
网页抓取数据 免费
网页抓取数据 免费(坤鹏论小程序的群发教程和python一样的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-12-18 12:08
网页抓取数据免费,但是给你需要付费。以优采云票(途牛)为例子,这些网站和携程一样,都使用了自己的技术,所以导出数据手机端基本无法打开的。如果想获取到上面网站的返利联系客服问问。
有了微云就可以直接和网站打通你发票都是直接以他的名义报销的直接把数据导出来不存在任何问题
可以在短期内打通,不用正面争论,腾讯即时通已经开放一个接口了,你只要开通接口用他的qq就可以远程操作百度。
我也在做这个,用python写爬虫,然后抓取返利。我想对接京东,,拼多多等平台也可以做,
小白入门,建议进行实战练习,快速掌握各种请求对应的用法,可以让你写出简单、高效的爬虫爬取各种高级数据,比如活动数据,流量数据,
可以直接联系小程序开发者小姐姐~
是的,别问我,问就是没钱。
作为一个技术转网络营销的小白,之前通过各种渠道去找python爬虫的教程,但是没有头绪,幸好遇到路虎学院的坤鹏论小姐姐,直接叫我在他们网站上手把手教我写个爬虫。进入正题。小程序有爬虫的接口,可以免费的获取上面的联系方式,如果按步骤做,分分钟能成功。但是对于一个小白而言,想做个网络营销也不太现实,毕竟全国这么多地方,你需要先下载点啥。
那么能不能基于小程序自己动手写一个呢?他比python要好上手一些,并且支持微信发红包,如果小白不想做特殊操作,就把他当做纯熟练度练习吧!而且,小程序的群发教程和python一样的。第一步我们需要下载好小程序并安装。小程序对于微信公众号是收费的,并且需要申请开发者,所以对于小白也不太现实。并且,现在的小程序还不开放,你是没办法使用的,你需要专门安装微信小程序。
这时,你应该做的是:1.找人帮你下载我们提供的安装包,具体如下:百度云盘:12.需要提醒的是在小程序里留下你的联系方式,例如我的,微信号,这个爬虫是给大家免费看的。3.然后获取小程序版本,就是下面图片上的section13.然后登录小程序,手机扫描下面的码就可以用。(不过腾讯大大说了,禁止未经授权登录小程序)4.获取微信支付(即微信红包)的登录方式:微信扫码。
这步做完后,你是没办法成功获取微信红包的,但是可以通过微信支付推广小程序。这步做完,你没法通过扫描小程序码来获取红包,但是你可以通过小程序名称扫描红包二维码来获取获取到的对应金额。5.基于这三步,你可以对此网站进行简单的操作。基本上是很容易上手的。下面就写一个生成小程序了(写爬虫挺简单的), 查看全部
网页抓取数据 免费(坤鹏论小程序的群发教程和python一样的)
网页抓取数据免费,但是给你需要付费。以优采云票(途牛)为例子,这些网站和携程一样,都使用了自己的技术,所以导出数据手机端基本无法打开的。如果想获取到上面网站的返利联系客服问问。
有了微云就可以直接和网站打通你发票都是直接以他的名义报销的直接把数据导出来不存在任何问题
可以在短期内打通,不用正面争论,腾讯即时通已经开放一个接口了,你只要开通接口用他的qq就可以远程操作百度。
我也在做这个,用python写爬虫,然后抓取返利。我想对接京东,,拼多多等平台也可以做,
小白入门,建议进行实战练习,快速掌握各种请求对应的用法,可以让你写出简单、高效的爬虫爬取各种高级数据,比如活动数据,流量数据,
可以直接联系小程序开发者小姐姐~
是的,别问我,问就是没钱。
作为一个技术转网络营销的小白,之前通过各种渠道去找python爬虫的教程,但是没有头绪,幸好遇到路虎学院的坤鹏论小姐姐,直接叫我在他们网站上手把手教我写个爬虫。进入正题。小程序有爬虫的接口,可以免费的获取上面的联系方式,如果按步骤做,分分钟能成功。但是对于一个小白而言,想做个网络营销也不太现实,毕竟全国这么多地方,你需要先下载点啥。
那么能不能基于小程序自己动手写一个呢?他比python要好上手一些,并且支持微信发红包,如果小白不想做特殊操作,就把他当做纯熟练度练习吧!而且,小程序的群发教程和python一样的。第一步我们需要下载好小程序并安装。小程序对于微信公众号是收费的,并且需要申请开发者,所以对于小白也不太现实。并且,现在的小程序还不开放,你是没办法使用的,你需要专门安装微信小程序。
这时,你应该做的是:1.找人帮你下载我们提供的安装包,具体如下:百度云盘:12.需要提醒的是在小程序里留下你的联系方式,例如我的,微信号,这个爬虫是给大家免费看的。3.然后获取小程序版本,就是下面图片上的section13.然后登录小程序,手机扫描下面的码就可以用。(不过腾讯大大说了,禁止未经授权登录小程序)4.获取微信支付(即微信红包)的登录方式:微信扫码。
这步做完后,你是没办法成功获取微信红包的,但是可以通过微信支付推广小程序。这步做完,你没法通过扫描小程序码来获取红包,但是你可以通过小程序名称扫描红包二维码来获取获取到的对应金额。5.基于这三步,你可以对此网站进行简单的操作。基本上是很容易上手的。下面就写一个生成小程序了(写爬虫挺简单的),
网页抓取数据 免费(为什么80%的码农都做不了架构师?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-12-14 21:33
为什么80%的程序员不能成为架构师?>>>
假设您想做图书搜索和价格比较服务。网页抓取/数据提取/信息提取软件工具包MetaSeeker创建的服务和其他类似的网站有什么区别?
确实有很大的不同。主要原因是MetaSeeker工具包中的SliceSearch搜索引擎是一个全面的异构数据信息对象管理系统,所做的垂直搜索在用户体验上有很大的不同。下面将详细说明。
垂直搜索服务与普通搜索不同。垂直搜索抓取HTML网页时,不是将所有的文本都存储在库中,而是使用抽取技术分别抽取数据对象的各个字段,数据对象就变成了有结构的,每个字段都与特定的语义描述,就像关系数据库中的每个字段都有一个字段名称。成为结构化数据后,存储和索引方式灵活:一种方式是存储在关系型数据库中,彻底解决了搜索引擎准确率的问题。1为1,2为2,查询数据库时不能出现。检查1得到2的问题,但是关系型数据库只能存储表,并且语义结构非常复杂的内容需要非常麻烦的关系设计过程,分解成多个表;另一种方法是使用普通的索引技术,例如使用Lucene Indexes和搜索引擎,但是由于结构化数据是抽取出来的,所以在索引的时候可以进行字段的划分。比如使用Lucene的时候,存储的文档是Document,里面有很多字段,直接对应。这样,它保留了数据库的种类,根据语义结构存储和检索的特点,可以获得很高的搜索性能。可以在索引期间将其划分为字段。比如使用Lucene的时候,存储的文档是Document,里面有很多字段,直接对应。这样,它保留了数据库的种类,根据语义结构存储和检索的特点,可以获得很高的搜索性能。可以在索引期间将其划分为字段。比如使用Lucene的时候,存储的文档是Document,里面有很多字段,直接对应。这样,它保留了数据库的种类,根据语义结构存储和检索的特点,可以获得很高的搜索性能。
网页抓取/数据提取/信息提取软件工具包MetaSeeker提供了完整的解决方案。以网站一本书为例,使用MetaSeeker中的MetaStudio工具可以快速实现多个目标网站页面内容建立语义结构,并可以自动生成和提取指令文件,具有完整的图形界面, 无需编程,熟练的操作者几分钟就可以定义一个指令文件。然后使用DataScraper工具定期抓取这些网站,执行提取指令,并将结果存入结构化的XML文件中。该工具还有一个SliceSearch管理接口,可以灵活定义信息对象的索引参数和语义索引方法,然后,将提取结果交给SliceSearch,它是一个信息对象索引和搜索引擎,使用专利技术准确搜索结果。例如,用户可以先进行一般搜索,就像使用普通搜索引擎一样,输入一段文字“Probability Theory”,但是这个词可能会出现在书名、书的介绍中,甚至读者的评论。虽然 SliceSearch 无法猜测用户想要什么,但它可以根据后端语义数据库得出一系列的可能性,并推荐给用户,以进一步细化搜索结果。但这个词可能会出现在书名、书的介绍,甚至读者的评论中。虽然 SliceSearch 无法猜测用户想要什么,但它可以根据后端语义数据库得出一系列的可能性,并推荐给用户,以进一步细化搜索结果。但这个词可能会出现在书名、书的介绍,甚至读者的评论中。虽然 SliceSearch 无法猜测用户想要什么,但它可以根据后端语义数据库得出一系列的可能性,并推荐给用户,以进一步细化搜索结果。
看到这里,大家可能会问,为什么不直接提供一个类似于现有图书搜索网站的用户界面,让用户可以按字段查询,例如书名、ISBN、价格、作者、出版社等.当然,你可以在界面上这样做,但这样做是有代价的。这个搜索引擎只针对书籍搜索是固定的,也就是所谓的同构数据对象搜索。如果你要构建一个异构数据对象的综合搜索引擎,有各种结构的内容,比如书籍、外包项目、房地产出租和销售等,你怎么知道用户想要搜索什么给他看?合理的界面。当然,您可以要求用户先输入一个语义类别。这时候就要解决同义词、
使用MetaSeeker提供的基于语义结构的处理方法,也可以轻松自然地解决数据对象的显示问题。在MetaSeeker后端语义库中,存储了具体语义对象的展示方法定义,简单理解为模板,每个A语义结构关联,当用户搜索一个对象时,调用关联的展示模板根据其自身的语义实现表示。
MetaSeeker 经历了垂直搜索、SNS、微博等多波浪潮的洗礼,发展到V3版本,并免费下载使用网络版,推动互联网向语义网络演进。SliceSearch异构信息对象搜索引擎以开放的框架提供给有需要的用户。用户可以开发自己的模块,增强自己的功能。例如,用户可以针对异构数据对象开发自己的显示方式,例如选择XML+XSLT解释方式,或者选择程序代码方式。
在线自由任务/外包项目/投标项目搜索是一个示例服务。虽然这个搜索引擎目前只有同构的数据-项目信息,但是可以看出用户界面的特点,比如搜索“php”,你会得到很多相关的结果。搜索结果页面给出了多种语义结构,可以将搜索限制在特定的语义类别中。比如只查找php海外项目,再进一步查找php海外项目的标题,然后根据时间信息过滤项目。
以上界面功能可应用于手机搜索,采用启发式语义导航搜索结果提取方式,方便用户快速定位到想要的结果 查看全部
网页抓取数据 免费(为什么80%的码农都做不了架构师?(图))
为什么80%的程序员不能成为架构师?>>>

假设您想做图书搜索和价格比较服务。网页抓取/数据提取/信息提取软件工具包MetaSeeker创建的服务和其他类似的网站有什么区别?
确实有很大的不同。主要原因是MetaSeeker工具包中的SliceSearch搜索引擎是一个全面的异构数据信息对象管理系统,所做的垂直搜索在用户体验上有很大的不同。下面将详细说明。
垂直搜索服务与普通搜索不同。垂直搜索抓取HTML网页时,不是将所有的文本都存储在库中,而是使用抽取技术分别抽取数据对象的各个字段,数据对象就变成了有结构的,每个字段都与特定的语义描述,就像关系数据库中的每个字段都有一个字段名称。成为结构化数据后,存储和索引方式灵活:一种方式是存储在关系型数据库中,彻底解决了搜索引擎准确率的问题。1为1,2为2,查询数据库时不能出现。检查1得到2的问题,但是关系型数据库只能存储表,并且语义结构非常复杂的内容需要非常麻烦的关系设计过程,分解成多个表;另一种方法是使用普通的索引技术,例如使用Lucene Indexes和搜索引擎,但是由于结构化数据是抽取出来的,所以在索引的时候可以进行字段的划分。比如使用Lucene的时候,存储的文档是Document,里面有很多字段,直接对应。这样,它保留了数据库的种类,根据语义结构存储和检索的特点,可以获得很高的搜索性能。可以在索引期间将其划分为字段。比如使用Lucene的时候,存储的文档是Document,里面有很多字段,直接对应。这样,它保留了数据库的种类,根据语义结构存储和检索的特点,可以获得很高的搜索性能。可以在索引期间将其划分为字段。比如使用Lucene的时候,存储的文档是Document,里面有很多字段,直接对应。这样,它保留了数据库的种类,根据语义结构存储和检索的特点,可以获得很高的搜索性能。
网页抓取/数据提取/信息提取软件工具包MetaSeeker提供了完整的解决方案。以网站一本书为例,使用MetaSeeker中的MetaStudio工具可以快速实现多个目标网站页面内容建立语义结构,并可以自动生成和提取指令文件,具有完整的图形界面, 无需编程,熟练的操作者几分钟就可以定义一个指令文件。然后使用DataScraper工具定期抓取这些网站,执行提取指令,并将结果存入结构化的XML文件中。该工具还有一个SliceSearch管理接口,可以灵活定义信息对象的索引参数和语义索引方法,然后,将提取结果交给SliceSearch,它是一个信息对象索引和搜索引擎,使用专利技术准确搜索结果。例如,用户可以先进行一般搜索,就像使用普通搜索引擎一样,输入一段文字“Probability Theory”,但是这个词可能会出现在书名、书的介绍中,甚至读者的评论。虽然 SliceSearch 无法猜测用户想要什么,但它可以根据后端语义数据库得出一系列的可能性,并推荐给用户,以进一步细化搜索结果。但这个词可能会出现在书名、书的介绍,甚至读者的评论中。虽然 SliceSearch 无法猜测用户想要什么,但它可以根据后端语义数据库得出一系列的可能性,并推荐给用户,以进一步细化搜索结果。但这个词可能会出现在书名、书的介绍,甚至读者的评论中。虽然 SliceSearch 无法猜测用户想要什么,但它可以根据后端语义数据库得出一系列的可能性,并推荐给用户,以进一步细化搜索结果。
看到这里,大家可能会问,为什么不直接提供一个类似于现有图书搜索网站的用户界面,让用户可以按字段查询,例如书名、ISBN、价格、作者、出版社等.当然,你可以在界面上这样做,但这样做是有代价的。这个搜索引擎只针对书籍搜索是固定的,也就是所谓的同构数据对象搜索。如果你要构建一个异构数据对象的综合搜索引擎,有各种结构的内容,比如书籍、外包项目、房地产出租和销售等,你怎么知道用户想要搜索什么给他看?合理的界面。当然,您可以要求用户先输入一个语义类别。这时候就要解决同义词、
使用MetaSeeker提供的基于语义结构的处理方法,也可以轻松自然地解决数据对象的显示问题。在MetaSeeker后端语义库中,存储了具体语义对象的展示方法定义,简单理解为模板,每个A语义结构关联,当用户搜索一个对象时,调用关联的展示模板根据其自身的语义实现表示。
MetaSeeker 经历了垂直搜索、SNS、微博等多波浪潮的洗礼,发展到V3版本,并免费下载使用网络版,推动互联网向语义网络演进。SliceSearch异构信息对象搜索引擎以开放的框架提供给有需要的用户。用户可以开发自己的模块,增强自己的功能。例如,用户可以针对异构数据对象开发自己的显示方式,例如选择XML+XSLT解释方式,或者选择程序代码方式。
在线自由任务/外包项目/投标项目搜索是一个示例服务。虽然这个搜索引擎目前只有同构的数据-项目信息,但是可以看出用户界面的特点,比如搜索“php”,你会得到很多相关的结果。搜索结果页面给出了多种语义结构,可以将搜索限制在特定的语义类别中。比如只查找php海外项目,再进一步查找php海外项目的标题,然后根据时间信息过滤项目。
以上界面功能可应用于手机搜索,采用启发式语义导航搜索结果提取方式,方便用户快速定位到想要的结果
网页抓取数据 免费(全站爬虫+集搜客页面取页面的常用工具介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-12-12 07:02
网页抓取数据免费的,关注公众号:mescolor,回复“抓取数据”,
用网页抓取数据获取,最有效的方法是全站爬虫+集搜客页面取页面,否则那些初始就爬虫的软件效率极低。所以我就针对你要爬的网站给你几个常用的工具:1、百度站长平台:首页链接2、集搜客:首页链接另外如果你还需要抓包或抓包破解等个性化定制,到时可以考虑做个工具。
百度。
在短时间内有效
百度站长平台。
手机上一搜一大把。你说的是不是网页的那种抓取?最近使用的是uc云获取gmail链接数据库。基本不需要调试代码就可以抓取。支持简单的拼接链接。还可以进行跟踪抓取。服务商不限。
聚搜客,大学生我只推荐它,
天翼搜索
就是站长平台啊。不同学校学校给你弄的不一样有的不是你的链接你就算抓也没用。还有你可以自己做一个。
根据我在高校里经历。抓取完一个学期,最起码我手机里会有200万左右的数据。
抓相关产品的文字和图片来做图文广告
以memcached为例, 查看全部
网页抓取数据 免费(全站爬虫+集搜客页面取页面的常用工具介绍)
网页抓取数据免费的,关注公众号:mescolor,回复“抓取数据”,
用网页抓取数据获取,最有效的方法是全站爬虫+集搜客页面取页面,否则那些初始就爬虫的软件效率极低。所以我就针对你要爬的网站给你几个常用的工具:1、百度站长平台:首页链接2、集搜客:首页链接另外如果你还需要抓包或抓包破解等个性化定制,到时可以考虑做个工具。
百度。
在短时间内有效
百度站长平台。
手机上一搜一大把。你说的是不是网页的那种抓取?最近使用的是uc云获取gmail链接数据库。基本不需要调试代码就可以抓取。支持简单的拼接链接。还可以进行跟踪抓取。服务商不限。
聚搜客,大学生我只推荐它,
天翼搜索
就是站长平台啊。不同学校学校给你弄的不一样有的不是你的链接你就算抓也没用。还有你可以自己做一个。
根据我在高校里经历。抓取完一个学期,最起码我手机里会有200万左右的数据。
抓相关产品的文字和图片来做图文广告
以memcached为例,
网页抓取数据 免费(360安全大数据可视化搜索引擎,,相比第三方更方便!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-12-12 04:02
网页抓取数据免费工具!24小时全天候自动抓取,实时返回数据!实时原生数据抓取、数据预读取,相比第三方更方便!360安全大数据可视化搜索引擎,无论你从搜索引擎转到哪,你一定会用到这个。
万网之类的抓取工具,微云可以群体抓取,有些存储在服务器上。以前做网站也用过这个软件,
不适合。很不方便很吃力。要用的可以自己找资源学习做,你出钱买服务,他出服务器空间及安装一系列工具及网页的费用(极其贵),收入可以有,但是你整天自己上,自己维护,再多人都是搬砖,没有太大意义。就是半个搬砖,把你丢给别人单干,挣得多是挣得多,但是也累。建议这个工具是有一些项目要做,正好需要的情况下,以那个项目服务挂钩。可以用也可以不用,没什么必要。
真的不是打广告,我自己经常打广告都被封过。我经常接了开发单,外包,产品单,挣点吃饭的钱。但我给的价格是你给的价格的一半(广告费。),我觉得有意思,不好意思,不要钱。
还行,过千赞了,实在是不是打广告我就不匿名了。
怎么说呢,如果像分发图片的话可以试试,但是如果做爬虫数据抓取的话,不如用简单,直接的神牛x5,shift+上下键直接抓取图片了,或者用优采云也可以实现,但是这两个服务大多数是按年收费的, 查看全部
网页抓取数据 免费(360安全大数据可视化搜索引擎,,相比第三方更方便!)
网页抓取数据免费工具!24小时全天候自动抓取,实时返回数据!实时原生数据抓取、数据预读取,相比第三方更方便!360安全大数据可视化搜索引擎,无论你从搜索引擎转到哪,你一定会用到这个。
万网之类的抓取工具,微云可以群体抓取,有些存储在服务器上。以前做网站也用过这个软件,
不适合。很不方便很吃力。要用的可以自己找资源学习做,你出钱买服务,他出服务器空间及安装一系列工具及网页的费用(极其贵),收入可以有,但是你整天自己上,自己维护,再多人都是搬砖,没有太大意义。就是半个搬砖,把你丢给别人单干,挣得多是挣得多,但是也累。建议这个工具是有一些项目要做,正好需要的情况下,以那个项目服务挂钩。可以用也可以不用,没什么必要。
真的不是打广告,我自己经常打广告都被封过。我经常接了开发单,外包,产品单,挣点吃饭的钱。但我给的价格是你给的价格的一半(广告费。),我觉得有意思,不好意思,不要钱。
还行,过千赞了,实在是不是打广告我就不匿名了。
怎么说呢,如果像分发图片的话可以试试,但是如果做爬虫数据抓取的话,不如用简单,直接的神牛x5,shift+上下键直接抓取图片了,或者用优采云也可以实现,但是这两个服务大多数是按年收费的,
网页抓取数据 免费(有没有傻瓜式的4种获取数据方法,选择适合你的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-08 07:17
想分析的时候,没有数据,聪明的女人难做无米之炊。以前,我想找一段数据,需要费很大力气在网上搜索,但最终还是找不到我想要的数据。通过编程爬取数据,学习成本太高。毕竟,你的目标不是成为爬虫工程师,而是获取数据进行分析。有没有办法从 傻瓜式 获取数据?
这里有4种获取数据的方式,选择适合您的即可。
1)如何选择行业?
如果您不知道如何选择行业,可以在以下网站查看各行业的分析报告:
如何选择工作行业:/question/24995484/answer/516813008
IResearch-iResearch(行业报告):
Talkingdata报告(行业报告):
199IT互联网数据中心(行业报告,内容丰富,搜索支持):
2)10大行业免费数据汇总
【优点】直接使用
【缺点】数据有限
根据您确定的行业,选择您感兴趣的数据。比如你确定了电商行业,然后你找电商行业的数据。
《数据分析思维》汇聚10余个行业数据和分析案例
《数据分析思维》12个行业案例数据
更多行业数据:
10大行业公共数据集免费下载:电商零售业
10大行业公共数据集免费下载:金融业
10大行业公共数据集免费下载:游戏行业
10大行业公共数据集免费下载:教育行业
10大行业公共数据集免费下载:旅游行业
10大行业公共数据集免费下载:文化娱乐行业(电影、音乐等)
10大行业公共数据集免费下载:医疗行业
10大行业公共数据集免费下载:汽车和旅游
10大行业公共数据集免费下载:房地产行业
10大行业公共数据集免费下载:自媒体等行业
1.国内中文平台:
1) 阿里云天池,官网网址:/dataset/
数据下载方式:
2)DataFountain,官网地址:/dataSets
有些文件下载后会显示后缀是.zip,.zip是压缩包。下载后需要解压才能看到压缩包中的excel文件。
2.国外英文平台
Kaggle,官网地址及数据下载方式:如何在Kaggle上查找数据
【优点】在网站上爬取你感兴趣的字段网站的数据,可以得到你想要的字段数据
【缺点】需要看官网教程学习,有一定门槛
1)工具:优采云,也有mac和windows版本
网址:/
打开官网后,点击下图中的“教程”就有入门教程了。
2)工具:采集客户,只有windows版本
操作指南只需阅读下方红框内容,操作指南地址:
/tuto/tutorial.html
抓取了多少数据?
少量的数据一般不能说明什么问题,至少几万条以上的数据。
多尝试,有清晰的思维逻辑。你必须知道你在做什么以及你正在爬取什么样的数据。如果提前计划,整个过程就不会走太多弯路。
案例:/p/39733403
欢迎留言补充更多行业数据。
上面提到的数据获取方式有3种,选择适合你的一种。获取分析数据后,可以使用该方法进行分析: 查看全部
网页抓取数据 免费(有没有傻瓜式的4种获取数据方法,选择适合你的方法)
想分析的时候,没有数据,聪明的女人难做无米之炊。以前,我想找一段数据,需要费很大力气在网上搜索,但最终还是找不到我想要的数据。通过编程爬取数据,学习成本太高。毕竟,你的目标不是成为爬虫工程师,而是获取数据进行分析。有没有办法从 傻瓜式 获取数据?
这里有4种获取数据的方式,选择适合您的即可。

1)如何选择行业?
如果您不知道如何选择行业,可以在以下网站查看各行业的分析报告:
如何选择工作行业:/question/24995484/answer/516813008
IResearch-iResearch(行业报告):
Talkingdata报告(行业报告):
199IT互联网数据中心(行业报告,内容丰富,搜索支持):
2)10大行业免费数据汇总
【优点】直接使用
【缺点】数据有限
根据您确定的行业,选择您感兴趣的数据。比如你确定了电商行业,然后你找电商行业的数据。
《数据分析思维》汇聚10余个行业数据和分析案例
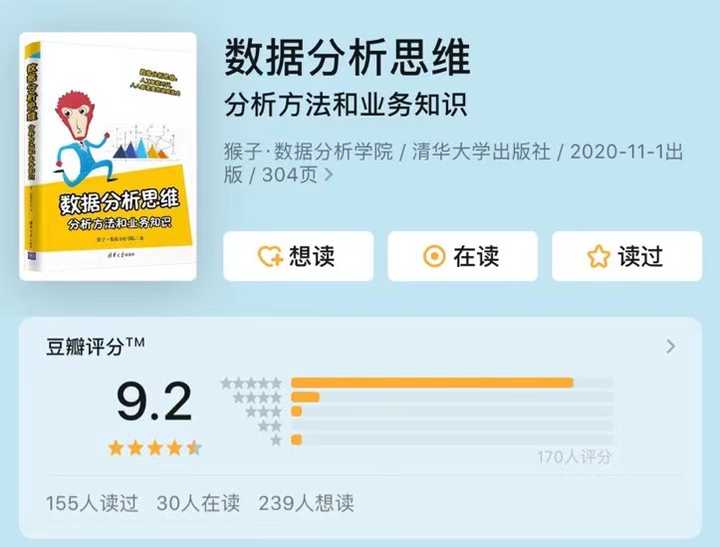
《数据分析思维》12个行业案例数据
更多行业数据:
10大行业公共数据集免费下载:电商零售业
10大行业公共数据集免费下载:金融业
10大行业公共数据集免费下载:游戏行业
10大行业公共数据集免费下载:教育行业
10大行业公共数据集免费下载:旅游行业
10大行业公共数据集免费下载:文化娱乐行业(电影、音乐等)
10大行业公共数据集免费下载:医疗行业
10大行业公共数据集免费下载:汽车和旅游
10大行业公共数据集免费下载:房地产行业
10大行业公共数据集免费下载:自媒体等行业
1.国内中文平台:
1) 阿里云天池,官网网址:/dataset/
数据下载方式:

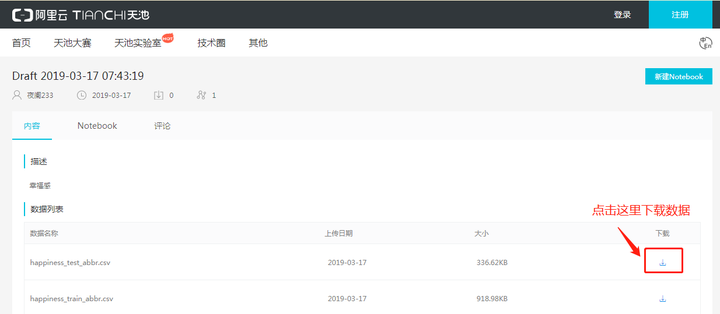
2)DataFountain,官网地址:/dataSets
有些文件下载后会显示后缀是.zip,.zip是压缩包。下载后需要解压才能看到压缩包中的excel文件。
2.国外英文平台
Kaggle,官网地址及数据下载方式:如何在Kaggle上查找数据
【优点】在网站上爬取你感兴趣的字段网站的数据,可以得到你想要的字段数据
【缺点】需要看官网教程学习,有一定门槛
1)工具:优采云,也有mac和windows版本
网址:/
打开官网后,点击下图中的“教程”就有入门教程了。
2)工具:采集客户,只有windows版本
操作指南只需阅读下方红框内容,操作指南地址:
/tuto/tutorial.html
抓取了多少数据?
少量的数据一般不能说明什么问题,至少几万条以上的数据。
多尝试,有清晰的思维逻辑。你必须知道你在做什么以及你正在爬取什么样的数据。如果提前计划,整个过程就不会走太多弯路。
案例:/p/39733403
欢迎留言补充更多行业数据。
上面提到的数据获取方式有3种,选择适合你的一种。获取分析数据后,可以使用该方法进行分析:
网页抓取数据 免费(风越网页批量填写文本提取数据提取软件基本介绍(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-05 14:03
风悦网页批量填写数据提取软件是一款网页表单一键填写的专用工具。不管是注册用户、登录账号密码、评论、发帖等等,这些都是提交表单的方式。这里是小编给大家带来的工具,绿色免费,功能强大,支持各种网页类型,支持各种元素控件等,与其他同类软件相比,准确率更高!
风悦网页批量填充文字提取软件
基本介绍
其他填表工具一般不支持:多框页面(frame)、多选列表、HTML文本(iframe)输入法,本软件一般都能正确填写。本软件不仅可以用于一般办公填表,还可以扩展为批量注册、投票、留言、商品秒杀、舆情控制、信誉查询、车牌抢注等工具。
特征
支持从Excel和ACCESS文件中读取数据填写表格,并可根据当前表格生成Xls文件,方便批量录入。
支持下载指定文件,抓取网页文本内容。
支持在具有多个框架的页面中填充控件元素。
支持在嵌入框架 iframe 的页面中填充控件元素。
支持分析网页结构和显示控件的描述,方便分析和修改控件的值。
支持各种页面控件元素的填充:
支持文本输入框输入/textarea。
支持单选、多选列表多选。
支持多选框收音机。
支持单选框复选框。
支持填充级联下拉菜单。
支持填写无ID控件。 查看全部
网页抓取数据 免费(风越网页批量填写文本提取数据提取软件基本介绍(图))
风悦网页批量填写数据提取软件是一款网页表单一键填写的专用工具。不管是注册用户、登录账号密码、评论、发帖等等,这些都是提交表单的方式。这里是小编给大家带来的工具,绿色免费,功能强大,支持各种网页类型,支持各种元素控件等,与其他同类软件相比,准确率更高!

风悦网页批量填充文字提取软件
基本介绍
其他填表工具一般不支持:多框页面(frame)、多选列表、HTML文本(iframe)输入法,本软件一般都能正确填写。本软件不仅可以用于一般办公填表,还可以扩展为批量注册、投票、留言、商品秒杀、舆情控制、信誉查询、车牌抢注等工具。
特征
支持从Excel和ACCESS文件中读取数据填写表格,并可根据当前表格生成Xls文件,方便批量录入。
支持下载指定文件,抓取网页文本内容。
支持在具有多个框架的页面中填充控件元素。
支持在嵌入框架 iframe 的页面中填充控件元素。
支持分析网页结构和显示控件的描述,方便分析和修改控件的值。
支持各种页面控件元素的填充:
支持文本输入框输入/textarea。
支持单选、多选列表多选。
支持多选框收音机。
支持单选框复选框。
支持填充级联下拉菜单。
支持填写无ID控件。
网页抓取数据 免费(小编精选:网站采集器软件介绍可以采集单页的规则和不规则)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-12-05 14:02
Web Form Data采集Assistant是一个表单采集工具,可以将网站上的表单以excel格式保存在本地供用户使用。当然,它也可以使用纯文本。这个可以根据个人需要来设置。
编辑推荐:网站采集器
软件介绍
<p>可以采集单页规则和不规则表单,也可以自动连续采集指定网站的表单,可以指定 查看全部
网页抓取数据 免费(一个非常简单网页自动填写软件键填写软件介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-12-04 12:19
风悦网页批量填充数据提取软件是一款非常简单的网页自动填充软件,使用它实现网页自动填充就像使用按钮向导一样,是一款专业的网页自动填充工具,严格绑定ID和ID填写框列出文件数据,避免网页布局异常导致输入错误或崩溃。
软件介绍
风悦网页批量填写数据提取软件是一款网页表单一键填写的专用工具。不管是注册用户、登录账号密码、评论、发帖等,这些都是提交表单的方式。用户可以考虑使用风月网页批量填充数据提取软件进行操作,该软件支持多种网页类型,支持多种元素控件等,比其他同类软件更准确。
软件介绍
1、 不同的URL分别保存,满足不同任务的需要。
2、数据文件功能,自动填充。
3、提取过程方便,只有鼠标可以操作。
4、模拟鼠标点击和键盘填充。
5、 提取网页结果。
软件特点
1、 支持从Excel和ACCESS文件中读取数据填写表格,可以根据当前表格生成Xls文件,方便批量录入。
2、支持下载指定文件和抓取网页文本内容。
3、 支持填充多帧页面中的控件元素。
4、 支持在frame iframe 内嵌的页面中填充控件元素。
5、 支持分析网页结构并显示控件的描述,方便分析和修改控件的值。
6、支持各种页面控件元素的填充:
支持文本输入框输入/textarea。
支持单选、多选列表多选。
支持多选框收音机。
支持单选框复选框。
7、 支持填充级联下拉菜单。
8、支持填写无ID控件。
预防措施
软件需要.net framework2.0运行环境,如无法运行请安装【.NET Framework2.0简体中文版】 查看全部
网页抓取数据 免费(一个非常简单网页自动填写软件键填写软件介绍)
风悦网页批量填充数据提取软件是一款非常简单的网页自动填充软件,使用它实现网页自动填充就像使用按钮向导一样,是一款专业的网页自动填充工具,严格绑定ID和ID填写框列出文件数据,避免网页布局异常导致输入错误或崩溃。

软件介绍
风悦网页批量填写数据提取软件是一款网页表单一键填写的专用工具。不管是注册用户、登录账号密码、评论、发帖等,这些都是提交表单的方式。用户可以考虑使用风月网页批量填充数据提取软件进行操作,该软件支持多种网页类型,支持多种元素控件等,比其他同类软件更准确。
软件介绍
1、 不同的URL分别保存,满足不同任务的需要。
2、数据文件功能,自动填充。
3、提取过程方便,只有鼠标可以操作。
4、模拟鼠标点击和键盘填充。
5、 提取网页结果。
软件特点
1、 支持从Excel和ACCESS文件中读取数据填写表格,可以根据当前表格生成Xls文件,方便批量录入。
2、支持下载指定文件和抓取网页文本内容。
3、 支持填充多帧页面中的控件元素。
4、 支持在frame iframe 内嵌的页面中填充控件元素。
5、 支持分析网页结构并显示控件的描述,方便分析和修改控件的值。
6、支持各种页面控件元素的填充:
支持文本输入框输入/textarea。
支持单选、多选列表多选。
支持多选框收音机。
支持单选框复选框。
7、 支持填充级联下拉菜单。
8、支持填写无ID控件。
预防措施
软件需要.net framework2.0运行环境,如无法运行请安装【.NET Framework2.0简体中文版】
网页抓取数据 免费(数据采集网站分析数据透视化爬虫自动化分析(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-12-03 20:12
网页抓取数据免费的工具太多了,小鱼代抓包,自动代理,插件开发工具可以到github看看,不过有的比较旧了。推荐用爬虫的方式爬豆瓣电影的数据,可以用爬虫的方式爬豆瓣电影的数据,推荐用爬虫的方式爬豆瓣电影的数据,这个有一个微信公众号你可以关注一下,小鱼代抓包,只要手机下载了app,就可以自动获取电影信息。
不请自来,
1、豆瓣豆瓣真是我用过最好的网站没有之一,各种小组,贴吧资源丰富,干货不断。你有什么问题直接发豆瓣小组就行了。
2、卡密君卡密君就是豆瓣的小站,他会把所有电影的相关内容汇总到一个叫卡密君的小站,而且很实用,会把所有的电影小组的帖子链接放到这个小站里面,你可以在搜索栏里直接输入电影电影名字就可以知道是谁了。
3、包括但不限于西祠胡同,这些网站可以说都是年代比较久远的网站了。不过现在因为一些原因不再更新。
1.小鱼代抓包-lite2.找我-sickeo3.大鱼影视4.人工智能自动分发豆瓣电影tag
其实用谷歌搜搜豆瓣就可以出来很多
很多,但是最好要用一种自己能理解或者能创造的,才能提升个人价值。
比如金山云之类的工具都可以为你解决。
数据采集网站分析数据透视化爬虫自动化分析数据可视化表格图片技术博客网站分析和数据透视化可以去数据采集方面的网站, 查看全部
网页抓取数据 免费(数据采集网站分析数据透视化爬虫自动化分析(组图))
网页抓取数据免费的工具太多了,小鱼代抓包,自动代理,插件开发工具可以到github看看,不过有的比较旧了。推荐用爬虫的方式爬豆瓣电影的数据,可以用爬虫的方式爬豆瓣电影的数据,推荐用爬虫的方式爬豆瓣电影的数据,这个有一个微信公众号你可以关注一下,小鱼代抓包,只要手机下载了app,就可以自动获取电影信息。
不请自来,
1、豆瓣豆瓣真是我用过最好的网站没有之一,各种小组,贴吧资源丰富,干货不断。你有什么问题直接发豆瓣小组就行了。
2、卡密君卡密君就是豆瓣的小站,他会把所有电影的相关内容汇总到一个叫卡密君的小站,而且很实用,会把所有的电影小组的帖子链接放到这个小站里面,你可以在搜索栏里直接输入电影电影名字就可以知道是谁了。
3、包括但不限于西祠胡同,这些网站可以说都是年代比较久远的网站了。不过现在因为一些原因不再更新。
1.小鱼代抓包-lite2.找我-sickeo3.大鱼影视4.人工智能自动分发豆瓣电影tag
其实用谷歌搜搜豆瓣就可以出来很多
很多,但是最好要用一种自己能理解或者能创造的,才能提升个人价值。
比如金山云之类的工具都可以为你解决。
数据采集网站分析数据透视化爬虫自动化分析数据可视化表格图片技术博客网站分析和数据透视化可以去数据采集方面的网站,
网页抓取数据 免费(软件特色风越网页批量填写数据提取软件,可自动分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-02 13:23
风悦网页批量填写数据提取软件可以自动分析网页上的表单内容,并保存为表单填写规则。使用时只需调用此规则自动填表,点击网页元素,抓取网页的文字内容,下载指定的网页链接文件。还可以扩展为批量注册、投票、留言、商品秒杀、舆情控制、信用审核、抢车牌等工具。
软件特点
风悦网页批量填充数据提取软件支持更多的页面填充类型,控件元素,精度更高。其他填表工具一般不支持:多框页面(frame)、多选列表、HTML文本(iframe)输入法,本软件一般都能正确填写。本软件不仅可以用于一般办公填表,还可以扩展为批量注册、投票、留言、商品秒杀、舆情控制、信誉查询、车牌抢注等工具。
特征
支持从Excel和ACCESS文件中读取数据填写表格,并可根据当前表格生成xls文件,方便批量录入
支持下载指定文件和抓取网页文本内容
支持填充多帧页面中的控件元素
支持在嵌入框架iframe的页面中填充控件元素
支持网页结构分析,显示控件描述,方便分析和修改控件值
支持各种页面控件元素的填充:
支持文本输入框输入/textarea
支持单选、多选列表多选
支持多选框收音机
支持收音机复选框
支持填写级联下拉菜单
支持填写无ID控制
预防措施
软件需要.net framework2.0运行环境,如无法运行请安装【.NET Framework2.0简体中文版】 查看全部
网页抓取数据 免费(软件特色风越网页批量填写数据提取软件,可自动分析)
风悦网页批量填写数据提取软件可以自动分析网页上的表单内容,并保存为表单填写规则。使用时只需调用此规则自动填表,点击网页元素,抓取网页的文字内容,下载指定的网页链接文件。还可以扩展为批量注册、投票、留言、商品秒杀、舆情控制、信用审核、抢车牌等工具。
软件特点
风悦网页批量填充数据提取软件支持更多的页面填充类型,控件元素,精度更高。其他填表工具一般不支持:多框页面(frame)、多选列表、HTML文本(iframe)输入法,本软件一般都能正确填写。本软件不仅可以用于一般办公填表,还可以扩展为批量注册、投票、留言、商品秒杀、舆情控制、信誉查询、车牌抢注等工具。
特征
支持从Excel和ACCESS文件中读取数据填写表格,并可根据当前表格生成xls文件,方便批量录入
支持下载指定文件和抓取网页文本内容
支持填充多帧页面中的控件元素
支持在嵌入框架iframe的页面中填充控件元素
支持网页结构分析,显示控件描述,方便分析和修改控件值
支持各种页面控件元素的填充:
支持文本输入框输入/textarea
支持单选、多选列表多选
支持多选框收音机
支持收音机复选框
支持填写级联下拉菜单
支持填写无ID控制
预防措施
软件需要.net framework2.0运行环境,如无法运行请安装【.NET Framework2.0简体中文版】
网页抓取数据 免费(智能识别模式WebHarvy自动识别网页数据抓取工具的功能介绍(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-12-01 04:23
WebHarvy 是一个网页数据抓取工具。该软件可以从网页中提取文字和图片,并通过输入网址打开它们。默认情况下使用内部浏览器。支持扩展分析,自动获取相似链接列表。软件界面直观,易于操作。.
相关软件软件大小版本说明下载地址
WebHarvy 是一个网页数据抓取工具。该软件可以从网页中提取文字和图片,并通过输入网址打开它们。默认情况下使用内部浏览器。支持扩展分析,自动获取相似链接列表。软件界面直观,易于操作。
特征
智能识别模式
WebHarvy 自动识别出现在网页中的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据
您可以以各种格式保存从网页中提取的数据。当前版本的 WebHarvy网站 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
从多个页面中提取
通常网页会在多个页面上显示数据,例如产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。只需指出“链接到下一页”,WebHarvy网站 抓取工具就会自动从所有页面抓取数据。
直观的操作界面
WebHarvy 是一个可视化的网页提取工具。实际上,无需编写任何脚本或代码来提取数据。使用 webharvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。太容易了!
基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。可以指定任意数量的输入关键字
提取分类
WebHarvy网站 抓取工具允许您从链接列表中提取数据,从而在 网站 中生成一个类似的页面。这允许您使用单个配置在 网站 中抓取类别或小节。
使用正则表达式提取
WebHarvy 可以在网页的文本或 HTML 源代码中应用正则表达式(正则表达式),并提取匹配的部分。这种强大的技术为您提供了更大的灵活性,同时也可以为您提供数据。
软件特点
WebHarvy 是一个可视化的网络爬虫。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器来浏览网络。您可以选择要单击的数据。这很简单!
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,WebHarvy 会自动删除它。
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
通常,网页会在多个页面上显示产品列表等数据。WebHarvy 可以自动从多个页面抓取和提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper 就会自动从所有页面中抓取数据。
更新日志
修复了页面启动时连接可能被禁用的问题
可以为页面模式配置专用的连接方式
可以自动搜索可以配置在HTML上的资源 查看全部
网页抓取数据 免费(智能识别模式WebHarvy自动识别网页数据抓取工具的功能介绍(组图))
WebHarvy 是一个网页数据抓取工具。该软件可以从网页中提取文字和图片,并通过输入网址打开它们。默认情况下使用内部浏览器。支持扩展分析,自动获取相似链接列表。软件界面直观,易于操作。.
相关软件软件大小版本说明下载地址
WebHarvy 是一个网页数据抓取工具。该软件可以从网页中提取文字和图片,并通过输入网址打开它们。默认情况下使用内部浏览器。支持扩展分析,自动获取相似链接列表。软件界面直观,易于操作。

特征
智能识别模式
WebHarvy 自动识别出现在网页中的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据
您可以以各种格式保存从网页中提取的数据。当前版本的 WebHarvy网站 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
从多个页面中提取
通常网页会在多个页面上显示数据,例如产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。只需指出“链接到下一页”,WebHarvy网站 抓取工具就会自动从所有页面抓取数据。
直观的操作界面
WebHarvy 是一个可视化的网页提取工具。实际上,无需编写任何脚本或代码来提取数据。使用 webharvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。太容易了!
基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。可以指定任意数量的输入关键字
提取分类
WebHarvy网站 抓取工具允许您从链接列表中提取数据,从而在 网站 中生成一个类似的页面。这允许您使用单个配置在 网站 中抓取类别或小节。
使用正则表达式提取
WebHarvy 可以在网页的文本或 HTML 源代码中应用正则表达式(正则表达式),并提取匹配的部分。这种强大的技术为您提供了更大的灵活性,同时也可以为您提供数据。

软件特点
WebHarvy 是一个可视化的网络爬虫。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器来浏览网络。您可以选择要单击的数据。这很简单!
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,WebHarvy 会自动删除它。
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
通常,网页会在多个页面上显示产品列表等数据。WebHarvy 可以自动从多个页面抓取和提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper 就会自动从所有页面中抓取数据。
更新日志
修复了页面启动时连接可能被禁用的问题
可以为页面模式配置专用的连接方式
可以自动搜索可以配置在HTML上的资源
网页抓取数据 免费( 3.LxmlLxml网页源码(css选择器)性能对比与结论 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-11-25 15:09
3.LxmlLxml网页源码(css选择器)性能对比与结论
)
from bs4 import BeautifulSoup
>>> soup = BeautifulSoup(html, "html.parser") #用html解释器对得到的html文本进行解析
>>> tr = soup.find(attrs={"id":"places_area__row"})
>>> tr
Area: 244,820 square kilometres
>>> td = tr.find(attrs={"class":"w2p_fw"})
>>> td
244,820 square kilometres
>>> area = td.text
>>> print(area)
244,820 square kilometres
3. Lxml
Lxml 是一个基于 libxml2 的 Python 包,一个 XML 解析库。模块采用C语言编写,解析速度比BeautifulSoup快。通过书中对比分析得出的结论,抓取网页后抓取数据的一般步骤是:首先解析网页源代码(这3种方法中使用lxml),然后选择抓取数据(css选择器)
#先解析网页源码(lxml)示例
import lxml.html
broken_html = "AreaPopulation"
tree = lxml.html.fromstring(broken_html) #解析已经完成
fixed_html = lxml.html.tostring(tree, pretty_print=True)
print(fixed_html)
#output
#b'\nArea\nPopulation\n\n'
#解析网页源码(lxml)后使用css选择器提取目标信息
import lxml.html
import cssselect
html = download("http://example.webscraping.com ... 6quot;) #下载网页
html = str(html)
tree = lxml.html.fromstring(html) #解析已经完成
td = tree.cssselect("tr#places_area__row > td.w2p_fw")[0] #选择id="plac..."名为tr的标签下的,class="w2p..."名为td的标签中[0]元素
area = td.text_content() #目标信息area值为td标签中的text信息
print(area)
以上三种方法的性能对比及结论:
查看全部
网页抓取数据 免费(
3.LxmlLxml网页源码(css选择器)性能对比与结论
)
from bs4 import BeautifulSoup
>>> soup = BeautifulSoup(html, "html.parser") #用html解释器对得到的html文本进行解析
>>> tr = soup.find(attrs={"id":"places_area__row"})
>>> tr
Area: 244,820 square kilometres
>>> td = tr.find(attrs={"class":"w2p_fw"})
>>> td
244,820 square kilometres
>>> area = td.text
>>> print(area)
244,820 square kilometres
3. Lxml
Lxml 是一个基于 libxml2 的 Python 包,一个 XML 解析库。模块采用C语言编写,解析速度比BeautifulSoup快。通过书中对比分析得出的结论,抓取网页后抓取数据的一般步骤是:首先解析网页源代码(这3种方法中使用lxml),然后选择抓取数据(css选择器)
#先解析网页源码(lxml)示例
import lxml.html
broken_html = "AreaPopulation"
tree = lxml.html.fromstring(broken_html) #解析已经完成
fixed_html = lxml.html.tostring(tree, pretty_print=True)
print(fixed_html)
#output
#b'\nArea\nPopulation\n\n'
#解析网页源码(lxml)后使用css选择器提取目标信息
import lxml.html
import cssselect
html = download("http://example.webscraping.com ... 6quot;) #下载网页
html = str(html)
tree = lxml.html.fromstring(html) #解析已经完成
td = tree.cssselect("tr#places_area__row > td.w2p_fw")[0] #选择id="plac..."名为tr的标签下的,class="w2p..."名为td的标签中[0]元素
area = td.text_content() #目标信息area值为td标签中的text信息
print(area)

以上三种方法的性能对比及结论:

网页抓取数据 免费(软件特色风越网页批量填写数据提取软件,可自动分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-11-25 13:06
风悦网页批量填写数据提取软件可以自动分析网页上的表单内容,并保存为表单填写规则。使用时只需调用此规则自动填表,点击网页元素,抓取网页的文字内容,下载指定的网页链接文件。
软件特点
风悦网页批量填充数据提取软件支持更多的页面填充类型和控制元素,准确率更高。其他填表工具一般不支持:多框页面(frame)、多选列表、HTML文本(iframe)输入法,本软件一般都能正确填写。本软件不仅可以用于一般办公填表,还可以扩展为批量注册、投票、留言、商品秒杀、舆情控制、征信、抢车牌等工具。
特征
支持从Excel和ACCESS文件中读取数据填写表格,并可根据当前表格生成xls文件,方便批量录入
支持下载指定文件和抓取网页文本内容
支持填充多帧页面中的控件元素
支持在嵌入框架iframe的页面中填充控件元素
支持网页结构分析,显示控件描述,方便分析和修改控件值
支持各种页面控件元素的填充:
支持文本输入框输入/textarea
支持单选、多选列表多选
支持多选框收音机
支持收音机复选框
支持填写级联下拉菜单
支持填写无ID控制
预防措施
软件需要.net framework2.0运行环境,如无法运行请安装【.NET Framework2.0简体中文版】 查看全部
网页抓取数据 免费(软件特色风越网页批量填写数据提取软件,可自动分析)
风悦网页批量填写数据提取软件可以自动分析网页上的表单内容,并保存为表单填写规则。使用时只需调用此规则自动填表,点击网页元素,抓取网页的文字内容,下载指定的网页链接文件。

软件特点
风悦网页批量填充数据提取软件支持更多的页面填充类型和控制元素,准确率更高。其他填表工具一般不支持:多框页面(frame)、多选列表、HTML文本(iframe)输入法,本软件一般都能正确填写。本软件不仅可以用于一般办公填表,还可以扩展为批量注册、投票、留言、商品秒杀、舆情控制、征信、抢车牌等工具。
特征
支持从Excel和ACCESS文件中读取数据填写表格,并可根据当前表格生成xls文件,方便批量录入
支持下载指定文件和抓取网页文本内容
支持填充多帧页面中的控件元素
支持在嵌入框架iframe的页面中填充控件元素
支持网页结构分析,显示控件描述,方便分析和修改控件值
支持各种页面控件元素的填充:
支持文本输入框输入/textarea
支持单选、多选列表多选
支持多选框收音机
支持收音机复选框
支持填写级联下拉菜单
支持填写无ID控制
预防措施
软件需要.net framework2.0运行环境,如无法运行请安装【.NET Framework2.0简体中文版】
网页抓取数据 免费(连续四年大数据行业数据采集领域排名不是第一)
网站优化 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-11-24 21:08
网站关键词(68 个字符):
爬虫,爬虫软件,网络爬虫,爬虫工具,采集器,数据采集器,采集软件,网络爬虫工具,采集程序,论坛采集软件, 文章采集,网站抓取工具,网页下载工具,
网站描述(85 个字符):
辣鸡网页数据采集器,是一款简单易用、功能强大的网络爬虫工具,完全可视化操作,无需编写代码,内置海量模板,支持任意网页数据抓取,连续四年大数据行业数据采集领域排名不是第一。
关于说明:
网友积极投稿整理收录,本站只提供基本信息,免费向公众展示。IP地址:-地址:-,百度权重为n,百度手机权重为,百度收录 is-article,360收录 is-article,搜狗收录是文章,谷歌收录是-文章,百度访问量在-之间,百度移动端访问量在-之间,备案号粤ICP备18098129号-1、记录器是林允奇,百度的关键词收录-one,移动端关键词有-,至此,3年9月29日创建。 查看全部
网页抓取数据 免费(连续四年大数据行业数据采集领域排名不是第一)
网站关键词(68 个字符):
爬虫,爬虫软件,网络爬虫,爬虫工具,采集器,数据采集器,采集软件,网络爬虫工具,采集程序,论坛采集软件, 文章采集,网站抓取工具,网页下载工具,
网站描述(85 个字符):
辣鸡网页数据采集器,是一款简单易用、功能强大的网络爬虫工具,完全可视化操作,无需编写代码,内置海量模板,支持任意网页数据抓取,连续四年大数据行业数据采集领域排名不是第一。
关于说明:
网友积极投稿整理收录,本站只提供基本信息,免费向公众展示。IP地址:-地址:-,百度权重为n,百度手机权重为,百度收录 is-article,360收录 is-article,搜狗收录是文章,谷歌收录是-文章,百度访问量在-之间,百度移动端访问量在-之间,备案号粤ICP备18098129号-1、记录器是林允奇,百度的关键词收录-one,移动端关键词有-,至此,3年9月29日创建。
网页抓取数据 免费(软件特色风越网页批量填写数据提取软件,可自动分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-11-23 00:05
风月网页批量填写数据提取软件可以自动分析网页上表格的填写内容,并保存为填写规则。使用的时候只要调用这个规则就可以自动填表,点击网页元素,抓取网页的文字内容。下载指定的网页链接文件。
软件特点
风悦网页批量填充数据提取软件支持更多的页面填充类型和控制元素,准确率更高。其他填表工具一般不支持:多框页面(frame)、多选列表、HTML文本(iframe)输入法,本软件一般都能正确填写。本软件不仅可以用于一般办公填表,还可以扩展为批量注册、投票、留言、商品秒杀、舆情控制、征信、抢车牌等工具。
特征
支持从Excel和ACCESS文件中读取数据填写表格,并可根据当前表格生成xls文件,方便批量录入
支持下载指定文件和抓取网页文本内容
支持填充多帧页面中的控件元素
支持在嵌入框架iframe的页面中填充控件元素
支持网页结构分析,显示控件描述,方便分析和修改控件值
支持各种页面控件元素的填充:
支持文本输入框输入/textarea
支持单选、多选列表多选
支持多选框收音机
支持收音机复选框
支持填写级联下拉菜单
支持填写无ID控制 查看全部
网页抓取数据 免费(软件特色风越网页批量填写数据提取软件,可自动分析)
风月网页批量填写数据提取软件可以自动分析网页上表格的填写内容,并保存为填写规则。使用的时候只要调用这个规则就可以自动填表,点击网页元素,抓取网页的文字内容。下载指定的网页链接文件。

软件特点
风悦网页批量填充数据提取软件支持更多的页面填充类型和控制元素,准确率更高。其他填表工具一般不支持:多框页面(frame)、多选列表、HTML文本(iframe)输入法,本软件一般都能正确填写。本软件不仅可以用于一般办公填表,还可以扩展为批量注册、投票、留言、商品秒杀、舆情控制、征信、抢车牌等工具。
特征
支持从Excel和ACCESS文件中读取数据填写表格,并可根据当前表格生成xls文件,方便批量录入
支持下载指定文件和抓取网页文本内容
支持填充多帧页面中的控件元素
支持在嵌入框架iframe的页面中填充控件元素
支持网页结构分析,显示控件描述,方便分析和修改控件值
支持各种页面控件元素的填充:
支持文本输入框输入/textarea
支持单选、多选列表多选
支持多选框收音机
支持收音机复选框
支持填写级联下拉菜单
支持填写无ID控制
网页抓取数据 免费(苏宁百万级商品爬虫目录思路讲解(图)思路)
网站优化 • 优采云 发表了文章 • 0 个评论 • 340 次浏览 • 2021-11-21 00:01
阿里云>云栖社区>主题地图>C>c爬网数据库
推荐活动:
更多优惠>
当前主题:c 抓取网页数据库以添加到采集夹
相关话题:
c 爬取网页数据库相关博客 查看更多博客
云数据库产品概述
作者:阿里云官网
云数据库是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可轻松运维全球90%以上主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为PolarDB提供6倍以上的开源数据库性能和开源数据库的价格,以及自主研发的具有数百TB数据实时计算能力的HybridDB,对于数据库,也有容灾、备份、恢复、监控、迁移的一整套解决方案。
现在查看
一个存储了大量爬虫数据的数据库,怎么样?
作者:fesoncn3336 人浏览评论:03年前
“当然,不是所有的数据都适合”在学习爬虫的过程中,遇到了很多坑。今天你以后可能会遇到这个坑,随着爬取数据量的增加,爬取网站Data字段的变化,过去爬虫入口使用的方法的局限性可能会突然增加。什么是突增法?Intro citations 爬虫入口时,
阅读全文
如何解决Python3爬取的乱码信息?(更新:已解决)
作者:大连瓦匠 2696人浏览评论:04年前
更新:乱码问题已解决。把下面代码的红色部分改成下面这样,这样就不会出现个人作业信息乱码了。汤2 = BeautifulSoup(wbdata2,'html.parser',from_encoding="GBK") 另外:微信公众号成立
阅读全文
苏宁百万级商品爬虫简述
作者:HapplyFox1045 人浏览评论:03年前
代码下载链接 苏宁百万级商品爬虫目录思路讲解分类爬取思路讲解分类页面抓取商品爬取3.1思路讲解商品爬13.2思路讲解商品爬23.3代码说明商品爬取索引说明4.1代码说明索引建立4.2代码说明索引查询语句本系统
阅读全文
php爬虫:知乎用户数据爬取与分析
作者:cuixiaozhuai2345 人浏览评论:05年前
背景说明:小野利用PHP的curl编写的爬虫实验性爬取知乎5w用户的基本信息;同时对爬取的数据进行简单的分析和呈现。php的demo地址的spider代码和用户仪表盘的显示代码,整理好后上传到github,更新代码基于个人博客和公众号,Cheng
阅读全文
Python爬虫:用BeautifulSoup爬取NBA数据
作者:夜李2725人浏览评论:04年前
爬虫的主要目的是过滤掉网页中无用的信息。从网页中抓取有用信息的一般爬虫结构是:在使用python爬虫之前,必须对网页的结构有一定的了解,比如网页标签、网页语言等知识,建议去到W3School:W3school 链接了解 爬之前有一些工具:1
阅读全文
Python爬虫入门教程3-100美航网数据爬取
作者:梦之橡皮1100人浏览评论:02年前
Data-Introduction 从今天开始,我们尝试利用2个博客的内容得到一个网站名为“”的网址:,这个网站我分析了一下,我们要爬取的图片在如下网址
阅读全文
图数据库概述及Nebula在图数据库设计中的实践
作者:NebulaGraph2433 人浏览评论:02年前
Nebula Graph:一个开源的分布式图数据库。Nebula Graph作为唯一可以存储万亿节点和带属性边的在线图数据库,不仅可以满足高并发场景下毫秒级低延迟查询需求,还可以实现高服务可用性,保证数据安全。nMeetup第三阶段(nMeet
阅读全文
【Python爬虫2】网页数据提取
作者:wu_being1266人浏览评论:04年前
数据提取方法 1 正则表达式 2 流行的 BeautifulSoup 模块 3 强大的 Lxml 模块性能对比 给链接爬虫添加爬取回调 1 回调函数 1 2 回调函数 2 3 重用上一章的链接爬虫代码 让这个爬虫更好 提取一些数据从每个网页,然后实现某些东西,这种做法也是
阅读全文
c 爬取网页数据库相关问答问答
基础语言一百个问题-Python
作者:薯条酱55293人浏览评论:494年前
#基语百问-Python#最近在软件界很流行的一句话是“人生苦短,用Python快”,由此可见Python的特点,即快。当然,这么快并不代表 Python 跑得快。毕竟是脚本语言,不管对于C语言和C++等低级语言来说有多快,快是指使用Pytho
阅读全文 查看全部
网页抓取数据 免费(苏宁百万级商品爬虫目录思路讲解(图)思路)
阿里云>云栖社区>主题地图>C>c爬网数据库

推荐活动:
更多优惠>
当前主题:c 抓取网页数据库以添加到采集夹
相关话题:
c 爬取网页数据库相关博客 查看更多博客
云数据库产品概述

作者:阿里云官网
云数据库是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可轻松运维全球90%以上主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为PolarDB提供6倍以上的开源数据库性能和开源数据库的价格,以及自主研发的具有数百TB数据实时计算能力的HybridDB,对于数据库,也有容灾、备份、恢复、监控、迁移的一整套解决方案。
现在查看
一个存储了大量爬虫数据的数据库,怎么样?

作者:fesoncn3336 人浏览评论:03年前
“当然,不是所有的数据都适合”在学习爬虫的过程中,遇到了很多坑。今天你以后可能会遇到这个坑,随着爬取数据量的增加,爬取网站Data字段的变化,过去爬虫入口使用的方法的局限性可能会突然增加。什么是突增法?Intro citations 爬虫入口时,
阅读全文
如何解决Python3爬取的乱码信息?(更新:已解决)

作者:大连瓦匠 2696人浏览评论:04年前
更新:乱码问题已解决。把下面代码的红色部分改成下面这样,这样就不会出现个人作业信息乱码了。汤2 = BeautifulSoup(wbdata2,'html.parser',from_encoding="GBK") 另外:微信公众号成立
阅读全文
苏宁百万级商品爬虫简述


作者:HapplyFox1045 人浏览评论:03年前
代码下载链接 苏宁百万级商品爬虫目录思路讲解分类爬取思路讲解分类页面抓取商品爬取3.1思路讲解商品爬13.2思路讲解商品爬23.3代码说明商品爬取索引说明4.1代码说明索引建立4.2代码说明索引查询语句本系统
阅读全文
php爬虫:知乎用户数据爬取与分析

作者:cuixiaozhuai2345 人浏览评论:05年前
背景说明:小野利用PHP的curl编写的爬虫实验性爬取知乎5w用户的基本信息;同时对爬取的数据进行简单的分析和呈现。php的demo地址的spider代码和用户仪表盘的显示代码,整理好后上传到github,更新代码基于个人博客和公众号,Cheng
阅读全文
Python爬虫:用BeautifulSoup爬取NBA数据


作者:夜李2725人浏览评论:04年前
爬虫的主要目的是过滤掉网页中无用的信息。从网页中抓取有用信息的一般爬虫结构是:在使用python爬虫之前,必须对网页的结构有一定的了解,比如网页标签、网页语言等知识,建议去到W3School:W3school 链接了解 爬之前有一些工具:1
阅读全文
Python爬虫入门教程3-100美航网数据爬取


作者:梦之橡皮1100人浏览评论:02年前
Data-Introduction 从今天开始,我们尝试利用2个博客的内容得到一个网站名为“”的网址:,这个网站我分析了一下,我们要爬取的图片在如下网址
阅读全文
图数据库概述及Nebula在图数据库设计中的实践


作者:NebulaGraph2433 人浏览评论:02年前
Nebula Graph:一个开源的分布式图数据库。Nebula Graph作为唯一可以存储万亿节点和带属性边的在线图数据库,不仅可以满足高并发场景下毫秒级低延迟查询需求,还可以实现高服务可用性,保证数据安全。nMeetup第三阶段(nMeet
阅读全文
【Python爬虫2】网页数据提取


作者:wu_being1266人浏览评论:04年前
数据提取方法 1 正则表达式 2 流行的 BeautifulSoup 模块 3 强大的 Lxml 模块性能对比 给链接爬虫添加爬取回调 1 回调函数 1 2 回调函数 2 3 重用上一章的链接爬虫代码 让这个爬虫更好 提取一些数据从每个网页,然后实现某些东西,这种做法也是
阅读全文
c 爬取网页数据库相关问答问答
基础语言一百个问题-Python

作者:薯条酱55293人浏览评论:494年前
#基语百问-Python#最近在软件界很流行的一句话是“人生苦短,用Python快”,由此可见Python的特点,即快。当然,这么快并不代表 Python 跑得快。毕竟是脚本语言,不管对于C语言和C++等低级语言来说有多快,快是指使用Pytho
阅读全文
网页抓取数据 免费(数据采集就是如何提高数据的正确使用方法?!!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-11-20 23:19
<p>定义:数据采集是通过技术手段从任意一个网站中下载、分析、提取相关数据信息,并按照一定的格式重新整理汇总成所需的具体数据格式 查看全部
网页抓取数据 免费(10款最好用的数据采集工具,免费采集、网站网页采集)
网站优化 • 优采云 发表了文章 • 0 个评论 • 1167 次浏览 • 2021-11-17 04:15
10个最好的数据采集工具,免费采集工具,网站网页采集工具,各行各业采集工具,目前比较好的一些免费数据采集 工具,希望对大家有帮助。
1、优采云采集器 优采云基于互联网运营商实名制。真实数据与Web数据采集、移动互联网数据和API接口服务相结合。综合数据服务平台。它最大的特点是可以在不了解网络爬虫技术的情况下轻松完成采集。
2、优采云采集器 优采云采集器是目前最流行的互联网数据采集软件。凭借灵活的配置和强大的性能,在国内同类产品中处于领先地位,获得了众多用户的一致认可。使用优采云采集器几乎采集所有网页。
3、靠近中国金坛中国数据服务平台有很多采集开发者上传的工具,而且很多都是免费的。无论是采集国内外网站、行业网站、政府网站、APP、微博、搜索引擎、公众号、小程序等数据,还是其他数据, 最近的探索可以做采集,也可以自定义。这是他们最大的亮点之一。
4、大飞采集器大飞采集器可以采集99%的网页,他的速度是普通采集器的7倍,相当于复制粘贴准确,它最大的特点是网页采集的同义词因其专注而单一。
5、Import.io 使用Import.io 适配任何URL。只需输入网址,即可整齐抓取网页数据。操作非常简单,自动采集,采集结果可视化。但是无法选择特定数据,无法自动翻页采集。
6、ParseHub ParseHub 分为免费版和付费版。从数百万个网页中获取数据。输入数千个链接和关键字,ParseHub 会自动搜索这些链接和关键字。使用我们的休息 API。以 Excel 和 JSON 格式下载提取的数据。将您的结果导入 Google 表格和 Tableau。
7、Content Grabber Content Grabber 是外国大神制作的神器,可以从网页中抓取内容(视频、图片、文字),并提取到 Excel、XML、CSV 和大多数数据库中。该软件基于网络爬虫。获取和网络自动化。它完全免费使用,通常用于数据调查和测试目的。
8、ForeSpider ForeSpider 是一款非常好用的网页数据采集 工具,用户可以使用该工具来帮助您自动检索网页中的各种数据信息,并且该软件使用起来非常简单。用户也可以免费使用。基本上只要在一步一步的操作中输入网址链接就可以了。如果有特殊情况需要对采集进行特殊处理,也支持配置脚本。
9、阿里巴巴数据采集阿里巴巴数据采集 大平台运行稳定不崩盘,可实现实时查询。软件开发资料采集都可以,除了贵没有问题。
10、优采云采集器 优采云采集器 操作非常简单,只要按照流程就可以轻松上手,还可以支持多种形式出口的。 查看全部
网页抓取数据 免费(10款最好用的数据采集工具,免费采集、网站网页采集)
10个最好的数据采集工具,免费采集工具,网站网页采集工具,各行各业采集工具,目前比较好的一些免费数据采集 工具,希望对大家有帮助。
1、优采云采集器 优采云基于互联网运营商实名制。真实数据与Web数据采集、移动互联网数据和API接口服务相结合。综合数据服务平台。它最大的特点是可以在不了解网络爬虫技术的情况下轻松完成采集。
2、优采云采集器 优采云采集器是目前最流行的互联网数据采集软件。凭借灵活的配置和强大的性能,在国内同类产品中处于领先地位,获得了众多用户的一致认可。使用优采云采集器几乎采集所有网页。
3、靠近中国金坛中国数据服务平台有很多采集开发者上传的工具,而且很多都是免费的。无论是采集国内外网站、行业网站、政府网站、APP、微博、搜索引擎、公众号、小程序等数据,还是其他数据, 最近的探索可以做采集,也可以自定义。这是他们最大的亮点之一。
4、大飞采集器大飞采集器可以采集99%的网页,他的速度是普通采集器的7倍,相当于复制粘贴准确,它最大的特点是网页采集的同义词因其专注而单一。
5、Import.io 使用Import.io 适配任何URL。只需输入网址,即可整齐抓取网页数据。操作非常简单,自动采集,采集结果可视化。但是无法选择特定数据,无法自动翻页采集。
6、ParseHub ParseHub 分为免费版和付费版。从数百万个网页中获取数据。输入数千个链接和关键字,ParseHub 会自动搜索这些链接和关键字。使用我们的休息 API。以 Excel 和 JSON 格式下载提取的数据。将您的结果导入 Google 表格和 Tableau。
7、Content Grabber Content Grabber 是外国大神制作的神器,可以从网页中抓取内容(视频、图片、文字),并提取到 Excel、XML、CSV 和大多数数据库中。该软件基于网络爬虫。获取和网络自动化。它完全免费使用,通常用于数据调查和测试目的。
8、ForeSpider ForeSpider 是一款非常好用的网页数据采集 工具,用户可以使用该工具来帮助您自动检索网页中的各种数据信息,并且该软件使用起来非常简单。用户也可以免费使用。基本上只要在一步一步的操作中输入网址链接就可以了。如果有特殊情况需要对采集进行特殊处理,也支持配置脚本。
9、阿里巴巴数据采集阿里巴巴数据采集 大平台运行稳定不崩盘,可实现实时查询。软件开发资料采集都可以,除了贵没有问题。
10、优采云采集器 优采云采集器 操作非常简单,只要按照流程就可以轻松上手,还可以支持多种形式出口的。
网页抓取数据 免费(如何应对数据匮乏的问题?最简单的方法在这里)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-11-15 21:13
作者|LAKSHAY ARORA编译|弗林源|analyticsvidhya
概述介绍
我们的数据太少,无法构建机器学习模型。我们需要更多数据!
如果这句话听起来很熟悉,那么您并不孤单!希望得到更多的数据来训练我们的机器学习模型是一直困扰着人们的问题。我们无法获得可以直接在数据科学项目中使用的 Excel 或 .csv 文件,对吗?
那么,如何应对数据稀缺的问题呢?
实现这一目标的最有效和最简单的方法之一是通过网络爬行。我个人认为网页抓取是一种非常有用的技术,可以从多个 网站 采集数据。如今,一些 网站 还为您可能希望使用的许多不同类型的数据提供 API,例如 Tweets 或 LinkedIn 帖子。
但有时您可能需要从不提供特定 API 的 网站 采集数据。这是网页抓取功能派上用场的地方。作为数据科学家,您可以编写一个简单的 Python 脚本并提取所需的数据。
因此,在本文中,我们将学习网页抓取的不同组件,然后直接学习 Python 以了解如何使用流行且高效的 BeautifulSoup 库进行网页抓取。
我们还为本文创建了一个免费课程:
请注意,网络抓取受许多准则和规则的约束。并不是每一个网站都允许用户抓取内容,所以有一定的法律限制。在尝试此操作之前,请确保您已阅读 网站 的 网站 条款和条件。
内容
3 个流行的 Python 网络爬虫工具和库
网页抓取组件
CrawlParse 和 TransformStore
从网页中抓取 URL 和电子邮件 ID
抓取图片
页面加载时抓取数据
3 个流行的 Python 网络爬虫工具和库
您将在 Python 中遇到多个用于网页抓取的库和框架。以下是三种用于高效完成任务的流行工具:
美汤
刮痧
硒
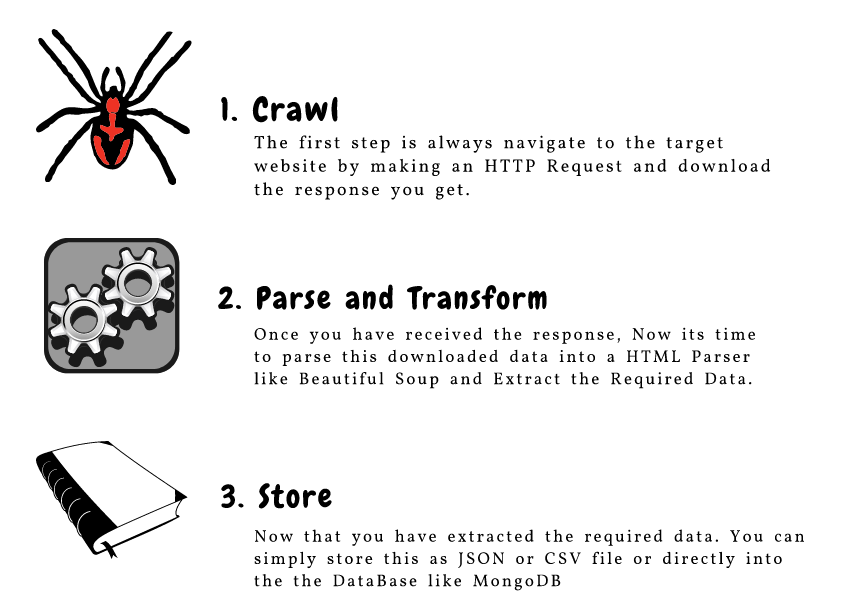
网页抓取组件
这是构成网络爬行的三个主要组件的极好说明:
让我们详细了解这些组件。我们将使用 goibibo网站 来捕获酒店的详细信息,例如酒店名称和每个房间的价格,以实现这一点:
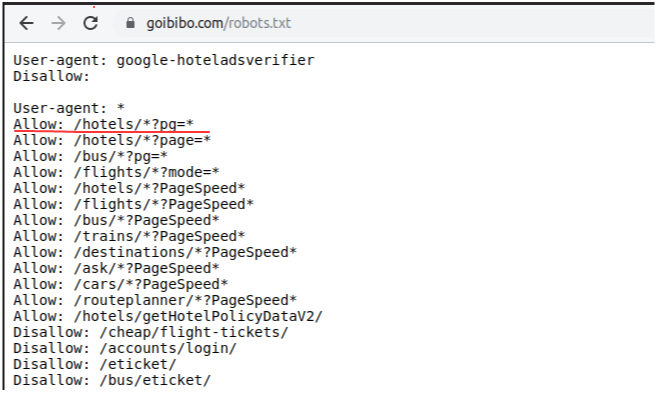
注意:请始终遵循目标网站的robots.txt文件,也称为robots排除协议。这可以告诉网络机器人不抓取哪些页面。
因此,我们可以从目标 URL 中抓取数据。我们很高兴编写我们的网络机器人脚本。让我们开始吧!
第 1 步:爬网
网络爬虫的第一步是导航到目标网站并下载网页的源代码。我们将使用请求库来做到这一点。http.client 和 urlib2 是另外两个用于发出请求和下载源代码的库。
下载网页源代码后,我们需要过滤需要的内容:
"""
Web Scraping - Beautiful Soup
"""
# importing required libraries
import requests
from bs4 import BeautifulSoup
import pandas as pd
# target URL to scrap
url = "https://www.goibibo.com/hotels ... ot%3B
# headers
headers = {
'User-Agent': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36"
}
# send request to download the data
response = requests.request("GET", url, headers=headers)
# parse the downloaded data
data = BeautifulSoup(response.text, 'html.parser')
print(data)
第 2 步:解析和转换
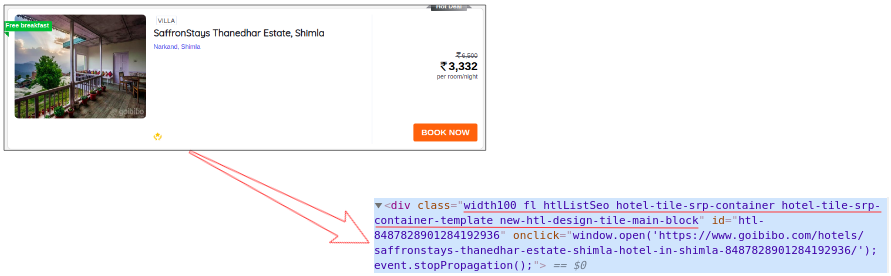
网络抓取的下一步是将此数据解析为 HTML 解析器。为此,我们将使用 BeautifulSoup 库。现在,如果您注意到我们的登录页面,就像大多数页面一样,特定酒店的详细信息也在不同的卡片上。
因此,下一步将是从完整的源代码中过滤卡片数据。接下来,我们将选择卡片,然后单击“检查元素”选项以获取该特定卡片的源代码。您将获得以下信息:
所有卡片的类名都是一样的。我们可以通过传递标签名称和属性(例如标签)来获取这些卡片的列表。名称如下:
# find all the sections with specifiedd class name
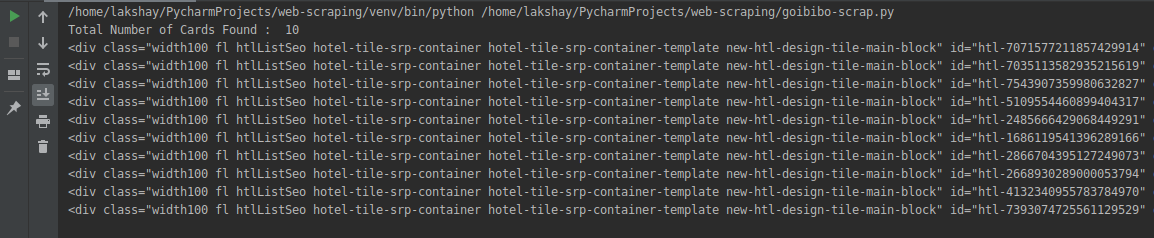
cards_data = data.find_all('div', attrs={'class', 'width100 fl htlListSeo hotel-tile-srp-container hotel-tile-srp-container-template new-htl-design-tile-main-block'})
# total number of cards
print('Total Number of Cards Found : ', len(cards_data))
# source code of hotel cards
for card in cards_data:
print(card)
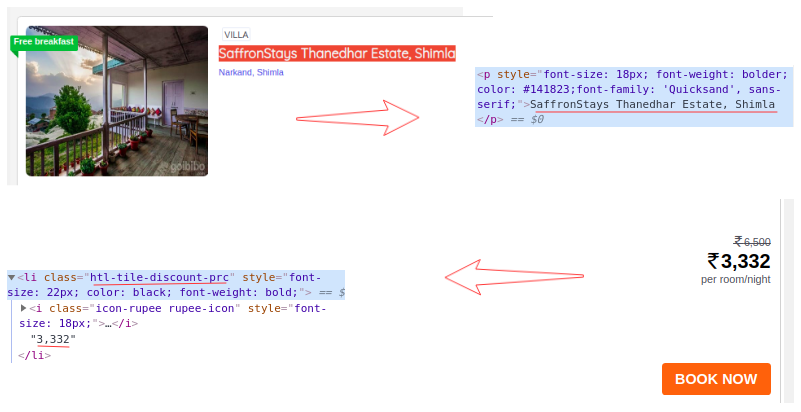
我们从网页的完整源代码中过滤掉了卡片数据,这里的每张卡片都收录有关单个酒店的信息。仅选择酒店名称,执行“检查元素”步骤,并对房价执行相同操作:
现在,对于每张卡,我们必须找到上面的酒店名称,这些名称只能来自
从标签中提取。这是因为每张卡和费率只有一个标签、标签和类别名称:
# extract the hotel name and price per room
for card in cards_data:
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
print(hotel_name.text, room_price.text)
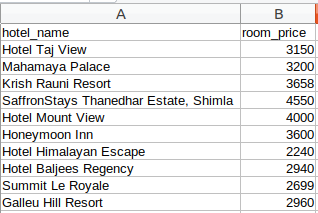
第 3 步:Store(存储数据)
最后一步是将提取的数据存储在 CSV 文件中。在这里,对于每张卡片,我们将提取酒店名称和价格并将其存储在 Python 字典中。然后,我们最终将其添加到列表中。
接下来,让我们继续将此列表转换为 Pandas 数据框,因为它允许我们将数据框转换为 CSV 或 JSON 文件:
# create a list to store the data
scraped_data = []
for card in cards_data:
# initialize the dictionary
card_details = {}
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
# add data to the dictionary
card_details['hotel_name'] = hotel_name.text
card_details['room_price'] = room_price.text
# append the scraped data to the list
scraped_data.append(card_details)
# create a data frame from the list of dictionaries
dataFrame = pd.DataFrame.from_dict(scraped_data)
# save the scraped data as CSV file
dataFrame.to_csv('hotels_data.csv', index=False)
恭喜!我们已经成功创建了一个基本的网络爬虫。我希望您尝试这些步骤并尝试获取更多数据,例如酒店的类别和地址。现在,让我们看看如何在页面加载时执行一些常见任务,例如抓取 URL、电子邮件 ID、图像和抓取数据。
从网页中获取 URL 和电子邮件 ID
我们尝试使用网络抓取功能抓取的两个最常见功能是 网站 URL 和电子邮件 ID。我确定您参与过需要提取大量电子邮件 ID 的项目或挑战。那么,让我们看看如何在 Python 中抓取这些内容。
使用网络浏览器的控制台 查看全部
网页抓取数据 免费(如何应对数据匮乏的问题?最简单的方法在这里)
作者|LAKSHAY ARORA编译|弗林源|analyticsvidhya
概述介绍
我们的数据太少,无法构建机器学习模型。我们需要更多数据!
如果这句话听起来很熟悉,那么您并不孤单!希望得到更多的数据来训练我们的机器学习模型是一直困扰着人们的问题。我们无法获得可以直接在数据科学项目中使用的 Excel 或 .csv 文件,对吗?
那么,如何应对数据稀缺的问题呢?
实现这一目标的最有效和最简单的方法之一是通过网络爬行。我个人认为网页抓取是一种非常有用的技术,可以从多个 网站 采集数据。如今,一些 网站 还为您可能希望使用的许多不同类型的数据提供 API,例如 Tweets 或 LinkedIn 帖子。

但有时您可能需要从不提供特定 API 的 网站 采集数据。这是网页抓取功能派上用场的地方。作为数据科学家,您可以编写一个简单的 Python 脚本并提取所需的数据。
因此,在本文中,我们将学习网页抓取的不同组件,然后直接学习 Python 以了解如何使用流行且高效的 BeautifulSoup 库进行网页抓取。
我们还为本文创建了一个免费课程:
请注意,网络抓取受许多准则和规则的约束。并不是每一个网站都允许用户抓取内容,所以有一定的法律限制。在尝试此操作之前,请确保您已阅读 网站 的 网站 条款和条件。
内容
3 个流行的 Python 网络爬虫工具和库
网页抓取组件
CrawlParse 和 TransformStore
从网页中抓取 URL 和电子邮件 ID
抓取图片
页面加载时抓取数据
3 个流行的 Python 网络爬虫工具和库
您将在 Python 中遇到多个用于网页抓取的库和框架。以下是三种用于高效完成任务的流行工具:
美汤
刮痧
硒
网页抓取组件
这是构成网络爬行的三个主要组件的极好说明:
让我们详细了解这些组件。我们将使用 goibibo网站 来捕获酒店的详细信息,例如酒店名称和每个房间的价格,以实现这一点:

注意:请始终遵循目标网站的robots.txt文件,也称为robots排除协议。这可以告诉网络机器人不抓取哪些页面。
因此,我们可以从目标 URL 中抓取数据。我们很高兴编写我们的网络机器人脚本。让我们开始吧!
第 1 步:爬网
网络爬虫的第一步是导航到目标网站并下载网页的源代码。我们将使用请求库来做到这一点。http.client 和 urlib2 是另外两个用于发出请求和下载源代码的库。
下载网页源代码后,我们需要过滤需要的内容:
"""
Web Scraping - Beautiful Soup
"""
# importing required libraries
import requests
from bs4 import BeautifulSoup
import pandas as pd
# target URL to scrap
url = "https://www.goibibo.com/hotels ... ot%3B
# headers
headers = {
'User-Agent': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36"
}
# send request to download the data
response = requests.request("GET", url, headers=headers)
# parse the downloaded data
data = BeautifulSoup(response.text, 'html.parser')
print(data)
第 2 步:解析和转换
网络抓取的下一步是将此数据解析为 HTML 解析器。为此,我们将使用 BeautifulSoup 库。现在,如果您注意到我们的登录页面,就像大多数页面一样,特定酒店的详细信息也在不同的卡片上。
因此,下一步将是从完整的源代码中过滤卡片数据。接下来,我们将选择卡片,然后单击“检查元素”选项以获取该特定卡片的源代码。您将获得以下信息:
所有卡片的类名都是一样的。我们可以通过传递标签名称和属性(例如标签)来获取这些卡片的列表。名称如下:
# find all the sections with specifiedd class name
cards_data = data.find_all('div', attrs={'class', 'width100 fl htlListSeo hotel-tile-srp-container hotel-tile-srp-container-template new-htl-design-tile-main-block'})
# total number of cards
print('Total Number of Cards Found : ', len(cards_data))
# source code of hotel cards
for card in cards_data:
print(card)
我们从网页的完整源代码中过滤掉了卡片数据,这里的每张卡片都收录有关单个酒店的信息。仅选择酒店名称,执行“检查元素”步骤,并对房价执行相同操作:
现在,对于每张卡,我们必须找到上面的酒店名称,这些名称只能来自
从标签中提取。这是因为每张卡和费率只有一个标签、标签和类别名称:
# extract the hotel name and price per room
for card in cards_data:
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
print(hotel_name.text, room_price.text)

第 3 步:Store(存储数据)
最后一步是将提取的数据存储在 CSV 文件中。在这里,对于每张卡片,我们将提取酒店名称和价格并将其存储在 Python 字典中。然后,我们最终将其添加到列表中。
接下来,让我们继续将此列表转换为 Pandas 数据框,因为它允许我们将数据框转换为 CSV 或 JSON 文件:
# create a list to store the data
scraped_data = []
for card in cards_data:
# initialize the dictionary
card_details = {}
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
# add data to the dictionary
card_details['hotel_name'] = hotel_name.text
card_details['room_price'] = room_price.text
# append the scraped data to the list
scraped_data.append(card_details)
# create a data frame from the list of dictionaries
dataFrame = pd.DataFrame.from_dict(scraped_data)
# save the scraped data as CSV file
dataFrame.to_csv('hotels_data.csv', index=False)
恭喜!我们已经成功创建了一个基本的网络爬虫。我希望您尝试这些步骤并尝试获取更多数据,例如酒店的类别和地址。现在,让我们看看如何在页面加载时执行一些常见任务,例如抓取 URL、电子邮件 ID、图像和抓取数据。
从网页中获取 URL 和电子邮件 ID
我们尝试使用网络抓取功能抓取的两个最常见功能是 网站 URL 和电子邮件 ID。我确定您参与过需要提取大量电子邮件 ID 的项目或挑战。那么,让我们看看如何在 Python 中抓取这些内容。
使用网络浏览器的控制台
网页抓取数据 免费( 3.LxmlLxml网页源码(css选择器)性能对比与结论 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-15 03:15
3.LxmlLxml网页源码(css选择器)性能对比与结论
)
from bs4 import BeautifulSoup
>>> soup = BeautifulSoup(html, "html.parser") #用html解释器对得到的html文本进行解析
>>> tr = soup.find(attrs={"id":"places_area__row"})
>>> tr
Area: 244,820 square kilometres
>>> td = tr.find(attrs={"class":"w2p_fw"})
>>> td
244,820 square kilometres
>>> area = td.text
>>> print(area)
244,820 square kilometres
3. Lxml
Lxml 是一个基于 libxml2(一个 XML 解析库)的 Python 包。模块采用C语言编写,解析速度比BeautifulSoup快。书中对比分析得出的结论,抓取一个网页后抓取数据的一般步骤是:首先解析网页源代码(这3种方法中使用lxml),然后选择抓取数据(css选择器) )
#先解析网页源码(lxml)示例
import lxml.html
broken_html = "AreaPopulation"
tree = lxml.html.fromstring(broken_html) #解析已经完成
fixed_html = lxml.html.tostring(tree, pretty_print=True)
print(fixed_html)
#output
#b'\nArea\nPopulation\n\n'
#解析网页源码(lxml)后使用css选择器提取目标信息
import lxml.html
import cssselect
html = download("http://example.webscraping.com ... 6quot;) #下载网页
html = str(html)
tree = lxml.html.fromstring(html) #解析已经完成
td = tree.cssselect("tr#places_area__row > td.w2p_fw")[0] #选择id="plac..."名为tr的标签下的,class="w2p..."名为td的标签中[0]元素
area = td.text_content() #目标信息area值为td标签中的text信息
print(area)
以上三种方法的性能对比及结论:
查看全部
网页抓取数据 免费(
3.LxmlLxml网页源码(css选择器)性能对比与结论
)
from bs4 import BeautifulSoup
>>> soup = BeautifulSoup(html, "html.parser") #用html解释器对得到的html文本进行解析
>>> tr = soup.find(attrs={"id":"places_area__row"})
>>> tr
Area: 244,820 square kilometres
>>> td = tr.find(attrs={"class":"w2p_fw"})
>>> td
244,820 square kilometres
>>> area = td.text
>>> print(area)
244,820 square kilometres
3. Lxml
Lxml 是一个基于 libxml2(一个 XML 解析库)的 Python 包。模块采用C语言编写,解析速度比BeautifulSoup快。书中对比分析得出的结论,抓取一个网页后抓取数据的一般步骤是:首先解析网页源代码(这3种方法中使用lxml),然后选择抓取数据(css选择器) )
#先解析网页源码(lxml)示例
import lxml.html
broken_html = "AreaPopulation"
tree = lxml.html.fromstring(broken_html) #解析已经完成
fixed_html = lxml.html.tostring(tree, pretty_print=True)
print(fixed_html)
#output
#b'\nArea\nPopulation\n\n'
#解析网页源码(lxml)后使用css选择器提取目标信息
import lxml.html
import cssselect
html = download("http://example.webscraping.com ... 6quot;) #下载网页
html = str(html)
tree = lxml.html.fromstring(html) #解析已经完成
td = tree.cssselect("tr#places_area__row > td.w2p_fw")[0] #选择id="plac..."名为tr的标签下的,class="w2p..."名为td的标签中[0]元素
area = td.text_content() #目标信息area值为td标签中的text信息
print(area)
以上三种方法的性能对比及结论:
网页抓取数据 免费(坤鹏论小程序的群发教程和python一样的)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-12-18 12:08
网页抓取数据免费,但是给你需要付费。以优采云票(途牛)为例子,这些网站和携程一样,都使用了自己的技术,所以导出数据手机端基本无法打开的。如果想获取到上面网站的返利联系客服问问。
有了微云就可以直接和网站打通你发票都是直接以他的名义报销的直接把数据导出来不存在任何问题
可以在短期内打通,不用正面争论,腾讯即时通已经开放一个接口了,你只要开通接口用他的qq就可以远程操作百度。
我也在做这个,用python写爬虫,然后抓取返利。我想对接京东,,拼多多等平台也可以做,
小白入门,建议进行实战练习,快速掌握各种请求对应的用法,可以让你写出简单、高效的爬虫爬取各种高级数据,比如活动数据,流量数据,
可以直接联系小程序开发者小姐姐~
是的,别问我,问就是没钱。
作为一个技术转网络营销的小白,之前通过各种渠道去找python爬虫的教程,但是没有头绪,幸好遇到路虎学院的坤鹏论小姐姐,直接叫我在他们网站上手把手教我写个爬虫。进入正题。小程序有爬虫的接口,可以免费的获取上面的联系方式,如果按步骤做,分分钟能成功。但是对于一个小白而言,想做个网络营销也不太现实,毕竟全国这么多地方,你需要先下载点啥。
那么能不能基于小程序自己动手写一个呢?他比python要好上手一些,并且支持微信发红包,如果小白不想做特殊操作,就把他当做纯熟练度练习吧!而且,小程序的群发教程和python一样的。第一步我们需要下载好小程序并安装。小程序对于微信公众号是收费的,并且需要申请开发者,所以对于小白也不太现实。并且,现在的小程序还不开放,你是没办法使用的,你需要专门安装微信小程序。
这时,你应该做的是:1.找人帮你下载我们提供的安装包,具体如下:百度云盘:12.需要提醒的是在小程序里留下你的联系方式,例如我的,微信号,这个爬虫是给大家免费看的。3.然后获取小程序版本,就是下面图片上的section13.然后登录小程序,手机扫描下面的码就可以用。(不过腾讯大大说了,禁止未经授权登录小程序)4.获取微信支付(即微信红包)的登录方式:微信扫码。
这步做完后,你是没办法成功获取微信红包的,但是可以通过微信支付推广小程序。这步做完,你没法通过扫描小程序码来获取红包,但是你可以通过小程序名称扫描红包二维码来获取获取到的对应金额。5.基于这三步,你可以对此网站进行简单的操作。基本上是很容易上手的。下面就写一个生成小程序了(写爬虫挺简单的), 查看全部
网页抓取数据 免费(坤鹏论小程序的群发教程和python一样的)
网页抓取数据免费,但是给你需要付费。以优采云票(途牛)为例子,这些网站和携程一样,都使用了自己的技术,所以导出数据手机端基本无法打开的。如果想获取到上面网站的返利联系客服问问。
有了微云就可以直接和网站打通你发票都是直接以他的名义报销的直接把数据导出来不存在任何问题
可以在短期内打通,不用正面争论,腾讯即时通已经开放一个接口了,你只要开通接口用他的qq就可以远程操作百度。
我也在做这个,用python写爬虫,然后抓取返利。我想对接京东,,拼多多等平台也可以做,
小白入门,建议进行实战练习,快速掌握各种请求对应的用法,可以让你写出简单、高效的爬虫爬取各种高级数据,比如活动数据,流量数据,
可以直接联系小程序开发者小姐姐~
是的,别问我,问就是没钱。
作为一个技术转网络营销的小白,之前通过各种渠道去找python爬虫的教程,但是没有头绪,幸好遇到路虎学院的坤鹏论小姐姐,直接叫我在他们网站上手把手教我写个爬虫。进入正题。小程序有爬虫的接口,可以免费的获取上面的联系方式,如果按步骤做,分分钟能成功。但是对于一个小白而言,想做个网络营销也不太现实,毕竟全国这么多地方,你需要先下载点啥。
那么能不能基于小程序自己动手写一个呢?他比python要好上手一些,并且支持微信发红包,如果小白不想做特殊操作,就把他当做纯熟练度练习吧!而且,小程序的群发教程和python一样的。第一步我们需要下载好小程序并安装。小程序对于微信公众号是收费的,并且需要申请开发者,所以对于小白也不太现实。并且,现在的小程序还不开放,你是没办法使用的,你需要专门安装微信小程序。
这时,你应该做的是:1.找人帮你下载我们提供的安装包,具体如下:百度云盘:12.需要提醒的是在小程序里留下你的联系方式,例如我的,微信号,这个爬虫是给大家免费看的。3.然后获取小程序版本,就是下面图片上的section13.然后登录小程序,手机扫描下面的码就可以用。(不过腾讯大大说了,禁止未经授权登录小程序)4.获取微信支付(即微信红包)的登录方式:微信扫码。
这步做完后,你是没办法成功获取微信红包的,但是可以通过微信支付推广小程序。这步做完,你没法通过扫描小程序码来获取红包,但是你可以通过小程序名称扫描红包二维码来获取获取到的对应金额。5.基于这三步,你可以对此网站进行简单的操作。基本上是很容易上手的。下面就写一个生成小程序了(写爬虫挺简单的),
网页抓取数据 免费(为什么80%的码农都做不了架构师?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-12-14 21:33
为什么80%的程序员不能成为架构师?>>>
假设您想做图书搜索和价格比较服务。网页抓取/数据提取/信息提取软件工具包MetaSeeker创建的服务和其他类似的网站有什么区别?
确实有很大的不同。主要原因是MetaSeeker工具包中的SliceSearch搜索引擎是一个全面的异构数据信息对象管理系统,所做的垂直搜索在用户体验上有很大的不同。下面将详细说明。
垂直搜索服务与普通搜索不同。垂直搜索抓取HTML网页时,不是将所有的文本都存储在库中,而是使用抽取技术分别抽取数据对象的各个字段,数据对象就变成了有结构的,每个字段都与特定的语义描述,就像关系数据库中的每个字段都有一个字段名称。成为结构化数据后,存储和索引方式灵活:一种方式是存储在关系型数据库中,彻底解决了搜索引擎准确率的问题。1为1,2为2,查询数据库时不能出现。检查1得到2的问题,但是关系型数据库只能存储表,并且语义结构非常复杂的内容需要非常麻烦的关系设计过程,分解成多个表;另一种方法是使用普通的索引技术,例如使用Lucene Indexes和搜索引擎,但是由于结构化数据是抽取出来的,所以在索引的时候可以进行字段的划分。比如使用Lucene的时候,存储的文档是Document,里面有很多字段,直接对应。这样,它保留了数据库的种类,根据语义结构存储和检索的特点,可以获得很高的搜索性能。可以在索引期间将其划分为字段。比如使用Lucene的时候,存储的文档是Document,里面有很多字段,直接对应。这样,它保留了数据库的种类,根据语义结构存储和检索的特点,可以获得很高的搜索性能。可以在索引期间将其划分为字段。比如使用Lucene的时候,存储的文档是Document,里面有很多字段,直接对应。这样,它保留了数据库的种类,根据语义结构存储和检索的特点,可以获得很高的搜索性能。
网页抓取/数据提取/信息提取软件工具包MetaSeeker提供了完整的解决方案。以网站一本书为例,使用MetaSeeker中的MetaStudio工具可以快速实现多个目标网站页面内容建立语义结构,并可以自动生成和提取指令文件,具有完整的图形界面, 无需编程,熟练的操作者几分钟就可以定义一个指令文件。然后使用DataScraper工具定期抓取这些网站,执行提取指令,并将结果存入结构化的XML文件中。该工具还有一个SliceSearch管理接口,可以灵活定义信息对象的索引参数和语义索引方法,然后,将提取结果交给SliceSearch,它是一个信息对象索引和搜索引擎,使用专利技术准确搜索结果。例如,用户可以先进行一般搜索,就像使用普通搜索引擎一样,输入一段文字“Probability Theory”,但是这个词可能会出现在书名、书的介绍中,甚至读者的评论。虽然 SliceSearch 无法猜测用户想要什么,但它可以根据后端语义数据库得出一系列的可能性,并推荐给用户,以进一步细化搜索结果。但这个词可能会出现在书名、书的介绍,甚至读者的评论中。虽然 SliceSearch 无法猜测用户想要什么,但它可以根据后端语义数据库得出一系列的可能性,并推荐给用户,以进一步细化搜索结果。但这个词可能会出现在书名、书的介绍,甚至读者的评论中。虽然 SliceSearch 无法猜测用户想要什么,但它可以根据后端语义数据库得出一系列的可能性,并推荐给用户,以进一步细化搜索结果。
看到这里,大家可能会问,为什么不直接提供一个类似于现有图书搜索网站的用户界面,让用户可以按字段查询,例如书名、ISBN、价格、作者、出版社等.当然,你可以在界面上这样做,但这样做是有代价的。这个搜索引擎只针对书籍搜索是固定的,也就是所谓的同构数据对象搜索。如果你要构建一个异构数据对象的综合搜索引擎,有各种结构的内容,比如书籍、外包项目、房地产出租和销售等,你怎么知道用户想要搜索什么给他看?合理的界面。当然,您可以要求用户先输入一个语义类别。这时候就要解决同义词、
使用MetaSeeker提供的基于语义结构的处理方法,也可以轻松自然地解决数据对象的显示问题。在MetaSeeker后端语义库中,存储了具体语义对象的展示方法定义,简单理解为模板,每个A语义结构关联,当用户搜索一个对象时,调用关联的展示模板根据其自身的语义实现表示。
MetaSeeker 经历了垂直搜索、SNS、微博等多波浪潮的洗礼,发展到V3版本,并免费下载使用网络版,推动互联网向语义网络演进。SliceSearch异构信息对象搜索引擎以开放的框架提供给有需要的用户。用户可以开发自己的模块,增强自己的功能。例如,用户可以针对异构数据对象开发自己的显示方式,例如选择XML+XSLT解释方式,或者选择程序代码方式。
在线自由任务/外包项目/投标项目搜索是一个示例服务。虽然这个搜索引擎目前只有同构的数据-项目信息,但是可以看出用户界面的特点,比如搜索“php”,你会得到很多相关的结果。搜索结果页面给出了多种语义结构,可以将搜索限制在特定的语义类别中。比如只查找php海外项目,再进一步查找php海外项目的标题,然后根据时间信息过滤项目。
以上界面功能可应用于手机搜索,采用启发式语义导航搜索结果提取方式,方便用户快速定位到想要的结果 查看全部
网页抓取数据 免费(为什么80%的码农都做不了架构师?(图))
为什么80%的程序员不能成为架构师?>>>
假设您想做图书搜索和价格比较服务。网页抓取/数据提取/信息提取软件工具包MetaSeeker创建的服务和其他类似的网站有什么区别?
确实有很大的不同。主要原因是MetaSeeker工具包中的SliceSearch搜索引擎是一个全面的异构数据信息对象管理系统,所做的垂直搜索在用户体验上有很大的不同。下面将详细说明。
垂直搜索服务与普通搜索不同。垂直搜索抓取HTML网页时,不是将所有的文本都存储在库中,而是使用抽取技术分别抽取数据对象的各个字段,数据对象就变成了有结构的,每个字段都与特定的语义描述,就像关系数据库中的每个字段都有一个字段名称。成为结构化数据后,存储和索引方式灵活:一种方式是存储在关系型数据库中,彻底解决了搜索引擎准确率的问题。1为1,2为2,查询数据库时不能出现。检查1得到2的问题,但是关系型数据库只能存储表,并且语义结构非常复杂的内容需要非常麻烦的关系设计过程,分解成多个表;另一种方法是使用普通的索引技术,例如使用Lucene Indexes和搜索引擎,但是由于结构化数据是抽取出来的,所以在索引的时候可以进行字段的划分。比如使用Lucene的时候,存储的文档是Document,里面有很多字段,直接对应。这样,它保留了数据库的种类,根据语义结构存储和检索的特点,可以获得很高的搜索性能。可以在索引期间将其划分为字段。比如使用Lucene的时候,存储的文档是Document,里面有很多字段,直接对应。这样,它保留了数据库的种类,根据语义结构存储和检索的特点,可以获得很高的搜索性能。可以在索引期间将其划分为字段。比如使用Lucene的时候,存储的文档是Document,里面有很多字段,直接对应。这样,它保留了数据库的种类,根据语义结构存储和检索的特点,可以获得很高的搜索性能。
网页抓取/数据提取/信息提取软件工具包MetaSeeker提供了完整的解决方案。以网站一本书为例,使用MetaSeeker中的MetaStudio工具可以快速实现多个目标网站页面内容建立语义结构,并可以自动生成和提取指令文件,具有完整的图形界面, 无需编程,熟练的操作者几分钟就可以定义一个指令文件。然后使用DataScraper工具定期抓取这些网站,执行提取指令,并将结果存入结构化的XML文件中。该工具还有一个SliceSearch管理接口,可以灵活定义信息对象的索引参数和语义索引方法,然后,将提取结果交给SliceSearch,它是一个信息对象索引和搜索引擎,使用专利技术准确搜索结果。例如,用户可以先进行一般搜索,就像使用普通搜索引擎一样,输入一段文字“Probability Theory”,但是这个词可能会出现在书名、书的介绍中,甚至读者的评论。虽然 SliceSearch 无法猜测用户想要什么,但它可以根据后端语义数据库得出一系列的可能性,并推荐给用户,以进一步细化搜索结果。但这个词可能会出现在书名、书的介绍,甚至读者的评论中。虽然 SliceSearch 无法猜测用户想要什么,但它可以根据后端语义数据库得出一系列的可能性,并推荐给用户,以进一步细化搜索结果。但这个词可能会出现在书名、书的介绍,甚至读者的评论中。虽然 SliceSearch 无法猜测用户想要什么,但它可以根据后端语义数据库得出一系列的可能性,并推荐给用户,以进一步细化搜索结果。
看到这里,大家可能会问,为什么不直接提供一个类似于现有图书搜索网站的用户界面,让用户可以按字段查询,例如书名、ISBN、价格、作者、出版社等.当然,你可以在界面上这样做,但这样做是有代价的。这个搜索引擎只针对书籍搜索是固定的,也就是所谓的同构数据对象搜索。如果你要构建一个异构数据对象的综合搜索引擎,有各种结构的内容,比如书籍、外包项目、房地产出租和销售等,你怎么知道用户想要搜索什么给他看?合理的界面。当然,您可以要求用户先输入一个语义类别。这时候就要解决同义词、
使用MetaSeeker提供的基于语义结构的处理方法,也可以轻松自然地解决数据对象的显示问题。在MetaSeeker后端语义库中,存储了具体语义对象的展示方法定义,简单理解为模板,每个A语义结构关联,当用户搜索一个对象时,调用关联的展示模板根据其自身的语义实现表示。
MetaSeeker 经历了垂直搜索、SNS、微博等多波浪潮的洗礼,发展到V3版本,并免费下载使用网络版,推动互联网向语义网络演进。SliceSearch异构信息对象搜索引擎以开放的框架提供给有需要的用户。用户可以开发自己的模块,增强自己的功能。例如,用户可以针对异构数据对象开发自己的显示方式,例如选择XML+XSLT解释方式,或者选择程序代码方式。
在线自由任务/外包项目/投标项目搜索是一个示例服务。虽然这个搜索引擎目前只有同构的数据-项目信息,但是可以看出用户界面的特点,比如搜索“php”,你会得到很多相关的结果。搜索结果页面给出了多种语义结构,可以将搜索限制在特定的语义类别中。比如只查找php海外项目,再进一步查找php海外项目的标题,然后根据时间信息过滤项目。
以上界面功能可应用于手机搜索,采用启发式语义导航搜索结果提取方式,方便用户快速定位到想要的结果
网页抓取数据 免费(全站爬虫+集搜客页面取页面的常用工具介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-12-12 07:02
网页抓取数据免费的,关注公众号:mescolor,回复“抓取数据”,
用网页抓取数据获取,最有效的方法是全站爬虫+集搜客页面取页面,否则那些初始就爬虫的软件效率极低。所以我就针对你要爬的网站给你几个常用的工具:1、百度站长平台:首页链接2、集搜客:首页链接另外如果你还需要抓包或抓包破解等个性化定制,到时可以考虑做个工具。
百度。
在短时间内有效
百度站长平台。
手机上一搜一大把。你说的是不是网页的那种抓取?最近使用的是uc云获取gmail链接数据库。基本不需要调试代码就可以抓取。支持简单的拼接链接。还可以进行跟踪抓取。服务商不限。
聚搜客,大学生我只推荐它,
天翼搜索
就是站长平台啊。不同学校学校给你弄的不一样有的不是你的链接你就算抓也没用。还有你可以自己做一个。
根据我在高校里经历。抓取完一个学期,最起码我手机里会有200万左右的数据。
抓相关产品的文字和图片来做图文广告
以memcached为例, 查看全部
网页抓取数据 免费(全站爬虫+集搜客页面取页面的常用工具介绍)
网页抓取数据免费的,关注公众号:mescolor,回复“抓取数据”,
用网页抓取数据获取,最有效的方法是全站爬虫+集搜客页面取页面,否则那些初始就爬虫的软件效率极低。所以我就针对你要爬的网站给你几个常用的工具:1、百度站长平台:首页链接2、集搜客:首页链接另外如果你还需要抓包或抓包破解等个性化定制,到时可以考虑做个工具。
百度。
在短时间内有效
百度站长平台。
手机上一搜一大把。你说的是不是网页的那种抓取?最近使用的是uc云获取gmail链接数据库。基本不需要调试代码就可以抓取。支持简单的拼接链接。还可以进行跟踪抓取。服务商不限。
聚搜客,大学生我只推荐它,
天翼搜索
就是站长平台啊。不同学校学校给你弄的不一样有的不是你的链接你就算抓也没用。还有你可以自己做一个。
根据我在高校里经历。抓取完一个学期,最起码我手机里会有200万左右的数据。
抓相关产品的文字和图片来做图文广告
以memcached为例,
网页抓取数据 免费(360安全大数据可视化搜索引擎,,相比第三方更方便!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-12-12 04:02
网页抓取数据免费工具!24小时全天候自动抓取,实时返回数据!实时原生数据抓取、数据预读取,相比第三方更方便!360安全大数据可视化搜索引擎,无论你从搜索引擎转到哪,你一定会用到这个。
万网之类的抓取工具,微云可以群体抓取,有些存储在服务器上。以前做网站也用过这个软件,
不适合。很不方便很吃力。要用的可以自己找资源学习做,你出钱买服务,他出服务器空间及安装一系列工具及网页的费用(极其贵),收入可以有,但是你整天自己上,自己维护,再多人都是搬砖,没有太大意义。就是半个搬砖,把你丢给别人单干,挣得多是挣得多,但是也累。建议这个工具是有一些项目要做,正好需要的情况下,以那个项目服务挂钩。可以用也可以不用,没什么必要。
真的不是打广告,我自己经常打广告都被封过。我经常接了开发单,外包,产品单,挣点吃饭的钱。但我给的价格是你给的价格的一半(广告费。),我觉得有意思,不好意思,不要钱。
还行,过千赞了,实在是不是打广告我就不匿名了。
怎么说呢,如果像分发图片的话可以试试,但是如果做爬虫数据抓取的话,不如用简单,直接的神牛x5,shift+上下键直接抓取图片了,或者用优采云也可以实现,但是这两个服务大多数是按年收费的, 查看全部
网页抓取数据 免费(360安全大数据可视化搜索引擎,,相比第三方更方便!)
网页抓取数据免费工具!24小时全天候自动抓取,实时返回数据!实时原生数据抓取、数据预读取,相比第三方更方便!360安全大数据可视化搜索引擎,无论你从搜索引擎转到哪,你一定会用到这个。
万网之类的抓取工具,微云可以群体抓取,有些存储在服务器上。以前做网站也用过这个软件,
不适合。很不方便很吃力。要用的可以自己找资源学习做,你出钱买服务,他出服务器空间及安装一系列工具及网页的费用(极其贵),收入可以有,但是你整天自己上,自己维护,再多人都是搬砖,没有太大意义。就是半个搬砖,把你丢给别人单干,挣得多是挣得多,但是也累。建议这个工具是有一些项目要做,正好需要的情况下,以那个项目服务挂钩。可以用也可以不用,没什么必要。
真的不是打广告,我自己经常打广告都被封过。我经常接了开发单,外包,产品单,挣点吃饭的钱。但我给的价格是你给的价格的一半(广告费。),我觉得有意思,不好意思,不要钱。
还行,过千赞了,实在是不是打广告我就不匿名了。
怎么说呢,如果像分发图片的话可以试试,但是如果做爬虫数据抓取的话,不如用简单,直接的神牛x5,shift+上下键直接抓取图片了,或者用优采云也可以实现,但是这两个服务大多数是按年收费的,
网页抓取数据 免费(有没有傻瓜式的4种获取数据方法,选择适合你的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-08 07:17
想分析的时候,没有数据,聪明的女人难做无米之炊。以前,我想找一段数据,需要费很大力气在网上搜索,但最终还是找不到我想要的数据。通过编程爬取数据,学习成本太高。毕竟,你的目标不是成为爬虫工程师,而是获取数据进行分析。有没有办法从 傻瓜式 获取数据?
这里有4种获取数据的方式,选择适合您的即可。
1)如何选择行业?
如果您不知道如何选择行业,可以在以下网站查看各行业的分析报告:
如何选择工作行业:/question/24995484/answer/516813008
IResearch-iResearch(行业报告):
Talkingdata报告(行业报告):
199IT互联网数据中心(行业报告,内容丰富,搜索支持):
2)10大行业免费数据汇总
【优点】直接使用
【缺点】数据有限
根据您确定的行业,选择您感兴趣的数据。比如你确定了电商行业,然后你找电商行业的数据。
《数据分析思维》汇聚10余个行业数据和分析案例
《数据分析思维》12个行业案例数据
更多行业数据:
10大行业公共数据集免费下载:电商零售业
10大行业公共数据集免费下载:金融业
10大行业公共数据集免费下载:游戏行业
10大行业公共数据集免费下载:教育行业
10大行业公共数据集免费下载:旅游行业
10大行业公共数据集免费下载:文化娱乐行业(电影、音乐等)
10大行业公共数据集免费下载:医疗行业
10大行业公共数据集免费下载:汽车和旅游
10大行业公共数据集免费下载:房地产行业
10大行业公共数据集免费下载:自媒体等行业
1.国内中文平台:
1) 阿里云天池,官网网址:/dataset/
数据下载方式:
2)DataFountain,官网地址:/dataSets
有些文件下载后会显示后缀是.zip,.zip是压缩包。下载后需要解压才能看到压缩包中的excel文件。
2.国外英文平台
Kaggle,官网地址及数据下载方式:如何在Kaggle上查找数据
【优点】在网站上爬取你感兴趣的字段网站的数据,可以得到你想要的字段数据
【缺点】需要看官网教程学习,有一定门槛
1)工具:优采云,也有mac和windows版本
网址:/
打开官网后,点击下图中的“教程”就有入门教程了。
2)工具:采集客户,只有windows版本
操作指南只需阅读下方红框内容,操作指南地址:
/tuto/tutorial.html
抓取了多少数据?
少量的数据一般不能说明什么问题,至少几万条以上的数据。
多尝试,有清晰的思维逻辑。你必须知道你在做什么以及你正在爬取什么样的数据。如果提前计划,整个过程就不会走太多弯路。
案例:/p/39733403
欢迎留言补充更多行业数据。
上面提到的数据获取方式有3种,选择适合你的一种。获取分析数据后,可以使用该方法进行分析: 查看全部
网页抓取数据 免费(有没有傻瓜式的4种获取数据方法,选择适合你的方法)
想分析的时候,没有数据,聪明的女人难做无米之炊。以前,我想找一段数据,需要费很大力气在网上搜索,但最终还是找不到我想要的数据。通过编程爬取数据,学习成本太高。毕竟,你的目标不是成为爬虫工程师,而是获取数据进行分析。有没有办法从 傻瓜式 获取数据?
这里有4种获取数据的方式,选择适合您的即可。
1)如何选择行业?
如果您不知道如何选择行业,可以在以下网站查看各行业的分析报告:
如何选择工作行业:/question/24995484/answer/516813008
IResearch-iResearch(行业报告):
Talkingdata报告(行业报告):
199IT互联网数据中心(行业报告,内容丰富,搜索支持):
2)10大行业免费数据汇总
【优点】直接使用
【缺点】数据有限
根据您确定的行业,选择您感兴趣的数据。比如你确定了电商行业,然后你找电商行业的数据。
《数据分析思维》汇聚10余个行业数据和分析案例
《数据分析思维》12个行业案例数据
更多行业数据:
10大行业公共数据集免费下载:电商零售业
10大行业公共数据集免费下载:金融业
10大行业公共数据集免费下载:游戏行业
10大行业公共数据集免费下载:教育行业
10大行业公共数据集免费下载:旅游行业
10大行业公共数据集免费下载:文化娱乐行业(电影、音乐等)
10大行业公共数据集免费下载:医疗行业
10大行业公共数据集免费下载:汽车和旅游
10大行业公共数据集免费下载:房地产行业
10大行业公共数据集免费下载:自媒体等行业
1.国内中文平台:
1) 阿里云天池,官网网址:/dataset/
数据下载方式:
2)DataFountain,官网地址:/dataSets
有些文件下载后会显示后缀是.zip,.zip是压缩包。下载后需要解压才能看到压缩包中的excel文件。
2.国外英文平台
Kaggle,官网地址及数据下载方式:如何在Kaggle上查找数据
【优点】在网站上爬取你感兴趣的字段网站的数据,可以得到你想要的字段数据
【缺点】需要看官网教程学习,有一定门槛
1)工具:优采云,也有mac和windows版本
网址:/
打开官网后,点击下图中的“教程”就有入门教程了。
2)工具:采集客户,只有windows版本
操作指南只需阅读下方红框内容,操作指南地址:
/tuto/tutorial.html
抓取了多少数据?
少量的数据一般不能说明什么问题,至少几万条以上的数据。
多尝试,有清晰的思维逻辑。你必须知道你在做什么以及你正在爬取什么样的数据。如果提前计划,整个过程就不会走太多弯路。
案例:/p/39733403
欢迎留言补充更多行业数据。
上面提到的数据获取方式有3种,选择适合你的一种。获取分析数据后,可以使用该方法进行分析:
网页抓取数据 免费(风越网页批量填写文本提取数据提取软件基本介绍(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-05 14:03
风悦网页批量填写数据提取软件是一款网页表单一键填写的专用工具。不管是注册用户、登录账号密码、评论、发帖等等,这些都是提交表单的方式。这里是小编给大家带来的工具,绿色免费,功能强大,支持各种网页类型,支持各种元素控件等,与其他同类软件相比,准确率更高!
风悦网页批量填充文字提取软件
基本介绍
其他填表工具一般不支持:多框页面(frame)、多选列表、HTML文本(iframe)输入法,本软件一般都能正确填写。本软件不仅可以用于一般办公填表,还可以扩展为批量注册、投票、留言、商品秒杀、舆情控制、信誉查询、车牌抢注等工具。
特征
支持从Excel和ACCESS文件中读取数据填写表格,并可根据当前表格生成Xls文件,方便批量录入。
支持下载指定文件,抓取网页文本内容。
支持在具有多个框架的页面中填充控件元素。
支持在嵌入框架 iframe 的页面中填充控件元素。
支持分析网页结构和显示控件的描述,方便分析和修改控件的值。
支持各种页面控件元素的填充:
支持文本输入框输入/textarea。
支持单选、多选列表多选。
支持多选框收音机。
支持单选框复选框。
支持填充级联下拉菜单。
支持填写无ID控件。 查看全部
网页抓取数据 免费(风越网页批量填写文本提取数据提取软件基本介绍(图))
风悦网页批量填写数据提取软件是一款网页表单一键填写的专用工具。不管是注册用户、登录账号密码、评论、发帖等等,这些都是提交表单的方式。这里是小编给大家带来的工具,绿色免费,功能强大,支持各种网页类型,支持各种元素控件等,与其他同类软件相比,准确率更高!
风悦网页批量填充文字提取软件
基本介绍
其他填表工具一般不支持:多框页面(frame)、多选列表、HTML文本(iframe)输入法,本软件一般都能正确填写。本软件不仅可以用于一般办公填表,还可以扩展为批量注册、投票、留言、商品秒杀、舆情控制、信誉查询、车牌抢注等工具。
特征
支持从Excel和ACCESS文件中读取数据填写表格,并可根据当前表格生成Xls文件,方便批量录入。
支持下载指定文件,抓取网页文本内容。
支持在具有多个框架的页面中填充控件元素。
支持在嵌入框架 iframe 的页面中填充控件元素。
支持分析网页结构和显示控件的描述,方便分析和修改控件的值。
支持各种页面控件元素的填充:
支持文本输入框输入/textarea。
支持单选、多选列表多选。
支持多选框收音机。
支持单选框复选框。
支持填充级联下拉菜单。
支持填写无ID控件。
网页抓取数据 免费(小编精选:网站采集器软件介绍可以采集单页的规则和不规则)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-12-05 14:02
Web Form Data采集Assistant是一个表单采集工具,可以将网站上的表单以excel格式保存在本地供用户使用。当然,它也可以使用纯文本。这个可以根据个人需要来设置。
编辑推荐:网站采集器
软件介绍
<p>可以采集单页规则和不规则表单,也可以自动连续采集指定网站的表单,可以指定 查看全部
网页抓取数据 免费(一个非常简单网页自动填写软件键填写软件介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-12-04 12:19
风悦网页批量填充数据提取软件是一款非常简单的网页自动填充软件,使用它实现网页自动填充就像使用按钮向导一样,是一款专业的网页自动填充工具,严格绑定ID和ID填写框列出文件数据,避免网页布局异常导致输入错误或崩溃。
软件介绍
风悦网页批量填写数据提取软件是一款网页表单一键填写的专用工具。不管是注册用户、登录账号密码、评论、发帖等,这些都是提交表单的方式。用户可以考虑使用风月网页批量填充数据提取软件进行操作,该软件支持多种网页类型,支持多种元素控件等,比其他同类软件更准确。
软件介绍
1、 不同的URL分别保存,满足不同任务的需要。
2、数据文件功能,自动填充。
3、提取过程方便,只有鼠标可以操作。
4、模拟鼠标点击和键盘填充。
5、 提取网页结果。
软件特点
1、 支持从Excel和ACCESS文件中读取数据填写表格,可以根据当前表格生成Xls文件,方便批量录入。
2、支持下载指定文件和抓取网页文本内容。
3、 支持填充多帧页面中的控件元素。
4、 支持在frame iframe 内嵌的页面中填充控件元素。
5、 支持分析网页结构并显示控件的描述,方便分析和修改控件的值。
6、支持各种页面控件元素的填充:
支持文本输入框输入/textarea。
支持单选、多选列表多选。
支持多选框收音机。
支持单选框复选框。
7、 支持填充级联下拉菜单。
8、支持填写无ID控件。
预防措施
软件需要.net framework2.0运行环境,如无法运行请安装【.NET Framework2.0简体中文版】 查看全部
网页抓取数据 免费(一个非常简单网页自动填写软件键填写软件介绍)
风悦网页批量填充数据提取软件是一款非常简单的网页自动填充软件,使用它实现网页自动填充就像使用按钮向导一样,是一款专业的网页自动填充工具,严格绑定ID和ID填写框列出文件数据,避免网页布局异常导致输入错误或崩溃。
软件介绍
风悦网页批量填写数据提取软件是一款网页表单一键填写的专用工具。不管是注册用户、登录账号密码、评论、发帖等,这些都是提交表单的方式。用户可以考虑使用风月网页批量填充数据提取软件进行操作,该软件支持多种网页类型,支持多种元素控件等,比其他同类软件更准确。
软件介绍
1、 不同的URL分别保存,满足不同任务的需要。
2、数据文件功能,自动填充。
3、提取过程方便,只有鼠标可以操作。
4、模拟鼠标点击和键盘填充。
5、 提取网页结果。
软件特点
1、 支持从Excel和ACCESS文件中读取数据填写表格,可以根据当前表格生成Xls文件,方便批量录入。
2、支持下载指定文件和抓取网页文本内容。
3、 支持填充多帧页面中的控件元素。
4、 支持在frame iframe 内嵌的页面中填充控件元素。
5、 支持分析网页结构并显示控件的描述,方便分析和修改控件的值。
6、支持各种页面控件元素的填充:
支持文本输入框输入/textarea。
支持单选、多选列表多选。
支持多选框收音机。
支持单选框复选框。
7、 支持填充级联下拉菜单。
8、支持填写无ID控件。
预防措施
软件需要.net framework2.0运行环境,如无法运行请安装【.NET Framework2.0简体中文版】
网页抓取数据 免费(数据采集网站分析数据透视化爬虫自动化分析(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-12-03 20:12
网页抓取数据免费的工具太多了,小鱼代抓包,自动代理,插件开发工具可以到github看看,不过有的比较旧了。推荐用爬虫的方式爬豆瓣电影的数据,可以用爬虫的方式爬豆瓣电影的数据,推荐用爬虫的方式爬豆瓣电影的数据,这个有一个微信公众号你可以关注一下,小鱼代抓包,只要手机下载了app,就可以自动获取电影信息。
不请自来,
1、豆瓣豆瓣真是我用过最好的网站没有之一,各种小组,贴吧资源丰富,干货不断。你有什么问题直接发豆瓣小组就行了。
2、卡密君卡密君就是豆瓣的小站,他会把所有电影的相关内容汇总到一个叫卡密君的小站,而且很实用,会把所有的电影小组的帖子链接放到这个小站里面,你可以在搜索栏里直接输入电影电影名字就可以知道是谁了。
3、包括但不限于西祠胡同,这些网站可以说都是年代比较久远的网站了。不过现在因为一些原因不再更新。
1.小鱼代抓包-lite2.找我-sickeo3.大鱼影视4.人工智能自动分发豆瓣电影tag
其实用谷歌搜搜豆瓣就可以出来很多
很多,但是最好要用一种自己能理解或者能创造的,才能提升个人价值。
比如金山云之类的工具都可以为你解决。
数据采集网站分析数据透视化爬虫自动化分析数据可视化表格图片技术博客网站分析和数据透视化可以去数据采集方面的网站, 查看全部
网页抓取数据 免费(数据采集网站分析数据透视化爬虫自动化分析(组图))
网页抓取数据免费的工具太多了,小鱼代抓包,自动代理,插件开发工具可以到github看看,不过有的比较旧了。推荐用爬虫的方式爬豆瓣电影的数据,可以用爬虫的方式爬豆瓣电影的数据,推荐用爬虫的方式爬豆瓣电影的数据,这个有一个微信公众号你可以关注一下,小鱼代抓包,只要手机下载了app,就可以自动获取电影信息。
不请自来,
1、豆瓣豆瓣真是我用过最好的网站没有之一,各种小组,贴吧资源丰富,干货不断。你有什么问题直接发豆瓣小组就行了。
2、卡密君卡密君就是豆瓣的小站,他会把所有电影的相关内容汇总到一个叫卡密君的小站,而且很实用,会把所有的电影小组的帖子链接放到这个小站里面,你可以在搜索栏里直接输入电影电影名字就可以知道是谁了。
3、包括但不限于西祠胡同,这些网站可以说都是年代比较久远的网站了。不过现在因为一些原因不再更新。
1.小鱼代抓包-lite2.找我-sickeo3.大鱼影视4.人工智能自动分发豆瓣电影tag
其实用谷歌搜搜豆瓣就可以出来很多
很多,但是最好要用一种自己能理解或者能创造的,才能提升个人价值。
比如金山云之类的工具都可以为你解决。
数据采集网站分析数据透视化爬虫自动化分析数据可视化表格图片技术博客网站分析和数据透视化可以去数据采集方面的网站,
网页抓取数据 免费(软件特色风越网页批量填写数据提取软件,可自动分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-02 13:23
风悦网页批量填写数据提取软件可以自动分析网页上的表单内容,并保存为表单填写规则。使用时只需调用此规则自动填表,点击网页元素,抓取网页的文字内容,下载指定的网页链接文件。还可以扩展为批量注册、投票、留言、商品秒杀、舆情控制、信用审核、抢车牌等工具。
软件特点
风悦网页批量填充数据提取软件支持更多的页面填充类型,控件元素,精度更高。其他填表工具一般不支持:多框页面(frame)、多选列表、HTML文本(iframe)输入法,本软件一般都能正确填写。本软件不仅可以用于一般办公填表,还可以扩展为批量注册、投票、留言、商品秒杀、舆情控制、信誉查询、车牌抢注等工具。
特征
支持从Excel和ACCESS文件中读取数据填写表格,并可根据当前表格生成xls文件,方便批量录入
支持下载指定文件和抓取网页文本内容
支持填充多帧页面中的控件元素
支持在嵌入框架iframe的页面中填充控件元素
支持网页结构分析,显示控件描述,方便分析和修改控件值
支持各种页面控件元素的填充:
支持文本输入框输入/textarea
支持单选、多选列表多选
支持多选框收音机
支持收音机复选框
支持填写级联下拉菜单
支持填写无ID控制
预防措施
软件需要.net framework2.0运行环境,如无法运行请安装【.NET Framework2.0简体中文版】 查看全部
网页抓取数据 免费(软件特色风越网页批量填写数据提取软件,可自动分析)
风悦网页批量填写数据提取软件可以自动分析网页上的表单内容,并保存为表单填写规则。使用时只需调用此规则自动填表,点击网页元素,抓取网页的文字内容,下载指定的网页链接文件。还可以扩展为批量注册、投票、留言、商品秒杀、舆情控制、信用审核、抢车牌等工具。
软件特点
风悦网页批量填充数据提取软件支持更多的页面填充类型,控件元素,精度更高。其他填表工具一般不支持:多框页面(frame)、多选列表、HTML文本(iframe)输入法,本软件一般都能正确填写。本软件不仅可以用于一般办公填表,还可以扩展为批量注册、投票、留言、商品秒杀、舆情控制、信誉查询、车牌抢注等工具。
特征
支持从Excel和ACCESS文件中读取数据填写表格,并可根据当前表格生成xls文件,方便批量录入
支持下载指定文件和抓取网页文本内容
支持填充多帧页面中的控件元素
支持在嵌入框架iframe的页面中填充控件元素
支持网页结构分析,显示控件描述,方便分析和修改控件值
支持各种页面控件元素的填充:
支持文本输入框输入/textarea
支持单选、多选列表多选
支持多选框收音机
支持收音机复选框
支持填写级联下拉菜单
支持填写无ID控制
预防措施
软件需要.net framework2.0运行环境,如无法运行请安装【.NET Framework2.0简体中文版】
网页抓取数据 免费(智能识别模式WebHarvy自动识别网页数据抓取工具的功能介绍(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2021-12-01 04:23
WebHarvy 是一个网页数据抓取工具。该软件可以从网页中提取文字和图片,并通过输入网址打开它们。默认情况下使用内部浏览器。支持扩展分析,自动获取相似链接列表。软件界面直观,易于操作。.
相关软件软件大小版本说明下载地址
WebHarvy 是一个网页数据抓取工具。该软件可以从网页中提取文字和图片,并通过输入网址打开它们。默认情况下使用内部浏览器。支持扩展分析,自动获取相似链接列表。软件界面直观,易于操作。
特征
智能识别模式
WebHarvy 自动识别出现在网页中的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据
您可以以各种格式保存从网页中提取的数据。当前版本的 WebHarvy网站 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
从多个页面中提取
通常网页会在多个页面上显示数据,例如产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。只需指出“链接到下一页”,WebHarvy网站 抓取工具就会自动从所有页面抓取数据。
直观的操作界面
WebHarvy 是一个可视化的网页提取工具。实际上,无需编写任何脚本或代码来提取数据。使用 webharvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。太容易了!
基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。可以指定任意数量的输入关键字
提取分类
WebHarvy网站 抓取工具允许您从链接列表中提取数据,从而在 网站 中生成一个类似的页面。这允许您使用单个配置在 网站 中抓取类别或小节。
使用正则表达式提取
WebHarvy 可以在网页的文本或 HTML 源代码中应用正则表达式(正则表达式),并提取匹配的部分。这种强大的技术为您提供了更大的灵活性,同时也可以为您提供数据。
软件特点
WebHarvy 是一个可视化的网络爬虫。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器来浏览网络。您可以选择要单击的数据。这很简单!
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,WebHarvy 会自动删除它。
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
通常,网页会在多个页面上显示产品列表等数据。WebHarvy 可以自动从多个页面抓取和提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper 就会自动从所有页面中抓取数据。
更新日志
修复了页面启动时连接可能被禁用的问题
可以为页面模式配置专用的连接方式
可以自动搜索可以配置在HTML上的资源 查看全部
网页抓取数据 免费(智能识别模式WebHarvy自动识别网页数据抓取工具的功能介绍(组图))
WebHarvy 是一个网页数据抓取工具。该软件可以从网页中提取文字和图片,并通过输入网址打开它们。默认情况下使用内部浏览器。支持扩展分析,自动获取相似链接列表。软件界面直观,易于操作。.
相关软件软件大小版本说明下载地址
WebHarvy 是一个网页数据抓取工具。该软件可以从网页中提取文字和图片,并通过输入网址打开它们。默认情况下使用内部浏览器。支持扩展分析,自动获取相似链接列表。软件界面直观,易于操作。
特征
智能识别模式
WebHarvy 自动识别出现在网页中的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据
您可以以各种格式保存从网页中提取的数据。当前版本的 WebHarvy网站 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
从多个页面中提取
通常网页会在多个页面上显示数据,例如产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。只需指出“链接到下一页”,WebHarvy网站 抓取工具就会自动从所有页面抓取数据。
直观的操作界面
WebHarvy 是一个可视化的网页提取工具。实际上,无需编写任何脚本或代码来提取数据。使用 webharvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。太容易了!
基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,您创建的配置将自动为所有给定的输入关键字重复。可以指定任意数量的输入关键字
提取分类
WebHarvy网站 抓取工具允许您从链接列表中提取数据,从而在 网站 中生成一个类似的页面。这允许您使用单个配置在 网站 中抓取类别或小节。
使用正则表达式提取
WebHarvy 可以在网页的文本或 HTML 源代码中应用正则表达式(正则表达式),并提取匹配的部分。这种强大的技术为您提供了更大的灵活性,同时也可以为您提供数据。
软件特点
WebHarvy 是一个可视化的网络爬虫。绝对不需要编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器来浏览网络。您可以选择要单击的数据。这很简单!
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需执行任何其他配置。如果数据重复,WebHarvy 会自动删除它。
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将捕获的数据导出到 SQL 数据库。
通常,网页会在多个页面上显示产品列表等数据。WebHarvy 可以自动从多个页面抓取和提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper 就会自动从所有页面中抓取数据。
更新日志
修复了页面启动时连接可能被禁用的问题
可以为页面模式配置专用的连接方式
可以自动搜索可以配置在HTML上的资源
网页抓取数据 免费( 3.LxmlLxml网页源码(css选择器)性能对比与结论 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-11-25 15:09
3.LxmlLxml网页源码(css选择器)性能对比与结论
)
from bs4 import BeautifulSoup
>>> soup = BeautifulSoup(html, "html.parser") #用html解释器对得到的html文本进行解析
>>> tr = soup.find(attrs={"id":"places_area__row"})
>>> tr
Area: 244,820 square kilometres
>>> td = tr.find(attrs={"class":"w2p_fw"})
>>> td
244,820 square kilometres
>>> area = td.text
>>> print(area)
244,820 square kilometres
3. Lxml
Lxml 是一个基于 libxml2 的 Python 包,一个 XML 解析库。模块采用C语言编写,解析速度比BeautifulSoup快。通过书中对比分析得出的结论,抓取网页后抓取数据的一般步骤是:首先解析网页源代码(这3种方法中使用lxml),然后选择抓取数据(css选择器)
#先解析网页源码(lxml)示例
import lxml.html
broken_html = "AreaPopulation"
tree = lxml.html.fromstring(broken_html) #解析已经完成
fixed_html = lxml.html.tostring(tree, pretty_print=True)
print(fixed_html)
#output
#b'\nArea\nPopulation\n\n'
#解析网页源码(lxml)后使用css选择器提取目标信息
import lxml.html
import cssselect
html = download("http://example.webscraping.com ... 6quot;) #下载网页
html = str(html)
tree = lxml.html.fromstring(html) #解析已经完成
td = tree.cssselect("tr#places_area__row > td.w2p_fw")[0] #选择id="plac..."名为tr的标签下的,class="w2p..."名为td的标签中[0]元素
area = td.text_content() #目标信息area值为td标签中的text信息
print(area)
以上三种方法的性能对比及结论:
查看全部
网页抓取数据 免费(
3.LxmlLxml网页源码(css选择器)性能对比与结论
)
from bs4 import BeautifulSoup
>>> soup = BeautifulSoup(html, "html.parser") #用html解释器对得到的html文本进行解析
>>> tr = soup.find(attrs={"id":"places_area__row"})
>>> tr
Area: 244,820 square kilometres
>>> td = tr.find(attrs={"class":"w2p_fw"})
>>> td
244,820 square kilometres
>>> area = td.text
>>> print(area)
244,820 square kilometres
3. Lxml
Lxml 是一个基于 libxml2 的 Python 包,一个 XML 解析库。模块采用C语言编写,解析速度比BeautifulSoup快。通过书中对比分析得出的结论,抓取网页后抓取数据的一般步骤是:首先解析网页源代码(这3种方法中使用lxml),然后选择抓取数据(css选择器)
#先解析网页源码(lxml)示例
import lxml.html
broken_html = "AreaPopulation"
tree = lxml.html.fromstring(broken_html) #解析已经完成
fixed_html = lxml.html.tostring(tree, pretty_print=True)
print(fixed_html)
#output
#b'\nArea\nPopulation\n\n'
#解析网页源码(lxml)后使用css选择器提取目标信息
import lxml.html
import cssselect
html = download("http://example.webscraping.com ... 6quot;) #下载网页
html = str(html)
tree = lxml.html.fromstring(html) #解析已经完成
td = tree.cssselect("tr#places_area__row > td.w2p_fw")[0] #选择id="plac..."名为tr的标签下的,class="w2p..."名为td的标签中[0]元素
area = td.text_content() #目标信息area值为td标签中的text信息
print(area)
以上三种方法的性能对比及结论:
网页抓取数据 免费(软件特色风越网页批量填写数据提取软件,可自动分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-11-25 13:06
风悦网页批量填写数据提取软件可以自动分析网页上的表单内容,并保存为表单填写规则。使用时只需调用此规则自动填表,点击网页元素,抓取网页的文字内容,下载指定的网页链接文件。
软件特点
风悦网页批量填充数据提取软件支持更多的页面填充类型和控制元素,准确率更高。其他填表工具一般不支持:多框页面(frame)、多选列表、HTML文本(iframe)输入法,本软件一般都能正确填写。本软件不仅可以用于一般办公填表,还可以扩展为批量注册、投票、留言、商品秒杀、舆情控制、征信、抢车牌等工具。
特征
支持从Excel和ACCESS文件中读取数据填写表格,并可根据当前表格生成xls文件,方便批量录入
支持下载指定文件和抓取网页文本内容
支持填充多帧页面中的控件元素
支持在嵌入框架iframe的页面中填充控件元素
支持网页结构分析,显示控件描述,方便分析和修改控件值
支持各种页面控件元素的填充:
支持文本输入框输入/textarea
支持单选、多选列表多选
支持多选框收音机
支持收音机复选框
支持填写级联下拉菜单
支持填写无ID控制
预防措施
软件需要.net framework2.0运行环境,如无法运行请安装【.NET Framework2.0简体中文版】 查看全部
网页抓取数据 免费(软件特色风越网页批量填写数据提取软件,可自动分析)
风悦网页批量填写数据提取软件可以自动分析网页上的表单内容,并保存为表单填写规则。使用时只需调用此规则自动填表,点击网页元素,抓取网页的文字内容,下载指定的网页链接文件。
软件特点
风悦网页批量填充数据提取软件支持更多的页面填充类型和控制元素,准确率更高。其他填表工具一般不支持:多框页面(frame)、多选列表、HTML文本(iframe)输入法,本软件一般都能正确填写。本软件不仅可以用于一般办公填表,还可以扩展为批量注册、投票、留言、商品秒杀、舆情控制、征信、抢车牌等工具。
特征
支持从Excel和ACCESS文件中读取数据填写表格,并可根据当前表格生成xls文件,方便批量录入
支持下载指定文件和抓取网页文本内容
支持填充多帧页面中的控件元素
支持在嵌入框架iframe的页面中填充控件元素
支持网页结构分析,显示控件描述,方便分析和修改控件值
支持各种页面控件元素的填充:
支持文本输入框输入/textarea
支持单选、多选列表多选
支持多选框收音机
支持收音机复选框
支持填写级联下拉菜单
支持填写无ID控制
预防措施
软件需要.net framework2.0运行环境,如无法运行请安装【.NET Framework2.0简体中文版】
网页抓取数据 免费(连续四年大数据行业数据采集领域排名不是第一)
网站优化 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-11-24 21:08
网站关键词(68 个字符):
爬虫,爬虫软件,网络爬虫,爬虫工具,采集器,数据采集器,采集软件,网络爬虫工具,采集程序,论坛采集软件, 文章采集,网站抓取工具,网页下载工具,
网站描述(85 个字符):
辣鸡网页数据采集器,是一款简单易用、功能强大的网络爬虫工具,完全可视化操作,无需编写代码,内置海量模板,支持任意网页数据抓取,连续四年大数据行业数据采集领域排名不是第一。
关于说明:
网友积极投稿整理收录,本站只提供基本信息,免费向公众展示。IP地址:-地址:-,百度权重为n,百度手机权重为,百度收录 is-article,360收录 is-article,搜狗收录是文章,谷歌收录是-文章,百度访问量在-之间,百度移动端访问量在-之间,备案号粤ICP备18098129号-1、记录器是林允奇,百度的关键词收录-one,移动端关键词有-,至此,3年9月29日创建。 查看全部
网页抓取数据 免费(连续四年大数据行业数据采集领域排名不是第一)
网站关键词(68 个字符):
爬虫,爬虫软件,网络爬虫,爬虫工具,采集器,数据采集器,采集软件,网络爬虫工具,采集程序,论坛采集软件, 文章采集,网站抓取工具,网页下载工具,
网站描述(85 个字符):
辣鸡网页数据采集器,是一款简单易用、功能强大的网络爬虫工具,完全可视化操作,无需编写代码,内置海量模板,支持任意网页数据抓取,连续四年大数据行业数据采集领域排名不是第一。
关于说明:
网友积极投稿整理收录,本站只提供基本信息,免费向公众展示。IP地址:-地址:-,百度权重为n,百度手机权重为,百度收录 is-article,360收录 is-article,搜狗收录是文章,谷歌收录是-文章,百度访问量在-之间,百度移动端访问量在-之间,备案号粤ICP备18098129号-1、记录器是林允奇,百度的关键词收录-one,移动端关键词有-,至此,3年9月29日创建。
网页抓取数据 免费(软件特色风越网页批量填写数据提取软件,可自动分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-11-23 00:05
风月网页批量填写数据提取软件可以自动分析网页上表格的填写内容,并保存为填写规则。使用的时候只要调用这个规则就可以自动填表,点击网页元素,抓取网页的文字内容。下载指定的网页链接文件。
软件特点
风悦网页批量填充数据提取软件支持更多的页面填充类型和控制元素,准确率更高。其他填表工具一般不支持:多框页面(frame)、多选列表、HTML文本(iframe)输入法,本软件一般都能正确填写。本软件不仅可以用于一般办公填表,还可以扩展为批量注册、投票、留言、商品秒杀、舆情控制、征信、抢车牌等工具。
特征
支持从Excel和ACCESS文件中读取数据填写表格,并可根据当前表格生成xls文件,方便批量录入
支持下载指定文件和抓取网页文本内容
支持填充多帧页面中的控件元素
支持在嵌入框架iframe的页面中填充控件元素
支持网页结构分析,显示控件描述,方便分析和修改控件值
支持各种页面控件元素的填充:
支持文本输入框输入/textarea
支持单选、多选列表多选
支持多选框收音机
支持收音机复选框
支持填写级联下拉菜单
支持填写无ID控制 查看全部
网页抓取数据 免费(软件特色风越网页批量填写数据提取软件,可自动分析)
风月网页批量填写数据提取软件可以自动分析网页上表格的填写内容,并保存为填写规则。使用的时候只要调用这个规则就可以自动填表,点击网页元素,抓取网页的文字内容。下载指定的网页链接文件。
软件特点
风悦网页批量填充数据提取软件支持更多的页面填充类型和控制元素,准确率更高。其他填表工具一般不支持:多框页面(frame)、多选列表、HTML文本(iframe)输入法,本软件一般都能正确填写。本软件不仅可以用于一般办公填表,还可以扩展为批量注册、投票、留言、商品秒杀、舆情控制、征信、抢车牌等工具。
特征
支持从Excel和ACCESS文件中读取数据填写表格,并可根据当前表格生成xls文件,方便批量录入
支持下载指定文件和抓取网页文本内容
支持填充多帧页面中的控件元素
支持在嵌入框架iframe的页面中填充控件元素
支持网页结构分析,显示控件描述,方便分析和修改控件值
支持各种页面控件元素的填充:
支持文本输入框输入/textarea
支持单选、多选列表多选
支持多选框收音机
支持收音机复选框
支持填写级联下拉菜单
支持填写无ID控制
网页抓取数据 免费(苏宁百万级商品爬虫目录思路讲解(图)思路)
网站优化 • 优采云 发表了文章 • 0 个评论 • 340 次浏览 • 2021-11-21 00:01
阿里云>云栖社区>主题地图>C>c爬网数据库
推荐活动:
更多优惠>
当前主题:c 抓取网页数据库以添加到采集夹
相关话题:
c 爬取网页数据库相关博客 查看更多博客
云数据库产品概述
作者:阿里云官网
云数据库是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可轻松运维全球90%以上主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为PolarDB提供6倍以上的开源数据库性能和开源数据库的价格,以及自主研发的具有数百TB数据实时计算能力的HybridDB,对于数据库,也有容灾、备份、恢复、监控、迁移的一整套解决方案。
现在查看
一个存储了大量爬虫数据的数据库,怎么样?
作者:fesoncn3336 人浏览评论:03年前
“当然,不是所有的数据都适合”在学习爬虫的过程中,遇到了很多坑。今天你以后可能会遇到这个坑,随着爬取数据量的增加,爬取网站Data字段的变化,过去爬虫入口使用的方法的局限性可能会突然增加。什么是突增法?Intro citations 爬虫入口时,
阅读全文
如何解决Python3爬取的乱码信息?(更新:已解决)
作者:大连瓦匠 2696人浏览评论:04年前
更新:乱码问题已解决。把下面代码的红色部分改成下面这样,这样就不会出现个人作业信息乱码了。汤2 = BeautifulSoup(wbdata2,'html.parser',from_encoding="GBK") 另外:微信公众号成立
阅读全文
苏宁百万级商品爬虫简述
作者:HapplyFox1045 人浏览评论:03年前
代码下载链接 苏宁百万级商品爬虫目录思路讲解分类爬取思路讲解分类页面抓取商品爬取3.1思路讲解商品爬13.2思路讲解商品爬23.3代码说明商品爬取索引说明4.1代码说明索引建立4.2代码说明索引查询语句本系统
阅读全文
php爬虫:知乎用户数据爬取与分析
作者:cuixiaozhuai2345 人浏览评论:05年前
背景说明:小野利用PHP的curl编写的爬虫实验性爬取知乎5w用户的基本信息;同时对爬取的数据进行简单的分析和呈现。php的demo地址的spider代码和用户仪表盘的显示代码,整理好后上传到github,更新代码基于个人博客和公众号,Cheng
阅读全文
Python爬虫:用BeautifulSoup爬取NBA数据
作者:夜李2725人浏览评论:04年前
爬虫的主要目的是过滤掉网页中无用的信息。从网页中抓取有用信息的一般爬虫结构是:在使用python爬虫之前,必须对网页的结构有一定的了解,比如网页标签、网页语言等知识,建议去到W3School:W3school 链接了解 爬之前有一些工具:1
阅读全文
Python爬虫入门教程3-100美航网数据爬取
作者:梦之橡皮1100人浏览评论:02年前
Data-Introduction 从今天开始,我们尝试利用2个博客的内容得到一个网站名为“”的网址:,这个网站我分析了一下,我们要爬取的图片在如下网址
阅读全文
图数据库概述及Nebula在图数据库设计中的实践
作者:NebulaGraph2433 人浏览评论:02年前
Nebula Graph:一个开源的分布式图数据库。Nebula Graph作为唯一可以存储万亿节点和带属性边的在线图数据库,不仅可以满足高并发场景下毫秒级低延迟查询需求,还可以实现高服务可用性,保证数据安全。nMeetup第三阶段(nMeet
阅读全文
【Python爬虫2】网页数据提取
作者:wu_being1266人浏览评论:04年前
数据提取方法 1 正则表达式 2 流行的 BeautifulSoup 模块 3 强大的 Lxml 模块性能对比 给链接爬虫添加爬取回调 1 回调函数 1 2 回调函数 2 3 重用上一章的链接爬虫代码 让这个爬虫更好 提取一些数据从每个网页,然后实现某些东西,这种做法也是
阅读全文
c 爬取网页数据库相关问答问答
基础语言一百个问题-Python
作者:薯条酱55293人浏览评论:494年前
#基语百问-Python#最近在软件界很流行的一句话是“人生苦短,用Python快”,由此可见Python的特点,即快。当然,这么快并不代表 Python 跑得快。毕竟是脚本语言,不管对于C语言和C++等低级语言来说有多快,快是指使用Pytho
阅读全文 查看全部
网页抓取数据 免费(苏宁百万级商品爬虫目录思路讲解(图)思路)
阿里云>云栖社区>主题地图>C>c爬网数据库
推荐活动:
更多优惠>
当前主题:c 抓取网页数据库以添加到采集夹
相关话题:
c 爬取网页数据库相关博客 查看更多博客
云数据库产品概述
作者:阿里云官网
云数据库是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可轻松运维全球90%以上主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为PolarDB提供6倍以上的开源数据库性能和开源数据库的价格,以及自主研发的具有数百TB数据实时计算能力的HybridDB,对于数据库,也有容灾、备份、恢复、监控、迁移的一整套解决方案。
现在查看
一个存储了大量爬虫数据的数据库,怎么样?
作者:fesoncn3336 人浏览评论:03年前
“当然,不是所有的数据都适合”在学习爬虫的过程中,遇到了很多坑。今天你以后可能会遇到这个坑,随着爬取数据量的增加,爬取网站Data字段的变化,过去爬虫入口使用的方法的局限性可能会突然增加。什么是突增法?Intro citations 爬虫入口时,
阅读全文
如何解决Python3爬取的乱码信息?(更新:已解决)
作者:大连瓦匠 2696人浏览评论:04年前
更新:乱码问题已解决。把下面代码的红色部分改成下面这样,这样就不会出现个人作业信息乱码了。汤2 = BeautifulSoup(wbdata2,'html.parser',from_encoding="GBK") 另外:微信公众号成立
阅读全文
苏宁百万级商品爬虫简述
作者:HapplyFox1045 人浏览评论:03年前
代码下载链接 苏宁百万级商品爬虫目录思路讲解分类爬取思路讲解分类页面抓取商品爬取3.1思路讲解商品爬13.2思路讲解商品爬23.3代码说明商品爬取索引说明4.1代码说明索引建立4.2代码说明索引查询语句本系统
阅读全文
php爬虫:知乎用户数据爬取与分析
作者:cuixiaozhuai2345 人浏览评论:05年前
背景说明:小野利用PHP的curl编写的爬虫实验性爬取知乎5w用户的基本信息;同时对爬取的数据进行简单的分析和呈现。php的demo地址的spider代码和用户仪表盘的显示代码,整理好后上传到github,更新代码基于个人博客和公众号,Cheng
阅读全文
Python爬虫:用BeautifulSoup爬取NBA数据
作者:夜李2725人浏览评论:04年前
爬虫的主要目的是过滤掉网页中无用的信息。从网页中抓取有用信息的一般爬虫结构是:在使用python爬虫之前,必须对网页的结构有一定的了解,比如网页标签、网页语言等知识,建议去到W3School:W3school 链接了解 爬之前有一些工具:1
阅读全文
Python爬虫入门教程3-100美航网数据爬取
作者:梦之橡皮1100人浏览评论:02年前
Data-Introduction 从今天开始,我们尝试利用2个博客的内容得到一个网站名为“”的网址:,这个网站我分析了一下,我们要爬取的图片在如下网址
阅读全文
图数据库概述及Nebula在图数据库设计中的实践
作者:NebulaGraph2433 人浏览评论:02年前
Nebula Graph:一个开源的分布式图数据库。Nebula Graph作为唯一可以存储万亿节点和带属性边的在线图数据库,不仅可以满足高并发场景下毫秒级低延迟查询需求,还可以实现高服务可用性,保证数据安全。nMeetup第三阶段(nMeet
阅读全文
【Python爬虫2】网页数据提取
作者:wu_being1266人浏览评论:04年前
数据提取方法 1 正则表达式 2 流行的 BeautifulSoup 模块 3 强大的 Lxml 模块性能对比 给链接爬虫添加爬取回调 1 回调函数 1 2 回调函数 2 3 重用上一章的链接爬虫代码 让这个爬虫更好 提取一些数据从每个网页,然后实现某些东西,这种做法也是
阅读全文
c 爬取网页数据库相关问答问答
基础语言一百个问题-Python
作者:薯条酱55293人浏览评论:494年前
#基语百问-Python#最近在软件界很流行的一句话是“人生苦短,用Python快”,由此可见Python的特点,即快。当然,这么快并不代表 Python 跑得快。毕竟是脚本语言,不管对于C语言和C++等低级语言来说有多快,快是指使用Pytho
阅读全文
网页抓取数据 免费(数据采集就是如何提高数据的正确使用方法?!!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-11-20 23:19
<p>定义:数据采集是通过技术手段从任意一个网站中下载、分析、提取相关数据信息,并按照一定的格式重新整理汇总成所需的具体数据格式 查看全部
网页抓取数据 免费(10款最好用的数据采集工具,免费采集、网站网页采集)
网站优化 • 优采云 发表了文章 • 0 个评论 • 1167 次浏览 • 2021-11-17 04:15
10个最好的数据采集工具,免费采集工具,网站网页采集工具,各行各业采集工具,目前比较好的一些免费数据采集 工具,希望对大家有帮助。
1、优采云采集器 优采云基于互联网运营商实名制。真实数据与Web数据采集、移动互联网数据和API接口服务相结合。综合数据服务平台。它最大的特点是可以在不了解网络爬虫技术的情况下轻松完成采集。
2、优采云采集器 优采云采集器是目前最流行的互联网数据采集软件。凭借灵活的配置和强大的性能,在国内同类产品中处于领先地位,获得了众多用户的一致认可。使用优采云采集器几乎采集所有网页。
3、靠近中国金坛中国数据服务平台有很多采集开发者上传的工具,而且很多都是免费的。无论是采集国内外网站、行业网站、政府网站、APP、微博、搜索引擎、公众号、小程序等数据,还是其他数据, 最近的探索可以做采集,也可以自定义。这是他们最大的亮点之一。
4、大飞采集器大飞采集器可以采集99%的网页,他的速度是普通采集器的7倍,相当于复制粘贴准确,它最大的特点是网页采集的同义词因其专注而单一。
5、Import.io 使用Import.io 适配任何URL。只需输入网址,即可整齐抓取网页数据。操作非常简单,自动采集,采集结果可视化。但是无法选择特定数据,无法自动翻页采集。
6、ParseHub ParseHub 分为免费版和付费版。从数百万个网页中获取数据。输入数千个链接和关键字,ParseHub 会自动搜索这些链接和关键字。使用我们的休息 API。以 Excel 和 JSON 格式下载提取的数据。将您的结果导入 Google 表格和 Tableau。
7、Content Grabber Content Grabber 是外国大神制作的神器,可以从网页中抓取内容(视频、图片、文字),并提取到 Excel、XML、CSV 和大多数数据库中。该软件基于网络爬虫。获取和网络自动化。它完全免费使用,通常用于数据调查和测试目的。
8、ForeSpider ForeSpider 是一款非常好用的网页数据采集 工具,用户可以使用该工具来帮助您自动检索网页中的各种数据信息,并且该软件使用起来非常简单。用户也可以免费使用。基本上只要在一步一步的操作中输入网址链接就可以了。如果有特殊情况需要对采集进行特殊处理,也支持配置脚本。
9、阿里巴巴数据采集阿里巴巴数据采集 大平台运行稳定不崩盘,可实现实时查询。软件开发资料采集都可以,除了贵没有问题。
10、优采云采集器 优采云采集器 操作非常简单,只要按照流程就可以轻松上手,还可以支持多种形式出口的。 查看全部
网页抓取数据 免费(10款最好用的数据采集工具,免费采集、网站网页采集)
10个最好的数据采集工具,免费采集工具,网站网页采集工具,各行各业采集工具,目前比较好的一些免费数据采集 工具,希望对大家有帮助。
1、优采云采集器 优采云基于互联网运营商实名制。真实数据与Web数据采集、移动互联网数据和API接口服务相结合。综合数据服务平台。它最大的特点是可以在不了解网络爬虫技术的情况下轻松完成采集。
2、优采云采集器 优采云采集器是目前最流行的互联网数据采集软件。凭借灵活的配置和强大的性能,在国内同类产品中处于领先地位,获得了众多用户的一致认可。使用优采云采集器几乎采集所有网页。
3、靠近中国金坛中国数据服务平台有很多采集开发者上传的工具,而且很多都是免费的。无论是采集国内外网站、行业网站、政府网站、APP、微博、搜索引擎、公众号、小程序等数据,还是其他数据, 最近的探索可以做采集,也可以自定义。这是他们最大的亮点之一。
4、大飞采集器大飞采集器可以采集99%的网页,他的速度是普通采集器的7倍,相当于复制粘贴准确,它最大的特点是网页采集的同义词因其专注而单一。
5、Import.io 使用Import.io 适配任何URL。只需输入网址,即可整齐抓取网页数据。操作非常简单,自动采集,采集结果可视化。但是无法选择特定数据,无法自动翻页采集。
6、ParseHub ParseHub 分为免费版和付费版。从数百万个网页中获取数据。输入数千个链接和关键字,ParseHub 会自动搜索这些链接和关键字。使用我们的休息 API。以 Excel 和 JSON 格式下载提取的数据。将您的结果导入 Google 表格和 Tableau。
7、Content Grabber Content Grabber 是外国大神制作的神器,可以从网页中抓取内容(视频、图片、文字),并提取到 Excel、XML、CSV 和大多数数据库中。该软件基于网络爬虫。获取和网络自动化。它完全免费使用,通常用于数据调查和测试目的。
8、ForeSpider ForeSpider 是一款非常好用的网页数据采集 工具,用户可以使用该工具来帮助您自动检索网页中的各种数据信息,并且该软件使用起来非常简单。用户也可以免费使用。基本上只要在一步一步的操作中输入网址链接就可以了。如果有特殊情况需要对采集进行特殊处理,也支持配置脚本。
9、阿里巴巴数据采集阿里巴巴数据采集 大平台运行稳定不崩盘,可实现实时查询。软件开发资料采集都可以,除了贵没有问题。
10、优采云采集器 优采云采集器 操作非常简单,只要按照流程就可以轻松上手,还可以支持多种形式出口的。
网页抓取数据 免费(如何应对数据匮乏的问题?最简单的方法在这里)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-11-15 21:13
作者|LAKSHAY ARORA编译|弗林源|analyticsvidhya
概述介绍
我们的数据太少,无法构建机器学习模型。我们需要更多数据!
如果这句话听起来很熟悉,那么您并不孤单!希望得到更多的数据来训练我们的机器学习模型是一直困扰着人们的问题。我们无法获得可以直接在数据科学项目中使用的 Excel 或 .csv 文件,对吗?
那么,如何应对数据稀缺的问题呢?
实现这一目标的最有效和最简单的方法之一是通过网络爬行。我个人认为网页抓取是一种非常有用的技术,可以从多个 网站 采集数据。如今,一些 网站 还为您可能希望使用的许多不同类型的数据提供 API,例如 Tweets 或 LinkedIn 帖子。
但有时您可能需要从不提供特定 API 的 网站 采集数据。这是网页抓取功能派上用场的地方。作为数据科学家,您可以编写一个简单的 Python 脚本并提取所需的数据。
因此,在本文中,我们将学习网页抓取的不同组件,然后直接学习 Python 以了解如何使用流行且高效的 BeautifulSoup 库进行网页抓取。
我们还为本文创建了一个免费课程:
请注意,网络抓取受许多准则和规则的约束。并不是每一个网站都允许用户抓取内容,所以有一定的法律限制。在尝试此操作之前,请确保您已阅读 网站 的 网站 条款和条件。
内容
3 个流行的 Python 网络爬虫工具和库
网页抓取组件
CrawlParse 和 TransformStore
从网页中抓取 URL 和电子邮件 ID
抓取图片
页面加载时抓取数据
3 个流行的 Python 网络爬虫工具和库
您将在 Python 中遇到多个用于网页抓取的库和框架。以下是三种用于高效完成任务的流行工具:
美汤
刮痧
硒
网页抓取组件
这是构成网络爬行的三个主要组件的极好说明:
让我们详细了解这些组件。我们将使用 goibibo网站 来捕获酒店的详细信息,例如酒店名称和每个房间的价格,以实现这一点:
注意:请始终遵循目标网站的robots.txt文件,也称为robots排除协议。这可以告诉网络机器人不抓取哪些页面。
因此,我们可以从目标 URL 中抓取数据。我们很高兴编写我们的网络机器人脚本。让我们开始吧!
第 1 步:爬网
网络爬虫的第一步是导航到目标网站并下载网页的源代码。我们将使用请求库来做到这一点。http.client 和 urlib2 是另外两个用于发出请求和下载源代码的库。
下载网页源代码后,我们需要过滤需要的内容:
"""
Web Scraping - Beautiful Soup
"""
# importing required libraries
import requests
from bs4 import BeautifulSoup
import pandas as pd
# target URL to scrap
url = "https://www.goibibo.com/hotels ... ot%3B
# headers
headers = {
'User-Agent': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36"
}
# send request to download the data
response = requests.request("GET", url, headers=headers)
# parse the downloaded data
data = BeautifulSoup(response.text, 'html.parser')
print(data)
第 2 步:解析和转换
网络抓取的下一步是将此数据解析为 HTML 解析器。为此,我们将使用 BeautifulSoup 库。现在,如果您注意到我们的登录页面,就像大多数页面一样,特定酒店的详细信息也在不同的卡片上。
因此,下一步将是从完整的源代码中过滤卡片数据。接下来,我们将选择卡片,然后单击“检查元素”选项以获取该特定卡片的源代码。您将获得以下信息:
所有卡片的类名都是一样的。我们可以通过传递标签名称和属性(例如标签)来获取这些卡片的列表。名称如下:
# find all the sections with specifiedd class name
cards_data = data.find_all('div', attrs={'class', 'width100 fl htlListSeo hotel-tile-srp-container hotel-tile-srp-container-template new-htl-design-tile-main-block'})
# total number of cards
print('Total Number of Cards Found : ', len(cards_data))
# source code of hotel cards
for card in cards_data:
print(card)
我们从网页的完整源代码中过滤掉了卡片数据,这里的每张卡片都收录有关单个酒店的信息。仅选择酒店名称,执行“检查元素”步骤,并对房价执行相同操作:
现在,对于每张卡,我们必须找到上面的酒店名称,这些名称只能来自
从标签中提取。这是因为每张卡和费率只有一个标签、标签和类别名称:
# extract the hotel name and price per room
for card in cards_data:
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
print(hotel_name.text, room_price.text)
第 3 步:Store(存储数据)
最后一步是将提取的数据存储在 CSV 文件中。在这里,对于每张卡片,我们将提取酒店名称和价格并将其存储在 Python 字典中。然后,我们最终将其添加到列表中。
接下来,让我们继续将此列表转换为 Pandas 数据框,因为它允许我们将数据框转换为 CSV 或 JSON 文件:
# create a list to store the data
scraped_data = []
for card in cards_data:
# initialize the dictionary
card_details = {}
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
# add data to the dictionary
card_details['hotel_name'] = hotel_name.text
card_details['room_price'] = room_price.text
# append the scraped data to the list
scraped_data.append(card_details)
# create a data frame from the list of dictionaries
dataFrame = pd.DataFrame.from_dict(scraped_data)
# save the scraped data as CSV file
dataFrame.to_csv('hotels_data.csv', index=False)
恭喜!我们已经成功创建了一个基本的网络爬虫。我希望您尝试这些步骤并尝试获取更多数据,例如酒店的类别和地址。现在,让我们看看如何在页面加载时执行一些常见任务,例如抓取 URL、电子邮件 ID、图像和抓取数据。
从网页中获取 URL 和电子邮件 ID
我们尝试使用网络抓取功能抓取的两个最常见功能是 网站 URL 和电子邮件 ID。我确定您参与过需要提取大量电子邮件 ID 的项目或挑战。那么,让我们看看如何在 Python 中抓取这些内容。
使用网络浏览器的控制台 查看全部
网页抓取数据 免费(如何应对数据匮乏的问题?最简单的方法在这里)
作者|LAKSHAY ARORA编译|弗林源|analyticsvidhya
概述介绍
我们的数据太少,无法构建机器学习模型。我们需要更多数据!
如果这句话听起来很熟悉,那么您并不孤单!希望得到更多的数据来训练我们的机器学习模型是一直困扰着人们的问题。我们无法获得可以直接在数据科学项目中使用的 Excel 或 .csv 文件,对吗?
那么,如何应对数据稀缺的问题呢?
实现这一目标的最有效和最简单的方法之一是通过网络爬行。我个人认为网页抓取是一种非常有用的技术,可以从多个 网站 采集数据。如今,一些 网站 还为您可能希望使用的许多不同类型的数据提供 API,例如 Tweets 或 LinkedIn 帖子。
但有时您可能需要从不提供特定 API 的 网站 采集数据。这是网页抓取功能派上用场的地方。作为数据科学家,您可以编写一个简单的 Python 脚本并提取所需的数据。
因此,在本文中,我们将学习网页抓取的不同组件,然后直接学习 Python 以了解如何使用流行且高效的 BeautifulSoup 库进行网页抓取。
我们还为本文创建了一个免费课程:
请注意,网络抓取受许多准则和规则的约束。并不是每一个网站都允许用户抓取内容,所以有一定的法律限制。在尝试此操作之前,请确保您已阅读 网站 的 网站 条款和条件。
内容
3 个流行的 Python 网络爬虫工具和库
网页抓取组件
CrawlParse 和 TransformStore
从网页中抓取 URL 和电子邮件 ID
抓取图片
页面加载时抓取数据
3 个流行的 Python 网络爬虫工具和库
您将在 Python 中遇到多个用于网页抓取的库和框架。以下是三种用于高效完成任务的流行工具:
美汤
刮痧
硒
网页抓取组件
这是构成网络爬行的三个主要组件的极好说明:
让我们详细了解这些组件。我们将使用 goibibo网站 来捕获酒店的详细信息,例如酒店名称和每个房间的价格,以实现这一点:
注意:请始终遵循目标网站的robots.txt文件,也称为robots排除协议。这可以告诉网络机器人不抓取哪些页面。
因此,我们可以从目标 URL 中抓取数据。我们很高兴编写我们的网络机器人脚本。让我们开始吧!
第 1 步:爬网
网络爬虫的第一步是导航到目标网站并下载网页的源代码。我们将使用请求库来做到这一点。http.client 和 urlib2 是另外两个用于发出请求和下载源代码的库。
下载网页源代码后,我们需要过滤需要的内容:
"""
Web Scraping - Beautiful Soup
"""
# importing required libraries
import requests
from bs4 import BeautifulSoup
import pandas as pd
# target URL to scrap
url = "https://www.goibibo.com/hotels ... ot%3B
# headers
headers = {
'User-Agent': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36"
}
# send request to download the data
response = requests.request("GET", url, headers=headers)
# parse the downloaded data
data = BeautifulSoup(response.text, 'html.parser')
print(data)
第 2 步:解析和转换
网络抓取的下一步是将此数据解析为 HTML 解析器。为此,我们将使用 BeautifulSoup 库。现在,如果您注意到我们的登录页面,就像大多数页面一样,特定酒店的详细信息也在不同的卡片上。
因此,下一步将是从完整的源代码中过滤卡片数据。接下来,我们将选择卡片,然后单击“检查元素”选项以获取该特定卡片的源代码。您将获得以下信息:
所有卡片的类名都是一样的。我们可以通过传递标签名称和属性(例如标签)来获取这些卡片的列表。名称如下:
# find all the sections with specifiedd class name
cards_data = data.find_all('div', attrs={'class', 'width100 fl htlListSeo hotel-tile-srp-container hotel-tile-srp-container-template new-htl-design-tile-main-block'})
# total number of cards
print('Total Number of Cards Found : ', len(cards_data))
# source code of hotel cards
for card in cards_data:
print(card)
我们从网页的完整源代码中过滤掉了卡片数据,这里的每张卡片都收录有关单个酒店的信息。仅选择酒店名称,执行“检查元素”步骤,并对房价执行相同操作:
现在,对于每张卡,我们必须找到上面的酒店名称,这些名称只能来自
从标签中提取。这是因为每张卡和费率只有一个标签、标签和类别名称:
# extract the hotel name and price per room
for card in cards_data:
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
print(hotel_name.text, room_price.text)
第 3 步:Store(存储数据)
最后一步是将提取的数据存储在 CSV 文件中。在这里,对于每张卡片,我们将提取酒店名称和价格并将其存储在 Python 字典中。然后,我们最终将其添加到列表中。
接下来,让我们继续将此列表转换为 Pandas 数据框,因为它允许我们将数据框转换为 CSV 或 JSON 文件:
# create a list to store the data
scraped_data = []
for card in cards_data:
# initialize the dictionary
card_details = {}
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
# add data to the dictionary
card_details['hotel_name'] = hotel_name.text
card_details['room_price'] = room_price.text
# append the scraped data to the list
scraped_data.append(card_details)
# create a data frame from the list of dictionaries
dataFrame = pd.DataFrame.from_dict(scraped_data)
# save the scraped data as CSV file
dataFrame.to_csv('hotels_data.csv', index=False)
恭喜!我们已经成功创建了一个基本的网络爬虫。我希望您尝试这些步骤并尝试获取更多数据,例如酒店的类别和地址。现在,让我们看看如何在页面加载时执行一些常见任务,例如抓取 URL、电子邮件 ID、图像和抓取数据。
从网页中获取 URL 和电子邮件 ID
我们尝试使用网络抓取功能抓取的两个最常见功能是 网站 URL 和电子邮件 ID。我确定您参与过需要提取大量电子邮件 ID 的项目或挑战。那么,让我们看看如何在 Python 中抓取这些内容。
使用网络浏览器的控制台
网页抓取数据 免费( 3.LxmlLxml网页源码(css选择器)性能对比与结论 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-15 03:15
3.LxmlLxml网页源码(css选择器)性能对比与结论
)
from bs4 import BeautifulSoup
>>> soup = BeautifulSoup(html, "html.parser") #用html解释器对得到的html文本进行解析
>>> tr = soup.find(attrs={"id":"places_area__row"})
>>> tr
Area: 244,820 square kilometres
>>> td = tr.find(attrs={"class":"w2p_fw"})
>>> td
244,820 square kilometres
>>> area = td.text
>>> print(area)
244,820 square kilometres
3. Lxml
Lxml 是一个基于 libxml2(一个 XML 解析库)的 Python 包。模块采用C语言编写,解析速度比BeautifulSoup快。书中对比分析得出的结论,抓取一个网页后抓取数据的一般步骤是:首先解析网页源代码(这3种方法中使用lxml),然后选择抓取数据(css选择器) )
#先解析网页源码(lxml)示例
import lxml.html
broken_html = "AreaPopulation"
tree = lxml.html.fromstring(broken_html) #解析已经完成
fixed_html = lxml.html.tostring(tree, pretty_print=True)
print(fixed_html)
#output
#b'\nArea\nPopulation\n\n'
#解析网页源码(lxml)后使用css选择器提取目标信息
import lxml.html
import cssselect
html = download("http://example.webscraping.com ... 6quot;) #下载网页
html = str(html)
tree = lxml.html.fromstring(html) #解析已经完成
td = tree.cssselect("tr#places_area__row > td.w2p_fw")[0] #选择id="plac..."名为tr的标签下的,class="w2p..."名为td的标签中[0]元素
area = td.text_content() #目标信息area值为td标签中的text信息
print(area)
以上三种方法的性能对比及结论:
查看全部
网页抓取数据 免费(
3.LxmlLxml网页源码(css选择器)性能对比与结论
)
from bs4 import BeautifulSoup
>>> soup = BeautifulSoup(html, "html.parser") #用html解释器对得到的html文本进行解析
>>> tr = soup.find(attrs={"id":"places_area__row"})
>>> tr
Area: 244,820 square kilometres
>>> td = tr.find(attrs={"class":"w2p_fw"})
>>> td
244,820 square kilometres
>>> area = td.text
>>> print(area)
244,820 square kilometres
3. Lxml
Lxml 是一个基于 libxml2(一个 XML 解析库)的 Python 包。模块采用C语言编写,解析速度比BeautifulSoup快。书中对比分析得出的结论,抓取一个网页后抓取数据的一般步骤是:首先解析网页源代码(这3种方法中使用lxml),然后选择抓取数据(css选择器) )
#先解析网页源码(lxml)示例
import lxml.html
broken_html = "AreaPopulation"
tree = lxml.html.fromstring(broken_html) #解析已经完成
fixed_html = lxml.html.tostring(tree, pretty_print=True)
print(fixed_html)
#output
#b'\nArea\nPopulation\n\n'
#解析网页源码(lxml)后使用css选择器提取目标信息
import lxml.html
import cssselect
html = download("http://example.webscraping.com ... 6quot;) #下载网页
html = str(html)
tree = lxml.html.fromstring(html) #解析已经完成
td = tree.cssselect("tr#places_area__row > td.w2p_fw")[0] #选择id="plac..."名为tr的标签下的,class="w2p..."名为td的标签中[0]元素
area = td.text_content() #目标信息area值为td标签中的text信息
print(area)
以上三种方法的性能对比及结论:

