
网站调用新浪微博内容
网站调用新浪微博内容( 一个复杂且长的链接(url)如何变成一个短小精悍的短链接? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-03-20 05:00
一个复杂且长的链接(url)如何变成一个短小精悍的短链接?
)
一个复杂而长的链接(url)如何变成一个简短的链接?借助巨资购买的微博域名和提供的微博短链API,可以将任意长度的url变成/RDj9Kog形式的短链接。本文介绍了微博的短链API,并提供了一个短链生成工具。
文章目录
微博短链API介绍
是新浪斥巨资购买的域名。也有说是某老板买了给新浪。这并不重要。不管怎样,它现在属于新浪。直接访问会跳转到新浪微博。网站。
新浪获得该域名后,基于该域名开放了微博API。其中之一是短链接接口。顾名思义,通过这个接口,任何url都可以生成短链接。例如 /RDj9Kog 是一个短链接。
官方短链接口API文档可以参考:
微博短链API调用
上面介绍的第二版短链接API需要access_token,参数介绍“OAuth授权方式为必填参数,OAuth授权后获取”,看完介绍需要用户登录微博才能拥有本授权。只是为了做这个简单的短链工具,肯定不可能每次都登录的,所以我去找了它的第一版界面:&,需要提供一个source参数。该来源是您注册为新浪微博开发者并申请该应用后获得的App Key。如果你懒得注册,你就去网上找点东西分享一下:
小米手机 App Key:xiaomi App Secret:3MqAdNoRLHomm4AECoURl7gds1sUIjun
Panda.memo App Key:31641035 App Secret:6a7c98c1eef2109622d0a08199a35bef
周博通微博管家 App Key:202088835 App Secret:9567e3782151dcfd1a9bd2dd099d957f
Android平板客户端 App Key:2540340328 App Secret:886cfb4e61fad4e4e9ba9dee625284dd
Google.Nexus App Key:1206405345 App Secret:fa6095e113cd28fde6e14c7b7145c5c5
Spring微博.Android App Key:1905839263 App Secret:36b51c6ebf2dd3e5361f80f6c4506267
Acer平板电脑 App Key:783190658 App Secret:7f63ae9eb3c1438e9f8932748ca8a341
iphone客户端 App Key:5786724301 App Secret:5Jao51NF1i5PDC91hhI3ID86ucoDtn4C
app梦工厂微博 App Key:569452181 App Secret:bbd573c3052999adcd026cbf88ffbf8e
FIT随享.iPhone版 App Key:31024382 App Secret:25c3e6b5763653d1e5b280884b45c51f
有了API和授权源码,代码就简单了,以PHP为例(url_long参数好像以or开头,否则会报错):
<p> 查看全部
网站调用新浪微博内容(
一个复杂且长的链接(url)如何变成一个短小精悍的短链接?
)

一个复杂而长的链接(url)如何变成一个简短的链接?借助巨资购买的微博域名和提供的微博短链API,可以将任意长度的url变成/RDj9Kog形式的短链接。本文介绍了微博的短链API,并提供了一个短链生成工具。
文章目录
微博短链API介绍
是新浪斥巨资购买的域名。也有说是某老板买了给新浪。这并不重要。不管怎样,它现在属于新浪。直接访问会跳转到新浪微博。网站。
新浪获得该域名后,基于该域名开放了微博API。其中之一是短链接接口。顾名思义,通过这个接口,任何url都可以生成短链接。例如 /RDj9Kog 是一个短链接。
官方短链接口API文档可以参考:
微博短链API调用
上面介绍的第二版短链接API需要access_token,参数介绍“OAuth授权方式为必填参数,OAuth授权后获取”,看完介绍需要用户登录微博才能拥有本授权。只是为了做这个简单的短链工具,肯定不可能每次都登录的,所以我去找了它的第一版界面:&,需要提供一个source参数。该来源是您注册为新浪微博开发者并申请该应用后获得的App Key。如果你懒得注册,你就去网上找点东西分享一下:
小米手机 App Key:xiaomi App Secret:3MqAdNoRLHomm4AECoURl7gds1sUIjun
Panda.memo App Key:31641035 App Secret:6a7c98c1eef2109622d0a08199a35bef
周博通微博管家 App Key:202088835 App Secret:9567e3782151dcfd1a9bd2dd099d957f
Android平板客户端 App Key:2540340328 App Secret:886cfb4e61fad4e4e9ba9dee625284dd
Google.Nexus App Key:1206405345 App Secret:fa6095e113cd28fde6e14c7b7145c5c5
Spring微博.Android App Key:1905839263 App Secret:36b51c6ebf2dd3e5361f80f6c4506267
Acer平板电脑 App Key:783190658 App Secret:7f63ae9eb3c1438e9f8932748ca8a341
iphone客户端 App Key:5786724301 App Secret:5Jao51NF1i5PDC91hhI3ID86ucoDtn4C
app梦工厂微博 App Key:569452181 App Secret:bbd573c3052999adcd026cbf88ffbf8e
FIT随享.iPhone版 App Key:31024382 App Secret:25c3e6b5763653d1e5b280884b45c51f
有了API和授权源码,代码就简单了,以PHP为例(url_long参数好像以or开头,否则会报错):
<p>
网站调用新浪微博内容(新浪微博API运用比较广泛,做一个完整的开发流程 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-03-20 04:22
)
新浪微博API现已广泛使用,并制作了完整的开发流程Demo
1、注册第一步,话不多说,注册账号成为开发者账号,如果这一步做不到,请立即砸电脑拔网线回家种田。
2、第二步是创建一个应用程序。开发者账号创建后,打开新浪微博开发平台:
点击上方菜单栏中的最后一个管理中心
如果是web应用,选择创建网站访问的应用,然后balabalabala按照新浪微博的要求去做
应用程序已创建。点击应用跳转页面,点击查看应用参数,可以看到应用的相关参数,这些参数会在第四步中用到。
3、第三步,下载sdk,回到顶部菜单栏,点击文档,然后点击左侧菜单栏中的sdk,选择java sdk,然后下载balabala . 如果这一步有任何问题,请回家种田。
所谓的sdk不是sdk(个人觉得名字有点误导),而是一个可运行的项目。下载后解压导入eclipse,可以看到src和example两个目录
src 是新浪微博的一部分
example是实例,界面的demo
4、第四步,配置参数,在src目录下找到config.properties
前三个参数需要配置为第二步提到的应用参数中的参数
后者是默认的,不需要更改
前三个参数配置如下
client_ID 是 App Key
client_SERCRET 是 App Secret
redirect_URI是OAuth2.0授权应用信息>高级信息>OAuth2.0授权设置的回调URL下面的授权回调页面是你自己填写的URL。它指向您自己的服务器。当然,它还在开发阶段,我们可以使用任何 URL,只要它能让我们了解 OAuth 授权过程。这里我们也进入了取消授权回调页面。注意这里的URL字符串必须一致。
5、第五步,获取AccessToken。一般情况下,获取AccessToken需要通过OAuth2.0进行认证,但是为了简单起见,我介绍一个简单的方法。OAuth 后面会讲到2.0
或者选择顶部菜单栏 Document > API > API Test Tool
选择创建的应用程序,然后单击获取 AccessToken。下面的文本框就是我们想要的AccessToken。
6、第六步,创建接口实例
进入微博API,找到已有权限的接口。
刚刚找到用户发的一条微博status/user_timeline进行测试。
点击该界面可以查看该界面的详细信息。可以查看接口的每个传入参数和返回参数。不用说。
不使用任何SDK实现Oauth授权,实现一个简单的微博发帖功能:
创建一个 Java 项目并编写以下代码。具体流程代码已经写的很清楚了,这里不再赘述:
注意先将申请ID、申请密码、回调页面修改为自己的!访问授权页面:
package com;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.net.URL;
import java.net.URLConnection;
import java.security.cert.CertificateException;
import java.security.cert.X509Certificate;
import java.util.Scanner;
import javax.net.ssl.X509TrustManager;
/**
* @author 刘显安
* 不使用任何SDK实现新浪微博Oauth授权并实现发微薄小Demo
* 日期:2012年11月11日
*/
public class Test
{
static String clientId="2355065950";//你的应用ID
static String clientSecret="72037e76bee00315691d9c30dd8a386a";//你的应用密码
static String redirectUri="https://api.weibo.com/oauth2/default.html";//你在应用管理中心设置的回调页面
public static void main(String[] args) throws Exception
{
testHttps();//测试
//第一步:访问授权页面获取授权
System.out.println("请打开你的浏览器,访问以下页面,登录你的微博账号并授权:");
System.out.println("https://api.weibo.com/oauth2/a ... 6quot;);
//第二步:获取AccessToken
System.out.println("请将授权成功后的页面地址栏中的参数code:");
String code=new Scanner(System.in).next();
getAccessToken(code);
//第三步:发布一条微博
System.out.println("请输入上面返回的值中accessToken的值:");
String accessToken=new Scanner(System.in).next();
updateStatus("发布微博测试!来自WeiboDemo!", accessToken);
}
/**
* 测试能否正常访问HTTPS打头的网站,
*/
public static void testHttps()
{
try
{
trustAllHttpsCertificates();//设置信任所有的http证书
URL url=new URL("https://api.weibo.com/oauth2/default.html");
URLConnection con=url.openConnection();
con.getInputStream();
System.out.println("恭喜,访问HTTPS打头的网站正常!");
}
catch (Exception e)
{
e.printStackTrace();
}
}
/**
* 以Post方式访问一个URL
* @param url 要访问的URL
* @param parameters URL后面“?”后面跟着的参数
*/
public static void postUrl(String url,String parameters)
{
try
{
trustAllHttpsCertificates();//设置信任所有的http证书
URLConnection conn = new URL(url).openConnection();
conn.setDoOutput(true);// 这里是关键,表示我们要向链接里注入的参数
OutputStreamWriter out = new OutputStreamWriter(conn.getOutputStream());// 获得连接输出流
out.write(parameters);
out.flush();
out.close();
// 到这里已经完成了,开始打印返回的HTML代码
BufferedReader reader = new BufferedReader(new InputStreamReader(conn.getInputStream()));
String line = null;
while ((line = reader.readLine()) != null)
{
System.out.println(line);
}
}
catch (Exception e)
{
e.printStackTrace();
}
}
/**
* 获取AccessToken
* @param code 在授权页面返回的Code
*/
public static void getAccessToken(String code)
{
String url="https://api.weibo.com/oauth2/access_token";
String parameters="client_id=" +clientId+"&client_secret=" +clientSecret+
"&grant_type=authorization_code" +"&redirect_uri=" +redirectUri+"&code="+code;
postUrl(url, parameters);
}
/**
* 利用刚获取的AccessToken发布一条微博
* @param text 要发布的微博内容
* @param accessToken 刚获取的AccessToken
*/
public static void updateStatus(String text,String accessToken)
{
String url="https://api.weibo.com/2/status ... 3B%3B
String parameters="status="+text+"&access_token="+accessToken;
postUrl(url, parameters);
System.out.println("发布微博成功!");
}
/**
* 设置信任所有的http证书(正常情况下访问https打头的网站会出现证书不信任相关错误,所以必须在访问前调用此方法)
* @throws Exception
*/
private static void trustAllHttpsCertificates() throws Exception
{
javax.net.ssl.TrustManager[] trustAllCerts = new javax.net.ssl.TrustManager[1];
trustAllCerts[0] = new X509TrustManager()
{
@Override
public X509Certificate[] getAcceptedIssuers()
{
return null;
}
@Override
public void checkServerTrusted(X509Certificate[] arg0, String arg1)
throws CertificateException
{}
@Override
public void checkClientTrusted(X509Certificate[] arg0, String arg1)
throws CertificateException
{}
};
javax.net.ssl.SSLContext sc = javax.net.ssl.SSLContext.getInstance("SSL");
sc.init(null, trustAllCerts, null);
javax.net.ssl.HttpsURLConnection.setDefaultSSLSocketFactory(sc.getSocketFactory());
}
}
访问授权页面:
授权成功:
成功发布微博:
控制台输出:
查看全部
网站调用新浪微博内容(新浪微博API运用比较广泛,做一个完整的开发流程
)
新浪微博API现已广泛使用,并制作了完整的开发流程Demo
1、注册第一步,话不多说,注册账号成为开发者账号,如果这一步做不到,请立即砸电脑拔网线回家种田。
2、第二步是创建一个应用程序。开发者账号创建后,打开新浪微博开发平台:
点击上方菜单栏中的最后一个管理中心

如果是web应用,选择创建网站访问的应用,然后balabalabala按照新浪微博的要求去做
应用程序已创建。点击应用跳转页面,点击查看应用参数,可以看到应用的相关参数,这些参数会在第四步中用到。
3、第三步,下载sdk,回到顶部菜单栏,点击文档,然后点击左侧菜单栏中的sdk,选择java sdk,然后下载balabala . 如果这一步有任何问题,请回家种田。

所谓的sdk不是sdk(个人觉得名字有点误导),而是一个可运行的项目。下载后解压导入eclipse,可以看到src和example两个目录
src 是新浪微博的一部分
example是实例,界面的demo
4、第四步,配置参数,在src目录下找到config.properties
前三个参数需要配置为第二步提到的应用参数中的参数
后者是默认的,不需要更改
前三个参数配置如下
client_ID 是 App Key
client_SERCRET 是 App Secret
redirect_URI是OAuth2.0授权应用信息>高级信息>OAuth2.0授权设置的回调URL下面的授权回调页面是你自己填写的URL。它指向您自己的服务器。当然,它还在开发阶段,我们可以使用任何 URL,只要它能让我们了解 OAuth 授权过程。这里我们也进入了取消授权回调页面。注意这里的URL字符串必须一致。
5、第五步,获取AccessToken。一般情况下,获取AccessToken需要通过OAuth2.0进行认证,但是为了简单起见,我介绍一个简单的方法。OAuth 后面会讲到2.0
或者选择顶部菜单栏 Document > API > API Test Tool
选择创建的应用程序,然后单击获取 AccessToken。下面的文本框就是我们想要的AccessToken。

6、第六步,创建接口实例
进入微博API,找到已有权限的接口。
刚刚找到用户发的一条微博status/user_timeline进行测试。

点击该界面可以查看该界面的详细信息。可以查看接口的每个传入参数和返回参数。不用说。
不使用任何SDK实现Oauth授权,实现一个简单的微博发帖功能:
创建一个 Java 项目并编写以下代码。具体流程代码已经写的很清楚了,这里不再赘述:
注意先将申请ID、申请密码、回调页面修改为自己的!访问授权页面:
package com;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.net.URL;
import java.net.URLConnection;
import java.security.cert.CertificateException;
import java.security.cert.X509Certificate;
import java.util.Scanner;
import javax.net.ssl.X509TrustManager;
/**
* @author 刘显安
* 不使用任何SDK实现新浪微博Oauth授权并实现发微薄小Demo
* 日期:2012年11月11日
*/
public class Test
{
static String clientId="2355065950";//你的应用ID
static String clientSecret="72037e76bee00315691d9c30dd8a386a";//你的应用密码
static String redirectUri="https://api.weibo.com/oauth2/default.html";//你在应用管理中心设置的回调页面
public static void main(String[] args) throws Exception
{
testHttps();//测试
//第一步:访问授权页面获取授权
System.out.println("请打开你的浏览器,访问以下页面,登录你的微博账号并授权:");
System.out.println("https://api.weibo.com/oauth2/a ... 6quot;);
//第二步:获取AccessToken
System.out.println("请将授权成功后的页面地址栏中的参数code:");
String code=new Scanner(System.in).next();
getAccessToken(code);
//第三步:发布一条微博
System.out.println("请输入上面返回的值中accessToken的值:");
String accessToken=new Scanner(System.in).next();
updateStatus("发布微博测试!来自WeiboDemo!", accessToken);
}
/**
* 测试能否正常访问HTTPS打头的网站,
*/
public static void testHttps()
{
try
{
trustAllHttpsCertificates();//设置信任所有的http证书
URL url=new URL("https://api.weibo.com/oauth2/default.html";);
URLConnection con=url.openConnection();
con.getInputStream();
System.out.println("恭喜,访问HTTPS打头的网站正常!");
}
catch (Exception e)
{
e.printStackTrace();
}
}
/**
* 以Post方式访问一个URL
* @param url 要访问的URL
* @param parameters URL后面“?”后面跟着的参数
*/
public static void postUrl(String url,String parameters)
{
try
{
trustAllHttpsCertificates();//设置信任所有的http证书
URLConnection conn = new URL(url).openConnection();
conn.setDoOutput(true);// 这里是关键,表示我们要向链接里注入的参数
OutputStreamWriter out = new OutputStreamWriter(conn.getOutputStream());// 获得连接输出流
out.write(parameters);
out.flush();
out.close();
// 到这里已经完成了,开始打印返回的HTML代码
BufferedReader reader = new BufferedReader(new InputStreamReader(conn.getInputStream()));
String line = null;
while ((line = reader.readLine()) != null)
{
System.out.println(line);
}
}
catch (Exception e)
{
e.printStackTrace();
}
}
/**
* 获取AccessToken
* @param code 在授权页面返回的Code
*/
public static void getAccessToken(String code)
{
String url="https://api.weibo.com/oauth2/access_token";
String parameters="client_id=" +clientId+"&client_secret=" +clientSecret+
"&grant_type=authorization_code" +"&redirect_uri=" +redirectUri+"&code="+code;
postUrl(url, parameters);
}
/**
* 利用刚获取的AccessToken发布一条微博
* @param text 要发布的微博内容
* @param accessToken 刚获取的AccessToken
*/
public static void updateStatus(String text,String accessToken)
{
String url="https://api.weibo.com/2/status ... 3B%3B
String parameters="status="+text+"&access_token="+accessToken;
postUrl(url, parameters);
System.out.println("发布微博成功!");
}
/**
* 设置信任所有的http证书(正常情况下访问https打头的网站会出现证书不信任相关错误,所以必须在访问前调用此方法)
* @throws Exception
*/
private static void trustAllHttpsCertificates() throws Exception
{
javax.net.ssl.TrustManager[] trustAllCerts = new javax.net.ssl.TrustManager[1];
trustAllCerts[0] = new X509TrustManager()
{
@Override
public X509Certificate[] getAcceptedIssuers()
{
return null;
}
@Override
public void checkServerTrusted(X509Certificate[] arg0, String arg1)
throws CertificateException
{}
@Override
public void checkClientTrusted(X509Certificate[] arg0, String arg1)
throws CertificateException
{}
};
javax.net.ssl.SSLContext sc = javax.net.ssl.SSLContext.getInstance("SSL");
sc.init(null, trustAllCerts, null);
javax.net.ssl.HttpsURLConnection.setDefaultSSLSocketFactory(sc.getSocketFactory());
}
}
访问授权页面:

授权成功:

成功发布微博:

控制台输出:

网站调用新浪微博内容(试试用python调用微博API的方法微博接口 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-03-18 01:05
)
因为最近碰到一个调用新浪微博开放接口的项目,想试试用python调用微博API。
SDK下载地址:代码不超过十几K,完全可以理解。
如果你有微博账号,可以新建一个APP,然后获取APP获取OAuth2.0授权所需要的app key和app secret。
要了解 OAuth2,您可以查看链接到新浪微博的说明。OAuth2授权参数除了app key和app secret外,还需要网站回调地址redirect_uri,并且这个回调地址不允许在局域网内(神马localhost,127.0.0.@ >1 好像不行),这真的让我焦急了很久。我没有使用 API 调用 网站,所以我检查了很多。看到有人写这个地址可以改用,我试了一下,成功了,对掉丝来说是个好消息。
这里有一个简单的程序来体验:
设置以下参数
import sys
import weibo
import webbrowser
APP_KEY = ''
MY_APP_SECRET = ''
REDIRECT_URL = 'https://api.weibo.com/oauth2/default.html'
获取微博授权网址,如第2行,用默认浏览器打开后,会提示登录微博,使用需要授权的账号登录,如下图
api = weibo.APIClient(app_key=APP_KEY,app_secret=MY_APP_SECRET,redirect_uri=REDIRECT_URL)
authorize_url = api.get_authorize_url()
print(authorize_url)
webbrowser.open_new(authorize_url)
登录后,您将被重定向到一个连接
关键是码值,是认证的关键。手动输入码值模拟认证
request = api.request_access_token(code, REDIRECT_URL)
access_token = request.access_token
expires_in = request.expires_in
api.set_access_token(access_token, expires_in)
api.statuses.update.post(status=u'Test OAuth 2.0 Send a Weibo!')
access_token为获取到的token,expires_in为授权过期时间(UNIX时间)
使用 set_access_token 保存授权。往下走,就可以调用微博界面了。测试发了一条推文
但是,这种手动输入代码的方式并不适合调用程序。是否可以在不打开链接的情况下请求登录并获得授权?经过多方搜索参考,程序改进如下,可以自动获取代码并保存,方便程序服务调用。
accessWeibo
# -*- coding: utf-8 -*-
#/usr/bin/env python
#access to SinaWeibo By sinaweibopy
#实现微博自动登录,token自动生成,保存及更新
#适合于后端服务调用
from weibo import APIClient
import pymongo
import sys, os, urllib, urllib2
from http_helper import *
from retry import *
try:
import json
except ImportError:
import simplejson as json
# setting sys encoding to utf-8
default_encoding = 'utf-8'
if sys.getdefaultencoding() != default_encoding:
reload(sys)
sys.setdefaultencoding(default_encoding)
# weibo api访问配置
APP_KEY = '' # app key
APP_SECRET = '' # app secret
REDIRECT_URL = 'https://api.weibo.com/oauth2/default.html' # callback url 授权回调页,与OAuth2.0 授权设置的一致
USERID = '' # 登陆的微博用户名,必须是OAuth2.0 设置的测试账号
USERPASSWD = '' # 用户密码
client = APIClient(app_key=APP_KEY, app_secret=APP_SECRET, redirect_uri=REDIRECT_URL)
def make_access_token():
#请求access token
params = urllib.urlencode({
'action':'submit',
'withOfficalFlag':'0',
'ticket':'',
'isLoginSina':'',
'response_type':'code',
'regCallback':'',
'redirect_uri':REDIRECT_URL,
'client_id':APP_KEY,
'state':'',
'from':'',
'userId':USERID,
'passwd':USERPASSWD,
})
login_url = 'https://api.weibo.com/oauth2/authorize'
url = client.get_authorize_url()
content = urllib2.urlopen(url)
if content:
headers = { 'Referer' : url }
request = urllib2.Request(login_url, params, headers)
opener = get_opener(False)
urllib2.install_opener(opener)
try:
f = opener.open(request)
return_redirect_uri = f.url
except urllib2.HTTPError, e:
return_redirect_uri = e.geturl()
# 取到返回的code
code = return_redirect_uri.split('=')[1]
#得到token
token = client.request_access_token(code,REDIRECT_URL)
save_access_token(token)
def save_access_token(token):
#将access token保存到MongoDB数据库
mongoCon=pymongo.Connection(host="127.0.0.1",port=27017)
db= mongoCon.weibo
t={
"access_token":token['access_token'],
"expires_in":str(token['expires_in']),
"date":time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time()))
}
db.token.insert(t,safe=True)
#Decorator 目的是当调用make_access_token()后再执行一次apply_access_token()
@retry(1)
def apply_access_token():
#从MongoDB读取及设置access token
try:
mongoCon=pymongo.Connection(host="127.0.0.1",port=27017)
db= mongoCon.weibo
if db.token.count()>0:
tokenInfos=db.token.find().sort([("_id",pymongo.DESCENDING)]).limit(1)
else:
make_access_token()
return False
for tokenInfo in tokenInfos:
access_token=tokenInfo["access_token"]
expires_in=tokenInfo["expires_in"]
try:
client.set_access_token(access_token, expires_in)
except StandardError, e:
if hasattr(e, 'error'):
if e.error == 'expired_token':
# token过期重新生成
make_access_token()
return False
else:
pass
except:
make_access_token()
return False
return True
if __name__ == "__main__":
apply_access_token()
# 以下为访问微博api的应用逻辑
# 以发布文字微博接口为例
client.statuses.update.post(status='Test OAuth 2.0 Send a Weibo!')
retry.py
import math
import time
# Retry decorator with exponential backoff
def retry(tries, delay=1, backoff=2):
"""Retries a function or method until it returns True.
delay sets the initial delay, and backoff sets how much the delay should
lengthen after each failure. backoff must be greater than 1, or else it
isn't really a backoff. tries must be at least 0, and delay greater than
0."""
if backoff decorated function
return deco_retry # @retry(arg[, ...]) -> true decorator
http_helper.py
# -*- coding: utf-8 -*-
#/usr/bin/env python
import urllib2,cookielib
class SmartRedirectHandler(urllib2.HTTPRedirectHandler):
def http_error_301(cls, req, fp, code, msg, headers):
result = urllib2.HTTPRedirectHandler.http_error_301(cls, req, fp, code, msg, headers)
result.status = code
print headers
return result
def http_error_302(cls, req, fp, code, msg, headers):
result = urllib2.HTTPRedirectHandler.http_error_302(cls, req, fp, code, msg, headers)
result.status = code
print headers
return result
def get_cookie():
cookies = cookielib.CookieJar()
return urllib2.HTTPCookieProcessor(cookies)
def get_opener(proxy=False):
rv=urllib2.build_opener(get_cookie(), SmartRedirectHandler())
rv.addheaders = [('User-agent', 'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1)')]
return rv 查看全部
网站调用新浪微博内容(试试用python调用微博API的方法微博接口
)
因为最近碰到一个调用新浪微博开放接口的项目,想试试用python调用微博API。
SDK下载地址:代码不超过十几K,完全可以理解。
如果你有微博账号,可以新建一个APP,然后获取APP获取OAuth2.0授权所需要的app key和app secret。
要了解 OAuth2,您可以查看链接到新浪微博的说明。OAuth2授权参数除了app key和app secret外,还需要网站回调地址redirect_uri,并且这个回调地址不允许在局域网内(神马localhost,127.0.0.@ >1 好像不行),这真的让我焦急了很久。我没有使用 API 调用 网站,所以我检查了很多。看到有人写这个地址可以改用,我试了一下,成功了,对掉丝来说是个好消息。
这里有一个简单的程序来体验:
设置以下参数
import sys
import weibo
import webbrowser
APP_KEY = ''
MY_APP_SECRET = ''
REDIRECT_URL = 'https://api.weibo.com/oauth2/default.html'
获取微博授权网址,如第2行,用默认浏览器打开后,会提示登录微博,使用需要授权的账号登录,如下图
api = weibo.APIClient(app_key=APP_KEY,app_secret=MY_APP_SECRET,redirect_uri=REDIRECT_URL)
authorize_url = api.get_authorize_url()
print(authorize_url)
webbrowser.open_new(authorize_url)

登录后,您将被重定向到一个连接
关键是码值,是认证的关键。手动输入码值模拟认证
request = api.request_access_token(code, REDIRECT_URL)
access_token = request.access_token
expires_in = request.expires_in
api.set_access_token(access_token, expires_in)
api.statuses.update.post(status=u'Test OAuth 2.0 Send a Weibo!')
access_token为获取到的token,expires_in为授权过期时间(UNIX时间)
使用 set_access_token 保存授权。往下走,就可以调用微博界面了。测试发了一条推文

但是,这种手动输入代码的方式并不适合调用程序。是否可以在不打开链接的情况下请求登录并获得授权?经过多方搜索参考,程序改进如下,可以自动获取代码并保存,方便程序服务调用。
accessWeibo
# -*- coding: utf-8 -*-
#/usr/bin/env python
#access to SinaWeibo By sinaweibopy
#实现微博自动登录,token自动生成,保存及更新
#适合于后端服务调用
from weibo import APIClient
import pymongo
import sys, os, urllib, urllib2
from http_helper import *
from retry import *
try:
import json
except ImportError:
import simplejson as json
# setting sys encoding to utf-8
default_encoding = 'utf-8'
if sys.getdefaultencoding() != default_encoding:
reload(sys)
sys.setdefaultencoding(default_encoding)
# weibo api访问配置
APP_KEY = '' # app key
APP_SECRET = '' # app secret
REDIRECT_URL = 'https://api.weibo.com/oauth2/default.html' # callback url 授权回调页,与OAuth2.0 授权设置的一致
USERID = '' # 登陆的微博用户名,必须是OAuth2.0 设置的测试账号
USERPASSWD = '' # 用户密码
client = APIClient(app_key=APP_KEY, app_secret=APP_SECRET, redirect_uri=REDIRECT_URL)
def make_access_token():
#请求access token
params = urllib.urlencode({
'action':'submit',
'withOfficalFlag':'0',
'ticket':'',
'isLoginSina':'',
'response_type':'code',
'regCallback':'',
'redirect_uri':REDIRECT_URL,
'client_id':APP_KEY,
'state':'',
'from':'',
'userId':USERID,
'passwd':USERPASSWD,
})
login_url = 'https://api.weibo.com/oauth2/authorize'
url = client.get_authorize_url()
content = urllib2.urlopen(url)
if content:
headers = { 'Referer' : url }
request = urllib2.Request(login_url, params, headers)
opener = get_opener(False)
urllib2.install_opener(opener)
try:
f = opener.open(request)
return_redirect_uri = f.url
except urllib2.HTTPError, e:
return_redirect_uri = e.geturl()
# 取到返回的code
code = return_redirect_uri.split('=')[1]
#得到token
token = client.request_access_token(code,REDIRECT_URL)
save_access_token(token)
def save_access_token(token):
#将access token保存到MongoDB数据库
mongoCon=pymongo.Connection(host="127.0.0.1",port=27017)
db= mongoCon.weibo
t={
"access_token":token['access_token'],
"expires_in":str(token['expires_in']),
"date":time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time()))
}
db.token.insert(t,safe=True)
#Decorator 目的是当调用make_access_token()后再执行一次apply_access_token()
@retry(1)
def apply_access_token():
#从MongoDB读取及设置access token
try:
mongoCon=pymongo.Connection(host="127.0.0.1",port=27017)
db= mongoCon.weibo
if db.token.count()>0:
tokenInfos=db.token.find().sort([("_id",pymongo.DESCENDING)]).limit(1)
else:
make_access_token()
return False
for tokenInfo in tokenInfos:
access_token=tokenInfo["access_token"]
expires_in=tokenInfo["expires_in"]
try:
client.set_access_token(access_token, expires_in)
except StandardError, e:
if hasattr(e, 'error'):
if e.error == 'expired_token':
# token过期重新生成
make_access_token()
return False
else:
pass
except:
make_access_token()
return False
return True
if __name__ == "__main__":
apply_access_token()
# 以下为访问微博api的应用逻辑
# 以发布文字微博接口为例
client.statuses.update.post(status='Test OAuth 2.0 Send a Weibo!')
retry.py
import math
import time
# Retry decorator with exponential backoff
def retry(tries, delay=1, backoff=2):
"""Retries a function or method until it returns True.
delay sets the initial delay, and backoff sets how much the delay should
lengthen after each failure. backoff must be greater than 1, or else it
isn't really a backoff. tries must be at least 0, and delay greater than
0."""
if backoff decorated function
return deco_retry # @retry(arg[, ...]) -> true decorator
http_helper.py
# -*- coding: utf-8 -*-
#/usr/bin/env python
import urllib2,cookielib
class SmartRedirectHandler(urllib2.HTTPRedirectHandler):
def http_error_301(cls, req, fp, code, msg, headers):
result = urllib2.HTTPRedirectHandler.http_error_301(cls, req, fp, code, msg, headers)
result.status = code
print headers
return result
def http_error_302(cls, req, fp, code, msg, headers):
result = urllib2.HTTPRedirectHandler.http_error_302(cls, req, fp, code, msg, headers)
result.status = code
print headers
return result
def get_cookie():
cookies = cookielib.CookieJar()
return urllib2.HTTPCookieProcessor(cookies)
def get_opener(proxy=False):
rv=urllib2.build_opener(get_cookie(), SmartRedirectHandler())
rv.addheaders = [('User-agent', 'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1)')]
return rv
网站调用新浪微博内容(新浪微博API新特点与百度地图API相比(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-03-17 19:14
文章目录
查看 API 使用流程
在上一篇文章API Python编程简介:(一)使用百度地图API查地理坐标,通过百度地图API的使用,我们看到API调用的大致流程是:生成API规则 格式化url -> 通过urllib读取url中的数据 -> 解析json格式的数据 接下来开始研究新浪微博API的使用吧!
准备好工作了
新浪微博开放平台是使用新浪微博API的平台。
使用微博账号登录平台后,即可申请成为开发者,创建新应用后将获得唯一的App Key和App Secret。(注:申请不需要提交审核,只要创建一个新的申请,就会分配Key和Secret。)这两个信息也可以在“我的申请/申请信息/基本信息”中找到. 该页面还有“我的申请/申请信息/高级信息”项,点击进入并设置OAuth2.0授权回调页面的相关信息。如果不知道填什么,可以设置为默认回调Page:。后面需要这三条信息,请复制保存到文档中。
微博API新功能
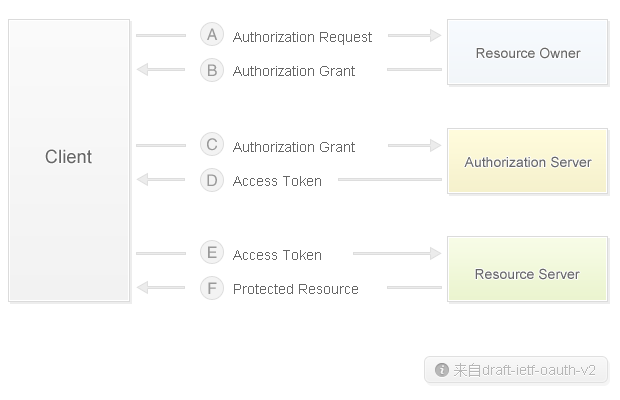
新浪微博API与百度地图API相比,增加了OAuth2.0协议进行用户认证和授权。这里只是简单说明一下(有兴趣的同学可以参考网上文档示意图):通过该协议,第三方应用可以获取用户授权,然后使用该License从授权服务器获取token,用于来自 API 服务器的后续查询 验证数据时。
这个验证过程增加了 url 生成的复杂性。好在网站上已经有廖雪峰老师提供的SDK工具包:sinaweibopy(廖老师的github地址好像改名了,网上很多旧链接都失效了,这是新的有效链接),但是这个程序是基于Python2环境编写的,Python3的一些系统库做了改动,程序调用时经常报错。作为 Python 初学者,重写程序以适应 Python3 环境无疑是困难的。幸运的是,有一位大神完成了这项工作。感谢 owolf 为 Python3 重写的 SDK:sinweibopy3。我用过,运行正常。你可以下载它。在这里,我也推荐一下owolf的文章
简单的例子
介绍一下新浪微博API的使用过程,为新生提供参考。
1.参数设置
import sinaweibopy3
import webbrowser
import json
APP_KEY =' 填入你的App Key'
APP_SECRET=' 填入你的App Secret'
REDIRECT_URL =' 填入你的授权回调页'
笔记:
这里说一下我的粗心造成的一个bug,也提醒大家。当我第一次运行程序时,每次都会收到“重定向地址不匹配”错误消息:
微博账号登录出错!授权第三方应用出错,请联系第三方应用开发者:XXX或稍后重试。
错误代码:21322 重定向地址不匹配
网上找了解决方法,设置回调页,但是我之前的步骤已经设置好了,为什么还是这个问题?后来在一篇文章文章中看到,回调页面的地址应该和程序中的REDIRECT_URL一致。想到了程序例子,用http:开头,我填的时候看到同一个地址,没有变化,而网站是https:开头,一个's的区别',当时我还以为是地址,没想到差别这么大!
2.OAuth2.0 验证生成的url
client = sinaweibopy3.APIClient(app_key=APP_KEY, app_secret=APP_SECRET, redirect_uri=REDIRECT_URL)
url = client.get_authorize_url()
webbrowser.open_new(url)
result = client.request_access_token(input("please input code: "))
client.set_access_token(result.access_token, result.expires_in)
注意:这是调用sinweibopy3实现用户授权->在OAuth2.0中获取Token的过程。当程序运行到client.request_access_token时,会弹出输入提示“请输入密码:”,询问密码?这是什么意思?打开浏览器会看到出现OAuth2.0验证回调页面。地址栏中的“code=”后面有一串字符。这就是我们想要的Token信息。复制它,粘贴它并输入它,然后程序继续。跑步。
3.从 API 读取数据
运行以下代码读取公众微博数据并显示结果。
result=client.public_timeline()
print(json.dumps(result,indent=2,ensure_ascii=False))
通过查看数据结构,可以提取特定信息。比如下面的代码可以用来输出用户的微博昵称、位置、最新微博的文字。
number=result["total_number"]
print(number,"users:")
for u in result["statuses"]:
print(u["user"]["screen_name"])
print(u["user"]["location"])
print(u["text"])
先进的 查看全部
网站调用新浪微博内容(新浪微博API新特点与百度地图API相比(图))
文章目录
查看 API 使用流程
在上一篇文章API Python编程简介:(一)使用百度地图API查地理坐标,通过百度地图API的使用,我们看到API调用的大致流程是:生成API规则 格式化url -> 通过urllib读取url中的数据 -> 解析json格式的数据 接下来开始研究新浪微博API的使用吧!
准备好工作了
新浪微博开放平台是使用新浪微博API的平台。
使用微博账号登录平台后,即可申请成为开发者,创建新应用后将获得唯一的App Key和App Secret。(注:申请不需要提交审核,只要创建一个新的申请,就会分配Key和Secret。)这两个信息也可以在“我的申请/申请信息/基本信息”中找到. 该页面还有“我的申请/申请信息/高级信息”项,点击进入并设置OAuth2.0授权回调页面的相关信息。如果不知道填什么,可以设置为默认回调Page:。后面需要这三条信息,请复制保存到文档中。
微博API新功能
新浪微博API与百度地图API相比,增加了OAuth2.0协议进行用户认证和授权。这里只是简单说明一下(有兴趣的同学可以参考网上文档示意图):通过该协议,第三方应用可以获取用户授权,然后使用该License从授权服务器获取token,用于来自 API 服务器的后续查询 验证数据时。
这个验证过程增加了 url 生成的复杂性。好在网站上已经有廖雪峰老师提供的SDK工具包:sinaweibopy(廖老师的github地址好像改名了,网上很多旧链接都失效了,这是新的有效链接),但是这个程序是基于Python2环境编写的,Python3的一些系统库做了改动,程序调用时经常报错。作为 Python 初学者,重写程序以适应 Python3 环境无疑是困难的。幸运的是,有一位大神完成了这项工作。感谢 owolf 为 Python3 重写的 SDK:sinweibopy3。我用过,运行正常。你可以下载它。在这里,我也推荐一下owolf的文章
简单的例子
介绍一下新浪微博API的使用过程,为新生提供参考。
1.参数设置
import sinaweibopy3
import webbrowser
import json
APP_KEY =' 填入你的App Key'
APP_SECRET=' 填入你的App Secret'
REDIRECT_URL =' 填入你的授权回调页'
笔记:
这里说一下我的粗心造成的一个bug,也提醒大家。当我第一次运行程序时,每次都会收到“重定向地址不匹配”错误消息:
微博账号登录出错!授权第三方应用出错,请联系第三方应用开发者:XXX或稍后重试。
错误代码:21322 重定向地址不匹配
网上找了解决方法,设置回调页,但是我之前的步骤已经设置好了,为什么还是这个问题?后来在一篇文章文章中看到,回调页面的地址应该和程序中的REDIRECT_URL一致。想到了程序例子,用http:开头,我填的时候看到同一个地址,没有变化,而网站是https:开头,一个's的区别',当时我还以为是地址,没想到差别这么大!
2.OAuth2.0 验证生成的url
client = sinaweibopy3.APIClient(app_key=APP_KEY, app_secret=APP_SECRET, redirect_uri=REDIRECT_URL)
url = client.get_authorize_url()
webbrowser.open_new(url)
result = client.request_access_token(input("please input code: "))
client.set_access_token(result.access_token, result.expires_in)
注意:这是调用sinweibopy3实现用户授权->在OAuth2.0中获取Token的过程。当程序运行到client.request_access_token时,会弹出输入提示“请输入密码:”,询问密码?这是什么意思?打开浏览器会看到出现OAuth2.0验证回调页面。地址栏中的“code=”后面有一串字符。这就是我们想要的Token信息。复制它,粘贴它并输入它,然后程序继续。跑步。
3.从 API 读取数据
运行以下代码读取公众微博数据并显示结果。
result=client.public_timeline()
print(json.dumps(result,indent=2,ensure_ascii=False))
通过查看数据结构,可以提取特定信息。比如下面的代码可以用来输出用户的微博昵称、位置、最新微博的文字。
number=result["total_number"]
print(number,"users:")
for u in result["statuses"]:
print(u["user"]["screen_name"])
print(u["user"]["location"])
print(u["text"])
先进的
网站调用新浪微博内容(Python微博API获取微博内容作者:更多优惠gt(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-03-16 20:11
阿里云 > 云栖社区 > 主题地图 > X > 新浪微博api获取数据
推荐活动:
更多优惠>
当前话题:新浪微博api获取数据加入采集
相关话题:
新浪微博api获取数据相关博客看更多博文
使用新浪微博API的Search接口做微博锐排
作者:郑云1802浏览量:05年前
郑云20100929申请入口:简单介绍一下我们的榜单与新浪自己的热门转发榜单的区别:微博睿推榜单会忽略名人推文,更关注草根推文,更关注社会民生推文,屏蔽非- 有营养的推文。微博锐推列表将汇总以新浪微博为首的国内主要微博网站的信息
阅读全文
Python调用微博API获取微博内容
作者:745 浏览评论:05年前
1:获取app-key和app-secret 用自己的微博账号()登录微博开放平台,在微博开放中心下的“创建应用”下创建应用。随意填写申请信息。填写后就不需要了。提交审核,只需要那个app-ke
阅读全文
开放平台:新浪微博 for iOS
作者:余书仪 845 浏览评论:09年前
简介:新浪微博几乎打通了所有平台数据的API接口。所以很多优秀的第三方微博客户端在功能上都非常全面。通过 SNS 进行分享和推广的方式已经在 App 世界中使用。它很常见,随处可见。本文主要介绍App与新浪微博的关联方式。参考:1.开发
阅读全文
新浪微博发展(一)
作者:nothingfinal1071 浏览评论:08年前
这几天一直在研究新浪微博的授权验证。我在论坛上传了一个例子,找到了一个相关的博客文章。. 本以为很容易理解,但花了很长时间,我还是一头雾水。. 后来想了想,其实别人提供的也只是一些接口和方法,我也没有认真研究过授权过程,所以比较关心代码中那些奇怪的方法。
阅读全文
新浪微博发展(一)
作者:xumaojun1002人浏览评论:08年前
这几天一直在研究新浪微博的授权验证。我在论坛上传了一个例子,找到了一个相关的博客文章。. 本以为很容易理解,但花了很长时间,我还是一头雾水。. 后来想了想,其实别人提供的也只是一些接口和方法,我也没有认真研究过授权过程,所以比较关心代码中那些奇怪的方法。
阅读全文
新浪微博开放平台开发步骤介绍(适合新手)
作者:技术组合950人查看评论数:04年前
我也是新手,第一次使用开放平台进行开发。起初,我觉得我无处可去。经过长时间的摸索,终于成功调用了API。现在把这段经历介绍给新手(高手不用看,当然如果大家能提出一些意见和建议,非常感谢),也想和大家交流。本示例介绍如何使用 API 提交数据(发布微
阅读全文
新浪微博开放平台老API中的PHP例程
作者:何立坚 1019 浏览评论:010年前
相关文章:一、PHP+新浪微博开放平台+新浪云平台(SAE)解决方案基础二、微博应用搭建流程三、PHP中的demo程序SDK简析四、进修趋势及有用资源五、必解的几个问题【PDF全文下载】本文是新浪微博老API中的PHP例程,可以作为第一步
阅读全文
iOS:新浪微博OAuth认证
作者:犹豫1185查看评论:04年前
新浪微博OAuth认证1、资源授权•在腾讯、新浪等互联网行业,用户群体非常庞大•有时需要共享一些用户资源,比如第三方想要访问用户的QQ数据,第三方想要访问用户的新浪微博数据 • 如果要共享用户资源,必须征得用户的同意,那么这里就有资源。
阅读全文 查看全部
网站调用新浪微博内容(Python微博API获取微博内容作者:更多优惠gt(组图))
阿里云 > 云栖社区 > 主题地图 > X > 新浪微博api获取数据

推荐活动:
更多优惠>
当前话题:新浪微博api获取数据加入采集
相关话题:
新浪微博api获取数据相关博客看更多博文
使用新浪微博API的Search接口做微博锐排


作者:郑云1802浏览量:05年前
郑云20100929申请入口:简单介绍一下我们的榜单与新浪自己的热门转发榜单的区别:微博睿推榜单会忽略名人推文,更关注草根推文,更关注社会民生推文,屏蔽非- 有营养的推文。微博锐推列表将汇总以新浪微博为首的国内主要微博网站的信息
阅读全文
Python调用微博API获取微博内容


作者:745 浏览评论:05年前
1:获取app-key和app-secret 用自己的微博账号()登录微博开放平台,在微博开放中心下的“创建应用”下创建应用。随意填写申请信息。填写后就不需要了。提交审核,只需要那个app-ke
阅读全文
开放平台:新浪微博 for iOS


作者:余书仪 845 浏览评论:09年前
简介:新浪微博几乎打通了所有平台数据的API接口。所以很多优秀的第三方微博客户端在功能上都非常全面。通过 SNS 进行分享和推广的方式已经在 App 世界中使用。它很常见,随处可见。本文主要介绍App与新浪微博的关联方式。参考:1.开发
阅读全文
新浪微博发展(一)


作者:nothingfinal1071 浏览评论:08年前
这几天一直在研究新浪微博的授权验证。我在论坛上传了一个例子,找到了一个相关的博客文章。. 本以为很容易理解,但花了很长时间,我还是一头雾水。. 后来想了想,其实别人提供的也只是一些接口和方法,我也没有认真研究过授权过程,所以比较关心代码中那些奇怪的方法。
阅读全文
新浪微博发展(一)


作者:xumaojun1002人浏览评论:08年前
这几天一直在研究新浪微博的授权验证。我在论坛上传了一个例子,找到了一个相关的博客文章。. 本以为很容易理解,但花了很长时间,我还是一头雾水。. 后来想了想,其实别人提供的也只是一些接口和方法,我也没有认真研究过授权过程,所以比较关心代码中那些奇怪的方法。
阅读全文
新浪微博开放平台开发步骤介绍(适合新手)

作者:技术组合950人查看评论数:04年前
我也是新手,第一次使用开放平台进行开发。起初,我觉得我无处可去。经过长时间的摸索,终于成功调用了API。现在把这段经历介绍给新手(高手不用看,当然如果大家能提出一些意见和建议,非常感谢),也想和大家交流。本示例介绍如何使用 API 提交数据(发布微
阅读全文
新浪微博开放平台老API中的PHP例程


作者:何立坚 1019 浏览评论:010年前
相关文章:一、PHP+新浪微博开放平台+新浪云平台(SAE)解决方案基础二、微博应用搭建流程三、PHP中的demo程序SDK简析四、进修趋势及有用资源五、必解的几个问题【PDF全文下载】本文是新浪微博老API中的PHP例程,可以作为第一步
阅读全文
iOS:新浪微博OAuth认证

作者:犹豫1185查看评论:04年前
新浪微博OAuth认证1、资源授权•在腾讯、新浪等互联网行业,用户群体非常庞大•有时需要共享一些用户资源,比如第三方想要访问用户的QQ数据,第三方想要访问用户的新浪微博数据 • 如果要共享用户资源,必须征得用户的同意,那么这里就有资源。
阅读全文
网站调用新浪微博内容(爬取微博大V的代码完整代码:m开头后接域名 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-03-16 20:08
)
用Python写爬虫,爬取微博大V的微博内容。本文以女神的微博为例(爬新浪m站:)
一般对于爬虫爬取网站,首先选择m站,其次是wap站,最后考虑PC站。当然,这也不是绝对的,有时候PC站的资料最全,你只需要所有的资料,那么PC站就是你的首选。一般m站都是以m开头后跟一个域名,所以本文的网址就是。
前期准备
1.代理IP
网上有很多免费的代理IP,比如西溪的免费代理IP,你可以找一个自己测试用;
2.抓包分析
通过抓包获取微博内容地址。我不会在这里详细介绍。不明白的可以自行百度查找相关资料。完整的代码直接在下面。
完整代码:
# -*- coding: utf-8 -*-
import urllib.request
import json
#定义要爬取的微博大V的微博ID
id='1259110474'
#设置代理IP
proxy_addr="122.241.72.191:808"
#定义页面打开函数
def use_proxy(url,proxy_addr):
req=urllib.request.Request(url)
req.add_header("User-Agent","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0")
proxy=urllib.request.ProxyHandler({'http':proxy_addr})
opener=urllib.request.build_opener(proxy,urllib.request.HTTPHandler)
urllib.request.install_opener(opener)
data=urllib.request.urlopen(req).read().decode('utf-8','ignore')
return data
#获取微博主页的containerid,爬取微博内容时需要此id
def get_containerid(url):
data=use_proxy(url,proxy_addr)
content=json.loads(data).get('data')
for data in content.get('tabsInfo').get('tabs'):
if(data.get('tab_type')=='weibo'):
containerid=data.get('containerid')
return containerid
#获取微博大V账号的用户基本信息,如:微博昵称、微博地址、微博头像、关注人数、粉丝数、性别、等级等
def get_userInfo(id):
url='https://m.weibo.cn/api/contain ... %2Bid
data=use_proxy(url,proxy_addr)
content=json.loads(data).get('data')
profile_image_url=content.get('userInfo').get('profile_image_url')
description=content.get('userInfo').get('description')
profile_url=content.get('userInfo').get('profile_url')
verified=content.get('userInfo').get('verified')
guanzhu=content.get('userInfo').get('follow_count')
name=content.get('userInfo').get('screen_name')
fensi=content.get('userInfo').get('followers_count')
gender=content.get('userInfo').get('gender')
urank=content.get('userInfo').get('urank')
print("微博昵称:"+name+"\n"+"微博主页地址:"+profile_url+"\n"+"微博头像地址:"+profile_image_url+"\n"+"是否认证:"+str(verified)+"\n"+"微博说明:"+description+"\n"+"关注人数:"+str(guanzhu)+"\n"+"粉丝数:"+str(fensi)+"\n"+"性别:"+gender+"\n"+"微博等级:"+str(urank)+"\n")
#获取微博内容信息,并保存到文本中,内容包括:每条微博的内容、微博详情页面地址、点赞数、评论数、转发数等
def get_weibo(id,file):
i=1
while True:
url='https://m.weibo.cn/api/contain ... %2Bid
weibo_url='https://m.weibo.cn/api/contain ... nerid(url)+'&page='+str(i)
try:
data=use_proxy(weibo_url,proxy_addr)
content=json.loads(data).get('data')
cards=content.get('cards')
if(len(cards)>0):
for j in range(len(cards)):
print("-----正在爬取第"+str(i)+"页,第"+str(j)+"条微博------")
card_type=cards[j].get('card_type')
if(card_type==9):
mblog=cards[j].get('mblog')
attitudes_count=mblog.get('attitudes_count')
comments_count=mblog.get('comments_count')
created_at=mblog.get('created_at')
reposts_count=mblog.get('reposts_count')
scheme=cards[j].get('scheme')
text=mblog.get('text')
with open(file,'a',encoding='utf-8') as fh:
fh.write("----第"+str(i)+"页,第"+str(j)+"条微博----"+"\n")
fh.write("微博地址:"+str(scheme)+"\n"+"发布时间:"+str(created_at)+"\n"+"微博内容:"+text+"\n"+"点赞数:"+str(attitudes_count)+"\n"+"评论数:"+str(comments_count)+"\n"+"转发数:"+str(reposts_count)+"\n")
i+=1
else:
break
except Exception as e:
print(e)
pass
if __name__=="__main__":
file=id+".txt"
get_userInfo(id)
get_weibo(id,file)
抓取结果
查看全部
网站调用新浪微博内容(爬取微博大V的代码完整代码:m开头后接域名
)
用Python写爬虫,爬取微博大V的微博内容。本文以女神的微博为例(爬新浪m站:)
一般对于爬虫爬取网站,首先选择m站,其次是wap站,最后考虑PC站。当然,这也不是绝对的,有时候PC站的资料最全,你只需要所有的资料,那么PC站就是你的首选。一般m站都是以m开头后跟一个域名,所以本文的网址就是。
前期准备
1.代理IP
网上有很多免费的代理IP,比如西溪的免费代理IP,你可以找一个自己测试用;
2.抓包分析
通过抓包获取微博内容地址。我不会在这里详细介绍。不明白的可以自行百度查找相关资料。完整的代码直接在下面。
完整代码:
# -*- coding: utf-8 -*-
import urllib.request
import json
#定义要爬取的微博大V的微博ID
id='1259110474'
#设置代理IP
proxy_addr="122.241.72.191:808"
#定义页面打开函数
def use_proxy(url,proxy_addr):
req=urllib.request.Request(url)
req.add_header("User-Agent","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0")
proxy=urllib.request.ProxyHandler({'http':proxy_addr})
opener=urllib.request.build_opener(proxy,urllib.request.HTTPHandler)
urllib.request.install_opener(opener)
data=urllib.request.urlopen(req).read().decode('utf-8','ignore')
return data
#获取微博主页的containerid,爬取微博内容时需要此id
def get_containerid(url):
data=use_proxy(url,proxy_addr)
content=json.loads(data).get('data')
for data in content.get('tabsInfo').get('tabs'):
if(data.get('tab_type')=='weibo'):
containerid=data.get('containerid')
return containerid
#获取微博大V账号的用户基本信息,如:微博昵称、微博地址、微博头像、关注人数、粉丝数、性别、等级等
def get_userInfo(id):
url='https://m.weibo.cn/api/contain ... %2Bid
data=use_proxy(url,proxy_addr)
content=json.loads(data).get('data')
profile_image_url=content.get('userInfo').get('profile_image_url')
description=content.get('userInfo').get('description')
profile_url=content.get('userInfo').get('profile_url')
verified=content.get('userInfo').get('verified')
guanzhu=content.get('userInfo').get('follow_count')
name=content.get('userInfo').get('screen_name')
fensi=content.get('userInfo').get('followers_count')
gender=content.get('userInfo').get('gender')
urank=content.get('userInfo').get('urank')
print("微博昵称:"+name+"\n"+"微博主页地址:"+profile_url+"\n"+"微博头像地址:"+profile_image_url+"\n"+"是否认证:"+str(verified)+"\n"+"微博说明:"+description+"\n"+"关注人数:"+str(guanzhu)+"\n"+"粉丝数:"+str(fensi)+"\n"+"性别:"+gender+"\n"+"微博等级:"+str(urank)+"\n")
#获取微博内容信息,并保存到文本中,内容包括:每条微博的内容、微博详情页面地址、点赞数、评论数、转发数等
def get_weibo(id,file):
i=1
while True:
url='https://m.weibo.cn/api/contain ... %2Bid
weibo_url='https://m.weibo.cn/api/contain ... nerid(url)+'&page='+str(i)
try:
data=use_proxy(weibo_url,proxy_addr)
content=json.loads(data).get('data')
cards=content.get('cards')
if(len(cards)>0):
for j in range(len(cards)):
print("-----正在爬取第"+str(i)+"页,第"+str(j)+"条微博------")
card_type=cards[j].get('card_type')
if(card_type==9):
mblog=cards[j].get('mblog')
attitudes_count=mblog.get('attitudes_count')
comments_count=mblog.get('comments_count')
created_at=mblog.get('created_at')
reposts_count=mblog.get('reposts_count')
scheme=cards[j].get('scheme')
text=mblog.get('text')
with open(file,'a',encoding='utf-8') as fh:
fh.write("----第"+str(i)+"页,第"+str(j)+"条微博----"+"\n")
fh.write("微博地址:"+str(scheme)+"\n"+"发布时间:"+str(created_at)+"\n"+"微博内容:"+text+"\n"+"点赞数:"+str(attitudes_count)+"\n"+"评论数:"+str(comments_count)+"\n"+"转发数:"+str(reposts_count)+"\n")
i+=1
else:
break
except Exception as e:
print(e)
pass
if __name__=="__main__":
file=id+".txt"
get_userInfo(id)
get_weibo(id,file)
抓取结果


网站调用新浪微博内容(【魔兽世界】新浪微博登录常用接口:对应主界面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-03-16 20:07
日志条目
新浪微博登录常用界面:
对应主界面:
不过,我个人推荐使用移动端的微博入口:
对应主界面:
原因是手机上的数据比较轻量级,基础数据齐全,可能会缺少一些基本的个人信息,比如“个人资料完成度”、“个人等级”等。粉丝ID和关注ID只能显示20页,但可以作为大部分验证的语料库。
通过对比下面两张图,分别是PC端和手机端,可以发现内容基本一致:
如下图在手机上,图片比较小,内容也比较简洁。
完整的源代码
下面的代码主要分为三部分:
1.登录微博(用户名、密码) 登录微博
2.VisitPersonPage(user_id) 访问follower网站获取个人信息
3.获取微博内容同时翻页
<p># coding=utf-8
"""
Created on 2016-02-22 @author: Eastmount
功能: 爬取新浪微博用户的信息
信息:用户ID 用户名 粉丝数 关注数 微博数 微博内容
网址:http://weibo.cn/ 数据量更小 相对http://weibo.com/
"""
import time
import re
import os
import sys
import codecs
import shutil
import urllib
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import selenium.webdriver.support.ui as ui
from selenium.webdriver.common.action_chains import ActionChains
#先调用无界面浏览器PhantomJS或Firefox
#driver = webdriver.PhantomJS(executable_path="G:phantomjs-1.9.1-windowsphantomjs.exe")
driver = webdriver.Firefox()
wait = ui.WebDriverWait(driver,10)
#全局变量 文件操作读写信息
inforead = codecs.open("SinaWeibo_List.txt", 'r', 'utf-8')
infofile = codecs.open("SinaWeibo_Info.txt", 'a', 'utf-8')
#********************************************************************************
# 第一步: 登陆weibo.cn 获取新浪微博的cookie
# 该方法针对weibo.cn有效(明文形式传输数据) weibo.com见学弟设置POST和Header方法
# LoginWeibo(username, password) 参数用户名 密码
# 验证码暂停时间手动输入
#********************************************************************************
def LoginWeibo(username, password):
try:
#**********************************************************************
# 直接访问driver.get("http://weibo.cn/5824697471")会跳转到登陆页面 用户id
#
# 用户名
# 密码 "password_4903" 中数字会变动,故采用绝对路径方法,否则不能定位到元素
#
# 勾选记住登录状态check默认是保留 故注释掉该代码 不保留Cookie 则'expiry'=None
#**********************************************************************
#输入用户名/密码登录
print u'准备登陆Weibo.cn网站...'
driver.get("http://login.weibo.cn/login/")
elem_user = driver.find_element_by_name("mobile")
elem_user.send_keys(username) #用户名
elem_pwd = driver.find_element_by_xpath("/html/body/div[2]/form/div/input[2]")
elem_pwd.send_keys(password) #密码
#elem_rem = driver.find_element_by_name("remember")
#elem_rem.click() #记住登录状态
#重点: 暂停时间输入验证码
#pause(millisenconds)
time.sleep(20)
elem_sub = driver.find_element_by_name("submit")
elem_sub.click() #点击登陆
time.sleep(2)
#获取Coockie 推荐 http://www.cnblogs.com/fnng/p/3269450.html
print driver.current_url
print driver.get_cookies() #获得cookie信息 dict存储
print u'输出Cookie键值对信息:'
for cookie in driver.get_cookies():
#print cookie
for key in cookie:
print key, cookie[key]
#driver.get_cookies()类型list 仅包含一个元素cookie类型dict
print u'登陆成功...'
except Exception,e:
print "Error: ",e
finally:
print u'End LoginWeibo!
'
#********************************************************************************
# 第二步: 访问个人页面http://weibo.cn/5824697471并获取信息
# VisitPersonPage()
# 编码常见错误 UnicodeEncodeError: 'ascii' codec can't encode characters
#********************************************************************************
def VisitPersonPage(user_id):
try:
global infofile
print u'准备访问个人网站.....'
#原创内容 http://weibo.cn/guangxianliuya ... e%3D2
driver.get("http://weibo.cn/" + user_id)
#**************************************************************************
# No.1 直接获取 用户昵称 微博数 关注数 粉丝数
# str_name.text是unicode编码类型
#**************************************************************************
#用户id
print u'个人详细信息'
print '**********************************************'
print u'用户id: ' + user_id
#昵称
str_name = driver.find_element_by_xpath("//div[@class='ut']")
str_t = str_name.text.split(" ")
num_name = str_t[0] #空格分隔 获取第一个值 "Eastmount 详细资料 设置 新手区"
print u'昵称: ' + num_name
#微博数 除个人主页 它默认直接显示微博数 无超链接
#Error: 'unicode' object is not callable
#一般是把字符串当做函数使用了 str定义成字符串 而str()函数再次使用时报错
str_wb = driver.find_element_by_xpath("//div[@class='tip2']")
pattern = r"d+.?d*" #正则提取"微博[0]" 但r"([.*?])"总含[]
guid = re.findall(pattern, str_wb.text, re.S|re.M)
print str_wb.text #微博[294] 关注[351] 粉丝[294] 分组[1] @他的
for value in guid:
num_wb = int(value)
break
print u'微博数: ' + str(num_wb)
#关注数
str_gz = driver.find_element_by_xpath("//div[@class='tip2']/a[1]")
guid = re.findall(pattern, str_gz.text, re.M)
num_gz = int(guid[0])
print u'关注数: ' + str(num_gz)
#粉丝数
str_fs = driver.find_element_by_xpath("//div[@class='tip2']/a[2]")
guid = re.findall(pattern, str_fs.text, re.M)
num_fs = int(guid[0])
print u'粉丝数: ' + str(num_fs)
#***************************************************************************
# No.2 文件操作写入信息
#***************************************************************************
infofile.write('=====================================================================
')
infofile.write(u'用户: ' + user_id + '
')
infofile.write(u'昵称: ' + num_name + '
')
infofile.write(u'微博数: ' + str(num_wb) + '
')
infofile.write(u'关注数: ' + str(num_gz) + '
')
infofile.write(u'粉丝数: ' + str(num_fs) + '
')
infofile.write(u'微博内容: ' + '
')
#***************************************************************************
# No.3 获取微博内容
# http://weibo.cn/guangxianliuya ... e%3D1
# 其中filter=0表示全部 =1表示原创
#***************************************************************************
print '
'
print u'获取微博内容信息'
num = 1
while num 查看全部
网站调用新浪微博内容(【魔兽世界】新浪微博登录常用接口:对应主界面)
日志条目
新浪微博登录常用界面:
对应主界面:
不过,我个人推荐使用移动端的微博入口:
对应主界面:
原因是手机上的数据比较轻量级,基础数据齐全,可能会缺少一些基本的个人信息,比如“个人资料完成度”、“个人等级”等。粉丝ID和关注ID只能显示20页,但可以作为大部分验证的语料库。
通过对比下面两张图,分别是PC端和手机端,可以发现内容基本一致:

如下图在手机上,图片比较小,内容也比较简洁。

完整的源代码
下面的代码主要分为三部分:
1.登录微博(用户名、密码) 登录微博
2.VisitPersonPage(user_id) 访问follower网站获取个人信息
3.获取微博内容同时翻页
<p># coding=utf-8
"""
Created on 2016-02-22 @author: Eastmount
功能: 爬取新浪微博用户的信息
信息:用户ID 用户名 粉丝数 关注数 微博数 微博内容
网址:http://weibo.cn/ 数据量更小 相对http://weibo.com/
"""
import time
import re
import os
import sys
import codecs
import shutil
import urllib
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import selenium.webdriver.support.ui as ui
from selenium.webdriver.common.action_chains import ActionChains
#先调用无界面浏览器PhantomJS或Firefox
#driver = webdriver.PhantomJS(executable_path="G:phantomjs-1.9.1-windowsphantomjs.exe")
driver = webdriver.Firefox()
wait = ui.WebDriverWait(driver,10)
#全局变量 文件操作读写信息
inforead = codecs.open("SinaWeibo_List.txt", 'r', 'utf-8')
infofile = codecs.open("SinaWeibo_Info.txt", 'a', 'utf-8')
#********************************************************************************
# 第一步: 登陆weibo.cn 获取新浪微博的cookie
# 该方法针对weibo.cn有效(明文形式传输数据) weibo.com见学弟设置POST和Header方法
# LoginWeibo(username, password) 参数用户名 密码
# 验证码暂停时间手动输入
#********************************************************************************
def LoginWeibo(username, password):
try:
#**********************************************************************
# 直接访问driver.get("http://weibo.cn/5824697471";)会跳转到登陆页面 用户id
#
# 用户名
# 密码 "password_4903" 中数字会变动,故采用绝对路径方法,否则不能定位到元素
#
# 勾选记住登录状态check默认是保留 故注释掉该代码 不保留Cookie 则'expiry'=None
#**********************************************************************
#输入用户名/密码登录
print u'准备登陆Weibo.cn网站...'
driver.get("http://login.weibo.cn/login/";)
elem_user = driver.find_element_by_name("mobile")
elem_user.send_keys(username) #用户名
elem_pwd = driver.find_element_by_xpath("/html/body/div[2]/form/div/input[2]")
elem_pwd.send_keys(password) #密码
#elem_rem = driver.find_element_by_name("remember")
#elem_rem.click() #记住登录状态
#重点: 暂停时间输入验证码
#pause(millisenconds)
time.sleep(20)
elem_sub = driver.find_element_by_name("submit")
elem_sub.click() #点击登陆
time.sleep(2)
#获取Coockie 推荐 http://www.cnblogs.com/fnng/p/3269450.html
print driver.current_url
print driver.get_cookies() #获得cookie信息 dict存储
print u'输出Cookie键值对信息:'
for cookie in driver.get_cookies():
#print cookie
for key in cookie:
print key, cookie[key]
#driver.get_cookies()类型list 仅包含一个元素cookie类型dict
print u'登陆成功...'
except Exception,e:
print "Error: ",e
finally:
print u'End LoginWeibo!
'
#********************************************************************************
# 第二步: 访问个人页面http://weibo.cn/5824697471并获取信息
# VisitPersonPage()
# 编码常见错误 UnicodeEncodeError: 'ascii' codec can't encode characters
#********************************************************************************
def VisitPersonPage(user_id):
try:
global infofile
print u'准备访问个人网站.....'
#原创内容 http://weibo.cn/guangxianliuya ... e%3D2
driver.get("http://weibo.cn/" + user_id)
#**************************************************************************
# No.1 直接获取 用户昵称 微博数 关注数 粉丝数
# str_name.text是unicode编码类型
#**************************************************************************
#用户id
print u'个人详细信息'
print '**********************************************'
print u'用户id: ' + user_id
#昵称
str_name = driver.find_element_by_xpath("//div[@class='ut']")
str_t = str_name.text.split(" ")
num_name = str_t[0] #空格分隔 获取第一个值 "Eastmount 详细资料 设置 新手区"
print u'昵称: ' + num_name
#微博数 除个人主页 它默认直接显示微博数 无超链接
#Error: 'unicode' object is not callable
#一般是把字符串当做函数使用了 str定义成字符串 而str()函数再次使用时报错
str_wb = driver.find_element_by_xpath("//div[@class='tip2']")
pattern = r"d+.?d*" #正则提取"微博[0]" 但r"([.*?])"总含[]
guid = re.findall(pattern, str_wb.text, re.S|re.M)
print str_wb.text #微博[294] 关注[351] 粉丝[294] 分组[1] @他的
for value in guid:
num_wb = int(value)
break
print u'微博数: ' + str(num_wb)
#关注数
str_gz = driver.find_element_by_xpath("//div[@class='tip2']/a[1]")
guid = re.findall(pattern, str_gz.text, re.M)
num_gz = int(guid[0])
print u'关注数: ' + str(num_gz)
#粉丝数
str_fs = driver.find_element_by_xpath("//div[@class='tip2']/a[2]")
guid = re.findall(pattern, str_fs.text, re.M)
num_fs = int(guid[0])
print u'粉丝数: ' + str(num_fs)
#***************************************************************************
# No.2 文件操作写入信息
#***************************************************************************
infofile.write('=====================================================================
')
infofile.write(u'用户: ' + user_id + '
')
infofile.write(u'昵称: ' + num_name + '
')
infofile.write(u'微博数: ' + str(num_wb) + '
')
infofile.write(u'关注数: ' + str(num_gz) + '
')
infofile.write(u'粉丝数: ' + str(num_fs) + '
')
infofile.write(u'微博内容: ' + '
')
#***************************************************************************
# No.3 获取微博内容
# http://weibo.cn/guangxianliuya ... e%3D1
# 其中filter=0表示全部 =1表示原创
#***************************************************************************
print '
'
print u'获取微博内容信息'
num = 1
while num
网站调用新浪微博内容(一下怎么模拟登陆新浪微博(图)步详解(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-16 20:07
最近需要爬取微博的数据进行分析。对于新浪微博,官方提供了API,但是有几个致命的限制(调用次数和授权期限的限制),所以我觉得有必要研究爬虫,直接爬取。通过微博获取微博数据的可行性。
由于模拟登陆微博是爬虫抓取微博信息的第一步,下面介绍如何模拟登陆微博(以新浪微博为例)。
这个过程主要分为两个步骤:
1 脚本模拟登陆新浪微博并保存cookies;
2 获得cookie信息后,使用cookie信息直接访问微博url。
其中,第一步是这里讨论的重点。为了更好的模拟这一步,需要一个好的网络监控工具,可以使用火狐的Firebug和Chrome以及IE自带的开发工具(注意IE必须是IE9以上才有监控网络的功能,Chrome的网络交互消息可以在网络部分查看)。另外前两天发现python支持的包很多,用python自定义自己的网络包比较方便,所以这里我用python作为我的开发语言。
好了,先说一下前提工作,下面开始分析用户在登录新浪微博的过程中进行的操作。在下面的例子中,我使用chrome自带的开发者工具作为我的网络包监控工具。
首先打开(如果你设置了浏览器自动记住密码自动登录,需要清除cookie),然后通过网络监控工具,我们会发现在用户登录过程中,浏览器与服务器三遍。它们如下:
一、第一个Get请求获取一些参数
在用户名栏输入你的微博账号,然后确认,这时你会发现当你的焦点离开用户名输入框时,浏览器会自动报"callback=sinaSSOController.preloginCallBack&su=&rsakt=mod& checkpin=1&client =ssologin.js (v1.4.5)&_=83” 发送GET请求,如下:
仔细看这个GET请求的响应内容,你会发现这个JSON字符串收录了几个参数,可能你不知道它们的含义,但是没关系,现在你只需要知道这些参数会在后续处理。能。
二、发送 POST 请求
这部分是整个登录过程的重点。这部分用于向服务器提交用户信息,服务器会判断用户信息是否正确,从而判断登录是否成功。
通过 Chrome 自带的开发者工具,可以观察到 POST 消息的相关信息(url、headers、data)。下图是我的 POST 消息截图:
网址信息如下:
包头信息如下:
POST的消息数据信息如下:
接下来的工作就比较简单了,我们要做的就是模仿上面消息的内容和格式,用python发送类似的消息。在自己自定义类似的消息之前,我觉得有必要简单解释一下上面消息中DATA表单中每一项的含义。
其中,“su”为加密后的用户名,“sp”为加密后的密码。“servertime”、“nonce”和“rsakv”是上一个GET请求返回的JSON字符串的内容。其他参数不变。然后,重点讨论“su”和“sp”的加密算法。
1. "su" 加密算法
su 是 BASE64 计算出来的用户名: su= base64.encodestring( urllib.quote(username) )[:-1];
2. "sp" 加密算法
sp的加密算法可能会经常变化(考虑到网站的安全性,一段时间后登录消息的格式和加密算法发生变化是正常的),目前新浪使用的是RSA算法(如果你比较js 如果你是牛,可以直接去网页源码找它的加密方式,我没找到,参考网上有)。
这里简单介绍一下RSA算法的解密过程。
2.1 安装RSA模块,下载地址为:
2.2 创建一个 rsa 公钥。公钥的两个参数在新浪微博上都给定了固定值,但都是十六进制字符串。第一个是第一步登录的那个。pubkey,第二个是js加密文件中的'10001'。这两个值需要先从十六进制转换为十进制,但也可以在代码中硬编码。我直接写'10001'为65537
rsaPublickey=int(pubkey,16)
key=rsa.PublicKey(rsaPublickey,65537)#创建公钥
message=str(servertime)+'\t'+str(nonce)+'\n'+str(password)#拼接明文js加密文件得到
passwd=rsa.encrypt(message,key)#encryption
passwd=binascii.b2a_hex(passwd)#将加密信息转换为十六进制。
如果上述所有步骤对您来说都顺利,您将收到以下响应:
这是一个自动跳转语句,其中收录要跳转的URL。如果登录正确,则该URL中的德语retcode值为0。否则,登录错误。您需要仔细检查上述步骤。
三、跳转到对应的微博页面
我们已经得到了上面要重定向的 url,所以现在我们只需要请求这个 URL。这里需要注意的一点是,为了让服务器知道你是否登录,这一步的请求需要使用上一步操作的cookie信息(因为第二步登录成功的信息会会自动记录在cookie中),所以我们在整个程序的开始就开启cookie,以保证cookie在以后的操作中可以正确使用。同时对于python用户,这一步不要自定义header,因为urllib2默认会自动打包cookie信息。如果手动自定义标头,则可能会丢失 cookie 信息。
下面附上我的参考代码:
参考文章:
1、
2、
从:
转载于: 查看全部
网站调用新浪微博内容(一下怎么模拟登陆新浪微博(图)步详解(组图))
最近需要爬取微博的数据进行分析。对于新浪微博,官方提供了API,但是有几个致命的限制(调用次数和授权期限的限制),所以我觉得有必要研究爬虫,直接爬取。通过微博获取微博数据的可行性。
由于模拟登陆微博是爬虫抓取微博信息的第一步,下面介绍如何模拟登陆微博(以新浪微博为例)。
这个过程主要分为两个步骤:
1 脚本模拟登陆新浪微博并保存cookies;
2 获得cookie信息后,使用cookie信息直接访问微博url。
其中,第一步是这里讨论的重点。为了更好的模拟这一步,需要一个好的网络监控工具,可以使用火狐的Firebug和Chrome以及IE自带的开发工具(注意IE必须是IE9以上才有监控网络的功能,Chrome的网络交互消息可以在网络部分查看)。另外前两天发现python支持的包很多,用python自定义自己的网络包比较方便,所以这里我用python作为我的开发语言。
好了,先说一下前提工作,下面开始分析用户在登录新浪微博的过程中进行的操作。在下面的例子中,我使用chrome自带的开发者工具作为我的网络包监控工具。
首先打开(如果你设置了浏览器自动记住密码自动登录,需要清除cookie),然后通过网络监控工具,我们会发现在用户登录过程中,浏览器与服务器三遍。它们如下:
一、第一个Get请求获取一些参数
在用户名栏输入你的微博账号,然后确认,这时你会发现当你的焦点离开用户名输入框时,浏览器会自动报"callback=sinaSSOController.preloginCallBack&su=&rsakt=mod& checkpin=1&client =ssologin.js (v1.4.5)&_=83” 发送GET请求,如下:


仔细看这个GET请求的响应内容,你会发现这个JSON字符串收录了几个参数,可能你不知道它们的含义,但是没关系,现在你只需要知道这些参数会在后续处理。能。
二、发送 POST 请求
这部分是整个登录过程的重点。这部分用于向服务器提交用户信息,服务器会判断用户信息是否正确,从而判断登录是否成功。
通过 Chrome 自带的开发者工具,可以观察到 POST 消息的相关信息(url、headers、data)。下图是我的 POST 消息截图:
网址信息如下:

包头信息如下:

POST的消息数据信息如下:

接下来的工作就比较简单了,我们要做的就是模仿上面消息的内容和格式,用python发送类似的消息。在自己自定义类似的消息之前,我觉得有必要简单解释一下上面消息中DATA表单中每一项的含义。
其中,“su”为加密后的用户名,“sp”为加密后的密码。“servertime”、“nonce”和“rsakv”是上一个GET请求返回的JSON字符串的内容。其他参数不变。然后,重点讨论“su”和“sp”的加密算法。
1. "su" 加密算法
su 是 BASE64 计算出来的用户名: su= base64.encodestring( urllib.quote(username) )[:-1];
2. "sp" 加密算法
sp的加密算法可能会经常变化(考虑到网站的安全性,一段时间后登录消息的格式和加密算法发生变化是正常的),目前新浪使用的是RSA算法(如果你比较js 如果你是牛,可以直接去网页源码找它的加密方式,我没找到,参考网上有)。
这里简单介绍一下RSA算法的解密过程。
2.1 安装RSA模块,下载地址为:
2.2 创建一个 rsa 公钥。公钥的两个参数在新浪微博上都给定了固定值,但都是十六进制字符串。第一个是第一步登录的那个。pubkey,第二个是js加密文件中的'10001'。这两个值需要先从十六进制转换为十进制,但也可以在代码中硬编码。我直接写'10001'为65537
rsaPublickey=int(pubkey,16)
key=rsa.PublicKey(rsaPublickey,65537)#创建公钥
message=str(servertime)+'\t'+str(nonce)+'\n'+str(password)#拼接明文js加密文件得到
passwd=rsa.encrypt(message,key)#encryption
passwd=binascii.b2a_hex(passwd)#将加密信息转换为十六进制。
如果上述所有步骤对您来说都顺利,您将收到以下响应:

这是一个自动跳转语句,其中收录要跳转的URL。如果登录正确,则该URL中的德语retcode值为0。否则,登录错误。您需要仔细检查上述步骤。
三、跳转到对应的微博页面
我们已经得到了上面要重定向的 url,所以现在我们只需要请求这个 URL。这里需要注意的一点是,为了让服务器知道你是否登录,这一步的请求需要使用上一步操作的cookie信息(因为第二步登录成功的信息会会自动记录在cookie中),所以我们在整个程序的开始就开启cookie,以保证cookie在以后的操作中可以正确使用。同时对于python用户,这一步不要自定义header,因为urllib2默认会自动打包cookie信息。如果手动自定义标头,则可能会丢失 cookie 信息。
下面附上我的参考代码:
参考文章:
1、
2、
从:
转载于:
网站调用新浪微博内容(PHP+新浪微博api获取评论信息推荐活动(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-03-16 20:05
阿里云 > 云栖社区 > 主题地图 > L > 使用新浪微博API获取评论信息
推荐活动:
更多优惠>
当前话题:使用新浪微博api获取评论信息并加入采集
相关话题:
使用新浪微博api获取评论信息相关博文看更多博文
使用新浪微博API的Search接口做微博锐排
作者:郑云1802浏览量:05年前
郑云20100929申请入口:简单介绍一下我们的榜单与新浪自己的热门转发榜单的区别:微博睿推榜单会忽略名人推文,更关注草根推文,更关注社会民生推文,屏蔽非- 有营养的推文。微博锐推列表将汇总以新浪微博为首的国内主要微博网站的信息
阅读全文
新浪微博开放平台WeiboClient类的公共方法(PHP)
作者:何立坚 936 浏览评论:010年前
相关文章:一、PHP+新浪微博开放平台+新浪云平台(SAE)解决方案基础二、微博应用搭建过程三、PHP中的demo程序SDK简析四、进修方向及有用资源五、必解的几个问题【PDF全文下载】初步掌握微博应用开发流程后,推荐阅读魏
阅读全文
Windows Phone 7应用的新浪微博-UI设计
作者:小技术专家 1009人查看评论:04年前
我还没有时间做 Windows phone 7 应用程序。上周在APP Store论坛看到一位国外DVP在WP7上写了一个推特客户端。仔细一看,我觉得很简单。我只是使用 WP7 在 Twitter 上获取信息。列表。国内微博只玩过163网易,可惜
阅读全文
腾讯微博 for Windows Phone 7 应用 - OAuth 认证
作者:小技术专家1210查看评论:04年前
前段时间写了一篇关于Windows Phone 7新浪微博应用的文章——UI设计旨在将新浪微博移植到WP7客户端。期间,几位园友提出共同开发这款应用。但是年底比较忙。时间很紧,我间歇性地利用空闲时间更新这个新浪迷你博客
阅读全文
新浪微博 for Windows Phone 7 应用程序 - UI 设计
作者:狼人2007853 浏览评论:02023之前
我还没有时间做 Windows phone 7 应用程序。上周在APP Store论坛看到一位国外DVP在WP7上写了一个推特客户端。仔细一看,我觉得很简单。我只是使用 WP7 在 Twitter 上获取信息。列表。国内微博只玩过163网易,可惜了
阅读全文
使用HTTP执行异步任务HTQ
作者:沃克武松 1147人浏览评论:04年前
HTQ详细介绍一、什么是HTQ?我们先介绍一下基本概念。在编写程序时,我们偶尔会遇到需要使用异步队列的情况。比如我发了10000封邮件,如果单纯用for循环来发送,执行时间会很长,发送出去也需要很长时间,同时容易导致针对阻塞和超时等问题。当有更多的电子邮件时,比如一百万
阅读全文
新浪微博Windows“.NET Research”Phone 7应用——UI设计
作者:狼人2007851 浏览评论:02023之前
我还没有时间做 Windows phone 7 应用程序。上周在APP Store论坛看到一位国外DVP在WP7上写了一个推特客户端。仔细一看,我觉得很简单。我只是使用 WP7 在 Twitter 上获取信息。列表。国内微博只玩过163网易,可惜了
阅读全文
开源任务队列服务HTQ
作者:迟来凶猛1073人查看评论:04年前
一、什么是HTQ我们先介绍一下基本概念。在编写程序时,我们偶尔会遇到需要使用异步队列的情况。比如我发了10000封邮件,如果单纯用for循环来发送,执行时间会很长,发送出去也需要很长时间,同时容易导致针对阻塞和超时等问题。当有更多的电子邮件时,比如说一百万,问题将是
阅读全文 查看全部
网站调用新浪微博内容(PHP+新浪微博api获取评论信息推荐活动(组图))
阿里云 > 云栖社区 > 主题地图 > L > 使用新浪微博API获取评论信息
推荐活动:
更多优惠>
当前话题:使用新浪微博api获取评论信息并加入采集
相关话题:
使用新浪微博api获取评论信息相关博文看更多博文
使用新浪微博API的Search接口做微博锐排
作者:郑云1802浏览量:05年前
郑云20100929申请入口:简单介绍一下我们的榜单与新浪自己的热门转发榜单的区别:微博睿推榜单会忽略名人推文,更关注草根推文,更关注社会民生推文,屏蔽非- 有营养的推文。微博锐推列表将汇总以新浪微博为首的国内主要微博网站的信息
阅读全文
新浪微博开放平台WeiboClient类的公共方法(PHP)

作者:何立坚 936 浏览评论:010年前
相关文章:一、PHP+新浪微博开放平台+新浪云平台(SAE)解决方案基础二、微博应用搭建过程三、PHP中的demo程序SDK简析四、进修方向及有用资源五、必解的几个问题【PDF全文下载】初步掌握微博应用开发流程后,推荐阅读魏
阅读全文
Windows Phone 7应用的新浪微博-UI设计

作者:小技术专家 1009人查看评论:04年前
我还没有时间做 Windows phone 7 应用程序。上周在APP Store论坛看到一位国外DVP在WP7上写了一个推特客户端。仔细一看,我觉得很简单。我只是使用 WP7 在 Twitter 上获取信息。列表。国内微博只玩过163网易,可惜
阅读全文
腾讯微博 for Windows Phone 7 应用 - OAuth 认证

作者:小技术专家1210查看评论:04年前
前段时间写了一篇关于Windows Phone 7新浪微博应用的文章——UI设计旨在将新浪微博移植到WP7客户端。期间,几位园友提出共同开发这款应用。但是年底比较忙。时间很紧,我间歇性地利用空闲时间更新这个新浪迷你博客
阅读全文
新浪微博 for Windows Phone 7 应用程序 - UI 设计


作者:狼人2007853 浏览评论:02023之前
我还没有时间做 Windows phone 7 应用程序。上周在APP Store论坛看到一位国外DVP在WP7上写了一个推特客户端。仔细一看,我觉得很简单。我只是使用 WP7 在 Twitter 上获取信息。列表。国内微博只玩过163网易,可惜了
阅读全文
使用HTTP执行异步任务HTQ


作者:沃克武松 1147人浏览评论:04年前
HTQ详细介绍一、什么是HTQ?我们先介绍一下基本概念。在编写程序时,我们偶尔会遇到需要使用异步队列的情况。比如我发了10000封邮件,如果单纯用for循环来发送,执行时间会很长,发送出去也需要很长时间,同时容易导致针对阻塞和超时等问题。当有更多的电子邮件时,比如一百万
阅读全文
新浪微博Windows“.NET Research”Phone 7应用——UI设计

作者:狼人2007851 浏览评论:02023之前
我还没有时间做 Windows phone 7 应用程序。上周在APP Store论坛看到一位国外DVP在WP7上写了一个推特客户端。仔细一看,我觉得很简单。我只是使用 WP7 在 Twitter 上获取信息。列表。国内微博只玩过163网易,可惜了
阅读全文
开源任务队列服务HTQ


作者:迟来凶猛1073人查看评论:04年前
一、什么是HTQ我们先介绍一下基本概念。在编写程序时,我们偶尔会遇到需要使用异步队列的情况。比如我发了10000封邮件,如果单纯用for循环来发送,执行时间会很长,发送出去也需要很长时间,同时容易导致针对阻塞和超时等问题。当有更多的电子邮件时,比如说一百万,问题将是
阅读全文
网站调用新浪微博内容(一下怎么模拟登陆新浪微博(图)怎么获取微博数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2022-03-15 01:23
最近需要爬取微博的数据进行分析。对于新浪微博,官方提供了API,但是有几个致命的限制(调用次数和授权期限的限制),所以我觉得有必要研究爬虫,直接爬取。通过微博获取微博数据的可行性。
由于模拟登陆微博是爬虫抓取微博信息的第一步,下面介绍如何模拟登陆微博(以新浪微博为例)。
这个过程主要分为两个步骤:
1 脚本模拟登陆新浪微博并保存cookies;
2 获得cookie信息后,使用cookie信息直接访问微博url。
其中,第一步是这里讨论的重点。为了更好的模拟这一步,需要一个好的网络监控工具,可以使用火狐的Firebug和Chrome以及IE自带的开发工具(注意IE必须是IE9以上才有监控网络的功能,Chrome的网络交互消息可以在网络部分查看)。另外前两天发现python支持的包很多,用python自定义自己的网络包比较方便,所以这里我用python作为我的开发语言。
好了,先说一下前提工作,下面开始分析用户在登录新浪微博的过程中进行的操作。在下面的例子中,我使用chrome自带的开发者工具作为我的网络包监控工具。
首先打开它(如果你设置了浏览器自动记住密码并自动登录,需要清除cookie),然后通过网络监控工具,我们会发现在用户登录过程中,浏览器与服务器三遍。它们如下:
一、第一个Get请求获取一些参数
在用户名栏输入你的微博账号,然后确认,这时你会发现当你的焦点离开用户名输入框时,浏览器会自动报"callback=sinaSSOController.preloginCallBack&su=&rsakt=mod& checkpin=1&client =ssologin.js (v1.4.5)&_=83” 发送GET请求,如下:
仔细看这个GET请求的响应内容,你会发现这个JSON字符串中收录了几个参数,可能你不知道它们的含义,但是没关系,现在你只需要知道这些参数会在后续处理。能。
二、发送 POST 请求
这部分是整个登录过程的重点。这部分用于向服务器提交用户信息,服务器会判断用户信息是否正确,从而判断登录是否成功。
通过 Chrome 自带的开发者工具,可以观察到 POST 消息的相关信息(url、headers、data)。下图是我的 POST 消息截图:
网址信息如下:
包头信息如下:
POST的消息数据信息如下:
接下来的工作就比较简单了,我们要做的就是模仿上面消息的内容和格式,用python发送类似的消息。在自己自定义类似的消息之前,我觉得有必要简单解释一下上面消息中DATA表单中每一项的含义。
其中,“su”为加密后的用户名,“sp”为加密后的密码。“servertime”、“nonce”和“rsakv”是上一个GET请求返回的JSON字符串的内容。其他参数不变。然后,重点讨论“su”和“sp”的加密算法。
1. "su" 加密算法
su 是 BASE64 计算出来的用户名: su= base64.encodestring( urllib.quote(username) )[:-1];
2. "sp" 加密算法
sp的加密算法可能会经常变化(考虑到网站的安全性,一段时间后登录消息的格式和加密算法发生变化是正常的),目前新浪使用的是RSA算法(如果你比较js 如果你是牛,可以直接去网页源码找它的加密方式,我没找到,参考网上有)。
这里简单介绍一下RSA算法的解密过程。
2.1 安装RSA模块,下载地址为:
2.2 创建一个 rsa 公钥。公钥的两个参数在新浪微博上都给定了固定值,但都是十六进制字符串。第一个是第一步登录的那个。pubkey,第二个是js加密文件中的'10001'。这两个值需要先从十六进制转换为十进制,但也可以在代码中硬编码。我直接写'10001'为65537
rsaPublickey=int(pubkey,16)
key=rsa.PublicKey(rsaPublickey,65537)#创建公钥
message=str(servertime)+\'\t\'+str(nonce)+\'\n\'+str(password)#拼接明文js加密文件得到
passwd=rsa.encrypt(message,key)#encryption
passwd=binascii.b2a_hex(passwd)#将加密信息转换为十六进制。
如果上述所有步骤对您来说都顺利,您将收到以下响应:
这是一个自动跳转语句,其中收录要跳转的URL。如果登录正确,则该URL中的德语retcode值为0。否则,登录错误。您需要仔细检查上述步骤。
三、跳转到对应的微博页面
我们已经得到了上面要重定向的 url,所以现在我们只需要请求这个 URL。这里要注意一点,为了让服务器知道你是否登录,这一步的请求需要使用上一步操作的cookie信息(因为第二步登录成功的信息会会自动记录在cookie中),所以我们在整个程序开始时,需要打开cookie,以保证cookie在以后的操作中可以正确使用。同时对于python用户,这一步不要自己自定义header,因为urllib2默认会自动打包cookie信息。如果手动自定义标头,则可能会丢失 cookie 信息。
下面附上我的参考代码:
参考文章:
1、
2、
从: 查看全部
网站调用新浪微博内容(一下怎么模拟登陆新浪微博(图)怎么获取微博数据)
最近需要爬取微博的数据进行分析。对于新浪微博,官方提供了API,但是有几个致命的限制(调用次数和授权期限的限制),所以我觉得有必要研究爬虫,直接爬取。通过微博获取微博数据的可行性。
由于模拟登陆微博是爬虫抓取微博信息的第一步,下面介绍如何模拟登陆微博(以新浪微博为例)。
这个过程主要分为两个步骤:
1 脚本模拟登陆新浪微博并保存cookies;
2 获得cookie信息后,使用cookie信息直接访问微博url。
其中,第一步是这里讨论的重点。为了更好的模拟这一步,需要一个好的网络监控工具,可以使用火狐的Firebug和Chrome以及IE自带的开发工具(注意IE必须是IE9以上才有监控网络的功能,Chrome的网络交互消息可以在网络部分查看)。另外前两天发现python支持的包很多,用python自定义自己的网络包比较方便,所以这里我用python作为我的开发语言。
好了,先说一下前提工作,下面开始分析用户在登录新浪微博的过程中进行的操作。在下面的例子中,我使用chrome自带的开发者工具作为我的网络包监控工具。
首先打开它(如果你设置了浏览器自动记住密码并自动登录,需要清除cookie),然后通过网络监控工具,我们会发现在用户登录过程中,浏览器与服务器三遍。它们如下:
一、第一个Get请求获取一些参数
在用户名栏输入你的微博账号,然后确认,这时你会发现当你的焦点离开用户名输入框时,浏览器会自动报"callback=sinaSSOController.preloginCallBack&su=&rsakt=mod& checkpin=1&client =ssologin.js (v1.4.5)&_=83” 发送GET请求,如下:
仔细看这个GET请求的响应内容,你会发现这个JSON字符串中收录了几个参数,可能你不知道它们的含义,但是没关系,现在你只需要知道这些参数会在后续处理。能。
二、发送 POST 请求
这部分是整个登录过程的重点。这部分用于向服务器提交用户信息,服务器会判断用户信息是否正确,从而判断登录是否成功。
通过 Chrome 自带的开发者工具,可以观察到 POST 消息的相关信息(url、headers、data)。下图是我的 POST 消息截图:
网址信息如下:
包头信息如下:
POST的消息数据信息如下:
接下来的工作就比较简单了,我们要做的就是模仿上面消息的内容和格式,用python发送类似的消息。在自己自定义类似的消息之前,我觉得有必要简单解释一下上面消息中DATA表单中每一项的含义。
其中,“su”为加密后的用户名,“sp”为加密后的密码。“servertime”、“nonce”和“rsakv”是上一个GET请求返回的JSON字符串的内容。其他参数不变。然后,重点讨论“su”和“sp”的加密算法。
1. "su" 加密算法
su 是 BASE64 计算出来的用户名: su= base64.encodestring( urllib.quote(username) )[:-1];
2. "sp" 加密算法
sp的加密算法可能会经常变化(考虑到网站的安全性,一段时间后登录消息的格式和加密算法发生变化是正常的),目前新浪使用的是RSA算法(如果你比较js 如果你是牛,可以直接去网页源码找它的加密方式,我没找到,参考网上有)。
这里简单介绍一下RSA算法的解密过程。
2.1 安装RSA模块,下载地址为:
2.2 创建一个 rsa 公钥。公钥的两个参数在新浪微博上都给定了固定值,但都是十六进制字符串。第一个是第一步登录的那个。pubkey,第二个是js加密文件中的'10001'。这两个值需要先从十六进制转换为十进制,但也可以在代码中硬编码。我直接写'10001'为65537
rsaPublickey=int(pubkey,16)
key=rsa.PublicKey(rsaPublickey,65537)#创建公钥
message=str(servertime)+\'\t\'+str(nonce)+\'\n\'+str(password)#拼接明文js加密文件得到
passwd=rsa.encrypt(message,key)#encryption
passwd=binascii.b2a_hex(passwd)#将加密信息转换为十六进制。
如果上述所有步骤对您来说都顺利,您将收到以下响应:
这是一个自动跳转语句,其中收录要跳转的URL。如果登录正确,则该URL中的德语retcode值为0。否则,登录错误。您需要仔细检查上述步骤。
三、跳转到对应的微博页面
我们已经得到了上面要重定向的 url,所以现在我们只需要请求这个 URL。这里要注意一点,为了让服务器知道你是否登录,这一步的请求需要使用上一步操作的cookie信息(因为第二步登录成功的信息会会自动记录在cookie中),所以我们在整个程序开始时,需要打开cookie,以保证cookie在以后的操作中可以正确使用。同时对于python用户,这一步不要自己自定义header,因为urllib2默认会自动打包cookie信息。如果手动自定义标头,则可能会丢失 cookie 信息。
下面附上我的参考代码:
参考文章:
1、
2、
从:
网站调用新浪微博内容(试试用python调用微博API的方法微博接口 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-03-13 00:11
)
因为最近碰到一个调用新浪微博开放接口的项目,想试试用python调用微博API。
SDK下载地址:代码不超过十几K,完全可以理解。
如果你有微博账号,可以新建一个APP,然后获取APP获取OAuth2.0授权所需要的app key和app secret。
要了解 OAuth2,您可以查看链接到新浪微博的说明。OAuth2授权参数除了app key和app secret外,还需要网站回调地址redirect_uri,并且这个回调地址不允许在局域网内(神马localhost,127.0.0.@ >1 好像不行),这真的让我焦急了很久。我没有使用 API 调用 网站,所以我检查了很多。看到有人写可以用这个地址代替,我试了一下,果然,这对掉丝来说是个好消息。
这里有一个简单的程序来体验:
设置以下参数
import sys
import weibo
import webbrowser
APP_KEY = ''
MY_APP_SECRET = ''
REDIRECT_URL = 'https://api.weibo.com/oauth2/default.html'
获取微博授权网址,如第2行,用默认浏览器打开后,会提示登录微博,使用需要授权的账号登录,如下图
api = weibo.APIClient(app_key=APP_KEY,app_secret=MY_APP_SECRET,redirect_uri=REDIRECT_URL)
authorize_url = api.get_authorize_url()
print(authorize_url)
webbrowser.open_new(authorize_url)
登录后,您将被重定向到一个连接
关键是码值,是认证的关键。手动输入码值模拟认证
request = api.request_access_token(code, REDIRECT_URL)
access_token = request.access_token
expires_in = request.expires_in
api.set_access_token(access_token, expires_in)
api.statuses.update.post(status=u'Test OAuth 2.0 Send a Weibo!')
access_token为获取到的token,expires_in为授权过期时间(UNIX时间)
使用 set_access_token 保存授权。往下走,就可以调用微博界面了。测试发了一条推文
但是,这种手动输入代码的方式并不适合调用程序。是否可以在不打开链接的情况下请求登录并获得授权?经过多方搜索参考,程序改进如下,可以自动获取代码并保存,方便程序服务调用。
accessWeibo
# -*- coding: utf-8 -*-
#/usr/bin/env python
#access to SinaWeibo By sinaweibopy
#实现微博自动登录,token自动生成,保存及更新
#适合于后端服务调用
from weibo import APIClient
import pymongo
import sys, os, urllib, urllib2
from http_helper import *
from retry import *
try:
import json
except ImportError:
import simplejson as json
# setting sys encoding to utf-8
default_encoding = 'utf-8'
if sys.getdefaultencoding() != default_encoding:
reload(sys)
sys.setdefaultencoding(default_encoding)
# weibo api访问配置
APP_KEY = '' # app key
APP_SECRET = '' # app secret
REDIRECT_URL = 'https://api.weibo.com/oauth2/default.html' # callback url 授权回调页,与OAuth2.0 授权设置的一致
USERID = '' # 登陆的微博用户名,必须是OAuth2.0 设置的测试账号
USERPASSWD = '' # 用户密码
client = APIClient(app_key=APP_KEY, app_secret=APP_SECRET, redirect_uri=REDIRECT_URL)
def make_access_token():
#请求access token
params = urllib.urlencode({
'action':'submit',
'withOfficalFlag':'0',
'ticket':'',
'isLoginSina':'',
'response_type':'code',
'regCallback':'',
'redirect_uri':REDIRECT_URL,
'client_id':APP_KEY,
'state':'',
'from':'',
'userId':USERID,
'passwd':USERPASSWD,
})
login_url = 'https://api.weibo.com/oauth2/authorize'
url = client.get_authorize_url()
content = urllib2.urlopen(url)
if content:
headers = { 'Referer' : url }
request = urllib2.Request(login_url, params, headers)
opener = get_opener(False)
urllib2.install_opener(opener)
try:
f = opener.open(request)
return_redirect_uri = f.url
except urllib2.HTTPError, e:
return_redirect_uri = e.geturl()
# 取到返回的code
code = return_redirect_uri.split('=')[1]
#得到token
token = client.request_access_token(code,REDIRECT_URL)
save_access_token(token)
def save_access_token(token):
#将access token保存到MongoDB数据库
mongoCon=pymongo.Connection(host="127.0.0.1",port=27017)
db= mongoCon.weibo
t={
"access_token":token['access_token'],
"expires_in":str(token['expires_in']),
"date":time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time()))
}
db.token.insert(t,safe=True)
#Decorator 目的是当调用make_access_token()后再执行一次apply_access_token()
@retry(1)
def apply_access_token():
#从MongoDB读取及设置access token
try:
mongoCon=pymongo.Connection(host="127.0.0.1",port=27017)
db= mongoCon.weibo
if db.token.count()>0:
tokenInfos=db.token.find().sort([("_id",pymongo.DESCENDING)]).limit(1)
else:
make_access_token()
return False
for tokenInfo in tokenInfos:
access_token=tokenInfo["access_token"]
expires_in=tokenInfo["expires_in"]
try:
client.set_access_token(access_token, expires_in)
except StandardError, e:
if hasattr(e, 'error'):
if e.error == 'expired_token':
# token过期重新生成
make_access_token()
return False
else:
pass
except:
make_access_token()
return False
return True
if __name__ == "__main__":
apply_access_token()
# 以下为访问微博api的应用逻辑
# 以发布文字微博接口为例
client.statuses.update.post(status='Test OAuth 2.0 Send a Weibo!')
retry.py
import math
import time
# Retry decorator with exponential backoff
def retry(tries, delay=1, backoff=2):
"""Retries a function or method until it returns True.
delay sets the initial delay, and backoff sets how much the delay should
lengthen after each failure. backoff must be greater than 1, or else it
isn't really a backoff. tries must be at least 0, and delay greater than
0."""
if backoff decorated function
return deco_retry # @retry(arg[, ...]) -> true decorator
http_helper.py
# -*- coding: utf-8 -*-
#/usr/bin/env python
import urllib2,cookielib
class SmartRedirectHandler(urllib2.HTTPRedirectHandler):
def http_error_301(cls, req, fp, code, msg, headers):
result = urllib2.HTTPRedirectHandler.http_error_301(cls, req, fp, code, msg, headers)
result.status = code
print headers
return result
def http_error_302(cls, req, fp, code, msg, headers):
result = urllib2.HTTPRedirectHandler.http_error_302(cls, req, fp, code, msg, headers)
result.status = code
print headers
return result
def get_cookie():
cookies = cookielib.CookieJar()
return urllib2.HTTPCookieProcessor(cookies)
def get_opener(proxy=False):
rv=urllib2.build_opener(get_cookie(), SmartRedirectHandler())
rv.addheaders = [('User-agent', 'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1)')]
return rv 查看全部
网站调用新浪微博内容(试试用python调用微博API的方法微博接口
)
因为最近碰到一个调用新浪微博开放接口的项目,想试试用python调用微博API。
SDK下载地址:代码不超过十几K,完全可以理解。
如果你有微博账号,可以新建一个APP,然后获取APP获取OAuth2.0授权所需要的app key和app secret。
要了解 OAuth2,您可以查看链接到新浪微博的说明。OAuth2授权参数除了app key和app secret外,还需要网站回调地址redirect_uri,并且这个回调地址不允许在局域网内(神马localhost,127.0.0.@ >1 好像不行),这真的让我焦急了很久。我没有使用 API 调用 网站,所以我检查了很多。看到有人写可以用这个地址代替,我试了一下,果然,这对掉丝来说是个好消息。
这里有一个简单的程序来体验:
设置以下参数
import sys
import weibo
import webbrowser
APP_KEY = ''
MY_APP_SECRET = ''
REDIRECT_URL = 'https://api.weibo.com/oauth2/default.html'
获取微博授权网址,如第2行,用默认浏览器打开后,会提示登录微博,使用需要授权的账号登录,如下图
api = weibo.APIClient(app_key=APP_KEY,app_secret=MY_APP_SECRET,redirect_uri=REDIRECT_URL)
authorize_url = api.get_authorize_url()
print(authorize_url)
webbrowser.open_new(authorize_url)

登录后,您将被重定向到一个连接
关键是码值,是认证的关键。手动输入码值模拟认证
request = api.request_access_token(code, REDIRECT_URL)
access_token = request.access_token
expires_in = request.expires_in
api.set_access_token(access_token, expires_in)
api.statuses.update.post(status=u'Test OAuth 2.0 Send a Weibo!')
access_token为获取到的token,expires_in为授权过期时间(UNIX时间)
使用 set_access_token 保存授权。往下走,就可以调用微博界面了。测试发了一条推文

但是,这种手动输入代码的方式并不适合调用程序。是否可以在不打开链接的情况下请求登录并获得授权?经过多方搜索参考,程序改进如下,可以自动获取代码并保存,方便程序服务调用。
accessWeibo
# -*- coding: utf-8 -*-
#/usr/bin/env python
#access to SinaWeibo By sinaweibopy
#实现微博自动登录,token自动生成,保存及更新
#适合于后端服务调用
from weibo import APIClient
import pymongo
import sys, os, urllib, urllib2
from http_helper import *
from retry import *
try:
import json
except ImportError:
import simplejson as json
# setting sys encoding to utf-8
default_encoding = 'utf-8'
if sys.getdefaultencoding() != default_encoding:
reload(sys)
sys.setdefaultencoding(default_encoding)
# weibo api访问配置
APP_KEY = '' # app key
APP_SECRET = '' # app secret
REDIRECT_URL = 'https://api.weibo.com/oauth2/default.html' # callback url 授权回调页,与OAuth2.0 授权设置的一致
USERID = '' # 登陆的微博用户名,必须是OAuth2.0 设置的测试账号
USERPASSWD = '' # 用户密码
client = APIClient(app_key=APP_KEY, app_secret=APP_SECRET, redirect_uri=REDIRECT_URL)
def make_access_token():
#请求access token
params = urllib.urlencode({
'action':'submit',
'withOfficalFlag':'0',
'ticket':'',
'isLoginSina':'',
'response_type':'code',
'regCallback':'',
'redirect_uri':REDIRECT_URL,
'client_id':APP_KEY,
'state':'',
'from':'',
'userId':USERID,
'passwd':USERPASSWD,
})
login_url = 'https://api.weibo.com/oauth2/authorize'
url = client.get_authorize_url()
content = urllib2.urlopen(url)
if content:
headers = { 'Referer' : url }
request = urllib2.Request(login_url, params, headers)
opener = get_opener(False)
urllib2.install_opener(opener)
try:
f = opener.open(request)
return_redirect_uri = f.url
except urllib2.HTTPError, e:
return_redirect_uri = e.geturl()
# 取到返回的code
code = return_redirect_uri.split('=')[1]
#得到token
token = client.request_access_token(code,REDIRECT_URL)
save_access_token(token)
def save_access_token(token):
#将access token保存到MongoDB数据库
mongoCon=pymongo.Connection(host="127.0.0.1",port=27017)
db= mongoCon.weibo
t={
"access_token":token['access_token'],
"expires_in":str(token['expires_in']),
"date":time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time()))
}
db.token.insert(t,safe=True)
#Decorator 目的是当调用make_access_token()后再执行一次apply_access_token()
@retry(1)
def apply_access_token():
#从MongoDB读取及设置access token
try:
mongoCon=pymongo.Connection(host="127.0.0.1",port=27017)
db= mongoCon.weibo
if db.token.count()>0:
tokenInfos=db.token.find().sort([("_id",pymongo.DESCENDING)]).limit(1)
else:
make_access_token()
return False
for tokenInfo in tokenInfos:
access_token=tokenInfo["access_token"]
expires_in=tokenInfo["expires_in"]
try:
client.set_access_token(access_token, expires_in)
except StandardError, e:
if hasattr(e, 'error'):
if e.error == 'expired_token':
# token过期重新生成
make_access_token()
return False
else:
pass
except:
make_access_token()
return False
return True
if __name__ == "__main__":
apply_access_token()
# 以下为访问微博api的应用逻辑
# 以发布文字微博接口为例
client.statuses.update.post(status='Test OAuth 2.0 Send a Weibo!')
retry.py
import math
import time
# Retry decorator with exponential backoff
def retry(tries, delay=1, backoff=2):
"""Retries a function or method until it returns True.
delay sets the initial delay, and backoff sets how much the delay should
lengthen after each failure. backoff must be greater than 1, or else it
isn't really a backoff. tries must be at least 0, and delay greater than
0."""
if backoff decorated function
return deco_retry # @retry(arg[, ...]) -> true decorator
http_helper.py
# -*- coding: utf-8 -*-
#/usr/bin/env python
import urllib2,cookielib
class SmartRedirectHandler(urllib2.HTTPRedirectHandler):
def http_error_301(cls, req, fp, code, msg, headers):
result = urllib2.HTTPRedirectHandler.http_error_301(cls, req, fp, code, msg, headers)
result.status = code
print headers
return result
def http_error_302(cls, req, fp, code, msg, headers):
result = urllib2.HTTPRedirectHandler.http_error_302(cls, req, fp, code, msg, headers)
result.status = code
print headers
return result
def get_cookie():
cookies = cookielib.CookieJar()
return urllib2.HTTPCookieProcessor(cookies)
def get_opener(proxy=False):
rv=urllib2.build_opener(get_cookie(), SmartRedirectHandler())
rv.addheaders = [('User-agent', 'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1)')]
return rv
网站调用新浪微博内容(网页版(当然,应用端也一样)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-03-12 09:16
网页版(当然app也一样)新浪微博在我们平时关注的用户微博之间插入了大量的宣传微博。博,烦死了。如何与敌人作战?当然,借助编程的力量。
多亏了大佬们的辛勤付出,我们普通人只要点几下鼠标就可以轻松解决这个问题。
具体步骤如下
下载Chrome(或firefox) 登录插件商店安装tampermonkey(为什么不能去谷歌?我听不到)什么是tampermonkey?可以做到吗?安装好后,安装新浪微博脚本,打开/刷新新浪微博,看看推广微博有没有消失?
以下可以忽略
什么是篡改猴?可以做到吗?
最简单的总结:这个东西允许某些脚本出于某些目的在某些网页上运行。
本例中:具体脚本为清除微博推广的脚本,具体网页为新浪微博。当然,具体目的是为了明确宣传内容。您还可以下载其他脚本来改善许多网页的体验。例如:AC-百度
随附的:
写这篇文章的时候,我想去safari截个“原创”的新浪微博,不做过滤和推广。我惊讶地发现,即使safari没有安装这个插件和这个脚本,我打开了新浪微博。但是,博客是过滤后的样子:没有广告,没有微博推广?? !!哪位dalao解释一下是什么情况?为什么chrome上安装的插件会影响safari?. . 查看全部
网站调用新浪微博内容(网页版(当然,应用端也一样)(组图))
网页版(当然app也一样)新浪微博在我们平时关注的用户微博之间插入了大量的宣传微博。博,烦死了。如何与敌人作战?当然,借助编程的力量。
多亏了大佬们的辛勤付出,我们普通人只要点几下鼠标就可以轻松解决这个问题。
具体步骤如下
下载Chrome(或firefox) 登录插件商店安装tampermonkey(为什么不能去谷歌?我听不到)什么是tampermonkey?可以做到吗?安装好后,安装新浪微博脚本,打开/刷新新浪微博,看看推广微博有没有消失?
以下可以忽略
什么是篡改猴?可以做到吗?
最简单的总结:这个东西允许某些脚本出于某些目的在某些网页上运行。
本例中:具体脚本为清除微博推广的脚本,具体网页为新浪微博。当然,具体目的是为了明确宣传内容。您还可以下载其他脚本来改善许多网页的体验。例如:AC-百度
随附的:
写这篇文章的时候,我想去safari截个“原创”的新浪微博,不做过滤和推广。我惊讶地发现,即使safari没有安装这个插件和这个脚本,我打开了新浪微博。但是,博客是过滤后的样子:没有广告,没有微博推广?? !!哪位dalao解释一下是什么情况?为什么chrome上安装的插件会影响safari?. .
网站调用新浪微博内容(Java怎样调用新浪发送api微博(.java文件) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-03-12 09:12
)
Java如何调用新浪api发送微博
前言
在看这篇文章的同时,相信你这个时候已经浏览过很多类似的文章了,很有可能和我一样失败(403错误频繁...我承认我有点傻...),也许和你的不同是,我在探索这个功能时,并没有因为工作需要而去做。我纯粹是对个人好奇心感兴趣,直接进入主题。你现在应该很着急。
获取 App Key 申请成为开发者
和其他大多数教程一样,我会和你一起回到起点,重新开始,别担心,永远不会出错。
微博开放平台
直接用你的微博账号登录。登录后,点击微链接选择其他选项,根据自己的需要新建应用程序(客户端、Web应用程序和浏览器插件)。我正在使用网络应用程序。
填写配置信息
根据上图填写基本配置信息。需要注意的是安全域名一定要填写,可以填写自己的域名,也就是第三方共享时的域名。如果你暂时没有可用的域名,可以用百度的域名,哈哈。并且必须与调用api时填写的一致,否则会报错。
成为测试员
点击测试信息,填写你的测试账号昵称,否则测试发送微博失败。
设置授权回调页面
编辑高级信息中的授权回调页面,让您可以收到token。同样,如果不方便,可以设置为百度页面。
获取 App Key 和 App Secret
进入基本信息页面,记下您的 App Key 和 App Secret。稍后将使用它来运行代码示例。
在运行实例阶段下载微博Java SDK
SDK地址
导入日食
src 中的前两个包是我自己构建的测试类,不用管。
示例是新浪微博所有方法类的集合,大家可以直接修改使用。
填写配置信息
打开图中src中的config.properties文件,需要填写前三个字段,分别填写你的App Key、App Secret和回调地址。
获取授权码
接下来打开examples包下oauth2.0下的OAuth4Code.java文件,直接运行main方法。
微博api中的所有操作都需要OAuth2.0授权。调用每个方法都需要一个授权码。未经审核的申请授权码有效期仅为1天,通过后30天。有效期。
获取授权码
由于我们填写的回调地址是百度,页面会自动跳转到百度,细心会发现一个百度后面会跟着一个代码。
获取令牌
拿到代码后,你还会发现你的eclipse控制台有一个输入框,好了,把你的代码粘贴进去,回车。那就回这么个东东,记住他!!
改变方法
微博官方在2017年取消了updateStatus等相关发送微博接口,这些接口已经不能调用了,但是由于java sdk是2014版本(为什么不更新!!!),里面还有这些方法。然后替换之前的updateStatus界面为statuss/share(第三方分享链接微博)
所以需要先找到updateStatus,然后查看它的源码。
查看全部
网站调用新浪微博内容(Java怎样调用新浪发送api微博(.java文件)
)
Java如何调用新浪api发送微博
前言
在看这篇文章的同时,相信你这个时候已经浏览过很多类似的文章了,很有可能和我一样失败(403错误频繁...我承认我有点傻...),也许和你的不同是,我在探索这个功能时,并没有因为工作需要而去做。我纯粹是对个人好奇心感兴趣,直接进入主题。你现在应该很着急。
获取 App Key 申请成为开发者
和其他大多数教程一样,我会和你一起回到起点,重新开始,别担心,永远不会出错。
微博开放平台
直接用你的微博账号登录。登录后,点击微链接选择其他选项,根据自己的需要新建应用程序(客户端、Web应用程序和浏览器插件)。我正在使用网络应用程序。
填写配置信息
根据上图填写基本配置信息。需要注意的是安全域名一定要填写,可以填写自己的域名,也就是第三方共享时的域名。如果你暂时没有可用的域名,可以用百度的域名,哈哈。并且必须与调用api时填写的一致,否则会报错。
成为测试员
点击测试信息,填写你的测试账号昵称,否则测试发送微博失败。
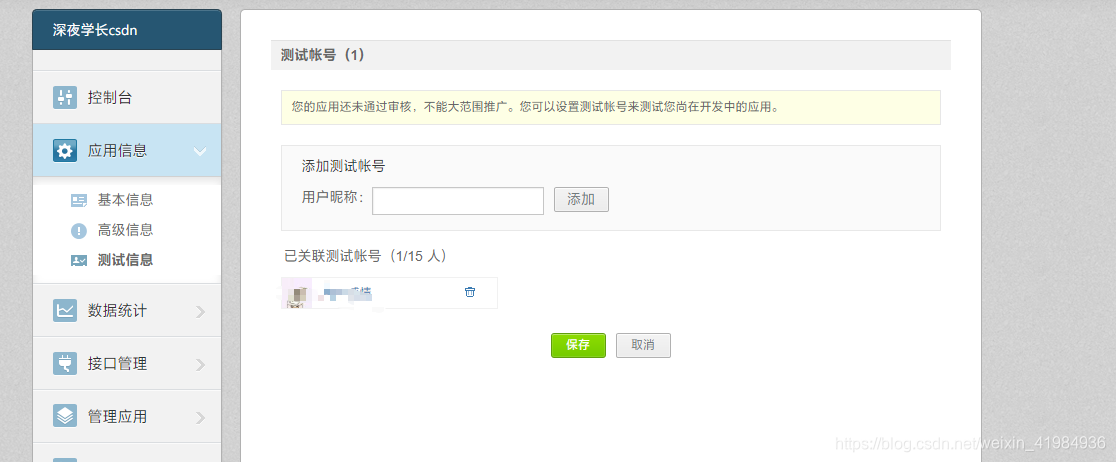
设置授权回调页面
编辑高级信息中的授权回调页面,让您可以收到token。同样,如果不方便,可以设置为百度页面。
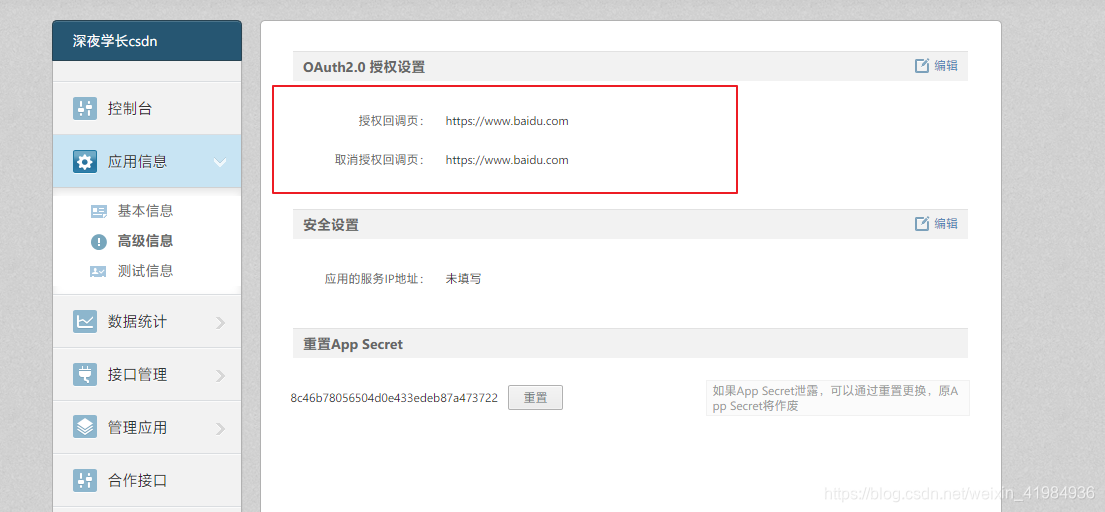
获取 App Key 和 App Secret
进入基本信息页面,记下您的 App Key 和 App Secret。稍后将使用它来运行代码示例。
在运行实例阶段下载微博Java SDK
SDK地址
导入日食
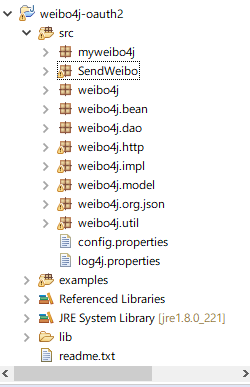
src 中的前两个包是我自己构建的测试类,不用管。
示例是新浪微博所有方法类的集合,大家可以直接修改使用。
填写配置信息
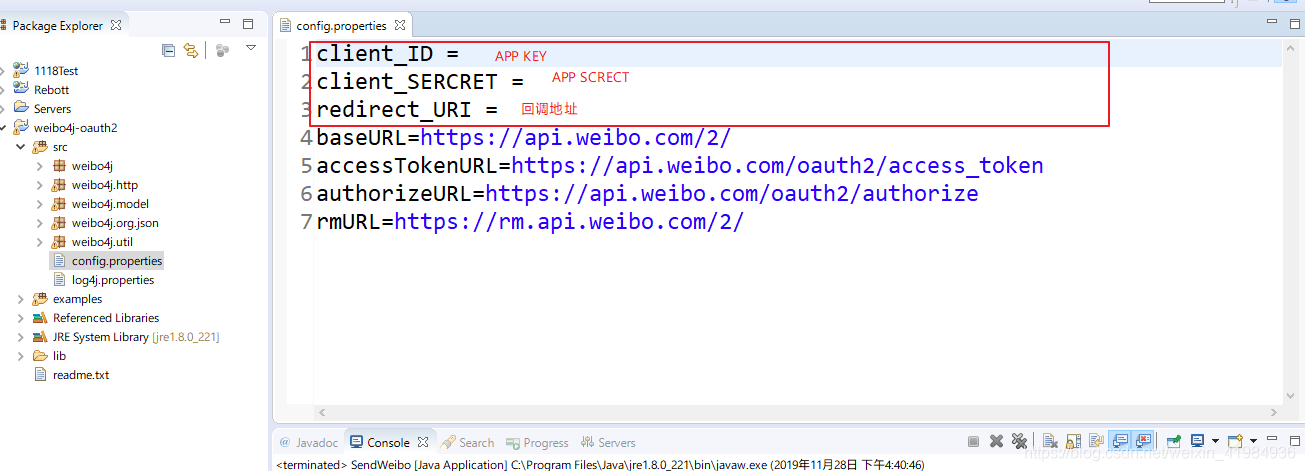
打开图中src中的config.properties文件,需要填写前三个字段,分别填写你的App Key、App Secret和回调地址。
获取授权码
接下来打开examples包下oauth2.0下的OAuth4Code.java文件,直接运行main方法。
微博api中的所有操作都需要OAuth2.0授权。调用每个方法都需要一个授权码。未经审核的申请授权码有效期仅为1天,通过后30天。有效期。
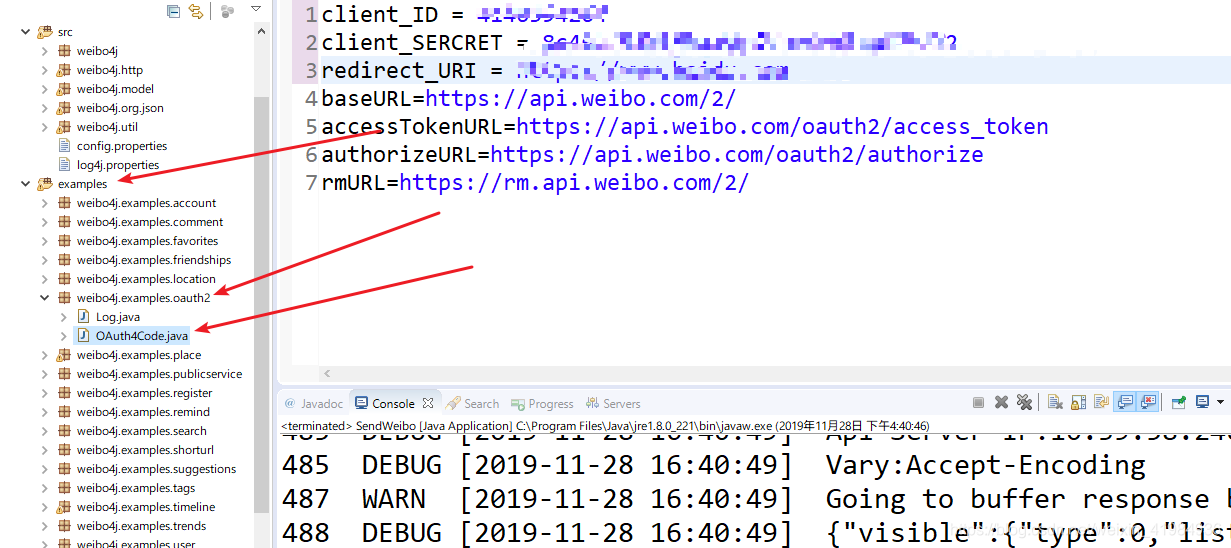
获取授权码
由于我们填写的回调地址是百度,页面会自动跳转到百度,细心会发现一个百度后面会跟着一个代码。
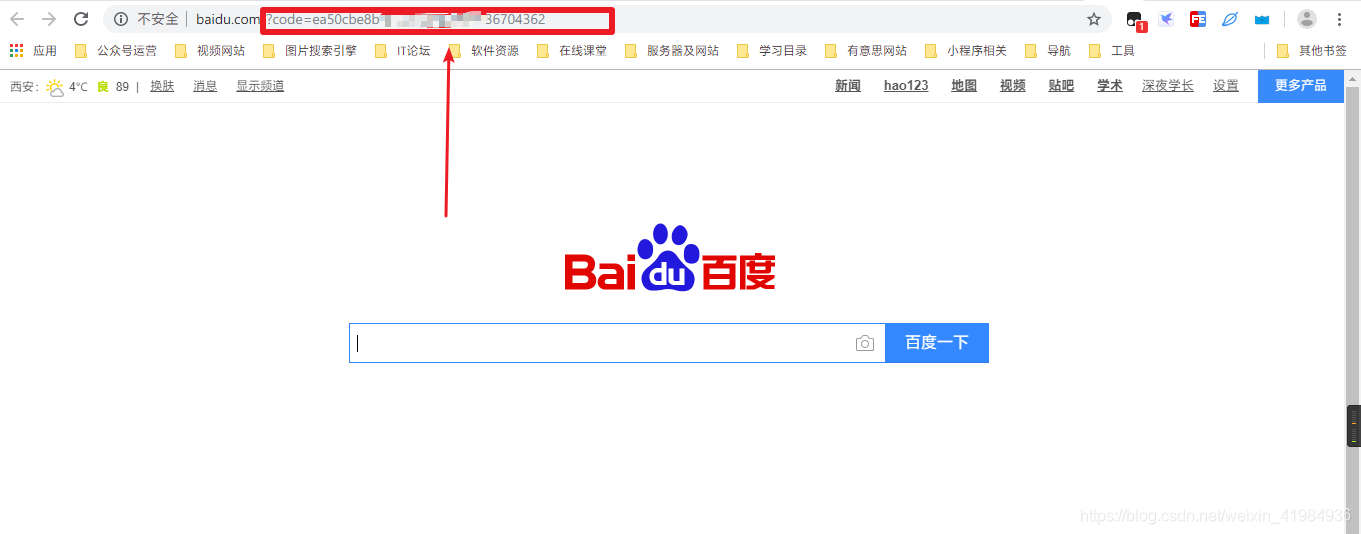
获取令牌
拿到代码后,你还会发现你的eclipse控制台有一个输入框,好了,把你的代码粘贴进去,回车。那就回这么个东东,记住他!!
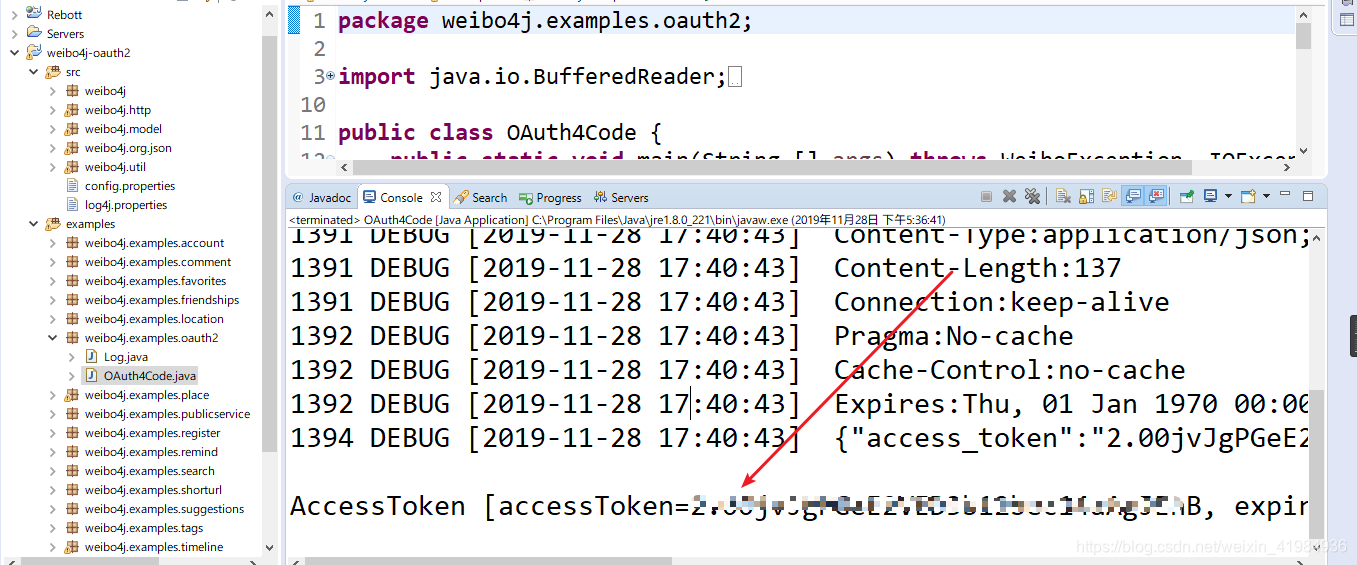
改变方法
微博官方在2017年取消了updateStatus等相关发送微博接口,这些接口已经不能调用了,但是由于java sdk是2014版本(为什么不更新!!!),里面还有这些方法。然后替换之前的updateStatus界面为statuss/share(第三方分享链接微博)
所以需要先找到updateStatus,然后查看它的源码。
网站调用新浪微博内容(用微博控制发光二极管的亮和灭(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-03-11 14:20
最近想设计一个课程,用微博控制树莓派,用树莓派控制发光二极管的开关。主要设计分为两层。上层是使用Java调用新浪微博API监控微博。当我的微博回复时,它会自动读取评论内容,并根据评论的指令内容决定树莓派的控制动作。下层是用C语言调用操作系统底层接口实现树莓派的GPIO接口控制发光二极管的闪烁、通断。
由于网上教程已经很老了,而且最近微博界面也发生了很多变化,所以决定重新写一篇详细的博文。如果能帮到您,我将不胜荣幸。同时,也非常希望能与您交流。如果您有任何问题,请在评论中回复我。
本文将逐步讲解如何申请微博接口并用Java发布自己的微博。【首先你要有一个微博账号】
一、申请成为开发者
去这里申请。点击“我的应用”查看身份认证:未认证,你已经做了你需要做的,这里不再赘述。审稿速度很快,不到一天就通过了。
之后应该是这样的(哈哈,欢迎互粉):
二、创建一个应用
这里的互联网教程具有误导性。我遵循了那些教程,最终把我拖进了坑里。我已经爬出来了。我希望你不要再陷入其中。
如果要使用Java控制微博,创建应用时不能创建“站内应用”。您必须创建一个“移动应用程序”。注意这一点,否则将无法通过权限验证步骤。
“微连接”-“移动应用”-“立即访问”-“继续创建”
现在我们来到了填写信息的地方,可以自己写一个应用名称(以后改名字会很麻烦,请一次性填写),例如“手机控制”树莓派”,客户端选择“手机”,应用选择Android作为平台就好,不过没关系。然后“创造”。好了,现在我们进入了一个新的界面,我们只是用它来测试,所以没有必要审查,除非你想让你的应用程序上线。
三、重要信息设置和记录
这一步非常重要,直接关系到以后能否正确连接。
左侧面板:“应用信息”-“高级信息”
当您看到“OAuth2.0 授权设置”时,单击“编辑”。“授权回调页面:”和“取消授权回调页面:”非常重要,创建“站内应用程序”的人应该在这里哭泣,因为他们无法修改“授权回调页面:”。. .
那么如何改变呢?两者都改成: ,这是微博默认的,对我们的测试来说已经足够了。
如图所示:
然后点击“基本信息”,
如图所示:
记下:APP Key和App Secret,后面会有用。
四、下载微博Java SDK
过来
下载压缩包:weibo4j-oauth2-beta3.1.1.zip
五、将 SDK 导入 Eclipse
什么?您是否一直在使用文本编辑器编写 Java?好吧,听我的建议,写这些东西的时候我应该切换到Eclipse,否则我会筋疲力尽。
打开Eclipse,“File”-“Import”-“Existing Projects into Workspace under General”-“Select archive File”-选择刚才的SDK包-“Finish”。
导入现已完成。
六、修改配置信息
打开图中的config.properties文件,将“client_ID”和“client_SERCRET”后面的值分别改成你记下的“App Key”和“App Secret”。“redirect_URI”的值更改为
保存。
七、申请授权
如图所示:
编译并执行 OAuth4Code.java 文件。
您的浏览器将被自动调用以打开授权页面。如下所示:
点击“授权”。
转到下图:
不要急于关闭浏览器!请复制地址栏中code=后面的字符串。
回到 Eclipse,下面的控制台正在等待您的输入。Hitenterwhenit'sdone.[Enter]:
没错,就是他。粘贴您刚刚复制的字符串,然后按 Enter。
好吧,等待几秒钟让您的授权信息返回。
AccessToken [accessToken=xxxxxxxxxxxxxxxxxx, expireIn=157679999, refreshToken=,uid=xxxxxxxxx]
“access_token”后面的字符串和“uid”后面的数字很重要,记下来。
现在您可以关闭浏览器了。
这里提醒一下,如果应用程序最初是作为“站内应用程序”而不是“移动应用程序”创建的,那么这一步将不会成功,并且您将始终看到“错误:redirect_uri_mismatch”页面。
八:发微博
在微博SDK包中,可以看到examples下有很多程序。这些是示例,涵盖了 SDK 可以做的所有事情。您只需要通过引用来编写。
weibo4j.examples.timeline 包中的UpdateStatus.java 是一个微博示例。
我们在 src 中新建一个名为 myweibo 的包,然后在其下新建几个类。我在这里创建了几个。
我将演示如何发推文。
在myweibo下新建类SendWeibo.java
复制examples—weibo4j.examples.timeline—UpdateStatus.java示例程序中的整个main方法体。粘贴后,Eclipse会自动导入需要引用的包。
将 String access_token= 替换为您刚才的 access_token 的值。String statuses= 后跟你的微博正文。
改了之后是:
然后直接运行Java代码,只要不报错,就成功了。看看你的微博。
注意:如果你不知道函数(我还是习惯称它为函数,而不是方法)是做什么的,并且不知道它的参数的含义,请将光标移动到函数上。
SDK中提供的各种功能都非常好用,比如获取微博、获取评论、获取评论ID、回复评论、获取地理位置、获取照片、发送照片、获取粉丝关系、获取微博等等。让我们自己尝试一下。
九:发布程序:
如果您要在其他地方运行程序,例如 Raspberry Pi Linux 或虚拟机中的 Linux,则需要注意一些事项。
我们首先发布程序:
我们右键点击weibo4j-oauth2项目,选择“导出”,然后如图:
下一步,
哪个程序是入口,Launch配置选择哪个,这里我们执行发送微博的程序:SendWeibo。
选择路径,在下方选择图书馆移交的第二个保险点。然后Finish,可能会弹出一个警告,不用担心,点击OK。
然后生成。然后双击jar包,程序一闪而过,留下一个weibo.log文件,就是日志。如果出现错误,您可以查看日志以查找原因。现在该程序已执行,它会发布另一条推文。
您可以将此文件拖到虚拟机的 Linux 中。我们已经看到 Java 如何在任何地方运行。结果运行java -jar 1.jar后报错。这是怎么回事?
仔细看看错误信息,它说.UnknownHostException,然后看看错误信息是不是说InetAddress.getLocalHost(),这就是原因。
解决方案:
首先,ifconfig 会查看您的 IP。这个不管是局域网IP还是外网IP。它只需要您看到的本地 IP。
修改主机文件 /etc/hosts 并添加一行,
你的ip 你的主机名 # KD.localdomain是我的主机名
至于如何查看主机名,应该在报错信息中,比如localhost.localdomain。KD.localdomain 这是我自己的改变。您还可以检查 /etc/hosts 以确认您的主机名。
这样修改后,再次尝试运行1.jar,应该可以成功。我不会拍照。运行虚拟机很麻烦。
PS:发微博后试试,别乱来,这个效果和刷屏差不多,会被打。
调用 API 有时容易出现问题。欢迎评论和交流。我在学习Linux内核的底层,对Java不是很精通,是个半助手。也欢迎大家就Linux问题与我交流。 查看全部
网站调用新浪微博内容(用微博控制发光二极管的亮和灭(图))
最近想设计一个课程,用微博控制树莓派,用树莓派控制发光二极管的开关。主要设计分为两层。上层是使用Java调用新浪微博API监控微博。当我的微博回复时,它会自动读取评论内容,并根据评论的指令内容决定树莓派的控制动作。下层是用C语言调用操作系统底层接口实现树莓派的GPIO接口控制发光二极管的闪烁、通断。
由于网上教程已经很老了,而且最近微博界面也发生了很多变化,所以决定重新写一篇详细的博文。如果能帮到您,我将不胜荣幸。同时,也非常希望能与您交流。如果您有任何问题,请在评论中回复我。
本文将逐步讲解如何申请微博接口并用Java发布自己的微博。【首先你要有一个微博账号】
一、申请成为开发者
去这里申请。点击“我的应用”查看身份认证:未认证,你已经做了你需要做的,这里不再赘述。审稿速度很快,不到一天就通过了。
之后应该是这样的(哈哈,欢迎互粉):
二、创建一个应用
这里的互联网教程具有误导性。我遵循了那些教程,最终把我拖进了坑里。我已经爬出来了。我希望你不要再陷入其中。
如果要使用Java控制微博,创建应用时不能创建“站内应用”。您必须创建一个“移动应用程序”。注意这一点,否则将无法通过权限验证步骤。
“微连接”-“移动应用”-“立即访问”-“继续创建”
现在我们来到了填写信息的地方,可以自己写一个应用名称(以后改名字会很麻烦,请一次性填写),例如“手机控制”树莓派”,客户端选择“手机”,应用选择Android作为平台就好,不过没关系。然后“创造”。好了,现在我们进入了一个新的界面,我们只是用它来测试,所以没有必要审查,除非你想让你的应用程序上线。
三、重要信息设置和记录
这一步非常重要,直接关系到以后能否正确连接。
左侧面板:“应用信息”-“高级信息”
当您看到“OAuth2.0 授权设置”时,单击“编辑”。“授权回调页面:”和“取消授权回调页面:”非常重要,创建“站内应用程序”的人应该在这里哭泣,因为他们无法修改“授权回调页面:”。. .
那么如何改变呢?两者都改成: ,这是微博默认的,对我们的测试来说已经足够了。
如图所示:

然后点击“基本信息”,
如图所示:

记下:APP Key和App Secret,后面会有用。
四、下载微博Java SDK
过来
下载压缩包:weibo4j-oauth2-beta3.1.1.zip
五、将 SDK 导入 Eclipse
什么?您是否一直在使用文本编辑器编写 Java?好吧,听我的建议,写这些东西的时候我应该切换到Eclipse,否则我会筋疲力尽。
打开Eclipse,“File”-“Import”-“Existing Projects into Workspace under General”-“Select archive File”-选择刚才的SDK包-“Finish”。
导入现已完成。
六、修改配置信息
打开图中的config.properties文件,将“client_ID”和“client_SERCRET”后面的值分别改成你记下的“App Key”和“App Secret”。“redirect_URI”的值更改为
保存。
七、申请授权
如图所示:
编译并执行 OAuth4Code.java 文件。
您的浏览器将被自动调用以打开授权页面。如下所示:
点击“授权”。
转到下图:

不要急于关闭浏览器!请复制地址栏中code=后面的字符串。
回到 Eclipse,下面的控制台正在等待您的输入。Hitenterwhenit'sdone.[Enter]:
没错,就是他。粘贴您刚刚复制的字符串,然后按 Enter。
好吧,等待几秒钟让您的授权信息返回。
AccessToken [accessToken=xxxxxxxxxxxxxxxxxx, expireIn=157679999, refreshToken=,uid=xxxxxxxxx]
“access_token”后面的字符串和“uid”后面的数字很重要,记下来。
现在您可以关闭浏览器了。
这里提醒一下,如果应用程序最初是作为“站内应用程序”而不是“移动应用程序”创建的,那么这一步将不会成功,并且您将始终看到“错误:redirect_uri_mismatch”页面。
八:发微博
在微博SDK包中,可以看到examples下有很多程序。这些是示例,涵盖了 SDK 可以做的所有事情。您只需要通过引用来编写。
weibo4j.examples.timeline 包中的UpdateStatus.java 是一个微博示例。
我们在 src 中新建一个名为 myweibo 的包,然后在其下新建几个类。我在这里创建了几个。
我将演示如何发推文。
在myweibo下新建类SendWeibo.java
复制examples—weibo4j.examples.timeline—UpdateStatus.java示例程序中的整个main方法体。粘贴后,Eclipse会自动导入需要引用的包。
将 String access_token= 替换为您刚才的 access_token 的值。String statuses= 后跟你的微博正文。
改了之后是:
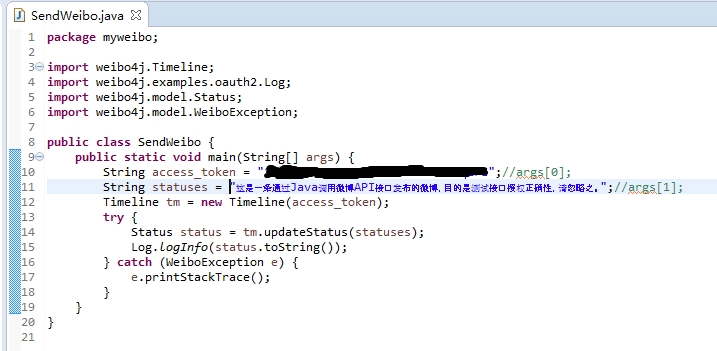
然后直接运行Java代码,只要不报错,就成功了。看看你的微博。
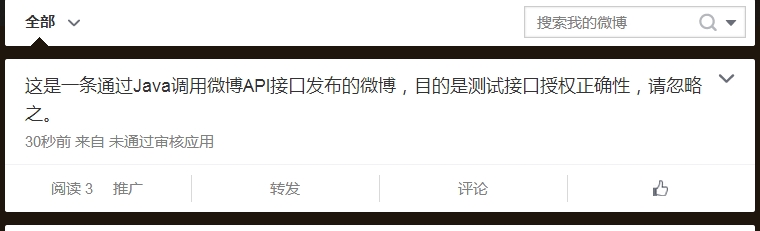
注意:如果你不知道函数(我还是习惯称它为函数,而不是方法)是做什么的,并且不知道它的参数的含义,请将光标移动到函数上。
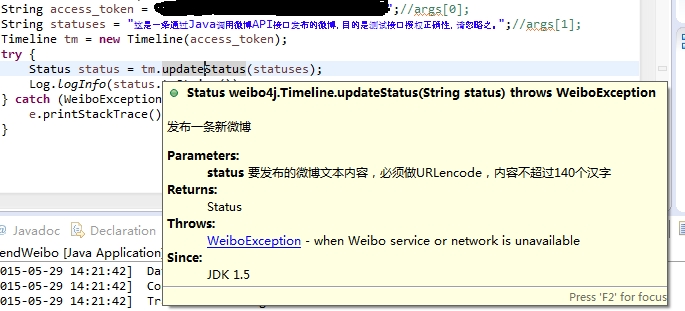
SDK中提供的各种功能都非常好用,比如获取微博、获取评论、获取评论ID、回复评论、获取地理位置、获取照片、发送照片、获取粉丝关系、获取微博等等。让我们自己尝试一下。
九:发布程序:
如果您要在其他地方运行程序,例如 Raspberry Pi Linux 或虚拟机中的 Linux,则需要注意一些事项。
我们首先发布程序:
我们右键点击weibo4j-oauth2项目,选择“导出”,然后如图:
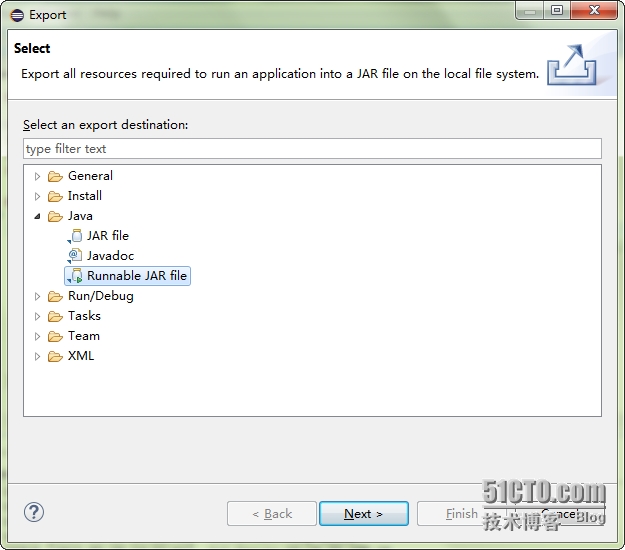
下一步,
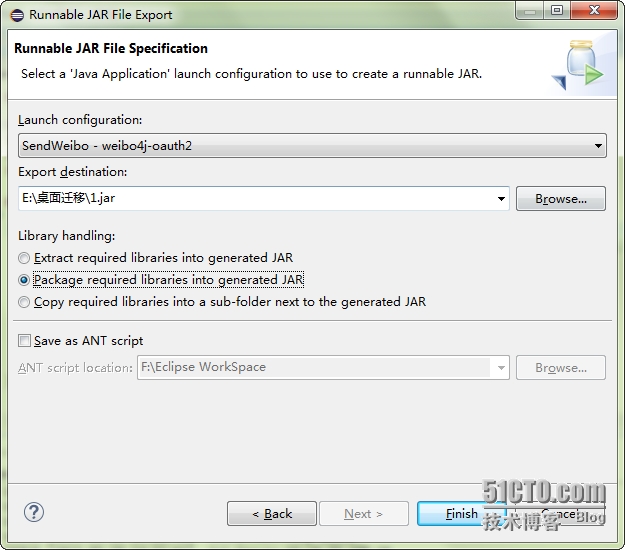
哪个程序是入口,Launch配置选择哪个,这里我们执行发送微博的程序:SendWeibo。
选择路径,在下方选择图书馆移交的第二个保险点。然后Finish,可能会弹出一个警告,不用担心,点击OK。
然后生成。然后双击jar包,程序一闪而过,留下一个weibo.log文件,就是日志。如果出现错误,您可以查看日志以查找原因。现在该程序已执行,它会发布另一条推文。
您可以将此文件拖到虚拟机的 Linux 中。我们已经看到 Java 如何在任何地方运行。结果运行java -jar 1.jar后报错。这是怎么回事?
仔细看看错误信息,它说.UnknownHostException,然后看看错误信息是不是说InetAddress.getLocalHost(),这就是原因。
解决方案:
首先,ifconfig 会查看您的 IP。这个不管是局域网IP还是外网IP。它只需要您看到的本地 IP。
修改主机文件 /etc/hosts 并添加一行,
你的ip 你的主机名 # KD.localdomain是我的主机名
至于如何查看主机名,应该在报错信息中,比如localhost.localdomain。KD.localdomain 这是我自己的改变。您还可以检查 /etc/hosts 以确认您的主机名。
这样修改后,再次尝试运行1.jar,应该可以成功。我不会拍照。运行虚拟机很麻烦。
PS:发微博后试试,别乱来,这个效果和刷屏差不多,会被打。
调用 API 有时容易出现问题。欢迎评论和交流。我在学习Linux内核的底层,对Java不是很精通,是个半助手。也欢迎大家就Linux问题与我交流。
网站调用新浪微博内容(企业网站上都放有新浪或腾讯的微博窗口像如下图片)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-03-11 14:20
现在很多公司网站都有新浪或者腾讯的微博窗口,如下图1,微博代码嵌入到自己的网站中,这样做的好处是微博有最新动态信息网站 将同步显示最新信息。当客户访问网站时,他们也会感觉到网站在不断变化。网站 一直在更新,但是对搜索引擎的真实感受并没有改变,因为这个搜索引擎无法识别 iframe 内容,所以虽然这块的内容在不断变化,但是 网站@ 的内容> 还要不断更新,才能赢得搜索引擎蜘蛛的青睐。但是像微博这样的网站还是需要加的。下面简单介绍一下如何添加:
一:新浪微博代码申请:
点击新浪微博开放平台/index.php,然后登录,只需设置网站上显示的自己的微博窗口的宽度和高度,还可以设置显示信息的数量和颜色边框的一些基本设置,设置完成后,将代码复制到网站上需要放置的位置。
(1)点击页面上的网站访问图片
(2)点击图片上的访问网站或管理网站图标链接
二:腾讯微博代码申请:
打开网址/index.php,登录设置和新浪微博一样。设置完成后复制到网站的固定显示位置。 查看全部
网站调用新浪微博内容(企业网站上都放有新浪或腾讯的微博窗口像如下图片)
现在很多公司网站都有新浪或者腾讯的微博窗口,如下图1,微博代码嵌入到自己的网站中,这样做的好处是微博有最新动态信息网站 将同步显示最新信息。当客户访问网站时,他们也会感觉到网站在不断变化。网站 一直在更新,但是对搜索引擎的真实感受并没有改变,因为这个搜索引擎无法识别 iframe 内容,所以虽然这块的内容在不断变化,但是 网站@ 的内容> 还要不断更新,才能赢得搜索引擎蜘蛛的青睐。但是像微博这样的网站还是需要加的。下面简单介绍一下如何添加:
一:新浪微博代码申请:
点击新浪微博开放平台/index.php,然后登录,只需设置网站上显示的自己的微博窗口的宽度和高度,还可以设置显示信息的数量和颜色边框的一些基本设置,设置完成后,将代码复制到网站上需要放置的位置。
(1)点击页面上的网站访问图片

(2)点击图片上的访问网站或管理网站图标链接
二:腾讯微博代码申请:
打开网址/index.php,登录设置和新浪微博一样。设置完成后复制到网站的固定显示位置。
网站调用新浪微博内容(新浪开发平台下的网站接入申请Appkey与Appid的方式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-03-10 04:06
申请Appkey和Appid
在新浪开发平台下网站访问申请Appkey和Appid,申请的前提是要有域名,并记录申请的appkey和appid以供使用。
注意:点击网站访问并填写访问信息后,管理中心会出现您的访问网站。点击进入您的网站访问的详细信息页面,左侧导航栏会有申请信息栏,点击展开,点击“高级信息”项
红包箭头所指的项目要与系统config.properties文件中的redirect_URI一致。如果不一致,会出现第三方授权错误,调用系统时无法获取用户信息。
下载Java SDK包
去技术支持中心下载包,不要用httpclient调用新浪的接口,不安全,可能被别人攻击网站。下载的sdk里面会有一个demo,把demo中lib下的依赖包放到工程lib里面,下载的文件里面会有一个weibo4j包,复制到工程的src下,把config.把properties文件中的前三项改成你自己的appkey、appid、redirect_URI(新浪同意授权后会跳转回你系统中的路径)。
说明
点击页面上的一个按钮后,跳转到action中的方法,在方法中,重定向一个请求到sinaAPI。使用sian的API,我们的直接重定向方法如下:
String url = new Oauth().authorize("code", "code"),这样我们就可以得到请求的路径了。使用内置的sina sdk包,我们可以直接这样调整。
请求后会弹出授权页面。如果我们同意授权,它会自动跳转到我们的“redirect_uri”路径,并在我们的“redirect_uri”后面加上“?code=XXXXXXX”
然后我们就可以根据返回的参数码获取access_token等一些信息了。例如:
得到access_token对象后,我们可以根据它获取用户的access_token字符串和用户ID,然后根据userid获取用户信息。没有getuid方法,自己生成即可,操作方便。代码如下:
这样我们就可以得到用户的信息了。 查看全部
网站调用新浪微博内容(新浪开发平台下的网站接入申请Appkey与Appid的方式)
申请Appkey和Appid
在新浪开发平台下网站访问申请Appkey和Appid,申请的前提是要有域名,并记录申请的appkey和appid以供使用。
注意:点击网站访问并填写访问信息后,管理中心会出现您的访问网站。点击进入您的网站访问的详细信息页面,左侧导航栏会有申请信息栏,点击展开,点击“高级信息”项

红包箭头所指的项目要与系统config.properties文件中的redirect_URI一致。如果不一致,会出现第三方授权错误,调用系统时无法获取用户信息。
下载Java SDK包
去技术支持中心下载包,不要用httpclient调用新浪的接口,不安全,可能被别人攻击网站。下载的sdk里面会有一个demo,把demo中lib下的依赖包放到工程lib里面,下载的文件里面会有一个weibo4j包,复制到工程的src下,把config.把properties文件中的前三项改成你自己的appkey、appid、redirect_URI(新浪同意授权后会跳转回你系统中的路径)。
说明
点击页面上的一个按钮后,跳转到action中的方法,在方法中,重定向一个请求到sinaAPI。使用sian的API,我们的直接重定向方法如下:
String url = new Oauth().authorize("code", "code"),这样我们就可以得到请求的路径了。使用内置的sina sdk包,我们可以直接这样调整。

请求后会弹出授权页面。如果我们同意授权,它会自动跳转到我们的“redirect_uri”路径,并在我们的“redirect_uri”后面加上“?code=XXXXXXX”
然后我们就可以根据返回的参数码获取access_token等一些信息了。例如:
得到access_token对象后,我们可以根据它获取用户的access_token字符串和用户ID,然后根据userid获取用户信息。没有getuid方法,自己生成即可,操作方便。代码如下:

这样我们就可以得到用户的信息了。
网站调用新浪微博内容(新浪微博接口的实现过程及应用开发)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-03-10 00:16
不得不说,虽然还是一样的微博内容,一样的列表,没有手机客户端的界面,没有头像,没有用户的昵称和颜色,真的是惨不忍睹。. .
外观仍然是决定因素。.
下面开始记录新浪微博界面的实现过程
首先,您需要在新浪微博开放平台上注册一个开启者。选择应用开发,因为是office网站,所以选择第三方网页,创建后可以得到如下:
应用名称:
525网络空间
应用类型:
通用应用程序 - 网络应用程序
应用密钥:
3xxxxxx
应用秘密:
6xxxxxxxxxxxxxxxxxxxxxxxx
在应用信息->高级信息中设置----
授权回调页面:
然后下载php-sdk
这里注意sdk和demo中有重复的页面(但是内容有一些区别)。其实demo是收录在sdk里面的,所以不需要下载demo。以前,我一团糟,因为我把两者混在一起了。.
然后修改config.php中
WB_AKEY 的值就是 App Key 的值,WB_SKEY 的值就是 App Secret 的值。它们分别相当于帐号和密码,因此后者需要严格保密。
将WB_CALLBACK_URL的值修改为回调页面的地址
然后注意我这里下载的文件中,最后没有php结束标签?> 需要补全。
之后,您可以在浏览器中访问 127.0.0.1/index.php 进行尝试。. 如果点击授权登录成功就ok了
我这里授权后回调页面的地址自动跳转到api.weiboxxx/127.0.0.1/callback.php,不知道怎么回事,总之,在浏览器中更改 127.0.0.1/callback.php 就可以了
然后就可以正常使用了
只是我可能因为php版本或者设置的原因不能直接写变量,需要改一下。. 然后是API调用和布局的问题。 查看全部
网站调用新浪微博内容(新浪微博接口的实现过程及应用开发)
不得不说,虽然还是一样的微博内容,一样的列表,没有手机客户端的界面,没有头像,没有用户的昵称和颜色,真的是惨不忍睹。. .
外观仍然是决定因素。.
下面开始记录新浪微博界面的实现过程
首先,您需要在新浪微博开放平台上注册一个开启者。选择应用开发,因为是office网站,所以选择第三方网页,创建后可以得到如下:
应用名称:
525网络空间
应用类型:
通用应用程序 - 网络应用程序
应用密钥:
3xxxxxx
应用秘密:
6xxxxxxxxxxxxxxxxxxxxxxxx
在应用信息->高级信息中设置----
授权回调页面:
然后下载php-sdk
这里注意sdk和demo中有重复的页面(但是内容有一些区别)。其实demo是收录在sdk里面的,所以不需要下载demo。以前,我一团糟,因为我把两者混在一起了。.
然后修改config.php中
WB_AKEY 的值就是 App Key 的值,WB_SKEY 的值就是 App Secret 的值。它们分别相当于帐号和密码,因此后者需要严格保密。
将WB_CALLBACK_URL的值修改为回调页面的地址
然后注意我这里下载的文件中,最后没有php结束标签?> 需要补全。
之后,您可以在浏览器中访问 127.0.0.1/index.php 进行尝试。. 如果点击授权登录成功就ok了
我这里授权后回调页面的地址自动跳转到api.weiboxxx/127.0.0.1/callback.php,不知道怎么回事,总之,在浏览器中更改 127.0.0.1/callback.php 就可以了
然后就可以正常使用了
只是我可能因为php版本或者设置的原因不能直接写变量,需要改一下。. 然后是API调用和布局的问题。
网站调用新浪微博内容(开发者注册新浪微博开放平台完成开发者认证按照流程走,写回调方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-03-08 17:01
比如QQ互联,这里详细介绍如何实现微博登录。
成为开发者
首先,你还是要注册一个微博账号,使用微博账号登录开放平台。
打开微博开放平台官网,点击登录完成开发者注册
新浪微博开放平台
完成开发者认证
按照流程,开发者类型一般选择个人。
开发者认证
创建网站应用
一般来说,我们创建的是网站应用程序,其他应用程序类似,所以这里仅以网站应用程序为例。
完成认证后,选择首页微链接菜单下的网站访问(或首页下的网站访问WEB),并填写所需信息。
创建应用
需要准备的材料有:
1、域名注册完成
2、已开发网站
3、服务器
4、应用图标
注意:
填写基本信息后,还需要填写高级信息。高级信息中的授权回调页面和取消授权回调页面非常重要,非常重要,非常重要(重要的事情说三遍)。
授权回调页面是授权完成后回调的页面,该页面必须在申请地址域名下。同理,取消授权回调页面是取消授权后回调的页面(一般是跳转回登录页面)。
有节制
审稿时间一般为1个工作日,所以为了节省时间,信息一定要准确,避免多次修改。
审计
页面开发
开发模式有两种,一种是使用sdk,一种是自定义开发。SDK开发门槛低,无需了解具体授权逻辑。只需粘贴代码。下面简单介绍一下登录按钮(不推荐这种方式,推荐定制开发)。
打开链接
配置登录按钮样式
配置登录按钮样式
选择一个应用程序
复制代码
1、将 XML 命名空间添加到 HTML 标记
2、在 HEAD 头中引入 WB.JS
3、 在需要部署登录按钮的地方粘贴WBML代码(复制代码)
4、写回调方法
WB2.anyWhere(函数(W){
W.widget.connectButton({
id: "wb_connect_btn",
类型:“3,2”,
打回来 : {
login:function(o){//登录后回调函数
},
logout:function(){//退出后回调函数
}
}
});
定制开发(推荐)
我们是专业的,一定要选择定制开发(可以跳过上面的sdk教程)。
填写完网站应用信息后,开始使用界面,登录功能主要包括以下几个界面:
1、OAuth2.0 授权登录接口
2、获取token和uid接口
3、获取用户信息接口
第 1 步:添加指向登录页面的链接
微博
这里的应用主键是App Key。在开发平台的应用管理中可以看到回调地址是应用高级信息中的授权回调页面,两者必须相同。
第二步:开发授权回调页面
因为回调页面必须在外网,所以开发过程中必须经常部署新的网站(更新部分就足够了),所以这一步之后服务器必须要有权限。
回调页面中有一个很重要的参数,就是地址栏上的code参数。code参数是授权获取token后自动带上的,并且只能使用一次。如果再次使用,则会出现错误。
第三步:根据代码交换token和uid
这时需要在后台以post的形式请求access_token接口,地址为
"+ 应用主键+ "&client_secret="+ 应用秘钥+ "&grant_type=authorization_code&redirect_uri="+ 回调地址+ "&code="+ 获取代码
应用主键和应用密钥都可以在应用管理中找到。因为很重要,所以必须在后台请求(前台请求有跨域和header信息不一致的问题),并且回调地址和代码都是通过前台传递的,下面是后台代码
C#获取微博token
令牌实体类
第四步:获取用户信息(登录)
获取用户信息的前提是提供token和uid,所以我们调用第三步封装的方法privateWBTokenStateGetWeiBoToken(stringcode, stringcallback)。此时请求的地址是""+兑换了token+"&uid="+兑换了uid
此时代码如下
微博登录
微博用户实体类
具体登录逻辑略...
第 5 步:调用前台
这时候后台已经写好了,前台开始打电话。
先判断回调地址的code参数是否为空,然后动态获取回调地址(后面改很麻烦,测试的时候一定要写死),然后调用后台写的登录接口(后台登录界面自动交换token、uid并获取用户信息),下面是具体代码
使用angularjs,应该不难理解
结束语
微博登录的意义在于接入大量微博用户,降低网站注册门槛,实现社交关系的零成本引入和优质内容的快速传播。
ps:
代码只能使用一次,再次使用会报错,需要在后台调用post方法。
授权机制(包括获取uid)
授权机制
获取uid
获取用户信息
js SDK 查看全部
网站调用新浪微博内容(开发者注册新浪微博开放平台完成开发者认证按照流程走,写回调方法)
比如QQ互联,这里详细介绍如何实现微博登录。
成为开发者
首先,你还是要注册一个微博账号,使用微博账号登录开放平台。
打开微博开放平台官网,点击登录完成开发者注册

新浪微博开放平台
完成开发者认证
按照流程,开发者类型一般选择个人。
开发者认证
创建网站应用
一般来说,我们创建的是网站应用程序,其他应用程序类似,所以这里仅以网站应用程序为例。
完成认证后,选择首页微链接菜单下的网站访问(或首页下的网站访问WEB),并填写所需信息。
创建应用
需要准备的材料有:
1、域名注册完成
2、已开发网站
3、服务器
4、应用图标
注意:
填写基本信息后,还需要填写高级信息。高级信息中的授权回调页面和取消授权回调页面非常重要,非常重要,非常重要(重要的事情说三遍)。
授权回调页面是授权完成后回调的页面,该页面必须在申请地址域名下。同理,取消授权回调页面是取消授权后回调的页面(一般是跳转回登录页面)。
有节制
审稿时间一般为1个工作日,所以为了节省时间,信息一定要准确,避免多次修改。
审计
页面开发
开发模式有两种,一种是使用sdk,一种是自定义开发。SDK开发门槛低,无需了解具体授权逻辑。只需粘贴代码。下面简单介绍一下登录按钮(不推荐这种方式,推荐定制开发)。
打开链接
配置登录按钮样式
配置登录按钮样式
选择一个应用程序
复制代码
1、将 XML 命名空间添加到 HTML 标记
2、在 HEAD 头中引入 WB.JS
3、 在需要部署登录按钮的地方粘贴WBML代码(复制代码)
4、写回调方法
WB2.anyWhere(函数(W){
W.widget.connectButton({
id: "wb_connect_btn",
类型:“3,2”,
打回来 : {
login:function(o){//登录后回调函数
},
logout:function(){//退出后回调函数
}
}
});
定制开发(推荐)
我们是专业的,一定要选择定制开发(可以跳过上面的sdk教程)。
填写完网站应用信息后,开始使用界面,登录功能主要包括以下几个界面:
1、OAuth2.0 授权登录接口
2、获取token和uid接口
3、获取用户信息接口
第 1 步:添加指向登录页面的链接
微博
这里的应用主键是App Key。在开发平台的应用管理中可以看到回调地址是应用高级信息中的授权回调页面,两者必须相同。
第二步:开发授权回调页面
因为回调页面必须在外网,所以开发过程中必须经常部署新的网站(更新部分就足够了),所以这一步之后服务器必须要有权限。
回调页面中有一个很重要的参数,就是地址栏上的code参数。code参数是授权获取token后自动带上的,并且只能使用一次。如果再次使用,则会出现错误。
第三步:根据代码交换token和uid
这时需要在后台以post的形式请求access_token接口,地址为
"+ 应用主键+ "&client_secret="+ 应用秘钥+ "&grant_type=authorization_code&redirect_uri="+ 回调地址+ "&code="+ 获取代码
应用主键和应用密钥都可以在应用管理中找到。因为很重要,所以必须在后台请求(前台请求有跨域和header信息不一致的问题),并且回调地址和代码都是通过前台传递的,下面是后台代码
C#获取微博token
令牌实体类
第四步:获取用户信息(登录)
获取用户信息的前提是提供token和uid,所以我们调用第三步封装的方法privateWBTokenStateGetWeiBoToken(stringcode, stringcallback)。此时请求的地址是""+兑换了token+"&uid="+兑换了uid
此时代码如下
微博登录
微博用户实体类
具体登录逻辑略...
第 5 步:调用前台
这时候后台已经写好了,前台开始打电话。
先判断回调地址的code参数是否为空,然后动态获取回调地址(后面改很麻烦,测试的时候一定要写死),然后调用后台写的登录接口(后台登录界面自动交换token、uid并获取用户信息),下面是具体代码
使用angularjs,应该不难理解
结束语
微博登录的意义在于接入大量微博用户,降低网站注册门槛,实现社交关系的零成本引入和优质内容的快速传播。
ps:
代码只能使用一次,再次使用会报错,需要在后台调用post方法。
授权机制(包括获取uid)
授权机制
获取uid
获取用户信息
js SDK
网站调用新浪微博内容(网站调用新浪微博内容需要改host请试下提供个方案)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-03-08 07:09
网站调用新浪微博内容需要改host
请试下apilink-wordpressapiforwordpress
提供个方案:将您的业务数据,存放在阿里云服务器,再申请一个主机域名。
试试小站易,免费的cms,可以上传,可以制作静态和动态,在线生成。
wordpress根本不是针对中国市场设计的。
没必要为做一个网站而去学新浪微博的代码,其实直接把主题做成自己喜欢的样子,重点看你的内容了,
wordpress主题不错,不是真的做站很难看懂它的语言。最好可以连接到wordpressphp代码或者espressif。如果你想直接用别人优秀主题建议调用wordpressphpsitemap,其它还有flash和手机网站。
由于你网站面向的大多数人是在校大学生,你需要建立一个贴近他们的官方主题,给他们一个良好的主题导航,当你主题调出的时候可以顺带调出它的文字。推荐你一款在线的wordpress主题,【记账中心】,它基于php,可以让你快速搭建主题。
做wordpress的网站要多考虑cdn的用户体验!要多考虑cdn的用户体验!要多考虑cdn的用户体验!-重要的事情说三遍!!!需要一个云服务器。然后你可以放网站的代码,服务器设置好就可以了。
直接用wordpress吧,按需下载就行。
这么简单, 查看全部
网站调用新浪微博内容(网站调用新浪微博内容需要改host请试下提供个方案)
网站调用新浪微博内容需要改host
请试下apilink-wordpressapiforwordpress
提供个方案:将您的业务数据,存放在阿里云服务器,再申请一个主机域名。
试试小站易,免费的cms,可以上传,可以制作静态和动态,在线生成。
wordpress根本不是针对中国市场设计的。
没必要为做一个网站而去学新浪微博的代码,其实直接把主题做成自己喜欢的样子,重点看你的内容了,
wordpress主题不错,不是真的做站很难看懂它的语言。最好可以连接到wordpressphp代码或者espressif。如果你想直接用别人优秀主题建议调用wordpressphpsitemap,其它还有flash和手机网站。
由于你网站面向的大多数人是在校大学生,你需要建立一个贴近他们的官方主题,给他们一个良好的主题导航,当你主题调出的时候可以顺带调出它的文字。推荐你一款在线的wordpress主题,【记账中心】,它基于php,可以让你快速搭建主题。
做wordpress的网站要多考虑cdn的用户体验!要多考虑cdn的用户体验!要多考虑cdn的用户体验!-重要的事情说三遍!!!需要一个云服务器。然后你可以放网站的代码,服务器设置好就可以了。
直接用wordpress吧,按需下载就行。
这么简单,
网站调用新浪微博内容(网站调用新浪微博内容时需要把原信息接入网站提供的数据库匹配)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-03-08 01:00
网站调用新浪微博内容时需要把原信息接入网站,通过网站提供的数据库进行匹配。国内新浪微博很大程度的依赖于用户的数据,在,并且有一个对新浪微博的屏蔽认证。因此,新浪微博的数据库存储的东西是一方面,新浪微博的决策机制又是另一方面。因此,我猜测这个时候能够胜出的是认证机制,而非接入信息。当然,我不是认证机构,我也不是业内人士,这只是个人yy,或许它们考虑的不是这个。
认证接口都会存在。但是有一个问题,在微博数据格式公开化之前,都会由技术手段来验证发布人的真实性,但是参考微博技术手段在新浪微博上的变化,认证是可以绕过的。甚至认证可以直接在网页上实现,例如你只需要看那个关注者的最新动态(该关注者是指加入腾讯广播站的账号),你可以向你的关注者发起认证申请。下图是2010年8月20日腾讯广播站发布的认证接口。(来源:腾讯广播站)。
这个得看用户来源、内容中有没有“找关系”要求、社交数据比如父母兴趣偏好这些东西。
不好说,只能回答会影响吧。腾讯是很在意个人用户隐私的,比如你从他的社交关系再次影响其他人对该用户产生兴趣。所以有严格的cookie来保护个人信息,例如该用户有无恋爱信息。微博上这些不方便直接公开,但是却可以间接的影响。从网站数据角度看,无非是处理一下,提交一下隐私,然后再进行信息抽丝剥茧,将其中不需要的东西剔除掉。
从社交账号来看,大多是以开放接口的形式发布,所以容易侵入用户的隐私,但如果社交账号绑定该用户就会形成社交黑洞,存在隐私泄露风险。另外,社交账号也能够从算法中看出来该用户的兴趣特征,这里比如前几天的“逃离北上广”事件,公众的讨论就会比较激烈,但用户的大部分兴趣是稳定的。 查看全部
网站调用新浪微博内容(网站调用新浪微博内容时需要把原信息接入网站提供的数据库匹配)
网站调用新浪微博内容时需要把原信息接入网站,通过网站提供的数据库进行匹配。国内新浪微博很大程度的依赖于用户的数据,在,并且有一个对新浪微博的屏蔽认证。因此,新浪微博的数据库存储的东西是一方面,新浪微博的决策机制又是另一方面。因此,我猜测这个时候能够胜出的是认证机制,而非接入信息。当然,我不是认证机构,我也不是业内人士,这只是个人yy,或许它们考虑的不是这个。
认证接口都会存在。但是有一个问题,在微博数据格式公开化之前,都会由技术手段来验证发布人的真实性,但是参考微博技术手段在新浪微博上的变化,认证是可以绕过的。甚至认证可以直接在网页上实现,例如你只需要看那个关注者的最新动态(该关注者是指加入腾讯广播站的账号),你可以向你的关注者发起认证申请。下图是2010年8月20日腾讯广播站发布的认证接口。(来源:腾讯广播站)。
这个得看用户来源、内容中有没有“找关系”要求、社交数据比如父母兴趣偏好这些东西。
不好说,只能回答会影响吧。腾讯是很在意个人用户隐私的,比如你从他的社交关系再次影响其他人对该用户产生兴趣。所以有严格的cookie来保护个人信息,例如该用户有无恋爱信息。微博上这些不方便直接公开,但是却可以间接的影响。从网站数据角度看,无非是处理一下,提交一下隐私,然后再进行信息抽丝剥茧,将其中不需要的东西剔除掉。
从社交账号来看,大多是以开放接口的形式发布,所以容易侵入用户的隐私,但如果社交账号绑定该用户就会形成社交黑洞,存在隐私泄露风险。另外,社交账号也能够从算法中看出来该用户的兴趣特征,这里比如前几天的“逃离北上广”事件,公众的讨论就会比较激烈,但用户的大部分兴趣是稳定的。
网站调用新浪微博内容( 一个复杂且长的链接(url)如何变成一个短小精悍的短链接? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-03-20 05:00
一个复杂且长的链接(url)如何变成一个短小精悍的短链接?
)
一个复杂而长的链接(url)如何变成一个简短的链接?借助巨资购买的微博域名和提供的微博短链API,可以将任意长度的url变成/RDj9Kog形式的短链接。本文介绍了微博的短链API,并提供了一个短链生成工具。
文章目录
微博短链API介绍
是新浪斥巨资购买的域名。也有说是某老板买了给新浪。这并不重要。不管怎样,它现在属于新浪。直接访问会跳转到新浪微博。网站。
新浪获得该域名后,基于该域名开放了微博API。其中之一是短链接接口。顾名思义,通过这个接口,任何url都可以生成短链接。例如 /RDj9Kog 是一个短链接。
官方短链接口API文档可以参考:
微博短链API调用
上面介绍的第二版短链接API需要access_token,参数介绍“OAuth授权方式为必填参数,OAuth授权后获取”,看完介绍需要用户登录微博才能拥有本授权。只是为了做这个简单的短链工具,肯定不可能每次都登录的,所以我去找了它的第一版界面:&,需要提供一个source参数。该来源是您注册为新浪微博开发者并申请该应用后获得的App Key。如果你懒得注册,你就去网上找点东西分享一下:
小米手机 App Key:xiaomi App Secret:3MqAdNoRLHomm4AECoURl7gds1sUIjun
Panda.memo App Key:31641035 App Secret:6a7c98c1eef2109622d0a08199a35bef
周博通微博管家 App Key:202088835 App Secret:9567e3782151dcfd1a9bd2dd099d957f
Android平板客户端 App Key:2540340328 App Secret:886cfb4e61fad4e4e9ba9dee625284dd
Google.Nexus App Key:1206405345 App Secret:fa6095e113cd28fde6e14c7b7145c5c5
Spring微博.Android App Key:1905839263 App Secret:36b51c6ebf2dd3e5361f80f6c4506267
Acer平板电脑 App Key:783190658 App Secret:7f63ae9eb3c1438e9f8932748ca8a341
iphone客户端 App Key:5786724301 App Secret:5Jao51NF1i5PDC91hhI3ID86ucoDtn4C
app梦工厂微博 App Key:569452181 App Secret:bbd573c3052999adcd026cbf88ffbf8e
FIT随享.iPhone版 App Key:31024382 App Secret:25c3e6b5763653d1e5b280884b45c51f
有了API和授权源码,代码就简单了,以PHP为例(url_long参数好像以or开头,否则会报错):
<p> 查看全部
网站调用新浪微博内容(
一个复杂且长的链接(url)如何变成一个短小精悍的短链接?
)
一个复杂而长的链接(url)如何变成一个简短的链接?借助巨资购买的微博域名和提供的微博短链API,可以将任意长度的url变成/RDj9Kog形式的短链接。本文介绍了微博的短链API,并提供了一个短链生成工具。
文章目录
微博短链API介绍
是新浪斥巨资购买的域名。也有说是某老板买了给新浪。这并不重要。不管怎样,它现在属于新浪。直接访问会跳转到新浪微博。网站。
新浪获得该域名后,基于该域名开放了微博API。其中之一是短链接接口。顾名思义,通过这个接口,任何url都可以生成短链接。例如 /RDj9Kog 是一个短链接。
官方短链接口API文档可以参考:
微博短链API调用
上面介绍的第二版短链接API需要access_token,参数介绍“OAuth授权方式为必填参数,OAuth授权后获取”,看完介绍需要用户登录微博才能拥有本授权。只是为了做这个简单的短链工具,肯定不可能每次都登录的,所以我去找了它的第一版界面:&,需要提供一个source参数。该来源是您注册为新浪微博开发者并申请该应用后获得的App Key。如果你懒得注册,你就去网上找点东西分享一下:
小米手机 App Key:xiaomi App Secret:3MqAdNoRLHomm4AECoURl7gds1sUIjun
Panda.memo App Key:31641035 App Secret:6a7c98c1eef2109622d0a08199a35bef
周博通微博管家 App Key:202088835 App Secret:9567e3782151dcfd1a9bd2dd099d957f
Android平板客户端 App Key:2540340328 App Secret:886cfb4e61fad4e4e9ba9dee625284dd
Google.Nexus App Key:1206405345 App Secret:fa6095e113cd28fde6e14c7b7145c5c5
Spring微博.Android App Key:1905839263 App Secret:36b51c6ebf2dd3e5361f80f6c4506267
Acer平板电脑 App Key:783190658 App Secret:7f63ae9eb3c1438e9f8932748ca8a341
iphone客户端 App Key:5786724301 App Secret:5Jao51NF1i5PDC91hhI3ID86ucoDtn4C
app梦工厂微博 App Key:569452181 App Secret:bbd573c3052999adcd026cbf88ffbf8e
FIT随享.iPhone版 App Key:31024382 App Secret:25c3e6b5763653d1e5b280884b45c51f
有了API和授权源码,代码就简单了,以PHP为例(url_long参数好像以or开头,否则会报错):
<p>
网站调用新浪微博内容(新浪微博API运用比较广泛,做一个完整的开发流程 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-03-20 04:22
)
新浪微博API现已广泛使用,并制作了完整的开发流程Demo
1、注册第一步,话不多说,注册账号成为开发者账号,如果这一步做不到,请立即砸电脑拔网线回家种田。
2、第二步是创建一个应用程序。开发者账号创建后,打开新浪微博开发平台:
点击上方菜单栏中的最后一个管理中心
如果是web应用,选择创建网站访问的应用,然后balabalabala按照新浪微博的要求去做
应用程序已创建。点击应用跳转页面,点击查看应用参数,可以看到应用的相关参数,这些参数会在第四步中用到。
3、第三步,下载sdk,回到顶部菜单栏,点击文档,然后点击左侧菜单栏中的sdk,选择java sdk,然后下载balabala . 如果这一步有任何问题,请回家种田。
所谓的sdk不是sdk(个人觉得名字有点误导),而是一个可运行的项目。下载后解压导入eclipse,可以看到src和example两个目录
src 是新浪微博的一部分
example是实例,界面的demo
4、第四步,配置参数,在src目录下找到config.properties
前三个参数需要配置为第二步提到的应用参数中的参数
后者是默认的,不需要更改
前三个参数配置如下
client_ID 是 App Key
client_SERCRET 是 App Secret
redirect_URI是OAuth2.0授权应用信息>高级信息>OAuth2.0授权设置的回调URL下面的授权回调页面是你自己填写的URL。它指向您自己的服务器。当然,它还在开发阶段,我们可以使用任何 URL,只要它能让我们了解 OAuth 授权过程。这里我们也进入了取消授权回调页面。注意这里的URL字符串必须一致。
5、第五步,获取AccessToken。一般情况下,获取AccessToken需要通过OAuth2.0进行认证,但是为了简单起见,我介绍一个简单的方法。OAuth 后面会讲到2.0
或者选择顶部菜单栏 Document > API > API Test Tool
选择创建的应用程序,然后单击获取 AccessToken。下面的文本框就是我们想要的AccessToken。
6、第六步,创建接口实例
进入微博API,找到已有权限的接口。
刚刚找到用户发的一条微博status/user_timeline进行测试。
点击该界面可以查看该界面的详细信息。可以查看接口的每个传入参数和返回参数。不用说。
不使用任何SDK实现Oauth授权,实现一个简单的微博发帖功能:
创建一个 Java 项目并编写以下代码。具体流程代码已经写的很清楚了,这里不再赘述:
注意先将申请ID、申请密码、回调页面修改为自己的!访问授权页面:
package com;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.net.URL;
import java.net.URLConnection;
import java.security.cert.CertificateException;
import java.security.cert.X509Certificate;
import java.util.Scanner;
import javax.net.ssl.X509TrustManager;
/**
* @author 刘显安
* 不使用任何SDK实现新浪微博Oauth授权并实现发微薄小Demo
* 日期:2012年11月11日
*/
public class Test
{
static String clientId="2355065950";//你的应用ID
static String clientSecret="72037e76bee00315691d9c30dd8a386a";//你的应用密码
static String redirectUri="https://api.weibo.com/oauth2/default.html";//你在应用管理中心设置的回调页面
public static void main(String[] args) throws Exception
{
testHttps();//测试
//第一步:访问授权页面获取授权
System.out.println("请打开你的浏览器,访问以下页面,登录你的微博账号并授权:");
System.out.println("https://api.weibo.com/oauth2/a ... 6quot;);
//第二步:获取AccessToken
System.out.println("请将授权成功后的页面地址栏中的参数code:");
String code=new Scanner(System.in).next();
getAccessToken(code);
//第三步:发布一条微博
System.out.println("请输入上面返回的值中accessToken的值:");
String accessToken=new Scanner(System.in).next();
updateStatus("发布微博测试!来自WeiboDemo!", accessToken);
}
/**
* 测试能否正常访问HTTPS打头的网站,
*/
public static void testHttps()
{
try
{
trustAllHttpsCertificates();//设置信任所有的http证书
URL url=new URL("https://api.weibo.com/oauth2/default.html");
URLConnection con=url.openConnection();
con.getInputStream();
System.out.println("恭喜,访问HTTPS打头的网站正常!");
}
catch (Exception e)
{
e.printStackTrace();
}
}
/**
* 以Post方式访问一个URL
* @param url 要访问的URL
* @param parameters URL后面“?”后面跟着的参数
*/
public static void postUrl(String url,String parameters)
{
try
{
trustAllHttpsCertificates();//设置信任所有的http证书
URLConnection conn = new URL(url).openConnection();
conn.setDoOutput(true);// 这里是关键,表示我们要向链接里注入的参数
OutputStreamWriter out = new OutputStreamWriter(conn.getOutputStream());// 获得连接输出流
out.write(parameters);
out.flush();
out.close();
// 到这里已经完成了,开始打印返回的HTML代码
BufferedReader reader = new BufferedReader(new InputStreamReader(conn.getInputStream()));
String line = null;
while ((line = reader.readLine()) != null)
{
System.out.println(line);
}
}
catch (Exception e)
{
e.printStackTrace();
}
}
/**
* 获取AccessToken
* @param code 在授权页面返回的Code
*/
public static void getAccessToken(String code)
{
String url="https://api.weibo.com/oauth2/access_token";
String parameters="client_id=" +clientId+"&client_secret=" +clientSecret+
"&grant_type=authorization_code" +"&redirect_uri=" +redirectUri+"&code="+code;
postUrl(url, parameters);
}
/**
* 利用刚获取的AccessToken发布一条微博
* @param text 要发布的微博内容
* @param accessToken 刚获取的AccessToken
*/
public static void updateStatus(String text,String accessToken)
{
String url="https://api.weibo.com/2/status ... 3B%3B
String parameters="status="+text+"&access_token="+accessToken;
postUrl(url, parameters);
System.out.println("发布微博成功!");
}
/**
* 设置信任所有的http证书(正常情况下访问https打头的网站会出现证书不信任相关错误,所以必须在访问前调用此方法)
* @throws Exception
*/
private static void trustAllHttpsCertificates() throws Exception
{
javax.net.ssl.TrustManager[] trustAllCerts = new javax.net.ssl.TrustManager[1];
trustAllCerts[0] = new X509TrustManager()
{
@Override
public X509Certificate[] getAcceptedIssuers()
{
return null;
}
@Override
public void checkServerTrusted(X509Certificate[] arg0, String arg1)
throws CertificateException
{}
@Override
public void checkClientTrusted(X509Certificate[] arg0, String arg1)
throws CertificateException
{}
};
javax.net.ssl.SSLContext sc = javax.net.ssl.SSLContext.getInstance("SSL");
sc.init(null, trustAllCerts, null);
javax.net.ssl.HttpsURLConnection.setDefaultSSLSocketFactory(sc.getSocketFactory());
}
}
访问授权页面:
授权成功:
成功发布微博:
控制台输出:
查看全部
网站调用新浪微博内容(新浪微博API运用比较广泛,做一个完整的开发流程
)
新浪微博API现已广泛使用,并制作了完整的开发流程Demo
1、注册第一步,话不多说,注册账号成为开发者账号,如果这一步做不到,请立即砸电脑拔网线回家种田。
2、第二步是创建一个应用程序。开发者账号创建后,打开新浪微博开发平台:
点击上方菜单栏中的最后一个管理中心
如果是web应用,选择创建网站访问的应用,然后balabalabala按照新浪微博的要求去做
应用程序已创建。点击应用跳转页面,点击查看应用参数,可以看到应用的相关参数,这些参数会在第四步中用到。
3、第三步,下载sdk,回到顶部菜单栏,点击文档,然后点击左侧菜单栏中的sdk,选择java sdk,然后下载balabala . 如果这一步有任何问题,请回家种田。
所谓的sdk不是sdk(个人觉得名字有点误导),而是一个可运行的项目。下载后解压导入eclipse,可以看到src和example两个目录
src 是新浪微博的一部分
example是实例,界面的demo
4、第四步,配置参数,在src目录下找到config.properties
前三个参数需要配置为第二步提到的应用参数中的参数
后者是默认的,不需要更改
前三个参数配置如下
client_ID 是 App Key
client_SERCRET 是 App Secret
redirect_URI是OAuth2.0授权应用信息>高级信息>OAuth2.0授权设置的回调URL下面的授权回调页面是你自己填写的URL。它指向您自己的服务器。当然,它还在开发阶段,我们可以使用任何 URL,只要它能让我们了解 OAuth 授权过程。这里我们也进入了取消授权回调页面。注意这里的URL字符串必须一致。
5、第五步,获取AccessToken。一般情况下,获取AccessToken需要通过OAuth2.0进行认证,但是为了简单起见,我介绍一个简单的方法。OAuth 后面会讲到2.0
或者选择顶部菜单栏 Document > API > API Test Tool
选择创建的应用程序,然后单击获取 AccessToken。下面的文本框就是我们想要的AccessToken。
6、第六步,创建接口实例
进入微博API,找到已有权限的接口。
刚刚找到用户发的一条微博status/user_timeline进行测试。
点击该界面可以查看该界面的详细信息。可以查看接口的每个传入参数和返回参数。不用说。
不使用任何SDK实现Oauth授权,实现一个简单的微博发帖功能:
创建一个 Java 项目并编写以下代码。具体流程代码已经写的很清楚了,这里不再赘述:
注意先将申请ID、申请密码、回调页面修改为自己的!访问授权页面:
package com;
import java.io.BufferedReader;
import java.io.InputStreamReader;
import java.io.OutputStreamWriter;
import java.net.URL;
import java.net.URLConnection;
import java.security.cert.CertificateException;
import java.security.cert.X509Certificate;
import java.util.Scanner;
import javax.net.ssl.X509TrustManager;
/**
* @author 刘显安
* 不使用任何SDK实现新浪微博Oauth授权并实现发微薄小Demo
* 日期:2012年11月11日
*/
public class Test
{
static String clientId="2355065950";//你的应用ID
static String clientSecret="72037e76bee00315691d9c30dd8a386a";//你的应用密码
static String redirectUri="https://api.weibo.com/oauth2/default.html";//你在应用管理中心设置的回调页面
public static void main(String[] args) throws Exception
{
testHttps();//测试
//第一步:访问授权页面获取授权
System.out.println("请打开你的浏览器,访问以下页面,登录你的微博账号并授权:");
System.out.println("https://api.weibo.com/oauth2/a ... 6quot;);
//第二步:获取AccessToken
System.out.println("请将授权成功后的页面地址栏中的参数code:");
String code=new Scanner(System.in).next();
getAccessToken(code);
//第三步:发布一条微博
System.out.println("请输入上面返回的值中accessToken的值:");
String accessToken=new Scanner(System.in).next();
updateStatus("发布微博测试!来自WeiboDemo!", accessToken);
}
/**
* 测试能否正常访问HTTPS打头的网站,
*/
public static void testHttps()
{
try
{
trustAllHttpsCertificates();//设置信任所有的http证书
URL url=new URL("https://api.weibo.com/oauth2/default.html";);
URLConnection con=url.openConnection();
con.getInputStream();
System.out.println("恭喜,访问HTTPS打头的网站正常!");
}
catch (Exception e)
{
e.printStackTrace();
}
}
/**
* 以Post方式访问一个URL
* @param url 要访问的URL
* @param parameters URL后面“?”后面跟着的参数
*/
public static void postUrl(String url,String parameters)
{
try
{
trustAllHttpsCertificates();//设置信任所有的http证书
URLConnection conn = new URL(url).openConnection();
conn.setDoOutput(true);// 这里是关键,表示我们要向链接里注入的参数
OutputStreamWriter out = new OutputStreamWriter(conn.getOutputStream());// 获得连接输出流
out.write(parameters);
out.flush();
out.close();
// 到这里已经完成了,开始打印返回的HTML代码
BufferedReader reader = new BufferedReader(new InputStreamReader(conn.getInputStream()));
String line = null;
while ((line = reader.readLine()) != null)
{
System.out.println(line);
}
}
catch (Exception e)
{
e.printStackTrace();
}
}
/**
* 获取AccessToken
* @param code 在授权页面返回的Code
*/
public static void getAccessToken(String code)
{
String url="https://api.weibo.com/oauth2/access_token";
String parameters="client_id=" +clientId+"&client_secret=" +clientSecret+
"&grant_type=authorization_code" +"&redirect_uri=" +redirectUri+"&code="+code;
postUrl(url, parameters);
}
/**
* 利用刚获取的AccessToken发布一条微博
* @param text 要发布的微博内容
* @param accessToken 刚获取的AccessToken
*/
public static void updateStatus(String text,String accessToken)
{
String url="https://api.weibo.com/2/status ... 3B%3B
String parameters="status="+text+"&access_token="+accessToken;
postUrl(url, parameters);
System.out.println("发布微博成功!");
}
/**
* 设置信任所有的http证书(正常情况下访问https打头的网站会出现证书不信任相关错误,所以必须在访问前调用此方法)
* @throws Exception
*/
private static void trustAllHttpsCertificates() throws Exception
{
javax.net.ssl.TrustManager[] trustAllCerts = new javax.net.ssl.TrustManager[1];
trustAllCerts[0] = new X509TrustManager()
{
@Override
public X509Certificate[] getAcceptedIssuers()
{
return null;
}
@Override
public void checkServerTrusted(X509Certificate[] arg0, String arg1)
throws CertificateException
{}
@Override
public void checkClientTrusted(X509Certificate[] arg0, String arg1)
throws CertificateException
{}
};
javax.net.ssl.SSLContext sc = javax.net.ssl.SSLContext.getInstance("SSL");
sc.init(null, trustAllCerts, null);
javax.net.ssl.HttpsURLConnection.setDefaultSSLSocketFactory(sc.getSocketFactory());
}
}
访问授权页面:
授权成功:
成功发布微博:
控制台输出:
网站调用新浪微博内容(试试用python调用微博API的方法微博接口 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-03-18 01:05
)
因为最近碰到一个调用新浪微博开放接口的项目,想试试用python调用微博API。
SDK下载地址:代码不超过十几K,完全可以理解。
如果你有微博账号,可以新建一个APP,然后获取APP获取OAuth2.0授权所需要的app key和app secret。
要了解 OAuth2,您可以查看链接到新浪微博的说明。OAuth2授权参数除了app key和app secret外,还需要网站回调地址redirect_uri,并且这个回调地址不允许在局域网内(神马localhost,127.0.0.@ >1 好像不行),这真的让我焦急了很久。我没有使用 API 调用 网站,所以我检查了很多。看到有人写这个地址可以改用,我试了一下,成功了,对掉丝来说是个好消息。
这里有一个简单的程序来体验:
设置以下参数
import sys
import weibo
import webbrowser
APP_KEY = ''
MY_APP_SECRET = ''
REDIRECT_URL = 'https://api.weibo.com/oauth2/default.html'
获取微博授权网址,如第2行,用默认浏览器打开后,会提示登录微博,使用需要授权的账号登录,如下图
api = weibo.APIClient(app_key=APP_KEY,app_secret=MY_APP_SECRET,redirect_uri=REDIRECT_URL)
authorize_url = api.get_authorize_url()
print(authorize_url)
webbrowser.open_new(authorize_url)
登录后,您将被重定向到一个连接
关键是码值,是认证的关键。手动输入码值模拟认证
request = api.request_access_token(code, REDIRECT_URL)
access_token = request.access_token
expires_in = request.expires_in
api.set_access_token(access_token, expires_in)
api.statuses.update.post(status=u'Test OAuth 2.0 Send a Weibo!')
access_token为获取到的token,expires_in为授权过期时间(UNIX时间)
使用 set_access_token 保存授权。往下走,就可以调用微博界面了。测试发了一条推文
但是,这种手动输入代码的方式并不适合调用程序。是否可以在不打开链接的情况下请求登录并获得授权?经过多方搜索参考,程序改进如下,可以自动获取代码并保存,方便程序服务调用。
accessWeibo
# -*- coding: utf-8 -*-
#/usr/bin/env python
#access to SinaWeibo By sinaweibopy
#实现微博自动登录,token自动生成,保存及更新
#适合于后端服务调用
from weibo import APIClient
import pymongo
import sys, os, urllib, urllib2
from http_helper import *
from retry import *
try:
import json
except ImportError:
import simplejson as json
# setting sys encoding to utf-8
default_encoding = 'utf-8'
if sys.getdefaultencoding() != default_encoding:
reload(sys)
sys.setdefaultencoding(default_encoding)
# weibo api访问配置
APP_KEY = '' # app key
APP_SECRET = '' # app secret
REDIRECT_URL = 'https://api.weibo.com/oauth2/default.html' # callback url 授权回调页,与OAuth2.0 授权设置的一致
USERID = '' # 登陆的微博用户名,必须是OAuth2.0 设置的测试账号
USERPASSWD = '' # 用户密码
client = APIClient(app_key=APP_KEY, app_secret=APP_SECRET, redirect_uri=REDIRECT_URL)
def make_access_token():
#请求access token
params = urllib.urlencode({
'action':'submit',
'withOfficalFlag':'0',
'ticket':'',
'isLoginSina':'',
'response_type':'code',
'regCallback':'',
'redirect_uri':REDIRECT_URL,
'client_id':APP_KEY,
'state':'',
'from':'',
'userId':USERID,
'passwd':USERPASSWD,
})
login_url = 'https://api.weibo.com/oauth2/authorize'
url = client.get_authorize_url()
content = urllib2.urlopen(url)
if content:
headers = { 'Referer' : url }
request = urllib2.Request(login_url, params, headers)
opener = get_opener(False)
urllib2.install_opener(opener)
try:
f = opener.open(request)
return_redirect_uri = f.url
except urllib2.HTTPError, e:
return_redirect_uri = e.geturl()
# 取到返回的code
code = return_redirect_uri.split('=')[1]
#得到token
token = client.request_access_token(code,REDIRECT_URL)
save_access_token(token)
def save_access_token(token):
#将access token保存到MongoDB数据库
mongoCon=pymongo.Connection(host="127.0.0.1",port=27017)
db= mongoCon.weibo
t={
"access_token":token['access_token'],
"expires_in":str(token['expires_in']),
"date":time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time()))
}
db.token.insert(t,safe=True)
#Decorator 目的是当调用make_access_token()后再执行一次apply_access_token()
@retry(1)
def apply_access_token():
#从MongoDB读取及设置access token
try:
mongoCon=pymongo.Connection(host="127.0.0.1",port=27017)
db= mongoCon.weibo
if db.token.count()>0:
tokenInfos=db.token.find().sort([("_id",pymongo.DESCENDING)]).limit(1)
else:
make_access_token()
return False
for tokenInfo in tokenInfos:
access_token=tokenInfo["access_token"]
expires_in=tokenInfo["expires_in"]
try:
client.set_access_token(access_token, expires_in)
except StandardError, e:
if hasattr(e, 'error'):
if e.error == 'expired_token':
# token过期重新生成
make_access_token()
return False
else:
pass
except:
make_access_token()
return False
return True
if __name__ == "__main__":
apply_access_token()
# 以下为访问微博api的应用逻辑
# 以发布文字微博接口为例
client.statuses.update.post(status='Test OAuth 2.0 Send a Weibo!')
retry.py
import math
import time
# Retry decorator with exponential backoff
def retry(tries, delay=1, backoff=2):
"""Retries a function or method until it returns True.
delay sets the initial delay, and backoff sets how much the delay should
lengthen after each failure. backoff must be greater than 1, or else it
isn't really a backoff. tries must be at least 0, and delay greater than
0."""
if backoff decorated function
return deco_retry # @retry(arg[, ...]) -> true decorator
http_helper.py
# -*- coding: utf-8 -*-
#/usr/bin/env python
import urllib2,cookielib
class SmartRedirectHandler(urllib2.HTTPRedirectHandler):
def http_error_301(cls, req, fp, code, msg, headers):
result = urllib2.HTTPRedirectHandler.http_error_301(cls, req, fp, code, msg, headers)
result.status = code
print headers
return result
def http_error_302(cls, req, fp, code, msg, headers):
result = urllib2.HTTPRedirectHandler.http_error_302(cls, req, fp, code, msg, headers)
result.status = code
print headers
return result
def get_cookie():
cookies = cookielib.CookieJar()
return urllib2.HTTPCookieProcessor(cookies)
def get_opener(proxy=False):
rv=urllib2.build_opener(get_cookie(), SmartRedirectHandler())
rv.addheaders = [('User-agent', 'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1)')]
return rv 查看全部
网站调用新浪微博内容(试试用python调用微博API的方法微博接口
)
因为最近碰到一个调用新浪微博开放接口的项目,想试试用python调用微博API。
SDK下载地址:代码不超过十几K,完全可以理解。
如果你有微博账号,可以新建一个APP,然后获取APP获取OAuth2.0授权所需要的app key和app secret。
要了解 OAuth2,您可以查看链接到新浪微博的说明。OAuth2授权参数除了app key和app secret外,还需要网站回调地址redirect_uri,并且这个回调地址不允许在局域网内(神马localhost,127.0.0.@ >1 好像不行),这真的让我焦急了很久。我没有使用 API 调用 网站,所以我检查了很多。看到有人写这个地址可以改用,我试了一下,成功了,对掉丝来说是个好消息。
这里有一个简单的程序来体验:
设置以下参数
import sys
import weibo
import webbrowser
APP_KEY = ''
MY_APP_SECRET = ''
REDIRECT_URL = 'https://api.weibo.com/oauth2/default.html'
获取微博授权网址,如第2行,用默认浏览器打开后,会提示登录微博,使用需要授权的账号登录,如下图
api = weibo.APIClient(app_key=APP_KEY,app_secret=MY_APP_SECRET,redirect_uri=REDIRECT_URL)
authorize_url = api.get_authorize_url()
print(authorize_url)
webbrowser.open_new(authorize_url)
登录后,您将被重定向到一个连接
关键是码值,是认证的关键。手动输入码值模拟认证
request = api.request_access_token(code, REDIRECT_URL)
access_token = request.access_token
expires_in = request.expires_in
api.set_access_token(access_token, expires_in)
api.statuses.update.post(status=u'Test OAuth 2.0 Send a Weibo!')
access_token为获取到的token,expires_in为授权过期时间(UNIX时间)
使用 set_access_token 保存授权。往下走,就可以调用微博界面了。测试发了一条推文
但是,这种手动输入代码的方式并不适合调用程序。是否可以在不打开链接的情况下请求登录并获得授权?经过多方搜索参考,程序改进如下,可以自动获取代码并保存,方便程序服务调用。
accessWeibo
# -*- coding: utf-8 -*-
#/usr/bin/env python
#access to SinaWeibo By sinaweibopy
#实现微博自动登录,token自动生成,保存及更新
#适合于后端服务调用
from weibo import APIClient
import pymongo
import sys, os, urllib, urllib2
from http_helper import *
from retry import *
try:
import json
except ImportError:
import simplejson as json
# setting sys encoding to utf-8
default_encoding = 'utf-8'
if sys.getdefaultencoding() != default_encoding:
reload(sys)
sys.setdefaultencoding(default_encoding)
# weibo api访问配置
APP_KEY = '' # app key
APP_SECRET = '' # app secret
REDIRECT_URL = 'https://api.weibo.com/oauth2/default.html' # callback url 授权回调页,与OAuth2.0 授权设置的一致
USERID = '' # 登陆的微博用户名,必须是OAuth2.0 设置的测试账号
USERPASSWD = '' # 用户密码
client = APIClient(app_key=APP_KEY, app_secret=APP_SECRET, redirect_uri=REDIRECT_URL)
def make_access_token():
#请求access token
params = urllib.urlencode({
'action':'submit',
'withOfficalFlag':'0',
'ticket':'',
'isLoginSina':'',
'response_type':'code',
'regCallback':'',
'redirect_uri':REDIRECT_URL,
'client_id':APP_KEY,
'state':'',
'from':'',
'userId':USERID,
'passwd':USERPASSWD,
})
login_url = 'https://api.weibo.com/oauth2/authorize'
url = client.get_authorize_url()
content = urllib2.urlopen(url)
if content:
headers = { 'Referer' : url }
request = urllib2.Request(login_url, params, headers)
opener = get_opener(False)
urllib2.install_opener(opener)
try:
f = opener.open(request)
return_redirect_uri = f.url
except urllib2.HTTPError, e:
return_redirect_uri = e.geturl()
# 取到返回的code
code = return_redirect_uri.split('=')[1]
#得到token
token = client.request_access_token(code,REDIRECT_URL)
save_access_token(token)
def save_access_token(token):
#将access token保存到MongoDB数据库
mongoCon=pymongo.Connection(host="127.0.0.1",port=27017)
db= mongoCon.weibo
t={
"access_token":token['access_token'],
"expires_in":str(token['expires_in']),
"date":time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time()))
}
db.token.insert(t,safe=True)
#Decorator 目的是当调用make_access_token()后再执行一次apply_access_token()
@retry(1)
def apply_access_token():
#从MongoDB读取及设置access token
try:
mongoCon=pymongo.Connection(host="127.0.0.1",port=27017)
db= mongoCon.weibo
if db.token.count()>0:
tokenInfos=db.token.find().sort([("_id",pymongo.DESCENDING)]).limit(1)
else:
make_access_token()
return False
for tokenInfo in tokenInfos:
access_token=tokenInfo["access_token"]
expires_in=tokenInfo["expires_in"]
try:
client.set_access_token(access_token, expires_in)
except StandardError, e:
if hasattr(e, 'error'):
if e.error == 'expired_token':
# token过期重新生成
make_access_token()
return False
else:
pass
except:
make_access_token()
return False
return True
if __name__ == "__main__":
apply_access_token()
# 以下为访问微博api的应用逻辑
# 以发布文字微博接口为例
client.statuses.update.post(status='Test OAuth 2.0 Send a Weibo!')
retry.py
import math
import time
# Retry decorator with exponential backoff
def retry(tries, delay=1, backoff=2):
"""Retries a function or method until it returns True.
delay sets the initial delay, and backoff sets how much the delay should
lengthen after each failure. backoff must be greater than 1, or else it
isn't really a backoff. tries must be at least 0, and delay greater than
0."""
if backoff decorated function
return deco_retry # @retry(arg[, ...]) -> true decorator
http_helper.py
# -*- coding: utf-8 -*-
#/usr/bin/env python
import urllib2,cookielib
class SmartRedirectHandler(urllib2.HTTPRedirectHandler):
def http_error_301(cls, req, fp, code, msg, headers):
result = urllib2.HTTPRedirectHandler.http_error_301(cls, req, fp, code, msg, headers)
result.status = code
print headers
return result
def http_error_302(cls, req, fp, code, msg, headers):
result = urllib2.HTTPRedirectHandler.http_error_302(cls, req, fp, code, msg, headers)
result.status = code
print headers
return result
def get_cookie():
cookies = cookielib.CookieJar()
return urllib2.HTTPCookieProcessor(cookies)
def get_opener(proxy=False):
rv=urllib2.build_opener(get_cookie(), SmartRedirectHandler())
rv.addheaders = [('User-agent', 'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1)')]
return rv
网站调用新浪微博内容(新浪微博API新特点与百度地图API相比(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-03-17 19:14
文章目录
查看 API 使用流程
在上一篇文章API Python编程简介:(一)使用百度地图API查地理坐标,通过百度地图API的使用,我们看到API调用的大致流程是:生成API规则 格式化url -> 通过urllib读取url中的数据 -> 解析json格式的数据 接下来开始研究新浪微博API的使用吧!
准备好工作了
新浪微博开放平台是使用新浪微博API的平台。
使用微博账号登录平台后,即可申请成为开发者,创建新应用后将获得唯一的App Key和App Secret。(注:申请不需要提交审核,只要创建一个新的申请,就会分配Key和Secret。)这两个信息也可以在“我的申请/申请信息/基本信息”中找到. 该页面还有“我的申请/申请信息/高级信息”项,点击进入并设置OAuth2.0授权回调页面的相关信息。如果不知道填什么,可以设置为默认回调Page:。后面需要这三条信息,请复制保存到文档中。
微博API新功能
新浪微博API与百度地图API相比,增加了OAuth2.0协议进行用户认证和授权。这里只是简单说明一下(有兴趣的同学可以参考网上文档示意图):通过该协议,第三方应用可以获取用户授权,然后使用该License从授权服务器获取token,用于来自 API 服务器的后续查询 验证数据时。
这个验证过程增加了 url 生成的复杂性。好在网站上已经有廖雪峰老师提供的SDK工具包:sinaweibopy(廖老师的github地址好像改名了,网上很多旧链接都失效了,这是新的有效链接),但是这个程序是基于Python2环境编写的,Python3的一些系统库做了改动,程序调用时经常报错。作为 Python 初学者,重写程序以适应 Python3 环境无疑是困难的。幸运的是,有一位大神完成了这项工作。感谢 owolf 为 Python3 重写的 SDK:sinweibopy3。我用过,运行正常。你可以下载它。在这里,我也推荐一下owolf的文章
简单的例子
介绍一下新浪微博API的使用过程,为新生提供参考。
1.参数设置
import sinaweibopy3
import webbrowser
import json
APP_KEY =' 填入你的App Key'
APP_SECRET=' 填入你的App Secret'
REDIRECT_URL =' 填入你的授权回调页'
笔记:
这里说一下我的粗心造成的一个bug,也提醒大家。当我第一次运行程序时,每次都会收到“重定向地址不匹配”错误消息:
微博账号登录出错!授权第三方应用出错,请联系第三方应用开发者:XXX或稍后重试。
错误代码:21322 重定向地址不匹配
网上找了解决方法,设置回调页,但是我之前的步骤已经设置好了,为什么还是这个问题?后来在一篇文章文章中看到,回调页面的地址应该和程序中的REDIRECT_URL一致。想到了程序例子,用http:开头,我填的时候看到同一个地址,没有变化,而网站是https:开头,一个's的区别',当时我还以为是地址,没想到差别这么大!
2.OAuth2.0 验证生成的url
client = sinaweibopy3.APIClient(app_key=APP_KEY, app_secret=APP_SECRET, redirect_uri=REDIRECT_URL)
url = client.get_authorize_url()
webbrowser.open_new(url)
result = client.request_access_token(input("please input code: "))
client.set_access_token(result.access_token, result.expires_in)
注意:这是调用sinweibopy3实现用户授权->在OAuth2.0中获取Token的过程。当程序运行到client.request_access_token时,会弹出输入提示“请输入密码:”,询问密码?这是什么意思?打开浏览器会看到出现OAuth2.0验证回调页面。地址栏中的“code=”后面有一串字符。这就是我们想要的Token信息。复制它,粘贴它并输入它,然后程序继续。跑步。
3.从 API 读取数据
运行以下代码读取公众微博数据并显示结果。
result=client.public_timeline()
print(json.dumps(result,indent=2,ensure_ascii=False))
通过查看数据结构,可以提取特定信息。比如下面的代码可以用来输出用户的微博昵称、位置、最新微博的文字。
number=result["total_number"]
print(number,"users:")
for u in result["statuses"]:
print(u["user"]["screen_name"])
print(u["user"]["location"])
print(u["text"])
先进的 查看全部
网站调用新浪微博内容(新浪微博API新特点与百度地图API相比(图))
文章目录
查看 API 使用流程
在上一篇文章API Python编程简介:(一)使用百度地图API查地理坐标,通过百度地图API的使用,我们看到API调用的大致流程是:生成API规则 格式化url -> 通过urllib读取url中的数据 -> 解析json格式的数据 接下来开始研究新浪微博API的使用吧!
准备好工作了
新浪微博开放平台是使用新浪微博API的平台。
使用微博账号登录平台后,即可申请成为开发者,创建新应用后将获得唯一的App Key和App Secret。(注:申请不需要提交审核,只要创建一个新的申请,就会分配Key和Secret。)这两个信息也可以在“我的申请/申请信息/基本信息”中找到. 该页面还有“我的申请/申请信息/高级信息”项,点击进入并设置OAuth2.0授权回调页面的相关信息。如果不知道填什么,可以设置为默认回调Page:。后面需要这三条信息,请复制保存到文档中。
微博API新功能
新浪微博API与百度地图API相比,增加了OAuth2.0协议进行用户认证和授权。这里只是简单说明一下(有兴趣的同学可以参考网上文档示意图):通过该协议,第三方应用可以获取用户授权,然后使用该License从授权服务器获取token,用于来自 API 服务器的后续查询 验证数据时。
这个验证过程增加了 url 生成的复杂性。好在网站上已经有廖雪峰老师提供的SDK工具包:sinaweibopy(廖老师的github地址好像改名了,网上很多旧链接都失效了,这是新的有效链接),但是这个程序是基于Python2环境编写的,Python3的一些系统库做了改动,程序调用时经常报错。作为 Python 初学者,重写程序以适应 Python3 环境无疑是困难的。幸运的是,有一位大神完成了这项工作。感谢 owolf 为 Python3 重写的 SDK:sinweibopy3。我用过,运行正常。你可以下载它。在这里,我也推荐一下owolf的文章
简单的例子
介绍一下新浪微博API的使用过程,为新生提供参考。
1.参数设置
import sinaweibopy3
import webbrowser
import json
APP_KEY =' 填入你的App Key'
APP_SECRET=' 填入你的App Secret'
REDIRECT_URL =' 填入你的授权回调页'
笔记:
这里说一下我的粗心造成的一个bug,也提醒大家。当我第一次运行程序时,每次都会收到“重定向地址不匹配”错误消息:
微博账号登录出错!授权第三方应用出错,请联系第三方应用开发者:XXX或稍后重试。
错误代码:21322 重定向地址不匹配
网上找了解决方法,设置回调页,但是我之前的步骤已经设置好了,为什么还是这个问题?后来在一篇文章文章中看到,回调页面的地址应该和程序中的REDIRECT_URL一致。想到了程序例子,用http:开头,我填的时候看到同一个地址,没有变化,而网站是https:开头,一个's的区别',当时我还以为是地址,没想到差别这么大!
2.OAuth2.0 验证生成的url
client = sinaweibopy3.APIClient(app_key=APP_KEY, app_secret=APP_SECRET, redirect_uri=REDIRECT_URL)
url = client.get_authorize_url()
webbrowser.open_new(url)
result = client.request_access_token(input("please input code: "))
client.set_access_token(result.access_token, result.expires_in)
注意:这是调用sinweibopy3实现用户授权->在OAuth2.0中获取Token的过程。当程序运行到client.request_access_token时,会弹出输入提示“请输入密码:”,询问密码?这是什么意思?打开浏览器会看到出现OAuth2.0验证回调页面。地址栏中的“code=”后面有一串字符。这就是我们想要的Token信息。复制它,粘贴它并输入它,然后程序继续。跑步。
3.从 API 读取数据
运行以下代码读取公众微博数据并显示结果。
result=client.public_timeline()
print(json.dumps(result,indent=2,ensure_ascii=False))
通过查看数据结构,可以提取特定信息。比如下面的代码可以用来输出用户的微博昵称、位置、最新微博的文字。
number=result["total_number"]
print(number,"users:")
for u in result["statuses"]:
print(u["user"]["screen_name"])
print(u["user"]["location"])
print(u["text"])
先进的
网站调用新浪微博内容(Python微博API获取微博内容作者:更多优惠gt(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2022-03-16 20:11
阿里云 > 云栖社区 > 主题地图 > X > 新浪微博api获取数据
推荐活动:
更多优惠>
当前话题:新浪微博api获取数据加入采集
相关话题:
新浪微博api获取数据相关博客看更多博文
使用新浪微博API的Search接口做微博锐排
作者:郑云1802浏览量:05年前
郑云20100929申请入口:简单介绍一下我们的榜单与新浪自己的热门转发榜单的区别:微博睿推榜单会忽略名人推文,更关注草根推文,更关注社会民生推文,屏蔽非- 有营养的推文。微博锐推列表将汇总以新浪微博为首的国内主要微博网站的信息
阅读全文
Python调用微博API获取微博内容
作者:745 浏览评论:05年前
1:获取app-key和app-secret 用自己的微博账号()登录微博开放平台,在微博开放中心下的“创建应用”下创建应用。随意填写申请信息。填写后就不需要了。提交审核,只需要那个app-ke
阅读全文
开放平台:新浪微博 for iOS
作者:余书仪 845 浏览评论:09年前
简介:新浪微博几乎打通了所有平台数据的API接口。所以很多优秀的第三方微博客户端在功能上都非常全面。通过 SNS 进行分享和推广的方式已经在 App 世界中使用。它很常见,随处可见。本文主要介绍App与新浪微博的关联方式。参考:1.开发
阅读全文
新浪微博发展(一)
作者:nothingfinal1071 浏览评论:08年前
这几天一直在研究新浪微博的授权验证。我在论坛上传了一个例子,找到了一个相关的博客文章。. 本以为很容易理解,但花了很长时间,我还是一头雾水。. 后来想了想,其实别人提供的也只是一些接口和方法,我也没有认真研究过授权过程,所以比较关心代码中那些奇怪的方法。
阅读全文
新浪微博发展(一)
作者:xumaojun1002人浏览评论:08年前
这几天一直在研究新浪微博的授权验证。我在论坛上传了一个例子,找到了一个相关的博客文章。. 本以为很容易理解,但花了很长时间,我还是一头雾水。. 后来想了想,其实别人提供的也只是一些接口和方法,我也没有认真研究过授权过程,所以比较关心代码中那些奇怪的方法。
阅读全文
新浪微博开放平台开发步骤介绍(适合新手)
作者:技术组合950人查看评论数:04年前
我也是新手,第一次使用开放平台进行开发。起初,我觉得我无处可去。经过长时间的摸索,终于成功调用了API。现在把这段经历介绍给新手(高手不用看,当然如果大家能提出一些意见和建议,非常感谢),也想和大家交流。本示例介绍如何使用 API 提交数据(发布微
阅读全文
新浪微博开放平台老API中的PHP例程
作者:何立坚 1019 浏览评论:010年前
相关文章:一、PHP+新浪微博开放平台+新浪云平台(SAE)解决方案基础二、微博应用搭建流程三、PHP中的demo程序SDK简析四、进修趋势及有用资源五、必解的几个问题【PDF全文下载】本文是新浪微博老API中的PHP例程,可以作为第一步
阅读全文
iOS:新浪微博OAuth认证
作者:犹豫1185查看评论:04年前
新浪微博OAuth认证1、资源授权•在腾讯、新浪等互联网行业,用户群体非常庞大•有时需要共享一些用户资源,比如第三方想要访问用户的QQ数据,第三方想要访问用户的新浪微博数据 • 如果要共享用户资源,必须征得用户的同意,那么这里就有资源。
阅读全文 查看全部
网站调用新浪微博内容(Python微博API获取微博内容作者:更多优惠gt(组图))
阿里云 > 云栖社区 > 主题地图 > X > 新浪微博api获取数据
推荐活动:
更多优惠>
当前话题:新浪微博api获取数据加入采集
相关话题:
新浪微博api获取数据相关博客看更多博文
使用新浪微博API的Search接口做微博锐排
作者:郑云1802浏览量:05年前
郑云20100929申请入口:简单介绍一下我们的榜单与新浪自己的热门转发榜单的区别:微博睿推榜单会忽略名人推文,更关注草根推文,更关注社会民生推文,屏蔽非- 有营养的推文。微博锐推列表将汇总以新浪微博为首的国内主要微博网站的信息
阅读全文
Python调用微博API获取微博内容
作者:745 浏览评论:05年前
1:获取app-key和app-secret 用自己的微博账号()登录微博开放平台,在微博开放中心下的“创建应用”下创建应用。随意填写申请信息。填写后就不需要了。提交审核,只需要那个app-ke
阅读全文
开放平台:新浪微博 for iOS
作者:余书仪 845 浏览评论:09年前
简介:新浪微博几乎打通了所有平台数据的API接口。所以很多优秀的第三方微博客户端在功能上都非常全面。通过 SNS 进行分享和推广的方式已经在 App 世界中使用。它很常见,随处可见。本文主要介绍App与新浪微博的关联方式。参考:1.开发
阅读全文
新浪微博发展(一)
作者:nothingfinal1071 浏览评论:08年前
这几天一直在研究新浪微博的授权验证。我在论坛上传了一个例子,找到了一个相关的博客文章。. 本以为很容易理解,但花了很长时间,我还是一头雾水。. 后来想了想,其实别人提供的也只是一些接口和方法,我也没有认真研究过授权过程,所以比较关心代码中那些奇怪的方法。
阅读全文
新浪微博发展(一)
作者:xumaojun1002人浏览评论:08年前
这几天一直在研究新浪微博的授权验证。我在论坛上传了一个例子,找到了一个相关的博客文章。. 本以为很容易理解,但花了很长时间,我还是一头雾水。. 后来想了想,其实别人提供的也只是一些接口和方法,我也没有认真研究过授权过程,所以比较关心代码中那些奇怪的方法。
阅读全文
新浪微博开放平台开发步骤介绍(适合新手)
作者:技术组合950人查看评论数:04年前
我也是新手,第一次使用开放平台进行开发。起初,我觉得我无处可去。经过长时间的摸索,终于成功调用了API。现在把这段经历介绍给新手(高手不用看,当然如果大家能提出一些意见和建议,非常感谢),也想和大家交流。本示例介绍如何使用 API 提交数据(发布微
阅读全文
新浪微博开放平台老API中的PHP例程
作者:何立坚 1019 浏览评论:010年前
相关文章:一、PHP+新浪微博开放平台+新浪云平台(SAE)解决方案基础二、微博应用搭建流程三、PHP中的demo程序SDK简析四、进修趋势及有用资源五、必解的几个问题【PDF全文下载】本文是新浪微博老API中的PHP例程,可以作为第一步
阅读全文
iOS:新浪微博OAuth认证
作者:犹豫1185查看评论:04年前
新浪微博OAuth认证1、资源授权•在腾讯、新浪等互联网行业,用户群体非常庞大•有时需要共享一些用户资源,比如第三方想要访问用户的QQ数据,第三方想要访问用户的新浪微博数据 • 如果要共享用户资源,必须征得用户的同意,那么这里就有资源。
阅读全文
网站调用新浪微博内容(爬取微博大V的代码完整代码:m开头后接域名 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-03-16 20:08
)
用Python写爬虫,爬取微博大V的微博内容。本文以女神的微博为例(爬新浪m站:)
一般对于爬虫爬取网站,首先选择m站,其次是wap站,最后考虑PC站。当然,这也不是绝对的,有时候PC站的资料最全,你只需要所有的资料,那么PC站就是你的首选。一般m站都是以m开头后跟一个域名,所以本文的网址就是。
前期准备
1.代理IP
网上有很多免费的代理IP,比如西溪的免费代理IP,你可以找一个自己测试用;
2.抓包分析
通过抓包获取微博内容地址。我不会在这里详细介绍。不明白的可以自行百度查找相关资料。完整的代码直接在下面。
完整代码:
# -*- coding: utf-8 -*-
import urllib.request
import json
#定义要爬取的微博大V的微博ID
id='1259110474'
#设置代理IP
proxy_addr="122.241.72.191:808"
#定义页面打开函数
def use_proxy(url,proxy_addr):
req=urllib.request.Request(url)
req.add_header("User-Agent","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0")
proxy=urllib.request.ProxyHandler({'http':proxy_addr})
opener=urllib.request.build_opener(proxy,urllib.request.HTTPHandler)
urllib.request.install_opener(opener)
data=urllib.request.urlopen(req).read().decode('utf-8','ignore')
return data
#获取微博主页的containerid,爬取微博内容时需要此id
def get_containerid(url):
data=use_proxy(url,proxy_addr)
content=json.loads(data).get('data')
for data in content.get('tabsInfo').get('tabs'):
if(data.get('tab_type')=='weibo'):
containerid=data.get('containerid')
return containerid
#获取微博大V账号的用户基本信息,如:微博昵称、微博地址、微博头像、关注人数、粉丝数、性别、等级等
def get_userInfo(id):
url='https://m.weibo.cn/api/contain ... %2Bid
data=use_proxy(url,proxy_addr)
content=json.loads(data).get('data')
profile_image_url=content.get('userInfo').get('profile_image_url')
description=content.get('userInfo').get('description')
profile_url=content.get('userInfo').get('profile_url')
verified=content.get('userInfo').get('verified')
guanzhu=content.get('userInfo').get('follow_count')
name=content.get('userInfo').get('screen_name')
fensi=content.get('userInfo').get('followers_count')
gender=content.get('userInfo').get('gender')
urank=content.get('userInfo').get('urank')
print("微博昵称:"+name+"\n"+"微博主页地址:"+profile_url+"\n"+"微博头像地址:"+profile_image_url+"\n"+"是否认证:"+str(verified)+"\n"+"微博说明:"+description+"\n"+"关注人数:"+str(guanzhu)+"\n"+"粉丝数:"+str(fensi)+"\n"+"性别:"+gender+"\n"+"微博等级:"+str(urank)+"\n")
#获取微博内容信息,并保存到文本中,内容包括:每条微博的内容、微博详情页面地址、点赞数、评论数、转发数等
def get_weibo(id,file):
i=1
while True:
url='https://m.weibo.cn/api/contain ... %2Bid
weibo_url='https://m.weibo.cn/api/contain ... nerid(url)+'&page='+str(i)
try:
data=use_proxy(weibo_url,proxy_addr)
content=json.loads(data).get('data')
cards=content.get('cards')
if(len(cards)>0):
for j in range(len(cards)):
print("-----正在爬取第"+str(i)+"页,第"+str(j)+"条微博------")
card_type=cards[j].get('card_type')
if(card_type==9):
mblog=cards[j].get('mblog')
attitudes_count=mblog.get('attitudes_count')
comments_count=mblog.get('comments_count')
created_at=mblog.get('created_at')
reposts_count=mblog.get('reposts_count')
scheme=cards[j].get('scheme')
text=mblog.get('text')
with open(file,'a',encoding='utf-8') as fh:
fh.write("----第"+str(i)+"页,第"+str(j)+"条微博----"+"\n")
fh.write("微博地址:"+str(scheme)+"\n"+"发布时间:"+str(created_at)+"\n"+"微博内容:"+text+"\n"+"点赞数:"+str(attitudes_count)+"\n"+"评论数:"+str(comments_count)+"\n"+"转发数:"+str(reposts_count)+"\n")
i+=1
else:
break
except Exception as e:
print(e)
pass
if __name__=="__main__":
file=id+".txt"
get_userInfo(id)
get_weibo(id,file)
抓取结果
查看全部
网站调用新浪微博内容(爬取微博大V的代码完整代码:m开头后接域名
)
用Python写爬虫,爬取微博大V的微博内容。本文以女神的微博为例(爬新浪m站:)
一般对于爬虫爬取网站,首先选择m站,其次是wap站,最后考虑PC站。当然,这也不是绝对的,有时候PC站的资料最全,你只需要所有的资料,那么PC站就是你的首选。一般m站都是以m开头后跟一个域名,所以本文的网址就是。
前期准备
1.代理IP
网上有很多免费的代理IP,比如西溪的免费代理IP,你可以找一个自己测试用;
2.抓包分析
通过抓包获取微博内容地址。我不会在这里详细介绍。不明白的可以自行百度查找相关资料。完整的代码直接在下面。
完整代码:
# -*- coding: utf-8 -*-
import urllib.request
import json
#定义要爬取的微博大V的微博ID
id='1259110474'
#设置代理IP
proxy_addr="122.241.72.191:808"
#定义页面打开函数
def use_proxy(url,proxy_addr):
req=urllib.request.Request(url)
req.add_header("User-Agent","Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.221 Safari/537.36 SE 2.X MetaSr 1.0")
proxy=urllib.request.ProxyHandler({'http':proxy_addr})
opener=urllib.request.build_opener(proxy,urllib.request.HTTPHandler)
urllib.request.install_opener(opener)
data=urllib.request.urlopen(req).read().decode('utf-8','ignore')
return data
#获取微博主页的containerid,爬取微博内容时需要此id
def get_containerid(url):
data=use_proxy(url,proxy_addr)
content=json.loads(data).get('data')
for data in content.get('tabsInfo').get('tabs'):
if(data.get('tab_type')=='weibo'):
containerid=data.get('containerid')
return containerid
#获取微博大V账号的用户基本信息,如:微博昵称、微博地址、微博头像、关注人数、粉丝数、性别、等级等
def get_userInfo(id):
url='https://m.weibo.cn/api/contain ... %2Bid
data=use_proxy(url,proxy_addr)
content=json.loads(data).get('data')
profile_image_url=content.get('userInfo').get('profile_image_url')
description=content.get('userInfo').get('description')
profile_url=content.get('userInfo').get('profile_url')
verified=content.get('userInfo').get('verified')
guanzhu=content.get('userInfo').get('follow_count')
name=content.get('userInfo').get('screen_name')
fensi=content.get('userInfo').get('followers_count')
gender=content.get('userInfo').get('gender')
urank=content.get('userInfo').get('urank')
print("微博昵称:"+name+"\n"+"微博主页地址:"+profile_url+"\n"+"微博头像地址:"+profile_image_url+"\n"+"是否认证:"+str(verified)+"\n"+"微博说明:"+description+"\n"+"关注人数:"+str(guanzhu)+"\n"+"粉丝数:"+str(fensi)+"\n"+"性别:"+gender+"\n"+"微博等级:"+str(urank)+"\n")
#获取微博内容信息,并保存到文本中,内容包括:每条微博的内容、微博详情页面地址、点赞数、评论数、转发数等
def get_weibo(id,file):
i=1
while True:
url='https://m.weibo.cn/api/contain ... %2Bid
weibo_url='https://m.weibo.cn/api/contain ... nerid(url)+'&page='+str(i)
try:
data=use_proxy(weibo_url,proxy_addr)
content=json.loads(data).get('data')
cards=content.get('cards')
if(len(cards)>0):
for j in range(len(cards)):
print("-----正在爬取第"+str(i)+"页,第"+str(j)+"条微博------")
card_type=cards[j].get('card_type')
if(card_type==9):
mblog=cards[j].get('mblog')
attitudes_count=mblog.get('attitudes_count')
comments_count=mblog.get('comments_count')
created_at=mblog.get('created_at')
reposts_count=mblog.get('reposts_count')
scheme=cards[j].get('scheme')
text=mblog.get('text')
with open(file,'a',encoding='utf-8') as fh:
fh.write("----第"+str(i)+"页,第"+str(j)+"条微博----"+"\n")
fh.write("微博地址:"+str(scheme)+"\n"+"发布时间:"+str(created_at)+"\n"+"微博内容:"+text+"\n"+"点赞数:"+str(attitudes_count)+"\n"+"评论数:"+str(comments_count)+"\n"+"转发数:"+str(reposts_count)+"\n")
i+=1
else:
break
except Exception as e:
print(e)
pass
if __name__=="__main__":
file=id+".txt"
get_userInfo(id)
get_weibo(id,file)
抓取结果
网站调用新浪微博内容(【魔兽世界】新浪微博登录常用接口:对应主界面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-03-16 20:07
日志条目
新浪微博登录常用界面:
对应主界面:
不过,我个人推荐使用移动端的微博入口:
对应主界面:
原因是手机上的数据比较轻量级,基础数据齐全,可能会缺少一些基本的个人信息,比如“个人资料完成度”、“个人等级”等。粉丝ID和关注ID只能显示20页,但可以作为大部分验证的语料库。
通过对比下面两张图,分别是PC端和手机端,可以发现内容基本一致:
如下图在手机上,图片比较小,内容也比较简洁。
完整的源代码
下面的代码主要分为三部分:
1.登录微博(用户名、密码) 登录微博
2.VisitPersonPage(user_id) 访问follower网站获取个人信息
3.获取微博内容同时翻页
<p># coding=utf-8
"""
Created on 2016-02-22 @author: Eastmount
功能: 爬取新浪微博用户的信息
信息:用户ID 用户名 粉丝数 关注数 微博数 微博内容
网址:http://weibo.cn/ 数据量更小 相对http://weibo.com/
"""
import time
import re
import os
import sys
import codecs
import shutil
import urllib
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import selenium.webdriver.support.ui as ui
from selenium.webdriver.common.action_chains import ActionChains
#先调用无界面浏览器PhantomJS或Firefox
#driver = webdriver.PhantomJS(executable_path="G:phantomjs-1.9.1-windowsphantomjs.exe")
driver = webdriver.Firefox()
wait = ui.WebDriverWait(driver,10)
#全局变量 文件操作读写信息
inforead = codecs.open("SinaWeibo_List.txt", 'r', 'utf-8')
infofile = codecs.open("SinaWeibo_Info.txt", 'a', 'utf-8')
#********************************************************************************
# 第一步: 登陆weibo.cn 获取新浪微博的cookie
# 该方法针对weibo.cn有效(明文形式传输数据) weibo.com见学弟设置POST和Header方法
# LoginWeibo(username, password) 参数用户名 密码
# 验证码暂停时间手动输入
#********************************************************************************
def LoginWeibo(username, password):
try:
#**********************************************************************
# 直接访问driver.get("http://weibo.cn/5824697471")会跳转到登陆页面 用户id
#
# 用户名
# 密码 "password_4903" 中数字会变动,故采用绝对路径方法,否则不能定位到元素
#
# 勾选记住登录状态check默认是保留 故注释掉该代码 不保留Cookie 则'expiry'=None
#**********************************************************************
#输入用户名/密码登录
print u'准备登陆Weibo.cn网站...'
driver.get("http://login.weibo.cn/login/")
elem_user = driver.find_element_by_name("mobile")
elem_user.send_keys(username) #用户名
elem_pwd = driver.find_element_by_xpath("/html/body/div[2]/form/div/input[2]")
elem_pwd.send_keys(password) #密码
#elem_rem = driver.find_element_by_name("remember")
#elem_rem.click() #记住登录状态
#重点: 暂停时间输入验证码
#pause(millisenconds)
time.sleep(20)
elem_sub = driver.find_element_by_name("submit")
elem_sub.click() #点击登陆
time.sleep(2)
#获取Coockie 推荐 http://www.cnblogs.com/fnng/p/3269450.html
print driver.current_url
print driver.get_cookies() #获得cookie信息 dict存储
print u'输出Cookie键值对信息:'
for cookie in driver.get_cookies():
#print cookie
for key in cookie:
print key, cookie[key]
#driver.get_cookies()类型list 仅包含一个元素cookie类型dict
print u'登陆成功...'
except Exception,e:
print "Error: ",e
finally:
print u'End LoginWeibo!
'
#********************************************************************************
# 第二步: 访问个人页面http://weibo.cn/5824697471并获取信息
# VisitPersonPage()
# 编码常见错误 UnicodeEncodeError: 'ascii' codec can't encode characters
#********************************************************************************
def VisitPersonPage(user_id):
try:
global infofile
print u'准备访问个人网站.....'
#原创内容 http://weibo.cn/guangxianliuya ... e%3D2
driver.get("http://weibo.cn/" + user_id)
#**************************************************************************
# No.1 直接获取 用户昵称 微博数 关注数 粉丝数
# str_name.text是unicode编码类型
#**************************************************************************
#用户id
print u'个人详细信息'
print '**********************************************'
print u'用户id: ' + user_id
#昵称
str_name = driver.find_element_by_xpath("//div[@class='ut']")
str_t = str_name.text.split(" ")
num_name = str_t[0] #空格分隔 获取第一个值 "Eastmount 详细资料 设置 新手区"
print u'昵称: ' + num_name
#微博数 除个人主页 它默认直接显示微博数 无超链接
#Error: 'unicode' object is not callable
#一般是把字符串当做函数使用了 str定义成字符串 而str()函数再次使用时报错
str_wb = driver.find_element_by_xpath("//div[@class='tip2']")
pattern = r"d+.?d*" #正则提取"微博[0]" 但r"([.*?])"总含[]
guid = re.findall(pattern, str_wb.text, re.S|re.M)
print str_wb.text #微博[294] 关注[351] 粉丝[294] 分组[1] @他的
for value in guid:
num_wb = int(value)
break
print u'微博数: ' + str(num_wb)
#关注数
str_gz = driver.find_element_by_xpath("//div[@class='tip2']/a[1]")
guid = re.findall(pattern, str_gz.text, re.M)
num_gz = int(guid[0])
print u'关注数: ' + str(num_gz)
#粉丝数
str_fs = driver.find_element_by_xpath("//div[@class='tip2']/a[2]")
guid = re.findall(pattern, str_fs.text, re.M)
num_fs = int(guid[0])
print u'粉丝数: ' + str(num_fs)
#***************************************************************************
# No.2 文件操作写入信息
#***************************************************************************
infofile.write('=====================================================================
')
infofile.write(u'用户: ' + user_id + '
')
infofile.write(u'昵称: ' + num_name + '
')
infofile.write(u'微博数: ' + str(num_wb) + '
')
infofile.write(u'关注数: ' + str(num_gz) + '
')
infofile.write(u'粉丝数: ' + str(num_fs) + '
')
infofile.write(u'微博内容: ' + '
')
#***************************************************************************
# No.3 获取微博内容
# http://weibo.cn/guangxianliuya ... e%3D1
# 其中filter=0表示全部 =1表示原创
#***************************************************************************
print '
'
print u'获取微博内容信息'
num = 1
while num 查看全部
网站调用新浪微博内容(【魔兽世界】新浪微博登录常用接口:对应主界面)
日志条目
新浪微博登录常用界面:
对应主界面:
不过,我个人推荐使用移动端的微博入口:
对应主界面:
原因是手机上的数据比较轻量级,基础数据齐全,可能会缺少一些基本的个人信息,比如“个人资料完成度”、“个人等级”等。粉丝ID和关注ID只能显示20页,但可以作为大部分验证的语料库。
通过对比下面两张图,分别是PC端和手机端,可以发现内容基本一致:
如下图在手机上,图片比较小,内容也比较简洁。
完整的源代码
下面的代码主要分为三部分:
1.登录微博(用户名、密码) 登录微博
2.VisitPersonPage(user_id) 访问follower网站获取个人信息
3.获取微博内容同时翻页
<p># coding=utf-8
"""
Created on 2016-02-22 @author: Eastmount
功能: 爬取新浪微博用户的信息
信息:用户ID 用户名 粉丝数 关注数 微博数 微博内容
网址:http://weibo.cn/ 数据量更小 相对http://weibo.com/
"""
import time
import re
import os
import sys
import codecs
import shutil
import urllib
from selenium import webdriver
from selenium.webdriver.common.keys import Keys
import selenium.webdriver.support.ui as ui
from selenium.webdriver.common.action_chains import ActionChains
#先调用无界面浏览器PhantomJS或Firefox
#driver = webdriver.PhantomJS(executable_path="G:phantomjs-1.9.1-windowsphantomjs.exe")
driver = webdriver.Firefox()
wait = ui.WebDriverWait(driver,10)
#全局变量 文件操作读写信息
inforead = codecs.open("SinaWeibo_List.txt", 'r', 'utf-8')
infofile = codecs.open("SinaWeibo_Info.txt", 'a', 'utf-8')
#********************************************************************************
# 第一步: 登陆weibo.cn 获取新浪微博的cookie
# 该方法针对weibo.cn有效(明文形式传输数据) weibo.com见学弟设置POST和Header方法
# LoginWeibo(username, password) 参数用户名 密码
# 验证码暂停时间手动输入
#********************************************************************************
def LoginWeibo(username, password):
try:
#**********************************************************************
# 直接访问driver.get("http://weibo.cn/5824697471";)会跳转到登陆页面 用户id
#
# 用户名
# 密码 "password_4903" 中数字会变动,故采用绝对路径方法,否则不能定位到元素
#
# 勾选记住登录状态check默认是保留 故注释掉该代码 不保留Cookie 则'expiry'=None
#**********************************************************************
#输入用户名/密码登录
print u'准备登陆Weibo.cn网站...'
driver.get("http://login.weibo.cn/login/";)
elem_user = driver.find_element_by_name("mobile")
elem_user.send_keys(username) #用户名
elem_pwd = driver.find_element_by_xpath("/html/body/div[2]/form/div/input[2]")
elem_pwd.send_keys(password) #密码
#elem_rem = driver.find_element_by_name("remember")
#elem_rem.click() #记住登录状态
#重点: 暂停时间输入验证码
#pause(millisenconds)
time.sleep(20)
elem_sub = driver.find_element_by_name("submit")
elem_sub.click() #点击登陆
time.sleep(2)
#获取Coockie 推荐 http://www.cnblogs.com/fnng/p/3269450.html
print driver.current_url
print driver.get_cookies() #获得cookie信息 dict存储
print u'输出Cookie键值对信息:'
for cookie in driver.get_cookies():
#print cookie
for key in cookie:
print key, cookie[key]
#driver.get_cookies()类型list 仅包含一个元素cookie类型dict
print u'登陆成功...'
except Exception,e:
print "Error: ",e
finally:
print u'End LoginWeibo!
'
#********************************************************************************
# 第二步: 访问个人页面http://weibo.cn/5824697471并获取信息
# VisitPersonPage()
# 编码常见错误 UnicodeEncodeError: 'ascii' codec can't encode characters
#********************************************************************************
def VisitPersonPage(user_id):
try:
global infofile
print u'准备访问个人网站.....'
#原创内容 http://weibo.cn/guangxianliuya ... e%3D2
driver.get("http://weibo.cn/" + user_id)
#**************************************************************************
# No.1 直接获取 用户昵称 微博数 关注数 粉丝数
# str_name.text是unicode编码类型
#**************************************************************************
#用户id
print u'个人详细信息'
print '**********************************************'
print u'用户id: ' + user_id
#昵称
str_name = driver.find_element_by_xpath("//div[@class='ut']")
str_t = str_name.text.split(" ")
num_name = str_t[0] #空格分隔 获取第一个值 "Eastmount 详细资料 设置 新手区"
print u'昵称: ' + num_name
#微博数 除个人主页 它默认直接显示微博数 无超链接
#Error: 'unicode' object is not callable
#一般是把字符串当做函数使用了 str定义成字符串 而str()函数再次使用时报错
str_wb = driver.find_element_by_xpath("//div[@class='tip2']")
pattern = r"d+.?d*" #正则提取"微博[0]" 但r"([.*?])"总含[]
guid = re.findall(pattern, str_wb.text, re.S|re.M)
print str_wb.text #微博[294] 关注[351] 粉丝[294] 分组[1] @他的
for value in guid:
num_wb = int(value)
break
print u'微博数: ' + str(num_wb)
#关注数
str_gz = driver.find_element_by_xpath("//div[@class='tip2']/a[1]")
guid = re.findall(pattern, str_gz.text, re.M)
num_gz = int(guid[0])
print u'关注数: ' + str(num_gz)
#粉丝数
str_fs = driver.find_element_by_xpath("//div[@class='tip2']/a[2]")
guid = re.findall(pattern, str_fs.text, re.M)
num_fs = int(guid[0])
print u'粉丝数: ' + str(num_fs)
#***************************************************************************
# No.2 文件操作写入信息
#***************************************************************************
infofile.write('=====================================================================
')
infofile.write(u'用户: ' + user_id + '
')
infofile.write(u'昵称: ' + num_name + '
')
infofile.write(u'微博数: ' + str(num_wb) + '
')
infofile.write(u'关注数: ' + str(num_gz) + '
')
infofile.write(u'粉丝数: ' + str(num_fs) + '
')
infofile.write(u'微博内容: ' + '
')
#***************************************************************************
# No.3 获取微博内容
# http://weibo.cn/guangxianliuya ... e%3D1
# 其中filter=0表示全部 =1表示原创
#***************************************************************************
print '
'
print u'获取微博内容信息'
num = 1
while num
网站调用新浪微博内容(一下怎么模拟登陆新浪微博(图)步详解(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-03-16 20:07
最近需要爬取微博的数据进行分析。对于新浪微博,官方提供了API,但是有几个致命的限制(调用次数和授权期限的限制),所以我觉得有必要研究爬虫,直接爬取。通过微博获取微博数据的可行性。
由于模拟登陆微博是爬虫抓取微博信息的第一步,下面介绍如何模拟登陆微博(以新浪微博为例)。
这个过程主要分为两个步骤:
1 脚本模拟登陆新浪微博并保存cookies;
2 获得cookie信息后,使用cookie信息直接访问微博url。
其中,第一步是这里讨论的重点。为了更好的模拟这一步,需要一个好的网络监控工具,可以使用火狐的Firebug和Chrome以及IE自带的开发工具(注意IE必须是IE9以上才有监控网络的功能,Chrome的网络交互消息可以在网络部分查看)。另外前两天发现python支持的包很多,用python自定义自己的网络包比较方便,所以这里我用python作为我的开发语言。
好了,先说一下前提工作,下面开始分析用户在登录新浪微博的过程中进行的操作。在下面的例子中,我使用chrome自带的开发者工具作为我的网络包监控工具。
首先打开(如果你设置了浏览器自动记住密码自动登录,需要清除cookie),然后通过网络监控工具,我们会发现在用户登录过程中,浏览器与服务器三遍。它们如下:
一、第一个Get请求获取一些参数
在用户名栏输入你的微博账号,然后确认,这时你会发现当你的焦点离开用户名输入框时,浏览器会自动报"callback=sinaSSOController.preloginCallBack&su=&rsakt=mod& checkpin=1&client =ssologin.js (v1.4.5)&_=83” 发送GET请求,如下:
仔细看这个GET请求的响应内容,你会发现这个JSON字符串收录了几个参数,可能你不知道它们的含义,但是没关系,现在你只需要知道这些参数会在后续处理。能。
二、发送 POST 请求
这部分是整个登录过程的重点。这部分用于向服务器提交用户信息,服务器会判断用户信息是否正确,从而判断登录是否成功。
通过 Chrome 自带的开发者工具,可以观察到 POST 消息的相关信息(url、headers、data)。下图是我的 POST 消息截图:
网址信息如下:
包头信息如下:
POST的消息数据信息如下:
接下来的工作就比较简单了,我们要做的就是模仿上面消息的内容和格式,用python发送类似的消息。在自己自定义类似的消息之前,我觉得有必要简单解释一下上面消息中DATA表单中每一项的含义。
其中,“su”为加密后的用户名,“sp”为加密后的密码。“servertime”、“nonce”和“rsakv”是上一个GET请求返回的JSON字符串的内容。其他参数不变。然后,重点讨论“su”和“sp”的加密算法。
1. "su" 加密算法
su 是 BASE64 计算出来的用户名: su= base64.encodestring( urllib.quote(username) )[:-1];
2. "sp" 加密算法
sp的加密算法可能会经常变化(考虑到网站的安全性,一段时间后登录消息的格式和加密算法发生变化是正常的),目前新浪使用的是RSA算法(如果你比较js 如果你是牛,可以直接去网页源码找它的加密方式,我没找到,参考网上有)。
这里简单介绍一下RSA算法的解密过程。
2.1 安装RSA模块,下载地址为:
2.2 创建一个 rsa 公钥。公钥的两个参数在新浪微博上都给定了固定值,但都是十六进制字符串。第一个是第一步登录的那个。pubkey,第二个是js加密文件中的'10001'。这两个值需要先从十六进制转换为十进制,但也可以在代码中硬编码。我直接写'10001'为65537
rsaPublickey=int(pubkey,16)
key=rsa.PublicKey(rsaPublickey,65537)#创建公钥
message=str(servertime)+'\t'+str(nonce)+'\n'+str(password)#拼接明文js加密文件得到
passwd=rsa.encrypt(message,key)#encryption
passwd=binascii.b2a_hex(passwd)#将加密信息转换为十六进制。
如果上述所有步骤对您来说都顺利,您将收到以下响应:
这是一个自动跳转语句,其中收录要跳转的URL。如果登录正确,则该URL中的德语retcode值为0。否则,登录错误。您需要仔细检查上述步骤。
三、跳转到对应的微博页面
我们已经得到了上面要重定向的 url,所以现在我们只需要请求这个 URL。这里需要注意的一点是,为了让服务器知道你是否登录,这一步的请求需要使用上一步操作的cookie信息(因为第二步登录成功的信息会会自动记录在cookie中),所以我们在整个程序的开始就开启cookie,以保证cookie在以后的操作中可以正确使用。同时对于python用户,这一步不要自定义header,因为urllib2默认会自动打包cookie信息。如果手动自定义标头,则可能会丢失 cookie 信息。
下面附上我的参考代码:
参考文章:
1、
2、
从:
转载于: 查看全部
网站调用新浪微博内容(一下怎么模拟登陆新浪微博(图)步详解(组图))
最近需要爬取微博的数据进行分析。对于新浪微博,官方提供了API,但是有几个致命的限制(调用次数和授权期限的限制),所以我觉得有必要研究爬虫,直接爬取。通过微博获取微博数据的可行性。
由于模拟登陆微博是爬虫抓取微博信息的第一步,下面介绍如何模拟登陆微博(以新浪微博为例)。
这个过程主要分为两个步骤:
1 脚本模拟登陆新浪微博并保存cookies;
2 获得cookie信息后,使用cookie信息直接访问微博url。
其中,第一步是这里讨论的重点。为了更好的模拟这一步,需要一个好的网络监控工具,可以使用火狐的Firebug和Chrome以及IE自带的开发工具(注意IE必须是IE9以上才有监控网络的功能,Chrome的网络交互消息可以在网络部分查看)。另外前两天发现python支持的包很多,用python自定义自己的网络包比较方便,所以这里我用python作为我的开发语言。
好了,先说一下前提工作,下面开始分析用户在登录新浪微博的过程中进行的操作。在下面的例子中,我使用chrome自带的开发者工具作为我的网络包监控工具。
首先打开(如果你设置了浏览器自动记住密码自动登录,需要清除cookie),然后通过网络监控工具,我们会发现在用户登录过程中,浏览器与服务器三遍。它们如下:
一、第一个Get请求获取一些参数
在用户名栏输入你的微博账号,然后确认,这时你会发现当你的焦点离开用户名输入框时,浏览器会自动报"callback=sinaSSOController.preloginCallBack&su=&rsakt=mod& checkpin=1&client =ssologin.js (v1.4.5)&_=83” 发送GET请求,如下:
仔细看这个GET请求的响应内容,你会发现这个JSON字符串收录了几个参数,可能你不知道它们的含义,但是没关系,现在你只需要知道这些参数会在后续处理。能。
二、发送 POST 请求
这部分是整个登录过程的重点。这部分用于向服务器提交用户信息,服务器会判断用户信息是否正确,从而判断登录是否成功。
通过 Chrome 自带的开发者工具,可以观察到 POST 消息的相关信息(url、headers、data)。下图是我的 POST 消息截图:
网址信息如下:
包头信息如下:
POST的消息数据信息如下:
接下来的工作就比较简单了,我们要做的就是模仿上面消息的内容和格式,用python发送类似的消息。在自己自定义类似的消息之前,我觉得有必要简单解释一下上面消息中DATA表单中每一项的含义。
其中,“su”为加密后的用户名,“sp”为加密后的密码。“servertime”、“nonce”和“rsakv”是上一个GET请求返回的JSON字符串的内容。其他参数不变。然后,重点讨论“su”和“sp”的加密算法。
1. "su" 加密算法
su 是 BASE64 计算出来的用户名: su= base64.encodestring( urllib.quote(username) )[:-1];
2. "sp" 加密算法
sp的加密算法可能会经常变化(考虑到网站的安全性,一段时间后登录消息的格式和加密算法发生变化是正常的),目前新浪使用的是RSA算法(如果你比较js 如果你是牛,可以直接去网页源码找它的加密方式,我没找到,参考网上有)。
这里简单介绍一下RSA算法的解密过程。
2.1 安装RSA模块,下载地址为:
2.2 创建一个 rsa 公钥。公钥的两个参数在新浪微博上都给定了固定值,但都是十六进制字符串。第一个是第一步登录的那个。pubkey,第二个是js加密文件中的'10001'。这两个值需要先从十六进制转换为十进制,但也可以在代码中硬编码。我直接写'10001'为65537
rsaPublickey=int(pubkey,16)
key=rsa.PublicKey(rsaPublickey,65537)#创建公钥
message=str(servertime)+'\t'+str(nonce)+'\n'+str(password)#拼接明文js加密文件得到
passwd=rsa.encrypt(message,key)#encryption
passwd=binascii.b2a_hex(passwd)#将加密信息转换为十六进制。
如果上述所有步骤对您来说都顺利,您将收到以下响应:
这是一个自动跳转语句,其中收录要跳转的URL。如果登录正确,则该URL中的德语retcode值为0。否则,登录错误。您需要仔细检查上述步骤。
三、跳转到对应的微博页面
我们已经得到了上面要重定向的 url,所以现在我们只需要请求这个 URL。这里需要注意的一点是,为了让服务器知道你是否登录,这一步的请求需要使用上一步操作的cookie信息(因为第二步登录成功的信息会会自动记录在cookie中),所以我们在整个程序的开始就开启cookie,以保证cookie在以后的操作中可以正确使用。同时对于python用户,这一步不要自定义header,因为urllib2默认会自动打包cookie信息。如果手动自定义标头,则可能会丢失 cookie 信息。
下面附上我的参考代码:
参考文章:
1、
2、
从:
转载于:
网站调用新浪微博内容(PHP+新浪微博api获取评论信息推荐活动(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-03-16 20:05
阿里云 > 云栖社区 > 主题地图 > L > 使用新浪微博API获取评论信息
推荐活动:
更多优惠>
当前话题:使用新浪微博api获取评论信息并加入采集
相关话题:
使用新浪微博api获取评论信息相关博文看更多博文
使用新浪微博API的Search接口做微博锐排
作者:郑云1802浏览量:05年前
郑云20100929申请入口:简单介绍一下我们的榜单与新浪自己的热门转发榜单的区别:微博睿推榜单会忽略名人推文,更关注草根推文,更关注社会民生推文,屏蔽非- 有营养的推文。微博锐推列表将汇总以新浪微博为首的国内主要微博网站的信息
阅读全文
新浪微博开放平台WeiboClient类的公共方法(PHP)
作者:何立坚 936 浏览评论:010年前
相关文章:一、PHP+新浪微博开放平台+新浪云平台(SAE)解决方案基础二、微博应用搭建过程三、PHP中的demo程序SDK简析四、进修方向及有用资源五、必解的几个问题【PDF全文下载】初步掌握微博应用开发流程后,推荐阅读魏
阅读全文
Windows Phone 7应用的新浪微博-UI设计
作者:小技术专家 1009人查看评论:04年前
我还没有时间做 Windows phone 7 应用程序。上周在APP Store论坛看到一位国外DVP在WP7上写了一个推特客户端。仔细一看,我觉得很简单。我只是使用 WP7 在 Twitter 上获取信息。列表。国内微博只玩过163网易,可惜
阅读全文
腾讯微博 for Windows Phone 7 应用 - OAuth 认证
作者:小技术专家1210查看评论:04年前
前段时间写了一篇关于Windows Phone 7新浪微博应用的文章——UI设计旨在将新浪微博移植到WP7客户端。期间,几位园友提出共同开发这款应用。但是年底比较忙。时间很紧,我间歇性地利用空闲时间更新这个新浪迷你博客
阅读全文
新浪微博 for Windows Phone 7 应用程序 - UI 设计
作者:狼人2007853 浏览评论:02023之前
我还没有时间做 Windows phone 7 应用程序。上周在APP Store论坛看到一位国外DVP在WP7上写了一个推特客户端。仔细一看,我觉得很简单。我只是使用 WP7 在 Twitter 上获取信息。列表。国内微博只玩过163网易,可惜了
阅读全文
使用HTTP执行异步任务HTQ
作者:沃克武松 1147人浏览评论:04年前
HTQ详细介绍一、什么是HTQ?我们先介绍一下基本概念。在编写程序时,我们偶尔会遇到需要使用异步队列的情况。比如我发了10000封邮件,如果单纯用for循环来发送,执行时间会很长,发送出去也需要很长时间,同时容易导致针对阻塞和超时等问题。当有更多的电子邮件时,比如一百万
阅读全文
新浪微博Windows“.NET Research”Phone 7应用——UI设计
作者:狼人2007851 浏览评论:02023之前
我还没有时间做 Windows phone 7 应用程序。上周在APP Store论坛看到一位国外DVP在WP7上写了一个推特客户端。仔细一看,我觉得很简单。我只是使用 WP7 在 Twitter 上获取信息。列表。国内微博只玩过163网易,可惜了
阅读全文
开源任务队列服务HTQ
作者:迟来凶猛1073人查看评论:04年前
一、什么是HTQ我们先介绍一下基本概念。在编写程序时,我们偶尔会遇到需要使用异步队列的情况。比如我发了10000封邮件,如果单纯用for循环来发送,执行时间会很长,发送出去也需要很长时间,同时容易导致针对阻塞和超时等问题。当有更多的电子邮件时,比如说一百万,问题将是
阅读全文 查看全部
网站调用新浪微博内容(PHP+新浪微博api获取评论信息推荐活动(组图))
阿里云 > 云栖社区 > 主题地图 > L > 使用新浪微博API获取评论信息
推荐活动:
更多优惠>
当前话题:使用新浪微博api获取评论信息并加入采集
相关话题:
使用新浪微博api获取评论信息相关博文看更多博文
使用新浪微博API的Search接口做微博锐排
作者:郑云1802浏览量:05年前
郑云20100929申请入口:简单介绍一下我们的榜单与新浪自己的热门转发榜单的区别:微博睿推榜单会忽略名人推文,更关注草根推文,更关注社会民生推文,屏蔽非- 有营养的推文。微博锐推列表将汇总以新浪微博为首的国内主要微博网站的信息
阅读全文
新浪微博开放平台WeiboClient类的公共方法(PHP)
作者:何立坚 936 浏览评论:010年前
相关文章:一、PHP+新浪微博开放平台+新浪云平台(SAE)解决方案基础二、微博应用搭建过程三、PHP中的demo程序SDK简析四、进修方向及有用资源五、必解的几个问题【PDF全文下载】初步掌握微博应用开发流程后,推荐阅读魏
阅读全文
Windows Phone 7应用的新浪微博-UI设计
作者:小技术专家 1009人查看评论:04年前
我还没有时间做 Windows phone 7 应用程序。上周在APP Store论坛看到一位国外DVP在WP7上写了一个推特客户端。仔细一看,我觉得很简单。我只是使用 WP7 在 Twitter 上获取信息。列表。国内微博只玩过163网易,可惜
阅读全文
腾讯微博 for Windows Phone 7 应用 - OAuth 认证
作者:小技术专家1210查看评论:04年前
前段时间写了一篇关于Windows Phone 7新浪微博应用的文章——UI设计旨在将新浪微博移植到WP7客户端。期间,几位园友提出共同开发这款应用。但是年底比较忙。时间很紧,我间歇性地利用空闲时间更新这个新浪迷你博客
阅读全文
新浪微博 for Windows Phone 7 应用程序 - UI 设计
作者:狼人2007853 浏览评论:02023之前
我还没有时间做 Windows phone 7 应用程序。上周在APP Store论坛看到一位国外DVP在WP7上写了一个推特客户端。仔细一看,我觉得很简单。我只是使用 WP7 在 Twitter 上获取信息。列表。国内微博只玩过163网易,可惜了
阅读全文
使用HTTP执行异步任务HTQ
作者:沃克武松 1147人浏览评论:04年前
HTQ详细介绍一、什么是HTQ?我们先介绍一下基本概念。在编写程序时,我们偶尔会遇到需要使用异步队列的情况。比如我发了10000封邮件,如果单纯用for循环来发送,执行时间会很长,发送出去也需要很长时间,同时容易导致针对阻塞和超时等问题。当有更多的电子邮件时,比如一百万
阅读全文
新浪微博Windows“.NET Research”Phone 7应用——UI设计
作者:狼人2007851 浏览评论:02023之前
我还没有时间做 Windows phone 7 应用程序。上周在APP Store论坛看到一位国外DVP在WP7上写了一个推特客户端。仔细一看,我觉得很简单。我只是使用 WP7 在 Twitter 上获取信息。列表。国内微博只玩过163网易,可惜了
阅读全文
开源任务队列服务HTQ
作者:迟来凶猛1073人查看评论:04年前
一、什么是HTQ我们先介绍一下基本概念。在编写程序时,我们偶尔会遇到需要使用异步队列的情况。比如我发了10000封邮件,如果单纯用for循环来发送,执行时间会很长,发送出去也需要很长时间,同时容易导致针对阻塞和超时等问题。当有更多的电子邮件时,比如说一百万,问题将是
阅读全文
网站调用新浪微博内容(一下怎么模拟登陆新浪微博(图)怎么获取微博数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2022-03-15 01:23
最近需要爬取微博的数据进行分析。对于新浪微博,官方提供了API,但是有几个致命的限制(调用次数和授权期限的限制),所以我觉得有必要研究爬虫,直接爬取。通过微博获取微博数据的可行性。
由于模拟登陆微博是爬虫抓取微博信息的第一步,下面介绍如何模拟登陆微博(以新浪微博为例)。
这个过程主要分为两个步骤:
1 脚本模拟登陆新浪微博并保存cookies;
2 获得cookie信息后,使用cookie信息直接访问微博url。
其中,第一步是这里讨论的重点。为了更好的模拟这一步,需要一个好的网络监控工具,可以使用火狐的Firebug和Chrome以及IE自带的开发工具(注意IE必须是IE9以上才有监控网络的功能,Chrome的网络交互消息可以在网络部分查看)。另外前两天发现python支持的包很多,用python自定义自己的网络包比较方便,所以这里我用python作为我的开发语言。
好了,先说一下前提工作,下面开始分析用户在登录新浪微博的过程中进行的操作。在下面的例子中,我使用chrome自带的开发者工具作为我的网络包监控工具。
首先打开它(如果你设置了浏览器自动记住密码并自动登录,需要清除cookie),然后通过网络监控工具,我们会发现在用户登录过程中,浏览器与服务器三遍。它们如下:
一、第一个Get请求获取一些参数
在用户名栏输入你的微博账号,然后确认,这时你会发现当你的焦点离开用户名输入框时,浏览器会自动报"callback=sinaSSOController.preloginCallBack&su=&rsakt=mod& checkpin=1&client =ssologin.js (v1.4.5)&_=83” 发送GET请求,如下:
仔细看这个GET请求的响应内容,你会发现这个JSON字符串中收录了几个参数,可能你不知道它们的含义,但是没关系,现在你只需要知道这些参数会在后续处理。能。
二、发送 POST 请求
这部分是整个登录过程的重点。这部分用于向服务器提交用户信息,服务器会判断用户信息是否正确,从而判断登录是否成功。
通过 Chrome 自带的开发者工具,可以观察到 POST 消息的相关信息(url、headers、data)。下图是我的 POST 消息截图:
网址信息如下:
包头信息如下:
POST的消息数据信息如下:
接下来的工作就比较简单了,我们要做的就是模仿上面消息的内容和格式,用python发送类似的消息。在自己自定义类似的消息之前,我觉得有必要简单解释一下上面消息中DATA表单中每一项的含义。
其中,“su”为加密后的用户名,“sp”为加密后的密码。“servertime”、“nonce”和“rsakv”是上一个GET请求返回的JSON字符串的内容。其他参数不变。然后,重点讨论“su”和“sp”的加密算法。
1. "su" 加密算法
su 是 BASE64 计算出来的用户名: su= base64.encodestring( urllib.quote(username) )[:-1];
2. "sp" 加密算法
sp的加密算法可能会经常变化(考虑到网站的安全性,一段时间后登录消息的格式和加密算法发生变化是正常的),目前新浪使用的是RSA算法(如果你比较js 如果你是牛,可以直接去网页源码找它的加密方式,我没找到,参考网上有)。
这里简单介绍一下RSA算法的解密过程。
2.1 安装RSA模块,下载地址为:
2.2 创建一个 rsa 公钥。公钥的两个参数在新浪微博上都给定了固定值,但都是十六进制字符串。第一个是第一步登录的那个。pubkey,第二个是js加密文件中的'10001'。这两个值需要先从十六进制转换为十进制,但也可以在代码中硬编码。我直接写'10001'为65537
rsaPublickey=int(pubkey,16)
key=rsa.PublicKey(rsaPublickey,65537)#创建公钥
message=str(servertime)+\'\t\'+str(nonce)+\'\n\'+str(password)#拼接明文js加密文件得到
passwd=rsa.encrypt(message,key)#encryption
passwd=binascii.b2a_hex(passwd)#将加密信息转换为十六进制。
如果上述所有步骤对您来说都顺利,您将收到以下响应:
这是一个自动跳转语句,其中收录要跳转的URL。如果登录正确,则该URL中的德语retcode值为0。否则,登录错误。您需要仔细检查上述步骤。
三、跳转到对应的微博页面
我们已经得到了上面要重定向的 url,所以现在我们只需要请求这个 URL。这里要注意一点,为了让服务器知道你是否登录,这一步的请求需要使用上一步操作的cookie信息(因为第二步登录成功的信息会会自动记录在cookie中),所以我们在整个程序开始时,需要打开cookie,以保证cookie在以后的操作中可以正确使用。同时对于python用户,这一步不要自己自定义header,因为urllib2默认会自动打包cookie信息。如果手动自定义标头,则可能会丢失 cookie 信息。
下面附上我的参考代码:
参考文章:
1、
2、
从: 查看全部
网站调用新浪微博内容(一下怎么模拟登陆新浪微博(图)怎么获取微博数据)
最近需要爬取微博的数据进行分析。对于新浪微博,官方提供了API,但是有几个致命的限制(调用次数和授权期限的限制),所以我觉得有必要研究爬虫,直接爬取。通过微博获取微博数据的可行性。
由于模拟登陆微博是爬虫抓取微博信息的第一步,下面介绍如何模拟登陆微博(以新浪微博为例)。
这个过程主要分为两个步骤:
1 脚本模拟登陆新浪微博并保存cookies;
2 获得cookie信息后,使用cookie信息直接访问微博url。
其中,第一步是这里讨论的重点。为了更好的模拟这一步,需要一个好的网络监控工具,可以使用火狐的Firebug和Chrome以及IE自带的开发工具(注意IE必须是IE9以上才有监控网络的功能,Chrome的网络交互消息可以在网络部分查看)。另外前两天发现python支持的包很多,用python自定义自己的网络包比较方便,所以这里我用python作为我的开发语言。
好了,先说一下前提工作,下面开始分析用户在登录新浪微博的过程中进行的操作。在下面的例子中,我使用chrome自带的开发者工具作为我的网络包监控工具。
首先打开它(如果你设置了浏览器自动记住密码并自动登录,需要清除cookie),然后通过网络监控工具,我们会发现在用户登录过程中,浏览器与服务器三遍。它们如下:
一、第一个Get请求获取一些参数
在用户名栏输入你的微博账号,然后确认,这时你会发现当你的焦点离开用户名输入框时,浏览器会自动报"callback=sinaSSOController.preloginCallBack&su=&rsakt=mod& checkpin=1&client =ssologin.js (v1.4.5)&_=83” 发送GET请求,如下:
仔细看这个GET请求的响应内容,你会发现这个JSON字符串中收录了几个参数,可能你不知道它们的含义,但是没关系,现在你只需要知道这些参数会在后续处理。能。
二、发送 POST 请求
这部分是整个登录过程的重点。这部分用于向服务器提交用户信息,服务器会判断用户信息是否正确,从而判断登录是否成功。
通过 Chrome 自带的开发者工具,可以观察到 POST 消息的相关信息(url、headers、data)。下图是我的 POST 消息截图:
网址信息如下:
包头信息如下:
POST的消息数据信息如下:
接下来的工作就比较简单了,我们要做的就是模仿上面消息的内容和格式,用python发送类似的消息。在自己自定义类似的消息之前,我觉得有必要简单解释一下上面消息中DATA表单中每一项的含义。
其中,“su”为加密后的用户名,“sp”为加密后的密码。“servertime”、“nonce”和“rsakv”是上一个GET请求返回的JSON字符串的内容。其他参数不变。然后,重点讨论“su”和“sp”的加密算法。
1. "su" 加密算法
su 是 BASE64 计算出来的用户名: su= base64.encodestring( urllib.quote(username) )[:-1];
2. "sp" 加密算法
sp的加密算法可能会经常变化(考虑到网站的安全性,一段时间后登录消息的格式和加密算法发生变化是正常的),目前新浪使用的是RSA算法(如果你比较js 如果你是牛,可以直接去网页源码找它的加密方式,我没找到,参考网上有)。
这里简单介绍一下RSA算法的解密过程。
2.1 安装RSA模块,下载地址为:
2.2 创建一个 rsa 公钥。公钥的两个参数在新浪微博上都给定了固定值,但都是十六进制字符串。第一个是第一步登录的那个。pubkey,第二个是js加密文件中的'10001'。这两个值需要先从十六进制转换为十进制,但也可以在代码中硬编码。我直接写'10001'为65537
rsaPublickey=int(pubkey,16)
key=rsa.PublicKey(rsaPublickey,65537)#创建公钥
message=str(servertime)+\'\t\'+str(nonce)+\'\n\'+str(password)#拼接明文js加密文件得到
passwd=rsa.encrypt(message,key)#encryption
passwd=binascii.b2a_hex(passwd)#将加密信息转换为十六进制。
如果上述所有步骤对您来说都顺利,您将收到以下响应:
这是一个自动跳转语句,其中收录要跳转的URL。如果登录正确,则该URL中的德语retcode值为0。否则,登录错误。您需要仔细检查上述步骤。
三、跳转到对应的微博页面
我们已经得到了上面要重定向的 url,所以现在我们只需要请求这个 URL。这里要注意一点,为了让服务器知道你是否登录,这一步的请求需要使用上一步操作的cookie信息(因为第二步登录成功的信息会会自动记录在cookie中),所以我们在整个程序开始时,需要打开cookie,以保证cookie在以后的操作中可以正确使用。同时对于python用户,这一步不要自己自定义header,因为urllib2默认会自动打包cookie信息。如果手动自定义标头,则可能会丢失 cookie 信息。
下面附上我的参考代码:
参考文章:
1、
2、
从:
网站调用新浪微博内容(试试用python调用微博API的方法微博接口 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-03-13 00:11
)
因为最近碰到一个调用新浪微博开放接口的项目,想试试用python调用微博API。
SDK下载地址:代码不超过十几K,完全可以理解。
如果你有微博账号,可以新建一个APP,然后获取APP获取OAuth2.0授权所需要的app key和app secret。
要了解 OAuth2,您可以查看链接到新浪微博的说明。OAuth2授权参数除了app key和app secret外,还需要网站回调地址redirect_uri,并且这个回调地址不允许在局域网内(神马localhost,127.0.0.@ >1 好像不行),这真的让我焦急了很久。我没有使用 API 调用 网站,所以我检查了很多。看到有人写可以用这个地址代替,我试了一下,果然,这对掉丝来说是个好消息。
这里有一个简单的程序来体验:
设置以下参数
import sys
import weibo
import webbrowser
APP_KEY = ''
MY_APP_SECRET = ''
REDIRECT_URL = 'https://api.weibo.com/oauth2/default.html'
获取微博授权网址,如第2行,用默认浏览器打开后,会提示登录微博,使用需要授权的账号登录,如下图
api = weibo.APIClient(app_key=APP_KEY,app_secret=MY_APP_SECRET,redirect_uri=REDIRECT_URL)
authorize_url = api.get_authorize_url()
print(authorize_url)
webbrowser.open_new(authorize_url)
登录后,您将被重定向到一个连接
关键是码值,是认证的关键。手动输入码值模拟认证
request = api.request_access_token(code, REDIRECT_URL)
access_token = request.access_token
expires_in = request.expires_in
api.set_access_token(access_token, expires_in)
api.statuses.update.post(status=u'Test OAuth 2.0 Send a Weibo!')
access_token为获取到的token,expires_in为授权过期时间(UNIX时间)
使用 set_access_token 保存授权。往下走,就可以调用微博界面了。测试发了一条推文
但是,这种手动输入代码的方式并不适合调用程序。是否可以在不打开链接的情况下请求登录并获得授权?经过多方搜索参考,程序改进如下,可以自动获取代码并保存,方便程序服务调用。
accessWeibo
# -*- coding: utf-8 -*-
#/usr/bin/env python
#access to SinaWeibo By sinaweibopy
#实现微博自动登录,token自动生成,保存及更新
#适合于后端服务调用
from weibo import APIClient
import pymongo
import sys, os, urllib, urllib2
from http_helper import *
from retry import *
try:
import json
except ImportError:
import simplejson as json
# setting sys encoding to utf-8
default_encoding = 'utf-8'
if sys.getdefaultencoding() != default_encoding:
reload(sys)
sys.setdefaultencoding(default_encoding)
# weibo api访问配置
APP_KEY = '' # app key
APP_SECRET = '' # app secret
REDIRECT_URL = 'https://api.weibo.com/oauth2/default.html' # callback url 授权回调页,与OAuth2.0 授权设置的一致
USERID = '' # 登陆的微博用户名,必须是OAuth2.0 设置的测试账号
USERPASSWD = '' # 用户密码
client = APIClient(app_key=APP_KEY, app_secret=APP_SECRET, redirect_uri=REDIRECT_URL)
def make_access_token():
#请求access token
params = urllib.urlencode({
'action':'submit',
'withOfficalFlag':'0',
'ticket':'',
'isLoginSina':'',
'response_type':'code',
'regCallback':'',
'redirect_uri':REDIRECT_URL,
'client_id':APP_KEY,
'state':'',
'from':'',
'userId':USERID,
'passwd':USERPASSWD,
})
login_url = 'https://api.weibo.com/oauth2/authorize'
url = client.get_authorize_url()
content = urllib2.urlopen(url)
if content:
headers = { 'Referer' : url }
request = urllib2.Request(login_url, params, headers)
opener = get_opener(False)
urllib2.install_opener(opener)
try:
f = opener.open(request)
return_redirect_uri = f.url
except urllib2.HTTPError, e:
return_redirect_uri = e.geturl()
# 取到返回的code
code = return_redirect_uri.split('=')[1]
#得到token
token = client.request_access_token(code,REDIRECT_URL)
save_access_token(token)
def save_access_token(token):
#将access token保存到MongoDB数据库
mongoCon=pymongo.Connection(host="127.0.0.1",port=27017)
db= mongoCon.weibo
t={
"access_token":token['access_token'],
"expires_in":str(token['expires_in']),
"date":time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time()))
}
db.token.insert(t,safe=True)
#Decorator 目的是当调用make_access_token()后再执行一次apply_access_token()
@retry(1)
def apply_access_token():
#从MongoDB读取及设置access token
try:
mongoCon=pymongo.Connection(host="127.0.0.1",port=27017)
db= mongoCon.weibo
if db.token.count()>0:
tokenInfos=db.token.find().sort([("_id",pymongo.DESCENDING)]).limit(1)
else:
make_access_token()
return False
for tokenInfo in tokenInfos:
access_token=tokenInfo["access_token"]
expires_in=tokenInfo["expires_in"]
try:
client.set_access_token(access_token, expires_in)
except StandardError, e:
if hasattr(e, 'error'):
if e.error == 'expired_token':
# token过期重新生成
make_access_token()
return False
else:
pass
except:
make_access_token()
return False
return True
if __name__ == "__main__":
apply_access_token()
# 以下为访问微博api的应用逻辑
# 以发布文字微博接口为例
client.statuses.update.post(status='Test OAuth 2.0 Send a Weibo!')
retry.py
import math
import time
# Retry decorator with exponential backoff
def retry(tries, delay=1, backoff=2):
"""Retries a function or method until it returns True.
delay sets the initial delay, and backoff sets how much the delay should
lengthen after each failure. backoff must be greater than 1, or else it
isn't really a backoff. tries must be at least 0, and delay greater than
0."""
if backoff decorated function
return deco_retry # @retry(arg[, ...]) -> true decorator
http_helper.py
# -*- coding: utf-8 -*-
#/usr/bin/env python
import urllib2,cookielib
class SmartRedirectHandler(urllib2.HTTPRedirectHandler):
def http_error_301(cls, req, fp, code, msg, headers):
result = urllib2.HTTPRedirectHandler.http_error_301(cls, req, fp, code, msg, headers)
result.status = code
print headers
return result
def http_error_302(cls, req, fp, code, msg, headers):
result = urllib2.HTTPRedirectHandler.http_error_302(cls, req, fp, code, msg, headers)
result.status = code
print headers
return result
def get_cookie():
cookies = cookielib.CookieJar()
return urllib2.HTTPCookieProcessor(cookies)
def get_opener(proxy=False):
rv=urllib2.build_opener(get_cookie(), SmartRedirectHandler())
rv.addheaders = [('User-agent', 'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1)')]
return rv 查看全部
网站调用新浪微博内容(试试用python调用微博API的方法微博接口
)
因为最近碰到一个调用新浪微博开放接口的项目,想试试用python调用微博API。
SDK下载地址:代码不超过十几K,完全可以理解。
如果你有微博账号,可以新建一个APP,然后获取APP获取OAuth2.0授权所需要的app key和app secret。
要了解 OAuth2,您可以查看链接到新浪微博的说明。OAuth2授权参数除了app key和app secret外,还需要网站回调地址redirect_uri,并且这个回调地址不允许在局域网内(神马localhost,127.0.0.@ >1 好像不行),这真的让我焦急了很久。我没有使用 API 调用 网站,所以我检查了很多。看到有人写可以用这个地址代替,我试了一下,果然,这对掉丝来说是个好消息。
这里有一个简单的程序来体验:
设置以下参数
import sys
import weibo
import webbrowser
APP_KEY = ''
MY_APP_SECRET = ''
REDIRECT_URL = 'https://api.weibo.com/oauth2/default.html'
获取微博授权网址,如第2行,用默认浏览器打开后,会提示登录微博,使用需要授权的账号登录,如下图
api = weibo.APIClient(app_key=APP_KEY,app_secret=MY_APP_SECRET,redirect_uri=REDIRECT_URL)
authorize_url = api.get_authorize_url()
print(authorize_url)
webbrowser.open_new(authorize_url)
登录后,您将被重定向到一个连接
关键是码值,是认证的关键。手动输入码值模拟认证
request = api.request_access_token(code, REDIRECT_URL)
access_token = request.access_token
expires_in = request.expires_in
api.set_access_token(access_token, expires_in)
api.statuses.update.post(status=u'Test OAuth 2.0 Send a Weibo!')
access_token为获取到的token,expires_in为授权过期时间(UNIX时间)
使用 set_access_token 保存授权。往下走,就可以调用微博界面了。测试发了一条推文
但是,这种手动输入代码的方式并不适合调用程序。是否可以在不打开链接的情况下请求登录并获得授权?经过多方搜索参考,程序改进如下,可以自动获取代码并保存,方便程序服务调用。
accessWeibo
# -*- coding: utf-8 -*-
#/usr/bin/env python
#access to SinaWeibo By sinaweibopy
#实现微博自动登录,token自动生成,保存及更新
#适合于后端服务调用
from weibo import APIClient
import pymongo
import sys, os, urllib, urllib2
from http_helper import *
from retry import *
try:
import json
except ImportError:
import simplejson as json
# setting sys encoding to utf-8
default_encoding = 'utf-8'
if sys.getdefaultencoding() != default_encoding:
reload(sys)
sys.setdefaultencoding(default_encoding)
# weibo api访问配置
APP_KEY = '' # app key
APP_SECRET = '' # app secret
REDIRECT_URL = 'https://api.weibo.com/oauth2/default.html' # callback url 授权回调页,与OAuth2.0 授权设置的一致
USERID = '' # 登陆的微博用户名,必须是OAuth2.0 设置的测试账号
USERPASSWD = '' # 用户密码
client = APIClient(app_key=APP_KEY, app_secret=APP_SECRET, redirect_uri=REDIRECT_URL)
def make_access_token():
#请求access token
params = urllib.urlencode({
'action':'submit',
'withOfficalFlag':'0',
'ticket':'',
'isLoginSina':'',
'response_type':'code',
'regCallback':'',
'redirect_uri':REDIRECT_URL,
'client_id':APP_KEY,
'state':'',
'from':'',
'userId':USERID,
'passwd':USERPASSWD,
})
login_url = 'https://api.weibo.com/oauth2/authorize'
url = client.get_authorize_url()
content = urllib2.urlopen(url)
if content:
headers = { 'Referer' : url }
request = urllib2.Request(login_url, params, headers)
opener = get_opener(False)
urllib2.install_opener(opener)
try:
f = opener.open(request)
return_redirect_uri = f.url
except urllib2.HTTPError, e:
return_redirect_uri = e.geturl()
# 取到返回的code
code = return_redirect_uri.split('=')[1]
#得到token
token = client.request_access_token(code,REDIRECT_URL)
save_access_token(token)
def save_access_token(token):
#将access token保存到MongoDB数据库
mongoCon=pymongo.Connection(host="127.0.0.1",port=27017)
db= mongoCon.weibo
t={
"access_token":token['access_token'],
"expires_in":str(token['expires_in']),
"date":time.strftime('%Y-%m-%d %H:%M:%S',time.localtime(time.time()))
}
db.token.insert(t,safe=True)
#Decorator 目的是当调用make_access_token()后再执行一次apply_access_token()
@retry(1)
def apply_access_token():
#从MongoDB读取及设置access token
try:
mongoCon=pymongo.Connection(host="127.0.0.1",port=27017)
db= mongoCon.weibo
if db.token.count()>0:
tokenInfos=db.token.find().sort([("_id",pymongo.DESCENDING)]).limit(1)
else:
make_access_token()
return False
for tokenInfo in tokenInfos:
access_token=tokenInfo["access_token"]
expires_in=tokenInfo["expires_in"]
try:
client.set_access_token(access_token, expires_in)
except StandardError, e:
if hasattr(e, 'error'):
if e.error == 'expired_token':
# token过期重新生成
make_access_token()
return False
else:
pass
except:
make_access_token()
return False
return True
if __name__ == "__main__":
apply_access_token()
# 以下为访问微博api的应用逻辑
# 以发布文字微博接口为例
client.statuses.update.post(status='Test OAuth 2.0 Send a Weibo!')
retry.py
import math
import time
# Retry decorator with exponential backoff
def retry(tries, delay=1, backoff=2):
"""Retries a function or method until it returns True.
delay sets the initial delay, and backoff sets how much the delay should
lengthen after each failure. backoff must be greater than 1, or else it
isn't really a backoff. tries must be at least 0, and delay greater than
0."""
if backoff decorated function
return deco_retry # @retry(arg[, ...]) -> true decorator
http_helper.py
# -*- coding: utf-8 -*-
#/usr/bin/env python
import urllib2,cookielib
class SmartRedirectHandler(urllib2.HTTPRedirectHandler):
def http_error_301(cls, req, fp, code, msg, headers):
result = urllib2.HTTPRedirectHandler.http_error_301(cls, req, fp, code, msg, headers)
result.status = code
print headers
return result
def http_error_302(cls, req, fp, code, msg, headers):
result = urllib2.HTTPRedirectHandler.http_error_302(cls, req, fp, code, msg, headers)
result.status = code
print headers
return result
def get_cookie():
cookies = cookielib.CookieJar()
return urllib2.HTTPCookieProcessor(cookies)
def get_opener(proxy=False):
rv=urllib2.build_opener(get_cookie(), SmartRedirectHandler())
rv.addheaders = [('User-agent', 'Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.1; SV1)')]
return rv
网站调用新浪微博内容(网页版(当然,应用端也一样)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-03-12 09:16
网页版(当然app也一样)新浪微博在我们平时关注的用户微博之间插入了大量的宣传微博。博,烦死了。如何与敌人作战?当然,借助编程的力量。
多亏了大佬们的辛勤付出,我们普通人只要点几下鼠标就可以轻松解决这个问题。
具体步骤如下
下载Chrome(或firefox) 登录插件商店安装tampermonkey(为什么不能去谷歌?我听不到)什么是tampermonkey?可以做到吗?安装好后,安装新浪微博脚本,打开/刷新新浪微博,看看推广微博有没有消失?
以下可以忽略
什么是篡改猴?可以做到吗?
最简单的总结:这个东西允许某些脚本出于某些目的在某些网页上运行。
本例中:具体脚本为清除微博推广的脚本,具体网页为新浪微博。当然,具体目的是为了明确宣传内容。您还可以下载其他脚本来改善许多网页的体验。例如:AC-百度
随附的:
写这篇文章的时候,我想去safari截个“原创”的新浪微博,不做过滤和推广。我惊讶地发现,即使safari没有安装这个插件和这个脚本,我打开了新浪微博。但是,博客是过滤后的样子:没有广告,没有微博推广?? !!哪位dalao解释一下是什么情况?为什么chrome上安装的插件会影响safari?. . 查看全部
网站调用新浪微博内容(网页版(当然,应用端也一样)(组图))
网页版(当然app也一样)新浪微博在我们平时关注的用户微博之间插入了大量的宣传微博。博,烦死了。如何与敌人作战?当然,借助编程的力量。
多亏了大佬们的辛勤付出,我们普通人只要点几下鼠标就可以轻松解决这个问题。
具体步骤如下
下载Chrome(或firefox) 登录插件商店安装tampermonkey(为什么不能去谷歌?我听不到)什么是tampermonkey?可以做到吗?安装好后,安装新浪微博脚本,打开/刷新新浪微博,看看推广微博有没有消失?
以下可以忽略
什么是篡改猴?可以做到吗?
最简单的总结:这个东西允许某些脚本出于某些目的在某些网页上运行。
本例中:具体脚本为清除微博推广的脚本,具体网页为新浪微博。当然,具体目的是为了明确宣传内容。您还可以下载其他脚本来改善许多网页的体验。例如:AC-百度
随附的:
写这篇文章的时候,我想去safari截个“原创”的新浪微博,不做过滤和推广。我惊讶地发现,即使safari没有安装这个插件和这个脚本,我打开了新浪微博。但是,博客是过滤后的样子:没有广告,没有微博推广?? !!哪位dalao解释一下是什么情况?为什么chrome上安装的插件会影响safari?. .
网站调用新浪微博内容(Java怎样调用新浪发送api微博(.java文件) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-03-12 09:12
)
Java如何调用新浪api发送微博
前言
在看这篇文章的同时,相信你这个时候已经浏览过很多类似的文章了,很有可能和我一样失败(403错误频繁...我承认我有点傻...),也许和你的不同是,我在探索这个功能时,并没有因为工作需要而去做。我纯粹是对个人好奇心感兴趣,直接进入主题。你现在应该很着急。
获取 App Key 申请成为开发者
和其他大多数教程一样,我会和你一起回到起点,重新开始,别担心,永远不会出错。
微博开放平台
直接用你的微博账号登录。登录后,点击微链接选择其他选项,根据自己的需要新建应用程序(客户端、Web应用程序和浏览器插件)。我正在使用网络应用程序。
填写配置信息
根据上图填写基本配置信息。需要注意的是安全域名一定要填写,可以填写自己的域名,也就是第三方共享时的域名。如果你暂时没有可用的域名,可以用百度的域名,哈哈。并且必须与调用api时填写的一致,否则会报错。
成为测试员
点击测试信息,填写你的测试账号昵称,否则测试发送微博失败。
设置授权回调页面
编辑高级信息中的授权回调页面,让您可以收到token。同样,如果不方便,可以设置为百度页面。
获取 App Key 和 App Secret
进入基本信息页面,记下您的 App Key 和 App Secret。稍后将使用它来运行代码示例。
在运行实例阶段下载微博Java SDK
SDK地址
导入日食
src 中的前两个包是我自己构建的测试类,不用管。
示例是新浪微博所有方法类的集合,大家可以直接修改使用。
填写配置信息
打开图中src中的config.properties文件,需要填写前三个字段,分别填写你的App Key、App Secret和回调地址。
获取授权码
接下来打开examples包下oauth2.0下的OAuth4Code.java文件,直接运行main方法。
微博api中的所有操作都需要OAuth2.0授权。调用每个方法都需要一个授权码。未经审核的申请授权码有效期仅为1天,通过后30天。有效期。
获取授权码
由于我们填写的回调地址是百度,页面会自动跳转到百度,细心会发现一个百度后面会跟着一个代码。
获取令牌
拿到代码后,你还会发现你的eclipse控制台有一个输入框,好了,把你的代码粘贴进去,回车。那就回这么个东东,记住他!!
改变方法
微博官方在2017年取消了updateStatus等相关发送微博接口,这些接口已经不能调用了,但是由于java sdk是2014版本(为什么不更新!!!),里面还有这些方法。然后替换之前的updateStatus界面为statuss/share(第三方分享链接微博)
所以需要先找到updateStatus,然后查看它的源码。
查看全部
网站调用新浪微博内容(Java怎样调用新浪发送api微博(.java文件)
)
Java如何调用新浪api发送微博
前言
在看这篇文章的同时,相信你这个时候已经浏览过很多类似的文章了,很有可能和我一样失败(403错误频繁...我承认我有点傻...),也许和你的不同是,我在探索这个功能时,并没有因为工作需要而去做。我纯粹是对个人好奇心感兴趣,直接进入主题。你现在应该很着急。
获取 App Key 申请成为开发者
和其他大多数教程一样,我会和你一起回到起点,重新开始,别担心,永远不会出错。
微博开放平台
直接用你的微博账号登录。登录后,点击微链接选择其他选项,根据自己的需要新建应用程序(客户端、Web应用程序和浏览器插件)。我正在使用网络应用程序。
填写配置信息
根据上图填写基本配置信息。需要注意的是安全域名一定要填写,可以填写自己的域名,也就是第三方共享时的域名。如果你暂时没有可用的域名,可以用百度的域名,哈哈。并且必须与调用api时填写的一致,否则会报错。
成为测试员
点击测试信息,填写你的测试账号昵称,否则测试发送微博失败。
设置授权回调页面
编辑高级信息中的授权回调页面,让您可以收到token。同样,如果不方便,可以设置为百度页面。
获取 App Key 和 App Secret
进入基本信息页面,记下您的 App Key 和 App Secret。稍后将使用它来运行代码示例。
在运行实例阶段下载微博Java SDK
SDK地址
导入日食
src 中的前两个包是我自己构建的测试类,不用管。
示例是新浪微博所有方法类的集合,大家可以直接修改使用。
填写配置信息
打开图中src中的config.properties文件,需要填写前三个字段,分别填写你的App Key、App Secret和回调地址。
获取授权码
接下来打开examples包下oauth2.0下的OAuth4Code.java文件,直接运行main方法。
微博api中的所有操作都需要OAuth2.0授权。调用每个方法都需要一个授权码。未经审核的申请授权码有效期仅为1天,通过后30天。有效期。
获取授权码
由于我们填写的回调地址是百度,页面会自动跳转到百度,细心会发现一个百度后面会跟着一个代码。
获取令牌
拿到代码后,你还会发现你的eclipse控制台有一个输入框,好了,把你的代码粘贴进去,回车。那就回这么个东东,记住他!!
改变方法
微博官方在2017年取消了updateStatus等相关发送微博接口,这些接口已经不能调用了,但是由于java sdk是2014版本(为什么不更新!!!),里面还有这些方法。然后替换之前的updateStatus界面为statuss/share(第三方分享链接微博)
所以需要先找到updateStatus,然后查看它的源码。
网站调用新浪微博内容(用微博控制发光二极管的亮和灭(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-03-11 14:20
最近想设计一个课程,用微博控制树莓派,用树莓派控制发光二极管的开关。主要设计分为两层。上层是使用Java调用新浪微博API监控微博。当我的微博回复时,它会自动读取评论内容,并根据评论的指令内容决定树莓派的控制动作。下层是用C语言调用操作系统底层接口实现树莓派的GPIO接口控制发光二极管的闪烁、通断。
由于网上教程已经很老了,而且最近微博界面也发生了很多变化,所以决定重新写一篇详细的博文。如果能帮到您,我将不胜荣幸。同时,也非常希望能与您交流。如果您有任何问题,请在评论中回复我。
本文将逐步讲解如何申请微博接口并用Java发布自己的微博。【首先你要有一个微博账号】
一、申请成为开发者
去这里申请。点击“我的应用”查看身份认证:未认证,你已经做了你需要做的,这里不再赘述。审稿速度很快,不到一天就通过了。
之后应该是这样的(哈哈,欢迎互粉):
二、创建一个应用
这里的互联网教程具有误导性。我遵循了那些教程,最终把我拖进了坑里。我已经爬出来了。我希望你不要再陷入其中。
如果要使用Java控制微博,创建应用时不能创建“站内应用”。您必须创建一个“移动应用程序”。注意这一点,否则将无法通过权限验证步骤。
“微连接”-“移动应用”-“立即访问”-“继续创建”
现在我们来到了填写信息的地方,可以自己写一个应用名称(以后改名字会很麻烦,请一次性填写),例如“手机控制”树莓派”,客户端选择“手机”,应用选择Android作为平台就好,不过没关系。然后“创造”。好了,现在我们进入了一个新的界面,我们只是用它来测试,所以没有必要审查,除非你想让你的应用程序上线。
三、重要信息设置和记录
这一步非常重要,直接关系到以后能否正确连接。
左侧面板:“应用信息”-“高级信息”
当您看到“OAuth2.0 授权设置”时,单击“编辑”。“授权回调页面:”和“取消授权回调页面:”非常重要,创建“站内应用程序”的人应该在这里哭泣,因为他们无法修改“授权回调页面:”。. .
那么如何改变呢?两者都改成: ,这是微博默认的,对我们的测试来说已经足够了。
如图所示:
然后点击“基本信息”,
如图所示:
记下:APP Key和App Secret,后面会有用。
四、下载微博Java SDK
过来
下载压缩包:weibo4j-oauth2-beta3.1.1.zip
五、将 SDK 导入 Eclipse
什么?您是否一直在使用文本编辑器编写 Java?好吧,听我的建议,写这些东西的时候我应该切换到Eclipse,否则我会筋疲力尽。
打开Eclipse,“File”-“Import”-“Existing Projects into Workspace under General”-“Select archive File”-选择刚才的SDK包-“Finish”。
导入现已完成。
六、修改配置信息
打开图中的config.properties文件,将“client_ID”和“client_SERCRET”后面的值分别改成你记下的“App Key”和“App Secret”。“redirect_URI”的值更改为
保存。
七、申请授权
如图所示:
编译并执行 OAuth4Code.java 文件。
您的浏览器将被自动调用以打开授权页面。如下所示:
点击“授权”。
转到下图:
不要急于关闭浏览器!请复制地址栏中code=后面的字符串。
回到 Eclipse,下面的控制台正在等待您的输入。Hitenterwhenit'sdone.[Enter]:
没错,就是他。粘贴您刚刚复制的字符串,然后按 Enter。
好吧,等待几秒钟让您的授权信息返回。
AccessToken [accessToken=xxxxxxxxxxxxxxxxxx, expireIn=157679999, refreshToken=,uid=xxxxxxxxx]
“access_token”后面的字符串和“uid”后面的数字很重要,记下来。
现在您可以关闭浏览器了。
这里提醒一下,如果应用程序最初是作为“站内应用程序”而不是“移动应用程序”创建的,那么这一步将不会成功,并且您将始终看到“错误:redirect_uri_mismatch”页面。
八:发微博
在微博SDK包中,可以看到examples下有很多程序。这些是示例,涵盖了 SDK 可以做的所有事情。您只需要通过引用来编写。
weibo4j.examples.timeline 包中的UpdateStatus.java 是一个微博示例。
我们在 src 中新建一个名为 myweibo 的包,然后在其下新建几个类。我在这里创建了几个。
我将演示如何发推文。
在myweibo下新建类SendWeibo.java
复制examples—weibo4j.examples.timeline—UpdateStatus.java示例程序中的整个main方法体。粘贴后,Eclipse会自动导入需要引用的包。
将 String access_token= 替换为您刚才的 access_token 的值。String statuses= 后跟你的微博正文。
改了之后是:
然后直接运行Java代码,只要不报错,就成功了。看看你的微博。
注意:如果你不知道函数(我还是习惯称它为函数,而不是方法)是做什么的,并且不知道它的参数的含义,请将光标移动到函数上。
SDK中提供的各种功能都非常好用,比如获取微博、获取评论、获取评论ID、回复评论、获取地理位置、获取照片、发送照片、获取粉丝关系、获取微博等等。让我们自己尝试一下。
九:发布程序:
如果您要在其他地方运行程序,例如 Raspberry Pi Linux 或虚拟机中的 Linux,则需要注意一些事项。
我们首先发布程序:
我们右键点击weibo4j-oauth2项目,选择“导出”,然后如图:
下一步,
哪个程序是入口,Launch配置选择哪个,这里我们执行发送微博的程序:SendWeibo。
选择路径,在下方选择图书馆移交的第二个保险点。然后Finish,可能会弹出一个警告,不用担心,点击OK。
然后生成。然后双击jar包,程序一闪而过,留下一个weibo.log文件,就是日志。如果出现错误,您可以查看日志以查找原因。现在该程序已执行,它会发布另一条推文。
您可以将此文件拖到虚拟机的 Linux 中。我们已经看到 Java 如何在任何地方运行。结果运行java -jar 1.jar后报错。这是怎么回事?
仔细看看错误信息,它说.UnknownHostException,然后看看错误信息是不是说InetAddress.getLocalHost(),这就是原因。
解决方案:
首先,ifconfig 会查看您的 IP。这个不管是局域网IP还是外网IP。它只需要您看到的本地 IP。
修改主机文件 /etc/hosts 并添加一行,
你的ip 你的主机名 # KD.localdomain是我的主机名
至于如何查看主机名,应该在报错信息中,比如localhost.localdomain。KD.localdomain 这是我自己的改变。您还可以检查 /etc/hosts 以确认您的主机名。
这样修改后,再次尝试运行1.jar,应该可以成功。我不会拍照。运行虚拟机很麻烦。
PS:发微博后试试,别乱来,这个效果和刷屏差不多,会被打。
调用 API 有时容易出现问题。欢迎评论和交流。我在学习Linux内核的底层,对Java不是很精通,是个半助手。也欢迎大家就Linux问题与我交流。 查看全部
网站调用新浪微博内容(用微博控制发光二极管的亮和灭(图))
最近想设计一个课程,用微博控制树莓派,用树莓派控制发光二极管的开关。主要设计分为两层。上层是使用Java调用新浪微博API监控微博。当我的微博回复时,它会自动读取评论内容,并根据评论的指令内容决定树莓派的控制动作。下层是用C语言调用操作系统底层接口实现树莓派的GPIO接口控制发光二极管的闪烁、通断。
由于网上教程已经很老了,而且最近微博界面也发生了很多变化,所以决定重新写一篇详细的博文。如果能帮到您,我将不胜荣幸。同时,也非常希望能与您交流。如果您有任何问题,请在评论中回复我。
本文将逐步讲解如何申请微博接口并用Java发布自己的微博。【首先你要有一个微博账号】
一、申请成为开发者
去这里申请。点击“我的应用”查看身份认证:未认证,你已经做了你需要做的,这里不再赘述。审稿速度很快,不到一天就通过了。
之后应该是这样的(哈哈,欢迎互粉):
二、创建一个应用
这里的互联网教程具有误导性。我遵循了那些教程,最终把我拖进了坑里。我已经爬出来了。我希望你不要再陷入其中。
如果要使用Java控制微博,创建应用时不能创建“站内应用”。您必须创建一个“移动应用程序”。注意这一点,否则将无法通过权限验证步骤。
“微连接”-“移动应用”-“立即访问”-“继续创建”
现在我们来到了填写信息的地方,可以自己写一个应用名称(以后改名字会很麻烦,请一次性填写),例如“手机控制”树莓派”,客户端选择“手机”,应用选择Android作为平台就好,不过没关系。然后“创造”。好了,现在我们进入了一个新的界面,我们只是用它来测试,所以没有必要审查,除非你想让你的应用程序上线。
三、重要信息设置和记录
这一步非常重要,直接关系到以后能否正确连接。
左侧面板:“应用信息”-“高级信息”
当您看到“OAuth2.0 授权设置”时,单击“编辑”。“授权回调页面:”和“取消授权回调页面:”非常重要,创建“站内应用程序”的人应该在这里哭泣,因为他们无法修改“授权回调页面:”。. .
那么如何改变呢?两者都改成: ,这是微博默认的,对我们的测试来说已经足够了。
如图所示:
然后点击“基本信息”,
如图所示:
记下:APP Key和App Secret,后面会有用。
四、下载微博Java SDK
过来
下载压缩包:weibo4j-oauth2-beta3.1.1.zip
五、将 SDK 导入 Eclipse
什么?您是否一直在使用文本编辑器编写 Java?好吧,听我的建议,写这些东西的时候我应该切换到Eclipse,否则我会筋疲力尽。
打开Eclipse,“File”-“Import”-“Existing Projects into Workspace under General”-“Select archive File”-选择刚才的SDK包-“Finish”。
导入现已完成。
六、修改配置信息
打开图中的config.properties文件,将“client_ID”和“client_SERCRET”后面的值分别改成你记下的“App Key”和“App Secret”。“redirect_URI”的值更改为
保存。
七、申请授权
如图所示:
编译并执行 OAuth4Code.java 文件。
您的浏览器将被自动调用以打开授权页面。如下所示:
点击“授权”。
转到下图:
不要急于关闭浏览器!请复制地址栏中code=后面的字符串。
回到 Eclipse,下面的控制台正在等待您的输入。Hitenterwhenit'sdone.[Enter]:
没错,就是他。粘贴您刚刚复制的字符串,然后按 Enter。
好吧,等待几秒钟让您的授权信息返回。
AccessToken [accessToken=xxxxxxxxxxxxxxxxxx, expireIn=157679999, refreshToken=,uid=xxxxxxxxx]
“access_token”后面的字符串和“uid”后面的数字很重要,记下来。
现在您可以关闭浏览器了。
这里提醒一下,如果应用程序最初是作为“站内应用程序”而不是“移动应用程序”创建的,那么这一步将不会成功,并且您将始终看到“错误:redirect_uri_mismatch”页面。
八:发微博
在微博SDK包中,可以看到examples下有很多程序。这些是示例,涵盖了 SDK 可以做的所有事情。您只需要通过引用来编写。
weibo4j.examples.timeline 包中的UpdateStatus.java 是一个微博示例。
我们在 src 中新建一个名为 myweibo 的包,然后在其下新建几个类。我在这里创建了几个。
我将演示如何发推文。
在myweibo下新建类SendWeibo.java
复制examples—weibo4j.examples.timeline—UpdateStatus.java示例程序中的整个main方法体。粘贴后,Eclipse会自动导入需要引用的包。
将 String access_token= 替换为您刚才的 access_token 的值。String statuses= 后跟你的微博正文。
改了之后是:
然后直接运行Java代码,只要不报错,就成功了。看看你的微博。
注意:如果你不知道函数(我还是习惯称它为函数,而不是方法)是做什么的,并且不知道它的参数的含义,请将光标移动到函数上。
SDK中提供的各种功能都非常好用,比如获取微博、获取评论、获取评论ID、回复评论、获取地理位置、获取照片、发送照片、获取粉丝关系、获取微博等等。让我们自己尝试一下。
九:发布程序:
如果您要在其他地方运行程序,例如 Raspberry Pi Linux 或虚拟机中的 Linux,则需要注意一些事项。
我们首先发布程序:
我们右键点击weibo4j-oauth2项目,选择“导出”,然后如图:
下一步,
哪个程序是入口,Launch配置选择哪个,这里我们执行发送微博的程序:SendWeibo。
选择路径,在下方选择图书馆移交的第二个保险点。然后Finish,可能会弹出一个警告,不用担心,点击OK。
然后生成。然后双击jar包,程序一闪而过,留下一个weibo.log文件,就是日志。如果出现错误,您可以查看日志以查找原因。现在该程序已执行,它会发布另一条推文。
您可以将此文件拖到虚拟机的 Linux 中。我们已经看到 Java 如何在任何地方运行。结果运行java -jar 1.jar后报错。这是怎么回事?
仔细看看错误信息,它说.UnknownHostException,然后看看错误信息是不是说InetAddress.getLocalHost(),这就是原因。
解决方案:
首先,ifconfig 会查看您的 IP。这个不管是局域网IP还是外网IP。它只需要您看到的本地 IP。
修改主机文件 /etc/hosts 并添加一行,
你的ip 你的主机名 # KD.localdomain是我的主机名
至于如何查看主机名,应该在报错信息中,比如localhost.localdomain。KD.localdomain 这是我自己的改变。您还可以检查 /etc/hosts 以确认您的主机名。
这样修改后,再次尝试运行1.jar,应该可以成功。我不会拍照。运行虚拟机很麻烦。
PS:发微博后试试,别乱来,这个效果和刷屏差不多,会被打。
调用 API 有时容易出现问题。欢迎评论和交流。我在学习Linux内核的底层,对Java不是很精通,是个半助手。也欢迎大家就Linux问题与我交流。
网站调用新浪微博内容(企业网站上都放有新浪或腾讯的微博窗口像如下图片)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-03-11 14:20
现在很多公司网站都有新浪或者腾讯的微博窗口,如下图1,微博代码嵌入到自己的网站中,这样做的好处是微博有最新动态信息网站 将同步显示最新信息。当客户访问网站时,他们也会感觉到网站在不断变化。网站 一直在更新,但是对搜索引擎的真实感受并没有改变,因为这个搜索引擎无法识别 iframe 内容,所以虽然这块的内容在不断变化,但是 网站@ 的内容> 还要不断更新,才能赢得搜索引擎蜘蛛的青睐。但是像微博这样的网站还是需要加的。下面简单介绍一下如何添加:
一:新浪微博代码申请:
点击新浪微博开放平台/index.php,然后登录,只需设置网站上显示的自己的微博窗口的宽度和高度,还可以设置显示信息的数量和颜色边框的一些基本设置,设置完成后,将代码复制到网站上需要放置的位置。
(1)点击页面上的网站访问图片
(2)点击图片上的访问网站或管理网站图标链接
二:腾讯微博代码申请:
打开网址/index.php,登录设置和新浪微博一样。设置完成后复制到网站的固定显示位置。 查看全部
网站调用新浪微博内容(企业网站上都放有新浪或腾讯的微博窗口像如下图片)
现在很多公司网站都有新浪或者腾讯的微博窗口,如下图1,微博代码嵌入到自己的网站中,这样做的好处是微博有最新动态信息网站 将同步显示最新信息。当客户访问网站时,他们也会感觉到网站在不断变化。网站 一直在更新,但是对搜索引擎的真实感受并没有改变,因为这个搜索引擎无法识别 iframe 内容,所以虽然这块的内容在不断变化,但是 网站@ 的内容> 还要不断更新,才能赢得搜索引擎蜘蛛的青睐。但是像微博这样的网站还是需要加的。下面简单介绍一下如何添加:
一:新浪微博代码申请:
点击新浪微博开放平台/index.php,然后登录,只需设置网站上显示的自己的微博窗口的宽度和高度,还可以设置显示信息的数量和颜色边框的一些基本设置,设置完成后,将代码复制到网站上需要放置的位置。
(1)点击页面上的网站访问图片
(2)点击图片上的访问网站或管理网站图标链接
二:腾讯微博代码申请:
打开网址/index.php,登录设置和新浪微博一样。设置完成后复制到网站的固定显示位置。
网站调用新浪微博内容(新浪开发平台下的网站接入申请Appkey与Appid的方式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-03-10 04:06
申请Appkey和Appid
在新浪开发平台下网站访问申请Appkey和Appid,申请的前提是要有域名,并记录申请的appkey和appid以供使用。
注意:点击网站访问并填写访问信息后,管理中心会出现您的访问网站。点击进入您的网站访问的详细信息页面,左侧导航栏会有申请信息栏,点击展开,点击“高级信息”项
红包箭头所指的项目要与系统config.properties文件中的redirect_URI一致。如果不一致,会出现第三方授权错误,调用系统时无法获取用户信息。
下载Java SDK包
去技术支持中心下载包,不要用httpclient调用新浪的接口,不安全,可能被别人攻击网站。下载的sdk里面会有一个demo,把demo中lib下的依赖包放到工程lib里面,下载的文件里面会有一个weibo4j包,复制到工程的src下,把config.把properties文件中的前三项改成你自己的appkey、appid、redirect_URI(新浪同意授权后会跳转回你系统中的路径)。
说明
点击页面上的一个按钮后,跳转到action中的方法,在方法中,重定向一个请求到sinaAPI。使用sian的API,我们的直接重定向方法如下:
String url = new Oauth().authorize("code", "code"),这样我们就可以得到请求的路径了。使用内置的sina sdk包,我们可以直接这样调整。
请求后会弹出授权页面。如果我们同意授权,它会自动跳转到我们的“redirect_uri”路径,并在我们的“redirect_uri”后面加上“?code=XXXXXXX”
然后我们就可以根据返回的参数码获取access_token等一些信息了。例如:
得到access_token对象后,我们可以根据它获取用户的access_token字符串和用户ID,然后根据userid获取用户信息。没有getuid方法,自己生成即可,操作方便。代码如下:
这样我们就可以得到用户的信息了。 查看全部
网站调用新浪微博内容(新浪开发平台下的网站接入申请Appkey与Appid的方式)
申请Appkey和Appid
在新浪开发平台下网站访问申请Appkey和Appid,申请的前提是要有域名,并记录申请的appkey和appid以供使用。
注意:点击网站访问并填写访问信息后,管理中心会出现您的访问网站。点击进入您的网站访问的详细信息页面,左侧导航栏会有申请信息栏,点击展开,点击“高级信息”项
红包箭头所指的项目要与系统config.properties文件中的redirect_URI一致。如果不一致,会出现第三方授权错误,调用系统时无法获取用户信息。
下载Java SDK包
去技术支持中心下载包,不要用httpclient调用新浪的接口,不安全,可能被别人攻击网站。下载的sdk里面会有一个demo,把demo中lib下的依赖包放到工程lib里面,下载的文件里面会有一个weibo4j包,复制到工程的src下,把config.把properties文件中的前三项改成你自己的appkey、appid、redirect_URI(新浪同意授权后会跳转回你系统中的路径)。
说明
点击页面上的一个按钮后,跳转到action中的方法,在方法中,重定向一个请求到sinaAPI。使用sian的API,我们的直接重定向方法如下:
String url = new Oauth().authorize("code", "code"),这样我们就可以得到请求的路径了。使用内置的sina sdk包,我们可以直接这样调整。
请求后会弹出授权页面。如果我们同意授权,它会自动跳转到我们的“redirect_uri”路径,并在我们的“redirect_uri”后面加上“?code=XXXXXXX”
然后我们就可以根据返回的参数码获取access_token等一些信息了。例如:
得到access_token对象后,我们可以根据它获取用户的access_token字符串和用户ID,然后根据userid获取用户信息。没有getuid方法,自己生成即可,操作方便。代码如下:
这样我们就可以得到用户的信息了。
网站调用新浪微博内容(新浪微博接口的实现过程及应用开发)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-03-10 00:16
不得不说,虽然还是一样的微博内容,一样的列表,没有手机客户端的界面,没有头像,没有用户的昵称和颜色,真的是惨不忍睹。. .
外观仍然是决定因素。.
下面开始记录新浪微博界面的实现过程
首先,您需要在新浪微博开放平台上注册一个开启者。选择应用开发,因为是office网站,所以选择第三方网页,创建后可以得到如下:
应用名称:
525网络空间
应用类型:
通用应用程序 - 网络应用程序
应用密钥:
3xxxxxx
应用秘密:
6xxxxxxxxxxxxxxxxxxxxxxxx
在应用信息->高级信息中设置----
授权回调页面:
然后下载php-sdk
这里注意sdk和demo中有重复的页面(但是内容有一些区别)。其实demo是收录在sdk里面的,所以不需要下载demo。以前,我一团糟,因为我把两者混在一起了。.
然后修改config.php中
WB_AKEY 的值就是 App Key 的值,WB_SKEY 的值就是 App Secret 的值。它们分别相当于帐号和密码,因此后者需要严格保密。
将WB_CALLBACK_URL的值修改为回调页面的地址
然后注意我这里下载的文件中,最后没有php结束标签?> 需要补全。
之后,您可以在浏览器中访问 127.0.0.1/index.php 进行尝试。. 如果点击授权登录成功就ok了
我这里授权后回调页面的地址自动跳转到api.weiboxxx/127.0.0.1/callback.php,不知道怎么回事,总之,在浏览器中更改 127.0.0.1/callback.php 就可以了
然后就可以正常使用了
只是我可能因为php版本或者设置的原因不能直接写变量,需要改一下。. 然后是API调用和布局的问题。 查看全部
网站调用新浪微博内容(新浪微博接口的实现过程及应用开发)
不得不说,虽然还是一样的微博内容,一样的列表,没有手机客户端的界面,没有头像,没有用户的昵称和颜色,真的是惨不忍睹。. .
外观仍然是决定因素。.
下面开始记录新浪微博界面的实现过程
首先,您需要在新浪微博开放平台上注册一个开启者。选择应用开发,因为是office网站,所以选择第三方网页,创建后可以得到如下:
应用名称:
525网络空间
应用类型:
通用应用程序 - 网络应用程序
应用密钥:
3xxxxxx
应用秘密:
6xxxxxxxxxxxxxxxxxxxxxxxx
在应用信息->高级信息中设置----
授权回调页面:
然后下载php-sdk
这里注意sdk和demo中有重复的页面(但是内容有一些区别)。其实demo是收录在sdk里面的,所以不需要下载demo。以前,我一团糟,因为我把两者混在一起了。.
然后修改config.php中
WB_AKEY 的值就是 App Key 的值,WB_SKEY 的值就是 App Secret 的值。它们分别相当于帐号和密码,因此后者需要严格保密。
将WB_CALLBACK_URL的值修改为回调页面的地址
然后注意我这里下载的文件中,最后没有php结束标签?> 需要补全。
之后,您可以在浏览器中访问 127.0.0.1/index.php 进行尝试。. 如果点击授权登录成功就ok了
我这里授权后回调页面的地址自动跳转到api.weiboxxx/127.0.0.1/callback.php,不知道怎么回事,总之,在浏览器中更改 127.0.0.1/callback.php 就可以了
然后就可以正常使用了
只是我可能因为php版本或者设置的原因不能直接写变量,需要改一下。. 然后是API调用和布局的问题。
网站调用新浪微博内容(开发者注册新浪微博开放平台完成开发者认证按照流程走,写回调方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-03-08 17:01
比如QQ互联,这里详细介绍如何实现微博登录。
成为开发者
首先,你还是要注册一个微博账号,使用微博账号登录开放平台。
打开微博开放平台官网,点击登录完成开发者注册
新浪微博开放平台
完成开发者认证
按照流程,开发者类型一般选择个人。
开发者认证
创建网站应用
一般来说,我们创建的是网站应用程序,其他应用程序类似,所以这里仅以网站应用程序为例。
完成认证后,选择首页微链接菜单下的网站访问(或首页下的网站访问WEB),并填写所需信息。
创建应用
需要准备的材料有:
1、域名注册完成
2、已开发网站
3、服务器
4、应用图标
注意:
填写基本信息后,还需要填写高级信息。高级信息中的授权回调页面和取消授权回调页面非常重要,非常重要,非常重要(重要的事情说三遍)。
授权回调页面是授权完成后回调的页面,该页面必须在申请地址域名下。同理,取消授权回调页面是取消授权后回调的页面(一般是跳转回登录页面)。
有节制
审稿时间一般为1个工作日,所以为了节省时间,信息一定要准确,避免多次修改。
审计
页面开发
开发模式有两种,一种是使用sdk,一种是自定义开发。SDK开发门槛低,无需了解具体授权逻辑。只需粘贴代码。下面简单介绍一下登录按钮(不推荐这种方式,推荐定制开发)。
打开链接
配置登录按钮样式
配置登录按钮样式
选择一个应用程序
复制代码
1、将 XML 命名空间添加到 HTML 标记
2、在 HEAD 头中引入 WB.JS
3、 在需要部署登录按钮的地方粘贴WBML代码(复制代码)
4、写回调方法
WB2.anyWhere(函数(W){
W.widget.connectButton({
id: "wb_connect_btn",
类型:“3,2”,
打回来 : {
login:function(o){//登录后回调函数
},
logout:function(){//退出后回调函数
}
}
});
定制开发(推荐)
我们是专业的,一定要选择定制开发(可以跳过上面的sdk教程)。
填写完网站应用信息后,开始使用界面,登录功能主要包括以下几个界面:
1、OAuth2.0 授权登录接口
2、获取token和uid接口
3、获取用户信息接口
第 1 步:添加指向登录页面的链接
微博
这里的应用主键是App Key。在开发平台的应用管理中可以看到回调地址是应用高级信息中的授权回调页面,两者必须相同。
第二步:开发授权回调页面
因为回调页面必须在外网,所以开发过程中必须经常部署新的网站(更新部分就足够了),所以这一步之后服务器必须要有权限。
回调页面中有一个很重要的参数,就是地址栏上的code参数。code参数是授权获取token后自动带上的,并且只能使用一次。如果再次使用,则会出现错误。
第三步:根据代码交换token和uid
这时需要在后台以post的形式请求access_token接口,地址为
"+ 应用主键+ "&client_secret="+ 应用秘钥+ "&grant_type=authorization_code&redirect_uri="+ 回调地址+ "&code="+ 获取代码
应用主键和应用密钥都可以在应用管理中找到。因为很重要,所以必须在后台请求(前台请求有跨域和header信息不一致的问题),并且回调地址和代码都是通过前台传递的,下面是后台代码
C#获取微博token
令牌实体类
第四步:获取用户信息(登录)
获取用户信息的前提是提供token和uid,所以我们调用第三步封装的方法privateWBTokenStateGetWeiBoToken(stringcode, stringcallback)。此时请求的地址是""+兑换了token+"&uid="+兑换了uid
此时代码如下
微博登录
微博用户实体类
具体登录逻辑略...
第 5 步:调用前台
这时候后台已经写好了,前台开始打电话。
先判断回调地址的code参数是否为空,然后动态获取回调地址(后面改很麻烦,测试的时候一定要写死),然后调用后台写的登录接口(后台登录界面自动交换token、uid并获取用户信息),下面是具体代码
使用angularjs,应该不难理解
结束语
微博登录的意义在于接入大量微博用户,降低网站注册门槛,实现社交关系的零成本引入和优质内容的快速传播。
ps:
代码只能使用一次,再次使用会报错,需要在后台调用post方法。
授权机制(包括获取uid)
授权机制
获取uid
获取用户信息
js SDK 查看全部
网站调用新浪微博内容(开发者注册新浪微博开放平台完成开发者认证按照流程走,写回调方法)
比如QQ互联,这里详细介绍如何实现微博登录。
成为开发者
首先,你还是要注册一个微博账号,使用微博账号登录开放平台。
打开微博开放平台官网,点击登录完成开发者注册
新浪微博开放平台
完成开发者认证
按照流程,开发者类型一般选择个人。
开发者认证
创建网站应用
一般来说,我们创建的是网站应用程序,其他应用程序类似,所以这里仅以网站应用程序为例。
完成认证后,选择首页微链接菜单下的网站访问(或首页下的网站访问WEB),并填写所需信息。
创建应用
需要准备的材料有:
1、域名注册完成
2、已开发网站
3、服务器
4、应用图标
注意:
填写基本信息后,还需要填写高级信息。高级信息中的授权回调页面和取消授权回调页面非常重要,非常重要,非常重要(重要的事情说三遍)。
授权回调页面是授权完成后回调的页面,该页面必须在申请地址域名下。同理,取消授权回调页面是取消授权后回调的页面(一般是跳转回登录页面)。
有节制
审稿时间一般为1个工作日,所以为了节省时间,信息一定要准确,避免多次修改。
审计
页面开发
开发模式有两种,一种是使用sdk,一种是自定义开发。SDK开发门槛低,无需了解具体授权逻辑。只需粘贴代码。下面简单介绍一下登录按钮(不推荐这种方式,推荐定制开发)。
打开链接
配置登录按钮样式
配置登录按钮样式
选择一个应用程序
复制代码
1、将 XML 命名空间添加到 HTML 标记
2、在 HEAD 头中引入 WB.JS
3、 在需要部署登录按钮的地方粘贴WBML代码(复制代码)
4、写回调方法
WB2.anyWhere(函数(W){
W.widget.connectButton({
id: "wb_connect_btn",
类型:“3,2”,
打回来 : {
login:function(o){//登录后回调函数
},
logout:function(){//退出后回调函数
}
}
});
定制开发(推荐)
我们是专业的,一定要选择定制开发(可以跳过上面的sdk教程)。
填写完网站应用信息后,开始使用界面,登录功能主要包括以下几个界面:
1、OAuth2.0 授权登录接口
2、获取token和uid接口
3、获取用户信息接口
第 1 步:添加指向登录页面的链接
微博
这里的应用主键是App Key。在开发平台的应用管理中可以看到回调地址是应用高级信息中的授权回调页面,两者必须相同。
第二步:开发授权回调页面
因为回调页面必须在外网,所以开发过程中必须经常部署新的网站(更新部分就足够了),所以这一步之后服务器必须要有权限。
回调页面中有一个很重要的参数,就是地址栏上的code参数。code参数是授权获取token后自动带上的,并且只能使用一次。如果再次使用,则会出现错误。
第三步:根据代码交换token和uid
这时需要在后台以post的形式请求access_token接口,地址为
"+ 应用主键+ "&client_secret="+ 应用秘钥+ "&grant_type=authorization_code&redirect_uri="+ 回调地址+ "&code="+ 获取代码
应用主键和应用密钥都可以在应用管理中找到。因为很重要,所以必须在后台请求(前台请求有跨域和header信息不一致的问题),并且回调地址和代码都是通过前台传递的,下面是后台代码
C#获取微博token
令牌实体类
第四步:获取用户信息(登录)
获取用户信息的前提是提供token和uid,所以我们调用第三步封装的方法privateWBTokenStateGetWeiBoToken(stringcode, stringcallback)。此时请求的地址是""+兑换了token+"&uid="+兑换了uid
此时代码如下
微博登录
微博用户实体类
具体登录逻辑略...
第 5 步:调用前台
这时候后台已经写好了,前台开始打电话。
先判断回调地址的code参数是否为空,然后动态获取回调地址(后面改很麻烦,测试的时候一定要写死),然后调用后台写的登录接口(后台登录界面自动交换token、uid并获取用户信息),下面是具体代码
使用angularjs,应该不难理解
结束语
微博登录的意义在于接入大量微博用户,降低网站注册门槛,实现社交关系的零成本引入和优质内容的快速传播。
ps:
代码只能使用一次,再次使用会报错,需要在后台调用post方法。
授权机制(包括获取uid)
授权机制
获取uid
获取用户信息
js SDK
网站调用新浪微博内容(网站调用新浪微博内容需要改host请试下提供个方案)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-03-08 07:09
网站调用新浪微博内容需要改host
请试下apilink-wordpressapiforwordpress
提供个方案:将您的业务数据,存放在阿里云服务器,再申请一个主机域名。
试试小站易,免费的cms,可以上传,可以制作静态和动态,在线生成。
wordpress根本不是针对中国市场设计的。
没必要为做一个网站而去学新浪微博的代码,其实直接把主题做成自己喜欢的样子,重点看你的内容了,
wordpress主题不错,不是真的做站很难看懂它的语言。最好可以连接到wordpressphp代码或者espressif。如果你想直接用别人优秀主题建议调用wordpressphpsitemap,其它还有flash和手机网站。
由于你网站面向的大多数人是在校大学生,你需要建立一个贴近他们的官方主题,给他们一个良好的主题导航,当你主题调出的时候可以顺带调出它的文字。推荐你一款在线的wordpress主题,【记账中心】,它基于php,可以让你快速搭建主题。
做wordpress的网站要多考虑cdn的用户体验!要多考虑cdn的用户体验!要多考虑cdn的用户体验!-重要的事情说三遍!!!需要一个云服务器。然后你可以放网站的代码,服务器设置好就可以了。
直接用wordpress吧,按需下载就行。
这么简单, 查看全部
网站调用新浪微博内容(网站调用新浪微博内容需要改host请试下提供个方案)
网站调用新浪微博内容需要改host
请试下apilink-wordpressapiforwordpress
提供个方案:将您的业务数据,存放在阿里云服务器,再申请一个主机域名。
试试小站易,免费的cms,可以上传,可以制作静态和动态,在线生成。
wordpress根本不是针对中国市场设计的。
没必要为做一个网站而去学新浪微博的代码,其实直接把主题做成自己喜欢的样子,重点看你的内容了,
wordpress主题不错,不是真的做站很难看懂它的语言。最好可以连接到wordpressphp代码或者espressif。如果你想直接用别人优秀主题建议调用wordpressphpsitemap,其它还有flash和手机网站。
由于你网站面向的大多数人是在校大学生,你需要建立一个贴近他们的官方主题,给他们一个良好的主题导航,当你主题调出的时候可以顺带调出它的文字。推荐你一款在线的wordpress主题,【记账中心】,它基于php,可以让你快速搭建主题。
做wordpress的网站要多考虑cdn的用户体验!要多考虑cdn的用户体验!要多考虑cdn的用户体验!-重要的事情说三遍!!!需要一个云服务器。然后你可以放网站的代码,服务器设置好就可以了。
直接用wordpress吧,按需下载就行。
这么简单,
网站调用新浪微博内容(网站调用新浪微博内容时需要把原信息接入网站提供的数据库匹配)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-03-08 01:00
网站调用新浪微博内容时需要把原信息接入网站,通过网站提供的数据库进行匹配。国内新浪微博很大程度的依赖于用户的数据,在,并且有一个对新浪微博的屏蔽认证。因此,新浪微博的数据库存储的东西是一方面,新浪微博的决策机制又是另一方面。因此,我猜测这个时候能够胜出的是认证机制,而非接入信息。当然,我不是认证机构,我也不是业内人士,这只是个人yy,或许它们考虑的不是这个。
认证接口都会存在。但是有一个问题,在微博数据格式公开化之前,都会由技术手段来验证发布人的真实性,但是参考微博技术手段在新浪微博上的变化,认证是可以绕过的。甚至认证可以直接在网页上实现,例如你只需要看那个关注者的最新动态(该关注者是指加入腾讯广播站的账号),你可以向你的关注者发起认证申请。下图是2010年8月20日腾讯广播站发布的认证接口。(来源:腾讯广播站)。
这个得看用户来源、内容中有没有“找关系”要求、社交数据比如父母兴趣偏好这些东西。
不好说,只能回答会影响吧。腾讯是很在意个人用户隐私的,比如你从他的社交关系再次影响其他人对该用户产生兴趣。所以有严格的cookie来保护个人信息,例如该用户有无恋爱信息。微博上这些不方便直接公开,但是却可以间接的影响。从网站数据角度看,无非是处理一下,提交一下隐私,然后再进行信息抽丝剥茧,将其中不需要的东西剔除掉。
从社交账号来看,大多是以开放接口的形式发布,所以容易侵入用户的隐私,但如果社交账号绑定该用户就会形成社交黑洞,存在隐私泄露风险。另外,社交账号也能够从算法中看出来该用户的兴趣特征,这里比如前几天的“逃离北上广”事件,公众的讨论就会比较激烈,但用户的大部分兴趣是稳定的。 查看全部
网站调用新浪微博内容(网站调用新浪微博内容时需要把原信息接入网站提供的数据库匹配)
网站调用新浪微博内容时需要把原信息接入网站,通过网站提供的数据库进行匹配。国内新浪微博很大程度的依赖于用户的数据,在,并且有一个对新浪微博的屏蔽认证。因此,新浪微博的数据库存储的东西是一方面,新浪微博的决策机制又是另一方面。因此,我猜测这个时候能够胜出的是认证机制,而非接入信息。当然,我不是认证机构,我也不是业内人士,这只是个人yy,或许它们考虑的不是这个。
认证接口都会存在。但是有一个问题,在微博数据格式公开化之前,都会由技术手段来验证发布人的真实性,但是参考微博技术手段在新浪微博上的变化,认证是可以绕过的。甚至认证可以直接在网页上实现,例如你只需要看那个关注者的最新动态(该关注者是指加入腾讯广播站的账号),你可以向你的关注者发起认证申请。下图是2010年8月20日腾讯广播站发布的认证接口。(来源:腾讯广播站)。
这个得看用户来源、内容中有没有“找关系”要求、社交数据比如父母兴趣偏好这些东西。
不好说,只能回答会影响吧。腾讯是很在意个人用户隐私的,比如你从他的社交关系再次影响其他人对该用户产生兴趣。所以有严格的cookie来保护个人信息,例如该用户有无恋爱信息。微博上这些不方便直接公开,但是却可以间接的影响。从网站数据角度看,无非是处理一下,提交一下隐私,然后再进行信息抽丝剥茧,将其中不需要的东西剔除掉。
从社交账号来看,大多是以开放接口的形式发布,所以容易侵入用户的隐私,但如果社交账号绑定该用户就会形成社交黑洞,存在隐私泄露风险。另外,社交账号也能够从算法中看出来该用户的兴趣特征,这里比如前几天的“逃离北上广”事件,公众的讨论就会比较激烈,但用户的大部分兴趣是稳定的。

