
网络爬虫
一个网站除了百度以外爬虫其爬虫是那什么呀
采集交流 • 优采云 发表了文章 • 0 个评论 • 317 次浏览 • 2020-05-06 08:02
网络爬虫根据系统结构和实现技术,大致可以分为以下几种类型:通用网路爬
虫(General Purpose Web Crawler)、聚焦网络爬虫(Focused Web
Crawler)、增量式网络爬虫(Incremental Web Crawler)、深层网络爬虫(Deep Web Crawler)。
实际的网路爬虫系统一般是几种爬虫技术相结合实现的[1]
。
通用网路爬虫
通用网路爬虫又称全网爬虫(Scalable Web
Crawler),爬行对象从一些种子 URL 扩充到整个 Web,主要为门户站点搜索引擎和小型 Web 服务提供商采集数据。
由于商业缘由,它们的技术细节甚少公布下来。
这类网路爬虫的爬行范围和数目巨大,对于爬行速率和储存空间要求较高,对于爬行页面的次序要求相对较低,同时因为待刷新的页面太多,通常采用并行工作方
式,但须要较长时间能够刷新一次页面。 虽然存在一定缺陷,通用网路爬虫适用于为搜索引擎搜索广泛的主题,有较强的应用价值[1]
。
通用网路爬虫的结构大致可以分为页面爬行模块 、页面剖析模块、链接过滤模块、页面数据库、URL 队列、初始 URL 集合几个部份。为提升工作效率,通用网路爬虫会采取一定的爬行策略。 常用的爬行策略有:深度优先策略、广度优先策略[1]
。
1)
深度优先策略:其基本方式是根据深度由低到高的次序,依次访问下一级网页链接,直到不能再深入为止。
爬虫在完成一个爬行分支后返回到上一链接节点进一步搜索其它链接。 当所有链接遍历完后e799bee5baa6e79fa5e98193e78988e69d8331333361313931,爬行任务结束。 这种策略比较适宜垂直搜索或站内搜索,
但爬行页面内容层次较深的站点时会导致资源的巨大浪费[1]
。
2)
广度优先策略:此策略根据网页内容目录层次深浅来爬行页面百度网络爬虫,处于较浅目录层次的页面首先被爬行。
当同一层次中的页面爬行完毕后,爬虫再深入下一层继续爬行。
这种策略才能有效控制页面的爬行深度,避免碰到一个无穷深层分支时未能结束爬行的问题百度网络爬虫,实现便捷,无需储存大量中间节点,不足之处在于需较长时间能够爬行
到目录层次较深的页面[1]
。
聚焦网络爬虫
聚焦网络爬虫(Focused
Crawler),又称主题网路爬虫(Topical Crawler),是指选择性地爬行这些与预先定义好的主题相关页面的网路爬虫[8]。
和通用网路爬虫相比,聚焦爬虫只须要爬行与主题相关的页面,极大地节约了硬件和网路资源,保存的页面也因为数目少而更新快,还可以挺好地满足一些特定人群
对特定领域信息的需求[1]
。
聚焦网络爬虫和通用网路爬虫相比,增加了链接评价模块以及内容评价模块。聚焦爬虫爬行策略实现的关键是评价页面内容和链接的重要性,不同的方式估算出的重要性不同,由此引起链接的访问次序也不同[1]
。
1)
基于内容评价的爬行策略:DeBra将文本相似度的估算方式引入到网路爬虫中,提出了 Fish Search
算法,它将用户输入的查询词作为主题,包含查询词的页面被视为与主题相关,其局限性在于难以评价页面与主题相关 度 的 高 低 。
Herseovic对 Fish Search 算 法 进 行 了 改 进 ,提 出 了 Sharksearch
算法,利用空间向量模型估算页面与主题的相关度大小[1]
。
2) 基于链接结构评价的爬行策略 :Web
页面作为一种半结构化文档,包含好多结构信息,可拿来评价链接重要性。 PageRank
算法最初用于搜索引擎信息检索中对查询结果进行排序,也可用于评价链接重要性,具体做法就是每次选择 PageRank 值较大页面中的链接来访问。
另一个借助 Web结构评价链接价值的方式是 HITS 方法,它通过估算每位已访问页面的 Authority 权重和 Hub
权重,并借此决定链接的访问次序[1]
。
3) 基于提高学习的爬行策略:Rennie 和 McCallum 将提高学习引入聚焦爬虫,利用贝叶斯分类器,根据整个网页文本和链接文本对超链接进行分类,为每位链接估算出重要性,从而决定链接的访问次序[1]
。
4) 基于语境图的爬行策略:Diligenti
等人提出了一种通过构建语境图(Context Graphs)学习网页之间的相关度,训练一个机器学习系统,通过该系统可估算当前页面到相关 Web
页面的距离,距离越逾的页面中的链接优先访问。印度理工大学(IIT)和 IBM 研究中心的研究人员开发了一个典型的聚焦网路爬虫。
该爬虫对主题的定义既不是采用关键词也不是加权矢量,而是一组具有相同主题的网页。
它包含两个重要模块:一个是分类器,用来估算所爬行的页面与主题的相关度,确定是否与主题相关;另一个是净化器,用来辨识通过较少链接联接到大量相关页面
的中心页面[1]
。
增量式网络爬虫
增量式网络爬虫(Incremental Web Crawler)是 指
对 已 下 载 网 页 采 取 增 量式更新和只爬行新形成的或则早已发生变化网页的爬虫,它还能在一定程度上保证所爬行的页面是尽可能新的页面。
和周期性爬行和刷新页面的网路爬虫相比,增量式爬虫只会在须要的时侯爬行新形成或发生更新的页面
,并不重新下载没有发生变化的页面,可有效降低数据下载量,及时更新已爬行的网页,减小时间和空间上的花费,但是降低了爬行算法的复杂度和实现难度。增量
式网路爬虫的体系结构[包含爬行模块、排序模块、更新模块、本地页面集、待爬行 URL 集以及本地页面URL 集[1]
。
增量式爬虫有两个目标:保持本地页面集中储存的页面为最新页面和提升本地
页面集中页面的质量。 为实现第一个目标,增量式爬虫须要通过重新访问网页来更新本地页面集中页面内容,常用的方式有:1)
统一更新法:爬虫以相同的频度访问所有网页,不考虑网页的改变频度;2) 个体更新法:爬虫依据个体网页的改变频度来重新访问各页面;3)
基于分类的更新法:爬虫依照网页改变频度将其分为更新较快网页子集和更新较慢网页子集两类,然后以不同的频度访问这两类网页[1]
。
为实现第二个目标,增量式爬虫须要对网页的重要性排序,常用的策略有:广
度优先策略、PageRank 优先策略等。IBM 开发的
WebFountain是一个功能强悍的增量式网路爬虫,它采用一个优化模型控制爬行过程,并没有对页面变化过程做任何统计假定,而是采用一种自适应的方
法依照当初爬行周期里爬行结果和网页实际变化速率对页面更新频度进行调整。北京大学的天网增量爬行系统致力爬行国外
Web,将网页分为变化网页和新网页两类,分别采用不同爬行策略。
为减轻对大量网页变化历史维护造成的性能困局,它依据网页变化时间局部性规律,在短时期内直接爬行多次变化的网页
,为尽早获取新网页,它借助索引型网页跟踪新出现网页[1]
。
Deep Web 爬虫
Web 页面按存在形式可以分为表层网页(Surface
Web)和深层网页(Deep Web,也称 Invisible Web Pages 或 Hidden Web)。
表层网页是指传统搜索引擎可以索引的页面,以超链接可以抵达的静态网页为主构成的 Web 页面。Deep Web
是这些大部分内容不能通过静态链接获取的、隐藏在搜索表单后的,只有用户递交一些关键词能够获得的 Web
页面。例如这些用户注册后内容才可见的网页就属于 Deep Web。 2000 年 Bright Planet 指出:Deep Web
中可访问信息容量是 Surface Web 的几百倍,是互联网上最大、发展最快的新型信息资源[1]
。
Deep Web 爬虫体系结构包含六个基本功能模块
(爬行控制器、解析器、表单分析器、表单处理器、响应分析器、LVS 控制器)和两个爬虫内部数据结构(URL 列表、LVS 表)。 其中
LVS(Label Value Set)表示标签/数值集合,用来表示填充表单的数据源[1]
。
Deep Web 爬虫爬行过程中最重要部份就是表单填写,包含两种类型:
1)
基于领域知识的表单填写:此方式通常会维持一个本体库,通过语义剖析来选定合适的关键词填写表单。 Yiyao Lu[25]等人提出一种获取 Form
表单信息的多注解方式,将数据表单按语义分配到各个组中
,对每组从多方面注解,结合各类注解结果来预测一个最终的注解标签;郑冬冬等人借助一个预定义的领域本体知识库来辨识 Deep Web 页面内容,
同时借助一些来自 Web 站点导航模式来辨识手动填写表单时所需进行的路径导航[1]
。
2) 基于网页结构剖析的表单填写:
此方式通常无领域知识或仅有有限的领域知识,将网页表单表示成 DOM 树,从中提取表单各数组值。 Desouky 等人提出一种 LEHW
方法,该方式将 HTML 网页表示为DOM 树方式,将表单分辨为单属性表单和多属性表单,分别进行处理;孙彬等人提出一种基于 XQuery
的搜索系统,它就能模拟表单和特殊页面标记切换,把网页关键字切换信息描述为三元组单元,按照一定规则排除无效表单,将 Web 文档构造成 DOM
树,利用 XQuery 将文字属性映射到表单数组[1]
。
Raghavan 等人提出的 HIWE 系统中,爬行管理器负责管理整个爬行过程,分析下载的页面,将包含表单的页面递交表单处理器处理,表单处理器先从页面中提取表单,从预先打算好的数据集中选择数据手动填充并递交表单,由爬行控制器下载相应的结果页面[1]
。 查看全部

网络爬虫根据系统结构和实现技术,大致可以分为以下几种类型:通用网路爬
虫(General Purpose Web Crawler)、聚焦网络爬虫(Focused Web
Crawler)、增量式网络爬虫(Incremental Web Crawler)、深层网络爬虫(Deep Web Crawler)。
实际的网路爬虫系统一般是几种爬虫技术相结合实现的[1]
。
通用网路爬虫
通用网路爬虫又称全网爬虫(Scalable Web
Crawler),爬行对象从一些种子 URL 扩充到整个 Web,主要为门户站点搜索引擎和小型 Web 服务提供商采集数据。
由于商业缘由,它们的技术细节甚少公布下来。
这类网路爬虫的爬行范围和数目巨大,对于爬行速率和储存空间要求较高,对于爬行页面的次序要求相对较低,同时因为待刷新的页面太多,通常采用并行工作方
式,但须要较长时间能够刷新一次页面。 虽然存在一定缺陷,通用网路爬虫适用于为搜索引擎搜索广泛的主题,有较强的应用价值[1]
。
通用网路爬虫的结构大致可以分为页面爬行模块 、页面剖析模块、链接过滤模块、页面数据库、URL 队列、初始 URL 集合几个部份。为提升工作效率,通用网路爬虫会采取一定的爬行策略。 常用的爬行策略有:深度优先策略、广度优先策略[1]
。
1)
深度优先策略:其基本方式是根据深度由低到高的次序,依次访问下一级网页链接,直到不能再深入为止。
爬虫在完成一个爬行分支后返回到上一链接节点进一步搜索其它链接。 当所有链接遍历完后e799bee5baa6e79fa5e98193e78988e69d8331333361313931,爬行任务结束。 这种策略比较适宜垂直搜索或站内搜索,
但爬行页面内容层次较深的站点时会导致资源的巨大浪费[1]
。
2)
广度优先策略:此策略根据网页内容目录层次深浅来爬行页面百度网络爬虫,处于较浅目录层次的页面首先被爬行。
当同一层次中的页面爬行完毕后,爬虫再深入下一层继续爬行。
这种策略才能有效控制页面的爬行深度,避免碰到一个无穷深层分支时未能结束爬行的问题百度网络爬虫,实现便捷,无需储存大量中间节点,不足之处在于需较长时间能够爬行
到目录层次较深的页面[1]
。
聚焦网络爬虫
聚焦网络爬虫(Focused
Crawler),又称主题网路爬虫(Topical Crawler),是指选择性地爬行这些与预先定义好的主题相关页面的网路爬虫[8]。
和通用网路爬虫相比,聚焦爬虫只须要爬行与主题相关的页面,极大地节约了硬件和网路资源,保存的页面也因为数目少而更新快,还可以挺好地满足一些特定人群
对特定领域信息的需求[1]
。
聚焦网络爬虫和通用网路爬虫相比,增加了链接评价模块以及内容评价模块。聚焦爬虫爬行策略实现的关键是评价页面内容和链接的重要性,不同的方式估算出的重要性不同,由此引起链接的访问次序也不同[1]
。
1)
基于内容评价的爬行策略:DeBra将文本相似度的估算方式引入到网路爬虫中,提出了 Fish Search
算法,它将用户输入的查询词作为主题,包含查询词的页面被视为与主题相关,其局限性在于难以评价页面与主题相关 度 的 高 低 。
Herseovic对 Fish Search 算 法 进 行 了 改 进 ,提 出 了 Sharksearch
算法,利用空间向量模型估算页面与主题的相关度大小[1]
。
2) 基于链接结构评价的爬行策略 :Web
页面作为一种半结构化文档,包含好多结构信息,可拿来评价链接重要性。 PageRank
算法最初用于搜索引擎信息检索中对查询结果进行排序,也可用于评价链接重要性,具体做法就是每次选择 PageRank 值较大页面中的链接来访问。
另一个借助 Web结构评价链接价值的方式是 HITS 方法,它通过估算每位已访问页面的 Authority 权重和 Hub
权重,并借此决定链接的访问次序[1]
。
3) 基于提高学习的爬行策略:Rennie 和 McCallum 将提高学习引入聚焦爬虫,利用贝叶斯分类器,根据整个网页文本和链接文本对超链接进行分类,为每位链接估算出重要性,从而决定链接的访问次序[1]
。
4) 基于语境图的爬行策略:Diligenti
等人提出了一种通过构建语境图(Context Graphs)学习网页之间的相关度,训练一个机器学习系统,通过该系统可估算当前页面到相关 Web
页面的距离,距离越逾的页面中的链接优先访问。印度理工大学(IIT)和 IBM 研究中心的研究人员开发了一个典型的聚焦网路爬虫。
该爬虫对主题的定义既不是采用关键词也不是加权矢量,而是一组具有相同主题的网页。
它包含两个重要模块:一个是分类器,用来估算所爬行的页面与主题的相关度,确定是否与主题相关;另一个是净化器,用来辨识通过较少链接联接到大量相关页面
的中心页面[1]
。
增量式网络爬虫
增量式网络爬虫(Incremental Web Crawler)是 指
对 已 下 载 网 页 采 取 增 量式更新和只爬行新形成的或则早已发生变化网页的爬虫,它还能在一定程度上保证所爬行的页面是尽可能新的页面。
和周期性爬行和刷新页面的网路爬虫相比,增量式爬虫只会在须要的时侯爬行新形成或发生更新的页面
,并不重新下载没有发生变化的页面,可有效降低数据下载量,及时更新已爬行的网页,减小时间和空间上的花费,但是降低了爬行算法的复杂度和实现难度。增量
式网路爬虫的体系结构[包含爬行模块、排序模块、更新模块、本地页面集、待爬行 URL 集以及本地页面URL 集[1]
。
增量式爬虫有两个目标:保持本地页面集中储存的页面为最新页面和提升本地
页面集中页面的质量。 为实现第一个目标,增量式爬虫须要通过重新访问网页来更新本地页面集中页面内容,常用的方式有:1)
统一更新法:爬虫以相同的频度访问所有网页,不考虑网页的改变频度;2) 个体更新法:爬虫依据个体网页的改变频度来重新访问各页面;3)
基于分类的更新法:爬虫依照网页改变频度将其分为更新较快网页子集和更新较慢网页子集两类,然后以不同的频度访问这两类网页[1]
。
为实现第二个目标,增量式爬虫须要对网页的重要性排序,常用的策略有:广
度优先策略、PageRank 优先策略等。IBM 开发的
WebFountain是一个功能强悍的增量式网路爬虫,它采用一个优化模型控制爬行过程,并没有对页面变化过程做任何统计假定,而是采用一种自适应的方
法依照当初爬行周期里爬行结果和网页实际变化速率对页面更新频度进行调整。北京大学的天网增量爬行系统致力爬行国外
Web,将网页分为变化网页和新网页两类,分别采用不同爬行策略。
为减轻对大量网页变化历史维护造成的性能困局,它依据网页变化时间局部性规律,在短时期内直接爬行多次变化的网页
,为尽早获取新网页,它借助索引型网页跟踪新出现网页[1]
。
Deep Web 爬虫
Web 页面按存在形式可以分为表层网页(Surface
Web)和深层网页(Deep Web,也称 Invisible Web Pages 或 Hidden Web)。
表层网页是指传统搜索引擎可以索引的页面,以超链接可以抵达的静态网页为主构成的 Web 页面。Deep Web
是这些大部分内容不能通过静态链接获取的、隐藏在搜索表单后的,只有用户递交一些关键词能够获得的 Web
页面。例如这些用户注册后内容才可见的网页就属于 Deep Web。 2000 年 Bright Planet 指出:Deep Web
中可访问信息容量是 Surface Web 的几百倍,是互联网上最大、发展最快的新型信息资源[1]
。
Deep Web 爬虫体系结构包含六个基本功能模块
(爬行控制器、解析器、表单分析器、表单处理器、响应分析器、LVS 控制器)和两个爬虫内部数据结构(URL 列表、LVS 表)。 其中
LVS(Label Value Set)表示标签/数值集合,用来表示填充表单的数据源[1]
。
Deep Web 爬虫爬行过程中最重要部份就是表单填写,包含两种类型:
1)
基于领域知识的表单填写:此方式通常会维持一个本体库,通过语义剖析来选定合适的关键词填写表单。 Yiyao Lu[25]等人提出一种获取 Form
表单信息的多注解方式,将数据表单按语义分配到各个组中
,对每组从多方面注解,结合各类注解结果来预测一个最终的注解标签;郑冬冬等人借助一个预定义的领域本体知识库来辨识 Deep Web 页面内容,
同时借助一些来自 Web 站点导航模式来辨识手动填写表单时所需进行的路径导航[1]
。
2) 基于网页结构剖析的表单填写:
此方式通常无领域知识或仅有有限的领域知识,将网页表单表示成 DOM 树,从中提取表单各数组值。 Desouky 等人提出一种 LEHW
方法,该方式将 HTML 网页表示为DOM 树方式,将表单分辨为单属性表单和多属性表单,分别进行处理;孙彬等人提出一种基于 XQuery
的搜索系统,它就能模拟表单和特殊页面标记切换,把网页关键字切换信息描述为三元组单元,按照一定规则排除无效表单,将 Web 文档构造成 DOM
树,利用 XQuery 将文字属性映射到表单数组[1]
。
Raghavan 等人提出的 HIWE 系统中,爬行管理器负责管理整个爬行过程,分析下载的页面,将包含表单的页面递交表单处理器处理,表单处理器先从页面中提取表单,从预先打算好的数据集中选择数据手动填充并递交表单,由爬行控制器下载相应的结果页面[1]
。
利用网路爬虫技术快速确切寻觅目的图书的方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 289 次浏览 • 2020-05-04 08:07
【专利摘要】本发明公开了一种借助网路爬虫技术快速确切找寻目的图书的方式,流程如下:录入电子图书构建电子图书库,将录入的图书分类装入不同的子网页中,输入须要阅读图书的关键词,利用网路爬虫技术对与目的图书有关的图书网页进行抓取,对抓取得网页进行剖析,分析后输出过滤后的图书,选择目的图书进行阅读。本发明电子图书库可以即时的录入新的电子图书,保证了该电子图书馆图书的图书种类的丰富性,采用网路爬虫技术获取目的图书愈发迅确切图书的种类仅限于文字类网络爬虫书籍,也有图片类,视频类等,该方式除了适用于电子图书馆,也适用于电子图书网站,将会为电子图书的发展带来一定的推动。
【专利说明】利用网路爬虫技术快速确切找寻目的图书的方式
发明领域
[0001]本发明涉及一种阅读电子图书过程中确切快速选购目的图书的方式,属于网路【技术领域】。
【背景技术】
[0002]电子图书馆,是随着电版物的出现,网络通信技术的发展,而渐渐出现的。电子图书馆,具有储存能力大、速度快、保存时间长、成本低、便于交流等特性。光盘这一海量存储器、能够储存比传统图书高几千倍的信息,比微缩胶卷要多得多,而且包括图像、视频、声音,等等。利用电子技术,在这一种图书馆,我们能很快地从浩如烟海的图书中,查找到自己所须要的信息资料。这种图书馆,保存信息量的时间要长得多,不存在腐烂、生虫等问题。利用网路,在远在几千里、万里的单位、家中,都可以使用这些图书,效率极高。在广袤的书海中,想要快速确切的找到目标图书并不是这么容易,为我们阅读电子图书带来了一定的困难,阻碍了电子图书的发展。
【发明内容】
[0003]本发明为解决目前在电子图书馆中快速找寻目的图书的问题,提供一种借助网路爬虫技术快速确切寻觅目的图书的方式。本发明包括以下步骤:
[0004]步骤一:录入电子图书构建电子图书库;
[0005]步骤二:将录入的图书分类装入不同的子网页中;
[0006]步骤三:输入须要阅读图书的关键词;
[0007]步骤四:利用网路爬虫技术对与目的图书有关的图书网页进行抓取;
[0008]步骤五:对抓取得网页进行剖析;
[0009]步骤六:分析后输出过滤后的图书,选择目的图书进行阅读。
[0010]发明疗效:本发明电子图书库可以即时的录入新的电子图书,保证了该电子图书馆图书的图书种类的丰富性,采用网路爬虫技术获取目的图书愈发迅确切图书的种类仅限于文字类,也有图片类,视频类等,该方式除了适用于电子图书馆,也适用于电子图书网站,将会为电子图书的发展带来一定的推动。
【专利附图】
【附图说明】
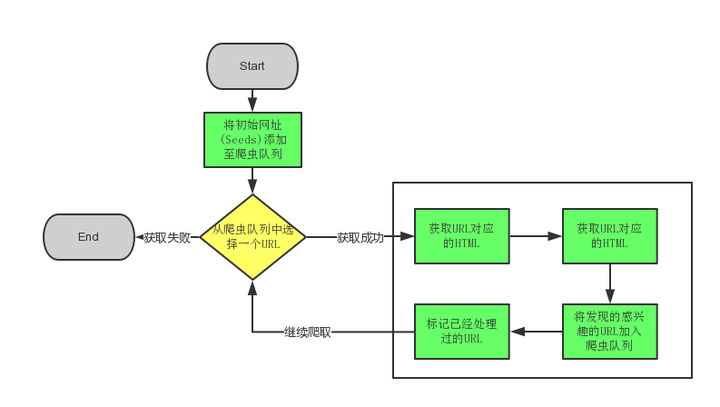
[0011]图1为借助网路爬虫技术快速确切找寻目的图书方式的流程图。
【具体施行方法】
[0012]【具体施行方法】:参见借助网路爬虫技术快速确切找寻目的图书方式的流程图1,本施行方法由以下步骤组成:
[0013]步骤一:录入电子图书构建电子图书库;
[0014]步骤二:将录入的图书分类装入不同的子网页中;[0015]步骤三:输入须要阅读图书的关键词;
[0016]步骤四:利用网路爬虫技术对与目的图书有关的图书网页进行抓取;
[0017]步骤五:对抓取得网页进行剖析;
[0018]步骤六:分析后输出过滤后的图书,选择目的图书进行阅读。
[0019]录入的电子图书必须对其按图书的种类对其进行命名,录入的图书的子网页早已录入图书的种类赋于了不同的域名,收索须要的电子图书须要输入该图书的图书名,或所属的学科种类,网络爬虫对目的图书的收索是快速抓取目的图书的网页,在对网页上的图书进行抓取,对抓取得网页进行剖析,主要是剖析出与输入图书最接近的图书。
[0020]对于本领域技术人员而言,显然本发明不限于上述示范性施行例的细节,而且在不背离本发明的精神或基本特点的情况下,能够以其他的具体方式实现本发明。因此网络爬虫书籍,无论从哪一点来看,均应将发明例看作是示范性的,而且是非限制性的,本发明的范围由所附权力要求而不是上述说明限定,因此借以将落在权力要求的等同要件的含意和范围内的所有变化涵盖在本发明内。不应将权力要求中的任何附图标记视为限制所涉及的权力要求。
【权利要求】
1.一种借助网路爬虫技术快速确切找寻目的图书的方式,其特点在于它由以下步骤实现: 步骤一:录入电子图书,建立电子图书库; 步骤二:将录入的图书分类装入不同的子网页中; 步骤三:输入须要阅读图书的关键词; 步骤四:利用网路爬虫技术对与目的图书有关的图书网页进行抓取; 步骤五:对抓取得网页进行剖析; 步骤六:分析后输出过滤后的图书,选择目的图书进行阅读。
2.根据权力要求书I所述一种借助网路爬虫技术快速确切找寻目的图书的方式,其特点在于:步骤二中所述录入的电子图书必须对其按图书的种类对其进行命名。
3.根据权力要求书I所述一种借助网路爬虫技术快速确切找寻目的图书的方式,其特点在于:步骤一中所述录入的图书的子网页早已录入图书的种类赋于了不同的域名。
4.根据权力要求书I所述一种借助网路爬虫技术快速确切找寻目的图书的方式,其特点在于:步骤一中所述收索须要的电子图书须要输入该图书的图书名,或所属的学科种类。
5.根据权力要求书I所述一种借助网路爬虫技术快速确切找寻目的图书的方式,其特点在于:步骤一中所述网路爬虫对目的图书的收索是快速抓取目的图书的网页,在对网页上的图书进行抓取。
6.根据权力要求书I所述一种借助网路爬虫技术快速确切找寻目的图书的方式,其特点在于:步骤一中所述对抓取得网页进行剖析,主要是剖析出与输入图书最接近的图书。
【文档编号】G06F17/30GK103744945SQ201310754637
【公开日】2014年4月23日 申请日期:2013年12月31日 优先权日:2013年12月31日
【发明者】朱龙腾 申请人:上海伯释信息科技有限公司 查看全部
利用网路爬虫技术快速确切寻觅目的图书的方式
【专利摘要】本发明公开了一种借助网路爬虫技术快速确切找寻目的图书的方式,流程如下:录入电子图书构建电子图书库,将录入的图书分类装入不同的子网页中,输入须要阅读图书的关键词,利用网路爬虫技术对与目的图书有关的图书网页进行抓取,对抓取得网页进行剖析,分析后输出过滤后的图书,选择目的图书进行阅读。本发明电子图书库可以即时的录入新的电子图书,保证了该电子图书馆图书的图书种类的丰富性,采用网路爬虫技术获取目的图书愈发迅确切图书的种类仅限于文字类网络爬虫书籍,也有图片类,视频类等,该方式除了适用于电子图书馆,也适用于电子图书网站,将会为电子图书的发展带来一定的推动。
【专利说明】利用网路爬虫技术快速确切找寻目的图书的方式
发明领域
[0001]本发明涉及一种阅读电子图书过程中确切快速选购目的图书的方式,属于网路【技术领域】。
【背景技术】
[0002]电子图书馆,是随着电版物的出现,网络通信技术的发展,而渐渐出现的。电子图书馆,具有储存能力大、速度快、保存时间长、成本低、便于交流等特性。光盘这一海量存储器、能够储存比传统图书高几千倍的信息,比微缩胶卷要多得多,而且包括图像、视频、声音,等等。利用电子技术,在这一种图书馆,我们能很快地从浩如烟海的图书中,查找到自己所须要的信息资料。这种图书馆,保存信息量的时间要长得多,不存在腐烂、生虫等问题。利用网路,在远在几千里、万里的单位、家中,都可以使用这些图书,效率极高。在广袤的书海中,想要快速确切的找到目标图书并不是这么容易,为我们阅读电子图书带来了一定的困难,阻碍了电子图书的发展。
【发明内容】
[0003]本发明为解决目前在电子图书馆中快速找寻目的图书的问题,提供一种借助网路爬虫技术快速确切寻觅目的图书的方式。本发明包括以下步骤:
[0004]步骤一:录入电子图书构建电子图书库;
[0005]步骤二:将录入的图书分类装入不同的子网页中;
[0006]步骤三:输入须要阅读图书的关键词;
[0007]步骤四:利用网路爬虫技术对与目的图书有关的图书网页进行抓取;
[0008]步骤五:对抓取得网页进行剖析;
[0009]步骤六:分析后输出过滤后的图书,选择目的图书进行阅读。
[0010]发明疗效:本发明电子图书库可以即时的录入新的电子图书,保证了该电子图书馆图书的图书种类的丰富性,采用网路爬虫技术获取目的图书愈发迅确切图书的种类仅限于文字类,也有图片类,视频类等,该方式除了适用于电子图书馆,也适用于电子图书网站,将会为电子图书的发展带来一定的推动。
【专利附图】
【附图说明】
[0011]图1为借助网路爬虫技术快速确切找寻目的图书方式的流程图。
【具体施行方法】
[0012]【具体施行方法】:参见借助网路爬虫技术快速确切找寻目的图书方式的流程图1,本施行方法由以下步骤组成:
[0013]步骤一:录入电子图书构建电子图书库;
[0014]步骤二:将录入的图书分类装入不同的子网页中;[0015]步骤三:输入须要阅读图书的关键词;
[0016]步骤四:利用网路爬虫技术对与目的图书有关的图书网页进行抓取;
[0017]步骤五:对抓取得网页进行剖析;
[0018]步骤六:分析后输出过滤后的图书,选择目的图书进行阅读。
[0019]录入的电子图书必须对其按图书的种类对其进行命名,录入的图书的子网页早已录入图书的种类赋于了不同的域名,收索须要的电子图书须要输入该图书的图书名,或所属的学科种类,网络爬虫对目的图书的收索是快速抓取目的图书的网页,在对网页上的图书进行抓取,对抓取得网页进行剖析,主要是剖析出与输入图书最接近的图书。
[0020]对于本领域技术人员而言,显然本发明不限于上述示范性施行例的细节,而且在不背离本发明的精神或基本特点的情况下,能够以其他的具体方式实现本发明。因此网络爬虫书籍,无论从哪一点来看,均应将发明例看作是示范性的,而且是非限制性的,本发明的范围由所附权力要求而不是上述说明限定,因此借以将落在权力要求的等同要件的含意和范围内的所有变化涵盖在本发明内。不应将权力要求中的任何附图标记视为限制所涉及的权力要求。
【权利要求】
1.一种借助网路爬虫技术快速确切找寻目的图书的方式,其特点在于它由以下步骤实现: 步骤一:录入电子图书,建立电子图书库; 步骤二:将录入的图书分类装入不同的子网页中; 步骤三:输入须要阅读图书的关键词; 步骤四:利用网路爬虫技术对与目的图书有关的图书网页进行抓取; 步骤五:对抓取得网页进行剖析; 步骤六:分析后输出过滤后的图书,选择目的图书进行阅读。
2.根据权力要求书I所述一种借助网路爬虫技术快速确切找寻目的图书的方式,其特点在于:步骤二中所述录入的电子图书必须对其按图书的种类对其进行命名。
3.根据权力要求书I所述一种借助网路爬虫技术快速确切找寻目的图书的方式,其特点在于:步骤一中所述录入的图书的子网页早已录入图书的种类赋于了不同的域名。
4.根据权力要求书I所述一种借助网路爬虫技术快速确切找寻目的图书的方式,其特点在于:步骤一中所述收索须要的电子图书须要输入该图书的图书名,或所属的学科种类。
5.根据权力要求书I所述一种借助网路爬虫技术快速确切找寻目的图书的方式,其特点在于:步骤一中所述网路爬虫对目的图书的收索是快速抓取目的图书的网页,在对网页上的图书进行抓取。
6.根据权力要求书I所述一种借助网路爬虫技术快速确切找寻目的图书的方式,其特点在于:步骤一中所述对抓取得网页进行剖析,主要是剖析出与输入图书最接近的图书。
【文档编号】G06F17/30GK103744945SQ201310754637
【公开日】2014年4月23日 申请日期:2013年12月31日 优先权日:2013年12月31日
【发明者】朱龙腾 申请人:上海伯释信息科技有限公司
关键词采集方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 660 次浏览 • 2020-05-04 08:07
八爪鱼·云采集网络爬虫软件 3)创建好循环文本输入后, 点击页面上的搜索框, 创建输入文本的步骤, 注意, 不需要输入任何文本即可,若是手动生成的是在循环外边,拖入进去,再勾选循 环即可。八爪鱼·云采集网络爬虫软件 4)右键选择页面上的搜索按键,设置好点击元素,这样,循环文本输入就设置 好了,流程下方就是搜索下来的长尾关键词。步骤 3:创建数字翻页1)由于该搜索结果页面没有下一页按键,只有数字页数,所以我们须要用到 xpath 的一些相关知识,来设置特殊的数字翻页。首先去火狐浏览器里把该网页 打开并搜索相应关键词后,打开浏览器右上角的 firebug 工具--小瓢虫(不懂的 同学可以去官网教程看一下相应的 xpath 教程)八爪鱼·云采集网络爬虫软件 2)翻到页面下方输入关键词采集文章, 找到数字位置的源码, 可以看见当前页面的数字跟其他数字, 在源码里节点的属性 class 是有所不同的八爪鱼·云采集网络爬虫软件 3)收 益 我 们 首 先 定 位 到 该 页 面 的 数 字 位 置 , 手 写 xpath : //div[@id="page"]/a[contains(@class,'current')]八爪鱼·云采集网络爬虫软件 4)再利用固定函数 following-sibling 来定位到该节点后的第一个同类节点, 注意,该函数前面接::是固定格式,a[1]是指该节点后的第一个同类节点八爪鱼·云采集网络爬虫软件 5)可以查看翻页后还是正常定位到下一页的数字上,说明该 xpath 没有问题6)再回到八爪鱼, 在两侧流程页面拖一个循环进来, 高级选项里选择单个元素, 并把 xpath 放入进去,点确定保存好八爪鱼·云采集网络爬虫软件 7)再从左边拖一个点击元素进来,并在中级选项里勾选好循环,特殊数字翻页 循环就创建好了八爪鱼·云采集网络爬虫软件 步骤 4:创建循环列表1)我们安装常规方式创建循环列表,发现,由于搜索结果后的表格中出现了这 个无用的一整行信息。
八爪鱼·云采集网络爬虫软件 2)于是在八爪鱼上面是难以正常的创建好循环列表的,因为这个无用的信息导 致八爪鱼手动生成的列表会定位不准八爪鱼·云采集网络爬虫软件 3)所以我们还是得用到 xpath 的知识,去火狐浏览器上面自动创建一个循环列 表的 xpath。首先定位到第一行第一列的源码位置4)再找到每一行的源码位置,发现她们都是 tbody 父节点下相同的 tr 标签八爪鱼·云采集网络爬虫软件 5)再观察每一行真正的 tr 节点里都有一个共同的属性“id”,并且 id 属性都 有 一 个 共 同 的 tr 值 , 所 以 我 们 以 此 为 共 同 点 ,手 写 该 xpath:.//tbody/tr[contains(@id,'tr')]输入关键词采集文章,来定位到所有的 tr 节点,并把所有无 用的 tr 给过滤掉,这样,循环列表的 xpath 就创建好了八爪鱼·云采集网络爬虫软件 6)再从左边拖一个循环进去,循环形式选择不固定元素,把该 xpath 放入八爪 鱼里,并以第一个循环为例,设置相应的采集字段(由于部份数组源码里是没有 的,所以采集不到),八爪鱼·云采集网络爬虫软件 步骤 5:启动采集八爪鱼·云采集网络爬虫软件 1)点击保存任务后,运行采集,以本地采集为例2)采集完成后,会跳出提示,选择“导出数据”。
选择“合适的导入方法”, 将采集好的数据导入。八爪鱼·云采集网络爬虫软件 本文来自于:相关采集教程:京东商品信息采集(通过搜索关键词) 阿里巴巴关键词采集: 八爪鱼·云采集网络爬虫软件 爱站关键词采集: 百度相关搜索关键词采集: 亚马逊关键词采集: 易迅关键词采集: 新浪微博关键词采集: 关键词提取八爪鱼——90 万用户选择的网页数据采集器。 1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。八爪鱼·云采集网络爬虫软件 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。 查看全部
八爪鱼·云采集网络爬虫软件 关键词采集方法本文将介绍怎样借助【词库】批量挖掘并采集长尾词的方式,对 SEOSEM 站长 来说十分实用。 本来还将介绍一款免费好用的数据采集工具 【八爪鱼数据采集】 , 让站长采集关键词的工作事半功倍。长尾词对于站长来说是提升网站流量的核心之技能之一, 是不容忽略的一项方法, 在搜索引擎营销中对关键词策略的拟定是十分重要的, 这些长尾关键词能为网站 贡献很大的一部分流量,并且带来的客人转化率也很不错。下面就以【词库】为例,教诸位站长怎么是用【八爪鱼数据采集器】批量采集关 键词。采集网站:本文就以一组(100 个 B2B 行业有指数的关键词)为例,来采集关于这一组关 键词的所有相关长尾关键词。八爪鱼·云采集网络爬虫软件 采集的内容包括:搜索后的长尾关键词,360 指数,该长尾关键词搜索量以及搜 索量的第一位网站(页面)这四个有效数组。使用功能点:? 循环文本输入?Xpathxpath 入门教程 1 xpath 入门 2 相对 XPATH 教程-7.0 版 ? 数字翻页步骤 1:创建词库网采集任务1)进入主界面,选择“自定义采集”八爪鱼·云采集网络爬虫软件 2)将要采集的网址 URL 复制粘贴到网站输入框中,点击“保存网址”八爪鱼·云采集网络爬虫软件 步骤 2:创建循环输入文本八爪鱼·云采集网络爬虫软件 1)打开网页以后,点开右上角的流程,然后从左边拖一个循环进来2)点击循环步骤,在它的中级选项哪里选择文本列表,再点开下边的 A,把复 制好的关键词全部粘贴进去,注意换行,再点击确定保存。
八爪鱼·云采集网络爬虫软件 3)创建好循环文本输入后, 点击页面上的搜索框, 创建输入文本的步骤, 注意, 不需要输入任何文本即可,若是手动生成的是在循环外边,拖入进去,再勾选循 环即可。八爪鱼·云采集网络爬虫软件 4)右键选择页面上的搜索按键,设置好点击元素,这样,循环文本输入就设置 好了,流程下方就是搜索下来的长尾关键词。步骤 3:创建数字翻页1)由于该搜索结果页面没有下一页按键,只有数字页数,所以我们须要用到 xpath 的一些相关知识,来设置特殊的数字翻页。首先去火狐浏览器里把该网页 打开并搜索相应关键词后,打开浏览器右上角的 firebug 工具--小瓢虫(不懂的 同学可以去官网教程看一下相应的 xpath 教程)八爪鱼·云采集网络爬虫软件 2)翻到页面下方输入关键词采集文章, 找到数字位置的源码, 可以看见当前页面的数字跟其他数字, 在源码里节点的属性 class 是有所不同的八爪鱼·云采集网络爬虫软件 3)收 益 我 们 首 先 定 位 到 该 页 面 的 数 字 位 置 , 手 写 xpath : //div[@id="page"]/a[contains(@class,'current')]八爪鱼·云采集网络爬虫软件 4)再利用固定函数 following-sibling 来定位到该节点后的第一个同类节点, 注意,该函数前面接::是固定格式,a[1]是指该节点后的第一个同类节点八爪鱼·云采集网络爬虫软件 5)可以查看翻页后还是正常定位到下一页的数字上,说明该 xpath 没有问题6)再回到八爪鱼, 在两侧流程页面拖一个循环进来, 高级选项里选择单个元素, 并把 xpath 放入进去,点确定保存好八爪鱼·云采集网络爬虫软件 7)再从左边拖一个点击元素进来,并在中级选项里勾选好循环,特殊数字翻页 循环就创建好了八爪鱼·云采集网络爬虫软件 步骤 4:创建循环列表1)我们安装常规方式创建循环列表,发现,由于搜索结果后的表格中出现了这 个无用的一整行信息。
八爪鱼·云采集网络爬虫软件 2)于是在八爪鱼上面是难以正常的创建好循环列表的,因为这个无用的信息导 致八爪鱼手动生成的列表会定位不准八爪鱼·云采集网络爬虫软件 3)所以我们还是得用到 xpath 的知识,去火狐浏览器上面自动创建一个循环列 表的 xpath。首先定位到第一行第一列的源码位置4)再找到每一行的源码位置,发现她们都是 tbody 父节点下相同的 tr 标签八爪鱼·云采集网络爬虫软件 5)再观察每一行真正的 tr 节点里都有一个共同的属性“id”,并且 id 属性都 有 一 个 共 同 的 tr 值 , 所 以 我 们 以 此 为 共 同 点 ,手 写 该 xpath:.//tbody/tr[contains(@id,'tr')]输入关键词采集文章,来定位到所有的 tr 节点,并把所有无 用的 tr 给过滤掉,这样,循环列表的 xpath 就创建好了八爪鱼·云采集网络爬虫软件 6)再从左边拖一个循环进去,循环形式选择不固定元素,把该 xpath 放入八爪 鱼里,并以第一个循环为例,设置相应的采集字段(由于部份数组源码里是没有 的,所以采集不到),八爪鱼·云采集网络爬虫软件 步骤 5:启动采集八爪鱼·云采集网络爬虫软件 1)点击保存任务后,运行采集,以本地采集为例2)采集完成后,会跳出提示,选择“导出数据”。
选择“合适的导入方法”, 将采集好的数据导入。八爪鱼·云采集网络爬虫软件 本文来自于:相关采集教程:京东商品信息采集(通过搜索关键词) 阿里巴巴关键词采集: 八爪鱼·云采集网络爬虫软件 爱站关键词采集: 百度相关搜索关键词采集: 亚马逊关键词采集: 易迅关键词采集: 新浪微博关键词采集: 关键词提取八爪鱼——90 万用户选择的网页数据采集器。 1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。八爪鱼·云采集网络爬虫软件 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。
网络爬虫:使用Scrapy框架编撰一个抓取书籍信息的爬虫服务
采集交流 • 优采云 发表了文章 • 0 个评论 • 284 次浏览 • 2020-05-04 08:06
BeautifulSoup是一个十分流行的Python网路抓取库,它提供了一个基于HTML结构的Python对象。
虽然简单易懂,又能非常好的处理HTML数据,
但是相比Scrapy而言网络爬虫程序书,BeautifulSoup有一个最大的缺点:慢。
Scrapy 是一个开源的 Python 数据抓取框架,速度快,强大,而且使用简单。
来看一个官网主页上的简单并完整的爬虫:
虽然只有10行左右的代码,但是它的确是一个完整的爬虫服务:
Scrapy所有的恳求都是异步的:
安装(Mac)
pip install scrapy
其他操作系统请参考完整安装指导:
Spider类想要抒发的是:如何抓取一个确定了的网站的数据。比如在start_urls里定义的去那个链接抓取,parse()方法中定义的要抓取什么样的数据。
当一个Spider开始执行的时侯,它首先从start_urls()中的第一个链接开始发起恳求网络爬虫程序书,然后在callback里处理返回的数据。
Item类提供低格的数据,可以理解为数据Model类。
Scrapy的Selector类基于lxml库,提供HTML或XML转换功能。以response对象作为参数生成的Selector实例即可通过实例对象的xpath()方法获取节点的数据。
接下来将上一个Beautiful Soup版的抓取书籍信息的事例( 使用Beautiful Soup编撰一个爬虫 系列随笔汇总)改写成Scrapy版本。
scrapy startproject book_project
这行命令会创建一个名为book_project的项目。
即实体类,代码如下:
import scrapy
class BookItem(scrapy.Item):
title = scrapy.Field()
isbn = scrapy.Field()
price = scrapy.Field()
设置这个Spider的名称,允许爬取的域名和从那个链接开始:
class BookInfoSpider(scrapy.Spider):
name = "bookinfo"
allowed_domains = ["allitebooks.com", "amazon.com"]
start_urls = [
"http://www.allitebooks.com/security/",
]
def parse(self, response):
# response.xpath('//a[contains(@title, "Last Page →")]/@href').re(r'(\d+)')[0]
num_pages = int(response.xpath('//a[contains(@title, "Last Page →")]/text()').extract_first())
base_url = "http://www.allitebooks.com/security/page/{0}/"
for page in range(1, num_pages):
yield scrapy.Request(base_url.format(page), dont_filter=True, callback=self.parse_page) 查看全部
上周学习了BeautifulSoup的基础知识并用它完成了一个网络爬虫( 使用Beautiful Soup编撰一个爬虫 系列随笔汇总),
BeautifulSoup是一个十分流行的Python网路抓取库,它提供了一个基于HTML结构的Python对象。
虽然简单易懂,又能非常好的处理HTML数据,
但是相比Scrapy而言网络爬虫程序书,BeautifulSoup有一个最大的缺点:慢。
Scrapy 是一个开源的 Python 数据抓取框架,速度快,强大,而且使用简单。
来看一个官网主页上的简单并完整的爬虫:

虽然只有10行左右的代码,但是它的确是一个完整的爬虫服务:
Scrapy所有的恳求都是异步的:
安装(Mac)
pip install scrapy
其他操作系统请参考完整安装指导:
Spider类想要抒发的是:如何抓取一个确定了的网站的数据。比如在start_urls里定义的去那个链接抓取,parse()方法中定义的要抓取什么样的数据。
当一个Spider开始执行的时侯,它首先从start_urls()中的第一个链接开始发起恳求网络爬虫程序书,然后在callback里处理返回的数据。
Item类提供低格的数据,可以理解为数据Model类。
Scrapy的Selector类基于lxml库,提供HTML或XML转换功能。以response对象作为参数生成的Selector实例即可通过实例对象的xpath()方法获取节点的数据。
接下来将上一个Beautiful Soup版的抓取书籍信息的事例( 使用Beautiful Soup编撰一个爬虫 系列随笔汇总)改写成Scrapy版本。
scrapy startproject book_project
这行命令会创建一个名为book_project的项目。
即实体类,代码如下:
import scrapy
class BookItem(scrapy.Item):
title = scrapy.Field()
isbn = scrapy.Field()
price = scrapy.Field()
设置这个Spider的名称,允许爬取的域名和从那个链接开始:
class BookInfoSpider(scrapy.Spider):
name = "bookinfo"
allowed_domains = ["allitebooks.com", "amazon.com"]
start_urls = [
"http://www.allitebooks.com/security/",
]
def parse(self, response):
# response.xpath('//a[contains(@title, "Last Page →")]/@href').re(r'(\d+)')[0]
num_pages = int(response.xpath('//a[contains(@title, "Last Page →")]/text()').extract_first())
base_url = "http://www.allitebooks.com/security/page/{0}/"
for page in range(1, num_pages):
yield scrapy.Request(base_url.format(page), dont_filter=True, callback=self.parse_page)
税务局怎么应用网路爬虫技术获取企业涉税信息
采集交流 • 优采云 发表了文章 • 0 个评论 • 555 次浏览 • 2020-05-03 08:09
那么,什么是网络爬虫呢?税务局怎么应用网路爬虫技术发觉企业的涉税谜团呢?本文将带你一步一步解开其中的奥秘。
网络爬虫称作“网页蜘蛛”,是一个手动提取网页的程序。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL装入队列,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要按照一定的网页剖析算法过滤与主题无关的链接,保留有用的链接并将其倒入等待抓取的URL队列。然后,它将按照一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止,另外,所有被爬虫抓取的网页将会被系统存储,进行一定的剖析、过滤,并构建索引,以便以后的查询和检索。
以上是引自网路专业的叙述,简单的说,“网络爬虫”是一个手动提取网页的程序,运用“网络爬虫”技术设定程序税务爬虫软件,可以按照既定的目标愈发精准选择抓取相关的网页信息,有助于在互联网海量信息中快捷获取有用的涉税信息。
税务局怎样利用网路爬虫举办工作呢?概括的说税务爬虫软件,不外乎这样几个方面:
一是有针对性的捕捉互联网上的企业相关信息;
二是利用大数据,整合其他相关涉税信息;
三是通过一系列预警指标剖析比对筛选案源;
四是构建企业交易行为轨迹,定位税收风险疑虑。
其实,网络爬虫收集的仅仅是纳税人公开在网路上的涉税信息,税务机关获取纳税人的涉税信息还有好多途径,比如,利用内部风控中心监控平台,与网路运营商、工商、统计、建设、技术监督、财政、公安、海关、金融机构、外汇管理、国土规划和货运中心等有关部门联网实现信息互通、数据互联、资源共享,并整合纳税人联网开票信息、申报数据、税款收取数据、财务报表数据、重点税源报表数据、备案信息等数据信息,实时更新纳税人信息库,使纳税人时时处在金税三期强悍的监控和预警范围之内。
所以,如果有三天,税务局直接找上门来或电话问询企业税务谜团,不要认为奇怪。
随着税务机关信息化手段的不断加强、税务稽查检测人员能力素养的不断提高,未来企业的税务风险曝露机会将会越来越大,那种以违法手段达到少收税的手法将很难有生存空间,而合法(利用税收优惠政策)、合理(符合商业目的)的税务筹划将是未来企业节税的主要途径。 查看全部
那么,什么是网络爬虫呢?税务局怎么应用网路爬虫技术发觉企业的涉税谜团呢?本文将带你一步一步解开其中的奥秘。
网络爬虫称作“网页蜘蛛”,是一个手动提取网页的程序。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL装入队列,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要按照一定的网页剖析算法过滤与主题无关的链接,保留有用的链接并将其倒入等待抓取的URL队列。然后,它将按照一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止,另外,所有被爬虫抓取的网页将会被系统存储,进行一定的剖析、过滤,并构建索引,以便以后的查询和检索。
以上是引自网路专业的叙述,简单的说,“网络爬虫”是一个手动提取网页的程序,运用“网络爬虫”技术设定程序税务爬虫软件,可以按照既定的目标愈发精准选择抓取相关的网页信息,有助于在互联网海量信息中快捷获取有用的涉税信息。
税务局怎样利用网路爬虫举办工作呢?概括的说税务爬虫软件,不外乎这样几个方面:
一是有针对性的捕捉互联网上的企业相关信息;
二是利用大数据,整合其他相关涉税信息;
三是通过一系列预警指标剖析比对筛选案源;
四是构建企业交易行为轨迹,定位税收风险疑虑。
其实,网络爬虫收集的仅仅是纳税人公开在网路上的涉税信息,税务机关获取纳税人的涉税信息还有好多途径,比如,利用内部风控中心监控平台,与网路运营商、工商、统计、建设、技术监督、财政、公安、海关、金融机构、外汇管理、国土规划和货运中心等有关部门联网实现信息互通、数据互联、资源共享,并整合纳税人联网开票信息、申报数据、税款收取数据、财务报表数据、重点税源报表数据、备案信息等数据信息,实时更新纳税人信息库,使纳税人时时处在金税三期强悍的监控和预警范围之内。
所以,如果有三天,税务局直接找上门来或电话问询企业税务谜团,不要认为奇怪。
随着税务机关信息化手段的不断加强、税务稽查检测人员能力素养的不断提高,未来企业的税务风险曝露机会将会越来越大,那种以违法手段达到少收税的手法将很难有生存空间,而合法(利用税收优惠政策)、合理(符合商业目的)的税务筹划将是未来企业节税的主要途径。
Python网路爬虫之必备工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 357 次浏览 • 2020-05-03 08:01
1 Python基础知识
Python作为现今最流行的编程语言之一爬虫工具,其强悍之处也是毋庸置疑的,利用Python写网路爬虫是最好不过的选择啦,所以万丈高楼平地起,学习网路爬虫最最基本的就是要把握Python编程的基础知识,了解以下几点即可:
基本数据结构数据类型控制流函数的使用模块的使用Python学习教程推荐:
(1)廖雪峰之Python教程。具体学习网址百度一下就可以,其讲解堪称通俗易懂,学习上去特别快。
(2)Python简明教程
2 开发环境
操作系统:Windows7及以上
Python版本:Python3.x
代码开发环境:个人比较推荐PyCharm作为自己的IDE,当然你也可以按照自己的使用习惯选择代码编辑器,如Notepad++等
3 Python库
一般网路爬虫所需根据的库有:
urllib和urllib2库
这两个库是学习爬虫最基本的库,其才能将URL所指定的网路资源(HTML)获得,并可用正则表达式对其内容进行提取爬虫工具,进而得到我们想要的结果。
Pythonre模块
re模块是Python提供的用于字符串匹配非常好用的工具,其设计思想就是借助一种描述性语言来定义字符串的规则,凡是符合这一规则的字符串,则表明就匹配成功,这就是我们熟悉的正则表达式。利用re模块提供的抒发功能,我们可以很方便从爬取到的网页内容中匹配出须要的内容数据。
BeautifulSoup库
此库是一个强悍的解析文档工具箱,其才能将我们爬取的到HTML页面内容解析成一个复杂的树状结构,每一个节点都是一个Python对象,具体讲在前面给你们详尽讲解。
以上介绍都是一些基本爬取所需的库,当然假如你想做一个有深度的爬虫,还须要把握如requests库、pymongo库、selenium库等,等把握的差不多了,还可以学习一下爬虫框架Scrapy。 查看全部
网络爬虫(又被称为网页蜘蛛,网络机器人),是一种根据一定的规则,自动的抓取万维网信息的程序或则脚本。那么要学会并精通Python网络爬虫,我们须要打算什么知识和工具那?

1 Python基础知识
Python作为现今最流行的编程语言之一爬虫工具,其强悍之处也是毋庸置疑的,利用Python写网路爬虫是最好不过的选择啦,所以万丈高楼平地起,学习网路爬虫最最基本的就是要把握Python编程的基础知识,了解以下几点即可:
基本数据结构数据类型控制流函数的使用模块的使用Python学习教程推荐:
(1)廖雪峰之Python教程。具体学习网址百度一下就可以,其讲解堪称通俗易懂,学习上去特别快。
(2)Python简明教程
2 开发环境
操作系统:Windows7及以上
Python版本:Python3.x
代码开发环境:个人比较推荐PyCharm作为自己的IDE,当然你也可以按照自己的使用习惯选择代码编辑器,如Notepad++等
3 Python库
一般网路爬虫所需根据的库有:
urllib和urllib2库
这两个库是学习爬虫最基本的库,其才能将URL所指定的网路资源(HTML)获得,并可用正则表达式对其内容进行提取爬虫工具,进而得到我们想要的结果。
Pythonre模块
re模块是Python提供的用于字符串匹配非常好用的工具,其设计思想就是借助一种描述性语言来定义字符串的规则,凡是符合这一规则的字符串,则表明就匹配成功,这就是我们熟悉的正则表达式。利用re模块提供的抒发功能,我们可以很方便从爬取到的网页内容中匹配出须要的内容数据。
BeautifulSoup库
此库是一个强悍的解析文档工具箱,其才能将我们爬取的到HTML页面内容解析成一个复杂的树状结构,每一个节点都是一个Python对象,具体讲在前面给你们详尽讲解。
以上介绍都是一些基本爬取所需的库,当然假如你想做一个有深度的爬虫,还须要把握如requests库、pymongo库、selenium库等,等把握的差不多了,还可以学习一下爬虫框架Scrapy。
【Golang实现网路爬虫】分布式爬虫系统构架
采集交流 • 优采云 发表了文章 • 0 个评论 • 346 次浏览 • 2020-05-03 08:01
分布式系统是一个硬件或软件组件分布在不同的网路计算机上,彼此之间仅仅通过消息传递进行通讯和协调的系统。简单来说就是一群独立计算机集合共同对外提供服务,但是对于系统的用户来说,就像是一台计算机在提供服务一样。分布式意味着可以采用更多的普通计算机(相对于高昂的大型机)组成分布式集群对外提供服务。计算机越多,CPU、内存、存储资源等也就越多,能够处理的并发访问量也就越大。
从分布式系统的概念中我们晓得,各个主机之间通讯和协调主要通过网路进行,所以分布式系统中的计算机在空间上几乎没有任何限制,这些计算机可能被置于不同的机柜上,也可能被布署在不同的机房中,还可能在不同的城市中,对于小型的网站甚至可能分布在不同的国家和地区。
不同的资料介绍起分布式系统的特性,虽然说法不同,但都大同小异,此处我们针对于要实现的分布式爬虫,总结为以下3个特征:
消息传递完成特定需求
消息传递的方式:
分布式系统的结构图:
一般对外会使用REST,模块内部会使用RPC,效率会更高一些,模块之前:中间件、REST
针对于目前我们遇见的问题,我们给予解决方案分布式爬虫架构,来设计分布式爬虫项目的构架:
1.限流问题
问题:
单节点承受的流量是有限
解决:
将Worker放在不同的节点
2.去重问题
问题:
单节点承受的去重数据量有限
无法保存之前去重结果(因为是存入到显存(map))
解决:
基于Key-Value Stroe(如Redis)进行分布式去重
3.数据储存问题
问题:
存储部份的结构,技术栈和爬虫部份区别很大
进一步优化须要特殊的ElasticSearch技术背景
解决:
存储服务
所以最终我们的分布式爬虫构架如下:
还有一个关键点:从Channel进化到分布式
之前我们为了实现并发,使用了大量的goroutine以及Channel。那我们就可以开启一个远程的RPC服务分布式爬虫架构,然后进行同步的调用。
RPC有很多种做法,本文采用jsonrpc。
源代码 查看全部

分布式系统是一个硬件或软件组件分布在不同的网路计算机上,彼此之间仅仅通过消息传递进行通讯和协调的系统。简单来说就是一群独立计算机集合共同对外提供服务,但是对于系统的用户来说,就像是一台计算机在提供服务一样。分布式意味着可以采用更多的普通计算机(相对于高昂的大型机)组成分布式集群对外提供服务。计算机越多,CPU、内存、存储资源等也就越多,能够处理的并发访问量也就越大。
从分布式系统的概念中我们晓得,各个主机之间通讯和协调主要通过网路进行,所以分布式系统中的计算机在空间上几乎没有任何限制,这些计算机可能被置于不同的机柜上,也可能被布署在不同的机房中,还可能在不同的城市中,对于小型的网站甚至可能分布在不同的国家和地区。
不同的资料介绍起分布式系统的特性,虽然说法不同,但都大同小异,此处我们针对于要实现的分布式爬虫,总结为以下3个特征:
消息传递完成特定需求
消息传递的方式:
分布式系统的结构图:

一般对外会使用REST,模块内部会使用RPC,效率会更高一些,模块之前:中间件、REST
针对于目前我们遇见的问题,我们给予解决方案分布式爬虫架构,来设计分布式爬虫项目的构架:
1.限流问题
问题:
单节点承受的流量是有限
解决:
将Worker放在不同的节点

2.去重问题
问题:
单节点承受的去重数据量有限
无法保存之前去重结果(因为是存入到显存(map))
解决:
基于Key-Value Stroe(如Redis)进行分布式去重


3.数据储存问题
问题:
存储部份的结构,技术栈和爬虫部份区别很大
进一步优化须要特殊的ElasticSearch技术背景
解决:
存储服务

所以最终我们的分布式爬虫构架如下:

还有一个关键点:从Channel进化到分布式
之前我们为了实现并发,使用了大量的goroutine以及Channel。那我们就可以开启一个远程的RPC服务分布式爬虫架构,然后进行同步的调用。

RPC有很多种做法,本文采用jsonrpc。
源代码
网络爬虫基本原理
采集交流 • 优采云 发表了文章 • 0 个评论 • 346 次浏览 • 2020-05-03 08:00
网络爬虫基本原理23.05.2019基本描述 需要理解的算法 数据分类抓取策略 更新策略23.05.2019网络爬虫网络爬虫(又被称为网页蜘蛛,网络机器人),是一种根据一定的规则,自动的 抓取万维网信息的程序或则脚本,是搜索引擎的重要组成。传统爬虫从一个或若 干初始网页的开始,获得初始网页上的,在抓取网页的过程中,不断从当前页面 上抽取新的装入队列,直到满足系统的一定停止条件。23.05.2019聚焦爬虫传统爬虫从一个或若干初始网页的开始,获得初始网页上的,在抓取网页的过程 中,不断从当前页面上抽取新的装入队列,直到满足系统的一定停止条件。聚焦爬 虫的工作流程较为复杂,需要按照一定的网页剖析算法过滤与主题无关的链接,保留有用的链接并将其倒入等待抓取的队列。然后网络爬虫原理,它将按照一定的搜索策略从 队列中选择下一步要抓取的网页,并重复上述过程,直到达到系统的某一条件时 停止。另外,所有被爬虫抓取的网页将会被系统储存,进行一定的剖析、过滤, 并构建索引,以便以后的查询和检索;对于聚焦爬虫来说,这一过程所得到的分 析结果还可能对之后的抓取过程给出反馈和指导。23.05.2019简单流程 ::作为初始解析 网页数据 分析下载网页库种子待抓取已抓取下载网页 进入已抓取队列从队列信息中抽 取新的23.05.2019须要理解的算法.关键字匹配 :: 字符串匹配 算法(算法) 有限自动机算法 *算法.网页内容冗余 :: 卡时.大数目网页处理 :: *分布式.防止重复遍历 :: 字符串23.05.2019数据分类.已下载未过期网页 .已下载已过期网页:抓取到的网页实际上是互联网内容的一个镜像与备份,互联网是动态变化的, 一部分互联网上的内容早已发生了变化,这时,这部份抓取到的网页就过期了。
.待下载网页:也就是待抓取队列中的这些页面。 .可知网页:还没有抓取出来,也没有在待抓取队列中,但是可以通过对已抓取页面或则待 抓取对应页面进行剖析获取到的,认为是可知网页。 .不可知网页:还有一部分网页,爬虫是难以直接抓取下载的23.05.2019数据分类 ::已知网页已抓取未过期 已抓取已过期23.05.2019数据分类 ::不可知网页23.05.2019抓取策略 :: 暴力.深度优先搜索 .广度优先搜索 .大站优先策略对于待抓取队列中的所有网页,根据所属的网站进行分类。对于待下载页面数 多的网站,优先下载。这个策略也因而称作大站优先策略。23.05.2019抓取策略 :: 技巧.反向链接数策略 反向链接数是指一个网页被其他网页链接指向的数目。反向链接数表示的是一个网页的内容遭到其他人的推荐的程度。因此,很多时侯搜索引擎的抓取系统会 使用这个指标来评价网页的重要程度,从而决定不同网页的抓取先后次序。在真实的网路环境中,由于广告链接、作弊链接的存在,反向链接数不能完全 准确评价网页的重要程度。因此,搜索引擎常常考虑一些可靠的反向链接数。23.05.2019抓取策略 :: 技巧策略 算法借鉴了算法的思想。
对于早已下载的网页,连同待抓取队列中的,形成网页集合网络爬虫原理,计算每位页面的值,计算完以后,将待抓取队列中的根据值的大小排列, 并根据该次序抓取页面。策略策略 该算法实际上也是对页面进行一个重要性打分。在算法开始前,给所有页面一个相同的初始现金()。当下载了某个页面然后,将的现金平摊给所有从中剖析 出的链接,并且将的现金清空。对于待抓取队列中的所有页面根据现金数进行排 序。23.05.2019更新策略 :: 可持久化数据结构.历史参考策略 顾名思义,根据页面往年的历史更新数据,预测该页面未来何时会发生变化。一般来说,是通过泊松过程进行建模进行预测。.用户体验策略 尽管搜索引擎针对于某个查询条件才能返回数目巨大的结果,但是用户常常只关注前几页结果。因此,抓取系统可以优先更新这些现实在查询结果前几页中的 网页,而后再更新这些旁边的网页。这种更新策略也是须要用到历史信息的。用 户体验策略保留网页的多个历史版本,并且依照过去每次内容变化对搜索质量的 影响,得出一个平均值,用这个值作为决定何时重新抓取的根据。23.05.2019更新策略 :: 统计学改进.聚类抽样策略 前面提及的两种更新策略都有一个前提:需要网页的历史信息。
这样就存在两个问题:第一,系统要是为每位系统保存多个版本的历史信息,无疑降低了好多 的系统负担;第二,要是新的网页完全没有历史信息,就难以确定更新策略。而降维抽样策略觉得,网页具有好多属性,类似属性的网页,可以觉得其更新 频率也是类似的。要估算某一个类别网页的更新频度,只须要对这一类网页抽样, 以她们的更新周期作为整个类别的更新周期。23.05.2019的个人博客《这就是搜索引擎——核心技术解读》 张俊林 电子工业出版社《搜索引擎技术基础》刘奕群等 清华大学出版社23.05.2019ACM2013 查看全部

网络爬虫基本原理23.05.2019基本描述 需要理解的算法 数据分类抓取策略 更新策略23.05.2019网络爬虫网络爬虫(又被称为网页蜘蛛,网络机器人),是一种根据一定的规则,自动的 抓取万维网信息的程序或则脚本,是搜索引擎的重要组成。传统爬虫从一个或若 干初始网页的开始,获得初始网页上的,在抓取网页的过程中,不断从当前页面 上抽取新的装入队列,直到满足系统的一定停止条件。23.05.2019聚焦爬虫传统爬虫从一个或若干初始网页的开始,获得初始网页上的,在抓取网页的过程 中,不断从当前页面上抽取新的装入队列,直到满足系统的一定停止条件。聚焦爬 虫的工作流程较为复杂,需要按照一定的网页剖析算法过滤与主题无关的链接,保留有用的链接并将其倒入等待抓取的队列。然后网络爬虫原理,它将按照一定的搜索策略从 队列中选择下一步要抓取的网页,并重复上述过程,直到达到系统的某一条件时 停止。另外,所有被爬虫抓取的网页将会被系统储存,进行一定的剖析、过滤, 并构建索引,以便以后的查询和检索;对于聚焦爬虫来说,这一过程所得到的分 析结果还可能对之后的抓取过程给出反馈和指导。23.05.2019简单流程 ::作为初始解析 网页数据 分析下载网页库种子待抓取已抓取下载网页 进入已抓取队列从队列信息中抽 取新的23.05.2019须要理解的算法.关键字匹配 :: 字符串匹配 算法(算法) 有限自动机算法 *算法.网页内容冗余 :: 卡时.大数目网页处理 :: *分布式.防止重复遍历 :: 字符串23.05.2019数据分类.已下载未过期网页 .已下载已过期网页:抓取到的网页实际上是互联网内容的一个镜像与备份,互联网是动态变化的, 一部分互联网上的内容早已发生了变化,这时,这部份抓取到的网页就过期了。
.待下载网页:也就是待抓取队列中的这些页面。 .可知网页:还没有抓取出来,也没有在待抓取队列中,但是可以通过对已抓取页面或则待 抓取对应页面进行剖析获取到的,认为是可知网页。 .不可知网页:还有一部分网页,爬虫是难以直接抓取下载的23.05.2019数据分类 ::已知网页已抓取未过期 已抓取已过期23.05.2019数据分类 ::不可知网页23.05.2019抓取策略 :: 暴力.深度优先搜索 .广度优先搜索 .大站优先策略对于待抓取队列中的所有网页,根据所属的网站进行分类。对于待下载页面数 多的网站,优先下载。这个策略也因而称作大站优先策略。23.05.2019抓取策略 :: 技巧.反向链接数策略 反向链接数是指一个网页被其他网页链接指向的数目。反向链接数表示的是一个网页的内容遭到其他人的推荐的程度。因此,很多时侯搜索引擎的抓取系统会 使用这个指标来评价网页的重要程度,从而决定不同网页的抓取先后次序。在真实的网路环境中,由于广告链接、作弊链接的存在,反向链接数不能完全 准确评价网页的重要程度。因此,搜索引擎常常考虑一些可靠的反向链接数。23.05.2019抓取策略 :: 技巧策略 算法借鉴了算法的思想。
对于早已下载的网页,连同待抓取队列中的,形成网页集合网络爬虫原理,计算每位页面的值,计算完以后,将待抓取队列中的根据值的大小排列, 并根据该次序抓取页面。策略策略 该算法实际上也是对页面进行一个重要性打分。在算法开始前,给所有页面一个相同的初始现金()。当下载了某个页面然后,将的现金平摊给所有从中剖析 出的链接,并且将的现金清空。对于待抓取队列中的所有页面根据现金数进行排 序。23.05.2019更新策略 :: 可持久化数据结构.历史参考策略 顾名思义,根据页面往年的历史更新数据,预测该页面未来何时会发生变化。一般来说,是通过泊松过程进行建模进行预测。.用户体验策略 尽管搜索引擎针对于某个查询条件才能返回数目巨大的结果,但是用户常常只关注前几页结果。因此,抓取系统可以优先更新这些现实在查询结果前几页中的 网页,而后再更新这些旁边的网页。这种更新策略也是须要用到历史信息的。用 户体验策略保留网页的多个历史版本,并且依照过去每次内容变化对搜索质量的 影响,得出一个平均值,用这个值作为决定何时重新抓取的根据。23.05.2019更新策略 :: 统计学改进.聚类抽样策略 前面提及的两种更新策略都有一个前提:需要网页的历史信息。
这样就存在两个问题:第一,系统要是为每位系统保存多个版本的历史信息,无疑降低了好多 的系统负担;第二,要是新的网页完全没有历史信息,就难以确定更新策略。而降维抽样策略觉得,网页具有好多属性,类似属性的网页,可以觉得其更新 频率也是类似的。要估算某一个类别网页的更新频度,只须要对这一类网页抽样, 以她们的更新周期作为整个类别的更新周期。23.05.2019的个人博客《这就是搜索引擎——核心技术解读》 张俊林 电子工业出版社《搜索引擎技术基础》刘奕群等 清华大学出版社23.05.2019ACM2013
网络爬虫是哪些?网络爬虫是怎样工作的?
采集交流 • 优采云 发表了文章 • 0 个评论 • 412 次浏览 • 2020-05-02 08:08
摘要:一篇文章了解爬虫的前世今生与未来
什么是网络爬虫?
网络爬虫,也称为网页抓取和网页数据提取,基本上是指通过超文本传输协议(HTTP)或通过网页浏览器获取万维网上可用的数据。(摘自Wikipedia)
网络爬虫是怎样工作的?
通常,爬取网页数据时,只须要2个步骤。
打开网页→将具体的数据从网页中复制并导入到表格或数据库中。
这一切是怎么开始的?
尽管对许多人来说,网络爬虫听上去象是“大数据”或“机器学习”一类的新概念,但实际上,网络数据抓取的历史要长得多,可以溯源到万维网(或浅显的“互联网”)诞生之时。
一开始,互联网还没有搜索。在搜索引擎被开发下来之前,互联网只是文件传输协议(FTP)站点的集合,用户可以在这种站点中导航以找到特定的共享文件。
为了查找和组合互联网上可用的分布式数据,人们创建了一个自动化程序,称为网络爬虫/机器人,可以抓取互联网上的所有网页,然后将所有页面上的内容复制到数据库中制做索引。
随后,互联网发展上去,最终有数百万级的网页生成,这些网页包含大量不同的方式的数据,其中包括文本、图像、视频和音频。互联网弄成了一个开放的数据源。
随着数据资源显得十分丰富且容易搜索,人们发觉从网页上找到她们想要的信息是一件极其简单的事情,他们一般分布在大量的网站上。但另一个问题出现了,当她们想要数据的时侯,并非每位网站都提供下载按键,如果进行自动复制其实是极其低效且平庸的。
这就是网路爬虫诞生的诱因。网络爬虫实际上是由网页机器人/爬虫驱动的,其功能与搜索引擎相同。简单来说就是,抓取和复制。唯一的不同可能是规模。网络数据抓取是从特定的网站提取特定的数据,而搜索引擎一般是在万维网上搜索出大部分的网站。
时间轴
1989年万维网的诞生
从技术上讲,万维网和因特网有所不同。前者是指信息空间,后者是由数台计算机联接上去的内部网路。
感谢Tim Berners-Lee,万维网的发明者,他发明的三件东西,往后成为了我们日常生活中的一部分。
1990年第一个网络浏览器
它也由Tim Berners-Lee发明,被称为WorldWide网页(无空间),以WWW项目命名。在网路出现一年后,人们有了一条途径去浏览它并与之互动。
1991年第一个网页服务器和第一个 网页页面
网页的数目以缓慢的速率下降。到1994年,HTTP服务器的数目超过200台。
1993年6月第一台网页机器人——万维网漫游器
虽然它的功能和昨天的网页机器人一样,但它只是拿来检测网页的大小。
1993年12月首个基于爬虫的网路搜索引擎—JumpStation
由于当时网路上的网站并不多,搜索引擎过去经常依赖人工网站管理员来搜集和编辑链接,使其成为一种特定的格式。
JumpStation带来了新的飞越。它是第一个借助网路机器人的WWW搜索引擎。
从那时起,人们开始使用这种程序化的网路爬虫程序来搜集和组织互联网。从Infoseek、Altavista和Excite,到现在的必应和微软,搜索引擎机器人的核心依旧保持不变:
找到一个网页页面,下载(获取)它,抓取网页页面上显示的所有信息,然后将其添加到搜索引擎的数据库中。
由于网页页面是为人类用户设计的,不是为了自动化使用,即使开发了网页机器人,计算机工程师和科学家一直很难进行网路数据抓取,更不用说普通人了。因此,人们仍然致力于让网路爬虫显得愈发容易使用。
2000年网页API和API爬虫
API表示应用程序编程插口。它是一个插口,通过提供搭建好的模块,使开发程序愈加方便。
2000年,Salesforce和eBay推出了自己的API,程序员可以用它访问并下载一些公开数据。
从那时起,许多网站都提供网页API使人们可以访问她们的公共数据库。
发送一组HTTP请求,然后接收JSON或XML的回馈。
网页API通过搜集网站提供的数据,为开发人员提供了一种更友好的网路爬虫形式。
2004 年Python Beautiful Soup
不是所有的网站都提供API。即使她们提供了,他们也不一定会提供你想要的所有数据。因此,程序员们仍在开发一种才能建立网路爬虫的方式。
2004年,Beautiful Soup发布。它是一个为Python设计的库。
在计算机编程中,库是脚本模块的集合,就像常用的算法一样,它容许不用重画就可以使用,从而简化了编程过程。
通过简单的命令,Beautiful Soup可以理解站点的结构,并帮助从HTML容器中解析内容。它被觉得是用于网路爬虫的最复杂和最先进的库,也是现今最常见和最流行的方式之一。
2005-2006年网路抓取软件的可视化
2006年,Stefan Andresen和他的Kapow软件(Kofax于2013年竞购)发布了网页集成平台6.0版本,这是一种可视化的网路爬虫软件,它容许用户轻松简单的选择网页内容,并将这种数据构造成可用的excel文件或数据库。
八爪鱼数据采集器
最终,可视化的网路数据抓取软件可以使大量非程序员自己进行网路爬虫。
从那时起,网络抓取开始成为主流。现在,对于非程序员来说,他们可以很容易地找到80多个可提供可视化过程的的数据采集软件。
网络爬虫未来将怎样发展?
我们总是想要更多的数据。我们搜集数据,处理数据,并把数据转换成各种各样的成品,比如研究,洞察剖析,信息,故事,资产等等。我们过去经常耗费大量的时间、精力和金钱在找寻和搜集数据上,以至于只有大公司和组织能够负担得起。
在2018年,我们所知的万维网网络爬虫技术是什么,或浅显的“互联网”,由超过18亿个网站组成。只需点击几下键盘,就可以获得这么巨大的数据量。随着越来越多的人上网,每秒形成的数据也越来越多。
如今,是一个比历史上任何时期都要便捷的时代。任何个人、公司和组织都还能获得她们想要的数据,只要这种数据在网页上是公开可用的。
多亏了网路爬虫/机器人、API、标准数据库和各类开箱即用的软件,一旦有人有了获取数据的意愿,就有了获取数据的方式。或者,他们也可以求救于这些她们接触得到又支付的起费用的专业人士。
在自由职业任务平台guru.com上搜索“网络爬虫”时,你可以得到10088个搜索结果,这意味着超过10000名自由职业者在这个网站上提供网路抓取服务。
而在同类的网站,Upwork上的搜索结果有13190个,fievere.com上的结果是1024个。
各行各业的公司对网路数据的需求不断下降,推动了网路抓取行业的发展,带来了新的市场、就业机会和商业机会。
与此同时,与其他新兴行业一样,网络抓取也伴随着法律方面的疑虑。
围绕网路爬虫合法性的讨论情况仍存在。它的合法与否与具体案例背景相关。目前,这种趋势下诞生的许多有趣的法律问题一直没有得到解答,或者取决于十分具体的案例背景。
虽然网路抓取早已存在了太长一段时间,但法庭才刚才开基础大数据相关的法律理论的应用。
由于与网路爬取和数据抓取的仍处于发展阶段,所以它的发展一直未稳定出来且难以预测。然而,有一件事是肯定的,那就是,只要有互联网,就有网路抓取。
是网路抓取使新生的互联网显得可以搜索,使爆炸式下降的互联网显得愈发容易访问和获取。
毫无疑问网络爬虫技术是什么,在可预见的未来,互联网和网路抓取,将继续稳定地往前迈向。 查看全部
摘要:一篇文章了解爬虫的前世今生与未来
什么是网络爬虫?
网络爬虫,也称为网页抓取和网页数据提取,基本上是指通过超文本传输协议(HTTP)或通过网页浏览器获取万维网上可用的数据。(摘自Wikipedia)
网络爬虫是怎样工作的?
通常,爬取网页数据时,只须要2个步骤。
打开网页→将具体的数据从网页中复制并导入到表格或数据库中。
这一切是怎么开始的?
尽管对许多人来说,网络爬虫听上去象是“大数据”或“机器学习”一类的新概念,但实际上,网络数据抓取的历史要长得多,可以溯源到万维网(或浅显的“互联网”)诞生之时。
一开始,互联网还没有搜索。在搜索引擎被开发下来之前,互联网只是文件传输协议(FTP)站点的集合,用户可以在这种站点中导航以找到特定的共享文件。
为了查找和组合互联网上可用的分布式数据,人们创建了一个自动化程序,称为网络爬虫/机器人,可以抓取互联网上的所有网页,然后将所有页面上的内容复制到数据库中制做索引。
随后,互联网发展上去,最终有数百万级的网页生成,这些网页包含大量不同的方式的数据,其中包括文本、图像、视频和音频。互联网弄成了一个开放的数据源。
随着数据资源显得十分丰富且容易搜索,人们发觉从网页上找到她们想要的信息是一件极其简单的事情,他们一般分布在大量的网站上。但另一个问题出现了,当她们想要数据的时侯,并非每位网站都提供下载按键,如果进行自动复制其实是极其低效且平庸的。

这就是网路爬虫诞生的诱因。网络爬虫实际上是由网页机器人/爬虫驱动的,其功能与搜索引擎相同。简单来说就是,抓取和复制。唯一的不同可能是规模。网络数据抓取是从特定的网站提取特定的数据,而搜索引擎一般是在万维网上搜索出大部分的网站。
时间轴
1989年万维网的诞生

从技术上讲,万维网和因特网有所不同。前者是指信息空间,后者是由数台计算机联接上去的内部网路。
感谢Tim Berners-Lee,万维网的发明者,他发明的三件东西,往后成为了我们日常生活中的一部分。
1990年第一个网络浏览器
它也由Tim Berners-Lee发明,被称为WorldWide网页(无空间),以WWW项目命名。在网路出现一年后,人们有了一条途径去浏览它并与之互动。
1991年第一个网页服务器和第一个 网页页面
网页的数目以缓慢的速率下降。到1994年,HTTP服务器的数目超过200台。
1993年6月第一台网页机器人——万维网漫游器
虽然它的功能和昨天的网页机器人一样,但它只是拿来检测网页的大小。
1993年12月首个基于爬虫的网路搜索引擎—JumpStation

由于当时网路上的网站并不多,搜索引擎过去经常依赖人工网站管理员来搜集和编辑链接,使其成为一种特定的格式。
JumpStation带来了新的飞越。它是第一个借助网路机器人的WWW搜索引擎。
从那时起,人们开始使用这种程序化的网路爬虫程序来搜集和组织互联网。从Infoseek、Altavista和Excite,到现在的必应和微软,搜索引擎机器人的核心依旧保持不变:
找到一个网页页面,下载(获取)它,抓取网页页面上显示的所有信息,然后将其添加到搜索引擎的数据库中。
由于网页页面是为人类用户设计的,不是为了自动化使用,即使开发了网页机器人,计算机工程师和科学家一直很难进行网路数据抓取,更不用说普通人了。因此,人们仍然致力于让网路爬虫显得愈发容易使用。
2000年网页API和API爬虫

API表示应用程序编程插口。它是一个插口,通过提供搭建好的模块,使开发程序愈加方便。
2000年,Salesforce和eBay推出了自己的API,程序员可以用它访问并下载一些公开数据。
从那时起,许多网站都提供网页API使人们可以访问她们的公共数据库。
发送一组HTTP请求,然后接收JSON或XML的回馈。
网页API通过搜集网站提供的数据,为开发人员提供了一种更友好的网路爬虫形式。
2004 年Python Beautiful Soup

不是所有的网站都提供API。即使她们提供了,他们也不一定会提供你想要的所有数据。因此,程序员们仍在开发一种才能建立网路爬虫的方式。
2004年,Beautiful Soup发布。它是一个为Python设计的库。
在计算机编程中,库是脚本模块的集合,就像常用的算法一样,它容许不用重画就可以使用,从而简化了编程过程。
通过简单的命令,Beautiful Soup可以理解站点的结构,并帮助从HTML容器中解析内容。它被觉得是用于网路爬虫的最复杂和最先进的库,也是现今最常见和最流行的方式之一。
2005-2006年网路抓取软件的可视化
2006年,Stefan Andresen和他的Kapow软件(Kofax于2013年竞购)发布了网页集成平台6.0版本,这是一种可视化的网路爬虫软件,它容许用户轻松简单的选择网页内容,并将这种数据构造成可用的excel文件或数据库。
八爪鱼数据采集器
最终,可视化的网路数据抓取软件可以使大量非程序员自己进行网路爬虫。
从那时起,网络抓取开始成为主流。现在,对于非程序员来说,他们可以很容易地找到80多个可提供可视化过程的的数据采集软件。
网络爬虫未来将怎样发展?
我们总是想要更多的数据。我们搜集数据,处理数据,并把数据转换成各种各样的成品,比如研究,洞察剖析,信息,故事,资产等等。我们过去经常耗费大量的时间、精力和金钱在找寻和搜集数据上,以至于只有大公司和组织能够负担得起。
在2018年,我们所知的万维网网络爬虫技术是什么,或浅显的“互联网”,由超过18亿个网站组成。只需点击几下键盘,就可以获得这么巨大的数据量。随着越来越多的人上网,每秒形成的数据也越来越多。

如今,是一个比历史上任何时期都要便捷的时代。任何个人、公司和组织都还能获得她们想要的数据,只要这种数据在网页上是公开可用的。
多亏了网路爬虫/机器人、API、标准数据库和各类开箱即用的软件,一旦有人有了获取数据的意愿,就有了获取数据的方式。或者,他们也可以求救于这些她们接触得到又支付的起费用的专业人士。
在自由职业任务平台guru.com上搜索“网络爬虫”时,你可以得到10088个搜索结果,这意味着超过10000名自由职业者在这个网站上提供网路抓取服务。
而在同类的网站,Upwork上的搜索结果有13190个,fievere.com上的结果是1024个。
各行各业的公司对网路数据的需求不断下降,推动了网路抓取行业的发展,带来了新的市场、就业机会和商业机会。

与此同时,与其他新兴行业一样,网络抓取也伴随着法律方面的疑虑。
围绕网路爬虫合法性的讨论情况仍存在。它的合法与否与具体案例背景相关。目前,这种趋势下诞生的许多有趣的法律问题一直没有得到解答,或者取决于十分具体的案例背景。
虽然网路抓取早已存在了太长一段时间,但法庭才刚才开基础大数据相关的法律理论的应用。
由于与网路爬取和数据抓取的仍处于发展阶段,所以它的发展一直未稳定出来且难以预测。然而,有一件事是肯定的,那就是,只要有互联网,就有网路抓取。

是网路抓取使新生的互联网显得可以搜索,使爆炸式下降的互联网显得愈发容易访问和获取。
毫无疑问网络爬虫技术是什么,在可预见的未来,互联网和网路抓取,将继续稳定地往前迈向。
网络爬虫的完整技术体系
采集交流 • 优采云 发表了文章 • 0 个评论 • 288 次浏览 • 2020-05-02 08:08
1、网络联接层:主要有TCP Socket联接的完善、数据传输以及联接管理组成。由于目前Web服务器支持的HTTP/1.0或1.1合同,在响应爬虫的恳求以后并不会关掉TCP联接,同时HTTP/1.1支持管线模式,因此当爬虫在多次抓取一个网站的页面时,Socket联接的完善、断开及URL恳求和结果的接收须要根据一定的次序进行。在爬虫执行过程中,可能须要重新联接Web服务器的情况,为了减少域名到IP地址转换的时间,爬虫一般要支持DNS缓存。
2、页面采集层:主要包括对URL的处理大数据网络爬虫原理,从中提取域名,并根据robots规范决定URL的抓取许可,同时在面对诸多的爬行任务时,需要根据一定的搜索策略来决定URL的抓取次序。在抓取页面时大数据网络爬虫原理,如果涉及到动态页面,可能须要考虑在爬虫中实现Session机制。最终的URL命令及结果是通过HTTP合同数据包发送的,其中的腹部信息中可以指定cookie信息。
3、页面提取层:该层完成了HTML文本信息的处理,主要是从中提取超链接、正文信息等内容,因此须要根据相应的HTML编码规范进行。同时,由于不同网站对Web页面信息的编码方法并不完全相同,例如UTF8、unicode、gbk等等,在解析文本信息时须要考虑页面的编码方法。当然目前有好多的开源框架支持页面解析,包括lxml、BeautifulSoup等,需要把握一些相应的规范,例如xpath。
4、领域处理层:这是指一些特定类型爬虫须要完成的功能,对于普通爬虫而言,这层并不需要。这些领域处理主要有:主题爬虫、DeepWeb爬虫,因此须要一定的文本剖析技术来支持,包括文本动词、主题建模等。
作者编绘的《互联网大数据处理技术与应用》专著(清华大学出版社,2017)、同名公众号,专注于大数据技术的相关科学和工程知识传播,同时也为读者提供一些拓展阅读材料。欢迎选用本书做大数据相关专业的教材,有相关教学资源共享。 查看全部
这四个层次的功能原理解释如下。
1、网络联接层:主要有TCP Socket联接的完善、数据传输以及联接管理组成。由于目前Web服务器支持的HTTP/1.0或1.1合同,在响应爬虫的恳求以后并不会关掉TCP联接,同时HTTP/1.1支持管线模式,因此当爬虫在多次抓取一个网站的页面时,Socket联接的完善、断开及URL恳求和结果的接收须要根据一定的次序进行。在爬虫执行过程中,可能须要重新联接Web服务器的情况,为了减少域名到IP地址转换的时间,爬虫一般要支持DNS缓存。
2、页面采集层:主要包括对URL的处理大数据网络爬虫原理,从中提取域名,并根据robots规范决定URL的抓取许可,同时在面对诸多的爬行任务时,需要根据一定的搜索策略来决定URL的抓取次序。在抓取页面时大数据网络爬虫原理,如果涉及到动态页面,可能须要考虑在爬虫中实现Session机制。最终的URL命令及结果是通过HTTP合同数据包发送的,其中的腹部信息中可以指定cookie信息。
3、页面提取层:该层完成了HTML文本信息的处理,主要是从中提取超链接、正文信息等内容,因此须要根据相应的HTML编码规范进行。同时,由于不同网站对Web页面信息的编码方法并不完全相同,例如UTF8、unicode、gbk等等,在解析文本信息时须要考虑页面的编码方法。当然目前有好多的开源框架支持页面解析,包括lxml、BeautifulSoup等,需要把握一些相应的规范,例如xpath。
4、领域处理层:这是指一些特定类型爬虫须要完成的功能,对于普通爬虫而言,这层并不需要。这些领域处理主要有:主题爬虫、DeepWeb爬虫,因此须要一定的文本剖析技术来支持,包括文本动词、主题建模等。
作者编绘的《互联网大数据处理技术与应用》专著(清华大学出版社,2017)、同名公众号,专注于大数据技术的相关科学和工程知识传播,同时也为读者提供一些拓展阅读材料。欢迎选用本书做大数据相关专业的教材,有相关教学资源共享。
新浪博客文章采集器
采集交流 • 优采云 发表了文章 • 0 个评论 • 582 次浏览 • 2020-04-18 11:03
八爪鱼·云采集网络爬虫软件 新浪博客文章采集器新浪博客拥有好多博主文章采集,会发布好多高质量的文章,有时候,有些同事看见那些 文章之后想采集下来, 但是一篇一篇文章去复制效率很慢了,这个时侯该怎样办 呢?使用八爪鱼采集器, 只需做好规则,即可全手动地将我们的想要的文章采集 下来。本文介绍使用八爪鱼采集新浪博客文章的技巧。采集网站: 采集的内容包括:博客文章正文,标题,标签,分类,日期。步骤 1:创建新浪博客文章采集任务1)进入主界面,选择“自定义采集”八爪鱼·云采集网络爬虫软件 2)将要采集的网址 URL 复制粘贴到网站输入框中,点击“保存网址”八爪鱼·云采集网络爬虫软件 步骤 2:创建翻页循环八爪鱼·云采集网络爬虫软件 1)打开网页以后博客文章采集,打开右上角的流程按键,使制做的流程可见状态。点击页面 下方的“下一页”,如图,选择“循环点击单个链接”,翻页循环创建完成。 (可 在左上角流程中自动点击 “循环翻页” 和 “点击翻页” 几次, 测试是否正常翻页。 )2)由于步入详情页时网页加载太慢,网址仍然在绕圈状态,无法立刻执行下一 个步骤,因此在“循环翻页”的中级选项里设置“ajax 加载数据”,超时时间 设置为 5 秒,点击“确定”。
八爪鱼·云采集网络爬虫软件 步骤 3:创建列表循环1)鼠标点击列表目录中第一个博文,选择操作提示框中的“选中全部”。2)鼠标点击“循环点击每位链接”,列表循环就创建完成,并步入到第一个循 环项的详情页面。八爪鱼·云采集网络爬虫软件 由于步入详情页时网页加载太慢,网址仍然在绕圈状态,无法立刻执行下一个步 骤,因此在“点击元素”的中级选项里设置“ajax 加载数据”,AJAX 超时设置 为 3 秒,点击“确定”。八爪鱼·云采集网络爬虫软件 3)数据提取,接下来采集具体数组,分别选中页面标题、标签、分类、时间, 点击“采集该元素的文本”,并在上方流程中更改数组名称。鼠标点击正文所在的地方,点击提示框中的右下角图标,扩大选项范围,直至包 括全部正文内容。(笔者测试点击 2 下就全部包括在内了)八爪鱼·云采集网络爬虫软件 同样选择“采集该元素的文本”,修改数组名称,数据提取完毕。八爪鱼·云采集网络爬虫软件 4)由于该网站网页加载速率十分慢,所以可在流程各个步骤的中级选项里设置 “执行前等待”几秒时间,也可避免访问页面较快出现防采集问题。设置后点击 “确定”。步骤 4:新浪博客数据采集及导入1)点击左上角的“保存”,然后点击“开始采集”。
八爪鱼·云采集网络爬虫软件 选择“启动本地采集”八爪鱼·云采集网络爬虫软件 2)采集完成后,会跳出提示,选择“导出数据”,选择“合适的导入方法”, 将采集好的数据导入, 这里我们选择 excel 作为导入为格式,这个时侯新浪博客 数据就导下来了博客文章采集,数据导入后如下图八爪鱼·云采集网络爬虫软件 相关采集教程:蚂蜂窝旅游小吃文章评论采集: 搜狗微信公众号文章采集: uc 头条文章采集: 网易自媒体文章采集: 百度搜索结果抓取和采集: 新浪微博评论数据的抓取与采集方法: 八爪鱼·云采集网络爬虫软件 八爪鱼——90 万用户选择的网页数据采集器。 1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。 查看全部

八爪鱼·云采集网络爬虫软件 新浪博客文章采集器新浪博客拥有好多博主文章采集,会发布好多高质量的文章,有时候,有些同事看见那些 文章之后想采集下来, 但是一篇一篇文章去复制效率很慢了,这个时侯该怎样办 呢?使用八爪鱼采集器, 只需做好规则,即可全手动地将我们的想要的文章采集 下来。本文介绍使用八爪鱼采集新浪博客文章的技巧。采集网站: 采集的内容包括:博客文章正文,标题,标签,分类,日期。步骤 1:创建新浪博客文章采集任务1)进入主界面,选择“自定义采集”八爪鱼·云采集网络爬虫软件 2)将要采集的网址 URL 复制粘贴到网站输入框中,点击“保存网址”八爪鱼·云采集网络爬虫软件 步骤 2:创建翻页循环八爪鱼·云采集网络爬虫软件 1)打开网页以后博客文章采集,打开右上角的流程按键,使制做的流程可见状态。点击页面 下方的“下一页”,如图,选择“循环点击单个链接”,翻页循环创建完成。 (可 在左上角流程中自动点击 “循环翻页” 和 “点击翻页” 几次, 测试是否正常翻页。 )2)由于步入详情页时网页加载太慢,网址仍然在绕圈状态,无法立刻执行下一 个步骤,因此在“循环翻页”的中级选项里设置“ajax 加载数据”,超时时间 设置为 5 秒,点击“确定”。
八爪鱼·云采集网络爬虫软件 步骤 3:创建列表循环1)鼠标点击列表目录中第一个博文,选择操作提示框中的“选中全部”。2)鼠标点击“循环点击每位链接”,列表循环就创建完成,并步入到第一个循 环项的详情页面。八爪鱼·云采集网络爬虫软件 由于步入详情页时网页加载太慢,网址仍然在绕圈状态,无法立刻执行下一个步 骤,因此在“点击元素”的中级选项里设置“ajax 加载数据”,AJAX 超时设置 为 3 秒,点击“确定”。八爪鱼·云采集网络爬虫软件 3)数据提取,接下来采集具体数组,分别选中页面标题、标签、分类、时间, 点击“采集该元素的文本”,并在上方流程中更改数组名称。鼠标点击正文所在的地方,点击提示框中的右下角图标,扩大选项范围,直至包 括全部正文内容。(笔者测试点击 2 下就全部包括在内了)八爪鱼·云采集网络爬虫软件 同样选择“采集该元素的文本”,修改数组名称,数据提取完毕。八爪鱼·云采集网络爬虫软件 4)由于该网站网页加载速率十分慢,所以可在流程各个步骤的中级选项里设置 “执行前等待”几秒时间,也可避免访问页面较快出现防采集问题。设置后点击 “确定”。步骤 4:新浪博客数据采集及导入1)点击左上角的“保存”,然后点击“开始采集”。
八爪鱼·云采集网络爬虫软件 选择“启动本地采集”八爪鱼·云采集网络爬虫软件 2)采集完成后,会跳出提示,选择“导出数据”,选择“合适的导入方法”, 将采集好的数据导入, 这里我们选择 excel 作为导入为格式,这个时侯新浪博客 数据就导下来了博客文章采集,数据导入后如下图八爪鱼·云采集网络爬虫软件 相关采集教程:蚂蜂窝旅游小吃文章评论采集: 搜狗微信公众号文章采集: uc 头条文章采集: 网易自媒体文章采集: 百度搜索结果抓取和采集: 新浪微博评论数据的抓取与采集方法: 八爪鱼·云采集网络爬虫软件 八爪鱼——90 万用户选择的网页数据采集器。 1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。
免费文章采集器使用教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 442 次浏览 • 2020-04-18 11:03
八爪鱼·云采集网络爬虫软件 免费文章采集器使用教程本文介绍使用八爪鱼采集器采集网易号文章的技巧。采集网址: 网易号前身为网易订阅,是网易传媒在完成“两端”融合升级后,全新构建的自 媒体内容分发与品牌推动平台。 本文以网易号首页列表为例,大家也可以更换采 集网址采集其他列表。采集内容:文章标题,发布时间,文章正文。使用功能点:? ? 列表循环 详情采集步骤 1:创建网易号文章采集任务八爪鱼·云采集网络爬虫软件 1)进入主界面,选择“自定义采集”2)将要采集的网址 URL 复制粘贴到网站输入框中,点击“保存网址”八爪鱼·云采集网络爬虫软件 步骤 2:创建循环点击加载更多1)打开网页以后,打开右上角的流程按键,从右侧的流程展示界面推入一个循 环的步骤,如下图八爪鱼·云采集网络爬虫软件 2)然后拉到页面顶部采集器,看到加载更多按键,因为想要查看更多内容就须要循环 的点击加载更多, 所以我们就须要设置一个点击 “加载更多” 的循环步骤。 注意: 采集更多内容就须要加载更多的内容, 本篇文章仅做演示, 所以选择执行点击 “加 载更多”20 次,根据自己实际需求加减即可。八爪鱼·云采集网络爬虫软件 八爪鱼·云采集网络爬虫软件 步骤 3:创建循环点击列表采集详情1)点击文章列表的第一个和第二个标题,然后选择“循环点击每位元素”按钮, 这样就创建了一个循环点击列表命令, 当前列表页的内容就都能在采集器中见到 了。
2)然后就可以提取我们须要的文本数据了,下图提取了文本的标题、时间、正 文等三个部份的文字内容, 还须要其他的信息可以自由删节编辑。然后就可以点 击保存,开始本地采集。八爪鱼·云采集网络爬虫软件 3)点击开始采集后,采集器就开始提取数据。八爪鱼·云采集网络爬虫软件 4)采集结束后导入即可。八爪鱼·云采集网络爬虫软件 免费文章相关采集器教程:新浪博客文章采集: uc 头条文章采集: 微信公众号热门文章采集(文本+图片): 今日头条采集: 新浪微博发布内容采集: 知乎信息采集: 八爪鱼——90 万用户选择的网页数据采集器。 1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。八爪鱼·云采集网络爬虫软件 2、功能强悍文章采集工具,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能文章采集工具,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。 查看全部

八爪鱼·云采集网络爬虫软件 免费文章采集器使用教程本文介绍使用八爪鱼采集器采集网易号文章的技巧。采集网址: 网易号前身为网易订阅,是网易传媒在完成“两端”融合升级后,全新构建的自 媒体内容分发与品牌推动平台。 本文以网易号首页列表为例,大家也可以更换采 集网址采集其他列表。采集内容:文章标题,发布时间,文章正文。使用功能点:? ? 列表循环 详情采集步骤 1:创建网易号文章采集任务八爪鱼·云采集网络爬虫软件 1)进入主界面,选择“自定义采集”2)将要采集的网址 URL 复制粘贴到网站输入框中,点击“保存网址”八爪鱼·云采集网络爬虫软件 步骤 2:创建循环点击加载更多1)打开网页以后,打开右上角的流程按键,从右侧的流程展示界面推入一个循 环的步骤,如下图八爪鱼·云采集网络爬虫软件 2)然后拉到页面顶部采集器,看到加载更多按键,因为想要查看更多内容就须要循环 的点击加载更多, 所以我们就须要设置一个点击 “加载更多” 的循环步骤。 注意: 采集更多内容就须要加载更多的内容, 本篇文章仅做演示, 所以选择执行点击 “加 载更多”20 次,根据自己实际需求加减即可。八爪鱼·云采集网络爬虫软件 八爪鱼·云采集网络爬虫软件 步骤 3:创建循环点击列表采集详情1)点击文章列表的第一个和第二个标题,然后选择“循环点击每位元素”按钮, 这样就创建了一个循环点击列表命令, 当前列表页的内容就都能在采集器中见到 了。
2)然后就可以提取我们须要的文本数据了,下图提取了文本的标题、时间、正 文等三个部份的文字内容, 还须要其他的信息可以自由删节编辑。然后就可以点 击保存,开始本地采集。八爪鱼·云采集网络爬虫软件 3)点击开始采集后,采集器就开始提取数据。八爪鱼·云采集网络爬虫软件 4)采集结束后导入即可。八爪鱼·云采集网络爬虫软件 免费文章相关采集器教程:新浪博客文章采集: uc 头条文章采集: 微信公众号热门文章采集(文本+图片): 今日头条采集: 新浪微博发布内容采集: 知乎信息采集: 八爪鱼——90 万用户选择的网页数据采集器。 1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。八爪鱼·云采集网络爬虫软件 2、功能强悍文章采集工具,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能文章采集工具,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。
网站文章标题采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 784 次浏览 • 2020-04-17 11:02
八爪鱼·云采集网络爬虫软件 网站文章标题采集当我们在网站优化, 或剖析词频权重,研究站点内什么类型的文章标题是频繁出 现时, 快速的获取站点内全部的文章标题就必不可少了。量少似乎能够通过复制 粘贴解决,但量若上来了,有成千甚至上万的文章标题须要获取。那自动复制黏 贴简直就是恶梦! 此时必然要寻求更快的解决方案。如通过爬虫工具快速批量获 取文章标题。 以下用做网易号文章例演示, 通过八爪鱼这个爬虫工具去获取数据,不单单获取 文章标题,还能获取文章内容。 示例网址:步骤 1:创建网易号文章采集任务1)进入主界面,选择“自定义采集”八爪鱼·云采集网络爬虫软件 2)将要采集的网址 URL 复制粘贴到网站输入框中,点击“保存网址”八爪鱼·云采集网络爬虫软件 步骤 2:创建循环点击加载更多1)打开网页以后,打开右上角的流程按键,从右侧的流程展示界面推入一个循 环的步骤,如下图八爪鱼·云采集网络爬虫软件 2)然后拉到页面顶部,看到加载更多按键,因为想要查看更多内容就须要循环 的点击加载更多, 所以我们就须要设置一个点击 “加载更多” 的循环步骤。 注意: 采集更多内容就须要加载更多的内容, 本篇文章仅做演示, 所以选择执行点击 “加 载更多”20 次,根据自己实际需求加减即可。
八爪鱼·云采集网络爬虫软件 步骤 3:创建循环点击列表采集详情1)点击文章列表的第一个和第二个标题,然后选择“循环点击每位元素”按钮, 这样就创建了一个循环点击列表命令, 当前列表页的内容就都能在采集器中见到八爪鱼·云采集网络爬虫软件 了。2)然后就可以提取我们须要的文本数据了,下图提取了文本的标题、时间、正 文等三个部份的文字内容, 还须要其他的信息可以自由删节编辑。然后就可以点八爪鱼·云采集网络爬虫软件 击保存,开始本地采集。3)点击开始采集后,采集器就开始提取数据。八爪鱼·云采集网络爬虫软件 4)采集结束后导入即可。八爪鱼·云采集网络爬虫软件 相关采集教程:新浪新闻采集 BBC 英文文章采集 新浪博客文章采集 uc 头条文章采集 百家号爆文采集 自媒体文章怎么采集 陌陌文章爬虫使用教程 八爪鱼采集原理 八爪鱼采集器 7.0 简介 八爪鱼——90 万用户选择的网页数据采集器。八爪鱼·云采集网络爬虫软件 1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作文章采集网站,2 分钟即可快速入门。 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集文章采集网站,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云) ,满足低端付费企业用户 的须要。 查看全部
八爪鱼·云采集网络爬虫软件 网站文章标题采集当我们在网站优化, 或剖析词频权重,研究站点内什么类型的文章标题是频繁出 现时, 快速的获取站点内全部的文章标题就必不可少了。量少似乎能够通过复制 粘贴解决,但量若上来了,有成千甚至上万的文章标题须要获取。那自动复制黏 贴简直就是恶梦! 此时必然要寻求更快的解决方案。如通过爬虫工具快速批量获 取文章标题。 以下用做网易号文章例演示, 通过八爪鱼这个爬虫工具去获取数据,不单单获取 文章标题,还能获取文章内容。 示例网址:步骤 1:创建网易号文章采集任务1)进入主界面,选择“自定义采集”八爪鱼·云采集网络爬虫软件 2)将要采集的网址 URL 复制粘贴到网站输入框中,点击“保存网址”八爪鱼·云采集网络爬虫软件 步骤 2:创建循环点击加载更多1)打开网页以后,打开右上角的流程按键,从右侧的流程展示界面推入一个循 环的步骤,如下图八爪鱼·云采集网络爬虫软件 2)然后拉到页面顶部,看到加载更多按键,因为想要查看更多内容就须要循环 的点击加载更多, 所以我们就须要设置一个点击 “加载更多” 的循环步骤。 注意: 采集更多内容就须要加载更多的内容, 本篇文章仅做演示, 所以选择执行点击 “加 载更多”20 次,根据自己实际需求加减即可。
八爪鱼·云采集网络爬虫软件 步骤 3:创建循环点击列表采集详情1)点击文章列表的第一个和第二个标题,然后选择“循环点击每位元素”按钮, 这样就创建了一个循环点击列表命令, 当前列表页的内容就都能在采集器中见到八爪鱼·云采集网络爬虫软件 了。2)然后就可以提取我们须要的文本数据了,下图提取了文本的标题、时间、正 文等三个部份的文字内容, 还须要其他的信息可以自由删节编辑。然后就可以点八爪鱼·云采集网络爬虫软件 击保存,开始本地采集。3)点击开始采集后,采集器就开始提取数据。八爪鱼·云采集网络爬虫软件 4)采集结束后导入即可。八爪鱼·云采集网络爬虫软件 相关采集教程:新浪新闻采集 BBC 英文文章采集 新浪博客文章采集 uc 头条文章采集 百家号爆文采集 自媒体文章怎么采集 陌陌文章爬虫使用教程 八爪鱼采集原理 八爪鱼采集器 7.0 简介 八爪鱼——90 万用户选择的网页数据采集器。八爪鱼·云采集网络爬虫软件 1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作文章采集网站,2 分钟即可快速入门。 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集文章采集网站,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云) ,满足低端付费企业用户 的须要。
一个网站除了百度以外爬虫其爬虫是那什么呀
采集交流 • 优采云 发表了文章 • 0 个评论 • 317 次浏览 • 2020-05-06 08:02
网络爬虫根据系统结构和实现技术,大致可以分为以下几种类型:通用网路爬
虫(General Purpose Web Crawler)、聚焦网络爬虫(Focused Web
Crawler)、增量式网络爬虫(Incremental Web Crawler)、深层网络爬虫(Deep Web Crawler)。
实际的网路爬虫系统一般是几种爬虫技术相结合实现的[1]
。
通用网路爬虫
通用网路爬虫又称全网爬虫(Scalable Web
Crawler),爬行对象从一些种子 URL 扩充到整个 Web,主要为门户站点搜索引擎和小型 Web 服务提供商采集数据。
由于商业缘由,它们的技术细节甚少公布下来。
这类网路爬虫的爬行范围和数目巨大,对于爬行速率和储存空间要求较高,对于爬行页面的次序要求相对较低,同时因为待刷新的页面太多,通常采用并行工作方
式,但须要较长时间能够刷新一次页面。 虽然存在一定缺陷,通用网路爬虫适用于为搜索引擎搜索广泛的主题,有较强的应用价值[1]
。
通用网路爬虫的结构大致可以分为页面爬行模块 、页面剖析模块、链接过滤模块、页面数据库、URL 队列、初始 URL 集合几个部份。为提升工作效率,通用网路爬虫会采取一定的爬行策略。 常用的爬行策略有:深度优先策略、广度优先策略[1]
。
1)
深度优先策略:其基本方式是根据深度由低到高的次序,依次访问下一级网页链接,直到不能再深入为止。
爬虫在完成一个爬行分支后返回到上一链接节点进一步搜索其它链接。 当所有链接遍历完后e799bee5baa6e79fa5e98193e78988e69d8331333361313931,爬行任务结束。 这种策略比较适宜垂直搜索或站内搜索,
但爬行页面内容层次较深的站点时会导致资源的巨大浪费[1]
。
2)
广度优先策略:此策略根据网页内容目录层次深浅来爬行页面百度网络爬虫,处于较浅目录层次的页面首先被爬行。
当同一层次中的页面爬行完毕后,爬虫再深入下一层继续爬行。
这种策略才能有效控制页面的爬行深度,避免碰到一个无穷深层分支时未能结束爬行的问题百度网络爬虫,实现便捷,无需储存大量中间节点,不足之处在于需较长时间能够爬行
到目录层次较深的页面[1]
。
聚焦网络爬虫
聚焦网络爬虫(Focused
Crawler),又称主题网路爬虫(Topical Crawler),是指选择性地爬行这些与预先定义好的主题相关页面的网路爬虫[8]。
和通用网路爬虫相比,聚焦爬虫只须要爬行与主题相关的页面,极大地节约了硬件和网路资源,保存的页面也因为数目少而更新快,还可以挺好地满足一些特定人群
对特定领域信息的需求[1]
。
聚焦网络爬虫和通用网路爬虫相比,增加了链接评价模块以及内容评价模块。聚焦爬虫爬行策略实现的关键是评价页面内容和链接的重要性,不同的方式估算出的重要性不同,由此引起链接的访问次序也不同[1]
。
1)
基于内容评价的爬行策略:DeBra将文本相似度的估算方式引入到网路爬虫中,提出了 Fish Search
算法,它将用户输入的查询词作为主题,包含查询词的页面被视为与主题相关,其局限性在于难以评价页面与主题相关 度 的 高 低 。
Herseovic对 Fish Search 算 法 进 行 了 改 进 ,提 出 了 Sharksearch
算法,利用空间向量模型估算页面与主题的相关度大小[1]
。
2) 基于链接结构评价的爬行策略 :Web
页面作为一种半结构化文档,包含好多结构信息,可拿来评价链接重要性。 PageRank
算法最初用于搜索引擎信息检索中对查询结果进行排序,也可用于评价链接重要性,具体做法就是每次选择 PageRank 值较大页面中的链接来访问。
另一个借助 Web结构评价链接价值的方式是 HITS 方法,它通过估算每位已访问页面的 Authority 权重和 Hub
权重,并借此决定链接的访问次序[1]
。
3) 基于提高学习的爬行策略:Rennie 和 McCallum 将提高学习引入聚焦爬虫,利用贝叶斯分类器,根据整个网页文本和链接文本对超链接进行分类,为每位链接估算出重要性,从而决定链接的访问次序[1]
。
4) 基于语境图的爬行策略:Diligenti
等人提出了一种通过构建语境图(Context Graphs)学习网页之间的相关度,训练一个机器学习系统,通过该系统可估算当前页面到相关 Web
页面的距离,距离越逾的页面中的链接优先访问。印度理工大学(IIT)和 IBM 研究中心的研究人员开发了一个典型的聚焦网路爬虫。
该爬虫对主题的定义既不是采用关键词也不是加权矢量,而是一组具有相同主题的网页。
它包含两个重要模块:一个是分类器,用来估算所爬行的页面与主题的相关度,确定是否与主题相关;另一个是净化器,用来辨识通过较少链接联接到大量相关页面
的中心页面[1]
。
增量式网络爬虫
增量式网络爬虫(Incremental Web Crawler)是 指
对 已 下 载 网 页 采 取 增 量式更新和只爬行新形成的或则早已发生变化网页的爬虫,它还能在一定程度上保证所爬行的页面是尽可能新的页面。
和周期性爬行和刷新页面的网路爬虫相比,增量式爬虫只会在须要的时侯爬行新形成或发生更新的页面
,并不重新下载没有发生变化的页面,可有效降低数据下载量,及时更新已爬行的网页,减小时间和空间上的花费,但是降低了爬行算法的复杂度和实现难度。增量
式网路爬虫的体系结构[包含爬行模块、排序模块、更新模块、本地页面集、待爬行 URL 集以及本地页面URL 集[1]
。
增量式爬虫有两个目标:保持本地页面集中储存的页面为最新页面和提升本地
页面集中页面的质量。 为实现第一个目标,增量式爬虫须要通过重新访问网页来更新本地页面集中页面内容,常用的方式有:1)
统一更新法:爬虫以相同的频度访问所有网页,不考虑网页的改变频度;2) 个体更新法:爬虫依据个体网页的改变频度来重新访问各页面;3)
基于分类的更新法:爬虫依照网页改变频度将其分为更新较快网页子集和更新较慢网页子集两类,然后以不同的频度访问这两类网页[1]
。
为实现第二个目标,增量式爬虫须要对网页的重要性排序,常用的策略有:广
度优先策略、PageRank 优先策略等。IBM 开发的
WebFountain是一个功能强悍的增量式网路爬虫,它采用一个优化模型控制爬行过程,并没有对页面变化过程做任何统计假定,而是采用一种自适应的方
法依照当初爬行周期里爬行结果和网页实际变化速率对页面更新频度进行调整。北京大学的天网增量爬行系统致力爬行国外
Web,将网页分为变化网页和新网页两类,分别采用不同爬行策略。
为减轻对大量网页变化历史维护造成的性能困局,它依据网页变化时间局部性规律,在短时期内直接爬行多次变化的网页
,为尽早获取新网页,它借助索引型网页跟踪新出现网页[1]
。
Deep Web 爬虫
Web 页面按存在形式可以分为表层网页(Surface
Web)和深层网页(Deep Web,也称 Invisible Web Pages 或 Hidden Web)。
表层网页是指传统搜索引擎可以索引的页面,以超链接可以抵达的静态网页为主构成的 Web 页面。Deep Web
是这些大部分内容不能通过静态链接获取的、隐藏在搜索表单后的,只有用户递交一些关键词能够获得的 Web
页面。例如这些用户注册后内容才可见的网页就属于 Deep Web。 2000 年 Bright Planet 指出:Deep Web
中可访问信息容量是 Surface Web 的几百倍,是互联网上最大、发展最快的新型信息资源[1]
。
Deep Web 爬虫体系结构包含六个基本功能模块
(爬行控制器、解析器、表单分析器、表单处理器、响应分析器、LVS 控制器)和两个爬虫内部数据结构(URL 列表、LVS 表)。 其中
LVS(Label Value Set)表示标签/数值集合,用来表示填充表单的数据源[1]
。
Deep Web 爬虫爬行过程中最重要部份就是表单填写,包含两种类型:
1)
基于领域知识的表单填写:此方式通常会维持一个本体库,通过语义剖析来选定合适的关键词填写表单。 Yiyao Lu[25]等人提出一种获取 Form
表单信息的多注解方式,将数据表单按语义分配到各个组中
,对每组从多方面注解,结合各类注解结果来预测一个最终的注解标签;郑冬冬等人借助一个预定义的领域本体知识库来辨识 Deep Web 页面内容,
同时借助一些来自 Web 站点导航模式来辨识手动填写表单时所需进行的路径导航[1]
。
2) 基于网页结构剖析的表单填写:
此方式通常无领域知识或仅有有限的领域知识,将网页表单表示成 DOM 树,从中提取表单各数组值。 Desouky 等人提出一种 LEHW
方法,该方式将 HTML 网页表示为DOM 树方式,将表单分辨为单属性表单和多属性表单,分别进行处理;孙彬等人提出一种基于 XQuery
的搜索系统,它就能模拟表单和特殊页面标记切换,把网页关键字切换信息描述为三元组单元,按照一定规则排除无效表单,将 Web 文档构造成 DOM
树,利用 XQuery 将文字属性映射到表单数组[1]
。
Raghavan 等人提出的 HIWE 系统中,爬行管理器负责管理整个爬行过程,分析下载的页面,将包含表单的页面递交表单处理器处理,表单处理器先从页面中提取表单,从预先打算好的数据集中选择数据手动填充并递交表单,由爬行控制器下载相应的结果页面[1]
。 查看全部
网络爬虫根据系统结构和实现技术,大致可以分为以下几种类型:通用网路爬
虫(General Purpose Web Crawler)、聚焦网络爬虫(Focused Web
Crawler)、增量式网络爬虫(Incremental Web Crawler)、深层网络爬虫(Deep Web Crawler)。
实际的网路爬虫系统一般是几种爬虫技术相结合实现的[1]
。
通用网路爬虫
通用网路爬虫又称全网爬虫(Scalable Web
Crawler),爬行对象从一些种子 URL 扩充到整个 Web,主要为门户站点搜索引擎和小型 Web 服务提供商采集数据。
由于商业缘由,它们的技术细节甚少公布下来。
这类网路爬虫的爬行范围和数目巨大,对于爬行速率和储存空间要求较高,对于爬行页面的次序要求相对较低,同时因为待刷新的页面太多,通常采用并行工作方
式,但须要较长时间能够刷新一次页面。 虽然存在一定缺陷,通用网路爬虫适用于为搜索引擎搜索广泛的主题,有较强的应用价值[1]
。
通用网路爬虫的结构大致可以分为页面爬行模块 、页面剖析模块、链接过滤模块、页面数据库、URL 队列、初始 URL 集合几个部份。为提升工作效率,通用网路爬虫会采取一定的爬行策略。 常用的爬行策略有:深度优先策略、广度优先策略[1]
。
1)
深度优先策略:其基本方式是根据深度由低到高的次序,依次访问下一级网页链接,直到不能再深入为止。
爬虫在完成一个爬行分支后返回到上一链接节点进一步搜索其它链接。 当所有链接遍历完后e799bee5baa6e79fa5e98193e78988e69d8331333361313931,爬行任务结束。 这种策略比较适宜垂直搜索或站内搜索,
但爬行页面内容层次较深的站点时会导致资源的巨大浪费[1]
。
2)
广度优先策略:此策略根据网页内容目录层次深浅来爬行页面百度网络爬虫,处于较浅目录层次的页面首先被爬行。
当同一层次中的页面爬行完毕后,爬虫再深入下一层继续爬行。
这种策略才能有效控制页面的爬行深度,避免碰到一个无穷深层分支时未能结束爬行的问题百度网络爬虫,实现便捷,无需储存大量中间节点,不足之处在于需较长时间能够爬行
到目录层次较深的页面[1]
。
聚焦网络爬虫
聚焦网络爬虫(Focused
Crawler),又称主题网路爬虫(Topical Crawler),是指选择性地爬行这些与预先定义好的主题相关页面的网路爬虫[8]。
和通用网路爬虫相比,聚焦爬虫只须要爬行与主题相关的页面,极大地节约了硬件和网路资源,保存的页面也因为数目少而更新快,还可以挺好地满足一些特定人群
对特定领域信息的需求[1]
。
聚焦网络爬虫和通用网路爬虫相比,增加了链接评价模块以及内容评价模块。聚焦爬虫爬行策略实现的关键是评价页面内容和链接的重要性,不同的方式估算出的重要性不同,由此引起链接的访问次序也不同[1]
。
1)
基于内容评价的爬行策略:DeBra将文本相似度的估算方式引入到网路爬虫中,提出了 Fish Search
算法,它将用户输入的查询词作为主题,包含查询词的页面被视为与主题相关,其局限性在于难以评价页面与主题相关 度 的 高 低 。
Herseovic对 Fish Search 算 法 进 行 了 改 进 ,提 出 了 Sharksearch
算法,利用空间向量模型估算页面与主题的相关度大小[1]
。
2) 基于链接结构评价的爬行策略 :Web
页面作为一种半结构化文档,包含好多结构信息,可拿来评价链接重要性。 PageRank
算法最初用于搜索引擎信息检索中对查询结果进行排序,也可用于评价链接重要性,具体做法就是每次选择 PageRank 值较大页面中的链接来访问。
另一个借助 Web结构评价链接价值的方式是 HITS 方法,它通过估算每位已访问页面的 Authority 权重和 Hub
权重,并借此决定链接的访问次序[1]
。
3) 基于提高学习的爬行策略:Rennie 和 McCallum 将提高学习引入聚焦爬虫,利用贝叶斯分类器,根据整个网页文本和链接文本对超链接进行分类,为每位链接估算出重要性,从而决定链接的访问次序[1]
。
4) 基于语境图的爬行策略:Diligenti
等人提出了一种通过构建语境图(Context Graphs)学习网页之间的相关度,训练一个机器学习系统,通过该系统可估算当前页面到相关 Web
页面的距离,距离越逾的页面中的链接优先访问。印度理工大学(IIT)和 IBM 研究中心的研究人员开发了一个典型的聚焦网路爬虫。
该爬虫对主题的定义既不是采用关键词也不是加权矢量,而是一组具有相同主题的网页。
它包含两个重要模块:一个是分类器,用来估算所爬行的页面与主题的相关度,确定是否与主题相关;另一个是净化器,用来辨识通过较少链接联接到大量相关页面
的中心页面[1]
。
增量式网络爬虫
增量式网络爬虫(Incremental Web Crawler)是 指
对 已 下 载 网 页 采 取 增 量式更新和只爬行新形成的或则早已发生变化网页的爬虫,它还能在一定程度上保证所爬行的页面是尽可能新的页面。
和周期性爬行和刷新页面的网路爬虫相比,增量式爬虫只会在须要的时侯爬行新形成或发生更新的页面
,并不重新下载没有发生变化的页面,可有效降低数据下载量,及时更新已爬行的网页,减小时间和空间上的花费,但是降低了爬行算法的复杂度和实现难度。增量
式网路爬虫的体系结构[包含爬行模块、排序模块、更新模块、本地页面集、待爬行 URL 集以及本地页面URL 集[1]
。
增量式爬虫有两个目标:保持本地页面集中储存的页面为最新页面和提升本地
页面集中页面的质量。 为实现第一个目标,增量式爬虫须要通过重新访问网页来更新本地页面集中页面内容,常用的方式有:1)
统一更新法:爬虫以相同的频度访问所有网页,不考虑网页的改变频度;2) 个体更新法:爬虫依据个体网页的改变频度来重新访问各页面;3)
基于分类的更新法:爬虫依照网页改变频度将其分为更新较快网页子集和更新较慢网页子集两类,然后以不同的频度访问这两类网页[1]
。
为实现第二个目标,增量式爬虫须要对网页的重要性排序,常用的策略有:广
度优先策略、PageRank 优先策略等。IBM 开发的
WebFountain是一个功能强悍的增量式网路爬虫,它采用一个优化模型控制爬行过程,并没有对页面变化过程做任何统计假定,而是采用一种自适应的方
法依照当初爬行周期里爬行结果和网页实际变化速率对页面更新频度进行调整。北京大学的天网增量爬行系统致力爬行国外
Web,将网页分为变化网页和新网页两类,分别采用不同爬行策略。
为减轻对大量网页变化历史维护造成的性能困局,它依据网页变化时间局部性规律,在短时期内直接爬行多次变化的网页
,为尽早获取新网页,它借助索引型网页跟踪新出现网页[1]
。
Deep Web 爬虫
Web 页面按存在形式可以分为表层网页(Surface
Web)和深层网页(Deep Web,也称 Invisible Web Pages 或 Hidden Web)。
表层网页是指传统搜索引擎可以索引的页面,以超链接可以抵达的静态网页为主构成的 Web 页面。Deep Web
是这些大部分内容不能通过静态链接获取的、隐藏在搜索表单后的,只有用户递交一些关键词能够获得的 Web
页面。例如这些用户注册后内容才可见的网页就属于 Deep Web。 2000 年 Bright Planet 指出:Deep Web
中可访问信息容量是 Surface Web 的几百倍,是互联网上最大、发展最快的新型信息资源[1]
。
Deep Web 爬虫体系结构包含六个基本功能模块
(爬行控制器、解析器、表单分析器、表单处理器、响应分析器、LVS 控制器)和两个爬虫内部数据结构(URL 列表、LVS 表)。 其中
LVS(Label Value Set)表示标签/数值集合,用来表示填充表单的数据源[1]
。
Deep Web 爬虫爬行过程中最重要部份就是表单填写,包含两种类型:
1)
基于领域知识的表单填写:此方式通常会维持一个本体库,通过语义剖析来选定合适的关键词填写表单。 Yiyao Lu[25]等人提出一种获取 Form
表单信息的多注解方式,将数据表单按语义分配到各个组中
,对每组从多方面注解,结合各类注解结果来预测一个最终的注解标签;郑冬冬等人借助一个预定义的领域本体知识库来辨识 Deep Web 页面内容,
同时借助一些来自 Web 站点导航模式来辨识手动填写表单时所需进行的路径导航[1]
。
2) 基于网页结构剖析的表单填写:
此方式通常无领域知识或仅有有限的领域知识,将网页表单表示成 DOM 树,从中提取表单各数组值。 Desouky 等人提出一种 LEHW
方法,该方式将 HTML 网页表示为DOM 树方式,将表单分辨为单属性表单和多属性表单,分别进行处理;孙彬等人提出一种基于 XQuery
的搜索系统,它就能模拟表单和特殊页面标记切换,把网页关键字切换信息描述为三元组单元,按照一定规则排除无效表单,将 Web 文档构造成 DOM
树,利用 XQuery 将文字属性映射到表单数组[1]
。
Raghavan 等人提出的 HIWE 系统中,爬行管理器负责管理整个爬行过程,分析下载的页面,将包含表单的页面递交表单处理器处理,表单处理器先从页面中提取表单,从预先打算好的数据集中选择数据手动填充并递交表单,由爬行控制器下载相应的结果页面[1]
。
利用网路爬虫技术快速确切寻觅目的图书的方式
采集交流 • 优采云 发表了文章 • 0 个评论 • 289 次浏览 • 2020-05-04 08:07
【专利摘要】本发明公开了一种借助网路爬虫技术快速确切找寻目的图书的方式,流程如下:录入电子图书构建电子图书库,将录入的图书分类装入不同的子网页中,输入须要阅读图书的关键词,利用网路爬虫技术对与目的图书有关的图书网页进行抓取,对抓取得网页进行剖析,分析后输出过滤后的图书,选择目的图书进行阅读。本发明电子图书库可以即时的录入新的电子图书,保证了该电子图书馆图书的图书种类的丰富性,采用网路爬虫技术获取目的图书愈发迅确切图书的种类仅限于文字类网络爬虫书籍,也有图片类,视频类等,该方式除了适用于电子图书馆,也适用于电子图书网站,将会为电子图书的发展带来一定的推动。
【专利说明】利用网路爬虫技术快速确切找寻目的图书的方式
发明领域
[0001]本发明涉及一种阅读电子图书过程中确切快速选购目的图书的方式,属于网路【技术领域】。
【背景技术】
[0002]电子图书馆,是随着电版物的出现,网络通信技术的发展,而渐渐出现的。电子图书馆,具有储存能力大、速度快、保存时间长、成本低、便于交流等特性。光盘这一海量存储器、能够储存比传统图书高几千倍的信息,比微缩胶卷要多得多,而且包括图像、视频、声音,等等。利用电子技术,在这一种图书馆,我们能很快地从浩如烟海的图书中,查找到自己所须要的信息资料。这种图书馆,保存信息量的时间要长得多,不存在腐烂、生虫等问题。利用网路,在远在几千里、万里的单位、家中,都可以使用这些图书,效率极高。在广袤的书海中,想要快速确切的找到目标图书并不是这么容易,为我们阅读电子图书带来了一定的困难,阻碍了电子图书的发展。
【发明内容】
[0003]本发明为解决目前在电子图书馆中快速找寻目的图书的问题,提供一种借助网路爬虫技术快速确切寻觅目的图书的方式。本发明包括以下步骤:
[0004]步骤一:录入电子图书构建电子图书库;
[0005]步骤二:将录入的图书分类装入不同的子网页中;
[0006]步骤三:输入须要阅读图书的关键词;
[0007]步骤四:利用网路爬虫技术对与目的图书有关的图书网页进行抓取;
[0008]步骤五:对抓取得网页进行剖析;
[0009]步骤六:分析后输出过滤后的图书,选择目的图书进行阅读。
[0010]发明疗效:本发明电子图书库可以即时的录入新的电子图书,保证了该电子图书馆图书的图书种类的丰富性,采用网路爬虫技术获取目的图书愈发迅确切图书的种类仅限于文字类,也有图片类,视频类等,该方式除了适用于电子图书馆,也适用于电子图书网站,将会为电子图书的发展带来一定的推动。
【专利附图】
【附图说明】
[0011]图1为借助网路爬虫技术快速确切找寻目的图书方式的流程图。
【具体施行方法】
[0012]【具体施行方法】:参见借助网路爬虫技术快速确切找寻目的图书方式的流程图1,本施行方法由以下步骤组成:
[0013]步骤一:录入电子图书构建电子图书库;
[0014]步骤二:将录入的图书分类装入不同的子网页中;[0015]步骤三:输入须要阅读图书的关键词;
[0016]步骤四:利用网路爬虫技术对与目的图书有关的图书网页进行抓取;
[0017]步骤五:对抓取得网页进行剖析;
[0018]步骤六:分析后输出过滤后的图书,选择目的图书进行阅读。
[0019]录入的电子图书必须对其按图书的种类对其进行命名,录入的图书的子网页早已录入图书的种类赋于了不同的域名,收索须要的电子图书须要输入该图书的图书名,或所属的学科种类,网络爬虫对目的图书的收索是快速抓取目的图书的网页,在对网页上的图书进行抓取,对抓取得网页进行剖析,主要是剖析出与输入图书最接近的图书。
[0020]对于本领域技术人员而言,显然本发明不限于上述示范性施行例的细节,而且在不背离本发明的精神或基本特点的情况下,能够以其他的具体方式实现本发明。因此网络爬虫书籍,无论从哪一点来看,均应将发明例看作是示范性的,而且是非限制性的,本发明的范围由所附权力要求而不是上述说明限定,因此借以将落在权力要求的等同要件的含意和范围内的所有变化涵盖在本发明内。不应将权力要求中的任何附图标记视为限制所涉及的权力要求。
【权利要求】
1.一种借助网路爬虫技术快速确切找寻目的图书的方式,其特点在于它由以下步骤实现: 步骤一:录入电子图书,建立电子图书库; 步骤二:将录入的图书分类装入不同的子网页中; 步骤三:输入须要阅读图书的关键词; 步骤四:利用网路爬虫技术对与目的图书有关的图书网页进行抓取; 步骤五:对抓取得网页进行剖析; 步骤六:分析后输出过滤后的图书,选择目的图书进行阅读。
2.根据权力要求书I所述一种借助网路爬虫技术快速确切找寻目的图书的方式,其特点在于:步骤二中所述录入的电子图书必须对其按图书的种类对其进行命名。
3.根据权力要求书I所述一种借助网路爬虫技术快速确切找寻目的图书的方式,其特点在于:步骤一中所述录入的图书的子网页早已录入图书的种类赋于了不同的域名。
4.根据权力要求书I所述一种借助网路爬虫技术快速确切找寻目的图书的方式,其特点在于:步骤一中所述收索须要的电子图书须要输入该图书的图书名,或所属的学科种类。
5.根据权力要求书I所述一种借助网路爬虫技术快速确切找寻目的图书的方式,其特点在于:步骤一中所述网路爬虫对目的图书的收索是快速抓取目的图书的网页,在对网页上的图书进行抓取。
6.根据权力要求书I所述一种借助网路爬虫技术快速确切找寻目的图书的方式,其特点在于:步骤一中所述对抓取得网页进行剖析,主要是剖析出与输入图书最接近的图书。
【文档编号】G06F17/30GK103744945SQ201310754637
【公开日】2014年4月23日 申请日期:2013年12月31日 优先权日:2013年12月31日
【发明者】朱龙腾 申请人:上海伯释信息科技有限公司 查看全部
利用网路爬虫技术快速确切寻觅目的图书的方式
【专利摘要】本发明公开了一种借助网路爬虫技术快速确切找寻目的图书的方式,流程如下:录入电子图书构建电子图书库,将录入的图书分类装入不同的子网页中,输入须要阅读图书的关键词,利用网路爬虫技术对与目的图书有关的图书网页进行抓取,对抓取得网页进行剖析,分析后输出过滤后的图书,选择目的图书进行阅读。本发明电子图书库可以即时的录入新的电子图书,保证了该电子图书馆图书的图书种类的丰富性,采用网路爬虫技术获取目的图书愈发迅确切图书的种类仅限于文字类网络爬虫书籍,也有图片类,视频类等,该方式除了适用于电子图书馆,也适用于电子图书网站,将会为电子图书的发展带来一定的推动。
【专利说明】利用网路爬虫技术快速确切找寻目的图书的方式
发明领域
[0001]本发明涉及一种阅读电子图书过程中确切快速选购目的图书的方式,属于网路【技术领域】。
【背景技术】
[0002]电子图书馆,是随着电版物的出现,网络通信技术的发展,而渐渐出现的。电子图书馆,具有储存能力大、速度快、保存时间长、成本低、便于交流等特性。光盘这一海量存储器、能够储存比传统图书高几千倍的信息,比微缩胶卷要多得多,而且包括图像、视频、声音,等等。利用电子技术,在这一种图书馆,我们能很快地从浩如烟海的图书中,查找到自己所须要的信息资料。这种图书馆,保存信息量的时间要长得多,不存在腐烂、生虫等问题。利用网路,在远在几千里、万里的单位、家中,都可以使用这些图书,效率极高。在广袤的书海中,想要快速确切的找到目标图书并不是这么容易,为我们阅读电子图书带来了一定的困难,阻碍了电子图书的发展。
【发明内容】
[0003]本发明为解决目前在电子图书馆中快速找寻目的图书的问题,提供一种借助网路爬虫技术快速确切寻觅目的图书的方式。本发明包括以下步骤:
[0004]步骤一:录入电子图书构建电子图书库;
[0005]步骤二:将录入的图书分类装入不同的子网页中;
[0006]步骤三:输入须要阅读图书的关键词;
[0007]步骤四:利用网路爬虫技术对与目的图书有关的图书网页进行抓取;
[0008]步骤五:对抓取得网页进行剖析;
[0009]步骤六:分析后输出过滤后的图书,选择目的图书进行阅读。
[0010]发明疗效:本发明电子图书库可以即时的录入新的电子图书,保证了该电子图书馆图书的图书种类的丰富性,采用网路爬虫技术获取目的图书愈发迅确切图书的种类仅限于文字类,也有图片类,视频类等,该方式除了适用于电子图书馆,也适用于电子图书网站,将会为电子图书的发展带来一定的推动。
【专利附图】
【附图说明】
[0011]图1为借助网路爬虫技术快速确切找寻目的图书方式的流程图。
【具体施行方法】
[0012]【具体施行方法】:参见借助网路爬虫技术快速确切找寻目的图书方式的流程图1,本施行方法由以下步骤组成:
[0013]步骤一:录入电子图书构建电子图书库;
[0014]步骤二:将录入的图书分类装入不同的子网页中;[0015]步骤三:输入须要阅读图书的关键词;
[0016]步骤四:利用网路爬虫技术对与目的图书有关的图书网页进行抓取;
[0017]步骤五:对抓取得网页进行剖析;
[0018]步骤六:分析后输出过滤后的图书,选择目的图书进行阅读。
[0019]录入的电子图书必须对其按图书的种类对其进行命名,录入的图书的子网页早已录入图书的种类赋于了不同的域名,收索须要的电子图书须要输入该图书的图书名,或所属的学科种类,网络爬虫对目的图书的收索是快速抓取目的图书的网页,在对网页上的图书进行抓取,对抓取得网页进行剖析,主要是剖析出与输入图书最接近的图书。
[0020]对于本领域技术人员而言,显然本发明不限于上述示范性施行例的细节,而且在不背离本发明的精神或基本特点的情况下,能够以其他的具体方式实现本发明。因此网络爬虫书籍,无论从哪一点来看,均应将发明例看作是示范性的,而且是非限制性的,本发明的范围由所附权力要求而不是上述说明限定,因此借以将落在权力要求的等同要件的含意和范围内的所有变化涵盖在本发明内。不应将权力要求中的任何附图标记视为限制所涉及的权力要求。
【权利要求】
1.一种借助网路爬虫技术快速确切找寻目的图书的方式,其特点在于它由以下步骤实现: 步骤一:录入电子图书,建立电子图书库; 步骤二:将录入的图书分类装入不同的子网页中; 步骤三:输入须要阅读图书的关键词; 步骤四:利用网路爬虫技术对与目的图书有关的图书网页进行抓取; 步骤五:对抓取得网页进行剖析; 步骤六:分析后输出过滤后的图书,选择目的图书进行阅读。
2.根据权力要求书I所述一种借助网路爬虫技术快速确切找寻目的图书的方式,其特点在于:步骤二中所述录入的电子图书必须对其按图书的种类对其进行命名。
3.根据权力要求书I所述一种借助网路爬虫技术快速确切找寻目的图书的方式,其特点在于:步骤一中所述录入的图书的子网页早已录入图书的种类赋于了不同的域名。
4.根据权力要求书I所述一种借助网路爬虫技术快速确切找寻目的图书的方式,其特点在于:步骤一中所述收索须要的电子图书须要输入该图书的图书名,或所属的学科种类。
5.根据权力要求书I所述一种借助网路爬虫技术快速确切找寻目的图书的方式,其特点在于:步骤一中所述网路爬虫对目的图书的收索是快速抓取目的图书的网页,在对网页上的图书进行抓取。
6.根据权力要求书I所述一种借助网路爬虫技术快速确切找寻目的图书的方式,其特点在于:步骤一中所述对抓取得网页进行剖析,主要是剖析出与输入图书最接近的图书。
【文档编号】G06F17/30GK103744945SQ201310754637
【公开日】2014年4月23日 申请日期:2013年12月31日 优先权日:2013年12月31日
【发明者】朱龙腾 申请人:上海伯释信息科技有限公司
关键词采集方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 660 次浏览 • 2020-05-04 08:07
八爪鱼·云采集网络爬虫软件 3)创建好循环文本输入后, 点击页面上的搜索框, 创建输入文本的步骤, 注意, 不需要输入任何文本即可,若是手动生成的是在循环外边,拖入进去,再勾选循 环即可。八爪鱼·云采集网络爬虫软件 4)右键选择页面上的搜索按键,设置好点击元素,这样,循环文本输入就设置 好了,流程下方就是搜索下来的长尾关键词。步骤 3:创建数字翻页1)由于该搜索结果页面没有下一页按键,只有数字页数,所以我们须要用到 xpath 的一些相关知识,来设置特殊的数字翻页。首先去火狐浏览器里把该网页 打开并搜索相应关键词后,打开浏览器右上角的 firebug 工具--小瓢虫(不懂的 同学可以去官网教程看一下相应的 xpath 教程)八爪鱼·云采集网络爬虫软件 2)翻到页面下方输入关键词采集文章, 找到数字位置的源码, 可以看见当前页面的数字跟其他数字, 在源码里节点的属性 class 是有所不同的八爪鱼·云采集网络爬虫软件 3)收 益 我 们 首 先 定 位 到 该 页 面 的 数 字 位 置 , 手 写 xpath : //div[@id="page"]/a[contains(@class,'current')]八爪鱼·云采集网络爬虫软件 4)再利用固定函数 following-sibling 来定位到该节点后的第一个同类节点, 注意,该函数前面接::是固定格式,a[1]是指该节点后的第一个同类节点八爪鱼·云采集网络爬虫软件 5)可以查看翻页后还是正常定位到下一页的数字上,说明该 xpath 没有问题6)再回到八爪鱼, 在两侧流程页面拖一个循环进来, 高级选项里选择单个元素, 并把 xpath 放入进去,点确定保存好八爪鱼·云采集网络爬虫软件 7)再从左边拖一个点击元素进来,并在中级选项里勾选好循环,特殊数字翻页 循环就创建好了八爪鱼·云采集网络爬虫软件 步骤 4:创建循环列表1)我们安装常规方式创建循环列表,发现,由于搜索结果后的表格中出现了这 个无用的一整行信息。
八爪鱼·云采集网络爬虫软件 2)于是在八爪鱼上面是难以正常的创建好循环列表的,因为这个无用的信息导 致八爪鱼手动生成的列表会定位不准八爪鱼·云采集网络爬虫软件 3)所以我们还是得用到 xpath 的知识,去火狐浏览器上面自动创建一个循环列 表的 xpath。首先定位到第一行第一列的源码位置4)再找到每一行的源码位置,发现她们都是 tbody 父节点下相同的 tr 标签八爪鱼·云采集网络爬虫软件 5)再观察每一行真正的 tr 节点里都有一个共同的属性“id”,并且 id 属性都 有 一 个 共 同 的 tr 值 , 所 以 我 们 以 此 为 共 同 点 ,手 写 该 xpath:.//tbody/tr[contains(@id,'tr')]输入关键词采集文章,来定位到所有的 tr 节点,并把所有无 用的 tr 给过滤掉,这样,循环列表的 xpath 就创建好了八爪鱼·云采集网络爬虫软件 6)再从左边拖一个循环进去,循环形式选择不固定元素,把该 xpath 放入八爪 鱼里,并以第一个循环为例,设置相应的采集字段(由于部份数组源码里是没有 的,所以采集不到),八爪鱼·云采集网络爬虫软件 步骤 5:启动采集八爪鱼·云采集网络爬虫软件 1)点击保存任务后,运行采集,以本地采集为例2)采集完成后,会跳出提示,选择“导出数据”。
选择“合适的导入方法”, 将采集好的数据导入。八爪鱼·云采集网络爬虫软件 本文来自于:相关采集教程:京东商品信息采集(通过搜索关键词) 阿里巴巴关键词采集: 八爪鱼·云采集网络爬虫软件 爱站关键词采集: 百度相关搜索关键词采集: 亚马逊关键词采集: 易迅关键词采集: 新浪微博关键词采集: 关键词提取八爪鱼——90 万用户选择的网页数据采集器。 1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。八爪鱼·云采集网络爬虫软件 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。 查看全部
八爪鱼·云采集网络爬虫软件 关键词采集方法本文将介绍怎样借助【词库】批量挖掘并采集长尾词的方式,对 SEOSEM 站长 来说十分实用。 本来还将介绍一款免费好用的数据采集工具 【八爪鱼数据采集】 , 让站长采集关键词的工作事半功倍。长尾词对于站长来说是提升网站流量的核心之技能之一, 是不容忽略的一项方法, 在搜索引擎营销中对关键词策略的拟定是十分重要的, 这些长尾关键词能为网站 贡献很大的一部分流量,并且带来的客人转化率也很不错。下面就以【词库】为例,教诸位站长怎么是用【八爪鱼数据采集器】批量采集关 键词。采集网站:本文就以一组(100 个 B2B 行业有指数的关键词)为例,来采集关于这一组关 键词的所有相关长尾关键词。八爪鱼·云采集网络爬虫软件 采集的内容包括:搜索后的长尾关键词,360 指数,该长尾关键词搜索量以及搜 索量的第一位网站(页面)这四个有效数组。使用功能点:? 循环文本输入?Xpathxpath 入门教程 1 xpath 入门 2 相对 XPATH 教程-7.0 版 ? 数字翻页步骤 1:创建词库网采集任务1)进入主界面,选择“自定义采集”八爪鱼·云采集网络爬虫软件 2)将要采集的网址 URL 复制粘贴到网站输入框中,点击“保存网址”八爪鱼·云采集网络爬虫软件 步骤 2:创建循环输入文本八爪鱼·云采集网络爬虫软件 1)打开网页以后,点开右上角的流程,然后从左边拖一个循环进来2)点击循环步骤,在它的中级选项哪里选择文本列表,再点开下边的 A,把复 制好的关键词全部粘贴进去,注意换行,再点击确定保存。
八爪鱼·云采集网络爬虫软件 3)创建好循环文本输入后, 点击页面上的搜索框, 创建输入文本的步骤, 注意, 不需要输入任何文本即可,若是手动生成的是在循环外边,拖入进去,再勾选循 环即可。八爪鱼·云采集网络爬虫软件 4)右键选择页面上的搜索按键,设置好点击元素,这样,循环文本输入就设置 好了,流程下方就是搜索下来的长尾关键词。步骤 3:创建数字翻页1)由于该搜索结果页面没有下一页按键,只有数字页数,所以我们须要用到 xpath 的一些相关知识,来设置特殊的数字翻页。首先去火狐浏览器里把该网页 打开并搜索相应关键词后,打开浏览器右上角的 firebug 工具--小瓢虫(不懂的 同学可以去官网教程看一下相应的 xpath 教程)八爪鱼·云采集网络爬虫软件 2)翻到页面下方输入关键词采集文章, 找到数字位置的源码, 可以看见当前页面的数字跟其他数字, 在源码里节点的属性 class 是有所不同的八爪鱼·云采集网络爬虫软件 3)收 益 我 们 首 先 定 位 到 该 页 面 的 数 字 位 置 , 手 写 xpath : //div[@id="page"]/a[contains(@class,'current')]八爪鱼·云采集网络爬虫软件 4)再利用固定函数 following-sibling 来定位到该节点后的第一个同类节点, 注意,该函数前面接::是固定格式,a[1]是指该节点后的第一个同类节点八爪鱼·云采集网络爬虫软件 5)可以查看翻页后还是正常定位到下一页的数字上,说明该 xpath 没有问题6)再回到八爪鱼, 在两侧流程页面拖一个循环进来, 高级选项里选择单个元素, 并把 xpath 放入进去,点确定保存好八爪鱼·云采集网络爬虫软件 7)再从左边拖一个点击元素进来,并在中级选项里勾选好循环,特殊数字翻页 循环就创建好了八爪鱼·云采集网络爬虫软件 步骤 4:创建循环列表1)我们安装常规方式创建循环列表,发现,由于搜索结果后的表格中出现了这 个无用的一整行信息。
八爪鱼·云采集网络爬虫软件 2)于是在八爪鱼上面是难以正常的创建好循环列表的,因为这个无用的信息导 致八爪鱼手动生成的列表会定位不准八爪鱼·云采集网络爬虫软件 3)所以我们还是得用到 xpath 的知识,去火狐浏览器上面自动创建一个循环列 表的 xpath。首先定位到第一行第一列的源码位置4)再找到每一行的源码位置,发现她们都是 tbody 父节点下相同的 tr 标签八爪鱼·云采集网络爬虫软件 5)再观察每一行真正的 tr 节点里都有一个共同的属性“id”,并且 id 属性都 有 一 个 共 同 的 tr 值 , 所 以 我 们 以 此 为 共 同 点 ,手 写 该 xpath:.//tbody/tr[contains(@id,'tr')]输入关键词采集文章,来定位到所有的 tr 节点,并把所有无 用的 tr 给过滤掉,这样,循环列表的 xpath 就创建好了八爪鱼·云采集网络爬虫软件 6)再从左边拖一个循环进去,循环形式选择不固定元素,把该 xpath 放入八爪 鱼里,并以第一个循环为例,设置相应的采集字段(由于部份数组源码里是没有 的,所以采集不到),八爪鱼·云采集网络爬虫软件 步骤 5:启动采集八爪鱼·云采集网络爬虫软件 1)点击保存任务后,运行采集,以本地采集为例2)采集完成后,会跳出提示,选择“导出数据”。
选择“合适的导入方法”, 将采集好的数据导入。八爪鱼·云采集网络爬虫软件 本文来自于:相关采集教程:京东商品信息采集(通过搜索关键词) 阿里巴巴关键词采集: 八爪鱼·云采集网络爬虫软件 爱站关键词采集: 百度相关搜索关键词采集: 亚马逊关键词采集: 易迅关键词采集: 新浪微博关键词采集: 关键词提取八爪鱼——90 万用户选择的网页数据采集器。 1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。八爪鱼·云采集网络爬虫软件 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。
网络爬虫:使用Scrapy框架编撰一个抓取书籍信息的爬虫服务
采集交流 • 优采云 发表了文章 • 0 个评论 • 284 次浏览 • 2020-05-04 08:06
BeautifulSoup是一个十分流行的Python网路抓取库,它提供了一个基于HTML结构的Python对象。
虽然简单易懂,又能非常好的处理HTML数据,
但是相比Scrapy而言网络爬虫程序书,BeautifulSoup有一个最大的缺点:慢。
Scrapy 是一个开源的 Python 数据抓取框架,速度快,强大,而且使用简单。
来看一个官网主页上的简单并完整的爬虫:
虽然只有10行左右的代码,但是它的确是一个完整的爬虫服务:
Scrapy所有的恳求都是异步的:
安装(Mac)
pip install scrapy
其他操作系统请参考完整安装指导:
Spider类想要抒发的是:如何抓取一个确定了的网站的数据。比如在start_urls里定义的去那个链接抓取,parse()方法中定义的要抓取什么样的数据。
当一个Spider开始执行的时侯,它首先从start_urls()中的第一个链接开始发起恳求网络爬虫程序书,然后在callback里处理返回的数据。
Item类提供低格的数据,可以理解为数据Model类。
Scrapy的Selector类基于lxml库,提供HTML或XML转换功能。以response对象作为参数生成的Selector实例即可通过实例对象的xpath()方法获取节点的数据。
接下来将上一个Beautiful Soup版的抓取书籍信息的事例( 使用Beautiful Soup编撰一个爬虫 系列随笔汇总)改写成Scrapy版本。
scrapy startproject book_project
这行命令会创建一个名为book_project的项目。
即实体类,代码如下:
import scrapy
class BookItem(scrapy.Item):
title = scrapy.Field()
isbn = scrapy.Field()
price = scrapy.Field()
设置这个Spider的名称,允许爬取的域名和从那个链接开始:
class BookInfoSpider(scrapy.Spider):
name = "bookinfo"
allowed_domains = ["allitebooks.com", "amazon.com"]
start_urls = [
"http://www.allitebooks.com/security/",
]
def parse(self, response):
# response.xpath('//a[contains(@title, "Last Page →")]/@href').re(r'(\d+)')[0]
num_pages = int(response.xpath('//a[contains(@title, "Last Page →")]/text()').extract_first())
base_url = "http://www.allitebooks.com/security/page/{0}/"
for page in range(1, num_pages):
yield scrapy.Request(base_url.format(page), dont_filter=True, callback=self.parse_page) 查看全部
上周学习了BeautifulSoup的基础知识并用它完成了一个网络爬虫( 使用Beautiful Soup编撰一个爬虫 系列随笔汇总),
BeautifulSoup是一个十分流行的Python网路抓取库,它提供了一个基于HTML结构的Python对象。
虽然简单易懂,又能非常好的处理HTML数据,
但是相比Scrapy而言网络爬虫程序书,BeautifulSoup有一个最大的缺点:慢。
Scrapy 是一个开源的 Python 数据抓取框架,速度快,强大,而且使用简单。
来看一个官网主页上的简单并完整的爬虫:
虽然只有10行左右的代码,但是它的确是一个完整的爬虫服务:
Scrapy所有的恳求都是异步的:
安装(Mac)
pip install scrapy
其他操作系统请参考完整安装指导:
Spider类想要抒发的是:如何抓取一个确定了的网站的数据。比如在start_urls里定义的去那个链接抓取,parse()方法中定义的要抓取什么样的数据。
当一个Spider开始执行的时侯,它首先从start_urls()中的第一个链接开始发起恳求网络爬虫程序书,然后在callback里处理返回的数据。
Item类提供低格的数据,可以理解为数据Model类。
Scrapy的Selector类基于lxml库,提供HTML或XML转换功能。以response对象作为参数生成的Selector实例即可通过实例对象的xpath()方法获取节点的数据。
接下来将上一个Beautiful Soup版的抓取书籍信息的事例( 使用Beautiful Soup编撰一个爬虫 系列随笔汇总)改写成Scrapy版本。
scrapy startproject book_project
这行命令会创建一个名为book_project的项目。
即实体类,代码如下:
import scrapy
class BookItem(scrapy.Item):
title = scrapy.Field()
isbn = scrapy.Field()
price = scrapy.Field()
设置这个Spider的名称,允许爬取的域名和从那个链接开始:
class BookInfoSpider(scrapy.Spider):
name = "bookinfo"
allowed_domains = ["allitebooks.com", "amazon.com"]
start_urls = [
"http://www.allitebooks.com/security/",
]
def parse(self, response):
# response.xpath('//a[contains(@title, "Last Page →")]/@href').re(r'(\d+)')[0]
num_pages = int(response.xpath('//a[contains(@title, "Last Page →")]/text()').extract_first())
base_url = "http://www.allitebooks.com/security/page/{0}/"
for page in range(1, num_pages):
yield scrapy.Request(base_url.format(page), dont_filter=True, callback=self.parse_page)
税务局怎么应用网路爬虫技术获取企业涉税信息
采集交流 • 优采云 发表了文章 • 0 个评论 • 555 次浏览 • 2020-05-03 08:09
那么,什么是网络爬虫呢?税务局怎么应用网路爬虫技术发觉企业的涉税谜团呢?本文将带你一步一步解开其中的奥秘。
网络爬虫称作“网页蜘蛛”,是一个手动提取网页的程序。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL装入队列,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要按照一定的网页剖析算法过滤与主题无关的链接,保留有用的链接并将其倒入等待抓取的URL队列。然后,它将按照一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止,另外,所有被爬虫抓取的网页将会被系统存储,进行一定的剖析、过滤,并构建索引,以便以后的查询和检索。
以上是引自网路专业的叙述,简单的说,“网络爬虫”是一个手动提取网页的程序,运用“网络爬虫”技术设定程序税务爬虫软件,可以按照既定的目标愈发精准选择抓取相关的网页信息,有助于在互联网海量信息中快捷获取有用的涉税信息。
税务局怎样利用网路爬虫举办工作呢?概括的说税务爬虫软件,不外乎这样几个方面:
一是有针对性的捕捉互联网上的企业相关信息;
二是利用大数据,整合其他相关涉税信息;
三是通过一系列预警指标剖析比对筛选案源;
四是构建企业交易行为轨迹,定位税收风险疑虑。
其实,网络爬虫收集的仅仅是纳税人公开在网路上的涉税信息,税务机关获取纳税人的涉税信息还有好多途径,比如,利用内部风控中心监控平台,与网路运营商、工商、统计、建设、技术监督、财政、公安、海关、金融机构、外汇管理、国土规划和货运中心等有关部门联网实现信息互通、数据互联、资源共享,并整合纳税人联网开票信息、申报数据、税款收取数据、财务报表数据、重点税源报表数据、备案信息等数据信息,实时更新纳税人信息库,使纳税人时时处在金税三期强悍的监控和预警范围之内。
所以,如果有三天,税务局直接找上门来或电话问询企业税务谜团,不要认为奇怪。
随着税务机关信息化手段的不断加强、税务稽查检测人员能力素养的不断提高,未来企业的税务风险曝露机会将会越来越大,那种以违法手段达到少收税的手法将很难有生存空间,而合法(利用税收优惠政策)、合理(符合商业目的)的税务筹划将是未来企业节税的主要途径。 查看全部
那么,什么是网络爬虫呢?税务局怎么应用网路爬虫技术发觉企业的涉税谜团呢?本文将带你一步一步解开其中的奥秘。
网络爬虫称作“网页蜘蛛”,是一个手动提取网页的程序。传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL装入队列,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要按照一定的网页剖析算法过滤与主题无关的链接,保留有用的链接并将其倒入等待抓取的URL队列。然后,它将按照一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止,另外,所有被爬虫抓取的网页将会被系统存储,进行一定的剖析、过滤,并构建索引,以便以后的查询和检索。
以上是引自网路专业的叙述,简单的说,“网络爬虫”是一个手动提取网页的程序,运用“网络爬虫”技术设定程序税务爬虫软件,可以按照既定的目标愈发精准选择抓取相关的网页信息,有助于在互联网海量信息中快捷获取有用的涉税信息。
税务局怎样利用网路爬虫举办工作呢?概括的说税务爬虫软件,不外乎这样几个方面:
一是有针对性的捕捉互联网上的企业相关信息;
二是利用大数据,整合其他相关涉税信息;
三是通过一系列预警指标剖析比对筛选案源;
四是构建企业交易行为轨迹,定位税收风险疑虑。
其实,网络爬虫收集的仅仅是纳税人公开在网路上的涉税信息,税务机关获取纳税人的涉税信息还有好多途径,比如,利用内部风控中心监控平台,与网路运营商、工商、统计、建设、技术监督、财政、公安、海关、金融机构、外汇管理、国土规划和货运中心等有关部门联网实现信息互通、数据互联、资源共享,并整合纳税人联网开票信息、申报数据、税款收取数据、财务报表数据、重点税源报表数据、备案信息等数据信息,实时更新纳税人信息库,使纳税人时时处在金税三期强悍的监控和预警范围之内。
所以,如果有三天,税务局直接找上门来或电话问询企业税务谜团,不要认为奇怪。
随着税务机关信息化手段的不断加强、税务稽查检测人员能力素养的不断提高,未来企业的税务风险曝露机会将会越来越大,那种以违法手段达到少收税的手法将很难有生存空间,而合法(利用税收优惠政策)、合理(符合商业目的)的税务筹划将是未来企业节税的主要途径。
Python网路爬虫之必备工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 357 次浏览 • 2020-05-03 08:01
1 Python基础知识
Python作为现今最流行的编程语言之一爬虫工具,其强悍之处也是毋庸置疑的,利用Python写网路爬虫是最好不过的选择啦,所以万丈高楼平地起,学习网路爬虫最最基本的就是要把握Python编程的基础知识,了解以下几点即可:
基本数据结构数据类型控制流函数的使用模块的使用Python学习教程推荐:
(1)廖雪峰之Python教程。具体学习网址百度一下就可以,其讲解堪称通俗易懂,学习上去特别快。
(2)Python简明教程
2 开发环境
操作系统:Windows7及以上
Python版本:Python3.x
代码开发环境:个人比较推荐PyCharm作为自己的IDE,当然你也可以按照自己的使用习惯选择代码编辑器,如Notepad++等
3 Python库
一般网路爬虫所需根据的库有:
urllib和urllib2库
这两个库是学习爬虫最基本的库,其才能将URL所指定的网路资源(HTML)获得,并可用正则表达式对其内容进行提取爬虫工具,进而得到我们想要的结果。
Pythonre模块
re模块是Python提供的用于字符串匹配非常好用的工具,其设计思想就是借助一种描述性语言来定义字符串的规则,凡是符合这一规则的字符串,则表明就匹配成功,这就是我们熟悉的正则表达式。利用re模块提供的抒发功能,我们可以很方便从爬取到的网页内容中匹配出须要的内容数据。
BeautifulSoup库
此库是一个强悍的解析文档工具箱,其才能将我们爬取的到HTML页面内容解析成一个复杂的树状结构,每一个节点都是一个Python对象,具体讲在前面给你们详尽讲解。
以上介绍都是一些基本爬取所需的库,当然假如你想做一个有深度的爬虫,还须要把握如requests库、pymongo库、selenium库等,等把握的差不多了,还可以学习一下爬虫框架Scrapy。 查看全部
网络爬虫(又被称为网页蜘蛛,网络机器人),是一种根据一定的规则,自动的抓取万维网信息的程序或则脚本。那么要学会并精通Python网络爬虫,我们须要打算什么知识和工具那?
1 Python基础知识
Python作为现今最流行的编程语言之一爬虫工具,其强悍之处也是毋庸置疑的,利用Python写网路爬虫是最好不过的选择啦,所以万丈高楼平地起,学习网路爬虫最最基本的就是要把握Python编程的基础知识,了解以下几点即可:
基本数据结构数据类型控制流函数的使用模块的使用Python学习教程推荐:
(1)廖雪峰之Python教程。具体学习网址百度一下就可以,其讲解堪称通俗易懂,学习上去特别快。
(2)Python简明教程
2 开发环境
操作系统:Windows7及以上
Python版本:Python3.x
代码开发环境:个人比较推荐PyCharm作为自己的IDE,当然你也可以按照自己的使用习惯选择代码编辑器,如Notepad++等
3 Python库
一般网路爬虫所需根据的库有:
urllib和urllib2库
这两个库是学习爬虫最基本的库,其才能将URL所指定的网路资源(HTML)获得,并可用正则表达式对其内容进行提取爬虫工具,进而得到我们想要的结果。
Pythonre模块
re模块是Python提供的用于字符串匹配非常好用的工具,其设计思想就是借助一种描述性语言来定义字符串的规则,凡是符合这一规则的字符串,则表明就匹配成功,这就是我们熟悉的正则表达式。利用re模块提供的抒发功能,我们可以很方便从爬取到的网页内容中匹配出须要的内容数据。
BeautifulSoup库
此库是一个强悍的解析文档工具箱,其才能将我们爬取的到HTML页面内容解析成一个复杂的树状结构,每一个节点都是一个Python对象,具体讲在前面给你们详尽讲解。
以上介绍都是一些基本爬取所需的库,当然假如你想做一个有深度的爬虫,还须要把握如requests库、pymongo库、selenium库等,等把握的差不多了,还可以学习一下爬虫框架Scrapy。
【Golang实现网路爬虫】分布式爬虫系统构架
采集交流 • 优采云 发表了文章 • 0 个评论 • 346 次浏览 • 2020-05-03 08:01
分布式系统是一个硬件或软件组件分布在不同的网路计算机上,彼此之间仅仅通过消息传递进行通讯和协调的系统。简单来说就是一群独立计算机集合共同对外提供服务,但是对于系统的用户来说,就像是一台计算机在提供服务一样。分布式意味着可以采用更多的普通计算机(相对于高昂的大型机)组成分布式集群对外提供服务。计算机越多,CPU、内存、存储资源等也就越多,能够处理的并发访问量也就越大。
从分布式系统的概念中我们晓得,各个主机之间通讯和协调主要通过网路进行,所以分布式系统中的计算机在空间上几乎没有任何限制,这些计算机可能被置于不同的机柜上,也可能被布署在不同的机房中,还可能在不同的城市中,对于小型的网站甚至可能分布在不同的国家和地区。
不同的资料介绍起分布式系统的特性,虽然说法不同,但都大同小异,此处我们针对于要实现的分布式爬虫,总结为以下3个特征:
消息传递完成特定需求
消息传递的方式:
分布式系统的结构图:
一般对外会使用REST,模块内部会使用RPC,效率会更高一些,模块之前:中间件、REST
针对于目前我们遇见的问题,我们给予解决方案分布式爬虫架构,来设计分布式爬虫项目的构架:
1.限流问题
问题:
单节点承受的流量是有限
解决:
将Worker放在不同的节点
2.去重问题
问题:
单节点承受的去重数据量有限
无法保存之前去重结果(因为是存入到显存(map))
解决:
基于Key-Value Stroe(如Redis)进行分布式去重
3.数据储存问题
问题:
存储部份的结构,技术栈和爬虫部份区别很大
进一步优化须要特殊的ElasticSearch技术背景
解决:
存储服务
所以最终我们的分布式爬虫构架如下:
还有一个关键点:从Channel进化到分布式
之前我们为了实现并发,使用了大量的goroutine以及Channel。那我们就可以开启一个远程的RPC服务分布式爬虫架构,然后进行同步的调用。
RPC有很多种做法,本文采用jsonrpc。
源代码 查看全部
分布式系统是一个硬件或软件组件分布在不同的网路计算机上,彼此之间仅仅通过消息传递进行通讯和协调的系统。简单来说就是一群独立计算机集合共同对外提供服务,但是对于系统的用户来说,就像是一台计算机在提供服务一样。分布式意味着可以采用更多的普通计算机(相对于高昂的大型机)组成分布式集群对外提供服务。计算机越多,CPU、内存、存储资源等也就越多,能够处理的并发访问量也就越大。
从分布式系统的概念中我们晓得,各个主机之间通讯和协调主要通过网路进行,所以分布式系统中的计算机在空间上几乎没有任何限制,这些计算机可能被置于不同的机柜上,也可能被布署在不同的机房中,还可能在不同的城市中,对于小型的网站甚至可能分布在不同的国家和地区。
不同的资料介绍起分布式系统的特性,虽然说法不同,但都大同小异,此处我们针对于要实现的分布式爬虫,总结为以下3个特征:
消息传递完成特定需求
消息传递的方式:
分布式系统的结构图:
一般对外会使用REST,模块内部会使用RPC,效率会更高一些,模块之前:中间件、REST
针对于目前我们遇见的问题,我们给予解决方案分布式爬虫架构,来设计分布式爬虫项目的构架:
1.限流问题
问题:
单节点承受的流量是有限
解决:
将Worker放在不同的节点
2.去重问题
问题:
单节点承受的去重数据量有限
无法保存之前去重结果(因为是存入到显存(map))
解决:
基于Key-Value Stroe(如Redis)进行分布式去重
3.数据储存问题
问题:
存储部份的结构,技术栈和爬虫部份区别很大
进一步优化须要特殊的ElasticSearch技术背景
解决:
存储服务
所以最终我们的分布式爬虫构架如下:
还有一个关键点:从Channel进化到分布式
之前我们为了实现并发,使用了大量的goroutine以及Channel。那我们就可以开启一个远程的RPC服务分布式爬虫架构,然后进行同步的调用。
RPC有很多种做法,本文采用jsonrpc。
源代码
网络爬虫基本原理
采集交流 • 优采云 发表了文章 • 0 个评论 • 346 次浏览 • 2020-05-03 08:00
网络爬虫基本原理23.05.2019基本描述 需要理解的算法 数据分类抓取策略 更新策略23.05.2019网络爬虫网络爬虫(又被称为网页蜘蛛,网络机器人),是一种根据一定的规则,自动的 抓取万维网信息的程序或则脚本,是搜索引擎的重要组成。传统爬虫从一个或若 干初始网页的开始,获得初始网页上的,在抓取网页的过程中,不断从当前页面 上抽取新的装入队列,直到满足系统的一定停止条件。23.05.2019聚焦爬虫传统爬虫从一个或若干初始网页的开始,获得初始网页上的,在抓取网页的过程 中,不断从当前页面上抽取新的装入队列,直到满足系统的一定停止条件。聚焦爬 虫的工作流程较为复杂,需要按照一定的网页剖析算法过滤与主题无关的链接,保留有用的链接并将其倒入等待抓取的队列。然后网络爬虫原理,它将按照一定的搜索策略从 队列中选择下一步要抓取的网页,并重复上述过程,直到达到系统的某一条件时 停止。另外,所有被爬虫抓取的网页将会被系统储存,进行一定的剖析、过滤, 并构建索引,以便以后的查询和检索;对于聚焦爬虫来说,这一过程所得到的分 析结果还可能对之后的抓取过程给出反馈和指导。23.05.2019简单流程 ::作为初始解析 网页数据 分析下载网页库种子待抓取已抓取下载网页 进入已抓取队列从队列信息中抽 取新的23.05.2019须要理解的算法.关键字匹配 :: 字符串匹配 算法(算法) 有限自动机算法 *算法.网页内容冗余 :: 卡时.大数目网页处理 :: *分布式.防止重复遍历 :: 字符串23.05.2019数据分类.已下载未过期网页 .已下载已过期网页:抓取到的网页实际上是互联网内容的一个镜像与备份,互联网是动态变化的, 一部分互联网上的内容早已发生了变化,这时,这部份抓取到的网页就过期了。
.待下载网页:也就是待抓取队列中的这些页面。 .可知网页:还没有抓取出来,也没有在待抓取队列中,但是可以通过对已抓取页面或则待 抓取对应页面进行剖析获取到的,认为是可知网页。 .不可知网页:还有一部分网页,爬虫是难以直接抓取下载的23.05.2019数据分类 ::已知网页已抓取未过期 已抓取已过期23.05.2019数据分类 ::不可知网页23.05.2019抓取策略 :: 暴力.深度优先搜索 .广度优先搜索 .大站优先策略对于待抓取队列中的所有网页,根据所属的网站进行分类。对于待下载页面数 多的网站,优先下载。这个策略也因而称作大站优先策略。23.05.2019抓取策略 :: 技巧.反向链接数策略 反向链接数是指一个网页被其他网页链接指向的数目。反向链接数表示的是一个网页的内容遭到其他人的推荐的程度。因此,很多时侯搜索引擎的抓取系统会 使用这个指标来评价网页的重要程度,从而决定不同网页的抓取先后次序。在真实的网路环境中,由于广告链接、作弊链接的存在,反向链接数不能完全 准确评价网页的重要程度。因此,搜索引擎常常考虑一些可靠的反向链接数。23.05.2019抓取策略 :: 技巧策略 算法借鉴了算法的思想。
对于早已下载的网页,连同待抓取队列中的,形成网页集合网络爬虫原理,计算每位页面的值,计算完以后,将待抓取队列中的根据值的大小排列, 并根据该次序抓取页面。策略策略 该算法实际上也是对页面进行一个重要性打分。在算法开始前,给所有页面一个相同的初始现金()。当下载了某个页面然后,将的现金平摊给所有从中剖析 出的链接,并且将的现金清空。对于待抓取队列中的所有页面根据现金数进行排 序。23.05.2019更新策略 :: 可持久化数据结构.历史参考策略 顾名思义,根据页面往年的历史更新数据,预测该页面未来何时会发生变化。一般来说,是通过泊松过程进行建模进行预测。.用户体验策略 尽管搜索引擎针对于某个查询条件才能返回数目巨大的结果,但是用户常常只关注前几页结果。因此,抓取系统可以优先更新这些现实在查询结果前几页中的 网页,而后再更新这些旁边的网页。这种更新策略也是须要用到历史信息的。用 户体验策略保留网页的多个历史版本,并且依照过去每次内容变化对搜索质量的 影响,得出一个平均值,用这个值作为决定何时重新抓取的根据。23.05.2019更新策略 :: 统计学改进.聚类抽样策略 前面提及的两种更新策略都有一个前提:需要网页的历史信息。
这样就存在两个问题:第一,系统要是为每位系统保存多个版本的历史信息,无疑降低了好多 的系统负担;第二,要是新的网页完全没有历史信息,就难以确定更新策略。而降维抽样策略觉得,网页具有好多属性,类似属性的网页,可以觉得其更新 频率也是类似的。要估算某一个类别网页的更新频度,只须要对这一类网页抽样, 以她们的更新周期作为整个类别的更新周期。23.05.2019的个人博客《这就是搜索引擎——核心技术解读》 张俊林 电子工业出版社《搜索引擎技术基础》刘奕群等 清华大学出版社23.05.2019ACM2013 查看全部
网络爬虫基本原理23.05.2019基本描述 需要理解的算法 数据分类抓取策略 更新策略23.05.2019网络爬虫网络爬虫(又被称为网页蜘蛛,网络机器人),是一种根据一定的规则,自动的 抓取万维网信息的程序或则脚本,是搜索引擎的重要组成。传统爬虫从一个或若 干初始网页的开始,获得初始网页上的,在抓取网页的过程中,不断从当前页面 上抽取新的装入队列,直到满足系统的一定停止条件。23.05.2019聚焦爬虫传统爬虫从一个或若干初始网页的开始,获得初始网页上的,在抓取网页的过程 中,不断从当前页面上抽取新的装入队列,直到满足系统的一定停止条件。聚焦爬 虫的工作流程较为复杂,需要按照一定的网页剖析算法过滤与主题无关的链接,保留有用的链接并将其倒入等待抓取的队列。然后网络爬虫原理,它将按照一定的搜索策略从 队列中选择下一步要抓取的网页,并重复上述过程,直到达到系统的某一条件时 停止。另外,所有被爬虫抓取的网页将会被系统储存,进行一定的剖析、过滤, 并构建索引,以便以后的查询和检索;对于聚焦爬虫来说,这一过程所得到的分 析结果还可能对之后的抓取过程给出反馈和指导。23.05.2019简单流程 ::作为初始解析 网页数据 分析下载网页库种子待抓取已抓取下载网页 进入已抓取队列从队列信息中抽 取新的23.05.2019须要理解的算法.关键字匹配 :: 字符串匹配 算法(算法) 有限自动机算法 *算法.网页内容冗余 :: 卡时.大数目网页处理 :: *分布式.防止重复遍历 :: 字符串23.05.2019数据分类.已下载未过期网页 .已下载已过期网页:抓取到的网页实际上是互联网内容的一个镜像与备份,互联网是动态变化的, 一部分互联网上的内容早已发生了变化,这时,这部份抓取到的网页就过期了。
.待下载网页:也就是待抓取队列中的这些页面。 .可知网页:还没有抓取出来,也没有在待抓取队列中,但是可以通过对已抓取页面或则待 抓取对应页面进行剖析获取到的,认为是可知网页。 .不可知网页:还有一部分网页,爬虫是难以直接抓取下载的23.05.2019数据分类 ::已知网页已抓取未过期 已抓取已过期23.05.2019数据分类 ::不可知网页23.05.2019抓取策略 :: 暴力.深度优先搜索 .广度优先搜索 .大站优先策略对于待抓取队列中的所有网页,根据所属的网站进行分类。对于待下载页面数 多的网站,优先下载。这个策略也因而称作大站优先策略。23.05.2019抓取策略 :: 技巧.反向链接数策略 反向链接数是指一个网页被其他网页链接指向的数目。反向链接数表示的是一个网页的内容遭到其他人的推荐的程度。因此,很多时侯搜索引擎的抓取系统会 使用这个指标来评价网页的重要程度,从而决定不同网页的抓取先后次序。在真实的网路环境中,由于广告链接、作弊链接的存在,反向链接数不能完全 准确评价网页的重要程度。因此,搜索引擎常常考虑一些可靠的反向链接数。23.05.2019抓取策略 :: 技巧策略 算法借鉴了算法的思想。
对于早已下载的网页,连同待抓取队列中的,形成网页集合网络爬虫原理,计算每位页面的值,计算完以后,将待抓取队列中的根据值的大小排列, 并根据该次序抓取页面。策略策略 该算法实际上也是对页面进行一个重要性打分。在算法开始前,给所有页面一个相同的初始现金()。当下载了某个页面然后,将的现金平摊给所有从中剖析 出的链接,并且将的现金清空。对于待抓取队列中的所有页面根据现金数进行排 序。23.05.2019更新策略 :: 可持久化数据结构.历史参考策略 顾名思义,根据页面往年的历史更新数据,预测该页面未来何时会发生变化。一般来说,是通过泊松过程进行建模进行预测。.用户体验策略 尽管搜索引擎针对于某个查询条件才能返回数目巨大的结果,但是用户常常只关注前几页结果。因此,抓取系统可以优先更新这些现实在查询结果前几页中的 网页,而后再更新这些旁边的网页。这种更新策略也是须要用到历史信息的。用 户体验策略保留网页的多个历史版本,并且依照过去每次内容变化对搜索质量的 影响,得出一个平均值,用这个值作为决定何时重新抓取的根据。23.05.2019更新策略 :: 统计学改进.聚类抽样策略 前面提及的两种更新策略都有一个前提:需要网页的历史信息。
这样就存在两个问题:第一,系统要是为每位系统保存多个版本的历史信息,无疑降低了好多 的系统负担;第二,要是新的网页完全没有历史信息,就难以确定更新策略。而降维抽样策略觉得,网页具有好多属性,类似属性的网页,可以觉得其更新 频率也是类似的。要估算某一个类别网页的更新频度,只须要对这一类网页抽样, 以她们的更新周期作为整个类别的更新周期。23.05.2019的个人博客《这就是搜索引擎——核心技术解读》 张俊林 电子工业出版社《搜索引擎技术基础》刘奕群等 清华大学出版社23.05.2019ACM2013
网络爬虫是哪些?网络爬虫是怎样工作的?
采集交流 • 优采云 发表了文章 • 0 个评论 • 412 次浏览 • 2020-05-02 08:08
摘要:一篇文章了解爬虫的前世今生与未来
什么是网络爬虫?
网络爬虫,也称为网页抓取和网页数据提取,基本上是指通过超文本传输协议(HTTP)或通过网页浏览器获取万维网上可用的数据。(摘自Wikipedia)
网络爬虫是怎样工作的?
通常,爬取网页数据时,只须要2个步骤。
打开网页→将具体的数据从网页中复制并导入到表格或数据库中。
这一切是怎么开始的?
尽管对许多人来说,网络爬虫听上去象是“大数据”或“机器学习”一类的新概念,但实际上,网络数据抓取的历史要长得多,可以溯源到万维网(或浅显的“互联网”)诞生之时。
一开始,互联网还没有搜索。在搜索引擎被开发下来之前,互联网只是文件传输协议(FTP)站点的集合,用户可以在这种站点中导航以找到特定的共享文件。
为了查找和组合互联网上可用的分布式数据,人们创建了一个自动化程序,称为网络爬虫/机器人,可以抓取互联网上的所有网页,然后将所有页面上的内容复制到数据库中制做索引。
随后,互联网发展上去,最终有数百万级的网页生成,这些网页包含大量不同的方式的数据,其中包括文本、图像、视频和音频。互联网弄成了一个开放的数据源。
随着数据资源显得十分丰富且容易搜索,人们发觉从网页上找到她们想要的信息是一件极其简单的事情,他们一般分布在大量的网站上。但另一个问题出现了,当她们想要数据的时侯,并非每位网站都提供下载按键,如果进行自动复制其实是极其低效且平庸的。
这就是网路爬虫诞生的诱因。网络爬虫实际上是由网页机器人/爬虫驱动的,其功能与搜索引擎相同。简单来说就是,抓取和复制。唯一的不同可能是规模。网络数据抓取是从特定的网站提取特定的数据,而搜索引擎一般是在万维网上搜索出大部分的网站。
时间轴
1989年万维网的诞生
从技术上讲,万维网和因特网有所不同。前者是指信息空间,后者是由数台计算机联接上去的内部网路。
感谢Tim Berners-Lee,万维网的发明者,他发明的三件东西,往后成为了我们日常生活中的一部分。
1990年第一个网络浏览器
它也由Tim Berners-Lee发明,被称为WorldWide网页(无空间),以WWW项目命名。在网路出现一年后,人们有了一条途径去浏览它并与之互动。
1991年第一个网页服务器和第一个 网页页面
网页的数目以缓慢的速率下降。到1994年,HTTP服务器的数目超过200台。
1993年6月第一台网页机器人——万维网漫游器
虽然它的功能和昨天的网页机器人一样,但它只是拿来检测网页的大小。
1993年12月首个基于爬虫的网路搜索引擎—JumpStation
由于当时网路上的网站并不多,搜索引擎过去经常依赖人工网站管理员来搜集和编辑链接,使其成为一种特定的格式。
JumpStation带来了新的飞越。它是第一个借助网路机器人的WWW搜索引擎。
从那时起,人们开始使用这种程序化的网路爬虫程序来搜集和组织互联网。从Infoseek、Altavista和Excite,到现在的必应和微软,搜索引擎机器人的核心依旧保持不变:
找到一个网页页面,下载(获取)它,抓取网页页面上显示的所有信息,然后将其添加到搜索引擎的数据库中。
由于网页页面是为人类用户设计的,不是为了自动化使用,即使开发了网页机器人,计算机工程师和科学家一直很难进行网路数据抓取,更不用说普通人了。因此,人们仍然致力于让网路爬虫显得愈发容易使用。
2000年网页API和API爬虫
API表示应用程序编程插口。它是一个插口,通过提供搭建好的模块,使开发程序愈加方便。
2000年,Salesforce和eBay推出了自己的API,程序员可以用它访问并下载一些公开数据。
从那时起,许多网站都提供网页API使人们可以访问她们的公共数据库。
发送一组HTTP请求,然后接收JSON或XML的回馈。
网页API通过搜集网站提供的数据,为开发人员提供了一种更友好的网路爬虫形式。
2004 年Python Beautiful Soup
不是所有的网站都提供API。即使她们提供了,他们也不一定会提供你想要的所有数据。因此,程序员们仍在开发一种才能建立网路爬虫的方式。
2004年,Beautiful Soup发布。它是一个为Python设计的库。
在计算机编程中,库是脚本模块的集合,就像常用的算法一样,它容许不用重画就可以使用,从而简化了编程过程。
通过简单的命令,Beautiful Soup可以理解站点的结构,并帮助从HTML容器中解析内容。它被觉得是用于网路爬虫的最复杂和最先进的库,也是现今最常见和最流行的方式之一。
2005-2006年网路抓取软件的可视化
2006年,Stefan Andresen和他的Kapow软件(Kofax于2013年竞购)发布了网页集成平台6.0版本,这是一种可视化的网路爬虫软件,它容许用户轻松简单的选择网页内容,并将这种数据构造成可用的excel文件或数据库。
八爪鱼数据采集器
最终,可视化的网路数据抓取软件可以使大量非程序员自己进行网路爬虫。
从那时起,网络抓取开始成为主流。现在,对于非程序员来说,他们可以很容易地找到80多个可提供可视化过程的的数据采集软件。
网络爬虫未来将怎样发展?
我们总是想要更多的数据。我们搜集数据,处理数据,并把数据转换成各种各样的成品,比如研究,洞察剖析,信息,故事,资产等等。我们过去经常耗费大量的时间、精力和金钱在找寻和搜集数据上,以至于只有大公司和组织能够负担得起。
在2018年,我们所知的万维网网络爬虫技术是什么,或浅显的“互联网”,由超过18亿个网站组成。只需点击几下键盘,就可以获得这么巨大的数据量。随着越来越多的人上网,每秒形成的数据也越来越多。
如今,是一个比历史上任何时期都要便捷的时代。任何个人、公司和组织都还能获得她们想要的数据,只要这种数据在网页上是公开可用的。
多亏了网路爬虫/机器人、API、标准数据库和各类开箱即用的软件,一旦有人有了获取数据的意愿,就有了获取数据的方式。或者,他们也可以求救于这些她们接触得到又支付的起费用的专业人士。
在自由职业任务平台guru.com上搜索“网络爬虫”时,你可以得到10088个搜索结果,这意味着超过10000名自由职业者在这个网站上提供网路抓取服务。
而在同类的网站,Upwork上的搜索结果有13190个,fievere.com上的结果是1024个。
各行各业的公司对网路数据的需求不断下降,推动了网路抓取行业的发展,带来了新的市场、就业机会和商业机会。
与此同时,与其他新兴行业一样,网络抓取也伴随着法律方面的疑虑。
围绕网路爬虫合法性的讨论情况仍存在。它的合法与否与具体案例背景相关。目前,这种趋势下诞生的许多有趣的法律问题一直没有得到解答,或者取决于十分具体的案例背景。
虽然网路抓取早已存在了太长一段时间,但法庭才刚才开基础大数据相关的法律理论的应用。
由于与网路爬取和数据抓取的仍处于发展阶段,所以它的发展一直未稳定出来且难以预测。然而,有一件事是肯定的,那就是,只要有互联网,就有网路抓取。
是网路抓取使新生的互联网显得可以搜索,使爆炸式下降的互联网显得愈发容易访问和获取。
毫无疑问网络爬虫技术是什么,在可预见的未来,互联网和网路抓取,将继续稳定地往前迈向。 查看全部
摘要:一篇文章了解爬虫的前世今生与未来
什么是网络爬虫?
网络爬虫,也称为网页抓取和网页数据提取,基本上是指通过超文本传输协议(HTTP)或通过网页浏览器获取万维网上可用的数据。(摘自Wikipedia)
网络爬虫是怎样工作的?
通常,爬取网页数据时,只须要2个步骤。
打开网页→将具体的数据从网页中复制并导入到表格或数据库中。
这一切是怎么开始的?
尽管对许多人来说,网络爬虫听上去象是“大数据”或“机器学习”一类的新概念,但实际上,网络数据抓取的历史要长得多,可以溯源到万维网(或浅显的“互联网”)诞生之时。
一开始,互联网还没有搜索。在搜索引擎被开发下来之前,互联网只是文件传输协议(FTP)站点的集合,用户可以在这种站点中导航以找到特定的共享文件。
为了查找和组合互联网上可用的分布式数据,人们创建了一个自动化程序,称为网络爬虫/机器人,可以抓取互联网上的所有网页,然后将所有页面上的内容复制到数据库中制做索引。
随后,互联网发展上去,最终有数百万级的网页生成,这些网页包含大量不同的方式的数据,其中包括文本、图像、视频和音频。互联网弄成了一个开放的数据源。
随着数据资源显得十分丰富且容易搜索,人们发觉从网页上找到她们想要的信息是一件极其简单的事情,他们一般分布在大量的网站上。但另一个问题出现了,当她们想要数据的时侯,并非每位网站都提供下载按键,如果进行自动复制其实是极其低效且平庸的。
这就是网路爬虫诞生的诱因。网络爬虫实际上是由网页机器人/爬虫驱动的,其功能与搜索引擎相同。简单来说就是,抓取和复制。唯一的不同可能是规模。网络数据抓取是从特定的网站提取特定的数据,而搜索引擎一般是在万维网上搜索出大部分的网站。
时间轴
1989年万维网的诞生
从技术上讲,万维网和因特网有所不同。前者是指信息空间,后者是由数台计算机联接上去的内部网路。
感谢Tim Berners-Lee,万维网的发明者,他发明的三件东西,往后成为了我们日常生活中的一部分。
1990年第一个网络浏览器
它也由Tim Berners-Lee发明,被称为WorldWide网页(无空间),以WWW项目命名。在网路出现一年后,人们有了一条途径去浏览它并与之互动。
1991年第一个网页服务器和第一个 网页页面
网页的数目以缓慢的速率下降。到1994年,HTTP服务器的数目超过200台。
1993年6月第一台网页机器人——万维网漫游器
虽然它的功能和昨天的网页机器人一样,但它只是拿来检测网页的大小。
1993年12月首个基于爬虫的网路搜索引擎—JumpStation
由于当时网路上的网站并不多,搜索引擎过去经常依赖人工网站管理员来搜集和编辑链接,使其成为一种特定的格式。
JumpStation带来了新的飞越。它是第一个借助网路机器人的WWW搜索引擎。
从那时起,人们开始使用这种程序化的网路爬虫程序来搜集和组织互联网。从Infoseek、Altavista和Excite,到现在的必应和微软,搜索引擎机器人的核心依旧保持不变:
找到一个网页页面,下载(获取)它,抓取网页页面上显示的所有信息,然后将其添加到搜索引擎的数据库中。
由于网页页面是为人类用户设计的,不是为了自动化使用,即使开发了网页机器人,计算机工程师和科学家一直很难进行网路数据抓取,更不用说普通人了。因此,人们仍然致力于让网路爬虫显得愈发容易使用。
2000年网页API和API爬虫
API表示应用程序编程插口。它是一个插口,通过提供搭建好的模块,使开发程序愈加方便。
2000年,Salesforce和eBay推出了自己的API,程序员可以用它访问并下载一些公开数据。
从那时起,许多网站都提供网页API使人们可以访问她们的公共数据库。
发送一组HTTP请求,然后接收JSON或XML的回馈。
网页API通过搜集网站提供的数据,为开发人员提供了一种更友好的网路爬虫形式。
2004 年Python Beautiful Soup
不是所有的网站都提供API。即使她们提供了,他们也不一定会提供你想要的所有数据。因此,程序员们仍在开发一种才能建立网路爬虫的方式。
2004年,Beautiful Soup发布。它是一个为Python设计的库。
在计算机编程中,库是脚本模块的集合,就像常用的算法一样,它容许不用重画就可以使用,从而简化了编程过程。
通过简单的命令,Beautiful Soup可以理解站点的结构,并帮助从HTML容器中解析内容。它被觉得是用于网路爬虫的最复杂和最先进的库,也是现今最常见和最流行的方式之一。
2005-2006年网路抓取软件的可视化
2006年,Stefan Andresen和他的Kapow软件(Kofax于2013年竞购)发布了网页集成平台6.0版本,这是一种可视化的网路爬虫软件,它容许用户轻松简单的选择网页内容,并将这种数据构造成可用的excel文件或数据库。
八爪鱼数据采集器
最终,可视化的网路数据抓取软件可以使大量非程序员自己进行网路爬虫。
从那时起,网络抓取开始成为主流。现在,对于非程序员来说,他们可以很容易地找到80多个可提供可视化过程的的数据采集软件。
网络爬虫未来将怎样发展?
我们总是想要更多的数据。我们搜集数据,处理数据,并把数据转换成各种各样的成品,比如研究,洞察剖析,信息,故事,资产等等。我们过去经常耗费大量的时间、精力和金钱在找寻和搜集数据上,以至于只有大公司和组织能够负担得起。
在2018年,我们所知的万维网网络爬虫技术是什么,或浅显的“互联网”,由超过18亿个网站组成。只需点击几下键盘,就可以获得这么巨大的数据量。随着越来越多的人上网,每秒形成的数据也越来越多。
如今,是一个比历史上任何时期都要便捷的时代。任何个人、公司和组织都还能获得她们想要的数据,只要这种数据在网页上是公开可用的。
多亏了网路爬虫/机器人、API、标准数据库和各类开箱即用的软件,一旦有人有了获取数据的意愿,就有了获取数据的方式。或者,他们也可以求救于这些她们接触得到又支付的起费用的专业人士。
在自由职业任务平台guru.com上搜索“网络爬虫”时,你可以得到10088个搜索结果,这意味着超过10000名自由职业者在这个网站上提供网路抓取服务。
而在同类的网站,Upwork上的搜索结果有13190个,fievere.com上的结果是1024个。
各行各业的公司对网路数据的需求不断下降,推动了网路抓取行业的发展,带来了新的市场、就业机会和商业机会。
与此同时,与其他新兴行业一样,网络抓取也伴随着法律方面的疑虑。
围绕网路爬虫合法性的讨论情况仍存在。它的合法与否与具体案例背景相关。目前,这种趋势下诞生的许多有趣的法律问题一直没有得到解答,或者取决于十分具体的案例背景。
虽然网路抓取早已存在了太长一段时间,但法庭才刚才开基础大数据相关的法律理论的应用。
由于与网路爬取和数据抓取的仍处于发展阶段,所以它的发展一直未稳定出来且难以预测。然而,有一件事是肯定的,那就是,只要有互联网,就有网路抓取。
是网路抓取使新生的互联网显得可以搜索,使爆炸式下降的互联网显得愈发容易访问和获取。
毫无疑问网络爬虫技术是什么,在可预见的未来,互联网和网路抓取,将继续稳定地往前迈向。
网络爬虫的完整技术体系
采集交流 • 优采云 发表了文章 • 0 个评论 • 288 次浏览 • 2020-05-02 08:08
1、网络联接层:主要有TCP Socket联接的完善、数据传输以及联接管理组成。由于目前Web服务器支持的HTTP/1.0或1.1合同,在响应爬虫的恳求以后并不会关掉TCP联接,同时HTTP/1.1支持管线模式,因此当爬虫在多次抓取一个网站的页面时,Socket联接的完善、断开及URL恳求和结果的接收须要根据一定的次序进行。在爬虫执行过程中,可能须要重新联接Web服务器的情况,为了减少域名到IP地址转换的时间,爬虫一般要支持DNS缓存。
2、页面采集层:主要包括对URL的处理大数据网络爬虫原理,从中提取域名,并根据robots规范决定URL的抓取许可,同时在面对诸多的爬行任务时,需要根据一定的搜索策略来决定URL的抓取次序。在抓取页面时大数据网络爬虫原理,如果涉及到动态页面,可能须要考虑在爬虫中实现Session机制。最终的URL命令及结果是通过HTTP合同数据包发送的,其中的腹部信息中可以指定cookie信息。
3、页面提取层:该层完成了HTML文本信息的处理,主要是从中提取超链接、正文信息等内容,因此须要根据相应的HTML编码规范进行。同时,由于不同网站对Web页面信息的编码方法并不完全相同,例如UTF8、unicode、gbk等等,在解析文本信息时须要考虑页面的编码方法。当然目前有好多的开源框架支持页面解析,包括lxml、BeautifulSoup等,需要把握一些相应的规范,例如xpath。
4、领域处理层:这是指一些特定类型爬虫须要完成的功能,对于普通爬虫而言,这层并不需要。这些领域处理主要有:主题爬虫、DeepWeb爬虫,因此须要一定的文本剖析技术来支持,包括文本动词、主题建模等。
作者编绘的《互联网大数据处理技术与应用》专著(清华大学出版社,2017)、同名公众号,专注于大数据技术的相关科学和工程知识传播,同时也为读者提供一些拓展阅读材料。欢迎选用本书做大数据相关专业的教材,有相关教学资源共享。 查看全部
这四个层次的功能原理解释如下。
1、网络联接层:主要有TCP Socket联接的完善、数据传输以及联接管理组成。由于目前Web服务器支持的HTTP/1.0或1.1合同,在响应爬虫的恳求以后并不会关掉TCP联接,同时HTTP/1.1支持管线模式,因此当爬虫在多次抓取一个网站的页面时,Socket联接的完善、断开及URL恳求和结果的接收须要根据一定的次序进行。在爬虫执行过程中,可能须要重新联接Web服务器的情况,为了减少域名到IP地址转换的时间,爬虫一般要支持DNS缓存。
2、页面采集层:主要包括对URL的处理大数据网络爬虫原理,从中提取域名,并根据robots规范决定URL的抓取许可,同时在面对诸多的爬行任务时,需要根据一定的搜索策略来决定URL的抓取次序。在抓取页面时大数据网络爬虫原理,如果涉及到动态页面,可能须要考虑在爬虫中实现Session机制。最终的URL命令及结果是通过HTTP合同数据包发送的,其中的腹部信息中可以指定cookie信息。
3、页面提取层:该层完成了HTML文本信息的处理,主要是从中提取超链接、正文信息等内容,因此须要根据相应的HTML编码规范进行。同时,由于不同网站对Web页面信息的编码方法并不完全相同,例如UTF8、unicode、gbk等等,在解析文本信息时须要考虑页面的编码方法。当然目前有好多的开源框架支持页面解析,包括lxml、BeautifulSoup等,需要把握一些相应的规范,例如xpath。
4、领域处理层:这是指一些特定类型爬虫须要完成的功能,对于普通爬虫而言,这层并不需要。这些领域处理主要有:主题爬虫、DeepWeb爬虫,因此须要一定的文本剖析技术来支持,包括文本动词、主题建模等。
作者编绘的《互联网大数据处理技术与应用》专著(清华大学出版社,2017)、同名公众号,专注于大数据技术的相关科学和工程知识传播,同时也为读者提供一些拓展阅读材料。欢迎选用本书做大数据相关专业的教材,有相关教学资源共享。
新浪博客文章采集器
采集交流 • 优采云 发表了文章 • 0 个评论 • 582 次浏览 • 2020-04-18 11:03
八爪鱼·云采集网络爬虫软件 新浪博客文章采集器新浪博客拥有好多博主文章采集,会发布好多高质量的文章,有时候,有些同事看见那些 文章之后想采集下来, 但是一篇一篇文章去复制效率很慢了,这个时侯该怎样办 呢?使用八爪鱼采集器, 只需做好规则,即可全手动地将我们的想要的文章采集 下来。本文介绍使用八爪鱼采集新浪博客文章的技巧。采集网站: 采集的内容包括:博客文章正文,标题,标签,分类,日期。步骤 1:创建新浪博客文章采集任务1)进入主界面,选择“自定义采集”八爪鱼·云采集网络爬虫软件 2)将要采集的网址 URL 复制粘贴到网站输入框中,点击“保存网址”八爪鱼·云采集网络爬虫软件 步骤 2:创建翻页循环八爪鱼·云采集网络爬虫软件 1)打开网页以后博客文章采集,打开右上角的流程按键,使制做的流程可见状态。点击页面 下方的“下一页”,如图,选择“循环点击单个链接”,翻页循环创建完成。 (可 在左上角流程中自动点击 “循环翻页” 和 “点击翻页” 几次, 测试是否正常翻页。 )2)由于步入详情页时网页加载太慢,网址仍然在绕圈状态,无法立刻执行下一 个步骤,因此在“循环翻页”的中级选项里设置“ajax 加载数据”,超时时间 设置为 5 秒,点击“确定”。
八爪鱼·云采集网络爬虫软件 步骤 3:创建列表循环1)鼠标点击列表目录中第一个博文,选择操作提示框中的“选中全部”。2)鼠标点击“循环点击每位链接”,列表循环就创建完成,并步入到第一个循 环项的详情页面。八爪鱼·云采集网络爬虫软件 由于步入详情页时网页加载太慢,网址仍然在绕圈状态,无法立刻执行下一个步 骤,因此在“点击元素”的中级选项里设置“ajax 加载数据”,AJAX 超时设置 为 3 秒,点击“确定”。八爪鱼·云采集网络爬虫软件 3)数据提取,接下来采集具体数组,分别选中页面标题、标签、分类、时间, 点击“采集该元素的文本”,并在上方流程中更改数组名称。鼠标点击正文所在的地方,点击提示框中的右下角图标,扩大选项范围,直至包 括全部正文内容。(笔者测试点击 2 下就全部包括在内了)八爪鱼·云采集网络爬虫软件 同样选择“采集该元素的文本”,修改数组名称,数据提取完毕。八爪鱼·云采集网络爬虫软件 4)由于该网站网页加载速率十分慢,所以可在流程各个步骤的中级选项里设置 “执行前等待”几秒时间,也可避免访问页面较快出现防采集问题。设置后点击 “确定”。步骤 4:新浪博客数据采集及导入1)点击左上角的“保存”,然后点击“开始采集”。
八爪鱼·云采集网络爬虫软件 选择“启动本地采集”八爪鱼·云采集网络爬虫软件 2)采集完成后,会跳出提示,选择“导出数据”,选择“合适的导入方法”, 将采集好的数据导入, 这里我们选择 excel 作为导入为格式,这个时侯新浪博客 数据就导下来了博客文章采集,数据导入后如下图八爪鱼·云采集网络爬虫软件 相关采集教程:蚂蜂窝旅游小吃文章评论采集: 搜狗微信公众号文章采集: uc 头条文章采集: 网易自媒体文章采集: 百度搜索结果抓取和采集: 新浪微博评论数据的抓取与采集方法: 八爪鱼·云采集网络爬虫软件 八爪鱼——90 万用户选择的网页数据采集器。 1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。 查看全部
八爪鱼·云采集网络爬虫软件 新浪博客文章采集器新浪博客拥有好多博主文章采集,会发布好多高质量的文章,有时候,有些同事看见那些 文章之后想采集下来, 但是一篇一篇文章去复制效率很慢了,这个时侯该怎样办 呢?使用八爪鱼采集器, 只需做好规则,即可全手动地将我们的想要的文章采集 下来。本文介绍使用八爪鱼采集新浪博客文章的技巧。采集网站: 采集的内容包括:博客文章正文,标题,标签,分类,日期。步骤 1:创建新浪博客文章采集任务1)进入主界面,选择“自定义采集”八爪鱼·云采集网络爬虫软件 2)将要采集的网址 URL 复制粘贴到网站输入框中,点击“保存网址”八爪鱼·云采集网络爬虫软件 步骤 2:创建翻页循环八爪鱼·云采集网络爬虫软件 1)打开网页以后博客文章采集,打开右上角的流程按键,使制做的流程可见状态。点击页面 下方的“下一页”,如图,选择“循环点击单个链接”,翻页循环创建完成。 (可 在左上角流程中自动点击 “循环翻页” 和 “点击翻页” 几次, 测试是否正常翻页。 )2)由于步入详情页时网页加载太慢,网址仍然在绕圈状态,无法立刻执行下一 个步骤,因此在“循环翻页”的中级选项里设置“ajax 加载数据”,超时时间 设置为 5 秒,点击“确定”。
八爪鱼·云采集网络爬虫软件 步骤 3:创建列表循环1)鼠标点击列表目录中第一个博文,选择操作提示框中的“选中全部”。2)鼠标点击“循环点击每位链接”,列表循环就创建完成,并步入到第一个循 环项的详情页面。八爪鱼·云采集网络爬虫软件 由于步入详情页时网页加载太慢,网址仍然在绕圈状态,无法立刻执行下一个步 骤,因此在“点击元素”的中级选项里设置“ajax 加载数据”,AJAX 超时设置 为 3 秒,点击“确定”。八爪鱼·云采集网络爬虫软件 3)数据提取,接下来采集具体数组,分别选中页面标题、标签、分类、时间, 点击“采集该元素的文本”,并在上方流程中更改数组名称。鼠标点击正文所在的地方,点击提示框中的右下角图标,扩大选项范围,直至包 括全部正文内容。(笔者测试点击 2 下就全部包括在内了)八爪鱼·云采集网络爬虫软件 同样选择“采集该元素的文本”,修改数组名称,数据提取完毕。八爪鱼·云采集网络爬虫软件 4)由于该网站网页加载速率十分慢,所以可在流程各个步骤的中级选项里设置 “执行前等待”几秒时间,也可避免访问页面较快出现防采集问题。设置后点击 “确定”。步骤 4:新浪博客数据采集及导入1)点击左上角的“保存”,然后点击“开始采集”。
八爪鱼·云采集网络爬虫软件 选择“启动本地采集”八爪鱼·云采集网络爬虫软件 2)采集完成后,会跳出提示,选择“导出数据”,选择“合适的导入方法”, 将采集好的数据导入, 这里我们选择 excel 作为导入为格式,这个时侯新浪博客 数据就导下来了博客文章采集,数据导入后如下图八爪鱼·云采集网络爬虫软件 相关采集教程:蚂蜂窝旅游小吃文章评论采集: 搜狗微信公众号文章采集: uc 头条文章采集: 网易自媒体文章采集: 百度搜索结果抓取和采集: 新浪微博评论数据的抓取与采集方法: 八爪鱼·云采集网络爬虫软件 八爪鱼——90 万用户选择的网页数据采集器。 1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。
免费文章采集器使用教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 442 次浏览 • 2020-04-18 11:03
八爪鱼·云采集网络爬虫软件 免费文章采集器使用教程本文介绍使用八爪鱼采集器采集网易号文章的技巧。采集网址: 网易号前身为网易订阅,是网易传媒在完成“两端”融合升级后,全新构建的自 媒体内容分发与品牌推动平台。 本文以网易号首页列表为例,大家也可以更换采 集网址采集其他列表。采集内容:文章标题,发布时间,文章正文。使用功能点:? ? 列表循环 详情采集步骤 1:创建网易号文章采集任务八爪鱼·云采集网络爬虫软件 1)进入主界面,选择“自定义采集”2)将要采集的网址 URL 复制粘贴到网站输入框中,点击“保存网址”八爪鱼·云采集网络爬虫软件 步骤 2:创建循环点击加载更多1)打开网页以后,打开右上角的流程按键,从右侧的流程展示界面推入一个循 环的步骤,如下图八爪鱼·云采集网络爬虫软件 2)然后拉到页面顶部采集器,看到加载更多按键,因为想要查看更多内容就须要循环 的点击加载更多, 所以我们就须要设置一个点击 “加载更多” 的循环步骤。 注意: 采集更多内容就须要加载更多的内容, 本篇文章仅做演示, 所以选择执行点击 “加 载更多”20 次,根据自己实际需求加减即可。八爪鱼·云采集网络爬虫软件 八爪鱼·云采集网络爬虫软件 步骤 3:创建循环点击列表采集详情1)点击文章列表的第一个和第二个标题,然后选择“循环点击每位元素”按钮, 这样就创建了一个循环点击列表命令, 当前列表页的内容就都能在采集器中见到 了。
2)然后就可以提取我们须要的文本数据了,下图提取了文本的标题、时间、正 文等三个部份的文字内容, 还须要其他的信息可以自由删节编辑。然后就可以点 击保存,开始本地采集。八爪鱼·云采集网络爬虫软件 3)点击开始采集后,采集器就开始提取数据。八爪鱼·云采集网络爬虫软件 4)采集结束后导入即可。八爪鱼·云采集网络爬虫软件 免费文章相关采集器教程:新浪博客文章采集: uc 头条文章采集: 微信公众号热门文章采集(文本+图片): 今日头条采集: 新浪微博发布内容采集: 知乎信息采集: 八爪鱼——90 万用户选择的网页数据采集器。 1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。八爪鱼·云采集网络爬虫软件 2、功能强悍文章采集工具,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能文章采集工具,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。 查看全部
八爪鱼·云采集网络爬虫软件 免费文章采集器使用教程本文介绍使用八爪鱼采集器采集网易号文章的技巧。采集网址: 网易号前身为网易订阅,是网易传媒在完成“两端”融合升级后,全新构建的自 媒体内容分发与品牌推动平台。 本文以网易号首页列表为例,大家也可以更换采 集网址采集其他列表。采集内容:文章标题,发布时间,文章正文。使用功能点:? ? 列表循环 详情采集步骤 1:创建网易号文章采集任务八爪鱼·云采集网络爬虫软件 1)进入主界面,选择“自定义采集”2)将要采集的网址 URL 复制粘贴到网站输入框中,点击“保存网址”八爪鱼·云采集网络爬虫软件 步骤 2:创建循环点击加载更多1)打开网页以后,打开右上角的流程按键,从右侧的流程展示界面推入一个循 环的步骤,如下图八爪鱼·云采集网络爬虫软件 2)然后拉到页面顶部采集器,看到加载更多按键,因为想要查看更多内容就须要循环 的点击加载更多, 所以我们就须要设置一个点击 “加载更多” 的循环步骤。 注意: 采集更多内容就须要加载更多的内容, 本篇文章仅做演示, 所以选择执行点击 “加 载更多”20 次,根据自己实际需求加减即可。八爪鱼·云采集网络爬虫软件 八爪鱼·云采集网络爬虫软件 步骤 3:创建循环点击列表采集详情1)点击文章列表的第一个和第二个标题,然后选择“循环点击每位元素”按钮, 这样就创建了一个循环点击列表命令, 当前列表页的内容就都能在采集器中见到 了。
2)然后就可以提取我们须要的文本数据了,下图提取了文本的标题、时间、正 文等三个部份的文字内容, 还须要其他的信息可以自由删节编辑。然后就可以点 击保存,开始本地采集。八爪鱼·云采集网络爬虫软件 3)点击开始采集后,采集器就开始提取数据。八爪鱼·云采集网络爬虫软件 4)采集结束后导入即可。八爪鱼·云采集网络爬虫软件 免费文章相关采集器教程:新浪博客文章采集: uc 头条文章采集: 微信公众号热门文章采集(文本+图片): 今日头条采集: 新浪微博发布内容采集: 知乎信息采集: 八爪鱼——90 万用户选择的网页数据采集器。 1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。八爪鱼·云采集网络爬虫软件 2、功能强悍文章采集工具,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能文章采集工具,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。
网站文章标题采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 784 次浏览 • 2020-04-17 11:02
八爪鱼·云采集网络爬虫软件 网站文章标题采集当我们在网站优化, 或剖析词频权重,研究站点内什么类型的文章标题是频繁出 现时, 快速的获取站点内全部的文章标题就必不可少了。量少似乎能够通过复制 粘贴解决,但量若上来了,有成千甚至上万的文章标题须要获取。那自动复制黏 贴简直就是恶梦! 此时必然要寻求更快的解决方案。如通过爬虫工具快速批量获 取文章标题。 以下用做网易号文章例演示, 通过八爪鱼这个爬虫工具去获取数据,不单单获取 文章标题,还能获取文章内容。 示例网址:步骤 1:创建网易号文章采集任务1)进入主界面,选择“自定义采集”八爪鱼·云采集网络爬虫软件 2)将要采集的网址 URL 复制粘贴到网站输入框中,点击“保存网址”八爪鱼·云采集网络爬虫软件 步骤 2:创建循环点击加载更多1)打开网页以后,打开右上角的流程按键,从右侧的流程展示界面推入一个循 环的步骤,如下图八爪鱼·云采集网络爬虫软件 2)然后拉到页面顶部,看到加载更多按键,因为想要查看更多内容就须要循环 的点击加载更多, 所以我们就须要设置一个点击 “加载更多” 的循环步骤。 注意: 采集更多内容就须要加载更多的内容, 本篇文章仅做演示, 所以选择执行点击 “加 载更多”20 次,根据自己实际需求加减即可。
八爪鱼·云采集网络爬虫软件 步骤 3:创建循环点击列表采集详情1)点击文章列表的第一个和第二个标题,然后选择“循环点击每位元素”按钮, 这样就创建了一个循环点击列表命令, 当前列表页的内容就都能在采集器中见到八爪鱼·云采集网络爬虫软件 了。2)然后就可以提取我们须要的文本数据了,下图提取了文本的标题、时间、正 文等三个部份的文字内容, 还须要其他的信息可以自由删节编辑。然后就可以点八爪鱼·云采集网络爬虫软件 击保存,开始本地采集。3)点击开始采集后,采集器就开始提取数据。八爪鱼·云采集网络爬虫软件 4)采集结束后导入即可。八爪鱼·云采集网络爬虫软件 相关采集教程:新浪新闻采集 BBC 英文文章采集 新浪博客文章采集 uc 头条文章采集 百家号爆文采集 自媒体文章怎么采集 陌陌文章爬虫使用教程 八爪鱼采集原理 八爪鱼采集器 7.0 简介 八爪鱼——90 万用户选择的网页数据采集器。八爪鱼·云采集网络爬虫软件 1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作文章采集网站,2 分钟即可快速入门。 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集文章采集网站,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云) ,满足低端付费企业用户 的须要。 查看全部
八爪鱼·云采集网络爬虫软件 网站文章标题采集当我们在网站优化, 或剖析词频权重,研究站点内什么类型的文章标题是频繁出 现时, 快速的获取站点内全部的文章标题就必不可少了。量少似乎能够通过复制 粘贴解决,但量若上来了,有成千甚至上万的文章标题须要获取。那自动复制黏 贴简直就是恶梦! 此时必然要寻求更快的解决方案。如通过爬虫工具快速批量获 取文章标题。 以下用做网易号文章例演示, 通过八爪鱼这个爬虫工具去获取数据,不单单获取 文章标题,还能获取文章内容。 示例网址:步骤 1:创建网易号文章采集任务1)进入主界面,选择“自定义采集”八爪鱼·云采集网络爬虫软件 2)将要采集的网址 URL 复制粘贴到网站输入框中,点击“保存网址”八爪鱼·云采集网络爬虫软件 步骤 2:创建循环点击加载更多1)打开网页以后,打开右上角的流程按键,从右侧的流程展示界面推入一个循 环的步骤,如下图八爪鱼·云采集网络爬虫软件 2)然后拉到页面顶部,看到加载更多按键,因为想要查看更多内容就须要循环 的点击加载更多, 所以我们就须要设置一个点击 “加载更多” 的循环步骤。 注意: 采集更多内容就须要加载更多的内容, 本篇文章仅做演示, 所以选择执行点击 “加 载更多”20 次,根据自己实际需求加减即可。
八爪鱼·云采集网络爬虫软件 步骤 3:创建循环点击列表采集详情1)点击文章列表的第一个和第二个标题,然后选择“循环点击每位元素”按钮, 这样就创建了一个循环点击列表命令, 当前列表页的内容就都能在采集器中见到八爪鱼·云采集网络爬虫软件 了。2)然后就可以提取我们须要的文本数据了,下图提取了文本的标题、时间、正 文等三个部份的文字内容, 还须要其他的信息可以自由删节编辑。然后就可以点八爪鱼·云采集网络爬虫软件 击保存,开始本地采集。3)点击开始采集后,采集器就开始提取数据。八爪鱼·云采集网络爬虫软件 4)采集结束后导入即可。八爪鱼·云采集网络爬虫软件 相关采集教程:新浪新闻采集 BBC 英文文章采集 新浪博客文章采集 uc 头条文章采集 百家号爆文采集 自媒体文章怎么采集 陌陌文章爬虫使用教程 八爪鱼采集原理 八爪鱼采集器 7.0 简介 八爪鱼——90 万用户选择的网页数据采集器。八爪鱼·云采集网络爬虫软件 1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作文章采集网站,2 分钟即可快速入门。 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集文章采集网站,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云) ,满足低端付费企业用户 的须要。

