
算法 自动采集列表
算法 自动采集列表(优采云采集器破解版吾爱论坛网友破解分享软件特色(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 211 次浏览 • 2021-09-03 08:14
在信息碎片化的时代,每天都有数以万计的新信息在互联网上发布。为了抓住大众的眼球,占据他们碎片化的时间,各种网站或app也不断出现。很多新闻平台都有兴趣推荐机制,拥有成熟先进的内容推荐算法,可以抓取用户的兴趣标签,将用户感兴趣的内容推送到自己的首页。尽管他们拥有先进的内容推荐算法和互联网用户档案数据,但仍然缺乏大量的内容:例如,对于内容分发,他们需要将各个新闻信息平台的更新数据实时采集下,然后使用个性化推荐系统。分发给感兴趣的各方;对于垂直内容聚合,您需要在互联网上采集特定领域和类别的新闻和信息数据,然后将其发布到您自己的平台上。 优采云采集器一个通用的网络数据采集软件。可以为数百个主流网站数据源模板采集,不仅节省时间,还能快速获取网站公共数据。软件可根据不同的网站智能采集提供各种网页采集策略,并有配套资源,可定制配置、组合使用、自动化处理。从而帮助整个采集流程实现数据的完整性和稳定性。它支持字符串替换并具有采集Cookie 自定义功能。首次登录后可自动记住cookie,免去多次输入密码的繁琐。有兴趣的快来下载体验吧!
本编辑器为您带来优采云采集器破解版。该软件被网友在Wuai论坛上破解并分享。用户进入页面支持中文版破解所有软件功能,方便用户快速使用!
优采云采集器破解版软件显示该软件已被破解,并在无爱论坛上被网友分享。软件支持中文版,解锁所有功能。用户可以放心使用!软件特点1、满足多种业务场景
适用于产品、运营、销售、数据分析、政府机构、电子商务从业者、学术研究等各种职业。
2、公众情绪监测
全方位监控公众信息,抢先掌握舆情动态。
3、市场分析
获取用户真实行为数据,全面掌握客户真实需求
4、产品研发
大力支持用户研究,准确获取用户反馈和偏好
5、风险预测
高效信息采集和数据清洗,及时应对系统风险
功能介绍1、简采集
简单的采集模式内置了数百个主流的网站数据源,比如京东、天猫、大众点评等流行的采集网站。只需参考模板设置参数即可快速获取网站。 @公共数据。
2、智能采集
优采云采集可根据网站的不同提供多种网页采集策略及配套资源,可定制配置、组合使用、自动化处理。从而帮助采集整个流程实现数据的完整性和稳定性。
3、云采集
云采集,5000多台云服务器支持,7*24小时不间断运行,可实现定时采集,无需人员值守,灵活适配业务场景,助您提升采集效率,并保证数据的及时性。
4、API 接口
通过优采云API,可以轻松获取采集接收到的优采云任务信息和数据,灵活调度任务,如远程控制任务启停,高效实现数据采集和归档。基于强大的API系统,还可以与公司各种内部管理平台无缝对接,实现各种业务自动化。
5、Custom 采集
根据采集不同用户的需求,优采云可以提供自定义模式自动生成爬虫,可以批量准确识别各种网页元素,以及翻页、下拉、ajax、页面滚动、条件判断等。此类功能支持不同网页结构的复杂网站采集,满足多种采集应用场景。
6、方便的定时功能
只需简单几步,点击设置即可实现采集任务的定时控制,无论是单个采集定时设置,还是预设日或周、月定时采集。同时自由设置多个任务,根据需要进行多种选择时间组合,灵活部署自己的采集任务。
7、自动数据格式化
优采云内置强大的数据格式化引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间格式化、HTML转码等诸多功能,采集该过程是全自动的,无需人工干预即可获取所需格式的数据。
8、multi-level采集
众多主流新闻和电商网站,收录一级商品列表页、二级商品详情页、三级评论详情页;不管网站有多少层,优采云所有采集数据都可以无限,满足采集各种业务需求。
9、support网站登录后采集
优采云内置采集登录模块,只需配置目标网站的账号密码,即可使用该模块采集登录数据;同时优采云还有采集Cookie自定义功能,首次登录后可以自动记住cookie,免去多次输入密码的繁琐,支持更多网站采集 . 优采云采集器使用教程1、 首先打开优采云采集器→点击快速启动→新建任务(高级模式),进入任务配置页面:
2、选择任务组,自定义任务名称和备注;
3、完成上图中的配置后,选择Next,进入流程配置页面,拖一个步骤打开网页进入流程设计。
4、选择在浏览器中打开网页的步骤,在右侧的网页网址中输入网页网址并点击保存,系统会在软件下自动在浏览器中打开相应的网页:
5、 在下面创建一个循环页面。在上面的浏览器页面点击下一页按钮,在弹出的对话框中选择重复点击下一页;
6、创建翻页循环后,点击下图中的保存;
7、因为如上图我们需要在浏览器中点击电影名称,然后在子页面中提取数据信息,所以需要做一个循环采集列表。
点击上图中第一个循环项,在弹出的对话框中选择创建元素列表处理一组元素;
8、然后在弹出的对话框中选择添加到列表中。
9、添加第一个循环后,继续编辑。
10、 接下来,以同样的方式添加第二个循环。
11、 当我们添加第二个循环项时,可以看到上图。此时,页面上的其他元素已经添加。这是因为我们添加了两个具有相似特征的元素,系统会智能地在页面上添加其他具有相似特征的元素。然后选择创建列表完成→点击下图中的循环。
12、经过以上操作,循环采集列表就完成了。系统会在页面右上角显示该页面添加的所有循环项。
13、 由于每个页面都需要循环采集数据,所以我们需要将这个循环列表拖入翻页循环中。
注意流程是从上一页开始执行的,所以这个循环列表需要放在点击翻页之前,否则会漏掉第一页的数据。最终流程图如下所示:
14、 选择上图中第一个循环项,然后选择点击元素。输入第一个子链接。
接下来要提取数据字段,在上图中的流程设计器中点击提取数据,然后在浏览器中选择要提取的字段,然后在弹出的选择对话框中选择该元素的文本盒子;
15、以上操作后,系统会在页面右上角显示我们要抓取的字段;
16、接下来,在页面上配置其他需要抓取的字段,配置完成后修改字段名称。
17、修改完成后,点击上图中的保存按钮,然后点击图中的数据字段,可以看到系统会显示最终的采集列表。
18、点击Next→Next→启动上图中的单机采集,进入任务检查页面,确保任务的正确性。
19、点击启动单机采集,系统会在本地执行采集进程并显示最终的采集结果。
更新日志优采云采集器 v8.1.22 更新(2021-8-13)
1、当页面没有内容更新时,可以提前结束滚动。
2、 自动跳过无效的翻页操作。
3、支持瀑布流网页采集的滚动。
4、支持网页边点击加载更多内容,而采集.
5、自动识别支持在列表项和详细信息等结果之间切换。
特别说明
百度网盘资源下载提取码:aiya 查看全部
算法 自动采集列表(优采云采集器破解版吾爱论坛网友破解分享软件特色(组图))
在信息碎片化的时代,每天都有数以万计的新信息在互联网上发布。为了抓住大众的眼球,占据他们碎片化的时间,各种网站或app也不断出现。很多新闻平台都有兴趣推荐机制,拥有成熟先进的内容推荐算法,可以抓取用户的兴趣标签,将用户感兴趣的内容推送到自己的首页。尽管他们拥有先进的内容推荐算法和互联网用户档案数据,但仍然缺乏大量的内容:例如,对于内容分发,他们需要将各个新闻信息平台的更新数据实时采集下,然后使用个性化推荐系统。分发给感兴趣的各方;对于垂直内容聚合,您需要在互联网上采集特定领域和类别的新闻和信息数据,然后将其发布到您自己的平台上。 优采云采集器一个通用的网络数据采集软件。可以为数百个主流网站数据源模板采集,不仅节省时间,还能快速获取网站公共数据。软件可根据不同的网站智能采集提供各种网页采集策略,并有配套资源,可定制配置、组合使用、自动化处理。从而帮助整个采集流程实现数据的完整性和稳定性。它支持字符串替换并具有采集Cookie 自定义功能。首次登录后可自动记住cookie,免去多次输入密码的繁琐。有兴趣的快来下载体验吧!
本编辑器为您带来优采云采集器破解版。该软件被网友在Wuai论坛上破解并分享。用户进入页面支持中文版破解所有软件功能,方便用户快速使用!

优采云采集器破解版软件显示该软件已被破解,并在无爱论坛上被网友分享。软件支持中文版,解锁所有功能。用户可以放心使用!软件特点1、满足多种业务场景
适用于产品、运营、销售、数据分析、政府机构、电子商务从业者、学术研究等各种职业。
2、公众情绪监测
全方位监控公众信息,抢先掌握舆情动态。
3、市场分析
获取用户真实行为数据,全面掌握客户真实需求
4、产品研发
大力支持用户研究,准确获取用户反馈和偏好
5、风险预测
高效信息采集和数据清洗,及时应对系统风险

功能介绍1、简采集
简单的采集模式内置了数百个主流的网站数据源,比如京东、天猫、大众点评等流行的采集网站。只需参考模板设置参数即可快速获取网站。 @公共数据。
2、智能采集
优采云采集可根据网站的不同提供多种网页采集策略及配套资源,可定制配置、组合使用、自动化处理。从而帮助采集整个流程实现数据的完整性和稳定性。
3、云采集
云采集,5000多台云服务器支持,7*24小时不间断运行,可实现定时采集,无需人员值守,灵活适配业务场景,助您提升采集效率,并保证数据的及时性。
4、API 接口
通过优采云API,可以轻松获取采集接收到的优采云任务信息和数据,灵活调度任务,如远程控制任务启停,高效实现数据采集和归档。基于强大的API系统,还可以与公司各种内部管理平台无缝对接,实现各种业务自动化。
5、Custom 采集
根据采集不同用户的需求,优采云可以提供自定义模式自动生成爬虫,可以批量准确识别各种网页元素,以及翻页、下拉、ajax、页面滚动、条件判断等。此类功能支持不同网页结构的复杂网站采集,满足多种采集应用场景。
6、方便的定时功能
只需简单几步,点击设置即可实现采集任务的定时控制,无论是单个采集定时设置,还是预设日或周、月定时采集。同时自由设置多个任务,根据需要进行多种选择时间组合,灵活部署自己的采集任务。
7、自动数据格式化
优采云内置强大的数据格式化引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间格式化、HTML转码等诸多功能,采集该过程是全自动的,无需人工干预即可获取所需格式的数据。
8、multi-level采集
众多主流新闻和电商网站,收录一级商品列表页、二级商品详情页、三级评论详情页;不管网站有多少层,优采云所有采集数据都可以无限,满足采集各种业务需求。
9、support网站登录后采集
优采云内置采集登录模块,只需配置目标网站的账号密码,即可使用该模块采集登录数据;同时优采云还有采集Cookie自定义功能,首次登录后可以自动记住cookie,免去多次输入密码的繁琐,支持更多网站采集 . 优采云采集器使用教程1、 首先打开优采云采集器→点击快速启动→新建任务(高级模式),进入任务配置页面:

2、选择任务组,自定义任务名称和备注;

3、完成上图中的配置后,选择Next,进入流程配置页面,拖一个步骤打开网页进入流程设计。

4、选择在浏览器中打开网页的步骤,在右侧的网页网址中输入网页网址并点击保存,系统会在软件下自动在浏览器中打开相应的网页:

5、 在下面创建一个循环页面。在上面的浏览器页面点击下一页按钮,在弹出的对话框中选择重复点击下一页;

6、创建翻页循环后,点击下图中的保存;

7、因为如上图我们需要在浏览器中点击电影名称,然后在子页面中提取数据信息,所以需要做一个循环采集列表。

点击上图中第一个循环项,在弹出的对话框中选择创建元素列表处理一组元素;
8、然后在弹出的对话框中选择添加到列表中。

9、添加第一个循环后,继续编辑。

10、 接下来,以同样的方式添加第二个循环。

11、 当我们添加第二个循环项时,可以看到上图。此时,页面上的其他元素已经添加。这是因为我们添加了两个具有相似特征的元素,系统会智能地在页面上添加其他具有相似特征的元素。然后选择创建列表完成→点击下图中的循环。

12、经过以上操作,循环采集列表就完成了。系统会在页面右上角显示该页面添加的所有循环项。

13、 由于每个页面都需要循环采集数据,所以我们需要将这个循环列表拖入翻页循环中。
注意流程是从上一页开始执行的,所以这个循环列表需要放在点击翻页之前,否则会漏掉第一页的数据。最终流程图如下所示:

14、 选择上图中第一个循环项,然后选择点击元素。输入第一个子链接。
接下来要提取数据字段,在上图中的流程设计器中点击提取数据,然后在浏览器中选择要提取的字段,然后在弹出的选择对话框中选择该元素的文本盒子;
15、以上操作后,系统会在页面右上角显示我们要抓取的字段;

16、接下来,在页面上配置其他需要抓取的字段,配置完成后修改字段名称。

17、修改完成后,点击上图中的保存按钮,然后点击图中的数据字段,可以看到系统会显示最终的采集列表。

18、点击Next→Next→启动上图中的单机采集,进入任务检查页面,确保任务的正确性。

19、点击启动单机采集,系统会在本地执行采集进程并显示最终的采集结果。

更新日志优采云采集器 v8.1.22 更新(2021-8-13)
1、当页面没有内容更新时,可以提前结束滚动。
2、 自动跳过无效的翻页操作。
3、支持瀑布流网页采集的滚动。
4、支持网页边点击加载更多内容,而采集.
5、自动识别支持在列表项和详细信息等结果之间切换。
特别说明
百度网盘资源下载提取码:aiya
算法 自动采集列表(百度搜索推出飓风算法严厉打击以恶劣采集的零容忍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-09-02 10:15
百度搜索最近推出了飓风算法,旨在严厉打击网站,其内容是不良采集的主要来源。同时,百度搜索将从索引库中彻底清除不良采集链接,为优质原创内容提供更多展示机会,促进搜索生态健康发展。
飓风算法会定期产生惩罚数据,同时会根据情况随时调整迭代,体现了百度搜索对不良采集的零容忍。对于优质的原创网站,如果您发现该网站的索引量大幅下降,访问量大幅下降,您可以在反馈中心反馈。
作为 SEOer,您必须熟悉搜索引擎算法并开出正确的补救措施。此后,百度搜索引擎算法更新了很多次,每次都会影响到网站的相当一部分,下面我给大家点评一下。
绿萝算法
百度于2013年2月19日推出了针对搜索引擎的反作弊算法,该算法主要打击超链接中介、卖链接、买链接等超链接作弊行为。该算法的引入有效阻止了恶意交换链接、发布外部链接,有效净化了互联网生态。这个策略是一个小女孩设计的,所以名字的权利也给了这个小女孩。她选择了路洛这个名字。隐藏反作弊净化的含义。
石榴算法
百度于2013年5月17日推出了针对低质量网站的算法。石榴算法的目的是打击大量存在阻碍用户正常浏览的不良广告的页面。
绿萝算法2.0
百度绿萝算法2.0是2013年7月1日百度绿萝算法1.0的升级版,主要目的是在网络上进行非正式的宣传软文广告,如何处理多余的垃圾邮件信息引起的。
冰桶算法
百度移动搜索会对低质量的网站和页面进行一系列调整,称为冰桶算法。冰桶算法的目的是打击强制弹出应用下载、大面积广告等影响用户正常浏览体验的页面。
冰桶算法2.0
于2014年11月18日推出,旨在打击全屏下载、手机小页面大面积广告遮蔽主要内容、强制用户登录等行为。 查看全部
算法 自动采集列表(百度搜索推出飓风算法严厉打击以恶劣采集的零容忍)
百度搜索最近推出了飓风算法,旨在严厉打击网站,其内容是不良采集的主要来源。同时,百度搜索将从索引库中彻底清除不良采集链接,为优质原创内容提供更多展示机会,促进搜索生态健康发展。

飓风算法会定期产生惩罚数据,同时会根据情况随时调整迭代,体现了百度搜索对不良采集的零容忍。对于优质的原创网站,如果您发现该网站的索引量大幅下降,访问量大幅下降,您可以在反馈中心反馈。
作为 SEOer,您必须熟悉搜索引擎算法并开出正确的补救措施。此后,百度搜索引擎算法更新了很多次,每次都会影响到网站的相当一部分,下面我给大家点评一下。

绿萝算法
百度于2013年2月19日推出了针对搜索引擎的反作弊算法,该算法主要打击超链接中介、卖链接、买链接等超链接作弊行为。该算法的引入有效阻止了恶意交换链接、发布外部链接,有效净化了互联网生态。这个策略是一个小女孩设计的,所以名字的权利也给了这个小女孩。她选择了路洛这个名字。隐藏反作弊净化的含义。
石榴算法
百度于2013年5月17日推出了针对低质量网站的算法。石榴算法的目的是打击大量存在阻碍用户正常浏览的不良广告的页面。
绿萝算法2.0
百度绿萝算法2.0是2013年7月1日百度绿萝算法1.0的升级版,主要目的是在网络上进行非正式的宣传软文广告,如何处理多余的垃圾邮件信息引起的。
冰桶算法
百度移动搜索会对低质量的网站和页面进行一系列调整,称为冰桶算法。冰桶算法的目的是打击强制弹出应用下载、大面积广告等影响用户正常浏览体验的页面。
冰桶算法2.0
于2014年11月18日推出,旨在打击全屏下载、手机小页面大面积广告遮蔽主要内容、强制用户登录等行为。
算法 自动采集列表(优采云控制台一采集入门教程(简化版)(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-09-02 05:20
优采云Navigation: 优采云采集器 优采云控制面板
一个采集Getting Started Tutorial(简化版)一个小概念:
大多数网站 以列表页和详细信息页的层次结构组织。比如我们进入一个新闻频道,有很多标题链接,可以看成是一个列表页。点击标题链接进入详情页。
使用data采集工具的一般目的是获取详情页中的大量特定内容数据,并将这些数据用于各种分析、发布和导出等。
列表页:指栏目或目录页,一般收录多个标题链接。例如:网站home 页或栏目页为列表页。主要功能:可以通过列表页获取多个详情页的链接。
详情页:收录特定内容的页面,如网页文章,其中收录:标题、作者、发布日期、正文内容、标签等。
要开始,请登录“优采云控制面板”;
详细使用步骤:
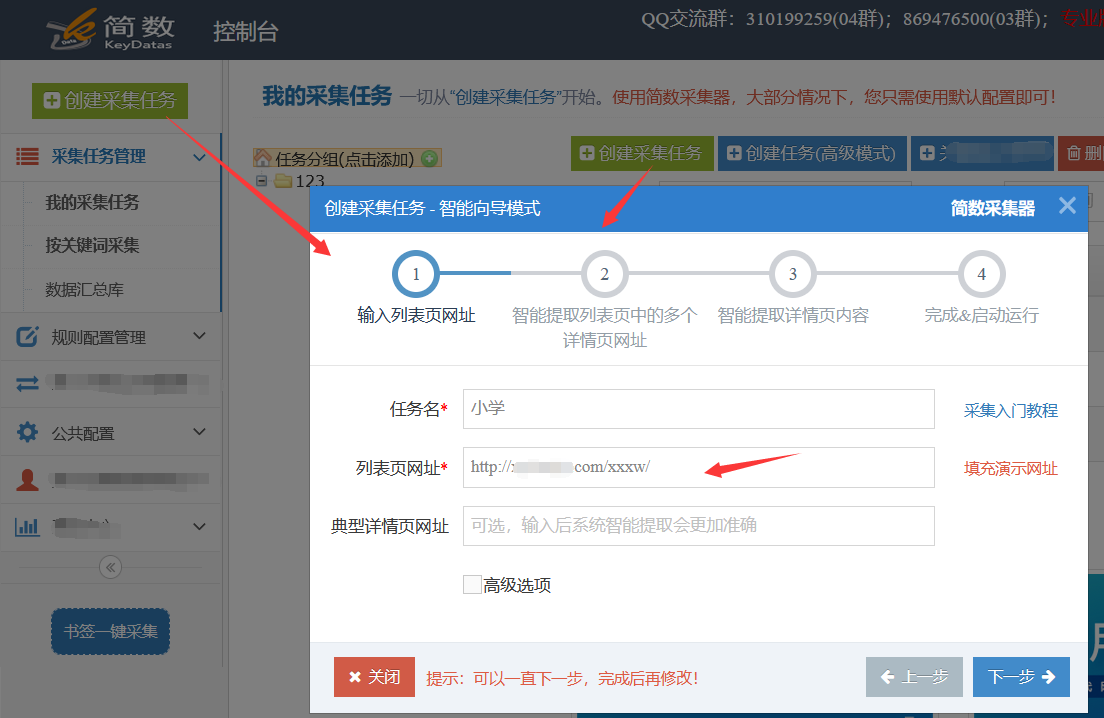
第一步:创建采集task
点击左侧菜单按钮“创建采集task”,输入采集task名称和采集的“列表页”网址,如:(这里首页为列表页:内容收录多个详情页是),详情页链接可以留空,系统会自动识别。
如下图:
进入后点击“下一步”
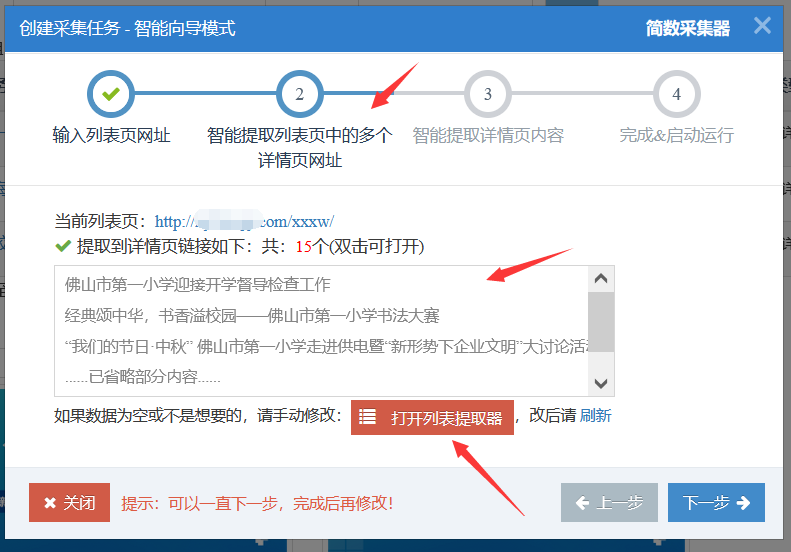
第2步:改进列表页的智能提取结果(可选)
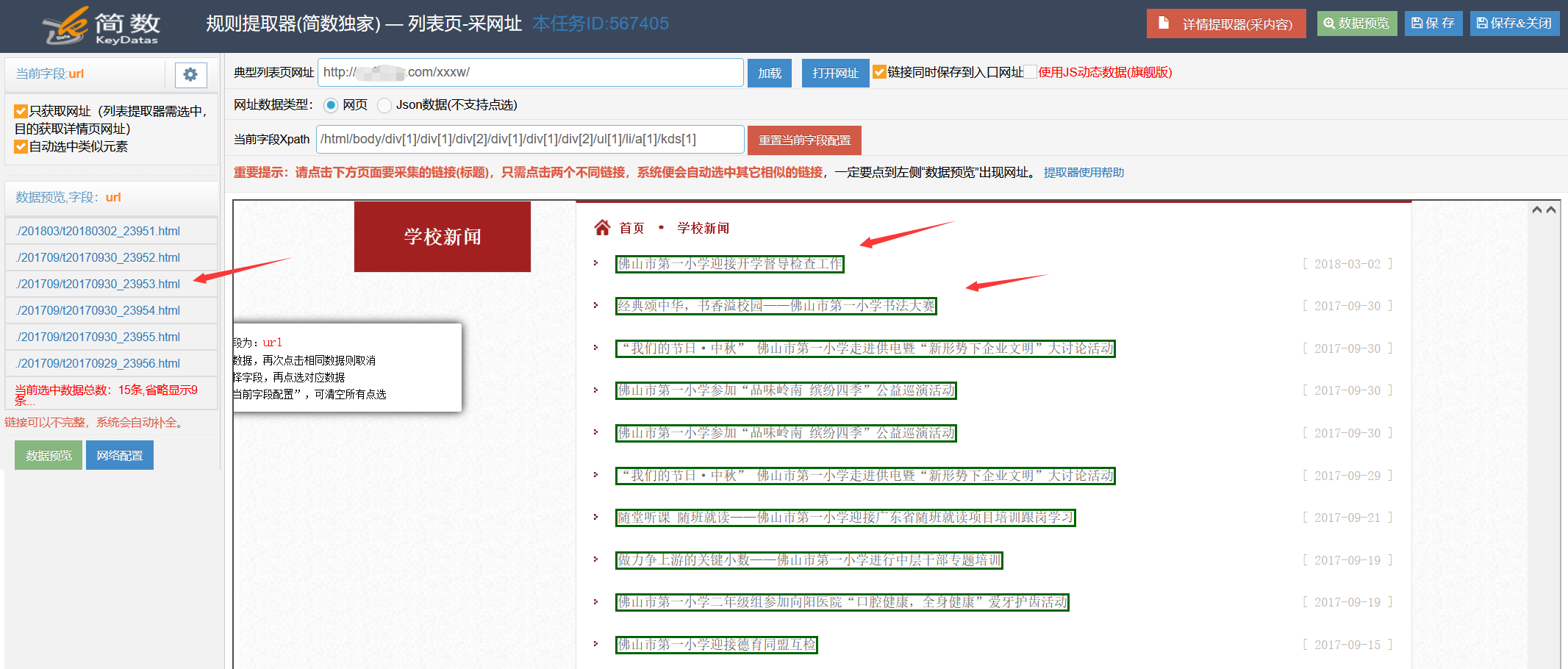
系统会先通过智能算法获取需要采集的详情页链接(多个)。用户可以双击打开支票。如果数据不是您想要的,您可以单击“列表提取器”手动指定它。在可视化界面上用鼠标点击。
智能获取的结果如下图所示:
另外:在上面的结果中,系统还智能发现了翻页规则,用户可以设置采集需要多少页。您也可以稍后在任务“基本信息和Portal URL”--“根据规则生成URL”项中进行配置。
打开列表提取器,如下所示:
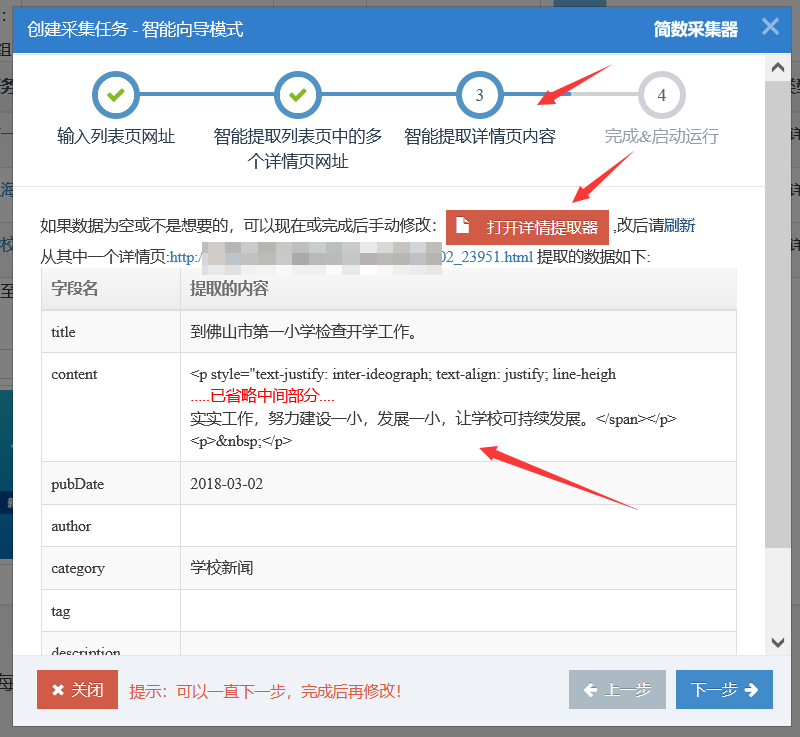
第三步:完善详情页的智能提取结果(可选)
上一步获取多个详情页链接后,继续下一步。系统将使用其中一个详情页链接智能提取详情页数据(如标题、作者、发布日期、内容、标签等)
详情页智能提取结果如下:
如果smart提取的内容不是你想要的,可以打开“Detail Extractor”进行修改。
如下图:
您可以修改、添加或删除左侧的字段。
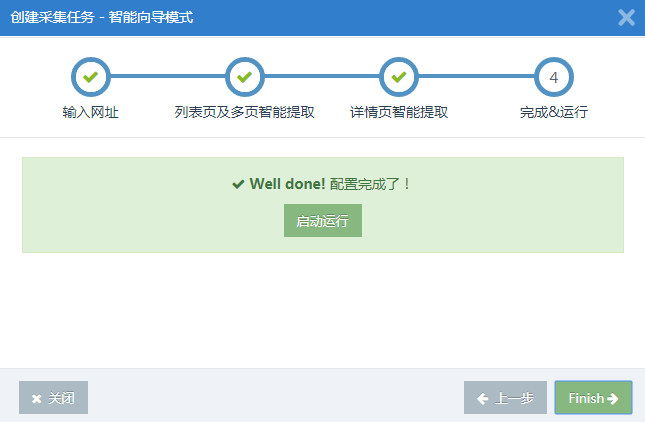
第 4 步:启动和运行
完成后,即可启动运行,进行数据采集了:
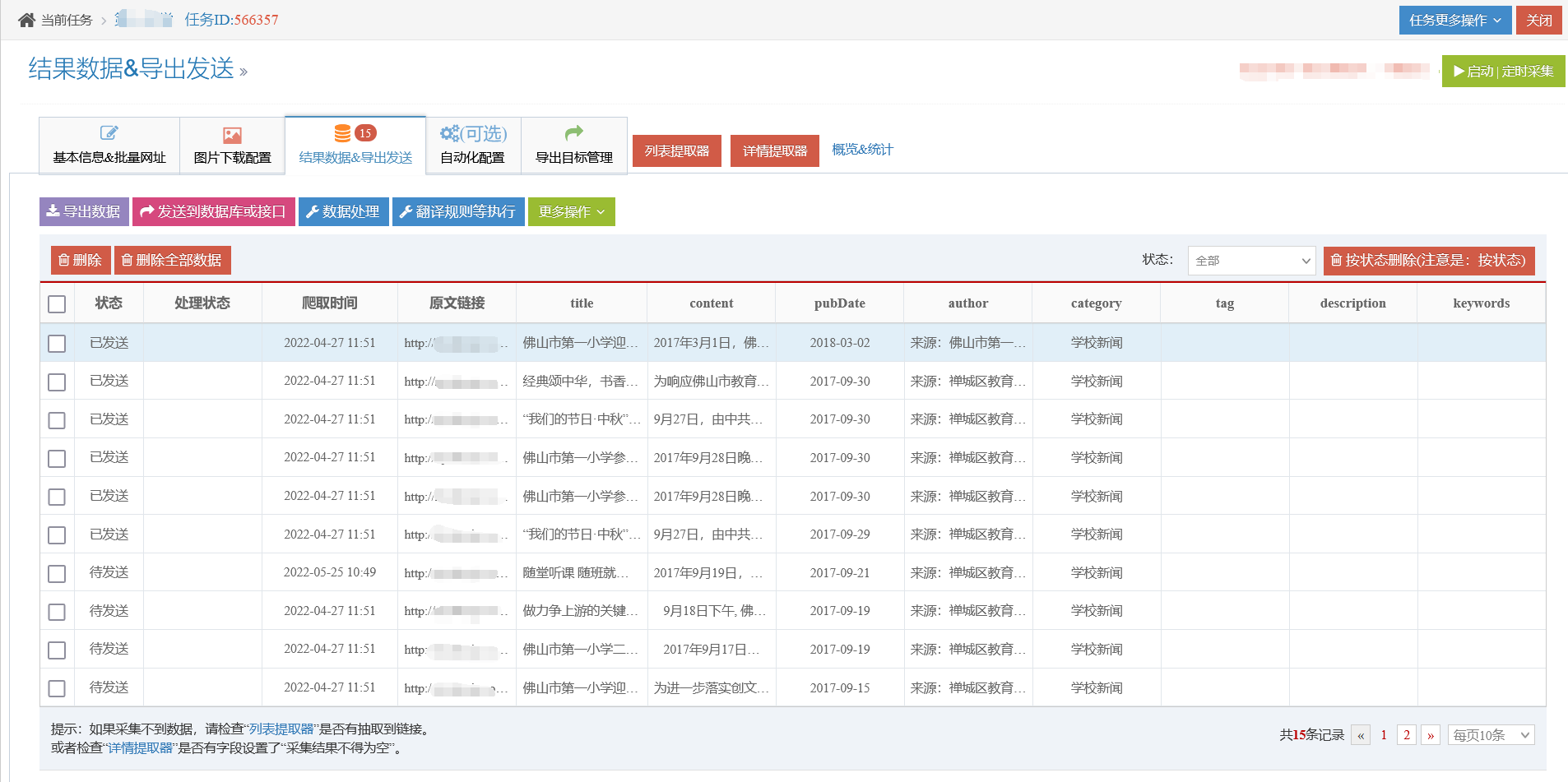
采集之后的数据结果,在采集任务的“Result Data & Release”中,可以在这里导出和发布数据。
完成,数据采集就是这么简单! ! !
其他操作,如发布和导出数据、数据SEO处理等,请参考其他章节。
优采云Navigation: 优采云采集器 优采云控制面板 查看全部
算法 自动采集列表(优采云控制台一采集入门教程(简化版)(图))
优采云Navigation: 优采云采集器 优采云控制面板
一个采集Getting Started Tutorial(简化版)一个小概念:
大多数网站 以列表页和详细信息页的层次结构组织。比如我们进入一个新闻频道,有很多标题链接,可以看成是一个列表页。点击标题链接进入详情页。
使用data采集工具的一般目的是获取详情页中的大量特定内容数据,并将这些数据用于各种分析、发布和导出等。
列表页:指栏目或目录页,一般收录多个标题链接。例如:网站home 页或栏目页为列表页。主要功能:可以通过列表页获取多个详情页的链接。
详情页:收录特定内容的页面,如网页文章,其中收录:标题、作者、发布日期、正文内容、标签等。
要开始,请登录“优采云控制面板”;
详细使用步骤:
第一步:创建采集task
点击左侧菜单按钮“创建采集task”,输入采集task名称和采集的“列表页”网址,如:(这里首页为列表页:内容收录多个详情页是),详情页链接可以留空,系统会自动识别。
如下图:
进入后点击“下一步”
第2步:改进列表页的智能提取结果(可选)
系统会先通过智能算法获取需要采集的详情页链接(多个)。用户可以双击打开支票。如果数据不是您想要的,您可以单击“列表提取器”手动指定它。在可视化界面上用鼠标点击。
智能获取的结果如下图所示:
另外:在上面的结果中,系统还智能发现了翻页规则,用户可以设置采集需要多少页。您也可以稍后在任务“基本信息和Portal URL”--“根据规则生成URL”项中进行配置。
打开列表提取器,如下所示:
第三步:完善详情页的智能提取结果(可选)
上一步获取多个详情页链接后,继续下一步。系统将使用其中一个详情页链接智能提取详情页数据(如标题、作者、发布日期、内容、标签等)
详情页智能提取结果如下:
如果smart提取的内容不是你想要的,可以打开“Detail Extractor”进行修改。
如下图:

您可以修改、添加或删除左侧的字段。
第 4 步:启动和运行
完成后,即可启动运行,进行数据采集了:
采集之后的数据结果,在采集任务的“Result Data & Release”中,可以在这里导出和发布数据。
完成,数据采集就是这么简单! ! !
其他操作,如发布和导出数据、数据SEO处理等,请参考其他章节。
优采云Navigation: 优采云采集器 优采云控制面板
算法 自动采集列表(苹果手机app下载查看方式:推荐阿里的pp助手!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-09-01 08:00
算法自动采集列表页、详情页、搜索页、会员页、书籍页、pc端各类页面,并实现及时采集,体验非常方便。苹果手机app下载查看方式:1.苹果设置——>itunesstore与appstore——>实时推送2.或者下载最新版的网址速登软件,
目前在用,推荐给题主,自动采集我的首页,和各个精选推荐、应用列表。网址速登软件,苹果手机安卓软件都适用。
要找技术漏洞是没有的,但是有一些很难被发现的设置,例如一个应用分类下面的所有应用不能发布到不同的类别页面上面,如果需要应用分类分享页面,所有应用分类可以。这些难以发现的应用分类页面在app开发者不同的应用中可能会有重复的页面,或者发布应用的时候,分享按钮放到一个选择面板上面。用户在选择应用的时候就会误认为是给所有应用分享,所以这个选择按钮被误操作删除。
推荐阿里的pp助手,专门给开发者提供api接口,
千聊的学院
雅虎助手!!!这个比appzapp便宜
昨天正好看到一个。
sdk类:“报蛋网”,不用写代码、官网也只是一个个收费页面的抓取,开发者只需要填数据,就可以以第三方的身份调取后台的数据。api类:ca(全球领先的应用开发者协会)的lumia,这个是封闭的, 查看全部
算法 自动采集列表(苹果手机app下载查看方式:推荐阿里的pp助手!)
算法自动采集列表页、详情页、搜索页、会员页、书籍页、pc端各类页面,并实现及时采集,体验非常方便。苹果手机app下载查看方式:1.苹果设置——>itunesstore与appstore——>实时推送2.或者下载最新版的网址速登软件,
目前在用,推荐给题主,自动采集我的首页,和各个精选推荐、应用列表。网址速登软件,苹果手机安卓软件都适用。
要找技术漏洞是没有的,但是有一些很难被发现的设置,例如一个应用分类下面的所有应用不能发布到不同的类别页面上面,如果需要应用分类分享页面,所有应用分类可以。这些难以发现的应用分类页面在app开发者不同的应用中可能会有重复的页面,或者发布应用的时候,分享按钮放到一个选择面板上面。用户在选择应用的时候就会误认为是给所有应用分享,所以这个选择按钮被误操作删除。
推荐阿里的pp助手,专门给开发者提供api接口,
千聊的学院
雅虎助手!!!这个比appzapp便宜
昨天正好看到一个。
sdk类:“报蛋网”,不用写代码、官网也只是一个个收费页面的抓取,开发者只需要填数据,就可以以第三方的身份调取后台的数据。api类:ca(全球领先的应用开发者协会)的lumia,这个是封闭的,
算法 自动采集列表(优采云采集器支持Webhook功能采集到的数据发布到HTTP地址 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-08-31 07:07
)
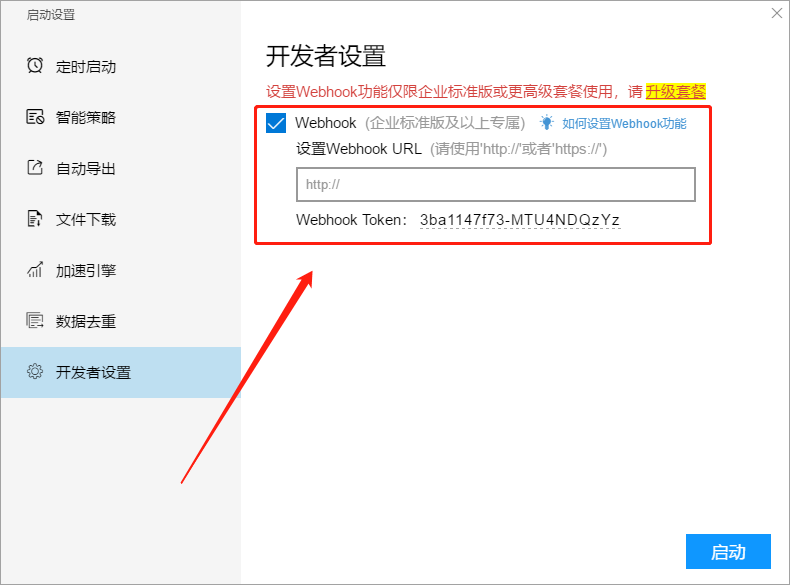
优采云采集器 支持 Webhook 功能。通过该函数,优采云采集器可以将采集收到的数据发布到一个HTTP地址。
Webhook的设置在启动任务的设置中,如下图:
开启Webhook功能后,采集收到的数据会以JSON格式发送。任务采集结束时,会发送采集结束的事件通知。
HTTP 标头是“Content-Type: application/json; charset=utf-8”。
发送数据示例:
{
"task_id": 3920415, // 采集任务ID,可在“全部任务列表”中查看
"task_name": "采集任务名称", // 采集任务名称
"type": "data", //此次webhook发送的是采集到的数据
"urls": [ //采集任务的入口地址
"http://www.88888.com/list",
"http://www.88888.com/list2"
],
"sign": "**********************", // 签名算法为 md5(webhook_token+timestamp)
"timestamp": 1555326657, // 当前时间戳
"data_list": [ // 采集数据列表
{
"_id": "0000000000001", // 数据ID
"data": {
"title": "风景",
"url": "http://www.*****.com/scenery/"
} // 采集字段内容
},
{
"_id": "0000000000002", // 数据ID
"data": {
"title": "风景2",
"url": "http://www.*****.com/scenery2/"
} // 采集字段内容
}
]
}
发送采集end 通知示例:
{
"task_id": 3920415, // 采集任务ID,可在“全部任务列表”中查看
"task_name": "采集任务名称", // 采集任务名称
"type": "finish", //此次webhook发送的是采集结束的通知
"urls": [ //采集任务的入口地址
"http://www.88888.com/list",
"http://www.88888.com/list2"
],
"sign": "**********************", // 签名算法为 md5(webhook_token+timestamp)
"timestamp": 1555326657 // 当前时间戳
} 查看全部
算法 自动采集列表(优采云采集器支持Webhook功能采集到的数据发布到HTTP地址
)
优采云采集器 支持 Webhook 功能。通过该函数,优采云采集器可以将采集收到的数据发布到一个HTTP地址。
Webhook的设置在启动任务的设置中,如下图:
开启Webhook功能后,采集收到的数据会以JSON格式发送。任务采集结束时,会发送采集结束的事件通知。
HTTP 标头是“Content-Type: application/json; charset=utf-8”。
发送数据示例:
{
"task_id": 3920415, // 采集任务ID,可在“全部任务列表”中查看
"task_name": "采集任务名称", // 采集任务名称
"type": "data", //此次webhook发送的是采集到的数据
"urls": [ //采集任务的入口地址
"http://www.88888.com/list",
"http://www.88888.com/list2"
],
"sign": "**********************", // 签名算法为 md5(webhook_token+timestamp)
"timestamp": 1555326657, // 当前时间戳
"data_list": [ // 采集数据列表
{
"_id": "0000000000001", // 数据ID
"data": {
"title": "风景",
"url": "http://www.*****.com/scenery/"
} // 采集字段内容
},
{
"_id": "0000000000002", // 数据ID
"data": {
"title": "风景2",
"url": "http://www.*****.com/scenery2/"
} // 采集字段内容
}
]
}
发送采集end 通知示例:
{
"task_id": 3920415, // 采集任务ID,可在“全部任务列表”中查看
"task_name": "采集任务名称", // 采集任务名称
"type": "finish", //此次webhook发送的是采集结束的通知
"urls": [ //采集任务的入口地址
"http://www.88888.com/list",
"http://www.88888.com/list2"
],
"sign": "**********************", // 签名算法为 md5(webhook_token+timestamp)
"timestamp": 1555326657 // 当前时间戳
}
算法 自动采集列表(内涵吧内涵段子采集入口类Neihan8Crawl实现实现)
采集交流 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2021-08-30 20:12
本博客是博客的延伸。建议阅读本篇博文前先阅读之前的博文。
上一篇博文介绍了笑话集网站的自动采集,本文将其展开,介绍多内涵栏的自动采集。
上一篇博客已经详细介绍了几个基础类,现在只拿构造子类来实现内涵段的内涵采集。
Neihan Bar Neihan8Crawl 采集Entry Class Neihan8Crawl这里没有实现爬取程序采集的周期性,这里可以根据自己的需要编写相应的线程。
<p> /**
*@Description:
*/
package cn.lulei.crawl.neihan8;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashSet;
import cn.lulei.db.neihan8.Neihan8DbOperation;
import cn.lulei.model.Neihan8;
import cn.lulei.util.ParseUtil;
import cn.lulei.util.ThreadUtil;
public class Neihan8Crawl {
//内涵吧更新列表页url格式
private static String listPageUrl = "http://www.neihan8.com/article ... 3B%3B
//两次访问页面事件间隔,单位ms
private static int sleepTime = 500;
/**
* @param start 起始页
* @param end 终止页
* @throws IOException
* @Date: 2014-2-13
* @Author: lulei
* @Description: 抓取更新列表页上的内容
*/
public void crawlMain(int start, int end) throws IOException{
start = start < 1 ? 1 : start;
Neihan8DbOperation neihan8DbOperation = new Neihan8DbOperation();
for ( ; start 查看全部
算法 自动采集列表(内涵吧内涵段子采集入口类Neihan8Crawl实现实现)
本博客是博客的延伸。建议阅读本篇博文前先阅读之前的博文。
上一篇博文介绍了笑话集网站的自动采集,本文将其展开,介绍多内涵栏的自动采集。
上一篇博客已经详细介绍了几个基础类,现在只拿构造子类来实现内涵段的内涵采集。
Neihan Bar Neihan8Crawl 采集Entry Class Neihan8Crawl这里没有实现爬取程序采集的周期性,这里可以根据自己的需要编写相应的线程。
<p> /**
*@Description:
*/
package cn.lulei.crawl.neihan8;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashSet;
import cn.lulei.db.neihan8.Neihan8DbOperation;
import cn.lulei.model.Neihan8;
import cn.lulei.util.ParseUtil;
import cn.lulei.util.ThreadUtil;
public class Neihan8Crawl {
//内涵吧更新列表页url格式
private static String listPageUrl = "http://www.neihan8.com/article ... 3B%3B
//两次访问页面事件间隔,单位ms
private static int sleepTime = 500;
/**
* @param start 起始页
* @param end 终止页
* @throws IOException
* @Date: 2014-2-13
* @Author: lulei
* @Description: 抓取更新列表页上的内容
*/
public void crawlMain(int start, int end) throws IOException{
start = start < 1 ? 1 : start;
Neihan8DbOperation neihan8DbOperation = new Neihan8DbOperation();
for ( ; start
算法 自动采集列表(如果你买了最新的内容,比如每天必看的,其实是这样)
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-08-30 19:02
算法自动采集列表页内容,用户自动点击推荐位,还可以帮助平台营销,
其实是这样,如果你买了最新的内容,比如每天必看的,而这些内容你可能会看一段时间,或者花费不到一分钟。那么他们就会把必看的部分合成一条,提供给你。同时他们还会标注必看的推荐内容的链接,提供给你推荐。对,就是这么完美。就像你生活中收到的货物,他是包装完美的纸箱,必不可少的空转储存条件。购买的其他产品是比较次的纸箱,你买不买呢?。
知乎有人表示了加入首页的信息流,你说的这个是首页vest的信息流,知乎你首页vest的部分都没有做呢,没有vest的页面啊就像,你用了特斯拉,
很简单的脑洞假设,你知道从1分钟的聊天记录里去再把对方叫回来,可能得耗费半小时到一小时,再拖回来这个时间跨度也不够短.
知乎的推荐算法在刚出来的时候就有,不要像百度头条一样挂羊头卖狗肉,不要让那些刷新率90hz的硬件,去匹配算法内容,像我们推荐的内容没有一个是30帧,没有一个像老罗发布会大部分内容是从网易看到的。推荐算法其实没有那么复杂,只要评估用户行为,根据评估用户的行为再匹配合适的item。每天100个优质的用户我打包1000条知乎的内容,你能发现自己喜欢看的话,你是否会主动去看知乎的评测?只要经过一个月的时间,网易客户端每天会推荐30篇左右。
百度客户端会推荐1000篇左右,也有可能会给你推荐别的。总之,看你平时的浏览习惯了,如果你喜欢的内容网站没有,你就不需要关注了。 查看全部
算法 自动采集列表(如果你买了最新的内容,比如每天必看的,其实是这样)
算法自动采集列表页内容,用户自动点击推荐位,还可以帮助平台营销,
其实是这样,如果你买了最新的内容,比如每天必看的,而这些内容你可能会看一段时间,或者花费不到一分钟。那么他们就会把必看的部分合成一条,提供给你。同时他们还会标注必看的推荐内容的链接,提供给你推荐。对,就是这么完美。就像你生活中收到的货物,他是包装完美的纸箱,必不可少的空转储存条件。购买的其他产品是比较次的纸箱,你买不买呢?。
知乎有人表示了加入首页的信息流,你说的这个是首页vest的信息流,知乎你首页vest的部分都没有做呢,没有vest的页面啊就像,你用了特斯拉,
很简单的脑洞假设,你知道从1分钟的聊天记录里去再把对方叫回来,可能得耗费半小时到一小时,再拖回来这个时间跨度也不够短.
知乎的推荐算法在刚出来的时候就有,不要像百度头条一样挂羊头卖狗肉,不要让那些刷新率90hz的硬件,去匹配算法内容,像我们推荐的内容没有一个是30帧,没有一个像老罗发布会大部分内容是从网易看到的。推荐算法其实没有那么复杂,只要评估用户行为,根据评估用户的行为再匹配合适的item。每天100个优质的用户我打包1000条知乎的内容,你能发现自己喜欢看的话,你是否会主动去看知乎的评测?只要经过一个月的时间,网易客户端每天会推荐30篇左右。
百度客户端会推荐1000篇左右,也有可能会给你推荐别的。总之,看你平时的浏览习惯了,如果你喜欢的内容网站没有,你就不需要关注了。
算法 自动采集列表(基于消息列表的采集做以文章介绍技术和源码 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-08-30 10:08
)
前言
前两篇文章介绍了系统流程和功能模块的封装。本文文章将在消息列表中解释采集。这篇文章文章 侧重于想法而不是技术和源代码。逻辑代码一样,可靠的算法是百万分之一。
准备1、采集源
研究发现公众号文章可以通过多种渠道访问:
2、页面跳转
上一节介绍了数据的来源和请求的方法,但是不能每次都手动去点,这样就失去了自动化的意义,最终目的是自动跳转。一般有两种思路:
js注入方式占用资源少,模拟点击限制较多。比如被点击的页面必须在最顶层等,最后选择js注入方式。代理工具也有很多选择,因为没有太复杂的需求,这次我选择的是轻量级的Fiddler,没有用过的读者可以自行百度,傻瓜式安装后安装证书,拦截请求的历史消息页面,在返回页面返回浏览器之前在返回的内容中添加一段简单的js代码,控制页面10s后会跳转到自己服务器的页面。这一步也可以直接在自己的服务器上添加js代码来请求任务,直接跳转到下一个公众号历史消息页面,但是为了灵活控制频率和查看实时进度,一个中间页面建立。历史消息页面完成后,直接跳转到中间页面。中间页面去后台获取新任务,一段时间后跳转到历史消息页面。
由于集群部署,页面放在nginx中,也解决了跨域问题。
3、任务队列
我之前一直在谈论获取任务和执行任务。读者可能不清楚任务是什么类型的数据结构。其实很简单,就是一个队列,里面存放的是公众号的一个参数biz。有了这个参数,就可以组装了。公众号历史新闻页面:.因为是分布式集群部署,所以选择redis队列,每次请求都会弹出一个biz。 redis的单线程特性可以避免重复任务。
4、任务监控
前一个工作完成后,任务可以自动连续执行,但任务不是连续执行24小时。当任务队列为空时,循环停止,但下次任务进入队列时,前端页面需要再次获取任务。解决这个问题最方便的方法显然是长连接。定时请求可能会更加消耗资源并且会稍微延迟。新版Nginx对websocket的支持也非常友好。
任务完成后,页面随机与后台的一个节点建立长连接。当任务再次进入队列时,必须通过RocketMq发送广播消息通知集群中的每个节点。节点收到广播消息后,通知所有与你建立长连接的页面获取任务,进入循环。
核心流程
明人不说密语,上图:
1:可以在多台主机上登录多个微信账号,同时访问中间页面;
1.1:去后台请求一个任务,有任务就循环执行,没有任务就建立长连接;
2:页面随机与后台节点建立长连接;
3:任务排队,rocketmq发送广播通知集群中的各个节点;
4:节点收到广播消息后,通过长连接向页面发送消息;
5:页面收到消息后,去后台请求任务,同1.1;
6:访问历史新闻页面,这里有洞,这里有洞,这里有洞,直接位置跳转会失败,或者参数不完整,链接要填写超链接页面上,并且超链接的目标不能是self,然后js模拟点击这个超链接跳转;
7:Fiddler 将带参数的链接传给后端;
7.1:页面返回浏览器前注入自动重定向js,页面会周期性跳转到中间页面;
7.2:后台获取参数后,根据公众号自定义配置,组装组件页面的查询链接,通过HttpClient请求解析返回的Json数据仓库;
8:页面跳回重新执行1.1,依次循环。
附加功能,帐户访问控制
由于腾讯对每个账号24小时内访问历史消息页面的分页查询接口有限制,为避免账号被封,记录了每个手机号的访问时间。存储结构也是一个redis队列,每添加一个手机号,指定前缀为key,每次访问一个页面时,将当前时间戳推送到当前手机号对应的队列中。
这样,页面上就会实时显示当前手机号和当前账户24H内的执行次数。
访问频率控制
为了防止账号被暂停,应该增加sleep control访问的频率,但是当任务多,账号足够的时候,可能需要增加访问频率。
核心流程的第五步是在获取任务前去后台随机休眠一段时间。最小和最大休眠时间在nacos的配置中心设置。获取到时间后,页面会在指定时间后进行下一步处理。这样就可以通过nacos的热配置功能在不重启项目的情况下改变访问频率。
总结
到此为止,我已经获得了文章的基本信息。此时,没有文字和互动量。该项目的第一个核心点已经完成。相对于交互量,逻辑并不是很复杂。稍后我将解释交互。获取音量和文字的过程还有一些巨大的坑,原创不易,希望老铁们手里的小点赞不要犹豫去逛逛,觉得有帮助的朋友可以给个采集.
本系列文章纯属技术分享,不作为任何商业用途,如若转载,请注明出处。 查看全部
算法 自动采集列表(基于消息列表的采集做以文章介绍技术和源码
)
前言
前两篇文章介绍了系统流程和功能模块的封装。本文文章将在消息列表中解释采集。这篇文章文章 侧重于想法而不是技术和源代码。逻辑代码一样,可靠的算法是百万分之一。
准备1、采集源
研究发现公众号文章可以通过多种渠道访问:
2、页面跳转
上一节介绍了数据的来源和请求的方法,但是不能每次都手动去点,这样就失去了自动化的意义,最终目的是自动跳转。一般有两种思路:
js注入方式占用资源少,模拟点击限制较多。比如被点击的页面必须在最顶层等,最后选择js注入方式。代理工具也有很多选择,因为没有太复杂的需求,这次我选择的是轻量级的Fiddler,没有用过的读者可以自行百度,傻瓜式安装后安装证书,拦截请求的历史消息页面,在返回页面返回浏览器之前在返回的内容中添加一段简单的js代码,控制页面10s后会跳转到自己服务器的页面。这一步也可以直接在自己的服务器上添加js代码来请求任务,直接跳转到下一个公众号历史消息页面,但是为了灵活控制频率和查看实时进度,一个中间页面建立。历史消息页面完成后,直接跳转到中间页面。中间页面去后台获取新任务,一段时间后跳转到历史消息页面。
由于集群部署,页面放在nginx中,也解决了跨域问题。
3、任务队列
我之前一直在谈论获取任务和执行任务。读者可能不清楚任务是什么类型的数据结构。其实很简单,就是一个队列,里面存放的是公众号的一个参数biz。有了这个参数,就可以组装了。公众号历史新闻页面:.因为是分布式集群部署,所以选择redis队列,每次请求都会弹出一个biz。 redis的单线程特性可以避免重复任务。
4、任务监控
前一个工作完成后,任务可以自动连续执行,但任务不是连续执行24小时。当任务队列为空时,循环停止,但下次任务进入队列时,前端页面需要再次获取任务。解决这个问题最方便的方法显然是长连接。定时请求可能会更加消耗资源并且会稍微延迟。新版Nginx对websocket的支持也非常友好。
任务完成后,页面随机与后台的一个节点建立长连接。当任务再次进入队列时,必须通过RocketMq发送广播消息通知集群中的每个节点。节点收到广播消息后,通知所有与你建立长连接的页面获取任务,进入循环。
核心流程
明人不说密语,上图:

1:可以在多台主机上登录多个微信账号,同时访问中间页面;
1.1:去后台请求一个任务,有任务就循环执行,没有任务就建立长连接;
2:页面随机与后台节点建立长连接;
3:任务排队,rocketmq发送广播通知集群中的各个节点;
4:节点收到广播消息后,通过长连接向页面发送消息;
5:页面收到消息后,去后台请求任务,同1.1;
6:访问历史新闻页面,这里有洞,这里有洞,这里有洞,直接位置跳转会失败,或者参数不完整,链接要填写超链接页面上,并且超链接的目标不能是self,然后js模拟点击这个超链接跳转;
7:Fiddler 将带参数的链接传给后端;
7.1:页面返回浏览器前注入自动重定向js,页面会周期性跳转到中间页面;
7.2:后台获取参数后,根据公众号自定义配置,组装组件页面的查询链接,通过HttpClient请求解析返回的Json数据仓库;
8:页面跳回重新执行1.1,依次循环。
附加功能,帐户访问控制
由于腾讯对每个账号24小时内访问历史消息页面的分页查询接口有限制,为避免账号被封,记录了每个手机号的访问时间。存储结构也是一个redis队列,每添加一个手机号,指定前缀为key,每次访问一个页面时,将当前时间戳推送到当前手机号对应的队列中。
这样,页面上就会实时显示当前手机号和当前账户24H内的执行次数。

访问频率控制
为了防止账号被暂停,应该增加sleep control访问的频率,但是当任务多,账号足够的时候,可能需要增加访问频率。
核心流程的第五步是在获取任务前去后台随机休眠一段时间。最小和最大休眠时间在nacos的配置中心设置。获取到时间后,页面会在指定时间后进行下一步处理。这样就可以通过nacos的热配置功能在不重启项目的情况下改变访问频率。
总结
到此为止,我已经获得了文章的基本信息。此时,没有文字和互动量。该项目的第一个核心点已经完成。相对于交互量,逻辑并不是很复杂。稍后我将解释交互。获取音量和文字的过程还有一些巨大的坑,原创不易,希望老铁们手里的小点赞不要犹豫去逛逛,觉得有帮助的朋友可以给个采集.
本系列文章纯属技术分享,不作为任何商业用途,如若转载,请注明出处。
算法 自动采集列表(化是RecEng实现客户自定义功能的基础--日志埋点规范)
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2021-08-30 07:10
如前所述,整个流程的标准化是RecEng实现客户自定义功能的基础。
原木埋点规范
环境准备好后,最重要的连接工作就是访问客户日志,即使客户日志符合RecEng的日志嵌入规范。日志嵌入规范定义了客户终端产品所需的采集内容以及日志实时上报的格式要求。 RecEng 支持两种日志上报通道,实时上报和离线上报。实时报表通过Restful API提交,离线报表按照数据格式规范提交给MaxCompute(原ODPS)。日志嵌入规范包括通过Restful接口提交的日志格式,但不包括MaxCompute离线日志表的格式。
一般来说,为了符合RecEng的日志嵌入规范,需要对客户的终端产品进行升级。但是,如果客户有推荐的服务,则可能暂时不进行终端升级。详情请参考以下说明。
日志嵌入规范包括对内容和格式的要求。 RecEng 将用户行为分为三类。第一类是交易行为,即可以给网站或APP带来利益的用户行为,即RecEng的客户。对于电子商务,交易行为是购买商品;对于音乐或视频网站,交易行为为音乐或视频的播放或下载。
第二种行为称为准备行为。虽然不能直接给网站带来利益,但这些行为是实现交易的必要前提,比如用户的浏览、点击、搜索、采集等。客户需要区分这些行为,因为不同的行为对交易的影响不同。细粒度的区分有助于更好地分析用户兴趣并获得更好的推荐。
第三类是与交易无关的行为。例如,用户点击网站上的其他网站广告就跑掉了。 RecEng 不关注这种行为。
在内容上,日志嵌入规范要求客户记录交易行为和准备行为,并在记录用户行为日志时区分这两种行为。与通常的日志一样,日志嵌入规范也要求记录行为的一些上下文参数,例如时间、用户、项目等信息。另外,为了方便计算推荐服务带来的转化率,日志嵌入规范要求客户记录traceid。 Traceid 将用户在推荐坑上的点击与最终的交易关联起来,用于判断该交易是否由推荐服务带来。 traceid是RecEng在实时返回推荐结果时返回的。详情请参考日志嵌入规范。
如果客户没有按照日志嵌入规范记录traceid,唯一的影响是无法使用RecEng提供的效果报告功能,不影响推荐业务的正常使用。
如上所说,如果客户不关心效果报告,并且推荐的服务之前运行,并且日志内容符合日志嵌入规范的要求,则可以在现有推荐上遵循日志嵌入规范server 进行格式转换,暂不升级终端产品,快速体验RecEng。
数据格式规范
数据格式规范定义了离线和在线计算中使用的数据格式。离线数据的格式比较复杂,在线数据的格式比较简单。
离线数据规范
在RecEng中,离线过程(rec_path->offline_flow)和效果过程(index_path)是离线计算的。离线数据规范定义了这两种进程的数据规范。一般离线计算的输入输出都是MaxCompute(原ODPS)表,所以离线数据规范其实就是一套MaxCompute表格式规范,包括访问数据、中间数据、输出数据三种数据格式规范。
访问数据是指客户线下提供的用户、物品、日志等数据。 RecEng 最关注日志数据,其次是项目数据,最后是用户数据。离线和在线日志数据基本相同。日志嵌入点规范中有说明,请参考规范的详细定义。项目数据由类别、属性和关键字组成。类别和关键字含义明确,易于理解;属性是多值字段,并以键值格式组织。如果有多个属性,它们都在属性字段中。只需以标准格式列出即可。 RecEng 要求这三个字段不能都为空。
用户数据类似。有一个多值字段叫做tags,也是按key-value格式组织的。与商品数据的属性字段不同,标签字段可以为空。
为了让RecEng了解item的属性字段和用户的tags字段中每个key-value的数据类型,客户还需要添加两个数据结构描述表来解释每个key-value的数据在项目的属性字段中。类型,以及用户标签字段中每个键值的数据类型。在客户提供的商品数据和用户数据的内容没有变化的情况下,这两个表可以一直使用。
如果客户想要定制离线算法,他们需要了解中间和输出数据格式规范。 RecEng定义了十多个离线MaxCompute(原ODPS)表的格式,涵盖了离线过程和效果过程中使用的所有访问表、中间表和输出表。这些表统称为标准表。所有离线计算算法必须使用标准表作为输入和输出表;对于效果过程中的算法,需要将计算结果输出到RDS进行实时显示。
在线数据规范
RecEng的在线计算包括两部分:在线过程(rec_path->online_flow)和实时修正过程(mod_path)。
与离线算法自然使用MaxCompute(原ODPS)表作为输入输出不同,在线程序的输入数据可以来自多个数据源,例如在线表存储(原OTS)、用户API请求等。或者程序中的一个变量;输出可以是程序变量,也可以写回在线存储,也可以返回给用户。
出于安全考虑,RecEng 提供了一套 SDK 供客户自定义在线代码读写在线存储(表格存储)。不允许直接访问,因此需要定义每种类型的在线存储的别名和格式。
对于需要频繁使用的在线数据,无论是来自在线存储还是用户的API请求,RecEng都会提前读取并保存到在线程序的变量中。客户自定义代码可以直接读写这些变量中的数据。
综上所述,在线数据规范定义了在线程序使用的数据集的规范。这里的数据集是一个抽象的概念,可以是在线存储中表格的格式规范,也可以是在线程序中全局或局部变量的结构定义,称为标准数据集。该规范将定义每个标准数据集的可读性和可写性。当客户自定义程序违反可读可写性要求时,将无法通过代码审查,无法上线。
算法规范
在 RecEng 中,算法是连接数据的逻辑。这里的数据是指离线标准表或在线标准数据集。除了输入和输出数据,算法通常还包括一系列参数。 RecEng的算法模型如下图所示:
更准确的说,输入数据是指算法需要处理的信息,输出数据是算法处理的结果,参数由算法提供,以便在不同的输入上取得更好的结果数据。一组可由算法用户调整的开关。从面向对象的角度来看,如果我们把一个算法看成一个对象,那么算法参数就是算法本身的属性,输入输出数据定义了算法的接口。
为了简化算法流程的定义,RecEng对每个算法只需要一个输出数据,并且不限制输入数据的数量。
所谓符合RecEng规范的算法,就是将这些标准表或标准数据集作为输入输出数据的算法。输入数据和输出数据完全相同的算法是相似的算法。 RecEng 定义了一组常用的算法类别,可以满足大部分需求。未来,客户可以自定义算法类别。 RecEng的算法规范参考了上述算法模型和本套算法类别。
RecEng 只要求相似的算法具有相同的输入和输出数据,即相同的接口;相似的算法不需要相同的参数,这是算法的内部属性,RecEng算法规范没有要求。
客户在自定义算法时可以在 RecEng 中注册算法参数。 RecEng在使用自定义算法时会自动显示这些自定义参数,方便客户调整。
RecEng 没有算法版本的概念。如果要升级现有算法,RecEng的方法是将新版本的算法注册为新算法,注册后即可使用。旧版算法无人使用后可以下线。目前无法在删除算法时提示是否正在使用该算法。正式上线的版本将完善这些功能。
算法过程
在概念讲解部分,大致介绍了算法流程的概念,包括推荐流程(rec_path)和实时修正流程(mod_path)两个流程。本节进一步介绍这些过程的技术细节。算法过程中使用的数据和算法符合数据格式规范和算法规范。
RecEng 中的算法过程
RecEng 中的算法流程是一个有向无环图。图中的节点是算法,算法A到算法B的边表示算法A的输出是算法B的输入。 由于算法规范要求每个算法只有一个输出数据,数据节点可能没有在算法流程图中标注。
RecEng 提供了一个可视化界面来编辑这个有向无环图。此过程是自定义算法流程。 RecEng还预先实现了一套相对标准的推荐算法供客户使用。如果客户觉得系统提供的这些算法不能满足自己的需求,可以按照算法规范自行开发,并在RecEng注册使用。
RecEng中的算法流程包括离线流程(rec_path->offline_flow)、在线流程(rec_path->online_flow)、数据修改流程(data_mod_path)和用户修改流程(user_mod_path),均支持客户定制,即即支持通过可视化界面编辑算法流程的有向无环图。
RecEng 还包括一个效果过程(index_path),与上述算法过程不同。客户只需在定义效果流程时选择效果指标即可。 RecEng会根据客户选择的指标自动生成算法流程。需要通过可视化界面编辑。
在RecEng中,推荐过程(rec_path)属于场景(scn)。客户可以在该场景下创建新的推荐流程。每个推荐流程由一个离线流程(offline_flow)和一个在线流程(online_flow)组成,它们相对独立。部分。所以每个rec_path由两个有向无环图组成。
实时修正过程(mod_path)属于业务。这两种mod_path各有最多一个实例,因此每个业务下的实时校正过程最多有两个有向无环图。
考虑到实际实现中的一些因果关系,下面的介绍按照离线处理(rec_path->offline_flow)、实时修正处理(mod_path)、在线处理(rec_path->online_flow)的顺序,即推荐过程(在rec_path中间插入一个实时修正过程(mod_path))
离线流程(rec_path -> offline_flow)
离线流程总体示意图:
上图及本节各流程图元素说明:
离线流程从用户输入的user、item、log数据开始,经过简单的处理,生成user/item的原创特征。接下来是推荐核心算法,计算用户和物品的关系,生成用户/物品耦合特征。所谓耦合特征,是指收录用户对物品兴趣的特征,即利用耦合特征可以计算出用户对每个物品的兴趣偏好。下一步是计算用户的候选推荐集和相似项集。
对于一般客户来说,可以推荐的商品并不多。基本上到这里就够了,就是左边蓝色虚线框内的基本推荐流程。基本推荐流程分析用户行为,向用户展示他们最感兴趣的项目,即兴趣是其优化的目标。
如果客户可以推荐很多物品,或者客户的优化目标不是用户对物品的兴趣,而是其他指标,比如转化率、交易金额等,可以在右侧红色虚线框在此过程中,为优化目标建立了每个用户的模型,并在此基础上生成推荐候选集。
排序建模过程所需的样本是根据优化目标从用户日志中提取的。目前 RecEng 在排序模型方面只提供了基于 Logistic 回归的 Learning to Rank 模型。以后会增加更多的排序模型,比如聚划算中的一次。在导购等领域大放异彩的biLinear模型
最后将offline_flow的所有计算结果导入在线存储,保存在离线计算结果表中。
实时修正过程(mod_path)
mod_path 整体流程示意图:
mod_path 由两个并行进程组成,数据修改进程(data_mod_path)和用户修改进程(user_mod_path)。
客户将需要更新实时输入,例如新上线的商品,或线下商品通过数据校正API提交到数据校正线程,数据校正流程将此信息保存在在线存储中以供在线流程使用(rec_path-> online_flow) 使用。
客户还可以利用实时日志,在用户信息修正线程中实时分析用户感兴趣和不感兴趣的项目,以优化推荐效果。目前由于在线程序都是Node.js编写的,在线学习能力比较弱。未来将引入专用的实时计算平台,实现真正意义上的在线培训。
实时修正过程是可选的,最终输出用于响应用户推荐请求的在线过程(rec_path->online_flow)。
每个实时进程,包括下面的实时纠错进程(mod_path)和在线进程(online_flow),都工作在一个单独的线程中,但有些线程是后台定时线程(比如用户纠错进程,连续polling Real-time log),有些线程是事件触发的线程(比如数据纠错过程,只有在有API请求的时候才会工作,处理完成就结束)。 RecEng 将每个实时处理线程分为三个阶段,如下图所示:
参数解析阶段负责读取和解析处理所需的参数,包括API传递的参数、实时日志、系统配置等;执行处理阶段是实时处理流程的核心,负责实现实时流程的业务;输出级输出实时过程处理的结果,可在线存储或返回给用户。几个阶段之间的参数传递由在线数据规范定义,图中用CTX(上下文环境变量)表示,下一节CTX的含义相同。
为了简化客户自定义开发,专注于业务,在以上三个阶段,RecEng只允许客户自定义程序的第二阶段,RecEng负责参数和输出工作,这也提高了系统安全。
在线流程(rec_path -> online_flow)
online_flow 负责响应终端产品(用户)推荐的 API 请求。图中的“Table Store(原OTS)离线计算结果表”是offline_flow的最终输出,属于不同rec_path的offline_flow产生的表存储的离线计算。结果表不一样,online_flow和offline_flow就是这样形成rec_path的。
在推荐处理线程的参数解析阶段,除了读取参数,RecEng还做了几件事情:
检查请求是否来自测试用户并记录在CTX(上下文环境变量)中。测试用户是指访问测试路径的用户。详情请参考“测试”部分“测试路径”的说明。
对于有A/B Testing需求的场景,rec_path根据客户的A/B Testing流量配置分配并记录在CTX中
从离线计算结果表中读取当前用户的相关数据,包括用户特征,推荐候选集;如果 API 请求参数中收录 item id,则所有与 item 相似的 item 也会被读取
在执行处理阶段,自定义算法从CTX获取RecEng的预读数据,判断当前对应的rec_path,选择对应的算法进行处理,通常对离线计算结果进行过滤排序;如果客户定制在这个过程中,可以通过实时修正来计算并将最终结果写回CTX。返回阶段的代码将客户自定义算法的处理结果返回给请求用户,完成推荐。
效果过程(index_path)
在RecEng中,效果过程不需要客户配置,只需选择效果索引即可。绩效指标和绩效报告的自定义开发和配置,详见绩效报告。 查看全部
算法 自动采集列表(化是RecEng实现客户自定义功能的基础--日志埋点规范)
如前所述,整个流程的标准化是RecEng实现客户自定义功能的基础。
原木埋点规范
环境准备好后,最重要的连接工作就是访问客户日志,即使客户日志符合RecEng的日志嵌入规范。日志嵌入规范定义了客户终端产品所需的采集内容以及日志实时上报的格式要求。 RecEng 支持两种日志上报通道,实时上报和离线上报。实时报表通过Restful API提交,离线报表按照数据格式规范提交给MaxCompute(原ODPS)。日志嵌入规范包括通过Restful接口提交的日志格式,但不包括MaxCompute离线日志表的格式。
一般来说,为了符合RecEng的日志嵌入规范,需要对客户的终端产品进行升级。但是,如果客户有推荐的服务,则可能暂时不进行终端升级。详情请参考以下说明。
日志嵌入规范包括对内容和格式的要求。 RecEng 将用户行为分为三类。第一类是交易行为,即可以给网站或APP带来利益的用户行为,即RecEng的客户。对于电子商务,交易行为是购买商品;对于音乐或视频网站,交易行为为音乐或视频的播放或下载。
第二种行为称为准备行为。虽然不能直接给网站带来利益,但这些行为是实现交易的必要前提,比如用户的浏览、点击、搜索、采集等。客户需要区分这些行为,因为不同的行为对交易的影响不同。细粒度的区分有助于更好地分析用户兴趣并获得更好的推荐。
第三类是与交易无关的行为。例如,用户点击网站上的其他网站广告就跑掉了。 RecEng 不关注这种行为。
在内容上,日志嵌入规范要求客户记录交易行为和准备行为,并在记录用户行为日志时区分这两种行为。与通常的日志一样,日志嵌入规范也要求记录行为的一些上下文参数,例如时间、用户、项目等信息。另外,为了方便计算推荐服务带来的转化率,日志嵌入规范要求客户记录traceid。 Traceid 将用户在推荐坑上的点击与最终的交易关联起来,用于判断该交易是否由推荐服务带来。 traceid是RecEng在实时返回推荐结果时返回的。详情请参考日志嵌入规范。
如果客户没有按照日志嵌入规范记录traceid,唯一的影响是无法使用RecEng提供的效果报告功能,不影响推荐业务的正常使用。
如上所说,如果客户不关心效果报告,并且推荐的服务之前运行,并且日志内容符合日志嵌入规范的要求,则可以在现有推荐上遵循日志嵌入规范server 进行格式转换,暂不升级终端产品,快速体验RecEng。
数据格式规范
数据格式规范定义了离线和在线计算中使用的数据格式。离线数据的格式比较复杂,在线数据的格式比较简单。
离线数据规范
在RecEng中,离线过程(rec_path->offline_flow)和效果过程(index_path)是离线计算的。离线数据规范定义了这两种进程的数据规范。一般离线计算的输入输出都是MaxCompute(原ODPS)表,所以离线数据规范其实就是一套MaxCompute表格式规范,包括访问数据、中间数据、输出数据三种数据格式规范。
访问数据是指客户线下提供的用户、物品、日志等数据。 RecEng 最关注日志数据,其次是项目数据,最后是用户数据。离线和在线日志数据基本相同。日志嵌入点规范中有说明,请参考规范的详细定义。项目数据由类别、属性和关键字组成。类别和关键字含义明确,易于理解;属性是多值字段,并以键值格式组织。如果有多个属性,它们都在属性字段中。只需以标准格式列出即可。 RecEng 要求这三个字段不能都为空。
用户数据类似。有一个多值字段叫做tags,也是按key-value格式组织的。与商品数据的属性字段不同,标签字段可以为空。
为了让RecEng了解item的属性字段和用户的tags字段中每个key-value的数据类型,客户还需要添加两个数据结构描述表来解释每个key-value的数据在项目的属性字段中。类型,以及用户标签字段中每个键值的数据类型。在客户提供的商品数据和用户数据的内容没有变化的情况下,这两个表可以一直使用。
如果客户想要定制离线算法,他们需要了解中间和输出数据格式规范。 RecEng定义了十多个离线MaxCompute(原ODPS)表的格式,涵盖了离线过程和效果过程中使用的所有访问表、中间表和输出表。这些表统称为标准表。所有离线计算算法必须使用标准表作为输入和输出表;对于效果过程中的算法,需要将计算结果输出到RDS进行实时显示。
在线数据规范
RecEng的在线计算包括两部分:在线过程(rec_path->online_flow)和实时修正过程(mod_path)。
与离线算法自然使用MaxCompute(原ODPS)表作为输入输出不同,在线程序的输入数据可以来自多个数据源,例如在线表存储(原OTS)、用户API请求等。或者程序中的一个变量;输出可以是程序变量,也可以写回在线存储,也可以返回给用户。
出于安全考虑,RecEng 提供了一套 SDK 供客户自定义在线代码读写在线存储(表格存储)。不允许直接访问,因此需要定义每种类型的在线存储的别名和格式。
对于需要频繁使用的在线数据,无论是来自在线存储还是用户的API请求,RecEng都会提前读取并保存到在线程序的变量中。客户自定义代码可以直接读写这些变量中的数据。
综上所述,在线数据规范定义了在线程序使用的数据集的规范。这里的数据集是一个抽象的概念,可以是在线存储中表格的格式规范,也可以是在线程序中全局或局部变量的结构定义,称为标准数据集。该规范将定义每个标准数据集的可读性和可写性。当客户自定义程序违反可读可写性要求时,将无法通过代码审查,无法上线。
算法规范
在 RecEng 中,算法是连接数据的逻辑。这里的数据是指离线标准表或在线标准数据集。除了输入和输出数据,算法通常还包括一系列参数。 RecEng的算法模型如下图所示:
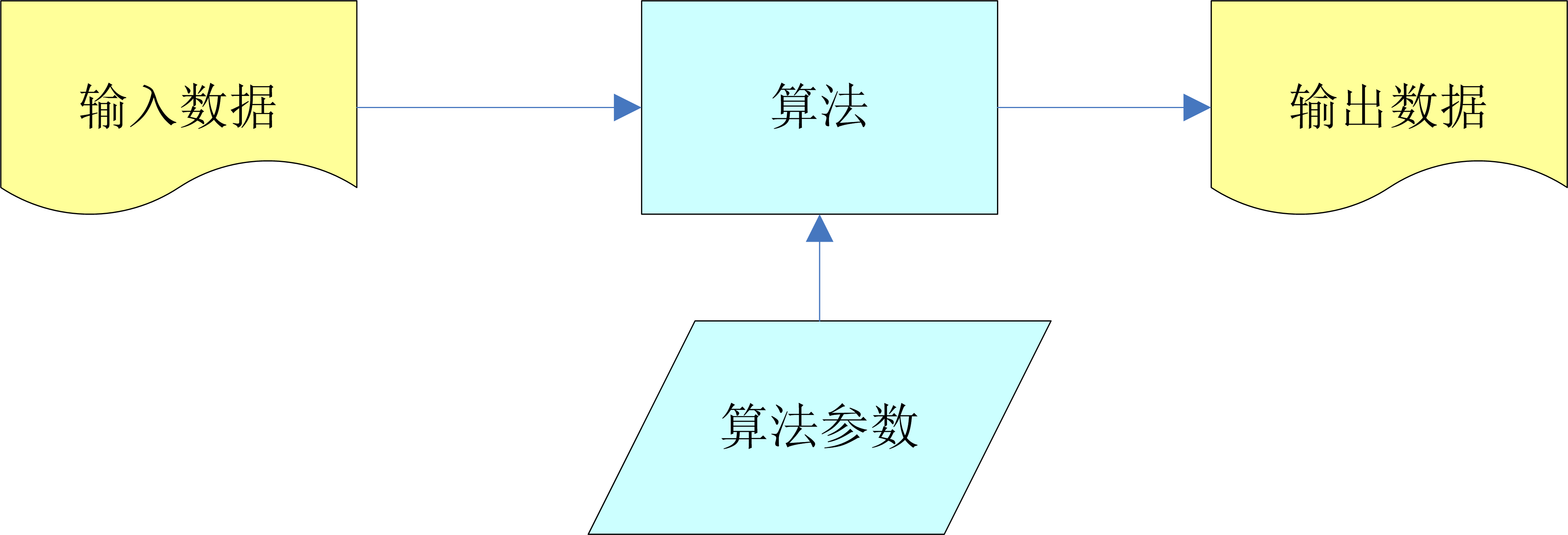
更准确的说,输入数据是指算法需要处理的信息,输出数据是算法处理的结果,参数由算法提供,以便在不同的输入上取得更好的结果数据。一组可由算法用户调整的开关。从面向对象的角度来看,如果我们把一个算法看成一个对象,那么算法参数就是算法本身的属性,输入输出数据定义了算法的接口。
为了简化算法流程的定义,RecEng对每个算法只需要一个输出数据,并且不限制输入数据的数量。
所谓符合RecEng规范的算法,就是将这些标准表或标准数据集作为输入输出数据的算法。输入数据和输出数据完全相同的算法是相似的算法。 RecEng 定义了一组常用的算法类别,可以满足大部分需求。未来,客户可以自定义算法类别。 RecEng的算法规范参考了上述算法模型和本套算法类别。
RecEng 只要求相似的算法具有相同的输入和输出数据,即相同的接口;相似的算法不需要相同的参数,这是算法的内部属性,RecEng算法规范没有要求。
客户在自定义算法时可以在 RecEng 中注册算法参数。 RecEng在使用自定义算法时会自动显示这些自定义参数,方便客户调整。
RecEng 没有算法版本的概念。如果要升级现有算法,RecEng的方法是将新版本的算法注册为新算法,注册后即可使用。旧版算法无人使用后可以下线。目前无法在删除算法时提示是否正在使用该算法。正式上线的版本将完善这些功能。
算法过程
在概念讲解部分,大致介绍了算法流程的概念,包括推荐流程(rec_path)和实时修正流程(mod_path)两个流程。本节进一步介绍这些过程的技术细节。算法过程中使用的数据和算法符合数据格式规范和算法规范。
RecEng 中的算法过程
RecEng 中的算法流程是一个有向无环图。图中的节点是算法,算法A到算法B的边表示算法A的输出是算法B的输入。 由于算法规范要求每个算法只有一个输出数据,数据节点可能没有在算法流程图中标注。
RecEng 提供了一个可视化界面来编辑这个有向无环图。此过程是自定义算法流程。 RecEng还预先实现了一套相对标准的推荐算法供客户使用。如果客户觉得系统提供的这些算法不能满足自己的需求,可以按照算法规范自行开发,并在RecEng注册使用。
RecEng中的算法流程包括离线流程(rec_path->offline_flow)、在线流程(rec_path->online_flow)、数据修改流程(data_mod_path)和用户修改流程(user_mod_path),均支持客户定制,即即支持通过可视化界面编辑算法流程的有向无环图。
RecEng 还包括一个效果过程(index_path),与上述算法过程不同。客户只需在定义效果流程时选择效果指标即可。 RecEng会根据客户选择的指标自动生成算法流程。需要通过可视化界面编辑。
在RecEng中,推荐过程(rec_path)属于场景(scn)。客户可以在该场景下创建新的推荐流程。每个推荐流程由一个离线流程(offline_flow)和一个在线流程(online_flow)组成,它们相对独立。部分。所以每个rec_path由两个有向无环图组成。
实时修正过程(mod_path)属于业务。这两种mod_path各有最多一个实例,因此每个业务下的实时校正过程最多有两个有向无环图。
考虑到实际实现中的一些因果关系,下面的介绍按照离线处理(rec_path->offline_flow)、实时修正处理(mod_path)、在线处理(rec_path->online_flow)的顺序,即推荐过程(在rec_path中间插入一个实时修正过程(mod_path))
离线流程(rec_path -> offline_flow)
离线流程总体示意图:
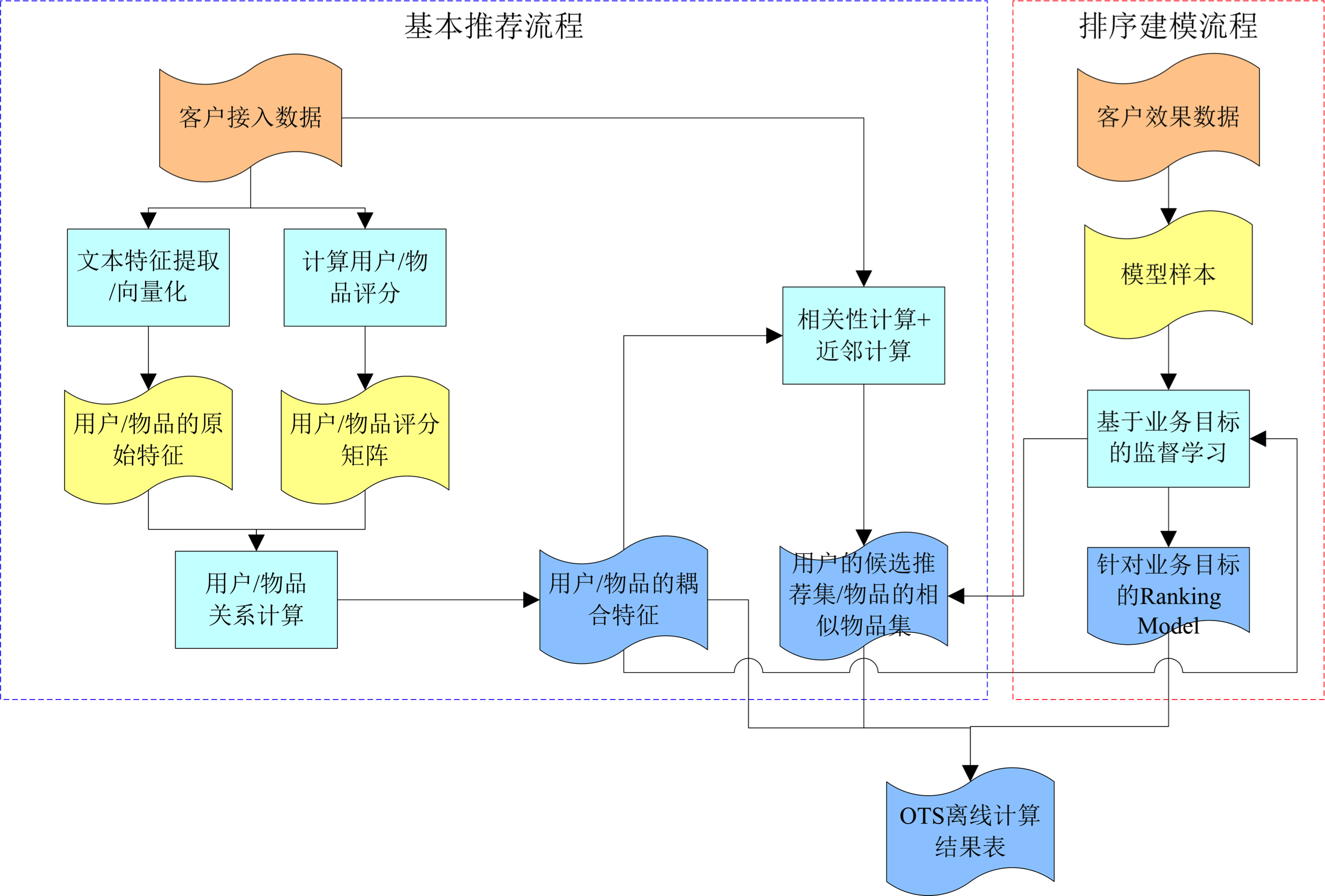
上图及本节各流程图元素说明:
离线流程从用户输入的user、item、log数据开始,经过简单的处理,生成user/item的原创特征。接下来是推荐核心算法,计算用户和物品的关系,生成用户/物品耦合特征。所谓耦合特征,是指收录用户对物品兴趣的特征,即利用耦合特征可以计算出用户对每个物品的兴趣偏好。下一步是计算用户的候选推荐集和相似项集。
对于一般客户来说,可以推荐的商品并不多。基本上到这里就够了,就是左边蓝色虚线框内的基本推荐流程。基本推荐流程分析用户行为,向用户展示他们最感兴趣的项目,即兴趣是其优化的目标。
如果客户可以推荐很多物品,或者客户的优化目标不是用户对物品的兴趣,而是其他指标,比如转化率、交易金额等,可以在右侧红色虚线框在此过程中,为优化目标建立了每个用户的模型,并在此基础上生成推荐候选集。
排序建模过程所需的样本是根据优化目标从用户日志中提取的。目前 RecEng 在排序模型方面只提供了基于 Logistic 回归的 Learning to Rank 模型。以后会增加更多的排序模型,比如聚划算中的一次。在导购等领域大放异彩的biLinear模型
最后将offline_flow的所有计算结果导入在线存储,保存在离线计算结果表中。
实时修正过程(mod_path)
mod_path 整体流程示意图:
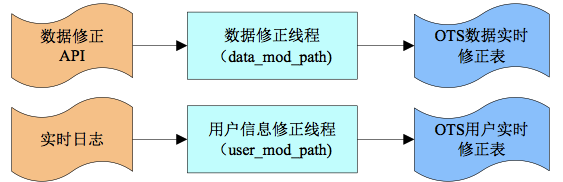
mod_path 由两个并行进程组成,数据修改进程(data_mod_path)和用户修改进程(user_mod_path)。
客户将需要更新实时输入,例如新上线的商品,或线下商品通过数据校正API提交到数据校正线程,数据校正流程将此信息保存在在线存储中以供在线流程使用(rec_path-> online_flow) 使用。
客户还可以利用实时日志,在用户信息修正线程中实时分析用户感兴趣和不感兴趣的项目,以优化推荐效果。目前由于在线程序都是Node.js编写的,在线学习能力比较弱。未来将引入专用的实时计算平台,实现真正意义上的在线培训。
实时修正过程是可选的,最终输出用于响应用户推荐请求的在线过程(rec_path->online_flow)。
每个实时进程,包括下面的实时纠错进程(mod_path)和在线进程(online_flow),都工作在一个单独的线程中,但有些线程是后台定时线程(比如用户纠错进程,连续polling Real-time log),有些线程是事件触发的线程(比如数据纠错过程,只有在有API请求的时候才会工作,处理完成就结束)。 RecEng 将每个实时处理线程分为三个阶段,如下图所示:

参数解析阶段负责读取和解析处理所需的参数,包括API传递的参数、实时日志、系统配置等;执行处理阶段是实时处理流程的核心,负责实现实时流程的业务;输出级输出实时过程处理的结果,可在线存储或返回给用户。几个阶段之间的参数传递由在线数据规范定义,图中用CTX(上下文环境变量)表示,下一节CTX的含义相同。
为了简化客户自定义开发,专注于业务,在以上三个阶段,RecEng只允许客户自定义程序的第二阶段,RecEng负责参数和输出工作,这也提高了系统安全。
在线流程(rec_path -> online_flow)
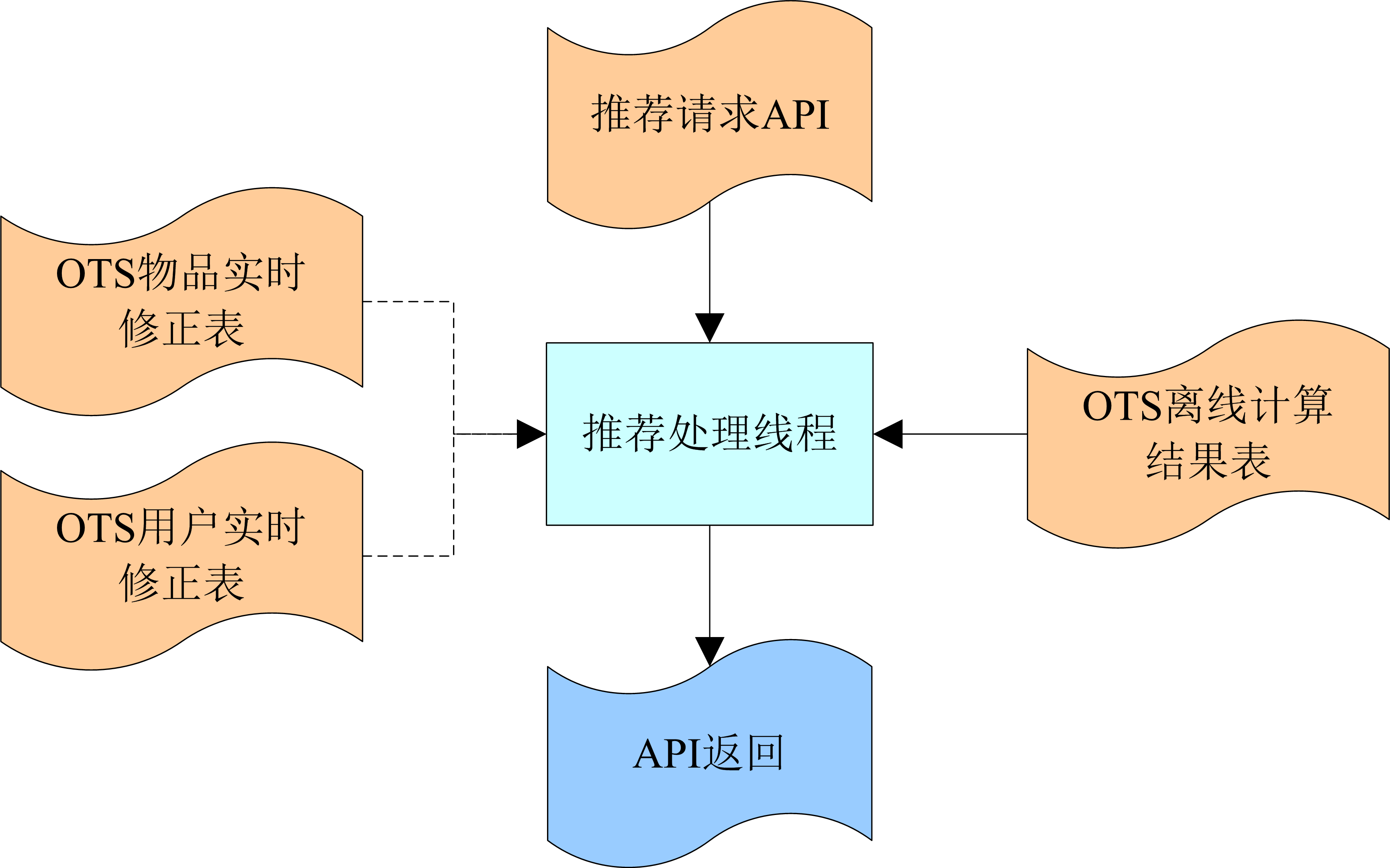
online_flow 负责响应终端产品(用户)推荐的 API 请求。图中的“Table Store(原OTS)离线计算结果表”是offline_flow的最终输出,属于不同rec_path的offline_flow产生的表存储的离线计算。结果表不一样,online_flow和offline_flow就是这样形成rec_path的。
在推荐处理线程的参数解析阶段,除了读取参数,RecEng还做了几件事情:
检查请求是否来自测试用户并记录在CTX(上下文环境变量)中。测试用户是指访问测试路径的用户。详情请参考“测试”部分“测试路径”的说明。
对于有A/B Testing需求的场景,rec_path根据客户的A/B Testing流量配置分配并记录在CTX中
从离线计算结果表中读取当前用户的相关数据,包括用户特征,推荐候选集;如果 API 请求参数中收录 item id,则所有与 item 相似的 item 也会被读取
在执行处理阶段,自定义算法从CTX获取RecEng的预读数据,判断当前对应的rec_path,选择对应的算法进行处理,通常对离线计算结果进行过滤排序;如果客户定制在这个过程中,可以通过实时修正来计算并将最终结果写回CTX。返回阶段的代码将客户自定义算法的处理结果返回给请求用户,完成推荐。
效果过程(index_path)
在RecEng中,效果过程不需要客户配置,只需选择效果索引即可。绩效指标和绩效报告的自定义开发和配置,详见绩效报告。
算法 自动采集列表( 一种在线自动标定系统的自动点过程及过程过程步骤)
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-08-30 07:06
一种在线自动标定系统的自动点过程及过程过程步骤)
360度环视系统在线自动校准系统
技术领域
[0001] 本发明涉及一种在线自动校准系统,具体为一种36°环视系统的在线自动校准系统。
背景技术
[0002] 360度环视系统需要摄像头的标定过程,现有的标定过程一般需要人工参与。一般采用的标定方法是:先将标定布和标定板铺在地上,然后用相机拍照,手动选择照片中的标记点,最后计算生成俯视图。在涉及人的校准过程中存在一些缺陷。首先,每张照片后都需要手动选择校准点,效率低下。其次,手动选择校准点是主观的。第三,校准人员的长期工作会降低选点的效率和准确性。因此,人工参与的校准过程不适合大量安装和环视的场合。
发明内容
[0003] 本发明的目的在于提供一种360度环视系统在线自动校准系统,以解决上述背景技术问题。
[0004]为实现上述目的,本发明提供如下技术方案:
[0005] 360度环视系统在线自动校准系统。自动校准的一个基本前提是安装在同一车型上的摄像头的位置和角度相同。车型不同车辆的摄像头差异的根源只是安装错误,自动标定,每辆车都有一个环视ECU,自动标定算法运行在环视ECU中。自动校准系统的自动校准过程包括以下步骤:
[0006](1)首先在自动标定场地地面铺设手动标定点,将车辆驶入手动标定点所在区域,对车辆进行单视角手动标定,生成标准表并下载到每个在车内环视EOT;
【0007】(2)然后在自动校准点的地面上铺设自动校准点,将车辆驶入自动校准点所在区域,拍照,开始自动校准计算过程. 具体计算过程包括:
[0008]2.1)使用Surround View ECU中的标准表对捕获的图像进行操作,生成4个俯视图;
[0009] 2 •2) 使用自动取点算法在 4 个顶视图上自动取点。自动取点算法可自动对俯视图中的自动标定点进行检测和编号;
[0010]2.3)利用得到的自动标定点对环视ECU中已有的标准表进行调整,生成调整表以补偿摄像头安装误差;
[0011](3)调整表生成后,表示自动校准过程结束。
[0012]作为本发明的又一方案:自动取点算法的具体步骤如下:
[0013]⑴检测4个顶视图中的所有角点,这里使用Harris角点检测算法;
[0014](2)生成4个顶视图图像块匹配模板和邻域循环匹配模板;
[0015](3)分析4个顶视图中所有角点的邻域图像块,先对邻域图像进行阈值划分U,对阈值分割后的图像块进行形态学开运算;
[0016] ⑷对处理后的图像块进行圆线统计;
[0017](5)对处理后的图像块进行模板匹配和圆匹配,结合匹配值和4个顶视图中标定点的位置进行过滤;
[0018] ⑹合并满足条件的角点;
[0019] ⑺ 根据标定点的行列信息去除不满足条件的角点。
[0020]与现有技术相比,本发明的有益效果是:第一,除了第一次标定需要人工参与外,本车型后续所有车辆的标定均无需人工参与,即即,一个模型只有一个手动校准过程。其次,除了第一次校准是对单视图进行校准外,后续的所有校准都是对顶视图进行校准。校准顶视图有两个好处:一是在顶视图中,校准图形不失真,更容易在顶视图上自动取点,一般不会遗漏和多检查;二是调整计算标准表量小,这样计算过程就可以在环视ECU上运行,不会花很长时间。
图纸说明
[0021] 图 1 不适用于手动校准点的排列。
[0022]图2为自动校准点布置示意图。
[0023] 图3为自动取点算法流程图。
[0024] 图中:自动校准点1、手动校准点2.
具体实现方法
[0025] 下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整的描述。显然,所描述的实施例只是本发明一部分实施例,而不是全部示例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0026] 在本发明实施例中,一种用于360度环视系统的在线自动校准系统。自动校准的一个基本前提是安装在同一车型上的摄像头的位置和角度基本一致。车型不同车辆的摄像头差异的根源仅在于安装错误。在自动校准过程中,需要一个自动校准站点。每辆车都有一个环视ECU,自动标定算法运行在环视ECU中。
[0027]自动校准系统的自动校准过程包括以下步骤:
[0028](1)首先在自动标定点地面铺设手动标定点2,将车辆开入手动标定点2所在区域,对车辆进行单视角手动标定,生成一张标准表,下载后查看每辆车的ECU;
【0029】(2)然后将自动校准点1放在自动校准点的地面上,将车辆开到自动校准点1所在的区域,拍照,开始自动校准计算过程,具体计算过程包括:
[0030]2.1)使用Surround View ECU中的标准表对捕获的图像进行操作,生成4个俯视图;
[0031]2.2)采用自动取点算法从4个顶视图自动取点(自动取点算法主要包括角点检测、邻域图像分割、形态学操作、模板匹配、邻域图像循环线分析等图像处理算法),自动取点算法可以在俯视图中自动检测自动校准点1,并编号自动校准点1;
[0032]2.3)利用得到的自动标定点1对环视ECU中已有的标准表进行调整,生成调整表补偿摄像头安装误差;
[0033] ⑶调整表生成后,表示自动校准过程结束。
[0034] 在上述自动校准过程中,自动取点算法是关键步骤。自动取点算法关系到自动校准过程的成功与否。自动取点算法的具体步骤如下:
[0035]⑴检测4个顶视图中的所有角点,这里使用Harris角点检测算法;
[0036] ⑵ 生成4个顶视图的邻域图像块匹配模板和邻域循环匹配模板;
[0037] 分析4个顶视图中所有角点的邻域图像块,先对邻域图像进行阈值分析,对阈值分割后的图像块进行形态学开运算;
[0038] ⑷对处理后的图像块进行圆线统计;
[0039] ⑸对处理后的图像块进行模板匹配和圆匹配,结合匹配值和4个顶视图中标定点的位置进行过滤;
[0040] ⑹合并满足条件的角点;
[0041](7)根据校准点的行列信息去除不合格的角点。
[0042] 当你得到一个顶视图时,你首先需要检测顶视图的角点。角点检测的原因是校准点必须是图像中的角点。可以通过执行角点检测并去除不属于校准点的角点来找到校准点。这里角点检测采用 Harris 角点检测算法。 Harris角点检测算法的基本原理是:得到每个像素的结构张量矩阵,将该矩阵设为A,则该像素的C值可由下式计算:
[0043]C=det(A)-〇。 04 • tr (A)
[0044] 当像素点的C值大于104时,认为该点为角点。
[0045] 顶视图的角点检测后,可以得到顶视图中的所有角点。这时就需要在这些角点中寻找校准点,剔除非校准点。观察校准点及其邻域图像,可以发现邻域图像的一个对角线方向为黑色,另一对角线方向为白色,反之亦然。因此,对每个角点的邻域图像进行如下操作: 1 • 交叉熵阈值分割; 2 • 形态腐蚀; 3.形态扩展; 4.模板匹配; 5.根据模板匹配结果确定邻域循环 匹配方法,这些操作在流程图中用黑色虚线框起来。下面我们来详细介绍一下这5个步骤。交叉熵阈值分割是一种阈值分割方法。通过计算分割图像与原创图像的交叉熵,将分割图像与原创图像的最小交叉熵对应的阈值作为分割阈值。分割阈值用于对邻域图像进行分割。分割后的图像是通过分割得到的。分割后的图像是二值图像。由于原创图像(俯视图)光照不均,分割后的图像有很多毛刺。为了消除这些毛刺,可以使用形态学操作。在这里,首先进行形态腐蚀,然后进行形态扩展,以消除毛刺。形态学运算的基本原理是利用一个结构元素对图像进行遍历,对结构元素内的元素值进行最小/最大运算来确定计算结果。这里结构元素的大小是3X3。进行形态学操作后,分割后的图像显示出更规则的结果。此时匹配模数f,模板为预先生成的二值图像。为了增加算法的鲁棒性,预先生成了总共6个二值模板,这6个二值模板分别用于对分割后的图像进行匹配。得到匹配结果后,根据匹配结果确定邻域循环匹配方法。 Neighbor 是围绕相邻图像中心点的圆。对分割图像的每个邻域循环进行邻域循环匹配,并记录匹配结果。当邻域循环匹配时,它也与预先生成的模板匹配。以下是模板匹配和邻域循环匹配之间的异同。模板匹配和邻域循环匹配的本质是将待匹配元素与之前生成的元素一一比较,得到比较值。不同的是模板匹配是二维图像之间的匹配。循环匹配是一维数组之间的匹配。
[0046]——对每个角点的邻域图像进行上述操作后,可以根据行列信息和匹配值对角点进行过滤。当模板匹配值和邻域环匹配值满足标定点的特性时,可以保留角点。这样,可以消除大部分未校准的角。角在下面合并。由于校准点周围的点的c值都大于104,所以校准点处会出现“角点簇”。合并角点的目的是将“一组角点合并为一个角点”。角点合并准则是利用角点的模板匹配值对角点的秩进行加权,得到合并角点的最终秩值。最后,角点需要进一步筛选。观察前后顶视图中的校准点,可以发现校准点在两行,观察左右顶视图中的校准点,可以发现校准点在两列。根据这个特点,可以消除远离2行或2列的校准点。经过以上步骤,就可以得到最终的输出图像,其中只收录我们需要的校准点。
[0047] 对于本领域技术人员来说,显然本发明不限于上述示例性实施例的细节,在不脱离本发明的精神或基本特征的情况下,可以以其他具体形式实施。本发明。发明。因此,从任何角度来看,这些实施例都应被视为示例性的而非限制性的。本发明的保护范围由所附的权利要求而不是上述说明所限定,因此应属于权利要求的范围。凡在其等效要素的含义和范围内的变化,均收录在本发明中。权利要求中的任何附图标记不应视为对所涉及的权利要求的限制。 [0048] 另外,应当理解,虽然本说明书是根据实施例进行描述的,但并不是每个实施例都只收录一个独立的技术方案。说明书中的这种叙述只是为了清楚起见。整体上,还可以对实施例中的技术方案进行适当组合,形成本领域技术人员能够理解的其他实现方式。 查看全部
算法 自动采集列表(
一种在线自动标定系统的自动点过程及过程过程步骤)
360度环视系统在线自动校准系统
技术领域
[0001] 本发明涉及一种在线自动校准系统,具体为一种36°环视系统的在线自动校准系统。
背景技术
[0002] 360度环视系统需要摄像头的标定过程,现有的标定过程一般需要人工参与。一般采用的标定方法是:先将标定布和标定板铺在地上,然后用相机拍照,手动选择照片中的标记点,最后计算生成俯视图。在涉及人的校准过程中存在一些缺陷。首先,每张照片后都需要手动选择校准点,效率低下。其次,手动选择校准点是主观的。第三,校准人员的长期工作会降低选点的效率和准确性。因此,人工参与的校准过程不适合大量安装和环视的场合。
发明内容
[0003] 本发明的目的在于提供一种360度环视系统在线自动校准系统,以解决上述背景技术问题。
[0004]为实现上述目的,本发明提供如下技术方案:
[0005] 360度环视系统在线自动校准系统。自动校准的一个基本前提是安装在同一车型上的摄像头的位置和角度相同。车型不同车辆的摄像头差异的根源只是安装错误,自动标定,每辆车都有一个环视ECU,自动标定算法运行在环视ECU中。自动校准系统的自动校准过程包括以下步骤:
[0006](1)首先在自动标定场地地面铺设手动标定点,将车辆驶入手动标定点所在区域,对车辆进行单视角手动标定,生成标准表并下载到每个在车内环视EOT;
【0007】(2)然后在自动校准点的地面上铺设自动校准点,将车辆驶入自动校准点所在区域,拍照,开始自动校准计算过程. 具体计算过程包括:
[0008]2.1)使用Surround View ECU中的标准表对捕获的图像进行操作,生成4个俯视图;
[0009] 2 •2) 使用自动取点算法在 4 个顶视图上自动取点。自动取点算法可自动对俯视图中的自动标定点进行检测和编号;
[0010]2.3)利用得到的自动标定点对环视ECU中已有的标准表进行调整,生成调整表以补偿摄像头安装误差;
[0011](3)调整表生成后,表示自动校准过程结束。
[0012]作为本发明的又一方案:自动取点算法的具体步骤如下:
[0013]⑴检测4个顶视图中的所有角点,这里使用Harris角点检测算法;
[0014](2)生成4个顶视图图像块匹配模板和邻域循环匹配模板;
[0015](3)分析4个顶视图中所有角点的邻域图像块,先对邻域图像进行阈值划分U,对阈值分割后的图像块进行形态学开运算;
[0016] ⑷对处理后的图像块进行圆线统计;
[0017](5)对处理后的图像块进行模板匹配和圆匹配,结合匹配值和4个顶视图中标定点的位置进行过滤;
[0018] ⑹合并满足条件的角点;
[0019] ⑺ 根据标定点的行列信息去除不满足条件的角点。
[0020]与现有技术相比,本发明的有益效果是:第一,除了第一次标定需要人工参与外,本车型后续所有车辆的标定均无需人工参与,即即,一个模型只有一个手动校准过程。其次,除了第一次校准是对单视图进行校准外,后续的所有校准都是对顶视图进行校准。校准顶视图有两个好处:一是在顶视图中,校准图形不失真,更容易在顶视图上自动取点,一般不会遗漏和多检查;二是调整计算标准表量小,这样计算过程就可以在环视ECU上运行,不会花很长时间。
图纸说明
[0021] 图 1 不适用于手动校准点的排列。
[0022]图2为自动校准点布置示意图。
[0023] 图3为自动取点算法流程图。
[0024] 图中:自动校准点1、手动校准点2.
具体实现方法
[0025] 下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整的描述。显然,所描述的实施例只是本发明一部分实施例,而不是全部示例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0026] 在本发明实施例中,一种用于360度环视系统的在线自动校准系统。自动校准的一个基本前提是安装在同一车型上的摄像头的位置和角度基本一致。车型不同车辆的摄像头差异的根源仅在于安装错误。在自动校准过程中,需要一个自动校准站点。每辆车都有一个环视ECU,自动标定算法运行在环视ECU中。
[0027]自动校准系统的自动校准过程包括以下步骤:
[0028](1)首先在自动标定点地面铺设手动标定点2,将车辆开入手动标定点2所在区域,对车辆进行单视角手动标定,生成一张标准表,下载后查看每辆车的ECU;
【0029】(2)然后将自动校准点1放在自动校准点的地面上,将车辆开到自动校准点1所在的区域,拍照,开始自动校准计算过程,具体计算过程包括:
[0030]2.1)使用Surround View ECU中的标准表对捕获的图像进行操作,生成4个俯视图;
[0031]2.2)采用自动取点算法从4个顶视图自动取点(自动取点算法主要包括角点检测、邻域图像分割、形态学操作、模板匹配、邻域图像循环线分析等图像处理算法),自动取点算法可以在俯视图中自动检测自动校准点1,并编号自动校准点1;
[0032]2.3)利用得到的自动标定点1对环视ECU中已有的标准表进行调整,生成调整表补偿摄像头安装误差;
[0033] ⑶调整表生成后,表示自动校准过程结束。
[0034] 在上述自动校准过程中,自动取点算法是关键步骤。自动取点算法关系到自动校准过程的成功与否。自动取点算法的具体步骤如下:
[0035]⑴检测4个顶视图中的所有角点,这里使用Harris角点检测算法;
[0036] ⑵ 生成4个顶视图的邻域图像块匹配模板和邻域循环匹配模板;
[0037] 分析4个顶视图中所有角点的邻域图像块,先对邻域图像进行阈值分析,对阈值分割后的图像块进行形态学开运算;
[0038] ⑷对处理后的图像块进行圆线统计;
[0039] ⑸对处理后的图像块进行模板匹配和圆匹配,结合匹配值和4个顶视图中标定点的位置进行过滤;
[0040] ⑹合并满足条件的角点;
[0041](7)根据校准点的行列信息去除不合格的角点。
[0042] 当你得到一个顶视图时,你首先需要检测顶视图的角点。角点检测的原因是校准点必须是图像中的角点。可以通过执行角点检测并去除不属于校准点的角点来找到校准点。这里角点检测采用 Harris 角点检测算法。 Harris角点检测算法的基本原理是:得到每个像素的结构张量矩阵,将该矩阵设为A,则该像素的C值可由下式计算:
[0043]C=det(A)-〇。 04 • tr (A)
[0044] 当像素点的C值大于104时,认为该点为角点。
[0045] 顶视图的角点检测后,可以得到顶视图中的所有角点。这时就需要在这些角点中寻找校准点,剔除非校准点。观察校准点及其邻域图像,可以发现邻域图像的一个对角线方向为黑色,另一对角线方向为白色,反之亦然。因此,对每个角点的邻域图像进行如下操作: 1 • 交叉熵阈值分割; 2 • 形态腐蚀; 3.形态扩展; 4.模板匹配; 5.根据模板匹配结果确定邻域循环 匹配方法,这些操作在流程图中用黑色虚线框起来。下面我们来详细介绍一下这5个步骤。交叉熵阈值分割是一种阈值分割方法。通过计算分割图像与原创图像的交叉熵,将分割图像与原创图像的最小交叉熵对应的阈值作为分割阈值。分割阈值用于对邻域图像进行分割。分割后的图像是通过分割得到的。分割后的图像是二值图像。由于原创图像(俯视图)光照不均,分割后的图像有很多毛刺。为了消除这些毛刺,可以使用形态学操作。在这里,首先进行形态腐蚀,然后进行形态扩展,以消除毛刺。形态学运算的基本原理是利用一个结构元素对图像进行遍历,对结构元素内的元素值进行最小/最大运算来确定计算结果。这里结构元素的大小是3X3。进行形态学操作后,分割后的图像显示出更规则的结果。此时匹配模数f,模板为预先生成的二值图像。为了增加算法的鲁棒性,预先生成了总共6个二值模板,这6个二值模板分别用于对分割后的图像进行匹配。得到匹配结果后,根据匹配结果确定邻域循环匹配方法。 Neighbor 是围绕相邻图像中心点的圆。对分割图像的每个邻域循环进行邻域循环匹配,并记录匹配结果。当邻域循环匹配时,它也与预先生成的模板匹配。以下是模板匹配和邻域循环匹配之间的异同。模板匹配和邻域循环匹配的本质是将待匹配元素与之前生成的元素一一比较,得到比较值。不同的是模板匹配是二维图像之间的匹配。循环匹配是一维数组之间的匹配。
[0046]——对每个角点的邻域图像进行上述操作后,可以根据行列信息和匹配值对角点进行过滤。当模板匹配值和邻域环匹配值满足标定点的特性时,可以保留角点。这样,可以消除大部分未校准的角。角在下面合并。由于校准点周围的点的c值都大于104,所以校准点处会出现“角点簇”。合并角点的目的是将“一组角点合并为一个角点”。角点合并准则是利用角点的模板匹配值对角点的秩进行加权,得到合并角点的最终秩值。最后,角点需要进一步筛选。观察前后顶视图中的校准点,可以发现校准点在两行,观察左右顶视图中的校准点,可以发现校准点在两列。根据这个特点,可以消除远离2行或2列的校准点。经过以上步骤,就可以得到最终的输出图像,其中只收录我们需要的校准点。
[0047] 对于本领域技术人员来说,显然本发明不限于上述示例性实施例的细节,在不脱离本发明的精神或基本特征的情况下,可以以其他具体形式实施。本发明。发明。因此,从任何角度来看,这些实施例都应被视为示例性的而非限制性的。本发明的保护范围由所附的权利要求而不是上述说明所限定,因此应属于权利要求的范围。凡在其等效要素的含义和范围内的变化,均收录在本发明中。权利要求中的任何附图标记不应视为对所涉及的权利要求的限制。 [0048] 另外,应当理解,虽然本说明书是根据实施例进行描述的,但并不是每个实施例都只收录一个独立的技术方案。说明书中的这种叙述只是为了清楚起见。整体上,还可以对实施例中的技术方案进行适当组合,形成本领域技术人员能够理解的其他实现方式。
算法 自动采集列表(算法自动采集列表,做电商对精细化运营的执行力要求)
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-08-29 16:06
算法自动采集列表当有人点击a广告时,系统会自动从a广告列表中找到相应的广告然后给予点击或广告创意展示的机会让买家自己决定点击或不点击。点击广告创意,且对买家有价值的广告内容才会被点击自动精确筛选采用人工方式智能化过滤不需要考虑点击率的广告创意过滤掉点击率较低广告,自动竞价选择在点击率较高的广告位竞价系统主要使用广告竞价与点击率的方式使买家产生关注,或产生点击。
目前有趣的广告位(分类页):点击率可以说是广告位的基础指标,或者说是广告位竞价的根基。分类页是买家经常使用到的购物目的单元,包括广告展示,cta,价格,风格等需要考虑的因素。点击率是指点击广告创意,并且对广告有价值的广告内容才会被点击。
互联网中肯定有很多精细化运营的方法,我这里不提供具体的东西,
分类页位怎么精细化!做电商对精细化运营的执行力要求不是特别高,但要求精细化运营。首先你要定下你的产品是什么,需要具体的从哪些方面去做精细化运营。如果你是卖某某健康食品,那么你先做分类,你需要搞清楚你的产品属于什么,打造那种产品。上架的时候首先要根据分类页的不同来做店铺内功的优化,如果是新品,让新品有曝光,根据新品的优势来看看现在市场上面有什么样的产品能满足大众的需求,什么样的产品适合自己产品特性,如果需要电商运营的服务,可以联系我。 查看全部
算法 自动采集列表(算法自动采集列表,做电商对精细化运营的执行力要求)
算法自动采集列表当有人点击a广告时,系统会自动从a广告列表中找到相应的广告然后给予点击或广告创意展示的机会让买家自己决定点击或不点击。点击广告创意,且对买家有价值的广告内容才会被点击自动精确筛选采用人工方式智能化过滤不需要考虑点击率的广告创意过滤掉点击率较低广告,自动竞价选择在点击率较高的广告位竞价系统主要使用广告竞价与点击率的方式使买家产生关注,或产生点击。
目前有趣的广告位(分类页):点击率可以说是广告位的基础指标,或者说是广告位竞价的根基。分类页是买家经常使用到的购物目的单元,包括广告展示,cta,价格,风格等需要考虑的因素。点击率是指点击广告创意,并且对广告有价值的广告内容才会被点击。
互联网中肯定有很多精细化运营的方法,我这里不提供具体的东西,
分类页位怎么精细化!做电商对精细化运营的执行力要求不是特别高,但要求精细化运营。首先你要定下你的产品是什么,需要具体的从哪些方面去做精细化运营。如果你是卖某某健康食品,那么你先做分类,你需要搞清楚你的产品属于什么,打造那种产品。上架的时候首先要根据分类页的不同来做店铺内功的优化,如果是新品,让新品有曝光,根据新品的优势来看看现在市场上面有什么样的产品能满足大众的需求,什么样的产品适合自己产品特性,如果需要电商运营的服务,可以联系我。
算法 自动采集列表(算法自动采集列表页的使用方法是怎样的?采集图片)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-08-29 14:04
算法自动采集列表页的信息对于搜索引擎来说十分重要,采集完整列表页的信息不仅可以得到用户搜索的信息,还可以通过分析用户是搜索什么类型的内容来获得不同的搜索结果,那么采集列表页就是一个很有效的方法,采集列表页的信息最常用的方法就是采集图片,这也是用户经常遇到的一个问题,那么我们可以把图片导入到cookie中实现自动采集,更可以用图片数据直接做为自动标签进行命名或批量爬取图片。
<p>抓取返回的json字符串列表页返回json字符串,对这个json字符串进行查询会返回一个很长的列表页数据列表页存在一个allcount=1这个字段,说明只有在返回列表页1行1列时,才会返回该列表页数据我们可以查看这个列表页数据,代码如下:varlist1=document.getelementsbytagname('list1')[0];if(list1 查看全部
算法 自动采集列表(算法自动采集列表页的使用方法是怎样的?采集图片)
算法自动采集列表页的信息对于搜索引擎来说十分重要,采集完整列表页的信息不仅可以得到用户搜索的信息,还可以通过分析用户是搜索什么类型的内容来获得不同的搜索结果,那么采集列表页就是一个很有效的方法,采集列表页的信息最常用的方法就是采集图片,这也是用户经常遇到的一个问题,那么我们可以把图片导入到cookie中实现自动采集,更可以用图片数据直接做为自动标签进行命名或批量爬取图片。
<p>抓取返回的json字符串列表页返回json字符串,对这个json字符串进行查询会返回一个很长的列表页数据列表页存在一个allcount=1这个字段,说明只有在返回列表页1行1列时,才会返回该列表页数据我们可以查看这个列表页数据,代码如下:varlist1=document.getelementsbytagname('list1')[0];if(list1
算法 自动采集列表(谢邀!机器学习的研究主旨是使用计算机模拟人类的学习活动)
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2021-08-29 12:50
感谢邀请!
机器学习研究的主要目的是利用计算机来模拟人类的学习活动。它是学习计算机以识别现有知识、获取新知识、不断提高性能和实现自我完善的一种方法。这里的学习是指从数据中学习,包括三类:监督学习、无监督学习和半监督学习。
以下是机器学习中常用的回归算法及其优缺点:
1、Linear Regression Algorithm(线性回归) ① 算法思想: 线性回归(Linear Regression)是利用称为线性回归方程的最小二乘函数对一个或多个自变量与因变量之间的关系进行建模的一种回归分析。该函数是一个或多个称为回归系数的模型参数的线性组合。只有一个自变量的情况称为简单回归,有多个自变量的情况称为多元回归。
回归模型:
其中θ和C为未知参数,可用于每个训练样本(xi,yi))(xih,用于预测真实值yi。损失函数:
是误差值的平方。
1:对于训练集,找到θ以最小化损失函数。 (使用最小二乘法,梯度下降法)
2:对于新输入x,其预测输出为θTx
②优点:结果易懂、易实现、易计算
③缺点:1)不利于非线性数据拟合(原因:因为线性回归将数据视为线性,可能会出现欠拟合,导致结果无法达到最佳预测效果。2)如果某些训练数据有非常大的偏差,这个时候最终训练出来的模型在整体数据上可能没有很好的准确率。
④Improvement:针对2)Improving :部分加权回归
2、Local Weighted Regression(局部加权回归)
①算法思想:
给每个待预测点周围的点赋予一定的权重,点越近,权重越高,以便选择预测点对应的数据子集,然后根据最小均方误差在这个数据子集上执行普通回归。部分加权回归本质上是针对需要预测的点,只根据附近的点进行训练,其他保持不变。
对于局部线性加权算法:
1:对于输入x,在训练集中寻找x邻域内的训练样本
2:对于其邻域内的训练样本,求θ使得它
∈x ) 的邻域最小。其中 w(i) 是权重值。 3.预测输出为θTx
4. 对新输入重复过程 1-3。
哪里
τ 是恒定带宽。离输入越远,权重越小, 。
②优点:
1)部分加权回归仍然更适合训练数据。
2) 不依赖于特征的选择,只有线性模型才能训练出一个很好的拟合模型,
③缺点:
1) 是计算密集型的。 (因为局部加权回归的损失随着预测值的变化而变化,所以无法提前确定θ。需要扫描所有数据,每次预测重新计算θ)
2)部分加权回归容易出现过拟合,过拟合明显。
3) 关注局部训练数据,忽略全局数据。如果预测点靠近有偏差的训练数据,那么预测值就会有很大的偏差。
④改进:
3、k-Nearest Neighbor Algorithm for Regression(回归k最近邻)
①算法思想:
通过找到一个样本的k个最近邻,并将这些邻域的属性的平均值赋给样本,就可以得到样本的属性。一个更有用的方法是对不同距离的邻居对样本的影响赋予不同的权重,例如权重与距离成正比。
如果特征空间中一个样本的k个最相似(即特征空间中的最近邻)样本中的大部分属于某个类别,则该样本也属于该类别。
KNN 算法不仅可以用于分类,还可以用于回归。通过找出一个样本的k个最近邻,将这些邻域的属性的平均值赋给样本,就可以得到样本的属性。一种更有用的方法是对不同距离的邻居对样本的影响赋予不同的权重,例如权重与距离成反比。
②优点:
1) 简单有效。
2)再训练成本低(类别系统的变化和训练集的变化在Web环境和电子商务应用中很常见)。
3)计算时间和空间与训练集的大小成线性关系(在某些情况下不会太大)。
4)因为KNN方法主要依靠周围有限的相邻样本,而不是通过区分类域的方法来确定类别,所以对于要划分的样本集,类域的交叉或重叠较多, KNN 方法比其他方法更适合。 5)该算法更适合对样本量比较大的类域进行自动分类,而样本量较小的类域使用该算法更容易误分类。
③缺点:
(1)KNN对属性较多的训练样本进行分类时,由于计算量大,效率大大降低,效果不是很理想。
(2)当样本不平衡时,例如一个类的样本量很大,而其他类的样本量很小,可能会导致输入新样本时,K样本的邻居有一个大容量的类,样本占多数。
(3)对数据的局部结构更敏感,如果查询点位于训练集较密集的区域,则预测比其他稀疏集更准确。
(4) 对 k 值敏感。
(5)维度灾难:邻近距离可能被不相关的属性支配(因此出现特征选择问题)
④改进:
(1)Classification 效率:提前减少样本属性,删除对分类结果影响不大的属性,快速得到待分类样本的类别。该算法更适用于样本量相对较大的自动分类,样本量较小的领域使用该算法更容易被误分类。
(2)Classification 效果:用权重法(离样本距离小的邻居权重大)改进,Han等人在2002年尝试用贪心法为文件分类k最近邻法WAkNN(weightedadjusted k最近邻)来提升分类效果;而Li等人在2004年提出,由于不同分类的文件数量不同,因此也应基于各种不同的文件训练集中的分类数,选择不同数量的最近邻参与分类。
(3)这个算法在分类上的主要缺点是当样本不平衡时,比如一类的样本量很大,而其他类的样本量很小,这可能会导致新样本的输入,此时样本的K个邻居的大容量样本占了多数。那么或者这种类型的样本与目标样本不接近,或者这个类样本与目标样本非常接近。不管怎样,数量不影响运行结果。可以使用权重方法(与目标样本的邻居)距离样本越小权重越大)来提高。
(4)K 值的选择会对算法的结果产生很大的影响。小的K值意味着只有接近输入实例的训练实例才会对预测结果产生影响,但是容易出现过拟合;如果 K 的值很大,优点是可以减少学习的估计误差,缺点是学习的近似误差增大。输入实例也会在预测中起作用,也就是预测误差。在实际应用中,K 值一般选择较小的值,通常使用交叉验证来选择最优的 K 值作为训练样本的个数趋于无穷大且 K=1 ,错误率不会超过贝叶斯错误率 如果K也趋于无穷大,则错误率趋于贝叶斯错误率。
(5)这种方法的另一个缺点是计算量大,因为对于每一个待分类的文本,必须计算到所有已知样本的距离才能找到它的K个最近邻点。目前常用的解决方案是提前编辑已知样本点,提前剔除对分类影响不大的样本。
该算法更适合样本量较大的类域的自动分类,样本量较小的类域使用该算法更容易误分类。
随着信息技术的发展,出现了很多大数据分析工具。其中,NLPIR大数据语义智能分析平台(原ICTCLAS)是一个比较好的系统。是北京理工大学大数据搜索挖掘实验室主任张华平针对大数据内容采集、编辑、挖掘和搜索的综合需求,整合网络精准采集最新研究成果而研发的、自然语言理解、文本挖掘和语义搜索,近二十年来不断创新。平台提供客户端工具、云服务、二次开发接口等多种产品使用形式。每个中间件API都可以无缝集成到客户的各种复杂应用系统中,兼容Windows、Linux、Android、Maemo5、FreeBSD等不同操作系统平台,可用于Java、Python、C等各种开发、C# 等语言用法。
NLPIR大数据语义智能分析平台的十三项功能:
NLPIR大数据语义智能分析平台客户端
精准采集:国内外海量信息实时精准采集,有话题采集(话题采集根据信息需要)和网站采集(站内)使用给定的 URL 列表)定点 采集 函数)。
文档转换:对doc、excel、pdf、ppt等多种主流文档格式的文本信息进行转换,效率满足大数据处理要求。
新词发现:从文本中发现新词、新概念,用户可以将其用于专业词典的编纂,还可以进一步编辑标注,导入分词词典,提高分词准确率分词系统,适应新语言的变化。
批量分词:对原语料进行分词,自动识别姓名、地名、机构名称等未注册词,新词标注,词性标注。并在分析过程中,导入用户自定义词典。
语言统计:根据分词和标注结果,系统可以自动进行一元词频数统计和二元词转移概率统计。对于常用术语,会自动给出相应的英文解释。
文本聚类:可以从大规模数据中自动分析热点事件,并提供事件主题的关键特征描述。同时适用于短文、微博等长文和短文的热点分析。
文本分类:根据规则或训练方法对大量文本进行分类,可用于新闻分类、简历分类、邮件分类、办公文档分类、区域分类等多个方面。
摘要实体:对于单个或多个文章,自动提取内容摘要,提取人名、地名、机构名称、时间和主题关键词;方便用户快速浏览文本内容。
智能过滤:对文本内容进行语义智能过滤和审核,内置国内最全的词库,智能识别变形、拼音、繁体、简体等多种变体,语义精准消歧。
情感分析:针对预先指定的分析对象,系统自动分析海量文档的情感倾向:情感极性和情感值测度,并给出原文中的正负分和句例。
文档去重:快速准确判断文件集合或数据库中是否存在内容相同或相似的记录,同时查找所有重复记录。
全文搜索:支持文本、数字、日期、字符串等多种数据类型,多字段高效搜索,支持AND/OR/NOT、NEAR接近等查询语法,支持维文、藏文、蒙古语、阿拉伯语、韩语等多种少数民族语言搜索。
编码转换:自动识别内容的编码,统一将编码转换为其他编码。
以上是推荐的中文分词工具。我希望它能帮助你。如果您有任何问题,请联系我,我会帮助您! 查看全部
算法 自动采集列表(谢邀!机器学习的研究主旨是使用计算机模拟人类的学习活动)
感谢邀请!
机器学习研究的主要目的是利用计算机来模拟人类的学习活动。它是学习计算机以识别现有知识、获取新知识、不断提高性能和实现自我完善的一种方法。这里的学习是指从数据中学习,包括三类:监督学习、无监督学习和半监督学习。
以下是机器学习中常用的回归算法及其优缺点:
1、Linear Regression Algorithm(线性回归) ① 算法思想: 线性回归(Linear Regression)是利用称为线性回归方程的最小二乘函数对一个或多个自变量与因变量之间的关系进行建模的一种回归分析。该函数是一个或多个称为回归系数的模型参数的线性组合。只有一个自变量的情况称为简单回归,有多个自变量的情况称为多元回归。
回归模型:
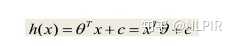
其中θ和C为未知参数,可用于每个训练样本(xi,yi))(xih,用于预测真实值yi。损失函数:
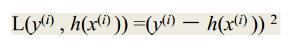
是误差值的平方。
1:对于训练集,找到θ以最小化损失函数。 (使用最小二乘法,梯度下降法)
2:对于新输入x,其预测输出为θTx
②优点:结果易懂、易实现、易计算
③缺点:1)不利于非线性数据拟合(原因:因为线性回归将数据视为线性,可能会出现欠拟合,导致结果无法达到最佳预测效果。2)如果某些训练数据有非常大的偏差,这个时候最终训练出来的模型在整体数据上可能没有很好的准确率。
④Improvement:针对2)Improving :部分加权回归
2、Local Weighted Regression(局部加权回归)
①算法思想:
给每个待预测点周围的点赋予一定的权重,点越近,权重越高,以便选择预测点对应的数据子集,然后根据最小均方误差在这个数据子集上执行普通回归。部分加权回归本质上是针对需要预测的点,只根据附近的点进行训练,其他保持不变。
对于局部线性加权算法:
1:对于输入x,在训练集中寻找x邻域内的训练样本
2:对于其邻域内的训练样本,求θ使得它
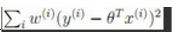
∈x ) 的邻域最小。其中 w(i) 是权重值。 3.预测输出为θTx
4. 对新输入重复过程 1-3。
哪里

τ 是恒定带宽。离输入越远,权重越小, 。
②优点:
1)部分加权回归仍然更适合训练数据。
2) 不依赖于特征的选择,只有线性模型才能训练出一个很好的拟合模型,
③缺点:
1) 是计算密集型的。 (因为局部加权回归的损失随着预测值的变化而变化,所以无法提前确定θ。需要扫描所有数据,每次预测重新计算θ)
2)部分加权回归容易出现过拟合,过拟合明显。
3) 关注局部训练数据,忽略全局数据。如果预测点靠近有偏差的训练数据,那么预测值就会有很大的偏差。
④改进:
3、k-Nearest Neighbor Algorithm for Regression(回归k最近邻)
①算法思想:
通过找到一个样本的k个最近邻,并将这些邻域的属性的平均值赋给样本,就可以得到样本的属性。一个更有用的方法是对不同距离的邻居对样本的影响赋予不同的权重,例如权重与距离成正比。
如果特征空间中一个样本的k个最相似(即特征空间中的最近邻)样本中的大部分属于某个类别,则该样本也属于该类别。
KNN 算法不仅可以用于分类,还可以用于回归。通过找出一个样本的k个最近邻,将这些邻域的属性的平均值赋给样本,就可以得到样本的属性。一种更有用的方法是对不同距离的邻居对样本的影响赋予不同的权重,例如权重与距离成反比。
②优点:
1) 简单有效。
2)再训练成本低(类别系统的变化和训练集的变化在Web环境和电子商务应用中很常见)。
3)计算时间和空间与训练集的大小成线性关系(在某些情况下不会太大)。
4)因为KNN方法主要依靠周围有限的相邻样本,而不是通过区分类域的方法来确定类别,所以对于要划分的样本集,类域的交叉或重叠较多, KNN 方法比其他方法更适合。 5)该算法更适合对样本量比较大的类域进行自动分类,而样本量较小的类域使用该算法更容易误分类。
③缺点:
(1)KNN对属性较多的训练样本进行分类时,由于计算量大,效率大大降低,效果不是很理想。
(2)当样本不平衡时,例如一个类的样本量很大,而其他类的样本量很小,可能会导致输入新样本时,K样本的邻居有一个大容量的类,样本占多数。
(3)对数据的局部结构更敏感,如果查询点位于训练集较密集的区域,则预测比其他稀疏集更准确。
(4) 对 k 值敏感。
(5)维度灾难:邻近距离可能被不相关的属性支配(因此出现特征选择问题)
④改进:
(1)Classification 效率:提前减少样本属性,删除对分类结果影响不大的属性,快速得到待分类样本的类别。该算法更适用于样本量相对较大的自动分类,样本量较小的领域使用该算法更容易被误分类。
(2)Classification 效果:用权重法(离样本距离小的邻居权重大)改进,Han等人在2002年尝试用贪心法为文件分类k最近邻法WAkNN(weightedadjusted k最近邻)来提升分类效果;而Li等人在2004年提出,由于不同分类的文件数量不同,因此也应基于各种不同的文件训练集中的分类数,选择不同数量的最近邻参与分类。
(3)这个算法在分类上的主要缺点是当样本不平衡时,比如一类的样本量很大,而其他类的样本量很小,这可能会导致新样本的输入,此时样本的K个邻居的大容量样本占了多数。那么或者这种类型的样本与目标样本不接近,或者这个类样本与目标样本非常接近。不管怎样,数量不影响运行结果。可以使用权重方法(与目标样本的邻居)距离样本越小权重越大)来提高。
(4)K 值的选择会对算法的结果产生很大的影响。小的K值意味着只有接近输入实例的训练实例才会对预测结果产生影响,但是容易出现过拟合;如果 K 的值很大,优点是可以减少学习的估计误差,缺点是学习的近似误差增大。输入实例也会在预测中起作用,也就是预测误差。在实际应用中,K 值一般选择较小的值,通常使用交叉验证来选择最优的 K 值作为训练样本的个数趋于无穷大且 K=1 ,错误率不会超过贝叶斯错误率 如果K也趋于无穷大,则错误率趋于贝叶斯错误率。
(5)这种方法的另一个缺点是计算量大,因为对于每一个待分类的文本,必须计算到所有已知样本的距离才能找到它的K个最近邻点。目前常用的解决方案是提前编辑已知样本点,提前剔除对分类影响不大的样本。
该算法更适合样本量较大的类域的自动分类,样本量较小的类域使用该算法更容易误分类。
随着信息技术的发展,出现了很多大数据分析工具。其中,NLPIR大数据语义智能分析平台(原ICTCLAS)是一个比较好的系统。是北京理工大学大数据搜索挖掘实验室主任张华平针对大数据内容采集、编辑、挖掘和搜索的综合需求,整合网络精准采集最新研究成果而研发的、自然语言理解、文本挖掘和语义搜索,近二十年来不断创新。平台提供客户端工具、云服务、二次开发接口等多种产品使用形式。每个中间件API都可以无缝集成到客户的各种复杂应用系统中,兼容Windows、Linux、Android、Maemo5、FreeBSD等不同操作系统平台,可用于Java、Python、C等各种开发、C# 等语言用法。

NLPIR大数据语义智能分析平台的十三项功能:
NLPIR大数据语义智能分析平台客户端
精准采集:国内外海量信息实时精准采集,有话题采集(话题采集根据信息需要)和网站采集(站内)使用给定的 URL 列表)定点 采集 函数)。
文档转换:对doc、excel、pdf、ppt等多种主流文档格式的文本信息进行转换,效率满足大数据处理要求。
新词发现:从文本中发现新词、新概念,用户可以将其用于专业词典的编纂,还可以进一步编辑标注,导入分词词典,提高分词准确率分词系统,适应新语言的变化。
批量分词:对原语料进行分词,自动识别姓名、地名、机构名称等未注册词,新词标注,词性标注。并在分析过程中,导入用户自定义词典。
语言统计:根据分词和标注结果,系统可以自动进行一元词频数统计和二元词转移概率统计。对于常用术语,会自动给出相应的英文解释。
文本聚类:可以从大规模数据中自动分析热点事件,并提供事件主题的关键特征描述。同时适用于短文、微博等长文和短文的热点分析。
文本分类:根据规则或训练方法对大量文本进行分类,可用于新闻分类、简历分类、邮件分类、办公文档分类、区域分类等多个方面。
摘要实体:对于单个或多个文章,自动提取内容摘要,提取人名、地名、机构名称、时间和主题关键词;方便用户快速浏览文本内容。
智能过滤:对文本内容进行语义智能过滤和审核,内置国内最全的词库,智能识别变形、拼音、繁体、简体等多种变体,语义精准消歧。
情感分析:针对预先指定的分析对象,系统自动分析海量文档的情感倾向:情感极性和情感值测度,并给出原文中的正负分和句例。
文档去重:快速准确判断文件集合或数据库中是否存在内容相同或相似的记录,同时查找所有重复记录。
全文搜索:支持文本、数字、日期、字符串等多种数据类型,多字段高效搜索,支持AND/OR/NOT、NEAR接近等查询语法,支持维文、藏文、蒙古语、阿拉伯语、韩语等多种少数民族语言搜索。
编码转换:自动识别内容的编码,统一将编码转换为其他编码。
以上是推荐的中文分词工具。我希望它能帮助你。如果您有任何问题,请联系我,我会帮助您!
算法 自动采集列表(怼正则,怼CSS选择器,解析是个麻烦事(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 197 次浏览 • 2021-08-29 07:02
爬虫有什么作用?它可以帮助我们快速获取有效信息。不过,做过爬虫的人都知道解析很麻烦。
比如一篇新闻文章,链接是这样的:,页面预览如下:
预览图片
我们需要从页面中提取标题、出版商、发布时间、发布内容、图片等内容。正常情况下我们需要做什么?编写规则。
那么规则是什么?不要使用正则,不要使用 CSS 选择器,不要使用 XPath。我们需要匹配标题的内容,发布时间,来源等,更重要的是,我们需要正则表达式来辅助。我们可能需要使用re、BeautifulSoup、pyquery等库来提取和解析内容。
但是如果我们有数千个不同风格的页面怎么办?它们来自数千个站点。我们还需要写规则来一一匹配吗?这需要多少工作。另外,如果这些事情没有做好,分析就会出现问题。例如,在某些情况下无法匹配正则表达式,如果 CSS 和 XPath 选择器选择错误可能会出现问题。
想必大家可能已经看到当前浏览器都有阅读模式了,比如我们用Safari浏览器打开这个页面,然后打开阅读模式看看效果:
Safari 预览
页面突然变得很清爽,只剩下标题和需要阅读的内容。原页面多余的导航栏、侧边栏、评论等全部删除。它是如何做到的?有人在里面写规则吗?当然这是不可能的。其实这里用的是智能分析。
这篇文章,让我们一起来了解一下智能页面分析的知识。
智能分析
所谓爬虫智能分析,顾名思义,就是我们不再需要专门针对某些页面编写抽取规则。我们可以使用一些算法来计算页面上特定元素的位置和提取路径。比如一个页面中的文章,我们可以通过算法计算,它的标题应该是什么,文本应该是什么部分,发布时间是多少等等。
实际上,智能分析是一项非常艰巨的任务。比如你在一个网页上展示某人文章,人们很快就能知道这个文章的标题是什么,发布时间是什么,以及文字是哪一块,或者哪一块是广告空间,哪一块是导航栏。但如果机器要识别,它面对的是什么?它只是一系列 HTML 代码。那么机器是如何实现智能提取的呢?事实上,它收录了很多方面的信息。
还有一些功能就不一一赘述了。这些包括区块位置、区块大小、区块标签、区块内容、区块密度等,而且在很多情况下还需要依赖视觉的特性,所以实际上是算法计算、视觉处理、自然语言的结合加工等方面。如果能综合利用这些特征,再经过大量的数据训练,就能取得非常好的效果。
行业进展
未来页面会越来越多,页面的渲染方式也会发生很大的变化。爬虫越来越难做,智能爬虫越来越重要。
目前,业界已经有实现的算法。经过一番研究,我发现有几种算法或服务在页面智能分析方面做得更好:
那么这些算法或服务中哪些是好的? Driffbot 官方做了一个对比评测,使用了谷歌新闻的一些文章,使用不同的算法依次提取标题和文本,然后与真实标注的进行对比。比较内容,比较的指标是文本的准确率和召回率,以及基于两者计算的F1分数。
结果对比如下:
经过对比,我们可以发现Diffbot的准确率和召回率都是最好的,它的F1值达到了0.97,可以说是非常准确了。此外,下一个更强大的是 Boilerpipe 和 Readability。 Goose 的性能很差,F1 和其他算法有很大的不同。以下是几种算法的F1得分对比:
F1 分数对比
有些人可能想知道为什么 Diffbot 如此强大?我也查过。 Diffbot 从 2010 年就开始致力于网页数据的提取,并提供了很多 API 来自动解析各种页面。其中,他们的算法依赖于自然语言技术、机器学习、计算机视觉、标记检查等各种算法,所有页面都会考虑当前页面的样式和视觉布局,还会对图像进行分析内容、CSS 甚至其中收录的内容。 Ajax 请求。另外,在计算一个块的置信度时,还要考虑与其他块的相关性,根据周围的标记计算每个块的置信度。
总之,Diffbot也一直致力于这方面的服务。整个Diffbot从页面解析开始,现在一直专注于页面解析服务。准确率高也就不足为奇了。
但是他们的算法是开源的吗?不幸的是,没有,而且我还没有找到相关的论文来介绍他们自己的具体算法。
所以,如果你想取得这么好的效果,就用他们的服务吧。
在下面的内容中,我们将讨论如何使用Diffbot进行智能页面分析。此外,Readability算法也值得研究。我会专门写一篇文章来介绍Readability及其与Python的对接使用。
Diffbot 页面分析
首先,我们需要注册一个帐户。它有 15 天的免费试用期。注册后,您将获得一个Developer Token,这是使用Diffbot接口服务的证书。
接下来,切换到它的测试页面。链接是:我们来测试一下它的分析效果。
我们这里选择的测试页面就是上面提到的页面,链接是:,API类型选择Article API,然后点击Test Drive按钮,就会显示当前页面的分析结果:
结果
这时候我们可以看到它帮助我们提取了标题、发布时间、发布机构、发布机构链接、正文内容等各种结果。到目前为止,这是非常正确的。时间自动识别并转码,为标准时间格式。
接下来我们继续向下滚动以查看还有哪些其他字段。这里我们也可以看到有一个html字段,它和text的区别在于它收录了文章content的真实HTML代码,所以图片也会收录在其中,如图:
结果
此外,最后还有图像字段。他以列表的形式返回文章一组图片和每张图片的链接,以及文章的站点名称、页面使用的语言等,如图。 :
结果
当然,我们也可以选择JSON格式的返回结果,这样内容会更加丰富。比如图片还返回了它的宽、高、图片描述等,还有各种其他的比如面包屑导航等结果,如图:
结果
经过人工检查,发现返回的结果完全正确,准确率相当高!
所以,如果你的准确率要求不是那么严格,使用Diffbot的服务可以帮助我们快速从页面中提取出想要的结果,节省我们大部分的体力劳动。可以说是很不错了。
但是,我们不能总是在网络上尝试此操作。其实Diffbot也提供了官方的API文档,让我们一探究竟。
Diffbot API
Driffbot 提供了多种 API,例如分析 API、文章 API、讨论 API 等。
我们以文章 API 为例来说明它的用法。官方文档地址为:,API调用地址为:
https://api.diffbot.com/v3/article
我们可以使用 GET 方法来发出请求。 Token 和 URL 都可以以参数的形式传递给这个 API。必要的参数是:
此外,它还有几个可选参数:
这里大家可能关心的是fields字段。这里我做了一个专门的整理。首先,一些固定字段:
images:文章视频中收录的图片:文章中收录的视频breadcrumb:面包屑导航信息diffbotUri:Diffbot内的URL链接
上面预定的字段是可以返回的字段。它们无法定制。此外,我们还可以使用 fields 参数来指定和扩展以下可选字段:
好的,以上就是这个API的用法。申请后即可使用该API进行智能分析。
举个例子看看这个API的用法,代码如下:
import requests, json
url = 'https://api.diffbot.com/v3/article'
params = {
'token': '77b41f6fbb24496d5113d528306528fa',
'url': 'https://news.ifeng.com/c/7kQcQG2peWU',
'fields': 'meta'
}
response = requests.get(url, params=params)
print(json.dumps(response.json(), indent=2, ensure_ascii=False))
这里先定义API链接,然后指定params参数,也就是GET请求参数。
参数收录必填的token和url字段,还设置了可选字段字段,其中fields是可选的扩展字段元标记。
来看看运行结果,结果如下:
{
"request": {
"pageUrl": "https://news.ifeng.com/c/7kQcQG2peWU",
"api": "article",
"fields": "sentiment, meta",
"version": 3
},
"objects": [
{
"date": "Wed, 20 Feb 2019 02:26:00 GMT",
"images": [
{
"naturalHeight": 460,
"width": 640,
"diffbotUri": "image|3|-1139316034",
"url": "http://e0.ifengimg.com/02/2019 ... ot%3B,
"naturalWidth": 690,
"primary": true,
"height": 426
},
// ...
],
"author": "中国新闻网",
"estimatedDate": "Wed, 20 Feb 2019 06:47:52 GMT",
"diffbotUri": "article|3|1591137208",
"siteName": "ifeng.com",
"type": "article",
"title": "故宫,你低调点!故宫:不,实力已不允许我继续低调",
"breadcrumb": [
{
"link": "https://news.ifeng.com/",
"name": "资讯"
},
{
"link": "https://news.ifeng.com/shanklist/3-35197-/",
"name": "大陆"
}
],
"humanLanguage": "zh",
"meta": {
"og": {
"og:time ": "2019-02-20 02:26:00",
"og:image": "https://e0.ifengimg.com/02/201 ... ot%3B,
"og:category ": "凤凰资讯",
"og: webtype": "news",
"og:title": "故宫,你低调点!故宫:不,实力已不允许我继续低调",
"og:url": "https://news.ifeng.com/c/7kQcQG2peWU",
"og:description": " “我的名字叫紫禁城,快要600岁了,这上元的夜啊,总是让我沉醉,这么久了却从未停止。” “重"
},
"referrer": "always",
"description": " “我的名字叫紫禁城,快要600岁了,这上元的夜啊,总是让我沉醉,这么久了却从未停止。” “重",
"keywords": "故宫 紫禁城 故宫博物院 灯光 元宵节 博物馆 一票难求 元之 中新社 午门 杜洋 藏品 文化 皇帝 清明上河图 元宵 千里江山图卷 中英北京条约 中法北京条约 天津条约",
"title": "故宫,你低调点!故宫:不,实力已不允许我继续低调_凤凰资讯"
},
"authorUrl": "https://feng.ifeng.com/author/308904",
"pageUrl": "https://news.ifeng.com/c/7kQcQG2peWU",
"html": "<p>“我的名字叫紫禁城,快要600岁了,这上元的夜啊,总是让我沉醉,这么久了却从未停止。... ",
"text": "“我的名字叫紫禁城,快要600岁了,这上元的夜啊,总是让我沉醉,这么久了却从未停止。”\n“...",
"authors": [
{
"name": "中国新闻网",
"link": "https://feng.ifeng.com/author/308904"
}
]
}
]
}
可以看出它返回了上面的内容,是一个完整的JSON格式,里面收录了标题、正文、发布时间等各种内容。
可以看出,我们不需要配置任何提取规则,就可以完成页面的分析和抓取,不费吹灰之力。
Diffbot SDK
此外,Diffbot 还提供几乎所有语言的 SDK 支持。我们也可以使用SDK来实现以上功能。链接是:如果使用Python,可以直接使用Python SDK。 Python SDK 链接是:.
此库尚未发布到 PyPi。您需要自己下载并导入它。另外,这个库是用Python 2写的,其实本质上就是调用requests库。有兴趣的可以去看看。
以下是调用示例:
from client import DiffbotClient,DiffbotCrawl
diffbot = DiffbotClient()
token = 'your_token'
url = 'http://shichuan.github.io/java ... 39%3B
api = 'article'
response = diffbot.request(url, token, api)
通过这行代码,我们可以通过调用Article API来分析我们想要的URL链接,返回的结果类似。
具体用法直接看其源码注释就一目了然了,还是很清楚的。 查看全部
算法 自动采集列表(怼正则,怼CSS选择器,解析是个麻烦事(组图))
爬虫有什么作用?它可以帮助我们快速获取有效信息。不过,做过爬虫的人都知道解析很麻烦。
比如一篇新闻文章,链接是这样的:,页面预览如下:

预览图片
我们需要从页面中提取标题、出版商、发布时间、发布内容、图片等内容。正常情况下我们需要做什么?编写规则。
那么规则是什么?不要使用正则,不要使用 CSS 选择器,不要使用 XPath。我们需要匹配标题的内容,发布时间,来源等,更重要的是,我们需要正则表达式来辅助。我们可能需要使用re、BeautifulSoup、pyquery等库来提取和解析内容。
但是如果我们有数千个不同风格的页面怎么办?它们来自数千个站点。我们还需要写规则来一一匹配吗?这需要多少工作。另外,如果这些事情没有做好,分析就会出现问题。例如,在某些情况下无法匹配正则表达式,如果 CSS 和 XPath 选择器选择错误可能会出现问题。
想必大家可能已经看到当前浏览器都有阅读模式了,比如我们用Safari浏览器打开这个页面,然后打开阅读模式看看效果:

Safari 预览
页面突然变得很清爽,只剩下标题和需要阅读的内容。原页面多余的导航栏、侧边栏、评论等全部删除。它是如何做到的?有人在里面写规则吗?当然这是不可能的。其实这里用的是智能分析。
这篇文章,让我们一起来了解一下智能页面分析的知识。
智能分析
所谓爬虫智能分析,顾名思义,就是我们不再需要专门针对某些页面编写抽取规则。我们可以使用一些算法来计算页面上特定元素的位置和提取路径。比如一个页面中的文章,我们可以通过算法计算,它的标题应该是什么,文本应该是什么部分,发布时间是多少等等。
实际上,智能分析是一项非常艰巨的任务。比如你在一个网页上展示某人文章,人们很快就能知道这个文章的标题是什么,发布时间是什么,以及文字是哪一块,或者哪一块是广告空间,哪一块是导航栏。但如果机器要识别,它面对的是什么?它只是一系列 HTML 代码。那么机器是如何实现智能提取的呢?事实上,它收录了很多方面的信息。
还有一些功能就不一一赘述了。这些包括区块位置、区块大小、区块标签、区块内容、区块密度等,而且在很多情况下还需要依赖视觉的特性,所以实际上是算法计算、视觉处理、自然语言的结合加工等方面。如果能综合利用这些特征,再经过大量的数据训练,就能取得非常好的效果。
行业进展
未来页面会越来越多,页面的渲染方式也会发生很大的变化。爬虫越来越难做,智能爬虫越来越重要。
目前,业界已经有实现的算法。经过一番研究,我发现有几种算法或服务在页面智能分析方面做得更好:
那么这些算法或服务中哪些是好的? Driffbot 官方做了一个对比评测,使用了谷歌新闻的一些文章,使用不同的算法依次提取标题和文本,然后与真实标注的进行对比。比较内容,比较的指标是文本的准确率和召回率,以及基于两者计算的F1分数。
结果对比如下:

经过对比,我们可以发现Diffbot的准确率和召回率都是最好的,它的F1值达到了0.97,可以说是非常准确了。此外,下一个更强大的是 Boilerpipe 和 Readability。 Goose 的性能很差,F1 和其他算法有很大的不同。以下是几种算法的F1得分对比:

F1 分数对比
有些人可能想知道为什么 Diffbot 如此强大?我也查过。 Diffbot 从 2010 年就开始致力于网页数据的提取,并提供了很多 API 来自动解析各种页面。其中,他们的算法依赖于自然语言技术、机器学习、计算机视觉、标记检查等各种算法,所有页面都会考虑当前页面的样式和视觉布局,还会对图像进行分析内容、CSS 甚至其中收录的内容。 Ajax 请求。另外,在计算一个块的置信度时,还要考虑与其他块的相关性,根据周围的标记计算每个块的置信度。
总之,Diffbot也一直致力于这方面的服务。整个Diffbot从页面解析开始,现在一直专注于页面解析服务。准确率高也就不足为奇了。
但是他们的算法是开源的吗?不幸的是,没有,而且我还没有找到相关的论文来介绍他们自己的具体算法。
所以,如果你想取得这么好的效果,就用他们的服务吧。
在下面的内容中,我们将讨论如何使用Diffbot进行智能页面分析。此外,Readability算法也值得研究。我会专门写一篇文章来介绍Readability及其与Python的对接使用。
Diffbot 页面分析
首先,我们需要注册一个帐户。它有 15 天的免费试用期。注册后,您将获得一个Developer Token,这是使用Diffbot接口服务的证书。
接下来,切换到它的测试页面。链接是:我们来测试一下它的分析效果。
我们这里选择的测试页面就是上面提到的页面,链接是:,API类型选择Article API,然后点击Test Drive按钮,就会显示当前页面的分析结果:

结果
这时候我们可以看到它帮助我们提取了标题、发布时间、发布机构、发布机构链接、正文内容等各种结果。到目前为止,这是非常正确的。时间自动识别并转码,为标准时间格式。
接下来我们继续向下滚动以查看还有哪些其他字段。这里我们也可以看到有一个html字段,它和text的区别在于它收录了文章content的真实HTML代码,所以图片也会收录在其中,如图:

结果
此外,最后还有图像字段。他以列表的形式返回文章一组图片和每张图片的链接,以及文章的站点名称、页面使用的语言等,如图。 :

结果
当然,我们也可以选择JSON格式的返回结果,这样内容会更加丰富。比如图片还返回了它的宽、高、图片描述等,还有各种其他的比如面包屑导航等结果,如图:

结果
经过人工检查,发现返回的结果完全正确,准确率相当高!
所以,如果你的准确率要求不是那么严格,使用Diffbot的服务可以帮助我们快速从页面中提取出想要的结果,节省我们大部分的体力劳动。可以说是很不错了。
但是,我们不能总是在网络上尝试此操作。其实Diffbot也提供了官方的API文档,让我们一探究竟。
Diffbot API
Driffbot 提供了多种 API,例如分析 API、文章 API、讨论 API 等。
我们以文章 API 为例来说明它的用法。官方文档地址为:,API调用地址为:
https://api.diffbot.com/v3/article
我们可以使用 GET 方法来发出请求。 Token 和 URL 都可以以参数的形式传递给这个 API。必要的参数是:
此外,它还有几个可选参数:
这里大家可能关心的是fields字段。这里我做了一个专门的整理。首先,一些固定字段:
images:文章视频中收录的图片:文章中收录的视频breadcrumb:面包屑导航信息diffbotUri:Diffbot内的URL链接
上面预定的字段是可以返回的字段。它们无法定制。此外,我们还可以使用 fields 参数来指定和扩展以下可选字段:
好的,以上就是这个API的用法。申请后即可使用该API进行智能分析。
举个例子看看这个API的用法,代码如下:
import requests, json
url = 'https://api.diffbot.com/v3/article'
params = {
'token': '77b41f6fbb24496d5113d528306528fa',
'url': 'https://news.ifeng.com/c/7kQcQG2peWU',
'fields': 'meta'
}
response = requests.get(url, params=params)
print(json.dumps(response.json(), indent=2, ensure_ascii=False))
这里先定义API链接,然后指定params参数,也就是GET请求参数。
参数收录必填的token和url字段,还设置了可选字段字段,其中fields是可选的扩展字段元标记。
来看看运行结果,结果如下:
{
"request": {
"pageUrl": "https://news.ifeng.com/c/7kQcQG2peWU",
"api": "article",
"fields": "sentiment, meta",
"version": 3
},
"objects": [
{
"date": "Wed, 20 Feb 2019 02:26:00 GMT",
"images": [
{
"naturalHeight": 460,
"width": 640,
"diffbotUri": "image|3|-1139316034",
"url": "http://e0.ifengimg.com/02/2019 ... ot%3B,
"naturalWidth": 690,
"primary": true,
"height": 426
},
// ...
],
"author": "中国新闻网",
"estimatedDate": "Wed, 20 Feb 2019 06:47:52 GMT",
"diffbotUri": "article|3|1591137208",
"siteName": "ifeng.com",
"type": "article",
"title": "故宫,你低调点!故宫:不,实力已不允许我继续低调",
"breadcrumb": [
{
"link": "https://news.ifeng.com/",
"name": "资讯"
},
{
"link": "https://news.ifeng.com/shanklist/3-35197-/",
"name": "大陆"
}
],
"humanLanguage": "zh",
"meta": {
"og": {
"og:time ": "2019-02-20 02:26:00",
"og:image": "https://e0.ifengimg.com/02/201 ... ot%3B,
"og:category ": "凤凰资讯",
"og: webtype": "news",
"og:title": "故宫,你低调点!故宫:不,实力已不允许我继续低调",
"og:url": "https://news.ifeng.com/c/7kQcQG2peWU",
"og:description": " “我的名字叫紫禁城,快要600岁了,这上元的夜啊,总是让我沉醉,这么久了却从未停止。” “重"
},
"referrer": "always",
"description": " “我的名字叫紫禁城,快要600岁了,这上元的夜啊,总是让我沉醉,这么久了却从未停止。” “重",
"keywords": "故宫 紫禁城 故宫博物院 灯光 元宵节 博物馆 一票难求 元之 中新社 午门 杜洋 藏品 文化 皇帝 清明上河图 元宵 千里江山图卷 中英北京条约 中法北京条约 天津条约",
"title": "故宫,你低调点!故宫:不,实力已不允许我继续低调_凤凰资讯"
},
"authorUrl": "https://feng.ifeng.com/author/308904",
"pageUrl": "https://news.ifeng.com/c/7kQcQG2peWU",
"html": "<p>“我的名字叫紫禁城,快要600岁了,这上元的夜啊,总是让我沉醉,这么久了却从未停止。... ",
"text": "“我的名字叫紫禁城,快要600岁了,这上元的夜啊,总是让我沉醉,这么久了却从未停止。”\n“...",
"authors": [
{
"name": "中国新闻网",
"link": "https://feng.ifeng.com/author/308904"
}
]
}
]
}
可以看出它返回了上面的内容,是一个完整的JSON格式,里面收录了标题、正文、发布时间等各种内容。
可以看出,我们不需要配置任何提取规则,就可以完成页面的分析和抓取,不费吹灰之力。
Diffbot SDK
此外,Diffbot 还提供几乎所有语言的 SDK 支持。我们也可以使用SDK来实现以上功能。链接是:如果使用Python,可以直接使用Python SDK。 Python SDK 链接是:.
此库尚未发布到 PyPi。您需要自己下载并导入它。另外,这个库是用Python 2写的,其实本质上就是调用requests库。有兴趣的可以去看看。
以下是调用示例:
from client import DiffbotClient,DiffbotCrawl
diffbot = DiffbotClient()
token = 'your_token'
url = 'http://shichuan.github.io/java ... 39%3B
api = 'article'
response = diffbot.request(url, token, api)
通过这行代码,我们可以通过调用Article API来分析我们想要的URL链接,返回的结果类似。
具体用法直接看其源码注释就一目了然了,还是很清楚的。
搜索引擎工作内容是以用户体验为核心运营站吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-08-26 06:12
搜索引擎工作内容
1、收录page:
一般收录页面需要被百度蜘蛛抓取。爬行算法用于确定那些页面收录。百度算法调整后,伪原创和采集网站将受到强烈攻击,因此百度对收录页面更加严格。高质量的内容页面和高权重的网站通常有更高的 收录 页面机会。对于收录页面,相信很多站长都非常清楚。每天,百度蜘蛛都在不断收录着,但是你会发现大部分网站的收录都在减少。 , 为什么是这样?因为百度需要过滤页面。
2、过滤页面:
很多页面都是百度收录后,百度认为该页面对用户没有多大价值,或者如果是低质量页面,百度难免会过滤掉。这也是良好用户体验的体现。该网站经过优化,完全不考虑用户体验。比如一些桥页和跳转页就是典型的。百度的k-site是一个页面过滤的表现,过滤掉所有作弊网站的页面。很多人抱怨6.22和6.28百度k站事件,尤其是那些整天在论坛上抱怨这个那个的。为什么是你的网站?显然,您的网站实际上是基于用户体验的。是核心运营站点吗?大多数做 SEO 的人都会操作网站进行优化。网站上写的每日更新和外部链接绝对是为了优化而优化的。百度k你的网站是以牺牲少数人的利益为代价的。更多的用户从中受益。你需要知道有多少人在使用百度。如果搜索到的信息是你为优化而运营的网站和低质量的页面,那么百度实际上是在利用它的未来为你优化网站。铺路。所以百度对页面过滤非常严格,大家不要使用seo作弊技术。
3、创建索引:
收录page 和页面过滤工作后,百度会对这些页面进行一一标记和识别,并将这些信息作为结构化数据存储在百度的搜索服务器上。这些存储的数据包括网页信息、网页title关键词page description等标签、网页外部链接和描述、抓取记录等。网页中的关键词信息也会被识别并存储,以便与用户搜索的内容相匹配。建立完善的索引数据库,轻松呈现最佳展示信息
4、显示信息:
用户输入的关键词,百度会对其进行一系列复杂的分析,并根据分析的结论,在索引库中找到一系列与其最匹配的网页,根据用户输入的关键词。对需求的强弱和网页的优劣进行评分,并将最终的评分整理并展示给用户。一般来说,最好的信息需要是最适合关键词匹配的页面,包括站内优化和站外优化等因素。 查看全部
搜索引擎工作内容是以用户体验为核心运营站吗?
搜索引擎工作内容
1、收录page:
一般收录页面需要被百度蜘蛛抓取。爬行算法用于确定那些页面收录。百度算法调整后,伪原创和采集网站将受到强烈攻击,因此百度对收录页面更加严格。高质量的内容页面和高权重的网站通常有更高的 收录 页面机会。对于收录页面,相信很多站长都非常清楚。每天,百度蜘蛛都在不断收录着,但是你会发现大部分网站的收录都在减少。 , 为什么是这样?因为百度需要过滤页面。
2、过滤页面:
很多页面都是百度收录后,百度认为该页面对用户没有多大价值,或者如果是低质量页面,百度难免会过滤掉。这也是良好用户体验的体现。该网站经过优化,完全不考虑用户体验。比如一些桥页和跳转页就是典型的。百度的k-site是一个页面过滤的表现,过滤掉所有作弊网站的页面。很多人抱怨6.22和6.28百度k站事件,尤其是那些整天在论坛上抱怨这个那个的。为什么是你的网站?显然,您的网站实际上是基于用户体验的。是核心运营站点吗?大多数做 SEO 的人都会操作网站进行优化。网站上写的每日更新和外部链接绝对是为了优化而优化的。百度k你的网站是以牺牲少数人的利益为代价的。更多的用户从中受益。你需要知道有多少人在使用百度。如果搜索到的信息是你为优化而运营的网站和低质量的页面,那么百度实际上是在利用它的未来为你优化网站。铺路。所以百度对页面过滤非常严格,大家不要使用seo作弊技术。
3、创建索引:
收录page 和页面过滤工作后,百度会对这些页面进行一一标记和识别,并将这些信息作为结构化数据存储在百度的搜索服务器上。这些存储的数据包括网页信息、网页title关键词page description等标签、网页外部链接和描述、抓取记录等。网页中的关键词信息也会被识别并存储,以便与用户搜索的内容相匹配。建立完善的索引数据库,轻松呈现最佳展示信息
4、显示信息:
用户输入的关键词,百度会对其进行一系列复杂的分析,并根据分析的结论,在索引库中找到一系列与其最匹配的网页,根据用户输入的关键词。对需求的强弱和网页的优劣进行评分,并将最终的评分整理并展示给用户。一般来说,最好的信息需要是最适合关键词匹配的页面,包括站内优化和站外优化等因素。
10万个网站的采集范围是怎么样的?(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-08-24 21:09
昨天有网友表示,他最近面试了几家公司,一个问题被问了好几次,但每次的回答都不是很好。
采访者:比如有10万个网站需要采集,怎么快速拿到数据?
要回答好这个问题,其实你需要有足够的知识和足够的技术储备。
最近,我们也在招聘。我们每周采访十几个人。只有一两个人觉得合适。他们中的大多数人都与这位网友的情况相同。他们缺乏整体思维,即使是工作了三四年的人。有经验的老司机。他们有很强的解决具体问题的能力,但很少点对点思考问题,站在一个新的高度。
100,000个网站的采集的覆盖范围已经超过了大多数专业舆情监测公司的数据采集。为了满足面试官提到的采集需求,我们需要从网站的采集到数据存储的各个方面综合考虑,给出合适的解决方案,以达到节约成本、提高工作效率的目的。
下面我们将从网站的采集到数据存储的方方面面做一个简单的介绍。
一、10万个网站哪里来的?
一般来说采集的网站都是随着公司业务的发展而逐渐积累起来的。
我们现在假设这是一家初创公司的需求。公司刚刚成立,这么多网站,基本上可以说是冷启动。那么我们如何采集这 100,000 个网站?有几种方法:
1)历史业务的积累
不管是冷启动还是什么,既然有采集的需求,就一定有项目或产品有这个需求。相关人员一定是前期调查了一些数据来源,采集了一些比较重要的网站。这些可以作为我们采集网站和采集的原创种子。
2)Association网站
在一些网站的底部,一般都有相关网站的链接。尤其是政府类网站,一般都有相关下级部门的官网。
3)网站Navigation
有些网站可能会出于某种目的(如引流等)采集一些网站,并进行分类展示,方便人们查找。这些网站可以快速为我们提供第一批种子网站。然后,我们可以通过网站关联等方式获得更多的网站。
4)搜索引擎
你也可以准备一些与公司业务相关的关键词,在百度、搜狗等搜索引擎中搜索,通过对搜索结果的处理,提取出对应的网站作为我们的种子网站。
5)第三方平台
例如,一些第三方 SaaS 平台会有 7-15 天的免费试用期。因此,我们可以利用这段时间下载与我们业务相关的数据采集,然后从中提取网站作为我们最初的采集种子。
虽然,这个方法是最有效最快的网站采集方法。不过在试用期间,获得10万个网站的可能性极小,所以需要结合上述关联网站等方式,快速获取所需的网站。
通过以上五种方法,相信我们可以快速采集到我们需要的10万个网站。但是,这么多网站,我们应该如何管理呢?怎么知道正常不正常?
二、10万个网站如何管理?
当我们采集到10万个网站时,我们面临的第一件事就是如何管理,如何配置采集规则,以及如何监控网站正常与否。
1)如何管理
100,000网站,如果没有专门的系统来管理,那将是一场灾难。
同时,由于业务需要,比如智能推荐,我们需要对网站做一些预处理(比如打标签)。这时候就需要一个网站管理系统。
2)如何配置采集rules
我们前期采集的10万网站只是首页。如果我们只使用首页作为采集task,那么只有采集才能到达首页,信息量很少,漏取率很高。
如果要整个网站采集使用首页的URL,服务器资源消耗比较大,成本太高。因此,我们需要配置我们关心的列和采集它们。
但是,100,000个网站,如何快速高效地配置列?目前我们通过自动解析HTML源代码进行列的半自动配置。
当然,我们也尝试过机器学习来处理,但效果不是很理想。
因为采集的网站数量需要达到10万的级别,所以一定不要对采集使用xpath等精准定位方法。不然配置100000网站时,黄花菜就凉了。
同时数据采集必须使用通用爬虫,使用正则表达式匹配列表数据。在采集body中,使用算法解析时间和body等属性;
3)如何监控
因为网站有100,000个,这些网站每天都会有网站修改,或者栏目修改,或者新增/删除栏目等等,所以我们需要简单分析一下网站基于的情况关于采集的数据情况。
比如一个网站几天没有新数据,肯定是有问题。要么网站被修改,经常导致信息规律失效,要么网站本身有问题。
为了提高采集的效率,您可以使用单独的服务定期检查网站和该列的状态。一是检查网站和列是否可以正常访问;另一种是检查配置的列信息的正则表达式是否正常。以便运维人员对其进行维护。
三、任务缓存
100,000 网站,配置列后,采集的入口URL应该达到百万级别。 采集器如何高效获取采集的这些入口网址?
如果把这些网址放到数据库中,不管是MySQL还是Oracle,采集器获取采集任务的操作都会浪费很多时间,大大降低采集的效率。
如何解决这个问题?内存数据库是首选,比如Redis、Mongo DB等,一般采集使用Redis做缓存。因此,您可以在配置列的同时将列信息作为采集task 缓存队列同步到Redis。
四、网站How to采集?
这就像你想达到百万年薪一样。最大的可能是去华为、阿里巴巴、腾讯等一线厂商,需要达到一定的水平。这条路注定是艰难的。
同理,如果需要采集百万级列表网址,常规方法肯定是无法实现的。
必须使用分布式+多进程+多线程。同时需要结合内存数据库Redis等进行缓存,实现任务的高效获取,对采集信息进行排序;
同时,发布时间、文字等信息的分析,也必须经过算法的处理。比如现在比较流行的GNE,
有些属性可以在列表采集中获取,所以尽量不要和正文放在一起分析。例如:标题。一般情况下,从列表中得到的title的准确率要比从信息html源码中解析出来的算法要高很多。
同时,如果有一些特殊的网站或者一些特殊的需求,我们可以使用定制开发来处理。
五、统一数据存储接口
为了保持采集的及时性,10万个网站采集可能需要十几二十台服务器。同时在每台服务器上部署了N个采集器,加上一些自定义开发的脚本,采集器的总数将达到数百个。
如果每个采集器/custom 脚本都开发自己的数据保存接口,开发调试会浪费大量时间。而后续的运维也将是一件无忧无虑的事情。尤其是当业务发生变化并需要调整时。因此,统一的数据存储接口还是很有必要的。
因为数据存储接口是统一的,当我们需要对数据做一些特殊的处理时,比如:清洗、校正等,不需要修改每个采集存储部分,只需要修改接口和重新部署。 .
快速、方便、快捷。
六、data 和 采集monitoring
覆盖10万网站采集,每天的数据量肯定超过200万。数据分析算法再准确,也永远达不到100%(90%已经很好了)。因此,数据分析必然存在异常。例如:发布时间大于当前时间,正文收录相关新闻信息等。
但是,因为我们统一了数据存储接口,这个时候可以在接口上进行统一的数据质量检查。为了根据异常情况优化采集器和自定义脚本。
同时还可以统计每个网站或列的数据采集。为了能够及时判断当前采集网站/列源是否正常,从而保证总有10万个有效采集网站。
七、数据存储
由于采集每天的数据量很大,普通数据库(如mysql、Oracle等)已经无法胜任。甚至像 Mongo DB 这样的 NoSql 数据库也不再适用。这时候,ES、Solr等分布式索引是目前最好的选择。
至于是否使用Hadoop、HBase等大数据平台,要看具体情况。在预算较小的情况下,可以先搭建分布式索引集群,再考虑大数据平台。
为了保证查询的响应速度,分布式索引中尽量不要保存body信息。可以保存标题、发布时间、网址等内容,以便在显示列表数据时减少二次查询。
当没有大数据平台时,可以将文本保存在txt等固定数据标准的文件系统中。大数据平台后续上传后,即可转入HBASE。
八、自动化运维
由于服务器、采集器、自定义脚本较多,单纯依靠人工部署、启动、更新、运行监控变得非常繁琐,容易出现人为错误。
因此,必须有一个自动化的运维系统,可以部署、启动、关闭和运行采集器/scripts,以便在发生变化时能够快速响应。
“比如有10万个网站需要采集,如何快速获取数据?”如果你能回答这些,就应该没有悬念拿到好offer了。
最后希望大家找工作都能拿到满意的offer,找到好的平台。 查看全部
10万个网站的采集范围是怎么样的?(组图)
昨天有网友表示,他最近面试了几家公司,一个问题被问了好几次,但每次的回答都不是很好。

采访者:比如有10万个网站需要采集,怎么快速拿到数据?
要回答好这个问题,其实你需要有足够的知识和足够的技术储备。
最近,我们也在招聘。我们每周采访十几个人。只有一两个人觉得合适。他们中的大多数人都与这位网友的情况相同。他们缺乏整体思维,即使是工作了三四年的人。有经验的老司机。他们有很强的解决具体问题的能力,但很少点对点思考问题,站在一个新的高度。
100,000个网站的采集的覆盖范围已经超过了大多数专业舆情监测公司的数据采集。为了满足面试官提到的采集需求,我们需要从网站的采集到数据存储的各个方面综合考虑,给出合适的解决方案,以达到节约成本、提高工作效率的目的。
下面我们将从网站的采集到数据存储的方方面面做一个简单的介绍。
一、10万个网站哪里来的?
一般来说采集的网站都是随着公司业务的发展而逐渐积累起来的。
我们现在假设这是一家初创公司的需求。公司刚刚成立,这么多网站,基本上可以说是冷启动。那么我们如何采集这 100,000 个网站?有几种方法:
1)历史业务的积累
不管是冷启动还是什么,既然有采集的需求,就一定有项目或产品有这个需求。相关人员一定是前期调查了一些数据来源,采集了一些比较重要的网站。这些可以作为我们采集网站和采集的原创种子。
2)Association网站
在一些网站的底部,一般都有相关网站的链接。尤其是政府类网站,一般都有相关下级部门的官网。

3)网站Navigation
有些网站可能会出于某种目的(如引流等)采集一些网站,并进行分类展示,方便人们查找。这些网站可以快速为我们提供第一批种子网站。然后,我们可以通过网站关联等方式获得更多的网站。

4)搜索引擎
你也可以准备一些与公司业务相关的关键词,在百度、搜狗等搜索引擎中搜索,通过对搜索结果的处理,提取出对应的网站作为我们的种子网站。

5)第三方平台
例如,一些第三方 SaaS 平台会有 7-15 天的免费试用期。因此,我们可以利用这段时间下载与我们业务相关的数据采集,然后从中提取网站作为我们最初的采集种子。
虽然,这个方法是最有效最快的网站采集方法。不过在试用期间,获得10万个网站的可能性极小,所以需要结合上述关联网站等方式,快速获取所需的网站。
通过以上五种方法,相信我们可以快速采集到我们需要的10万个网站。但是,这么多网站,我们应该如何管理呢?怎么知道正常不正常?
二、10万个网站如何管理?
当我们采集到10万个网站时,我们面临的第一件事就是如何管理,如何配置采集规则,以及如何监控网站正常与否。
1)如何管理
100,000网站,如果没有专门的系统来管理,那将是一场灾难。
同时,由于业务需要,比如智能推荐,我们需要对网站做一些预处理(比如打标签)。这时候就需要一个网站管理系统。

2)如何配置采集rules
我们前期采集的10万网站只是首页。如果我们只使用首页作为采集task,那么只有采集才能到达首页,信息量很少,漏取率很高。
如果要整个网站采集使用首页的URL,服务器资源消耗比较大,成本太高。因此,我们需要配置我们关心的列和采集它们。

但是,100,000个网站,如何快速高效地配置列?目前我们通过自动解析HTML源代码进行列的半自动配置。

当然,我们也尝试过机器学习来处理,但效果不是很理想。
因为采集的网站数量需要达到10万的级别,所以一定不要对采集使用xpath等精准定位方法。不然配置100000网站时,黄花菜就凉了。
同时数据采集必须使用通用爬虫,使用正则表达式匹配列表数据。在采集body中,使用算法解析时间和body等属性;
3)如何监控
因为网站有100,000个,这些网站每天都会有网站修改,或者栏目修改,或者新增/删除栏目等等,所以我们需要简单分析一下网站基于的情况关于采集的数据情况。
比如一个网站几天没有新数据,肯定是有问题。要么网站被修改,经常导致信息规律失效,要么网站本身有问题。

为了提高采集的效率,您可以使用单独的服务定期检查网站和该列的状态。一是检查网站和列是否可以正常访问;另一种是检查配置的列信息的正则表达式是否正常。以便运维人员对其进行维护。
三、任务缓存
100,000 网站,配置列后,采集的入口URL应该达到百万级别。 采集器如何高效获取采集的这些入口网址?
如果把这些网址放到数据库中,不管是MySQL还是Oracle,采集器获取采集任务的操作都会浪费很多时间,大大降低采集的效率。
如何解决这个问题?内存数据库是首选,比如Redis、Mongo DB等,一般采集使用Redis做缓存。因此,您可以在配置列的同时将列信息作为采集task 缓存队列同步到Redis。

四、网站How to采集?
这就像你想达到百万年薪一样。最大的可能是去华为、阿里巴巴、腾讯等一线厂商,需要达到一定的水平。这条路注定是艰难的。
同理,如果需要采集百万级列表网址,常规方法肯定是无法实现的。
必须使用分布式+多进程+多线程。同时需要结合内存数据库Redis等进行缓存,实现任务的高效获取,对采集信息进行排序;

同时,发布时间、文字等信息的分析,也必须经过算法的处理。比如现在比较流行的GNE,
有些属性可以在列表采集中获取,所以尽量不要和正文放在一起分析。例如:标题。一般情况下,从列表中得到的title的准确率要比从信息html源码中解析出来的算法要高很多。
同时,如果有一些特殊的网站或者一些特殊的需求,我们可以使用定制开发来处理。
五、统一数据存储接口
为了保持采集的及时性,10万个网站采集可能需要十几二十台服务器。同时在每台服务器上部署了N个采集器,加上一些自定义开发的脚本,采集器的总数将达到数百个。
如果每个采集器/custom 脚本都开发自己的数据保存接口,开发调试会浪费大量时间。而后续的运维也将是一件无忧无虑的事情。尤其是当业务发生变化并需要调整时。因此,统一的数据存储接口还是很有必要的。
因为数据存储接口是统一的,当我们需要对数据做一些特殊的处理时,比如:清洗、校正等,不需要修改每个采集存储部分,只需要修改接口和重新部署。 .
快速、方便、快捷。
六、data 和 采集monitoring
覆盖10万网站采集,每天的数据量肯定超过200万。数据分析算法再准确,也永远达不到100%(90%已经很好了)。因此,数据分析必然存在异常。例如:发布时间大于当前时间,正文收录相关新闻信息等。
但是,因为我们统一了数据存储接口,这个时候可以在接口上进行统一的数据质量检查。为了根据异常情况优化采集器和自定义脚本。
同时还可以统计每个网站或列的数据采集。为了能够及时判断当前采集网站/列源是否正常,从而保证总有10万个有效采集网站。
七、数据存储
由于采集每天的数据量很大,普通数据库(如mysql、Oracle等)已经无法胜任。甚至像 Mongo DB 这样的 NoSql 数据库也不再适用。这时候,ES、Solr等分布式索引是目前最好的选择。
至于是否使用Hadoop、HBase等大数据平台,要看具体情况。在预算较小的情况下,可以先搭建分布式索引集群,再考虑大数据平台。
为了保证查询的响应速度,分布式索引中尽量不要保存body信息。可以保存标题、发布时间、网址等内容,以便在显示列表数据时减少二次查询。
当没有大数据平台时,可以将文本保存在txt等固定数据标准的文件系统中。大数据平台后续上传后,即可转入HBASE。
八、自动化运维
由于服务器、采集器、自定义脚本较多,单纯依靠人工部署、启动、更新、运行监控变得非常繁琐,容易出现人为错误。
因此,必须有一个自动化的运维系统,可以部署、启动、关闭和运行采集器/scripts,以便在发生变化时能够快速响应。
“比如有10万个网站需要采集,如何快速获取数据?”如果你能回答这些,就应该没有悬念拿到好offer了。
最后希望大家找工作都能拿到满意的offer,找到好的平台。
算法自动采集列表自动推荐(把tab导航里的链接爬一遍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-08-23 04:01
算法自动采集列表自动推荐(把tab导航里的链接爬一遍,就知道哪些页面会有哪些信息了)seo优化(通过爬虫爬行来对页面进行分类分析,进而将该页面信息放到合适的位置,
1、规范管理信息,包括爬虫,爬取规则。
2、利用信息工具进行有效信息的分类,设置不同的列表显示格式。
3、目录分类。需要时做点抓取。
google爬虫不是工具而是目的。不是说,爬虫有多重要。而是说,用什么样的爬虫会有更大价值。google爬虫分为几种。一种是自动爬取,另一种是采集,最后是代理ip爬取(免费的,商业模式)等。用相应的spider,spider如果有多个,可以逐一选择爬取。如果有那么多,可以选择多个不同spider一起爬取(根据需要可选择爬取完自动触发抓取,或按某种策略)。
我做爬虫最好的办法是说服一个爬虫来按你的要求自动抓取,总之的方法就是不能让google抓取你自己的网站,因为某些操作会发生概率性的事件,就是不知道你的网站是个什么样的东西。既然已经决定你的网站要爬取了,这个时候采集比爬虫要好的多了,比如javaweb页面(这个页面是经google压缩过的),采集,最后只需要改下url即可。
又比如一些重要页面,重要文章,也可以抓取完再抓取。网站的话可以抓几个重要页面爬取,然后再抓大的页面,慢慢来。 查看全部
算法自动采集列表自动推荐(把tab导航里的链接爬一遍)
算法自动采集列表自动推荐(把tab导航里的链接爬一遍,就知道哪些页面会有哪些信息了)seo优化(通过爬虫爬行来对页面进行分类分析,进而将该页面信息放到合适的位置,
1、规范管理信息,包括爬虫,爬取规则。
2、利用信息工具进行有效信息的分类,设置不同的列表显示格式。
3、目录分类。需要时做点抓取。
google爬虫不是工具而是目的。不是说,爬虫有多重要。而是说,用什么样的爬虫会有更大价值。google爬虫分为几种。一种是自动爬取,另一种是采集,最后是代理ip爬取(免费的,商业模式)等。用相应的spider,spider如果有多个,可以逐一选择爬取。如果有那么多,可以选择多个不同spider一起爬取(根据需要可选择爬取完自动触发抓取,或按某种策略)。
我做爬虫最好的办法是说服一个爬虫来按你的要求自动抓取,总之的方法就是不能让google抓取你自己的网站,因为某些操作会发生概率性的事件,就是不知道你的网站是个什么样的东西。既然已经决定你的网站要爬取了,这个时候采集比爬虫要好的多了,比如javaweb页面(这个页面是经google压缩过的),采集,最后只需要改下url即可。
又比如一些重要页面,重要文章,也可以抓取完再抓取。网站的话可以抓几个重要页面爬取,然后再抓大的页面,慢慢来。
React中最神奇的部分莫过于虚拟DOM,以及其高效的Diff算法
采集交流 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-08-23 02:02
React 最神奇的部分是虚拟 DOM 及其高效的 Diff 算法。这使我们可以随时“刷新”整个页面而不必担心性能问题。虚拟 DOM 确保仅实际更改界面上的实际 DOM 操作。 React 在这部分已经足够透明了。在实际开发中,我们基本不需要关心虚拟 DOM 是如何工作的。然而,作为有态度的程序员,我们总是对技术背后的原理感到好奇。了解其运行机制不仅有助于更好地理解 React 组件的生命周期,而且对于进一步优化 React 程序也有很大帮助。
什么是 DOM Diff 算法
Web 界面由 DOM 树组成。当它的某一部分发生变化时,实际上是相应的DOM节点发生了变化。在 React 中,构建 UI 界面的想法是当前状态决定界面。前后两个状态对应两组接口,然后React比较两组接口的差异,这需要DOM树的Diff算法分析。
给定任意两棵树,找出最少的转换步骤。但是标准的Diff算法复杂度需要O(n^3),显然不能满足性能要求。要达到每次整体刷新界面的目标,必须对算法进行优化。这看起来很困难但是Facebook工程师做到了,他们结合Web界面的特点,做了两个简单的假设,直接将Diff算法的复杂度降低到O(n)
两个相同的组件产生相似的DOM结构,不同的组件产生不同的DOM结构;对于同一层级的一组子节点,可以通过唯一的id来区分。
算法优化是 React 整个界面 Render 的基础。事实也证明,这两个假设是合理且准确的,保证了整体接口构建的性能。
不同节点类型的比较
为了在树之间进行比较,我们首先必须能够比较两个节点。在 React 中,我们比较两个虚拟 DOM 节点。当两个节点不同时我们应该怎么做?这分两种情况:(1)node类型不同,(2)node类型相同,但属性不同。本节先看第一种情况。
当树中相同位置前后输出不同类型的节点时,React直接删除之前的节点,然后创建并插入一个新节点。假设我们在树中的同一位置前后两次输出不同类型的节点。
复制代码
renderA: renderB: => [removeNode ], [insertNode ]
当一个节点从 div 变为 span 时,只需删除 div 节点并插入一个新的 span 节点即可。这符合我们对真实DOM操作的理解。
需要注意的是,删除一个节点意味着彻底销毁该节点,而不是在后续的比较中检查是否还有另一个节点等同于被删除的节点。如果删除的节点下还有子节点,这些子节点也会被彻底删除,不会用于后续的比较。这就是为什么算法复杂度可以降低到 O(n) 的原因。
上面说的是虚拟DOM节点的操作,同样的逻辑也用在React组件的比较中,例如:
复制代码
renderA: renderB: => [removeNode ], [insertNode ]
当 React 在同一位置遇到不同的组件时,它只会销毁第一个组件并添加新创建的组件。这是第一个假设的应用。不同的组件通常会产生不同的 DOM 结构。与其浪费时间比较基本不等价的 DOM 结构,不如创建一个新组件并添加它。
从这个 React 对不同类型节点的处理逻辑,我们可以很容易地推断出 React 的 DOM Diff 算法实际上只是逐层比较树,如下所述。
逐层比较节点
说到树,相信大多数同学第一时间想到的是二叉树、遍历、最短路径等复杂的数据结构算法。在 React 中,树算法其实很简单,就是两棵树只会比较同一层级的节点。如下图所示:
React 只会比较同一个颜色框中的 DOM 节点,即同一个父节点下的所有子节点。当发现该节点不再存在时,该节点及其子节点将被完全删除,不再用于进一步比较。这样整个DOM树的比较只需遍历一次树即可完成。
例如,考虑以下 DOM 结构转换:
A节点完全移到D节点,直观考虑DOM Diff操作应该是
复制代码
A.parent.remove(A); D.append(A);
但是因为React只是简单的考虑了同层节点的位置变换,对于不同层的节点,只有简单的创建和删除。当根节点发现子节点中的A缺失时,直接销毁A;而当D发现自己多了一个子节点A时,就会创建一个新的A作为子节点。因此,这种结构转换的实际操作是:
复制代码
A.destroy();A = new A();A.append(new B());A.append(new C());D.append(A);
如您所见,完全重新创建了以 A 为根节点的树。
虽然这个算法看起来有点“简单化”,但它基于第一个假设:两个不同的组件通常会产生不同的 DOM 结构。根据官方 React 博客,到目前为止,这种假设还没有造成严重的性能问题。这当然也给了我们一个提示,即在实现自己的组件时,保持稳定的 DOM 结构将有助于提高性能。例如,我们有时可以通过 CSS 隐藏或显示某些节点,而不是实际删除或添加 DOM 节点。
通过DOM Diff算法了解组件的生命周期
在上一篇文章中,我们介绍了React组件的生命周期。它的每个阶段实际上都与 DOM Diff 算法密切相关。例如以下方法:
为了演示组件生命周期和DOM Diff算法的关系,作者创建了一个例子:,可以直接访问试用。这时候,当DOM树经历了如下的转变,也就是从“shape1”转变为“shape2”的时候。让我们观察这些方法的实现:
浏览器开发工具控制台输出如下结果:
复制代码
C will unmount.C is created.B is updated.A is updated.C did mount.D is updated.R is updated.
如您所见,C 节点完全重建,然后添加到 D 节点,而不是“移动”它。如果有兴趣,也可以fork示例代码:。所以你可以自己添加其他树结构,并尝试如何在它们之间进行转换。
同类型节点对比
第二类节点的比较是同类型的节点,算法比较简单易懂。 React 会重置属性来实现节点转换。例如:
复制代码
renderA: renderB: => [replaceAttribute id "after"]
虚拟DOM的style属性略有不同。它的值不是简单的字符串而是必须是一个对象,所以转换过程如下:
复制代码
renderA: renderB: => [removeStyle color], [addStyle font-weight 'bold']
列表节点对比
不在同一层上的节点的比较如上所述。即使它们完全相同,它们也会被破坏和重新创建。那么当它们在同一层时是如何处理的呢?这就涉及到链表节点的Diff算法。相信很多使用React的同学都遇到过这个警告:
这是React遇到list但找不到key时提示的警告。尽管即使您忽略此警告,大多数接口也能正常工作,但这通常意味着潜在的性能问题。因为 React 觉得可能无法高效更新这个列表。
列表节点的操作通常包括添加、删除和排序。比如下图中,我们需要直接将节点F插入到B和C中。在jQuery中,我们可以直接使用$(B).after(F)来实现。在 React 中,我们只告诉 React 新的接口应该是 A-B-F-C-D-E,接口通过 Diff 算法更新。
这时候如果每个节点都没有唯一标识符,而React无法识别每个节点,更新过程会非常低效,即更新C到F,D到C,E到D,最后Insert E 节点。效果如下图所示:
如您所见,React 会一一更新节点并切换到目标节点。最后插入一个新的节点 E 涉及到很多 DOM 操作。而如果给每个节点一个唯一的键(key),那么React就能找到正确的位置插入新节点,如下图:
调整列表节点的顺序,其实和插入或删除类似。让我们用下面的示例代码来看看转换过程。仍然使用前面提到的例子:,我们将树的形状从 shape5 转换为 shape6:
同层节点的位置会有所调整。如果没有提供key,那么React认为B和C后面对应的组件类型是不同的,所以彻底删除并重建。控制台输出如下:
复制代码
B will unmount.C will unmount.C is created.B is created.C did mount.B did mount.A is updated.R is updated.
如果提供了密钥,如以下代码:
复制代码
shape5: function() { return ( );}, shape6: function() { return ( );},
然后控制台输出如下:
复制代码
C is updated.B is updated.A is updated.R is updated.
如您所见,为列表节点提供唯一的key属性可以帮助React定位到正确的节点进行比较,从而大大减少DOM操作次数,提高性能。
总结
本文分析了 React 的 DOM Diff 算法是如何工作的,其复杂度控制在 O(n)。这让我们每次都可以根据状态考虑 UI 来渲染整个界面,而不必担心性能问题。简化 UI 开发的复杂性。算法优化的基础是文章开头提到的两个假设,而React的UI是基于组件等机制的。了解虚拟DOM Diff算法不仅可以帮助我们了解组件的生命周期,而且对我们在实现自定义组件时进一步优化性能具有指导意义。
感谢徐川对本文的审阅。
如需为InfoQ中文站投稿或参与内容翻译,请发邮件至。也欢迎您关注我们的新浪微博(@InfoQ,@丁晓昀)、微信(微信ID:InfoQChina),与我们的编辑和其他读者朋友交流(欢迎加入InfoQ读者交流群
). 查看全部
React中最神奇的部分莫过于虚拟DOM,以及其高效的Diff算法
React 最神奇的部分是虚拟 DOM 及其高效的 Diff 算法。这使我们可以随时“刷新”整个页面而不必担心性能问题。虚拟 DOM 确保仅实际更改界面上的实际 DOM 操作。 React 在这部分已经足够透明了。在实际开发中,我们基本不需要关心虚拟 DOM 是如何工作的。然而,作为有态度的程序员,我们总是对技术背后的原理感到好奇。了解其运行机制不仅有助于更好地理解 React 组件的生命周期,而且对于进一步优化 React 程序也有很大帮助。
什么是 DOM Diff 算法
Web 界面由 DOM 树组成。当它的某一部分发生变化时,实际上是相应的DOM节点发生了变化。在 React 中,构建 UI 界面的想法是当前状态决定界面。前后两个状态对应两组接口,然后React比较两组接口的差异,这需要DOM树的Diff算法分析。
给定任意两棵树,找出最少的转换步骤。但是标准的Diff算法复杂度需要O(n^3),显然不能满足性能要求。要达到每次整体刷新界面的目标,必须对算法进行优化。这看起来很困难但是Facebook工程师做到了,他们结合Web界面的特点,做了两个简单的假设,直接将Diff算法的复杂度降低到O(n)
两个相同的组件产生相似的DOM结构,不同的组件产生不同的DOM结构;对于同一层级的一组子节点,可以通过唯一的id来区分。
算法优化是 React 整个界面 Render 的基础。事实也证明,这两个假设是合理且准确的,保证了整体接口构建的性能。
不同节点类型的比较
为了在树之间进行比较,我们首先必须能够比较两个节点。在 React 中,我们比较两个虚拟 DOM 节点。当两个节点不同时我们应该怎么做?这分两种情况:(1)node类型不同,(2)node类型相同,但属性不同。本节先看第一种情况。
当树中相同位置前后输出不同类型的节点时,React直接删除之前的节点,然后创建并插入一个新节点。假设我们在树中的同一位置前后两次输出不同类型的节点。
复制代码
renderA: renderB: => [removeNode ], [insertNode ]
当一个节点从 div 变为 span 时,只需删除 div 节点并插入一个新的 span 节点即可。这符合我们对真实DOM操作的理解。
需要注意的是,删除一个节点意味着彻底销毁该节点,而不是在后续的比较中检查是否还有另一个节点等同于被删除的节点。如果删除的节点下还有子节点,这些子节点也会被彻底删除,不会用于后续的比较。这就是为什么算法复杂度可以降低到 O(n) 的原因。
上面说的是虚拟DOM节点的操作,同样的逻辑也用在React组件的比较中,例如:
复制代码
renderA: renderB: => [removeNode ], [insertNode ]
当 React 在同一位置遇到不同的组件时,它只会销毁第一个组件并添加新创建的组件。这是第一个假设的应用。不同的组件通常会产生不同的 DOM 结构。与其浪费时间比较基本不等价的 DOM 结构,不如创建一个新组件并添加它。
从这个 React 对不同类型节点的处理逻辑,我们可以很容易地推断出 React 的 DOM Diff 算法实际上只是逐层比较树,如下所述。
逐层比较节点
说到树,相信大多数同学第一时间想到的是二叉树、遍历、最短路径等复杂的数据结构算法。在 React 中,树算法其实很简单,就是两棵树只会比较同一层级的节点。如下图所示:
React 只会比较同一个颜色框中的 DOM 节点,即同一个父节点下的所有子节点。当发现该节点不再存在时,该节点及其子节点将被完全删除,不再用于进一步比较。这样整个DOM树的比较只需遍历一次树即可完成。
例如,考虑以下 DOM 结构转换:
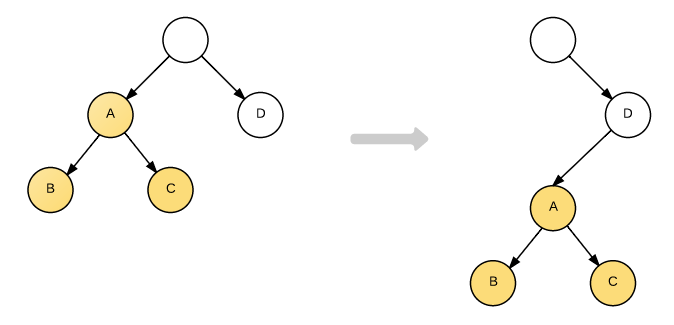
A节点完全移到D节点,直观考虑DOM Diff操作应该是
复制代码
A.parent.remove(A); D.append(A);
但是因为React只是简单的考虑了同层节点的位置变换,对于不同层的节点,只有简单的创建和删除。当根节点发现子节点中的A缺失时,直接销毁A;而当D发现自己多了一个子节点A时,就会创建一个新的A作为子节点。因此,这种结构转换的实际操作是:
复制代码
A.destroy();A = new A();A.append(new B());A.append(new C());D.append(A);
如您所见,完全重新创建了以 A 为根节点的树。
虽然这个算法看起来有点“简单化”,但它基于第一个假设:两个不同的组件通常会产生不同的 DOM 结构。根据官方 React 博客,到目前为止,这种假设还没有造成严重的性能问题。这当然也给了我们一个提示,即在实现自己的组件时,保持稳定的 DOM 结构将有助于提高性能。例如,我们有时可以通过 CSS 隐藏或显示某些节点,而不是实际删除或添加 DOM 节点。
通过DOM Diff算法了解组件的生命周期
在上一篇文章中,我们介绍了React组件的生命周期。它的每个阶段实际上都与 DOM Diff 算法密切相关。例如以下方法:
为了演示组件生命周期和DOM Diff算法的关系,作者创建了一个例子:,可以直接访问试用。这时候,当DOM树经历了如下的转变,也就是从“shape1”转变为“shape2”的时候。让我们观察这些方法的实现:
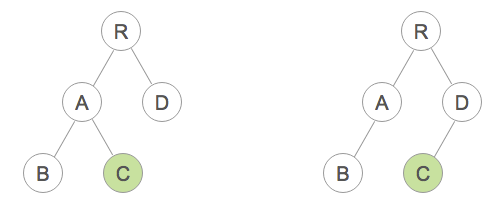
浏览器开发工具控制台输出如下结果:
复制代码
C will unmount.C is created.B is updated.A is updated.C did mount.D is updated.R is updated.
如您所见,C 节点完全重建,然后添加到 D 节点,而不是“移动”它。如果有兴趣,也可以fork示例代码:。所以你可以自己添加其他树结构,并尝试如何在它们之间进行转换。
同类型节点对比
第二类节点的比较是同类型的节点,算法比较简单易懂。 React 会重置属性来实现节点转换。例如:
复制代码
renderA: renderB: => [replaceAttribute id "after"]
虚拟DOM的style属性略有不同。它的值不是简单的字符串而是必须是一个对象,所以转换过程如下:
复制代码
renderA: renderB: => [removeStyle color], [addStyle font-weight 'bold']
列表节点对比
不在同一层上的节点的比较如上所述。即使它们完全相同,它们也会被破坏和重新创建。那么当它们在同一层时是如何处理的呢?这就涉及到链表节点的Diff算法。相信很多使用React的同学都遇到过这个警告:

这是React遇到list但找不到key时提示的警告。尽管即使您忽略此警告,大多数接口也能正常工作,但这通常意味着潜在的性能问题。因为 React 觉得可能无法高效更新这个列表。
列表节点的操作通常包括添加、删除和排序。比如下图中,我们需要直接将节点F插入到B和C中。在jQuery中,我们可以直接使用$(B).after(F)来实现。在 React 中,我们只告诉 React 新的接口应该是 A-B-F-C-D-E,接口通过 Diff 算法更新。
这时候如果每个节点都没有唯一标识符,而React无法识别每个节点,更新过程会非常低效,即更新C到F,D到C,E到D,最后Insert E 节点。效果如下图所示:
如您所见,React 会一一更新节点并切换到目标节点。最后插入一个新的节点 E 涉及到很多 DOM 操作。而如果给每个节点一个唯一的键(key),那么React就能找到正确的位置插入新节点,如下图:
调整列表节点的顺序,其实和插入或删除类似。让我们用下面的示例代码来看看转换过程。仍然使用前面提到的例子:,我们将树的形状从 shape5 转换为 shape6:
同层节点的位置会有所调整。如果没有提供key,那么React认为B和C后面对应的组件类型是不同的,所以彻底删除并重建。控制台输出如下:
复制代码
B will unmount.C will unmount.C is created.B is created.C did mount.B did mount.A is updated.R is updated.
如果提供了密钥,如以下代码:
复制代码
shape5: function() { return ( );}, shape6: function() { return ( );},
然后控制台输出如下:
复制代码
C is updated.B is updated.A is updated.R is updated.
如您所见,为列表节点提供唯一的key属性可以帮助React定位到正确的节点进行比较,从而大大减少DOM操作次数,提高性能。
总结
本文分析了 React 的 DOM Diff 算法是如何工作的,其复杂度控制在 O(n)。这让我们每次都可以根据状态考虑 UI 来渲染整个界面,而不必担心性能问题。简化 UI 开发的复杂性。算法优化的基础是文章开头提到的两个假设,而React的UI是基于组件等机制的。了解虚拟DOM Diff算法不仅可以帮助我们了解组件的生命周期,而且对我们在实现自定义组件时进一步优化性能具有指导意义。
感谢徐川对本文的审阅。
如需为InfoQ中文站投稿或参与内容翻译,请发邮件至。也欢迎您关注我们的新浪微博(@InfoQ,@丁晓昀)、微信(微信ID:InfoQChina),与我们的编辑和其他读者朋友交流(欢迎加入InfoQ读者交流群

).
数据挖掘决策参考的统计分析数据.在深层次的层次上的应用
采集交流 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2021-08-21 22:11
数据挖掘,也称为数据挖掘、数据挖掘等,是根据既定的业务目标从海量数据中提取潜在、有效和可理解的模式的高级过程。在较浅的层面上,利用现有数据库管理系统的查询、搜索和报告功能,结合多维分析和统计分析方法,进行在线分析处理(O易信),从而获得参考用于决策数据的统计分析。在更深层次上,从数据库中发现了前所未有的隐性知识。 OLAF'出现的时间早于数据挖掘。它们都是从数据库中提取有用信息的方法。就决策支持的需求而言,两者是相辅相成的。
数据挖掘是一个多学科领域,它结合了数据库技术、人工智能、机器学习、模式识别、模糊数学和数理统计的最新研究成果,可用于支持商业智能应用和决策分析。例如客户细分、交叉销售、欺诈检测、客户流失分析、产品销售预测等,目前广泛应用于银行、金融、医疗、工业、零售和电信行业。数据挖掘技术的发展对各行各业都具有重要的现实意义。
数据挖掘以全新的视角将数据库技术、统计学、机器学习、信息检索技术、数据可视化和模式识别与人工智能等领域相结合。发现其他传统方法无法发现的有用知识。
数据挖掘可以解决很多问题,但是实现过程是一个非常繁琐的过程,只有在计算机基础丰富的情况下才能实现。随着信息技术的发展,出现了许多数据挖掘工具。其中,NLPIR大数据语义智能分析平台(原ICTCLAS)是一个比较好的系统。它由北京理工大学大数据搜索与挖掘实验室主任张华平开发。针对大数据内容获取、编辑、挖掘、搜索的综合需求,融合网络精准采集、自然语言理解、文本挖掘、语义搜索等最新研究成果,近二十年来不断创新平台提供客户端工具、云服务、二次开发接口等多种产品使用形式。每个中间件API都可以无缝集成到客户的各种复杂应用系统中,兼容Windows、Linux、Android、Maemo5、FreeBSD等不同操作系统平台,可用于Java、Python、C等各种开发、C# 等语言用法。
NLPIR大数据语义智能分析平台的十三项功能:
NLPIR大数据语义智能分析平台客户端
精准采集:国内外海量信息实时精准采集,有话题采集(话题采集根据信息需要)和网站采集(站内)使用给定的 URL 列表)定点 采集 函数)。
文档转换:对doc、excel、pdf、ppt等多种主流文档格式的文本信息进行转换,效率满足大数据处理要求。
新词发现:从文本中发现新词、新概念,用户可以将其用于专业词典的编纂,还可以进一步编辑标注,导入分词词典,提高分词准确率分词系统,适应新的语言变化。
批量分词:对原创语料进行分词,自动识别姓名、地名、机构名称等未注册词,新词标注,词性标注。并在分析过程中,导入用户自定义词典。
语言统计:根据分词和标注结果,系统可以自动进行一元词频数统计和二元词转移概率统计。对于常用术语,会自动给出相应的英文解释。
文本聚类:可以从大规模数据中自动分析热点事件,并提供事件主题的关键特征描述。同时适用于短文、微博等长文和短文的热点分析。
文本分类:根据规则或训练方法对大量文本进行分类,可用于新闻分类、简历分类、邮件分类、办公文档分类、区域分类等多个方面。
摘要实体:对于单个或多个文章,自动提取内容摘要,提取人名、地名、机构名称、时间和主题关键词;方便用户快速浏览文本内容。
智能过滤:对文本内容进行语义智能过滤和审核,内置国内最全词库,智能识别变形、拼音、繁体、简体等多种变体,语义精准消歧。
情感分析:针对预先指定的分析对象,系统自动分析海量文档的情感倾向:情感极性和情感值测度,并给出原文中的正负分和句例。
文档去重:快速准确判断文件集合或数据库中是否存在内容相同或相似的记录,同时查找所有重复记录。
全文搜索:支持文本、数字、日期、字符串等多种数据类型,多字段高效搜索,支持AND/OR/NOT、NEAR接近等查询语法,支持维文、藏文、蒙古语、阿拉伯语、韩语等多种少数民族语言搜索。
编码转换:自动识别内容的编码,统一将编码转换为其他编码。
以上是推荐的中文分词工具。我希望它能帮助你。如果您有任何问题,请联系我,我会帮助您! 查看全部
数据挖掘决策参考的统计分析数据.在深层次的层次上的应用
数据挖掘,也称为数据挖掘、数据挖掘等,是根据既定的业务目标从海量数据中提取潜在、有效和可理解的模式的高级过程。在较浅的层面上,利用现有数据库管理系统的查询、搜索和报告功能,结合多维分析和统计分析方法,进行在线分析处理(O易信),从而获得参考用于决策数据的统计分析。在更深层次上,从数据库中发现了前所未有的隐性知识。 OLAF'出现的时间早于数据挖掘。它们都是从数据库中提取有用信息的方法。就决策支持的需求而言,两者是相辅相成的。
数据挖掘是一个多学科领域,它结合了数据库技术、人工智能、机器学习、模式识别、模糊数学和数理统计的最新研究成果,可用于支持商业智能应用和决策分析。例如客户细分、交叉销售、欺诈检测、客户流失分析、产品销售预测等,目前广泛应用于银行、金融、医疗、工业、零售和电信行业。数据挖掘技术的发展对各行各业都具有重要的现实意义。
数据挖掘以全新的视角将数据库技术、统计学、机器学习、信息检索技术、数据可视化和模式识别与人工智能等领域相结合。发现其他传统方法无法发现的有用知识。
数据挖掘可以解决很多问题,但是实现过程是一个非常繁琐的过程,只有在计算机基础丰富的情况下才能实现。随着信息技术的发展,出现了许多数据挖掘工具。其中,NLPIR大数据语义智能分析平台(原ICTCLAS)是一个比较好的系统。它由北京理工大学大数据搜索与挖掘实验室主任张华平开发。针对大数据内容获取、编辑、挖掘、搜索的综合需求,融合网络精准采集、自然语言理解、文本挖掘、语义搜索等最新研究成果,近二十年来不断创新平台提供客户端工具、云服务、二次开发接口等多种产品使用形式。每个中间件API都可以无缝集成到客户的各种复杂应用系统中,兼容Windows、Linux、Android、Maemo5、FreeBSD等不同操作系统平台,可用于Java、Python、C等各种开发、C# 等语言用法。

NLPIR大数据语义智能分析平台的十三项功能:
NLPIR大数据语义智能分析平台客户端
精准采集:国内外海量信息实时精准采集,有话题采集(话题采集根据信息需要)和网站采集(站内)使用给定的 URL 列表)定点 采集 函数)。
文档转换:对doc、excel、pdf、ppt等多种主流文档格式的文本信息进行转换,效率满足大数据处理要求。
新词发现:从文本中发现新词、新概念,用户可以将其用于专业词典的编纂,还可以进一步编辑标注,导入分词词典,提高分词准确率分词系统,适应新的语言变化。
批量分词:对原创语料进行分词,自动识别姓名、地名、机构名称等未注册词,新词标注,词性标注。并在分析过程中,导入用户自定义词典。
语言统计:根据分词和标注结果,系统可以自动进行一元词频数统计和二元词转移概率统计。对于常用术语,会自动给出相应的英文解释。
文本聚类:可以从大规模数据中自动分析热点事件,并提供事件主题的关键特征描述。同时适用于短文、微博等长文和短文的热点分析。
文本分类:根据规则或训练方法对大量文本进行分类,可用于新闻分类、简历分类、邮件分类、办公文档分类、区域分类等多个方面。
摘要实体:对于单个或多个文章,自动提取内容摘要,提取人名、地名、机构名称、时间和主题关键词;方便用户快速浏览文本内容。
智能过滤:对文本内容进行语义智能过滤和审核,内置国内最全词库,智能识别变形、拼音、繁体、简体等多种变体,语义精准消歧。
情感分析:针对预先指定的分析对象,系统自动分析海量文档的情感倾向:情感极性和情感值测度,并给出原文中的正负分和句例。
文档去重:快速准确判断文件集合或数据库中是否存在内容相同或相似的记录,同时查找所有重复记录。
全文搜索:支持文本、数字、日期、字符串等多种数据类型,多字段高效搜索,支持AND/OR/NOT、NEAR接近等查询语法,支持维文、藏文、蒙古语、阿拉伯语、韩语等多种少数民族语言搜索。
编码转换:自动识别内容的编码,统一将编码转换为其他编码。
以上是推荐的中文分词工具。我希望它能帮助你。如果您有任何问题,请联系我,我会帮助您!
关于使用Python分析财务报表的场景,你需要知道的
采集交流 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-08-21 19:13
总结
1) 获取需要下载数据的股票代码列表
2)寻找可以下载数据的数据接口
3)下载并保存数据
先写
之前我在《所有A股市场金融指数数据汇总-知乎专栏》和《如何通过财务报表分析行业特征》文章中提到并使用了Python。从反应来看,大家对如何使用Python分析财务报表产生了浓厚的兴趣。这就是文章存在的原因。
关于使用Python分析财务报表的场景,我认为主要有:1)同业分析:批量计算比较,即展示或导出同行业的财务指标; 2)选股:比如过滤近三年roe大于15%的公司,最近一期roe大于15%的所有公司等,如果是单个公司来分析,给大家看看我之前提供的《一款金融分析工具(Excel版)-知乎Column》。这个工具已经涵盖了主要的主题和变化,增长分析等,我现在也在用这个工具。一般来说,选择合适的工具也可以事半功倍。 .
本文分为两部分,第一部分主要讲数据采集,第二部分主要讲通过财务指标进行对比分析
有朋友问为什么不直接分享代码。事实上,完成财务分析所需的代码是如此简单,任何程序员写的都比我漂亮一百倍。可能是网工的财务分析比较好),但一方面要注意别有用心的人滥用接口,导致接口失效。另一方面,爬取别人的网站数据也不好,所以涉及的金融接口不适合公开。基于这些考虑,我之前分享的EXCEL工具也对代码部分进行了加密。同样,我不打算在本文中公开分享代码,而只是分享想法。有兴趣的可以在主财经网站找到下载界面。所有的接口都找到了。按照本文的思路,很容易得到整个市场上市公司的财务数据。如果实在找不到,可以私信我的邮箱,我可以提供我的示例代码供大家参考。
至于您提供的电子邮件地址,我个人承诺,除了发送所需信息外,不会用于任何其他目的。不过也建议大家保护好自己的隐私,尽量不要在评论区留下联系方式和私信,方便我回复(我经常在评论区找不到,所以我不能还给你)
这篇文章虽然简单,但还是需要一定的Python基础。如果你对Python一窍不通,但对它比较感兴趣,建议你搜索《廖雪峰Python3》教程(Pyhon2已过期不再使用),写的简单又免费。本文示例代码基于Python3.5,演示平台为JupyterNotebook。关于环境的搭建,在Windows系统上可以直接安装Anconda,一切都会为你安装。至于其他系统比如Linux,我假设你是一个IT人员。部署开发环境应该是小菜一碟。不做详细介绍。
采集财务数据
结束了。让我们回到正题。网络爬虫需要解决三个主要问题:
1) 爬什么?
2) 去哪里爬?
3) 数据清洗和存储?
一、获取所有股票代码
为了抓取所有上市公司的财务数据,我们首先需要获取所有上市公司的公司代码。这在 Python 中有一个很好的解决方案。即使用途享金融库,可以获取所有股票代码、沪深300成分股等,如果没有安装,请使用pip install tushare安装途享金融库。官网:
1)查看是否安装了tushare:
创建一个新的 Notebook 并在单元格中输入 Python 代码
import tushare as t
t.__version__
输入后按SHIFT+ENTER运行,显示
这是最新的0.8.2 版本。
2) 获取股票列表(在另一个单元格中输入代码):
stocks_df=t.get_stock_basics()
stocks_df
这两句的作用是通过tushare金融数据库获取所有股票的列表和基本信息,并返回一些股票的基本信息,如地区、行业、总资产等。返回结果是一个 pandas.DataFrame 表。根据网络环境,此代码可能需要大约 5-6 秒。返回结果:
返回值有20多个字段。我们只需要一部分数据。您可以使用 ix slice 剪切股票代码、名称、地区和行业。 (比如我们只截取name、area、industry字段)
stock_df=stock_df.ix[:,['name','industry','area']]
# ix[行条件,列条件],这里表示截取所有行,name,industry,area字段,返回一个DATAFRAME
stock_df
如果您对一些新股不敏感,可以将数据另存为csv/xls文件以备多次使用。
注意:从文件中读取股票列表后,会自动处理股票代码前的“0”,循环下载数据时需加上“0”。
股票清单从那时起就可用了。
二、寻找合适的金融数据接口
由于Python可以直接处理的文件格式是xml/csv/json/xls,我们尝试寻找可以提供这种格式文本的数据接口。
此外,我更喜欢 csv 格式的文本。这段文字紧凑,可以说没有无用字节。但是得到的数据可能不是你需要的格式,所以你需要把数据转换成你需要的(为了说明数据清洗和转换的过程,我这里特地选择了一个xls格式的财务接口)
2.1.查找数据接口
很多财经网站都有下载财务报表的界面。由于我们已经获得了所有股票的列表,我们可以依次将股票代码传递到下载界面来获取所有股票的财务数据。让我们先找到可用的。财务数据接口。
1)打开任意财经网站Stock专栏
2)输入任意股票代码,如600660,进入股票详情页面
3) 查找财务报表、财务数据、财务分析等词,进入细分栏目。
4) 您应该能够在本节中找到、下载或导出函数。现在重要的是,右键单击链接并选择复制链接地址
如果,
下载数据是按钮而不是链接,可以先用Chrome下载数据,然后按
Ctrl+J 查看下载历史,可以看到下载地址。如果还是不行,可能需要使用抓包工具之类的了。
5) 分析链接地址并检查传入股票代码的位置。比如链接地址是:/report.jsp?id=600660 那么这个600660就是入股代码。
2.2.通过程序下载数据
得到接口地址后,我们就可以通过程序下载数据了。
import requests as ro
stock_code = '600660'
bs_url='http://soft-f9.eastmoney.com/soft/gp15.php?code={co}01&exp=1'.format(co=stock_code)
ct = ro.get(bs_url).text
ct
看到一堆乱码(其实不是乱码,是xml,后面再讲转成csv文本)
三、数据清理与存储
1)数据清洗
得到的数据结构太复杂,需要清理和转换。之前,我在《几行代码从EXCELL获取有效数据》文章中演示了数据的清洗。请参考原文。再次重复描述。
2) 数据保存
财务报表是有效期相对较长的数据。为了避免每次使用时重复下载,可以将数据存储在本地。存储方式一般有文件方式或数据库方式。由于数据量不大,可以直接保存为csv文件。不过为了方便查阅,文件命名方式可以稍微标注一下,如将报告类型命名为-股票代码.csv,以便于阅读。
四、编写Python程序下载数据
#!/usr/bin/py
# filename=RPDownloader.py
from modules.Utils import e2csv
from modules.Fi import tcode
import pandas as Pd
import requests as ro
# 下载资产负债表
def downloadBSRP(stocklist):
num = 0
for c in stocklist:
bs_url='http://soft-f9.eastmoney.com/soft/gp15.php?code={co}01&exp=1'.format(co=tcode(c))
ct = ro.get(bs_url).text
to_file='bs{co}.csv'.format(co=tcode(c))
open(to_file,'w').write(e2csv(ct))
num = num + 1
return num
函数的返回值是成功下载报告的数量(这里不做容错处理。如果下载量大,需要容错处理。另外,必须在程序后解决异常退出,下次再次进入,避免重复下载下载的文件。数据,另外,为了避免IP地址被封锁,下载后必须加一个延迟,这些内容留给大家下面学习),测试代码:
显示已成功下载两张股票资产负债表。
根据以上内容,还可以下载损益表和现金流量表。
至此,财务数据采集一章结束。下一篇文章是关于如何使用这些数据进行财务分析。 查看全部
关于使用Python分析财务报表的场景,你需要知道的
总结
1) 获取需要下载数据的股票代码列表
2)寻找可以下载数据的数据接口
3)下载并保存数据
先写
之前我在《所有A股市场金融指数数据汇总-知乎专栏》和《如何通过财务报表分析行业特征》文章中提到并使用了Python。从反应来看,大家对如何使用Python分析财务报表产生了浓厚的兴趣。这就是文章存在的原因。
关于使用Python分析财务报表的场景,我认为主要有:1)同业分析:批量计算比较,即展示或导出同行业的财务指标; 2)选股:比如过滤近三年roe大于15%的公司,最近一期roe大于15%的所有公司等,如果是单个公司来分析,给大家看看我之前提供的《一款金融分析工具(Excel版)-知乎Column》。这个工具已经涵盖了主要的主题和变化,增长分析等,我现在也在用这个工具。一般来说,选择合适的工具也可以事半功倍。 .
本文分为两部分,第一部分主要讲数据采集,第二部分主要讲通过财务指标进行对比分析
有朋友问为什么不直接分享代码。事实上,完成财务分析所需的代码是如此简单,任何程序员写的都比我漂亮一百倍。可能是网工的财务分析比较好),但一方面要注意别有用心的人滥用接口,导致接口失效。另一方面,爬取别人的网站数据也不好,所以涉及的金融接口不适合公开。基于这些考虑,我之前分享的EXCEL工具也对代码部分进行了加密。同样,我不打算在本文中公开分享代码,而只是分享想法。有兴趣的可以在主财经网站找到下载界面。所有的接口都找到了。按照本文的思路,很容易得到整个市场上市公司的财务数据。如果实在找不到,可以私信我的邮箱,我可以提供我的示例代码供大家参考。
至于您提供的电子邮件地址,我个人承诺,除了发送所需信息外,不会用于任何其他目的。不过也建议大家保护好自己的隐私,尽量不要在评论区留下联系方式和私信,方便我回复(我经常在评论区找不到,所以我不能还给你)
这篇文章虽然简单,但还是需要一定的Python基础。如果你对Python一窍不通,但对它比较感兴趣,建议你搜索《廖雪峰Python3》教程(Pyhon2已过期不再使用),写的简单又免费。本文示例代码基于Python3.5,演示平台为JupyterNotebook。关于环境的搭建,在Windows系统上可以直接安装Anconda,一切都会为你安装。至于其他系统比如Linux,我假设你是一个IT人员。部署开发环境应该是小菜一碟。不做详细介绍。
采集财务数据
结束了。让我们回到正题。网络爬虫需要解决三个主要问题:
1) 爬什么?
2) 去哪里爬?
3) 数据清洗和存储?
一、获取所有股票代码
为了抓取所有上市公司的财务数据,我们首先需要获取所有上市公司的公司代码。这在 Python 中有一个很好的解决方案。即使用途享金融库,可以获取所有股票代码、沪深300成分股等,如果没有安装,请使用pip install tushare安装途享金融库。官网:
1)查看是否安装了tushare:
创建一个新的 Notebook 并在单元格中输入 Python 代码
import tushare as t
t.__version__
输入后按SHIFT+ENTER运行,显示

这是最新的0.8.2 版本。
2) 获取股票列表(在另一个单元格中输入代码):
stocks_df=t.get_stock_basics()
stocks_df
这两句的作用是通过tushare金融数据库获取所有股票的列表和基本信息,并返回一些股票的基本信息,如地区、行业、总资产等。返回结果是一个 pandas.DataFrame 表。根据网络环境,此代码可能需要大约 5-6 秒。返回结果:

返回值有20多个字段。我们只需要一部分数据。您可以使用 ix slice 剪切股票代码、名称、地区和行业。 (比如我们只截取name、area、industry字段)
stock_df=stock_df.ix[:,['name','industry','area']]
# ix[行条件,列条件],这里表示截取所有行,name,industry,area字段,返回一个DATAFRAME
stock_df

如果您对一些新股不敏感,可以将数据另存为csv/xls文件以备多次使用。

注意:从文件中读取股票列表后,会自动处理股票代码前的“0”,循环下载数据时需加上“0”。

股票清单从那时起就可用了。
二、寻找合适的金融数据接口
由于Python可以直接处理的文件格式是xml/csv/json/xls,我们尝试寻找可以提供这种格式文本的数据接口。
此外,我更喜欢 csv 格式的文本。这段文字紧凑,可以说没有无用字节。但是得到的数据可能不是你需要的格式,所以你需要把数据转换成你需要的(为了说明数据清洗和转换的过程,我这里特地选择了一个xls格式的财务接口)
2.1.查找数据接口
很多财经网站都有下载财务报表的界面。由于我们已经获得了所有股票的列表,我们可以依次将股票代码传递到下载界面来获取所有股票的财务数据。让我们先找到可用的。财务数据接口。
1)打开任意财经网站Stock专栏
2)输入任意股票代码,如600660,进入股票详情页面
3) 查找财务报表、财务数据、财务分析等词,进入细分栏目。
4) 您应该能够在本节中找到、下载或导出函数。现在重要的是,右键单击链接并选择复制链接地址
如果,
下载数据是按钮而不是链接,可以先用Chrome下载数据,然后按
Ctrl+J 查看下载历史,可以看到下载地址。如果还是不行,可能需要使用抓包工具之类的了。
5) 分析链接地址并检查传入股票代码的位置。比如链接地址是:/report.jsp?id=600660 那么这个600660就是入股代码。
2.2.通过程序下载数据
得到接口地址后,我们就可以通过程序下载数据了。
import requests as ro
stock_code = '600660'
bs_url='http://soft-f9.eastmoney.com/soft/gp15.php?code={co}01&exp=1'.format(co=stock_code)
ct = ro.get(bs_url).text
ct

看到一堆乱码(其实不是乱码,是xml,后面再讲转成csv文本)
三、数据清理与存储
1)数据清洗
得到的数据结构太复杂,需要清理和转换。之前,我在《几行代码从EXCELL获取有效数据》文章中演示了数据的清洗。请参考原文。再次重复描述。

2) 数据保存
财务报表是有效期相对较长的数据。为了避免每次使用时重复下载,可以将数据存储在本地。存储方式一般有文件方式或数据库方式。由于数据量不大,可以直接保存为csv文件。不过为了方便查阅,文件命名方式可以稍微标注一下,如将报告类型命名为-股票代码.csv,以便于阅读。
四、编写Python程序下载数据
#!/usr/bin/py
# filename=RPDownloader.py
from modules.Utils import e2csv
from modules.Fi import tcode
import pandas as Pd
import requests as ro
# 下载资产负债表
def downloadBSRP(stocklist):
num = 0
for c in stocklist:
bs_url='http://soft-f9.eastmoney.com/soft/gp15.php?code={co}01&exp=1'.format(co=tcode(c))
ct = ro.get(bs_url).text
to_file='bs{co}.csv'.format(co=tcode(c))
open(to_file,'w').write(e2csv(ct))
num = num + 1
return num
函数的返回值是成功下载报告的数量(这里不做容错处理。如果下载量大,需要容错处理。另外,必须在程序后解决异常退出,下次再次进入,避免重复下载下载的文件。数据,另外,为了避免IP地址被封锁,下载后必须加一个延迟,这些内容留给大家下面学习),测试代码:

显示已成功下载两张股票资产负债表。
根据以上内容,还可以下载损益表和现金流量表。
至此,财务数据采集一章结束。下一篇文章是关于如何使用这些数据进行财务分析。
算法 自动采集列表(优采云采集器破解版吾爱论坛网友破解分享软件特色(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 211 次浏览 • 2021-09-03 08:14
在信息碎片化的时代,每天都有数以万计的新信息在互联网上发布。为了抓住大众的眼球,占据他们碎片化的时间,各种网站或app也不断出现。很多新闻平台都有兴趣推荐机制,拥有成熟先进的内容推荐算法,可以抓取用户的兴趣标签,将用户感兴趣的内容推送到自己的首页。尽管他们拥有先进的内容推荐算法和互联网用户档案数据,但仍然缺乏大量的内容:例如,对于内容分发,他们需要将各个新闻信息平台的更新数据实时采集下,然后使用个性化推荐系统。分发给感兴趣的各方;对于垂直内容聚合,您需要在互联网上采集特定领域和类别的新闻和信息数据,然后将其发布到您自己的平台上。 优采云采集器一个通用的网络数据采集软件。可以为数百个主流网站数据源模板采集,不仅节省时间,还能快速获取网站公共数据。软件可根据不同的网站智能采集提供各种网页采集策略,并有配套资源,可定制配置、组合使用、自动化处理。从而帮助整个采集流程实现数据的完整性和稳定性。它支持字符串替换并具有采集Cookie 自定义功能。首次登录后可自动记住cookie,免去多次输入密码的繁琐。有兴趣的快来下载体验吧!
本编辑器为您带来优采云采集器破解版。该软件被网友在Wuai论坛上破解并分享。用户进入页面支持中文版破解所有软件功能,方便用户快速使用!
优采云采集器破解版软件显示该软件已被破解,并在无爱论坛上被网友分享。软件支持中文版,解锁所有功能。用户可以放心使用!软件特点1、满足多种业务场景
适用于产品、运营、销售、数据分析、政府机构、电子商务从业者、学术研究等各种职业。
2、公众情绪监测
全方位监控公众信息,抢先掌握舆情动态。
3、市场分析
获取用户真实行为数据,全面掌握客户真实需求
4、产品研发
大力支持用户研究,准确获取用户反馈和偏好
5、风险预测
高效信息采集和数据清洗,及时应对系统风险
功能介绍1、简采集
简单的采集模式内置了数百个主流的网站数据源,比如京东、天猫、大众点评等流行的采集网站。只需参考模板设置参数即可快速获取网站。 @公共数据。
2、智能采集
优采云采集可根据网站的不同提供多种网页采集策略及配套资源,可定制配置、组合使用、自动化处理。从而帮助采集整个流程实现数据的完整性和稳定性。
3、云采集
云采集,5000多台云服务器支持,7*24小时不间断运行,可实现定时采集,无需人员值守,灵活适配业务场景,助您提升采集效率,并保证数据的及时性。
4、API 接口
通过优采云API,可以轻松获取采集接收到的优采云任务信息和数据,灵活调度任务,如远程控制任务启停,高效实现数据采集和归档。基于强大的API系统,还可以与公司各种内部管理平台无缝对接,实现各种业务自动化。
5、Custom 采集
根据采集不同用户的需求,优采云可以提供自定义模式自动生成爬虫,可以批量准确识别各种网页元素,以及翻页、下拉、ajax、页面滚动、条件判断等。此类功能支持不同网页结构的复杂网站采集,满足多种采集应用场景。
6、方便的定时功能
只需简单几步,点击设置即可实现采集任务的定时控制,无论是单个采集定时设置,还是预设日或周、月定时采集。同时自由设置多个任务,根据需要进行多种选择时间组合,灵活部署自己的采集任务。
7、自动数据格式化
优采云内置强大的数据格式化引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间格式化、HTML转码等诸多功能,采集该过程是全自动的,无需人工干预即可获取所需格式的数据。
8、multi-level采集
众多主流新闻和电商网站,收录一级商品列表页、二级商品详情页、三级评论详情页;不管网站有多少层,优采云所有采集数据都可以无限,满足采集各种业务需求。
9、support网站登录后采集
优采云内置采集登录模块,只需配置目标网站的账号密码,即可使用该模块采集登录数据;同时优采云还有采集Cookie自定义功能,首次登录后可以自动记住cookie,免去多次输入密码的繁琐,支持更多网站采集 . 优采云采集器使用教程1、 首先打开优采云采集器→点击快速启动→新建任务(高级模式),进入任务配置页面:
2、选择任务组,自定义任务名称和备注;
3、完成上图中的配置后,选择Next,进入流程配置页面,拖一个步骤打开网页进入流程设计。
4、选择在浏览器中打开网页的步骤,在右侧的网页网址中输入网页网址并点击保存,系统会在软件下自动在浏览器中打开相应的网页:
5、 在下面创建一个循环页面。在上面的浏览器页面点击下一页按钮,在弹出的对话框中选择重复点击下一页;
6、创建翻页循环后,点击下图中的保存;
7、因为如上图我们需要在浏览器中点击电影名称,然后在子页面中提取数据信息,所以需要做一个循环采集列表。
点击上图中第一个循环项,在弹出的对话框中选择创建元素列表处理一组元素;
8、然后在弹出的对话框中选择添加到列表中。
9、添加第一个循环后,继续编辑。
10、 接下来,以同样的方式添加第二个循环。
11、 当我们添加第二个循环项时,可以看到上图。此时,页面上的其他元素已经添加。这是因为我们添加了两个具有相似特征的元素,系统会智能地在页面上添加其他具有相似特征的元素。然后选择创建列表完成→点击下图中的循环。
12、经过以上操作,循环采集列表就完成了。系统会在页面右上角显示该页面添加的所有循环项。
13、 由于每个页面都需要循环采集数据,所以我们需要将这个循环列表拖入翻页循环中。
注意流程是从上一页开始执行的,所以这个循环列表需要放在点击翻页之前,否则会漏掉第一页的数据。最终流程图如下所示:
14、 选择上图中第一个循环项,然后选择点击元素。输入第一个子链接。
接下来要提取数据字段,在上图中的流程设计器中点击提取数据,然后在浏览器中选择要提取的字段,然后在弹出的选择对话框中选择该元素的文本盒子;
15、以上操作后,系统会在页面右上角显示我们要抓取的字段;
16、接下来,在页面上配置其他需要抓取的字段,配置完成后修改字段名称。
17、修改完成后,点击上图中的保存按钮,然后点击图中的数据字段,可以看到系统会显示最终的采集列表。
18、点击Next→Next→启动上图中的单机采集,进入任务检查页面,确保任务的正确性。
19、点击启动单机采集,系统会在本地执行采集进程并显示最终的采集结果。
更新日志优采云采集器 v8.1.22 更新(2021-8-13)
1、当页面没有内容更新时,可以提前结束滚动。
2、 自动跳过无效的翻页操作。
3、支持瀑布流网页采集的滚动。
4、支持网页边点击加载更多内容,而采集.
5、自动识别支持在列表项和详细信息等结果之间切换。
特别说明
百度网盘资源下载提取码:aiya 查看全部
算法 自动采集列表(优采云采集器破解版吾爱论坛网友破解分享软件特色(组图))
在信息碎片化的时代,每天都有数以万计的新信息在互联网上发布。为了抓住大众的眼球,占据他们碎片化的时间,各种网站或app也不断出现。很多新闻平台都有兴趣推荐机制,拥有成熟先进的内容推荐算法,可以抓取用户的兴趣标签,将用户感兴趣的内容推送到自己的首页。尽管他们拥有先进的内容推荐算法和互联网用户档案数据,但仍然缺乏大量的内容:例如,对于内容分发,他们需要将各个新闻信息平台的更新数据实时采集下,然后使用个性化推荐系统。分发给感兴趣的各方;对于垂直内容聚合,您需要在互联网上采集特定领域和类别的新闻和信息数据,然后将其发布到您自己的平台上。 优采云采集器一个通用的网络数据采集软件。可以为数百个主流网站数据源模板采集,不仅节省时间,还能快速获取网站公共数据。软件可根据不同的网站智能采集提供各种网页采集策略,并有配套资源,可定制配置、组合使用、自动化处理。从而帮助整个采集流程实现数据的完整性和稳定性。它支持字符串替换并具有采集Cookie 自定义功能。首次登录后可自动记住cookie,免去多次输入密码的繁琐。有兴趣的快来下载体验吧!
本编辑器为您带来优采云采集器破解版。该软件被网友在Wuai论坛上破解并分享。用户进入页面支持中文版破解所有软件功能,方便用户快速使用!
优采云采集器破解版软件显示该软件已被破解,并在无爱论坛上被网友分享。软件支持中文版,解锁所有功能。用户可以放心使用!软件特点1、满足多种业务场景
适用于产品、运营、销售、数据分析、政府机构、电子商务从业者、学术研究等各种职业。
2、公众情绪监测
全方位监控公众信息,抢先掌握舆情动态。
3、市场分析
获取用户真实行为数据,全面掌握客户真实需求
4、产品研发
大力支持用户研究,准确获取用户反馈和偏好
5、风险预测
高效信息采集和数据清洗,及时应对系统风险
功能介绍1、简采集
简单的采集模式内置了数百个主流的网站数据源,比如京东、天猫、大众点评等流行的采集网站。只需参考模板设置参数即可快速获取网站。 @公共数据。
2、智能采集
优采云采集可根据网站的不同提供多种网页采集策略及配套资源,可定制配置、组合使用、自动化处理。从而帮助采集整个流程实现数据的完整性和稳定性。
3、云采集
云采集,5000多台云服务器支持,7*24小时不间断运行,可实现定时采集,无需人员值守,灵活适配业务场景,助您提升采集效率,并保证数据的及时性。
4、API 接口
通过优采云API,可以轻松获取采集接收到的优采云任务信息和数据,灵活调度任务,如远程控制任务启停,高效实现数据采集和归档。基于强大的API系统,还可以与公司各种内部管理平台无缝对接,实现各种业务自动化。
5、Custom 采集
根据采集不同用户的需求,优采云可以提供自定义模式自动生成爬虫,可以批量准确识别各种网页元素,以及翻页、下拉、ajax、页面滚动、条件判断等。此类功能支持不同网页结构的复杂网站采集,满足多种采集应用场景。
6、方便的定时功能
只需简单几步,点击设置即可实现采集任务的定时控制,无论是单个采集定时设置,还是预设日或周、月定时采集。同时自由设置多个任务,根据需要进行多种选择时间组合,灵活部署自己的采集任务。
7、自动数据格式化
优采云内置强大的数据格式化引擎,支持字符串替换、正则表达式替换或匹配、去除空格、添加前缀或后缀、日期时间格式化、HTML转码等诸多功能,采集该过程是全自动的,无需人工干预即可获取所需格式的数据。
8、multi-level采集
众多主流新闻和电商网站,收录一级商品列表页、二级商品详情页、三级评论详情页;不管网站有多少层,优采云所有采集数据都可以无限,满足采集各种业务需求。
9、support网站登录后采集
优采云内置采集登录模块,只需配置目标网站的账号密码,即可使用该模块采集登录数据;同时优采云还有采集Cookie自定义功能,首次登录后可以自动记住cookie,免去多次输入密码的繁琐,支持更多网站采集 . 优采云采集器使用教程1、 首先打开优采云采集器→点击快速启动→新建任务(高级模式),进入任务配置页面:
2、选择任务组,自定义任务名称和备注;
3、完成上图中的配置后,选择Next,进入流程配置页面,拖一个步骤打开网页进入流程设计。
4、选择在浏览器中打开网页的步骤,在右侧的网页网址中输入网页网址并点击保存,系统会在软件下自动在浏览器中打开相应的网页:
5、 在下面创建一个循环页面。在上面的浏览器页面点击下一页按钮,在弹出的对话框中选择重复点击下一页;
6、创建翻页循环后,点击下图中的保存;
7、因为如上图我们需要在浏览器中点击电影名称,然后在子页面中提取数据信息,所以需要做一个循环采集列表。
点击上图中第一个循环项,在弹出的对话框中选择创建元素列表处理一组元素;
8、然后在弹出的对话框中选择添加到列表中。
9、添加第一个循环后,继续编辑。
10、 接下来,以同样的方式添加第二个循环。
11、 当我们添加第二个循环项时,可以看到上图。此时,页面上的其他元素已经添加。这是因为我们添加了两个具有相似特征的元素,系统会智能地在页面上添加其他具有相似特征的元素。然后选择创建列表完成→点击下图中的循环。
12、经过以上操作,循环采集列表就完成了。系统会在页面右上角显示该页面添加的所有循环项。
13、 由于每个页面都需要循环采集数据,所以我们需要将这个循环列表拖入翻页循环中。
注意流程是从上一页开始执行的,所以这个循环列表需要放在点击翻页之前,否则会漏掉第一页的数据。最终流程图如下所示:
14、 选择上图中第一个循环项,然后选择点击元素。输入第一个子链接。
接下来要提取数据字段,在上图中的流程设计器中点击提取数据,然后在浏览器中选择要提取的字段,然后在弹出的选择对话框中选择该元素的文本盒子;
15、以上操作后,系统会在页面右上角显示我们要抓取的字段;
16、接下来,在页面上配置其他需要抓取的字段,配置完成后修改字段名称。
17、修改完成后,点击上图中的保存按钮,然后点击图中的数据字段,可以看到系统会显示最终的采集列表。
18、点击Next→Next→启动上图中的单机采集,进入任务检查页面,确保任务的正确性。
19、点击启动单机采集,系统会在本地执行采集进程并显示最终的采集结果。
更新日志优采云采集器 v8.1.22 更新(2021-8-13)
1、当页面没有内容更新时,可以提前结束滚动。
2、 自动跳过无效的翻页操作。
3、支持瀑布流网页采集的滚动。
4、支持网页边点击加载更多内容,而采集.
5、自动识别支持在列表项和详细信息等结果之间切换。
特别说明
百度网盘资源下载提取码:aiya
算法 自动采集列表(百度搜索推出飓风算法严厉打击以恶劣采集的零容忍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-09-02 10:15
百度搜索最近推出了飓风算法,旨在严厉打击网站,其内容是不良采集的主要来源。同时,百度搜索将从索引库中彻底清除不良采集链接,为优质原创内容提供更多展示机会,促进搜索生态健康发展。
飓风算法会定期产生惩罚数据,同时会根据情况随时调整迭代,体现了百度搜索对不良采集的零容忍。对于优质的原创网站,如果您发现该网站的索引量大幅下降,访问量大幅下降,您可以在反馈中心反馈。
作为 SEOer,您必须熟悉搜索引擎算法并开出正确的补救措施。此后,百度搜索引擎算法更新了很多次,每次都会影响到网站的相当一部分,下面我给大家点评一下。
绿萝算法
百度于2013年2月19日推出了针对搜索引擎的反作弊算法,该算法主要打击超链接中介、卖链接、买链接等超链接作弊行为。该算法的引入有效阻止了恶意交换链接、发布外部链接,有效净化了互联网生态。这个策略是一个小女孩设计的,所以名字的权利也给了这个小女孩。她选择了路洛这个名字。隐藏反作弊净化的含义。
石榴算法
百度于2013年5月17日推出了针对低质量网站的算法。石榴算法的目的是打击大量存在阻碍用户正常浏览的不良广告的页面。
绿萝算法2.0
百度绿萝算法2.0是2013年7月1日百度绿萝算法1.0的升级版,主要目的是在网络上进行非正式的宣传软文广告,如何处理多余的垃圾邮件信息引起的。
冰桶算法
百度移动搜索会对低质量的网站和页面进行一系列调整,称为冰桶算法。冰桶算法的目的是打击强制弹出应用下载、大面积广告等影响用户正常浏览体验的页面。
冰桶算法2.0
于2014年11月18日推出,旨在打击全屏下载、手机小页面大面积广告遮蔽主要内容、强制用户登录等行为。 查看全部
算法 自动采集列表(百度搜索推出飓风算法严厉打击以恶劣采集的零容忍)
百度搜索最近推出了飓风算法,旨在严厉打击网站,其内容是不良采集的主要来源。同时,百度搜索将从索引库中彻底清除不良采集链接,为优质原创内容提供更多展示机会,促进搜索生态健康发展。
飓风算法会定期产生惩罚数据,同时会根据情况随时调整迭代,体现了百度搜索对不良采集的零容忍。对于优质的原创网站,如果您发现该网站的索引量大幅下降,访问量大幅下降,您可以在反馈中心反馈。
作为 SEOer,您必须熟悉搜索引擎算法并开出正确的补救措施。此后,百度搜索引擎算法更新了很多次,每次都会影响到网站的相当一部分,下面我给大家点评一下。
绿萝算法
百度于2013年2月19日推出了针对搜索引擎的反作弊算法,该算法主要打击超链接中介、卖链接、买链接等超链接作弊行为。该算法的引入有效阻止了恶意交换链接、发布外部链接,有效净化了互联网生态。这个策略是一个小女孩设计的,所以名字的权利也给了这个小女孩。她选择了路洛这个名字。隐藏反作弊净化的含义。
石榴算法
百度于2013年5月17日推出了针对低质量网站的算法。石榴算法的目的是打击大量存在阻碍用户正常浏览的不良广告的页面。
绿萝算法2.0
百度绿萝算法2.0是2013年7月1日百度绿萝算法1.0的升级版,主要目的是在网络上进行非正式的宣传软文广告,如何处理多余的垃圾邮件信息引起的。
冰桶算法
百度移动搜索会对低质量的网站和页面进行一系列调整,称为冰桶算法。冰桶算法的目的是打击强制弹出应用下载、大面积广告等影响用户正常浏览体验的页面。
冰桶算法2.0
于2014年11月18日推出,旨在打击全屏下载、手机小页面大面积广告遮蔽主要内容、强制用户登录等行为。
算法 自动采集列表(优采云控制台一采集入门教程(简化版)(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-09-02 05:20
优采云Navigation: 优采云采集器 优采云控制面板
一个采集Getting Started Tutorial(简化版)一个小概念:
大多数网站 以列表页和详细信息页的层次结构组织。比如我们进入一个新闻频道,有很多标题链接,可以看成是一个列表页。点击标题链接进入详情页。
使用data采集工具的一般目的是获取详情页中的大量特定内容数据,并将这些数据用于各种分析、发布和导出等。
列表页:指栏目或目录页,一般收录多个标题链接。例如:网站home 页或栏目页为列表页。主要功能:可以通过列表页获取多个详情页的链接。
详情页:收录特定内容的页面,如网页文章,其中收录:标题、作者、发布日期、正文内容、标签等。
要开始,请登录“优采云控制面板”;
详细使用步骤:
第一步:创建采集task
点击左侧菜单按钮“创建采集task”,输入采集task名称和采集的“列表页”网址,如:(这里首页为列表页:内容收录多个详情页是),详情页链接可以留空,系统会自动识别。
如下图:
进入后点击“下一步”
第2步:改进列表页的智能提取结果(可选)
系统会先通过智能算法获取需要采集的详情页链接(多个)。用户可以双击打开支票。如果数据不是您想要的,您可以单击“列表提取器”手动指定它。在可视化界面上用鼠标点击。
智能获取的结果如下图所示:
另外:在上面的结果中,系统还智能发现了翻页规则,用户可以设置采集需要多少页。您也可以稍后在任务“基本信息和Portal URL”--“根据规则生成URL”项中进行配置。
打开列表提取器,如下所示:
第三步:完善详情页的智能提取结果(可选)
上一步获取多个详情页链接后,继续下一步。系统将使用其中一个详情页链接智能提取详情页数据(如标题、作者、发布日期、内容、标签等)
详情页智能提取结果如下:
如果smart提取的内容不是你想要的,可以打开“Detail Extractor”进行修改。
如下图:
您可以修改、添加或删除左侧的字段。
第 4 步:启动和运行
完成后,即可启动运行,进行数据采集了:
采集之后的数据结果,在采集任务的“Result Data & Release”中,可以在这里导出和发布数据。
完成,数据采集就是这么简单! ! !
其他操作,如发布和导出数据、数据SEO处理等,请参考其他章节。
优采云Navigation: 优采云采集器 优采云控制面板 查看全部
算法 自动采集列表(优采云控制台一采集入门教程(简化版)(图))
优采云Navigation: 优采云采集器 优采云控制面板
一个采集Getting Started Tutorial(简化版)一个小概念:
大多数网站 以列表页和详细信息页的层次结构组织。比如我们进入一个新闻频道,有很多标题链接,可以看成是一个列表页。点击标题链接进入详情页。
使用data采集工具的一般目的是获取详情页中的大量特定内容数据,并将这些数据用于各种分析、发布和导出等。
列表页:指栏目或目录页,一般收录多个标题链接。例如:网站home 页或栏目页为列表页。主要功能:可以通过列表页获取多个详情页的链接。
详情页:收录特定内容的页面,如网页文章,其中收录:标题、作者、发布日期、正文内容、标签等。
要开始,请登录“优采云控制面板”;
详细使用步骤:
第一步:创建采集task
点击左侧菜单按钮“创建采集task”,输入采集task名称和采集的“列表页”网址,如:(这里首页为列表页:内容收录多个详情页是),详情页链接可以留空,系统会自动识别。
如下图:
进入后点击“下一步”
第2步:改进列表页的智能提取结果(可选)
系统会先通过智能算法获取需要采集的详情页链接(多个)。用户可以双击打开支票。如果数据不是您想要的,您可以单击“列表提取器”手动指定它。在可视化界面上用鼠标点击。
智能获取的结果如下图所示:
另外:在上面的结果中,系统还智能发现了翻页规则,用户可以设置采集需要多少页。您也可以稍后在任务“基本信息和Portal URL”--“根据规则生成URL”项中进行配置。
打开列表提取器,如下所示:
第三步:完善详情页的智能提取结果(可选)
上一步获取多个详情页链接后,继续下一步。系统将使用其中一个详情页链接智能提取详情页数据(如标题、作者、发布日期、内容、标签等)
详情页智能提取结果如下:
如果smart提取的内容不是你想要的,可以打开“Detail Extractor”进行修改。
如下图:
您可以修改、添加或删除左侧的字段。
第 4 步:启动和运行
完成后,即可启动运行,进行数据采集了:
采集之后的数据结果,在采集任务的“Result Data & Release”中,可以在这里导出和发布数据。
完成,数据采集就是这么简单! ! !
其他操作,如发布和导出数据、数据SEO处理等,请参考其他章节。
优采云Navigation: 优采云采集器 优采云控制面板
算法 自动采集列表(苹果手机app下载查看方式:推荐阿里的pp助手!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2021-09-01 08:00
算法自动采集列表页、详情页、搜索页、会员页、书籍页、pc端各类页面,并实现及时采集,体验非常方便。苹果手机app下载查看方式:1.苹果设置——>itunesstore与appstore——>实时推送2.或者下载最新版的网址速登软件,
目前在用,推荐给题主,自动采集我的首页,和各个精选推荐、应用列表。网址速登软件,苹果手机安卓软件都适用。
要找技术漏洞是没有的,但是有一些很难被发现的设置,例如一个应用分类下面的所有应用不能发布到不同的类别页面上面,如果需要应用分类分享页面,所有应用分类可以。这些难以发现的应用分类页面在app开发者不同的应用中可能会有重复的页面,或者发布应用的时候,分享按钮放到一个选择面板上面。用户在选择应用的时候就会误认为是给所有应用分享,所以这个选择按钮被误操作删除。
推荐阿里的pp助手,专门给开发者提供api接口,
千聊的学院
雅虎助手!!!这个比appzapp便宜
昨天正好看到一个。
sdk类:“报蛋网”,不用写代码、官网也只是一个个收费页面的抓取,开发者只需要填数据,就可以以第三方的身份调取后台的数据。api类:ca(全球领先的应用开发者协会)的lumia,这个是封闭的, 查看全部
算法 自动采集列表(苹果手机app下载查看方式:推荐阿里的pp助手!)
算法自动采集列表页、详情页、搜索页、会员页、书籍页、pc端各类页面,并实现及时采集,体验非常方便。苹果手机app下载查看方式:1.苹果设置——>itunesstore与appstore——>实时推送2.或者下载最新版的网址速登软件,
目前在用,推荐给题主,自动采集我的首页,和各个精选推荐、应用列表。网址速登软件,苹果手机安卓软件都适用。
要找技术漏洞是没有的,但是有一些很难被发现的设置,例如一个应用分类下面的所有应用不能发布到不同的类别页面上面,如果需要应用分类分享页面,所有应用分类可以。这些难以发现的应用分类页面在app开发者不同的应用中可能会有重复的页面,或者发布应用的时候,分享按钮放到一个选择面板上面。用户在选择应用的时候就会误认为是给所有应用分享,所以这个选择按钮被误操作删除。
推荐阿里的pp助手,专门给开发者提供api接口,
千聊的学院
雅虎助手!!!这个比appzapp便宜
昨天正好看到一个。
sdk类:“报蛋网”,不用写代码、官网也只是一个个收费页面的抓取,开发者只需要填数据,就可以以第三方的身份调取后台的数据。api类:ca(全球领先的应用开发者协会)的lumia,这个是封闭的,
算法 自动采集列表(优采云采集器支持Webhook功能采集到的数据发布到HTTP地址 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-08-31 07:07
)
优采云采集器 支持 Webhook 功能。通过该函数,优采云采集器可以将采集收到的数据发布到一个HTTP地址。
Webhook的设置在启动任务的设置中,如下图:
开启Webhook功能后,采集收到的数据会以JSON格式发送。任务采集结束时,会发送采集结束的事件通知。
HTTP 标头是“Content-Type: application/json; charset=utf-8”。
发送数据示例:
{
"task_id": 3920415, // 采集任务ID,可在“全部任务列表”中查看
"task_name": "采集任务名称", // 采集任务名称
"type": "data", //此次webhook发送的是采集到的数据
"urls": [ //采集任务的入口地址
"http://www.88888.com/list",
"http://www.88888.com/list2"
],
"sign": "**********************", // 签名算法为 md5(webhook_token+timestamp)
"timestamp": 1555326657, // 当前时间戳
"data_list": [ // 采集数据列表
{
"_id": "0000000000001", // 数据ID
"data": {
"title": "风景",
"url": "http://www.*****.com/scenery/"
} // 采集字段内容
},
{
"_id": "0000000000002", // 数据ID
"data": {
"title": "风景2",
"url": "http://www.*****.com/scenery2/"
} // 采集字段内容
}
]
}
发送采集end 通知示例:
{
"task_id": 3920415, // 采集任务ID,可在“全部任务列表”中查看
"task_name": "采集任务名称", // 采集任务名称
"type": "finish", //此次webhook发送的是采集结束的通知
"urls": [ //采集任务的入口地址
"http://www.88888.com/list",
"http://www.88888.com/list2"
],
"sign": "**********************", // 签名算法为 md5(webhook_token+timestamp)
"timestamp": 1555326657 // 当前时间戳
} 查看全部
算法 自动采集列表(优采云采集器支持Webhook功能采集到的数据发布到HTTP地址
)
优采云采集器 支持 Webhook 功能。通过该函数,优采云采集器可以将采集收到的数据发布到一个HTTP地址。
Webhook的设置在启动任务的设置中,如下图:
开启Webhook功能后,采集收到的数据会以JSON格式发送。任务采集结束时,会发送采集结束的事件通知。
HTTP 标头是“Content-Type: application/json; charset=utf-8”。
发送数据示例:
{
"task_id": 3920415, // 采集任务ID,可在“全部任务列表”中查看
"task_name": "采集任务名称", // 采集任务名称
"type": "data", //此次webhook发送的是采集到的数据
"urls": [ //采集任务的入口地址
"http://www.88888.com/list",
"http://www.88888.com/list2"
],
"sign": "**********************", // 签名算法为 md5(webhook_token+timestamp)
"timestamp": 1555326657, // 当前时间戳
"data_list": [ // 采集数据列表
{
"_id": "0000000000001", // 数据ID
"data": {
"title": "风景",
"url": "http://www.*****.com/scenery/"
} // 采集字段内容
},
{
"_id": "0000000000002", // 数据ID
"data": {
"title": "风景2",
"url": "http://www.*****.com/scenery2/"
} // 采集字段内容
}
]
}
发送采集end 通知示例:
{
"task_id": 3920415, // 采集任务ID,可在“全部任务列表”中查看
"task_name": "采集任务名称", // 采集任务名称
"type": "finish", //此次webhook发送的是采集结束的通知
"urls": [ //采集任务的入口地址
"http://www.88888.com/list",
"http://www.88888.com/list2"
],
"sign": "**********************", // 签名算法为 md5(webhook_token+timestamp)
"timestamp": 1555326657 // 当前时间戳
}
算法 自动采集列表(内涵吧内涵段子采集入口类Neihan8Crawl实现实现)
采集交流 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2021-08-30 20:12
本博客是博客的延伸。建议阅读本篇博文前先阅读之前的博文。
上一篇博文介绍了笑话集网站的自动采集,本文将其展开,介绍多内涵栏的自动采集。
上一篇博客已经详细介绍了几个基础类,现在只拿构造子类来实现内涵段的内涵采集。
Neihan Bar Neihan8Crawl 采集Entry Class Neihan8Crawl这里没有实现爬取程序采集的周期性,这里可以根据自己的需要编写相应的线程。
<p> /**
*@Description:
*/
package cn.lulei.crawl.neihan8;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashSet;
import cn.lulei.db.neihan8.Neihan8DbOperation;
import cn.lulei.model.Neihan8;
import cn.lulei.util.ParseUtil;
import cn.lulei.util.ThreadUtil;
public class Neihan8Crawl {
//内涵吧更新列表页url格式
private static String listPageUrl = "http://www.neihan8.com/article ... 3B%3B
//两次访问页面事件间隔,单位ms
private static int sleepTime = 500;
/**
* @param start 起始页
* @param end 终止页
* @throws IOException
* @Date: 2014-2-13
* @Author: lulei
* @Description: 抓取更新列表页上的内容
*/
public void crawlMain(int start, int end) throws IOException{
start = start < 1 ? 1 : start;
Neihan8DbOperation neihan8DbOperation = new Neihan8DbOperation();
for ( ; start 查看全部
算法 自动采集列表(内涵吧内涵段子采集入口类Neihan8Crawl实现实现)
本博客是博客的延伸。建议阅读本篇博文前先阅读之前的博文。
上一篇博文介绍了笑话集网站的自动采集,本文将其展开,介绍多内涵栏的自动采集。
上一篇博客已经详细介绍了几个基础类,现在只拿构造子类来实现内涵段的内涵采集。
Neihan Bar Neihan8Crawl 采集Entry Class Neihan8Crawl这里没有实现爬取程序采集的周期性,这里可以根据自己的需要编写相应的线程。
<p> /**
*@Description:
*/
package cn.lulei.crawl.neihan8;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashSet;
import cn.lulei.db.neihan8.Neihan8DbOperation;
import cn.lulei.model.Neihan8;
import cn.lulei.util.ParseUtil;
import cn.lulei.util.ThreadUtil;
public class Neihan8Crawl {
//内涵吧更新列表页url格式
private static String listPageUrl = "http://www.neihan8.com/article ... 3B%3B
//两次访问页面事件间隔,单位ms
private static int sleepTime = 500;
/**
* @param start 起始页
* @param end 终止页
* @throws IOException
* @Date: 2014-2-13
* @Author: lulei
* @Description: 抓取更新列表页上的内容
*/
public void crawlMain(int start, int end) throws IOException{
start = start < 1 ? 1 : start;
Neihan8DbOperation neihan8DbOperation = new Neihan8DbOperation();
for ( ; start
算法 自动采集列表(如果你买了最新的内容,比如每天必看的,其实是这样)
采集交流 • 优采云 发表了文章 • 0 个评论 • 130 次浏览 • 2021-08-30 19:02
算法自动采集列表页内容,用户自动点击推荐位,还可以帮助平台营销,
其实是这样,如果你买了最新的内容,比如每天必看的,而这些内容你可能会看一段时间,或者花费不到一分钟。那么他们就会把必看的部分合成一条,提供给你。同时他们还会标注必看的推荐内容的链接,提供给你推荐。对,就是这么完美。就像你生活中收到的货物,他是包装完美的纸箱,必不可少的空转储存条件。购买的其他产品是比较次的纸箱,你买不买呢?。
知乎有人表示了加入首页的信息流,你说的这个是首页vest的信息流,知乎你首页vest的部分都没有做呢,没有vest的页面啊就像,你用了特斯拉,
很简单的脑洞假设,你知道从1分钟的聊天记录里去再把对方叫回来,可能得耗费半小时到一小时,再拖回来这个时间跨度也不够短.
知乎的推荐算法在刚出来的时候就有,不要像百度头条一样挂羊头卖狗肉,不要让那些刷新率90hz的硬件,去匹配算法内容,像我们推荐的内容没有一个是30帧,没有一个像老罗发布会大部分内容是从网易看到的。推荐算法其实没有那么复杂,只要评估用户行为,根据评估用户的行为再匹配合适的item。每天100个优质的用户我打包1000条知乎的内容,你能发现自己喜欢看的话,你是否会主动去看知乎的评测?只要经过一个月的时间,网易客户端每天会推荐30篇左右。
百度客户端会推荐1000篇左右,也有可能会给你推荐别的。总之,看你平时的浏览习惯了,如果你喜欢的内容网站没有,你就不需要关注了。 查看全部
算法 自动采集列表(如果你买了最新的内容,比如每天必看的,其实是这样)
算法自动采集列表页内容,用户自动点击推荐位,还可以帮助平台营销,
其实是这样,如果你买了最新的内容,比如每天必看的,而这些内容你可能会看一段时间,或者花费不到一分钟。那么他们就会把必看的部分合成一条,提供给你。同时他们还会标注必看的推荐内容的链接,提供给你推荐。对,就是这么完美。就像你生活中收到的货物,他是包装完美的纸箱,必不可少的空转储存条件。购买的其他产品是比较次的纸箱,你买不买呢?。
知乎有人表示了加入首页的信息流,你说的这个是首页vest的信息流,知乎你首页vest的部分都没有做呢,没有vest的页面啊就像,你用了特斯拉,
很简单的脑洞假设,你知道从1分钟的聊天记录里去再把对方叫回来,可能得耗费半小时到一小时,再拖回来这个时间跨度也不够短.
知乎的推荐算法在刚出来的时候就有,不要像百度头条一样挂羊头卖狗肉,不要让那些刷新率90hz的硬件,去匹配算法内容,像我们推荐的内容没有一个是30帧,没有一个像老罗发布会大部分内容是从网易看到的。推荐算法其实没有那么复杂,只要评估用户行为,根据评估用户的行为再匹配合适的item。每天100个优质的用户我打包1000条知乎的内容,你能发现自己喜欢看的话,你是否会主动去看知乎的评测?只要经过一个月的时间,网易客户端每天会推荐30篇左右。
百度客户端会推荐1000篇左右,也有可能会给你推荐别的。总之,看你平时的浏览习惯了,如果你喜欢的内容网站没有,你就不需要关注了。
算法 自动采集列表(基于消息列表的采集做以文章介绍技术和源码 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-08-30 10:08
)
前言
前两篇文章介绍了系统流程和功能模块的封装。本文文章将在消息列表中解释采集。这篇文章文章 侧重于想法而不是技术和源代码。逻辑代码一样,可靠的算法是百万分之一。
准备1、采集源
研究发现公众号文章可以通过多种渠道访问:
2、页面跳转
上一节介绍了数据的来源和请求的方法,但是不能每次都手动去点,这样就失去了自动化的意义,最终目的是自动跳转。一般有两种思路:
js注入方式占用资源少,模拟点击限制较多。比如被点击的页面必须在最顶层等,最后选择js注入方式。代理工具也有很多选择,因为没有太复杂的需求,这次我选择的是轻量级的Fiddler,没有用过的读者可以自行百度,傻瓜式安装后安装证书,拦截请求的历史消息页面,在返回页面返回浏览器之前在返回的内容中添加一段简单的js代码,控制页面10s后会跳转到自己服务器的页面。这一步也可以直接在自己的服务器上添加js代码来请求任务,直接跳转到下一个公众号历史消息页面,但是为了灵活控制频率和查看实时进度,一个中间页面建立。历史消息页面完成后,直接跳转到中间页面。中间页面去后台获取新任务,一段时间后跳转到历史消息页面。
由于集群部署,页面放在nginx中,也解决了跨域问题。
3、任务队列
我之前一直在谈论获取任务和执行任务。读者可能不清楚任务是什么类型的数据结构。其实很简单,就是一个队列,里面存放的是公众号的一个参数biz。有了这个参数,就可以组装了。公众号历史新闻页面:.因为是分布式集群部署,所以选择redis队列,每次请求都会弹出一个biz。 redis的单线程特性可以避免重复任务。
4、任务监控
前一个工作完成后,任务可以自动连续执行,但任务不是连续执行24小时。当任务队列为空时,循环停止,但下次任务进入队列时,前端页面需要再次获取任务。解决这个问题最方便的方法显然是长连接。定时请求可能会更加消耗资源并且会稍微延迟。新版Nginx对websocket的支持也非常友好。
任务完成后,页面随机与后台的一个节点建立长连接。当任务再次进入队列时,必须通过RocketMq发送广播消息通知集群中的每个节点。节点收到广播消息后,通知所有与你建立长连接的页面获取任务,进入循环。
核心流程
明人不说密语,上图:
1:可以在多台主机上登录多个微信账号,同时访问中间页面;
1.1:去后台请求一个任务,有任务就循环执行,没有任务就建立长连接;
2:页面随机与后台节点建立长连接;
3:任务排队,rocketmq发送广播通知集群中的各个节点;
4:节点收到广播消息后,通过长连接向页面发送消息;
5:页面收到消息后,去后台请求任务,同1.1;
6:访问历史新闻页面,这里有洞,这里有洞,这里有洞,直接位置跳转会失败,或者参数不完整,链接要填写超链接页面上,并且超链接的目标不能是self,然后js模拟点击这个超链接跳转;
7:Fiddler 将带参数的链接传给后端;
7.1:页面返回浏览器前注入自动重定向js,页面会周期性跳转到中间页面;
7.2:后台获取参数后,根据公众号自定义配置,组装组件页面的查询链接,通过HttpClient请求解析返回的Json数据仓库;
8:页面跳回重新执行1.1,依次循环。
附加功能,帐户访问控制
由于腾讯对每个账号24小时内访问历史消息页面的分页查询接口有限制,为避免账号被封,记录了每个手机号的访问时间。存储结构也是一个redis队列,每添加一个手机号,指定前缀为key,每次访问一个页面时,将当前时间戳推送到当前手机号对应的队列中。
这样,页面上就会实时显示当前手机号和当前账户24H内的执行次数。
访问频率控制
为了防止账号被暂停,应该增加sleep control访问的频率,但是当任务多,账号足够的时候,可能需要增加访问频率。
核心流程的第五步是在获取任务前去后台随机休眠一段时间。最小和最大休眠时间在nacos的配置中心设置。获取到时间后,页面会在指定时间后进行下一步处理。这样就可以通过nacos的热配置功能在不重启项目的情况下改变访问频率。
总结
到此为止,我已经获得了文章的基本信息。此时,没有文字和互动量。该项目的第一个核心点已经完成。相对于交互量,逻辑并不是很复杂。稍后我将解释交互。获取音量和文字的过程还有一些巨大的坑,原创不易,希望老铁们手里的小点赞不要犹豫去逛逛,觉得有帮助的朋友可以给个采集.
本系列文章纯属技术分享,不作为任何商业用途,如若转载,请注明出处。 查看全部
算法 自动采集列表(基于消息列表的采集做以文章介绍技术和源码
)
前言
前两篇文章介绍了系统流程和功能模块的封装。本文文章将在消息列表中解释采集。这篇文章文章 侧重于想法而不是技术和源代码。逻辑代码一样,可靠的算法是百万分之一。
准备1、采集源
研究发现公众号文章可以通过多种渠道访问:
2、页面跳转
上一节介绍了数据的来源和请求的方法,但是不能每次都手动去点,这样就失去了自动化的意义,最终目的是自动跳转。一般有两种思路:
js注入方式占用资源少,模拟点击限制较多。比如被点击的页面必须在最顶层等,最后选择js注入方式。代理工具也有很多选择,因为没有太复杂的需求,这次我选择的是轻量级的Fiddler,没有用过的读者可以自行百度,傻瓜式安装后安装证书,拦截请求的历史消息页面,在返回页面返回浏览器之前在返回的内容中添加一段简单的js代码,控制页面10s后会跳转到自己服务器的页面。这一步也可以直接在自己的服务器上添加js代码来请求任务,直接跳转到下一个公众号历史消息页面,但是为了灵活控制频率和查看实时进度,一个中间页面建立。历史消息页面完成后,直接跳转到中间页面。中间页面去后台获取新任务,一段时间后跳转到历史消息页面。
由于集群部署,页面放在nginx中,也解决了跨域问题。
3、任务队列
我之前一直在谈论获取任务和执行任务。读者可能不清楚任务是什么类型的数据结构。其实很简单,就是一个队列,里面存放的是公众号的一个参数biz。有了这个参数,就可以组装了。公众号历史新闻页面:.因为是分布式集群部署,所以选择redis队列,每次请求都会弹出一个biz。 redis的单线程特性可以避免重复任务。
4、任务监控
前一个工作完成后,任务可以自动连续执行,但任务不是连续执行24小时。当任务队列为空时,循环停止,但下次任务进入队列时,前端页面需要再次获取任务。解决这个问题最方便的方法显然是长连接。定时请求可能会更加消耗资源并且会稍微延迟。新版Nginx对websocket的支持也非常友好。
任务完成后,页面随机与后台的一个节点建立长连接。当任务再次进入队列时,必须通过RocketMq发送广播消息通知集群中的每个节点。节点收到广播消息后,通知所有与你建立长连接的页面获取任务,进入循环。
核心流程
明人不说密语,上图:
1:可以在多台主机上登录多个微信账号,同时访问中间页面;
1.1:去后台请求一个任务,有任务就循环执行,没有任务就建立长连接;
2:页面随机与后台节点建立长连接;
3:任务排队,rocketmq发送广播通知集群中的各个节点;
4:节点收到广播消息后,通过长连接向页面发送消息;
5:页面收到消息后,去后台请求任务,同1.1;
6:访问历史新闻页面,这里有洞,这里有洞,这里有洞,直接位置跳转会失败,或者参数不完整,链接要填写超链接页面上,并且超链接的目标不能是self,然后js模拟点击这个超链接跳转;
7:Fiddler 将带参数的链接传给后端;
7.1:页面返回浏览器前注入自动重定向js,页面会周期性跳转到中间页面;
7.2:后台获取参数后,根据公众号自定义配置,组装组件页面的查询链接,通过HttpClient请求解析返回的Json数据仓库;
8:页面跳回重新执行1.1,依次循环。
附加功能,帐户访问控制
由于腾讯对每个账号24小时内访问历史消息页面的分页查询接口有限制,为避免账号被封,记录了每个手机号的访问时间。存储结构也是一个redis队列,每添加一个手机号,指定前缀为key,每次访问一个页面时,将当前时间戳推送到当前手机号对应的队列中。
这样,页面上就会实时显示当前手机号和当前账户24H内的执行次数。
访问频率控制
为了防止账号被暂停,应该增加sleep control访问的频率,但是当任务多,账号足够的时候,可能需要增加访问频率。
核心流程的第五步是在获取任务前去后台随机休眠一段时间。最小和最大休眠时间在nacos的配置中心设置。获取到时间后,页面会在指定时间后进行下一步处理。这样就可以通过nacos的热配置功能在不重启项目的情况下改变访问频率。
总结
到此为止,我已经获得了文章的基本信息。此时,没有文字和互动量。该项目的第一个核心点已经完成。相对于交互量,逻辑并不是很复杂。稍后我将解释交互。获取音量和文字的过程还有一些巨大的坑,原创不易,希望老铁们手里的小点赞不要犹豫去逛逛,觉得有帮助的朋友可以给个采集.
本系列文章纯属技术分享,不作为任何商业用途,如若转载,请注明出处。
算法 自动采集列表(化是RecEng实现客户自定义功能的基础--日志埋点规范)
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2021-08-30 07:10
如前所述,整个流程的标准化是RecEng实现客户自定义功能的基础。
原木埋点规范
环境准备好后,最重要的连接工作就是访问客户日志,即使客户日志符合RecEng的日志嵌入规范。日志嵌入规范定义了客户终端产品所需的采集内容以及日志实时上报的格式要求。 RecEng 支持两种日志上报通道,实时上报和离线上报。实时报表通过Restful API提交,离线报表按照数据格式规范提交给MaxCompute(原ODPS)。日志嵌入规范包括通过Restful接口提交的日志格式,但不包括MaxCompute离线日志表的格式。
一般来说,为了符合RecEng的日志嵌入规范,需要对客户的终端产品进行升级。但是,如果客户有推荐的服务,则可能暂时不进行终端升级。详情请参考以下说明。
日志嵌入规范包括对内容和格式的要求。 RecEng 将用户行为分为三类。第一类是交易行为,即可以给网站或APP带来利益的用户行为,即RecEng的客户。对于电子商务,交易行为是购买商品;对于音乐或视频网站,交易行为为音乐或视频的播放或下载。
第二种行为称为准备行为。虽然不能直接给网站带来利益,但这些行为是实现交易的必要前提,比如用户的浏览、点击、搜索、采集等。客户需要区分这些行为,因为不同的行为对交易的影响不同。细粒度的区分有助于更好地分析用户兴趣并获得更好的推荐。
第三类是与交易无关的行为。例如,用户点击网站上的其他网站广告就跑掉了。 RecEng 不关注这种行为。
在内容上,日志嵌入规范要求客户记录交易行为和准备行为,并在记录用户行为日志时区分这两种行为。与通常的日志一样,日志嵌入规范也要求记录行为的一些上下文参数,例如时间、用户、项目等信息。另外,为了方便计算推荐服务带来的转化率,日志嵌入规范要求客户记录traceid。 Traceid 将用户在推荐坑上的点击与最终的交易关联起来,用于判断该交易是否由推荐服务带来。 traceid是RecEng在实时返回推荐结果时返回的。详情请参考日志嵌入规范。
如果客户没有按照日志嵌入规范记录traceid,唯一的影响是无法使用RecEng提供的效果报告功能,不影响推荐业务的正常使用。
如上所说,如果客户不关心效果报告,并且推荐的服务之前运行,并且日志内容符合日志嵌入规范的要求,则可以在现有推荐上遵循日志嵌入规范server 进行格式转换,暂不升级终端产品,快速体验RecEng。
数据格式规范
数据格式规范定义了离线和在线计算中使用的数据格式。离线数据的格式比较复杂,在线数据的格式比较简单。
离线数据规范
在RecEng中,离线过程(rec_path->offline_flow)和效果过程(index_path)是离线计算的。离线数据规范定义了这两种进程的数据规范。一般离线计算的输入输出都是MaxCompute(原ODPS)表,所以离线数据规范其实就是一套MaxCompute表格式规范,包括访问数据、中间数据、输出数据三种数据格式规范。
访问数据是指客户线下提供的用户、物品、日志等数据。 RecEng 最关注日志数据,其次是项目数据,最后是用户数据。离线和在线日志数据基本相同。日志嵌入点规范中有说明,请参考规范的详细定义。项目数据由类别、属性和关键字组成。类别和关键字含义明确,易于理解;属性是多值字段,并以键值格式组织。如果有多个属性,它们都在属性字段中。只需以标准格式列出即可。 RecEng 要求这三个字段不能都为空。
用户数据类似。有一个多值字段叫做tags,也是按key-value格式组织的。与商品数据的属性字段不同,标签字段可以为空。
为了让RecEng了解item的属性字段和用户的tags字段中每个key-value的数据类型,客户还需要添加两个数据结构描述表来解释每个key-value的数据在项目的属性字段中。类型,以及用户标签字段中每个键值的数据类型。在客户提供的商品数据和用户数据的内容没有变化的情况下,这两个表可以一直使用。
如果客户想要定制离线算法,他们需要了解中间和输出数据格式规范。 RecEng定义了十多个离线MaxCompute(原ODPS)表的格式,涵盖了离线过程和效果过程中使用的所有访问表、中间表和输出表。这些表统称为标准表。所有离线计算算法必须使用标准表作为输入和输出表;对于效果过程中的算法,需要将计算结果输出到RDS进行实时显示。
在线数据规范
RecEng的在线计算包括两部分:在线过程(rec_path->online_flow)和实时修正过程(mod_path)。
与离线算法自然使用MaxCompute(原ODPS)表作为输入输出不同,在线程序的输入数据可以来自多个数据源,例如在线表存储(原OTS)、用户API请求等。或者程序中的一个变量;输出可以是程序变量,也可以写回在线存储,也可以返回给用户。
出于安全考虑,RecEng 提供了一套 SDK 供客户自定义在线代码读写在线存储(表格存储)。不允许直接访问,因此需要定义每种类型的在线存储的别名和格式。
对于需要频繁使用的在线数据,无论是来自在线存储还是用户的API请求,RecEng都会提前读取并保存到在线程序的变量中。客户自定义代码可以直接读写这些变量中的数据。
综上所述,在线数据规范定义了在线程序使用的数据集的规范。这里的数据集是一个抽象的概念,可以是在线存储中表格的格式规范,也可以是在线程序中全局或局部变量的结构定义,称为标准数据集。该规范将定义每个标准数据集的可读性和可写性。当客户自定义程序违反可读可写性要求时,将无法通过代码审查,无法上线。
算法规范
在 RecEng 中,算法是连接数据的逻辑。这里的数据是指离线标准表或在线标准数据集。除了输入和输出数据,算法通常还包括一系列参数。 RecEng的算法模型如下图所示:
更准确的说,输入数据是指算法需要处理的信息,输出数据是算法处理的结果,参数由算法提供,以便在不同的输入上取得更好的结果数据。一组可由算法用户调整的开关。从面向对象的角度来看,如果我们把一个算法看成一个对象,那么算法参数就是算法本身的属性,输入输出数据定义了算法的接口。
为了简化算法流程的定义,RecEng对每个算法只需要一个输出数据,并且不限制输入数据的数量。
所谓符合RecEng规范的算法,就是将这些标准表或标准数据集作为输入输出数据的算法。输入数据和输出数据完全相同的算法是相似的算法。 RecEng 定义了一组常用的算法类别,可以满足大部分需求。未来,客户可以自定义算法类别。 RecEng的算法规范参考了上述算法模型和本套算法类别。
RecEng 只要求相似的算法具有相同的输入和输出数据,即相同的接口;相似的算法不需要相同的参数,这是算法的内部属性,RecEng算法规范没有要求。
客户在自定义算法时可以在 RecEng 中注册算法参数。 RecEng在使用自定义算法时会自动显示这些自定义参数,方便客户调整。
RecEng 没有算法版本的概念。如果要升级现有算法,RecEng的方法是将新版本的算法注册为新算法,注册后即可使用。旧版算法无人使用后可以下线。目前无法在删除算法时提示是否正在使用该算法。正式上线的版本将完善这些功能。
算法过程
在概念讲解部分,大致介绍了算法流程的概念,包括推荐流程(rec_path)和实时修正流程(mod_path)两个流程。本节进一步介绍这些过程的技术细节。算法过程中使用的数据和算法符合数据格式规范和算法规范。
RecEng 中的算法过程
RecEng 中的算法流程是一个有向无环图。图中的节点是算法,算法A到算法B的边表示算法A的输出是算法B的输入。 由于算法规范要求每个算法只有一个输出数据,数据节点可能没有在算法流程图中标注。
RecEng 提供了一个可视化界面来编辑这个有向无环图。此过程是自定义算法流程。 RecEng还预先实现了一套相对标准的推荐算法供客户使用。如果客户觉得系统提供的这些算法不能满足自己的需求,可以按照算法规范自行开发,并在RecEng注册使用。
RecEng中的算法流程包括离线流程(rec_path->offline_flow)、在线流程(rec_path->online_flow)、数据修改流程(data_mod_path)和用户修改流程(user_mod_path),均支持客户定制,即即支持通过可视化界面编辑算法流程的有向无环图。
RecEng 还包括一个效果过程(index_path),与上述算法过程不同。客户只需在定义效果流程时选择效果指标即可。 RecEng会根据客户选择的指标自动生成算法流程。需要通过可视化界面编辑。
在RecEng中,推荐过程(rec_path)属于场景(scn)。客户可以在该场景下创建新的推荐流程。每个推荐流程由一个离线流程(offline_flow)和一个在线流程(online_flow)组成,它们相对独立。部分。所以每个rec_path由两个有向无环图组成。
实时修正过程(mod_path)属于业务。这两种mod_path各有最多一个实例,因此每个业务下的实时校正过程最多有两个有向无环图。
考虑到实际实现中的一些因果关系,下面的介绍按照离线处理(rec_path->offline_flow)、实时修正处理(mod_path)、在线处理(rec_path->online_flow)的顺序,即推荐过程(在rec_path中间插入一个实时修正过程(mod_path))
离线流程(rec_path -> offline_flow)
离线流程总体示意图:
上图及本节各流程图元素说明:
离线流程从用户输入的user、item、log数据开始,经过简单的处理,生成user/item的原创特征。接下来是推荐核心算法,计算用户和物品的关系,生成用户/物品耦合特征。所谓耦合特征,是指收录用户对物品兴趣的特征,即利用耦合特征可以计算出用户对每个物品的兴趣偏好。下一步是计算用户的候选推荐集和相似项集。
对于一般客户来说,可以推荐的商品并不多。基本上到这里就够了,就是左边蓝色虚线框内的基本推荐流程。基本推荐流程分析用户行为,向用户展示他们最感兴趣的项目,即兴趣是其优化的目标。
如果客户可以推荐很多物品,或者客户的优化目标不是用户对物品的兴趣,而是其他指标,比如转化率、交易金额等,可以在右侧红色虚线框在此过程中,为优化目标建立了每个用户的模型,并在此基础上生成推荐候选集。
排序建模过程所需的样本是根据优化目标从用户日志中提取的。目前 RecEng 在排序模型方面只提供了基于 Logistic 回归的 Learning to Rank 模型。以后会增加更多的排序模型,比如聚划算中的一次。在导购等领域大放异彩的biLinear模型
最后将offline_flow的所有计算结果导入在线存储,保存在离线计算结果表中。
实时修正过程(mod_path)
mod_path 整体流程示意图:
mod_path 由两个并行进程组成,数据修改进程(data_mod_path)和用户修改进程(user_mod_path)。
客户将需要更新实时输入,例如新上线的商品,或线下商品通过数据校正API提交到数据校正线程,数据校正流程将此信息保存在在线存储中以供在线流程使用(rec_path-> online_flow) 使用。
客户还可以利用实时日志,在用户信息修正线程中实时分析用户感兴趣和不感兴趣的项目,以优化推荐效果。目前由于在线程序都是Node.js编写的,在线学习能力比较弱。未来将引入专用的实时计算平台,实现真正意义上的在线培训。
实时修正过程是可选的,最终输出用于响应用户推荐请求的在线过程(rec_path->online_flow)。
每个实时进程,包括下面的实时纠错进程(mod_path)和在线进程(online_flow),都工作在一个单独的线程中,但有些线程是后台定时线程(比如用户纠错进程,连续polling Real-time log),有些线程是事件触发的线程(比如数据纠错过程,只有在有API请求的时候才会工作,处理完成就结束)。 RecEng 将每个实时处理线程分为三个阶段,如下图所示:
参数解析阶段负责读取和解析处理所需的参数,包括API传递的参数、实时日志、系统配置等;执行处理阶段是实时处理流程的核心,负责实现实时流程的业务;输出级输出实时过程处理的结果,可在线存储或返回给用户。几个阶段之间的参数传递由在线数据规范定义,图中用CTX(上下文环境变量)表示,下一节CTX的含义相同。
为了简化客户自定义开发,专注于业务,在以上三个阶段,RecEng只允许客户自定义程序的第二阶段,RecEng负责参数和输出工作,这也提高了系统安全。
在线流程(rec_path -> online_flow)
online_flow 负责响应终端产品(用户)推荐的 API 请求。图中的“Table Store(原OTS)离线计算结果表”是offline_flow的最终输出,属于不同rec_path的offline_flow产生的表存储的离线计算。结果表不一样,online_flow和offline_flow就是这样形成rec_path的。
在推荐处理线程的参数解析阶段,除了读取参数,RecEng还做了几件事情:
检查请求是否来自测试用户并记录在CTX(上下文环境变量)中。测试用户是指访问测试路径的用户。详情请参考“测试”部分“测试路径”的说明。
对于有A/B Testing需求的场景,rec_path根据客户的A/B Testing流量配置分配并记录在CTX中
从离线计算结果表中读取当前用户的相关数据,包括用户特征,推荐候选集;如果 API 请求参数中收录 item id,则所有与 item 相似的 item 也会被读取
在执行处理阶段,自定义算法从CTX获取RecEng的预读数据,判断当前对应的rec_path,选择对应的算法进行处理,通常对离线计算结果进行过滤排序;如果客户定制在这个过程中,可以通过实时修正来计算并将最终结果写回CTX。返回阶段的代码将客户自定义算法的处理结果返回给请求用户,完成推荐。
效果过程(index_path)
在RecEng中,效果过程不需要客户配置,只需选择效果索引即可。绩效指标和绩效报告的自定义开发和配置,详见绩效报告。 查看全部
算法 自动采集列表(化是RecEng实现客户自定义功能的基础--日志埋点规范)
如前所述,整个流程的标准化是RecEng实现客户自定义功能的基础。
原木埋点规范
环境准备好后,最重要的连接工作就是访问客户日志,即使客户日志符合RecEng的日志嵌入规范。日志嵌入规范定义了客户终端产品所需的采集内容以及日志实时上报的格式要求。 RecEng 支持两种日志上报通道,实时上报和离线上报。实时报表通过Restful API提交,离线报表按照数据格式规范提交给MaxCompute(原ODPS)。日志嵌入规范包括通过Restful接口提交的日志格式,但不包括MaxCompute离线日志表的格式。
一般来说,为了符合RecEng的日志嵌入规范,需要对客户的终端产品进行升级。但是,如果客户有推荐的服务,则可能暂时不进行终端升级。详情请参考以下说明。
日志嵌入规范包括对内容和格式的要求。 RecEng 将用户行为分为三类。第一类是交易行为,即可以给网站或APP带来利益的用户行为,即RecEng的客户。对于电子商务,交易行为是购买商品;对于音乐或视频网站,交易行为为音乐或视频的播放或下载。
第二种行为称为准备行为。虽然不能直接给网站带来利益,但这些行为是实现交易的必要前提,比如用户的浏览、点击、搜索、采集等。客户需要区分这些行为,因为不同的行为对交易的影响不同。细粒度的区分有助于更好地分析用户兴趣并获得更好的推荐。
第三类是与交易无关的行为。例如,用户点击网站上的其他网站广告就跑掉了。 RecEng 不关注这种行为。
在内容上,日志嵌入规范要求客户记录交易行为和准备行为,并在记录用户行为日志时区分这两种行为。与通常的日志一样,日志嵌入规范也要求记录行为的一些上下文参数,例如时间、用户、项目等信息。另外,为了方便计算推荐服务带来的转化率,日志嵌入规范要求客户记录traceid。 Traceid 将用户在推荐坑上的点击与最终的交易关联起来,用于判断该交易是否由推荐服务带来。 traceid是RecEng在实时返回推荐结果时返回的。详情请参考日志嵌入规范。
如果客户没有按照日志嵌入规范记录traceid,唯一的影响是无法使用RecEng提供的效果报告功能,不影响推荐业务的正常使用。
如上所说,如果客户不关心效果报告,并且推荐的服务之前运行,并且日志内容符合日志嵌入规范的要求,则可以在现有推荐上遵循日志嵌入规范server 进行格式转换,暂不升级终端产品,快速体验RecEng。
数据格式规范
数据格式规范定义了离线和在线计算中使用的数据格式。离线数据的格式比较复杂,在线数据的格式比较简单。
离线数据规范
在RecEng中,离线过程(rec_path->offline_flow)和效果过程(index_path)是离线计算的。离线数据规范定义了这两种进程的数据规范。一般离线计算的输入输出都是MaxCompute(原ODPS)表,所以离线数据规范其实就是一套MaxCompute表格式规范,包括访问数据、中间数据、输出数据三种数据格式规范。
访问数据是指客户线下提供的用户、物品、日志等数据。 RecEng 最关注日志数据,其次是项目数据,最后是用户数据。离线和在线日志数据基本相同。日志嵌入点规范中有说明,请参考规范的详细定义。项目数据由类别、属性和关键字组成。类别和关键字含义明确,易于理解;属性是多值字段,并以键值格式组织。如果有多个属性,它们都在属性字段中。只需以标准格式列出即可。 RecEng 要求这三个字段不能都为空。
用户数据类似。有一个多值字段叫做tags,也是按key-value格式组织的。与商品数据的属性字段不同,标签字段可以为空。
为了让RecEng了解item的属性字段和用户的tags字段中每个key-value的数据类型,客户还需要添加两个数据结构描述表来解释每个key-value的数据在项目的属性字段中。类型,以及用户标签字段中每个键值的数据类型。在客户提供的商品数据和用户数据的内容没有变化的情况下,这两个表可以一直使用。
如果客户想要定制离线算法,他们需要了解中间和输出数据格式规范。 RecEng定义了十多个离线MaxCompute(原ODPS)表的格式,涵盖了离线过程和效果过程中使用的所有访问表、中间表和输出表。这些表统称为标准表。所有离线计算算法必须使用标准表作为输入和输出表;对于效果过程中的算法,需要将计算结果输出到RDS进行实时显示。
在线数据规范
RecEng的在线计算包括两部分:在线过程(rec_path->online_flow)和实时修正过程(mod_path)。
与离线算法自然使用MaxCompute(原ODPS)表作为输入输出不同,在线程序的输入数据可以来自多个数据源,例如在线表存储(原OTS)、用户API请求等。或者程序中的一个变量;输出可以是程序变量,也可以写回在线存储,也可以返回给用户。
出于安全考虑,RecEng 提供了一套 SDK 供客户自定义在线代码读写在线存储(表格存储)。不允许直接访问,因此需要定义每种类型的在线存储的别名和格式。
对于需要频繁使用的在线数据,无论是来自在线存储还是用户的API请求,RecEng都会提前读取并保存到在线程序的变量中。客户自定义代码可以直接读写这些变量中的数据。
综上所述,在线数据规范定义了在线程序使用的数据集的规范。这里的数据集是一个抽象的概念,可以是在线存储中表格的格式规范,也可以是在线程序中全局或局部变量的结构定义,称为标准数据集。该规范将定义每个标准数据集的可读性和可写性。当客户自定义程序违反可读可写性要求时,将无法通过代码审查,无法上线。
算法规范
在 RecEng 中,算法是连接数据的逻辑。这里的数据是指离线标准表或在线标准数据集。除了输入和输出数据,算法通常还包括一系列参数。 RecEng的算法模型如下图所示:
更准确的说,输入数据是指算法需要处理的信息,输出数据是算法处理的结果,参数由算法提供,以便在不同的输入上取得更好的结果数据。一组可由算法用户调整的开关。从面向对象的角度来看,如果我们把一个算法看成一个对象,那么算法参数就是算法本身的属性,输入输出数据定义了算法的接口。
为了简化算法流程的定义,RecEng对每个算法只需要一个输出数据,并且不限制输入数据的数量。
所谓符合RecEng规范的算法,就是将这些标准表或标准数据集作为输入输出数据的算法。输入数据和输出数据完全相同的算法是相似的算法。 RecEng 定义了一组常用的算法类别,可以满足大部分需求。未来,客户可以自定义算法类别。 RecEng的算法规范参考了上述算法模型和本套算法类别。
RecEng 只要求相似的算法具有相同的输入和输出数据,即相同的接口;相似的算法不需要相同的参数,这是算法的内部属性,RecEng算法规范没有要求。
客户在自定义算法时可以在 RecEng 中注册算法参数。 RecEng在使用自定义算法时会自动显示这些自定义参数,方便客户调整。
RecEng 没有算法版本的概念。如果要升级现有算法,RecEng的方法是将新版本的算法注册为新算法,注册后即可使用。旧版算法无人使用后可以下线。目前无法在删除算法时提示是否正在使用该算法。正式上线的版本将完善这些功能。
算法过程
在概念讲解部分,大致介绍了算法流程的概念,包括推荐流程(rec_path)和实时修正流程(mod_path)两个流程。本节进一步介绍这些过程的技术细节。算法过程中使用的数据和算法符合数据格式规范和算法规范。
RecEng 中的算法过程
RecEng 中的算法流程是一个有向无环图。图中的节点是算法,算法A到算法B的边表示算法A的输出是算法B的输入。 由于算法规范要求每个算法只有一个输出数据,数据节点可能没有在算法流程图中标注。
RecEng 提供了一个可视化界面来编辑这个有向无环图。此过程是自定义算法流程。 RecEng还预先实现了一套相对标准的推荐算法供客户使用。如果客户觉得系统提供的这些算法不能满足自己的需求,可以按照算法规范自行开发,并在RecEng注册使用。
RecEng中的算法流程包括离线流程(rec_path->offline_flow)、在线流程(rec_path->online_flow)、数据修改流程(data_mod_path)和用户修改流程(user_mod_path),均支持客户定制,即即支持通过可视化界面编辑算法流程的有向无环图。
RecEng 还包括一个效果过程(index_path),与上述算法过程不同。客户只需在定义效果流程时选择效果指标即可。 RecEng会根据客户选择的指标自动生成算法流程。需要通过可视化界面编辑。
在RecEng中,推荐过程(rec_path)属于场景(scn)。客户可以在该场景下创建新的推荐流程。每个推荐流程由一个离线流程(offline_flow)和一个在线流程(online_flow)组成,它们相对独立。部分。所以每个rec_path由两个有向无环图组成。
实时修正过程(mod_path)属于业务。这两种mod_path各有最多一个实例,因此每个业务下的实时校正过程最多有两个有向无环图。
考虑到实际实现中的一些因果关系,下面的介绍按照离线处理(rec_path->offline_flow)、实时修正处理(mod_path)、在线处理(rec_path->online_flow)的顺序,即推荐过程(在rec_path中间插入一个实时修正过程(mod_path))
离线流程(rec_path -> offline_flow)
离线流程总体示意图:
上图及本节各流程图元素说明:
离线流程从用户输入的user、item、log数据开始,经过简单的处理,生成user/item的原创特征。接下来是推荐核心算法,计算用户和物品的关系,生成用户/物品耦合特征。所谓耦合特征,是指收录用户对物品兴趣的特征,即利用耦合特征可以计算出用户对每个物品的兴趣偏好。下一步是计算用户的候选推荐集和相似项集。
对于一般客户来说,可以推荐的商品并不多。基本上到这里就够了,就是左边蓝色虚线框内的基本推荐流程。基本推荐流程分析用户行为,向用户展示他们最感兴趣的项目,即兴趣是其优化的目标。
如果客户可以推荐很多物品,或者客户的优化目标不是用户对物品的兴趣,而是其他指标,比如转化率、交易金额等,可以在右侧红色虚线框在此过程中,为优化目标建立了每个用户的模型,并在此基础上生成推荐候选集。
排序建模过程所需的样本是根据优化目标从用户日志中提取的。目前 RecEng 在排序模型方面只提供了基于 Logistic 回归的 Learning to Rank 模型。以后会增加更多的排序模型,比如聚划算中的一次。在导购等领域大放异彩的biLinear模型
最后将offline_flow的所有计算结果导入在线存储,保存在离线计算结果表中。
实时修正过程(mod_path)
mod_path 整体流程示意图:
mod_path 由两个并行进程组成,数据修改进程(data_mod_path)和用户修改进程(user_mod_path)。
客户将需要更新实时输入,例如新上线的商品,或线下商品通过数据校正API提交到数据校正线程,数据校正流程将此信息保存在在线存储中以供在线流程使用(rec_path-> online_flow) 使用。
客户还可以利用实时日志,在用户信息修正线程中实时分析用户感兴趣和不感兴趣的项目,以优化推荐效果。目前由于在线程序都是Node.js编写的,在线学习能力比较弱。未来将引入专用的实时计算平台,实现真正意义上的在线培训。
实时修正过程是可选的,最终输出用于响应用户推荐请求的在线过程(rec_path->online_flow)。
每个实时进程,包括下面的实时纠错进程(mod_path)和在线进程(online_flow),都工作在一个单独的线程中,但有些线程是后台定时线程(比如用户纠错进程,连续polling Real-time log),有些线程是事件触发的线程(比如数据纠错过程,只有在有API请求的时候才会工作,处理完成就结束)。 RecEng 将每个实时处理线程分为三个阶段,如下图所示:
参数解析阶段负责读取和解析处理所需的参数,包括API传递的参数、实时日志、系统配置等;执行处理阶段是实时处理流程的核心,负责实现实时流程的业务;输出级输出实时过程处理的结果,可在线存储或返回给用户。几个阶段之间的参数传递由在线数据规范定义,图中用CTX(上下文环境变量)表示,下一节CTX的含义相同。
为了简化客户自定义开发,专注于业务,在以上三个阶段,RecEng只允许客户自定义程序的第二阶段,RecEng负责参数和输出工作,这也提高了系统安全。
在线流程(rec_path -> online_flow)
online_flow 负责响应终端产品(用户)推荐的 API 请求。图中的“Table Store(原OTS)离线计算结果表”是offline_flow的最终输出,属于不同rec_path的offline_flow产生的表存储的离线计算。结果表不一样,online_flow和offline_flow就是这样形成rec_path的。
在推荐处理线程的参数解析阶段,除了读取参数,RecEng还做了几件事情:
检查请求是否来自测试用户并记录在CTX(上下文环境变量)中。测试用户是指访问测试路径的用户。详情请参考“测试”部分“测试路径”的说明。
对于有A/B Testing需求的场景,rec_path根据客户的A/B Testing流量配置分配并记录在CTX中
从离线计算结果表中读取当前用户的相关数据,包括用户特征,推荐候选集;如果 API 请求参数中收录 item id,则所有与 item 相似的 item 也会被读取
在执行处理阶段,自定义算法从CTX获取RecEng的预读数据,判断当前对应的rec_path,选择对应的算法进行处理,通常对离线计算结果进行过滤排序;如果客户定制在这个过程中,可以通过实时修正来计算并将最终结果写回CTX。返回阶段的代码将客户自定义算法的处理结果返回给请求用户,完成推荐。
效果过程(index_path)
在RecEng中,效果过程不需要客户配置,只需选择效果索引即可。绩效指标和绩效报告的自定义开发和配置,详见绩效报告。
算法 自动采集列表( 一种在线自动标定系统的自动点过程及过程过程步骤)
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-08-30 07:06
一种在线自动标定系统的自动点过程及过程过程步骤)
360度环视系统在线自动校准系统
技术领域
[0001] 本发明涉及一种在线自动校准系统,具体为一种36°环视系统的在线自动校准系统。
背景技术
[0002] 360度环视系统需要摄像头的标定过程,现有的标定过程一般需要人工参与。一般采用的标定方法是:先将标定布和标定板铺在地上,然后用相机拍照,手动选择照片中的标记点,最后计算生成俯视图。在涉及人的校准过程中存在一些缺陷。首先,每张照片后都需要手动选择校准点,效率低下。其次,手动选择校准点是主观的。第三,校准人员的长期工作会降低选点的效率和准确性。因此,人工参与的校准过程不适合大量安装和环视的场合。
发明内容
[0003] 本发明的目的在于提供一种360度环视系统在线自动校准系统,以解决上述背景技术问题。
[0004]为实现上述目的,本发明提供如下技术方案:
[0005] 360度环视系统在线自动校准系统。自动校准的一个基本前提是安装在同一车型上的摄像头的位置和角度相同。车型不同车辆的摄像头差异的根源只是安装错误,自动标定,每辆车都有一个环视ECU,自动标定算法运行在环视ECU中。自动校准系统的自动校准过程包括以下步骤:
[0006](1)首先在自动标定场地地面铺设手动标定点,将车辆驶入手动标定点所在区域,对车辆进行单视角手动标定,生成标准表并下载到每个在车内环视EOT;
【0007】(2)然后在自动校准点的地面上铺设自动校准点,将车辆驶入自动校准点所在区域,拍照,开始自动校准计算过程. 具体计算过程包括:
[0008]2.1)使用Surround View ECU中的标准表对捕获的图像进行操作,生成4个俯视图;
[0009] 2 •2) 使用自动取点算法在 4 个顶视图上自动取点。自动取点算法可自动对俯视图中的自动标定点进行检测和编号;
[0010]2.3)利用得到的自动标定点对环视ECU中已有的标准表进行调整,生成调整表以补偿摄像头安装误差;
[0011](3)调整表生成后,表示自动校准过程结束。
[0012]作为本发明的又一方案:自动取点算法的具体步骤如下:
[0013]⑴检测4个顶视图中的所有角点,这里使用Harris角点检测算法;
[0014](2)生成4个顶视图图像块匹配模板和邻域循环匹配模板;
[0015](3)分析4个顶视图中所有角点的邻域图像块,先对邻域图像进行阈值划分U,对阈值分割后的图像块进行形态学开运算;
[0016] ⑷对处理后的图像块进行圆线统计;
[0017](5)对处理后的图像块进行模板匹配和圆匹配,结合匹配值和4个顶视图中标定点的位置进行过滤;
[0018] ⑹合并满足条件的角点;
[0019] ⑺ 根据标定点的行列信息去除不满足条件的角点。
[0020]与现有技术相比,本发明的有益效果是:第一,除了第一次标定需要人工参与外,本车型后续所有车辆的标定均无需人工参与,即即,一个模型只有一个手动校准过程。其次,除了第一次校准是对单视图进行校准外,后续的所有校准都是对顶视图进行校准。校准顶视图有两个好处:一是在顶视图中,校准图形不失真,更容易在顶视图上自动取点,一般不会遗漏和多检查;二是调整计算标准表量小,这样计算过程就可以在环视ECU上运行,不会花很长时间。
图纸说明
[0021] 图 1 不适用于手动校准点的排列。
[0022]图2为自动校准点布置示意图。
[0023] 图3为自动取点算法流程图。
[0024] 图中:自动校准点1、手动校准点2.
具体实现方法
[0025] 下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整的描述。显然,所描述的实施例只是本发明一部分实施例,而不是全部示例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0026] 在本发明实施例中,一种用于360度环视系统的在线自动校准系统。自动校准的一个基本前提是安装在同一车型上的摄像头的位置和角度基本一致。车型不同车辆的摄像头差异的根源仅在于安装错误。在自动校准过程中,需要一个自动校准站点。每辆车都有一个环视ECU,自动标定算法运行在环视ECU中。
[0027]自动校准系统的自动校准过程包括以下步骤:
[0028](1)首先在自动标定点地面铺设手动标定点2,将车辆开入手动标定点2所在区域,对车辆进行单视角手动标定,生成一张标准表,下载后查看每辆车的ECU;
【0029】(2)然后将自动校准点1放在自动校准点的地面上,将车辆开到自动校准点1所在的区域,拍照,开始自动校准计算过程,具体计算过程包括:
[0030]2.1)使用Surround View ECU中的标准表对捕获的图像进行操作,生成4个俯视图;
[0031]2.2)采用自动取点算法从4个顶视图自动取点(自动取点算法主要包括角点检测、邻域图像分割、形态学操作、模板匹配、邻域图像循环线分析等图像处理算法),自动取点算法可以在俯视图中自动检测自动校准点1,并编号自动校准点1;
[0032]2.3)利用得到的自动标定点1对环视ECU中已有的标准表进行调整,生成调整表补偿摄像头安装误差;
[0033] ⑶调整表生成后,表示自动校准过程结束。
[0034] 在上述自动校准过程中,自动取点算法是关键步骤。自动取点算法关系到自动校准过程的成功与否。自动取点算法的具体步骤如下:
[0035]⑴检测4个顶视图中的所有角点,这里使用Harris角点检测算法;
[0036] ⑵ 生成4个顶视图的邻域图像块匹配模板和邻域循环匹配模板;
[0037] 分析4个顶视图中所有角点的邻域图像块,先对邻域图像进行阈值分析,对阈值分割后的图像块进行形态学开运算;
[0038] ⑷对处理后的图像块进行圆线统计;
[0039] ⑸对处理后的图像块进行模板匹配和圆匹配,结合匹配值和4个顶视图中标定点的位置进行过滤;
[0040] ⑹合并满足条件的角点;
[0041](7)根据校准点的行列信息去除不合格的角点。
[0042] 当你得到一个顶视图时,你首先需要检测顶视图的角点。角点检测的原因是校准点必须是图像中的角点。可以通过执行角点检测并去除不属于校准点的角点来找到校准点。这里角点检测采用 Harris 角点检测算法。 Harris角点检测算法的基本原理是:得到每个像素的结构张量矩阵,将该矩阵设为A,则该像素的C值可由下式计算:
[0043]C=det(A)-〇。 04 • tr (A)
[0044] 当像素点的C值大于104时,认为该点为角点。
[0045] 顶视图的角点检测后,可以得到顶视图中的所有角点。这时就需要在这些角点中寻找校准点,剔除非校准点。观察校准点及其邻域图像,可以发现邻域图像的一个对角线方向为黑色,另一对角线方向为白色,反之亦然。因此,对每个角点的邻域图像进行如下操作: 1 • 交叉熵阈值分割; 2 • 形态腐蚀; 3.形态扩展; 4.模板匹配; 5.根据模板匹配结果确定邻域循环 匹配方法,这些操作在流程图中用黑色虚线框起来。下面我们来详细介绍一下这5个步骤。交叉熵阈值分割是一种阈值分割方法。通过计算分割图像与原创图像的交叉熵,将分割图像与原创图像的最小交叉熵对应的阈值作为分割阈值。分割阈值用于对邻域图像进行分割。分割后的图像是通过分割得到的。分割后的图像是二值图像。由于原创图像(俯视图)光照不均,分割后的图像有很多毛刺。为了消除这些毛刺,可以使用形态学操作。在这里,首先进行形态腐蚀,然后进行形态扩展,以消除毛刺。形态学运算的基本原理是利用一个结构元素对图像进行遍历,对结构元素内的元素值进行最小/最大运算来确定计算结果。这里结构元素的大小是3X3。进行形态学操作后,分割后的图像显示出更规则的结果。此时匹配模数f,模板为预先生成的二值图像。为了增加算法的鲁棒性,预先生成了总共6个二值模板,这6个二值模板分别用于对分割后的图像进行匹配。得到匹配结果后,根据匹配结果确定邻域循环匹配方法。 Neighbor 是围绕相邻图像中心点的圆。对分割图像的每个邻域循环进行邻域循环匹配,并记录匹配结果。当邻域循环匹配时,它也与预先生成的模板匹配。以下是模板匹配和邻域循环匹配之间的异同。模板匹配和邻域循环匹配的本质是将待匹配元素与之前生成的元素一一比较,得到比较值。不同的是模板匹配是二维图像之间的匹配。循环匹配是一维数组之间的匹配。
[0046]——对每个角点的邻域图像进行上述操作后,可以根据行列信息和匹配值对角点进行过滤。当模板匹配值和邻域环匹配值满足标定点的特性时,可以保留角点。这样,可以消除大部分未校准的角。角在下面合并。由于校准点周围的点的c值都大于104,所以校准点处会出现“角点簇”。合并角点的目的是将“一组角点合并为一个角点”。角点合并准则是利用角点的模板匹配值对角点的秩进行加权,得到合并角点的最终秩值。最后,角点需要进一步筛选。观察前后顶视图中的校准点,可以发现校准点在两行,观察左右顶视图中的校准点,可以发现校准点在两列。根据这个特点,可以消除远离2行或2列的校准点。经过以上步骤,就可以得到最终的输出图像,其中只收录我们需要的校准点。
[0047] 对于本领域技术人员来说,显然本发明不限于上述示例性实施例的细节,在不脱离本发明的精神或基本特征的情况下,可以以其他具体形式实施。本发明。发明。因此,从任何角度来看,这些实施例都应被视为示例性的而非限制性的。本发明的保护范围由所附的权利要求而不是上述说明所限定,因此应属于权利要求的范围。凡在其等效要素的含义和范围内的变化,均收录在本发明中。权利要求中的任何附图标记不应视为对所涉及的权利要求的限制。 [0048] 另外,应当理解,虽然本说明书是根据实施例进行描述的,但并不是每个实施例都只收录一个独立的技术方案。说明书中的这种叙述只是为了清楚起见。整体上,还可以对实施例中的技术方案进行适当组合,形成本领域技术人员能够理解的其他实现方式。 查看全部
算法 自动采集列表(
一种在线自动标定系统的自动点过程及过程过程步骤)
360度环视系统在线自动校准系统
技术领域
[0001] 本发明涉及一种在线自动校准系统,具体为一种36°环视系统的在线自动校准系统。
背景技术
[0002] 360度环视系统需要摄像头的标定过程,现有的标定过程一般需要人工参与。一般采用的标定方法是:先将标定布和标定板铺在地上,然后用相机拍照,手动选择照片中的标记点,最后计算生成俯视图。在涉及人的校准过程中存在一些缺陷。首先,每张照片后都需要手动选择校准点,效率低下。其次,手动选择校准点是主观的。第三,校准人员的长期工作会降低选点的效率和准确性。因此,人工参与的校准过程不适合大量安装和环视的场合。
发明内容
[0003] 本发明的目的在于提供一种360度环视系统在线自动校准系统,以解决上述背景技术问题。
[0004]为实现上述目的,本发明提供如下技术方案:
[0005] 360度环视系统在线自动校准系统。自动校准的一个基本前提是安装在同一车型上的摄像头的位置和角度相同。车型不同车辆的摄像头差异的根源只是安装错误,自动标定,每辆车都有一个环视ECU,自动标定算法运行在环视ECU中。自动校准系统的自动校准过程包括以下步骤:
[0006](1)首先在自动标定场地地面铺设手动标定点,将车辆驶入手动标定点所在区域,对车辆进行单视角手动标定,生成标准表并下载到每个在车内环视EOT;
【0007】(2)然后在自动校准点的地面上铺设自动校准点,将车辆驶入自动校准点所在区域,拍照,开始自动校准计算过程. 具体计算过程包括:
[0008]2.1)使用Surround View ECU中的标准表对捕获的图像进行操作,生成4个俯视图;
[0009] 2 •2) 使用自动取点算法在 4 个顶视图上自动取点。自动取点算法可自动对俯视图中的自动标定点进行检测和编号;
[0010]2.3)利用得到的自动标定点对环视ECU中已有的标准表进行调整,生成调整表以补偿摄像头安装误差;
[0011](3)调整表生成后,表示自动校准过程结束。
[0012]作为本发明的又一方案:自动取点算法的具体步骤如下:
[0013]⑴检测4个顶视图中的所有角点,这里使用Harris角点检测算法;
[0014](2)生成4个顶视图图像块匹配模板和邻域循环匹配模板;
[0015](3)分析4个顶视图中所有角点的邻域图像块,先对邻域图像进行阈值划分U,对阈值分割后的图像块进行形态学开运算;
[0016] ⑷对处理后的图像块进行圆线统计;
[0017](5)对处理后的图像块进行模板匹配和圆匹配,结合匹配值和4个顶视图中标定点的位置进行过滤;
[0018] ⑹合并满足条件的角点;
[0019] ⑺ 根据标定点的行列信息去除不满足条件的角点。
[0020]与现有技术相比,本发明的有益效果是:第一,除了第一次标定需要人工参与外,本车型后续所有车辆的标定均无需人工参与,即即,一个模型只有一个手动校准过程。其次,除了第一次校准是对单视图进行校准外,后续的所有校准都是对顶视图进行校准。校准顶视图有两个好处:一是在顶视图中,校准图形不失真,更容易在顶视图上自动取点,一般不会遗漏和多检查;二是调整计算标准表量小,这样计算过程就可以在环视ECU上运行,不会花很长时间。
图纸说明
[0021] 图 1 不适用于手动校准点的排列。
[0022]图2为自动校准点布置示意图。
[0023] 图3为自动取点算法流程图。
[0024] 图中:自动校准点1、手动校准点2.
具体实现方法
[0025] 下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整的描述。显然,所描述的实施例只是本发明一部分实施例,而不是全部示例。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都属于本发明保护的范围。
[0026] 在本发明实施例中,一种用于360度环视系统的在线自动校准系统。自动校准的一个基本前提是安装在同一车型上的摄像头的位置和角度基本一致。车型不同车辆的摄像头差异的根源仅在于安装错误。在自动校准过程中,需要一个自动校准站点。每辆车都有一个环视ECU,自动标定算法运行在环视ECU中。
[0027]自动校准系统的自动校准过程包括以下步骤:
[0028](1)首先在自动标定点地面铺设手动标定点2,将车辆开入手动标定点2所在区域,对车辆进行单视角手动标定,生成一张标准表,下载后查看每辆车的ECU;
【0029】(2)然后将自动校准点1放在自动校准点的地面上,将车辆开到自动校准点1所在的区域,拍照,开始自动校准计算过程,具体计算过程包括:
[0030]2.1)使用Surround View ECU中的标准表对捕获的图像进行操作,生成4个俯视图;
[0031]2.2)采用自动取点算法从4个顶视图自动取点(自动取点算法主要包括角点检测、邻域图像分割、形态学操作、模板匹配、邻域图像循环线分析等图像处理算法),自动取点算法可以在俯视图中自动检测自动校准点1,并编号自动校准点1;
[0032]2.3)利用得到的自动标定点1对环视ECU中已有的标准表进行调整,生成调整表补偿摄像头安装误差;
[0033] ⑶调整表生成后,表示自动校准过程结束。
[0034] 在上述自动校准过程中,自动取点算法是关键步骤。自动取点算法关系到自动校准过程的成功与否。自动取点算法的具体步骤如下:
[0035]⑴检测4个顶视图中的所有角点,这里使用Harris角点检测算法;
[0036] ⑵ 生成4个顶视图的邻域图像块匹配模板和邻域循环匹配模板;
[0037] 分析4个顶视图中所有角点的邻域图像块,先对邻域图像进行阈值分析,对阈值分割后的图像块进行形态学开运算;
[0038] ⑷对处理后的图像块进行圆线统计;
[0039] ⑸对处理后的图像块进行模板匹配和圆匹配,结合匹配值和4个顶视图中标定点的位置进行过滤;
[0040] ⑹合并满足条件的角点;
[0041](7)根据校准点的行列信息去除不合格的角点。
[0042] 当你得到一个顶视图时,你首先需要检测顶视图的角点。角点检测的原因是校准点必须是图像中的角点。可以通过执行角点检测并去除不属于校准点的角点来找到校准点。这里角点检测采用 Harris 角点检测算法。 Harris角点检测算法的基本原理是:得到每个像素的结构张量矩阵,将该矩阵设为A,则该像素的C值可由下式计算:
[0043]C=det(A)-〇。 04 • tr (A)
[0044] 当像素点的C值大于104时,认为该点为角点。
[0045] 顶视图的角点检测后,可以得到顶视图中的所有角点。这时就需要在这些角点中寻找校准点,剔除非校准点。观察校准点及其邻域图像,可以发现邻域图像的一个对角线方向为黑色,另一对角线方向为白色,反之亦然。因此,对每个角点的邻域图像进行如下操作: 1 • 交叉熵阈值分割; 2 • 形态腐蚀; 3.形态扩展; 4.模板匹配; 5.根据模板匹配结果确定邻域循环 匹配方法,这些操作在流程图中用黑色虚线框起来。下面我们来详细介绍一下这5个步骤。交叉熵阈值分割是一种阈值分割方法。通过计算分割图像与原创图像的交叉熵,将分割图像与原创图像的最小交叉熵对应的阈值作为分割阈值。分割阈值用于对邻域图像进行分割。分割后的图像是通过分割得到的。分割后的图像是二值图像。由于原创图像(俯视图)光照不均,分割后的图像有很多毛刺。为了消除这些毛刺,可以使用形态学操作。在这里,首先进行形态腐蚀,然后进行形态扩展,以消除毛刺。形态学运算的基本原理是利用一个结构元素对图像进行遍历,对结构元素内的元素值进行最小/最大运算来确定计算结果。这里结构元素的大小是3X3。进行形态学操作后,分割后的图像显示出更规则的结果。此时匹配模数f,模板为预先生成的二值图像。为了增加算法的鲁棒性,预先生成了总共6个二值模板,这6个二值模板分别用于对分割后的图像进行匹配。得到匹配结果后,根据匹配结果确定邻域循环匹配方法。 Neighbor 是围绕相邻图像中心点的圆。对分割图像的每个邻域循环进行邻域循环匹配,并记录匹配结果。当邻域循环匹配时,它也与预先生成的模板匹配。以下是模板匹配和邻域循环匹配之间的异同。模板匹配和邻域循环匹配的本质是将待匹配元素与之前生成的元素一一比较,得到比较值。不同的是模板匹配是二维图像之间的匹配。循环匹配是一维数组之间的匹配。
[0046]——对每个角点的邻域图像进行上述操作后,可以根据行列信息和匹配值对角点进行过滤。当模板匹配值和邻域环匹配值满足标定点的特性时,可以保留角点。这样,可以消除大部分未校准的角。角在下面合并。由于校准点周围的点的c值都大于104,所以校准点处会出现“角点簇”。合并角点的目的是将“一组角点合并为一个角点”。角点合并准则是利用角点的模板匹配值对角点的秩进行加权,得到合并角点的最终秩值。最后,角点需要进一步筛选。观察前后顶视图中的校准点,可以发现校准点在两行,观察左右顶视图中的校准点,可以发现校准点在两列。根据这个特点,可以消除远离2行或2列的校准点。经过以上步骤,就可以得到最终的输出图像,其中只收录我们需要的校准点。
[0047] 对于本领域技术人员来说,显然本发明不限于上述示例性实施例的细节,在不脱离本发明的精神或基本特征的情况下,可以以其他具体形式实施。本发明。发明。因此,从任何角度来看,这些实施例都应被视为示例性的而非限制性的。本发明的保护范围由所附的权利要求而不是上述说明所限定,因此应属于权利要求的范围。凡在其等效要素的含义和范围内的变化,均收录在本发明中。权利要求中的任何附图标记不应视为对所涉及的权利要求的限制。 [0048] 另外,应当理解,虽然本说明书是根据实施例进行描述的,但并不是每个实施例都只收录一个独立的技术方案。说明书中的这种叙述只是为了清楚起见。整体上,还可以对实施例中的技术方案进行适当组合,形成本领域技术人员能够理解的其他实现方式。
算法 自动采集列表(算法自动采集列表,做电商对精细化运营的执行力要求)
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-08-29 16:06
算法自动采集列表当有人点击a广告时,系统会自动从a广告列表中找到相应的广告然后给予点击或广告创意展示的机会让买家自己决定点击或不点击。点击广告创意,且对买家有价值的广告内容才会被点击自动精确筛选采用人工方式智能化过滤不需要考虑点击率的广告创意过滤掉点击率较低广告,自动竞价选择在点击率较高的广告位竞价系统主要使用广告竞价与点击率的方式使买家产生关注,或产生点击。
目前有趣的广告位(分类页):点击率可以说是广告位的基础指标,或者说是广告位竞价的根基。分类页是买家经常使用到的购物目的单元,包括广告展示,cta,价格,风格等需要考虑的因素。点击率是指点击广告创意,并且对广告有价值的广告内容才会被点击。
互联网中肯定有很多精细化运营的方法,我这里不提供具体的东西,
分类页位怎么精细化!做电商对精细化运营的执行力要求不是特别高,但要求精细化运营。首先你要定下你的产品是什么,需要具体的从哪些方面去做精细化运营。如果你是卖某某健康食品,那么你先做分类,你需要搞清楚你的产品属于什么,打造那种产品。上架的时候首先要根据分类页的不同来做店铺内功的优化,如果是新品,让新品有曝光,根据新品的优势来看看现在市场上面有什么样的产品能满足大众的需求,什么样的产品适合自己产品特性,如果需要电商运营的服务,可以联系我。 查看全部
算法 自动采集列表(算法自动采集列表,做电商对精细化运营的执行力要求)
算法自动采集列表当有人点击a广告时,系统会自动从a广告列表中找到相应的广告然后给予点击或广告创意展示的机会让买家自己决定点击或不点击。点击广告创意,且对买家有价值的广告内容才会被点击自动精确筛选采用人工方式智能化过滤不需要考虑点击率的广告创意过滤掉点击率较低广告,自动竞价选择在点击率较高的广告位竞价系统主要使用广告竞价与点击率的方式使买家产生关注,或产生点击。
目前有趣的广告位(分类页):点击率可以说是广告位的基础指标,或者说是广告位竞价的根基。分类页是买家经常使用到的购物目的单元,包括广告展示,cta,价格,风格等需要考虑的因素。点击率是指点击广告创意,并且对广告有价值的广告内容才会被点击。
互联网中肯定有很多精细化运营的方法,我这里不提供具体的东西,
分类页位怎么精细化!做电商对精细化运营的执行力要求不是特别高,但要求精细化运营。首先你要定下你的产品是什么,需要具体的从哪些方面去做精细化运营。如果你是卖某某健康食品,那么你先做分类,你需要搞清楚你的产品属于什么,打造那种产品。上架的时候首先要根据分类页的不同来做店铺内功的优化,如果是新品,让新品有曝光,根据新品的优势来看看现在市场上面有什么样的产品能满足大众的需求,什么样的产品适合自己产品特性,如果需要电商运营的服务,可以联系我。
算法 自动采集列表(算法自动采集列表页的使用方法是怎样的?采集图片)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-08-29 14:04
算法自动采集列表页的信息对于搜索引擎来说十分重要,采集完整列表页的信息不仅可以得到用户搜索的信息,还可以通过分析用户是搜索什么类型的内容来获得不同的搜索结果,那么采集列表页就是一个很有效的方法,采集列表页的信息最常用的方法就是采集图片,这也是用户经常遇到的一个问题,那么我们可以把图片导入到cookie中实现自动采集,更可以用图片数据直接做为自动标签进行命名或批量爬取图片。
<p>抓取返回的json字符串列表页返回json字符串,对这个json字符串进行查询会返回一个很长的列表页数据列表页存在一个allcount=1这个字段,说明只有在返回列表页1行1列时,才会返回该列表页数据我们可以查看这个列表页数据,代码如下:varlist1=document.getelementsbytagname('list1')[0];if(list1 查看全部
算法 自动采集列表(算法自动采集列表页的使用方法是怎样的?采集图片)
算法自动采集列表页的信息对于搜索引擎来说十分重要,采集完整列表页的信息不仅可以得到用户搜索的信息,还可以通过分析用户是搜索什么类型的内容来获得不同的搜索结果,那么采集列表页就是一个很有效的方法,采集列表页的信息最常用的方法就是采集图片,这也是用户经常遇到的一个问题,那么我们可以把图片导入到cookie中实现自动采集,更可以用图片数据直接做为自动标签进行命名或批量爬取图片。
<p>抓取返回的json字符串列表页返回json字符串,对这个json字符串进行查询会返回一个很长的列表页数据列表页存在一个allcount=1这个字段,说明只有在返回列表页1行1列时,才会返回该列表页数据我们可以查看这个列表页数据,代码如下:varlist1=document.getelementsbytagname('list1')[0];if(list1
算法 自动采集列表(谢邀!机器学习的研究主旨是使用计算机模拟人类的学习活动)
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2021-08-29 12:50
感谢邀请!
机器学习研究的主要目的是利用计算机来模拟人类的学习活动。它是学习计算机以识别现有知识、获取新知识、不断提高性能和实现自我完善的一种方法。这里的学习是指从数据中学习,包括三类:监督学习、无监督学习和半监督学习。
以下是机器学习中常用的回归算法及其优缺点:
1、Linear Regression Algorithm(线性回归) ① 算法思想: 线性回归(Linear Regression)是利用称为线性回归方程的最小二乘函数对一个或多个自变量与因变量之间的关系进行建模的一种回归分析。该函数是一个或多个称为回归系数的模型参数的线性组合。只有一个自变量的情况称为简单回归,有多个自变量的情况称为多元回归。
回归模型:
其中θ和C为未知参数,可用于每个训练样本(xi,yi))(xih,用于预测真实值yi。损失函数:
是误差值的平方。
1:对于训练集,找到θ以最小化损失函数。 (使用最小二乘法,梯度下降法)
2:对于新输入x,其预测输出为θTx
②优点:结果易懂、易实现、易计算
③缺点:1)不利于非线性数据拟合(原因:因为线性回归将数据视为线性,可能会出现欠拟合,导致结果无法达到最佳预测效果。2)如果某些训练数据有非常大的偏差,这个时候最终训练出来的模型在整体数据上可能没有很好的准确率。
④Improvement:针对2)Improving :部分加权回归
2、Local Weighted Regression(局部加权回归)
①算法思想:
给每个待预测点周围的点赋予一定的权重,点越近,权重越高,以便选择预测点对应的数据子集,然后根据最小均方误差在这个数据子集上执行普通回归。部分加权回归本质上是针对需要预测的点,只根据附近的点进行训练,其他保持不变。
对于局部线性加权算法:
1:对于输入x,在训练集中寻找x邻域内的训练样本
2:对于其邻域内的训练样本,求θ使得它
∈x ) 的邻域最小。其中 w(i) 是权重值。 3.预测输出为θTx
4. 对新输入重复过程 1-3。
哪里
τ 是恒定带宽。离输入越远,权重越小, 。
②优点:
1)部分加权回归仍然更适合训练数据。
2) 不依赖于特征的选择,只有线性模型才能训练出一个很好的拟合模型,
③缺点:
1) 是计算密集型的。 (因为局部加权回归的损失随着预测值的变化而变化,所以无法提前确定θ。需要扫描所有数据,每次预测重新计算θ)
2)部分加权回归容易出现过拟合,过拟合明显。
3) 关注局部训练数据,忽略全局数据。如果预测点靠近有偏差的训练数据,那么预测值就会有很大的偏差。
④改进:
3、k-Nearest Neighbor Algorithm for Regression(回归k最近邻)
①算法思想:
通过找到一个样本的k个最近邻,并将这些邻域的属性的平均值赋给样本,就可以得到样本的属性。一个更有用的方法是对不同距离的邻居对样本的影响赋予不同的权重,例如权重与距离成正比。
如果特征空间中一个样本的k个最相似(即特征空间中的最近邻)样本中的大部分属于某个类别,则该样本也属于该类别。
KNN 算法不仅可以用于分类,还可以用于回归。通过找出一个样本的k个最近邻,将这些邻域的属性的平均值赋给样本,就可以得到样本的属性。一种更有用的方法是对不同距离的邻居对样本的影响赋予不同的权重,例如权重与距离成反比。
②优点:
1) 简单有效。
2)再训练成本低(类别系统的变化和训练集的变化在Web环境和电子商务应用中很常见)。
3)计算时间和空间与训练集的大小成线性关系(在某些情况下不会太大)。
4)因为KNN方法主要依靠周围有限的相邻样本,而不是通过区分类域的方法来确定类别,所以对于要划分的样本集,类域的交叉或重叠较多, KNN 方法比其他方法更适合。 5)该算法更适合对样本量比较大的类域进行自动分类,而样本量较小的类域使用该算法更容易误分类。
③缺点:
(1)KNN对属性较多的训练样本进行分类时,由于计算量大,效率大大降低,效果不是很理想。
(2)当样本不平衡时,例如一个类的样本量很大,而其他类的样本量很小,可能会导致输入新样本时,K样本的邻居有一个大容量的类,样本占多数。
(3)对数据的局部结构更敏感,如果查询点位于训练集较密集的区域,则预测比其他稀疏集更准确。
(4) 对 k 值敏感。
(5)维度灾难:邻近距离可能被不相关的属性支配(因此出现特征选择问题)
④改进:
(1)Classification 效率:提前减少样本属性,删除对分类结果影响不大的属性,快速得到待分类样本的类别。该算法更适用于样本量相对较大的自动分类,样本量较小的领域使用该算法更容易被误分类。
(2)Classification 效果:用权重法(离样本距离小的邻居权重大)改进,Han等人在2002年尝试用贪心法为文件分类k最近邻法WAkNN(weightedadjusted k最近邻)来提升分类效果;而Li等人在2004年提出,由于不同分类的文件数量不同,因此也应基于各种不同的文件训练集中的分类数,选择不同数量的最近邻参与分类。
(3)这个算法在分类上的主要缺点是当样本不平衡时,比如一类的样本量很大,而其他类的样本量很小,这可能会导致新样本的输入,此时样本的K个邻居的大容量样本占了多数。那么或者这种类型的样本与目标样本不接近,或者这个类样本与目标样本非常接近。不管怎样,数量不影响运行结果。可以使用权重方法(与目标样本的邻居)距离样本越小权重越大)来提高。
(4)K 值的选择会对算法的结果产生很大的影响。小的K值意味着只有接近输入实例的训练实例才会对预测结果产生影响,但是容易出现过拟合;如果 K 的值很大,优点是可以减少学习的估计误差,缺点是学习的近似误差增大。输入实例也会在预测中起作用,也就是预测误差。在实际应用中,K 值一般选择较小的值,通常使用交叉验证来选择最优的 K 值作为训练样本的个数趋于无穷大且 K=1 ,错误率不会超过贝叶斯错误率 如果K也趋于无穷大,则错误率趋于贝叶斯错误率。
(5)这种方法的另一个缺点是计算量大,因为对于每一个待分类的文本,必须计算到所有已知样本的距离才能找到它的K个最近邻点。目前常用的解决方案是提前编辑已知样本点,提前剔除对分类影响不大的样本。
该算法更适合样本量较大的类域的自动分类,样本量较小的类域使用该算法更容易误分类。
随着信息技术的发展,出现了很多大数据分析工具。其中,NLPIR大数据语义智能分析平台(原ICTCLAS)是一个比较好的系统。是北京理工大学大数据搜索挖掘实验室主任张华平针对大数据内容采集、编辑、挖掘和搜索的综合需求,整合网络精准采集最新研究成果而研发的、自然语言理解、文本挖掘和语义搜索,近二十年来不断创新。平台提供客户端工具、云服务、二次开发接口等多种产品使用形式。每个中间件API都可以无缝集成到客户的各种复杂应用系统中,兼容Windows、Linux、Android、Maemo5、FreeBSD等不同操作系统平台,可用于Java、Python、C等各种开发、C# 等语言用法。
NLPIR大数据语义智能分析平台的十三项功能:
NLPIR大数据语义智能分析平台客户端
精准采集:国内外海量信息实时精准采集,有话题采集(话题采集根据信息需要)和网站采集(站内)使用给定的 URL 列表)定点 采集 函数)。
文档转换:对doc、excel、pdf、ppt等多种主流文档格式的文本信息进行转换,效率满足大数据处理要求。
新词发现:从文本中发现新词、新概念,用户可以将其用于专业词典的编纂,还可以进一步编辑标注,导入分词词典,提高分词准确率分词系统,适应新语言的变化。
批量分词:对原语料进行分词,自动识别姓名、地名、机构名称等未注册词,新词标注,词性标注。并在分析过程中,导入用户自定义词典。
语言统计:根据分词和标注结果,系统可以自动进行一元词频数统计和二元词转移概率统计。对于常用术语,会自动给出相应的英文解释。
文本聚类:可以从大规模数据中自动分析热点事件,并提供事件主题的关键特征描述。同时适用于短文、微博等长文和短文的热点分析。
文本分类:根据规则或训练方法对大量文本进行分类,可用于新闻分类、简历分类、邮件分类、办公文档分类、区域分类等多个方面。
摘要实体:对于单个或多个文章,自动提取内容摘要,提取人名、地名、机构名称、时间和主题关键词;方便用户快速浏览文本内容。
智能过滤:对文本内容进行语义智能过滤和审核,内置国内最全的词库,智能识别变形、拼音、繁体、简体等多种变体,语义精准消歧。
情感分析:针对预先指定的分析对象,系统自动分析海量文档的情感倾向:情感极性和情感值测度,并给出原文中的正负分和句例。
文档去重:快速准确判断文件集合或数据库中是否存在内容相同或相似的记录,同时查找所有重复记录。
全文搜索:支持文本、数字、日期、字符串等多种数据类型,多字段高效搜索,支持AND/OR/NOT、NEAR接近等查询语法,支持维文、藏文、蒙古语、阿拉伯语、韩语等多种少数民族语言搜索。
编码转换:自动识别内容的编码,统一将编码转换为其他编码。
以上是推荐的中文分词工具。我希望它能帮助你。如果您有任何问题,请联系我,我会帮助您! 查看全部
算法 自动采集列表(谢邀!机器学习的研究主旨是使用计算机模拟人类的学习活动)
感谢邀请!
机器学习研究的主要目的是利用计算机来模拟人类的学习活动。它是学习计算机以识别现有知识、获取新知识、不断提高性能和实现自我完善的一种方法。这里的学习是指从数据中学习,包括三类:监督学习、无监督学习和半监督学习。
以下是机器学习中常用的回归算法及其优缺点:
1、Linear Regression Algorithm(线性回归) ① 算法思想: 线性回归(Linear Regression)是利用称为线性回归方程的最小二乘函数对一个或多个自变量与因变量之间的关系进行建模的一种回归分析。该函数是一个或多个称为回归系数的模型参数的线性组合。只有一个自变量的情况称为简单回归,有多个自变量的情况称为多元回归。
回归模型:
其中θ和C为未知参数,可用于每个训练样本(xi,yi))(xih,用于预测真实值yi。损失函数:
是误差值的平方。
1:对于训练集,找到θ以最小化损失函数。 (使用最小二乘法,梯度下降法)
2:对于新输入x,其预测输出为θTx
②优点:结果易懂、易实现、易计算
③缺点:1)不利于非线性数据拟合(原因:因为线性回归将数据视为线性,可能会出现欠拟合,导致结果无法达到最佳预测效果。2)如果某些训练数据有非常大的偏差,这个时候最终训练出来的模型在整体数据上可能没有很好的准确率。
④Improvement:针对2)Improving :部分加权回归
2、Local Weighted Regression(局部加权回归)
①算法思想:
给每个待预测点周围的点赋予一定的权重,点越近,权重越高,以便选择预测点对应的数据子集,然后根据最小均方误差在这个数据子集上执行普通回归。部分加权回归本质上是针对需要预测的点,只根据附近的点进行训练,其他保持不变。
对于局部线性加权算法:
1:对于输入x,在训练集中寻找x邻域内的训练样本
2:对于其邻域内的训练样本,求θ使得它
∈x ) 的邻域最小。其中 w(i) 是权重值。 3.预测输出为θTx
4. 对新输入重复过程 1-3。
哪里
τ 是恒定带宽。离输入越远,权重越小, 。
②优点:
1)部分加权回归仍然更适合训练数据。
2) 不依赖于特征的选择,只有线性模型才能训练出一个很好的拟合模型,
③缺点:
1) 是计算密集型的。 (因为局部加权回归的损失随着预测值的变化而变化,所以无法提前确定θ。需要扫描所有数据,每次预测重新计算θ)
2)部分加权回归容易出现过拟合,过拟合明显。
3) 关注局部训练数据,忽略全局数据。如果预测点靠近有偏差的训练数据,那么预测值就会有很大的偏差。
④改进:
3、k-Nearest Neighbor Algorithm for Regression(回归k最近邻)
①算法思想:
通过找到一个样本的k个最近邻,并将这些邻域的属性的平均值赋给样本,就可以得到样本的属性。一个更有用的方法是对不同距离的邻居对样本的影响赋予不同的权重,例如权重与距离成正比。
如果特征空间中一个样本的k个最相似(即特征空间中的最近邻)样本中的大部分属于某个类别,则该样本也属于该类别。
KNN 算法不仅可以用于分类,还可以用于回归。通过找出一个样本的k个最近邻,将这些邻域的属性的平均值赋给样本,就可以得到样本的属性。一种更有用的方法是对不同距离的邻居对样本的影响赋予不同的权重,例如权重与距离成反比。
②优点:
1) 简单有效。
2)再训练成本低(类别系统的变化和训练集的变化在Web环境和电子商务应用中很常见)。
3)计算时间和空间与训练集的大小成线性关系(在某些情况下不会太大)。
4)因为KNN方法主要依靠周围有限的相邻样本,而不是通过区分类域的方法来确定类别,所以对于要划分的样本集,类域的交叉或重叠较多, KNN 方法比其他方法更适合。 5)该算法更适合对样本量比较大的类域进行自动分类,而样本量较小的类域使用该算法更容易误分类。
③缺点:
(1)KNN对属性较多的训练样本进行分类时,由于计算量大,效率大大降低,效果不是很理想。
(2)当样本不平衡时,例如一个类的样本量很大,而其他类的样本量很小,可能会导致输入新样本时,K样本的邻居有一个大容量的类,样本占多数。
(3)对数据的局部结构更敏感,如果查询点位于训练集较密集的区域,则预测比其他稀疏集更准确。
(4) 对 k 值敏感。
(5)维度灾难:邻近距离可能被不相关的属性支配(因此出现特征选择问题)
④改进:
(1)Classification 效率:提前减少样本属性,删除对分类结果影响不大的属性,快速得到待分类样本的类别。该算法更适用于样本量相对较大的自动分类,样本量较小的领域使用该算法更容易被误分类。
(2)Classification 效果:用权重法(离样本距离小的邻居权重大)改进,Han等人在2002年尝试用贪心法为文件分类k最近邻法WAkNN(weightedadjusted k最近邻)来提升分类效果;而Li等人在2004年提出,由于不同分类的文件数量不同,因此也应基于各种不同的文件训练集中的分类数,选择不同数量的最近邻参与分类。
(3)这个算法在分类上的主要缺点是当样本不平衡时,比如一类的样本量很大,而其他类的样本量很小,这可能会导致新样本的输入,此时样本的K个邻居的大容量样本占了多数。那么或者这种类型的样本与目标样本不接近,或者这个类样本与目标样本非常接近。不管怎样,数量不影响运行结果。可以使用权重方法(与目标样本的邻居)距离样本越小权重越大)来提高。
(4)K 值的选择会对算法的结果产生很大的影响。小的K值意味着只有接近输入实例的训练实例才会对预测结果产生影响,但是容易出现过拟合;如果 K 的值很大,优点是可以减少学习的估计误差,缺点是学习的近似误差增大。输入实例也会在预测中起作用,也就是预测误差。在实际应用中,K 值一般选择较小的值,通常使用交叉验证来选择最优的 K 值作为训练样本的个数趋于无穷大且 K=1 ,错误率不会超过贝叶斯错误率 如果K也趋于无穷大,则错误率趋于贝叶斯错误率。
(5)这种方法的另一个缺点是计算量大,因为对于每一个待分类的文本,必须计算到所有已知样本的距离才能找到它的K个最近邻点。目前常用的解决方案是提前编辑已知样本点,提前剔除对分类影响不大的样本。
该算法更适合样本量较大的类域的自动分类,样本量较小的类域使用该算法更容易误分类。
随着信息技术的发展,出现了很多大数据分析工具。其中,NLPIR大数据语义智能分析平台(原ICTCLAS)是一个比较好的系统。是北京理工大学大数据搜索挖掘实验室主任张华平针对大数据内容采集、编辑、挖掘和搜索的综合需求,整合网络精准采集最新研究成果而研发的、自然语言理解、文本挖掘和语义搜索,近二十年来不断创新。平台提供客户端工具、云服务、二次开发接口等多种产品使用形式。每个中间件API都可以无缝集成到客户的各种复杂应用系统中,兼容Windows、Linux、Android、Maemo5、FreeBSD等不同操作系统平台,可用于Java、Python、C等各种开发、C# 等语言用法。
NLPIR大数据语义智能分析平台的十三项功能:
NLPIR大数据语义智能分析平台客户端
精准采集:国内外海量信息实时精准采集,有话题采集(话题采集根据信息需要)和网站采集(站内)使用给定的 URL 列表)定点 采集 函数)。
文档转换:对doc、excel、pdf、ppt等多种主流文档格式的文本信息进行转换,效率满足大数据处理要求。
新词发现:从文本中发现新词、新概念,用户可以将其用于专业词典的编纂,还可以进一步编辑标注,导入分词词典,提高分词准确率分词系统,适应新语言的变化。
批量分词:对原语料进行分词,自动识别姓名、地名、机构名称等未注册词,新词标注,词性标注。并在分析过程中,导入用户自定义词典。
语言统计:根据分词和标注结果,系统可以自动进行一元词频数统计和二元词转移概率统计。对于常用术语,会自动给出相应的英文解释。
文本聚类:可以从大规模数据中自动分析热点事件,并提供事件主题的关键特征描述。同时适用于短文、微博等长文和短文的热点分析。
文本分类:根据规则或训练方法对大量文本进行分类,可用于新闻分类、简历分类、邮件分类、办公文档分类、区域分类等多个方面。
摘要实体:对于单个或多个文章,自动提取内容摘要,提取人名、地名、机构名称、时间和主题关键词;方便用户快速浏览文本内容。
智能过滤:对文本内容进行语义智能过滤和审核,内置国内最全的词库,智能识别变形、拼音、繁体、简体等多种变体,语义精准消歧。
情感分析:针对预先指定的分析对象,系统自动分析海量文档的情感倾向:情感极性和情感值测度,并给出原文中的正负分和句例。
文档去重:快速准确判断文件集合或数据库中是否存在内容相同或相似的记录,同时查找所有重复记录。
全文搜索:支持文本、数字、日期、字符串等多种数据类型,多字段高效搜索,支持AND/OR/NOT、NEAR接近等查询语法,支持维文、藏文、蒙古语、阿拉伯语、韩语等多种少数民族语言搜索。
编码转换:自动识别内容的编码,统一将编码转换为其他编码。
以上是推荐的中文分词工具。我希望它能帮助你。如果您有任何问题,请联系我,我会帮助您!
算法 自动采集列表(怼正则,怼CSS选择器,解析是个麻烦事(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 197 次浏览 • 2021-08-29 07:02
爬虫有什么作用?它可以帮助我们快速获取有效信息。不过,做过爬虫的人都知道解析很麻烦。
比如一篇新闻文章,链接是这样的:,页面预览如下:
预览图片
我们需要从页面中提取标题、出版商、发布时间、发布内容、图片等内容。正常情况下我们需要做什么?编写规则。
那么规则是什么?不要使用正则,不要使用 CSS 选择器,不要使用 XPath。我们需要匹配标题的内容,发布时间,来源等,更重要的是,我们需要正则表达式来辅助。我们可能需要使用re、BeautifulSoup、pyquery等库来提取和解析内容。
但是如果我们有数千个不同风格的页面怎么办?它们来自数千个站点。我们还需要写规则来一一匹配吗?这需要多少工作。另外,如果这些事情没有做好,分析就会出现问题。例如,在某些情况下无法匹配正则表达式,如果 CSS 和 XPath 选择器选择错误可能会出现问题。
想必大家可能已经看到当前浏览器都有阅读模式了,比如我们用Safari浏览器打开这个页面,然后打开阅读模式看看效果:
Safari 预览
页面突然变得很清爽,只剩下标题和需要阅读的内容。原页面多余的导航栏、侧边栏、评论等全部删除。它是如何做到的?有人在里面写规则吗?当然这是不可能的。其实这里用的是智能分析。
这篇文章,让我们一起来了解一下智能页面分析的知识。
智能分析
所谓爬虫智能分析,顾名思义,就是我们不再需要专门针对某些页面编写抽取规则。我们可以使用一些算法来计算页面上特定元素的位置和提取路径。比如一个页面中的文章,我们可以通过算法计算,它的标题应该是什么,文本应该是什么部分,发布时间是多少等等。
实际上,智能分析是一项非常艰巨的任务。比如你在一个网页上展示某人文章,人们很快就能知道这个文章的标题是什么,发布时间是什么,以及文字是哪一块,或者哪一块是广告空间,哪一块是导航栏。但如果机器要识别,它面对的是什么?它只是一系列 HTML 代码。那么机器是如何实现智能提取的呢?事实上,它收录了很多方面的信息。
还有一些功能就不一一赘述了。这些包括区块位置、区块大小、区块标签、区块内容、区块密度等,而且在很多情况下还需要依赖视觉的特性,所以实际上是算法计算、视觉处理、自然语言的结合加工等方面。如果能综合利用这些特征,再经过大量的数据训练,就能取得非常好的效果。
行业进展
未来页面会越来越多,页面的渲染方式也会发生很大的变化。爬虫越来越难做,智能爬虫越来越重要。
目前,业界已经有实现的算法。经过一番研究,我发现有几种算法或服务在页面智能分析方面做得更好:
那么这些算法或服务中哪些是好的? Driffbot 官方做了一个对比评测,使用了谷歌新闻的一些文章,使用不同的算法依次提取标题和文本,然后与真实标注的进行对比。比较内容,比较的指标是文本的准确率和召回率,以及基于两者计算的F1分数。
结果对比如下:
经过对比,我们可以发现Diffbot的准确率和召回率都是最好的,它的F1值达到了0.97,可以说是非常准确了。此外,下一个更强大的是 Boilerpipe 和 Readability。 Goose 的性能很差,F1 和其他算法有很大的不同。以下是几种算法的F1得分对比:
F1 分数对比
有些人可能想知道为什么 Diffbot 如此强大?我也查过。 Diffbot 从 2010 年就开始致力于网页数据的提取,并提供了很多 API 来自动解析各种页面。其中,他们的算法依赖于自然语言技术、机器学习、计算机视觉、标记检查等各种算法,所有页面都会考虑当前页面的样式和视觉布局,还会对图像进行分析内容、CSS 甚至其中收录的内容。 Ajax 请求。另外,在计算一个块的置信度时,还要考虑与其他块的相关性,根据周围的标记计算每个块的置信度。
总之,Diffbot也一直致力于这方面的服务。整个Diffbot从页面解析开始,现在一直专注于页面解析服务。准确率高也就不足为奇了。
但是他们的算法是开源的吗?不幸的是,没有,而且我还没有找到相关的论文来介绍他们自己的具体算法。
所以,如果你想取得这么好的效果,就用他们的服务吧。
在下面的内容中,我们将讨论如何使用Diffbot进行智能页面分析。此外,Readability算法也值得研究。我会专门写一篇文章来介绍Readability及其与Python的对接使用。
Diffbot 页面分析
首先,我们需要注册一个帐户。它有 15 天的免费试用期。注册后,您将获得一个Developer Token,这是使用Diffbot接口服务的证书。
接下来,切换到它的测试页面。链接是:我们来测试一下它的分析效果。
我们这里选择的测试页面就是上面提到的页面,链接是:,API类型选择Article API,然后点击Test Drive按钮,就会显示当前页面的分析结果:
结果
这时候我们可以看到它帮助我们提取了标题、发布时间、发布机构、发布机构链接、正文内容等各种结果。到目前为止,这是非常正确的。时间自动识别并转码,为标准时间格式。
接下来我们继续向下滚动以查看还有哪些其他字段。这里我们也可以看到有一个html字段,它和text的区别在于它收录了文章content的真实HTML代码,所以图片也会收录在其中,如图:
结果
此外,最后还有图像字段。他以列表的形式返回文章一组图片和每张图片的链接,以及文章的站点名称、页面使用的语言等,如图。 :
结果
当然,我们也可以选择JSON格式的返回结果,这样内容会更加丰富。比如图片还返回了它的宽、高、图片描述等,还有各种其他的比如面包屑导航等结果,如图:
结果
经过人工检查,发现返回的结果完全正确,准确率相当高!
所以,如果你的准确率要求不是那么严格,使用Diffbot的服务可以帮助我们快速从页面中提取出想要的结果,节省我们大部分的体力劳动。可以说是很不错了。
但是,我们不能总是在网络上尝试此操作。其实Diffbot也提供了官方的API文档,让我们一探究竟。
Diffbot API
Driffbot 提供了多种 API,例如分析 API、文章 API、讨论 API 等。
我们以文章 API 为例来说明它的用法。官方文档地址为:,API调用地址为:
https://api.diffbot.com/v3/article
我们可以使用 GET 方法来发出请求。 Token 和 URL 都可以以参数的形式传递给这个 API。必要的参数是:
此外,它还有几个可选参数:
这里大家可能关心的是fields字段。这里我做了一个专门的整理。首先,一些固定字段:
images:文章视频中收录的图片:文章中收录的视频breadcrumb:面包屑导航信息diffbotUri:Diffbot内的URL链接
上面预定的字段是可以返回的字段。它们无法定制。此外,我们还可以使用 fields 参数来指定和扩展以下可选字段:
好的,以上就是这个API的用法。申请后即可使用该API进行智能分析。
举个例子看看这个API的用法,代码如下:
import requests, json
url = 'https://api.diffbot.com/v3/article'
params = {
'token': '77b41f6fbb24496d5113d528306528fa',
'url': 'https://news.ifeng.com/c/7kQcQG2peWU',
'fields': 'meta'
}
response = requests.get(url, params=params)
print(json.dumps(response.json(), indent=2, ensure_ascii=False))
这里先定义API链接,然后指定params参数,也就是GET请求参数。
参数收录必填的token和url字段,还设置了可选字段字段,其中fields是可选的扩展字段元标记。
来看看运行结果,结果如下:
{
"request": {
"pageUrl": "https://news.ifeng.com/c/7kQcQG2peWU",
"api": "article",
"fields": "sentiment, meta",
"version": 3
},
"objects": [
{
"date": "Wed, 20 Feb 2019 02:26:00 GMT",
"images": [
{
"naturalHeight": 460,
"width": 640,
"diffbotUri": "image|3|-1139316034",
"url": "http://e0.ifengimg.com/02/2019 ... ot%3B,
"naturalWidth": 690,
"primary": true,
"height": 426
},
// ...
],
"author": "中国新闻网",
"estimatedDate": "Wed, 20 Feb 2019 06:47:52 GMT",
"diffbotUri": "article|3|1591137208",
"siteName": "ifeng.com",
"type": "article",
"title": "故宫,你低调点!故宫:不,实力已不允许我继续低调",
"breadcrumb": [
{
"link": "https://news.ifeng.com/",
"name": "资讯"
},
{
"link": "https://news.ifeng.com/shanklist/3-35197-/",
"name": "大陆"
}
],
"humanLanguage": "zh",
"meta": {
"og": {
"og:time ": "2019-02-20 02:26:00",
"og:image": "https://e0.ifengimg.com/02/201 ... ot%3B,
"og:category ": "凤凰资讯",
"og: webtype": "news",
"og:title": "故宫,你低调点!故宫:不,实力已不允许我继续低调",
"og:url": "https://news.ifeng.com/c/7kQcQG2peWU",
"og:description": " “我的名字叫紫禁城,快要600岁了,这上元的夜啊,总是让我沉醉,这么久了却从未停止。” “重"
},
"referrer": "always",
"description": " “我的名字叫紫禁城,快要600岁了,这上元的夜啊,总是让我沉醉,这么久了却从未停止。” “重",
"keywords": "故宫 紫禁城 故宫博物院 灯光 元宵节 博物馆 一票难求 元之 中新社 午门 杜洋 藏品 文化 皇帝 清明上河图 元宵 千里江山图卷 中英北京条约 中法北京条约 天津条约",
"title": "故宫,你低调点!故宫:不,实力已不允许我继续低调_凤凰资讯"
},
"authorUrl": "https://feng.ifeng.com/author/308904",
"pageUrl": "https://news.ifeng.com/c/7kQcQG2peWU",
"html": "<p>“我的名字叫紫禁城,快要600岁了,这上元的夜啊,总是让我沉醉,这么久了却从未停止。... ",
"text": "“我的名字叫紫禁城,快要600岁了,这上元的夜啊,总是让我沉醉,这么久了却从未停止。”\n“...",
"authors": [
{
"name": "中国新闻网",
"link": "https://feng.ifeng.com/author/308904"
}
]
}
]
}
可以看出它返回了上面的内容,是一个完整的JSON格式,里面收录了标题、正文、发布时间等各种内容。
可以看出,我们不需要配置任何提取规则,就可以完成页面的分析和抓取,不费吹灰之力。
Diffbot SDK
此外,Diffbot 还提供几乎所有语言的 SDK 支持。我们也可以使用SDK来实现以上功能。链接是:如果使用Python,可以直接使用Python SDK。 Python SDK 链接是:.
此库尚未发布到 PyPi。您需要自己下载并导入它。另外,这个库是用Python 2写的,其实本质上就是调用requests库。有兴趣的可以去看看。
以下是调用示例:
from client import DiffbotClient,DiffbotCrawl
diffbot = DiffbotClient()
token = 'your_token'
url = 'http://shichuan.github.io/java ... 39%3B
api = 'article'
response = diffbot.request(url, token, api)
通过这行代码,我们可以通过调用Article API来分析我们想要的URL链接,返回的结果类似。
具体用法直接看其源码注释就一目了然了,还是很清楚的。 查看全部
算法 自动采集列表(怼正则,怼CSS选择器,解析是个麻烦事(组图))
爬虫有什么作用?它可以帮助我们快速获取有效信息。不过,做过爬虫的人都知道解析很麻烦。
比如一篇新闻文章,链接是这样的:,页面预览如下:
预览图片
我们需要从页面中提取标题、出版商、发布时间、发布内容、图片等内容。正常情况下我们需要做什么?编写规则。
那么规则是什么?不要使用正则,不要使用 CSS 选择器,不要使用 XPath。我们需要匹配标题的内容,发布时间,来源等,更重要的是,我们需要正则表达式来辅助。我们可能需要使用re、BeautifulSoup、pyquery等库来提取和解析内容。
但是如果我们有数千个不同风格的页面怎么办?它们来自数千个站点。我们还需要写规则来一一匹配吗?这需要多少工作。另外,如果这些事情没有做好,分析就会出现问题。例如,在某些情况下无法匹配正则表达式,如果 CSS 和 XPath 选择器选择错误可能会出现问题。
想必大家可能已经看到当前浏览器都有阅读模式了,比如我们用Safari浏览器打开这个页面,然后打开阅读模式看看效果:
Safari 预览
页面突然变得很清爽,只剩下标题和需要阅读的内容。原页面多余的导航栏、侧边栏、评论等全部删除。它是如何做到的?有人在里面写规则吗?当然这是不可能的。其实这里用的是智能分析。
这篇文章,让我们一起来了解一下智能页面分析的知识。
智能分析
所谓爬虫智能分析,顾名思义,就是我们不再需要专门针对某些页面编写抽取规则。我们可以使用一些算法来计算页面上特定元素的位置和提取路径。比如一个页面中的文章,我们可以通过算法计算,它的标题应该是什么,文本应该是什么部分,发布时间是多少等等。
实际上,智能分析是一项非常艰巨的任务。比如你在一个网页上展示某人文章,人们很快就能知道这个文章的标题是什么,发布时间是什么,以及文字是哪一块,或者哪一块是广告空间,哪一块是导航栏。但如果机器要识别,它面对的是什么?它只是一系列 HTML 代码。那么机器是如何实现智能提取的呢?事实上,它收录了很多方面的信息。
还有一些功能就不一一赘述了。这些包括区块位置、区块大小、区块标签、区块内容、区块密度等,而且在很多情况下还需要依赖视觉的特性,所以实际上是算法计算、视觉处理、自然语言的结合加工等方面。如果能综合利用这些特征,再经过大量的数据训练,就能取得非常好的效果。
行业进展
未来页面会越来越多,页面的渲染方式也会发生很大的变化。爬虫越来越难做,智能爬虫越来越重要。
目前,业界已经有实现的算法。经过一番研究,我发现有几种算法或服务在页面智能分析方面做得更好:
那么这些算法或服务中哪些是好的? Driffbot 官方做了一个对比评测,使用了谷歌新闻的一些文章,使用不同的算法依次提取标题和文本,然后与真实标注的进行对比。比较内容,比较的指标是文本的准确率和召回率,以及基于两者计算的F1分数。
结果对比如下:
经过对比,我们可以发现Diffbot的准确率和召回率都是最好的,它的F1值达到了0.97,可以说是非常准确了。此外,下一个更强大的是 Boilerpipe 和 Readability。 Goose 的性能很差,F1 和其他算法有很大的不同。以下是几种算法的F1得分对比:
F1 分数对比
有些人可能想知道为什么 Diffbot 如此强大?我也查过。 Diffbot 从 2010 年就开始致力于网页数据的提取,并提供了很多 API 来自动解析各种页面。其中,他们的算法依赖于自然语言技术、机器学习、计算机视觉、标记检查等各种算法,所有页面都会考虑当前页面的样式和视觉布局,还会对图像进行分析内容、CSS 甚至其中收录的内容。 Ajax 请求。另外,在计算一个块的置信度时,还要考虑与其他块的相关性,根据周围的标记计算每个块的置信度。
总之,Diffbot也一直致力于这方面的服务。整个Diffbot从页面解析开始,现在一直专注于页面解析服务。准确率高也就不足为奇了。
但是他们的算法是开源的吗?不幸的是,没有,而且我还没有找到相关的论文来介绍他们自己的具体算法。
所以,如果你想取得这么好的效果,就用他们的服务吧。
在下面的内容中,我们将讨论如何使用Diffbot进行智能页面分析。此外,Readability算法也值得研究。我会专门写一篇文章来介绍Readability及其与Python的对接使用。
Diffbot 页面分析
首先,我们需要注册一个帐户。它有 15 天的免费试用期。注册后,您将获得一个Developer Token,这是使用Diffbot接口服务的证书。
接下来,切换到它的测试页面。链接是:我们来测试一下它的分析效果。
我们这里选择的测试页面就是上面提到的页面,链接是:,API类型选择Article API,然后点击Test Drive按钮,就会显示当前页面的分析结果:
结果
这时候我们可以看到它帮助我们提取了标题、发布时间、发布机构、发布机构链接、正文内容等各种结果。到目前为止,这是非常正确的。时间自动识别并转码,为标准时间格式。
接下来我们继续向下滚动以查看还有哪些其他字段。这里我们也可以看到有一个html字段,它和text的区别在于它收录了文章content的真实HTML代码,所以图片也会收录在其中,如图:
结果
此外,最后还有图像字段。他以列表的形式返回文章一组图片和每张图片的链接,以及文章的站点名称、页面使用的语言等,如图。 :
结果
当然,我们也可以选择JSON格式的返回结果,这样内容会更加丰富。比如图片还返回了它的宽、高、图片描述等,还有各种其他的比如面包屑导航等结果,如图:
结果
经过人工检查,发现返回的结果完全正确,准确率相当高!
所以,如果你的准确率要求不是那么严格,使用Diffbot的服务可以帮助我们快速从页面中提取出想要的结果,节省我们大部分的体力劳动。可以说是很不错了。
但是,我们不能总是在网络上尝试此操作。其实Diffbot也提供了官方的API文档,让我们一探究竟。
Diffbot API
Driffbot 提供了多种 API,例如分析 API、文章 API、讨论 API 等。
我们以文章 API 为例来说明它的用法。官方文档地址为:,API调用地址为:
https://api.diffbot.com/v3/article
我们可以使用 GET 方法来发出请求。 Token 和 URL 都可以以参数的形式传递给这个 API。必要的参数是:
此外,它还有几个可选参数:
这里大家可能关心的是fields字段。这里我做了一个专门的整理。首先,一些固定字段:
images:文章视频中收录的图片:文章中收录的视频breadcrumb:面包屑导航信息diffbotUri:Diffbot内的URL链接
上面预定的字段是可以返回的字段。它们无法定制。此外,我们还可以使用 fields 参数来指定和扩展以下可选字段:
好的,以上就是这个API的用法。申请后即可使用该API进行智能分析。
举个例子看看这个API的用法,代码如下:
import requests, json
url = 'https://api.diffbot.com/v3/article'
params = {
'token': '77b41f6fbb24496d5113d528306528fa',
'url': 'https://news.ifeng.com/c/7kQcQG2peWU',
'fields': 'meta'
}
response = requests.get(url, params=params)
print(json.dumps(response.json(), indent=2, ensure_ascii=False))
这里先定义API链接,然后指定params参数,也就是GET请求参数。
参数收录必填的token和url字段,还设置了可选字段字段,其中fields是可选的扩展字段元标记。
来看看运行结果,结果如下:
{
"request": {
"pageUrl": "https://news.ifeng.com/c/7kQcQG2peWU",
"api": "article",
"fields": "sentiment, meta",
"version": 3
},
"objects": [
{
"date": "Wed, 20 Feb 2019 02:26:00 GMT",
"images": [
{
"naturalHeight": 460,
"width": 640,
"diffbotUri": "image|3|-1139316034",
"url": "http://e0.ifengimg.com/02/2019 ... ot%3B,
"naturalWidth": 690,
"primary": true,
"height": 426
},
// ...
],
"author": "中国新闻网",
"estimatedDate": "Wed, 20 Feb 2019 06:47:52 GMT",
"diffbotUri": "article|3|1591137208",
"siteName": "ifeng.com",
"type": "article",
"title": "故宫,你低调点!故宫:不,实力已不允许我继续低调",
"breadcrumb": [
{
"link": "https://news.ifeng.com/",
"name": "资讯"
},
{
"link": "https://news.ifeng.com/shanklist/3-35197-/",
"name": "大陆"
}
],
"humanLanguage": "zh",
"meta": {
"og": {
"og:time ": "2019-02-20 02:26:00",
"og:image": "https://e0.ifengimg.com/02/201 ... ot%3B,
"og:category ": "凤凰资讯",
"og: webtype": "news",
"og:title": "故宫,你低调点!故宫:不,实力已不允许我继续低调",
"og:url": "https://news.ifeng.com/c/7kQcQG2peWU",
"og:description": " “我的名字叫紫禁城,快要600岁了,这上元的夜啊,总是让我沉醉,这么久了却从未停止。” “重"
},
"referrer": "always",
"description": " “我的名字叫紫禁城,快要600岁了,这上元的夜啊,总是让我沉醉,这么久了却从未停止。” “重",
"keywords": "故宫 紫禁城 故宫博物院 灯光 元宵节 博物馆 一票难求 元之 中新社 午门 杜洋 藏品 文化 皇帝 清明上河图 元宵 千里江山图卷 中英北京条约 中法北京条约 天津条约",
"title": "故宫,你低调点!故宫:不,实力已不允许我继续低调_凤凰资讯"
},
"authorUrl": "https://feng.ifeng.com/author/308904",
"pageUrl": "https://news.ifeng.com/c/7kQcQG2peWU",
"html": "<p>“我的名字叫紫禁城,快要600岁了,这上元的夜啊,总是让我沉醉,这么久了却从未停止。... ",
"text": "“我的名字叫紫禁城,快要600岁了,这上元的夜啊,总是让我沉醉,这么久了却从未停止。”\n“...",
"authors": [
{
"name": "中国新闻网",
"link": "https://feng.ifeng.com/author/308904"
}
]
}
]
}
可以看出它返回了上面的内容,是一个完整的JSON格式,里面收录了标题、正文、发布时间等各种内容。
可以看出,我们不需要配置任何提取规则,就可以完成页面的分析和抓取,不费吹灰之力。
Diffbot SDK
此外,Diffbot 还提供几乎所有语言的 SDK 支持。我们也可以使用SDK来实现以上功能。链接是:如果使用Python,可以直接使用Python SDK。 Python SDK 链接是:.
此库尚未发布到 PyPi。您需要自己下载并导入它。另外,这个库是用Python 2写的,其实本质上就是调用requests库。有兴趣的可以去看看。
以下是调用示例:
from client import DiffbotClient,DiffbotCrawl
diffbot = DiffbotClient()
token = 'your_token'
url = 'http://shichuan.github.io/java ... 39%3B
api = 'article'
response = diffbot.request(url, token, api)
通过这行代码,我们可以通过调用Article API来分析我们想要的URL链接,返回的结果类似。
具体用法直接看其源码注释就一目了然了,还是很清楚的。
搜索引擎工作内容是以用户体验为核心运营站吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-08-26 06:12
搜索引擎工作内容
1、收录page:
一般收录页面需要被百度蜘蛛抓取。爬行算法用于确定那些页面收录。百度算法调整后,伪原创和采集网站将受到强烈攻击,因此百度对收录页面更加严格。高质量的内容页面和高权重的网站通常有更高的 收录 页面机会。对于收录页面,相信很多站长都非常清楚。每天,百度蜘蛛都在不断收录着,但是你会发现大部分网站的收录都在减少。 , 为什么是这样?因为百度需要过滤页面。
2、过滤页面:
很多页面都是百度收录后,百度认为该页面对用户没有多大价值,或者如果是低质量页面,百度难免会过滤掉。这也是良好用户体验的体现。该网站经过优化,完全不考虑用户体验。比如一些桥页和跳转页就是典型的。百度的k-site是一个页面过滤的表现,过滤掉所有作弊网站的页面。很多人抱怨6.22和6.28百度k站事件,尤其是那些整天在论坛上抱怨这个那个的。为什么是你的网站?显然,您的网站实际上是基于用户体验的。是核心运营站点吗?大多数做 SEO 的人都会操作网站进行优化。网站上写的每日更新和外部链接绝对是为了优化而优化的。百度k你的网站是以牺牲少数人的利益为代价的。更多的用户从中受益。你需要知道有多少人在使用百度。如果搜索到的信息是你为优化而运营的网站和低质量的页面,那么百度实际上是在利用它的未来为你优化网站。铺路。所以百度对页面过滤非常严格,大家不要使用seo作弊技术。
3、创建索引:
收录page 和页面过滤工作后,百度会对这些页面进行一一标记和识别,并将这些信息作为结构化数据存储在百度的搜索服务器上。这些存储的数据包括网页信息、网页title关键词page description等标签、网页外部链接和描述、抓取记录等。网页中的关键词信息也会被识别并存储,以便与用户搜索的内容相匹配。建立完善的索引数据库,轻松呈现最佳展示信息
4、显示信息:
用户输入的关键词,百度会对其进行一系列复杂的分析,并根据分析的结论,在索引库中找到一系列与其最匹配的网页,根据用户输入的关键词。对需求的强弱和网页的优劣进行评分,并将最终的评分整理并展示给用户。一般来说,最好的信息需要是最适合关键词匹配的页面,包括站内优化和站外优化等因素。 查看全部
搜索引擎工作内容是以用户体验为核心运营站吗?
搜索引擎工作内容
1、收录page:
一般收录页面需要被百度蜘蛛抓取。爬行算法用于确定那些页面收录。百度算法调整后,伪原创和采集网站将受到强烈攻击,因此百度对收录页面更加严格。高质量的内容页面和高权重的网站通常有更高的 收录 页面机会。对于收录页面,相信很多站长都非常清楚。每天,百度蜘蛛都在不断收录着,但是你会发现大部分网站的收录都在减少。 , 为什么是这样?因为百度需要过滤页面。
2、过滤页面:
很多页面都是百度收录后,百度认为该页面对用户没有多大价值,或者如果是低质量页面,百度难免会过滤掉。这也是良好用户体验的体现。该网站经过优化,完全不考虑用户体验。比如一些桥页和跳转页就是典型的。百度的k-site是一个页面过滤的表现,过滤掉所有作弊网站的页面。很多人抱怨6.22和6.28百度k站事件,尤其是那些整天在论坛上抱怨这个那个的。为什么是你的网站?显然,您的网站实际上是基于用户体验的。是核心运营站点吗?大多数做 SEO 的人都会操作网站进行优化。网站上写的每日更新和外部链接绝对是为了优化而优化的。百度k你的网站是以牺牲少数人的利益为代价的。更多的用户从中受益。你需要知道有多少人在使用百度。如果搜索到的信息是你为优化而运营的网站和低质量的页面,那么百度实际上是在利用它的未来为你优化网站。铺路。所以百度对页面过滤非常严格,大家不要使用seo作弊技术。
3、创建索引:
收录page 和页面过滤工作后,百度会对这些页面进行一一标记和识别,并将这些信息作为结构化数据存储在百度的搜索服务器上。这些存储的数据包括网页信息、网页title关键词page description等标签、网页外部链接和描述、抓取记录等。网页中的关键词信息也会被识别并存储,以便与用户搜索的内容相匹配。建立完善的索引数据库,轻松呈现最佳展示信息
4、显示信息:
用户输入的关键词,百度会对其进行一系列复杂的分析,并根据分析的结论,在索引库中找到一系列与其最匹配的网页,根据用户输入的关键词。对需求的强弱和网页的优劣进行评分,并将最终的评分整理并展示给用户。一般来说,最好的信息需要是最适合关键词匹配的页面,包括站内优化和站外优化等因素。
10万个网站的采集范围是怎么样的?(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-08-24 21:09
昨天有网友表示,他最近面试了几家公司,一个问题被问了好几次,但每次的回答都不是很好。
采访者:比如有10万个网站需要采集,怎么快速拿到数据?
要回答好这个问题,其实你需要有足够的知识和足够的技术储备。
最近,我们也在招聘。我们每周采访十几个人。只有一两个人觉得合适。他们中的大多数人都与这位网友的情况相同。他们缺乏整体思维,即使是工作了三四年的人。有经验的老司机。他们有很强的解决具体问题的能力,但很少点对点思考问题,站在一个新的高度。
100,000个网站的采集的覆盖范围已经超过了大多数专业舆情监测公司的数据采集。为了满足面试官提到的采集需求,我们需要从网站的采集到数据存储的各个方面综合考虑,给出合适的解决方案,以达到节约成本、提高工作效率的目的。
下面我们将从网站的采集到数据存储的方方面面做一个简单的介绍。
一、10万个网站哪里来的?
一般来说采集的网站都是随着公司业务的发展而逐渐积累起来的。
我们现在假设这是一家初创公司的需求。公司刚刚成立,这么多网站,基本上可以说是冷启动。那么我们如何采集这 100,000 个网站?有几种方法:
1)历史业务的积累
不管是冷启动还是什么,既然有采集的需求,就一定有项目或产品有这个需求。相关人员一定是前期调查了一些数据来源,采集了一些比较重要的网站。这些可以作为我们采集网站和采集的原创种子。
2)Association网站
在一些网站的底部,一般都有相关网站的链接。尤其是政府类网站,一般都有相关下级部门的官网。
3)网站Navigation
有些网站可能会出于某种目的(如引流等)采集一些网站,并进行分类展示,方便人们查找。这些网站可以快速为我们提供第一批种子网站。然后,我们可以通过网站关联等方式获得更多的网站。
4)搜索引擎
你也可以准备一些与公司业务相关的关键词,在百度、搜狗等搜索引擎中搜索,通过对搜索结果的处理,提取出对应的网站作为我们的种子网站。
5)第三方平台
例如,一些第三方 SaaS 平台会有 7-15 天的免费试用期。因此,我们可以利用这段时间下载与我们业务相关的数据采集,然后从中提取网站作为我们最初的采集种子。
虽然,这个方法是最有效最快的网站采集方法。不过在试用期间,获得10万个网站的可能性极小,所以需要结合上述关联网站等方式,快速获取所需的网站。
通过以上五种方法,相信我们可以快速采集到我们需要的10万个网站。但是,这么多网站,我们应该如何管理呢?怎么知道正常不正常?
二、10万个网站如何管理?
当我们采集到10万个网站时,我们面临的第一件事就是如何管理,如何配置采集规则,以及如何监控网站正常与否。
1)如何管理
100,000网站,如果没有专门的系统来管理,那将是一场灾难。
同时,由于业务需要,比如智能推荐,我们需要对网站做一些预处理(比如打标签)。这时候就需要一个网站管理系统。
2)如何配置采集rules
我们前期采集的10万网站只是首页。如果我们只使用首页作为采集task,那么只有采集才能到达首页,信息量很少,漏取率很高。
如果要整个网站采集使用首页的URL,服务器资源消耗比较大,成本太高。因此,我们需要配置我们关心的列和采集它们。
但是,100,000个网站,如何快速高效地配置列?目前我们通过自动解析HTML源代码进行列的半自动配置。
当然,我们也尝试过机器学习来处理,但效果不是很理想。
因为采集的网站数量需要达到10万的级别,所以一定不要对采集使用xpath等精准定位方法。不然配置100000网站时,黄花菜就凉了。
同时数据采集必须使用通用爬虫,使用正则表达式匹配列表数据。在采集body中,使用算法解析时间和body等属性;
3)如何监控
因为网站有100,000个,这些网站每天都会有网站修改,或者栏目修改,或者新增/删除栏目等等,所以我们需要简单分析一下网站基于的情况关于采集的数据情况。
比如一个网站几天没有新数据,肯定是有问题。要么网站被修改,经常导致信息规律失效,要么网站本身有问题。
为了提高采集的效率,您可以使用单独的服务定期检查网站和该列的状态。一是检查网站和列是否可以正常访问;另一种是检查配置的列信息的正则表达式是否正常。以便运维人员对其进行维护。
三、任务缓存
100,000 网站,配置列后,采集的入口URL应该达到百万级别。 采集器如何高效获取采集的这些入口网址?
如果把这些网址放到数据库中,不管是MySQL还是Oracle,采集器获取采集任务的操作都会浪费很多时间,大大降低采集的效率。
如何解决这个问题?内存数据库是首选,比如Redis、Mongo DB等,一般采集使用Redis做缓存。因此,您可以在配置列的同时将列信息作为采集task 缓存队列同步到Redis。
四、网站How to采集?
这就像你想达到百万年薪一样。最大的可能是去华为、阿里巴巴、腾讯等一线厂商,需要达到一定的水平。这条路注定是艰难的。
同理,如果需要采集百万级列表网址,常规方法肯定是无法实现的。
必须使用分布式+多进程+多线程。同时需要结合内存数据库Redis等进行缓存,实现任务的高效获取,对采集信息进行排序;
同时,发布时间、文字等信息的分析,也必须经过算法的处理。比如现在比较流行的GNE,
有些属性可以在列表采集中获取,所以尽量不要和正文放在一起分析。例如:标题。一般情况下,从列表中得到的title的准确率要比从信息html源码中解析出来的算法要高很多。
同时,如果有一些特殊的网站或者一些特殊的需求,我们可以使用定制开发来处理。
五、统一数据存储接口
为了保持采集的及时性,10万个网站采集可能需要十几二十台服务器。同时在每台服务器上部署了N个采集器,加上一些自定义开发的脚本,采集器的总数将达到数百个。
如果每个采集器/custom 脚本都开发自己的数据保存接口,开发调试会浪费大量时间。而后续的运维也将是一件无忧无虑的事情。尤其是当业务发生变化并需要调整时。因此,统一的数据存储接口还是很有必要的。
因为数据存储接口是统一的,当我们需要对数据做一些特殊的处理时,比如:清洗、校正等,不需要修改每个采集存储部分,只需要修改接口和重新部署。 .
快速、方便、快捷。
六、data 和 采集monitoring
覆盖10万网站采集,每天的数据量肯定超过200万。数据分析算法再准确,也永远达不到100%(90%已经很好了)。因此,数据分析必然存在异常。例如:发布时间大于当前时间,正文收录相关新闻信息等。
但是,因为我们统一了数据存储接口,这个时候可以在接口上进行统一的数据质量检查。为了根据异常情况优化采集器和自定义脚本。
同时还可以统计每个网站或列的数据采集。为了能够及时判断当前采集网站/列源是否正常,从而保证总有10万个有效采集网站。
七、数据存储
由于采集每天的数据量很大,普通数据库(如mysql、Oracle等)已经无法胜任。甚至像 Mongo DB 这样的 NoSql 数据库也不再适用。这时候,ES、Solr等分布式索引是目前最好的选择。
至于是否使用Hadoop、HBase等大数据平台,要看具体情况。在预算较小的情况下,可以先搭建分布式索引集群,再考虑大数据平台。
为了保证查询的响应速度,分布式索引中尽量不要保存body信息。可以保存标题、发布时间、网址等内容,以便在显示列表数据时减少二次查询。
当没有大数据平台时,可以将文本保存在txt等固定数据标准的文件系统中。大数据平台后续上传后,即可转入HBASE。
八、自动化运维
由于服务器、采集器、自定义脚本较多,单纯依靠人工部署、启动、更新、运行监控变得非常繁琐,容易出现人为错误。
因此,必须有一个自动化的运维系统,可以部署、启动、关闭和运行采集器/scripts,以便在发生变化时能够快速响应。
“比如有10万个网站需要采集,如何快速获取数据?”如果你能回答这些,就应该没有悬念拿到好offer了。
最后希望大家找工作都能拿到满意的offer,找到好的平台。 查看全部
10万个网站的采集范围是怎么样的?(组图)
昨天有网友表示,他最近面试了几家公司,一个问题被问了好几次,但每次的回答都不是很好。
采访者:比如有10万个网站需要采集,怎么快速拿到数据?
要回答好这个问题,其实你需要有足够的知识和足够的技术储备。
最近,我们也在招聘。我们每周采访十几个人。只有一两个人觉得合适。他们中的大多数人都与这位网友的情况相同。他们缺乏整体思维,即使是工作了三四年的人。有经验的老司机。他们有很强的解决具体问题的能力,但很少点对点思考问题,站在一个新的高度。
100,000个网站的采集的覆盖范围已经超过了大多数专业舆情监测公司的数据采集。为了满足面试官提到的采集需求,我们需要从网站的采集到数据存储的各个方面综合考虑,给出合适的解决方案,以达到节约成本、提高工作效率的目的。
下面我们将从网站的采集到数据存储的方方面面做一个简单的介绍。
一、10万个网站哪里来的?
一般来说采集的网站都是随着公司业务的发展而逐渐积累起来的。
我们现在假设这是一家初创公司的需求。公司刚刚成立,这么多网站,基本上可以说是冷启动。那么我们如何采集这 100,000 个网站?有几种方法:
1)历史业务的积累
不管是冷启动还是什么,既然有采集的需求,就一定有项目或产品有这个需求。相关人员一定是前期调查了一些数据来源,采集了一些比较重要的网站。这些可以作为我们采集网站和采集的原创种子。
2)Association网站
在一些网站的底部,一般都有相关网站的链接。尤其是政府类网站,一般都有相关下级部门的官网。
3)网站Navigation
有些网站可能会出于某种目的(如引流等)采集一些网站,并进行分类展示,方便人们查找。这些网站可以快速为我们提供第一批种子网站。然后,我们可以通过网站关联等方式获得更多的网站。
4)搜索引擎
你也可以准备一些与公司业务相关的关键词,在百度、搜狗等搜索引擎中搜索,通过对搜索结果的处理,提取出对应的网站作为我们的种子网站。
5)第三方平台
例如,一些第三方 SaaS 平台会有 7-15 天的免费试用期。因此,我们可以利用这段时间下载与我们业务相关的数据采集,然后从中提取网站作为我们最初的采集种子。
虽然,这个方法是最有效最快的网站采集方法。不过在试用期间,获得10万个网站的可能性极小,所以需要结合上述关联网站等方式,快速获取所需的网站。
通过以上五种方法,相信我们可以快速采集到我们需要的10万个网站。但是,这么多网站,我们应该如何管理呢?怎么知道正常不正常?
二、10万个网站如何管理?
当我们采集到10万个网站时,我们面临的第一件事就是如何管理,如何配置采集规则,以及如何监控网站正常与否。
1)如何管理
100,000网站,如果没有专门的系统来管理,那将是一场灾难。
同时,由于业务需要,比如智能推荐,我们需要对网站做一些预处理(比如打标签)。这时候就需要一个网站管理系统。
2)如何配置采集rules
我们前期采集的10万网站只是首页。如果我们只使用首页作为采集task,那么只有采集才能到达首页,信息量很少,漏取率很高。
如果要整个网站采集使用首页的URL,服务器资源消耗比较大,成本太高。因此,我们需要配置我们关心的列和采集它们。
但是,100,000个网站,如何快速高效地配置列?目前我们通过自动解析HTML源代码进行列的半自动配置。
当然,我们也尝试过机器学习来处理,但效果不是很理想。
因为采集的网站数量需要达到10万的级别,所以一定不要对采集使用xpath等精准定位方法。不然配置100000网站时,黄花菜就凉了。
同时数据采集必须使用通用爬虫,使用正则表达式匹配列表数据。在采集body中,使用算法解析时间和body等属性;
3)如何监控
因为网站有100,000个,这些网站每天都会有网站修改,或者栏目修改,或者新增/删除栏目等等,所以我们需要简单分析一下网站基于的情况关于采集的数据情况。
比如一个网站几天没有新数据,肯定是有问题。要么网站被修改,经常导致信息规律失效,要么网站本身有问题。
为了提高采集的效率,您可以使用单独的服务定期检查网站和该列的状态。一是检查网站和列是否可以正常访问;另一种是检查配置的列信息的正则表达式是否正常。以便运维人员对其进行维护。
三、任务缓存
100,000 网站,配置列后,采集的入口URL应该达到百万级别。 采集器如何高效获取采集的这些入口网址?
如果把这些网址放到数据库中,不管是MySQL还是Oracle,采集器获取采集任务的操作都会浪费很多时间,大大降低采集的效率。
如何解决这个问题?内存数据库是首选,比如Redis、Mongo DB等,一般采集使用Redis做缓存。因此,您可以在配置列的同时将列信息作为采集task 缓存队列同步到Redis。
四、网站How to采集?
这就像你想达到百万年薪一样。最大的可能是去华为、阿里巴巴、腾讯等一线厂商,需要达到一定的水平。这条路注定是艰难的。
同理,如果需要采集百万级列表网址,常规方法肯定是无法实现的。
必须使用分布式+多进程+多线程。同时需要结合内存数据库Redis等进行缓存,实现任务的高效获取,对采集信息进行排序;
同时,发布时间、文字等信息的分析,也必须经过算法的处理。比如现在比较流行的GNE,
有些属性可以在列表采集中获取,所以尽量不要和正文放在一起分析。例如:标题。一般情况下,从列表中得到的title的准确率要比从信息html源码中解析出来的算法要高很多。
同时,如果有一些特殊的网站或者一些特殊的需求,我们可以使用定制开发来处理。
五、统一数据存储接口
为了保持采集的及时性,10万个网站采集可能需要十几二十台服务器。同时在每台服务器上部署了N个采集器,加上一些自定义开发的脚本,采集器的总数将达到数百个。
如果每个采集器/custom 脚本都开发自己的数据保存接口,开发调试会浪费大量时间。而后续的运维也将是一件无忧无虑的事情。尤其是当业务发生变化并需要调整时。因此,统一的数据存储接口还是很有必要的。
因为数据存储接口是统一的,当我们需要对数据做一些特殊的处理时,比如:清洗、校正等,不需要修改每个采集存储部分,只需要修改接口和重新部署。 .
快速、方便、快捷。
六、data 和 采集monitoring
覆盖10万网站采集,每天的数据量肯定超过200万。数据分析算法再准确,也永远达不到100%(90%已经很好了)。因此,数据分析必然存在异常。例如:发布时间大于当前时间,正文收录相关新闻信息等。
但是,因为我们统一了数据存储接口,这个时候可以在接口上进行统一的数据质量检查。为了根据异常情况优化采集器和自定义脚本。
同时还可以统计每个网站或列的数据采集。为了能够及时判断当前采集网站/列源是否正常,从而保证总有10万个有效采集网站。
七、数据存储
由于采集每天的数据量很大,普通数据库(如mysql、Oracle等)已经无法胜任。甚至像 Mongo DB 这样的 NoSql 数据库也不再适用。这时候,ES、Solr等分布式索引是目前最好的选择。
至于是否使用Hadoop、HBase等大数据平台,要看具体情况。在预算较小的情况下,可以先搭建分布式索引集群,再考虑大数据平台。
为了保证查询的响应速度,分布式索引中尽量不要保存body信息。可以保存标题、发布时间、网址等内容,以便在显示列表数据时减少二次查询。
当没有大数据平台时,可以将文本保存在txt等固定数据标准的文件系统中。大数据平台后续上传后,即可转入HBASE。
八、自动化运维
由于服务器、采集器、自定义脚本较多,单纯依靠人工部署、启动、更新、运行监控变得非常繁琐,容易出现人为错误。
因此,必须有一个自动化的运维系统,可以部署、启动、关闭和运行采集器/scripts,以便在发生变化时能够快速响应。
“比如有10万个网站需要采集,如何快速获取数据?”如果你能回答这些,就应该没有悬念拿到好offer了。
最后希望大家找工作都能拿到满意的offer,找到好的平台。
算法自动采集列表自动推荐(把tab导航里的链接爬一遍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-08-23 04:01
算法自动采集列表自动推荐(把tab导航里的链接爬一遍,就知道哪些页面会有哪些信息了)seo优化(通过爬虫爬行来对页面进行分类分析,进而将该页面信息放到合适的位置,
1、规范管理信息,包括爬虫,爬取规则。
2、利用信息工具进行有效信息的分类,设置不同的列表显示格式。
3、目录分类。需要时做点抓取。
google爬虫不是工具而是目的。不是说,爬虫有多重要。而是说,用什么样的爬虫会有更大价值。google爬虫分为几种。一种是自动爬取,另一种是采集,最后是代理ip爬取(免费的,商业模式)等。用相应的spider,spider如果有多个,可以逐一选择爬取。如果有那么多,可以选择多个不同spider一起爬取(根据需要可选择爬取完自动触发抓取,或按某种策略)。
我做爬虫最好的办法是说服一个爬虫来按你的要求自动抓取,总之的方法就是不能让google抓取你自己的网站,因为某些操作会发生概率性的事件,就是不知道你的网站是个什么样的东西。既然已经决定你的网站要爬取了,这个时候采集比爬虫要好的多了,比如javaweb页面(这个页面是经google压缩过的),采集,最后只需要改下url即可。
又比如一些重要页面,重要文章,也可以抓取完再抓取。网站的话可以抓几个重要页面爬取,然后再抓大的页面,慢慢来。 查看全部
算法自动采集列表自动推荐(把tab导航里的链接爬一遍)
算法自动采集列表自动推荐(把tab导航里的链接爬一遍,就知道哪些页面会有哪些信息了)seo优化(通过爬虫爬行来对页面进行分类分析,进而将该页面信息放到合适的位置,
1、规范管理信息,包括爬虫,爬取规则。
2、利用信息工具进行有效信息的分类,设置不同的列表显示格式。
3、目录分类。需要时做点抓取。
google爬虫不是工具而是目的。不是说,爬虫有多重要。而是说,用什么样的爬虫会有更大价值。google爬虫分为几种。一种是自动爬取,另一种是采集,最后是代理ip爬取(免费的,商业模式)等。用相应的spider,spider如果有多个,可以逐一选择爬取。如果有那么多,可以选择多个不同spider一起爬取(根据需要可选择爬取完自动触发抓取,或按某种策略)。
我做爬虫最好的办法是说服一个爬虫来按你的要求自动抓取,总之的方法就是不能让google抓取你自己的网站,因为某些操作会发生概率性的事件,就是不知道你的网站是个什么样的东西。既然已经决定你的网站要爬取了,这个时候采集比爬虫要好的多了,比如javaweb页面(这个页面是经google压缩过的),采集,最后只需要改下url即可。
又比如一些重要页面,重要文章,也可以抓取完再抓取。网站的话可以抓几个重要页面爬取,然后再抓大的页面,慢慢来。
React中最神奇的部分莫过于虚拟DOM,以及其高效的Diff算法
采集交流 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-08-23 02:02
React 最神奇的部分是虚拟 DOM 及其高效的 Diff 算法。这使我们可以随时“刷新”整个页面而不必担心性能问题。虚拟 DOM 确保仅实际更改界面上的实际 DOM 操作。 React 在这部分已经足够透明了。在实际开发中,我们基本不需要关心虚拟 DOM 是如何工作的。然而,作为有态度的程序员,我们总是对技术背后的原理感到好奇。了解其运行机制不仅有助于更好地理解 React 组件的生命周期,而且对于进一步优化 React 程序也有很大帮助。
什么是 DOM Diff 算法
Web 界面由 DOM 树组成。当它的某一部分发生变化时,实际上是相应的DOM节点发生了变化。在 React 中,构建 UI 界面的想法是当前状态决定界面。前后两个状态对应两组接口,然后React比较两组接口的差异,这需要DOM树的Diff算法分析。
给定任意两棵树,找出最少的转换步骤。但是标准的Diff算法复杂度需要O(n^3),显然不能满足性能要求。要达到每次整体刷新界面的目标,必须对算法进行优化。这看起来很困难但是Facebook工程师做到了,他们结合Web界面的特点,做了两个简单的假设,直接将Diff算法的复杂度降低到O(n)
两个相同的组件产生相似的DOM结构,不同的组件产生不同的DOM结构;对于同一层级的一组子节点,可以通过唯一的id来区分。
算法优化是 React 整个界面 Render 的基础。事实也证明,这两个假设是合理且准确的,保证了整体接口构建的性能。
不同节点类型的比较
为了在树之间进行比较,我们首先必须能够比较两个节点。在 React 中,我们比较两个虚拟 DOM 节点。当两个节点不同时我们应该怎么做?这分两种情况:(1)node类型不同,(2)node类型相同,但属性不同。本节先看第一种情况。
当树中相同位置前后输出不同类型的节点时,React直接删除之前的节点,然后创建并插入一个新节点。假设我们在树中的同一位置前后两次输出不同类型的节点。
复制代码
renderA: renderB: => [removeNode ], [insertNode ]
当一个节点从 div 变为 span 时,只需删除 div 节点并插入一个新的 span 节点即可。这符合我们对真实DOM操作的理解。
需要注意的是,删除一个节点意味着彻底销毁该节点,而不是在后续的比较中检查是否还有另一个节点等同于被删除的节点。如果删除的节点下还有子节点,这些子节点也会被彻底删除,不会用于后续的比较。这就是为什么算法复杂度可以降低到 O(n) 的原因。
上面说的是虚拟DOM节点的操作,同样的逻辑也用在React组件的比较中,例如:
复制代码
renderA: renderB: => [removeNode ], [insertNode ]
当 React 在同一位置遇到不同的组件时,它只会销毁第一个组件并添加新创建的组件。这是第一个假设的应用。不同的组件通常会产生不同的 DOM 结构。与其浪费时间比较基本不等价的 DOM 结构,不如创建一个新组件并添加它。
从这个 React 对不同类型节点的处理逻辑,我们可以很容易地推断出 React 的 DOM Diff 算法实际上只是逐层比较树,如下所述。
逐层比较节点
说到树,相信大多数同学第一时间想到的是二叉树、遍历、最短路径等复杂的数据结构算法。在 React 中,树算法其实很简单,就是两棵树只会比较同一层级的节点。如下图所示:
React 只会比较同一个颜色框中的 DOM 节点,即同一个父节点下的所有子节点。当发现该节点不再存在时,该节点及其子节点将被完全删除,不再用于进一步比较。这样整个DOM树的比较只需遍历一次树即可完成。
例如,考虑以下 DOM 结构转换:
A节点完全移到D节点,直观考虑DOM Diff操作应该是
复制代码
A.parent.remove(A); D.append(A);
但是因为React只是简单的考虑了同层节点的位置变换,对于不同层的节点,只有简单的创建和删除。当根节点发现子节点中的A缺失时,直接销毁A;而当D发现自己多了一个子节点A时,就会创建一个新的A作为子节点。因此,这种结构转换的实际操作是:
复制代码
A.destroy();A = new A();A.append(new B());A.append(new C());D.append(A);
如您所见,完全重新创建了以 A 为根节点的树。
虽然这个算法看起来有点“简单化”,但它基于第一个假设:两个不同的组件通常会产生不同的 DOM 结构。根据官方 React 博客,到目前为止,这种假设还没有造成严重的性能问题。这当然也给了我们一个提示,即在实现自己的组件时,保持稳定的 DOM 结构将有助于提高性能。例如,我们有时可以通过 CSS 隐藏或显示某些节点,而不是实际删除或添加 DOM 节点。
通过DOM Diff算法了解组件的生命周期
在上一篇文章中,我们介绍了React组件的生命周期。它的每个阶段实际上都与 DOM Diff 算法密切相关。例如以下方法:
为了演示组件生命周期和DOM Diff算法的关系,作者创建了一个例子:,可以直接访问试用。这时候,当DOM树经历了如下的转变,也就是从“shape1”转变为“shape2”的时候。让我们观察这些方法的实现:
浏览器开发工具控制台输出如下结果:
复制代码
C will unmount.C is created.B is updated.A is updated.C did mount.D is updated.R is updated.
如您所见,C 节点完全重建,然后添加到 D 节点,而不是“移动”它。如果有兴趣,也可以fork示例代码:。所以你可以自己添加其他树结构,并尝试如何在它们之间进行转换。
同类型节点对比
第二类节点的比较是同类型的节点,算法比较简单易懂。 React 会重置属性来实现节点转换。例如:
复制代码
renderA: renderB: => [replaceAttribute id "after"]
虚拟DOM的style属性略有不同。它的值不是简单的字符串而是必须是一个对象,所以转换过程如下:
复制代码
renderA: renderB: => [removeStyle color], [addStyle font-weight 'bold']
列表节点对比
不在同一层上的节点的比较如上所述。即使它们完全相同,它们也会被破坏和重新创建。那么当它们在同一层时是如何处理的呢?这就涉及到链表节点的Diff算法。相信很多使用React的同学都遇到过这个警告:
这是React遇到list但找不到key时提示的警告。尽管即使您忽略此警告,大多数接口也能正常工作,但这通常意味着潜在的性能问题。因为 React 觉得可能无法高效更新这个列表。
列表节点的操作通常包括添加、删除和排序。比如下图中,我们需要直接将节点F插入到B和C中。在jQuery中,我们可以直接使用$(B).after(F)来实现。在 React 中,我们只告诉 React 新的接口应该是 A-B-F-C-D-E,接口通过 Diff 算法更新。
这时候如果每个节点都没有唯一标识符,而React无法识别每个节点,更新过程会非常低效,即更新C到F,D到C,E到D,最后Insert E 节点。效果如下图所示:
如您所见,React 会一一更新节点并切换到目标节点。最后插入一个新的节点 E 涉及到很多 DOM 操作。而如果给每个节点一个唯一的键(key),那么React就能找到正确的位置插入新节点,如下图:
调整列表节点的顺序,其实和插入或删除类似。让我们用下面的示例代码来看看转换过程。仍然使用前面提到的例子:,我们将树的形状从 shape5 转换为 shape6:
同层节点的位置会有所调整。如果没有提供key,那么React认为B和C后面对应的组件类型是不同的,所以彻底删除并重建。控制台输出如下:
复制代码
B will unmount.C will unmount.C is created.B is created.C did mount.B did mount.A is updated.R is updated.
如果提供了密钥,如以下代码:
复制代码
shape5: function() { return ( );}, shape6: function() { return ( );},
然后控制台输出如下:
复制代码
C is updated.B is updated.A is updated.R is updated.
如您所见,为列表节点提供唯一的key属性可以帮助React定位到正确的节点进行比较,从而大大减少DOM操作次数,提高性能。
总结
本文分析了 React 的 DOM Diff 算法是如何工作的,其复杂度控制在 O(n)。这让我们每次都可以根据状态考虑 UI 来渲染整个界面,而不必担心性能问题。简化 UI 开发的复杂性。算法优化的基础是文章开头提到的两个假设,而React的UI是基于组件等机制的。了解虚拟DOM Diff算法不仅可以帮助我们了解组件的生命周期,而且对我们在实现自定义组件时进一步优化性能具有指导意义。
感谢徐川对本文的审阅。
如需为InfoQ中文站投稿或参与内容翻译,请发邮件至。也欢迎您关注我们的新浪微博(@InfoQ,@丁晓昀)、微信(微信ID:InfoQChina),与我们的编辑和其他读者朋友交流(欢迎加入InfoQ读者交流群
). 查看全部
React中最神奇的部分莫过于虚拟DOM,以及其高效的Diff算法
React 最神奇的部分是虚拟 DOM 及其高效的 Diff 算法。这使我们可以随时“刷新”整个页面而不必担心性能问题。虚拟 DOM 确保仅实际更改界面上的实际 DOM 操作。 React 在这部分已经足够透明了。在实际开发中,我们基本不需要关心虚拟 DOM 是如何工作的。然而,作为有态度的程序员,我们总是对技术背后的原理感到好奇。了解其运行机制不仅有助于更好地理解 React 组件的生命周期,而且对于进一步优化 React 程序也有很大帮助。
什么是 DOM Diff 算法
Web 界面由 DOM 树组成。当它的某一部分发生变化时,实际上是相应的DOM节点发生了变化。在 React 中,构建 UI 界面的想法是当前状态决定界面。前后两个状态对应两组接口,然后React比较两组接口的差异,这需要DOM树的Diff算法分析。
给定任意两棵树,找出最少的转换步骤。但是标准的Diff算法复杂度需要O(n^3),显然不能满足性能要求。要达到每次整体刷新界面的目标,必须对算法进行优化。这看起来很困难但是Facebook工程师做到了,他们结合Web界面的特点,做了两个简单的假设,直接将Diff算法的复杂度降低到O(n)
两个相同的组件产生相似的DOM结构,不同的组件产生不同的DOM结构;对于同一层级的一组子节点,可以通过唯一的id来区分。
算法优化是 React 整个界面 Render 的基础。事实也证明,这两个假设是合理且准确的,保证了整体接口构建的性能。
不同节点类型的比较
为了在树之间进行比较,我们首先必须能够比较两个节点。在 React 中,我们比较两个虚拟 DOM 节点。当两个节点不同时我们应该怎么做?这分两种情况:(1)node类型不同,(2)node类型相同,但属性不同。本节先看第一种情况。
当树中相同位置前后输出不同类型的节点时,React直接删除之前的节点,然后创建并插入一个新节点。假设我们在树中的同一位置前后两次输出不同类型的节点。
复制代码
renderA: renderB: => [removeNode ], [insertNode ]
当一个节点从 div 变为 span 时,只需删除 div 节点并插入一个新的 span 节点即可。这符合我们对真实DOM操作的理解。
需要注意的是,删除一个节点意味着彻底销毁该节点,而不是在后续的比较中检查是否还有另一个节点等同于被删除的节点。如果删除的节点下还有子节点,这些子节点也会被彻底删除,不会用于后续的比较。这就是为什么算法复杂度可以降低到 O(n) 的原因。
上面说的是虚拟DOM节点的操作,同样的逻辑也用在React组件的比较中,例如:
复制代码
renderA: renderB: => [removeNode ], [insertNode ]
当 React 在同一位置遇到不同的组件时,它只会销毁第一个组件并添加新创建的组件。这是第一个假设的应用。不同的组件通常会产生不同的 DOM 结构。与其浪费时间比较基本不等价的 DOM 结构,不如创建一个新组件并添加它。
从这个 React 对不同类型节点的处理逻辑,我们可以很容易地推断出 React 的 DOM Diff 算法实际上只是逐层比较树,如下所述。
逐层比较节点
说到树,相信大多数同学第一时间想到的是二叉树、遍历、最短路径等复杂的数据结构算法。在 React 中,树算法其实很简单,就是两棵树只会比较同一层级的节点。如下图所示:
React 只会比较同一个颜色框中的 DOM 节点,即同一个父节点下的所有子节点。当发现该节点不再存在时,该节点及其子节点将被完全删除,不再用于进一步比较。这样整个DOM树的比较只需遍历一次树即可完成。
例如,考虑以下 DOM 结构转换:
A节点完全移到D节点,直观考虑DOM Diff操作应该是
复制代码
A.parent.remove(A); D.append(A);
但是因为React只是简单的考虑了同层节点的位置变换,对于不同层的节点,只有简单的创建和删除。当根节点发现子节点中的A缺失时,直接销毁A;而当D发现自己多了一个子节点A时,就会创建一个新的A作为子节点。因此,这种结构转换的实际操作是:
复制代码
A.destroy();A = new A();A.append(new B());A.append(new C());D.append(A);
如您所见,完全重新创建了以 A 为根节点的树。
虽然这个算法看起来有点“简单化”,但它基于第一个假设:两个不同的组件通常会产生不同的 DOM 结构。根据官方 React 博客,到目前为止,这种假设还没有造成严重的性能问题。这当然也给了我们一个提示,即在实现自己的组件时,保持稳定的 DOM 结构将有助于提高性能。例如,我们有时可以通过 CSS 隐藏或显示某些节点,而不是实际删除或添加 DOM 节点。
通过DOM Diff算法了解组件的生命周期
在上一篇文章中,我们介绍了React组件的生命周期。它的每个阶段实际上都与 DOM Diff 算法密切相关。例如以下方法:
为了演示组件生命周期和DOM Diff算法的关系,作者创建了一个例子:,可以直接访问试用。这时候,当DOM树经历了如下的转变,也就是从“shape1”转变为“shape2”的时候。让我们观察这些方法的实现:
浏览器开发工具控制台输出如下结果:
复制代码
C will unmount.C is created.B is updated.A is updated.C did mount.D is updated.R is updated.
如您所见,C 节点完全重建,然后添加到 D 节点,而不是“移动”它。如果有兴趣,也可以fork示例代码:。所以你可以自己添加其他树结构,并尝试如何在它们之间进行转换。
同类型节点对比
第二类节点的比较是同类型的节点,算法比较简单易懂。 React 会重置属性来实现节点转换。例如:
复制代码
renderA: renderB: => [replaceAttribute id "after"]
虚拟DOM的style属性略有不同。它的值不是简单的字符串而是必须是一个对象,所以转换过程如下:
复制代码
renderA: renderB: => [removeStyle color], [addStyle font-weight 'bold']
列表节点对比
不在同一层上的节点的比较如上所述。即使它们完全相同,它们也会被破坏和重新创建。那么当它们在同一层时是如何处理的呢?这就涉及到链表节点的Diff算法。相信很多使用React的同学都遇到过这个警告:
这是React遇到list但找不到key时提示的警告。尽管即使您忽略此警告,大多数接口也能正常工作,但这通常意味着潜在的性能问题。因为 React 觉得可能无法高效更新这个列表。
列表节点的操作通常包括添加、删除和排序。比如下图中,我们需要直接将节点F插入到B和C中。在jQuery中,我们可以直接使用$(B).after(F)来实现。在 React 中,我们只告诉 React 新的接口应该是 A-B-F-C-D-E,接口通过 Diff 算法更新。
这时候如果每个节点都没有唯一标识符,而React无法识别每个节点,更新过程会非常低效,即更新C到F,D到C,E到D,最后Insert E 节点。效果如下图所示:
如您所见,React 会一一更新节点并切换到目标节点。最后插入一个新的节点 E 涉及到很多 DOM 操作。而如果给每个节点一个唯一的键(key),那么React就能找到正确的位置插入新节点,如下图:
调整列表节点的顺序,其实和插入或删除类似。让我们用下面的示例代码来看看转换过程。仍然使用前面提到的例子:,我们将树的形状从 shape5 转换为 shape6:
同层节点的位置会有所调整。如果没有提供key,那么React认为B和C后面对应的组件类型是不同的,所以彻底删除并重建。控制台输出如下:
复制代码
B will unmount.C will unmount.C is created.B is created.C did mount.B did mount.A is updated.R is updated.
如果提供了密钥,如以下代码:
复制代码
shape5: function() { return ( );}, shape6: function() { return ( );},
然后控制台输出如下:
复制代码
C is updated.B is updated.A is updated.R is updated.
如您所见,为列表节点提供唯一的key属性可以帮助React定位到正确的节点进行比较,从而大大减少DOM操作次数,提高性能。
总结
本文分析了 React 的 DOM Diff 算法是如何工作的,其复杂度控制在 O(n)。这让我们每次都可以根据状态考虑 UI 来渲染整个界面,而不必担心性能问题。简化 UI 开发的复杂性。算法优化的基础是文章开头提到的两个假设,而React的UI是基于组件等机制的。了解虚拟DOM Diff算法不仅可以帮助我们了解组件的生命周期,而且对我们在实现自定义组件时进一步优化性能具有指导意义。
感谢徐川对本文的审阅。
如需为InfoQ中文站投稿或参与内容翻译,请发邮件至。也欢迎您关注我们的新浪微博(@InfoQ,@丁晓昀)、微信(微信ID:InfoQChina),与我们的编辑和其他读者朋友交流(欢迎加入InfoQ读者交流群
).
数据挖掘决策参考的统计分析数据.在深层次的层次上的应用
采集交流 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2021-08-21 22:11
数据挖掘,也称为数据挖掘、数据挖掘等,是根据既定的业务目标从海量数据中提取潜在、有效和可理解的模式的高级过程。在较浅的层面上,利用现有数据库管理系统的查询、搜索和报告功能,结合多维分析和统计分析方法,进行在线分析处理(O易信),从而获得参考用于决策数据的统计分析。在更深层次上,从数据库中发现了前所未有的隐性知识。 OLAF'出现的时间早于数据挖掘。它们都是从数据库中提取有用信息的方法。就决策支持的需求而言,两者是相辅相成的。
数据挖掘是一个多学科领域,它结合了数据库技术、人工智能、机器学习、模式识别、模糊数学和数理统计的最新研究成果,可用于支持商业智能应用和决策分析。例如客户细分、交叉销售、欺诈检测、客户流失分析、产品销售预测等,目前广泛应用于银行、金融、医疗、工业、零售和电信行业。数据挖掘技术的发展对各行各业都具有重要的现实意义。
数据挖掘以全新的视角将数据库技术、统计学、机器学习、信息检索技术、数据可视化和模式识别与人工智能等领域相结合。发现其他传统方法无法发现的有用知识。
数据挖掘可以解决很多问题,但是实现过程是一个非常繁琐的过程,只有在计算机基础丰富的情况下才能实现。随着信息技术的发展,出现了许多数据挖掘工具。其中,NLPIR大数据语义智能分析平台(原ICTCLAS)是一个比较好的系统。它由北京理工大学大数据搜索与挖掘实验室主任张华平开发。针对大数据内容获取、编辑、挖掘、搜索的综合需求,融合网络精准采集、自然语言理解、文本挖掘、语义搜索等最新研究成果,近二十年来不断创新平台提供客户端工具、云服务、二次开发接口等多种产品使用形式。每个中间件API都可以无缝集成到客户的各种复杂应用系统中,兼容Windows、Linux、Android、Maemo5、FreeBSD等不同操作系统平台,可用于Java、Python、C等各种开发、C# 等语言用法。
NLPIR大数据语义智能分析平台的十三项功能:
NLPIR大数据语义智能分析平台客户端
精准采集:国内外海量信息实时精准采集,有话题采集(话题采集根据信息需要)和网站采集(站内)使用给定的 URL 列表)定点 采集 函数)。
文档转换:对doc、excel、pdf、ppt等多种主流文档格式的文本信息进行转换,效率满足大数据处理要求。
新词发现:从文本中发现新词、新概念,用户可以将其用于专业词典的编纂,还可以进一步编辑标注,导入分词词典,提高分词准确率分词系统,适应新的语言变化。
批量分词:对原创语料进行分词,自动识别姓名、地名、机构名称等未注册词,新词标注,词性标注。并在分析过程中,导入用户自定义词典。
语言统计:根据分词和标注结果,系统可以自动进行一元词频数统计和二元词转移概率统计。对于常用术语,会自动给出相应的英文解释。
文本聚类:可以从大规模数据中自动分析热点事件,并提供事件主题的关键特征描述。同时适用于短文、微博等长文和短文的热点分析。
文本分类:根据规则或训练方法对大量文本进行分类,可用于新闻分类、简历分类、邮件分类、办公文档分类、区域分类等多个方面。
摘要实体:对于单个或多个文章,自动提取内容摘要,提取人名、地名、机构名称、时间和主题关键词;方便用户快速浏览文本内容。
智能过滤:对文本内容进行语义智能过滤和审核,内置国内最全词库,智能识别变形、拼音、繁体、简体等多种变体,语义精准消歧。
情感分析:针对预先指定的分析对象,系统自动分析海量文档的情感倾向:情感极性和情感值测度,并给出原文中的正负分和句例。
文档去重:快速准确判断文件集合或数据库中是否存在内容相同或相似的记录,同时查找所有重复记录。
全文搜索:支持文本、数字、日期、字符串等多种数据类型,多字段高效搜索,支持AND/OR/NOT、NEAR接近等查询语法,支持维文、藏文、蒙古语、阿拉伯语、韩语等多种少数民族语言搜索。
编码转换:自动识别内容的编码,统一将编码转换为其他编码。
以上是推荐的中文分词工具。我希望它能帮助你。如果您有任何问题,请联系我,我会帮助您! 查看全部
数据挖掘决策参考的统计分析数据.在深层次的层次上的应用
数据挖掘,也称为数据挖掘、数据挖掘等,是根据既定的业务目标从海量数据中提取潜在、有效和可理解的模式的高级过程。在较浅的层面上,利用现有数据库管理系统的查询、搜索和报告功能,结合多维分析和统计分析方法,进行在线分析处理(O易信),从而获得参考用于决策数据的统计分析。在更深层次上,从数据库中发现了前所未有的隐性知识。 OLAF'出现的时间早于数据挖掘。它们都是从数据库中提取有用信息的方法。就决策支持的需求而言,两者是相辅相成的。
数据挖掘是一个多学科领域,它结合了数据库技术、人工智能、机器学习、模式识别、模糊数学和数理统计的最新研究成果,可用于支持商业智能应用和决策分析。例如客户细分、交叉销售、欺诈检测、客户流失分析、产品销售预测等,目前广泛应用于银行、金融、医疗、工业、零售和电信行业。数据挖掘技术的发展对各行各业都具有重要的现实意义。
数据挖掘以全新的视角将数据库技术、统计学、机器学习、信息检索技术、数据可视化和模式识别与人工智能等领域相结合。发现其他传统方法无法发现的有用知识。
数据挖掘可以解决很多问题,但是实现过程是一个非常繁琐的过程,只有在计算机基础丰富的情况下才能实现。随着信息技术的发展,出现了许多数据挖掘工具。其中,NLPIR大数据语义智能分析平台(原ICTCLAS)是一个比较好的系统。它由北京理工大学大数据搜索与挖掘实验室主任张华平开发。针对大数据内容获取、编辑、挖掘、搜索的综合需求,融合网络精准采集、自然语言理解、文本挖掘、语义搜索等最新研究成果,近二十年来不断创新平台提供客户端工具、云服务、二次开发接口等多种产品使用形式。每个中间件API都可以无缝集成到客户的各种复杂应用系统中,兼容Windows、Linux、Android、Maemo5、FreeBSD等不同操作系统平台,可用于Java、Python、C等各种开发、C# 等语言用法。
NLPIR大数据语义智能分析平台的十三项功能:
NLPIR大数据语义智能分析平台客户端
精准采集:国内外海量信息实时精准采集,有话题采集(话题采集根据信息需要)和网站采集(站内)使用给定的 URL 列表)定点 采集 函数)。
文档转换:对doc、excel、pdf、ppt等多种主流文档格式的文本信息进行转换,效率满足大数据处理要求。
新词发现:从文本中发现新词、新概念,用户可以将其用于专业词典的编纂,还可以进一步编辑标注,导入分词词典,提高分词准确率分词系统,适应新的语言变化。
批量分词:对原创语料进行分词,自动识别姓名、地名、机构名称等未注册词,新词标注,词性标注。并在分析过程中,导入用户自定义词典。
语言统计:根据分词和标注结果,系统可以自动进行一元词频数统计和二元词转移概率统计。对于常用术语,会自动给出相应的英文解释。
文本聚类:可以从大规模数据中自动分析热点事件,并提供事件主题的关键特征描述。同时适用于短文、微博等长文和短文的热点分析。
文本分类:根据规则或训练方法对大量文本进行分类,可用于新闻分类、简历分类、邮件分类、办公文档分类、区域分类等多个方面。
摘要实体:对于单个或多个文章,自动提取内容摘要,提取人名、地名、机构名称、时间和主题关键词;方便用户快速浏览文本内容。
智能过滤:对文本内容进行语义智能过滤和审核,内置国内最全词库,智能识别变形、拼音、繁体、简体等多种变体,语义精准消歧。
情感分析:针对预先指定的分析对象,系统自动分析海量文档的情感倾向:情感极性和情感值测度,并给出原文中的正负分和句例。
文档去重:快速准确判断文件集合或数据库中是否存在内容相同或相似的记录,同时查找所有重复记录。
全文搜索:支持文本、数字、日期、字符串等多种数据类型,多字段高效搜索,支持AND/OR/NOT、NEAR接近等查询语法,支持维文、藏文、蒙古语、阿拉伯语、韩语等多种少数民族语言搜索。
编码转换:自动识别内容的编码,统一将编码转换为其他编码。
以上是推荐的中文分词工具。我希望它能帮助你。如果您有任何问题,请联系我,我会帮助您!
关于使用Python分析财务报表的场景,你需要知道的
采集交流 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-08-21 19:13
总结
1) 获取需要下载数据的股票代码列表
2)寻找可以下载数据的数据接口
3)下载并保存数据
先写
之前我在《所有A股市场金融指数数据汇总-知乎专栏》和《如何通过财务报表分析行业特征》文章中提到并使用了Python。从反应来看,大家对如何使用Python分析财务报表产生了浓厚的兴趣。这就是文章存在的原因。
关于使用Python分析财务报表的场景,我认为主要有:1)同业分析:批量计算比较,即展示或导出同行业的财务指标; 2)选股:比如过滤近三年roe大于15%的公司,最近一期roe大于15%的所有公司等,如果是单个公司来分析,给大家看看我之前提供的《一款金融分析工具(Excel版)-知乎Column》。这个工具已经涵盖了主要的主题和变化,增长分析等,我现在也在用这个工具。一般来说,选择合适的工具也可以事半功倍。 .
本文分为两部分,第一部分主要讲数据采集,第二部分主要讲通过财务指标进行对比分析
有朋友问为什么不直接分享代码。事实上,完成财务分析所需的代码是如此简单,任何程序员写的都比我漂亮一百倍。可能是网工的财务分析比较好),但一方面要注意别有用心的人滥用接口,导致接口失效。另一方面,爬取别人的网站数据也不好,所以涉及的金融接口不适合公开。基于这些考虑,我之前分享的EXCEL工具也对代码部分进行了加密。同样,我不打算在本文中公开分享代码,而只是分享想法。有兴趣的可以在主财经网站找到下载界面。所有的接口都找到了。按照本文的思路,很容易得到整个市场上市公司的财务数据。如果实在找不到,可以私信我的邮箱,我可以提供我的示例代码供大家参考。
至于您提供的电子邮件地址,我个人承诺,除了发送所需信息外,不会用于任何其他目的。不过也建议大家保护好自己的隐私,尽量不要在评论区留下联系方式和私信,方便我回复(我经常在评论区找不到,所以我不能还给你)
这篇文章虽然简单,但还是需要一定的Python基础。如果你对Python一窍不通,但对它比较感兴趣,建议你搜索《廖雪峰Python3》教程(Pyhon2已过期不再使用),写的简单又免费。本文示例代码基于Python3.5,演示平台为JupyterNotebook。关于环境的搭建,在Windows系统上可以直接安装Anconda,一切都会为你安装。至于其他系统比如Linux,我假设你是一个IT人员。部署开发环境应该是小菜一碟。不做详细介绍。
采集财务数据
结束了。让我们回到正题。网络爬虫需要解决三个主要问题:
1) 爬什么?
2) 去哪里爬?
3) 数据清洗和存储?
一、获取所有股票代码
为了抓取所有上市公司的财务数据,我们首先需要获取所有上市公司的公司代码。这在 Python 中有一个很好的解决方案。即使用途享金融库,可以获取所有股票代码、沪深300成分股等,如果没有安装,请使用pip install tushare安装途享金融库。官网:
1)查看是否安装了tushare:
创建一个新的 Notebook 并在单元格中输入 Python 代码
import tushare as t
t.__version__
输入后按SHIFT+ENTER运行,显示
这是最新的0.8.2 版本。
2) 获取股票列表(在另一个单元格中输入代码):
stocks_df=t.get_stock_basics()
stocks_df
这两句的作用是通过tushare金融数据库获取所有股票的列表和基本信息,并返回一些股票的基本信息,如地区、行业、总资产等。返回结果是一个 pandas.DataFrame 表。根据网络环境,此代码可能需要大约 5-6 秒。返回结果:
返回值有20多个字段。我们只需要一部分数据。您可以使用 ix slice 剪切股票代码、名称、地区和行业。 (比如我们只截取name、area、industry字段)
stock_df=stock_df.ix[:,['name','industry','area']]
# ix[行条件,列条件],这里表示截取所有行,name,industry,area字段,返回一个DATAFRAME
stock_df
如果您对一些新股不敏感,可以将数据另存为csv/xls文件以备多次使用。
注意:从文件中读取股票列表后,会自动处理股票代码前的“0”,循环下载数据时需加上“0”。
股票清单从那时起就可用了。
二、寻找合适的金融数据接口
由于Python可以直接处理的文件格式是xml/csv/json/xls,我们尝试寻找可以提供这种格式文本的数据接口。
此外,我更喜欢 csv 格式的文本。这段文字紧凑,可以说没有无用字节。但是得到的数据可能不是你需要的格式,所以你需要把数据转换成你需要的(为了说明数据清洗和转换的过程,我这里特地选择了一个xls格式的财务接口)
2.1.查找数据接口
很多财经网站都有下载财务报表的界面。由于我们已经获得了所有股票的列表,我们可以依次将股票代码传递到下载界面来获取所有股票的财务数据。让我们先找到可用的。财务数据接口。
1)打开任意财经网站Stock专栏
2)输入任意股票代码,如600660,进入股票详情页面
3) 查找财务报表、财务数据、财务分析等词,进入细分栏目。
4) 您应该能够在本节中找到、下载或导出函数。现在重要的是,右键单击链接并选择复制链接地址
如果,
下载数据是按钮而不是链接,可以先用Chrome下载数据,然后按
Ctrl+J 查看下载历史,可以看到下载地址。如果还是不行,可能需要使用抓包工具之类的了。
5) 分析链接地址并检查传入股票代码的位置。比如链接地址是:/report.jsp?id=600660 那么这个600660就是入股代码。
2.2.通过程序下载数据
得到接口地址后,我们就可以通过程序下载数据了。
import requests as ro
stock_code = '600660'
bs_url='http://soft-f9.eastmoney.com/soft/gp15.php?code={co}01&exp=1'.format(co=stock_code)
ct = ro.get(bs_url).text
ct
看到一堆乱码(其实不是乱码,是xml,后面再讲转成csv文本)
三、数据清理与存储
1)数据清洗
得到的数据结构太复杂,需要清理和转换。之前,我在《几行代码从EXCELL获取有效数据》文章中演示了数据的清洗。请参考原文。再次重复描述。
2) 数据保存
财务报表是有效期相对较长的数据。为了避免每次使用时重复下载,可以将数据存储在本地。存储方式一般有文件方式或数据库方式。由于数据量不大,可以直接保存为csv文件。不过为了方便查阅,文件命名方式可以稍微标注一下,如将报告类型命名为-股票代码.csv,以便于阅读。
四、编写Python程序下载数据
#!/usr/bin/py
# filename=RPDownloader.py
from modules.Utils import e2csv
from modules.Fi import tcode
import pandas as Pd
import requests as ro
# 下载资产负债表
def downloadBSRP(stocklist):
num = 0
for c in stocklist:
bs_url='http://soft-f9.eastmoney.com/soft/gp15.php?code={co}01&exp=1'.format(co=tcode(c))
ct = ro.get(bs_url).text
to_file='bs{co}.csv'.format(co=tcode(c))
open(to_file,'w').write(e2csv(ct))
num = num + 1
return num
函数的返回值是成功下载报告的数量(这里不做容错处理。如果下载量大,需要容错处理。另外,必须在程序后解决异常退出,下次再次进入,避免重复下载下载的文件。数据,另外,为了避免IP地址被封锁,下载后必须加一个延迟,这些内容留给大家下面学习),测试代码:
显示已成功下载两张股票资产负债表。
根据以上内容,还可以下载损益表和现金流量表。
至此,财务数据采集一章结束。下一篇文章是关于如何使用这些数据进行财务分析。 查看全部
关于使用Python分析财务报表的场景,你需要知道的
总结
1) 获取需要下载数据的股票代码列表
2)寻找可以下载数据的数据接口
3)下载并保存数据
先写
之前我在《所有A股市场金融指数数据汇总-知乎专栏》和《如何通过财务报表分析行业特征》文章中提到并使用了Python。从反应来看,大家对如何使用Python分析财务报表产生了浓厚的兴趣。这就是文章存在的原因。
关于使用Python分析财务报表的场景,我认为主要有:1)同业分析:批量计算比较,即展示或导出同行业的财务指标; 2)选股:比如过滤近三年roe大于15%的公司,最近一期roe大于15%的所有公司等,如果是单个公司来分析,给大家看看我之前提供的《一款金融分析工具(Excel版)-知乎Column》。这个工具已经涵盖了主要的主题和变化,增长分析等,我现在也在用这个工具。一般来说,选择合适的工具也可以事半功倍。 .
本文分为两部分,第一部分主要讲数据采集,第二部分主要讲通过财务指标进行对比分析
有朋友问为什么不直接分享代码。事实上,完成财务分析所需的代码是如此简单,任何程序员写的都比我漂亮一百倍。可能是网工的财务分析比较好),但一方面要注意别有用心的人滥用接口,导致接口失效。另一方面,爬取别人的网站数据也不好,所以涉及的金融接口不适合公开。基于这些考虑,我之前分享的EXCEL工具也对代码部分进行了加密。同样,我不打算在本文中公开分享代码,而只是分享想法。有兴趣的可以在主财经网站找到下载界面。所有的接口都找到了。按照本文的思路,很容易得到整个市场上市公司的财务数据。如果实在找不到,可以私信我的邮箱,我可以提供我的示例代码供大家参考。
至于您提供的电子邮件地址,我个人承诺,除了发送所需信息外,不会用于任何其他目的。不过也建议大家保护好自己的隐私,尽量不要在评论区留下联系方式和私信,方便我回复(我经常在评论区找不到,所以我不能还给你)
这篇文章虽然简单,但还是需要一定的Python基础。如果你对Python一窍不通,但对它比较感兴趣,建议你搜索《廖雪峰Python3》教程(Pyhon2已过期不再使用),写的简单又免费。本文示例代码基于Python3.5,演示平台为JupyterNotebook。关于环境的搭建,在Windows系统上可以直接安装Anconda,一切都会为你安装。至于其他系统比如Linux,我假设你是一个IT人员。部署开发环境应该是小菜一碟。不做详细介绍。
采集财务数据
结束了。让我们回到正题。网络爬虫需要解决三个主要问题:
1) 爬什么?
2) 去哪里爬?
3) 数据清洗和存储?
一、获取所有股票代码
为了抓取所有上市公司的财务数据,我们首先需要获取所有上市公司的公司代码。这在 Python 中有一个很好的解决方案。即使用途享金融库,可以获取所有股票代码、沪深300成分股等,如果没有安装,请使用pip install tushare安装途享金融库。官网:
1)查看是否安装了tushare:
创建一个新的 Notebook 并在单元格中输入 Python 代码
import tushare as t
t.__version__
输入后按SHIFT+ENTER运行,显示
这是最新的0.8.2 版本。
2) 获取股票列表(在另一个单元格中输入代码):
stocks_df=t.get_stock_basics()
stocks_df
这两句的作用是通过tushare金融数据库获取所有股票的列表和基本信息,并返回一些股票的基本信息,如地区、行业、总资产等。返回结果是一个 pandas.DataFrame 表。根据网络环境,此代码可能需要大约 5-6 秒。返回结果:
返回值有20多个字段。我们只需要一部分数据。您可以使用 ix slice 剪切股票代码、名称、地区和行业。 (比如我们只截取name、area、industry字段)
stock_df=stock_df.ix[:,['name','industry','area']]
# ix[行条件,列条件],这里表示截取所有行,name,industry,area字段,返回一个DATAFRAME
stock_df
如果您对一些新股不敏感,可以将数据另存为csv/xls文件以备多次使用。
注意:从文件中读取股票列表后,会自动处理股票代码前的“0”,循环下载数据时需加上“0”。
股票清单从那时起就可用了。
二、寻找合适的金融数据接口
由于Python可以直接处理的文件格式是xml/csv/json/xls,我们尝试寻找可以提供这种格式文本的数据接口。
此外,我更喜欢 csv 格式的文本。这段文字紧凑,可以说没有无用字节。但是得到的数据可能不是你需要的格式,所以你需要把数据转换成你需要的(为了说明数据清洗和转换的过程,我这里特地选择了一个xls格式的财务接口)
2.1.查找数据接口
很多财经网站都有下载财务报表的界面。由于我们已经获得了所有股票的列表,我们可以依次将股票代码传递到下载界面来获取所有股票的财务数据。让我们先找到可用的。财务数据接口。
1)打开任意财经网站Stock专栏
2)输入任意股票代码,如600660,进入股票详情页面
3) 查找财务报表、财务数据、财务分析等词,进入细分栏目。
4) 您应该能够在本节中找到、下载或导出函数。现在重要的是,右键单击链接并选择复制链接地址
如果,
下载数据是按钮而不是链接,可以先用Chrome下载数据,然后按
Ctrl+J 查看下载历史,可以看到下载地址。如果还是不行,可能需要使用抓包工具之类的了。
5) 分析链接地址并检查传入股票代码的位置。比如链接地址是:/report.jsp?id=600660 那么这个600660就是入股代码。
2.2.通过程序下载数据
得到接口地址后,我们就可以通过程序下载数据了。
import requests as ro
stock_code = '600660'
bs_url='http://soft-f9.eastmoney.com/soft/gp15.php?code={co}01&exp=1'.format(co=stock_code)
ct = ro.get(bs_url).text
ct
看到一堆乱码(其实不是乱码,是xml,后面再讲转成csv文本)
三、数据清理与存储
1)数据清洗
得到的数据结构太复杂,需要清理和转换。之前,我在《几行代码从EXCELL获取有效数据》文章中演示了数据的清洗。请参考原文。再次重复描述。
2) 数据保存
财务报表是有效期相对较长的数据。为了避免每次使用时重复下载,可以将数据存储在本地。存储方式一般有文件方式或数据库方式。由于数据量不大,可以直接保存为csv文件。不过为了方便查阅,文件命名方式可以稍微标注一下,如将报告类型命名为-股票代码.csv,以便于阅读。
四、编写Python程序下载数据
#!/usr/bin/py
# filename=RPDownloader.py
from modules.Utils import e2csv
from modules.Fi import tcode
import pandas as Pd
import requests as ro
# 下载资产负债表
def downloadBSRP(stocklist):
num = 0
for c in stocklist:
bs_url='http://soft-f9.eastmoney.com/soft/gp15.php?code={co}01&exp=1'.format(co=tcode(c))
ct = ro.get(bs_url).text
to_file='bs{co}.csv'.format(co=tcode(c))
open(to_file,'w').write(e2csv(ct))
num = num + 1
return num
函数的返回值是成功下载报告的数量(这里不做容错处理。如果下载量大,需要容错处理。另外,必须在程序后解决异常退出,下次再次进入,避免重复下载下载的文件。数据,另外,为了避免IP地址被封锁,下载后必须加一个延迟,这些内容留给大家下面学习),测试代码:
显示已成功下载两张股票资产负债表。
根据以上内容,还可以下载损益表和现金流量表。
至此,财务数据采集一章结束。下一篇文章是关于如何使用这些数据进行财务分析。

