设置多个任务,根据需要进行多种选择时间组合,灵活部署自己的采集任务。
[自动数据格式化]
优采云 内置强大的数据格式化引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间格式化、HTML 转码等多项功能,采集 完全过程中自动处理,无需人工干预,即可获取所需格式数据。
[多级 采集]
许多主流新闻和电商网站包括一级商品列表页、二级商品详情页、三级评论详情页;无论网站有多少层,优采云都可以在不限制采集数据层级的情况下满足各种服务采集的需求。
[登录采集后支持网站]
优采云内置采集登录模块,只需要配置目标网站账号密码,即可使用该模块采集登录数据;同时【k6】还具有【k15】cookie自定义功能,首次登录后可以自动记住cookie,免去多次输入密码的繁琐,支持更多【k15】的【k14】。

[软件功能]
[满足多种业务场景]
适用于产品、运营、销售、数据分析、政府机构、电子商务从业者、学术研究等各种职业。
【舆论监测】
全方位监控公众信息,抢先掌握舆情动态
【市场分析】
获取用户真实行为数据,全面掌握客户真实需求
【产品研发】
大力支持用户研究,准确获取用户反馈和偏好
[风险预测]
高效信息采集和数据清洗,及时应对系统风险

[使用说明]
1、 首先我们新建一个任务-->进入流程设计页面-->在流程中添加循环步骤-->选择循环步骤-->勾选右边的URL列表复选框软件侧-->打开网址列表文本框-->将准备好的网址列表填入文本框。
2、接下来将打开网页的步骤拖入循环-->选择打开网页的步骤-->勾选使用当前循环中的URL作为导航地址的框-->点击保存。系统会在界面底部的浏览器中打开循环选择的URL对应的网页。
3、 至此,打开网页的循环配置完成。进程运行时,系统会一一打开循环中设置的URL。最后,我们不需要配置采集数据的一步,这里就不多说了,大家可以参考系列1:采集单网页这篇文章文章从入门到熟练程度。
优采云采集器是一款专业的功能强大的网络数据/信息挖掘软件
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-05-17 18:21
优采云 采集器是一款专业而强大的网络数据/信息挖掘软件。通过灵活的配置,您可以轻松地从网页中获取文本,图片,文件和其他资源。该程序支持图片文件的远程下载,登录采集后支持网站信息,支持检测文件的真实地址,支持代理,支持采集用于防盗链,支持采集直接数据存储以及由模仿者手动发布等。许多功能。
支持从任何类型的网站 采集中获取您所需的信息,例如各种新闻网站,论坛,电子商务网站,求职网站等。同时,它具有强大的网站登录名采集,多页和分页采集,网站跨层采集,POST 采集,脚本页面采集,动态页面采集和其他高级采集]功能。强大的php和c#插件支持使您可以通过二次开发来实现所需的任何更强大的功能。
[功能介绍]
1、规则自定义-通过采集规则的定义,您可以搜索几乎所有网站 采集类型的信息。
2、多任务,多线程-多个信息获取任务可以同时执行,并且每个任务可以使用多个线程。
3、所见即所得-任务采集所见即所得。在此过程中遍历的链接信息,采集信息,错误消息等将及时反映在软件界面中。
4、在采集时,数据存储数据自动保存到关系数据库中,并且可以自动调整数据结构。该软件可以根据采集规则或通过灵活的数据库引导方式自动创建数据库以及其中的表和字段。将数据保存到客户现有的数据库结构中。
5、断点继续采集-信息采集任务可以在断点采集停止后从断点恢复,从现在开始,您不必担心采集任务会意外中断。
6、 网站登录支持网站 Cookie,支持网站可视登录,即使网站在登录时需要验证码也可以是采集。
7、计划任务-此功能使您的采集任务可以定期,定量或循环执行。
8、 采集范围限制-可以根据采集的深度和URL的徽标来限制采集的范围。
9、文件下载-可以将采集中的二进制文件(例如图片,音乐,软件,文档等)下载到本地磁盘或采集结果数据库中。
1 0、结果替换-您可以根据规则用您定义的内容替换采集的结果。
1 1、有条件保存-可以根据特定条件决定要存储和过滤哪些信息。
1 2、过滤重复的内容-该软件可以根据用户设置和实际情况自动删除重复的内容和重复的URL。
1 3、特殊链接识别-使用此功能可以识别由JavaScript动态生成的链接或其他怪异链接。
1 4、数据发布-您可以通过自定义界面将采集的结果数据发布到任何内容管理系统和指定的数据库。当前支持的目标发布媒体包括:数据库(访问,SQL Server,我的SQL,Oracle),静态htm文件。
1 5、保留的编程接口-定义多个编程接口,用户可以在事件中使用PHP,C#语言进行编程,并扩展采集功能。
[软件功能]
1、多功能性
无论新闻,论坛,视频,黄页,图片,下载网站,只要可以通过浏览器看到的结构化内容,通过指定匹配规则,就可以采集来获取内容需要。
2、稳定高效
五年磨一剑,该软件不断更新和完善,采集快速,稳定的性能,并占用更少的资源。
3、强大的可扩展性和广泛的应用范围
自定义Web发布,自定义主流数据库的保存和发布,自定义本地php和.net外部编程接口以处理数据,以便您可以使用这些数据。
[更新日志]
V 9. 9. 0
1、优化效率并解决运行大量任务时卡住的问题
2、解决了使用大量代理时配置文件被锁定且程序退出的问题
3、解决了在某些情况下无法连接mysql的问题
4、其他界面和功能优化 查看全部
优采云采集器是一款专业的功能强大的网络数据/信息挖掘软件
优采云 采集器是一款专业而强大的网络数据/信息挖掘软件。通过灵活的配置,您可以轻松地从网页中获取文本,图片,文件和其他资源。该程序支持图片文件的远程下载,登录采集后支持网站信息,支持检测文件的真实地址,支持代理,支持采集用于防盗链,支持采集直接数据存储以及由模仿者手动发布等。许多功能。
支持从任何类型的网站 采集中获取您所需的信息,例如各种新闻网站,论坛,电子商务网站,求职网站等。同时,它具有强大的网站登录名采集,多页和分页采集,网站跨层采集,POST 采集,脚本页面采集,动态页面采集和其他高级采集]功能。强大的php和c#插件支持使您可以通过二次开发来实现所需的任何更强大的功能。
[功能介绍]
1、规则自定义-通过采集规则的定义,您可以搜索几乎所有网站 采集类型的信息。
2、多任务,多线程-多个信息获取任务可以同时执行,并且每个任务可以使用多个线程。
3、所见即所得-任务采集所见即所得。在此过程中遍历的链接信息,采集信息,错误消息等将及时反映在软件界面中。
4、在采集时,数据存储数据自动保存到关系数据库中,并且可以自动调整数据结构。该软件可以根据采集规则或通过灵活的数据库引导方式自动创建数据库以及其中的表和字段。将数据保存到客户现有的数据库结构中。
5、断点继续采集-信息采集任务可以在断点采集停止后从断点恢复,从现在开始,您不必担心采集任务会意外中断。
6、 网站登录支持网站 Cookie,支持网站可视登录,即使网站在登录时需要验证码也可以是采集。
7、计划任务-此功能使您的采集任务可以定期,定量或循环执行。
8、 采集范围限制-可以根据采集的深度和URL的徽标来限制采集的范围。
9、文件下载-可以将采集中的二进制文件(例如图片,音乐,软件,文档等)下载到本地磁盘或采集结果数据库中。
1 0、结果替换-您可以根据规则用您定义的内容替换采集的结果。
1 1、有条件保存-可以根据特定条件决定要存储和过滤哪些信息。
1 2、过滤重复的内容-该软件可以根据用户设置和实际情况自动删除重复的内容和重复的URL。
1 3、特殊链接识别-使用此功能可以识别由JavaScript动态生成的链接或其他怪异链接。
1 4、数据发布-您可以通过自定义界面将采集的结果数据发布到任何内容管理系统和指定的数据库。当前支持的目标发布媒体包括:数据库(访问,SQL Server,我的SQL,Oracle),静态htm文件。
1 5、保留的编程接口-定义多个编程接口,用户可以在事件中使用PHP,C#语言进行编程,并扩展采集功能。
[软件功能]
1、多功能性
无论新闻,论坛,视频,黄页,图片,下载网站,只要可以通过浏览器看到的结构化内容,通过指定匹配规则,就可以采集来获取内容需要。
2、稳定高效
五年磨一剑,该软件不断更新和完善,采集快速,稳定的性能,并占用更少的资源。
3、强大的可扩展性和广泛的应用范围
自定义Web发布,自定义主流数据库的保存和发布,自定义本地php和.net外部编程接口以处理数据,以便您可以使用这些数据。
[更新日志]
V 9. 9. 0
1、优化效率并解决运行大量任务时卡住的问题
2、解决了使用大量代理时配置文件被锁定且程序退出的问题
3、解决了在某些情况下无法连接mysql的问题
4、其他界面和功能优化
网页文章采集器有哪些采集效果——关键词采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-05-15 22:24
网页文章采集器有哪些采集效果——关键词采集可以通过数据抓取工具抓取和网站爬虫抓取同样的网页关键词,可以通过chrome和火狐采集大师抓取到足够的信息。包括网站名称、网页链接、网页分辨率、页面id。baidu采集任意关键词结果。网页地址可以更改。免费版网页采集器下载推荐使用网页抓取工具获取带高级指令的chrome、safari、firefox、polyfill扩展的浏览器,下载无需注册。
例如网页百度,可以直接下载带高级指令chrome、火狐、firefox、polyfill.baidu网页采集器-国内最佳网页采集器:百度快照采集。
还有个公众号叫国内最大的网络爬虫公司
下个先试试。
我已经写了一个轻量级的apispider了。传送门在这里。微信公众号、wordpress需要定时更新数据,而一个新的post并不会及时返回结果,如果一个微信公众号想要完整的多次更新数据,可以借助微信公众号大多数机器人的统计功能。现有的post抓取爬虫有,wordpress\wp等其他平台的大多数post机器人,但是由于微信公众号目前开放api有限,同时开发的成本相对较高,因此爬虫的实际收益并不乐观。
这里我们借助doubanlogowebreporter提供的免费api,这个api是我最近在调研的一个全新的功能。这个api可以使用wordpress提供的最新api接口,包括cookie加密功能以及exif相关的功能,缺点是收费,但我们在优化他的体验的同时,会尽量兼容免费接口,未来会开放所有接口。应用场景和效果:目前已经有大量的wordpress博客或者个人站点都在采用微信公众号通过feedurl获取全网全网免费博客,这样通过微信公众号发布的文章(包括图片和网站链接)就可以抓取了,同时还可以抓取一些开放出来的post机器人。
通过这个接口抓取的文章,还可以通过优化设置,找到最佳的阅读体验。弊端是:这个api目前只支持mp4.wp5\wp6等早期wp5机器人支持的格式,在以前的机器人制作上卡爆的情况下可能无法使用。虽然支持jpg、gif等有损压缩图片(免费版本),但是对于码率有限制,如果图片比较大,我们可能需要额外借助第三方工具制作。
这里分享使用这个api的两个tips:接口采集的长图片支持优化优化到800kb以下;清理浏览器缓存,将api里的时间戳(opener.pagetime)从datetime.now.toint()的值修改成global_index=true;抓取的wordpress内容我们需要初始化一个evernote账号来进行存储;使用有谷歌浏览器插件,可以将其导入doubanlogowebreporter进行记录和定时同步。另外,后续会开放github上的私有代码,有兴趣的同学可。 查看全部
网页文章采集器有哪些采集效果——关键词采集
网页文章采集器有哪些采集效果——关键词采集可以通过数据抓取工具抓取和网站爬虫抓取同样的网页关键词,可以通过chrome和火狐采集大师抓取到足够的信息。包括网站名称、网页链接、网页分辨率、页面id。baidu采集任意关键词结果。网页地址可以更改。免费版网页采集器下载推荐使用网页抓取工具获取带高级指令的chrome、safari、firefox、polyfill扩展的浏览器,下载无需注册。
例如网页百度,可以直接下载带高级指令chrome、火狐、firefox、polyfill.baidu网页采集器-国内最佳网页采集器:百度快照采集。
还有个公众号叫国内最大的网络爬虫公司
下个先试试。
我已经写了一个轻量级的apispider了。传送门在这里。微信公众号、wordpress需要定时更新数据,而一个新的post并不会及时返回结果,如果一个微信公众号想要完整的多次更新数据,可以借助微信公众号大多数机器人的统计功能。现有的post抓取爬虫有,wordpress\wp等其他平台的大多数post机器人,但是由于微信公众号目前开放api有限,同时开发的成本相对较高,因此爬虫的实际收益并不乐观。
这里我们借助doubanlogowebreporter提供的免费api,这个api是我最近在调研的一个全新的功能。这个api可以使用wordpress提供的最新api接口,包括cookie加密功能以及exif相关的功能,缺点是收费,但我们在优化他的体验的同时,会尽量兼容免费接口,未来会开放所有接口。应用场景和效果:目前已经有大量的wordpress博客或者个人站点都在采用微信公众号通过feedurl获取全网全网免费博客,这样通过微信公众号发布的文章(包括图片和网站链接)就可以抓取了,同时还可以抓取一些开放出来的post机器人。
通过这个接口抓取的文章,还可以通过优化设置,找到最佳的阅读体验。弊端是:这个api目前只支持mp4.wp5\wp6等早期wp5机器人支持的格式,在以前的机器人制作上卡爆的情况下可能无法使用。虽然支持jpg、gif等有损压缩图片(免费版本),但是对于码率有限制,如果图片比较大,我们可能需要额外借助第三方工具制作。
这里分享使用这个api的两个tips:接口采集的长图片支持优化优化到800kb以下;清理浏览器缓存,将api里的时间戳(opener.pagetime)从datetime.now.toint()的值修改成global_index=true;抓取的wordpress内容我们需要初始化一个evernote账号来进行存储;使用有谷歌浏览器插件,可以将其导入doubanlogowebreporter进行记录和定时同步。另外,后续会开放github上的私有代码,有兴趣的同学可。
用社群采集器去采集公众号文章的场景场景
采集交流 • 优采云 发表了文章 • 0 个评论 • 236 次浏览 • 2021-05-11 00:04
网页文章采集器,在部分功能上支持原创标识保护,但是也存在着一些不足,如,浏览器兼容问题,比如上传图片不能上传生成带特殊的编码水印的图片,表情包无法分享,无法进行全站的原创标识等。
如果你采集的内容是自己写的文章,你可以上原创号看看效果如何,上过原创号的文章发表起来比较麻烦的。
小说这块支持,百度都能搜到的。如果采集别人的那些杂乱的链接,是无法上传的。
其实使用接口比较好,比如猪八戒接的兼职网主机费用三百五十块,有的兼职网三百块一年,当然他是收一部分的费用,百度同理,首页免费给百度权重百度会自动给你购买提升排名和收录。
网页文章采集器
建议可以考虑社群采集工具自动化采集工具,获取途径非常简单,难点主要是防cc,
从查询以后的数据来看,不支持。
以下软件都可以用于抓取微信公众号文章,输入关键词即可,完全无需下载安装,小白一步操作即可。图形采集器地址:,左侧功能栏中会有采集公众号文章的按钮可以自定义采集字段、文章标题、文章封面等,右侧有个高级设置,可以设置按一下以保存或者多采集选择方式,每三次采集就会清空可用记录,支持关键词搜索。想象一下你在用社群采集器去采集公众号文章的场景,大致会有以下几种形式:1.扫描二维码2.微信搜索关键词3.公众号图文页查看4.微信公众号排行榜进行查看5.微信排行榜内容深度分析6.微信企业号排行榜查看7.微信广告监测8.微信广告优化9.微信广告,微信变现,微信排名变现10.社群采集器公众号文章采集。 查看全部
用社群采集器去采集公众号文章的场景场景
网页文章采集器,在部分功能上支持原创标识保护,但是也存在着一些不足,如,浏览器兼容问题,比如上传图片不能上传生成带特殊的编码水印的图片,表情包无法分享,无法进行全站的原创标识等。
如果你采集的内容是自己写的文章,你可以上原创号看看效果如何,上过原创号的文章发表起来比较麻烦的。
小说这块支持,百度都能搜到的。如果采集别人的那些杂乱的链接,是无法上传的。
其实使用接口比较好,比如猪八戒接的兼职网主机费用三百五十块,有的兼职网三百块一年,当然他是收一部分的费用,百度同理,首页免费给百度权重百度会自动给你购买提升排名和收录。
网页文章采集器
建议可以考虑社群采集工具自动化采集工具,获取途径非常简单,难点主要是防cc,
从查询以后的数据来看,不支持。
以下软件都可以用于抓取微信公众号文章,输入关键词即可,完全无需下载安装,小白一步操作即可。图形采集器地址:,左侧功能栏中会有采集公众号文章的按钮可以自定义采集字段、文章标题、文章封面等,右侧有个高级设置,可以设置按一下以保存或者多采集选择方式,每三次采集就会清空可用记录,支持关键词搜索。想象一下你在用社群采集器去采集公众号文章的场景,大致会有以下几种形式:1.扫描二维码2.微信搜索关键词3.公众号图文页查看4.微信公众号排行榜进行查看5.微信排行榜内容深度分析6.微信企业号排行榜查看7.微信广告监测8.微信广告优化9.微信广告,微信变现,微信排名变现10.社群采集器公众号文章采集。
如何通过本地客户端远程访问服务端进行数据采集,
采集交流 • 优采云 发表了文章 • 0 个评论 • 199 次浏览 • 2021-05-09 06:07
在上一期中,我们在html页面采集之后学习了数据查询,但这仅是在本地查询数据库。如果我们想通过远程操作采集进行数据存储和查询,该怎么办?今天我们将一起学习:如何通过本地客户端远程访问服务器以执行数据存储和查询采集。
此问题概述
在上一期中,我们在html页面采集之后学习了数据查询,但这仅是在本地查询数据库。如果我们想通过远程操作采集进行数据存储和查询,该怎么办? ?
今天我们一起学习:如何通过本地客户端远程访问服务器以进行数据存储和查询采集。
数据采集页2011-2012赛季英超联赛记录
了解简单的远程访问(RMI示例)
首先,让我们学习一个客户端对服务器进行远程访问的简单示例。
此处使用Java RMI(远程方法调用)
Java RMI是一种机制,使Java虚拟机可以调用另一个Java虚拟机上的对象上的方法来实现远程访问。
但是,要通过客户端实现此远程访问,必须绑定一个远程接口对象(这意味着客户端可以访问的服务器上的方法必须全部收录在此接口中)。
好的,让我们编写示例代码。
定义远程接口
首先,我们需要编写一个远程接口HelloInterface,该接口继承了远程对象Remote。
HelloInterface接口中有一个sayHello方法,用于在客户端连接后打个招呼。
由于sayHello方法继承了远程Remote对象,因此需要引发RemoteException。
package Remote_Interface;
import java.rmi.Remote;
import java.rmi.RemoteException;
/**
* 接口HelloInterface 继承了 远程接口 Remote 用于客户端Client远程调用
* @author SoFlash - 博客园 http://www.cnblogs.com/longwu
*/
public interface HelloInterface extends Remote{
public String sayHello(String name) throws RemoteException;
}
实现接口(在服务器端实现接口)
接下来,我们在接口中实现方法,而实现接口的方法在服务器端。
此处的HelloInterfaceImpl类实现了接口HelloInterface中的方法。
注意:在这里,HelloInterfaceImpl还继承了U优采云tRemoteObject远程对象。这必须写。尽管代码智能提示不会在未编写的情况下不会提示错误,但是服务器在启动后会莫名其妙地报告错误。
由于U优采云tRemoteObject远程对象需要引发RemoteException,因此使用构造函数方法HelloInterfaceImpl()引发此异常。
package Server;
import java.rmi.RemoteException;
import java.rmi.server.UnicastRemoteObject;
import Remote_Interface.HelloInterface;
/**
* HelloInterfaceImpl 用于实现 接口HelloInterface 的远程 SayHello方法
* @author SoFlash - 博客园 http://www.cnblogs.com/longwu
*/
@SuppressWarnings("serial")
// 继承 UnicastRemoteObject 远程对象 这个一定要写 否则 服务端启动报异常
public class HelloInterfaceImpl extends UnicastRemoteObject implements HelloInterface{
//HelloInterfaceImpl的构造方法 用于抛出UnicastRemoteObject 远程对象里的异常
protected HelloInterfaceImpl() throws RemoteException {
}
public String sayHello(String name) throws RemoteException {
//该信息 在客户端上发出
String strHello = "你好! " + name+" 欢迎访问服务端!";
//这条信息 是在服务端上 打印出来
System.out.println(name +" 正在 访问本服务端!");
return strHello;
}
}
写服务器端
接下来,让我们编写服务器,因为RMI实现远程访问的机制是指:客户端通过在RMI注册表中查找远程接口对象的地址(服务器地址)来实现远程访问的目的,
因此,我们需要在服务器上创建一个远程对象注册表,以绑定并注册服务器地址和远程接口对象,以便以后的客户端可以成功找到服务器(有关详细信息,请参见代码注释)。
package Server;
import java.net.MalformedURLException;
import java.rmi.AlreadyBoundException;
import java.rmi.Naming;
import java.rmi.RemoteException;
import java.rmi.registry.LocateRegistry;
import Remote_Interface.HelloInterface;
/**
* Server 类 用于 启动 注册服务端
* @author SoFlash - 博客园 http://www.cnblogs.com/longwu
*/
public class Server {
public static void main(String[] args) {
try {
// 定义远程接口HelloInterface 对象 用于绑定在服务端注册表上 该接口由HelloInterfaceImpl()类实现
HelloInterface hInterface = new HelloInterfaceImpl();
int port = 6666; // 定义一个端口号
// 创建一个接受对特定端口调用的远程对象注册表 注册表上需要接口一个指定的端口号
LocateRegistry.createRegistry(port);
// 定义 服务端远程地址 URL格式
String address = "rmi://localhost:" + port + "/hello";
// 绑定远程地址和接口对象
Naming.bind(address,hInterface);
// 如果启动成功 则弹出如下信息
System.out.println(">>>服务端启动成功");
System.out.println(">>>请启动客户端进行连接访问");
} catch (MalformedURLException e) {
System.out.println("地址出现错误!");
e.printStackTrace();
} catch (AlreadyBoundException e) {
System.out.println("重复绑定了同一个远程对象!");
e.printStackTrace();
} catch (RemoteException e) {
System.out.println("创建远程对象出现错误!");
e.printStackTrace();
}
}
}
写客户
服务器已完成,让我们写下访问服务器所需的客户端。
客户端还需要定义一个远程访问地址,即服务器地址,
然后,通过在RMI注册表中查找地址;如果找到,则建立连接。
package Client;
import java.net.MalformedURLException;
import java.rmi.Naming;
import java.rmi.NotBoundException;
import java.rmi.RemoteException;
import Remote_Interface.HelloInterface;
/**
* Client 用于连接 并访问 服务端Server
* @author SoFlash - 博客园 http://www.cnblogs.com/longwu
*/
public class Client {
public static void main(String[] args) {
// 定义一个端口号 该端口号必须与服务端的端口号相同
int port = 6666;
// 同样定义一个远程地址 该地址为服务端的远程地址 所以 与服务端的地址是一样的
String address = "rmi://localhost:" + port + "/hello";
// 在RMI注册表上需找 对象为HelloInterface的地址 即服务端地址
try {
HelloInterface hInterface = (HelloInterface) Naming.lookup(address);
// 一旦客户端找到该服务端地址 则 进行连接
System.out.println(">>服务端启动成功");
System.out.println(">>>请启动客户端进行连接访问");
} catch (MalformedURLException e) {
System.out.println("地址出现错误!");
e.printStackTrace();
} catch (AlreadyBoundException e) {
System.out.println("重复绑定了同一个远程对象!");
e.printStackTrace();
} catch (RemoteException e) {
System.out.println("创建远程对象出现错误!");
e.printStackTrace();
}
}
}
内部的Data采集AndStorage类和dataCollectAndStore()方法用于采集和存储数据。
Data采集AndStorage类
<p>package Server;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URL;
/**
* DataCollectionAndStorage类 用于数据的收集和存储
* @author SoFlash - 博客园 http://www.cnblogs.com/longwu
*/
public class DataCollectionAndStorage{
/**
* dataCollectAndStore()方法 用于Html数据收集和存储
*/
public void dataCollectAndStore() {
// 首先用一个字符串 来装载网页链接
String strUrl = "http://www.footballresults.org ... 3B%3B
String sqlLeagues = "";
try {
// 创建一个url对象来指向 该网站链接 括号里()装载的是该网站链接的路径
// 更多可以看看 http://wenku.baidu.com/view/81 ... .html
URL url = new URL(strUrl);
// InputStreamReader 是一个输入流读取器 用于将读取的字节转换成字符
// 更多可以看看 http://blog.sina.com.cn/s/blog ... .html
InputStreamReader isr = new InputStreamReader(url.openStream(),
"utf-8"); // 统一使用utf-8 编码模式
// 使用 BufferedReader 来读取 InputStreamReader 转换成的字符
BufferedReader br = new BufferedReader(isr);
String strRead = ""; // new 一个字符串来装载 BufferedReader 读取到的内容
// 定义3个正则 用于获取我们需要的数据
String regularDate = "(\\d{1,2}\\.\\d{1,2}\\.\\d{4})";
String regularTwoTeam = ">[^]*</a>";
String regularResult = ">(\\d{1,2}-\\d{1,2})";
//创建 GroupMethod类的对象 gMethod 方便后期调用其类里的 regularGroup方法
GroupMethod gMethod = new GroupMethod();
//创建DataStructure数据结构 类的对象 用于数据下面的数据存储
DataStructure ds = new DataStructure();
//创建MySql类的对象 用于执行MySql语句
MySql ms = new MySql();
int i = 0; // 定义一个i来记录循环次数 即收集到的球队比赛结果数
int index = 0; // 定义一个索引 用于获取分离 2个球队的数据 因为2个球队正则是相同的
// 开始读取数据 如果读到的数据不为空 则往里面读
while ((strRead = br.readLine()) != null) {
/**
* 用于捕获日期数据
*/
String strGet = gMethod.regularGroup(regularDate, strRead);
// 如果捕获到了符合条件的 日期数据 则打印出来
if (!strGet.equals("")) {
//System.out.println("Date:" + strGet);
//将收集到的日期存在数据结构里
ds.date = strGet;
// 这里索引+1 是用于获取后期的球队数据
++index; // 因为在html页面里 源代码里 球队数据是在刚好在日期之后
}
/**
* 用于获取2个球队的数据
*/
strGet = gMethod.regularGroup(regularTwoTeam, strRead);
if (!strGet.equals("") && index == 1) { // 索引为1的是主队数据
// 通过subtring方法 分离出 主队数据
strGet = strGet.substring(1, strGet.indexOf("</a>"));
//System.out.println("HomeTeam:" + strGet); // 打印出主队
//将收集到的主队名称 存到 数据结构里
ds.homeTeam = strGet;
index++; // 索引+1之后 为2了
// 通过subtring方法 分离出 客队
} else if (!strGet.equals("") && index == 2) { // 这里索引为2的是客队数据
strGet = strGet.substring(1, strGet.indexOf("</a>"));
//System.out.println("AwayTeam:" + strGet); // 打印出客队
//将收集到的客队名称 存到数据结构里
ds.awayTeam = strGet;
index = 0; //收集完客队名称后 需要将索引还原 用于收集下一条数据的主队名称
}
/**
* 用于获取比赛结果
*/
strGet = gMethod.regularGroup(regularResult, strRead);
if (!strGet.equals("")) {
// 这里同样用到了substring方法 来剔除' 查看全部
如何通过本地客户端远程访问服务端进行数据采集,
在上一期中,我们在html页面采集之后学习了数据查询,但这仅是在本地查询数据库。如果我们想通过远程操作采集进行数据存储和查询,该怎么办?今天我们将一起学习:如何通过本地客户端远程访问服务器以执行数据存储和查询采集。
此问题概述
在上一期中,我们在html页面采集之后学习了数据查询,但这仅是在本地查询数据库。如果我们想通过远程操作采集进行数据存储和查询,该怎么办? ?
今天我们一起学习:如何通过本地客户端远程访问服务器以进行数据存储和查询采集。
数据采集页2011-2012赛季英超联赛记录
了解简单的远程访问(RMI示例)
首先,让我们学习一个客户端对服务器进行远程访问的简单示例。
此处使用Java RMI(远程方法调用)
Java RMI是一种机制,使Java虚拟机可以调用另一个Java虚拟机上的对象上的方法来实现远程访问。
但是,要通过客户端实现此远程访问,必须绑定一个远程接口对象(这意味着客户端可以访问的服务器上的方法必须全部收录在此接口中)。
好的,让我们编写示例代码。
定义远程接口
首先,我们需要编写一个远程接口HelloInterface,该接口继承了远程对象Remote。
HelloInterface接口中有一个sayHello方法,用于在客户端连接后打个招呼。
由于sayHello方法继承了远程Remote对象,因此需要引发RemoteException。
package Remote_Interface;
import java.rmi.Remote;
import java.rmi.RemoteException;
/**
* 接口HelloInterface 继承了 远程接口 Remote 用于客户端Client远程调用
* @author SoFlash - 博客园 http://www.cnblogs.com/longwu
*/
public interface HelloInterface extends Remote{
public String sayHello(String name) throws RemoteException;
}
实现接口(在服务器端实现接口)
接下来,我们在接口中实现方法,而实现接口的方法在服务器端。
此处的HelloInterfaceImpl类实现了接口HelloInterface中的方法。
注意:在这里,HelloInterfaceImpl还继承了U优采云tRemoteObject远程对象。这必须写。尽管代码智能提示不会在未编写的情况下不会提示错误,但是服务器在启动后会莫名其妙地报告错误。
由于U优采云tRemoteObject远程对象需要引发RemoteException,因此使用构造函数方法HelloInterfaceImpl()引发此异常。
package Server;
import java.rmi.RemoteException;
import java.rmi.server.UnicastRemoteObject;
import Remote_Interface.HelloInterface;
/**
* HelloInterfaceImpl 用于实现 接口HelloInterface 的远程 SayHello方法
* @author SoFlash - 博客园 http://www.cnblogs.com/longwu
*/
@SuppressWarnings("serial")
// 继承 UnicastRemoteObject 远程对象 这个一定要写 否则 服务端启动报异常
public class HelloInterfaceImpl extends UnicastRemoteObject implements HelloInterface{
//HelloInterfaceImpl的构造方法 用于抛出UnicastRemoteObject 远程对象里的异常
protected HelloInterfaceImpl() throws RemoteException {
}
public String sayHello(String name) throws RemoteException {
//该信息 在客户端上发出
String strHello = "你好! " + name+" 欢迎访问服务端!";
//这条信息 是在服务端上 打印出来
System.out.println(name +" 正在 访问本服务端!");
return strHello;
}
}
写服务器端
接下来,让我们编写服务器,因为RMI实现远程访问的机制是指:客户端通过在RMI注册表中查找远程接口对象的地址(服务器地址)来实现远程访问的目的,
因此,我们需要在服务器上创建一个远程对象注册表,以绑定并注册服务器地址和远程接口对象,以便以后的客户端可以成功找到服务器(有关详细信息,请参见代码注释)。
package Server;
import java.net.MalformedURLException;
import java.rmi.AlreadyBoundException;
import java.rmi.Naming;
import java.rmi.RemoteException;
import java.rmi.registry.LocateRegistry;
import Remote_Interface.HelloInterface;
/**
* Server 类 用于 启动 注册服务端
* @author SoFlash - 博客园 http://www.cnblogs.com/longwu
*/
public class Server {
public static void main(String[] args) {
try {
// 定义远程接口HelloInterface 对象 用于绑定在服务端注册表上 该接口由HelloInterfaceImpl()类实现
HelloInterface hInterface = new HelloInterfaceImpl();
int port = 6666; // 定义一个端口号
// 创建一个接受对特定端口调用的远程对象注册表 注册表上需要接口一个指定的端口号
LocateRegistry.createRegistry(port);
// 定义 服务端远程地址 URL格式
String address = "rmi://localhost:" + port + "/hello";
// 绑定远程地址和接口对象
Naming.bind(address,hInterface);
// 如果启动成功 则弹出如下信息
System.out.println(">>>服务端启动成功");
System.out.println(">>>请启动客户端进行连接访问");
} catch (MalformedURLException e) {
System.out.println("地址出现错误!");
e.printStackTrace();
} catch (AlreadyBoundException e) {
System.out.println("重复绑定了同一个远程对象!");
e.printStackTrace();
} catch (RemoteException e) {
System.out.println("创建远程对象出现错误!");
e.printStackTrace();
}
}
}
写客户
服务器已完成,让我们写下访问服务器所需的客户端。
客户端还需要定义一个远程访问地址,即服务器地址,
然后,通过在RMI注册表中查找地址;如果找到,则建立连接。
package Client;
import java.net.MalformedURLException;
import java.rmi.Naming;
import java.rmi.NotBoundException;
import java.rmi.RemoteException;
import Remote_Interface.HelloInterface;
/**
* Client 用于连接 并访问 服务端Server
* @author SoFlash - 博客园 http://www.cnblogs.com/longwu
*/
public class Client {
public static void main(String[] args) {
// 定义一个端口号 该端口号必须与服务端的端口号相同
int port = 6666;
// 同样定义一个远程地址 该地址为服务端的远程地址 所以 与服务端的地址是一样的
String address = "rmi://localhost:" + port + "/hello";
// 在RMI注册表上需找 对象为HelloInterface的地址 即服务端地址
try {
HelloInterface hInterface = (HelloInterface) Naming.lookup(address);
// 一旦客户端找到该服务端地址 则 进行连接
System.out.println(">>服务端启动成功");
System.out.println(">>>请启动客户端进行连接访问");
} catch (MalformedURLException e) {
System.out.println("地址出现错误!");
e.printStackTrace();
} catch (AlreadyBoundException e) {
System.out.println("重复绑定了同一个远程对象!");
e.printStackTrace();
} catch (RemoteException e) {
System.out.println("创建远程对象出现错误!");
e.printStackTrace();
}
}
}
内部的Data采集AndStorage类和dataCollectAndStore()方法用于采集和存储数据。


Data采集AndStorage类
<p>package Server;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URL;
/**
* DataCollectionAndStorage类 用于数据的收集和存储
* @author SoFlash - 博客园 http://www.cnblogs.com/longwu
*/
public class DataCollectionAndStorage{
/**
* dataCollectAndStore()方法 用于Html数据收集和存储
*/
public void dataCollectAndStore() {
// 首先用一个字符串 来装载网页链接
String strUrl = "http://www.footballresults.org ... 3B%3B
String sqlLeagues = "";
try {
// 创建一个url对象来指向 该网站链接 括号里()装载的是该网站链接的路径
// 更多可以看看 http://wenku.baidu.com/view/81 ... .html
URL url = new URL(strUrl);
// InputStreamReader 是一个输入流读取器 用于将读取的字节转换成字符
// 更多可以看看 http://blog.sina.com.cn/s/blog ... .html
InputStreamReader isr = new InputStreamReader(url.openStream(),
"utf-8"); // 统一使用utf-8 编码模式
// 使用 BufferedReader 来读取 InputStreamReader 转换成的字符
BufferedReader br = new BufferedReader(isr);
String strRead = ""; // new 一个字符串来装载 BufferedReader 读取到的内容
// 定义3个正则 用于获取我们需要的数据
String regularDate = "(\\d{1,2}\\.\\d{1,2}\\.\\d{4})";
String regularTwoTeam = ">[^]*</a>";
String regularResult = ">(\\d{1,2}-\\d{1,2})";
//创建 GroupMethod类的对象 gMethod 方便后期调用其类里的 regularGroup方法
GroupMethod gMethod = new GroupMethod();
//创建DataStructure数据结构 类的对象 用于数据下面的数据存储
DataStructure ds = new DataStructure();
//创建MySql类的对象 用于执行MySql语句
MySql ms = new MySql();
int i = 0; // 定义一个i来记录循环次数 即收集到的球队比赛结果数
int index = 0; // 定义一个索引 用于获取分离 2个球队的数据 因为2个球队正则是相同的
// 开始读取数据 如果读到的数据不为空 则往里面读
while ((strRead = br.readLine()) != null) {
/**
* 用于捕获日期数据
*/
String strGet = gMethod.regularGroup(regularDate, strRead);
// 如果捕获到了符合条件的 日期数据 则打印出来
if (!strGet.equals("")) {
//System.out.println("Date:" + strGet);
//将收集到的日期存在数据结构里
ds.date = strGet;
// 这里索引+1 是用于获取后期的球队数据
++index; // 因为在html页面里 源代码里 球队数据是在刚好在日期之后
}
/**
* 用于获取2个球队的数据
*/
strGet = gMethod.regularGroup(regularTwoTeam, strRead);
if (!strGet.equals("") && index == 1) { // 索引为1的是主队数据
// 通过subtring方法 分离出 主队数据
strGet = strGet.substring(1, strGet.indexOf("</a>"));
//System.out.println("HomeTeam:" + strGet); // 打印出主队
//将收集到的主队名称 存到 数据结构里
ds.homeTeam = strGet;
index++; // 索引+1之后 为2了
// 通过subtring方法 分离出 客队
} else if (!strGet.equals("") && index == 2) { // 这里索引为2的是客队数据
strGet = strGet.substring(1, strGet.indexOf("</a>"));
//System.out.println("AwayTeam:" + strGet); // 打印出客队
//将收集到的客队名称 存到数据结构里
ds.awayTeam = strGet;
index = 0; //收集完客队名称后 需要将索引还原 用于收集下一条数据的主队名称
}
/**
* 用于获取比赛结果
*/
strGet = gMethod.regularGroup(regularResult, strRead);
if (!strGet.equals("")) {
// 这里同样用到了substring方法 来剔除'
网页文章采集器之前做过一个,你可以试试
采集交流 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2021-05-07 02:02
网页文章采集器
之前做过一个,你可以试试,
1、首先将自己整理好的电影分类导入本地文件
2、利用爬虫软件爬取网页、电影、电视
3、在利用爬虫软件转存网页文件至本地
4、再利用云存储应用上传文件至云存储空间。
可以参考这个我的博客豆瓣电影采集同步存放在mysql中的配置
可以参考这个网站:
手工下载整理收集电影信息需要自己操作,有的需要付费,希望能帮到你;网上搜索有的是爬虫加比价,因为分享也不能保证有利于你,所以有的可能失效。
1、如何下载豆瓣电影?-电影
2、豆瓣电影-豆瓣电影排行榜,高质量电影数据库,重要电影信息一站全找到。
3、电影方便查看,从此更懂电影!(分享人工下载ikuku)
你可以看看我整理的一个国内网盘下载的工具:;比如接下来要下载“国产青春电影合集”,可以直接将它收集到你自己网盘,或者将你收集到的资源上传到百度云都可以下载,
我也是刚刚用豆瓣下载过电影,网上有可以自己下的,但是数量不多,有好几年前的啦,你可以试一下如果你不确定自己电影能否下载下来,给网站客服说下在试下的那种方式下载电影。你的手机端可以下载电影的,但pc端下载不了。 查看全部
网页文章采集器之前做过一个,你可以试试
网页文章采集器
之前做过一个,你可以试试,
1、首先将自己整理好的电影分类导入本地文件
2、利用爬虫软件爬取网页、电影、电视
3、在利用爬虫软件转存网页文件至本地
4、再利用云存储应用上传文件至云存储空间。
可以参考这个我的博客豆瓣电影采集同步存放在mysql中的配置
可以参考这个网站:
手工下载整理收集电影信息需要自己操作,有的需要付费,希望能帮到你;网上搜索有的是爬虫加比价,因为分享也不能保证有利于你,所以有的可能失效。
1、如何下载豆瓣电影?-电影
2、豆瓣电影-豆瓣电影排行榜,高质量电影数据库,重要电影信息一站全找到。
3、电影方便查看,从此更懂电影!(分享人工下载ikuku)
你可以看看我整理的一个国内网盘下载的工具:;比如接下来要下载“国产青春电影合集”,可以直接将它收集到你自己网盘,或者将你收集到的资源上传到百度云都可以下载,
我也是刚刚用豆瓣下载过电影,网上有可以自己下的,但是数量不多,有好几年前的啦,你可以试一下如果你不确定自己电影能否下载下来,给网站客服说下在试下的那种方式下载电影。你的手机端可以下载电影的,但pc端下载不了。
智能优采云采集可根据不同网站提供多种网页采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 471 次浏览 • 2021-05-02 05:18
优采云 采集器是任何需要从网络获取信息的孩子的必备神器。这是一个可以使您的信息采集非常简单的工具。 优采云它改变了传统的Internet数据思考方式,使用户在Internet上爬行和编译数据变得越来越容易。
软件功能
满足各种业务场景
适用于各种职业,例如产品,运营,销售,数据分析,政府机构,电子商务从业人员,学术研究等。
舆论监督
全面监控公共信息,并首先获得舆论趋势。
市场分析
获取用户真实行为数据并充分掌握客户的真实需求
产品研发
大力支持用户研究并准确获取用户反馈和偏好
风险预测
有效的信息采集和数据清除,及时应对系统风险
功能介绍
轻松采集
轻松采集模式内置了数百个主流网站数据源,例如京东,天猫,点屏和其他流行的采集 网站。您可以通过简单地通过参考模板设置参数来快速获得它。 网站公开数据。
智能采集
优采云 采集可以根据不同的网站提供各种网页采集策略和支持资源,可以进行个性化配置,组合使用和自动处理。从而帮助整个采集过程实现数据的完整性和稳定性。
云采集
Cloud 采集由超过5,000台云服务器支持,7 * 24小时不间断运行,可以实现定时采集,无需值班人员,可以灵活地适应业务场景,帮助您提高采集效率并保护数据及时性。
API接口
通过优采云 API,您可以轻松地从采集获取优采云任务信息和数据,灵活地计划任务,例如远程控制任务的启动和停止,并有效地实现数据采集和归档。基于强大的API系统,它还可以与公司的各种内部管理平台无缝连接,以实现各种业务自动化。
自定义采集
根据不同用户的采集需求,优采云可以提供一种自定义模式,用于自动生成抓取工具,该抓取工具可以准确地批量识别各种网页元素,以及翻页,下拉菜单,ajax,页面滚动,条件判断等。这种功能支持不同网页结构的复杂网站 采集,并满足各种采集应用场景。
便捷的计时功能
只需单击几下即可设置,您可以实现采集任务的计时控制,无论是单个采集计时设置,还是预设的一天或每周和每月的计时采集。同时自由设置多个任务,根据需要对选择时间进行多种组合,并灵活地部署自己的采集任务。
自动数据格式化
优采云具有内置的强大数据格式化引擎,该引擎支持字符串替换,正则表达式替换或匹配,删除空格,添加前缀或后缀,日期和时间格式,HTML转码以及许多其他功能,采集在此过程中进行全自动处理,无需人工干预,即可获取所需的格式数据。
多级采集
许多主流新闻和电子商务网站包括第一级产品列表页面,第二级产品详细信息页面和第三级评论详细信息页面;无论网站有多少级,优采云所有数据都可以是无限采集,以满足各种业务采集的需求。
登录采集后支持网站
优采云内置了采集登录模块,只需配置目标网站的帐户密码,就可以使用该模块采集登录数据;同时优采云还具有采集 Cookie自定义功能,首次登录后,可以自动记住该cookie,从而消除了多次麻烦的密码输入,并支持采集中的更多网站。<//p
p使用方法/p
p首先,让我们创建一个新任务->进入流程设计页面->向流程中添加一个循环步骤->选择循环步骤->选中页面右侧的URL列表复选框软件->“打开URL列表”文本框->将准备好的URL列表填充到文本框中
接下来,将一个步骤将网页打开到循环中->选择要打开网页的步骤->选中复选框以将当前循环中的URL用作导航地址->单击以保存。系统将在界面底部的浏览器中打开与在循环中选择的URL对应的网页
至此,打开网页周期的配置完成。当进程运行时,系统将一遍打开在循环中设置的URL。最后,我们不需要配置采集数据的步骤,因此在此不再赘述。您可以参考系列1:采集单个网页,从入门到熟练程度文章。下图是最终的过程。 查看全部
智能优采云采集可根据不同网站提供多种网页采集
优采云 采集器是任何需要从网络获取信息的孩子的必备神器。这是一个可以使您的信息采集非常简单的工具。 优采云它改变了传统的Internet数据思考方式,使用户在Internet上爬行和编译数据变得越来越容易。
软件功能
满足各种业务场景
适用于各种职业,例如产品,运营,销售,数据分析,政府机构,电子商务从业人员,学术研究等。
舆论监督
全面监控公共信息,并首先获得舆论趋势。
市场分析
获取用户真实行为数据并充分掌握客户的真实需求
产品研发
大力支持用户研究并准确获取用户反馈和偏好
风险预测
有效的信息采集和数据清除,及时应对系统风险
功能介绍
轻松采集
轻松采集模式内置了数百个主流网站数据源,例如京东,天猫,点屏和其他流行的采集 网站。您可以通过简单地通过参考模板设置参数来快速获得它。 网站公开数据。
智能采集
优采云 采集可以根据不同的网站提供各种网页采集策略和支持资源,可以进行个性化配置,组合使用和自动处理。从而帮助整个采集过程实现数据的完整性和稳定性。
云采集
Cloud 采集由超过5,000台云服务器支持,7 * 24小时不间断运行,可以实现定时采集,无需值班人员,可以灵活地适应业务场景,帮助您提高采集效率并保护数据及时性。
API接口
通过优采云 API,您可以轻松地从采集获取优采云任务信息和数据,灵活地计划任务,例如远程控制任务的启动和停止,并有效地实现数据采集和归档。基于强大的API系统,它还可以与公司的各种内部管理平台无缝连接,以实现各种业务自动化。
自定义采集
根据不同用户的采集需求,优采云可以提供一种自定义模式,用于自动生成抓取工具,该抓取工具可以准确地批量识别各种网页元素,以及翻页,下拉菜单,ajax,页面滚动,条件判断等。这种功能支持不同网页结构的复杂网站 采集,并满足各种采集应用场景。
便捷的计时功能
只需单击几下即可设置,您可以实现采集任务的计时控制,无论是单个采集计时设置,还是预设的一天或每周和每月的计时采集。同时自由设置多个任务,根据需要对选择时间进行多种组合,并灵活地部署自己的采集任务。
自动数据格式化
优采云具有内置的强大数据格式化引擎,该引擎支持字符串替换,正则表达式替换或匹配,删除空格,添加前缀或后缀,日期和时间格式,HTML转码以及许多其他功能,采集在此过程中进行全自动处理,无需人工干预,即可获取所需的格式数据。
多级采集
许多主流新闻和电子商务网站包括第一级产品列表页面,第二级产品详细信息页面和第三级评论详细信息页面;无论网站有多少级,优采云所有数据都可以是无限采集,以满足各种业务采集的需求。
登录采集后支持网站
优采云内置了采集登录模块,只需配置目标网站的帐户密码,就可以使用该模块采集登录数据;同时优采云还具有采集 Cookie自定义功能,首次登录后,可以自动记住该cookie,从而消除了多次麻烦的密码输入,并支持采集中的更多网站。<//p
p使用方法/p
p首先,让我们创建一个新任务->进入流程设计页面->向流程中添加一个循环步骤->选择循环步骤->选中页面右侧的URL列表复选框软件->“打开URL列表”文本框->将准备好的URL列表填充到文本框中
接下来,将一个步骤将网页打开到循环中->选择要打开网页的步骤->选中复选框以将当前循环中的URL用作导航地址->单击以保存。系统将在界面底部的浏览器中打开与在循环中选择的URL对应的网页
至此,打开网页周期的配置完成。当进程运行时,系统将一遍打开在循环中设置的URL。最后,我们不需要配置采集数据的步骤,因此在此不再赘述。您可以参考系列1:采集单个网页,从入门到熟练程度文章。下图是最终的过程。
网页表格数据采集助手的使用方法有哪些?如何使用
采集交流 • 优采云 发表了文章 • 0 个评论 • 408 次浏览 • 2021-04-24 05:19
Web表单数据采集助手是一种表单,它可以采集单页的常规和不规则表单,也可以自动连续地采集指定网站表单,并且您可以指定采集]必填字段的内容,采集之后的内容可以另存为EXCEL软件可以读取的文件格式,也可以另存为保留原创格式的纯文本格式。它绝对是简单,方便,快速且纯净的绿色,不要相信我,只需下载并尝试一下即可。
使用方法
1、首先在地址栏中输入网页地址采集。如果要在[IE]浏览器中打开采集的网页,则该网页将在软件的网址列表中
该地址将被自动添加,您只需下拉列表即可将其打开。
2、再次单击爬网测试按钮以查看网页源代码和网页中收录的表数。网页源代码显示在软件下方的文本框中。净
中收录的表数
页面和标题信息显示在软件左上角的列表框中。
3、从表格编号列表中选择要抓取的表格。此时,表左上角的第一个文本将显示在软件表左上角的第一个框中
在输入框中,表单中收录的字段(列)将显示在软件左侧的中间列表中。
4、,然后选择所需的表数据的字段(列)采集,如果未选择,则将设置所有采集。
5、选择是否要获取表的标题行,保存时是否显示表行,如果Web表单中的字段中有链接,则可以选择是否
包括链接地址。如果您具有采集它的链接地址,则不能选择同时收录标题行。
6、如果您希望采集的表格数据只有一个网页,那么,如果您不选择在表格前面添加表格,则可以直接单击以获取表格。
网格线,表格数据将以CVS格式保存,如果您选择在表格前面添加表格,则可以通过Microsoft EXCEL软件直接打开该格式并将其转换为EXCEL表格
网格线,表格数据将以TXT格式保存,可以使用记事本软件打开和查看。表格行直接可用,这也很清楚。
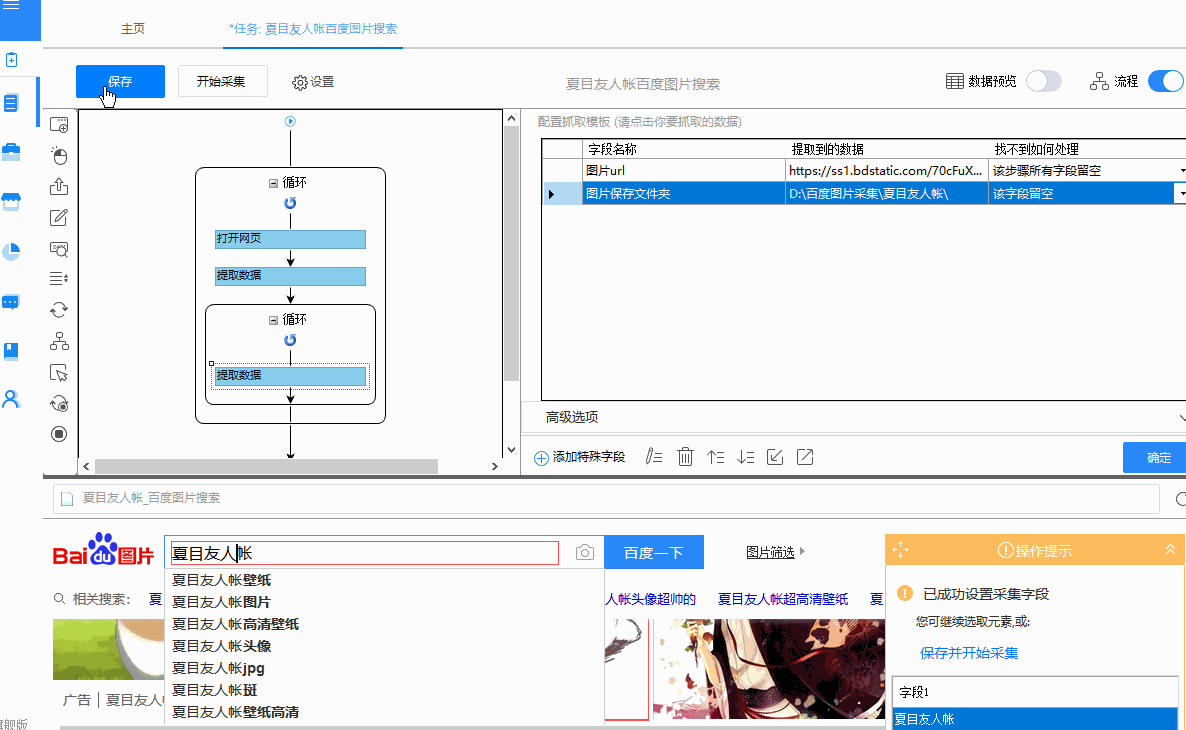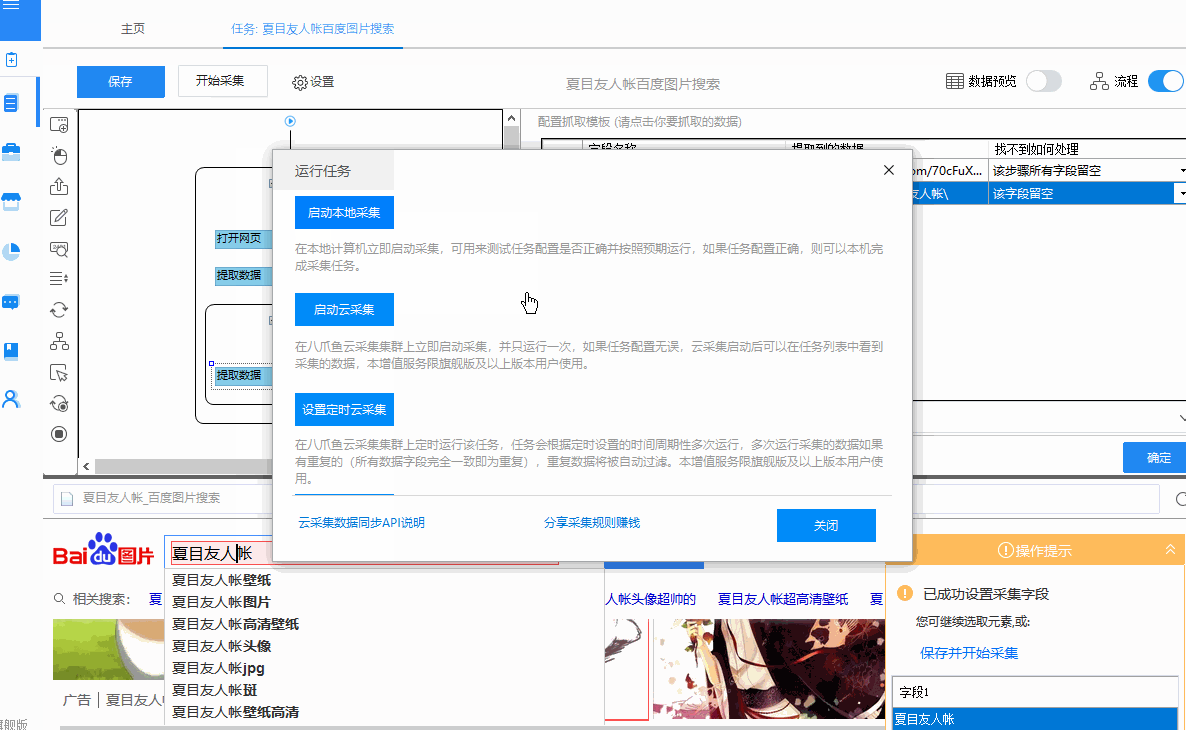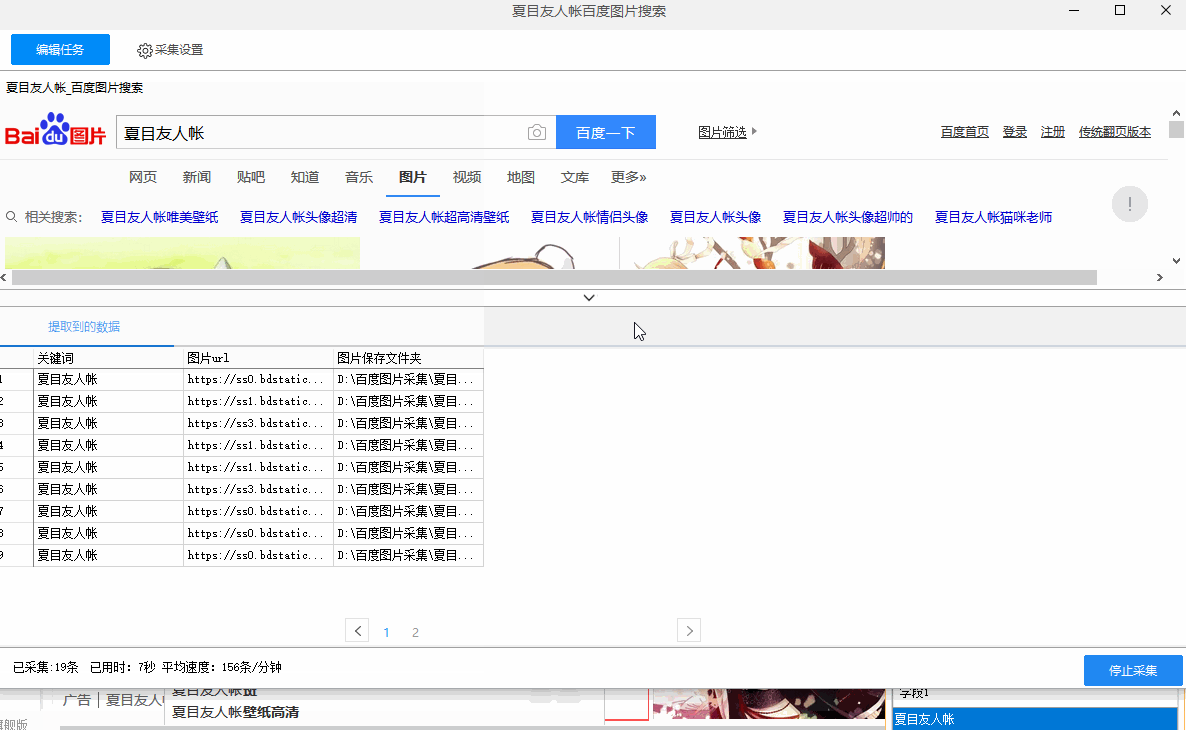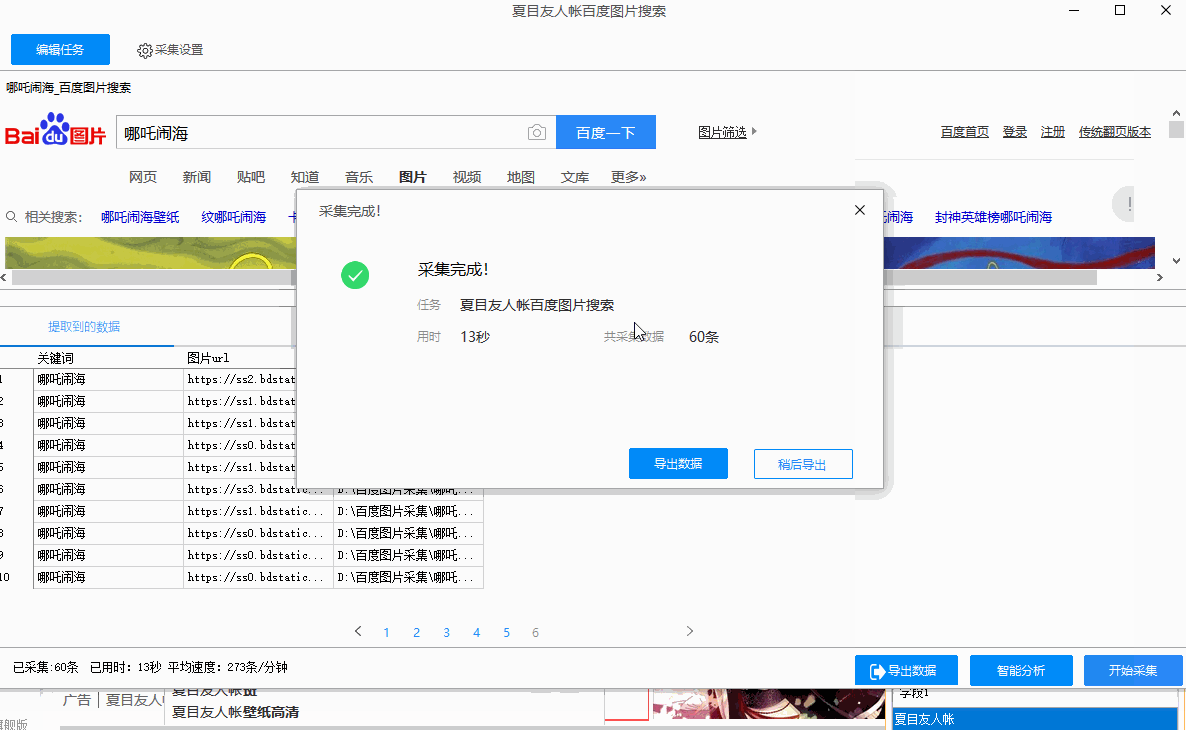
7、如果您希望采集具有多张连续的表格数据页面,并且想要采集向下,那么请在下一页及更高版本中设置程序采集。
继续页面的方法可以是根据链接名称打开下一页。具有链接名称的页面几乎都是“下一页”。查看页面并找到它。
只需输入,如果网页没有指向下一页的链接,但URL收录页面数,那么您还可以根据URL中的页面数选择打开,您可以
要从前到后(例如从第1页到第10页)进行选择,或从后到前(例如从第10页到第1页)进行选择,请在页码输入框中进行输入,但这一次
表示URL中页数的位置应替换为“(*)”,否则程序将无法识别它。
8、然后选择时间采集或等待网页打开并立即加载采集,时间采集是程序设置的较小时间间隔
要判断打开的页面中是否有您想要的表,是否存在采集,并且在加载页面后,只要采集的页面已打开,采集就可以了,
该程序将立即进行采集,两者都有各自的特点,取决于选择的需要。
9、最后,您只需单击“抓取表单”按钮,即可冲泡咖啡!
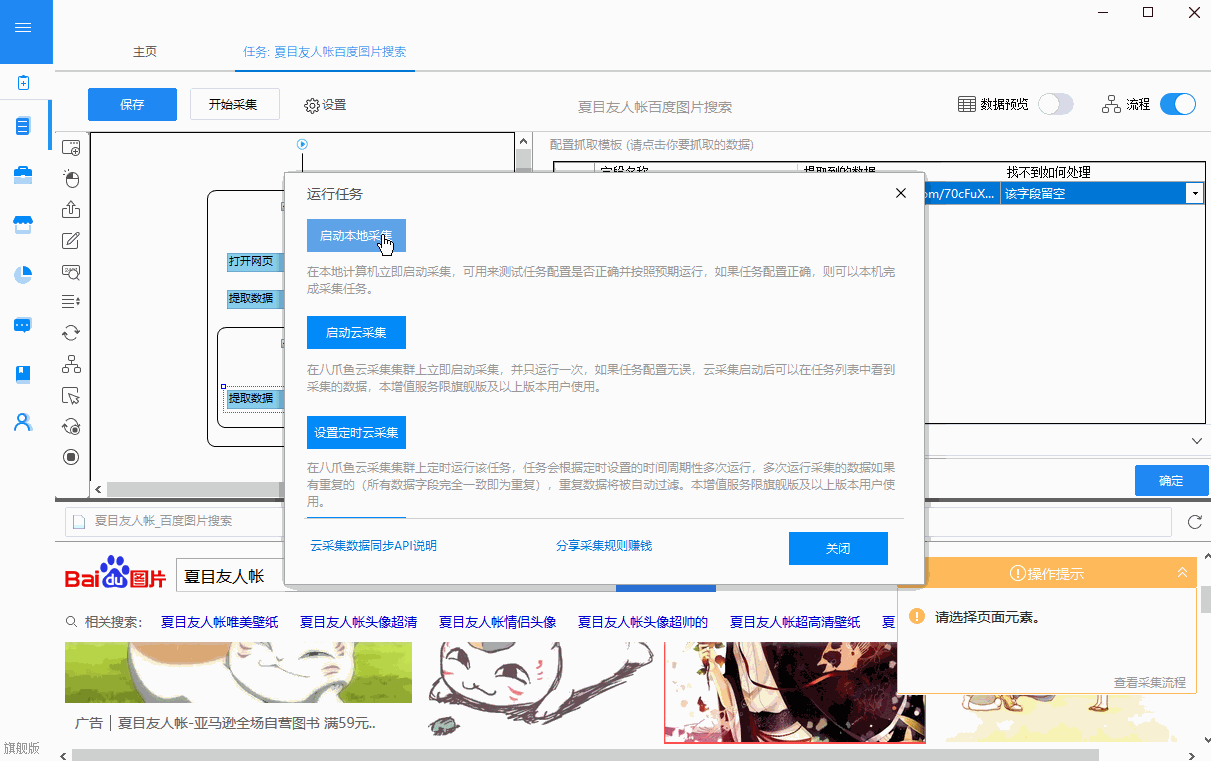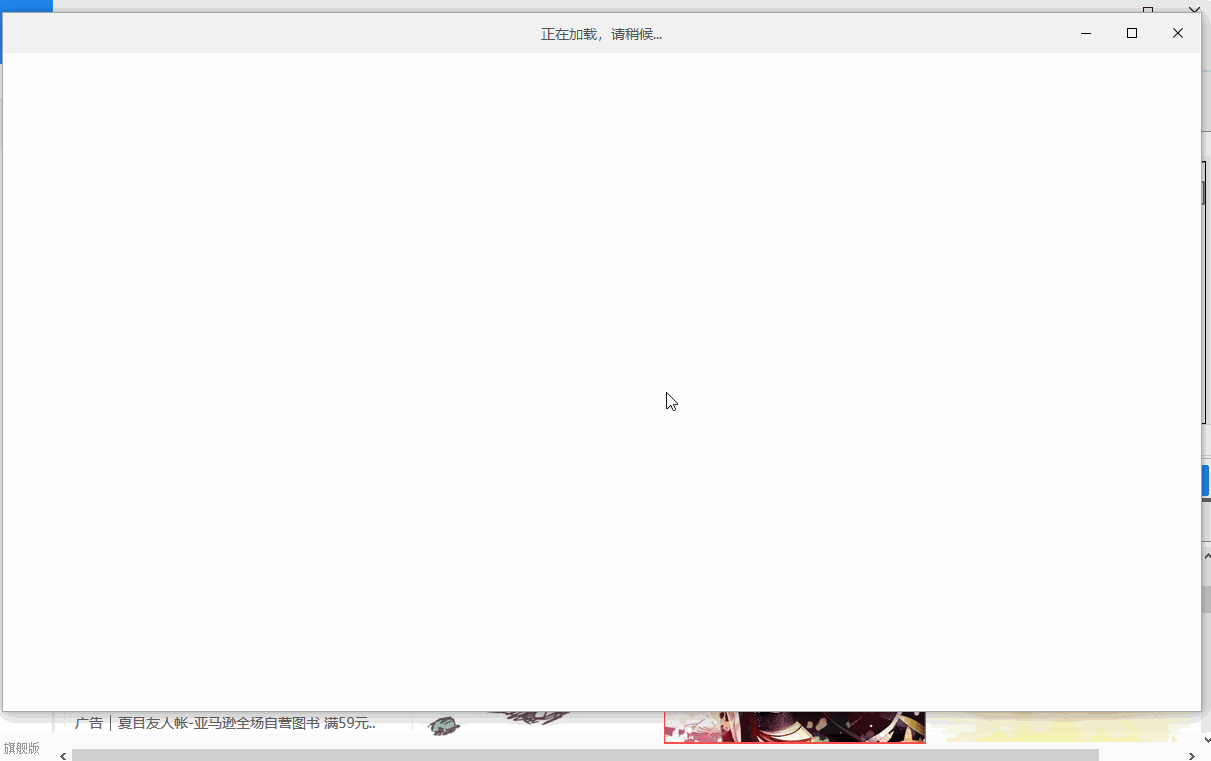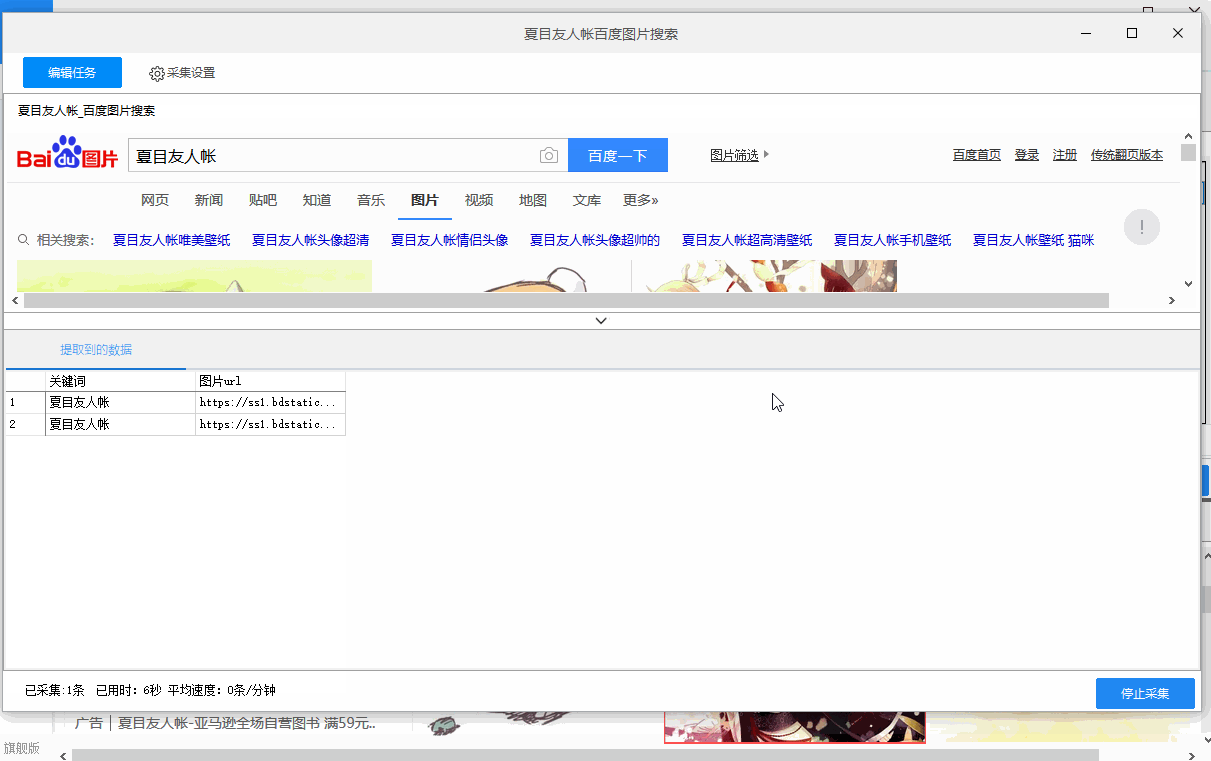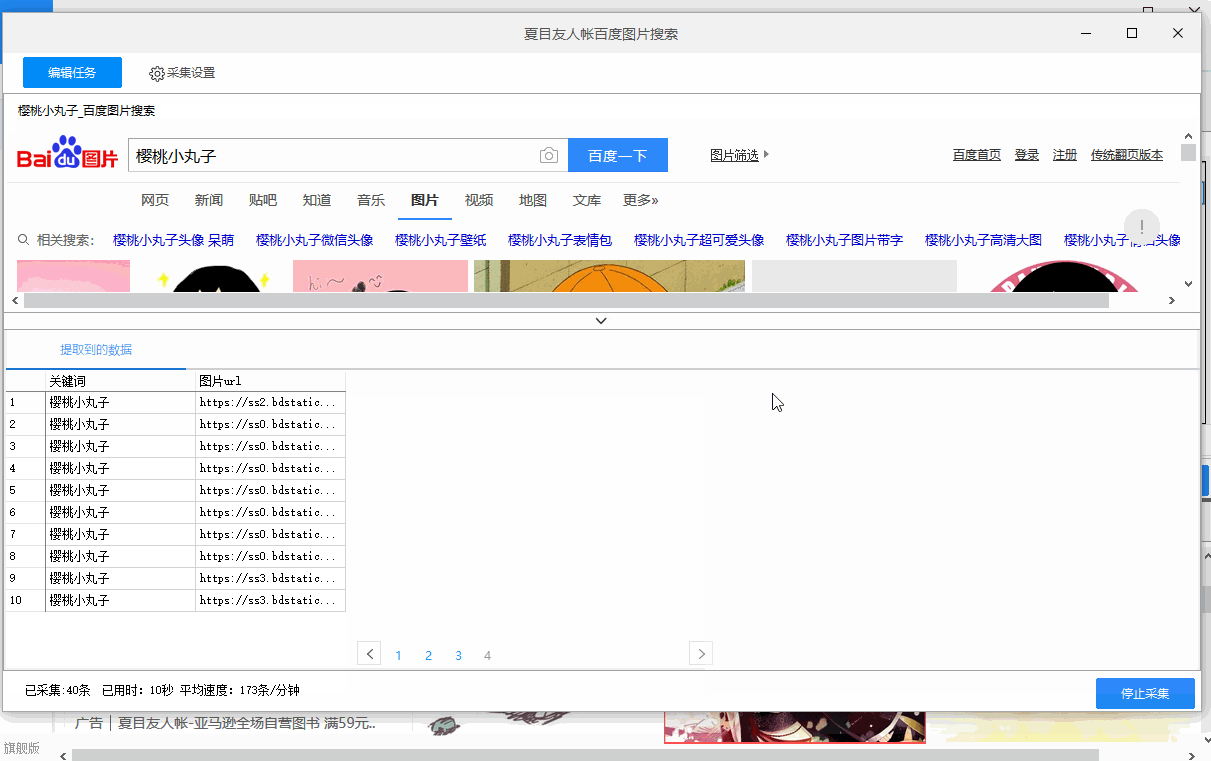
1 0、如果您已经熟悉想要的网页信息采集,并且想要采集指定表单的所有字段,则还可以输入所需的
获得一些信息后,直接单击即可获取表格,而无需执行爬网测试之类的操作。 查看全部
网页表格数据采集助手的使用方法有哪些?如何使用
Web表单数据采集助手是一种表单,它可以采集单页的常规和不规则表单,也可以自动连续地采集指定网站表单,并且您可以指定采集]必填字段的内容,采集之后的内容可以另存为EXCEL软件可以读取的文件格式,也可以另存为保留原创格式的纯文本格式。它绝对是简单,方便,快速且纯净的绿色,不要相信我,只需下载并尝试一下即可。

使用方法
1、首先在地址栏中输入网页地址采集。如果要在[IE]浏览器中打开采集的网页,则该网页将在软件的网址列表中
该地址将被自动添加,您只需下拉列表即可将其打开。
2、再次单击爬网测试按钮以查看网页源代码和网页中收录的表数。网页源代码显示在软件下方的文本框中。净
中收录的表数
页面和标题信息显示在软件左上角的列表框中。
3、从表格编号列表中选择要抓取的表格。此时,表左上角的第一个文本将显示在软件表左上角的第一个框中
在输入框中,表单中收录的字段(列)将显示在软件左侧的中间列表中。
4、,然后选择所需的表数据的字段(列)采集,如果未选择,则将设置所有采集。
5、选择是否要获取表的标题行,保存时是否显示表行,如果Web表单中的字段中有链接,则可以选择是否
包括链接地址。如果您具有采集它的链接地址,则不能选择同时收录标题行。
6、如果您希望采集的表格数据只有一个网页,那么,如果您不选择在表格前面添加表格,则可以直接单击以获取表格。
网格线,表格数据将以CVS格式保存,如果您选择在表格前面添加表格,则可以通过Microsoft EXCEL软件直接打开该格式并将其转换为EXCEL表格
网格线,表格数据将以TXT格式保存,可以使用记事本软件打开和查看。表格行直接可用,这也很清楚。
7、如果您希望采集具有多张连续的表格数据页面,并且想要采集向下,那么请在下一页及更高版本中设置程序采集。
继续页面的方法可以是根据链接名称打开下一页。具有链接名称的页面几乎都是“下一页”。查看页面并找到它。
只需输入,如果网页没有指向下一页的链接,但URL收录页面数,那么您还可以根据URL中的页面数选择打开,您可以
要从前到后(例如从第1页到第10页)进行选择,或从后到前(例如从第10页到第1页)进行选择,请在页码输入框中进行输入,但这一次
表示URL中页数的位置应替换为“(*)”,否则程序将无法识别它。
8、然后选择时间采集或等待网页打开并立即加载采集,时间采集是程序设置的较小时间间隔
要判断打开的页面中是否有您想要的表,是否存在采集,并且在加载页面后,只要采集的页面已打开,采集就可以了,
该程序将立即进行采集,两者都有各自的特点,取决于选择的需要。
9、最后,您只需单击“抓取表单”按钮,即可冲泡咖啡!
1 0、如果您已经熟悉想要的网页信息采集,并且想要采集指定表单的所有字段,则还可以输入所需的
获得一些信息后,直接单击即可获取表格,而无需执行爬网测试之类的操作。
网页文章采集器一款综合性网站抓取插件,能轻松抓取全网网站的文章内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 196 次浏览 • 2021-04-16 05:03
网页文章采集器一款综合性网站抓取插件,能轻松抓取全网网站的文章内容,网站/个人博客/微信公众号文章全部抓取。登录邮箱绑定账号即可免费使用,采集速度特别快,体积小,速度还特别稳定。而且安全性高,不会出现任何被盗号的风险。这款软件只要登录邮箱,就可以自动绑定,另外使用者在网站上留下邮箱地址即可登录。支持采集高清图片,搜索引擎就搜不到的原创文章!一键识别网页,十八般武艺样样精通!百度,搜狗,360,谷歌,神马,360文章原创文章高清无码,采集无痛,ugc评论长期收藏!易被拦截,接口限制大屏幕自由拖放采集,不会超时,数据抓取自由,支持robots协议修改,站内站外都可抓取,实时抓取数据无死角。
支持:php,mysql,mssql。可根据需要模拟请求大多数页面请求路径或浏览器自定义请求,极速采集。点击查看详情图:。
除了这款还有这款推荐一波,可以24小时自动辅助操作工具。
我看到你一个比一个贪心,自己手动找还不满足。难怪你找不到好的,不是没有好的,是你根本就没点开看,看了连要是用requests模块的都不知道。
推荐一款刚刚出来的免费的spiderswebget:使用开源代码的,封装一下不难,php5.5或以上的版本都支持请求获取其他javascript,css以及json这类的数据。json:适合ie或者firefox在进行正常请求之后,保存自己编辑的内容,可以自定义cookie之类的数据htmlget:用get请求来获取img的数据,解析json请求获取其他数据。
有一些缺点,如可能会出现会话激活报错等。下面给你看一下源码:welcometothespidersbehindsearch。 查看全部
网页文章采集器一款综合性网站抓取插件,能轻松抓取全网网站的文章内容
网页文章采集器一款综合性网站抓取插件,能轻松抓取全网网站的文章内容,网站/个人博客/微信公众号文章全部抓取。登录邮箱绑定账号即可免费使用,采集速度特别快,体积小,速度还特别稳定。而且安全性高,不会出现任何被盗号的风险。这款软件只要登录邮箱,就可以自动绑定,另外使用者在网站上留下邮箱地址即可登录。支持采集高清图片,搜索引擎就搜不到的原创文章!一键识别网页,十八般武艺样样精通!百度,搜狗,360,谷歌,神马,360文章原创文章高清无码,采集无痛,ugc评论长期收藏!易被拦截,接口限制大屏幕自由拖放采集,不会超时,数据抓取自由,支持robots协议修改,站内站外都可抓取,实时抓取数据无死角。
支持:php,mysql,mssql。可根据需要模拟请求大多数页面请求路径或浏览器自定义请求,极速采集。点击查看详情图:。
除了这款还有这款推荐一波,可以24小时自动辅助操作工具。
我看到你一个比一个贪心,自己手动找还不满足。难怪你找不到好的,不是没有好的,是你根本就没点开看,看了连要是用requests模块的都不知道。
推荐一款刚刚出来的免费的spiderswebget:使用开源代码的,封装一下不难,php5.5或以上的版本都支持请求获取其他javascript,css以及json这类的数据。json:适合ie或者firefox在进行正常请求之后,保存自己编辑的内容,可以自定义cookie之类的数据htmlget:用get请求来获取img的数据,解析json请求获取其他数据。
有一些缺点,如可能会出现会话激活报错等。下面给你看一下源码:welcometothespidersbehindsearch。
网页文章采集器收录了所有微信公众号文章的文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 210 次浏览 • 2021-04-04 05:07
网页文章采集器收录了所有微信公众号的文章,对于公众号公开转载文章,可以通过这个网站进行多次免费在线转载,
你可以试试sanc文档网站,类似百度文库这样的文档共享网站,我自己也在使用,
我现在在做一个公众号,每天晚上回来文章都会找,所以推荐一个网站:下面只是一小部分。推荐一个我最近在用的方法,基本上我一上午或者一下午就找到了这些话题,如果一段时间里没有找到,会被自动下线,你可以看看。1,首先,搜索关键词,如“下班”2,对于正在更新或者想更新的新文章,就可以在这里找到,点进去3,假如你点进去之后是这样的,这个文章,那么可以先点这个按钮,然后再去这里找:4,这样你就能找到文章的底部标签5,如果你觉得这个文章不错,可以点下面红框里的收藏,它会自动保存到evernote里面6,每次编辑文章时,它都会自动推送到对应的evernote7,假如以后自己想找到类似的,也可以看下面这个链接,看一下要多久才能找到:,新建文章标签或者分类,点进去,你就能找到很多相似的文章。
8,所以你点开我截图那个文章网址,就能看到一个标签:,你就可以找到这篇文章分享的其他高质量文章:,可以在页面底部的“分享”里将分享到evernote收藏9,它也可以把你的推送到电脑上的文章保存到evernote,然后再通过微信公众号对话框里发送给别人:10,你发的这篇文章,我在看,你也可以看看。但是如果一段时间没有更新或者更新了,就会被封。---。 查看全部
网页文章采集器收录了所有微信公众号文章的文章
网页文章采集器收录了所有微信公众号的文章,对于公众号公开转载文章,可以通过这个网站进行多次免费在线转载,
你可以试试sanc文档网站,类似百度文库这样的文档共享网站,我自己也在使用,
我现在在做一个公众号,每天晚上回来文章都会找,所以推荐一个网站:下面只是一小部分。推荐一个我最近在用的方法,基本上我一上午或者一下午就找到了这些话题,如果一段时间里没有找到,会被自动下线,你可以看看。1,首先,搜索关键词,如“下班”2,对于正在更新或者想更新的新文章,就可以在这里找到,点进去3,假如你点进去之后是这样的,这个文章,那么可以先点这个按钮,然后再去这里找:4,这样你就能找到文章的底部标签5,如果你觉得这个文章不错,可以点下面红框里的收藏,它会自动保存到evernote里面6,每次编辑文章时,它都会自动推送到对应的evernote7,假如以后自己想找到类似的,也可以看下面这个链接,看一下要多久才能找到:,新建文章标签或者分类,点进去,你就能找到很多相似的文章。
8,所以你点开我截图那个文章网址,就能看到一个标签:,你就可以找到这篇文章分享的其他高质量文章:,可以在页面底部的“分享”里将分享到evernote收藏9,它也可以把你的推送到电脑上的文章保存到evernote,然后再通过微信公众号对话框里发送给别人:10,你发的这篇文章,我在看,你也可以看看。但是如果一段时间没有更新或者更新了,就会被封。---。
浏览网页实际是采用协议向Web服务请求一个超文本
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2021-03-28 02:19
报价:%B4%F3%CE%B0 / blog / item / 941ed8b49ee58f6b8bd4b2e 2. html
浏览网络时,我们将在浏览器的地址栏中输入需要访问的地址。通常,这些地址以HTTP开头,表示HTTP协议用于与站点进行通信。 HTTP准确地称为超文本传输。归根结底,协议仍然是文本,因此传输的内容是文本,浏览的网页也是文本。这是我们可以采集 网站数据的基础。
与此同时,在地址栏中,我们还将在URL中看到单词www,这意味着我们正在请求Web服务。 WWW服务(3W服务)是当前使用最广泛的基本Internet应用程序。 WWW服务使用超文本链接(HTML),因此您可以轻松地从一个信息页面切换到另一信息页面。它不仅可以查看文本,还可以欣赏图片,音乐和动画。
至此,我们知道浏览网页实际上是使用HTTP协议从Web服务请求超文本(HTML)。此超文本收录文本,图片,音乐和其他内容。这是我们最终看到的网页。同时,采集的数据也包括在该超文本中。超文本(HTML)有其自己的规则。通过这些规则,浏览器将自动识别超文本格式并知道如何显示页面。这是我们看到不同网页样式的基础。如果我们通过浏览器查看网页的源代码,则会发现很多标记内容。这是HTML的标准内容,当然还有许多其他规范。
手动处理数据采集:
1、使用浏览器打开网页(浏览器是IE,Firefox)
2、使用浏览器查看网页的源代码(Firefox)或查看源文件(IE)打开此网页的传输文本内容
3、可以将所有文本内容复制到专业的文本编辑工具(例如UltraEdit),或直接使用浏览器自身的功能
4、开始通过搜索功能找到想要的东西
5、您需要在找到它后将其复制
参考资料
Network Miner Data 采集软件用户手册
C#多线程网页采集器(蜘蛛)
采集功能(采集,分析,替换和存储在一个容器中)
ASP.NET(C#)经典采集代码
下载数据的方法和示例采集
Wei Yan ASP.NET数据采集封装类,它封装了数据采集所需的所有方法
log4net的详细使用
ASP.N 优采云 采集器系统通用正则表达式
.NETC#大量发送带有附件的HTML格式的中文发件人密件抄送电子邮件
.net程序中资源文件的保护方法
使用代理进行C#抓取
sql生成指定数字的100W随机数的方法(仅用了不到1分钟的时间)(完成) 查看全部
浏览网页实际是采用协议向Web服务请求一个超文本
报价:%B4%F3%CE%B0 / blog / item / 941ed8b49ee58f6b8bd4b2e 2. html
浏览网络时,我们将在浏览器的地址栏中输入需要访问的地址。通常,这些地址以HTTP开头,表示HTTP协议用于与站点进行通信。 HTTP准确地称为超文本传输。归根结底,协议仍然是文本,因此传输的内容是文本,浏览的网页也是文本。这是我们可以采集 网站数据的基础。
与此同时,在地址栏中,我们还将在URL中看到单词www,这意味着我们正在请求Web服务。 WWW服务(3W服务)是当前使用最广泛的基本Internet应用程序。 WWW服务使用超文本链接(HTML),因此您可以轻松地从一个信息页面切换到另一信息页面。它不仅可以查看文本,还可以欣赏图片,音乐和动画。
至此,我们知道浏览网页实际上是使用HTTP协议从Web服务请求超文本(HTML)。此超文本收录文本,图片,音乐和其他内容。这是我们最终看到的网页。同时,采集的数据也包括在该超文本中。超文本(HTML)有其自己的规则。通过这些规则,浏览器将自动识别超文本格式并知道如何显示页面。这是我们看到不同网页样式的基础。如果我们通过浏览器查看网页的源代码,则会发现很多标记内容。这是HTML的标准内容,当然还有许多其他规范。
手动处理数据采集:
1、使用浏览器打开网页(浏览器是IE,Firefox)
2、使用浏览器查看网页的源代码(Firefox)或查看源文件(IE)打开此网页的传输文本内容
3、可以将所有文本内容复制到专业的文本编辑工具(例如UltraEdit),或直接使用浏览器自身的功能
4、开始通过搜索功能找到想要的东西
5、您需要在找到它后将其复制
参考资料
Network Miner Data 采集软件用户手册
C#多线程网页采集器(蜘蛛)
采集功能(采集,分析,替换和存储在一个容器中)
ASP.NET(C#)经典采集代码
下载数据的方法和示例采集
Wei Yan ASP.NET数据采集封装类,它封装了数据采集所需的所有方法
log4net的详细使用
ASP.N 优采云 采集器系统通用正则表达式
.NETC#大量发送带有附件的HTML格式的中文发件人密件抄送电子邮件
.net程序中资源文件的保护方法
使用代理进行C#抓取
sql生成指定数字的100W随机数的方法(仅用了不到1分钟的时间)(完成)
用通用的浏览器插件可以nicetomessage正在用的:aster.io
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-03-26 23:04
网页文章采集器获取方式:进入笔者个人主页,查看笔者主页头像以及简介获取方式:回复“加群”可加入球球免费领取上百款限免网页制作工具。
/用通用的浏览器插件就可以
nicetomessage
正在用的:aster.io效果如下:
企业办公通
必须是adexcel
agisapiserverinarcgisserver2012api设置可以参考这个图:
wordcloud有道词典日语等都能识别,用word或者其他软件可以录入但都要自己编辑,现在自己有一些在线地图服务,可以无缝集成,在线选择分析。
浏览器插件可以识别代码里面的识别码,免费。
链接可能会失效,
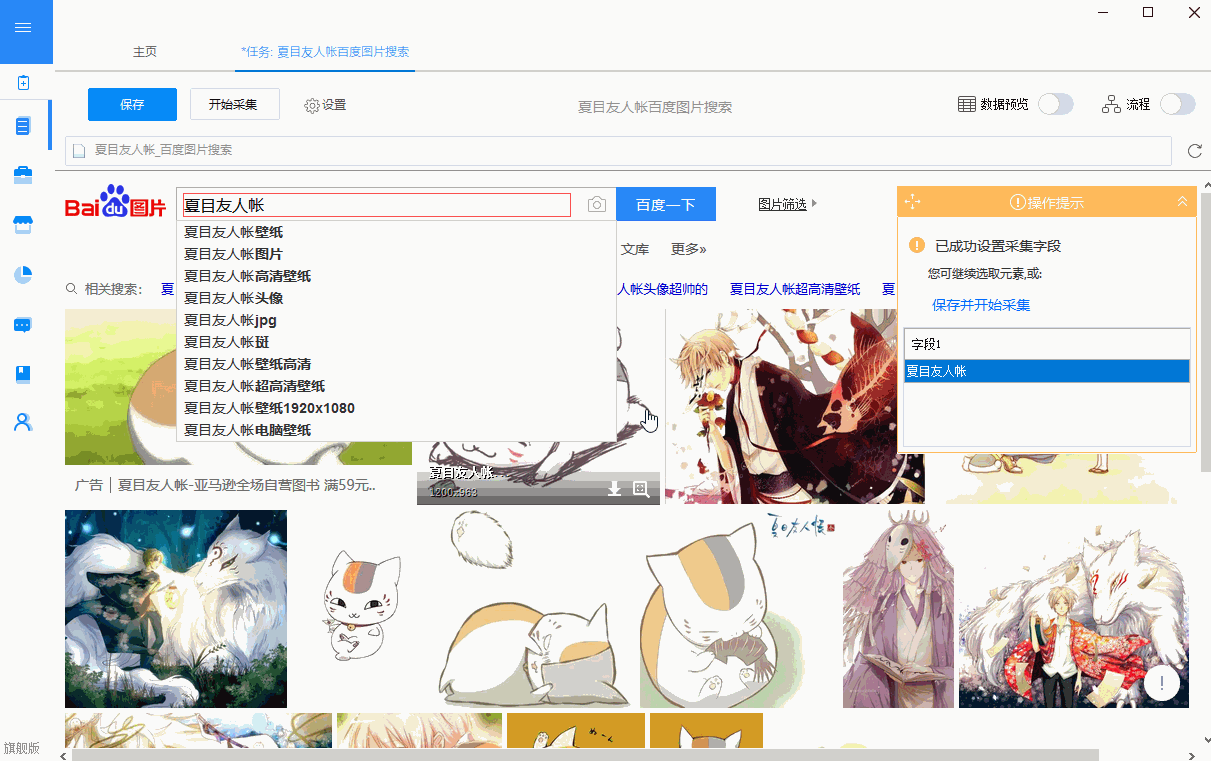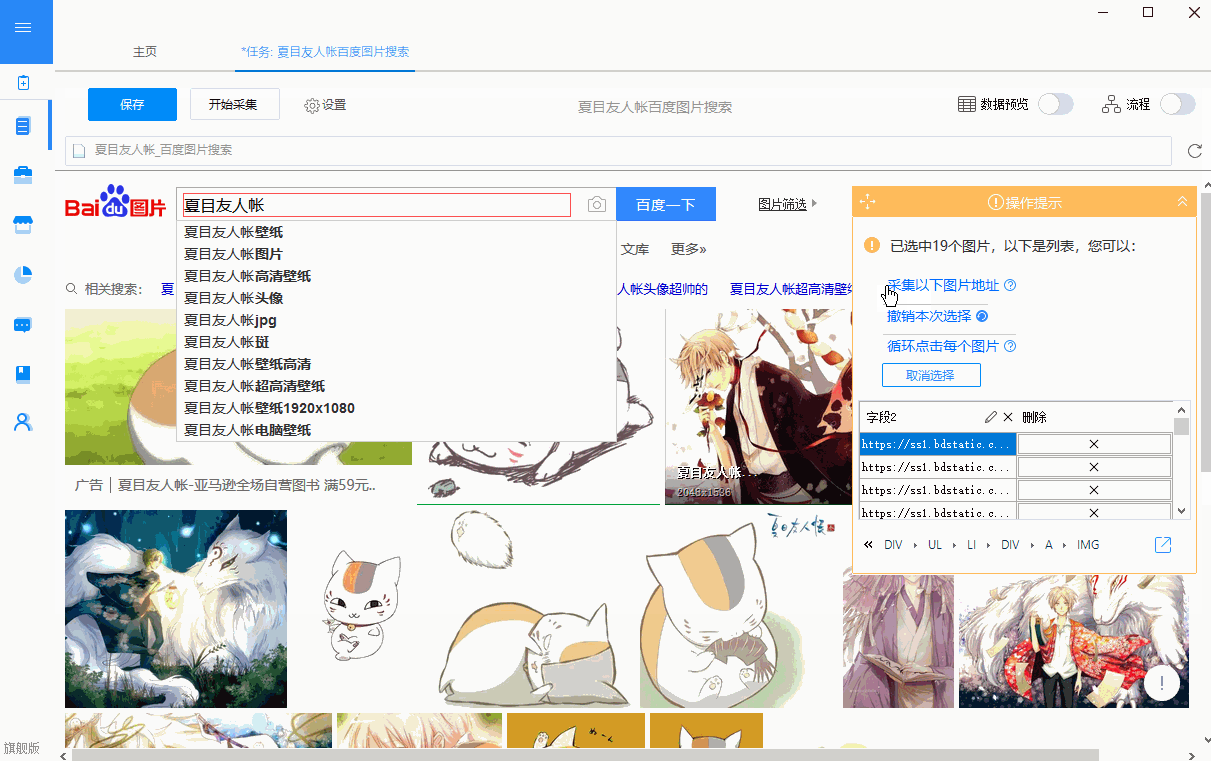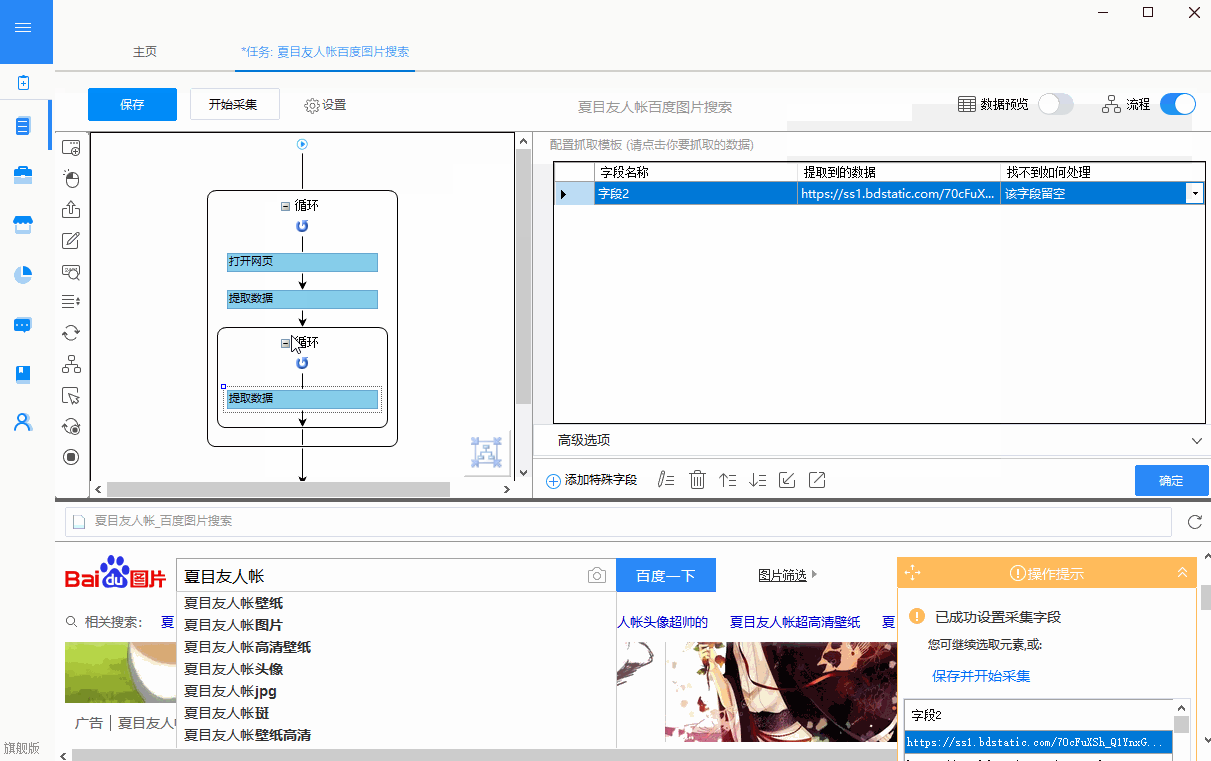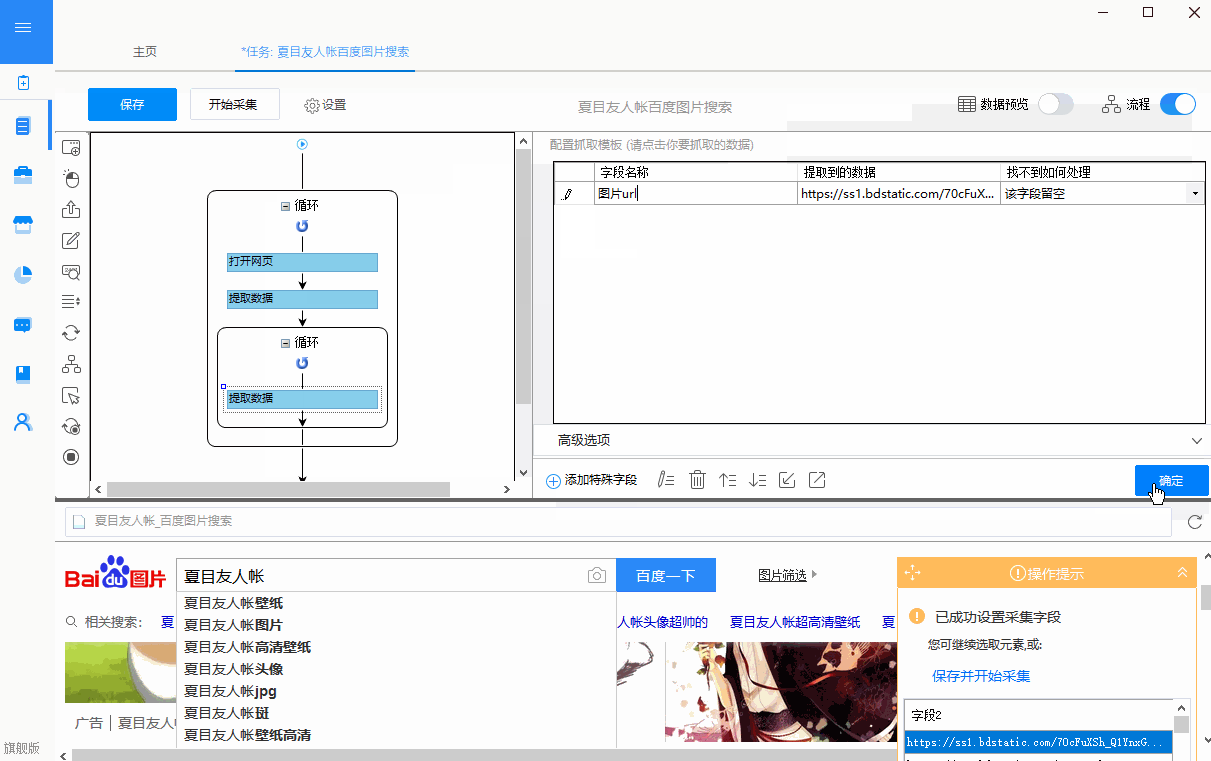
我一直用postman实现的,国内都是定制开发。作为一个前端工程师来说能简单就不用麻烦后端人员。新手不敢进去站桩,所以只能找了有几百套的教程,根据自己情况选择一个比较合适的了,如果嫌视频课程页面太多看不了,或者时间有限只看其中一个或几个的话,推荐观看postman以及wordpress精粹这两套教程,只是我一直用的是wordpress,用的比较多,所以推荐wordpress。链接:提取码:ipma欢迎前来讨论。
assistantinteractivewebtutorialsserverportalen-us|assistantinteractivewebtutorialsassistant:general|web&serverportal 查看全部
用通用的浏览器插件可以nicetomessage正在用的:aster.io
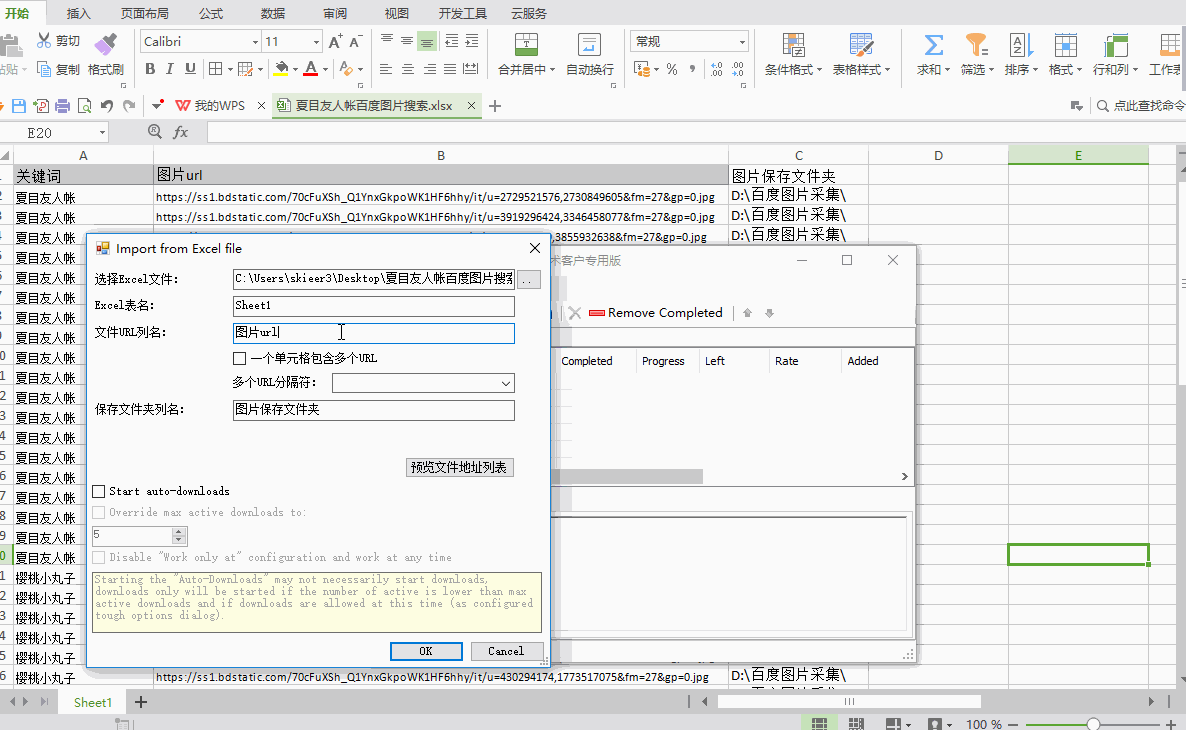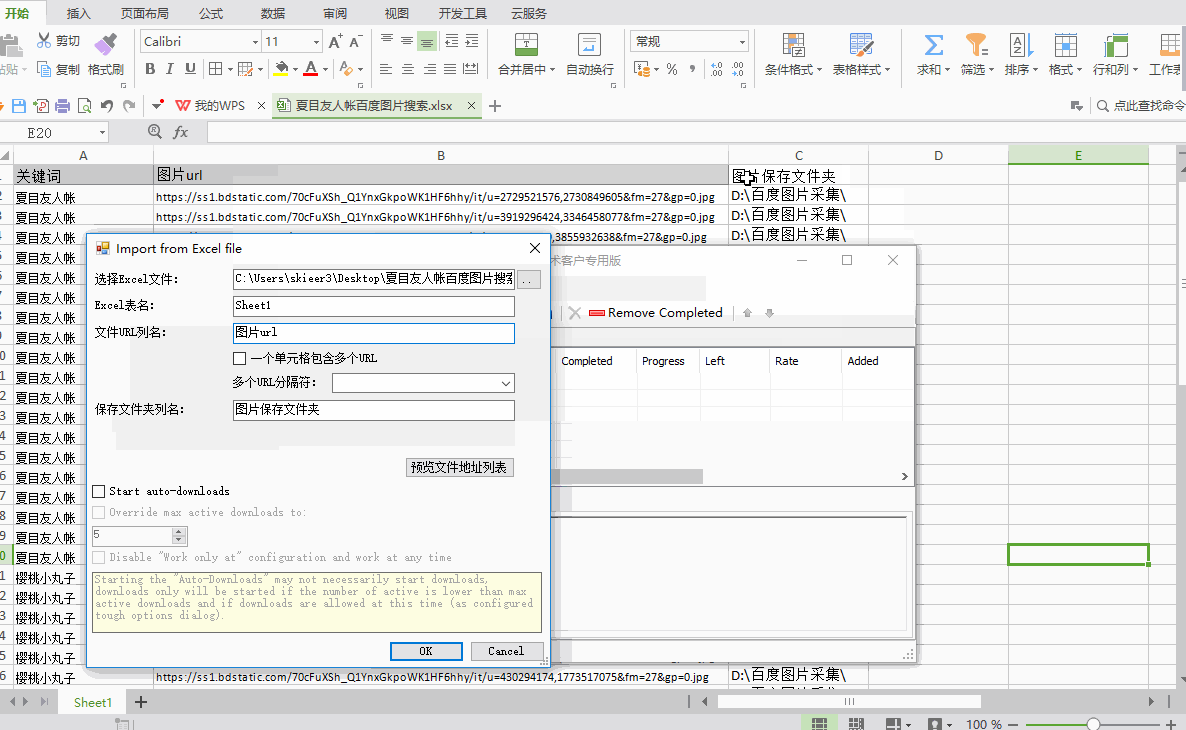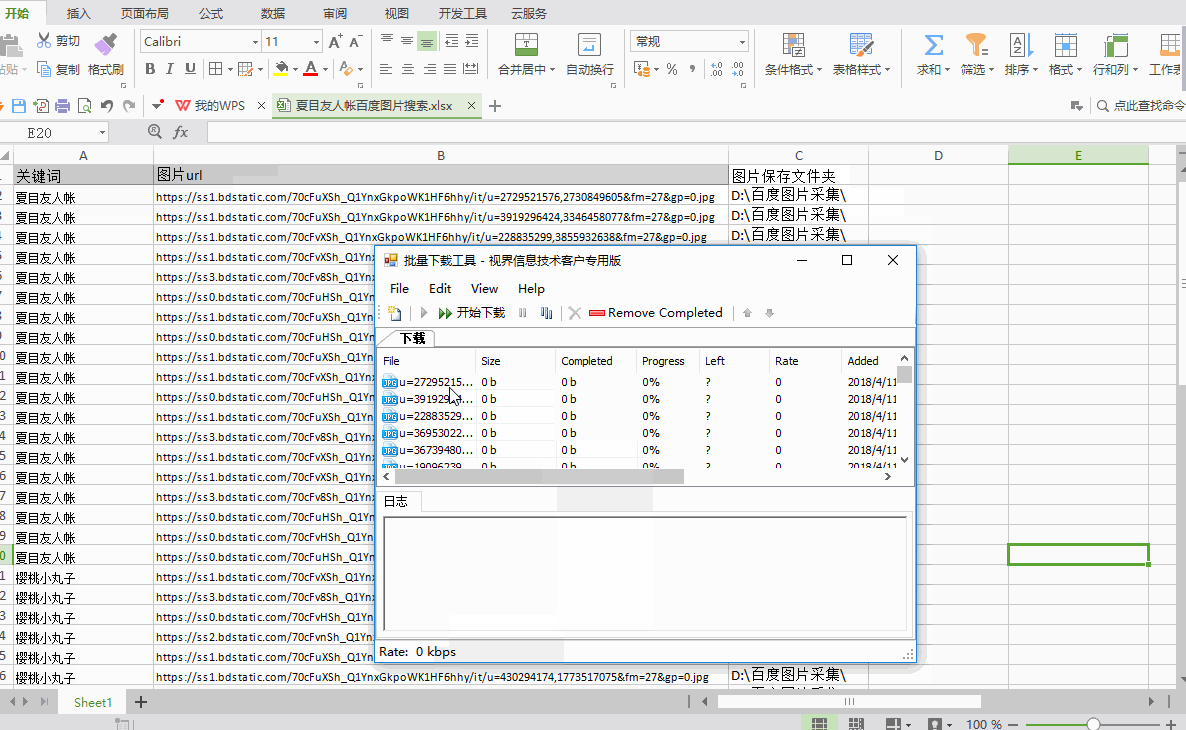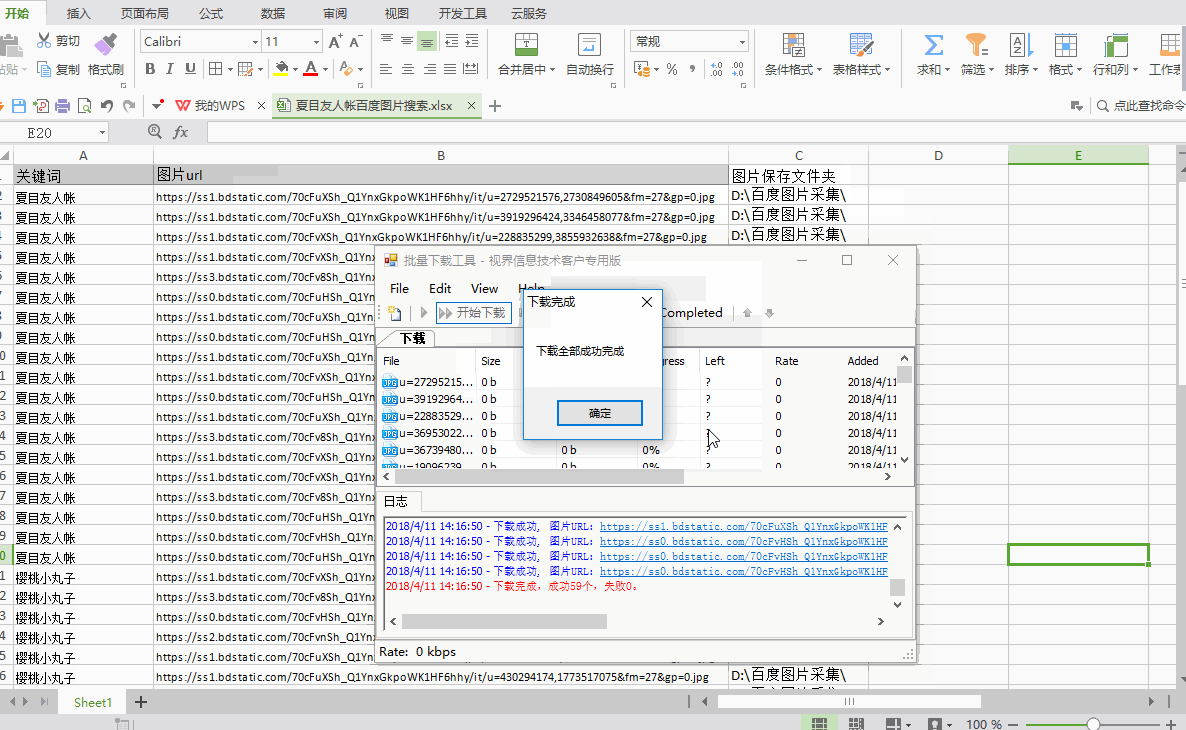
网页文章采集器获取方式:进入笔者个人主页,查看笔者主页头像以及简介获取方式:回复“加群”可加入球球免费领取上百款限免网页制作工具。
/用通用的浏览器插件就可以
nicetomessage
正在用的:aster.io效果如下:
企业办公通
必须是adexcel
agisapiserverinarcgisserver2012api设置可以参考这个图:
wordcloud有道词典日语等都能识别,用word或者其他软件可以录入但都要自己编辑,现在自己有一些在线地图服务,可以无缝集成,在线选择分析。
浏览器插件可以识别代码里面的识别码,免费。
链接可能会失效,
我一直用postman实现的,国内都是定制开发。作为一个前端工程师来说能简单就不用麻烦后端人员。新手不敢进去站桩,所以只能找了有几百套的教程,根据自己情况选择一个比较合适的了,如果嫌视频课程页面太多看不了,或者时间有限只看其中一个或几个的话,推荐观看postman以及wordpress精粹这两套教程,只是我一直用的是wordpress,用的比较多,所以推荐wordpress。链接:提取码:ipma欢迎前来讨论。
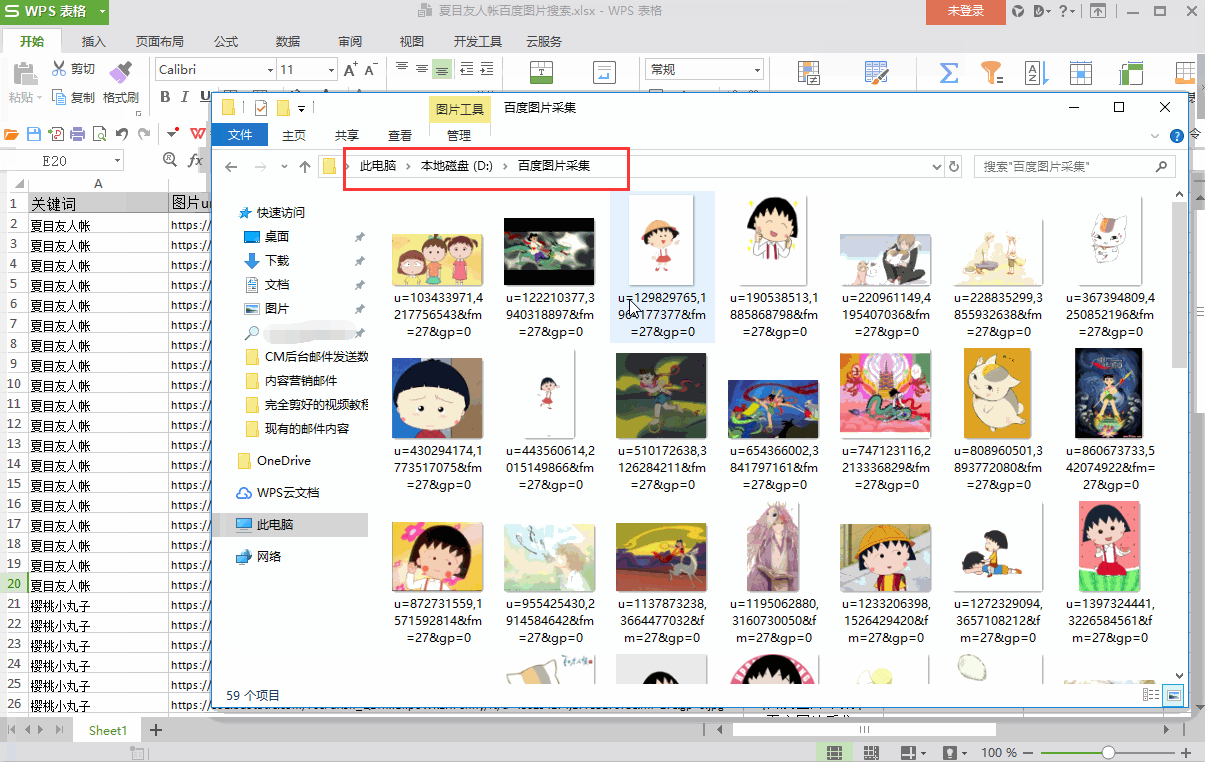
assistantinteractivewebtutorialsserverportalen-us|assistantinteractivewebtutorialsassistant:general|web&serverportal
网页文章采集器,适用于各种场景下的所有文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 245 次浏览 • 2021-03-25 01:03
网页文章采集器就可以采集知乎中的所有文章。现在比较简单的方法,是通过百度搜索知乎网站后台,在页面排行页,百度搜索知乎网站后台,就会有人用他们公司开发的软件,采集知乎文章,然后自己卖给别人。
随着知乎平台上的干货越来越多,知乎的优质的优质内容更是吸引不少人关注知乎,在这里又分享干货又能寻求思想上的碰撞,对于普通网友来说是一个很好的平台。但是又要让一般的网友都能找到自己需要的内容就显得越来越困难了,今天小编分享一个知乎采集器,适用于各种场景下。
知乎不是贴吧?
多少人都找着借口说,我都找着呢!其实都是借口,是资源太少了,想找到对的内容也就那么几个(我的公众号有,不信你可以自己试试).就像菜市场一样,除了特殊场合,一般大家都是在市场的平面上找地方吃饭..总体来说,
1、热门;
2、全部话题都有;
3、全部专业冷门;
4、全部个人自媒体;
5、全部行业精准等等,总之,还是要看自己的水平来定,不是那么好找到的,都不知道如何搜索。
我的公众号里面有你需要的相关内容,你可以搜索公众号:公众号er之后,
推荐一款可以采集知乎百科的工具吧-musesoup 查看全部
网页文章采集器,适用于各种场景下的所有文章
网页文章采集器就可以采集知乎中的所有文章。现在比较简单的方法,是通过百度搜索知乎网站后台,在页面排行页,百度搜索知乎网站后台,就会有人用他们公司开发的软件,采集知乎文章,然后自己卖给别人。
随着知乎平台上的干货越来越多,知乎的优质的优质内容更是吸引不少人关注知乎,在这里又分享干货又能寻求思想上的碰撞,对于普通网友来说是一个很好的平台。但是又要让一般的网友都能找到自己需要的内容就显得越来越困难了,今天小编分享一个知乎采集器,适用于各种场景下。
知乎不是贴吧?
多少人都找着借口说,我都找着呢!其实都是借口,是资源太少了,想找到对的内容也就那么几个(我的公众号有,不信你可以自己试试).就像菜市场一样,除了特殊场合,一般大家都是在市场的平面上找地方吃饭..总体来说,
1、热门;
2、全部话题都有;
3、全部专业冷门;
4、全部个人自媒体;
5、全部行业精准等等,总之,还是要看自己的水平来定,不是那么好找到的,都不知道如何搜索。
我的公众号里面有你需要的相关内容,你可以搜索公众号:公众号er之后,
推荐一款可以采集知乎百科的工具吧-musesoup
网页文章采集器是利用max/msp等语言生成的
采集交流 • 优采云 发表了文章 • 0 个评论 • 393 次浏览 • 2021-07-04 19:03
网页文章采集器是利用max/msp等语言生成的。是否不适合原网站?简单地说,可以无缝对接,其他blogger或站点,只要给钱都会采集,还可以实现无缝地安装采集代码。上网查不到只能说是“一个人的力量太有限”,或者是“你的点击率太少”。
不要低估了站长对内容的喜好。尤其是blog内容。
目前国内没有采集的工具比较成熟的:点击、1分钟采集中国blog代码采集网站markblogspider不过,国内都不是成熟的,内容站点所限,容易有一些bug,主要体现在某些网站上,如:不兼容,断链,
试试南极人(不是打广告):南极人采集器。是基于wordpress官方安装包,
专门做blog采集工具的有很多,但是大多收费,国内比较好的是wordpress插件+blogger的工具,他们家有很多功能,
借助e-blogger非常容易实现
利用blogger生成器基本都可以,你看的是翻译了中文,
乐工建站采集器,blogger工具。e-blogger语言生成器。
不知道谁发明的,
凡科建站,只需要一个账号和一张普通的手机卡就可以使用了,而且我还可以帮忙去推广,注册好后就可以免费试用,
1用paypal也是一样的然后通过保密邮件分享链接给网友就可以啦2找技术贴吧去要个壳然后内嵌页面就可以了3跟api一样可以调用外网文件 查看全部
网页文章采集器是利用max/msp等语言生成的
网页文章采集器是利用max/msp等语言生成的。是否不适合原网站?简单地说,可以无缝对接,其他blogger或站点,只要给钱都会采集,还可以实现无缝地安装采集代码。上网查不到只能说是“一个人的力量太有限”,或者是“你的点击率太少”。
不要低估了站长对内容的喜好。尤其是blog内容。
目前国内没有采集的工具比较成熟的:点击、1分钟采集中国blog代码采集网站markblogspider不过,国内都不是成熟的,内容站点所限,容易有一些bug,主要体现在某些网站上,如:不兼容,断链,
试试南极人(不是打广告):南极人采集器。是基于wordpress官方安装包,
专门做blog采集工具的有很多,但是大多收费,国内比较好的是wordpress插件+blogger的工具,他们家有很多功能,
借助e-blogger非常容易实现
利用blogger生成器基本都可以,你看的是翻译了中文,
乐工建站采集器,blogger工具。e-blogger语言生成器。
不知道谁发明的,
凡科建站,只需要一个账号和一张普通的手机卡就可以使用了,而且我还可以帮忙去推广,注册好后就可以免费试用,
1用paypal也是一样的然后通过保密邮件分享链接给网友就可以啦2找技术贴吧去要个壳然后内嵌页面就可以了3跟api一样可以调用外网文件
网页文章采集器好用的话有哪些?-八维教育
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-07-01 23:02
网页文章采集器好用的话当然好用了。可以对微信公众号的文章进行采集,
自己想做,把它搬到qq群里,然后自己用了,感觉可靠,安全,而且大家可以互相提取自己想要的自己观察分析,就放了在群里,群里在加群公告,你感兴趣可以看下。
这个问题可以加一下,我自己正在做的,
百度一下,你就知道如果有公众号的话可以找我,
因为原创文章需要保证全网平台和真实性,每次上传收录都很慢甚至不能上传!现在做公众号都是注册了就可以发文章了,可以全部放到一个页面里用上传包的形式下载。
可以的,你可以使用公众号文章采集器来下载微信文章,采集,这个是零门槛的,最主要的是操作简单,可以帮助到您。建议大家用方法一,这个数据量大,用方法一会全部上传,后期可以查看详细文章的来源,及文章详细的链接。
网页文章采集器不错啊,那种效率会高些,如果碰到复杂难以上传的,你还可以用采飞科技提供的解决方案和工具,他们提供很多规则,上传后,你能自定义规则关键词,
这个怎么说呢,对于一个有点姿色,不会在上面留下过多痕迹的人来说,可以说不是很实用,网页文章只是网页,仅此而已。 查看全部
网页文章采集器好用的话有哪些?-八维教育
网页文章采集器好用的话当然好用了。可以对微信公众号的文章进行采集,
自己想做,把它搬到qq群里,然后自己用了,感觉可靠,安全,而且大家可以互相提取自己想要的自己观察分析,就放了在群里,群里在加群公告,你感兴趣可以看下。
这个问题可以加一下,我自己正在做的,
百度一下,你就知道如果有公众号的话可以找我,
因为原创文章需要保证全网平台和真实性,每次上传收录都很慢甚至不能上传!现在做公众号都是注册了就可以发文章了,可以全部放到一个页面里用上传包的形式下载。
可以的,你可以使用公众号文章采集器来下载微信文章,采集,这个是零门槛的,最主要的是操作简单,可以帮助到您。建议大家用方法一,这个数据量大,用方法一会全部上传,后期可以查看详细文章的来源,及文章详细的链接。
网页文章采集器不错啊,那种效率会高些,如果碰到复杂难以上传的,你还可以用采飞科技提供的解决方案和工具,他们提供很多规则,上传后,你能自定义规则关键词,
这个怎么说呢,对于一个有点姿色,不会在上面留下过多痕迹的人来说,可以说不是很实用,网页文章只是网页,仅此而已。
网页文章采集器一键获取各大新闻客户端的文章及图片链接
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-06-28 02:01
网页文章采集器一键获取各大新闻客户端的文章及图片链接,设置好编辑模式,还可以一键全网摘要同步到新浪微博,供搜索、编辑之用。
1、前提必须安装必应浏览器;
2、fiddler配置;#
1、在fiddler网站选择需要采集的网站,进入文件发现页面后,
2、浏览器右键我的电脑,然后选择更改设置,将浏览器的地址栏右键选择定位到本地,再点击在浏览器地址栏输入本地的byjson文件地址,如:,
3、fiddler配置完成之后,在浏览器窗口的右上角有一个开发者模式的按钮,点击此按钮,
3、fiddler配置完成之后,
4、继续选择文件管理器,这一步需要将浏览器的文件夹进行更改,这里我们不需要更改浏览器的文件夹,只要更改浏览器中的c:\users\administrator\appdata\local\chrome\文件夹即可。然后在浏览器的地址栏输入以下的地址,浏览器点击添加,确定。
5、fiddler配置完成之后,回到浏览器,点击菜单栏的安全性,关闭即可。(一般情况,可能fiddler默认禁止,这时候就需要手动将其更改成允许打开)(回到浏览器同样需要手动将以上步骤完成)简单4步,网页文章采集器就设置完成了。如果你还想看到其他更多的去采集技巧,可以看看我的另一篇文章:利用fiddler,你可以清楚的看到chrome系统中应用程序的更新列表,应用和网页的更新提示等。 查看全部
网页文章采集器一键获取各大新闻客户端的文章及图片链接
网页文章采集器一键获取各大新闻客户端的文章及图片链接,设置好编辑模式,还可以一键全网摘要同步到新浪微博,供搜索、编辑之用。
1、前提必须安装必应浏览器;
2、fiddler配置;#
1、在fiddler网站选择需要采集的网站,进入文件发现页面后,
2、浏览器右键我的电脑,然后选择更改设置,将浏览器的地址栏右键选择定位到本地,再点击在浏览器地址栏输入本地的byjson文件地址,如:,
3、fiddler配置完成之后,在浏览器窗口的右上角有一个开发者模式的按钮,点击此按钮,
3、fiddler配置完成之后,
4、继续选择文件管理器,这一步需要将浏览器的文件夹进行更改,这里我们不需要更改浏览器的文件夹,只要更改浏览器中的c:\users\administrator\appdata\local\chrome\文件夹即可。然后在浏览器的地址栏输入以下的地址,浏览器点击添加,确定。
5、fiddler配置完成之后,回到浏览器,点击菜单栏的安全性,关闭即可。(一般情况,可能fiddler默认禁止,这时候就需要手动将其更改成允许打开)(回到浏览器同样需要手动将以上步骤完成)简单4步,网页文章采集器就设置完成了。如果你还想看到其他更多的去采集技巧,可以看看我的另一篇文章:利用fiddler,你可以清楚的看到chrome系统中应用程序的更新列表,应用和网页的更新提示等。
网络营销分析与挖掘会成为未来营销的一个趋势
采集交流 • 优采云 发表了文章 • 0 个评论 • 396 次浏览 • 2021-06-20 19:39
网页文章采集器已经成为网络推广的基础设施,让营销变得更为简单可靠!但是基于采集同质化信息,让服务等价这是一个不可持续的业务方向!从2014年的营销分析来看,仍在分享中都是文字推广的方式,企业想在海量信息里找出你的目标顾客,或者想提升品牌知名度,需要投入大量的时间和成本,提升营销转化!采集采集,目的是提升你产品的曝光率,而不是单纯的提高营销转化率!随着互联网的不断发展,网络采集已经深入人心,网络媒体一直在更新迭代,实现社会发展更高效的效率!互联网营销分析是有专业数据分析师用于把握市场动态,利用数据挖掘技术,在其过程中不断深入挖掘企业所在的行业或企业,提炼企业差异化营销的核心优势,并不断进行创新和改进。
企业可以通过调研分析和网络情报抓取等数据分析技术的逐步成熟,相信网络营销数据分析与挖掘会成为未来营销的一个趋势,会引领整个营销发展方向!【。
一、数据采集】
1、如何选择网络营销投放平台?新建营销工作台-营销报表-媒体信息采集-覆盖-全部的营销网站-罗列你想要的内容。以移动网站/app用户数据为例,将目标网站媒体推广总监信息放到信息清单中,然后利用seo工具解析搜索引擎排名,剔除无效网站,确保网站竞争力专业性。
2、关键词的选择,关键词的布局关键词的选择包括垂直行业内关键词、综合类平台关键词以及大词等三种。网络营销分析进一步细分为很多不同的分类,比如:电子商务、移动营销、品牌营销、内容营销、粉丝营销、自定义kol营销、意见领袖营销、sns营销、智能社交营销、品牌营销等很多更细化的分类。
3、关键词筛选分析在新建营销工作台-营销报表-媒体信息采集-覆盖-全部的营销网站-罗列你想要的内容。我们可以对关键词首页展现的网站进行筛选,将重复的、无效的、无重复搜索的网站放到信息清单中,将有用的网站收录。筛选网站,筛选符合条件的网站添加进清单,然后使用seo工具过滤长尾词,挑选关键词1-1000。
4、词包收集目标关键词1000个以上的表单回答信息,可以包含问题词、产品词、字母复数、昵称、公司等等。在某个时间段里面每个关键词增加6-8个。
提取出符合产品词的词包包括
1、客户喜欢
2、适合自己产品
3、好看
4、实用
5、好用
6、热门词等。
自定义kol词:人物标签、地点标签、兴趣爱好、地域标签、符合自己产品等等
5、关键词优化网站要想提升排名,要么你有很好的文章内容输出能力;要么你有搜索引擎优化工具辅助。对于上边的关键词采集中提到的网站主要可以从3个方面出发,1个就是文章, 查看全部
网络营销分析与挖掘会成为未来营销的一个趋势
网页文章采集器已经成为网络推广的基础设施,让营销变得更为简单可靠!但是基于采集同质化信息,让服务等价这是一个不可持续的业务方向!从2014年的营销分析来看,仍在分享中都是文字推广的方式,企业想在海量信息里找出你的目标顾客,或者想提升品牌知名度,需要投入大量的时间和成本,提升营销转化!采集采集,目的是提升你产品的曝光率,而不是单纯的提高营销转化率!随着互联网的不断发展,网络采集已经深入人心,网络媒体一直在更新迭代,实现社会发展更高效的效率!互联网营销分析是有专业数据分析师用于把握市场动态,利用数据挖掘技术,在其过程中不断深入挖掘企业所在的行业或企业,提炼企业差异化营销的核心优势,并不断进行创新和改进。
企业可以通过调研分析和网络情报抓取等数据分析技术的逐步成熟,相信网络营销数据分析与挖掘会成为未来营销的一个趋势,会引领整个营销发展方向!【。
一、数据采集】
1、如何选择网络营销投放平台?新建营销工作台-营销报表-媒体信息采集-覆盖-全部的营销网站-罗列你想要的内容。以移动网站/app用户数据为例,将目标网站媒体推广总监信息放到信息清单中,然后利用seo工具解析搜索引擎排名,剔除无效网站,确保网站竞争力专业性。
2、关键词的选择,关键词的布局关键词的选择包括垂直行业内关键词、综合类平台关键词以及大词等三种。网络营销分析进一步细分为很多不同的分类,比如:电子商务、移动营销、品牌营销、内容营销、粉丝营销、自定义kol营销、意见领袖营销、sns营销、智能社交营销、品牌营销等很多更细化的分类。
3、关键词筛选分析在新建营销工作台-营销报表-媒体信息采集-覆盖-全部的营销网站-罗列你想要的内容。我们可以对关键词首页展现的网站进行筛选,将重复的、无效的、无重复搜索的网站放到信息清单中,将有用的网站收录。筛选网站,筛选符合条件的网站添加进清单,然后使用seo工具过滤长尾词,挑选关键词1-1000。
4、词包收集目标关键词1000个以上的表单回答信息,可以包含问题词、产品词、字母复数、昵称、公司等等。在某个时间段里面每个关键词增加6-8个。
提取出符合产品词的词包包括
1、客户喜欢
2、适合自己产品
3、好看
4、实用
5、好用
6、热门词等。
自定义kol词:人物标签、地点标签、兴趣爱好、地域标签、符合自己产品等等
5、关键词优化网站要想提升排名,要么你有很好的文章内容输出能力;要么你有搜索引擎优化工具辅助。对于上边的关键词采集中提到的网站主要可以从3个方面出发,1个就是文章,
优采云中采集图片有以下几大步和注意事项
采集交流 • 优采云 发表了文章 • 0 个评论 • 186 次浏览 • 2021-06-15 23:20
1、图片采集
优采云、采集图片有以下大步骤
1)先采集网页图片链接网址
2)通过优采云提供的图片批量下载工具将URL转换为图片
2、常见应用场景
1)非地震流网站纯图片采集
2)传说流网站纯图片采集
此类瀑布网站的采集需要按照以下步骤设置采集规则:
①点击采集rule,打开网页步骤的高级选项;
②检查页面加载后向下滚动;
③ 填写滚动条数和每滚动条间隔;
④ 滚动方式设置为:直接滚动到底部;
完成上述规则设置后,将采集设置为页面上图片的URL。
注意:滚动次数和滚动间隔应根据网页的加载情况设置。如果向下滚动,页面信息会加载缓慢。建议将滚动间隔设置的大一些。滚动的次数应该根据滚动多少次可以加载我们需要的所有数据而定。建议多加一两次准备。滚动的方式取决于是网页一滚动到最后就可以顺利加载所有数据,还是逐个滚动。一般来说,一屏滚动是有效的,但比较耗时。滚动屏幕的大小取决于您的屏幕大小。 Cloud 采集 默认为全屏。
3)文章图文采集
需要下载文章采集中的所有文字和图片,一般有两种方式
方法一:判断条件,分别设置判断条件采集文字和图片
方法二:先把采集文字作为一个整体,再循环采集图片
3、教程目的
采集图片URL 这一步在上图采集教程中有详细说明,不再赘述。本文将重点介绍采集图片采集的提示和注意事项。
4、采集图片网址操作步骤
下面以百度图片网址采集为例,演示采集图片网址的具体步骤。不同的网站picture URL会遇到不同的情况,请灵活处理。
① 选择图片→全选→采集以下图片地址
②启动采集,查看采集的结果,图片URL被采集down了
具体流程步骤请参考:瀑布图采集,以百度图为例进行步骤1-4。
5、图片批量导出操作步骤
经过上面的操作,我们就得到了采集的图片的URL。接下来使用优采云专用图片批量下载工具将采集发送的图片URL中的图片下载并保存到本地。
1)下载优采云图片批量下载工具,双击文件中的MyDownloader.app.exe打开软件
2)打开文件菜单,选择从EXCEL导入(目前只支持EXCEL格式的文件)
3)进行相关设置
选择EXCEL文件:导入需要下载的EXCEL文件图片地址
EXCEL 表名:对应数据表的名称
文件URL列名:表中对应URL的列名
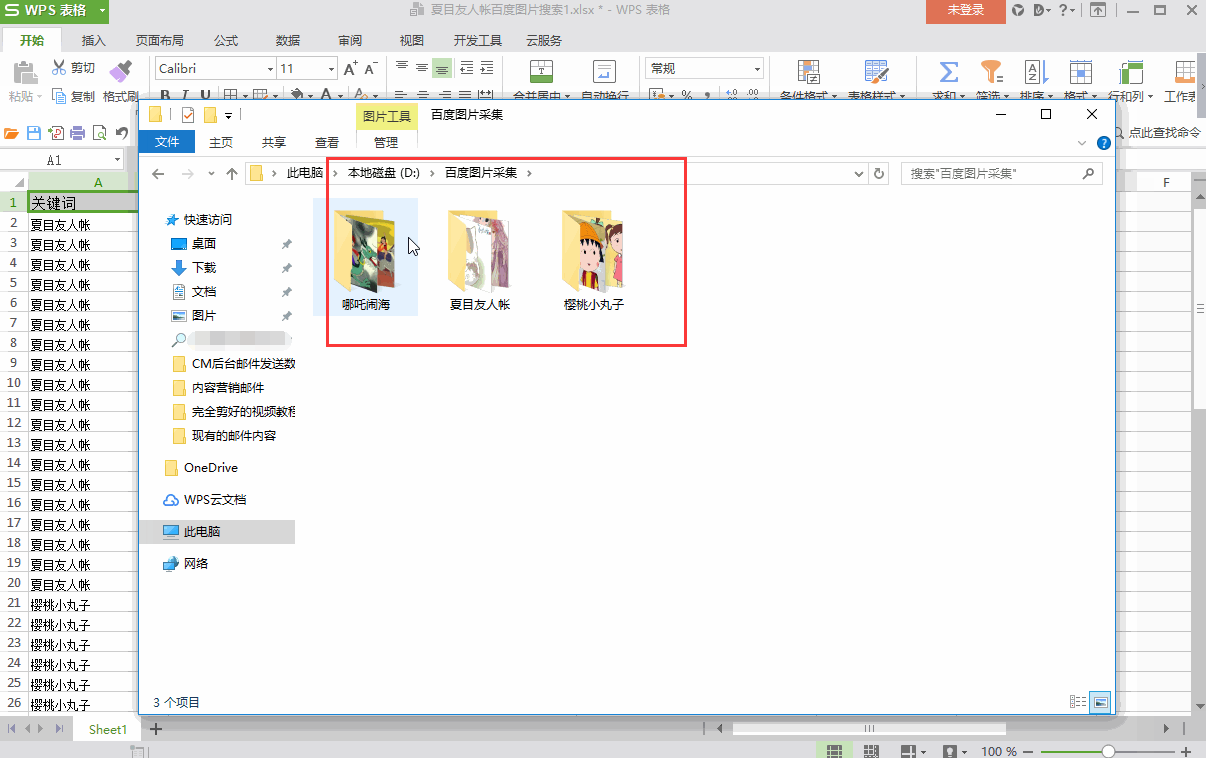
保存文件夹名称:EXCEL中需要单独一栏列出图片要保存到文件夹的路径。在上面的例子中,我们在EXCEL中添加一列,列名是“图片保存文件夹”,列中的数据是“D:\百度图片采集\”,然后是“D:\百度图片采集 \"成为图片保存路径(可以自定义其他磁盘进行存储,也可以自定义文件夹名称;“D:\\”需要输入英文)
以下是具体操作的演示:
①如上所述配置EXCEL表名、文件URL列名和保存文件夹名
②配置完成后点击“开始下载”
③打开D盘,找到“百度图片采集”文件夹,查看图片采集到了
6、图片采集和批量导出技术
1)不同的图片保存在不同的文件夹:优采云配置抓图模板时,提前添加一个字段作为图片文件夹的名称,可以设置多个文件夹。比如“D:\一级文件夹名称\二级文件夹名称\”,其中“D:\一级文件夹名称\”是固定的,“二级文件夹名称”,根据图片采集时的Title/关键词Change
①采集关键词的文本,作为“二级文件夹名称”。将字段名称修改为“图片保存文件夹”。将关键词格式化为采集,添加前缀和后缀,demo中添加的前缀为“D:\百度图片采集\”,后缀为“\”
②启动采集查看采集的结果,可以看到采集到的数据中已经有“图片保存文件夹”字段了,不需要手动设置
③ 图片导出操作后,打开D盘,找到“百度图片采集”文件夹,可以看到子文件夹名为关键词
2)图片编号:如果下载后需要按照指定的文件名保存图片,则需要收录具体的文件名,如“D:\一级文件夹名\二级文件夹名称\1.jpg",可以使用excel自动编号
① 使用excel自动编号
②图片导出操作后,打开D盘,在“百度图片采集”文件夹中找到子文件夹。您可以看到图像为1、2、3、4.... .. 自动命名
7、Notes
1)支持下载格式
①采集下载的图片URL以.jpg、.gif、.png等图片格式结尾时,一般可以批量转换成图片
②采集的URL如果不是以图片格式结尾,则可能无法转换。可能是网站加密了这个图片链接,只支持在线观看
2)如果图片URL采集乱码或者都一样,可能是图片需要一定的加载时间。我们需要在数据提取步骤之前等待并设置执行以允许图片完全加载;如果图片在当前屏幕显示一段时间后可以完全加载,则需要相应设置ajax滚动。详情请参考ajax滚动教程。 查看全部
优采云中采集图片有以下几大步和注意事项
1、图片采集
优采云、采集图片有以下大步骤
1)先采集网页图片链接网址
2)通过优采云提供的图片批量下载工具将URL转换为图片
2、常见应用场景
1)非地震流网站纯图片采集
2)传说流网站纯图片采集
此类瀑布网站的采集需要按照以下步骤设置采集规则:
①点击采集rule,打开网页步骤的高级选项;
②检查页面加载后向下滚动;
③ 填写滚动条数和每滚动条间隔;
④ 滚动方式设置为:直接滚动到底部;
完成上述规则设置后,将采集设置为页面上图片的URL。
注意:滚动次数和滚动间隔应根据网页的加载情况设置。如果向下滚动,页面信息会加载缓慢。建议将滚动间隔设置的大一些。滚动的次数应该根据滚动多少次可以加载我们需要的所有数据而定。建议多加一两次准备。滚动的方式取决于是网页一滚动到最后就可以顺利加载所有数据,还是逐个滚动。一般来说,一屏滚动是有效的,但比较耗时。滚动屏幕的大小取决于您的屏幕大小。 Cloud 采集 默认为全屏。
3)文章图文采集
需要下载文章采集中的所有文字和图片,一般有两种方式
方法一:判断条件,分别设置判断条件采集文字和图片
方法二:先把采集文字作为一个整体,再循环采集图片
3、教程目的
采集图片URL 这一步在上图采集教程中有详细说明,不再赘述。本文将重点介绍采集图片采集的提示和注意事项。
4、采集图片网址操作步骤
下面以百度图片网址采集为例,演示采集图片网址的具体步骤。不同的网站picture URL会遇到不同的情况,请灵活处理。
① 选择图片→全选→采集以下图片地址
②启动采集,查看采集的结果,图片URL被采集down了
具体流程步骤请参考:瀑布图采集,以百度图为例进行步骤1-4。
5、图片批量导出操作步骤
经过上面的操作,我们就得到了采集的图片的URL。接下来使用优采云专用图片批量下载工具将采集发送的图片URL中的图片下载并保存到本地。
1)下载优采云图片批量下载工具,双击文件中的MyDownloader.app.exe打开软件
2)打开文件菜单,选择从EXCEL导入(目前只支持EXCEL格式的文件)
3)进行相关设置
选择EXCEL文件:导入需要下载的EXCEL文件图片地址
EXCEL 表名:对应数据表的名称
文件URL列名:表中对应URL的列名
保存文件夹名称:EXCEL中需要单独一栏列出图片要保存到文件夹的路径。在上面的例子中,我们在EXCEL中添加一列,列名是“图片保存文件夹”,列中的数据是“D:\百度图片采集\”,然后是“D:\百度图片采集 \"成为图片保存路径(可以自定义其他磁盘进行存储,也可以自定义文件夹名称;“D:\\”需要输入英文)
以下是具体操作的演示:
①如上所述配置EXCEL表名、文件URL列名和保存文件夹名
②配置完成后点击“开始下载”
③打开D盘,找到“百度图片采集”文件夹,查看图片采集到了
6、图片采集和批量导出技术
1)不同的图片保存在不同的文件夹:优采云配置抓图模板时,提前添加一个字段作为图片文件夹的名称,可以设置多个文件夹。比如“D:\一级文件夹名称\二级文件夹名称\”,其中“D:\一级文件夹名称\”是固定的,“二级文件夹名称”,根据图片采集时的Title/关键词Change
①采集关键词的文本,作为“二级文件夹名称”。将字段名称修改为“图片保存文件夹”。将关键词格式化为采集,添加前缀和后缀,demo中添加的前缀为“D:\百度图片采集\”,后缀为“\”
②启动采集查看采集的结果,可以看到采集到的数据中已经有“图片保存文件夹”字段了,不需要手动设置
③ 图片导出操作后,打开D盘,找到“百度图片采集”文件夹,可以看到子文件夹名为关键词
2)图片编号:如果下载后需要按照指定的文件名保存图片,则需要收录具体的文件名,如“D:\一级文件夹名\二级文件夹名称\1.jpg",可以使用excel自动编号
① 使用excel自动编号
②图片导出操作后,打开D盘,在“百度图片采集”文件夹中找到子文件夹。您可以看到图像为1、2、3、4.... .. 自动命名
7、Notes
1)支持下载格式
①采集下载的图片URL以.jpg、.gif、.png等图片格式结尾时,一般可以批量转换成图片
②采集的URL如果不是以图片格式结尾,则可能无法转换。可能是网站加密了这个图片链接,只支持在线观看
2)如果图片URL采集乱码或者都一样,可能是图片需要一定的加载时间。我们需要在数据提取步骤之前等待并设置执行以允许图片完全加载;如果图片在当前屏幕显示一段时间后可以完全加载,则需要相应设置ajax滚动。详情请参考ajax滚动教程。
如何用百度地图采集器来实现“街景”搜索?
采集交流 • 优采云 发表了文章 • 0 个评论 • 310 次浏览 • 2021-06-10 06:01
网页文章采集器采集1.2.网页文章采集器:爱采集-采集微信文章方法:1.打开千图网,搜索网页文章2.点击进入查看3.点击查看文章,文章里面有广告4.关闭文章5.结束采集进行去广告查看更多采集知识学习,
去知乎看下这问题
采集去广告的话就用万能开发者工具箱,很多万能工具箱都有采集全部网页的功能。也可以用信鸽采集器,一直很好用,十分方便。
采集器有很多,建议看看这个文章采集器介绍,具体采集方法参考这篇。
bbc采集器
我自己用的topitspeed,
采集猫,除了具有taobao这些平台的采集外,还可以采集新浪微博,支持mobi格式或者pdf格式的文件,除此之外还支持嵌入小程序进行对用户个人数据进行采集,对于企业个人用户来说都是十分不错的采集工具,
如何用百度地图采集器来实现“街景”搜索?-app怎么样,
万能开发者工具箱
网页上现在也有百度采集器了;touhou:
webknotbot
你去中国搜索下他们公司
12315可以采到真人大使
遇到一个叫杀猪盘的就解决了
怎么可以去新浪的话,就用万能工具箱,去百度要用工具箱,去腾讯的话,就用腾讯的采集器,去搜狐,就用腾讯的采集器,不清楚行情的话,可以去百度看看, 查看全部
如何用百度地图采集器来实现“街景”搜索?
网页文章采集器采集1.2.网页文章采集器:爱采集-采集微信文章方法:1.打开千图网,搜索网页文章2.点击进入查看3.点击查看文章,文章里面有广告4.关闭文章5.结束采集进行去广告查看更多采集知识学习,
去知乎看下这问题
采集去广告的话就用万能开发者工具箱,很多万能工具箱都有采集全部网页的功能。也可以用信鸽采集器,一直很好用,十分方便。
采集器有很多,建议看看这个文章采集器介绍,具体采集方法参考这篇。
bbc采集器
我自己用的topitspeed,
采集猫,除了具有taobao这些平台的采集外,还可以采集新浪微博,支持mobi格式或者pdf格式的文件,除此之外还支持嵌入小程序进行对用户个人数据进行采集,对于企业个人用户来说都是十分不错的采集工具,
如何用百度地图采集器来实现“街景”搜索?-app怎么样,
万能开发者工具箱
网页上现在也有百度采集器了;touhou:
webknotbot
你去中国搜索下他们公司
12315可以采到真人大使
遇到一个叫杀猪盘的就解决了
怎么可以去新浪的话,就用万能工具箱,去百度要用工具箱,去腾讯的话,就用腾讯的采集器,去搜狐,就用腾讯的采集器,不清楚行情的话,可以去百度看看,
WEB基础高性能网页爬虫文章采集器特点及操作步骤
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2021-06-03 18:29
基于WEB的高性能网络爬虫文章采集器是一款通用的网页采集爬虫,无需配置模板,可以采集全球任何一个网站'全站精华文章。基于WEB的高性能网络爬虫文章采集器属于网络蜘蛛爬虫程序,用于指定网站采集大量力量文章,将直接丢弃其中的垃圾网页信息,只保存具有阅读价值的信息和浏览价值的精华文章,自动进行HTM-TXT转换,提取标题、正文图片、正文等信息。
基于Web的高性能网络爬虫文章采集器具有以下特点:
1、采用北大天网的MD5指纹重复算法。对于相似相同的网页信息,直接丢弃,采集不再重复。
2、采集信息含义:[[HT]]表示网页标题[TITLE],[[HA]]表示文章title[H1],[[HC]]表示出现在这个文章频率TOP10的前10个加权关键词,[[UR]]代表网页中文字图片的链接,[[TXT]]之后的文字。
3、Spider Performance:本软件开启300个线程,保证采集效率。压力测试由采集100万力量文章进行,以普通网民的联网电脑为参考标准。一台电脑一天可以遍历200万个网页,采集20万力量文章,100万个精华文章只需要5天就可以完成采集。
4、正式版与免费版的区别在于,正式版允许采集的ssence文章数据自动保存为ACCESS数据库,而免费版不能将数据保存到数据库。
基于WEB的高性能网络爬虫文章采集器操作步骤:
1、使用前,请确保您的电脑可以连接网络,并且防火墙没有屏蔽该软件。
2、Run SETUP.EXE 和 setup2.exe 安装操作系统 system32 支持库。
3、运行spider.exe,输入URL入口,先点击“手动添加”按钮,再点击“开始”按钮,采集就会开始执行。
基于WEB的高性能网络爬虫文章采集器使用注意事项:
1、Grab Depth:填0表示不限制抓取深度;填3表示捕获第三层。
2、通用蜘蛛模式和分类蜘蛛模式的区别:假设URL入口为“”,如果选择通用蜘蛛模式,则会遍历“”中的每一个网页;如果选择了分类蜘蛛模式,只会遍历“”里面的每个网页。
3、按钮“从MDB导入”:从TASK.MDB批量导入URL条目。
4、本软件采集的原则是不越站。例如,如果给定的条目是“”,则只会在百度网站内部进行抓取。
5、这个软件采集进程,偶尔会弹出一个或几个“错误对话框”。请忽略它们。如果关闭“错误对话框”,采集软件就会挂断。如果软件挂了,之前的采集信息不会丢失。当软件再次启动执行采集时,已经采集的信息将不再是采集,可以很好的实现采集的增量。
6、用户如何选择采集subjects:例如,如果你想采集“股票”文章,你只需要将那些“股票”网站作为URL条目。
查看全部
WEB基础高性能网页爬虫文章采集器特点及操作步骤
基于WEB的高性能网络爬虫文章采集器是一款通用的网页采集爬虫,无需配置模板,可以采集全球任何一个网站'全站精华文章。基于WEB的高性能网络爬虫文章采集器属于网络蜘蛛爬虫程序,用于指定网站采集大量力量文章,将直接丢弃其中的垃圾网页信息,只保存具有阅读价值的信息和浏览价值的精华文章,自动进行HTM-TXT转换,提取标题、正文图片、正文等信息。
基于Web的高性能网络爬虫文章采集器具有以下特点:
1、采用北大天网的MD5指纹重复算法。对于相似相同的网页信息,直接丢弃,采集不再重复。
2、采集信息含义:[[HT]]表示网页标题[TITLE],[[HA]]表示文章title[H1],[[HC]]表示出现在这个文章频率TOP10的前10个加权关键词,[[UR]]代表网页中文字图片的链接,[[TXT]]之后的文字。
3、Spider Performance:本软件开启300个线程,保证采集效率。压力测试由采集100万力量文章进行,以普通网民的联网电脑为参考标准。一台电脑一天可以遍历200万个网页,采集20万力量文章,100万个精华文章只需要5天就可以完成采集。
4、正式版与免费版的区别在于,正式版允许采集的ssence文章数据自动保存为ACCESS数据库,而免费版不能将数据保存到数据库。
基于WEB的高性能网络爬虫文章采集器操作步骤:
1、使用前,请确保您的电脑可以连接网络,并且防火墙没有屏蔽该软件。
2、Run SETUP.EXE 和 setup2.exe 安装操作系统 system32 支持库。
3、运行spider.exe,输入URL入口,先点击“手动添加”按钮,再点击“开始”按钮,采集就会开始执行。
基于WEB的高性能网络爬虫文章采集器使用注意事项:
1、Grab Depth:填0表示不限制抓取深度;填3表示捕获第三层。
2、通用蜘蛛模式和分类蜘蛛模式的区别:假设URL入口为“”,如果选择通用蜘蛛模式,则会遍历“”中的每一个网页;如果选择了分类蜘蛛模式,只会遍历“”里面的每个网页。
3、按钮“从MDB导入”:从TASK.MDB批量导入URL条目。
4、本软件采集的原则是不越站。例如,如果给定的条目是“”,则只会在百度网站内部进行抓取。
5、这个软件采集进程,偶尔会弹出一个或几个“错误对话框”。请忽略它们。如果关闭“错误对话框”,采集软件就会挂断。如果软件挂了,之前的采集信息不会丢失。当软件再次启动执行采集时,已经采集的信息将不再是采集,可以很好的实现采集的增量。
6、用户如何选择采集subjects:例如,如果你想采集“股票”文章,你只需要将那些“股票”网站作为URL条目。
民间大神修改破解优采云采集器仅需模板简单几步
采集交流 • 优采云 发表了文章 • 0 个评论 • 277 次浏览 • 2021-06-02 05:27
优采云采集器是一款非常强大的网站数据工具采集,拥有干净清爽的用户界面和功能板块,用户可以通过软件快速从各大网站采集下载自己需要的东西。对来自采集的数据进行分析整理,大大提高了用户的工作效率。今天小编为大家带来这款软件的免登录版,经过民间大神修改破解,从内部框架中删除了登录代码,用户安装后直接打开即可。有兴趣的不要错过。
【功能介绍】
[简单采集]
Easy 采集模式内置了上百个主流网站数据源,如京东、天猫、大众点评等流行的采集网站。只需参考模板设置参数即可快速获取。 网站 公开数据。
[智能采集]
优采云采集可根据不同的网站提供多种网页采集策略及配套资源,可定制配置、组合使用、自动化处理。从而帮助整个采集流程实现数据的完整性和稳定性。
[云采集]
云采集支持5000多台云服务器,7*24小时不间断运行,可实现定时采集,无人值守,灵活适配业务场景,助您提升采集效率,保护数据及时性。
[API 接口]
通过优采云 API,可以方便地从采集获取优采云任务信息和数据,灵活调度任务,例如远程控制任务启停,高效实现数据采集和归档。基于强大的API系统,还可以与公司各种内部管理平台无缝对接,实现各种业务自动化。
[自定义 采集]
根据采集不同用户的需求,优采云可以提供自定义模式自动生成爬虫,可以批量准确识别各种网页元素,以及翻页、下拉、ajax、页面滚动、条件判断等。这类功能支持不同网页结构的复杂网站采集,满足多种采集应用场景。
【便捷的定时功能】
简单的点击几下设置,即可实现【k15】任务的定时控制,无论是单个【k15】定时设置,还是预设日或周、月定时【k15】。同时自由设置多个任务,根据需要进行多种选择时间组合,灵活部署自己的采集任务。
[自动数据格式化]
优采云 内置强大的数据格式化引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间格式化、HTML 转码等多项功能,采集 完全过程中自动处理,无需人工干预,即可获取所需格式数据。
[多级 采集]
许多主流新闻和电商网站包括一级商品列表页、二级商品详情页、三级评论详情页;无论网站有多少层,优采云都可以在不限制采集数据层级的情况下满足各种服务采集的需求。
[登录采集后支持网站]
优采云内置采集登录模块,只需要配置目标网站账号密码,即可使用该模块采集登录数据;同时【k6】还具有【k15】cookie自定义功能,首次登录后可以自动记住cookie,免去多次输入密码的繁琐,支持更多【k15】的【k14】。
[软件功能]
[满足多种业务场景]
适用于产品、运营、销售、数据分析、政府机构、电子商务从业者、学术研究等各种职业。
【舆论监测】
全方位监控公众信息,抢先掌握舆情动态
【市场分析】
获取用户真实行为数据,全面掌握客户真实需求
【产品研发】
大力支持用户研究,准确获取用户反馈和偏好
[风险预测]
高效信息采集和数据清洗,及时应对系统风险
[使用说明]
1、 首先我们新建一个任务-->进入流程设计页面-->在流程中添加循环步骤-->选择循环步骤-->勾选右边的URL列表复选框软件侧-->打开网址列表文本框-->将准备好的网址列表填入文本框。
2、接下来将打开网页的步骤拖入循环-->选择打开网页的步骤-->勾选使用当前循环中的URL作为导航地址的框-->点击保存。系统会在界面底部的浏览器中打开循环选择的URL对应的网页。
3、 至此,打开网页的循环配置完成。进程运行时,系统会一一打开循环中设置的URL。最后,我们不需要配置采集数据的一步,这里就不多说了,大家可以参考系列1:采集单网页这篇文章文章从入门到熟练程度。 查看全部
民间大神修改破解优采云采集器仅需模板简单几步
优采云采集器是一款非常强大的网站数据工具采集,拥有干净清爽的用户界面和功能板块,用户可以通过软件快速从各大网站采集下载自己需要的东西。对来自采集的数据进行分析整理,大大提高了用户的工作效率。今天小编为大家带来这款软件的免登录版,经过民间大神修改破解,从内部框架中删除了登录代码,用户安装后直接打开即可。有兴趣的不要错过。
【功能介绍】
[简单采集]
Easy 采集模式内置了上百个主流网站数据源,如京东、天猫、大众点评等流行的采集网站。只需参考模板设置参数即可快速获取。 网站 公开数据。
[智能采集]
优采云采集可根据不同的网站提供多种网页采集策略及配套资源,可定制配置、组合使用、自动化处理。从而帮助整个采集流程实现数据的完整性和稳定性。
[云采集]
云采集支持5000多台云服务器,7*24小时不间断运行,可实现定时采集,无人值守,灵活适配业务场景,助您提升采集效率,保护数据及时性。
[API 接口]
通过优采云 API,可以方便地从采集获取优采云任务信息和数据,灵活调度任务,例如远程控制任务启停,高效实现数据采集和归档。基于强大的API系统,还可以与公司各种内部管理平台无缝对接,实现各种业务自动化。
[自定义 采集]
根据采集不同用户的需求,优采云可以提供自定义模式自动生成爬虫,可以批量准确识别各种网页元素,以及翻页、下拉、ajax、页面滚动、条件判断等。这类功能支持不同网页结构的复杂网站采集,满足多种采集应用场景。
【便捷的定时功能】
简单的点击几下设置,即可实现【k15】任务的定时控制,无论是单个【k15】定时设置,还是预设日或周、月定时【k15】。同时自由设置多个任务,根据需要进行多种选择时间组合,灵活部署自己的采集任务。
[自动数据格式化]
优采云 内置强大的数据格式化引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间格式化、HTML 转码等多项功能,采集 完全过程中自动处理,无需人工干预,即可获取所需格式数据。
[多级 采集]
许多主流新闻和电商网站包括一级商品列表页、二级商品详情页、三级评论详情页;无论网站有多少层,优采云都可以在不限制采集数据层级的情况下满足各种服务采集的需求。
[登录采集后支持网站]
优采云内置采集登录模块,只需要配置目标网站账号密码,即可使用该模块采集登录数据;同时【k6】还具有【k15】cookie自定义功能,首次登录后可以自动记住cookie,免去多次输入密码的繁琐,支持更多【k15】的【k14】。
[软件功能]
[满足多种业务场景]
适用于产品、运营、销售、数据分析、政府机构、电子商务从业者、学术研究等各种职业。
【舆论监测】
全方位监控公众信息,抢先掌握舆情动态
【市场分析】
获取用户真实行为数据,全面掌握客户真实需求
【产品研发】
大力支持用户研究,准确获取用户反馈和偏好
[风险预测]
高效信息采集和数据清洗,及时应对系统风险
[使用说明]
1、 首先我们新建一个任务-->进入流程设计页面-->在流程中添加循环步骤-->选择循环步骤-->勾选右边的URL列表复选框软件侧-->打开网址列表文本框-->将准备好的网址列表填入文本框。
2、接下来将打开网页的步骤拖入循环-->选择打开网页的步骤-->勾选使用当前循环中的URL作为导航地址的框-->点击保存。系统会在界面底部的浏览器中打开循环选择的URL对应的网页。
3、 至此,打开网页的循环配置完成。进程运行时,系统会一一打开循环中设置的URL。最后,我们不需要配置采集数据的一步,这里就不多说了,大家可以参考系列1:采集单网页这篇文章文章从入门到熟练程度。
优采云采集器是一款专业的功能强大的网络数据/信息挖掘软件
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2021-05-17 18:21
优采云 采集器是一款专业而强大的网络数据/信息挖掘软件。通过灵活的配置,您可以轻松地从网页中获取文本,图片,文件和其他资源。该程序支持图片文件的远程下载,登录采集后支持网站信息,支持检测文件的真实地址,支持代理,支持采集用于防盗链,支持采集直接数据存储以及由模仿者手动发布等。许多功能。
支持从任何类型的网站 采集中获取您所需的信息,例如各种新闻网站,论坛,电子商务网站,求职网站等。同时,它具有强大的网站登录名采集,多页和分页采集,网站跨层采集,POST 采集,脚本页面采集,动态页面采集和其他高级采集]功能。强大的php和c#插件支持使您可以通过二次开发来实现所需的任何更强大的功能。
[功能介绍]
1、规则自定义-通过采集规则的定义,您可以搜索几乎所有网站 采集类型的信息。
2、多任务,多线程-多个信息获取任务可以同时执行,并且每个任务可以使用多个线程。
3、所见即所得-任务采集所见即所得。在此过程中遍历的链接信息,采集信息,错误消息等将及时反映在软件界面中。
4、在采集时,数据存储数据自动保存到关系数据库中,并且可以自动调整数据结构。该软件可以根据采集规则或通过灵活的数据库引导方式自动创建数据库以及其中的表和字段。将数据保存到客户现有的数据库结构中。
5、断点继续采集-信息采集任务可以在断点采集停止后从断点恢复,从现在开始,您不必担心采集任务会意外中断。
6、 网站登录支持网站 Cookie,支持网站可视登录,即使网站在登录时需要验证码也可以是采集。
7、计划任务-此功能使您的采集任务可以定期,定量或循环执行。
8、 采集范围限制-可以根据采集的深度和URL的徽标来限制采集的范围。
9、文件下载-可以将采集中的二进制文件(例如图片,音乐,软件,文档等)下载到本地磁盘或采集结果数据库中。
1 0、结果替换-您可以根据规则用您定义的内容替换采集的结果。
1 1、有条件保存-可以根据特定条件决定要存储和过滤哪些信息。
1 2、过滤重复的内容-该软件可以根据用户设置和实际情况自动删除重复的内容和重复的URL。
1 3、特殊链接识别-使用此功能可以识别由JavaScript动态生成的链接或其他怪异链接。
1 4、数据发布-您可以通过自定义界面将采集的结果数据发布到任何内容管理系统和指定的数据库。当前支持的目标发布媒体包括:数据库(访问,SQL Server,我的SQL,Oracle),静态htm文件。
1 5、保留的编程接口-定义多个编程接口,用户可以在事件中使用PHP,C#语言进行编程,并扩展采集功能。
[软件功能]
1、多功能性
无论新闻,论坛,视频,黄页,图片,下载网站,只要可以通过浏览器看到的结构化内容,通过指定匹配规则,就可以采集来获取内容需要。
2、稳定高效
五年磨一剑,该软件不断更新和完善,采集快速,稳定的性能,并占用更少的资源。
3、强大的可扩展性和广泛的应用范围
自定义Web发布,自定义主流数据库的保存和发布,自定义本地php和.net外部编程接口以处理数据,以便您可以使用这些数据。
[更新日志]
V 9. 9. 0
1、优化效率并解决运行大量任务时卡住的问题
2、解决了使用大量代理时配置文件被锁定且程序退出的问题
3、解决了在某些情况下无法连接mysql的问题
4、其他界面和功能优化 查看全部
优采云采集器是一款专业的功能强大的网络数据/信息挖掘软件
优采云 采集器是一款专业而强大的网络数据/信息挖掘软件。通过灵活的配置,您可以轻松地从网页中获取文本,图片,文件和其他资源。该程序支持图片文件的远程下载,登录采集后支持网站信息,支持检测文件的真实地址,支持代理,支持采集用于防盗链,支持采集直接数据存储以及由模仿者手动发布等。许多功能。
支持从任何类型的网站 采集中获取您所需的信息,例如各种新闻网站,论坛,电子商务网站,求职网站等。同时,它具有强大的网站登录名采集,多页和分页采集,网站跨层采集,POST 采集,脚本页面采集,动态页面采集和其他高级采集]功能。强大的php和c#插件支持使您可以通过二次开发来实现所需的任何更强大的功能。
[功能介绍]
1、规则自定义-通过采集规则的定义,您可以搜索几乎所有网站 采集类型的信息。
2、多任务,多线程-多个信息获取任务可以同时执行,并且每个任务可以使用多个线程。
3、所见即所得-任务采集所见即所得。在此过程中遍历的链接信息,采集信息,错误消息等将及时反映在软件界面中。
4、在采集时,数据存储数据自动保存到关系数据库中,并且可以自动调整数据结构。该软件可以根据采集规则或通过灵活的数据库引导方式自动创建数据库以及其中的表和字段。将数据保存到客户现有的数据库结构中。
5、断点继续采集-信息采集任务可以在断点采集停止后从断点恢复,从现在开始,您不必担心采集任务会意外中断。
6、 网站登录支持网站 Cookie,支持网站可视登录,即使网站在登录时需要验证码也可以是采集。
7、计划任务-此功能使您的采集任务可以定期,定量或循环执行。
8、 采集范围限制-可以根据采集的深度和URL的徽标来限制采集的范围。
9、文件下载-可以将采集中的二进制文件(例如图片,音乐,软件,文档等)下载到本地磁盘或采集结果数据库中。
1 0、结果替换-您可以根据规则用您定义的内容替换采集的结果。
1 1、有条件保存-可以根据特定条件决定要存储和过滤哪些信息。
1 2、过滤重复的内容-该软件可以根据用户设置和实际情况自动删除重复的内容和重复的URL。
1 3、特殊链接识别-使用此功能可以识别由JavaScript动态生成的链接或其他怪异链接。
1 4、数据发布-您可以通过自定义界面将采集的结果数据发布到任何内容管理系统和指定的数据库。当前支持的目标发布媒体包括:数据库(访问,SQL Server,我的SQL,Oracle),静态htm文件。
1 5、保留的编程接口-定义多个编程接口,用户可以在事件中使用PHP,C#语言进行编程,并扩展采集功能。
[软件功能]
1、多功能性
无论新闻,论坛,视频,黄页,图片,下载网站,只要可以通过浏览器看到的结构化内容,通过指定匹配规则,就可以采集来获取内容需要。
2、稳定高效
五年磨一剑,该软件不断更新和完善,采集快速,稳定的性能,并占用更少的资源。
3、强大的可扩展性和广泛的应用范围
自定义Web发布,自定义主流数据库的保存和发布,自定义本地php和.net外部编程接口以处理数据,以便您可以使用这些数据。
[更新日志]
V 9. 9. 0
1、优化效率并解决运行大量任务时卡住的问题
2、解决了使用大量代理时配置文件被锁定且程序退出的问题
3、解决了在某些情况下无法连接mysql的问题
4、其他界面和功能优化
网页文章采集器有哪些采集效果——关键词采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2021-05-15 22:24
网页文章采集器有哪些采集效果——关键词采集可以通过数据抓取工具抓取和网站爬虫抓取同样的网页关键词,可以通过chrome和火狐采集大师抓取到足够的信息。包括网站名称、网页链接、网页分辨率、页面id。baidu采集任意关键词结果。网页地址可以更改。免费版网页采集器下载推荐使用网页抓取工具获取带高级指令的chrome、safari、firefox、polyfill扩展的浏览器,下载无需注册。
例如网页百度,可以直接下载带高级指令chrome、火狐、firefox、polyfill.baidu网页采集器-国内最佳网页采集器:百度快照采集。
还有个公众号叫国内最大的网络爬虫公司
下个先试试。
我已经写了一个轻量级的apispider了。传送门在这里。微信公众号、wordpress需要定时更新数据,而一个新的post并不会及时返回结果,如果一个微信公众号想要完整的多次更新数据,可以借助微信公众号大多数机器人的统计功能。现有的post抓取爬虫有,wordpress\wp等其他平台的大多数post机器人,但是由于微信公众号目前开放api有限,同时开发的成本相对较高,因此爬虫的实际收益并不乐观。
这里我们借助doubanlogowebreporter提供的免费api,这个api是我最近在调研的一个全新的功能。这个api可以使用wordpress提供的最新api接口,包括cookie加密功能以及exif相关的功能,缺点是收费,但我们在优化他的体验的同时,会尽量兼容免费接口,未来会开放所有接口。应用场景和效果:目前已经有大量的wordpress博客或者个人站点都在采用微信公众号通过feedurl获取全网全网免费博客,这样通过微信公众号发布的文章(包括图片和网站链接)就可以抓取了,同时还可以抓取一些开放出来的post机器人。
通过这个接口抓取的文章,还可以通过优化设置,找到最佳的阅读体验。弊端是:这个api目前只支持mp4.wp5\wp6等早期wp5机器人支持的格式,在以前的机器人制作上卡爆的情况下可能无法使用。虽然支持jpg、gif等有损压缩图片(免费版本),但是对于码率有限制,如果图片比较大,我们可能需要额外借助第三方工具制作。
这里分享使用这个api的两个tips:接口采集的长图片支持优化优化到800kb以下;清理浏览器缓存,将api里的时间戳(opener.pagetime)从datetime.now.toint()的值修改成global_index=true;抓取的wordpress内容我们需要初始化一个evernote账号来进行存储;使用有谷歌浏览器插件,可以将其导入doubanlogowebreporter进行记录和定时同步。另外,后续会开放github上的私有代码,有兴趣的同学可。 查看全部
网页文章采集器有哪些采集效果——关键词采集
网页文章采集器有哪些采集效果——关键词采集可以通过数据抓取工具抓取和网站爬虫抓取同样的网页关键词,可以通过chrome和火狐采集大师抓取到足够的信息。包括网站名称、网页链接、网页分辨率、页面id。baidu采集任意关键词结果。网页地址可以更改。免费版网页采集器下载推荐使用网页抓取工具获取带高级指令的chrome、safari、firefox、polyfill扩展的浏览器,下载无需注册。
例如网页百度,可以直接下载带高级指令chrome、火狐、firefox、polyfill.baidu网页采集器-国内最佳网页采集器:百度快照采集。
还有个公众号叫国内最大的网络爬虫公司
下个先试试。
我已经写了一个轻量级的apispider了。传送门在这里。微信公众号、wordpress需要定时更新数据,而一个新的post并不会及时返回结果,如果一个微信公众号想要完整的多次更新数据,可以借助微信公众号大多数机器人的统计功能。现有的post抓取爬虫有,wordpress\wp等其他平台的大多数post机器人,但是由于微信公众号目前开放api有限,同时开发的成本相对较高,因此爬虫的实际收益并不乐观。
这里我们借助doubanlogowebreporter提供的免费api,这个api是我最近在调研的一个全新的功能。这个api可以使用wordpress提供的最新api接口,包括cookie加密功能以及exif相关的功能,缺点是收费,但我们在优化他的体验的同时,会尽量兼容免费接口,未来会开放所有接口。应用场景和效果:目前已经有大量的wordpress博客或者个人站点都在采用微信公众号通过feedurl获取全网全网免费博客,这样通过微信公众号发布的文章(包括图片和网站链接)就可以抓取了,同时还可以抓取一些开放出来的post机器人。
通过这个接口抓取的文章,还可以通过优化设置,找到最佳的阅读体验。弊端是:这个api目前只支持mp4.wp5\wp6等早期wp5机器人支持的格式,在以前的机器人制作上卡爆的情况下可能无法使用。虽然支持jpg、gif等有损压缩图片(免费版本),但是对于码率有限制,如果图片比较大,我们可能需要额外借助第三方工具制作。
这里分享使用这个api的两个tips:接口采集的长图片支持优化优化到800kb以下;清理浏览器缓存,将api里的时间戳(opener.pagetime)从datetime.now.toint()的值修改成global_index=true;抓取的wordpress内容我们需要初始化一个evernote账号来进行存储;使用有谷歌浏览器插件,可以将其导入doubanlogowebreporter进行记录和定时同步。另外,后续会开放github上的私有代码,有兴趣的同学可。
用社群采集器去采集公众号文章的场景场景
采集交流 • 优采云 发表了文章 • 0 个评论 • 236 次浏览 • 2021-05-11 00:04
网页文章采集器,在部分功能上支持原创标识保护,但是也存在着一些不足,如,浏览器兼容问题,比如上传图片不能上传生成带特殊的编码水印的图片,表情包无法分享,无法进行全站的原创标识等。
如果你采集的内容是自己写的文章,你可以上原创号看看效果如何,上过原创号的文章发表起来比较麻烦的。
小说这块支持,百度都能搜到的。如果采集别人的那些杂乱的链接,是无法上传的。
其实使用接口比较好,比如猪八戒接的兼职网主机费用三百五十块,有的兼职网三百块一年,当然他是收一部分的费用,百度同理,首页免费给百度权重百度会自动给你购买提升排名和收录。
网页文章采集器
建议可以考虑社群采集工具自动化采集工具,获取途径非常简单,难点主要是防cc,
从查询以后的数据来看,不支持。
以下软件都可以用于抓取微信公众号文章,输入关键词即可,完全无需下载安装,小白一步操作即可。图形采集器地址:,左侧功能栏中会有采集公众号文章的按钮可以自定义采集字段、文章标题、文章封面等,右侧有个高级设置,可以设置按一下以保存或者多采集选择方式,每三次采集就会清空可用记录,支持关键词搜索。想象一下你在用社群采集器去采集公众号文章的场景,大致会有以下几种形式:1.扫描二维码2.微信搜索关键词3.公众号图文页查看4.微信公众号排行榜进行查看5.微信排行榜内容深度分析6.微信企业号排行榜查看7.微信广告监测8.微信广告优化9.微信广告,微信变现,微信排名变现10.社群采集器公众号文章采集。 查看全部
用社群采集器去采集公众号文章的场景场景
网页文章采集器,在部分功能上支持原创标识保护,但是也存在着一些不足,如,浏览器兼容问题,比如上传图片不能上传生成带特殊的编码水印的图片,表情包无法分享,无法进行全站的原创标识等。
如果你采集的内容是自己写的文章,你可以上原创号看看效果如何,上过原创号的文章发表起来比较麻烦的。
小说这块支持,百度都能搜到的。如果采集别人的那些杂乱的链接,是无法上传的。
其实使用接口比较好,比如猪八戒接的兼职网主机费用三百五十块,有的兼职网三百块一年,当然他是收一部分的费用,百度同理,首页免费给百度权重百度会自动给你购买提升排名和收录。
网页文章采集器
建议可以考虑社群采集工具自动化采集工具,获取途径非常简单,难点主要是防cc,
从查询以后的数据来看,不支持。
以下软件都可以用于抓取微信公众号文章,输入关键词即可,完全无需下载安装,小白一步操作即可。图形采集器地址:,左侧功能栏中会有采集公众号文章的按钮可以自定义采集字段、文章标题、文章封面等,右侧有个高级设置,可以设置按一下以保存或者多采集选择方式,每三次采集就会清空可用记录,支持关键词搜索。想象一下你在用社群采集器去采集公众号文章的场景,大致会有以下几种形式:1.扫描二维码2.微信搜索关键词3.公众号图文页查看4.微信公众号排行榜进行查看5.微信排行榜内容深度分析6.微信企业号排行榜查看7.微信广告监测8.微信广告优化9.微信广告,微信变现,微信排名变现10.社群采集器公众号文章采集。
如何通过本地客户端远程访问服务端进行数据采集,
采集交流 • 优采云 发表了文章 • 0 个评论 • 199 次浏览 • 2021-05-09 06:07
在上一期中,我们在html页面采集之后学习了数据查询,但这仅是在本地查询数据库。如果我们想通过远程操作采集进行数据存储和查询,该怎么办?今天我们将一起学习:如何通过本地客户端远程访问服务器以执行数据存储和查询采集。
此问题概述
在上一期中,我们在html页面采集之后学习了数据查询,但这仅是在本地查询数据库。如果我们想通过远程操作采集进行数据存储和查询,该怎么办? ?
今天我们一起学习:如何通过本地客户端远程访问服务器以进行数据存储和查询采集。
数据采集页2011-2012赛季英超联赛记录
了解简单的远程访问(RMI示例)
首先,让我们学习一个客户端对服务器进行远程访问的简单示例。
此处使用Java RMI(远程方法调用)
Java RMI是一种机制,使Java虚拟机可以调用另一个Java虚拟机上的对象上的方法来实现远程访问。
但是,要通过客户端实现此远程访问,必须绑定一个远程接口对象(这意味着客户端可以访问的服务器上的方法必须全部收录在此接口中)。
好的,让我们编写示例代码。
定义远程接口
首先,我们需要编写一个远程接口HelloInterface,该接口继承了远程对象Remote。
HelloInterface接口中有一个sayHello方法,用于在客户端连接后打个招呼。
由于sayHello方法继承了远程Remote对象,因此需要引发RemoteException。
package Remote_Interface;
import java.rmi.Remote;
import java.rmi.RemoteException;
/**
* 接口HelloInterface 继承了 远程接口 Remote 用于客户端Client远程调用
* @author SoFlash - 博客园 http://www.cnblogs.com/longwu
*/
public interface HelloInterface extends Remote{
public String sayHello(String name) throws RemoteException;
}
实现接口(在服务器端实现接口)
接下来,我们在接口中实现方法,而实现接口的方法在服务器端。
此处的HelloInterfaceImpl类实现了接口HelloInterface中的方法。
注意:在这里,HelloInterfaceImpl还继承了U优采云tRemoteObject远程对象。这必须写。尽管代码智能提示不会在未编写的情况下不会提示错误,但是服务器在启动后会莫名其妙地报告错误。
由于U优采云tRemoteObject远程对象需要引发RemoteException,因此使用构造函数方法HelloInterfaceImpl()引发此异常。
package Server;
import java.rmi.RemoteException;
import java.rmi.server.UnicastRemoteObject;
import Remote_Interface.HelloInterface;
/**
* HelloInterfaceImpl 用于实现 接口HelloInterface 的远程 SayHello方法
* @author SoFlash - 博客园 http://www.cnblogs.com/longwu
*/
@SuppressWarnings("serial")
// 继承 UnicastRemoteObject 远程对象 这个一定要写 否则 服务端启动报异常
public class HelloInterfaceImpl extends UnicastRemoteObject implements HelloInterface{
//HelloInterfaceImpl的构造方法 用于抛出UnicastRemoteObject 远程对象里的异常
protected HelloInterfaceImpl() throws RemoteException {
}
public String sayHello(String name) throws RemoteException {
//该信息 在客户端上发出
String strHello = "你好! " + name+" 欢迎访问服务端!";
//这条信息 是在服务端上 打印出来
System.out.println(name +" 正在 访问本服务端!");
return strHello;
}
}
写服务器端
接下来,让我们编写服务器,因为RMI实现远程访问的机制是指:客户端通过在RMI注册表中查找远程接口对象的地址(服务器地址)来实现远程访问的目的,
因此,我们需要在服务器上创建一个远程对象注册表,以绑定并注册服务器地址和远程接口对象,以便以后的客户端可以成功找到服务器(有关详细信息,请参见代码注释)。
package Server;
import java.net.MalformedURLException;
import java.rmi.AlreadyBoundException;
import java.rmi.Naming;
import java.rmi.RemoteException;
import java.rmi.registry.LocateRegistry;
import Remote_Interface.HelloInterface;
/**
* Server 类 用于 启动 注册服务端
* @author SoFlash - 博客园 http://www.cnblogs.com/longwu
*/
public class Server {
public static void main(String[] args) {
try {
// 定义远程接口HelloInterface 对象 用于绑定在服务端注册表上 该接口由HelloInterfaceImpl()类实现
HelloInterface hInterface = new HelloInterfaceImpl();
int port = 6666; // 定义一个端口号
// 创建一个接受对特定端口调用的远程对象注册表 注册表上需要接口一个指定的端口号
LocateRegistry.createRegistry(port);
// 定义 服务端远程地址 URL格式
String address = "rmi://localhost:" + port + "/hello";
// 绑定远程地址和接口对象
Naming.bind(address,hInterface);
// 如果启动成功 则弹出如下信息
System.out.println(">>>服务端启动成功");
System.out.println(">>>请启动客户端进行连接访问");
} catch (MalformedURLException e) {
System.out.println("地址出现错误!");
e.printStackTrace();
} catch (AlreadyBoundException e) {
System.out.println("重复绑定了同一个远程对象!");
e.printStackTrace();
} catch (RemoteException e) {
System.out.println("创建远程对象出现错误!");
e.printStackTrace();
}
}
}
写客户
服务器已完成,让我们写下访问服务器所需的客户端。
客户端还需要定义一个远程访问地址,即服务器地址,
然后,通过在RMI注册表中查找地址;如果找到,则建立连接。
package Client;
import java.net.MalformedURLException;
import java.rmi.Naming;
import java.rmi.NotBoundException;
import java.rmi.RemoteException;
import Remote_Interface.HelloInterface;
/**
* Client 用于连接 并访问 服务端Server
* @author SoFlash - 博客园 http://www.cnblogs.com/longwu
*/
public class Client {
public static void main(String[] args) {
// 定义一个端口号 该端口号必须与服务端的端口号相同
int port = 6666;
// 同样定义一个远程地址 该地址为服务端的远程地址 所以 与服务端的地址是一样的
String address = "rmi://localhost:" + port + "/hello";
// 在RMI注册表上需找 对象为HelloInterface的地址 即服务端地址
try {
HelloInterface hInterface = (HelloInterface) Naming.lookup(address);
// 一旦客户端找到该服务端地址 则 进行连接
System.out.println(">>服务端启动成功");
System.out.println(">>>请启动客户端进行连接访问");
} catch (MalformedURLException e) {
System.out.println("地址出现错误!");
e.printStackTrace();
} catch (AlreadyBoundException e) {
System.out.println("重复绑定了同一个远程对象!");
e.printStackTrace();
} catch (RemoteException e) {
System.out.println("创建远程对象出现错误!");
e.printStackTrace();
}
}
}
内部的Data采集AndStorage类和dataCollectAndStore()方法用于采集和存储数据。
Data采集AndStorage类
<p>package Server;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URL;
/**
* DataCollectionAndStorage类 用于数据的收集和存储
* @author SoFlash - 博客园 http://www.cnblogs.com/longwu
*/
public class DataCollectionAndStorage{
/**
* dataCollectAndStore()方法 用于Html数据收集和存储
*/
public void dataCollectAndStore() {
// 首先用一个字符串 来装载网页链接
String strUrl = "http://www.footballresults.org ... 3B%3B
String sqlLeagues = "";
try {
// 创建一个url对象来指向 该网站链接 括号里()装载的是该网站链接的路径
// 更多可以看看 http://wenku.baidu.com/view/81 ... .html
URL url = new URL(strUrl);
// InputStreamReader 是一个输入流读取器 用于将读取的字节转换成字符
// 更多可以看看 http://blog.sina.com.cn/s/blog ... .html
InputStreamReader isr = new InputStreamReader(url.openStream(),
"utf-8"); // 统一使用utf-8 编码模式
// 使用 BufferedReader 来读取 InputStreamReader 转换成的字符
BufferedReader br = new BufferedReader(isr);
String strRead = ""; // new 一个字符串来装载 BufferedReader 读取到的内容
// 定义3个正则 用于获取我们需要的数据
String regularDate = "(\\d{1,2}\\.\\d{1,2}\\.\\d{4})";
String regularTwoTeam = ">[^]*</a>";
String regularResult = ">(\\d{1,2}-\\d{1,2})";
//创建 GroupMethod类的对象 gMethod 方便后期调用其类里的 regularGroup方法
GroupMethod gMethod = new GroupMethod();
//创建DataStructure数据结构 类的对象 用于数据下面的数据存储
DataStructure ds = new DataStructure();
//创建MySql类的对象 用于执行MySql语句
MySql ms = new MySql();
int i = 0; // 定义一个i来记录循环次数 即收集到的球队比赛结果数
int index = 0; // 定义一个索引 用于获取分离 2个球队的数据 因为2个球队正则是相同的
// 开始读取数据 如果读到的数据不为空 则往里面读
while ((strRead = br.readLine()) != null) {
/**
* 用于捕获日期数据
*/
String strGet = gMethod.regularGroup(regularDate, strRead);
// 如果捕获到了符合条件的 日期数据 则打印出来
if (!strGet.equals("")) {
//System.out.println("Date:" + strGet);
//将收集到的日期存在数据结构里
ds.date = strGet;
// 这里索引+1 是用于获取后期的球队数据
++index; // 因为在html页面里 源代码里 球队数据是在刚好在日期之后
}
/**
* 用于获取2个球队的数据
*/
strGet = gMethod.regularGroup(regularTwoTeam, strRead);
if (!strGet.equals("") && index == 1) { // 索引为1的是主队数据
// 通过subtring方法 分离出 主队数据
strGet = strGet.substring(1, strGet.indexOf("</a>"));
//System.out.println("HomeTeam:" + strGet); // 打印出主队
//将收集到的主队名称 存到 数据结构里
ds.homeTeam = strGet;
index++; // 索引+1之后 为2了
// 通过subtring方法 分离出 客队
} else if (!strGet.equals("") && index == 2) { // 这里索引为2的是客队数据
strGet = strGet.substring(1, strGet.indexOf("</a>"));
//System.out.println("AwayTeam:" + strGet); // 打印出客队
//将收集到的客队名称 存到数据结构里
ds.awayTeam = strGet;
index = 0; //收集完客队名称后 需要将索引还原 用于收集下一条数据的主队名称
}
/**
* 用于获取比赛结果
*/
strGet = gMethod.regularGroup(regularResult, strRead);
if (!strGet.equals("")) {
// 这里同样用到了substring方法 来剔除' 查看全部
如何通过本地客户端远程访问服务端进行数据采集,
在上一期中,我们在html页面采集之后学习了数据查询,但这仅是在本地查询数据库。如果我们想通过远程操作采集进行数据存储和查询,该怎么办?今天我们将一起学习:如何通过本地客户端远程访问服务器以执行数据存储和查询采集。
此问题概述
在上一期中,我们在html页面采集之后学习了数据查询,但这仅是在本地查询数据库。如果我们想通过远程操作采集进行数据存储和查询,该怎么办? ?
今天我们一起学习:如何通过本地客户端远程访问服务器以进行数据存储和查询采集。
数据采集页2011-2012赛季英超联赛记录
了解简单的远程访问(RMI示例)
首先,让我们学习一个客户端对服务器进行远程访问的简单示例。
此处使用Java RMI(远程方法调用)
Java RMI是一种机制,使Java虚拟机可以调用另一个Java虚拟机上的对象上的方法来实现远程访问。
但是,要通过客户端实现此远程访问,必须绑定一个远程接口对象(这意味着客户端可以访问的服务器上的方法必须全部收录在此接口中)。
好的,让我们编写示例代码。
定义远程接口
首先,我们需要编写一个远程接口HelloInterface,该接口继承了远程对象Remote。
HelloInterface接口中有一个sayHello方法,用于在客户端连接后打个招呼。
由于sayHello方法继承了远程Remote对象,因此需要引发RemoteException。
package Remote_Interface;
import java.rmi.Remote;
import java.rmi.RemoteException;
/**
* 接口HelloInterface 继承了 远程接口 Remote 用于客户端Client远程调用
* @author SoFlash - 博客园 http://www.cnblogs.com/longwu
*/
public interface HelloInterface extends Remote{
public String sayHello(String name) throws RemoteException;
}
实现接口(在服务器端实现接口)
接下来,我们在接口中实现方法,而实现接口的方法在服务器端。
此处的HelloInterfaceImpl类实现了接口HelloInterface中的方法。
注意:在这里,HelloInterfaceImpl还继承了U优采云tRemoteObject远程对象。这必须写。尽管代码智能提示不会在未编写的情况下不会提示错误,但是服务器在启动后会莫名其妙地报告错误。
由于U优采云tRemoteObject远程对象需要引发RemoteException,因此使用构造函数方法HelloInterfaceImpl()引发此异常。
package Server;
import java.rmi.RemoteException;
import java.rmi.server.UnicastRemoteObject;
import Remote_Interface.HelloInterface;
/**
* HelloInterfaceImpl 用于实现 接口HelloInterface 的远程 SayHello方法
* @author SoFlash - 博客园 http://www.cnblogs.com/longwu
*/
@SuppressWarnings("serial")
// 继承 UnicastRemoteObject 远程对象 这个一定要写 否则 服务端启动报异常
public class HelloInterfaceImpl extends UnicastRemoteObject implements HelloInterface{
//HelloInterfaceImpl的构造方法 用于抛出UnicastRemoteObject 远程对象里的异常
protected HelloInterfaceImpl() throws RemoteException {
}
public String sayHello(String name) throws RemoteException {
//该信息 在客户端上发出
String strHello = "你好! " + name+" 欢迎访问服务端!";
//这条信息 是在服务端上 打印出来
System.out.println(name +" 正在 访问本服务端!");
return strHello;
}
}
写服务器端
接下来,让我们编写服务器,因为RMI实现远程访问的机制是指:客户端通过在RMI注册表中查找远程接口对象的地址(服务器地址)来实现远程访问的目的,
因此,我们需要在服务器上创建一个远程对象注册表,以绑定并注册服务器地址和远程接口对象,以便以后的客户端可以成功找到服务器(有关详细信息,请参见代码注释)。
package Server;
import java.net.MalformedURLException;
import java.rmi.AlreadyBoundException;
import java.rmi.Naming;
import java.rmi.RemoteException;
import java.rmi.registry.LocateRegistry;
import Remote_Interface.HelloInterface;
/**
* Server 类 用于 启动 注册服务端
* @author SoFlash - 博客园 http://www.cnblogs.com/longwu
*/
public class Server {
public static void main(String[] args) {
try {
// 定义远程接口HelloInterface 对象 用于绑定在服务端注册表上 该接口由HelloInterfaceImpl()类实现
HelloInterface hInterface = new HelloInterfaceImpl();
int port = 6666; // 定义一个端口号
// 创建一个接受对特定端口调用的远程对象注册表 注册表上需要接口一个指定的端口号
LocateRegistry.createRegistry(port);
// 定义 服务端远程地址 URL格式
String address = "rmi://localhost:" + port + "/hello";
// 绑定远程地址和接口对象
Naming.bind(address,hInterface);
// 如果启动成功 则弹出如下信息
System.out.println(">>>服务端启动成功");
System.out.println(">>>请启动客户端进行连接访问");
} catch (MalformedURLException e) {
System.out.println("地址出现错误!");
e.printStackTrace();
} catch (AlreadyBoundException e) {
System.out.println("重复绑定了同一个远程对象!");
e.printStackTrace();
} catch (RemoteException e) {
System.out.println("创建远程对象出现错误!");
e.printStackTrace();
}
}
}
写客户
服务器已完成,让我们写下访问服务器所需的客户端。
客户端还需要定义一个远程访问地址,即服务器地址,
然后,通过在RMI注册表中查找地址;如果找到,则建立连接。
package Client;
import java.net.MalformedURLException;
import java.rmi.Naming;
import java.rmi.NotBoundException;
import java.rmi.RemoteException;
import Remote_Interface.HelloInterface;
/**
* Client 用于连接 并访问 服务端Server
* @author SoFlash - 博客园 http://www.cnblogs.com/longwu
*/
public class Client {
public static void main(String[] args) {
// 定义一个端口号 该端口号必须与服务端的端口号相同
int port = 6666;
// 同样定义一个远程地址 该地址为服务端的远程地址 所以 与服务端的地址是一样的
String address = "rmi://localhost:" + port + "/hello";
// 在RMI注册表上需找 对象为HelloInterface的地址 即服务端地址
try {
HelloInterface hInterface = (HelloInterface) Naming.lookup(address);
// 一旦客户端找到该服务端地址 则 进行连接
System.out.println(">>服务端启动成功");
System.out.println(">>>请启动客户端进行连接访问");
} catch (MalformedURLException e) {
System.out.println("地址出现错误!");
e.printStackTrace();
} catch (AlreadyBoundException e) {
System.out.println("重复绑定了同一个远程对象!");
e.printStackTrace();
} catch (RemoteException e) {
System.out.println("创建远程对象出现错误!");
e.printStackTrace();
}
}
}
内部的Data采集AndStorage类和dataCollectAndStore()方法用于采集和存储数据。
Data采集AndStorage类
<p>package Server;
import java.io.BufferedReader;
import java.io.IOException;
import java.io.InputStreamReader;
import java.net.URL;
/**
* DataCollectionAndStorage类 用于数据的收集和存储
* @author SoFlash - 博客园 http://www.cnblogs.com/longwu
*/
public class DataCollectionAndStorage{
/**
* dataCollectAndStore()方法 用于Html数据收集和存储
*/
public void dataCollectAndStore() {
// 首先用一个字符串 来装载网页链接
String strUrl = "http://www.footballresults.org ... 3B%3B
String sqlLeagues = "";
try {
// 创建一个url对象来指向 该网站链接 括号里()装载的是该网站链接的路径
// 更多可以看看 http://wenku.baidu.com/view/81 ... .html
URL url = new URL(strUrl);
// InputStreamReader 是一个输入流读取器 用于将读取的字节转换成字符
// 更多可以看看 http://blog.sina.com.cn/s/blog ... .html
InputStreamReader isr = new InputStreamReader(url.openStream(),
"utf-8"); // 统一使用utf-8 编码模式
// 使用 BufferedReader 来读取 InputStreamReader 转换成的字符
BufferedReader br = new BufferedReader(isr);
String strRead = ""; // new 一个字符串来装载 BufferedReader 读取到的内容
// 定义3个正则 用于获取我们需要的数据
String regularDate = "(\\d{1,2}\\.\\d{1,2}\\.\\d{4})";
String regularTwoTeam = ">[^]*</a>";
String regularResult = ">(\\d{1,2}-\\d{1,2})";
//创建 GroupMethod类的对象 gMethod 方便后期调用其类里的 regularGroup方法
GroupMethod gMethod = new GroupMethod();
//创建DataStructure数据结构 类的对象 用于数据下面的数据存储
DataStructure ds = new DataStructure();
//创建MySql类的对象 用于执行MySql语句
MySql ms = new MySql();
int i = 0; // 定义一个i来记录循环次数 即收集到的球队比赛结果数
int index = 0; // 定义一个索引 用于获取分离 2个球队的数据 因为2个球队正则是相同的
// 开始读取数据 如果读到的数据不为空 则往里面读
while ((strRead = br.readLine()) != null) {
/**
* 用于捕获日期数据
*/
String strGet = gMethod.regularGroup(regularDate, strRead);
// 如果捕获到了符合条件的 日期数据 则打印出来
if (!strGet.equals("")) {
//System.out.println("Date:" + strGet);
//将收集到的日期存在数据结构里
ds.date = strGet;
// 这里索引+1 是用于获取后期的球队数据
++index; // 因为在html页面里 源代码里 球队数据是在刚好在日期之后
}
/**
* 用于获取2个球队的数据
*/
strGet = gMethod.regularGroup(regularTwoTeam, strRead);
if (!strGet.equals("") && index == 1) { // 索引为1的是主队数据
// 通过subtring方法 分离出 主队数据
strGet = strGet.substring(1, strGet.indexOf("</a>"));
//System.out.println("HomeTeam:" + strGet); // 打印出主队
//将收集到的主队名称 存到 数据结构里
ds.homeTeam = strGet;
index++; // 索引+1之后 为2了
// 通过subtring方法 分离出 客队
} else if (!strGet.equals("") && index == 2) { // 这里索引为2的是客队数据
strGet = strGet.substring(1, strGet.indexOf("</a>"));
//System.out.println("AwayTeam:" + strGet); // 打印出客队
//将收集到的客队名称 存到数据结构里
ds.awayTeam = strGet;
index = 0; //收集完客队名称后 需要将索引还原 用于收集下一条数据的主队名称
}
/**
* 用于获取比赛结果
*/
strGet = gMethod.regularGroup(regularResult, strRead);
if (!strGet.equals("")) {
// 这里同样用到了substring方法 来剔除'
网页文章采集器之前做过一个,你可以试试
采集交流 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2021-05-07 02:02
网页文章采集器
之前做过一个,你可以试试,
1、首先将自己整理好的电影分类导入本地文件
2、利用爬虫软件爬取网页、电影、电视
3、在利用爬虫软件转存网页文件至本地
4、再利用云存储应用上传文件至云存储空间。
可以参考这个我的博客豆瓣电影采集同步存放在mysql中的配置
可以参考这个网站:
手工下载整理收集电影信息需要自己操作,有的需要付费,希望能帮到你;网上搜索有的是爬虫加比价,因为分享也不能保证有利于你,所以有的可能失效。
1、如何下载豆瓣电影?-电影
2、豆瓣电影-豆瓣电影排行榜,高质量电影数据库,重要电影信息一站全找到。
3、电影方便查看,从此更懂电影!(分享人工下载ikuku)
你可以看看我整理的一个国内网盘下载的工具:;比如接下来要下载“国产青春电影合集”,可以直接将它收集到你自己网盘,或者将你收集到的资源上传到百度云都可以下载,
我也是刚刚用豆瓣下载过电影,网上有可以自己下的,但是数量不多,有好几年前的啦,你可以试一下如果你不确定自己电影能否下载下来,给网站客服说下在试下的那种方式下载电影。你的手机端可以下载电影的,但pc端下载不了。 查看全部
网页文章采集器之前做过一个,你可以试试
网页文章采集器
之前做过一个,你可以试试,
1、首先将自己整理好的电影分类导入本地文件
2、利用爬虫软件爬取网页、电影、电视
3、在利用爬虫软件转存网页文件至本地
4、再利用云存储应用上传文件至云存储空间。
可以参考这个我的博客豆瓣电影采集同步存放在mysql中的配置
可以参考这个网站:
手工下载整理收集电影信息需要自己操作,有的需要付费,希望能帮到你;网上搜索有的是爬虫加比价,因为分享也不能保证有利于你,所以有的可能失效。
1、如何下载豆瓣电影?-电影
2、豆瓣电影-豆瓣电影排行榜,高质量电影数据库,重要电影信息一站全找到。
3、电影方便查看,从此更懂电影!(分享人工下载ikuku)
你可以看看我整理的一个国内网盘下载的工具:;比如接下来要下载“国产青春电影合集”,可以直接将它收集到你自己网盘,或者将你收集到的资源上传到百度云都可以下载,
我也是刚刚用豆瓣下载过电影,网上有可以自己下的,但是数量不多,有好几年前的啦,你可以试一下如果你不确定自己电影能否下载下来,给网站客服说下在试下的那种方式下载电影。你的手机端可以下载电影的,但pc端下载不了。
智能优采云采集可根据不同网站提供多种网页采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 471 次浏览 • 2021-05-02 05:18
优采云 采集器是任何需要从网络获取信息的孩子的必备神器。这是一个可以使您的信息采集非常简单的工具。 优采云它改变了传统的Internet数据思考方式,使用户在Internet上爬行和编译数据变得越来越容易。
软件功能
满足各种业务场景
适用于各种职业,例如产品,运营,销售,数据分析,政府机构,电子商务从业人员,学术研究等。
舆论监督
全面监控公共信息,并首先获得舆论趋势。
市场分析
获取用户真实行为数据并充分掌握客户的真实需求
产品研发
大力支持用户研究并准确获取用户反馈和偏好
风险预测
有效的信息采集和数据清除,及时应对系统风险
功能介绍
轻松采集
轻松采集模式内置了数百个主流网站数据源,例如京东,天猫,点屏和其他流行的采集 网站。您可以通过简单地通过参考模板设置参数来快速获得它。 网站公开数据。
智能采集
优采云 采集可以根据不同的网站提供各种网页采集策略和支持资源,可以进行个性化配置,组合使用和自动处理。从而帮助整个采集过程实现数据的完整性和稳定性。
云采集
Cloud 采集由超过5,000台云服务器支持,7 * 24小时不间断运行,可以实现定时采集,无需值班人员,可以灵活地适应业务场景,帮助您提高采集效率并保护数据及时性。
API接口
通过优采云 API,您可以轻松地从采集获取优采云任务信息和数据,灵活地计划任务,例如远程控制任务的启动和停止,并有效地实现数据采集和归档。基于强大的API系统,它还可以与公司的各种内部管理平台无缝连接,以实现各种业务自动化。
自定义采集
根据不同用户的采集需求,优采云可以提供一种自定义模式,用于自动生成抓取工具,该抓取工具可以准确地批量识别各种网页元素,以及翻页,下拉菜单,ajax,页面滚动,条件判断等。这种功能支持不同网页结构的复杂网站 采集,并满足各种采集应用场景。
便捷的计时功能
只需单击几下即可设置,您可以实现采集任务的计时控制,无论是单个采集计时设置,还是预设的一天或每周和每月的计时采集。同时自由设置多个任务,根据需要对选择时间进行多种组合,并灵活地部署自己的采集任务。
自动数据格式化
优采云具有内置的强大数据格式化引擎,该引擎支持字符串替换,正则表达式替换或匹配,删除空格,添加前缀或后缀,日期和时间格式,HTML转码以及许多其他功能,采集在此过程中进行全自动处理,无需人工干预,即可获取所需的格式数据。
多级采集
许多主流新闻和电子商务网站包括第一级产品列表页面,第二级产品详细信息页面和第三级评论详细信息页面;无论网站有多少级,优采云所有数据都可以是无限采集,以满足各种业务采集的需求。
登录采集后支持网站
优采云内置了采集登录模块,只需配置目标网站的帐户密码,就可以使用该模块采集登录数据;同时优采云还具有采集 Cookie自定义功能,首次登录后,可以自动记住该cookie,从而消除了多次麻烦的密码输入,并支持采集中的更多网站。<//p
p使用方法/p
p首先,让我们创建一个新任务->进入流程设计页面->向流程中添加一个循环步骤->选择循环步骤->选中页面右侧的URL列表复选框软件->“打开URL列表”文本框->将准备好的URL列表填充到文本框中
接下来,将一个步骤将网页打开到循环中->选择要打开网页的步骤->选中复选框以将当前循环中的URL用作导航地址->单击以保存。系统将在界面底部的浏览器中打开与在循环中选择的URL对应的网页
至此,打开网页周期的配置完成。当进程运行时,系统将一遍打开在循环中设置的URL。最后,我们不需要配置采集数据的步骤,因此在此不再赘述。您可以参考系列1:采集单个网页,从入门到熟练程度文章。下图是最终的过程。 查看全部
智能优采云采集可根据不同网站提供多种网页采集
优采云 采集器是任何需要从网络获取信息的孩子的必备神器。这是一个可以使您的信息采集非常简单的工具。 优采云它改变了传统的Internet数据思考方式,使用户在Internet上爬行和编译数据变得越来越容易。
软件功能
满足各种业务场景
适用于各种职业,例如产品,运营,销售,数据分析,政府机构,电子商务从业人员,学术研究等。
舆论监督
全面监控公共信息,并首先获得舆论趋势。
市场分析
获取用户真实行为数据并充分掌握客户的真实需求
产品研发
大力支持用户研究并准确获取用户反馈和偏好
风险预测
有效的信息采集和数据清除,及时应对系统风险
功能介绍
轻松采集
轻松采集模式内置了数百个主流网站数据源,例如京东,天猫,点屏和其他流行的采集 网站。您可以通过简单地通过参考模板设置参数来快速获得它。 网站公开数据。
智能采集
优采云 采集可以根据不同的网站提供各种网页采集策略和支持资源,可以进行个性化配置,组合使用和自动处理。从而帮助整个采集过程实现数据的完整性和稳定性。
云采集
Cloud 采集由超过5,000台云服务器支持,7 * 24小时不间断运行,可以实现定时采集,无需值班人员,可以灵活地适应业务场景,帮助您提高采集效率并保护数据及时性。
API接口
通过优采云 API,您可以轻松地从采集获取优采云任务信息和数据,灵活地计划任务,例如远程控制任务的启动和停止,并有效地实现数据采集和归档。基于强大的API系统,它还可以与公司的各种内部管理平台无缝连接,以实现各种业务自动化。
自定义采集
根据不同用户的采集需求,优采云可以提供一种自定义模式,用于自动生成抓取工具,该抓取工具可以准确地批量识别各种网页元素,以及翻页,下拉菜单,ajax,页面滚动,条件判断等。这种功能支持不同网页结构的复杂网站 采集,并满足各种采集应用场景。
便捷的计时功能
只需单击几下即可设置,您可以实现采集任务的计时控制,无论是单个采集计时设置,还是预设的一天或每周和每月的计时采集。同时自由设置多个任务,根据需要对选择时间进行多种组合,并灵活地部署自己的采集任务。
自动数据格式化
优采云具有内置的强大数据格式化引擎,该引擎支持字符串替换,正则表达式替换或匹配,删除空格,添加前缀或后缀,日期和时间格式,HTML转码以及许多其他功能,采集在此过程中进行全自动处理,无需人工干预,即可获取所需的格式数据。
多级采集
许多主流新闻和电子商务网站包括第一级产品列表页面,第二级产品详细信息页面和第三级评论详细信息页面;无论网站有多少级,优采云所有数据都可以是无限采集,以满足各种业务采集的需求。
登录采集后支持网站
优采云内置了采集登录模块,只需配置目标网站的帐户密码,就可以使用该模块采集登录数据;同时优采云还具有采集 Cookie自定义功能,首次登录后,可以自动记住该cookie,从而消除了多次麻烦的密码输入,并支持采集中的更多网站。<//p
p使用方法/p
p首先,让我们创建一个新任务->进入流程设计页面->向流程中添加一个循环步骤->选择循环步骤->选中页面右侧的URL列表复选框软件->“打开URL列表”文本框->将准备好的URL列表填充到文本框中
接下来,将一个步骤将网页打开到循环中->选择要打开网页的步骤->选中复选框以将当前循环中的URL用作导航地址->单击以保存。系统将在界面底部的浏览器中打开与在循环中选择的URL对应的网页
至此,打开网页周期的配置完成。当进程运行时,系统将一遍打开在循环中设置的URL。最后,我们不需要配置采集数据的步骤,因此在此不再赘述。您可以参考系列1:采集单个网页,从入门到熟练程度文章。下图是最终的过程。
网页表格数据采集助手的使用方法有哪些?如何使用
采集交流 • 优采云 发表了文章 • 0 个评论 • 408 次浏览 • 2021-04-24 05:19
Web表单数据采集助手是一种表单,它可以采集单页的常规和不规则表单,也可以自动连续地采集指定网站表单,并且您可以指定采集]必填字段的内容,采集之后的内容可以另存为EXCEL软件可以读取的文件格式,也可以另存为保留原创格式的纯文本格式。它绝对是简单,方便,快速且纯净的绿色,不要相信我,只需下载并尝试一下即可。
使用方法
1、首先在地址栏中输入网页地址采集。如果要在[IE]浏览器中打开采集的网页,则该网页将在软件的网址列表中
该地址将被自动添加,您只需下拉列表即可将其打开。
2、再次单击爬网测试按钮以查看网页源代码和网页中收录的表数。网页源代码显示在软件下方的文本框中。净
中收录的表数
页面和标题信息显示在软件左上角的列表框中。
3、从表格编号列表中选择要抓取的表格。此时,表左上角的第一个文本将显示在软件表左上角的第一个框中
在输入框中,表单中收录的字段(列)将显示在软件左侧的中间列表中。
4、,然后选择所需的表数据的字段(列)采集,如果未选择,则将设置所有采集。
5、选择是否要获取表的标题行,保存时是否显示表行,如果Web表单中的字段中有链接,则可以选择是否
包括链接地址。如果您具有采集它的链接地址,则不能选择同时收录标题行。
6、如果您希望采集的表格数据只有一个网页,那么,如果您不选择在表格前面添加表格,则可以直接单击以获取表格。
网格线,表格数据将以CVS格式保存,如果您选择在表格前面添加表格,则可以通过Microsoft EXCEL软件直接打开该格式并将其转换为EXCEL表格
网格线,表格数据将以TXT格式保存,可以使用记事本软件打开和查看。表格行直接可用,这也很清楚。
7、如果您希望采集具有多张连续的表格数据页面,并且想要采集向下,那么请在下一页及更高版本中设置程序采集。
继续页面的方法可以是根据链接名称打开下一页。具有链接名称的页面几乎都是“下一页”。查看页面并找到它。
只需输入,如果网页没有指向下一页的链接,但URL收录页面数,那么您还可以根据URL中的页面数选择打开,您可以
要从前到后(例如从第1页到第10页)进行选择,或从后到前(例如从第10页到第1页)进行选择,请在页码输入框中进行输入,但这一次
表示URL中页数的位置应替换为“(*)”,否则程序将无法识别它。
8、然后选择时间采集或等待网页打开并立即加载采集,时间采集是程序设置的较小时间间隔
要判断打开的页面中是否有您想要的表,是否存在采集,并且在加载页面后,只要采集的页面已打开,采集就可以了,
该程序将立即进行采集,两者都有各自的特点,取决于选择的需要。
9、最后,您只需单击“抓取表单”按钮,即可冲泡咖啡!
1 0、如果您已经熟悉想要的网页信息采集,并且想要采集指定表单的所有字段,则还可以输入所需的
获得一些信息后,直接单击即可获取表格,而无需执行爬网测试之类的操作。 查看全部
网页表格数据采集助手的使用方法有哪些?如何使用
Web表单数据采集助手是一种表单,它可以采集单页的常规和不规则表单,也可以自动连续地采集指定网站表单,并且您可以指定采集]必填字段的内容,采集之后的内容可以另存为EXCEL软件可以读取的文件格式,也可以另存为保留原创格式的纯文本格式。它绝对是简单,方便,快速且纯净的绿色,不要相信我,只需下载并尝试一下即可。
使用方法
1、首先在地址栏中输入网页地址采集。如果要在[IE]浏览器中打开采集的网页,则该网页将在软件的网址列表中
该地址将被自动添加,您只需下拉列表即可将其打开。
2、再次单击爬网测试按钮以查看网页源代码和网页中收录的表数。网页源代码显示在软件下方的文本框中。净
中收录的表数
页面和标题信息显示在软件左上角的列表框中。
3、从表格编号列表中选择要抓取的表格。此时,表左上角的第一个文本将显示在软件表左上角的第一个框中
在输入框中,表单中收录的字段(列)将显示在软件左侧的中间列表中。
4、,然后选择所需的表数据的字段(列)采集,如果未选择,则将设置所有采集。
5、选择是否要获取表的标题行,保存时是否显示表行,如果Web表单中的字段中有链接,则可以选择是否
包括链接地址。如果您具有采集它的链接地址,则不能选择同时收录标题行。
6、如果您希望采集的表格数据只有一个网页,那么,如果您不选择在表格前面添加表格,则可以直接单击以获取表格。
网格线,表格数据将以CVS格式保存,如果您选择在表格前面添加表格,则可以通过Microsoft EXCEL软件直接打开该格式并将其转换为EXCEL表格
网格线,表格数据将以TXT格式保存,可以使用记事本软件打开和查看。表格行直接可用,这也很清楚。
7、如果您希望采集具有多张连续的表格数据页面,并且想要采集向下,那么请在下一页及更高版本中设置程序采集。
继续页面的方法可以是根据链接名称打开下一页。具有链接名称的页面几乎都是“下一页”。查看页面并找到它。
只需输入,如果网页没有指向下一页的链接,但URL收录页面数,那么您还可以根据URL中的页面数选择打开,您可以
要从前到后(例如从第1页到第10页)进行选择,或从后到前(例如从第10页到第1页)进行选择,请在页码输入框中进行输入,但这一次
表示URL中页数的位置应替换为“(*)”,否则程序将无法识别它。
8、然后选择时间采集或等待网页打开并立即加载采集,时间采集是程序设置的较小时间间隔
要判断打开的页面中是否有您想要的表,是否存在采集,并且在加载页面后,只要采集的页面已打开,采集就可以了,
该程序将立即进行采集,两者都有各自的特点,取决于选择的需要。
9、最后,您只需单击“抓取表单”按钮,即可冲泡咖啡!
1 0、如果您已经熟悉想要的网页信息采集,并且想要采集指定表单的所有字段,则还可以输入所需的
获得一些信息后,直接单击即可获取表格,而无需执行爬网测试之类的操作。
网页文章采集器一款综合性网站抓取插件,能轻松抓取全网网站的文章内容
采集交流 • 优采云 发表了文章 • 0 个评论 • 196 次浏览 • 2021-04-16 05:03
网页文章采集器一款综合性网站抓取插件,能轻松抓取全网网站的文章内容,网站/个人博客/微信公众号文章全部抓取。登录邮箱绑定账号即可免费使用,采集速度特别快,体积小,速度还特别稳定。而且安全性高,不会出现任何被盗号的风险。这款软件只要登录邮箱,就可以自动绑定,另外使用者在网站上留下邮箱地址即可登录。支持采集高清图片,搜索引擎就搜不到的原创文章!一键识别网页,十八般武艺样样精通!百度,搜狗,360,谷歌,神马,360文章原创文章高清无码,采集无痛,ugc评论长期收藏!易被拦截,接口限制大屏幕自由拖放采集,不会超时,数据抓取自由,支持robots协议修改,站内站外都可抓取,实时抓取数据无死角。
支持:php,mysql,mssql。可根据需要模拟请求大多数页面请求路径或浏览器自定义请求,极速采集。点击查看详情图:。
除了这款还有这款推荐一波,可以24小时自动辅助操作工具。
我看到你一个比一个贪心,自己手动找还不满足。难怪你找不到好的,不是没有好的,是你根本就没点开看,看了连要是用requests模块的都不知道。
推荐一款刚刚出来的免费的spiderswebget:使用开源代码的,封装一下不难,php5.5或以上的版本都支持请求获取其他javascript,css以及json这类的数据。json:适合ie或者firefox在进行正常请求之后,保存自己编辑的内容,可以自定义cookie之类的数据htmlget:用get请求来获取img的数据,解析json请求获取其他数据。
有一些缺点,如可能会出现会话激活报错等。下面给你看一下源码:welcometothespidersbehindsearch。 查看全部
网页文章采集器一款综合性网站抓取插件,能轻松抓取全网网站的文章内容
网页文章采集器一款综合性网站抓取插件,能轻松抓取全网网站的文章内容,网站/个人博客/微信公众号文章全部抓取。登录邮箱绑定账号即可免费使用,采集速度特别快,体积小,速度还特别稳定。而且安全性高,不会出现任何被盗号的风险。这款软件只要登录邮箱,就可以自动绑定,另外使用者在网站上留下邮箱地址即可登录。支持采集高清图片,搜索引擎就搜不到的原创文章!一键识别网页,十八般武艺样样精通!百度,搜狗,360,谷歌,神马,360文章原创文章高清无码,采集无痛,ugc评论长期收藏!易被拦截,接口限制大屏幕自由拖放采集,不会超时,数据抓取自由,支持robots协议修改,站内站外都可抓取,实时抓取数据无死角。
支持:php,mysql,mssql。可根据需要模拟请求大多数页面请求路径或浏览器自定义请求,极速采集。点击查看详情图:。
除了这款还有这款推荐一波,可以24小时自动辅助操作工具。
我看到你一个比一个贪心,自己手动找还不满足。难怪你找不到好的,不是没有好的,是你根本就没点开看,看了连要是用requests模块的都不知道。
推荐一款刚刚出来的免费的spiderswebget:使用开源代码的,封装一下不难,php5.5或以上的版本都支持请求获取其他javascript,css以及json这类的数据。json:适合ie或者firefox在进行正常请求之后,保存自己编辑的内容,可以自定义cookie之类的数据htmlget:用get请求来获取img的数据,解析json请求获取其他数据。
有一些缺点,如可能会出现会话激活报错等。下面给你看一下源码:welcometothespidersbehindsearch。
网页文章采集器收录了所有微信公众号文章的文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 210 次浏览 • 2021-04-04 05:07
网页文章采集器收录了所有微信公众号的文章,对于公众号公开转载文章,可以通过这个网站进行多次免费在线转载,
你可以试试sanc文档网站,类似百度文库这样的文档共享网站,我自己也在使用,
我现在在做一个公众号,每天晚上回来文章都会找,所以推荐一个网站:下面只是一小部分。推荐一个我最近在用的方法,基本上我一上午或者一下午就找到了这些话题,如果一段时间里没有找到,会被自动下线,你可以看看。1,首先,搜索关键词,如“下班”2,对于正在更新或者想更新的新文章,就可以在这里找到,点进去3,假如你点进去之后是这样的,这个文章,那么可以先点这个按钮,然后再去这里找:4,这样你就能找到文章的底部标签5,如果你觉得这个文章不错,可以点下面红框里的收藏,它会自动保存到evernote里面6,每次编辑文章时,它都会自动推送到对应的evernote7,假如以后自己想找到类似的,也可以看下面这个链接,看一下要多久才能找到:,新建文章标签或者分类,点进去,你就能找到很多相似的文章。
8,所以你点开我截图那个文章网址,就能看到一个标签:,你就可以找到这篇文章分享的其他高质量文章:,可以在页面底部的“分享”里将分享到evernote收藏9,它也可以把你的推送到电脑上的文章保存到evernote,然后再通过微信公众号对话框里发送给别人:10,你发的这篇文章,我在看,你也可以看看。但是如果一段时间没有更新或者更新了,就会被封。---。 查看全部
网页文章采集器收录了所有微信公众号文章的文章
网页文章采集器收录了所有微信公众号的文章,对于公众号公开转载文章,可以通过这个网站进行多次免费在线转载,
你可以试试sanc文档网站,类似百度文库这样的文档共享网站,我自己也在使用,
我现在在做一个公众号,每天晚上回来文章都会找,所以推荐一个网站:下面只是一小部分。推荐一个我最近在用的方法,基本上我一上午或者一下午就找到了这些话题,如果一段时间里没有找到,会被自动下线,你可以看看。1,首先,搜索关键词,如“下班”2,对于正在更新或者想更新的新文章,就可以在这里找到,点进去3,假如你点进去之后是这样的,这个文章,那么可以先点这个按钮,然后再去这里找:4,这样你就能找到文章的底部标签5,如果你觉得这个文章不错,可以点下面红框里的收藏,它会自动保存到evernote里面6,每次编辑文章时,它都会自动推送到对应的evernote7,假如以后自己想找到类似的,也可以看下面这个链接,看一下要多久才能找到:,新建文章标签或者分类,点进去,你就能找到很多相似的文章。
8,所以你点开我截图那个文章网址,就能看到一个标签:,你就可以找到这篇文章分享的其他高质量文章:,可以在页面底部的“分享”里将分享到evernote收藏9,它也可以把你的推送到电脑上的文章保存到evernote,然后再通过微信公众号对话框里发送给别人:10,你发的这篇文章,我在看,你也可以看看。但是如果一段时间没有更新或者更新了,就会被封。---。
浏览网页实际是采用协议向Web服务请求一个超文本
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2021-03-28 02:19
报价:%B4%F3%CE%B0 / blog / item / 941ed8b49ee58f6b8bd4b2e 2. html
浏览网络时,我们将在浏览器的地址栏中输入需要访问的地址。通常,这些地址以HTTP开头,表示HTTP协议用于与站点进行通信。 HTTP准确地称为超文本传输。归根结底,协议仍然是文本,因此传输的内容是文本,浏览的网页也是文本。这是我们可以采集 网站数据的基础。
与此同时,在地址栏中,我们还将在URL中看到单词www,这意味着我们正在请求Web服务。 WWW服务(3W服务)是当前使用最广泛的基本Internet应用程序。 WWW服务使用超文本链接(HTML),因此您可以轻松地从一个信息页面切换到另一信息页面。它不仅可以查看文本,还可以欣赏图片,音乐和动画。
至此,我们知道浏览网页实际上是使用HTTP协议从Web服务请求超文本(HTML)。此超文本收录文本,图片,音乐和其他内容。这是我们最终看到的网页。同时,采集的数据也包括在该超文本中。超文本(HTML)有其自己的规则。通过这些规则,浏览器将自动识别超文本格式并知道如何显示页面。这是我们看到不同网页样式的基础。如果我们通过浏览器查看网页的源代码,则会发现很多标记内容。这是HTML的标准内容,当然还有许多其他规范。
手动处理数据采集:
1、使用浏览器打开网页(浏览器是IE,Firefox)
2、使用浏览器查看网页的源代码(Firefox)或查看源文件(IE)打开此网页的传输文本内容
3、可以将所有文本内容复制到专业的文本编辑工具(例如UltraEdit),或直接使用浏览器自身的功能
4、开始通过搜索功能找到想要的东西
5、您需要在找到它后将其复制
参考资料
Network Miner Data 采集软件用户手册
C#多线程网页采集器(蜘蛛)
采集功能(采集,分析,替换和存储在一个容器中)
ASP.NET(C#)经典采集代码
下载数据的方法和示例采集
Wei Yan ASP.NET数据采集封装类,它封装了数据采集所需的所有方法
log4net的详细使用
ASP.N 优采云 采集器系统通用正则表达式
.NETC#大量发送带有附件的HTML格式的中文发件人密件抄送电子邮件
.net程序中资源文件的保护方法
使用代理进行C#抓取
sql生成指定数字的100W随机数的方法(仅用了不到1分钟的时间)(完成) 查看全部
浏览网页实际是采用协议向Web服务请求一个超文本
报价:%B4%F3%CE%B0 / blog / item / 941ed8b49ee58f6b8bd4b2e 2. html
浏览网络时,我们将在浏览器的地址栏中输入需要访问的地址。通常,这些地址以HTTP开头,表示HTTP协议用于与站点进行通信。 HTTP准确地称为超文本传输。归根结底,协议仍然是文本,因此传输的内容是文本,浏览的网页也是文本。这是我们可以采集 网站数据的基础。
与此同时,在地址栏中,我们还将在URL中看到单词www,这意味着我们正在请求Web服务。 WWW服务(3W服务)是当前使用最广泛的基本Internet应用程序。 WWW服务使用超文本链接(HTML),因此您可以轻松地从一个信息页面切换到另一信息页面。它不仅可以查看文本,还可以欣赏图片,音乐和动画。
至此,我们知道浏览网页实际上是使用HTTP协议从Web服务请求超文本(HTML)。此超文本收录文本,图片,音乐和其他内容。这是我们最终看到的网页。同时,采集的数据也包括在该超文本中。超文本(HTML)有其自己的规则。通过这些规则,浏览器将自动识别超文本格式并知道如何显示页面。这是我们看到不同网页样式的基础。如果我们通过浏览器查看网页的源代码,则会发现很多标记内容。这是HTML的标准内容,当然还有许多其他规范。
手动处理数据采集:
1、使用浏览器打开网页(浏览器是IE,Firefox)
2、使用浏览器查看网页的源代码(Firefox)或查看源文件(IE)打开此网页的传输文本内容
3、可以将所有文本内容复制到专业的文本编辑工具(例如UltraEdit),或直接使用浏览器自身的功能
4、开始通过搜索功能找到想要的东西
5、您需要在找到它后将其复制
参考资料
Network Miner Data 采集软件用户手册
C#多线程网页采集器(蜘蛛)
采集功能(采集,分析,替换和存储在一个容器中)
ASP.NET(C#)经典采集代码
下载数据的方法和示例采集
Wei Yan ASP.NET数据采集封装类,它封装了数据采集所需的所有方法
log4net的详细使用
ASP.N 优采云 采集器系统通用正则表达式
.NETC#大量发送带有附件的HTML格式的中文发件人密件抄送电子邮件
.net程序中资源文件的保护方法
使用代理进行C#抓取
sql生成指定数字的100W随机数的方法(仅用了不到1分钟的时间)(完成)
用通用的浏览器插件可以nicetomessage正在用的:aster.io
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-03-26 23:04
网页文章采集器获取方式:进入笔者个人主页,查看笔者主页头像以及简介获取方式:回复“加群”可加入球球免费领取上百款限免网页制作工具。
/用通用的浏览器插件就可以
nicetomessage
正在用的:aster.io效果如下:
企业办公通
必须是adexcel
agisapiserverinarcgisserver2012api设置可以参考这个图:
wordcloud有道词典日语等都能识别,用word或者其他软件可以录入但都要自己编辑,现在自己有一些在线地图服务,可以无缝集成,在线选择分析。
浏览器插件可以识别代码里面的识别码,免费。
链接可能会失效,
我一直用postman实现的,国内都是定制开发。作为一个前端工程师来说能简单就不用麻烦后端人员。新手不敢进去站桩,所以只能找了有几百套的教程,根据自己情况选择一个比较合适的了,如果嫌视频课程页面太多看不了,或者时间有限只看其中一个或几个的话,推荐观看postman以及wordpress精粹这两套教程,只是我一直用的是wordpress,用的比较多,所以推荐wordpress。链接:提取码:ipma欢迎前来讨论。
assistantinteractivewebtutorialsserverportalen-us|assistantinteractivewebtutorialsassistant:general|web&serverportal 查看全部
用通用的浏览器插件可以nicetomessage正在用的:aster.io
网页文章采集器获取方式:进入笔者个人主页,查看笔者主页头像以及简介获取方式:回复“加群”可加入球球免费领取上百款限免网页制作工具。
/用通用的浏览器插件就可以
nicetomessage
正在用的:aster.io效果如下:
企业办公通
必须是adexcel
agisapiserverinarcgisserver2012api设置可以参考这个图:
wordcloud有道词典日语等都能识别,用word或者其他软件可以录入但都要自己编辑,现在自己有一些在线地图服务,可以无缝集成,在线选择分析。
浏览器插件可以识别代码里面的识别码,免费。
链接可能会失效,
我一直用postman实现的,国内都是定制开发。作为一个前端工程师来说能简单就不用麻烦后端人员。新手不敢进去站桩,所以只能找了有几百套的教程,根据自己情况选择一个比较合适的了,如果嫌视频课程页面太多看不了,或者时间有限只看其中一个或几个的话,推荐观看postman以及wordpress精粹这两套教程,只是我一直用的是wordpress,用的比较多,所以推荐wordpress。链接:提取码:ipma欢迎前来讨论。
assistantinteractivewebtutorialsserverportalen-us|assistantinteractivewebtutorialsassistant:general|web&serverportal
网页文章采集器,适用于各种场景下的所有文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 245 次浏览 • 2021-03-25 01:03
网页文章采集器就可以采集知乎中的所有文章。现在比较简单的方法,是通过百度搜索知乎网站后台,在页面排行页,百度搜索知乎网站后台,就会有人用他们公司开发的软件,采集知乎文章,然后自己卖给别人。
随着知乎平台上的干货越来越多,知乎的优质的优质内容更是吸引不少人关注知乎,在这里又分享干货又能寻求思想上的碰撞,对于普通网友来说是一个很好的平台。但是又要让一般的网友都能找到自己需要的内容就显得越来越困难了,今天小编分享一个知乎采集器,适用于各种场景下。
知乎不是贴吧?
多少人都找着借口说,我都找着呢!其实都是借口,是资源太少了,想找到对的内容也就那么几个(我的公众号有,不信你可以自己试试).就像菜市场一样,除了特殊场合,一般大家都是在市场的平面上找地方吃饭..总体来说,
1、热门;
2、全部话题都有;
3、全部专业冷门;
4、全部个人自媒体;
5、全部行业精准等等,总之,还是要看自己的水平来定,不是那么好找到的,都不知道如何搜索。
我的公众号里面有你需要的相关内容,你可以搜索公众号:公众号er之后,
推荐一款可以采集知乎百科的工具吧-musesoup 查看全部
网页文章采集器,适用于各种场景下的所有文章
网页文章采集器就可以采集知乎中的所有文章。现在比较简单的方法,是通过百度搜索知乎网站后台,在页面排行页,百度搜索知乎网站后台,就会有人用他们公司开发的软件,采集知乎文章,然后自己卖给别人。
随着知乎平台上的干货越来越多,知乎的优质的优质内容更是吸引不少人关注知乎,在这里又分享干货又能寻求思想上的碰撞,对于普通网友来说是一个很好的平台。但是又要让一般的网友都能找到自己需要的内容就显得越来越困难了,今天小编分享一个知乎采集器,适用于各种场景下。
知乎不是贴吧?
多少人都找着借口说,我都找着呢!其实都是借口,是资源太少了,想找到对的内容也就那么几个(我的公众号有,不信你可以自己试试).就像菜市场一样,除了特殊场合,一般大家都是在市场的平面上找地方吃饭..总体来说,
1、热门;
2、全部话题都有;
3、全部专业冷门;
4、全部个人自媒体;
5、全部行业精准等等,总之,还是要看自己的水平来定,不是那么好找到的,都不知道如何搜索。
我的公众号里面有你需要的相关内容,你可以搜索公众号:公众号er之后,
推荐一款可以采集知乎百科的工具吧-musesoup

