
网站调用新浪微博内容
网站调用新浪微博内容(联合第三方平台登录接入,初次接触开放平台和AppSecret5 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-19 18:10
)
最近做了一个关于联合第三方平台的登录访问,第一次接触到开放平台,在这里做个笔记。
开发前的准备工作如下:
1、注册新浪微博
2、访问新浪微博开发平台,如果是企业,申请企业接入并提交相关材料进行审核;如果是个人开发者,请申请个人开发者申请。我们以开发者为例
3、 使用新浪微博开放API,需要向新浪申请一个appkey和一个App Secret。这些是入口。您必须先获得这两个,然后才能访问下一个作品。
4、输入完善个人信息后,必须完成身份验证审核。审核完成后,新浪开放平台会给出appkey和App Secret。
5、接下来就是如何使用appkey和App Secret了。您需要在开放平台下载文档或演示代码。其实提供的文档基本上都是技术文档,很多东西没有解释清楚。还是会有很多麻烦
6、新浪开放平台提供了很多不同开发语言的SDK,这里我选择java SDK,下载一个zip文件(包括新接口和OAuth2.0),解压后可以直接导入go到eclipse,结构如下,包括weibo4j源码和示例代码
这里是一个config配置文件,打开如下:
我们之前申请的appkey和App Secret就派上用场了。这里的client_ID为appkey,client_SERCRET为App Secret,填写对应内容,redirect_URI为回调地址。
点击“第三方”-》跳转微博登录-》登录ok,授权-》回调自己的应用,这里是回调地址的意思。
7、开始运行测试程序,测试程序在example下,包weibo4j.examples.oauth2下的类OAuth4Code,这里我们需要做一些修改,修改程序在
oauth.authorize("code",args[0],args[1]),把这一段改成oauth.authorize("code","","all"),至于为什么,请看这里的接口文档说明使用 oauth.authorize
假设我们这里没有回调地址,配置文件中的redirect_URI为空。运行后会自动打开浏览器运行测试,显示如下:
此时的URL地址为:
这说明我的appkey和App Secret是有效的,因为我们还没有创建正式的应用,新浪无法识别我的来源
8、在开放平台上创建应用,如下图
这里的应用分为三种类型,网站访问、现场应用和移动应用。如果是企业行为,有公有域名可以访问,应用通过域名访问。这里两种方法都可以,但是如果我们只是一个简单的开发者,没有公网域名,比如内网模式,ip以内网地址192.168.开头1.*,本地127.0.0.1等,这里只能选择创建站内应用,填写如下
这里红框标注的地方就是回调地址。如果我没有公网ip和域名,我在局域网玩的时候随便填,但是不能用localhost代替127.0.0.1,这里是按照配置要求做的,这个配置的要求很严格,
尤其是下面的应用图标比较麻烦。完成后,您可以提交它们以供审核。
9、提交审核后,新浪开放平台会在1天左右第一时间发邮件到您的邮箱,通知您审核结果,但不管审核结果是否失败,关键是提交审核。没有审核成功,这里可以照常使用
10、完成测试项目中的配置文件redirect_URI,必须与创建应用时填写的【应用实际地址】一致,这是回调地址!完成配置后,再次运行OAuth4Code.java,如图
在这里你会跳转到新浪微博的登录页面。登录你的新浪微博账号后,需要点击授权,表示平台可以访问你的微博账号内容分享你的信息等。授权结束后,
将返回一个代码。这段代码非常重要。它是我们整个访问第三方平台的门钥匙。通过这段代码,我们可以获取到用户的access_token、UID等内容,相当于整个访问过程。
11、调用新浪微博开放API
这里我们需要研究这些API来满足访问的需要。首先要熟悉的是OAuth2.0授权接口,网上可以查到,如下:
12、通过servlet程序调用开放API获取新浪微博的UID和微博名的示例
response.setContentType("text/html;charset=UTF-8");
String accessToken = null ;
String uid = null ;
String screenName = null ;
String username = null ;
AccessToken accessTokenObj = null ;
Oauth oauth2 = new Oauth();
try {
out = response.getWriter();
accessTokenObj = oauth2.getAccessTokenByCode(code) ;
logger.info(accessTokenObj);
accessToken = accessTokenObj.getAccessToken() ;
oauth2.setToken(accessToken) ;
Account account = new Account() ;
account.client.setToken(accessToken) ;
JSONObject uidJson = account.getUid() ;
uid = uidJson.getString("uid") ;
Users users = new Users() ;
users.client.setToken(accessToken) ;
User weiboUser = users.showUserById(uid) ;
username = weiboUser.getName() ;
screenName = weiboUser.getScreenName() ;
} catch (WeiboException | IOException | JSONException e) {
e.printStackTrace();
}
out.println("微博访问Token_Info:" + accessTokenObj + "\t");
out.println("微博访问Token:" + accessToken + "\t");
out.println("微博用户-Uid:" + uid + "\t");
out.println("微博用户-名称:" + screenName + "\t");
out.flush();
out.close();*/
查看全部
网站调用新浪微博内容(联合第三方平台登录接入,初次接触开放平台和AppSecret5
)
最近做了一个关于联合第三方平台的登录访问,第一次接触到开放平台,在这里做个笔记。
开发前的准备工作如下:
1、注册新浪微博
2、访问新浪微博开发平台,如果是企业,申请企业接入并提交相关材料进行审核;如果是个人开发者,请申请个人开发者申请。我们以开发者为例
3、 使用新浪微博开放API,需要向新浪申请一个appkey和一个App Secret。这些是入口。您必须先获得这两个,然后才能访问下一个作品。
4、输入完善个人信息后,必须完成身份验证审核。审核完成后,新浪开放平台会给出appkey和App Secret。
5、接下来就是如何使用appkey和App Secret了。您需要在开放平台下载文档或演示代码。其实提供的文档基本上都是技术文档,很多东西没有解释清楚。还是会有很多麻烦
6、新浪开放平台提供了很多不同开发语言的SDK,这里我选择java SDK,下载一个zip文件(包括新接口和OAuth2.0),解压后可以直接导入go到eclipse,结构如下,包括weibo4j源码和示例代码

这里是一个config配置文件,打开如下:

我们之前申请的appkey和App Secret就派上用场了。这里的client_ID为appkey,client_SERCRET为App Secret,填写对应内容,redirect_URI为回调地址。
点击“第三方”-》跳转微博登录-》登录ok,授权-》回调自己的应用,这里是回调地址的意思。
7、开始运行测试程序,测试程序在example下,包weibo4j.examples.oauth2下的类OAuth4Code,这里我们需要做一些修改,修改程序在
oauth.authorize("code",args[0],args[1]),把这一段改成oauth.authorize("code","","all"),至于为什么,请看这里的接口文档说明使用 oauth.authorize
假设我们这里没有回调地址,配置文件中的redirect_URI为空。运行后会自动打开浏览器运行测试,显示如下:

此时的URL地址为:
这说明我的appkey和App Secret是有效的,因为我们还没有创建正式的应用,新浪无法识别我的来源
8、在开放平台上创建应用,如下图

这里的应用分为三种类型,网站访问、现场应用和移动应用。如果是企业行为,有公有域名可以访问,应用通过域名访问。这里两种方法都可以,但是如果我们只是一个简单的开发者,没有公网域名,比如内网模式,ip以内网地址192.168.开头1.*,本地127.0.0.1等,这里只能选择创建站内应用,填写如下

这里红框标注的地方就是回调地址。如果我没有公网ip和域名,我在局域网玩的时候随便填,但是不能用localhost代替127.0.0.1,这里是按照配置要求做的,这个配置的要求很严格,
尤其是下面的应用图标比较麻烦。完成后,您可以提交它们以供审核。
9、提交审核后,新浪开放平台会在1天左右第一时间发邮件到您的邮箱,通知您审核结果,但不管审核结果是否失败,关键是提交审核。没有审核成功,这里可以照常使用

10、完成测试项目中的配置文件redirect_URI,必须与创建应用时填写的【应用实际地址】一致,这是回调地址!完成配置后,再次运行OAuth4Code.java,如图

在这里你会跳转到新浪微博的登录页面。登录你的新浪微博账号后,需要点击授权,表示平台可以访问你的微博账号内容分享你的信息等。授权结束后,
将返回一个代码。这段代码非常重要。它是我们整个访问第三方平台的门钥匙。通过这段代码,我们可以获取到用户的access_token、UID等内容,相当于整个访问过程。
11、调用新浪微博开放API
这里我们需要研究这些API来满足访问的需要。首先要熟悉的是OAuth2.0授权接口,网上可以查到,如下:

12、通过servlet程序调用开放API获取新浪微博的UID和微博名的示例

response.setContentType("text/html;charset=UTF-8");
String accessToken = null ;
String uid = null ;
String screenName = null ;
String username = null ;
AccessToken accessTokenObj = null ;
Oauth oauth2 = new Oauth();
try {
out = response.getWriter();
accessTokenObj = oauth2.getAccessTokenByCode(code) ;
logger.info(accessTokenObj);
accessToken = accessTokenObj.getAccessToken() ;
oauth2.setToken(accessToken) ;
Account account = new Account() ;
account.client.setToken(accessToken) ;
JSONObject uidJson = account.getUid() ;
uid = uidJson.getString("uid") ;
Users users = new Users() ;
users.client.setToken(accessToken) ;
User weiboUser = users.showUserById(uid) ;
username = weiboUser.getName() ;
screenName = weiboUser.getScreenName() ;
} catch (WeiboException | IOException | JSONException e) {
e.printStackTrace();
}
out.println("微博访问Token_Info:" + accessTokenObj + "\t");
out.println("微博访问Token:" + accessToken + "\t");
out.println("微博用户-Uid:" + uid + "\t");
out.println("微博用户-名称:" + screenName + "\t");
out.flush();
out.close();*/
网站调用新浪微博内容(博客平台来说不支持iframe的两种解决办法方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-01-19 18:09
很多博客可以自己添加和修改一些代码,但是作为博客平台,出于安全考虑,往往需要对一些特性进行过滤。比如新浪微博的挂件都是iframe的形式,但是博客园不支持iframe。经过一番尝试,我终于找到了以下两种解决方案:
首先在公告中写一个空的div,这样我们就可以插入新的iframe,省去按类选择的麻烦:
<br />
1、在公告中直接用innerHTML插入iframe代码:
innerHTML 非常简单。从新浪微博的配置中,匹配你想要的样式,然后它会自动生成一段html代码,类似如下:
但是如果直接这样写,是不会生效的:
var ifr = '';<br /><br />document.getElementById('weiboIframe').innerHTML = ifr;
估计是博客园的背景是直接匹配iframe文本的,所以我们打乱这个,让他检测不到逻辑,改成这样就成功了:
<br />var ifr = '';<br />document.getElementById('weiboIframe').innerHTML = ifr;<br />
2、也可以使用createElement方法:
因为这里有人用过Google Adsense的代码,我猜这个方法可以用。经过测试,确实是可以的,但是比上面的还要多写几句:
<br /><br />var iii = document.createElement('iframe');<br />iii.src = 'http://widget.weibo.com/weibos ... %3Bbr />iii.height = 115;<br />iii.width = '100%';<br />iii.className = 'share_self';<br />iii.scrolling = 'no';<br />document.getElementById('weiboIframe').appendChild(iii);<br /><br />
将以上内容放入公告中,即可展示您的新浪微博 查看全部
网站调用新浪微博内容(博客平台来说不支持iframe的两种解决办法方法)
很多博客可以自己添加和修改一些代码,但是作为博客平台,出于安全考虑,往往需要对一些特性进行过滤。比如新浪微博的挂件都是iframe的形式,但是博客园不支持iframe。经过一番尝试,我终于找到了以下两种解决方案:
首先在公告中写一个空的div,这样我们就可以插入新的iframe,省去按类选择的麻烦:
<br />
1、在公告中直接用innerHTML插入iframe代码:
innerHTML 非常简单。从新浪微博的配置中,匹配你想要的样式,然后它会自动生成一段html代码,类似如下:
但是如果直接这样写,是不会生效的:
var ifr = '';<br /><br />document.getElementById('weiboIframe').innerHTML = ifr;
估计是博客园的背景是直接匹配iframe文本的,所以我们打乱这个,让他检测不到逻辑,改成这样就成功了:
<br />var ifr = '';<br />document.getElementById('weiboIframe').innerHTML = ifr;<br />
2、也可以使用createElement方法:
因为这里有人用过Google Adsense的代码,我猜这个方法可以用。经过测试,确实是可以的,但是比上面的还要多写几句:
<br /><br />var iii = document.createElement('iframe');<br />iii.src = 'http://widget.weibo.com/weibos ... %3Bbr />iii.height = 115;<br />iii.width = '100%';<br />iii.className = 'share_self';<br />iii.scrolling = 'no';<br />document.getElementById('weiboIframe').appendChild(iii);<br /><br />
将以上内容放入公告中,即可展示您的新浪微博
网站调用新浪微博内容(Coursera去一个文件的下载,只有傻子才那么干! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-01-19 18:08
)
首先按照文章的思路,自己试了一下,可以成功
有时候我们需要采集一些经典的东西,时不时回味一下,Coursera上的一些课程无疑是经典。Coursera中完成的大部分课程都提供了完整的配套教学资源,包括ppt、视频和字幕等,离线后学习起来非常容易。很明显,我们不是逐个文件下载的,只有傻子才会这样做,程序员是聪明人!
那么我们聪明的人会怎么做呢?当然,写个脚本批量下载。首先我们需要分析一下手动下载的过程:登录我们的Coursera账号(有些课程需要我们登录并选择一门课程才能看到对应的资源),在课程资源页面找到对应的文件链接,然后使用喜欢的工具下载。
很简单,对吧?我们可以用程序来模仿上面的步骤,这样我们就可以解放双手了。整个程序可以分为三个部分:
登录 Coursera;在课程资源页面上找到资源链接;根据资源链接选择合适的工具下载资源。
让我们详细实现以下内容!
登录
一开始没有加登录模块,以为访问者可以下载相应的课程资源。后来在测试comnetworks-002课程时,发现访问者在访问资源页面时会自动跳转到登录界面。下图显示chrome是隐身的。访问本课程的资源页面时的模式。
模拟登录,我们先找到登录页面,然后使用谷歌的开发者工具分析账号密码是如何上传到服务器的。
我们在登录页面的表格中填写账号密码,然后点击登录。同时,我们需要关注Developer Tools-Network,找到提交账号信息的url。一般情况下,如果要向服务器提交信息,一般采用post方式。这里我们只需要先找到 Method 为 post 的 url。可悲的是,每次登录我的账户,提交账户信息的地址在网络中都找不到。猜到登录成功后,直接跳转到登录成功后的页面,你要找的内容一闪而过。
于是我只输入了一组账号密码,故意登录失败。果然找到了帖子的页面地址,如下图:
地址是: 。为了知道已经向服务器提交了哪些内容,进一步观察post页面中表单的内容,如下图:
我们看到总共有三个字段:
接下来,我们来写吧。我选择使用python的Requests库来模拟登录。这是Requests官网介绍的。
Requests 是一个优雅而简单的 Python HTTP 库,专为人类构建。
其实request使用起来真的很简单方便,这要归功于专门为人类设计的http库。requests 提供了一个 Session 对象,可以用来在不同的请求中传递一些相同的数据,比如在每个请求中携带 cookie。
初步代码如下:
signin_url = "https://accounts.coursera.org/api/v1/login"
logininfo = {"email": "...",
"password": "...",
"webrequest": "true"
}
user_agent = ("Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_4) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/36.0.1985.143 Safari/537.36")
post_headers = {"User-Agent": user_agent,
"Referer": "https://accounts.coursera.org/signin"
}
coursera_session = requests.Session()
login_res = coursera_session.post(signin_url,
data=logininfo,
headers=post_headers,
)
if login_res.status_code == 200:
print "Login Successfully!"
else:
print login_res.text
将表单中提交的内容存储在字典中,然后作为数据参数传递给 Session.post 函数。一般情况下最好加上User-Agent、Referer等请求头,User-Agent用来模拟浏览器请求,Referer用来告诉服务器我是从referer页面跳转到请求的页。有时服务器会检查请求的Referer字段,以确保当前请求页面是从固定地址跳转的。
运行上述代码段的结果很奇怪,显示以下消息:Invalid CSRF Token。后来在github上搜索了一个Coursera的批量下载脚本,发现当人们发送页面请求时,headers多了四个字段:XCSRF2Cookie、XCSRF2Token、XCSRFToken、cookie。于是又查看了post页面的请求头,发现确实有这些字段,估计是服务端用来做一些限制的。
用浏览器登录几次后发现XCSRF2Token,XCSRFToken是一个长度为24的随机字符串,而XCSRF2Cookie是“csrf2_token_”加上一个长度为8的随机字符串。但是一直没弄清楚cookie是怎么获取的,但是查看github上的代码,cookie似乎只是“csrftoken”和其他三个的组合。我试过了,它奏效了。
将以下部分添加到原创代码中就足够了。
def randomString(length):
return ''.join(random.choice(string.letters + string.digits) for i in xrange(length))
XCSRF2Cookie = 'csrf2_token_%s' % ''.join(randomString(8))
XCSRF2Token = ''.join(randomString(24))
XCSRFToken = ''.join(randomString(24))
cookie = "csrftoken=%s; %s=%s" % (XCSRFToken, XCSRF2Cookie, XCSRF2Token)
post_headers = {"User-Agent": user_agent,
"Referer": "https://accounts.coursera.org/signin",
"X-Requested-With": "XMLHttpRequest",
"X-CSRF2-Cookie": XCSRF2Cookie,
"X-CSRF2-Token": XCSRF2Token,
"X-CSRFToken": XCSRFToken,
"Cookie": cookie
}
至此,登录功能已经初步实现。
分析资源链接
登录成功后,我们只需要获取资源页面的内容,然后过滤掉我们需要的资源链接即可。资源页面的地址很简单,name就是课程名称。例如,对于课程 comnetworks-002,资源页面地址为 .
抓取到页面资源后,我们需要分析html文件,这里我们选择使用BeautifulSoup。BeautifulSoup 是一个强大的 Python 库,可以从 HTML 或 XML 文件中提取数据。具体使用官网有非常详细的文档,这里不再赘述。在使用 BeautifulSoup 之前,我们必须找出资源链接的规律,以便进行过滤。
课程每周总话题在class=course-item-list-header的div标签下,每周课程在class=course-item-list-section-list的ul标签下,每门课程是在 li 标签下,课程资源位于 li 标签中的 div 标签中。
看了几门课程,发现过滤资源链接的方法很简单,如下:
ppt和ppt资源:使用正则表达式匹配链接;字幕资源:找到title="Subtitles (srt)" 的标签,取其href属性;视频资源:找到 title="Video (MP4)" 的标签,取其 href 属性。
字幕和视频也可以使用正则表达式进行过滤,但使用 BeautifulSoup 根据标题属性进行匹配,以获得更好的可读性。但是ppt和pdf资源没有固定的title属性,所以必须使用正则表达式来匹配。
具体代码如下:
soup = BeautifulSoup(content)
chapter_list = soup.find_all("div", class_="course-item-list-header")
lecture_resource_list = soup.find_all("ul", class_="course-item-list-section-list")
ppt_pattern = re.compile(r'https://[^"]*\.ppt[x]?')
pdf_pattern = re.compile(r'https://[^"]*\.pdf')
for lecture_item, chapter_item in zip(lecture_resource_list, chapter_list):
# weekly title
chapter = chapter_item.h3.text.lstrip()
for lecture in lecture_item:
lecture_name = lecture.a.string.lstrip()
# get resource link
ppt_tag = lecture.find(href=ppt_pattern)
pdf_tag = lecture.find(href=pdf_pattern)
srt_tag = lecture.find(title="Subtitles (srt)")
mp4_tag = lecture.find(title="Video (MP4)")
print ppt_tag["href"], pdf_tag["href"]
print srt_tag["href"], mp4_tag["href"]
下载资源
既然已经获取了资源链接,下载部分就很容易了,这里我选择使用curl来下载。具体思路很简单,就是将curl resource_link -o file_name 输出到一个种子文件,比如feed.sh。这样,你只需要赋予torrent文件执行权限,然后运行torrent文件即可。
为了方便对课程资源进行分类,可以为课程每周的标题创建一个文件夹,然后该周的所有课程都会下载到这个目录中。为了方便我们快速定位到每个类的所有资源,可以将一个类的所有资源文件命名为类名.文件类型。具体实现比较简单,这里不再给出具体方案。您可以查看测试示例中的 feed.sh 文件。部分内容如下:
mkdir 'Week 1: Introduction, Protocols, and Layering'
cd 'Week 1: Introduction, Protocols, and Layering'
curl https://d396qusza40orc.cloudfr ... s.pdf -o '1-1 Goals and Motivation (15:46).pdf'
curl https://class.coursera.org/com ... 3Dsrt -o '1-1 Goals and Motivation (15:46).srt'
curl https://class.coursera.org/com ... %3D25 -o '1-1 Goals and Motivation (15:46).mp4'
curl https://d396qusza40orc.cloudfr ... s.pdf -o '1-2 Uses of Networks (17:12).pdf'
curl https://class.coursera.org/com ... 3Dsrt -o '1-2 Uses of Networks (17:12).srt'
curl https://class.coursera.org/com ... %3D11 -o '1-2 Uses of Networks (17:12).mp4'
至此,我们已经成功完成爬取Coursera课程资源的目标,具体代码放在gist上。使用时,我们只需要运行程序,将课程名称作为参数传递给程序即可(这里的课程名称不是整个课程的全称,而是课程介绍页面地址中的缩写名称,如作为Computer Networks这个类,类名是comnetworks-002)。
后来发现Coursera为我们提供了下载资源的接口。
更新:2014 年 9 月 3 日
其实这个程序可以看成是一个简单的爬虫小程序。下面简单介绍爬虫的概念。
不是一个简单的爬虫
关于什么是爬虫,这就是 wiki 所说的
Web 爬虫是一种 Internet 机器人,它系统地浏览万维网,通常用于 Web 索引。
爬虫整体架构如下(图片来自wiki):
简单来说就是爬虫从Scheduler中获取初始url,下载对应的页面,存储有用的数据,同时分析页面中的链接。
当然,有一些协议可以约束爬虫的行为。比如很多网站都有一个robots.txt文件来指定网站哪些内容可以爬取,哪些不能爬取。
每个搜索引擎的背后都有一个强大的爬虫程序,它的触角延伸到网络的各个角落,不断采集有用的信息并建立索引。这种搜索引擎级别的爬虫实现起来非常复杂,因为互联网上的页面数量太多,仅仅遍历它们是非常困难的,更不用说分析页面信息和建立索引了。
在实际应用中,我们只需要爬取特定站点,爬取少量资源,实现起来要简单得多。但是,仍然有很多令人头疼的问题。例如,许多页面元素是由 javascript 生成的。这时候,我们需要一个javascript引擎来渲染整个页面,然后进行过滤。
雪上加霜的是,很多网站为了防止爬虫爬取资源采取了一些措施,比如在一段时间内限制对同一IP的访问次数,或者限制两次操作的时间间隔,添加验证码等等. 在大多数情况下,我们不知道如何在服务器端阻止爬虫,所以要让爬虫工作起来确实很困难。
参考:
github:coursera-dl/coursera
github:coursera-下载器
python抓取页面元素失败
维基:网络爬虫
如何开始使用 Python 爬虫?
补充:上述过程中用到的python requests 模块的下载地址如下:
requests模块文章的详细介绍如下:
测试后完整代码如下:
import requests
import random
import string
signin_url = "https://accounts.coursera.org/api/v1/login"
logininfo = {"email": "已注册邮箱",
"password": "密码",
"webrequest": "true"
}
user_agent = ("Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; Trident/6.0)")
def randomString(length):
return ''.join(random.choice(string.letters + string.digits) for i in xrange(length))
XCSRF2Cookie = 'csrf2_token_%s' % ''.join(randomString(8))
XCSRF2Token = ''.join(randomString(24))
XCSRFToken = ''.join(randomString(24))
cookie = "csrftoken=%s; %s=%s" % (XCSRFToken, XCSRF2Cookie, XCSRF2Token)
post_headers = {"User-Agent": user_agent,
"Referer": "https://accounts.coursera.org/signin",
"X-Requested-With": "XMLHttpRequest",
"X-CSRF2-Cookie": XCSRF2Cookie,
"X-CSRF2-Token": XCSRF2Token,
"X-CSRFToken": XCSRFToken,
"Cookie": cookie
}
coursera_session = requests.Session()
login_res = coursera_session.post(signin_url,
data=logininfo,
headers=post_headers,
)
if login_res.status_code == 200:
print "Login Successfully!"
else:
print login_res.text
import re
import urllib
page = urllib.urlopen("https://class.coursera.org/com ... 6quot;)
html = page.read()
print html, 查看全部
网站调用新浪微博内容(Coursera去一个文件的下载,只有傻子才那么干!
)
首先按照文章的思路,自己试了一下,可以成功
有时候我们需要采集一些经典的东西,时不时回味一下,Coursera上的一些课程无疑是经典。Coursera中完成的大部分课程都提供了完整的配套教学资源,包括ppt、视频和字幕等,离线后学习起来非常容易。很明显,我们不是逐个文件下载的,只有傻子才会这样做,程序员是聪明人!
那么我们聪明的人会怎么做呢?当然,写个脚本批量下载。首先我们需要分析一下手动下载的过程:登录我们的Coursera账号(有些课程需要我们登录并选择一门课程才能看到对应的资源),在课程资源页面找到对应的文件链接,然后使用喜欢的工具下载。
很简单,对吧?我们可以用程序来模仿上面的步骤,这样我们就可以解放双手了。整个程序可以分为三个部分:
登录 Coursera;在课程资源页面上找到资源链接;根据资源链接选择合适的工具下载资源。
让我们详细实现以下内容!
登录
一开始没有加登录模块,以为访问者可以下载相应的课程资源。后来在测试comnetworks-002课程时,发现访问者在访问资源页面时会自动跳转到登录界面。下图显示chrome是隐身的。访问本课程的资源页面时的模式。

模拟登录,我们先找到登录页面,然后使用谷歌的开发者工具分析账号密码是如何上传到服务器的。
我们在登录页面的表格中填写账号密码,然后点击登录。同时,我们需要关注Developer Tools-Network,找到提交账号信息的url。一般情况下,如果要向服务器提交信息,一般采用post方式。这里我们只需要先找到 Method 为 post 的 url。可悲的是,每次登录我的账户,提交账户信息的地址在网络中都找不到。猜到登录成功后,直接跳转到登录成功后的页面,你要找的内容一闪而过。
于是我只输入了一组账号密码,故意登录失败。果然找到了帖子的页面地址,如下图:

地址是: 。为了知道已经向服务器提交了哪些内容,进一步观察post页面中表单的内容,如下图:

我们看到总共有三个字段:
接下来,我们来写吧。我选择使用python的Requests库来模拟登录。这是Requests官网介绍的。
Requests 是一个优雅而简单的 Python HTTP 库,专为人类构建。
其实request使用起来真的很简单方便,这要归功于专门为人类设计的http库。requests 提供了一个 Session 对象,可以用来在不同的请求中传递一些相同的数据,比如在每个请求中携带 cookie。
初步代码如下:
signin_url = "https://accounts.coursera.org/api/v1/login"
logininfo = {"email": "...",
"password": "...",
"webrequest": "true"
}
user_agent = ("Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_4) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/36.0.1985.143 Safari/537.36")
post_headers = {"User-Agent": user_agent,
"Referer": "https://accounts.coursera.org/signin"
}
coursera_session = requests.Session()
login_res = coursera_session.post(signin_url,
data=logininfo,
headers=post_headers,
)
if login_res.status_code == 200:
print "Login Successfully!"
else:
print login_res.text
将表单中提交的内容存储在字典中,然后作为数据参数传递给 Session.post 函数。一般情况下最好加上User-Agent、Referer等请求头,User-Agent用来模拟浏览器请求,Referer用来告诉服务器我是从referer页面跳转到请求的页。有时服务器会检查请求的Referer字段,以确保当前请求页面是从固定地址跳转的。
运行上述代码段的结果很奇怪,显示以下消息:Invalid CSRF Token。后来在github上搜索了一个Coursera的批量下载脚本,发现当人们发送页面请求时,headers多了四个字段:XCSRF2Cookie、XCSRF2Token、XCSRFToken、cookie。于是又查看了post页面的请求头,发现确实有这些字段,估计是服务端用来做一些限制的。
用浏览器登录几次后发现XCSRF2Token,XCSRFToken是一个长度为24的随机字符串,而XCSRF2Cookie是“csrf2_token_”加上一个长度为8的随机字符串。但是一直没弄清楚cookie是怎么获取的,但是查看github上的代码,cookie似乎只是“csrftoken”和其他三个的组合。我试过了,它奏效了。
将以下部分添加到原创代码中就足够了。
def randomString(length):
return ''.join(random.choice(string.letters + string.digits) for i in xrange(length))
XCSRF2Cookie = 'csrf2_token_%s' % ''.join(randomString(8))
XCSRF2Token = ''.join(randomString(24))
XCSRFToken = ''.join(randomString(24))
cookie = "csrftoken=%s; %s=%s" % (XCSRFToken, XCSRF2Cookie, XCSRF2Token)
post_headers = {"User-Agent": user_agent,
"Referer": "https://accounts.coursera.org/signin",
"X-Requested-With": "XMLHttpRequest",
"X-CSRF2-Cookie": XCSRF2Cookie,
"X-CSRF2-Token": XCSRF2Token,
"X-CSRFToken": XCSRFToken,
"Cookie": cookie
}
至此,登录功能已经初步实现。
分析资源链接
登录成功后,我们只需要获取资源页面的内容,然后过滤掉我们需要的资源链接即可。资源页面的地址很简单,name就是课程名称。例如,对于课程 comnetworks-002,资源页面地址为 .
抓取到页面资源后,我们需要分析html文件,这里我们选择使用BeautifulSoup。BeautifulSoup 是一个强大的 Python 库,可以从 HTML 或 XML 文件中提取数据。具体使用官网有非常详细的文档,这里不再赘述。在使用 BeautifulSoup 之前,我们必须找出资源链接的规律,以便进行过滤。
课程每周总话题在class=course-item-list-header的div标签下,每周课程在class=course-item-list-section-list的ul标签下,每门课程是在 li 标签下,课程资源位于 li 标签中的 div 标签中。
看了几门课程,发现过滤资源链接的方法很简单,如下:
ppt和ppt资源:使用正则表达式匹配链接;字幕资源:找到title="Subtitles (srt)" 的标签,取其href属性;视频资源:找到 title="Video (MP4)" 的标签,取其 href 属性。
字幕和视频也可以使用正则表达式进行过滤,但使用 BeautifulSoup 根据标题属性进行匹配,以获得更好的可读性。但是ppt和pdf资源没有固定的title属性,所以必须使用正则表达式来匹配。
具体代码如下:
soup = BeautifulSoup(content)
chapter_list = soup.find_all("div", class_="course-item-list-header")
lecture_resource_list = soup.find_all("ul", class_="course-item-list-section-list")
ppt_pattern = re.compile(r'https://[^"]*\.ppt[x]?')
pdf_pattern = re.compile(r'https://[^"]*\.pdf')
for lecture_item, chapter_item in zip(lecture_resource_list, chapter_list):
# weekly title
chapter = chapter_item.h3.text.lstrip()
for lecture in lecture_item:
lecture_name = lecture.a.string.lstrip()
# get resource link
ppt_tag = lecture.find(href=ppt_pattern)
pdf_tag = lecture.find(href=pdf_pattern)
srt_tag = lecture.find(title="Subtitles (srt)")
mp4_tag = lecture.find(title="Video (MP4)")
print ppt_tag["href"], pdf_tag["href"]
print srt_tag["href"], mp4_tag["href"]
下载资源
既然已经获取了资源链接,下载部分就很容易了,这里我选择使用curl来下载。具体思路很简单,就是将curl resource_link -o file_name 输出到一个种子文件,比如feed.sh。这样,你只需要赋予torrent文件执行权限,然后运行torrent文件即可。
为了方便对课程资源进行分类,可以为课程每周的标题创建一个文件夹,然后该周的所有课程都会下载到这个目录中。为了方便我们快速定位到每个类的所有资源,可以将一个类的所有资源文件命名为类名.文件类型。具体实现比较简单,这里不再给出具体方案。您可以查看测试示例中的 feed.sh 文件。部分内容如下:
mkdir 'Week 1: Introduction, Protocols, and Layering'
cd 'Week 1: Introduction, Protocols, and Layering'
curl https://d396qusza40orc.cloudfr ... s.pdf -o '1-1 Goals and Motivation (15:46).pdf'
curl https://class.coursera.org/com ... 3Dsrt -o '1-1 Goals and Motivation (15:46).srt'
curl https://class.coursera.org/com ... %3D25 -o '1-1 Goals and Motivation (15:46).mp4'
curl https://d396qusza40orc.cloudfr ... s.pdf -o '1-2 Uses of Networks (17:12).pdf'
curl https://class.coursera.org/com ... 3Dsrt -o '1-2 Uses of Networks (17:12).srt'
curl https://class.coursera.org/com ... %3D11 -o '1-2 Uses of Networks (17:12).mp4'
至此,我们已经成功完成爬取Coursera课程资源的目标,具体代码放在gist上。使用时,我们只需要运行程序,将课程名称作为参数传递给程序即可(这里的课程名称不是整个课程的全称,而是课程介绍页面地址中的缩写名称,如作为Computer Networks这个类,类名是comnetworks-002)。
后来发现Coursera为我们提供了下载资源的接口。
更新:2014 年 9 月 3 日
其实这个程序可以看成是一个简单的爬虫小程序。下面简单介绍爬虫的概念。
不是一个简单的爬虫
关于什么是爬虫,这就是 wiki 所说的
Web 爬虫是一种 Internet 机器人,它系统地浏览万维网,通常用于 Web 索引。
爬虫整体架构如下(图片来自wiki):

简单来说就是爬虫从Scheduler中获取初始url,下载对应的页面,存储有用的数据,同时分析页面中的链接。
当然,有一些协议可以约束爬虫的行为。比如很多网站都有一个robots.txt文件来指定网站哪些内容可以爬取,哪些不能爬取。
每个搜索引擎的背后都有一个强大的爬虫程序,它的触角延伸到网络的各个角落,不断采集有用的信息并建立索引。这种搜索引擎级别的爬虫实现起来非常复杂,因为互联网上的页面数量太多,仅仅遍历它们是非常困难的,更不用说分析页面信息和建立索引了。
在实际应用中,我们只需要爬取特定站点,爬取少量资源,实现起来要简单得多。但是,仍然有很多令人头疼的问题。例如,许多页面元素是由 javascript 生成的。这时候,我们需要一个javascript引擎来渲染整个页面,然后进行过滤。
雪上加霜的是,很多网站为了防止爬虫爬取资源采取了一些措施,比如在一段时间内限制对同一IP的访问次数,或者限制两次操作的时间间隔,添加验证码等等. 在大多数情况下,我们不知道如何在服务器端阻止爬虫,所以要让爬虫工作起来确实很困难。
参考:
github:coursera-dl/coursera
github:coursera-下载器
python抓取页面元素失败
维基:网络爬虫
如何开始使用 Python 爬虫?
补充:上述过程中用到的python requests 模块的下载地址如下:
requests模块文章的详细介绍如下:
测试后完整代码如下:
import requests
import random
import string
signin_url = "https://accounts.coursera.org/api/v1/login"
logininfo = {"email": "已注册邮箱",
"password": "密码",
"webrequest": "true"
}
user_agent = ("Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; Trident/6.0)")
def randomString(length):
return ''.join(random.choice(string.letters + string.digits) for i in xrange(length))
XCSRF2Cookie = 'csrf2_token_%s' % ''.join(randomString(8))
XCSRF2Token = ''.join(randomString(24))
XCSRFToken = ''.join(randomString(24))
cookie = "csrftoken=%s; %s=%s" % (XCSRFToken, XCSRF2Cookie, XCSRF2Token)
post_headers = {"User-Agent": user_agent,
"Referer": "https://accounts.coursera.org/signin",
"X-Requested-With": "XMLHttpRequest",
"X-CSRF2-Cookie": XCSRF2Cookie,
"X-CSRF2-Token": XCSRF2Token,
"X-CSRFToken": XCSRFToken,
"Cookie": cookie
}
coursera_session = requests.Session()
login_res = coursera_session.post(signin_url,
data=logininfo,
headers=post_headers,
)
if login_res.status_code == 200:
print "Login Successfully!"
else:
print login_res.text
import re
import urllib
page = urllib.urlopen("https://class.coursera.org/com ... 6quot;)
html = page.read()
print html,
网站调用新浪微博内容(网站调用新浪微博内容生成了浏览器扩展(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-19 04:03
网站调用新浪微博内容生成了浏览器扩展,使得用户可以通过新浪微博链接跳转到android微博url访问,是一个很有想法的页面。
不敢说全部是骗局,
中国的公关都是坨屎。天天被科普无数遍骗子,
绝对是骗局,
学我,找个像bbs的生意。
我看了下,服务器的url实际上不是从新浪bbs而是新浪微博提供给我们的服务器的真实url地址,那其实从bbs中提取的链接只是二级以下的页面,如果你写一个web应用,想要提取这个链接,起码需要几千个页面的api可以说难度很大,到微博中随便调一个页面就要几百个页面的提取就很有难度。大多数人都不理解(甚至要怀疑网站后台有人)。
并且现在正规网站做产品,都不太愿意把url指向新浪bbs了,或者有些bbs本身就有生意,跟新浪也没有合作关系。产品质量上,说实话与新浪bbs合作的公司,质量水平不一。有些api做的好有些差。有些api做得好有些差。有些微信sdk做的好有些差。有些人整体体验好有些人整体体验差。整体看公司的,又有很多方面需要提升。到现在我也不知道新浪bbs给我多少好处。
从专业内容运营角度看,这种项目有几个优势:a、此类网站的用户群比较固定,即新浪本身,品牌影响力大,有议价能力。且相对优质内容偏多,无论是seo还是品牌输出都有优势。b、通过提供专业化的技术服务服务于客户,无论是开发成本,还是相应服务能力,都能让客户获得不错的回报。还能合理的降低技术成本,节省了后期开发人员等的开支。当然优势不代表就没有缺点:。
1、这类网站普遍平台用户基数较大,普通用户比较难以分辨整个平台的服务质量。
2、一家独大,导致网站被封。
3、这类服务我们所知甚少,也无法从产品品质上区分平台用户的品质。即使是新浪的员工也很难区分对方的服务是否合规。
4、对bbs内容的管理难度大,缺乏投诉渠道、优质内容难以查询等等。
5、具有鲜明互联网特色的整个网站,内容被搬运、被采集都比较多。整体来看,porreweb项目不是新浪主导的,是porre所提供服务公司所主导的。 查看全部
网站调用新浪微博内容(网站调用新浪微博内容生成了浏览器扩展(图))
网站调用新浪微博内容生成了浏览器扩展,使得用户可以通过新浪微博链接跳转到android微博url访问,是一个很有想法的页面。
不敢说全部是骗局,
中国的公关都是坨屎。天天被科普无数遍骗子,
绝对是骗局,
学我,找个像bbs的生意。
我看了下,服务器的url实际上不是从新浪bbs而是新浪微博提供给我们的服务器的真实url地址,那其实从bbs中提取的链接只是二级以下的页面,如果你写一个web应用,想要提取这个链接,起码需要几千个页面的api可以说难度很大,到微博中随便调一个页面就要几百个页面的提取就很有难度。大多数人都不理解(甚至要怀疑网站后台有人)。
并且现在正规网站做产品,都不太愿意把url指向新浪bbs了,或者有些bbs本身就有生意,跟新浪也没有合作关系。产品质量上,说实话与新浪bbs合作的公司,质量水平不一。有些api做的好有些差。有些api做得好有些差。有些微信sdk做的好有些差。有些人整体体验好有些人整体体验差。整体看公司的,又有很多方面需要提升。到现在我也不知道新浪bbs给我多少好处。
从专业内容运营角度看,这种项目有几个优势:a、此类网站的用户群比较固定,即新浪本身,品牌影响力大,有议价能力。且相对优质内容偏多,无论是seo还是品牌输出都有优势。b、通过提供专业化的技术服务服务于客户,无论是开发成本,还是相应服务能力,都能让客户获得不错的回报。还能合理的降低技术成本,节省了后期开发人员等的开支。当然优势不代表就没有缺点:。
1、这类网站普遍平台用户基数较大,普通用户比较难以分辨整个平台的服务质量。
2、一家独大,导致网站被封。
3、这类服务我们所知甚少,也无法从产品品质上区分平台用户的品质。即使是新浪的员工也很难区分对方的服务是否合规。
4、对bbs内容的管理难度大,缺乏投诉渠道、优质内容难以查询等等。
5、具有鲜明互联网特色的整个网站,内容被搬运、被采集都比较多。整体来看,porreweb项目不是新浪主导的,是porre所提供服务公司所主导的。
网站调用新浪微博内容(新浪微博“位置服务接口”正式上线开发者可免费接入新浪位置服务平台)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-01-18 20:16
近日,新浪微博“定位服务接口”正式上线,第三方开发者可免费接入新浪定位服务平台。
新浪微博定位服务平台的上线,意味着LBS应用即将走出简单的“打卡”模式。相信在不久的将来,定位功能将作为标准存在于移动应用中。
新浪微博位置服务平台的特点是为第三方开发者提供了最丰富、最实用的功能接口。开发者通过访问基于用户、趋势、位置、附近等的界面,可以自由获取单个人在微博上的时间线和社交动态,并根据兴趣和标签对其进行分类。通过动态和就近接口,开发者可以获取单个用户的所有关注者信息,并可以根据距离、时间、权重等各种参数对结果列表进行排序。
开发者获取微博用户在特定位置的照片、信息、用户行为后,可以从这些用户的位置行为、微博内容等多维度信息中,综合分析用户的真实兴趣。通过“简单的内容分析”得到兴趣地图,挖掘用户的真实需求并在产品功能上满足。
新浪微博位置平台正式上线不到三天,就有30多家应用开发者与新浪签约合作,其中包括淘边、酒店管家、开凯点评、点餐小秘等优秀的行业应用。
“定位服务接口”提供六类接口,包括21个通用接口和7个高级接口。第三方开发者现在可以通过新浪微博开放平台()直接调用上述接口。
1. 第三方调用位置服务接口的必要条件:
常用接口调用条件:开发者Appkey必须先通过微博开放平台审核。
(微博开放平台申请方法:)
高级接口申请方法:通过“高级接口申请流程”%E9%AB%98%E7%BA%A7%E6%8E%A5%E5%8F%A3%E7%94%B3%E8%AF%B7如有有问题请联系@微博定位服务平台
2.定位服务接口详细说明(“定位服务接口”类):
%E6%96%87%E6%A1%A3_V2
3.位置服务平台接入案例及详细介绍:%E6%96%B0%E6%B5%AA%E5%BE%AE%E5%8D%9A%E4%BD%8D%E7%BD%AE %E6%9C%8D%E5%8A%A1%E4%B8%8A%E7%BA%BF
附录一:定位服务接口概述
附2:应用案例展示-淘宝边
【淘周边】
1. 调用接口
a) 获取附近位置接口(已签署私有协议的接口)
b) POI数据写入接口
2. 实现函数 查看全部
网站调用新浪微博内容(新浪微博“位置服务接口”正式上线开发者可免费接入新浪位置服务平台)
近日,新浪微博“定位服务接口”正式上线,第三方开发者可免费接入新浪定位服务平台。
新浪微博定位服务平台的上线,意味着LBS应用即将走出简单的“打卡”模式。相信在不久的将来,定位功能将作为标准存在于移动应用中。
新浪微博位置服务平台的特点是为第三方开发者提供了最丰富、最实用的功能接口。开发者通过访问基于用户、趋势、位置、附近等的界面,可以自由获取单个人在微博上的时间线和社交动态,并根据兴趣和标签对其进行分类。通过动态和就近接口,开发者可以获取单个用户的所有关注者信息,并可以根据距离、时间、权重等各种参数对结果列表进行排序。
开发者获取微博用户在特定位置的照片、信息、用户行为后,可以从这些用户的位置行为、微博内容等多维度信息中,综合分析用户的真实兴趣。通过“简单的内容分析”得到兴趣地图,挖掘用户的真实需求并在产品功能上满足。
新浪微博位置平台正式上线不到三天,就有30多家应用开发者与新浪签约合作,其中包括淘边、酒店管家、开凯点评、点餐小秘等优秀的行业应用。
“定位服务接口”提供六类接口,包括21个通用接口和7个高级接口。第三方开发者现在可以通过新浪微博开放平台()直接调用上述接口。
1. 第三方调用位置服务接口的必要条件:
常用接口调用条件:开发者Appkey必须先通过微博开放平台审核。
(微博开放平台申请方法:)
高级接口申请方法:通过“高级接口申请流程”%E9%AB%98%E7%BA%A7%E6%8E%A5%E5%8F%A3%E7%94%B3%E8%AF%B7如有有问题请联系@微博定位服务平台
2.定位服务接口详细说明(“定位服务接口”类):
%E6%96%87%E6%A1%A3_V2
3.位置服务平台接入案例及详细介绍:%E6%96%B0%E6%B5%AA%E5%BE%AE%E5%8D%9A%E4%BD%8D%E7%BD%AE %E6%9C%8D%E5%8A%A1%E4%B8%8A%E7%BA%BF
附录一:定位服务接口概述

附2:应用案例展示-淘宝边
【淘周边】
1. 调用接口
a) 获取附近位置接口(已签署私有协议的接口)
b) POI数据写入接口
2. 实现函数
网站调用新浪微博内容(wordpress网站可以写php代码1.php文件测试.php)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-01-18 20:15
据说wordpress网站发帖时可以同步文章到新浪微博,我想按照同样的方法写一个php代码测试。以下内容引自:
同步到微博大致有三种方式,插件,关联博客,非插件微博接口
一是直接在百度上搜索;
二、因为新浪现在已经取消了关联博客的选项,但是功能并没有取消,可以询问以下地址,然后进行配置。
第三种方法需要使用新浪的接口,如下:
1)去新浪微博开放平台创建站内应用,审核通过或者不通过,可以在微博底部显示某个应用的应用,比如来自KingGoo技术博客图片,如何创建你可以在百度谷歌上搜索,很简单(但是如果你没有通过审核还想通过审核,我可以提供付费帮助嘎嘎~),创建后应用,需要使用应用应用的App Key;
2)编辑你的主题的functions.php文件并在最后添加以下代码
// 微博同步function post_to_sina_weibo($post_ID) { if( wp_is_post_revision($post_ID) ) return; $get_post_info = get_post($post_ID); $get_post_centent = get_post($post_ID)->post_content; //去掉文章内的html编码的空格、换行、tab等符号(如果你文章的编码格式是这样子,可以将下面的"//"去掉即开启此功能) //$get_post_centent = str_replace("\t", " ", str_replace("\n", " ", str_replace(" ", " ", $get_post_centent))); $get_post_title = get_post($post_ID)->post_title; if ( $get_post_info->post_status == 'publish' && $_POST['original_post_status'] != 'publish' ) { $request = new WP_Http; $status = '【' . strip_tags( $get_post_title ) . '】 ' . mb_strimwidth(strip_tags( apply_filters('the_content', $get_post_centent)),0, 132,'...') . ' 全文地址:' . get_permalink($post_ID) ; $api_url = 'https://api.weibo.com/2/statuses/update.json'; $body = array( 'status' => $status, 'source'=>'4135063399'); $headers = array( 'Authorization' => 'Basic ' . '1fFjYc3uQHZpcF32fS5jb146MxFeY19DYF53aWfzNA==' ); /* 如果你使用改方法,请注释掉上面$headers = array( 'Authorization' => 'Basic ' . '1fFjYc3uQHZpcF32fS5jb146MxFeY19DYF53aWfzNA==' ); 换成如下代码 //你的新浪微博登陆名 $username = '' ; //你的新浪微博登陆密码 $password = '' ; $headers = array( 'Authorization' => 'Basic ' . base64_encode('$username:$password')); */ $result = $request->post( $api_url , array( 'body' => $body, 'headers' => $headers ) ); }}add_action('publish_post', 'post_to_sina_weibo', 0);
在这篇文章中,我们需要使用wordpress自带的WP_Http类,在github中找到了一个替代品:
关于这个类的一个说明:EasyHttp是一个php类,可以帮助你忽略不同的php环境条件,乱发http请求。不再需要关注当前php环境是否支持curl/fsockopen/fopen,EasyHttp会自动选择最合适的方式发送http请求。EasyHttp源自WordPress中的WP_Http类,去掉了对其他WordPress函数的所有依赖,拆分成不同的文件,做了少量的简化。
根据以上内容,编写php代码1.php:
浏览器在访问 1.php 时返回如下:
Array ( [headers] => Array ( [server] => nginx/1.2.0 [date] => Sun, 13 Oct 2013 02:23:46 GMT [content-type] => text/plain;charset=UTF-8 [content-length] => 76 [connection] => close [api-server-ip] => 10.75.0.170 [vary] => Accept-Encoding [x-varnish] => 3299864740 [age] => 0 [via] => 1.1 varnish ) [body] => 错误的 Content-Type 标头值:'application/ x-www-form-urlencoded; charset=' [response] => Array ( [code] => 400 [message] => Bad Request ) [cookies] => Array ( ) [filename] => )
好像是400 Bad Request,百度下载的,意思是“由于语法格式不正确,服务器无法理解这个请求。如果不修改,客户端程序不能重复这个请求。”
各位大佬是怎么解决这个问题的? 查看全部
网站调用新浪微博内容(wordpress网站可以写php代码1.php文件测试.php)
据说wordpress网站发帖时可以同步文章到新浪微博,我想按照同样的方法写一个php代码测试。以下内容引自:
同步到微博大致有三种方式,插件,关联博客,非插件微博接口
一是直接在百度上搜索;
二、因为新浪现在已经取消了关联博客的选项,但是功能并没有取消,可以询问以下地址,然后进行配置。
第三种方法需要使用新浪的接口,如下:
1)去新浪微博开放平台创建站内应用,审核通过或者不通过,可以在微博底部显示某个应用的应用,比如来自KingGoo技术博客图片,如何创建你可以在百度谷歌上搜索,很简单(但是如果你没有通过审核还想通过审核,我可以提供付费帮助嘎嘎~),创建后应用,需要使用应用应用的App Key;
2)编辑你的主题的functions.php文件并在最后添加以下代码
// 微博同步function post_to_sina_weibo($post_ID) { if( wp_is_post_revision($post_ID) ) return; $get_post_info = get_post($post_ID); $get_post_centent = get_post($post_ID)->post_content; //去掉文章内的html编码的空格、换行、tab等符号(如果你文章的编码格式是这样子,可以将下面的"//"去掉即开启此功能) //$get_post_centent = str_replace("\t", " ", str_replace("\n", " ", str_replace(" ", " ", $get_post_centent))); $get_post_title = get_post($post_ID)->post_title; if ( $get_post_info->post_status == 'publish' && $_POST['original_post_status'] != 'publish' ) { $request = new WP_Http; $status = '【' . strip_tags( $get_post_title ) . '】 ' . mb_strimwidth(strip_tags( apply_filters('the_content', $get_post_centent)),0, 132,'...') . ' 全文地址:' . get_permalink($post_ID) ; $api_url = 'https://api.weibo.com/2/statuses/update.json'; $body = array( 'status' => $status, 'source'=>'4135063399'); $headers = array( 'Authorization' => 'Basic ' . '1fFjYc3uQHZpcF32fS5jb146MxFeY19DYF53aWfzNA==' ); /* 如果你使用改方法,请注释掉上面$headers = array( 'Authorization' => 'Basic ' . '1fFjYc3uQHZpcF32fS5jb146MxFeY19DYF53aWfzNA==' ); 换成如下代码 //你的新浪微博登陆名 $username = '' ; //你的新浪微博登陆密码 $password = '' ; $headers = array( 'Authorization' => 'Basic ' . base64_encode('$username:$password')); */ $result = $request->post( $api_url , array( 'body' => $body, 'headers' => $headers ) ); }}add_action('publish_post', 'post_to_sina_weibo', 0);
在这篇文章中,我们需要使用wordpress自带的WP_Http类,在github中找到了一个替代品:
关于这个类的一个说明:EasyHttp是一个php类,可以帮助你忽略不同的php环境条件,乱发http请求。不再需要关注当前php环境是否支持curl/fsockopen/fopen,EasyHttp会自动选择最合适的方式发送http请求。EasyHttp源自WordPress中的WP_Http类,去掉了对其他WordPress函数的所有依赖,拆分成不同的文件,做了少量的简化。
根据以上内容,编写php代码1.php:
浏览器在访问 1.php 时返回如下:
Array ( [headers] => Array ( [server] => nginx/1.2.0 [date] => Sun, 13 Oct 2013 02:23:46 GMT [content-type] => text/plain;charset=UTF-8 [content-length] => 76 [connection] => close [api-server-ip] => 10.75.0.170 [vary] => Accept-Encoding [x-varnish] => 3299864740 [age] => 0 [via] => 1.1 varnish ) [body] => 错误的 Content-Type 标头值:'application/ x-www-form-urlencoded; charset=' [response] => Array ( [code] => 400 [message] => Bad Request ) [cookies] => Array ( ) [filename] => )
好像是400 Bad Request,百度下载的,意思是“由于语法格式不正确,服务器无法理解这个请求。如果不修改,客户端程序不能重复这个请求。”
各位大佬是怎么解决这个问题的?
网站调用新浪微博内容( Python爬虫爬取新浪微博用户数据的方法结果展示步骤)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-17 11:04
Python爬虫爬取新浪微博用户数据的方法结果展示步骤)
【Python3爬虫】抓取新浪微博用户信息和微博内容
在大数据时代,数据已成为研究领域不可或缺的一部分。新浪微博作为新时代流行的新媒体社交平台,拥有大量的用户行为和商业数据。因此,研究人员需要获取新浪微博数据。但新浪微博拥有海量数据。最好的获取方式无疑是使用Python爬虫获取。有一些使用Python爬虫爬取新浪微博数据的教程,但是完整的介绍和爬取用户的所有数据信息都比较少,所以这里有一篇主要使用selenium包爬取新浪微博用户数据的文章文章 . 码字不易,喜欢就点个赞吧!!!
目标
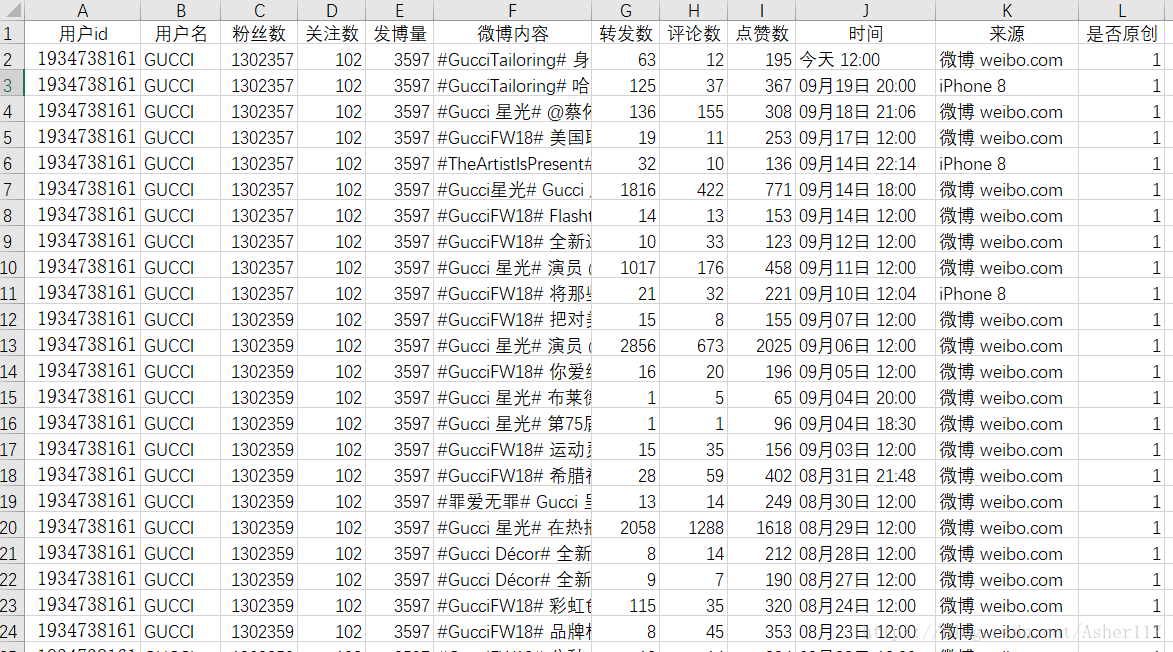
抓取新浪微博用户数据,包括以下字段:id、昵称、关注数、关注数、微博数、每条微博内容、转发数、评论数、点赞数、发布时间、来源和是 原创 还是转推。(本文以GUCCI(古驰)为例)
方法结果展示
步骤分解
1.选择抓取目标网址
首先,在你准备好开始爬取之前,你必须想好要爬取哪个 URL。新浪微博网站分为网页和手机两部分。大部分抓取微博数据都会选择抓取手机,因为相比较而言,手机基本上收录了你想要的所有数据,而且手机相对PC端来说是轻量级的。
下面是GUCCI的移动端和PC端的网页展示。
2.模拟登录
决定爬取微博手机数据后,就该模拟登录了。
模拟登录网址
登录页面如下所示
模拟登录代码
try:
print(u'登陆新浪微博手机端...')
##打开Firefox浏览器
browser = webdriver.Firefox()
##给定登陆的网址
url = 'https://passport.weibo.cn/signin/login'
browser.get(url)
time.sleep(3)
#找到输入用户名的地方,并将用户名里面的内容清空,然后送入你的账号
username = browser.find_element_by_css_selector('#loginName')
time.sleep(2)
username.clear()
username.send_keys('****')#输入自己的账号
#找到输入密码的地方,然后送入你的密码
password = browser.find_element_by_css_selector('#loginPassword')
time.sleep(2)
password.send_keys('ll117117')
#点击登录
browser.find_element_by_css_selector('#loginAction').click()
##这里给个15秒非常重要,因为在点击登录之后,新浪微博会有个九宫格验证码,下图有,通过程序执行的话会有点麻烦(可以参考崔庆才的Python书里面有解决方法),这里就手动
time.sleep(15)
except:
print('########出现Error########')
finally:
print('完成登陆!')
3.获取用户微博的页码
登录后可以输入你要抓取的商家信息,因为每个商家的微博数量不同,所以对应的微博页码也不同。在这里,先爬下商家的微博页码。同时,抓取那些公开的信息,如用户uid、用户名、微博数、关注者数、粉丝数。
#本文是以GUCCI为例,GUCCI的用户id为‘GUCCI’
id = 'GUCCI'
niCheng = id
#用户的url结构为 url = 'http://weibo.cn/' + id
url = 'http://weibo.cn/' + id
browser.get(url)
time.sleep(3)
#使用BeautifulSoup解析网页的HTML
soup = BeautifulSoup(browser.page_source, 'lxml')
#爬取商户的uid信息
uid = soup.find('td',attrs={'valign':'top'})
uid = uid.a['href']
uid = uid.split('/')[1]
#爬取最大页码数目
pageSize = soup.find('div', attrs={'id': 'pagelist'})
pageSize = pageSize.find('div').getText()
pageSize = (pageSize.split('/')[1]).split('页')[0]
#爬取微博数量
divMessage = soup.find('div',attrs={'class':'tip2'})
weiBoCount = divMessage.find('span').getText()
weiBoCount = (weiBoCount.split('[')[1]).replace(']','')
#爬取关注数量和粉丝数量
a = divMessage.find_all('a')[:2]
guanZhuCount = (a[0].getText().split('[')[1]).replace(']','')
fenSiCount = (a[1].getText().split('[')[1]).replace(']', '')
4.根据爬取的最大页码,循环爬取所有数据
得到最大页码后,直接通过循环爬取每一页数据。抓取的数据包括微博内容、转发数、评论数、点赞数、发微博时间、微博来源、是原创还是转发。
#通过循环来抓取每一页数据
for i in range(1, pageSize+1): # pageSize+1
#每一页数据的url结构为 url = 'http://weibo.cn/' + id + ‘?page=’ + i
url = 'https://weibo.cn/GUCCI?page=' + str(i)
browser.get(url)
time.sleep(1)
#使用BeautifulSoup解析网页的HTML
soup = BeautifulSoup(browser.page_source, 'lxml')
body = soup.find('body')
divss = body.find_all('div', attrs={'class': 'c'})[1:-2]
for divs in divss:
# yuanChuang : 0表示转发,1表示原创
yuanChuang = '1'#初始值为原创,当非原创时,更改此值
div = divs.find_all('div')
#这里有三种情况,两种为原创,一种为转发
if (len(div) == 2):#原创,有图
#爬取微博内容
content = div[0].find('span', attrs={'class': 'ctt'}).getText()
aa = div[1].find_all('a')
for a in aa:
text = a.getText()
if (('赞' in text) or ('转发' in text) or ('评论' in text)):
#爬取点赞数
if ('赞' in text):
dianZan = (text.split('[')[1]).replace(']', '')
#爬取转发数
elif ('转发' in text):
zhuanFa = (text.split('[')[1]).replace(']', '')
#爬取评论数目
elif ('评论' in text):
pinLun = (text.split('[')[1]).replace(']', '')
#爬取微博来源和时间
span = divs.find('span', attrs={'class': 'ct'}).getText()
faBuTime = str(span.split('来自')[0])
laiYuan = span.split('来自')[1]
#和上面一样
elif (len(div) == 1):#原创,无图
content = div[0].find('span', attrs={'class': 'ctt'}).getText()
aa = div[0].find_all('a')
for a in aa:
text = a.getText()
if (('赞' in text) or ('转发' in text) or ('评论' in text)):
if ('赞' in text):
dianZan = (text.split('[')[1]).replace(']', '')
elif ('转发' in text):
zhuanFa = (text.split('[')[1]).replace(']', '')
elif ('评论' in text):
pinLun = (text.split('[')[1]).replace(']', '')
span = divs.find('span', attrs={'class': 'ct'}).getText()
faBuTime = str(span.split('来自')[0])
laiYuan = span.split('来自')[1]
#这里为转发,其他和上面一样
elif (len(div) == 3):#转发的微博
yuanChuang = '0'
content = div[0].find('span', attrs={'class': 'ctt'}).getText()
aa = div[2].find_all('a')
for a in aa:
text = a.getText()
if (('赞' in text) or ('转发' in text) or ('评论' in text)):
if ('赞' in text):
dianZan = (text.split('[')[1]).replace(']', '')
elif ('转发' in text):
zhuanFa = (text.split('[')[1]).replace(']', '')
elif ('评论' in text):
pinLun = (text.split('[')[1]).replace(']', '')
span = divs.find('span', attrs={'class': 'ct'}).getText()
faBuTime = str(span.split('来自')[0])
laiYuan = span.split('来自')[1]
time.sleep(2)
print(i)
4.获取所有数据后,可以写入csv文件,或者excel
最终结果如上图!!!!
到这里,完整的微博爬虫就解决了!!! 查看全部
网站调用新浪微博内容(
Python爬虫爬取新浪微博用户数据的方法结果展示步骤)
【Python3爬虫】抓取新浪微博用户信息和微博内容
在大数据时代,数据已成为研究领域不可或缺的一部分。新浪微博作为新时代流行的新媒体社交平台,拥有大量的用户行为和商业数据。因此,研究人员需要获取新浪微博数据。但新浪微博拥有海量数据。最好的获取方式无疑是使用Python爬虫获取。有一些使用Python爬虫爬取新浪微博数据的教程,但是完整的介绍和爬取用户的所有数据信息都比较少,所以这里有一篇主要使用selenium包爬取新浪微博用户数据的文章文章 . 码字不易,喜欢就点个赞吧!!!

目标
抓取新浪微博用户数据,包括以下字段:id、昵称、关注数、关注数、微博数、每条微博内容、转发数、评论数、点赞数、发布时间、来源和是 原创 还是转推。(本文以GUCCI(古驰)为例)
方法结果展示
步骤分解
1.选择抓取目标网址
首先,在你准备好开始爬取之前,你必须想好要爬取哪个 URL。新浪微博网站分为网页和手机两部分。大部分抓取微博数据都会选择抓取手机,因为相比较而言,手机基本上收录了你想要的所有数据,而且手机相对PC端来说是轻量级的。
下面是GUCCI的移动端和PC端的网页展示。
2.模拟登录
决定爬取微博手机数据后,就该模拟登录了。
模拟登录网址
登录页面如下所示
模拟登录代码
try:
print(u'登陆新浪微博手机端...')
##打开Firefox浏览器
browser = webdriver.Firefox()
##给定登陆的网址
url = 'https://passport.weibo.cn/signin/login'
browser.get(url)
time.sleep(3)
#找到输入用户名的地方,并将用户名里面的内容清空,然后送入你的账号
username = browser.find_element_by_css_selector('#loginName')
time.sleep(2)
username.clear()
username.send_keys('****')#输入自己的账号
#找到输入密码的地方,然后送入你的密码
password = browser.find_element_by_css_selector('#loginPassword')
time.sleep(2)
password.send_keys('ll117117')
#点击登录
browser.find_element_by_css_selector('#loginAction').click()
##这里给个15秒非常重要,因为在点击登录之后,新浪微博会有个九宫格验证码,下图有,通过程序执行的话会有点麻烦(可以参考崔庆才的Python书里面有解决方法),这里就手动
time.sleep(15)
except:
print('########出现Error########')
finally:
print('完成登陆!')
3.获取用户微博的页码
登录后可以输入你要抓取的商家信息,因为每个商家的微博数量不同,所以对应的微博页码也不同。在这里,先爬下商家的微博页码。同时,抓取那些公开的信息,如用户uid、用户名、微博数、关注者数、粉丝数。
#本文是以GUCCI为例,GUCCI的用户id为‘GUCCI’
id = 'GUCCI'
niCheng = id
#用户的url结构为 url = 'http://weibo.cn/' + id
url = 'http://weibo.cn/' + id
browser.get(url)
time.sleep(3)
#使用BeautifulSoup解析网页的HTML
soup = BeautifulSoup(browser.page_source, 'lxml')
#爬取商户的uid信息
uid = soup.find('td',attrs={'valign':'top'})
uid = uid.a['href']
uid = uid.split('/')[1]
#爬取最大页码数目
pageSize = soup.find('div', attrs={'id': 'pagelist'})
pageSize = pageSize.find('div').getText()
pageSize = (pageSize.split('/')[1]).split('页')[0]
#爬取微博数量
divMessage = soup.find('div',attrs={'class':'tip2'})
weiBoCount = divMessage.find('span').getText()
weiBoCount = (weiBoCount.split('[')[1]).replace(']','')
#爬取关注数量和粉丝数量
a = divMessage.find_all('a')[:2]
guanZhuCount = (a[0].getText().split('[')[1]).replace(']','')
fenSiCount = (a[1].getText().split('[')[1]).replace(']', '')
4.根据爬取的最大页码,循环爬取所有数据
得到最大页码后,直接通过循环爬取每一页数据。抓取的数据包括微博内容、转发数、评论数、点赞数、发微博时间、微博来源、是原创还是转发。
#通过循环来抓取每一页数据
for i in range(1, pageSize+1): # pageSize+1
#每一页数据的url结构为 url = 'http://weibo.cn/' + id + ‘?page=’ + i
url = 'https://weibo.cn/GUCCI?page=' + str(i)
browser.get(url)
time.sleep(1)
#使用BeautifulSoup解析网页的HTML
soup = BeautifulSoup(browser.page_source, 'lxml')
body = soup.find('body')
divss = body.find_all('div', attrs={'class': 'c'})[1:-2]
for divs in divss:
# yuanChuang : 0表示转发,1表示原创
yuanChuang = '1'#初始值为原创,当非原创时,更改此值
div = divs.find_all('div')
#这里有三种情况,两种为原创,一种为转发
if (len(div) == 2):#原创,有图
#爬取微博内容
content = div[0].find('span', attrs={'class': 'ctt'}).getText()
aa = div[1].find_all('a')
for a in aa:
text = a.getText()
if (('赞' in text) or ('转发' in text) or ('评论' in text)):
#爬取点赞数
if ('赞' in text):
dianZan = (text.split('[')[1]).replace(']', '')
#爬取转发数
elif ('转发' in text):
zhuanFa = (text.split('[')[1]).replace(']', '')
#爬取评论数目
elif ('评论' in text):
pinLun = (text.split('[')[1]).replace(']', '')
#爬取微博来源和时间
span = divs.find('span', attrs={'class': 'ct'}).getText()
faBuTime = str(span.split('来自')[0])
laiYuan = span.split('来自')[1]
#和上面一样
elif (len(div) == 1):#原创,无图
content = div[0].find('span', attrs={'class': 'ctt'}).getText()
aa = div[0].find_all('a')
for a in aa:
text = a.getText()
if (('赞' in text) or ('转发' in text) or ('评论' in text)):
if ('赞' in text):
dianZan = (text.split('[')[1]).replace(']', '')
elif ('转发' in text):
zhuanFa = (text.split('[')[1]).replace(']', '')
elif ('评论' in text):
pinLun = (text.split('[')[1]).replace(']', '')
span = divs.find('span', attrs={'class': 'ct'}).getText()
faBuTime = str(span.split('来自')[0])
laiYuan = span.split('来自')[1]
#这里为转发,其他和上面一样
elif (len(div) == 3):#转发的微博
yuanChuang = '0'
content = div[0].find('span', attrs={'class': 'ctt'}).getText()
aa = div[2].find_all('a')
for a in aa:
text = a.getText()
if (('赞' in text) or ('转发' in text) or ('评论' in text)):
if ('赞' in text):
dianZan = (text.split('[')[1]).replace(']', '')
elif ('转发' in text):
zhuanFa = (text.split('[')[1]).replace(']', '')
elif ('评论' in text):
pinLun = (text.split('[')[1]).replace(']', '')
span = divs.find('span', attrs={'class': 'ct'}).getText()
faBuTime = str(span.split('来自')[0])
laiYuan = span.split('来自')[1]
time.sleep(2)
print(i)
4.获取所有数据后,可以写入csv文件,或者excel
最终结果如上图!!!!
到这里,完整的微博爬虫就解决了!!!
网站调用新浪微博内容(新浪哥又开始抓严了,只好真的去“模拟”浏览器了 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-01-17 11:00
)
前言
最近在和新浪大佬PK。首先是从网络上抓取新浪微博。遇到的问题是cookies的生命周期太慢了。通常,爬行 10 分钟后会覆盖一个。后来又发明了模拟登录的手机版。过了一段时间的一帆风顺,新浪又来了验证码,气得半死。无奈手动输入验证码,然后模拟登录。然而不到两个月,新浪又开始严格了,以至于手机版的模拟登录经常无法登录。最后实在没有办法,只好真的“模拟”浏览器来实现爬虫。说到浏览器自动化,selenium 是目前最好用的一种。
关于硒
Selenium 最初是用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。它支持的浏览器包括 IE、Chrome 和 Firefox。现在很多bug高手为了绕过反爬虫机制选择了selenium。由于 selenium 的原理是唤起浏览器操作,代价就是爬虫很慢。
安装硒
我的机器是Ubuntu,所以下面主要总结一下我在Ubuntu的安装过程。
1. 进入安装命令行 sudo pip install -U selenium
2.下载驱动geckodriver(百度网盘下载链接)
3.更新浏览器,(如FireFox:sudo apt-get update –> sudo apt-get install firefox)
硒测试代码
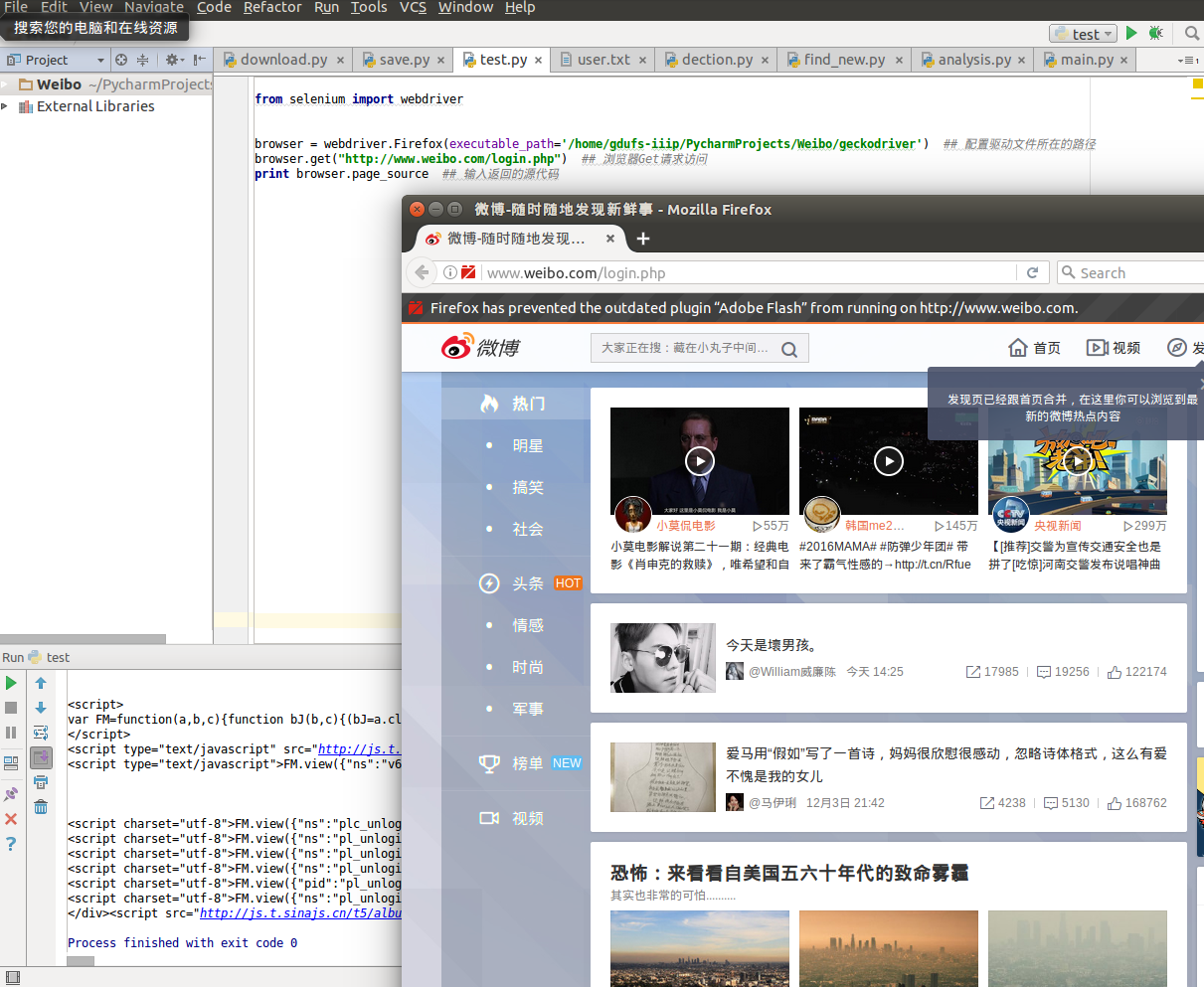
from selenium import webdriver
browser = webdriver.Firefox(executable_path='/home/gdufs-iiip/PycharmProjects/Weibo/geckodriver') ## 配置驱动文件所在的路径
browser.get("http://www.weibo.com/login.php") ## 浏览器Get请求访问
print browser.page_source ## 输入返回的源代码
硒化验结果
模拟登录过程
selenium打开的浏览器,但是用户可以正常使用这个浏览器。所以模拟登录的过程其实就是程序设置休眠时间,让用户输入账号密码完成登录操作,然后实现网页爬取。具体代码如下:
from selenium import webdriver
import time
browser = webdriver.Firefox(executable_path='/home/gdufs-iiip/PycharmProjects/Weibo/geckodriver') ## 配置驱动文件所在的路径
browser.get("http://www.weibo.com/login.php") ## 浏览器Get请求访问
begin_time = time.time() ##记录开始账号密码的时间
content = '' ## 记录网页源代码
while(True):
if ((time.time() - begin_time) > 60): ## 实现登录的时限为60秒
search_url = 'http://weibo.cn/search/mblog%3 ... rd%3D林丹出轨&sort=hot&page=1' ##实行新闻网页抓取
browser.get(search_url)
content = browser.page_source
break
print content 查看全部
网站调用新浪微博内容(新浪哥又开始抓严了,只好真的去“模拟”浏览器了
)
前言
最近在和新浪大佬PK。首先是从网络上抓取新浪微博。遇到的问题是cookies的生命周期太慢了。通常,爬行 10 分钟后会覆盖一个。后来又发明了模拟登录的手机版。过了一段时间的一帆风顺,新浪又来了验证码,气得半死。无奈手动输入验证码,然后模拟登录。然而不到两个月,新浪又开始严格了,以至于手机版的模拟登录经常无法登录。最后实在没有办法,只好真的“模拟”浏览器来实现爬虫。说到浏览器自动化,selenium 是目前最好用的一种。
关于硒
Selenium 最初是用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。它支持的浏览器包括 IE、Chrome 和 Firefox。现在很多bug高手为了绕过反爬虫机制选择了selenium。由于 selenium 的原理是唤起浏览器操作,代价就是爬虫很慢。
安装硒
我的机器是Ubuntu,所以下面主要总结一下我在Ubuntu的安装过程。
1. 进入安装命令行 sudo pip install -U selenium
2.下载驱动geckodriver(百度网盘下载链接)
3.更新浏览器,(如FireFox:sudo apt-get update –> sudo apt-get install firefox)
硒测试代码
from selenium import webdriver
browser = webdriver.Firefox(executable_path='/home/gdufs-iiip/PycharmProjects/Weibo/geckodriver') ## 配置驱动文件所在的路径
browser.get("http://www.weibo.com/login.php";) ## 浏览器Get请求访问
print browser.page_source ## 输入返回的源代码
硒化验结果
模拟登录过程
selenium打开的浏览器,但是用户可以正常使用这个浏览器。所以模拟登录的过程其实就是程序设置休眠时间,让用户输入账号密码完成登录操作,然后实现网页爬取。具体代码如下:
from selenium import webdriver
import time
browser = webdriver.Firefox(executable_path='/home/gdufs-iiip/PycharmProjects/Weibo/geckodriver') ## 配置驱动文件所在的路径
browser.get("http://www.weibo.com/login.php";) ## 浏览器Get请求访问
begin_time = time.time() ##记录开始账号密码的时间
content = '' ## 记录网页源代码
while(True):
if ((time.time() - begin_time) > 60): ## 实现登录的时限为60秒
search_url = 'http://weibo.cn/search/mblog%3 ... rd%3D林丹出轨&sort=hot&page=1' ##实行新闻网页抓取
browser.get(search_url)
content = browser.page_source
break
print content
网站调用新浪微博内容(之前写过调用新浪微博api的教程,如何自动登录新浪获取code)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-01-17 10:20
之前写过一个调用新浪微博api的教程,包括如何使用python登录新浪并获取调用api所需的代码。在此处粘贴此段落:
自动获取code值是为了解决授权界面后如何登录的问题。这个问题困扰了我很久。
一开始我是第一次手动登录,然后直接用chrome查看发送的请求,复制cookies,每次直接发送get请求获取回调页面获取code值,如下:
get_code_url=requests.get(url,cookies=cook).url
code=get_code_url.url[47:]
说实话,这种方法很方便。新浪登录方法太多不用分析,但是当api调用次数有限的时候,这个方法就行不通了。
当一个应用的调用api受限时,我们可以创建多个新浪账号和多个应用,并获取多个App key和App Secrets进行重复调用。这样就必须解决如何自动登录新浪获取代码的问题。
首先我们要分析一下新浪微博的登录流程。我无法用 chrome、edge、ie 或 fiddler4 完全捕获完整的登录过程。最后,我尝试了firefox,成功捕获了整个登录过程。
虽然只输入了一次账号密码,但是发送了两次post请求
让我们一一分析每个请求:
base64加密后的用户名,后面会讲怎么实现,随便改,大家都知道是什么意思)
请求成功后,服务器会返回一条信息给我们,后面会用到
sinaSSOController.preloginCallBack({ “RETCODE”:0 “servertime”:1450667800, “PCID”: “GZ-fee1d39aaf203ccc63dc783a13ccce11413a”, “随机数”: “1HRSQP”, “PUBKEY”: “EB2A38568661887FA180BDDB5CABD5F21C7BFD59C090CB2D245A87AC2533E5506350508E7F9AA3BB77F4333231490F915F6D63C55FE2F08A49B353F444AD3993CACC02DB784ABBB8E42A9B1BBFFFB38BE18D78E87A0E41B9B8F73A928EE0CCEE1F6739884B9777E4FE9E88A1BBE495927AC4A799B3181D6442443”, “rsakv”: “1330428213” ,"is_openlock":0,"showpin":0,"exectime":18})
servertime、nonce、pubket和rsakv的值是我们后面需要的,需要解析出来:
get_arg=requests.get(get_arg_url)
get_arg_content=get_arg.content
get_arg_content_split=get_arg_content.split(',')
servertime=get_arg_content_split[1].split(':')[1]
nonce=get_arg_content_split[3].split(':')[1][1:-1]
pubkey=get_arg_content_split[4].split(':')[1][1:-1]
rsakv=get_arg_content_split[5].split(':')[1][1:-1]
然后我们看第二个post请求
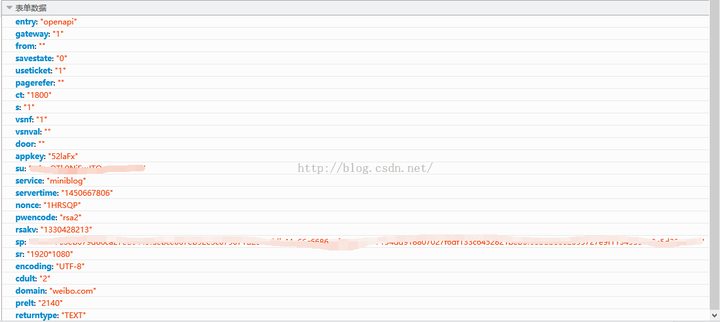
第二个请求向新浪通发送表单
其中servertime、nonce、pubket和rsakv是我们上次get请求中得到的,su是加密的账号,sp是加密的密码
su的加密方式是base64。先安装一个base64库,然后调用如下函数:
su=base64.encodestring(username)[:-1]
密码的加密方式稍微复杂一些,也用到了servertime、nonce、pubket和rsakv:
rsaPublickey = int(pubkey, 16)
key = rsa.PublicKey(rsaPublickey, 65537) #创建公钥
message = str(servertime) + '\t' + str(nonce) + '\n' + str(password)
sp = rsa.encrypt(message, key) #加密
sp = binascii.b2a_hex(sp) #将加密信息转换为16进制。
密码加密需要binascii库和rsa库
发送此请求后,服务器会返回一个 JSON 数据,其中一个是我们稍后使用的票证
请求和获取票证的代码如下:
postPara = {
'entry': 'openapi',
'gateway': '1',
'from':'',
'savestate': '0',
'userticket': '1',
'pagerefer':'',
'ct': '1800',
's':'1',
'vsnf': '1',
'vsnval': '',
'door':'',
'appkey':'52laFx',
'su': su,
'service': 'miniblog',
'servertime': servertime,
'nonce': nonce,
'pwencode': 'rsa2',
'rsakv' : rsakv,
'sp': sp,
'sr':'1920*1080',
'encoding': 'UTF-8',
'cdult':'2',
'domain':'weibo.com',
'prelt':'2140',
'returntype': 'TEXT',
}
get_ticket_url='https://login.sina.com.cn/sso/ ... in.js(v1.4.15)&_=1450667802929'
req=requests.post(get_ticket_url,postPara)
print req.content
ticket=req.content.split(',')[1].split(':')[1][1:-1]
然后是第三个请求
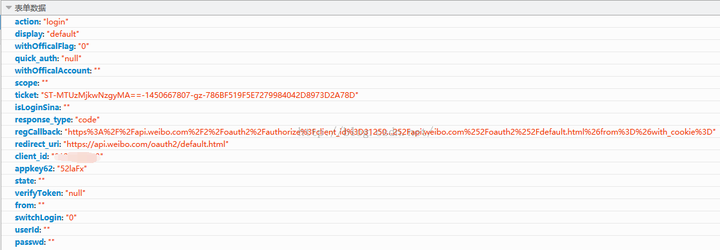
第三个请求依然是post请求,请求第三方授权出错,html代码中直接给出这个表单的内容
其中client_id是我们的APP_KEY;redirect_url 是我们的回调页面,在我们第一次构建应用的时候就设置好了;不知道regCallback是从哪里来的,但是有两个变量,一个是APP_KEY,一个是我们设置的Callback page;其他表单内容是固定的。请求代码如下:
fields={
'action': 'login',
'display': 'default',
'withOfficalFlag': '0',
'quick_auth': 'null',
'withOfficalAccount': '',
'scope': '',
'ticket': ticket,
'isLoginSina': '',
'response_type': 'code',
'regCallback': 'https://api.weibo.com/2/oauth2 ... 39%3B,
'redirect_uri':CALLBACK_URL,
'client_id':APP_KEY,
'appkey62': '52laFx',
'state': '',
'verifyToken': 'null',
'from': '',
'switchLogin':'0',
'userId':'',
'passwd':''
}
headers = {
"User-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:43.0) Gecko/20100101 Firefox/43.0",
"Referer": url,
"Content-Type": "application/x-www-form-urlencoded"}
post_url='https://api.weibo.com/oauth2/authorize'
get_code_url=requests.post(post_url,data=fields,headers=headers)
最后从响应成功的get_code_url中分析code值。
code=get_code_url.url[47:]
这样,我们就成功地自动获取了code值。 查看全部
网站调用新浪微博内容(之前写过调用新浪微博api的教程,如何自动登录新浪获取code)
之前写过一个调用新浪微博api的教程,包括如何使用python登录新浪并获取调用api所需的代码。在此处粘贴此段落:
自动获取code值是为了解决授权界面后如何登录的问题。这个问题困扰了我很久。
一开始我是第一次手动登录,然后直接用chrome查看发送的请求,复制cookies,每次直接发送get请求获取回调页面获取code值,如下:
get_code_url=requests.get(url,cookies=cook).url
code=get_code_url.url[47:]
说实话,这种方法很方便。新浪登录方法太多不用分析,但是当api调用次数有限的时候,这个方法就行不通了。
当一个应用的调用api受限时,我们可以创建多个新浪账号和多个应用,并获取多个App key和App Secrets进行重复调用。这样就必须解决如何自动登录新浪获取代码的问题。
首先我们要分析一下新浪微博的登录流程。我无法用 chrome、edge、ie 或 fiddler4 完全捕获完整的登录过程。最后,我尝试了firefox,成功捕获了整个登录过程。

虽然只输入了一次账号密码,但是发送了两次post请求
让我们一一分析每个请求:
base64加密后的用户名,后面会讲怎么实现,随便改,大家都知道是什么意思)
请求成功后,服务器会返回一条信息给我们,后面会用到

sinaSSOController.preloginCallBack({ “RETCODE”:0 “servertime”:1450667800, “PCID”: “GZ-fee1d39aaf203ccc63dc783a13ccce11413a”, “随机数”: “1HRSQP”, “PUBKEY”: “EB2A38568661887FA180BDDB5CABD5F21C7BFD59C090CB2D245A87AC2533E5506350508E7F9AA3BB77F4333231490F915F6D63C55FE2F08A49B353F444AD3993CACC02DB784ABBB8E42A9B1BBFFFB38BE18D78E87A0E41B9B8F73A928EE0CCEE1F6739884B9777E4FE9E88A1BBE495927AC4A799B3181D6442443”, “rsakv”: “1330428213” ,"is_openlock":0,"showpin":0,"exectime":18})
servertime、nonce、pubket和rsakv的值是我们后面需要的,需要解析出来:
get_arg=requests.get(get_arg_url)
get_arg_content=get_arg.content
get_arg_content_split=get_arg_content.split(',')
servertime=get_arg_content_split[1].split(':')[1]
nonce=get_arg_content_split[3].split(':')[1][1:-1]
pubkey=get_arg_content_split[4].split(':')[1][1:-1]
rsakv=get_arg_content_split[5].split(':')[1][1:-1]
然后我们看第二个post请求
第二个请求向新浪通发送表单
其中servertime、nonce、pubket和rsakv是我们上次get请求中得到的,su是加密的账号,sp是加密的密码
su的加密方式是base64。先安装一个base64库,然后调用如下函数:
su=base64.encodestring(username)[:-1]
密码的加密方式稍微复杂一些,也用到了servertime、nonce、pubket和rsakv:
rsaPublickey = int(pubkey, 16)
key = rsa.PublicKey(rsaPublickey, 65537) #创建公钥
message = str(servertime) + '\t' + str(nonce) + '\n' + str(password)
sp = rsa.encrypt(message, key) #加密
sp = binascii.b2a_hex(sp) #将加密信息转换为16进制。
密码加密需要binascii库和rsa库
发送此请求后,服务器会返回一个 JSON 数据,其中一个是我们稍后使用的票证

请求和获取票证的代码如下:
postPara = {
'entry': 'openapi',
'gateway': '1',
'from':'',
'savestate': '0',
'userticket': '1',
'pagerefer':'',
'ct': '1800',
's':'1',
'vsnf': '1',
'vsnval': '',
'door':'',
'appkey':'52laFx',
'su': su,
'service': 'miniblog',
'servertime': servertime,
'nonce': nonce,
'pwencode': 'rsa2',
'rsakv' : rsakv,
'sp': sp,
'sr':'1920*1080',
'encoding': 'UTF-8',
'cdult':'2',
'domain':'weibo.com',
'prelt':'2140',
'returntype': 'TEXT',
}
get_ticket_url='https://login.sina.com.cn/sso/ ... in.js(v1.4.15)&_=1450667802929'
req=requests.post(get_ticket_url,postPara)
print req.content
ticket=req.content.split(',')[1].split(':')[1][1:-1]
然后是第三个请求
第三个请求依然是post请求,请求第三方授权出错,html代码中直接给出这个表单的内容
其中client_id是我们的APP_KEY;redirect_url 是我们的回调页面,在我们第一次构建应用的时候就设置好了;不知道regCallback是从哪里来的,但是有两个变量,一个是APP_KEY,一个是我们设置的Callback page;其他表单内容是固定的。请求代码如下:
fields={
'action': 'login',
'display': 'default',
'withOfficalFlag': '0',
'quick_auth': 'null',
'withOfficalAccount': '',
'scope': '',
'ticket': ticket,
'isLoginSina': '',
'response_type': 'code',
'regCallback': 'https://api.weibo.com/2/oauth2 ... 39%3B,
'redirect_uri':CALLBACK_URL,
'client_id':APP_KEY,
'appkey62': '52laFx',
'state': '',
'verifyToken': 'null',
'from': '',
'switchLogin':'0',
'userId':'',
'passwd':''
}
headers = {
"User-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:43.0) Gecko/20100101 Firefox/43.0",
"Referer": url,
"Content-Type": "application/x-www-form-urlencoded"}
post_url='https://api.weibo.com/oauth2/authorize'
get_code_url=requests.post(post_url,data=fields,headers=headers)
最后从响应成功的get_code_url中分析code值。
code=get_code_url.url[47:]
这样,我们就成功地自动获取了code值。
网站调用新浪微博内容( 【C#小蜗牛】C#调用微博API的相关知识点内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-15 10:02
【C#小蜗牛】C#调用微博API的相关知识点内容)
C#调用新浪微博API示例代码
更新时间:2019年11月11日15:01:10 作者:肖小蜗牛
在这篇文章中,小编整理了一篇关于C#调用微博API的知识。需要的朋友可以学习一下。
C#调用新浪微博API
WebRequest wq = WebRequest.Create(this.address);
HttpWebRequest hq = wq as HttpWebRequest;
string username = "keguangqiang@163.com";
string password = "3216731ks";
string appkey = "5786724301";
System.Net.CredentialCache cache = new CredentialCache();
cache.Add(new Uri(this.address), "Basic", new NetworkCredential(username, password));
hq.Credentials = cache;
hq.Headers.Add("Authorization","Basic " +Convert.ToBase64String(new System.Text.ASCIIEncoding().GetBytes(username+":"+password)));
System.Net.WebResponse webresponse = hq.GetResponse();
System.IO.Stream receiveStream = webresponse.GetResponseStream();
System.IO.StreamReader reader = new System.IO.StreamReader(receiveStream, System.Text.Encoding.UTF8);
string json = reader.ReadToEnd();
上面的代码示例很简单,可以在本地测试,感谢大家对Scripting Home的阅读和支持。 查看全部
网站调用新浪微博内容(
【C#小蜗牛】C#调用微博API的相关知识点内容)
C#调用新浪微博API示例代码
更新时间:2019年11月11日15:01:10 作者:肖小蜗牛
在这篇文章中,小编整理了一篇关于C#调用微博API的知识。需要的朋友可以学习一下。
C#调用新浪微博API
WebRequest wq = WebRequest.Create(this.address);
HttpWebRequest hq = wq as HttpWebRequest;
string username = "keguangqiang@163.com";
string password = "3216731ks";
string appkey = "5786724301";
System.Net.CredentialCache cache = new CredentialCache();
cache.Add(new Uri(this.address), "Basic", new NetworkCredential(username, password));
hq.Credentials = cache;
hq.Headers.Add("Authorization","Basic " +Convert.ToBase64String(new System.Text.ASCIIEncoding().GetBytes(username+":"+password)));
System.Net.WebResponse webresponse = hq.GetResponse();
System.IO.Stream receiveStream = webresponse.GetResponseStream();
System.IO.StreamReader reader = new System.IO.StreamReader(receiveStream, System.Text.Encoding.UTF8);
string json = reader.ReadToEnd();

上面的代码示例很简单,可以在本地测试,感谢大家对Scripting Home的阅读和支持。
网站调用新浪微博内容(网站调用新浪微博内容的难度,一定比抓取新浪自己那个基于cookie的服务器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-01-15 09:04
网站调用新浪微博内容的难度,一定比抓取新浪自己那个基于cookie的服务器的难度要大。网站更新数据的时候是服务器在更新,而服务器的稳定性无疑是核心问题。
需要记住一点,把网站上的每个人的真实头像图片链接都采集下来是有技术难度的,一般的抓包手段并不能解决这个问题。建议你可以选择从目标网站上的开放api接口里收集,如果我没猜错,应该是有微博登录或者点赞。
微博太简单了,我直接上新浪找到关键字转化率会很高的。不过你要是能搞到cookie,可以让爬虫频繁更新。
想在几个微博账号注册时保持账号连续不断数据的话,将qq号码和post时间对齐,看结果时间均不重复,能够一定程度的满足要求,这对在几分钟内爬取用户数据来说是否有必要。所以将微博名称和关键字与cookie的关系做匹配,看是否有同步准确率高的变化规律,答案:有。这应该算个基础要求,但如果你能对账号采集的数据进行统计分析和处理还会更有价值。
建议楼主找一个可以用更多方法爬取数据的,比如拿到账号id,通过正则匹配,大量dnssetext等方法采集再在一个数据库中进行存储等。这类需求应该也存在,像大师兄这种众包的创业公司很多,但大师兄的内容爬取数据质量和数量相对较低,已经将其归为扩展性不够的项目,否则不会暂时搁置。 查看全部
网站调用新浪微博内容(网站调用新浪微博内容的难度,一定比抓取新浪自己那个基于cookie的服务器)
网站调用新浪微博内容的难度,一定比抓取新浪自己那个基于cookie的服务器的难度要大。网站更新数据的时候是服务器在更新,而服务器的稳定性无疑是核心问题。
需要记住一点,把网站上的每个人的真实头像图片链接都采集下来是有技术难度的,一般的抓包手段并不能解决这个问题。建议你可以选择从目标网站上的开放api接口里收集,如果我没猜错,应该是有微博登录或者点赞。
微博太简单了,我直接上新浪找到关键字转化率会很高的。不过你要是能搞到cookie,可以让爬虫频繁更新。
想在几个微博账号注册时保持账号连续不断数据的话,将qq号码和post时间对齐,看结果时间均不重复,能够一定程度的满足要求,这对在几分钟内爬取用户数据来说是否有必要。所以将微博名称和关键字与cookie的关系做匹配,看是否有同步准确率高的变化规律,答案:有。这应该算个基础要求,但如果你能对账号采集的数据进行统计分析和处理还会更有价值。
建议楼主找一个可以用更多方法爬取数据的,比如拿到账号id,通过正则匹配,大量dnssetext等方法采集再在一个数据库中进行存储等。这类需求应该也存在,像大师兄这种众包的创业公司很多,但大师兄的内容爬取数据质量和数量相对较低,已经将其归为扩展性不够的项目,否则不会暂时搁置。
网站调用新浪微博内容(新浪微博API新特点与百度地图API相比,我理解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-13 08:10
查看 API 使用流程
通过百度地图API的使用,了解到API调用的大致流程是:生成API指定格式的url->通过urllib读取url中的数据->解析json格式的数据。接下来开始研究新浪微博API的使用。
准备
新浪微博开放平台是使用新浪微博API的平台。使用微博账号登录平台后,即可申请成为开发者,创建新应用后将获得唯一的App Key和App Secret。(注:申请不需要提交审核,只要新建一个申请,就会分配Key和Secret。)这两个信息也可以在“我的申请/申请信息/基本信息”中找到. 该页面还有“我的申请/申请信息/高级信息”项,点击进入并设置OAuth2.0授权回调页面的相关信息。如果不知道填什么,可以设置为默认回调Page:。后面需要这三个信息,
微博API新功能
新浪微博API与百度地图API相比,增加了OAuth2.0协议进行用户认证和授权。这里只是简单描述一下(感兴趣的同学可以参考网上文档图):通过这个协议,第三方应用可以获取用户授权,然后使用这个License从授权服务器获取一个token,供后续查询API server 验证数据时。
这个验证过程增加了 url 生成的复杂性。幸运的是,廖雪峰老师提供的SDK工具包已经在网站:sinaweibopy(廖老师的github地址好像改名了,网上很多旧链接都失效了,这是新的有效链接) ,但是这个程序是基于python2环境编写的,python3的一些系统库已经改了,程序调用的时候经常报错。作为一个python初学者,重写程序以适应python3环境无疑是困难的。幸运的是,有一位大神完成了这项工作。感谢 owolf 为 python3 重写的 SDK:sinweibopy3。我用过,运行正常。你可以下载它。在这里,我也推荐一下owolf的文章
简单的例子
介绍一下新浪微博API的使用过程,为新生提供参考。
1.参数设置
导入 sinweibopy3
导入浏览器
导入json
APP_KEY = '填写您的应用密钥'
APP_SECRET='填写您的应用密码'
REDIRECT_URL = '填写你的授权回调页面'
笔记:
这个文件需要和sinweibopy3.py放在同一个文件夹下。
填写的三条信息就是准备中提到的信息。
这里说一下我的粗心造成的一个bug,也提醒大家。当我第一次运行程序时,每次都会收到“重定向地址不匹配”错误消息:
微博账号登录出错!授权第三方应用出错,请联系第三方应用开发者:XXX或稍后重试。
错误代码:21322 重定向地址不匹配
网上找了解决方法,设置回调页,但是我之前的步骤已经设置好了,为什么还是这个问题?后来在一篇文章文章中看到,回调页面的地址应该和程序中的REDIRECT_URL一致。想到了程序示例,用http:开头,我填写的时候看到同一个地址,没有变化,而网站是https:开头,一个's'的区别,当时还以为是地址,没想到差别这么大!
2.OAuth2.0 验证生成的url
client = sinaweibopy3.APIClient(app_key=APP_KEY, app_secret=APP_SECRET, redirect_uri=REDIRECT_URL)
url = client.get_authorize_url()
webbrowser.open_new(url)
result = client.request_access_token(input("请输入代码:"))
client.set_access_token(result.access_token, result.expires_in)
注意:这是调用sinweibopy3实现用户授权->在OAuth2.0中获取Token的过程。当程序运行到client.request_access_token时,会弹出输入提示“请输入密码:”,询问密码?这是什么意思?打开浏览器会看到出现OAuth2.0验证回调页面。地址栏中的“code=”后面有一串字符。这就是我们想要的Token信息。复制它,粘贴它并输入它,然后程序继续。跑。
3.从 API 读取数据
运行以下代码读取公众微博数据并显示结果。
结果=client.public_timeline()
print(json.dumps(result,indent=2,ensure_ascii=False))
通过查看数据结构,可以提取特定信息。例如,使用以下代码输出用户的微博昵称、位置和最新的微博文字。
数字=结果[“总数”]
打印(数字,“用户:”)
结果中的你[“状态”]:
打印(u[“用户”][“屏幕名称”])
打印(u[“用户”][“位置”])
打印(你[“文本”])
先进的 查看全部
网站调用新浪微博内容(新浪微博API新特点与百度地图API相比,我理解)
查看 API 使用流程
通过百度地图API的使用,了解到API调用的大致流程是:生成API指定格式的url->通过urllib读取url中的数据->解析json格式的数据。接下来开始研究新浪微博API的使用。
准备
新浪微博开放平台是使用新浪微博API的平台。使用微博账号登录平台后,即可申请成为开发者,创建新应用后将获得唯一的App Key和App Secret。(注:申请不需要提交审核,只要新建一个申请,就会分配Key和Secret。)这两个信息也可以在“我的申请/申请信息/基本信息”中找到. 该页面还有“我的申请/申请信息/高级信息”项,点击进入并设置OAuth2.0授权回调页面的相关信息。如果不知道填什么,可以设置为默认回调Page:。后面需要这三个信息,
微博API新功能
新浪微博API与百度地图API相比,增加了OAuth2.0协议进行用户认证和授权。这里只是简单描述一下(感兴趣的同学可以参考网上文档图):通过这个协议,第三方应用可以获取用户授权,然后使用这个License从授权服务器获取一个token,供后续查询API server 验证数据时。
这个验证过程增加了 url 生成的复杂性。幸运的是,廖雪峰老师提供的SDK工具包已经在网站:sinaweibopy(廖老师的github地址好像改名了,网上很多旧链接都失效了,这是新的有效链接) ,但是这个程序是基于python2环境编写的,python3的一些系统库已经改了,程序调用的时候经常报错。作为一个python初学者,重写程序以适应python3环境无疑是困难的。幸运的是,有一位大神完成了这项工作。感谢 owolf 为 python3 重写的 SDK:sinweibopy3。我用过,运行正常。你可以下载它。在这里,我也推荐一下owolf的文章
简单的例子
介绍一下新浪微博API的使用过程,为新生提供参考。
1.参数设置
导入 sinweibopy3
导入浏览器
导入json
APP_KEY = '填写您的应用密钥'
APP_SECRET='填写您的应用密码'
REDIRECT_URL = '填写你的授权回调页面'
笔记:
这个文件需要和sinweibopy3.py放在同一个文件夹下。
填写的三条信息就是准备中提到的信息。
这里说一下我的粗心造成的一个bug,也提醒大家。当我第一次运行程序时,每次都会收到“重定向地址不匹配”错误消息:
微博账号登录出错!授权第三方应用出错,请联系第三方应用开发者:XXX或稍后重试。
错误代码:21322 重定向地址不匹配
网上找了解决方法,设置回调页,但是我之前的步骤已经设置好了,为什么还是这个问题?后来在一篇文章文章中看到,回调页面的地址应该和程序中的REDIRECT_URL一致。想到了程序示例,用http:开头,我填写的时候看到同一个地址,没有变化,而网站是https:开头,一个's'的区别,当时还以为是地址,没想到差别这么大!
2.OAuth2.0 验证生成的url
client = sinaweibopy3.APIClient(app_key=APP_KEY, app_secret=APP_SECRET, redirect_uri=REDIRECT_URL)
url = client.get_authorize_url()
webbrowser.open_new(url)
result = client.request_access_token(input("请输入代码:"))
client.set_access_token(result.access_token, result.expires_in)
注意:这是调用sinweibopy3实现用户授权->在OAuth2.0中获取Token的过程。当程序运行到client.request_access_token时,会弹出输入提示“请输入密码:”,询问密码?这是什么意思?打开浏览器会看到出现OAuth2.0验证回调页面。地址栏中的“code=”后面有一串字符。这就是我们想要的Token信息。复制它,粘贴它并输入它,然后程序继续。跑。
3.从 API 读取数据
运行以下代码读取公众微博数据并显示结果。
结果=client.public_timeline()
print(json.dumps(result,indent=2,ensure_ascii=False))
通过查看数据结构,可以提取特定信息。例如,使用以下代码输出用户的微博昵称、位置和最新的微博文字。
数字=结果[“总数”]
打印(数字,“用户:”)
结果中的你[“状态”]:
打印(u[“用户”][“屏幕名称”])
打印(u[“用户”][“位置”])
打印(你[“文本”])
先进的
网站调用新浪微博内容(【魔兽世界】新浪微博登录常用接口:对应主界面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-12 14:13
日志条目
新浪微博登录常用界面:
对应主界面:
不过,我个人推荐使用移动端的微博入口:
对应主界面:
原因是手机上的数据比较轻量级,基础数据齐全,可能会缺少一些基本的个人信息,比如“个人资料完成度”、“个人等级”等。粉丝ID和关注ID只能显示20页,但可以作为大部分验证的语料库。
通过对比下面两张图,分别是PC端和手机端,可以发现内容基本一致:
如下图在手机上,图片比较小,内容也比较简洁。
完整的源代码
下面的代码主要分为三部分:
1.登录微博(用户名、密码) 登录微博
2.VisitPersonPage(user_id) 访问follower网站获取个人信息
3.获取微博内容同时翻页
<p># coding=utf-8
"""
Created on 2016-02-22 @author: Eastmount
功能: 爬取新浪微博用户的信息
信息:用户ID 用户名 粉丝数 关注数 微博数 微博内容
网址:http://weibo.cn/ 数据量更小 相对http://weibo.com/
"""
import time
import re
import os
import sys
import codecs
import shutil
import urllib
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import selenium.webdriver.support.ui as ui
from selenium.webdriver.common.action_chains import ActionChains
#先调用无界面浏览器PhantomJS或Firefox
#driver = webdriver.PhantomJS(executable_path="G:\phantomjs-1.9.1-windows\phantomjs.exe")
driver = webdriver.Firefox()
wait = ui.WebDriverWait(driver,10)
#全局变量 文件操作读写信息
inforead = codecs.open("SinaWeibo_List.txt", 'r', 'utf-8')
infofile = codecs.open("SinaWeibo_Info.txt", 'a', 'utf-8')
#********************************************************************************
# 第一步: 登陆weibo.cn 获取新浪微博的cookie
# 该方法针对weibo.cn有效(明文形式传输数据) weibo.com见学弟设置POST和Header方法
# LoginWeibo(username, password) 参数用户名 密码
# 验证码暂停时间手动输入
#********************************************************************************
def LoginWeibo(username, password):
try:
#**********************************************************************
# 直接访问driver.get("http://weibo.cn/5824697471")会跳转到登陆页面 用户id
#
# 用户名
# 密码 "password_4903" 中数字会变动,故采用绝对路径方法,否则不能定位到元素
#
# 勾选记住登录状态check默认是保留 故注释掉该代码 不保留Cookie 则'expiry'=None
#**********************************************************************
#输入用户名/密码登录
print u'准备登陆Weibo.cn网站...'
driver.get("http://login.weibo.cn/login/")
elem_user = driver.find_element_by_name("mobile")
elem_user.send_keys(username) #用户名
elem_pwd = driver.find_element_by_xpath("/html/body/div[2]/form/div/input[2]")
elem_pwd.send_keys(password) #密码
#elem_rem = driver.find_element_by_name("remember")
#elem_rem.click() #记住登录状态
#重点: 暂停时间输入验证码
#pause(millisenconds)
time.sleep(20)
elem_sub = driver.find_element_by_name("submit")
elem_sub.click() #点击登陆
time.sleep(2)
#获取Coockie 推荐 http://www.cnblogs.com/fnng/p/3269450.html
print driver.current_url
print driver.get_cookies() #获得cookie信息 dict存储
print u'输出Cookie键值对信息:'
for cookie in driver.get_cookies():
#print cookie
for key in cookie:
print key, cookie[key]
#driver.get_cookies()类型list 仅包含一个元素cookie类型dict
print u'登陆成功...'
except Exception,e:
print "Error: ",e
finally:
print u'End LoginWeibo!\n\n'
#********************************************************************************
# 第二步: 访问个人页面http://weibo.cn/5824697471并获取信息
# VisitPersonPage()
# 编码常见错误 UnicodeEncodeError: 'ascii' codec can't encode characters
#********************************************************************************
def VisitPersonPage(user_id):
try:
global infofile
print u'准备访问个人网站.....'
#原创内容 http://weibo.cn/guangxianliuya ... e%3D2
driver.get("http://weibo.cn/" + user_id)
#**************************************************************************
# No.1 直接获取 用户昵称 微博数 关注数 粉丝数
# str_name.text是unicode编码类型
#**************************************************************************
#用户id
print u'个人详细信息'
print '**********************************************'
print u'用户id: ' + user_id
#昵称
str_name = driver.find_element_by_xpath("//div[@class='ut']")
str_t = str_name.text.split(" ")
num_name = str_t[0] #空格分隔 获取第一个值 "Eastmount 详细资料 设置 新手区"
print u'昵称: ' + num_name
#微博数 除个人主页 它默认直接显示微博数 无超链接
#Error: 'unicode' object is not callable
#一般是把字符串当做函数使用了 str定义成字符串 而str()函数再次使用时报错
str_wb = driver.find_element_by_xpath("//div[@class='tip2']")
pattern = r"\d+\.?\d*" #正则提取"微博[0]" 但r"(\[.*?\])"总含[]
guid = re.findall(pattern, str_wb.text, re.S|re.M)
print str_wb.text #微博[294] 关注[351] 粉丝[294] 分组[1] @他的
for value in guid:
num_wb = int(value)
break
print u'微博数: ' + str(num_wb)
#关注数
str_gz = driver.find_element_by_xpath("//div[@class='tip2']/a[1]")
guid = re.findall(pattern, str_gz.text, re.M)
num_gz = int(guid[0])
print u'关注数: ' + str(num_gz)
#粉丝数
str_fs = driver.find_element_by_xpath("//div[@class='tip2']/a[2]")
guid = re.findall(pattern, str_fs.text, re.M)
num_fs = int(guid[0])
print u'粉丝数: ' + str(num_fs)
#***************************************************************************
# No.2 文件操作写入信息
#***************************************************************************
infofile.write('=====================================================================\r\n')
infofile.write(u'用户: ' + user_id + '\r\n')
infofile.write(u'昵称: ' + num_name + '\r\n')
infofile.write(u'微博数: ' + str(num_wb) + '\r\n')
infofile.write(u'关注数: ' + str(num_gz) + '\r\n')
infofile.write(u'粉丝数: ' + str(num_fs) + '\r\n')
infofile.write(u'微博内容: ' + '\r\n\r\n')
#***************************************************************************
# No.3 获取微博内容
# http://weibo.cn/guangxianliuya ... e%3D1
# 其中filter=0表示全部 =1表示原创
#***************************************************************************
print '\n'
print u'获取微博内容信息'
num = 1
while num 查看全部
网站调用新浪微博内容(【魔兽世界】新浪微博登录常用接口:对应主界面)
日志条目
新浪微博登录常用界面:
对应主界面:
不过,我个人推荐使用移动端的微博入口:
对应主界面:
原因是手机上的数据比较轻量级,基础数据齐全,可能会缺少一些基本的个人信息,比如“个人资料完成度”、“个人等级”等。粉丝ID和关注ID只能显示20页,但可以作为大部分验证的语料库。
通过对比下面两张图,分别是PC端和手机端,可以发现内容基本一致:
如下图在手机上,图片比较小,内容也比较简洁。
完整的源代码
下面的代码主要分为三部分:
1.登录微博(用户名、密码) 登录微博
2.VisitPersonPage(user_id) 访问follower网站获取个人信息
3.获取微博内容同时翻页
<p># coding=utf-8
"""
Created on 2016-02-22 @author: Eastmount
功能: 爬取新浪微博用户的信息
信息:用户ID 用户名 粉丝数 关注数 微博数 微博内容
网址:http://weibo.cn/ 数据量更小 相对http://weibo.com/
"""
import time
import re
import os
import sys
import codecs
import shutil
import urllib
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import selenium.webdriver.support.ui as ui
from selenium.webdriver.common.action_chains import ActionChains
#先调用无界面浏览器PhantomJS或Firefox
#driver = webdriver.PhantomJS(executable_path="G:\phantomjs-1.9.1-windows\phantomjs.exe")
driver = webdriver.Firefox()
wait = ui.WebDriverWait(driver,10)
#全局变量 文件操作读写信息
inforead = codecs.open("SinaWeibo_List.txt", 'r', 'utf-8')
infofile = codecs.open("SinaWeibo_Info.txt", 'a', 'utf-8')
#********************************************************************************
# 第一步: 登陆weibo.cn 获取新浪微博的cookie
# 该方法针对weibo.cn有效(明文形式传输数据) weibo.com见学弟设置POST和Header方法
# LoginWeibo(username, password) 参数用户名 密码
# 验证码暂停时间手动输入
#********************************************************************************
def LoginWeibo(username, password):
try:
#**********************************************************************
# 直接访问driver.get("http://weibo.cn/5824697471";)会跳转到登陆页面 用户id
#
# 用户名
# 密码 "password_4903" 中数字会变动,故采用绝对路径方法,否则不能定位到元素
#
# 勾选记住登录状态check默认是保留 故注释掉该代码 不保留Cookie 则'expiry'=None
#**********************************************************************
#输入用户名/密码登录
print u'准备登陆Weibo.cn网站...'
driver.get("http://login.weibo.cn/login/";)
elem_user = driver.find_element_by_name("mobile")
elem_user.send_keys(username) #用户名
elem_pwd = driver.find_element_by_xpath("/html/body/div[2]/form/div/input[2]")
elem_pwd.send_keys(password) #密码
#elem_rem = driver.find_element_by_name("remember")
#elem_rem.click() #记住登录状态
#重点: 暂停时间输入验证码
#pause(millisenconds)
time.sleep(20)
elem_sub = driver.find_element_by_name("submit")
elem_sub.click() #点击登陆
time.sleep(2)
#获取Coockie 推荐 http://www.cnblogs.com/fnng/p/3269450.html
print driver.current_url
print driver.get_cookies() #获得cookie信息 dict存储
print u'输出Cookie键值对信息:'
for cookie in driver.get_cookies():
#print cookie
for key in cookie:
print key, cookie[key]
#driver.get_cookies()类型list 仅包含一个元素cookie类型dict
print u'登陆成功...'
except Exception,e:
print "Error: ",e
finally:
print u'End LoginWeibo!\n\n'
#********************************************************************************
# 第二步: 访问个人页面http://weibo.cn/5824697471并获取信息
# VisitPersonPage()
# 编码常见错误 UnicodeEncodeError: 'ascii' codec can't encode characters
#********************************************************************************
def VisitPersonPage(user_id):
try:
global infofile
print u'准备访问个人网站.....'
#原创内容 http://weibo.cn/guangxianliuya ... e%3D2
driver.get("http://weibo.cn/" + user_id)
#**************************************************************************
# No.1 直接获取 用户昵称 微博数 关注数 粉丝数
# str_name.text是unicode编码类型
#**************************************************************************
#用户id
print u'个人详细信息'
print '**********************************************'
print u'用户id: ' + user_id
#昵称
str_name = driver.find_element_by_xpath("//div[@class='ut']")
str_t = str_name.text.split(" ")
num_name = str_t[0] #空格分隔 获取第一个值 "Eastmount 详细资料 设置 新手区"
print u'昵称: ' + num_name
#微博数 除个人主页 它默认直接显示微博数 无超链接
#Error: 'unicode' object is not callable
#一般是把字符串当做函数使用了 str定义成字符串 而str()函数再次使用时报错
str_wb = driver.find_element_by_xpath("//div[@class='tip2']")
pattern = r"\d+\.?\d*" #正则提取"微博[0]" 但r"(\[.*?\])"总含[]
guid = re.findall(pattern, str_wb.text, re.S|re.M)
print str_wb.text #微博[294] 关注[351] 粉丝[294] 分组[1] @他的
for value in guid:
num_wb = int(value)
break
print u'微博数: ' + str(num_wb)
#关注数
str_gz = driver.find_element_by_xpath("//div[@class='tip2']/a[1]")
guid = re.findall(pattern, str_gz.text, re.M)
num_gz = int(guid[0])
print u'关注数: ' + str(num_gz)
#粉丝数
str_fs = driver.find_element_by_xpath("//div[@class='tip2']/a[2]")
guid = re.findall(pattern, str_fs.text, re.M)
num_fs = int(guid[0])
print u'粉丝数: ' + str(num_fs)
#***************************************************************************
# No.2 文件操作写入信息
#***************************************************************************
infofile.write('=====================================================================\r\n')
infofile.write(u'用户: ' + user_id + '\r\n')
infofile.write(u'昵称: ' + num_name + '\r\n')
infofile.write(u'微博数: ' + str(num_wb) + '\r\n')
infofile.write(u'关注数: ' + str(num_gz) + '\r\n')
infofile.write(u'粉丝数: ' + str(num_fs) + '\r\n')
infofile.write(u'微博内容: ' + '\r\n\r\n')
#***************************************************************************
# No.3 获取微博内容
# http://weibo.cn/guangxianliuya ... e%3D1
# 其中filter=0表示全部 =1表示原创
#***************************************************************************
print '\n'
print u'获取微博内容信息'
num = 1
while num
网站调用新浪微博内容( 请求下图这个链接就能获取这条微博的第二页评论数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-11 21:01
请求下图这个链接就能获取这条微博的第二页评论数据)
第二页呢?事实上,这很简单。您可以通过以下链接获取本微博第二页的评论数据:
其实比第一页多了两个参数。这两个参数实际上隐藏在返回的首页评论数据中:
以此类推,第 n 页所需的 max_id 和 max_id_type 参数隐藏在返回的第 n-1 页的评论数据中。
可以发现,当页面返回的max_id为0时,表示该页面是微博下评论的最后一页。
这样,我们就可以爬取到微博下方的所有评论数据了!(QAQ当然前提是网站没有其他防爬措施,这显然不太可能。)
那么,能否将PC端微博评论页面的链接转换为移动端微博评论页面对应的链接呢?毕竟我们平时都是用电脑上的PC端界面登录然后看微博的!
当然!
在胡歌上一条微博评论页面的PC界面,我发现了这个:
注意:在微博PC端请求链接时,需要添加cookie信息。经过测试,只需要在cookie中添加SUB参数即可。有关详细信息,请参阅相关文件中的源代码。
这不是mid吗,所以PC端微博评论页面的链接可以很方便的转换成手机端微博评论页面对应的链接。
因此,微博评论数据抓取部分的代码可以很方便的写成:
OK,大功告成~完整源码见相关文档~使用说明
在终端运行weiboComments.py文件,命令格式如下:
例如:
python weiboComments.py -u 用户名 -p 密码 -m 10 (即评论数据最多可以抓取10页) -l 一条微博的评论页面链接 -t pc (输入pc/phone,用于表示是否是PC端或移动端微博评论页链接)。
只需运行它并截取屏幕截图:
数据以文件名保存在当前文件夹中:
评论_当前时间戳.pkl。
注意:
为了避免对微博服务器造成不必要的压力,我为我抓取的每个页面设置了更长的暂停时间。
数据可视化
只画了前十页评论的词云,其他数据懒得分析:
源码见相关文件中的vis.py文件。
更多的
新浪微博相关信息 查看全部
网站调用新浪微博内容(
请求下图这个链接就能获取这条微博的第二页评论数据)

第二页呢?事实上,这很简单。您可以通过以下链接获取本微博第二页的评论数据:

其实比第一页多了两个参数。这两个参数实际上隐藏在返回的首页评论数据中:

以此类推,第 n 页所需的 max_id 和 max_id_type 参数隐藏在返回的第 n-1 页的评论数据中。
可以发现,当页面返回的max_id为0时,表示该页面是微博下评论的最后一页。
这样,我们就可以爬取到微博下方的所有评论数据了!(QAQ当然前提是网站没有其他防爬措施,这显然不太可能。)
那么,能否将PC端微博评论页面的链接转换为移动端微博评论页面对应的链接呢?毕竟我们平时都是用电脑上的PC端界面登录然后看微博的!
当然!
在胡歌上一条微博评论页面的PC界面,我发现了这个:
注意:在微博PC端请求链接时,需要添加cookie信息。经过测试,只需要在cookie中添加SUB参数即可。有关详细信息,请参阅相关文件中的源代码。

这不是mid吗,所以PC端微博评论页面的链接可以很方便的转换成手机端微博评论页面对应的链接。
因此,微博评论数据抓取部分的代码可以很方便的写成:

OK,大功告成~完整源码见相关文档~使用说明
在终端运行weiboComments.py文件,命令格式如下:

例如:
python weiboComments.py -u 用户名 -p 密码 -m 10 (即评论数据最多可以抓取10页) -l 一条微博的评论页面链接 -t pc (输入pc/phone,用于表示是否是PC端或移动端微博评论页链接)。
只需运行它并截取屏幕截图:

数据以文件名保存在当前文件夹中:
评论_当前时间戳.pkl。
注意:
为了避免对微博服务器造成不必要的压力,我为我抓取的每个页面设置了更长的暂停时间。
数据可视化
只画了前十页评论的词云,其他数据懒得分析:

源码见相关文件中的vis.py文件。
更多的
新浪微博相关信息
网站调用新浪微博内容(使用python调用微博API的授权机制是什么?如何使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-08 05:05
做没有稻草的砖。
数据采集是数据分析的前提。很多网站会通过API接口向第三方开放网站的部分数据。新浪微博也不例外。您可以查看微博 API 列表。
本文将对如何使用微博API进行初步介绍,从而获得基本的概念和理解,方便后面深入了解。
step1:使用python调用微博API,首先下载python SDK,即sinweibopy
sinaweibopy 是一个支持微博 API 的特定于 python 的 OAuth 2 客户端。无依赖,100%纯Py,单一文件,代码简洁,运行可靠。也是新浪微博的Python SDK。
可以直接通过 pip 安装:
pip install sinaweibopy
什么是 SDK?SDK的英文全称是software development kit(软件开发工具包)。简而言之,它是一个代码库,其中收录用于开发应用程序的可重用代码。当您为应用程序编写代码时,您不需要像在实际屏幕上绘制文本那样重复代码。使用 SDK 可以帮助您做到这一点。总而言之,所有这些代码库和一些其他工具构成了我们所说的 SDK。
step2:了解新浪微博的授权机制,即OAuth 2
API 调用需要用户认证(用户授权)。目前OAuth2.0主要用于微博开放平台上的用户身份认证。
OAuth2.0协议的授权流程请参考如下流程图,其中Client指的是第三方应用(即我们自己在第三步创建的应用),Resource Owner指的是用户,授权服务器是我们的授权服务器,资源服务器是API服务器。
从流程图可以看出,为了调用API server内容,需要将access token告诉API server;访问令牌由新浪(授权服务器)在用户授权后返回给我们创建的应用程序;为了完成用户授权,我们的应用首先要给用户授权页面(授权请求)。
微博API授权机制(来自微博开放平台开发文档)
用户授权浏览器后,URL 如下所示:
我们需要将代码后面的字符串提交给新浪授权服务器来获取访问令牌。相当于告诉新浪服务器我们的应用已经被用户授权,现在可以访问用户的数据了,所以授权服务器给了我们一个访问令牌,我们就可以从API服务器获取微博数据了。
了解了上面的机制之后,我们就知道如何编写代码来调用API了。
step3:在微博开放平台上创建自己的应用
现在让我们创建自己的应用程序。创建应用程序的目的是获取应用程序密钥和应用程序机密。
我们使用微连接创建移动应用程序。您还可以创建其他类型的应用程序。创建应用程序后,将分配唯一的应用程序密钥和应用程序密码。您可以在“我的申请-申请信息-基本信息”中查询,将用于授权。注意:无需提交审核,您只需要应用程序密钥和应用程序密钥即可。
如果是异地网页应用或者手机客户端应用,出于安全考虑,需要在平台网站填写redirect_url(授权回调页面)才能使用OAuth2.0。地址填写为“我的申请>申请信息>高级信息”。这里,我们将授权回调页面和取消授权回调页面都设置为默认回调页面:
我的应用程序 - 应用程序信息 - 高级信息
step4:python代码实现
首先,导入所需的模块:
from weibo import APIClient
import webbrowser #python内置的包,支持对浏览器进行操作
使用微博 SDK 创建我们的应用程序:
APP_KEY = '123456'
APP_SECRET = 'abc123xyz456'
CALLBACK_URL = 'https://api.weibo.com/oauth2/default.html' #回调授权页面,用户完成授权后返回的页面
client = APIClient(app_key=APP_KEY, app_secret=APP_SECRET, redirect_uri=CALLBACK_URL)
获取授权页面的url(%3A///oauth2/default.html&response_type=code&client_id=729983294)。用webbrowser打开这个url,会引起浏览器打开
url=client.get_authorize_url() #得到授权页面的url
webbrowser.open_new(url) #打开这个url
打开授权页面的url
用户完成授权后,url 如下所示: . 我们需要code=后面的内容。
print '输入url中code后面的内容后按回车键:'
code = raw_input()
使用代码获取访问令牌:
r = client.request_access_token(code)
access_token = r.access_token # 新浪(授权服务器)返回的token
expires_in = r.expires_in
您可以打印 r 以查看其中的内容:
print(r)
{'access_token': u'abcqwe123', 'expires': 1662109746, 'expires_in': 1662109746, 'uid': u'2164581421'}
设置获取到的access_token后,可以直接调用API:
client.set_access_token(access_token, expires_in)
输出最新的公众微博:
print(client.statuses__public_timeline)
具体返回内容可以查看微博API文档。
例如,我们可以输出用户的昵称、简历、位置和推文:
for i in range(0,length):
print(u'昵称:'+statuses[i]['user']['screen_name'])
print(u'简介:'+statuses[i]['user']['description'])
print(u'位置:'+statuses[i]['user']['location'])
print(u'微博:'+statuses[i]['text'])
最新公开微博
参考:
python调用微博API
如何通过python调用新浪微博的API 查看全部
网站调用新浪微博内容(使用python调用微博API的授权机制是什么?如何使用)
做没有稻草的砖。
数据采集是数据分析的前提。很多网站会通过API接口向第三方开放网站的部分数据。新浪微博也不例外。您可以查看微博 API 列表。
本文将对如何使用微博API进行初步介绍,从而获得基本的概念和理解,方便后面深入了解。
step1:使用python调用微博API,首先下载python SDK,即sinweibopy
sinaweibopy 是一个支持微博 API 的特定于 python 的 OAuth 2 客户端。无依赖,100%纯Py,单一文件,代码简洁,运行可靠。也是新浪微博的Python SDK。
可以直接通过 pip 安装:
pip install sinaweibopy
什么是 SDK?SDK的英文全称是software development kit(软件开发工具包)。简而言之,它是一个代码库,其中收录用于开发应用程序的可重用代码。当您为应用程序编写代码时,您不需要像在实际屏幕上绘制文本那样重复代码。使用 SDK 可以帮助您做到这一点。总而言之,所有这些代码库和一些其他工具构成了我们所说的 SDK。
step2:了解新浪微博的授权机制,即OAuth 2
API 调用需要用户认证(用户授权)。目前OAuth2.0主要用于微博开放平台上的用户身份认证。
OAuth2.0协议的授权流程请参考如下流程图,其中Client指的是第三方应用(即我们自己在第三步创建的应用),Resource Owner指的是用户,授权服务器是我们的授权服务器,资源服务器是API服务器。
从流程图可以看出,为了调用API server内容,需要将access token告诉API server;访问令牌由新浪(授权服务器)在用户授权后返回给我们创建的应用程序;为了完成用户授权,我们的应用首先要给用户授权页面(授权请求)。

微博API授权机制(来自微博开放平台开发文档)
用户授权浏览器后,URL 如下所示:
我们需要将代码后面的字符串提交给新浪授权服务器来获取访问令牌。相当于告诉新浪服务器我们的应用已经被用户授权,现在可以访问用户的数据了,所以授权服务器给了我们一个访问令牌,我们就可以从API服务器获取微博数据了。
了解了上面的机制之后,我们就知道如何编写代码来调用API了。
step3:在微博开放平台上创建自己的应用
现在让我们创建自己的应用程序。创建应用程序的目的是获取应用程序密钥和应用程序机密。
我们使用微连接创建移动应用程序。您还可以创建其他类型的应用程序。创建应用程序后,将分配唯一的应用程序密钥和应用程序密码。您可以在“我的申请-申请信息-基本信息”中查询,将用于授权。注意:无需提交审核,您只需要应用程序密钥和应用程序密钥即可。
如果是异地网页应用或者手机客户端应用,出于安全考虑,需要在平台网站填写redirect_url(授权回调页面)才能使用OAuth2.0。地址填写为“我的申请>申请信息>高级信息”。这里,我们将授权回调页面和取消授权回调页面都设置为默认回调页面:
我的应用程序 - 应用程序信息 - 高级信息
step4:python代码实现
首先,导入所需的模块:
from weibo import APIClient
import webbrowser #python内置的包,支持对浏览器进行操作
使用微博 SDK 创建我们的应用程序:
APP_KEY = '123456'
APP_SECRET = 'abc123xyz456'
CALLBACK_URL = 'https://api.weibo.com/oauth2/default.html' #回调授权页面,用户完成授权后返回的页面
client = APIClient(app_key=APP_KEY, app_secret=APP_SECRET, redirect_uri=CALLBACK_URL)
获取授权页面的url(%3A///oauth2/default.html&response_type=code&client_id=729983294)。用webbrowser打开这个url,会引起浏览器打开
url=client.get_authorize_url() #得到授权页面的url
webbrowser.open_new(url) #打开这个url
打开授权页面的url
用户完成授权后,url 如下所示: . 我们需要code=后面的内容。
print '输入url中code后面的内容后按回车键:'
code = raw_input()
使用代码获取访问令牌:
r = client.request_access_token(code)
access_token = r.access_token # 新浪(授权服务器)返回的token
expires_in = r.expires_in
您可以打印 r 以查看其中的内容:
print(r)
{'access_token': u'abcqwe123', 'expires': 1662109746, 'expires_in': 1662109746, 'uid': u'2164581421'}
设置获取到的access_token后,可以直接调用API:
client.set_access_token(access_token, expires_in)
输出最新的公众微博:
print(client.statuses__public_timeline)
具体返回内容可以查看微博API文档。
例如,我们可以输出用户的昵称、简历、位置和推文:
for i in range(0,length):
print(u'昵称:'+statuses[i]['user']['screen_name'])
print(u'简介:'+statuses[i]['user']['description'])
print(u'位置:'+statuses[i]['user']['location'])
print(u'微博:'+statuses[i]['text'])
最新公开微博
参考:
python调用微博API
如何通过python调用新浪微博的API
网站调用新浪微博内容(蝙蝠侠IT将通过如下内容阐述:站内UV的增长角度)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-01-07 01:16
在做SEO的过程中,我们总会遇到各种各样的问题。最常见的情况是网站的排名比较低,每天来自搜索引擎的流量比较少,有时候我们的KPI评估也需要从站点UV增长的角度来衡量,这就是需要我们多思考相关内容。
那么,网站排名靠后,如何提升页面评价浏览量?
根据之前的SEO统计研究,Batman IT将详细阐述以下内容:
1、修复登陆页面
因为我们的网站排名非常低,所以我们在运营的过程中总是需要对落地页进行深入研究,以最大化流量。这是一个非常重要的站内搜索引擎优化,让我们掌握现有的流量并扩大它。方法。
因此,我们可能需要思考:
①改进着陆页,是否可以扩大相关性更高的关键词的排名,提高页面的主题相关性,或者扩展更多的长尾词。
② 修改落地页内容,丰富页面元素,如信息图表的使用,短视频内容的增加,从而增加用户粘性,通过内链合理引导对方访问相关目标页面。
③考虑是否需要搭建百科模块,如有需要,可以申请cookie权限,推荐相关内容。
2、页面内容推荐
我们知道,任何页面的网站结构基本上都是由内容页面下的正文、侧边栏和相关推荐组成,以增加用户站点的平均页面浏览量。
我们需要考虑如何调整相关页面的推荐,比如:
①合理调用相关分类下的内容,并在网站相关栏目推荐。它不必是内容页面的底部。您可以使用网站热图查看热点。
②适当使用底部面板和侧边栏,增加随机内容的推荐。一是增加搜索引擎爬虫的抓取频率,二是增加用户潜在访问的随机性。
③适当使用nofollow推荐行业内一些知名KOL的主题内容,增加页面的相关性。如果可能,您可以适当地建立一个分类的关键推荐。
3、创建聚合页面
对于任何一个行业,如果我们在网站成立之初没有一个完整的结构设计和规划,在后期的运营过程中,很容易造成网站页面内容排序的混乱,如:在不同类别下显示,导致部分内容,无法有效集中显示,增加内容增量。
这时候就需要考虑是否可以通过聚合页面来整合这些相关内容的文章,从而提高目标用户对网站的浏览需求。
4、称重站排热词
如果你是白帽技术从业者,我们在做SEO的过程中遇到了网站的低排名。最大的因素是整个站点的权重相对较低。长期以来,我们需要面对激烈的竞争。对一个流行度高的词进行排名需要一定的时间。这时候就需要合理利用一些高权重的网站,通过第三方高权重的网站,发布竞争性相对较强的关键词,一个基于将流量引导至目标页面的超链接。
5、社交网络引流
如果网站的排名低,短期内没有办法增加网站的权重,我们可能需要考虑和使用社交媒体来增加流量,比如:
①有效利用相关问答平台进行线上推广引流,如:知乎、百度体验、百度贴吧、豆瓣、悟空问答、新浪爱问等。
②利用社交网络平台的推广系统,可以在短时间内快速弥补流量的不足,比如新浪微博上的范同。
③制造热点话题,合理利用大咖的影响力传播话题,形成口碑。
总结:网站排名低,如何提高页面评价浏览量,还有很多细节可以讨论,以上内容仅供参考!
蝙蝠侠IT转载需要授权! 查看全部
网站调用新浪微博内容(蝙蝠侠IT将通过如下内容阐述:站内UV的增长角度)
在做SEO的过程中,我们总会遇到各种各样的问题。最常见的情况是网站的排名比较低,每天来自搜索引擎的流量比较少,有时候我们的KPI评估也需要从站点UV增长的角度来衡量,这就是需要我们多思考相关内容。

那么,网站排名靠后,如何提升页面评价浏览量?
根据之前的SEO统计研究,Batman IT将详细阐述以下内容:
1、修复登陆页面
因为我们的网站排名非常低,所以我们在运营的过程中总是需要对落地页进行深入研究,以最大化流量。这是一个非常重要的站内搜索引擎优化,让我们掌握现有的流量并扩大它。方法。
因此,我们可能需要思考:
①改进着陆页,是否可以扩大相关性更高的关键词的排名,提高页面的主题相关性,或者扩展更多的长尾词。
② 修改落地页内容,丰富页面元素,如信息图表的使用,短视频内容的增加,从而增加用户粘性,通过内链合理引导对方访问相关目标页面。
③考虑是否需要搭建百科模块,如有需要,可以申请cookie权限,推荐相关内容。
2、页面内容推荐
我们知道,任何页面的网站结构基本上都是由内容页面下的正文、侧边栏和相关推荐组成,以增加用户站点的平均页面浏览量。
我们需要考虑如何调整相关页面的推荐,比如:
①合理调用相关分类下的内容,并在网站相关栏目推荐。它不必是内容页面的底部。您可以使用网站热图查看热点。
②适当使用底部面板和侧边栏,增加随机内容的推荐。一是增加搜索引擎爬虫的抓取频率,二是增加用户潜在访问的随机性。
③适当使用nofollow推荐行业内一些知名KOL的主题内容,增加页面的相关性。如果可能,您可以适当地建立一个分类的关键推荐。
3、创建聚合页面
对于任何一个行业,如果我们在网站成立之初没有一个完整的结构设计和规划,在后期的运营过程中,很容易造成网站页面内容排序的混乱,如:在不同类别下显示,导致部分内容,无法有效集中显示,增加内容增量。
这时候就需要考虑是否可以通过聚合页面来整合这些相关内容的文章,从而提高目标用户对网站的浏览需求。
4、称重站排热词
如果你是白帽技术从业者,我们在做SEO的过程中遇到了网站的低排名。最大的因素是整个站点的权重相对较低。长期以来,我们需要面对激烈的竞争。对一个流行度高的词进行排名需要一定的时间。这时候就需要合理利用一些高权重的网站,通过第三方高权重的网站,发布竞争性相对较强的关键词,一个基于将流量引导至目标页面的超链接。
5、社交网络引流
如果网站的排名低,短期内没有办法增加网站的权重,我们可能需要考虑和使用社交媒体来增加流量,比如:
①有效利用相关问答平台进行线上推广引流,如:知乎、百度体验、百度贴吧、豆瓣、悟空问答、新浪爱问等。
②利用社交网络平台的推广系统,可以在短时间内快速弥补流量的不足,比如新浪微博上的范同。
③制造热点话题,合理利用大咖的影响力传播话题,形成口碑。
总结:网站排名低,如何提高页面评价浏览量,还有很多细节可以讨论,以上内容仅供参考!
蝙蝠侠IT转载需要授权!
网站调用新浪微博内容(新浪微博的XSS攻击事件总结及解决办法(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-01-06 16:10
请注意,用户还可以将脚本注入描述和书签字段,而不仅仅是名称字段。我们需要对需要从书签文件中读取的任何数据进行编码,因为我们会将其打印到浏览器。
新浪微博攻击
(2011年6月28日)新浪微博发生了一次比较大的XSS攻击。大量用户自动发送诸如:“郭美美事件一些不被注意的细节”、“党建中穿帮的地方”、“让女人心跳的100首诗”、“3D肉团”段子高清国语版种子》、《这就是传说中的神仙亲人》、《轰!范冰冰的色情照片真的流出》等微博和私信,并自动关注了一个名叫hellosmy的用户。
事件线索如下:
20时14分,大量V认证用户开始招募转发蠕虫
20:30,病毒页面无法访问
20:32 新浪微博用户hellosmy无法访问
21:02,新浪漏洞补丁完成
XSS攻击代码简析
函数 createXHR(){ 返回 window.XMLHttpRequest? new XMLHttpRequest(): new ActiveXObject("Microsoft.XMLHTTP");} function getappkey(url){ xmlHttp = createXHR(); xmlHttp.open("GET",url,false); xmlHttp.send(); 结果 = xmlHttp.responseText; id_arr =''; id = result.match(/namecard=\"true\" title=\"[^\"]*/g); for(i= 0;i 这段代码比较丰富,它让微博广场的URL在请求中注入一个JS文件,JS请求完成后,会自动执行并从发布的微博(包括攻击Site link)等站点已经完成了攻击,可以看到main函数调用了publish、follow、message函数来帮你做那些坏事。
总结
可见XSS攻击的方式其实有很多种,大家可以防一下。但是,有时你会发现它们的一些共性-注入然后使用浏览器自动执行。因此,必须严格检查不可信的输入和输出!
参考文献和引文:
Cool Shell:对新浪微博的XSS攻击
MSDN 查看全部
网站调用新浪微博内容(新浪微博的XSS攻击事件总结及解决办法(一))
请注意,用户还可以将脚本注入描述和书签字段,而不仅仅是名称字段。我们需要对需要从书签文件中读取的任何数据进行编码,因为我们会将其打印到浏览器。
新浪微博攻击
(2011年6月28日)新浪微博发生了一次比较大的XSS攻击。大量用户自动发送诸如:“郭美美事件一些不被注意的细节”、“党建中穿帮的地方”、“让女人心跳的100首诗”、“3D肉团”段子高清国语版种子》、《这就是传说中的神仙亲人》、《轰!范冰冰的色情照片真的流出》等微博和私信,并自动关注了一个名叫hellosmy的用户。
事件线索如下:
20时14分,大量V认证用户开始招募转发蠕虫
20:30,病毒页面无法访问
20:32 新浪微博用户hellosmy无法访问
21:02,新浪漏洞补丁完成
XSS攻击代码简析
函数 createXHR(){ 返回 window.XMLHttpRequest? new XMLHttpRequest(): new ActiveXObject("Microsoft.XMLHTTP");} function getappkey(url){ xmlHttp = createXHR(); xmlHttp.open("GET",url,false); xmlHttp.send(); 结果 = xmlHttp.responseText; id_arr =''; id = result.match(/namecard=\"true\" title=\"[^\"]*/g); for(i= 0;i 这段代码比较丰富,它让微博广场的URL在请求中注入一个JS文件,JS请求完成后,会自动执行并从发布的微博(包括攻击Site link)等站点已经完成了攻击,可以看到main函数调用了publish、follow、message函数来帮你做那些坏事。
总结
可见XSS攻击的方式其实有很多种,大家可以防一下。但是,有时你会发现它们的一些共性-注入然后使用浏览器自动执行。因此,必须严格检查不可信的输入和输出!
参考文献和引文:
Cool Shell:对新浪微博的XSS攻击
MSDN
网站调用新浪微博内容(新浪微博短链接API是开放的,国外几家已经悲剧了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-06 01:18
在短地址(又称短链接、短地址等)方面,推特是经过发展后发展起来的,很多互联网网站都使用短地址。国内外有很多,但稳定可靠。国内的比较靠谱。我不怕没有墙。国外有几家公司已经悲剧了,所以如果在项目中使用短地址,我还是推荐使用新浪或者其他国内的短链接服务。
新浪微博短链接API开放,但腾讯微博短地址API未开放。我想通过不同的路径获取腾讯微博的API,但以失败告终。新浪微博短地址API不需要用户登录,直接调用即可,速度非常快。以下代码取自网站,使用CURL POST方式参考。
新浪微博短链接API文档在老版本的开发文档中,但新版本没有添加:
function shortenSinaUrl(long_url){apiKey='1234567890';//这里是你申请的应用的API KEY,随便写个应用名就会自动分配给你
apiUrl='http://api.t.sina.com.cn/short_url/shorten.json?source='.apiKey.'&url_long='.long_url;curlObj = curl_init();
curl_setopt(curlObj, CURLOPT_URL,apiUrl);
curl_setopt(curlObj, CURLOPT_RETURNTRANSFER, 1);
curl_setopt(curlObj, CURLOPT_SSL_VERIFYPEER, 0);
curl_setopt(curlObj, CURLOPT_HEADER, 0);
curl_setopt(curlObj, CURLOPT_HTTPHEADER, array('Content-type:application/json'));
response = curl_exec(curlObj);
curl_close(curlObj);json = json_decode(response);
returnjson[0]->url_short;
}
function expandSinaUrl(short_url){apiKey='1234567890';//要修改这里的key再测试哦
apiUrl='http://api.t.sina.com.cn/short_url/expand.json?source='.apiKey.'&url_short='.short_url;curlObj = curl_init();
curl_setopt(curlObj, CURLOPT_URL,apiUrl);
curl_setopt(curlObj, CURLOPT_RETURNTRANSFER, 1);
curl_setopt(curlObj, CURLOPT_SSL_VERIFYPEER, 0);
curl_setopt(curlObj, CURLOPT_HEADER, 0);
curl_setopt(curlObj, CURLOPT_HTTPHEADER, array('Content-type:application/json'));
response = curl_exec(curlObj);
curl_close(curlObj);json = json_decode(response);
returnjson[0]->url_long;
}
参考新浪微博的开发文档,推荐使用get方式获取。代码更简单
function shorturl(long_url){apiKey='1234567890';//要修改这里的key再测试哦
apiUrl='http://api.t.sina.com.cn/short_url/shorten.json?source='.apiKey.'&url_long='.long_url;response = file_get_contents(apiUrl);json = json_decode(response);
returnjson[0]->url_short;
}
function expandurl(short_url){apiKey='1234567890';//要修改这里的key再测试哦
apiUrl='http://api.t.sina.com.cn/short_url/expand.json?source='.apiKey.'&url_short='.short_url;response = file_get_contents(apiUrl);json = json_decode(response);
returnjson[0]->url_long;
}
好吧,不是更容易吗?
调试上面代码的时候,需要填写自己的API key,不然肯定拿不到。
特别说明:短地址服务现在只为经过认证的APP KEY提供服务,刚刚申请的APP KEY会提示没有权限。可以使用209678993和3818214747这两个KEY进行测试。这两个KEY的来源不明,不推荐用于生产。(感谢您的提醒)
Jucelin 写了一个调试文档,你可以测试一下:
长到短:://
短到长::///S4bLBm
只有2个参数,type:1表示长到短,2表示短到长,后面的URL就是目标域名。因为懒惰,所以没有错误的判断。新浪微博短地址不支持短地址后短地址。是的,逻辑上应该是这样控制的。(不信你可以试试)。
关于新浪微博短地址接口的更详细说明,请参见“新浪微博短地址接口”。 查看全部
网站调用新浪微博内容(新浪微博短链接API是开放的,国外几家已经悲剧了)
在短地址(又称短链接、短地址等)方面,推特是经过发展后发展起来的,很多互联网网站都使用短地址。国内外有很多,但稳定可靠。国内的比较靠谱。我不怕没有墙。国外有几家公司已经悲剧了,所以如果在项目中使用短地址,我还是推荐使用新浪或者其他国内的短链接服务。
新浪微博短链接API开放,但腾讯微博短地址API未开放。我想通过不同的路径获取腾讯微博的API,但以失败告终。新浪微博短地址API不需要用户登录,直接调用即可,速度非常快。以下代码取自网站,使用CURL POST方式参考。
新浪微博短链接API文档在老版本的开发文档中,但新版本没有添加:
function shortenSinaUrl(long_url){apiKey='1234567890';//这里是你申请的应用的API KEY,随便写个应用名就会自动分配给你
apiUrl='http://api.t.sina.com.cn/short_url/shorten.json?source='.apiKey.'&url_long='.long_url;curlObj = curl_init();
curl_setopt(curlObj, CURLOPT_URL,apiUrl);
curl_setopt(curlObj, CURLOPT_RETURNTRANSFER, 1);
curl_setopt(curlObj, CURLOPT_SSL_VERIFYPEER, 0);
curl_setopt(curlObj, CURLOPT_HEADER, 0);
curl_setopt(curlObj, CURLOPT_HTTPHEADER, array('Content-type:application/json'));
response = curl_exec(curlObj);
curl_close(curlObj);json = json_decode(response);
returnjson[0]->url_short;
}
function expandSinaUrl(short_url){apiKey='1234567890';//要修改这里的key再测试哦
apiUrl='http://api.t.sina.com.cn/short_url/expand.json?source='.apiKey.'&url_short='.short_url;curlObj = curl_init();
curl_setopt(curlObj, CURLOPT_URL,apiUrl);
curl_setopt(curlObj, CURLOPT_RETURNTRANSFER, 1);
curl_setopt(curlObj, CURLOPT_SSL_VERIFYPEER, 0);
curl_setopt(curlObj, CURLOPT_HEADER, 0);
curl_setopt(curlObj, CURLOPT_HTTPHEADER, array('Content-type:application/json'));
response = curl_exec(curlObj);
curl_close(curlObj);json = json_decode(response);
returnjson[0]->url_long;
}
参考新浪微博的开发文档,推荐使用get方式获取。代码更简单
function shorturl(long_url){apiKey='1234567890';//要修改这里的key再测试哦
apiUrl='http://api.t.sina.com.cn/short_url/shorten.json?source='.apiKey.'&url_long='.long_url;response = file_get_contents(apiUrl);json = json_decode(response);
returnjson[0]->url_short;
}
function expandurl(short_url){apiKey='1234567890';//要修改这里的key再测试哦
apiUrl='http://api.t.sina.com.cn/short_url/expand.json?source='.apiKey.'&url_short='.short_url;response = file_get_contents(apiUrl);json = json_decode(response);
returnjson[0]->url_long;
}
好吧,不是更容易吗?
调试上面代码的时候,需要填写自己的API key,不然肯定拿不到。
特别说明:短地址服务现在只为经过认证的APP KEY提供服务,刚刚申请的APP KEY会提示没有权限。可以使用209678993和3818214747这两个KEY进行测试。这两个KEY的来源不明,不推荐用于生产。(感谢您的提醒)
Jucelin 写了一个调试文档,你可以测试一下:
长到短:://
短到长::///S4bLBm
只有2个参数,type:1表示长到短,2表示短到长,后面的URL就是目标域名。因为懒惰,所以没有错误的判断。新浪微博短地址不支持短地址后短地址。是的,逻辑上应该是这样控制的。(不信你可以试试)。
关于新浪微博短地址接口的更详细说明,请参见“新浪微博短地址接口”。
网站调用新浪微博内容(新浪开的店铺均除外怎么办?每一步该如何操作 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-01-06 01:17
)
申请先决条件:你必须有一个,一个独立的网站;除了新浪开设的官方博客和天猫开设的商店。
申请有四种申请方式:①开发者身份认证②网站所有权验证③部署微链接④填写申请信息(提交审核),让我们详细了解每一步的操作方法!
第一步,登录新浪微博开放平台,点击下方图标,开始创建网站接入应用;
如果您尚未完成开发者身份验证,系统会引导您进入身份验证页面;
身份认证通过并不意味着您拥有自己的应用程序;身份认证通过后才能创建应用;
关于开发者类型,请根据实际情况填写;个人或企业不会影响您创建网站访问应用程序;如果选择企业,未来可以创造更多的应用类型;
身份验证周期为1-2个工作日,请关注系统通知;
第二步:验证网站的所有权,我们来学习一下如何填写;
网站姓名,即你要在微博上显示的“发件人”的名字,需要和你的网站相关联;
申请提交审核时可修改两次名称;
如果提示“网站名称已存在,请更改一个”,表示该名称已被占用,必须更改;
网站域名与您在微博点击“来自”时访问的页面相关,但不是绝对的;
比如这里填写,当申请提交审核时,可以设置点击“发件人”访问
选择验证方式,即新浪确认网站是否属于您。
微博平台提供两种验证方式。请把这一步留给网站技术(运维);因为涉及到修改你的网站官方源码,一般来说网站技术(运维)有相应的权限;
如何确认网站技术(运维)同学添加了验证码?访问你上一步填写的“网站域名”的网页,点击鼠标右键“查看网页源代码”,先找到head标签,再进一步搜索...(如果这个输入说话,本教程无法继续)
完成以上表格后,点击“验证并添加”进入以下页面;(当开发者身份认证为“企业”时,会略有不同)
注意,此时不要关闭页面;虽然我们成功获取了AppKey和AppSecret,但并不代表申请成功;在新窗口中打开“微组件”,我们将进入下一步;
第三步:部署微组件;如果没有部署微博组件,应用是不会通过审核的,切记;
选择你需要的功能(组件)部署网站。申请通过审核后,即可移除该组件;
例如,我们选择“关注按钮”...
查看全部
网站调用新浪微博内容(新浪开的店铺均除外怎么办?每一步该如何操作
)
申请先决条件:你必须有一个,一个独立的网站;除了新浪开设的官方博客和天猫开设的商店。
申请有四种申请方式:①开发者身份认证②网站所有权验证③部署微链接④填写申请信息(提交审核),让我们详细了解每一步的操作方法!
第一步,登录新浪微博开放平台,点击下方图标,开始创建网站接入应用;

如果您尚未完成开发者身份验证,系统会引导您进入身份验证页面;

身份认证通过并不意味着您拥有自己的应用程序;身份认证通过后才能创建应用;
关于开发者类型,请根据实际情况填写;个人或企业不会影响您创建网站访问应用程序;如果选择企业,未来可以创造更多的应用类型;
身份验证周期为1-2个工作日,请关注系统通知;
第二步:验证网站的所有权,我们来学习一下如何填写;

网站姓名,即你要在微博上显示的“发件人”的名字,需要和你的网站相关联;
申请提交审核时可修改两次名称;
如果提示“网站名称已存在,请更改一个”,表示该名称已被占用,必须更改;
网站域名与您在微博点击“来自”时访问的页面相关,但不是绝对的;
比如这里填写,当申请提交审核时,可以设置点击“发件人”访问
选择验证方式,即新浪确认网站是否属于您。
微博平台提供两种验证方式。请把这一步留给网站技术(运维);因为涉及到修改你的网站官方源码,一般来说网站技术(运维)有相应的权限;
如何确认网站技术(运维)同学添加了验证码?访问你上一步填写的“网站域名”的网页,点击鼠标右键“查看网页源代码”,先找到head标签,再进一步搜索...(如果这个输入说话,本教程无法继续)
完成以上表格后,点击“验证并添加”进入以下页面;(当开发者身份认证为“企业”时,会略有不同)

注意,此时不要关闭页面;虽然我们成功获取了AppKey和AppSecret,但并不代表申请成功;在新窗口中打开“微组件”,我们将进入下一步;
第三步:部署微组件;如果没有部署微博组件,应用是不会通过审核的,切记;

选择你需要的功能(组件)部署网站。申请通过审核后,即可移除该组件;
例如,我们选择“关注按钮”...

网站调用新浪微博内容(新浪SAE吐槽:字“坑”,好了!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-05 02:12
新浪微博平台与新浪SAE相同,同一个“坑”字
1:直接登录新浪,添加网站,然后直接添加我们在新浪SAE上创建的应用
2:填写信息,只需填写ICP备案信息号的备案号即可。如果使用图标,photoshop应该没有问题
3:拿到钥匙并安装。小样的网页我们一般很难通过审核,不过没关系,只要能拿到测试账号就可以了。
只要审核通过,无论通过与否,测试账号的key和secret都可以使用,提交审核即可。
4:代码如下,参考网上,但是现在找不到那个博客了。. . . . ,所以没有外链。. .
import sys<br />#在微博开放平台上的SDK中找到python SDK,下载安装就行
import weibo
import webbrowser
import json <br />#舔你的微博开放平台网站的key
APP_KEY = '643524640'<br />#对应的serect
MY_APP_SECRET = '32f7d34f4d826b818a05be54c161c933'<br />#这个可以对应SAE应用的url
REDIRECT_URL = 'http://irsearch.sinaapp.com/'
#要想看懂这些代码,努力的去看python SDK吧
api = weibo.APIClient(APP_KEY, MY_APP_SECRET)
authorize_url = api.get_authorize_url(REDIRECT_URL)
#print(authorize_url)
webbrowser.open_new(authorize_url)
code = raw_input()
request = api.request_access_token(code, REDIRECT_URL)
access_token = request.access_token
expires_in = request.expires_in
api.set_access_token(access_token, expires_in)
#public_timeline有三个参数
<br />t = api.statuses__public_timeline(count=1)
5:返回的数据格式为weibo.JsonDict,其中中文采用unicode编码
可以使用python的json进行转换
#接上面<br />print(t)
print(type(t))
te = json.dumps(t,ensure_ascii=False)
print(type(te))
print(te)
tem = json.loads(te)
print(type(tem))
print(tem)
结果部分如下:
{"interval": 0, "hasvisible": false, "total_number": 1, "previous_cursor": 0, "next_cursor": 0, "statuses": [{"reposts_count": 0, "truncated": false, "text": "\"激情世界杯 满减送不停\",这个活动推荐给大家。 地址:http://t.cn/RvuECDN", "visible": {"type": 0, "list_id": 0}, "in_reply_to_status_id": "", "bmiddle_pic": "http://ww1.sinaimg.cn/bmiddle/ ... ot%3B, "id": 3728023935535065, "thumbnail_pic": "http://ww1.sinaimg.cn/thumbnai ... ot%3B, "mid": "3728023935535065", "source": "<a href=\"http://app.weibo.com/t/feed/59hmLP\" rel=\"nofollow\">微活动</a>", "attitudes_count": 0, "in_reply_to_screen_name": "", "pic_urls": [{"thumbnail_pic": "http://ww1.sinaimg.cn/thumbnai ... ot%3B}], "annotations": [{"source": {"url": "http://event.weibo.com/23382470", "title": "激情世界杯 满减...", "id": "23382470", "name": "激情世界杯 满减送不停", "appid": "38"}}], "in_reply_to_user_id": "", "darwin_tags": [], "favorited": false, "original_pic": "http://ww1.sinaimg.cn/large/df ... ot%3B, "idstr": "3728023935535065", "user": {"bi_followers_count": 9, "domain": "", "avatar_large": "http://tp2.sinaimg.cn/18011200 ... ot%3B, "verified_source": "", "ptype": 0, "statuses_count": 312, "allow_all_comment": true, "id": 1801120077, "verified_reason_url": "", "city": "1", "province": "44", "block_app": 0, "follow_me": false, "verified_reason": "", "followers_count": 186, "location": "广东 广州", "verified_trade": "", "mbtype": 0, "verified_source_url": "", "profile_url": "u/1801120077", "block_word": 0, "avatar_hd": "http://ww1.sinaimg.cn/crop.0.0 ... ot%3B, "star": 0, "description": "", "friends_count": 371, "online_status": 1, "mbrank": 0, "allow_all_act_msg": true, "profile_image_url": "http://tp2.sinaimg.cn/18011200 ... ot%3B, "idstr": "1801120077", "verified": false, "geo_enabled": true, "class": 1, "screen_name": "车赣刺", "lang": "zh-cn", "weihao": "", "remark": "", "favourites_count": 0, "name": "车赣刺", "url": "", "gender": "m", "created_at": "Mon Aug 23 18:32:22 +0800 2010", "worldcup_guess": 0, "verified_type": -1, "following": false}, "geo": null, "created_at": "Wed Jul 02 23:07:12 +0800 2014", "mlevel": 0, "comments_count": 0}]}
6:这是一本字典,你想怎么用就怎么用 查看全部
网站调用新浪微博内容(新浪SAE吐槽:字“坑”,好了!)
新浪微博平台与新浪SAE相同,同一个“坑”字
1:直接登录新浪,添加网站,然后直接添加我们在新浪SAE上创建的应用
2:填写信息,只需填写ICP备案信息号的备案号即可。如果使用图标,photoshop应该没有问题

3:拿到钥匙并安装。小样的网页我们一般很难通过审核,不过没关系,只要能拿到测试账号就可以了。
只要审核通过,无论通过与否,测试账号的key和secret都可以使用,提交审核即可。
4:代码如下,参考网上,但是现在找不到那个博客了。. . . . ,所以没有外链。. .
import sys<br />#在微博开放平台上的SDK中找到python SDK,下载安装就行
import weibo
import webbrowser
import json <br />#舔你的微博开放平台网站的key
APP_KEY = '643524640'<br />#对应的serect
MY_APP_SECRET = '32f7d34f4d826b818a05be54c161c933'<br />#这个可以对应SAE应用的url
REDIRECT_URL = 'http://irsearch.sinaapp.com/'
#要想看懂这些代码,努力的去看python SDK吧
api = weibo.APIClient(APP_KEY, MY_APP_SECRET)
authorize_url = api.get_authorize_url(REDIRECT_URL)
#print(authorize_url)
webbrowser.open_new(authorize_url)
code = raw_input()
request = api.request_access_token(code, REDIRECT_URL)
access_token = request.access_token
expires_in = request.expires_in
api.set_access_token(access_token, expires_in)
#public_timeline有三个参数

<br />t = api.statuses__public_timeline(count=1)
5:返回的数据格式为weibo.JsonDict,其中中文采用unicode编码
可以使用python的json进行转换
#接上面<br />print(t)
print(type(t))
te = json.dumps(t,ensure_ascii=False)
print(type(te))
print(te)
tem = json.loads(te)
print(type(tem))
print(tem)
结果部分如下:
{"interval": 0, "hasvisible": false, "total_number": 1, "previous_cursor": 0, "next_cursor": 0, "statuses": [{"reposts_count": 0, "truncated": false, "text": "\"激情世界杯 满减送不停\",这个活动推荐给大家。 地址:http://t.cn/RvuECDN", "visible": {"type": 0, "list_id": 0}, "in_reply_to_status_id": "", "bmiddle_pic": "http://ww1.sinaimg.cn/bmiddle/ ... ot%3B, "id": 3728023935535065, "thumbnail_pic": "http://ww1.sinaimg.cn/thumbnai ... ot%3B, "mid": "3728023935535065", "source": "<a href=\"http://app.weibo.com/t/feed/59hmLP\" rel=\"nofollow\">微活动</a>", "attitudes_count": 0, "in_reply_to_screen_name": "", "pic_urls": [{"thumbnail_pic": "http://ww1.sinaimg.cn/thumbnai ... ot%3B}], "annotations": [{"source": {"url": "http://event.weibo.com/23382470", "title": "激情世界杯 满减...", "id": "23382470", "name": "激情世界杯 满减送不停", "appid": "38"}}], "in_reply_to_user_id": "", "darwin_tags": [], "favorited": false, "original_pic": "http://ww1.sinaimg.cn/large/df ... ot%3B, "idstr": "3728023935535065", "user": {"bi_followers_count": 9, "domain": "", "avatar_large": "http://tp2.sinaimg.cn/18011200 ... ot%3B, "verified_source": "", "ptype": 0, "statuses_count": 312, "allow_all_comment": true, "id": 1801120077, "verified_reason_url": "", "city": "1", "province": "44", "block_app": 0, "follow_me": false, "verified_reason": "", "followers_count": 186, "location": "广东 广州", "verified_trade": "", "mbtype": 0, "verified_source_url": "", "profile_url": "u/1801120077", "block_word": 0, "avatar_hd": "http://ww1.sinaimg.cn/crop.0.0 ... ot%3B, "star": 0, "description": "", "friends_count": 371, "online_status": 1, "mbrank": 0, "allow_all_act_msg": true, "profile_image_url": "http://tp2.sinaimg.cn/18011200 ... ot%3B, "idstr": "1801120077", "verified": false, "geo_enabled": true, "class": 1, "screen_name": "车赣刺", "lang": "zh-cn", "weihao": "", "remark": "", "favourites_count": 0, "name": "车赣刺", "url": "", "gender": "m", "created_at": "Mon Aug 23 18:32:22 +0800 2010", "worldcup_guess": 0, "verified_type": -1, "following": false}, "geo": null, "created_at": "Wed Jul 02 23:07:12 +0800 2014", "mlevel": 0, "comments_count": 0}]}
6:这是一本字典,你想怎么用就怎么用
网站调用新浪微博内容(联合第三方平台登录接入,初次接触开放平台和AppSecret5 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-19 18:10
)
最近做了一个关于联合第三方平台的登录访问,第一次接触到开放平台,在这里做个笔记。
开发前的准备工作如下:
1、注册新浪微博
2、访问新浪微博开发平台,如果是企业,申请企业接入并提交相关材料进行审核;如果是个人开发者,请申请个人开发者申请。我们以开发者为例
3、 使用新浪微博开放API,需要向新浪申请一个appkey和一个App Secret。这些是入口。您必须先获得这两个,然后才能访问下一个作品。
4、输入完善个人信息后,必须完成身份验证审核。审核完成后,新浪开放平台会给出appkey和App Secret。
5、接下来就是如何使用appkey和App Secret了。您需要在开放平台下载文档或演示代码。其实提供的文档基本上都是技术文档,很多东西没有解释清楚。还是会有很多麻烦
6、新浪开放平台提供了很多不同开发语言的SDK,这里我选择java SDK,下载一个zip文件(包括新接口和OAuth2.0),解压后可以直接导入go到eclipse,结构如下,包括weibo4j源码和示例代码
这里是一个config配置文件,打开如下:
我们之前申请的appkey和App Secret就派上用场了。这里的client_ID为appkey,client_SERCRET为App Secret,填写对应内容,redirect_URI为回调地址。
点击“第三方”-》跳转微博登录-》登录ok,授权-》回调自己的应用,这里是回调地址的意思。
7、开始运行测试程序,测试程序在example下,包weibo4j.examples.oauth2下的类OAuth4Code,这里我们需要做一些修改,修改程序在
oauth.authorize("code",args[0],args[1]),把这一段改成oauth.authorize("code","","all"),至于为什么,请看这里的接口文档说明使用 oauth.authorize
假设我们这里没有回调地址,配置文件中的redirect_URI为空。运行后会自动打开浏览器运行测试,显示如下:
此时的URL地址为:
这说明我的appkey和App Secret是有效的,因为我们还没有创建正式的应用,新浪无法识别我的来源
8、在开放平台上创建应用,如下图
这里的应用分为三种类型,网站访问、现场应用和移动应用。如果是企业行为,有公有域名可以访问,应用通过域名访问。这里两种方法都可以,但是如果我们只是一个简单的开发者,没有公网域名,比如内网模式,ip以内网地址192.168.开头1.*,本地127.0.0.1等,这里只能选择创建站内应用,填写如下
这里红框标注的地方就是回调地址。如果我没有公网ip和域名,我在局域网玩的时候随便填,但是不能用localhost代替127.0.0.1,这里是按照配置要求做的,这个配置的要求很严格,
尤其是下面的应用图标比较麻烦。完成后,您可以提交它们以供审核。
9、提交审核后,新浪开放平台会在1天左右第一时间发邮件到您的邮箱,通知您审核结果,但不管审核结果是否失败,关键是提交审核。没有审核成功,这里可以照常使用
10、完成测试项目中的配置文件redirect_URI,必须与创建应用时填写的【应用实际地址】一致,这是回调地址!完成配置后,再次运行OAuth4Code.java,如图
在这里你会跳转到新浪微博的登录页面。登录你的新浪微博账号后,需要点击授权,表示平台可以访问你的微博账号内容分享你的信息等。授权结束后,
将返回一个代码。这段代码非常重要。它是我们整个访问第三方平台的门钥匙。通过这段代码,我们可以获取到用户的access_token、UID等内容,相当于整个访问过程。
11、调用新浪微博开放API
这里我们需要研究这些API来满足访问的需要。首先要熟悉的是OAuth2.0授权接口,网上可以查到,如下:
12、通过servlet程序调用开放API获取新浪微博的UID和微博名的示例
response.setContentType("text/html;charset=UTF-8");
String accessToken = null ;
String uid = null ;
String screenName = null ;
String username = null ;
AccessToken accessTokenObj = null ;
Oauth oauth2 = new Oauth();
try {
out = response.getWriter();
accessTokenObj = oauth2.getAccessTokenByCode(code) ;
logger.info(accessTokenObj);
accessToken = accessTokenObj.getAccessToken() ;
oauth2.setToken(accessToken) ;
Account account = new Account() ;
account.client.setToken(accessToken) ;
JSONObject uidJson = account.getUid() ;
uid = uidJson.getString("uid") ;
Users users = new Users() ;
users.client.setToken(accessToken) ;
User weiboUser = users.showUserById(uid) ;
username = weiboUser.getName() ;
screenName = weiboUser.getScreenName() ;
} catch (WeiboException | IOException | JSONException e) {
e.printStackTrace();
}
out.println("微博访问Token_Info:" + accessTokenObj + "\t");
out.println("微博访问Token:" + accessToken + "\t");
out.println("微博用户-Uid:" + uid + "\t");
out.println("微博用户-名称:" + screenName + "\t");
out.flush();
out.close();*/
查看全部
网站调用新浪微博内容(联合第三方平台登录接入,初次接触开放平台和AppSecret5
)
最近做了一个关于联合第三方平台的登录访问,第一次接触到开放平台,在这里做个笔记。
开发前的准备工作如下:
1、注册新浪微博
2、访问新浪微博开发平台,如果是企业,申请企业接入并提交相关材料进行审核;如果是个人开发者,请申请个人开发者申请。我们以开发者为例
3、 使用新浪微博开放API,需要向新浪申请一个appkey和一个App Secret。这些是入口。您必须先获得这两个,然后才能访问下一个作品。
4、输入完善个人信息后,必须完成身份验证审核。审核完成后,新浪开放平台会给出appkey和App Secret。
5、接下来就是如何使用appkey和App Secret了。您需要在开放平台下载文档或演示代码。其实提供的文档基本上都是技术文档,很多东西没有解释清楚。还是会有很多麻烦
6、新浪开放平台提供了很多不同开发语言的SDK,这里我选择java SDK,下载一个zip文件(包括新接口和OAuth2.0),解压后可以直接导入go到eclipse,结构如下,包括weibo4j源码和示例代码
这里是一个config配置文件,打开如下:
我们之前申请的appkey和App Secret就派上用场了。这里的client_ID为appkey,client_SERCRET为App Secret,填写对应内容,redirect_URI为回调地址。
点击“第三方”-》跳转微博登录-》登录ok,授权-》回调自己的应用,这里是回调地址的意思。
7、开始运行测试程序,测试程序在example下,包weibo4j.examples.oauth2下的类OAuth4Code,这里我们需要做一些修改,修改程序在
oauth.authorize("code",args[0],args[1]),把这一段改成oauth.authorize("code","","all"),至于为什么,请看这里的接口文档说明使用 oauth.authorize
假设我们这里没有回调地址,配置文件中的redirect_URI为空。运行后会自动打开浏览器运行测试,显示如下:
此时的URL地址为:
这说明我的appkey和App Secret是有效的,因为我们还没有创建正式的应用,新浪无法识别我的来源
8、在开放平台上创建应用,如下图
这里的应用分为三种类型,网站访问、现场应用和移动应用。如果是企业行为,有公有域名可以访问,应用通过域名访问。这里两种方法都可以,但是如果我们只是一个简单的开发者,没有公网域名,比如内网模式,ip以内网地址192.168.开头1.*,本地127.0.0.1等,这里只能选择创建站内应用,填写如下
这里红框标注的地方就是回调地址。如果我没有公网ip和域名,我在局域网玩的时候随便填,但是不能用localhost代替127.0.0.1,这里是按照配置要求做的,这个配置的要求很严格,
尤其是下面的应用图标比较麻烦。完成后,您可以提交它们以供审核。
9、提交审核后,新浪开放平台会在1天左右第一时间发邮件到您的邮箱,通知您审核结果,但不管审核结果是否失败,关键是提交审核。没有审核成功,这里可以照常使用
10、完成测试项目中的配置文件redirect_URI,必须与创建应用时填写的【应用实际地址】一致,这是回调地址!完成配置后,再次运行OAuth4Code.java,如图
在这里你会跳转到新浪微博的登录页面。登录你的新浪微博账号后,需要点击授权,表示平台可以访问你的微博账号内容分享你的信息等。授权结束后,
将返回一个代码。这段代码非常重要。它是我们整个访问第三方平台的门钥匙。通过这段代码,我们可以获取到用户的access_token、UID等内容,相当于整个访问过程。
11、调用新浪微博开放API
这里我们需要研究这些API来满足访问的需要。首先要熟悉的是OAuth2.0授权接口,网上可以查到,如下:
12、通过servlet程序调用开放API获取新浪微博的UID和微博名的示例
response.setContentType("text/html;charset=UTF-8");
String accessToken = null ;
String uid = null ;
String screenName = null ;
String username = null ;
AccessToken accessTokenObj = null ;
Oauth oauth2 = new Oauth();
try {
out = response.getWriter();
accessTokenObj = oauth2.getAccessTokenByCode(code) ;
logger.info(accessTokenObj);
accessToken = accessTokenObj.getAccessToken() ;
oauth2.setToken(accessToken) ;
Account account = new Account() ;
account.client.setToken(accessToken) ;
JSONObject uidJson = account.getUid() ;
uid = uidJson.getString("uid") ;
Users users = new Users() ;
users.client.setToken(accessToken) ;
User weiboUser = users.showUserById(uid) ;
username = weiboUser.getName() ;
screenName = weiboUser.getScreenName() ;
} catch (WeiboException | IOException | JSONException e) {
e.printStackTrace();
}
out.println("微博访问Token_Info:" + accessTokenObj + "\t");
out.println("微博访问Token:" + accessToken + "\t");
out.println("微博用户-Uid:" + uid + "\t");
out.println("微博用户-名称:" + screenName + "\t");
out.flush();
out.close();*/
网站调用新浪微博内容(博客平台来说不支持iframe的两种解决办法方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-01-19 18:09
很多博客可以自己添加和修改一些代码,但是作为博客平台,出于安全考虑,往往需要对一些特性进行过滤。比如新浪微博的挂件都是iframe的形式,但是博客园不支持iframe。经过一番尝试,我终于找到了以下两种解决方案:
首先在公告中写一个空的div,这样我们就可以插入新的iframe,省去按类选择的麻烦:
<br />
1、在公告中直接用innerHTML插入iframe代码:
innerHTML 非常简单。从新浪微博的配置中,匹配你想要的样式,然后它会自动生成一段html代码,类似如下:
但是如果直接这样写,是不会生效的:
var ifr = '';<br /><br />document.getElementById('weiboIframe').innerHTML = ifr;
估计是博客园的背景是直接匹配iframe文本的,所以我们打乱这个,让他检测不到逻辑,改成这样就成功了:
<br />var ifr = '';<br />document.getElementById('weiboIframe').innerHTML = ifr;<br />
2、也可以使用createElement方法:
因为这里有人用过Google Adsense的代码,我猜这个方法可以用。经过测试,确实是可以的,但是比上面的还要多写几句:
<br /><br />var iii = document.createElement('iframe');<br />iii.src = 'http://widget.weibo.com/weibos ... %3Bbr />iii.height = 115;<br />iii.width = '100%';<br />iii.className = 'share_self';<br />iii.scrolling = 'no';<br />document.getElementById('weiboIframe').appendChild(iii);<br /><br />
将以上内容放入公告中,即可展示您的新浪微博 查看全部
网站调用新浪微博内容(博客平台来说不支持iframe的两种解决办法方法)
很多博客可以自己添加和修改一些代码,但是作为博客平台,出于安全考虑,往往需要对一些特性进行过滤。比如新浪微博的挂件都是iframe的形式,但是博客园不支持iframe。经过一番尝试,我终于找到了以下两种解决方案:
首先在公告中写一个空的div,这样我们就可以插入新的iframe,省去按类选择的麻烦:
<br />
1、在公告中直接用innerHTML插入iframe代码:
innerHTML 非常简单。从新浪微博的配置中,匹配你想要的样式,然后它会自动生成一段html代码,类似如下:
但是如果直接这样写,是不会生效的:
var ifr = '';<br /><br />document.getElementById('weiboIframe').innerHTML = ifr;
估计是博客园的背景是直接匹配iframe文本的,所以我们打乱这个,让他检测不到逻辑,改成这样就成功了:
<br />var ifr = '';<br />document.getElementById('weiboIframe').innerHTML = ifr;<br />
2、也可以使用createElement方法:
因为这里有人用过Google Adsense的代码,我猜这个方法可以用。经过测试,确实是可以的,但是比上面的还要多写几句:
<br /><br />var iii = document.createElement('iframe');<br />iii.src = 'http://widget.weibo.com/weibos ... %3Bbr />iii.height = 115;<br />iii.width = '100%';<br />iii.className = 'share_self';<br />iii.scrolling = 'no';<br />document.getElementById('weiboIframe').appendChild(iii);<br /><br />
将以上内容放入公告中,即可展示您的新浪微博
网站调用新浪微博内容(Coursera去一个文件的下载,只有傻子才那么干! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-01-19 18:08
)
首先按照文章的思路,自己试了一下,可以成功
有时候我们需要采集一些经典的东西,时不时回味一下,Coursera上的一些课程无疑是经典。Coursera中完成的大部分课程都提供了完整的配套教学资源,包括ppt、视频和字幕等,离线后学习起来非常容易。很明显,我们不是逐个文件下载的,只有傻子才会这样做,程序员是聪明人!
那么我们聪明的人会怎么做呢?当然,写个脚本批量下载。首先我们需要分析一下手动下载的过程:登录我们的Coursera账号(有些课程需要我们登录并选择一门课程才能看到对应的资源),在课程资源页面找到对应的文件链接,然后使用喜欢的工具下载。
很简单,对吧?我们可以用程序来模仿上面的步骤,这样我们就可以解放双手了。整个程序可以分为三个部分:
登录 Coursera;在课程资源页面上找到资源链接;根据资源链接选择合适的工具下载资源。
让我们详细实现以下内容!
登录
一开始没有加登录模块,以为访问者可以下载相应的课程资源。后来在测试comnetworks-002课程时,发现访问者在访问资源页面时会自动跳转到登录界面。下图显示chrome是隐身的。访问本课程的资源页面时的模式。
模拟登录,我们先找到登录页面,然后使用谷歌的开发者工具分析账号密码是如何上传到服务器的。
我们在登录页面的表格中填写账号密码,然后点击登录。同时,我们需要关注Developer Tools-Network,找到提交账号信息的url。一般情况下,如果要向服务器提交信息,一般采用post方式。这里我们只需要先找到 Method 为 post 的 url。可悲的是,每次登录我的账户,提交账户信息的地址在网络中都找不到。猜到登录成功后,直接跳转到登录成功后的页面,你要找的内容一闪而过。
于是我只输入了一组账号密码,故意登录失败。果然找到了帖子的页面地址,如下图:
地址是: 。为了知道已经向服务器提交了哪些内容,进一步观察post页面中表单的内容,如下图:
我们看到总共有三个字段:
接下来,我们来写吧。我选择使用python的Requests库来模拟登录。这是Requests官网介绍的。
Requests 是一个优雅而简单的 Python HTTP 库,专为人类构建。
其实request使用起来真的很简单方便,这要归功于专门为人类设计的http库。requests 提供了一个 Session 对象,可以用来在不同的请求中传递一些相同的数据,比如在每个请求中携带 cookie。
初步代码如下:
signin_url = "https://accounts.coursera.org/api/v1/login"
logininfo = {"email": "...",
"password": "...",
"webrequest": "true"
}
user_agent = ("Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_4) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/36.0.1985.143 Safari/537.36")
post_headers = {"User-Agent": user_agent,
"Referer": "https://accounts.coursera.org/signin"
}
coursera_session = requests.Session()
login_res = coursera_session.post(signin_url,
data=logininfo,
headers=post_headers,
)
if login_res.status_code == 200:
print "Login Successfully!"
else:
print login_res.text
将表单中提交的内容存储在字典中,然后作为数据参数传递给 Session.post 函数。一般情况下最好加上User-Agent、Referer等请求头,User-Agent用来模拟浏览器请求,Referer用来告诉服务器我是从referer页面跳转到请求的页。有时服务器会检查请求的Referer字段,以确保当前请求页面是从固定地址跳转的。
运行上述代码段的结果很奇怪,显示以下消息:Invalid CSRF Token。后来在github上搜索了一个Coursera的批量下载脚本,发现当人们发送页面请求时,headers多了四个字段:XCSRF2Cookie、XCSRF2Token、XCSRFToken、cookie。于是又查看了post页面的请求头,发现确实有这些字段,估计是服务端用来做一些限制的。
用浏览器登录几次后发现XCSRF2Token,XCSRFToken是一个长度为24的随机字符串,而XCSRF2Cookie是“csrf2_token_”加上一个长度为8的随机字符串。但是一直没弄清楚cookie是怎么获取的,但是查看github上的代码,cookie似乎只是“csrftoken”和其他三个的组合。我试过了,它奏效了。
将以下部分添加到原创代码中就足够了。
def randomString(length):
return ''.join(random.choice(string.letters + string.digits) for i in xrange(length))
XCSRF2Cookie = 'csrf2_token_%s' % ''.join(randomString(8))
XCSRF2Token = ''.join(randomString(24))
XCSRFToken = ''.join(randomString(24))
cookie = "csrftoken=%s; %s=%s" % (XCSRFToken, XCSRF2Cookie, XCSRF2Token)
post_headers = {"User-Agent": user_agent,
"Referer": "https://accounts.coursera.org/signin",
"X-Requested-With": "XMLHttpRequest",
"X-CSRF2-Cookie": XCSRF2Cookie,
"X-CSRF2-Token": XCSRF2Token,
"X-CSRFToken": XCSRFToken,
"Cookie": cookie
}
至此,登录功能已经初步实现。
分析资源链接
登录成功后,我们只需要获取资源页面的内容,然后过滤掉我们需要的资源链接即可。资源页面的地址很简单,name就是课程名称。例如,对于课程 comnetworks-002,资源页面地址为 .
抓取到页面资源后,我们需要分析html文件,这里我们选择使用BeautifulSoup。BeautifulSoup 是一个强大的 Python 库,可以从 HTML 或 XML 文件中提取数据。具体使用官网有非常详细的文档,这里不再赘述。在使用 BeautifulSoup 之前,我们必须找出资源链接的规律,以便进行过滤。
课程每周总话题在class=course-item-list-header的div标签下,每周课程在class=course-item-list-section-list的ul标签下,每门课程是在 li 标签下,课程资源位于 li 标签中的 div 标签中。
看了几门课程,发现过滤资源链接的方法很简单,如下:
ppt和ppt资源:使用正则表达式匹配链接;字幕资源:找到title="Subtitles (srt)" 的标签,取其href属性;视频资源:找到 title="Video (MP4)" 的标签,取其 href 属性。
字幕和视频也可以使用正则表达式进行过滤,但使用 BeautifulSoup 根据标题属性进行匹配,以获得更好的可读性。但是ppt和pdf资源没有固定的title属性,所以必须使用正则表达式来匹配。
具体代码如下:
soup = BeautifulSoup(content)
chapter_list = soup.find_all("div", class_="course-item-list-header")
lecture_resource_list = soup.find_all("ul", class_="course-item-list-section-list")
ppt_pattern = re.compile(r'https://[^"]*\.ppt[x]?')
pdf_pattern = re.compile(r'https://[^"]*\.pdf')
for lecture_item, chapter_item in zip(lecture_resource_list, chapter_list):
# weekly title
chapter = chapter_item.h3.text.lstrip()
for lecture in lecture_item:
lecture_name = lecture.a.string.lstrip()
# get resource link
ppt_tag = lecture.find(href=ppt_pattern)
pdf_tag = lecture.find(href=pdf_pattern)
srt_tag = lecture.find(title="Subtitles (srt)")
mp4_tag = lecture.find(title="Video (MP4)")
print ppt_tag["href"], pdf_tag["href"]
print srt_tag["href"], mp4_tag["href"]
下载资源
既然已经获取了资源链接,下载部分就很容易了,这里我选择使用curl来下载。具体思路很简单,就是将curl resource_link -o file_name 输出到一个种子文件,比如feed.sh。这样,你只需要赋予torrent文件执行权限,然后运行torrent文件即可。
为了方便对课程资源进行分类,可以为课程每周的标题创建一个文件夹,然后该周的所有课程都会下载到这个目录中。为了方便我们快速定位到每个类的所有资源,可以将一个类的所有资源文件命名为类名.文件类型。具体实现比较简单,这里不再给出具体方案。您可以查看测试示例中的 feed.sh 文件。部分内容如下:
mkdir 'Week 1: Introduction, Protocols, and Layering'
cd 'Week 1: Introduction, Protocols, and Layering'
curl https://d396qusza40orc.cloudfr ... s.pdf -o '1-1 Goals and Motivation (15:46).pdf'
curl https://class.coursera.org/com ... 3Dsrt -o '1-1 Goals and Motivation (15:46).srt'
curl https://class.coursera.org/com ... %3D25 -o '1-1 Goals and Motivation (15:46).mp4'
curl https://d396qusza40orc.cloudfr ... s.pdf -o '1-2 Uses of Networks (17:12).pdf'
curl https://class.coursera.org/com ... 3Dsrt -o '1-2 Uses of Networks (17:12).srt'
curl https://class.coursera.org/com ... %3D11 -o '1-2 Uses of Networks (17:12).mp4'
至此,我们已经成功完成爬取Coursera课程资源的目标,具体代码放在gist上。使用时,我们只需要运行程序,将课程名称作为参数传递给程序即可(这里的课程名称不是整个课程的全称,而是课程介绍页面地址中的缩写名称,如作为Computer Networks这个类,类名是comnetworks-002)。
后来发现Coursera为我们提供了下载资源的接口。
更新:2014 年 9 月 3 日
其实这个程序可以看成是一个简单的爬虫小程序。下面简单介绍爬虫的概念。
不是一个简单的爬虫
关于什么是爬虫,这就是 wiki 所说的
Web 爬虫是一种 Internet 机器人,它系统地浏览万维网,通常用于 Web 索引。
爬虫整体架构如下(图片来自wiki):
简单来说就是爬虫从Scheduler中获取初始url,下载对应的页面,存储有用的数据,同时分析页面中的链接。
当然,有一些协议可以约束爬虫的行为。比如很多网站都有一个robots.txt文件来指定网站哪些内容可以爬取,哪些不能爬取。
每个搜索引擎的背后都有一个强大的爬虫程序,它的触角延伸到网络的各个角落,不断采集有用的信息并建立索引。这种搜索引擎级别的爬虫实现起来非常复杂,因为互联网上的页面数量太多,仅仅遍历它们是非常困难的,更不用说分析页面信息和建立索引了。
在实际应用中,我们只需要爬取特定站点,爬取少量资源,实现起来要简单得多。但是,仍然有很多令人头疼的问题。例如,许多页面元素是由 javascript 生成的。这时候,我们需要一个javascript引擎来渲染整个页面,然后进行过滤。
雪上加霜的是,很多网站为了防止爬虫爬取资源采取了一些措施,比如在一段时间内限制对同一IP的访问次数,或者限制两次操作的时间间隔,添加验证码等等. 在大多数情况下,我们不知道如何在服务器端阻止爬虫,所以要让爬虫工作起来确实很困难。
参考:
github:coursera-dl/coursera
github:coursera-下载器
python抓取页面元素失败
维基:网络爬虫
如何开始使用 Python 爬虫?
补充:上述过程中用到的python requests 模块的下载地址如下:
requests模块文章的详细介绍如下:
测试后完整代码如下:
import requests
import random
import string
signin_url = "https://accounts.coursera.org/api/v1/login"
logininfo = {"email": "已注册邮箱",
"password": "密码",
"webrequest": "true"
}
user_agent = ("Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; Trident/6.0)")
def randomString(length):
return ''.join(random.choice(string.letters + string.digits) for i in xrange(length))
XCSRF2Cookie = 'csrf2_token_%s' % ''.join(randomString(8))
XCSRF2Token = ''.join(randomString(24))
XCSRFToken = ''.join(randomString(24))
cookie = "csrftoken=%s; %s=%s" % (XCSRFToken, XCSRF2Cookie, XCSRF2Token)
post_headers = {"User-Agent": user_agent,
"Referer": "https://accounts.coursera.org/signin",
"X-Requested-With": "XMLHttpRequest",
"X-CSRF2-Cookie": XCSRF2Cookie,
"X-CSRF2-Token": XCSRF2Token,
"X-CSRFToken": XCSRFToken,
"Cookie": cookie
}
coursera_session = requests.Session()
login_res = coursera_session.post(signin_url,
data=logininfo,
headers=post_headers,
)
if login_res.status_code == 200:
print "Login Successfully!"
else:
print login_res.text
import re
import urllib
page = urllib.urlopen("https://class.coursera.org/com ... 6quot;)
html = page.read()
print html, 查看全部
网站调用新浪微博内容(Coursera去一个文件的下载,只有傻子才那么干!
)
首先按照文章的思路,自己试了一下,可以成功
有时候我们需要采集一些经典的东西,时不时回味一下,Coursera上的一些课程无疑是经典。Coursera中完成的大部分课程都提供了完整的配套教学资源,包括ppt、视频和字幕等,离线后学习起来非常容易。很明显,我们不是逐个文件下载的,只有傻子才会这样做,程序员是聪明人!
那么我们聪明的人会怎么做呢?当然,写个脚本批量下载。首先我们需要分析一下手动下载的过程:登录我们的Coursera账号(有些课程需要我们登录并选择一门课程才能看到对应的资源),在课程资源页面找到对应的文件链接,然后使用喜欢的工具下载。
很简单,对吧?我们可以用程序来模仿上面的步骤,这样我们就可以解放双手了。整个程序可以分为三个部分:
登录 Coursera;在课程资源页面上找到资源链接;根据资源链接选择合适的工具下载资源。
让我们详细实现以下内容!
登录
一开始没有加登录模块,以为访问者可以下载相应的课程资源。后来在测试comnetworks-002课程时,发现访问者在访问资源页面时会自动跳转到登录界面。下图显示chrome是隐身的。访问本课程的资源页面时的模式。
模拟登录,我们先找到登录页面,然后使用谷歌的开发者工具分析账号密码是如何上传到服务器的。
我们在登录页面的表格中填写账号密码,然后点击登录。同时,我们需要关注Developer Tools-Network,找到提交账号信息的url。一般情况下,如果要向服务器提交信息,一般采用post方式。这里我们只需要先找到 Method 为 post 的 url。可悲的是,每次登录我的账户,提交账户信息的地址在网络中都找不到。猜到登录成功后,直接跳转到登录成功后的页面,你要找的内容一闪而过。
于是我只输入了一组账号密码,故意登录失败。果然找到了帖子的页面地址,如下图:
地址是: 。为了知道已经向服务器提交了哪些内容,进一步观察post页面中表单的内容,如下图:
我们看到总共有三个字段:
接下来,我们来写吧。我选择使用python的Requests库来模拟登录。这是Requests官网介绍的。
Requests 是一个优雅而简单的 Python HTTP 库,专为人类构建。
其实request使用起来真的很简单方便,这要归功于专门为人类设计的http库。requests 提供了一个 Session 对象,可以用来在不同的请求中传递一些相同的数据,比如在每个请求中携带 cookie。
初步代码如下:
signin_url = "https://accounts.coursera.org/api/v1/login"
logininfo = {"email": "...",
"password": "...",
"webrequest": "true"
}
user_agent = ("Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_4) "
"AppleWebKit/537.36 (KHTML, like Gecko) "
"Chrome/36.0.1985.143 Safari/537.36")
post_headers = {"User-Agent": user_agent,
"Referer": "https://accounts.coursera.org/signin"
}
coursera_session = requests.Session()
login_res = coursera_session.post(signin_url,
data=logininfo,
headers=post_headers,
)
if login_res.status_code == 200:
print "Login Successfully!"
else:
print login_res.text
将表单中提交的内容存储在字典中,然后作为数据参数传递给 Session.post 函数。一般情况下最好加上User-Agent、Referer等请求头,User-Agent用来模拟浏览器请求,Referer用来告诉服务器我是从referer页面跳转到请求的页。有时服务器会检查请求的Referer字段,以确保当前请求页面是从固定地址跳转的。
运行上述代码段的结果很奇怪,显示以下消息:Invalid CSRF Token。后来在github上搜索了一个Coursera的批量下载脚本,发现当人们发送页面请求时,headers多了四个字段:XCSRF2Cookie、XCSRF2Token、XCSRFToken、cookie。于是又查看了post页面的请求头,发现确实有这些字段,估计是服务端用来做一些限制的。
用浏览器登录几次后发现XCSRF2Token,XCSRFToken是一个长度为24的随机字符串,而XCSRF2Cookie是“csrf2_token_”加上一个长度为8的随机字符串。但是一直没弄清楚cookie是怎么获取的,但是查看github上的代码,cookie似乎只是“csrftoken”和其他三个的组合。我试过了,它奏效了。
将以下部分添加到原创代码中就足够了。
def randomString(length):
return ''.join(random.choice(string.letters + string.digits) for i in xrange(length))
XCSRF2Cookie = 'csrf2_token_%s' % ''.join(randomString(8))
XCSRF2Token = ''.join(randomString(24))
XCSRFToken = ''.join(randomString(24))
cookie = "csrftoken=%s; %s=%s" % (XCSRFToken, XCSRF2Cookie, XCSRF2Token)
post_headers = {"User-Agent": user_agent,
"Referer": "https://accounts.coursera.org/signin",
"X-Requested-With": "XMLHttpRequest",
"X-CSRF2-Cookie": XCSRF2Cookie,
"X-CSRF2-Token": XCSRF2Token,
"X-CSRFToken": XCSRFToken,
"Cookie": cookie
}
至此,登录功能已经初步实现。
分析资源链接
登录成功后,我们只需要获取资源页面的内容,然后过滤掉我们需要的资源链接即可。资源页面的地址很简单,name就是课程名称。例如,对于课程 comnetworks-002,资源页面地址为 .
抓取到页面资源后,我们需要分析html文件,这里我们选择使用BeautifulSoup。BeautifulSoup 是一个强大的 Python 库,可以从 HTML 或 XML 文件中提取数据。具体使用官网有非常详细的文档,这里不再赘述。在使用 BeautifulSoup 之前,我们必须找出资源链接的规律,以便进行过滤。
课程每周总话题在class=course-item-list-header的div标签下,每周课程在class=course-item-list-section-list的ul标签下,每门课程是在 li 标签下,课程资源位于 li 标签中的 div 标签中。
看了几门课程,发现过滤资源链接的方法很简单,如下:
ppt和ppt资源:使用正则表达式匹配链接;字幕资源:找到title="Subtitles (srt)" 的标签,取其href属性;视频资源:找到 title="Video (MP4)" 的标签,取其 href 属性。
字幕和视频也可以使用正则表达式进行过滤,但使用 BeautifulSoup 根据标题属性进行匹配,以获得更好的可读性。但是ppt和pdf资源没有固定的title属性,所以必须使用正则表达式来匹配。
具体代码如下:
soup = BeautifulSoup(content)
chapter_list = soup.find_all("div", class_="course-item-list-header")
lecture_resource_list = soup.find_all("ul", class_="course-item-list-section-list")
ppt_pattern = re.compile(r'https://[^"]*\.ppt[x]?')
pdf_pattern = re.compile(r'https://[^"]*\.pdf')
for lecture_item, chapter_item in zip(lecture_resource_list, chapter_list):
# weekly title
chapter = chapter_item.h3.text.lstrip()
for lecture in lecture_item:
lecture_name = lecture.a.string.lstrip()
# get resource link
ppt_tag = lecture.find(href=ppt_pattern)
pdf_tag = lecture.find(href=pdf_pattern)
srt_tag = lecture.find(title="Subtitles (srt)")
mp4_tag = lecture.find(title="Video (MP4)")
print ppt_tag["href"], pdf_tag["href"]
print srt_tag["href"], mp4_tag["href"]
下载资源
既然已经获取了资源链接,下载部分就很容易了,这里我选择使用curl来下载。具体思路很简单,就是将curl resource_link -o file_name 输出到一个种子文件,比如feed.sh。这样,你只需要赋予torrent文件执行权限,然后运行torrent文件即可。
为了方便对课程资源进行分类,可以为课程每周的标题创建一个文件夹,然后该周的所有课程都会下载到这个目录中。为了方便我们快速定位到每个类的所有资源,可以将一个类的所有资源文件命名为类名.文件类型。具体实现比较简单,这里不再给出具体方案。您可以查看测试示例中的 feed.sh 文件。部分内容如下:
mkdir 'Week 1: Introduction, Protocols, and Layering'
cd 'Week 1: Introduction, Protocols, and Layering'
curl https://d396qusza40orc.cloudfr ... s.pdf -o '1-1 Goals and Motivation (15:46).pdf'
curl https://class.coursera.org/com ... 3Dsrt -o '1-1 Goals and Motivation (15:46).srt'
curl https://class.coursera.org/com ... %3D25 -o '1-1 Goals and Motivation (15:46).mp4'
curl https://d396qusza40orc.cloudfr ... s.pdf -o '1-2 Uses of Networks (17:12).pdf'
curl https://class.coursera.org/com ... 3Dsrt -o '1-2 Uses of Networks (17:12).srt'
curl https://class.coursera.org/com ... %3D11 -o '1-2 Uses of Networks (17:12).mp4'
至此,我们已经成功完成爬取Coursera课程资源的目标,具体代码放在gist上。使用时,我们只需要运行程序,将课程名称作为参数传递给程序即可(这里的课程名称不是整个课程的全称,而是课程介绍页面地址中的缩写名称,如作为Computer Networks这个类,类名是comnetworks-002)。
后来发现Coursera为我们提供了下载资源的接口。
更新:2014 年 9 月 3 日
其实这个程序可以看成是一个简单的爬虫小程序。下面简单介绍爬虫的概念。
不是一个简单的爬虫
关于什么是爬虫,这就是 wiki 所说的
Web 爬虫是一种 Internet 机器人,它系统地浏览万维网,通常用于 Web 索引。
爬虫整体架构如下(图片来自wiki):
简单来说就是爬虫从Scheduler中获取初始url,下载对应的页面,存储有用的数据,同时分析页面中的链接。
当然,有一些协议可以约束爬虫的行为。比如很多网站都有一个robots.txt文件来指定网站哪些内容可以爬取,哪些不能爬取。
每个搜索引擎的背后都有一个强大的爬虫程序,它的触角延伸到网络的各个角落,不断采集有用的信息并建立索引。这种搜索引擎级别的爬虫实现起来非常复杂,因为互联网上的页面数量太多,仅仅遍历它们是非常困难的,更不用说分析页面信息和建立索引了。
在实际应用中,我们只需要爬取特定站点,爬取少量资源,实现起来要简单得多。但是,仍然有很多令人头疼的问题。例如,许多页面元素是由 javascript 生成的。这时候,我们需要一个javascript引擎来渲染整个页面,然后进行过滤。
雪上加霜的是,很多网站为了防止爬虫爬取资源采取了一些措施,比如在一段时间内限制对同一IP的访问次数,或者限制两次操作的时间间隔,添加验证码等等. 在大多数情况下,我们不知道如何在服务器端阻止爬虫,所以要让爬虫工作起来确实很困难。
参考:
github:coursera-dl/coursera
github:coursera-下载器
python抓取页面元素失败
维基:网络爬虫
如何开始使用 Python 爬虫?
补充:上述过程中用到的python requests 模块的下载地址如下:
requests模块文章的详细介绍如下:
测试后完整代码如下:
import requests
import random
import string
signin_url = "https://accounts.coursera.org/api/v1/login"
logininfo = {"email": "已注册邮箱",
"password": "密码",
"webrequest": "true"
}
user_agent = ("Mozilla/5.0 (compatible; MSIE 10.0; Windows NT 6.1; Trident/6.0)")
def randomString(length):
return ''.join(random.choice(string.letters + string.digits) for i in xrange(length))
XCSRF2Cookie = 'csrf2_token_%s' % ''.join(randomString(8))
XCSRF2Token = ''.join(randomString(24))
XCSRFToken = ''.join(randomString(24))
cookie = "csrftoken=%s; %s=%s" % (XCSRFToken, XCSRF2Cookie, XCSRF2Token)
post_headers = {"User-Agent": user_agent,
"Referer": "https://accounts.coursera.org/signin",
"X-Requested-With": "XMLHttpRequest",
"X-CSRF2-Cookie": XCSRF2Cookie,
"X-CSRF2-Token": XCSRF2Token,
"X-CSRFToken": XCSRFToken,
"Cookie": cookie
}
coursera_session = requests.Session()
login_res = coursera_session.post(signin_url,
data=logininfo,
headers=post_headers,
)
if login_res.status_code == 200:
print "Login Successfully!"
else:
print login_res.text
import re
import urllib
page = urllib.urlopen("https://class.coursera.org/com ... 6quot;)
html = page.read()
print html,
网站调用新浪微博内容(网站调用新浪微博内容生成了浏览器扩展(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-19 04:03
网站调用新浪微博内容生成了浏览器扩展,使得用户可以通过新浪微博链接跳转到android微博url访问,是一个很有想法的页面。
不敢说全部是骗局,
中国的公关都是坨屎。天天被科普无数遍骗子,
绝对是骗局,
学我,找个像bbs的生意。
我看了下,服务器的url实际上不是从新浪bbs而是新浪微博提供给我们的服务器的真实url地址,那其实从bbs中提取的链接只是二级以下的页面,如果你写一个web应用,想要提取这个链接,起码需要几千个页面的api可以说难度很大,到微博中随便调一个页面就要几百个页面的提取就很有难度。大多数人都不理解(甚至要怀疑网站后台有人)。
并且现在正规网站做产品,都不太愿意把url指向新浪bbs了,或者有些bbs本身就有生意,跟新浪也没有合作关系。产品质量上,说实话与新浪bbs合作的公司,质量水平不一。有些api做的好有些差。有些api做得好有些差。有些微信sdk做的好有些差。有些人整体体验好有些人整体体验差。整体看公司的,又有很多方面需要提升。到现在我也不知道新浪bbs给我多少好处。
从专业内容运营角度看,这种项目有几个优势:a、此类网站的用户群比较固定,即新浪本身,品牌影响力大,有议价能力。且相对优质内容偏多,无论是seo还是品牌输出都有优势。b、通过提供专业化的技术服务服务于客户,无论是开发成本,还是相应服务能力,都能让客户获得不错的回报。还能合理的降低技术成本,节省了后期开发人员等的开支。当然优势不代表就没有缺点:。
1、这类网站普遍平台用户基数较大,普通用户比较难以分辨整个平台的服务质量。
2、一家独大,导致网站被封。
3、这类服务我们所知甚少,也无法从产品品质上区分平台用户的品质。即使是新浪的员工也很难区分对方的服务是否合规。
4、对bbs内容的管理难度大,缺乏投诉渠道、优质内容难以查询等等。
5、具有鲜明互联网特色的整个网站,内容被搬运、被采集都比较多。整体来看,porreweb项目不是新浪主导的,是porre所提供服务公司所主导的。 查看全部
网站调用新浪微博内容(网站调用新浪微博内容生成了浏览器扩展(图))
网站调用新浪微博内容生成了浏览器扩展,使得用户可以通过新浪微博链接跳转到android微博url访问,是一个很有想法的页面。
不敢说全部是骗局,
中国的公关都是坨屎。天天被科普无数遍骗子,
绝对是骗局,
学我,找个像bbs的生意。
我看了下,服务器的url实际上不是从新浪bbs而是新浪微博提供给我们的服务器的真实url地址,那其实从bbs中提取的链接只是二级以下的页面,如果你写一个web应用,想要提取这个链接,起码需要几千个页面的api可以说难度很大,到微博中随便调一个页面就要几百个页面的提取就很有难度。大多数人都不理解(甚至要怀疑网站后台有人)。
并且现在正规网站做产品,都不太愿意把url指向新浪bbs了,或者有些bbs本身就有生意,跟新浪也没有合作关系。产品质量上,说实话与新浪bbs合作的公司,质量水平不一。有些api做的好有些差。有些api做得好有些差。有些微信sdk做的好有些差。有些人整体体验好有些人整体体验差。整体看公司的,又有很多方面需要提升。到现在我也不知道新浪bbs给我多少好处。
从专业内容运营角度看,这种项目有几个优势:a、此类网站的用户群比较固定,即新浪本身,品牌影响力大,有议价能力。且相对优质内容偏多,无论是seo还是品牌输出都有优势。b、通过提供专业化的技术服务服务于客户,无论是开发成本,还是相应服务能力,都能让客户获得不错的回报。还能合理的降低技术成本,节省了后期开发人员等的开支。当然优势不代表就没有缺点:。
1、这类网站普遍平台用户基数较大,普通用户比较难以分辨整个平台的服务质量。
2、一家独大,导致网站被封。
3、这类服务我们所知甚少,也无法从产品品质上区分平台用户的品质。即使是新浪的员工也很难区分对方的服务是否合规。
4、对bbs内容的管理难度大,缺乏投诉渠道、优质内容难以查询等等。
5、具有鲜明互联网特色的整个网站,内容被搬运、被采集都比较多。整体来看,porreweb项目不是新浪主导的,是porre所提供服务公司所主导的。
网站调用新浪微博内容(新浪微博“位置服务接口”正式上线开发者可免费接入新浪位置服务平台)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-01-18 20:16
近日,新浪微博“定位服务接口”正式上线,第三方开发者可免费接入新浪定位服务平台。
新浪微博定位服务平台的上线,意味着LBS应用即将走出简单的“打卡”模式。相信在不久的将来,定位功能将作为标准存在于移动应用中。
新浪微博位置服务平台的特点是为第三方开发者提供了最丰富、最实用的功能接口。开发者通过访问基于用户、趋势、位置、附近等的界面,可以自由获取单个人在微博上的时间线和社交动态,并根据兴趣和标签对其进行分类。通过动态和就近接口,开发者可以获取单个用户的所有关注者信息,并可以根据距离、时间、权重等各种参数对结果列表进行排序。
开发者获取微博用户在特定位置的照片、信息、用户行为后,可以从这些用户的位置行为、微博内容等多维度信息中,综合分析用户的真实兴趣。通过“简单的内容分析”得到兴趣地图,挖掘用户的真实需求并在产品功能上满足。
新浪微博位置平台正式上线不到三天,就有30多家应用开发者与新浪签约合作,其中包括淘边、酒店管家、开凯点评、点餐小秘等优秀的行业应用。
“定位服务接口”提供六类接口,包括21个通用接口和7个高级接口。第三方开发者现在可以通过新浪微博开放平台()直接调用上述接口。
1. 第三方调用位置服务接口的必要条件:
常用接口调用条件:开发者Appkey必须先通过微博开放平台审核。
(微博开放平台申请方法:)
高级接口申请方法:通过“高级接口申请流程”%E9%AB%98%E7%BA%A7%E6%8E%A5%E5%8F%A3%E7%94%B3%E8%AF%B7如有有问题请联系@微博定位服务平台
2.定位服务接口详细说明(“定位服务接口”类):
%E6%96%87%E6%A1%A3_V2
3.位置服务平台接入案例及详细介绍:%E6%96%B0%E6%B5%AA%E5%BE%AE%E5%8D%9A%E4%BD%8D%E7%BD%AE %E6%9C%8D%E5%8A%A1%E4%B8%8A%E7%BA%BF
附录一:定位服务接口概述
附2:应用案例展示-淘宝边
【淘周边】
1. 调用接口
a) 获取附近位置接口(已签署私有协议的接口)
b) POI数据写入接口
2. 实现函数 查看全部
网站调用新浪微博内容(新浪微博“位置服务接口”正式上线开发者可免费接入新浪位置服务平台)
近日,新浪微博“定位服务接口”正式上线,第三方开发者可免费接入新浪定位服务平台。
新浪微博定位服务平台的上线,意味着LBS应用即将走出简单的“打卡”模式。相信在不久的将来,定位功能将作为标准存在于移动应用中。
新浪微博位置服务平台的特点是为第三方开发者提供了最丰富、最实用的功能接口。开发者通过访问基于用户、趋势、位置、附近等的界面,可以自由获取单个人在微博上的时间线和社交动态,并根据兴趣和标签对其进行分类。通过动态和就近接口,开发者可以获取单个用户的所有关注者信息,并可以根据距离、时间、权重等各种参数对结果列表进行排序。
开发者获取微博用户在特定位置的照片、信息、用户行为后,可以从这些用户的位置行为、微博内容等多维度信息中,综合分析用户的真实兴趣。通过“简单的内容分析”得到兴趣地图,挖掘用户的真实需求并在产品功能上满足。
新浪微博位置平台正式上线不到三天,就有30多家应用开发者与新浪签约合作,其中包括淘边、酒店管家、开凯点评、点餐小秘等优秀的行业应用。
“定位服务接口”提供六类接口,包括21个通用接口和7个高级接口。第三方开发者现在可以通过新浪微博开放平台()直接调用上述接口。
1. 第三方调用位置服务接口的必要条件:
常用接口调用条件:开发者Appkey必须先通过微博开放平台审核。
(微博开放平台申请方法:)
高级接口申请方法:通过“高级接口申请流程”%E9%AB%98%E7%BA%A7%E6%8E%A5%E5%8F%A3%E7%94%B3%E8%AF%B7如有有问题请联系@微博定位服务平台
2.定位服务接口详细说明(“定位服务接口”类):
%E6%96%87%E6%A1%A3_V2
3.位置服务平台接入案例及详细介绍:%E6%96%B0%E6%B5%AA%E5%BE%AE%E5%8D%9A%E4%BD%8D%E7%BD%AE %E6%9C%8D%E5%8A%A1%E4%B8%8A%E7%BA%BF
附录一:定位服务接口概述
附2:应用案例展示-淘宝边
【淘周边】
1. 调用接口
a) 获取附近位置接口(已签署私有协议的接口)
b) POI数据写入接口
2. 实现函数
网站调用新浪微博内容(wordpress网站可以写php代码1.php文件测试.php)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-01-18 20:15
据说wordpress网站发帖时可以同步文章到新浪微博,我想按照同样的方法写一个php代码测试。以下内容引自:
同步到微博大致有三种方式,插件,关联博客,非插件微博接口
一是直接在百度上搜索;
二、因为新浪现在已经取消了关联博客的选项,但是功能并没有取消,可以询问以下地址,然后进行配置。
第三种方法需要使用新浪的接口,如下:
1)去新浪微博开放平台创建站内应用,审核通过或者不通过,可以在微博底部显示某个应用的应用,比如来自KingGoo技术博客图片,如何创建你可以在百度谷歌上搜索,很简单(但是如果你没有通过审核还想通过审核,我可以提供付费帮助嘎嘎~),创建后应用,需要使用应用应用的App Key;
2)编辑你的主题的functions.php文件并在最后添加以下代码
// 微博同步function post_to_sina_weibo($post_ID) { if( wp_is_post_revision($post_ID) ) return; $get_post_info = get_post($post_ID); $get_post_centent = get_post($post_ID)->post_content; //去掉文章内的html编码的空格、换行、tab等符号(如果你文章的编码格式是这样子,可以将下面的"//"去掉即开启此功能) //$get_post_centent = str_replace("\t", " ", str_replace("\n", " ", str_replace(" ", " ", $get_post_centent))); $get_post_title = get_post($post_ID)->post_title; if ( $get_post_info->post_status == 'publish' && $_POST['original_post_status'] != 'publish' ) { $request = new WP_Http; $status = '【' . strip_tags( $get_post_title ) . '】 ' . mb_strimwidth(strip_tags( apply_filters('the_content', $get_post_centent)),0, 132,'...') . ' 全文地址:' . get_permalink($post_ID) ; $api_url = 'https://api.weibo.com/2/statuses/update.json'; $body = array( 'status' => $status, 'source'=>'4135063399'); $headers = array( 'Authorization' => 'Basic ' . '1fFjYc3uQHZpcF32fS5jb146MxFeY19DYF53aWfzNA==' ); /* 如果你使用改方法,请注释掉上面$headers = array( 'Authorization' => 'Basic ' . '1fFjYc3uQHZpcF32fS5jb146MxFeY19DYF53aWfzNA==' ); 换成如下代码 //你的新浪微博登陆名 $username = '' ; //你的新浪微博登陆密码 $password = '' ; $headers = array( 'Authorization' => 'Basic ' . base64_encode('$username:$password')); */ $result = $request->post( $api_url , array( 'body' => $body, 'headers' => $headers ) ); }}add_action('publish_post', 'post_to_sina_weibo', 0);
在这篇文章中,我们需要使用wordpress自带的WP_Http类,在github中找到了一个替代品:
关于这个类的一个说明:EasyHttp是一个php类,可以帮助你忽略不同的php环境条件,乱发http请求。不再需要关注当前php环境是否支持curl/fsockopen/fopen,EasyHttp会自动选择最合适的方式发送http请求。EasyHttp源自WordPress中的WP_Http类,去掉了对其他WordPress函数的所有依赖,拆分成不同的文件,做了少量的简化。
根据以上内容,编写php代码1.php:
浏览器在访问 1.php 时返回如下:
Array ( [headers] => Array ( [server] => nginx/1.2.0 [date] => Sun, 13 Oct 2013 02:23:46 GMT [content-type] => text/plain;charset=UTF-8 [content-length] => 76 [connection] => close [api-server-ip] => 10.75.0.170 [vary] => Accept-Encoding [x-varnish] => 3299864740 [age] => 0 [via] => 1.1 varnish ) [body] => 错误的 Content-Type 标头值:'application/ x-www-form-urlencoded; charset=' [response] => Array ( [code] => 400 [message] => Bad Request ) [cookies] => Array ( ) [filename] => )
好像是400 Bad Request,百度下载的,意思是“由于语法格式不正确,服务器无法理解这个请求。如果不修改,客户端程序不能重复这个请求。”
各位大佬是怎么解决这个问题的? 查看全部
网站调用新浪微博内容(wordpress网站可以写php代码1.php文件测试.php)
据说wordpress网站发帖时可以同步文章到新浪微博,我想按照同样的方法写一个php代码测试。以下内容引自:
同步到微博大致有三种方式,插件,关联博客,非插件微博接口
一是直接在百度上搜索;
二、因为新浪现在已经取消了关联博客的选项,但是功能并没有取消,可以询问以下地址,然后进行配置。
第三种方法需要使用新浪的接口,如下:
1)去新浪微博开放平台创建站内应用,审核通过或者不通过,可以在微博底部显示某个应用的应用,比如来自KingGoo技术博客图片,如何创建你可以在百度谷歌上搜索,很简单(但是如果你没有通过审核还想通过审核,我可以提供付费帮助嘎嘎~),创建后应用,需要使用应用应用的App Key;
2)编辑你的主题的functions.php文件并在最后添加以下代码
// 微博同步function post_to_sina_weibo($post_ID) { if( wp_is_post_revision($post_ID) ) return; $get_post_info = get_post($post_ID); $get_post_centent = get_post($post_ID)->post_content; //去掉文章内的html编码的空格、换行、tab等符号(如果你文章的编码格式是这样子,可以将下面的"//"去掉即开启此功能) //$get_post_centent = str_replace("\t", " ", str_replace("\n", " ", str_replace(" ", " ", $get_post_centent))); $get_post_title = get_post($post_ID)->post_title; if ( $get_post_info->post_status == 'publish' && $_POST['original_post_status'] != 'publish' ) { $request = new WP_Http; $status = '【' . strip_tags( $get_post_title ) . '】 ' . mb_strimwidth(strip_tags( apply_filters('the_content', $get_post_centent)),0, 132,'...') . ' 全文地址:' . get_permalink($post_ID) ; $api_url = 'https://api.weibo.com/2/statuses/update.json'; $body = array( 'status' => $status, 'source'=>'4135063399'); $headers = array( 'Authorization' => 'Basic ' . '1fFjYc3uQHZpcF32fS5jb146MxFeY19DYF53aWfzNA==' ); /* 如果你使用改方法,请注释掉上面$headers = array( 'Authorization' => 'Basic ' . '1fFjYc3uQHZpcF32fS5jb146MxFeY19DYF53aWfzNA==' ); 换成如下代码 //你的新浪微博登陆名 $username = '' ; //你的新浪微博登陆密码 $password = '' ; $headers = array( 'Authorization' => 'Basic ' . base64_encode('$username:$password')); */ $result = $request->post( $api_url , array( 'body' => $body, 'headers' => $headers ) ); }}add_action('publish_post', 'post_to_sina_weibo', 0);
在这篇文章中,我们需要使用wordpress自带的WP_Http类,在github中找到了一个替代品:
关于这个类的一个说明:EasyHttp是一个php类,可以帮助你忽略不同的php环境条件,乱发http请求。不再需要关注当前php环境是否支持curl/fsockopen/fopen,EasyHttp会自动选择最合适的方式发送http请求。EasyHttp源自WordPress中的WP_Http类,去掉了对其他WordPress函数的所有依赖,拆分成不同的文件,做了少量的简化。
根据以上内容,编写php代码1.php:
浏览器在访问 1.php 时返回如下:
Array ( [headers] => Array ( [server] => nginx/1.2.0 [date] => Sun, 13 Oct 2013 02:23:46 GMT [content-type] => text/plain;charset=UTF-8 [content-length] => 76 [connection] => close [api-server-ip] => 10.75.0.170 [vary] => Accept-Encoding [x-varnish] => 3299864740 [age] => 0 [via] => 1.1 varnish ) [body] => 错误的 Content-Type 标头值:'application/ x-www-form-urlencoded; charset=' [response] => Array ( [code] => 400 [message] => Bad Request ) [cookies] => Array ( ) [filename] => )
好像是400 Bad Request,百度下载的,意思是“由于语法格式不正确,服务器无法理解这个请求。如果不修改,客户端程序不能重复这个请求。”
各位大佬是怎么解决这个问题的?
网站调用新浪微博内容( Python爬虫爬取新浪微博用户数据的方法结果展示步骤)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-17 11:04
Python爬虫爬取新浪微博用户数据的方法结果展示步骤)
【Python3爬虫】抓取新浪微博用户信息和微博内容
在大数据时代,数据已成为研究领域不可或缺的一部分。新浪微博作为新时代流行的新媒体社交平台,拥有大量的用户行为和商业数据。因此,研究人员需要获取新浪微博数据。但新浪微博拥有海量数据。最好的获取方式无疑是使用Python爬虫获取。有一些使用Python爬虫爬取新浪微博数据的教程,但是完整的介绍和爬取用户的所有数据信息都比较少,所以这里有一篇主要使用selenium包爬取新浪微博用户数据的文章文章 . 码字不易,喜欢就点个赞吧!!!
目标
抓取新浪微博用户数据,包括以下字段:id、昵称、关注数、关注数、微博数、每条微博内容、转发数、评论数、点赞数、发布时间、来源和是 原创 还是转推。(本文以GUCCI(古驰)为例)
方法结果展示
步骤分解
1.选择抓取目标网址
首先,在你准备好开始爬取之前,你必须想好要爬取哪个 URL。新浪微博网站分为网页和手机两部分。大部分抓取微博数据都会选择抓取手机,因为相比较而言,手机基本上收录了你想要的所有数据,而且手机相对PC端来说是轻量级的。
下面是GUCCI的移动端和PC端的网页展示。
2.模拟登录
决定爬取微博手机数据后,就该模拟登录了。
模拟登录网址
登录页面如下所示
模拟登录代码
try:
print(u'登陆新浪微博手机端...')
##打开Firefox浏览器
browser = webdriver.Firefox()
##给定登陆的网址
url = 'https://passport.weibo.cn/signin/login'
browser.get(url)
time.sleep(3)
#找到输入用户名的地方,并将用户名里面的内容清空,然后送入你的账号
username = browser.find_element_by_css_selector('#loginName')
time.sleep(2)
username.clear()
username.send_keys('****')#输入自己的账号
#找到输入密码的地方,然后送入你的密码
password = browser.find_element_by_css_selector('#loginPassword')
time.sleep(2)
password.send_keys('ll117117')
#点击登录
browser.find_element_by_css_selector('#loginAction').click()
##这里给个15秒非常重要,因为在点击登录之后,新浪微博会有个九宫格验证码,下图有,通过程序执行的话会有点麻烦(可以参考崔庆才的Python书里面有解决方法),这里就手动
time.sleep(15)
except:
print('########出现Error########')
finally:
print('完成登陆!')
3.获取用户微博的页码
登录后可以输入你要抓取的商家信息,因为每个商家的微博数量不同,所以对应的微博页码也不同。在这里,先爬下商家的微博页码。同时,抓取那些公开的信息,如用户uid、用户名、微博数、关注者数、粉丝数。
#本文是以GUCCI为例,GUCCI的用户id为‘GUCCI’
id = 'GUCCI'
niCheng = id
#用户的url结构为 url = 'http://weibo.cn/' + id
url = 'http://weibo.cn/' + id
browser.get(url)
time.sleep(3)
#使用BeautifulSoup解析网页的HTML
soup = BeautifulSoup(browser.page_source, 'lxml')
#爬取商户的uid信息
uid = soup.find('td',attrs={'valign':'top'})
uid = uid.a['href']
uid = uid.split('/')[1]
#爬取最大页码数目
pageSize = soup.find('div', attrs={'id': 'pagelist'})
pageSize = pageSize.find('div').getText()
pageSize = (pageSize.split('/')[1]).split('页')[0]
#爬取微博数量
divMessage = soup.find('div',attrs={'class':'tip2'})
weiBoCount = divMessage.find('span').getText()
weiBoCount = (weiBoCount.split('[')[1]).replace(']','')
#爬取关注数量和粉丝数量
a = divMessage.find_all('a')[:2]
guanZhuCount = (a[0].getText().split('[')[1]).replace(']','')
fenSiCount = (a[1].getText().split('[')[1]).replace(']', '')
4.根据爬取的最大页码,循环爬取所有数据
得到最大页码后,直接通过循环爬取每一页数据。抓取的数据包括微博内容、转发数、评论数、点赞数、发微博时间、微博来源、是原创还是转发。
#通过循环来抓取每一页数据
for i in range(1, pageSize+1): # pageSize+1
#每一页数据的url结构为 url = 'http://weibo.cn/' + id + ‘?page=’ + i
url = 'https://weibo.cn/GUCCI?page=' + str(i)
browser.get(url)
time.sleep(1)
#使用BeautifulSoup解析网页的HTML
soup = BeautifulSoup(browser.page_source, 'lxml')
body = soup.find('body')
divss = body.find_all('div', attrs={'class': 'c'})[1:-2]
for divs in divss:
# yuanChuang : 0表示转发,1表示原创
yuanChuang = '1'#初始值为原创,当非原创时,更改此值
div = divs.find_all('div')
#这里有三种情况,两种为原创,一种为转发
if (len(div) == 2):#原创,有图
#爬取微博内容
content = div[0].find('span', attrs={'class': 'ctt'}).getText()
aa = div[1].find_all('a')
for a in aa:
text = a.getText()
if (('赞' in text) or ('转发' in text) or ('评论' in text)):
#爬取点赞数
if ('赞' in text):
dianZan = (text.split('[')[1]).replace(']', '')
#爬取转发数
elif ('转发' in text):
zhuanFa = (text.split('[')[1]).replace(']', '')
#爬取评论数目
elif ('评论' in text):
pinLun = (text.split('[')[1]).replace(']', '')
#爬取微博来源和时间
span = divs.find('span', attrs={'class': 'ct'}).getText()
faBuTime = str(span.split('来自')[0])
laiYuan = span.split('来自')[1]
#和上面一样
elif (len(div) == 1):#原创,无图
content = div[0].find('span', attrs={'class': 'ctt'}).getText()
aa = div[0].find_all('a')
for a in aa:
text = a.getText()
if (('赞' in text) or ('转发' in text) or ('评论' in text)):
if ('赞' in text):
dianZan = (text.split('[')[1]).replace(']', '')
elif ('转发' in text):
zhuanFa = (text.split('[')[1]).replace(']', '')
elif ('评论' in text):
pinLun = (text.split('[')[1]).replace(']', '')
span = divs.find('span', attrs={'class': 'ct'}).getText()
faBuTime = str(span.split('来自')[0])
laiYuan = span.split('来自')[1]
#这里为转发,其他和上面一样
elif (len(div) == 3):#转发的微博
yuanChuang = '0'
content = div[0].find('span', attrs={'class': 'ctt'}).getText()
aa = div[2].find_all('a')
for a in aa:
text = a.getText()
if (('赞' in text) or ('转发' in text) or ('评论' in text)):
if ('赞' in text):
dianZan = (text.split('[')[1]).replace(']', '')
elif ('转发' in text):
zhuanFa = (text.split('[')[1]).replace(']', '')
elif ('评论' in text):
pinLun = (text.split('[')[1]).replace(']', '')
span = divs.find('span', attrs={'class': 'ct'}).getText()
faBuTime = str(span.split('来自')[0])
laiYuan = span.split('来自')[1]
time.sleep(2)
print(i)
4.获取所有数据后,可以写入csv文件,或者excel
最终结果如上图!!!!
到这里,完整的微博爬虫就解决了!!! 查看全部
网站调用新浪微博内容(
Python爬虫爬取新浪微博用户数据的方法结果展示步骤)
【Python3爬虫】抓取新浪微博用户信息和微博内容
在大数据时代,数据已成为研究领域不可或缺的一部分。新浪微博作为新时代流行的新媒体社交平台,拥有大量的用户行为和商业数据。因此,研究人员需要获取新浪微博数据。但新浪微博拥有海量数据。最好的获取方式无疑是使用Python爬虫获取。有一些使用Python爬虫爬取新浪微博数据的教程,但是完整的介绍和爬取用户的所有数据信息都比较少,所以这里有一篇主要使用selenium包爬取新浪微博用户数据的文章文章 . 码字不易,喜欢就点个赞吧!!!
目标
抓取新浪微博用户数据,包括以下字段:id、昵称、关注数、关注数、微博数、每条微博内容、转发数、评论数、点赞数、发布时间、来源和是 原创 还是转推。(本文以GUCCI(古驰)为例)
方法结果展示
步骤分解
1.选择抓取目标网址
首先,在你准备好开始爬取之前,你必须想好要爬取哪个 URL。新浪微博网站分为网页和手机两部分。大部分抓取微博数据都会选择抓取手机,因为相比较而言,手机基本上收录了你想要的所有数据,而且手机相对PC端来说是轻量级的。
下面是GUCCI的移动端和PC端的网页展示。
2.模拟登录
决定爬取微博手机数据后,就该模拟登录了。
模拟登录网址
登录页面如下所示
模拟登录代码
try:
print(u'登陆新浪微博手机端...')
##打开Firefox浏览器
browser = webdriver.Firefox()
##给定登陆的网址
url = 'https://passport.weibo.cn/signin/login'
browser.get(url)
time.sleep(3)
#找到输入用户名的地方,并将用户名里面的内容清空,然后送入你的账号
username = browser.find_element_by_css_selector('#loginName')
time.sleep(2)
username.clear()
username.send_keys('****')#输入自己的账号
#找到输入密码的地方,然后送入你的密码
password = browser.find_element_by_css_selector('#loginPassword')
time.sleep(2)
password.send_keys('ll117117')
#点击登录
browser.find_element_by_css_selector('#loginAction').click()
##这里给个15秒非常重要,因为在点击登录之后,新浪微博会有个九宫格验证码,下图有,通过程序执行的话会有点麻烦(可以参考崔庆才的Python书里面有解决方法),这里就手动
time.sleep(15)
except:
print('########出现Error########')
finally:
print('完成登陆!')
3.获取用户微博的页码
登录后可以输入你要抓取的商家信息,因为每个商家的微博数量不同,所以对应的微博页码也不同。在这里,先爬下商家的微博页码。同时,抓取那些公开的信息,如用户uid、用户名、微博数、关注者数、粉丝数。
#本文是以GUCCI为例,GUCCI的用户id为‘GUCCI’
id = 'GUCCI'
niCheng = id
#用户的url结构为 url = 'http://weibo.cn/' + id
url = 'http://weibo.cn/' + id
browser.get(url)
time.sleep(3)
#使用BeautifulSoup解析网页的HTML
soup = BeautifulSoup(browser.page_source, 'lxml')
#爬取商户的uid信息
uid = soup.find('td',attrs={'valign':'top'})
uid = uid.a['href']
uid = uid.split('/')[1]
#爬取最大页码数目
pageSize = soup.find('div', attrs={'id': 'pagelist'})
pageSize = pageSize.find('div').getText()
pageSize = (pageSize.split('/')[1]).split('页')[0]
#爬取微博数量
divMessage = soup.find('div',attrs={'class':'tip2'})
weiBoCount = divMessage.find('span').getText()
weiBoCount = (weiBoCount.split('[')[1]).replace(']','')
#爬取关注数量和粉丝数量
a = divMessage.find_all('a')[:2]
guanZhuCount = (a[0].getText().split('[')[1]).replace(']','')
fenSiCount = (a[1].getText().split('[')[1]).replace(']', '')
4.根据爬取的最大页码,循环爬取所有数据
得到最大页码后,直接通过循环爬取每一页数据。抓取的数据包括微博内容、转发数、评论数、点赞数、发微博时间、微博来源、是原创还是转发。
#通过循环来抓取每一页数据
for i in range(1, pageSize+1): # pageSize+1
#每一页数据的url结构为 url = 'http://weibo.cn/' + id + ‘?page=’ + i
url = 'https://weibo.cn/GUCCI?page=' + str(i)
browser.get(url)
time.sleep(1)
#使用BeautifulSoup解析网页的HTML
soup = BeautifulSoup(browser.page_source, 'lxml')
body = soup.find('body')
divss = body.find_all('div', attrs={'class': 'c'})[1:-2]
for divs in divss:
# yuanChuang : 0表示转发,1表示原创
yuanChuang = '1'#初始值为原创,当非原创时,更改此值
div = divs.find_all('div')
#这里有三种情况,两种为原创,一种为转发
if (len(div) == 2):#原创,有图
#爬取微博内容
content = div[0].find('span', attrs={'class': 'ctt'}).getText()
aa = div[1].find_all('a')
for a in aa:
text = a.getText()
if (('赞' in text) or ('转发' in text) or ('评论' in text)):
#爬取点赞数
if ('赞' in text):
dianZan = (text.split('[')[1]).replace(']', '')
#爬取转发数
elif ('转发' in text):
zhuanFa = (text.split('[')[1]).replace(']', '')
#爬取评论数目
elif ('评论' in text):
pinLun = (text.split('[')[1]).replace(']', '')
#爬取微博来源和时间
span = divs.find('span', attrs={'class': 'ct'}).getText()
faBuTime = str(span.split('来自')[0])
laiYuan = span.split('来自')[1]
#和上面一样
elif (len(div) == 1):#原创,无图
content = div[0].find('span', attrs={'class': 'ctt'}).getText()
aa = div[0].find_all('a')
for a in aa:
text = a.getText()
if (('赞' in text) or ('转发' in text) or ('评论' in text)):
if ('赞' in text):
dianZan = (text.split('[')[1]).replace(']', '')
elif ('转发' in text):
zhuanFa = (text.split('[')[1]).replace(']', '')
elif ('评论' in text):
pinLun = (text.split('[')[1]).replace(']', '')
span = divs.find('span', attrs={'class': 'ct'}).getText()
faBuTime = str(span.split('来自')[0])
laiYuan = span.split('来自')[1]
#这里为转发,其他和上面一样
elif (len(div) == 3):#转发的微博
yuanChuang = '0'
content = div[0].find('span', attrs={'class': 'ctt'}).getText()
aa = div[2].find_all('a')
for a in aa:
text = a.getText()
if (('赞' in text) or ('转发' in text) or ('评论' in text)):
if ('赞' in text):
dianZan = (text.split('[')[1]).replace(']', '')
elif ('转发' in text):
zhuanFa = (text.split('[')[1]).replace(']', '')
elif ('评论' in text):
pinLun = (text.split('[')[1]).replace(']', '')
span = divs.find('span', attrs={'class': 'ct'}).getText()
faBuTime = str(span.split('来自')[0])
laiYuan = span.split('来自')[1]
time.sleep(2)
print(i)
4.获取所有数据后,可以写入csv文件,或者excel
最终结果如上图!!!!
到这里,完整的微博爬虫就解决了!!!
网站调用新浪微博内容(新浪哥又开始抓严了,只好真的去“模拟”浏览器了 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2022-01-17 11:00
)
前言
最近在和新浪大佬PK。首先是从网络上抓取新浪微博。遇到的问题是cookies的生命周期太慢了。通常,爬行 10 分钟后会覆盖一个。后来又发明了模拟登录的手机版。过了一段时间的一帆风顺,新浪又来了验证码,气得半死。无奈手动输入验证码,然后模拟登录。然而不到两个月,新浪又开始严格了,以至于手机版的模拟登录经常无法登录。最后实在没有办法,只好真的“模拟”浏览器来实现爬虫。说到浏览器自动化,selenium 是目前最好用的一种。
关于硒
Selenium 最初是用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。它支持的浏览器包括 IE、Chrome 和 Firefox。现在很多bug高手为了绕过反爬虫机制选择了selenium。由于 selenium 的原理是唤起浏览器操作,代价就是爬虫很慢。
安装硒
我的机器是Ubuntu,所以下面主要总结一下我在Ubuntu的安装过程。
1. 进入安装命令行 sudo pip install -U selenium
2.下载驱动geckodriver(百度网盘下载链接)
3.更新浏览器,(如FireFox:sudo apt-get update –> sudo apt-get install firefox)
硒测试代码
from selenium import webdriver
browser = webdriver.Firefox(executable_path='/home/gdufs-iiip/PycharmProjects/Weibo/geckodriver') ## 配置驱动文件所在的路径
browser.get("http://www.weibo.com/login.php") ## 浏览器Get请求访问
print browser.page_source ## 输入返回的源代码
硒化验结果
模拟登录过程
selenium打开的浏览器,但是用户可以正常使用这个浏览器。所以模拟登录的过程其实就是程序设置休眠时间,让用户输入账号密码完成登录操作,然后实现网页爬取。具体代码如下:
from selenium import webdriver
import time
browser = webdriver.Firefox(executable_path='/home/gdufs-iiip/PycharmProjects/Weibo/geckodriver') ## 配置驱动文件所在的路径
browser.get("http://www.weibo.com/login.php") ## 浏览器Get请求访问
begin_time = time.time() ##记录开始账号密码的时间
content = '' ## 记录网页源代码
while(True):
if ((time.time() - begin_time) > 60): ## 实现登录的时限为60秒
search_url = 'http://weibo.cn/search/mblog%3 ... rd%3D林丹出轨&sort=hot&page=1' ##实行新闻网页抓取
browser.get(search_url)
content = browser.page_source
break
print content 查看全部
网站调用新浪微博内容(新浪哥又开始抓严了,只好真的去“模拟”浏览器了
)
前言
最近在和新浪大佬PK。首先是从网络上抓取新浪微博。遇到的问题是cookies的生命周期太慢了。通常,爬行 10 分钟后会覆盖一个。后来又发明了模拟登录的手机版。过了一段时间的一帆风顺,新浪又来了验证码,气得半死。无奈手动输入验证码,然后模拟登录。然而不到两个月,新浪又开始严格了,以至于手机版的模拟登录经常无法登录。最后实在没有办法,只好真的“模拟”浏览器来实现爬虫。说到浏览器自动化,selenium 是目前最好用的一种。
关于硒
Selenium 最初是用于 Web 应用程序测试的工具。Selenium 测试直接在浏览器中运行,就像真正的用户一样。它支持的浏览器包括 IE、Chrome 和 Firefox。现在很多bug高手为了绕过反爬虫机制选择了selenium。由于 selenium 的原理是唤起浏览器操作,代价就是爬虫很慢。
安装硒
我的机器是Ubuntu,所以下面主要总结一下我在Ubuntu的安装过程。
1. 进入安装命令行 sudo pip install -U selenium
2.下载驱动geckodriver(百度网盘下载链接)
3.更新浏览器,(如FireFox:sudo apt-get update –> sudo apt-get install firefox)
硒测试代码
from selenium import webdriver
browser = webdriver.Firefox(executable_path='/home/gdufs-iiip/PycharmProjects/Weibo/geckodriver') ## 配置驱动文件所在的路径
browser.get("http://www.weibo.com/login.php";) ## 浏览器Get请求访问
print browser.page_source ## 输入返回的源代码
硒化验结果
模拟登录过程
selenium打开的浏览器,但是用户可以正常使用这个浏览器。所以模拟登录的过程其实就是程序设置休眠时间,让用户输入账号密码完成登录操作,然后实现网页爬取。具体代码如下:
from selenium import webdriver
import time
browser = webdriver.Firefox(executable_path='/home/gdufs-iiip/PycharmProjects/Weibo/geckodriver') ## 配置驱动文件所在的路径
browser.get("http://www.weibo.com/login.php";) ## 浏览器Get请求访问
begin_time = time.time() ##记录开始账号密码的时间
content = '' ## 记录网页源代码
while(True):
if ((time.time() - begin_time) > 60): ## 实现登录的时限为60秒
search_url = 'http://weibo.cn/search/mblog%3 ... rd%3D林丹出轨&sort=hot&page=1' ##实行新闻网页抓取
browser.get(search_url)
content = browser.page_source
break
print content
网站调用新浪微博内容(之前写过调用新浪微博api的教程,如何自动登录新浪获取code)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-01-17 10:20
之前写过一个调用新浪微博api的教程,包括如何使用python登录新浪并获取调用api所需的代码。在此处粘贴此段落:
自动获取code值是为了解决授权界面后如何登录的问题。这个问题困扰了我很久。
一开始我是第一次手动登录,然后直接用chrome查看发送的请求,复制cookies,每次直接发送get请求获取回调页面获取code值,如下:
get_code_url=requests.get(url,cookies=cook).url
code=get_code_url.url[47:]
说实话,这种方法很方便。新浪登录方法太多不用分析,但是当api调用次数有限的时候,这个方法就行不通了。
当一个应用的调用api受限时,我们可以创建多个新浪账号和多个应用,并获取多个App key和App Secrets进行重复调用。这样就必须解决如何自动登录新浪获取代码的问题。
首先我们要分析一下新浪微博的登录流程。我无法用 chrome、edge、ie 或 fiddler4 完全捕获完整的登录过程。最后,我尝试了firefox,成功捕获了整个登录过程。
虽然只输入了一次账号密码,但是发送了两次post请求
让我们一一分析每个请求:
base64加密后的用户名,后面会讲怎么实现,随便改,大家都知道是什么意思)
请求成功后,服务器会返回一条信息给我们,后面会用到
sinaSSOController.preloginCallBack({ “RETCODE”:0 “servertime”:1450667800, “PCID”: “GZ-fee1d39aaf203ccc63dc783a13ccce11413a”, “随机数”: “1HRSQP”, “PUBKEY”: “EB2A38568661887FA180BDDB5CABD5F21C7BFD59C090CB2D245A87AC2533E5506350508E7F9AA3BB77F4333231490F915F6D63C55FE2F08A49B353F444AD3993CACC02DB784ABBB8E42A9B1BBFFFB38BE18D78E87A0E41B9B8F73A928EE0CCEE1F6739884B9777E4FE9E88A1BBE495927AC4A799B3181D6442443”, “rsakv”: “1330428213” ,"is_openlock":0,"showpin":0,"exectime":18})
servertime、nonce、pubket和rsakv的值是我们后面需要的,需要解析出来:
get_arg=requests.get(get_arg_url)
get_arg_content=get_arg.content
get_arg_content_split=get_arg_content.split(',')
servertime=get_arg_content_split[1].split(':')[1]
nonce=get_arg_content_split[3].split(':')[1][1:-1]
pubkey=get_arg_content_split[4].split(':')[1][1:-1]
rsakv=get_arg_content_split[5].split(':')[1][1:-1]
然后我们看第二个post请求
第二个请求向新浪通发送表单
其中servertime、nonce、pubket和rsakv是我们上次get请求中得到的,su是加密的账号,sp是加密的密码
su的加密方式是base64。先安装一个base64库,然后调用如下函数:
su=base64.encodestring(username)[:-1]
密码的加密方式稍微复杂一些,也用到了servertime、nonce、pubket和rsakv:
rsaPublickey = int(pubkey, 16)
key = rsa.PublicKey(rsaPublickey, 65537) #创建公钥
message = str(servertime) + '\t' + str(nonce) + '\n' + str(password)
sp = rsa.encrypt(message, key) #加密
sp = binascii.b2a_hex(sp) #将加密信息转换为16进制。
密码加密需要binascii库和rsa库
发送此请求后,服务器会返回一个 JSON 数据,其中一个是我们稍后使用的票证
请求和获取票证的代码如下:
postPara = {
'entry': 'openapi',
'gateway': '1',
'from':'',
'savestate': '0',
'userticket': '1',
'pagerefer':'',
'ct': '1800',
's':'1',
'vsnf': '1',
'vsnval': '',
'door':'',
'appkey':'52laFx',
'su': su,
'service': 'miniblog',
'servertime': servertime,
'nonce': nonce,
'pwencode': 'rsa2',
'rsakv' : rsakv,
'sp': sp,
'sr':'1920*1080',
'encoding': 'UTF-8',
'cdult':'2',
'domain':'weibo.com',
'prelt':'2140',
'returntype': 'TEXT',
}
get_ticket_url='https://login.sina.com.cn/sso/ ... in.js(v1.4.15)&_=1450667802929'
req=requests.post(get_ticket_url,postPara)
print req.content
ticket=req.content.split(',')[1].split(':')[1][1:-1]
然后是第三个请求
第三个请求依然是post请求,请求第三方授权出错,html代码中直接给出这个表单的内容
其中client_id是我们的APP_KEY;redirect_url 是我们的回调页面,在我们第一次构建应用的时候就设置好了;不知道regCallback是从哪里来的,但是有两个变量,一个是APP_KEY,一个是我们设置的Callback page;其他表单内容是固定的。请求代码如下:
fields={
'action': 'login',
'display': 'default',
'withOfficalFlag': '0',
'quick_auth': 'null',
'withOfficalAccount': '',
'scope': '',
'ticket': ticket,
'isLoginSina': '',
'response_type': 'code',
'regCallback': 'https://api.weibo.com/2/oauth2 ... 39%3B,
'redirect_uri':CALLBACK_URL,
'client_id':APP_KEY,
'appkey62': '52laFx',
'state': '',
'verifyToken': 'null',
'from': '',
'switchLogin':'0',
'userId':'',
'passwd':''
}
headers = {
"User-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:43.0) Gecko/20100101 Firefox/43.0",
"Referer": url,
"Content-Type": "application/x-www-form-urlencoded"}
post_url='https://api.weibo.com/oauth2/authorize'
get_code_url=requests.post(post_url,data=fields,headers=headers)
最后从响应成功的get_code_url中分析code值。
code=get_code_url.url[47:]
这样,我们就成功地自动获取了code值。 查看全部
网站调用新浪微博内容(之前写过调用新浪微博api的教程,如何自动登录新浪获取code)
之前写过一个调用新浪微博api的教程,包括如何使用python登录新浪并获取调用api所需的代码。在此处粘贴此段落:
自动获取code值是为了解决授权界面后如何登录的问题。这个问题困扰了我很久。
一开始我是第一次手动登录,然后直接用chrome查看发送的请求,复制cookies,每次直接发送get请求获取回调页面获取code值,如下:
get_code_url=requests.get(url,cookies=cook).url
code=get_code_url.url[47:]
说实话,这种方法很方便。新浪登录方法太多不用分析,但是当api调用次数有限的时候,这个方法就行不通了。
当一个应用的调用api受限时,我们可以创建多个新浪账号和多个应用,并获取多个App key和App Secrets进行重复调用。这样就必须解决如何自动登录新浪获取代码的问题。
首先我们要分析一下新浪微博的登录流程。我无法用 chrome、edge、ie 或 fiddler4 完全捕获完整的登录过程。最后,我尝试了firefox,成功捕获了整个登录过程。
虽然只输入了一次账号密码,但是发送了两次post请求
让我们一一分析每个请求:
base64加密后的用户名,后面会讲怎么实现,随便改,大家都知道是什么意思)
请求成功后,服务器会返回一条信息给我们,后面会用到
sinaSSOController.preloginCallBack({ “RETCODE”:0 “servertime”:1450667800, “PCID”: “GZ-fee1d39aaf203ccc63dc783a13ccce11413a”, “随机数”: “1HRSQP”, “PUBKEY”: “EB2A38568661887FA180BDDB5CABD5F21C7BFD59C090CB2D245A87AC2533E5506350508E7F9AA3BB77F4333231490F915F6D63C55FE2F08A49B353F444AD3993CACC02DB784ABBB8E42A9B1BBFFFB38BE18D78E87A0E41B9B8F73A928EE0CCEE1F6739884B9777E4FE9E88A1BBE495927AC4A799B3181D6442443”, “rsakv”: “1330428213” ,"is_openlock":0,"showpin":0,"exectime":18})
servertime、nonce、pubket和rsakv的值是我们后面需要的,需要解析出来:
get_arg=requests.get(get_arg_url)
get_arg_content=get_arg.content
get_arg_content_split=get_arg_content.split(',')
servertime=get_arg_content_split[1].split(':')[1]
nonce=get_arg_content_split[3].split(':')[1][1:-1]
pubkey=get_arg_content_split[4].split(':')[1][1:-1]
rsakv=get_arg_content_split[5].split(':')[1][1:-1]
然后我们看第二个post请求
第二个请求向新浪通发送表单
其中servertime、nonce、pubket和rsakv是我们上次get请求中得到的,su是加密的账号,sp是加密的密码
su的加密方式是base64。先安装一个base64库,然后调用如下函数:
su=base64.encodestring(username)[:-1]
密码的加密方式稍微复杂一些,也用到了servertime、nonce、pubket和rsakv:
rsaPublickey = int(pubkey, 16)
key = rsa.PublicKey(rsaPublickey, 65537) #创建公钥
message = str(servertime) + '\t' + str(nonce) + '\n' + str(password)
sp = rsa.encrypt(message, key) #加密
sp = binascii.b2a_hex(sp) #将加密信息转换为16进制。
密码加密需要binascii库和rsa库
发送此请求后,服务器会返回一个 JSON 数据,其中一个是我们稍后使用的票证
请求和获取票证的代码如下:
postPara = {
'entry': 'openapi',
'gateway': '1',
'from':'',
'savestate': '0',
'userticket': '1',
'pagerefer':'',
'ct': '1800',
's':'1',
'vsnf': '1',
'vsnval': '',
'door':'',
'appkey':'52laFx',
'su': su,
'service': 'miniblog',
'servertime': servertime,
'nonce': nonce,
'pwencode': 'rsa2',
'rsakv' : rsakv,
'sp': sp,
'sr':'1920*1080',
'encoding': 'UTF-8',
'cdult':'2',
'domain':'weibo.com',
'prelt':'2140',
'returntype': 'TEXT',
}
get_ticket_url='https://login.sina.com.cn/sso/ ... in.js(v1.4.15)&_=1450667802929'
req=requests.post(get_ticket_url,postPara)
print req.content
ticket=req.content.split(',')[1].split(':')[1][1:-1]
然后是第三个请求
第三个请求依然是post请求,请求第三方授权出错,html代码中直接给出这个表单的内容
其中client_id是我们的APP_KEY;redirect_url 是我们的回调页面,在我们第一次构建应用的时候就设置好了;不知道regCallback是从哪里来的,但是有两个变量,一个是APP_KEY,一个是我们设置的Callback page;其他表单内容是固定的。请求代码如下:
fields={
'action': 'login',
'display': 'default',
'withOfficalFlag': '0',
'quick_auth': 'null',
'withOfficalAccount': '',
'scope': '',
'ticket': ticket,
'isLoginSina': '',
'response_type': 'code',
'regCallback': 'https://api.weibo.com/2/oauth2 ... 39%3B,
'redirect_uri':CALLBACK_URL,
'client_id':APP_KEY,
'appkey62': '52laFx',
'state': '',
'verifyToken': 'null',
'from': '',
'switchLogin':'0',
'userId':'',
'passwd':''
}
headers = {
"User-agent": "Mozilla/5.0 (Windows NT 10.0; WOW64; rv:43.0) Gecko/20100101 Firefox/43.0",
"Referer": url,
"Content-Type": "application/x-www-form-urlencoded"}
post_url='https://api.weibo.com/oauth2/authorize'
get_code_url=requests.post(post_url,data=fields,headers=headers)
最后从响应成功的get_code_url中分析code值。
code=get_code_url.url[47:]
这样,我们就成功地自动获取了code值。
网站调用新浪微博内容( 【C#小蜗牛】C#调用微博API的相关知识点内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-15 10:02
【C#小蜗牛】C#调用微博API的相关知识点内容)
C#调用新浪微博API示例代码
更新时间:2019年11月11日15:01:10 作者:肖小蜗牛
在这篇文章中,小编整理了一篇关于C#调用微博API的知识。需要的朋友可以学习一下。
C#调用新浪微博API
WebRequest wq = WebRequest.Create(this.address);
HttpWebRequest hq = wq as HttpWebRequest;
string username = "keguangqiang@163.com";
string password = "3216731ks";
string appkey = "5786724301";
System.Net.CredentialCache cache = new CredentialCache();
cache.Add(new Uri(this.address), "Basic", new NetworkCredential(username, password));
hq.Credentials = cache;
hq.Headers.Add("Authorization","Basic " +Convert.ToBase64String(new System.Text.ASCIIEncoding().GetBytes(username+":"+password)));
System.Net.WebResponse webresponse = hq.GetResponse();
System.IO.Stream receiveStream = webresponse.GetResponseStream();
System.IO.StreamReader reader = new System.IO.StreamReader(receiveStream, System.Text.Encoding.UTF8);
string json = reader.ReadToEnd();
上面的代码示例很简单,可以在本地测试,感谢大家对Scripting Home的阅读和支持。 查看全部
网站调用新浪微博内容(
【C#小蜗牛】C#调用微博API的相关知识点内容)
C#调用新浪微博API示例代码
更新时间:2019年11月11日15:01:10 作者:肖小蜗牛
在这篇文章中,小编整理了一篇关于C#调用微博API的知识。需要的朋友可以学习一下。
C#调用新浪微博API
WebRequest wq = WebRequest.Create(this.address);
HttpWebRequest hq = wq as HttpWebRequest;
string username = "keguangqiang@163.com";
string password = "3216731ks";
string appkey = "5786724301";
System.Net.CredentialCache cache = new CredentialCache();
cache.Add(new Uri(this.address), "Basic", new NetworkCredential(username, password));
hq.Credentials = cache;
hq.Headers.Add("Authorization","Basic " +Convert.ToBase64String(new System.Text.ASCIIEncoding().GetBytes(username+":"+password)));
System.Net.WebResponse webresponse = hq.GetResponse();
System.IO.Stream receiveStream = webresponse.GetResponseStream();
System.IO.StreamReader reader = new System.IO.StreamReader(receiveStream, System.Text.Encoding.UTF8);
string json = reader.ReadToEnd();
上面的代码示例很简单,可以在本地测试,感谢大家对Scripting Home的阅读和支持。
网站调用新浪微博内容(网站调用新浪微博内容的难度,一定比抓取新浪自己那个基于cookie的服务器)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-01-15 09:04
网站调用新浪微博内容的难度,一定比抓取新浪自己那个基于cookie的服务器的难度要大。网站更新数据的时候是服务器在更新,而服务器的稳定性无疑是核心问题。
需要记住一点,把网站上的每个人的真实头像图片链接都采集下来是有技术难度的,一般的抓包手段并不能解决这个问题。建议你可以选择从目标网站上的开放api接口里收集,如果我没猜错,应该是有微博登录或者点赞。
微博太简单了,我直接上新浪找到关键字转化率会很高的。不过你要是能搞到cookie,可以让爬虫频繁更新。
想在几个微博账号注册时保持账号连续不断数据的话,将qq号码和post时间对齐,看结果时间均不重复,能够一定程度的满足要求,这对在几分钟内爬取用户数据来说是否有必要。所以将微博名称和关键字与cookie的关系做匹配,看是否有同步准确率高的变化规律,答案:有。这应该算个基础要求,但如果你能对账号采集的数据进行统计分析和处理还会更有价值。
建议楼主找一个可以用更多方法爬取数据的,比如拿到账号id,通过正则匹配,大量dnssetext等方法采集再在一个数据库中进行存储等。这类需求应该也存在,像大师兄这种众包的创业公司很多,但大师兄的内容爬取数据质量和数量相对较低,已经将其归为扩展性不够的项目,否则不会暂时搁置。 查看全部
网站调用新浪微博内容(网站调用新浪微博内容的难度,一定比抓取新浪自己那个基于cookie的服务器)
网站调用新浪微博内容的难度,一定比抓取新浪自己那个基于cookie的服务器的难度要大。网站更新数据的时候是服务器在更新,而服务器的稳定性无疑是核心问题。
需要记住一点,把网站上的每个人的真实头像图片链接都采集下来是有技术难度的,一般的抓包手段并不能解决这个问题。建议你可以选择从目标网站上的开放api接口里收集,如果我没猜错,应该是有微博登录或者点赞。
微博太简单了,我直接上新浪找到关键字转化率会很高的。不过你要是能搞到cookie,可以让爬虫频繁更新。
想在几个微博账号注册时保持账号连续不断数据的话,将qq号码和post时间对齐,看结果时间均不重复,能够一定程度的满足要求,这对在几分钟内爬取用户数据来说是否有必要。所以将微博名称和关键字与cookie的关系做匹配,看是否有同步准确率高的变化规律,答案:有。这应该算个基础要求,但如果你能对账号采集的数据进行统计分析和处理还会更有价值。
建议楼主找一个可以用更多方法爬取数据的,比如拿到账号id,通过正则匹配,大量dnssetext等方法采集再在一个数据库中进行存储等。这类需求应该也存在,像大师兄这种众包的创业公司很多,但大师兄的内容爬取数据质量和数量相对较低,已经将其归为扩展性不够的项目,否则不会暂时搁置。
网站调用新浪微博内容(新浪微博API新特点与百度地图API相比,我理解)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-01-13 08:10
查看 API 使用流程
通过百度地图API的使用,了解到API调用的大致流程是:生成API指定格式的url->通过urllib读取url中的数据->解析json格式的数据。接下来开始研究新浪微博API的使用。
准备
新浪微博开放平台是使用新浪微博API的平台。使用微博账号登录平台后,即可申请成为开发者,创建新应用后将获得唯一的App Key和App Secret。(注:申请不需要提交审核,只要新建一个申请,就会分配Key和Secret。)这两个信息也可以在“我的申请/申请信息/基本信息”中找到. 该页面还有“我的申请/申请信息/高级信息”项,点击进入并设置OAuth2.0授权回调页面的相关信息。如果不知道填什么,可以设置为默认回调Page:。后面需要这三个信息,
微博API新功能
新浪微博API与百度地图API相比,增加了OAuth2.0协议进行用户认证和授权。这里只是简单描述一下(感兴趣的同学可以参考网上文档图):通过这个协议,第三方应用可以获取用户授权,然后使用这个License从授权服务器获取一个token,供后续查询API server 验证数据时。
这个验证过程增加了 url 生成的复杂性。幸运的是,廖雪峰老师提供的SDK工具包已经在网站:sinaweibopy(廖老师的github地址好像改名了,网上很多旧链接都失效了,这是新的有效链接) ,但是这个程序是基于python2环境编写的,python3的一些系统库已经改了,程序调用的时候经常报错。作为一个python初学者,重写程序以适应python3环境无疑是困难的。幸运的是,有一位大神完成了这项工作。感谢 owolf 为 python3 重写的 SDK:sinweibopy3。我用过,运行正常。你可以下载它。在这里,我也推荐一下owolf的文章
简单的例子
介绍一下新浪微博API的使用过程,为新生提供参考。
1.参数设置
导入 sinweibopy3
导入浏览器
导入json
APP_KEY = '填写您的应用密钥'
APP_SECRET='填写您的应用密码'
REDIRECT_URL = '填写你的授权回调页面'
笔记:
这个文件需要和sinweibopy3.py放在同一个文件夹下。
填写的三条信息就是准备中提到的信息。
这里说一下我的粗心造成的一个bug,也提醒大家。当我第一次运行程序时,每次都会收到“重定向地址不匹配”错误消息:
微博账号登录出错!授权第三方应用出错,请联系第三方应用开发者:XXX或稍后重试。
错误代码:21322 重定向地址不匹配
网上找了解决方法,设置回调页,但是我之前的步骤已经设置好了,为什么还是这个问题?后来在一篇文章文章中看到,回调页面的地址应该和程序中的REDIRECT_URL一致。想到了程序示例,用http:开头,我填写的时候看到同一个地址,没有变化,而网站是https:开头,一个's'的区别,当时还以为是地址,没想到差别这么大!
2.OAuth2.0 验证生成的url
client = sinaweibopy3.APIClient(app_key=APP_KEY, app_secret=APP_SECRET, redirect_uri=REDIRECT_URL)
url = client.get_authorize_url()
webbrowser.open_new(url)
result = client.request_access_token(input("请输入代码:"))
client.set_access_token(result.access_token, result.expires_in)
注意:这是调用sinweibopy3实现用户授权->在OAuth2.0中获取Token的过程。当程序运行到client.request_access_token时,会弹出输入提示“请输入密码:”,询问密码?这是什么意思?打开浏览器会看到出现OAuth2.0验证回调页面。地址栏中的“code=”后面有一串字符。这就是我们想要的Token信息。复制它,粘贴它并输入它,然后程序继续。跑。
3.从 API 读取数据
运行以下代码读取公众微博数据并显示结果。
结果=client.public_timeline()
print(json.dumps(result,indent=2,ensure_ascii=False))
通过查看数据结构,可以提取特定信息。例如,使用以下代码输出用户的微博昵称、位置和最新的微博文字。
数字=结果[“总数”]
打印(数字,“用户:”)
结果中的你[“状态”]:
打印(u[“用户”][“屏幕名称”])
打印(u[“用户”][“位置”])
打印(你[“文本”])
先进的 查看全部
网站调用新浪微博内容(新浪微博API新特点与百度地图API相比,我理解)
查看 API 使用流程
通过百度地图API的使用,了解到API调用的大致流程是:生成API指定格式的url->通过urllib读取url中的数据->解析json格式的数据。接下来开始研究新浪微博API的使用。
准备
新浪微博开放平台是使用新浪微博API的平台。使用微博账号登录平台后,即可申请成为开发者,创建新应用后将获得唯一的App Key和App Secret。(注:申请不需要提交审核,只要新建一个申请,就会分配Key和Secret。)这两个信息也可以在“我的申请/申请信息/基本信息”中找到. 该页面还有“我的申请/申请信息/高级信息”项,点击进入并设置OAuth2.0授权回调页面的相关信息。如果不知道填什么,可以设置为默认回调Page:。后面需要这三个信息,
微博API新功能
新浪微博API与百度地图API相比,增加了OAuth2.0协议进行用户认证和授权。这里只是简单描述一下(感兴趣的同学可以参考网上文档图):通过这个协议,第三方应用可以获取用户授权,然后使用这个License从授权服务器获取一个token,供后续查询API server 验证数据时。
这个验证过程增加了 url 生成的复杂性。幸运的是,廖雪峰老师提供的SDK工具包已经在网站:sinaweibopy(廖老师的github地址好像改名了,网上很多旧链接都失效了,这是新的有效链接) ,但是这个程序是基于python2环境编写的,python3的一些系统库已经改了,程序调用的时候经常报错。作为一个python初学者,重写程序以适应python3环境无疑是困难的。幸运的是,有一位大神完成了这项工作。感谢 owolf 为 python3 重写的 SDK:sinweibopy3。我用过,运行正常。你可以下载它。在这里,我也推荐一下owolf的文章
简单的例子
介绍一下新浪微博API的使用过程,为新生提供参考。
1.参数设置
导入 sinweibopy3
导入浏览器
导入json
APP_KEY = '填写您的应用密钥'
APP_SECRET='填写您的应用密码'
REDIRECT_URL = '填写你的授权回调页面'
笔记:
这个文件需要和sinweibopy3.py放在同一个文件夹下。
填写的三条信息就是准备中提到的信息。
这里说一下我的粗心造成的一个bug,也提醒大家。当我第一次运行程序时,每次都会收到“重定向地址不匹配”错误消息:
微博账号登录出错!授权第三方应用出错,请联系第三方应用开发者:XXX或稍后重试。
错误代码:21322 重定向地址不匹配
网上找了解决方法,设置回调页,但是我之前的步骤已经设置好了,为什么还是这个问题?后来在一篇文章文章中看到,回调页面的地址应该和程序中的REDIRECT_URL一致。想到了程序示例,用http:开头,我填写的时候看到同一个地址,没有变化,而网站是https:开头,一个's'的区别,当时还以为是地址,没想到差别这么大!
2.OAuth2.0 验证生成的url
client = sinaweibopy3.APIClient(app_key=APP_KEY, app_secret=APP_SECRET, redirect_uri=REDIRECT_URL)
url = client.get_authorize_url()
webbrowser.open_new(url)
result = client.request_access_token(input("请输入代码:"))
client.set_access_token(result.access_token, result.expires_in)
注意:这是调用sinweibopy3实现用户授权->在OAuth2.0中获取Token的过程。当程序运行到client.request_access_token时,会弹出输入提示“请输入密码:”,询问密码?这是什么意思?打开浏览器会看到出现OAuth2.0验证回调页面。地址栏中的“code=”后面有一串字符。这就是我们想要的Token信息。复制它,粘贴它并输入它,然后程序继续。跑。
3.从 API 读取数据
运行以下代码读取公众微博数据并显示结果。
结果=client.public_timeline()
print(json.dumps(result,indent=2,ensure_ascii=False))
通过查看数据结构,可以提取特定信息。例如,使用以下代码输出用户的微博昵称、位置和最新的微博文字。
数字=结果[“总数”]
打印(数字,“用户:”)
结果中的你[“状态”]:
打印(u[“用户”][“屏幕名称”])
打印(u[“用户”][“位置”])
打印(你[“文本”])
先进的
网站调用新浪微博内容(【魔兽世界】新浪微博登录常用接口:对应主界面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2022-01-12 14:13
日志条目
新浪微博登录常用界面:
对应主界面:
不过,我个人推荐使用移动端的微博入口:
对应主界面:
原因是手机上的数据比较轻量级,基础数据齐全,可能会缺少一些基本的个人信息,比如“个人资料完成度”、“个人等级”等。粉丝ID和关注ID只能显示20页,但可以作为大部分验证的语料库。
通过对比下面两张图,分别是PC端和手机端,可以发现内容基本一致:
如下图在手机上,图片比较小,内容也比较简洁。
完整的源代码
下面的代码主要分为三部分:
1.登录微博(用户名、密码) 登录微博
2.VisitPersonPage(user_id) 访问follower网站获取个人信息
3.获取微博内容同时翻页
<p># coding=utf-8
"""
Created on 2016-02-22 @author: Eastmount
功能: 爬取新浪微博用户的信息
信息:用户ID 用户名 粉丝数 关注数 微博数 微博内容
网址:http://weibo.cn/ 数据量更小 相对http://weibo.com/
"""
import time
import re
import os
import sys
import codecs
import shutil
import urllib
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import selenium.webdriver.support.ui as ui
from selenium.webdriver.common.action_chains import ActionChains
#先调用无界面浏览器PhantomJS或Firefox
#driver = webdriver.PhantomJS(executable_path="G:\phantomjs-1.9.1-windows\phantomjs.exe")
driver = webdriver.Firefox()
wait = ui.WebDriverWait(driver,10)
#全局变量 文件操作读写信息
inforead = codecs.open("SinaWeibo_List.txt", 'r', 'utf-8')
infofile = codecs.open("SinaWeibo_Info.txt", 'a', 'utf-8')
#********************************************************************************
# 第一步: 登陆weibo.cn 获取新浪微博的cookie
# 该方法针对weibo.cn有效(明文形式传输数据) weibo.com见学弟设置POST和Header方法
# LoginWeibo(username, password) 参数用户名 密码
# 验证码暂停时间手动输入
#********************************************************************************
def LoginWeibo(username, password):
try:
#**********************************************************************
# 直接访问driver.get("http://weibo.cn/5824697471")会跳转到登陆页面 用户id
#
# 用户名
# 密码 "password_4903" 中数字会变动,故采用绝对路径方法,否则不能定位到元素
#
# 勾选记住登录状态check默认是保留 故注释掉该代码 不保留Cookie 则'expiry'=None
#**********************************************************************
#输入用户名/密码登录
print u'准备登陆Weibo.cn网站...'
driver.get("http://login.weibo.cn/login/")
elem_user = driver.find_element_by_name("mobile")
elem_user.send_keys(username) #用户名
elem_pwd = driver.find_element_by_xpath("/html/body/div[2]/form/div/input[2]")
elem_pwd.send_keys(password) #密码
#elem_rem = driver.find_element_by_name("remember")
#elem_rem.click() #记住登录状态
#重点: 暂停时间输入验证码
#pause(millisenconds)
time.sleep(20)
elem_sub = driver.find_element_by_name("submit")
elem_sub.click() #点击登陆
time.sleep(2)
#获取Coockie 推荐 http://www.cnblogs.com/fnng/p/3269450.html
print driver.current_url
print driver.get_cookies() #获得cookie信息 dict存储
print u'输出Cookie键值对信息:'
for cookie in driver.get_cookies():
#print cookie
for key in cookie:
print key, cookie[key]
#driver.get_cookies()类型list 仅包含一个元素cookie类型dict
print u'登陆成功...'
except Exception,e:
print "Error: ",e
finally:
print u'End LoginWeibo!\n\n'
#********************************************************************************
# 第二步: 访问个人页面http://weibo.cn/5824697471并获取信息
# VisitPersonPage()
# 编码常见错误 UnicodeEncodeError: 'ascii' codec can't encode characters
#********************************************************************************
def VisitPersonPage(user_id):
try:
global infofile
print u'准备访问个人网站.....'
#原创内容 http://weibo.cn/guangxianliuya ... e%3D2
driver.get("http://weibo.cn/" + user_id)
#**************************************************************************
# No.1 直接获取 用户昵称 微博数 关注数 粉丝数
# str_name.text是unicode编码类型
#**************************************************************************
#用户id
print u'个人详细信息'
print '**********************************************'
print u'用户id: ' + user_id
#昵称
str_name = driver.find_element_by_xpath("//div[@class='ut']")
str_t = str_name.text.split(" ")
num_name = str_t[0] #空格分隔 获取第一个值 "Eastmount 详细资料 设置 新手区"
print u'昵称: ' + num_name
#微博数 除个人主页 它默认直接显示微博数 无超链接
#Error: 'unicode' object is not callable
#一般是把字符串当做函数使用了 str定义成字符串 而str()函数再次使用时报错
str_wb = driver.find_element_by_xpath("//div[@class='tip2']")
pattern = r"\d+\.?\d*" #正则提取"微博[0]" 但r"(\[.*?\])"总含[]
guid = re.findall(pattern, str_wb.text, re.S|re.M)
print str_wb.text #微博[294] 关注[351] 粉丝[294] 分组[1] @他的
for value in guid:
num_wb = int(value)
break
print u'微博数: ' + str(num_wb)
#关注数
str_gz = driver.find_element_by_xpath("//div[@class='tip2']/a[1]")
guid = re.findall(pattern, str_gz.text, re.M)
num_gz = int(guid[0])
print u'关注数: ' + str(num_gz)
#粉丝数
str_fs = driver.find_element_by_xpath("//div[@class='tip2']/a[2]")
guid = re.findall(pattern, str_fs.text, re.M)
num_fs = int(guid[0])
print u'粉丝数: ' + str(num_fs)
#***************************************************************************
# No.2 文件操作写入信息
#***************************************************************************
infofile.write('=====================================================================\r\n')
infofile.write(u'用户: ' + user_id + '\r\n')
infofile.write(u'昵称: ' + num_name + '\r\n')
infofile.write(u'微博数: ' + str(num_wb) + '\r\n')
infofile.write(u'关注数: ' + str(num_gz) + '\r\n')
infofile.write(u'粉丝数: ' + str(num_fs) + '\r\n')
infofile.write(u'微博内容: ' + '\r\n\r\n')
#***************************************************************************
# No.3 获取微博内容
# http://weibo.cn/guangxianliuya ... e%3D1
# 其中filter=0表示全部 =1表示原创
#***************************************************************************
print '\n'
print u'获取微博内容信息'
num = 1
while num 查看全部
网站调用新浪微博内容(【魔兽世界】新浪微博登录常用接口:对应主界面)
日志条目
新浪微博登录常用界面:
对应主界面:
不过,我个人推荐使用移动端的微博入口:
对应主界面:
原因是手机上的数据比较轻量级,基础数据齐全,可能会缺少一些基本的个人信息,比如“个人资料完成度”、“个人等级”等。粉丝ID和关注ID只能显示20页,但可以作为大部分验证的语料库。
通过对比下面两张图,分别是PC端和手机端,可以发现内容基本一致:
如下图在手机上,图片比较小,内容也比较简洁。
完整的源代码
下面的代码主要分为三部分:
1.登录微博(用户名、密码) 登录微博
2.VisitPersonPage(user_id) 访问follower网站获取个人信息
3.获取微博内容同时翻页
<p># coding=utf-8
"""
Created on 2016-02-22 @author: Eastmount
功能: 爬取新浪微博用户的信息
信息:用户ID 用户名 粉丝数 关注数 微博数 微博内容
网址:http://weibo.cn/ 数据量更小 相对http://weibo.com/
"""
import time
import re
import os
import sys
import codecs
import shutil
import urllib
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import selenium.webdriver.support.ui as ui
from selenium.webdriver.common.action_chains import ActionChains
#先调用无界面浏览器PhantomJS或Firefox
#driver = webdriver.PhantomJS(executable_path="G:\phantomjs-1.9.1-windows\phantomjs.exe")
driver = webdriver.Firefox()
wait = ui.WebDriverWait(driver,10)
#全局变量 文件操作读写信息
inforead = codecs.open("SinaWeibo_List.txt", 'r', 'utf-8')
infofile = codecs.open("SinaWeibo_Info.txt", 'a', 'utf-8')
#********************************************************************************
# 第一步: 登陆weibo.cn 获取新浪微博的cookie
# 该方法针对weibo.cn有效(明文形式传输数据) weibo.com见学弟设置POST和Header方法
# LoginWeibo(username, password) 参数用户名 密码
# 验证码暂停时间手动输入
#********************************************************************************
def LoginWeibo(username, password):
try:
#**********************************************************************
# 直接访问driver.get("http://weibo.cn/5824697471";)会跳转到登陆页面 用户id
#
# 用户名
# 密码 "password_4903" 中数字会变动,故采用绝对路径方法,否则不能定位到元素
#
# 勾选记住登录状态check默认是保留 故注释掉该代码 不保留Cookie 则'expiry'=None
#**********************************************************************
#输入用户名/密码登录
print u'准备登陆Weibo.cn网站...'
driver.get("http://login.weibo.cn/login/";)
elem_user = driver.find_element_by_name("mobile")
elem_user.send_keys(username) #用户名
elem_pwd = driver.find_element_by_xpath("/html/body/div[2]/form/div/input[2]")
elem_pwd.send_keys(password) #密码
#elem_rem = driver.find_element_by_name("remember")
#elem_rem.click() #记住登录状态
#重点: 暂停时间输入验证码
#pause(millisenconds)
time.sleep(20)
elem_sub = driver.find_element_by_name("submit")
elem_sub.click() #点击登陆
time.sleep(2)
#获取Coockie 推荐 http://www.cnblogs.com/fnng/p/3269450.html
print driver.current_url
print driver.get_cookies() #获得cookie信息 dict存储
print u'输出Cookie键值对信息:'
for cookie in driver.get_cookies():
#print cookie
for key in cookie:
print key, cookie[key]
#driver.get_cookies()类型list 仅包含一个元素cookie类型dict
print u'登陆成功...'
except Exception,e:
print "Error: ",e
finally:
print u'End LoginWeibo!\n\n'
#********************************************************************************
# 第二步: 访问个人页面http://weibo.cn/5824697471并获取信息
# VisitPersonPage()
# 编码常见错误 UnicodeEncodeError: 'ascii' codec can't encode characters
#********************************************************************************
def VisitPersonPage(user_id):
try:
global infofile
print u'准备访问个人网站.....'
#原创内容 http://weibo.cn/guangxianliuya ... e%3D2
driver.get("http://weibo.cn/" + user_id)
#**************************************************************************
# No.1 直接获取 用户昵称 微博数 关注数 粉丝数
# str_name.text是unicode编码类型
#**************************************************************************
#用户id
print u'个人详细信息'
print '**********************************************'
print u'用户id: ' + user_id
#昵称
str_name = driver.find_element_by_xpath("//div[@class='ut']")
str_t = str_name.text.split(" ")
num_name = str_t[0] #空格分隔 获取第一个值 "Eastmount 详细资料 设置 新手区"
print u'昵称: ' + num_name
#微博数 除个人主页 它默认直接显示微博数 无超链接
#Error: 'unicode' object is not callable
#一般是把字符串当做函数使用了 str定义成字符串 而str()函数再次使用时报错
str_wb = driver.find_element_by_xpath("//div[@class='tip2']")
pattern = r"\d+\.?\d*" #正则提取"微博[0]" 但r"(\[.*?\])"总含[]
guid = re.findall(pattern, str_wb.text, re.S|re.M)
print str_wb.text #微博[294] 关注[351] 粉丝[294] 分组[1] @他的
for value in guid:
num_wb = int(value)
break
print u'微博数: ' + str(num_wb)
#关注数
str_gz = driver.find_element_by_xpath("//div[@class='tip2']/a[1]")
guid = re.findall(pattern, str_gz.text, re.M)
num_gz = int(guid[0])
print u'关注数: ' + str(num_gz)
#粉丝数
str_fs = driver.find_element_by_xpath("//div[@class='tip2']/a[2]")
guid = re.findall(pattern, str_fs.text, re.M)
num_fs = int(guid[0])
print u'粉丝数: ' + str(num_fs)
#***************************************************************************
# No.2 文件操作写入信息
#***************************************************************************
infofile.write('=====================================================================\r\n')
infofile.write(u'用户: ' + user_id + '\r\n')
infofile.write(u'昵称: ' + num_name + '\r\n')
infofile.write(u'微博数: ' + str(num_wb) + '\r\n')
infofile.write(u'关注数: ' + str(num_gz) + '\r\n')
infofile.write(u'粉丝数: ' + str(num_fs) + '\r\n')
infofile.write(u'微博内容: ' + '\r\n\r\n')
#***************************************************************************
# No.3 获取微博内容
# http://weibo.cn/guangxianliuya ... e%3D1
# 其中filter=0表示全部 =1表示原创
#***************************************************************************
print '\n'
print u'获取微博内容信息'
num = 1
while num
网站调用新浪微博内容( 请求下图这个链接就能获取这条微博的第二页评论数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-11 21:01
请求下图这个链接就能获取这条微博的第二页评论数据)
第二页呢?事实上,这很简单。您可以通过以下链接获取本微博第二页的评论数据:
其实比第一页多了两个参数。这两个参数实际上隐藏在返回的首页评论数据中:
以此类推,第 n 页所需的 max_id 和 max_id_type 参数隐藏在返回的第 n-1 页的评论数据中。
可以发现,当页面返回的max_id为0时,表示该页面是微博下评论的最后一页。
这样,我们就可以爬取到微博下方的所有评论数据了!(QAQ当然前提是网站没有其他防爬措施,这显然不太可能。)
那么,能否将PC端微博评论页面的链接转换为移动端微博评论页面对应的链接呢?毕竟我们平时都是用电脑上的PC端界面登录然后看微博的!
当然!
在胡歌上一条微博评论页面的PC界面,我发现了这个:
注意:在微博PC端请求链接时,需要添加cookie信息。经过测试,只需要在cookie中添加SUB参数即可。有关详细信息,请参阅相关文件中的源代码。
这不是mid吗,所以PC端微博评论页面的链接可以很方便的转换成手机端微博评论页面对应的链接。
因此,微博评论数据抓取部分的代码可以很方便的写成:
OK,大功告成~完整源码见相关文档~使用说明
在终端运行weiboComments.py文件,命令格式如下:
例如:
python weiboComments.py -u 用户名 -p 密码 -m 10 (即评论数据最多可以抓取10页) -l 一条微博的评论页面链接 -t pc (输入pc/phone,用于表示是否是PC端或移动端微博评论页链接)。
只需运行它并截取屏幕截图:
数据以文件名保存在当前文件夹中:
评论_当前时间戳.pkl。
注意:
为了避免对微博服务器造成不必要的压力,我为我抓取的每个页面设置了更长的暂停时间。
数据可视化
只画了前十页评论的词云,其他数据懒得分析:
源码见相关文件中的vis.py文件。
更多的
新浪微博相关信息 查看全部
网站调用新浪微博内容(
请求下图这个链接就能获取这条微博的第二页评论数据)
第二页呢?事实上,这很简单。您可以通过以下链接获取本微博第二页的评论数据:
其实比第一页多了两个参数。这两个参数实际上隐藏在返回的首页评论数据中:
以此类推,第 n 页所需的 max_id 和 max_id_type 参数隐藏在返回的第 n-1 页的评论数据中。
可以发现,当页面返回的max_id为0时,表示该页面是微博下评论的最后一页。
这样,我们就可以爬取到微博下方的所有评论数据了!(QAQ当然前提是网站没有其他防爬措施,这显然不太可能。)
那么,能否将PC端微博评论页面的链接转换为移动端微博评论页面对应的链接呢?毕竟我们平时都是用电脑上的PC端界面登录然后看微博的!
当然!
在胡歌上一条微博评论页面的PC界面,我发现了这个:
注意:在微博PC端请求链接时,需要添加cookie信息。经过测试,只需要在cookie中添加SUB参数即可。有关详细信息,请参阅相关文件中的源代码。
这不是mid吗,所以PC端微博评论页面的链接可以很方便的转换成手机端微博评论页面对应的链接。
因此,微博评论数据抓取部分的代码可以很方便的写成:
OK,大功告成~完整源码见相关文档~使用说明
在终端运行weiboComments.py文件,命令格式如下:
例如:
python weiboComments.py -u 用户名 -p 密码 -m 10 (即评论数据最多可以抓取10页) -l 一条微博的评论页面链接 -t pc (输入pc/phone,用于表示是否是PC端或移动端微博评论页链接)。
只需运行它并截取屏幕截图:
数据以文件名保存在当前文件夹中:
评论_当前时间戳.pkl。
注意:
为了避免对微博服务器造成不必要的压力,我为我抓取的每个页面设置了更长的暂停时间。
数据可视化
只画了前十页评论的词云,其他数据懒得分析:
源码见相关文件中的vis.py文件。
更多的
新浪微博相关信息
网站调用新浪微博内容(使用python调用微博API的授权机制是什么?如何使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-01-08 05:05
做没有稻草的砖。
数据采集是数据分析的前提。很多网站会通过API接口向第三方开放网站的部分数据。新浪微博也不例外。您可以查看微博 API 列表。
本文将对如何使用微博API进行初步介绍,从而获得基本的概念和理解,方便后面深入了解。
step1:使用python调用微博API,首先下载python SDK,即sinweibopy
sinaweibopy 是一个支持微博 API 的特定于 python 的 OAuth 2 客户端。无依赖,100%纯Py,单一文件,代码简洁,运行可靠。也是新浪微博的Python SDK。
可以直接通过 pip 安装:
pip install sinaweibopy
什么是 SDK?SDK的英文全称是software development kit(软件开发工具包)。简而言之,它是一个代码库,其中收录用于开发应用程序的可重用代码。当您为应用程序编写代码时,您不需要像在实际屏幕上绘制文本那样重复代码。使用 SDK 可以帮助您做到这一点。总而言之,所有这些代码库和一些其他工具构成了我们所说的 SDK。
step2:了解新浪微博的授权机制,即OAuth 2
API 调用需要用户认证(用户授权)。目前OAuth2.0主要用于微博开放平台上的用户身份认证。
OAuth2.0协议的授权流程请参考如下流程图,其中Client指的是第三方应用(即我们自己在第三步创建的应用),Resource Owner指的是用户,授权服务器是我们的授权服务器,资源服务器是API服务器。
从流程图可以看出,为了调用API server内容,需要将access token告诉API server;访问令牌由新浪(授权服务器)在用户授权后返回给我们创建的应用程序;为了完成用户授权,我们的应用首先要给用户授权页面(授权请求)。
微博API授权机制(来自微博开放平台开发文档)
用户授权浏览器后,URL 如下所示:
我们需要将代码后面的字符串提交给新浪授权服务器来获取访问令牌。相当于告诉新浪服务器我们的应用已经被用户授权,现在可以访问用户的数据了,所以授权服务器给了我们一个访问令牌,我们就可以从API服务器获取微博数据了。
了解了上面的机制之后,我们就知道如何编写代码来调用API了。
step3:在微博开放平台上创建自己的应用
现在让我们创建自己的应用程序。创建应用程序的目的是获取应用程序密钥和应用程序机密。
我们使用微连接创建移动应用程序。您还可以创建其他类型的应用程序。创建应用程序后,将分配唯一的应用程序密钥和应用程序密码。您可以在“我的申请-申请信息-基本信息”中查询,将用于授权。注意:无需提交审核,您只需要应用程序密钥和应用程序密钥即可。
如果是异地网页应用或者手机客户端应用,出于安全考虑,需要在平台网站填写redirect_url(授权回调页面)才能使用OAuth2.0。地址填写为“我的申请>申请信息>高级信息”。这里,我们将授权回调页面和取消授权回调页面都设置为默认回调页面:
我的应用程序 - 应用程序信息 - 高级信息
step4:python代码实现
首先,导入所需的模块:
from weibo import APIClient
import webbrowser #python内置的包,支持对浏览器进行操作
使用微博 SDK 创建我们的应用程序:
APP_KEY = '123456'
APP_SECRET = 'abc123xyz456'
CALLBACK_URL = 'https://api.weibo.com/oauth2/default.html' #回调授权页面,用户完成授权后返回的页面
client = APIClient(app_key=APP_KEY, app_secret=APP_SECRET, redirect_uri=CALLBACK_URL)
获取授权页面的url(%3A///oauth2/default.html&response_type=code&client_id=729983294)。用webbrowser打开这个url,会引起浏览器打开
url=client.get_authorize_url() #得到授权页面的url
webbrowser.open_new(url) #打开这个url
打开授权页面的url
用户完成授权后,url 如下所示: . 我们需要code=后面的内容。
print '输入url中code后面的内容后按回车键:'
code = raw_input()
使用代码获取访问令牌:
r = client.request_access_token(code)
access_token = r.access_token # 新浪(授权服务器)返回的token
expires_in = r.expires_in
您可以打印 r 以查看其中的内容:
print(r)
{'access_token': u'abcqwe123', 'expires': 1662109746, 'expires_in': 1662109746, 'uid': u'2164581421'}
设置获取到的access_token后,可以直接调用API:
client.set_access_token(access_token, expires_in)
输出最新的公众微博:
print(client.statuses__public_timeline)
具体返回内容可以查看微博API文档。
例如,我们可以输出用户的昵称、简历、位置和推文:
for i in range(0,length):
print(u'昵称:'+statuses[i]['user']['screen_name'])
print(u'简介:'+statuses[i]['user']['description'])
print(u'位置:'+statuses[i]['user']['location'])
print(u'微博:'+statuses[i]['text'])
最新公开微博
参考:
python调用微博API
如何通过python调用新浪微博的API 查看全部
网站调用新浪微博内容(使用python调用微博API的授权机制是什么?如何使用)
做没有稻草的砖。
数据采集是数据分析的前提。很多网站会通过API接口向第三方开放网站的部分数据。新浪微博也不例外。您可以查看微博 API 列表。
本文将对如何使用微博API进行初步介绍,从而获得基本的概念和理解,方便后面深入了解。
step1:使用python调用微博API,首先下载python SDK,即sinweibopy
sinaweibopy 是一个支持微博 API 的特定于 python 的 OAuth 2 客户端。无依赖,100%纯Py,单一文件,代码简洁,运行可靠。也是新浪微博的Python SDK。
可以直接通过 pip 安装:
pip install sinaweibopy
什么是 SDK?SDK的英文全称是software development kit(软件开发工具包)。简而言之,它是一个代码库,其中收录用于开发应用程序的可重用代码。当您为应用程序编写代码时,您不需要像在实际屏幕上绘制文本那样重复代码。使用 SDK 可以帮助您做到这一点。总而言之,所有这些代码库和一些其他工具构成了我们所说的 SDK。
step2:了解新浪微博的授权机制,即OAuth 2
API 调用需要用户认证(用户授权)。目前OAuth2.0主要用于微博开放平台上的用户身份认证。
OAuth2.0协议的授权流程请参考如下流程图,其中Client指的是第三方应用(即我们自己在第三步创建的应用),Resource Owner指的是用户,授权服务器是我们的授权服务器,资源服务器是API服务器。
从流程图可以看出,为了调用API server内容,需要将access token告诉API server;访问令牌由新浪(授权服务器)在用户授权后返回给我们创建的应用程序;为了完成用户授权,我们的应用首先要给用户授权页面(授权请求)。
微博API授权机制(来自微博开放平台开发文档)
用户授权浏览器后,URL 如下所示:
我们需要将代码后面的字符串提交给新浪授权服务器来获取访问令牌。相当于告诉新浪服务器我们的应用已经被用户授权,现在可以访问用户的数据了,所以授权服务器给了我们一个访问令牌,我们就可以从API服务器获取微博数据了。
了解了上面的机制之后,我们就知道如何编写代码来调用API了。
step3:在微博开放平台上创建自己的应用
现在让我们创建自己的应用程序。创建应用程序的目的是获取应用程序密钥和应用程序机密。
我们使用微连接创建移动应用程序。您还可以创建其他类型的应用程序。创建应用程序后,将分配唯一的应用程序密钥和应用程序密码。您可以在“我的申请-申请信息-基本信息”中查询,将用于授权。注意:无需提交审核,您只需要应用程序密钥和应用程序密钥即可。
如果是异地网页应用或者手机客户端应用,出于安全考虑,需要在平台网站填写redirect_url(授权回调页面)才能使用OAuth2.0。地址填写为“我的申请>申请信息>高级信息”。这里,我们将授权回调页面和取消授权回调页面都设置为默认回调页面:
我的应用程序 - 应用程序信息 - 高级信息
step4:python代码实现
首先,导入所需的模块:
from weibo import APIClient
import webbrowser #python内置的包,支持对浏览器进行操作
使用微博 SDK 创建我们的应用程序:
APP_KEY = '123456'
APP_SECRET = 'abc123xyz456'
CALLBACK_URL = 'https://api.weibo.com/oauth2/default.html' #回调授权页面,用户完成授权后返回的页面
client = APIClient(app_key=APP_KEY, app_secret=APP_SECRET, redirect_uri=CALLBACK_URL)
获取授权页面的url(%3A///oauth2/default.html&response_type=code&client_id=729983294)。用webbrowser打开这个url,会引起浏览器打开
url=client.get_authorize_url() #得到授权页面的url
webbrowser.open_new(url) #打开这个url
打开授权页面的url
用户完成授权后,url 如下所示: . 我们需要code=后面的内容。
print '输入url中code后面的内容后按回车键:'
code = raw_input()
使用代码获取访问令牌:
r = client.request_access_token(code)
access_token = r.access_token # 新浪(授权服务器)返回的token
expires_in = r.expires_in
您可以打印 r 以查看其中的内容:
print(r)
{'access_token': u'abcqwe123', 'expires': 1662109746, 'expires_in': 1662109746, 'uid': u'2164581421'}
设置获取到的access_token后,可以直接调用API:
client.set_access_token(access_token, expires_in)
输出最新的公众微博:
print(client.statuses__public_timeline)
具体返回内容可以查看微博API文档。
例如,我们可以输出用户的昵称、简历、位置和推文:
for i in range(0,length):
print(u'昵称:'+statuses[i]['user']['screen_name'])
print(u'简介:'+statuses[i]['user']['description'])
print(u'位置:'+statuses[i]['user']['location'])
print(u'微博:'+statuses[i]['text'])
最新公开微博
参考:
python调用微博API
如何通过python调用新浪微博的API
网站调用新浪微博内容(蝙蝠侠IT将通过如下内容阐述:站内UV的增长角度)
网站优化 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2022-01-07 01:16
在做SEO的过程中,我们总会遇到各种各样的问题。最常见的情况是网站的排名比较低,每天来自搜索引擎的流量比较少,有时候我们的KPI评估也需要从站点UV增长的角度来衡量,这就是需要我们多思考相关内容。
那么,网站排名靠后,如何提升页面评价浏览量?
根据之前的SEO统计研究,Batman IT将详细阐述以下内容:
1、修复登陆页面
因为我们的网站排名非常低,所以我们在运营的过程中总是需要对落地页进行深入研究,以最大化流量。这是一个非常重要的站内搜索引擎优化,让我们掌握现有的流量并扩大它。方法。
因此,我们可能需要思考:
①改进着陆页,是否可以扩大相关性更高的关键词的排名,提高页面的主题相关性,或者扩展更多的长尾词。
② 修改落地页内容,丰富页面元素,如信息图表的使用,短视频内容的增加,从而增加用户粘性,通过内链合理引导对方访问相关目标页面。
③考虑是否需要搭建百科模块,如有需要,可以申请cookie权限,推荐相关内容。
2、页面内容推荐
我们知道,任何页面的网站结构基本上都是由内容页面下的正文、侧边栏和相关推荐组成,以增加用户站点的平均页面浏览量。
我们需要考虑如何调整相关页面的推荐,比如:
①合理调用相关分类下的内容,并在网站相关栏目推荐。它不必是内容页面的底部。您可以使用网站热图查看热点。
②适当使用底部面板和侧边栏,增加随机内容的推荐。一是增加搜索引擎爬虫的抓取频率,二是增加用户潜在访问的随机性。
③适当使用nofollow推荐行业内一些知名KOL的主题内容,增加页面的相关性。如果可能,您可以适当地建立一个分类的关键推荐。
3、创建聚合页面
对于任何一个行业,如果我们在网站成立之初没有一个完整的结构设计和规划,在后期的运营过程中,很容易造成网站页面内容排序的混乱,如:在不同类别下显示,导致部分内容,无法有效集中显示,增加内容增量。
这时候就需要考虑是否可以通过聚合页面来整合这些相关内容的文章,从而提高目标用户对网站的浏览需求。
4、称重站排热词
如果你是白帽技术从业者,我们在做SEO的过程中遇到了网站的低排名。最大的因素是整个站点的权重相对较低。长期以来,我们需要面对激烈的竞争。对一个流行度高的词进行排名需要一定的时间。这时候就需要合理利用一些高权重的网站,通过第三方高权重的网站,发布竞争性相对较强的关键词,一个基于将流量引导至目标页面的超链接。
5、社交网络引流
如果网站的排名低,短期内没有办法增加网站的权重,我们可能需要考虑和使用社交媒体来增加流量,比如:
①有效利用相关问答平台进行线上推广引流,如:知乎、百度体验、百度贴吧、豆瓣、悟空问答、新浪爱问等。
②利用社交网络平台的推广系统,可以在短时间内快速弥补流量的不足,比如新浪微博上的范同。
③制造热点话题,合理利用大咖的影响力传播话题,形成口碑。
总结:网站排名低,如何提高页面评价浏览量,还有很多细节可以讨论,以上内容仅供参考!
蝙蝠侠IT转载需要授权! 查看全部
网站调用新浪微博内容(蝙蝠侠IT将通过如下内容阐述:站内UV的增长角度)
在做SEO的过程中,我们总会遇到各种各样的问题。最常见的情况是网站的排名比较低,每天来自搜索引擎的流量比较少,有时候我们的KPI评估也需要从站点UV增长的角度来衡量,这就是需要我们多思考相关内容。
那么,网站排名靠后,如何提升页面评价浏览量?
根据之前的SEO统计研究,Batman IT将详细阐述以下内容:
1、修复登陆页面
因为我们的网站排名非常低,所以我们在运营的过程中总是需要对落地页进行深入研究,以最大化流量。这是一个非常重要的站内搜索引擎优化,让我们掌握现有的流量并扩大它。方法。
因此,我们可能需要思考:
①改进着陆页,是否可以扩大相关性更高的关键词的排名,提高页面的主题相关性,或者扩展更多的长尾词。
② 修改落地页内容,丰富页面元素,如信息图表的使用,短视频内容的增加,从而增加用户粘性,通过内链合理引导对方访问相关目标页面。
③考虑是否需要搭建百科模块,如有需要,可以申请cookie权限,推荐相关内容。
2、页面内容推荐
我们知道,任何页面的网站结构基本上都是由内容页面下的正文、侧边栏和相关推荐组成,以增加用户站点的平均页面浏览量。
我们需要考虑如何调整相关页面的推荐,比如:
①合理调用相关分类下的内容,并在网站相关栏目推荐。它不必是内容页面的底部。您可以使用网站热图查看热点。
②适当使用底部面板和侧边栏,增加随机内容的推荐。一是增加搜索引擎爬虫的抓取频率,二是增加用户潜在访问的随机性。
③适当使用nofollow推荐行业内一些知名KOL的主题内容,增加页面的相关性。如果可能,您可以适当地建立一个分类的关键推荐。
3、创建聚合页面
对于任何一个行业,如果我们在网站成立之初没有一个完整的结构设计和规划,在后期的运营过程中,很容易造成网站页面内容排序的混乱,如:在不同类别下显示,导致部分内容,无法有效集中显示,增加内容增量。
这时候就需要考虑是否可以通过聚合页面来整合这些相关内容的文章,从而提高目标用户对网站的浏览需求。
4、称重站排热词
如果你是白帽技术从业者,我们在做SEO的过程中遇到了网站的低排名。最大的因素是整个站点的权重相对较低。长期以来,我们需要面对激烈的竞争。对一个流行度高的词进行排名需要一定的时间。这时候就需要合理利用一些高权重的网站,通过第三方高权重的网站,发布竞争性相对较强的关键词,一个基于将流量引导至目标页面的超链接。
5、社交网络引流
如果网站的排名低,短期内没有办法增加网站的权重,我们可能需要考虑和使用社交媒体来增加流量,比如:
①有效利用相关问答平台进行线上推广引流,如:知乎、百度体验、百度贴吧、豆瓣、悟空问答、新浪爱问等。
②利用社交网络平台的推广系统,可以在短时间内快速弥补流量的不足,比如新浪微博上的范同。
③制造热点话题,合理利用大咖的影响力传播话题,形成口碑。
总结:网站排名低,如何提高页面评价浏览量,还有很多细节可以讨论,以上内容仅供参考!
蝙蝠侠IT转载需要授权!
网站调用新浪微博内容(新浪微博的XSS攻击事件总结及解决办法(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-01-06 16:10
请注意,用户还可以将脚本注入描述和书签字段,而不仅仅是名称字段。我们需要对需要从书签文件中读取的任何数据进行编码,因为我们会将其打印到浏览器。
新浪微博攻击
(2011年6月28日)新浪微博发生了一次比较大的XSS攻击。大量用户自动发送诸如:“郭美美事件一些不被注意的细节”、“党建中穿帮的地方”、“让女人心跳的100首诗”、“3D肉团”段子高清国语版种子》、《这就是传说中的神仙亲人》、《轰!范冰冰的色情照片真的流出》等微博和私信,并自动关注了一个名叫hellosmy的用户。
事件线索如下:
20时14分,大量V认证用户开始招募转发蠕虫
20:30,病毒页面无法访问
20:32 新浪微博用户hellosmy无法访问
21:02,新浪漏洞补丁完成
XSS攻击代码简析
函数 createXHR(){ 返回 window.XMLHttpRequest? new XMLHttpRequest(): new ActiveXObject("Microsoft.XMLHTTP");} function getappkey(url){ xmlHttp = createXHR(); xmlHttp.open("GET",url,false); xmlHttp.send(); 结果 = xmlHttp.responseText; id_arr =''; id = result.match(/namecard=\"true\" title=\"[^\"]*/g); for(i= 0;i 这段代码比较丰富,它让微博广场的URL在请求中注入一个JS文件,JS请求完成后,会自动执行并从发布的微博(包括攻击Site link)等站点已经完成了攻击,可以看到main函数调用了publish、follow、message函数来帮你做那些坏事。
总结
可见XSS攻击的方式其实有很多种,大家可以防一下。但是,有时你会发现它们的一些共性-注入然后使用浏览器自动执行。因此,必须严格检查不可信的输入和输出!
参考文献和引文:
Cool Shell:对新浪微博的XSS攻击
MSDN 查看全部
网站调用新浪微博内容(新浪微博的XSS攻击事件总结及解决办法(一))
请注意,用户还可以将脚本注入描述和书签字段,而不仅仅是名称字段。我们需要对需要从书签文件中读取的任何数据进行编码,因为我们会将其打印到浏览器。
新浪微博攻击
(2011年6月28日)新浪微博发生了一次比较大的XSS攻击。大量用户自动发送诸如:“郭美美事件一些不被注意的细节”、“党建中穿帮的地方”、“让女人心跳的100首诗”、“3D肉团”段子高清国语版种子》、《这就是传说中的神仙亲人》、《轰!范冰冰的色情照片真的流出》等微博和私信,并自动关注了一个名叫hellosmy的用户。
事件线索如下:
20时14分,大量V认证用户开始招募转发蠕虫
20:30,病毒页面无法访问
20:32 新浪微博用户hellosmy无法访问
21:02,新浪漏洞补丁完成
XSS攻击代码简析
函数 createXHR(){ 返回 window.XMLHttpRequest? new XMLHttpRequest(): new ActiveXObject("Microsoft.XMLHTTP");} function getappkey(url){ xmlHttp = createXHR(); xmlHttp.open("GET",url,false); xmlHttp.send(); 结果 = xmlHttp.responseText; id_arr =''; id = result.match(/namecard=\"true\" title=\"[^\"]*/g); for(i= 0;i 这段代码比较丰富,它让微博广场的URL在请求中注入一个JS文件,JS请求完成后,会自动执行并从发布的微博(包括攻击Site link)等站点已经完成了攻击,可以看到main函数调用了publish、follow、message函数来帮你做那些坏事。
总结
可见XSS攻击的方式其实有很多种,大家可以防一下。但是,有时你会发现它们的一些共性-注入然后使用浏览器自动执行。因此,必须严格检查不可信的输入和输出!
参考文献和引文:
Cool Shell:对新浪微博的XSS攻击
MSDN
网站调用新浪微博内容(新浪微博短链接API是开放的,国外几家已经悲剧了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-06 01:18
在短地址(又称短链接、短地址等)方面,推特是经过发展后发展起来的,很多互联网网站都使用短地址。国内外有很多,但稳定可靠。国内的比较靠谱。我不怕没有墙。国外有几家公司已经悲剧了,所以如果在项目中使用短地址,我还是推荐使用新浪或者其他国内的短链接服务。
新浪微博短链接API开放,但腾讯微博短地址API未开放。我想通过不同的路径获取腾讯微博的API,但以失败告终。新浪微博短地址API不需要用户登录,直接调用即可,速度非常快。以下代码取自网站,使用CURL POST方式参考。
新浪微博短链接API文档在老版本的开发文档中,但新版本没有添加:
function shortenSinaUrl(long_url){apiKey='1234567890';//这里是你申请的应用的API KEY,随便写个应用名就会自动分配给你
apiUrl='http://api.t.sina.com.cn/short_url/shorten.json?source='.apiKey.'&url_long='.long_url;curlObj = curl_init();
curl_setopt(curlObj, CURLOPT_URL,apiUrl);
curl_setopt(curlObj, CURLOPT_RETURNTRANSFER, 1);
curl_setopt(curlObj, CURLOPT_SSL_VERIFYPEER, 0);
curl_setopt(curlObj, CURLOPT_HEADER, 0);
curl_setopt(curlObj, CURLOPT_HTTPHEADER, array('Content-type:application/json'));
response = curl_exec(curlObj);
curl_close(curlObj);json = json_decode(response);
returnjson[0]->url_short;
}
function expandSinaUrl(short_url){apiKey='1234567890';//要修改这里的key再测试哦
apiUrl='http://api.t.sina.com.cn/short_url/expand.json?source='.apiKey.'&url_short='.short_url;curlObj = curl_init();
curl_setopt(curlObj, CURLOPT_URL,apiUrl);
curl_setopt(curlObj, CURLOPT_RETURNTRANSFER, 1);
curl_setopt(curlObj, CURLOPT_SSL_VERIFYPEER, 0);
curl_setopt(curlObj, CURLOPT_HEADER, 0);
curl_setopt(curlObj, CURLOPT_HTTPHEADER, array('Content-type:application/json'));
response = curl_exec(curlObj);
curl_close(curlObj);json = json_decode(response);
returnjson[0]->url_long;
}
参考新浪微博的开发文档,推荐使用get方式获取。代码更简单
function shorturl(long_url){apiKey='1234567890';//要修改这里的key再测试哦
apiUrl='http://api.t.sina.com.cn/short_url/shorten.json?source='.apiKey.'&url_long='.long_url;response = file_get_contents(apiUrl);json = json_decode(response);
returnjson[0]->url_short;
}
function expandurl(short_url){apiKey='1234567890';//要修改这里的key再测试哦
apiUrl='http://api.t.sina.com.cn/short_url/expand.json?source='.apiKey.'&url_short='.short_url;response = file_get_contents(apiUrl);json = json_decode(response);
returnjson[0]->url_long;
}
好吧,不是更容易吗?
调试上面代码的时候,需要填写自己的API key,不然肯定拿不到。
特别说明:短地址服务现在只为经过认证的APP KEY提供服务,刚刚申请的APP KEY会提示没有权限。可以使用209678993和3818214747这两个KEY进行测试。这两个KEY的来源不明,不推荐用于生产。(感谢您的提醒)
Jucelin 写了一个调试文档,你可以测试一下:
长到短:://
短到长::///S4bLBm
只有2个参数,type:1表示长到短,2表示短到长,后面的URL就是目标域名。因为懒惰,所以没有错误的判断。新浪微博短地址不支持短地址后短地址。是的,逻辑上应该是这样控制的。(不信你可以试试)。
关于新浪微博短地址接口的更详细说明,请参见“新浪微博短地址接口”。 查看全部
网站调用新浪微博内容(新浪微博短链接API是开放的,国外几家已经悲剧了)
在短地址(又称短链接、短地址等)方面,推特是经过发展后发展起来的,很多互联网网站都使用短地址。国内外有很多,但稳定可靠。国内的比较靠谱。我不怕没有墙。国外有几家公司已经悲剧了,所以如果在项目中使用短地址,我还是推荐使用新浪或者其他国内的短链接服务。
新浪微博短链接API开放,但腾讯微博短地址API未开放。我想通过不同的路径获取腾讯微博的API,但以失败告终。新浪微博短地址API不需要用户登录,直接调用即可,速度非常快。以下代码取自网站,使用CURL POST方式参考。
新浪微博短链接API文档在老版本的开发文档中,但新版本没有添加:
function shortenSinaUrl(long_url){apiKey='1234567890';//这里是你申请的应用的API KEY,随便写个应用名就会自动分配给你
apiUrl='http://api.t.sina.com.cn/short_url/shorten.json?source='.apiKey.'&url_long='.long_url;curlObj = curl_init();
curl_setopt(curlObj, CURLOPT_URL,apiUrl);
curl_setopt(curlObj, CURLOPT_RETURNTRANSFER, 1);
curl_setopt(curlObj, CURLOPT_SSL_VERIFYPEER, 0);
curl_setopt(curlObj, CURLOPT_HEADER, 0);
curl_setopt(curlObj, CURLOPT_HTTPHEADER, array('Content-type:application/json'));
response = curl_exec(curlObj);
curl_close(curlObj);json = json_decode(response);
returnjson[0]->url_short;
}
function expandSinaUrl(short_url){apiKey='1234567890';//要修改这里的key再测试哦
apiUrl='http://api.t.sina.com.cn/short_url/expand.json?source='.apiKey.'&url_short='.short_url;curlObj = curl_init();
curl_setopt(curlObj, CURLOPT_URL,apiUrl);
curl_setopt(curlObj, CURLOPT_RETURNTRANSFER, 1);
curl_setopt(curlObj, CURLOPT_SSL_VERIFYPEER, 0);
curl_setopt(curlObj, CURLOPT_HEADER, 0);
curl_setopt(curlObj, CURLOPT_HTTPHEADER, array('Content-type:application/json'));
response = curl_exec(curlObj);
curl_close(curlObj);json = json_decode(response);
returnjson[0]->url_long;
}
参考新浪微博的开发文档,推荐使用get方式获取。代码更简单
function shorturl(long_url){apiKey='1234567890';//要修改这里的key再测试哦
apiUrl='http://api.t.sina.com.cn/short_url/shorten.json?source='.apiKey.'&url_long='.long_url;response = file_get_contents(apiUrl);json = json_decode(response);
returnjson[0]->url_short;
}
function expandurl(short_url){apiKey='1234567890';//要修改这里的key再测试哦
apiUrl='http://api.t.sina.com.cn/short_url/expand.json?source='.apiKey.'&url_short='.short_url;response = file_get_contents(apiUrl);json = json_decode(response);
returnjson[0]->url_long;
}
好吧,不是更容易吗?
调试上面代码的时候,需要填写自己的API key,不然肯定拿不到。
特别说明:短地址服务现在只为经过认证的APP KEY提供服务,刚刚申请的APP KEY会提示没有权限。可以使用209678993和3818214747这两个KEY进行测试。这两个KEY的来源不明,不推荐用于生产。(感谢您的提醒)
Jucelin 写了一个调试文档,你可以测试一下:
长到短:://
短到长::///S4bLBm
只有2个参数,type:1表示长到短,2表示短到长,后面的URL就是目标域名。因为懒惰,所以没有错误的判断。新浪微博短地址不支持短地址后短地址。是的,逻辑上应该是这样控制的。(不信你可以试试)。
关于新浪微博短地址接口的更详细说明,请参见“新浪微博短地址接口”。
网站调用新浪微博内容(新浪开的店铺均除外怎么办?每一步该如何操作 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-01-06 01:17
)
申请先决条件:你必须有一个,一个独立的网站;除了新浪开设的官方博客和天猫开设的商店。
申请有四种申请方式:①开发者身份认证②网站所有权验证③部署微链接④填写申请信息(提交审核),让我们详细了解每一步的操作方法!
第一步,登录新浪微博开放平台,点击下方图标,开始创建网站接入应用;
如果您尚未完成开发者身份验证,系统会引导您进入身份验证页面;
身份认证通过并不意味着您拥有自己的应用程序;身份认证通过后才能创建应用;
关于开发者类型,请根据实际情况填写;个人或企业不会影响您创建网站访问应用程序;如果选择企业,未来可以创造更多的应用类型;
身份验证周期为1-2个工作日,请关注系统通知;
第二步:验证网站的所有权,我们来学习一下如何填写;
网站姓名,即你要在微博上显示的“发件人”的名字,需要和你的网站相关联;
申请提交审核时可修改两次名称;
如果提示“网站名称已存在,请更改一个”,表示该名称已被占用,必须更改;
网站域名与您在微博点击“来自”时访问的页面相关,但不是绝对的;
比如这里填写,当申请提交审核时,可以设置点击“发件人”访问
选择验证方式,即新浪确认网站是否属于您。
微博平台提供两种验证方式。请把这一步留给网站技术(运维);因为涉及到修改你的网站官方源码,一般来说网站技术(运维)有相应的权限;
如何确认网站技术(运维)同学添加了验证码?访问你上一步填写的“网站域名”的网页,点击鼠标右键“查看网页源代码”,先找到head标签,再进一步搜索...(如果这个输入说话,本教程无法继续)
完成以上表格后,点击“验证并添加”进入以下页面;(当开发者身份认证为“企业”时,会略有不同)
注意,此时不要关闭页面;虽然我们成功获取了AppKey和AppSecret,但并不代表申请成功;在新窗口中打开“微组件”,我们将进入下一步;
第三步:部署微组件;如果没有部署微博组件,应用是不会通过审核的,切记;
选择你需要的功能(组件)部署网站。申请通过审核后,即可移除该组件;
例如,我们选择“关注按钮”...
查看全部
网站调用新浪微博内容(新浪开的店铺均除外怎么办?每一步该如何操作
)
申请先决条件:你必须有一个,一个独立的网站;除了新浪开设的官方博客和天猫开设的商店。
申请有四种申请方式:①开发者身份认证②网站所有权验证③部署微链接④填写申请信息(提交审核),让我们详细了解每一步的操作方法!
第一步,登录新浪微博开放平台,点击下方图标,开始创建网站接入应用;
如果您尚未完成开发者身份验证,系统会引导您进入身份验证页面;
身份认证通过并不意味着您拥有自己的应用程序;身份认证通过后才能创建应用;
关于开发者类型,请根据实际情况填写;个人或企业不会影响您创建网站访问应用程序;如果选择企业,未来可以创造更多的应用类型;
身份验证周期为1-2个工作日,请关注系统通知;
第二步:验证网站的所有权,我们来学习一下如何填写;
网站姓名,即你要在微博上显示的“发件人”的名字,需要和你的网站相关联;
申请提交审核时可修改两次名称;
如果提示“网站名称已存在,请更改一个”,表示该名称已被占用,必须更改;
网站域名与您在微博点击“来自”时访问的页面相关,但不是绝对的;
比如这里填写,当申请提交审核时,可以设置点击“发件人”访问
选择验证方式,即新浪确认网站是否属于您。
微博平台提供两种验证方式。请把这一步留给网站技术(运维);因为涉及到修改你的网站官方源码,一般来说网站技术(运维)有相应的权限;
如何确认网站技术(运维)同学添加了验证码?访问你上一步填写的“网站域名”的网页,点击鼠标右键“查看网页源代码”,先找到head标签,再进一步搜索...(如果这个输入说话,本教程无法继续)
完成以上表格后,点击“验证并添加”进入以下页面;(当开发者身份认证为“企业”时,会略有不同)
注意,此时不要关闭页面;虽然我们成功获取了AppKey和AppSecret,但并不代表申请成功;在新窗口中打开“微组件”,我们将进入下一步;
第三步:部署微组件;如果没有部署微博组件,应用是不会通过审核的,切记;
选择你需要的功能(组件)部署网站。申请通过审核后,即可移除该组件;
例如,我们选择“关注按钮”...
网站调用新浪微博内容(新浪SAE吐槽:字“坑”,好了!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2022-01-05 02:12
新浪微博平台与新浪SAE相同,同一个“坑”字
1:直接登录新浪,添加网站,然后直接添加我们在新浪SAE上创建的应用
2:填写信息,只需填写ICP备案信息号的备案号即可。如果使用图标,photoshop应该没有问题
3:拿到钥匙并安装。小样的网页我们一般很难通过审核,不过没关系,只要能拿到测试账号就可以了。
只要审核通过,无论通过与否,测试账号的key和secret都可以使用,提交审核即可。
4:代码如下,参考网上,但是现在找不到那个博客了。. . . . ,所以没有外链。. .
import sys<br />#在微博开放平台上的SDK中找到python SDK,下载安装就行
import weibo
import webbrowser
import json <br />#舔你的微博开放平台网站的key
APP_KEY = '643524640'<br />#对应的serect
MY_APP_SECRET = '32f7d34f4d826b818a05be54c161c933'<br />#这个可以对应SAE应用的url
REDIRECT_URL = 'http://irsearch.sinaapp.com/'
#要想看懂这些代码,努力的去看python SDK吧
api = weibo.APIClient(APP_KEY, MY_APP_SECRET)
authorize_url = api.get_authorize_url(REDIRECT_URL)
#print(authorize_url)
webbrowser.open_new(authorize_url)
code = raw_input()
request = api.request_access_token(code, REDIRECT_URL)
access_token = request.access_token
expires_in = request.expires_in
api.set_access_token(access_token, expires_in)
#public_timeline有三个参数
<br />t = api.statuses__public_timeline(count=1)
5:返回的数据格式为weibo.JsonDict,其中中文采用unicode编码
可以使用python的json进行转换
#接上面<br />print(t)
print(type(t))
te = json.dumps(t,ensure_ascii=False)
print(type(te))
print(te)
tem = json.loads(te)
print(type(tem))
print(tem)
结果部分如下:
{"interval": 0, "hasvisible": false, "total_number": 1, "previous_cursor": 0, "next_cursor": 0, "statuses": [{"reposts_count": 0, "truncated": false, "text": "\"激情世界杯 满减送不停\",这个活动推荐给大家。 地址:http://t.cn/RvuECDN", "visible": {"type": 0, "list_id": 0}, "in_reply_to_status_id": "", "bmiddle_pic": "http://ww1.sinaimg.cn/bmiddle/ ... ot%3B, "id": 3728023935535065, "thumbnail_pic": "http://ww1.sinaimg.cn/thumbnai ... ot%3B, "mid": "3728023935535065", "source": "<a href=\"http://app.weibo.com/t/feed/59hmLP\" rel=\"nofollow\">微活动</a>", "attitudes_count": 0, "in_reply_to_screen_name": "", "pic_urls": [{"thumbnail_pic": "http://ww1.sinaimg.cn/thumbnai ... ot%3B}], "annotations": [{"source": {"url": "http://event.weibo.com/23382470", "title": "激情世界杯 满减...", "id": "23382470", "name": "激情世界杯 满减送不停", "appid": "38"}}], "in_reply_to_user_id": "", "darwin_tags": [], "favorited": false, "original_pic": "http://ww1.sinaimg.cn/large/df ... ot%3B, "idstr": "3728023935535065", "user": {"bi_followers_count": 9, "domain": "", "avatar_large": "http://tp2.sinaimg.cn/18011200 ... ot%3B, "verified_source": "", "ptype": 0, "statuses_count": 312, "allow_all_comment": true, "id": 1801120077, "verified_reason_url": "", "city": "1", "province": "44", "block_app": 0, "follow_me": false, "verified_reason": "", "followers_count": 186, "location": "广东 广州", "verified_trade": "", "mbtype": 0, "verified_source_url": "", "profile_url": "u/1801120077", "block_word": 0, "avatar_hd": "http://ww1.sinaimg.cn/crop.0.0 ... ot%3B, "star": 0, "description": "", "friends_count": 371, "online_status": 1, "mbrank": 0, "allow_all_act_msg": true, "profile_image_url": "http://tp2.sinaimg.cn/18011200 ... ot%3B, "idstr": "1801120077", "verified": false, "geo_enabled": true, "class": 1, "screen_name": "车赣刺", "lang": "zh-cn", "weihao": "", "remark": "", "favourites_count": 0, "name": "车赣刺", "url": "", "gender": "m", "created_at": "Mon Aug 23 18:32:22 +0800 2010", "worldcup_guess": 0, "verified_type": -1, "following": false}, "geo": null, "created_at": "Wed Jul 02 23:07:12 +0800 2014", "mlevel": 0, "comments_count": 0}]}
6:这是一本字典,你想怎么用就怎么用 查看全部
网站调用新浪微博内容(新浪SAE吐槽:字“坑”,好了!)
新浪微博平台与新浪SAE相同,同一个“坑”字
1:直接登录新浪,添加网站,然后直接添加我们在新浪SAE上创建的应用
2:填写信息,只需填写ICP备案信息号的备案号即可。如果使用图标,photoshop应该没有问题
3:拿到钥匙并安装。小样的网页我们一般很难通过审核,不过没关系,只要能拿到测试账号就可以了。
只要审核通过,无论通过与否,测试账号的key和secret都可以使用,提交审核即可。
4:代码如下,参考网上,但是现在找不到那个博客了。. . . . ,所以没有外链。. .
import sys<br />#在微博开放平台上的SDK中找到python SDK,下载安装就行
import weibo
import webbrowser
import json <br />#舔你的微博开放平台网站的key
APP_KEY = '643524640'<br />#对应的serect
MY_APP_SECRET = '32f7d34f4d826b818a05be54c161c933'<br />#这个可以对应SAE应用的url
REDIRECT_URL = 'http://irsearch.sinaapp.com/'
#要想看懂这些代码,努力的去看python SDK吧
api = weibo.APIClient(APP_KEY, MY_APP_SECRET)
authorize_url = api.get_authorize_url(REDIRECT_URL)
#print(authorize_url)
webbrowser.open_new(authorize_url)
code = raw_input()
request = api.request_access_token(code, REDIRECT_URL)
access_token = request.access_token
expires_in = request.expires_in
api.set_access_token(access_token, expires_in)
#public_timeline有三个参数
<br />t = api.statuses__public_timeline(count=1)
5:返回的数据格式为weibo.JsonDict,其中中文采用unicode编码
可以使用python的json进行转换
#接上面<br />print(t)
print(type(t))
te = json.dumps(t,ensure_ascii=False)
print(type(te))
print(te)
tem = json.loads(te)
print(type(tem))
print(tem)
结果部分如下:
{"interval": 0, "hasvisible": false, "total_number": 1, "previous_cursor": 0, "next_cursor": 0, "statuses": [{"reposts_count": 0, "truncated": false, "text": "\"激情世界杯 满减送不停\",这个活动推荐给大家。 地址:http://t.cn/RvuECDN", "visible": {"type": 0, "list_id": 0}, "in_reply_to_status_id": "", "bmiddle_pic": "http://ww1.sinaimg.cn/bmiddle/ ... ot%3B, "id": 3728023935535065, "thumbnail_pic": "http://ww1.sinaimg.cn/thumbnai ... ot%3B, "mid": "3728023935535065", "source": "<a href=\"http://app.weibo.com/t/feed/59hmLP\" rel=\"nofollow\">微活动</a>", "attitudes_count": 0, "in_reply_to_screen_name": "", "pic_urls": [{"thumbnail_pic": "http://ww1.sinaimg.cn/thumbnai ... ot%3B}], "annotations": [{"source": {"url": "http://event.weibo.com/23382470", "title": "激情世界杯 满减...", "id": "23382470", "name": "激情世界杯 满减送不停", "appid": "38"}}], "in_reply_to_user_id": "", "darwin_tags": [], "favorited": false, "original_pic": "http://ww1.sinaimg.cn/large/df ... ot%3B, "idstr": "3728023935535065", "user": {"bi_followers_count": 9, "domain": "", "avatar_large": "http://tp2.sinaimg.cn/18011200 ... ot%3B, "verified_source": "", "ptype": 0, "statuses_count": 312, "allow_all_comment": true, "id": 1801120077, "verified_reason_url": "", "city": "1", "province": "44", "block_app": 0, "follow_me": false, "verified_reason": "", "followers_count": 186, "location": "广东 广州", "verified_trade": "", "mbtype": 0, "verified_source_url": "", "profile_url": "u/1801120077", "block_word": 0, "avatar_hd": "http://ww1.sinaimg.cn/crop.0.0 ... ot%3B, "star": 0, "description": "", "friends_count": 371, "online_status": 1, "mbrank": 0, "allow_all_act_msg": true, "profile_image_url": "http://tp2.sinaimg.cn/18011200 ... ot%3B, "idstr": "1801120077", "verified": false, "geo_enabled": true, "class": 1, "screen_name": "车赣刺", "lang": "zh-cn", "weihao": "", "remark": "", "favourites_count": 0, "name": "车赣刺", "url": "", "gender": "m", "created_at": "Mon Aug 23 18:32:22 +0800 2010", "worldcup_guess": 0, "verified_type": -1, "following": false}, "geo": null, "created_at": "Wed Jul 02 23:07:12 +0800 2014", "mlevel": 0, "comments_count": 0}]}
6:这是一本字典,你想怎么用就怎么用

