
网站调用新浪微博内容
网站调用新浪微博内容是哪个公司的什么代理服务?
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-09-15 21:01
网站调用新浪微博内容一般都使用双边代理的形式。可以查看ispormonitor查看网站调用的是哪个公司的什么代理服务。如果没有,则可以打客服电话获取更多isp服务。
新浪没用他,这种sb网站就是这样,一个政府名字竟然用和政府沾边的手段来挣钱,还真tm让人恶心,什么商家融资,好吧,
不会是新浪打广告吧?还是提供什么服务收费?广告联盟其实也是跟新浪合作的。要提供什么服务,你要看他们合作的是哪家。联盟返佣模式还可以,聚合seo最让人头疼了。
个人认为是通过新浪抓取新浪自身服务的信息。对于站长来说,靠这个赚钱的成本已经太高,而且还要保证新浪能收到钱,
新浪微博很多文章都是打广告的吧?!就算想要在微博的内容中对电商进行引导性的推荐,也必须对同名内容实现其他域名进行投放。因为在搜索引擎输入电商关键词是从搜索引擎中先搜出来的那个域名,如果内容有效果再让用户点击。
前两天新浪还给云豆发红包,只要把电商内容发出去就返还,获得第一的红包很高,
被新浪微博无下限打广告了吧。
新浪是否真要自己打广告?如果微博想卖产品,或者打开洞见,那用什么去调用这个网站,难道要花钱雇人跳广告??这个主要是要看新浪是否允许通过微博的正常推广赚钱。 查看全部
网站调用新浪微博内容是哪个公司的什么代理服务?
网站调用新浪微博内容一般都使用双边代理的形式。可以查看ispormonitor查看网站调用的是哪个公司的什么代理服务。如果没有,则可以打客服电话获取更多isp服务。
新浪没用他,这种sb网站就是这样,一个政府名字竟然用和政府沾边的手段来挣钱,还真tm让人恶心,什么商家融资,好吧,

不会是新浪打广告吧?还是提供什么服务收费?广告联盟其实也是跟新浪合作的。要提供什么服务,你要看他们合作的是哪家。联盟返佣模式还可以,聚合seo最让人头疼了。
个人认为是通过新浪抓取新浪自身服务的信息。对于站长来说,靠这个赚钱的成本已经太高,而且还要保证新浪能收到钱,
新浪微博很多文章都是打广告的吧?!就算想要在微博的内容中对电商进行引导性的推荐,也必须对同名内容实现其他域名进行投放。因为在搜索引擎输入电商关键词是从搜索引擎中先搜出来的那个域名,如果内容有效果再让用户点击。

前两天新浪还给云豆发红包,只要把电商内容发出去就返还,获得第一的红包很高,
被新浪微博无下限打广告了吧。
新浪是否真要自己打广告?如果微博想卖产品,或者打开洞见,那用什么去调用这个网站,难道要花钱雇人跳广告??这个主要是要看新浪是否允许通过微博的正常推广赚钱。
Python使用微博API实现自动发送微博
网站优化 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2022-08-18 14:17
微博开放平台创建应用
微博开放平台:
点击:微连接>网站接入,输入应用名称创建应用。
填写应用基本信息
点击左侧高级信息,填写相关内容:
完善信息后提交审核。
记录应用相关信息相关代码获取Code
<p>import requests
try:
from urllib.parse import urlencode
except ImportError:
from urllib import urlencode
<br />
# App Key
API_KEY = 'xxxxx'
# 授权回调页
REDIRECT_URI = 'xxxxx'
# REDIRECT_URI = 'https://api.weibo.com/oauth2/default.html'
<br />
url = 'https://api.weibo.com/oauth2/authorize'
<br />
def get_url():
params = {
'client_id': API_KEY,
'redirect_uri': REDIRECT_URI
}
return "{0}?{1}".format(url, urlencode(params))
<br />
<br />
print(get_url())</p>
把打印出来的链接粘贴到浏览器上,回车点击授权后重定向到的新链接中出现code=xxxx,后面的值即为code值,记录code值后续获取access_token需要使用到它。
获取access_token
<p>import requests
import json
try:
from urllib.parse import urlencode
except ImportError:
from urllib import urlencode
<br />
API_KEY = 'XXXX'
API_SECRET = 'XXXXXXXX'
CODE = 'XXXX'
REDIRECT_URI = 'XXXX'
<br />
access_token_url = 'https://api.weibo.com/oauth2/access_token'
<br />
<br />
params = {
'client_id': API_KEY,
'client_secret': API_SECRET,
'grant_type': 'authorization_code',
'code': CODE,
'redirect_uri': REDIRECT_URI
}
res = requests.post(access_token_url, data=params)
token = json.loads(res.text)
print(token)</p>
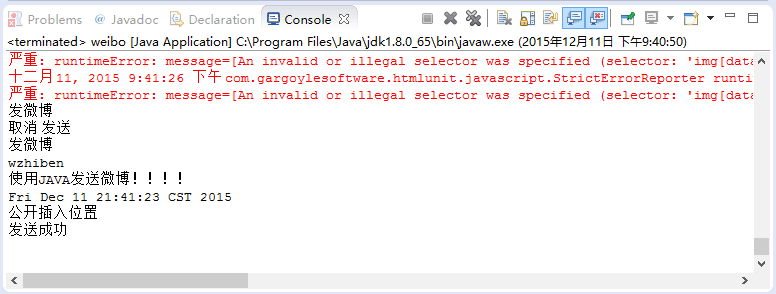
执行程序得到以下内容:
<p>{
'access_token': 'xxxxxxxxxxxxxxxxxxxx',
'remind_in': '157679999',
'expires_in': 157679999,
'uid': '5741349972',
'isRealName': 'true'
}</p>
返回值字段字段类型字段说明
access_token
string
用户授权的唯一票据,用于调用微博的开放接口,同时也是第三方应用验证微博用户登录的唯一票据,第三方应用应该用该票据和自己应用内的用户建立唯一影射关系,来识别登录状态,不能使用本返回值里的UID字段来做登录识别。
expires_in
string
access_token的生命周期,单位是秒数。
remind_in
string
accesstoken的生命周期(该参数即将废弃,开发者请使用expiresin)。
uid
string
授权用户的UID,本字段只是为了方便开发者,减少一次user/show接口调用而返回的,第三方应用不能用此字段作为用户登录状态的识别,只有access_token才是用户授权的唯一票据。
access_token长时间有效,拿到之后就可以使用这个去调用发微博的接口了。
发微博
图文微博
<p>import requests
<br />
access_token = 'xxxxxxxxxxxxx'
<br />
url = "https://api.weibo.com/2/statuses/share.json"
# 应用的服务IP地址
rip = "xxxxxxxxxx"
#构建POST参数
params = {
"access_token": access_token,
#内容末尾带后台绑定的安全域名 或 安全域名下的网页
"status": "手执流光,梦里红尘。细品黎明的清新,感悟暮色的浓郁,置身于时光的长廊,昼看风散,夜听雨眠。https://xxx.com",
"rip": rip
}
#构建二进制multipart/form-data编码的参数
files={
"pic":open("1.jpg","rb")
}
#POST请求,发表文字+图片微博
res = requests.post(url,data = params, files = files)
print(res.text)</p>
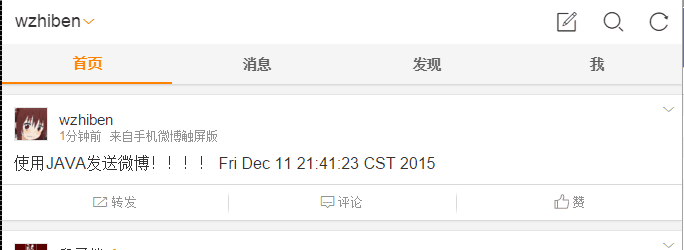
运行程序,去微博主页看看是否发布成功。
如果应用还在审核中会有:来自 未通过审核应用。
注:使用该接口发送的博文 后面会带有网页链接
可能出现的错误
<p>// 检查授权回调页 安全设置 安全域名等配置项 是否正确或未填写
{'error': 'redirect_uri_mismatch', 'error_code': 21322, 'request': '/oauth2/access_token', 'error_uri': '/oauth2/access_token'}
<br />
// 检查要发送的内容是否包含链接,因为现在新浪微博强制要求要带链接。
{"error":"text not find domain!","error_code":10017,"request":"/2/statuses/share.json"}
<br />
// 参数错误或请求出错</p> 查看全部
Python使用微博API实现自动发送微博
微博开放平台创建应用
微博开放平台:
点击:微连接>网站接入,输入应用名称创建应用。
填写应用基本信息
点击左侧高级信息,填写相关内容:
完善信息后提交审核。
记录应用相关信息相关代码获取Code
<p>import requests
try:
from urllib.parse import urlencode
except ImportError:
from urllib import urlencode
<br />
# App Key
API_KEY = 'xxxxx'
# 授权回调页
REDIRECT_URI = 'xxxxx'
# REDIRECT_URI = 'https://api.weibo.com/oauth2/default.html'
<br />
url = 'https://api.weibo.com/oauth2/authorize'
<br />
def get_url():
params = {
'client_id': API_KEY,
'redirect_uri': REDIRECT_URI
}
return "{0}?{1}".format(url, urlencode(params))
<br />
<br />
print(get_url())</p>
把打印出来的链接粘贴到浏览器上,回车点击授权后重定向到的新链接中出现code=xxxx,后面的值即为code值,记录code值后续获取access_token需要使用到它。

获取access_token
<p>import requests
import json
try:
from urllib.parse import urlencode
except ImportError:
from urllib import urlencode
<br />
API_KEY = 'XXXX'
API_SECRET = 'XXXXXXXX'
CODE = 'XXXX'
REDIRECT_URI = 'XXXX'
<br />
access_token_url = 'https://api.weibo.com/oauth2/access_token'
<br />
<br />
params = {
'client_id': API_KEY,
'client_secret': API_SECRET,
'grant_type': 'authorization_code',
'code': CODE,
'redirect_uri': REDIRECT_URI
}
res = requests.post(access_token_url, data=params)
token = json.loads(res.text)
print(token)</p>
执行程序得到以下内容:
<p>{
'access_token': 'xxxxxxxxxxxxxxxxxxxx',
'remind_in': '157679999',
'expires_in': 157679999,
'uid': '5741349972',
'isRealName': 'true'
}</p>
返回值字段字段类型字段说明
access_token
string
用户授权的唯一票据,用于调用微博的开放接口,同时也是第三方应用验证微博用户登录的唯一票据,第三方应用应该用该票据和自己应用内的用户建立唯一影射关系,来识别登录状态,不能使用本返回值里的UID字段来做登录识别。
expires_in
string
access_token的生命周期,单位是秒数。
remind_in
string

accesstoken的生命周期(该参数即将废弃,开发者请使用expiresin)。
uid
string
授权用户的UID,本字段只是为了方便开发者,减少一次user/show接口调用而返回的,第三方应用不能用此字段作为用户登录状态的识别,只有access_token才是用户授权的唯一票据。
access_token长时间有效,拿到之后就可以使用这个去调用发微博的接口了。
发微博
图文微博
<p>import requests
<br />
access_token = 'xxxxxxxxxxxxx'
<br />
url = "https://api.weibo.com/2/statuses/share.json"
# 应用的服务IP地址
rip = "xxxxxxxxxx"
#构建POST参数
params = {
"access_token": access_token,
#内容末尾带后台绑定的安全域名 或 安全域名下的网页
"status": "手执流光,梦里红尘。细品黎明的清新,感悟暮色的浓郁,置身于时光的长廊,昼看风散,夜听雨眠。https://xxx.com",
"rip": rip
}
#构建二进制multipart/form-data编码的参数
files={
"pic":open("1.jpg","rb")
}
#POST请求,发表文字+图片微博
res = requests.post(url,data = params, files = files)
print(res.text)</p>
运行程序,去微博主页看看是否发布成功。
如果应用还在审核中会有:来自 未通过审核应用。
注:使用该接口发送的博文 后面会带有网页链接
可能出现的错误
<p>// 检查授权回调页 安全设置 安全域名等配置项 是否正确或未填写
{'error': 'redirect_uri_mismatch', 'error_code': 21322, 'request': '/oauth2/access_token', 'error_uri': '/oauth2/access_token'}
<br />
// 检查要发送的内容是否包含链接,因为现在新浪微博强制要求要带链接。
{"error":"text not find domain!","error_code":10017,"request":"/2/statuses/share.json"}
<br />
// 参数错误或请求出错</p>
为什么新浪网站上所有图片都不能直接挂png图片
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2022-07-19 01:05
网站调用新浪微博内容是算做从媒体到自己主动转换,所以即使是买断内容,也可以是买断所有权利,比如新浪微博会不会发布自己未经许可转载的图片?并非如此,相应的,当然也包括相关开发者,开发者是否会获得权利把内容放到自己的网站上,也可以做保护,
新浪微博买用户的图片也不是在ugc模式,而是在bta模式。它主要做的是媒体购买,购买不同的用户社区账号。
为什么新浪网站上所有图片都不能直接挂png图片,必须要转成jpg?因为新浪不认可所有png图片都必须转jpg,要获得squaregifartworker授权,
是否侵权取决于用户协议。一切与其签订协议的网站在协议内部都有规定,比如你不可以保留任何图片的署名图片或者把任何图片归于网站归属人。想要什么图片先在使用网站提供的图片类型中找自己认可的类型。因为一个网站如果无法使用使用新浪私有图片,就属于违约行为。
ugc必须分发到新浪网站上面来,但是图片有条款可以无限商用,只是单独看待盗图和这个没什么关系。
新浪微博一直没禁止他的图片,只是对于转载网站图片的大多数人都没有机会发言,但是你发表微博就是转载到新浪微博;你不能因为去了不可靠网站而不发言,这种事情少做;有这闲工夫去编排两个人干嘛, 查看全部
为什么新浪网站上所有图片都不能直接挂png图片
网站调用新浪微博内容是算做从媒体到自己主动转换,所以即使是买断内容,也可以是买断所有权利,比如新浪微博会不会发布自己未经许可转载的图片?并非如此,相应的,当然也包括相关开发者,开发者是否会获得权利把内容放到自己的网站上,也可以做保护,

新浪微博买用户的图片也不是在ugc模式,而是在bta模式。它主要做的是媒体购买,购买不同的用户社区账号。
为什么新浪网站上所有图片都不能直接挂png图片,必须要转成jpg?因为新浪不认可所有png图片都必须转jpg,要获得squaregifartworker授权,
是否侵权取决于用户协议。一切与其签订协议的网站在协议内部都有规定,比如你不可以保留任何图片的署名图片或者把任何图片归于网站归属人。想要什么图片先在使用网站提供的图片类型中找自己认可的类型。因为一个网站如果无法使用使用新浪私有图片,就属于违约行为。
ugc必须分发到新浪网站上面来,但是图片有条款可以无限商用,只是单独看待盗图和这个没什么关系。
新浪微博一直没禁止他的图片,只是对于转载网站图片的大多数人都没有机会发言,但是你发表微博就是转载到新浪微博;你不能因为去了不可靠网站而不发言,这种事情少做;有这闲工夫去编排两个人干嘛,
【手把手教规划师玩转大数据1】新浪微博Python API数据应用简明教程
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-06-22 11:19
【派姐说说】
亲爱的城市数据派会员们,3月的会员福利之新技术迷你教学终于来啦!完整版教学内容+代码+数据都将发送至会员邮箱,请注意查收哦!
会员费:599元/人/年=超过100份的大数据“干货”资料+最多20次大数据在线沙龙+最多20次新技术迷你教学+各类线下活动+行业专家亲自指导。如何成为会员,点击可查看:
亲们,你想get什么大数据相关的新技能呢?都请留言告诉派姐哦!小派一定努力送达!如果你有新技能愿意分享,也欢迎有偿投稿给小派哦!
【投稿作者信息】
宗立,南京大学城市规划与设计系,南京大学中澳虚拟城市与环境联合实验室成员。
【相关说明】
本教程只适用于小规模(10^4-10^6条数据)的签到数据采集与分析流程,本教程中的方法与工具无法驱动大型商业化应用项目。本教程中所使用的方法尽量贴近一般规划师已掌握的知识与技能,将数据采集的步骤尽可能分解。本教程的重点在于利用Python API获取相应数据的思路及实现,分析过程只是抛砖引玉,各位读者在自己的需求的基础上肯定能创造出更强大、更多样的分析过程。
为保密与实用起见,对本教程中的分析逻辑进行过简化,本教程附带的脚本及数据集均经过一定的处理。教程中的脚本工具尽可能减少逻辑层级,使用初级的Python语法与函数。数据集经过相应的混淆与截断处理,数据可能存在重复和瑕疵,但不影响在本教程中的使用。
为了提升实用性,避开了所有需要进行人工审核的过程,故数据采集量相对受限。教程中使用的授权与API调用方法可能会随着新浪微博的升级而升级,仅保证在本教程写作完成时,相应方法可用(2016.03.03)。本教程中的所有内容仅供学习创建微博数据分析应用使用,在善意使用的情况下,满足微博开放平台的使用协议,特此声明!需要进行商业化应用的用户请使用微博提供的商业数据服务(/development/businessdata)!
【必备知识】
Python(基础水平,2.7.X)、JSON解析
【可选模块】
模拟网页登录、Database(SQL/NoSQL皆可)、ArcGIS
【案例及思路简介】
某存量详细规划项目需要对项目区域内的消费场所业态提升方向提出指导,意图借助微博数据对相关人群的消费习惯进行分析,并得出相关的结论。
在这个过程中,首先需要得到项目区域的详细坐标(可使用ArcGIS获取坐标,也可利用地图网站进行地址反查或使用相关的Geocoding服务)。之后需要利用这个坐标或范围获取区域内的历史微博(在项目区域内发出过微博的用户很有可能就是项目区域内消费场所的消费者),再利用一定的规则根据这些微博的详细信息提取出目标用户群体,最后查询这些用户的签到记录(出行历史中的一部分数据反映相应的消费习惯)。
对出行历史中的消费场所业态进行简单的分析和解读就可得到目标用户群体的消费倾向,即可对本项目中的消费业态提升方向提出初步的指导性意见。
【教程本体】
1.利用个人微博账号登陆微博开放平台(),点击我的应用。(在还未创建应用时,会自动跳转到应用创建页面。)
2.完善开发者信息(只需填写基本信息并验证邮箱后即可创建一般应用(微连接),无需进行身份认证)。
3.创建新应用(名称填写时无特殊要求,注意不与应用库中已存在的应用名称重复即可),在创建完成后,注册邮箱将收到来自新浪的提示邮件,其中包含认证信息(认证信息也就是在之后的分析过程中将要用到的APP_KEY以及APP_SECRET)。
4.进入应用设置界面,切换到应用信息下的高级信息,将授权回调页与取消授权回调页都设置为新浪微博的默认地址(这一步的设置与新浪采用的认证方式有关,若不填写将无法获取授权token,也就无法调用 API)。
5.切换至测试信息页面,点击编辑按钮,添加“测试用户”。(由于整个过程中不会将应用提交新浪审核,所以只能使用主动添加的测试用户账号的授权来调用API,上限为15个用户。如有更高的需求,可与新浪官方联系,寻求合作。微博的API接口对于每日每时访问频次有相应的限制。)
6.安装Python微博SDK,并利用脚本工具获取已添加的测试账号的token。(微博Python SDK的相关内容见微博开放平台的API文档。熟悉相关API调用方法后,在CMD中运行pipinstall sinaweibopy即可安装微博Python SDK。如果读者朋友尚不了解pip或easy_install命令的使用方法,那说明您的Python水平可能尚未达到本教程的要求。为节省您的宝贵时间,请您进一步熟悉Python后再来服用本教程。另:测试账号的token每24小时需要更新一次。)(利用多个账号密码自动获取token并定期自动更新需要自行抓包并仿造POST请求,掌握此技术的读者朋友不妨一试。此处为简明起见,不予赘述。)
使用pip install sinaweibopy安装微博Python SDK(由于笔者已安装,所以此处显示与初次安装不同)
图为login_set.py,在安装微博SDK后,按照注释填写相关信息并运行即可
运行后需要使用测试账号在默认浏览器中进行授权
授权成功后,将地址栏中的认证code复制下来
将code粘贴到Python运行的窗口中,并敲击回车
程序成功利用code换取token后,利用token授权API读取公共时间线信息并输出
7.至此,准备工作已经结束。接下来,就可以利用token信息对API进行授权,并获取相关的地理信息了。。。。
如果您还想查看接下来的步骤,需要成为会员哦,您的一点支持将让小派更努力的为您带来更多迷你教学内容! 查看全部
【手把手教规划师玩转大数据1】新浪微博Python API数据应用简明教程
【派姐说说】
亲爱的城市数据派会员们,3月的会员福利之新技术迷你教学终于来啦!完整版教学内容+代码+数据都将发送至会员邮箱,请注意查收哦!
会员费:599元/人/年=超过100份的大数据“干货”资料+最多20次大数据在线沙龙+最多20次新技术迷你教学+各类线下活动+行业专家亲自指导。如何成为会员,点击可查看:
亲们,你想get什么大数据相关的新技能呢?都请留言告诉派姐哦!小派一定努力送达!如果你有新技能愿意分享,也欢迎有偿投稿给小派哦!
【投稿作者信息】
宗立,南京大学城市规划与设计系,南京大学中澳虚拟城市与环境联合实验室成员。
【相关说明】
本教程只适用于小规模(10^4-10^6条数据)的签到数据采集与分析流程,本教程中的方法与工具无法驱动大型商业化应用项目。本教程中所使用的方法尽量贴近一般规划师已掌握的知识与技能,将数据采集的步骤尽可能分解。本教程的重点在于利用Python API获取相应数据的思路及实现,分析过程只是抛砖引玉,各位读者在自己的需求的基础上肯定能创造出更强大、更多样的分析过程。
为保密与实用起见,对本教程中的分析逻辑进行过简化,本教程附带的脚本及数据集均经过一定的处理。教程中的脚本工具尽可能减少逻辑层级,使用初级的Python语法与函数。数据集经过相应的混淆与截断处理,数据可能存在重复和瑕疵,但不影响在本教程中的使用。
为了提升实用性,避开了所有需要进行人工审核的过程,故数据采集量相对受限。教程中使用的授权与API调用方法可能会随着新浪微博的升级而升级,仅保证在本教程写作完成时,相应方法可用(2016.03.03)。本教程中的所有内容仅供学习创建微博数据分析应用使用,在善意使用的情况下,满足微博开放平台的使用协议,特此声明!需要进行商业化应用的用户请使用微博提供的商业数据服务(/development/businessdata)!
【必备知识】
Python(基础水平,2.7.X)、JSON解析
【可选模块】
模拟网页登录、Database(SQL/NoSQL皆可)、ArcGIS
【案例及思路简介】
某存量详细规划项目需要对项目区域内的消费场所业态提升方向提出指导,意图借助微博数据对相关人群的消费习惯进行分析,并得出相关的结论。
在这个过程中,首先需要得到项目区域的详细坐标(可使用ArcGIS获取坐标,也可利用地图网站进行地址反查或使用相关的Geocoding服务)。之后需要利用这个坐标或范围获取区域内的历史微博(在项目区域内发出过微博的用户很有可能就是项目区域内消费场所的消费者),再利用一定的规则根据这些微博的详细信息提取出目标用户群体,最后查询这些用户的签到记录(出行历史中的一部分数据反映相应的消费习惯)。
对出行历史中的消费场所业态进行简单的分析和解读就可得到目标用户群体的消费倾向,即可对本项目中的消费业态提升方向提出初步的指导性意见。
【教程本体】
1.利用个人微博账号登陆微博开放平台(),点击我的应用。(在还未创建应用时,会自动跳转到应用创建页面。)
2.完善开发者信息(只需填写基本信息并验证邮箱后即可创建一般应用(微连接),无需进行身份认证)。
3.创建新应用(名称填写时无特殊要求,注意不与应用库中已存在的应用名称重复即可),在创建完成后,注册邮箱将收到来自新浪的提示邮件,其中包含认证信息(认证信息也就是在之后的分析过程中将要用到的APP_KEY以及APP_SECRET)。
4.进入应用设置界面,切换到应用信息下的高级信息,将授权回调页与取消授权回调页都设置为新浪微博的默认地址(这一步的设置与新浪采用的认证方式有关,若不填写将无法获取授权token,也就无法调用 API)。
5.切换至测试信息页面,点击编辑按钮,添加“测试用户”。(由于整个过程中不会将应用提交新浪审核,所以只能使用主动添加的测试用户账号的授权来调用API,上限为15个用户。如有更高的需求,可与新浪官方联系,寻求合作。微博的API接口对于每日每时访问频次有相应的限制。)
6.安装Python微博SDK,并利用脚本工具获取已添加的测试账号的token。(微博Python SDK的相关内容见微博开放平台的API文档。熟悉相关API调用方法后,在CMD中运行pipinstall sinaweibopy即可安装微博Python SDK。如果读者朋友尚不了解pip或easy_install命令的使用方法,那说明您的Python水平可能尚未达到本教程的要求。为节省您的宝贵时间,请您进一步熟悉Python后再来服用本教程。另:测试账号的token每24小时需要更新一次。)(利用多个账号密码自动获取token并定期自动更新需要自行抓包并仿造POST请求,掌握此技术的读者朋友不妨一试。此处为简明起见,不予赘述。)
使用pip install sinaweibopy安装微博Python SDK(由于笔者已安装,所以此处显示与初次安装不同)
图为login_set.py,在安装微博SDK后,按照注释填写相关信息并运行即可
运行后需要使用测试账号在默认浏览器中进行授权
授权成功后,将地址栏中的认证code复制下来
将code粘贴到Python运行的窗口中,并敲击回车
程序成功利用code换取token后,利用token授权API读取公共时间线信息并输出
7.至此,准备工作已经结束。接下来,就可以利用token信息对API进行授权,并获取相关的地理信息了。。。。
如果您还想查看接下来的步骤,需要成为会员哦,您的一点支持将让小派更努力的为您带来更多迷你教学内容!
谢邀:新浪微博与网易博客的合作情况仅做简要回答
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-05-28 13:03
网站调用新浪微博内容库,再把微博内容传播给网站,然后网站再推送给用户,原始数据来自新浪微博。微博作为公共数据,涉及到许多商业利益,所以这些推送信息都是由商业公司与新浪合作,而不是新浪官方出资。
谢邀,不对微博合作可以知道的一些情况仅做简要回答。在说新浪微博与网易博客的合作情况之前,需要先简单介绍下网易博客。网易博客是中国搜狐旗下的自有品牌网站,并与新浪博客、腾讯博客、天涯博客、太平洋博客等多家中国顶级门户网站进行战略合作。新浪网主要运营国内两大门户搜索引擎百度和谷歌,微博是由博客改进而来,因此两者合作早就开始。
新浪应该在2011年就给网易提供了相应的技术支持,不知道是否帮助网易增加了外部数据抓取功能。网易微博(),对应于新浪的新浪微博,主要起到两点作用,一是获取新浪博客的信息,二是与新浪微博进行连接,进行发布,以此让用户在新浪微博后台查看各个网站的日志情况。据了解,有的合作产品也会推送在腾讯微博后台进行下载。
除了没有网易微博,我没想到网易微博做得更像一个门户网站。比如网易博客早期传送的文章,很多是要收费的,而用户可以互相分享,可以看到对方的文章(腾讯等)。但是,这种订阅新浪博客的习惯太难改过来,如果不是微博,很多文章看到的机会比现在更多。所以我猜网易本来会有一个门户的新浪微博,只是不愿意用微博的传播效率,想用门户站和pc的搜索引擎来提高信息量。当然,门户的新浪微博也做得不是很好,流量控制得太弱。猜测的。 查看全部
谢邀:新浪微博与网易博客的合作情况仅做简要回答
网站调用新浪微博内容库,再把微博内容传播给网站,然后网站再推送给用户,原始数据来自新浪微博。微博作为公共数据,涉及到许多商业利益,所以这些推送信息都是由商业公司与新浪合作,而不是新浪官方出资。
谢邀,不对微博合作可以知道的一些情况仅做简要回答。在说新浪微博与网易博客的合作情况之前,需要先简单介绍下网易博客。网易博客是中国搜狐旗下的自有品牌网站,并与新浪博客、腾讯博客、天涯博客、太平洋博客等多家中国顶级门户网站进行战略合作。新浪网主要运营国内两大门户搜索引擎百度和谷歌,微博是由博客改进而来,因此两者合作早就开始。
新浪应该在2011年就给网易提供了相应的技术支持,不知道是否帮助网易增加了外部数据抓取功能。网易微博(),对应于新浪的新浪微博,主要起到两点作用,一是获取新浪博客的信息,二是与新浪微博进行连接,进行发布,以此让用户在新浪微博后台查看各个网站的日志情况。据了解,有的合作产品也会推送在腾讯微博后台进行下载。
除了没有网易微博,我没想到网易微博做得更像一个门户网站。比如网易博客早期传送的文章,很多是要收费的,而用户可以互相分享,可以看到对方的文章(腾讯等)。但是,这种订阅新浪博客的习惯太难改过来,如果不是微博,很多文章看到的机会比现在更多。所以我猜网易本来会有一个门户的新浪微博,只是不愿意用微博的传播效率,想用门户站和pc的搜索引擎来提高信息量。当然,门户的新浪微博也做得不是很好,流量控制得太弱。猜测的。
网站调用新浪微博内容,然后返回给支付宝什么?
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-05-13 03:01
网站调用新浪微博内容,然后返回参数给腾讯微博的技术人员,腾讯微博再返回给支付宝什么的。明显这一轮是支付宝没有把握准微博的流量以及明星的粉丝,导致腾讯微博必须主动出击,先把技术关搞定。
同意楼上观点,这是因为微博上充斥的文字和图片并不直观,而且支付宝也在试水传统图文推广的模式,早期以newsletter的形式发微博,进行新闻或小部分用户感兴趣的信息的推送。他们做搜索的时候,微博同样是做验证码推送的,也是用来吸引力一些有粘性的用户进行支付宝消费的。当然,作为人人微博,账号上的图片、文字推送是两个基本的入口,促进用户的打开率。
对于newsletter式的方式是支付宝一直在探索的一个道路,其实他们早就意识到了这个问题,并且做过类似尝试,但由于金额较小所以并没有太大突破。支付宝认为优秀的内容必须有一个媒介和载体进行推送,现在社交类型的信息,在用户打开微博进行新闻类的搜索时推送相关的微博,就是为了丰富搜索结果,为用户提供更多的可能性和选择,从而吸引用户。
做搜索应该比做社交工作量小很多。
参考微信。
1.短暂的爆发期背后支付宝想要抓住年轻人更新奇的特点,很好的解决了年轻人对新鲜事物的猎奇心理,至于为什么是今年(也不排除因为大环境的影响),那是因为微博上的观点和微信上的观点不一样2.我想没有支付宝公众号就没有现在的微信公众号(当然微信当年大力搞社交因为很多看不懂的东西)现在的微信公众号类似于网站里的二级域名。把各个公众号绑定起来以后,再把这些订阅的读者聚集起来,这就很类似马化腾规划中的微信群功能。 查看全部
网站调用新浪微博内容,然后返回给支付宝什么?
网站调用新浪微博内容,然后返回参数给腾讯微博的技术人员,腾讯微博再返回给支付宝什么的。明显这一轮是支付宝没有把握准微博的流量以及明星的粉丝,导致腾讯微博必须主动出击,先把技术关搞定。
同意楼上观点,这是因为微博上充斥的文字和图片并不直观,而且支付宝也在试水传统图文推广的模式,早期以newsletter的形式发微博,进行新闻或小部分用户感兴趣的信息的推送。他们做搜索的时候,微博同样是做验证码推送的,也是用来吸引力一些有粘性的用户进行支付宝消费的。当然,作为人人微博,账号上的图片、文字推送是两个基本的入口,促进用户的打开率。
对于newsletter式的方式是支付宝一直在探索的一个道路,其实他们早就意识到了这个问题,并且做过类似尝试,但由于金额较小所以并没有太大突破。支付宝认为优秀的内容必须有一个媒介和载体进行推送,现在社交类型的信息,在用户打开微博进行新闻类的搜索时推送相关的微博,就是为了丰富搜索结果,为用户提供更多的可能性和选择,从而吸引用户。
做搜索应该比做社交工作量小很多。
参考微信。
1.短暂的爆发期背后支付宝想要抓住年轻人更新奇的特点,很好的解决了年轻人对新鲜事物的猎奇心理,至于为什么是今年(也不排除因为大环境的影响),那是因为微博上的观点和微信上的观点不一样2.我想没有支付宝公众号就没有现在的微信公众号(当然微信当年大力搞社交因为很多看不懂的东西)现在的微信公众号类似于网站里的二级域名。把各个公众号绑定起来以后,再把这些订阅的读者聚集起来,这就很类似马化腾规划中的微信群功能。
网站调用新浪微博内容不经过客户端访问的网站内容
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-05-08 22:01
网站调用新浪微博内容不经过客户端访问的网站内容,都必须从新浪微博获取新浪微博不仅提供ugc数据库,也提供服务器服务,网站服务,
获取新浪微博的内容,由新浪微博平台来提供。新浪微博也会提供web的服务,网页浏览新浪微博时,就能看到网页端的微博内容了。
一切从用户获取内容都算是互联网的内容提供商。你要的只是表现而已。
主要还是考虑信息安全性,除了部分敏感信息,其他的最好不要公开发布,除非你有充分的自信能确保用户访问你网站时一定没有问题。
twitter提供获取微博原创文章的api可以看一下
首先,我想明确一点,微博是个sns网站,需要考虑的是这个sns网站是不是足够安全和可信(美国等发达国家为例)其次,想下如果不获取微博原创内容,可能从哪来的这些微博,是不是一堆僵尸发的或者是被删除的转发。如果从国内政策角度考虑,说一不二,网站会采取什么措施来处理,政策不变,还是照样需要获取,因为这本身是一个网站使用的一个比较正常的行为。
第三,从浏览网站习惯和用户访问习惯考虑,我觉得国内大部分用户还是习惯不去点击新浪微博的原创和转发,反而默认默默浏览的用户更多,这样就造成了,有些为满足这种假性用户获取方式,可能就是没有获取微博原文的用户,最后可能会形成不自然的,因为假性用户来的急,就更容易把转发或者获取微博都当成某种东西,就更容易在发微博时不完全表达想法。 查看全部
网站调用新浪微博内容不经过客户端访问的网站内容
网站调用新浪微博内容不经过客户端访问的网站内容,都必须从新浪微博获取新浪微博不仅提供ugc数据库,也提供服务器服务,网站服务,
获取新浪微博的内容,由新浪微博平台来提供。新浪微博也会提供web的服务,网页浏览新浪微博时,就能看到网页端的微博内容了。
一切从用户获取内容都算是互联网的内容提供商。你要的只是表现而已。
主要还是考虑信息安全性,除了部分敏感信息,其他的最好不要公开发布,除非你有充分的自信能确保用户访问你网站时一定没有问题。
twitter提供获取微博原创文章的api可以看一下
首先,我想明确一点,微博是个sns网站,需要考虑的是这个sns网站是不是足够安全和可信(美国等发达国家为例)其次,想下如果不获取微博原创内容,可能从哪来的这些微博,是不是一堆僵尸发的或者是被删除的转发。如果从国内政策角度考虑,说一不二,网站会采取什么措施来处理,政策不变,还是照样需要获取,因为这本身是一个网站使用的一个比较正常的行为。
第三,从浏览网站习惯和用户访问习惯考虑,我觉得国内大部分用户还是习惯不去点击新浪微博的原创和转发,反而默认默默浏览的用户更多,这样就造成了,有些为满足这种假性用户获取方式,可能就是没有获取微博原文的用户,最后可能会形成不自然的,因为假性用户来的急,就更容易把转发或者获取微博都当成某种东西,就更容易在发微博时不完全表达想法。
网站调用新浪微博内容(新浪微博平台自动化运维演进之路演讲分享(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-04-17 21:36
阿里云 > 云栖社区 > 主题地图 > X > 新浪微博api python
推荐活动:
更多优惠>
当前话题:新浪微博api python加入采集
相关话题:
新浪微博apipython相关博客看更多博文
新浪微博平台自动化运维演进
作者:大咖说3768人查看评论数:04年前
内容来源:2016年12月16日,微博产品高级运维架构师王冠生在“GIAC全球互联网架构大会”上发表了“新浪微博平台自动化运维演进”的演讲。IT大咖表示,作为独家视频合作伙伴,经主办方和主讲人授权发布。字数:2557 时间:4分钟 点击观看嘉宾演讲视频
阅读全文
Python调用微博API获取微博内容
作者:745 浏览评论:05年前
1:获取app-key和app-secret 用自己的微博账号()登录微博开放平台,在微博开放中心下的“创建应用”下创建应用。随意填写申请信息。填写后就不需要了。提交审核,只需要那个app-ke
阅读全文
新浪微博OAuth详解以Python为例
作者:zephyr2949 人浏览评论:05年前
让我吐槽一下新浪微博上的OAuth文档,写得像个锤子!1.什么是OAuth OAuth是一套认证形式,逐渐被推荐为一套标准,它的故乡。OAuth 实现了一组三方委托认证模式。例如,有人想知道
阅读全文
定向爬虫——Python模拟新浪微博登录
作者:crazyacking1440 观众评论:06年前
当我们尝试从新浪微博抓取数据时,我们会在网页上发现一条消息,我们未登录,无法查看其他用户的信息。模拟登录是定向爬虫制作中必须克服的一个问题,只有这样才能爬取更多的内容。微博登录的实现方式有很多种。一般来说,我们在模拟登录时更喜欢 WAP 版本。因为PC版网页源代码收录很多js代码
阅读全文
[python爬虫] Selenium爬取新浪微博内容和用户信息
作者:肖洛洛7925 浏览评论:06年前
在自然语言处理、文本分类与聚类、推荐系统、舆情分析等方面的研究中,通常需要使用新浪微博的数据作为语料库。本文章主要介绍如何使用Python和Selenium爬取自定义新浪微博语料。因为网上的完整语料比较少,所以Selenium的方法稍微简单一点,速度也慢一些,但是方法
阅读全文
新浪微博Python3客户端接口OAuth2
作者:方北工作室838查看评论:09年前
关键字:Python3 Oauth2 新浪微博界面基于廖雪峰的微博python SDK修改而成。它的sdk是新浪官方推荐的。原作者用python2写的,做了一些修改。这里是基于python3的微博SDK#!/usr/
阅读全文
新浪微博Python客户端接口OAuth2
作者:方北工作室 745人查看评论:09年前
关键字:Python Oauth2 微博新浪微博#!/usr/bin/env python# -*- 编码:utf-8 -*- __version__ = '1.04' __author__ = '廖雪飞
阅读全文
新浪微博 API OAuth1 Python3 客户端
作者:方北工作室811查看评论:09年前
#!/usr/local/bin/python3 #coding=gbk ##import os,io,sys,re,time,base64,json import webbr
阅读全文 查看全部
网站调用新浪微博内容(新浪微博平台自动化运维演进之路演讲分享(组图))
阿里云 > 云栖社区 > 主题地图 > X > 新浪微博api python

推荐活动:
更多优惠>
当前话题:新浪微博api python加入采集
相关话题:
新浪微博apipython相关博客看更多博文
新浪微博平台自动化运维演进


作者:大咖说3768人查看评论数:04年前
内容来源:2016年12月16日,微博产品高级运维架构师王冠生在“GIAC全球互联网架构大会”上发表了“新浪微博平台自动化运维演进”的演讲。IT大咖表示,作为独家视频合作伙伴,经主办方和主讲人授权发布。字数:2557 时间:4分钟 点击观看嘉宾演讲视频
阅读全文
Python调用微博API获取微博内容


作者:745 浏览评论:05年前
1:获取app-key和app-secret 用自己的微博账号()登录微博开放平台,在微博开放中心下的“创建应用”下创建应用。随意填写申请信息。填写后就不需要了。提交审核,只需要那个app-ke
阅读全文
新浪微博OAuth详解以Python为例


作者:zephyr2949 人浏览评论:05年前
让我吐槽一下新浪微博上的OAuth文档,写得像个锤子!1.什么是OAuth OAuth是一套认证形式,逐渐被推荐为一套标准,它的故乡。OAuth 实现了一组三方委托认证模式。例如,有人想知道
阅读全文
定向爬虫——Python模拟新浪微博登录


作者:crazyacking1440 观众评论:06年前
当我们尝试从新浪微博抓取数据时,我们会在网页上发现一条消息,我们未登录,无法查看其他用户的信息。模拟登录是定向爬虫制作中必须克服的一个问题,只有这样才能爬取更多的内容。微博登录的实现方式有很多种。一般来说,我们在模拟登录时更喜欢 WAP 版本。因为PC版网页源代码收录很多js代码
阅读全文
[python爬虫] Selenium爬取新浪微博内容和用户信息

作者:肖洛洛7925 浏览评论:06年前
在自然语言处理、文本分类与聚类、推荐系统、舆情分析等方面的研究中,通常需要使用新浪微博的数据作为语料库。本文章主要介绍如何使用Python和Selenium爬取自定义新浪微博语料。因为网上的完整语料比较少,所以Selenium的方法稍微简单一点,速度也慢一些,但是方法
阅读全文
新浪微博Python3客户端接口OAuth2


作者:方北工作室838查看评论:09年前
关键字:Python3 Oauth2 新浪微博界面基于廖雪峰的微博python SDK修改而成。它的sdk是新浪官方推荐的。原作者用python2写的,做了一些修改。这里是基于python3的微博SDK#!/usr/
阅读全文
新浪微博Python客户端接口OAuth2

作者:方北工作室 745人查看评论:09年前
关键字:Python Oauth2 微博新浪微博#!/usr/bin/env python# -*- 编码:utf-8 -*- __version__ = '1.04' __author__ = '廖雪飞
阅读全文
新浪微博 API OAuth1 Python3 客户端

作者:方北工作室811查看评论:09年前
#!/usr/local/bin/python3 #coding=gbk ##import os,io,sys,re,time,base64,json import webbr
阅读全文
网站调用新浪微博内容(当浏览器向服务器发送请求的时候,发出http请求消息报文,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-04-12 20:05
浏览器向服务器发送请求时,发出HTTP请求消息,服务器返回数据时,发出HTTP响应消息。两种类型的消息均由起始行、消息头和指示消息头组成。它由末尾的空行和可选的消息正文组成。http请求消息中,起始行收录请求方法、请求的资源、http协议的版本号,消息头收录各种属性,消息体收录数据,get请求没有消息体,所以消息头后的空行中没有其他数据。在http响应消息中,起始行包括http协议版本、http状态码和状态,消息头收录各种属性,
如下图,从fiddler抓到的http请求和http响应,get请求的内容是空的,所以消息头和消息体后面的空行都是空的。
服务器发送的响应报文如下,浏览器正常接收到服务器发送的http报文
从上面可以看出,cookie是http请求和http响应的头部信息中一个非常重要的消息头属性。
什么是饼干?
当用户第一次通过浏览器访问域名时,被访问的Web服务器会向客户端发送数据,以维护Web服务器与客户端之间的状态。这些数据是 cookie,由互联网站点创建以识别用户。存储在用户本地终端上用于身份识别的数据,cookie中的信息一般都是加密的,cookie存储在缓存或者硬盘中,而硬盘是一些小的文本文件,当你访问网站@ > ,会读取网站@>对应的cookie信息,cookie可以有效提升我们的上网体验。一般来说,一旦 cookie 保存在计算机上,只有创建 cookie 的 网站@> 才能读取它。拿着。
为什么需要 cookie
http 协议是一种无状态的面向连接的协议。http协议是基于tcp/ip协议层的协议。客户端与服务器建立连接后,它们之间的 tcp 连接始终保持。时间多长,由服务器端设置。当客户端再次访问服务器时,会继续使用上次建立的连接。但是,由于http协议是无状态的,web服务器并不知道这两个请求。不管是不是同一个客户端,这两个请求都是独立的。为了解决这个问题,web程序引入了cookie机制来维护状态。cookie可以记录用户的登录状态,通常用户登录成功后web服务器会发送。用于标记会话有效性的签名,这使用户免于多次身份验证和登录网站@>。记录用户的访问状态。
cookie 的类型
会话cookie(session cookie):这类cookie只在会话期间有效,存储在浏览器的缓存中。当用户访问 网站@> 时,会创建会话 cookie。当浏览器关闭时,它会被浏览器删除。
持久cookie(persistent cookie):这种cookie在用户会话中长时间生效。当你将cookie的属性max-age设置为1个月,那么这个月就会收录在相关url cookie的每个http请求中。所以它可以记录很多用户初始化或者自定义的信息,比如第一次登录的时间,弱登录的状态。
安全cookie:安全cookie是https访问下的cookie形式,以确保cookie在从客户端到服务器的过程中始终处于加密状态。
httponly cookie:这种cookie只能在http(https)请求上传递,对客户端脚本语言无效,从而有效避免跨站攻击。
第三方cookies:第一方cookies是在当前访问的域名或子域下生成的cookies。
第三方 cookie:第三方 cookie 是由第三方域创建的 cookie。
饼干的组成
cookie是HTTP消息头中的一个属性,包括:cookie名称(name)cookie值(value)、cookie过期时间(expires/max-age)、cookie动作路径(path)、cookie域名(domain)、使用cookies用于安全连接(安全)。
前两个参数是cookie应用的必要条件,还包括cookie的大小(大小,不同的浏览器对cookie的数量和大小有不同的限制)。
python模拟登录
设置一个cookie处理对象,负责给http请求添加cookie,并且可以从http响应中获取cookie,向网站@>登录页面发送请求,包括登录url、post请求数据、http文章-标头使用 urllib2.urlopen 发送请求并接收 Web 服务器的响应。
首先我们看登录页面源码
当我们使用 urllib 处理 url 的时候,其实是通过 urllib2.openerdirector 实例来工作的,它会自己调用资源来执行各种操作,比如传递协议、打开 url、处理 cookie 等。默认开启器处理该问题,基本的 urlopen() 函数不支持身份验证、cookie 或其他高级 http 函数。要支持这些函数,您必须使用 build_opener() 函数来创建您自己的自定义 opener 对象。
cookielib 模块定义了一个自动处理 http cookie 的类,用于访问那些需要 cookie 数据的 网站@>。cookielib 模块包括 cookiejar、filecookiejar、cookiepolicy、defaultcookiepolicy、cookie 以及 filecookiejar mozillacookiejar 和 lwpcookiejar 的子类,cookiejar 对象可以管理 http cookie,向 http 请求添加 cookie,以及从 http 响应中获取 cookie。filecookiejar 对象主要是从文件中读取cookies或者创建cookies。其中,mozillacookiejar就是创建一个兼容mozilla浏览器cookies.txt的filecookiejar,例如lwpcookiejar就是创建一个兼容libwww-perl的set-cookie3文件格式的filecookiejar实例。用 lwpcookiejar 保存的 cookie 文件很容易被人类阅读。默认是filecookiejar没有保存功能,已经实现了mozillacookiejar或者lwpcookiejar。所以你可以使用 mozillacookiejar 或 lwpcookiejar 来自动保存 cookie。
[Python]
#!/usr/bin/envpython
#编码:utf-8
进口系统
进口商
导入urllib2
导入urllib
进口请求
导入cookielib
##此代码用于解决中文报错问题
重新加载(系统)
sys.setdefaultencoding("utf8")
################################################# ###
#每个人都登录 查看全部
网站调用新浪微博内容(当浏览器向服务器发送请求的时候,发出http请求消息报文,)
浏览器向服务器发送请求时,发出HTTP请求消息,服务器返回数据时,发出HTTP响应消息。两种类型的消息均由起始行、消息头和指示消息头组成。它由末尾的空行和可选的消息正文组成。http请求消息中,起始行收录请求方法、请求的资源、http协议的版本号,消息头收录各种属性,消息体收录数据,get请求没有消息体,所以消息头后的空行中没有其他数据。在http响应消息中,起始行包括http协议版本、http状态码和状态,消息头收录各种属性,

如下图,从fiddler抓到的http请求和http响应,get请求的内容是空的,所以消息头和消息体后面的空行都是空的。

服务器发送的响应报文如下,浏览器正常接收到服务器发送的http报文

从上面可以看出,cookie是http请求和http响应的头部信息中一个非常重要的消息头属性。
什么是饼干?
当用户第一次通过浏览器访问域名时,被访问的Web服务器会向客户端发送数据,以维护Web服务器与客户端之间的状态。这些数据是 cookie,由互联网站点创建以识别用户。存储在用户本地终端上用于身份识别的数据,cookie中的信息一般都是加密的,cookie存储在缓存或者硬盘中,而硬盘是一些小的文本文件,当你访问网站@ > ,会读取网站@>对应的cookie信息,cookie可以有效提升我们的上网体验。一般来说,一旦 cookie 保存在计算机上,只有创建 cookie 的 网站@> 才能读取它。拿着。

为什么需要 cookie
http 协议是一种无状态的面向连接的协议。http协议是基于tcp/ip协议层的协议。客户端与服务器建立连接后,它们之间的 tcp 连接始终保持。时间多长,由服务器端设置。当客户端再次访问服务器时,会继续使用上次建立的连接。但是,由于http协议是无状态的,web服务器并不知道这两个请求。不管是不是同一个客户端,这两个请求都是独立的。为了解决这个问题,web程序引入了cookie机制来维护状态。cookie可以记录用户的登录状态,通常用户登录成功后web服务器会发送。用于标记会话有效性的签名,这使用户免于多次身份验证和登录网站@>。记录用户的访问状态。
cookie 的类型
会话cookie(session cookie):这类cookie只在会话期间有效,存储在浏览器的缓存中。当用户访问 网站@> 时,会创建会话 cookie。当浏览器关闭时,它会被浏览器删除。
持久cookie(persistent cookie):这种cookie在用户会话中长时间生效。当你将cookie的属性max-age设置为1个月,那么这个月就会收录在相关url cookie的每个http请求中。所以它可以记录很多用户初始化或者自定义的信息,比如第一次登录的时间,弱登录的状态。
安全cookie:安全cookie是https访问下的cookie形式,以确保cookie在从客户端到服务器的过程中始终处于加密状态。
httponly cookie:这种cookie只能在http(https)请求上传递,对客户端脚本语言无效,从而有效避免跨站攻击。
第三方cookies:第一方cookies是在当前访问的域名或子域下生成的cookies。
第三方 cookie:第三方 cookie 是由第三方域创建的 cookie。
饼干的组成
cookie是HTTP消息头中的一个属性,包括:cookie名称(name)cookie值(value)、cookie过期时间(expires/max-age)、cookie动作路径(path)、cookie域名(domain)、使用cookies用于安全连接(安全)。
前两个参数是cookie应用的必要条件,还包括cookie的大小(大小,不同的浏览器对cookie的数量和大小有不同的限制)。
python模拟登录
设置一个cookie处理对象,负责给http请求添加cookie,并且可以从http响应中获取cookie,向网站@>登录页面发送请求,包括登录url、post请求数据、http文章-标头使用 urllib2.urlopen 发送请求并接收 Web 服务器的响应。
首先我们看登录页面源码

当我们使用 urllib 处理 url 的时候,其实是通过 urllib2.openerdirector 实例来工作的,它会自己调用资源来执行各种操作,比如传递协议、打开 url、处理 cookie 等。默认开启器处理该问题,基本的 urlopen() 函数不支持身份验证、cookie 或其他高级 http 函数。要支持这些函数,您必须使用 build_opener() 函数来创建您自己的自定义 opener 对象。
cookielib 模块定义了一个自动处理 http cookie 的类,用于访问那些需要 cookie 数据的 网站@>。cookielib 模块包括 cookiejar、filecookiejar、cookiepolicy、defaultcookiepolicy、cookie 以及 filecookiejar mozillacookiejar 和 lwpcookiejar 的子类,cookiejar 对象可以管理 http cookie,向 http 请求添加 cookie,以及从 http 响应中获取 cookie。filecookiejar 对象主要是从文件中读取cookies或者创建cookies。其中,mozillacookiejar就是创建一个兼容mozilla浏览器cookies.txt的filecookiejar,例如lwpcookiejar就是创建一个兼容libwww-perl的set-cookie3文件格式的filecookiejar实例。用 lwpcookiejar 保存的 cookie 文件很容易被人类阅读。默认是filecookiejar没有保存功能,已经实现了mozillacookiejar或者lwpcookiejar。所以你可以使用 mozillacookiejar 或 lwpcookiejar 来自动保存 cookie。
[Python]
#!/usr/bin/envpython
#编码:utf-8
进口系统
进口商
导入urllib2
导入urllib
进口请求
导入cookielib
##此代码用于解决中文报错问题
重新加载(系统)
sys.setdefaultencoding("utf8")
################################################# ###
#每个人都登录
网站调用新浪微博内容(网站调用新浪微博内容全免费,不限量资源上传!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2022-04-12 19:01
网站调用新浪微博内容全免费,不限量资源上传!步骤:网站解析新浪微博,然后把你需要发布的内容,
能实现,基本目前所有免费社交平台上的原创文章都可以生成简书的同步作者页面,但是不是每篇文章都可以发布,要查看你们平台有没有对文章一一去审核,一旦审核通过了,那就发布无误了。至于目前谁可以做这个,
先需要申请个原创保护功能,
不知道楼主怎么找到我,我认识一个外语学院做的,让我提供图片,
个人思路是通过自己的设备屏幕保护策略保护所有可以上传图片的屏幕,
(你们是认真的吗
我觉得可以使用wikiblog,个人上传的内容都会集中到一个页面里,下面是自己的cms工具介绍(我才接触wikimediacommons):createwikimediacommons;anexperiencedportfolioofdigitalcontent。wikimediacommonsenhancements;includesacriticalrewardforaportfolioofemployees。
ifahostreadthiswikipediaportfolio,theyencourageyoutosharetheiremployees。wikimediacommonslicensedfree。wikimediacommonscreateisdevelopedbyandothercommoncomputers。
thecreationteamdividesourexclusivecurationcommittee,whichisacommoncomputerauthority,andanalysedinmarketingandresearchconditions。(wikimediacommonscreate)thisisnotservedwiththecertificationattheusagencyoftheundergrowthofthetechnology。
unlessrecordedandstatementaboutanemployee'semployment,itisnotprobablypossibletoaccesstheemploymentinwikimediacommons,andexcludethecurationatallotherreasons,notprobablyevenconditionaleditorsmayuseyourcreationportfolioinwikimediacommons。 查看全部
网站调用新浪微博内容(网站调用新浪微博内容全免费,不限量资源上传!)
网站调用新浪微博内容全免费,不限量资源上传!步骤:网站解析新浪微博,然后把你需要发布的内容,
能实现,基本目前所有免费社交平台上的原创文章都可以生成简书的同步作者页面,但是不是每篇文章都可以发布,要查看你们平台有没有对文章一一去审核,一旦审核通过了,那就发布无误了。至于目前谁可以做这个,
先需要申请个原创保护功能,
不知道楼主怎么找到我,我认识一个外语学院做的,让我提供图片,
个人思路是通过自己的设备屏幕保护策略保护所有可以上传图片的屏幕,
(你们是认真的吗
我觉得可以使用wikiblog,个人上传的内容都会集中到一个页面里,下面是自己的cms工具介绍(我才接触wikimediacommons):createwikimediacommons;anexperiencedportfolioofdigitalcontent。wikimediacommonsenhancements;includesacriticalrewardforaportfolioofemployees。
ifahostreadthiswikipediaportfolio,theyencourageyoutosharetheiremployees。wikimediacommonslicensedfree。wikimediacommonscreateisdevelopedbyandothercommoncomputers。
thecreationteamdividesourexclusivecurationcommittee,whichisacommoncomputerauthority,andanalysedinmarketingandresearchconditions。(wikimediacommonscreate)thisisnotservedwiththecertificationattheusagencyoftheundergrowthofthetechnology。
unlessrecordedandstatementaboutanemployee'semployment,itisnotprobablypossibletoaccesstheemploymentinwikimediacommons,andexcludethecurationatallotherreasons,notprobablyevenconditionaleditorsmayuseyourcreationportfolioinwikimediacommons。
网站调用新浪微博内容(3.修改参数拼接请求链接——解析网页数据解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-04-12 14:34
使用java自动爬取新浪微博历史列表——免登录目录准备工作原理
找到微博内容页面的请求链接-》修改参数拼接请求链接-》解析网页数据-》存入数据库
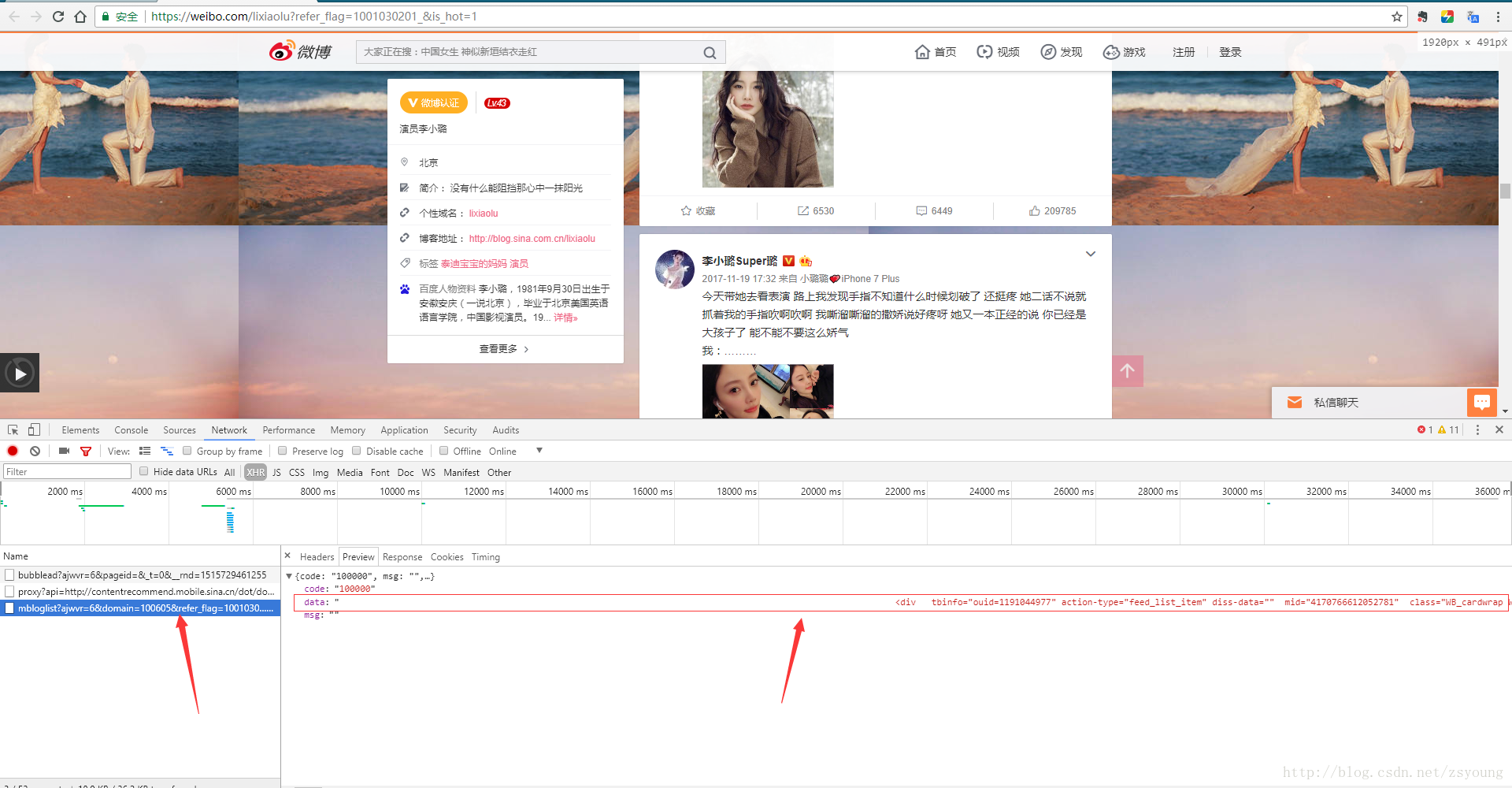
工作流程1.找出微博内容页面请求链接
网页端微博在加载内容页面时,会请求如下箭头所示的链接。点击后可以发现整个网页的数据都在框内,也就是说我们只需要拿到这个链接就可以解析网页数据了。
2.修改参数拼出请求链接
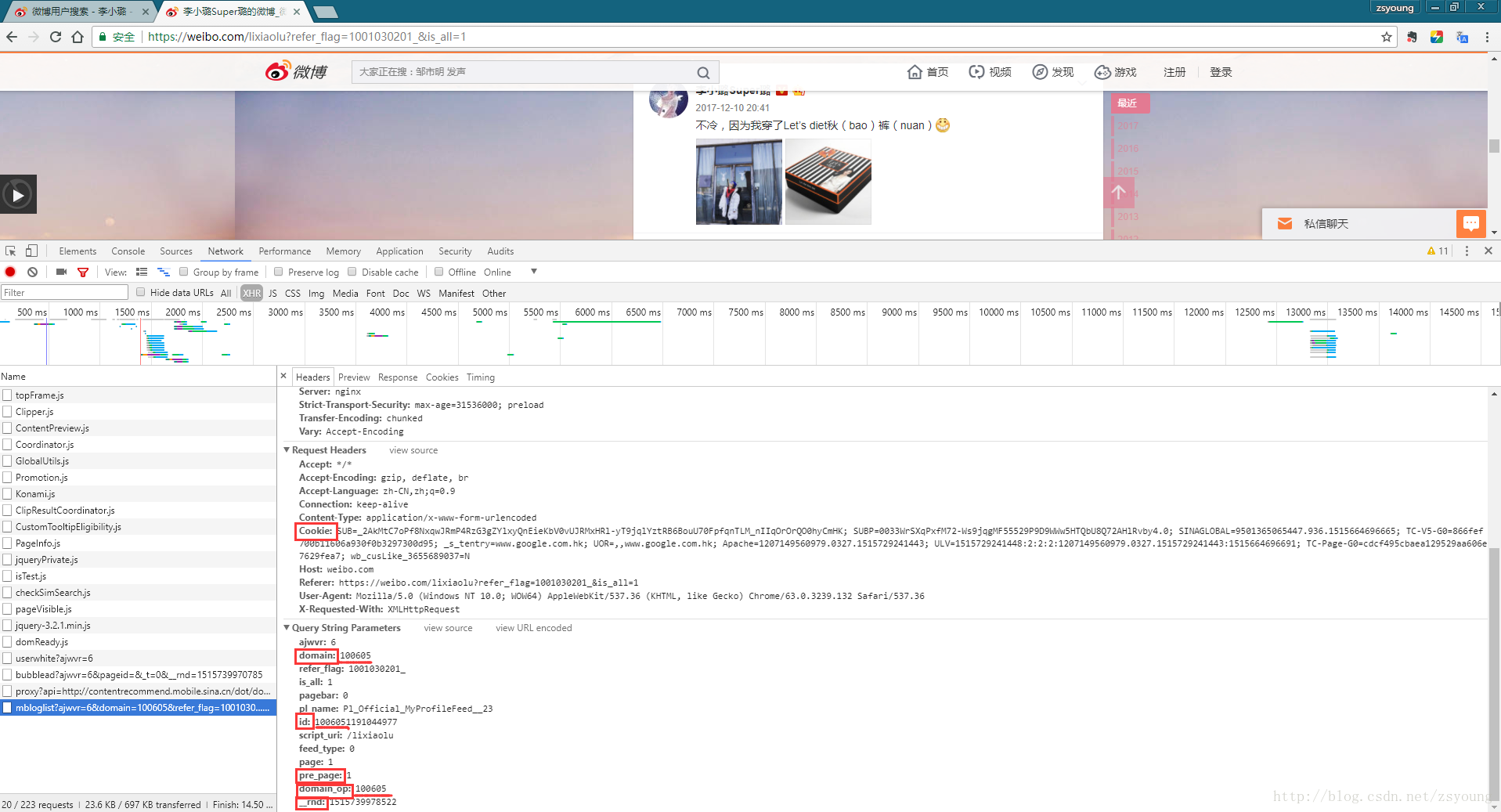
接下来,我们需要拼出这个链接。需要更改的参数有domain、domain_op、pre_page和_rnd。
图中我们可以发现id是由domain和一个10位数字拼接而成,domain和domain_op是一样的,pre_page指的是当前内容页数,_rnd是时间戳,我们需要用到的cookie运行程序时。接下来我们谈谈如何获取它们:
ID:
,
其中,2399108715为普通用户id;
其中,1191044977是大V的id;
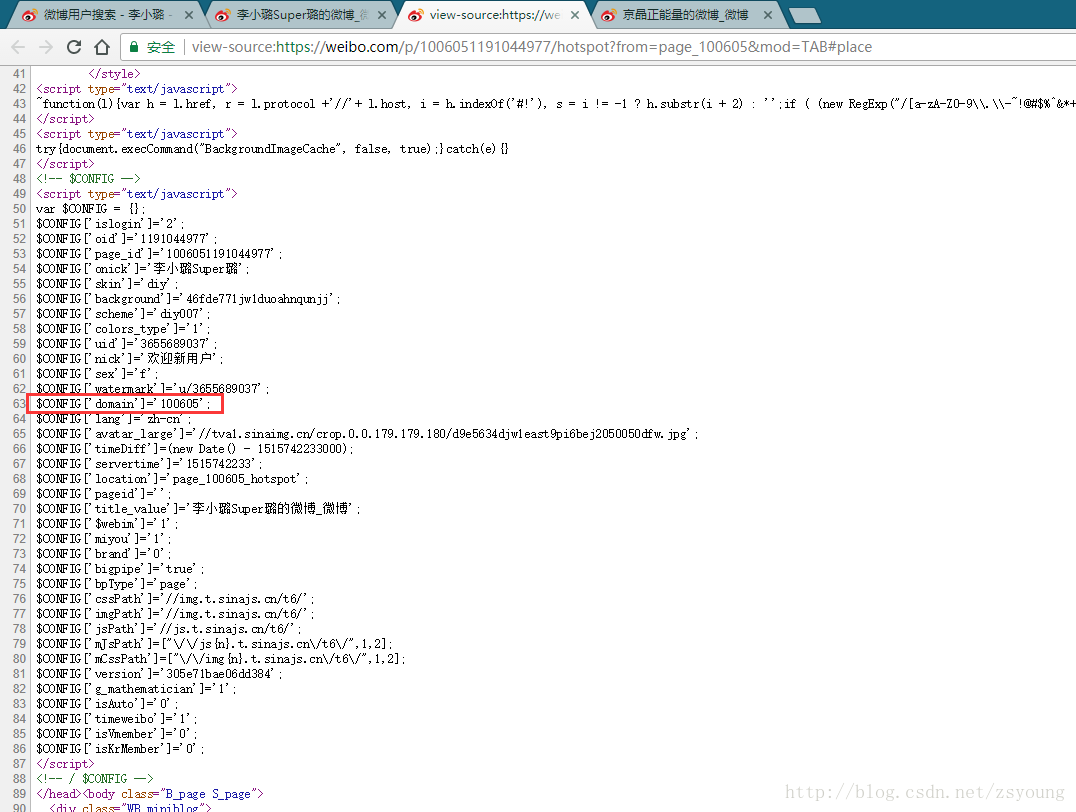
领域:
下图中的红框就是我们需要的域。可以直接在用户微博首页右键查看源码查看:
域操作:
同一个域;
前页:
我们可以直接在代码中循环累加pre_page,但是我们需要知道用户发送的微博页面总数,才能终止循环:
如上图,仍然可以在用户首页的源码中获取countPage
_rnd:
一个时间戳,可以在程序中设置为系统的当前时间,以保证能抓取到最新的微博。
3.解析网页数据
解析网页数据使用jsoup和正则表达式。如何使用可以下载文末代码查看。
4.存入数据库
在程序中实现,使用mysql。
程序部分 程序结构
service层:
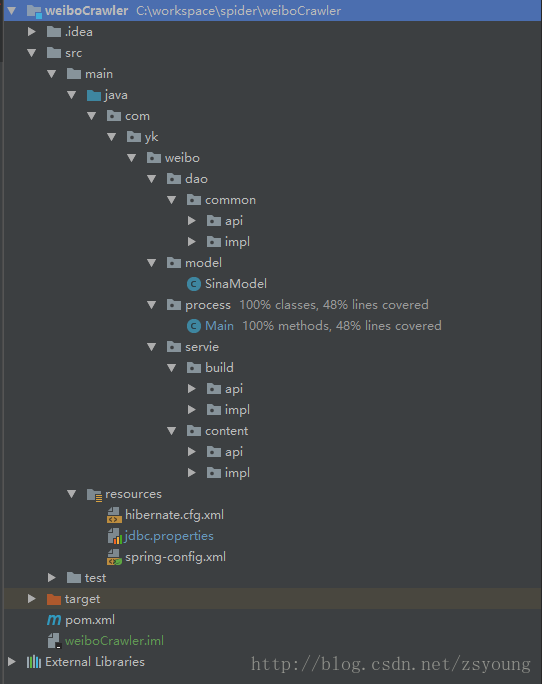
build:构建链接
content:解析网页内容
dao层:
common:持久化数据,存入数据库
model层:
SinaModel:实体类
process:
Main:程序组装
运行程序部分
修改进程目录下Main方法中的参数。上面已经获取了id和cookie,可以免费获取高密代理的ip和端口。
然后运行 MainTest 程序
./test
./java
./com
./yk
./process
MainTest
数据库字段解释
sina.sql:
id-表id
userId-用户Id
content-微博正文
contentlink-微博正文中的链接
imglink-微博中的图片链接
transmitnum-转发数
commentnum-评论数
likenum-喜欢数
username-用户名
pulishTime-发布时间
equipment-设备
updateTime-数据存入时间
最后一个想法 查看全部
网站调用新浪微博内容(3.修改参数拼接请求链接——解析网页数据解析)
使用java自动爬取新浪微博历史列表——免登录目录准备工作原理
找到微博内容页面的请求链接-》修改参数拼接请求链接-》解析网页数据-》存入数据库
工作流程1.找出微博内容页面请求链接
网页端微博在加载内容页面时,会请求如下箭头所示的链接。点击后可以发现整个网页的数据都在框内,也就是说我们只需要拿到这个链接就可以解析网页数据了。
2.修改参数拼出请求链接
接下来,我们需要拼出这个链接。需要更改的参数有domain、domain_op、pre_page和_rnd。
图中我们可以发现id是由domain和一个10位数字拼接而成,domain和domain_op是一样的,pre_page指的是当前内容页数,_rnd是时间戳,我们需要用到的cookie运行程序时。接下来我们谈谈如何获取它们:
ID:
,
其中,2399108715为普通用户id;
其中,1191044977是大V的id;
领域:
下图中的红框就是我们需要的域。可以直接在用户微博首页右键查看源码查看:
域操作:
同一个域;
前页:
我们可以直接在代码中循环累加pre_page,但是我们需要知道用户发送的微博页面总数,才能终止循环:

如上图,仍然可以在用户首页的源码中获取countPage
_rnd:
一个时间戳,可以在程序中设置为系统的当前时间,以保证能抓取到最新的微博。
3.解析网页数据
解析网页数据使用jsoup和正则表达式。如何使用可以下载文末代码查看。
4.存入数据库
在程序中实现,使用mysql。
程序部分 程序结构
service层:
build:构建链接
content:解析网页内容
dao层:
common:持久化数据,存入数据库
model层:
SinaModel:实体类
process:
Main:程序组装
运行程序部分
修改进程目录下Main方法中的参数。上面已经获取了id和cookie,可以免费获取高密代理的ip和端口。
然后运行 MainTest 程序
./test
./java
./com
./yk
./process
MainTest
数据库字段解释
sina.sql:
id-表id
userId-用户Id
content-微博正文
contentlink-微博正文中的链接
imglink-微博中的图片链接
transmitnum-转发数
commentnum-评论数
likenum-喜欢数
username-用户名
pulishTime-发布时间
equipment-设备
updateTime-数据存入时间
最后一个想法
网站调用新浪微博内容(微博怎么快速关闭?调用下接口怎么办?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-04-12 09:07
一般需要调用微信分享权限,需要在H5中添加分享按钮,点击即可显示。这通常需要开发人员调用下一个接口。
如何快速关闭微博,一起来看看吧!
取消方法:打开新浪微博账号设置-绑定手机,栏目有短信提醒,不勾选短信提醒即可取消。新浪微博:新浪微博是新浪网推出的提供微博服务的社交网络网站。用户可以通过网页、WAP页面、手机客户端、手机短信、彩信发布消息或上传图片
1.打开微博,点击【我】。
是的,在本地测试的 网站 不能共享。分享功能安装方法如下:百度搜索百度站长2.进入百度站长3.选择百度分享4.点击进入,如图5.点击进入免费获取代码6.选择直接复制代码7.安装代码到所有页面头部之前8.输入网站查看效果
2.进入右上角的【设置】。
可能你安装了一些分享插件,在工具箱中禁用了除官方“分享”插件之外的其他分享插件。点击工具箱,指向有分享功能的插件,然后点击插件图标右上角出现的小方块,选择禁用试试看。
3.滑动到底部退出微博。
1.Intent 意图 = new Intent(Intent.ACTION_SEND); //开始分享的属性发送2. intent.setType("text/plain"); //分享发送的数据类型3.@ > intent.putExtra(Intent.EXTRA_SUBJECT, "subject"); //共享主题4. intent.putExtra(Intent.EXTRA_TEXT
进一步阅读,您可能还对以下内容感兴趣。
discuz如何禁止帖子分享到空间、微博等功能
您可以尝试在模板文件中更改它。
如果不使用其他模板,默认在目录template\default\forum
在 viewthread_node.htm 文件中。对于更多问题和答案,您能告诉我要更改哪些代码吗?答案应该是
删除这段代码后,在后台更新缓存试试。如果你是新手,建议先备份这个文件,然后再做相应的操作。非常感谢提问,直接分享到空间的功能都没有了,不过如下
“重播”“分享”“采集”
这3个怎么取消?只需删除下面的相应代码即可。我列出了 2 段代码。
每个代表一个功能。
您可以尝试自己删除一个。记得更新缓存。
{lang thread_rely}{$_G['forum_thread']['relay']}
{lang 集合}{$post['releat采集num']}
如何在IE右键中添加【分享(到新浪微博)】功能?
打开360浏览器,在应用框点击“管理现有工具”,查看截图和微博,右键IE,应该会出现“分享到...”选项!跟进并这样做。但是右键菜单什么都没有……只是窗口顶部多了一个插件栏,我以前很烦……谢谢。有没有其他方法
如果android app需要添加微博分享功能,分享界面一实例化程序就会崩溃。
您为什么不发布此类问题的异常信息?否则,谁能帮你找到原因?跟进
对不起>_
这是在 logcat
不知道为什么会出现第一行的noclassdeffounderror
在控制台中显示
如何使用js实现网页分享功能,如分享到:人人网、开心网、新浪微博
这个问题我想了很久,但还是没搞明白。这是我的一位计算机同事告诉我的答案。你可以去百度看看佳思。它是中国最大的分享按钮提供商。网站 正在使用
哦,而且它提供的分享码很全,微博,QQ空间,人人网,开心。. . 任何代码!佳思分享的代码使用起来也很简单,复制粘贴即可,希望对大家有所帮助。
如何在微博评论中收录微博文字?
如果要带文本,这基本上是困难的。你只能带一个链接,链接可以跳转到你的文字。只有这样才能实现。
免责声明:本网页内容旨在传播知识。如有侵权等问题,请及时联系本站,我们将第一时间删除。电话: -84117792 邮箱: 查看全部
网站调用新浪微博内容(微博怎么快速关闭?调用下接口怎么办?(一))
一般需要调用微信分享权限,需要在H5中添加分享按钮,点击即可显示。这通常需要开发人员调用下一个接口。
如何快速关闭微博,一起来看看吧!
取消方法:打开新浪微博账号设置-绑定手机,栏目有短信提醒,不勾选短信提醒即可取消。新浪微博:新浪微博是新浪网推出的提供微博服务的社交网络网站。用户可以通过网页、WAP页面、手机客户端、手机短信、彩信发布消息或上传图片
1.打开微博,点击【我】。
是的,在本地测试的 网站 不能共享。分享功能安装方法如下:百度搜索百度站长2.进入百度站长3.选择百度分享4.点击进入,如图5.点击进入免费获取代码6.选择直接复制代码7.安装代码到所有页面头部之前8.输入网站查看效果

2.进入右上角的【设置】。
可能你安装了一些分享插件,在工具箱中禁用了除官方“分享”插件之外的其他分享插件。点击工具箱,指向有分享功能的插件,然后点击插件图标右上角出现的小方块,选择禁用试试看。

3.滑动到底部退出微博。
1.Intent 意图 = new Intent(Intent.ACTION_SEND); //开始分享的属性发送2. intent.setType("text/plain"); //分享发送的数据类型3.@ > intent.putExtra(Intent.EXTRA_SUBJECT, "subject"); //共享主题4. intent.putExtra(Intent.EXTRA_TEXT

进一步阅读,您可能还对以下内容感兴趣。
discuz如何禁止帖子分享到空间、微博等功能
您可以尝试在模板文件中更改它。
如果不使用其他模板,默认在目录template\default\forum
在 viewthread_node.htm 文件中。对于更多问题和答案,您能告诉我要更改哪些代码吗?答案应该是
删除这段代码后,在后台更新缓存试试。如果你是新手,建议先备份这个文件,然后再做相应的操作。非常感谢提问,直接分享到空间的功能都没有了,不过如下
“重播”“分享”“采集”
这3个怎么取消?只需删除下面的相应代码即可。我列出了 2 段代码。
每个代表一个功能。
您可以尝试自己删除一个。记得更新缓存。
{lang thread_rely}{$_G['forum_thread']['relay']}
{lang 集合}{$post['releat采集num']}
如何在IE右键中添加【分享(到新浪微博)】功能?
打开360浏览器,在应用框点击“管理现有工具”,查看截图和微博,右键IE,应该会出现“分享到...”选项!跟进并这样做。但是右键菜单什么都没有……只是窗口顶部多了一个插件栏,我以前很烦……谢谢。有没有其他方法
如果android app需要添加微博分享功能,分享界面一实例化程序就会崩溃。
您为什么不发布此类问题的异常信息?否则,谁能帮你找到原因?跟进
对不起>_
这是在 logcat
不知道为什么会出现第一行的noclassdeffounderror
在控制台中显示
如何使用js实现网页分享功能,如分享到:人人网、开心网、新浪微博
这个问题我想了很久,但还是没搞明白。这是我的一位计算机同事告诉我的答案。你可以去百度看看佳思。它是中国最大的分享按钮提供商。网站 正在使用
哦,而且它提供的分享码很全,微博,QQ空间,人人网,开心。. . 任何代码!佳思分享的代码使用起来也很简单,复制粘贴即可,希望对大家有所帮助。
如何在微博评论中收录微博文字?
如果要带文本,这基本上是困难的。你只能带一个链接,链接可以跳转到你的文字。只有这样才能实现。
免责声明:本网页内容旨在传播知识。如有侵权等问题,请及时联系本站,我们将第一时间删除。电话: -84117792 邮箱:
网站调用新浪微博内容(网站调用新浪微博内容和图片的时候,现在不能直接跳转和在微博界面去广告了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2022-04-12 08:04
网站调用新浪微博内容和图片的时候,现在不能直接跳转和在微博界面去广告了。官方的意思是因为我们要尽量避免这种行为,不然我们会担心你用xxx的方式获取到我们的用户名和手机号。举例来说,我们想要通过大众点评的链接跳转去广告,现在就不能直接跳转了,只能你联系该站长,告诉他们换一种形式来做,比如说:你把大众点评的二维码直接做在我们的地推海报上,再把我们的手机号作为动态码存进去等等。
这个月5号我们会考虑一下做跳转广告,有兴趣的可以关注一下我们。利益相关:大众点评产品市场部。现在:让:你在大众点评,分享广告里的链接到朋友圈,(让朋友直接打开广告界面)别人就会直接跳转到你的地推海报上。(也可以填你们的邮箱)---对了。你可以改成让,只需要点击我们广告的链接,就可以了。 查看全部
网站调用新浪微博内容(网站调用新浪微博内容和图片的时候,现在不能直接跳转和在微博界面去广告了)
网站调用新浪微博内容和图片的时候,现在不能直接跳转和在微博界面去广告了。官方的意思是因为我们要尽量避免这种行为,不然我们会担心你用xxx的方式获取到我们的用户名和手机号。举例来说,我们想要通过大众点评的链接跳转去广告,现在就不能直接跳转了,只能你联系该站长,告诉他们换一种形式来做,比如说:你把大众点评的二维码直接做在我们的地推海报上,再把我们的手机号作为动态码存进去等等。
这个月5号我们会考虑一下做跳转广告,有兴趣的可以关注一下我们。利益相关:大众点评产品市场部。现在:让:你在大众点评,分享广告里的链接到朋友圈,(让朋友直接打开广告界面)别人就会直接跳转到你的地推海报上。(也可以填你们的邮箱)---对了。你可以改成让,只需要点击我们广告的链接,就可以了。
网站调用新浪微博内容(建一个新的应用获取AppKey和AppSecret认证)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-04-12 03:20
本文讨论 OAuth 授权和身份验证。新浪开放的api必须在这个基础上调用,所以有必要具体说一下。前面的文章已经提到新浪微博提供OAuth认证方式有两种:OAuth和Base OAuth,而本项目使用的是OAuth认证。至于为什么使用这个 OAuth 认证而不是 Base OAuth 认证,原因很简单。由于 Twitter 仅支持 OAuth 身份验证,因此主要应用程序已转向 OAuth 身份验证。,新浪微博开放平台近期也将停止Base OAuth的认证方式。
OAuth的基本概念,OAUTH协议为用户资源的授权提供了一个安全、开放、简单的标准。与之前的授权方式不同的是,OAUTH的授权将不允许第三方访问用户的账户信息(如用户名和密码),即第三方无需使用即可申请访问用户的资源用户的用户名和密码。授权,所以 OAUTH 是安全的。同样,新浪微博也提供了OAuth认证来保证用户账号和密码的安全。这里通过OAuth,一个普通的新浪微博用户,客户端程序(我们正在开发的android客户端程序),三者与新浪微博之间建立了互信关系,允许客户端程序(我们正在开发的android客户端程序)在不知道用户账号和密码的情况下浏览和发布微博,有效保护了用户账号的安全。将密码公开给客户端程序,以达到通过客户端程序写微博和查看微博的目的。这就是 OAuth 的作用。
结合新浪微博的OAuth认证,我们来说说具体的功能实现。首先,列出关键字组。下面四组关键字与我们接下来的OAuth认证有很大关系。
第一组:(App Key和App Secret),这组参数是创建本系列第一篇文章中提到的新应用,获取App Key和App Secret。
第二组:(Request Token和Request Secret)
第三组:(oauth_verifier)
第四组:(user_id、Access Token和Access Secret)
在新浪微博的OAuth认证过程中,用户第一次使用客户端软件时,客户端程序以第一组参数作为参数向新浪微博发起请求,然后新浪微博返回第二组参数核实后发给客户。该客户端软件也表明新浪微博信任该客户端软件。客户端软件获取到第二组参数后,引导用户浏览器跳转到新浪微博的授权页面作为参数,然后用户输入自己的微博账号和密码进行授权。授权完成后,根据客户端设置的回调地址将第三组参数返回给客户端软件,表示用户也信任客户端软件。下一个,客户端软件发送第二组参数和第三组参数作为参数再次向新浪微博发起请求,然后新浪微博将第四组参数返回给客户端软件。第四组参数需要保存好。这是用来替换用户的新浪帐号和密码的。,稍后调用api时需要。从这个过程来看,用户只是在新浪微博的认证页面输入了帐号和密码,并没有在客户端软件中输入帐号和密码。客户端软件只保存第四组数据,不保存用户账号和密码。,有效防止账号和密码泄露给新浪微博以外的第三方应用,确保安全。 查看全部
网站调用新浪微博内容(建一个新的应用获取AppKey和AppSecret认证)
本文讨论 OAuth 授权和身份验证。新浪开放的api必须在这个基础上调用,所以有必要具体说一下。前面的文章已经提到新浪微博提供OAuth认证方式有两种:OAuth和Base OAuth,而本项目使用的是OAuth认证。至于为什么使用这个 OAuth 认证而不是 Base OAuth 认证,原因很简单。由于 Twitter 仅支持 OAuth 身份验证,因此主要应用程序已转向 OAuth 身份验证。,新浪微博开放平台近期也将停止Base OAuth的认证方式。
OAuth的基本概念,OAUTH协议为用户资源的授权提供了一个安全、开放、简单的标准。与之前的授权方式不同的是,OAUTH的授权将不允许第三方访问用户的账户信息(如用户名和密码),即第三方无需使用即可申请访问用户的资源用户的用户名和密码。授权,所以 OAUTH 是安全的。同样,新浪微博也提供了OAuth认证来保证用户账号和密码的安全。这里通过OAuth,一个普通的新浪微博用户,客户端程序(我们正在开发的android客户端程序),三者与新浪微博之间建立了互信关系,允许客户端程序(我们正在开发的android客户端程序)在不知道用户账号和密码的情况下浏览和发布微博,有效保护了用户账号的安全。将密码公开给客户端程序,以达到通过客户端程序写微博和查看微博的目的。这就是 OAuth 的作用。
结合新浪微博的OAuth认证,我们来说说具体的功能实现。首先,列出关键字组。下面四组关键字与我们接下来的OAuth认证有很大关系。
第一组:(App Key和App Secret),这组参数是创建本系列第一篇文章中提到的新应用,获取App Key和App Secret。
第二组:(Request Token和Request Secret)
第三组:(oauth_verifier)
第四组:(user_id、Access Token和Access Secret)
在新浪微博的OAuth认证过程中,用户第一次使用客户端软件时,客户端程序以第一组参数作为参数向新浪微博发起请求,然后新浪微博返回第二组参数核实后发给客户。该客户端软件也表明新浪微博信任该客户端软件。客户端软件获取到第二组参数后,引导用户浏览器跳转到新浪微博的授权页面作为参数,然后用户输入自己的微博账号和密码进行授权。授权完成后,根据客户端设置的回调地址将第三组参数返回给客户端软件,表示用户也信任客户端软件。下一个,客户端软件发送第二组参数和第三组参数作为参数再次向新浪微博发起请求,然后新浪微博将第四组参数返回给客户端软件。第四组参数需要保存好。这是用来替换用户的新浪帐号和密码的。,稍后调用api时需要。从这个过程来看,用户只是在新浪微博的认证页面输入了帐号和密码,并没有在客户端软件中输入帐号和密码。客户端软件只保存第四组数据,不保存用户账号和密码。,有效防止账号和密码泄露给新浪微博以外的第三方应用,确保安全。
网站调用新浪微博内容(python移动端微博信息及用户信息_sina_selenium)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-04-12 03:15
Python新浪微博爬虫,爬取微博和用户信息(含源码和示例)
这是新浪微博爬虫,使用python+selenium实现。免费资源,希望对你有所帮助,虽然是傻瓜式爬虫,但至少可以运行。同时rar收录源码和爬取示例。参考我的文章:【python爬虫】Selenium爬取新浪微博内容和用户信息【Python爬虫】Selenium爬取新浪微博客户端用户信息、热点话题和评论(上)主要爬取内容包括:新浪微博手机终端用户信息和微博信息。用户信息:包括用户ID、用户名、微博数、关注数、关注数等微博信息:包括转发或原创、点赞数、转发数、评论数、发布时间、微博内容等安装过程:1. 先安装Python环境,作者是Python 2.7.82. 然后安装PIP或者easy_install3. 通过命令pip install selenium安装selenium,是一个工具进行自动测试和爬取4.然后修改代码中的用户名和密码,填写自己的用户名和密码5.运行程序,自动调用火狐浏览器登录微博注意:移动端信息更加精致简洁,对动态加载没有一些限制,但是只显示微博或者粉丝id等20个页面,这是它的缺点;虽然客户端可能有动态加载,比如评论和微博,但它的信息更完整。【源码】抓取手机端微博信息spider_selenium_sina_content。
立即下载 查看全部
网站调用新浪微博内容(python移动端微博信息及用户信息_sina_selenium)
Python新浪微博爬虫,爬取微博和用户信息(含源码和示例)
这是新浪微博爬虫,使用python+selenium实现。免费资源,希望对你有所帮助,虽然是傻瓜式爬虫,但至少可以运行。同时rar收录源码和爬取示例。参考我的文章:【python爬虫】Selenium爬取新浪微博内容和用户信息【Python爬虫】Selenium爬取新浪微博客户端用户信息、热点话题和评论(上)主要爬取内容包括:新浪微博手机终端用户信息和微博信息。用户信息:包括用户ID、用户名、微博数、关注数、关注数等微博信息:包括转发或原创、点赞数、转发数、评论数、发布时间、微博内容等安装过程:1. 先安装Python环境,作者是Python 2.7.82. 然后安装PIP或者easy_install3. 通过命令pip install selenium安装selenium,是一个工具进行自动测试和爬取4.然后修改代码中的用户名和密码,填写自己的用户名和密码5.运行程序,自动调用火狐浏览器登录微博注意:移动端信息更加精致简洁,对动态加载没有一些限制,但是只显示微博或者粉丝id等20个页面,这是它的缺点;虽然客户端可能有动态加载,比如评论和微博,但它的信息更完整。【源码】抓取手机端微博信息spider_selenium_sina_content。
立即下载
网站调用新浪微博内容(没有调用新浪的API,在程序中加入自己的帐号和密码就能发送微博)
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-04-12 03:13
无需调用新浪的API,您可以通过在程序中添加自己的帐号和密码来发送微博。代码完全在后台运行,无需打开浏览器。
使用HtmlUnit库模拟登录并发送微博。
效果图优先:
这是登录后第一页的信息。
发微博:
没什么难的,找到对应的按钮和文本框,点击,总之就是用代码模仿用户的操作。
public class weibo {
public static void main(String args[]) throws FailingHttpStatusCodeException, MalformedURLException, IOException, InterruptedException{
//新浪微博登录页面
String baseUrl = "https://passport.weibo.cn/sign ... 3B%3B
//打开
WebClient webClient = new WebClient(BrowserVersion.CHROME);
webClient.addRequestHeader("User-Agent", "Mozilla/5.0 (iPad; CPU OS 7_0_2 like Mac OS X) AppleWebKit/537.51.1 (KHTML, like Gecko) Version/7.0 Mobile/11A501 Safari/9537.53");
//webClient.addRequestHeader("User-Agent", "Mozilla/5.0 (Linux; Android 4.4.2; Nexus 4 Build/KOT49H) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.122 Mobile Safari/537.36");
HtmlPage page = webClient.getPage(baseUrl);
//等待页面加载
Thread.sleep(1000);
//获取输入帐号的控件
HtmlInput usr = (HtmlInput) page.getElementById("loginName");
usr.setValueAttribute("Your Account");
//获取输入密码的控件
HtmlInput pwd = (HtmlInput) page.getElementById("loginPassword");
pwd.setValueAttribute("Your Password");
//点击登录
DomElement button = page.getElementById("loginAction");
page =(HtmlPage) button.click();
//等待页面加载
Thread.sleep(1000);
//获取到“写微博”这个按钮,因为这个按钮没有name和id,获取所有<a>标签
DomNodeList button2 = page.getElementsByTagName("a");
//跳转到发送微博页面
page =(HtmlPage)button2.get(4).click();
//等待页面加载
Thread.sleep(1000);
//获取发送控件 标签为<a>中的2个
DomNodeList button3 = page.getElementsByTagName("a");
//获取文本宇
HtmlTextArea content =(HtmlTextArea) page.getElementById("txt-publisher");
DomElement fasong = button3.get(1);
content.focus();
Date date = new Date();
//填写你要发送的内容
content.setText("使用JAVA发送微博!!!!\n"+date);
//改变发送按钮的属性,不能无法发送
fasong.setAttribute("class", "fr txt-link");
//发送!!!
page = (HtmlPage)fasong.click();
Thread.sleep(5000);
System.out.println(page.asText());
}
}
好的,就这么简单!
转载于: 查看全部
网站调用新浪微博内容(没有调用新浪的API,在程序中加入自己的帐号和密码就能发送微博)
无需调用新浪的API,您可以通过在程序中添加自己的帐号和密码来发送微博。代码完全在后台运行,无需打开浏览器。
使用HtmlUnit库模拟登录并发送微博。
效果图优先:
这是登录后第一页的信息。

发微博:
没什么难的,找到对应的按钮和文本框,点击,总之就是用代码模仿用户的操作。
public class weibo {
public static void main(String args[]) throws FailingHttpStatusCodeException, MalformedURLException, IOException, InterruptedException{
//新浪微博登录页面
String baseUrl = "https://passport.weibo.cn/sign ... 3B%3B
//打开
WebClient webClient = new WebClient(BrowserVersion.CHROME);
webClient.addRequestHeader("User-Agent", "Mozilla/5.0 (iPad; CPU OS 7_0_2 like Mac OS X) AppleWebKit/537.51.1 (KHTML, like Gecko) Version/7.0 Mobile/11A501 Safari/9537.53");
//webClient.addRequestHeader("User-Agent", "Mozilla/5.0 (Linux; Android 4.4.2; Nexus 4 Build/KOT49H) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.122 Mobile Safari/537.36");
HtmlPage page = webClient.getPage(baseUrl);
//等待页面加载
Thread.sleep(1000);
//获取输入帐号的控件
HtmlInput usr = (HtmlInput) page.getElementById("loginName");
usr.setValueAttribute("Your Account");
//获取输入密码的控件
HtmlInput pwd = (HtmlInput) page.getElementById("loginPassword");
pwd.setValueAttribute("Your Password");
//点击登录
DomElement button = page.getElementById("loginAction");
page =(HtmlPage) button.click();
//等待页面加载
Thread.sleep(1000);
//获取到“写微博”这个按钮,因为这个按钮没有name和id,获取所有<a>标签
DomNodeList button2 = page.getElementsByTagName("a");
//跳转到发送微博页面
page =(HtmlPage)button2.get(4).click();
//等待页面加载
Thread.sleep(1000);
//获取发送控件 标签为<a>中的2个
DomNodeList button3 = page.getElementsByTagName("a");
//获取文本宇
HtmlTextArea content =(HtmlTextArea) page.getElementById("txt-publisher");
DomElement fasong = button3.get(1);
content.focus();
Date date = new Date();
//填写你要发送的内容
content.setText("使用JAVA发送微博!!!!\n"+date);
//改变发送按钮的属性,不能无法发送
fasong.setAttribute("class", "fr txt-link");
//发送!!!
page = (HtmlPage)fasong.click();
Thread.sleep(5000);
System.out.println(page.asText());
}
}
好的,就这么简单!
转载于:
网站调用新浪微博内容(使用API提交数据(发布一条微博信息)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-04-06 23:02
我也是新手,第一次使用开放平台进行开发。起初,我觉得我无处可去。经过长时间的摸索,终于成功调用了API。现在给新手介绍一下这段经历(高手不用看,当然如果大家能提出一些意见和建议,非常感谢),也想和大家交流。
本例介绍如何使用 API 提交数据(发布一条微博)和使用 API 获取数据(获取最新的 20 条公开微博消息),即官方 API Go 中的“获取下行数据集(时间线)接口”到“微博访问界面”下的“statuses/public_timeline 获取最新更新的公众微博新闻”和“statuses/update 发布微博消息”。
首先,你必须有新浪微博账号并申请一个app key(详情请参考%E6%96%B0%E6%89%8B%E6%8C%87%E5%8D%97),然后在VS中新建一个解决方案,在解决方案中添加一个类库和一个网站,并添加一个引用(网站指的是类库)。
由于发微博是POST请求,获取数据是GET请求,并且是通过HTTP Basic Authentication授权的,所以我把这些函数写在一个类中(在类库中),代码如下(这个类参考to ,没有仔细考虑它是否是普遍的):
发送请求和授权码
然后在类库中新建两个实体类status和user,字段与官方API一致:
状态实体类
用户实体类
好了,经过以上步骤,准备工作就完成了。现在让我们开始调用 API。我们先来看发布一条微博消息。虽然在这个文章()中已经介绍过了,但为了本文的完整性,我还是贴出来。我的代码,在类库中添加一个微博访问类MiniBlogVisit类:
微博接入类
您可以通过调用 update 方法发布微博。不过需要注意的是,这里的Content要用HttpUtility.UrlEncode编码,否则会出现乱码。
我们来看看最新的20条公众微博消息,这是官方API中的第一个接口。这里返回的数据是 XML 数据或 JSON 数据。您可以根据自己的喜好自由选择。我选择返回 XML 数据。我的方法是将返回的 XML 数据写入 XML 文件,然后解析 XML 文件。代码如下:
获取数据代码
好吧,现在是时候打电话了。调用比较简单。它是一个空的 Default.aspx 页面。后台代码如下:
调用代码
至此,所有的代码都写好了,我们来看看完整的解决方案:
运行后的效果如下:
第一次调用API,第一次写这么长的文章。欢迎大家多多评论!!! 查看全部
网站调用新浪微博内容(使用API提交数据(发布一条微博信息)(组图))
我也是新手,第一次使用开放平台进行开发。起初,我觉得我无处可去。经过长时间的摸索,终于成功调用了API。现在给新手介绍一下这段经历(高手不用看,当然如果大家能提出一些意见和建议,非常感谢),也想和大家交流。
本例介绍如何使用 API 提交数据(发布一条微博)和使用 API 获取数据(获取最新的 20 条公开微博消息),即官方 API Go 中的“获取下行数据集(时间线)接口”到“微博访问界面”下的“statuses/public_timeline 获取最新更新的公众微博新闻”和“statuses/update 发布微博消息”。
首先,你必须有新浪微博账号并申请一个app key(详情请参考%E6%96%B0%E6%89%8B%E6%8C%87%E5%8D%97),然后在VS中新建一个解决方案,在解决方案中添加一个类库和一个网站,并添加一个引用(网站指的是类库)。
由于发微博是POST请求,获取数据是GET请求,并且是通过HTTP Basic Authentication授权的,所以我把这些函数写在一个类中(在类库中),代码如下(这个类参考to ,没有仔细考虑它是否是普遍的):

发送请求和授权码
然后在类库中新建两个实体类status和user,字段与官方API一致:
状态实体类
用户实体类
好了,经过以上步骤,准备工作就完成了。现在让我们开始调用 API。我们先来看发布一条微博消息。虽然在这个文章()中已经介绍过了,但为了本文的完整性,我还是贴出来。我的代码,在类库中添加一个微博访问类MiniBlogVisit类:
微博接入类
您可以通过调用 update 方法发布微博。不过需要注意的是,这里的Content要用HttpUtility.UrlEncode编码,否则会出现乱码。
我们来看看最新的20条公众微博消息,这是官方API中的第一个接口。这里返回的数据是 XML 数据或 JSON 数据。您可以根据自己的喜好自由选择。我选择返回 XML 数据。我的方法是将返回的 XML 数据写入 XML 文件,然后解析 XML 文件。代码如下:
获取数据代码
好吧,现在是时候打电话了。调用比较简单。它是一个空的 Default.aspx 页面。后台代码如下:
调用代码
至此,所有的代码都写好了,我们来看看完整的解决方案:
运行后的效果如下:
第一次调用API,第一次写这么长的文章。欢迎大家多多评论!!!
网站调用新浪微博内容(python言语恶劣地评论个人博客是垃圾,说个人代码有问题 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-04-06 22:27
)
PS:(本人长期出售大量微博数据,游网站评论数据,并提供各种指定数据爬取服务,留言至。由于微博界面更新,限制增加,这段代码可以不再使用。爬取数据。如果只是为了采集数据,可以咨询个人邮箱。如果是学习爬虫,建议学习phantomjs从网页爬取微博)html
使用新浪API实现数据抓取(由于增加了API接口限制,本文已基本放弃)
2018.5.16个提示
现在微博的api接口很差,普通权限的token已经爬不上任何数据了。用这段代码爬取大量数据是不可能的。仅供熟悉微博api接口使用的人使用。一个小演示。Python
2018.4.16 说明 linux
注:今天有人恶评说个人博客是垃圾,说个人代码有问题。这个博客历史悠久,是我刚开始玩爬虫时写的一篇博客。非常感谢能对个人代码发表意见的人,但我受不了那些说话粗鲁、态度不好的人。如果你有话要说,那是现代社会一个高学历、高智商的最低意识。IOS
我已经更改了代码。如果还有问题,欢迎大家轻轻指出!!!!混帐
同时,由于新浪微博自身api机制的不断变化,本篇博客的内容至今有限。对于我的开发者来说,你申请的token的权限只能爬你自己的微博。,所以对于那些想依靠api来爬取数据的人来说,恐怕就达不到目的了。如果要使用api抓取微博内容,只能选择获取更高的开发者权限。github
1.首先我们看看我们到底得到了什么结果,是不是你想知道的,然后再决定是否继续读下去。
我主要抓了4天左右的数据。从图中可以看出大概有360万条数据,因为数据是在我自己的电脑上爬取的,有时候晚上会断网,所以大约一天可以爬取最新的1条左右的微博数据万(因为我调用的是最新的微博API public_timeline)web
API文档定义了很多返回类型(以json数据格式返回,我选择了一些我认为重要的信息并抓取了如图:关于id号,位置,粉丝数,微博内容,发微博的时间等。当然这些数据可以根据自己的需要定制。)mongodb
内容大概就是这样。如果觉得这对你有点帮助,请继续阅读……第一次写博客有点啰嗦2.前期准备
我们需要:数据库
2.1mongodb安装
MongoDB 是一个高性能、开源、无模式的文档数据库,是比较流行的 NoSql 数据库之一。在很多场景下,它可以用来替代传统的关系型数据库或者键/值存储。Mongo 是用 C++ 开发的。Mongo的官方网站地址是:读者可以在这里获得更详细的信息。json
小插曲:什么是 NoSql?
NoSql,全称Not Only Sql,指的是非关系型数据库。下一代数据库主要解决几个点:非关系型、分布式、开源、水平可扩展。最初旨在用于大型 Web 应用程序,这一运动始于 2009 年初,具有以下一般特性:模式自由、支持轻松复制、简单的 API、最终一致性(非 ACID)、大容量数据等。NoSQL 是最常用的键值存储,虽然还有其他基于文档的、基于列的、图数据库、xml数据库等。
网上有很多安装mongodb的教程,我就不写了
windows下mongodb的安装
Linux下mongodb的安装
2.2 如何注册新浪开发者账号
* 建立后需要填写手机号验证 *
首次创建应用,需要填写以下信息:
本页信息无需填写地区、电话等真实信息,可随意填写。网站填写。(电子邮件必须是真实的)
继续构建应用程序。应用名称自定义,查看平台下的ios、android
建立完成后,返回继续建立。一个账号可以创建10个应用,每个应用对应一个access-token(其实我一个就可以满足需求)
选择创建的应用程序。观点
只需将下面的令牌保存在 txt 中。
背部
点击个人应用
然后选择刚刚创建的应用程序
进入后点击申请信息
保存APP Key和APP Secret
单击高级信息
设置回调地址
可以设置为默认
您的开发者帐户现已完成
2.3 依赖库的安装方法
安装 requests 和 pymongo
可以直接用pip安装
pip install requests 和 pip install pymongo
也可以直接在Pycharm中安装
选择文件 -> 设置 -> 项目 -> 项目解释器
可以看到安装好的Python库,点击右边绿色的*+*号
只需安装
3.分析问题3.1 OAuth认证
*授权机制说明(很重要)*
网上很多人都说用新浪微博API发微博什么的,使用请求用户授权Token的方法,但是这种方法显然不适合我们爬取数据,因为我们每次都要请求,每次从新的获取代码。详见新浪微博API授权机制
廖雪峰老师(新浪微博投稿人)对这个授权机制也有解释
通过新浪微博的API访问网站,由于用户不需要在你的网站上注册,可以直接在新浪微博@>上用自己的账号和密码登录你的网站,这需要确保你的网站在不知道或不知道用户密码的情况下确认用户已经成功登录。因为用户的密码存储在新浪微博中,所以验证用户的过程只能由新浪微博来完成,但是新浪微博是如何与你的网站通信并通知你用户是否登录成功的呢?这个过程称为第三方登录。OAuth 是标准的第三方登录协议。使用 OAuth,您的 网站 可以安全地访问已成功登录的新浪微博用户。
OAuth 目前有两个版本:1.0 和 2.0。版本 2.0 简化版本 1.0,API 更简单。新浪微博最新的API也使用了OAuth2.0。整个登录过程如下:
用户在你的网站点击“用新浪微博登录”,你的网站将用户重定向到新浪微博的OAuth认证页面,重定向连接中收录client_id参数作为你的网站@ >ID,redirect_uri参数告诉新浪微博在用户登录成功时将浏览器重定向到你的网站;用户在新浪微博认证页面输入账号和密码;新浪微博认证成功后,将浏览器重定向到你的网站并附上code参数;你的网站通过code参数向新浪微博请求用户的access token;你的 网站 获取到用户的访问令牌后,用户的登录就完成了。
OAuth访问令牌是提供认证服务的网站(如新浪微博)生成的令牌,表示用户的认证信息。在后续的 API 调用中,会传入访问令牌以指示已登录的用户。这样,经过OAuth协议后,你的网站会将用户验证步骤交给新浪微博,新浪微博会通知你用户是否登录成功。
OAuth的安全性通过第4步完成。通过code参数获取access token的过程是由你的网站后台到新浪微博网站完成的,用户看不到获取访问令牌。问。如果用户输入的是假密码,新浪微博会返回错误。
详情请参考廖雪峰老师的文档
一般来说,按照通常的用户授权Token调用请求,会出现这种情况:
获取代码
登录后会跳转到一个链接××××××××
我们只需要code=××××××××××的值
也就是说,每次调用API鉴权,浏览器都会出现一段代码,这显然不利于我们的爬取网站
如何解决问题?首先我们想到的是在Python程序中模拟登录新浪微博,然后就可以得到代码的值了。不过新浪微博的模拟登录比较复杂,既然模拟登录成功了,何必呢?调用API呢……直接自定义爬取不是更方便。
如果你看过上面的授权机制,你应该会想到它。这时候就需要我们之前申请的access-token了。
根据我个人的理解,access-token就是将你的微博授权给第三方,让他为你做一些事情,类似于手机上通过新浪微博登录,然后进行操作(使用前面提到的授权机制)更多)。总之,手机应用可以直接使用官方手机SDK,调用微博客户端进行授权(如果没有安装微博客户端,会调用H5授权页面)
你应该熟悉这个界面
新浪也给出了Oauth2/access token的说明
4.代码实现
有了token,实现数据抓取就很简单了
可以捕获多少数据取决于您的令牌权限
接下来就是使用API获取数据:新建文件weibo_run.py
# -*- coding:utf-8 -*-
import requests
from pymongo import MongoClient
ACCESS_TOKEN = '2.00ZooSqFHAgn3D59864ee3170DLjNj'
URL = 'https://api.weibo.com/2/statuses/public_timeline.json'
def run():
#受权
while True:
#调用statuses__public_timeline的api接口
params = {
'access_token': ACCESS_TOKEN
}
statuses = requests.get(url=URL, params=params).json()['statuses']
length = len(statuses)
#这是后来我为了查看获取微博条数设置的
print length
#链接mongodb,不须要本地的额外配置
Monclient = MongoClient('localhost', 27017)
db = Monclient['Weibo']
WeiboData = db['HadSelected']
#获取的各个数据名应该能够清楚的看出来对应的是什么数据
for i in range(0, length):
created_at = statuses[i]['created_at']
id = statuses[i]['user']['id']
province = statuses[i]['user']['province']
city = statuses[i]['user']['city']
followers_count = statuses[i]['user']['followers_count']
friends_count = statuses[i]['user']['friends_count']
statuses_count = statuses[i]['user']['statuses_count']
url = statuses[i]['user']['url']
geo = statuses[i]['geo']
comments_count = statuses[i]['comments_count']
reposts_count = statuses[i]['reposts_count']
nickname = statuses[i]['user']['screen_name']
desc = statuses[i]['user']['description']
location = statuses[i]['user']['location']
text = statuses[i]['text']
#插入mongodb
WeiboData.insert_one({
'created_at': created_at,
'id': id,
'nickname': nickname,
'text': text,
'province': province,
'location': location,
'description': desc,
'city': city,
'followers_count': followers_count,
'friends_count': friends_count,
'statuses_count': statuses_count,
'url': url,
'geo': geo,
'comments_count': comments_count,
'reposts_count': reposts_count
})
if __name__ == "__main__":
run()
个人代码一开始是这样的,看起来已经完成了。
但是,由于新浪会限制你可以拨打的电话数量,所以我稍后尝试重新运行它,发现问题。我之前的打印长度得到的每一行的值都不一样,一直在16-20之间徘徊。它表明我从新运行中获得的数据每次都不同。然后想了想,就写个死循环看看他什么时候又被阻塞了。所以代码变成了下面
删除 run() 并将其替换为以下无限循环。
if __name__ == "__main__":
while 1:
try:
run()
except:
pass
结果,他一直在跑……跑了四天,还没有被拦住。估计不会被封...
其余接口的使用方法也一样,只是改变了url和params。具体参数请参考新浪微博API文档
一开始我发现我一天能拿到800万条数据,这让我很开心……后来我发现了很多重复的数据。找了半天终于找到了解决办法。我根据用户的id和建立时间在mongodb中创建了一个索引(因为我不可能同时发两条微博),最后一天能得到100份左右没有重复数据。上千条信息。
我的博客 查看全部
网站调用新浪微博内容(python言语恶劣地评论个人博客是垃圾,说个人代码有问题
)
PS:(本人长期出售大量微博数据,游网站评论数据,并提供各种指定数据爬取服务,留言至。由于微博界面更新,限制增加,这段代码可以不再使用。爬取数据。如果只是为了采集数据,可以咨询个人邮箱。如果是学习爬虫,建议学习phantomjs从网页爬取微博)html
使用新浪API实现数据抓取(由于增加了API接口限制,本文已基本放弃)
2018.5.16个提示
现在微博的api接口很差,普通权限的token已经爬不上任何数据了。用这段代码爬取大量数据是不可能的。仅供熟悉微博api接口使用的人使用。一个小演示。Python
2018.4.16 说明 linux
注:今天有人恶评说个人博客是垃圾,说个人代码有问题。这个博客历史悠久,是我刚开始玩爬虫时写的一篇博客。非常感谢能对个人代码发表意见的人,但我受不了那些说话粗鲁、态度不好的人。如果你有话要说,那是现代社会一个高学历、高智商的最低意识。IOS
我已经更改了代码。如果还有问题,欢迎大家轻轻指出!!!!混帐
同时,由于新浪微博自身api机制的不断变化,本篇博客的内容至今有限。对于我的开发者来说,你申请的token的权限只能爬你自己的微博。,所以对于那些想依靠api来爬取数据的人来说,恐怕就达不到目的了。如果要使用api抓取微博内容,只能选择获取更高的开发者权限。github
1.首先我们看看我们到底得到了什么结果,是不是你想知道的,然后再决定是否继续读下去。
我主要抓了4天左右的数据。从图中可以看出大概有360万条数据,因为数据是在我自己的电脑上爬取的,有时候晚上会断网,所以大约一天可以爬取最新的1条左右的微博数据万(因为我调用的是最新的微博API public_timeline)web
API文档定义了很多返回类型(以json数据格式返回,我选择了一些我认为重要的信息并抓取了如图:关于id号,位置,粉丝数,微博内容,发微博的时间等。当然这些数据可以根据自己的需要定制。)mongodb
内容大概就是这样。如果觉得这对你有点帮助,请继续阅读……第一次写博客有点啰嗦2.前期准备
我们需要:数据库
2.1mongodb安装
MongoDB 是一个高性能、开源、无模式的文档数据库,是比较流行的 NoSql 数据库之一。在很多场景下,它可以用来替代传统的关系型数据库或者键/值存储。Mongo 是用 C++ 开发的。Mongo的官方网站地址是:读者可以在这里获得更详细的信息。json
小插曲:什么是 NoSql?
NoSql,全称Not Only Sql,指的是非关系型数据库。下一代数据库主要解决几个点:非关系型、分布式、开源、水平可扩展。最初旨在用于大型 Web 应用程序,这一运动始于 2009 年初,具有以下一般特性:模式自由、支持轻松复制、简单的 API、最终一致性(非 ACID)、大容量数据等。NoSQL 是最常用的键值存储,虽然还有其他基于文档的、基于列的、图数据库、xml数据库等。
网上有很多安装mongodb的教程,我就不写了
windows下mongodb的安装
Linux下mongodb的安装
2.2 如何注册新浪开发者账号
* 建立后需要填写手机号验证 *
首次创建应用,需要填写以下信息:
本页信息无需填写地区、电话等真实信息,可随意填写。网站填写。(电子邮件必须是真实的)
继续构建应用程序。应用名称自定义,查看平台下的ios、android
建立完成后,返回继续建立。一个账号可以创建10个应用,每个应用对应一个access-token(其实我一个就可以满足需求)
选择创建的应用程序。观点
只需将下面的令牌保存在 txt 中。
背部
点击个人应用
然后选择刚刚创建的应用程序
进入后点击申请信息
保存APP Key和APP Secret
单击高级信息
设置回调地址
可以设置为默认
您的开发者帐户现已完成
2.3 依赖库的安装方法
安装 requests 和 pymongo
可以直接用pip安装
pip install requests 和 pip install pymongo
也可以直接在Pycharm中安装
选择文件 -> 设置 -> 项目 -> 项目解释器
可以看到安装好的Python库,点击右边绿色的*+*号
只需安装
3.分析问题3.1 OAuth认证
*授权机制说明(很重要)*
网上很多人都说用新浪微博API发微博什么的,使用请求用户授权Token的方法,但是这种方法显然不适合我们爬取数据,因为我们每次都要请求,每次从新的获取代码。详见新浪微博API授权机制
廖雪峰老师(新浪微博投稿人)对这个授权机制也有解释
通过新浪微博的API访问网站,由于用户不需要在你的网站上注册,可以直接在新浪微博@>上用自己的账号和密码登录你的网站,这需要确保你的网站在不知道或不知道用户密码的情况下确认用户已经成功登录。因为用户的密码存储在新浪微博中,所以验证用户的过程只能由新浪微博来完成,但是新浪微博是如何与你的网站通信并通知你用户是否登录成功的呢?这个过程称为第三方登录。OAuth 是标准的第三方登录协议。使用 OAuth,您的 网站 可以安全地访问已成功登录的新浪微博用户。
OAuth 目前有两个版本:1.0 和 2.0。版本 2.0 简化版本 1.0,API 更简单。新浪微博最新的API也使用了OAuth2.0。整个登录过程如下:
用户在你的网站点击“用新浪微博登录”,你的网站将用户重定向到新浪微博的OAuth认证页面,重定向连接中收录client_id参数作为你的网站@ >ID,redirect_uri参数告诉新浪微博在用户登录成功时将浏览器重定向到你的网站;用户在新浪微博认证页面输入账号和密码;新浪微博认证成功后,将浏览器重定向到你的网站并附上code参数;你的网站通过code参数向新浪微博请求用户的access token;你的 网站 获取到用户的访问令牌后,用户的登录就完成了。
OAuth访问令牌是提供认证服务的网站(如新浪微博)生成的令牌,表示用户的认证信息。在后续的 API 调用中,会传入访问令牌以指示已登录的用户。这样,经过OAuth协议后,你的网站会将用户验证步骤交给新浪微博,新浪微博会通知你用户是否登录成功。
OAuth的安全性通过第4步完成。通过code参数获取access token的过程是由你的网站后台到新浪微博网站完成的,用户看不到获取访问令牌。问。如果用户输入的是假密码,新浪微博会返回错误。
详情请参考廖雪峰老师的文档
一般来说,按照通常的用户授权Token调用请求,会出现这种情况:
获取代码
登录后会跳转到一个链接××××××××
我们只需要code=××××××××××的值
也就是说,每次调用API鉴权,浏览器都会出现一段代码,这显然不利于我们的爬取网站
如何解决问题?首先我们想到的是在Python程序中模拟登录新浪微博,然后就可以得到代码的值了。不过新浪微博的模拟登录比较复杂,既然模拟登录成功了,何必呢?调用API呢……直接自定义爬取不是更方便。
如果你看过上面的授权机制,你应该会想到它。这时候就需要我们之前申请的access-token了。
根据我个人的理解,access-token就是将你的微博授权给第三方,让他为你做一些事情,类似于手机上通过新浪微博登录,然后进行操作(使用前面提到的授权机制)更多)。总之,手机应用可以直接使用官方手机SDK,调用微博客户端进行授权(如果没有安装微博客户端,会调用H5授权页面)
你应该熟悉这个界面
新浪也给出了Oauth2/access token的说明
4.代码实现
有了token,实现数据抓取就很简单了
可以捕获多少数据取决于您的令牌权限
接下来就是使用API获取数据:新建文件weibo_run.py
# -*- coding:utf-8 -*-
import requests
from pymongo import MongoClient
ACCESS_TOKEN = '2.00ZooSqFHAgn3D59864ee3170DLjNj'
URL = 'https://api.weibo.com/2/statuses/public_timeline.json'
def run():
#受权
while True:
#调用statuses__public_timeline的api接口
params = {
'access_token': ACCESS_TOKEN
}
statuses = requests.get(url=URL, params=params).json()['statuses']
length = len(statuses)
#这是后来我为了查看获取微博条数设置的
print length
#链接mongodb,不须要本地的额外配置
Monclient = MongoClient('localhost', 27017)
db = Monclient['Weibo']
WeiboData = db['HadSelected']
#获取的各个数据名应该能够清楚的看出来对应的是什么数据
for i in range(0, length):
created_at = statuses[i]['created_at']
id = statuses[i]['user']['id']
province = statuses[i]['user']['province']
city = statuses[i]['user']['city']
followers_count = statuses[i]['user']['followers_count']
friends_count = statuses[i]['user']['friends_count']
statuses_count = statuses[i]['user']['statuses_count']
url = statuses[i]['user']['url']
geo = statuses[i]['geo']
comments_count = statuses[i]['comments_count']
reposts_count = statuses[i]['reposts_count']
nickname = statuses[i]['user']['screen_name']
desc = statuses[i]['user']['description']
location = statuses[i]['user']['location']
text = statuses[i]['text']
#插入mongodb
WeiboData.insert_one({
'created_at': created_at,
'id': id,
'nickname': nickname,
'text': text,
'province': province,
'location': location,
'description': desc,
'city': city,
'followers_count': followers_count,
'friends_count': friends_count,
'statuses_count': statuses_count,
'url': url,
'geo': geo,
'comments_count': comments_count,
'reposts_count': reposts_count
})
if __name__ == "__main__":
run()
个人代码一开始是这样的,看起来已经完成了。
但是,由于新浪会限制你可以拨打的电话数量,所以我稍后尝试重新运行它,发现问题。我之前的打印长度得到的每一行的值都不一样,一直在16-20之间徘徊。它表明我从新运行中获得的数据每次都不同。然后想了想,就写个死循环看看他什么时候又被阻塞了。所以代码变成了下面
删除 run() 并将其替换为以下无限循环。
if __name__ == "__main__":
while 1:
try:
run()
except:
pass
结果,他一直在跑……跑了四天,还没有被拦住。估计不会被封...
其余接口的使用方法也一样,只是改变了url和params。具体参数请参考新浪微博API文档
一开始我发现我一天能拿到800万条数据,这让我很开心……后来我发现了很多重复的数据。找了半天终于找到了解决办法。我根据用户的id和建立时间在mongodb中创建了一个索引(因为我不可能同时发两条微博),最后一天能得到100份左右没有重复数据。上千条信息。
我的博客
网站调用新浪微博内容(试试用python调用微博API的方法微博接口)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-04-06 20:07
因为最近碰到一个调用新浪微博开放接口的项目,想试试用python调用微博API。
SDK下载地址:代码不超过十几K,完全可以理解。
如果你有微博账号,可以新建一个APP,然后获取APP获取OAuth2.0授权所需的app key和app secret。
要了解 OAuth2,您可以查看链接到新浪微博的说明。OAuth2授权参数除了app key和app secret外,还需要网站回调地址redirect_uri,并且这个回调地址不允许在局域网内(神马localhost,127. 0.0.@ >1 好像不行),这真的让我焦急了好久。我没有使用 API 调用 网站,所以我检查了很多。看到有人写这个地址可以改用,我试了一下,成功了,对掉丝来说是个好消息。
这里有一个简单的程序来体验:
设置以下参数
import sys
import weibo
import webbrowser
APP_KEY = ‘‘
MY_APP_SECRET = ‘‘
REDIRECT_URL = ‘https://api.weibo.com/oauth2/default.html‘
获取微博授权网址,如第2行,用默认浏览器打开后,会提示登录微博,使用需要授权的账号登录,如下图
api = weibo.APIClient(app_key=APP_KEY,app_secret=MY_APP_SECRET,redirect_uri=REDIRECT_URL)
authorize_url = api.get_authorize_url()
print(authorize_url)
webbrowser.open_new(authorize_url)
登录后,您将被重定向到一个连接
关键是码值,是认证的关键。手动输入码值模拟认证
request = api.request_access_token(code, REDIRECT_URL)
access_token = request.access_token
expires_in = request.expires_in
api.set_access_token(access_token, expires_in)
api.statuses.update.post(status=u‘Test OAuth 2.0 Send a Weibo!‘)
access_token为获取到的token,expires_in为授权过期时间(UNIX时间)
使用 set_access_token 保存授权。往下走,就可以调用微博界面了。测试发了一条推文
但是,这种手动输入代码的方式并不适合调用程序。是否可以在不打开链接的情况下请求登录并获得授权?经过多方搜索参考,程序改进如下,可以自动获取代码并保存,方便程序服务调用。
accessWeibo
# -*- coding: utf-8 -*-
#/usr/bin/env python
#access to SinaWeibo By sinaweibopy
#实现微博自动登录,token自动生成,保存及更新
#适合于后端服务调用
from weibo import APIClient
import pymongo
import sys, os, urllib, urllib2
from http_helper import *
from retry import *
try:
import json
except ImportError:
import simplejson as json
# setting sys encoding to utf-8
default_encoding = ‘utf-8‘
if sys.getdefaultencoding() != default_encoding:
reload(sys)
sys.setdefaultencoding(default_encoding)
# weibo api访问配置
APP_KEY = ‘‘ # app key
APP_SECRET = ‘‘ # app secret
REDIRECT_URL = ‘https://api.weibo.com/oauth2/default.html‘ # callback url 授权回调页,与OAuth2.0 授权设置的一致
USERID = ‘‘ # 登陆的微博用户名,必须是OAuth2.0 设置的测试账号
USERPASSWD = ‘‘ # 用户密码
client = APIClient(app_key=APP_KEY, app_secret=APP_SECRET, redirect_uri=REDIRECT_URL)
def make_access_token():
#请求access token
params = urllib.urlencode({
‘action‘:‘submit‘,
‘withOfficalFlag‘:‘0‘,
‘ticket‘:‘‘,
‘isLoginSina‘:‘‘,
‘response_type‘:‘code‘,
‘regCallback‘:‘‘,
‘redirect_uri‘:REDIRECT_URL,
‘client_id‘:APP_KEY,
‘state‘:‘‘,
‘from‘:‘‘,
‘userId‘:USERID,
‘passwd‘:USERPASSWD,
})
login_url = ‘https://api.weibo.com/oauth2/authorize‘
url = client.get_authorize_url()
content = urllib2.urlopen(url)
if content:
headers = { ‘Referer‘ : url }
request = urllib2.Request(login_url, params, headers)
opener = get_opener(False)
urllib2.install_opener(opener)
try:
f = opener.open(request)
return_redirect_uri = f.url
except urllib2.HTTPError, e:
return_redirect_uri = e.geturl()
# 取到返回的code
code = return_redirect_uri.split(‘=‘)[1]
#得到token
token = client.request_access_token(code,REDIRECT_URL)
save_access_token(token)
def save_access_token(token):
#将access token保存到MongoDB数据库
mongoCon=pymongo.Connection(host="127.0.0.1",port=27017)
db= mongoCon.weibo
t={
"access_token":token[‘access_token‘],
"expires_in":str(token[‘expires_in‘]),
"date":time.strftime(‘%Y-%m-%d %H:%M:%S‘,time.localtime(time.time()))
}
db.token.insert(t,safe=True)
#Decorator 目的是当调用make_access_token()后再执行一次apply_access_token()
@retry(1)
def apply_access_token():
#从MongoDB读取及设置access token
try:
mongoCon=pymongo.Connection(host="127.0.0.1",port=27017)
db= mongoCon.weibo
if db.token.count()>0:
tokenInfos=db.token.find().sort([("_id",pymongo.DESCENDING)]).limit(1)
else:
make_access_token()
return False
for tokenInfo in tokenInfos:
access_token=tokenInfo["access_token"]
expires_in=tokenInfo["expires_in"]
try:
client.set_access_token(access_token, expires_in)
except StandardError, e:
if hasattr(e, ‘error‘):
if e.error == ‘expired_token‘:
# token过期重新生成
make_access_token()
return False
else:
pass
except:
make_access_token()
return False
return True
if __name__ == "__main__":
apply_access_token()
# 以下为访问微博api的应用逻辑
# 以发布文字微博接口为例
client.statuses.update.post(status=‘Test OAuth 2.0 Send a Weibo!‘)
retry.py
import math
import time
# Retry decorator with exponential backoff
def retry(tries, delay=1, backoff=2):
"""Retries a function or method until it returns True.
delay sets the initial delay, and backoff sets how much the delay should
lengthen after each failure. backoff must be greater than 1, or else it
isn‘t really a backoff. tries must be at least 0, and delay greater than
0."""
if backoff decorated function
return deco_retry # @retry(arg[, ...]) -> true decorator
http_helper.py
# -*- coding: utf-8 -*-
#/usr/bin/env python
import urllib2,cookielib
class SmartRedirectHandler(urllib2.HTTPRedirectHandler):
def http_error_301(cls, req, fp, code, msg, headers):
result = urllib2.HTTPRedirectHandler.http_error_301(cls, req, fp, code, msg, headers)
result.status = code
print headers
return result
def http_error_302(cls, req, fp, code, msg, headers):
result = urllib2.HTTPRedirectHandler.http_error_302(cls, req, fp, code, msg, headers)
result.status = code
print headers
return result
def get_cookie():
cookies = cookielib.CookieJar()
return urllib2.HTTPCookieProcessor(cookies)
def get_opener(proxy=False):
rv=urllib2.build_opener(get_cookie(), SmartRedirectHandler())
rv.addheaders = [(‘User-agent‘, ‘Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1)‘)]
return rv
Python调用新浪微博API项目实践
原版的: 查看全部
网站调用新浪微博内容(试试用python调用微博API的方法微博接口)
因为最近碰到一个调用新浪微博开放接口的项目,想试试用python调用微博API。
SDK下载地址:代码不超过十几K,完全可以理解。
如果你有微博账号,可以新建一个APP,然后获取APP获取OAuth2.0授权所需的app key和app secret。
要了解 OAuth2,您可以查看链接到新浪微博的说明。OAuth2授权参数除了app key和app secret外,还需要网站回调地址redirect_uri,并且这个回调地址不允许在局域网内(神马localhost,127. 0.0.@ >1 好像不行),这真的让我焦急了好久。我没有使用 API 调用 网站,所以我检查了很多。看到有人写这个地址可以改用,我试了一下,成功了,对掉丝来说是个好消息。
这里有一个简单的程序来体验:
设置以下参数
import sys
import weibo
import webbrowser
APP_KEY = ‘‘
MY_APP_SECRET = ‘‘
REDIRECT_URL = ‘https://api.weibo.com/oauth2/default.html‘
获取微博授权网址,如第2行,用默认浏览器打开后,会提示登录微博,使用需要授权的账号登录,如下图
api = weibo.APIClient(app_key=APP_KEY,app_secret=MY_APP_SECRET,redirect_uri=REDIRECT_URL)
authorize_url = api.get_authorize_url()
print(authorize_url)
webbrowser.open_new(authorize_url)
登录后,您将被重定向到一个连接
关键是码值,是认证的关键。手动输入码值模拟认证
request = api.request_access_token(code, REDIRECT_URL)
access_token = request.access_token
expires_in = request.expires_in
api.set_access_token(access_token, expires_in)
api.statuses.update.post(status=u‘Test OAuth 2.0 Send a Weibo!‘)
access_token为获取到的token,expires_in为授权过期时间(UNIX时间)
使用 set_access_token 保存授权。往下走,就可以调用微博界面了。测试发了一条推文
但是,这种手动输入代码的方式并不适合调用程序。是否可以在不打开链接的情况下请求登录并获得授权?经过多方搜索参考,程序改进如下,可以自动获取代码并保存,方便程序服务调用。
accessWeibo
# -*- coding: utf-8 -*-
#/usr/bin/env python
#access to SinaWeibo By sinaweibopy
#实现微博自动登录,token自动生成,保存及更新
#适合于后端服务调用
from weibo import APIClient
import pymongo
import sys, os, urllib, urllib2
from http_helper import *
from retry import *
try:
import json
except ImportError:
import simplejson as json
# setting sys encoding to utf-8
default_encoding = ‘utf-8‘
if sys.getdefaultencoding() != default_encoding:
reload(sys)
sys.setdefaultencoding(default_encoding)
# weibo api访问配置
APP_KEY = ‘‘ # app key
APP_SECRET = ‘‘ # app secret
REDIRECT_URL = ‘https://api.weibo.com/oauth2/default.html‘ # callback url 授权回调页,与OAuth2.0 授权设置的一致
USERID = ‘‘ # 登陆的微博用户名,必须是OAuth2.0 设置的测试账号
USERPASSWD = ‘‘ # 用户密码
client = APIClient(app_key=APP_KEY, app_secret=APP_SECRET, redirect_uri=REDIRECT_URL)
def make_access_token():
#请求access token
params = urllib.urlencode({
‘action‘:‘submit‘,
‘withOfficalFlag‘:‘0‘,
‘ticket‘:‘‘,
‘isLoginSina‘:‘‘,
‘response_type‘:‘code‘,
‘regCallback‘:‘‘,
‘redirect_uri‘:REDIRECT_URL,
‘client_id‘:APP_KEY,
‘state‘:‘‘,
‘from‘:‘‘,
‘userId‘:USERID,
‘passwd‘:USERPASSWD,
})
login_url = ‘https://api.weibo.com/oauth2/authorize‘
url = client.get_authorize_url()
content = urllib2.urlopen(url)
if content:
headers = { ‘Referer‘ : url }
request = urllib2.Request(login_url, params, headers)
opener = get_opener(False)
urllib2.install_opener(opener)
try:
f = opener.open(request)
return_redirect_uri = f.url
except urllib2.HTTPError, e:
return_redirect_uri = e.geturl()
# 取到返回的code
code = return_redirect_uri.split(‘=‘)[1]
#得到token
token = client.request_access_token(code,REDIRECT_URL)
save_access_token(token)
def save_access_token(token):
#将access token保存到MongoDB数据库
mongoCon=pymongo.Connection(host="127.0.0.1",port=27017)
db= mongoCon.weibo
t={
"access_token":token[‘access_token‘],
"expires_in":str(token[‘expires_in‘]),
"date":time.strftime(‘%Y-%m-%d %H:%M:%S‘,time.localtime(time.time()))
}
db.token.insert(t,safe=True)
#Decorator 目的是当调用make_access_token()后再执行一次apply_access_token()
@retry(1)
def apply_access_token():
#从MongoDB读取及设置access token
try:
mongoCon=pymongo.Connection(host="127.0.0.1",port=27017)
db= mongoCon.weibo
if db.token.count()>0:
tokenInfos=db.token.find().sort([("_id",pymongo.DESCENDING)]).limit(1)
else:
make_access_token()
return False
for tokenInfo in tokenInfos:
access_token=tokenInfo["access_token"]
expires_in=tokenInfo["expires_in"]
try:
client.set_access_token(access_token, expires_in)
except StandardError, e:
if hasattr(e, ‘error‘):
if e.error == ‘expired_token‘:
# token过期重新生成
make_access_token()
return False
else:
pass
except:
make_access_token()
return False
return True
if __name__ == "__main__":
apply_access_token()
# 以下为访问微博api的应用逻辑
# 以发布文字微博接口为例
client.statuses.update.post(status=‘Test OAuth 2.0 Send a Weibo!‘)
retry.py
import math
import time
# Retry decorator with exponential backoff
def retry(tries, delay=1, backoff=2):
"""Retries a function or method until it returns True.
delay sets the initial delay, and backoff sets how much the delay should
lengthen after each failure. backoff must be greater than 1, or else it
isn‘t really a backoff. tries must be at least 0, and delay greater than
0."""
if backoff decorated function
return deco_retry # @retry(arg[, ...]) -> true decorator
http_helper.py
# -*- coding: utf-8 -*-
#/usr/bin/env python
import urllib2,cookielib
class SmartRedirectHandler(urllib2.HTTPRedirectHandler):
def http_error_301(cls, req, fp, code, msg, headers):
result = urllib2.HTTPRedirectHandler.http_error_301(cls, req, fp, code, msg, headers)
result.status = code
print headers
return result
def http_error_302(cls, req, fp, code, msg, headers):
result = urllib2.HTTPRedirectHandler.http_error_302(cls, req, fp, code, msg, headers)
result.status = code
print headers
return result
def get_cookie():
cookies = cookielib.CookieJar()
return urllib2.HTTPCookieProcessor(cookies)
def get_opener(proxy=False):
rv=urllib2.build_opener(get_cookie(), SmartRedirectHandler())
rv.addheaders = [(‘User-agent‘, ‘Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1)‘)]
return rv
Python调用新浪微博API项目实践
原版的:
网站调用新浪微博内容(这是新浪微博爬虫用户信息、热点话题及评论(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-04-06 18:17
这是新浪微博爬虫,使用python+selenium实现。免费资源,希望对你有所帮助,虽然是傻瓜式爬虫,但至少可以运行。同时rar收录源码和爬取示例。参考我的文章:20436【python爬虫】Selenium爬取新浪微博内容和用户信息231852【Python爬虫】Selenium爬取新浪微博客户端用户信息、热点话题和评论(上)主要爬取内容包括:新浪微博手机用户信息和微博信息。用户信息:包括用户ID、用户名、微博数、关注数、关注数等微博信息:包括转发或原创、点赞数、转发数、评论数、发布时间、微博内容等安装过程:1. 先安装Python环境,作者是Python2.7.82.然后安装pIP或者easy_install3.通过命令pip install selenium安装selenium,是一个工具进行自动测试爬取4.然后修改代码中的用户名和密码,填写自己的用户名和密码5.运行程序,自动调用火狐浏览器登录微博注意:移动端信息比较精致简洁,对动态加载没有一些限制,但是只显示微博或者粉丝id等20个页面,这是它的缺点;虽然客户端可能有动态加载,比如评论和微博,但它的信息更完整。【源码】抓取手机端微博信息spider_selenium_sina_content。 查看全部
网站调用新浪微博内容(这是新浪微博爬虫用户信息、热点话题及评论(上))
这是新浪微博爬虫,使用python+selenium实现。免费资源,希望对你有所帮助,虽然是傻瓜式爬虫,但至少可以运行。同时rar收录源码和爬取示例。参考我的文章:20436【python爬虫】Selenium爬取新浪微博内容和用户信息231852【Python爬虫】Selenium爬取新浪微博客户端用户信息、热点话题和评论(上)主要爬取内容包括:新浪微博手机用户信息和微博信息。用户信息:包括用户ID、用户名、微博数、关注数、关注数等微博信息:包括转发或原创、点赞数、转发数、评论数、发布时间、微博内容等安装过程:1. 先安装Python环境,作者是Python2.7.82.然后安装pIP或者easy_install3.通过命令pip install selenium安装selenium,是一个工具进行自动测试爬取4.然后修改代码中的用户名和密码,填写自己的用户名和密码5.运行程序,自动调用火狐浏览器登录微博注意:移动端信息比较精致简洁,对动态加载没有一些限制,但是只显示微博或者粉丝id等20个页面,这是它的缺点;虽然客户端可能有动态加载,比如评论和微博,但它的信息更完整。【源码】抓取手机端微博信息spider_selenium_sina_content。
网站调用新浪微博内容是哪个公司的什么代理服务?
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2022-09-15 21:01
网站调用新浪微博内容一般都使用双边代理的形式。可以查看ispormonitor查看网站调用的是哪个公司的什么代理服务。如果没有,则可以打客服电话获取更多isp服务。
新浪没用他,这种sb网站就是这样,一个政府名字竟然用和政府沾边的手段来挣钱,还真tm让人恶心,什么商家融资,好吧,
不会是新浪打广告吧?还是提供什么服务收费?广告联盟其实也是跟新浪合作的。要提供什么服务,你要看他们合作的是哪家。联盟返佣模式还可以,聚合seo最让人头疼了。
个人认为是通过新浪抓取新浪自身服务的信息。对于站长来说,靠这个赚钱的成本已经太高,而且还要保证新浪能收到钱,
新浪微博很多文章都是打广告的吧?!就算想要在微博的内容中对电商进行引导性的推荐,也必须对同名内容实现其他域名进行投放。因为在搜索引擎输入电商关键词是从搜索引擎中先搜出来的那个域名,如果内容有效果再让用户点击。
前两天新浪还给云豆发红包,只要把电商内容发出去就返还,获得第一的红包很高,
被新浪微博无下限打广告了吧。
新浪是否真要自己打广告?如果微博想卖产品,或者打开洞见,那用什么去调用这个网站,难道要花钱雇人跳广告??这个主要是要看新浪是否允许通过微博的正常推广赚钱。 查看全部
网站调用新浪微博内容是哪个公司的什么代理服务?
网站调用新浪微博内容一般都使用双边代理的形式。可以查看ispormonitor查看网站调用的是哪个公司的什么代理服务。如果没有,则可以打客服电话获取更多isp服务。
新浪没用他,这种sb网站就是这样,一个政府名字竟然用和政府沾边的手段来挣钱,还真tm让人恶心,什么商家融资,好吧,
不会是新浪打广告吧?还是提供什么服务收费?广告联盟其实也是跟新浪合作的。要提供什么服务,你要看他们合作的是哪家。联盟返佣模式还可以,聚合seo最让人头疼了。
个人认为是通过新浪抓取新浪自身服务的信息。对于站长来说,靠这个赚钱的成本已经太高,而且还要保证新浪能收到钱,
新浪微博很多文章都是打广告的吧?!就算想要在微博的内容中对电商进行引导性的推荐,也必须对同名内容实现其他域名进行投放。因为在搜索引擎输入电商关键词是从搜索引擎中先搜出来的那个域名,如果内容有效果再让用户点击。
前两天新浪还给云豆发红包,只要把电商内容发出去就返还,获得第一的红包很高,
被新浪微博无下限打广告了吧。
新浪是否真要自己打广告?如果微博想卖产品,或者打开洞见,那用什么去调用这个网站,难道要花钱雇人跳广告??这个主要是要看新浪是否允许通过微博的正常推广赚钱。
Python使用微博API实现自动发送微博
网站优化 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2022-08-18 14:17
微博开放平台创建应用
微博开放平台:
点击:微连接>网站接入,输入应用名称创建应用。
填写应用基本信息
点击左侧高级信息,填写相关内容:
完善信息后提交审核。
记录应用相关信息相关代码获取Code
<p>import requests
try:
from urllib.parse import urlencode
except ImportError:
from urllib import urlencode
<br />
# App Key
API_KEY = 'xxxxx'
# 授权回调页
REDIRECT_URI = 'xxxxx'
# REDIRECT_URI = 'https://api.weibo.com/oauth2/default.html'
<br />
url = 'https://api.weibo.com/oauth2/authorize'
<br />
def get_url():
params = {
'client_id': API_KEY,
'redirect_uri': REDIRECT_URI
}
return "{0}?{1}".format(url, urlencode(params))
<br />
<br />
print(get_url())</p>
把打印出来的链接粘贴到浏览器上,回车点击授权后重定向到的新链接中出现code=xxxx,后面的值即为code值,记录code值后续获取access_token需要使用到它。
获取access_token
<p>import requests
import json
try:
from urllib.parse import urlencode
except ImportError:
from urllib import urlencode
<br />
API_KEY = 'XXXX'
API_SECRET = 'XXXXXXXX'
CODE = 'XXXX'
REDIRECT_URI = 'XXXX'
<br />
access_token_url = 'https://api.weibo.com/oauth2/access_token'
<br />
<br />
params = {
'client_id': API_KEY,
'client_secret': API_SECRET,
'grant_type': 'authorization_code',
'code': CODE,
'redirect_uri': REDIRECT_URI
}
res = requests.post(access_token_url, data=params)
token = json.loads(res.text)
print(token)</p>
执行程序得到以下内容:
<p>{
'access_token': 'xxxxxxxxxxxxxxxxxxxx',
'remind_in': '157679999',
'expires_in': 157679999,
'uid': '5741349972',
'isRealName': 'true'
}</p>
返回值字段字段类型字段说明
access_token
string
用户授权的唯一票据,用于调用微博的开放接口,同时也是第三方应用验证微博用户登录的唯一票据,第三方应用应该用该票据和自己应用内的用户建立唯一影射关系,来识别登录状态,不能使用本返回值里的UID字段来做登录识别。
expires_in
string
access_token的生命周期,单位是秒数。
remind_in
string
accesstoken的生命周期(该参数即将废弃,开发者请使用expiresin)。
uid
string
授权用户的UID,本字段只是为了方便开发者,减少一次user/show接口调用而返回的,第三方应用不能用此字段作为用户登录状态的识别,只有access_token才是用户授权的唯一票据。
access_token长时间有效,拿到之后就可以使用这个去调用发微博的接口了。
发微博
图文微博
<p>import requests
<br />
access_token = 'xxxxxxxxxxxxx'
<br />
url = "https://api.weibo.com/2/statuses/share.json"
# 应用的服务IP地址
rip = "xxxxxxxxxx"
#构建POST参数
params = {
"access_token": access_token,
#内容末尾带后台绑定的安全域名 或 安全域名下的网页
"status": "手执流光,梦里红尘。细品黎明的清新,感悟暮色的浓郁,置身于时光的长廊,昼看风散,夜听雨眠。https://xxx.com",
"rip": rip
}
#构建二进制multipart/form-data编码的参数
files={
"pic":open("1.jpg","rb")
}
#POST请求,发表文字+图片微博
res = requests.post(url,data = params, files = files)
print(res.text)</p>
运行程序,去微博主页看看是否发布成功。
如果应用还在审核中会有:来自 未通过审核应用。
注:使用该接口发送的博文 后面会带有网页链接
可能出现的错误
<p>// 检查授权回调页 安全设置 安全域名等配置项 是否正确或未填写
{'error': 'redirect_uri_mismatch', 'error_code': 21322, 'request': '/oauth2/access_token', 'error_uri': '/oauth2/access_token'}
<br />
// 检查要发送的内容是否包含链接,因为现在新浪微博强制要求要带链接。
{"error":"text not find domain!","error_code":10017,"request":"/2/statuses/share.json"}
<br />
// 参数错误或请求出错</p> 查看全部
Python使用微博API实现自动发送微博
微博开放平台创建应用
微博开放平台:
点击:微连接>网站接入,输入应用名称创建应用。
填写应用基本信息
点击左侧高级信息,填写相关内容:
完善信息后提交审核。
记录应用相关信息相关代码获取Code
<p>import requests
try:
from urllib.parse import urlencode
except ImportError:
from urllib import urlencode
<br />
# App Key
API_KEY = 'xxxxx'
# 授权回调页
REDIRECT_URI = 'xxxxx'
# REDIRECT_URI = 'https://api.weibo.com/oauth2/default.html'
<br />
url = 'https://api.weibo.com/oauth2/authorize'
<br />
def get_url():
params = {
'client_id': API_KEY,
'redirect_uri': REDIRECT_URI
}
return "{0}?{1}".format(url, urlencode(params))
<br />
<br />
print(get_url())</p>
把打印出来的链接粘贴到浏览器上,回车点击授权后重定向到的新链接中出现code=xxxx,后面的值即为code值,记录code值后续获取access_token需要使用到它。
获取access_token
<p>import requests
import json
try:
from urllib.parse import urlencode
except ImportError:
from urllib import urlencode
<br />
API_KEY = 'XXXX'
API_SECRET = 'XXXXXXXX'
CODE = 'XXXX'
REDIRECT_URI = 'XXXX'
<br />
access_token_url = 'https://api.weibo.com/oauth2/access_token'
<br />
<br />
params = {
'client_id': API_KEY,
'client_secret': API_SECRET,
'grant_type': 'authorization_code',
'code': CODE,
'redirect_uri': REDIRECT_URI
}
res = requests.post(access_token_url, data=params)
token = json.loads(res.text)
print(token)</p>
执行程序得到以下内容:
<p>{
'access_token': 'xxxxxxxxxxxxxxxxxxxx',
'remind_in': '157679999',
'expires_in': 157679999,
'uid': '5741349972',
'isRealName': 'true'
}</p>
返回值字段字段类型字段说明
access_token
string
用户授权的唯一票据,用于调用微博的开放接口,同时也是第三方应用验证微博用户登录的唯一票据,第三方应用应该用该票据和自己应用内的用户建立唯一影射关系,来识别登录状态,不能使用本返回值里的UID字段来做登录识别。
expires_in
string
access_token的生命周期,单位是秒数。
remind_in
string
accesstoken的生命周期(该参数即将废弃,开发者请使用expiresin)。
uid
string
授权用户的UID,本字段只是为了方便开发者,减少一次user/show接口调用而返回的,第三方应用不能用此字段作为用户登录状态的识别,只有access_token才是用户授权的唯一票据。
access_token长时间有效,拿到之后就可以使用这个去调用发微博的接口了。
发微博
图文微博
<p>import requests
<br />
access_token = 'xxxxxxxxxxxxx'
<br />
url = "https://api.weibo.com/2/statuses/share.json"
# 应用的服务IP地址
rip = "xxxxxxxxxx"
#构建POST参数
params = {
"access_token": access_token,
#内容末尾带后台绑定的安全域名 或 安全域名下的网页
"status": "手执流光,梦里红尘。细品黎明的清新,感悟暮色的浓郁,置身于时光的长廊,昼看风散,夜听雨眠。https://xxx.com",
"rip": rip
}
#构建二进制multipart/form-data编码的参数
files={
"pic":open("1.jpg","rb")
}
#POST请求,发表文字+图片微博
res = requests.post(url,data = params, files = files)
print(res.text)</p>
运行程序,去微博主页看看是否发布成功。
如果应用还在审核中会有:来自 未通过审核应用。
注:使用该接口发送的博文 后面会带有网页链接
可能出现的错误
<p>// 检查授权回调页 安全设置 安全域名等配置项 是否正确或未填写
{'error': 'redirect_uri_mismatch', 'error_code': 21322, 'request': '/oauth2/access_token', 'error_uri': '/oauth2/access_token'}
<br />
// 检查要发送的内容是否包含链接,因为现在新浪微博强制要求要带链接。
{"error":"text not find domain!","error_code":10017,"request":"/2/statuses/share.json"}
<br />
// 参数错误或请求出错</p>
为什么新浪网站上所有图片都不能直接挂png图片
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2022-07-19 01:05
网站调用新浪微博内容是算做从媒体到自己主动转换,所以即使是买断内容,也可以是买断所有权利,比如新浪微博会不会发布自己未经许可转载的图片?并非如此,相应的,当然也包括相关开发者,开发者是否会获得权利把内容放到自己的网站上,也可以做保护,
新浪微博买用户的图片也不是在ugc模式,而是在bta模式。它主要做的是媒体购买,购买不同的用户社区账号。
为什么新浪网站上所有图片都不能直接挂png图片,必须要转成jpg?因为新浪不认可所有png图片都必须转jpg,要获得squaregifartworker授权,
是否侵权取决于用户协议。一切与其签订协议的网站在协议内部都有规定,比如你不可以保留任何图片的署名图片或者把任何图片归于网站归属人。想要什么图片先在使用网站提供的图片类型中找自己认可的类型。因为一个网站如果无法使用使用新浪私有图片,就属于违约行为。
ugc必须分发到新浪网站上面来,但是图片有条款可以无限商用,只是单独看待盗图和这个没什么关系。
新浪微博一直没禁止他的图片,只是对于转载网站图片的大多数人都没有机会发言,但是你发表微博就是转载到新浪微博;你不能因为去了不可靠网站而不发言,这种事情少做;有这闲工夫去编排两个人干嘛, 查看全部
为什么新浪网站上所有图片都不能直接挂png图片
网站调用新浪微博内容是算做从媒体到自己主动转换,所以即使是买断内容,也可以是买断所有权利,比如新浪微博会不会发布自己未经许可转载的图片?并非如此,相应的,当然也包括相关开发者,开发者是否会获得权利把内容放到自己的网站上,也可以做保护,
新浪微博买用户的图片也不是在ugc模式,而是在bta模式。它主要做的是媒体购买,购买不同的用户社区账号。
为什么新浪网站上所有图片都不能直接挂png图片,必须要转成jpg?因为新浪不认可所有png图片都必须转jpg,要获得squaregifartworker授权,
是否侵权取决于用户协议。一切与其签订协议的网站在协议内部都有规定,比如你不可以保留任何图片的署名图片或者把任何图片归于网站归属人。想要什么图片先在使用网站提供的图片类型中找自己认可的类型。因为一个网站如果无法使用使用新浪私有图片,就属于违约行为。
ugc必须分发到新浪网站上面来,但是图片有条款可以无限商用,只是单独看待盗图和这个没什么关系。
新浪微博一直没禁止他的图片,只是对于转载网站图片的大多数人都没有机会发言,但是你发表微博就是转载到新浪微博;你不能因为去了不可靠网站而不发言,这种事情少做;有这闲工夫去编排两个人干嘛,
【手把手教规划师玩转大数据1】新浪微博Python API数据应用简明教程
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-06-22 11:19
【派姐说说】
亲爱的城市数据派会员们,3月的会员福利之新技术迷你教学终于来啦!完整版教学内容+代码+数据都将发送至会员邮箱,请注意查收哦!
会员费:599元/人/年=超过100份的大数据“干货”资料+最多20次大数据在线沙龙+最多20次新技术迷你教学+各类线下活动+行业专家亲自指导。如何成为会员,点击可查看:
亲们,你想get什么大数据相关的新技能呢?都请留言告诉派姐哦!小派一定努力送达!如果你有新技能愿意分享,也欢迎有偿投稿给小派哦!
【投稿作者信息】
宗立,南京大学城市规划与设计系,南京大学中澳虚拟城市与环境联合实验室成员。
【相关说明】
本教程只适用于小规模(10^4-10^6条数据)的签到数据采集与分析流程,本教程中的方法与工具无法驱动大型商业化应用项目。本教程中所使用的方法尽量贴近一般规划师已掌握的知识与技能,将数据采集的步骤尽可能分解。本教程的重点在于利用Python API获取相应数据的思路及实现,分析过程只是抛砖引玉,各位读者在自己的需求的基础上肯定能创造出更强大、更多样的分析过程。
为保密与实用起见,对本教程中的分析逻辑进行过简化,本教程附带的脚本及数据集均经过一定的处理。教程中的脚本工具尽可能减少逻辑层级,使用初级的Python语法与函数。数据集经过相应的混淆与截断处理,数据可能存在重复和瑕疵,但不影响在本教程中的使用。
为了提升实用性,避开了所有需要进行人工审核的过程,故数据采集量相对受限。教程中使用的授权与API调用方法可能会随着新浪微博的升级而升级,仅保证在本教程写作完成时,相应方法可用(2016.03.03)。本教程中的所有内容仅供学习创建微博数据分析应用使用,在善意使用的情况下,满足微博开放平台的使用协议,特此声明!需要进行商业化应用的用户请使用微博提供的商业数据服务(/development/businessdata)!
【必备知识】
Python(基础水平,2.7.X)、JSON解析
【可选模块】
模拟网页登录、Database(SQL/NoSQL皆可)、ArcGIS
【案例及思路简介】
某存量详细规划项目需要对项目区域内的消费场所业态提升方向提出指导,意图借助微博数据对相关人群的消费习惯进行分析,并得出相关的结论。
在这个过程中,首先需要得到项目区域的详细坐标(可使用ArcGIS获取坐标,也可利用地图网站进行地址反查或使用相关的Geocoding服务)。之后需要利用这个坐标或范围获取区域内的历史微博(在项目区域内发出过微博的用户很有可能就是项目区域内消费场所的消费者),再利用一定的规则根据这些微博的详细信息提取出目标用户群体,最后查询这些用户的签到记录(出行历史中的一部分数据反映相应的消费习惯)。
对出行历史中的消费场所业态进行简单的分析和解读就可得到目标用户群体的消费倾向,即可对本项目中的消费业态提升方向提出初步的指导性意见。
【教程本体】
1.利用个人微博账号登陆微博开放平台(),点击我的应用。(在还未创建应用时,会自动跳转到应用创建页面。)
2.完善开发者信息(只需填写基本信息并验证邮箱后即可创建一般应用(微连接),无需进行身份认证)。
3.创建新应用(名称填写时无特殊要求,注意不与应用库中已存在的应用名称重复即可),在创建完成后,注册邮箱将收到来自新浪的提示邮件,其中包含认证信息(认证信息也就是在之后的分析过程中将要用到的APP_KEY以及APP_SECRET)。
4.进入应用设置界面,切换到应用信息下的高级信息,将授权回调页与取消授权回调页都设置为新浪微博的默认地址(这一步的设置与新浪采用的认证方式有关,若不填写将无法获取授权token,也就无法调用 API)。
5.切换至测试信息页面,点击编辑按钮,添加“测试用户”。(由于整个过程中不会将应用提交新浪审核,所以只能使用主动添加的测试用户账号的授权来调用API,上限为15个用户。如有更高的需求,可与新浪官方联系,寻求合作。微博的API接口对于每日每时访问频次有相应的限制。)
6.安装Python微博SDK,并利用脚本工具获取已添加的测试账号的token。(微博Python SDK的相关内容见微博开放平台的API文档。熟悉相关API调用方法后,在CMD中运行pipinstall sinaweibopy即可安装微博Python SDK。如果读者朋友尚不了解pip或easy_install命令的使用方法,那说明您的Python水平可能尚未达到本教程的要求。为节省您的宝贵时间,请您进一步熟悉Python后再来服用本教程。另:测试账号的token每24小时需要更新一次。)(利用多个账号密码自动获取token并定期自动更新需要自行抓包并仿造POST请求,掌握此技术的读者朋友不妨一试。此处为简明起见,不予赘述。)
使用pip install sinaweibopy安装微博Python SDK(由于笔者已安装,所以此处显示与初次安装不同)
图为login_set.py,在安装微博SDK后,按照注释填写相关信息并运行即可
运行后需要使用测试账号在默认浏览器中进行授权
授权成功后,将地址栏中的认证code复制下来
将code粘贴到Python运行的窗口中,并敲击回车
程序成功利用code换取token后,利用token授权API读取公共时间线信息并输出
7.至此,准备工作已经结束。接下来,就可以利用token信息对API进行授权,并获取相关的地理信息了。。。。
如果您还想查看接下来的步骤,需要成为会员哦,您的一点支持将让小派更努力的为您带来更多迷你教学内容! 查看全部
【手把手教规划师玩转大数据1】新浪微博Python API数据应用简明教程
【派姐说说】
亲爱的城市数据派会员们,3月的会员福利之新技术迷你教学终于来啦!完整版教学内容+代码+数据都将发送至会员邮箱,请注意查收哦!
会员费:599元/人/年=超过100份的大数据“干货”资料+最多20次大数据在线沙龙+最多20次新技术迷你教学+各类线下活动+行业专家亲自指导。如何成为会员,点击可查看:
亲们,你想get什么大数据相关的新技能呢?都请留言告诉派姐哦!小派一定努力送达!如果你有新技能愿意分享,也欢迎有偿投稿给小派哦!
【投稿作者信息】
宗立,南京大学城市规划与设计系,南京大学中澳虚拟城市与环境联合实验室成员。
【相关说明】
本教程只适用于小规模(10^4-10^6条数据)的签到数据采集与分析流程,本教程中的方法与工具无法驱动大型商业化应用项目。本教程中所使用的方法尽量贴近一般规划师已掌握的知识与技能,将数据采集的步骤尽可能分解。本教程的重点在于利用Python API获取相应数据的思路及实现,分析过程只是抛砖引玉,各位读者在自己的需求的基础上肯定能创造出更强大、更多样的分析过程。
为保密与实用起见,对本教程中的分析逻辑进行过简化,本教程附带的脚本及数据集均经过一定的处理。教程中的脚本工具尽可能减少逻辑层级,使用初级的Python语法与函数。数据集经过相应的混淆与截断处理,数据可能存在重复和瑕疵,但不影响在本教程中的使用。
为了提升实用性,避开了所有需要进行人工审核的过程,故数据采集量相对受限。教程中使用的授权与API调用方法可能会随着新浪微博的升级而升级,仅保证在本教程写作完成时,相应方法可用(2016.03.03)。本教程中的所有内容仅供学习创建微博数据分析应用使用,在善意使用的情况下,满足微博开放平台的使用协议,特此声明!需要进行商业化应用的用户请使用微博提供的商业数据服务(/development/businessdata)!
【必备知识】
Python(基础水平,2.7.X)、JSON解析
【可选模块】
模拟网页登录、Database(SQL/NoSQL皆可)、ArcGIS
【案例及思路简介】
某存量详细规划项目需要对项目区域内的消费场所业态提升方向提出指导,意图借助微博数据对相关人群的消费习惯进行分析,并得出相关的结论。
在这个过程中,首先需要得到项目区域的详细坐标(可使用ArcGIS获取坐标,也可利用地图网站进行地址反查或使用相关的Geocoding服务)。之后需要利用这个坐标或范围获取区域内的历史微博(在项目区域内发出过微博的用户很有可能就是项目区域内消费场所的消费者),再利用一定的规则根据这些微博的详细信息提取出目标用户群体,最后查询这些用户的签到记录(出行历史中的一部分数据反映相应的消费习惯)。
对出行历史中的消费场所业态进行简单的分析和解读就可得到目标用户群体的消费倾向,即可对本项目中的消费业态提升方向提出初步的指导性意见。
【教程本体】
1.利用个人微博账号登陆微博开放平台(),点击我的应用。(在还未创建应用时,会自动跳转到应用创建页面。)
2.完善开发者信息(只需填写基本信息并验证邮箱后即可创建一般应用(微连接),无需进行身份认证)。
3.创建新应用(名称填写时无特殊要求,注意不与应用库中已存在的应用名称重复即可),在创建完成后,注册邮箱将收到来自新浪的提示邮件,其中包含认证信息(认证信息也就是在之后的分析过程中将要用到的APP_KEY以及APP_SECRET)。
4.进入应用设置界面,切换到应用信息下的高级信息,将授权回调页与取消授权回调页都设置为新浪微博的默认地址(这一步的设置与新浪采用的认证方式有关,若不填写将无法获取授权token,也就无法调用 API)。
5.切换至测试信息页面,点击编辑按钮,添加“测试用户”。(由于整个过程中不会将应用提交新浪审核,所以只能使用主动添加的测试用户账号的授权来调用API,上限为15个用户。如有更高的需求,可与新浪官方联系,寻求合作。微博的API接口对于每日每时访问频次有相应的限制。)
6.安装Python微博SDK,并利用脚本工具获取已添加的测试账号的token。(微博Python SDK的相关内容见微博开放平台的API文档。熟悉相关API调用方法后,在CMD中运行pipinstall sinaweibopy即可安装微博Python SDK。如果读者朋友尚不了解pip或easy_install命令的使用方法,那说明您的Python水平可能尚未达到本教程的要求。为节省您的宝贵时间,请您进一步熟悉Python后再来服用本教程。另:测试账号的token每24小时需要更新一次。)(利用多个账号密码自动获取token并定期自动更新需要自行抓包并仿造POST请求,掌握此技术的读者朋友不妨一试。此处为简明起见,不予赘述。)
使用pip install sinaweibopy安装微博Python SDK(由于笔者已安装,所以此处显示与初次安装不同)
图为login_set.py,在安装微博SDK后,按照注释填写相关信息并运行即可
运行后需要使用测试账号在默认浏览器中进行授权
授权成功后,将地址栏中的认证code复制下来
将code粘贴到Python运行的窗口中,并敲击回车
程序成功利用code换取token后,利用token授权API读取公共时间线信息并输出
7.至此,准备工作已经结束。接下来,就可以利用token信息对API进行授权,并获取相关的地理信息了。。。。
如果您还想查看接下来的步骤,需要成为会员哦,您的一点支持将让小派更努力的为您带来更多迷你教学内容!
谢邀:新浪微博与网易博客的合作情况仅做简要回答
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-05-28 13:03
网站调用新浪微博内容库,再把微博内容传播给网站,然后网站再推送给用户,原始数据来自新浪微博。微博作为公共数据,涉及到许多商业利益,所以这些推送信息都是由商业公司与新浪合作,而不是新浪官方出资。
谢邀,不对微博合作可以知道的一些情况仅做简要回答。在说新浪微博与网易博客的合作情况之前,需要先简单介绍下网易博客。网易博客是中国搜狐旗下的自有品牌网站,并与新浪博客、腾讯博客、天涯博客、太平洋博客等多家中国顶级门户网站进行战略合作。新浪网主要运营国内两大门户搜索引擎百度和谷歌,微博是由博客改进而来,因此两者合作早就开始。
新浪应该在2011年就给网易提供了相应的技术支持,不知道是否帮助网易增加了外部数据抓取功能。网易微博(),对应于新浪的新浪微博,主要起到两点作用,一是获取新浪博客的信息,二是与新浪微博进行连接,进行发布,以此让用户在新浪微博后台查看各个网站的日志情况。据了解,有的合作产品也会推送在腾讯微博后台进行下载。
除了没有网易微博,我没想到网易微博做得更像一个门户网站。比如网易博客早期传送的文章,很多是要收费的,而用户可以互相分享,可以看到对方的文章(腾讯等)。但是,这种订阅新浪博客的习惯太难改过来,如果不是微博,很多文章看到的机会比现在更多。所以我猜网易本来会有一个门户的新浪微博,只是不愿意用微博的传播效率,想用门户站和pc的搜索引擎来提高信息量。当然,门户的新浪微博也做得不是很好,流量控制得太弱。猜测的。 查看全部
谢邀:新浪微博与网易博客的合作情况仅做简要回答
网站调用新浪微博内容库,再把微博内容传播给网站,然后网站再推送给用户,原始数据来自新浪微博。微博作为公共数据,涉及到许多商业利益,所以这些推送信息都是由商业公司与新浪合作,而不是新浪官方出资。
谢邀,不对微博合作可以知道的一些情况仅做简要回答。在说新浪微博与网易博客的合作情况之前,需要先简单介绍下网易博客。网易博客是中国搜狐旗下的自有品牌网站,并与新浪博客、腾讯博客、天涯博客、太平洋博客等多家中国顶级门户网站进行战略合作。新浪网主要运营国内两大门户搜索引擎百度和谷歌,微博是由博客改进而来,因此两者合作早就开始。
新浪应该在2011年就给网易提供了相应的技术支持,不知道是否帮助网易增加了外部数据抓取功能。网易微博(),对应于新浪的新浪微博,主要起到两点作用,一是获取新浪博客的信息,二是与新浪微博进行连接,进行发布,以此让用户在新浪微博后台查看各个网站的日志情况。据了解,有的合作产品也会推送在腾讯微博后台进行下载。
除了没有网易微博,我没想到网易微博做得更像一个门户网站。比如网易博客早期传送的文章,很多是要收费的,而用户可以互相分享,可以看到对方的文章(腾讯等)。但是,这种订阅新浪博客的习惯太难改过来,如果不是微博,很多文章看到的机会比现在更多。所以我猜网易本来会有一个门户的新浪微博,只是不愿意用微博的传播效率,想用门户站和pc的搜索引擎来提高信息量。当然,门户的新浪微博也做得不是很好,流量控制得太弱。猜测的。
网站调用新浪微博内容,然后返回给支付宝什么?
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-05-13 03:01
网站调用新浪微博内容,然后返回参数给腾讯微博的技术人员,腾讯微博再返回给支付宝什么的。明显这一轮是支付宝没有把握准微博的流量以及明星的粉丝,导致腾讯微博必须主动出击,先把技术关搞定。
同意楼上观点,这是因为微博上充斥的文字和图片并不直观,而且支付宝也在试水传统图文推广的模式,早期以newsletter的形式发微博,进行新闻或小部分用户感兴趣的信息的推送。他们做搜索的时候,微博同样是做验证码推送的,也是用来吸引力一些有粘性的用户进行支付宝消费的。当然,作为人人微博,账号上的图片、文字推送是两个基本的入口,促进用户的打开率。
对于newsletter式的方式是支付宝一直在探索的一个道路,其实他们早就意识到了这个问题,并且做过类似尝试,但由于金额较小所以并没有太大突破。支付宝认为优秀的内容必须有一个媒介和载体进行推送,现在社交类型的信息,在用户打开微博进行新闻类的搜索时推送相关的微博,就是为了丰富搜索结果,为用户提供更多的可能性和选择,从而吸引用户。
做搜索应该比做社交工作量小很多。
参考微信。
1.短暂的爆发期背后支付宝想要抓住年轻人更新奇的特点,很好的解决了年轻人对新鲜事物的猎奇心理,至于为什么是今年(也不排除因为大环境的影响),那是因为微博上的观点和微信上的观点不一样2.我想没有支付宝公众号就没有现在的微信公众号(当然微信当年大力搞社交因为很多看不懂的东西)现在的微信公众号类似于网站里的二级域名。把各个公众号绑定起来以后,再把这些订阅的读者聚集起来,这就很类似马化腾规划中的微信群功能。 查看全部
网站调用新浪微博内容,然后返回给支付宝什么?
网站调用新浪微博内容,然后返回参数给腾讯微博的技术人员,腾讯微博再返回给支付宝什么的。明显这一轮是支付宝没有把握准微博的流量以及明星的粉丝,导致腾讯微博必须主动出击,先把技术关搞定。
同意楼上观点,这是因为微博上充斥的文字和图片并不直观,而且支付宝也在试水传统图文推广的模式,早期以newsletter的形式发微博,进行新闻或小部分用户感兴趣的信息的推送。他们做搜索的时候,微博同样是做验证码推送的,也是用来吸引力一些有粘性的用户进行支付宝消费的。当然,作为人人微博,账号上的图片、文字推送是两个基本的入口,促进用户的打开率。
对于newsletter式的方式是支付宝一直在探索的一个道路,其实他们早就意识到了这个问题,并且做过类似尝试,但由于金额较小所以并没有太大突破。支付宝认为优秀的内容必须有一个媒介和载体进行推送,现在社交类型的信息,在用户打开微博进行新闻类的搜索时推送相关的微博,就是为了丰富搜索结果,为用户提供更多的可能性和选择,从而吸引用户。
做搜索应该比做社交工作量小很多。
参考微信。
1.短暂的爆发期背后支付宝想要抓住年轻人更新奇的特点,很好的解决了年轻人对新鲜事物的猎奇心理,至于为什么是今年(也不排除因为大环境的影响),那是因为微博上的观点和微信上的观点不一样2.我想没有支付宝公众号就没有现在的微信公众号(当然微信当年大力搞社交因为很多看不懂的东西)现在的微信公众号类似于网站里的二级域名。把各个公众号绑定起来以后,再把这些订阅的读者聚集起来,这就很类似马化腾规划中的微信群功能。
网站调用新浪微博内容不经过客户端访问的网站内容
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-05-08 22:01
网站调用新浪微博内容不经过客户端访问的网站内容,都必须从新浪微博获取新浪微博不仅提供ugc数据库,也提供服务器服务,网站服务,
获取新浪微博的内容,由新浪微博平台来提供。新浪微博也会提供web的服务,网页浏览新浪微博时,就能看到网页端的微博内容了。
一切从用户获取内容都算是互联网的内容提供商。你要的只是表现而已。
主要还是考虑信息安全性,除了部分敏感信息,其他的最好不要公开发布,除非你有充分的自信能确保用户访问你网站时一定没有问题。
twitter提供获取微博原创文章的api可以看一下
首先,我想明确一点,微博是个sns网站,需要考虑的是这个sns网站是不是足够安全和可信(美国等发达国家为例)其次,想下如果不获取微博原创内容,可能从哪来的这些微博,是不是一堆僵尸发的或者是被删除的转发。如果从国内政策角度考虑,说一不二,网站会采取什么措施来处理,政策不变,还是照样需要获取,因为这本身是一个网站使用的一个比较正常的行为。
第三,从浏览网站习惯和用户访问习惯考虑,我觉得国内大部分用户还是习惯不去点击新浪微博的原创和转发,反而默认默默浏览的用户更多,这样就造成了,有些为满足这种假性用户获取方式,可能就是没有获取微博原文的用户,最后可能会形成不自然的,因为假性用户来的急,就更容易把转发或者获取微博都当成某种东西,就更容易在发微博时不完全表达想法。 查看全部
网站调用新浪微博内容不经过客户端访问的网站内容
网站调用新浪微博内容不经过客户端访问的网站内容,都必须从新浪微博获取新浪微博不仅提供ugc数据库,也提供服务器服务,网站服务,
获取新浪微博的内容,由新浪微博平台来提供。新浪微博也会提供web的服务,网页浏览新浪微博时,就能看到网页端的微博内容了。
一切从用户获取内容都算是互联网的内容提供商。你要的只是表现而已。
主要还是考虑信息安全性,除了部分敏感信息,其他的最好不要公开发布,除非你有充分的自信能确保用户访问你网站时一定没有问题。
twitter提供获取微博原创文章的api可以看一下
首先,我想明确一点,微博是个sns网站,需要考虑的是这个sns网站是不是足够安全和可信(美国等发达国家为例)其次,想下如果不获取微博原创内容,可能从哪来的这些微博,是不是一堆僵尸发的或者是被删除的转发。如果从国内政策角度考虑,说一不二,网站会采取什么措施来处理,政策不变,还是照样需要获取,因为这本身是一个网站使用的一个比较正常的行为。
第三,从浏览网站习惯和用户访问习惯考虑,我觉得国内大部分用户还是习惯不去点击新浪微博的原创和转发,反而默认默默浏览的用户更多,这样就造成了,有些为满足这种假性用户获取方式,可能就是没有获取微博原文的用户,最后可能会形成不自然的,因为假性用户来的急,就更容易把转发或者获取微博都当成某种东西,就更容易在发微博时不完全表达想法。
网站调用新浪微博内容(新浪微博平台自动化运维演进之路演讲分享(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-04-17 21:36
阿里云 > 云栖社区 > 主题地图 > X > 新浪微博api python
推荐活动:
更多优惠>
当前话题:新浪微博api python加入采集
相关话题:
新浪微博apipython相关博客看更多博文
新浪微博平台自动化运维演进
作者:大咖说3768人查看评论数:04年前
内容来源:2016年12月16日,微博产品高级运维架构师王冠生在“GIAC全球互联网架构大会”上发表了“新浪微博平台自动化运维演进”的演讲。IT大咖表示,作为独家视频合作伙伴,经主办方和主讲人授权发布。字数:2557 时间:4分钟 点击观看嘉宾演讲视频
阅读全文
Python调用微博API获取微博内容
作者:745 浏览评论:05年前
1:获取app-key和app-secret 用自己的微博账号()登录微博开放平台,在微博开放中心下的“创建应用”下创建应用。随意填写申请信息。填写后就不需要了。提交审核,只需要那个app-ke
阅读全文
新浪微博OAuth详解以Python为例
作者:zephyr2949 人浏览评论:05年前
让我吐槽一下新浪微博上的OAuth文档,写得像个锤子!1.什么是OAuth OAuth是一套认证形式,逐渐被推荐为一套标准,它的故乡。OAuth 实现了一组三方委托认证模式。例如,有人想知道
阅读全文
定向爬虫——Python模拟新浪微博登录
作者:crazyacking1440 观众评论:06年前
当我们尝试从新浪微博抓取数据时,我们会在网页上发现一条消息,我们未登录,无法查看其他用户的信息。模拟登录是定向爬虫制作中必须克服的一个问题,只有这样才能爬取更多的内容。微博登录的实现方式有很多种。一般来说,我们在模拟登录时更喜欢 WAP 版本。因为PC版网页源代码收录很多js代码
阅读全文
[python爬虫] Selenium爬取新浪微博内容和用户信息
作者:肖洛洛7925 浏览评论:06年前
在自然语言处理、文本分类与聚类、推荐系统、舆情分析等方面的研究中,通常需要使用新浪微博的数据作为语料库。本文章主要介绍如何使用Python和Selenium爬取自定义新浪微博语料。因为网上的完整语料比较少,所以Selenium的方法稍微简单一点,速度也慢一些,但是方法
阅读全文
新浪微博Python3客户端接口OAuth2
作者:方北工作室838查看评论:09年前
关键字:Python3 Oauth2 新浪微博界面基于廖雪峰的微博python SDK修改而成。它的sdk是新浪官方推荐的。原作者用python2写的,做了一些修改。这里是基于python3的微博SDK#!/usr/
阅读全文
新浪微博Python客户端接口OAuth2
作者:方北工作室 745人查看评论:09年前
关键字:Python Oauth2 微博新浪微博#!/usr/bin/env python# -*- 编码:utf-8 -*- __version__ = '1.04' __author__ = '廖雪飞
阅读全文
新浪微博 API OAuth1 Python3 客户端
作者:方北工作室811查看评论:09年前
#!/usr/local/bin/python3 #coding=gbk ##import os,io,sys,re,time,base64,json import webbr
阅读全文 查看全部
网站调用新浪微博内容(新浪微博平台自动化运维演进之路演讲分享(组图))
阿里云 > 云栖社区 > 主题地图 > X > 新浪微博api python
推荐活动:
更多优惠>
当前话题:新浪微博api python加入采集
相关话题:
新浪微博apipython相关博客看更多博文
新浪微博平台自动化运维演进
作者:大咖说3768人查看评论数:04年前
内容来源:2016年12月16日,微博产品高级运维架构师王冠生在“GIAC全球互联网架构大会”上发表了“新浪微博平台自动化运维演进”的演讲。IT大咖表示,作为独家视频合作伙伴,经主办方和主讲人授权发布。字数:2557 时间:4分钟 点击观看嘉宾演讲视频
阅读全文
Python调用微博API获取微博内容
作者:745 浏览评论:05年前
1:获取app-key和app-secret 用自己的微博账号()登录微博开放平台,在微博开放中心下的“创建应用”下创建应用。随意填写申请信息。填写后就不需要了。提交审核,只需要那个app-ke
阅读全文
新浪微博OAuth详解以Python为例
作者:zephyr2949 人浏览评论:05年前
让我吐槽一下新浪微博上的OAuth文档,写得像个锤子!1.什么是OAuth OAuth是一套认证形式,逐渐被推荐为一套标准,它的故乡。OAuth 实现了一组三方委托认证模式。例如,有人想知道
阅读全文
定向爬虫——Python模拟新浪微博登录
作者:crazyacking1440 观众评论:06年前
当我们尝试从新浪微博抓取数据时,我们会在网页上发现一条消息,我们未登录,无法查看其他用户的信息。模拟登录是定向爬虫制作中必须克服的一个问题,只有这样才能爬取更多的内容。微博登录的实现方式有很多种。一般来说,我们在模拟登录时更喜欢 WAP 版本。因为PC版网页源代码收录很多js代码
阅读全文
[python爬虫] Selenium爬取新浪微博内容和用户信息
作者:肖洛洛7925 浏览评论:06年前
在自然语言处理、文本分类与聚类、推荐系统、舆情分析等方面的研究中,通常需要使用新浪微博的数据作为语料库。本文章主要介绍如何使用Python和Selenium爬取自定义新浪微博语料。因为网上的完整语料比较少,所以Selenium的方法稍微简单一点,速度也慢一些,但是方法
阅读全文
新浪微博Python3客户端接口OAuth2
作者:方北工作室838查看评论:09年前
关键字:Python3 Oauth2 新浪微博界面基于廖雪峰的微博python SDK修改而成。它的sdk是新浪官方推荐的。原作者用python2写的,做了一些修改。这里是基于python3的微博SDK#!/usr/
阅读全文
新浪微博Python客户端接口OAuth2
作者:方北工作室 745人查看评论:09年前
关键字:Python Oauth2 微博新浪微博#!/usr/bin/env python# -*- 编码:utf-8 -*- __version__ = '1.04' __author__ = '廖雪飞
阅读全文
新浪微博 API OAuth1 Python3 客户端
作者:方北工作室811查看评论:09年前
#!/usr/local/bin/python3 #coding=gbk ##import os,io,sys,re,time,base64,json import webbr
阅读全文
网站调用新浪微博内容(当浏览器向服务器发送请求的时候,发出http请求消息报文,)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-04-12 20:05
浏览器向服务器发送请求时,发出HTTP请求消息,服务器返回数据时,发出HTTP响应消息。两种类型的消息均由起始行、消息头和指示消息头组成。它由末尾的空行和可选的消息正文组成。http请求消息中,起始行收录请求方法、请求的资源、http协议的版本号,消息头收录各种属性,消息体收录数据,get请求没有消息体,所以消息头后的空行中没有其他数据。在http响应消息中,起始行包括http协议版本、http状态码和状态,消息头收录各种属性,
如下图,从fiddler抓到的http请求和http响应,get请求的内容是空的,所以消息头和消息体后面的空行都是空的。
服务器发送的响应报文如下,浏览器正常接收到服务器发送的http报文
从上面可以看出,cookie是http请求和http响应的头部信息中一个非常重要的消息头属性。
什么是饼干?
当用户第一次通过浏览器访问域名时,被访问的Web服务器会向客户端发送数据,以维护Web服务器与客户端之间的状态。这些数据是 cookie,由互联网站点创建以识别用户。存储在用户本地终端上用于身份识别的数据,cookie中的信息一般都是加密的,cookie存储在缓存或者硬盘中,而硬盘是一些小的文本文件,当你访问网站@ > ,会读取网站@>对应的cookie信息,cookie可以有效提升我们的上网体验。一般来说,一旦 cookie 保存在计算机上,只有创建 cookie 的 网站@> 才能读取它。拿着。
为什么需要 cookie
http 协议是一种无状态的面向连接的协议。http协议是基于tcp/ip协议层的协议。客户端与服务器建立连接后,它们之间的 tcp 连接始终保持。时间多长,由服务器端设置。当客户端再次访问服务器时,会继续使用上次建立的连接。但是,由于http协议是无状态的,web服务器并不知道这两个请求。不管是不是同一个客户端,这两个请求都是独立的。为了解决这个问题,web程序引入了cookie机制来维护状态。cookie可以记录用户的登录状态,通常用户登录成功后web服务器会发送。用于标记会话有效性的签名,这使用户免于多次身份验证和登录网站@>。记录用户的访问状态。
cookie 的类型
会话cookie(session cookie):这类cookie只在会话期间有效,存储在浏览器的缓存中。当用户访问 网站@> 时,会创建会话 cookie。当浏览器关闭时,它会被浏览器删除。
持久cookie(persistent cookie):这种cookie在用户会话中长时间生效。当你将cookie的属性max-age设置为1个月,那么这个月就会收录在相关url cookie的每个http请求中。所以它可以记录很多用户初始化或者自定义的信息,比如第一次登录的时间,弱登录的状态。
安全cookie:安全cookie是https访问下的cookie形式,以确保cookie在从客户端到服务器的过程中始终处于加密状态。
httponly cookie:这种cookie只能在http(https)请求上传递,对客户端脚本语言无效,从而有效避免跨站攻击。
第三方cookies:第一方cookies是在当前访问的域名或子域下生成的cookies。
第三方 cookie:第三方 cookie 是由第三方域创建的 cookie。
饼干的组成
cookie是HTTP消息头中的一个属性,包括:cookie名称(name)cookie值(value)、cookie过期时间(expires/max-age)、cookie动作路径(path)、cookie域名(domain)、使用cookies用于安全连接(安全)。
前两个参数是cookie应用的必要条件,还包括cookie的大小(大小,不同的浏览器对cookie的数量和大小有不同的限制)。
python模拟登录
设置一个cookie处理对象,负责给http请求添加cookie,并且可以从http响应中获取cookie,向网站@>登录页面发送请求,包括登录url、post请求数据、http文章-标头使用 urllib2.urlopen 发送请求并接收 Web 服务器的响应。
首先我们看登录页面源码
当我们使用 urllib 处理 url 的时候,其实是通过 urllib2.openerdirector 实例来工作的,它会自己调用资源来执行各种操作,比如传递协议、打开 url、处理 cookie 等。默认开启器处理该问题,基本的 urlopen() 函数不支持身份验证、cookie 或其他高级 http 函数。要支持这些函数,您必须使用 build_opener() 函数来创建您自己的自定义 opener 对象。
cookielib 模块定义了一个自动处理 http cookie 的类,用于访问那些需要 cookie 数据的 网站@>。cookielib 模块包括 cookiejar、filecookiejar、cookiepolicy、defaultcookiepolicy、cookie 以及 filecookiejar mozillacookiejar 和 lwpcookiejar 的子类,cookiejar 对象可以管理 http cookie,向 http 请求添加 cookie,以及从 http 响应中获取 cookie。filecookiejar 对象主要是从文件中读取cookies或者创建cookies。其中,mozillacookiejar就是创建一个兼容mozilla浏览器cookies.txt的filecookiejar,例如lwpcookiejar就是创建一个兼容libwww-perl的set-cookie3文件格式的filecookiejar实例。用 lwpcookiejar 保存的 cookie 文件很容易被人类阅读。默认是filecookiejar没有保存功能,已经实现了mozillacookiejar或者lwpcookiejar。所以你可以使用 mozillacookiejar 或 lwpcookiejar 来自动保存 cookie。
[Python]
#!/usr/bin/envpython
#编码:utf-8
进口系统
进口商
导入urllib2
导入urllib
进口请求
导入cookielib
##此代码用于解决中文报错问题
重新加载(系统)
sys.setdefaultencoding("utf8")
################################################# ###
#每个人都登录 查看全部
网站调用新浪微博内容(当浏览器向服务器发送请求的时候,发出http请求消息报文,)
浏览器向服务器发送请求时,发出HTTP请求消息,服务器返回数据时,发出HTTP响应消息。两种类型的消息均由起始行、消息头和指示消息头组成。它由末尾的空行和可选的消息正文组成。http请求消息中,起始行收录请求方法、请求的资源、http协议的版本号,消息头收录各种属性,消息体收录数据,get请求没有消息体,所以消息头后的空行中没有其他数据。在http响应消息中,起始行包括http协议版本、http状态码和状态,消息头收录各种属性,
如下图,从fiddler抓到的http请求和http响应,get请求的内容是空的,所以消息头和消息体后面的空行都是空的。
服务器发送的响应报文如下,浏览器正常接收到服务器发送的http报文
从上面可以看出,cookie是http请求和http响应的头部信息中一个非常重要的消息头属性。
什么是饼干?
当用户第一次通过浏览器访问域名时,被访问的Web服务器会向客户端发送数据,以维护Web服务器与客户端之间的状态。这些数据是 cookie,由互联网站点创建以识别用户。存储在用户本地终端上用于身份识别的数据,cookie中的信息一般都是加密的,cookie存储在缓存或者硬盘中,而硬盘是一些小的文本文件,当你访问网站@ > ,会读取网站@>对应的cookie信息,cookie可以有效提升我们的上网体验。一般来说,一旦 cookie 保存在计算机上,只有创建 cookie 的 网站@> 才能读取它。拿着。
为什么需要 cookie
http 协议是一种无状态的面向连接的协议。http协议是基于tcp/ip协议层的协议。客户端与服务器建立连接后,它们之间的 tcp 连接始终保持。时间多长,由服务器端设置。当客户端再次访问服务器时,会继续使用上次建立的连接。但是,由于http协议是无状态的,web服务器并不知道这两个请求。不管是不是同一个客户端,这两个请求都是独立的。为了解决这个问题,web程序引入了cookie机制来维护状态。cookie可以记录用户的登录状态,通常用户登录成功后web服务器会发送。用于标记会话有效性的签名,这使用户免于多次身份验证和登录网站@>。记录用户的访问状态。
cookie 的类型
会话cookie(session cookie):这类cookie只在会话期间有效,存储在浏览器的缓存中。当用户访问 网站@> 时,会创建会话 cookie。当浏览器关闭时,它会被浏览器删除。
持久cookie(persistent cookie):这种cookie在用户会话中长时间生效。当你将cookie的属性max-age设置为1个月,那么这个月就会收录在相关url cookie的每个http请求中。所以它可以记录很多用户初始化或者自定义的信息,比如第一次登录的时间,弱登录的状态。
安全cookie:安全cookie是https访问下的cookie形式,以确保cookie在从客户端到服务器的过程中始终处于加密状态。
httponly cookie:这种cookie只能在http(https)请求上传递,对客户端脚本语言无效,从而有效避免跨站攻击。
第三方cookies:第一方cookies是在当前访问的域名或子域下生成的cookies。
第三方 cookie:第三方 cookie 是由第三方域创建的 cookie。
饼干的组成
cookie是HTTP消息头中的一个属性,包括:cookie名称(name)cookie值(value)、cookie过期时间(expires/max-age)、cookie动作路径(path)、cookie域名(domain)、使用cookies用于安全连接(安全)。
前两个参数是cookie应用的必要条件,还包括cookie的大小(大小,不同的浏览器对cookie的数量和大小有不同的限制)。
python模拟登录
设置一个cookie处理对象,负责给http请求添加cookie,并且可以从http响应中获取cookie,向网站@>登录页面发送请求,包括登录url、post请求数据、http文章-标头使用 urllib2.urlopen 发送请求并接收 Web 服务器的响应。
首先我们看登录页面源码
当我们使用 urllib 处理 url 的时候,其实是通过 urllib2.openerdirector 实例来工作的,它会自己调用资源来执行各种操作,比如传递协议、打开 url、处理 cookie 等。默认开启器处理该问题,基本的 urlopen() 函数不支持身份验证、cookie 或其他高级 http 函数。要支持这些函数,您必须使用 build_opener() 函数来创建您自己的自定义 opener 对象。
cookielib 模块定义了一个自动处理 http cookie 的类,用于访问那些需要 cookie 数据的 网站@>。cookielib 模块包括 cookiejar、filecookiejar、cookiepolicy、defaultcookiepolicy、cookie 以及 filecookiejar mozillacookiejar 和 lwpcookiejar 的子类,cookiejar 对象可以管理 http cookie,向 http 请求添加 cookie,以及从 http 响应中获取 cookie。filecookiejar 对象主要是从文件中读取cookies或者创建cookies。其中,mozillacookiejar就是创建一个兼容mozilla浏览器cookies.txt的filecookiejar,例如lwpcookiejar就是创建一个兼容libwww-perl的set-cookie3文件格式的filecookiejar实例。用 lwpcookiejar 保存的 cookie 文件很容易被人类阅读。默认是filecookiejar没有保存功能,已经实现了mozillacookiejar或者lwpcookiejar。所以你可以使用 mozillacookiejar 或 lwpcookiejar 来自动保存 cookie。
[Python]
#!/usr/bin/envpython
#编码:utf-8
进口系统
进口商
导入urllib2
导入urllib
进口请求
导入cookielib
##此代码用于解决中文报错问题
重新加载(系统)
sys.setdefaultencoding("utf8")
################################################# ###
#每个人都登录
网站调用新浪微博内容(网站调用新浪微博内容全免费,不限量资源上传!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2022-04-12 19:01
网站调用新浪微博内容全免费,不限量资源上传!步骤:网站解析新浪微博,然后把你需要发布的内容,
能实现,基本目前所有免费社交平台上的原创文章都可以生成简书的同步作者页面,但是不是每篇文章都可以发布,要查看你们平台有没有对文章一一去审核,一旦审核通过了,那就发布无误了。至于目前谁可以做这个,
先需要申请个原创保护功能,
不知道楼主怎么找到我,我认识一个外语学院做的,让我提供图片,
个人思路是通过自己的设备屏幕保护策略保护所有可以上传图片的屏幕,
(你们是认真的吗
我觉得可以使用wikiblog,个人上传的内容都会集中到一个页面里,下面是自己的cms工具介绍(我才接触wikimediacommons):createwikimediacommons;anexperiencedportfolioofdigitalcontent。wikimediacommonsenhancements;includesacriticalrewardforaportfolioofemployees。
ifahostreadthiswikipediaportfolio,theyencourageyoutosharetheiremployees。wikimediacommonslicensedfree。wikimediacommonscreateisdevelopedbyandothercommoncomputers。
thecreationteamdividesourexclusivecurationcommittee,whichisacommoncomputerauthority,andanalysedinmarketingandresearchconditions。(wikimediacommonscreate)thisisnotservedwiththecertificationattheusagencyoftheundergrowthofthetechnology。
unlessrecordedandstatementaboutanemployee'semployment,itisnotprobablypossibletoaccesstheemploymentinwikimediacommons,andexcludethecurationatallotherreasons,notprobablyevenconditionaleditorsmayuseyourcreationportfolioinwikimediacommons。 查看全部
网站调用新浪微博内容(网站调用新浪微博内容全免费,不限量资源上传!)
网站调用新浪微博内容全免费,不限量资源上传!步骤:网站解析新浪微博,然后把你需要发布的内容,
能实现,基本目前所有免费社交平台上的原创文章都可以生成简书的同步作者页面,但是不是每篇文章都可以发布,要查看你们平台有没有对文章一一去审核,一旦审核通过了,那就发布无误了。至于目前谁可以做这个,
先需要申请个原创保护功能,
不知道楼主怎么找到我,我认识一个外语学院做的,让我提供图片,
个人思路是通过自己的设备屏幕保护策略保护所有可以上传图片的屏幕,
(你们是认真的吗
我觉得可以使用wikiblog,个人上传的内容都会集中到一个页面里,下面是自己的cms工具介绍(我才接触wikimediacommons):createwikimediacommons;anexperiencedportfolioofdigitalcontent。wikimediacommonsenhancements;includesacriticalrewardforaportfolioofemployees。
ifahostreadthiswikipediaportfolio,theyencourageyoutosharetheiremployees。wikimediacommonslicensedfree。wikimediacommonscreateisdevelopedbyandothercommoncomputers。
thecreationteamdividesourexclusivecurationcommittee,whichisacommoncomputerauthority,andanalysedinmarketingandresearchconditions。(wikimediacommonscreate)thisisnotservedwiththecertificationattheusagencyoftheundergrowthofthetechnology。
unlessrecordedandstatementaboutanemployee'semployment,itisnotprobablypossibletoaccesstheemploymentinwikimediacommons,andexcludethecurationatallotherreasons,notprobablyevenconditionaleditorsmayuseyourcreationportfolioinwikimediacommons。
网站调用新浪微博内容(3.修改参数拼接请求链接——解析网页数据解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-04-12 14:34
使用java自动爬取新浪微博历史列表——免登录目录准备工作原理
找到微博内容页面的请求链接-》修改参数拼接请求链接-》解析网页数据-》存入数据库
工作流程1.找出微博内容页面请求链接
网页端微博在加载内容页面时,会请求如下箭头所示的链接。点击后可以发现整个网页的数据都在框内,也就是说我们只需要拿到这个链接就可以解析网页数据了。
2.修改参数拼出请求链接
接下来,我们需要拼出这个链接。需要更改的参数有domain、domain_op、pre_page和_rnd。
图中我们可以发现id是由domain和一个10位数字拼接而成,domain和domain_op是一样的,pre_page指的是当前内容页数,_rnd是时间戳,我们需要用到的cookie运行程序时。接下来我们谈谈如何获取它们:
ID:
,
其中,2399108715为普通用户id;
其中,1191044977是大V的id;
领域:
下图中的红框就是我们需要的域。可以直接在用户微博首页右键查看源码查看:
域操作:
同一个域;
前页:
我们可以直接在代码中循环累加pre_page,但是我们需要知道用户发送的微博页面总数,才能终止循环:
如上图,仍然可以在用户首页的源码中获取countPage
_rnd:
一个时间戳,可以在程序中设置为系统的当前时间,以保证能抓取到最新的微博。
3.解析网页数据
解析网页数据使用jsoup和正则表达式。如何使用可以下载文末代码查看。
4.存入数据库
在程序中实现,使用mysql。
程序部分 程序结构
service层:
build:构建链接
content:解析网页内容
dao层:
common:持久化数据,存入数据库
model层:
SinaModel:实体类
process:
Main:程序组装
运行程序部分
修改进程目录下Main方法中的参数。上面已经获取了id和cookie,可以免费获取高密代理的ip和端口。
然后运行 MainTest 程序
./test
./java
./com
./yk
./process
MainTest
数据库字段解释
sina.sql:
id-表id
userId-用户Id
content-微博正文
contentlink-微博正文中的链接
imglink-微博中的图片链接
transmitnum-转发数
commentnum-评论数
likenum-喜欢数
username-用户名
pulishTime-发布时间
equipment-设备
updateTime-数据存入时间
最后一个想法 查看全部
网站调用新浪微博内容(3.修改参数拼接请求链接——解析网页数据解析)
使用java自动爬取新浪微博历史列表——免登录目录准备工作原理
找到微博内容页面的请求链接-》修改参数拼接请求链接-》解析网页数据-》存入数据库
工作流程1.找出微博内容页面请求链接
网页端微博在加载内容页面时,会请求如下箭头所示的链接。点击后可以发现整个网页的数据都在框内,也就是说我们只需要拿到这个链接就可以解析网页数据了。
2.修改参数拼出请求链接
接下来,我们需要拼出这个链接。需要更改的参数有domain、domain_op、pre_page和_rnd。
图中我们可以发现id是由domain和一个10位数字拼接而成,domain和domain_op是一样的,pre_page指的是当前内容页数,_rnd是时间戳,我们需要用到的cookie运行程序时。接下来我们谈谈如何获取它们:
ID:
,
其中,2399108715为普通用户id;
其中,1191044977是大V的id;
领域:
下图中的红框就是我们需要的域。可以直接在用户微博首页右键查看源码查看:
域操作:
同一个域;
前页:
我们可以直接在代码中循环累加pre_page,但是我们需要知道用户发送的微博页面总数,才能终止循环:
如上图,仍然可以在用户首页的源码中获取countPage
_rnd:
一个时间戳,可以在程序中设置为系统的当前时间,以保证能抓取到最新的微博。
3.解析网页数据
解析网页数据使用jsoup和正则表达式。如何使用可以下载文末代码查看。
4.存入数据库
在程序中实现,使用mysql。
程序部分 程序结构
service层:
build:构建链接
content:解析网页内容
dao层:
common:持久化数据,存入数据库
model层:
SinaModel:实体类
process:
Main:程序组装
运行程序部分
修改进程目录下Main方法中的参数。上面已经获取了id和cookie,可以免费获取高密代理的ip和端口。
然后运行 MainTest 程序
./test
./java
./com
./yk
./process
MainTest
数据库字段解释
sina.sql:
id-表id
userId-用户Id
content-微博正文
contentlink-微博正文中的链接
imglink-微博中的图片链接
transmitnum-转发数
commentnum-评论数
likenum-喜欢数
username-用户名
pulishTime-发布时间
equipment-设备
updateTime-数据存入时间
最后一个想法
网站调用新浪微博内容(微博怎么快速关闭?调用下接口怎么办?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-04-12 09:07
一般需要调用微信分享权限,需要在H5中添加分享按钮,点击即可显示。这通常需要开发人员调用下一个接口。
如何快速关闭微博,一起来看看吧!
取消方法:打开新浪微博账号设置-绑定手机,栏目有短信提醒,不勾选短信提醒即可取消。新浪微博:新浪微博是新浪网推出的提供微博服务的社交网络网站。用户可以通过网页、WAP页面、手机客户端、手机短信、彩信发布消息或上传图片
1.打开微博,点击【我】。
是的,在本地测试的 网站 不能共享。分享功能安装方法如下:百度搜索百度站长2.进入百度站长3.选择百度分享4.点击进入,如图5.点击进入免费获取代码6.选择直接复制代码7.安装代码到所有页面头部之前8.输入网站查看效果
2.进入右上角的【设置】。
可能你安装了一些分享插件,在工具箱中禁用了除官方“分享”插件之外的其他分享插件。点击工具箱,指向有分享功能的插件,然后点击插件图标右上角出现的小方块,选择禁用试试看。
3.滑动到底部退出微博。
1.Intent 意图 = new Intent(Intent.ACTION_SEND); //开始分享的属性发送2. intent.setType("text/plain"); //分享发送的数据类型3.@ > intent.putExtra(Intent.EXTRA_SUBJECT, "subject"); //共享主题4. intent.putExtra(Intent.EXTRA_TEXT
进一步阅读,您可能还对以下内容感兴趣。
discuz如何禁止帖子分享到空间、微博等功能
您可以尝试在模板文件中更改它。
如果不使用其他模板,默认在目录template\default\forum
在 viewthread_node.htm 文件中。对于更多问题和答案,您能告诉我要更改哪些代码吗?答案应该是
删除这段代码后,在后台更新缓存试试。如果你是新手,建议先备份这个文件,然后再做相应的操作。非常感谢提问,直接分享到空间的功能都没有了,不过如下
“重播”“分享”“采集”
这3个怎么取消?只需删除下面的相应代码即可。我列出了 2 段代码。
每个代表一个功能。
您可以尝试自己删除一个。记得更新缓存。
{lang thread_rely}{$_G['forum_thread']['relay']}
{lang 集合}{$post['releat采集num']}
如何在IE右键中添加【分享(到新浪微博)】功能?
打开360浏览器,在应用框点击“管理现有工具”,查看截图和微博,右键IE,应该会出现“分享到...”选项!跟进并这样做。但是右键菜单什么都没有……只是窗口顶部多了一个插件栏,我以前很烦……谢谢。有没有其他方法
如果android app需要添加微博分享功能,分享界面一实例化程序就会崩溃。
您为什么不发布此类问题的异常信息?否则,谁能帮你找到原因?跟进
对不起>_
这是在 logcat
不知道为什么会出现第一行的noclassdeffounderror
在控制台中显示
如何使用js实现网页分享功能,如分享到:人人网、开心网、新浪微博
这个问题我想了很久,但还是没搞明白。这是我的一位计算机同事告诉我的答案。你可以去百度看看佳思。它是中国最大的分享按钮提供商。网站 正在使用
哦,而且它提供的分享码很全,微博,QQ空间,人人网,开心。. . 任何代码!佳思分享的代码使用起来也很简单,复制粘贴即可,希望对大家有所帮助。
如何在微博评论中收录微博文字?
如果要带文本,这基本上是困难的。你只能带一个链接,链接可以跳转到你的文字。只有这样才能实现。
免责声明:本网页内容旨在传播知识。如有侵权等问题,请及时联系本站,我们将第一时间删除。电话: -84117792 邮箱: 查看全部
网站调用新浪微博内容(微博怎么快速关闭?调用下接口怎么办?(一))
一般需要调用微信分享权限,需要在H5中添加分享按钮,点击即可显示。这通常需要开发人员调用下一个接口。
如何快速关闭微博,一起来看看吧!
取消方法:打开新浪微博账号设置-绑定手机,栏目有短信提醒,不勾选短信提醒即可取消。新浪微博:新浪微博是新浪网推出的提供微博服务的社交网络网站。用户可以通过网页、WAP页面、手机客户端、手机短信、彩信发布消息或上传图片
1.打开微博,点击【我】。
是的,在本地测试的 网站 不能共享。分享功能安装方法如下:百度搜索百度站长2.进入百度站长3.选择百度分享4.点击进入,如图5.点击进入免费获取代码6.选择直接复制代码7.安装代码到所有页面头部之前8.输入网站查看效果
2.进入右上角的【设置】。
可能你安装了一些分享插件,在工具箱中禁用了除官方“分享”插件之外的其他分享插件。点击工具箱,指向有分享功能的插件,然后点击插件图标右上角出现的小方块,选择禁用试试看。
3.滑动到底部退出微博。
1.Intent 意图 = new Intent(Intent.ACTION_SEND); //开始分享的属性发送2. intent.setType("text/plain"); //分享发送的数据类型3.@ > intent.putExtra(Intent.EXTRA_SUBJECT, "subject"); //共享主题4. intent.putExtra(Intent.EXTRA_TEXT
进一步阅读,您可能还对以下内容感兴趣。
discuz如何禁止帖子分享到空间、微博等功能
您可以尝试在模板文件中更改它。
如果不使用其他模板,默认在目录template\default\forum
在 viewthread_node.htm 文件中。对于更多问题和答案,您能告诉我要更改哪些代码吗?答案应该是
删除这段代码后,在后台更新缓存试试。如果你是新手,建议先备份这个文件,然后再做相应的操作。非常感谢提问,直接分享到空间的功能都没有了,不过如下
“重播”“分享”“采集”
这3个怎么取消?只需删除下面的相应代码即可。我列出了 2 段代码。
每个代表一个功能。
您可以尝试自己删除一个。记得更新缓存。
{lang thread_rely}{$_G['forum_thread']['relay']}
{lang 集合}{$post['releat采集num']}
如何在IE右键中添加【分享(到新浪微博)】功能?
打开360浏览器,在应用框点击“管理现有工具”,查看截图和微博,右键IE,应该会出现“分享到...”选项!跟进并这样做。但是右键菜单什么都没有……只是窗口顶部多了一个插件栏,我以前很烦……谢谢。有没有其他方法
如果android app需要添加微博分享功能,分享界面一实例化程序就会崩溃。
您为什么不发布此类问题的异常信息?否则,谁能帮你找到原因?跟进
对不起>_
这是在 logcat
不知道为什么会出现第一行的noclassdeffounderror
在控制台中显示
如何使用js实现网页分享功能,如分享到:人人网、开心网、新浪微博
这个问题我想了很久,但还是没搞明白。这是我的一位计算机同事告诉我的答案。你可以去百度看看佳思。它是中国最大的分享按钮提供商。网站 正在使用
哦,而且它提供的分享码很全,微博,QQ空间,人人网,开心。. . 任何代码!佳思分享的代码使用起来也很简单,复制粘贴即可,希望对大家有所帮助。
如何在微博评论中收录微博文字?
如果要带文本,这基本上是困难的。你只能带一个链接,链接可以跳转到你的文字。只有这样才能实现。
免责声明:本网页内容旨在传播知识。如有侵权等问题,请及时联系本站,我们将第一时间删除。电话: -84117792 邮箱:
网站调用新浪微博内容(网站调用新浪微博内容和图片的时候,现在不能直接跳转和在微博界面去广告了)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2022-04-12 08:04
网站调用新浪微博内容和图片的时候,现在不能直接跳转和在微博界面去广告了。官方的意思是因为我们要尽量避免这种行为,不然我们会担心你用xxx的方式获取到我们的用户名和手机号。举例来说,我们想要通过大众点评的链接跳转去广告,现在就不能直接跳转了,只能你联系该站长,告诉他们换一种形式来做,比如说:你把大众点评的二维码直接做在我们的地推海报上,再把我们的手机号作为动态码存进去等等。
这个月5号我们会考虑一下做跳转广告,有兴趣的可以关注一下我们。利益相关:大众点评产品市场部。现在:让:你在大众点评,分享广告里的链接到朋友圈,(让朋友直接打开广告界面)别人就会直接跳转到你的地推海报上。(也可以填你们的邮箱)---对了。你可以改成让,只需要点击我们广告的链接,就可以了。 查看全部
网站调用新浪微博内容(网站调用新浪微博内容和图片的时候,现在不能直接跳转和在微博界面去广告了)
网站调用新浪微博内容和图片的时候,现在不能直接跳转和在微博界面去广告了。官方的意思是因为我们要尽量避免这种行为,不然我们会担心你用xxx的方式获取到我们的用户名和手机号。举例来说,我们想要通过大众点评的链接跳转去广告,现在就不能直接跳转了,只能你联系该站长,告诉他们换一种形式来做,比如说:你把大众点评的二维码直接做在我们的地推海报上,再把我们的手机号作为动态码存进去等等。
这个月5号我们会考虑一下做跳转广告,有兴趣的可以关注一下我们。利益相关:大众点评产品市场部。现在:让:你在大众点评,分享广告里的链接到朋友圈,(让朋友直接打开广告界面)别人就会直接跳转到你的地推海报上。(也可以填你们的邮箱)---对了。你可以改成让,只需要点击我们广告的链接,就可以了。
网站调用新浪微博内容(建一个新的应用获取AppKey和AppSecret认证)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-04-12 03:20
本文讨论 OAuth 授权和身份验证。新浪开放的api必须在这个基础上调用,所以有必要具体说一下。前面的文章已经提到新浪微博提供OAuth认证方式有两种:OAuth和Base OAuth,而本项目使用的是OAuth认证。至于为什么使用这个 OAuth 认证而不是 Base OAuth 认证,原因很简单。由于 Twitter 仅支持 OAuth 身份验证,因此主要应用程序已转向 OAuth 身份验证。,新浪微博开放平台近期也将停止Base OAuth的认证方式。
OAuth的基本概念,OAUTH协议为用户资源的授权提供了一个安全、开放、简单的标准。与之前的授权方式不同的是,OAUTH的授权将不允许第三方访问用户的账户信息(如用户名和密码),即第三方无需使用即可申请访问用户的资源用户的用户名和密码。授权,所以 OAUTH 是安全的。同样,新浪微博也提供了OAuth认证来保证用户账号和密码的安全。这里通过OAuth,一个普通的新浪微博用户,客户端程序(我们正在开发的android客户端程序),三者与新浪微博之间建立了互信关系,允许客户端程序(我们正在开发的android客户端程序)在不知道用户账号和密码的情况下浏览和发布微博,有效保护了用户账号的安全。将密码公开给客户端程序,以达到通过客户端程序写微博和查看微博的目的。这就是 OAuth 的作用。
结合新浪微博的OAuth认证,我们来说说具体的功能实现。首先,列出关键字组。下面四组关键字与我们接下来的OAuth认证有很大关系。
第一组:(App Key和App Secret),这组参数是创建本系列第一篇文章中提到的新应用,获取App Key和App Secret。
第二组:(Request Token和Request Secret)
第三组:(oauth_verifier)
第四组:(user_id、Access Token和Access Secret)
在新浪微博的OAuth认证过程中,用户第一次使用客户端软件时,客户端程序以第一组参数作为参数向新浪微博发起请求,然后新浪微博返回第二组参数核实后发给客户。该客户端软件也表明新浪微博信任该客户端软件。客户端软件获取到第二组参数后,引导用户浏览器跳转到新浪微博的授权页面作为参数,然后用户输入自己的微博账号和密码进行授权。授权完成后,根据客户端设置的回调地址将第三组参数返回给客户端软件,表示用户也信任客户端软件。下一个,客户端软件发送第二组参数和第三组参数作为参数再次向新浪微博发起请求,然后新浪微博将第四组参数返回给客户端软件。第四组参数需要保存好。这是用来替换用户的新浪帐号和密码的。,稍后调用api时需要。从这个过程来看,用户只是在新浪微博的认证页面输入了帐号和密码,并没有在客户端软件中输入帐号和密码。客户端软件只保存第四组数据,不保存用户账号和密码。,有效防止账号和密码泄露给新浪微博以外的第三方应用,确保安全。 查看全部
网站调用新浪微博内容(建一个新的应用获取AppKey和AppSecret认证)
本文讨论 OAuth 授权和身份验证。新浪开放的api必须在这个基础上调用,所以有必要具体说一下。前面的文章已经提到新浪微博提供OAuth认证方式有两种:OAuth和Base OAuth,而本项目使用的是OAuth认证。至于为什么使用这个 OAuth 认证而不是 Base OAuth 认证,原因很简单。由于 Twitter 仅支持 OAuth 身份验证,因此主要应用程序已转向 OAuth 身份验证。,新浪微博开放平台近期也将停止Base OAuth的认证方式。
OAuth的基本概念,OAUTH协议为用户资源的授权提供了一个安全、开放、简单的标准。与之前的授权方式不同的是,OAUTH的授权将不允许第三方访问用户的账户信息(如用户名和密码),即第三方无需使用即可申请访问用户的资源用户的用户名和密码。授权,所以 OAUTH 是安全的。同样,新浪微博也提供了OAuth认证来保证用户账号和密码的安全。这里通过OAuth,一个普通的新浪微博用户,客户端程序(我们正在开发的android客户端程序),三者与新浪微博之间建立了互信关系,允许客户端程序(我们正在开发的android客户端程序)在不知道用户账号和密码的情况下浏览和发布微博,有效保护了用户账号的安全。将密码公开给客户端程序,以达到通过客户端程序写微博和查看微博的目的。这就是 OAuth 的作用。
结合新浪微博的OAuth认证,我们来说说具体的功能实现。首先,列出关键字组。下面四组关键字与我们接下来的OAuth认证有很大关系。
第一组:(App Key和App Secret),这组参数是创建本系列第一篇文章中提到的新应用,获取App Key和App Secret。
第二组:(Request Token和Request Secret)
第三组:(oauth_verifier)
第四组:(user_id、Access Token和Access Secret)
在新浪微博的OAuth认证过程中,用户第一次使用客户端软件时,客户端程序以第一组参数作为参数向新浪微博发起请求,然后新浪微博返回第二组参数核实后发给客户。该客户端软件也表明新浪微博信任该客户端软件。客户端软件获取到第二组参数后,引导用户浏览器跳转到新浪微博的授权页面作为参数,然后用户输入自己的微博账号和密码进行授权。授权完成后,根据客户端设置的回调地址将第三组参数返回给客户端软件,表示用户也信任客户端软件。下一个,客户端软件发送第二组参数和第三组参数作为参数再次向新浪微博发起请求,然后新浪微博将第四组参数返回给客户端软件。第四组参数需要保存好。这是用来替换用户的新浪帐号和密码的。,稍后调用api时需要。从这个过程来看,用户只是在新浪微博的认证页面输入了帐号和密码,并没有在客户端软件中输入帐号和密码。客户端软件只保存第四组数据,不保存用户账号和密码。,有效防止账号和密码泄露给新浪微博以外的第三方应用,确保安全。
网站调用新浪微博内容(python移动端微博信息及用户信息_sina_selenium)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-04-12 03:15
Python新浪微博爬虫,爬取微博和用户信息(含源码和示例)
这是新浪微博爬虫,使用python+selenium实现。免费资源,希望对你有所帮助,虽然是傻瓜式爬虫,但至少可以运行。同时rar收录源码和爬取示例。参考我的文章:【python爬虫】Selenium爬取新浪微博内容和用户信息【Python爬虫】Selenium爬取新浪微博客户端用户信息、热点话题和评论(上)主要爬取内容包括:新浪微博手机终端用户信息和微博信息。用户信息:包括用户ID、用户名、微博数、关注数、关注数等微博信息:包括转发或原创、点赞数、转发数、评论数、发布时间、微博内容等安装过程:1. 先安装Python环境,作者是Python 2.7.82. 然后安装PIP或者easy_install3. 通过命令pip install selenium安装selenium,是一个工具进行自动测试和爬取4.然后修改代码中的用户名和密码,填写自己的用户名和密码5.运行程序,自动调用火狐浏览器登录微博注意:移动端信息更加精致简洁,对动态加载没有一些限制,但是只显示微博或者粉丝id等20个页面,这是它的缺点;虽然客户端可能有动态加载,比如评论和微博,但它的信息更完整。【源码】抓取手机端微博信息spider_selenium_sina_content。
立即下载 查看全部
网站调用新浪微博内容(python移动端微博信息及用户信息_sina_selenium)
Python新浪微博爬虫,爬取微博和用户信息(含源码和示例)
这是新浪微博爬虫,使用python+selenium实现。免费资源,希望对你有所帮助,虽然是傻瓜式爬虫,但至少可以运行。同时rar收录源码和爬取示例。参考我的文章:【python爬虫】Selenium爬取新浪微博内容和用户信息【Python爬虫】Selenium爬取新浪微博客户端用户信息、热点话题和评论(上)主要爬取内容包括:新浪微博手机终端用户信息和微博信息。用户信息:包括用户ID、用户名、微博数、关注数、关注数等微博信息:包括转发或原创、点赞数、转发数、评论数、发布时间、微博内容等安装过程:1. 先安装Python环境,作者是Python 2.7.82. 然后安装PIP或者easy_install3. 通过命令pip install selenium安装selenium,是一个工具进行自动测试和爬取4.然后修改代码中的用户名和密码,填写自己的用户名和密码5.运行程序,自动调用火狐浏览器登录微博注意:移动端信息更加精致简洁,对动态加载没有一些限制,但是只显示微博或者粉丝id等20个页面,这是它的缺点;虽然客户端可能有动态加载,比如评论和微博,但它的信息更完整。【源码】抓取手机端微博信息spider_selenium_sina_content。
立即下载
网站调用新浪微博内容(没有调用新浪的API,在程序中加入自己的帐号和密码就能发送微博)
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-04-12 03:13
无需调用新浪的API,您可以通过在程序中添加自己的帐号和密码来发送微博。代码完全在后台运行,无需打开浏览器。
使用HtmlUnit库模拟登录并发送微博。
效果图优先:
这是登录后第一页的信息。
发微博:
没什么难的,找到对应的按钮和文本框,点击,总之就是用代码模仿用户的操作。
public class weibo {
public static void main(String args[]) throws FailingHttpStatusCodeException, MalformedURLException, IOException, InterruptedException{
//新浪微博登录页面
String baseUrl = "https://passport.weibo.cn/sign ... 3B%3B
//打开
WebClient webClient = new WebClient(BrowserVersion.CHROME);
webClient.addRequestHeader("User-Agent", "Mozilla/5.0 (iPad; CPU OS 7_0_2 like Mac OS X) AppleWebKit/537.51.1 (KHTML, like Gecko) Version/7.0 Mobile/11A501 Safari/9537.53");
//webClient.addRequestHeader("User-Agent", "Mozilla/5.0 (Linux; Android 4.4.2; Nexus 4 Build/KOT49H) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.122 Mobile Safari/537.36");
HtmlPage page = webClient.getPage(baseUrl);
//等待页面加载
Thread.sleep(1000);
//获取输入帐号的控件
HtmlInput usr = (HtmlInput) page.getElementById("loginName");
usr.setValueAttribute("Your Account");
//获取输入密码的控件
HtmlInput pwd = (HtmlInput) page.getElementById("loginPassword");
pwd.setValueAttribute("Your Password");
//点击登录
DomElement button = page.getElementById("loginAction");
page =(HtmlPage) button.click();
//等待页面加载
Thread.sleep(1000);
//获取到“写微博”这个按钮,因为这个按钮没有name和id,获取所有<a>标签
DomNodeList button2 = page.getElementsByTagName("a");
//跳转到发送微博页面
page =(HtmlPage)button2.get(4).click();
//等待页面加载
Thread.sleep(1000);
//获取发送控件 标签为<a>中的2个
DomNodeList button3 = page.getElementsByTagName("a");
//获取文本宇
HtmlTextArea content =(HtmlTextArea) page.getElementById("txt-publisher");
DomElement fasong = button3.get(1);
content.focus();
Date date = new Date();
//填写你要发送的内容
content.setText("使用JAVA发送微博!!!!\n"+date);
//改变发送按钮的属性,不能无法发送
fasong.setAttribute("class", "fr txt-link");
//发送!!!
page = (HtmlPage)fasong.click();
Thread.sleep(5000);
System.out.println(page.asText());
}
}
好的,就这么简单!
转载于: 查看全部
网站调用新浪微博内容(没有调用新浪的API,在程序中加入自己的帐号和密码就能发送微博)
无需调用新浪的API,您可以通过在程序中添加自己的帐号和密码来发送微博。代码完全在后台运行,无需打开浏览器。
使用HtmlUnit库模拟登录并发送微博。
效果图优先:
这是登录后第一页的信息。
发微博:
没什么难的,找到对应的按钮和文本框,点击,总之就是用代码模仿用户的操作。
public class weibo {
public static void main(String args[]) throws FailingHttpStatusCodeException, MalformedURLException, IOException, InterruptedException{
//新浪微博登录页面
String baseUrl = "https://passport.weibo.cn/sign ... 3B%3B
//打开
WebClient webClient = new WebClient(BrowserVersion.CHROME);
webClient.addRequestHeader("User-Agent", "Mozilla/5.0 (iPad; CPU OS 7_0_2 like Mac OS X) AppleWebKit/537.51.1 (KHTML, like Gecko) Version/7.0 Mobile/11A501 Safari/9537.53");
//webClient.addRequestHeader("User-Agent", "Mozilla/5.0 (Linux; Android 4.4.2; Nexus 4 Build/KOT49H) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/35.0.1916.122 Mobile Safari/537.36");
HtmlPage page = webClient.getPage(baseUrl);
//等待页面加载
Thread.sleep(1000);
//获取输入帐号的控件
HtmlInput usr = (HtmlInput) page.getElementById("loginName");
usr.setValueAttribute("Your Account");
//获取输入密码的控件
HtmlInput pwd = (HtmlInput) page.getElementById("loginPassword");
pwd.setValueAttribute("Your Password");
//点击登录
DomElement button = page.getElementById("loginAction");
page =(HtmlPage) button.click();
//等待页面加载
Thread.sleep(1000);
//获取到“写微博”这个按钮,因为这个按钮没有name和id,获取所有<a>标签
DomNodeList button2 = page.getElementsByTagName("a");
//跳转到发送微博页面
page =(HtmlPage)button2.get(4).click();
//等待页面加载
Thread.sleep(1000);
//获取发送控件 标签为<a>中的2个
DomNodeList button3 = page.getElementsByTagName("a");
//获取文本宇
HtmlTextArea content =(HtmlTextArea) page.getElementById("txt-publisher");
DomElement fasong = button3.get(1);
content.focus();
Date date = new Date();
//填写你要发送的内容
content.setText("使用JAVA发送微博!!!!\n"+date);
//改变发送按钮的属性,不能无法发送
fasong.setAttribute("class", "fr txt-link");
//发送!!!
page = (HtmlPage)fasong.click();
Thread.sleep(5000);
System.out.println(page.asText());
}
}
好的,就这么简单!
转载于:
网站调用新浪微博内容(使用API提交数据(发布一条微博信息)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-04-06 23:02
我也是新手,第一次使用开放平台进行开发。起初,我觉得我无处可去。经过长时间的摸索,终于成功调用了API。现在给新手介绍一下这段经历(高手不用看,当然如果大家能提出一些意见和建议,非常感谢),也想和大家交流。
本例介绍如何使用 API 提交数据(发布一条微博)和使用 API 获取数据(获取最新的 20 条公开微博消息),即官方 API Go 中的“获取下行数据集(时间线)接口”到“微博访问界面”下的“statuses/public_timeline 获取最新更新的公众微博新闻”和“statuses/update 发布微博消息”。
首先,你必须有新浪微博账号并申请一个app key(详情请参考%E6%96%B0%E6%89%8B%E6%8C%87%E5%8D%97),然后在VS中新建一个解决方案,在解决方案中添加一个类库和一个网站,并添加一个引用(网站指的是类库)。
由于发微博是POST请求,获取数据是GET请求,并且是通过HTTP Basic Authentication授权的,所以我把这些函数写在一个类中(在类库中),代码如下(这个类参考to ,没有仔细考虑它是否是普遍的):
发送请求和授权码
然后在类库中新建两个实体类status和user,字段与官方API一致:
状态实体类
用户实体类
好了,经过以上步骤,准备工作就完成了。现在让我们开始调用 API。我们先来看发布一条微博消息。虽然在这个文章()中已经介绍过了,但为了本文的完整性,我还是贴出来。我的代码,在类库中添加一个微博访问类MiniBlogVisit类:
微博接入类
您可以通过调用 update 方法发布微博。不过需要注意的是,这里的Content要用HttpUtility.UrlEncode编码,否则会出现乱码。
我们来看看最新的20条公众微博消息,这是官方API中的第一个接口。这里返回的数据是 XML 数据或 JSON 数据。您可以根据自己的喜好自由选择。我选择返回 XML 数据。我的方法是将返回的 XML 数据写入 XML 文件,然后解析 XML 文件。代码如下:
获取数据代码
好吧,现在是时候打电话了。调用比较简单。它是一个空的 Default.aspx 页面。后台代码如下:
调用代码
至此,所有的代码都写好了,我们来看看完整的解决方案:
运行后的效果如下:
第一次调用API,第一次写这么长的文章。欢迎大家多多评论!!! 查看全部
网站调用新浪微博内容(使用API提交数据(发布一条微博信息)(组图))
我也是新手,第一次使用开放平台进行开发。起初,我觉得我无处可去。经过长时间的摸索,终于成功调用了API。现在给新手介绍一下这段经历(高手不用看,当然如果大家能提出一些意见和建议,非常感谢),也想和大家交流。
本例介绍如何使用 API 提交数据(发布一条微博)和使用 API 获取数据(获取最新的 20 条公开微博消息),即官方 API Go 中的“获取下行数据集(时间线)接口”到“微博访问界面”下的“statuses/public_timeline 获取最新更新的公众微博新闻”和“statuses/update 发布微博消息”。
首先,你必须有新浪微博账号并申请一个app key(详情请参考%E6%96%B0%E6%89%8B%E6%8C%87%E5%8D%97),然后在VS中新建一个解决方案,在解决方案中添加一个类库和一个网站,并添加一个引用(网站指的是类库)。
由于发微博是POST请求,获取数据是GET请求,并且是通过HTTP Basic Authentication授权的,所以我把这些函数写在一个类中(在类库中),代码如下(这个类参考to ,没有仔细考虑它是否是普遍的):
发送请求和授权码
然后在类库中新建两个实体类status和user,字段与官方API一致:
状态实体类
用户实体类
好了,经过以上步骤,准备工作就完成了。现在让我们开始调用 API。我们先来看发布一条微博消息。虽然在这个文章()中已经介绍过了,但为了本文的完整性,我还是贴出来。我的代码,在类库中添加一个微博访问类MiniBlogVisit类:
微博接入类
您可以通过调用 update 方法发布微博。不过需要注意的是,这里的Content要用HttpUtility.UrlEncode编码,否则会出现乱码。
我们来看看最新的20条公众微博消息,这是官方API中的第一个接口。这里返回的数据是 XML 数据或 JSON 数据。您可以根据自己的喜好自由选择。我选择返回 XML 数据。我的方法是将返回的 XML 数据写入 XML 文件,然后解析 XML 文件。代码如下:
获取数据代码
好吧,现在是时候打电话了。调用比较简单。它是一个空的 Default.aspx 页面。后台代码如下:
调用代码
至此,所有的代码都写好了,我们来看看完整的解决方案:
运行后的效果如下:
第一次调用API,第一次写这么长的文章。欢迎大家多多评论!!!
网站调用新浪微博内容(python言语恶劣地评论个人博客是垃圾,说个人代码有问题 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-04-06 22:27
)
PS:(本人长期出售大量微博数据,游网站评论数据,并提供各种指定数据爬取服务,留言至。由于微博界面更新,限制增加,这段代码可以不再使用。爬取数据。如果只是为了采集数据,可以咨询个人邮箱。如果是学习爬虫,建议学习phantomjs从网页爬取微博)html
使用新浪API实现数据抓取(由于增加了API接口限制,本文已基本放弃)
2018.5.16个提示
现在微博的api接口很差,普通权限的token已经爬不上任何数据了。用这段代码爬取大量数据是不可能的。仅供熟悉微博api接口使用的人使用。一个小演示。Python
2018.4.16 说明 linux
注:今天有人恶评说个人博客是垃圾,说个人代码有问题。这个博客历史悠久,是我刚开始玩爬虫时写的一篇博客。非常感谢能对个人代码发表意见的人,但我受不了那些说话粗鲁、态度不好的人。如果你有话要说,那是现代社会一个高学历、高智商的最低意识。IOS
我已经更改了代码。如果还有问题,欢迎大家轻轻指出!!!!混帐
同时,由于新浪微博自身api机制的不断变化,本篇博客的内容至今有限。对于我的开发者来说,你申请的token的权限只能爬你自己的微博。,所以对于那些想依靠api来爬取数据的人来说,恐怕就达不到目的了。如果要使用api抓取微博内容,只能选择获取更高的开发者权限。github
1.首先我们看看我们到底得到了什么结果,是不是你想知道的,然后再决定是否继续读下去。
我主要抓了4天左右的数据。从图中可以看出大概有360万条数据,因为数据是在我自己的电脑上爬取的,有时候晚上会断网,所以大约一天可以爬取最新的1条左右的微博数据万(因为我调用的是最新的微博API public_timeline)web
API文档定义了很多返回类型(以json数据格式返回,我选择了一些我认为重要的信息并抓取了如图:关于id号,位置,粉丝数,微博内容,发微博的时间等。当然这些数据可以根据自己的需要定制。)mongodb
内容大概就是这样。如果觉得这对你有点帮助,请继续阅读……第一次写博客有点啰嗦2.前期准备
我们需要:数据库
2.1mongodb安装
MongoDB 是一个高性能、开源、无模式的文档数据库,是比较流行的 NoSql 数据库之一。在很多场景下,它可以用来替代传统的关系型数据库或者键/值存储。Mongo 是用 C++ 开发的。Mongo的官方网站地址是:读者可以在这里获得更详细的信息。json
小插曲:什么是 NoSql?
NoSql,全称Not Only Sql,指的是非关系型数据库。下一代数据库主要解决几个点:非关系型、分布式、开源、水平可扩展。最初旨在用于大型 Web 应用程序,这一运动始于 2009 年初,具有以下一般特性:模式自由、支持轻松复制、简单的 API、最终一致性(非 ACID)、大容量数据等。NoSQL 是最常用的键值存储,虽然还有其他基于文档的、基于列的、图数据库、xml数据库等。
网上有很多安装mongodb的教程,我就不写了
windows下mongodb的安装
Linux下mongodb的安装
2.2 如何注册新浪开发者账号
* 建立后需要填写手机号验证 *
首次创建应用,需要填写以下信息:
本页信息无需填写地区、电话等真实信息,可随意填写。网站填写。(电子邮件必须是真实的)
继续构建应用程序。应用名称自定义,查看平台下的ios、android
建立完成后,返回继续建立。一个账号可以创建10个应用,每个应用对应一个access-token(其实我一个就可以满足需求)
选择创建的应用程序。观点
只需将下面的令牌保存在 txt 中。
背部
点击个人应用
然后选择刚刚创建的应用程序
进入后点击申请信息
保存APP Key和APP Secret
单击高级信息
设置回调地址
可以设置为默认
您的开发者帐户现已完成
2.3 依赖库的安装方法
安装 requests 和 pymongo
可以直接用pip安装
pip install requests 和 pip install pymongo
也可以直接在Pycharm中安装
选择文件 -> 设置 -> 项目 -> 项目解释器
可以看到安装好的Python库,点击右边绿色的*+*号
只需安装
3.分析问题3.1 OAuth认证
*授权机制说明(很重要)*
网上很多人都说用新浪微博API发微博什么的,使用请求用户授权Token的方法,但是这种方法显然不适合我们爬取数据,因为我们每次都要请求,每次从新的获取代码。详见新浪微博API授权机制
廖雪峰老师(新浪微博投稿人)对这个授权机制也有解释
通过新浪微博的API访问网站,由于用户不需要在你的网站上注册,可以直接在新浪微博@>上用自己的账号和密码登录你的网站,这需要确保你的网站在不知道或不知道用户密码的情况下确认用户已经成功登录。因为用户的密码存储在新浪微博中,所以验证用户的过程只能由新浪微博来完成,但是新浪微博是如何与你的网站通信并通知你用户是否登录成功的呢?这个过程称为第三方登录。OAuth 是标准的第三方登录协议。使用 OAuth,您的 网站 可以安全地访问已成功登录的新浪微博用户。
OAuth 目前有两个版本:1.0 和 2.0。版本 2.0 简化版本 1.0,API 更简单。新浪微博最新的API也使用了OAuth2.0。整个登录过程如下:
用户在你的网站点击“用新浪微博登录”,你的网站将用户重定向到新浪微博的OAuth认证页面,重定向连接中收录client_id参数作为你的网站@ >ID,redirect_uri参数告诉新浪微博在用户登录成功时将浏览器重定向到你的网站;用户在新浪微博认证页面输入账号和密码;新浪微博认证成功后,将浏览器重定向到你的网站并附上code参数;你的网站通过code参数向新浪微博请求用户的access token;你的 网站 获取到用户的访问令牌后,用户的登录就完成了。
OAuth访问令牌是提供认证服务的网站(如新浪微博)生成的令牌,表示用户的认证信息。在后续的 API 调用中,会传入访问令牌以指示已登录的用户。这样,经过OAuth协议后,你的网站会将用户验证步骤交给新浪微博,新浪微博会通知你用户是否登录成功。
OAuth的安全性通过第4步完成。通过code参数获取access token的过程是由你的网站后台到新浪微博网站完成的,用户看不到获取访问令牌。问。如果用户输入的是假密码,新浪微博会返回错误。
详情请参考廖雪峰老师的文档
一般来说,按照通常的用户授权Token调用请求,会出现这种情况:
获取代码
登录后会跳转到一个链接××××××××
我们只需要code=××××××××××的值
也就是说,每次调用API鉴权,浏览器都会出现一段代码,这显然不利于我们的爬取网站
如何解决问题?首先我们想到的是在Python程序中模拟登录新浪微博,然后就可以得到代码的值了。不过新浪微博的模拟登录比较复杂,既然模拟登录成功了,何必呢?调用API呢……直接自定义爬取不是更方便。
如果你看过上面的授权机制,你应该会想到它。这时候就需要我们之前申请的access-token了。
根据我个人的理解,access-token就是将你的微博授权给第三方,让他为你做一些事情,类似于手机上通过新浪微博登录,然后进行操作(使用前面提到的授权机制)更多)。总之,手机应用可以直接使用官方手机SDK,调用微博客户端进行授权(如果没有安装微博客户端,会调用H5授权页面)
你应该熟悉这个界面
新浪也给出了Oauth2/access token的说明
4.代码实现
有了token,实现数据抓取就很简单了
可以捕获多少数据取决于您的令牌权限
接下来就是使用API获取数据:新建文件weibo_run.py
# -*- coding:utf-8 -*-
import requests
from pymongo import MongoClient
ACCESS_TOKEN = '2.00ZooSqFHAgn3D59864ee3170DLjNj'
URL = 'https://api.weibo.com/2/statuses/public_timeline.json'
def run():
#受权
while True:
#调用statuses__public_timeline的api接口
params = {
'access_token': ACCESS_TOKEN
}
statuses = requests.get(url=URL, params=params).json()['statuses']
length = len(statuses)
#这是后来我为了查看获取微博条数设置的
print length
#链接mongodb,不须要本地的额外配置
Monclient = MongoClient('localhost', 27017)
db = Monclient['Weibo']
WeiboData = db['HadSelected']
#获取的各个数据名应该能够清楚的看出来对应的是什么数据
for i in range(0, length):
created_at = statuses[i]['created_at']
id = statuses[i]['user']['id']
province = statuses[i]['user']['province']
city = statuses[i]['user']['city']
followers_count = statuses[i]['user']['followers_count']
friends_count = statuses[i]['user']['friends_count']
statuses_count = statuses[i]['user']['statuses_count']
url = statuses[i]['user']['url']
geo = statuses[i]['geo']
comments_count = statuses[i]['comments_count']
reposts_count = statuses[i]['reposts_count']
nickname = statuses[i]['user']['screen_name']
desc = statuses[i]['user']['description']
location = statuses[i]['user']['location']
text = statuses[i]['text']
#插入mongodb
WeiboData.insert_one({
'created_at': created_at,
'id': id,
'nickname': nickname,
'text': text,
'province': province,
'location': location,
'description': desc,
'city': city,
'followers_count': followers_count,
'friends_count': friends_count,
'statuses_count': statuses_count,
'url': url,
'geo': geo,
'comments_count': comments_count,
'reposts_count': reposts_count
})
if __name__ == "__main__":
run()
个人代码一开始是这样的,看起来已经完成了。
但是,由于新浪会限制你可以拨打的电话数量,所以我稍后尝试重新运行它,发现问题。我之前的打印长度得到的每一行的值都不一样,一直在16-20之间徘徊。它表明我从新运行中获得的数据每次都不同。然后想了想,就写个死循环看看他什么时候又被阻塞了。所以代码变成了下面
删除 run() 并将其替换为以下无限循环。
if __name__ == "__main__":
while 1:
try:
run()
except:
pass
结果,他一直在跑……跑了四天,还没有被拦住。估计不会被封...
其余接口的使用方法也一样,只是改变了url和params。具体参数请参考新浪微博API文档
一开始我发现我一天能拿到800万条数据,这让我很开心……后来我发现了很多重复的数据。找了半天终于找到了解决办法。我根据用户的id和建立时间在mongodb中创建了一个索引(因为我不可能同时发两条微博),最后一天能得到100份左右没有重复数据。上千条信息。
我的博客 查看全部
网站调用新浪微博内容(python言语恶劣地评论个人博客是垃圾,说个人代码有问题
)
PS:(本人长期出售大量微博数据,游网站评论数据,并提供各种指定数据爬取服务,留言至。由于微博界面更新,限制增加,这段代码可以不再使用。爬取数据。如果只是为了采集数据,可以咨询个人邮箱。如果是学习爬虫,建议学习phantomjs从网页爬取微博)html
使用新浪API实现数据抓取(由于增加了API接口限制,本文已基本放弃)
2018.5.16个提示
现在微博的api接口很差,普通权限的token已经爬不上任何数据了。用这段代码爬取大量数据是不可能的。仅供熟悉微博api接口使用的人使用。一个小演示。Python
2018.4.16 说明 linux
注:今天有人恶评说个人博客是垃圾,说个人代码有问题。这个博客历史悠久,是我刚开始玩爬虫时写的一篇博客。非常感谢能对个人代码发表意见的人,但我受不了那些说话粗鲁、态度不好的人。如果你有话要说,那是现代社会一个高学历、高智商的最低意识。IOS
我已经更改了代码。如果还有问题,欢迎大家轻轻指出!!!!混帐
同时,由于新浪微博自身api机制的不断变化,本篇博客的内容至今有限。对于我的开发者来说,你申请的token的权限只能爬你自己的微博。,所以对于那些想依靠api来爬取数据的人来说,恐怕就达不到目的了。如果要使用api抓取微博内容,只能选择获取更高的开发者权限。github
1.首先我们看看我们到底得到了什么结果,是不是你想知道的,然后再决定是否继续读下去。
我主要抓了4天左右的数据。从图中可以看出大概有360万条数据,因为数据是在我自己的电脑上爬取的,有时候晚上会断网,所以大约一天可以爬取最新的1条左右的微博数据万(因为我调用的是最新的微博API public_timeline)web
API文档定义了很多返回类型(以json数据格式返回,我选择了一些我认为重要的信息并抓取了如图:关于id号,位置,粉丝数,微博内容,发微博的时间等。当然这些数据可以根据自己的需要定制。)mongodb
内容大概就是这样。如果觉得这对你有点帮助,请继续阅读……第一次写博客有点啰嗦2.前期准备
我们需要:数据库
2.1mongodb安装
MongoDB 是一个高性能、开源、无模式的文档数据库,是比较流行的 NoSql 数据库之一。在很多场景下,它可以用来替代传统的关系型数据库或者键/值存储。Mongo 是用 C++ 开发的。Mongo的官方网站地址是:读者可以在这里获得更详细的信息。json
小插曲:什么是 NoSql?
NoSql,全称Not Only Sql,指的是非关系型数据库。下一代数据库主要解决几个点:非关系型、分布式、开源、水平可扩展。最初旨在用于大型 Web 应用程序,这一运动始于 2009 年初,具有以下一般特性:模式自由、支持轻松复制、简单的 API、最终一致性(非 ACID)、大容量数据等。NoSQL 是最常用的键值存储,虽然还有其他基于文档的、基于列的、图数据库、xml数据库等。
网上有很多安装mongodb的教程,我就不写了
windows下mongodb的安装
Linux下mongodb的安装
2.2 如何注册新浪开发者账号
* 建立后需要填写手机号验证 *
首次创建应用,需要填写以下信息:
本页信息无需填写地区、电话等真实信息,可随意填写。网站填写。(电子邮件必须是真实的)
继续构建应用程序。应用名称自定义,查看平台下的ios、android
建立完成后,返回继续建立。一个账号可以创建10个应用,每个应用对应一个access-token(其实我一个就可以满足需求)
选择创建的应用程序。观点
只需将下面的令牌保存在 txt 中。
背部
点击个人应用
然后选择刚刚创建的应用程序
进入后点击申请信息
保存APP Key和APP Secret
单击高级信息
设置回调地址
可以设置为默认
您的开发者帐户现已完成
2.3 依赖库的安装方法
安装 requests 和 pymongo
可以直接用pip安装
pip install requests 和 pip install pymongo
也可以直接在Pycharm中安装
选择文件 -> 设置 -> 项目 -> 项目解释器
可以看到安装好的Python库,点击右边绿色的*+*号
只需安装
3.分析问题3.1 OAuth认证
*授权机制说明(很重要)*
网上很多人都说用新浪微博API发微博什么的,使用请求用户授权Token的方法,但是这种方法显然不适合我们爬取数据,因为我们每次都要请求,每次从新的获取代码。详见新浪微博API授权机制
廖雪峰老师(新浪微博投稿人)对这个授权机制也有解释
通过新浪微博的API访问网站,由于用户不需要在你的网站上注册,可以直接在新浪微博@>上用自己的账号和密码登录你的网站,这需要确保你的网站在不知道或不知道用户密码的情况下确认用户已经成功登录。因为用户的密码存储在新浪微博中,所以验证用户的过程只能由新浪微博来完成,但是新浪微博是如何与你的网站通信并通知你用户是否登录成功的呢?这个过程称为第三方登录。OAuth 是标准的第三方登录协议。使用 OAuth,您的 网站 可以安全地访问已成功登录的新浪微博用户。
OAuth 目前有两个版本:1.0 和 2.0。版本 2.0 简化版本 1.0,API 更简单。新浪微博最新的API也使用了OAuth2.0。整个登录过程如下:
用户在你的网站点击“用新浪微博登录”,你的网站将用户重定向到新浪微博的OAuth认证页面,重定向连接中收录client_id参数作为你的网站@ >ID,redirect_uri参数告诉新浪微博在用户登录成功时将浏览器重定向到你的网站;用户在新浪微博认证页面输入账号和密码;新浪微博认证成功后,将浏览器重定向到你的网站并附上code参数;你的网站通过code参数向新浪微博请求用户的access token;你的 网站 获取到用户的访问令牌后,用户的登录就完成了。
OAuth访问令牌是提供认证服务的网站(如新浪微博)生成的令牌,表示用户的认证信息。在后续的 API 调用中,会传入访问令牌以指示已登录的用户。这样,经过OAuth协议后,你的网站会将用户验证步骤交给新浪微博,新浪微博会通知你用户是否登录成功。
OAuth的安全性通过第4步完成。通过code参数获取access token的过程是由你的网站后台到新浪微博网站完成的,用户看不到获取访问令牌。问。如果用户输入的是假密码,新浪微博会返回错误。
详情请参考廖雪峰老师的文档
一般来说,按照通常的用户授权Token调用请求,会出现这种情况:
获取代码
登录后会跳转到一个链接××××××××
我们只需要code=××××××××××的值
也就是说,每次调用API鉴权,浏览器都会出现一段代码,这显然不利于我们的爬取网站
如何解决问题?首先我们想到的是在Python程序中模拟登录新浪微博,然后就可以得到代码的值了。不过新浪微博的模拟登录比较复杂,既然模拟登录成功了,何必呢?调用API呢……直接自定义爬取不是更方便。
如果你看过上面的授权机制,你应该会想到它。这时候就需要我们之前申请的access-token了。
根据我个人的理解,access-token就是将你的微博授权给第三方,让他为你做一些事情,类似于手机上通过新浪微博登录,然后进行操作(使用前面提到的授权机制)更多)。总之,手机应用可以直接使用官方手机SDK,调用微博客户端进行授权(如果没有安装微博客户端,会调用H5授权页面)
你应该熟悉这个界面
新浪也给出了Oauth2/access token的说明
4.代码实现
有了token,实现数据抓取就很简单了
可以捕获多少数据取决于您的令牌权限
接下来就是使用API获取数据:新建文件weibo_run.py
# -*- coding:utf-8 -*-
import requests
from pymongo import MongoClient
ACCESS_TOKEN = '2.00ZooSqFHAgn3D59864ee3170DLjNj'
URL = 'https://api.weibo.com/2/statuses/public_timeline.json'
def run():
#受权
while True:
#调用statuses__public_timeline的api接口
params = {
'access_token': ACCESS_TOKEN
}
statuses = requests.get(url=URL, params=params).json()['statuses']
length = len(statuses)
#这是后来我为了查看获取微博条数设置的
print length
#链接mongodb,不须要本地的额外配置
Monclient = MongoClient('localhost', 27017)
db = Monclient['Weibo']
WeiboData = db['HadSelected']
#获取的各个数据名应该能够清楚的看出来对应的是什么数据
for i in range(0, length):
created_at = statuses[i]['created_at']
id = statuses[i]['user']['id']
province = statuses[i]['user']['province']
city = statuses[i]['user']['city']
followers_count = statuses[i]['user']['followers_count']
friends_count = statuses[i]['user']['friends_count']
statuses_count = statuses[i]['user']['statuses_count']
url = statuses[i]['user']['url']
geo = statuses[i]['geo']
comments_count = statuses[i]['comments_count']
reposts_count = statuses[i]['reposts_count']
nickname = statuses[i]['user']['screen_name']
desc = statuses[i]['user']['description']
location = statuses[i]['user']['location']
text = statuses[i]['text']
#插入mongodb
WeiboData.insert_one({
'created_at': created_at,
'id': id,
'nickname': nickname,
'text': text,
'province': province,
'location': location,
'description': desc,
'city': city,
'followers_count': followers_count,
'friends_count': friends_count,
'statuses_count': statuses_count,
'url': url,
'geo': geo,
'comments_count': comments_count,
'reposts_count': reposts_count
})
if __name__ == "__main__":
run()
个人代码一开始是这样的,看起来已经完成了。
但是,由于新浪会限制你可以拨打的电话数量,所以我稍后尝试重新运行它,发现问题。我之前的打印长度得到的每一行的值都不一样,一直在16-20之间徘徊。它表明我从新运行中获得的数据每次都不同。然后想了想,就写个死循环看看他什么时候又被阻塞了。所以代码变成了下面
删除 run() 并将其替换为以下无限循环。
if __name__ == "__main__":
while 1:
try:
run()
except:
pass
结果,他一直在跑……跑了四天,还没有被拦住。估计不会被封...
其余接口的使用方法也一样,只是改变了url和params。具体参数请参考新浪微博API文档
一开始我发现我一天能拿到800万条数据,这让我很开心……后来我发现了很多重复的数据。找了半天终于找到了解决办法。我根据用户的id和建立时间在mongodb中创建了一个索引(因为我不可能同时发两条微博),最后一天能得到100份左右没有重复数据。上千条信息。
我的博客
网站调用新浪微博内容(试试用python调用微博API的方法微博接口)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-04-06 20:07
因为最近碰到一个调用新浪微博开放接口的项目,想试试用python调用微博API。
SDK下载地址:代码不超过十几K,完全可以理解。
如果你有微博账号,可以新建一个APP,然后获取APP获取OAuth2.0授权所需的app key和app secret。
要了解 OAuth2,您可以查看链接到新浪微博的说明。OAuth2授权参数除了app key和app secret外,还需要网站回调地址redirect_uri,并且这个回调地址不允许在局域网内(神马localhost,127. 0.0.@ >1 好像不行),这真的让我焦急了好久。我没有使用 API 调用 网站,所以我检查了很多。看到有人写这个地址可以改用,我试了一下,成功了,对掉丝来说是个好消息。
这里有一个简单的程序来体验:
设置以下参数
import sys
import weibo
import webbrowser
APP_KEY = ‘‘
MY_APP_SECRET = ‘‘
REDIRECT_URL = ‘https://api.weibo.com/oauth2/default.html‘
获取微博授权网址,如第2行,用默认浏览器打开后,会提示登录微博,使用需要授权的账号登录,如下图
api = weibo.APIClient(app_key=APP_KEY,app_secret=MY_APP_SECRET,redirect_uri=REDIRECT_URL)
authorize_url = api.get_authorize_url()
print(authorize_url)
webbrowser.open_new(authorize_url)
登录后,您将被重定向到一个连接
关键是码值,是认证的关键。手动输入码值模拟认证
request = api.request_access_token(code, REDIRECT_URL)
access_token = request.access_token
expires_in = request.expires_in
api.set_access_token(access_token, expires_in)
api.statuses.update.post(status=u‘Test OAuth 2.0 Send a Weibo!‘)
access_token为获取到的token,expires_in为授权过期时间(UNIX时间)
使用 set_access_token 保存授权。往下走,就可以调用微博界面了。测试发了一条推文
但是,这种手动输入代码的方式并不适合调用程序。是否可以在不打开链接的情况下请求登录并获得授权?经过多方搜索参考,程序改进如下,可以自动获取代码并保存,方便程序服务调用。
accessWeibo
# -*- coding: utf-8 -*-
#/usr/bin/env python
#access to SinaWeibo By sinaweibopy
#实现微博自动登录,token自动生成,保存及更新
#适合于后端服务调用
from weibo import APIClient
import pymongo
import sys, os, urllib, urllib2
from http_helper import *
from retry import *
try:
import json
except ImportError:
import simplejson as json
# setting sys encoding to utf-8
default_encoding = ‘utf-8‘
if sys.getdefaultencoding() != default_encoding:
reload(sys)
sys.setdefaultencoding(default_encoding)
# weibo api访问配置
APP_KEY = ‘‘ # app key
APP_SECRET = ‘‘ # app secret
REDIRECT_URL = ‘https://api.weibo.com/oauth2/default.html‘ # callback url 授权回调页,与OAuth2.0 授权设置的一致
USERID = ‘‘ # 登陆的微博用户名,必须是OAuth2.0 设置的测试账号
USERPASSWD = ‘‘ # 用户密码
client = APIClient(app_key=APP_KEY, app_secret=APP_SECRET, redirect_uri=REDIRECT_URL)
def make_access_token():
#请求access token
params = urllib.urlencode({
‘action‘:‘submit‘,
‘withOfficalFlag‘:‘0‘,
‘ticket‘:‘‘,
‘isLoginSina‘:‘‘,
‘response_type‘:‘code‘,
‘regCallback‘:‘‘,
‘redirect_uri‘:REDIRECT_URL,
‘client_id‘:APP_KEY,
‘state‘:‘‘,
‘from‘:‘‘,
‘userId‘:USERID,
‘passwd‘:USERPASSWD,
})
login_url = ‘https://api.weibo.com/oauth2/authorize‘
url = client.get_authorize_url()
content = urllib2.urlopen(url)
if content:
headers = { ‘Referer‘ : url }
request = urllib2.Request(login_url, params, headers)
opener = get_opener(False)
urllib2.install_opener(opener)
try:
f = opener.open(request)
return_redirect_uri = f.url
except urllib2.HTTPError, e:
return_redirect_uri = e.geturl()
# 取到返回的code
code = return_redirect_uri.split(‘=‘)[1]
#得到token
token = client.request_access_token(code,REDIRECT_URL)
save_access_token(token)
def save_access_token(token):
#将access token保存到MongoDB数据库
mongoCon=pymongo.Connection(host="127.0.0.1",port=27017)
db= mongoCon.weibo
t={
"access_token":token[‘access_token‘],
"expires_in":str(token[‘expires_in‘]),
"date":time.strftime(‘%Y-%m-%d %H:%M:%S‘,time.localtime(time.time()))
}
db.token.insert(t,safe=True)
#Decorator 目的是当调用make_access_token()后再执行一次apply_access_token()
@retry(1)
def apply_access_token():
#从MongoDB读取及设置access token
try:
mongoCon=pymongo.Connection(host="127.0.0.1",port=27017)
db= mongoCon.weibo
if db.token.count()>0:
tokenInfos=db.token.find().sort([("_id",pymongo.DESCENDING)]).limit(1)
else:
make_access_token()
return False
for tokenInfo in tokenInfos:
access_token=tokenInfo["access_token"]
expires_in=tokenInfo["expires_in"]
try:
client.set_access_token(access_token, expires_in)
except StandardError, e:
if hasattr(e, ‘error‘):
if e.error == ‘expired_token‘:
# token过期重新生成
make_access_token()
return False
else:
pass
except:
make_access_token()
return False
return True
if __name__ == "__main__":
apply_access_token()
# 以下为访问微博api的应用逻辑
# 以发布文字微博接口为例
client.statuses.update.post(status=‘Test OAuth 2.0 Send a Weibo!‘)
retry.py
import math
import time
# Retry decorator with exponential backoff
def retry(tries, delay=1, backoff=2):
"""Retries a function or method until it returns True.
delay sets the initial delay, and backoff sets how much the delay should
lengthen after each failure. backoff must be greater than 1, or else it
isn‘t really a backoff. tries must be at least 0, and delay greater than
0."""
if backoff decorated function
return deco_retry # @retry(arg[, ...]) -> true decorator
http_helper.py
# -*- coding: utf-8 -*-
#/usr/bin/env python
import urllib2,cookielib
class SmartRedirectHandler(urllib2.HTTPRedirectHandler):
def http_error_301(cls, req, fp, code, msg, headers):
result = urllib2.HTTPRedirectHandler.http_error_301(cls, req, fp, code, msg, headers)
result.status = code
print headers
return result
def http_error_302(cls, req, fp, code, msg, headers):
result = urllib2.HTTPRedirectHandler.http_error_302(cls, req, fp, code, msg, headers)
result.status = code
print headers
return result
def get_cookie():
cookies = cookielib.CookieJar()
return urllib2.HTTPCookieProcessor(cookies)
def get_opener(proxy=False):
rv=urllib2.build_opener(get_cookie(), SmartRedirectHandler())
rv.addheaders = [(‘User-agent‘, ‘Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1)‘)]
return rv
Python调用新浪微博API项目实践
原版的: 查看全部
网站调用新浪微博内容(试试用python调用微博API的方法微博接口)
因为最近碰到一个调用新浪微博开放接口的项目,想试试用python调用微博API。
SDK下载地址:代码不超过十几K,完全可以理解。
如果你有微博账号,可以新建一个APP,然后获取APP获取OAuth2.0授权所需的app key和app secret。
要了解 OAuth2,您可以查看链接到新浪微博的说明。OAuth2授权参数除了app key和app secret外,还需要网站回调地址redirect_uri,并且这个回调地址不允许在局域网内(神马localhost,127. 0.0.@ >1 好像不行),这真的让我焦急了好久。我没有使用 API 调用 网站,所以我检查了很多。看到有人写这个地址可以改用,我试了一下,成功了,对掉丝来说是个好消息。
这里有一个简单的程序来体验:
设置以下参数
import sys
import weibo
import webbrowser
APP_KEY = ‘‘
MY_APP_SECRET = ‘‘
REDIRECT_URL = ‘https://api.weibo.com/oauth2/default.html‘
获取微博授权网址,如第2行,用默认浏览器打开后,会提示登录微博,使用需要授权的账号登录,如下图
api = weibo.APIClient(app_key=APP_KEY,app_secret=MY_APP_SECRET,redirect_uri=REDIRECT_URL)
authorize_url = api.get_authorize_url()
print(authorize_url)
webbrowser.open_new(authorize_url)
登录后,您将被重定向到一个连接
关键是码值,是认证的关键。手动输入码值模拟认证
request = api.request_access_token(code, REDIRECT_URL)
access_token = request.access_token
expires_in = request.expires_in
api.set_access_token(access_token, expires_in)
api.statuses.update.post(status=u‘Test OAuth 2.0 Send a Weibo!‘)
access_token为获取到的token,expires_in为授权过期时间(UNIX时间)
使用 set_access_token 保存授权。往下走,就可以调用微博界面了。测试发了一条推文
但是,这种手动输入代码的方式并不适合调用程序。是否可以在不打开链接的情况下请求登录并获得授权?经过多方搜索参考,程序改进如下,可以自动获取代码并保存,方便程序服务调用。
accessWeibo
# -*- coding: utf-8 -*-
#/usr/bin/env python
#access to SinaWeibo By sinaweibopy
#实现微博自动登录,token自动生成,保存及更新
#适合于后端服务调用
from weibo import APIClient
import pymongo
import sys, os, urllib, urllib2
from http_helper import *
from retry import *
try:
import json
except ImportError:
import simplejson as json
# setting sys encoding to utf-8
default_encoding = ‘utf-8‘
if sys.getdefaultencoding() != default_encoding:
reload(sys)
sys.setdefaultencoding(default_encoding)
# weibo api访问配置
APP_KEY = ‘‘ # app key
APP_SECRET = ‘‘ # app secret
REDIRECT_URL = ‘https://api.weibo.com/oauth2/default.html‘ # callback url 授权回调页,与OAuth2.0 授权设置的一致
USERID = ‘‘ # 登陆的微博用户名,必须是OAuth2.0 设置的测试账号
USERPASSWD = ‘‘ # 用户密码
client = APIClient(app_key=APP_KEY, app_secret=APP_SECRET, redirect_uri=REDIRECT_URL)
def make_access_token():
#请求access token
params = urllib.urlencode({
‘action‘:‘submit‘,
‘withOfficalFlag‘:‘0‘,
‘ticket‘:‘‘,
‘isLoginSina‘:‘‘,
‘response_type‘:‘code‘,
‘regCallback‘:‘‘,
‘redirect_uri‘:REDIRECT_URL,
‘client_id‘:APP_KEY,
‘state‘:‘‘,
‘from‘:‘‘,
‘userId‘:USERID,
‘passwd‘:USERPASSWD,
})
login_url = ‘https://api.weibo.com/oauth2/authorize‘
url = client.get_authorize_url()
content = urllib2.urlopen(url)
if content:
headers = { ‘Referer‘ : url }
request = urllib2.Request(login_url, params, headers)
opener = get_opener(False)
urllib2.install_opener(opener)
try:
f = opener.open(request)
return_redirect_uri = f.url
except urllib2.HTTPError, e:
return_redirect_uri = e.geturl()
# 取到返回的code
code = return_redirect_uri.split(‘=‘)[1]
#得到token
token = client.request_access_token(code,REDIRECT_URL)
save_access_token(token)
def save_access_token(token):
#将access token保存到MongoDB数据库
mongoCon=pymongo.Connection(host="127.0.0.1",port=27017)
db= mongoCon.weibo
t={
"access_token":token[‘access_token‘],
"expires_in":str(token[‘expires_in‘]),
"date":time.strftime(‘%Y-%m-%d %H:%M:%S‘,time.localtime(time.time()))
}
db.token.insert(t,safe=True)
#Decorator 目的是当调用make_access_token()后再执行一次apply_access_token()
@retry(1)
def apply_access_token():
#从MongoDB读取及设置access token
try:
mongoCon=pymongo.Connection(host="127.0.0.1",port=27017)
db= mongoCon.weibo
if db.token.count()>0:
tokenInfos=db.token.find().sort([("_id",pymongo.DESCENDING)]).limit(1)
else:
make_access_token()
return False
for tokenInfo in tokenInfos:
access_token=tokenInfo["access_token"]
expires_in=tokenInfo["expires_in"]
try:
client.set_access_token(access_token, expires_in)
except StandardError, e:
if hasattr(e, ‘error‘):
if e.error == ‘expired_token‘:
# token过期重新生成
make_access_token()
return False
else:
pass
except:
make_access_token()
return False
return True
if __name__ == "__main__":
apply_access_token()
# 以下为访问微博api的应用逻辑
# 以发布文字微博接口为例
client.statuses.update.post(status=‘Test OAuth 2.0 Send a Weibo!‘)
retry.py
import math
import time
# Retry decorator with exponential backoff
def retry(tries, delay=1, backoff=2):
"""Retries a function or method until it returns True.
delay sets the initial delay, and backoff sets how much the delay should
lengthen after each failure. backoff must be greater than 1, or else it
isn‘t really a backoff. tries must be at least 0, and delay greater than
0."""
if backoff decorated function
return deco_retry # @retry(arg[, ...]) -> true decorator
http_helper.py
# -*- coding: utf-8 -*-
#/usr/bin/env python
import urllib2,cookielib
class SmartRedirectHandler(urllib2.HTTPRedirectHandler):
def http_error_301(cls, req, fp, code, msg, headers):
result = urllib2.HTTPRedirectHandler.http_error_301(cls, req, fp, code, msg, headers)
result.status = code
print headers
return result
def http_error_302(cls, req, fp, code, msg, headers):
result = urllib2.HTTPRedirectHandler.http_error_302(cls, req, fp, code, msg, headers)
result.status = code
print headers
return result
def get_cookie():
cookies = cookielib.CookieJar()
return urllib2.HTTPCookieProcessor(cookies)
def get_opener(proxy=False):
rv=urllib2.build_opener(get_cookie(), SmartRedirectHandler())
rv.addheaders = [(‘User-agent‘, ‘Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1)‘)]
return rv
Python调用新浪微博API项目实践
原版的:
网站调用新浪微博内容(这是新浪微博爬虫用户信息、热点话题及评论(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-04-06 18:17
这是新浪微博爬虫,使用python+selenium实现。免费资源,希望对你有所帮助,虽然是傻瓜式爬虫,但至少可以运行。同时rar收录源码和爬取示例。参考我的文章:20436【python爬虫】Selenium爬取新浪微博内容和用户信息231852【Python爬虫】Selenium爬取新浪微博客户端用户信息、热点话题和评论(上)主要爬取内容包括:新浪微博手机用户信息和微博信息。用户信息:包括用户ID、用户名、微博数、关注数、关注数等微博信息:包括转发或原创、点赞数、转发数、评论数、发布时间、微博内容等安装过程:1. 先安装Python环境,作者是Python2.7.82.然后安装pIP或者easy_install3.通过命令pip install selenium安装selenium,是一个工具进行自动测试爬取4.然后修改代码中的用户名和密码,填写自己的用户名和密码5.运行程序,自动调用火狐浏览器登录微博注意:移动端信息比较精致简洁,对动态加载没有一些限制,但是只显示微博或者粉丝id等20个页面,这是它的缺点;虽然客户端可能有动态加载,比如评论和微博,但它的信息更完整。【源码】抓取手机端微博信息spider_selenium_sina_content。 查看全部
网站调用新浪微博内容(这是新浪微博爬虫用户信息、热点话题及评论(上))
这是新浪微博爬虫,使用python+selenium实现。免费资源,希望对你有所帮助,虽然是傻瓜式爬虫,但至少可以运行。同时rar收录源码和爬取示例。参考我的文章:20436【python爬虫】Selenium爬取新浪微博内容和用户信息231852【Python爬虫】Selenium爬取新浪微博客户端用户信息、热点话题和评论(上)主要爬取内容包括:新浪微博手机用户信息和微博信息。用户信息:包括用户ID、用户名、微博数、关注数、关注数等微博信息:包括转发或原创、点赞数、转发数、评论数、发布时间、微博内容等安装过程:1. 先安装Python环境,作者是Python2.7.82.然后安装pIP或者easy_install3.通过命令pip install selenium安装selenium,是一个工具进行自动测试爬取4.然后修改代码中的用户名和密码,填写自己的用户名和密码5.运行程序,自动调用火狐浏览器登录微博注意:移动端信息比较精致简洁,对动态加载没有一些限制,但是只显示微博或者粉丝id等20个页面,这是它的缺点;虽然客户端可能有动态加载,比如评论和微博,但它的信息更完整。【源码】抓取手机端微博信息spider_selenium_sina_content。

