
网络爬虫
邮箱采集软件那个好?怎么使用?
采集交流 • 优采云 发表了文章 • 0 个评论 • 692 次浏览 • 2020-05-12 08:04
(cookie 有效时间以具体情况为准,到一定时间会失效,失效 需重新登陆获取 cookie,另外假如是点击头像(电脑登入的)需要把之前的点 击头像登陆的点击元素删掉)八爪鱼·云采集网络爬虫软件 邮箱采集软件使用步骤 4步骤 3:Ajax 点击登陆后,选择须要采集的 QQ 群,然后在右边的提示框中选择“点击该元素”八爪鱼·云采集网络爬虫软件 邮箱采集软件使用步骤 5因为网页涉及 Ajax 技术。 所以须要选中点击元素, 打开 “高级选项” , 勾选 “Ajax 加载数据”,设置时间为“15 秒”。执行前等待设置 7 秒, 因为页面打开后需 要向上滑动才可以出现更多内容,所以还须要设置页面滚动,滚动次数选择 20 次,(滚动次数具体看群成员的数目,如果 500 个人,一般来说选择 25 次能全 部加载完)每次间隔 1 秒,完成后,点击“确定”。八爪鱼·云采集网络爬虫软件 邮箱采集软件使用步骤 6步骤 4:提取元素1)选择第一个 QQ 号码,然后在右边的提示框中选择“选中全部”,随后选择 “采集元素”。八爪鱼·云采集网络爬虫软件 邮箱采集软件使用步骤 7步骤 5:修改 Xpath1) 手动执行规则, 发现循环列表里并没有定位到所有元素, 所以须要更改 xpath, 在循环形式中选择不固定元素列表,修改 xpath 为 //tbody[@class="list"]/tr八爪鱼·云采集网络爬虫软件 邮箱采集软件使用步骤 82)因为提取到的数据是 QQ 号邮箱爬虫软件,所以要更改一下,转化成邮箱 选中 QQ 号数组→点击中级选项中自定义数据字段(如下图)→格式化数据→八爪鱼·云采集网络爬虫软件 邮箱采集软件使用步骤 9添加步骤→添加后缀八爪鱼·云采集网络爬虫软件 邮箱采集软件使用步骤 103)修改完成之后,点击确定,效果如下图八爪鱼·云采集网络爬虫软件 邮箱采集软件使用步骤 11步骤 5:QQ 邮箱数据采集及导入1)打开流程按键,修改采集字段名称,点击“保存并开始采集”八爪鱼·云采集网络爬虫软件 邮箱采集软件使用步骤 12启动本地采集八爪鱼·云采集网络爬虫软件 邮箱采集软件使用步骤 13采集完成后,会跳出提示,选择“导出数据”选择“合适的导入方法”,将采集 好的数据导入这儿我们选择 excel 作为导入为格式,数据导入后如下图八爪鱼·云采集网络爬虫软件 邮箱采集软件使用步骤 14相关采集教程:黄页 88 企业名录采集方法 顺企网企业黄页采集详细步骤 114 黄页企业信息采集详细教程步骤 企业信息采集软件 八爪鱼·云采集网络爬虫软件 使用八爪鱼采集天眼查企业信息 企查查企业邮箱采集 帖吧邮箱采集 八爪鱼——90 万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。 查看全部
八爪鱼·云采集网络爬虫软件 邮箱采集软件那个好?怎么使用?电子邮件营销是常见的一种形式,有时候你有了一个极佳的电子邮件方案,希望 通过发送电子邮件获得大量用户转化,但是在邮箱搜集上假如只是随便的去弄, 肯定疗效不会挺好的。 所以邮箱采集是一个十分重要的步骤,如何去采集精准的 客户邮箱是每位电子邮件营销人员应当考虑的事情。 下面为你们推荐一款电邮采 集软件,可以依照自己的需求,自定义的采集网页上的邮箱,从而达到精准的目 的。本教程以采集 QQ 邮箱为例,介绍该软件的使用方式,其它情况下的邮箱也是 一样配置规则,进行采集。采集网站:步骤 1:创建 QQ 邮箱采集任务1)进入主界面,选择“自定义采集”八爪鱼·云采集网络爬虫软件 邮箱采集软件使用步骤 12)将要采集的网站 URL 复制粘贴到输入框中,点击“保存网址”八爪鱼·云采集网络爬虫软件 邮箱采集软件使用步骤 2步骤 2:Cookie 登录1)打开网页后,需要先登入,可以先在手机登陆 QQ, 采集时点击登陆按键邮箱爬虫软件,之 后扫码就可以成功登陆。或者笔记本登陆,点击二维码一侧的头像进行登陆。八爪鱼·云采集网络爬虫软件 邮箱采集软件使用步骤 32) 登陆后, 在中级选项中选择自定义 cookie, 勾选打开网页时使用固定 cookie, 再点击获取当前页面 cookie,最后点击“确定”,这样之后再采集时就不用重 复登陆 QQ 了。
(cookie 有效时间以具体情况为准,到一定时间会失效,失效 需重新登陆获取 cookie,另外假如是点击头像(电脑登入的)需要把之前的点 击头像登陆的点击元素删掉)八爪鱼·云采集网络爬虫软件 邮箱采集软件使用步骤 4步骤 3:Ajax 点击登陆后,选择须要采集的 QQ 群,然后在右边的提示框中选择“点击该元素”八爪鱼·云采集网络爬虫软件 邮箱采集软件使用步骤 5因为网页涉及 Ajax 技术。 所以须要选中点击元素, 打开 “高级选项” , 勾选 “Ajax 加载数据”,设置时间为“15 秒”。执行前等待设置 7 秒, 因为页面打开后需 要向上滑动才可以出现更多内容,所以还须要设置页面滚动,滚动次数选择 20 次,(滚动次数具体看群成员的数目,如果 500 个人,一般来说选择 25 次能全 部加载完)每次间隔 1 秒,完成后,点击“确定”。八爪鱼·云采集网络爬虫软件 邮箱采集软件使用步骤 6步骤 4:提取元素1)选择第一个 QQ 号码,然后在右边的提示框中选择“选中全部”,随后选择 “采集元素”。八爪鱼·云采集网络爬虫软件 邮箱采集软件使用步骤 7步骤 5:修改 Xpath1) 手动执行规则, 发现循环列表里并没有定位到所有元素, 所以须要更改 xpath, 在循环形式中选择不固定元素列表,修改 xpath 为 //tbody[@class="list"]/tr八爪鱼·云采集网络爬虫软件 邮箱采集软件使用步骤 82)因为提取到的数据是 QQ 号邮箱爬虫软件,所以要更改一下,转化成邮箱 选中 QQ 号数组→点击中级选项中自定义数据字段(如下图)→格式化数据→八爪鱼·云采集网络爬虫软件 邮箱采集软件使用步骤 9添加步骤→添加后缀八爪鱼·云采集网络爬虫软件 邮箱采集软件使用步骤 103)修改完成之后,点击确定,效果如下图八爪鱼·云采集网络爬虫软件 邮箱采集软件使用步骤 11步骤 5:QQ 邮箱数据采集及导入1)打开流程按键,修改采集字段名称,点击“保存并开始采集”八爪鱼·云采集网络爬虫软件 邮箱采集软件使用步骤 12启动本地采集八爪鱼·云采集网络爬虫软件 邮箱采集软件使用步骤 13采集完成后,会跳出提示,选择“导出数据”选择“合适的导入方法”,将采集 好的数据导入这儿我们选择 excel 作为导入为格式,数据导入后如下图八爪鱼·云采集网络爬虫软件 邮箱采集软件使用步骤 14相关采集教程:黄页 88 企业名录采集方法 顺企网企业黄页采集详细步骤 114 黄页企业信息采集详细教程步骤 企业信息采集软件 八爪鱼·云采集网络爬虫软件 使用八爪鱼采集天眼查企业信息 企查查企业邮箱采集 帖吧邮箱采集 八爪鱼——90 万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。
[读后笔记] python网路爬虫实战 (李松涛)
采集交流 • 优采云 发表了文章 • 0 个评论 • 341 次浏览 • 2020-05-12 08:03
用了大约一个晚上的时间,就把这本书看完了。
前面4章是基础的python知识,有基础的朋友可以略过。
scrapy爬虫部份,用了实例给你们说明scrapy的用法网络爬虫实例,不过若果之前没用过scrapy的话,需要渐渐上机敲击代码。
其实书中的事例都是很简单的事例,基本没哪些反爬的限制,书中一句话说的十分赞成,用scrapy写爬虫,就是做填空题,而用urllib2写爬虫,就是习作题,可以自由发挥。
书中没有用更为便捷的requests库。 内容搜索用的最多的是beatifulsoup, 对于xpah或则lxml介绍的比较少。 因为scrapy自带的response就是可以直接用xpath,更为便捷。
对于scrapy的中间和pipeline的使用了一个事例,也是比较简单的反例。
书中没有对验证码,分布式等流行的反爬进行讲解,应该适宜爬虫入门的朋友去看吧。
书中一点挺好的就是代码都十分规范,而且虽然是写习作的使用urllib2,也有意模仿scrapy的框架去写, 需要抓取的数据 独立一个类,类似于scrapy的item,数据处理用的也是叫pipleline的方式。
这样写的益处就是, 每个模块的功能都一目了然,看完第一个反例的类和函数定义,后面的事例都是大同小异,可以推动读者的阅读速率,非常赞。(这一点之后自己要学习,增加代码的可复用性)
很多页面url如今早已过期了,再次运行作者的源码会返回好多404的结果。
失效的项目:
金逸影城
天气预报
获取代理:
本书的一些错误的地方:
1. 获取金逸影厅的spider中,所有关于movie的拼写都拼错为moive了。这个属于德语错误。
2. 在testProxy.py 代码中网络爬虫实例, 由于在同一个类中,一直在形成线程,最后造成线程过多,不能再形成线程。程序会中途退出。
File "C:\Python27\lib\threading.py", line 736, in start<br />
_start_new_thread(self.__bootstrap, ())<br />
thread.error: can't start new thread
可以更改成独立函数的方式,而不是类函数。
待续。 查看全部

用了大约一个晚上的时间,就把这本书看完了。
前面4章是基础的python知识,有基础的朋友可以略过。
scrapy爬虫部份,用了实例给你们说明scrapy的用法网络爬虫实例,不过若果之前没用过scrapy的话,需要渐渐上机敲击代码。
其实书中的事例都是很简单的事例,基本没哪些反爬的限制,书中一句话说的十分赞成,用scrapy写爬虫,就是做填空题,而用urllib2写爬虫,就是习作题,可以自由发挥。
书中没有用更为便捷的requests库。 内容搜索用的最多的是beatifulsoup, 对于xpah或则lxml介绍的比较少。 因为scrapy自带的response就是可以直接用xpath,更为便捷。
对于scrapy的中间和pipeline的使用了一个事例,也是比较简单的反例。
书中没有对验证码,分布式等流行的反爬进行讲解,应该适宜爬虫入门的朋友去看吧。
书中一点挺好的就是代码都十分规范,而且虽然是写习作的使用urllib2,也有意模仿scrapy的框架去写, 需要抓取的数据 独立一个类,类似于scrapy的item,数据处理用的也是叫pipleline的方式。
这样写的益处就是, 每个模块的功能都一目了然,看完第一个反例的类和函数定义,后面的事例都是大同小异,可以推动读者的阅读速率,非常赞。(这一点之后自己要学习,增加代码的可复用性)
很多页面url如今早已过期了,再次运行作者的源码会返回好多404的结果。
失效的项目:
金逸影城
天气预报
获取代理:
本书的一些错误的地方:
1. 获取金逸影厅的spider中,所有关于movie的拼写都拼错为moive了。这个属于德语错误。
2. 在testProxy.py 代码中网络爬虫实例, 由于在同一个类中,一直在形成线程,最后造成线程过多,不能再形成线程。程序会中途退出。
File "C:\Python27\lib\threading.py", line 736, in start<br />
_start_new_thread(self.__bootstrap, ())<br />
thread.error: can't start new thread
可以更改成独立函数的方式,而不是类函数。
待续。
Java 网络爬虫基础入门
采集交流 • 优采云 发表了文章 • 0 个评论 • 254 次浏览 • 2020-05-11 08:03
作为网路爬虫的入门教程,本达人课采用 Java 开发语言java爬虫教程入门超级,内容涵括了网路爬虫的原理以及开发逻辑,Java 网络爬虫基础知识,网络抓包介绍,jsoup 的介绍与使用,HttpClient 的介绍与使用等内容。本课程在介绍网路爬虫基本原理的同时,注重具体的代码实现,加深读者对爬虫的理解,加强读者的实战能力。
本达人课共计14课,主要包含五大部份。
第一部分(第01-03课),主要介绍网路爬虫的原理、开发逻辑以及 Java 网络爬虫基础知识,网络抓包等内容。
第二部份(第04-06课),主要介绍现有的一些页面内容获取及页面解析工具。包括 jsoup、HttpClient、URLConnection。
第三部份(第07-08课),针对已获得的页面内容java爬虫教程入门超级,带你们选择合适的解析工具进行页面解析,包括 HTML、XML、JSON 主流数据格式的解析。
第四部份(第09-11课),针对已解析的内容,介绍怎么封装数据并储存数据。包括通过 MySQL 数据库储存数据,以及文本文件储存和 Excel 格式储存。
第五部份(第12-14课),以典型网站为案例,开启实战演练。
钱洋,机器学习方向博士生,CSDN 博客专家,主要从事文本挖掘方面的研究。目前,正参与几个大数据相关项目的研究工作。乐于分享自己的经验,擅长撰写技术类博客。 查看全部
大数据环境下,数据剖析已由业务驱动转变为数据驱动,网络数据资源呈指数级下降,且洒落在不同的数据源之中。对大多数企业和研究者而言,用“数据说话”仿佛成了大数据时代的重要装备。网络爬虫作为网路数据获取的重要技术,受到了越来越多数据需求者的偏爱和青睐。
作为网路爬虫的入门教程,本达人课采用 Java 开发语言java爬虫教程入门超级,内容涵括了网路爬虫的原理以及开发逻辑,Java 网络爬虫基础知识,网络抓包介绍,jsoup 的介绍与使用,HttpClient 的介绍与使用等内容。本课程在介绍网路爬虫基本原理的同时,注重具体的代码实现,加深读者对爬虫的理解,加强读者的实战能力。
本达人课共计14课,主要包含五大部份。
第一部分(第01-03课),主要介绍网路爬虫的原理、开发逻辑以及 Java 网络爬虫基础知识,网络抓包等内容。
第二部份(第04-06课),主要介绍现有的一些页面内容获取及页面解析工具。包括 jsoup、HttpClient、URLConnection。
第三部份(第07-08课),针对已获得的页面内容java爬虫教程入门超级,带你们选择合适的解析工具进行页面解析,包括 HTML、XML、JSON 主流数据格式的解析。
第四部份(第09-11课),针对已解析的内容,介绍怎么封装数据并储存数据。包括通过 MySQL 数据库储存数据,以及文本文件储存和 Excel 格式储存。
第五部份(第12-14课),以典型网站为案例,开启实战演练。
钱洋,机器学习方向博士生,CSDN 博客专家,主要从事文本挖掘方面的研究。目前,正参与几个大数据相关项目的研究工作。乐于分享自己的经验,擅长撰写技术类博客。
网络爬虫技术的定义与反爬虫方法剖析
采集交流 • 优采云 发表了文章 • 0 个评论 • 449 次浏览 • 2020-05-11 08:03
有很多人觉得Web应该一直秉持开放的精神,呈现在页面中的信息应该毫无保留地分享给整个互联网。然而我觉得,在IT行业发展至明天,Web早已不再是当初那种和PDF一争高下的所谓“超文本”信息载体了,它早已是以一种轻量级客户端软件的意识形态的存在了。而商业软件发展到明天,Web也不得不面对知识产权保护的问题,试想假如原创的高质量内容得不到保护,抄袭和盗版横行网路世界,这显然对Web生态的良性发展是不利的,也很难鼓励更多的优质原创内容的生产。
未授权的爬虫抓取程序是害处Web原创内容生态的一大诱因,因此要保护网站的内容,首先就要考虑怎样反爬虫。
从爬虫的攻守角度来讲
最简单的爬虫,是几乎所有服务端、客户端编程语言都支持的http恳求,只要向目标页面的url发起一个http get恳求,即可获得到浏览器加载这个页面时的完整html文档,这被我们称之为“同步页”。
作为逼抢的一方,服务端可以按照http请求头中的User-Agent来检测客户端是否是一个合法的浏览器程序,亦或是一个脚本编撰的抓取程序,从而决定是否将真实的页面信息内容下发给你。
这其实是最小儿科的防御手段,爬虫作为逼抢的一方,完全可以伪造User-Agent数组,甚至,只要你乐意,http的get方式里, request header的 Referrer 、 Cookie 等等所有数组爬虫都可以轻而易举的伪造。
此时服务端可以借助浏览器http头指纹,根据你申明的自己的浏览器厂商和版本(来自 User-Agent ),来分辨你的http header中的各个数组是否符合该浏览器的特点,如不符合则作为爬虫程序对待。这个技术有一个典型的应用,就是PhantomJS1.x版本中,由于其底层调用了Qt框架的网路库,因此http头里有显著的Qt框架网路恳求的特点,可以被服务端直接辨识并拦截。
除此之外,还有一种愈发变态的服务端爬虫检查机制,就是对所有访问页面的http请求,在 http response 中种下一个 cookie token ,然后在这个页面内异步执行的一些ajax插口里去校准来访恳求是否富含cookie token,将token回传回去则表明这是一个合法的浏览器来访,否则说明刚才被下发了那种token的用户访问了页面html却没有访问html内执行js后调用的ajax恳求,很有可能是一个爬虫程序。
如果你不携带token直接访问一个插口,这也就意味着你没恳求过html页面直接向本应由页面内ajax访问的插口发起了网路恳求,这也似乎证明了你是一个可疑的爬虫。知名电商网站amazon就是采用的这些防御策略。
以上则是基于服务端校准爬虫程序,可以玩出的一些套路手段。
基于客户端js运行时的测量
现代浏览器赋于了强悍的能力,因此我们可以把页面的所有核心内容都弄成js异步恳求 ajax 获取数据后渲染在页面中的,这也许提升了爬虫抓取内容的门槛。依靠这些方法,我们把对抓取与反抓取的对抗战场从服务端转移到了客户端浏览器中的js运行时,接下来说一说结合客户端js运行时的爬虫抓取技术。
刚刚提到的各类服务端校准,对于普通的python、java语言编撰的http抓取程序而言,具有一定的技术门槛,毕竟一个web应用对于未授权抓取者而言是黑盒的,很多东西须要一点一点去尝试,而耗费大量人力物力开发好的一套抓取程序,web站作为逼抢一方只要轻易调整一些策略,攻击者就须要再度耗费同等的时间去更改爬虫抓取逻辑。
此时就须要使用headless browser了,这是哪些技术呢?其实说白了就是,让程序可以操作浏览器去访问网页,这样编撰爬虫的人可以通过调用浏览器曝露下来给程序调用的api去实现复杂的抓取业务逻辑。
其实近些年来这早已不算是哪些新鲜的技术了,从前有基于webkit内核的PhantomJS,基于Firefox浏览器内核的SlimerJS,甚至基于IE内核的trifleJS,有兴趣可以瞧瞧这儿和这儿 是两个headless browser的搜集列表。
这些headless browser程序实现的原理虽然是把开源的一些浏览器内核C++++代码加以整修和封装,实现一个简易的无GUI界面渲染的browser程序。但这种项目普遍存在的问题是,由于她们的代码基于fork官方webkit等内核的某一个版本的主干代码,因此难以跟进一些最新的css属性和js句型,并且存在一些兼容性的问题,不如真正的release版GUI浏览器。
这其中最为成熟、使用率最高的应当当属PhantonJS了,对这些爬虫的辨识我之前曾写过一篇博客,这里不再赘言。PhantomJS存在众多问题,因为是单进程模型,没有必要的沙箱保护,浏览器内核的安全性较差。
如今Google Chrome团队在chrome 59 release版本中开放了headless mode api,并开源了一个基于Node.js调用的headless chromium dirver库,我也为这个库贡献了一个centos环境的布署依赖安装列表。
headless chrome堪称是headless browser中独树一帜的大杀器,由于其自身就是一个chrome浏览器,因此支持各类新的css渲染特点和js运行时句型。
基于这样的手段,爬虫作为逼抢的一方可以绕开几乎所有服务端校准逻辑,但是这种爬虫在客户端的js运行时中仍然存在着一些纰漏,诸如:
基于plugin对象的检测
基于language的检测
基于webgl的检测
基于浏览器hairline特点的检测
基于错误img src属性生成的img对象的检测
基于以上的一些浏览器特点的判定,基本可以通杀市面上大多数headless browser程序。在这一点上,实际上是将网页抓取的门槛提升,要求编撰爬虫程序的开发者不得不更改浏览器内核的C++代码,重新编译一个浏览器,并且,以上几点特点是对浏览器内核的改动虽然并不小。
更进一步,我们还可以基于浏览器的UserAgent数组描述的浏览器品牌、版本机型信息,对js运行时、DOM和BOM的各个原生对象的属性及技巧进行检验,观察其特点是否符合该版本的浏览器所应具备的特点。
这种方法被称为浏览器指纹检测技术,依托于小型web站对各机型浏览器api信息的搜集。而作为编撰爬虫程序的逼抢一方,则可以在headless browser运行时里预注入一些js逻辑,伪造浏览器的特点。
另外,在研究浏览器端借助js api进行robots browser detect时网络爬虫 技术,我们发觉了一个有趣的小技巧,你可以把一个预注入的js函数,伪装成一个native function,来瞧瞧下边代码:
爬虫进攻方可能会预注入一些js方式,把原生的一些api外边包装一层proxy function作为hook,然后再用这个假的js api去覆盖原生api。如果防御者在对此做检测判定时是基于把函数toString以后对[native code]的检测,那么都会被绕开。所以须要更严格的检测,因为bind(null)伪造的方式,在toString以后是不带函数名的。
反爬虫的手炮
目前的反抓取、机器人检测手段,最可靠的还是验证码技术。但验证码并不意味着一定要逼迫用户输入一连串字母数字,也有好多基于用户键盘、触屏(移动端)等行为的行为验证技术,这其中最为成熟的当属Google reCAPTCHA。
基于以上众多对用户与爬虫的辨识分辨技术,网站的防御方最终要做的是封禁ip地址或是对这个ip的来访用户施以高硬度的验证码策略。这样一来,进攻方不得不订购ip代理池来抓取网站信息内容,否则单个ip地址很容易被封造成难以抓取。抓取与反抓取的门槛被提升到了ip代理池经济费用的层面。
机器人协议
除此之外,在爬虫抓取技术领域还有一个“白道”的手段,叫做robots协议。你可以在一个网站的根目录下访问/robots.txt,比如使我们一起来瞧瞧github的机器人合同,Allow和Disallow申明了对各个UA爬虫的抓取授权。
不过,这只是一个君子合同,虽具有法律效益,但只能够限制这些商业搜索引擎的蜘蛛程序,你没法对这些“野爬爱好者”加以限制。
写在最后
对网页内容的抓取与反制,注定是一个魔高一尺道高一丈的猫鼠游戏,你永远不可能以某一种技术彻底封死爬虫程序的街网络爬虫 技术,你能做的只是增强攻击者的抓取成本,并对于未授权的抓取行为做到较为精确的据悉。 查看全部
Web是一个开放的平台,这也奠定了Web从90年代初诞生直到明日将近30年来蓬勃的发展。然而,正所谓成也萧何败也萧何,开放的特型、搜索引擎以及简单易学的HTML、CSS技术促使Web成为了互联网领域里最为流行和成熟的信息传播媒介;但现在作为商业化软件,Web这个平台上的内容信息的版权却毫无保证,因为相比软件客户端而言,你的网页中的内容可以被太低成本、很低的技术门槛实现出的一些抓取程序获取到,这也就是这一系列文章将要阐述的话题——网络爬虫。

有很多人觉得Web应该一直秉持开放的精神,呈现在页面中的信息应该毫无保留地分享给整个互联网。然而我觉得,在IT行业发展至明天,Web早已不再是当初那种和PDF一争高下的所谓“超文本”信息载体了,它早已是以一种轻量级客户端软件的意识形态的存在了。而商业软件发展到明天,Web也不得不面对知识产权保护的问题,试想假如原创的高质量内容得不到保护,抄袭和盗版横行网路世界,这显然对Web生态的良性发展是不利的,也很难鼓励更多的优质原创内容的生产。
未授权的爬虫抓取程序是害处Web原创内容生态的一大诱因,因此要保护网站的内容,首先就要考虑怎样反爬虫。
从爬虫的攻守角度来讲
最简单的爬虫,是几乎所有服务端、客户端编程语言都支持的http恳求,只要向目标页面的url发起一个http get恳求,即可获得到浏览器加载这个页面时的完整html文档,这被我们称之为“同步页”。
作为逼抢的一方,服务端可以按照http请求头中的User-Agent来检测客户端是否是一个合法的浏览器程序,亦或是一个脚本编撰的抓取程序,从而决定是否将真实的页面信息内容下发给你。
这其实是最小儿科的防御手段,爬虫作为逼抢的一方,完全可以伪造User-Agent数组,甚至,只要你乐意,http的get方式里, request header的 Referrer 、 Cookie 等等所有数组爬虫都可以轻而易举的伪造。
此时服务端可以借助浏览器http头指纹,根据你申明的自己的浏览器厂商和版本(来自 User-Agent ),来分辨你的http header中的各个数组是否符合该浏览器的特点,如不符合则作为爬虫程序对待。这个技术有一个典型的应用,就是PhantomJS1.x版本中,由于其底层调用了Qt框架的网路库,因此http头里有显著的Qt框架网路恳求的特点,可以被服务端直接辨识并拦截。
除此之外,还有一种愈发变态的服务端爬虫检查机制,就是对所有访问页面的http请求,在 http response 中种下一个 cookie token ,然后在这个页面内异步执行的一些ajax插口里去校准来访恳求是否富含cookie token,将token回传回去则表明这是一个合法的浏览器来访,否则说明刚才被下发了那种token的用户访问了页面html却没有访问html内执行js后调用的ajax恳求,很有可能是一个爬虫程序。
如果你不携带token直接访问一个插口,这也就意味着你没恳求过html页面直接向本应由页面内ajax访问的插口发起了网路恳求,这也似乎证明了你是一个可疑的爬虫。知名电商网站amazon就是采用的这些防御策略。
以上则是基于服务端校准爬虫程序,可以玩出的一些套路手段。
基于客户端js运行时的测量
现代浏览器赋于了强悍的能力,因此我们可以把页面的所有核心内容都弄成js异步恳求 ajax 获取数据后渲染在页面中的,这也许提升了爬虫抓取内容的门槛。依靠这些方法,我们把对抓取与反抓取的对抗战场从服务端转移到了客户端浏览器中的js运行时,接下来说一说结合客户端js运行时的爬虫抓取技术。
刚刚提到的各类服务端校准,对于普通的python、java语言编撰的http抓取程序而言,具有一定的技术门槛,毕竟一个web应用对于未授权抓取者而言是黑盒的,很多东西须要一点一点去尝试,而耗费大量人力物力开发好的一套抓取程序,web站作为逼抢一方只要轻易调整一些策略,攻击者就须要再度耗费同等的时间去更改爬虫抓取逻辑。
此时就须要使用headless browser了,这是哪些技术呢?其实说白了就是,让程序可以操作浏览器去访问网页,这样编撰爬虫的人可以通过调用浏览器曝露下来给程序调用的api去实现复杂的抓取业务逻辑。
其实近些年来这早已不算是哪些新鲜的技术了,从前有基于webkit内核的PhantomJS,基于Firefox浏览器内核的SlimerJS,甚至基于IE内核的trifleJS,有兴趣可以瞧瞧这儿和这儿 是两个headless browser的搜集列表。
这些headless browser程序实现的原理虽然是把开源的一些浏览器内核C++++代码加以整修和封装,实现一个简易的无GUI界面渲染的browser程序。但这种项目普遍存在的问题是,由于她们的代码基于fork官方webkit等内核的某一个版本的主干代码,因此难以跟进一些最新的css属性和js句型,并且存在一些兼容性的问题,不如真正的release版GUI浏览器。
这其中最为成熟、使用率最高的应当当属PhantonJS了,对这些爬虫的辨识我之前曾写过一篇博客,这里不再赘言。PhantomJS存在众多问题,因为是单进程模型,没有必要的沙箱保护,浏览器内核的安全性较差。
如今Google Chrome团队在chrome 59 release版本中开放了headless mode api,并开源了一个基于Node.js调用的headless chromium dirver库,我也为这个库贡献了一个centos环境的布署依赖安装列表。
headless chrome堪称是headless browser中独树一帜的大杀器,由于其自身就是一个chrome浏览器,因此支持各类新的css渲染特点和js运行时句型。
基于这样的手段,爬虫作为逼抢的一方可以绕开几乎所有服务端校准逻辑,但是这种爬虫在客户端的js运行时中仍然存在着一些纰漏,诸如:
基于plugin对象的检测

基于language的检测

基于webgl的检测

基于浏览器hairline特点的检测

基于错误img src属性生成的img对象的检测

基于以上的一些浏览器特点的判定,基本可以通杀市面上大多数headless browser程序。在这一点上,实际上是将网页抓取的门槛提升,要求编撰爬虫程序的开发者不得不更改浏览器内核的C++代码,重新编译一个浏览器,并且,以上几点特点是对浏览器内核的改动虽然并不小。
更进一步,我们还可以基于浏览器的UserAgent数组描述的浏览器品牌、版本机型信息,对js运行时、DOM和BOM的各个原生对象的属性及技巧进行检验,观察其特点是否符合该版本的浏览器所应具备的特点。
这种方法被称为浏览器指纹检测技术,依托于小型web站对各机型浏览器api信息的搜集。而作为编撰爬虫程序的逼抢一方,则可以在headless browser运行时里预注入一些js逻辑,伪造浏览器的特点。
另外,在研究浏览器端借助js api进行robots browser detect时网络爬虫 技术,我们发觉了一个有趣的小技巧,你可以把一个预注入的js函数,伪装成一个native function,来瞧瞧下边代码:

爬虫进攻方可能会预注入一些js方式,把原生的一些api外边包装一层proxy function作为hook,然后再用这个假的js api去覆盖原生api。如果防御者在对此做检测判定时是基于把函数toString以后对[native code]的检测,那么都会被绕开。所以须要更严格的检测,因为bind(null)伪造的方式,在toString以后是不带函数名的。
反爬虫的手炮
目前的反抓取、机器人检测手段,最可靠的还是验证码技术。但验证码并不意味着一定要逼迫用户输入一连串字母数字,也有好多基于用户键盘、触屏(移动端)等行为的行为验证技术,这其中最为成熟的当属Google reCAPTCHA。
基于以上众多对用户与爬虫的辨识分辨技术,网站的防御方最终要做的是封禁ip地址或是对这个ip的来访用户施以高硬度的验证码策略。这样一来,进攻方不得不订购ip代理池来抓取网站信息内容,否则单个ip地址很容易被封造成难以抓取。抓取与反抓取的门槛被提升到了ip代理池经济费用的层面。
机器人协议
除此之外,在爬虫抓取技术领域还有一个“白道”的手段,叫做robots协议。你可以在一个网站的根目录下访问/robots.txt,比如使我们一起来瞧瞧github的机器人合同,Allow和Disallow申明了对各个UA爬虫的抓取授权。
不过,这只是一个君子合同,虽具有法律效益,但只能够限制这些商业搜索引擎的蜘蛛程序,你没法对这些“野爬爱好者”加以限制。
写在最后
对网页内容的抓取与反制,注定是一个魔高一尺道高一丈的猫鼠游戏,你永远不可能以某一种技术彻底封死爬虫程序的街网络爬虫 技术,你能做的只是增强攻击者的抓取成本,并对于未授权的抓取行为做到较为精确的据悉。
python网络爬虫书籍推荐
采集交流 • 优采云 发表了文章 • 0 个评论 • 370 次浏览 • 2020-05-11 08:02
Python3网路爬虫开发实战
书籍介绍:
《Python3网络爬虫开发实战》介绍了怎样借助Python 3开发网络爬虫,书中首先介绍了环境配置和基础知识,然后讨论了urllib、requests、正则表达式、Beautiful Soup、XPath、pyquery、数据储存、Ajax数据爬取等内容,接着通过多个案例介绍了不同场景下怎样实现数据爬取,后介绍了pyspider框架、Scrapy框架和分布式爬虫。
作者介绍:
崔庆才,北京航空航天大学硕士,静觅博客()博主,爬虫博文访问量已过百万,喜欢钻研,热爱生活,乐于分享。欢迎关注个人微信公众号“进击的Coder”。
下载地址:
《Python网路数据采集》
书籍介绍:
《Python网路数据采集》采用简约强悍的Python语言网络爬虫技术书籍,介绍了网路数据采集,并为采集新式网路中的各类数据类型提供了全面的指导。第一部分重点介绍网路数据采集的基本原理:如何用Python从网路服务器恳求信息,如何对服务器的响应进行基本处理,以及怎样以自动化手段与网站进行交互。第二部份介绍怎样用网络爬虫测试网站,自动化处理,以及怎样通过更多的形式接入网路。
下载地址:
《从零开始学Python网络爬虫》
书籍介绍:
《从零开始学Python网络爬虫》是一本教初学者学习怎么爬取网路数据和信息的入门读物。书中除了有Python的相关内容,而且还有数据处理和数据挖掘等方面的内容。本书内容十分实用,讲解时穿插了22个爬虫实战案例,可以大大增强读者的实际动手能力。
本书共分12章,核心主题包括Python零基础句型入门、爬虫原理和网页构造、我的第一个爬虫程序、正则表达式、Lxml库与Xpath句型、使用API、数据库储存、多进程爬虫、异步加载、表单交互与模拟登陆、Selenium模拟浏览器、Scrapy爬虫框架。此外,书中通过一些典型爬虫案例,讲解了有经纬信息的地图图表和词云的制做方式,让读者体验数据背后的乐趣。
下载地址:
图解 HTTP
书籍介绍:
《图解 HTTP》对互联网基盘——HTTP协议进行了全面系统的介绍。作者由HTTP合同的发展历史娓娓道来,严谨细致地分析了HTTP合同的结构,列举众多常见通讯场景及实战案例网络爬虫技术书籍,最后延展到Web安全、最新技术动向等方面。本书的特色为在讲解的同时,辅以大量生动形象的通讯图例,更好地帮助读者深刻理解HTTP通讯过程中客户端与服务器之间的交互情况。读者可通过本书快速了解并把握HTTP协议的基础,前端工程师剖析抓包数据,后端工程师实现REST API、实现自己的HTTP服务器等过程中所需的HTTP相关知识点本书均有介绍。
下载地址:
《精通Python网路爬虫 核心技术、框架与项目实战》
书籍介绍:
本书从系统化的视角,为这些想学习Python网路爬虫或则正在研究Python网路爬虫的朋友们提供了一个全面的参考,让读者可以系统地学习Python网路爬虫的方方面面,在理解并把握了本书的实例以后,能够独立编撰出自己的Python网路爬虫项目,并且还能胜任Python网路爬虫工程师相关岗位的工作。
同时,本书的另一个目的是,希望可以给大数据或则数据挖掘方向的从业者一定的参考,以帮助那些读者从海量的互联网信息中爬取须要的数据。所谓巧妇难为无米之炊,有了这种数据以后,从事大数据或则数据挖掘方向工作的读者就可以进行后续的剖析处理了。
本书的主要内容和特色
本书是一本系统介绍Python网络爬虫的书籍,全书讲求实战,涵盖网路爬虫原理、如何手写Python网络爬虫、如何使用Scrapy框架编撰网路爬虫项目等关于Python网络爬虫的方方面面。
本书的主要特色如下:
系统讲解Python网络爬虫的编撰方式,体系清晰。
结合实战,让读者才能从零开始把握网路爬虫的基本原理,学会编撰Python网络爬虫以及Scrapy爬虫项目,从而编写出通用爬虫及聚焦爬虫,并把握常见网站的爬虫反屏蔽手段。
下载地址:
边境之旅下载 查看全部

Python3网路爬虫开发实战
书籍介绍:
《Python3网络爬虫开发实战》介绍了怎样借助Python 3开发网络爬虫,书中首先介绍了环境配置和基础知识,然后讨论了urllib、requests、正则表达式、Beautiful Soup、XPath、pyquery、数据储存、Ajax数据爬取等内容,接着通过多个案例介绍了不同场景下怎样实现数据爬取,后介绍了pyspider框架、Scrapy框架和分布式爬虫。
作者介绍:
崔庆才,北京航空航天大学硕士,静觅博客()博主,爬虫博文访问量已过百万,喜欢钻研,热爱生活,乐于分享。欢迎关注个人微信公众号“进击的Coder”。
下载地址:
《Python网路数据采集》
书籍介绍:
《Python网路数据采集》采用简约强悍的Python语言网络爬虫技术书籍,介绍了网路数据采集,并为采集新式网路中的各类数据类型提供了全面的指导。第一部分重点介绍网路数据采集的基本原理:如何用Python从网路服务器恳求信息,如何对服务器的响应进行基本处理,以及怎样以自动化手段与网站进行交互。第二部份介绍怎样用网络爬虫测试网站,自动化处理,以及怎样通过更多的形式接入网路。
下载地址:
《从零开始学Python网络爬虫》
书籍介绍:
《从零开始学Python网络爬虫》是一本教初学者学习怎么爬取网路数据和信息的入门读物。书中除了有Python的相关内容,而且还有数据处理和数据挖掘等方面的内容。本书内容十分实用,讲解时穿插了22个爬虫实战案例,可以大大增强读者的实际动手能力。
本书共分12章,核心主题包括Python零基础句型入门、爬虫原理和网页构造、我的第一个爬虫程序、正则表达式、Lxml库与Xpath句型、使用API、数据库储存、多进程爬虫、异步加载、表单交互与模拟登陆、Selenium模拟浏览器、Scrapy爬虫框架。此外,书中通过一些典型爬虫案例,讲解了有经纬信息的地图图表和词云的制做方式,让读者体验数据背后的乐趣。
下载地址:
图解 HTTP
书籍介绍:
《图解 HTTP》对互联网基盘——HTTP协议进行了全面系统的介绍。作者由HTTP合同的发展历史娓娓道来,严谨细致地分析了HTTP合同的结构,列举众多常见通讯场景及实战案例网络爬虫技术书籍,最后延展到Web安全、最新技术动向等方面。本书的特色为在讲解的同时,辅以大量生动形象的通讯图例,更好地帮助读者深刻理解HTTP通讯过程中客户端与服务器之间的交互情况。读者可通过本书快速了解并把握HTTP协议的基础,前端工程师剖析抓包数据,后端工程师实现REST API、实现自己的HTTP服务器等过程中所需的HTTP相关知识点本书均有介绍。
下载地址:
《精通Python网路爬虫 核心技术、框架与项目实战》
书籍介绍:
本书从系统化的视角,为这些想学习Python网路爬虫或则正在研究Python网路爬虫的朋友们提供了一个全面的参考,让读者可以系统地学习Python网路爬虫的方方面面,在理解并把握了本书的实例以后,能够独立编撰出自己的Python网路爬虫项目,并且还能胜任Python网路爬虫工程师相关岗位的工作。
同时,本书的另一个目的是,希望可以给大数据或则数据挖掘方向的从业者一定的参考,以帮助那些读者从海量的互联网信息中爬取须要的数据。所谓巧妇难为无米之炊,有了这种数据以后,从事大数据或则数据挖掘方向工作的读者就可以进行后续的剖析处理了。
本书的主要内容和特色
本书是一本系统介绍Python网络爬虫的书籍,全书讲求实战,涵盖网路爬虫原理、如何手写Python网络爬虫、如何使用Scrapy框架编撰网路爬虫项目等关于Python网络爬虫的方方面面。
本书的主要特色如下:
系统讲解Python网络爬虫的编撰方式,体系清晰。
结合实战,让读者才能从零开始把握网路爬虫的基本原理,学会编撰Python网络爬虫以及Scrapy爬虫项目,从而编写出通用爬虫及聚焦爬虫,并把握常见网站的爬虫反屏蔽手段。
下载地址:
边境之旅下载
浅谈网络爬虫及其发展趋势
采集交流 • 优采云 发表了文章 • 0 个评论 • 332 次浏览 • 2020-05-11 08:02
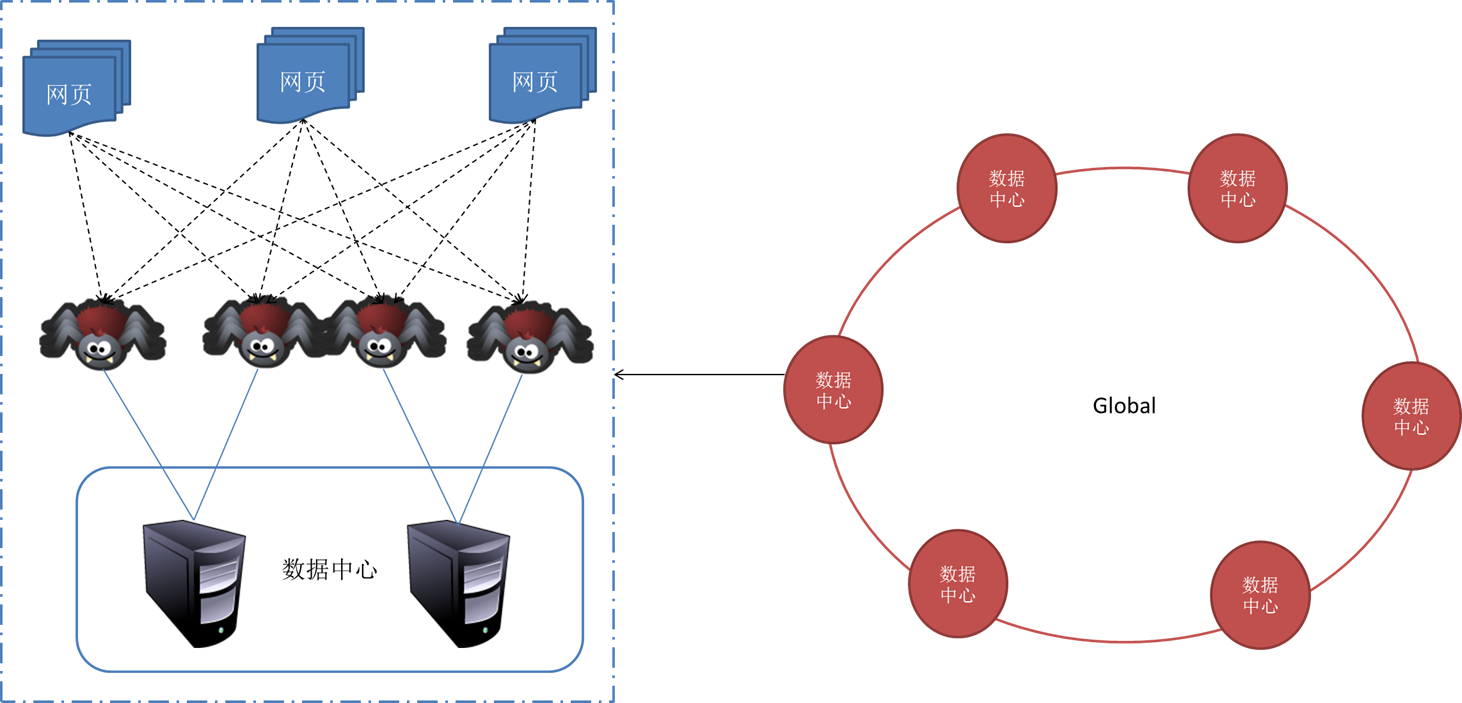
随着的发展壮大,人们获取信息的途径渐渐被网路所代替。互联网发展早期,人们主要通过浏览门户网站的方法获取所需信息,但是随着Web的飞速发展, 用这些方法找寻自己所需信息显得越来越困难。目前,人们大多通过搜索引擎获取有用信息网络爬虫 技术,因此,搜索引擎技术的发展将直接影响人们获取所需信息的速率和质量。
1994 年世界上第一个网络检索工具Web Crawler 问世, 目前较流行的搜索引擎有、、Yahoo、Info seek、Inktomi、Teoma、Live Search 等。出于商业机密的考虑,现在各个搜索引擎使用的Crawler 系统的技术黑幕通常都不公开,现有的文献资料也仅限于概要性介绍。随着网路信息资源呈指数级下降及网路信息资源动态变化,传统的搜索引擎提供的信息检索服务已难以满足人们愈加下降的对个性化服务的需求,正面临着巨大的挑战。以何种策略访问网路,提高搜索效率,已成为近些年来专业搜索引擎研究的主要问题之一。
1、搜索引擎分类
搜索引擎按其形式主要分为全文搜索引擎、目录索引类搜索引擎和元搜索引擎三种。
1.1 全文搜索引擎
全文搜索引擎是名副其实的搜索引擎,通过从互联网上提取的各个网站信息(以网页文字为主)而构建的中,检索与用户查询条件匹配的相关记录,然后按一定的排列次序将结果返回给用户。
全文搜索引擎又可细分为两种:a)拥有自己的检索程序(Indexer),俗称“蜘蛛”(Spider)程序或“机器人”(Robot)程序,自建网页数据库,搜索结果直接从自身的数据库中调用。b)租用其他引擎的数据库,按自定的格式排列搜索结果。
1.2 目录索引型搜索引擎
与全文搜索引擎不同的是,目录索引型搜索引擎的索引数据库是由编辑人员人工构建上去的,这些编辑人员在访问过某个Web 站点后,根据一套自定的衡量标准及主观印象作出对该站点的描述,并按照站点的内容和性质将其归为一个预先分好的类别,分门别类地储存在相应的目录中。用户在查询时,可以通过关键词搜索,也可以按分类目录逐层检索。
因为目录索引型的索引数据库是借助人工来评价一个网站的内容,所以用户从目录搜索到的结果常常比全文检索到的结果更具有参考价值。实际上,目前好多的搜索网站都同时提供目录和全文搜索的搜索服务,尽可能为用户提供全面的查询结果。
1.3 元搜索引擎
元搜索引擎是将用户递交的检索恳求送到多个独立的搜索引擎搜索,将检索结果集中统一处理,以统一的格式提供给用户,因此有搜索引擎之上的搜索引擎之称。它将主要精力放到提升搜索速率、智能化处理搜索结果、个性搜索功能的设置和用户检索界面的友好性上,其查全率和查准率相对较高。它的特征是本身没有储存网页信息的数据库,当用户查询一个关键词时,它将用户恳求转换成其他搜索引擎能接受的命令格式,并行地访问数个搜索引擎来查询这个关键词,将这种搜索引擎返回的结果经过处理后再返回给用户。在搜索结果排列方面,有的直接按来源引擎排列搜索结果,有的则按自定的规则将结果重新排列组合。
2、网络爬虫技术
2.1 网络爬虫的工作原理
网络爬虫源自Spider(或Crawler、robots、wanderer)等的译音。网络爬虫的定义有广义和狭义之分,狭义的定义为:利用标准的http 协议,根据超级链接和Web 文档检索的方式遍历万维网信息空间的软件程序。广义的定义为:所有能借助http协议检索Web 文档的软件都称之为网路爬虫。
网络爬虫是一个功能太强悍的手动提取网页的程序,它为搜索引擎从万维网下载网页,是搜索引擎的重要组成部份。它通过恳求站点上的HTML 文档访问某一站点。它遍历Web 空间,不断从一个站点到另一个站点,自动构建索引,并加入到网页数据库中。网络爬虫步入某个超级文本时,利用HTML 语言的标记结构来搜索信息及获取指向其他超级文本的URL 地址,可以完全不依赖用户干预实现网路上的手动“爬行”和搜索。网络爬虫在搜索时常常采用一定的搜索策略。
2.2 网络爬虫的搜索策略
1)深度优先搜索策略
深度优先搜索是在开发爬虫初期使用较多的方式,它的目的是要达到被搜索结构的叶结点(即这些不包含任何超级链接的HTML文件)。在一个HTML文件中,当一个超级链接被选择后,被链接的HTML文件将执行深度优先搜索,即在搜索其余的超级链接结果之前必须先完整地搜索单独的一条链。深度优先搜索顺着HTML文件上的超级链接走到不能再深入为止,然后返回到某一个HTML文件,再继续选择该HTML文件中的其他超级链接。当不再有其他超级链接可选择时,说明搜索早已结束。其优点是能遍历一个Web站点或深层嵌套的文档集合。缺点是因为Web结构相当深,有可能导致一旦进去再也出不来的情况发生。
2)宽度优先搜索策略
在长度优先搜索中,先搜索完一个Web页面中所有的超级链接,然后再继续搜索下一层,直到底层为止。例如,一个HTML 文件中有3个超级链接,选择其中之一,处理相应的HTML文件,然后不再选择第二个HTML文件中的任何超级链接,而是返回,选择第二个超级链接,处理相应的HTML文件,再返回,选择第三个超级链接,并处理相应的HTML文件。一旦一层上的所有超级链接都被选择过,就可以开始在刚刚处理过的HIML文件中搜索其余的超级链接。这就保证了对浅层的首先处理。当遇见一个无穷尽的深层分支时网络爬虫 技术,不会造成陷进WWW的深层文档中出不来的情况发生。宽度优先搜索策略还有一个优点,它能在两个HTML文件之间找到最短路径。宽度优先搜索策略一般是实现爬虫的最佳策略,因为它容易实现,而且具备大多数期望的功能。但是假如要遍历一个指定的站点或则深层嵌套的HTML文件集,用长度优先搜索策略则须要耗费较长时间能够抵达深层的HTML文件。
综合考虑以上几种策略和国外信息导航系统搜索信息的特性,国内通常采用以长度优先搜索策略为主,线性搜索策略为辅的搜索策略。对于个别不被引用的或极少被引用的HTML文件,宽度优先搜索策略可能会遗漏那些孤立的信息源,可以用线性搜索策略作为它的补充。
3)聚焦搜索策略
聚焦爬虫的爬行策略只跳出某个特定主题的页面,根据“最好优先原则”进行访问,快速、有效地获得更多的与主题相关的页面,主要通过内容与Web的链接结构指导进一步的页面抓取。聚焦爬虫会给它所下载的页面一个评价分,根据得分排序插入到一个队列中。最好的下一个搜索对弹出队列中的第一个页面进行剖析后执行,这种策略保证爬虫能优先跟踪这些最有可能链接到目标页面的页面。决定网路爬虫搜索策略的关键是怎样评价链接价值,即链接价值的估算方式,不同的价值评价方式估算出的链接的价值不同,表现出的链接的“重要程度”也不同,从而决定了不同的搜索策略。由于链接包含于页面之中,而一般具有较高价值的页面包含的链接也具有较高价值,因而对链接价值的评价有时也转换为对页面价值的评价。这种策略一般运用在专业搜索引擎中,因为这些搜索引擎只关心某一特定主题的页面。
【福利】填问卷送精选测试礼包+接口测试课程!为测试行业做点事! 查看全部
随着的发展壮大,人们获取信息的途径渐渐被网路所代替。互联网发展早期,人们主要通过浏览门户网站的方法获取所需信息,但是随着Web的飞速发展, 用这些方法找寻自己所需信息显得越来越困难。目前,人们大多通过搜索引擎获取有用信息网络爬虫 技术,因此,搜索引擎技术的发展将直接影响人们获取所需信息的速率和质量。
1994 年世界上第一个网络检索工具Web Crawler 问世, 目前较流行的搜索引擎有、、Yahoo、Info seek、Inktomi、Teoma、Live Search 等。出于商业机密的考虑,现在各个搜索引擎使用的Crawler 系统的技术黑幕通常都不公开,现有的文献资料也仅限于概要性介绍。随着网路信息资源呈指数级下降及网路信息资源动态变化,传统的搜索引擎提供的信息检索服务已难以满足人们愈加下降的对个性化服务的需求,正面临着巨大的挑战。以何种策略访问网路,提高搜索效率,已成为近些年来专业搜索引擎研究的主要问题之一。
1、搜索引擎分类
搜索引擎按其形式主要分为全文搜索引擎、目录索引类搜索引擎和元搜索引擎三种。
1.1 全文搜索引擎
全文搜索引擎是名副其实的搜索引擎,通过从互联网上提取的各个网站信息(以网页文字为主)而构建的中,检索与用户查询条件匹配的相关记录,然后按一定的排列次序将结果返回给用户。
全文搜索引擎又可细分为两种:a)拥有自己的检索程序(Indexer),俗称“蜘蛛”(Spider)程序或“机器人”(Robot)程序,自建网页数据库,搜索结果直接从自身的数据库中调用。b)租用其他引擎的数据库,按自定的格式排列搜索结果。
1.2 目录索引型搜索引擎
与全文搜索引擎不同的是,目录索引型搜索引擎的索引数据库是由编辑人员人工构建上去的,这些编辑人员在访问过某个Web 站点后,根据一套自定的衡量标准及主观印象作出对该站点的描述,并按照站点的内容和性质将其归为一个预先分好的类别,分门别类地储存在相应的目录中。用户在查询时,可以通过关键词搜索,也可以按分类目录逐层检索。
因为目录索引型的索引数据库是借助人工来评价一个网站的内容,所以用户从目录搜索到的结果常常比全文检索到的结果更具有参考价值。实际上,目前好多的搜索网站都同时提供目录和全文搜索的搜索服务,尽可能为用户提供全面的查询结果。
1.3 元搜索引擎
元搜索引擎是将用户递交的检索恳求送到多个独立的搜索引擎搜索,将检索结果集中统一处理,以统一的格式提供给用户,因此有搜索引擎之上的搜索引擎之称。它将主要精力放到提升搜索速率、智能化处理搜索结果、个性搜索功能的设置和用户检索界面的友好性上,其查全率和查准率相对较高。它的特征是本身没有储存网页信息的数据库,当用户查询一个关键词时,它将用户恳求转换成其他搜索引擎能接受的命令格式,并行地访问数个搜索引擎来查询这个关键词,将这种搜索引擎返回的结果经过处理后再返回给用户。在搜索结果排列方面,有的直接按来源引擎排列搜索结果,有的则按自定的规则将结果重新排列组合。
2、网络爬虫技术
2.1 网络爬虫的工作原理
网络爬虫源自Spider(或Crawler、robots、wanderer)等的译音。网络爬虫的定义有广义和狭义之分,狭义的定义为:利用标准的http 协议,根据超级链接和Web 文档检索的方式遍历万维网信息空间的软件程序。广义的定义为:所有能借助http协议检索Web 文档的软件都称之为网路爬虫。
网络爬虫是一个功能太强悍的手动提取网页的程序,它为搜索引擎从万维网下载网页,是搜索引擎的重要组成部份。它通过恳求站点上的HTML 文档访问某一站点。它遍历Web 空间,不断从一个站点到另一个站点,自动构建索引,并加入到网页数据库中。网络爬虫步入某个超级文本时,利用HTML 语言的标记结构来搜索信息及获取指向其他超级文本的URL 地址,可以完全不依赖用户干预实现网路上的手动“爬行”和搜索。网络爬虫在搜索时常常采用一定的搜索策略。
2.2 网络爬虫的搜索策略
1)深度优先搜索策略
深度优先搜索是在开发爬虫初期使用较多的方式,它的目的是要达到被搜索结构的叶结点(即这些不包含任何超级链接的HTML文件)。在一个HTML文件中,当一个超级链接被选择后,被链接的HTML文件将执行深度优先搜索,即在搜索其余的超级链接结果之前必须先完整地搜索单独的一条链。深度优先搜索顺着HTML文件上的超级链接走到不能再深入为止,然后返回到某一个HTML文件,再继续选择该HTML文件中的其他超级链接。当不再有其他超级链接可选择时,说明搜索早已结束。其优点是能遍历一个Web站点或深层嵌套的文档集合。缺点是因为Web结构相当深,有可能导致一旦进去再也出不来的情况发生。
2)宽度优先搜索策略
在长度优先搜索中,先搜索完一个Web页面中所有的超级链接,然后再继续搜索下一层,直到底层为止。例如,一个HTML 文件中有3个超级链接,选择其中之一,处理相应的HTML文件,然后不再选择第二个HTML文件中的任何超级链接,而是返回,选择第二个超级链接,处理相应的HTML文件,再返回,选择第三个超级链接,并处理相应的HTML文件。一旦一层上的所有超级链接都被选择过,就可以开始在刚刚处理过的HIML文件中搜索其余的超级链接。这就保证了对浅层的首先处理。当遇见一个无穷尽的深层分支时网络爬虫 技术,不会造成陷进WWW的深层文档中出不来的情况发生。宽度优先搜索策略还有一个优点,它能在两个HTML文件之间找到最短路径。宽度优先搜索策略一般是实现爬虫的最佳策略,因为它容易实现,而且具备大多数期望的功能。但是假如要遍历一个指定的站点或则深层嵌套的HTML文件集,用长度优先搜索策略则须要耗费较长时间能够抵达深层的HTML文件。
综合考虑以上几种策略和国外信息导航系统搜索信息的特性,国内通常采用以长度优先搜索策略为主,线性搜索策略为辅的搜索策略。对于个别不被引用的或极少被引用的HTML文件,宽度优先搜索策略可能会遗漏那些孤立的信息源,可以用线性搜索策略作为它的补充。
3)聚焦搜索策略
聚焦爬虫的爬行策略只跳出某个特定主题的页面,根据“最好优先原则”进行访问,快速、有效地获得更多的与主题相关的页面,主要通过内容与Web的链接结构指导进一步的页面抓取。聚焦爬虫会给它所下载的页面一个评价分,根据得分排序插入到一个队列中。最好的下一个搜索对弹出队列中的第一个页面进行剖析后执行,这种策略保证爬虫能优先跟踪这些最有可能链接到目标页面的页面。决定网路爬虫搜索策略的关键是怎样评价链接价值,即链接价值的估算方式,不同的价值评价方式估算出的链接的价值不同,表现出的链接的“重要程度”也不同,从而决定了不同的搜索策略。由于链接包含于页面之中,而一般具有较高价值的页面包含的链接也具有较高价值,因而对链接价值的评价有时也转换为对页面价值的评价。这种策略一般运用在专业搜索引擎中,因为这些搜索引擎只关心某一特定主题的页面。
【福利】填问卷送精选测试礼包+接口测试课程!为测试行业做点事!
基于Java的小型分布式网路爬虫体系结构
采集交流 • 优采云 发表了文章 • 0 个评论 • 294 次浏览 • 2020-05-11 08:02
分布式网路爬虫包含多个爬虫,每个爬虫须要完成的任务和单个的爬行器类似,它们从互联网上下载网页,并把网页保存在本地的c盘分布式爬虫架构,从中抽取URL并顺着这种URL的指向继续爬行。由于并行爬行器须要分割下载任务,可能爬虫会将自己抽取的URL发送给其他爬虫。这些爬虫可能分布在同一个局域网之中,或者分散在不同的地理位置。
根据爬虫的分散程度不同,可以把分布式爬行器分成以下两大类:
1、基于局域网分布式网路爬虫:这种分布式爬行器的所有爬虫在同一个局域网里运行,通过高速的网路联接互相通讯。这些爬虫通过同一个网路去访问外部互联网,下载网页,所有的网路负载都集中在她们所在的那种局域网的出口上。由于局域网的带宽较高,爬虫之间的通讯的效率能否得到保证;但是网路出口的总带宽上限是固定的,爬虫的数目会遭到局域网出口带宽的限制。
2、基于广域网分布式网路爬虫:当并行爬行器的爬虫分别运行在不同地理位置(或网路位置),我们称这些并行爬行器为分布式爬行器。例如,分布式爬行器的爬虫可能坐落中国,日本,和英国,分别负责下载这三地的网页;或者坐落CHINANET,CERNET,CEINET,分别负责下载这三个网路的中的网页。分布式爬行器的优势在于可以子在一定程度上分散网路流量,减小网路出口的负载。如果爬虫分布在不同的地理位置(或网路位置),需要间隔多长时间进行一次互相通讯就成为了一个值得考虑的问题。爬虫之间的通信带宽可能是有限的,通常须要通过互联网进行通讯。
大型分布式网路爬虫体系结构图
分布式网路爬虫是一项非常复杂系统。需要考虑好多方面诱因。性能可以说是它这重要的指标。当然硬件层面的资源也是必须的。
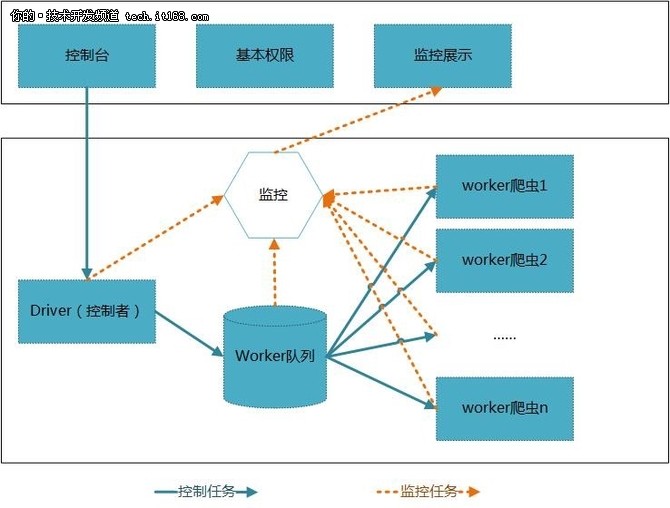
架构
下面是项目的总体构架,第一个版本基于此方案来做。
上面的web层包括:控制台、基本权限、监控展示等,还可以依据须要再一步进行扩充。
核心层由控制者统一调度,将任务发给工人队列中的工人进行爬取操作。各个结点动态的向监控模块发送模块状态等信息,统一由展示层展示。
项目目标
众推,开源版的明日头条!
基于hadoop思维的分布式网路爬虫。
目前早已将fourinone、jeesite、webmagic整合进来,并且进一步进行改进。想最终弄成一个基于设计器的动态可配置的分布式爬虫系统,这个是第一阶段的目标。
项目目前情况
目前项目进展情况:
1、sourceer,可以接入多种数据源,接口早已定义(加入builder封装,可以使用简单爬虫)。
2、web构架工程(web工程上传并测试成功,权限、基础框架改建,导入等早已录成视频,删除activiti,删除cms部分)。
3、分布式框架研究(分布式项目发包,添加部份注释,测试单机单工人爬取)。
4、插件化整合。
5、文章等各类去重形式及算法(目前已实现bloomfilter分布式爬虫架构,指纹算法去重,已经实现simhash,分词算法(ansj))。
6、分类器测试(bayes,文本分类单机测试成功)。
项目地址:
(分布式爬虫)
(去重过滤器)
(文本分类器)
(文档目录)
项目界面:
启动jetty,目前皮肤暂时还未换。
总结
目前项目正在进一步建立当中,希望能得到你更多的意见! 查看全部
【IT168技术】分类
分布式网路爬虫包含多个爬虫,每个爬虫须要完成的任务和单个的爬行器类似,它们从互联网上下载网页,并把网页保存在本地的c盘分布式爬虫架构,从中抽取URL并顺着这种URL的指向继续爬行。由于并行爬行器须要分割下载任务,可能爬虫会将自己抽取的URL发送给其他爬虫。这些爬虫可能分布在同一个局域网之中,或者分散在不同的地理位置。
根据爬虫的分散程度不同,可以把分布式爬行器分成以下两大类:
1、基于局域网分布式网路爬虫:这种分布式爬行器的所有爬虫在同一个局域网里运行,通过高速的网路联接互相通讯。这些爬虫通过同一个网路去访问外部互联网,下载网页,所有的网路负载都集中在她们所在的那种局域网的出口上。由于局域网的带宽较高,爬虫之间的通讯的效率能否得到保证;但是网路出口的总带宽上限是固定的,爬虫的数目会遭到局域网出口带宽的限制。
2、基于广域网分布式网路爬虫:当并行爬行器的爬虫分别运行在不同地理位置(或网路位置),我们称这些并行爬行器为分布式爬行器。例如,分布式爬行器的爬虫可能坐落中国,日本,和英国,分别负责下载这三地的网页;或者坐落CHINANET,CERNET,CEINET,分别负责下载这三个网路的中的网页。分布式爬行器的优势在于可以子在一定程度上分散网路流量,减小网路出口的负载。如果爬虫分布在不同的地理位置(或网路位置),需要间隔多长时间进行一次互相通讯就成为了一个值得考虑的问题。爬虫之间的通信带宽可能是有限的,通常须要通过互联网进行通讯。
大型分布式网路爬虫体系结构图

分布式网路爬虫是一项非常复杂系统。需要考虑好多方面诱因。性能可以说是它这重要的指标。当然硬件层面的资源也是必须的。
架构
下面是项目的总体构架,第一个版本基于此方案来做。
上面的web层包括:控制台、基本权限、监控展示等,还可以依据须要再一步进行扩充。
核心层由控制者统一调度,将任务发给工人队列中的工人进行爬取操作。各个结点动态的向监控模块发送模块状态等信息,统一由展示层展示。
项目目标
众推,开源版的明日头条!
基于hadoop思维的分布式网路爬虫。
目前早已将fourinone、jeesite、webmagic整合进来,并且进一步进行改进。想最终弄成一个基于设计器的动态可配置的分布式爬虫系统,这个是第一阶段的目标。
项目目前情况
目前项目进展情况:
1、sourceer,可以接入多种数据源,接口早已定义(加入builder封装,可以使用简单爬虫)。
2、web构架工程(web工程上传并测试成功,权限、基础框架改建,导入等早已录成视频,删除activiti,删除cms部分)。
3、分布式框架研究(分布式项目发包,添加部份注释,测试单机单工人爬取)。
4、插件化整合。
5、文章等各类去重形式及算法(目前已实现bloomfilter分布式爬虫架构,指纹算法去重,已经实现simhash,分词算法(ansj))。
6、分类器测试(bayes,文本分类单机测试成功)。
项目地址:
(分布式爬虫)
(去重过滤器)
(文本分类器)
(文档目录)
项目界面:
启动jetty,目前皮肤暂时还未换。
总结
目前项目正在进一步建立当中,希望能得到你更多的意见!
网络爬虫|图文|百度文库
采集交流 • 优采云 发表了文章 • 0 个评论 • 330 次浏览 • 2020-05-11 08:01
网络爬虫序言-爬虫? Crawler ,即Spider(网络爬虫),其定义有广义 和狭义之分。狭义上指遵守标准的 http 协议,利 用超链接和 Web 文档检索方式遍历万维网的软件 程序;而广义的定义则是能遵守 http 协议,检索 Web 文档的软件都称之为网路爬虫。 ? 网络爬虫是一个功能太强的手动提取网页的程序, 它为搜索引擎从万维网上下载网页,是搜索引擎的 重要组成部份。聚焦爬虫? 随着网路的迅速发展,万维网成为大量信息的载体 ,如何有效地提取并借助这种信息成为一个巨大的 挑战。搜索引擎(Search Engine),例如传统的通 用搜索引擎AltaVista,Yahoo!和Google等,作为 一个辅助人们检索信息的工具成为用户访问万维网 的入口和 指南。但是,这些通用性搜索引擎也存在 着一定的局限性,如:聚焦爬虫? (1) 不同领域、不同背景的用户常常具有不同的检索目的和 需求,通用搜索引擎所返回的结果包含大量用户不关心的网 页。? ? (2) 通用搜索引擎的目标是尽可能大的网路覆盖率,有限的 搜索引擎服务器资源与无限的网路数据资源之间的矛盾将进 一步加深。? ? (3) 万维网数据方式的丰富和网路技术的不断发展,图片、 数据库、音频/视频多媒体等不同数据大量出现,通用搜索引 擎常常对这种信息浓度密集且具有一定结构的数据无能为力 ,不能挺好地发觉和获取。
? ? (4) 通用搜索引擎大多提供基于关键字的检索,难以支持根 据语义信息提出的查询。?聚焦爬虫? 为了解决上述问题,定向抓取相关网页资源的聚焦 爬虫应运而生。聚焦爬虫是一个手动下载网页的程 序,它按照既定的抓取目标,有选择的访问万维网 上的网页与相关的链接,获取所须要的信息。 ? 与通用爬虫(general purpose web crawler)不同 ,聚焦爬虫并不追求大的覆盖,而将目标定为抓取 与某一特定主题内容相关的网页,为面向主题的用 户查询打算数据资源。垂直搜索的本质?从主题相关的领域内,获取、加工与搜索行 为相匹配的结构化数据和元数据信息。如数码产品mp3:内存、尺寸、大小、电池机型、价格、生产 厂家等,还可以提供比价服务爬虫基本原理?网络爬虫是通过网页的链接地址来找寻网页, 从一个或若干初始网页的URL开始(通常是某 网站首页),遍历 Web 空间,读取网页的内容 ,不断从一个站点联通到另一个站点,自动建 立索引。在抓取网页的过程中,找到在网页中 的其他链接地址,对 HTML 文件进行解析,取 出其页面中的子链接,并加入到网页数据库中 ,不断从当前页面上抽取新的URL装入队列, 这样仍然循环下去,直到把这个网站所有的网 页都抓取完,满足系统的一定停止条件。
爬虫基本原理?另外,所有被爬虫抓取的网页将会被系统储存 ,进行一定的剖析、过滤,并构建索引,以便 之后的查询和检索。网络爬虫剖析某个网页时 ,利用 HTML 语言的标记结构来获取指向其他 网页的 URL 地址,可以完全不依赖用户干预。 ?如果把整个互联网当作一个网站,理论上讲网 络爬虫可以把互联网上所有的网页都抓取出来爬虫基本原理?而且对于个别主题爬虫来说,这一过程所得到 的剖析结果还可能对之后抓取过程给出反馈和 指导。正是这些行为方法,这些程序才被称为 爬虫( spider )、crawler、机器人。爬虫基本原理?Spider如何抓取所有的 Web 页面呢? ?在Web出现曾经,传统的文本集合,如目录数 据库、期刊文摘储存在磁带或光碟里,用作索 引系统。 ?与此相对应,Web 中所有可访问的URL都是未 分类的,收集 URL 的惟一方法就是通过扫描收 集这些链向其他页面的超链接,这些页面还未 被搜集过。爬虫基本原理? 从给定的 URL 集出发,逐步来抓取和扫描这些新 的出链。这样周而复始的抓取那些页面。这些新发 现的 URL 将作为爬行器的未来的抓取的工作。 ? 随着抓取的进行,这些未来工作集也会随着膨胀, 由写入器将这种数据写入c盘来释放寻址,以及避 免爬行器崩溃数据遗失。
没有保证所有的 Web 页 面的访问都是根据这些方法进行,爬行器从不会停 下来,Spider 运行时页面也会急剧不断降低。 ? 页面中所包含的文本也将呈交给文本索引器,用于 基于关键词的信息索引。工作流程? 网络爬虫是搜索引擎中最核心的部份,整个搜索引擎的 素材库来源于网路爬虫的采集,从搜索引擎整个产业链 来看,网络爬虫是处于最上游的产业。其性能优劣直接 影响着搜索引擎整体性能和处理速率。 ? 通用网路爬虫是从一个或若干个初始网页的上的 URL 开始,获得初始网页上的 URL 列表,在抓取网页过程 中,不断从当前页面上抽取新的 URL 放入待爬行队列网络爬虫,直到满足系统的停止条件。工作流程? 网络爬虫基本构架如图所示,其各个部份的主要功能介 绍如下: ? 1.页面采集模块:该模块是爬虫和因特网的插口,主 要作用是通过各类 web 协议(一般以 HTTP.FTP 为主 )来完成对网页数据的采集,保存后将采集到的页面交 由后续模块作进一步处理。 其过程类似于用户使用浏览器打开网页,保存的网页供 其它后续模块处理,例如,页面剖析、链接抽取。工作流程? 2.页面剖析模块:该模块的主要功能是将页面采集模 块采集下来的页面进行剖析,提取其中满足用户要求的 超链接,加入到超链接队列中。
页面链接中给出的 URL 一般是多种格式的,可能是完 整的包括合同、站点和路径的,也可能是省略了部份内 容的,或者是一个相对路径。所以为处理便捷,一般进 行规范化处理,先将其转化成统一的格式。工作流程?3、链接过滤模块:该模块主要是用于对重复链 接和循环链接的过滤。例如,相对路径须要补 全 URL ,然后加入到待采集 URL 队列中。 此时,一般会过滤掉队列中早已包含的 URL , 以及循环链接的URL。工作流程?4.页面库:用来储存早已采集下来的页面,以 备后期处理。 ?5.待采集 URL 队列:从采集网页中抽取并作 相应处理后得到的 URL ,当 URL 为空时爬虫 程序中止。 ?6.初始 URL :提供 URL 种子,以启动爬虫关键技术剖析?抓取目标的定义与描述 ?网页URL的搜索策略 ?网页的剖析与信息的提取抓取目标的定义与描述?针对有目标网页特点的网页级信息对应网页库级垂直搜索,抓取目标网页,后续还要从 中抽取出须要的结构化信息。稳定性和数目上占优, 但成本高、性活性差。?针对目标网页上的结构化数据对应模板级垂直搜索,直接解析页面,提取并加工出 结构化数据信息。快速施行、成本低、灵活性强,但 后期维护成本高。
URL 的搜索策略网路爬虫 URL 抓取策略有: ?IP 地址搜索策略 ?广度优先 ?深度优先 ?最佳优先URL 的搜索策略? 基于IP地址的搜索策略 ? 先赋于爬虫一个起始的 IP 地址网络爬虫,然后按照 IP 地址 递增的形式搜索本口地址段后的每一个 WWW 地 址中的文档,它完全不考虑各文档中指向其它 Web 站点的超级链接地址。 ? 优点是搜索全面,能够发觉这些没被其它文档引用 的新文档的信息源 ? 缺点是不适宜大规模搜索URL 的搜索策略? 广度优先搜索策略 ? 广度优先搜索策略是指在抓取过程中,在完成当前层次 的搜索后,才进行下一层次的搜索。这样逐层搜索,依 此类推。 ? 该算法的设计和实现相对简单。在目前为覆盖尽可能多 的网页,一般使用广度优先搜索方式。 ? 很多研究者通过将广度优先搜索策略应用于主题爬虫中 。他们觉得与初始 URL 在一定链接距离内的网页具有 主题相关性的机率很大。URL 的搜索策略? 另外一种方式是将广度优先搜索与网页过滤技术结合让 用,先用广度优先策略抓取网页,再将其中无关的网页 过滤掉。这些技巧的缺点在于,随着抓取网页的增多, 大量的无关网页将被下载并过滤,算法的效率将变低。
? 使用广度优先策略抓取的次序为:A-B、C、D、E、F-G 、H-I 。URL 的搜索策略? 深度优先搜索策略 ? 深度优先搜索在开发网路爬虫初期使用较多的方式之一 ,目的是要达到叶结点,即这些不包含任何超链接的页 面文件。 ? 从起始页开始在当前 HTML 文件中,当一个超链被选 择后,被链接的 HTML 文件将执行深度优先搜索,一 个链接一个链接跟踪下去,处理完这条线路以后再转到 下一个起始页,继续跟踪链接。即在搜索其余的超链结 果之前必须先完整地搜索单独的一条链。URL 的搜索策略? 深度优先搜索顺着 HTML 文件上的超链走到不能再深 入为止,然后返回到某一个 HTML 文件,再继续选择 该 HTML 文件中的其他超链。当不再有其他超链可选 择时,说明搜索早已结束。 ? 这个方式有个优点是网路蜘蛛在设计的时侯比较容易。? 使用深度优先策略抓取的次序为:A-F-G、E-H-I、B、 C、D 。 ? 目前常见的是广度优先和最佳优先方式。URL 的搜索策略? 最佳优先搜索策略 ? 最佳优先搜索策略根据一定的网页剖析算法,先估算出 URL 描述文本的目标网页的相似度,设定一个值,并选 取评价得分超过该值的一个或几个 URL 进行抓取。
它 只访问经过网页分析算法估算出的相关度小于给定的值 的网页。 ? 存在的一个问题是,在爬虫抓取路径上的好多相关网页 可能被忽视,因为最佳优先策略是一种局部最优搜索算 法。因此须要将最佳优先结合具体的应用进行改进,以 跳出局部最优点。 ? 有研究表明,这样的闭环调整可以将无关网页数目增加 30%--90%。网页的剖析及信息的提取? 基于网路拓扑关系的剖析算法 根据页面间超链接引用关系,来对与已知网页有直接或 间接关系对象做出评价的算法。网页细度PageRank ,网站粒度 SiteRank。 ? 基于网页内容的剖析算法 从最初的文本检索方式,向涉及网页数据抽取、机器学 习、数据挖掘、自然语言等多领域综合的方向发展。 ? 基于用户访问行为的剖析算法 有代表性的是基于领域概念的剖析算法,涉及本体论。例子说明简述页面源代码?定位的爬取目标是娱乐博文,故在首页的源 代码中搜救“娱乐”之后,发现了如下数组 : ?<div class="nav"><a href=";class= "a2 fblack">首页</a> <a href=" /"target="_blank"class="fw">娱乐 </a>解析html的形式? 实现网路爬虫,顾名思义另要程序手动解析网页。
考虑 到垂直爬虫及站内搜索的重要性,凡是涉及到对页面的 处理,就须要一个强悍的 HTML/XML Parser 支持解 析,通过对目标文件的低格处理,才能够实现特定信 息提取、特定信息删掉和遍历等操作。 ? HTMLParser ,它是 Python拿来的解析 html 的模 块。它可以剖析出 html 里面的标签、数据等等,是一 种处理html的简便途径。 查看全部

网络爬虫序言-爬虫? Crawler ,即Spider(网络爬虫),其定义有广义 和狭义之分。狭义上指遵守标准的 http 协议,利 用超链接和 Web 文档检索方式遍历万维网的软件 程序;而广义的定义则是能遵守 http 协议,检索 Web 文档的软件都称之为网路爬虫。 ? 网络爬虫是一个功能太强的手动提取网页的程序, 它为搜索引擎从万维网上下载网页,是搜索引擎的 重要组成部份。聚焦爬虫? 随着网路的迅速发展,万维网成为大量信息的载体 ,如何有效地提取并借助这种信息成为一个巨大的 挑战。搜索引擎(Search Engine),例如传统的通 用搜索引擎AltaVista,Yahoo!和Google等,作为 一个辅助人们检索信息的工具成为用户访问万维网 的入口和 指南。但是,这些通用性搜索引擎也存在 着一定的局限性,如:聚焦爬虫? (1) 不同领域、不同背景的用户常常具有不同的检索目的和 需求,通用搜索引擎所返回的结果包含大量用户不关心的网 页。? ? (2) 通用搜索引擎的目标是尽可能大的网路覆盖率,有限的 搜索引擎服务器资源与无限的网路数据资源之间的矛盾将进 一步加深。? ? (3) 万维网数据方式的丰富和网路技术的不断发展,图片、 数据库、音频/视频多媒体等不同数据大量出现,通用搜索引 擎常常对这种信息浓度密集且具有一定结构的数据无能为力 ,不能挺好地发觉和获取。
? ? (4) 通用搜索引擎大多提供基于关键字的检索,难以支持根 据语义信息提出的查询。?聚焦爬虫? 为了解决上述问题,定向抓取相关网页资源的聚焦 爬虫应运而生。聚焦爬虫是一个手动下载网页的程 序,它按照既定的抓取目标,有选择的访问万维网 上的网页与相关的链接,获取所须要的信息。 ? 与通用爬虫(general purpose web crawler)不同 ,聚焦爬虫并不追求大的覆盖,而将目标定为抓取 与某一特定主题内容相关的网页,为面向主题的用 户查询打算数据资源。垂直搜索的本质?从主题相关的领域内,获取、加工与搜索行 为相匹配的结构化数据和元数据信息。如数码产品mp3:内存、尺寸、大小、电池机型、价格、生产 厂家等,还可以提供比价服务爬虫基本原理?网络爬虫是通过网页的链接地址来找寻网页, 从一个或若干初始网页的URL开始(通常是某 网站首页),遍历 Web 空间,读取网页的内容 ,不断从一个站点联通到另一个站点,自动建 立索引。在抓取网页的过程中,找到在网页中 的其他链接地址,对 HTML 文件进行解析,取 出其页面中的子链接,并加入到网页数据库中 ,不断从当前页面上抽取新的URL装入队列, 这样仍然循环下去,直到把这个网站所有的网 页都抓取完,满足系统的一定停止条件。
爬虫基本原理?另外,所有被爬虫抓取的网页将会被系统储存 ,进行一定的剖析、过滤,并构建索引,以便 之后的查询和检索。网络爬虫剖析某个网页时 ,利用 HTML 语言的标记结构来获取指向其他 网页的 URL 地址,可以完全不依赖用户干预。 ?如果把整个互联网当作一个网站,理论上讲网 络爬虫可以把互联网上所有的网页都抓取出来爬虫基本原理?而且对于个别主题爬虫来说,这一过程所得到 的剖析结果还可能对之后抓取过程给出反馈和 指导。正是这些行为方法,这些程序才被称为 爬虫( spider )、crawler、机器人。爬虫基本原理?Spider如何抓取所有的 Web 页面呢? ?在Web出现曾经,传统的文本集合,如目录数 据库、期刊文摘储存在磁带或光碟里,用作索 引系统。 ?与此相对应,Web 中所有可访问的URL都是未 分类的,收集 URL 的惟一方法就是通过扫描收 集这些链向其他页面的超链接,这些页面还未 被搜集过。爬虫基本原理? 从给定的 URL 集出发,逐步来抓取和扫描这些新 的出链。这样周而复始的抓取那些页面。这些新发 现的 URL 将作为爬行器的未来的抓取的工作。 ? 随着抓取的进行,这些未来工作集也会随着膨胀, 由写入器将这种数据写入c盘来释放寻址,以及避 免爬行器崩溃数据遗失。
没有保证所有的 Web 页 面的访问都是根据这些方法进行,爬行器从不会停 下来,Spider 运行时页面也会急剧不断降低。 ? 页面中所包含的文本也将呈交给文本索引器,用于 基于关键词的信息索引。工作流程? 网络爬虫是搜索引擎中最核心的部份,整个搜索引擎的 素材库来源于网路爬虫的采集,从搜索引擎整个产业链 来看,网络爬虫是处于最上游的产业。其性能优劣直接 影响着搜索引擎整体性能和处理速率。 ? 通用网路爬虫是从一个或若干个初始网页的上的 URL 开始,获得初始网页上的 URL 列表,在抓取网页过程 中,不断从当前页面上抽取新的 URL 放入待爬行队列网络爬虫,直到满足系统的停止条件。工作流程? 网络爬虫基本构架如图所示,其各个部份的主要功能介 绍如下: ? 1.页面采集模块:该模块是爬虫和因特网的插口,主 要作用是通过各类 web 协议(一般以 HTTP.FTP 为主 )来完成对网页数据的采集,保存后将采集到的页面交 由后续模块作进一步处理。 其过程类似于用户使用浏览器打开网页,保存的网页供 其它后续模块处理,例如,页面剖析、链接抽取。工作流程? 2.页面剖析模块:该模块的主要功能是将页面采集模 块采集下来的页面进行剖析,提取其中满足用户要求的 超链接,加入到超链接队列中。
页面链接中给出的 URL 一般是多种格式的,可能是完 整的包括合同、站点和路径的,也可能是省略了部份内 容的,或者是一个相对路径。所以为处理便捷,一般进 行规范化处理,先将其转化成统一的格式。工作流程?3、链接过滤模块:该模块主要是用于对重复链 接和循环链接的过滤。例如,相对路径须要补 全 URL ,然后加入到待采集 URL 队列中。 此时,一般会过滤掉队列中早已包含的 URL , 以及循环链接的URL。工作流程?4.页面库:用来储存早已采集下来的页面,以 备后期处理。 ?5.待采集 URL 队列:从采集网页中抽取并作 相应处理后得到的 URL ,当 URL 为空时爬虫 程序中止。 ?6.初始 URL :提供 URL 种子,以启动爬虫关键技术剖析?抓取目标的定义与描述 ?网页URL的搜索策略 ?网页的剖析与信息的提取抓取目标的定义与描述?针对有目标网页特点的网页级信息对应网页库级垂直搜索,抓取目标网页,后续还要从 中抽取出须要的结构化信息。稳定性和数目上占优, 但成本高、性活性差。?针对目标网页上的结构化数据对应模板级垂直搜索,直接解析页面,提取并加工出 结构化数据信息。快速施行、成本低、灵活性强,但 后期维护成本高。
URL 的搜索策略网路爬虫 URL 抓取策略有: ?IP 地址搜索策略 ?广度优先 ?深度优先 ?最佳优先URL 的搜索策略? 基于IP地址的搜索策略 ? 先赋于爬虫一个起始的 IP 地址网络爬虫,然后按照 IP 地址 递增的形式搜索本口地址段后的每一个 WWW 地 址中的文档,它完全不考虑各文档中指向其它 Web 站点的超级链接地址。 ? 优点是搜索全面,能够发觉这些没被其它文档引用 的新文档的信息源 ? 缺点是不适宜大规模搜索URL 的搜索策略? 广度优先搜索策略 ? 广度优先搜索策略是指在抓取过程中,在完成当前层次 的搜索后,才进行下一层次的搜索。这样逐层搜索,依 此类推。 ? 该算法的设计和实现相对简单。在目前为覆盖尽可能多 的网页,一般使用广度优先搜索方式。 ? 很多研究者通过将广度优先搜索策略应用于主题爬虫中 。他们觉得与初始 URL 在一定链接距离内的网页具有 主题相关性的机率很大。URL 的搜索策略? 另外一种方式是将广度优先搜索与网页过滤技术结合让 用,先用广度优先策略抓取网页,再将其中无关的网页 过滤掉。这些技巧的缺点在于,随着抓取网页的增多, 大量的无关网页将被下载并过滤,算法的效率将变低。
? 使用广度优先策略抓取的次序为:A-B、C、D、E、F-G 、H-I 。URL 的搜索策略? 深度优先搜索策略 ? 深度优先搜索在开发网路爬虫初期使用较多的方式之一 ,目的是要达到叶结点,即这些不包含任何超链接的页 面文件。 ? 从起始页开始在当前 HTML 文件中,当一个超链被选 择后,被链接的 HTML 文件将执行深度优先搜索,一 个链接一个链接跟踪下去,处理完这条线路以后再转到 下一个起始页,继续跟踪链接。即在搜索其余的超链结 果之前必须先完整地搜索单独的一条链。URL 的搜索策略? 深度优先搜索顺着 HTML 文件上的超链走到不能再深 入为止,然后返回到某一个 HTML 文件,再继续选择 该 HTML 文件中的其他超链。当不再有其他超链可选 择时,说明搜索早已结束。 ? 这个方式有个优点是网路蜘蛛在设计的时侯比较容易。? 使用深度优先策略抓取的次序为:A-F-G、E-H-I、B、 C、D 。 ? 目前常见的是广度优先和最佳优先方式。URL 的搜索策略? 最佳优先搜索策略 ? 最佳优先搜索策略根据一定的网页剖析算法,先估算出 URL 描述文本的目标网页的相似度,设定一个值,并选 取评价得分超过该值的一个或几个 URL 进行抓取。
它 只访问经过网页分析算法估算出的相关度小于给定的值 的网页。 ? 存在的一个问题是,在爬虫抓取路径上的好多相关网页 可能被忽视,因为最佳优先策略是一种局部最优搜索算 法。因此须要将最佳优先结合具体的应用进行改进,以 跳出局部最优点。 ? 有研究表明,这样的闭环调整可以将无关网页数目增加 30%--90%。网页的剖析及信息的提取? 基于网路拓扑关系的剖析算法 根据页面间超链接引用关系,来对与已知网页有直接或 间接关系对象做出评价的算法。网页细度PageRank ,网站粒度 SiteRank。 ? 基于网页内容的剖析算法 从最初的文本检索方式,向涉及网页数据抽取、机器学 习、数据挖掘、自然语言等多领域综合的方向发展。 ? 基于用户访问行为的剖析算法 有代表性的是基于领域概念的剖析算法,涉及本体论。例子说明简述页面源代码?定位的爬取目标是娱乐博文,故在首页的源 代码中搜救“娱乐”之后,发现了如下数组 : ?<div class="nav"><a href=";class= "a2 fblack">首页</a> <a href=" /"target="_blank"class="fw">娱乐 </a>解析html的形式? 实现网路爬虫,顾名思义另要程序手动解析网页。
考虑 到垂直爬虫及站内搜索的重要性,凡是涉及到对页面的 处理,就须要一个强悍的 HTML/XML Parser 支持解 析,通过对目标文件的低格处理,才能够实现特定信 息提取、特定信息删掉和遍历等操作。 ? HTMLParser ,它是 Python拿来的解析 html 的模 块。它可以剖析出 html 里面的标签、数据等等,是一 种处理html的简便途径。
自己动手写网路爬虫
采集交流 • 优采云 发表了文章 • 0 个评论 • 257 次浏览 • 2020-05-10 08:03
《自己动手写网络爬虫》介绍了网路爬虫开发中的关键问题与Java实现。主要包括从互联网获取信息与提取信息和对Web信息挖掘等内容。《自己动手写网络爬虫》在介绍基本原理的同时重视辅以具体代码实现来帮助读者加深理解,书中部份代码甚至可以直接使用。 《自己动手写网络爬虫》适用于有Java程序设计基础的开发人员。同时也可以作为计算机相关专业本科生或研究生的参考教材。《自己动手写网络爬虫》介绍了网路爬虫发中的关键问题与Java实现。主要包括从互联网获取信息与提取信息和对Web信息挖掘等内容。《自己动手写网络爬虫》在介绍基本原理的同时重视辅以具体代码实现来帮助读者加深理解,书中部份代码甚至可以直使用。 《自己动手写网络爬虫》适用于有Java程序设计基础的发人员。同时也可以作为计算机相关专业本科生或研究生的参考教材。
【推荐语】
《自己动手写网络爬虫》是国外**本专门讲解网路爬虫发的书籍,介绍怎么应用云计算架构发分布式爬虫。猎兔搜索工程师多年项目经验总结 深介绍Web数据挖掘实现过程 光碟中提供了高效的代码解决方案 案例均使用流行的Java语言编撰
【作者】
罗刚,计算机软件硕士自己动手写网络爬虫,毕业于吉林工业大学。2005年成立北京盈智星科技发展有限公司,2008年联合成立北京数聚软件公司。猎兔搜索创始人,当前猎兔搜索在上海和北京以及广州均设有研制部。带领猎兔搜索技术发团队先后发出猎兔英文动词系统、猎兔文本挖掘系统,智能垂直搜索系统以及网路信息检测系统等,实现互联网信息的采集、过滤、搜索和实时检测自己动手写网络爬虫,其发的搜索软件日用户访问量上万次以上。 查看全部

《自己动手写网络爬虫》介绍了网路爬虫开发中的关键问题与Java实现。主要包括从互联网获取信息与提取信息和对Web信息挖掘等内容。《自己动手写网络爬虫》在介绍基本原理的同时重视辅以具体代码实现来帮助读者加深理解,书中部份代码甚至可以直接使用。 《自己动手写网络爬虫》适用于有Java程序设计基础的开发人员。同时也可以作为计算机相关专业本科生或研究生的参考教材。《自己动手写网络爬虫》介绍了网路爬虫发中的关键问题与Java实现。主要包括从互联网获取信息与提取信息和对Web信息挖掘等内容。《自己动手写网络爬虫》在介绍基本原理的同时重视辅以具体代码实现来帮助读者加深理解,书中部份代码甚至可以直使用。 《自己动手写网络爬虫》适用于有Java程序设计基础的发人员。同时也可以作为计算机相关专业本科生或研究生的参考教材。
【推荐语】
《自己动手写网络爬虫》是国外**本专门讲解网路爬虫发的书籍,介绍怎么应用云计算架构发分布式爬虫。猎兔搜索工程师多年项目经验总结 深介绍Web数据挖掘实现过程 光碟中提供了高效的代码解决方案 案例均使用流行的Java语言编撰
【作者】
罗刚,计算机软件硕士自己动手写网络爬虫,毕业于吉林工业大学。2005年成立北京盈智星科技发展有限公司,2008年联合成立北京数聚软件公司。猎兔搜索创始人,当前猎兔搜索在上海和北京以及广州均设有研制部。带领猎兔搜索技术发团队先后发出猎兔英文动词系统、猎兔文本挖掘系统,智能垂直搜索系统以及网路信息检测系统等,实现互联网信息的采集、过滤、搜索和实时检测自己动手写网络爬虫,其发的搜索软件日用户访问量上万次以上。
关于爬虫程序的合法性?
采集交流 • 优采云 发表了文章 • 0 个评论 • 310 次浏览 • 2020-05-10 08:03
希望本回答能解决楼主的问题。此回答摘录自本人所写的书《Python 网络爬虫:从入门到实践》第一章
从目前的情况来看,如果抓取的数据属于个人使用或科研范畴爬虫程序,基本不存在问题; 而假如数据属于商业赢利范畴,就要就事而论,有可能属于违法行为,也有可能不违规。
网络爬虫领域目前还属于拓荒阶段,虽然互联网世界早已通过自身的合同构建起一定的道德规范(Robots 协议),但法律部份还在完善和建立中。也就是说,现在这个领域暂时还是灰色地带。
Robots 协议
Robots协议(也称为爬虫协议)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎什么页面可以抓取,哪些页面不能抓取。它是国际互联网界通行的道德规范,虽然没有写入法律,但是每一个爬虫都应当遵循这项合同。
下面以淘宝网的robots.txt为例:
这里仅截取部份,查看完整可以访问taobao.com/robots.txt
User-agent: Baiduspider #百度爬虫引擎
Allow: /article #允许访问/article.htm,/article/12345.com
Allow: /oshtml
Allow: /wenzhang
Disallow: /product/ #禁止访问/product/12345.com
Disallow: / #禁止了访问除Allow规定页面的其他所有页面
User-Agent: Googlebot #谷歌爬虫引擎
Allow: /article
Allow: /oshtml
Allow: /product #允许访问/product.htm,/product/12345.com
Allow: /spu
Allow: /dianpu
Allow: /wenzhang
Allow: /oversea
Disallow: /
在前面的robots文件中,淘宝网对用户代理为百度爬虫引擎进行规定。
以”Allow”项的值开头的URL 是容许robot访问的。例如,”Allow: /article”允许百度爬虫引擎访问”/article.htm,/article/12345.com”等等。
以Disallow项为开头的链接是不容许百度爬虫引擎访问的。例如,”Disallow: /product/”不容许百度爬虫引擎访问 ”/product/12345.com” 等等。
最后一行,”Disallow: /”则严禁了百度爬虫访问不仅”Allow”规定页面的其他所有页面。
因此,当你在百度搜索“淘宝”的时侯,搜索结果下方的篆字会出现:“由于该网站的robots.txt文件存在限制指令(限制搜索引擎抓取),系统未能提供该页面的内容描述”。百度作为一个搜索引擎,良好地遵循了淘宝网的 robot.txt 协议,所以你是不能从百度上搜索到天猫内部的产品信息的。
淘宝的Robots协议对微软爬虫的待遇则不一样,和百度爬虫不同的是,它容许微软爬虫爬取产品的页面,”Allow: /product”。因此,当你在微软搜索“淘宝 iphone7”的时侯,可以搜索到天猫中的产品。
因此,当你爬取网站数据时,无论你是否仅仅用来个人使用,都应当遵循robots协议。
2. 网络爬虫的约束
除了上述的 Robot 协议之外,我们使用网路爬虫的时侯要对自己进行约束:过于快速或则频密的网络爬虫就会对服务器形成巨大的压力,网站可能封锁你的IP,甚至采取进一步的法律行动。
各大互联网大鳄也早已开始调集资源,限制爬虫,保护真正用户的流量和降低有价值数据的流失。
2007年,爱帮网借助垂直搜索技术获取了大众点评网上的商户简介和消费者点评爬虫程序,并且直接大量使用,于是大众点评网多次要求爱帮停止使用大众点评网的内容。而爱帮网则以自己是垂直搜索网站为由,拒绝停止抓取大众点评网上的内容,并且指责大众点评网对那些内容所享有的著作权。为此,双方开打了两场官司。2011年1月,北京海淀法院作出裁定:爱帮网侵害大众点评网著作权创立,爱帮网应该停止侵权并赔付大众点评网经济损失和诉讼必要开支。
2013年10月,百度诉360违背Robots协议,百度方面觉得,360违背了Robots协议,擅自抓取、复制百度网站内容并生成快照向用户提供。2014年08月07日,北京市第一中级人民法院做出二审裁定,法院觉得被告奇虎360的行为违背了《反不正当竞争法》相关规定,应赔付上诉百度公司70万元。
虽然说,大众点评上的点评数据,百度知道的问答由用户创建而非企业,但是搭建平台须要投入营运、技术和人力成本,那么平台拥有对数据的所有权,使用权和分发权。
以上两起败诉告诉我们,在爬取网站的时侯,需要限制自己的爬虫,遵守Robots协议和约束网路爬虫程序的速率;在使用数据的时侯,必须要遵循网站的知识产权。如果违犯了这种规定,很可能会吃官司,并且败诉机率相当高。
以上回答摘录自本人所写的书《Python 网络爬虫:从入门到实践》第一章:网络爬虫合法吗? 查看全部

希望本回答能解决楼主的问题。此回答摘录自本人所写的书《Python 网络爬虫:从入门到实践》第一章
从目前的情况来看,如果抓取的数据属于个人使用或科研范畴爬虫程序,基本不存在问题; 而假如数据属于商业赢利范畴,就要就事而论,有可能属于违法行为,也有可能不违规。
网络爬虫领域目前还属于拓荒阶段,虽然互联网世界早已通过自身的合同构建起一定的道德规范(Robots 协议),但法律部份还在完善和建立中。也就是说,现在这个领域暂时还是灰色地带。
Robots 协议
Robots协议(也称为爬虫协议)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎什么页面可以抓取,哪些页面不能抓取。它是国际互联网界通行的道德规范,虽然没有写入法律,但是每一个爬虫都应当遵循这项合同。
下面以淘宝网的robots.txt为例:
这里仅截取部份,查看完整可以访问taobao.com/robots.txt
User-agent: Baiduspider #百度爬虫引擎
Allow: /article #允许访问/article.htm,/article/12345.com
Allow: /oshtml
Allow: /wenzhang
Disallow: /product/ #禁止访问/product/12345.com
Disallow: / #禁止了访问除Allow规定页面的其他所有页面
User-Agent: Googlebot #谷歌爬虫引擎
Allow: /article
Allow: /oshtml
Allow: /product #允许访问/product.htm,/product/12345.com
Allow: /spu
Allow: /dianpu
Allow: /wenzhang
Allow: /oversea
Disallow: /
在前面的robots文件中,淘宝网对用户代理为百度爬虫引擎进行规定。
以”Allow”项的值开头的URL 是容许robot访问的。例如,”Allow: /article”允许百度爬虫引擎访问”/article.htm,/article/12345.com”等等。
以Disallow项为开头的链接是不容许百度爬虫引擎访问的。例如,”Disallow: /product/”不容许百度爬虫引擎访问 ”/product/12345.com” 等等。
最后一行,”Disallow: /”则严禁了百度爬虫访问不仅”Allow”规定页面的其他所有页面。
因此,当你在百度搜索“淘宝”的时侯,搜索结果下方的篆字会出现:“由于该网站的robots.txt文件存在限制指令(限制搜索引擎抓取),系统未能提供该页面的内容描述”。百度作为一个搜索引擎,良好地遵循了淘宝网的 robot.txt 协议,所以你是不能从百度上搜索到天猫内部的产品信息的。
淘宝的Robots协议对微软爬虫的待遇则不一样,和百度爬虫不同的是,它容许微软爬虫爬取产品的页面,”Allow: /product”。因此,当你在微软搜索“淘宝 iphone7”的时侯,可以搜索到天猫中的产品。
因此,当你爬取网站数据时,无论你是否仅仅用来个人使用,都应当遵循robots协议。
2. 网络爬虫的约束
除了上述的 Robot 协议之外,我们使用网路爬虫的时侯要对自己进行约束:过于快速或则频密的网络爬虫就会对服务器形成巨大的压力,网站可能封锁你的IP,甚至采取进一步的法律行动。
各大互联网大鳄也早已开始调集资源,限制爬虫,保护真正用户的流量和降低有价值数据的流失。
2007年,爱帮网借助垂直搜索技术获取了大众点评网上的商户简介和消费者点评爬虫程序,并且直接大量使用,于是大众点评网多次要求爱帮停止使用大众点评网的内容。而爱帮网则以自己是垂直搜索网站为由,拒绝停止抓取大众点评网上的内容,并且指责大众点评网对那些内容所享有的著作权。为此,双方开打了两场官司。2011年1月,北京海淀法院作出裁定:爱帮网侵害大众点评网著作权创立,爱帮网应该停止侵权并赔付大众点评网经济损失和诉讼必要开支。
2013年10月,百度诉360违背Robots协议,百度方面觉得,360违背了Robots协议,擅自抓取、复制百度网站内容并生成快照向用户提供。2014年08月07日,北京市第一中级人民法院做出二审裁定,法院觉得被告奇虎360的行为违背了《反不正当竞争法》相关规定,应赔付上诉百度公司70万元。
虽然说,大众点评上的点评数据,百度知道的问答由用户创建而非企业,但是搭建平台须要投入营运、技术和人力成本,那么平台拥有对数据的所有权,使用权和分发权。
以上两起败诉告诉我们,在爬取网站的时侯,需要限制自己的爬虫,遵守Robots协议和约束网路爬虫程序的速率;在使用数据的时侯,必须要遵循网站的知识产权。如果违犯了这种规定,很可能会吃官司,并且败诉机率相当高。
以上回答摘录自本人所写的书《Python 网络爬虫:从入门到实践》第一章:网络爬虫合法吗?
网络爬虫可以爬到什么有用行业数据?
采集交流 • 优采云 发表了文章 • 0 个评论 • 254 次浏览 • 2020-05-10 08:02
网络爬虫可以按照你的不同需求,选择爬取对象、爬取数组进行爬取(必须是公开数据)爬虫软件数据,比如:
电商顾客,我们采集的数据信息主要为商品信息数据、商品评论信息数据、区域库存价钱数据、电商舆情数据等。
金融行业顾客,采集主要的信息为公开的顾客信息、投融资信息、金融舆情信息、市场数据、公开的财务报表、股票、基金、利率等信息。
在网络舆情方面,采集主要信息为综合峰会、新闻门户、知识问答、自媒体网站、社交平台等网路媒体上的相关舆情信息。
在机票采集方面:包含日期、航空公司、航班号、经济舱价钱、经济舱折扣、公务舱价钱、公务舱折扣、税费、附加费、机 型、起飞城市三字码、到达城市三字码、起飞时间等所有相关信息。
题主所说到的行业数据爬虫软件数据,可以依照具体需求选择网站进行定向爬取。
我给题主分享一些国内外公开数据平台,在这种平台里其实有你须要的资源:
【Open Data】国外开放数据中心及政府数据开放平台汇总
最全的中国开放数据(open data)及政府数据开放平台汇总
当然数据采集不仅仅是这几个方面,更多的相关知识也可以在我们官网获得。 查看全部
爬虫采集数据称作网路数据,是指非传统数据源,这种类型的数据可以是结构化的,也可以是非结构化的(更有可能的),可以由网路链接,文本数据,数据表,图像,视频等组成。
网络爬虫可以按照你的不同需求,选择爬取对象、爬取数组进行爬取(必须是公开数据)爬虫软件数据,比如:
电商顾客,我们采集的数据信息主要为商品信息数据、商品评论信息数据、区域库存价钱数据、电商舆情数据等。
金融行业顾客,采集主要的信息为公开的顾客信息、投融资信息、金融舆情信息、市场数据、公开的财务报表、股票、基金、利率等信息。
在网络舆情方面,采集主要信息为综合峰会、新闻门户、知识问答、自媒体网站、社交平台等网路媒体上的相关舆情信息。
在机票采集方面:包含日期、航空公司、航班号、经济舱价钱、经济舱折扣、公务舱价钱、公务舱折扣、税费、附加费、机 型、起飞城市三字码、到达城市三字码、起飞时间等所有相关信息。
题主所说到的行业数据爬虫软件数据,可以依照具体需求选择网站进行定向爬取。
我给题主分享一些国内外公开数据平台,在这种平台里其实有你须要的资源:
【Open Data】国外开放数据中心及政府数据开放平台汇总
最全的中国开放数据(open data)及政府数据开放平台汇总
当然数据采集不仅仅是这几个方面,更多的相关知识也可以在我们官网获得。
《Python3网络爬虫开发实战》来了!
采集交流 • 优采云 发表了文章 • 0 个评论 • 304 次浏览 • 2020-05-09 08:03
嗨~ 给你们重磅推荐一本新书!还未上市前就早已再版 3 次的 Python 爬虫书!那么它就是由静觅博客博主崔庆才所作的《Python3网络爬虫开发实战》!!!
本书《Python3网络爬虫开发实战》全面介绍了借助 Python3 开发网路爬虫的知识,书中首先详尽介绍了各类类型的环境配置过程和爬虫基础知识,还讨论了urllib、requests等恳请库和Beautiful Soup、XPath、pyquery等解析库以及文本和各种数据库的储存方式,另外本书通过多个真实新鲜案例介绍了剖析Ajax进行数据爬取,Selenium和Splash进行动态网站爬取的过程,接着又分享了一些切实可行的爬虫方法,比如使用代理爬取和维护动态代理池的方式、ADSL拨号代理的使用、各类验证码(图形、极验、点触、宫格等)的破解方式、模拟登陆网站爬取的方式及Cookies 池的维护等等。
此外,本书的内容还远远不止这种爬虫软件开发,作者还结合联通互联网的特征阐述了使用Charles、mitmdump、Appium等多种工具实现App 抓包剖析、加密参数插口爬取、微信同学圈爬取的方式。此外本书还详尽介绍了pyspider框架、Scrapy框架的使用和分布式爬虫的知识,另外对于优化及布署工作,本书还包括Bloom Filter效率优化、Docker和Scrapyd爬虫布署、分布式爬虫管理框架Gerapy的分享。
全书共604页,足足两斤重呢~ 定价为99元!
看书就先看看谁写的嘛,我们来了解一下~
崔庆才,静觅博客博主(),博客 Python 爬虫博文已过百万,北京航空航天大学硕士,微软小冰大数据工程师,有多个小型分布式爬虫项目经验,乐于技术分享,文章通俗易懂 ^_^
附皂片一张 ~(@^_^@)~
呕心沥血设计的宣传图也得放一下~
书是好是坏,得使专家看评一评呀,那么下边就是几位专家的精彩评论,快来瞧瞧吧~
在互联网软件开发工程师的分类中,爬虫工程师是极其重要的。爬虫工作常常是一个公司核心业务举办的基础,数据抓取出来,才有后续的加工处理和最终诠释。此时数据的抓取规模、稳定性、实时性、准确性就变得十分重要。早期的互联网充分开放互联,数据获取的难度太小。随着各大公司对数据资产日渐看重,反爬水平也在不断提升,各种新技术不断给爬虫软件提出新的课题。本书作者对爬虫的各个领域都有深刻研究,书中阐述了Ajax数据的抓取、动态渲染页面的抓取、验证码识别、模拟登陆等中级话题,同时也结合联通互联网的特征阐述了App的抓取等。更重要的是,本书提供了大量源码,可以帮助读者更好地理解相关内容。强烈推荐给诸位技术爱好者阅读!
——梁斌,八友科技总经理
数据既是现今大数据剖析的前提,也是各类人工智能应用场景的基础。得数据者得天下,会爬虫者踏遍天下也不怕!一册在手,让小白到老司机都能有所收获!
——李舟军,北京航空航天大学院士,博士生导师
本书从爬虫入门到分布式抓取,详细介绍了爬虫技术的各个要点,并针对不同的场景提出了对应的解决方案。另外,书中通过大量的实例来帮助读者更好地学习爬虫技术,通俗易懂,干货满满。强烈推荐给你们!
——宋睿华,微软小冰首席科学家
有人说中国互联网的带宽全给各类爬虫抢占了,这说明网路爬虫的重要性以及中国互联网数据封闭垄断的现况。爬是一种能力,爬是为了不爬。
——施水才爬虫软件开发,北京拓尔思信息技术股份有限公司总裁 查看全部
嗨~ 给你们重磅推荐一本新书!还未上市前就早已再版 3 次的 Python 爬虫书!那么它就是由静觅博客博主崔庆才所作的《Python3网络爬虫开发实战》!!!

本书《Python3网络爬虫开发实战》全面介绍了借助 Python3 开发网路爬虫的知识,书中首先详尽介绍了各类类型的环境配置过程和爬虫基础知识,还讨论了urllib、requests等恳请库和Beautiful Soup、XPath、pyquery等解析库以及文本和各种数据库的储存方式,另外本书通过多个真实新鲜案例介绍了剖析Ajax进行数据爬取,Selenium和Splash进行动态网站爬取的过程,接着又分享了一些切实可行的爬虫方法,比如使用代理爬取和维护动态代理池的方式、ADSL拨号代理的使用、各类验证码(图形、极验、点触、宫格等)的破解方式、模拟登陆网站爬取的方式及Cookies 池的维护等等。
此外,本书的内容还远远不止这种爬虫软件开发,作者还结合联通互联网的特征阐述了使用Charles、mitmdump、Appium等多种工具实现App 抓包剖析、加密参数插口爬取、微信同学圈爬取的方式。此外本书还详尽介绍了pyspider框架、Scrapy框架的使用和分布式爬虫的知识,另外对于优化及布署工作,本书还包括Bloom Filter效率优化、Docker和Scrapyd爬虫布署、分布式爬虫管理框架Gerapy的分享。
全书共604页,足足两斤重呢~ 定价为99元!
看书就先看看谁写的嘛,我们来了解一下~
崔庆才,静觅博客博主(),博客 Python 爬虫博文已过百万,北京航空航天大学硕士,微软小冰大数据工程师,有多个小型分布式爬虫项目经验,乐于技术分享,文章通俗易懂 ^_^
附皂片一张 ~(@^_^@)~
呕心沥血设计的宣传图也得放一下~
书是好是坏,得使专家看评一评呀,那么下边就是几位专家的精彩评论,快来瞧瞧吧~
在互联网软件开发工程师的分类中,爬虫工程师是极其重要的。爬虫工作常常是一个公司核心业务举办的基础,数据抓取出来,才有后续的加工处理和最终诠释。此时数据的抓取规模、稳定性、实时性、准确性就变得十分重要。早期的互联网充分开放互联,数据获取的难度太小。随着各大公司对数据资产日渐看重,反爬水平也在不断提升,各种新技术不断给爬虫软件提出新的课题。本书作者对爬虫的各个领域都有深刻研究,书中阐述了Ajax数据的抓取、动态渲染页面的抓取、验证码识别、模拟登陆等中级话题,同时也结合联通互联网的特征阐述了App的抓取等。更重要的是,本书提供了大量源码,可以帮助读者更好地理解相关内容。强烈推荐给诸位技术爱好者阅读!
——梁斌,八友科技总经理
数据既是现今大数据剖析的前提,也是各类人工智能应用场景的基础。得数据者得天下,会爬虫者踏遍天下也不怕!一册在手,让小白到老司机都能有所收获!
——李舟军,北京航空航天大学院士,博士生导师
本书从爬虫入门到分布式抓取,详细介绍了爬虫技术的各个要点,并针对不同的场景提出了对应的解决方案。另外,书中通过大量的实例来帮助读者更好地学习爬虫技术,通俗易懂,干货满满。强烈推荐给你们!
——宋睿华,微软小冰首席科学家
有人说中国互联网的带宽全给各类爬虫抢占了,这说明网路爬虫的重要性以及中国互联网数据封闭垄断的现况。爬是一种能力,爬是为了不爬。
——施水才爬虫软件开发,北京拓尔思信息技术股份有限公司总裁
分布式网路爬虫关键技术剖析与实现
采集交流 • 优采云 发表了文章 • 0 个评论 • 360 次浏览 • 2020-05-09 08:02
分布式网路爬虫关键技术剖析与实现——分布式网路爬虫体系结构设计 分布式网路爬虫体系结构设计 分布式网路爬虫关键技术剖析与实现?一、 研究所属范围分布式网路爬虫包含多个爬虫, 每个爬虫须要完成的任务和单个的爬行器类似, 它们从互联 网上下载网页,并把网页保存在本地的c盘,从中抽取 URL 并顺着这种 URL 的指向继续爬 行。由于并行爬行器须要分割下载任务,可能爬虫会将自己抽取的 URL 发送给其他爬虫。 这些爬虫可能分布在同一个局域网之中,或者分散在不同的地理位置。根据爬虫的分散程度不同,可以把分布式爬行器分成以下两大类: 1、基于局域网分布式网路爬虫:这种分布式爬行器的所有爬虫在同一个局域网里运行,通过高 速的网路联接互相通讯。这些爬虫通过同一个网路去访问外部互联网,下载网页,所有的网 络负载都集中在她们所在的那种局域网的出口上。 由于局域网的带宽较高, 爬虫之间的通讯 的效率能否得到保证; 但是网路出口的总带宽上限是固定的, 爬虫的数目会遭到局域网出口 带宽的限制。 2、基于广域网分布式网路爬虫:当并行爬行器的爬虫分别运行在不同地理位置(或网路位置), 我们称这些并行爬行器为分布式爬行器。
例如,分布式爬行器的爬虫可能坐落中国,日本, 和英国,分别负责下载这三地的网页;或者坐落 CHINANET,CERNET,CEINET,分别负责 下载这三个网路的中的网页。分布式爬行器的优势在于可以子在一定程度上分散网路流量, 减小网路出口的负载。如果爬虫分布在不同的地理位置(或网路位置),需要间隔多长时间 进行一次互相通讯就成为了一个值得考虑的问题。 爬虫之间的通信带宽可能是有限的, 通常 需要通过互联网进行通讯。 在实际应用中, 基于局域网分布式网路爬虫应用的更广一些, 而基于广域网的爬虫因为 实现复杂, 设计和实现成本偏高, 一般只有实力雄厚和采集任务较重的大公司才能使用这些 爬虫。本论文所设计的爬虫就是基于局域网分布式网路爬虫。二、分布式网路爬虫整体剖析分布式网路爬虫的整体设计重点应当在于爬虫怎样进行通讯。目前分布式网 络爬虫按通讯方法不同分布式网络爬虫可以分为主从模式、 自治模式与混和模式 三种。主从模式是指由一台主机作为控制节点负责所有运行网路爬虫的主机进行管理, 爬虫只 需要从控制节点哪里接收任务, 并把新生成任务递交给控制节点就可以了, 在这个过程中不 必与其他爬虫通讯,这种方法实现简单利于管理。
而控制节点则须要与所有爬虫进行通讯, 它须要一个地址列表来保存系统中所有爬虫的信息。 当系统中的爬虫数目发生变化时, 协调 者须要更新地址列表里的数据, 这一过程对于系统中的爬虫是透明的。 但是随着爬虫网页数 量的降低。 控制节点会成为整个系统的困局而造成整个分布式网路爬虫系统性能增长。 主从 模式的整体结构图:自治模式是指系统中没有协调者,所有的爬虫都必须互相通讯,比主从模式 下爬虫要复杂一些。自治模式的通讯方法可以使用全联接通讯或环型通讯。全连 接通讯是指所用爬虫都可以互相发送信息, 使用这些方法的每位网络爬虫会维护 一个地址列表,表中储存着整个系统中所有爬虫的位置,每次通讯时可以直接把 数据发送给须要此数据的爬虫。当系统中的爬虫数目发生变化时,每个爬虫的地 址列表都须要进行更新。环形通讯是指爬虫在逻辑上构成一个环形网,数据在环 上按顺时针或逆时针双向传输, 每个爬虫的地址列表中只保存其前驱和后继的信 息。爬虫接收到数据然后判定数据是否是发送给自己的,如果数据不是发送给自 己的,就把数据转发给后继;如果数据是发送给自己的,就不再发送。假设整个 系统中有 n 个爬虫, 当系统中的爬虫数目发生变化时, 系统中只有 n-1 个爬虫的 地址列表须要进行更新。
混合模式是结合前面两种模式的特性的一种折中模式。该模式所有的爬虫都可以 相互通讯同时都具有任务分配功能。不过所有爬虫中有个特殊的爬虫,该爬虫主 要功能对早已经过爬虫任务分配后未能分配的任务进行集中分配。 使用这个方法 的每位网路爬虫只需维护自己采集范围的地址列表。 而特殊爬虫需不仅保存自己 采集范围的地址列表外还保存须要进行集中分配的地址列表。 混合模式的整体结 构图:三、大型分布式网路爬虫体系结构图: 大型分布式网路爬虫体系结构图:从这种图可以看出,分布式网路爬虫是一项非常复杂系统。需要考虑好多方面诱因。性 能可以说是它这重要的指标。当然硬件层面的资源也是必须的。不过不在本系列考虑范围。 从上篇开始, 我将从单机网路爬虫一步步介绍我们须要考虑的问题的解决方案。 如果你们有 更好的解决方案。欢迎指教。 吉日的一句话说的太有道理, 一个人一辈子只能做好几件事。 希望你们支持我的这个系 列。谈谈网路爬虫设计中的问题?网络蜘蛛现今开源的早已有好几个了,Larbin,Nutch,Heritrix 都各有用户之地,要做 一个自己的爬虫要解决很多个问题分词技术 爬虫,比如调度算法、更新策略、分布式存储等,我们来一一 看一下。
一个爬虫要做的事主要有以下这种 1. 2. 3. 从一个网页入口,分析链接,一层一层的遍历,或者从一组网页入口,或者 从一个 rss 源列表开始爬 rss; 获取每位页面的源码保存在c盘或则数据库里; 遍历抓出来的网页进行处理,比如提取正文,消重等;4. 根据用途把处理后的文本进行索引、分类、聚类等操作。 以上是个人理解哦,呵呵。这些过程中,大约有如下问题 如何获取网页源或则 RSS 源 如果是通常的爬虫的话, 就是给几个入口页面, 然后沿着超链接以遍历图的算法一个页面一 个页面的爬,这种情况网页源极少,可以选择从 hao123 等网址大全的网站为入口开始爬。 如果做垂直搜索的话就人工去搜集一些这个行业的网站, 形成一个列表, 从这个列表开始爬。 如果是爬 RSS 的话,需要先搜集 RSS 源,现在大的门户的新闻频道和主流的博客系统都有 rss 的功能,可以先爬一遍网站,找出 rss 的链接,要获取每位链接的内容,分析是否是 rss 格式,如果是就把这个链接保存到 rss 源数据库里,以后就专门爬这个 rss 源的 rss。还有一 种就是人工来整理,一般 blog 的 rss 都是有规律的,主域名跟一个用户名旁边再跟上一个 rss 的固定页面,比如 ,这样就弄一个用户字典,拼接 rss 地址, 然后用程序去侦测是否有这个页面来整理出每位网站的 rss 源。
整理出 rss 源后再 人工设置 rss 源的权重及刷新时间间隔等。 如果源页面好多,如何用多线程去有效的调度处理, 如果源页面好多,如何用多线程去有效的调度处理,而不会相互等待或则重复处理 如果现今有 500 万个页面要去爬,肯定要用多线程或则分布式多进程去处理了。可以把页 面进行水平分割,每个线程处理一段儿,这样每位线程之间不需要同步,各自处理各自的就 行了。比如给这 500W 个页面分配一个自增 ID,2 个线程的话就让第一个线程去爬 1,3,5 的网页,第二个线程去爬 2,4,6 的网页,这样做空个线程间基本上能均衡,而且不会相 互等待,而且不会重复处理,也不会拉掉网页。每个线程一次取出 1w 个页面,并记录最高 的源页面 ID 号,处理完这一批后再从数据库里提取小于这个源页面 ID 号的下 1W 个页面, 直到抓取完本线程要处理的所有页面。1w 这个值按照机器的显存可做适当的调整。为了防 止抓了半截儿关机,所以要支持断点续抓,要为每位线程的处理进度保存状态,每取一批网 页都要记录本线程最大的网页 ID,记录到数据库里,进程重启后可以读取这个 ID,接着抓 后面的页面。 如何尽量的借助 CPU,尽量的不使线程处于等待、休眠、阻塞等空闲状态并且要尽量用少 ,尽量的不使线程处于等待、休眠、 的线程以降低上下文切换。
的线程以降低上下文切换。 爬虫有两个地方须要 IO 操作,抓网页的时侯须要通过网卡访问网路,抓到网页后要把内容 写到c盘或则数据库里。所以这两个部份要用异步 IO 操作,这样可以不用线程阻塞在那里 等待网页抓过来或则写完磁盘文件,网卡和硬碟都支持显存直接读取,大量的 IO 操作会在 硬件驱动的队列里排队,而不消耗任何 CPU。.net 的异步操作使用了线程池,不用自己频繁 的创建和销毁线程,减少了开支,所以线程模型不用考虑,IO 模型也不用考虑,.net 的异 步 IO 操作直接使用了完成端口,很高效了,内存模型也不需要考虑,整个抓取过程各线程不需要访问共享资源分词技术 爬虫,除了数据库里的源页面,各管各的,而且也是每位线程分段处理,可 以实现无锁编程。 如何不采集重复的网页 去重可以使用 king 总监的布隆过滤器,每个线程使用一个 bitarray,里面保存本批源页面先前 抓取的页面的哈希值情况,抓取出来的源页面剖析链接后,去这个 bitarray 里判定曾经有没 有抓过这个页面,没有的话就抓出来,抓过的话就不管了。假设一个源页面有 30 个链接把, 一批 10W 个源页面, 300w 个链接的 bitarray 应该也不会占很大显存。
所以有个五六个线程 同时处理也是没问题的。 抓出来的页面更快的保存保存到分布式文件系统还是保存在数据库里 如果保存到c盘, 可以每位域名创建一个文件夹, 凡是这个网站的页面都放在这个文件夹下, 只要文件名不一样,就不会出现冲突。如果把页面保存到c盘,数据库有自己的一套锁管理 机制,直接用 bulk copy 放数据库就行了。一般频繁的写c盘可能会导致 CPU 过高,而频繁 的写数据库 CPU 还好一些。而且 sqlserver2008 支持 filestream 类型的数组,在保存大文本字 段的时侯有挺好的性能,并且能够使用数据库的 API 来访问。所以我认为假如没有 GFS 那 样高效成熟的分布式文件系统的话还不如存 sqlserver 里面呢。 如何有效的依据网页的更新频度来调整爬虫的采集时间间隔 做爬虫要了解一些 HTTP 协议,如果要抓的网页支持 Last-Modified 或者 ETag 头,我们可以先 发个 head 请求来试探这个页面有没有变化来决定是否要重新抓取,但是很多网站根本就不 支持这个东西,所以使爬虫也太费力,让自己的网站也会损失更多的性能。这样我们就要自 己去标明每个源页面的更新时间间隔及权重,再依照这两个值去用一定的算法制订蜘蛛的更 新策略。
采集下来的数据做什么用 可以抓取一个行业的网站,在本地进行动词和索引,做成垂直搜索引擎。可以用一定的训练 算法对抓取出来的页面进行自动分类,做成新闻门户。也可以用死小风行的文本相似度算法处理 后进行文本降维处理。 如何不影响对方网站的性能 现在很多网站都被爬虫爬怕了, 因为有些蜘蛛弄住一个网站可劲儿的爬, 爬的人家网站的正 常用户都未能访问了。所以很多站长想了很多办法来对付爬虫,所以我们写爬虫也要遵守机器 人合同,控制单位时间内对一个网站的访问量。 查看全部

分布式网路爬虫关键技术剖析与实现——分布式网路爬虫体系结构设计 分布式网路爬虫体系结构设计 分布式网路爬虫关键技术剖析与实现?一、 研究所属范围分布式网路爬虫包含多个爬虫, 每个爬虫须要完成的任务和单个的爬行器类似, 它们从互联 网上下载网页,并把网页保存在本地的c盘,从中抽取 URL 并顺着这种 URL 的指向继续爬 行。由于并行爬行器须要分割下载任务,可能爬虫会将自己抽取的 URL 发送给其他爬虫。 这些爬虫可能分布在同一个局域网之中,或者分散在不同的地理位置。根据爬虫的分散程度不同,可以把分布式爬行器分成以下两大类: 1、基于局域网分布式网路爬虫:这种分布式爬行器的所有爬虫在同一个局域网里运行,通过高 速的网路联接互相通讯。这些爬虫通过同一个网路去访问外部互联网,下载网页,所有的网 络负载都集中在她们所在的那种局域网的出口上。 由于局域网的带宽较高, 爬虫之间的通讯 的效率能否得到保证; 但是网路出口的总带宽上限是固定的, 爬虫的数目会遭到局域网出口 带宽的限制。 2、基于广域网分布式网路爬虫:当并行爬行器的爬虫分别运行在不同地理位置(或网路位置), 我们称这些并行爬行器为分布式爬行器。
例如,分布式爬行器的爬虫可能坐落中国,日本, 和英国,分别负责下载这三地的网页;或者坐落 CHINANET,CERNET,CEINET,分别负责 下载这三个网路的中的网页。分布式爬行器的优势在于可以子在一定程度上分散网路流量, 减小网路出口的负载。如果爬虫分布在不同的地理位置(或网路位置),需要间隔多长时间 进行一次互相通讯就成为了一个值得考虑的问题。 爬虫之间的通信带宽可能是有限的, 通常 需要通过互联网进行通讯。 在实际应用中, 基于局域网分布式网路爬虫应用的更广一些, 而基于广域网的爬虫因为 实现复杂, 设计和实现成本偏高, 一般只有实力雄厚和采集任务较重的大公司才能使用这些 爬虫。本论文所设计的爬虫就是基于局域网分布式网路爬虫。二、分布式网路爬虫整体剖析分布式网路爬虫的整体设计重点应当在于爬虫怎样进行通讯。目前分布式网 络爬虫按通讯方法不同分布式网络爬虫可以分为主从模式、 自治模式与混和模式 三种。主从模式是指由一台主机作为控制节点负责所有运行网路爬虫的主机进行管理, 爬虫只 需要从控制节点哪里接收任务, 并把新生成任务递交给控制节点就可以了, 在这个过程中不 必与其他爬虫通讯,这种方法实现简单利于管理。
而控制节点则须要与所有爬虫进行通讯, 它须要一个地址列表来保存系统中所有爬虫的信息。 当系统中的爬虫数目发生变化时, 协调 者须要更新地址列表里的数据, 这一过程对于系统中的爬虫是透明的。 但是随着爬虫网页数 量的降低。 控制节点会成为整个系统的困局而造成整个分布式网路爬虫系统性能增长。 主从 模式的整体结构图:自治模式是指系统中没有协调者,所有的爬虫都必须互相通讯,比主从模式 下爬虫要复杂一些。自治模式的通讯方法可以使用全联接通讯或环型通讯。全连 接通讯是指所用爬虫都可以互相发送信息, 使用这些方法的每位网络爬虫会维护 一个地址列表,表中储存着整个系统中所有爬虫的位置,每次通讯时可以直接把 数据发送给须要此数据的爬虫。当系统中的爬虫数目发生变化时,每个爬虫的地 址列表都须要进行更新。环形通讯是指爬虫在逻辑上构成一个环形网,数据在环 上按顺时针或逆时针双向传输, 每个爬虫的地址列表中只保存其前驱和后继的信 息。爬虫接收到数据然后判定数据是否是发送给自己的,如果数据不是发送给自 己的,就把数据转发给后继;如果数据是发送给自己的,就不再发送。假设整个 系统中有 n 个爬虫, 当系统中的爬虫数目发生变化时, 系统中只有 n-1 个爬虫的 地址列表须要进行更新。
混合模式是结合前面两种模式的特性的一种折中模式。该模式所有的爬虫都可以 相互通讯同时都具有任务分配功能。不过所有爬虫中有个特殊的爬虫,该爬虫主 要功能对早已经过爬虫任务分配后未能分配的任务进行集中分配。 使用这个方法 的每位网路爬虫只需维护自己采集范围的地址列表。 而特殊爬虫需不仅保存自己 采集范围的地址列表外还保存须要进行集中分配的地址列表。 混合模式的整体结 构图:三、大型分布式网路爬虫体系结构图: 大型分布式网路爬虫体系结构图:从这种图可以看出,分布式网路爬虫是一项非常复杂系统。需要考虑好多方面诱因。性 能可以说是它这重要的指标。当然硬件层面的资源也是必须的。不过不在本系列考虑范围。 从上篇开始, 我将从单机网路爬虫一步步介绍我们须要考虑的问题的解决方案。 如果你们有 更好的解决方案。欢迎指教。 吉日的一句话说的太有道理, 一个人一辈子只能做好几件事。 希望你们支持我的这个系 列。谈谈网路爬虫设计中的问题?网络蜘蛛现今开源的早已有好几个了,Larbin,Nutch,Heritrix 都各有用户之地,要做 一个自己的爬虫要解决很多个问题分词技术 爬虫,比如调度算法、更新策略、分布式存储等,我们来一一 看一下。
一个爬虫要做的事主要有以下这种 1. 2. 3. 从一个网页入口,分析链接,一层一层的遍历,或者从一组网页入口,或者 从一个 rss 源列表开始爬 rss; 获取每位页面的源码保存在c盘或则数据库里; 遍历抓出来的网页进行处理,比如提取正文,消重等;4. 根据用途把处理后的文本进行索引、分类、聚类等操作。 以上是个人理解哦,呵呵。这些过程中,大约有如下问题 如何获取网页源或则 RSS 源 如果是通常的爬虫的话, 就是给几个入口页面, 然后沿着超链接以遍历图的算法一个页面一 个页面的爬,这种情况网页源极少,可以选择从 hao123 等网址大全的网站为入口开始爬。 如果做垂直搜索的话就人工去搜集一些这个行业的网站, 形成一个列表, 从这个列表开始爬。 如果是爬 RSS 的话,需要先搜集 RSS 源,现在大的门户的新闻频道和主流的博客系统都有 rss 的功能,可以先爬一遍网站,找出 rss 的链接,要获取每位链接的内容,分析是否是 rss 格式,如果是就把这个链接保存到 rss 源数据库里,以后就专门爬这个 rss 源的 rss。还有一 种就是人工来整理,一般 blog 的 rss 都是有规律的,主域名跟一个用户名旁边再跟上一个 rss 的固定页面,比如 ,这样就弄一个用户字典,拼接 rss 地址, 然后用程序去侦测是否有这个页面来整理出每位网站的 rss 源。
整理出 rss 源后再 人工设置 rss 源的权重及刷新时间间隔等。 如果源页面好多,如何用多线程去有效的调度处理, 如果源页面好多,如何用多线程去有效的调度处理,而不会相互等待或则重复处理 如果现今有 500 万个页面要去爬,肯定要用多线程或则分布式多进程去处理了。可以把页 面进行水平分割,每个线程处理一段儿,这样每位线程之间不需要同步,各自处理各自的就 行了。比如给这 500W 个页面分配一个自增 ID,2 个线程的话就让第一个线程去爬 1,3,5 的网页,第二个线程去爬 2,4,6 的网页,这样做空个线程间基本上能均衡,而且不会相 互等待,而且不会重复处理,也不会拉掉网页。每个线程一次取出 1w 个页面,并记录最高 的源页面 ID 号,处理完这一批后再从数据库里提取小于这个源页面 ID 号的下 1W 个页面, 直到抓取完本线程要处理的所有页面。1w 这个值按照机器的显存可做适当的调整。为了防 止抓了半截儿关机,所以要支持断点续抓,要为每位线程的处理进度保存状态,每取一批网 页都要记录本线程最大的网页 ID,记录到数据库里,进程重启后可以读取这个 ID,接着抓 后面的页面。 如何尽量的借助 CPU,尽量的不使线程处于等待、休眠、阻塞等空闲状态并且要尽量用少 ,尽量的不使线程处于等待、休眠、 的线程以降低上下文切换。
的线程以降低上下文切换。 爬虫有两个地方须要 IO 操作,抓网页的时侯须要通过网卡访问网路,抓到网页后要把内容 写到c盘或则数据库里。所以这两个部份要用异步 IO 操作,这样可以不用线程阻塞在那里 等待网页抓过来或则写完磁盘文件,网卡和硬碟都支持显存直接读取,大量的 IO 操作会在 硬件驱动的队列里排队,而不消耗任何 CPU。.net 的异步操作使用了线程池,不用自己频繁 的创建和销毁线程,减少了开支,所以线程模型不用考虑,IO 模型也不用考虑,.net 的异 步 IO 操作直接使用了完成端口,很高效了,内存模型也不需要考虑,整个抓取过程各线程不需要访问共享资源分词技术 爬虫,除了数据库里的源页面,各管各的,而且也是每位线程分段处理,可 以实现无锁编程。 如何不采集重复的网页 去重可以使用 king 总监的布隆过滤器,每个线程使用一个 bitarray,里面保存本批源页面先前 抓取的页面的哈希值情况,抓取出来的源页面剖析链接后,去这个 bitarray 里判定曾经有没 有抓过这个页面,没有的话就抓出来,抓过的话就不管了。假设一个源页面有 30 个链接把, 一批 10W 个源页面, 300w 个链接的 bitarray 应该也不会占很大显存。
所以有个五六个线程 同时处理也是没问题的。 抓出来的页面更快的保存保存到分布式文件系统还是保存在数据库里 如果保存到c盘, 可以每位域名创建一个文件夹, 凡是这个网站的页面都放在这个文件夹下, 只要文件名不一样,就不会出现冲突。如果把页面保存到c盘,数据库有自己的一套锁管理 机制,直接用 bulk copy 放数据库就行了。一般频繁的写c盘可能会导致 CPU 过高,而频繁 的写数据库 CPU 还好一些。而且 sqlserver2008 支持 filestream 类型的数组,在保存大文本字 段的时侯有挺好的性能,并且能够使用数据库的 API 来访问。所以我认为假如没有 GFS 那 样高效成熟的分布式文件系统的话还不如存 sqlserver 里面呢。 如何有效的依据网页的更新频度来调整爬虫的采集时间间隔 做爬虫要了解一些 HTTP 协议,如果要抓的网页支持 Last-Modified 或者 ETag 头,我们可以先 发个 head 请求来试探这个页面有没有变化来决定是否要重新抓取,但是很多网站根本就不 支持这个东西,所以使爬虫也太费力,让自己的网站也会损失更多的性能。这样我们就要自 己去标明每个源页面的更新时间间隔及权重,再依照这两个值去用一定的算法制订蜘蛛的更 新策略。
采集下来的数据做什么用 可以抓取一个行业的网站,在本地进行动词和索引,做成垂直搜索引擎。可以用一定的训练 算法对抓取出来的页面进行自动分类,做成新闻门户。也可以用死小风行的文本相似度算法处理 后进行文本降维处理。 如何不影响对方网站的性能 现在很多网站都被爬虫爬怕了, 因为有些蜘蛛弄住一个网站可劲儿的爬, 爬的人家网站的正 常用户都未能访问了。所以很多站长想了很多办法来对付爬虫,所以我们写爬虫也要遵守机器 人合同,控制单位时间内对一个网站的访问量。
网络爬虫简介
采集交流 • 优采云 发表了文章 • 0 个评论 • 312 次浏览 • 2020-05-09 08:01
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更时不时的称为网页追逐者),是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。
传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL装入队列,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要按照一定的网页剖析算法过滤与主题无关的链接,保留有用的链接并将其倒入等待抓取的URL队列。然后,它将按照一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。
另外,所有被爬虫抓取的网页将会被系统储存,进行一定的剖析、过滤,并构建索引,以便以后的查询和检索;对于聚焦爬虫来说,这一过程所得到的剖析结果还可能对之后的抓取过程给出反馈和指导。
以下为文章主要内容:
初见爬虫
使用Python中的Requests第三方库。在Requests的7个主要方式中,最常使用的就是get()方法,通过该方式构造一个向服务器恳求资源的Request对象,结果返回一个包含服务器资源的额Response对象。通过Response对象则可以获取恳求的返回状态、HTTP响应的字符串即URL对应的页面内容、页面的编码方法以及页面内容的二进制方式。
在了解get()方法之前我们先了解一下HTTP合同,通过对HTTP协议来理解我们访问网页这个过程究竟都进行了什么工作。
1.1 浅析HTTP协议
超文本传输协议(HTTP,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网路合同。所有的www文件都必须遵循这个标准。HTTP协议主要有几个特征:
支持客户/服务器模式
简单快捷:客服向服务器发出恳求,只须要传送恳求方式和路径。请求方式常用的有GET, HEAD, POST。每种方式规定了顾客与服务器联系的类型不同。由于HTTP协议简单,使得HTTP服务器的程序规模小,因而通讯速度快。
灵活:HTTP容许传输任意类型的数据对象。
无联接:无联接的涵义是限制每次联接恳求只处理一个恳求。服务器处理完顾客的恳求,收到顾客的应答后即断掉联接,这种方法可以节约传输时间。
无状态:HTTP合同是无状态合同。无状态是指合同对于事物处理没有记忆能力。缺少状态意味着假如后续处理须要上面的信息,则它必须重传,这样可能造成每次联接传送的数据量减小,另一方面,在服务器不需要原本信息时它的应答就较快。
爬取过程
首先浏览器领到网址以后先将主机名解析下来。如 则会将主机名 解析下来。
查找ip,根据主机名,会首先查找ip,首先查询hosts文件,成功则返回对应的ip地址,如果没有查询到,则去DNS服务器查询,成功就返回ip,否则会报告联接错误。
发送http请求,浏览器会把自身相关信息与恳求相关信息封装成HTTP请求 消息发送给服务器。
服务器处理恳求,服务器读取HTTP请求中的内容,在经过解析主机,解析站点名称,解析访问资源后,会查找相关资源,如果查找成功,则返回状态码200,失败才会返回大名鼎鼎的404了,在服务器检测到恳求不在的资源后,可以根据程序员设置的跳转到别的页面。所以有各类有个性的404错误页面。
服务器返回HTTP响应,浏览器得到返回数据后就可以提取数据,然后调用解析内核进行翻译,最后显示出页面。之后浏览器会对其引用的文件例如图片,css,js等文件不断进行上述过程,直到所有文件都被下载出来以后,网页都会显示下来。
HTTP请求,http请求由三部份组成,分别是:请求行、消息报头、请求正文。请求方式(所有方式全为小写)有多种,各个方式的解释如下:
GET恳求获取Request-URI所标示的资源
POST 在Request-URI所标示的资源后附加新的数据
HEAD 恳求获取由Request-URI所标示的资源的响应消息报头
PUT恳求服务器储存一个资源,并用Request-URI作为其标示
DELETE 恳求服务器删掉Request-URI所标示的资源
TRACE 恳求服务器回送收到的恳求信息,主要用于测试或确诊
CONNECT 保留将来使用
OPTIONS 恳求查询服务器的性能,或者查询与资源相关的选项和需求
GET方式应用举例:在浏览器的地址栏中输入网址的形式访问网页时,浏览器采用GET方式向服务器获取资源,eg:GET /form.html HTTP/1.1 (CRLF)
HTTP响应也是由三个部份组成,分别是:状态行、消息报头、响应正文。
状态行格式如下:HTTP-Version Status-Code Reason-Phrase CRLF,其中,HTTP-Version表示服务器HTTP合同的版本;Status-Code表示服务器发回的响应状态代码;Reason-Phrase表示状态代码的文本描述。
状态代码有三位数字组成,第一个数字定义了响应的类别,且有五种可能取值:
1xx:指示信息--表示恳求已接收,继续处理
2xx:成功--表示恳求已被成功接收、理解、接受
3xx:重定向--要完成恳求必须进行更进一步的操作
4xx:客户端错误--请求有句型错误或恳求未能实现
5xx:服务器端错误--服务器无法实现合法的恳求
常见状态代码、状态描述、说明:
200 OK//客户端恳求成功
400 Bad Request //客户端恳求有句型错误,不能被服务器所理解
401 Unauthorized //请求未经授权网络爬虫,这个状态代码必须和WWW-Authenticate报头域一起使用
403 Forbidden //服务器收到恳求,但是拒绝提供服务
404 Not Found //恳求资源不存在,eg:输入了错误的URL
500 Internal Server Error //服务器发生不可预期的错误
503 Server Unavailable //服务器当前不能处理客户端的恳求,一段时间后可能恢复正常。
eg:HTTP/1.1 200 OK (CRLF)
详细的HTTP合同可以参考这篇文章:
前面我们了解了HTTP合同,那么我们访问网页的过程,那么网页在是哪些样子的。爬虫眼里的网页又是哪些样子的。
网是静态的,但爬虫是动态的,所以爬虫的基本思想就是顺着网页(蜘蛛网的节点)上的链接的爬取有效信息。当然网页也有动态(一般用PHP或ASP等写成,例如用户登录界面就是动态网页)的,但若果一张蛛网摇摇欲坠,蜘蛛会倍感不这么安稳,所以动态网页的优先级通常会被搜索引擎排在静态网页的旁边。
知道了爬虫的基本思想,那么具体怎么操作呢?这得从网页的基本概念说起。一个网页有三大构成要素,分别是html文件、css文件和JavaScript文件。如果把一个网页看做一栋房屋,那么html相当于房屋壳体;css相当于瓷砖油墨,美化房屋外形内饰;JavaScript则相当于灯具家电浴场等,增加房屋的功能。从上述比喻可以看出,html才是网页的根本,毕竟瓷砖染料在市场上也有,家具家电都可以露天摆饰,而房屋壳体才是独一无二的。
下面就是一个简单网页的事例:
而在爬虫眼中网络爬虫,这个网页是这样的:
因此网页实质上就是超文本(hypertext),网页上的所有内容都是在形如“<>...</>”这样的标签之内的。如果我们要收集网页上的所有超链接,只需找寻所有标签中后面是"href="的字符串,并查看提取下来的字符串是否以"http"(超文本转换合同,https表示安全的http合同)开头即可。如果超链接不以"http"开头,那么该链接太可能是网页所在的本地文件或则ftp或smtp(文件或电邮转换合同),应该过滤掉。
在Python中我们使用Requests库中的方式来帮助我们实现对网页的恳求,从而达到实现爬虫的过程。
1.2 Requests库的7个主要方式:
最常用的方式get拿来实现一个简单的小爬虫,通过示例代码展示:
Robots协议
Robots协议(也称为爬虫协议、机器人合同等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎什么页面可以抓取,哪些页面不能抓取。通过几个小反例来剖析一下robots.txt中的内容,robots.txt默认放置于网站的根目录小,对于一个没有robots.txt文件的网站,默认是容许所有爬虫获取其网站内容的。
,
如果是商业利益我们是必须要遵循robots协议内容,否则会承当相应的法律责任。当只是个人玩转网页、练习则是建议遵循,提高自己编撰爬虫的友好程度。
网页解析
BeautifulSoup尝试化平静为神奇,通过定位HTML标签来低格和组织复杂的网路信息,用简单易用的Python对象为我们展示XML结构信息。
BeautifulSoup是解析、遍历、维护“标签树”的功能库。
3.1 BeautifulSoup的解析器
BeautifulSoup通过以上四种解析器来对我们获取的网页内容进行解析。使用官网的事例来看一下解析结果:
首先获取以上的一段HTML内容,我们通过BeautifulSoup解析然后,并且输出解析后的结果来对比一下:
查看全部
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更时不时的称为网页追逐者),是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。
传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL装入队列,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要按照一定的网页剖析算法过滤与主题无关的链接,保留有用的链接并将其倒入等待抓取的URL队列。然后,它将按照一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。
另外,所有被爬虫抓取的网页将会被系统储存,进行一定的剖析、过滤,并构建索引,以便以后的查询和检索;对于聚焦爬虫来说,这一过程所得到的剖析结果还可能对之后的抓取过程给出反馈和指导。
以下为文章主要内容:

初见爬虫
使用Python中的Requests第三方库。在Requests的7个主要方式中,最常使用的就是get()方法,通过该方式构造一个向服务器恳求资源的Request对象,结果返回一个包含服务器资源的额Response对象。通过Response对象则可以获取恳求的返回状态、HTTP响应的字符串即URL对应的页面内容、页面的编码方法以及页面内容的二进制方式。
在了解get()方法之前我们先了解一下HTTP合同,通过对HTTP协议来理解我们访问网页这个过程究竟都进行了什么工作。
1.1 浅析HTTP协议
超文本传输协议(HTTP,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网路合同。所有的www文件都必须遵循这个标准。HTTP协议主要有几个特征:
支持客户/服务器模式
简单快捷:客服向服务器发出恳求,只须要传送恳求方式和路径。请求方式常用的有GET, HEAD, POST。每种方式规定了顾客与服务器联系的类型不同。由于HTTP协议简单,使得HTTP服务器的程序规模小,因而通讯速度快。
灵活:HTTP容许传输任意类型的数据对象。
无联接:无联接的涵义是限制每次联接恳求只处理一个恳求。服务器处理完顾客的恳求,收到顾客的应答后即断掉联接,这种方法可以节约传输时间。
无状态:HTTP合同是无状态合同。无状态是指合同对于事物处理没有记忆能力。缺少状态意味着假如后续处理须要上面的信息,则它必须重传,这样可能造成每次联接传送的数据量减小,另一方面,在服务器不需要原本信息时它的应答就较快。
爬取过程
首先浏览器领到网址以后先将主机名解析下来。如 则会将主机名 解析下来。
查找ip,根据主机名,会首先查找ip,首先查询hosts文件,成功则返回对应的ip地址,如果没有查询到,则去DNS服务器查询,成功就返回ip,否则会报告联接错误。
发送http请求,浏览器会把自身相关信息与恳求相关信息封装成HTTP请求 消息发送给服务器。
服务器处理恳求,服务器读取HTTP请求中的内容,在经过解析主机,解析站点名称,解析访问资源后,会查找相关资源,如果查找成功,则返回状态码200,失败才会返回大名鼎鼎的404了,在服务器检测到恳求不在的资源后,可以根据程序员设置的跳转到别的页面。所以有各类有个性的404错误页面。
服务器返回HTTP响应,浏览器得到返回数据后就可以提取数据,然后调用解析内核进行翻译,最后显示出页面。之后浏览器会对其引用的文件例如图片,css,js等文件不断进行上述过程,直到所有文件都被下载出来以后,网页都会显示下来。
HTTP请求,http请求由三部份组成,分别是:请求行、消息报头、请求正文。请求方式(所有方式全为小写)有多种,各个方式的解释如下:
GET恳求获取Request-URI所标示的资源
POST 在Request-URI所标示的资源后附加新的数据
HEAD 恳求获取由Request-URI所标示的资源的响应消息报头
PUT恳求服务器储存一个资源,并用Request-URI作为其标示
DELETE 恳求服务器删掉Request-URI所标示的资源
TRACE 恳求服务器回送收到的恳求信息,主要用于测试或确诊
CONNECT 保留将来使用
OPTIONS 恳求查询服务器的性能,或者查询与资源相关的选项和需求
GET方式应用举例:在浏览器的地址栏中输入网址的形式访问网页时,浏览器采用GET方式向服务器获取资源,eg:GET /form.html HTTP/1.1 (CRLF)
HTTP响应也是由三个部份组成,分别是:状态行、消息报头、响应正文。
状态行格式如下:HTTP-Version Status-Code Reason-Phrase CRLF,其中,HTTP-Version表示服务器HTTP合同的版本;Status-Code表示服务器发回的响应状态代码;Reason-Phrase表示状态代码的文本描述。
状态代码有三位数字组成,第一个数字定义了响应的类别,且有五种可能取值:
1xx:指示信息--表示恳求已接收,继续处理
2xx:成功--表示恳求已被成功接收、理解、接受
3xx:重定向--要完成恳求必须进行更进一步的操作
4xx:客户端错误--请求有句型错误或恳求未能实现
5xx:服务器端错误--服务器无法实现合法的恳求
常见状态代码、状态描述、说明:
200 OK//客户端恳求成功
400 Bad Request //客户端恳求有句型错误,不能被服务器所理解
401 Unauthorized //请求未经授权网络爬虫,这个状态代码必须和WWW-Authenticate报头域一起使用
403 Forbidden //服务器收到恳求,但是拒绝提供服务
404 Not Found //恳求资源不存在,eg:输入了错误的URL
500 Internal Server Error //服务器发生不可预期的错误
503 Server Unavailable //服务器当前不能处理客户端的恳求,一段时间后可能恢复正常。
eg:HTTP/1.1 200 OK (CRLF)
详细的HTTP合同可以参考这篇文章:
前面我们了解了HTTP合同,那么我们访问网页的过程,那么网页在是哪些样子的。爬虫眼里的网页又是哪些样子的。
网是静态的,但爬虫是动态的,所以爬虫的基本思想就是顺着网页(蜘蛛网的节点)上的链接的爬取有效信息。当然网页也有动态(一般用PHP或ASP等写成,例如用户登录界面就是动态网页)的,但若果一张蛛网摇摇欲坠,蜘蛛会倍感不这么安稳,所以动态网页的优先级通常会被搜索引擎排在静态网页的旁边。
知道了爬虫的基本思想,那么具体怎么操作呢?这得从网页的基本概念说起。一个网页有三大构成要素,分别是html文件、css文件和JavaScript文件。如果把一个网页看做一栋房屋,那么html相当于房屋壳体;css相当于瓷砖油墨,美化房屋外形内饰;JavaScript则相当于灯具家电浴场等,增加房屋的功能。从上述比喻可以看出,html才是网页的根本,毕竟瓷砖染料在市场上也有,家具家电都可以露天摆饰,而房屋壳体才是独一无二的。
下面就是一个简单网页的事例:

而在爬虫眼中网络爬虫,这个网页是这样的:

因此网页实质上就是超文本(hypertext),网页上的所有内容都是在形如“<>...</>”这样的标签之内的。如果我们要收集网页上的所有超链接,只需找寻所有标签中后面是"href="的字符串,并查看提取下来的字符串是否以"http"(超文本转换合同,https表示安全的http合同)开头即可。如果超链接不以"http"开头,那么该链接太可能是网页所在的本地文件或则ftp或smtp(文件或电邮转换合同),应该过滤掉。
在Python中我们使用Requests库中的方式来帮助我们实现对网页的恳求,从而达到实现爬虫的过程。
1.2 Requests库的7个主要方式:

最常用的方式get拿来实现一个简单的小爬虫,通过示例代码展示:

Robots协议
Robots协议(也称为爬虫协议、机器人合同等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎什么页面可以抓取,哪些页面不能抓取。通过几个小反例来剖析一下robots.txt中的内容,robots.txt默认放置于网站的根目录小,对于一个没有robots.txt文件的网站,默认是容许所有爬虫获取其网站内容的。

,
如果是商业利益我们是必须要遵循robots协议内容,否则会承当相应的法律责任。当只是个人玩转网页、练习则是建议遵循,提高自己编撰爬虫的友好程度。
网页解析
BeautifulSoup尝试化平静为神奇,通过定位HTML标签来低格和组织复杂的网路信息,用简单易用的Python对象为我们展示XML结构信息。
BeautifulSoup是解析、遍历、维护“标签树”的功能库。
3.1 BeautifulSoup的解析器

BeautifulSoup通过以上四种解析器来对我们获取的网页内容进行解析。使用官网的事例来看一下解析结果:

首先获取以上的一段HTML内容,我们通过BeautifulSoup解析然后,并且输出解析后的结果来对比一下:


20款最常使用的网路爬虫工具推荐(2018)教程文件
采集交流 • 优采云 发表了文章 • 0 个评论 • 383 次浏览 • 2020-05-09 08:00
另外八爪鱼提供手动辨识验 证码以及代理 IP 切换功能,可以有效的防止网站防采集。 总之,八爪鱼可以满足用户最基本或中级的采集需求,而无需任何编程技能。2. HTTrack作为免费的网站爬虫软件,HTTrack 提供的功能十分适宜从互联网下载整个网站 到你的 PC。它提供了适用于 Windows,Linux,Sun Solaris 和其他 Unix 系统 的版本。它可以将一个站点或多个站点镜像在一起(使用共享链接)。你可以在 “设置选项”下下载网页时决定要同时打开的连接数。你可以从整个目录中获取 照片,文件,HTML 代码,更新当前镜像的网站并恢复中断的下载。精品文档精品文档据悉,HTTTrack 还提供代理支持,以通过可选身分验证最大限度地提升速率。 HTTrack 用作命令行程序,或通过 shell 用于私有(捕获)或专业(在线 Web 镜像)使用。 有了这样的说法,HTTrack 应该是首选,并且具有中级编程技能 的人更多地使用它。3、 ScraperScraper 是 Chrome 扩展程序,具有有限的数据提取功能,但它有助于进行在 线研究并将数据导入到 Google sheets。
此工具适用于初学者以及可以使用 OAuth 轻松将数据复制到剪贴板或储存到电子表格的专家。Scraper 是一个免 费的网路爬虫工具,可以在你的浏览器中正常工作,并手动生成较小的 XPath 来定义要抓取的 URL。4、OutWit Hub精品文档精品文档Outwit Hub 是一个 Firefox 添加件,它有两个目的:搜集信息和管理信息。它 可以分别用在网站上不同的部份提供不同的窗口条。还提供用户一个快速步入信 息的方式,虚拟移除网站上别的部份。 OutWit Hub 提供单一界面,可依照须要抓取微小或大量数据。OutWit Hub 允许你从浏览器本身抓取任何网页,甚至可以创建手动代理来提取数据并按照设 置对其进行低格。 OutWit Hub 大多功能都是免费的,能够深入剖析网站,自动搜集整理组织互联 网中的各项数据,并将网站信息分割开来,然后提取有效信息,形成可用的集合。 但是要手动提取精确数据就须要付费版本了,同时免费版一次提取的数据量也是 有限制的,如果须要大批量的操作,可以选择订购专业版。 5. ParseHub精品文档精品文档Parsehub 是一个太棒的网路爬虫,支持从使用 AJAX 技术,JavaScript,cookie 等的网站收集数据。
它的机器学习技术可以读取,分析之后将 Web 文档转换为 相关数据。 Parsehub 的桌面应用程序支持 Windows,Mac OS X 和 Linux 等系统,或者 你可以使用浏览器中外置的 Web 应用程序。 作为免费软件,你可以在 Parsehub 中设置不超过五个 publice 项目。付费版本 允许你创建起码 20private 项目来抓取网站。6. ScrapinghubScrapinghub 是一种基于云的数据提取工具,可帮助数千名开发人员获取有价 值的数据。它的开源视觉抓取工具,允许用户在没有任何编程知识的情况下抓取 网站。 Scrapinghub 使用 Crawlera,一家代理 IP 第三方平台,支持绕开防采集对策。 它使用户就能从多个 IP 和位置进行网页抓取,而无需通过简单的 HTTP API 进 行代理管理。 Scrapinghub 将整个网页转换为有组织的内容。如果其爬虫工具难以满足你的 要求,其专家团队可以提供帮助。。精品文档精品文档7. Dexi.io作为基于浏览器的网路爬虫,Dexi.io 允许你从任何网站基于浏览器抓取数据, 并提供三种类型的爬虫来创建采集任务。
免费软件为你的网路抓取提供匿名 Web 代理服务器,你提取的数据将在存档数据之前在 Dexi.io 的服务器上托管 两周,或者你可以直接将提取的数据导入到 JSON 或 CSV 文件。它提供付费服 务,以满足你获取实时数据的需求。8. Webhose.ioWebhose.io 使用户才能将来自世界各地的在线资源抓取的实时数据转换为各 种标准的格式。通过此 Web 爬网程序,你可以使用囊括各类来源的多个过滤器 来抓取数据并进一步提取多种语言的关键字。 你可以将删掉的数据保存为 XML,JSON 和 RSS 格式。并且容许用户从其存档 访问历史数据。此外,webhose.io 支持最多 80 种语言及其爬行数据结果。用 户可以轻松索引和搜索 Webhose.io 抓取的结构化数据。精品文档精品文档总的来说,Webhose.io 可以满足用户的基本爬行要求。9.Import.io用户只需从特定网页导出数据并将数据导入到 CSV 即可产生自己的数据集。 你可以在几分钟内轻松抓取数千个网页,而无需编撰任何代码,并按照你的要求 构建 1000 多个 API。公共 API 提供了强悍而灵活的功能来以编程方法控制 Import.io 并获得对数据的手动访问,Import.io 通过将 Web 数据集成到你自己 的应用程序或网站中,只需点击几下就可以轻松实现爬网。
为了更好地满足用户的爬行需求,它还提供适用于 Windows,Mac OS X 和 Linux 的免费应用程序,以建立数据提取器和抓取工具,下载数据并与在线账户 同步。此外,用户还可以每周网络爬虫软件下载,每天或每小时安排抓取任务。10.80legs精品文档精品文档80legs 是一个功能强悍的网路抓取工具,可以按照自定义要求进行配置。它支 持获取大量数据以及立刻下载提取数据的选项。80legs 提供高性能的 Web 爬 行,可以快速工作并在几秒钟内获取所需的数据11. Content GraberContent Graber 是一款面向企业的网路爬行软件。它容许你创建独立的 Web 爬网代理。它可以从几乎任何网站中提取内容,并以你选择的格式将其保存为结 构化数据,包括 Excel 报告,XML,CSV 和大多数数据库。它更适宜具有中级编程技能的人,因为它为有须要的人提供了许多强悍的脚本编 辑和调试界面。允许用户使用 C#或 VB.NET 调试或编撰脚本来编程控制爬网过 程。例如,Content Grabber 可以与 Visual Studio 2013 集成,以便按照用户 的特定需求为中级且机智的自定义爬虫提供最强悍的脚本编辑,调试和单元测 试。
精品文档精品文档12. UiPathUiPath 是一款用于免费网路抓取的机器人过程自动化软件。它可以手动从大多 数第三方应用程序中抓取 Web 和桌面数据。如果运行 Windows 系统,则可以 安装机械手过程自动化软件。Uipath 能够跨多个网页提取表格和基于模式的数 据。 Uipath 提供了用于进一步爬行的外置工具。处理复杂的 UI 时,此方式十分有效。 Screen Scraping Tool 可以处理单个文本元素,文本组和文本块,例如表格格 式的数据提取。 此外,创建智能 Web 代理不需要编程,但你内部的.NET 黑客可以完全控制数 据。精品文档精品文档其实,在里面我提及的爬虫可以满足大多数用户的基本爬行需求,这些工具中各 自的功能依然存在好多差别,大家可以按照自己的需求选择合适的。八爪鱼——90 万用户选择的网页数据采集器。 1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。精品文档精品文档2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。精品文档 查看全部
精品文档20 款最常使用的网路爬虫工具推荐 (2018)网络爬虫在现今的许多领域得到广泛应用。它的作用是从任何网站获取特定的或 更新的数据并储存出来。网络爬虫工具越来越为人所熟知,因为网路爬虫简化并 自动化了整个爬取过程,使每个人都可以轻松访问网站数据资源。使用网路爬虫 工具可以使人们免予重复打字或复制粘贴,我们可以太轻松的去采集网页上的数 据。此外,这些网路爬虫工具可以使用户就能以有条不紊和快速的抓取网页,而 无需编程并将数据转换为符合其需求的各类格式。在这篇文章中网络爬虫软件下载,我将介绍目前比较流行的 20 款网路爬虫工具供你参考。希望你 能找到最适宜你需求的工具。1. 八爪鱼八爪鱼是一款免费且功能强悍的网站爬虫,用于从网站上提取你须要的几乎所有 类型的数据。你可以使用八爪鱼来采集市面上几乎所有的网站。八爪鱼提供两种精品文档精品文档采集模式 - 简易模式和自定义采集模式,非程序员可以快速习惯使用八爪鱼。 下载免费软件后,其可视化界面容许你从网站上获取所有文本,因此你可以下载 几乎所有网站内容并将其保存为结构化格式,如 EXCEL,TXT,HTML 或你的数 据库。 你可以使用其外置的正则表达式工具从复杂的网站布局中提取许多棘手网站的 数据,并使用 XPath 配置工具精确定位 Web 元素。
另外八爪鱼提供手动辨识验 证码以及代理 IP 切换功能,可以有效的防止网站防采集。 总之,八爪鱼可以满足用户最基本或中级的采集需求,而无需任何编程技能。2. HTTrack作为免费的网站爬虫软件,HTTrack 提供的功能十分适宜从互联网下载整个网站 到你的 PC。它提供了适用于 Windows,Linux,Sun Solaris 和其他 Unix 系统 的版本。它可以将一个站点或多个站点镜像在一起(使用共享链接)。你可以在 “设置选项”下下载网页时决定要同时打开的连接数。你可以从整个目录中获取 照片,文件,HTML 代码,更新当前镜像的网站并恢复中断的下载。精品文档精品文档据悉,HTTTrack 还提供代理支持,以通过可选身分验证最大限度地提升速率。 HTTrack 用作命令行程序,或通过 shell 用于私有(捕获)或专业(在线 Web 镜像)使用。 有了这样的说法,HTTrack 应该是首选,并且具有中级编程技能 的人更多地使用它。3、 ScraperScraper 是 Chrome 扩展程序,具有有限的数据提取功能,但它有助于进行在 线研究并将数据导入到 Google sheets。
此工具适用于初学者以及可以使用 OAuth 轻松将数据复制到剪贴板或储存到电子表格的专家。Scraper 是一个免 费的网路爬虫工具,可以在你的浏览器中正常工作,并手动生成较小的 XPath 来定义要抓取的 URL。4、OutWit Hub精品文档精品文档Outwit Hub 是一个 Firefox 添加件,它有两个目的:搜集信息和管理信息。它 可以分别用在网站上不同的部份提供不同的窗口条。还提供用户一个快速步入信 息的方式,虚拟移除网站上别的部份。 OutWit Hub 提供单一界面,可依照须要抓取微小或大量数据。OutWit Hub 允许你从浏览器本身抓取任何网页,甚至可以创建手动代理来提取数据并按照设 置对其进行低格。 OutWit Hub 大多功能都是免费的,能够深入剖析网站,自动搜集整理组织互联 网中的各项数据,并将网站信息分割开来,然后提取有效信息,形成可用的集合。 但是要手动提取精确数据就须要付费版本了,同时免费版一次提取的数据量也是 有限制的,如果须要大批量的操作,可以选择订购专业版。 5. ParseHub精品文档精品文档Parsehub 是一个太棒的网路爬虫,支持从使用 AJAX 技术,JavaScript,cookie 等的网站收集数据。
它的机器学习技术可以读取,分析之后将 Web 文档转换为 相关数据。 Parsehub 的桌面应用程序支持 Windows,Mac OS X 和 Linux 等系统,或者 你可以使用浏览器中外置的 Web 应用程序。 作为免费软件,你可以在 Parsehub 中设置不超过五个 publice 项目。付费版本 允许你创建起码 20private 项目来抓取网站。6. ScrapinghubScrapinghub 是一种基于云的数据提取工具,可帮助数千名开发人员获取有价 值的数据。它的开源视觉抓取工具,允许用户在没有任何编程知识的情况下抓取 网站。 Scrapinghub 使用 Crawlera,一家代理 IP 第三方平台,支持绕开防采集对策。 它使用户就能从多个 IP 和位置进行网页抓取,而无需通过简单的 HTTP API 进 行代理管理。 Scrapinghub 将整个网页转换为有组织的内容。如果其爬虫工具难以满足你的 要求,其专家团队可以提供帮助。。精品文档精品文档7. Dexi.io作为基于浏览器的网路爬虫,Dexi.io 允许你从任何网站基于浏览器抓取数据, 并提供三种类型的爬虫来创建采集任务。
免费软件为你的网路抓取提供匿名 Web 代理服务器,你提取的数据将在存档数据之前在 Dexi.io 的服务器上托管 两周,或者你可以直接将提取的数据导入到 JSON 或 CSV 文件。它提供付费服 务,以满足你获取实时数据的需求。8. Webhose.ioWebhose.io 使用户才能将来自世界各地的在线资源抓取的实时数据转换为各 种标准的格式。通过此 Web 爬网程序,你可以使用囊括各类来源的多个过滤器 来抓取数据并进一步提取多种语言的关键字。 你可以将删掉的数据保存为 XML,JSON 和 RSS 格式。并且容许用户从其存档 访问历史数据。此外,webhose.io 支持最多 80 种语言及其爬行数据结果。用 户可以轻松索引和搜索 Webhose.io 抓取的结构化数据。精品文档精品文档总的来说,Webhose.io 可以满足用户的基本爬行要求。9.Import.io用户只需从特定网页导出数据并将数据导入到 CSV 即可产生自己的数据集。 你可以在几分钟内轻松抓取数千个网页,而无需编撰任何代码,并按照你的要求 构建 1000 多个 API。公共 API 提供了强悍而灵活的功能来以编程方法控制 Import.io 并获得对数据的手动访问,Import.io 通过将 Web 数据集成到你自己 的应用程序或网站中,只需点击几下就可以轻松实现爬网。
为了更好地满足用户的爬行需求,它还提供适用于 Windows,Mac OS X 和 Linux 的免费应用程序,以建立数据提取器和抓取工具,下载数据并与在线账户 同步。此外,用户还可以每周网络爬虫软件下载,每天或每小时安排抓取任务。10.80legs精品文档精品文档80legs 是一个功能强悍的网路抓取工具,可以按照自定义要求进行配置。它支 持获取大量数据以及立刻下载提取数据的选项。80legs 提供高性能的 Web 爬 行,可以快速工作并在几秒钟内获取所需的数据11. Content GraberContent Graber 是一款面向企业的网路爬行软件。它容许你创建独立的 Web 爬网代理。它可以从几乎任何网站中提取内容,并以你选择的格式将其保存为结 构化数据,包括 Excel 报告,XML,CSV 和大多数数据库。它更适宜具有中级编程技能的人,因为它为有须要的人提供了许多强悍的脚本编 辑和调试界面。允许用户使用 C#或 VB.NET 调试或编撰脚本来编程控制爬网过 程。例如,Content Grabber 可以与 Visual Studio 2013 集成,以便按照用户 的特定需求为中级且机智的自定义爬虫提供最强悍的脚本编辑,调试和单元测 试。
精品文档精品文档12. UiPathUiPath 是一款用于免费网路抓取的机器人过程自动化软件。它可以手动从大多 数第三方应用程序中抓取 Web 和桌面数据。如果运行 Windows 系统,则可以 安装机械手过程自动化软件。Uipath 能够跨多个网页提取表格和基于模式的数 据。 Uipath 提供了用于进一步爬行的外置工具。处理复杂的 UI 时,此方式十分有效。 Screen Scraping Tool 可以处理单个文本元素,文本组和文本块,例如表格格 式的数据提取。 此外,创建智能 Web 代理不需要编程,但你内部的.NET 黑客可以完全控制数 据。精品文档精品文档其实,在里面我提及的爬虫可以满足大多数用户的基本爬行需求,这些工具中各 自的功能依然存在好多差别,大家可以按照自己的需求选择合适的。八爪鱼——90 万用户选择的网页数据采集器。 1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。精品文档精品文档2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。精品文档
网络爬虫技术,为什么说使用Python最合适?请听四星教育讲解
采集交流 • 优采云 发表了文章 • 0 个评论 • 350 次浏览 • 2020-05-07 08:00
但是你晓得Python与其他编程语言最主要的区别吗?
网络爬虫技术人才,一直是被各企业争相抢劫。而网路爬虫主要是用Python来编撰,所以缔造了Python与之不同的地位。
也许会有人指责,难道就不能用其他语言来编撰么?
答案是可以的,像java、c、c++、php都可以做爬虫。但是,我们运用一种语言常常并不是说这个会不会做就可以了,还取决于过程中的运行速率、开发效率、人力成本等不同诱因,最后互相比较一下,Python是最合适的。就好象一份工作,大家都可以去做,但是老总肯定会选择更适宜更经济更有能力的人去做。
在写爬虫的过程中,往往是一边写,一边测试爬虫技术用什么语言,测试不过再改改。这个过程用 python 写上去最方便。并且python 相关的库也是最方便,有 request, jieba, redis,gevent,NLTK, lxml,pyquery爬虫技术用什么语言,BeautifulSoup,Pillow,不论是简单的爬虫还是复杂的爬虫都轻松搞定。
这也是Python的又一大特点,与其他编程语言显著不同。
网络爬虫常常被称为网页追逐者,是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。另外一些不常使用的名子还有蚂蚁、自动索引、模拟程序或则蠕虫。
网络爬虫根据系统结构和实现技术,大致可以分为以下几种类型:通用网路爬虫、聚焦网路爬虫、增量式网路爬虫、深层网路爬虫。
通用网路爬虫又称全网爬虫,爬行对象从一些种子 URL 扩充到整个 Web,主要为门户站点搜索引擎和小型 Web 服务提供商采集数据。
聚焦网路爬虫,是指选择性地爬行这些与预先定义好的主题相关页面的网路爬虫。只须要爬行与主题相关的页面,极大地节约了硬件和网路资源,保存的页面也因为数目少而更新快,还可以挺好地满足一些特定人群对特定领域信息的需求。
增量式网路爬虫,是指对已下载网页采取增量式更新和只爬行新形成的或则早已发生变化网页的爬虫,它还能在一定程度上保证所爬行的页面是尽可能新的页面。
随着互联网的发展,网络爬虫技术在未来10年里,都不会有衰落的现象。人生苦短,我学Python,如果听到此文的你正好不知道学哪些语言,六星教育诚挚推荐Python。
六星教育Python全栈VIP课程,囊括了Python各个方面的知识点,内含基础、高级、进阶、商业项目实战等内容,一站式提供从小白到大鳄课程。 查看全部

但是你晓得Python与其他编程语言最主要的区别吗?
网络爬虫技术人才,一直是被各企业争相抢劫。而网路爬虫主要是用Python来编撰,所以缔造了Python与之不同的地位。
也许会有人指责,难道就不能用其他语言来编撰么?
答案是可以的,像java、c、c++、php都可以做爬虫。但是,我们运用一种语言常常并不是说这个会不会做就可以了,还取决于过程中的运行速率、开发效率、人力成本等不同诱因,最后互相比较一下,Python是最合适的。就好象一份工作,大家都可以去做,但是老总肯定会选择更适宜更经济更有能力的人去做。
在写爬虫的过程中,往往是一边写,一边测试爬虫技术用什么语言,测试不过再改改。这个过程用 python 写上去最方便。并且python 相关的库也是最方便,有 request, jieba, redis,gevent,NLTK, lxml,pyquery爬虫技术用什么语言,BeautifulSoup,Pillow,不论是简单的爬虫还是复杂的爬虫都轻松搞定。
这也是Python的又一大特点,与其他编程语言显著不同。

网络爬虫常常被称为网页追逐者,是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。另外一些不常使用的名子还有蚂蚁、自动索引、模拟程序或则蠕虫。
网络爬虫根据系统结构和实现技术,大致可以分为以下几种类型:通用网路爬虫、聚焦网路爬虫、增量式网路爬虫、深层网路爬虫。
通用网路爬虫又称全网爬虫,爬行对象从一些种子 URL 扩充到整个 Web,主要为门户站点搜索引擎和小型 Web 服务提供商采集数据。
聚焦网路爬虫,是指选择性地爬行这些与预先定义好的主题相关页面的网路爬虫。只须要爬行与主题相关的页面,极大地节约了硬件和网路资源,保存的页面也因为数目少而更新快,还可以挺好地满足一些特定人群对特定领域信息的需求。
增量式网路爬虫,是指对已下载网页采取增量式更新和只爬行新形成的或则早已发生变化网页的爬虫,它还能在一定程度上保证所爬行的页面是尽可能新的页面。
随着互联网的发展,网络爬虫技术在未来10年里,都不会有衰落的现象。人生苦短,我学Python,如果听到此文的你正好不知道学哪些语言,六星教育诚挚推荐Python。
六星教育Python全栈VIP课程,囊括了Python各个方面的知识点,内含基础、高级、进阶、商业项目实战等内容,一站式提供从小白到大鳄课程。
网络爬虫程序员被抓,我们还敢爬虫吗?细数这些Java爬虫技术
采集交流 • 优采云 发表了文章 • 0 个评论 • 417 次浏览 • 2020-05-06 08:04
最近,某大数据科技公司由于涉嫌非法抓取某急聘网站用户的简历信息,公司被查封,负责编撰抓取程序的程序员也将面临入狱。
事情的大约经过是这样的:
某大数据科技公司老总丢给一个小小的程序员一个网站,告诉他把这个网站的数据抓取出来,咱们做一做剖析。这个小小的程序员就吭哧吭哧的写了一段抓取代码,测试了一下网络爬虫技术是什么,程序没问题,可以正常的把这个网站的数据给抓取出来,然后就毫不犹豫的上线了。过了几天,这个小小的程序员发觉抓取的速率有点慢啊,然后他就将1个线程改成10个线程,发布上线,开始抓取,程序跑的没毛病。
过了一段时间,网站主的老总发觉近来网站访问量飙升,并且还常常宕机。然后组织公司程序员排查系统问题,经过排查发觉,系统某一个插口频繁访问,遂怀疑有人恶意功击,于是就报警了。警察通过访问来源IP顺藤摸瓜,查到小小程序员所在的公司,把公司全员200人全部扣押调查,这名小小程序员因为负责抓取程序的编撰,将面临入狱。小小程序员一脸懵逼,我只负责老总交给我的任务,我犯哪些法了?
看了这个新闻,程序员同学还不快点将你的爬虫程序下线,要不下一个抓的就是你,怕不怕?
爬虫技术对于大多数程序员来说一点不陌生,大多数程序员都干过爬虫的事情吧!我记得我刚结业入职的第一家公司我就是负责爬虫的。主要爬取各大院校官网的新闻资讯信息,然后借助这种信息给院校做手机微官网。当然,我们是经过了大多数院校的默认的。
今天我们姑且不论爬虫是否违规,这个问题我们也论不清楚。国内现今这么多做大数据剖析公司,他们可以提供各类数据分,他们的数据是从那里来的?有几家是正当来源?恐怕大多都是爬来的。今天我们细数这些java爬虫技术。
一、Jsoup
的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套特别省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。这也是我最早使用的爬虫技术。
二、HtmlUnit
HtmlUnit是一款java的无界面浏览器程序库。它可以模拟HTML文档,并提供相应的API,允许您调用页面,填写表单,点击链接等操作。它是一种模拟浏览器以用于测试目的的方式。使用HtmlUnit你就觉得你是在操作浏览器,他对于css和js都可以挺好的支持。
三、Selenium
Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等。
Selenium我感觉是最好的爬虫工具了,因为它完全模拟浏览器。由程序掉起浏览器网络爬虫技术是什么,模拟人的操作。关于Selenium在我的文章[Selenium神器!解放测试程序员的右手]有专门讲解。
最后,爬虫有风险,使用需谨慎。希望广大程序员同学在使用爬虫技术的时侯,要有数据隐私的意识。 查看全部

最近,某大数据科技公司由于涉嫌非法抓取某急聘网站用户的简历信息,公司被查封,负责编撰抓取程序的程序员也将面临入狱。

事情的大约经过是这样的:
某大数据科技公司老总丢给一个小小的程序员一个网站,告诉他把这个网站的数据抓取出来,咱们做一做剖析。这个小小的程序员就吭哧吭哧的写了一段抓取代码,测试了一下网络爬虫技术是什么,程序没问题,可以正常的把这个网站的数据给抓取出来,然后就毫不犹豫的上线了。过了几天,这个小小的程序员发觉抓取的速率有点慢啊,然后他就将1个线程改成10个线程,发布上线,开始抓取,程序跑的没毛病。
过了一段时间,网站主的老总发觉近来网站访问量飙升,并且还常常宕机。然后组织公司程序员排查系统问题,经过排查发觉,系统某一个插口频繁访问,遂怀疑有人恶意功击,于是就报警了。警察通过访问来源IP顺藤摸瓜,查到小小程序员所在的公司,把公司全员200人全部扣押调查,这名小小程序员因为负责抓取程序的编撰,将面临入狱。小小程序员一脸懵逼,我只负责老总交给我的任务,我犯哪些法了?
看了这个新闻,程序员同学还不快点将你的爬虫程序下线,要不下一个抓的就是你,怕不怕?
爬虫技术对于大多数程序员来说一点不陌生,大多数程序员都干过爬虫的事情吧!我记得我刚结业入职的第一家公司我就是负责爬虫的。主要爬取各大院校官网的新闻资讯信息,然后借助这种信息给院校做手机微官网。当然,我们是经过了大多数院校的默认的。
今天我们姑且不论爬虫是否违规,这个问题我们也论不清楚。国内现今这么多做大数据剖析公司,他们可以提供各类数据分,他们的数据是从那里来的?有几家是正当来源?恐怕大多都是爬来的。今天我们细数这些java爬虫技术。
一、Jsoup
的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套特别省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。这也是我最早使用的爬虫技术。
二、HtmlUnit
HtmlUnit是一款java的无界面浏览器程序库。它可以模拟HTML文档,并提供相应的API,允许您调用页面,填写表单,点击链接等操作。它是一种模拟浏览器以用于测试目的的方式。使用HtmlUnit你就觉得你是在操作浏览器,他对于css和js都可以挺好的支持。
三、Selenium
Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等。
Selenium我感觉是最好的爬虫工具了,因为它完全模拟浏览器。由程序掉起浏览器网络爬虫技术是什么,模拟人的操作。关于Selenium在我的文章[Selenium神器!解放测试程序员的右手]有专门讲解。
最后,爬虫有风险,使用需谨慎。希望广大程序员同学在使用爬虫技术的时侯,要有数据隐私的意识。
20款最常使用的网路爬虫工具推荐(2018)
采集交流 • 优采云 发表了文章 • 0 个评论 • 455 次浏览 • 2020-05-06 08:04
八爪鱼·云采集网络爬虫软件 20 款最常使用的网路爬虫工具推荐 (2018)网络爬虫在现今的许多领域得到广泛应用。 它的作用是从任何网站获取特定的或 更新的数据并储存出来。 网络爬虫工具越来越为人所熟知,因为网路爬虫简化并 自动化了整个爬取过程, 使每个人都可以轻松访问网站数据资源。使用网路爬虫 工具可以使人们免予重复打字或复制粘贴, 我们可以太轻松的去采集网页上的数 据。此外,这些网路爬虫工具可以使用户就能以有条不紊和快速的抓取网页,而 无需编程并将数据转换为符合其需求的各类格式。在这篇文章中,我将介绍目前比较流行的 20 款网路爬虫工具供你参考。希望你 能找到最适宜你需求的工具。1. 八爪鱼八爪鱼·云采集网络爬虫软件 八爪鱼是一款免费且功能强悍的网站爬虫, 用于从网站上提取你须要的几乎所有 类型的数据。 你可以使用八爪鱼来采集市面上几乎所有的网站。 八爪鱼提供两种 采集模式 - 简易模式和自定义采集模式,非程序员可以快速习惯使用八爪鱼。 下载免费软件后, 其可视化界面容许你从网站上获取所有文本,因此你可以下载 几乎所有网站内容并将其保存为结构化格式,如 EXCEL,TXT,HTML 或你的数 据库。
你可以使用其外置的正则表达式工具从复杂的网站布局中提取许多棘手网站的 数据,并使用 XPath 配置工具精确定位 Web 元素。另外八爪鱼提供手动辨识验 证码以及代理 IP 切换功能,可以有效的防止网站防采集。 总之,八爪鱼可以满足用户最基本或中级的采集需求,而无需任何编程技能。2. HTTrack八爪鱼·云采集网络爬虫软件 作为免费的网站爬虫软件,HTTrack 提供的功能十分适宜从互联网下载整个网站 到你的 PC。它提供了适用于 Windows网站爬虫软件,Linux,Sun Solaris 和其他 Unix 系统 的版本。它可以将一个站点或多个站点镜像在一起(使用共享链接)。你可以在 “设置选项”下下载网页时决定要同时打开的连接数。 你可以从整个目录中获取 照片,文件,HTML 代码,更新当前镜像的网站并恢复中断的下载。此外,HTTTrack 还提供代理支持,以通过可选身分验证最大限度地提升速率。 HTTrack 用作命令行程序,或通过 shell 用于私有(捕获)或专业(在线 Web 镜像)使用。 有了这样的说法,HTTrack 应该是首选,并且具有中级编程技能 的人更多地使用它。3、 Scraper八爪鱼·云采集网络爬虫软件 Scraper 是 Chrome 扩展程序,具有有限的数据提取功能,但它有助于进行在 线研究并将数据导入到 Google sheets 。
此工具适用于初学者以及可以使用 OAuth 轻松将数据复制到剪贴板或储存到电子表格的专家。Scraper 是一个免 费的网路爬虫工具,可以在你的浏览器中正常工作,并手动生成较小的 XPath 来定义要抓取的 URL。4、OutWit Hub八爪鱼·云采集网络爬虫软件 Outwit Hub 是一个 Firefox 添加件,它有两个目的:搜集信息和管理信息。它 可以分别用在网站上不同的部份提供不同的窗口条。 还提供用户一个快速步入信 息的方式,虚拟移除网站上别的部份。 OutWit Hub 提供单一界面,可依照须要抓取微小或大量数据。OutWit Hub 允许你从浏览器本身抓取任何网页, 甚至可以创建手动代理来提取数据并按照设 置对其进行低格。 OutWit Hub 大多功能都是免费的,能够深入剖析网站,自动搜集整理组织互联 网中的各项数据, 并将网站信息分割开来, 然后提取有效信息, 形成可用的集合。 但是要手动提取精确数据就须要付费版本了, 同时免费版一次提取的数据量也是 有限制的,如果须要大批量的操作,可以选择订购专业版。 5. ParseHubParsehub 是一个太棒的网路爬虫, 支持从使用 AJAX 技术, JavaScript, cookie 等的网站收集数据。
它的机器学习技术可以读取,分析之后将 Web 文档转换为 相关数据。八爪鱼·云采集网络爬虫软件 Parsehub 的桌面应用程序支持 Windows,Mac OS X 和 Linux 等系统,或者 你可以使用浏览器中外置的 Web 应用程序。 作为免费软件,你可以在 Parsehub 中设置不超过五个 publice 项目。付费版本 允许你创建起码 20private 项目来抓取网站。6. ScrapinghubScrapinghub 是一种基于云的数据提取工具,可帮助数千名开发人员获取有价 值的数据。 它的开源视觉抓取工具,允许用户在没有任何编程知识的情况下抓取 网站。 Scrapinghub 使用 Crawlera,一家代理 IP 第三方平台,支持绕开防采集对策。 它使用户就能从多个 IP 和位置进行网页抓取,而无需通过简单的 HTTP API 进 行代理管理。 Scrapinghub 将整个网页转换为有组织的内容。如果其爬虫工具难以满足你的 要求,其专家团队可以提供帮助。。八爪鱼·云采集网络爬虫软件 7. Dexi.io作为基于浏览器的网路爬虫,Dexi.io 允许你从任何网站基于浏览器抓取数据, 并提供三种类型的爬虫来创建采集任务。
免费软件为你的网路抓取提供匿名 Web 代理服务器,你提取的数据将在存档数据之前在 Dexi.io 的服务器上托管 两周网站爬虫软件,或者你可以直接将提取的数据导入到 JSON 或 CSV 文件。它提供付费服 务,以满足你获取实时数据的需求。8. Webhose.ioWebhose.io 使用户才能将来自世界各地的在线资源抓取的实时数据转换为各 种标准的格式。通过此 Web 爬网程序,你可以使用囊括各类来源的多个过滤器 来抓取数据并进一步提取多种语言的关键字。八爪鱼·云采集网络爬虫软件 你可以将删掉的数据保存为 XML,JSON 和 RSS 格式。并且容许用户从其存档 访问历史数据。此外,webhose.io 支持最多 80 种语言及其爬行数据结果。用 户可以轻松索引和搜索 Webhose.io 抓取的结构化数据。 总的来说,Webhose.io 可以满足用户的基本爬行要求。9.Import.io用户只需从特定网页导出数据并将数据导入到 CSV 即可产生自己的数据集。 你可以在几分钟内轻松抓取数千个网页,而无需编撰任何代码,并按照你的要求 构建 1000 多个 API。公共 API 提供了强悍而灵活的功能来以编程方法控制 Import.io 并获得对数据的手动访问, Import.io 通过将 Web 数据集成到你自己 的应用程序或网站中,只需点击几下就可以轻松实现爬网。
八爪鱼·云采集网络爬虫软件 为了更好地满足用户的爬行需求,它还提供适用于 Windows,Mac OS X 和 Linux 的免费应用程序,以建立数据提取器和抓取工具,下载数据并与在线账户 同步。此外,用户还可以每周,每天或每小时安排抓取任务。10.80legs80legs 是一个功能强悍的网路抓取工具,可以按照自定义要求进行配置。它支 持获取大量数据以及立刻下载提取数据的选项。80legs 提供高性能的 Web 爬 行,可以快速工作并在几秒钟内获取所需的数据11. Content Graber八爪鱼·云采集网络爬虫软件 Content Graber 是一款面向企业的网路爬行软件。它容许你创建独立的 Web 爬网代理。 它可以从几乎任何网站中提取内容,并以你选择的格式将其保存为结 构化数据,包括 Excel 报告,XML,CSV 和大多数数据库。 它更适宜具有中级编程技能的人, 因为它为有须要的人提供了许多强悍的脚本编 辑和调试界面。 允许用户使用 C#或 VB.NET 调试或编撰脚本来编程控制爬网过 程。例如,Content Grabber 可以与 Visual Studio 2013 集成,以便按照用户 的特定需求为中级且机智的自定义爬虫提供最强悍的脚本编辑,调试和单元测 试。
12. UiPath八爪鱼·云采集网络爬虫软件 UiPath 是一款用于免费网路抓取的机器人过程自动化软件。它可以手动从大多 数第三方应用程序中抓取 Web 和桌面数据。如果运行 Windows 系统,则可以 安装机械手过程自动化软件。Uipath 能够跨多个网页提取表格和基于模式的数 据。 Uipath 提供了用于进一步爬行的外置工具。 处理复杂的 UI 时, 此方式十分有效。 Screen Scraping Tool 可以处理单个文本元素,文本组和文本块,例如表格格 式的数据提取。 此外,创建智能 Web 代理不需要编程,但你内部的.NET 黑客可以完全控制数 据。八爪鱼·云采集网络爬虫软件 总之, 在里面我提及的爬虫可以满足大多数用户的基本爬行需求,这些工具中各 自的功能依然存在好多差别,大家可以按照自己的需求选择合适的。八爪鱼——90 万用户选择的网页数据采集器。 1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。 查看全部

八爪鱼·云采集网络爬虫软件 20 款最常使用的网路爬虫工具推荐 (2018)网络爬虫在现今的许多领域得到广泛应用。 它的作用是从任何网站获取特定的或 更新的数据并储存出来。 网络爬虫工具越来越为人所熟知,因为网路爬虫简化并 自动化了整个爬取过程, 使每个人都可以轻松访问网站数据资源。使用网路爬虫 工具可以使人们免予重复打字或复制粘贴, 我们可以太轻松的去采集网页上的数 据。此外,这些网路爬虫工具可以使用户就能以有条不紊和快速的抓取网页,而 无需编程并将数据转换为符合其需求的各类格式。在这篇文章中,我将介绍目前比较流行的 20 款网路爬虫工具供你参考。希望你 能找到最适宜你需求的工具。1. 八爪鱼八爪鱼·云采集网络爬虫软件 八爪鱼是一款免费且功能强悍的网站爬虫, 用于从网站上提取你须要的几乎所有 类型的数据。 你可以使用八爪鱼来采集市面上几乎所有的网站。 八爪鱼提供两种 采集模式 - 简易模式和自定义采集模式,非程序员可以快速习惯使用八爪鱼。 下载免费软件后, 其可视化界面容许你从网站上获取所有文本,因此你可以下载 几乎所有网站内容并将其保存为结构化格式,如 EXCEL,TXT,HTML 或你的数 据库。
你可以使用其外置的正则表达式工具从复杂的网站布局中提取许多棘手网站的 数据,并使用 XPath 配置工具精确定位 Web 元素。另外八爪鱼提供手动辨识验 证码以及代理 IP 切换功能,可以有效的防止网站防采集。 总之,八爪鱼可以满足用户最基本或中级的采集需求,而无需任何编程技能。2. HTTrack八爪鱼·云采集网络爬虫软件 作为免费的网站爬虫软件,HTTrack 提供的功能十分适宜从互联网下载整个网站 到你的 PC。它提供了适用于 Windows网站爬虫软件,Linux,Sun Solaris 和其他 Unix 系统 的版本。它可以将一个站点或多个站点镜像在一起(使用共享链接)。你可以在 “设置选项”下下载网页时决定要同时打开的连接数。 你可以从整个目录中获取 照片,文件,HTML 代码,更新当前镜像的网站并恢复中断的下载。此外,HTTTrack 还提供代理支持,以通过可选身分验证最大限度地提升速率。 HTTrack 用作命令行程序,或通过 shell 用于私有(捕获)或专业(在线 Web 镜像)使用。 有了这样的说法,HTTrack 应该是首选,并且具有中级编程技能 的人更多地使用它。3、 Scraper八爪鱼·云采集网络爬虫软件 Scraper 是 Chrome 扩展程序,具有有限的数据提取功能,但它有助于进行在 线研究并将数据导入到 Google sheets 。
此工具适用于初学者以及可以使用 OAuth 轻松将数据复制到剪贴板或储存到电子表格的专家。Scraper 是一个免 费的网路爬虫工具,可以在你的浏览器中正常工作,并手动生成较小的 XPath 来定义要抓取的 URL。4、OutWit Hub八爪鱼·云采集网络爬虫软件 Outwit Hub 是一个 Firefox 添加件,它有两个目的:搜集信息和管理信息。它 可以分别用在网站上不同的部份提供不同的窗口条。 还提供用户一个快速步入信 息的方式,虚拟移除网站上别的部份。 OutWit Hub 提供单一界面,可依照须要抓取微小或大量数据。OutWit Hub 允许你从浏览器本身抓取任何网页, 甚至可以创建手动代理来提取数据并按照设 置对其进行低格。 OutWit Hub 大多功能都是免费的,能够深入剖析网站,自动搜集整理组织互联 网中的各项数据, 并将网站信息分割开来, 然后提取有效信息, 形成可用的集合。 但是要手动提取精确数据就须要付费版本了, 同时免费版一次提取的数据量也是 有限制的,如果须要大批量的操作,可以选择订购专业版。 5. ParseHubParsehub 是一个太棒的网路爬虫, 支持从使用 AJAX 技术, JavaScript, cookie 等的网站收集数据。
它的机器学习技术可以读取,分析之后将 Web 文档转换为 相关数据。八爪鱼·云采集网络爬虫软件 Parsehub 的桌面应用程序支持 Windows,Mac OS X 和 Linux 等系统,或者 你可以使用浏览器中外置的 Web 应用程序。 作为免费软件,你可以在 Parsehub 中设置不超过五个 publice 项目。付费版本 允许你创建起码 20private 项目来抓取网站。6. ScrapinghubScrapinghub 是一种基于云的数据提取工具,可帮助数千名开发人员获取有价 值的数据。 它的开源视觉抓取工具,允许用户在没有任何编程知识的情况下抓取 网站。 Scrapinghub 使用 Crawlera,一家代理 IP 第三方平台,支持绕开防采集对策。 它使用户就能从多个 IP 和位置进行网页抓取,而无需通过简单的 HTTP API 进 行代理管理。 Scrapinghub 将整个网页转换为有组织的内容。如果其爬虫工具难以满足你的 要求,其专家团队可以提供帮助。。八爪鱼·云采集网络爬虫软件 7. Dexi.io作为基于浏览器的网路爬虫,Dexi.io 允许你从任何网站基于浏览器抓取数据, 并提供三种类型的爬虫来创建采集任务。
免费软件为你的网路抓取提供匿名 Web 代理服务器,你提取的数据将在存档数据之前在 Dexi.io 的服务器上托管 两周网站爬虫软件,或者你可以直接将提取的数据导入到 JSON 或 CSV 文件。它提供付费服 务,以满足你获取实时数据的需求。8. Webhose.ioWebhose.io 使用户才能将来自世界各地的在线资源抓取的实时数据转换为各 种标准的格式。通过此 Web 爬网程序,你可以使用囊括各类来源的多个过滤器 来抓取数据并进一步提取多种语言的关键字。八爪鱼·云采集网络爬虫软件 你可以将删掉的数据保存为 XML,JSON 和 RSS 格式。并且容许用户从其存档 访问历史数据。此外,webhose.io 支持最多 80 种语言及其爬行数据结果。用 户可以轻松索引和搜索 Webhose.io 抓取的结构化数据。 总的来说,Webhose.io 可以满足用户的基本爬行要求。9.Import.io用户只需从特定网页导出数据并将数据导入到 CSV 即可产生自己的数据集。 你可以在几分钟内轻松抓取数千个网页,而无需编撰任何代码,并按照你的要求 构建 1000 多个 API。公共 API 提供了强悍而灵活的功能来以编程方法控制 Import.io 并获得对数据的手动访问, Import.io 通过将 Web 数据集成到你自己 的应用程序或网站中,只需点击几下就可以轻松实现爬网。
八爪鱼·云采集网络爬虫软件 为了更好地满足用户的爬行需求,它还提供适用于 Windows,Mac OS X 和 Linux 的免费应用程序,以建立数据提取器和抓取工具,下载数据并与在线账户 同步。此外,用户还可以每周,每天或每小时安排抓取任务。10.80legs80legs 是一个功能强悍的网路抓取工具,可以按照自定义要求进行配置。它支 持获取大量数据以及立刻下载提取数据的选项。80legs 提供高性能的 Web 爬 行,可以快速工作并在几秒钟内获取所需的数据11. Content Graber八爪鱼·云采集网络爬虫软件 Content Graber 是一款面向企业的网路爬行软件。它容许你创建独立的 Web 爬网代理。 它可以从几乎任何网站中提取内容,并以你选择的格式将其保存为结 构化数据,包括 Excel 报告,XML,CSV 和大多数数据库。 它更适宜具有中级编程技能的人, 因为它为有须要的人提供了许多强悍的脚本编 辑和调试界面。 允许用户使用 C#或 VB.NET 调试或编撰脚本来编程控制爬网过 程。例如,Content Grabber 可以与 Visual Studio 2013 集成,以便按照用户 的特定需求为中级且机智的自定义爬虫提供最强悍的脚本编辑,调试和单元测 试。
12. UiPath八爪鱼·云采集网络爬虫软件 UiPath 是一款用于免费网路抓取的机器人过程自动化软件。它可以手动从大多 数第三方应用程序中抓取 Web 和桌面数据。如果运行 Windows 系统,则可以 安装机械手过程自动化软件。Uipath 能够跨多个网页提取表格和基于模式的数 据。 Uipath 提供了用于进一步爬行的外置工具。 处理复杂的 UI 时, 此方式十分有效。 Screen Scraping Tool 可以处理单个文本元素,文本组和文本块,例如表格格 式的数据提取。 此外,创建智能 Web 代理不需要编程,但你内部的.NET 黑客可以完全控制数 据。八爪鱼·云采集网络爬虫软件 总之, 在里面我提及的爬虫可以满足大多数用户的基本爬行需求,这些工具中各 自的功能依然存在好多差别,大家可以按照自己的需求选择合适的。八爪鱼——90 万用户选择的网页数据采集器。 1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。
通俗的讲,网络爬虫到底是什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 289 次浏览 • 2020-05-06 08:03
爬虫的起源可以溯源到万维网(互联网)诞生之初,一开始互联网还没有搜索。在搜索引擎没有被开发之前,互联网只是文件传输协议(FTP)站点的集合,用户可以在这种站点中导航以找到特定的共享文件。
为了查找和组合互联网上可用的分布式数据,人们创建了一个自动化程序,称为网络爬虫/机器人,可以抓取互联网上的所有网页,然后将所有页面上的内容复制到数据库中制做索引。
爬虫的发展
随着互联网的发展,网络上的资源显得愈发丰富但却粗疏不堪,信息的获取成本显得更高了。
相应地,也渐渐发展出愈发智能,且适用性更强的爬虫软件。
它们类似于蜘蛛通过幅射出去的蛛网来获取信息,继而从中捕获到它想要的猎物,所以爬虫也被称为网页蜘蛛,当然相较蛛网而言,爬虫软件更具主动性。另外,爬虫还有一些不常用的名子,像蚂蚁/模拟程序/蠕虫。
爬虫的工作流程大致如下:
通常,爬取网页数据时,只须要2个步骤:
打开网页→将具体的数据从网页中复制并导入到表格或资源库中。
简单来说就是,抓取和复制。
爬虫的君子合同
搜索引擎的爬虫是善意的,可以检索你的一切信息,并提供给其他用户访问,为此它们还专门定义了robots.txt文件,作为君子合同。
Robots协议(爬虫协议)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎什么页面可以抓取,哪些页面不能抓取。该合同是国际互联网界通行的道德规范,虽然没有写入法律,但是每一个爬虫都应当遵循这项合同。
以淘宝网的robots.txt为例,
以 Allow 项的值开头的 URL 是容许 robot 访问的。例如,Allow:/article 允许百度爬虫引擎访问 /article.htm、/article/http://12345.com 等。
以 Disallow 项为开头的链接是不容许百度爬虫引擎访问的。例如,Disallow:/product/ 不容许百度爬虫引擎访问 /product/http://12345.com 等。
最后一行,Disallow:/ 禁止百度爬虫访问不仅 Allow 规定页面外的其他所有页面。
所以你是不能从百度上搜索到淘宝内部的产品信息的。
君子合同虽好,然而事情很快就被一些人破坏了,于是就有了反爬虫。
爬虫与反爬虫
爬虫与反爬虫是“矛”与“盾”的攻防关系,有了爬虫自然也就有了反爬虫。
一些企业为了保证服务器的正常运转,降低服务器的运转压力与成本,不得不使出各种各样的手段来制止爬虫工程师毫无节制地向服务器索要资源,这种行为我们称之为反爬虫。
在爬虫与反爬虫的对决上,一些反爬手段往往会使人津津乐道,比如,文本混淆反爬虫、动态渲染反爬虫、信息校准反爬虫、代码混淆反爬虫……等等。
反爬虫技术是怎样对爬虫进行防御的,其实现原理是哪些?以下就以信息校准反爬为例,请《鹿鼎记》的韦香主给你们做一下演示。
假设天地会赤火堂香主派人从京城抵达南京将一封特别重要的密函交给青木堂香主韦小宝,我们可以将这件事具象为下图:
这件事的核心是「帮派成员-甲将重要密函交给帮会成员-乙」。假设乙、乙双方互不相恋亦未曾有过会面,那「帮派成员-甲」如何判定密函交给了「帮派成员-乙」,而不是给错人——给了其他「帮派成员-丁」呢?
在历史实践中肯定喝过这样的亏爬虫软件是什么,遂天地会采用了接头暗号这些方法来确保乙、乙双方是同一帮会成员,这才有了:
暗号只有帮会成员才晓得,且不可泄露。甲、乙双方碰面时由「帮派成员-甲」说出「地乡高岗,一派溪山千古秀」,「帮派成员-乙」听到后必须接下一句「门朝大海,三河合水万年流」。如果「帮派成员-乙」不知道下一句是哪些,或者胡扯一气,那么「帮派成员-甲」就可以判断他不是接头人,而是假扮的。
同样的,「帮派成员-乙」要看到帮会成员-甲说出「地乡高岗,一派溪山千古秀」。否则「帮派成员-甲」就是假扮的,很有可能会将假的密函交给青木堂韦小宝。
天地会接头人相互传递消息(密函)很象是我们在开发 WEB 应用时的 Client 和 Server,抽象地看起来象这样:
那么问题来了,Client 和 Server 之间需不需要天地会这样的暗号呢?
答案是须要!
Client 就像「帮派成员-甲」,Server 就像「帮派成员-乙」,而她们的密函很有可能会被其他「帮派成员-丁」拿走或伪造。既然天地会有接头暗号,那么 Client 和 Server 之间用哪些来保障传递消息是第一手发出,而不是被拦截伪造的呢?
没错,签名验证!
签名验证是目前 IT 技术领域应用广泛的 API 接口数据保护方法之一,它还能有效避免消息接收端将被篡改或伪造的消息当成正常消息处理。
要注意的是,它的作用是避免消息接收端将被篡改或伪造的消息当成正常消息处理,而不是避免消息接受端接收假消息,事实上插口在收到消息的那一刻难以判定消息的真伪。这一点十分重要爬虫软件是什么,千万不要混淆了。
假设 Client 要将「下个月 5 号暗杀鳌拜」这封重要密函交给 Server,抽象图如下:
这时候倘若发生假扮风波,会带来哪些影响:
其他「帮派成员-丁」从 Client 那里获得消息后进行了伪造,将暗杀鳌拜的时间从 5 号改为 6号,导致 Server 收到的暗杀时间是 6 号。这么一来,里应外合暗杀鳌拜的事都会弄成一方延后动手,这次筹谋已久的暗杀行动大几率会失败,而且会导致不小的损失。
我们使用签名验证来改善这个消息传递和验证的事。这里可以简单将签名验证理解为在原消息的基础上进行一定规则的运算和加密,最终将加密结果放在消息中一并发送,消息接收者领到消息后根据相同的规则进行运算和加密,将自己运算得到的加密值和传递过来的加密值进行比对,如果两值相同则代表消息没有被拦截伪造,反之可以判断消息被拦截伪造。
签名验证被广泛应用,例如下载操作系统镜像文件时官方网站会提供文件的 MD5 值、阿里巴巴/腾讯/华为等企业对外开放的插口中信令部份的 sign 值等。
以上反爬方式选自《Python3 反爬虫原理与绕开实战》
写在最后
爬虫本身并未违背法律。但程序运行过程中可能对别人经营网站造成破坏,爬取的数据有可能涉及隐私或绝密,数据本身也可能形成法律纠纷。
【编辑推荐】
拒绝低效!Python教你爬虫公众号文章和链接5分钟撸了个小小爬虫....重点来了,Python网站爬虫原理!瓜子,矿泉水备好,慢慢品!我花 1 分钟写了一段爬虫,帮助小姐姐解放了右手怎样用 100 行 Python 代码实现新闻爬虫?这样可算成功? 查看全部
爬虫的起源
爬虫的起源可以溯源到万维网(互联网)诞生之初,一开始互联网还没有搜索。在搜索引擎没有被开发之前,互联网只是文件传输协议(FTP)站点的集合,用户可以在这种站点中导航以找到特定的共享文件。
为了查找和组合互联网上可用的分布式数据,人们创建了一个自动化程序,称为网络爬虫/机器人,可以抓取互联网上的所有网页,然后将所有页面上的内容复制到数据库中制做索引。

爬虫的发展
随着互联网的发展,网络上的资源显得愈发丰富但却粗疏不堪,信息的获取成本显得更高了。
相应地,也渐渐发展出愈发智能,且适用性更强的爬虫软件。
它们类似于蜘蛛通过幅射出去的蛛网来获取信息,继而从中捕获到它想要的猎物,所以爬虫也被称为网页蜘蛛,当然相较蛛网而言,爬虫软件更具主动性。另外,爬虫还有一些不常用的名子,像蚂蚁/模拟程序/蠕虫。
爬虫的工作流程大致如下:
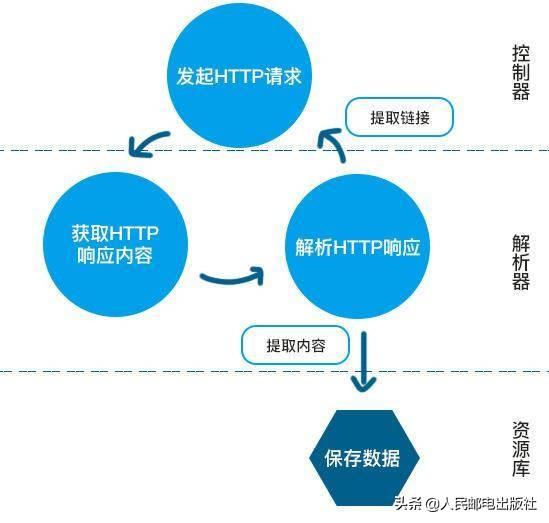
通常,爬取网页数据时,只须要2个步骤:
打开网页→将具体的数据从网页中复制并导入到表格或资源库中。
简单来说就是,抓取和复制。
爬虫的君子合同
搜索引擎的爬虫是善意的,可以检索你的一切信息,并提供给其他用户访问,为此它们还专门定义了robots.txt文件,作为君子合同。
Robots协议(爬虫协议)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎什么页面可以抓取,哪些页面不能抓取。该合同是国际互联网界通行的道德规范,虽然没有写入法律,但是每一个爬虫都应当遵循这项合同。
以淘宝网的robots.txt为例,

以 Allow 项的值开头的 URL 是容许 robot 访问的。例如,Allow:/article 允许百度爬虫引擎访问 /article.htm、/article/http://12345.com 等。
以 Disallow 项为开头的链接是不容许百度爬虫引擎访问的。例如,Disallow:/product/ 不容许百度爬虫引擎访问 /product/http://12345.com 等。
最后一行,Disallow:/ 禁止百度爬虫访问不仅 Allow 规定页面外的其他所有页面。
所以你是不能从百度上搜索到淘宝内部的产品信息的。
君子合同虽好,然而事情很快就被一些人破坏了,于是就有了反爬虫。
爬虫与反爬虫
爬虫与反爬虫是“矛”与“盾”的攻防关系,有了爬虫自然也就有了反爬虫。
一些企业为了保证服务器的正常运转,降低服务器的运转压力与成本,不得不使出各种各样的手段来制止爬虫工程师毫无节制地向服务器索要资源,这种行为我们称之为反爬虫。
在爬虫与反爬虫的对决上,一些反爬手段往往会使人津津乐道,比如,文本混淆反爬虫、动态渲染反爬虫、信息校准反爬虫、代码混淆反爬虫……等等。
反爬虫技术是怎样对爬虫进行防御的,其实现原理是哪些?以下就以信息校准反爬为例,请《鹿鼎记》的韦香主给你们做一下演示。

假设天地会赤火堂香主派人从京城抵达南京将一封特别重要的密函交给青木堂香主韦小宝,我们可以将这件事具象为下图:
这件事的核心是「帮派成员-甲将重要密函交给帮会成员-乙」。假设乙、乙双方互不相恋亦未曾有过会面,那「帮派成员-甲」如何判定密函交给了「帮派成员-乙」,而不是给错人——给了其他「帮派成员-丁」呢?
在历史实践中肯定喝过这样的亏爬虫软件是什么,遂天地会采用了接头暗号这些方法来确保乙、乙双方是同一帮会成员,这才有了:
暗号只有帮会成员才晓得,且不可泄露。甲、乙双方碰面时由「帮派成员-甲」说出「地乡高岗,一派溪山千古秀」,「帮派成员-乙」听到后必须接下一句「门朝大海,三河合水万年流」。如果「帮派成员-乙」不知道下一句是哪些,或者胡扯一气,那么「帮派成员-甲」就可以判断他不是接头人,而是假扮的。
同样的,「帮派成员-乙」要看到帮会成员-甲说出「地乡高岗,一派溪山千古秀」。否则「帮派成员-甲」就是假扮的,很有可能会将假的密函交给青木堂韦小宝。
天地会接头人相互传递消息(密函)很象是我们在开发 WEB 应用时的 Client 和 Server,抽象地看起来象这样:

那么问题来了,Client 和 Server 之间需不需要天地会这样的暗号呢?
答案是须要!
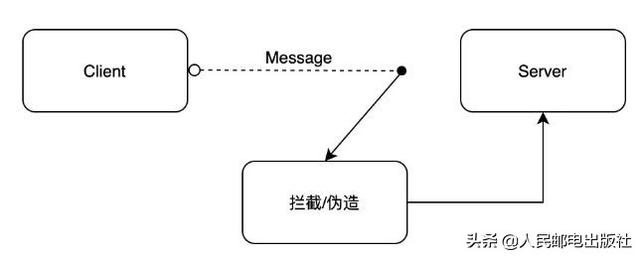
Client 就像「帮派成员-甲」,Server 就像「帮派成员-乙」,而她们的密函很有可能会被其他「帮派成员-丁」拿走或伪造。既然天地会有接头暗号,那么 Client 和 Server 之间用哪些来保障传递消息是第一手发出,而不是被拦截伪造的呢?
没错,签名验证!
签名验证是目前 IT 技术领域应用广泛的 API 接口数据保护方法之一,它还能有效避免消息接收端将被篡改或伪造的消息当成正常消息处理。
要注意的是,它的作用是避免消息接收端将被篡改或伪造的消息当成正常消息处理,而不是避免消息接受端接收假消息,事实上插口在收到消息的那一刻难以判定消息的真伪。这一点十分重要爬虫软件是什么,千万不要混淆了。
假设 Client 要将「下个月 5 号暗杀鳌拜」这封重要密函交给 Server,抽象图如下:
这时候倘若发生假扮风波,会带来哪些影响:
其他「帮派成员-丁」从 Client 那里获得消息后进行了伪造,将暗杀鳌拜的时间从 5 号改为 6号,导致 Server 收到的暗杀时间是 6 号。这么一来,里应外合暗杀鳌拜的事都会弄成一方延后动手,这次筹谋已久的暗杀行动大几率会失败,而且会导致不小的损失。
我们使用签名验证来改善这个消息传递和验证的事。这里可以简单将签名验证理解为在原消息的基础上进行一定规则的运算和加密,最终将加密结果放在消息中一并发送,消息接收者领到消息后根据相同的规则进行运算和加密,将自己运算得到的加密值和传递过来的加密值进行比对,如果两值相同则代表消息没有被拦截伪造,反之可以判断消息被拦截伪造。
签名验证被广泛应用,例如下载操作系统镜像文件时官方网站会提供文件的 MD5 值、阿里巴巴/腾讯/华为等企业对外开放的插口中信令部份的 sign 值等。
以上反爬方式选自《Python3 反爬虫原理与绕开实战》
写在最后
爬虫本身并未违背法律。但程序运行过程中可能对别人经营网站造成破坏,爬取的数据有可能涉及隐私或绝密,数据本身也可能形成法律纠纷。
【编辑推荐】
拒绝低效!Python教你爬虫公众号文章和链接5分钟撸了个小小爬虫....重点来了,Python网站爬虫原理!瓜子,矿泉水备好,慢慢品!我花 1 分钟写了一段爬虫,帮助小姐姐解放了右手怎样用 100 行 Python 代码实现新闻爬虫?这样可算成功?
从零开始学Python网络爬虫中文pdf完整版[144MB]
采集交流 • 优采云 发表了文章 • 0 个评论 • 321 次浏览 • 2020-05-06 08:02
本书共分12章,核心主题包括Python零基础句型入门、爬虫原理和网页构造、我的第一个爬虫程序、正则表达式、Lxml库与Xpath句型、使用API、数据库储存、多进程爬虫、异步加载、表单交互与模拟登陆、Selenium模拟浏览器、Scrapy爬虫框架。此外,书中通过一些典型爬虫案例数据挖掘爬虫书籍,讲解了有经纬信息的地图图表和词云的制做方式,让读者体验数据背后的乐趣。
本书适宜爬虫技术初学者、爱好者及高等院校的相关中学生,也适宜数据爬虫工程师作为参考读物,同时也适宜各大Python数据剖析的培训机构作为教材使用
第1章 Python零基础句型入门 1
第2章 爬虫原理和网页构造 17
第3章 我的第一个爬虫程序 26
第4章 正则表达式 45
第5章 Lxml库与Xpath句型 63
第6章 使用API 88
第7章 数据库储存 109
第8章 多进程爬虫 139
第9章 异步加载 159
第10章 表单交互与模拟登陆 182
第11章 Selenium模拟浏览器 209
第12章 Scrapy爬虫框架 229 查看全部
本书共分12章,核心主题包括Python零基础句型入门、爬虫原理和网页构造、我的第一个爬虫程序、正则表达式、Lxml库与Xpath句型、使用API、数据库储存、多进程爬虫、异步加载、表单交互与模拟登陆、Selenium模拟浏览器、Scrapy爬虫框架。此外,书中通过一些典型爬虫案例数据挖掘爬虫书籍,讲解了有经纬信息的地图图表和词云的制做方式,让读者体验数据背后的乐趣。
本书适宜爬虫技术初学者、爱好者及高等院校的相关中学生,也适宜数据爬虫工程师作为参考读物,同时也适宜各大Python数据剖析的培训机构作为教材使用
第1章 Python零基础句型入门 1
第2章 爬虫原理和网页构造 17
第3章 我的第一个爬虫程序 26
第4章 正则表达式 45
第5章 Lxml库与Xpath句型 63
第6章 使用API 88
第7章 数据库储存 109
第8章 多进程爬虫 139
第9章 异步加载 159
第10章 表单交互与模拟登陆 182
第11章 Selenium模拟浏览器 209
第12章 Scrapy爬虫框架 229
邮箱采集软件那个好?怎么使用?
采集交流 • 优采云 发表了文章 • 0 个评论 • 692 次浏览 • 2020-05-12 08:04
(cookie 有效时间以具体情况为准,到一定时间会失效,失效 需重新登陆获取 cookie,另外假如是点击头像(电脑登入的)需要把之前的点 击头像登陆的点击元素删掉)八爪鱼·云采集网络爬虫软件 邮箱采集软件使用步骤 4步骤 3:Ajax 点击登陆后,选择须要采集的 QQ 群,然后在右边的提示框中选择“点击该元素”八爪鱼·云采集网络爬虫软件 邮箱采集软件使用步骤 5因为网页涉及 Ajax 技术。 所以须要选中点击元素, 打开 “高级选项” , 勾选 “Ajax 加载数据”,设置时间为“15 秒”。执行前等待设置 7 秒, 因为页面打开后需 要向上滑动才可以出现更多内容,所以还须要设置页面滚动,滚动次数选择 20 次,(滚动次数具体看群成员的数目,如果 500 个人,一般来说选择 25 次能全 部加载完)每次间隔 1 秒,完成后,点击“确定”。八爪鱼·云采集网络爬虫软件 邮箱采集软件使用步骤 6步骤 4:提取元素1)选择第一个 QQ 号码,然后在右边的提示框中选择“选中全部”,随后选择 “采集元素”。八爪鱼·云采集网络爬虫软件 邮箱采集软件使用步骤 7步骤 5:修改 Xpath1) 手动执行规则, 发现循环列表里并没有定位到所有元素, 所以须要更改 xpath, 在循环形式中选择不固定元素列表,修改 xpath 为 //tbody[@class="list"]/tr八爪鱼·云采集网络爬虫软件 邮箱采集软件使用步骤 82)因为提取到的数据是 QQ 号邮箱爬虫软件,所以要更改一下,转化成邮箱 选中 QQ 号数组→点击中级选项中自定义数据字段(如下图)→格式化数据→八爪鱼·云采集网络爬虫软件 邮箱采集软件使用步骤 9添加步骤→添加后缀八爪鱼·云采集网络爬虫软件 邮箱采集软件使用步骤 103)修改完成之后,点击确定,效果如下图八爪鱼·云采集网络爬虫软件 邮箱采集软件使用步骤 11步骤 5:QQ 邮箱数据采集及导入1)打开流程按键,修改采集字段名称,点击“保存并开始采集”八爪鱼·云采集网络爬虫软件 邮箱采集软件使用步骤 12启动本地采集八爪鱼·云采集网络爬虫软件 邮箱采集软件使用步骤 13采集完成后,会跳出提示,选择“导出数据”选择“合适的导入方法”,将采集 好的数据导入这儿我们选择 excel 作为导入为格式,数据导入后如下图八爪鱼·云采集网络爬虫软件 邮箱采集软件使用步骤 14相关采集教程:黄页 88 企业名录采集方法 顺企网企业黄页采集详细步骤 114 黄页企业信息采集详细教程步骤 企业信息采集软件 八爪鱼·云采集网络爬虫软件 使用八爪鱼采集天眼查企业信息 企查查企业邮箱采集 帖吧邮箱采集 八爪鱼——90 万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。 查看全部
八爪鱼·云采集网络爬虫软件 邮箱采集软件那个好?怎么使用?电子邮件营销是常见的一种形式,有时候你有了一个极佳的电子邮件方案,希望 通过发送电子邮件获得大量用户转化,但是在邮箱搜集上假如只是随便的去弄, 肯定疗效不会挺好的。 所以邮箱采集是一个十分重要的步骤,如何去采集精准的 客户邮箱是每位电子邮件营销人员应当考虑的事情。 下面为你们推荐一款电邮采 集软件,可以依照自己的需求,自定义的采集网页上的邮箱,从而达到精准的目 的。本教程以采集 QQ 邮箱为例,介绍该软件的使用方式,其它情况下的邮箱也是 一样配置规则,进行采集。采集网站:步骤 1:创建 QQ 邮箱采集任务1)进入主界面,选择“自定义采集”八爪鱼·云采集网络爬虫软件 邮箱采集软件使用步骤 12)将要采集的网站 URL 复制粘贴到输入框中,点击“保存网址”八爪鱼·云采集网络爬虫软件 邮箱采集软件使用步骤 2步骤 2:Cookie 登录1)打开网页后,需要先登入,可以先在手机登陆 QQ, 采集时点击登陆按键邮箱爬虫软件,之 后扫码就可以成功登陆。或者笔记本登陆,点击二维码一侧的头像进行登陆。八爪鱼·云采集网络爬虫软件 邮箱采集软件使用步骤 32) 登陆后, 在中级选项中选择自定义 cookie, 勾选打开网页时使用固定 cookie, 再点击获取当前页面 cookie,最后点击“确定”,这样之后再采集时就不用重 复登陆 QQ 了。
(cookie 有效时间以具体情况为准,到一定时间会失效,失效 需重新登陆获取 cookie,另外假如是点击头像(电脑登入的)需要把之前的点 击头像登陆的点击元素删掉)八爪鱼·云采集网络爬虫软件 邮箱采集软件使用步骤 4步骤 3:Ajax 点击登陆后,选择须要采集的 QQ 群,然后在右边的提示框中选择“点击该元素”八爪鱼·云采集网络爬虫软件 邮箱采集软件使用步骤 5因为网页涉及 Ajax 技术。 所以须要选中点击元素, 打开 “高级选项” , 勾选 “Ajax 加载数据”,设置时间为“15 秒”。执行前等待设置 7 秒, 因为页面打开后需 要向上滑动才可以出现更多内容,所以还须要设置页面滚动,滚动次数选择 20 次,(滚动次数具体看群成员的数目,如果 500 个人,一般来说选择 25 次能全 部加载完)每次间隔 1 秒,完成后,点击“确定”。八爪鱼·云采集网络爬虫软件 邮箱采集软件使用步骤 6步骤 4:提取元素1)选择第一个 QQ 号码,然后在右边的提示框中选择“选中全部”,随后选择 “采集元素”。八爪鱼·云采集网络爬虫软件 邮箱采集软件使用步骤 7步骤 5:修改 Xpath1) 手动执行规则, 发现循环列表里并没有定位到所有元素, 所以须要更改 xpath, 在循环形式中选择不固定元素列表,修改 xpath 为 //tbody[@class="list"]/tr八爪鱼·云采集网络爬虫软件 邮箱采集软件使用步骤 82)因为提取到的数据是 QQ 号邮箱爬虫软件,所以要更改一下,转化成邮箱 选中 QQ 号数组→点击中级选项中自定义数据字段(如下图)→格式化数据→八爪鱼·云采集网络爬虫软件 邮箱采集软件使用步骤 9添加步骤→添加后缀八爪鱼·云采集网络爬虫软件 邮箱采集软件使用步骤 103)修改完成之后,点击确定,效果如下图八爪鱼·云采集网络爬虫软件 邮箱采集软件使用步骤 11步骤 5:QQ 邮箱数据采集及导入1)打开流程按键,修改采集字段名称,点击“保存并开始采集”八爪鱼·云采集网络爬虫软件 邮箱采集软件使用步骤 12启动本地采集八爪鱼·云采集网络爬虫软件 邮箱采集软件使用步骤 13采集完成后,会跳出提示,选择“导出数据”选择“合适的导入方法”,将采集 好的数据导入这儿我们选择 excel 作为导入为格式,数据导入后如下图八爪鱼·云采集网络爬虫软件 邮箱采集软件使用步骤 14相关采集教程:黄页 88 企业名录采集方法 顺企网企业黄页采集详细步骤 114 黄页企业信息采集详细教程步骤 企业信息采集软件 八爪鱼·云采集网络爬虫软件 使用八爪鱼采集天眼查企业信息 企查查企业邮箱采集 帖吧邮箱采集 八爪鱼——90 万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。
[读后笔记] python网路爬虫实战 (李松涛)
采集交流 • 优采云 发表了文章 • 0 个评论 • 341 次浏览 • 2020-05-12 08:03
用了大约一个晚上的时间,就把这本书看完了。
前面4章是基础的python知识,有基础的朋友可以略过。
scrapy爬虫部份,用了实例给你们说明scrapy的用法网络爬虫实例,不过若果之前没用过scrapy的话,需要渐渐上机敲击代码。
其实书中的事例都是很简单的事例,基本没哪些反爬的限制,书中一句话说的十分赞成,用scrapy写爬虫,就是做填空题,而用urllib2写爬虫,就是习作题,可以自由发挥。
书中没有用更为便捷的requests库。 内容搜索用的最多的是beatifulsoup, 对于xpah或则lxml介绍的比较少。 因为scrapy自带的response就是可以直接用xpath,更为便捷。
对于scrapy的中间和pipeline的使用了一个事例,也是比较简单的反例。
书中没有对验证码,分布式等流行的反爬进行讲解,应该适宜爬虫入门的朋友去看吧。
书中一点挺好的就是代码都十分规范,而且虽然是写习作的使用urllib2,也有意模仿scrapy的框架去写, 需要抓取的数据 独立一个类,类似于scrapy的item,数据处理用的也是叫pipleline的方式。
这样写的益处就是, 每个模块的功能都一目了然,看完第一个反例的类和函数定义,后面的事例都是大同小异,可以推动读者的阅读速率,非常赞。(这一点之后自己要学习,增加代码的可复用性)
很多页面url如今早已过期了,再次运行作者的源码会返回好多404的结果。
失效的项目:
金逸影城
天气预报
获取代理:
本书的一些错误的地方:
1. 获取金逸影厅的spider中,所有关于movie的拼写都拼错为moive了。这个属于德语错误。
2. 在testProxy.py 代码中网络爬虫实例, 由于在同一个类中,一直在形成线程,最后造成线程过多,不能再形成线程。程序会中途退出。
File "C:\Python27\lib\threading.py", line 736, in start<br />
_start_new_thread(self.__bootstrap, ())<br />
thread.error: can't start new thread
可以更改成独立函数的方式,而不是类函数。
待续。 查看全部
用了大约一个晚上的时间,就把这本书看完了。
前面4章是基础的python知识,有基础的朋友可以略过。
scrapy爬虫部份,用了实例给你们说明scrapy的用法网络爬虫实例,不过若果之前没用过scrapy的话,需要渐渐上机敲击代码。
其实书中的事例都是很简单的事例,基本没哪些反爬的限制,书中一句话说的十分赞成,用scrapy写爬虫,就是做填空题,而用urllib2写爬虫,就是习作题,可以自由发挥。
书中没有用更为便捷的requests库。 内容搜索用的最多的是beatifulsoup, 对于xpah或则lxml介绍的比较少。 因为scrapy自带的response就是可以直接用xpath,更为便捷。
对于scrapy的中间和pipeline的使用了一个事例,也是比较简单的反例。
书中没有对验证码,分布式等流行的反爬进行讲解,应该适宜爬虫入门的朋友去看吧。
书中一点挺好的就是代码都十分规范,而且虽然是写习作的使用urllib2,也有意模仿scrapy的框架去写, 需要抓取的数据 独立一个类,类似于scrapy的item,数据处理用的也是叫pipleline的方式。
这样写的益处就是, 每个模块的功能都一目了然,看完第一个反例的类和函数定义,后面的事例都是大同小异,可以推动读者的阅读速率,非常赞。(这一点之后自己要学习,增加代码的可复用性)
很多页面url如今早已过期了,再次运行作者的源码会返回好多404的结果。
失效的项目:
金逸影城
天气预报
获取代理:
本书的一些错误的地方:
1. 获取金逸影厅的spider中,所有关于movie的拼写都拼错为moive了。这个属于德语错误。
2. 在testProxy.py 代码中网络爬虫实例, 由于在同一个类中,一直在形成线程,最后造成线程过多,不能再形成线程。程序会中途退出。
File "C:\Python27\lib\threading.py", line 736, in start<br />
_start_new_thread(self.__bootstrap, ())<br />
thread.error: can't start new thread
可以更改成独立函数的方式,而不是类函数。
待续。
Java 网络爬虫基础入门
采集交流 • 优采云 发表了文章 • 0 个评论 • 254 次浏览 • 2020-05-11 08:03
作为网路爬虫的入门教程,本达人课采用 Java 开发语言java爬虫教程入门超级,内容涵括了网路爬虫的原理以及开发逻辑,Java 网络爬虫基础知识,网络抓包介绍,jsoup 的介绍与使用,HttpClient 的介绍与使用等内容。本课程在介绍网路爬虫基本原理的同时,注重具体的代码实现,加深读者对爬虫的理解,加强读者的实战能力。
本达人课共计14课,主要包含五大部份。
第一部分(第01-03课),主要介绍网路爬虫的原理、开发逻辑以及 Java 网络爬虫基础知识,网络抓包等内容。
第二部份(第04-06课),主要介绍现有的一些页面内容获取及页面解析工具。包括 jsoup、HttpClient、URLConnection。
第三部份(第07-08课),针对已获得的页面内容java爬虫教程入门超级,带你们选择合适的解析工具进行页面解析,包括 HTML、XML、JSON 主流数据格式的解析。
第四部份(第09-11课),针对已解析的内容,介绍怎么封装数据并储存数据。包括通过 MySQL 数据库储存数据,以及文本文件储存和 Excel 格式储存。
第五部份(第12-14课),以典型网站为案例,开启实战演练。
钱洋,机器学习方向博士生,CSDN 博客专家,主要从事文本挖掘方面的研究。目前,正参与几个大数据相关项目的研究工作。乐于分享自己的经验,擅长撰写技术类博客。 查看全部
大数据环境下,数据剖析已由业务驱动转变为数据驱动,网络数据资源呈指数级下降,且洒落在不同的数据源之中。对大多数企业和研究者而言,用“数据说话”仿佛成了大数据时代的重要装备。网络爬虫作为网路数据获取的重要技术,受到了越来越多数据需求者的偏爱和青睐。
作为网路爬虫的入门教程,本达人课采用 Java 开发语言java爬虫教程入门超级,内容涵括了网路爬虫的原理以及开发逻辑,Java 网络爬虫基础知识,网络抓包介绍,jsoup 的介绍与使用,HttpClient 的介绍与使用等内容。本课程在介绍网路爬虫基本原理的同时,注重具体的代码实现,加深读者对爬虫的理解,加强读者的实战能力。
本达人课共计14课,主要包含五大部份。
第一部分(第01-03课),主要介绍网路爬虫的原理、开发逻辑以及 Java 网络爬虫基础知识,网络抓包等内容。
第二部份(第04-06课),主要介绍现有的一些页面内容获取及页面解析工具。包括 jsoup、HttpClient、URLConnection。
第三部份(第07-08课),针对已获得的页面内容java爬虫教程入门超级,带你们选择合适的解析工具进行页面解析,包括 HTML、XML、JSON 主流数据格式的解析。
第四部份(第09-11课),针对已解析的内容,介绍怎么封装数据并储存数据。包括通过 MySQL 数据库储存数据,以及文本文件储存和 Excel 格式储存。
第五部份(第12-14课),以典型网站为案例,开启实战演练。
钱洋,机器学习方向博士生,CSDN 博客专家,主要从事文本挖掘方面的研究。目前,正参与几个大数据相关项目的研究工作。乐于分享自己的经验,擅长撰写技术类博客。
网络爬虫技术的定义与反爬虫方法剖析
采集交流 • 优采云 发表了文章 • 0 个评论 • 449 次浏览 • 2020-05-11 08:03
有很多人觉得Web应该一直秉持开放的精神,呈现在页面中的信息应该毫无保留地分享给整个互联网。然而我觉得,在IT行业发展至明天,Web早已不再是当初那种和PDF一争高下的所谓“超文本”信息载体了,它早已是以一种轻量级客户端软件的意识形态的存在了。而商业软件发展到明天,Web也不得不面对知识产权保护的问题,试想假如原创的高质量内容得不到保护,抄袭和盗版横行网路世界,这显然对Web生态的良性发展是不利的,也很难鼓励更多的优质原创内容的生产。
未授权的爬虫抓取程序是害处Web原创内容生态的一大诱因,因此要保护网站的内容,首先就要考虑怎样反爬虫。
从爬虫的攻守角度来讲
最简单的爬虫,是几乎所有服务端、客户端编程语言都支持的http恳求,只要向目标页面的url发起一个http get恳求,即可获得到浏览器加载这个页面时的完整html文档,这被我们称之为“同步页”。
作为逼抢的一方,服务端可以按照http请求头中的User-Agent来检测客户端是否是一个合法的浏览器程序,亦或是一个脚本编撰的抓取程序,从而决定是否将真实的页面信息内容下发给你。
这其实是最小儿科的防御手段,爬虫作为逼抢的一方,完全可以伪造User-Agent数组,甚至,只要你乐意,http的get方式里, request header的 Referrer 、 Cookie 等等所有数组爬虫都可以轻而易举的伪造。
此时服务端可以借助浏览器http头指纹,根据你申明的自己的浏览器厂商和版本(来自 User-Agent ),来分辨你的http header中的各个数组是否符合该浏览器的特点,如不符合则作为爬虫程序对待。这个技术有一个典型的应用,就是PhantomJS1.x版本中,由于其底层调用了Qt框架的网路库,因此http头里有显著的Qt框架网路恳求的特点,可以被服务端直接辨识并拦截。
除此之外,还有一种愈发变态的服务端爬虫检查机制,就是对所有访问页面的http请求,在 http response 中种下一个 cookie token ,然后在这个页面内异步执行的一些ajax插口里去校准来访恳求是否富含cookie token,将token回传回去则表明这是一个合法的浏览器来访,否则说明刚才被下发了那种token的用户访问了页面html却没有访问html内执行js后调用的ajax恳求,很有可能是一个爬虫程序。
如果你不携带token直接访问一个插口,这也就意味着你没恳求过html页面直接向本应由页面内ajax访问的插口发起了网路恳求,这也似乎证明了你是一个可疑的爬虫。知名电商网站amazon就是采用的这些防御策略。
以上则是基于服务端校准爬虫程序,可以玩出的一些套路手段。
基于客户端js运行时的测量
现代浏览器赋于了强悍的能力,因此我们可以把页面的所有核心内容都弄成js异步恳求 ajax 获取数据后渲染在页面中的,这也许提升了爬虫抓取内容的门槛。依靠这些方法,我们把对抓取与反抓取的对抗战场从服务端转移到了客户端浏览器中的js运行时,接下来说一说结合客户端js运行时的爬虫抓取技术。
刚刚提到的各类服务端校准,对于普通的python、java语言编撰的http抓取程序而言,具有一定的技术门槛,毕竟一个web应用对于未授权抓取者而言是黑盒的,很多东西须要一点一点去尝试,而耗费大量人力物力开发好的一套抓取程序,web站作为逼抢一方只要轻易调整一些策略,攻击者就须要再度耗费同等的时间去更改爬虫抓取逻辑。
此时就须要使用headless browser了,这是哪些技术呢?其实说白了就是,让程序可以操作浏览器去访问网页,这样编撰爬虫的人可以通过调用浏览器曝露下来给程序调用的api去实现复杂的抓取业务逻辑。
其实近些年来这早已不算是哪些新鲜的技术了,从前有基于webkit内核的PhantomJS,基于Firefox浏览器内核的SlimerJS,甚至基于IE内核的trifleJS,有兴趣可以瞧瞧这儿和这儿 是两个headless browser的搜集列表。
这些headless browser程序实现的原理虽然是把开源的一些浏览器内核C++++代码加以整修和封装,实现一个简易的无GUI界面渲染的browser程序。但这种项目普遍存在的问题是,由于她们的代码基于fork官方webkit等内核的某一个版本的主干代码,因此难以跟进一些最新的css属性和js句型,并且存在一些兼容性的问题,不如真正的release版GUI浏览器。
这其中最为成熟、使用率最高的应当当属PhantonJS了,对这些爬虫的辨识我之前曾写过一篇博客,这里不再赘言。PhantomJS存在众多问题,因为是单进程模型,没有必要的沙箱保护,浏览器内核的安全性较差。
如今Google Chrome团队在chrome 59 release版本中开放了headless mode api,并开源了一个基于Node.js调用的headless chromium dirver库,我也为这个库贡献了一个centos环境的布署依赖安装列表。
headless chrome堪称是headless browser中独树一帜的大杀器,由于其自身就是一个chrome浏览器,因此支持各类新的css渲染特点和js运行时句型。
基于这样的手段,爬虫作为逼抢的一方可以绕开几乎所有服务端校准逻辑,但是这种爬虫在客户端的js运行时中仍然存在着一些纰漏,诸如:
基于plugin对象的检测
基于language的检测
基于webgl的检测
基于浏览器hairline特点的检测
基于错误img src属性生成的img对象的检测
基于以上的一些浏览器特点的判定,基本可以通杀市面上大多数headless browser程序。在这一点上,实际上是将网页抓取的门槛提升,要求编撰爬虫程序的开发者不得不更改浏览器内核的C++代码,重新编译一个浏览器,并且,以上几点特点是对浏览器内核的改动虽然并不小。
更进一步,我们还可以基于浏览器的UserAgent数组描述的浏览器品牌、版本机型信息,对js运行时、DOM和BOM的各个原生对象的属性及技巧进行检验,观察其特点是否符合该版本的浏览器所应具备的特点。
这种方法被称为浏览器指纹检测技术,依托于小型web站对各机型浏览器api信息的搜集。而作为编撰爬虫程序的逼抢一方,则可以在headless browser运行时里预注入一些js逻辑,伪造浏览器的特点。
另外,在研究浏览器端借助js api进行robots browser detect时网络爬虫 技术,我们发觉了一个有趣的小技巧,你可以把一个预注入的js函数,伪装成一个native function,来瞧瞧下边代码:
爬虫进攻方可能会预注入一些js方式,把原生的一些api外边包装一层proxy function作为hook,然后再用这个假的js api去覆盖原生api。如果防御者在对此做检测判定时是基于把函数toString以后对[native code]的检测,那么都会被绕开。所以须要更严格的检测,因为bind(null)伪造的方式,在toString以后是不带函数名的。
反爬虫的手炮
目前的反抓取、机器人检测手段,最可靠的还是验证码技术。但验证码并不意味着一定要逼迫用户输入一连串字母数字,也有好多基于用户键盘、触屏(移动端)等行为的行为验证技术,这其中最为成熟的当属Google reCAPTCHA。
基于以上众多对用户与爬虫的辨识分辨技术,网站的防御方最终要做的是封禁ip地址或是对这个ip的来访用户施以高硬度的验证码策略。这样一来,进攻方不得不订购ip代理池来抓取网站信息内容,否则单个ip地址很容易被封造成难以抓取。抓取与反抓取的门槛被提升到了ip代理池经济费用的层面。
机器人协议
除此之外,在爬虫抓取技术领域还有一个“白道”的手段,叫做robots协议。你可以在一个网站的根目录下访问/robots.txt,比如使我们一起来瞧瞧github的机器人合同,Allow和Disallow申明了对各个UA爬虫的抓取授权。
不过,这只是一个君子合同,虽具有法律效益,但只能够限制这些商业搜索引擎的蜘蛛程序,你没法对这些“野爬爱好者”加以限制。
写在最后
对网页内容的抓取与反制,注定是一个魔高一尺道高一丈的猫鼠游戏,你永远不可能以某一种技术彻底封死爬虫程序的街网络爬虫 技术,你能做的只是增强攻击者的抓取成本,并对于未授权的抓取行为做到较为精确的据悉。 查看全部
Web是一个开放的平台,这也奠定了Web从90年代初诞生直到明日将近30年来蓬勃的发展。然而,正所谓成也萧何败也萧何,开放的特型、搜索引擎以及简单易学的HTML、CSS技术促使Web成为了互联网领域里最为流行和成熟的信息传播媒介;但现在作为商业化软件,Web这个平台上的内容信息的版权却毫无保证,因为相比软件客户端而言,你的网页中的内容可以被太低成本、很低的技术门槛实现出的一些抓取程序获取到,这也就是这一系列文章将要阐述的话题——网络爬虫。
有很多人觉得Web应该一直秉持开放的精神,呈现在页面中的信息应该毫无保留地分享给整个互联网。然而我觉得,在IT行业发展至明天,Web早已不再是当初那种和PDF一争高下的所谓“超文本”信息载体了,它早已是以一种轻量级客户端软件的意识形态的存在了。而商业软件发展到明天,Web也不得不面对知识产权保护的问题,试想假如原创的高质量内容得不到保护,抄袭和盗版横行网路世界,这显然对Web生态的良性发展是不利的,也很难鼓励更多的优质原创内容的生产。
未授权的爬虫抓取程序是害处Web原创内容生态的一大诱因,因此要保护网站的内容,首先就要考虑怎样反爬虫。
从爬虫的攻守角度来讲
最简单的爬虫,是几乎所有服务端、客户端编程语言都支持的http恳求,只要向目标页面的url发起一个http get恳求,即可获得到浏览器加载这个页面时的完整html文档,这被我们称之为“同步页”。
作为逼抢的一方,服务端可以按照http请求头中的User-Agent来检测客户端是否是一个合法的浏览器程序,亦或是一个脚本编撰的抓取程序,从而决定是否将真实的页面信息内容下发给你。
这其实是最小儿科的防御手段,爬虫作为逼抢的一方,完全可以伪造User-Agent数组,甚至,只要你乐意,http的get方式里, request header的 Referrer 、 Cookie 等等所有数组爬虫都可以轻而易举的伪造。
此时服务端可以借助浏览器http头指纹,根据你申明的自己的浏览器厂商和版本(来自 User-Agent ),来分辨你的http header中的各个数组是否符合该浏览器的特点,如不符合则作为爬虫程序对待。这个技术有一个典型的应用,就是PhantomJS1.x版本中,由于其底层调用了Qt框架的网路库,因此http头里有显著的Qt框架网路恳求的特点,可以被服务端直接辨识并拦截。
除此之外,还有一种愈发变态的服务端爬虫检查机制,就是对所有访问页面的http请求,在 http response 中种下一个 cookie token ,然后在这个页面内异步执行的一些ajax插口里去校准来访恳求是否富含cookie token,将token回传回去则表明这是一个合法的浏览器来访,否则说明刚才被下发了那种token的用户访问了页面html却没有访问html内执行js后调用的ajax恳求,很有可能是一个爬虫程序。
如果你不携带token直接访问一个插口,这也就意味着你没恳求过html页面直接向本应由页面内ajax访问的插口发起了网路恳求,这也似乎证明了你是一个可疑的爬虫。知名电商网站amazon就是采用的这些防御策略。
以上则是基于服务端校准爬虫程序,可以玩出的一些套路手段。
基于客户端js运行时的测量
现代浏览器赋于了强悍的能力,因此我们可以把页面的所有核心内容都弄成js异步恳求 ajax 获取数据后渲染在页面中的,这也许提升了爬虫抓取内容的门槛。依靠这些方法,我们把对抓取与反抓取的对抗战场从服务端转移到了客户端浏览器中的js运行时,接下来说一说结合客户端js运行时的爬虫抓取技术。
刚刚提到的各类服务端校准,对于普通的python、java语言编撰的http抓取程序而言,具有一定的技术门槛,毕竟一个web应用对于未授权抓取者而言是黑盒的,很多东西须要一点一点去尝试,而耗费大量人力物力开发好的一套抓取程序,web站作为逼抢一方只要轻易调整一些策略,攻击者就须要再度耗费同等的时间去更改爬虫抓取逻辑。
此时就须要使用headless browser了,这是哪些技术呢?其实说白了就是,让程序可以操作浏览器去访问网页,这样编撰爬虫的人可以通过调用浏览器曝露下来给程序调用的api去实现复杂的抓取业务逻辑。
其实近些年来这早已不算是哪些新鲜的技术了,从前有基于webkit内核的PhantomJS,基于Firefox浏览器内核的SlimerJS,甚至基于IE内核的trifleJS,有兴趣可以瞧瞧这儿和这儿 是两个headless browser的搜集列表。
这些headless browser程序实现的原理虽然是把开源的一些浏览器内核C++++代码加以整修和封装,实现一个简易的无GUI界面渲染的browser程序。但这种项目普遍存在的问题是,由于她们的代码基于fork官方webkit等内核的某一个版本的主干代码,因此难以跟进一些最新的css属性和js句型,并且存在一些兼容性的问题,不如真正的release版GUI浏览器。
这其中最为成熟、使用率最高的应当当属PhantonJS了,对这些爬虫的辨识我之前曾写过一篇博客,这里不再赘言。PhantomJS存在众多问题,因为是单进程模型,没有必要的沙箱保护,浏览器内核的安全性较差。
如今Google Chrome团队在chrome 59 release版本中开放了headless mode api,并开源了一个基于Node.js调用的headless chromium dirver库,我也为这个库贡献了一个centos环境的布署依赖安装列表。
headless chrome堪称是headless browser中独树一帜的大杀器,由于其自身就是一个chrome浏览器,因此支持各类新的css渲染特点和js运行时句型。
基于这样的手段,爬虫作为逼抢的一方可以绕开几乎所有服务端校准逻辑,但是这种爬虫在客户端的js运行时中仍然存在着一些纰漏,诸如:
基于plugin对象的检测
基于language的检测
基于webgl的检测
基于浏览器hairline特点的检测
基于错误img src属性生成的img对象的检测
基于以上的一些浏览器特点的判定,基本可以通杀市面上大多数headless browser程序。在这一点上,实际上是将网页抓取的门槛提升,要求编撰爬虫程序的开发者不得不更改浏览器内核的C++代码,重新编译一个浏览器,并且,以上几点特点是对浏览器内核的改动虽然并不小。
更进一步,我们还可以基于浏览器的UserAgent数组描述的浏览器品牌、版本机型信息,对js运行时、DOM和BOM的各个原生对象的属性及技巧进行检验,观察其特点是否符合该版本的浏览器所应具备的特点。
这种方法被称为浏览器指纹检测技术,依托于小型web站对各机型浏览器api信息的搜集。而作为编撰爬虫程序的逼抢一方,则可以在headless browser运行时里预注入一些js逻辑,伪造浏览器的特点。
另外,在研究浏览器端借助js api进行robots browser detect时网络爬虫 技术,我们发觉了一个有趣的小技巧,你可以把一个预注入的js函数,伪装成一个native function,来瞧瞧下边代码:
爬虫进攻方可能会预注入一些js方式,把原生的一些api外边包装一层proxy function作为hook,然后再用这个假的js api去覆盖原生api。如果防御者在对此做检测判定时是基于把函数toString以后对[native code]的检测,那么都会被绕开。所以须要更严格的检测,因为bind(null)伪造的方式,在toString以后是不带函数名的。
反爬虫的手炮
目前的反抓取、机器人检测手段,最可靠的还是验证码技术。但验证码并不意味着一定要逼迫用户输入一连串字母数字,也有好多基于用户键盘、触屏(移动端)等行为的行为验证技术,这其中最为成熟的当属Google reCAPTCHA。
基于以上众多对用户与爬虫的辨识分辨技术,网站的防御方最终要做的是封禁ip地址或是对这个ip的来访用户施以高硬度的验证码策略。这样一来,进攻方不得不订购ip代理池来抓取网站信息内容,否则单个ip地址很容易被封造成难以抓取。抓取与反抓取的门槛被提升到了ip代理池经济费用的层面。
机器人协议
除此之外,在爬虫抓取技术领域还有一个“白道”的手段,叫做robots协议。你可以在一个网站的根目录下访问/robots.txt,比如使我们一起来瞧瞧github的机器人合同,Allow和Disallow申明了对各个UA爬虫的抓取授权。
不过,这只是一个君子合同,虽具有法律效益,但只能够限制这些商业搜索引擎的蜘蛛程序,你没法对这些“野爬爱好者”加以限制。
写在最后
对网页内容的抓取与反制,注定是一个魔高一尺道高一丈的猫鼠游戏,你永远不可能以某一种技术彻底封死爬虫程序的街网络爬虫 技术,你能做的只是增强攻击者的抓取成本,并对于未授权的抓取行为做到较为精确的据悉。
python网络爬虫书籍推荐
采集交流 • 优采云 发表了文章 • 0 个评论 • 370 次浏览 • 2020-05-11 08:02
Python3网路爬虫开发实战
书籍介绍:
《Python3网络爬虫开发实战》介绍了怎样借助Python 3开发网络爬虫,书中首先介绍了环境配置和基础知识,然后讨论了urllib、requests、正则表达式、Beautiful Soup、XPath、pyquery、数据储存、Ajax数据爬取等内容,接着通过多个案例介绍了不同场景下怎样实现数据爬取,后介绍了pyspider框架、Scrapy框架和分布式爬虫。
作者介绍:
崔庆才,北京航空航天大学硕士,静觅博客()博主,爬虫博文访问量已过百万,喜欢钻研,热爱生活,乐于分享。欢迎关注个人微信公众号“进击的Coder”。
下载地址:
《Python网路数据采集》
书籍介绍:
《Python网路数据采集》采用简约强悍的Python语言网络爬虫技术书籍,介绍了网路数据采集,并为采集新式网路中的各类数据类型提供了全面的指导。第一部分重点介绍网路数据采集的基本原理:如何用Python从网路服务器恳求信息,如何对服务器的响应进行基本处理,以及怎样以自动化手段与网站进行交互。第二部份介绍怎样用网络爬虫测试网站,自动化处理,以及怎样通过更多的形式接入网路。
下载地址:
《从零开始学Python网络爬虫》
书籍介绍:
《从零开始学Python网络爬虫》是一本教初学者学习怎么爬取网路数据和信息的入门读物。书中除了有Python的相关内容,而且还有数据处理和数据挖掘等方面的内容。本书内容十分实用,讲解时穿插了22个爬虫实战案例,可以大大增强读者的实际动手能力。
本书共分12章,核心主题包括Python零基础句型入门、爬虫原理和网页构造、我的第一个爬虫程序、正则表达式、Lxml库与Xpath句型、使用API、数据库储存、多进程爬虫、异步加载、表单交互与模拟登陆、Selenium模拟浏览器、Scrapy爬虫框架。此外,书中通过一些典型爬虫案例,讲解了有经纬信息的地图图表和词云的制做方式,让读者体验数据背后的乐趣。
下载地址:
图解 HTTP
书籍介绍:
《图解 HTTP》对互联网基盘——HTTP协议进行了全面系统的介绍。作者由HTTP合同的发展历史娓娓道来,严谨细致地分析了HTTP合同的结构,列举众多常见通讯场景及实战案例网络爬虫技术书籍,最后延展到Web安全、最新技术动向等方面。本书的特色为在讲解的同时,辅以大量生动形象的通讯图例,更好地帮助读者深刻理解HTTP通讯过程中客户端与服务器之间的交互情况。读者可通过本书快速了解并把握HTTP协议的基础,前端工程师剖析抓包数据,后端工程师实现REST API、实现自己的HTTP服务器等过程中所需的HTTP相关知识点本书均有介绍。
下载地址:
《精通Python网路爬虫 核心技术、框架与项目实战》
书籍介绍:
本书从系统化的视角,为这些想学习Python网路爬虫或则正在研究Python网路爬虫的朋友们提供了一个全面的参考,让读者可以系统地学习Python网路爬虫的方方面面,在理解并把握了本书的实例以后,能够独立编撰出自己的Python网路爬虫项目,并且还能胜任Python网路爬虫工程师相关岗位的工作。
同时,本书的另一个目的是,希望可以给大数据或则数据挖掘方向的从业者一定的参考,以帮助那些读者从海量的互联网信息中爬取须要的数据。所谓巧妇难为无米之炊,有了这种数据以后,从事大数据或则数据挖掘方向工作的读者就可以进行后续的剖析处理了。
本书的主要内容和特色
本书是一本系统介绍Python网络爬虫的书籍,全书讲求实战,涵盖网路爬虫原理、如何手写Python网络爬虫、如何使用Scrapy框架编撰网路爬虫项目等关于Python网络爬虫的方方面面。
本书的主要特色如下:
系统讲解Python网络爬虫的编撰方式,体系清晰。
结合实战,让读者才能从零开始把握网路爬虫的基本原理,学会编撰Python网络爬虫以及Scrapy爬虫项目,从而编写出通用爬虫及聚焦爬虫,并把握常见网站的爬虫反屏蔽手段。
下载地址:
边境之旅下载 查看全部
Python3网路爬虫开发实战
书籍介绍:
《Python3网络爬虫开发实战》介绍了怎样借助Python 3开发网络爬虫,书中首先介绍了环境配置和基础知识,然后讨论了urllib、requests、正则表达式、Beautiful Soup、XPath、pyquery、数据储存、Ajax数据爬取等内容,接着通过多个案例介绍了不同场景下怎样实现数据爬取,后介绍了pyspider框架、Scrapy框架和分布式爬虫。
作者介绍:
崔庆才,北京航空航天大学硕士,静觅博客()博主,爬虫博文访问量已过百万,喜欢钻研,热爱生活,乐于分享。欢迎关注个人微信公众号“进击的Coder”。
下载地址:
《Python网路数据采集》
书籍介绍:
《Python网路数据采集》采用简约强悍的Python语言网络爬虫技术书籍,介绍了网路数据采集,并为采集新式网路中的各类数据类型提供了全面的指导。第一部分重点介绍网路数据采集的基本原理:如何用Python从网路服务器恳求信息,如何对服务器的响应进行基本处理,以及怎样以自动化手段与网站进行交互。第二部份介绍怎样用网络爬虫测试网站,自动化处理,以及怎样通过更多的形式接入网路。
下载地址:
《从零开始学Python网络爬虫》
书籍介绍:
《从零开始学Python网络爬虫》是一本教初学者学习怎么爬取网路数据和信息的入门读物。书中除了有Python的相关内容,而且还有数据处理和数据挖掘等方面的内容。本书内容十分实用,讲解时穿插了22个爬虫实战案例,可以大大增强读者的实际动手能力。
本书共分12章,核心主题包括Python零基础句型入门、爬虫原理和网页构造、我的第一个爬虫程序、正则表达式、Lxml库与Xpath句型、使用API、数据库储存、多进程爬虫、异步加载、表单交互与模拟登陆、Selenium模拟浏览器、Scrapy爬虫框架。此外,书中通过一些典型爬虫案例,讲解了有经纬信息的地图图表和词云的制做方式,让读者体验数据背后的乐趣。
下载地址:
图解 HTTP
书籍介绍:
《图解 HTTP》对互联网基盘——HTTP协议进行了全面系统的介绍。作者由HTTP合同的发展历史娓娓道来,严谨细致地分析了HTTP合同的结构,列举众多常见通讯场景及实战案例网络爬虫技术书籍,最后延展到Web安全、最新技术动向等方面。本书的特色为在讲解的同时,辅以大量生动形象的通讯图例,更好地帮助读者深刻理解HTTP通讯过程中客户端与服务器之间的交互情况。读者可通过本书快速了解并把握HTTP协议的基础,前端工程师剖析抓包数据,后端工程师实现REST API、实现自己的HTTP服务器等过程中所需的HTTP相关知识点本书均有介绍。
下载地址:
《精通Python网路爬虫 核心技术、框架与项目实战》
书籍介绍:
本书从系统化的视角,为这些想学习Python网路爬虫或则正在研究Python网路爬虫的朋友们提供了一个全面的参考,让读者可以系统地学习Python网路爬虫的方方面面,在理解并把握了本书的实例以后,能够独立编撰出自己的Python网路爬虫项目,并且还能胜任Python网路爬虫工程师相关岗位的工作。
同时,本书的另一个目的是,希望可以给大数据或则数据挖掘方向的从业者一定的参考,以帮助那些读者从海量的互联网信息中爬取须要的数据。所谓巧妇难为无米之炊,有了这种数据以后,从事大数据或则数据挖掘方向工作的读者就可以进行后续的剖析处理了。
本书的主要内容和特色
本书是一本系统介绍Python网络爬虫的书籍,全书讲求实战,涵盖网路爬虫原理、如何手写Python网络爬虫、如何使用Scrapy框架编撰网路爬虫项目等关于Python网络爬虫的方方面面。
本书的主要特色如下:
系统讲解Python网络爬虫的编撰方式,体系清晰。
结合实战,让读者才能从零开始把握网路爬虫的基本原理,学会编撰Python网络爬虫以及Scrapy爬虫项目,从而编写出通用爬虫及聚焦爬虫,并把握常见网站的爬虫反屏蔽手段。
下载地址:
边境之旅下载
浅谈网络爬虫及其发展趋势
采集交流 • 优采云 发表了文章 • 0 个评论 • 332 次浏览 • 2020-05-11 08:02
随着的发展壮大,人们获取信息的途径渐渐被网路所代替。互联网发展早期,人们主要通过浏览门户网站的方法获取所需信息,但是随着Web的飞速发展, 用这些方法找寻自己所需信息显得越来越困难。目前,人们大多通过搜索引擎获取有用信息网络爬虫 技术,因此,搜索引擎技术的发展将直接影响人们获取所需信息的速率和质量。
1994 年世界上第一个网络检索工具Web Crawler 问世, 目前较流行的搜索引擎有、、Yahoo、Info seek、Inktomi、Teoma、Live Search 等。出于商业机密的考虑,现在各个搜索引擎使用的Crawler 系统的技术黑幕通常都不公开,现有的文献资料也仅限于概要性介绍。随着网路信息资源呈指数级下降及网路信息资源动态变化,传统的搜索引擎提供的信息检索服务已难以满足人们愈加下降的对个性化服务的需求,正面临着巨大的挑战。以何种策略访问网路,提高搜索效率,已成为近些年来专业搜索引擎研究的主要问题之一。
1、搜索引擎分类
搜索引擎按其形式主要分为全文搜索引擎、目录索引类搜索引擎和元搜索引擎三种。
1.1 全文搜索引擎
全文搜索引擎是名副其实的搜索引擎,通过从互联网上提取的各个网站信息(以网页文字为主)而构建的中,检索与用户查询条件匹配的相关记录,然后按一定的排列次序将结果返回给用户。
全文搜索引擎又可细分为两种:a)拥有自己的检索程序(Indexer),俗称“蜘蛛”(Spider)程序或“机器人”(Robot)程序,自建网页数据库,搜索结果直接从自身的数据库中调用。b)租用其他引擎的数据库,按自定的格式排列搜索结果。
1.2 目录索引型搜索引擎
与全文搜索引擎不同的是,目录索引型搜索引擎的索引数据库是由编辑人员人工构建上去的,这些编辑人员在访问过某个Web 站点后,根据一套自定的衡量标准及主观印象作出对该站点的描述,并按照站点的内容和性质将其归为一个预先分好的类别,分门别类地储存在相应的目录中。用户在查询时,可以通过关键词搜索,也可以按分类目录逐层检索。
因为目录索引型的索引数据库是借助人工来评价一个网站的内容,所以用户从目录搜索到的结果常常比全文检索到的结果更具有参考价值。实际上,目前好多的搜索网站都同时提供目录和全文搜索的搜索服务,尽可能为用户提供全面的查询结果。
1.3 元搜索引擎
元搜索引擎是将用户递交的检索恳求送到多个独立的搜索引擎搜索,将检索结果集中统一处理,以统一的格式提供给用户,因此有搜索引擎之上的搜索引擎之称。它将主要精力放到提升搜索速率、智能化处理搜索结果、个性搜索功能的设置和用户检索界面的友好性上,其查全率和查准率相对较高。它的特征是本身没有储存网页信息的数据库,当用户查询一个关键词时,它将用户恳求转换成其他搜索引擎能接受的命令格式,并行地访问数个搜索引擎来查询这个关键词,将这种搜索引擎返回的结果经过处理后再返回给用户。在搜索结果排列方面,有的直接按来源引擎排列搜索结果,有的则按自定的规则将结果重新排列组合。
2、网络爬虫技术
2.1 网络爬虫的工作原理
网络爬虫源自Spider(或Crawler、robots、wanderer)等的译音。网络爬虫的定义有广义和狭义之分,狭义的定义为:利用标准的http 协议,根据超级链接和Web 文档检索的方式遍历万维网信息空间的软件程序。广义的定义为:所有能借助http协议检索Web 文档的软件都称之为网路爬虫。
网络爬虫是一个功能太强悍的手动提取网页的程序,它为搜索引擎从万维网下载网页,是搜索引擎的重要组成部份。它通过恳求站点上的HTML 文档访问某一站点。它遍历Web 空间,不断从一个站点到另一个站点,自动构建索引,并加入到网页数据库中。网络爬虫步入某个超级文本时,利用HTML 语言的标记结构来搜索信息及获取指向其他超级文本的URL 地址,可以完全不依赖用户干预实现网路上的手动“爬行”和搜索。网络爬虫在搜索时常常采用一定的搜索策略。
2.2 网络爬虫的搜索策略
1)深度优先搜索策略
深度优先搜索是在开发爬虫初期使用较多的方式,它的目的是要达到被搜索结构的叶结点(即这些不包含任何超级链接的HTML文件)。在一个HTML文件中,当一个超级链接被选择后,被链接的HTML文件将执行深度优先搜索,即在搜索其余的超级链接结果之前必须先完整地搜索单独的一条链。深度优先搜索顺着HTML文件上的超级链接走到不能再深入为止,然后返回到某一个HTML文件,再继续选择该HTML文件中的其他超级链接。当不再有其他超级链接可选择时,说明搜索早已结束。其优点是能遍历一个Web站点或深层嵌套的文档集合。缺点是因为Web结构相当深,有可能导致一旦进去再也出不来的情况发生。
2)宽度优先搜索策略
在长度优先搜索中,先搜索完一个Web页面中所有的超级链接,然后再继续搜索下一层,直到底层为止。例如,一个HTML 文件中有3个超级链接,选择其中之一,处理相应的HTML文件,然后不再选择第二个HTML文件中的任何超级链接,而是返回,选择第二个超级链接,处理相应的HTML文件,再返回,选择第三个超级链接,并处理相应的HTML文件。一旦一层上的所有超级链接都被选择过,就可以开始在刚刚处理过的HIML文件中搜索其余的超级链接。这就保证了对浅层的首先处理。当遇见一个无穷尽的深层分支时网络爬虫 技术,不会造成陷进WWW的深层文档中出不来的情况发生。宽度优先搜索策略还有一个优点,它能在两个HTML文件之间找到最短路径。宽度优先搜索策略一般是实现爬虫的最佳策略,因为它容易实现,而且具备大多数期望的功能。但是假如要遍历一个指定的站点或则深层嵌套的HTML文件集,用长度优先搜索策略则须要耗费较长时间能够抵达深层的HTML文件。
综合考虑以上几种策略和国外信息导航系统搜索信息的特性,国内通常采用以长度优先搜索策略为主,线性搜索策略为辅的搜索策略。对于个别不被引用的或极少被引用的HTML文件,宽度优先搜索策略可能会遗漏那些孤立的信息源,可以用线性搜索策略作为它的补充。
3)聚焦搜索策略
聚焦爬虫的爬行策略只跳出某个特定主题的页面,根据“最好优先原则”进行访问,快速、有效地获得更多的与主题相关的页面,主要通过内容与Web的链接结构指导进一步的页面抓取。聚焦爬虫会给它所下载的页面一个评价分,根据得分排序插入到一个队列中。最好的下一个搜索对弹出队列中的第一个页面进行剖析后执行,这种策略保证爬虫能优先跟踪这些最有可能链接到目标页面的页面。决定网路爬虫搜索策略的关键是怎样评价链接价值,即链接价值的估算方式,不同的价值评价方式估算出的链接的价值不同,表现出的链接的“重要程度”也不同,从而决定了不同的搜索策略。由于链接包含于页面之中,而一般具有较高价值的页面包含的链接也具有较高价值,因而对链接价值的评价有时也转换为对页面价值的评价。这种策略一般运用在专业搜索引擎中,因为这些搜索引擎只关心某一特定主题的页面。
【福利】填问卷送精选测试礼包+接口测试课程!为测试行业做点事! 查看全部
随着的发展壮大,人们获取信息的途径渐渐被网路所代替。互联网发展早期,人们主要通过浏览门户网站的方法获取所需信息,但是随着Web的飞速发展, 用这些方法找寻自己所需信息显得越来越困难。目前,人们大多通过搜索引擎获取有用信息网络爬虫 技术,因此,搜索引擎技术的发展将直接影响人们获取所需信息的速率和质量。
1994 年世界上第一个网络检索工具Web Crawler 问世, 目前较流行的搜索引擎有、、Yahoo、Info seek、Inktomi、Teoma、Live Search 等。出于商业机密的考虑,现在各个搜索引擎使用的Crawler 系统的技术黑幕通常都不公开,现有的文献资料也仅限于概要性介绍。随着网路信息资源呈指数级下降及网路信息资源动态变化,传统的搜索引擎提供的信息检索服务已难以满足人们愈加下降的对个性化服务的需求,正面临着巨大的挑战。以何种策略访问网路,提高搜索效率,已成为近些年来专业搜索引擎研究的主要问题之一。
1、搜索引擎分类
搜索引擎按其形式主要分为全文搜索引擎、目录索引类搜索引擎和元搜索引擎三种。
1.1 全文搜索引擎
全文搜索引擎是名副其实的搜索引擎,通过从互联网上提取的各个网站信息(以网页文字为主)而构建的中,检索与用户查询条件匹配的相关记录,然后按一定的排列次序将结果返回给用户。
全文搜索引擎又可细分为两种:a)拥有自己的检索程序(Indexer),俗称“蜘蛛”(Spider)程序或“机器人”(Robot)程序,自建网页数据库,搜索结果直接从自身的数据库中调用。b)租用其他引擎的数据库,按自定的格式排列搜索结果。
1.2 目录索引型搜索引擎
与全文搜索引擎不同的是,目录索引型搜索引擎的索引数据库是由编辑人员人工构建上去的,这些编辑人员在访问过某个Web 站点后,根据一套自定的衡量标准及主观印象作出对该站点的描述,并按照站点的内容和性质将其归为一个预先分好的类别,分门别类地储存在相应的目录中。用户在查询时,可以通过关键词搜索,也可以按分类目录逐层检索。
因为目录索引型的索引数据库是借助人工来评价一个网站的内容,所以用户从目录搜索到的结果常常比全文检索到的结果更具有参考价值。实际上,目前好多的搜索网站都同时提供目录和全文搜索的搜索服务,尽可能为用户提供全面的查询结果。
1.3 元搜索引擎
元搜索引擎是将用户递交的检索恳求送到多个独立的搜索引擎搜索,将检索结果集中统一处理,以统一的格式提供给用户,因此有搜索引擎之上的搜索引擎之称。它将主要精力放到提升搜索速率、智能化处理搜索结果、个性搜索功能的设置和用户检索界面的友好性上,其查全率和查准率相对较高。它的特征是本身没有储存网页信息的数据库,当用户查询一个关键词时,它将用户恳求转换成其他搜索引擎能接受的命令格式,并行地访问数个搜索引擎来查询这个关键词,将这种搜索引擎返回的结果经过处理后再返回给用户。在搜索结果排列方面,有的直接按来源引擎排列搜索结果,有的则按自定的规则将结果重新排列组合。
2、网络爬虫技术
2.1 网络爬虫的工作原理
网络爬虫源自Spider(或Crawler、robots、wanderer)等的译音。网络爬虫的定义有广义和狭义之分,狭义的定义为:利用标准的http 协议,根据超级链接和Web 文档检索的方式遍历万维网信息空间的软件程序。广义的定义为:所有能借助http协议检索Web 文档的软件都称之为网路爬虫。
网络爬虫是一个功能太强悍的手动提取网页的程序,它为搜索引擎从万维网下载网页,是搜索引擎的重要组成部份。它通过恳求站点上的HTML 文档访问某一站点。它遍历Web 空间,不断从一个站点到另一个站点,自动构建索引,并加入到网页数据库中。网络爬虫步入某个超级文本时,利用HTML 语言的标记结构来搜索信息及获取指向其他超级文本的URL 地址,可以完全不依赖用户干预实现网路上的手动“爬行”和搜索。网络爬虫在搜索时常常采用一定的搜索策略。
2.2 网络爬虫的搜索策略
1)深度优先搜索策略
深度优先搜索是在开发爬虫初期使用较多的方式,它的目的是要达到被搜索结构的叶结点(即这些不包含任何超级链接的HTML文件)。在一个HTML文件中,当一个超级链接被选择后,被链接的HTML文件将执行深度优先搜索,即在搜索其余的超级链接结果之前必须先完整地搜索单独的一条链。深度优先搜索顺着HTML文件上的超级链接走到不能再深入为止,然后返回到某一个HTML文件,再继续选择该HTML文件中的其他超级链接。当不再有其他超级链接可选择时,说明搜索早已结束。其优点是能遍历一个Web站点或深层嵌套的文档集合。缺点是因为Web结构相当深,有可能导致一旦进去再也出不来的情况发生。
2)宽度优先搜索策略
在长度优先搜索中,先搜索完一个Web页面中所有的超级链接,然后再继续搜索下一层,直到底层为止。例如,一个HTML 文件中有3个超级链接,选择其中之一,处理相应的HTML文件,然后不再选择第二个HTML文件中的任何超级链接,而是返回,选择第二个超级链接,处理相应的HTML文件,再返回,选择第三个超级链接,并处理相应的HTML文件。一旦一层上的所有超级链接都被选择过,就可以开始在刚刚处理过的HIML文件中搜索其余的超级链接。这就保证了对浅层的首先处理。当遇见一个无穷尽的深层分支时网络爬虫 技术,不会造成陷进WWW的深层文档中出不来的情况发生。宽度优先搜索策略还有一个优点,它能在两个HTML文件之间找到最短路径。宽度优先搜索策略一般是实现爬虫的最佳策略,因为它容易实现,而且具备大多数期望的功能。但是假如要遍历一个指定的站点或则深层嵌套的HTML文件集,用长度优先搜索策略则须要耗费较长时间能够抵达深层的HTML文件。
综合考虑以上几种策略和国外信息导航系统搜索信息的特性,国内通常采用以长度优先搜索策略为主,线性搜索策略为辅的搜索策略。对于个别不被引用的或极少被引用的HTML文件,宽度优先搜索策略可能会遗漏那些孤立的信息源,可以用线性搜索策略作为它的补充。
3)聚焦搜索策略
聚焦爬虫的爬行策略只跳出某个特定主题的页面,根据“最好优先原则”进行访问,快速、有效地获得更多的与主题相关的页面,主要通过内容与Web的链接结构指导进一步的页面抓取。聚焦爬虫会给它所下载的页面一个评价分,根据得分排序插入到一个队列中。最好的下一个搜索对弹出队列中的第一个页面进行剖析后执行,这种策略保证爬虫能优先跟踪这些最有可能链接到目标页面的页面。决定网路爬虫搜索策略的关键是怎样评价链接价值,即链接价值的估算方式,不同的价值评价方式估算出的链接的价值不同,表现出的链接的“重要程度”也不同,从而决定了不同的搜索策略。由于链接包含于页面之中,而一般具有较高价值的页面包含的链接也具有较高价值,因而对链接价值的评价有时也转换为对页面价值的评价。这种策略一般运用在专业搜索引擎中,因为这些搜索引擎只关心某一特定主题的页面。
【福利】填问卷送精选测试礼包+接口测试课程!为测试行业做点事!
基于Java的小型分布式网路爬虫体系结构
采集交流 • 优采云 发表了文章 • 0 个评论 • 294 次浏览 • 2020-05-11 08:02
分布式网路爬虫包含多个爬虫,每个爬虫须要完成的任务和单个的爬行器类似,它们从互联网上下载网页,并把网页保存在本地的c盘分布式爬虫架构,从中抽取URL并顺着这种URL的指向继续爬行。由于并行爬行器须要分割下载任务,可能爬虫会将自己抽取的URL发送给其他爬虫。这些爬虫可能分布在同一个局域网之中,或者分散在不同的地理位置。
根据爬虫的分散程度不同,可以把分布式爬行器分成以下两大类:
1、基于局域网分布式网路爬虫:这种分布式爬行器的所有爬虫在同一个局域网里运行,通过高速的网路联接互相通讯。这些爬虫通过同一个网路去访问外部互联网,下载网页,所有的网路负载都集中在她们所在的那种局域网的出口上。由于局域网的带宽较高,爬虫之间的通讯的效率能否得到保证;但是网路出口的总带宽上限是固定的,爬虫的数目会遭到局域网出口带宽的限制。
2、基于广域网分布式网路爬虫:当并行爬行器的爬虫分别运行在不同地理位置(或网路位置),我们称这些并行爬行器为分布式爬行器。例如,分布式爬行器的爬虫可能坐落中国,日本,和英国,分别负责下载这三地的网页;或者坐落CHINANET,CERNET,CEINET,分别负责下载这三个网路的中的网页。分布式爬行器的优势在于可以子在一定程度上分散网路流量,减小网路出口的负载。如果爬虫分布在不同的地理位置(或网路位置),需要间隔多长时间进行一次互相通讯就成为了一个值得考虑的问题。爬虫之间的通信带宽可能是有限的,通常须要通过互联网进行通讯。
大型分布式网路爬虫体系结构图
分布式网路爬虫是一项非常复杂系统。需要考虑好多方面诱因。性能可以说是它这重要的指标。当然硬件层面的资源也是必须的。
架构
下面是项目的总体构架,第一个版本基于此方案来做。
上面的web层包括:控制台、基本权限、监控展示等,还可以依据须要再一步进行扩充。
核心层由控制者统一调度,将任务发给工人队列中的工人进行爬取操作。各个结点动态的向监控模块发送模块状态等信息,统一由展示层展示。
项目目标
众推,开源版的明日头条!
基于hadoop思维的分布式网路爬虫。
目前早已将fourinone、jeesite、webmagic整合进来,并且进一步进行改进。想最终弄成一个基于设计器的动态可配置的分布式爬虫系统,这个是第一阶段的目标。
项目目前情况
目前项目进展情况:
1、sourceer,可以接入多种数据源,接口早已定义(加入builder封装,可以使用简单爬虫)。
2、web构架工程(web工程上传并测试成功,权限、基础框架改建,导入等早已录成视频,删除activiti,删除cms部分)。
3、分布式框架研究(分布式项目发包,添加部份注释,测试单机单工人爬取)。
4、插件化整合。
5、文章等各类去重形式及算法(目前已实现bloomfilter分布式爬虫架构,指纹算法去重,已经实现simhash,分词算法(ansj))。
6、分类器测试(bayes,文本分类单机测试成功)。
项目地址:
(分布式爬虫)
(去重过滤器)
(文本分类器)
(文档目录)
项目界面:
启动jetty,目前皮肤暂时还未换。
总结
目前项目正在进一步建立当中,希望能得到你更多的意见! 查看全部
【IT168技术】分类
分布式网路爬虫包含多个爬虫,每个爬虫须要完成的任务和单个的爬行器类似,它们从互联网上下载网页,并把网页保存在本地的c盘分布式爬虫架构,从中抽取URL并顺着这种URL的指向继续爬行。由于并行爬行器须要分割下载任务,可能爬虫会将自己抽取的URL发送给其他爬虫。这些爬虫可能分布在同一个局域网之中,或者分散在不同的地理位置。
根据爬虫的分散程度不同,可以把分布式爬行器分成以下两大类:
1、基于局域网分布式网路爬虫:这种分布式爬行器的所有爬虫在同一个局域网里运行,通过高速的网路联接互相通讯。这些爬虫通过同一个网路去访问外部互联网,下载网页,所有的网路负载都集中在她们所在的那种局域网的出口上。由于局域网的带宽较高,爬虫之间的通讯的效率能否得到保证;但是网路出口的总带宽上限是固定的,爬虫的数目会遭到局域网出口带宽的限制。
2、基于广域网分布式网路爬虫:当并行爬行器的爬虫分别运行在不同地理位置(或网路位置),我们称这些并行爬行器为分布式爬行器。例如,分布式爬行器的爬虫可能坐落中国,日本,和英国,分别负责下载这三地的网页;或者坐落CHINANET,CERNET,CEINET,分别负责下载这三个网路的中的网页。分布式爬行器的优势在于可以子在一定程度上分散网路流量,减小网路出口的负载。如果爬虫分布在不同的地理位置(或网路位置),需要间隔多长时间进行一次互相通讯就成为了一个值得考虑的问题。爬虫之间的通信带宽可能是有限的,通常须要通过互联网进行通讯。
大型分布式网路爬虫体系结构图
分布式网路爬虫是一项非常复杂系统。需要考虑好多方面诱因。性能可以说是它这重要的指标。当然硬件层面的资源也是必须的。
架构
下面是项目的总体构架,第一个版本基于此方案来做。
上面的web层包括:控制台、基本权限、监控展示等,还可以依据须要再一步进行扩充。
核心层由控制者统一调度,将任务发给工人队列中的工人进行爬取操作。各个结点动态的向监控模块发送模块状态等信息,统一由展示层展示。
项目目标
众推,开源版的明日头条!
基于hadoop思维的分布式网路爬虫。
目前早已将fourinone、jeesite、webmagic整合进来,并且进一步进行改进。想最终弄成一个基于设计器的动态可配置的分布式爬虫系统,这个是第一阶段的目标。
项目目前情况
目前项目进展情况:
1、sourceer,可以接入多种数据源,接口早已定义(加入builder封装,可以使用简单爬虫)。
2、web构架工程(web工程上传并测试成功,权限、基础框架改建,导入等早已录成视频,删除activiti,删除cms部分)。
3、分布式框架研究(分布式项目发包,添加部份注释,测试单机单工人爬取)。
4、插件化整合。
5、文章等各类去重形式及算法(目前已实现bloomfilter分布式爬虫架构,指纹算法去重,已经实现simhash,分词算法(ansj))。
6、分类器测试(bayes,文本分类单机测试成功)。
项目地址:
(分布式爬虫)
(去重过滤器)
(文本分类器)
(文档目录)
项目界面:
启动jetty,目前皮肤暂时还未换。
总结
目前项目正在进一步建立当中,希望能得到你更多的意见!
网络爬虫|图文|百度文库
采集交流 • 优采云 发表了文章 • 0 个评论 • 330 次浏览 • 2020-05-11 08:01
网络爬虫序言-爬虫? Crawler ,即Spider(网络爬虫),其定义有广义 和狭义之分。狭义上指遵守标准的 http 协议,利 用超链接和 Web 文档检索方式遍历万维网的软件 程序;而广义的定义则是能遵守 http 协议,检索 Web 文档的软件都称之为网路爬虫。 ? 网络爬虫是一个功能太强的手动提取网页的程序, 它为搜索引擎从万维网上下载网页,是搜索引擎的 重要组成部份。聚焦爬虫? 随着网路的迅速发展,万维网成为大量信息的载体 ,如何有效地提取并借助这种信息成为一个巨大的 挑战。搜索引擎(Search Engine),例如传统的通 用搜索引擎AltaVista,Yahoo!和Google等,作为 一个辅助人们检索信息的工具成为用户访问万维网 的入口和 指南。但是,这些通用性搜索引擎也存在 着一定的局限性,如:聚焦爬虫? (1) 不同领域、不同背景的用户常常具有不同的检索目的和 需求,通用搜索引擎所返回的结果包含大量用户不关心的网 页。? ? (2) 通用搜索引擎的目标是尽可能大的网路覆盖率,有限的 搜索引擎服务器资源与无限的网路数据资源之间的矛盾将进 一步加深。? ? (3) 万维网数据方式的丰富和网路技术的不断发展,图片、 数据库、音频/视频多媒体等不同数据大量出现,通用搜索引 擎常常对这种信息浓度密集且具有一定结构的数据无能为力 ,不能挺好地发觉和获取。
? ? (4) 通用搜索引擎大多提供基于关键字的检索,难以支持根 据语义信息提出的查询。?聚焦爬虫? 为了解决上述问题,定向抓取相关网页资源的聚焦 爬虫应运而生。聚焦爬虫是一个手动下载网页的程 序,它按照既定的抓取目标,有选择的访问万维网 上的网页与相关的链接,获取所须要的信息。 ? 与通用爬虫(general purpose web crawler)不同 ,聚焦爬虫并不追求大的覆盖,而将目标定为抓取 与某一特定主题内容相关的网页,为面向主题的用 户查询打算数据资源。垂直搜索的本质?从主题相关的领域内,获取、加工与搜索行 为相匹配的结构化数据和元数据信息。如数码产品mp3:内存、尺寸、大小、电池机型、价格、生产 厂家等,还可以提供比价服务爬虫基本原理?网络爬虫是通过网页的链接地址来找寻网页, 从一个或若干初始网页的URL开始(通常是某 网站首页),遍历 Web 空间,读取网页的内容 ,不断从一个站点联通到另一个站点,自动建 立索引。在抓取网页的过程中,找到在网页中 的其他链接地址,对 HTML 文件进行解析,取 出其页面中的子链接,并加入到网页数据库中 ,不断从当前页面上抽取新的URL装入队列, 这样仍然循环下去,直到把这个网站所有的网 页都抓取完,满足系统的一定停止条件。
爬虫基本原理?另外,所有被爬虫抓取的网页将会被系统储存 ,进行一定的剖析、过滤,并构建索引,以便 之后的查询和检索。网络爬虫剖析某个网页时 ,利用 HTML 语言的标记结构来获取指向其他 网页的 URL 地址,可以完全不依赖用户干预。 ?如果把整个互联网当作一个网站,理论上讲网 络爬虫可以把互联网上所有的网页都抓取出来爬虫基本原理?而且对于个别主题爬虫来说,这一过程所得到 的剖析结果还可能对之后抓取过程给出反馈和 指导。正是这些行为方法,这些程序才被称为 爬虫( spider )、crawler、机器人。爬虫基本原理?Spider如何抓取所有的 Web 页面呢? ?在Web出现曾经,传统的文本集合,如目录数 据库、期刊文摘储存在磁带或光碟里,用作索 引系统。 ?与此相对应,Web 中所有可访问的URL都是未 分类的,收集 URL 的惟一方法就是通过扫描收 集这些链向其他页面的超链接,这些页面还未 被搜集过。爬虫基本原理? 从给定的 URL 集出发,逐步来抓取和扫描这些新 的出链。这样周而复始的抓取那些页面。这些新发 现的 URL 将作为爬行器的未来的抓取的工作。 ? 随着抓取的进行,这些未来工作集也会随着膨胀, 由写入器将这种数据写入c盘来释放寻址,以及避 免爬行器崩溃数据遗失。
没有保证所有的 Web 页 面的访问都是根据这些方法进行,爬行器从不会停 下来,Spider 运行时页面也会急剧不断降低。 ? 页面中所包含的文本也将呈交给文本索引器,用于 基于关键词的信息索引。工作流程? 网络爬虫是搜索引擎中最核心的部份,整个搜索引擎的 素材库来源于网路爬虫的采集,从搜索引擎整个产业链 来看,网络爬虫是处于最上游的产业。其性能优劣直接 影响着搜索引擎整体性能和处理速率。 ? 通用网路爬虫是从一个或若干个初始网页的上的 URL 开始,获得初始网页上的 URL 列表,在抓取网页过程 中,不断从当前页面上抽取新的 URL 放入待爬行队列网络爬虫,直到满足系统的停止条件。工作流程? 网络爬虫基本构架如图所示,其各个部份的主要功能介 绍如下: ? 1.页面采集模块:该模块是爬虫和因特网的插口,主 要作用是通过各类 web 协议(一般以 HTTP.FTP 为主 )来完成对网页数据的采集,保存后将采集到的页面交 由后续模块作进一步处理。 其过程类似于用户使用浏览器打开网页,保存的网页供 其它后续模块处理,例如,页面剖析、链接抽取。工作流程? 2.页面剖析模块:该模块的主要功能是将页面采集模 块采集下来的页面进行剖析,提取其中满足用户要求的 超链接,加入到超链接队列中。
页面链接中给出的 URL 一般是多种格式的,可能是完 整的包括合同、站点和路径的,也可能是省略了部份内 容的,或者是一个相对路径。所以为处理便捷,一般进 行规范化处理,先将其转化成统一的格式。工作流程?3、链接过滤模块:该模块主要是用于对重复链 接和循环链接的过滤。例如,相对路径须要补 全 URL ,然后加入到待采集 URL 队列中。 此时,一般会过滤掉队列中早已包含的 URL , 以及循环链接的URL。工作流程?4.页面库:用来储存早已采集下来的页面,以 备后期处理。 ?5.待采集 URL 队列:从采集网页中抽取并作 相应处理后得到的 URL ,当 URL 为空时爬虫 程序中止。 ?6.初始 URL :提供 URL 种子,以启动爬虫关键技术剖析?抓取目标的定义与描述 ?网页URL的搜索策略 ?网页的剖析与信息的提取抓取目标的定义与描述?针对有目标网页特点的网页级信息对应网页库级垂直搜索,抓取目标网页,后续还要从 中抽取出须要的结构化信息。稳定性和数目上占优, 但成本高、性活性差。?针对目标网页上的结构化数据对应模板级垂直搜索,直接解析页面,提取并加工出 结构化数据信息。快速施行、成本低、灵活性强,但 后期维护成本高。
URL 的搜索策略网路爬虫 URL 抓取策略有: ?IP 地址搜索策略 ?广度优先 ?深度优先 ?最佳优先URL 的搜索策略? 基于IP地址的搜索策略 ? 先赋于爬虫一个起始的 IP 地址网络爬虫,然后按照 IP 地址 递增的形式搜索本口地址段后的每一个 WWW 地 址中的文档,它完全不考虑各文档中指向其它 Web 站点的超级链接地址。 ? 优点是搜索全面,能够发觉这些没被其它文档引用 的新文档的信息源 ? 缺点是不适宜大规模搜索URL 的搜索策略? 广度优先搜索策略 ? 广度优先搜索策略是指在抓取过程中,在完成当前层次 的搜索后,才进行下一层次的搜索。这样逐层搜索,依 此类推。 ? 该算法的设计和实现相对简单。在目前为覆盖尽可能多 的网页,一般使用广度优先搜索方式。 ? 很多研究者通过将广度优先搜索策略应用于主题爬虫中 。他们觉得与初始 URL 在一定链接距离内的网页具有 主题相关性的机率很大。URL 的搜索策略? 另外一种方式是将广度优先搜索与网页过滤技术结合让 用,先用广度优先策略抓取网页,再将其中无关的网页 过滤掉。这些技巧的缺点在于,随着抓取网页的增多, 大量的无关网页将被下载并过滤,算法的效率将变低。
? 使用广度优先策略抓取的次序为:A-B、C、D、E、F-G 、H-I 。URL 的搜索策略? 深度优先搜索策略 ? 深度优先搜索在开发网路爬虫初期使用较多的方式之一 ,目的是要达到叶结点,即这些不包含任何超链接的页 面文件。 ? 从起始页开始在当前 HTML 文件中,当一个超链被选 择后,被链接的 HTML 文件将执行深度优先搜索,一 个链接一个链接跟踪下去,处理完这条线路以后再转到 下一个起始页,继续跟踪链接。即在搜索其余的超链结 果之前必须先完整地搜索单独的一条链。URL 的搜索策略? 深度优先搜索顺着 HTML 文件上的超链走到不能再深 入为止,然后返回到某一个 HTML 文件,再继续选择 该 HTML 文件中的其他超链。当不再有其他超链可选 择时,说明搜索早已结束。 ? 这个方式有个优点是网路蜘蛛在设计的时侯比较容易。? 使用深度优先策略抓取的次序为:A-F-G、E-H-I、B、 C、D 。 ? 目前常见的是广度优先和最佳优先方式。URL 的搜索策略? 最佳优先搜索策略 ? 最佳优先搜索策略根据一定的网页剖析算法,先估算出 URL 描述文本的目标网页的相似度,设定一个值,并选 取评价得分超过该值的一个或几个 URL 进行抓取。
它 只访问经过网页分析算法估算出的相关度小于给定的值 的网页。 ? 存在的一个问题是,在爬虫抓取路径上的好多相关网页 可能被忽视,因为最佳优先策略是一种局部最优搜索算 法。因此须要将最佳优先结合具体的应用进行改进,以 跳出局部最优点。 ? 有研究表明,这样的闭环调整可以将无关网页数目增加 30%--90%。网页的剖析及信息的提取? 基于网路拓扑关系的剖析算法 根据页面间超链接引用关系,来对与已知网页有直接或 间接关系对象做出评价的算法。网页细度PageRank ,网站粒度 SiteRank。 ? 基于网页内容的剖析算法 从最初的文本检索方式,向涉及网页数据抽取、机器学 习、数据挖掘、自然语言等多领域综合的方向发展。 ? 基于用户访问行为的剖析算法 有代表性的是基于领域概念的剖析算法,涉及本体论。例子说明简述页面源代码?定位的爬取目标是娱乐博文,故在首页的源 代码中搜救“娱乐”之后,发现了如下数组 : ?<div class="nav"><a href=";class= "a2 fblack">首页</a> <a href=" /"target="_blank"class="fw">娱乐 </a>解析html的形式? 实现网路爬虫,顾名思义另要程序手动解析网页。
考虑 到垂直爬虫及站内搜索的重要性,凡是涉及到对页面的 处理,就须要一个强悍的 HTML/XML Parser 支持解 析,通过对目标文件的低格处理,才能够实现特定信 息提取、特定信息删掉和遍历等操作。 ? HTMLParser ,它是 Python拿来的解析 html 的模 块。它可以剖析出 html 里面的标签、数据等等,是一 种处理html的简便途径。 查看全部
网络爬虫序言-爬虫? Crawler ,即Spider(网络爬虫),其定义有广义 和狭义之分。狭义上指遵守标准的 http 协议,利 用超链接和 Web 文档检索方式遍历万维网的软件 程序;而广义的定义则是能遵守 http 协议,检索 Web 文档的软件都称之为网路爬虫。 ? 网络爬虫是一个功能太强的手动提取网页的程序, 它为搜索引擎从万维网上下载网页,是搜索引擎的 重要组成部份。聚焦爬虫? 随着网路的迅速发展,万维网成为大量信息的载体 ,如何有效地提取并借助这种信息成为一个巨大的 挑战。搜索引擎(Search Engine),例如传统的通 用搜索引擎AltaVista,Yahoo!和Google等,作为 一个辅助人们检索信息的工具成为用户访问万维网 的入口和 指南。但是,这些通用性搜索引擎也存在 着一定的局限性,如:聚焦爬虫? (1) 不同领域、不同背景的用户常常具有不同的检索目的和 需求,通用搜索引擎所返回的结果包含大量用户不关心的网 页。? ? (2) 通用搜索引擎的目标是尽可能大的网路覆盖率,有限的 搜索引擎服务器资源与无限的网路数据资源之间的矛盾将进 一步加深。? ? (3) 万维网数据方式的丰富和网路技术的不断发展,图片、 数据库、音频/视频多媒体等不同数据大量出现,通用搜索引 擎常常对这种信息浓度密集且具有一定结构的数据无能为力 ,不能挺好地发觉和获取。
? ? (4) 通用搜索引擎大多提供基于关键字的检索,难以支持根 据语义信息提出的查询。?聚焦爬虫? 为了解决上述问题,定向抓取相关网页资源的聚焦 爬虫应运而生。聚焦爬虫是一个手动下载网页的程 序,它按照既定的抓取目标,有选择的访问万维网 上的网页与相关的链接,获取所须要的信息。 ? 与通用爬虫(general purpose web crawler)不同 ,聚焦爬虫并不追求大的覆盖,而将目标定为抓取 与某一特定主题内容相关的网页,为面向主题的用 户查询打算数据资源。垂直搜索的本质?从主题相关的领域内,获取、加工与搜索行 为相匹配的结构化数据和元数据信息。如数码产品mp3:内存、尺寸、大小、电池机型、价格、生产 厂家等,还可以提供比价服务爬虫基本原理?网络爬虫是通过网页的链接地址来找寻网页, 从一个或若干初始网页的URL开始(通常是某 网站首页),遍历 Web 空间,读取网页的内容 ,不断从一个站点联通到另一个站点,自动建 立索引。在抓取网页的过程中,找到在网页中 的其他链接地址,对 HTML 文件进行解析,取 出其页面中的子链接,并加入到网页数据库中 ,不断从当前页面上抽取新的URL装入队列, 这样仍然循环下去,直到把这个网站所有的网 页都抓取完,满足系统的一定停止条件。
爬虫基本原理?另外,所有被爬虫抓取的网页将会被系统储存 ,进行一定的剖析、过滤,并构建索引,以便 之后的查询和检索。网络爬虫剖析某个网页时 ,利用 HTML 语言的标记结构来获取指向其他 网页的 URL 地址,可以完全不依赖用户干预。 ?如果把整个互联网当作一个网站,理论上讲网 络爬虫可以把互联网上所有的网页都抓取出来爬虫基本原理?而且对于个别主题爬虫来说,这一过程所得到 的剖析结果还可能对之后抓取过程给出反馈和 指导。正是这些行为方法,这些程序才被称为 爬虫( spider )、crawler、机器人。爬虫基本原理?Spider如何抓取所有的 Web 页面呢? ?在Web出现曾经,传统的文本集合,如目录数 据库、期刊文摘储存在磁带或光碟里,用作索 引系统。 ?与此相对应,Web 中所有可访问的URL都是未 分类的,收集 URL 的惟一方法就是通过扫描收 集这些链向其他页面的超链接,这些页面还未 被搜集过。爬虫基本原理? 从给定的 URL 集出发,逐步来抓取和扫描这些新 的出链。这样周而复始的抓取那些页面。这些新发 现的 URL 将作为爬行器的未来的抓取的工作。 ? 随着抓取的进行,这些未来工作集也会随着膨胀, 由写入器将这种数据写入c盘来释放寻址,以及避 免爬行器崩溃数据遗失。
没有保证所有的 Web 页 面的访问都是根据这些方法进行,爬行器从不会停 下来,Spider 运行时页面也会急剧不断降低。 ? 页面中所包含的文本也将呈交给文本索引器,用于 基于关键词的信息索引。工作流程? 网络爬虫是搜索引擎中最核心的部份,整个搜索引擎的 素材库来源于网路爬虫的采集,从搜索引擎整个产业链 来看,网络爬虫是处于最上游的产业。其性能优劣直接 影响着搜索引擎整体性能和处理速率。 ? 通用网路爬虫是从一个或若干个初始网页的上的 URL 开始,获得初始网页上的 URL 列表,在抓取网页过程 中,不断从当前页面上抽取新的 URL 放入待爬行队列网络爬虫,直到满足系统的停止条件。工作流程? 网络爬虫基本构架如图所示,其各个部份的主要功能介 绍如下: ? 1.页面采集模块:该模块是爬虫和因特网的插口,主 要作用是通过各类 web 协议(一般以 HTTP.FTP 为主 )来完成对网页数据的采集,保存后将采集到的页面交 由后续模块作进一步处理。 其过程类似于用户使用浏览器打开网页,保存的网页供 其它后续模块处理,例如,页面剖析、链接抽取。工作流程? 2.页面剖析模块:该模块的主要功能是将页面采集模 块采集下来的页面进行剖析,提取其中满足用户要求的 超链接,加入到超链接队列中。
页面链接中给出的 URL 一般是多种格式的,可能是完 整的包括合同、站点和路径的,也可能是省略了部份内 容的,或者是一个相对路径。所以为处理便捷,一般进 行规范化处理,先将其转化成统一的格式。工作流程?3、链接过滤模块:该模块主要是用于对重复链 接和循环链接的过滤。例如,相对路径须要补 全 URL ,然后加入到待采集 URL 队列中。 此时,一般会过滤掉队列中早已包含的 URL , 以及循环链接的URL。工作流程?4.页面库:用来储存早已采集下来的页面,以 备后期处理。 ?5.待采集 URL 队列:从采集网页中抽取并作 相应处理后得到的 URL ,当 URL 为空时爬虫 程序中止。 ?6.初始 URL :提供 URL 种子,以启动爬虫关键技术剖析?抓取目标的定义与描述 ?网页URL的搜索策略 ?网页的剖析与信息的提取抓取目标的定义与描述?针对有目标网页特点的网页级信息对应网页库级垂直搜索,抓取目标网页,后续还要从 中抽取出须要的结构化信息。稳定性和数目上占优, 但成本高、性活性差。?针对目标网页上的结构化数据对应模板级垂直搜索,直接解析页面,提取并加工出 结构化数据信息。快速施行、成本低、灵活性强,但 后期维护成本高。
URL 的搜索策略网路爬虫 URL 抓取策略有: ?IP 地址搜索策略 ?广度优先 ?深度优先 ?最佳优先URL 的搜索策略? 基于IP地址的搜索策略 ? 先赋于爬虫一个起始的 IP 地址网络爬虫,然后按照 IP 地址 递增的形式搜索本口地址段后的每一个 WWW 地 址中的文档,它完全不考虑各文档中指向其它 Web 站点的超级链接地址。 ? 优点是搜索全面,能够发觉这些没被其它文档引用 的新文档的信息源 ? 缺点是不适宜大规模搜索URL 的搜索策略? 广度优先搜索策略 ? 广度优先搜索策略是指在抓取过程中,在完成当前层次 的搜索后,才进行下一层次的搜索。这样逐层搜索,依 此类推。 ? 该算法的设计和实现相对简单。在目前为覆盖尽可能多 的网页,一般使用广度优先搜索方式。 ? 很多研究者通过将广度优先搜索策略应用于主题爬虫中 。他们觉得与初始 URL 在一定链接距离内的网页具有 主题相关性的机率很大。URL 的搜索策略? 另外一种方式是将广度优先搜索与网页过滤技术结合让 用,先用广度优先策略抓取网页,再将其中无关的网页 过滤掉。这些技巧的缺点在于,随着抓取网页的增多, 大量的无关网页将被下载并过滤,算法的效率将变低。
? 使用广度优先策略抓取的次序为:A-B、C、D、E、F-G 、H-I 。URL 的搜索策略? 深度优先搜索策略 ? 深度优先搜索在开发网路爬虫初期使用较多的方式之一 ,目的是要达到叶结点,即这些不包含任何超链接的页 面文件。 ? 从起始页开始在当前 HTML 文件中,当一个超链被选 择后,被链接的 HTML 文件将执行深度优先搜索,一 个链接一个链接跟踪下去,处理完这条线路以后再转到 下一个起始页,继续跟踪链接。即在搜索其余的超链结 果之前必须先完整地搜索单独的一条链。URL 的搜索策略? 深度优先搜索顺着 HTML 文件上的超链走到不能再深 入为止,然后返回到某一个 HTML 文件,再继续选择 该 HTML 文件中的其他超链。当不再有其他超链可选 择时,说明搜索早已结束。 ? 这个方式有个优点是网路蜘蛛在设计的时侯比较容易。? 使用深度优先策略抓取的次序为:A-F-G、E-H-I、B、 C、D 。 ? 目前常见的是广度优先和最佳优先方式。URL 的搜索策略? 最佳优先搜索策略 ? 最佳优先搜索策略根据一定的网页剖析算法,先估算出 URL 描述文本的目标网页的相似度,设定一个值,并选 取评价得分超过该值的一个或几个 URL 进行抓取。
它 只访问经过网页分析算法估算出的相关度小于给定的值 的网页。 ? 存在的一个问题是,在爬虫抓取路径上的好多相关网页 可能被忽视,因为最佳优先策略是一种局部最优搜索算 法。因此须要将最佳优先结合具体的应用进行改进,以 跳出局部最优点。 ? 有研究表明,这样的闭环调整可以将无关网页数目增加 30%--90%。网页的剖析及信息的提取? 基于网路拓扑关系的剖析算法 根据页面间超链接引用关系,来对与已知网页有直接或 间接关系对象做出评价的算法。网页细度PageRank ,网站粒度 SiteRank。 ? 基于网页内容的剖析算法 从最初的文本检索方式,向涉及网页数据抽取、机器学 习、数据挖掘、自然语言等多领域综合的方向发展。 ? 基于用户访问行为的剖析算法 有代表性的是基于领域概念的剖析算法,涉及本体论。例子说明简述页面源代码?定位的爬取目标是娱乐博文,故在首页的源 代码中搜救“娱乐”之后,发现了如下数组 : ?<div class="nav"><a href=";class= "a2 fblack">首页</a> <a href=" /"target="_blank"class="fw">娱乐 </a>解析html的形式? 实现网路爬虫,顾名思义另要程序手动解析网页。
考虑 到垂直爬虫及站内搜索的重要性,凡是涉及到对页面的 处理,就须要一个强悍的 HTML/XML Parser 支持解 析,通过对目标文件的低格处理,才能够实现特定信 息提取、特定信息删掉和遍历等操作。 ? HTMLParser ,它是 Python拿来的解析 html 的模 块。它可以剖析出 html 里面的标签、数据等等,是一 种处理html的简便途径。
自己动手写网路爬虫
采集交流 • 优采云 发表了文章 • 0 个评论 • 257 次浏览 • 2020-05-10 08:03
《自己动手写网络爬虫》介绍了网路爬虫开发中的关键问题与Java实现。主要包括从互联网获取信息与提取信息和对Web信息挖掘等内容。《自己动手写网络爬虫》在介绍基本原理的同时重视辅以具体代码实现来帮助读者加深理解,书中部份代码甚至可以直接使用。 《自己动手写网络爬虫》适用于有Java程序设计基础的开发人员。同时也可以作为计算机相关专业本科生或研究生的参考教材。《自己动手写网络爬虫》介绍了网路爬虫发中的关键问题与Java实现。主要包括从互联网获取信息与提取信息和对Web信息挖掘等内容。《自己动手写网络爬虫》在介绍基本原理的同时重视辅以具体代码实现来帮助读者加深理解,书中部份代码甚至可以直使用。 《自己动手写网络爬虫》适用于有Java程序设计基础的发人员。同时也可以作为计算机相关专业本科生或研究生的参考教材。
【推荐语】
《自己动手写网络爬虫》是国外**本专门讲解网路爬虫发的书籍,介绍怎么应用云计算架构发分布式爬虫。猎兔搜索工程师多年项目经验总结 深介绍Web数据挖掘实现过程 光碟中提供了高效的代码解决方案 案例均使用流行的Java语言编撰
【作者】
罗刚,计算机软件硕士自己动手写网络爬虫,毕业于吉林工业大学。2005年成立北京盈智星科技发展有限公司,2008年联合成立北京数聚软件公司。猎兔搜索创始人,当前猎兔搜索在上海和北京以及广州均设有研制部。带领猎兔搜索技术发团队先后发出猎兔英文动词系统、猎兔文本挖掘系统,智能垂直搜索系统以及网路信息检测系统等,实现互联网信息的采集、过滤、搜索和实时检测自己动手写网络爬虫,其发的搜索软件日用户访问量上万次以上。 查看全部
《自己动手写网络爬虫》介绍了网路爬虫开发中的关键问题与Java实现。主要包括从互联网获取信息与提取信息和对Web信息挖掘等内容。《自己动手写网络爬虫》在介绍基本原理的同时重视辅以具体代码实现来帮助读者加深理解,书中部份代码甚至可以直接使用。 《自己动手写网络爬虫》适用于有Java程序设计基础的开发人员。同时也可以作为计算机相关专业本科生或研究生的参考教材。《自己动手写网络爬虫》介绍了网路爬虫发中的关键问题与Java实现。主要包括从互联网获取信息与提取信息和对Web信息挖掘等内容。《自己动手写网络爬虫》在介绍基本原理的同时重视辅以具体代码实现来帮助读者加深理解,书中部份代码甚至可以直使用。 《自己动手写网络爬虫》适用于有Java程序设计基础的发人员。同时也可以作为计算机相关专业本科生或研究生的参考教材。
【推荐语】
《自己动手写网络爬虫》是国外**本专门讲解网路爬虫发的书籍,介绍怎么应用云计算架构发分布式爬虫。猎兔搜索工程师多年项目经验总结 深介绍Web数据挖掘实现过程 光碟中提供了高效的代码解决方案 案例均使用流行的Java语言编撰
【作者】
罗刚,计算机软件硕士自己动手写网络爬虫,毕业于吉林工业大学。2005年成立北京盈智星科技发展有限公司,2008年联合成立北京数聚软件公司。猎兔搜索创始人,当前猎兔搜索在上海和北京以及广州均设有研制部。带领猎兔搜索技术发团队先后发出猎兔英文动词系统、猎兔文本挖掘系统,智能垂直搜索系统以及网路信息检测系统等,实现互联网信息的采集、过滤、搜索和实时检测自己动手写网络爬虫,其发的搜索软件日用户访问量上万次以上。
关于爬虫程序的合法性?
采集交流 • 优采云 发表了文章 • 0 个评论 • 310 次浏览 • 2020-05-10 08:03
希望本回答能解决楼主的问题。此回答摘录自本人所写的书《Python 网络爬虫:从入门到实践》第一章
从目前的情况来看,如果抓取的数据属于个人使用或科研范畴爬虫程序,基本不存在问题; 而假如数据属于商业赢利范畴,就要就事而论,有可能属于违法行为,也有可能不违规。
网络爬虫领域目前还属于拓荒阶段,虽然互联网世界早已通过自身的合同构建起一定的道德规范(Robots 协议),但法律部份还在完善和建立中。也就是说,现在这个领域暂时还是灰色地带。
Robots 协议
Robots协议(也称为爬虫协议)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎什么页面可以抓取,哪些页面不能抓取。它是国际互联网界通行的道德规范,虽然没有写入法律,但是每一个爬虫都应当遵循这项合同。
下面以淘宝网的robots.txt为例:
这里仅截取部份,查看完整可以访问taobao.com/robots.txt
User-agent: Baiduspider #百度爬虫引擎
Allow: /article #允许访问/article.htm,/article/12345.com
Allow: /oshtml
Allow: /wenzhang
Disallow: /product/ #禁止访问/product/12345.com
Disallow: / #禁止了访问除Allow规定页面的其他所有页面
User-Agent: Googlebot #谷歌爬虫引擎
Allow: /article
Allow: /oshtml
Allow: /product #允许访问/product.htm,/product/12345.com
Allow: /spu
Allow: /dianpu
Allow: /wenzhang
Allow: /oversea
Disallow: /
在前面的robots文件中,淘宝网对用户代理为百度爬虫引擎进行规定。
以”Allow”项的值开头的URL 是容许robot访问的。例如,”Allow: /article”允许百度爬虫引擎访问”/article.htm,/article/12345.com”等等。
以Disallow项为开头的链接是不容许百度爬虫引擎访问的。例如,”Disallow: /product/”不容许百度爬虫引擎访问 ”/product/12345.com” 等等。
最后一行,”Disallow: /”则严禁了百度爬虫访问不仅”Allow”规定页面的其他所有页面。
因此,当你在百度搜索“淘宝”的时侯,搜索结果下方的篆字会出现:“由于该网站的robots.txt文件存在限制指令(限制搜索引擎抓取),系统未能提供该页面的内容描述”。百度作为一个搜索引擎,良好地遵循了淘宝网的 robot.txt 协议,所以你是不能从百度上搜索到天猫内部的产品信息的。
淘宝的Robots协议对微软爬虫的待遇则不一样,和百度爬虫不同的是,它容许微软爬虫爬取产品的页面,”Allow: /product”。因此,当你在微软搜索“淘宝 iphone7”的时侯,可以搜索到天猫中的产品。
因此,当你爬取网站数据时,无论你是否仅仅用来个人使用,都应当遵循robots协议。
2. 网络爬虫的约束
除了上述的 Robot 协议之外,我们使用网路爬虫的时侯要对自己进行约束:过于快速或则频密的网络爬虫就会对服务器形成巨大的压力,网站可能封锁你的IP,甚至采取进一步的法律行动。
各大互联网大鳄也早已开始调集资源,限制爬虫,保护真正用户的流量和降低有价值数据的流失。
2007年,爱帮网借助垂直搜索技术获取了大众点评网上的商户简介和消费者点评爬虫程序,并且直接大量使用,于是大众点评网多次要求爱帮停止使用大众点评网的内容。而爱帮网则以自己是垂直搜索网站为由,拒绝停止抓取大众点评网上的内容,并且指责大众点评网对那些内容所享有的著作权。为此,双方开打了两场官司。2011年1月,北京海淀法院作出裁定:爱帮网侵害大众点评网著作权创立,爱帮网应该停止侵权并赔付大众点评网经济损失和诉讼必要开支。
2013年10月,百度诉360违背Robots协议,百度方面觉得,360违背了Robots协议,擅自抓取、复制百度网站内容并生成快照向用户提供。2014年08月07日,北京市第一中级人民法院做出二审裁定,法院觉得被告奇虎360的行为违背了《反不正当竞争法》相关规定,应赔付上诉百度公司70万元。
虽然说,大众点评上的点评数据,百度知道的问答由用户创建而非企业,但是搭建平台须要投入营运、技术和人力成本,那么平台拥有对数据的所有权,使用权和分发权。
以上两起败诉告诉我们,在爬取网站的时侯,需要限制自己的爬虫,遵守Robots协议和约束网路爬虫程序的速率;在使用数据的时侯,必须要遵循网站的知识产权。如果违犯了这种规定,很可能会吃官司,并且败诉机率相当高。
以上回答摘录自本人所写的书《Python 网络爬虫:从入门到实践》第一章:网络爬虫合法吗? 查看全部
希望本回答能解决楼主的问题。此回答摘录自本人所写的书《Python 网络爬虫:从入门到实践》第一章
从目前的情况来看,如果抓取的数据属于个人使用或科研范畴爬虫程序,基本不存在问题; 而假如数据属于商业赢利范畴,就要就事而论,有可能属于违法行为,也有可能不违规。
网络爬虫领域目前还属于拓荒阶段,虽然互联网世界早已通过自身的合同构建起一定的道德规范(Robots 协议),但法律部份还在完善和建立中。也就是说,现在这个领域暂时还是灰色地带。
Robots 协议
Robots协议(也称为爬虫协议)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎什么页面可以抓取,哪些页面不能抓取。它是国际互联网界通行的道德规范,虽然没有写入法律,但是每一个爬虫都应当遵循这项合同。
下面以淘宝网的robots.txt为例:
这里仅截取部份,查看完整可以访问taobao.com/robots.txt
User-agent: Baiduspider #百度爬虫引擎
Allow: /article #允许访问/article.htm,/article/12345.com
Allow: /oshtml
Allow: /wenzhang
Disallow: /product/ #禁止访问/product/12345.com
Disallow: / #禁止了访问除Allow规定页面的其他所有页面
User-Agent: Googlebot #谷歌爬虫引擎
Allow: /article
Allow: /oshtml
Allow: /product #允许访问/product.htm,/product/12345.com
Allow: /spu
Allow: /dianpu
Allow: /wenzhang
Allow: /oversea
Disallow: /
在前面的robots文件中,淘宝网对用户代理为百度爬虫引擎进行规定。
以”Allow”项的值开头的URL 是容许robot访问的。例如,”Allow: /article”允许百度爬虫引擎访问”/article.htm,/article/12345.com”等等。
以Disallow项为开头的链接是不容许百度爬虫引擎访问的。例如,”Disallow: /product/”不容许百度爬虫引擎访问 ”/product/12345.com” 等等。
最后一行,”Disallow: /”则严禁了百度爬虫访问不仅”Allow”规定页面的其他所有页面。
因此,当你在百度搜索“淘宝”的时侯,搜索结果下方的篆字会出现:“由于该网站的robots.txt文件存在限制指令(限制搜索引擎抓取),系统未能提供该页面的内容描述”。百度作为一个搜索引擎,良好地遵循了淘宝网的 robot.txt 协议,所以你是不能从百度上搜索到天猫内部的产品信息的。
淘宝的Robots协议对微软爬虫的待遇则不一样,和百度爬虫不同的是,它容许微软爬虫爬取产品的页面,”Allow: /product”。因此,当你在微软搜索“淘宝 iphone7”的时侯,可以搜索到天猫中的产品。
因此,当你爬取网站数据时,无论你是否仅仅用来个人使用,都应当遵循robots协议。
2. 网络爬虫的约束
除了上述的 Robot 协议之外,我们使用网路爬虫的时侯要对自己进行约束:过于快速或则频密的网络爬虫就会对服务器形成巨大的压力,网站可能封锁你的IP,甚至采取进一步的法律行动。
各大互联网大鳄也早已开始调集资源,限制爬虫,保护真正用户的流量和降低有价值数据的流失。
2007年,爱帮网借助垂直搜索技术获取了大众点评网上的商户简介和消费者点评爬虫程序,并且直接大量使用,于是大众点评网多次要求爱帮停止使用大众点评网的内容。而爱帮网则以自己是垂直搜索网站为由,拒绝停止抓取大众点评网上的内容,并且指责大众点评网对那些内容所享有的著作权。为此,双方开打了两场官司。2011年1月,北京海淀法院作出裁定:爱帮网侵害大众点评网著作权创立,爱帮网应该停止侵权并赔付大众点评网经济损失和诉讼必要开支。
2013年10月,百度诉360违背Robots协议,百度方面觉得,360违背了Robots协议,擅自抓取、复制百度网站内容并生成快照向用户提供。2014年08月07日,北京市第一中级人民法院做出二审裁定,法院觉得被告奇虎360的行为违背了《反不正当竞争法》相关规定,应赔付上诉百度公司70万元。
虽然说,大众点评上的点评数据,百度知道的问答由用户创建而非企业,但是搭建平台须要投入营运、技术和人力成本,那么平台拥有对数据的所有权,使用权和分发权。
以上两起败诉告诉我们,在爬取网站的时侯,需要限制自己的爬虫,遵守Robots协议和约束网路爬虫程序的速率;在使用数据的时侯,必须要遵循网站的知识产权。如果违犯了这种规定,很可能会吃官司,并且败诉机率相当高。
以上回答摘录自本人所写的书《Python 网络爬虫:从入门到实践》第一章:网络爬虫合法吗?
网络爬虫可以爬到什么有用行业数据?
采集交流 • 优采云 发表了文章 • 0 个评论 • 254 次浏览 • 2020-05-10 08:02
网络爬虫可以按照你的不同需求,选择爬取对象、爬取数组进行爬取(必须是公开数据)爬虫软件数据,比如:
电商顾客,我们采集的数据信息主要为商品信息数据、商品评论信息数据、区域库存价钱数据、电商舆情数据等。
金融行业顾客,采集主要的信息为公开的顾客信息、投融资信息、金融舆情信息、市场数据、公开的财务报表、股票、基金、利率等信息。
在网络舆情方面,采集主要信息为综合峰会、新闻门户、知识问答、自媒体网站、社交平台等网路媒体上的相关舆情信息。
在机票采集方面:包含日期、航空公司、航班号、经济舱价钱、经济舱折扣、公务舱价钱、公务舱折扣、税费、附加费、机 型、起飞城市三字码、到达城市三字码、起飞时间等所有相关信息。
题主所说到的行业数据爬虫软件数据,可以依照具体需求选择网站进行定向爬取。
我给题主分享一些国内外公开数据平台,在这种平台里其实有你须要的资源:
【Open Data】国外开放数据中心及政府数据开放平台汇总
最全的中国开放数据(open data)及政府数据开放平台汇总
当然数据采集不仅仅是这几个方面,更多的相关知识也可以在我们官网获得。 查看全部
爬虫采集数据称作网路数据,是指非传统数据源,这种类型的数据可以是结构化的,也可以是非结构化的(更有可能的),可以由网路链接,文本数据,数据表,图像,视频等组成。
网络爬虫可以按照你的不同需求,选择爬取对象、爬取数组进行爬取(必须是公开数据)爬虫软件数据,比如:
电商顾客,我们采集的数据信息主要为商品信息数据、商品评论信息数据、区域库存价钱数据、电商舆情数据等。
金融行业顾客,采集主要的信息为公开的顾客信息、投融资信息、金融舆情信息、市场数据、公开的财务报表、股票、基金、利率等信息。
在网络舆情方面,采集主要信息为综合峰会、新闻门户、知识问答、自媒体网站、社交平台等网路媒体上的相关舆情信息。
在机票采集方面:包含日期、航空公司、航班号、经济舱价钱、经济舱折扣、公务舱价钱、公务舱折扣、税费、附加费、机 型、起飞城市三字码、到达城市三字码、起飞时间等所有相关信息。
题主所说到的行业数据爬虫软件数据,可以依照具体需求选择网站进行定向爬取。
我给题主分享一些国内外公开数据平台,在这种平台里其实有你须要的资源:
【Open Data】国外开放数据中心及政府数据开放平台汇总
最全的中国开放数据(open data)及政府数据开放平台汇总
当然数据采集不仅仅是这几个方面,更多的相关知识也可以在我们官网获得。
《Python3网络爬虫开发实战》来了!
采集交流 • 优采云 发表了文章 • 0 个评论 • 304 次浏览 • 2020-05-09 08:03
嗨~ 给你们重磅推荐一本新书!还未上市前就早已再版 3 次的 Python 爬虫书!那么它就是由静觅博客博主崔庆才所作的《Python3网络爬虫开发实战》!!!
本书《Python3网络爬虫开发实战》全面介绍了借助 Python3 开发网路爬虫的知识,书中首先详尽介绍了各类类型的环境配置过程和爬虫基础知识,还讨论了urllib、requests等恳请库和Beautiful Soup、XPath、pyquery等解析库以及文本和各种数据库的储存方式,另外本书通过多个真实新鲜案例介绍了剖析Ajax进行数据爬取,Selenium和Splash进行动态网站爬取的过程,接着又分享了一些切实可行的爬虫方法,比如使用代理爬取和维护动态代理池的方式、ADSL拨号代理的使用、各类验证码(图形、极验、点触、宫格等)的破解方式、模拟登陆网站爬取的方式及Cookies 池的维护等等。
此外,本书的内容还远远不止这种爬虫软件开发,作者还结合联通互联网的特征阐述了使用Charles、mitmdump、Appium等多种工具实现App 抓包剖析、加密参数插口爬取、微信同学圈爬取的方式。此外本书还详尽介绍了pyspider框架、Scrapy框架的使用和分布式爬虫的知识,另外对于优化及布署工作,本书还包括Bloom Filter效率优化、Docker和Scrapyd爬虫布署、分布式爬虫管理框架Gerapy的分享。
全书共604页,足足两斤重呢~ 定价为99元!
看书就先看看谁写的嘛,我们来了解一下~
崔庆才,静觅博客博主(),博客 Python 爬虫博文已过百万,北京航空航天大学硕士,微软小冰大数据工程师,有多个小型分布式爬虫项目经验,乐于技术分享,文章通俗易懂 ^_^
附皂片一张 ~(@^_^@)~
呕心沥血设计的宣传图也得放一下~
书是好是坏,得使专家看评一评呀,那么下边就是几位专家的精彩评论,快来瞧瞧吧~
在互联网软件开发工程师的分类中,爬虫工程师是极其重要的。爬虫工作常常是一个公司核心业务举办的基础,数据抓取出来,才有后续的加工处理和最终诠释。此时数据的抓取规模、稳定性、实时性、准确性就变得十分重要。早期的互联网充分开放互联,数据获取的难度太小。随着各大公司对数据资产日渐看重,反爬水平也在不断提升,各种新技术不断给爬虫软件提出新的课题。本书作者对爬虫的各个领域都有深刻研究,书中阐述了Ajax数据的抓取、动态渲染页面的抓取、验证码识别、模拟登陆等中级话题,同时也结合联通互联网的特征阐述了App的抓取等。更重要的是,本书提供了大量源码,可以帮助读者更好地理解相关内容。强烈推荐给诸位技术爱好者阅读!
——梁斌,八友科技总经理
数据既是现今大数据剖析的前提,也是各类人工智能应用场景的基础。得数据者得天下,会爬虫者踏遍天下也不怕!一册在手,让小白到老司机都能有所收获!
——李舟军,北京航空航天大学院士,博士生导师
本书从爬虫入门到分布式抓取,详细介绍了爬虫技术的各个要点,并针对不同的场景提出了对应的解决方案。另外,书中通过大量的实例来帮助读者更好地学习爬虫技术,通俗易懂,干货满满。强烈推荐给你们!
——宋睿华,微软小冰首席科学家
有人说中国互联网的带宽全给各类爬虫抢占了,这说明网路爬虫的重要性以及中国互联网数据封闭垄断的现况。爬是一种能力,爬是为了不爬。
——施水才爬虫软件开发,北京拓尔思信息技术股份有限公司总裁 查看全部
嗨~ 给你们重磅推荐一本新书!还未上市前就早已再版 3 次的 Python 爬虫书!那么它就是由静觅博客博主崔庆才所作的《Python3网络爬虫开发实战》!!!
本书《Python3网络爬虫开发实战》全面介绍了借助 Python3 开发网路爬虫的知识,书中首先详尽介绍了各类类型的环境配置过程和爬虫基础知识,还讨论了urllib、requests等恳请库和Beautiful Soup、XPath、pyquery等解析库以及文本和各种数据库的储存方式,另外本书通过多个真实新鲜案例介绍了剖析Ajax进行数据爬取,Selenium和Splash进行动态网站爬取的过程,接着又分享了一些切实可行的爬虫方法,比如使用代理爬取和维护动态代理池的方式、ADSL拨号代理的使用、各类验证码(图形、极验、点触、宫格等)的破解方式、模拟登陆网站爬取的方式及Cookies 池的维护等等。
此外,本书的内容还远远不止这种爬虫软件开发,作者还结合联通互联网的特征阐述了使用Charles、mitmdump、Appium等多种工具实现App 抓包剖析、加密参数插口爬取、微信同学圈爬取的方式。此外本书还详尽介绍了pyspider框架、Scrapy框架的使用和分布式爬虫的知识,另外对于优化及布署工作,本书还包括Bloom Filter效率优化、Docker和Scrapyd爬虫布署、分布式爬虫管理框架Gerapy的分享。
全书共604页,足足两斤重呢~ 定价为99元!
看书就先看看谁写的嘛,我们来了解一下~
崔庆才,静觅博客博主(),博客 Python 爬虫博文已过百万,北京航空航天大学硕士,微软小冰大数据工程师,有多个小型分布式爬虫项目经验,乐于技术分享,文章通俗易懂 ^_^
附皂片一张 ~(@^_^@)~
呕心沥血设计的宣传图也得放一下~
书是好是坏,得使专家看评一评呀,那么下边就是几位专家的精彩评论,快来瞧瞧吧~
在互联网软件开发工程师的分类中,爬虫工程师是极其重要的。爬虫工作常常是一个公司核心业务举办的基础,数据抓取出来,才有后续的加工处理和最终诠释。此时数据的抓取规模、稳定性、实时性、准确性就变得十分重要。早期的互联网充分开放互联,数据获取的难度太小。随着各大公司对数据资产日渐看重,反爬水平也在不断提升,各种新技术不断给爬虫软件提出新的课题。本书作者对爬虫的各个领域都有深刻研究,书中阐述了Ajax数据的抓取、动态渲染页面的抓取、验证码识别、模拟登陆等中级话题,同时也结合联通互联网的特征阐述了App的抓取等。更重要的是,本书提供了大量源码,可以帮助读者更好地理解相关内容。强烈推荐给诸位技术爱好者阅读!
——梁斌,八友科技总经理
数据既是现今大数据剖析的前提,也是各类人工智能应用场景的基础。得数据者得天下,会爬虫者踏遍天下也不怕!一册在手,让小白到老司机都能有所收获!
——李舟军,北京航空航天大学院士,博士生导师
本书从爬虫入门到分布式抓取,详细介绍了爬虫技术的各个要点,并针对不同的场景提出了对应的解决方案。另外,书中通过大量的实例来帮助读者更好地学习爬虫技术,通俗易懂,干货满满。强烈推荐给你们!
——宋睿华,微软小冰首席科学家
有人说中国互联网的带宽全给各类爬虫抢占了,这说明网路爬虫的重要性以及中国互联网数据封闭垄断的现况。爬是一种能力,爬是为了不爬。
——施水才爬虫软件开发,北京拓尔思信息技术股份有限公司总裁
分布式网路爬虫关键技术剖析与实现
采集交流 • 优采云 发表了文章 • 0 个评论 • 360 次浏览 • 2020-05-09 08:02
分布式网路爬虫关键技术剖析与实现——分布式网路爬虫体系结构设计 分布式网路爬虫体系结构设计 分布式网路爬虫关键技术剖析与实现?一、 研究所属范围分布式网路爬虫包含多个爬虫, 每个爬虫须要完成的任务和单个的爬行器类似, 它们从互联 网上下载网页,并把网页保存在本地的c盘,从中抽取 URL 并顺着这种 URL 的指向继续爬 行。由于并行爬行器须要分割下载任务,可能爬虫会将自己抽取的 URL 发送给其他爬虫。 这些爬虫可能分布在同一个局域网之中,或者分散在不同的地理位置。根据爬虫的分散程度不同,可以把分布式爬行器分成以下两大类: 1、基于局域网分布式网路爬虫:这种分布式爬行器的所有爬虫在同一个局域网里运行,通过高 速的网路联接互相通讯。这些爬虫通过同一个网路去访问外部互联网,下载网页,所有的网 络负载都集中在她们所在的那种局域网的出口上。 由于局域网的带宽较高, 爬虫之间的通讯 的效率能否得到保证; 但是网路出口的总带宽上限是固定的, 爬虫的数目会遭到局域网出口 带宽的限制。 2、基于广域网分布式网路爬虫:当并行爬行器的爬虫分别运行在不同地理位置(或网路位置), 我们称这些并行爬行器为分布式爬行器。
例如,分布式爬行器的爬虫可能坐落中国,日本, 和英国,分别负责下载这三地的网页;或者坐落 CHINANET,CERNET,CEINET,分别负责 下载这三个网路的中的网页。分布式爬行器的优势在于可以子在一定程度上分散网路流量, 减小网路出口的负载。如果爬虫分布在不同的地理位置(或网路位置),需要间隔多长时间 进行一次互相通讯就成为了一个值得考虑的问题。 爬虫之间的通信带宽可能是有限的, 通常 需要通过互联网进行通讯。 在实际应用中, 基于局域网分布式网路爬虫应用的更广一些, 而基于广域网的爬虫因为 实现复杂, 设计和实现成本偏高, 一般只有实力雄厚和采集任务较重的大公司才能使用这些 爬虫。本论文所设计的爬虫就是基于局域网分布式网路爬虫。二、分布式网路爬虫整体剖析分布式网路爬虫的整体设计重点应当在于爬虫怎样进行通讯。目前分布式网 络爬虫按通讯方法不同分布式网络爬虫可以分为主从模式、 自治模式与混和模式 三种。主从模式是指由一台主机作为控制节点负责所有运行网路爬虫的主机进行管理, 爬虫只 需要从控制节点哪里接收任务, 并把新生成任务递交给控制节点就可以了, 在这个过程中不 必与其他爬虫通讯,这种方法实现简单利于管理。
而控制节点则须要与所有爬虫进行通讯, 它须要一个地址列表来保存系统中所有爬虫的信息。 当系统中的爬虫数目发生变化时, 协调 者须要更新地址列表里的数据, 这一过程对于系统中的爬虫是透明的。 但是随着爬虫网页数 量的降低。 控制节点会成为整个系统的困局而造成整个分布式网路爬虫系统性能增长。 主从 模式的整体结构图:自治模式是指系统中没有协调者,所有的爬虫都必须互相通讯,比主从模式 下爬虫要复杂一些。自治模式的通讯方法可以使用全联接通讯或环型通讯。全连 接通讯是指所用爬虫都可以互相发送信息, 使用这些方法的每位网络爬虫会维护 一个地址列表,表中储存着整个系统中所有爬虫的位置,每次通讯时可以直接把 数据发送给须要此数据的爬虫。当系统中的爬虫数目发生变化时,每个爬虫的地 址列表都须要进行更新。环形通讯是指爬虫在逻辑上构成一个环形网,数据在环 上按顺时针或逆时针双向传输, 每个爬虫的地址列表中只保存其前驱和后继的信 息。爬虫接收到数据然后判定数据是否是发送给自己的,如果数据不是发送给自 己的,就把数据转发给后继;如果数据是发送给自己的,就不再发送。假设整个 系统中有 n 个爬虫, 当系统中的爬虫数目发生变化时, 系统中只有 n-1 个爬虫的 地址列表须要进行更新。
混合模式是结合前面两种模式的特性的一种折中模式。该模式所有的爬虫都可以 相互通讯同时都具有任务分配功能。不过所有爬虫中有个特殊的爬虫,该爬虫主 要功能对早已经过爬虫任务分配后未能分配的任务进行集中分配。 使用这个方法 的每位网路爬虫只需维护自己采集范围的地址列表。 而特殊爬虫需不仅保存自己 采集范围的地址列表外还保存须要进行集中分配的地址列表。 混合模式的整体结 构图:三、大型分布式网路爬虫体系结构图: 大型分布式网路爬虫体系结构图:从这种图可以看出,分布式网路爬虫是一项非常复杂系统。需要考虑好多方面诱因。性 能可以说是它这重要的指标。当然硬件层面的资源也是必须的。不过不在本系列考虑范围。 从上篇开始, 我将从单机网路爬虫一步步介绍我们须要考虑的问题的解决方案。 如果你们有 更好的解决方案。欢迎指教。 吉日的一句话说的太有道理, 一个人一辈子只能做好几件事。 希望你们支持我的这个系 列。谈谈网路爬虫设计中的问题?网络蜘蛛现今开源的早已有好几个了,Larbin,Nutch,Heritrix 都各有用户之地,要做 一个自己的爬虫要解决很多个问题分词技术 爬虫,比如调度算法、更新策略、分布式存储等,我们来一一 看一下。
一个爬虫要做的事主要有以下这种 1. 2. 3. 从一个网页入口,分析链接,一层一层的遍历,或者从一组网页入口,或者 从一个 rss 源列表开始爬 rss; 获取每位页面的源码保存在c盘或则数据库里; 遍历抓出来的网页进行处理,比如提取正文,消重等;4. 根据用途把处理后的文本进行索引、分类、聚类等操作。 以上是个人理解哦,呵呵。这些过程中,大约有如下问题 如何获取网页源或则 RSS 源 如果是通常的爬虫的话, 就是给几个入口页面, 然后沿着超链接以遍历图的算法一个页面一 个页面的爬,这种情况网页源极少,可以选择从 hao123 等网址大全的网站为入口开始爬。 如果做垂直搜索的话就人工去搜集一些这个行业的网站, 形成一个列表, 从这个列表开始爬。 如果是爬 RSS 的话,需要先搜集 RSS 源,现在大的门户的新闻频道和主流的博客系统都有 rss 的功能,可以先爬一遍网站,找出 rss 的链接,要获取每位链接的内容,分析是否是 rss 格式,如果是就把这个链接保存到 rss 源数据库里,以后就专门爬这个 rss 源的 rss。还有一 种就是人工来整理,一般 blog 的 rss 都是有规律的,主域名跟一个用户名旁边再跟上一个 rss 的固定页面,比如 ,这样就弄一个用户字典,拼接 rss 地址, 然后用程序去侦测是否有这个页面来整理出每位网站的 rss 源。
整理出 rss 源后再 人工设置 rss 源的权重及刷新时间间隔等。 如果源页面好多,如何用多线程去有效的调度处理, 如果源页面好多,如何用多线程去有效的调度处理,而不会相互等待或则重复处理 如果现今有 500 万个页面要去爬,肯定要用多线程或则分布式多进程去处理了。可以把页 面进行水平分割,每个线程处理一段儿,这样每位线程之间不需要同步,各自处理各自的就 行了。比如给这 500W 个页面分配一个自增 ID,2 个线程的话就让第一个线程去爬 1,3,5 的网页,第二个线程去爬 2,4,6 的网页,这样做空个线程间基本上能均衡,而且不会相 互等待,而且不会重复处理,也不会拉掉网页。每个线程一次取出 1w 个页面,并记录最高 的源页面 ID 号,处理完这一批后再从数据库里提取小于这个源页面 ID 号的下 1W 个页面, 直到抓取完本线程要处理的所有页面。1w 这个值按照机器的显存可做适当的调整。为了防 止抓了半截儿关机,所以要支持断点续抓,要为每位线程的处理进度保存状态,每取一批网 页都要记录本线程最大的网页 ID,记录到数据库里,进程重启后可以读取这个 ID,接着抓 后面的页面。 如何尽量的借助 CPU,尽量的不使线程处于等待、休眠、阻塞等空闲状态并且要尽量用少 ,尽量的不使线程处于等待、休眠、 的线程以降低上下文切换。
的线程以降低上下文切换。 爬虫有两个地方须要 IO 操作,抓网页的时侯须要通过网卡访问网路,抓到网页后要把内容 写到c盘或则数据库里。所以这两个部份要用异步 IO 操作,这样可以不用线程阻塞在那里 等待网页抓过来或则写完磁盘文件,网卡和硬碟都支持显存直接读取,大量的 IO 操作会在 硬件驱动的队列里排队,而不消耗任何 CPU。.net 的异步操作使用了线程池,不用自己频繁 的创建和销毁线程,减少了开支,所以线程模型不用考虑,IO 模型也不用考虑,.net 的异 步 IO 操作直接使用了完成端口,很高效了,内存模型也不需要考虑,整个抓取过程各线程不需要访问共享资源分词技术 爬虫,除了数据库里的源页面,各管各的,而且也是每位线程分段处理,可 以实现无锁编程。 如何不采集重复的网页 去重可以使用 king 总监的布隆过滤器,每个线程使用一个 bitarray,里面保存本批源页面先前 抓取的页面的哈希值情况,抓取出来的源页面剖析链接后,去这个 bitarray 里判定曾经有没 有抓过这个页面,没有的话就抓出来,抓过的话就不管了。假设一个源页面有 30 个链接把, 一批 10W 个源页面, 300w 个链接的 bitarray 应该也不会占很大显存。
所以有个五六个线程 同时处理也是没问题的。 抓出来的页面更快的保存保存到分布式文件系统还是保存在数据库里 如果保存到c盘, 可以每位域名创建一个文件夹, 凡是这个网站的页面都放在这个文件夹下, 只要文件名不一样,就不会出现冲突。如果把页面保存到c盘,数据库有自己的一套锁管理 机制,直接用 bulk copy 放数据库就行了。一般频繁的写c盘可能会导致 CPU 过高,而频繁 的写数据库 CPU 还好一些。而且 sqlserver2008 支持 filestream 类型的数组,在保存大文本字 段的时侯有挺好的性能,并且能够使用数据库的 API 来访问。所以我认为假如没有 GFS 那 样高效成熟的分布式文件系统的话还不如存 sqlserver 里面呢。 如何有效的依据网页的更新频度来调整爬虫的采集时间间隔 做爬虫要了解一些 HTTP 协议,如果要抓的网页支持 Last-Modified 或者 ETag 头,我们可以先 发个 head 请求来试探这个页面有没有变化来决定是否要重新抓取,但是很多网站根本就不 支持这个东西,所以使爬虫也太费力,让自己的网站也会损失更多的性能。这样我们就要自 己去标明每个源页面的更新时间间隔及权重,再依照这两个值去用一定的算法制订蜘蛛的更 新策略。
采集下来的数据做什么用 可以抓取一个行业的网站,在本地进行动词和索引,做成垂直搜索引擎。可以用一定的训练 算法对抓取出来的页面进行自动分类,做成新闻门户。也可以用死小风行的文本相似度算法处理 后进行文本降维处理。 如何不影响对方网站的性能 现在很多网站都被爬虫爬怕了, 因为有些蜘蛛弄住一个网站可劲儿的爬, 爬的人家网站的正 常用户都未能访问了。所以很多站长想了很多办法来对付爬虫,所以我们写爬虫也要遵守机器 人合同,控制单位时间内对一个网站的访问量。 查看全部
分布式网路爬虫关键技术剖析与实现——分布式网路爬虫体系结构设计 分布式网路爬虫体系结构设计 分布式网路爬虫关键技术剖析与实现?一、 研究所属范围分布式网路爬虫包含多个爬虫, 每个爬虫须要完成的任务和单个的爬行器类似, 它们从互联 网上下载网页,并把网页保存在本地的c盘,从中抽取 URL 并顺着这种 URL 的指向继续爬 行。由于并行爬行器须要分割下载任务,可能爬虫会将自己抽取的 URL 发送给其他爬虫。 这些爬虫可能分布在同一个局域网之中,或者分散在不同的地理位置。根据爬虫的分散程度不同,可以把分布式爬行器分成以下两大类: 1、基于局域网分布式网路爬虫:这种分布式爬行器的所有爬虫在同一个局域网里运行,通过高 速的网路联接互相通讯。这些爬虫通过同一个网路去访问外部互联网,下载网页,所有的网 络负载都集中在她们所在的那种局域网的出口上。 由于局域网的带宽较高, 爬虫之间的通讯 的效率能否得到保证; 但是网路出口的总带宽上限是固定的, 爬虫的数目会遭到局域网出口 带宽的限制。 2、基于广域网分布式网路爬虫:当并行爬行器的爬虫分别运行在不同地理位置(或网路位置), 我们称这些并行爬行器为分布式爬行器。
例如,分布式爬行器的爬虫可能坐落中国,日本, 和英国,分别负责下载这三地的网页;或者坐落 CHINANET,CERNET,CEINET,分别负责 下载这三个网路的中的网页。分布式爬行器的优势在于可以子在一定程度上分散网路流量, 减小网路出口的负载。如果爬虫分布在不同的地理位置(或网路位置),需要间隔多长时间 进行一次互相通讯就成为了一个值得考虑的问题。 爬虫之间的通信带宽可能是有限的, 通常 需要通过互联网进行通讯。 在实际应用中, 基于局域网分布式网路爬虫应用的更广一些, 而基于广域网的爬虫因为 实现复杂, 设计和实现成本偏高, 一般只有实力雄厚和采集任务较重的大公司才能使用这些 爬虫。本论文所设计的爬虫就是基于局域网分布式网路爬虫。二、分布式网路爬虫整体剖析分布式网路爬虫的整体设计重点应当在于爬虫怎样进行通讯。目前分布式网 络爬虫按通讯方法不同分布式网络爬虫可以分为主从模式、 自治模式与混和模式 三种。主从模式是指由一台主机作为控制节点负责所有运行网路爬虫的主机进行管理, 爬虫只 需要从控制节点哪里接收任务, 并把新生成任务递交给控制节点就可以了, 在这个过程中不 必与其他爬虫通讯,这种方法实现简单利于管理。
而控制节点则须要与所有爬虫进行通讯, 它须要一个地址列表来保存系统中所有爬虫的信息。 当系统中的爬虫数目发生变化时, 协调 者须要更新地址列表里的数据, 这一过程对于系统中的爬虫是透明的。 但是随着爬虫网页数 量的降低。 控制节点会成为整个系统的困局而造成整个分布式网路爬虫系统性能增长。 主从 模式的整体结构图:自治模式是指系统中没有协调者,所有的爬虫都必须互相通讯,比主从模式 下爬虫要复杂一些。自治模式的通讯方法可以使用全联接通讯或环型通讯。全连 接通讯是指所用爬虫都可以互相发送信息, 使用这些方法的每位网络爬虫会维护 一个地址列表,表中储存着整个系统中所有爬虫的位置,每次通讯时可以直接把 数据发送给须要此数据的爬虫。当系统中的爬虫数目发生变化时,每个爬虫的地 址列表都须要进行更新。环形通讯是指爬虫在逻辑上构成一个环形网,数据在环 上按顺时针或逆时针双向传输, 每个爬虫的地址列表中只保存其前驱和后继的信 息。爬虫接收到数据然后判定数据是否是发送给自己的,如果数据不是发送给自 己的,就把数据转发给后继;如果数据是发送给自己的,就不再发送。假设整个 系统中有 n 个爬虫, 当系统中的爬虫数目发生变化时, 系统中只有 n-1 个爬虫的 地址列表须要进行更新。
混合模式是结合前面两种模式的特性的一种折中模式。该模式所有的爬虫都可以 相互通讯同时都具有任务分配功能。不过所有爬虫中有个特殊的爬虫,该爬虫主 要功能对早已经过爬虫任务分配后未能分配的任务进行集中分配。 使用这个方法 的每位网路爬虫只需维护自己采集范围的地址列表。 而特殊爬虫需不仅保存自己 采集范围的地址列表外还保存须要进行集中分配的地址列表。 混合模式的整体结 构图:三、大型分布式网路爬虫体系结构图: 大型分布式网路爬虫体系结构图:从这种图可以看出,分布式网路爬虫是一项非常复杂系统。需要考虑好多方面诱因。性 能可以说是它这重要的指标。当然硬件层面的资源也是必须的。不过不在本系列考虑范围。 从上篇开始, 我将从单机网路爬虫一步步介绍我们须要考虑的问题的解决方案。 如果你们有 更好的解决方案。欢迎指教。 吉日的一句话说的太有道理, 一个人一辈子只能做好几件事。 希望你们支持我的这个系 列。谈谈网路爬虫设计中的问题?网络蜘蛛现今开源的早已有好几个了,Larbin,Nutch,Heritrix 都各有用户之地,要做 一个自己的爬虫要解决很多个问题分词技术 爬虫,比如调度算法、更新策略、分布式存储等,我们来一一 看一下。
一个爬虫要做的事主要有以下这种 1. 2. 3. 从一个网页入口,分析链接,一层一层的遍历,或者从一组网页入口,或者 从一个 rss 源列表开始爬 rss; 获取每位页面的源码保存在c盘或则数据库里; 遍历抓出来的网页进行处理,比如提取正文,消重等;4. 根据用途把处理后的文本进行索引、分类、聚类等操作。 以上是个人理解哦,呵呵。这些过程中,大约有如下问题 如何获取网页源或则 RSS 源 如果是通常的爬虫的话, 就是给几个入口页面, 然后沿着超链接以遍历图的算法一个页面一 个页面的爬,这种情况网页源极少,可以选择从 hao123 等网址大全的网站为入口开始爬。 如果做垂直搜索的话就人工去搜集一些这个行业的网站, 形成一个列表, 从这个列表开始爬。 如果是爬 RSS 的话,需要先搜集 RSS 源,现在大的门户的新闻频道和主流的博客系统都有 rss 的功能,可以先爬一遍网站,找出 rss 的链接,要获取每位链接的内容,分析是否是 rss 格式,如果是就把这个链接保存到 rss 源数据库里,以后就专门爬这个 rss 源的 rss。还有一 种就是人工来整理,一般 blog 的 rss 都是有规律的,主域名跟一个用户名旁边再跟上一个 rss 的固定页面,比如 ,这样就弄一个用户字典,拼接 rss 地址, 然后用程序去侦测是否有这个页面来整理出每位网站的 rss 源。
整理出 rss 源后再 人工设置 rss 源的权重及刷新时间间隔等。 如果源页面好多,如何用多线程去有效的调度处理, 如果源页面好多,如何用多线程去有效的调度处理,而不会相互等待或则重复处理 如果现今有 500 万个页面要去爬,肯定要用多线程或则分布式多进程去处理了。可以把页 面进行水平分割,每个线程处理一段儿,这样每位线程之间不需要同步,各自处理各自的就 行了。比如给这 500W 个页面分配一个自增 ID,2 个线程的话就让第一个线程去爬 1,3,5 的网页,第二个线程去爬 2,4,6 的网页,这样做空个线程间基本上能均衡,而且不会相 互等待,而且不会重复处理,也不会拉掉网页。每个线程一次取出 1w 个页面,并记录最高 的源页面 ID 号,处理完这一批后再从数据库里提取小于这个源页面 ID 号的下 1W 个页面, 直到抓取完本线程要处理的所有页面。1w 这个值按照机器的显存可做适当的调整。为了防 止抓了半截儿关机,所以要支持断点续抓,要为每位线程的处理进度保存状态,每取一批网 页都要记录本线程最大的网页 ID,记录到数据库里,进程重启后可以读取这个 ID,接着抓 后面的页面。 如何尽量的借助 CPU,尽量的不使线程处于等待、休眠、阻塞等空闲状态并且要尽量用少 ,尽量的不使线程处于等待、休眠、 的线程以降低上下文切换。
的线程以降低上下文切换。 爬虫有两个地方须要 IO 操作,抓网页的时侯须要通过网卡访问网路,抓到网页后要把内容 写到c盘或则数据库里。所以这两个部份要用异步 IO 操作,这样可以不用线程阻塞在那里 等待网页抓过来或则写完磁盘文件,网卡和硬碟都支持显存直接读取,大量的 IO 操作会在 硬件驱动的队列里排队,而不消耗任何 CPU。.net 的异步操作使用了线程池,不用自己频繁 的创建和销毁线程,减少了开支,所以线程模型不用考虑,IO 模型也不用考虑,.net 的异 步 IO 操作直接使用了完成端口,很高效了,内存模型也不需要考虑,整个抓取过程各线程不需要访问共享资源分词技术 爬虫,除了数据库里的源页面,各管各的,而且也是每位线程分段处理,可 以实现无锁编程。 如何不采集重复的网页 去重可以使用 king 总监的布隆过滤器,每个线程使用一个 bitarray,里面保存本批源页面先前 抓取的页面的哈希值情况,抓取出来的源页面剖析链接后,去这个 bitarray 里判定曾经有没 有抓过这个页面,没有的话就抓出来,抓过的话就不管了。假设一个源页面有 30 个链接把, 一批 10W 个源页面, 300w 个链接的 bitarray 应该也不会占很大显存。
所以有个五六个线程 同时处理也是没问题的。 抓出来的页面更快的保存保存到分布式文件系统还是保存在数据库里 如果保存到c盘, 可以每位域名创建一个文件夹, 凡是这个网站的页面都放在这个文件夹下, 只要文件名不一样,就不会出现冲突。如果把页面保存到c盘,数据库有自己的一套锁管理 机制,直接用 bulk copy 放数据库就行了。一般频繁的写c盘可能会导致 CPU 过高,而频繁 的写数据库 CPU 还好一些。而且 sqlserver2008 支持 filestream 类型的数组,在保存大文本字 段的时侯有挺好的性能,并且能够使用数据库的 API 来访问。所以我认为假如没有 GFS 那 样高效成熟的分布式文件系统的话还不如存 sqlserver 里面呢。 如何有效的依据网页的更新频度来调整爬虫的采集时间间隔 做爬虫要了解一些 HTTP 协议,如果要抓的网页支持 Last-Modified 或者 ETag 头,我们可以先 发个 head 请求来试探这个页面有没有变化来决定是否要重新抓取,但是很多网站根本就不 支持这个东西,所以使爬虫也太费力,让自己的网站也会损失更多的性能。这样我们就要自 己去标明每个源页面的更新时间间隔及权重,再依照这两个值去用一定的算法制订蜘蛛的更 新策略。
采集下来的数据做什么用 可以抓取一个行业的网站,在本地进行动词和索引,做成垂直搜索引擎。可以用一定的训练 算法对抓取出来的页面进行自动分类,做成新闻门户。也可以用死小风行的文本相似度算法处理 后进行文本降维处理。 如何不影响对方网站的性能 现在很多网站都被爬虫爬怕了, 因为有些蜘蛛弄住一个网站可劲儿的爬, 爬的人家网站的正 常用户都未能访问了。所以很多站长想了很多办法来对付爬虫,所以我们写爬虫也要遵守机器 人合同,控制单位时间内对一个网站的访问量。
网络爬虫简介
采集交流 • 优采云 发表了文章 • 0 个评论 • 312 次浏览 • 2020-05-09 08:01
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更时不时的称为网页追逐者),是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。
传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL装入队列,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要按照一定的网页剖析算法过滤与主题无关的链接,保留有用的链接并将其倒入等待抓取的URL队列。然后,它将按照一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。
另外,所有被爬虫抓取的网页将会被系统储存,进行一定的剖析、过滤,并构建索引,以便以后的查询和检索;对于聚焦爬虫来说,这一过程所得到的剖析结果还可能对之后的抓取过程给出反馈和指导。
以下为文章主要内容:
初见爬虫
使用Python中的Requests第三方库。在Requests的7个主要方式中,最常使用的就是get()方法,通过该方式构造一个向服务器恳求资源的Request对象,结果返回一个包含服务器资源的额Response对象。通过Response对象则可以获取恳求的返回状态、HTTP响应的字符串即URL对应的页面内容、页面的编码方法以及页面内容的二进制方式。
在了解get()方法之前我们先了解一下HTTP合同,通过对HTTP协议来理解我们访问网页这个过程究竟都进行了什么工作。
1.1 浅析HTTP协议
超文本传输协议(HTTP,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网路合同。所有的www文件都必须遵循这个标准。HTTP协议主要有几个特征:
支持客户/服务器模式
简单快捷:客服向服务器发出恳求,只须要传送恳求方式和路径。请求方式常用的有GET, HEAD, POST。每种方式规定了顾客与服务器联系的类型不同。由于HTTP协议简单,使得HTTP服务器的程序规模小,因而通讯速度快。
灵活:HTTP容许传输任意类型的数据对象。
无联接:无联接的涵义是限制每次联接恳求只处理一个恳求。服务器处理完顾客的恳求,收到顾客的应答后即断掉联接,这种方法可以节约传输时间。
无状态:HTTP合同是无状态合同。无状态是指合同对于事物处理没有记忆能力。缺少状态意味着假如后续处理须要上面的信息,则它必须重传,这样可能造成每次联接传送的数据量减小,另一方面,在服务器不需要原本信息时它的应答就较快。
爬取过程
首先浏览器领到网址以后先将主机名解析下来。如 则会将主机名 解析下来。
查找ip,根据主机名,会首先查找ip,首先查询hosts文件,成功则返回对应的ip地址,如果没有查询到,则去DNS服务器查询,成功就返回ip,否则会报告联接错误。
发送http请求,浏览器会把自身相关信息与恳求相关信息封装成HTTP请求 消息发送给服务器。
服务器处理恳求,服务器读取HTTP请求中的内容,在经过解析主机,解析站点名称,解析访问资源后,会查找相关资源,如果查找成功,则返回状态码200,失败才会返回大名鼎鼎的404了,在服务器检测到恳求不在的资源后,可以根据程序员设置的跳转到别的页面。所以有各类有个性的404错误页面。
服务器返回HTTP响应,浏览器得到返回数据后就可以提取数据,然后调用解析内核进行翻译,最后显示出页面。之后浏览器会对其引用的文件例如图片,css,js等文件不断进行上述过程,直到所有文件都被下载出来以后,网页都会显示下来。
HTTP请求,http请求由三部份组成,分别是:请求行、消息报头、请求正文。请求方式(所有方式全为小写)有多种,各个方式的解释如下:
GET恳求获取Request-URI所标示的资源
POST 在Request-URI所标示的资源后附加新的数据
HEAD 恳求获取由Request-URI所标示的资源的响应消息报头
PUT恳求服务器储存一个资源,并用Request-URI作为其标示
DELETE 恳求服务器删掉Request-URI所标示的资源
TRACE 恳求服务器回送收到的恳求信息,主要用于测试或确诊
CONNECT 保留将来使用
OPTIONS 恳求查询服务器的性能,或者查询与资源相关的选项和需求
GET方式应用举例:在浏览器的地址栏中输入网址的形式访问网页时,浏览器采用GET方式向服务器获取资源,eg:GET /form.html HTTP/1.1 (CRLF)
HTTP响应也是由三个部份组成,分别是:状态行、消息报头、响应正文。
状态行格式如下:HTTP-Version Status-Code Reason-Phrase CRLF,其中,HTTP-Version表示服务器HTTP合同的版本;Status-Code表示服务器发回的响应状态代码;Reason-Phrase表示状态代码的文本描述。
状态代码有三位数字组成,第一个数字定义了响应的类别,且有五种可能取值:
1xx:指示信息--表示恳求已接收,继续处理
2xx:成功--表示恳求已被成功接收、理解、接受
3xx:重定向--要完成恳求必须进行更进一步的操作
4xx:客户端错误--请求有句型错误或恳求未能实现
5xx:服务器端错误--服务器无法实现合法的恳求
常见状态代码、状态描述、说明:
200 OK//客户端恳求成功
400 Bad Request //客户端恳求有句型错误,不能被服务器所理解
401 Unauthorized //请求未经授权网络爬虫,这个状态代码必须和WWW-Authenticate报头域一起使用
403 Forbidden //服务器收到恳求,但是拒绝提供服务
404 Not Found //恳求资源不存在,eg:输入了错误的URL
500 Internal Server Error //服务器发生不可预期的错误
503 Server Unavailable //服务器当前不能处理客户端的恳求,一段时间后可能恢复正常。
eg:HTTP/1.1 200 OK (CRLF)
详细的HTTP合同可以参考这篇文章:
前面我们了解了HTTP合同,那么我们访问网页的过程,那么网页在是哪些样子的。爬虫眼里的网页又是哪些样子的。
网是静态的,但爬虫是动态的,所以爬虫的基本思想就是顺着网页(蜘蛛网的节点)上的链接的爬取有效信息。当然网页也有动态(一般用PHP或ASP等写成,例如用户登录界面就是动态网页)的,但若果一张蛛网摇摇欲坠,蜘蛛会倍感不这么安稳,所以动态网页的优先级通常会被搜索引擎排在静态网页的旁边。
知道了爬虫的基本思想,那么具体怎么操作呢?这得从网页的基本概念说起。一个网页有三大构成要素,分别是html文件、css文件和JavaScript文件。如果把一个网页看做一栋房屋,那么html相当于房屋壳体;css相当于瓷砖油墨,美化房屋外形内饰;JavaScript则相当于灯具家电浴场等,增加房屋的功能。从上述比喻可以看出,html才是网页的根本,毕竟瓷砖染料在市场上也有,家具家电都可以露天摆饰,而房屋壳体才是独一无二的。
下面就是一个简单网页的事例:
而在爬虫眼中网络爬虫,这个网页是这样的:
因此网页实质上就是超文本(hypertext),网页上的所有内容都是在形如“<>...</>”这样的标签之内的。如果我们要收集网页上的所有超链接,只需找寻所有标签中后面是"href="的字符串,并查看提取下来的字符串是否以"http"(超文本转换合同,https表示安全的http合同)开头即可。如果超链接不以"http"开头,那么该链接太可能是网页所在的本地文件或则ftp或smtp(文件或电邮转换合同),应该过滤掉。
在Python中我们使用Requests库中的方式来帮助我们实现对网页的恳求,从而达到实现爬虫的过程。
1.2 Requests库的7个主要方式:
最常用的方式get拿来实现一个简单的小爬虫,通过示例代码展示:
Robots协议
Robots协议(也称为爬虫协议、机器人合同等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎什么页面可以抓取,哪些页面不能抓取。通过几个小反例来剖析一下robots.txt中的内容,robots.txt默认放置于网站的根目录小,对于一个没有robots.txt文件的网站,默认是容许所有爬虫获取其网站内容的。
,
如果是商业利益我们是必须要遵循robots协议内容,否则会承当相应的法律责任。当只是个人玩转网页、练习则是建议遵循,提高自己编撰爬虫的友好程度。
网页解析
BeautifulSoup尝试化平静为神奇,通过定位HTML标签来低格和组织复杂的网路信息,用简单易用的Python对象为我们展示XML结构信息。
BeautifulSoup是解析、遍历、维护“标签树”的功能库。
3.1 BeautifulSoup的解析器
BeautifulSoup通过以上四种解析器来对我们获取的网页内容进行解析。使用官网的事例来看一下解析结果:
首先获取以上的一段HTML内容,我们通过BeautifulSoup解析然后,并且输出解析后的结果来对比一下:
查看全部
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更时不时的称为网页追逐者),是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。
传统爬虫从一个或若干初始网页的URL开始,获得初始网页上的URL,在抓取网页的过程中,不断从当前页面上抽取新的URL装入队列,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要按照一定的网页剖析算法过滤与主题无关的链接,保留有用的链接并将其倒入等待抓取的URL队列。然后,它将按照一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。
另外,所有被爬虫抓取的网页将会被系统储存,进行一定的剖析、过滤,并构建索引,以便以后的查询和检索;对于聚焦爬虫来说,这一过程所得到的剖析结果还可能对之后的抓取过程给出反馈和指导。
以下为文章主要内容:
初见爬虫
使用Python中的Requests第三方库。在Requests的7个主要方式中,最常使用的就是get()方法,通过该方式构造一个向服务器恳求资源的Request对象,结果返回一个包含服务器资源的额Response对象。通过Response对象则可以获取恳求的返回状态、HTTP响应的字符串即URL对应的页面内容、页面的编码方法以及页面内容的二进制方式。
在了解get()方法之前我们先了解一下HTTP合同,通过对HTTP协议来理解我们访问网页这个过程究竟都进行了什么工作。
1.1 浅析HTTP协议
超文本传输协议(HTTP,HyperText Transfer Protocol)是互联网上应用最为广泛的一种网路合同。所有的www文件都必须遵循这个标准。HTTP协议主要有几个特征:
支持客户/服务器模式
简单快捷:客服向服务器发出恳求,只须要传送恳求方式和路径。请求方式常用的有GET, HEAD, POST。每种方式规定了顾客与服务器联系的类型不同。由于HTTP协议简单,使得HTTP服务器的程序规模小,因而通讯速度快。
灵活:HTTP容许传输任意类型的数据对象。
无联接:无联接的涵义是限制每次联接恳求只处理一个恳求。服务器处理完顾客的恳求,收到顾客的应答后即断掉联接,这种方法可以节约传输时间。
无状态:HTTP合同是无状态合同。无状态是指合同对于事物处理没有记忆能力。缺少状态意味着假如后续处理须要上面的信息,则它必须重传,这样可能造成每次联接传送的数据量减小,另一方面,在服务器不需要原本信息时它的应答就较快。
爬取过程
首先浏览器领到网址以后先将主机名解析下来。如 则会将主机名 解析下来。
查找ip,根据主机名,会首先查找ip,首先查询hosts文件,成功则返回对应的ip地址,如果没有查询到,则去DNS服务器查询,成功就返回ip,否则会报告联接错误。
发送http请求,浏览器会把自身相关信息与恳求相关信息封装成HTTP请求 消息发送给服务器。
服务器处理恳求,服务器读取HTTP请求中的内容,在经过解析主机,解析站点名称,解析访问资源后,会查找相关资源,如果查找成功,则返回状态码200,失败才会返回大名鼎鼎的404了,在服务器检测到恳求不在的资源后,可以根据程序员设置的跳转到别的页面。所以有各类有个性的404错误页面。
服务器返回HTTP响应,浏览器得到返回数据后就可以提取数据,然后调用解析内核进行翻译,最后显示出页面。之后浏览器会对其引用的文件例如图片,css,js等文件不断进行上述过程,直到所有文件都被下载出来以后,网页都会显示下来。
HTTP请求,http请求由三部份组成,分别是:请求行、消息报头、请求正文。请求方式(所有方式全为小写)有多种,各个方式的解释如下:
GET恳求获取Request-URI所标示的资源
POST 在Request-URI所标示的资源后附加新的数据
HEAD 恳求获取由Request-URI所标示的资源的响应消息报头
PUT恳求服务器储存一个资源,并用Request-URI作为其标示
DELETE 恳求服务器删掉Request-URI所标示的资源
TRACE 恳求服务器回送收到的恳求信息,主要用于测试或确诊
CONNECT 保留将来使用
OPTIONS 恳求查询服务器的性能,或者查询与资源相关的选项和需求
GET方式应用举例:在浏览器的地址栏中输入网址的形式访问网页时,浏览器采用GET方式向服务器获取资源,eg:GET /form.html HTTP/1.1 (CRLF)
HTTP响应也是由三个部份组成,分别是:状态行、消息报头、响应正文。
状态行格式如下:HTTP-Version Status-Code Reason-Phrase CRLF,其中,HTTP-Version表示服务器HTTP合同的版本;Status-Code表示服务器发回的响应状态代码;Reason-Phrase表示状态代码的文本描述。
状态代码有三位数字组成,第一个数字定义了响应的类别,且有五种可能取值:
1xx:指示信息--表示恳求已接收,继续处理
2xx:成功--表示恳求已被成功接收、理解、接受
3xx:重定向--要完成恳求必须进行更进一步的操作
4xx:客户端错误--请求有句型错误或恳求未能实现
5xx:服务器端错误--服务器无法实现合法的恳求
常见状态代码、状态描述、说明:
200 OK//客户端恳求成功
400 Bad Request //客户端恳求有句型错误,不能被服务器所理解
401 Unauthorized //请求未经授权网络爬虫,这个状态代码必须和WWW-Authenticate报头域一起使用
403 Forbidden //服务器收到恳求,但是拒绝提供服务
404 Not Found //恳求资源不存在,eg:输入了错误的URL
500 Internal Server Error //服务器发生不可预期的错误
503 Server Unavailable //服务器当前不能处理客户端的恳求,一段时间后可能恢复正常。
eg:HTTP/1.1 200 OK (CRLF)
详细的HTTP合同可以参考这篇文章:
前面我们了解了HTTP合同,那么我们访问网页的过程,那么网页在是哪些样子的。爬虫眼里的网页又是哪些样子的。
网是静态的,但爬虫是动态的,所以爬虫的基本思想就是顺着网页(蜘蛛网的节点)上的链接的爬取有效信息。当然网页也有动态(一般用PHP或ASP等写成,例如用户登录界面就是动态网页)的,但若果一张蛛网摇摇欲坠,蜘蛛会倍感不这么安稳,所以动态网页的优先级通常会被搜索引擎排在静态网页的旁边。
知道了爬虫的基本思想,那么具体怎么操作呢?这得从网页的基本概念说起。一个网页有三大构成要素,分别是html文件、css文件和JavaScript文件。如果把一个网页看做一栋房屋,那么html相当于房屋壳体;css相当于瓷砖油墨,美化房屋外形内饰;JavaScript则相当于灯具家电浴场等,增加房屋的功能。从上述比喻可以看出,html才是网页的根本,毕竟瓷砖染料在市场上也有,家具家电都可以露天摆饰,而房屋壳体才是独一无二的。
下面就是一个简单网页的事例:
而在爬虫眼中网络爬虫,这个网页是这样的:
因此网页实质上就是超文本(hypertext),网页上的所有内容都是在形如“<>...</>”这样的标签之内的。如果我们要收集网页上的所有超链接,只需找寻所有标签中后面是"href="的字符串,并查看提取下来的字符串是否以"http"(超文本转换合同,https表示安全的http合同)开头即可。如果超链接不以"http"开头,那么该链接太可能是网页所在的本地文件或则ftp或smtp(文件或电邮转换合同),应该过滤掉。
在Python中我们使用Requests库中的方式来帮助我们实现对网页的恳求,从而达到实现爬虫的过程。
1.2 Requests库的7个主要方式:
最常用的方式get拿来实现一个简单的小爬虫,通过示例代码展示:
Robots协议
Robots协议(也称为爬虫协议、机器人合同等)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎什么页面可以抓取,哪些页面不能抓取。通过几个小反例来剖析一下robots.txt中的内容,robots.txt默认放置于网站的根目录小,对于一个没有robots.txt文件的网站,默认是容许所有爬虫获取其网站内容的。
,
如果是商业利益我们是必须要遵循robots协议内容,否则会承当相应的法律责任。当只是个人玩转网页、练习则是建议遵循,提高自己编撰爬虫的友好程度。
网页解析
BeautifulSoup尝试化平静为神奇,通过定位HTML标签来低格和组织复杂的网路信息,用简单易用的Python对象为我们展示XML结构信息。
BeautifulSoup是解析、遍历、维护“标签树”的功能库。
3.1 BeautifulSoup的解析器
BeautifulSoup通过以上四种解析器来对我们获取的网页内容进行解析。使用官网的事例来看一下解析结果:
首先获取以上的一段HTML内容,我们通过BeautifulSoup解析然后,并且输出解析后的结果来对比一下:
20款最常使用的网路爬虫工具推荐(2018)教程文件
采集交流 • 优采云 发表了文章 • 0 个评论 • 383 次浏览 • 2020-05-09 08:00
另外八爪鱼提供手动辨识验 证码以及代理 IP 切换功能,可以有效的防止网站防采集。 总之,八爪鱼可以满足用户最基本或中级的采集需求,而无需任何编程技能。2. HTTrack作为免费的网站爬虫软件,HTTrack 提供的功能十分适宜从互联网下载整个网站 到你的 PC。它提供了适用于 Windows,Linux,Sun Solaris 和其他 Unix 系统 的版本。它可以将一个站点或多个站点镜像在一起(使用共享链接)。你可以在 “设置选项”下下载网页时决定要同时打开的连接数。你可以从整个目录中获取 照片,文件,HTML 代码,更新当前镜像的网站并恢复中断的下载。精品文档精品文档据悉,HTTTrack 还提供代理支持,以通过可选身分验证最大限度地提升速率。 HTTrack 用作命令行程序,或通过 shell 用于私有(捕获)或专业(在线 Web 镜像)使用。 有了这样的说法,HTTrack 应该是首选,并且具有中级编程技能 的人更多地使用它。3、 ScraperScraper 是 Chrome 扩展程序,具有有限的数据提取功能,但它有助于进行在 线研究并将数据导入到 Google sheets。
此工具适用于初学者以及可以使用 OAuth 轻松将数据复制到剪贴板或储存到电子表格的专家。Scraper 是一个免 费的网路爬虫工具,可以在你的浏览器中正常工作,并手动生成较小的 XPath 来定义要抓取的 URL。4、OutWit Hub精品文档精品文档Outwit Hub 是一个 Firefox 添加件,它有两个目的:搜集信息和管理信息。它 可以分别用在网站上不同的部份提供不同的窗口条。还提供用户一个快速步入信 息的方式,虚拟移除网站上别的部份。 OutWit Hub 提供单一界面,可依照须要抓取微小或大量数据。OutWit Hub 允许你从浏览器本身抓取任何网页,甚至可以创建手动代理来提取数据并按照设 置对其进行低格。 OutWit Hub 大多功能都是免费的,能够深入剖析网站,自动搜集整理组织互联 网中的各项数据,并将网站信息分割开来,然后提取有效信息,形成可用的集合。 但是要手动提取精确数据就须要付费版本了,同时免费版一次提取的数据量也是 有限制的,如果须要大批量的操作,可以选择订购专业版。 5. ParseHub精品文档精品文档Parsehub 是一个太棒的网路爬虫,支持从使用 AJAX 技术,JavaScript,cookie 等的网站收集数据。
它的机器学习技术可以读取,分析之后将 Web 文档转换为 相关数据。 Parsehub 的桌面应用程序支持 Windows,Mac OS X 和 Linux 等系统,或者 你可以使用浏览器中外置的 Web 应用程序。 作为免费软件,你可以在 Parsehub 中设置不超过五个 publice 项目。付费版本 允许你创建起码 20private 项目来抓取网站。6. ScrapinghubScrapinghub 是一种基于云的数据提取工具,可帮助数千名开发人员获取有价 值的数据。它的开源视觉抓取工具,允许用户在没有任何编程知识的情况下抓取 网站。 Scrapinghub 使用 Crawlera,一家代理 IP 第三方平台,支持绕开防采集对策。 它使用户就能从多个 IP 和位置进行网页抓取,而无需通过简单的 HTTP API 进 行代理管理。 Scrapinghub 将整个网页转换为有组织的内容。如果其爬虫工具难以满足你的 要求,其专家团队可以提供帮助。。精品文档精品文档7. Dexi.io作为基于浏览器的网路爬虫,Dexi.io 允许你从任何网站基于浏览器抓取数据, 并提供三种类型的爬虫来创建采集任务。
免费软件为你的网路抓取提供匿名 Web 代理服务器,你提取的数据将在存档数据之前在 Dexi.io 的服务器上托管 两周,或者你可以直接将提取的数据导入到 JSON 或 CSV 文件。它提供付费服 务,以满足你获取实时数据的需求。8. Webhose.ioWebhose.io 使用户才能将来自世界各地的在线资源抓取的实时数据转换为各 种标准的格式。通过此 Web 爬网程序,你可以使用囊括各类来源的多个过滤器 来抓取数据并进一步提取多种语言的关键字。 你可以将删掉的数据保存为 XML,JSON 和 RSS 格式。并且容许用户从其存档 访问历史数据。此外,webhose.io 支持最多 80 种语言及其爬行数据结果。用 户可以轻松索引和搜索 Webhose.io 抓取的结构化数据。精品文档精品文档总的来说,Webhose.io 可以满足用户的基本爬行要求。9.Import.io用户只需从特定网页导出数据并将数据导入到 CSV 即可产生自己的数据集。 你可以在几分钟内轻松抓取数千个网页,而无需编撰任何代码,并按照你的要求 构建 1000 多个 API。公共 API 提供了强悍而灵活的功能来以编程方法控制 Import.io 并获得对数据的手动访问,Import.io 通过将 Web 数据集成到你自己 的应用程序或网站中,只需点击几下就可以轻松实现爬网。
为了更好地满足用户的爬行需求,它还提供适用于 Windows,Mac OS X 和 Linux 的免费应用程序,以建立数据提取器和抓取工具,下载数据并与在线账户 同步。此外,用户还可以每周网络爬虫软件下载,每天或每小时安排抓取任务。10.80legs精品文档精品文档80legs 是一个功能强悍的网路抓取工具,可以按照自定义要求进行配置。它支 持获取大量数据以及立刻下载提取数据的选项。80legs 提供高性能的 Web 爬 行,可以快速工作并在几秒钟内获取所需的数据11. Content GraberContent Graber 是一款面向企业的网路爬行软件。它容许你创建独立的 Web 爬网代理。它可以从几乎任何网站中提取内容,并以你选择的格式将其保存为结 构化数据,包括 Excel 报告,XML,CSV 和大多数数据库。它更适宜具有中级编程技能的人,因为它为有须要的人提供了许多强悍的脚本编 辑和调试界面。允许用户使用 C#或 VB.NET 调试或编撰脚本来编程控制爬网过 程。例如,Content Grabber 可以与 Visual Studio 2013 集成,以便按照用户 的特定需求为中级且机智的自定义爬虫提供最强悍的脚本编辑,调试和单元测 试。
精品文档精品文档12. UiPathUiPath 是一款用于免费网路抓取的机器人过程自动化软件。它可以手动从大多 数第三方应用程序中抓取 Web 和桌面数据。如果运行 Windows 系统,则可以 安装机械手过程自动化软件。Uipath 能够跨多个网页提取表格和基于模式的数 据。 Uipath 提供了用于进一步爬行的外置工具。处理复杂的 UI 时,此方式十分有效。 Screen Scraping Tool 可以处理单个文本元素,文本组和文本块,例如表格格 式的数据提取。 此外,创建智能 Web 代理不需要编程,但你内部的.NET 黑客可以完全控制数 据。精品文档精品文档其实,在里面我提及的爬虫可以满足大多数用户的基本爬行需求,这些工具中各 自的功能依然存在好多差别,大家可以按照自己的需求选择合适的。八爪鱼——90 万用户选择的网页数据采集器。 1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。精品文档精品文档2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。精品文档 查看全部
精品文档20 款最常使用的网路爬虫工具推荐 (2018)网络爬虫在现今的许多领域得到广泛应用。它的作用是从任何网站获取特定的或 更新的数据并储存出来。网络爬虫工具越来越为人所熟知,因为网路爬虫简化并 自动化了整个爬取过程,使每个人都可以轻松访问网站数据资源。使用网路爬虫 工具可以使人们免予重复打字或复制粘贴,我们可以太轻松的去采集网页上的数 据。此外,这些网路爬虫工具可以使用户就能以有条不紊和快速的抓取网页,而 无需编程并将数据转换为符合其需求的各类格式。在这篇文章中网络爬虫软件下载,我将介绍目前比较流行的 20 款网路爬虫工具供你参考。希望你 能找到最适宜你需求的工具。1. 八爪鱼八爪鱼是一款免费且功能强悍的网站爬虫,用于从网站上提取你须要的几乎所有 类型的数据。你可以使用八爪鱼来采集市面上几乎所有的网站。八爪鱼提供两种精品文档精品文档采集模式 - 简易模式和自定义采集模式,非程序员可以快速习惯使用八爪鱼。 下载免费软件后,其可视化界面容许你从网站上获取所有文本,因此你可以下载 几乎所有网站内容并将其保存为结构化格式,如 EXCEL,TXT,HTML 或你的数 据库。 你可以使用其外置的正则表达式工具从复杂的网站布局中提取许多棘手网站的 数据,并使用 XPath 配置工具精确定位 Web 元素。
另外八爪鱼提供手动辨识验 证码以及代理 IP 切换功能,可以有效的防止网站防采集。 总之,八爪鱼可以满足用户最基本或中级的采集需求,而无需任何编程技能。2. HTTrack作为免费的网站爬虫软件,HTTrack 提供的功能十分适宜从互联网下载整个网站 到你的 PC。它提供了适用于 Windows,Linux,Sun Solaris 和其他 Unix 系统 的版本。它可以将一个站点或多个站点镜像在一起(使用共享链接)。你可以在 “设置选项”下下载网页时决定要同时打开的连接数。你可以从整个目录中获取 照片,文件,HTML 代码,更新当前镜像的网站并恢复中断的下载。精品文档精品文档据悉,HTTTrack 还提供代理支持,以通过可选身分验证最大限度地提升速率。 HTTrack 用作命令行程序,或通过 shell 用于私有(捕获)或专业(在线 Web 镜像)使用。 有了这样的说法,HTTrack 应该是首选,并且具有中级编程技能 的人更多地使用它。3、 ScraperScraper 是 Chrome 扩展程序,具有有限的数据提取功能,但它有助于进行在 线研究并将数据导入到 Google sheets。
此工具适用于初学者以及可以使用 OAuth 轻松将数据复制到剪贴板或储存到电子表格的专家。Scraper 是一个免 费的网路爬虫工具,可以在你的浏览器中正常工作,并手动生成较小的 XPath 来定义要抓取的 URL。4、OutWit Hub精品文档精品文档Outwit Hub 是一个 Firefox 添加件,它有两个目的:搜集信息和管理信息。它 可以分别用在网站上不同的部份提供不同的窗口条。还提供用户一个快速步入信 息的方式,虚拟移除网站上别的部份。 OutWit Hub 提供单一界面,可依照须要抓取微小或大量数据。OutWit Hub 允许你从浏览器本身抓取任何网页,甚至可以创建手动代理来提取数据并按照设 置对其进行低格。 OutWit Hub 大多功能都是免费的,能够深入剖析网站,自动搜集整理组织互联 网中的各项数据,并将网站信息分割开来,然后提取有效信息,形成可用的集合。 但是要手动提取精确数据就须要付费版本了,同时免费版一次提取的数据量也是 有限制的,如果须要大批量的操作,可以选择订购专业版。 5. ParseHub精品文档精品文档Parsehub 是一个太棒的网路爬虫,支持从使用 AJAX 技术,JavaScript,cookie 等的网站收集数据。
它的机器学习技术可以读取,分析之后将 Web 文档转换为 相关数据。 Parsehub 的桌面应用程序支持 Windows,Mac OS X 和 Linux 等系统,或者 你可以使用浏览器中外置的 Web 应用程序。 作为免费软件,你可以在 Parsehub 中设置不超过五个 publice 项目。付费版本 允许你创建起码 20private 项目来抓取网站。6. ScrapinghubScrapinghub 是一种基于云的数据提取工具,可帮助数千名开发人员获取有价 值的数据。它的开源视觉抓取工具,允许用户在没有任何编程知识的情况下抓取 网站。 Scrapinghub 使用 Crawlera,一家代理 IP 第三方平台,支持绕开防采集对策。 它使用户就能从多个 IP 和位置进行网页抓取,而无需通过简单的 HTTP API 进 行代理管理。 Scrapinghub 将整个网页转换为有组织的内容。如果其爬虫工具难以满足你的 要求,其专家团队可以提供帮助。。精品文档精品文档7. Dexi.io作为基于浏览器的网路爬虫,Dexi.io 允许你从任何网站基于浏览器抓取数据, 并提供三种类型的爬虫来创建采集任务。
免费软件为你的网路抓取提供匿名 Web 代理服务器,你提取的数据将在存档数据之前在 Dexi.io 的服务器上托管 两周,或者你可以直接将提取的数据导入到 JSON 或 CSV 文件。它提供付费服 务,以满足你获取实时数据的需求。8. Webhose.ioWebhose.io 使用户才能将来自世界各地的在线资源抓取的实时数据转换为各 种标准的格式。通过此 Web 爬网程序,你可以使用囊括各类来源的多个过滤器 来抓取数据并进一步提取多种语言的关键字。 你可以将删掉的数据保存为 XML,JSON 和 RSS 格式。并且容许用户从其存档 访问历史数据。此外,webhose.io 支持最多 80 种语言及其爬行数据结果。用 户可以轻松索引和搜索 Webhose.io 抓取的结构化数据。精品文档精品文档总的来说,Webhose.io 可以满足用户的基本爬行要求。9.Import.io用户只需从特定网页导出数据并将数据导入到 CSV 即可产生自己的数据集。 你可以在几分钟内轻松抓取数千个网页,而无需编撰任何代码,并按照你的要求 构建 1000 多个 API。公共 API 提供了强悍而灵活的功能来以编程方法控制 Import.io 并获得对数据的手动访问,Import.io 通过将 Web 数据集成到你自己 的应用程序或网站中,只需点击几下就可以轻松实现爬网。
为了更好地满足用户的爬行需求,它还提供适用于 Windows,Mac OS X 和 Linux 的免费应用程序,以建立数据提取器和抓取工具,下载数据并与在线账户 同步。此外,用户还可以每周网络爬虫软件下载,每天或每小时安排抓取任务。10.80legs精品文档精品文档80legs 是一个功能强悍的网路抓取工具,可以按照自定义要求进行配置。它支 持获取大量数据以及立刻下载提取数据的选项。80legs 提供高性能的 Web 爬 行,可以快速工作并在几秒钟内获取所需的数据11. Content GraberContent Graber 是一款面向企业的网路爬行软件。它容许你创建独立的 Web 爬网代理。它可以从几乎任何网站中提取内容,并以你选择的格式将其保存为结 构化数据,包括 Excel 报告,XML,CSV 和大多数数据库。它更适宜具有中级编程技能的人,因为它为有须要的人提供了许多强悍的脚本编 辑和调试界面。允许用户使用 C#或 VB.NET 调试或编撰脚本来编程控制爬网过 程。例如,Content Grabber 可以与 Visual Studio 2013 集成,以便按照用户 的特定需求为中级且机智的自定义爬虫提供最强悍的脚本编辑,调试和单元测 试。
精品文档精品文档12. UiPathUiPath 是一款用于免费网路抓取的机器人过程自动化软件。它可以手动从大多 数第三方应用程序中抓取 Web 和桌面数据。如果运行 Windows 系统,则可以 安装机械手过程自动化软件。Uipath 能够跨多个网页提取表格和基于模式的数 据。 Uipath 提供了用于进一步爬行的外置工具。处理复杂的 UI 时,此方式十分有效。 Screen Scraping Tool 可以处理单个文本元素,文本组和文本块,例如表格格 式的数据提取。 此外,创建智能 Web 代理不需要编程,但你内部的.NET 黑客可以完全控制数 据。精品文档精品文档其实,在里面我提及的爬虫可以满足大多数用户的基本爬行需求,这些工具中各 自的功能依然存在好多差别,大家可以按照自己的需求选择合适的。八爪鱼——90 万用户选择的网页数据采集器。 1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。精品文档精品文档2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。精品文档
网络爬虫技术,为什么说使用Python最合适?请听四星教育讲解
采集交流 • 优采云 发表了文章 • 0 个评论 • 350 次浏览 • 2020-05-07 08:00
但是你晓得Python与其他编程语言最主要的区别吗?
网络爬虫技术人才,一直是被各企业争相抢劫。而网路爬虫主要是用Python来编撰,所以缔造了Python与之不同的地位。
也许会有人指责,难道就不能用其他语言来编撰么?
答案是可以的,像java、c、c++、php都可以做爬虫。但是,我们运用一种语言常常并不是说这个会不会做就可以了,还取决于过程中的运行速率、开发效率、人力成本等不同诱因,最后互相比较一下,Python是最合适的。就好象一份工作,大家都可以去做,但是老总肯定会选择更适宜更经济更有能力的人去做。
在写爬虫的过程中,往往是一边写,一边测试爬虫技术用什么语言,测试不过再改改。这个过程用 python 写上去最方便。并且python 相关的库也是最方便,有 request, jieba, redis,gevent,NLTK, lxml,pyquery爬虫技术用什么语言,BeautifulSoup,Pillow,不论是简单的爬虫还是复杂的爬虫都轻松搞定。
这也是Python的又一大特点,与其他编程语言显著不同。
网络爬虫常常被称为网页追逐者,是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。另外一些不常使用的名子还有蚂蚁、自动索引、模拟程序或则蠕虫。
网络爬虫根据系统结构和实现技术,大致可以分为以下几种类型:通用网路爬虫、聚焦网路爬虫、增量式网路爬虫、深层网路爬虫。
通用网路爬虫又称全网爬虫,爬行对象从一些种子 URL 扩充到整个 Web,主要为门户站点搜索引擎和小型 Web 服务提供商采集数据。
聚焦网路爬虫,是指选择性地爬行这些与预先定义好的主题相关页面的网路爬虫。只须要爬行与主题相关的页面,极大地节约了硬件和网路资源,保存的页面也因为数目少而更新快,还可以挺好地满足一些特定人群对特定领域信息的需求。
增量式网路爬虫,是指对已下载网页采取增量式更新和只爬行新形成的或则早已发生变化网页的爬虫,它还能在一定程度上保证所爬行的页面是尽可能新的页面。
随着互联网的发展,网络爬虫技术在未来10年里,都不会有衰落的现象。人生苦短,我学Python,如果听到此文的你正好不知道学哪些语言,六星教育诚挚推荐Python。
六星教育Python全栈VIP课程,囊括了Python各个方面的知识点,内含基础、高级、进阶、商业项目实战等内容,一站式提供从小白到大鳄课程。 查看全部
但是你晓得Python与其他编程语言最主要的区别吗?
网络爬虫技术人才,一直是被各企业争相抢劫。而网路爬虫主要是用Python来编撰,所以缔造了Python与之不同的地位。
也许会有人指责,难道就不能用其他语言来编撰么?
答案是可以的,像java、c、c++、php都可以做爬虫。但是,我们运用一种语言常常并不是说这个会不会做就可以了,还取决于过程中的运行速率、开发效率、人力成本等不同诱因,最后互相比较一下,Python是最合适的。就好象一份工作,大家都可以去做,但是老总肯定会选择更适宜更经济更有能力的人去做。
在写爬虫的过程中,往往是一边写,一边测试爬虫技术用什么语言,测试不过再改改。这个过程用 python 写上去最方便。并且python 相关的库也是最方便,有 request, jieba, redis,gevent,NLTK, lxml,pyquery爬虫技术用什么语言,BeautifulSoup,Pillow,不论是简单的爬虫还是复杂的爬虫都轻松搞定。
这也是Python的又一大特点,与其他编程语言显著不同。
网络爬虫常常被称为网页追逐者,是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。另外一些不常使用的名子还有蚂蚁、自动索引、模拟程序或则蠕虫。
网络爬虫根据系统结构和实现技术,大致可以分为以下几种类型:通用网路爬虫、聚焦网路爬虫、增量式网路爬虫、深层网路爬虫。
通用网路爬虫又称全网爬虫,爬行对象从一些种子 URL 扩充到整个 Web,主要为门户站点搜索引擎和小型 Web 服务提供商采集数据。
聚焦网路爬虫,是指选择性地爬行这些与预先定义好的主题相关页面的网路爬虫。只须要爬行与主题相关的页面,极大地节约了硬件和网路资源,保存的页面也因为数目少而更新快,还可以挺好地满足一些特定人群对特定领域信息的需求。
增量式网路爬虫,是指对已下载网页采取增量式更新和只爬行新形成的或则早已发生变化网页的爬虫,它还能在一定程度上保证所爬行的页面是尽可能新的页面。
随着互联网的发展,网络爬虫技术在未来10年里,都不会有衰落的现象。人生苦短,我学Python,如果听到此文的你正好不知道学哪些语言,六星教育诚挚推荐Python。
六星教育Python全栈VIP课程,囊括了Python各个方面的知识点,内含基础、高级、进阶、商业项目实战等内容,一站式提供从小白到大鳄课程。
网络爬虫程序员被抓,我们还敢爬虫吗?细数这些Java爬虫技术
采集交流 • 优采云 发表了文章 • 0 个评论 • 417 次浏览 • 2020-05-06 08:04
最近,某大数据科技公司由于涉嫌非法抓取某急聘网站用户的简历信息,公司被查封,负责编撰抓取程序的程序员也将面临入狱。
事情的大约经过是这样的:
某大数据科技公司老总丢给一个小小的程序员一个网站,告诉他把这个网站的数据抓取出来,咱们做一做剖析。这个小小的程序员就吭哧吭哧的写了一段抓取代码,测试了一下网络爬虫技术是什么,程序没问题,可以正常的把这个网站的数据给抓取出来,然后就毫不犹豫的上线了。过了几天,这个小小的程序员发觉抓取的速率有点慢啊,然后他就将1个线程改成10个线程,发布上线,开始抓取,程序跑的没毛病。
过了一段时间,网站主的老总发觉近来网站访问量飙升,并且还常常宕机。然后组织公司程序员排查系统问题,经过排查发觉,系统某一个插口频繁访问,遂怀疑有人恶意功击,于是就报警了。警察通过访问来源IP顺藤摸瓜,查到小小程序员所在的公司,把公司全员200人全部扣押调查,这名小小程序员因为负责抓取程序的编撰,将面临入狱。小小程序员一脸懵逼,我只负责老总交给我的任务,我犯哪些法了?
看了这个新闻,程序员同学还不快点将你的爬虫程序下线,要不下一个抓的就是你,怕不怕?
爬虫技术对于大多数程序员来说一点不陌生,大多数程序员都干过爬虫的事情吧!我记得我刚结业入职的第一家公司我就是负责爬虫的。主要爬取各大院校官网的新闻资讯信息,然后借助这种信息给院校做手机微官网。当然,我们是经过了大多数院校的默认的。
今天我们姑且不论爬虫是否违规,这个问题我们也论不清楚。国内现今这么多做大数据剖析公司,他们可以提供各类数据分,他们的数据是从那里来的?有几家是正当来源?恐怕大多都是爬来的。今天我们细数这些java爬虫技术。
一、Jsoup
的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套特别省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。这也是我最早使用的爬虫技术。
二、HtmlUnit
HtmlUnit是一款java的无界面浏览器程序库。它可以模拟HTML文档,并提供相应的API,允许您调用页面,填写表单,点击链接等操作。它是一种模拟浏览器以用于测试目的的方式。使用HtmlUnit你就觉得你是在操作浏览器,他对于css和js都可以挺好的支持。
三、Selenium
Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等。
Selenium我感觉是最好的爬虫工具了,因为它完全模拟浏览器。由程序掉起浏览器网络爬虫技术是什么,模拟人的操作。关于Selenium在我的文章[Selenium神器!解放测试程序员的右手]有专门讲解。
最后,爬虫有风险,使用需谨慎。希望广大程序员同学在使用爬虫技术的时侯,要有数据隐私的意识。 查看全部
最近,某大数据科技公司由于涉嫌非法抓取某急聘网站用户的简历信息,公司被查封,负责编撰抓取程序的程序员也将面临入狱。
事情的大约经过是这样的:
某大数据科技公司老总丢给一个小小的程序员一个网站,告诉他把这个网站的数据抓取出来,咱们做一做剖析。这个小小的程序员就吭哧吭哧的写了一段抓取代码,测试了一下网络爬虫技术是什么,程序没问题,可以正常的把这个网站的数据给抓取出来,然后就毫不犹豫的上线了。过了几天,这个小小的程序员发觉抓取的速率有点慢啊,然后他就将1个线程改成10个线程,发布上线,开始抓取,程序跑的没毛病。
过了一段时间,网站主的老总发觉近来网站访问量飙升,并且还常常宕机。然后组织公司程序员排查系统问题,经过排查发觉,系统某一个插口频繁访问,遂怀疑有人恶意功击,于是就报警了。警察通过访问来源IP顺藤摸瓜,查到小小程序员所在的公司,把公司全员200人全部扣押调查,这名小小程序员因为负责抓取程序的编撰,将面临入狱。小小程序员一脸懵逼,我只负责老总交给我的任务,我犯哪些法了?
看了这个新闻,程序员同学还不快点将你的爬虫程序下线,要不下一个抓的就是你,怕不怕?
爬虫技术对于大多数程序员来说一点不陌生,大多数程序员都干过爬虫的事情吧!我记得我刚结业入职的第一家公司我就是负责爬虫的。主要爬取各大院校官网的新闻资讯信息,然后借助这种信息给院校做手机微官网。当然,我们是经过了大多数院校的默认的。
今天我们姑且不论爬虫是否违规,这个问题我们也论不清楚。国内现今这么多做大数据剖析公司,他们可以提供各类数据分,他们的数据是从那里来的?有几家是正当来源?恐怕大多都是爬来的。今天我们细数这些java爬虫技术。
一、Jsoup
的HTML解析器,可直接解析某个URL地址、HTML文本内容。它提供了一套特别省力的API,可通过DOM,CSS以及类似于jQuery的操作方法来取出和操作数据。这也是我最早使用的爬虫技术。
二、HtmlUnit
HtmlUnit是一款java的无界面浏览器程序库。它可以模拟HTML文档,并提供相应的API,允许您调用页面,填写表单,点击链接等操作。它是一种模拟浏览器以用于测试目的的方式。使用HtmlUnit你就觉得你是在操作浏览器,他对于css和js都可以挺好的支持。
三、Selenium
Selenium是一个用于Web应用程序测试的工具。Selenium测试直接运行在浏览器中,就像真正的用户在操作一样。支持的浏览器包括IE(7, 8, 9, 10, 11),Mozilla Firefox,Safari,Google Chrome,Opera等。
Selenium我感觉是最好的爬虫工具了,因为它完全模拟浏览器。由程序掉起浏览器网络爬虫技术是什么,模拟人的操作。关于Selenium在我的文章[Selenium神器!解放测试程序员的右手]有专门讲解。
最后,爬虫有风险,使用需谨慎。希望广大程序员同学在使用爬虫技术的时侯,要有数据隐私的意识。
20款最常使用的网路爬虫工具推荐(2018)
采集交流 • 优采云 发表了文章 • 0 个评论 • 455 次浏览 • 2020-05-06 08:04
八爪鱼·云采集网络爬虫软件 20 款最常使用的网路爬虫工具推荐 (2018)网络爬虫在现今的许多领域得到广泛应用。 它的作用是从任何网站获取特定的或 更新的数据并储存出来。 网络爬虫工具越来越为人所熟知,因为网路爬虫简化并 自动化了整个爬取过程, 使每个人都可以轻松访问网站数据资源。使用网路爬虫 工具可以使人们免予重复打字或复制粘贴, 我们可以太轻松的去采集网页上的数 据。此外,这些网路爬虫工具可以使用户就能以有条不紊和快速的抓取网页,而 无需编程并将数据转换为符合其需求的各类格式。在这篇文章中,我将介绍目前比较流行的 20 款网路爬虫工具供你参考。希望你 能找到最适宜你需求的工具。1. 八爪鱼八爪鱼·云采集网络爬虫软件 八爪鱼是一款免费且功能强悍的网站爬虫, 用于从网站上提取你须要的几乎所有 类型的数据。 你可以使用八爪鱼来采集市面上几乎所有的网站。 八爪鱼提供两种 采集模式 - 简易模式和自定义采集模式,非程序员可以快速习惯使用八爪鱼。 下载免费软件后, 其可视化界面容许你从网站上获取所有文本,因此你可以下载 几乎所有网站内容并将其保存为结构化格式,如 EXCEL,TXT,HTML 或你的数 据库。
你可以使用其外置的正则表达式工具从复杂的网站布局中提取许多棘手网站的 数据,并使用 XPath 配置工具精确定位 Web 元素。另外八爪鱼提供手动辨识验 证码以及代理 IP 切换功能,可以有效的防止网站防采集。 总之,八爪鱼可以满足用户最基本或中级的采集需求,而无需任何编程技能。2. HTTrack八爪鱼·云采集网络爬虫软件 作为免费的网站爬虫软件,HTTrack 提供的功能十分适宜从互联网下载整个网站 到你的 PC。它提供了适用于 Windows网站爬虫软件,Linux,Sun Solaris 和其他 Unix 系统 的版本。它可以将一个站点或多个站点镜像在一起(使用共享链接)。你可以在 “设置选项”下下载网页时决定要同时打开的连接数。 你可以从整个目录中获取 照片,文件,HTML 代码,更新当前镜像的网站并恢复中断的下载。此外,HTTTrack 还提供代理支持,以通过可选身分验证最大限度地提升速率。 HTTrack 用作命令行程序,或通过 shell 用于私有(捕获)或专业(在线 Web 镜像)使用。 有了这样的说法,HTTrack 应该是首选,并且具有中级编程技能 的人更多地使用它。3、 Scraper八爪鱼·云采集网络爬虫软件 Scraper 是 Chrome 扩展程序,具有有限的数据提取功能,但它有助于进行在 线研究并将数据导入到 Google sheets 。
此工具适用于初学者以及可以使用 OAuth 轻松将数据复制到剪贴板或储存到电子表格的专家。Scraper 是一个免 费的网路爬虫工具,可以在你的浏览器中正常工作,并手动生成较小的 XPath 来定义要抓取的 URL。4、OutWit Hub八爪鱼·云采集网络爬虫软件 Outwit Hub 是一个 Firefox 添加件,它有两个目的:搜集信息和管理信息。它 可以分别用在网站上不同的部份提供不同的窗口条。 还提供用户一个快速步入信 息的方式,虚拟移除网站上别的部份。 OutWit Hub 提供单一界面,可依照须要抓取微小或大量数据。OutWit Hub 允许你从浏览器本身抓取任何网页, 甚至可以创建手动代理来提取数据并按照设 置对其进行低格。 OutWit Hub 大多功能都是免费的,能够深入剖析网站,自动搜集整理组织互联 网中的各项数据, 并将网站信息分割开来, 然后提取有效信息, 形成可用的集合。 但是要手动提取精确数据就须要付费版本了, 同时免费版一次提取的数据量也是 有限制的,如果须要大批量的操作,可以选择订购专业版。 5. ParseHubParsehub 是一个太棒的网路爬虫, 支持从使用 AJAX 技术, JavaScript, cookie 等的网站收集数据。
它的机器学习技术可以读取,分析之后将 Web 文档转换为 相关数据。八爪鱼·云采集网络爬虫软件 Parsehub 的桌面应用程序支持 Windows,Mac OS X 和 Linux 等系统,或者 你可以使用浏览器中外置的 Web 应用程序。 作为免费软件,你可以在 Parsehub 中设置不超过五个 publice 项目。付费版本 允许你创建起码 20private 项目来抓取网站。6. ScrapinghubScrapinghub 是一种基于云的数据提取工具,可帮助数千名开发人员获取有价 值的数据。 它的开源视觉抓取工具,允许用户在没有任何编程知识的情况下抓取 网站。 Scrapinghub 使用 Crawlera,一家代理 IP 第三方平台,支持绕开防采集对策。 它使用户就能从多个 IP 和位置进行网页抓取,而无需通过简单的 HTTP API 进 行代理管理。 Scrapinghub 将整个网页转换为有组织的内容。如果其爬虫工具难以满足你的 要求,其专家团队可以提供帮助。。八爪鱼·云采集网络爬虫软件 7. Dexi.io作为基于浏览器的网路爬虫,Dexi.io 允许你从任何网站基于浏览器抓取数据, 并提供三种类型的爬虫来创建采集任务。
免费软件为你的网路抓取提供匿名 Web 代理服务器,你提取的数据将在存档数据之前在 Dexi.io 的服务器上托管 两周网站爬虫软件,或者你可以直接将提取的数据导入到 JSON 或 CSV 文件。它提供付费服 务,以满足你获取实时数据的需求。8. Webhose.ioWebhose.io 使用户才能将来自世界各地的在线资源抓取的实时数据转换为各 种标准的格式。通过此 Web 爬网程序,你可以使用囊括各类来源的多个过滤器 来抓取数据并进一步提取多种语言的关键字。八爪鱼·云采集网络爬虫软件 你可以将删掉的数据保存为 XML,JSON 和 RSS 格式。并且容许用户从其存档 访问历史数据。此外,webhose.io 支持最多 80 种语言及其爬行数据结果。用 户可以轻松索引和搜索 Webhose.io 抓取的结构化数据。 总的来说,Webhose.io 可以满足用户的基本爬行要求。9.Import.io用户只需从特定网页导出数据并将数据导入到 CSV 即可产生自己的数据集。 你可以在几分钟内轻松抓取数千个网页,而无需编撰任何代码,并按照你的要求 构建 1000 多个 API。公共 API 提供了强悍而灵活的功能来以编程方法控制 Import.io 并获得对数据的手动访问, Import.io 通过将 Web 数据集成到你自己 的应用程序或网站中,只需点击几下就可以轻松实现爬网。
八爪鱼·云采集网络爬虫软件 为了更好地满足用户的爬行需求,它还提供适用于 Windows,Mac OS X 和 Linux 的免费应用程序,以建立数据提取器和抓取工具,下载数据并与在线账户 同步。此外,用户还可以每周,每天或每小时安排抓取任务。10.80legs80legs 是一个功能强悍的网路抓取工具,可以按照自定义要求进行配置。它支 持获取大量数据以及立刻下载提取数据的选项。80legs 提供高性能的 Web 爬 行,可以快速工作并在几秒钟内获取所需的数据11. Content Graber八爪鱼·云采集网络爬虫软件 Content Graber 是一款面向企业的网路爬行软件。它容许你创建独立的 Web 爬网代理。 它可以从几乎任何网站中提取内容,并以你选择的格式将其保存为结 构化数据,包括 Excel 报告,XML,CSV 和大多数数据库。 它更适宜具有中级编程技能的人, 因为它为有须要的人提供了许多强悍的脚本编 辑和调试界面。 允许用户使用 C#或 VB.NET 调试或编撰脚本来编程控制爬网过 程。例如,Content Grabber 可以与 Visual Studio 2013 集成,以便按照用户 的特定需求为中级且机智的自定义爬虫提供最强悍的脚本编辑,调试和单元测 试。
12. UiPath八爪鱼·云采集网络爬虫软件 UiPath 是一款用于免费网路抓取的机器人过程自动化软件。它可以手动从大多 数第三方应用程序中抓取 Web 和桌面数据。如果运行 Windows 系统,则可以 安装机械手过程自动化软件。Uipath 能够跨多个网页提取表格和基于模式的数 据。 Uipath 提供了用于进一步爬行的外置工具。 处理复杂的 UI 时, 此方式十分有效。 Screen Scraping Tool 可以处理单个文本元素,文本组和文本块,例如表格格 式的数据提取。 此外,创建智能 Web 代理不需要编程,但你内部的.NET 黑客可以完全控制数 据。八爪鱼·云采集网络爬虫软件 总之, 在里面我提及的爬虫可以满足大多数用户的基本爬行需求,这些工具中各 自的功能依然存在好多差别,大家可以按照自己的需求选择合适的。八爪鱼——90 万用户选择的网页数据采集器。 1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。 查看全部
八爪鱼·云采集网络爬虫软件 20 款最常使用的网路爬虫工具推荐 (2018)网络爬虫在现今的许多领域得到广泛应用。 它的作用是从任何网站获取特定的或 更新的数据并储存出来。 网络爬虫工具越来越为人所熟知,因为网路爬虫简化并 自动化了整个爬取过程, 使每个人都可以轻松访问网站数据资源。使用网路爬虫 工具可以使人们免予重复打字或复制粘贴, 我们可以太轻松的去采集网页上的数 据。此外,这些网路爬虫工具可以使用户就能以有条不紊和快速的抓取网页,而 无需编程并将数据转换为符合其需求的各类格式。在这篇文章中,我将介绍目前比较流行的 20 款网路爬虫工具供你参考。希望你 能找到最适宜你需求的工具。1. 八爪鱼八爪鱼·云采集网络爬虫软件 八爪鱼是一款免费且功能强悍的网站爬虫, 用于从网站上提取你须要的几乎所有 类型的数据。 你可以使用八爪鱼来采集市面上几乎所有的网站。 八爪鱼提供两种 采集模式 - 简易模式和自定义采集模式,非程序员可以快速习惯使用八爪鱼。 下载免费软件后, 其可视化界面容许你从网站上获取所有文本,因此你可以下载 几乎所有网站内容并将其保存为结构化格式,如 EXCEL,TXT,HTML 或你的数 据库。
你可以使用其外置的正则表达式工具从复杂的网站布局中提取许多棘手网站的 数据,并使用 XPath 配置工具精确定位 Web 元素。另外八爪鱼提供手动辨识验 证码以及代理 IP 切换功能,可以有效的防止网站防采集。 总之,八爪鱼可以满足用户最基本或中级的采集需求,而无需任何编程技能。2. HTTrack八爪鱼·云采集网络爬虫软件 作为免费的网站爬虫软件,HTTrack 提供的功能十分适宜从互联网下载整个网站 到你的 PC。它提供了适用于 Windows网站爬虫软件,Linux,Sun Solaris 和其他 Unix 系统 的版本。它可以将一个站点或多个站点镜像在一起(使用共享链接)。你可以在 “设置选项”下下载网页时决定要同时打开的连接数。 你可以从整个目录中获取 照片,文件,HTML 代码,更新当前镜像的网站并恢复中断的下载。此外,HTTTrack 还提供代理支持,以通过可选身分验证最大限度地提升速率。 HTTrack 用作命令行程序,或通过 shell 用于私有(捕获)或专业(在线 Web 镜像)使用。 有了这样的说法,HTTrack 应该是首选,并且具有中级编程技能 的人更多地使用它。3、 Scraper八爪鱼·云采集网络爬虫软件 Scraper 是 Chrome 扩展程序,具有有限的数据提取功能,但它有助于进行在 线研究并将数据导入到 Google sheets 。
此工具适用于初学者以及可以使用 OAuth 轻松将数据复制到剪贴板或储存到电子表格的专家。Scraper 是一个免 费的网路爬虫工具,可以在你的浏览器中正常工作,并手动生成较小的 XPath 来定义要抓取的 URL。4、OutWit Hub八爪鱼·云采集网络爬虫软件 Outwit Hub 是一个 Firefox 添加件,它有两个目的:搜集信息和管理信息。它 可以分别用在网站上不同的部份提供不同的窗口条。 还提供用户一个快速步入信 息的方式,虚拟移除网站上别的部份。 OutWit Hub 提供单一界面,可依照须要抓取微小或大量数据。OutWit Hub 允许你从浏览器本身抓取任何网页, 甚至可以创建手动代理来提取数据并按照设 置对其进行低格。 OutWit Hub 大多功能都是免费的,能够深入剖析网站,自动搜集整理组织互联 网中的各项数据, 并将网站信息分割开来, 然后提取有效信息, 形成可用的集合。 但是要手动提取精确数据就须要付费版本了, 同时免费版一次提取的数据量也是 有限制的,如果须要大批量的操作,可以选择订购专业版。 5. ParseHubParsehub 是一个太棒的网路爬虫, 支持从使用 AJAX 技术, JavaScript, cookie 等的网站收集数据。
它的机器学习技术可以读取,分析之后将 Web 文档转换为 相关数据。八爪鱼·云采集网络爬虫软件 Parsehub 的桌面应用程序支持 Windows,Mac OS X 和 Linux 等系统,或者 你可以使用浏览器中外置的 Web 应用程序。 作为免费软件,你可以在 Parsehub 中设置不超过五个 publice 项目。付费版本 允许你创建起码 20private 项目来抓取网站。6. ScrapinghubScrapinghub 是一种基于云的数据提取工具,可帮助数千名开发人员获取有价 值的数据。 它的开源视觉抓取工具,允许用户在没有任何编程知识的情况下抓取 网站。 Scrapinghub 使用 Crawlera,一家代理 IP 第三方平台,支持绕开防采集对策。 它使用户就能从多个 IP 和位置进行网页抓取,而无需通过简单的 HTTP API 进 行代理管理。 Scrapinghub 将整个网页转换为有组织的内容。如果其爬虫工具难以满足你的 要求,其专家团队可以提供帮助。。八爪鱼·云采集网络爬虫软件 7. Dexi.io作为基于浏览器的网路爬虫,Dexi.io 允许你从任何网站基于浏览器抓取数据, 并提供三种类型的爬虫来创建采集任务。
免费软件为你的网路抓取提供匿名 Web 代理服务器,你提取的数据将在存档数据之前在 Dexi.io 的服务器上托管 两周网站爬虫软件,或者你可以直接将提取的数据导入到 JSON 或 CSV 文件。它提供付费服 务,以满足你获取实时数据的需求。8. Webhose.ioWebhose.io 使用户才能将来自世界各地的在线资源抓取的实时数据转换为各 种标准的格式。通过此 Web 爬网程序,你可以使用囊括各类来源的多个过滤器 来抓取数据并进一步提取多种语言的关键字。八爪鱼·云采集网络爬虫软件 你可以将删掉的数据保存为 XML,JSON 和 RSS 格式。并且容许用户从其存档 访问历史数据。此外,webhose.io 支持最多 80 种语言及其爬行数据结果。用 户可以轻松索引和搜索 Webhose.io 抓取的结构化数据。 总的来说,Webhose.io 可以满足用户的基本爬行要求。9.Import.io用户只需从特定网页导出数据并将数据导入到 CSV 即可产生自己的数据集。 你可以在几分钟内轻松抓取数千个网页,而无需编撰任何代码,并按照你的要求 构建 1000 多个 API。公共 API 提供了强悍而灵活的功能来以编程方法控制 Import.io 并获得对数据的手动访问, Import.io 通过将 Web 数据集成到你自己 的应用程序或网站中,只需点击几下就可以轻松实现爬网。
八爪鱼·云采集网络爬虫软件 为了更好地满足用户的爬行需求,它还提供适用于 Windows,Mac OS X 和 Linux 的免费应用程序,以建立数据提取器和抓取工具,下载数据并与在线账户 同步。此外,用户还可以每周,每天或每小时安排抓取任务。10.80legs80legs 是一个功能强悍的网路抓取工具,可以按照自定义要求进行配置。它支 持获取大量数据以及立刻下载提取数据的选项。80legs 提供高性能的 Web 爬 行,可以快速工作并在几秒钟内获取所需的数据11. Content Graber八爪鱼·云采集网络爬虫软件 Content Graber 是一款面向企业的网路爬行软件。它容许你创建独立的 Web 爬网代理。 它可以从几乎任何网站中提取内容,并以你选择的格式将其保存为结 构化数据,包括 Excel 报告,XML,CSV 和大多数数据库。 它更适宜具有中级编程技能的人, 因为它为有须要的人提供了许多强悍的脚本编 辑和调试界面。 允许用户使用 C#或 VB.NET 调试或编撰脚本来编程控制爬网过 程。例如,Content Grabber 可以与 Visual Studio 2013 集成,以便按照用户 的特定需求为中级且机智的自定义爬虫提供最强悍的脚本编辑,调试和单元测 试。
12. UiPath八爪鱼·云采集网络爬虫软件 UiPath 是一款用于免费网路抓取的机器人过程自动化软件。它可以手动从大多 数第三方应用程序中抓取 Web 和桌面数据。如果运行 Windows 系统,则可以 安装机械手过程自动化软件。Uipath 能够跨多个网页提取表格和基于模式的数 据。 Uipath 提供了用于进一步爬行的外置工具。 处理复杂的 UI 时, 此方式十分有效。 Screen Scraping Tool 可以处理单个文本元素,文本组和文本块,例如表格格 式的数据提取。 此外,创建智能 Web 代理不需要编程,但你内部的.NET 黑客可以完全控制数 据。八爪鱼·云采集网络爬虫软件 总之, 在里面我提及的爬虫可以满足大多数用户的基本爬行需求,这些工具中各 自的功能依然存在好多差别,大家可以按照自己的需求选择合适的。八爪鱼——90 万用户选择的网页数据采集器。 1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。
通俗的讲,网络爬虫到底是什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 289 次浏览 • 2020-05-06 08:03
爬虫的起源可以溯源到万维网(互联网)诞生之初,一开始互联网还没有搜索。在搜索引擎没有被开发之前,互联网只是文件传输协议(FTP)站点的集合,用户可以在这种站点中导航以找到特定的共享文件。
为了查找和组合互联网上可用的分布式数据,人们创建了一个自动化程序,称为网络爬虫/机器人,可以抓取互联网上的所有网页,然后将所有页面上的内容复制到数据库中制做索引。
爬虫的发展
随着互联网的发展,网络上的资源显得愈发丰富但却粗疏不堪,信息的获取成本显得更高了。
相应地,也渐渐发展出愈发智能,且适用性更强的爬虫软件。
它们类似于蜘蛛通过幅射出去的蛛网来获取信息,继而从中捕获到它想要的猎物,所以爬虫也被称为网页蜘蛛,当然相较蛛网而言,爬虫软件更具主动性。另外,爬虫还有一些不常用的名子,像蚂蚁/模拟程序/蠕虫。
爬虫的工作流程大致如下:
通常,爬取网页数据时,只须要2个步骤:
打开网页→将具体的数据从网页中复制并导入到表格或资源库中。
简单来说就是,抓取和复制。
爬虫的君子合同
搜索引擎的爬虫是善意的,可以检索你的一切信息,并提供给其他用户访问,为此它们还专门定义了robots.txt文件,作为君子合同。
Robots协议(爬虫协议)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎什么页面可以抓取,哪些页面不能抓取。该合同是国际互联网界通行的道德规范,虽然没有写入法律,但是每一个爬虫都应当遵循这项合同。
以淘宝网的robots.txt为例,
以 Allow 项的值开头的 URL 是容许 robot 访问的。例如,Allow:/article 允许百度爬虫引擎访问 /article.htm、/article/http://12345.com 等。
以 Disallow 项为开头的链接是不容许百度爬虫引擎访问的。例如,Disallow:/product/ 不容许百度爬虫引擎访问 /product/http://12345.com 等。
最后一行,Disallow:/ 禁止百度爬虫访问不仅 Allow 规定页面外的其他所有页面。
所以你是不能从百度上搜索到淘宝内部的产品信息的。
君子合同虽好,然而事情很快就被一些人破坏了,于是就有了反爬虫。
爬虫与反爬虫
爬虫与反爬虫是“矛”与“盾”的攻防关系,有了爬虫自然也就有了反爬虫。
一些企业为了保证服务器的正常运转,降低服务器的运转压力与成本,不得不使出各种各样的手段来制止爬虫工程师毫无节制地向服务器索要资源,这种行为我们称之为反爬虫。
在爬虫与反爬虫的对决上,一些反爬手段往往会使人津津乐道,比如,文本混淆反爬虫、动态渲染反爬虫、信息校准反爬虫、代码混淆反爬虫……等等。
反爬虫技术是怎样对爬虫进行防御的,其实现原理是哪些?以下就以信息校准反爬为例,请《鹿鼎记》的韦香主给你们做一下演示。
假设天地会赤火堂香主派人从京城抵达南京将一封特别重要的密函交给青木堂香主韦小宝,我们可以将这件事具象为下图:
这件事的核心是「帮派成员-甲将重要密函交给帮会成员-乙」。假设乙、乙双方互不相恋亦未曾有过会面,那「帮派成员-甲」如何判定密函交给了「帮派成员-乙」,而不是给错人——给了其他「帮派成员-丁」呢?
在历史实践中肯定喝过这样的亏爬虫软件是什么,遂天地会采用了接头暗号这些方法来确保乙、乙双方是同一帮会成员,这才有了:
暗号只有帮会成员才晓得,且不可泄露。甲、乙双方碰面时由「帮派成员-甲」说出「地乡高岗,一派溪山千古秀」,「帮派成员-乙」听到后必须接下一句「门朝大海,三河合水万年流」。如果「帮派成员-乙」不知道下一句是哪些,或者胡扯一气,那么「帮派成员-甲」就可以判断他不是接头人,而是假扮的。
同样的,「帮派成员-乙」要看到帮会成员-甲说出「地乡高岗,一派溪山千古秀」。否则「帮派成员-甲」就是假扮的,很有可能会将假的密函交给青木堂韦小宝。
天地会接头人相互传递消息(密函)很象是我们在开发 WEB 应用时的 Client 和 Server,抽象地看起来象这样:
那么问题来了,Client 和 Server 之间需不需要天地会这样的暗号呢?
答案是须要!
Client 就像「帮派成员-甲」,Server 就像「帮派成员-乙」,而她们的密函很有可能会被其他「帮派成员-丁」拿走或伪造。既然天地会有接头暗号,那么 Client 和 Server 之间用哪些来保障传递消息是第一手发出,而不是被拦截伪造的呢?
没错,签名验证!
签名验证是目前 IT 技术领域应用广泛的 API 接口数据保护方法之一,它还能有效避免消息接收端将被篡改或伪造的消息当成正常消息处理。
要注意的是,它的作用是避免消息接收端将被篡改或伪造的消息当成正常消息处理,而不是避免消息接受端接收假消息,事实上插口在收到消息的那一刻难以判定消息的真伪。这一点十分重要爬虫软件是什么,千万不要混淆了。
假设 Client 要将「下个月 5 号暗杀鳌拜」这封重要密函交给 Server,抽象图如下:
这时候倘若发生假扮风波,会带来哪些影响:
其他「帮派成员-丁」从 Client 那里获得消息后进行了伪造,将暗杀鳌拜的时间从 5 号改为 6号,导致 Server 收到的暗杀时间是 6 号。这么一来,里应外合暗杀鳌拜的事都会弄成一方延后动手,这次筹谋已久的暗杀行动大几率会失败,而且会导致不小的损失。
我们使用签名验证来改善这个消息传递和验证的事。这里可以简单将签名验证理解为在原消息的基础上进行一定规则的运算和加密,最终将加密结果放在消息中一并发送,消息接收者领到消息后根据相同的规则进行运算和加密,将自己运算得到的加密值和传递过来的加密值进行比对,如果两值相同则代表消息没有被拦截伪造,反之可以判断消息被拦截伪造。
签名验证被广泛应用,例如下载操作系统镜像文件时官方网站会提供文件的 MD5 值、阿里巴巴/腾讯/华为等企业对外开放的插口中信令部份的 sign 值等。
以上反爬方式选自《Python3 反爬虫原理与绕开实战》
写在最后
爬虫本身并未违背法律。但程序运行过程中可能对别人经营网站造成破坏,爬取的数据有可能涉及隐私或绝密,数据本身也可能形成法律纠纷。
【编辑推荐】
拒绝低效!Python教你爬虫公众号文章和链接5分钟撸了个小小爬虫....重点来了,Python网站爬虫原理!瓜子,矿泉水备好,慢慢品!我花 1 分钟写了一段爬虫,帮助小姐姐解放了右手怎样用 100 行 Python 代码实现新闻爬虫?这样可算成功? 查看全部
爬虫的起源
爬虫的起源可以溯源到万维网(互联网)诞生之初,一开始互联网还没有搜索。在搜索引擎没有被开发之前,互联网只是文件传输协议(FTP)站点的集合,用户可以在这种站点中导航以找到特定的共享文件。
为了查找和组合互联网上可用的分布式数据,人们创建了一个自动化程序,称为网络爬虫/机器人,可以抓取互联网上的所有网页,然后将所有页面上的内容复制到数据库中制做索引。
爬虫的发展
随着互联网的发展,网络上的资源显得愈发丰富但却粗疏不堪,信息的获取成本显得更高了。
相应地,也渐渐发展出愈发智能,且适用性更强的爬虫软件。
它们类似于蜘蛛通过幅射出去的蛛网来获取信息,继而从中捕获到它想要的猎物,所以爬虫也被称为网页蜘蛛,当然相较蛛网而言,爬虫软件更具主动性。另外,爬虫还有一些不常用的名子,像蚂蚁/模拟程序/蠕虫。
爬虫的工作流程大致如下:
通常,爬取网页数据时,只须要2个步骤:
打开网页→将具体的数据从网页中复制并导入到表格或资源库中。
简单来说就是,抓取和复制。
爬虫的君子合同
搜索引擎的爬虫是善意的,可以检索你的一切信息,并提供给其他用户访问,为此它们还专门定义了robots.txt文件,作为君子合同。
Robots协议(爬虫协议)的全称是“网络爬虫排除标准”(Robots Exclusion Protocol),网站通过Robots协议告诉搜索引擎什么页面可以抓取,哪些页面不能抓取。该合同是国际互联网界通行的道德规范,虽然没有写入法律,但是每一个爬虫都应当遵循这项合同。
以淘宝网的robots.txt为例,
以 Allow 项的值开头的 URL 是容许 robot 访问的。例如,Allow:/article 允许百度爬虫引擎访问 /article.htm、/article/http://12345.com 等。
以 Disallow 项为开头的链接是不容许百度爬虫引擎访问的。例如,Disallow:/product/ 不容许百度爬虫引擎访问 /product/http://12345.com 等。
最后一行,Disallow:/ 禁止百度爬虫访问不仅 Allow 规定页面外的其他所有页面。
所以你是不能从百度上搜索到淘宝内部的产品信息的。
君子合同虽好,然而事情很快就被一些人破坏了,于是就有了反爬虫。
爬虫与反爬虫
爬虫与反爬虫是“矛”与“盾”的攻防关系,有了爬虫自然也就有了反爬虫。
一些企业为了保证服务器的正常运转,降低服务器的运转压力与成本,不得不使出各种各样的手段来制止爬虫工程师毫无节制地向服务器索要资源,这种行为我们称之为反爬虫。
在爬虫与反爬虫的对决上,一些反爬手段往往会使人津津乐道,比如,文本混淆反爬虫、动态渲染反爬虫、信息校准反爬虫、代码混淆反爬虫……等等。
反爬虫技术是怎样对爬虫进行防御的,其实现原理是哪些?以下就以信息校准反爬为例,请《鹿鼎记》的韦香主给你们做一下演示。
假设天地会赤火堂香主派人从京城抵达南京将一封特别重要的密函交给青木堂香主韦小宝,我们可以将这件事具象为下图:
这件事的核心是「帮派成员-甲将重要密函交给帮会成员-乙」。假设乙、乙双方互不相恋亦未曾有过会面,那「帮派成员-甲」如何判定密函交给了「帮派成员-乙」,而不是给错人——给了其他「帮派成员-丁」呢?
在历史实践中肯定喝过这样的亏爬虫软件是什么,遂天地会采用了接头暗号这些方法来确保乙、乙双方是同一帮会成员,这才有了:
暗号只有帮会成员才晓得,且不可泄露。甲、乙双方碰面时由「帮派成员-甲」说出「地乡高岗,一派溪山千古秀」,「帮派成员-乙」听到后必须接下一句「门朝大海,三河合水万年流」。如果「帮派成员-乙」不知道下一句是哪些,或者胡扯一气,那么「帮派成员-甲」就可以判断他不是接头人,而是假扮的。
同样的,「帮派成员-乙」要看到帮会成员-甲说出「地乡高岗,一派溪山千古秀」。否则「帮派成员-甲」就是假扮的,很有可能会将假的密函交给青木堂韦小宝。
天地会接头人相互传递消息(密函)很象是我们在开发 WEB 应用时的 Client 和 Server,抽象地看起来象这样:
那么问题来了,Client 和 Server 之间需不需要天地会这样的暗号呢?
答案是须要!
Client 就像「帮派成员-甲」,Server 就像「帮派成员-乙」,而她们的密函很有可能会被其他「帮派成员-丁」拿走或伪造。既然天地会有接头暗号,那么 Client 和 Server 之间用哪些来保障传递消息是第一手发出,而不是被拦截伪造的呢?
没错,签名验证!
签名验证是目前 IT 技术领域应用广泛的 API 接口数据保护方法之一,它还能有效避免消息接收端将被篡改或伪造的消息当成正常消息处理。
要注意的是,它的作用是避免消息接收端将被篡改或伪造的消息当成正常消息处理,而不是避免消息接受端接收假消息,事实上插口在收到消息的那一刻难以判定消息的真伪。这一点十分重要爬虫软件是什么,千万不要混淆了。
假设 Client 要将「下个月 5 号暗杀鳌拜」这封重要密函交给 Server,抽象图如下:
这时候倘若发生假扮风波,会带来哪些影响:
其他「帮派成员-丁」从 Client 那里获得消息后进行了伪造,将暗杀鳌拜的时间从 5 号改为 6号,导致 Server 收到的暗杀时间是 6 号。这么一来,里应外合暗杀鳌拜的事都会弄成一方延后动手,这次筹谋已久的暗杀行动大几率会失败,而且会导致不小的损失。
我们使用签名验证来改善这个消息传递和验证的事。这里可以简单将签名验证理解为在原消息的基础上进行一定规则的运算和加密,最终将加密结果放在消息中一并发送,消息接收者领到消息后根据相同的规则进行运算和加密,将自己运算得到的加密值和传递过来的加密值进行比对,如果两值相同则代表消息没有被拦截伪造,反之可以判断消息被拦截伪造。
签名验证被广泛应用,例如下载操作系统镜像文件时官方网站会提供文件的 MD5 值、阿里巴巴/腾讯/华为等企业对外开放的插口中信令部份的 sign 值等。
以上反爬方式选自《Python3 反爬虫原理与绕开实战》
写在最后
爬虫本身并未违背法律。但程序运行过程中可能对别人经营网站造成破坏,爬取的数据有可能涉及隐私或绝密,数据本身也可能形成法律纠纷。
【编辑推荐】
拒绝低效!Python教你爬虫公众号文章和链接5分钟撸了个小小爬虫....重点来了,Python网站爬虫原理!瓜子,矿泉水备好,慢慢品!我花 1 分钟写了一段爬虫,帮助小姐姐解放了右手怎样用 100 行 Python 代码实现新闻爬虫?这样可算成功?
从零开始学Python网络爬虫中文pdf完整版[144MB]
采集交流 • 优采云 发表了文章 • 0 个评论 • 321 次浏览 • 2020-05-06 08:02
本书共分12章,核心主题包括Python零基础句型入门、爬虫原理和网页构造、我的第一个爬虫程序、正则表达式、Lxml库与Xpath句型、使用API、数据库储存、多进程爬虫、异步加载、表单交互与模拟登陆、Selenium模拟浏览器、Scrapy爬虫框架。此外,书中通过一些典型爬虫案例数据挖掘爬虫书籍,讲解了有经纬信息的地图图表和词云的制做方式,让读者体验数据背后的乐趣。
本书适宜爬虫技术初学者、爱好者及高等院校的相关中学生,也适宜数据爬虫工程师作为参考读物,同时也适宜各大Python数据剖析的培训机构作为教材使用
第1章 Python零基础句型入门 1
第2章 爬虫原理和网页构造 17
第3章 我的第一个爬虫程序 26
第4章 正则表达式 45
第5章 Lxml库与Xpath句型 63
第6章 使用API 88
第7章 数据库储存 109
第8章 多进程爬虫 139
第9章 异步加载 159
第10章 表单交互与模拟登陆 182
第11章 Selenium模拟浏览器 209
第12章 Scrapy爬虫框架 229 查看全部
本书共分12章,核心主题包括Python零基础句型入门、爬虫原理和网页构造、我的第一个爬虫程序、正则表达式、Lxml库与Xpath句型、使用API、数据库储存、多进程爬虫、异步加载、表单交互与模拟登陆、Selenium模拟浏览器、Scrapy爬虫框架。此外,书中通过一些典型爬虫案例数据挖掘爬虫书籍,讲解了有经纬信息的地图图表和词云的制做方式,让读者体验数据背后的乐趣。
本书适宜爬虫技术初学者、爱好者及高等院校的相关中学生,也适宜数据爬虫工程师作为参考读物,同时也适宜各大Python数据剖析的培训机构作为教材使用
第1章 Python零基础句型入门 1
第2章 爬虫原理和网页构造 17
第3章 我的第一个爬虫程序 26
第4章 正则表达式 45
第5章 Lxml库与Xpath句型 63
第6章 使用API 88
第7章 数据库储存 109
第8章 多进程爬虫 139
第9章 异步加载 159
第10章 表单交互与模拟登陆 182
第11章 Selenium模拟浏览器 209
第12章 Scrapy爬虫框架 229

