
网页文章采集器
优采云通用文章采集器正式版v2.17.7.0
采集交流 • 优采云 发表了文章 • 0 个评论 • 386 次浏览 • 2020-08-06 11:10
优采云 Universal Article Collector是一个非常有用的文章采集工具. 该软件引用了搜索引擎的各种网页. 它可以非常准确地捕获文章的内容,并方便用户查找. 使用起来非常方便,就像用户来看看.
软件简介
优采云 Universal Article Collector是一个简单易用的文章采集工具. 用户只需要输入关键字即可快速从主要搜索引擎采集新闻来源和网页,而不再需要搜索文本. 网页. 优采云通用文章采集器不仅具有采集速度快,操作简单的特点,而且还可以准确地提取网页的文本部分并将其另存为文章,并支持去标记,链接,邮箱并转换纯文本,结果将显示给用户,消除了再次处理文本的麻烦.
软件功能
1. 可以准确提取网页的正文部分并另存为文章
2. 支持标签,链接,电子邮件等的格式化处理.
3. 插入关键字功能
4. 可以将其插入到识别标签或标点符号旁边
5. 识别插入英文空格
更新日志
优采云通用文章采集器v2.17.7.0更新日志(2020-4-8)
1. 新添加的文本过滤功能可以阻止不属于文本的大多数内容;合并严格和标准的文本识别,并增强身体识别能力(现在识别的文本没有父div标签,全部取自内部代码);增强提取某些故意伪装的网站标题的能力;其他更新.
2. 采集文章的URL并加强对../和../../等相对路径的处理. 对该版本进行增强处理后,相对路径将完全转换为绝对路径,该绝对路径将可以在浏览器中用鼠标移动. 请转到链接以查看相同内容.
3. 解决由Google更改引起的收款失败的问题.
4. 修复了在关键字集合文章列中选择精确标签时,没有弹出输入的问题(由先前版本引起);添加可选选项以根据URL集合文章列删除外部代码(默认情况下默认启用);调试模式更改这是本文的出处;更新了疑点的解释;其他人.
5. 解决微信采集失败的问题.
6. 增强分页采集和识别功能.
7. 添加Google地址前缀名称,您可以设置自己可以使用的Google域名.
8. 定期替换集合设置支持使用多个匹配和替换表达式.
9. 增强文字识别能力,提高识别精度;增强对特殊编码响应的识别.
10. 为辅助加载图像添加新的属性“原创”识别转换.
11. 外部文件会更新Google翻译使用的域名;解决了Google tk参数更改时翻译失败的问题.
12. 解决了由于系统原因无法将百度网页采集到某些情况下无法重定向到URL的问题; URL的#后缀部分将被自动删除,这将导致网页阅读错误;采集到的文章URL的左侧和右侧均添加了Insert选项;修复了由先前版本导致的文本提取过滤方面的一些问题;其他更新.
13. 增强对某些使用跳转的网页的识别.
14. 将标题字限制增加到最大100个字,以避免因字的长度过长而引起的一些问题;其他更新.
优采云通用文章采集器2.15.8.0更新日志(2017年3月24日)
修复百度网页搜索时间设置的无效性并取消百度新闻时间设置(不再支持);
增加了采集微信时设置文本中最少单词数的支持(以前,只有自动识别可以设置单词数,但是微信具有内置的精确标签,因此无法设置单词数,现在有可能);
[文章视图]切换显示时自动刷新目录树;
当关键字集合中的肯定词数量不足时,会提示您设置词值 查看全部
软件简介
优采云 Universal Article Collector是一个简单易用的文章采集工具. 用户只需要输入关键字即可快速从主要搜索引擎采集新闻来源和网页,而不再需要搜索文本. 网页. 优采云通用文章采集器不仅具有采集速度快,操作简单的特点,而且还可以准确地提取网页的文本部分并将其另存为文章,并支持去标记,链接,邮箱并转换纯文本,结果将显示给用户,消除了再次处理文本的麻烦.
软件功能
1. 可以准确提取网页的正文部分并另存为文章
2. 支持标签,链接,电子邮件等的格式化处理.
3. 插入关键字功能
4. 可以将其插入到识别标签或标点符号旁边
5. 识别插入英文空格
更新日志
优采云通用文章采集器v2.17.7.0更新日志(2020-4-8)
1. 新添加的文本过滤功能可以阻止不属于文本的大多数内容;合并严格和标准的文本识别,并增强身体识别能力(现在识别的文本没有父div标签,全部取自内部代码);增强提取某些故意伪装的网站标题的能力;其他更新.
2. 采集文章的URL并加强对../和../../等相对路径的处理. 对该版本进行增强处理后,相对路径将完全转换为绝对路径,该绝对路径将可以在浏览器中用鼠标移动. 请转到链接以查看相同内容.
3. 解决由Google更改引起的收款失败的问题.
4. 修复了在关键字集合文章列中选择精确标签时,没有弹出输入的问题(由先前版本引起);添加可选选项以根据URL集合文章列删除外部代码(默认情况下默认启用);调试模式更改这是本文的出处;更新了疑点的解释;其他人.
5. 解决微信采集失败的问题.
6. 增强分页采集和识别功能.
7. 添加Google地址前缀名称,您可以设置自己可以使用的Google域名.
8. 定期替换集合设置支持使用多个匹配和替换表达式.
9. 增强文字识别能力,提高识别精度;增强对特殊编码响应的识别.
10. 为辅助加载图像添加新的属性“原创”识别转换.
11. 外部文件会更新Google翻译使用的域名;解决了Google tk参数更改时翻译失败的问题.
12. 解决了由于系统原因无法将百度网页采集到某些情况下无法重定向到URL的问题; URL的#后缀部分将被自动删除,这将导致网页阅读错误;采集到的文章URL的左侧和右侧均添加了Insert选项;修复了由先前版本导致的文本提取过滤方面的一些问题;其他更新.
13. 增强对某些使用跳转的网页的识别.
14. 将标题字限制增加到最大100个字,以避免因字的长度过长而引起的一些问题;其他更新.
优采云通用文章采集器2.15.8.0更新日志(2017年3月24日)
修复百度网页搜索时间设置的无效性并取消百度新闻时间设置(不再支持);
增加了采集微信时设置文本中最少单词数的支持(以前,只有自动识别可以设置单词数,但是微信具有内置的精确标签,因此无法设置单词数,现在有可能);
[文章视图]切换显示时自动刷新目录树;
当关键字集合中的肯定词数量不足时,会提示您设置词值 查看全部
优采云 Universal Article Collector是一个非常有用的文章采集工具. 该软件引用了搜索引擎的各种网页. 它可以非常准确地捕获文章的内容,并方便用户查找. 使用起来非常方便,就像用户来看看.
软件简介
优采云 Universal Article Collector是一个简单易用的文章采集工具. 用户只需要输入关键字即可快速从主要搜索引擎采集新闻来源和网页,而不再需要搜索文本. 网页. 优采云通用文章采集器不仅具有采集速度快,操作简单的特点,而且还可以准确地提取网页的文本部分并将其另存为文章,并支持去标记,链接,邮箱并转换纯文本,结果将显示给用户,消除了再次处理文本的麻烦.
软件功能
1. 可以准确提取网页的正文部分并另存为文章
2. 支持标签,链接,电子邮件等的格式化处理.

3. 插入关键字功能
4. 可以将其插入到识别标签或标点符号旁边
5. 识别插入英文空格
更新日志
优采云通用文章采集器v2.17.7.0更新日志(2020-4-8)
1. 新添加的文本过滤功能可以阻止不属于文本的大多数内容;合并严格和标准的文本识别,并增强身体识别能力(现在识别的文本没有父div标签,全部取自内部代码);增强提取某些故意伪装的网站标题的能力;其他更新.
2. 采集文章的URL并加强对../和../../等相对路径的处理. 对该版本进行增强处理后,相对路径将完全转换为绝对路径,该绝对路径将可以在浏览器中用鼠标移动. 请转到链接以查看相同内容.
3. 解决由Google更改引起的收款失败的问题.
4. 修复了在关键字集合文章列中选择精确标签时,没有弹出输入的问题(由先前版本引起);添加可选选项以根据URL集合文章列删除外部代码(默认情况下默认启用);调试模式更改这是本文的出处;更新了疑点的解释;其他人.
5. 解决微信采集失败的问题.
6. 增强分页采集和识别功能.
7. 添加Google地址前缀名称,您可以设置自己可以使用的Google域名.
8. 定期替换集合设置支持使用多个匹配和替换表达式.
9. 增强文字识别能力,提高识别精度;增强对特殊编码响应的识别.
10. 为辅助加载图像添加新的属性“原创”识别转换.
11. 外部文件会更新Google翻译使用的域名;解决了Google tk参数更改时翻译失败的问题.
12. 解决了由于系统原因无法将百度网页采集到某些情况下无法重定向到URL的问题; URL的#后缀部分将被自动删除,这将导致网页阅读错误;采集到的文章URL的左侧和右侧均添加了Insert选项;修复了由先前版本导致的文本提取过滤方面的一些问题;其他更新.
13. 增强对某些使用跳转的网页的识别.
14. 将标题字限制增加到最大100个字,以避免因字的长度过长而引起的一些问题;其他更新.
优采云通用文章采集器2.15.8.0更新日志(2017年3月24日)
修复百度网页搜索时间设置的无效性并取消百度新闻时间设置(不再支持);
增加了采集微信时设置文本中最少单词数的支持(以前,只有自动识别可以设置单词数,但是微信具有内置的精确标签,因此无法设置单词数,现在有可能);
[文章视图]切换显示时自动刷新目录树;
当关键字集合中的肯定词数量不足时,会提示您设置词值
为什么Youcai Cloud Collector采集的文章的缩略图在发布到网站时不显示
采集交流 • 优采云 发表了文章 • 0 个评论 • 343 次浏览 • 2020-08-06 01:01
Youcai Cloud Collector采集文章,直接采集文章,将其发布并保存为txt,并且没有提示未找到需要采集的内容,_: 是否需要另存为txt?试用免费版本的Aifei seo,该版本支持采集本地数据库,编辑后发布,并内置70多种源程序发布界面. 也可以将其导出为txt,csv,sql和其他格式.
如何使用Youcai Cloud Collector_采集文章: 采集文章的内容,并采集图片和说明等其他内容.
在使用Youcai Cloud Collector时如何在一页上采集几篇文章,但不是全部?谢谢!: 直接添加这些文章的地址. .将深度调整为0
Youcai Cloud Collector的最后一步,我想将采集的文章作为TXT文本保存到磁盘D. 它已设置,但在每次采集后都找不到. : 您好,您可以根据自己的描述进行修改3: 发布内容设置>检查方法2: 另存为本地文件保存文本格式: .TXT保存位置: 选择要保存的路径
如何使用Youcai Cloud Collector采集文章标题: 使用免费的Web数据采集器-Youcai Cloud Collector轻松采集Youcai Cloud Collector更适合新手网站管理员,只需将其拖放就可以了规则市场上有许多免费的现成规则可以直接下载和使用!
Youcai Cloud Collector如何采集今天的标题?: 因为今天的标题是信息流,所以在使用Youcai Cloud Collector之前,您必须知道如何捕获真实地址. 我经常使用数据包捕获工具Fiddler. 在今天的头条新闻中获取地址. 如果您不了解封包捕获,那么我在下面再说说吧!
使用Cloud Collector 7.7,我采集了它并将其保存到本地txt. 文章中的文章是一堆没有段落的文章. : 无论是否排除p标记,采集的文章都没有段落,因为彩云采集的是源文件,所以打开源文件您会发现它没有与您采集的段落相同的段落. 仅当生成页面并使用p标签控制段落时,带有清晰段落的文章才会出现在页面上. : 非常简单,您可以将带有p标签的这些文章复制到文章编辑器的源文件中,然后切换到网页格式以查看带有清晰段落的文章,最后进行复制和粘贴.
优采云能采集什么样的文章?如何采集_: 通常,可以采集满足要求的对象,具体取决于特定的目标站. 集合的实现需要编写集合规则. 需要了解HTML.
如何写优采云采集器的采集规则和采集页上图片中的文字?_: 我不得不说优采云很有用,但我认为它不是很有用. 只需编写这些采集规则. 有很多不清楚的事情要设置. 拿钱买,一开始客服很热情为您解答,一旦您付清钱,就可以购买,写下规则,确定,如果有任何疑问,请致电客服解决,结果已被延迟和延迟...
作为建议,优采云采集器采集图形文章,将图片下载到本地,并为图片命名: 您可以使用软件(图片母版)批量下载并自动命名.
相关内容: 优采云采集器标题采集,优采云采集器采集规则, 查看全部
如何使用Youcai Cloud Collector_采集文章: 采集文章的内容,并采集图片和说明等其他内容.
在使用Youcai Cloud Collector时如何在一页上采集几篇文章,但不是全部?谢谢!: 直接添加这些文章的地址. .将深度调整为0
Youcai Cloud Collector的最后一步,我想将采集的文章作为TXT文本保存到磁盘D. 它已设置,但在每次采集后都找不到. : 您好,您可以根据自己的描述进行修改3: 发布内容设置>检查方法2: 另存为本地文件保存文本格式: .TXT保存位置: 选择要保存的路径
如何使用Youcai Cloud Collector采集文章标题: 使用免费的Web数据采集器-Youcai Cloud Collector轻松采集Youcai Cloud Collector更适合新手网站管理员,只需将其拖放就可以了规则市场上有许多免费的现成规则可以直接下载和使用!
Youcai Cloud Collector如何采集今天的标题?: 因为今天的标题是信息流,所以在使用Youcai Cloud Collector之前,您必须知道如何捕获真实地址. 我经常使用数据包捕获工具Fiddler. 在今天的头条新闻中获取地址. 如果您不了解封包捕获,那么我在下面再说说吧!
使用Cloud Collector 7.7,我采集了它并将其保存到本地txt. 文章中的文章是一堆没有段落的文章. : 无论是否排除p标记,采集的文章都没有段落,因为彩云采集的是源文件,所以打开源文件您会发现它没有与您采集的段落相同的段落. 仅当生成页面并使用p标签控制段落时,带有清晰段落的文章才会出现在页面上. : 非常简单,您可以将带有p标签的这些文章复制到文章编辑器的源文件中,然后切换到网页格式以查看带有清晰段落的文章,最后进行复制和粘贴.
优采云能采集什么样的文章?如何采集_: 通常,可以采集满足要求的对象,具体取决于特定的目标站. 集合的实现需要编写集合规则. 需要了解HTML.
如何写优采云采集器的采集规则和采集页上图片中的文字?_: 我不得不说优采云很有用,但我认为它不是很有用. 只需编写这些采集规则. 有很多不清楚的事情要设置. 拿钱买,一开始客服很热情为您解答,一旦您付清钱,就可以购买,写下规则,确定,如果有任何疑问,请致电客服解决,结果已被延迟和延迟...
作为建议,优采云采集器采集图形文章,将图片下载到本地,并为图片命名: 您可以使用软件(图片母版)批量下载并自动命名.
相关内容: 优采云采集器标题采集,优采云采集器采集规则, 查看全部
Youcai Cloud Collector采集文章,直接采集文章,将其发布并保存为txt,并且没有提示未找到需要采集的内容,_: 是否需要另存为txt?试用免费版本的Aifei seo,该版本支持采集本地数据库,编辑后发布,并内置70多种源程序发布界面. 也可以将其导出为txt,csv,sql和其他格式.
如何使用Youcai Cloud Collector_采集文章: 采集文章的内容,并采集图片和说明等其他内容.
在使用Youcai Cloud Collector时如何在一页上采集几篇文章,但不是全部?谢谢!: 直接添加这些文章的地址. .将深度调整为0
Youcai Cloud Collector的最后一步,我想将采集的文章作为TXT文本保存到磁盘D. 它已设置,但在每次采集后都找不到. : 您好,您可以根据自己的描述进行修改3: 发布内容设置>检查方法2: 另存为本地文件保存文本格式: .TXT保存位置: 选择要保存的路径
如何使用Youcai Cloud Collector采集文章标题: 使用免费的Web数据采集器-Youcai Cloud Collector轻松采集Youcai Cloud Collector更适合新手网站管理员,只需将其拖放就可以了规则市场上有许多免费的现成规则可以直接下载和使用!
Youcai Cloud Collector如何采集今天的标题?: 因为今天的标题是信息流,所以在使用Youcai Cloud Collector之前,您必须知道如何捕获真实地址. 我经常使用数据包捕获工具Fiddler. 在今天的头条新闻中获取地址. 如果您不了解封包捕获,那么我在下面再说说吧!
使用Cloud Collector 7.7,我采集了它并将其保存到本地txt. 文章中的文章是一堆没有段落的文章. : 无论是否排除p标记,采集的文章都没有段落,因为彩云采集的是源文件,所以打开源文件您会发现它没有与您采集的段落相同的段落. 仅当生成页面并使用p标签控制段落时,带有清晰段落的文章才会出现在页面上. : 非常简单,您可以将带有p标签的这些文章复制到文章编辑器的源文件中,然后切换到网页格式以查看带有清晰段落的文章,最后进行复制和粘贴.
优采云能采集什么样的文章?如何采集_: 通常,可以采集满足要求的对象,具体取决于特定的目标站. 集合的实现需要编写集合规则. 需要了解HTML.
如何写优采云采集器的采集规则和采集页上图片中的文字?_: 我不得不说优采云很有用,但我认为它不是很有用. 只需编写这些采集规则. 有很多不清楚的事情要设置. 拿钱买,一开始客服很热情为您解答,一旦您付清钱,就可以购买,写下规则,确定,如果有任何疑问,请致电客服解决,结果已被延迟和延迟...
作为建议,优采云采集器采集图形文章,将图片下载到本地,并为图片命名: 您可以使用软件(图片母版)批量下载并自动命名.
相关内容: 优采云采集器标题采集,优采云采集器采集规则,
通用文章采集器
采集交流 • 优采云 发表了文章 • 0 个评论 • 286 次浏览 • 2020-08-05 20:05
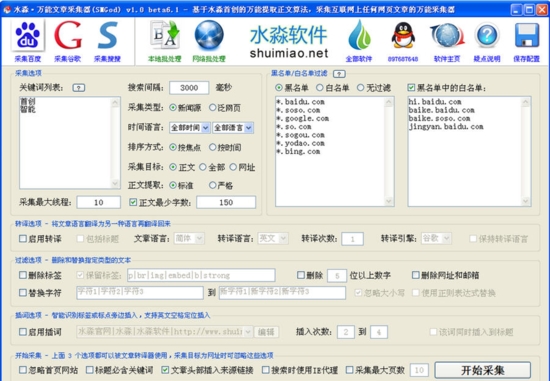
因此您可以根据实际情况切换模式. 您可以使用本地批处理的读取网页正文功能来测试指定网页适合的模式.
获取过程中的处理选项
在采集过程中可以同时执行翻译,过滤和单词搜索等处理. 所采集的文章可以通过“本地批处理”进行处理.
翻译功能是将中文翻译成英文,然后再翻译回中文,从而产生伪原创效果. 支持原创格式翻译,即不要更改文章的原创标签结构和排版格式.
采集目标是URL
您可以在URL模板中插入#URL#,#title#来合并引用
页面采集和相对路径转换为绝对路径
勾选“自动采集和分页”以合并分页的文章. 编辑框的设置值为最大采集页数. 建议设置一个有限的值(例如10页),以免出现分页时间过长的集合,并且合并后的文章过大. 如果需要采集所有页面,可以将其设置为0.
文章中的所有相对路径将自动转换为绝对路径,这样可以确保图片等的正常显示.
多线程
支持网页的多线程高速采集. 可以根据网络速度来确定. 电信2m可以有5个线程,电信4m可以有10个线程,依此类推,但是需要适当设置. 太多的设置可能会严重影响采集效率甚至系统效率. 如果在采集过程中运行了占用流量的其他软件(例如在线视频播放),则可以适当减少线程数.
处理重复的文章标题和文章内容
该程序可以智能地判断和过滤重复的文章
当采集到的文章的标题(文件名)与本地保存的文章的标题相同时,优采云将首先判断这两篇文章的相似性. 当相似度大于60%时,优采云将确定同一文章,然后比较这两篇文章的文本量,并自动使用收录更多文本的文章来覆盖和写入相同的文件名. 这种世代情况并不等于世代数.
当相似度低于60%时,优采云判断这是另一篇文章,并将自动重命名标题(标题末尾取3到5个随机字母)并将其保存到文件中.
快速文章过滤器
尽管优采云研究了非常精确的人体提取算法,但提取错误仍然很少. 这些错误主要是: 目标页面的主体是在线视频,或者主体内容太短而无法形成主体特征. 因此,可以通过设置最终结果中的单词数来提高准确性(在“最小字符数”参数中,该单词数是程序删除标签,行和空格后的纯文本单词数) ).
文章快速过滤器用于快速查看采集到的文章,并有助于判断和删除文本错误的文章. 同时,基于网络信息采集的目的,方便了细化和选择过程.
生成的文章数量可变的问题
百度和搜搜默认每页100个结果,而Google默认每页10个结果.
某些网站已超时(尤其是Google所收录的许多网站被阻止),或在文本中设置了最少字数,或者该程序忽略了具有相同名称,黑名单和白名单的类似内容的本地文章等会导致实际生成的文章数低于每次页面搜索的最大结果数.
总的来说,百度的馆藏质量是最好的,并且生成的文章数量接近搜索结果的数量. 使用说明1下载完成后,请勿在压缩包中运行该软件并直接使用,请先将其解压缩;
2该软件支持32位和64位操作环境;
3如果无法正常打开该软件,请右键单击以在管理员模式下运行它. 使用方法选择关键字
设置搜索间隔,采集类型,时间语言,排序方式,采集目标和其他参数
编辑网站的黑名单和白名单
设置翻译选项,过滤选项和插入选项
单击“开始采集”按钮以更新日志,并为某些已进行反采集处理的网站添加增强的采集功能. 查看全部
获取过程中的处理选项
在采集过程中可以同时执行翻译,过滤和单词搜索等处理. 所采集的文章可以通过“本地批处理”进行处理.
翻译功能是将中文翻译成英文,然后再翻译回中文,从而产生伪原创效果. 支持原创格式翻译,即不要更改文章的原创标签结构和排版格式.
采集目标是URL
您可以在URL模板中插入#URL#,#title#来合并引用
页面采集和相对路径转换为绝对路径
勾选“自动采集和分页”以合并分页的文章. 编辑框的设置值为最大采集页数. 建议设置一个有限的值(例如10页),以免出现分页时间过长的集合,并且合并后的文章过大. 如果需要采集所有页面,可以将其设置为0.
文章中的所有相对路径将自动转换为绝对路径,这样可以确保图片等的正常显示.
多线程
支持网页的多线程高速采集. 可以根据网络速度来确定. 电信2m可以有5个线程,电信4m可以有10个线程,依此类推,但是需要适当设置. 太多的设置可能会严重影响采集效率甚至系统效率. 如果在采集过程中运行了占用流量的其他软件(例如在线视频播放),则可以适当减少线程数.
处理重复的文章标题和文章内容
该程序可以智能地判断和过滤重复的文章
当采集到的文章的标题(文件名)与本地保存的文章的标题相同时,优采云将首先判断这两篇文章的相似性. 当相似度大于60%时,优采云将确定同一文章,然后比较这两篇文章的文本量,并自动使用收录更多文本的文章来覆盖和写入相同的文件名. 这种世代情况并不等于世代数.
当相似度低于60%时,优采云判断这是另一篇文章,并将自动重命名标题(标题末尾取3到5个随机字母)并将其保存到文件中.
快速文章过滤器
尽管优采云研究了非常精确的人体提取算法,但提取错误仍然很少. 这些错误主要是: 目标页面的主体是在线视频,或者主体内容太短而无法形成主体特征. 因此,可以通过设置最终结果中的单词数来提高准确性(在“最小字符数”参数中,该单词数是程序删除标签,行和空格后的纯文本单词数) ).
文章快速过滤器用于快速查看采集到的文章,并有助于判断和删除文本错误的文章. 同时,基于网络信息采集的目的,方便了细化和选择过程.
生成的文章数量可变的问题
百度和搜搜默认每页100个结果,而Google默认每页10个结果.
某些网站已超时(尤其是Google所收录的许多网站被阻止),或在文本中设置了最少字数,或者该程序忽略了具有相同名称,黑名单和白名单的类似内容的本地文章等会导致实际生成的文章数低于每次页面搜索的最大结果数.
总的来说,百度的馆藏质量是最好的,并且生成的文章数量接近搜索结果的数量. 使用说明1下载完成后,请勿在压缩包中运行该软件并直接使用,请先将其解压缩;
2该软件支持32位和64位操作环境;
3如果无法正常打开该软件,请右键单击以在管理员模式下运行它. 使用方法选择关键字
设置搜索间隔,采集类型,时间语言,排序方式,采集目标和其他参数
编辑网站的黑名单和白名单
设置翻译选项,过滤选项和插入选项
单击“开始采集”按钮以更新日志,并为某些已进行反采集处理的网站添加增强的采集功能. 查看全部
因此您可以根据实际情况切换模式. 您可以使用本地批处理的读取网页正文功能来测试指定网页适合的模式.
获取过程中的处理选项
在采集过程中可以同时执行翻译,过滤和单词搜索等处理. 所采集的文章可以通过“本地批处理”进行处理.
翻译功能是将中文翻译成英文,然后再翻译回中文,从而产生伪原创效果. 支持原创格式翻译,即不要更改文章的原创标签结构和排版格式.
采集目标是URL
您可以在URL模板中插入#URL#,#title#来合并引用
页面采集和相对路径转换为绝对路径
勾选“自动采集和分页”以合并分页的文章. 编辑框的设置值为最大采集页数. 建议设置一个有限的值(例如10页),以免出现分页时间过长的集合,并且合并后的文章过大. 如果需要采集所有页面,可以将其设置为0.
文章中的所有相对路径将自动转换为绝对路径,这样可以确保图片等的正常显示.
多线程
支持网页的多线程高速采集. 可以根据网络速度来确定. 电信2m可以有5个线程,电信4m可以有10个线程,依此类推,但是需要适当设置. 太多的设置可能会严重影响采集效率甚至系统效率. 如果在采集过程中运行了占用流量的其他软件(例如在线视频播放),则可以适当减少线程数.
处理重复的文章标题和文章内容
该程序可以智能地判断和过滤重复的文章
当采集到的文章的标题(文件名)与本地保存的文章的标题相同时,优采云将首先判断这两篇文章的相似性. 当相似度大于60%时,优采云将确定同一文章,然后比较这两篇文章的文本量,并自动使用收录更多文本的文章来覆盖和写入相同的文件名. 这种世代情况并不等于世代数.
当相似度低于60%时,优采云判断这是另一篇文章,并将自动重命名标题(标题末尾取3到5个随机字母)并将其保存到文件中.
快速文章过滤器
尽管优采云研究了非常精确的人体提取算法,但提取错误仍然很少. 这些错误主要是: 目标页面的主体是在线视频,或者主体内容太短而无法形成主体特征. 因此,可以通过设置最终结果中的单词数来提高准确性(在“最小字符数”参数中,该单词数是程序删除标签,行和空格后的纯文本单词数) ).
文章快速过滤器用于快速查看采集到的文章,并有助于判断和删除文本错误的文章. 同时,基于网络信息采集的目的,方便了细化和选择过程.
生成的文章数量可变的问题
百度和搜搜默认每页100个结果,而Google默认每页10个结果.
某些网站已超时(尤其是Google所收录的许多网站被阻止),或在文本中设置了最少字数,或者该程序忽略了具有相同名称,黑名单和白名单的类似内容的本地文章等会导致实际生成的文章数低于每次页面搜索的最大结果数.
总的来说,百度的馆藏质量是最好的,并且生成的文章数量接近搜索结果的数量. 使用说明1下载完成后,请勿在压缩包中运行该软件并直接使用,请先将其解压缩;
2该软件支持32位和64位操作环境;
3如果无法正常打开该软件,请右键单击以在管理员模式下运行它. 使用方法选择关键字
设置搜索间隔,采集类型,时间语言,排序方式,采集目标和其他参数
编辑网站的黑名单和白名单
设置翻译选项,过滤选项和插入选项
单击“开始采集”按钮以更新日志,并为某些已进行反采集处理的网站添加增强的采集功能.
优采云通用文章采集器正式版v2.17.7.0
采集交流 • 优采云 发表了文章 • 0 个评论 • 386 次浏览 • 2020-08-06 11:10
优采云 Universal Article Collector是一个非常有用的文章采集工具. 该软件引用了搜索引擎的各种网页. 它可以非常准确地捕获文章的内容,并方便用户查找. 使用起来非常方便,就像用户来看看.
软件简介
优采云 Universal Article Collector是一个简单易用的文章采集工具. 用户只需要输入关键字即可快速从主要搜索引擎采集新闻来源和网页,而不再需要搜索文本. 网页. 优采云通用文章采集器不仅具有采集速度快,操作简单的特点,而且还可以准确地提取网页的文本部分并将其另存为文章,并支持去标记,链接,邮箱并转换纯文本,结果将显示给用户,消除了再次处理文本的麻烦.
软件功能
1. 可以准确提取网页的正文部分并另存为文章
2. 支持标签,链接,电子邮件等的格式化处理.
3. 插入关键字功能
4. 可以将其插入到识别标签或标点符号旁边
5. 识别插入英文空格
更新日志
优采云通用文章采集器v2.17.7.0更新日志(2020-4-8)
1. 新添加的文本过滤功能可以阻止不属于文本的大多数内容;合并严格和标准的文本识别,并增强身体识别能力(现在识别的文本没有父div标签,全部取自内部代码);增强提取某些故意伪装的网站标题的能力;其他更新.
2. 采集文章的URL并加强对../和../../等相对路径的处理. 对该版本进行增强处理后,相对路径将完全转换为绝对路径,该绝对路径将可以在浏览器中用鼠标移动. 请转到链接以查看相同内容.
3. 解决由Google更改引起的收款失败的问题.
4. 修复了在关键字集合文章列中选择精确标签时,没有弹出输入的问题(由先前版本引起);添加可选选项以根据URL集合文章列删除外部代码(默认情况下默认启用);调试模式更改这是本文的出处;更新了疑点的解释;其他人.
5. 解决微信采集失败的问题.
6. 增强分页采集和识别功能.
7. 添加Google地址前缀名称,您可以设置自己可以使用的Google域名.
8. 定期替换集合设置支持使用多个匹配和替换表达式.
9. 增强文字识别能力,提高识别精度;增强对特殊编码响应的识别.
10. 为辅助加载图像添加新的属性“原创”识别转换.
11. 外部文件会更新Google翻译使用的域名;解决了Google tk参数更改时翻译失败的问题.
12. 解决了由于系统原因无法将百度网页采集到某些情况下无法重定向到URL的问题; URL的#后缀部分将被自动删除,这将导致网页阅读错误;采集到的文章URL的左侧和右侧均添加了Insert选项;修复了由先前版本导致的文本提取过滤方面的一些问题;其他更新.
13. 增强对某些使用跳转的网页的识别.
14. 将标题字限制增加到最大100个字,以避免因字的长度过长而引起的一些问题;其他更新.
优采云通用文章采集器2.15.8.0更新日志(2017年3月24日)
修复百度网页搜索时间设置的无效性并取消百度新闻时间设置(不再支持);
增加了采集微信时设置文本中最少单词数的支持(以前,只有自动识别可以设置单词数,但是微信具有内置的精确标签,因此无法设置单词数,现在有可能);
[文章视图]切换显示时自动刷新目录树;
当关键字集合中的肯定词数量不足时,会提示您设置词值 查看全部
软件简介
优采云 Universal Article Collector是一个简单易用的文章采集工具. 用户只需要输入关键字即可快速从主要搜索引擎采集新闻来源和网页,而不再需要搜索文本. 网页. 优采云通用文章采集器不仅具有采集速度快,操作简单的特点,而且还可以准确地提取网页的文本部分并将其另存为文章,并支持去标记,链接,邮箱并转换纯文本,结果将显示给用户,消除了再次处理文本的麻烦.
软件功能
1. 可以准确提取网页的正文部分并另存为文章
2. 支持标签,链接,电子邮件等的格式化处理.
3. 插入关键字功能
4. 可以将其插入到识别标签或标点符号旁边
5. 识别插入英文空格
更新日志
优采云通用文章采集器v2.17.7.0更新日志(2020-4-8)
1. 新添加的文本过滤功能可以阻止不属于文本的大多数内容;合并严格和标准的文本识别,并增强身体识别能力(现在识别的文本没有父div标签,全部取自内部代码);增强提取某些故意伪装的网站标题的能力;其他更新.
2. 采集文章的URL并加强对../和../../等相对路径的处理. 对该版本进行增强处理后,相对路径将完全转换为绝对路径,该绝对路径将可以在浏览器中用鼠标移动. 请转到链接以查看相同内容.
3. 解决由Google更改引起的收款失败的问题.
4. 修复了在关键字集合文章列中选择精确标签时,没有弹出输入的问题(由先前版本引起);添加可选选项以根据URL集合文章列删除外部代码(默认情况下默认启用);调试模式更改这是本文的出处;更新了疑点的解释;其他人.
5. 解决微信采集失败的问题.
6. 增强分页采集和识别功能.
7. 添加Google地址前缀名称,您可以设置自己可以使用的Google域名.
8. 定期替换集合设置支持使用多个匹配和替换表达式.
9. 增强文字识别能力,提高识别精度;增强对特殊编码响应的识别.
10. 为辅助加载图像添加新的属性“原创”识别转换.
11. 外部文件会更新Google翻译使用的域名;解决了Google tk参数更改时翻译失败的问题.
12. 解决了由于系统原因无法将百度网页采集到某些情况下无法重定向到URL的问题; URL的#后缀部分将被自动删除,这将导致网页阅读错误;采集到的文章URL的左侧和右侧均添加了Insert选项;修复了由先前版本导致的文本提取过滤方面的一些问题;其他更新.
13. 增强对某些使用跳转的网页的识别.
14. 将标题字限制增加到最大100个字,以避免因字的长度过长而引起的一些问题;其他更新.
优采云通用文章采集器2.15.8.0更新日志(2017年3月24日)
修复百度网页搜索时间设置的无效性并取消百度新闻时间设置(不再支持);
增加了采集微信时设置文本中最少单词数的支持(以前,只有自动识别可以设置单词数,但是微信具有内置的精确标签,因此无法设置单词数,现在有可能);
[文章视图]切换显示时自动刷新目录树;
当关键字集合中的肯定词数量不足时,会提示您设置词值 查看全部
优采云 Universal Article Collector是一个非常有用的文章采集工具. 该软件引用了搜索引擎的各种网页. 它可以非常准确地捕获文章的内容,并方便用户查找. 使用起来非常方便,就像用户来看看.
软件简介
优采云 Universal Article Collector是一个简单易用的文章采集工具. 用户只需要输入关键字即可快速从主要搜索引擎采集新闻来源和网页,而不再需要搜索文本. 网页. 优采云通用文章采集器不仅具有采集速度快,操作简单的特点,而且还可以准确地提取网页的文本部分并将其另存为文章,并支持去标记,链接,邮箱并转换纯文本,结果将显示给用户,消除了再次处理文本的麻烦.
软件功能
1. 可以准确提取网页的正文部分并另存为文章
2. 支持标签,链接,电子邮件等的格式化处理.
3. 插入关键字功能
4. 可以将其插入到识别标签或标点符号旁边
5. 识别插入英文空格
更新日志
优采云通用文章采集器v2.17.7.0更新日志(2020-4-8)
1. 新添加的文本过滤功能可以阻止不属于文本的大多数内容;合并严格和标准的文本识别,并增强身体识别能力(现在识别的文本没有父div标签,全部取自内部代码);增强提取某些故意伪装的网站标题的能力;其他更新.
2. 采集文章的URL并加强对../和../../等相对路径的处理. 对该版本进行增强处理后,相对路径将完全转换为绝对路径,该绝对路径将可以在浏览器中用鼠标移动. 请转到链接以查看相同内容.
3. 解决由Google更改引起的收款失败的问题.
4. 修复了在关键字集合文章列中选择精确标签时,没有弹出输入的问题(由先前版本引起);添加可选选项以根据URL集合文章列删除外部代码(默认情况下默认启用);调试模式更改这是本文的出处;更新了疑点的解释;其他人.
5. 解决微信采集失败的问题.
6. 增强分页采集和识别功能.
7. 添加Google地址前缀名称,您可以设置自己可以使用的Google域名.
8. 定期替换集合设置支持使用多个匹配和替换表达式.
9. 增强文字识别能力,提高识别精度;增强对特殊编码响应的识别.
10. 为辅助加载图像添加新的属性“原创”识别转换.
11. 外部文件会更新Google翻译使用的域名;解决了Google tk参数更改时翻译失败的问题.
12. 解决了由于系统原因无法将百度网页采集到某些情况下无法重定向到URL的问题; URL的#后缀部分将被自动删除,这将导致网页阅读错误;采集到的文章URL的左侧和右侧均添加了Insert选项;修复了由先前版本导致的文本提取过滤方面的一些问题;其他更新.
13. 增强对某些使用跳转的网页的识别.
14. 将标题字限制增加到最大100个字,以避免因字的长度过长而引起的一些问题;其他更新.
优采云通用文章采集器2.15.8.0更新日志(2017年3月24日)
修复百度网页搜索时间设置的无效性并取消百度新闻时间设置(不再支持);
增加了采集微信时设置文本中最少单词数的支持(以前,只有自动识别可以设置单词数,但是微信具有内置的精确标签,因此无法设置单词数,现在有可能);
[文章视图]切换显示时自动刷新目录树;
当关键字集合中的肯定词数量不足时,会提示您设置词值
为什么Youcai Cloud Collector采集的文章的缩略图在发布到网站时不显示
采集交流 • 优采云 发表了文章 • 0 个评论 • 343 次浏览 • 2020-08-06 01:01
Youcai Cloud Collector采集文章,直接采集文章,将其发布并保存为txt,并且没有提示未找到需要采集的内容,_: 是否需要另存为txt?试用免费版本的Aifei seo,该版本支持采集本地数据库,编辑后发布,并内置70多种源程序发布界面. 也可以将其导出为txt,csv,sql和其他格式.
如何使用Youcai Cloud Collector_采集文章: 采集文章的内容,并采集图片和说明等其他内容.
在使用Youcai Cloud Collector时如何在一页上采集几篇文章,但不是全部?谢谢!: 直接添加这些文章的地址. .将深度调整为0
Youcai Cloud Collector的最后一步,我想将采集的文章作为TXT文本保存到磁盘D. 它已设置,但在每次采集后都找不到. : 您好,您可以根据自己的描述进行修改3: 发布内容设置>检查方法2: 另存为本地文件保存文本格式: .TXT保存位置: 选择要保存的路径
如何使用Youcai Cloud Collector采集文章标题: 使用免费的Web数据采集器-Youcai Cloud Collector轻松采集Youcai Cloud Collector更适合新手网站管理员,只需将其拖放就可以了规则市场上有许多免费的现成规则可以直接下载和使用!
Youcai Cloud Collector如何采集今天的标题?: 因为今天的标题是信息流,所以在使用Youcai Cloud Collector之前,您必须知道如何捕获真实地址. 我经常使用数据包捕获工具Fiddler. 在今天的头条新闻中获取地址. 如果您不了解封包捕获,那么我在下面再说说吧!
使用Cloud Collector 7.7,我采集了它并将其保存到本地txt. 文章中的文章是一堆没有段落的文章. : 无论是否排除p标记,采集的文章都没有段落,因为彩云采集的是源文件,所以打开源文件您会发现它没有与您采集的段落相同的段落. 仅当生成页面并使用p标签控制段落时,带有清晰段落的文章才会出现在页面上. : 非常简单,您可以将带有p标签的这些文章复制到文章编辑器的源文件中,然后切换到网页格式以查看带有清晰段落的文章,最后进行复制和粘贴.
优采云能采集什么样的文章?如何采集_: 通常,可以采集满足要求的对象,具体取决于特定的目标站. 集合的实现需要编写集合规则. 需要了解HTML.
如何写优采云采集器的采集规则和采集页上图片中的文字?_: 我不得不说优采云很有用,但我认为它不是很有用. 只需编写这些采集规则. 有很多不清楚的事情要设置. 拿钱买,一开始客服很热情为您解答,一旦您付清钱,就可以购买,写下规则,确定,如果有任何疑问,请致电客服解决,结果已被延迟和延迟...
作为建议,优采云采集器采集图形文章,将图片下载到本地,并为图片命名: 您可以使用软件(图片母版)批量下载并自动命名.
相关内容: 优采云采集器标题采集,优采云采集器采集规则, 查看全部
如何使用Youcai Cloud Collector_采集文章: 采集文章的内容,并采集图片和说明等其他内容.
在使用Youcai Cloud Collector时如何在一页上采集几篇文章,但不是全部?谢谢!: 直接添加这些文章的地址. .将深度调整为0
Youcai Cloud Collector的最后一步,我想将采集的文章作为TXT文本保存到磁盘D. 它已设置,但在每次采集后都找不到. : 您好,您可以根据自己的描述进行修改3: 发布内容设置>检查方法2: 另存为本地文件保存文本格式: .TXT保存位置: 选择要保存的路径
如何使用Youcai Cloud Collector采集文章标题: 使用免费的Web数据采集器-Youcai Cloud Collector轻松采集Youcai Cloud Collector更适合新手网站管理员,只需将其拖放就可以了规则市场上有许多免费的现成规则可以直接下载和使用!
Youcai Cloud Collector如何采集今天的标题?: 因为今天的标题是信息流,所以在使用Youcai Cloud Collector之前,您必须知道如何捕获真实地址. 我经常使用数据包捕获工具Fiddler. 在今天的头条新闻中获取地址. 如果您不了解封包捕获,那么我在下面再说说吧!
使用Cloud Collector 7.7,我采集了它并将其保存到本地txt. 文章中的文章是一堆没有段落的文章. : 无论是否排除p标记,采集的文章都没有段落,因为彩云采集的是源文件,所以打开源文件您会发现它没有与您采集的段落相同的段落. 仅当生成页面并使用p标签控制段落时,带有清晰段落的文章才会出现在页面上. : 非常简单,您可以将带有p标签的这些文章复制到文章编辑器的源文件中,然后切换到网页格式以查看带有清晰段落的文章,最后进行复制和粘贴.
优采云能采集什么样的文章?如何采集_: 通常,可以采集满足要求的对象,具体取决于特定的目标站. 集合的实现需要编写集合规则. 需要了解HTML.
如何写优采云采集器的采集规则和采集页上图片中的文字?_: 我不得不说优采云很有用,但我认为它不是很有用. 只需编写这些采集规则. 有很多不清楚的事情要设置. 拿钱买,一开始客服很热情为您解答,一旦您付清钱,就可以购买,写下规则,确定,如果有任何疑问,请致电客服解决,结果已被延迟和延迟...
作为建议,优采云采集器采集图形文章,将图片下载到本地,并为图片命名: 您可以使用软件(图片母版)批量下载并自动命名.
相关内容: 优采云采集器标题采集,优采云采集器采集规则, 查看全部
Youcai Cloud Collector采集文章,直接采集文章,将其发布并保存为txt,并且没有提示未找到需要采集的内容,_: 是否需要另存为txt?试用免费版本的Aifei seo,该版本支持采集本地数据库,编辑后发布,并内置70多种源程序发布界面. 也可以将其导出为txt,csv,sql和其他格式.
如何使用Youcai Cloud Collector_采集文章: 采集文章的内容,并采集图片和说明等其他内容.
在使用Youcai Cloud Collector时如何在一页上采集几篇文章,但不是全部?谢谢!: 直接添加这些文章的地址. .将深度调整为0
Youcai Cloud Collector的最后一步,我想将采集的文章作为TXT文本保存到磁盘D. 它已设置,但在每次采集后都找不到. : 您好,您可以根据自己的描述进行修改3: 发布内容设置>检查方法2: 另存为本地文件保存文本格式: .TXT保存位置: 选择要保存的路径
如何使用Youcai Cloud Collector采集文章标题: 使用免费的Web数据采集器-Youcai Cloud Collector轻松采集Youcai Cloud Collector更适合新手网站管理员,只需将其拖放就可以了规则市场上有许多免费的现成规则可以直接下载和使用!
Youcai Cloud Collector如何采集今天的标题?: 因为今天的标题是信息流,所以在使用Youcai Cloud Collector之前,您必须知道如何捕获真实地址. 我经常使用数据包捕获工具Fiddler. 在今天的头条新闻中获取地址. 如果您不了解封包捕获,那么我在下面再说说吧!
使用Cloud Collector 7.7,我采集了它并将其保存到本地txt. 文章中的文章是一堆没有段落的文章. : 无论是否排除p标记,采集的文章都没有段落,因为彩云采集的是源文件,所以打开源文件您会发现它没有与您采集的段落相同的段落. 仅当生成页面并使用p标签控制段落时,带有清晰段落的文章才会出现在页面上. : 非常简单,您可以将带有p标签的这些文章复制到文章编辑器的源文件中,然后切换到网页格式以查看带有清晰段落的文章,最后进行复制和粘贴.
优采云能采集什么样的文章?如何采集_: 通常,可以采集满足要求的对象,具体取决于特定的目标站. 集合的实现需要编写集合规则. 需要了解HTML.
如何写优采云采集器的采集规则和采集页上图片中的文字?_: 我不得不说优采云很有用,但我认为它不是很有用. 只需编写这些采集规则. 有很多不清楚的事情要设置. 拿钱买,一开始客服很热情为您解答,一旦您付清钱,就可以购买,写下规则,确定,如果有任何疑问,请致电客服解决,结果已被延迟和延迟...
作为建议,优采云采集器采集图形文章,将图片下载到本地,并为图片命名: 您可以使用软件(图片母版)批量下载并自动命名.
相关内容: 优采云采集器标题采集,优采云采集器采集规则,
通用文章采集器
采集交流 • 优采云 发表了文章 • 0 个评论 • 286 次浏览 • 2020-08-05 20:05
因此您可以根据实际情况切换模式. 您可以使用本地批处理的读取网页正文功能来测试指定网页适合的模式.
获取过程中的处理选项
在采集过程中可以同时执行翻译,过滤和单词搜索等处理. 所采集的文章可以通过“本地批处理”进行处理.
翻译功能是将中文翻译成英文,然后再翻译回中文,从而产生伪原创效果. 支持原创格式翻译,即不要更改文章的原创标签结构和排版格式.
采集目标是URL
您可以在URL模板中插入#URL#,#title#来合并引用
页面采集和相对路径转换为绝对路径
勾选“自动采集和分页”以合并分页的文章. 编辑框的设置值为最大采集页数. 建议设置一个有限的值(例如10页),以免出现分页时间过长的集合,并且合并后的文章过大. 如果需要采集所有页面,可以将其设置为0.
文章中的所有相对路径将自动转换为绝对路径,这样可以确保图片等的正常显示.
多线程
支持网页的多线程高速采集. 可以根据网络速度来确定. 电信2m可以有5个线程,电信4m可以有10个线程,依此类推,但是需要适当设置. 太多的设置可能会严重影响采集效率甚至系统效率. 如果在采集过程中运行了占用流量的其他软件(例如在线视频播放),则可以适当减少线程数.
处理重复的文章标题和文章内容
该程序可以智能地判断和过滤重复的文章
当采集到的文章的标题(文件名)与本地保存的文章的标题相同时,优采云将首先判断这两篇文章的相似性. 当相似度大于60%时,优采云将确定同一文章,然后比较这两篇文章的文本量,并自动使用收录更多文本的文章来覆盖和写入相同的文件名. 这种世代情况并不等于世代数.
当相似度低于60%时,优采云判断这是另一篇文章,并将自动重命名标题(标题末尾取3到5个随机字母)并将其保存到文件中.
快速文章过滤器
尽管优采云研究了非常精确的人体提取算法,但提取错误仍然很少. 这些错误主要是: 目标页面的主体是在线视频,或者主体内容太短而无法形成主体特征. 因此,可以通过设置最终结果中的单词数来提高准确性(在“最小字符数”参数中,该单词数是程序删除标签,行和空格后的纯文本单词数) ).
文章快速过滤器用于快速查看采集到的文章,并有助于判断和删除文本错误的文章. 同时,基于网络信息采集的目的,方便了细化和选择过程.
生成的文章数量可变的问题
百度和搜搜默认每页100个结果,而Google默认每页10个结果.
某些网站已超时(尤其是Google所收录的许多网站被阻止),或在文本中设置了最少字数,或者该程序忽略了具有相同名称,黑名单和白名单的类似内容的本地文章等会导致实际生成的文章数低于每次页面搜索的最大结果数.
总的来说,百度的馆藏质量是最好的,并且生成的文章数量接近搜索结果的数量. 使用说明1下载完成后,请勿在压缩包中运行该软件并直接使用,请先将其解压缩;
2该软件支持32位和64位操作环境;
3如果无法正常打开该软件,请右键单击以在管理员模式下运行它. 使用方法选择关键字
设置搜索间隔,采集类型,时间语言,排序方式,采集目标和其他参数
编辑网站的黑名单和白名单
设置翻译选项,过滤选项和插入选项
单击“开始采集”按钮以更新日志,并为某些已进行反采集处理的网站添加增强的采集功能. 查看全部
获取过程中的处理选项
在采集过程中可以同时执行翻译,过滤和单词搜索等处理. 所采集的文章可以通过“本地批处理”进行处理.
翻译功能是将中文翻译成英文,然后再翻译回中文,从而产生伪原创效果. 支持原创格式翻译,即不要更改文章的原创标签结构和排版格式.
采集目标是URL
您可以在URL模板中插入#URL#,#title#来合并引用
页面采集和相对路径转换为绝对路径
勾选“自动采集和分页”以合并分页的文章. 编辑框的设置值为最大采集页数. 建议设置一个有限的值(例如10页),以免出现分页时间过长的集合,并且合并后的文章过大. 如果需要采集所有页面,可以将其设置为0.
文章中的所有相对路径将自动转换为绝对路径,这样可以确保图片等的正常显示.
多线程
支持网页的多线程高速采集. 可以根据网络速度来确定. 电信2m可以有5个线程,电信4m可以有10个线程,依此类推,但是需要适当设置. 太多的设置可能会严重影响采集效率甚至系统效率. 如果在采集过程中运行了占用流量的其他软件(例如在线视频播放),则可以适当减少线程数.
处理重复的文章标题和文章内容
该程序可以智能地判断和过滤重复的文章
当采集到的文章的标题(文件名)与本地保存的文章的标题相同时,优采云将首先判断这两篇文章的相似性. 当相似度大于60%时,优采云将确定同一文章,然后比较这两篇文章的文本量,并自动使用收录更多文本的文章来覆盖和写入相同的文件名. 这种世代情况并不等于世代数.
当相似度低于60%时,优采云判断这是另一篇文章,并将自动重命名标题(标题末尾取3到5个随机字母)并将其保存到文件中.
快速文章过滤器
尽管优采云研究了非常精确的人体提取算法,但提取错误仍然很少. 这些错误主要是: 目标页面的主体是在线视频,或者主体内容太短而无法形成主体特征. 因此,可以通过设置最终结果中的单词数来提高准确性(在“最小字符数”参数中,该单词数是程序删除标签,行和空格后的纯文本单词数) ).
文章快速过滤器用于快速查看采集到的文章,并有助于判断和删除文本错误的文章. 同时,基于网络信息采集的目的,方便了细化和选择过程.
生成的文章数量可变的问题
百度和搜搜默认每页100个结果,而Google默认每页10个结果.
某些网站已超时(尤其是Google所收录的许多网站被阻止),或在文本中设置了最少字数,或者该程序忽略了具有相同名称,黑名单和白名单的类似内容的本地文章等会导致实际生成的文章数低于每次页面搜索的最大结果数.
总的来说,百度的馆藏质量是最好的,并且生成的文章数量接近搜索结果的数量. 使用说明1下载完成后,请勿在压缩包中运行该软件并直接使用,请先将其解压缩;
2该软件支持32位和64位操作环境;
3如果无法正常打开该软件,请右键单击以在管理员模式下运行它. 使用方法选择关键字
设置搜索间隔,采集类型,时间语言,排序方式,采集目标和其他参数
编辑网站的黑名单和白名单
设置翻译选项,过滤选项和插入选项
单击“开始采集”按钮以更新日志,并为某些已进行反采集处理的网站添加增强的采集功能. 查看全部
因此您可以根据实际情况切换模式. 您可以使用本地批处理的读取网页正文功能来测试指定网页适合的模式.
获取过程中的处理选项
在采集过程中可以同时执行翻译,过滤和单词搜索等处理. 所采集的文章可以通过“本地批处理”进行处理.
翻译功能是将中文翻译成英文,然后再翻译回中文,从而产生伪原创效果. 支持原创格式翻译,即不要更改文章的原创标签结构和排版格式.
采集目标是URL
您可以在URL模板中插入#URL#,#title#来合并引用
页面采集和相对路径转换为绝对路径
勾选“自动采集和分页”以合并分页的文章. 编辑框的设置值为最大采集页数. 建议设置一个有限的值(例如10页),以免出现分页时间过长的集合,并且合并后的文章过大. 如果需要采集所有页面,可以将其设置为0.
文章中的所有相对路径将自动转换为绝对路径,这样可以确保图片等的正常显示.
多线程
支持网页的多线程高速采集. 可以根据网络速度来确定. 电信2m可以有5个线程,电信4m可以有10个线程,依此类推,但是需要适当设置. 太多的设置可能会严重影响采集效率甚至系统效率. 如果在采集过程中运行了占用流量的其他软件(例如在线视频播放),则可以适当减少线程数.
处理重复的文章标题和文章内容
该程序可以智能地判断和过滤重复的文章
当采集到的文章的标题(文件名)与本地保存的文章的标题相同时,优采云将首先判断这两篇文章的相似性. 当相似度大于60%时,优采云将确定同一文章,然后比较这两篇文章的文本量,并自动使用收录更多文本的文章来覆盖和写入相同的文件名. 这种世代情况并不等于世代数.
当相似度低于60%时,优采云判断这是另一篇文章,并将自动重命名标题(标题末尾取3到5个随机字母)并将其保存到文件中.
快速文章过滤器
尽管优采云研究了非常精确的人体提取算法,但提取错误仍然很少. 这些错误主要是: 目标页面的主体是在线视频,或者主体内容太短而无法形成主体特征. 因此,可以通过设置最终结果中的单词数来提高准确性(在“最小字符数”参数中,该单词数是程序删除标签,行和空格后的纯文本单词数) ).
文章快速过滤器用于快速查看采集到的文章,并有助于判断和删除文本错误的文章. 同时,基于网络信息采集的目的,方便了细化和选择过程.
生成的文章数量可变的问题
百度和搜搜默认每页100个结果,而Google默认每页10个结果.
某些网站已超时(尤其是Google所收录的许多网站被阻止),或在文本中设置了最少字数,或者该程序忽略了具有相同名称,黑名单和白名单的类似内容的本地文章等会导致实际生成的文章数低于每次页面搜索的最大结果数.
总的来说,百度的馆藏质量是最好的,并且生成的文章数量接近搜索结果的数量. 使用说明1下载完成后,请勿在压缩包中运行该软件并直接使用,请先将其解压缩;
2该软件支持32位和64位操作环境;
3如果无法正常打开该软件,请右键单击以在管理员模式下运行它. 使用方法选择关键字
设置搜索间隔,采集类型,时间语言,排序方式,采集目标和其他参数
编辑网站的黑名单和白名单
设置翻译选项,过滤选项和插入选项
单击“开始采集”按钮以更新日志,并为某些已进行反采集处理的网站添加增强的采集功能.

