
网络爬虫
如何高效抓取网站文章_互联网_IT/计算机_专业资料
采集交流 • 优采云 发表了文章 • 0 个评论 • 308 次浏览 • 2020-08-03 15:02
网页打开后,默认显示“推荐”文章。观察发觉,此网页没有翻页按 钮,而是通过下拉加载,不断加载出新的内容 因而,我们选中“打开网页”步骤,在中级选项中,勾选“页面加载完成后向上 滚动” , 滚动次数依照自身需求进行设置, 间隔时间依照网页加载情况进行设置, 滚动形式为“向下滚动一屏”,然后点击“确定”优采云·云采集网络爬虫软件 (注意: 间隔时间须要针对网站情况进行设置,并不是绝对的。一般情况下,间隔时间> 网站加载时间即可。有时候网速较慢,网页加载太慢,还需依照具体情况进行调整。具体请 看:优采云 7.0 教程——AJAX 滚动教程)步骤 2:创建翻页循环及提取数据优采云·云采集网络爬虫软件 1)移动滑鼠,选中页面里第一条文章链接。系统会手动辨识相像链接,在操作 提示框中网站文章采集,选择“选中全部”2)选择“循环点击每位链接”优采云·云采集网络爬虫软件 3)系统会手动步入文章详情页。 点击须要采集的数组 (这里先点击了文章标题) , 在操作提示框中,选择“采集该元素的文本”优采云·云采集网络爬虫软件 文章发布时间、文章作者、文章发布时间、文章正文内容采集方法同上。以下采 集的是文章正文优采云·云采集网络爬虫软件 步骤 3:提取 UC 头条文章图片地址1)接下来开始采集图片地址。
先点击文章中第一张图片,再点击页面中第二张 图片,在弹出的操作提示框中,选择“采集以下图片地址”优采云·云采集网络爬虫软件 2)修改数组名称,再点击“确定”优采云·云采集网络爬虫软件 3)现在我们早已采集到了图片 URL,接下来为批量导入图片做打算。批量导入 图片的时侯, 我们想要同一篇文章中的图片放进同一个文件中,文件夹以文章标 题命名。 首先,我们选中标题,在操作提示框中,选择“采集该元素的文本”优采云·云采集网络爬虫软件 选中标题数组,点击如图所示按键优采云·云采集网络爬虫软件 选择“格式化数据”优采云·云采集网络爬虫软件 点击添加步骤优采云·云采集网络爬虫软件 选择“添加前缀”优采云·云采集网络爬虫软件 在如图位置,输入前缀:“D:\UC 头条图片采集\”,然后点击“确定”优采云·云采集网络爬虫软件 以同样的形式添加后缀“\”,然后点击“确定”优采云·云采集网络爬虫软件 4)修改数组名为“图片储存地址”,最后展示出的“D:\UC 头条图片采集\ 文章标题”即为图片保存文件夹名,其中“D:\UC 头条图片采集\”是固定的,文章标题是变化的优采云·云采集网络爬虫软件 步骤 4:修改 Xpath1)选中整个“循环”步骤网站文章采集,打开“高级选项”,可以看见,优采云默认生成的 是固定元素列表,定位的是前 13 篇文章的链接优采云·云采集网络爬虫软件 2)在火狐浏览器中打开要采集的网页并观察源码。
我们发觉,通过此条 Xpath: //DIV[@class='news-list']/UL[1]/LI/DIV[1]/DIV[1]/A ,页面中所需的所有文 章均被定位了优采云·云采集网络爬虫软件 3)将修改后的 Xpath,复制粘贴到优采云中所示位置,然后点击“确定”优采云·云采集网络爬虫软件 步骤 5:文章数据采集及导入1)点击左上角的“保存”,然后点击“开始采集”,选择“启动本地采集”优采云·云采集网络爬虫软件 注: 本地采集占用当前笔记本资源进行采集, 如果存在采集时间要求或当前笔记本未能长时间进 行采集可以使用云采集功能, 云采集在网路中进行采集, 无需当前笔记本支持, 电脑可以死机, 可以设置多个云节点平摊任务,10 个节点相当于 10 台笔记本分配任务帮你采集,速度增加 为原先的十分之一;采集到的数据可以在云上保存三个月,可以随时进行导入操作。2)采集完成后,会跳出提示,选择“导出数据”,选择“合适的导入方法”, 将采集好的数据导入优采云·云采集网络爬虫软件 3)这里我们选择 excel 作为导入为格式,数据导入后如下图优采云·云采集网络爬虫软件 步骤 6:将图片 URL 批量转换为图片经过如上操作,我们早已得到了要采集的图片的 URL。
接下来,再通过优采云 专用的图片批量下载工具,将采集到的图片 URL 中的图片,下载并保存到本地 电脑中。 图片批量下载工具:优采云·云采集网络爬虫软件 1)下载优采云图片批量下载工具,双击文件中的 MyDownloader.app.exe 文 件,打开软件2)打开 File 菜单,选择从 EXCEL 导入(目前只支持 EXCEL 格式文件)优采云·云采集网络爬虫软件 3)进行相关设置,设置完成后,点击 OK 即可导出文件 选择 EXCEL 文件:导入你须要下载图片地址的 EXCEL 文件 EXCEL 表名:对应数据表的名称 文件 URL 列名:表内对应 URL 的列名称,在这里为“图片 URL” 保存文件夹名:EXCEL 中须要单独一个列,列出图片想要保存到文件夹的路径, 可以设置不同图片储存至不同文件夹,在这里为“图片储存地址” 可以设置不同图片储存至不同文件夹,在这里我们早已于前期打算好了,同一篇 文章中的图片会放进同一个文件中,文件夹以文章标题命名优采云·云采集网络爬虫软件 4)点击 OK 后,界面如图所示,再点击“开始下载”优采云·云采集网络爬虫软件 5)页面下方会显示图片下载状态优采云·云采集网络爬虫软件 6)全部下载完成后,找到自己设定的图片保存文件夹,可以看见,图片 URL 已经批量转换为图片了,且同一篇文章中的图片会放进同一个文件中,文件夹以 文章标题命名优采云·云采集网络爬虫软件 本文来自:相关采集教程:赶集中介房源采集 拼多多商品数据抓取 优采云·云采集网络爬虫软件 饿了么店家评论采集 腾讯地图数据采集 腾讯新闻采集 网易自媒体文章采集 微博图片采集 微博粉丝信息采集 当当图书采集 优采云——90 万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。优采云·云采集网络爬虫软件 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云) ,满足低端付费企业用户 的须要。 查看全部
优采云·云采集网络爬虫软件 如何高效抓取网站文章现在大多数做内容的都是须要参考好多网页文章的, 那在互联网告告诉发展 的明天应当如何高效的去抓取网站文章呢,本文以 UO 头条为例,UC 头条是 UC 浏览器团队潜力构建的新闻资讯推荐平台,拥有大量的新闻资讯内容,并通 过阿里大数据推荐和机器学习算法,为广大用户提供优质贴心的文章。很多用户 可能有采集 UC 头条文章采集的需求,这里采集了文章的文本和图片。文本可直 接采集,图片需先将图片 URL 采集下来,然后将图片 URL 批量转换为图片。本文将采集 UC 头条的文章,采集的数组为:标题、发布者、发布时间、文章内 容、页面网址、图片 URL、图片储存地址。采集网站:使用功能点:? Xpath优采云·云采集网络爬虫软件 xpath 入门教程 1 xpath 入门 2 相对 XPATH 教程-7.0 版 ?AJAX 滚动教程步骤 1:创建 UC 头条文章采集任务1)进入主界面,选择“自定义模式”优采云·云采集网络爬虫软件 2)将要采集的网址 URL 复制粘贴到网站输入框中,点击“保存网址”优采云·云采集网络爬虫软件 3)在页面右上角,打开“流程”,以突显出“流程设计器”和“定制当前操作” 两个蓝筹股。
网页打开后,默认显示“推荐”文章。观察发觉,此网页没有翻页按 钮,而是通过下拉加载,不断加载出新的内容 因而,我们选中“打开网页”步骤,在中级选项中,勾选“页面加载完成后向上 滚动” , 滚动次数依照自身需求进行设置, 间隔时间依照网页加载情况进行设置, 滚动形式为“向下滚动一屏”,然后点击“确定”优采云·云采集网络爬虫软件 (注意: 间隔时间须要针对网站情况进行设置,并不是绝对的。一般情况下,间隔时间> 网站加载时间即可。有时候网速较慢,网页加载太慢,还需依照具体情况进行调整。具体请 看:优采云 7.0 教程——AJAX 滚动教程)步骤 2:创建翻页循环及提取数据优采云·云采集网络爬虫软件 1)移动滑鼠,选中页面里第一条文章链接。系统会手动辨识相像链接,在操作 提示框中网站文章采集,选择“选中全部”2)选择“循环点击每位链接”优采云·云采集网络爬虫软件 3)系统会手动步入文章详情页。 点击须要采集的数组 (这里先点击了文章标题) , 在操作提示框中,选择“采集该元素的文本”优采云·云采集网络爬虫软件 文章发布时间、文章作者、文章发布时间、文章正文内容采集方法同上。以下采 集的是文章正文优采云·云采集网络爬虫软件 步骤 3:提取 UC 头条文章图片地址1)接下来开始采集图片地址。
先点击文章中第一张图片,再点击页面中第二张 图片,在弹出的操作提示框中,选择“采集以下图片地址”优采云·云采集网络爬虫软件 2)修改数组名称,再点击“确定”优采云·云采集网络爬虫软件 3)现在我们早已采集到了图片 URL,接下来为批量导入图片做打算。批量导入 图片的时侯, 我们想要同一篇文章中的图片放进同一个文件中,文件夹以文章标 题命名。 首先,我们选中标题,在操作提示框中,选择“采集该元素的文本”优采云·云采集网络爬虫软件 选中标题数组,点击如图所示按键优采云·云采集网络爬虫软件 选择“格式化数据”优采云·云采集网络爬虫软件 点击添加步骤优采云·云采集网络爬虫软件 选择“添加前缀”优采云·云采集网络爬虫软件 在如图位置,输入前缀:“D:\UC 头条图片采集\”,然后点击“确定”优采云·云采集网络爬虫软件 以同样的形式添加后缀“\”,然后点击“确定”优采云·云采集网络爬虫软件 4)修改数组名为“图片储存地址”,最后展示出的“D:\UC 头条图片采集\ 文章标题”即为图片保存文件夹名,其中“D:\UC 头条图片采集\”是固定的,文章标题是变化的优采云·云采集网络爬虫软件 步骤 4:修改 Xpath1)选中整个“循环”步骤网站文章采集,打开“高级选项”,可以看见,优采云默认生成的 是固定元素列表,定位的是前 13 篇文章的链接优采云·云采集网络爬虫软件 2)在火狐浏览器中打开要采集的网页并观察源码。
我们发觉,通过此条 Xpath: //DIV[@class='news-list']/UL[1]/LI/DIV[1]/DIV[1]/A ,页面中所需的所有文 章均被定位了优采云·云采集网络爬虫软件 3)将修改后的 Xpath,复制粘贴到优采云中所示位置,然后点击“确定”优采云·云采集网络爬虫软件 步骤 5:文章数据采集及导入1)点击左上角的“保存”,然后点击“开始采集”,选择“启动本地采集”优采云·云采集网络爬虫软件 注: 本地采集占用当前笔记本资源进行采集, 如果存在采集时间要求或当前笔记本未能长时间进 行采集可以使用云采集功能, 云采集在网路中进行采集, 无需当前笔记本支持, 电脑可以死机, 可以设置多个云节点平摊任务,10 个节点相当于 10 台笔记本分配任务帮你采集,速度增加 为原先的十分之一;采集到的数据可以在云上保存三个月,可以随时进行导入操作。2)采集完成后,会跳出提示,选择“导出数据”,选择“合适的导入方法”, 将采集好的数据导入优采云·云采集网络爬虫软件 3)这里我们选择 excel 作为导入为格式,数据导入后如下图优采云·云采集网络爬虫软件 步骤 6:将图片 URL 批量转换为图片经过如上操作,我们早已得到了要采集的图片的 URL。
接下来,再通过优采云 专用的图片批量下载工具,将采集到的图片 URL 中的图片,下载并保存到本地 电脑中。 图片批量下载工具:优采云·云采集网络爬虫软件 1)下载优采云图片批量下载工具,双击文件中的 MyDownloader.app.exe 文 件,打开软件2)打开 File 菜单,选择从 EXCEL 导入(目前只支持 EXCEL 格式文件)优采云·云采集网络爬虫软件 3)进行相关设置,设置完成后,点击 OK 即可导出文件 选择 EXCEL 文件:导入你须要下载图片地址的 EXCEL 文件 EXCEL 表名:对应数据表的名称 文件 URL 列名:表内对应 URL 的列名称,在这里为“图片 URL” 保存文件夹名:EXCEL 中须要单独一个列,列出图片想要保存到文件夹的路径, 可以设置不同图片储存至不同文件夹,在这里为“图片储存地址” 可以设置不同图片储存至不同文件夹,在这里我们早已于前期打算好了,同一篇 文章中的图片会放进同一个文件中,文件夹以文章标题命名优采云·云采集网络爬虫软件 4)点击 OK 后,界面如图所示,再点击“开始下载”优采云·云采集网络爬虫软件 5)页面下方会显示图片下载状态优采云·云采集网络爬虫软件 6)全部下载完成后,找到自己设定的图片保存文件夹,可以看见,图片 URL 已经批量转换为图片了,且同一篇文章中的图片会放进同一个文件中,文件夹以 文章标题命名优采云·云采集网络爬虫软件 本文来自:相关采集教程:赶集中介房源采集 拼多多商品数据抓取 优采云·云采集网络爬虫软件 饿了么店家评论采集 腾讯地图数据采集 腾讯新闻采集 网易自媒体文章采集 微博图片采集 微博粉丝信息采集 当当图书采集 优采云——90 万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。优采云·云采集网络爬虫软件 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云) ,满足低端付费企业用户 的须要。
微信文章简单采集方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 483 次浏览 • 2020-07-13 01:08
表现特点:a、点击网页中某个选项时,大部分网站的网址不会改变; b、网页 不是完全加载,只是局部进行了数据加载,有所变化。 验证方法:点击操作后,在浏览器中,网址输入栏不会出现加载中的状态或则转 圈状态。优采云·云采集网络爬虫软件 观察网页,我们发觉,通过 5 次点击“加载更多内容”,页面加载到最顶部,一 共显示 100 篇文章。因此,我们设置整个“循环翻页”步骤执行 5 次。选中“循 环翻页”步骤,打开“高级选项”,打开“满足以下条件时退出循环”,设置循 环次数等于“5 次”,点击“确定”搜狗微信公众号热门文章如何采集图 5优采云·云采集网络爬虫软件 步骤 3:创建列表循环并提取数据1)移动滑鼠,选中页面里第一篇文章的区块。系统会辨识此区块中的子元素, 在操作提示框中,选择“选中子元素”搜狗微信公众号热门文章如何采集图 62) 继续选中页面中第二篇文章的区块, 系统会手动选中第二篇文章中的子元素, 并辨识出页面中的其他 10 组同类元素,在操作提示框中,选择“选中全部”优采云·云采集网络爬虫软件 搜狗微信公众号热门文章如何采集图 73)我们可以看见,页面中文章区块里的所有元素均被选中,变为红色。
右侧操 作提示框中,出现数组预览表,将滑鼠移到表头,点击垃圾桶图标,可删掉不需 要的主键。字段选择完成后,选择“采集以下数据”优采云·云采集网络爬虫软件 搜狗微信公众号热门文章如何采集图 84)我们还想要采集每篇文章的 URL,因而还须要提取一个主键。点击第一篇文 章的链接,系统会手动选中页面中的一组文章链接。在左侧操作提示框中,选择 “选中全部”优采云·云采集网络爬虫软件 搜狗微信公众号热门文章如何采集图 95)选择“采集以下链接地址”优采云·云采集网络爬虫软件 搜狗微信公众号热门文章如何采集图 106)字段选择完成后,选中相应的数组,可以进行数组的自定义命名优采云·云采集网络爬虫软件 搜狗微信公众号热门文章如何采集图 11步骤 4:修改 Xpath我们继续观察,通过 5 次点击“加载更多内容”后,此网页加载出全部 100 篇 文章。因而我们配置规则的思路是,先构建翻页循环,加载出全部 100 篇文章, 再完善循环列表,提取数据优采云·云采集网络爬虫软件 1)选中整个“循环”步骤,将其拖出“循环翻页”步骤。如果不进行此项操作, 那么将会出现好多重复数据搜狗微信公众号热门文章如何采集图 12拖动完成后,如下图所示优采云·云采集网络爬虫软件 搜狗微信公众号热门文章如何采集图 132)在“列表循环”步骤中,我们构建 100 篇文章的循环列表。
选中整个“循环 步骤”,打开“高级选项”采集微信文章,将不固定元素列表中的这条 Xpath: //BODY[@id='loginWrap']/DIV[4]/DIV[1]/DIV[3]/UL[1]/LI ,复制粘贴到火 狐浏览器中的相应位置优采云·云采集网络爬虫软件 搜狗微信公众号热门文章如何采集图 14Xpath:是一种路径查询语言,简单的说就是借助一个路径表达式找到我们须要 的数据位置。 Xpath 是用于 XML 中顺着路径查找数据用的采集微信文章,但是优采云采集器内部有一套针 对 HTML 的 Xpath 引擎,使得直接用 XPATH 就能精准的查找定位网页上面的 数据。优采云·云采集网络爬虫软件 3)在火狐浏览器中,我们发觉,通过这条 Xpath: //BODY[@id='loginWrap']/DIV[4]/DIV[1]/DIV[3]/UL[1]/LI ,页面中被定位 的是 20 篇文章搜狗微信公众号热门文章如何采集图 154) 将 Xpath 修改为: //BODY[@id='loginWrap']/DIV/DIV[1]/DIV[3]/UL/LI, 我们发觉页面中所有要采集的文章都被定位了优采云·云采集网络爬虫软件 搜狗微信公众号热门文章如何采集图 165)将改好的 Xpath://BODY[@id='loginWrap']/DIV/DIV[1]/DIV[3]/UL/LI, 复制粘贴到图片中所示的位置,然后点击“确定”优采云·云采集网络爬虫软件 搜狗微信公众号热门文章如何采集图 176)点击左上角的“保存并启动”,选择“启动本地采集”优采云·云采集网络爬虫软件 搜狗微信公众号热门文章如何采集图 18步骤 5:数据采集及导入1)采集完成后,会跳出提示,选择“导出数据”,选择“合适的导入方法”, 将采集好的搜狗陌陌文章的数据导入优采云·云采集网络爬虫软件 搜狗微信公众号热门文章如何采集图 192)这里我们选择 excel 作为导入为格式,数据导入后如下图优采云·云采集网络爬虫软件 搜狗微信公众号热门文章如何采集图 20相关采集教程 地图数据采集 旅游信息采集 点评数据采集优采云·云采集网络爬虫软件 分类信息采集教程 网站文章采集 网站文章采集教程 网站图片采集 网页邮箱采集 公告信息抓取 优采云·云采集网络爬虫软件 关键词提取 优采云——70 万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云) ,满足低端付费企业用户 的须要。 查看全部
表现特点:a、点击网页中某个选项时,大部分网站的网址不会改变; b、网页 不是完全加载,只是局部进行了数据加载,有所变化。 验证方法:点击操作后,在浏览器中,网址输入栏不会出现加载中的状态或则转 圈状态。优采云·云采集网络爬虫软件 观察网页,我们发觉,通过 5 次点击“加载更多内容”,页面加载到最顶部,一 共显示 100 篇文章。因此,我们设置整个“循环翻页”步骤执行 5 次。选中“循 环翻页”步骤,打开“高级选项”,打开“满足以下条件时退出循环”,设置循 环次数等于“5 次”,点击“确定”搜狗微信公众号热门文章如何采集图 5优采云·云采集网络爬虫软件 步骤 3:创建列表循环并提取数据1)移动滑鼠,选中页面里第一篇文章的区块。系统会辨识此区块中的子元素, 在操作提示框中,选择“选中子元素”搜狗微信公众号热门文章如何采集图 62) 继续选中页面中第二篇文章的区块, 系统会手动选中第二篇文章中的子元素, 并辨识出页面中的其他 10 组同类元素,在操作提示框中,选择“选中全部”优采云·云采集网络爬虫软件 搜狗微信公众号热门文章如何采集图 73)我们可以看见,页面中文章区块里的所有元素均被选中,变为红色。
右侧操 作提示框中,出现数组预览表,将滑鼠移到表头,点击垃圾桶图标,可删掉不需 要的主键。字段选择完成后,选择“采集以下数据”优采云·云采集网络爬虫软件 搜狗微信公众号热门文章如何采集图 84)我们还想要采集每篇文章的 URL,因而还须要提取一个主键。点击第一篇文 章的链接,系统会手动选中页面中的一组文章链接。在左侧操作提示框中,选择 “选中全部”优采云·云采集网络爬虫软件 搜狗微信公众号热门文章如何采集图 95)选择“采集以下链接地址”优采云·云采集网络爬虫软件 搜狗微信公众号热门文章如何采集图 106)字段选择完成后,选中相应的数组,可以进行数组的自定义命名优采云·云采集网络爬虫软件 搜狗微信公众号热门文章如何采集图 11步骤 4:修改 Xpath我们继续观察,通过 5 次点击“加载更多内容”后,此网页加载出全部 100 篇 文章。因而我们配置规则的思路是,先构建翻页循环,加载出全部 100 篇文章, 再完善循环列表,提取数据优采云·云采集网络爬虫软件 1)选中整个“循环”步骤,将其拖出“循环翻页”步骤。如果不进行此项操作, 那么将会出现好多重复数据搜狗微信公众号热门文章如何采集图 12拖动完成后,如下图所示优采云·云采集网络爬虫软件 搜狗微信公众号热门文章如何采集图 132)在“列表循环”步骤中,我们构建 100 篇文章的循环列表。
选中整个“循环 步骤”,打开“高级选项”采集微信文章,将不固定元素列表中的这条 Xpath: //BODY[@id='loginWrap']/DIV[4]/DIV[1]/DIV[3]/UL[1]/LI ,复制粘贴到火 狐浏览器中的相应位置优采云·云采集网络爬虫软件 搜狗微信公众号热门文章如何采集图 14Xpath:是一种路径查询语言,简单的说就是借助一个路径表达式找到我们须要 的数据位置。 Xpath 是用于 XML 中顺着路径查找数据用的采集微信文章,但是优采云采集器内部有一套针 对 HTML 的 Xpath 引擎,使得直接用 XPATH 就能精准的查找定位网页上面的 数据。优采云·云采集网络爬虫软件 3)在火狐浏览器中,我们发觉,通过这条 Xpath: //BODY[@id='loginWrap']/DIV[4]/DIV[1]/DIV[3]/UL[1]/LI ,页面中被定位 的是 20 篇文章搜狗微信公众号热门文章如何采集图 154) 将 Xpath 修改为: //BODY[@id='loginWrap']/DIV/DIV[1]/DIV[3]/UL/LI, 我们发觉页面中所有要采集的文章都被定位了优采云·云采集网络爬虫软件 搜狗微信公众号热门文章如何采集图 165)将改好的 Xpath://BODY[@id='loginWrap']/DIV/DIV[1]/DIV[3]/UL/LI, 复制粘贴到图片中所示的位置,然后点击“确定”优采云·云采集网络爬虫软件 搜狗微信公众号热门文章如何采集图 176)点击左上角的“保存并启动”,选择“启动本地采集”优采云·云采集网络爬虫软件 搜狗微信公众号热门文章如何采集图 18步骤 5:数据采集及导入1)采集完成后,会跳出提示,选择“导出数据”,选择“合适的导入方法”, 将采集好的搜狗陌陌文章的数据导入优采云·云采集网络爬虫软件 搜狗微信公众号热门文章如何采集图 192)这里我们选择 excel 作为导入为格式,数据导入后如下图优采云·云采集网络爬虫软件 搜狗微信公众号热门文章如何采集图 20相关采集教程 地图数据采集 旅游信息采集 点评数据采集优采云·云采集网络爬虫软件 分类信息采集教程 网站文章采集 网站文章采集教程 网站图片采集 网页邮箱采集 公告信息抓取 优采云·云采集网络爬虫软件 关键词提取 优采云——70 万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云) ,满足低端付费企业用户 的须要。
网络爬虫软件那个好用?看完这篇就够了
采集交流 • 优采云 发表了文章 • 0 个评论 • 643 次浏览 • 2020-07-06 08:03
前市面上常见的爬虫软件通常可以界定为云爬虫和采集器两种:
所谓云爬虫就是无需下载安装软件,直接在网页上创建爬虫并在网站服务器运行,享用网站提供的带宽和24小时服务;
采集器通常就是要下载安装在本机,然后在本机创建爬虫,使用的是自己的带宽,受限于自己的笔记本是否死机。
当然,以上不包括自己开发的爬虫工具和爬虫框架之类的。
其实每位爬虫都有自己的特性,我们可以按照自己的须要进行选择,下面针对常见的网路爬虫做一些简单介绍,给你们做一些参考:
首先是云爬虫,国内目前主要是:优采云云爬虫
官网:
简介:优采云云是一个大数据应用开发平台多可网络爬虫软件怎么用,为开发者提供成套的数据采集、数据剖析和机器学习开发工具,为企业提供专业化的数据抓取、数据实时监控和数据剖析服务。
优点:功能强悍,涉及云爬虫、API、机器学习、数据清洗、数据转让、数据定制和私有化布署等;
纯云端运行,跨系统操作无压力,隐私保护,可隐藏用户IP。
提供云爬虫市场,零基础使用者可直接调用开发好的爬虫,开发者基于官方的云端开发环境开发并上传转让自己的爬虫程序;
领先的反爬技术,例如直接接入代理IP和手动登入验证码识别等,全程自动化无需人工参与;
丰富的发布插口,采集结果以丰富表格化方式诠释;
缺点:它的优点同时也在一定程度上成了它的缺点,因为它是一个面向开发者的爬虫开发系统,提供了丰富的开发功能,网站看起来特别的偏技术十分专业,尽管官方也提供了云爬虫市场这样的现成爬虫产品,并且开放给广大爬虫开发者,从而使爬虫市场的内容愈发丰富,但是对于零技术基础的用户而言并不是这么容易理解,所以有一定的使用门槛。
是否免费:免费用户无采集功能和导入限制多可网络爬虫软件怎么用,无需积分。
具备开发能力的用户可以自行开发爬虫,达到免费疗效,没有开发能力的用户须要从爬虫市场找寻是否有免费的爬虫。
然后是采集器,目前国外主要包括以下这种(百度/谷歌搜采集器,刨去广告,排名靠前的):
优采云采集器:
官网:
简介:火车采集器是一款网页数据抓取、处理、分析,挖掘软件。可以灵活迅速地抓取网页上散乱分布的信息,并通过强悍的处理功能确切挖掘出所需数据。
优点:国内老牌的采集器,经过多年的积累,具有丰富的采集功能;
采集速度比较快,接口比较齐全,支持PHP和C#插件扩充;
支持多种数据格式导入,可以进行数据替换等处理。
缺点:越是年头长的产品越容易身陷自己的固有经验中,优采云也无法甩掉这问题。
虽说功能丰富,但是功能都拼凑在那里,用户体验不好,让人不知道从何下手;
学会了的人会认为功能强悍,但是对于菜鸟而言有一定使用门槛,不学习一段时间很难上手,零基础上手基本不可能。
只支持Windows版本,不支持其他操作系统;
是否免费:号称免费,但是实际上免费功能限制好多,只能导入单个txt或html文件,基本上可以说是不免费的。
优采云采集器:
官网:
简介:优采云采集器是一款可视化采集器,内置采集模板,支持各类网页数据采集。
优点:支持自定义模式,可视化采集操作,容易上手;
支持简易采集模式,提供官方采集模板,支持云采集操作;
支持防屏蔽举措,例如代理IP切换和验证码服务;
支持多种数据格式导入。
缺点:功能使用门槛较高,本地采集时好多功能受限,而云采集收费较高;
采集速度较慢,很多操作都要卡一下,云端采集说10倍提速并且并不显著;
只支持Windows版本,不支持其他操作系统。
是否免费:号称免费,但是实际上导入数据须要积分,可以做任务攒积分,但是正常情况下基本都须要订购积分。
后羿采集器:
官网:
简介:后羿采集器是由前微软搜索技术团队基于人工智能技术研制的新一代网页采集软件,该软件功能强悍,操作非常简单。
优点:支持智能采集模式,输入网址能够智能辨识采集对象,无需配置采集规则,操作十分简单;
支持流程图模式,可视化操作流程,能够通过简单的操作生成各类复杂的采集规则;
支持防屏蔽举措,例如代理IP切换验证码打码等;
支持多种数据导入方法(文件,数据库和网站);
支持定时采集和手动导入,发布插口丰富;
支持文件下载(图片,文件,视频,音频等);
支持电商大图和SKU手动辨识;
支持网页加密内容解码;
支持API功能;
支持Windows、Mac和Linux版本。
缺点:暂不支持云采集功能
是否免费:完全免费,采集数据和自动导入采集结果到本地文件和数据库没有数目限制,不需要积分。 查看全部
前市面上常见的爬虫软件通常可以界定为云爬虫和采集器两种:
所谓云爬虫就是无需下载安装软件,直接在网页上创建爬虫并在网站服务器运行,享用网站提供的带宽和24小时服务;
采集器通常就是要下载安装在本机,然后在本机创建爬虫,使用的是自己的带宽,受限于自己的笔记本是否死机。
当然,以上不包括自己开发的爬虫工具和爬虫框架之类的。

其实每位爬虫都有自己的特性,我们可以按照自己的须要进行选择,下面针对常见的网路爬虫做一些简单介绍,给你们做一些参考:
首先是云爬虫,国内目前主要是:优采云云爬虫
官网:
简介:优采云云是一个大数据应用开发平台多可网络爬虫软件怎么用,为开发者提供成套的数据采集、数据剖析和机器学习开发工具,为企业提供专业化的数据抓取、数据实时监控和数据剖析服务。
优点:功能强悍,涉及云爬虫、API、机器学习、数据清洗、数据转让、数据定制和私有化布署等;
纯云端运行,跨系统操作无压力,隐私保护,可隐藏用户IP。
提供云爬虫市场,零基础使用者可直接调用开发好的爬虫,开发者基于官方的云端开发环境开发并上传转让自己的爬虫程序;
领先的反爬技术,例如直接接入代理IP和手动登入验证码识别等,全程自动化无需人工参与;
丰富的发布插口,采集结果以丰富表格化方式诠释;
缺点:它的优点同时也在一定程度上成了它的缺点,因为它是一个面向开发者的爬虫开发系统,提供了丰富的开发功能,网站看起来特别的偏技术十分专业,尽管官方也提供了云爬虫市场这样的现成爬虫产品,并且开放给广大爬虫开发者,从而使爬虫市场的内容愈发丰富,但是对于零技术基础的用户而言并不是这么容易理解,所以有一定的使用门槛。
是否免费:免费用户无采集功能和导入限制多可网络爬虫软件怎么用,无需积分。
具备开发能力的用户可以自行开发爬虫,达到免费疗效,没有开发能力的用户须要从爬虫市场找寻是否有免费的爬虫。
然后是采集器,目前国外主要包括以下这种(百度/谷歌搜采集器,刨去广告,排名靠前的):
优采云采集器:
官网:
简介:火车采集器是一款网页数据抓取、处理、分析,挖掘软件。可以灵活迅速地抓取网页上散乱分布的信息,并通过强悍的处理功能确切挖掘出所需数据。
优点:国内老牌的采集器,经过多年的积累,具有丰富的采集功能;
采集速度比较快,接口比较齐全,支持PHP和C#插件扩充;
支持多种数据格式导入,可以进行数据替换等处理。
缺点:越是年头长的产品越容易身陷自己的固有经验中,优采云也无法甩掉这问题。
虽说功能丰富,但是功能都拼凑在那里,用户体验不好,让人不知道从何下手;
学会了的人会认为功能强悍,但是对于菜鸟而言有一定使用门槛,不学习一段时间很难上手,零基础上手基本不可能。
只支持Windows版本,不支持其他操作系统;
是否免费:号称免费,但是实际上免费功能限制好多,只能导入单个txt或html文件,基本上可以说是不免费的。
优采云采集器:
官网:
简介:优采云采集器是一款可视化采集器,内置采集模板,支持各类网页数据采集。
优点:支持自定义模式,可视化采集操作,容易上手;
支持简易采集模式,提供官方采集模板,支持云采集操作;
支持防屏蔽举措,例如代理IP切换和验证码服务;
支持多种数据格式导入。
缺点:功能使用门槛较高,本地采集时好多功能受限,而云采集收费较高;
采集速度较慢,很多操作都要卡一下,云端采集说10倍提速并且并不显著;
只支持Windows版本,不支持其他操作系统。
是否免费:号称免费,但是实际上导入数据须要积分,可以做任务攒积分,但是正常情况下基本都须要订购积分。
后羿采集器:
官网:
简介:后羿采集器是由前微软搜索技术团队基于人工智能技术研制的新一代网页采集软件,该软件功能强悍,操作非常简单。
优点:支持智能采集模式,输入网址能够智能辨识采集对象,无需配置采集规则,操作十分简单;
支持流程图模式,可视化操作流程,能够通过简单的操作生成各类复杂的采集规则;
支持防屏蔽举措,例如代理IP切换验证码打码等;
支持多种数据导入方法(文件,数据库和网站);
支持定时采集和手动导入,发布插口丰富;
支持文件下载(图片,文件,视频,音频等);
支持电商大图和SKU手动辨识;
支持网页加密内容解码;
支持API功能;
支持Windows、Mac和Linux版本。
缺点:暂不支持云采集功能
是否免费:完全免费,采集数据和自动导入采集结果到本地文件和数据库没有数目限制,不需要积分。
从零开始基于Scrapy框架的网路爬虫开发流程
采集交流 • 优采云 发表了文章 • 0 个评论 • 409 次浏览 • 2020-07-06 08:01
前节介绍了哪些网路爬虫,什么是Scrapy框架并怎样安装
本节介绍基于Scrapy框架的网路爬虫开发流程
安装好Scrapy框架后,就可以基于Scrapy框架开发爬虫项目了。基于框架开发项目,不需要从零开始编撰代码,只须要把握怎样使用框架,如何添加与自己应用相关的代码即可。
进入准备新建爬虫项目的路径中,使用命令:
scrapy startproject project_name
请用爬虫项目名称替换命令中的project_name爬虫软件开发,例如,本文准备创建一个爬取新浪网的爬虫,取名为sina_spider,则新建爬虫项目的命令为:
scrapy startproject sina_spider
命令运行结果,如下图所示。
新建爬虫项目
“scrapy startproject sina_spider”命令会创建包含下述内容的sina_spider目录,如图13-5所示。
爬虫文件夹结构
新建好Scrapy爬虫项目后,接下来就是创建爬虫文件。请先步入sina_spider项目路径,用命令:
scrapy genspider spider_filename(爬虫文件名) (待爬取的网站域名)
创建爬虫文件。例如,本文的爬虫文件名为:sinaSpider,待爬取的网站域名:,则创建爬虫文件sinaSpider的命令为:
scrapy genspider sinaSpider
现在好多网站都有防爬虫举措,为了反网站的防爬虫举措,需要添加user agent信息。请settings.py文件的第19行更改如下所示:
18. # Crawl responsibly by identifying yourself (and your website) on the user-agent
19. import random
20. # user agent 列表
21. USER_AGENT_LIST = [
22. "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
23. "Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
24. "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
25. "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
26. "Mozilla/4.76 [en_jp] (X11; U; SunOS 5.8 sun4u)",
27. "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
28. "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:5.0) Gecko/20100101 Firefox/5.0",
29. "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:9.0) Gecko/20100101 Firefox/9.0",
30. "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.8; rv:16.0) Gecko/20120813 Firefox/16.0",
31. "Mozilla/4.77 [en] (X11; I; IRIX;64 6.5 IP30)",
32. "Mozilla/4.8 [en] (X11; U; SunOS; 5.7 sun4u)" ]
33. USER_AGENT = random.choice(USER_AGENT_LIST) # 随机生成user agent
网站的服务器中保存一个robots.txt 文件,其作用是,告诉搜索引擎爬虫,本网站哪些目录下的网页不希望被爬取收录。Scrapy启动后,会在第一时间访问网站的 robots.txt 文件,然后决定该网站的爬取范围。
由于本文的项目并非搜索引擎爬虫,而且很有可能我们想要获取的内容恰恰是被 robots.txt所严禁访问的,所以请把settings.py文件的ROBOTSTXT_OBEY值设置为False,表示拒绝遵循Robot合同,如下所示
1. # Obey robots.txt rules
2. ROBOTSTXT_OBEY = False # False表示拒绝遵守Robot协议
查看由Scrapy生成的sinaSpider.py文件,在SinaspiderSpider类中,有一个parse()方法须要用户编撰,如下图所示
编写parse()方法
Scrapy框架把爬取出来的网页源代码储存在response对象中爬虫软件开发,我们只须要对response对象中的网页源代码做解析,提取想要的数据即可。本范例目标是抓取新浪网页的新闻的标题和对应的链接,如下图所示。
HTML源代码
parse()方法的实现代码,如下所示
1. # -*- coding: utf-8 -*-
2. import scrapy
3.
4. class SinaspiderSpider(scrapy.Spider):
5. name = 'sinaSpider'
6. allowed_domains = ['www.sina.com.cn']
7. start_urls = ['http://www.sina.com.cn/']
8.
9. def parse(self, response):
10. data_list = [] #用于存储解析到的数据
11. #解析HTML源代码,定位新闻内容
12. lis = response.xpath("//div[@class='top_newslist']/ul[@class='list-a news_top']//li")
13. #将新闻主题和超链接解析出来并整理到列表中
14. for li in lis:
15. titles = li.xpath(".//a/text()")
16. linkes = li.xpath(".//a/@href")
17. for title, link in zip(titles, linkes):
18. #将新闻主题和对应的超链接组合成字典
19. data_dict = {'标题': title.extract(), '链接': link.extract()}
20. #将字典数据存储到data_list这个列表中
21. data_list.append(data_dict)
22. return data_list
parse()方法在解析HTML源代码时,使用了XPath路径表达式。XPath是一门在HTML/XML文档中查找信息的语言,常用于在网页HTML源代码中,查找特定标签里的数据。在网络爬虫中使用XPath,只须要把握 XPath路径表达式即可。XPath 使用路径表达式来选定 HTML/XML文档中的节点或则节点集。
parse()方法编撰好后,就可以运行爬虫程序并保存抓取数据了。用命令:
scrapy crawl 爬虫文件名 –o 保存数据文件名.[csv|json|xml]
保存数据的文件格式可以是csv 或 json 或 xml,本例的爬虫文件名为:sinaSpider.py,数据储存选择csv格式,命令为:
scrapy crawl sinaSpider -o sinaNews.csv
运行疗效,如下图所示
运行爬虫
到此,本例基于Scrapy框架从零开始实现了一个网络爬虫程序,爬取了新浪网页并从中解析出新闻的标题和对应的超链接,最后把解析出的数据保存为csv文件供后续使用。 查看全部
前节介绍了哪些网路爬虫,什么是Scrapy框架并怎样安装
本节介绍基于Scrapy框架的网路爬虫开发流程
安装好Scrapy框架后,就可以基于Scrapy框架开发爬虫项目了。基于框架开发项目,不需要从零开始编撰代码,只须要把握怎样使用框架,如何添加与自己应用相关的代码即可。
进入准备新建爬虫项目的路径中,使用命令:
scrapy startproject project_name
请用爬虫项目名称替换命令中的project_name爬虫软件开发,例如,本文准备创建一个爬取新浪网的爬虫,取名为sina_spider,则新建爬虫项目的命令为:
scrapy startproject sina_spider
命令运行结果,如下图所示。

新建爬虫项目
“scrapy startproject sina_spider”命令会创建包含下述内容的sina_spider目录,如图13-5所示。

爬虫文件夹结构
新建好Scrapy爬虫项目后,接下来就是创建爬虫文件。请先步入sina_spider项目路径,用命令:
scrapy genspider spider_filename(爬虫文件名) (待爬取的网站域名)
创建爬虫文件。例如,本文的爬虫文件名为:sinaSpider,待爬取的网站域名:,则创建爬虫文件sinaSpider的命令为:
scrapy genspider sinaSpider
现在好多网站都有防爬虫举措,为了反网站的防爬虫举措,需要添加user agent信息。请settings.py文件的第19行更改如下所示:
18. # Crawl responsibly by identifying yourself (and your website) on the user-agent
19. import random
20. # user agent 列表
21. USER_AGENT_LIST = [
22. "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
23. "Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
24. "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
25. "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
26. "Mozilla/4.76 [en_jp] (X11; U; SunOS 5.8 sun4u)",
27. "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
28. "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:5.0) Gecko/20100101 Firefox/5.0",
29. "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:9.0) Gecko/20100101 Firefox/9.0",
30. "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.8; rv:16.0) Gecko/20120813 Firefox/16.0",
31. "Mozilla/4.77 [en] (X11; I; IRIX;64 6.5 IP30)",
32. "Mozilla/4.8 [en] (X11; U; SunOS; 5.7 sun4u)" ]
33. USER_AGENT = random.choice(USER_AGENT_LIST) # 随机生成user agent
网站的服务器中保存一个robots.txt 文件,其作用是,告诉搜索引擎爬虫,本网站哪些目录下的网页不希望被爬取收录。Scrapy启动后,会在第一时间访问网站的 robots.txt 文件,然后决定该网站的爬取范围。
由于本文的项目并非搜索引擎爬虫,而且很有可能我们想要获取的内容恰恰是被 robots.txt所严禁访问的,所以请把settings.py文件的ROBOTSTXT_OBEY值设置为False,表示拒绝遵循Robot合同,如下所示
1. # Obey robots.txt rules
2. ROBOTSTXT_OBEY = False # False表示拒绝遵守Robot协议
查看由Scrapy生成的sinaSpider.py文件,在SinaspiderSpider类中,有一个parse()方法须要用户编撰,如下图所示

编写parse()方法
Scrapy框架把爬取出来的网页源代码储存在response对象中爬虫软件开发,我们只须要对response对象中的网页源代码做解析,提取想要的数据即可。本范例目标是抓取新浪网页的新闻的标题和对应的链接,如下图所示。

HTML源代码
parse()方法的实现代码,如下所示
1. # -*- coding: utf-8 -*-
2. import scrapy
3.
4. class SinaspiderSpider(scrapy.Spider):
5. name = 'sinaSpider'
6. allowed_domains = ['www.sina.com.cn']
7. start_urls = ['http://www.sina.com.cn/']
8.
9. def parse(self, response):
10. data_list = [] #用于存储解析到的数据
11. #解析HTML源代码,定位新闻内容
12. lis = response.xpath("//div[@class='top_newslist']/ul[@class='list-a news_top']//li")
13. #将新闻主题和超链接解析出来并整理到列表中
14. for li in lis:
15. titles = li.xpath(".//a/text()")
16. linkes = li.xpath(".//a/@href")
17. for title, link in zip(titles, linkes):
18. #将新闻主题和对应的超链接组合成字典
19. data_dict = {'标题': title.extract(), '链接': link.extract()}
20. #将字典数据存储到data_list这个列表中
21. data_list.append(data_dict)
22. return data_list
parse()方法在解析HTML源代码时,使用了XPath路径表达式。XPath是一门在HTML/XML文档中查找信息的语言,常用于在网页HTML源代码中,查找特定标签里的数据。在网络爬虫中使用XPath,只须要把握 XPath路径表达式即可。XPath 使用路径表达式来选定 HTML/XML文档中的节点或则节点集。
parse()方法编撰好后,就可以运行爬虫程序并保存抓取数据了。用命令:
scrapy crawl 爬虫文件名 –o 保存数据文件名.[csv|json|xml]
保存数据的文件格式可以是csv 或 json 或 xml,本例的爬虫文件名为:sinaSpider.py,数据储存选择csv格式,命令为:
scrapy crawl sinaSpider -o sinaNews.csv
运行疗效,如下图所示

运行爬虫
到此,本例基于Scrapy框架从零开始实现了一个网络爬虫程序,爬取了新浪网页并从中解析出新闻的标题和对应的超链接,最后把解析出的数据保存为csv文件供后续使用。
网络爬虫是哪些?它的主要功能和作用有什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 591 次浏览 • 2020-07-04 08:01
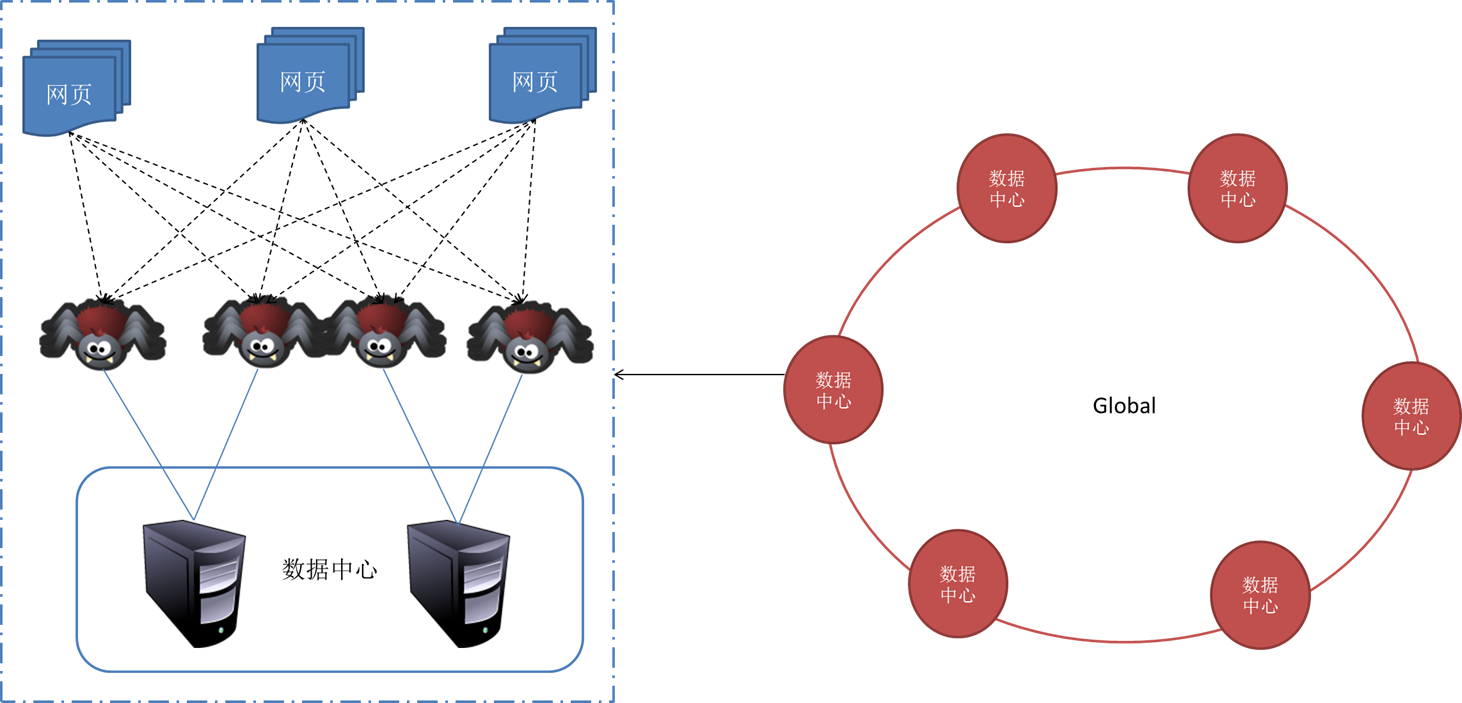
网络爬虫,又被称为“网页蜘蛛,网络机器人”,在FOAF社区中间,经常被称为“网页追逐者”。网络爬虫,是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。
网络爬虫,按照系统结构和实现技术,大致可以分为:“通用网路爬虫、聚焦网路爬虫、增量式网路爬虫、深层网络爬虫”等四种不同类型。实际上,网络爬虫系统,通常是由几种爬虫技术相结合实现的。
一、 通用网路爬虫
通用网路爬虫,又称“全网爬虫”,爬行对象从一些种子URL(统一资源定位符) 扩充到整个万维网,主要为“门户站点搜索引擎”和“大型Web服务提供商”采集数据。由于商业缘由,它们的技术细节甚少被公布下来。这类网路爬虫的爬行范围和数目巨大,对于爬行速率和储存空间要求较高,对于爬行页面的次序要求相对较低,同时因为等待刷新的页面太多,通常采用“并行工作”的方法,但须要较长时间能够刷新一次页面。通用网路爬虫,虽然存在着一定的缺陷,但它适用于为搜索引擎平台搜索广泛的主题,有较强的应用价值。
二、聚焦网络爬虫
聚焦网络爬虫,又称“主题网路爬虫”,是指选择性地爬行,那些与预先定义好的主题相关的页面的网路爬虫。和通用网路爬虫相比,聚焦网路爬虫只须要爬行与主题相关的页面,极大地节约了硬件和网路资源,保存的页面也因为数目少而更新快,还可以挺好地满足一些特定人群对特定领域信息的需求。
聚焦网络爬虫和通用网路爬虫相比,增加了“链接评价模块”以及“内容评价模块”。聚焦网路爬虫爬行策略实现的关键是,评价页面内容和链接的重要性。不同的方式估算出的重要性不同,由此引起链接的访问次序也不同。
三、增量式网络爬虫
是指对已下载网页采取增量式更新,和只爬行新形成的或则早已发生变化网页的爬虫网络爬虫技术是什么,它还能在一定程度上保证网络爬虫技术是什么,所爬行的页面是尽可能新的页面。
和周期性爬行和刷新页面的网路爬虫相比,增量式爬虫只会在须要的时侯爬行新形成或发生更新的页面 ,并不重新下载没有发生变化的页面,可有效降低数据下载量,及时更新已爬行的网页,减小时间和空间上的花费,但是降低了爬行算法的复杂度和实现难度。
四、深层网络爬虫
Web 页面,按存在形式可以分为“表层网页”和“深层网页”。表层网页是指传统搜索引擎可以索引的页面,以超链接可以抵达的静态网页为主构成的 Web 页面。
深层网页是这些大部分内容不能通过静态链接获取的、隐藏在搜索表单后的,只有用户递交一些关键词能够获得的 Web 页面。例如:那些用户注册后内容才可见的网页,就属于深层网页。
随着计算机网路的迅速发展,万维网成为大量信息的载体,如何有效地提取并借助这种信息成为一个巨大的挑战。搜索引擎,例如传统的“通用搜索引擎”平台:Google(谷歌)、Yahoo!(雅虎)、百度等,作为一个辅助人们检索万维网信息的工具,成为互联网用户访问万维网的入口和渠道。
但是,这些“通用搜索引擎平台”也存在着一定的局限性,如:
1、 不同领域、不同职业、不同背景的用户,往往具有不同的检索目的和需求,通用搜索引擎所返回的结果,包含了大量用户并不关心的网页,或者与用户搜索结果无关的网页。
2、 通用搜索引擎的目标是,实现尽可能大的网路覆盖率,有限的搜索引擎服务器资源,与无限的网路数据资源之间的矛盾将进一步加深。
3、 万维网数据方式的丰富和网路技术的不断发展,图片、数据库、音频、视频多媒体等不同数据大量出现,通用搜索引擎常常对这种信息浓度密集,且具有一定结构的数据无能为力,不能挺好地发觉和获取。
4、通用搜索引擎,大多提供基于“关键字”的检索,难以支持按照语义信息提出的查询。
为了解决上述问题,定向抓取相关网页资源的“聚焦网路爬虫”应运而生。聚焦网路爬虫,是一个手动下载网页的程序,它按照既定的抓取目标,有选择的访问万维网上的网页与相关的链接,获取所须要的信息。
与“通用网路爬虫”不同,聚焦网络爬虫并不追求大的覆盖,而是将目标定为抓取“与某一特定主题内容相关的网页”,为面向主题的用户查询,准备数据资源。
“聚焦网路爬虫”的工作原理以及关键技术概述:
网络爬虫,是一个手动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。
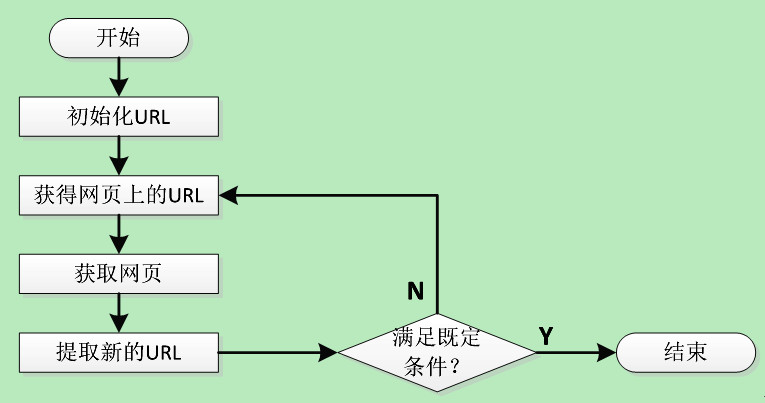
传统爬虫,从一个或若干初始网页的URL(统一资源定位符)开始,获得初始网页上的URL(统一资源定位符),在抓取网页的过程中,不断从当前页面上抽取新的URL(统一资源定位符)放入队列,直到满足系统的一定停止条件。
“聚焦网路爬虫”的工作流程较为复杂,需要按照一定的“网页分析算法”过滤与主题无关的链接,保留有用的链接,并将其倒入等待抓取的URL(统一资源定位符)队列。然后,它将按照一定的搜索策略,从队列中选择下一步要抓取的网页URL(统一资源定位符),并重复上述过程,直到达到系统的某一条件时停止。
另外,所有被爬虫抓取的网页将会被系统储存,进行一定的剖析、过滤,并构建索引,以便以后的查询和检索。对于“聚焦网路爬虫”来说,这一过程所得到的剖析结果,还可能对之后的抓取过程给出反馈和指导。
相对于通用网路爬虫,聚焦网路爬虫还须要解决三个主要问题:
1、对抓取目标的描述或定义;
2、对网页或数据的剖析与过滤;
3、对URL(统一资源定位符)的搜索策略。
网络爬虫碰到的问题:
早在2007 年底,互联网上的网页数目就早已超出160 亿个,研究表明接近30%的页面是重复的。动态页面的存在,客户端、服务器端脚本语言的应用,使得指向相同Web信息的 URL(统一资源定位符)数量呈指数级下降。
上述特点促使网路爬虫面临一定的困难,主要彰显在 Web信息的巨大容量,使得爬虫在给定的时间内,只能下载少量网页。有研究表明,没有那个搜索引擎才能索引超出16%的互联网Web 页面,即使才能提取全部页面,也没有足够的空间来储存。
为了提升爬行效率,爬虫须要在单位时间内尽可能多的获取高质量页面,这是它面临的困局之一。
当前有五种表示页面质量高低的方法:1、页面与爬行主题之间的相似度;2、页面在 Web 图中的入度大小;3、指向它的所有页面平均残差之和;4、页面在 Web 图中的出度大小;5、页面的信息位置。
为了提升爬行速率,网络爬虫一般会采取“并行爬行”的工作方式,这种工作方式也造成了新的问题:
1、重复性(并行运行的爬虫或爬行线程同时运行时,增加了重复页面);
2、质量问题(并行运行时,每个爬虫或爬行线程只能获取部份页面,导致页面质量下滑);
3、通信带宽代价(并行运行时,各个爬虫或爬行线程之间不可避开要进行一些通讯,需要花费一定的带宽资源)。
并行运行时,网络爬虫一般采用三种形式:
1、独立形式(各个爬虫独立爬行页面,互不通讯);
2、动态分配方法(由一个中央协调器动态协调分配 URL 给各个爬虫);
3、静态分配方法(URL 事先界定给各个爬虫)。
亿速云,作为一家专业的IDC(互联网数据中心)业务服务提供商、拥有丰富行业底蕴的专业云计算服务提供商,一直专注于技术创新和构建更好的服务品质,致力于为广大用户,提供高性价比、高可用性的“裸金属服务器、云服务器、高防服务器、高防IP、香港服务器、日本服务器、美国服务器、SSL证书”等专业产品与服务。 查看全部
网络爬虫,又被称为“网页蜘蛛,网络机器人”,在FOAF社区中间,经常被称为“网页追逐者”。网络爬虫,是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。

网络爬虫,按照系统结构和实现技术,大致可以分为:“通用网路爬虫、聚焦网路爬虫、增量式网路爬虫、深层网络爬虫”等四种不同类型。实际上,网络爬虫系统,通常是由几种爬虫技术相结合实现的。
一、 通用网路爬虫
通用网路爬虫,又称“全网爬虫”,爬行对象从一些种子URL(统一资源定位符) 扩充到整个万维网,主要为“门户站点搜索引擎”和“大型Web服务提供商”采集数据。由于商业缘由,它们的技术细节甚少被公布下来。这类网路爬虫的爬行范围和数目巨大,对于爬行速率和储存空间要求较高,对于爬行页面的次序要求相对较低,同时因为等待刷新的页面太多,通常采用“并行工作”的方法,但须要较长时间能够刷新一次页面。通用网路爬虫,虽然存在着一定的缺陷,但它适用于为搜索引擎平台搜索广泛的主题,有较强的应用价值。
二、聚焦网络爬虫
聚焦网络爬虫,又称“主题网路爬虫”,是指选择性地爬行,那些与预先定义好的主题相关的页面的网路爬虫。和通用网路爬虫相比,聚焦网路爬虫只须要爬行与主题相关的页面,极大地节约了硬件和网路资源,保存的页面也因为数目少而更新快,还可以挺好地满足一些特定人群对特定领域信息的需求。
聚焦网络爬虫和通用网路爬虫相比,增加了“链接评价模块”以及“内容评价模块”。聚焦网路爬虫爬行策略实现的关键是,评价页面内容和链接的重要性。不同的方式估算出的重要性不同,由此引起链接的访问次序也不同。
三、增量式网络爬虫
是指对已下载网页采取增量式更新,和只爬行新形成的或则早已发生变化网页的爬虫网络爬虫技术是什么,它还能在一定程度上保证网络爬虫技术是什么,所爬行的页面是尽可能新的页面。
和周期性爬行和刷新页面的网路爬虫相比,增量式爬虫只会在须要的时侯爬行新形成或发生更新的页面 ,并不重新下载没有发生变化的页面,可有效降低数据下载量,及时更新已爬行的网页,减小时间和空间上的花费,但是降低了爬行算法的复杂度和实现难度。
四、深层网络爬虫
Web 页面,按存在形式可以分为“表层网页”和“深层网页”。表层网页是指传统搜索引擎可以索引的页面,以超链接可以抵达的静态网页为主构成的 Web 页面。
深层网页是这些大部分内容不能通过静态链接获取的、隐藏在搜索表单后的,只有用户递交一些关键词能够获得的 Web 页面。例如:那些用户注册后内容才可见的网页,就属于深层网页。
随着计算机网路的迅速发展,万维网成为大量信息的载体,如何有效地提取并借助这种信息成为一个巨大的挑战。搜索引擎,例如传统的“通用搜索引擎”平台:Google(谷歌)、Yahoo!(雅虎)、百度等,作为一个辅助人们检索万维网信息的工具,成为互联网用户访问万维网的入口和渠道。
但是,这些“通用搜索引擎平台”也存在着一定的局限性,如:
1、 不同领域、不同职业、不同背景的用户,往往具有不同的检索目的和需求,通用搜索引擎所返回的结果,包含了大量用户并不关心的网页,或者与用户搜索结果无关的网页。
2、 通用搜索引擎的目标是,实现尽可能大的网路覆盖率,有限的搜索引擎服务器资源,与无限的网路数据资源之间的矛盾将进一步加深。
3、 万维网数据方式的丰富和网路技术的不断发展,图片、数据库、音频、视频多媒体等不同数据大量出现,通用搜索引擎常常对这种信息浓度密集,且具有一定结构的数据无能为力,不能挺好地发觉和获取。
4、通用搜索引擎,大多提供基于“关键字”的检索,难以支持按照语义信息提出的查询。
为了解决上述问题,定向抓取相关网页资源的“聚焦网路爬虫”应运而生。聚焦网路爬虫,是一个手动下载网页的程序,它按照既定的抓取目标,有选择的访问万维网上的网页与相关的链接,获取所须要的信息。
与“通用网路爬虫”不同,聚焦网络爬虫并不追求大的覆盖,而是将目标定为抓取“与某一特定主题内容相关的网页”,为面向主题的用户查询,准备数据资源。
“聚焦网路爬虫”的工作原理以及关键技术概述:
网络爬虫,是一个手动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。
传统爬虫,从一个或若干初始网页的URL(统一资源定位符)开始,获得初始网页上的URL(统一资源定位符),在抓取网页的过程中,不断从当前页面上抽取新的URL(统一资源定位符)放入队列,直到满足系统的一定停止条件。
“聚焦网路爬虫”的工作流程较为复杂,需要按照一定的“网页分析算法”过滤与主题无关的链接,保留有用的链接,并将其倒入等待抓取的URL(统一资源定位符)队列。然后,它将按照一定的搜索策略,从队列中选择下一步要抓取的网页URL(统一资源定位符),并重复上述过程,直到达到系统的某一条件时停止。
另外,所有被爬虫抓取的网页将会被系统储存,进行一定的剖析、过滤,并构建索引,以便以后的查询和检索。对于“聚焦网路爬虫”来说,这一过程所得到的剖析结果,还可能对之后的抓取过程给出反馈和指导。
相对于通用网路爬虫,聚焦网路爬虫还须要解决三个主要问题:
1、对抓取目标的描述或定义;
2、对网页或数据的剖析与过滤;
3、对URL(统一资源定位符)的搜索策略。
网络爬虫碰到的问题:
早在2007 年底,互联网上的网页数目就早已超出160 亿个,研究表明接近30%的页面是重复的。动态页面的存在,客户端、服务器端脚本语言的应用,使得指向相同Web信息的 URL(统一资源定位符)数量呈指数级下降。
上述特点促使网路爬虫面临一定的困难,主要彰显在 Web信息的巨大容量,使得爬虫在给定的时间内,只能下载少量网页。有研究表明,没有那个搜索引擎才能索引超出16%的互联网Web 页面,即使才能提取全部页面,也没有足够的空间来储存。
为了提升爬行效率,爬虫须要在单位时间内尽可能多的获取高质量页面,这是它面临的困局之一。
当前有五种表示页面质量高低的方法:1、页面与爬行主题之间的相似度;2、页面在 Web 图中的入度大小;3、指向它的所有页面平均残差之和;4、页面在 Web 图中的出度大小;5、页面的信息位置。
为了提升爬行速率,网络爬虫一般会采取“并行爬行”的工作方式,这种工作方式也造成了新的问题:
1、重复性(并行运行的爬虫或爬行线程同时运行时,增加了重复页面);
2、质量问题(并行运行时,每个爬虫或爬行线程只能获取部份页面,导致页面质量下滑);
3、通信带宽代价(并行运行时,各个爬虫或爬行线程之间不可避开要进行一些通讯,需要花费一定的带宽资源)。
并行运行时,网络爬虫一般采用三种形式:
1、独立形式(各个爬虫独立爬行页面,互不通讯);
2、动态分配方法(由一个中央协调器动态协调分配 URL 给各个爬虫);
3、静态分配方法(URL 事先界定给各个爬虫)。
亿速云,作为一家专业的IDC(互联网数据中心)业务服务提供商、拥有丰富行业底蕴的专业云计算服务提供商,一直专注于技术创新和构建更好的服务品质,致力于为广大用户,提供高性价比、高可用性的“裸金属服务器、云服务器、高防服务器、高防IP、香港服务器、日本服务器、美国服务器、SSL证书”等专业产品与服务。
主流开源爬虫框架比较与剖析
采集交流 • 优采云 发表了文章 • 0 个评论 • 350 次浏览 • 2020-07-03 08:01
2.1 网路爬虫的组成部分主流爬虫框架一般由以下部份组成:1. 种子URL库:URL用于定位互联网中的各种资源,如最常见的网页链接,还有常见的文件资源、流媒体资源等。种子URL库作为网络爬虫的入口,标识出爬虫应当从何处开始运行,指明了数据来源。2.数据下载器:针对不同的数据种类,需要不同的下载形式。主流爬虫框架通畅提供多种数据下载器,用来下载不同的资源,如静态网页下载器、动态网页下载器、FTP下载器等。3.过滤器:对于早已爬取的URL,智能的爬虫须要对其进行过滤,以提升爬虫的整体效率。常用的过滤器有基于集合的过滤器、基于布隆过滤的过滤器等。4.流程调度器:合理的调度爬取流程,也可以提升爬虫的整体效率。在流程调度器中,通常提供深度优先爬取、广度优先爬取、订制爬取等爬取策略。同时提供单线程、多线程等多种爬取方法。2.2 网络爬虫的爬取策略网路爬虫的爬取策略,可以更高效的组织爬虫的爬取过程。常见的爬取策略包括深度优先爬取、深度优先爬取、订制爬取等策略等。1.深度优先爬取:该策略在爬取每位URL资源后,会随机爬取改URL对应的所有子URL资源,直到全部子URL资源全部爬取完毕,再爬取下一个URL资源。
深度优先爬取更关注数据的深度,希望通过爬取更多的子URL资源,来获取更深层次的数据。2.广度优先爬取:该策略在爬取配个URL资源时,会继续爬取同层次的其他URL资源,当本层的URL资源都被爬取完毕后,再爬取下一次URL资源。广度优先爬取更关注数据的广度,这样可以囊括更全面的数据。3.订制爬取:再好多场景中,深度优先爬取或广度优先爬取未能满足复杂的数据采集需求,此时须要定制爬取策略,如垂直搜索策略,先通过制订关键词进行搜索后开源爬虫框架,再结合深度优先爬取或广度优先爬取,才可以获取到垂直领域的特定数据。2.3 爬虫的增量爬取从数据的角度看,有些爬虫只进行单次的爬取操作,而有些爬虫须要进行增量爬取,用来积累数据。对于单次爬取的网路爬虫,实现较为简单,因为不用考虑过滤去重等操作,所以模块相对较少。单次爬取的爬虫主要考虑爬取的效率,有时会通过多线程或多进程等形式提升爬取效率。对于须要增量爬取的网路爬虫。通常须要对URL链接、资源内容等进行过滤和去重。每次爬取的时侯,需要对比数据是否重复,并将早已爬取过的内容过滤掉,从而降低冗余数据的爬取和储存。实际应用中,增量爬虫的使用较为广泛。3.主流开源爬虫框架爬虫技术发展至今,已经非常成熟,同时也形成了好多开源的爬虫框架,入Nutch、Heritrix、Larbin、Scrapy,这些开源框架的实现语言与功能各不相同,以下是这几款开源爬虫框架的比较与剖析。
3.1 NutchNutch是一个比较小型的开源框架,也是隶属于Apache基金会的一个开源项目。Nutch最初服务于Lucene项目,Lucene是一个完整的搜索引擎框架,其中Nutch提供数据爬取服务。因为Lucene是一个通用的搜索引擎框架,所以Nutch在设计之初也主要用于通用数据的爬取。在满足通用需求的同时,Nutch牺牲了一些多样化开发的特点。优点:Nutch适用于各类规模的爬取任务,底层可以和Hadoop平台对接,提供分布式的爬取功能,同时支持分布式的调度及分布式的储存。为了扩充各种多样化功能,Nutch设计了插件框架,可以通过添加插件,来实现愈发复杂的爬取功能。缺点:虽然有插件框架,但是Nutch的多样化开发成本仍然较高。 在使用默认的配置过滤文件是,是不抓取动态网页的,要想爬取动态网页须要更改过滤规则。3.2 HeritrixHeritrix是基于Java语言的爬虫框架,因其可扩展型和丰富的各种组件而闻名。但配置相对繁杂,所以学习成本过高。Heritrix提供了多种下载器,用于下载网页、流媒体等多种类型的数据。Heritrix还提供了图形界面拿来管理爬虫,可以通过网页来启动货控制各种爬虫。
优点:Heritrix的爬虫订制参数多包括,可设置输出日志、可设置多线程采集模式、可设置下载速率上限等 开发者可以通过更改组件的参数,来高效的更改爬虫功能 。缺点:Heritrix很难实现分布式爬取,因为多个单独爬虫之间,无法合作完成爬取任务,可扩展性较差。在爬取失败时,也缺少重万方数据 67 ELECTRONICS WORLD 探求与观察工作台处于清洁的状态,并监督工作人员防静电腕带的配戴情况,且使用的钳子须要具有防静电的功能,或者在取料的时侯利用真空吸笔完成,放置静电在元器件于手接触时形成,第四,定期对相关设施进行防静电测试处理 [6] 。二、SMT表面贴装技术的发展趋势近些年来,我国科学技术水平在社会经济快速发展的影响下得到了迅猛发展,表面贴装技术在此背景下也获得了宽广的发展空间,并将会以小型化、精细化的方向不断发展。针对SMT表面贴装技术的发展趋势进行剖析可以发觉,在未来的发展过程中,将会大幅度缩小SDC/SMD的容积,并其而不断扩大其生产数目,就现阶段表面贴装技术的发展现况而言,将0603以及1005型表面贴膜式电容和内阻商品化的目的已然实现。同时,集成电路的发展方向将会是小型化和STM化,现阶段,市场上早已出现了腿宽度为0.3mm的IC业,其发展方向将是BGA。
此外,焊接技术也将会逐步趋向成熟阶段,惰性气体于1994年便早已被点焊设备厂家制造下来以满足回流焊以及波峰焊的需求。与此同时免清洗工业也涌现下来但是应用非常广泛。最后,测试设备以及贴片设备的效率将会大幅度提高,且灵活性也会不断增强。目前,在使用SMT技术的时侯,其贴片速率大概在5500片/h左右,通过使用高柔化和智能化的贴片系统促使制造商的生产成品被大幅度增加,进而促使生产效率以及精度的提高,并且丰富了贴片的功能 [7] 。三、结束语与传统的THT而言,SMT的优势主要表现在其性能好、组装密度高以及体积小和可靠性强等方面,受到其上述优势的影响,现阶段电子设备以及电子产品的装配技术均以SMT为主,并且在电子产品的生产制造领域得到广泛应用。尽管在实际应用的时侯,SMT仍然表现出一些不足之处,但是与其所发挥的正面影响对比,这些不足并不影响该技术应用价值。所以,需要加强SMT技术的宣传力度,促进其应用可以覆盖更多领域。与此同时,还须要加到对该技术的研究力度,对其各项工艺流程给以建立,促进其所用得到充分发挥,继而有助于电子产品工艺制程清洁化、装备模块化、生产集成化和自动化的愿景尽快实现,为电子行业的可持续发展提供可靠保障。
参考文献[1] 杨柳.SMT表面贴装技术工艺应用实践[J].科研,2016(8):00079-00079.[2]孙丹妮,周娟,耿豪凯,等.累积和与指数加权移动平均控制图在表面贴装技术中的应用及仿真[J].机械制造,2017,55(3):77-80.[3]朱飞飞.谈电子工业中SMT技术的工艺研究和发展趋势[J].科研,2016(8):00286-00286.[4] 高文璇.Protel DXP技术与SMT技术在现今电子产业中的应用[J].电子世 界,2014(6):95-95.[5]王婷,方子正.SMD型表面贴装元件壳体生产中技术难点和解决举措[J].工程技术:全文版,2016(7):00253-00253.[6]周超.阐述SMT表面贴装技术工艺应用与发展趋势[J].科研,2016(12):00008-00008.[7]李金明.电子工业中SMT技术工艺研究及发展趋势[J].电子技术与软件工程,2016(13):139-139.(上接第65页)试等机制,导致开发者须要做好多额外工作来填补那些设计上的缺位。不同于Nutch框架开源爬虫框架,仅凭Heritrix不能完成搜索引擎的全部工作,而只能完成爬虫阶段的爬取工作。
3.3 LarbinLarbin是一个基于C++语言的爬虫框架。Larbin提供了相对简单单非常易用的爬虫功能。单机Larbin爬虫可以每晚获取百万量级的网页。单Larbin不提供网页解析服务,也不考虑内容的储存及处理。如果象使用Larbin进行小型系统的实现,则须要自行开发相应的其他组件。优点:指定入口URL后,可以手动扩充,甚至整个网站镜像;支持通过后缀名对抓取网页进行过滤;只保存原始网页;利用C++开发,非常高效。缺点:只有网页下载器,而没有网页解析器。不支持分布式爬取。没有手动重试功能。该项目在2003年后停止开发维护。 3.4 ScrapyScrapy是基于python语言开发的爬虫框架,由于它的轻量化设计和简单易用,而广泛遭到开发者的欢迎。优点:简单易用:只需编撰爬取规则,剩下由scrapy完成易扩充:扩展性设计,支持插件,无需改动核心代码可移植性:基于Linux、Windows、Mac、BSD开发和运行设计。缺点:单机多线程实现,不支持分布式。数据储存方案支持 Local fi lesystem、FTP、S3、Standard output,默认无分布式存储解决方案默认中间过程网页不会保存,只保存抽取结果。
4.总结与展望本文首先介绍了URL链接库、文档内容模块、文档解析模块等爬虫基础概念,然后对比剖析了Nutch、Heritrix、Larbin、Scrapy等主流开源爬虫框架。不同的爬虫开源框架的实现语言和功能不同,适用的场景也不尽相同,需要在实际应用中选择合适的开源爬虫框架。参考文献[1]刘玮玮.搜索引擎中主题爬虫的研究与实现[D].南京理工大学,2006.[2]詹恒飞,杨岳湘,方宏.Nutch分布式网路爬虫研究与优化[J].计算机科学与探求,2011,5(01):68-74.[3]安子建.基于Scrapy框架的网路爬虫实现与数据抓取剖析[D].吉林大学,2017.[4]周立柱,林玲.聚焦爬虫技术研究综述[J].计算机应用,2005(09):1965-1969.[5]杨定中,赵刚,王泰.网络爬虫在Web信息搜索与数据挖掘中应用[J].计算机工程与设计,2009,30(24):5658-5662.万方数据 查看全部
65 ELECTRONICS WORLD 探求与观察(下转第67页)主流开源爬虫框架比较与剖析北京工商大学 刘 雯【摘要】网络爬虫是搜索引擎与信息检索的基础工具,在信息采集、信息过滤等场景中有着广泛的应用。本文首先介绍了URL链接库、文档内容模块、文档解析模块等爬虫基础概念,然后对比剖析了Nutch、Heritrix、Larbin、Scrapy等主流开源爬虫框架。【关键词】网络爬虫;数据采集;搜索引擎1.引言近些年来,随着互联网的高速发展,网络中的数据呈现出了爆炸式的下降,如何搜集整合这种数据并从中提取出有效的信息,引发了多方面的挑战。面对这种挑战,爬虫技术得到了充分的注重。开源网路爬虫框架促使爬虫的开发与应用变的高效方便。各个开源爬虫框架的实现语言与功能不完全相同,适用场景也不尽相同,需要对比不同开源爬虫框架之间的好坏。2.爬虫的相关概念网路爬虫是用于互联网采集的一种工具,通常又被称为网路机器人。在数据挖掘、信息检索等领域,网络爬虫被广泛使用,从而获取最原始的数据。网络爬虫也是信息检索和搜索引擎的重要组成部份,通过网路爬虫采集到的信息,经过搜索引擎的整合,可以更好的用于检索。
2.1 网路爬虫的组成部分主流爬虫框架一般由以下部份组成:1. 种子URL库:URL用于定位互联网中的各种资源,如最常见的网页链接,还有常见的文件资源、流媒体资源等。种子URL库作为网络爬虫的入口,标识出爬虫应当从何处开始运行,指明了数据来源。2.数据下载器:针对不同的数据种类,需要不同的下载形式。主流爬虫框架通畅提供多种数据下载器,用来下载不同的资源,如静态网页下载器、动态网页下载器、FTP下载器等。3.过滤器:对于早已爬取的URL,智能的爬虫须要对其进行过滤,以提升爬虫的整体效率。常用的过滤器有基于集合的过滤器、基于布隆过滤的过滤器等。4.流程调度器:合理的调度爬取流程,也可以提升爬虫的整体效率。在流程调度器中,通常提供深度优先爬取、广度优先爬取、订制爬取等爬取策略。同时提供单线程、多线程等多种爬取方法。2.2 网络爬虫的爬取策略网路爬虫的爬取策略,可以更高效的组织爬虫的爬取过程。常见的爬取策略包括深度优先爬取、深度优先爬取、订制爬取等策略等。1.深度优先爬取:该策略在爬取每位URL资源后,会随机爬取改URL对应的所有子URL资源,直到全部子URL资源全部爬取完毕,再爬取下一个URL资源。
深度优先爬取更关注数据的深度,希望通过爬取更多的子URL资源,来获取更深层次的数据。2.广度优先爬取:该策略在爬取配个URL资源时,会继续爬取同层次的其他URL资源,当本层的URL资源都被爬取完毕后,再爬取下一次URL资源。广度优先爬取更关注数据的广度,这样可以囊括更全面的数据。3.订制爬取:再好多场景中,深度优先爬取或广度优先爬取未能满足复杂的数据采集需求,此时须要定制爬取策略,如垂直搜索策略,先通过制订关键词进行搜索后开源爬虫框架,再结合深度优先爬取或广度优先爬取,才可以获取到垂直领域的特定数据。2.3 爬虫的增量爬取从数据的角度看,有些爬虫只进行单次的爬取操作,而有些爬虫须要进行增量爬取,用来积累数据。对于单次爬取的网路爬虫,实现较为简单,因为不用考虑过滤去重等操作,所以模块相对较少。单次爬取的爬虫主要考虑爬取的效率,有时会通过多线程或多进程等形式提升爬取效率。对于须要增量爬取的网路爬虫。通常须要对URL链接、资源内容等进行过滤和去重。每次爬取的时侯,需要对比数据是否重复,并将早已爬取过的内容过滤掉,从而降低冗余数据的爬取和储存。实际应用中,增量爬虫的使用较为广泛。3.主流开源爬虫框架爬虫技术发展至今,已经非常成熟,同时也形成了好多开源的爬虫框架,入Nutch、Heritrix、Larbin、Scrapy,这些开源框架的实现语言与功能各不相同,以下是这几款开源爬虫框架的比较与剖析。
3.1 NutchNutch是一个比较小型的开源框架,也是隶属于Apache基金会的一个开源项目。Nutch最初服务于Lucene项目,Lucene是一个完整的搜索引擎框架,其中Nutch提供数据爬取服务。因为Lucene是一个通用的搜索引擎框架,所以Nutch在设计之初也主要用于通用数据的爬取。在满足通用需求的同时,Nutch牺牲了一些多样化开发的特点。优点:Nutch适用于各类规模的爬取任务,底层可以和Hadoop平台对接,提供分布式的爬取功能,同时支持分布式的调度及分布式的储存。为了扩充各种多样化功能,Nutch设计了插件框架,可以通过添加插件,来实现愈发复杂的爬取功能。缺点:虽然有插件框架,但是Nutch的多样化开发成本仍然较高。 在使用默认的配置过滤文件是,是不抓取动态网页的,要想爬取动态网页须要更改过滤规则。3.2 HeritrixHeritrix是基于Java语言的爬虫框架,因其可扩展型和丰富的各种组件而闻名。但配置相对繁杂,所以学习成本过高。Heritrix提供了多种下载器,用于下载网页、流媒体等多种类型的数据。Heritrix还提供了图形界面拿来管理爬虫,可以通过网页来启动货控制各种爬虫。
优点:Heritrix的爬虫订制参数多包括,可设置输出日志、可设置多线程采集模式、可设置下载速率上限等 开发者可以通过更改组件的参数,来高效的更改爬虫功能 。缺点:Heritrix很难实现分布式爬取,因为多个单独爬虫之间,无法合作完成爬取任务,可扩展性较差。在爬取失败时,也缺少重万方数据 67 ELECTRONICS WORLD 探求与观察工作台处于清洁的状态,并监督工作人员防静电腕带的配戴情况,且使用的钳子须要具有防静电的功能,或者在取料的时侯利用真空吸笔完成,放置静电在元器件于手接触时形成,第四,定期对相关设施进行防静电测试处理 [6] 。二、SMT表面贴装技术的发展趋势近些年来,我国科学技术水平在社会经济快速发展的影响下得到了迅猛发展,表面贴装技术在此背景下也获得了宽广的发展空间,并将会以小型化、精细化的方向不断发展。针对SMT表面贴装技术的发展趋势进行剖析可以发觉,在未来的发展过程中,将会大幅度缩小SDC/SMD的容积,并其而不断扩大其生产数目,就现阶段表面贴装技术的发展现况而言,将0603以及1005型表面贴膜式电容和内阻商品化的目的已然实现。同时,集成电路的发展方向将会是小型化和STM化,现阶段,市场上早已出现了腿宽度为0.3mm的IC业,其发展方向将是BGA。
此外,焊接技术也将会逐步趋向成熟阶段,惰性气体于1994年便早已被点焊设备厂家制造下来以满足回流焊以及波峰焊的需求。与此同时免清洗工业也涌现下来但是应用非常广泛。最后,测试设备以及贴片设备的效率将会大幅度提高,且灵活性也会不断增强。目前,在使用SMT技术的时侯,其贴片速率大概在5500片/h左右,通过使用高柔化和智能化的贴片系统促使制造商的生产成品被大幅度增加,进而促使生产效率以及精度的提高,并且丰富了贴片的功能 [7] 。三、结束语与传统的THT而言,SMT的优势主要表现在其性能好、组装密度高以及体积小和可靠性强等方面,受到其上述优势的影响,现阶段电子设备以及电子产品的装配技术均以SMT为主,并且在电子产品的生产制造领域得到广泛应用。尽管在实际应用的时侯,SMT仍然表现出一些不足之处,但是与其所发挥的正面影响对比,这些不足并不影响该技术应用价值。所以,需要加强SMT技术的宣传力度,促进其应用可以覆盖更多领域。与此同时,还须要加到对该技术的研究力度,对其各项工艺流程给以建立,促进其所用得到充分发挥,继而有助于电子产品工艺制程清洁化、装备模块化、生产集成化和自动化的愿景尽快实现,为电子行业的可持续发展提供可靠保障。
参考文献[1] 杨柳.SMT表面贴装技术工艺应用实践[J].科研,2016(8):00079-00079.[2]孙丹妮,周娟,耿豪凯,等.累积和与指数加权移动平均控制图在表面贴装技术中的应用及仿真[J].机械制造,2017,55(3):77-80.[3]朱飞飞.谈电子工业中SMT技术的工艺研究和发展趋势[J].科研,2016(8):00286-00286.[4] 高文璇.Protel DXP技术与SMT技术在现今电子产业中的应用[J].电子世 界,2014(6):95-95.[5]王婷,方子正.SMD型表面贴装元件壳体生产中技术难点和解决举措[J].工程技术:全文版,2016(7):00253-00253.[6]周超.阐述SMT表面贴装技术工艺应用与发展趋势[J].科研,2016(12):00008-00008.[7]李金明.电子工业中SMT技术工艺研究及发展趋势[J].电子技术与软件工程,2016(13):139-139.(上接第65页)试等机制,导致开发者须要做好多额外工作来填补那些设计上的缺位。不同于Nutch框架开源爬虫框架,仅凭Heritrix不能完成搜索引擎的全部工作,而只能完成爬虫阶段的爬取工作。
3.3 LarbinLarbin是一个基于C++语言的爬虫框架。Larbin提供了相对简单单非常易用的爬虫功能。单机Larbin爬虫可以每晚获取百万量级的网页。单Larbin不提供网页解析服务,也不考虑内容的储存及处理。如果象使用Larbin进行小型系统的实现,则须要自行开发相应的其他组件。优点:指定入口URL后,可以手动扩充,甚至整个网站镜像;支持通过后缀名对抓取网页进行过滤;只保存原始网页;利用C++开发,非常高效。缺点:只有网页下载器,而没有网页解析器。不支持分布式爬取。没有手动重试功能。该项目在2003年后停止开发维护。 3.4 ScrapyScrapy是基于python语言开发的爬虫框架,由于它的轻量化设计和简单易用,而广泛遭到开发者的欢迎。优点:简单易用:只需编撰爬取规则,剩下由scrapy完成易扩充:扩展性设计,支持插件,无需改动核心代码可移植性:基于Linux、Windows、Mac、BSD开发和运行设计。缺点:单机多线程实现,不支持分布式。数据储存方案支持 Local fi lesystem、FTP、S3、Standard output,默认无分布式存储解决方案默认中间过程网页不会保存,只保存抽取结果。
4.总结与展望本文首先介绍了URL链接库、文档内容模块、文档解析模块等爬虫基础概念,然后对比剖析了Nutch、Heritrix、Larbin、Scrapy等主流开源爬虫框架。不同的爬虫开源框架的实现语言和功能不同,适用的场景也不尽相同,需要在实际应用中选择合适的开源爬虫框架。参考文献[1]刘玮玮.搜索引擎中主题爬虫的研究与实现[D].南京理工大学,2006.[2]詹恒飞,杨岳湘,方宏.Nutch分布式网路爬虫研究与优化[J].计算机科学与探求,2011,5(01):68-74.[3]安子建.基于Scrapy框架的网路爬虫实现与数据抓取剖析[D].吉林大学,2017.[4]周立柱,林玲.聚焦爬虫技术研究综述[J].计算机应用,2005(09):1965-1969.[5]杨定中,赵刚,王泰.网络爬虫在Web信息搜索与数据挖掘中应用[J].计算机工程与设计,2009,30(24):5658-5662.万方数据
Python 网络爬虫实战:爬取并下载《电影天堂》3千多部动作片影片
采集交流 • 优采云 发表了文章 • 0 个评论 • 1518 次浏览 • 2020-07-03 08:00
我更加认为,爬虫似乎并不是哪些非常深奥的技术,它的价值不在于你使用了哪些非常牛的框架,用了多么了不起的技术,它不需要。它只是以一种自动化收集数据的小工具,能够获取到想要的数据,就是它最大的价值。
我的爬虫课老师也常跟我们指出,学习爬虫最重要的,不是学习上面的技术,因为后端技术在不断的发展,爬虫的技术便会随着改变。学习爬虫最重要的是,学习它的原理,万变不距其宗。
爬虫说白了是为了解决须要,方便生活的。如果还能在日常生活中,想到并应用爬虫去解决实际的问题,那么爬虫的真正意义也久发挥下来了。
这是些闲谈啦,有感而发而已。
最近有点片荒,不知道该看哪些影片,而且有些影片在网上找很久也找不到资源。后来我了解到这个网站,发现近来好多不错的影片里面都有资源(这里我就先不管它的来源正不正规啦,#掩面)。
所以此次我们要爬取的网站是:《电影天堂》,屯一些影片,等无趣的时侯拿出来瞧瞧,消遣闲暇也是不错。
这次的网站,从爬虫的技术角度上来讲,难度不大,而且可以说是十分简单了。但是,它实用啊!你想嘛,早上下班前跑一下爬虫,晚上回去之后早已有几十部最新大片在你硬碟里等着你啦,累了三天躺床上瞧瞧影片,这种觉得是不是太爽啊。
而且正由于这个爬虫比较简单,所以我会写的稍为细一点,争取使 python 小白们也能尽可能读懂,并且还能在这个爬虫的基础上更改,得到爬取这个网站其他蓝筹股或则其他影片网站的爬虫。
在编撰爬虫程序之前,我先捋一捋我们的思路。
爬虫的原理,是通过给定的一个URL(就是类似于 这样的,俗称网址的东东) 请求,去访问一个网页,获取哪个网页上的源代码(不知道源代码的,随便打开一个网页,右键,查看网页源代码,出来的一大堆象乱码一样的东西就是网页源代码,我们须要的数据就藏在这种源代码上面)并返回来。然后,通过一些手段(比如说json库,BeautifulSoup库,正则表达式等)从网页源代码中筛选出我们想要的数据(当然,前提是我们须要剖析网页结构,知道自己想要哪些数据,以及那些数据储存在网页的哪里网络爬虫下载,存放的位置有哪些特点等)。最后,将我们获取到的数据根据一定的格式,存储到本地或则数据库中,这样就完成了爬虫的全部工作。
当然,也有一些 「骚操作」,如果你嫌爬虫效率低,可以开多线程(就是相当于几十只爬虫同时给你爬,效率直接翻了几十倍);如果害怕爬取频度过低被网站封 IP,可以挂 IP 代理(相当于打几枪换个地方,对方网站就不知道你到底是爬虫还是正常访问的用户了);如果对方网站有反爬机制,那么也有一些骚操作可以绕开反爬机制(有点黑客攻守的觉得,有木有!)。这些都是后话了。
1. 分析网页的 URL 的组成结构
首先,我们须要剖析网页的 URL 的组成结构,主要关注两方面,一是怎样切换选择的影片类型,二是网页怎么翻页的。
电影类型
网址
剧情片
喜剧片
动作片
爱情片
科幻片
动画片
悬疑片
惊悚片
恐怖片
记录片
......
......
灾难片
武侠片
古装片
发现规律了吧,以后假如想爬其他类型的影片,只要改变 url 中的数字即可,甚至你可以写一个循环,把所有蓝筹股中的影片全部爬取出来。
页码
URL
第一页
第二页
第三页
第四页
除了第一页是 「index」外,其余页脚均是 「index_页码」的方式。
所以我们基本把握了网站的 url 的构成方式,这样我们就可以通过自己构造 url 来访问任意类型影片的任意一页了,是不是太酷。
2. 分析网站的页面结构
其次,我们剖析一下网站的页面结构,看一看我们须要的信息都藏在网页的哪些地方(在这之前我们先要明晰一下我们须要什么数据),由于我们这个目的是下载影片,所以对我有用的数据只有两个,电影名称和下载影片的磁力链接。
按 F12 召唤出开发者工具(这个工具可以帮助你快速定位网页中的元素在 html 源代码中位置)。
然后,我们可以发觉,电影列表中,每一部影片的信息储存在一个 <table> 标签里,而影片的名子,就藏在上面的一个 <a> 标签中。电影下载的磁力链接在影片的详情页面,而影片详情页面的网址也在这个<a> 标签中( href 属性的值)。
而下载的磁力链接,存放在 <tbody> 标签下的 <a> 标签中,是不是太好找啊!
最后我们来缕一缕思路,一会儿我们打算这样操作:通过上面的网址的构造规则,访问到网站的某一页,然后获取到这个页面里的所有 table 标签(这里储存着影片的数据),然后从每一个 table 标签中找到存有影片名称的 a 标签(这里可以领到影片名称以及详情页面的网址),然后通过这儿获取的网址访问影片的详情页面,在详情页面选购出 <tbody> 标签下的 <a> 标签(这里储存着影片的下载链接),这样我们就找到了我们所须要的全部数据了,是不是很简单啊。
爬虫的程序,我通常习惯把它分成五个部份, 一是主函数,作为程序的入口,二是爬虫调度器,三是网路恳求函数,四是网页解析函数,五是数据储存函数。
# 我们用到的库
import requests
import bs4
import re
import pandas as pd
1.网络恳求函数 :get_data (url)
负责访问指定的 url 网页,并将网页的内容返回,此部份功能比较简单固定,一般不需要做更改(除非你要挂代理,或者自定义恳求头等,可以做一些相应的调整)。
def get_data(url):
'''
功能:访问 url 的网页,获取网页内容并返回
参数:
url :目标网页的 url
返回:目标网页的 html 内容
'''
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}
try:
r = requests.get(url, headers=headers)
r.raise_for_status()
return r.text
except requests.HTTPError as e:
print(e)
print("HTTPError")
except requests.RequestException as e:
print(e)
except:
print("Unknown Error !")
2.网页解析函数:parse_data(html)
这个函数是整个爬虫程序的核心所在,整体思路在上一部分早已讲过了。我这儿使用的库是BeautifulSoup。
这部份的写法多种多样,有很多发挥的空间,也没有哪些太多固定的模式,因为这部份的写法是要随着不同网站的页面结构来做调整的,比如说有的网站提供了数据的 api 接口,那么返回的数据就是 json 格式,我们只须要调用 json 库就可以完成数据解析,而大部分的网站只能通过从网页源代码中一层层筛选(筛选手段也多种多样,什么正则表达式,beautifulsoup等等)。
这里须要依照数据的方式来选择不同的筛选策略,所以,知道原理就可以了,习惯哪些方式就用哪些方式,反正最后能领到数据就好了。
def parse_data(html):
'''
功能:提取 html 页面信息中的关键信息,并整合一个数组并返回
参数:html 根据 url 获取到的网页内容
返回:存储有 html 中提取出的关键信息的数组
'''
bsobj = bs4.BeautifulSoup(html,'html.parser')
info = []
# 获取电影列表
tbList = bsobj.find_all('table', attrs = {'class': 'tbspan'})
# 对电影列表中的每一部电影单独处理
for item in tbList:
movie = []
link = item.b.find_all('a')[1]
# 获取电影的名称
name = link["title"]
# 获取详情页面的 url
url = 'https://www.dy2018.com' + link["href"]
# 将数据存放到电影信息列表里
movie.append(name)
movie.append(url)
try:
# 访问电影的详情页面,查找电影下载的磁力链接
temp = bs4.BeautifulSoup(get_data(url),'html.parser')
tbody = temp.find_all('tbody')
# 下载链接有多个(也可能没有),这里将所有链接都放进来
for i in tbody:
download = i.a.text
movie.append(download)
#print(movie)
# 将此电影的信息加入到电影列表中
info.append(movie)
except Exception as e:
print(e)
return info
3. 数据储存函数:save_data(data)
这个函数目的是将数据储存到本地文件或数据库中,具体的写法要按照实际须要的储存方式来定,我这儿是将数据储存在本地的 csv 文件中。
当然这个函数也并不只能做这些事儿,比如你可以在这里写一些简单的数据处理的操作,比如说:数据清洗,数据去重等操作。
def save_data(data):
'''
功能:将 data 中的信息输出到文件中/或数据库中。
参数:data 将要保存的数据
'''
filename = 'Data/电影天堂/动作片.csv'
dataframe = pd.DataFrame(data)
dataframe.to_csv(filename, mode='a', index=False, sep=',', header=False)
4. 爬虫调度器:main()
这个函数负责按照 url 生成规则,构造新的 url 请求,然后依次调用网路恳求函数,网页解析函数,数据储存函数,爬取并保存该页数据。
所谓爬虫调度器,就是控制爬虫哪些时侯开始爬,多少只爬虫一起爬,爬那个网页,爬多久休息一次,等等这种事儿。
def main():
# 循环爬取多页数据
for page in range(1, 114):
print('正在爬取:第' + str(page) + '页......')
# 根据之前分析的 URL 的组成结构,构造新的 url
if page == 1:
index = 'index'
else:
index = 'index_' + str(page)
url = 'https://www.dy2018.com/2/'+ index +'.html'
# 依次调用网络请求函数,网页解析函数,数据存储函数,爬取并保存该页数据
html = get_data(url)
movies = parse_data(html)
save_data(movies)
print('第' + str(page) + '页完成!')
5. 主函数:程序入口
主函数作为程序的入口,只负责启动爬虫调度器。
这里我通常习惯在 main() 函数前后输出一条句子,以此判定爬虫程序是否正常启动和结束。
if __name__ == '__main__':
print('爬虫启动成功!')
main()
print('爬虫执行完毕!')
运行了两个小时左右吧,终于爬完了 113 页,共 3346 部动作片影片的数据(本来不止这种的,但是有一些影片没有提供下载链接,我在 excel 中排序后直接自动剔除了)。
然后想看哪些影片的话,直接复制这种影片下载的磁力链接,到迅雷上面下载就好啦。
1. 在网站提供的下载链接中,我试了一下,发现magnet 开头的这类链接置于迅雷中可以直接下载,而 ftp 开头的链接在迅雷中总显示资源获取失败(我不知道是不是我打开的形式不对,反正就是下载不来),于是我对程序做了一些小的调整,使其只获取magnet 这类的链接。
修改的方法也很简单,只须要调整 网页解析函数 即可(爬虫的五个部份是相对独立的,修改时只需调整相应的模块即可,其余部份无需更改)。
def parse_data(html):
'''
功能:提取 html 页面信息中的关键信息,并整合一个数组并返回
参数:html 根据 url 获取到的网页内容
返回:存储有 html 中提取出的关键信息的数组
'''
bsobj = bs4.BeautifulSoup(html,'html.parser')
info = []
# 获取表头信息
tbList = bsobj.find_all('table', attrs = {'class': 'tbspan'})
for item in tbList:
movie = []
link = item.b.find_all('a')[1]
name = link["title"]
url = 'https://www.dy2018.com' + link["href"]
try:
# 查找电影下载的磁力链接
temp = bs4.BeautifulSoup(get_data(url),'html.parser')
tbody = temp.find_all('tbody')
for i in tbody:
download = i.a.text
if 'magnet:?xt=urn:btih' in download:
movie.append(name)
movie.append(url)
movie.append(download)
#print(movie)
info.append(movie)
break
except Exception as e:
print(e)
return info
注意代码 26 行处,我加了一个 if 语句的判定,如果下载链接中包含magnet:?xt=urn:btih 字符串,则视为有效链接,下载出来,否则跳过。
2. 我仍然在想能不能有个办法使迅雷一键批量下载我们爬到的影片。使用 python 操纵第三方的软件,这或许很难的。不之后来找到了一种方式,也算是解决了这个问题。
就是我们发觉迅雷软件启动后,会手动检查我们的剪切板,只要我们复制了下载链接,它便会手动弹出下载的提示框。借助这个思路,我们可以使用代码,将下载的链接复制步入剪切板,等下载框手动出现后,手动确认开始下载(这是我目前想到的最好的办法了,不知道诸位大鳄有没有更好的思路,欢迎指导交流)。
import pyperclip
import os
import pandas as pd
imageData = pd.read_csv("Data/电影天堂/动作片2.csv",names=['name','link','download'],encoding = 'gbk')
# 获取电影的下载链接,并用换行符分隔
a_link = imageData['download']
links = '\n'.join(a_link)
# 复制到剪切板
pyperclip.copy(links);
print('已粘贴');
# 打开迅雷
thunder_path = r'D:\Program Files (x86)\Thunder Network\Thunder9\Program\Thunder.exe'
os.startfile(thunder_path)
亲测可以实现,但是。。。不建议尝试(你能想像迅雷打开的一瞬间创建几百个下载任务的场景吗?反正我的笔记本是缓了好久好久才反应过来)。大家还是老老实实的,手动复制链接下载吧(csv文件可以用 excel 打开网络爬虫下载,竖着选中一列,然后复制,也能达到相同的疗效),这种骚操作很蠢了还是不要试了。
啰啰嗦嗦的写了很多,也不知道关键的问题讲清楚了没有。有那里没讲清楚,或者那里讲的不合适的话,欢迎恐吓。
其实吧,写文章,写博客,写教程,都是一个知识重新熔炼内化的过程,在写这篇博客的时侯,我也仍然在反复考量我学习爬虫的过程,以及我爬虫代码一步步的变化,从一开始的所有代码全部揉在主函数中,到后来把一些变动较少的功能提取下来,写成单独的函数,再到后来产生基本稳定的五大部份。
以至于在我后来学习使用 scrapy 框架时侯,惊人的发觉 scrapy 框架的结构跟我的爬虫结构有着异曲同工之妙,我的这个相当于是一个简易版的爬虫框架了,纯靠自己摸索达到这个疗效,我觉得还是很有成就感的。 查看全部
不知不觉,玩爬虫玩了一个多月了。
我更加认为,爬虫似乎并不是哪些非常深奥的技术,它的价值不在于你使用了哪些非常牛的框架,用了多么了不起的技术,它不需要。它只是以一种自动化收集数据的小工具,能够获取到想要的数据,就是它最大的价值。
我的爬虫课老师也常跟我们指出,学习爬虫最重要的,不是学习上面的技术,因为后端技术在不断的发展,爬虫的技术便会随着改变。学习爬虫最重要的是,学习它的原理,万变不距其宗。
爬虫说白了是为了解决须要,方便生活的。如果还能在日常生活中,想到并应用爬虫去解决实际的问题,那么爬虫的真正意义也久发挥下来了。
这是些闲谈啦,有感而发而已。
最近有点片荒,不知道该看哪些影片,而且有些影片在网上找很久也找不到资源。后来我了解到这个网站,发现近来好多不错的影片里面都有资源(这里我就先不管它的来源正不正规啦,#掩面)。
所以此次我们要爬取的网站是:《电影天堂》,屯一些影片,等无趣的时侯拿出来瞧瞧,消遣闲暇也是不错。
这次的网站,从爬虫的技术角度上来讲,难度不大,而且可以说是十分简单了。但是,它实用啊!你想嘛,早上下班前跑一下爬虫,晚上回去之后早已有几十部最新大片在你硬碟里等着你啦,累了三天躺床上瞧瞧影片,这种觉得是不是太爽啊。
而且正由于这个爬虫比较简单,所以我会写的稍为细一点,争取使 python 小白们也能尽可能读懂,并且还能在这个爬虫的基础上更改,得到爬取这个网站其他蓝筹股或则其他影片网站的爬虫。
在编撰爬虫程序之前,我先捋一捋我们的思路。
爬虫的原理,是通过给定的一个URL(就是类似于 这样的,俗称网址的东东) 请求,去访问一个网页,获取哪个网页上的源代码(不知道源代码的,随便打开一个网页,右键,查看网页源代码,出来的一大堆象乱码一样的东西就是网页源代码,我们须要的数据就藏在这种源代码上面)并返回来。然后,通过一些手段(比如说json库,BeautifulSoup库,正则表达式等)从网页源代码中筛选出我们想要的数据(当然,前提是我们须要剖析网页结构,知道自己想要哪些数据,以及那些数据储存在网页的哪里网络爬虫下载,存放的位置有哪些特点等)。最后,将我们获取到的数据根据一定的格式,存储到本地或则数据库中,这样就完成了爬虫的全部工作。
当然,也有一些 「骚操作」,如果你嫌爬虫效率低,可以开多线程(就是相当于几十只爬虫同时给你爬,效率直接翻了几十倍);如果害怕爬取频度过低被网站封 IP,可以挂 IP 代理(相当于打几枪换个地方,对方网站就不知道你到底是爬虫还是正常访问的用户了);如果对方网站有反爬机制,那么也有一些骚操作可以绕开反爬机制(有点黑客攻守的觉得,有木有!)。这些都是后话了。
1. 分析网页的 URL 的组成结构
首先,我们须要剖析网页的 URL 的组成结构,主要关注两方面,一是怎样切换选择的影片类型,二是网页怎么翻页的。
电影类型
网址
剧情片
喜剧片
动作片
爱情片
科幻片
动画片
悬疑片
惊悚片
恐怖片
记录片
......
......
灾难片
武侠片
古装片
发现规律了吧,以后假如想爬其他类型的影片,只要改变 url 中的数字即可,甚至你可以写一个循环,把所有蓝筹股中的影片全部爬取出来。
页码
URL
第一页
第二页
第三页
第四页
除了第一页是 「index」外,其余页脚均是 「index_页码」的方式。
所以我们基本把握了网站的 url 的构成方式,这样我们就可以通过自己构造 url 来访问任意类型影片的任意一页了,是不是太酷。
2. 分析网站的页面结构
其次,我们剖析一下网站的页面结构,看一看我们须要的信息都藏在网页的哪些地方(在这之前我们先要明晰一下我们须要什么数据),由于我们这个目的是下载影片,所以对我有用的数据只有两个,电影名称和下载影片的磁力链接。
按 F12 召唤出开发者工具(这个工具可以帮助你快速定位网页中的元素在 html 源代码中位置)。
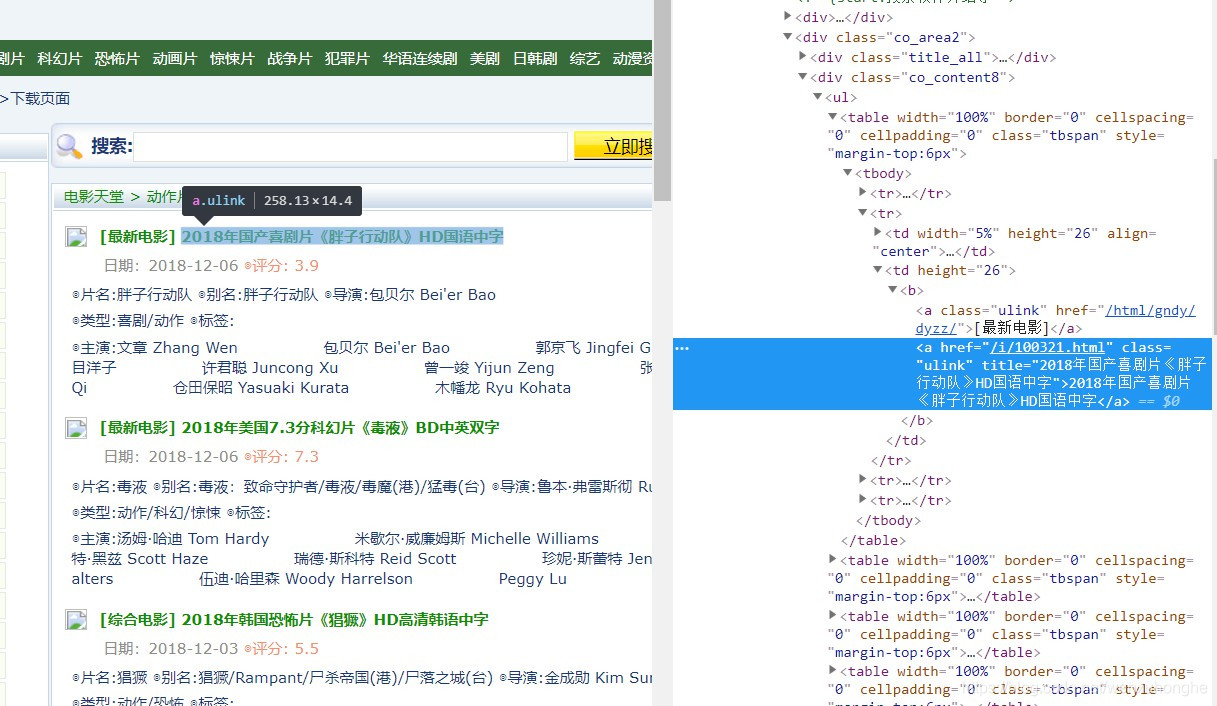
然后,我们可以发觉,电影列表中,每一部影片的信息储存在一个 <table> 标签里,而影片的名子,就藏在上面的一个 <a> 标签中。电影下载的磁力链接在影片的详情页面,而影片详情页面的网址也在这个<a> 标签中( href 属性的值)。
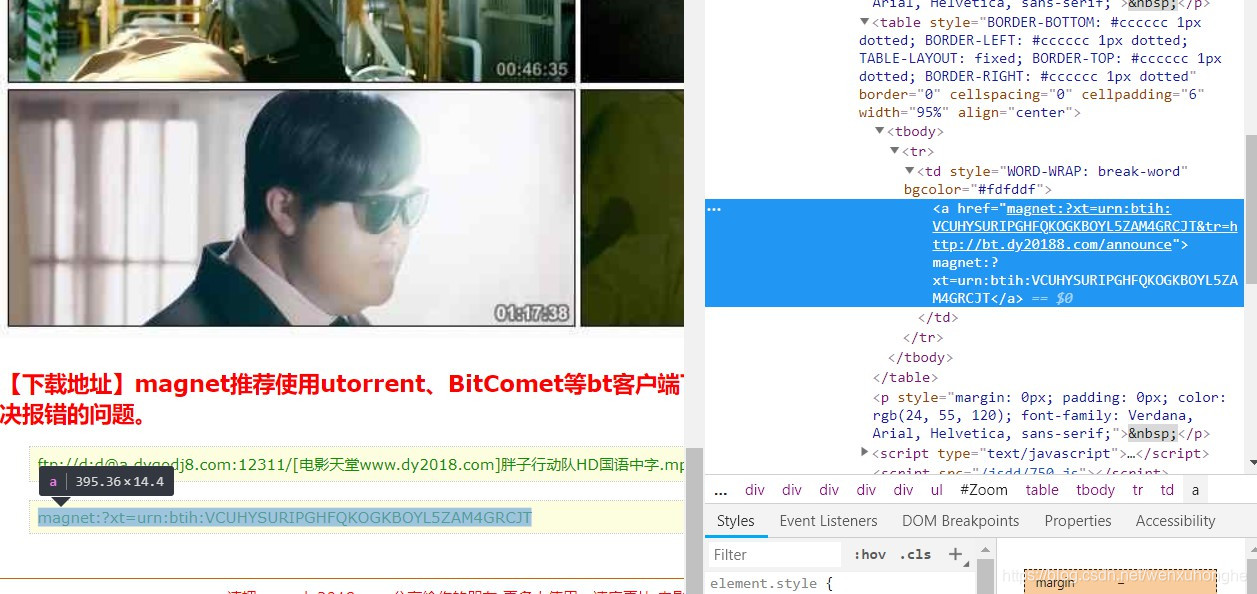
而下载的磁力链接,存放在 <tbody> 标签下的 <a> 标签中,是不是太好找啊!
最后我们来缕一缕思路,一会儿我们打算这样操作:通过上面的网址的构造规则,访问到网站的某一页,然后获取到这个页面里的所有 table 标签(这里储存着影片的数据),然后从每一个 table 标签中找到存有影片名称的 a 标签(这里可以领到影片名称以及详情页面的网址),然后通过这儿获取的网址访问影片的详情页面,在详情页面选购出 <tbody> 标签下的 <a> 标签(这里储存着影片的下载链接),这样我们就找到了我们所须要的全部数据了,是不是很简单啊。
爬虫的程序,我通常习惯把它分成五个部份, 一是主函数,作为程序的入口,二是爬虫调度器,三是网路恳求函数,四是网页解析函数,五是数据储存函数。
# 我们用到的库
import requests
import bs4
import re
import pandas as pd
1.网络恳求函数 :get_data (url)
负责访问指定的 url 网页,并将网页的内容返回,此部份功能比较简单固定,一般不需要做更改(除非你要挂代理,或者自定义恳求头等,可以做一些相应的调整)。
def get_data(url):
'''
功能:访问 url 的网页,获取网页内容并返回
参数:
url :目标网页的 url
返回:目标网页的 html 内容
'''
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}
try:
r = requests.get(url, headers=headers)
r.raise_for_status()
return r.text
except requests.HTTPError as e:
print(e)
print("HTTPError")
except requests.RequestException as e:
print(e)
except:
print("Unknown Error !")
2.网页解析函数:parse_data(html)
这个函数是整个爬虫程序的核心所在,整体思路在上一部分早已讲过了。我这儿使用的库是BeautifulSoup。
这部份的写法多种多样,有很多发挥的空间,也没有哪些太多固定的模式,因为这部份的写法是要随着不同网站的页面结构来做调整的,比如说有的网站提供了数据的 api 接口,那么返回的数据就是 json 格式,我们只须要调用 json 库就可以完成数据解析,而大部分的网站只能通过从网页源代码中一层层筛选(筛选手段也多种多样,什么正则表达式,beautifulsoup等等)。
这里须要依照数据的方式来选择不同的筛选策略,所以,知道原理就可以了,习惯哪些方式就用哪些方式,反正最后能领到数据就好了。
def parse_data(html):
'''
功能:提取 html 页面信息中的关键信息,并整合一个数组并返回
参数:html 根据 url 获取到的网页内容
返回:存储有 html 中提取出的关键信息的数组
'''
bsobj = bs4.BeautifulSoup(html,'html.parser')
info = []
# 获取电影列表
tbList = bsobj.find_all('table', attrs = {'class': 'tbspan'})
# 对电影列表中的每一部电影单独处理
for item in tbList:
movie = []
link = item.b.find_all('a')[1]
# 获取电影的名称
name = link["title"]
# 获取详情页面的 url
url = 'https://www.dy2018.com' + link["href"]
# 将数据存放到电影信息列表里
movie.append(name)
movie.append(url)
try:
# 访问电影的详情页面,查找电影下载的磁力链接
temp = bs4.BeautifulSoup(get_data(url),'html.parser')
tbody = temp.find_all('tbody')
# 下载链接有多个(也可能没有),这里将所有链接都放进来
for i in tbody:
download = i.a.text
movie.append(download)
#print(movie)
# 将此电影的信息加入到电影列表中
info.append(movie)
except Exception as e:
print(e)
return info
3. 数据储存函数:save_data(data)
这个函数目的是将数据储存到本地文件或数据库中,具体的写法要按照实际须要的储存方式来定,我这儿是将数据储存在本地的 csv 文件中。
当然这个函数也并不只能做这些事儿,比如你可以在这里写一些简单的数据处理的操作,比如说:数据清洗,数据去重等操作。
def save_data(data):
'''
功能:将 data 中的信息输出到文件中/或数据库中。
参数:data 将要保存的数据
'''
filename = 'Data/电影天堂/动作片.csv'
dataframe = pd.DataFrame(data)
dataframe.to_csv(filename, mode='a', index=False, sep=',', header=False)
4. 爬虫调度器:main()
这个函数负责按照 url 生成规则,构造新的 url 请求,然后依次调用网路恳求函数,网页解析函数,数据储存函数,爬取并保存该页数据。
所谓爬虫调度器,就是控制爬虫哪些时侯开始爬,多少只爬虫一起爬,爬那个网页,爬多久休息一次,等等这种事儿。
def main():
# 循环爬取多页数据
for page in range(1, 114):
print('正在爬取:第' + str(page) + '页......')
# 根据之前分析的 URL 的组成结构,构造新的 url
if page == 1:
index = 'index'
else:
index = 'index_' + str(page)
url = 'https://www.dy2018.com/2/'+ index +'.html'
# 依次调用网络请求函数,网页解析函数,数据存储函数,爬取并保存该页数据
html = get_data(url)
movies = parse_data(html)
save_data(movies)
print('第' + str(page) + '页完成!')
5. 主函数:程序入口
主函数作为程序的入口,只负责启动爬虫调度器。
这里我通常习惯在 main() 函数前后输出一条句子,以此判定爬虫程序是否正常启动和结束。
if __name__ == '__main__':
print('爬虫启动成功!')
main()
print('爬虫执行完毕!')
运行了两个小时左右吧,终于爬完了 113 页,共 3346 部动作片影片的数据(本来不止这种的,但是有一些影片没有提供下载链接,我在 excel 中排序后直接自动剔除了)。
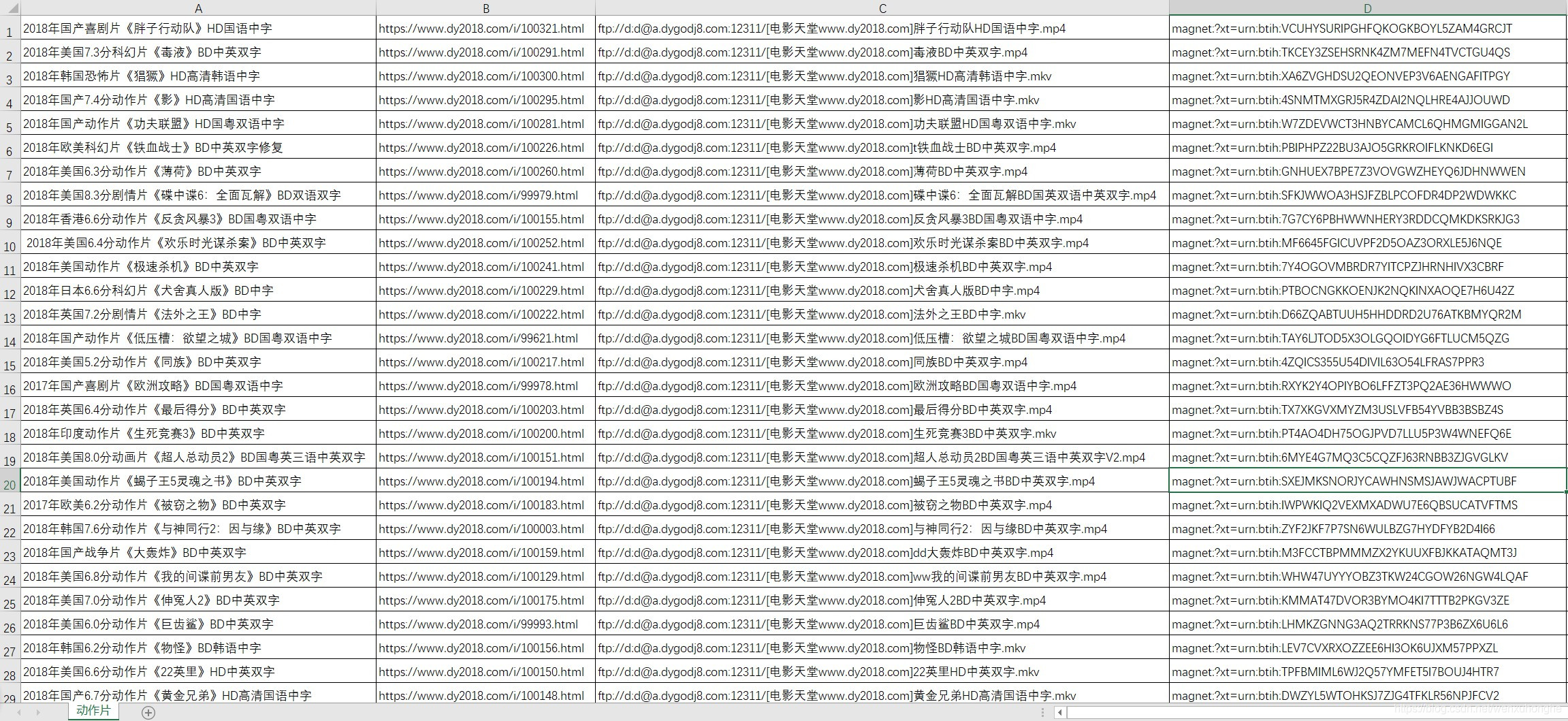
然后想看哪些影片的话,直接复制这种影片下载的磁力链接,到迅雷上面下载就好啦。
1. 在网站提供的下载链接中,我试了一下,发现magnet 开头的这类链接置于迅雷中可以直接下载,而 ftp 开头的链接在迅雷中总显示资源获取失败(我不知道是不是我打开的形式不对,反正就是下载不来),于是我对程序做了一些小的调整,使其只获取magnet 这类的链接。
修改的方法也很简单,只须要调整 网页解析函数 即可(爬虫的五个部份是相对独立的,修改时只需调整相应的模块即可,其余部份无需更改)。
def parse_data(html):
'''
功能:提取 html 页面信息中的关键信息,并整合一个数组并返回
参数:html 根据 url 获取到的网页内容
返回:存储有 html 中提取出的关键信息的数组
'''
bsobj = bs4.BeautifulSoup(html,'html.parser')
info = []
# 获取表头信息
tbList = bsobj.find_all('table', attrs = {'class': 'tbspan'})
for item in tbList:
movie = []
link = item.b.find_all('a')[1]
name = link["title"]
url = 'https://www.dy2018.com' + link["href"]
try:
# 查找电影下载的磁力链接
temp = bs4.BeautifulSoup(get_data(url),'html.parser')
tbody = temp.find_all('tbody')
for i in tbody:
download = i.a.text
if 'magnet:?xt=urn:btih' in download:
movie.append(name)
movie.append(url)
movie.append(download)
#print(movie)
info.append(movie)
break
except Exception as e:
print(e)
return info
注意代码 26 行处,我加了一个 if 语句的判定,如果下载链接中包含magnet:?xt=urn:btih 字符串,则视为有效链接,下载出来,否则跳过。
2. 我仍然在想能不能有个办法使迅雷一键批量下载我们爬到的影片。使用 python 操纵第三方的软件,这或许很难的。不之后来找到了一种方式,也算是解决了这个问题。
就是我们发觉迅雷软件启动后,会手动检查我们的剪切板,只要我们复制了下载链接,它便会手动弹出下载的提示框。借助这个思路,我们可以使用代码,将下载的链接复制步入剪切板,等下载框手动出现后,手动确认开始下载(这是我目前想到的最好的办法了,不知道诸位大鳄有没有更好的思路,欢迎指导交流)。
import pyperclip
import os
import pandas as pd
imageData = pd.read_csv("Data/电影天堂/动作片2.csv",names=['name','link','download'],encoding = 'gbk')
# 获取电影的下载链接,并用换行符分隔
a_link = imageData['download']
links = '\n'.join(a_link)
# 复制到剪切板
pyperclip.copy(links);
print('已粘贴');
# 打开迅雷
thunder_path = r'D:\Program Files (x86)\Thunder Network\Thunder9\Program\Thunder.exe'
os.startfile(thunder_path)
亲测可以实现,但是。。。不建议尝试(你能想像迅雷打开的一瞬间创建几百个下载任务的场景吗?反正我的笔记本是缓了好久好久才反应过来)。大家还是老老实实的,手动复制链接下载吧(csv文件可以用 excel 打开网络爬虫下载,竖着选中一列,然后复制,也能达到相同的疗效),这种骚操作很蠢了还是不要试了。
啰啰嗦嗦的写了很多,也不知道关键的问题讲清楚了没有。有那里没讲清楚,或者那里讲的不合适的话,欢迎恐吓。
其实吧,写文章,写博客,写教程,都是一个知识重新熔炼内化的过程,在写这篇博客的时侯,我也仍然在反复考量我学习爬虫的过程,以及我爬虫代码一步步的变化,从一开始的所有代码全部揉在主函数中,到后来把一些变动较少的功能提取下来,写成单独的函数,再到后来产生基本稳定的五大部份。
以至于在我后来学习使用 scrapy 框架时侯,惊人的发觉 scrapy 框架的结构跟我的爬虫结构有着异曲同工之妙,我的这个相当于是一个简易版的爬虫框架了,纯靠自己摸索达到这个疗效,我觉得还是很有成就感的。
网络爬虫的设计与实现
采集交流 • 优采云 发表了文章 • 0 个评论 • 376 次浏览 • 2020-07-02 08:01
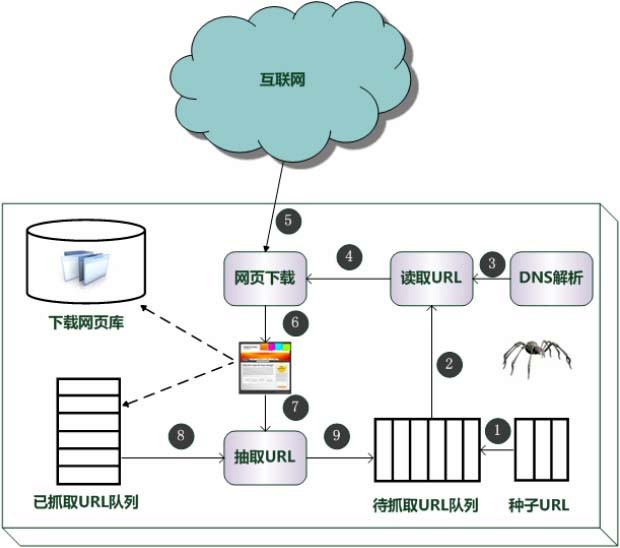
页面下载后页面解析器除去页面上的 HTML标记后得到页面内容,将摘要、URL 等信息保存到 Web数据库中,同时抽取当前页面上新的 URL,保存到 URL队列,直到满足系统停止条件。其原理如图 1 所示。1. 2 爬行策略为提升工作效率,通用网路爬虫会采取一定的爬行策略优先爬取重要的网页。常用的有深度优先和长度优先策略。宽度优先算法的设计和实现相对简单,可以覆盖尽可能多的网页网络爬虫设计,是使用最广泛的一种爬行策略。一个爬虫怎样借助长度优先遍历来抓取网页呢?在爬虫中,每个链接对应一个 HTML 页面或则其它文件,通常将 HTML 页面上的超链接称为"子节点"。整个长度优文章编号 :1672-7800(2012)001-0136-02先爬虫就是从一系列的种子节点开始,把这种网页中的"子节点"提取下来,放到队列中依次进行抓取。被访问过的节点装入到另一张表中,过程如图 2 所示。新解析出的URL图 1 通用爬虫工作流程 图 2 宽度优先爬虫过程1. 3 爬虫队列设计爬虫队列设计是网路爬虫的关键。因为爬虫队列要储存大量的 URL,所以借助本地数组或则队列肯定是不够的,应当找寻一个性价比高的数据库来储存 URL 队列,Berkeley DB 是目前一种比较流行的内存数据库。
根据爬虫的特性, Hash 表成为了一种比较好的选择。但是在使用 Hash 存储 URL 字符串的时侯常用 MD5 算法来对URL 进行压缩。在实现了爬虫队列以后就要继续实现 Visited 表了。如何在大量的 URL 中分辨什么是新的、哪些是被访问过的呢?通常使用的技术就是布隆过滤器 (Bloom Filter) 。利用布隆过滤器判定一个元素是否在集合中是目前比较高效实用的方式。1. 4 设计爬虫构架爬虫框架结构如图 3 所示。图 3 爬虫结构作者简介:王娟 0983一) ,女,湖南宁乡人,硕士,贵州民族学院讲师,研究方向为数据挖掘、网络安全;吴金鹏 0989 一) ,男,山西大同人,贵州民族学院本科生,研究方向为计算机科学与技术。第 4 期 王 娟,吴金鹏:网络爬虫的设计与实现 137 其中:① URL Frontier 含有爬虫当前打算抓取的URL;②DNS 解析模块拿来解析域名(根据给定的 URL决定从那个 Web 获取网页) ;③解析模块提取文本和网页的链接集合;④重复清除模块决定一个解析下来的链接是否早已在 URL Fronier 或者是否近来下载过。下面通过实验来比较一下我们设计的爬虫抓取网页与原网页的对比,见图 4 、图 5 。
μ 溢圈圈酷自自" .. ‘';"也明i:::~:.O: ::汇图 4 原网页 图 5 抓取网页通过比较可以发觉,由于原网页有动漫等多媒体元素,虽然爬虫未能抓取出来全部内容,但基本上是一个完整的爬虫。2 限定爬虫的设计与实现限定爬虫就是对爬虫所爬取的主机的范围作一些限制。通常限定爬虫包含以下内容:①限定域名的爬虫;②限定爬取层数的爬虫;③限定 IP 的抓取;④限定语言的抓取。限定域名的抓取,是一种最简单的限定抓取,只须要依照当前 URL 字符串的值来做出限定即可。限定爬虫爬取的层次要比限定域名更复杂。限定 IP是限定抓取中最难的一部分。通常分为限定特定 IP 和限定某一地区的 IP。限定特定 IP 抓取较为容易,只要通过URL 就可以获得主机 IP 地址,如果主机 IP 在被限制的列表中就不抓取。否则正常工作。想要限定 IP 抓取,首先要按照主机字符串获得 IP 地址。下面我们通过实验来得到 IP 地址:贵州民族学院:主机域名: IP 地址 :210.40.132.8贵州大学:主机域名: IP 地址 :210.40.0.58根据 URL 得到 IP 地址以后,就要按照 IP 地址对某一地区的 IP 作出限制。
但是须要有一个 IP 与地区对应的数据库,网上好多这样的数据库都是收费的,在此我们使用的是腾讯公司推出的一款免费数据库 "QQWry.da t". ,只要输入 IP 地址就可以查到对应 IP 地址所在的区域。输入 :210.40.0.58输出 2贵州省贵阳市:贵州大学输入: 210.40. 132.8 输出:贵州省贵阳市:贵州民族学院按照 IP 地址制做一张列表,将限制地区的 IP 地址写入列表,爬虫假如检查到要抓取的 IP 地址属于该列表,就舍弃抓取,这样一个限定爬虫就完成了。3 结束语本文介绍了爬虫的工作原理,重点介绍了通用爬虫和限定爬虫的设计及实现,并通过实验证明本文设计的爬虫可以达到预期疗效。参考文献:[lJ 孙立伟,何国辉,吴礼发.网络爬虫技术的研究[J].电脑知识与技术, 20100日.[2J 于成龙,于洪波.网络爬虫技术研究[J].东莞理工学院学报, 2011(3). [3J 罗刚.自己动手写搜索引擎[M]. 北京:电子工业出版社, 2009.[4J 唐泼.网络爬虫的设计与实现[J].电脑知识与技术, 2009( 1).[5J 龚勇.搜索引擎中网路爬虫的研究[DJ. 武汉:武汉理工大学, 2010.(责任编辑 2 杜能钢)The Design and Implementation of 飞布eb Crawler Abstract: With the growing of Internet , search engine technology develops rapidly. As an indispensable part of search en-gine , web crawler is particularly important , its p巳rformance directly determines the quality of gathering webpage informa tion in large Internet . This paper designs and implements general crawler and limitative crawler. Key Words: Web Crawler; General Crawler; Limitative Crawler 查看全部
第11卷第4期2012年 4月软件导刊Software Guide Vo l. ll NO.4 组己旦2网路爬虫的设计与实现王娟,吴金鹏(贵州|民族学院计算机与信息工程学院,贵州l 贵阳 550025)摘 要:搜索引擎技术随着互联网的日渐壮大而急速发展。作为搜索引擎不可或缺的组成部分,网络爬虫的作用变得尤为重要网络爬虫设计,它的性能直接决定了在庞大的互联网上进行网页信息采集的质量。设计并实现了通用爬虫和限定爬虫。关键词:网络爬虫;通用爬虫;限定爬虫中图分类号 :TP393 文献标识码 :A。哥|言网路爬虫称作网路蜘蛛,它为搜索引擎从万维网上下载网页,并顺着网页的相关链接在 Web 中采集资源,是一个功能太强的网页手动抓取程序,也是搜索引擎的重要组成部份,爬虫设计的优劣直接决定着整个搜索引擎的性能及扩充能力。网络爬虫根据系统结构和实现技术,大致可以分为:通用网路爬虫、主题网路爬虫、增量式网路爬虫、深层网路爬虫 o 实际应用中一般是将几种爬虫技术相结合。1 通用爬虫的设计与实现1. 1 工作原理通用网路爬虫按照预先设定的一个或若干初始种子URL 开始,以此获得初始网页上的 URL 列表,在爬行过程中不断从 URL 队列中获一个个的 URL,进而访问并下载该页面。
页面下载后页面解析器除去页面上的 HTML标记后得到页面内容,将摘要、URL 等信息保存到 Web数据库中,同时抽取当前页面上新的 URL,保存到 URL队列,直到满足系统停止条件。其原理如图 1 所示。1. 2 爬行策略为提升工作效率,通用网路爬虫会采取一定的爬行策略优先爬取重要的网页。常用的有深度优先和长度优先策略。宽度优先算法的设计和实现相对简单,可以覆盖尽可能多的网页网络爬虫设计,是使用最广泛的一种爬行策略。一个爬虫怎样借助长度优先遍历来抓取网页呢?在爬虫中,每个链接对应一个 HTML 页面或则其它文件,通常将 HTML 页面上的超链接称为"子节点"。整个长度优文章编号 :1672-7800(2012)001-0136-02先爬虫就是从一系列的种子节点开始,把这种网页中的"子节点"提取下来,放到队列中依次进行抓取。被访问过的节点装入到另一张表中,过程如图 2 所示。新解析出的URL图 1 通用爬虫工作流程 图 2 宽度优先爬虫过程1. 3 爬虫队列设计爬虫队列设计是网路爬虫的关键。因为爬虫队列要储存大量的 URL,所以借助本地数组或则队列肯定是不够的,应当找寻一个性价比高的数据库来储存 URL 队列,Berkeley DB 是目前一种比较流行的内存数据库。
根据爬虫的特性, Hash 表成为了一种比较好的选择。但是在使用 Hash 存储 URL 字符串的时侯常用 MD5 算法来对URL 进行压缩。在实现了爬虫队列以后就要继续实现 Visited 表了。如何在大量的 URL 中分辨什么是新的、哪些是被访问过的呢?通常使用的技术就是布隆过滤器 (Bloom Filter) 。利用布隆过滤器判定一个元素是否在集合中是目前比较高效实用的方式。1. 4 设计爬虫构架爬虫框架结构如图 3 所示。图 3 爬虫结构作者简介:王娟 0983一) ,女,湖南宁乡人,硕士,贵州民族学院讲师,研究方向为数据挖掘、网络安全;吴金鹏 0989 一) ,男,山西大同人,贵州民族学院本科生,研究方向为计算机科学与技术。第 4 期 王 娟,吴金鹏:网络爬虫的设计与实现 137 其中:① URL Frontier 含有爬虫当前打算抓取的URL;②DNS 解析模块拿来解析域名(根据给定的 URL决定从那个 Web 获取网页) ;③解析模块提取文本和网页的链接集合;④重复清除模块决定一个解析下来的链接是否早已在 URL Fronier 或者是否近来下载过。下面通过实验来比较一下我们设计的爬虫抓取网页与原网页的对比,见图 4 、图 5 。
μ 溢圈圈酷自自" .. ‘';"也明i:::~:.O: ::汇图 4 原网页 图 5 抓取网页通过比较可以发觉,由于原网页有动漫等多媒体元素,虽然爬虫未能抓取出来全部内容,但基本上是一个完整的爬虫。2 限定爬虫的设计与实现限定爬虫就是对爬虫所爬取的主机的范围作一些限制。通常限定爬虫包含以下内容:①限定域名的爬虫;②限定爬取层数的爬虫;③限定 IP 的抓取;④限定语言的抓取。限定域名的抓取,是一种最简单的限定抓取,只须要依照当前 URL 字符串的值来做出限定即可。限定爬虫爬取的层次要比限定域名更复杂。限定 IP是限定抓取中最难的一部分。通常分为限定特定 IP 和限定某一地区的 IP。限定特定 IP 抓取较为容易,只要通过URL 就可以获得主机 IP 地址,如果主机 IP 在被限制的列表中就不抓取。否则正常工作。想要限定 IP 抓取,首先要按照主机字符串获得 IP 地址。下面我们通过实验来得到 IP 地址:贵州民族学院:主机域名: IP 地址 :210.40.132.8贵州大学:主机域名: IP 地址 :210.40.0.58根据 URL 得到 IP 地址以后,就要按照 IP 地址对某一地区的 IP 作出限制。
但是须要有一个 IP 与地区对应的数据库,网上好多这样的数据库都是收费的,在此我们使用的是腾讯公司推出的一款免费数据库 "QQWry.da t". ,只要输入 IP 地址就可以查到对应 IP 地址所在的区域。输入 :210.40.0.58输出 2贵州省贵阳市:贵州大学输入: 210.40. 132.8 输出:贵州省贵阳市:贵州民族学院按照 IP 地址制做一张列表,将限制地区的 IP 地址写入列表,爬虫假如检查到要抓取的 IP 地址属于该列表,就舍弃抓取,这样一个限定爬虫就完成了。3 结束语本文介绍了爬虫的工作原理,重点介绍了通用爬虫和限定爬虫的设计及实现,并通过实验证明本文设计的爬虫可以达到预期疗效。参考文献:[lJ 孙立伟,何国辉,吴礼发.网络爬虫技术的研究[J].电脑知识与技术, 20100日.[2J 于成龙,于洪波.网络爬虫技术研究[J].东莞理工学院学报, 2011(3). [3J 罗刚.自己动手写搜索引擎[M]. 北京:电子工业出版社, 2009.[4J 唐泼.网络爬虫的设计与实现[J].电脑知识与技术, 2009( 1).[5J 龚勇.搜索引擎中网路爬虫的研究[DJ. 武汉:武汉理工大学, 2010.(责任编辑 2 杜能钢)The Design and Implementation of 飞布eb Crawler Abstract: With the growing of Internet , search engine technology develops rapidly. As an indispensable part of search en-gine , web crawler is particularly important , its p巳rformance directly determines the quality of gathering webpage informa tion in large Internet . This paper designs and implements general crawler and limitative crawler. Key Words: Web Crawler; General Crawler; Limitative Crawler
【原创源码】网络爬虫
采集交流 • 优采云 发表了文章 • 0 个评论 • 365 次浏览 • 2020-07-02 08:01
最近因为女朋友工作需求,需要获取各大团购网站上的店家信息,这样自动一个一个点不得气死,于是我就写了一个网络爬虫来解决这个问题,是用java写的,主要用到了两个开源库,httpclient和jsoup...用来获取网页数据和得到想要的数据,不过最好是有点web基础网络爬虫代码,这样就可以只要想要的值,不然会有很多没用的数据,后期还要自动删掉,比较麻烦...下面附上源码和说明...
[Asm] 纯文本查看 复制代码
public static String getHtmlByUrl(String url){
String html = null;
HttpClient httpClient = new DefaultHttpClient();//创建httpClient对象
HttpGet httpget = new HttpGet(url);//以get方式请求该URL
try {
HttpResponse responce = httpClient.execute(httpget);//得到responce对象
int resStatu = responce.getStatusLine().getStatusCode();//返回码
if (resStatu==HttpStatus.SC_OK) {//200正常 其他就不对
//获得相应实体
HttpEntity entity = responce.getEntity();
if (entity!=null) {
//html = EntityUtils.toString(entity);//获得html源代码
InputStream in = entity.getContent();
entity.getContentType();
Scanner sc = new Scanner(in);
StringBuffer str = new StringBuffer("utf-8");
while(sc.hasNextLine()){
str.append(sc.nextLine());
}
html = str.toString();
//sc.close();
}
}
} catch (Exception e) {
System.out.println("访问【"+url+"】出现异常!");
e.printStackTrace();
} finally {
httpClient.getConnectionManager().shutdown();
}
return html;
}
上面的就是httpclient库的内容,用它来获取html页面的数据
[Java] 纯文本查看 复制代码
public static void main(String[] args) throws WriteException, IOException {
String html = getHtmlByUrl("需要获取数据的网址");
if (html!=null&&!"".equals(html)) {
Document doc = Jsoup.parse(html);
Elements linksElements = doc.select("div.basic>a"); //如果有web基础的话,可以设置一下这里,知道自己想要的数据
for (Element ele:linksElements) {
String href = ele.attr("href");
String title = ele.text();
System.out.println(href+","+title);
}
}
}
这个就是解析获取来的html数据,找到自己想要的数据....
然后把取到的数据存入excel获取txt里就随大伙便了,不过这个方式有一个漏洞就是,只能取静态页面,动态页面未能实现,我还要再继续研究一下,研究下来了,再发下来,如果有哪些不懂的网络爬虫代码,可以问我,知道的一定告诉你们,希望你们多评分,多鼓励,非常谢谢!!!! 查看全部

最近因为女朋友工作需求,需要获取各大团购网站上的店家信息,这样自动一个一个点不得气死,于是我就写了一个网络爬虫来解决这个问题,是用java写的,主要用到了两个开源库,httpclient和jsoup...用来获取网页数据和得到想要的数据,不过最好是有点web基础网络爬虫代码,这样就可以只要想要的值,不然会有很多没用的数据,后期还要自动删掉,比较麻烦...下面附上源码和说明...
[Asm] 纯文本查看 复制代码
public static String getHtmlByUrl(String url){
String html = null;
HttpClient httpClient = new DefaultHttpClient();//创建httpClient对象
HttpGet httpget = new HttpGet(url);//以get方式请求该URL
try {
HttpResponse responce = httpClient.execute(httpget);//得到responce对象
int resStatu = responce.getStatusLine().getStatusCode();//返回码
if (resStatu==HttpStatus.SC_OK) {//200正常 其他就不对
//获得相应实体
HttpEntity entity = responce.getEntity();
if (entity!=null) {
//html = EntityUtils.toString(entity);//获得html源代码
InputStream in = entity.getContent();
entity.getContentType();
Scanner sc = new Scanner(in);
StringBuffer str = new StringBuffer("utf-8");
while(sc.hasNextLine()){
str.append(sc.nextLine());
}
html = str.toString();
//sc.close();
}
}
} catch (Exception e) {
System.out.println("访问【"+url+"】出现异常!");
e.printStackTrace();
} finally {
httpClient.getConnectionManager().shutdown();
}
return html;
}
上面的就是httpclient库的内容,用它来获取html页面的数据
[Java] 纯文本查看 复制代码
public static void main(String[] args) throws WriteException, IOException {
String html = getHtmlByUrl("需要获取数据的网址");
if (html!=null&&!"".equals(html)) {
Document doc = Jsoup.parse(html);
Elements linksElements = doc.select("div.basic>a"); //如果有web基础的话,可以设置一下这里,知道自己想要的数据
for (Element ele:linksElements) {
String href = ele.attr("href");
String title = ele.text();
System.out.println(href+","+title);
}
}
}
这个就是解析获取来的html数据,找到自己想要的数据....
然后把取到的数据存入excel获取txt里就随大伙便了,不过这个方式有一个漏洞就是,只能取静态页面,动态页面未能实现,我还要再继续研究一下,研究下来了,再发下来,如果有哪些不懂的网络爬虫代码,可以问我,知道的一定告诉你们,希望你们多评分,多鼓励,非常谢谢!!!!
推荐10款流行的java开源的网络爬虫
采集交流 • 优采云 发表了文章 • 0 个评论 • 362 次浏览 • 2020-06-29 08:03
爬虫简介: WebCollector是一个无须配置、便于二次开发的JAVA爬虫框架(内核)java单机爬虫框架,它提供精简的的API,只需少量代码即可实现一个功能强悍的爬虫。WebCollector-Hadoop是WebCollector的Hadoop版本java单机爬虫框架,支持分布式爬取。 爬虫内核: WebCollector致...
2:开源通用爬虫框架YayCrawler(Star:91)
YayCrawler是一个基于WebMagic开发的分布式通用爬虫框架,开发语言是Java。我们晓得目前爬虫框架好多,有简单的,也有复杂的,有轻 量型的,也有重量型的
3:垂直爬虫WebMagic(Star:1213)
webmagic的是一个无须配置、便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代码即可实现一个爬虫。 以下是爬取oschina博客的一段代码: Spider.create(newSimplePageProcessor("", "http...
4:雅虎开源的Nutch爬虫插件 Anthelion(Star:2888)
Anthelion 是 Nutch 插件,专注于爬取语义数据。 注意:此项目包括完整的 Nutch 1.6 版本,此插件放置在 /src/plugin/parse-anth Anthelion 使用在线学习方式来基于页面上下文预测富数据 Web 页面,从之前查看的页面提取的元数据获取反馈。 主要有三个扩充: AnthelionScoringFilter WdcParser TripleExtractor 示例:...
5:Java开源网路爬虫项目Nutch
Nutch是一个开源Java实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具。包括全文搜索和Web爬虫。 Nutch的创始人是Doug Cutting,他同时也是Lucene、Hadoop和Avro开源项目的创始人。 Nutch诞生于2002年8月,是Apache旗下的一个用Java实现的开源搜索引擎项目,自Nutch1.2版本以后,Nutch早已从搜索引擎演...
6:Java网路蜘蛛/网络爬虫Spiderman(Star:1801)
Spiderman - 又一个Java网路蜘蛛/爬虫 Spiderman 是一个基于微内核+插件式构架的网路蜘蛛,它的目标是通过简单的方式能够将复杂的目标网页信息抓取并解析为自己所须要的业务数据。 最新提示:欢迎来体验最新版本Spiderman2,
7:轻量化的Java网路爬虫 GECCO(Star:658)
Gecco是哪些 Gecco是一款用java语言开发的轻量化的易用的网路爬虫。Gecco整合了jsoup、httpclient、fastjson、spring、htmlunit、redission等优秀框架,让您只须要配置一些jquery风格的选择器能够很快的写出一个爬虫。Gecco框架有优秀的可扩展性,框架基于开闭原则进行设计,对更改关掉、对扩充开放。同时Gecco基于非常开...
8:开源爬虫框架WebPasser(Star:15)
WebPasser是一款可配置的开源爬虫框架,提供爬虫控制台管理界面,通过配置解析各种网页内容,无需写一句java代码即可抽取所需数据。 1.包含强悍的页面解析引擎,提供jsoup、xpath、正则表达式等处理链,通过简单配置即可抽取所需的指定内容。 2.提供爬虫控制管理界面,可实时监控抓取状...
9:一个敏捷强悍的Java爬虫框架SeimiCrawler(Star:635)
SeimiCrawler是一个敏捷的,独立布署的,支持分布式的Java爬虫框架,希望能在最大程度上减少菜鸟开发一个可用性高且性能不差的爬虫系统的门槛,以及提高开发爬虫系统的开发效率。
10:爬虫系统NEOCrawler(Star:258)
NEOCrawler(中文名:牛咖),是nodejs、redis、phantomjs实现的爬虫系统。代码完全开源,适合用于垂直领域的数据采集和爬虫二次开发。 【主要特征】 使用nodejs实现,javascipt简单、高效、易学、为爬虫的开发以及爬虫使用者的二次开发节省不少时间;nodejs让...
推荐10款流行的java开源的网络爬虫 查看全部
1:JAVA爬虫WebCollector(Star:1345)
爬虫简介: WebCollector是一个无须配置、便于二次开发的JAVA爬虫框架(内核)java单机爬虫框架,它提供精简的的API,只需少量代码即可实现一个功能强悍的爬虫。WebCollector-Hadoop是WebCollector的Hadoop版本java单机爬虫框架,支持分布式爬取。 爬虫内核: WebCollector致...
2:开源通用爬虫框架YayCrawler(Star:91)
YayCrawler是一个基于WebMagic开发的分布式通用爬虫框架,开发语言是Java。我们晓得目前爬虫框架好多,有简单的,也有复杂的,有轻 量型的,也有重量型的
3:垂直爬虫WebMagic(Star:1213)
webmagic的是一个无须配置、便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代码即可实现一个爬虫。 以下是爬取oschina博客的一段代码: Spider.create(newSimplePageProcessor("", "http...
4:雅虎开源的Nutch爬虫插件 Anthelion(Star:2888)
Anthelion 是 Nutch 插件,专注于爬取语义数据。 注意:此项目包括完整的 Nutch 1.6 版本,此插件放置在 /src/plugin/parse-anth Anthelion 使用在线学习方式来基于页面上下文预测富数据 Web 页面,从之前查看的页面提取的元数据获取反馈。 主要有三个扩充: AnthelionScoringFilter WdcParser TripleExtractor 示例:...
5:Java开源网路爬虫项目Nutch
Nutch是一个开源Java实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具。包括全文搜索和Web爬虫。 Nutch的创始人是Doug Cutting,他同时也是Lucene、Hadoop和Avro开源项目的创始人。 Nutch诞生于2002年8月,是Apache旗下的一个用Java实现的开源搜索引擎项目,自Nutch1.2版本以后,Nutch早已从搜索引擎演...
6:Java网路蜘蛛/网络爬虫Spiderman(Star:1801)
Spiderman - 又一个Java网路蜘蛛/爬虫 Spiderman 是一个基于微内核+插件式构架的网路蜘蛛,它的目标是通过简单的方式能够将复杂的目标网页信息抓取并解析为自己所须要的业务数据。 最新提示:欢迎来体验最新版本Spiderman2,
7:轻量化的Java网路爬虫 GECCO(Star:658)
Gecco是哪些 Gecco是一款用java语言开发的轻量化的易用的网路爬虫。Gecco整合了jsoup、httpclient、fastjson、spring、htmlunit、redission等优秀框架,让您只须要配置一些jquery风格的选择器能够很快的写出一个爬虫。Gecco框架有优秀的可扩展性,框架基于开闭原则进行设计,对更改关掉、对扩充开放。同时Gecco基于非常开...
8:开源爬虫框架WebPasser(Star:15)
WebPasser是一款可配置的开源爬虫框架,提供爬虫控制台管理界面,通过配置解析各种网页内容,无需写一句java代码即可抽取所需数据。 1.包含强悍的页面解析引擎,提供jsoup、xpath、正则表达式等处理链,通过简单配置即可抽取所需的指定内容。 2.提供爬虫控制管理界面,可实时监控抓取状...
9:一个敏捷强悍的Java爬虫框架SeimiCrawler(Star:635)
SeimiCrawler是一个敏捷的,独立布署的,支持分布式的Java爬虫框架,希望能在最大程度上减少菜鸟开发一个可用性高且性能不差的爬虫系统的门槛,以及提高开发爬虫系统的开发效率。
10:爬虫系统NEOCrawler(Star:258)
NEOCrawler(中文名:牛咖),是nodejs、redis、phantomjs实现的爬虫系统。代码完全开源,适合用于垂直领域的数据采集和爬虫二次开发。 【主要特征】 使用nodejs实现,javascipt简单、高效、易学、为爬虫的开发以及爬虫使用者的二次开发节省不少时间;nodejs让...
推荐10款流行的java开源的网络爬虫
2019最新30个小时搞定Python网络爬虫(全套详尽版) 零基础入门 视频教
采集交流 • 优采云 发表了文章 • 0 个评论 • 381 次浏览 • 2020-06-26 08:01
1、零基础对Python网络爬虫感兴趣的开发者
2、想从事Python网路爬虫工程师相关工作的开发者
3、想学习Python网路爬虫作为技术储备的开发者
1、本课程的目标是将你们培养成Python网路爬虫工程师。薪资基本在13k-36k左右;
2、学完才能从零开始把握Python爬虫项目的编撰,学会独立开发常见的爬虫项目;
3、学完能把握常见的反爬处理手段爬虫入门书籍,比如验证码处理、浏览器伪装、代理IP池技术和用户代理池技术等;
4、学完才能熟练使用正则表达式和XPath表达式进行信息提取;
5、学完把握抓包技术,掌握屏蔽的数据信息怎样进行提取,学会手动模拟加载行为、进行网址构造和手动模拟Ajax异步恳求数据;
6、熟练把握urllib模块,熟练使用Scrapy框架进行爬虫项目开发。
第一章节:Python 网络爬虫之基础
第二章节:Python网路爬虫之工作原理
第三章节:Python网路爬虫之正则表达式
第五章节:Python网路爬虫之用户和IP代理池
第六章节 :Python网路爬虫之腾讯陌陌和视频实战
第七章节:Python网路爬虫之Scrapy框架
第八章节:Python网路爬虫之Scrapy与Urllib的整合
第九章节:Python网路爬虫之扩充学习
第十章节:Python网路爬虫之分布式爬虫 查看全部
这是一套完整的网路爬虫课程,通过该课程把握网路爬虫的相关知识,以便把握网路爬虫方方面面的知识,学完后胜任网路爬虫相关工作。 1、体系完整科学,可以系统化学习; 2、课程通俗易懂爬虫入门书籍,可以使学员真正学会; 3、从零开始教学直至深入,零基础的朋友亦可以学习!
1、零基础对Python网络爬虫感兴趣的开发者
2、想从事Python网路爬虫工程师相关工作的开发者
3、想学习Python网路爬虫作为技术储备的开发者
1、本课程的目标是将你们培养成Python网路爬虫工程师。薪资基本在13k-36k左右;
2、学完才能从零开始把握Python爬虫项目的编撰,学会独立开发常见的爬虫项目;
3、学完能把握常见的反爬处理手段爬虫入门书籍,比如验证码处理、浏览器伪装、代理IP池技术和用户代理池技术等;
4、学完才能熟练使用正则表达式和XPath表达式进行信息提取;
5、学完把握抓包技术,掌握屏蔽的数据信息怎样进行提取,学会手动模拟加载行为、进行网址构造和手动模拟Ajax异步恳求数据;
6、熟练把握urllib模块,熟练使用Scrapy框架进行爬虫项目开发。
第一章节:Python 网络爬虫之基础
第二章节:Python网路爬虫之工作原理
第三章节:Python网路爬虫之正则表达式
第五章节:Python网路爬虫之用户和IP代理池
第六章节 :Python网路爬虫之腾讯陌陌和视频实战
第七章节:Python网路爬虫之Scrapy框架
第八章节:Python网路爬虫之Scrapy与Urllib的整合
第九章节:Python网路爬虫之扩充学习
第十章节:Python网路爬虫之分布式爬虫
网络爬虫技术之同时抓取多个网页
采集交流 • 优采云 发表了文章 • 0 个评论 • 879 次浏览 • 2020-06-26 08:01
$curlobj = curl_init(); //创建一个curl 的资源,下面要用的curl_setopt($curlobj,CURLOPT_URL,""); //获取资源curl_setopt($curlobj,CURLOPT_RETURNTRANSFER,true); //请求结果不直接复印 $output = curl_exec($cu
爬虫爬取多个不相同网页
任务四‘’’本任务要求你们完成一个简单的爬虫项目,包括网页爬取、信息提取以及数据保存在完成本次任务时,建议你们认真思索,结合自己的逻辑,完成任务。注意:本任务的得分将根据任务递交时间的先后次序与任务正确率结合来估算,由于每个朋友的题目都不相同,建议不要剽窃,一旦发觉剽窃情况,本次任务判为0分’’’from typing import Any, Tuple‘’’第一题:请使用爬虫技术...
Scrapy爬取多层级网页内容的方法
# -*- coding: utf-8 -*-import scrapyfrom Avv.items import AvvItemclass AvSpider(scrapy.Spider):name = 'av' # 爬虫名allowed_domains = ['/'] # 爬虫作用域# 爬取第2页到最后一页的代码url = ...
爬虫——scrapy框架爬取多个页面影片的二级子页面的详尽信息
文章目录需求:总结:代码:movieinfo.pyitems.pymiddleware.pypipelines.py结果:附加:需求:scrapy框架,爬取某影片网页面的每位影片的一级页面的名子爬取每部影片二级页面的详尽信息使用代理ip保存日志文件存为csv文件总结:1、xpath解析使用extract()的各类情况剖析
网络爬虫初步:从一个入口链接开始不断抓取页面中的网址并入库
前言: 在上一篇《网络爬虫初步:从访问网页到数据解析》中,我们讨论了怎样爬取网页,对爬取的网页进行解析,以及访问被拒绝的网站。在这一篇博客中,我们可以来了解一下领到解析的数据可以做的风波。在这篇博客中,我主要是说明要做的两件事,一是入库,二是遍历领到的链接继续访问。如此往复,这样就构成了一个网络爬虫的雏型。笔者环境: 系统: Windows 7...
php爬虫
Php爬虫,爬取数据,识图猜词语一、寻找数据1,寻找相关网站数据剖析网站换页特点剖析得出不仅第一页,第二页开始index加页面数写一个函数,专门拼接须要访问的页面public function getcy($id=3,$num=3){$i=$id;...
爬取多个页面的数据
代码如下:# -*- coding:utf8 -*-#导入requests库,取别称resimport requests as res#导入bs4包,取别称bsfrom bs4 import BeautifulSoup as bs#导入数据库驱动包import MySQLdb#声明页面从哪开始j = 1#循环遍历每位页面while j 111:##获取目标网站的网页
Python爬虫实例(3)-用BeautifulSoup爬取多个可翻页网页上的多张相片
# -*- coding: utf-8 -*-#导入第三方包和模块import requestsfrom bs4 import BeautifulSoupimport os#在本地新建一个文件夹,命名为test_img,用以保存下载的图片folder = 'test_img'if not os.path.exists(folder):os.makedirs(folder)#定义
用WebMagic框架 爬某网站(多个页面)的内容 、启动爬虫有时候能抓取成功、
用WebMagic框架 爬某网站(多个页面)的内容 、启动爬虫有时候能抓取成功、有时候启动以后没任何反应3S然后程序停止。问哪些会这样,求解
webmagic爬虫自学(三)爬取CSDN【列表+详情的基本页面组合】的页面,使用基于注解的方法
1
如何实现两个页面的跳转
_addEvent:function(){var btn;btn=this._getWidgetByName(this._startGav,"Button_7");//获取按键的点击实风波btn.addTouchEventListener(this._inputHandler.bind(this),this._startGav);},_inputHandler:
爬虫——第二次试验(网站多页爬取代码)
实验目的熟练把握requests库中get技巧的使用把握借助requests库爬取多页网页内容的方式2.1 爬取百度贴吧与某主题相关的贴子,并将爬取到的内容保存到文件中(爬取多页)import requestsdef get_page(url):headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) ...
给你们推荐几种实现网页数据抓取的方法
相信所有个人网站的站长都有抓取他人数据的经历吧,目前抓取他人网站数据的方法无非两种形式: 一、使用第三方工具,其中最知名的是优采云采集器,在此不做介绍。 二、自己写程序抓取,这种方法要求站长自己写程序
java爬取百度百科词条
lz在之前的一篇博客中,用python实现了爬取百度百科的词条,就在怎么用java来实现相同的功能,果不其然,java用一个jsoup的第三方库工具就可以很简单地实现爬取百度百科的词条。同样的,将这个爬取过程分成5个部份来实现。分别是connectnet联接url部份、parsehtml获取html相关内容部份、startspyder部份、store储存url部份、urlmanager的url管理
关于使用Java实现的简单网路爬虫Demo
什么是网络爬虫?网络爬虫又叫蜘蛛,网络蜘蛛是通过网页的链接地址来找寻网页,从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这种链接地址找寻下一个网页,这样仍然循环下去,直到把这个网站所有的网页都抓取完为止。如果把整个互联网当作一个网站,那么网路蜘蛛就可以用这个原理把互联网上所有的网页都抓取出来。所以要想抓取网路上的数据,不仅须要爬虫程序还须要一个可以接受
Java爬虫爬取python百度百科词条及相关词条页面
Java爬虫爬取python百度百科词条及相关词条页面本实例爬取关于python词条页面及关联词条页面的简介网络爬虫论坛,把词条的简介写入txt文本中, 本实例疗效:实例基于使用第三方jar包Jsoup1首先剖析python词条页面:可以发觉其他词条的超链接都带有"/item"以及词条的简介都包含在class为
python scrapy项目下spiders内多个爬虫同时运行
一般创建了scrapy文件夹后,可能须要写多个爬虫,如果想使它们同时运行而不是顺次运行的话,得怎样做?a、在spiders目录的同级目录下创建一个commands目录网络爬虫论坛,并在该目录中创建一个crawlall.py,将scrapy源代码里的commands文件夹里的crawl.py源码复制过来,只更改run()方法即可!import osfrom ...
算法设计中关于优先队列式分支限界法解装载问题的代码下载
分支限界法中的优先队列式分支限界法解装载问题相关下载链接:
软件调试张银奎(7)下载
软件调试张银奎(4)软件调试张银奎(4)软件调试张银奎(4)相关下载链接:
WimTool-WIM文件处理工具安装版下载
WimTool-WIM文件处理工具安装版相关下载链接:
相关热词c#如何获得线程名c# usb 采集器c# sort()c#面对对象的三大特点c# 打印 等比缩放c#弹出右键菜单c# 系统托盘图标c# 键值对 键可以重复c# 鼠标移起来提示c#结构体定义
我们是挺有底线的 查看全部
$curlobj = curl_init(); //创建一个curl 的资源,下面要用的curl_setopt($curlobj,CURLOPT_URL,""); //获取资源curl_setopt($curlobj,CURLOPT_RETURNTRANSFER,true); //请求结果不直接复印 $output = curl_exec($cu
爬虫爬取多个不相同网页
任务四‘’’本任务要求你们完成一个简单的爬虫项目,包括网页爬取、信息提取以及数据保存在完成本次任务时,建议你们认真思索,结合自己的逻辑,完成任务。注意:本任务的得分将根据任务递交时间的先后次序与任务正确率结合来估算,由于每个朋友的题目都不相同,建议不要剽窃,一旦发觉剽窃情况,本次任务判为0分’’’from typing import Any, Tuple‘’’第一题:请使用爬虫技术...
Scrapy爬取多层级网页内容的方法
# -*- coding: utf-8 -*-import scrapyfrom Avv.items import AvvItemclass AvSpider(scrapy.Spider):name = 'av' # 爬虫名allowed_domains = ['/'] # 爬虫作用域# 爬取第2页到最后一页的代码url = ...

爬虫——scrapy框架爬取多个页面影片的二级子页面的详尽信息
文章目录需求:总结:代码:movieinfo.pyitems.pymiddleware.pypipelines.py结果:附加:需求:scrapy框架,爬取某影片网页面的每位影片的一级页面的名子爬取每部影片二级页面的详尽信息使用代理ip保存日志文件存为csv文件总结:1、xpath解析使用extract()的各类情况剖析
网络爬虫初步:从一个入口链接开始不断抓取页面中的网址并入库
前言: 在上一篇《网络爬虫初步:从访问网页到数据解析》中,我们讨论了怎样爬取网页,对爬取的网页进行解析,以及访问被拒绝的网站。在这一篇博客中,我们可以来了解一下领到解析的数据可以做的风波。在这篇博客中,我主要是说明要做的两件事,一是入库,二是遍历领到的链接继续访问。如此往复,这样就构成了一个网络爬虫的雏型。笔者环境: 系统: Windows 7...
php爬虫
Php爬虫,爬取数据,识图猜词语一、寻找数据1,寻找相关网站数据剖析网站换页特点剖析得出不仅第一页,第二页开始index加页面数写一个函数,专门拼接须要访问的页面public function getcy($id=3,$num=3){$i=$id;...
爬取多个页面的数据
代码如下:# -*- coding:utf8 -*-#导入requests库,取别称resimport requests as res#导入bs4包,取别称bsfrom bs4 import BeautifulSoup as bs#导入数据库驱动包import MySQLdb#声明页面从哪开始j = 1#循环遍历每位页面while j 111:##获取目标网站的网页
Python爬虫实例(3)-用BeautifulSoup爬取多个可翻页网页上的多张相片
# -*- coding: utf-8 -*-#导入第三方包和模块import requestsfrom bs4 import BeautifulSoupimport os#在本地新建一个文件夹,命名为test_img,用以保存下载的图片folder = 'test_img'if not os.path.exists(folder):os.makedirs(folder)#定义

用WebMagic框架 爬某网站(多个页面)的内容 、启动爬虫有时候能抓取成功、
用WebMagic框架 爬某网站(多个页面)的内容 、启动爬虫有时候能抓取成功、有时候启动以后没任何反应3S然后程序停止。问哪些会这样,求解
webmagic爬虫自学(三)爬取CSDN【列表+详情的基本页面组合】的页面,使用基于注解的方法
1
如何实现两个页面的跳转
_addEvent:function(){var btn;btn=this._getWidgetByName(this._startGav,"Button_7");//获取按键的点击实风波btn.addTouchEventListener(this._inputHandler.bind(this),this._startGav);},_inputHandler:
爬虫——第二次试验(网站多页爬取代码)
实验目的熟练把握requests库中get技巧的使用把握借助requests库爬取多页网页内容的方式2.1 爬取百度贴吧与某主题相关的贴子,并将爬取到的内容保存到文件中(爬取多页)import requestsdef get_page(url):headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) ...
给你们推荐几种实现网页数据抓取的方法
相信所有个人网站的站长都有抓取他人数据的经历吧,目前抓取他人网站数据的方法无非两种形式: 一、使用第三方工具,其中最知名的是优采云采集器,在此不做介绍。 二、自己写程序抓取,这种方法要求站长自己写程序
java爬取百度百科词条
lz在之前的一篇博客中,用python实现了爬取百度百科的词条,就在怎么用java来实现相同的功能,果不其然,java用一个jsoup的第三方库工具就可以很简单地实现爬取百度百科的词条。同样的,将这个爬取过程分成5个部份来实现。分别是connectnet联接url部份、parsehtml获取html相关内容部份、startspyder部份、store储存url部份、urlmanager的url管理
关于使用Java实现的简单网路爬虫Demo
什么是网络爬虫?网络爬虫又叫蜘蛛,网络蜘蛛是通过网页的链接地址来找寻网页,从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这种链接地址找寻下一个网页,这样仍然循环下去,直到把这个网站所有的网页都抓取完为止。如果把整个互联网当作一个网站,那么网路蜘蛛就可以用这个原理把互联网上所有的网页都抓取出来。所以要想抓取网路上的数据,不仅须要爬虫程序还须要一个可以接受
Java爬虫爬取python百度百科词条及相关词条页面
Java爬虫爬取python百度百科词条及相关词条页面本实例爬取关于python词条页面及关联词条页面的简介网络爬虫论坛,把词条的简介写入txt文本中, 本实例疗效:实例基于使用第三方jar包Jsoup1首先剖析python词条页面:可以发觉其他词条的超链接都带有"/item"以及词条的简介都包含在class为
python scrapy项目下spiders内多个爬虫同时运行
一般创建了scrapy文件夹后,可能须要写多个爬虫,如果想使它们同时运行而不是顺次运行的话,得怎样做?a、在spiders目录的同级目录下创建一个commands目录网络爬虫论坛,并在该目录中创建一个crawlall.py,将scrapy源代码里的commands文件夹里的crawl.py源码复制过来,只更改run()方法即可!import osfrom ...
算法设计中关于优先队列式分支限界法解装载问题的代码下载
分支限界法中的优先队列式分支限界法解装载问题相关下载链接:
软件调试张银奎(7)下载
软件调试张银奎(4)软件调试张银奎(4)软件调试张银奎(4)相关下载链接:
WimTool-WIM文件处理工具安装版下载
WimTool-WIM文件处理工具安装版相关下载链接:
相关热词c#如何获得线程名c# usb 采集器c# sort()c#面对对象的三大特点c# 打印 等比缩放c#弹出右键菜单c# 系统托盘图标c# 键值对 键可以重复c# 鼠标移起来提示c#结构体定义
我们是挺有底线的
开源的网路爬虫larbin
采集交流 • 优采云 发表了文章 • 0 个评论 • 323 次浏览 • 2020-06-26 08:00
利用larbin,我们可以轻易的获取/确定单个网站的所有连结,甚至可以镜像一个网站;也可以用它完善url 列表群,例如针对所有的网页进行 url retrive后,进行xml的连结的获取。或者是 mp3,或者订制larbin,可以作为搜索引擎的信息的来源。
不过它的最大的亮点还是开源,相信很多人领到larbin源代码的时侯会觉得无从入手,下面是一篇特别不错的开源的网络爬虫/网络蜘蛛larbin结构剖析的文章,有兴趣的最好仔细阅读尝试一下。
互联网是一个庞大的非结构化的数据库,将数据有效的检索并组织呈现下来有着巨大的应用前景,尤其是类似RSS的以XML为基础的结构化的数据越来越 多,内容的组织形式越来越灵活,检索组织并呈现会有着越来越广泛的应用范围,同时在时效性和可读性上也会有越来越高的要求。这一切的基础是爬虫,信息的来 源入口。一个高效,灵活可扩充的爬虫对以上应用都有着无可替代的重要意义。
要设计一个爬虫,首先须要考虑的效率。对于网路而言,基于TCP/IP的通讯编程有几种方式。
第一种是单线程阻塞,这是最简单也最容易实现的一种,一个事例:在Shell中通过curl,pcregrep等一系统命令可以直接实现一个简单的 爬虫,但同时它的效率问题也显而易见:由于是阻塞方法读取,dns解析,建立联接,写入恳求,读取结果这种步骤上就会形成时间的延后,从而未能有效的借助 服务器的全部资源。
第二种是多线程阻塞。建立多个阻塞的线程,分别恳求不同的url。相对于第一种方式,它可以更有效的借助机器的资源,特别是网路资源开源网络爬虫,因为无数线程 在同时工作,所以网路会比较充分的借助,但同时对机器CPU资源的消耗也是比较大,在用户级多线程间的频繁切换对于性能的影响早已值得我们考虑。
第三种是单线程非阻塞。这是目前使用的比较多的一种做法,无论在client还是server都有着广泛的应用。在一个线程内打开多个非阻塞的连 接,通过poll/epoll /select对联接状态进行判定,在第一时间响应恳求,不但充分利用了网路资源,同时也将本机CPU资源的消耗降至最低。这种方式须要对dns恳求,连 接,读写操作都采用异步非阻塞操作,其中第一种比较复杂,可以采用adns作为解决方案,后面三个操作相对简单可以直接在程序内实现。
效率问题解决后就须要考虑具体的设计问题了。
url肯定须要一个单独的类进行处理,包括显示,分析url,得到主机,端口,文件数据。
然后须要对url进行排重,需要一个比较大的url Hash表。
如果还要对网页内容进行排重,则还须要一个Document Hash表。
爬过的url须要记录出来,由于量比较大,我们将它讲到c盘上,所以还须要一个FIFO的类(记作urlsDisk)。
现在须要爬的url同样须要一个FIFO类来处理,重新开始时,url会从定时从爬过的url FIFO里取下来,写到这个FIFO里。正在运行的爬虫须要从这个FIFO里读数据下来,加入到主机类的url列表里。当然,也会从前一个FIFO里直接 读url下来,不过优先级应当比这个上面下来的url低,毕竟是早已爬过的。
爬虫通常是对多个网站进行爬取,但在同时站点内dns的恳求可以只做一次开源网络爬虫,这就须要将主机名独立于url,单独有一个类进行处理。
主机名解析完成后须要有一个解析完成的IP类与之应用,用于connect的时侯使用。
HTML文档的解析类也要有一个,用来剖析网页,取出上面的url,加入到urlsDisk。
再加上一些字符串,调度类,一个简单的爬虫基本上就完成了。
以上基本上是Larbin的设计思路,Larbin在具体实现上还有一些特殊的处理,例如带了一个webserver,以及对特殊文件的处理。 Larbin有一点设计不不太好,就是慢的访问会越来越多,占用大量的联接,需要改进,另外假如对于大规模的爬虫,这仅仅实现了抓取的部份,要分布式的扩 展还须要降低url的集中管理与调度以及前台spider的分布式算法。
Larbin网站爬虫简明使用说明
larbin是一种爬虫工具,我也是前段时间网上见到 Larbin 一种高效的搜索引擎爬虫工具 一文时才晓得有这么个东西,初步认定,我比较喜欢这个工具(比起nutch的crawl来说),因为它是C++写的,类似C嘛,我熟,可以自己改改,顺便 学习一下C++(几年来的经验告诉我说:改他人的东西来学一种技术比从头写helloworld快好多)。于是开始了我辛酸的larbin试用之旅。
回头瞧瞧自己遇见的问题都是因为没认真看文档造成的,唉,老毛病了。下次虽然是E文的也得好好看,不能盲目的试,浪费时间。
larbin官方地址:
一,编译
这也好说,whahahaha,那是!因为从官方网站下出来的代码不能编译通过(linux gcc下)
./configure
make
gcc -O3 -Wall -D_REENTRANT -c -o parse.o parse.c
parse.c:115: error: conflicting types for ’adns__parse_domain’
internal.h:571: error: previous declaration of ’adns__parse_domain’ was here
parse.c:115: error: conflicting types for ’adns__parse_domain’
internal.h:571: error: previous declaration of ’adns__parse_domain’ was here
gmake[1]: *** [parse.o] 错误 1
gmake[1]: Leaving directory `/home/leo/leo/larbin-2.6.3/adns’
make: *** [all] 错误 2
函数原型和定义不一致这个好改:
打开./adns/internal.h文件,把568-571行直接注释掉就行了。
二,运行
这个就不说了,./larbin就运行了,larbin.conf中先进行配置就可以了,这个配置就不说了。。
运行后可以:8081 看运行状态,不错的看法。 larbin.conf中有个:inputPort 1976配置,就是可以运行时降低要抓取的URL,这个看法非常好,可是?怎么加呢?象原本那样::1976那样是不行的,报 错???试了很久没结果,最后GDB跟踪了一下,唉,原来直接telnet host 1976进行降低就可以了。后来见到文档里写的亲亲楚楚,晕倒。。。。。
三,结果
哈哈,下班后找了台机子跑了上去,那晚午睡的时侯都梦到自己的搜索引擎赶GOOGLE超BAIDU了,那个激动啊。
第二天下班的时侯取看结果,发现目录下不仅些fifo*文件外哪些都没有,那个纠结。没办法啊,再看文档 How to customize Larbin 发现如此段说明:
The first thing you can define is the module you want to use for ouput. This defines what you want to do with the pages larbin gets. Here are the different options :
DEFAULT_OUTPUT : This module mainly does nothing, except statistics.
SIMPLE_SAVE : This module saves pages on disk. It stores 2000 files per directory (with an index).
MIRROR_SAVE : This module saves pages on disk with the hierarchy of the site they come from. It uses one directory per site.
STATS_OUTPUT : This modules makes some stats on the pages. In order to see the results, see :8081/output.html.
靠,默认哪些都没输出,于是认真的看了官方网站上仅有的两个文档,修改了options.h再编译,终于有结果了。
我的option中改了:
SIMPLE_SAVE 简单输出一个目录两千个文件,包含索引。
CGILEVEL=0 处理服务器端程序,也就是但url中包含? & = 之类的querString时也处理。
NO_DUP
其余可依据各自须要更改,详见: How to customize Larbin 一文。
四,问题
在使用过程中发觉,在抓网页的时侯,如果URL中包含未编码(encodurl)中文时,无法抓取,简单的看了一下在: src/utils/中的fileNormalize 有涉及。于是写了个encodurl函数加在url类的构造函数里,问题就解决了。
由于须要比较好的可定制性,这个工具其实还不大满足我的需求,最终我没使用她,而是自己用perl在WWW:SimpleRobot的基础上搞了个适宜我的。。再说了perl在字符蹿处理上应当不比C++慢,总的来说那种小工具性能还不错。。呵呵。
不过还是把这种写下来,给没看文档的同学(希望极少),也警示自己一定要认真看文档 查看全部
larbin是一种开源的网路爬虫/网路蜘蛛,由美国的年轻人 Sébastien Ailleret独立开发。larbin目的是能否跟踪页面的url进行扩充的抓取,最后为搜索引擎提供广泛的数据来源。Larbin只是一个爬虫,也就 是说larbin只抓取网页,至于怎样parse的事情则由用户自己完成。另外,如何储存到数据库以及完善索引的事情 larbin也不提供。一个简单的larbin的爬虫可以每晚获取500万的网页。
利用larbin,我们可以轻易的获取/确定单个网站的所有连结,甚至可以镜像一个网站;也可以用它完善url 列表群,例如针对所有的网页进行 url retrive后,进行xml的连结的获取。或者是 mp3,或者订制larbin,可以作为搜索引擎的信息的来源。
不过它的最大的亮点还是开源,相信很多人领到larbin源代码的时侯会觉得无从入手,下面是一篇特别不错的开源的网络爬虫/网络蜘蛛larbin结构剖析的文章,有兴趣的最好仔细阅读尝试一下。
互联网是一个庞大的非结构化的数据库,将数据有效的检索并组织呈现下来有着巨大的应用前景,尤其是类似RSS的以XML为基础的结构化的数据越来越 多,内容的组织形式越来越灵活,检索组织并呈现会有着越来越广泛的应用范围,同时在时效性和可读性上也会有越来越高的要求。这一切的基础是爬虫,信息的来 源入口。一个高效,灵活可扩充的爬虫对以上应用都有着无可替代的重要意义。
要设计一个爬虫,首先须要考虑的效率。对于网路而言,基于TCP/IP的通讯编程有几种方式。
第一种是单线程阻塞,这是最简单也最容易实现的一种,一个事例:在Shell中通过curl,pcregrep等一系统命令可以直接实现一个简单的 爬虫,但同时它的效率问题也显而易见:由于是阻塞方法读取,dns解析,建立联接,写入恳求,读取结果这种步骤上就会形成时间的延后,从而未能有效的借助 服务器的全部资源。
第二种是多线程阻塞。建立多个阻塞的线程,分别恳求不同的url。相对于第一种方式,它可以更有效的借助机器的资源,特别是网路资源开源网络爬虫,因为无数线程 在同时工作,所以网路会比较充分的借助,但同时对机器CPU资源的消耗也是比较大,在用户级多线程间的频繁切换对于性能的影响早已值得我们考虑。
第三种是单线程非阻塞。这是目前使用的比较多的一种做法,无论在client还是server都有着广泛的应用。在一个线程内打开多个非阻塞的连 接,通过poll/epoll /select对联接状态进行判定,在第一时间响应恳求,不但充分利用了网路资源,同时也将本机CPU资源的消耗降至最低。这种方式须要对dns恳求,连 接,读写操作都采用异步非阻塞操作,其中第一种比较复杂,可以采用adns作为解决方案,后面三个操作相对简单可以直接在程序内实现。
效率问题解决后就须要考虑具体的设计问题了。
url肯定须要一个单独的类进行处理,包括显示,分析url,得到主机,端口,文件数据。
然后须要对url进行排重,需要一个比较大的url Hash表。
如果还要对网页内容进行排重,则还须要一个Document Hash表。
爬过的url须要记录出来,由于量比较大,我们将它讲到c盘上,所以还须要一个FIFO的类(记作urlsDisk)。
现在须要爬的url同样须要一个FIFO类来处理,重新开始时,url会从定时从爬过的url FIFO里取下来,写到这个FIFO里。正在运行的爬虫须要从这个FIFO里读数据下来,加入到主机类的url列表里。当然,也会从前一个FIFO里直接 读url下来,不过优先级应当比这个上面下来的url低,毕竟是早已爬过的。
爬虫通常是对多个网站进行爬取,但在同时站点内dns的恳求可以只做一次开源网络爬虫,这就须要将主机名独立于url,单独有一个类进行处理。
主机名解析完成后须要有一个解析完成的IP类与之应用,用于connect的时侯使用。
HTML文档的解析类也要有一个,用来剖析网页,取出上面的url,加入到urlsDisk。
再加上一些字符串,调度类,一个简单的爬虫基本上就完成了。
以上基本上是Larbin的设计思路,Larbin在具体实现上还有一些特殊的处理,例如带了一个webserver,以及对特殊文件的处理。 Larbin有一点设计不不太好,就是慢的访问会越来越多,占用大量的联接,需要改进,另外假如对于大规模的爬虫,这仅仅实现了抓取的部份,要分布式的扩 展还须要降低url的集中管理与调度以及前台spider的分布式算法。
Larbin网站爬虫简明使用说明
larbin是一种爬虫工具,我也是前段时间网上见到 Larbin 一种高效的搜索引擎爬虫工具 一文时才晓得有这么个东西,初步认定,我比较喜欢这个工具(比起nutch的crawl来说),因为它是C++写的,类似C嘛,我熟,可以自己改改,顺便 学习一下C++(几年来的经验告诉我说:改他人的东西来学一种技术比从头写helloworld快好多)。于是开始了我辛酸的larbin试用之旅。
回头瞧瞧自己遇见的问题都是因为没认真看文档造成的,唉,老毛病了。下次虽然是E文的也得好好看,不能盲目的试,浪费时间。
larbin官方地址:
一,编译
这也好说,whahahaha,那是!因为从官方网站下出来的代码不能编译通过(linux gcc下)
./configure
make
gcc -O3 -Wall -D_REENTRANT -c -o parse.o parse.c
parse.c:115: error: conflicting types for ’adns__parse_domain’
internal.h:571: error: previous declaration of ’adns__parse_domain’ was here
parse.c:115: error: conflicting types for ’adns__parse_domain’
internal.h:571: error: previous declaration of ’adns__parse_domain’ was here
gmake[1]: *** [parse.o] 错误 1
gmake[1]: Leaving directory `/home/leo/leo/larbin-2.6.3/adns’
make: *** [all] 错误 2
函数原型和定义不一致这个好改:
打开./adns/internal.h文件,把568-571行直接注释掉就行了。
二,运行
这个就不说了,./larbin就运行了,larbin.conf中先进行配置就可以了,这个配置就不说了。。
运行后可以:8081 看运行状态,不错的看法。 larbin.conf中有个:inputPort 1976配置,就是可以运行时降低要抓取的URL,这个看法非常好,可是?怎么加呢?象原本那样::1976那样是不行的,报 错???试了很久没结果,最后GDB跟踪了一下,唉,原来直接telnet host 1976进行降低就可以了。后来见到文档里写的亲亲楚楚,晕倒。。。。。
三,结果
哈哈,下班后找了台机子跑了上去,那晚午睡的时侯都梦到自己的搜索引擎赶GOOGLE超BAIDU了,那个激动啊。
第二天下班的时侯取看结果,发现目录下不仅些fifo*文件外哪些都没有,那个纠结。没办法啊,再看文档 How to customize Larbin 发现如此段说明:
The first thing you can define is the module you want to use for ouput. This defines what you want to do with the pages larbin gets. Here are the different options :
DEFAULT_OUTPUT : This module mainly does nothing, except statistics.
SIMPLE_SAVE : This module saves pages on disk. It stores 2000 files per directory (with an index).
MIRROR_SAVE : This module saves pages on disk with the hierarchy of the site they come from. It uses one directory per site.
STATS_OUTPUT : This modules makes some stats on the pages. In order to see the results, see :8081/output.html.
靠,默认哪些都没输出,于是认真的看了官方网站上仅有的两个文档,修改了options.h再编译,终于有结果了。
我的option中改了:
SIMPLE_SAVE 简单输出一个目录两千个文件,包含索引。
CGILEVEL=0 处理服务器端程序,也就是但url中包含? & = 之类的querString时也处理。
NO_DUP
其余可依据各自须要更改,详见: How to customize Larbin 一文。
四,问题
在使用过程中发觉,在抓网页的时侯,如果URL中包含未编码(encodurl)中文时,无法抓取,简单的看了一下在: src/utils/中的fileNormalize 有涉及。于是写了个encodurl函数加在url类的构造函数里,问题就解决了。
由于须要比较好的可定制性,这个工具其实还不大满足我的需求,最终我没使用她,而是自己用perl在WWW:SimpleRobot的基础上搞了个适宜我的。。再说了perl在字符蹿处理上应当不比C++慢,总的来说那种小工具性能还不错。。呵呵。
不过还是把这种写下来,给没看文档的同学(希望极少),也警示自己一定要认真看文档
优采云采集器好用吗?网络爬虫软件怎么样? 爱钻杂谈
采集交流 • 优采云 发表了文章 • 0 个评论 • 398 次浏览 • 2020-06-25 08:02
优采云介绍:优采云网页数据采集器,是一款使用简单、功能强悍的网路爬虫工具,完全可视化操作,无需编撰代码,内置海量模板,支持任意网路数据抓取,连续四年大数据行业数据采集领域排行第一。
这个采集的行业内也有好几个这个采集工具,之后在渐渐的说,这个优采云在网站上了解了下,本来想学着自己搞个采集,结果如何搞都弄不到一块,最后舍弃了,或许是我天分不够,不会用这个采集软件吧,采集软件这个东西便捷是便捷挺,比如一些新闻站点或则购物站几乎都用的采集软件,新闻都是一样的,就是标题有所改变。
但是网赚站若果是一个新站或则权重不高的站,被其他权重高的站采集过去,还不给留链接的话,那么对于新站的严打还是挺严重的八爪鱼采集器是干什么的,越不想写越没有收录排行,然而即使你不写他人还采集其他站,他站没有事,你不写你的站起不来,就是如此嘲弄,这真是靠天吃饭呀。 查看全部
优采云采集器好用吗?网络爬虫软件怎么样?优采云采集器是个哪些东西?这个优采云就是一个采集工具,可能对不太会搞代码的人,比如我爱兼职网就不会用这个,怎么看哪个教程都看不懂,特么的,但是对于通常原创的站点来说八爪鱼采集器是干什么的,这类采集器真的么特的反胃,自己写得东西网站上上传后没有收录呢,别的站采集过去,反倒比原创站收录快,并且排行还比原创站高,搞得原创站如同是采集站一样,这都不是最重要的,最重要的是这些采集后发表在自己站上的,居然不留原文链接,这个才是最可笑的,毕竟人心不古,既然不乐意留链接就不要转载和采集不就完了嘛,
优采云介绍:优采云网页数据采集器,是一款使用简单、功能强悍的网路爬虫工具,完全可视化操作,无需编撰代码,内置海量模板,支持任意网路数据抓取,连续四年大数据行业数据采集领域排行第一。
这个采集的行业内也有好几个这个采集工具,之后在渐渐的说,这个优采云在网站上了解了下,本来想学着自己搞个采集,结果如何搞都弄不到一块,最后舍弃了,或许是我天分不够,不会用这个采集软件吧,采集软件这个东西便捷是便捷挺,比如一些新闻站点或则购物站几乎都用的采集软件,新闻都是一样的,就是标题有所改变。
但是网赚站若果是一个新站或则权重不高的站,被其他权重高的站采集过去,还不给留链接的话,那么对于新站的严打还是挺严重的八爪鱼采集器是干什么的,越不想写越没有收录排行,然而即使你不写他人还采集其他站,他站没有事,你不写你的站起不来,就是如此嘲弄,这真是靠天吃饭呀。
初探爬虫 ||《python 3 网络爬虫开发实践》读书笔记 | 小蒋不素小蒋
采集交流 • 优采云 发表了文章 • 0 个评论 • 417 次浏览 • 2020-06-24 08:02
从 Python3.5 版本开始,Python 中加入了 async/await。
接口抓取的缺点是抓不到 js 渲染后的页面,而下边介绍的模拟抓取能挺好的解决问题。
也就是可见即可爬。
Splash 是一个 javascript 渲染服务。它是一个带有 HTTP API 的轻量级 Web 浏览器。
Selenium 是一个自动化测试工具,利用它我们可以驱动测览器执行特定的动作,如点击、下拉等操作。
Selenium + Chrome Driver,可以驱动 Chrome 浏览器完成相应的操作。
Selenium + Phantoms,这样在运行的时侯就不会再弹出一个浏览器了。而且 Phantoms 的运行效率也很高。
Phantoms 是一个无界面的、可脚本编程的 Webkit 7 浏览器引擎。
Appium 是 App 版的 Selenium。
抓取网页代码以后,下一步就是从网页中提取信息。
正则是最原始的形式,写上去繁杂,可读性差。
lxml 是 Python 的一个解析库,支持 HTML 和 XML 的解析,支持 XPah 解析方法。
Beautiful Soup 的 HTML 和 XML 解析器是依赖于 lxml 库的,所以在此之前请确保早已成功安装好了 lxml。
Beautiful Soup提供好几个解析器:
pyquery 同样是一个强悍的网页解析工具,它提供了和 jquery 类似的句型来解析 HTML 文档。
推荐:
Beautiful Soup(lxml)。lxml 解析器有解析 HTML 和 XML 的功能,而且速度快,容错能力强。
如果本身就熟悉 css 和 jquery 的话,就推荐 pyquery。
NOSQL,全称 Not Only SQL,意为不仅仅是 SQL,泛指非关系型数据库。包括:
口 键值储存数据库:代表有 Redis、Voldemort 和 Oracle BDB 等
口 列存储数据库:代表有 Cassandra、Hbase 和 Riak 等。
口 文档型数据库:代表有 COUCHDB 和 Mongodb 等。
口 图形数据库:代表有 Neo4J、infogrid 和 Infinite Graph 等。
针对一些复杂应用,尤其是 app,请求不象在 chrome 的 console 里这么容易看见,这就须要抓包工具。
mitmproxy(mitmdump) 比 Charles 更强大的是爬虫软件开发,可以支持对接 Python 脚本去处理 resquest / response。
方案:Appium + mitmdump
做法:用 mitmdump 去窃听插口数据,用 Appium 去模拟 App 的操作。
好处:即可绕开复杂的插口参数又能实现自动化提升效率。
缺点:有一些 app,如微信朋友圈的数据又经过了一次加密造成难以解析,这种情况只能纯用 Appium 了。但是对于大多数 App 来说,此种方式是奏效的。
pyspide 框架有一些缺点,比如可配置化程度不高,异常处理能力有限等,它对于一些反爬程度特别强的网站的爬取变得力不从心。
所以这儿不多做介绍。
Scrapy 是一个基于 Twisted 的异步处理框架,是纯 Python 实现的爬虫框架。
Scrapy 包括:
Scrapy-Splash:一个 Scrapy 中支持 Javascript 渲染的工具。
Scrapy-Redis :Scrap 的分布式扩充模块。
Scrapyd :一个用于布署和运行 Scrapy 项目的工具。
Scrapyrt :为 Scrap 提供了一个调度的 HTTP 接口。
Gerapy :一个 Scrapy 分布式管理模块。
Scrapy 可对接:
Crawlspider : Scrap 提供的一个通用 Spider,我们可以指定一些爬取规则来实现页面的提取,
Splash / Selenium :自动化爬取
Docker
具体使用:待写
URI 的全称为 Uniform Resource Identifier,即统一资源标志符。
URL 的全称为 Universal Resource Locator,即统一资源定位符。
URN 的全称为 Universal Resource Name,即统一资源名称。
URI 可以进一步界定为URL、URN或二者兼具。URL 和 URN 都是 URI 子集。
URN 如同一个人的名称,而 URL 代表一个人的住址。换言之,URN 定义某事物的身分,而 URL 提供查找该事物的技巧。
现在常用的http网址,如 就是URL。
而用于标示惟一书目的 ISBN 系统, 如:isbn:0-486-27557-4 ,就是 URN 。
但是在目前的互联网中,URN 用得十分少,所以几乎所有的 URI 都是 URL。
Robots 协议也叫做爬虫协议、机器人合同,它的全名叫作网路爬虫排除标准(Robots Exclusion Protocol),用来告诉爬虫和搜索引擎什么页面可以抓取,哪些不可以抓取。它一般是一个叫作robots.txt 的文本文件,一般置于网站的根目录下。
当搜索爬虫访问一个站点时,它首先会检测这个站点根目录下是否存在 robots.txt 文件,如果存在搜索爬虫会按照其中定义的爬取范围来爬取。如果没有找到这个文件爬虫软件开发,搜索爬虫便会访问所有可直接访问的页面。
robotx.txt 需要置于网站根目录。
User-agent: *
Disallow: /
Allow: /public/
Disallow表示不容许爬的页面,Allow表示准许爬的页面,User-agent表示针对那个常用搜索引擎。
User-agent 为约定好的值,取值如下表:
1、测试环境
2、管理后台(如 cms)
3、其它
1、Google的 Robots.txt 规范。
2、站长工具的 robots文件生成 工具。
Xpath,全称 XML Path Language,即 XML 路径语言,它是一门在 XML 文档中査找信息的语言。它最初是拿来搜救 XML 文档的,但是它同样适用于 HTML 文档的搜索。
Xpath 的选择功能非常强悍,它提供了十分简约明了的路径选择表达式。另外,它还提供了超过 100 个内建函数,用于字符串、数值、时间的匹配以及节点、序列的处理等。
Xpath 于 1999 年 11 月 16 日成为 W3C 标准。
就好象 css 选择器。
可以使用 Tesseract ,它是 Python 的一个 OCR 识别库。
市面上用的最多的是这家提供的滑动验证码: ,如 bilibili。
可以用自动化库,如 Selenium 模拟滑动(注意人去滑动按键是先快后慢)。
解决思路:模板匹配+模拟拖动
还有一个专门提供点触验证码服务的站点 Touclick,例如 12306 网站。
上面说的第四个:点触验证码,应该是最难辨识的了。
但互联网上有好多验证码服务平台,平台 7×24 小时提供验证码辨识服务,一张图片几秒都会获得辨识结果,准确率可达 90%以上。
个人比较推荐的一个平台是超级鹰,其官网为 。其提供的服务种类十分广泛,可辨识的验证码类型特别多,其中就包括点触验证码。
ロ FTP 代理服务器:主要用于访问 FTP 服务器,一般有上传、下载以及缓存功能,端口通常为 21、2121 等。
ロ HTP 代理服务器:主要用于访问网页,一般有内容过滤和缓存功能,端口通常为 80、8080、3128等。
口 SSL/TLS代理:主要用于访问加密网站,一般有SSL或TLS加密功能(最高支持 128 位加密硬度),端口通常为 443。
口 RTSP 代理:主要用于访问 Real 流媒体服务器,一般有缓存功能,端口通常为 554。
口 Telnet 代理:主要用于 telnet 远程控制(黑客入侵计算机时常用于隐藏身份),端口通常为 23。
口 POP3 SMTP 代理:主要用于 POP3 SMTP 方式收发短信,一般有缓存功能,端口通常为 11025 。
口 SOCKS 代理:只是单纯传递数据包,不关心具体合同和用法,所以速度快好多,一般有缓存功能,端口通常为 1080。SOCKS 代理合同又分为 SOCKS4 和 SOCKS5,前者只支持 TCP,而后者支持 TCP 和 UDP,还支持各类身分验证机制、服务器端域名解析等。简单来说,SOCKS4 能做到的 SOCKS5 都可以做到,但 SOCKS5 能做到的 SOCKS4 不一定能做到。
口 高度匿名代理:会将数据包原封不动地转发,在服务端看来就似乎真的是一个普通客户端在访问,而记录的 IP 是代理服务器的 IP。
ロ 普通匿名代理:会在数据包上做一些改动,服务端上有可能发觉这是个代理服务器,也有一定概率彻查到客户端的真实 IP。代理服务器一般会加入的 HTIP 头有 HTTPVIA 和 HTTPXFORWARDEDFOR。
口 透明代理:不但改动了数据包,还会告诉服务器客户端的真实 IP。这种代理不仅能用缓存技术提升浏览速率,能用内容过滤提升安全性之外,并无其他明显作用,最常见的事例是外网中的硬件防火墙。
口 间谍代理:指组织或个人创建的用于记录用户传输的数据,然后进行研究、监控等目的的代理服务器。
网站上会有很多免费代理,比如南刺: 。但是这种免费代理大多数情况下都是不好用的,所以比较靠谱的方式是订购付费代理。
1、提供插口获取海量代理,按天或则按时收费,如讯代理;
如果信赖讯代理的话,我们也可以不做代理池筛选,直接使用代理。不过我个人还是推荐使用代理池筛选,以提升代理可用机率。自己再做一次筛选,以确保代理可用。
2、搭建了代理隧洞,直接设置固定域名代理,如阿布云代理。云代理在云端维护一个全局 IP 池供代理隧洞使用,池中的 IP 会不间断更新。代理隧洞,配置简单,代理速率快且十分稳定。
等于帮你做了一个云端的代理池,不用自己实现了。
需要注意的是,代理 IP 池中部份 IP 可能会在当日重复出现多次。
3、ADSL 拨号代理
ADSL (Asymmetric Digital Subscriber Line,非对称数字用户支路),它的上行和下行带宽不对称,它采用频分复用技术把普通的电话线分成了电话、上行和下行 3 个相对独立的信道,从而防止了互相之间的干扰。
我们借助了 ADSL 通过拔号的形式上网,需要输入 ADSL 账号和密码,每次拔号就更换一个 IP 这个特点。
所以我们可以先订购一台动态拔号 VPS 主机,这样的主机服务商相当多。在这里使用了云立方,官方网站:
代理不论是免费的还是付费的,都不能保证都是可用的,因为:
1、此 IP 可能被其他人使用来爬取同样的目标站点而被封禁。
2、代理服务器忽然发生故障。
3、网络忙碌。
4、购买的代理到期。
5、等等
所以,我们须要提早做筛选,将不可用的代理剔除掉,保留可用代理。这就须要代理池,来获取随机可用的代理。
代理池分为 4 个模块: 存储模块、获取模块、检测模块、接口模块。
口 存储模块使用 Redis 的有序集合,用来做代理的去重和状态标示,同时它也是中心模块和基础模块,将其他模块串联上去。
口 获取模块定时从代理网站获取代理,将获取的代理传递给储存模块,并保存到数据库。
口 检测模块定时通过储存模块获取所有代理,并对代理进行检查,根据不同的测量结果对代理设置不同的标示。
口 接口模块通过WebAPI 提供服务插口,接口通过联接数据库并通过Web 形式返回可用的代理。
对于这儿的测量模块,建议使用 aiohttp 而不是 requests,原因是:
对于响应速率比较快的网站来说,requests 同步恳求和 aiohttp 异步恳求的疗效差别没这么大。但对于测量代理来说,检测一个代理通常须要十多秒甚至几十秒的时间,这时候使用 aiohttp 异步恳求库的优势就大大彰显下来了,效率可能会提升几十倍不止。
(1)有的数据必须要登陆能够抓取。
(2)有时候,登录帐号也可以减少被封禁的几率。
做大规模抓取,我们就须要拥有好多帐号,每次恳求随机选定一个帐号,这样就减少了单个帐号的访问颍率,被封的机率又会大大增加。
所以,我们可以维护一个登陆用的 Cookies 池。
架构跟代理池一样。可参考上文。
待写
python 的 open() 支持的模式可以是只读/写入/追加,也是可以它们的组合型,具体如下:
模式描述
r
以只读方法打开文件。文件的表针将会放到文件的开头。这是默认模式。
rb
以二进制格式打开一个文件用于只读。文件表针将会放到文件的开头。这是默认模式。
r+
打开一个文件用于读写。文件表针将会放到文件的开头。
rb+
以二进制格式打开一个文件用于读写。文件表针将会放到文件的开头。
w
打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
wb
以二进制格式打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
w+
打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
wb+
以二进制格式打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
a
打开一个文件用于追加。如果该文件已存在,文件指针将会放到文件的结尾。也就是说,新的内容将会被写入到已有内容然后。如果该文件不存在,创建新文件进行写入。
ab
以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放到文件的结尾。也就是说,新的内容将会被写入到已有内容然后。如果该文件不存在,创建新文件进行写入。
a+
打开一个文件用于读写。如果该文件已存在,文件指针将会放到文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。
ab+
以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放到文件的结尾。如果该文件不存在,创建新文件用于读写。
1、r+ 和 w+ 都是读写,有哪些区别?
答:前者是假如没有找到文件则抛错,后者是假如没有找到文件则手动创建文件。
2、a 可以看成是 w 的变种,附加上了”追加内容“的特点。
一般调用 open() 的时侯还须要再调用 close()。 python 提供了一种缩写方式,那就是使用 with as 语法。在 with 控制块结束时,文件会手动关掉,不需要 close() 了。调用写法如下: 查看全部

从 Python3.5 版本开始,Python 中加入了 async/await。
接口抓取的缺点是抓不到 js 渲染后的页面,而下边介绍的模拟抓取能挺好的解决问题。
也就是可见即可爬。
Splash 是一个 javascript 渲染服务。它是一个带有 HTTP API 的轻量级 Web 浏览器。
Selenium 是一个自动化测试工具,利用它我们可以驱动测览器执行特定的动作,如点击、下拉等操作。
Selenium + Chrome Driver,可以驱动 Chrome 浏览器完成相应的操作。
Selenium + Phantoms,这样在运行的时侯就不会再弹出一个浏览器了。而且 Phantoms 的运行效率也很高。
Phantoms 是一个无界面的、可脚本编程的 Webkit 7 浏览器引擎。
Appium 是 App 版的 Selenium。
抓取网页代码以后,下一步就是从网页中提取信息。
正则是最原始的形式,写上去繁杂,可读性差。
lxml 是 Python 的一个解析库,支持 HTML 和 XML 的解析,支持 XPah 解析方法。
Beautiful Soup 的 HTML 和 XML 解析器是依赖于 lxml 库的,所以在此之前请确保早已成功安装好了 lxml。
Beautiful Soup提供好几个解析器:

pyquery 同样是一个强悍的网页解析工具,它提供了和 jquery 类似的句型来解析 HTML 文档。
推荐:
Beautiful Soup(lxml)。lxml 解析器有解析 HTML 和 XML 的功能,而且速度快,容错能力强。
如果本身就熟悉 css 和 jquery 的话,就推荐 pyquery。
NOSQL,全称 Not Only SQL,意为不仅仅是 SQL,泛指非关系型数据库。包括:
口 键值储存数据库:代表有 Redis、Voldemort 和 Oracle BDB 等
口 列存储数据库:代表有 Cassandra、Hbase 和 Riak 等。
口 文档型数据库:代表有 COUCHDB 和 Mongodb 等。
口 图形数据库:代表有 Neo4J、infogrid 和 Infinite Graph 等。
针对一些复杂应用,尤其是 app,请求不象在 chrome 的 console 里这么容易看见,这就须要抓包工具。
mitmproxy(mitmdump) 比 Charles 更强大的是爬虫软件开发,可以支持对接 Python 脚本去处理 resquest / response。
方案:Appium + mitmdump
做法:用 mitmdump 去窃听插口数据,用 Appium 去模拟 App 的操作。
好处:即可绕开复杂的插口参数又能实现自动化提升效率。
缺点:有一些 app,如微信朋友圈的数据又经过了一次加密造成难以解析,这种情况只能纯用 Appium 了。但是对于大多数 App 来说,此种方式是奏效的。
pyspide 框架有一些缺点,比如可配置化程度不高,异常处理能力有限等,它对于一些反爬程度特别强的网站的爬取变得力不从心。
所以这儿不多做介绍。
Scrapy 是一个基于 Twisted 的异步处理框架,是纯 Python 实现的爬虫框架。
Scrapy 包括:
Scrapy-Splash:一个 Scrapy 中支持 Javascript 渲染的工具。
Scrapy-Redis :Scrap 的分布式扩充模块。
Scrapyd :一个用于布署和运行 Scrapy 项目的工具。
Scrapyrt :为 Scrap 提供了一个调度的 HTTP 接口。
Gerapy :一个 Scrapy 分布式管理模块。
Scrapy 可对接:
Crawlspider : Scrap 提供的一个通用 Spider,我们可以指定一些爬取规则来实现页面的提取,
Splash / Selenium :自动化爬取
Docker
具体使用:待写
URI 的全称为 Uniform Resource Identifier,即统一资源标志符。
URL 的全称为 Universal Resource Locator,即统一资源定位符。
URN 的全称为 Universal Resource Name,即统一资源名称。

URI 可以进一步界定为URL、URN或二者兼具。URL 和 URN 都是 URI 子集。
URN 如同一个人的名称,而 URL 代表一个人的住址。换言之,URN 定义某事物的身分,而 URL 提供查找该事物的技巧。
现在常用的http网址,如 就是URL。
而用于标示惟一书目的 ISBN 系统, 如:isbn:0-486-27557-4 ,就是 URN 。
但是在目前的互联网中,URN 用得十分少,所以几乎所有的 URI 都是 URL。
Robots 协议也叫做爬虫协议、机器人合同,它的全名叫作网路爬虫排除标准(Robots Exclusion Protocol),用来告诉爬虫和搜索引擎什么页面可以抓取,哪些不可以抓取。它一般是一个叫作robots.txt 的文本文件,一般置于网站的根目录下。
当搜索爬虫访问一个站点时,它首先会检测这个站点根目录下是否存在 robots.txt 文件,如果存在搜索爬虫会按照其中定义的爬取范围来爬取。如果没有找到这个文件爬虫软件开发,搜索爬虫便会访问所有可直接访问的页面。
robotx.txt 需要置于网站根目录。
User-agent: *
Disallow: /
Allow: /public/
Disallow表示不容许爬的页面,Allow表示准许爬的页面,User-agent表示针对那个常用搜索引擎。
User-agent 为约定好的值,取值如下表:
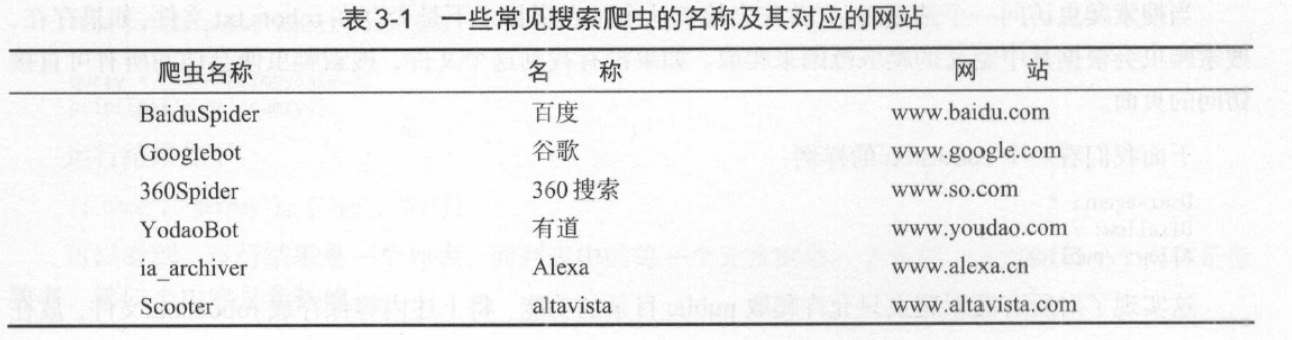
1、测试环境
2、管理后台(如 cms)
3、其它
1、Google的 Robots.txt 规范。
2、站长工具的 robots文件生成 工具。
Xpath,全称 XML Path Language,即 XML 路径语言,它是一门在 XML 文档中査找信息的语言。它最初是拿来搜救 XML 文档的,但是它同样适用于 HTML 文档的搜索。
Xpath 的选择功能非常强悍,它提供了十分简约明了的路径选择表达式。另外,它还提供了超过 100 个内建函数,用于字符串、数值、时间的匹配以及节点、序列的处理等。
Xpath 于 1999 年 11 月 16 日成为 W3C 标准。
就好象 css 选择器。
可以使用 Tesseract ,它是 Python 的一个 OCR 识别库。
市面上用的最多的是这家提供的滑动验证码: ,如 bilibili。
可以用自动化库,如 Selenium 模拟滑动(注意人去滑动按键是先快后慢)。
解决思路:模板匹配+模拟拖动
还有一个专门提供点触验证码服务的站点 Touclick,例如 12306 网站。
上面说的第四个:点触验证码,应该是最难辨识的了。
但互联网上有好多验证码服务平台,平台 7×24 小时提供验证码辨识服务,一张图片几秒都会获得辨识结果,准确率可达 90%以上。
个人比较推荐的一个平台是超级鹰,其官网为 。其提供的服务种类十分广泛,可辨识的验证码类型特别多,其中就包括点触验证码。
ロ FTP 代理服务器:主要用于访问 FTP 服务器,一般有上传、下载以及缓存功能,端口通常为 21、2121 等。
ロ HTP 代理服务器:主要用于访问网页,一般有内容过滤和缓存功能,端口通常为 80、8080、3128等。
口 SSL/TLS代理:主要用于访问加密网站,一般有SSL或TLS加密功能(最高支持 128 位加密硬度),端口通常为 443。
口 RTSP 代理:主要用于访问 Real 流媒体服务器,一般有缓存功能,端口通常为 554。
口 Telnet 代理:主要用于 telnet 远程控制(黑客入侵计算机时常用于隐藏身份),端口通常为 23。
口 POP3 SMTP 代理:主要用于 POP3 SMTP 方式收发短信,一般有缓存功能,端口通常为 11025 。
口 SOCKS 代理:只是单纯传递数据包,不关心具体合同和用法,所以速度快好多,一般有缓存功能,端口通常为 1080。SOCKS 代理合同又分为 SOCKS4 和 SOCKS5,前者只支持 TCP,而后者支持 TCP 和 UDP,还支持各类身分验证机制、服务器端域名解析等。简单来说,SOCKS4 能做到的 SOCKS5 都可以做到,但 SOCKS5 能做到的 SOCKS4 不一定能做到。
口 高度匿名代理:会将数据包原封不动地转发,在服务端看来就似乎真的是一个普通客户端在访问,而记录的 IP 是代理服务器的 IP。
ロ 普通匿名代理:会在数据包上做一些改动,服务端上有可能发觉这是个代理服务器,也有一定概率彻查到客户端的真实 IP。代理服务器一般会加入的 HTIP 头有 HTTPVIA 和 HTTPXFORWARDEDFOR。
口 透明代理:不但改动了数据包,还会告诉服务器客户端的真实 IP。这种代理不仅能用缓存技术提升浏览速率,能用内容过滤提升安全性之外,并无其他明显作用,最常见的事例是外网中的硬件防火墙。
口 间谍代理:指组织或个人创建的用于记录用户传输的数据,然后进行研究、监控等目的的代理服务器。
网站上会有很多免费代理,比如南刺: 。但是这种免费代理大多数情况下都是不好用的,所以比较靠谱的方式是订购付费代理。
1、提供插口获取海量代理,按天或则按时收费,如讯代理;
如果信赖讯代理的话,我们也可以不做代理池筛选,直接使用代理。不过我个人还是推荐使用代理池筛选,以提升代理可用机率。自己再做一次筛选,以确保代理可用。
2、搭建了代理隧洞,直接设置固定域名代理,如阿布云代理。云代理在云端维护一个全局 IP 池供代理隧洞使用,池中的 IP 会不间断更新。代理隧洞,配置简单,代理速率快且十分稳定。
等于帮你做了一个云端的代理池,不用自己实现了。
需要注意的是,代理 IP 池中部份 IP 可能会在当日重复出现多次。
3、ADSL 拨号代理
ADSL (Asymmetric Digital Subscriber Line,非对称数字用户支路),它的上行和下行带宽不对称,它采用频分复用技术把普通的电话线分成了电话、上行和下行 3 个相对独立的信道,从而防止了互相之间的干扰。
我们借助了 ADSL 通过拔号的形式上网,需要输入 ADSL 账号和密码,每次拔号就更换一个 IP 这个特点。
所以我们可以先订购一台动态拔号 VPS 主机,这样的主机服务商相当多。在这里使用了云立方,官方网站:
代理不论是免费的还是付费的,都不能保证都是可用的,因为:
1、此 IP 可能被其他人使用来爬取同样的目标站点而被封禁。
2、代理服务器忽然发生故障。
3、网络忙碌。
4、购买的代理到期。
5、等等
所以,我们须要提早做筛选,将不可用的代理剔除掉,保留可用代理。这就须要代理池,来获取随机可用的代理。

代理池分为 4 个模块: 存储模块、获取模块、检测模块、接口模块。
口 存储模块使用 Redis 的有序集合,用来做代理的去重和状态标示,同时它也是中心模块和基础模块,将其他模块串联上去。
口 获取模块定时从代理网站获取代理,将获取的代理传递给储存模块,并保存到数据库。
口 检测模块定时通过储存模块获取所有代理,并对代理进行检查,根据不同的测量结果对代理设置不同的标示。
口 接口模块通过WebAPI 提供服务插口,接口通过联接数据库并通过Web 形式返回可用的代理。
对于这儿的测量模块,建议使用 aiohttp 而不是 requests,原因是:
对于响应速率比较快的网站来说,requests 同步恳求和 aiohttp 异步恳求的疗效差别没这么大。但对于测量代理来说,检测一个代理通常须要十多秒甚至几十秒的时间,这时候使用 aiohttp 异步恳求库的优势就大大彰显下来了,效率可能会提升几十倍不止。
(1)有的数据必须要登陆能够抓取。
(2)有时候,登录帐号也可以减少被封禁的几率。
做大规模抓取,我们就须要拥有好多帐号,每次恳求随机选定一个帐号,这样就减少了单个帐号的访问颍率,被封的机率又会大大增加。
所以,我们可以维护一个登陆用的 Cookies 池。
架构跟代理池一样。可参考上文。
待写
python 的 open() 支持的模式可以是只读/写入/追加,也是可以它们的组合型,具体如下:
模式描述
r
以只读方法打开文件。文件的表针将会放到文件的开头。这是默认模式。
rb
以二进制格式打开一个文件用于只读。文件表针将会放到文件的开头。这是默认模式。
r+
打开一个文件用于读写。文件表针将会放到文件的开头。
rb+
以二进制格式打开一个文件用于读写。文件表针将会放到文件的开头。
w
打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
wb
以二进制格式打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
w+
打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
wb+
以二进制格式打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
a
打开一个文件用于追加。如果该文件已存在,文件指针将会放到文件的结尾。也就是说,新的内容将会被写入到已有内容然后。如果该文件不存在,创建新文件进行写入。
ab
以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放到文件的结尾。也就是说,新的内容将会被写入到已有内容然后。如果该文件不存在,创建新文件进行写入。
a+
打开一个文件用于读写。如果该文件已存在,文件指针将会放到文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。
ab+
以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放到文件的结尾。如果该文件不存在,创建新文件用于读写。
1、r+ 和 w+ 都是读写,有哪些区别?
答:前者是假如没有找到文件则抛错,后者是假如没有找到文件则手动创建文件。
2、a 可以看成是 w 的变种,附加上了”追加内容“的特点。
一般调用 open() 的时侯还须要再调用 close()。 python 提供了一种缩写方式,那就是使用 with as 语法。在 with 控制块结束时,文件会手动关掉,不需要 close() 了。调用写法如下:
【热门】税务局怎么应用网路爬虫技术获取企业涉税信息
采集交流 • 优采云 发表了文章 • 0 个评论 • 326 次浏览 • 2020-06-22 08:01
税务局怎样利用网路爬虫举办工作呢?概括的说,不外乎这样几个方面: 一是有针对性的捕捉互联网上的企业相关信息; 二是利用大数据,整合其他相关涉税信息; 三是通过一系列预警指标剖析比对筛选案源; 四是构建企业交易行为轨迹,定位税收风险疑虑。 其实,网络爬虫收集的仅仅是纳税人公开在网路上的涉税信息,税务机关获取纳税人的涉 税信息还有好多途径,比如,利用内部风控中心监控平台,与网路运营商、工商、统计、 建设、技术监督、财政、公安、海关、金融机构、外汇管理、国土规划和物流中心等有关 部门联网实现信息互通、数据互联、资源共享,并整合纳税人联网开票信息、申报数据、 税款收取数据、财务报表数据、重点税源报表数据、备案信息等数据信息,实时更新纳税 人信息库,使纳税人时时处在金税三期强悍的监控和预警范围之内。 所以,如果有三天,税务局直接找上门来或电话问询企业税务谜团,不要认为奇怪。 随着税务机关信息化手段的不断加强、税务稽查检测人员能力素养的不断提高,未来企业 的税务风险曝露机会将会越来越大,那种以违法手段达到少收税的手法将很难有生存空间, 而合法(利用税收优惠政策)、合理(符合商业目的)的税务筹划将是未来企业节税的主要 途径。 查看全部
税务局怎么应用网路爬虫技术获取企业涉税信息 在互联网上,经常能看到某某税务局借助网路爬虫技术发觉某甲企业涉税问题,并进一步 被取缔的信息。 那么,什么是网络爬虫呢?税务局怎么应用网路爬虫技术发觉企业的涉税谜团呢?本文将 带你一步一步解开其中的奥秘。 网络爬虫称作“网页蜘蛛”,是一个手动提取网页的程序。传统爬虫从一个或若干初始网 页的 URL 开始,获得初始网页上的 URL,在抓取网页的过程中,不断从当前页面上抽取新 的 URL 放入队列税务爬虫软件,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要根 据一定的网页剖析算法过滤与主题无关的链接,保留有用的链接并将其倒入等待抓取的 URL 队列。然后税务爬虫软件,它将按照一定的搜索策略从队列中选择下一步要抓取的网页 URL,并重复上 述过程,直到达到系统的某一条件时停止,另外,所有被爬虫抓取的网页将会被系统存储, 进行一定的剖析、过滤,并构建索引,以便以后的查询和检索。 以上是引自网路专业的叙述,简单的说,“网络爬虫”是一个手动提取网页的程序,运用 “网络爬虫”技术设定程序,可以按照既定的目标愈发精准选择抓取相关的网页信息,有 助于在互联网海量信息中快捷获取有用的涉税信息。
税务局怎样利用网路爬虫举办工作呢?概括的说,不外乎这样几个方面: 一是有针对性的捕捉互联网上的企业相关信息; 二是利用大数据,整合其他相关涉税信息; 三是通过一系列预警指标剖析比对筛选案源; 四是构建企业交易行为轨迹,定位税收风险疑虑。 其实,网络爬虫收集的仅仅是纳税人公开在网路上的涉税信息,税务机关获取纳税人的涉 税信息还有好多途径,比如,利用内部风控中心监控平台,与网路运营商、工商、统计、 建设、技术监督、财政、公安、海关、金融机构、外汇管理、国土规划和物流中心等有关 部门联网实现信息互通、数据互联、资源共享,并整合纳税人联网开票信息、申报数据、 税款收取数据、财务报表数据、重点税源报表数据、备案信息等数据信息,实时更新纳税 人信息库,使纳税人时时处在金税三期强悍的监控和预警范围之内。 所以,如果有三天,税务局直接找上门来或电话问询企业税务谜团,不要认为奇怪。 随着税务机关信息化手段的不断加强、税务稽查检测人员能力素养的不断提高,未来企业 的税务风险曝露机会将会越来越大,那种以违法手段达到少收税的手法将很难有生存空间, 而合法(利用税收优惠政策)、合理(符合商业目的)的税务筹划将是未来企业节税的主要 途径。
网络爬虫技术(新)
采集交流 • 优采云 发表了文章 • 0 个评论 • 350 次浏览 • 2020-06-22 08:00
网络爬虫技术网路机器人1.概念: 它们是 Web 上孤身运行的软件程序,它们不断地筛选数据,做出自己的 决定, 能够使用 Web 获取文本或则进行搜索查询,按部就班地完成各自的任务。 2.分类: 购物机器人、聊天机器人、搜索机器人(网络爬虫)等。搜索引擎1.概念: 从网路上获得网站网页资料,能够构建数据库并提供查询的系统 。 2.分类(按工作原理) : 全文搜索引擎、分类目录。 1> 全文搜索引擎数据库是借助网路爬虫通过网路上的各类链接手动获取大量 网页信息内容,并按一定的规则剖析整理产生的。 (百度、Google) 2> 分类目录:按目录分类的网站链接列表而已 ,通过人工的方法搜集整理网 站资料产生的数据库。(国内的搜狐)网络爬虫1.概念: 网络爬虫也叫网路蜘蛛,它是一个根据一定的规则手动提取网页程序,其会手动 的通过网路抓取互联网上的网页,这种技术通常可能拿来检测你的站点上所有的链接 是否是都是有效的。当然爬虫技术,更为中级的技术是把网页中的相关数据保存出来,可以成 为搜索引擎。 搜索引擎使用网络爬虫找寻网路内容,网络上的 HTML 文档使用超链接联接了上去, 就像织成了一张网,网络爬虫也叫网路蜘蛛,顺着这张网爬行,每到一个网页就用抓取程序 将这个网页抓出来,将内容抽取下来,同时抽取超链接,作为进一步爬行的线索。
网络爬虫 总是要从某个起点开始爬,这个起点称作种子,你可以告诉它,也可以到一些网址列表网站 上获取。 2.区别: 网络爬虫 分类 工作原理 通用爬虫 从一个或多个初始网页的 URL 开 始,获取初始网页的 URL,抓取网 页的同时爬虫技术,从当前网页提取相关的 URL 放入队列中,直到满足程序的 停止条件。 聚集爬虫 根据一定的网页剖析算法过滤与主题无 关的链接,保留有用的链接(爬行的范围 是受控的)放到待抓取的队列中,通过一 定的搜索策略从队列中选择下一步要抓 取的 URL,重复以上步骤,直到满足程 序的停止条件。 1. 增加了一些网页分析算法和网页搜 索策略 2. 对 被 爬 虫 抓 取 的 网 页 将 会 被 系 统 存贮,进行一定的剖析、过滤,并 建立索引,以便以后的查询和检 索,这一过程所得到的剖析结果还 可能对之后的抓取过程给出反馈不同点和指导。 缺点 1. 不同领域、 不同背景的用户有 不同的检索目的和需求, 通用 搜索引擎所返回的结果包含 大量用户不关心的网页。 2. 通用引擎的目标是大的网路覆 盖率。 3. 只支持关键字搜索, 不支持按照 语义的搜索。 4. 通用搜索引擎对一些象图片、 音 频等信 息 含 量 密 集 且 具 有 一 定结构的数据难以获取。
广度优先算法 1. 对抓取目标的描述或定义。 2. 对网页和数据的剖析和过滤。 3. 对 URL 的搜索策略。 以上三个是须要解决的问题。算法现有聚焦爬虫对抓取目标的描述可分为基于目标网页特点、 基于目标数据模式和基于领 域概念 3 种。 基于目标网页特点的爬虫所抓取、 存储并索引的对象通常为网站或网页。 根据种子样本 获取方法可分为: (1)预先给定的初始抓取种子样本; (2)预先给定的网页分类目录和与分类目录对应的种子样本,如 Yahoo!分类结构等; (3)通过用户行为确定的抓取目标样例,分为: a) 用户浏览过程中显示标明的抓取样本; b) 通过用户日志挖掘得到访问模式及相关样本。 其中,网页特点可以是网页的内容特点,也可以是网页的链接结构特点,等等。 3.算法/策略 名称 分类 网页分析算法 1.基于网路拓扑结构 1>网页细度剖析算法 2>网站粒度剖析算法 3>网页块细度剖析算法 2.基于网页内容 1>针对以文本和超链接为主的 网页 2>针对从结构化的数据源动态生 成的网页。 3>针对数据介于第一类和第二类 之间 3.基于用户访问行为 网页搜索策略 1.深度优先策略 2.广度优先策略 3.最佳优先策略一些算法的介绍 1> 网页分析算法1.1 基于网路拓扑的剖析算法? 基于网页之间的链接, 通过已知的网页或数据, 来对与其有直接或间接链接关系的对象 (可以是网页或网站等) 作出评价的算法。
又分为网页细度、 网站粒度和网页块细度这三种。 1.1.1 网页(Webpage)粒度的剖析算法 PageRank 和 HITS 算法是最常见的链接剖析算法, 两者都是通过对网页间链接度的递归 和规范化估算,得到每位网页的重要度评价。PageRank 算法其实考虑了用户访问行为的随 机性和 Sink 网页的存在,但忽视了绝大多数用户访问时带有目的性,即网页和链接与查询 主题的相关性。针对这个问题,HITS 算法提出了两个关键的概念:权威型网页(authority) 和中心型网页(hub) 。 基于链接的抓取的问题是相关页面主题团之间的隧洞现象, 即好多在抓取路径上偏离主 题的网页也指向目标网页,局部评价策略中断了在当前路径上的抓取行为。文献[21]提出了 一种基于反向链接(BackLink)的分层式上下文模型(Context Model) ,用于描述指向目标 网页一定化学跳数直径内的网页拓扑图的中心 Layer0 为目标网页,将网页根据指向目标网 页的数学跳数进行层次界定,从内层网页指向外层网页的链接称为反向链接。? 1.1.2 网站粒度的剖析算法 网站粒度的资源发觉和管理策略也比网页细度的更简单有效。
网站粒度的爬虫抓取的关 键之处在于站点的界定和站点等级(SiteRank)的估算。 SiteRank 的估算方式与 PageRank 类似, 但是须要对网站之间的链接作一定程度具象,并在一定的模型下估算链接的权重。 网站划分情况分为按域名界定和按 IP 地址界定两种。文献[18]讨论了在分布式情况下, 通过对同一个域名下不同主机、服务器的 IP 地址进行站点界定,构造站点图,利用类似 Pa geRank 的方式评价 SiteRank。同时,根据不同文件在各个站点上的分布情况,构造文档图, 结合 SiteRank 分布式估算得到 DocRank。文献[18]证明,利用分布式的 SiteRank 计算,不仅 大大增加了单机站点的算法代价, 而且克服了单独站点对整个网路覆盖率有限的缺点。 附带 的一个优点是,常见 PageRank 造假无法对 SiteRank 进行愚弄。? 1.1.3 网页块细度的剖析算法 在一个页面中, 往往富含多个指向其他页面的链接, 这些链接中只有一部分是指向主题 相关网页的,或依照网页的链接锚文本表明其具有较高重要性。但是,在 PageRank 和 HIT S 算法中,没有对那些链接作分辨,因此经常给网页剖析带来广告等噪音链接的干扰。
在网 页块级别(Block?level) 进行链接剖析的算法的基本思想是通过 VIPS 网页分割算法将网页分 为不同的网页块(page block),然后对这种网页块构建 page?to?block block?to?page的 和 链接矩阵,? 分别记为 Z 和 X。于是,在 page?to? page 图上的网页块级别的 PageRank 为? W?p=X×Z ? block?to?block图上的 BlockRank 为?W?b=Z×X ? ; 在 。 已经有人实现了块级 别的 PageRank 和 HITS 算法,并通过实验证明,效率和准确率都比传统的对应算法要好。 1.2 基于网页内容的网页分析算法 基于网页内容的剖析算法指的是借助网页内容(文本、数据等资源)特征进行的网页评 价。网页的内容从原先的以超文本为主,发展到后来动态页面(或称为 Hidden Web)数据 为主,后者的数据量约为直接可见页面数据(PIW,Publicly Indexable Web)的 400~500 倍。另一方面,多媒体数据、Web Service 等各类网路资源方式也日渐丰富。因此,基于网页内容的剖析算法也从原先的较为单纯的文本检索方式, 发展为囊括网页数据抽取、 机器学 习、数据挖掘、语义理解等多种方式的综合应用。
本节按照网页数据方式的不同,将基于网 页内容的剖析算法, 归纳以下三类: 第一种针对以文本和超链接为主的无结构或结构很简单 的网页;第二种针对从结构化的数据源(如 RDBMS)动态生成的页面,其数据不能直接批 量访问;第三种针对的数据界于第一和第二类数据之间,具有较好的结构,显示遵照一定模 式或风格,且可以直接访问。 1.2.1 基于文本的网页剖析算法 1) 纯文本分类与聚类算法 很大程度上借用了文本检索的技术。 文本剖析算法可以快速有效的对网页进行分类和聚 类,但是因为忽视了网页间和网页内部的结构信息,很少单独使用。? 2) 超文本分类和聚类算法 2> 网页搜索策略 2. 广度优先搜索策略 广度优先搜索策略是指在抓取过程中, 在完成当前层次的搜索后, 才进行下一层次的搜 索。该算法的设计和实现相对简单。在目前为覆盖尽可能多的网页,一般使用广度优先搜索 方法。 也有好多研究将广度优先搜索策略应用于聚焦爬虫中。 其基本思想是觉得与初始 URL 在一定链接距离内的网页具有主题相关性的机率很大。 另外一种方式是将广度优先搜索与网 页过滤技术结合使用,先用广度优先策略抓取网页,再将其中无关的网页过滤掉。
这些方式 的缺点在于,随着抓取网页的增多,大量的无关网页将被下载并过滤,算法的效率将变低。 2. 最佳优先搜索策略 最佳优先搜索策略根据一定的网页分析算法,预测候选 URL 与目标网页的相似度,或 与主题的相关性,并选定评价最好的一个或几个 URL 进行抓取。它只访问经过网页剖析算 法预测为“有用”的网页。 存在的一个问题是, 在爬虫抓取路径上的好多相关网页可能被忽视, 因为最佳优先策略是一种局部最优搜索算法。因此须要将最佳优先结合具体的应用进行改 进,以跳出局部最优点。将在第 4 节中结合网页分析算法作具体的讨论。研究表明,这样的 闭环调整可以将无关网页数目减少 30%~90%。 3. 搜索引擎原理之网路爬虫是怎样工作的? 在互联网中,网页之间的链接关系是无规律的,它们的关系十分复杂。如果一个爬虫从 一个起点开始爬行,那么它将会碰到无数的分支,由此生成无数条的爬行路径,如果聘期爬 行,就有可能永远也爬不到头,因此要对它加以控制,制定其爬行的规则。世界上没有一种 爬虫还能抓取到互联网所有的网页, 所以就要在提升其爬行速率的同时, 也要提升其爬行网 页的质量。 网络爬虫在搜索引擎中占有重要位置,对搜索引擎的查全、查准都有影响,决定了搜索 引擎数据容量的大小, 而且网路爬虫的优劣之间影响搜索引擎结果页中的死链接的个数。
搜 索引擎爬虫有深度优先策略和广度优先策略,另外,识别垃圾网页,避免抓取重复网页,也 是高性能爬虫的设计目标。 爬虫的作用是为了搜索引擎抓取大量的数据, 抓取的对象是整个互联网上的网页。 爬虫 程序不可能抓取所有的网页,因为在抓取的同时,Web 的规模也在减小,所以一个好的爬 虫程序通常就能在短时间内抓取更多的网页。 一般爬虫程序的起点都选择在一个小型综合型的网站,这样的网站已经囊括了大部分高质量的站点,爬虫程序就顺着那些链接爬行。在爬 行过程中,最重要的就是判定一个网页是否早已被爬行过。 在爬虫开始的时侯, 需要给爬虫输送一个 URL 列表, 这个列表中的 URL 地址便是爬虫 的起始位置,爬虫从这种 URL 出发,开始了爬行,一直不断地发觉新的 URL,然后再按照 策略爬行这种新发觉的 URL,如此永远反复下去。一般的爬虫都自己完善 DNS 缓冲,建立 DNS 缓冲的目的是推动 URL 解析成 IP 地址的速率。 查看全部

网络爬虫技术网路机器人1.概念: 它们是 Web 上孤身运行的软件程序,它们不断地筛选数据,做出自己的 决定, 能够使用 Web 获取文本或则进行搜索查询,按部就班地完成各自的任务。 2.分类: 购物机器人、聊天机器人、搜索机器人(网络爬虫)等。搜索引擎1.概念: 从网路上获得网站网页资料,能够构建数据库并提供查询的系统 。 2.分类(按工作原理) : 全文搜索引擎、分类目录。 1> 全文搜索引擎数据库是借助网路爬虫通过网路上的各类链接手动获取大量 网页信息内容,并按一定的规则剖析整理产生的。 (百度、Google) 2> 分类目录:按目录分类的网站链接列表而已 ,通过人工的方法搜集整理网 站资料产生的数据库。(国内的搜狐)网络爬虫1.概念: 网络爬虫也叫网路蜘蛛,它是一个根据一定的规则手动提取网页程序,其会手动 的通过网路抓取互联网上的网页,这种技术通常可能拿来检测你的站点上所有的链接 是否是都是有效的。当然爬虫技术,更为中级的技术是把网页中的相关数据保存出来,可以成 为搜索引擎。 搜索引擎使用网络爬虫找寻网路内容,网络上的 HTML 文档使用超链接联接了上去, 就像织成了一张网,网络爬虫也叫网路蜘蛛,顺着这张网爬行,每到一个网页就用抓取程序 将这个网页抓出来,将内容抽取下来,同时抽取超链接,作为进一步爬行的线索。
网络爬虫 总是要从某个起点开始爬,这个起点称作种子,你可以告诉它,也可以到一些网址列表网站 上获取。 2.区别: 网络爬虫 分类 工作原理 通用爬虫 从一个或多个初始网页的 URL 开 始,获取初始网页的 URL,抓取网 页的同时爬虫技术,从当前网页提取相关的 URL 放入队列中,直到满足程序的 停止条件。 聚集爬虫 根据一定的网页剖析算法过滤与主题无 关的链接,保留有用的链接(爬行的范围 是受控的)放到待抓取的队列中,通过一 定的搜索策略从队列中选择下一步要抓 取的 URL,重复以上步骤,直到满足程 序的停止条件。 1. 增加了一些网页分析算法和网页搜 索策略 2. 对 被 爬 虫 抓 取 的 网 页 将 会 被 系 统 存贮,进行一定的剖析、过滤,并 建立索引,以便以后的查询和检 索,这一过程所得到的剖析结果还 可能对之后的抓取过程给出反馈不同点和指导。 缺点 1. 不同领域、 不同背景的用户有 不同的检索目的和需求, 通用 搜索引擎所返回的结果包含 大量用户不关心的网页。 2. 通用引擎的目标是大的网路覆 盖率。 3. 只支持关键字搜索, 不支持按照 语义的搜索。 4. 通用搜索引擎对一些象图片、 音 频等信 息 含 量 密 集 且 具 有 一 定结构的数据难以获取。
广度优先算法 1. 对抓取目标的描述或定义。 2. 对网页和数据的剖析和过滤。 3. 对 URL 的搜索策略。 以上三个是须要解决的问题。算法现有聚焦爬虫对抓取目标的描述可分为基于目标网页特点、 基于目标数据模式和基于领 域概念 3 种。 基于目标网页特点的爬虫所抓取、 存储并索引的对象通常为网站或网页。 根据种子样本 获取方法可分为: (1)预先给定的初始抓取种子样本; (2)预先给定的网页分类目录和与分类目录对应的种子样本,如 Yahoo!分类结构等; (3)通过用户行为确定的抓取目标样例,分为: a) 用户浏览过程中显示标明的抓取样本; b) 通过用户日志挖掘得到访问模式及相关样本。 其中,网页特点可以是网页的内容特点,也可以是网页的链接结构特点,等等。 3.算法/策略 名称 分类 网页分析算法 1.基于网路拓扑结构 1>网页细度剖析算法 2>网站粒度剖析算法 3>网页块细度剖析算法 2.基于网页内容 1>针对以文本和超链接为主的 网页 2>针对从结构化的数据源动态生 成的网页。 3>针对数据介于第一类和第二类 之间 3.基于用户访问行为 网页搜索策略 1.深度优先策略 2.广度优先策略 3.最佳优先策略一些算法的介绍 1> 网页分析算法1.1 基于网路拓扑的剖析算法? 基于网页之间的链接, 通过已知的网页或数据, 来对与其有直接或间接链接关系的对象 (可以是网页或网站等) 作出评价的算法。
又分为网页细度、 网站粒度和网页块细度这三种。 1.1.1 网页(Webpage)粒度的剖析算法 PageRank 和 HITS 算法是最常见的链接剖析算法, 两者都是通过对网页间链接度的递归 和规范化估算,得到每位网页的重要度评价。PageRank 算法其实考虑了用户访问行为的随 机性和 Sink 网页的存在,但忽视了绝大多数用户访问时带有目的性,即网页和链接与查询 主题的相关性。针对这个问题,HITS 算法提出了两个关键的概念:权威型网页(authority) 和中心型网页(hub) 。 基于链接的抓取的问题是相关页面主题团之间的隧洞现象, 即好多在抓取路径上偏离主 题的网页也指向目标网页,局部评价策略中断了在当前路径上的抓取行为。文献[21]提出了 一种基于反向链接(BackLink)的分层式上下文模型(Context Model) ,用于描述指向目标 网页一定化学跳数直径内的网页拓扑图的中心 Layer0 为目标网页,将网页根据指向目标网 页的数学跳数进行层次界定,从内层网页指向外层网页的链接称为反向链接。? 1.1.2 网站粒度的剖析算法 网站粒度的资源发觉和管理策略也比网页细度的更简单有效。
网站粒度的爬虫抓取的关 键之处在于站点的界定和站点等级(SiteRank)的估算。 SiteRank 的估算方式与 PageRank 类似, 但是须要对网站之间的链接作一定程度具象,并在一定的模型下估算链接的权重。 网站划分情况分为按域名界定和按 IP 地址界定两种。文献[18]讨论了在分布式情况下, 通过对同一个域名下不同主机、服务器的 IP 地址进行站点界定,构造站点图,利用类似 Pa geRank 的方式评价 SiteRank。同时,根据不同文件在各个站点上的分布情况,构造文档图, 结合 SiteRank 分布式估算得到 DocRank。文献[18]证明,利用分布式的 SiteRank 计算,不仅 大大增加了单机站点的算法代价, 而且克服了单独站点对整个网路覆盖率有限的缺点。 附带 的一个优点是,常见 PageRank 造假无法对 SiteRank 进行愚弄。? 1.1.3 网页块细度的剖析算法 在一个页面中, 往往富含多个指向其他页面的链接, 这些链接中只有一部分是指向主题 相关网页的,或依照网页的链接锚文本表明其具有较高重要性。但是,在 PageRank 和 HIT S 算法中,没有对那些链接作分辨,因此经常给网页剖析带来广告等噪音链接的干扰。
在网 页块级别(Block?level) 进行链接剖析的算法的基本思想是通过 VIPS 网页分割算法将网页分 为不同的网页块(page block),然后对这种网页块构建 page?to?block block?to?page的 和 链接矩阵,? 分别记为 Z 和 X。于是,在 page?to? page 图上的网页块级别的 PageRank 为? W?p=X×Z ? block?to?block图上的 BlockRank 为?W?b=Z×X ? ; 在 。 已经有人实现了块级 别的 PageRank 和 HITS 算法,并通过实验证明,效率和准确率都比传统的对应算法要好。 1.2 基于网页内容的网页分析算法 基于网页内容的剖析算法指的是借助网页内容(文本、数据等资源)特征进行的网页评 价。网页的内容从原先的以超文本为主,发展到后来动态页面(或称为 Hidden Web)数据 为主,后者的数据量约为直接可见页面数据(PIW,Publicly Indexable Web)的 400~500 倍。另一方面,多媒体数据、Web Service 等各类网路资源方式也日渐丰富。因此,基于网页内容的剖析算法也从原先的较为单纯的文本检索方式, 发展为囊括网页数据抽取、 机器学 习、数据挖掘、语义理解等多种方式的综合应用。
本节按照网页数据方式的不同,将基于网 页内容的剖析算法, 归纳以下三类: 第一种针对以文本和超链接为主的无结构或结构很简单 的网页;第二种针对从结构化的数据源(如 RDBMS)动态生成的页面,其数据不能直接批 量访问;第三种针对的数据界于第一和第二类数据之间,具有较好的结构,显示遵照一定模 式或风格,且可以直接访问。 1.2.1 基于文本的网页剖析算法 1) 纯文本分类与聚类算法 很大程度上借用了文本检索的技术。 文本剖析算法可以快速有效的对网页进行分类和聚 类,但是因为忽视了网页间和网页内部的结构信息,很少单独使用。? 2) 超文本分类和聚类算法 2> 网页搜索策略 2. 广度优先搜索策略 广度优先搜索策略是指在抓取过程中, 在完成当前层次的搜索后, 才进行下一层次的搜 索。该算法的设计和实现相对简单。在目前为覆盖尽可能多的网页,一般使用广度优先搜索 方法。 也有好多研究将广度优先搜索策略应用于聚焦爬虫中。 其基本思想是觉得与初始 URL 在一定链接距离内的网页具有主题相关性的机率很大。 另外一种方式是将广度优先搜索与网 页过滤技术结合使用,先用广度优先策略抓取网页,再将其中无关的网页过滤掉。
这些方式 的缺点在于,随着抓取网页的增多,大量的无关网页将被下载并过滤,算法的效率将变低。 2. 最佳优先搜索策略 最佳优先搜索策略根据一定的网页分析算法,预测候选 URL 与目标网页的相似度,或 与主题的相关性,并选定评价最好的一个或几个 URL 进行抓取。它只访问经过网页剖析算 法预测为“有用”的网页。 存在的一个问题是, 在爬虫抓取路径上的好多相关网页可能被忽视, 因为最佳优先策略是一种局部最优搜索算法。因此须要将最佳优先结合具体的应用进行改 进,以跳出局部最优点。将在第 4 节中结合网页分析算法作具体的讨论。研究表明,这样的 闭环调整可以将无关网页数目减少 30%~90%。 3. 搜索引擎原理之网路爬虫是怎样工作的? 在互联网中,网页之间的链接关系是无规律的,它们的关系十分复杂。如果一个爬虫从 一个起点开始爬行,那么它将会碰到无数的分支,由此生成无数条的爬行路径,如果聘期爬 行,就有可能永远也爬不到头,因此要对它加以控制,制定其爬行的规则。世界上没有一种 爬虫还能抓取到互联网所有的网页, 所以就要在提升其爬行速率的同时, 也要提升其爬行网 页的质量。 网络爬虫在搜索引擎中占有重要位置,对搜索引擎的查全、查准都有影响,决定了搜索 引擎数据容量的大小, 而且网路爬虫的优劣之间影响搜索引擎结果页中的死链接的个数。
搜 索引擎爬虫有深度优先策略和广度优先策略,另外,识别垃圾网页,避免抓取重复网页,也 是高性能爬虫的设计目标。 爬虫的作用是为了搜索引擎抓取大量的数据, 抓取的对象是整个互联网上的网页。 爬虫 程序不可能抓取所有的网页,因为在抓取的同时,Web 的规模也在减小,所以一个好的爬 虫程序通常就能在短时间内抓取更多的网页。 一般爬虫程序的起点都选择在一个小型综合型的网站,这样的网站已经囊括了大部分高质量的站点,爬虫程序就顺着那些链接爬行。在爬 行过程中,最重要的就是判定一个网页是否早已被爬行过。 在爬虫开始的时侯, 需要给爬虫输送一个 URL 列表, 这个列表中的 URL 地址便是爬虫 的起始位置,爬虫从这种 URL 出发,开始了爬行,一直不断地发觉新的 URL,然后再按照 策略爬行这种新发觉的 URL,如此永远反复下去。一般的爬虫都自己完善 DNS 缓冲,建立 DNS 缓冲的目的是推动 URL 解析成 IP 地址的速率。
手把手教你写网络爬虫(2):迷你爬虫构架-通用网路爬虫
采集交流 • 优采云 发表了文章 • 0 个评论 • 366 次浏览 • 2020-06-20 08:00
介绍
大家好!回顾上一期,我们在介绍了爬虫的基本概念以后,就借助各类工具横冲直撞的完成了一个小爬虫,目的就是猛、糙、快,方便初学者上手,建立信心。对于有一定基础的读者,请不要着急,以后我们会学习主流的开源框架,打造出一个强悍专业的爬虫系统!不过在此之前,要继续打好基础,本期我们先介绍爬虫的种类,然后选定最典型的通用网路爬虫,为其设计一个迷你框架。有了自己对框架的思索后爬虫结构,再学习复杂的开源框架就有头绪了。
今天我们会把更多的时间用在思索上,而不是一根筋的coding。用80%的时间思索,20%的时间敲按键,这样更有利于进步。
语言&环境
语言:带足弹药,继续用Python开路!
一个迷你框架
下面以比较典型的通用爬虫为例爬虫结构,分析其工程要点,设计并实现一个迷你框架。架构图如下:
代码结构:
config_load.py 配置文件加载
crawl_thread.py 爬取线程
mini_spider.py 主线程
spider.conf 配置文件
url_table.py url队列、url表
urls.txt 种子url集合
webpage_parse.py 网页剖析
webpage_save.py 网页储存
看看配置文件里有哪些内容:
spider.conf
url_table.py
Step 3. 记录什么网页早已下载过的小笔记本——URL表。
在互联网上,一个网页可能被多个网页中的超链接所指向。这样在遍历互联网这张图的时侯,这个网页可能被多次访问到。为了避免一个网页被下载和解析多次,需要一个URL表记录什么网页早已下载过。再碰到这个网页的时侯,我们就可以跳过它。
crawl_thread.py
Step 5. 页面剖析模块
从网页中解析出URLs或则其他有用的数据。这个是下期重点介绍的,可以参考之前的代码。
Step 6. 页面储存模块
保存页面的模块,目前将文件保存为文件,以后可以扩充出多种储存方法,如mysql,mongodb,hbase等等。
webpage_save.py
写到这儿,整个框架早已清晰的呈如今大伙眼前了,千万不要小看它,不管多么复杂的框架都是在这种基本要素上扩充下来的。
下一步
基础知识的学习暂时告一段落,希望还能帮助你们打下一定的基础。下期开始为你们介绍强悍成熟的爬虫框架Scrapy,它提供了好多强悍的特点来促使爬取更为简单高效,更多精彩,敬请期盼!
【编辑推荐】
如何用Python来找你喜欢的女生?初识Python:全局、局部和非局部变量(带示例)教你用Python解决非平衡数据问题(附代码)调查显示:你是否是一个合格的Python开发者?手把手教你写网络爬虫(1):网易云音乐歌单 查看全部

介绍
大家好!回顾上一期,我们在介绍了爬虫的基本概念以后,就借助各类工具横冲直撞的完成了一个小爬虫,目的就是猛、糙、快,方便初学者上手,建立信心。对于有一定基础的读者,请不要着急,以后我们会学习主流的开源框架,打造出一个强悍专业的爬虫系统!不过在此之前,要继续打好基础,本期我们先介绍爬虫的种类,然后选定最典型的通用网路爬虫,为其设计一个迷你框架。有了自己对框架的思索后爬虫结构,再学习复杂的开源框架就有头绪了。
今天我们会把更多的时间用在思索上,而不是一根筋的coding。用80%的时间思索,20%的时间敲按键,这样更有利于进步。

语言&环境
语言:带足弹药,继续用Python开路!






一个迷你框架
下面以比较典型的通用爬虫为例爬虫结构,分析其工程要点,设计并实现一个迷你框架。架构图如下:
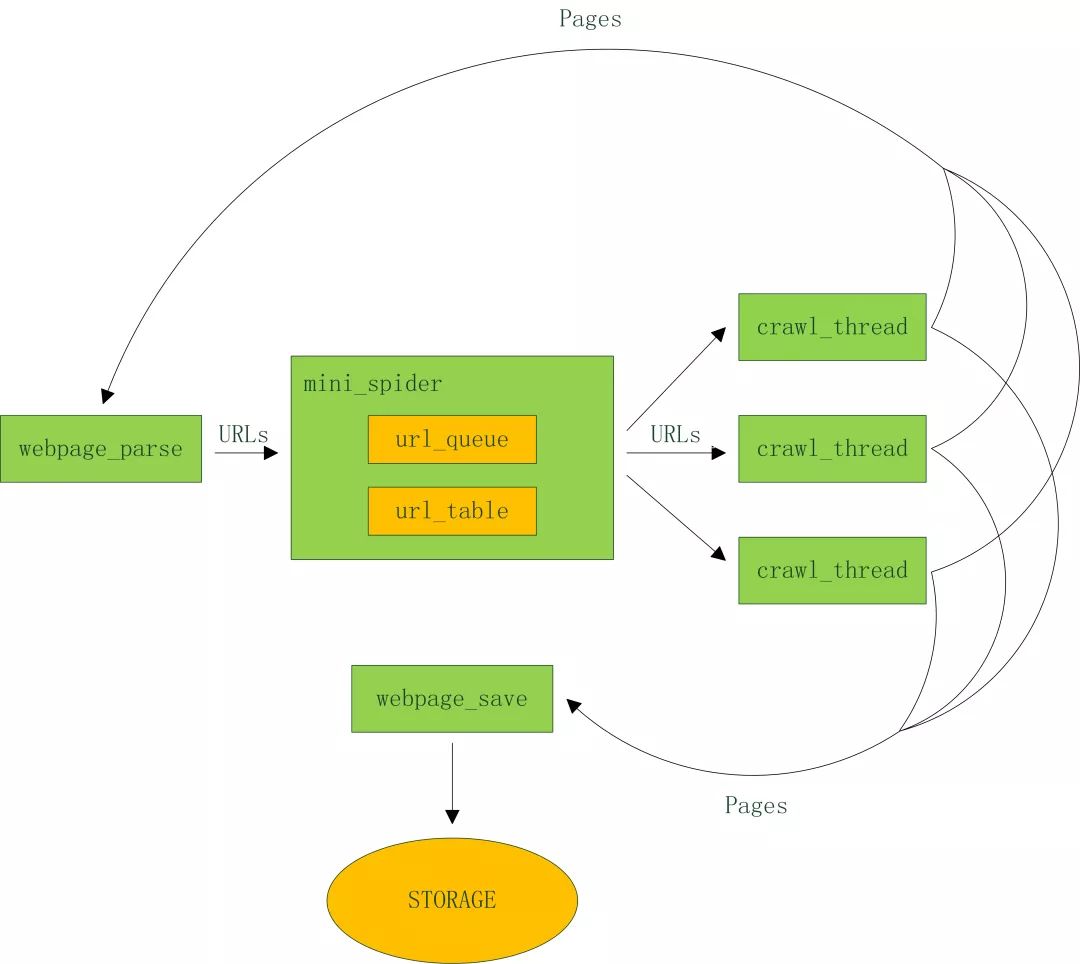
代码结构:

config_load.py 配置文件加载
crawl_thread.py 爬取线程
mini_spider.py 主线程
spider.conf 配置文件
url_table.py url队列、url表
urls.txt 种子url集合
webpage_parse.py 网页剖析
webpage_save.py 网页储存
看看配置文件里有哪些内容:
spider.conf





url_table.py

Step 3. 记录什么网页早已下载过的小笔记本——URL表。
在互联网上,一个网页可能被多个网页中的超链接所指向。这样在遍历互联网这张图的时侯,这个网页可能被多次访问到。为了避免一个网页被下载和解析多次,需要一个URL表记录什么网页早已下载过。再碰到这个网页的时侯,我们就可以跳过它。
crawl_thread.py



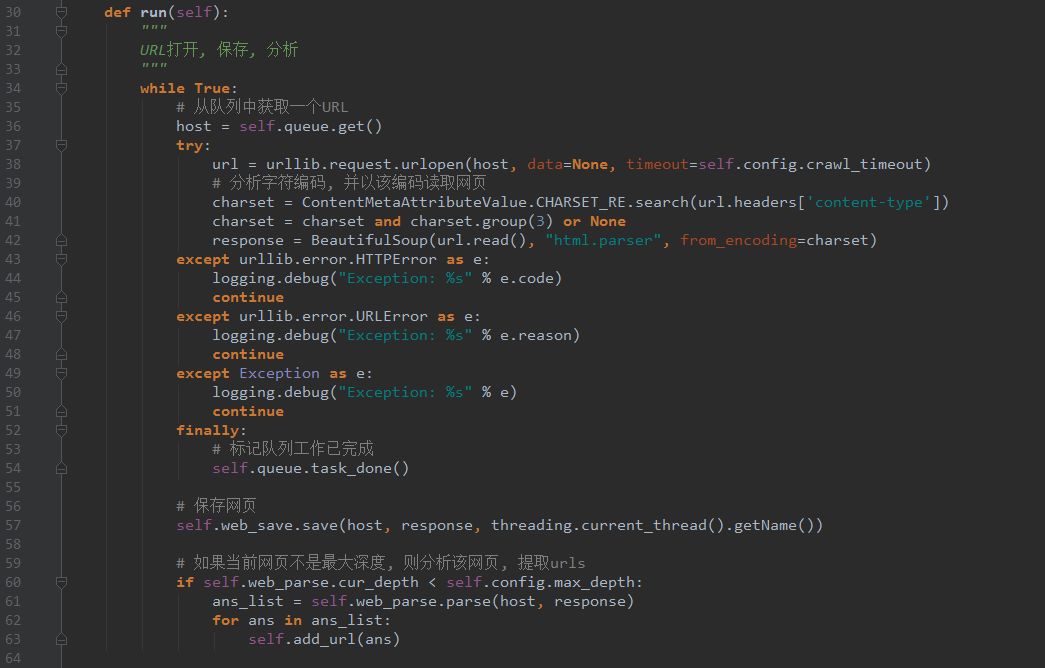
Step 5. 页面剖析模块
从网页中解析出URLs或则其他有用的数据。这个是下期重点介绍的,可以参考之前的代码。
Step 6. 页面储存模块
保存页面的模块,目前将文件保存为文件,以后可以扩充出多种储存方法,如mysql,mongodb,hbase等等。
webpage_save.py

写到这儿,整个框架早已清晰的呈如今大伙眼前了,千万不要小看它,不管多么复杂的框架都是在这种基本要素上扩充下来的。
下一步
基础知识的学习暂时告一段落,希望还能帮助你们打下一定的基础。下期开始为你们介绍强悍成熟的爬虫框架Scrapy,它提供了好多强悍的特点来促使爬取更为简单高效,更多精彩,敬请期盼!
【编辑推荐】
如何用Python来找你喜欢的女生?初识Python:全局、局部和非局部变量(带示例)教你用Python解决非平衡数据问题(附代码)调查显示:你是否是一个合格的Python开发者?手把手教你写网络爬虫(1):网易云音乐歌单
Ipidea丨网络爬虫正则表达式的使用
采集交流 • 优采云 发表了文章 • 0 个评论 • 398 次浏览 • 2020-06-17 08:00
## 网络爬虫正则表达式的使用
---
我们在处理网页文本内容时有时会碰到一些特殊的情况网络爬虫 正则表达式,或者须要匹配某类字符串方式,通常都会用到正则表达式。许多程序语言都支持使用正则表达式,python中正则表达式可以实现字符串的匹配、检索和替换等功能,是一个比较强悍的工具。
### 1.正则表达式句型
Python中实现正则表达式功能一般使用re模块,可以实现对文本字符串的匹配,检索和替换,但不仅引入正则模块网络爬虫 正则表达式,还须要把握正则表达式字符和基本句型,才能正确使用python进行正则表达式提取。
部分常用的正则表达式:
| 字符 | 功能 |
| :--: | :--: |
| \ |转义字符,标记下一个字符为特殊字符|
| ^ |匹配输入字符串的开始位置|
| $ |匹配输入字符串的结束位置|
| * |匹配上面的子表达式零次或多次 |
| + |匹配上面的子表达式一次或多次 |
| ? |匹配上面的子表达式零次或一次 |
| . |匹配除“\n”之外的任何单个字符 |
| () | 匹配括弧里的表达式 |
| \d | 匹配一个数字字符 |
| \D | 匹配一个非数字字符 |
| \w |匹配包括顿号的任何词组字符|
| \W |匹配任何非词组字符|
|{n}|n是一个非负整数,匹配确定的n次|
|{n,m}|m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次|
|[x,y,z]| 匹配一组字符集 |
| \^[x,y,z] | 匹配不在[]中的字符 |
| a\|b | 匹配a或b | 查看全部

## 网络爬虫正则表达式的使用
---
我们在处理网页文本内容时有时会碰到一些特殊的情况网络爬虫 正则表达式,或者须要匹配某类字符串方式,通常都会用到正则表达式。许多程序语言都支持使用正则表达式,python中正则表达式可以实现字符串的匹配、检索和替换等功能,是一个比较强悍的工具。
### 1.正则表达式句型
Python中实现正则表达式功能一般使用re模块,可以实现对文本字符串的匹配,检索和替换,但不仅引入正则模块网络爬虫 正则表达式,还须要把握正则表达式字符和基本句型,才能正确使用python进行正则表达式提取。
部分常用的正则表达式:
| 字符 | 功能 |
| :--: | :--: |
| \ |转义字符,标记下一个字符为特殊字符|
| ^ |匹配输入字符串的开始位置|
| $ |匹配输入字符串的结束位置|
| * |匹配上面的子表达式零次或多次 |
| + |匹配上面的子表达式一次或多次 |
| ? |匹配上面的子表达式零次或一次 |
| . |匹配除“\n”之外的任何单个字符 |
| () | 匹配括弧里的表达式 |
| \d | 匹配一个数字字符 |
| \D | 匹配一个非数字字符 |
| \w |匹配包括顿号的任何词组字符|
| \W |匹配任何非词组字符|
|{n}|n是一个非负整数,匹配确定的n次|
|{n,m}|m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次|
|[x,y,z]| 匹配一组字符集 |
| \^[x,y,z] | 匹配不在[]中的字符 |
| a\|b | 匹配a或b |
网络爬虫技术有什么用途和害处?
采集交流 • 优采云 发表了文章 • 0 个评论 • 319 次浏览 • 2020-06-16 08:02
不论是固定的笔记本网路还是以手机为终端的联通网路。使用者会时常遇见一种最常见的现象,这就是只要搜索或则关注某方面的信息,那么马上都会有网路上大量的、与之相类似的信息被“推荐”。绝大部分都是网路小广G,甚至有大量的垃圾信息。那么在信息流量可谓浩如烟海的网路上,怎么会被精确到每位用户究竟关注哪些呢?其实这就是运用了网路爬虫技术。估计有人对爬虫二字看起来就发毛。与自然接触少的城里长大的人,很多都天生怕蟑螂,不过对从小火锅蒸煮过无数蟑螂蚱蜢的老一代人来说,虫子又有哪些可怕的?网络爬虫说究竟就是一种小程序,属于根据一定的规则,自动抓取全球网路上的程序和脚本。对网路用户关注的信息进行剖析和统计,最终作为一种网路剖析资源来获得特定的利益。
网络爬虫技术和搜索引擎有天然的近亲关系。全球各大搜索引擎,都是网路爬虫技术应用的超级大户。可以海量的抓取一定范围内的特定主体和内容的网路信息网络爬虫是什么作用,作为向搜索和查询相关内容的储备数据资源。简单来说网络爬虫是什么作用,网络爬虫如同一群不止疲惫的搜索机器虫,可以海量的替代人工对全球网路进行搜索,对早已传到网上的任何有价值无价值的信息资源都象蚂蚁一样背回去堆在那里等用户,因此被称作网路爬虫。有统计显示,目前全球固定和联通互联网上,被下载的信息中,只有不到55%是真正的活人在抢占流量资源;而另外的45%,也就是接近一半,是网路爬虫和各类“机器人”在抢占流量。可见网路爬虫的厉害。那么网络爬虫是怎样从技术上实现对特定信息下载的呢?在于网络爬虫首先是一个下载小程序。
其从一个或若干初始网页的URL开始,获得正常网路用户初始网页上的URL。在抓取网页的过程中,不断从当前页面上抽取新的URL装入队列。再剖析算法过滤与主题无关的链接,保留有用的链接并将其倒入等待抓取的URL队列。然后,它将按照一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。所有被爬虫抓取的网页将会被系统储存,进行一定的剖析、过滤,并构建索引,以便以后的查询和检索。爬虫程序本身具备有用的一面,如果没有网路爬虫技术,那么就不可能有各类用途极大的搜索引擎,所有的网路用户就在海量的信息中走散了。但是瀚海狼山(匈奴狼山)还是那句话:过犹不及。凡事就怕被滥用。很多没有搜索引擎的公司和操作者,也能开发出简单的爬虫技术,来进行自己的网路推广。在网上的爬虫越来越多,不受控制以后,普通的网路用户就都成了最终的受害者。这等于有无数个看不见的刺探者,躲在暗处盯住每一个毫无提防的用户。
你每晚看哪些页面,点击的哪些内容,订购哪些商品,消费了多少钱,都在不知不觉的被记录被剖析。让普通用户没有任何网路隐私可言。谁也不喜欢自己的一言一行都被别人记录并且还被随时剖析借助。因此无处不在的爬虫程序是对用户利益的直接侵害。而且网络爬虫也有军事上的用途和风险。当代社会经济、ZZ和军事活动虽然很难分家。虽然有保密途径,也可释放一些真真假假的信息。但是用爬虫技术,通过机率剖析,仍然可影响国际舆论甚至是判别出对手真正的目的。因此对网路爬虫技术的正反两方面的作用都要有清醒的认识。 查看全部
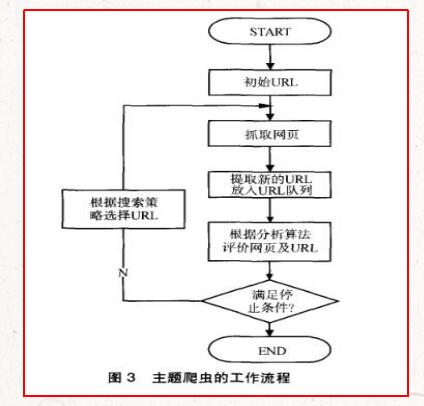
不论是固定的笔记本网路还是以手机为终端的联通网路。使用者会时常遇见一种最常见的现象,这就是只要搜索或则关注某方面的信息,那么马上都会有网路上大量的、与之相类似的信息被“推荐”。绝大部分都是网路小广G,甚至有大量的垃圾信息。那么在信息流量可谓浩如烟海的网路上,怎么会被精确到每位用户究竟关注哪些呢?其实这就是运用了网路爬虫技术。估计有人对爬虫二字看起来就发毛。与自然接触少的城里长大的人,很多都天生怕蟑螂,不过对从小火锅蒸煮过无数蟑螂蚱蜢的老一代人来说,虫子又有哪些可怕的?网络爬虫说究竟就是一种小程序,属于根据一定的规则,自动抓取全球网路上的程序和脚本。对网路用户关注的信息进行剖析和统计,最终作为一种网路剖析资源来获得特定的利益。
网络爬虫技术和搜索引擎有天然的近亲关系。全球各大搜索引擎,都是网路爬虫技术应用的超级大户。可以海量的抓取一定范围内的特定主体和内容的网路信息网络爬虫是什么作用,作为向搜索和查询相关内容的储备数据资源。简单来说网络爬虫是什么作用,网络爬虫如同一群不止疲惫的搜索机器虫,可以海量的替代人工对全球网路进行搜索,对早已传到网上的任何有价值无价值的信息资源都象蚂蚁一样背回去堆在那里等用户,因此被称作网路爬虫。有统计显示,目前全球固定和联通互联网上,被下载的信息中,只有不到55%是真正的活人在抢占流量资源;而另外的45%,也就是接近一半,是网路爬虫和各类“机器人”在抢占流量。可见网路爬虫的厉害。那么网络爬虫是怎样从技术上实现对特定信息下载的呢?在于网络爬虫首先是一个下载小程序。
其从一个或若干初始网页的URL开始,获得正常网路用户初始网页上的URL。在抓取网页的过程中,不断从当前页面上抽取新的URL装入队列。再剖析算法过滤与主题无关的链接,保留有用的链接并将其倒入等待抓取的URL队列。然后,它将按照一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。所有被爬虫抓取的网页将会被系统储存,进行一定的剖析、过滤,并构建索引,以便以后的查询和检索。爬虫程序本身具备有用的一面,如果没有网路爬虫技术,那么就不可能有各类用途极大的搜索引擎,所有的网路用户就在海量的信息中走散了。但是瀚海狼山(匈奴狼山)还是那句话:过犹不及。凡事就怕被滥用。很多没有搜索引擎的公司和操作者,也能开发出简单的爬虫技术,来进行自己的网路推广。在网上的爬虫越来越多,不受控制以后,普通的网路用户就都成了最终的受害者。这等于有无数个看不见的刺探者,躲在暗处盯住每一个毫无提防的用户。
你每晚看哪些页面,点击的哪些内容,订购哪些商品,消费了多少钱,都在不知不觉的被记录被剖析。让普通用户没有任何网路隐私可言。谁也不喜欢自己的一言一行都被别人记录并且还被随时剖析借助。因此无处不在的爬虫程序是对用户利益的直接侵害。而且网络爬虫也有军事上的用途和风险。当代社会经济、ZZ和军事活动虽然很难分家。虽然有保密途径,也可释放一些真真假假的信息。但是用爬虫技术,通过机率剖析,仍然可影响国际舆论甚至是判别出对手真正的目的。因此对网路爬虫技术的正反两方面的作用都要有清醒的认识。
如何高效抓取网站文章_互联网_IT/计算机_专业资料
采集交流 • 优采云 发表了文章 • 0 个评论 • 308 次浏览 • 2020-08-03 15:02
网页打开后,默认显示“推荐”文章。观察发觉,此网页没有翻页按 钮,而是通过下拉加载,不断加载出新的内容 因而,我们选中“打开网页”步骤,在中级选项中,勾选“页面加载完成后向上 滚动” , 滚动次数依照自身需求进行设置, 间隔时间依照网页加载情况进行设置, 滚动形式为“向下滚动一屏”,然后点击“确定”优采云·云采集网络爬虫软件 (注意: 间隔时间须要针对网站情况进行设置,并不是绝对的。一般情况下,间隔时间> 网站加载时间即可。有时候网速较慢,网页加载太慢,还需依照具体情况进行调整。具体请 看:优采云 7.0 教程——AJAX 滚动教程)步骤 2:创建翻页循环及提取数据优采云·云采集网络爬虫软件 1)移动滑鼠,选中页面里第一条文章链接。系统会手动辨识相像链接,在操作 提示框中网站文章采集,选择“选中全部”2)选择“循环点击每位链接”优采云·云采集网络爬虫软件 3)系统会手动步入文章详情页。 点击须要采集的数组 (这里先点击了文章标题) , 在操作提示框中,选择“采集该元素的文本”优采云·云采集网络爬虫软件 文章发布时间、文章作者、文章发布时间、文章正文内容采集方法同上。以下采 集的是文章正文优采云·云采集网络爬虫软件 步骤 3:提取 UC 头条文章图片地址1)接下来开始采集图片地址。
先点击文章中第一张图片,再点击页面中第二张 图片,在弹出的操作提示框中,选择“采集以下图片地址”优采云·云采集网络爬虫软件 2)修改数组名称,再点击“确定”优采云·云采集网络爬虫软件 3)现在我们早已采集到了图片 URL,接下来为批量导入图片做打算。批量导入 图片的时侯, 我们想要同一篇文章中的图片放进同一个文件中,文件夹以文章标 题命名。 首先,我们选中标题,在操作提示框中,选择“采集该元素的文本”优采云·云采集网络爬虫软件 选中标题数组,点击如图所示按键优采云·云采集网络爬虫软件 选择“格式化数据”优采云·云采集网络爬虫软件 点击添加步骤优采云·云采集网络爬虫软件 选择“添加前缀”优采云·云采集网络爬虫软件 在如图位置,输入前缀:“D:\UC 头条图片采集\”,然后点击“确定”优采云·云采集网络爬虫软件 以同样的形式添加后缀“\”,然后点击“确定”优采云·云采集网络爬虫软件 4)修改数组名为“图片储存地址”,最后展示出的“D:\UC 头条图片采集\ 文章标题”即为图片保存文件夹名,其中“D:\UC 头条图片采集\”是固定的,文章标题是变化的优采云·云采集网络爬虫软件 步骤 4:修改 Xpath1)选中整个“循环”步骤网站文章采集,打开“高级选项”,可以看见,优采云默认生成的 是固定元素列表,定位的是前 13 篇文章的链接优采云·云采集网络爬虫软件 2)在火狐浏览器中打开要采集的网页并观察源码。
我们发觉,通过此条 Xpath: //DIV[@class='news-list']/UL[1]/LI/DIV[1]/DIV[1]/A ,页面中所需的所有文 章均被定位了优采云·云采集网络爬虫软件 3)将修改后的 Xpath,复制粘贴到优采云中所示位置,然后点击“确定”优采云·云采集网络爬虫软件 步骤 5:文章数据采集及导入1)点击左上角的“保存”,然后点击“开始采集”,选择“启动本地采集”优采云·云采集网络爬虫软件 注: 本地采集占用当前笔记本资源进行采集, 如果存在采集时间要求或当前笔记本未能长时间进 行采集可以使用云采集功能, 云采集在网路中进行采集, 无需当前笔记本支持, 电脑可以死机, 可以设置多个云节点平摊任务,10 个节点相当于 10 台笔记本分配任务帮你采集,速度增加 为原先的十分之一;采集到的数据可以在云上保存三个月,可以随时进行导入操作。2)采集完成后,会跳出提示,选择“导出数据”,选择“合适的导入方法”, 将采集好的数据导入优采云·云采集网络爬虫软件 3)这里我们选择 excel 作为导入为格式,数据导入后如下图优采云·云采集网络爬虫软件 步骤 6:将图片 URL 批量转换为图片经过如上操作,我们早已得到了要采集的图片的 URL。
接下来,再通过优采云 专用的图片批量下载工具,将采集到的图片 URL 中的图片,下载并保存到本地 电脑中。 图片批量下载工具:优采云·云采集网络爬虫软件 1)下载优采云图片批量下载工具,双击文件中的 MyDownloader.app.exe 文 件,打开软件2)打开 File 菜单,选择从 EXCEL 导入(目前只支持 EXCEL 格式文件)优采云·云采集网络爬虫软件 3)进行相关设置,设置完成后,点击 OK 即可导出文件 选择 EXCEL 文件:导入你须要下载图片地址的 EXCEL 文件 EXCEL 表名:对应数据表的名称 文件 URL 列名:表内对应 URL 的列名称,在这里为“图片 URL” 保存文件夹名:EXCEL 中须要单独一个列,列出图片想要保存到文件夹的路径, 可以设置不同图片储存至不同文件夹,在这里为“图片储存地址” 可以设置不同图片储存至不同文件夹,在这里我们早已于前期打算好了,同一篇 文章中的图片会放进同一个文件中,文件夹以文章标题命名优采云·云采集网络爬虫软件 4)点击 OK 后,界面如图所示,再点击“开始下载”优采云·云采集网络爬虫软件 5)页面下方会显示图片下载状态优采云·云采集网络爬虫软件 6)全部下载完成后,找到自己设定的图片保存文件夹,可以看见,图片 URL 已经批量转换为图片了,且同一篇文章中的图片会放进同一个文件中,文件夹以 文章标题命名优采云·云采集网络爬虫软件 本文来自:相关采集教程:赶集中介房源采集 拼多多商品数据抓取 优采云·云采集网络爬虫软件 饿了么店家评论采集 腾讯地图数据采集 腾讯新闻采集 网易自媒体文章采集 微博图片采集 微博粉丝信息采集 当当图书采集 优采云——90 万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。优采云·云采集网络爬虫软件 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云) ,满足低端付费企业用户 的须要。 查看全部
优采云·云采集网络爬虫软件 如何高效抓取网站文章现在大多数做内容的都是须要参考好多网页文章的, 那在互联网告告诉发展 的明天应当如何高效的去抓取网站文章呢,本文以 UO 头条为例,UC 头条是 UC 浏览器团队潜力构建的新闻资讯推荐平台,拥有大量的新闻资讯内容,并通 过阿里大数据推荐和机器学习算法,为广大用户提供优质贴心的文章。很多用户 可能有采集 UC 头条文章采集的需求,这里采集了文章的文本和图片。文本可直 接采集,图片需先将图片 URL 采集下来,然后将图片 URL 批量转换为图片。本文将采集 UC 头条的文章,采集的数组为:标题、发布者、发布时间、文章内 容、页面网址、图片 URL、图片储存地址。采集网站:使用功能点:? Xpath优采云·云采集网络爬虫软件 xpath 入门教程 1 xpath 入门 2 相对 XPATH 教程-7.0 版 ?AJAX 滚动教程步骤 1:创建 UC 头条文章采集任务1)进入主界面,选择“自定义模式”优采云·云采集网络爬虫软件 2)将要采集的网址 URL 复制粘贴到网站输入框中,点击“保存网址”优采云·云采集网络爬虫软件 3)在页面右上角,打开“流程”,以突显出“流程设计器”和“定制当前操作” 两个蓝筹股。
网页打开后,默认显示“推荐”文章。观察发觉,此网页没有翻页按 钮,而是通过下拉加载,不断加载出新的内容 因而,我们选中“打开网页”步骤,在中级选项中,勾选“页面加载完成后向上 滚动” , 滚动次数依照自身需求进行设置, 间隔时间依照网页加载情况进行设置, 滚动形式为“向下滚动一屏”,然后点击“确定”优采云·云采集网络爬虫软件 (注意: 间隔时间须要针对网站情况进行设置,并不是绝对的。一般情况下,间隔时间> 网站加载时间即可。有时候网速较慢,网页加载太慢,还需依照具体情况进行调整。具体请 看:优采云 7.0 教程——AJAX 滚动教程)步骤 2:创建翻页循环及提取数据优采云·云采集网络爬虫软件 1)移动滑鼠,选中页面里第一条文章链接。系统会手动辨识相像链接,在操作 提示框中网站文章采集,选择“选中全部”2)选择“循环点击每位链接”优采云·云采集网络爬虫软件 3)系统会手动步入文章详情页。 点击须要采集的数组 (这里先点击了文章标题) , 在操作提示框中,选择“采集该元素的文本”优采云·云采集网络爬虫软件 文章发布时间、文章作者、文章发布时间、文章正文内容采集方法同上。以下采 集的是文章正文优采云·云采集网络爬虫软件 步骤 3:提取 UC 头条文章图片地址1)接下来开始采集图片地址。
先点击文章中第一张图片,再点击页面中第二张 图片,在弹出的操作提示框中,选择“采集以下图片地址”优采云·云采集网络爬虫软件 2)修改数组名称,再点击“确定”优采云·云采集网络爬虫软件 3)现在我们早已采集到了图片 URL,接下来为批量导入图片做打算。批量导入 图片的时侯, 我们想要同一篇文章中的图片放进同一个文件中,文件夹以文章标 题命名。 首先,我们选中标题,在操作提示框中,选择“采集该元素的文本”优采云·云采集网络爬虫软件 选中标题数组,点击如图所示按键优采云·云采集网络爬虫软件 选择“格式化数据”优采云·云采集网络爬虫软件 点击添加步骤优采云·云采集网络爬虫软件 选择“添加前缀”优采云·云采集网络爬虫软件 在如图位置,输入前缀:“D:\UC 头条图片采集\”,然后点击“确定”优采云·云采集网络爬虫软件 以同样的形式添加后缀“\”,然后点击“确定”优采云·云采集网络爬虫软件 4)修改数组名为“图片储存地址”,最后展示出的“D:\UC 头条图片采集\ 文章标题”即为图片保存文件夹名,其中“D:\UC 头条图片采集\”是固定的,文章标题是变化的优采云·云采集网络爬虫软件 步骤 4:修改 Xpath1)选中整个“循环”步骤网站文章采集,打开“高级选项”,可以看见,优采云默认生成的 是固定元素列表,定位的是前 13 篇文章的链接优采云·云采集网络爬虫软件 2)在火狐浏览器中打开要采集的网页并观察源码。
我们发觉,通过此条 Xpath: //DIV[@class='news-list']/UL[1]/LI/DIV[1]/DIV[1]/A ,页面中所需的所有文 章均被定位了优采云·云采集网络爬虫软件 3)将修改后的 Xpath,复制粘贴到优采云中所示位置,然后点击“确定”优采云·云采集网络爬虫软件 步骤 5:文章数据采集及导入1)点击左上角的“保存”,然后点击“开始采集”,选择“启动本地采集”优采云·云采集网络爬虫软件 注: 本地采集占用当前笔记本资源进行采集, 如果存在采集时间要求或当前笔记本未能长时间进 行采集可以使用云采集功能, 云采集在网路中进行采集, 无需当前笔记本支持, 电脑可以死机, 可以设置多个云节点平摊任务,10 个节点相当于 10 台笔记本分配任务帮你采集,速度增加 为原先的十分之一;采集到的数据可以在云上保存三个月,可以随时进行导入操作。2)采集完成后,会跳出提示,选择“导出数据”,选择“合适的导入方法”, 将采集好的数据导入优采云·云采集网络爬虫软件 3)这里我们选择 excel 作为导入为格式,数据导入后如下图优采云·云采集网络爬虫软件 步骤 6:将图片 URL 批量转换为图片经过如上操作,我们早已得到了要采集的图片的 URL。
接下来,再通过优采云 专用的图片批量下载工具,将采集到的图片 URL 中的图片,下载并保存到本地 电脑中。 图片批量下载工具:优采云·云采集网络爬虫软件 1)下载优采云图片批量下载工具,双击文件中的 MyDownloader.app.exe 文 件,打开软件2)打开 File 菜单,选择从 EXCEL 导入(目前只支持 EXCEL 格式文件)优采云·云采集网络爬虫软件 3)进行相关设置,设置完成后,点击 OK 即可导出文件 选择 EXCEL 文件:导入你须要下载图片地址的 EXCEL 文件 EXCEL 表名:对应数据表的名称 文件 URL 列名:表内对应 URL 的列名称,在这里为“图片 URL” 保存文件夹名:EXCEL 中须要单独一个列,列出图片想要保存到文件夹的路径, 可以设置不同图片储存至不同文件夹,在这里为“图片储存地址” 可以设置不同图片储存至不同文件夹,在这里我们早已于前期打算好了,同一篇 文章中的图片会放进同一个文件中,文件夹以文章标题命名优采云·云采集网络爬虫软件 4)点击 OK 后,界面如图所示,再点击“开始下载”优采云·云采集网络爬虫软件 5)页面下方会显示图片下载状态优采云·云采集网络爬虫软件 6)全部下载完成后,找到自己设定的图片保存文件夹,可以看见,图片 URL 已经批量转换为图片了,且同一篇文章中的图片会放进同一个文件中,文件夹以 文章标题命名优采云·云采集网络爬虫软件 本文来自:相关采集教程:赶集中介房源采集 拼多多商品数据抓取 优采云·云采集网络爬虫软件 饿了么店家评论采集 腾讯地图数据采集 腾讯新闻采集 网易自媒体文章采集 微博图片采集 微博粉丝信息采集 当当图书采集 优采云——90 万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。优采云·云采集网络爬虫软件 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云) ,满足低端付费企业用户 的须要。
微信文章简单采集方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 483 次浏览 • 2020-07-13 01:08
表现特点:a、点击网页中某个选项时,大部分网站的网址不会改变; b、网页 不是完全加载,只是局部进行了数据加载,有所变化。 验证方法:点击操作后,在浏览器中,网址输入栏不会出现加载中的状态或则转 圈状态。优采云·云采集网络爬虫软件 观察网页,我们发觉,通过 5 次点击“加载更多内容”,页面加载到最顶部,一 共显示 100 篇文章。因此,我们设置整个“循环翻页”步骤执行 5 次。选中“循 环翻页”步骤,打开“高级选项”,打开“满足以下条件时退出循环”,设置循 环次数等于“5 次”,点击“确定”搜狗微信公众号热门文章如何采集图 5优采云·云采集网络爬虫软件 步骤 3:创建列表循环并提取数据1)移动滑鼠,选中页面里第一篇文章的区块。系统会辨识此区块中的子元素, 在操作提示框中,选择“选中子元素”搜狗微信公众号热门文章如何采集图 62) 继续选中页面中第二篇文章的区块, 系统会手动选中第二篇文章中的子元素, 并辨识出页面中的其他 10 组同类元素,在操作提示框中,选择“选中全部”优采云·云采集网络爬虫软件 搜狗微信公众号热门文章如何采集图 73)我们可以看见,页面中文章区块里的所有元素均被选中,变为红色。
右侧操 作提示框中,出现数组预览表,将滑鼠移到表头,点击垃圾桶图标,可删掉不需 要的主键。字段选择完成后,选择“采集以下数据”优采云·云采集网络爬虫软件 搜狗微信公众号热门文章如何采集图 84)我们还想要采集每篇文章的 URL,因而还须要提取一个主键。点击第一篇文 章的链接,系统会手动选中页面中的一组文章链接。在左侧操作提示框中,选择 “选中全部”优采云·云采集网络爬虫软件 搜狗微信公众号热门文章如何采集图 95)选择“采集以下链接地址”优采云·云采集网络爬虫软件 搜狗微信公众号热门文章如何采集图 106)字段选择完成后,选中相应的数组,可以进行数组的自定义命名优采云·云采集网络爬虫软件 搜狗微信公众号热门文章如何采集图 11步骤 4:修改 Xpath我们继续观察,通过 5 次点击“加载更多内容”后,此网页加载出全部 100 篇 文章。因而我们配置规则的思路是,先构建翻页循环,加载出全部 100 篇文章, 再完善循环列表,提取数据优采云·云采集网络爬虫软件 1)选中整个“循环”步骤,将其拖出“循环翻页”步骤。如果不进行此项操作, 那么将会出现好多重复数据搜狗微信公众号热门文章如何采集图 12拖动完成后,如下图所示优采云·云采集网络爬虫软件 搜狗微信公众号热门文章如何采集图 132)在“列表循环”步骤中,我们构建 100 篇文章的循环列表。
选中整个“循环 步骤”,打开“高级选项”采集微信文章,将不固定元素列表中的这条 Xpath: //BODY[@id='loginWrap']/DIV[4]/DIV[1]/DIV[3]/UL[1]/LI ,复制粘贴到火 狐浏览器中的相应位置优采云·云采集网络爬虫软件 搜狗微信公众号热门文章如何采集图 14Xpath:是一种路径查询语言,简单的说就是借助一个路径表达式找到我们须要 的数据位置。 Xpath 是用于 XML 中顺着路径查找数据用的采集微信文章,但是优采云采集器内部有一套针 对 HTML 的 Xpath 引擎,使得直接用 XPATH 就能精准的查找定位网页上面的 数据。优采云·云采集网络爬虫软件 3)在火狐浏览器中,我们发觉,通过这条 Xpath: //BODY[@id='loginWrap']/DIV[4]/DIV[1]/DIV[3]/UL[1]/LI ,页面中被定位 的是 20 篇文章搜狗微信公众号热门文章如何采集图 154) 将 Xpath 修改为: //BODY[@id='loginWrap']/DIV/DIV[1]/DIV[3]/UL/LI, 我们发觉页面中所有要采集的文章都被定位了优采云·云采集网络爬虫软件 搜狗微信公众号热门文章如何采集图 165)将改好的 Xpath://BODY[@id='loginWrap']/DIV/DIV[1]/DIV[3]/UL/LI, 复制粘贴到图片中所示的位置,然后点击“确定”优采云·云采集网络爬虫软件 搜狗微信公众号热门文章如何采集图 176)点击左上角的“保存并启动”,选择“启动本地采集”优采云·云采集网络爬虫软件 搜狗微信公众号热门文章如何采集图 18步骤 5:数据采集及导入1)采集完成后,会跳出提示,选择“导出数据”,选择“合适的导入方法”, 将采集好的搜狗陌陌文章的数据导入优采云·云采集网络爬虫软件 搜狗微信公众号热门文章如何采集图 192)这里我们选择 excel 作为导入为格式,数据导入后如下图优采云·云采集网络爬虫软件 搜狗微信公众号热门文章如何采集图 20相关采集教程 地图数据采集 旅游信息采集 点评数据采集优采云·云采集网络爬虫软件 分类信息采集教程 网站文章采集 网站文章采集教程 网站图片采集 网页邮箱采集 公告信息抓取 优采云·云采集网络爬虫软件 关键词提取 优采云——70 万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云) ,满足低端付费企业用户 的须要。 查看全部
表现特点:a、点击网页中某个选项时,大部分网站的网址不会改变; b、网页 不是完全加载,只是局部进行了数据加载,有所变化。 验证方法:点击操作后,在浏览器中,网址输入栏不会出现加载中的状态或则转 圈状态。优采云·云采集网络爬虫软件 观察网页,我们发觉,通过 5 次点击“加载更多内容”,页面加载到最顶部,一 共显示 100 篇文章。因此,我们设置整个“循环翻页”步骤执行 5 次。选中“循 环翻页”步骤,打开“高级选项”,打开“满足以下条件时退出循环”,设置循 环次数等于“5 次”,点击“确定”搜狗微信公众号热门文章如何采集图 5优采云·云采集网络爬虫软件 步骤 3:创建列表循环并提取数据1)移动滑鼠,选中页面里第一篇文章的区块。系统会辨识此区块中的子元素, 在操作提示框中,选择“选中子元素”搜狗微信公众号热门文章如何采集图 62) 继续选中页面中第二篇文章的区块, 系统会手动选中第二篇文章中的子元素, 并辨识出页面中的其他 10 组同类元素,在操作提示框中,选择“选中全部”优采云·云采集网络爬虫软件 搜狗微信公众号热门文章如何采集图 73)我们可以看见,页面中文章区块里的所有元素均被选中,变为红色。
右侧操 作提示框中,出现数组预览表,将滑鼠移到表头,点击垃圾桶图标,可删掉不需 要的主键。字段选择完成后,选择“采集以下数据”优采云·云采集网络爬虫软件 搜狗微信公众号热门文章如何采集图 84)我们还想要采集每篇文章的 URL,因而还须要提取一个主键。点击第一篇文 章的链接,系统会手动选中页面中的一组文章链接。在左侧操作提示框中,选择 “选中全部”优采云·云采集网络爬虫软件 搜狗微信公众号热门文章如何采集图 95)选择“采集以下链接地址”优采云·云采集网络爬虫软件 搜狗微信公众号热门文章如何采集图 106)字段选择完成后,选中相应的数组,可以进行数组的自定义命名优采云·云采集网络爬虫软件 搜狗微信公众号热门文章如何采集图 11步骤 4:修改 Xpath我们继续观察,通过 5 次点击“加载更多内容”后,此网页加载出全部 100 篇 文章。因而我们配置规则的思路是,先构建翻页循环,加载出全部 100 篇文章, 再完善循环列表,提取数据优采云·云采集网络爬虫软件 1)选中整个“循环”步骤,将其拖出“循环翻页”步骤。如果不进行此项操作, 那么将会出现好多重复数据搜狗微信公众号热门文章如何采集图 12拖动完成后,如下图所示优采云·云采集网络爬虫软件 搜狗微信公众号热门文章如何采集图 132)在“列表循环”步骤中,我们构建 100 篇文章的循环列表。
选中整个“循环 步骤”,打开“高级选项”采集微信文章,将不固定元素列表中的这条 Xpath: //BODY[@id='loginWrap']/DIV[4]/DIV[1]/DIV[3]/UL[1]/LI ,复制粘贴到火 狐浏览器中的相应位置优采云·云采集网络爬虫软件 搜狗微信公众号热门文章如何采集图 14Xpath:是一种路径查询语言,简单的说就是借助一个路径表达式找到我们须要 的数据位置。 Xpath 是用于 XML 中顺着路径查找数据用的采集微信文章,但是优采云采集器内部有一套针 对 HTML 的 Xpath 引擎,使得直接用 XPATH 就能精准的查找定位网页上面的 数据。优采云·云采集网络爬虫软件 3)在火狐浏览器中,我们发觉,通过这条 Xpath: //BODY[@id='loginWrap']/DIV[4]/DIV[1]/DIV[3]/UL[1]/LI ,页面中被定位 的是 20 篇文章搜狗微信公众号热门文章如何采集图 154) 将 Xpath 修改为: //BODY[@id='loginWrap']/DIV/DIV[1]/DIV[3]/UL/LI, 我们发觉页面中所有要采集的文章都被定位了优采云·云采集网络爬虫软件 搜狗微信公众号热门文章如何采集图 165)将改好的 Xpath://BODY[@id='loginWrap']/DIV/DIV[1]/DIV[3]/UL/LI, 复制粘贴到图片中所示的位置,然后点击“确定”优采云·云采集网络爬虫软件 搜狗微信公众号热门文章如何采集图 176)点击左上角的“保存并启动”,选择“启动本地采集”优采云·云采集网络爬虫软件 搜狗微信公众号热门文章如何采集图 18步骤 5:数据采集及导入1)采集完成后,会跳出提示,选择“导出数据”,选择“合适的导入方法”, 将采集好的搜狗陌陌文章的数据导入优采云·云采集网络爬虫软件 搜狗微信公众号热门文章如何采集图 192)这里我们选择 excel 作为导入为格式,数据导入后如下图优采云·云采集网络爬虫软件 搜狗微信公众号热门文章如何采集图 20相关采集教程 地图数据采集 旅游信息采集 点评数据采集优采云·云采集网络爬虫软件 分类信息采集教程 网站文章采集 网站文章采集教程 网站图片采集 网页邮箱采集 公告信息抓取 优采云·云采集网络爬虫软件 关键词提取 优采云——70 万用户选择的网页数据采集器。
1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云) ,满足低端付费企业用户 的须要。
网络爬虫软件那个好用?看完这篇就够了
采集交流 • 优采云 发表了文章 • 0 个评论 • 643 次浏览 • 2020-07-06 08:03
前市面上常见的爬虫软件通常可以界定为云爬虫和采集器两种:
所谓云爬虫就是无需下载安装软件,直接在网页上创建爬虫并在网站服务器运行,享用网站提供的带宽和24小时服务;
采集器通常就是要下载安装在本机,然后在本机创建爬虫,使用的是自己的带宽,受限于自己的笔记本是否死机。
当然,以上不包括自己开发的爬虫工具和爬虫框架之类的。
其实每位爬虫都有自己的特性,我们可以按照自己的须要进行选择,下面针对常见的网路爬虫做一些简单介绍,给你们做一些参考:
首先是云爬虫,国内目前主要是:优采云云爬虫
官网:
简介:优采云云是一个大数据应用开发平台多可网络爬虫软件怎么用,为开发者提供成套的数据采集、数据剖析和机器学习开发工具,为企业提供专业化的数据抓取、数据实时监控和数据剖析服务。
优点:功能强悍,涉及云爬虫、API、机器学习、数据清洗、数据转让、数据定制和私有化布署等;
纯云端运行,跨系统操作无压力,隐私保护,可隐藏用户IP。
提供云爬虫市场,零基础使用者可直接调用开发好的爬虫,开发者基于官方的云端开发环境开发并上传转让自己的爬虫程序;
领先的反爬技术,例如直接接入代理IP和手动登入验证码识别等,全程自动化无需人工参与;
丰富的发布插口,采集结果以丰富表格化方式诠释;
缺点:它的优点同时也在一定程度上成了它的缺点,因为它是一个面向开发者的爬虫开发系统,提供了丰富的开发功能,网站看起来特别的偏技术十分专业,尽管官方也提供了云爬虫市场这样的现成爬虫产品,并且开放给广大爬虫开发者,从而使爬虫市场的内容愈发丰富,但是对于零技术基础的用户而言并不是这么容易理解,所以有一定的使用门槛。
是否免费:免费用户无采集功能和导入限制多可网络爬虫软件怎么用,无需积分。
具备开发能力的用户可以自行开发爬虫,达到免费疗效,没有开发能力的用户须要从爬虫市场找寻是否有免费的爬虫。
然后是采集器,目前国外主要包括以下这种(百度/谷歌搜采集器,刨去广告,排名靠前的):
优采云采集器:
官网:
简介:火车采集器是一款网页数据抓取、处理、分析,挖掘软件。可以灵活迅速地抓取网页上散乱分布的信息,并通过强悍的处理功能确切挖掘出所需数据。
优点:国内老牌的采集器,经过多年的积累,具有丰富的采集功能;
采集速度比较快,接口比较齐全,支持PHP和C#插件扩充;
支持多种数据格式导入,可以进行数据替换等处理。
缺点:越是年头长的产品越容易身陷自己的固有经验中,优采云也无法甩掉这问题。
虽说功能丰富,但是功能都拼凑在那里,用户体验不好,让人不知道从何下手;
学会了的人会认为功能强悍,但是对于菜鸟而言有一定使用门槛,不学习一段时间很难上手,零基础上手基本不可能。
只支持Windows版本,不支持其他操作系统;
是否免费:号称免费,但是实际上免费功能限制好多,只能导入单个txt或html文件,基本上可以说是不免费的。
优采云采集器:
官网:
简介:优采云采集器是一款可视化采集器,内置采集模板,支持各类网页数据采集。
优点:支持自定义模式,可视化采集操作,容易上手;
支持简易采集模式,提供官方采集模板,支持云采集操作;
支持防屏蔽举措,例如代理IP切换和验证码服务;
支持多种数据格式导入。
缺点:功能使用门槛较高,本地采集时好多功能受限,而云采集收费较高;
采集速度较慢,很多操作都要卡一下,云端采集说10倍提速并且并不显著;
只支持Windows版本,不支持其他操作系统。
是否免费:号称免费,但是实际上导入数据须要积分,可以做任务攒积分,但是正常情况下基本都须要订购积分。
后羿采集器:
官网:
简介:后羿采集器是由前微软搜索技术团队基于人工智能技术研制的新一代网页采集软件,该软件功能强悍,操作非常简单。
优点:支持智能采集模式,输入网址能够智能辨识采集对象,无需配置采集规则,操作十分简单;
支持流程图模式,可视化操作流程,能够通过简单的操作生成各类复杂的采集规则;
支持防屏蔽举措,例如代理IP切换验证码打码等;
支持多种数据导入方法(文件,数据库和网站);
支持定时采集和手动导入,发布插口丰富;
支持文件下载(图片,文件,视频,音频等);
支持电商大图和SKU手动辨识;
支持网页加密内容解码;
支持API功能;
支持Windows、Mac和Linux版本。
缺点:暂不支持云采集功能
是否免费:完全免费,采集数据和自动导入采集结果到本地文件和数据库没有数目限制,不需要积分。 查看全部
前市面上常见的爬虫软件通常可以界定为云爬虫和采集器两种:
所谓云爬虫就是无需下载安装软件,直接在网页上创建爬虫并在网站服务器运行,享用网站提供的带宽和24小时服务;
采集器通常就是要下载安装在本机,然后在本机创建爬虫,使用的是自己的带宽,受限于自己的笔记本是否死机。
当然,以上不包括自己开发的爬虫工具和爬虫框架之类的。
其实每位爬虫都有自己的特性,我们可以按照自己的须要进行选择,下面针对常见的网路爬虫做一些简单介绍,给你们做一些参考:
首先是云爬虫,国内目前主要是:优采云云爬虫
官网:
简介:优采云云是一个大数据应用开发平台多可网络爬虫软件怎么用,为开发者提供成套的数据采集、数据剖析和机器学习开发工具,为企业提供专业化的数据抓取、数据实时监控和数据剖析服务。
优点:功能强悍,涉及云爬虫、API、机器学习、数据清洗、数据转让、数据定制和私有化布署等;
纯云端运行,跨系统操作无压力,隐私保护,可隐藏用户IP。
提供云爬虫市场,零基础使用者可直接调用开发好的爬虫,开发者基于官方的云端开发环境开发并上传转让自己的爬虫程序;
领先的反爬技术,例如直接接入代理IP和手动登入验证码识别等,全程自动化无需人工参与;
丰富的发布插口,采集结果以丰富表格化方式诠释;
缺点:它的优点同时也在一定程度上成了它的缺点,因为它是一个面向开发者的爬虫开发系统,提供了丰富的开发功能,网站看起来特别的偏技术十分专业,尽管官方也提供了云爬虫市场这样的现成爬虫产品,并且开放给广大爬虫开发者,从而使爬虫市场的内容愈发丰富,但是对于零技术基础的用户而言并不是这么容易理解,所以有一定的使用门槛。
是否免费:免费用户无采集功能和导入限制多可网络爬虫软件怎么用,无需积分。
具备开发能力的用户可以自行开发爬虫,达到免费疗效,没有开发能力的用户须要从爬虫市场找寻是否有免费的爬虫。
然后是采集器,目前国外主要包括以下这种(百度/谷歌搜采集器,刨去广告,排名靠前的):
优采云采集器:
官网:
简介:火车采集器是一款网页数据抓取、处理、分析,挖掘软件。可以灵活迅速地抓取网页上散乱分布的信息,并通过强悍的处理功能确切挖掘出所需数据。
优点:国内老牌的采集器,经过多年的积累,具有丰富的采集功能;
采集速度比较快,接口比较齐全,支持PHP和C#插件扩充;
支持多种数据格式导入,可以进行数据替换等处理。
缺点:越是年头长的产品越容易身陷自己的固有经验中,优采云也无法甩掉这问题。
虽说功能丰富,但是功能都拼凑在那里,用户体验不好,让人不知道从何下手;
学会了的人会认为功能强悍,但是对于菜鸟而言有一定使用门槛,不学习一段时间很难上手,零基础上手基本不可能。
只支持Windows版本,不支持其他操作系统;
是否免费:号称免费,但是实际上免费功能限制好多,只能导入单个txt或html文件,基本上可以说是不免费的。
优采云采集器:
官网:
简介:优采云采集器是一款可视化采集器,内置采集模板,支持各类网页数据采集。
优点:支持自定义模式,可视化采集操作,容易上手;
支持简易采集模式,提供官方采集模板,支持云采集操作;
支持防屏蔽举措,例如代理IP切换和验证码服务;
支持多种数据格式导入。
缺点:功能使用门槛较高,本地采集时好多功能受限,而云采集收费较高;
采集速度较慢,很多操作都要卡一下,云端采集说10倍提速并且并不显著;
只支持Windows版本,不支持其他操作系统。
是否免费:号称免费,但是实际上导入数据须要积分,可以做任务攒积分,但是正常情况下基本都须要订购积分。
后羿采集器:
官网:
简介:后羿采集器是由前微软搜索技术团队基于人工智能技术研制的新一代网页采集软件,该软件功能强悍,操作非常简单。
优点:支持智能采集模式,输入网址能够智能辨识采集对象,无需配置采集规则,操作十分简单;
支持流程图模式,可视化操作流程,能够通过简单的操作生成各类复杂的采集规则;
支持防屏蔽举措,例如代理IP切换验证码打码等;
支持多种数据导入方法(文件,数据库和网站);
支持定时采集和手动导入,发布插口丰富;
支持文件下载(图片,文件,视频,音频等);
支持电商大图和SKU手动辨识;
支持网页加密内容解码;
支持API功能;
支持Windows、Mac和Linux版本。
缺点:暂不支持云采集功能
是否免费:完全免费,采集数据和自动导入采集结果到本地文件和数据库没有数目限制,不需要积分。
从零开始基于Scrapy框架的网路爬虫开发流程
采集交流 • 优采云 发表了文章 • 0 个评论 • 409 次浏览 • 2020-07-06 08:01
前节介绍了哪些网路爬虫,什么是Scrapy框架并怎样安装
本节介绍基于Scrapy框架的网路爬虫开发流程
安装好Scrapy框架后,就可以基于Scrapy框架开发爬虫项目了。基于框架开发项目,不需要从零开始编撰代码,只须要把握怎样使用框架,如何添加与自己应用相关的代码即可。
进入准备新建爬虫项目的路径中,使用命令:
scrapy startproject project_name
请用爬虫项目名称替换命令中的project_name爬虫软件开发,例如,本文准备创建一个爬取新浪网的爬虫,取名为sina_spider,则新建爬虫项目的命令为:
scrapy startproject sina_spider
命令运行结果,如下图所示。
新建爬虫项目
“scrapy startproject sina_spider”命令会创建包含下述内容的sina_spider目录,如图13-5所示。
爬虫文件夹结构
新建好Scrapy爬虫项目后,接下来就是创建爬虫文件。请先步入sina_spider项目路径,用命令:
scrapy genspider spider_filename(爬虫文件名) (待爬取的网站域名)
创建爬虫文件。例如,本文的爬虫文件名为:sinaSpider,待爬取的网站域名:,则创建爬虫文件sinaSpider的命令为:
scrapy genspider sinaSpider
现在好多网站都有防爬虫举措,为了反网站的防爬虫举措,需要添加user agent信息。请settings.py文件的第19行更改如下所示:
18. # Crawl responsibly by identifying yourself (and your website) on the user-agent
19. import random
20. # user agent 列表
21. USER_AGENT_LIST = [
22. "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
23. "Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
24. "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
25. "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
26. "Mozilla/4.76 [en_jp] (X11; U; SunOS 5.8 sun4u)",
27. "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
28. "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:5.0) Gecko/20100101 Firefox/5.0",
29. "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:9.0) Gecko/20100101 Firefox/9.0",
30. "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.8; rv:16.0) Gecko/20120813 Firefox/16.0",
31. "Mozilla/4.77 [en] (X11; I; IRIX;64 6.5 IP30)",
32. "Mozilla/4.8 [en] (X11; U; SunOS; 5.7 sun4u)" ]
33. USER_AGENT = random.choice(USER_AGENT_LIST) # 随机生成user agent
网站的服务器中保存一个robots.txt 文件,其作用是,告诉搜索引擎爬虫,本网站哪些目录下的网页不希望被爬取收录。Scrapy启动后,会在第一时间访问网站的 robots.txt 文件,然后决定该网站的爬取范围。
由于本文的项目并非搜索引擎爬虫,而且很有可能我们想要获取的内容恰恰是被 robots.txt所严禁访问的,所以请把settings.py文件的ROBOTSTXT_OBEY值设置为False,表示拒绝遵循Robot合同,如下所示
1. # Obey robots.txt rules
2. ROBOTSTXT_OBEY = False # False表示拒绝遵守Robot协议
查看由Scrapy生成的sinaSpider.py文件,在SinaspiderSpider类中,有一个parse()方法须要用户编撰,如下图所示
编写parse()方法
Scrapy框架把爬取出来的网页源代码储存在response对象中爬虫软件开发,我们只须要对response对象中的网页源代码做解析,提取想要的数据即可。本范例目标是抓取新浪网页的新闻的标题和对应的链接,如下图所示。
HTML源代码
parse()方法的实现代码,如下所示
1. # -*- coding: utf-8 -*-
2. import scrapy
3.
4. class SinaspiderSpider(scrapy.Spider):
5. name = 'sinaSpider'
6. allowed_domains = ['www.sina.com.cn']
7. start_urls = ['http://www.sina.com.cn/']
8.
9. def parse(self, response):
10. data_list = [] #用于存储解析到的数据
11. #解析HTML源代码,定位新闻内容
12. lis = response.xpath("//div[@class='top_newslist']/ul[@class='list-a news_top']//li")
13. #将新闻主题和超链接解析出来并整理到列表中
14. for li in lis:
15. titles = li.xpath(".//a/text()")
16. linkes = li.xpath(".//a/@href")
17. for title, link in zip(titles, linkes):
18. #将新闻主题和对应的超链接组合成字典
19. data_dict = {'标题': title.extract(), '链接': link.extract()}
20. #将字典数据存储到data_list这个列表中
21. data_list.append(data_dict)
22. return data_list
parse()方法在解析HTML源代码时,使用了XPath路径表达式。XPath是一门在HTML/XML文档中查找信息的语言,常用于在网页HTML源代码中,查找特定标签里的数据。在网络爬虫中使用XPath,只须要把握 XPath路径表达式即可。XPath 使用路径表达式来选定 HTML/XML文档中的节点或则节点集。
parse()方法编撰好后,就可以运行爬虫程序并保存抓取数据了。用命令:
scrapy crawl 爬虫文件名 –o 保存数据文件名.[csv|json|xml]
保存数据的文件格式可以是csv 或 json 或 xml,本例的爬虫文件名为:sinaSpider.py,数据储存选择csv格式,命令为:
scrapy crawl sinaSpider -o sinaNews.csv
运行疗效,如下图所示
运行爬虫
到此,本例基于Scrapy框架从零开始实现了一个网络爬虫程序,爬取了新浪网页并从中解析出新闻的标题和对应的超链接,最后把解析出的数据保存为csv文件供后续使用。 查看全部
前节介绍了哪些网路爬虫,什么是Scrapy框架并怎样安装
本节介绍基于Scrapy框架的网路爬虫开发流程
安装好Scrapy框架后,就可以基于Scrapy框架开发爬虫项目了。基于框架开发项目,不需要从零开始编撰代码,只须要把握怎样使用框架,如何添加与自己应用相关的代码即可。
进入准备新建爬虫项目的路径中,使用命令:
scrapy startproject project_name
请用爬虫项目名称替换命令中的project_name爬虫软件开发,例如,本文准备创建一个爬取新浪网的爬虫,取名为sina_spider,则新建爬虫项目的命令为:
scrapy startproject sina_spider
命令运行结果,如下图所示。
新建爬虫项目
“scrapy startproject sina_spider”命令会创建包含下述内容的sina_spider目录,如图13-5所示。
爬虫文件夹结构
新建好Scrapy爬虫项目后,接下来就是创建爬虫文件。请先步入sina_spider项目路径,用命令:
scrapy genspider spider_filename(爬虫文件名) (待爬取的网站域名)
创建爬虫文件。例如,本文的爬虫文件名为:sinaSpider,待爬取的网站域名:,则创建爬虫文件sinaSpider的命令为:
scrapy genspider sinaSpider
现在好多网站都有防爬虫举措,为了反网站的防爬虫举措,需要添加user agent信息。请settings.py文件的第19行更改如下所示:
18. # Crawl responsibly by identifying yourself (and your website) on the user-agent
19. import random
20. # user agent 列表
21. USER_AGENT_LIST = [
22. "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.1 (KHTML, like Gecko) Chrome/22.0.1207.1 Safari/537.1",
23. "Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.11 (KHTML, like Gecko) Chrome/20.0.1132.57 Safari/536.11",
24. "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1092.0 Safari/536.6",
25. "Mozilla/5.0 (Windows NT 6.2) AppleWebKit/536.6 (KHTML, like Gecko) Chrome/20.0.1090.0 Safari/536.6",
26. "Mozilla/4.76 [en_jp] (X11; U; SunOS 5.8 sun4u)",
27. "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/535.24 (KHTML, like Gecko) Chrome/19.0.1055.1 Safari/535.24",
28. "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:5.0) Gecko/20100101 Firefox/5.0",
29. "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.6; rv:9.0) Gecko/20100101 Firefox/9.0",
30. "Mozilla/5.0 (Macintosh; Intel Mac OS X 10.8; rv:16.0) Gecko/20120813 Firefox/16.0",
31. "Mozilla/4.77 [en] (X11; I; IRIX;64 6.5 IP30)",
32. "Mozilla/4.8 [en] (X11; U; SunOS; 5.7 sun4u)" ]
33. USER_AGENT = random.choice(USER_AGENT_LIST) # 随机生成user agent
网站的服务器中保存一个robots.txt 文件,其作用是,告诉搜索引擎爬虫,本网站哪些目录下的网页不希望被爬取收录。Scrapy启动后,会在第一时间访问网站的 robots.txt 文件,然后决定该网站的爬取范围。
由于本文的项目并非搜索引擎爬虫,而且很有可能我们想要获取的内容恰恰是被 robots.txt所严禁访问的,所以请把settings.py文件的ROBOTSTXT_OBEY值设置为False,表示拒绝遵循Robot合同,如下所示
1. # Obey robots.txt rules
2. ROBOTSTXT_OBEY = False # False表示拒绝遵守Robot协议
查看由Scrapy生成的sinaSpider.py文件,在SinaspiderSpider类中,有一个parse()方法须要用户编撰,如下图所示
编写parse()方法
Scrapy框架把爬取出来的网页源代码储存在response对象中爬虫软件开发,我们只须要对response对象中的网页源代码做解析,提取想要的数据即可。本范例目标是抓取新浪网页的新闻的标题和对应的链接,如下图所示。
HTML源代码
parse()方法的实现代码,如下所示
1. # -*- coding: utf-8 -*-
2. import scrapy
3.
4. class SinaspiderSpider(scrapy.Spider):
5. name = 'sinaSpider'
6. allowed_domains = ['www.sina.com.cn']
7. start_urls = ['http://www.sina.com.cn/']
8.
9. def parse(self, response):
10. data_list = [] #用于存储解析到的数据
11. #解析HTML源代码,定位新闻内容
12. lis = response.xpath("//div[@class='top_newslist']/ul[@class='list-a news_top']//li")
13. #将新闻主题和超链接解析出来并整理到列表中
14. for li in lis:
15. titles = li.xpath(".//a/text()")
16. linkes = li.xpath(".//a/@href")
17. for title, link in zip(titles, linkes):
18. #将新闻主题和对应的超链接组合成字典
19. data_dict = {'标题': title.extract(), '链接': link.extract()}
20. #将字典数据存储到data_list这个列表中
21. data_list.append(data_dict)
22. return data_list
parse()方法在解析HTML源代码时,使用了XPath路径表达式。XPath是一门在HTML/XML文档中查找信息的语言,常用于在网页HTML源代码中,查找特定标签里的数据。在网络爬虫中使用XPath,只须要把握 XPath路径表达式即可。XPath 使用路径表达式来选定 HTML/XML文档中的节点或则节点集。
parse()方法编撰好后,就可以运行爬虫程序并保存抓取数据了。用命令:
scrapy crawl 爬虫文件名 –o 保存数据文件名.[csv|json|xml]
保存数据的文件格式可以是csv 或 json 或 xml,本例的爬虫文件名为:sinaSpider.py,数据储存选择csv格式,命令为:
scrapy crawl sinaSpider -o sinaNews.csv
运行疗效,如下图所示
运行爬虫
到此,本例基于Scrapy框架从零开始实现了一个网络爬虫程序,爬取了新浪网页并从中解析出新闻的标题和对应的超链接,最后把解析出的数据保存为csv文件供后续使用。
网络爬虫是哪些?它的主要功能和作用有什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 591 次浏览 • 2020-07-04 08:01
网络爬虫,又被称为“网页蜘蛛,网络机器人”,在FOAF社区中间,经常被称为“网页追逐者”。网络爬虫,是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。
网络爬虫,按照系统结构和实现技术,大致可以分为:“通用网路爬虫、聚焦网路爬虫、增量式网路爬虫、深层网络爬虫”等四种不同类型。实际上,网络爬虫系统,通常是由几种爬虫技术相结合实现的。
一、 通用网路爬虫
通用网路爬虫,又称“全网爬虫”,爬行对象从一些种子URL(统一资源定位符) 扩充到整个万维网,主要为“门户站点搜索引擎”和“大型Web服务提供商”采集数据。由于商业缘由,它们的技术细节甚少被公布下来。这类网路爬虫的爬行范围和数目巨大,对于爬行速率和储存空间要求较高,对于爬行页面的次序要求相对较低,同时因为等待刷新的页面太多,通常采用“并行工作”的方法,但须要较长时间能够刷新一次页面。通用网路爬虫,虽然存在着一定的缺陷,但它适用于为搜索引擎平台搜索广泛的主题,有较强的应用价值。
二、聚焦网络爬虫
聚焦网络爬虫,又称“主题网路爬虫”,是指选择性地爬行,那些与预先定义好的主题相关的页面的网路爬虫。和通用网路爬虫相比,聚焦网路爬虫只须要爬行与主题相关的页面,极大地节约了硬件和网路资源,保存的页面也因为数目少而更新快,还可以挺好地满足一些特定人群对特定领域信息的需求。
聚焦网络爬虫和通用网路爬虫相比,增加了“链接评价模块”以及“内容评价模块”。聚焦网路爬虫爬行策略实现的关键是,评价页面内容和链接的重要性。不同的方式估算出的重要性不同,由此引起链接的访问次序也不同。
三、增量式网络爬虫
是指对已下载网页采取增量式更新,和只爬行新形成的或则早已发生变化网页的爬虫网络爬虫技术是什么,它还能在一定程度上保证网络爬虫技术是什么,所爬行的页面是尽可能新的页面。
和周期性爬行和刷新页面的网路爬虫相比,增量式爬虫只会在须要的时侯爬行新形成或发生更新的页面 ,并不重新下载没有发生变化的页面,可有效降低数据下载量,及时更新已爬行的网页,减小时间和空间上的花费,但是降低了爬行算法的复杂度和实现难度。
四、深层网络爬虫
Web 页面,按存在形式可以分为“表层网页”和“深层网页”。表层网页是指传统搜索引擎可以索引的页面,以超链接可以抵达的静态网页为主构成的 Web 页面。
深层网页是这些大部分内容不能通过静态链接获取的、隐藏在搜索表单后的,只有用户递交一些关键词能够获得的 Web 页面。例如:那些用户注册后内容才可见的网页,就属于深层网页。
随着计算机网路的迅速发展,万维网成为大量信息的载体,如何有效地提取并借助这种信息成为一个巨大的挑战。搜索引擎,例如传统的“通用搜索引擎”平台:Google(谷歌)、Yahoo!(雅虎)、百度等,作为一个辅助人们检索万维网信息的工具,成为互联网用户访问万维网的入口和渠道。
但是,这些“通用搜索引擎平台”也存在着一定的局限性,如:
1、 不同领域、不同职业、不同背景的用户,往往具有不同的检索目的和需求,通用搜索引擎所返回的结果,包含了大量用户并不关心的网页,或者与用户搜索结果无关的网页。
2、 通用搜索引擎的目标是,实现尽可能大的网路覆盖率,有限的搜索引擎服务器资源,与无限的网路数据资源之间的矛盾将进一步加深。
3、 万维网数据方式的丰富和网路技术的不断发展,图片、数据库、音频、视频多媒体等不同数据大量出现,通用搜索引擎常常对这种信息浓度密集,且具有一定结构的数据无能为力,不能挺好地发觉和获取。
4、通用搜索引擎,大多提供基于“关键字”的检索,难以支持按照语义信息提出的查询。
为了解决上述问题,定向抓取相关网页资源的“聚焦网路爬虫”应运而生。聚焦网路爬虫,是一个手动下载网页的程序,它按照既定的抓取目标,有选择的访问万维网上的网页与相关的链接,获取所须要的信息。
与“通用网路爬虫”不同,聚焦网络爬虫并不追求大的覆盖,而是将目标定为抓取“与某一特定主题内容相关的网页”,为面向主题的用户查询,准备数据资源。
“聚焦网路爬虫”的工作原理以及关键技术概述:
网络爬虫,是一个手动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。
传统爬虫,从一个或若干初始网页的URL(统一资源定位符)开始,获得初始网页上的URL(统一资源定位符),在抓取网页的过程中,不断从当前页面上抽取新的URL(统一资源定位符)放入队列,直到满足系统的一定停止条件。
“聚焦网路爬虫”的工作流程较为复杂,需要按照一定的“网页分析算法”过滤与主题无关的链接,保留有用的链接,并将其倒入等待抓取的URL(统一资源定位符)队列。然后,它将按照一定的搜索策略,从队列中选择下一步要抓取的网页URL(统一资源定位符),并重复上述过程,直到达到系统的某一条件时停止。
另外,所有被爬虫抓取的网页将会被系统储存,进行一定的剖析、过滤,并构建索引,以便以后的查询和检索。对于“聚焦网路爬虫”来说,这一过程所得到的剖析结果,还可能对之后的抓取过程给出反馈和指导。
相对于通用网路爬虫,聚焦网路爬虫还须要解决三个主要问题:
1、对抓取目标的描述或定义;
2、对网页或数据的剖析与过滤;
3、对URL(统一资源定位符)的搜索策略。
网络爬虫碰到的问题:
早在2007 年底,互联网上的网页数目就早已超出160 亿个,研究表明接近30%的页面是重复的。动态页面的存在,客户端、服务器端脚本语言的应用,使得指向相同Web信息的 URL(统一资源定位符)数量呈指数级下降。
上述特点促使网路爬虫面临一定的困难,主要彰显在 Web信息的巨大容量,使得爬虫在给定的时间内,只能下载少量网页。有研究表明,没有那个搜索引擎才能索引超出16%的互联网Web 页面,即使才能提取全部页面,也没有足够的空间来储存。
为了提升爬行效率,爬虫须要在单位时间内尽可能多的获取高质量页面,这是它面临的困局之一。
当前有五种表示页面质量高低的方法:1、页面与爬行主题之间的相似度;2、页面在 Web 图中的入度大小;3、指向它的所有页面平均残差之和;4、页面在 Web 图中的出度大小;5、页面的信息位置。
为了提升爬行速率,网络爬虫一般会采取“并行爬行”的工作方式,这种工作方式也造成了新的问题:
1、重复性(并行运行的爬虫或爬行线程同时运行时,增加了重复页面);
2、质量问题(并行运行时,每个爬虫或爬行线程只能获取部份页面,导致页面质量下滑);
3、通信带宽代价(并行运行时,各个爬虫或爬行线程之间不可避开要进行一些通讯,需要花费一定的带宽资源)。
并行运行时,网络爬虫一般采用三种形式:
1、独立形式(各个爬虫独立爬行页面,互不通讯);
2、动态分配方法(由一个中央协调器动态协调分配 URL 给各个爬虫);
3、静态分配方法(URL 事先界定给各个爬虫)。
亿速云,作为一家专业的IDC(互联网数据中心)业务服务提供商、拥有丰富行业底蕴的专业云计算服务提供商,一直专注于技术创新和构建更好的服务品质,致力于为广大用户,提供高性价比、高可用性的“裸金属服务器、云服务器、高防服务器、高防IP、香港服务器、日本服务器、美国服务器、SSL证书”等专业产品与服务。 查看全部
网络爬虫,又被称为“网页蜘蛛,网络机器人”,在FOAF社区中间,经常被称为“网页追逐者”。网络爬虫,是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。
网络爬虫,按照系统结构和实现技术,大致可以分为:“通用网路爬虫、聚焦网路爬虫、增量式网路爬虫、深层网络爬虫”等四种不同类型。实际上,网络爬虫系统,通常是由几种爬虫技术相结合实现的。
一、 通用网路爬虫
通用网路爬虫,又称“全网爬虫”,爬行对象从一些种子URL(统一资源定位符) 扩充到整个万维网,主要为“门户站点搜索引擎”和“大型Web服务提供商”采集数据。由于商业缘由,它们的技术细节甚少被公布下来。这类网路爬虫的爬行范围和数目巨大,对于爬行速率和储存空间要求较高,对于爬行页面的次序要求相对较低,同时因为等待刷新的页面太多,通常采用“并行工作”的方法,但须要较长时间能够刷新一次页面。通用网路爬虫,虽然存在着一定的缺陷,但它适用于为搜索引擎平台搜索广泛的主题,有较强的应用价值。
二、聚焦网络爬虫
聚焦网络爬虫,又称“主题网路爬虫”,是指选择性地爬行,那些与预先定义好的主题相关的页面的网路爬虫。和通用网路爬虫相比,聚焦网路爬虫只须要爬行与主题相关的页面,极大地节约了硬件和网路资源,保存的页面也因为数目少而更新快,还可以挺好地满足一些特定人群对特定领域信息的需求。
聚焦网络爬虫和通用网路爬虫相比,增加了“链接评价模块”以及“内容评价模块”。聚焦网路爬虫爬行策略实现的关键是,评价页面内容和链接的重要性。不同的方式估算出的重要性不同,由此引起链接的访问次序也不同。
三、增量式网络爬虫
是指对已下载网页采取增量式更新,和只爬行新形成的或则早已发生变化网页的爬虫网络爬虫技术是什么,它还能在一定程度上保证网络爬虫技术是什么,所爬行的页面是尽可能新的页面。
和周期性爬行和刷新页面的网路爬虫相比,增量式爬虫只会在须要的时侯爬行新形成或发生更新的页面 ,并不重新下载没有发生变化的页面,可有效降低数据下载量,及时更新已爬行的网页,减小时间和空间上的花费,但是降低了爬行算法的复杂度和实现难度。
四、深层网络爬虫
Web 页面,按存在形式可以分为“表层网页”和“深层网页”。表层网页是指传统搜索引擎可以索引的页面,以超链接可以抵达的静态网页为主构成的 Web 页面。
深层网页是这些大部分内容不能通过静态链接获取的、隐藏在搜索表单后的,只有用户递交一些关键词能够获得的 Web 页面。例如:那些用户注册后内容才可见的网页,就属于深层网页。
随着计算机网路的迅速发展,万维网成为大量信息的载体,如何有效地提取并借助这种信息成为一个巨大的挑战。搜索引擎,例如传统的“通用搜索引擎”平台:Google(谷歌)、Yahoo!(雅虎)、百度等,作为一个辅助人们检索万维网信息的工具,成为互联网用户访问万维网的入口和渠道。
但是,这些“通用搜索引擎平台”也存在着一定的局限性,如:
1、 不同领域、不同职业、不同背景的用户,往往具有不同的检索目的和需求,通用搜索引擎所返回的结果,包含了大量用户并不关心的网页,或者与用户搜索结果无关的网页。
2、 通用搜索引擎的目标是,实现尽可能大的网路覆盖率,有限的搜索引擎服务器资源,与无限的网路数据资源之间的矛盾将进一步加深。
3、 万维网数据方式的丰富和网路技术的不断发展,图片、数据库、音频、视频多媒体等不同数据大量出现,通用搜索引擎常常对这种信息浓度密集,且具有一定结构的数据无能为力,不能挺好地发觉和获取。
4、通用搜索引擎,大多提供基于“关键字”的检索,难以支持按照语义信息提出的查询。
为了解决上述问题,定向抓取相关网页资源的“聚焦网路爬虫”应运而生。聚焦网路爬虫,是一个手动下载网页的程序,它按照既定的抓取目标,有选择的访问万维网上的网页与相关的链接,获取所须要的信息。
与“通用网路爬虫”不同,聚焦网络爬虫并不追求大的覆盖,而是将目标定为抓取“与某一特定主题内容相关的网页”,为面向主题的用户查询,准备数据资源。
“聚焦网路爬虫”的工作原理以及关键技术概述:
网络爬虫,是一个手动提取网页的程序,它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成。
传统爬虫,从一个或若干初始网页的URL(统一资源定位符)开始,获得初始网页上的URL(统一资源定位符),在抓取网页的过程中,不断从当前页面上抽取新的URL(统一资源定位符)放入队列,直到满足系统的一定停止条件。
“聚焦网路爬虫”的工作流程较为复杂,需要按照一定的“网页分析算法”过滤与主题无关的链接,保留有用的链接,并将其倒入等待抓取的URL(统一资源定位符)队列。然后,它将按照一定的搜索策略,从队列中选择下一步要抓取的网页URL(统一资源定位符),并重复上述过程,直到达到系统的某一条件时停止。
另外,所有被爬虫抓取的网页将会被系统储存,进行一定的剖析、过滤,并构建索引,以便以后的查询和检索。对于“聚焦网路爬虫”来说,这一过程所得到的剖析结果,还可能对之后的抓取过程给出反馈和指导。
相对于通用网路爬虫,聚焦网路爬虫还须要解决三个主要问题:
1、对抓取目标的描述或定义;
2、对网页或数据的剖析与过滤;
3、对URL(统一资源定位符)的搜索策略。
网络爬虫碰到的问题:
早在2007 年底,互联网上的网页数目就早已超出160 亿个,研究表明接近30%的页面是重复的。动态页面的存在,客户端、服务器端脚本语言的应用,使得指向相同Web信息的 URL(统一资源定位符)数量呈指数级下降。
上述特点促使网路爬虫面临一定的困难,主要彰显在 Web信息的巨大容量,使得爬虫在给定的时间内,只能下载少量网页。有研究表明,没有那个搜索引擎才能索引超出16%的互联网Web 页面,即使才能提取全部页面,也没有足够的空间来储存。
为了提升爬行效率,爬虫须要在单位时间内尽可能多的获取高质量页面,这是它面临的困局之一。
当前有五种表示页面质量高低的方法:1、页面与爬行主题之间的相似度;2、页面在 Web 图中的入度大小;3、指向它的所有页面平均残差之和;4、页面在 Web 图中的出度大小;5、页面的信息位置。
为了提升爬行速率,网络爬虫一般会采取“并行爬行”的工作方式,这种工作方式也造成了新的问题:
1、重复性(并行运行的爬虫或爬行线程同时运行时,增加了重复页面);
2、质量问题(并行运行时,每个爬虫或爬行线程只能获取部份页面,导致页面质量下滑);
3、通信带宽代价(并行运行时,各个爬虫或爬行线程之间不可避开要进行一些通讯,需要花费一定的带宽资源)。
并行运行时,网络爬虫一般采用三种形式:
1、独立形式(各个爬虫独立爬行页面,互不通讯);
2、动态分配方法(由一个中央协调器动态协调分配 URL 给各个爬虫);
3、静态分配方法(URL 事先界定给各个爬虫)。
亿速云,作为一家专业的IDC(互联网数据中心)业务服务提供商、拥有丰富行业底蕴的专业云计算服务提供商,一直专注于技术创新和构建更好的服务品质,致力于为广大用户,提供高性价比、高可用性的“裸金属服务器、云服务器、高防服务器、高防IP、香港服务器、日本服务器、美国服务器、SSL证书”等专业产品与服务。
主流开源爬虫框架比较与剖析
采集交流 • 优采云 发表了文章 • 0 个评论 • 350 次浏览 • 2020-07-03 08:01
2.1 网路爬虫的组成部分主流爬虫框架一般由以下部份组成:1. 种子URL库:URL用于定位互联网中的各种资源,如最常见的网页链接,还有常见的文件资源、流媒体资源等。种子URL库作为网络爬虫的入口,标识出爬虫应当从何处开始运行,指明了数据来源。2.数据下载器:针对不同的数据种类,需要不同的下载形式。主流爬虫框架通畅提供多种数据下载器,用来下载不同的资源,如静态网页下载器、动态网页下载器、FTP下载器等。3.过滤器:对于早已爬取的URL,智能的爬虫须要对其进行过滤,以提升爬虫的整体效率。常用的过滤器有基于集合的过滤器、基于布隆过滤的过滤器等。4.流程调度器:合理的调度爬取流程,也可以提升爬虫的整体效率。在流程调度器中,通常提供深度优先爬取、广度优先爬取、订制爬取等爬取策略。同时提供单线程、多线程等多种爬取方法。2.2 网络爬虫的爬取策略网路爬虫的爬取策略,可以更高效的组织爬虫的爬取过程。常见的爬取策略包括深度优先爬取、深度优先爬取、订制爬取等策略等。1.深度优先爬取:该策略在爬取每位URL资源后,会随机爬取改URL对应的所有子URL资源,直到全部子URL资源全部爬取完毕,再爬取下一个URL资源。
深度优先爬取更关注数据的深度,希望通过爬取更多的子URL资源,来获取更深层次的数据。2.广度优先爬取:该策略在爬取配个URL资源时,会继续爬取同层次的其他URL资源,当本层的URL资源都被爬取完毕后,再爬取下一次URL资源。广度优先爬取更关注数据的广度,这样可以囊括更全面的数据。3.订制爬取:再好多场景中,深度优先爬取或广度优先爬取未能满足复杂的数据采集需求,此时须要定制爬取策略,如垂直搜索策略,先通过制订关键词进行搜索后开源爬虫框架,再结合深度优先爬取或广度优先爬取,才可以获取到垂直领域的特定数据。2.3 爬虫的增量爬取从数据的角度看,有些爬虫只进行单次的爬取操作,而有些爬虫须要进行增量爬取,用来积累数据。对于单次爬取的网路爬虫,实现较为简单,因为不用考虑过滤去重等操作,所以模块相对较少。单次爬取的爬虫主要考虑爬取的效率,有时会通过多线程或多进程等形式提升爬取效率。对于须要增量爬取的网路爬虫。通常须要对URL链接、资源内容等进行过滤和去重。每次爬取的时侯,需要对比数据是否重复,并将早已爬取过的内容过滤掉,从而降低冗余数据的爬取和储存。实际应用中,增量爬虫的使用较为广泛。3.主流开源爬虫框架爬虫技术发展至今,已经非常成熟,同时也形成了好多开源的爬虫框架,入Nutch、Heritrix、Larbin、Scrapy,这些开源框架的实现语言与功能各不相同,以下是这几款开源爬虫框架的比较与剖析。
3.1 NutchNutch是一个比较小型的开源框架,也是隶属于Apache基金会的一个开源项目。Nutch最初服务于Lucene项目,Lucene是一个完整的搜索引擎框架,其中Nutch提供数据爬取服务。因为Lucene是一个通用的搜索引擎框架,所以Nutch在设计之初也主要用于通用数据的爬取。在满足通用需求的同时,Nutch牺牲了一些多样化开发的特点。优点:Nutch适用于各类规模的爬取任务,底层可以和Hadoop平台对接,提供分布式的爬取功能,同时支持分布式的调度及分布式的储存。为了扩充各种多样化功能,Nutch设计了插件框架,可以通过添加插件,来实现愈发复杂的爬取功能。缺点:虽然有插件框架,但是Nutch的多样化开发成本仍然较高。 在使用默认的配置过滤文件是,是不抓取动态网页的,要想爬取动态网页须要更改过滤规则。3.2 HeritrixHeritrix是基于Java语言的爬虫框架,因其可扩展型和丰富的各种组件而闻名。但配置相对繁杂,所以学习成本过高。Heritrix提供了多种下载器,用于下载网页、流媒体等多种类型的数据。Heritrix还提供了图形界面拿来管理爬虫,可以通过网页来启动货控制各种爬虫。
优点:Heritrix的爬虫订制参数多包括,可设置输出日志、可设置多线程采集模式、可设置下载速率上限等 开发者可以通过更改组件的参数,来高效的更改爬虫功能 。缺点:Heritrix很难实现分布式爬取,因为多个单独爬虫之间,无法合作完成爬取任务,可扩展性较差。在爬取失败时,也缺少重万方数据 67 ELECTRONICS WORLD 探求与观察工作台处于清洁的状态,并监督工作人员防静电腕带的配戴情况,且使用的钳子须要具有防静电的功能,或者在取料的时侯利用真空吸笔完成,放置静电在元器件于手接触时形成,第四,定期对相关设施进行防静电测试处理 [6] 。二、SMT表面贴装技术的发展趋势近些年来,我国科学技术水平在社会经济快速发展的影响下得到了迅猛发展,表面贴装技术在此背景下也获得了宽广的发展空间,并将会以小型化、精细化的方向不断发展。针对SMT表面贴装技术的发展趋势进行剖析可以发觉,在未来的发展过程中,将会大幅度缩小SDC/SMD的容积,并其而不断扩大其生产数目,就现阶段表面贴装技术的发展现况而言,将0603以及1005型表面贴膜式电容和内阻商品化的目的已然实现。同时,集成电路的发展方向将会是小型化和STM化,现阶段,市场上早已出现了腿宽度为0.3mm的IC业,其发展方向将是BGA。
此外,焊接技术也将会逐步趋向成熟阶段,惰性气体于1994年便早已被点焊设备厂家制造下来以满足回流焊以及波峰焊的需求。与此同时免清洗工业也涌现下来但是应用非常广泛。最后,测试设备以及贴片设备的效率将会大幅度提高,且灵活性也会不断增强。目前,在使用SMT技术的时侯,其贴片速率大概在5500片/h左右,通过使用高柔化和智能化的贴片系统促使制造商的生产成品被大幅度增加,进而促使生产效率以及精度的提高,并且丰富了贴片的功能 [7] 。三、结束语与传统的THT而言,SMT的优势主要表现在其性能好、组装密度高以及体积小和可靠性强等方面,受到其上述优势的影响,现阶段电子设备以及电子产品的装配技术均以SMT为主,并且在电子产品的生产制造领域得到广泛应用。尽管在实际应用的时侯,SMT仍然表现出一些不足之处,但是与其所发挥的正面影响对比,这些不足并不影响该技术应用价值。所以,需要加强SMT技术的宣传力度,促进其应用可以覆盖更多领域。与此同时,还须要加到对该技术的研究力度,对其各项工艺流程给以建立,促进其所用得到充分发挥,继而有助于电子产品工艺制程清洁化、装备模块化、生产集成化和自动化的愿景尽快实现,为电子行业的可持续发展提供可靠保障。
参考文献[1] 杨柳.SMT表面贴装技术工艺应用实践[J].科研,2016(8):00079-00079.[2]孙丹妮,周娟,耿豪凯,等.累积和与指数加权移动平均控制图在表面贴装技术中的应用及仿真[J].机械制造,2017,55(3):77-80.[3]朱飞飞.谈电子工业中SMT技术的工艺研究和发展趋势[J].科研,2016(8):00286-00286.[4] 高文璇.Protel DXP技术与SMT技术在现今电子产业中的应用[J].电子世 界,2014(6):95-95.[5]王婷,方子正.SMD型表面贴装元件壳体生产中技术难点和解决举措[J].工程技术:全文版,2016(7):00253-00253.[6]周超.阐述SMT表面贴装技术工艺应用与发展趋势[J].科研,2016(12):00008-00008.[7]李金明.电子工业中SMT技术工艺研究及发展趋势[J].电子技术与软件工程,2016(13):139-139.(上接第65页)试等机制,导致开发者须要做好多额外工作来填补那些设计上的缺位。不同于Nutch框架开源爬虫框架,仅凭Heritrix不能完成搜索引擎的全部工作,而只能完成爬虫阶段的爬取工作。
3.3 LarbinLarbin是一个基于C++语言的爬虫框架。Larbin提供了相对简单单非常易用的爬虫功能。单机Larbin爬虫可以每晚获取百万量级的网页。单Larbin不提供网页解析服务,也不考虑内容的储存及处理。如果象使用Larbin进行小型系统的实现,则须要自行开发相应的其他组件。优点:指定入口URL后,可以手动扩充,甚至整个网站镜像;支持通过后缀名对抓取网页进行过滤;只保存原始网页;利用C++开发,非常高效。缺点:只有网页下载器,而没有网页解析器。不支持分布式爬取。没有手动重试功能。该项目在2003年后停止开发维护。 3.4 ScrapyScrapy是基于python语言开发的爬虫框架,由于它的轻量化设计和简单易用,而广泛遭到开发者的欢迎。优点:简单易用:只需编撰爬取规则,剩下由scrapy完成易扩充:扩展性设计,支持插件,无需改动核心代码可移植性:基于Linux、Windows、Mac、BSD开发和运行设计。缺点:单机多线程实现,不支持分布式。数据储存方案支持 Local fi lesystem、FTP、S3、Standard output,默认无分布式存储解决方案默认中间过程网页不会保存,只保存抽取结果。
4.总结与展望本文首先介绍了URL链接库、文档内容模块、文档解析模块等爬虫基础概念,然后对比剖析了Nutch、Heritrix、Larbin、Scrapy等主流开源爬虫框架。不同的爬虫开源框架的实现语言和功能不同,适用的场景也不尽相同,需要在实际应用中选择合适的开源爬虫框架。参考文献[1]刘玮玮.搜索引擎中主题爬虫的研究与实现[D].南京理工大学,2006.[2]詹恒飞,杨岳湘,方宏.Nutch分布式网路爬虫研究与优化[J].计算机科学与探求,2011,5(01):68-74.[3]安子建.基于Scrapy框架的网路爬虫实现与数据抓取剖析[D].吉林大学,2017.[4]周立柱,林玲.聚焦爬虫技术研究综述[J].计算机应用,2005(09):1965-1969.[5]杨定中,赵刚,王泰.网络爬虫在Web信息搜索与数据挖掘中应用[J].计算机工程与设计,2009,30(24):5658-5662.万方数据 查看全部
65 ELECTRONICS WORLD 探求与观察(下转第67页)主流开源爬虫框架比较与剖析北京工商大学 刘 雯【摘要】网络爬虫是搜索引擎与信息检索的基础工具,在信息采集、信息过滤等场景中有着广泛的应用。本文首先介绍了URL链接库、文档内容模块、文档解析模块等爬虫基础概念,然后对比剖析了Nutch、Heritrix、Larbin、Scrapy等主流开源爬虫框架。【关键词】网络爬虫;数据采集;搜索引擎1.引言近些年来,随着互联网的高速发展,网络中的数据呈现出了爆炸式的下降,如何搜集整合这种数据并从中提取出有效的信息,引发了多方面的挑战。面对这种挑战,爬虫技术得到了充分的注重。开源网路爬虫框架促使爬虫的开发与应用变的高效方便。各个开源爬虫框架的实现语言与功能不完全相同,适用场景也不尽相同,需要对比不同开源爬虫框架之间的好坏。2.爬虫的相关概念网路爬虫是用于互联网采集的一种工具,通常又被称为网路机器人。在数据挖掘、信息检索等领域,网络爬虫被广泛使用,从而获取最原始的数据。网络爬虫也是信息检索和搜索引擎的重要组成部份,通过网路爬虫采集到的信息,经过搜索引擎的整合,可以更好的用于检索。
2.1 网路爬虫的组成部分主流爬虫框架一般由以下部份组成:1. 种子URL库:URL用于定位互联网中的各种资源,如最常见的网页链接,还有常见的文件资源、流媒体资源等。种子URL库作为网络爬虫的入口,标识出爬虫应当从何处开始运行,指明了数据来源。2.数据下载器:针对不同的数据种类,需要不同的下载形式。主流爬虫框架通畅提供多种数据下载器,用来下载不同的资源,如静态网页下载器、动态网页下载器、FTP下载器等。3.过滤器:对于早已爬取的URL,智能的爬虫须要对其进行过滤,以提升爬虫的整体效率。常用的过滤器有基于集合的过滤器、基于布隆过滤的过滤器等。4.流程调度器:合理的调度爬取流程,也可以提升爬虫的整体效率。在流程调度器中,通常提供深度优先爬取、广度优先爬取、订制爬取等爬取策略。同时提供单线程、多线程等多种爬取方法。2.2 网络爬虫的爬取策略网路爬虫的爬取策略,可以更高效的组织爬虫的爬取过程。常见的爬取策略包括深度优先爬取、深度优先爬取、订制爬取等策略等。1.深度优先爬取:该策略在爬取每位URL资源后,会随机爬取改URL对应的所有子URL资源,直到全部子URL资源全部爬取完毕,再爬取下一个URL资源。
深度优先爬取更关注数据的深度,希望通过爬取更多的子URL资源,来获取更深层次的数据。2.广度优先爬取:该策略在爬取配个URL资源时,会继续爬取同层次的其他URL资源,当本层的URL资源都被爬取完毕后,再爬取下一次URL资源。广度优先爬取更关注数据的广度,这样可以囊括更全面的数据。3.订制爬取:再好多场景中,深度优先爬取或广度优先爬取未能满足复杂的数据采集需求,此时须要定制爬取策略,如垂直搜索策略,先通过制订关键词进行搜索后开源爬虫框架,再结合深度优先爬取或广度优先爬取,才可以获取到垂直领域的特定数据。2.3 爬虫的增量爬取从数据的角度看,有些爬虫只进行单次的爬取操作,而有些爬虫须要进行增量爬取,用来积累数据。对于单次爬取的网路爬虫,实现较为简单,因为不用考虑过滤去重等操作,所以模块相对较少。单次爬取的爬虫主要考虑爬取的效率,有时会通过多线程或多进程等形式提升爬取效率。对于须要增量爬取的网路爬虫。通常须要对URL链接、资源内容等进行过滤和去重。每次爬取的时侯,需要对比数据是否重复,并将早已爬取过的内容过滤掉,从而降低冗余数据的爬取和储存。实际应用中,增量爬虫的使用较为广泛。3.主流开源爬虫框架爬虫技术发展至今,已经非常成熟,同时也形成了好多开源的爬虫框架,入Nutch、Heritrix、Larbin、Scrapy,这些开源框架的实现语言与功能各不相同,以下是这几款开源爬虫框架的比较与剖析。
3.1 NutchNutch是一个比较小型的开源框架,也是隶属于Apache基金会的一个开源项目。Nutch最初服务于Lucene项目,Lucene是一个完整的搜索引擎框架,其中Nutch提供数据爬取服务。因为Lucene是一个通用的搜索引擎框架,所以Nutch在设计之初也主要用于通用数据的爬取。在满足通用需求的同时,Nutch牺牲了一些多样化开发的特点。优点:Nutch适用于各类规模的爬取任务,底层可以和Hadoop平台对接,提供分布式的爬取功能,同时支持分布式的调度及分布式的储存。为了扩充各种多样化功能,Nutch设计了插件框架,可以通过添加插件,来实现愈发复杂的爬取功能。缺点:虽然有插件框架,但是Nutch的多样化开发成本仍然较高。 在使用默认的配置过滤文件是,是不抓取动态网页的,要想爬取动态网页须要更改过滤规则。3.2 HeritrixHeritrix是基于Java语言的爬虫框架,因其可扩展型和丰富的各种组件而闻名。但配置相对繁杂,所以学习成本过高。Heritrix提供了多种下载器,用于下载网页、流媒体等多种类型的数据。Heritrix还提供了图形界面拿来管理爬虫,可以通过网页来启动货控制各种爬虫。
优点:Heritrix的爬虫订制参数多包括,可设置输出日志、可设置多线程采集模式、可设置下载速率上限等 开发者可以通过更改组件的参数,来高效的更改爬虫功能 。缺点:Heritrix很难实现分布式爬取,因为多个单独爬虫之间,无法合作完成爬取任务,可扩展性较差。在爬取失败时,也缺少重万方数据 67 ELECTRONICS WORLD 探求与观察工作台处于清洁的状态,并监督工作人员防静电腕带的配戴情况,且使用的钳子须要具有防静电的功能,或者在取料的时侯利用真空吸笔完成,放置静电在元器件于手接触时形成,第四,定期对相关设施进行防静电测试处理 [6] 。二、SMT表面贴装技术的发展趋势近些年来,我国科学技术水平在社会经济快速发展的影响下得到了迅猛发展,表面贴装技术在此背景下也获得了宽广的发展空间,并将会以小型化、精细化的方向不断发展。针对SMT表面贴装技术的发展趋势进行剖析可以发觉,在未来的发展过程中,将会大幅度缩小SDC/SMD的容积,并其而不断扩大其生产数目,就现阶段表面贴装技术的发展现况而言,将0603以及1005型表面贴膜式电容和内阻商品化的目的已然实现。同时,集成电路的发展方向将会是小型化和STM化,现阶段,市场上早已出现了腿宽度为0.3mm的IC业,其发展方向将是BGA。
此外,焊接技术也将会逐步趋向成熟阶段,惰性气体于1994年便早已被点焊设备厂家制造下来以满足回流焊以及波峰焊的需求。与此同时免清洗工业也涌现下来但是应用非常广泛。最后,测试设备以及贴片设备的效率将会大幅度提高,且灵活性也会不断增强。目前,在使用SMT技术的时侯,其贴片速率大概在5500片/h左右,通过使用高柔化和智能化的贴片系统促使制造商的生产成品被大幅度增加,进而促使生产效率以及精度的提高,并且丰富了贴片的功能 [7] 。三、结束语与传统的THT而言,SMT的优势主要表现在其性能好、组装密度高以及体积小和可靠性强等方面,受到其上述优势的影响,现阶段电子设备以及电子产品的装配技术均以SMT为主,并且在电子产品的生产制造领域得到广泛应用。尽管在实际应用的时侯,SMT仍然表现出一些不足之处,但是与其所发挥的正面影响对比,这些不足并不影响该技术应用价值。所以,需要加强SMT技术的宣传力度,促进其应用可以覆盖更多领域。与此同时,还须要加到对该技术的研究力度,对其各项工艺流程给以建立,促进其所用得到充分发挥,继而有助于电子产品工艺制程清洁化、装备模块化、生产集成化和自动化的愿景尽快实现,为电子行业的可持续发展提供可靠保障。
参考文献[1] 杨柳.SMT表面贴装技术工艺应用实践[J].科研,2016(8):00079-00079.[2]孙丹妮,周娟,耿豪凯,等.累积和与指数加权移动平均控制图在表面贴装技术中的应用及仿真[J].机械制造,2017,55(3):77-80.[3]朱飞飞.谈电子工业中SMT技术的工艺研究和发展趋势[J].科研,2016(8):00286-00286.[4] 高文璇.Protel DXP技术与SMT技术在现今电子产业中的应用[J].电子世 界,2014(6):95-95.[5]王婷,方子正.SMD型表面贴装元件壳体生产中技术难点和解决举措[J].工程技术:全文版,2016(7):00253-00253.[6]周超.阐述SMT表面贴装技术工艺应用与发展趋势[J].科研,2016(12):00008-00008.[7]李金明.电子工业中SMT技术工艺研究及发展趋势[J].电子技术与软件工程,2016(13):139-139.(上接第65页)试等机制,导致开发者须要做好多额外工作来填补那些设计上的缺位。不同于Nutch框架开源爬虫框架,仅凭Heritrix不能完成搜索引擎的全部工作,而只能完成爬虫阶段的爬取工作。
3.3 LarbinLarbin是一个基于C++语言的爬虫框架。Larbin提供了相对简单单非常易用的爬虫功能。单机Larbin爬虫可以每晚获取百万量级的网页。单Larbin不提供网页解析服务,也不考虑内容的储存及处理。如果象使用Larbin进行小型系统的实现,则须要自行开发相应的其他组件。优点:指定入口URL后,可以手动扩充,甚至整个网站镜像;支持通过后缀名对抓取网页进行过滤;只保存原始网页;利用C++开发,非常高效。缺点:只有网页下载器,而没有网页解析器。不支持分布式爬取。没有手动重试功能。该项目在2003年后停止开发维护。 3.4 ScrapyScrapy是基于python语言开发的爬虫框架,由于它的轻量化设计和简单易用,而广泛遭到开发者的欢迎。优点:简单易用:只需编撰爬取规则,剩下由scrapy完成易扩充:扩展性设计,支持插件,无需改动核心代码可移植性:基于Linux、Windows、Mac、BSD开发和运行设计。缺点:单机多线程实现,不支持分布式。数据储存方案支持 Local fi lesystem、FTP、S3、Standard output,默认无分布式存储解决方案默认中间过程网页不会保存,只保存抽取结果。
4.总结与展望本文首先介绍了URL链接库、文档内容模块、文档解析模块等爬虫基础概念,然后对比剖析了Nutch、Heritrix、Larbin、Scrapy等主流开源爬虫框架。不同的爬虫开源框架的实现语言和功能不同,适用的场景也不尽相同,需要在实际应用中选择合适的开源爬虫框架。参考文献[1]刘玮玮.搜索引擎中主题爬虫的研究与实现[D].南京理工大学,2006.[2]詹恒飞,杨岳湘,方宏.Nutch分布式网路爬虫研究与优化[J].计算机科学与探求,2011,5(01):68-74.[3]安子建.基于Scrapy框架的网路爬虫实现与数据抓取剖析[D].吉林大学,2017.[4]周立柱,林玲.聚焦爬虫技术研究综述[J].计算机应用,2005(09):1965-1969.[5]杨定中,赵刚,王泰.网络爬虫在Web信息搜索与数据挖掘中应用[J].计算机工程与设计,2009,30(24):5658-5662.万方数据
Python 网络爬虫实战:爬取并下载《电影天堂》3千多部动作片影片
采集交流 • 优采云 发表了文章 • 0 个评论 • 1518 次浏览 • 2020-07-03 08:00
我更加认为,爬虫似乎并不是哪些非常深奥的技术,它的价值不在于你使用了哪些非常牛的框架,用了多么了不起的技术,它不需要。它只是以一种自动化收集数据的小工具,能够获取到想要的数据,就是它最大的价值。
我的爬虫课老师也常跟我们指出,学习爬虫最重要的,不是学习上面的技术,因为后端技术在不断的发展,爬虫的技术便会随着改变。学习爬虫最重要的是,学习它的原理,万变不距其宗。
爬虫说白了是为了解决须要,方便生活的。如果还能在日常生活中,想到并应用爬虫去解决实际的问题,那么爬虫的真正意义也久发挥下来了。
这是些闲谈啦,有感而发而已。
最近有点片荒,不知道该看哪些影片,而且有些影片在网上找很久也找不到资源。后来我了解到这个网站,发现近来好多不错的影片里面都有资源(这里我就先不管它的来源正不正规啦,#掩面)。
所以此次我们要爬取的网站是:《电影天堂》,屯一些影片,等无趣的时侯拿出来瞧瞧,消遣闲暇也是不错。
这次的网站,从爬虫的技术角度上来讲,难度不大,而且可以说是十分简单了。但是,它实用啊!你想嘛,早上下班前跑一下爬虫,晚上回去之后早已有几十部最新大片在你硬碟里等着你啦,累了三天躺床上瞧瞧影片,这种觉得是不是太爽啊。
而且正由于这个爬虫比较简单,所以我会写的稍为细一点,争取使 python 小白们也能尽可能读懂,并且还能在这个爬虫的基础上更改,得到爬取这个网站其他蓝筹股或则其他影片网站的爬虫。
在编撰爬虫程序之前,我先捋一捋我们的思路。
爬虫的原理,是通过给定的一个URL(就是类似于 这样的,俗称网址的东东) 请求,去访问一个网页,获取哪个网页上的源代码(不知道源代码的,随便打开一个网页,右键,查看网页源代码,出来的一大堆象乱码一样的东西就是网页源代码,我们须要的数据就藏在这种源代码上面)并返回来。然后,通过一些手段(比如说json库,BeautifulSoup库,正则表达式等)从网页源代码中筛选出我们想要的数据(当然,前提是我们须要剖析网页结构,知道自己想要哪些数据,以及那些数据储存在网页的哪里网络爬虫下载,存放的位置有哪些特点等)。最后,将我们获取到的数据根据一定的格式,存储到本地或则数据库中,这样就完成了爬虫的全部工作。
当然,也有一些 「骚操作」,如果你嫌爬虫效率低,可以开多线程(就是相当于几十只爬虫同时给你爬,效率直接翻了几十倍);如果害怕爬取频度过低被网站封 IP,可以挂 IP 代理(相当于打几枪换个地方,对方网站就不知道你到底是爬虫还是正常访问的用户了);如果对方网站有反爬机制,那么也有一些骚操作可以绕开反爬机制(有点黑客攻守的觉得,有木有!)。这些都是后话了。
1. 分析网页的 URL 的组成结构
首先,我们须要剖析网页的 URL 的组成结构,主要关注两方面,一是怎样切换选择的影片类型,二是网页怎么翻页的。
电影类型
网址
剧情片
喜剧片
动作片
爱情片
科幻片
动画片
悬疑片
惊悚片
恐怖片
记录片
......
......
灾难片
武侠片
古装片
发现规律了吧,以后假如想爬其他类型的影片,只要改变 url 中的数字即可,甚至你可以写一个循环,把所有蓝筹股中的影片全部爬取出来。
页码
URL
第一页
第二页
第三页
第四页
除了第一页是 「index」外,其余页脚均是 「index_页码」的方式。
所以我们基本把握了网站的 url 的构成方式,这样我们就可以通过自己构造 url 来访问任意类型影片的任意一页了,是不是太酷。
2. 分析网站的页面结构
其次,我们剖析一下网站的页面结构,看一看我们须要的信息都藏在网页的哪些地方(在这之前我们先要明晰一下我们须要什么数据),由于我们这个目的是下载影片,所以对我有用的数据只有两个,电影名称和下载影片的磁力链接。
按 F12 召唤出开发者工具(这个工具可以帮助你快速定位网页中的元素在 html 源代码中位置)。
然后,我们可以发觉,电影列表中,每一部影片的信息储存在一个 <table> 标签里,而影片的名子,就藏在上面的一个 <a> 标签中。电影下载的磁力链接在影片的详情页面,而影片详情页面的网址也在这个<a> 标签中( href 属性的值)。
而下载的磁力链接,存放在 <tbody> 标签下的 <a> 标签中,是不是太好找啊!
最后我们来缕一缕思路,一会儿我们打算这样操作:通过上面的网址的构造规则,访问到网站的某一页,然后获取到这个页面里的所有 table 标签(这里储存着影片的数据),然后从每一个 table 标签中找到存有影片名称的 a 标签(这里可以领到影片名称以及详情页面的网址),然后通过这儿获取的网址访问影片的详情页面,在详情页面选购出 <tbody> 标签下的 <a> 标签(这里储存着影片的下载链接),这样我们就找到了我们所须要的全部数据了,是不是很简单啊。
爬虫的程序,我通常习惯把它分成五个部份, 一是主函数,作为程序的入口,二是爬虫调度器,三是网路恳求函数,四是网页解析函数,五是数据储存函数。
# 我们用到的库
import requests
import bs4
import re
import pandas as pd
1.网络恳求函数 :get_data (url)
负责访问指定的 url 网页,并将网页的内容返回,此部份功能比较简单固定,一般不需要做更改(除非你要挂代理,或者自定义恳求头等,可以做一些相应的调整)。
def get_data(url):
'''
功能:访问 url 的网页,获取网页内容并返回
参数:
url :目标网页的 url
返回:目标网页的 html 内容
'''
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}
try:
r = requests.get(url, headers=headers)
r.raise_for_status()
return r.text
except requests.HTTPError as e:
print(e)
print("HTTPError")
except requests.RequestException as e:
print(e)
except:
print("Unknown Error !")
2.网页解析函数:parse_data(html)
这个函数是整个爬虫程序的核心所在,整体思路在上一部分早已讲过了。我这儿使用的库是BeautifulSoup。
这部份的写法多种多样,有很多发挥的空间,也没有哪些太多固定的模式,因为这部份的写法是要随着不同网站的页面结构来做调整的,比如说有的网站提供了数据的 api 接口,那么返回的数据就是 json 格式,我们只须要调用 json 库就可以完成数据解析,而大部分的网站只能通过从网页源代码中一层层筛选(筛选手段也多种多样,什么正则表达式,beautifulsoup等等)。
这里须要依照数据的方式来选择不同的筛选策略,所以,知道原理就可以了,习惯哪些方式就用哪些方式,反正最后能领到数据就好了。
def parse_data(html):
'''
功能:提取 html 页面信息中的关键信息,并整合一个数组并返回
参数:html 根据 url 获取到的网页内容
返回:存储有 html 中提取出的关键信息的数组
'''
bsobj = bs4.BeautifulSoup(html,'html.parser')
info = []
# 获取电影列表
tbList = bsobj.find_all('table', attrs = {'class': 'tbspan'})
# 对电影列表中的每一部电影单独处理
for item in tbList:
movie = []
link = item.b.find_all('a')[1]
# 获取电影的名称
name = link["title"]
# 获取详情页面的 url
url = 'https://www.dy2018.com' + link["href"]
# 将数据存放到电影信息列表里
movie.append(name)
movie.append(url)
try:
# 访问电影的详情页面,查找电影下载的磁力链接
temp = bs4.BeautifulSoup(get_data(url),'html.parser')
tbody = temp.find_all('tbody')
# 下载链接有多个(也可能没有),这里将所有链接都放进来
for i in tbody:
download = i.a.text
movie.append(download)
#print(movie)
# 将此电影的信息加入到电影列表中
info.append(movie)
except Exception as e:
print(e)
return info
3. 数据储存函数:save_data(data)
这个函数目的是将数据储存到本地文件或数据库中,具体的写法要按照实际须要的储存方式来定,我这儿是将数据储存在本地的 csv 文件中。
当然这个函数也并不只能做这些事儿,比如你可以在这里写一些简单的数据处理的操作,比如说:数据清洗,数据去重等操作。
def save_data(data):
'''
功能:将 data 中的信息输出到文件中/或数据库中。
参数:data 将要保存的数据
'''
filename = 'Data/电影天堂/动作片.csv'
dataframe = pd.DataFrame(data)
dataframe.to_csv(filename, mode='a', index=False, sep=',', header=False)
4. 爬虫调度器:main()
这个函数负责按照 url 生成规则,构造新的 url 请求,然后依次调用网路恳求函数,网页解析函数,数据储存函数,爬取并保存该页数据。
所谓爬虫调度器,就是控制爬虫哪些时侯开始爬,多少只爬虫一起爬,爬那个网页,爬多久休息一次,等等这种事儿。
def main():
# 循环爬取多页数据
for page in range(1, 114):
print('正在爬取:第' + str(page) + '页......')
# 根据之前分析的 URL 的组成结构,构造新的 url
if page == 1:
index = 'index'
else:
index = 'index_' + str(page)
url = 'https://www.dy2018.com/2/'+ index +'.html'
# 依次调用网络请求函数,网页解析函数,数据存储函数,爬取并保存该页数据
html = get_data(url)
movies = parse_data(html)
save_data(movies)
print('第' + str(page) + '页完成!')
5. 主函数:程序入口
主函数作为程序的入口,只负责启动爬虫调度器。
这里我通常习惯在 main() 函数前后输出一条句子,以此判定爬虫程序是否正常启动和结束。
if __name__ == '__main__':
print('爬虫启动成功!')
main()
print('爬虫执行完毕!')
运行了两个小时左右吧,终于爬完了 113 页,共 3346 部动作片影片的数据(本来不止这种的,但是有一些影片没有提供下载链接,我在 excel 中排序后直接自动剔除了)。
然后想看哪些影片的话,直接复制这种影片下载的磁力链接,到迅雷上面下载就好啦。
1. 在网站提供的下载链接中,我试了一下,发现magnet 开头的这类链接置于迅雷中可以直接下载,而 ftp 开头的链接在迅雷中总显示资源获取失败(我不知道是不是我打开的形式不对,反正就是下载不来),于是我对程序做了一些小的调整,使其只获取magnet 这类的链接。
修改的方法也很简单,只须要调整 网页解析函数 即可(爬虫的五个部份是相对独立的,修改时只需调整相应的模块即可,其余部份无需更改)。
def parse_data(html):
'''
功能:提取 html 页面信息中的关键信息,并整合一个数组并返回
参数:html 根据 url 获取到的网页内容
返回:存储有 html 中提取出的关键信息的数组
'''
bsobj = bs4.BeautifulSoup(html,'html.parser')
info = []
# 获取表头信息
tbList = bsobj.find_all('table', attrs = {'class': 'tbspan'})
for item in tbList:
movie = []
link = item.b.find_all('a')[1]
name = link["title"]
url = 'https://www.dy2018.com' + link["href"]
try:
# 查找电影下载的磁力链接
temp = bs4.BeautifulSoup(get_data(url),'html.parser')
tbody = temp.find_all('tbody')
for i in tbody:
download = i.a.text
if 'magnet:?xt=urn:btih' in download:
movie.append(name)
movie.append(url)
movie.append(download)
#print(movie)
info.append(movie)
break
except Exception as e:
print(e)
return info
注意代码 26 行处,我加了一个 if 语句的判定,如果下载链接中包含magnet:?xt=urn:btih 字符串,则视为有效链接,下载出来,否则跳过。
2. 我仍然在想能不能有个办法使迅雷一键批量下载我们爬到的影片。使用 python 操纵第三方的软件,这或许很难的。不之后来找到了一种方式,也算是解决了这个问题。
就是我们发觉迅雷软件启动后,会手动检查我们的剪切板,只要我们复制了下载链接,它便会手动弹出下载的提示框。借助这个思路,我们可以使用代码,将下载的链接复制步入剪切板,等下载框手动出现后,手动确认开始下载(这是我目前想到的最好的办法了,不知道诸位大鳄有没有更好的思路,欢迎指导交流)。
import pyperclip
import os
import pandas as pd
imageData = pd.read_csv("Data/电影天堂/动作片2.csv",names=['name','link','download'],encoding = 'gbk')
# 获取电影的下载链接,并用换行符分隔
a_link = imageData['download']
links = '\n'.join(a_link)
# 复制到剪切板
pyperclip.copy(links);
print('已粘贴');
# 打开迅雷
thunder_path = r'D:\Program Files (x86)\Thunder Network\Thunder9\Program\Thunder.exe'
os.startfile(thunder_path)
亲测可以实现,但是。。。不建议尝试(你能想像迅雷打开的一瞬间创建几百个下载任务的场景吗?反正我的笔记本是缓了好久好久才反应过来)。大家还是老老实实的,手动复制链接下载吧(csv文件可以用 excel 打开网络爬虫下载,竖着选中一列,然后复制,也能达到相同的疗效),这种骚操作很蠢了还是不要试了。
啰啰嗦嗦的写了很多,也不知道关键的问题讲清楚了没有。有那里没讲清楚,或者那里讲的不合适的话,欢迎恐吓。
其实吧,写文章,写博客,写教程,都是一个知识重新熔炼内化的过程,在写这篇博客的时侯,我也仍然在反复考量我学习爬虫的过程,以及我爬虫代码一步步的变化,从一开始的所有代码全部揉在主函数中,到后来把一些变动较少的功能提取下来,写成单独的函数,再到后来产生基本稳定的五大部份。
以至于在我后来学习使用 scrapy 框架时侯,惊人的发觉 scrapy 框架的结构跟我的爬虫结构有着异曲同工之妙,我的这个相当于是一个简易版的爬虫框架了,纯靠自己摸索达到这个疗效,我觉得还是很有成就感的。 查看全部
不知不觉,玩爬虫玩了一个多月了。
我更加认为,爬虫似乎并不是哪些非常深奥的技术,它的价值不在于你使用了哪些非常牛的框架,用了多么了不起的技术,它不需要。它只是以一种自动化收集数据的小工具,能够获取到想要的数据,就是它最大的价值。
我的爬虫课老师也常跟我们指出,学习爬虫最重要的,不是学习上面的技术,因为后端技术在不断的发展,爬虫的技术便会随着改变。学习爬虫最重要的是,学习它的原理,万变不距其宗。
爬虫说白了是为了解决须要,方便生活的。如果还能在日常生活中,想到并应用爬虫去解决实际的问题,那么爬虫的真正意义也久发挥下来了。
这是些闲谈啦,有感而发而已。
最近有点片荒,不知道该看哪些影片,而且有些影片在网上找很久也找不到资源。后来我了解到这个网站,发现近来好多不错的影片里面都有资源(这里我就先不管它的来源正不正规啦,#掩面)。
所以此次我们要爬取的网站是:《电影天堂》,屯一些影片,等无趣的时侯拿出来瞧瞧,消遣闲暇也是不错。
这次的网站,从爬虫的技术角度上来讲,难度不大,而且可以说是十分简单了。但是,它实用啊!你想嘛,早上下班前跑一下爬虫,晚上回去之后早已有几十部最新大片在你硬碟里等着你啦,累了三天躺床上瞧瞧影片,这种觉得是不是太爽啊。
而且正由于这个爬虫比较简单,所以我会写的稍为细一点,争取使 python 小白们也能尽可能读懂,并且还能在这个爬虫的基础上更改,得到爬取这个网站其他蓝筹股或则其他影片网站的爬虫。
在编撰爬虫程序之前,我先捋一捋我们的思路。
爬虫的原理,是通过给定的一个URL(就是类似于 这样的,俗称网址的东东) 请求,去访问一个网页,获取哪个网页上的源代码(不知道源代码的,随便打开一个网页,右键,查看网页源代码,出来的一大堆象乱码一样的东西就是网页源代码,我们须要的数据就藏在这种源代码上面)并返回来。然后,通过一些手段(比如说json库,BeautifulSoup库,正则表达式等)从网页源代码中筛选出我们想要的数据(当然,前提是我们须要剖析网页结构,知道自己想要哪些数据,以及那些数据储存在网页的哪里网络爬虫下载,存放的位置有哪些特点等)。最后,将我们获取到的数据根据一定的格式,存储到本地或则数据库中,这样就完成了爬虫的全部工作。
当然,也有一些 「骚操作」,如果你嫌爬虫效率低,可以开多线程(就是相当于几十只爬虫同时给你爬,效率直接翻了几十倍);如果害怕爬取频度过低被网站封 IP,可以挂 IP 代理(相当于打几枪换个地方,对方网站就不知道你到底是爬虫还是正常访问的用户了);如果对方网站有反爬机制,那么也有一些骚操作可以绕开反爬机制(有点黑客攻守的觉得,有木有!)。这些都是后话了。
1. 分析网页的 URL 的组成结构
首先,我们须要剖析网页的 URL 的组成结构,主要关注两方面,一是怎样切换选择的影片类型,二是网页怎么翻页的。
电影类型
网址
剧情片
喜剧片
动作片
爱情片
科幻片
动画片
悬疑片
惊悚片
恐怖片
记录片
......
......
灾难片
武侠片
古装片
发现规律了吧,以后假如想爬其他类型的影片,只要改变 url 中的数字即可,甚至你可以写一个循环,把所有蓝筹股中的影片全部爬取出来。
页码
URL
第一页
第二页
第三页
第四页
除了第一页是 「index」外,其余页脚均是 「index_页码」的方式。
所以我们基本把握了网站的 url 的构成方式,这样我们就可以通过自己构造 url 来访问任意类型影片的任意一页了,是不是太酷。
2. 分析网站的页面结构
其次,我们剖析一下网站的页面结构,看一看我们须要的信息都藏在网页的哪些地方(在这之前我们先要明晰一下我们须要什么数据),由于我们这个目的是下载影片,所以对我有用的数据只有两个,电影名称和下载影片的磁力链接。
按 F12 召唤出开发者工具(这个工具可以帮助你快速定位网页中的元素在 html 源代码中位置)。
然后,我们可以发觉,电影列表中,每一部影片的信息储存在一个 <table> 标签里,而影片的名子,就藏在上面的一个 <a> 标签中。电影下载的磁力链接在影片的详情页面,而影片详情页面的网址也在这个<a> 标签中( href 属性的值)。
而下载的磁力链接,存放在 <tbody> 标签下的 <a> 标签中,是不是太好找啊!
最后我们来缕一缕思路,一会儿我们打算这样操作:通过上面的网址的构造规则,访问到网站的某一页,然后获取到这个页面里的所有 table 标签(这里储存着影片的数据),然后从每一个 table 标签中找到存有影片名称的 a 标签(这里可以领到影片名称以及详情页面的网址),然后通过这儿获取的网址访问影片的详情页面,在详情页面选购出 <tbody> 标签下的 <a> 标签(这里储存着影片的下载链接),这样我们就找到了我们所须要的全部数据了,是不是很简单啊。
爬虫的程序,我通常习惯把它分成五个部份, 一是主函数,作为程序的入口,二是爬虫调度器,三是网路恳求函数,四是网页解析函数,五是数据储存函数。
# 我们用到的库
import requests
import bs4
import re
import pandas as pd
1.网络恳求函数 :get_data (url)
负责访问指定的 url 网页,并将网页的内容返回,此部份功能比较简单固定,一般不需要做更改(除非你要挂代理,或者自定义恳求头等,可以做一些相应的调整)。
def get_data(url):
'''
功能:访问 url 的网页,获取网页内容并返回
参数:
url :目标网页的 url
返回:目标网页的 html 内容
'''
headers = {
'accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,image/apng,*/*;q=0.8',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.106 Safari/537.36',
}
try:
r = requests.get(url, headers=headers)
r.raise_for_status()
return r.text
except requests.HTTPError as e:
print(e)
print("HTTPError")
except requests.RequestException as e:
print(e)
except:
print("Unknown Error !")
2.网页解析函数:parse_data(html)
这个函数是整个爬虫程序的核心所在,整体思路在上一部分早已讲过了。我这儿使用的库是BeautifulSoup。
这部份的写法多种多样,有很多发挥的空间,也没有哪些太多固定的模式,因为这部份的写法是要随着不同网站的页面结构来做调整的,比如说有的网站提供了数据的 api 接口,那么返回的数据就是 json 格式,我们只须要调用 json 库就可以完成数据解析,而大部分的网站只能通过从网页源代码中一层层筛选(筛选手段也多种多样,什么正则表达式,beautifulsoup等等)。
这里须要依照数据的方式来选择不同的筛选策略,所以,知道原理就可以了,习惯哪些方式就用哪些方式,反正最后能领到数据就好了。
def parse_data(html):
'''
功能:提取 html 页面信息中的关键信息,并整合一个数组并返回
参数:html 根据 url 获取到的网页内容
返回:存储有 html 中提取出的关键信息的数组
'''
bsobj = bs4.BeautifulSoup(html,'html.parser')
info = []
# 获取电影列表
tbList = bsobj.find_all('table', attrs = {'class': 'tbspan'})
# 对电影列表中的每一部电影单独处理
for item in tbList:
movie = []
link = item.b.find_all('a')[1]
# 获取电影的名称
name = link["title"]
# 获取详情页面的 url
url = 'https://www.dy2018.com' + link["href"]
# 将数据存放到电影信息列表里
movie.append(name)
movie.append(url)
try:
# 访问电影的详情页面,查找电影下载的磁力链接
temp = bs4.BeautifulSoup(get_data(url),'html.parser')
tbody = temp.find_all('tbody')
# 下载链接有多个(也可能没有),这里将所有链接都放进来
for i in tbody:
download = i.a.text
movie.append(download)
#print(movie)
# 将此电影的信息加入到电影列表中
info.append(movie)
except Exception as e:
print(e)
return info
3. 数据储存函数:save_data(data)
这个函数目的是将数据储存到本地文件或数据库中,具体的写法要按照实际须要的储存方式来定,我这儿是将数据储存在本地的 csv 文件中。
当然这个函数也并不只能做这些事儿,比如你可以在这里写一些简单的数据处理的操作,比如说:数据清洗,数据去重等操作。
def save_data(data):
'''
功能:将 data 中的信息输出到文件中/或数据库中。
参数:data 将要保存的数据
'''
filename = 'Data/电影天堂/动作片.csv'
dataframe = pd.DataFrame(data)
dataframe.to_csv(filename, mode='a', index=False, sep=',', header=False)
4. 爬虫调度器:main()
这个函数负责按照 url 生成规则,构造新的 url 请求,然后依次调用网路恳求函数,网页解析函数,数据储存函数,爬取并保存该页数据。
所谓爬虫调度器,就是控制爬虫哪些时侯开始爬,多少只爬虫一起爬,爬那个网页,爬多久休息一次,等等这种事儿。
def main():
# 循环爬取多页数据
for page in range(1, 114):
print('正在爬取:第' + str(page) + '页......')
# 根据之前分析的 URL 的组成结构,构造新的 url
if page == 1:
index = 'index'
else:
index = 'index_' + str(page)
url = 'https://www.dy2018.com/2/'+ index +'.html'
# 依次调用网络请求函数,网页解析函数,数据存储函数,爬取并保存该页数据
html = get_data(url)
movies = parse_data(html)
save_data(movies)
print('第' + str(page) + '页完成!')
5. 主函数:程序入口
主函数作为程序的入口,只负责启动爬虫调度器。
这里我通常习惯在 main() 函数前后输出一条句子,以此判定爬虫程序是否正常启动和结束。
if __name__ == '__main__':
print('爬虫启动成功!')
main()
print('爬虫执行完毕!')
运行了两个小时左右吧,终于爬完了 113 页,共 3346 部动作片影片的数据(本来不止这种的,但是有一些影片没有提供下载链接,我在 excel 中排序后直接自动剔除了)。
然后想看哪些影片的话,直接复制这种影片下载的磁力链接,到迅雷上面下载就好啦。
1. 在网站提供的下载链接中,我试了一下,发现magnet 开头的这类链接置于迅雷中可以直接下载,而 ftp 开头的链接在迅雷中总显示资源获取失败(我不知道是不是我打开的形式不对,反正就是下载不来),于是我对程序做了一些小的调整,使其只获取magnet 这类的链接。
修改的方法也很简单,只须要调整 网页解析函数 即可(爬虫的五个部份是相对独立的,修改时只需调整相应的模块即可,其余部份无需更改)。
def parse_data(html):
'''
功能:提取 html 页面信息中的关键信息,并整合一个数组并返回
参数:html 根据 url 获取到的网页内容
返回:存储有 html 中提取出的关键信息的数组
'''
bsobj = bs4.BeautifulSoup(html,'html.parser')
info = []
# 获取表头信息
tbList = bsobj.find_all('table', attrs = {'class': 'tbspan'})
for item in tbList:
movie = []
link = item.b.find_all('a')[1]
name = link["title"]
url = 'https://www.dy2018.com' + link["href"]
try:
# 查找电影下载的磁力链接
temp = bs4.BeautifulSoup(get_data(url),'html.parser')
tbody = temp.find_all('tbody')
for i in tbody:
download = i.a.text
if 'magnet:?xt=urn:btih' in download:
movie.append(name)
movie.append(url)
movie.append(download)
#print(movie)
info.append(movie)
break
except Exception as e:
print(e)
return info
注意代码 26 行处,我加了一个 if 语句的判定,如果下载链接中包含magnet:?xt=urn:btih 字符串,则视为有效链接,下载出来,否则跳过。
2. 我仍然在想能不能有个办法使迅雷一键批量下载我们爬到的影片。使用 python 操纵第三方的软件,这或许很难的。不之后来找到了一种方式,也算是解决了这个问题。
就是我们发觉迅雷软件启动后,会手动检查我们的剪切板,只要我们复制了下载链接,它便会手动弹出下载的提示框。借助这个思路,我们可以使用代码,将下载的链接复制步入剪切板,等下载框手动出现后,手动确认开始下载(这是我目前想到的最好的办法了,不知道诸位大鳄有没有更好的思路,欢迎指导交流)。
import pyperclip
import os
import pandas as pd
imageData = pd.read_csv("Data/电影天堂/动作片2.csv",names=['name','link','download'],encoding = 'gbk')
# 获取电影的下载链接,并用换行符分隔
a_link = imageData['download']
links = '\n'.join(a_link)
# 复制到剪切板
pyperclip.copy(links);
print('已粘贴');
# 打开迅雷
thunder_path = r'D:\Program Files (x86)\Thunder Network\Thunder9\Program\Thunder.exe'
os.startfile(thunder_path)
亲测可以实现,但是。。。不建议尝试(你能想像迅雷打开的一瞬间创建几百个下载任务的场景吗?反正我的笔记本是缓了好久好久才反应过来)。大家还是老老实实的,手动复制链接下载吧(csv文件可以用 excel 打开网络爬虫下载,竖着选中一列,然后复制,也能达到相同的疗效),这种骚操作很蠢了还是不要试了。
啰啰嗦嗦的写了很多,也不知道关键的问题讲清楚了没有。有那里没讲清楚,或者那里讲的不合适的话,欢迎恐吓。
其实吧,写文章,写博客,写教程,都是一个知识重新熔炼内化的过程,在写这篇博客的时侯,我也仍然在反复考量我学习爬虫的过程,以及我爬虫代码一步步的变化,从一开始的所有代码全部揉在主函数中,到后来把一些变动较少的功能提取下来,写成单独的函数,再到后来产生基本稳定的五大部份。
以至于在我后来学习使用 scrapy 框架时侯,惊人的发觉 scrapy 框架的结构跟我的爬虫结构有着异曲同工之妙,我的这个相当于是一个简易版的爬虫框架了,纯靠自己摸索达到这个疗效,我觉得还是很有成就感的。
网络爬虫的设计与实现
采集交流 • 优采云 发表了文章 • 0 个评论 • 376 次浏览 • 2020-07-02 08:01
页面下载后页面解析器除去页面上的 HTML标记后得到页面内容,将摘要、URL 等信息保存到 Web数据库中,同时抽取当前页面上新的 URL,保存到 URL队列,直到满足系统停止条件。其原理如图 1 所示。1. 2 爬行策略为提升工作效率,通用网路爬虫会采取一定的爬行策略优先爬取重要的网页。常用的有深度优先和长度优先策略。宽度优先算法的设计和实现相对简单,可以覆盖尽可能多的网页网络爬虫设计,是使用最广泛的一种爬行策略。一个爬虫怎样借助长度优先遍历来抓取网页呢?在爬虫中,每个链接对应一个 HTML 页面或则其它文件,通常将 HTML 页面上的超链接称为"子节点"。整个长度优文章编号 :1672-7800(2012)001-0136-02先爬虫就是从一系列的种子节点开始,把这种网页中的"子节点"提取下来,放到队列中依次进行抓取。被访问过的节点装入到另一张表中,过程如图 2 所示。新解析出的URL图 1 通用爬虫工作流程 图 2 宽度优先爬虫过程1. 3 爬虫队列设计爬虫队列设计是网路爬虫的关键。因为爬虫队列要储存大量的 URL,所以借助本地数组或则队列肯定是不够的,应当找寻一个性价比高的数据库来储存 URL 队列,Berkeley DB 是目前一种比较流行的内存数据库。
根据爬虫的特性, Hash 表成为了一种比较好的选择。但是在使用 Hash 存储 URL 字符串的时侯常用 MD5 算法来对URL 进行压缩。在实现了爬虫队列以后就要继续实现 Visited 表了。如何在大量的 URL 中分辨什么是新的、哪些是被访问过的呢?通常使用的技术就是布隆过滤器 (Bloom Filter) 。利用布隆过滤器判定一个元素是否在集合中是目前比较高效实用的方式。1. 4 设计爬虫构架爬虫框架结构如图 3 所示。图 3 爬虫结构作者简介:王娟 0983一) ,女,湖南宁乡人,硕士,贵州民族学院讲师,研究方向为数据挖掘、网络安全;吴金鹏 0989 一) ,男,山西大同人,贵州民族学院本科生,研究方向为计算机科学与技术。第 4 期 王 娟,吴金鹏:网络爬虫的设计与实现 137 其中:① URL Frontier 含有爬虫当前打算抓取的URL;②DNS 解析模块拿来解析域名(根据给定的 URL决定从那个 Web 获取网页) ;③解析模块提取文本和网页的链接集合;④重复清除模块决定一个解析下来的链接是否早已在 URL Fronier 或者是否近来下载过。下面通过实验来比较一下我们设计的爬虫抓取网页与原网页的对比,见图 4 、图 5 。
μ 溢圈圈酷自自" .. ‘';"也明i:::~:.O: ::汇图 4 原网页 图 5 抓取网页通过比较可以发觉,由于原网页有动漫等多媒体元素,虽然爬虫未能抓取出来全部内容,但基本上是一个完整的爬虫。2 限定爬虫的设计与实现限定爬虫就是对爬虫所爬取的主机的范围作一些限制。通常限定爬虫包含以下内容:①限定域名的爬虫;②限定爬取层数的爬虫;③限定 IP 的抓取;④限定语言的抓取。限定域名的抓取,是一种最简单的限定抓取,只须要依照当前 URL 字符串的值来做出限定即可。限定爬虫爬取的层次要比限定域名更复杂。限定 IP是限定抓取中最难的一部分。通常分为限定特定 IP 和限定某一地区的 IP。限定特定 IP 抓取较为容易,只要通过URL 就可以获得主机 IP 地址,如果主机 IP 在被限制的列表中就不抓取。否则正常工作。想要限定 IP 抓取,首先要按照主机字符串获得 IP 地址。下面我们通过实验来得到 IP 地址:贵州民族学院:主机域名: IP 地址 :210.40.132.8贵州大学:主机域名: IP 地址 :210.40.0.58根据 URL 得到 IP 地址以后,就要按照 IP 地址对某一地区的 IP 作出限制。
但是须要有一个 IP 与地区对应的数据库,网上好多这样的数据库都是收费的,在此我们使用的是腾讯公司推出的一款免费数据库 "QQWry.da t". ,只要输入 IP 地址就可以查到对应 IP 地址所在的区域。输入 :210.40.0.58输出 2贵州省贵阳市:贵州大学输入: 210.40. 132.8 输出:贵州省贵阳市:贵州民族学院按照 IP 地址制做一张列表,将限制地区的 IP 地址写入列表,爬虫假如检查到要抓取的 IP 地址属于该列表,就舍弃抓取,这样一个限定爬虫就完成了。3 结束语本文介绍了爬虫的工作原理,重点介绍了通用爬虫和限定爬虫的设计及实现,并通过实验证明本文设计的爬虫可以达到预期疗效。参考文献:[lJ 孙立伟,何国辉,吴礼发.网络爬虫技术的研究[J].电脑知识与技术, 20100日.[2J 于成龙,于洪波.网络爬虫技术研究[J].东莞理工学院学报, 2011(3). [3J 罗刚.自己动手写搜索引擎[M]. 北京:电子工业出版社, 2009.[4J 唐泼.网络爬虫的设计与实现[J].电脑知识与技术, 2009( 1).[5J 龚勇.搜索引擎中网路爬虫的研究[DJ. 武汉:武汉理工大学, 2010.(责任编辑 2 杜能钢)The Design and Implementation of 飞布eb Crawler Abstract: With the growing of Internet , search engine technology develops rapidly. As an indispensable part of search en-gine , web crawler is particularly important , its p巳rformance directly determines the quality of gathering webpage informa tion in large Internet . This paper designs and implements general crawler and limitative crawler. Key Words: Web Crawler; General Crawler; Limitative Crawler 查看全部
第11卷第4期2012年 4月软件导刊Software Guide Vo l. ll NO.4 组己旦2网路爬虫的设计与实现王娟,吴金鹏(贵州|民族学院计算机与信息工程学院,贵州l 贵阳 550025)摘 要:搜索引擎技术随着互联网的日渐壮大而急速发展。作为搜索引擎不可或缺的组成部分,网络爬虫的作用变得尤为重要网络爬虫设计,它的性能直接决定了在庞大的互联网上进行网页信息采集的质量。设计并实现了通用爬虫和限定爬虫。关键词:网络爬虫;通用爬虫;限定爬虫中图分类号 :TP393 文献标识码 :A。哥|言网路爬虫称作网路蜘蛛,它为搜索引擎从万维网上下载网页,并顺着网页的相关链接在 Web 中采集资源,是一个功能太强的网页手动抓取程序,也是搜索引擎的重要组成部份,爬虫设计的优劣直接决定着整个搜索引擎的性能及扩充能力。网络爬虫根据系统结构和实现技术,大致可以分为:通用网路爬虫、主题网路爬虫、增量式网路爬虫、深层网路爬虫 o 实际应用中一般是将几种爬虫技术相结合。1 通用爬虫的设计与实现1. 1 工作原理通用网路爬虫按照预先设定的一个或若干初始种子URL 开始,以此获得初始网页上的 URL 列表,在爬行过程中不断从 URL 队列中获一个个的 URL,进而访问并下载该页面。
页面下载后页面解析器除去页面上的 HTML标记后得到页面内容,将摘要、URL 等信息保存到 Web数据库中,同时抽取当前页面上新的 URL,保存到 URL队列,直到满足系统停止条件。其原理如图 1 所示。1. 2 爬行策略为提升工作效率,通用网路爬虫会采取一定的爬行策略优先爬取重要的网页。常用的有深度优先和长度优先策略。宽度优先算法的设计和实现相对简单,可以覆盖尽可能多的网页网络爬虫设计,是使用最广泛的一种爬行策略。一个爬虫怎样借助长度优先遍历来抓取网页呢?在爬虫中,每个链接对应一个 HTML 页面或则其它文件,通常将 HTML 页面上的超链接称为"子节点"。整个长度优文章编号 :1672-7800(2012)001-0136-02先爬虫就是从一系列的种子节点开始,把这种网页中的"子节点"提取下来,放到队列中依次进行抓取。被访问过的节点装入到另一张表中,过程如图 2 所示。新解析出的URL图 1 通用爬虫工作流程 图 2 宽度优先爬虫过程1. 3 爬虫队列设计爬虫队列设计是网路爬虫的关键。因为爬虫队列要储存大量的 URL,所以借助本地数组或则队列肯定是不够的,应当找寻一个性价比高的数据库来储存 URL 队列,Berkeley DB 是目前一种比较流行的内存数据库。
根据爬虫的特性, Hash 表成为了一种比较好的选择。但是在使用 Hash 存储 URL 字符串的时侯常用 MD5 算法来对URL 进行压缩。在实现了爬虫队列以后就要继续实现 Visited 表了。如何在大量的 URL 中分辨什么是新的、哪些是被访问过的呢?通常使用的技术就是布隆过滤器 (Bloom Filter) 。利用布隆过滤器判定一个元素是否在集合中是目前比较高效实用的方式。1. 4 设计爬虫构架爬虫框架结构如图 3 所示。图 3 爬虫结构作者简介:王娟 0983一) ,女,湖南宁乡人,硕士,贵州民族学院讲师,研究方向为数据挖掘、网络安全;吴金鹏 0989 一) ,男,山西大同人,贵州民族学院本科生,研究方向为计算机科学与技术。第 4 期 王 娟,吴金鹏:网络爬虫的设计与实现 137 其中:① URL Frontier 含有爬虫当前打算抓取的URL;②DNS 解析模块拿来解析域名(根据给定的 URL决定从那个 Web 获取网页) ;③解析模块提取文本和网页的链接集合;④重复清除模块决定一个解析下来的链接是否早已在 URL Fronier 或者是否近来下载过。下面通过实验来比较一下我们设计的爬虫抓取网页与原网页的对比,见图 4 、图 5 。
μ 溢圈圈酷自自" .. ‘';"也明i:::~:.O: ::汇图 4 原网页 图 5 抓取网页通过比较可以发觉,由于原网页有动漫等多媒体元素,虽然爬虫未能抓取出来全部内容,但基本上是一个完整的爬虫。2 限定爬虫的设计与实现限定爬虫就是对爬虫所爬取的主机的范围作一些限制。通常限定爬虫包含以下内容:①限定域名的爬虫;②限定爬取层数的爬虫;③限定 IP 的抓取;④限定语言的抓取。限定域名的抓取,是一种最简单的限定抓取,只须要依照当前 URL 字符串的值来做出限定即可。限定爬虫爬取的层次要比限定域名更复杂。限定 IP是限定抓取中最难的一部分。通常分为限定特定 IP 和限定某一地区的 IP。限定特定 IP 抓取较为容易,只要通过URL 就可以获得主机 IP 地址,如果主机 IP 在被限制的列表中就不抓取。否则正常工作。想要限定 IP 抓取,首先要按照主机字符串获得 IP 地址。下面我们通过实验来得到 IP 地址:贵州民族学院:主机域名: IP 地址 :210.40.132.8贵州大学:主机域名: IP 地址 :210.40.0.58根据 URL 得到 IP 地址以后,就要按照 IP 地址对某一地区的 IP 作出限制。
但是须要有一个 IP 与地区对应的数据库,网上好多这样的数据库都是收费的,在此我们使用的是腾讯公司推出的一款免费数据库 "QQWry.da t". ,只要输入 IP 地址就可以查到对应 IP 地址所在的区域。输入 :210.40.0.58输出 2贵州省贵阳市:贵州大学输入: 210.40. 132.8 输出:贵州省贵阳市:贵州民族学院按照 IP 地址制做一张列表,将限制地区的 IP 地址写入列表,爬虫假如检查到要抓取的 IP 地址属于该列表,就舍弃抓取,这样一个限定爬虫就完成了。3 结束语本文介绍了爬虫的工作原理,重点介绍了通用爬虫和限定爬虫的设计及实现,并通过实验证明本文设计的爬虫可以达到预期疗效。参考文献:[lJ 孙立伟,何国辉,吴礼发.网络爬虫技术的研究[J].电脑知识与技术, 20100日.[2J 于成龙,于洪波.网络爬虫技术研究[J].东莞理工学院学报, 2011(3). [3J 罗刚.自己动手写搜索引擎[M]. 北京:电子工业出版社, 2009.[4J 唐泼.网络爬虫的设计与实现[J].电脑知识与技术, 2009( 1).[5J 龚勇.搜索引擎中网路爬虫的研究[DJ. 武汉:武汉理工大学, 2010.(责任编辑 2 杜能钢)The Design and Implementation of 飞布eb Crawler Abstract: With the growing of Internet , search engine technology develops rapidly. As an indispensable part of search en-gine , web crawler is particularly important , its p巳rformance directly determines the quality of gathering webpage informa tion in large Internet . This paper designs and implements general crawler and limitative crawler. Key Words: Web Crawler; General Crawler; Limitative Crawler
【原创源码】网络爬虫
采集交流 • 优采云 发表了文章 • 0 个评论 • 365 次浏览 • 2020-07-02 08:01
最近因为女朋友工作需求,需要获取各大团购网站上的店家信息,这样自动一个一个点不得气死,于是我就写了一个网络爬虫来解决这个问题,是用java写的,主要用到了两个开源库,httpclient和jsoup...用来获取网页数据和得到想要的数据,不过最好是有点web基础网络爬虫代码,这样就可以只要想要的值,不然会有很多没用的数据,后期还要自动删掉,比较麻烦...下面附上源码和说明...
[Asm] 纯文本查看 复制代码
public static String getHtmlByUrl(String url){
String html = null;
HttpClient httpClient = new DefaultHttpClient();//创建httpClient对象
HttpGet httpget = new HttpGet(url);//以get方式请求该URL
try {
HttpResponse responce = httpClient.execute(httpget);//得到responce对象
int resStatu = responce.getStatusLine().getStatusCode();//返回码
if (resStatu==HttpStatus.SC_OK) {//200正常 其他就不对
//获得相应实体
HttpEntity entity = responce.getEntity();
if (entity!=null) {
//html = EntityUtils.toString(entity);//获得html源代码
InputStream in = entity.getContent();
entity.getContentType();
Scanner sc = new Scanner(in);
StringBuffer str = new StringBuffer("utf-8");
while(sc.hasNextLine()){
str.append(sc.nextLine());
}
html = str.toString();
//sc.close();
}
}
} catch (Exception e) {
System.out.println("访问【"+url+"】出现异常!");
e.printStackTrace();
} finally {
httpClient.getConnectionManager().shutdown();
}
return html;
}
上面的就是httpclient库的内容,用它来获取html页面的数据
[Java] 纯文本查看 复制代码
public static void main(String[] args) throws WriteException, IOException {
String html = getHtmlByUrl("需要获取数据的网址");
if (html!=null&&!"".equals(html)) {
Document doc = Jsoup.parse(html);
Elements linksElements = doc.select("div.basic>a"); //如果有web基础的话,可以设置一下这里,知道自己想要的数据
for (Element ele:linksElements) {
String href = ele.attr("href");
String title = ele.text();
System.out.println(href+","+title);
}
}
}
这个就是解析获取来的html数据,找到自己想要的数据....
然后把取到的数据存入excel获取txt里就随大伙便了,不过这个方式有一个漏洞就是,只能取静态页面,动态页面未能实现,我还要再继续研究一下,研究下来了,再发下来,如果有哪些不懂的网络爬虫代码,可以问我,知道的一定告诉你们,希望你们多评分,多鼓励,非常谢谢!!!! 查看全部
最近因为女朋友工作需求,需要获取各大团购网站上的店家信息,这样自动一个一个点不得气死,于是我就写了一个网络爬虫来解决这个问题,是用java写的,主要用到了两个开源库,httpclient和jsoup...用来获取网页数据和得到想要的数据,不过最好是有点web基础网络爬虫代码,这样就可以只要想要的值,不然会有很多没用的数据,后期还要自动删掉,比较麻烦...下面附上源码和说明...
[Asm] 纯文本查看 复制代码
public static String getHtmlByUrl(String url){
String html = null;
HttpClient httpClient = new DefaultHttpClient();//创建httpClient对象
HttpGet httpget = new HttpGet(url);//以get方式请求该URL
try {
HttpResponse responce = httpClient.execute(httpget);//得到responce对象
int resStatu = responce.getStatusLine().getStatusCode();//返回码
if (resStatu==HttpStatus.SC_OK) {//200正常 其他就不对
//获得相应实体
HttpEntity entity = responce.getEntity();
if (entity!=null) {
//html = EntityUtils.toString(entity);//获得html源代码
InputStream in = entity.getContent();
entity.getContentType();
Scanner sc = new Scanner(in);
StringBuffer str = new StringBuffer("utf-8");
while(sc.hasNextLine()){
str.append(sc.nextLine());
}
html = str.toString();
//sc.close();
}
}
} catch (Exception e) {
System.out.println("访问【"+url+"】出现异常!");
e.printStackTrace();
} finally {
httpClient.getConnectionManager().shutdown();
}
return html;
}
上面的就是httpclient库的内容,用它来获取html页面的数据
[Java] 纯文本查看 复制代码
public static void main(String[] args) throws WriteException, IOException {
String html = getHtmlByUrl("需要获取数据的网址");
if (html!=null&&!"".equals(html)) {
Document doc = Jsoup.parse(html);
Elements linksElements = doc.select("div.basic>a"); //如果有web基础的话,可以设置一下这里,知道自己想要的数据
for (Element ele:linksElements) {
String href = ele.attr("href");
String title = ele.text();
System.out.println(href+","+title);
}
}
}
这个就是解析获取来的html数据,找到自己想要的数据....
然后把取到的数据存入excel获取txt里就随大伙便了,不过这个方式有一个漏洞就是,只能取静态页面,动态页面未能实现,我还要再继续研究一下,研究下来了,再发下来,如果有哪些不懂的网络爬虫代码,可以问我,知道的一定告诉你们,希望你们多评分,多鼓励,非常谢谢!!!!
推荐10款流行的java开源的网络爬虫
采集交流 • 优采云 发表了文章 • 0 个评论 • 362 次浏览 • 2020-06-29 08:03
爬虫简介: WebCollector是一个无须配置、便于二次开发的JAVA爬虫框架(内核)java单机爬虫框架,它提供精简的的API,只需少量代码即可实现一个功能强悍的爬虫。WebCollector-Hadoop是WebCollector的Hadoop版本java单机爬虫框架,支持分布式爬取。 爬虫内核: WebCollector致...
2:开源通用爬虫框架YayCrawler(Star:91)
YayCrawler是一个基于WebMagic开发的分布式通用爬虫框架,开发语言是Java。我们晓得目前爬虫框架好多,有简单的,也有复杂的,有轻 量型的,也有重量型的
3:垂直爬虫WebMagic(Star:1213)
webmagic的是一个无须配置、便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代码即可实现一个爬虫。 以下是爬取oschina博客的一段代码: Spider.create(newSimplePageProcessor("", "http...
4:雅虎开源的Nutch爬虫插件 Anthelion(Star:2888)
Anthelion 是 Nutch 插件,专注于爬取语义数据。 注意:此项目包括完整的 Nutch 1.6 版本,此插件放置在 /src/plugin/parse-anth Anthelion 使用在线学习方式来基于页面上下文预测富数据 Web 页面,从之前查看的页面提取的元数据获取反馈。 主要有三个扩充: AnthelionScoringFilter WdcParser TripleExtractor 示例:...
5:Java开源网路爬虫项目Nutch
Nutch是一个开源Java实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具。包括全文搜索和Web爬虫。 Nutch的创始人是Doug Cutting,他同时也是Lucene、Hadoop和Avro开源项目的创始人。 Nutch诞生于2002年8月,是Apache旗下的一个用Java实现的开源搜索引擎项目,自Nutch1.2版本以后,Nutch早已从搜索引擎演...
6:Java网路蜘蛛/网络爬虫Spiderman(Star:1801)
Spiderman - 又一个Java网路蜘蛛/爬虫 Spiderman 是一个基于微内核+插件式构架的网路蜘蛛,它的目标是通过简单的方式能够将复杂的目标网页信息抓取并解析为自己所须要的业务数据。 最新提示:欢迎来体验最新版本Spiderman2,
7:轻量化的Java网路爬虫 GECCO(Star:658)
Gecco是哪些 Gecco是一款用java语言开发的轻量化的易用的网路爬虫。Gecco整合了jsoup、httpclient、fastjson、spring、htmlunit、redission等优秀框架,让您只须要配置一些jquery风格的选择器能够很快的写出一个爬虫。Gecco框架有优秀的可扩展性,框架基于开闭原则进行设计,对更改关掉、对扩充开放。同时Gecco基于非常开...
8:开源爬虫框架WebPasser(Star:15)
WebPasser是一款可配置的开源爬虫框架,提供爬虫控制台管理界面,通过配置解析各种网页内容,无需写一句java代码即可抽取所需数据。 1.包含强悍的页面解析引擎,提供jsoup、xpath、正则表达式等处理链,通过简单配置即可抽取所需的指定内容。 2.提供爬虫控制管理界面,可实时监控抓取状...
9:一个敏捷强悍的Java爬虫框架SeimiCrawler(Star:635)
SeimiCrawler是一个敏捷的,独立布署的,支持分布式的Java爬虫框架,希望能在最大程度上减少菜鸟开发一个可用性高且性能不差的爬虫系统的门槛,以及提高开发爬虫系统的开发效率。
10:爬虫系统NEOCrawler(Star:258)
NEOCrawler(中文名:牛咖),是nodejs、redis、phantomjs实现的爬虫系统。代码完全开源,适合用于垂直领域的数据采集和爬虫二次开发。 【主要特征】 使用nodejs实现,javascipt简单、高效、易学、为爬虫的开发以及爬虫使用者的二次开发节省不少时间;nodejs让...
推荐10款流行的java开源的网络爬虫 查看全部
1:JAVA爬虫WebCollector(Star:1345)
爬虫简介: WebCollector是一个无须配置、便于二次开发的JAVA爬虫框架(内核)java单机爬虫框架,它提供精简的的API,只需少量代码即可实现一个功能强悍的爬虫。WebCollector-Hadoop是WebCollector的Hadoop版本java单机爬虫框架,支持分布式爬取。 爬虫内核: WebCollector致...
2:开源通用爬虫框架YayCrawler(Star:91)
YayCrawler是一个基于WebMagic开发的分布式通用爬虫框架,开发语言是Java。我们晓得目前爬虫框架好多,有简单的,也有复杂的,有轻 量型的,也有重量型的
3:垂直爬虫WebMagic(Star:1213)
webmagic的是一个无须配置、便于二次开发的爬虫框架,它提供简单灵活的API,只需少量代码即可实现一个爬虫。 以下是爬取oschina博客的一段代码: Spider.create(newSimplePageProcessor("", "http...
4:雅虎开源的Nutch爬虫插件 Anthelion(Star:2888)
Anthelion 是 Nutch 插件,专注于爬取语义数据。 注意:此项目包括完整的 Nutch 1.6 版本,此插件放置在 /src/plugin/parse-anth Anthelion 使用在线学习方式来基于页面上下文预测富数据 Web 页面,从之前查看的页面提取的元数据获取反馈。 主要有三个扩充: AnthelionScoringFilter WdcParser TripleExtractor 示例:...
5:Java开源网路爬虫项目Nutch
Nutch是一个开源Java实现的搜索引擎。它提供了我们运行自己的搜索引擎所需的全部工具。包括全文搜索和Web爬虫。 Nutch的创始人是Doug Cutting,他同时也是Lucene、Hadoop和Avro开源项目的创始人。 Nutch诞生于2002年8月,是Apache旗下的一个用Java实现的开源搜索引擎项目,自Nutch1.2版本以后,Nutch早已从搜索引擎演...
6:Java网路蜘蛛/网络爬虫Spiderman(Star:1801)
Spiderman - 又一个Java网路蜘蛛/爬虫 Spiderman 是一个基于微内核+插件式构架的网路蜘蛛,它的目标是通过简单的方式能够将复杂的目标网页信息抓取并解析为自己所须要的业务数据。 最新提示:欢迎来体验最新版本Spiderman2,
7:轻量化的Java网路爬虫 GECCO(Star:658)
Gecco是哪些 Gecco是一款用java语言开发的轻量化的易用的网路爬虫。Gecco整合了jsoup、httpclient、fastjson、spring、htmlunit、redission等优秀框架,让您只须要配置一些jquery风格的选择器能够很快的写出一个爬虫。Gecco框架有优秀的可扩展性,框架基于开闭原则进行设计,对更改关掉、对扩充开放。同时Gecco基于非常开...
8:开源爬虫框架WebPasser(Star:15)
WebPasser是一款可配置的开源爬虫框架,提供爬虫控制台管理界面,通过配置解析各种网页内容,无需写一句java代码即可抽取所需数据。 1.包含强悍的页面解析引擎,提供jsoup、xpath、正则表达式等处理链,通过简单配置即可抽取所需的指定内容。 2.提供爬虫控制管理界面,可实时监控抓取状...
9:一个敏捷强悍的Java爬虫框架SeimiCrawler(Star:635)
SeimiCrawler是一个敏捷的,独立布署的,支持分布式的Java爬虫框架,希望能在最大程度上减少菜鸟开发一个可用性高且性能不差的爬虫系统的门槛,以及提高开发爬虫系统的开发效率。
10:爬虫系统NEOCrawler(Star:258)
NEOCrawler(中文名:牛咖),是nodejs、redis、phantomjs实现的爬虫系统。代码完全开源,适合用于垂直领域的数据采集和爬虫二次开发。 【主要特征】 使用nodejs实现,javascipt简单、高效、易学、为爬虫的开发以及爬虫使用者的二次开发节省不少时间;nodejs让...
推荐10款流行的java开源的网络爬虫
2019最新30个小时搞定Python网络爬虫(全套详尽版) 零基础入门 视频教
采集交流 • 优采云 发表了文章 • 0 个评论 • 381 次浏览 • 2020-06-26 08:01
1、零基础对Python网络爬虫感兴趣的开发者
2、想从事Python网路爬虫工程师相关工作的开发者
3、想学习Python网路爬虫作为技术储备的开发者
1、本课程的目标是将你们培养成Python网路爬虫工程师。薪资基本在13k-36k左右;
2、学完才能从零开始把握Python爬虫项目的编撰,学会独立开发常见的爬虫项目;
3、学完能把握常见的反爬处理手段爬虫入门书籍,比如验证码处理、浏览器伪装、代理IP池技术和用户代理池技术等;
4、学完才能熟练使用正则表达式和XPath表达式进行信息提取;
5、学完把握抓包技术,掌握屏蔽的数据信息怎样进行提取,学会手动模拟加载行为、进行网址构造和手动模拟Ajax异步恳求数据;
6、熟练把握urllib模块,熟练使用Scrapy框架进行爬虫项目开发。
第一章节:Python 网络爬虫之基础
第二章节:Python网路爬虫之工作原理
第三章节:Python网路爬虫之正则表达式
第五章节:Python网路爬虫之用户和IP代理池
第六章节 :Python网路爬虫之腾讯陌陌和视频实战
第七章节:Python网路爬虫之Scrapy框架
第八章节:Python网路爬虫之Scrapy与Urllib的整合
第九章节:Python网路爬虫之扩充学习
第十章节:Python网路爬虫之分布式爬虫 查看全部
这是一套完整的网路爬虫课程,通过该课程把握网路爬虫的相关知识,以便把握网路爬虫方方面面的知识,学完后胜任网路爬虫相关工作。 1、体系完整科学,可以系统化学习; 2、课程通俗易懂爬虫入门书籍,可以使学员真正学会; 3、从零开始教学直至深入,零基础的朋友亦可以学习!
1、零基础对Python网络爬虫感兴趣的开发者
2、想从事Python网路爬虫工程师相关工作的开发者
3、想学习Python网路爬虫作为技术储备的开发者
1、本课程的目标是将你们培养成Python网路爬虫工程师。薪资基本在13k-36k左右;
2、学完才能从零开始把握Python爬虫项目的编撰,学会独立开发常见的爬虫项目;
3、学完能把握常见的反爬处理手段爬虫入门书籍,比如验证码处理、浏览器伪装、代理IP池技术和用户代理池技术等;
4、学完才能熟练使用正则表达式和XPath表达式进行信息提取;
5、学完把握抓包技术,掌握屏蔽的数据信息怎样进行提取,学会手动模拟加载行为、进行网址构造和手动模拟Ajax异步恳求数据;
6、熟练把握urllib模块,熟练使用Scrapy框架进行爬虫项目开发。
第一章节:Python 网络爬虫之基础
第二章节:Python网路爬虫之工作原理
第三章节:Python网路爬虫之正则表达式
第五章节:Python网路爬虫之用户和IP代理池
第六章节 :Python网路爬虫之腾讯陌陌和视频实战
第七章节:Python网路爬虫之Scrapy框架
第八章节:Python网路爬虫之Scrapy与Urllib的整合
第九章节:Python网路爬虫之扩充学习
第十章节:Python网路爬虫之分布式爬虫
网络爬虫技术之同时抓取多个网页
采集交流 • 优采云 发表了文章 • 0 个评论 • 879 次浏览 • 2020-06-26 08:01
$curlobj = curl_init(); //创建一个curl 的资源,下面要用的curl_setopt($curlobj,CURLOPT_URL,""); //获取资源curl_setopt($curlobj,CURLOPT_RETURNTRANSFER,true); //请求结果不直接复印 $output = curl_exec($cu
爬虫爬取多个不相同网页
任务四‘’’本任务要求你们完成一个简单的爬虫项目,包括网页爬取、信息提取以及数据保存在完成本次任务时,建议你们认真思索,结合自己的逻辑,完成任务。注意:本任务的得分将根据任务递交时间的先后次序与任务正确率结合来估算,由于每个朋友的题目都不相同,建议不要剽窃,一旦发觉剽窃情况,本次任务判为0分’’’from typing import Any, Tuple‘’’第一题:请使用爬虫技术...
Scrapy爬取多层级网页内容的方法
# -*- coding: utf-8 -*-import scrapyfrom Avv.items import AvvItemclass AvSpider(scrapy.Spider):name = 'av' # 爬虫名allowed_domains = ['/'] # 爬虫作用域# 爬取第2页到最后一页的代码url = ...
爬虫——scrapy框架爬取多个页面影片的二级子页面的详尽信息
文章目录需求:总结:代码:movieinfo.pyitems.pymiddleware.pypipelines.py结果:附加:需求:scrapy框架,爬取某影片网页面的每位影片的一级页面的名子爬取每部影片二级页面的详尽信息使用代理ip保存日志文件存为csv文件总结:1、xpath解析使用extract()的各类情况剖析
网络爬虫初步:从一个入口链接开始不断抓取页面中的网址并入库
前言: 在上一篇《网络爬虫初步:从访问网页到数据解析》中,我们讨论了怎样爬取网页,对爬取的网页进行解析,以及访问被拒绝的网站。在这一篇博客中,我们可以来了解一下领到解析的数据可以做的风波。在这篇博客中,我主要是说明要做的两件事,一是入库,二是遍历领到的链接继续访问。如此往复,这样就构成了一个网络爬虫的雏型。笔者环境: 系统: Windows 7...
php爬虫
Php爬虫,爬取数据,识图猜词语一、寻找数据1,寻找相关网站数据剖析网站换页特点剖析得出不仅第一页,第二页开始index加页面数写一个函数,专门拼接须要访问的页面public function getcy($id=3,$num=3){$i=$id;...
爬取多个页面的数据
代码如下:# -*- coding:utf8 -*-#导入requests库,取别称resimport requests as res#导入bs4包,取别称bsfrom bs4 import BeautifulSoup as bs#导入数据库驱动包import MySQLdb#声明页面从哪开始j = 1#循环遍历每位页面while j 111:##获取目标网站的网页
Python爬虫实例(3)-用BeautifulSoup爬取多个可翻页网页上的多张相片
# -*- coding: utf-8 -*-#导入第三方包和模块import requestsfrom bs4 import BeautifulSoupimport os#在本地新建一个文件夹,命名为test_img,用以保存下载的图片folder = 'test_img'if not os.path.exists(folder):os.makedirs(folder)#定义
用WebMagic框架 爬某网站(多个页面)的内容 、启动爬虫有时候能抓取成功、
用WebMagic框架 爬某网站(多个页面)的内容 、启动爬虫有时候能抓取成功、有时候启动以后没任何反应3S然后程序停止。问哪些会这样,求解
webmagic爬虫自学(三)爬取CSDN【列表+详情的基本页面组合】的页面,使用基于注解的方法
1
如何实现两个页面的跳转
_addEvent:function(){var btn;btn=this._getWidgetByName(this._startGav,"Button_7");//获取按键的点击实风波btn.addTouchEventListener(this._inputHandler.bind(this),this._startGav);},_inputHandler:
爬虫——第二次试验(网站多页爬取代码)
实验目的熟练把握requests库中get技巧的使用把握借助requests库爬取多页网页内容的方式2.1 爬取百度贴吧与某主题相关的贴子,并将爬取到的内容保存到文件中(爬取多页)import requestsdef get_page(url):headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) ...
给你们推荐几种实现网页数据抓取的方法
相信所有个人网站的站长都有抓取他人数据的经历吧,目前抓取他人网站数据的方法无非两种形式: 一、使用第三方工具,其中最知名的是优采云采集器,在此不做介绍。 二、自己写程序抓取,这种方法要求站长自己写程序
java爬取百度百科词条
lz在之前的一篇博客中,用python实现了爬取百度百科的词条,就在怎么用java来实现相同的功能,果不其然,java用一个jsoup的第三方库工具就可以很简单地实现爬取百度百科的词条。同样的,将这个爬取过程分成5个部份来实现。分别是connectnet联接url部份、parsehtml获取html相关内容部份、startspyder部份、store储存url部份、urlmanager的url管理
关于使用Java实现的简单网路爬虫Demo
什么是网络爬虫?网络爬虫又叫蜘蛛,网络蜘蛛是通过网页的链接地址来找寻网页,从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这种链接地址找寻下一个网页,这样仍然循环下去,直到把这个网站所有的网页都抓取完为止。如果把整个互联网当作一个网站,那么网路蜘蛛就可以用这个原理把互联网上所有的网页都抓取出来。所以要想抓取网路上的数据,不仅须要爬虫程序还须要一个可以接受
Java爬虫爬取python百度百科词条及相关词条页面
Java爬虫爬取python百度百科词条及相关词条页面本实例爬取关于python词条页面及关联词条页面的简介网络爬虫论坛,把词条的简介写入txt文本中, 本实例疗效:实例基于使用第三方jar包Jsoup1首先剖析python词条页面:可以发觉其他词条的超链接都带有"/item"以及词条的简介都包含在class为
python scrapy项目下spiders内多个爬虫同时运行
一般创建了scrapy文件夹后,可能须要写多个爬虫,如果想使它们同时运行而不是顺次运行的话,得怎样做?a、在spiders目录的同级目录下创建一个commands目录网络爬虫论坛,并在该目录中创建一个crawlall.py,将scrapy源代码里的commands文件夹里的crawl.py源码复制过来,只更改run()方法即可!import osfrom ...
算法设计中关于优先队列式分支限界法解装载问题的代码下载
分支限界法中的优先队列式分支限界法解装载问题相关下载链接:
软件调试张银奎(7)下载
软件调试张银奎(4)软件调试张银奎(4)软件调试张银奎(4)相关下载链接:
WimTool-WIM文件处理工具安装版下载
WimTool-WIM文件处理工具安装版相关下载链接:
相关热词c#如何获得线程名c# usb 采集器c# sort()c#面对对象的三大特点c# 打印 等比缩放c#弹出右键菜单c# 系统托盘图标c# 键值对 键可以重复c# 鼠标移起来提示c#结构体定义
我们是挺有底线的 查看全部
$curlobj = curl_init(); //创建一个curl 的资源,下面要用的curl_setopt($curlobj,CURLOPT_URL,""); //获取资源curl_setopt($curlobj,CURLOPT_RETURNTRANSFER,true); //请求结果不直接复印 $output = curl_exec($cu
爬虫爬取多个不相同网页
任务四‘’’本任务要求你们完成一个简单的爬虫项目,包括网页爬取、信息提取以及数据保存在完成本次任务时,建议你们认真思索,结合自己的逻辑,完成任务。注意:本任务的得分将根据任务递交时间的先后次序与任务正确率结合来估算,由于每个朋友的题目都不相同,建议不要剽窃,一旦发觉剽窃情况,本次任务判为0分’’’from typing import Any, Tuple‘’’第一题:请使用爬虫技术...
Scrapy爬取多层级网页内容的方法
# -*- coding: utf-8 -*-import scrapyfrom Avv.items import AvvItemclass AvSpider(scrapy.Spider):name = 'av' # 爬虫名allowed_domains = ['/'] # 爬虫作用域# 爬取第2页到最后一页的代码url = ...
爬虫——scrapy框架爬取多个页面影片的二级子页面的详尽信息
文章目录需求:总结:代码:movieinfo.pyitems.pymiddleware.pypipelines.py结果:附加:需求:scrapy框架,爬取某影片网页面的每位影片的一级页面的名子爬取每部影片二级页面的详尽信息使用代理ip保存日志文件存为csv文件总结:1、xpath解析使用extract()的各类情况剖析
网络爬虫初步:从一个入口链接开始不断抓取页面中的网址并入库
前言: 在上一篇《网络爬虫初步:从访问网页到数据解析》中,我们讨论了怎样爬取网页,对爬取的网页进行解析,以及访问被拒绝的网站。在这一篇博客中,我们可以来了解一下领到解析的数据可以做的风波。在这篇博客中,我主要是说明要做的两件事,一是入库,二是遍历领到的链接继续访问。如此往复,这样就构成了一个网络爬虫的雏型。笔者环境: 系统: Windows 7...
php爬虫
Php爬虫,爬取数据,识图猜词语一、寻找数据1,寻找相关网站数据剖析网站换页特点剖析得出不仅第一页,第二页开始index加页面数写一个函数,专门拼接须要访问的页面public function getcy($id=3,$num=3){$i=$id;...
爬取多个页面的数据
代码如下:# -*- coding:utf8 -*-#导入requests库,取别称resimport requests as res#导入bs4包,取别称bsfrom bs4 import BeautifulSoup as bs#导入数据库驱动包import MySQLdb#声明页面从哪开始j = 1#循环遍历每位页面while j 111:##获取目标网站的网页
Python爬虫实例(3)-用BeautifulSoup爬取多个可翻页网页上的多张相片
# -*- coding: utf-8 -*-#导入第三方包和模块import requestsfrom bs4 import BeautifulSoupimport os#在本地新建一个文件夹,命名为test_img,用以保存下载的图片folder = 'test_img'if not os.path.exists(folder):os.makedirs(folder)#定义
用WebMagic框架 爬某网站(多个页面)的内容 、启动爬虫有时候能抓取成功、
用WebMagic框架 爬某网站(多个页面)的内容 、启动爬虫有时候能抓取成功、有时候启动以后没任何反应3S然后程序停止。问哪些会这样,求解
webmagic爬虫自学(三)爬取CSDN【列表+详情的基本页面组合】的页面,使用基于注解的方法
1
如何实现两个页面的跳转
_addEvent:function(){var btn;btn=this._getWidgetByName(this._startGav,"Button_7");//获取按键的点击实风波btn.addTouchEventListener(this._inputHandler.bind(this),this._startGav);},_inputHandler:
爬虫——第二次试验(网站多页爬取代码)
实验目的熟练把握requests库中get技巧的使用把握借助requests库爬取多页网页内容的方式2.1 爬取百度贴吧与某主题相关的贴子,并将爬取到的内容保存到文件中(爬取多页)import requestsdef get_page(url):headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) ...
给你们推荐几种实现网页数据抓取的方法
相信所有个人网站的站长都有抓取他人数据的经历吧,目前抓取他人网站数据的方法无非两种形式: 一、使用第三方工具,其中最知名的是优采云采集器,在此不做介绍。 二、自己写程序抓取,这种方法要求站长自己写程序
java爬取百度百科词条
lz在之前的一篇博客中,用python实现了爬取百度百科的词条,就在怎么用java来实现相同的功能,果不其然,java用一个jsoup的第三方库工具就可以很简单地实现爬取百度百科的词条。同样的,将这个爬取过程分成5个部份来实现。分别是connectnet联接url部份、parsehtml获取html相关内容部份、startspyder部份、store储存url部份、urlmanager的url管理
关于使用Java实现的简单网路爬虫Demo
什么是网络爬虫?网络爬虫又叫蜘蛛,网络蜘蛛是通过网页的链接地址来找寻网页,从网站某一个页面(通常是首页)开始,读取网页的内容,找到在网页中的其它链接地址,然后通过这种链接地址找寻下一个网页,这样仍然循环下去,直到把这个网站所有的网页都抓取完为止。如果把整个互联网当作一个网站,那么网路蜘蛛就可以用这个原理把互联网上所有的网页都抓取出来。所以要想抓取网路上的数据,不仅须要爬虫程序还须要一个可以接受
Java爬虫爬取python百度百科词条及相关词条页面
Java爬虫爬取python百度百科词条及相关词条页面本实例爬取关于python词条页面及关联词条页面的简介网络爬虫论坛,把词条的简介写入txt文本中, 本实例疗效:实例基于使用第三方jar包Jsoup1首先剖析python词条页面:可以发觉其他词条的超链接都带有"/item"以及词条的简介都包含在class为
python scrapy项目下spiders内多个爬虫同时运行
一般创建了scrapy文件夹后,可能须要写多个爬虫,如果想使它们同时运行而不是顺次运行的话,得怎样做?a、在spiders目录的同级目录下创建一个commands目录网络爬虫论坛,并在该目录中创建一个crawlall.py,将scrapy源代码里的commands文件夹里的crawl.py源码复制过来,只更改run()方法即可!import osfrom ...
算法设计中关于优先队列式分支限界法解装载问题的代码下载
分支限界法中的优先队列式分支限界法解装载问题相关下载链接:
软件调试张银奎(7)下载
软件调试张银奎(4)软件调试张银奎(4)软件调试张银奎(4)相关下载链接:
WimTool-WIM文件处理工具安装版下载
WimTool-WIM文件处理工具安装版相关下载链接:
相关热词c#如何获得线程名c# usb 采集器c# sort()c#面对对象的三大特点c# 打印 等比缩放c#弹出右键菜单c# 系统托盘图标c# 键值对 键可以重复c# 鼠标移起来提示c#结构体定义
我们是挺有底线的
开源的网路爬虫larbin
采集交流 • 优采云 发表了文章 • 0 个评论 • 323 次浏览 • 2020-06-26 08:00
利用larbin,我们可以轻易的获取/确定单个网站的所有连结,甚至可以镜像一个网站;也可以用它完善url 列表群,例如针对所有的网页进行 url retrive后,进行xml的连结的获取。或者是 mp3,或者订制larbin,可以作为搜索引擎的信息的来源。
不过它的最大的亮点还是开源,相信很多人领到larbin源代码的时侯会觉得无从入手,下面是一篇特别不错的开源的网络爬虫/网络蜘蛛larbin结构剖析的文章,有兴趣的最好仔细阅读尝试一下。
互联网是一个庞大的非结构化的数据库,将数据有效的检索并组织呈现下来有着巨大的应用前景,尤其是类似RSS的以XML为基础的结构化的数据越来越 多,内容的组织形式越来越灵活,检索组织并呈现会有着越来越广泛的应用范围,同时在时效性和可读性上也会有越来越高的要求。这一切的基础是爬虫,信息的来 源入口。一个高效,灵活可扩充的爬虫对以上应用都有着无可替代的重要意义。
要设计一个爬虫,首先须要考虑的效率。对于网路而言,基于TCP/IP的通讯编程有几种方式。
第一种是单线程阻塞,这是最简单也最容易实现的一种,一个事例:在Shell中通过curl,pcregrep等一系统命令可以直接实现一个简单的 爬虫,但同时它的效率问题也显而易见:由于是阻塞方法读取,dns解析,建立联接,写入恳求,读取结果这种步骤上就会形成时间的延后,从而未能有效的借助 服务器的全部资源。
第二种是多线程阻塞。建立多个阻塞的线程,分别恳求不同的url。相对于第一种方式,它可以更有效的借助机器的资源,特别是网路资源开源网络爬虫,因为无数线程 在同时工作,所以网路会比较充分的借助,但同时对机器CPU资源的消耗也是比较大,在用户级多线程间的频繁切换对于性能的影响早已值得我们考虑。
第三种是单线程非阻塞。这是目前使用的比较多的一种做法,无论在client还是server都有着广泛的应用。在一个线程内打开多个非阻塞的连 接,通过poll/epoll /select对联接状态进行判定,在第一时间响应恳求,不但充分利用了网路资源,同时也将本机CPU资源的消耗降至最低。这种方式须要对dns恳求,连 接,读写操作都采用异步非阻塞操作,其中第一种比较复杂,可以采用adns作为解决方案,后面三个操作相对简单可以直接在程序内实现。
效率问题解决后就须要考虑具体的设计问题了。
url肯定须要一个单独的类进行处理,包括显示,分析url,得到主机,端口,文件数据。
然后须要对url进行排重,需要一个比较大的url Hash表。
如果还要对网页内容进行排重,则还须要一个Document Hash表。
爬过的url须要记录出来,由于量比较大,我们将它讲到c盘上,所以还须要一个FIFO的类(记作urlsDisk)。
现在须要爬的url同样须要一个FIFO类来处理,重新开始时,url会从定时从爬过的url FIFO里取下来,写到这个FIFO里。正在运行的爬虫须要从这个FIFO里读数据下来,加入到主机类的url列表里。当然,也会从前一个FIFO里直接 读url下来,不过优先级应当比这个上面下来的url低,毕竟是早已爬过的。
爬虫通常是对多个网站进行爬取,但在同时站点内dns的恳求可以只做一次开源网络爬虫,这就须要将主机名独立于url,单独有一个类进行处理。
主机名解析完成后须要有一个解析完成的IP类与之应用,用于connect的时侯使用。
HTML文档的解析类也要有一个,用来剖析网页,取出上面的url,加入到urlsDisk。
再加上一些字符串,调度类,一个简单的爬虫基本上就完成了。
以上基本上是Larbin的设计思路,Larbin在具体实现上还有一些特殊的处理,例如带了一个webserver,以及对特殊文件的处理。 Larbin有一点设计不不太好,就是慢的访问会越来越多,占用大量的联接,需要改进,另外假如对于大规模的爬虫,这仅仅实现了抓取的部份,要分布式的扩 展还须要降低url的集中管理与调度以及前台spider的分布式算法。
Larbin网站爬虫简明使用说明
larbin是一种爬虫工具,我也是前段时间网上见到 Larbin 一种高效的搜索引擎爬虫工具 一文时才晓得有这么个东西,初步认定,我比较喜欢这个工具(比起nutch的crawl来说),因为它是C++写的,类似C嘛,我熟,可以自己改改,顺便 学习一下C++(几年来的经验告诉我说:改他人的东西来学一种技术比从头写helloworld快好多)。于是开始了我辛酸的larbin试用之旅。
回头瞧瞧自己遇见的问题都是因为没认真看文档造成的,唉,老毛病了。下次虽然是E文的也得好好看,不能盲目的试,浪费时间。
larbin官方地址:
一,编译
这也好说,whahahaha,那是!因为从官方网站下出来的代码不能编译通过(linux gcc下)
./configure
make
gcc -O3 -Wall -D_REENTRANT -c -o parse.o parse.c
parse.c:115: error: conflicting types for ’adns__parse_domain’
internal.h:571: error: previous declaration of ’adns__parse_domain’ was here
parse.c:115: error: conflicting types for ’adns__parse_domain’
internal.h:571: error: previous declaration of ’adns__parse_domain’ was here
gmake[1]: *** [parse.o] 错误 1
gmake[1]: Leaving directory `/home/leo/leo/larbin-2.6.3/adns’
make: *** [all] 错误 2
函数原型和定义不一致这个好改:
打开./adns/internal.h文件,把568-571行直接注释掉就行了。
二,运行
这个就不说了,./larbin就运行了,larbin.conf中先进行配置就可以了,这个配置就不说了。。
运行后可以:8081 看运行状态,不错的看法。 larbin.conf中有个:inputPort 1976配置,就是可以运行时降低要抓取的URL,这个看法非常好,可是?怎么加呢?象原本那样::1976那样是不行的,报 错???试了很久没结果,最后GDB跟踪了一下,唉,原来直接telnet host 1976进行降低就可以了。后来见到文档里写的亲亲楚楚,晕倒。。。。。
三,结果
哈哈,下班后找了台机子跑了上去,那晚午睡的时侯都梦到自己的搜索引擎赶GOOGLE超BAIDU了,那个激动啊。
第二天下班的时侯取看结果,发现目录下不仅些fifo*文件外哪些都没有,那个纠结。没办法啊,再看文档 How to customize Larbin 发现如此段说明:
The first thing you can define is the module you want to use for ouput. This defines what you want to do with the pages larbin gets. Here are the different options :
DEFAULT_OUTPUT : This module mainly does nothing, except statistics.
SIMPLE_SAVE : This module saves pages on disk. It stores 2000 files per directory (with an index).
MIRROR_SAVE : This module saves pages on disk with the hierarchy of the site they come from. It uses one directory per site.
STATS_OUTPUT : This modules makes some stats on the pages. In order to see the results, see :8081/output.html.
靠,默认哪些都没输出,于是认真的看了官方网站上仅有的两个文档,修改了options.h再编译,终于有结果了。
我的option中改了:
SIMPLE_SAVE 简单输出一个目录两千个文件,包含索引。
CGILEVEL=0 处理服务器端程序,也就是但url中包含? & = 之类的querString时也处理。
NO_DUP
其余可依据各自须要更改,详见: How to customize Larbin 一文。
四,问题
在使用过程中发觉,在抓网页的时侯,如果URL中包含未编码(encodurl)中文时,无法抓取,简单的看了一下在: src/utils/中的fileNormalize 有涉及。于是写了个encodurl函数加在url类的构造函数里,问题就解决了。
由于须要比较好的可定制性,这个工具其实还不大满足我的需求,最终我没使用她,而是自己用perl在WWW:SimpleRobot的基础上搞了个适宜我的。。再说了perl在字符蹿处理上应当不比C++慢,总的来说那种小工具性能还不错。。呵呵。
不过还是把这种写下来,给没看文档的同学(希望极少),也警示自己一定要认真看文档 查看全部
larbin是一种开源的网路爬虫/网路蜘蛛,由美国的年轻人 Sébastien Ailleret独立开发。larbin目的是能否跟踪页面的url进行扩充的抓取,最后为搜索引擎提供广泛的数据来源。Larbin只是一个爬虫,也就 是说larbin只抓取网页,至于怎样parse的事情则由用户自己完成。另外,如何储存到数据库以及完善索引的事情 larbin也不提供。一个简单的larbin的爬虫可以每晚获取500万的网页。
利用larbin,我们可以轻易的获取/确定单个网站的所有连结,甚至可以镜像一个网站;也可以用它完善url 列表群,例如针对所有的网页进行 url retrive后,进行xml的连结的获取。或者是 mp3,或者订制larbin,可以作为搜索引擎的信息的来源。
不过它的最大的亮点还是开源,相信很多人领到larbin源代码的时侯会觉得无从入手,下面是一篇特别不错的开源的网络爬虫/网络蜘蛛larbin结构剖析的文章,有兴趣的最好仔细阅读尝试一下。
互联网是一个庞大的非结构化的数据库,将数据有效的检索并组织呈现下来有着巨大的应用前景,尤其是类似RSS的以XML为基础的结构化的数据越来越 多,内容的组织形式越来越灵活,检索组织并呈现会有着越来越广泛的应用范围,同时在时效性和可读性上也会有越来越高的要求。这一切的基础是爬虫,信息的来 源入口。一个高效,灵活可扩充的爬虫对以上应用都有着无可替代的重要意义。
要设计一个爬虫,首先须要考虑的效率。对于网路而言,基于TCP/IP的通讯编程有几种方式。
第一种是单线程阻塞,这是最简单也最容易实现的一种,一个事例:在Shell中通过curl,pcregrep等一系统命令可以直接实现一个简单的 爬虫,但同时它的效率问题也显而易见:由于是阻塞方法读取,dns解析,建立联接,写入恳求,读取结果这种步骤上就会形成时间的延后,从而未能有效的借助 服务器的全部资源。
第二种是多线程阻塞。建立多个阻塞的线程,分别恳求不同的url。相对于第一种方式,它可以更有效的借助机器的资源,特别是网路资源开源网络爬虫,因为无数线程 在同时工作,所以网路会比较充分的借助,但同时对机器CPU资源的消耗也是比较大,在用户级多线程间的频繁切换对于性能的影响早已值得我们考虑。
第三种是单线程非阻塞。这是目前使用的比较多的一种做法,无论在client还是server都有着广泛的应用。在一个线程内打开多个非阻塞的连 接,通过poll/epoll /select对联接状态进行判定,在第一时间响应恳求,不但充分利用了网路资源,同时也将本机CPU资源的消耗降至最低。这种方式须要对dns恳求,连 接,读写操作都采用异步非阻塞操作,其中第一种比较复杂,可以采用adns作为解决方案,后面三个操作相对简单可以直接在程序内实现。
效率问题解决后就须要考虑具体的设计问题了。
url肯定须要一个单独的类进行处理,包括显示,分析url,得到主机,端口,文件数据。
然后须要对url进行排重,需要一个比较大的url Hash表。
如果还要对网页内容进行排重,则还须要一个Document Hash表。
爬过的url须要记录出来,由于量比较大,我们将它讲到c盘上,所以还须要一个FIFO的类(记作urlsDisk)。
现在须要爬的url同样须要一个FIFO类来处理,重新开始时,url会从定时从爬过的url FIFO里取下来,写到这个FIFO里。正在运行的爬虫须要从这个FIFO里读数据下来,加入到主机类的url列表里。当然,也会从前一个FIFO里直接 读url下来,不过优先级应当比这个上面下来的url低,毕竟是早已爬过的。
爬虫通常是对多个网站进行爬取,但在同时站点内dns的恳求可以只做一次开源网络爬虫,这就须要将主机名独立于url,单独有一个类进行处理。
主机名解析完成后须要有一个解析完成的IP类与之应用,用于connect的时侯使用。
HTML文档的解析类也要有一个,用来剖析网页,取出上面的url,加入到urlsDisk。
再加上一些字符串,调度类,一个简单的爬虫基本上就完成了。
以上基本上是Larbin的设计思路,Larbin在具体实现上还有一些特殊的处理,例如带了一个webserver,以及对特殊文件的处理。 Larbin有一点设计不不太好,就是慢的访问会越来越多,占用大量的联接,需要改进,另外假如对于大规模的爬虫,这仅仅实现了抓取的部份,要分布式的扩 展还须要降低url的集中管理与调度以及前台spider的分布式算法。
Larbin网站爬虫简明使用说明
larbin是一种爬虫工具,我也是前段时间网上见到 Larbin 一种高效的搜索引擎爬虫工具 一文时才晓得有这么个东西,初步认定,我比较喜欢这个工具(比起nutch的crawl来说),因为它是C++写的,类似C嘛,我熟,可以自己改改,顺便 学习一下C++(几年来的经验告诉我说:改他人的东西来学一种技术比从头写helloworld快好多)。于是开始了我辛酸的larbin试用之旅。
回头瞧瞧自己遇见的问题都是因为没认真看文档造成的,唉,老毛病了。下次虽然是E文的也得好好看,不能盲目的试,浪费时间。
larbin官方地址:
一,编译
这也好说,whahahaha,那是!因为从官方网站下出来的代码不能编译通过(linux gcc下)
./configure
make
gcc -O3 -Wall -D_REENTRANT -c -o parse.o parse.c
parse.c:115: error: conflicting types for ’adns__parse_domain’
internal.h:571: error: previous declaration of ’adns__parse_domain’ was here
parse.c:115: error: conflicting types for ’adns__parse_domain’
internal.h:571: error: previous declaration of ’adns__parse_domain’ was here
gmake[1]: *** [parse.o] 错误 1
gmake[1]: Leaving directory `/home/leo/leo/larbin-2.6.3/adns’
make: *** [all] 错误 2
函数原型和定义不一致这个好改:
打开./adns/internal.h文件,把568-571行直接注释掉就行了。
二,运行
这个就不说了,./larbin就运行了,larbin.conf中先进行配置就可以了,这个配置就不说了。。
运行后可以:8081 看运行状态,不错的看法。 larbin.conf中有个:inputPort 1976配置,就是可以运行时降低要抓取的URL,这个看法非常好,可是?怎么加呢?象原本那样::1976那样是不行的,报 错???试了很久没结果,最后GDB跟踪了一下,唉,原来直接telnet host 1976进行降低就可以了。后来见到文档里写的亲亲楚楚,晕倒。。。。。
三,结果
哈哈,下班后找了台机子跑了上去,那晚午睡的时侯都梦到自己的搜索引擎赶GOOGLE超BAIDU了,那个激动啊。
第二天下班的时侯取看结果,发现目录下不仅些fifo*文件外哪些都没有,那个纠结。没办法啊,再看文档 How to customize Larbin 发现如此段说明:
The first thing you can define is the module you want to use for ouput. This defines what you want to do with the pages larbin gets. Here are the different options :
DEFAULT_OUTPUT : This module mainly does nothing, except statistics.
SIMPLE_SAVE : This module saves pages on disk. It stores 2000 files per directory (with an index).
MIRROR_SAVE : This module saves pages on disk with the hierarchy of the site they come from. It uses one directory per site.
STATS_OUTPUT : This modules makes some stats on the pages. In order to see the results, see :8081/output.html.
靠,默认哪些都没输出,于是认真的看了官方网站上仅有的两个文档,修改了options.h再编译,终于有结果了。
我的option中改了:
SIMPLE_SAVE 简单输出一个目录两千个文件,包含索引。
CGILEVEL=0 处理服务器端程序,也就是但url中包含? & = 之类的querString时也处理。
NO_DUP
其余可依据各自须要更改,详见: How to customize Larbin 一文。
四,问题
在使用过程中发觉,在抓网页的时侯,如果URL中包含未编码(encodurl)中文时,无法抓取,简单的看了一下在: src/utils/中的fileNormalize 有涉及。于是写了个encodurl函数加在url类的构造函数里,问题就解决了。
由于须要比较好的可定制性,这个工具其实还不大满足我的需求,最终我没使用她,而是自己用perl在WWW:SimpleRobot的基础上搞了个适宜我的。。再说了perl在字符蹿处理上应当不比C++慢,总的来说那种小工具性能还不错。。呵呵。
不过还是把这种写下来,给没看文档的同学(希望极少),也警示自己一定要认真看文档
优采云采集器好用吗?网络爬虫软件怎么样? 爱钻杂谈
采集交流 • 优采云 发表了文章 • 0 个评论 • 398 次浏览 • 2020-06-25 08:02
优采云介绍:优采云网页数据采集器,是一款使用简单、功能强悍的网路爬虫工具,完全可视化操作,无需编撰代码,内置海量模板,支持任意网路数据抓取,连续四年大数据行业数据采集领域排行第一。
这个采集的行业内也有好几个这个采集工具,之后在渐渐的说,这个优采云在网站上了解了下,本来想学着自己搞个采集,结果如何搞都弄不到一块,最后舍弃了,或许是我天分不够,不会用这个采集软件吧,采集软件这个东西便捷是便捷挺,比如一些新闻站点或则购物站几乎都用的采集软件,新闻都是一样的,就是标题有所改变。
但是网赚站若果是一个新站或则权重不高的站,被其他权重高的站采集过去,还不给留链接的话,那么对于新站的严打还是挺严重的八爪鱼采集器是干什么的,越不想写越没有收录排行,然而即使你不写他人还采集其他站,他站没有事,你不写你的站起不来,就是如此嘲弄,这真是靠天吃饭呀。 查看全部
优采云采集器好用吗?网络爬虫软件怎么样?优采云采集器是个哪些东西?这个优采云就是一个采集工具,可能对不太会搞代码的人,比如我爱兼职网就不会用这个,怎么看哪个教程都看不懂,特么的,但是对于通常原创的站点来说八爪鱼采集器是干什么的,这类采集器真的么特的反胃,自己写得东西网站上上传后没有收录呢,别的站采集过去,反倒比原创站收录快,并且排行还比原创站高,搞得原创站如同是采集站一样,这都不是最重要的,最重要的是这些采集后发表在自己站上的,居然不留原文链接,这个才是最可笑的,毕竟人心不古,既然不乐意留链接就不要转载和采集不就完了嘛,
优采云介绍:优采云网页数据采集器,是一款使用简单、功能强悍的网路爬虫工具,完全可视化操作,无需编撰代码,内置海量模板,支持任意网路数据抓取,连续四年大数据行业数据采集领域排行第一。
这个采集的行业内也有好几个这个采集工具,之后在渐渐的说,这个优采云在网站上了解了下,本来想学着自己搞个采集,结果如何搞都弄不到一块,最后舍弃了,或许是我天分不够,不会用这个采集软件吧,采集软件这个东西便捷是便捷挺,比如一些新闻站点或则购物站几乎都用的采集软件,新闻都是一样的,就是标题有所改变。
但是网赚站若果是一个新站或则权重不高的站,被其他权重高的站采集过去,还不给留链接的话,那么对于新站的严打还是挺严重的八爪鱼采集器是干什么的,越不想写越没有收录排行,然而即使你不写他人还采集其他站,他站没有事,你不写你的站起不来,就是如此嘲弄,这真是靠天吃饭呀。
初探爬虫 ||《python 3 网络爬虫开发实践》读书笔记 | 小蒋不素小蒋
采集交流 • 优采云 发表了文章 • 0 个评论 • 417 次浏览 • 2020-06-24 08:02
从 Python3.5 版本开始,Python 中加入了 async/await。
接口抓取的缺点是抓不到 js 渲染后的页面,而下边介绍的模拟抓取能挺好的解决问题。
也就是可见即可爬。
Splash 是一个 javascript 渲染服务。它是一个带有 HTTP API 的轻量级 Web 浏览器。
Selenium 是一个自动化测试工具,利用它我们可以驱动测览器执行特定的动作,如点击、下拉等操作。
Selenium + Chrome Driver,可以驱动 Chrome 浏览器完成相应的操作。
Selenium + Phantoms,这样在运行的时侯就不会再弹出一个浏览器了。而且 Phantoms 的运行效率也很高。
Phantoms 是一个无界面的、可脚本编程的 Webkit 7 浏览器引擎。
Appium 是 App 版的 Selenium。
抓取网页代码以后,下一步就是从网页中提取信息。
正则是最原始的形式,写上去繁杂,可读性差。
lxml 是 Python 的一个解析库,支持 HTML 和 XML 的解析,支持 XPah 解析方法。
Beautiful Soup 的 HTML 和 XML 解析器是依赖于 lxml 库的,所以在此之前请确保早已成功安装好了 lxml。
Beautiful Soup提供好几个解析器:
pyquery 同样是一个强悍的网页解析工具,它提供了和 jquery 类似的句型来解析 HTML 文档。
推荐:
Beautiful Soup(lxml)。lxml 解析器有解析 HTML 和 XML 的功能,而且速度快,容错能力强。
如果本身就熟悉 css 和 jquery 的话,就推荐 pyquery。
NOSQL,全称 Not Only SQL,意为不仅仅是 SQL,泛指非关系型数据库。包括:
口 键值储存数据库:代表有 Redis、Voldemort 和 Oracle BDB 等
口 列存储数据库:代表有 Cassandra、Hbase 和 Riak 等。
口 文档型数据库:代表有 COUCHDB 和 Mongodb 等。
口 图形数据库:代表有 Neo4J、infogrid 和 Infinite Graph 等。
针对一些复杂应用,尤其是 app,请求不象在 chrome 的 console 里这么容易看见,这就须要抓包工具。
mitmproxy(mitmdump) 比 Charles 更强大的是爬虫软件开发,可以支持对接 Python 脚本去处理 resquest / response。
方案:Appium + mitmdump
做法:用 mitmdump 去窃听插口数据,用 Appium 去模拟 App 的操作。
好处:即可绕开复杂的插口参数又能实现自动化提升效率。
缺点:有一些 app,如微信朋友圈的数据又经过了一次加密造成难以解析,这种情况只能纯用 Appium 了。但是对于大多数 App 来说,此种方式是奏效的。
pyspide 框架有一些缺点,比如可配置化程度不高,异常处理能力有限等,它对于一些反爬程度特别强的网站的爬取变得力不从心。
所以这儿不多做介绍。
Scrapy 是一个基于 Twisted 的异步处理框架,是纯 Python 实现的爬虫框架。
Scrapy 包括:
Scrapy-Splash:一个 Scrapy 中支持 Javascript 渲染的工具。
Scrapy-Redis :Scrap 的分布式扩充模块。
Scrapyd :一个用于布署和运行 Scrapy 项目的工具。
Scrapyrt :为 Scrap 提供了一个调度的 HTTP 接口。
Gerapy :一个 Scrapy 分布式管理模块。
Scrapy 可对接:
Crawlspider : Scrap 提供的一个通用 Spider,我们可以指定一些爬取规则来实现页面的提取,
Splash / Selenium :自动化爬取
Docker
具体使用:待写
URI 的全称为 Uniform Resource Identifier,即统一资源标志符。
URL 的全称为 Universal Resource Locator,即统一资源定位符。
URN 的全称为 Universal Resource Name,即统一资源名称。
URI 可以进一步界定为URL、URN或二者兼具。URL 和 URN 都是 URI 子集。
URN 如同一个人的名称,而 URL 代表一个人的住址。换言之,URN 定义某事物的身分,而 URL 提供查找该事物的技巧。
现在常用的http网址,如 就是URL。
而用于标示惟一书目的 ISBN 系统, 如:isbn:0-486-27557-4 ,就是 URN 。
但是在目前的互联网中,URN 用得十分少,所以几乎所有的 URI 都是 URL。
Robots 协议也叫做爬虫协议、机器人合同,它的全名叫作网路爬虫排除标准(Robots Exclusion Protocol),用来告诉爬虫和搜索引擎什么页面可以抓取,哪些不可以抓取。它一般是一个叫作robots.txt 的文本文件,一般置于网站的根目录下。
当搜索爬虫访问一个站点时,它首先会检测这个站点根目录下是否存在 robots.txt 文件,如果存在搜索爬虫会按照其中定义的爬取范围来爬取。如果没有找到这个文件爬虫软件开发,搜索爬虫便会访问所有可直接访问的页面。
robotx.txt 需要置于网站根目录。
User-agent: *
Disallow: /
Allow: /public/
Disallow表示不容许爬的页面,Allow表示准许爬的页面,User-agent表示针对那个常用搜索引擎。
User-agent 为约定好的值,取值如下表:
1、测试环境
2、管理后台(如 cms)
3、其它
1、Google的 Robots.txt 规范。
2、站长工具的 robots文件生成 工具。
Xpath,全称 XML Path Language,即 XML 路径语言,它是一门在 XML 文档中査找信息的语言。它最初是拿来搜救 XML 文档的,但是它同样适用于 HTML 文档的搜索。
Xpath 的选择功能非常强悍,它提供了十分简约明了的路径选择表达式。另外,它还提供了超过 100 个内建函数,用于字符串、数值、时间的匹配以及节点、序列的处理等。
Xpath 于 1999 年 11 月 16 日成为 W3C 标准。
就好象 css 选择器。
可以使用 Tesseract ,它是 Python 的一个 OCR 识别库。
市面上用的最多的是这家提供的滑动验证码: ,如 bilibili。
可以用自动化库,如 Selenium 模拟滑动(注意人去滑动按键是先快后慢)。
解决思路:模板匹配+模拟拖动
还有一个专门提供点触验证码服务的站点 Touclick,例如 12306 网站。
上面说的第四个:点触验证码,应该是最难辨识的了。
但互联网上有好多验证码服务平台,平台 7×24 小时提供验证码辨识服务,一张图片几秒都会获得辨识结果,准确率可达 90%以上。
个人比较推荐的一个平台是超级鹰,其官网为 。其提供的服务种类十分广泛,可辨识的验证码类型特别多,其中就包括点触验证码。
ロ FTP 代理服务器:主要用于访问 FTP 服务器,一般有上传、下载以及缓存功能,端口通常为 21、2121 等。
ロ HTP 代理服务器:主要用于访问网页,一般有内容过滤和缓存功能,端口通常为 80、8080、3128等。
口 SSL/TLS代理:主要用于访问加密网站,一般有SSL或TLS加密功能(最高支持 128 位加密硬度),端口通常为 443。
口 RTSP 代理:主要用于访问 Real 流媒体服务器,一般有缓存功能,端口通常为 554。
口 Telnet 代理:主要用于 telnet 远程控制(黑客入侵计算机时常用于隐藏身份),端口通常为 23。
口 POP3 SMTP 代理:主要用于 POP3 SMTP 方式收发短信,一般有缓存功能,端口通常为 11025 。
口 SOCKS 代理:只是单纯传递数据包,不关心具体合同和用法,所以速度快好多,一般有缓存功能,端口通常为 1080。SOCKS 代理合同又分为 SOCKS4 和 SOCKS5,前者只支持 TCP,而后者支持 TCP 和 UDP,还支持各类身分验证机制、服务器端域名解析等。简单来说,SOCKS4 能做到的 SOCKS5 都可以做到,但 SOCKS5 能做到的 SOCKS4 不一定能做到。
口 高度匿名代理:会将数据包原封不动地转发,在服务端看来就似乎真的是一个普通客户端在访问,而记录的 IP 是代理服务器的 IP。
ロ 普通匿名代理:会在数据包上做一些改动,服务端上有可能发觉这是个代理服务器,也有一定概率彻查到客户端的真实 IP。代理服务器一般会加入的 HTIP 头有 HTTPVIA 和 HTTPXFORWARDEDFOR。
口 透明代理:不但改动了数据包,还会告诉服务器客户端的真实 IP。这种代理不仅能用缓存技术提升浏览速率,能用内容过滤提升安全性之外,并无其他明显作用,最常见的事例是外网中的硬件防火墙。
口 间谍代理:指组织或个人创建的用于记录用户传输的数据,然后进行研究、监控等目的的代理服务器。
网站上会有很多免费代理,比如南刺: 。但是这种免费代理大多数情况下都是不好用的,所以比较靠谱的方式是订购付费代理。
1、提供插口获取海量代理,按天或则按时收费,如讯代理;
如果信赖讯代理的话,我们也可以不做代理池筛选,直接使用代理。不过我个人还是推荐使用代理池筛选,以提升代理可用机率。自己再做一次筛选,以确保代理可用。
2、搭建了代理隧洞,直接设置固定域名代理,如阿布云代理。云代理在云端维护一个全局 IP 池供代理隧洞使用,池中的 IP 会不间断更新。代理隧洞,配置简单,代理速率快且十分稳定。
等于帮你做了一个云端的代理池,不用自己实现了。
需要注意的是,代理 IP 池中部份 IP 可能会在当日重复出现多次。
3、ADSL 拨号代理
ADSL (Asymmetric Digital Subscriber Line,非对称数字用户支路),它的上行和下行带宽不对称,它采用频分复用技术把普通的电话线分成了电话、上行和下行 3 个相对独立的信道,从而防止了互相之间的干扰。
我们借助了 ADSL 通过拔号的形式上网,需要输入 ADSL 账号和密码,每次拔号就更换一个 IP 这个特点。
所以我们可以先订购一台动态拔号 VPS 主机,这样的主机服务商相当多。在这里使用了云立方,官方网站:
代理不论是免费的还是付费的,都不能保证都是可用的,因为:
1、此 IP 可能被其他人使用来爬取同样的目标站点而被封禁。
2、代理服务器忽然发生故障。
3、网络忙碌。
4、购买的代理到期。
5、等等
所以,我们须要提早做筛选,将不可用的代理剔除掉,保留可用代理。这就须要代理池,来获取随机可用的代理。
代理池分为 4 个模块: 存储模块、获取模块、检测模块、接口模块。
口 存储模块使用 Redis 的有序集合,用来做代理的去重和状态标示,同时它也是中心模块和基础模块,将其他模块串联上去。
口 获取模块定时从代理网站获取代理,将获取的代理传递给储存模块,并保存到数据库。
口 检测模块定时通过储存模块获取所有代理,并对代理进行检查,根据不同的测量结果对代理设置不同的标示。
口 接口模块通过WebAPI 提供服务插口,接口通过联接数据库并通过Web 形式返回可用的代理。
对于这儿的测量模块,建议使用 aiohttp 而不是 requests,原因是:
对于响应速率比较快的网站来说,requests 同步恳求和 aiohttp 异步恳求的疗效差别没这么大。但对于测量代理来说,检测一个代理通常须要十多秒甚至几十秒的时间,这时候使用 aiohttp 异步恳求库的优势就大大彰显下来了,效率可能会提升几十倍不止。
(1)有的数据必须要登陆能够抓取。
(2)有时候,登录帐号也可以减少被封禁的几率。
做大规模抓取,我们就须要拥有好多帐号,每次恳求随机选定一个帐号,这样就减少了单个帐号的访问颍率,被封的机率又会大大增加。
所以,我们可以维护一个登陆用的 Cookies 池。
架构跟代理池一样。可参考上文。
待写
python 的 open() 支持的模式可以是只读/写入/追加,也是可以它们的组合型,具体如下:
模式描述
r
以只读方法打开文件。文件的表针将会放到文件的开头。这是默认模式。
rb
以二进制格式打开一个文件用于只读。文件表针将会放到文件的开头。这是默认模式。
r+
打开一个文件用于读写。文件表针将会放到文件的开头。
rb+
以二进制格式打开一个文件用于读写。文件表针将会放到文件的开头。
w
打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
wb
以二进制格式打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
w+
打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
wb+
以二进制格式打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
a
打开一个文件用于追加。如果该文件已存在,文件指针将会放到文件的结尾。也就是说,新的内容将会被写入到已有内容然后。如果该文件不存在,创建新文件进行写入。
ab
以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放到文件的结尾。也就是说,新的内容将会被写入到已有内容然后。如果该文件不存在,创建新文件进行写入。
a+
打开一个文件用于读写。如果该文件已存在,文件指针将会放到文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。
ab+
以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放到文件的结尾。如果该文件不存在,创建新文件用于读写。
1、r+ 和 w+ 都是读写,有哪些区别?
答:前者是假如没有找到文件则抛错,后者是假如没有找到文件则手动创建文件。
2、a 可以看成是 w 的变种,附加上了”追加内容“的特点。
一般调用 open() 的时侯还须要再调用 close()。 python 提供了一种缩写方式,那就是使用 with as 语法。在 with 控制块结束时,文件会手动关掉,不需要 close() 了。调用写法如下: 查看全部
从 Python3.5 版本开始,Python 中加入了 async/await。
接口抓取的缺点是抓不到 js 渲染后的页面,而下边介绍的模拟抓取能挺好的解决问题。
也就是可见即可爬。
Splash 是一个 javascript 渲染服务。它是一个带有 HTTP API 的轻量级 Web 浏览器。
Selenium 是一个自动化测试工具,利用它我们可以驱动测览器执行特定的动作,如点击、下拉等操作。
Selenium + Chrome Driver,可以驱动 Chrome 浏览器完成相应的操作。
Selenium + Phantoms,这样在运行的时侯就不会再弹出一个浏览器了。而且 Phantoms 的运行效率也很高。
Phantoms 是一个无界面的、可脚本编程的 Webkit 7 浏览器引擎。
Appium 是 App 版的 Selenium。
抓取网页代码以后,下一步就是从网页中提取信息。
正则是最原始的形式,写上去繁杂,可读性差。
lxml 是 Python 的一个解析库,支持 HTML 和 XML 的解析,支持 XPah 解析方法。
Beautiful Soup 的 HTML 和 XML 解析器是依赖于 lxml 库的,所以在此之前请确保早已成功安装好了 lxml。
Beautiful Soup提供好几个解析器:
pyquery 同样是一个强悍的网页解析工具,它提供了和 jquery 类似的句型来解析 HTML 文档。
推荐:
Beautiful Soup(lxml)。lxml 解析器有解析 HTML 和 XML 的功能,而且速度快,容错能力强。
如果本身就熟悉 css 和 jquery 的话,就推荐 pyquery。
NOSQL,全称 Not Only SQL,意为不仅仅是 SQL,泛指非关系型数据库。包括:
口 键值储存数据库:代表有 Redis、Voldemort 和 Oracle BDB 等
口 列存储数据库:代表有 Cassandra、Hbase 和 Riak 等。
口 文档型数据库:代表有 COUCHDB 和 Mongodb 等。
口 图形数据库:代表有 Neo4J、infogrid 和 Infinite Graph 等。
针对一些复杂应用,尤其是 app,请求不象在 chrome 的 console 里这么容易看见,这就须要抓包工具。
mitmproxy(mitmdump) 比 Charles 更强大的是爬虫软件开发,可以支持对接 Python 脚本去处理 resquest / response。
方案:Appium + mitmdump
做法:用 mitmdump 去窃听插口数据,用 Appium 去模拟 App 的操作。
好处:即可绕开复杂的插口参数又能实现自动化提升效率。
缺点:有一些 app,如微信朋友圈的数据又经过了一次加密造成难以解析,这种情况只能纯用 Appium 了。但是对于大多数 App 来说,此种方式是奏效的。
pyspide 框架有一些缺点,比如可配置化程度不高,异常处理能力有限等,它对于一些反爬程度特别强的网站的爬取变得力不从心。
所以这儿不多做介绍。
Scrapy 是一个基于 Twisted 的异步处理框架,是纯 Python 实现的爬虫框架。
Scrapy 包括:
Scrapy-Splash:一个 Scrapy 中支持 Javascript 渲染的工具。
Scrapy-Redis :Scrap 的分布式扩充模块。
Scrapyd :一个用于布署和运行 Scrapy 项目的工具。
Scrapyrt :为 Scrap 提供了一个调度的 HTTP 接口。
Gerapy :一个 Scrapy 分布式管理模块。
Scrapy 可对接:
Crawlspider : Scrap 提供的一个通用 Spider,我们可以指定一些爬取规则来实现页面的提取,
Splash / Selenium :自动化爬取
Docker
具体使用:待写
URI 的全称为 Uniform Resource Identifier,即统一资源标志符。
URL 的全称为 Universal Resource Locator,即统一资源定位符。
URN 的全称为 Universal Resource Name,即统一资源名称。
URI 可以进一步界定为URL、URN或二者兼具。URL 和 URN 都是 URI 子集。
URN 如同一个人的名称,而 URL 代表一个人的住址。换言之,URN 定义某事物的身分,而 URL 提供查找该事物的技巧。
现在常用的http网址,如 就是URL。
而用于标示惟一书目的 ISBN 系统, 如:isbn:0-486-27557-4 ,就是 URN 。
但是在目前的互联网中,URN 用得十分少,所以几乎所有的 URI 都是 URL。
Robots 协议也叫做爬虫协议、机器人合同,它的全名叫作网路爬虫排除标准(Robots Exclusion Protocol),用来告诉爬虫和搜索引擎什么页面可以抓取,哪些不可以抓取。它一般是一个叫作robots.txt 的文本文件,一般置于网站的根目录下。
当搜索爬虫访问一个站点时,它首先会检测这个站点根目录下是否存在 robots.txt 文件,如果存在搜索爬虫会按照其中定义的爬取范围来爬取。如果没有找到这个文件爬虫软件开发,搜索爬虫便会访问所有可直接访问的页面。
robotx.txt 需要置于网站根目录。
User-agent: *
Disallow: /
Allow: /public/
Disallow表示不容许爬的页面,Allow表示准许爬的页面,User-agent表示针对那个常用搜索引擎。
User-agent 为约定好的值,取值如下表:
1、测试环境
2、管理后台(如 cms)
3、其它
1、Google的 Robots.txt 规范。
2、站长工具的 robots文件生成 工具。
Xpath,全称 XML Path Language,即 XML 路径语言,它是一门在 XML 文档中査找信息的语言。它最初是拿来搜救 XML 文档的,但是它同样适用于 HTML 文档的搜索。
Xpath 的选择功能非常强悍,它提供了十分简约明了的路径选择表达式。另外,它还提供了超过 100 个内建函数,用于字符串、数值、时间的匹配以及节点、序列的处理等。
Xpath 于 1999 年 11 月 16 日成为 W3C 标准。
就好象 css 选择器。
可以使用 Tesseract ,它是 Python 的一个 OCR 识别库。
市面上用的最多的是这家提供的滑动验证码: ,如 bilibili。
可以用自动化库,如 Selenium 模拟滑动(注意人去滑动按键是先快后慢)。
解决思路:模板匹配+模拟拖动
还有一个专门提供点触验证码服务的站点 Touclick,例如 12306 网站。
上面说的第四个:点触验证码,应该是最难辨识的了。
但互联网上有好多验证码服务平台,平台 7×24 小时提供验证码辨识服务,一张图片几秒都会获得辨识结果,准确率可达 90%以上。
个人比较推荐的一个平台是超级鹰,其官网为 。其提供的服务种类十分广泛,可辨识的验证码类型特别多,其中就包括点触验证码。
ロ FTP 代理服务器:主要用于访问 FTP 服务器,一般有上传、下载以及缓存功能,端口通常为 21、2121 等。
ロ HTP 代理服务器:主要用于访问网页,一般有内容过滤和缓存功能,端口通常为 80、8080、3128等。
口 SSL/TLS代理:主要用于访问加密网站,一般有SSL或TLS加密功能(最高支持 128 位加密硬度),端口通常为 443。
口 RTSP 代理:主要用于访问 Real 流媒体服务器,一般有缓存功能,端口通常为 554。
口 Telnet 代理:主要用于 telnet 远程控制(黑客入侵计算机时常用于隐藏身份),端口通常为 23。
口 POP3 SMTP 代理:主要用于 POP3 SMTP 方式收发短信,一般有缓存功能,端口通常为 11025 。
口 SOCKS 代理:只是单纯传递数据包,不关心具体合同和用法,所以速度快好多,一般有缓存功能,端口通常为 1080。SOCKS 代理合同又分为 SOCKS4 和 SOCKS5,前者只支持 TCP,而后者支持 TCP 和 UDP,还支持各类身分验证机制、服务器端域名解析等。简单来说,SOCKS4 能做到的 SOCKS5 都可以做到,但 SOCKS5 能做到的 SOCKS4 不一定能做到。
口 高度匿名代理:会将数据包原封不动地转发,在服务端看来就似乎真的是一个普通客户端在访问,而记录的 IP 是代理服务器的 IP。
ロ 普通匿名代理:会在数据包上做一些改动,服务端上有可能发觉这是个代理服务器,也有一定概率彻查到客户端的真实 IP。代理服务器一般会加入的 HTIP 头有 HTTPVIA 和 HTTPXFORWARDEDFOR。
口 透明代理:不但改动了数据包,还会告诉服务器客户端的真实 IP。这种代理不仅能用缓存技术提升浏览速率,能用内容过滤提升安全性之外,并无其他明显作用,最常见的事例是外网中的硬件防火墙。
口 间谍代理:指组织或个人创建的用于记录用户传输的数据,然后进行研究、监控等目的的代理服务器。
网站上会有很多免费代理,比如南刺: 。但是这种免费代理大多数情况下都是不好用的,所以比较靠谱的方式是订购付费代理。
1、提供插口获取海量代理,按天或则按时收费,如讯代理;
如果信赖讯代理的话,我们也可以不做代理池筛选,直接使用代理。不过我个人还是推荐使用代理池筛选,以提升代理可用机率。自己再做一次筛选,以确保代理可用。
2、搭建了代理隧洞,直接设置固定域名代理,如阿布云代理。云代理在云端维护一个全局 IP 池供代理隧洞使用,池中的 IP 会不间断更新。代理隧洞,配置简单,代理速率快且十分稳定。
等于帮你做了一个云端的代理池,不用自己实现了。
需要注意的是,代理 IP 池中部份 IP 可能会在当日重复出现多次。
3、ADSL 拨号代理
ADSL (Asymmetric Digital Subscriber Line,非对称数字用户支路),它的上行和下行带宽不对称,它采用频分复用技术把普通的电话线分成了电话、上行和下行 3 个相对独立的信道,从而防止了互相之间的干扰。
我们借助了 ADSL 通过拔号的形式上网,需要输入 ADSL 账号和密码,每次拔号就更换一个 IP 这个特点。
所以我们可以先订购一台动态拔号 VPS 主机,这样的主机服务商相当多。在这里使用了云立方,官方网站:
代理不论是免费的还是付费的,都不能保证都是可用的,因为:
1、此 IP 可能被其他人使用来爬取同样的目标站点而被封禁。
2、代理服务器忽然发生故障。
3、网络忙碌。
4、购买的代理到期。
5、等等
所以,我们须要提早做筛选,将不可用的代理剔除掉,保留可用代理。这就须要代理池,来获取随机可用的代理。
代理池分为 4 个模块: 存储模块、获取模块、检测模块、接口模块。
口 存储模块使用 Redis 的有序集合,用来做代理的去重和状态标示,同时它也是中心模块和基础模块,将其他模块串联上去。
口 获取模块定时从代理网站获取代理,将获取的代理传递给储存模块,并保存到数据库。
口 检测模块定时通过储存模块获取所有代理,并对代理进行检查,根据不同的测量结果对代理设置不同的标示。
口 接口模块通过WebAPI 提供服务插口,接口通过联接数据库并通过Web 形式返回可用的代理。
对于这儿的测量模块,建议使用 aiohttp 而不是 requests,原因是:
对于响应速率比较快的网站来说,requests 同步恳求和 aiohttp 异步恳求的疗效差别没这么大。但对于测量代理来说,检测一个代理通常须要十多秒甚至几十秒的时间,这时候使用 aiohttp 异步恳求库的优势就大大彰显下来了,效率可能会提升几十倍不止。
(1)有的数据必须要登陆能够抓取。
(2)有时候,登录帐号也可以减少被封禁的几率。
做大规模抓取,我们就须要拥有好多帐号,每次恳求随机选定一个帐号,这样就减少了单个帐号的访问颍率,被封的机率又会大大增加。
所以,我们可以维护一个登陆用的 Cookies 池。
架构跟代理池一样。可参考上文。
待写
python 的 open() 支持的模式可以是只读/写入/追加,也是可以它们的组合型,具体如下:
模式描述
r
以只读方法打开文件。文件的表针将会放到文件的开头。这是默认模式。
rb
以二进制格式打开一个文件用于只读。文件表针将会放到文件的开头。这是默认模式。
r+
打开一个文件用于读写。文件表针将会放到文件的开头。
rb+
以二进制格式打开一个文件用于读写。文件表针将会放到文件的开头。
w
打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
wb
以二进制格式打开一个文件只用于写入。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
w+
打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
wb+
以二进制格式打开一个文件用于读写。如果该文件已存在则将其覆盖。如果该文件不存在,创建新文件。
a
打开一个文件用于追加。如果该文件已存在,文件指针将会放到文件的结尾。也就是说,新的内容将会被写入到已有内容然后。如果该文件不存在,创建新文件进行写入。
ab
以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放到文件的结尾。也就是说,新的内容将会被写入到已有内容然后。如果该文件不存在,创建新文件进行写入。
a+
打开一个文件用于读写。如果该文件已存在,文件指针将会放到文件的结尾。文件打开时会是追加模式。如果该文件不存在,创建新文件用于读写。
ab+
以二进制格式打开一个文件用于追加。如果该文件已存在,文件指针将会放到文件的结尾。如果该文件不存在,创建新文件用于读写。
1、r+ 和 w+ 都是读写,有哪些区别?
答:前者是假如没有找到文件则抛错,后者是假如没有找到文件则手动创建文件。
2、a 可以看成是 w 的变种,附加上了”追加内容“的特点。
一般调用 open() 的时侯还须要再调用 close()。 python 提供了一种缩写方式,那就是使用 with as 语法。在 with 控制块结束时,文件会手动关掉,不需要 close() 了。调用写法如下:
【热门】税务局怎么应用网路爬虫技术获取企业涉税信息
采集交流 • 优采云 发表了文章 • 0 个评论 • 326 次浏览 • 2020-06-22 08:01
税务局怎样利用网路爬虫举办工作呢?概括的说,不外乎这样几个方面: 一是有针对性的捕捉互联网上的企业相关信息; 二是利用大数据,整合其他相关涉税信息; 三是通过一系列预警指标剖析比对筛选案源; 四是构建企业交易行为轨迹,定位税收风险疑虑。 其实,网络爬虫收集的仅仅是纳税人公开在网路上的涉税信息,税务机关获取纳税人的涉 税信息还有好多途径,比如,利用内部风控中心监控平台,与网路运营商、工商、统计、 建设、技术监督、财政、公安、海关、金融机构、外汇管理、国土规划和物流中心等有关 部门联网实现信息互通、数据互联、资源共享,并整合纳税人联网开票信息、申报数据、 税款收取数据、财务报表数据、重点税源报表数据、备案信息等数据信息,实时更新纳税 人信息库,使纳税人时时处在金税三期强悍的监控和预警范围之内。 所以,如果有三天,税务局直接找上门来或电话问询企业税务谜团,不要认为奇怪。 随着税务机关信息化手段的不断加强、税务稽查检测人员能力素养的不断提高,未来企业 的税务风险曝露机会将会越来越大,那种以违法手段达到少收税的手法将很难有生存空间, 而合法(利用税收优惠政策)、合理(符合商业目的)的税务筹划将是未来企业节税的主要 途径。 查看全部
税务局怎么应用网路爬虫技术获取企业涉税信息 在互联网上,经常能看到某某税务局借助网路爬虫技术发觉某甲企业涉税问题,并进一步 被取缔的信息。 那么,什么是网络爬虫呢?税务局怎么应用网路爬虫技术发觉企业的涉税谜团呢?本文将 带你一步一步解开其中的奥秘。 网络爬虫称作“网页蜘蛛”,是一个手动提取网页的程序。传统爬虫从一个或若干初始网 页的 URL 开始,获得初始网页上的 URL,在抓取网页的过程中,不断从当前页面上抽取新 的 URL 放入队列税务爬虫软件,直到满足系统的一定停止条件。聚焦爬虫的工作流程较为复杂,需要根 据一定的网页剖析算法过滤与主题无关的链接,保留有用的链接并将其倒入等待抓取的 URL 队列。然后税务爬虫软件,它将按照一定的搜索策略从队列中选择下一步要抓取的网页 URL,并重复上 述过程,直到达到系统的某一条件时停止,另外,所有被爬虫抓取的网页将会被系统存储, 进行一定的剖析、过滤,并构建索引,以便以后的查询和检索。 以上是引自网路专业的叙述,简单的说,“网络爬虫”是一个手动提取网页的程序,运用 “网络爬虫”技术设定程序,可以按照既定的目标愈发精准选择抓取相关的网页信息,有 助于在互联网海量信息中快捷获取有用的涉税信息。
税务局怎样利用网路爬虫举办工作呢?概括的说,不外乎这样几个方面: 一是有针对性的捕捉互联网上的企业相关信息; 二是利用大数据,整合其他相关涉税信息; 三是通过一系列预警指标剖析比对筛选案源; 四是构建企业交易行为轨迹,定位税收风险疑虑。 其实,网络爬虫收集的仅仅是纳税人公开在网路上的涉税信息,税务机关获取纳税人的涉 税信息还有好多途径,比如,利用内部风控中心监控平台,与网路运营商、工商、统计、 建设、技术监督、财政、公安、海关、金融机构、外汇管理、国土规划和物流中心等有关 部门联网实现信息互通、数据互联、资源共享,并整合纳税人联网开票信息、申报数据、 税款收取数据、财务报表数据、重点税源报表数据、备案信息等数据信息,实时更新纳税 人信息库,使纳税人时时处在金税三期强悍的监控和预警范围之内。 所以,如果有三天,税务局直接找上门来或电话问询企业税务谜团,不要认为奇怪。 随着税务机关信息化手段的不断加强、税务稽查检测人员能力素养的不断提高,未来企业 的税务风险曝露机会将会越来越大,那种以违法手段达到少收税的手法将很难有生存空间, 而合法(利用税收优惠政策)、合理(符合商业目的)的税务筹划将是未来企业节税的主要 途径。
网络爬虫技术(新)
采集交流 • 优采云 发表了文章 • 0 个评论 • 350 次浏览 • 2020-06-22 08:00
网络爬虫技术网路机器人1.概念: 它们是 Web 上孤身运行的软件程序,它们不断地筛选数据,做出自己的 决定, 能够使用 Web 获取文本或则进行搜索查询,按部就班地完成各自的任务。 2.分类: 购物机器人、聊天机器人、搜索机器人(网络爬虫)等。搜索引擎1.概念: 从网路上获得网站网页资料,能够构建数据库并提供查询的系统 。 2.分类(按工作原理) : 全文搜索引擎、分类目录。 1> 全文搜索引擎数据库是借助网路爬虫通过网路上的各类链接手动获取大量 网页信息内容,并按一定的规则剖析整理产生的。 (百度、Google) 2> 分类目录:按目录分类的网站链接列表而已 ,通过人工的方法搜集整理网 站资料产生的数据库。(国内的搜狐)网络爬虫1.概念: 网络爬虫也叫网路蜘蛛,它是一个根据一定的规则手动提取网页程序,其会手动 的通过网路抓取互联网上的网页,这种技术通常可能拿来检测你的站点上所有的链接 是否是都是有效的。当然爬虫技术,更为中级的技术是把网页中的相关数据保存出来,可以成 为搜索引擎。 搜索引擎使用网络爬虫找寻网路内容,网络上的 HTML 文档使用超链接联接了上去, 就像织成了一张网,网络爬虫也叫网路蜘蛛,顺着这张网爬行,每到一个网页就用抓取程序 将这个网页抓出来,将内容抽取下来,同时抽取超链接,作为进一步爬行的线索。
网络爬虫 总是要从某个起点开始爬,这个起点称作种子,你可以告诉它,也可以到一些网址列表网站 上获取。 2.区别: 网络爬虫 分类 工作原理 通用爬虫 从一个或多个初始网页的 URL 开 始,获取初始网页的 URL,抓取网 页的同时爬虫技术,从当前网页提取相关的 URL 放入队列中,直到满足程序的 停止条件。 聚集爬虫 根据一定的网页剖析算法过滤与主题无 关的链接,保留有用的链接(爬行的范围 是受控的)放到待抓取的队列中,通过一 定的搜索策略从队列中选择下一步要抓 取的 URL,重复以上步骤,直到满足程 序的停止条件。 1. 增加了一些网页分析算法和网页搜 索策略 2. 对 被 爬 虫 抓 取 的 网 页 将 会 被 系 统 存贮,进行一定的剖析、过滤,并 建立索引,以便以后的查询和检 索,这一过程所得到的剖析结果还 可能对之后的抓取过程给出反馈不同点和指导。 缺点 1. 不同领域、 不同背景的用户有 不同的检索目的和需求, 通用 搜索引擎所返回的结果包含 大量用户不关心的网页。 2. 通用引擎的目标是大的网路覆 盖率。 3. 只支持关键字搜索, 不支持按照 语义的搜索。 4. 通用搜索引擎对一些象图片、 音 频等信 息 含 量 密 集 且 具 有 一 定结构的数据难以获取。
广度优先算法 1. 对抓取目标的描述或定义。 2. 对网页和数据的剖析和过滤。 3. 对 URL 的搜索策略。 以上三个是须要解决的问题。算法现有聚焦爬虫对抓取目标的描述可分为基于目标网页特点、 基于目标数据模式和基于领 域概念 3 种。 基于目标网页特点的爬虫所抓取、 存储并索引的对象通常为网站或网页。 根据种子样本 获取方法可分为: (1)预先给定的初始抓取种子样本; (2)预先给定的网页分类目录和与分类目录对应的种子样本,如 Yahoo!分类结构等; (3)通过用户行为确定的抓取目标样例,分为: a) 用户浏览过程中显示标明的抓取样本; b) 通过用户日志挖掘得到访问模式及相关样本。 其中,网页特点可以是网页的内容特点,也可以是网页的链接结构特点,等等。 3.算法/策略 名称 分类 网页分析算法 1.基于网路拓扑结构 1>网页细度剖析算法 2>网站粒度剖析算法 3>网页块细度剖析算法 2.基于网页内容 1>针对以文本和超链接为主的 网页 2>针对从结构化的数据源动态生 成的网页。 3>针对数据介于第一类和第二类 之间 3.基于用户访问行为 网页搜索策略 1.深度优先策略 2.广度优先策略 3.最佳优先策略一些算法的介绍 1> 网页分析算法1.1 基于网路拓扑的剖析算法? 基于网页之间的链接, 通过已知的网页或数据, 来对与其有直接或间接链接关系的对象 (可以是网页或网站等) 作出评价的算法。
又分为网页细度、 网站粒度和网页块细度这三种。 1.1.1 网页(Webpage)粒度的剖析算法 PageRank 和 HITS 算法是最常见的链接剖析算法, 两者都是通过对网页间链接度的递归 和规范化估算,得到每位网页的重要度评价。PageRank 算法其实考虑了用户访问行为的随 机性和 Sink 网页的存在,但忽视了绝大多数用户访问时带有目的性,即网页和链接与查询 主题的相关性。针对这个问题,HITS 算法提出了两个关键的概念:权威型网页(authority) 和中心型网页(hub) 。 基于链接的抓取的问题是相关页面主题团之间的隧洞现象, 即好多在抓取路径上偏离主 题的网页也指向目标网页,局部评价策略中断了在当前路径上的抓取行为。文献[21]提出了 一种基于反向链接(BackLink)的分层式上下文模型(Context Model) ,用于描述指向目标 网页一定化学跳数直径内的网页拓扑图的中心 Layer0 为目标网页,将网页根据指向目标网 页的数学跳数进行层次界定,从内层网页指向外层网页的链接称为反向链接。? 1.1.2 网站粒度的剖析算法 网站粒度的资源发觉和管理策略也比网页细度的更简单有效。
网站粒度的爬虫抓取的关 键之处在于站点的界定和站点等级(SiteRank)的估算。 SiteRank 的估算方式与 PageRank 类似, 但是须要对网站之间的链接作一定程度具象,并在一定的模型下估算链接的权重。 网站划分情况分为按域名界定和按 IP 地址界定两种。文献[18]讨论了在分布式情况下, 通过对同一个域名下不同主机、服务器的 IP 地址进行站点界定,构造站点图,利用类似 Pa geRank 的方式评价 SiteRank。同时,根据不同文件在各个站点上的分布情况,构造文档图, 结合 SiteRank 分布式估算得到 DocRank。文献[18]证明,利用分布式的 SiteRank 计算,不仅 大大增加了单机站点的算法代价, 而且克服了单独站点对整个网路覆盖率有限的缺点。 附带 的一个优点是,常见 PageRank 造假无法对 SiteRank 进行愚弄。? 1.1.3 网页块细度的剖析算法 在一个页面中, 往往富含多个指向其他页面的链接, 这些链接中只有一部分是指向主题 相关网页的,或依照网页的链接锚文本表明其具有较高重要性。但是,在 PageRank 和 HIT S 算法中,没有对那些链接作分辨,因此经常给网页剖析带来广告等噪音链接的干扰。
在网 页块级别(Block?level) 进行链接剖析的算法的基本思想是通过 VIPS 网页分割算法将网页分 为不同的网页块(page block),然后对这种网页块构建 page?to?block block?to?page的 和 链接矩阵,? 分别记为 Z 和 X。于是,在 page?to? page 图上的网页块级别的 PageRank 为? W?p=X×Z ? block?to?block图上的 BlockRank 为?W?b=Z×X ? ; 在 。 已经有人实现了块级 别的 PageRank 和 HITS 算法,并通过实验证明,效率和准确率都比传统的对应算法要好。 1.2 基于网页内容的网页分析算法 基于网页内容的剖析算法指的是借助网页内容(文本、数据等资源)特征进行的网页评 价。网页的内容从原先的以超文本为主,发展到后来动态页面(或称为 Hidden Web)数据 为主,后者的数据量约为直接可见页面数据(PIW,Publicly Indexable Web)的 400~500 倍。另一方面,多媒体数据、Web Service 等各类网路资源方式也日渐丰富。因此,基于网页内容的剖析算法也从原先的较为单纯的文本检索方式, 发展为囊括网页数据抽取、 机器学 习、数据挖掘、语义理解等多种方式的综合应用。
本节按照网页数据方式的不同,将基于网 页内容的剖析算法, 归纳以下三类: 第一种针对以文本和超链接为主的无结构或结构很简单 的网页;第二种针对从结构化的数据源(如 RDBMS)动态生成的页面,其数据不能直接批 量访问;第三种针对的数据界于第一和第二类数据之间,具有较好的结构,显示遵照一定模 式或风格,且可以直接访问。 1.2.1 基于文本的网页剖析算法 1) 纯文本分类与聚类算法 很大程度上借用了文本检索的技术。 文本剖析算法可以快速有效的对网页进行分类和聚 类,但是因为忽视了网页间和网页内部的结构信息,很少单独使用。? 2) 超文本分类和聚类算法 2> 网页搜索策略 2. 广度优先搜索策略 广度优先搜索策略是指在抓取过程中, 在完成当前层次的搜索后, 才进行下一层次的搜 索。该算法的设计和实现相对简单。在目前为覆盖尽可能多的网页,一般使用广度优先搜索 方法。 也有好多研究将广度优先搜索策略应用于聚焦爬虫中。 其基本思想是觉得与初始 URL 在一定链接距离内的网页具有主题相关性的机率很大。 另外一种方式是将广度优先搜索与网 页过滤技术结合使用,先用广度优先策略抓取网页,再将其中无关的网页过滤掉。
这些方式 的缺点在于,随着抓取网页的增多,大量的无关网页将被下载并过滤,算法的效率将变低。 2. 最佳优先搜索策略 最佳优先搜索策略根据一定的网页分析算法,预测候选 URL 与目标网页的相似度,或 与主题的相关性,并选定评价最好的一个或几个 URL 进行抓取。它只访问经过网页剖析算 法预测为“有用”的网页。 存在的一个问题是, 在爬虫抓取路径上的好多相关网页可能被忽视, 因为最佳优先策略是一种局部最优搜索算法。因此须要将最佳优先结合具体的应用进行改 进,以跳出局部最优点。将在第 4 节中结合网页分析算法作具体的讨论。研究表明,这样的 闭环调整可以将无关网页数目减少 30%~90%。 3. 搜索引擎原理之网路爬虫是怎样工作的? 在互联网中,网页之间的链接关系是无规律的,它们的关系十分复杂。如果一个爬虫从 一个起点开始爬行,那么它将会碰到无数的分支,由此生成无数条的爬行路径,如果聘期爬 行,就有可能永远也爬不到头,因此要对它加以控制,制定其爬行的规则。世界上没有一种 爬虫还能抓取到互联网所有的网页, 所以就要在提升其爬行速率的同时, 也要提升其爬行网 页的质量。 网络爬虫在搜索引擎中占有重要位置,对搜索引擎的查全、查准都有影响,决定了搜索 引擎数据容量的大小, 而且网路爬虫的优劣之间影响搜索引擎结果页中的死链接的个数。
搜 索引擎爬虫有深度优先策略和广度优先策略,另外,识别垃圾网页,避免抓取重复网页,也 是高性能爬虫的设计目标。 爬虫的作用是为了搜索引擎抓取大量的数据, 抓取的对象是整个互联网上的网页。 爬虫 程序不可能抓取所有的网页,因为在抓取的同时,Web 的规模也在减小,所以一个好的爬 虫程序通常就能在短时间内抓取更多的网页。 一般爬虫程序的起点都选择在一个小型综合型的网站,这样的网站已经囊括了大部分高质量的站点,爬虫程序就顺着那些链接爬行。在爬 行过程中,最重要的就是判定一个网页是否早已被爬行过。 在爬虫开始的时侯, 需要给爬虫输送一个 URL 列表, 这个列表中的 URL 地址便是爬虫 的起始位置,爬虫从这种 URL 出发,开始了爬行,一直不断地发觉新的 URL,然后再按照 策略爬行这种新发觉的 URL,如此永远反复下去。一般的爬虫都自己完善 DNS 缓冲,建立 DNS 缓冲的目的是推动 URL 解析成 IP 地址的速率。 查看全部
网络爬虫技术网路机器人1.概念: 它们是 Web 上孤身运行的软件程序,它们不断地筛选数据,做出自己的 决定, 能够使用 Web 获取文本或则进行搜索查询,按部就班地完成各自的任务。 2.分类: 购物机器人、聊天机器人、搜索机器人(网络爬虫)等。搜索引擎1.概念: 从网路上获得网站网页资料,能够构建数据库并提供查询的系统 。 2.分类(按工作原理) : 全文搜索引擎、分类目录。 1> 全文搜索引擎数据库是借助网路爬虫通过网路上的各类链接手动获取大量 网页信息内容,并按一定的规则剖析整理产生的。 (百度、Google) 2> 分类目录:按目录分类的网站链接列表而已 ,通过人工的方法搜集整理网 站资料产生的数据库。(国内的搜狐)网络爬虫1.概念: 网络爬虫也叫网路蜘蛛,它是一个根据一定的规则手动提取网页程序,其会手动 的通过网路抓取互联网上的网页,这种技术通常可能拿来检测你的站点上所有的链接 是否是都是有效的。当然爬虫技术,更为中级的技术是把网页中的相关数据保存出来,可以成 为搜索引擎。 搜索引擎使用网络爬虫找寻网路内容,网络上的 HTML 文档使用超链接联接了上去, 就像织成了一张网,网络爬虫也叫网路蜘蛛,顺着这张网爬行,每到一个网页就用抓取程序 将这个网页抓出来,将内容抽取下来,同时抽取超链接,作为进一步爬行的线索。
网络爬虫 总是要从某个起点开始爬,这个起点称作种子,你可以告诉它,也可以到一些网址列表网站 上获取。 2.区别: 网络爬虫 分类 工作原理 通用爬虫 从一个或多个初始网页的 URL 开 始,获取初始网页的 URL,抓取网 页的同时爬虫技术,从当前网页提取相关的 URL 放入队列中,直到满足程序的 停止条件。 聚集爬虫 根据一定的网页剖析算法过滤与主题无 关的链接,保留有用的链接(爬行的范围 是受控的)放到待抓取的队列中,通过一 定的搜索策略从队列中选择下一步要抓 取的 URL,重复以上步骤,直到满足程 序的停止条件。 1. 增加了一些网页分析算法和网页搜 索策略 2. 对 被 爬 虫 抓 取 的 网 页 将 会 被 系 统 存贮,进行一定的剖析、过滤,并 建立索引,以便以后的查询和检 索,这一过程所得到的剖析结果还 可能对之后的抓取过程给出反馈不同点和指导。 缺点 1. 不同领域、 不同背景的用户有 不同的检索目的和需求, 通用 搜索引擎所返回的结果包含 大量用户不关心的网页。 2. 通用引擎的目标是大的网路覆 盖率。 3. 只支持关键字搜索, 不支持按照 语义的搜索。 4. 通用搜索引擎对一些象图片、 音 频等信 息 含 量 密 集 且 具 有 一 定结构的数据难以获取。
广度优先算法 1. 对抓取目标的描述或定义。 2. 对网页和数据的剖析和过滤。 3. 对 URL 的搜索策略。 以上三个是须要解决的问题。算法现有聚焦爬虫对抓取目标的描述可分为基于目标网页特点、 基于目标数据模式和基于领 域概念 3 种。 基于目标网页特点的爬虫所抓取、 存储并索引的对象通常为网站或网页。 根据种子样本 获取方法可分为: (1)预先给定的初始抓取种子样本; (2)预先给定的网页分类目录和与分类目录对应的种子样本,如 Yahoo!分类结构等; (3)通过用户行为确定的抓取目标样例,分为: a) 用户浏览过程中显示标明的抓取样本; b) 通过用户日志挖掘得到访问模式及相关样本。 其中,网页特点可以是网页的内容特点,也可以是网页的链接结构特点,等等。 3.算法/策略 名称 分类 网页分析算法 1.基于网路拓扑结构 1>网页细度剖析算法 2>网站粒度剖析算法 3>网页块细度剖析算法 2.基于网页内容 1>针对以文本和超链接为主的 网页 2>针对从结构化的数据源动态生 成的网页。 3>针对数据介于第一类和第二类 之间 3.基于用户访问行为 网页搜索策略 1.深度优先策略 2.广度优先策略 3.最佳优先策略一些算法的介绍 1> 网页分析算法1.1 基于网路拓扑的剖析算法? 基于网页之间的链接, 通过已知的网页或数据, 来对与其有直接或间接链接关系的对象 (可以是网页或网站等) 作出评价的算法。
又分为网页细度、 网站粒度和网页块细度这三种。 1.1.1 网页(Webpage)粒度的剖析算法 PageRank 和 HITS 算法是最常见的链接剖析算法, 两者都是通过对网页间链接度的递归 和规范化估算,得到每位网页的重要度评价。PageRank 算法其实考虑了用户访问行为的随 机性和 Sink 网页的存在,但忽视了绝大多数用户访问时带有目的性,即网页和链接与查询 主题的相关性。针对这个问题,HITS 算法提出了两个关键的概念:权威型网页(authority) 和中心型网页(hub) 。 基于链接的抓取的问题是相关页面主题团之间的隧洞现象, 即好多在抓取路径上偏离主 题的网页也指向目标网页,局部评价策略中断了在当前路径上的抓取行为。文献[21]提出了 一种基于反向链接(BackLink)的分层式上下文模型(Context Model) ,用于描述指向目标 网页一定化学跳数直径内的网页拓扑图的中心 Layer0 为目标网页,将网页根据指向目标网 页的数学跳数进行层次界定,从内层网页指向外层网页的链接称为反向链接。? 1.1.2 网站粒度的剖析算法 网站粒度的资源发觉和管理策略也比网页细度的更简单有效。
网站粒度的爬虫抓取的关 键之处在于站点的界定和站点等级(SiteRank)的估算。 SiteRank 的估算方式与 PageRank 类似, 但是须要对网站之间的链接作一定程度具象,并在一定的模型下估算链接的权重。 网站划分情况分为按域名界定和按 IP 地址界定两种。文献[18]讨论了在分布式情况下, 通过对同一个域名下不同主机、服务器的 IP 地址进行站点界定,构造站点图,利用类似 Pa geRank 的方式评价 SiteRank。同时,根据不同文件在各个站点上的分布情况,构造文档图, 结合 SiteRank 分布式估算得到 DocRank。文献[18]证明,利用分布式的 SiteRank 计算,不仅 大大增加了单机站点的算法代价, 而且克服了单独站点对整个网路覆盖率有限的缺点。 附带 的一个优点是,常见 PageRank 造假无法对 SiteRank 进行愚弄。? 1.1.3 网页块细度的剖析算法 在一个页面中, 往往富含多个指向其他页面的链接, 这些链接中只有一部分是指向主题 相关网页的,或依照网页的链接锚文本表明其具有较高重要性。但是,在 PageRank 和 HIT S 算法中,没有对那些链接作分辨,因此经常给网页剖析带来广告等噪音链接的干扰。
在网 页块级别(Block?level) 进行链接剖析的算法的基本思想是通过 VIPS 网页分割算法将网页分 为不同的网页块(page block),然后对这种网页块构建 page?to?block block?to?page的 和 链接矩阵,? 分别记为 Z 和 X。于是,在 page?to? page 图上的网页块级别的 PageRank 为? W?p=X×Z ? block?to?block图上的 BlockRank 为?W?b=Z×X ? ; 在 。 已经有人实现了块级 别的 PageRank 和 HITS 算法,并通过实验证明,效率和准确率都比传统的对应算法要好。 1.2 基于网页内容的网页分析算法 基于网页内容的剖析算法指的是借助网页内容(文本、数据等资源)特征进行的网页评 价。网页的内容从原先的以超文本为主,发展到后来动态页面(或称为 Hidden Web)数据 为主,后者的数据量约为直接可见页面数据(PIW,Publicly Indexable Web)的 400~500 倍。另一方面,多媒体数据、Web Service 等各类网路资源方式也日渐丰富。因此,基于网页内容的剖析算法也从原先的较为单纯的文本检索方式, 发展为囊括网页数据抽取、 机器学 习、数据挖掘、语义理解等多种方式的综合应用。
本节按照网页数据方式的不同,将基于网 页内容的剖析算法, 归纳以下三类: 第一种针对以文本和超链接为主的无结构或结构很简单 的网页;第二种针对从结构化的数据源(如 RDBMS)动态生成的页面,其数据不能直接批 量访问;第三种针对的数据界于第一和第二类数据之间,具有较好的结构,显示遵照一定模 式或风格,且可以直接访问。 1.2.1 基于文本的网页剖析算法 1) 纯文本分类与聚类算法 很大程度上借用了文本检索的技术。 文本剖析算法可以快速有效的对网页进行分类和聚 类,但是因为忽视了网页间和网页内部的结构信息,很少单独使用。? 2) 超文本分类和聚类算法 2> 网页搜索策略 2. 广度优先搜索策略 广度优先搜索策略是指在抓取过程中, 在完成当前层次的搜索后, 才进行下一层次的搜 索。该算法的设计和实现相对简单。在目前为覆盖尽可能多的网页,一般使用广度优先搜索 方法。 也有好多研究将广度优先搜索策略应用于聚焦爬虫中。 其基本思想是觉得与初始 URL 在一定链接距离内的网页具有主题相关性的机率很大。 另外一种方式是将广度优先搜索与网 页过滤技术结合使用,先用广度优先策略抓取网页,再将其中无关的网页过滤掉。
这些方式 的缺点在于,随着抓取网页的增多,大量的无关网页将被下载并过滤,算法的效率将变低。 2. 最佳优先搜索策略 最佳优先搜索策略根据一定的网页分析算法,预测候选 URL 与目标网页的相似度,或 与主题的相关性,并选定评价最好的一个或几个 URL 进行抓取。它只访问经过网页剖析算 法预测为“有用”的网页。 存在的一个问题是, 在爬虫抓取路径上的好多相关网页可能被忽视, 因为最佳优先策略是一种局部最优搜索算法。因此须要将最佳优先结合具体的应用进行改 进,以跳出局部最优点。将在第 4 节中结合网页分析算法作具体的讨论。研究表明,这样的 闭环调整可以将无关网页数目减少 30%~90%。 3. 搜索引擎原理之网路爬虫是怎样工作的? 在互联网中,网页之间的链接关系是无规律的,它们的关系十分复杂。如果一个爬虫从 一个起点开始爬行,那么它将会碰到无数的分支,由此生成无数条的爬行路径,如果聘期爬 行,就有可能永远也爬不到头,因此要对它加以控制,制定其爬行的规则。世界上没有一种 爬虫还能抓取到互联网所有的网页, 所以就要在提升其爬行速率的同时, 也要提升其爬行网 页的质量。 网络爬虫在搜索引擎中占有重要位置,对搜索引擎的查全、查准都有影响,决定了搜索 引擎数据容量的大小, 而且网路爬虫的优劣之间影响搜索引擎结果页中的死链接的个数。
搜 索引擎爬虫有深度优先策略和广度优先策略,另外,识别垃圾网页,避免抓取重复网页,也 是高性能爬虫的设计目标。 爬虫的作用是为了搜索引擎抓取大量的数据, 抓取的对象是整个互联网上的网页。 爬虫 程序不可能抓取所有的网页,因为在抓取的同时,Web 的规模也在减小,所以一个好的爬 虫程序通常就能在短时间内抓取更多的网页。 一般爬虫程序的起点都选择在一个小型综合型的网站,这样的网站已经囊括了大部分高质量的站点,爬虫程序就顺着那些链接爬行。在爬 行过程中,最重要的就是判定一个网页是否早已被爬行过。 在爬虫开始的时侯, 需要给爬虫输送一个 URL 列表, 这个列表中的 URL 地址便是爬虫 的起始位置,爬虫从这种 URL 出发,开始了爬行,一直不断地发觉新的 URL,然后再按照 策略爬行这种新发觉的 URL,如此永远反复下去。一般的爬虫都自己完善 DNS 缓冲,建立 DNS 缓冲的目的是推动 URL 解析成 IP 地址的速率。
手把手教你写网络爬虫(2):迷你爬虫构架-通用网路爬虫
采集交流 • 优采云 发表了文章 • 0 个评论 • 366 次浏览 • 2020-06-20 08:00
介绍
大家好!回顾上一期,我们在介绍了爬虫的基本概念以后,就借助各类工具横冲直撞的完成了一个小爬虫,目的就是猛、糙、快,方便初学者上手,建立信心。对于有一定基础的读者,请不要着急,以后我们会学习主流的开源框架,打造出一个强悍专业的爬虫系统!不过在此之前,要继续打好基础,本期我们先介绍爬虫的种类,然后选定最典型的通用网路爬虫,为其设计一个迷你框架。有了自己对框架的思索后爬虫结构,再学习复杂的开源框架就有头绪了。
今天我们会把更多的时间用在思索上,而不是一根筋的coding。用80%的时间思索,20%的时间敲按键,这样更有利于进步。
语言&环境
语言:带足弹药,继续用Python开路!
一个迷你框架
下面以比较典型的通用爬虫为例爬虫结构,分析其工程要点,设计并实现一个迷你框架。架构图如下:
代码结构:
config_load.py 配置文件加载
crawl_thread.py 爬取线程
mini_spider.py 主线程
spider.conf 配置文件
url_table.py url队列、url表
urls.txt 种子url集合
webpage_parse.py 网页剖析
webpage_save.py 网页储存
看看配置文件里有哪些内容:
spider.conf
url_table.py
Step 3. 记录什么网页早已下载过的小笔记本——URL表。
在互联网上,一个网页可能被多个网页中的超链接所指向。这样在遍历互联网这张图的时侯,这个网页可能被多次访问到。为了避免一个网页被下载和解析多次,需要一个URL表记录什么网页早已下载过。再碰到这个网页的时侯,我们就可以跳过它。
crawl_thread.py
Step 5. 页面剖析模块
从网页中解析出URLs或则其他有用的数据。这个是下期重点介绍的,可以参考之前的代码。
Step 6. 页面储存模块
保存页面的模块,目前将文件保存为文件,以后可以扩充出多种储存方法,如mysql,mongodb,hbase等等。
webpage_save.py
写到这儿,整个框架早已清晰的呈如今大伙眼前了,千万不要小看它,不管多么复杂的框架都是在这种基本要素上扩充下来的。
下一步
基础知识的学习暂时告一段落,希望还能帮助你们打下一定的基础。下期开始为你们介绍强悍成熟的爬虫框架Scrapy,它提供了好多强悍的特点来促使爬取更为简单高效,更多精彩,敬请期盼!
【编辑推荐】
如何用Python来找你喜欢的女生?初识Python:全局、局部和非局部变量(带示例)教你用Python解决非平衡数据问题(附代码)调查显示:你是否是一个合格的Python开发者?手把手教你写网络爬虫(1):网易云音乐歌单 查看全部
介绍
大家好!回顾上一期,我们在介绍了爬虫的基本概念以后,就借助各类工具横冲直撞的完成了一个小爬虫,目的就是猛、糙、快,方便初学者上手,建立信心。对于有一定基础的读者,请不要着急,以后我们会学习主流的开源框架,打造出一个强悍专业的爬虫系统!不过在此之前,要继续打好基础,本期我们先介绍爬虫的种类,然后选定最典型的通用网路爬虫,为其设计一个迷你框架。有了自己对框架的思索后爬虫结构,再学习复杂的开源框架就有头绪了。
今天我们会把更多的时间用在思索上,而不是一根筋的coding。用80%的时间思索,20%的时间敲按键,这样更有利于进步。
语言&环境
语言:带足弹药,继续用Python开路!
一个迷你框架
下面以比较典型的通用爬虫为例爬虫结构,分析其工程要点,设计并实现一个迷你框架。架构图如下:
代码结构:
config_load.py 配置文件加载
crawl_thread.py 爬取线程
mini_spider.py 主线程
spider.conf 配置文件
url_table.py url队列、url表
urls.txt 种子url集合
webpage_parse.py 网页剖析
webpage_save.py 网页储存
看看配置文件里有哪些内容:
spider.conf
url_table.py
Step 3. 记录什么网页早已下载过的小笔记本——URL表。
在互联网上,一个网页可能被多个网页中的超链接所指向。这样在遍历互联网这张图的时侯,这个网页可能被多次访问到。为了避免一个网页被下载和解析多次,需要一个URL表记录什么网页早已下载过。再碰到这个网页的时侯,我们就可以跳过它。
crawl_thread.py
Step 5. 页面剖析模块
从网页中解析出URLs或则其他有用的数据。这个是下期重点介绍的,可以参考之前的代码。
Step 6. 页面储存模块
保存页面的模块,目前将文件保存为文件,以后可以扩充出多种储存方法,如mysql,mongodb,hbase等等。
webpage_save.py
写到这儿,整个框架早已清晰的呈如今大伙眼前了,千万不要小看它,不管多么复杂的框架都是在这种基本要素上扩充下来的。
下一步
基础知识的学习暂时告一段落,希望还能帮助你们打下一定的基础。下期开始为你们介绍强悍成熟的爬虫框架Scrapy,它提供了好多强悍的特点来促使爬取更为简单高效,更多精彩,敬请期盼!
【编辑推荐】
如何用Python来找你喜欢的女生?初识Python:全局、局部和非局部变量(带示例)教你用Python解决非平衡数据问题(附代码)调查显示:你是否是一个合格的Python开发者?手把手教你写网络爬虫(1):网易云音乐歌单
Ipidea丨网络爬虫正则表达式的使用
采集交流 • 优采云 发表了文章 • 0 个评论 • 398 次浏览 • 2020-06-17 08:00
## 网络爬虫正则表达式的使用
---
我们在处理网页文本内容时有时会碰到一些特殊的情况网络爬虫 正则表达式,或者须要匹配某类字符串方式,通常都会用到正则表达式。许多程序语言都支持使用正则表达式,python中正则表达式可以实现字符串的匹配、检索和替换等功能,是一个比较强悍的工具。
### 1.正则表达式句型
Python中实现正则表达式功能一般使用re模块,可以实现对文本字符串的匹配,检索和替换,但不仅引入正则模块网络爬虫 正则表达式,还须要把握正则表达式字符和基本句型,才能正确使用python进行正则表达式提取。
部分常用的正则表达式:
| 字符 | 功能 |
| :--: | :--: |
| \ |转义字符,标记下一个字符为特殊字符|
| ^ |匹配输入字符串的开始位置|
| $ |匹配输入字符串的结束位置|
| * |匹配上面的子表达式零次或多次 |
| + |匹配上面的子表达式一次或多次 |
| ? |匹配上面的子表达式零次或一次 |
| . |匹配除“\n”之外的任何单个字符 |
| () | 匹配括弧里的表达式 |
| \d | 匹配一个数字字符 |
| \D | 匹配一个非数字字符 |
| \w |匹配包括顿号的任何词组字符|
| \W |匹配任何非词组字符|
|{n}|n是一个非负整数,匹配确定的n次|
|{n,m}|m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次|
|[x,y,z]| 匹配一组字符集 |
| \^[x,y,z] | 匹配不在[]中的字符 |
| a\|b | 匹配a或b | 查看全部
## 网络爬虫正则表达式的使用
---
我们在处理网页文本内容时有时会碰到一些特殊的情况网络爬虫 正则表达式,或者须要匹配某类字符串方式,通常都会用到正则表达式。许多程序语言都支持使用正则表达式,python中正则表达式可以实现字符串的匹配、检索和替换等功能,是一个比较强悍的工具。
### 1.正则表达式句型
Python中实现正则表达式功能一般使用re模块,可以实现对文本字符串的匹配,检索和替换,但不仅引入正则模块网络爬虫 正则表达式,还须要把握正则表达式字符和基本句型,才能正确使用python进行正则表达式提取。
部分常用的正则表达式:
| 字符 | 功能 |
| :--: | :--: |
| \ |转义字符,标记下一个字符为特殊字符|
| ^ |匹配输入字符串的开始位置|
| $ |匹配输入字符串的结束位置|
| * |匹配上面的子表达式零次或多次 |
| + |匹配上面的子表达式一次或多次 |
| ? |匹配上面的子表达式零次或一次 |
| . |匹配除“\n”之外的任何单个字符 |
| () | 匹配括弧里的表达式 |
| \d | 匹配一个数字字符 |
| \D | 匹配一个非数字字符 |
| \w |匹配包括顿号的任何词组字符|
| \W |匹配任何非词组字符|
|{n}|n是一个非负整数,匹配确定的n次|
|{n,m}|m和n均为非负整数,其中n<=m。最少匹配n次且最多匹配m次|
|[x,y,z]| 匹配一组字符集 |
| \^[x,y,z] | 匹配不在[]中的字符 |
| a\|b | 匹配a或b |
网络爬虫技术有什么用途和害处?
采集交流 • 优采云 发表了文章 • 0 个评论 • 319 次浏览 • 2020-06-16 08:02
不论是固定的笔记本网路还是以手机为终端的联通网路。使用者会时常遇见一种最常见的现象,这就是只要搜索或则关注某方面的信息,那么马上都会有网路上大量的、与之相类似的信息被“推荐”。绝大部分都是网路小广G,甚至有大量的垃圾信息。那么在信息流量可谓浩如烟海的网路上,怎么会被精确到每位用户究竟关注哪些呢?其实这就是运用了网路爬虫技术。估计有人对爬虫二字看起来就发毛。与自然接触少的城里长大的人,很多都天生怕蟑螂,不过对从小火锅蒸煮过无数蟑螂蚱蜢的老一代人来说,虫子又有哪些可怕的?网络爬虫说究竟就是一种小程序,属于根据一定的规则,自动抓取全球网路上的程序和脚本。对网路用户关注的信息进行剖析和统计,最终作为一种网路剖析资源来获得特定的利益。
网络爬虫技术和搜索引擎有天然的近亲关系。全球各大搜索引擎,都是网路爬虫技术应用的超级大户。可以海量的抓取一定范围内的特定主体和内容的网路信息网络爬虫是什么作用,作为向搜索和查询相关内容的储备数据资源。简单来说网络爬虫是什么作用,网络爬虫如同一群不止疲惫的搜索机器虫,可以海量的替代人工对全球网路进行搜索,对早已传到网上的任何有价值无价值的信息资源都象蚂蚁一样背回去堆在那里等用户,因此被称作网路爬虫。有统计显示,目前全球固定和联通互联网上,被下载的信息中,只有不到55%是真正的活人在抢占流量资源;而另外的45%,也就是接近一半,是网路爬虫和各类“机器人”在抢占流量。可见网路爬虫的厉害。那么网络爬虫是怎样从技术上实现对特定信息下载的呢?在于网络爬虫首先是一个下载小程序。
其从一个或若干初始网页的URL开始,获得正常网路用户初始网页上的URL。在抓取网页的过程中,不断从当前页面上抽取新的URL装入队列。再剖析算法过滤与主题无关的链接,保留有用的链接并将其倒入等待抓取的URL队列。然后,它将按照一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。所有被爬虫抓取的网页将会被系统储存,进行一定的剖析、过滤,并构建索引,以便以后的查询和检索。爬虫程序本身具备有用的一面,如果没有网路爬虫技术,那么就不可能有各类用途极大的搜索引擎,所有的网路用户就在海量的信息中走散了。但是瀚海狼山(匈奴狼山)还是那句话:过犹不及。凡事就怕被滥用。很多没有搜索引擎的公司和操作者,也能开发出简单的爬虫技术,来进行自己的网路推广。在网上的爬虫越来越多,不受控制以后,普通的网路用户就都成了最终的受害者。这等于有无数个看不见的刺探者,躲在暗处盯住每一个毫无提防的用户。
你每晚看哪些页面,点击的哪些内容,订购哪些商品,消费了多少钱,都在不知不觉的被记录被剖析。让普通用户没有任何网路隐私可言。谁也不喜欢自己的一言一行都被别人记录并且还被随时剖析借助。因此无处不在的爬虫程序是对用户利益的直接侵害。而且网络爬虫也有军事上的用途和风险。当代社会经济、ZZ和军事活动虽然很难分家。虽然有保密途径,也可释放一些真真假假的信息。但是用爬虫技术,通过机率剖析,仍然可影响国际舆论甚至是判别出对手真正的目的。因此对网路爬虫技术的正反两方面的作用都要有清醒的认识。 查看全部
不论是固定的笔记本网路还是以手机为终端的联通网路。使用者会时常遇见一种最常见的现象,这就是只要搜索或则关注某方面的信息,那么马上都会有网路上大量的、与之相类似的信息被“推荐”。绝大部分都是网路小广G,甚至有大量的垃圾信息。那么在信息流量可谓浩如烟海的网路上,怎么会被精确到每位用户究竟关注哪些呢?其实这就是运用了网路爬虫技术。估计有人对爬虫二字看起来就发毛。与自然接触少的城里长大的人,很多都天生怕蟑螂,不过对从小火锅蒸煮过无数蟑螂蚱蜢的老一代人来说,虫子又有哪些可怕的?网络爬虫说究竟就是一种小程序,属于根据一定的规则,自动抓取全球网路上的程序和脚本。对网路用户关注的信息进行剖析和统计,最终作为一种网路剖析资源来获得特定的利益。
网络爬虫技术和搜索引擎有天然的近亲关系。全球各大搜索引擎,都是网路爬虫技术应用的超级大户。可以海量的抓取一定范围内的特定主体和内容的网路信息网络爬虫是什么作用,作为向搜索和查询相关内容的储备数据资源。简单来说网络爬虫是什么作用,网络爬虫如同一群不止疲惫的搜索机器虫,可以海量的替代人工对全球网路进行搜索,对早已传到网上的任何有价值无价值的信息资源都象蚂蚁一样背回去堆在那里等用户,因此被称作网路爬虫。有统计显示,目前全球固定和联通互联网上,被下载的信息中,只有不到55%是真正的活人在抢占流量资源;而另外的45%,也就是接近一半,是网路爬虫和各类“机器人”在抢占流量。可见网路爬虫的厉害。那么网络爬虫是怎样从技术上实现对特定信息下载的呢?在于网络爬虫首先是一个下载小程序。
其从一个或若干初始网页的URL开始,获得正常网路用户初始网页上的URL。在抓取网页的过程中,不断从当前页面上抽取新的URL装入队列。再剖析算法过滤与主题无关的链接,保留有用的链接并将其倒入等待抓取的URL队列。然后,它将按照一定的搜索策略从队列中选择下一步要抓取的网页URL,并重复上述过程,直到达到系统的某一条件时停止。所有被爬虫抓取的网页将会被系统储存,进行一定的剖析、过滤,并构建索引,以便以后的查询和检索。爬虫程序本身具备有用的一面,如果没有网路爬虫技术,那么就不可能有各类用途极大的搜索引擎,所有的网路用户就在海量的信息中走散了。但是瀚海狼山(匈奴狼山)还是那句话:过犹不及。凡事就怕被滥用。很多没有搜索引擎的公司和操作者,也能开发出简单的爬虫技术,来进行自己的网路推广。在网上的爬虫越来越多,不受控制以后,普通的网路用户就都成了最终的受害者。这等于有无数个看不见的刺探者,躲在暗处盯住每一个毫无提防的用户。
你每晚看哪些页面,点击的哪些内容,订购哪些商品,消费了多少钱,都在不知不觉的被记录被剖析。让普通用户没有任何网路隐私可言。谁也不喜欢自己的一言一行都被别人记录并且还被随时剖析借助。因此无处不在的爬虫程序是对用户利益的直接侵害。而且网络爬虫也有军事上的用途和风险。当代社会经济、ZZ和军事活动虽然很难分家。虽然有保密途径,也可释放一些真真假假的信息。但是用爬虫技术,通过机率剖析,仍然可影响国际舆论甚至是判别出对手真正的目的。因此对网路爬虫技术的正反两方面的作用都要有清醒的认识。

