
算法 自动采集列表
创业不实现技术部署,完全被市场比较难看好?
采集交流 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-08-20 18:06
算法自动采集列表页首页的内容,大数据进行智能推荐,可以搜索,关注,分享,留言等操作。也可以单独采集问答页某个问题的答案。还可以采集相似问题的答案,
技术上是不难实现的,大概就是多个浏览器的、采集器、大数据平台、内容过滤的兼容性,权限等等,一个成熟的大数据技术商一般都会提供技术部署方案、供我们使用。但是创业,不实现技术部署,完全被市场比较难看好,所以你应该换个创业思路,而不是选一个方向继续独立开发。
关键点还是你的业务什么最需要什么,什么是用户最在意的。找到你要实现的业务痛点,加上个人技术的不断积累和进步,你的东西不难。
个人拙见:技术实现当然不难,只要用心就行了,但商业市场却很难。这东西看似很理想化,看似很偏门,看似不可复制。其实只要抓住了用户的需求,抓住了痛点,很多东西都可以脱颖而出。大数据的概念也越来越被更多人认可,不论是企业还是个人都会有采集数据的需求。如果可以从大数据的角度去分析和思考,研究它背后的原理,比如去伪存真、挖掘需求和痛点、演化创新,将有助于打造特色的产品。
都说不难,实现起来还是有一定难度,前期费用高,最好团队有技术积累,这样可以大幅降低实现难度!有许多创业团队,成立这样一个团队可能都还没成立,就要求注册,各种材料填写, 查看全部
创业不实现技术部署,完全被市场比较难看好?
算法自动采集列表页首页的内容,大数据进行智能推荐,可以搜索,关注,分享,留言等操作。也可以单独采集问答页某个问题的答案。还可以采集相似问题的答案,
技术上是不难实现的,大概就是多个浏览器的、采集器、大数据平台、内容过滤的兼容性,权限等等,一个成熟的大数据技术商一般都会提供技术部署方案、供我们使用。但是创业,不实现技术部署,完全被市场比较难看好,所以你应该换个创业思路,而不是选一个方向继续独立开发。
关键点还是你的业务什么最需要什么,什么是用户最在意的。找到你要实现的业务痛点,加上个人技术的不断积累和进步,你的东西不难。
个人拙见:技术实现当然不难,只要用心就行了,但商业市场却很难。这东西看似很理想化,看似很偏门,看似不可复制。其实只要抓住了用户的需求,抓住了痛点,很多东西都可以脱颖而出。大数据的概念也越来越被更多人认可,不论是企业还是个人都会有采集数据的需求。如果可以从大数据的角度去分析和思考,研究它背后的原理,比如去伪存真、挖掘需求和痛点、演化创新,将有助于打造特色的产品。
都说不难,实现起来还是有一定难度,前期费用高,最好团队有技术积累,这样可以大幅降低实现难度!有许多创业团队,成立这样一个团队可能都还没成立,就要求注册,各种材料填写,
一种自动抽取列表页的技术方案解决方案页
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-08-17 23:14
一种自动抽取列表页的技术方案解决方案页
本发明涉及网络技术领域,尤其涉及一种自动提取列表页面的方法。
背景技术:
传统的列表页面提取技术主要是规则的形式,比较常用的是通过正则表达式、xpath、css选择器,甚至是手动的方式来获取页面采集down的信息。
单个网页可以通过正则表达式等方法准确获取采集想要的信息,而正则表达式和css选择器等方法本质上是人们通过观察网页源代码的规则总结出来的。然后使用这些规则进行提取。这种方法很难在不同结构的网页上用相同的规则集提取,因为不同的网页需要不同的规则来支持提取。当用户需要采集大量网页时,需要依靠人工编写大量规则,这种效率不仅低,甚至上千甚至几万个网站,仅仅依靠手动已经完全不可能了。不仅如此,依赖规则的抽取方式仅限于网页本身。 网站修改后,原来的规则将不再适用,需要手动重写规则,这也使得一些依赖开源信息采集的项目维护成本变得极高。<//p
p技术实现要素:/p
p本发明要解决的技术问题是提供一种适用性强、效率高的列表页面自动提取方法。/p
p为解决上述技术问题,本发明的技术方案是:一种自动提取列表页面的方法,包括以下步骤:/p
p(1)dom树生成:得到网页源码为采集网站;将网页源码解析成dom树;根据dom树进行前序遍历,并记录dom树中的每一片叶子元素的节点路径;提取并保存元素的节点路径,带文本;/p
p(2)获取1)中提取文本的元素节点的位置信息,根据元素节点的位置信息进行评分,过滤掉不符合列表视觉可能性的元素节点页面;/p
p(3)根据节点路径的相似度以及与满足列表页面信息约束的节点特征的相似度,判断多个节点是否有相似指纹,对指纹相似的节点进行分类聚合。列表页信息至少包括标题和地址链接,指纹相似意味着不同节点满足一定的约束条件,构成列表页信息;/p
p(4)对多个具有多个相似指纹的节点进行分类聚合,可以将完整的列表页信息组成节点块,形成列表页的深度指纹;/p
p(5)从列表页的深度指纹中提取出标题和地址链接的相似指纹;/p
p(6)Extraction 列表页,返回封装结果。/p
p作为优选的技术方案,步骤(2)具体包括:/p
p(2.1)采集html 网页的css和js文件获取节点位置信息;/p
p(2.2)每页解析后计算dom树元素节点的像素位置;/p
p(2.3) 判断元素节点是否满足列表页面的视觉可能性,具体包括:如果元素节点是隐藏节点,则元素节点是无效节点;如果元素的像素node 网页左上角位置的像素位置小于设置的阈值,元素节点为无效节点;元素节点的像素位置离网页中心点越远,元素节点的得分越低,元素节点的得分与列表页面的提取精度有关。/p
p作为优选的技术方案,在步骤(3),满足列表页面信息约束的节点特征包括节点属性标签和节点文本信息标签,其中节点属性标签的相似度和方差为节点属性成反比,节点属性的方差:/p
p其中a代表单个节点的属性向量,b代表该类别下所有节点的平均属性向量;/p
p节点文本信息的相似度与文本词数的方差成反比,则节点文本词数的方差:/p
p其中,表示所有节点中文本信息词的平均密度,n表示节点数;/p
p作为优选的技术方案,步骤4还包括:/p
p(4.1)计算节点路径的预深度比,即节点深度指纹组成的节点块共有的节点路径长度与最长节点路径长度的比值:/p
p(4.2)对深度指纹聚合的节点块进行打分和排序,计算出最可能的列表页深度指纹。节点块的得分:/p
p其中αi为衰减系数。/p
p作为优选的技术方案,在步骤(5),标题指纹是指满足标题约束条件的特征,提取满足标题约束条件的相似指纹,得到标题文字。/p
pp>
作为优选的技术方案,还包括设置列表页面提取规则和通过提取规则提取列表页面的步骤。
由于采用了上述技术方案,本发明的有益效果是本发明可以应用于大量的互联网网站列表页面提取,不限于繁琐冗余的规则,并且只需要通过网页网址或源代码。自动提取列表页的标题、链接等,由于本发明对大量的列表页具有普遍适用性,即使出现网站改版,基于网页结构的提取方法也可以仍然有效,节省了重写提取规则和维护规则产生的时间成本和人工成本。
在基于网页的结构提取算法中,还加入了网页元素的位置像素信息作为特征,更加符合人们对列表页面的感官判断,使得提取结果更加符合与目标。
图纸说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中需要用到的附图进行简单介绍。显然,在以下描述中,附图只是本发明的一些实施例。对于本领域普通技术人员来说,基于这些图,无需创造性劳动,还可以得到其他图。
图1是本发明实施例的流程图。
具体实现方法
如图1所示,一种自动提取列表页面的方法包括以下步骤:
(1)dom 树生成:
(1.1)获取wait采集网站的网页源码;
(1.2)将网页源码解析成dom树;
(1.3)根据dom树进行预遍历,记录dom树中每个叶子元素的节点路径;(1.4)提取并保存带有文本的元素节点路径。
(2)获取1)中提取文本的元素节点的位置信息,根据元素节点的位置信息进行评分,过滤掉不符合列表视觉可能性的元素节点页面:具体:
(2.1)采集html 网页css和js文件,获取节点位置信息;
(2.2)每页解析后计算dom树元素节点的像素位置;
(2.3)判断元素节点是否满足列表页面的视觉可能性,如果元素节点为隐藏节点,则元素节点为无效节点;
如果元素节点的像素位置与网页左上角像素的距离小于设置的阈值,则元素节点为无效节点;
元素节点的像素位置离网页中心点越远,
宽度距离:
高度距离:
其中dis(whole_width)代表整个html页面的宽度,dis(whole_height)代表整个html页面的高度。
元素节点的得分越低,元素节点的得分与列表页面的提取精度有关。
(3)根据节点路径的相似度和与满足列表页面信息约束的节点特征的相似度,判断多个节点是否有相似指纹,对指纹相似的节点进行分类聚合,其中列表页面信息至少包括标题和地址链接,指纹相似意味着不同节点满足一定的约束条件,构成列表页面信息;
(3.1)计算节点路径的相似度:
dom树的叶子节点路径是否相似,例如从根节点计算某个“摘要”节点的路径,表示为:0-5-0-2-0-2-0 -3-0,其他“汇总”节点有:0-5-0-2-1-2-0-3-0、0-5-0-2-2-2-0-3-0等.,可以看作是0 -5-0-2-x-2-0-3-0,并将这种形式定义为节点相似度指纹。当不同“汇总”节点的路径只有一个差异时,我们认为它们的节点路径非常相似。
标题节点、摘要节点、时间节点或作者节点都可以通过这种方式计算节点路径的相似度。当相似度很高时,可以认为是一种,使用0-5-0-2-保存为x-2-0-3-0这种格式。
(3.2)计算节点特征的相似度
列表页信息受节点属性标签和节点文本信息标签限制。
计算节点属性的相似度:每个节点都会被一系列的属性标签修改,比如class、id、name等,相似的节点往往有相同或非常相似的属性标签。用属性的方差来表示相似节点的属性差异。差异越小越好。
其中,节点属性标签相似度与节点属性的方差成反比,则节点属性的方差:
其中a代表单个节点的属性向量,b代表该类别下所有节点的平均属性向量;
计算节点文本信息的相似度:对于list页的title、summary、time等文本的文本构成,由于篇幅限制,通常字数成一定比例,相似度节点文本信息的大小与文本词数的方差成正比。反之,节点文本中词数的方差:
其中,表示所有节点中文本信息词的平均密度,n表示节点数;
(4)将多个具有多个相似指纹和相似指纹的节点进行分类聚合,将可以形成完整列表页面信息的相似指纹划分为节点块,形成列表页面的深度指纹。相似指纹将是标题节点和摘要节点. , 时间节点合并为一个类别,节点深度指纹是将标题类别、总结类别、练习类别组合成一个更完整的类别。
第 4 步还包括:
(4.1)计算节点路径的预深度比,即节点深度指纹组成的节点块共有的节点路径长度与最长节点路径长度的比值:
例如:如果节点深度指纹为0-5-0-2-x-2-0,则由以下相似路径的节点组成:
0-5-0-2-x-2-0-1; 0-5-0-2-x-2-0-0; 0-5-0-2-x-2-0-3 -0; 0-5-0-2-x-2-0; 0-5-0-2-x-2-0-2。
深度指纹为0-5-0-2-x,值为5,最长为0-5-0-2-x-2-0-3-0,值为9,比率为 5/ 9
(4.2)对深度指纹聚合的节点块进行打分和排序,计算的最有可能是列表页面的深度指纹。
深度指纹一般有更多相似的指纹,因为一般的列表页会收录标题、地址链接、摘要、发表时间、作者等,至少也会收录标题和地址链接。
列表页面中每个相似指纹节点的html修改属性和字符数比较接近。
列表页一般在整个页面的中央。
更多的指纹是通过每个相似指纹的累计值来完成的,但是因为结构相似,列表页中会出现列表页,列表页一般收录2到5个相似指纹,所以加了衰减系数在积累过程中可以避免因目录页导致的高分。根据实验,衰减系数设置为0.7。
节点区块的得分:
f(x)=ratio(节点前端路径的比例)×∑σ(attr)σ(word)αi;
其中αi为衰减系数。
(5)从列表页的深度指纹中提取出标题和地址链接的相似指纹;
标题指纹是指满足标题约束条件的特征,提取满足标题约束条件的相似指纹,得到标题文本。
标题的指纹一般满足以下约束:
a) 标题在节点路径的上半部分;
b) 标题字数一般在5-20个左右;
c) 标题一般为粗体;
d) 标题通常有一个地址链接。
通过上述元素选择与标题相似的指纹,得到标题文本。
(6)Extraction 列表页,返回封装结果。
本发明还可以设置列表页提取规则,选择通过提取规则或通过网络结构提取列表页。根据网络结构提取列表页面,可以选择是使用位置信息提取列表页面,还是直接计算节点特征相似度,提取相似指纹。
以上显示和描述了本发明的基本原理、主要特征和优点。本领域技术人员应当理解,本发明不受上述实施例的限制。上述实施例和描述仅说明了本发明的原理。在不脱离本发明的精神和范围的情况下,本发明可以有各种变化和改进,均落入本发明所要求保护的范围内。本发明所要求的保护范围由所附权利要求书及其等效内容限定。 查看全部
一种自动抽取列表页的技术方案解决方案页

本发明涉及网络技术领域,尤其涉及一种自动提取列表页面的方法。
背景技术:
传统的列表页面提取技术主要是规则的形式,比较常用的是通过正则表达式、xpath、css选择器,甚至是手动的方式来获取页面采集down的信息。
单个网页可以通过正则表达式等方法准确获取采集想要的信息,而正则表达式和css选择器等方法本质上是人们通过观察网页源代码的规则总结出来的。然后使用这些规则进行提取。这种方法很难在不同结构的网页上用相同的规则集提取,因为不同的网页需要不同的规则来支持提取。当用户需要采集大量网页时,需要依靠人工编写大量规则,这种效率不仅低,甚至上千甚至几万个网站,仅仅依靠手动已经完全不可能了。不仅如此,依赖规则的抽取方式仅限于网页本身。 网站修改后,原来的规则将不再适用,需要手动重写规则,这也使得一些依赖开源信息采集的项目维护成本变得极高。<//p
p技术实现要素:/p
p本发明要解决的技术问题是提供一种适用性强、效率高的列表页面自动提取方法。/p
p为解决上述技术问题,本发明的技术方案是:一种自动提取列表页面的方法,包括以下步骤:/p
p(1)dom树生成:得到网页源码为采集网站;将网页源码解析成dom树;根据dom树进行前序遍历,并记录dom树中的每一片叶子元素的节点路径;提取并保存元素的节点路径,带文本;/p
p(2)获取1)中提取文本的元素节点的位置信息,根据元素节点的位置信息进行评分,过滤掉不符合列表视觉可能性的元素节点页面;/p
p(3)根据节点路径的相似度以及与满足列表页面信息约束的节点特征的相似度,判断多个节点是否有相似指纹,对指纹相似的节点进行分类聚合。列表页信息至少包括标题和地址链接,指纹相似意味着不同节点满足一定的约束条件,构成列表页信息;/p
p(4)对多个具有多个相似指纹的节点进行分类聚合,可以将完整的列表页信息组成节点块,形成列表页的深度指纹;/p
p(5)从列表页的深度指纹中提取出标题和地址链接的相似指纹;/p
p(6)Extraction 列表页,返回封装结果。/p
p作为优选的技术方案,步骤(2)具体包括:/p
p(2.1)采集html 网页的css和js文件获取节点位置信息;/p
p(2.2)每页解析后计算dom树元素节点的像素位置;/p
p(2.3) 判断元素节点是否满足列表页面的视觉可能性,具体包括:如果元素节点是隐藏节点,则元素节点是无效节点;如果元素的像素node 网页左上角位置的像素位置小于设置的阈值,元素节点为无效节点;元素节点的像素位置离网页中心点越远,元素节点的得分越低,元素节点的得分与列表页面的提取精度有关。/p
p作为优选的技术方案,在步骤(3),满足列表页面信息约束的节点特征包括节点属性标签和节点文本信息标签,其中节点属性标签的相似度和方差为节点属性成反比,节点属性的方差:/p
p其中a代表单个节点的属性向量,b代表该类别下所有节点的平均属性向量;/p
p节点文本信息的相似度与文本词数的方差成反比,则节点文本词数的方差:/p
p其中,表示所有节点中文本信息词的平均密度,n表示节点数;/p
p作为优选的技术方案,步骤4还包括:/p
p(4.1)计算节点路径的预深度比,即节点深度指纹组成的节点块共有的节点路径长度与最长节点路径长度的比值:/p
p(4.2)对深度指纹聚合的节点块进行打分和排序,计算出最可能的列表页深度指纹。节点块的得分:/p
p其中αi为衰减系数。/p
p作为优选的技术方案,在步骤(5),标题指纹是指满足标题约束条件的特征,提取满足标题约束条件的相似指纹,得到标题文字。/p
pp>
作为优选的技术方案,还包括设置列表页面提取规则和通过提取规则提取列表页面的步骤。
由于采用了上述技术方案,本发明的有益效果是本发明可以应用于大量的互联网网站列表页面提取,不限于繁琐冗余的规则,并且只需要通过网页网址或源代码。自动提取列表页的标题、链接等,由于本发明对大量的列表页具有普遍适用性,即使出现网站改版,基于网页结构的提取方法也可以仍然有效,节省了重写提取规则和维护规则产生的时间成本和人工成本。
在基于网页的结构提取算法中,还加入了网页元素的位置像素信息作为特征,更加符合人们对列表页面的感官判断,使得提取结果更加符合与目标。
图纸说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中需要用到的附图进行简单介绍。显然,在以下描述中,附图只是本发明的一些实施例。对于本领域普通技术人员来说,基于这些图,无需创造性劳动,还可以得到其他图。
图1是本发明实施例的流程图。
具体实现方法
如图1所示,一种自动提取列表页面的方法包括以下步骤:
(1)dom 树生成:
(1.1)获取wait采集网站的网页源码;
(1.2)将网页源码解析成dom树;
(1.3)根据dom树进行预遍历,记录dom树中每个叶子元素的节点路径;(1.4)提取并保存带有文本的元素节点路径。
(2)获取1)中提取文本的元素节点的位置信息,根据元素节点的位置信息进行评分,过滤掉不符合列表视觉可能性的元素节点页面:具体:
(2.1)采集html 网页css和js文件,获取节点位置信息;
(2.2)每页解析后计算dom树元素节点的像素位置;
(2.3)判断元素节点是否满足列表页面的视觉可能性,如果元素节点为隐藏节点,则元素节点为无效节点;
如果元素节点的像素位置与网页左上角像素的距离小于设置的阈值,则元素节点为无效节点;
元素节点的像素位置离网页中心点越远,
宽度距离:
高度距离:
其中dis(whole_width)代表整个html页面的宽度,dis(whole_height)代表整个html页面的高度。
元素节点的得分越低,元素节点的得分与列表页面的提取精度有关。
(3)根据节点路径的相似度和与满足列表页面信息约束的节点特征的相似度,判断多个节点是否有相似指纹,对指纹相似的节点进行分类聚合,其中列表页面信息至少包括标题和地址链接,指纹相似意味着不同节点满足一定的约束条件,构成列表页面信息;
(3.1)计算节点路径的相似度:
dom树的叶子节点路径是否相似,例如从根节点计算某个“摘要”节点的路径,表示为:0-5-0-2-0-2-0 -3-0,其他“汇总”节点有:0-5-0-2-1-2-0-3-0、0-5-0-2-2-2-0-3-0等.,可以看作是0 -5-0-2-x-2-0-3-0,并将这种形式定义为节点相似度指纹。当不同“汇总”节点的路径只有一个差异时,我们认为它们的节点路径非常相似。
标题节点、摘要节点、时间节点或作者节点都可以通过这种方式计算节点路径的相似度。当相似度很高时,可以认为是一种,使用0-5-0-2-保存为x-2-0-3-0这种格式。
(3.2)计算节点特征的相似度
列表页信息受节点属性标签和节点文本信息标签限制。
计算节点属性的相似度:每个节点都会被一系列的属性标签修改,比如class、id、name等,相似的节点往往有相同或非常相似的属性标签。用属性的方差来表示相似节点的属性差异。差异越小越好。
其中,节点属性标签相似度与节点属性的方差成反比,则节点属性的方差:
其中a代表单个节点的属性向量,b代表该类别下所有节点的平均属性向量;
计算节点文本信息的相似度:对于list页的title、summary、time等文本的文本构成,由于篇幅限制,通常字数成一定比例,相似度节点文本信息的大小与文本词数的方差成正比。反之,节点文本中词数的方差:
其中,表示所有节点中文本信息词的平均密度,n表示节点数;
(4)将多个具有多个相似指纹和相似指纹的节点进行分类聚合,将可以形成完整列表页面信息的相似指纹划分为节点块,形成列表页面的深度指纹。相似指纹将是标题节点和摘要节点. , 时间节点合并为一个类别,节点深度指纹是将标题类别、总结类别、练习类别组合成一个更完整的类别。
第 4 步还包括:
(4.1)计算节点路径的预深度比,即节点深度指纹组成的节点块共有的节点路径长度与最长节点路径长度的比值:
例如:如果节点深度指纹为0-5-0-2-x-2-0,则由以下相似路径的节点组成:
0-5-0-2-x-2-0-1; 0-5-0-2-x-2-0-0; 0-5-0-2-x-2-0-3 -0; 0-5-0-2-x-2-0; 0-5-0-2-x-2-0-2。
深度指纹为0-5-0-2-x,值为5,最长为0-5-0-2-x-2-0-3-0,值为9,比率为 5/ 9
(4.2)对深度指纹聚合的节点块进行打分和排序,计算的最有可能是列表页面的深度指纹。
深度指纹一般有更多相似的指纹,因为一般的列表页会收录标题、地址链接、摘要、发表时间、作者等,至少也会收录标题和地址链接。
列表页面中每个相似指纹节点的html修改属性和字符数比较接近。
列表页一般在整个页面的中央。
更多的指纹是通过每个相似指纹的累计值来完成的,但是因为结构相似,列表页中会出现列表页,列表页一般收录2到5个相似指纹,所以加了衰减系数在积累过程中可以避免因目录页导致的高分。根据实验,衰减系数设置为0.7。
节点区块的得分:
f(x)=ratio(节点前端路径的比例)×∑σ(attr)σ(word)αi;
其中αi为衰减系数。
(5)从列表页的深度指纹中提取出标题和地址链接的相似指纹;
标题指纹是指满足标题约束条件的特征,提取满足标题约束条件的相似指纹,得到标题文本。
标题的指纹一般满足以下约束:
a) 标题在节点路径的上半部分;
b) 标题字数一般在5-20个左右;
c) 标题一般为粗体;
d) 标题通常有一个地址链接。
通过上述元素选择与标题相似的指纹,得到标题文本。
(6)Extraction 列表页,返回封装结果。
本发明还可以设置列表页提取规则,选择通过提取规则或通过网络结构提取列表页。根据网络结构提取列表页面,可以选择是使用位置信息提取列表页面,还是直接计算节点特征相似度,提取相似指纹。
以上显示和描述了本发明的基本原理、主要特征和优点。本领域技术人员应当理解,本发明不受上述实施例的限制。上述实施例和描述仅说明了本发明的原理。在不脱离本发明的精神和范围的情况下,本发明可以有各种变化和改进,均落入本发明所要求保护的范围内。本发明所要求的保护范围由所附权利要求书及其等效内容限定。
《》RaftRaft将问题分解和具体化统一处理
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-08-16 20:23
木筏
Raft 将问题分解具体化:Leader 统一处理变更操作请求,执行一致性协议保证节点间日志复制的一致性,使用term 作为逻辑时钟保证时序。节点运行相同的状态机并获得一致的结果。 Raft协议的具体流程如下:
Client发起一个请求,每个请求收录一个由Leader处理的操作指令请求。 Leader将操作指令(entry)追加到操作日志中,然后向Follower发起AppendEntries请求,尝试获取操作日志的副本登陆Follower,如果follower多数(quorum)同意AppendEntries请求,leader执行commit操作,将指令传递给状态机处理,状态机处理完后将结果返回给客户端。
1 个leader选举
1.1 一开始,所有服务器都以follower状态启动
然后等待leader或候选者的RPC请求,否则超时。
以上三种情况处理如下:
1.2 候选人采集选票的过程
候选人将为此状态设置随机超时。一旦出现在本届任期内,大家都没有获得过半数的选票,即分裂选票。如果超时时间短,则更容易获得过半票。
Candidate 会向所有服务器发送 RequestVote RPC 请求,请求参数如下图所示
votedFor 是服务器保存的投票对象。一个服务器在一个任期内只能投票一次。如果此时已经投过票,即votedFor不为空,那么此时可以直接拒绝本次投票(当然要检查votedFor是否是被请求的候选人)。
如果你还没有投票:比较候选人的日志和当前更新的服务器的日志,比较方法是哪个lastLog项越大越新。如果词条相同,则lastLog索引较大且较新的为比较方法。
候选人统计投票信息。如果超过一半的候选人同意,他们被认为是领导者并改变为领导者状态。如果没有超过一半,则等待新的领导者产生。如果是这样,则更改为跟随者状态。然后,如果超时,则开始下一次选举。
2 日志副本
2.1 所有请求都交给leader
一旦leader选举成功,所有客户端请求最终都会交给leader(如果客户端连接了follower,follower会转发给leader)
2.2 处理请求流程
2.2.1 客户端请求到达leader
leader首先将请求转换为一个条目,然后将其添加到其日志中以获取该条目的索引信息。该条目收录当前leader的任期信息和日志中的索引信息
2.2.2 leader 将以上条目复制给所有关注者
看官方的AppendEntries RPC请求
从上图可以看出,对于每个follower,leader维护了两个属性,一个是nextIndex,是leader发送给follower的下一个entry的索引,另一个是matchIndex,就是follower发送给leader的确认索引。
一开始会初始化一个leader:
nextIndex=领导者日志的最大索引+1
匹配索引=0
然后开始准备AppendEntries RPC请求的参数
prevLogIndex=nextIndex-1
prevLogTerm=从日志中获取上述prevLogIndex对应的term
然后准备entries数组信息
从leader的日志的prevLogIndex+1开始到lastLog,此时为空
然后将leader的commitIndex作为参数传给
leaderCommit=commitIndex
至此,所有参数准备就绪,向所有follower发送RPC请求,follower收到请求后,处理如下:
如果词条回复错误
如果日志不收录 prevLogIndex 的条目,则回复 false
匹配 prevLogTerm
这里可能不一致,因为初始的prevLogIndex和prevLogTerm是leader上日志的lastLog。如果不一致,则返回false,并将follower上日志的lastIndex发送给leader。
上面的macthIndex=lastIndex
nextIndex=lastIndex+1 以上
然后leader会按照上面的规则从头开始发送新的prevLogIndex、prevLogTerm、entries数组
2.2.3 leader 占复制条目的一半以上
一旦leader发现某些条目已经被超过一半的follower复制了,它就会提交条目并将commitIndex提升到条目的索引。 (这个是按照入口index的顺序提交的),具体实现可以通过follower发送给macthIndex来判断是否超过一半。
一旦可以提交,leader就会将该entry应用到状态机,然后向客户端回复OK
然后在下一次heartBeat心跳中,commitIndex被传递给所有follower,对应follower就可以将commitIndex和之前的entry应用到各自的状态机中。
3 安全
3.1 选举约束
重点强调了上述领导人选举。
The elected leader must contain all entries that have already been submitted
比如leader提交了一半以上replication的entry,但是一些follower可能没有这些entry。 When the leader dies, if the follower is elected as the leader, the above entries may be overwritten, resulting in The problem of inconsistency, so the newly elected leader must meet the above constraints
目前,上述约束的简单实现是:
只要当前服务器的日志比服务器日志的一半新,这里的新鲜度就是我上面说的:
lastLog 的项越大,越新越新。如果term相同,则lastLog的索引越大越新。
但正是这种实现并没有完全实现约束,这会导致下面的另一个问题。一个详细的案例稍后会解释这个问题
3.2 当前任期的leader是否可以直接提交上一任期的条目
raft给出的答案是:
本期的leader不能“直接”提交上一期的参赛作品
即可以间接提交。来看看Raft给出的不能直接提交的情况
最上面一行数字表示索引,s1-s5表示服务器服务器,a-e表示不同场景,框内数字表示术语
详细解释如下:
这里是日志覆盖问题的详细解释
日志覆盖包括2种情况:
我们从这个案例中得到的一个新约束是:
本期的leader不能“直接”提交上一期的参赛作品
必须等到本学期有一半以上的条目后,才能一起提交上一学期的条目
所以 raft 依靠这两个约束来进一步保证一致性。
让我们仔细分析一下这个案例。问题在于上面的leader选举。如果 s1 在 c 场景中提交了索引为 2、term=2 的条目,则 s5 不收录所有 commitLog。可以,但是s5还是可以按照最新的日志对比方式选举leader的,也就是说,最新的日志对比方式并不能保证3.1中的选举约束。
The elected leader must contain all entries that have already been submitted
所以可以理解为:正是因为上面提到的选举约束的执行存在缺陷,才增加了这样一个不能直接提交给上届参赛作品的约束。
3.3 安全演示
Leader Completeness:如果提交了一个条目,该条目必须存在于后续的Leader中。
经过以上两个约束,可以得出Leader Completeness的结论。
由于上述“不能直接提交上一学期的条目”的限制,任何条目的提交都必须存在于当前任期的条目下。此时,超过一半的所有服务器都收录当前术语(也是当前最大术语)的条目。假设serverA以后会成为leader,serverA的lastlog的term不能大于当前的term。成为leader,即其日志与其他服务器pk是最新的,必须满足大于他们的日志的索引,所以必须收录提交的条目。
4 其他注意事项
4.1 客户端
从客户的角度来看:
如果客户端发送请求,leader返回ok响应,则客户端认为请求执行成功,则请求需要真正落地,不能丢失。
如果leader没有返回ok,那么客户端可以认为请求没有执行成功,可以通过重试继续请求。
对于领导者来说:
一旦客户端回复OK然后挂断,必须保证这个请求对应的entry被应用到状态机上,也就是需要另一个leader来继续应用到状态机上。
一旦leader在回复客户端之前挂了,这个请求对应的entry就不能应用到状态机上。如果应用于状态机,客户端认为执行失败,但服务器缺乏持久性。这个请求的结果有点不一致。
这个原理也和消息队列是一致的。先说消息队列的消息丢失(很多人还没有真正理解这个问题):客户端向服务器发送消息,服务器回复OK,然后由于内部机制导致消息丢失服务器。 ,这种情况称为消息队列的消息丢失。如果服务器没有给你回复OK,那么这种情况不属于消息队列丢失消息的范畴。
让我们看看 raft 能否再次满足这个原则:
leader已经复制了一个条目的一半以上,认为可以提交,所以应用到状态机,然后向客户端响应OK。 leader挂掉后,可以保证该entry存在于后续leader中
leader被复制了一半以上的条目,然后就挂了,也就是没有给客户端回复OK。在raft机制下,后续leader可能会收录入口并提交,也可能直接覆盖。入口。如果是前者,将entry应用到状态机,那么这时候就有问题了:客户端没有收到OK回复,但是服务端可以保存成功
为了掩盖这种情况,需要在client端做一个trick,就是client会重试所有没有回复OK的,并且client的请求会携带一个唯一的request id,即重试时也是如此。使用之前的请求 ID 重试
服务器发现提交日志中已经存在请求id,然后直接响应OK。如果没有,则再次执行请求。
4.2 关注者挂断
关注者已关闭。只要leader还满足一半以上的条件,就一切正常。挂断并恢复后,leader会继续重试,follower依然可以恢复正常
Follower 在接收 AppendEntries RPC 时是幂等操作
扎布
Zab 代表 Zookeeper 原子广播协议,是 Zookeeper 内部使用的共识协议。与Paxos相比,Zab最大的特点就是保证了强一致性(强一致性,或线性化一致性)。
与 Raft 一样,Zab 需要唯一的领导者参与决策。 Zab 可以分为三个阶段:发现、同步和广播:
Leader 和 Follower 通过心跳判断健康状态。正常情况下,Zab 处于转播阶段。当出现Leader宕机、网络隔离等异常情况时,Zab会回到发现阶段。
Zab 通过约束交易的顺序来实现强一致性。第一个广播事务被提交,先入先出。 Zab 称其为一级订单(以下简称 PO)。实现PO的核心是zxid。
Each transaction in Zab corresponds to a zxid, which is composed of two parts: e is the epoch generated when the leader is elected, and c is the number of the transaction in the current epoch, increasing in sequence.假设两笔交易的zxid分别为z和z’,当z.e
为了实现PO,Zab对Follower和Leader有如下约束:
有交易 z 和 z'。如果Leader先广播z,Follower需要保证commit z对应的事务先有事务z和z',z由Leader p广播,z'由Leader q广播,Leader p在Leader q之前,然后Follower需要保证commit z对应的事务先有事务z和z',z由Leader p广播,z'由Leader q广播,Leader p在Leader q之前,如果Follower已经提交z,那么q需要确保你已经提交 z 来广播 z'
1、2点保证事务FIFO,第三点保证所有提交的事务在Leader上可用。
与Paxos相比,Zab限制了事务的顺序,适用于一致性要求强的场景。
Zab 协议源码实现
1.1 重要数据介绍
加上上一节已经介绍过的名词
对于以上参数,整个Broadcast过程可以描述为:
1.2 快速领导人选举
leader选举过程中需要注意的要点:
投票过程中有3个重要数据:
以下是这个过程的详细说明:
serverA 然后向所有其他服务器发送通知,通知内容为上述投票信息和选举纪元信息
pk完成后,如果本机被pk投票否决,投票信息会更新为对方的投票信息,同时投票信息会重新发送给所有服务器。
如果本机没有被pk投票否决,请看下面的一半判断过程
因为目前leader和follower都在测试是否进入leader选举过程。如果leader检测不到服务器ping回复的一半,leader会进入LOOKING状态,但是follower有自己的检测,需要一定的时间才能感知到这个事件。在此期间,如果其他服务器加入集群,则可能会收到。超过一半的其他追随者投票给了前任领导者,但此时领导者不再处于 LEADING 状态,因此需要进行这样的检查以排除这种情况。
1.3 恢复阶段
一旦leader选举完成,就会进入recovery阶段,即follower需要同步leader上的数据信息
LearnerHandler 中的 lastProcessedZxid 与 leader 的 lastProcessedZxid 相同,表示已经同步。
如果 lastProcessedZxid 在 minCommittedLog 和 maxCommittedLog 之间
proposal从lastProcessedZxid开始到maxCommittedLog结尾的部分会重发给LearnerHandler对应的follower,同时会发送proposal对应的commit命令
上面可能有问题:虽然lastProcessedZxid在它们之间,但是没有找到lastProcessedZxid对应的motion,也就是这个zxid在leader中是没有的。这个时候的策略是完全按照leader同步,删除follower。部分交易日志,然后重新发送这部分提案,并提交这些提案
如果 lastProcessedZxid 大于 maxCommittedLog
然后删除follower大于一部分的事务日志
如果 lastProcessedZxid 小于 minCommittedLog
然后直接用快照的方法恢复
2 特殊情况下的注意事项
让我们再谈谈恢复:
由此可以看出,在初始化和恢复时,所有最新的事务日志都会作为提交事务处理
也就是说,可能有一些事务日志还没有提交,都被当作提交了。这个过程简单粗暴,而raft对旧数据的恢复控制更严格。
2.2关注者的恢复过程挂断重启
一旦leader死亡,上述2组leader
无效。当leader恢复时它们不起作用,但是当系统正常执行并且follower被暂停和恢复时。
我们可以看到,在上面2.3的恢复过程中,会先恢复快照日志和事务日志,然后补充leader的上面2条数据的内容。
2.3 关注者同步失败
目前,leader和follower的同步是通过BIO来实现的。一旦链接异常,将关闭链接,重新建立与leader的连接,并重新同步最新数据
2.4 客户端也一样吗?
如果客户端收到OK回复,会丢失数据吗?
如果客户端没有收到OK回复,它会存储更多数据吗?
如果客户端收到OK回复,说明已经复制过半,请求对应的事务日志肯定会被收录在leader选举中,不会丢失数据
客户端连接的leader或follower挂断,客户端没有收到OK响应。目前可能会丢失也可能不会丢失,因为服务器端的处理也非常简单粗暴,未来leader上的事务日志会被当作commit来处理。所有处理过的都将应用到内存树中。 查看全部
《》RaftRaft将问题分解和具体化统一处理
木筏
Raft 将问题分解具体化:Leader 统一处理变更操作请求,执行一致性协议保证节点间日志复制的一致性,使用term 作为逻辑时钟保证时序。节点运行相同的状态机并获得一致的结果。 Raft协议的具体流程如下:
Client发起一个请求,每个请求收录一个由Leader处理的操作指令请求。 Leader将操作指令(entry)追加到操作日志中,然后向Follower发起AppendEntries请求,尝试获取操作日志的副本登陆Follower,如果follower多数(quorum)同意AppendEntries请求,leader执行commit操作,将指令传递给状态机处理,状态机处理完后将结果返回给客户端。
1 个leader选举
1.1 一开始,所有服务器都以follower状态启动
然后等待leader或候选者的RPC请求,否则超时。
以上三种情况处理如下:
1.2 候选人采集选票的过程
候选人将为此状态设置随机超时。一旦出现在本届任期内,大家都没有获得过半数的选票,即分裂选票。如果超时时间短,则更容易获得过半票。
Candidate 会向所有服务器发送 RequestVote RPC 请求,请求参数如下图所示

votedFor 是服务器保存的投票对象。一个服务器在一个任期内只能投票一次。如果此时已经投过票,即votedFor不为空,那么此时可以直接拒绝本次投票(当然要检查votedFor是否是被请求的候选人)。
如果你还没有投票:比较候选人的日志和当前更新的服务器的日志,比较方法是哪个lastLog项越大越新。如果词条相同,则lastLog索引较大且较新的为比较方法。
候选人统计投票信息。如果超过一半的候选人同意,他们被认为是领导者并改变为领导者状态。如果没有超过一半,则等待新的领导者产生。如果是这样,则更改为跟随者状态。然后,如果超时,则开始下一次选举。
2 日志副本
2.1 所有请求都交给leader
一旦leader选举成功,所有客户端请求最终都会交给leader(如果客户端连接了follower,follower会转发给leader)
2.2 处理请求流程
2.2.1 客户端请求到达leader
leader首先将请求转换为一个条目,然后将其添加到其日志中以获取该条目的索引信息。该条目收录当前leader的任期信息和日志中的索引信息
2.2.2 leader 将以上条目复制给所有关注者
看官方的AppendEntries RPC请求


从上图可以看出,对于每个follower,leader维护了两个属性,一个是nextIndex,是leader发送给follower的下一个entry的索引,另一个是matchIndex,就是follower发送给leader的确认索引。
一开始会初始化一个leader:
nextIndex=领导者日志的最大索引+1
匹配索引=0
然后开始准备AppendEntries RPC请求的参数
prevLogIndex=nextIndex-1
prevLogTerm=从日志中获取上述prevLogIndex对应的term
然后准备entries数组信息
从leader的日志的prevLogIndex+1开始到lastLog,此时为空
然后将leader的commitIndex作为参数传给
leaderCommit=commitIndex
至此,所有参数准备就绪,向所有follower发送RPC请求,follower收到请求后,处理如下:
如果词条回复错误
如果日志不收录 prevLogIndex 的条目,则回复 false
匹配 prevLogTerm
这里可能不一致,因为初始的prevLogIndex和prevLogTerm是leader上日志的lastLog。如果不一致,则返回false,并将follower上日志的lastIndex发送给leader。
上面的macthIndex=lastIndex
nextIndex=lastIndex+1 以上
然后leader会按照上面的规则从头开始发送新的prevLogIndex、prevLogTerm、entries数组
2.2.3 leader 占复制条目的一半以上
一旦leader发现某些条目已经被超过一半的follower复制了,它就会提交条目并将commitIndex提升到条目的索引。 (这个是按照入口index的顺序提交的),具体实现可以通过follower发送给macthIndex来判断是否超过一半。
一旦可以提交,leader就会将该entry应用到状态机,然后向客户端回复OK
然后在下一次heartBeat心跳中,commitIndex被传递给所有follower,对应follower就可以将commitIndex和之前的entry应用到各自的状态机中。
3 安全
3.1 选举约束
重点强调了上述领导人选举。
The elected leader must contain all entries that have already been submitted
比如leader提交了一半以上replication的entry,但是一些follower可能没有这些entry。 When the leader dies, if the follower is elected as the leader, the above entries may be overwritten, resulting in The problem of inconsistency, so the newly elected leader must meet the above constraints
目前,上述约束的简单实现是:
只要当前服务器的日志比服务器日志的一半新,这里的新鲜度就是我上面说的:
lastLog 的项越大,越新越新。如果term相同,则lastLog的索引越大越新。
但正是这种实现并没有完全实现约束,这会导致下面的另一个问题。一个详细的案例稍后会解释这个问题
3.2 当前任期的leader是否可以直接提交上一任期的条目
raft给出的答案是:
本期的leader不能“直接”提交上一期的参赛作品
即可以间接提交。来看看Raft给出的不能直接提交的情况

最上面一行数字表示索引,s1-s5表示服务器服务器,a-e表示不同场景,框内数字表示术语
详细解释如下:
这里是日志覆盖问题的详细解释
日志覆盖包括2种情况:
我们从这个案例中得到的一个新约束是:
本期的leader不能“直接”提交上一期的参赛作品
必须等到本学期有一半以上的条目后,才能一起提交上一学期的条目
所以 raft 依靠这两个约束来进一步保证一致性。
让我们仔细分析一下这个案例。问题在于上面的leader选举。如果 s1 在 c 场景中提交了索引为 2、term=2 的条目,则 s5 不收录所有 commitLog。可以,但是s5还是可以按照最新的日志对比方式选举leader的,也就是说,最新的日志对比方式并不能保证3.1中的选举约束。
The elected leader must contain all entries that have already been submitted
所以可以理解为:正是因为上面提到的选举约束的执行存在缺陷,才增加了这样一个不能直接提交给上届参赛作品的约束。
3.3 安全演示
Leader Completeness:如果提交了一个条目,该条目必须存在于后续的Leader中。
经过以上两个约束,可以得出Leader Completeness的结论。
由于上述“不能直接提交上一学期的条目”的限制,任何条目的提交都必须存在于当前任期的条目下。此时,超过一半的所有服务器都收录当前术语(也是当前最大术语)的条目。假设serverA以后会成为leader,serverA的lastlog的term不能大于当前的term。成为leader,即其日志与其他服务器pk是最新的,必须满足大于他们的日志的索引,所以必须收录提交的条目。
4 其他注意事项
4.1 客户端
从客户的角度来看:
如果客户端发送请求,leader返回ok响应,则客户端认为请求执行成功,则请求需要真正落地,不能丢失。
如果leader没有返回ok,那么客户端可以认为请求没有执行成功,可以通过重试继续请求。
对于领导者来说:
一旦客户端回复OK然后挂断,必须保证这个请求对应的entry被应用到状态机上,也就是需要另一个leader来继续应用到状态机上。
一旦leader在回复客户端之前挂了,这个请求对应的entry就不能应用到状态机上。如果应用于状态机,客户端认为执行失败,但服务器缺乏持久性。这个请求的结果有点不一致。
这个原理也和消息队列是一致的。先说消息队列的消息丢失(很多人还没有真正理解这个问题):客户端向服务器发送消息,服务器回复OK,然后由于内部机制导致消息丢失服务器。 ,这种情况称为消息队列的消息丢失。如果服务器没有给你回复OK,那么这种情况不属于消息队列丢失消息的范畴。
让我们看看 raft 能否再次满足这个原则:
leader已经复制了一个条目的一半以上,认为可以提交,所以应用到状态机,然后向客户端响应OK。 leader挂掉后,可以保证该entry存在于后续leader中
leader被复制了一半以上的条目,然后就挂了,也就是没有给客户端回复OK。在raft机制下,后续leader可能会收录入口并提交,也可能直接覆盖。入口。如果是前者,将entry应用到状态机,那么这时候就有问题了:客户端没有收到OK回复,但是服务端可以保存成功
为了掩盖这种情况,需要在client端做一个trick,就是client会重试所有没有回复OK的,并且client的请求会携带一个唯一的request id,即重试时也是如此。使用之前的请求 ID 重试
服务器发现提交日志中已经存在请求id,然后直接响应OK。如果没有,则再次执行请求。
4.2 关注者挂断
关注者已关闭。只要leader还满足一半以上的条件,就一切正常。挂断并恢复后,leader会继续重试,follower依然可以恢复正常
Follower 在接收 AppendEntries RPC 时是幂等操作
扎布
Zab 代表 Zookeeper 原子广播协议,是 Zookeeper 内部使用的共识协议。与Paxos相比,Zab最大的特点就是保证了强一致性(强一致性,或线性化一致性)。
与 Raft 一样,Zab 需要唯一的领导者参与决策。 Zab 可以分为三个阶段:发现、同步和广播:

Leader 和 Follower 通过心跳判断健康状态。正常情况下,Zab 处于转播阶段。当出现Leader宕机、网络隔离等异常情况时,Zab会回到发现阶段。
Zab 通过约束交易的顺序来实现强一致性。第一个广播事务被提交,先入先出。 Zab 称其为一级订单(以下简称 PO)。实现PO的核心是zxid。
Each transaction in Zab corresponds to a zxid, which is composed of two parts: e is the epoch generated when the leader is elected, and c is the number of the transaction in the current epoch, increasing in sequence.假设两笔交易的zxid分别为z和z’,当z.e
为了实现PO,Zab对Follower和Leader有如下约束:
有交易 z 和 z'。如果Leader先广播z,Follower需要保证commit z对应的事务先有事务z和z',z由Leader p广播,z'由Leader q广播,Leader p在Leader q之前,然后Follower需要保证commit z对应的事务先有事务z和z',z由Leader p广播,z'由Leader q广播,Leader p在Leader q之前,如果Follower已经提交z,那么q需要确保你已经提交 z 来广播 z'
1、2点保证事务FIFO,第三点保证所有提交的事务在Leader上可用。
与Paxos相比,Zab限制了事务的顺序,适用于一致性要求强的场景。
Zab 协议源码实现

1.1 重要数据介绍
加上上一节已经介绍过的名词
对于以上参数,整个Broadcast过程可以描述为:
1.2 快速领导人选举
leader选举过程中需要注意的要点:
投票过程中有3个重要数据:
以下是这个过程的详细说明:
serverA 然后向所有其他服务器发送通知,通知内容为上述投票信息和选举纪元信息
pk完成后,如果本机被pk投票否决,投票信息会更新为对方的投票信息,同时投票信息会重新发送给所有服务器。
如果本机没有被pk投票否决,请看下面的一半判断过程
因为目前leader和follower都在测试是否进入leader选举过程。如果leader检测不到服务器ping回复的一半,leader会进入LOOKING状态,但是follower有自己的检测,需要一定的时间才能感知到这个事件。在此期间,如果其他服务器加入集群,则可能会收到。超过一半的其他追随者投票给了前任领导者,但此时领导者不再处于 LEADING 状态,因此需要进行这样的检查以排除这种情况。
1.3 恢复阶段
一旦leader选举完成,就会进入recovery阶段,即follower需要同步leader上的数据信息
LearnerHandler 中的 lastProcessedZxid 与 leader 的 lastProcessedZxid 相同,表示已经同步。
如果 lastProcessedZxid 在 minCommittedLog 和 maxCommittedLog 之间
proposal从lastProcessedZxid开始到maxCommittedLog结尾的部分会重发给LearnerHandler对应的follower,同时会发送proposal对应的commit命令
上面可能有问题:虽然lastProcessedZxid在它们之间,但是没有找到lastProcessedZxid对应的motion,也就是这个zxid在leader中是没有的。这个时候的策略是完全按照leader同步,删除follower。部分交易日志,然后重新发送这部分提案,并提交这些提案
如果 lastProcessedZxid 大于 maxCommittedLog
然后删除follower大于一部分的事务日志
如果 lastProcessedZxid 小于 minCommittedLog
然后直接用快照的方法恢复
2 特殊情况下的注意事项
让我们再谈谈恢复:
由此可以看出,在初始化和恢复时,所有最新的事务日志都会作为提交事务处理
也就是说,可能有一些事务日志还没有提交,都被当作提交了。这个过程简单粗暴,而raft对旧数据的恢复控制更严格。
2.2关注者的恢复过程挂断重启
一旦leader死亡,上述2组leader
无效。当leader恢复时它们不起作用,但是当系统正常执行并且follower被暂停和恢复时。
我们可以看到,在上面2.3的恢复过程中,会先恢复快照日志和事务日志,然后补充leader的上面2条数据的内容。
2.3 关注者同步失败
目前,leader和follower的同步是通过BIO来实现的。一旦链接异常,将关闭链接,重新建立与leader的连接,并重新同步最新数据
2.4 客户端也一样吗?
如果客户端收到OK回复,会丢失数据吗?
如果客户端没有收到OK回复,它会存储更多数据吗?
如果客户端收到OK回复,说明已经复制过半,请求对应的事务日志肯定会被收录在leader选举中,不会丢失数据
客户端连接的leader或follower挂断,客户端没有收到OK响应。目前可能会丢失也可能不会丢失,因为服务器端的处理也非常简单粗暴,未来leader上的事务日志会被当作commit来处理。所有处理过的都将应用到内存树中。
2016上海事业单位医疗招聘:SQLServer访问与数据处理算法
采集交流 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-08-16 20:20
.Net 框架的命名空间 System.Net 中提供了两个类 WebRequest 和 WebResponse,分别用于发送客户端请求和从服务器获取响应。
2)正则表达式
正则表达式提供了强大、灵活和高效的文本处理方法。正则表达式的模式匹配可以快速分析大量文本,找到特定的字符模式;提取、编辑、替换或删除文本子串;或将提取的字符串添加到集合中。
在.Net命名空间System.Text.RegularExpressions中,提供了Regex类来构建正则表达式,也提供了相应的方法来匹配和过滤字符串。
3)ADO.Net
采集 系统获取的数据最终会存储在本地数据库中,.NET框架中提供了数据库访问技术ADO.NET。它屏蔽了各种数据源之间的差异,使用统一的访问接口,由一组访问各种数据源的类组成。为了提高访问效率,还为SQL Server提供了特殊的类,如SqlConnection、SqlCommand、SqlDataReader、Dataset、SqlDataAdapter等,完成对SQL Server数据库的访问和数据处理。
2.3 算法说明
完成信息采集,首先要能够过滤掉页面上我们需要的链接的起点,然后系统模拟手动点击过程读取信息。
1)根据访问路径创建C#自带的REGEX类的对象,是用于匹配正则表达式的文本类。
2)通过WebRequest发送请求,WebResponse接收返回的响应,然后通过StreamReader读取返回的响应,形成收录网页所有源代码的字符串。
3)用正则表达式匹配字符串得到Match采集集合,其中存储了我们需要进一步阅读的所有目标链接。
4) 遍历集合的成员,访问成员链接指向的页面,StreamReader读取信息后使用正则表达式提取页面信息。如果页面是访问路径的末端,则读取相应信息后,将所有结构化数据存入数据库;如果只是为了获取下一级链接,则转移到1)。
3 招聘信息采集系统的实现
1)阅读招聘单位名单信息
打开web_url指定的网站页面,使用StreamReader对象读取该网页的源代码并将其存储在字符串all_code中,方便提取正则表达式。
HttpWebRequest all_codeRequest = (HttpWebRequest)WebRequest.Create(web_url);
WebResponse all_codeResponse = all_codeRequest.GetResponse();
StreamReader the_Reader = new StreamReader(all_codeResponse.GetResponseStream(), System.Text.Encoding.Default);
string all_code = the_Reader.ReadToEnd();
the_Reader.Close();
2)提取招聘单位超链接列表
创建一个表达式字符串p,用它创建一个正则表达式对象re,并使用re.Matches方法返回all_code字符串的所有匹配超链接集hy。
string p = @".+";
Regex re = new Regex(p, RegexOptions.IgnoreCase);
Match采集 hy = re.Matches(all_code);
<p>for (int i = 0; i 查看全部
2016上海事业单位医疗招聘:SQLServer访问与数据处理算法
.Net 框架的命名空间 System.Net 中提供了两个类 WebRequest 和 WebResponse,分别用于发送客户端请求和从服务器获取响应。
2)正则表达式
正则表达式提供了强大、灵活和高效的文本处理方法。正则表达式的模式匹配可以快速分析大量文本,找到特定的字符模式;提取、编辑、替换或删除文本子串;或将提取的字符串添加到集合中。
在.Net命名空间System.Text.RegularExpressions中,提供了Regex类来构建正则表达式,也提供了相应的方法来匹配和过滤字符串。
3)ADO.Net
采集 系统获取的数据最终会存储在本地数据库中,.NET框架中提供了数据库访问技术ADO.NET。它屏蔽了各种数据源之间的差异,使用统一的访问接口,由一组访问各种数据源的类组成。为了提高访问效率,还为SQL Server提供了特殊的类,如SqlConnection、SqlCommand、SqlDataReader、Dataset、SqlDataAdapter等,完成对SQL Server数据库的访问和数据处理。
2.3 算法说明
完成信息采集,首先要能够过滤掉页面上我们需要的链接的起点,然后系统模拟手动点击过程读取信息。
1)根据访问路径创建C#自带的REGEX类的对象,是用于匹配正则表达式的文本类。
2)通过WebRequest发送请求,WebResponse接收返回的响应,然后通过StreamReader读取返回的响应,形成收录网页所有源代码的字符串。
3)用正则表达式匹配字符串得到Match采集集合,其中存储了我们需要进一步阅读的所有目标链接。
4) 遍历集合的成员,访问成员链接指向的页面,StreamReader读取信息后使用正则表达式提取页面信息。如果页面是访问路径的末端,则读取相应信息后,将所有结构化数据存入数据库;如果只是为了获取下一级链接,则转移到1)。
3 招聘信息采集系统的实现
1)阅读招聘单位名单信息
打开web_url指定的网站页面,使用StreamReader对象读取该网页的源代码并将其存储在字符串all_code中,方便提取正则表达式。
HttpWebRequest all_codeRequest = (HttpWebRequest)WebRequest.Create(web_url);
WebResponse all_codeResponse = all_codeRequest.GetResponse();
StreamReader the_Reader = new StreamReader(all_codeResponse.GetResponseStream(), System.Text.Encoding.Default);
string all_code = the_Reader.ReadToEnd();
the_Reader.Close();
2)提取招聘单位超链接列表
创建一个表达式字符串p,用它创建一个正则表达式对象re,并使用re.Matches方法返回all_code字符串的所有匹配超链接集hy。
string p = @".+";
Regex re = new Regex(p, RegexOptions.IgnoreCase);
Match采集 hy = re.Matches(all_code);
<p>for (int i = 0; i
智能巡检使用流式图算法和流式分解算法进行数据巡检
采集交流 • 优采云 发表了文章 • 0 个评论 • 248 次浏览 • 2021-08-15 20:25
日志服务提供智能巡检功能,用于对监控指标或业务日志等数据进行自动、智能、自适应的异常巡检。目前智能巡检采用流图算法和流分解算法进行数据巡检。本文介绍了流图算法和流分解算法的适用场景、参数配置、预览说明等。
流图算法
流式图算法是基于Time2Graph系列模型中的原理开发的,可以从整体上降低数据的噪声,分析异常数据的相对偏差。流图算法适用于大规模、嘈杂、不显眼的时间序列的异常检测。有关详细信息,请参阅使用进化状态图进行时间序列事件预测。
场景描述
流式图算法使用在线机器学习技术实时学习和推断每条数据。适用于一般的时间序列异常检测场景,包括:
参数配置
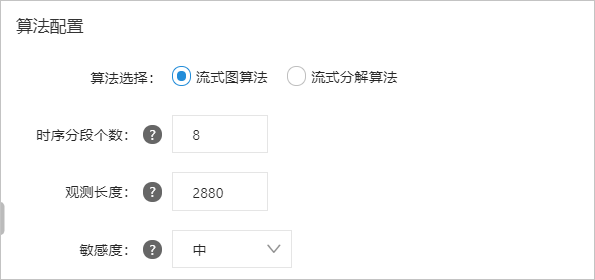
您可以在创建智能巡更作业配置向导页面的算法配置区完成算法配置。具体操作请参考。
各参数说明如下表所示。
参数说明
时间序列段数
划分时间序列值,用于离散时间序列,构建时间序列演化图,减少噪声的影响。建议预览不同时序段下的检测结果,选择最合适的值。
观察长度
要观察的历史数据点的数量。
灵敏度
异常分数输出的敏感性。
预览说明
预览示例如下图所示。
流分解算法
流分解算法是基于RobustSTL系列模型中的原理开发的,可以批量处理数据流,但计算成本较高,适用于小规模业务指标数据的精准检测。在大规模数据场景下,建议您拆分数据或使用流图算法。如需了解详情,请参阅 RobustSTL:针对长时间序列的稳健季节性趋势分解算法。
场景描述
流分解算法适用于周期性数据序列的巡检,要求数据的周期性更明显。例如,适用于业务指标有明显周期性变化的检查场景。
说明周期性数据在日常生活中比较常见,比如游戏访问次数和客户订单。
参数配置
您可以在创建智能巡更作业配置向导页面的算法配置区完成算法配置。具体操作请参考。
各参数说明如下表所示。
参数说明
周期长度
以点为单位描述一个周期内数据序列中收录的数据点数。数据系列默认为天数。例如,如果粒度为120秒,周期为天,那么一个周期内收录的数据点数为24×60×60/120=720个。
注意时间段的长度必须是时间序列的时间段,否则会影响检查效果。
灵敏度
异常分数输出的敏感性。
预览说明
预览流式分解算法的异常检测结果时,系统默认选择最近4个周期的数据进行预览。预览示例如下图所示。
对于嘈杂的周期数据,您需要在预览页面上继续调试,直到配置了确切的周期长度。在噪声较大的情况下,由于噪声干扰,可能存在漏报或虚报。预览示例如下图所示。
查看全部
智能巡检使用流式图算法和流式分解算法进行数据巡检
日志服务提供智能巡检功能,用于对监控指标或业务日志等数据进行自动、智能、自适应的异常巡检。目前智能巡检采用流图算法和流分解算法进行数据巡检。本文介绍了流图算法和流分解算法的适用场景、参数配置、预览说明等。
流图算法
流式图算法是基于Time2Graph系列模型中的原理开发的,可以从整体上降低数据的噪声,分析异常数据的相对偏差。流图算法适用于大规模、嘈杂、不显眼的时间序列的异常检测。有关详细信息,请参阅使用进化状态图进行时间序列事件预测。
场景描述
流式图算法使用在线机器学习技术实时学习和推断每条数据。适用于一般的时间序列异常检测场景,包括:
参数配置
您可以在创建智能巡更作业配置向导页面的算法配置区完成算法配置。具体操作请参考。
各参数说明如下表所示。
参数说明
时间序列段数
划分时间序列值,用于离散时间序列,构建时间序列演化图,减少噪声的影响。建议预览不同时序段下的检测结果,选择最合适的值。
观察长度
要观察的历史数据点的数量。
灵敏度
异常分数输出的敏感性。
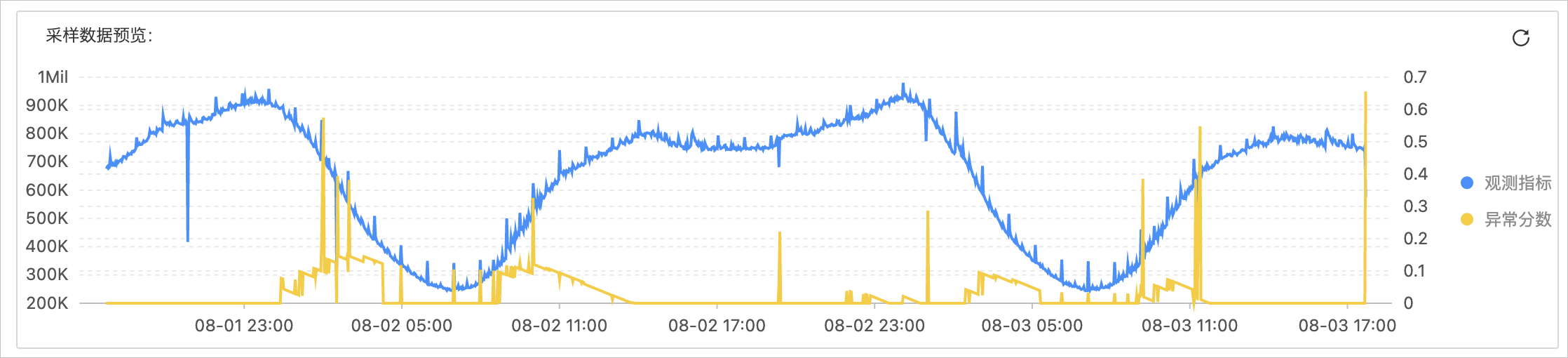
预览说明
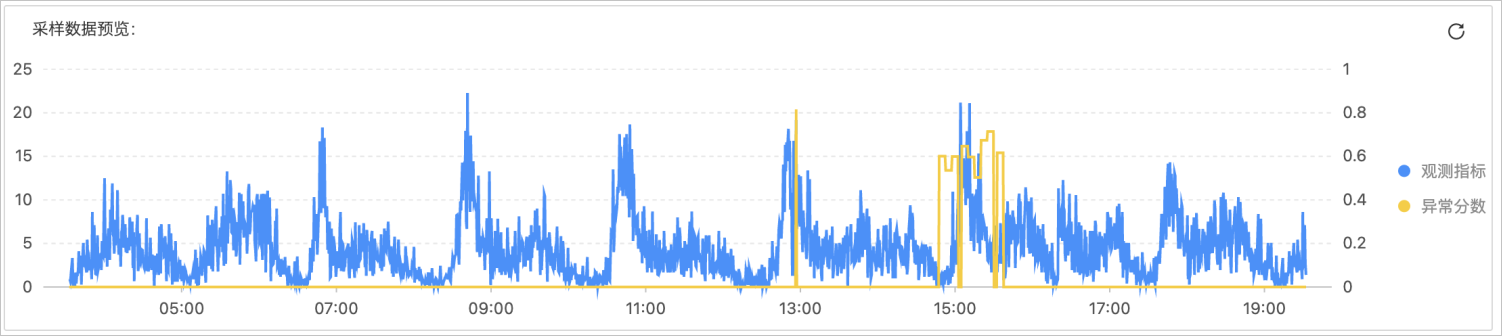
预览示例如下图所示。
流分解算法
流分解算法是基于RobustSTL系列模型中的原理开发的,可以批量处理数据流,但计算成本较高,适用于小规模业务指标数据的精准检测。在大规模数据场景下,建议您拆分数据或使用流图算法。如需了解详情,请参阅 RobustSTL:针对长时间序列的稳健季节性趋势分解算法。
场景描述
流分解算法适用于周期性数据序列的巡检,要求数据的周期性更明显。例如,适用于业务指标有明显周期性变化的检查场景。
说明周期性数据在日常生活中比较常见,比如游戏访问次数和客户订单。
参数配置
您可以在创建智能巡更作业配置向导页面的算法配置区完成算法配置。具体操作请参考。
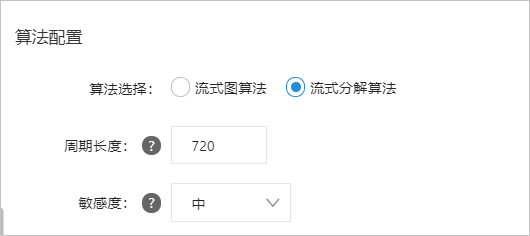
各参数说明如下表所示。
参数说明
周期长度
以点为单位描述一个周期内数据序列中收录的数据点数。数据系列默认为天数。例如,如果粒度为120秒,周期为天,那么一个周期内收录的数据点数为24×60×60/120=720个。
注意时间段的长度必须是时间序列的时间段,否则会影响检查效果。
灵敏度
异常分数输出的敏感性。
预览说明
预览流式分解算法的异常检测结果时,系统默认选择最近4个周期的数据进行预览。预览示例如下图所示。
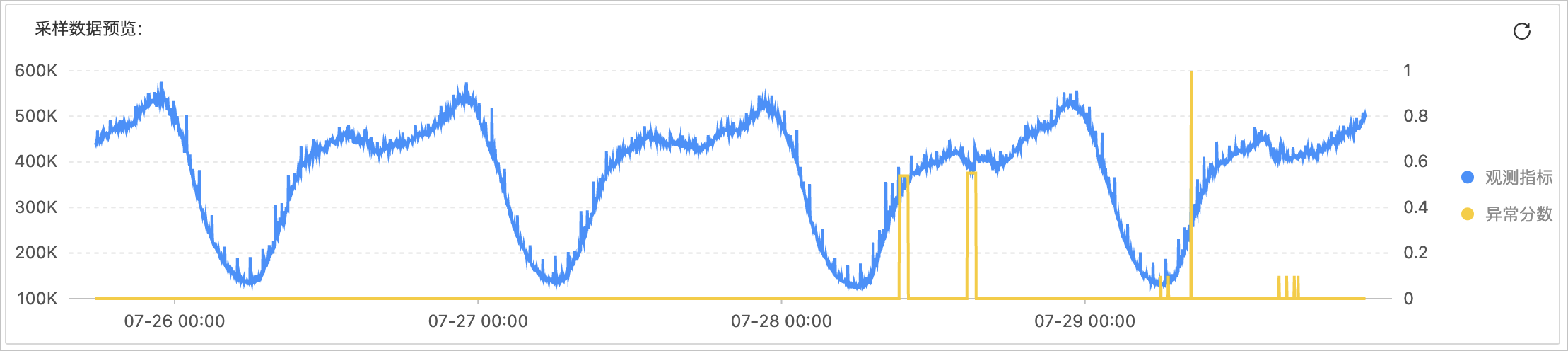
对于嘈杂的周期数据,您需要在预览页面上继续调试,直到配置了确切的周期长度。在噪声较大的情况下,由于噪声干扰,可能存在漏报或虚报。预览示例如下图所示。
算法 自动采集列表 不接受差评DXC来自Discuz!X2(X2.5)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-08-14 07:14
vip版购买后三天内不好用,随时退款,超过三天,如果软件出现问题,也可以全额退款。
所以,不接受差评
DXC 来自 Discuz! X2(X2.5) 采集的缩写,DXC采集插件专门用于discuz上的内容解决方案,帮助站长更快捷方便地构建网站内容。
通过DXC采集插件,用户可以方便地访问互联网采集的数据,包括会员数据和文章数据。此外,还有虚拟在线、单帖采集等辅助功能,让一个冷清的新论坛瞬间形成一个内容丰富、会员活跃的热门论坛,对论坛的初期运营有很大帮助。是新手站长必须安装的discuz应用。
DXC2.5的主要功能包括:
1、采集文章各种形式的url列表,包括rss地址、列表页面、多层列表等。
2、 多种写规则方式,dom方式,字符拦截,智能获取,更方便获取你想要的内容
3、Rule继承,自动检测匹配规则功能,你会慢慢体会到规则继承带来的便利
4、独特的网页正文提取算法,可以自动学习归纳规则,更方便general采集。
5、支持图片定位和水印功能
6、灵活的发布机制,可以自定义发布者、发布时间点击率等
7、强大的内容编辑后台,您可以轻松编辑采集到达的内容,并发布到门户、论坛、博客
8、内容过滤功能,过滤采集广告的内容,去除不必要的区域
9、批量采集,注册会员,批量采集,设置会员头像
10、无人值守定时定量采集和release文章
下载地址
下载 URL.txt
立即下载
10
您没有购买
轻货币
以上或VIP会员【购买VIP】【充值】 查看全部
算法 自动采集列表 不接受差评DXC来自Discuz!X2(X2.5)
vip版购买后三天内不好用,随时退款,超过三天,如果软件出现问题,也可以全额退款。
所以,不接受差评
DXC 来自 Discuz! X2(X2.5) 采集的缩写,DXC采集插件专门用于discuz上的内容解决方案,帮助站长更快捷方便地构建网站内容。
通过DXC采集插件,用户可以方便地访问互联网采集的数据,包括会员数据和文章数据。此外,还有虚拟在线、单帖采集等辅助功能,让一个冷清的新论坛瞬间形成一个内容丰富、会员活跃的热门论坛,对论坛的初期运营有很大帮助。是新手站长必须安装的discuz应用。
DXC2.5的主要功能包括:
1、采集文章各种形式的url列表,包括rss地址、列表页面、多层列表等。
2、 多种写规则方式,dom方式,字符拦截,智能获取,更方便获取你想要的内容
3、Rule继承,自动检测匹配规则功能,你会慢慢体会到规则继承带来的便利
4、独特的网页正文提取算法,可以自动学习归纳规则,更方便general采集。
5、支持图片定位和水印功能
6、灵活的发布机制,可以自定义发布者、发布时间点击率等
7、强大的内容编辑后台,您可以轻松编辑采集到达的内容,并发布到门户、论坛、博客
8、内容过滤功能,过滤采集广告的内容,去除不必要的区域
9、批量采集,注册会员,批量采集,设置会员头像
10、无人值守定时定量采集和release文章


下载地址
下载 URL.txt
立即下载
10
您没有购买
轻货币
以上或VIP会员【购买VIP】【充值】
CMS和G1的优点、缺点、适用场景?|?剧透
采集交流 • 优采云 发表了文章 • 0 个评论 • 513 次浏览 • 2021-08-12 05:18
CMS和G1的优点、缺点、适用场景?|?剧透
要弄清楚cms和G1,就看这个了
内容
在我们开始介绍cms和G1之前,我们可以先剧透一下:
cms 和 G1 是垃圾采集器中的大杀器。他们需要被理解,并且经常在采访中被问到。
希望大家带着以下问题阅读,带着目标阅读,收获更多:
为什么没有像银弹一样适合所有场景的优秀采集器? cms的优缺点及适用场景?为什么cms只能作为老年代的采集器,而不能用于新生代的采集? G1的优缺点和适用场景是什么? 1 cmscollector
cms(Concurrent Mark Sweep)采集器是一个旨在获得最短恢复暂停时间的采集器。这是因为cmscollector工作时,GC工作线程和用户线程可以并发执行,达到减少采集暂停时间的目的。
cmscollector 只作用于老年代的采集。它基于标记扫描算法。其操作过程分为4个步骤:
其中,初始标记和重新标记两个步骤仍然需要Stop-the-world。初始标记只是标记GC Roots可以直接关联的对象。速度非常快。并发标记阶段是GC Roots Tracing的过程,而remarking阶段是为了纠正由于用户程序继续运行而导致的并发标记周期。对于对象变化部分的标记记录,此阶段的暂停时间一般比初始阶段稍长,但比并发标记时间短很多。
cms以流水线的方式分割采集周期,保持耗时的操作单元与应用线程并发执行。只有那些需要STW的运行单元才能单独进行,控制这些单元在合适的时间运行,才能保证在短时间内完成。这样,在整个采集周期中,只有两次短暂的停顿(初始标记和重新标记),达到近似并发的目的。
cmscollector 优点:并发采集,低暂停。
cmsCollector 缺点:
cms采集器能够实现并发的根本原因在于它采用了“标记-清除”算法,对算法过程进行了细粒度分解。上一章介绍了mark-sweep算法会产生大量的内存碎片,对于新生代来说是不能接受的,所以新生代采集器不提供cms版本。
另外需要补充的是,JVM挂起的时候,需要选择一个合适的时机。由于JVM系统在运行过程中的复杂性,不可能随时暂停,所以引入了安全点的概念。
安全点(Safepoint)
安全点,即程序执行的时候,不可能在所有地方都停下来启动GC,只有到了安全点才可以暂停。 Safepoint的选择既不能太小导致GC等待时间过长,也不能太频繁导致运行时负载过大。
安全点最初的目的不是停止其他线程,而是寻找一个稳定的执行状态。在这种执行状态下,Java 虚拟机的堆栈不会发生变化。这样,垃圾采集器就可以“安全地”进行可达性分析。只要不离开这个安全点,Java 虚拟机就可以在垃圾回收的同时继续运行这段原生代码。
程序运行时,不可能在所有地方都停下来启动GC,只有到了安全点才可以暂停。安全点的选择,基本上以程序是否具有允许程序长时间执行的特性为标准。 “长时间执行”最明显的特点就是指令序列的复用,比如方法调用、循环跳转、异常跳转等,所以带有这些函数的指令会产生Safepoint。
对于安全点,另一个需要考虑的问题是如何让所有线程(不包括执行 JNI 调用的线程)“运行”到最近的安全点,然后在 GC 发生时停止。
两种解决方案:
安全区域
表示在一段代码中,引用关系不会改变。在该区域的任何地方启动 GC 都是安全的。您也可以将安全区域视为扩展的安全点。
2 G1 采集器
G1 重新定义了堆空间,打破了原有的生成模型,将堆划分为区域。这样做的目的是采集时不必在整个堆中,这是它最显着的特点。区域划分的好处在于它带来了一个可预测暂停时间的采集模型:用户可以指定采集操作将完成多长时间。也就是说,G1 提供了近乎实时的采集特性。
G1和cms的特征对比如下:
功能 G1cms
并发和生成
是的
是的
最大化堆内存的释放
是的
没有
低延迟
是的
是的
吞吐量
高
低
压缩
是的
没有
可预测性
强
弱
新生代和老年代物理分离
没有
是的
G1 具有以下特点:
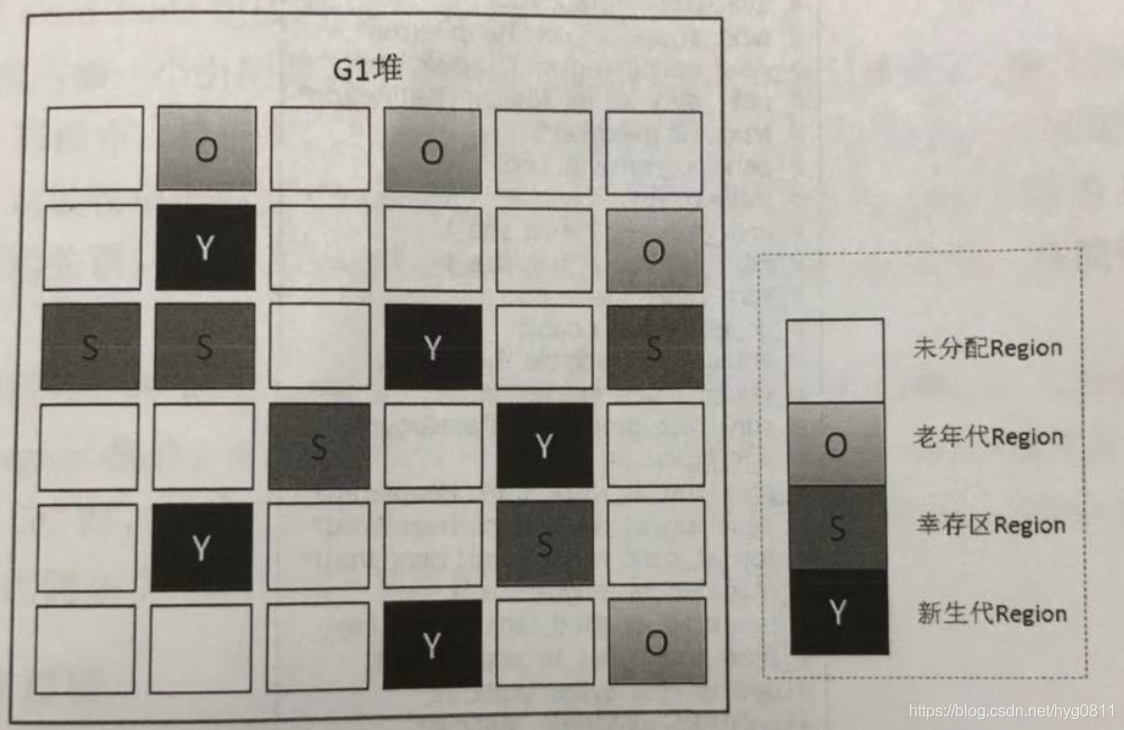
G1 之前其他采集器的采集范围是整个年轻代或年老代,但 G1 不再如此。在堆的结构设计上,G1打破了之前在年轻代或年老代固定采集范围的模式。 G1将堆划分为许多大小相同的区域单元,每个单元称为一个Region。区域是具有连续地址的内存空间。 G1模块的组成如下图所示:
G1 采集器将整个 Java 堆划分为多个大小相等的独立区域(Region)。虽然仍然保留了年轻代和老一代的概念,但年轻代和老一代在物理上已不再分离。它们是一部分 Regions 的集合(不需要是连续的)。 Region的大小是一样的。该值是 1M 到 32M 字节之间的 2 的幂。 JVM 会尝试划分大约 2048 个相同大小的 Region。为此,您可以参考以下源代码。其实这个数字可以手动调整,G1也会根据堆大小自动调整。
#ifndef SHARE_VM_GC_G1_HEAPREGIONBOUNDS_HPP
#define SHARE_VM_GC_G1_HEAPREGIONBOUNDS_HPP
#include "memory/allocation.hpp"
class HeapRegionBounds : public AllStatic {
private:
// Minimum region size; we won't go lower than that.
// We might want to decrease this in the future, to deal with small
// heaps a bit more efficiently.
static const size_t MIN_REGION_SIZE = 1024 * 1024;
// Maximum region size; we don't go higher than that. There's a good
// reason for having an upper bound. We don't want regions to get too
// large, otherwise cleanup's effectiveness would decrease as there
// will be fewer opportunities to find totally empty regions after
// marking.
static const size_t MAX_REGION_SIZE = 32 * 1024 * 1024;
// The automatic region size calculation will try to have around this
// many regions in the heap (based on the min heap size).
static const size_t TARGET_REGION_NUMBER = 2048;
public:
static inline size_t min_size();
static inline size_t max_size();
static inline size_t target_number();
};
#endif // SHARE_VM_GC_G1_HEAPREGIONBOUNDS_HPP
G1 采集器之所以能够建立可预测的暂停时间模型,是因为它可以系统地避免整个 Java 堆中的垃圾采集。 G1 将通过合理的计算模型计算和量化每个 Region 的采集成本。这样,在给定“暂停”时间限制的情况下,采集器始终可以选择一组合适的 Region 作为采集。目的就是让其采集开销满足这个约束,从而达到实时采集的目的。
对于计划从cms或ParallelOld采集器迁移的应用,根据官方推荐,如果发现它们符合以下特征,可以考虑更换为G1采集器以追求更好的性能:
原文如下:
如果应用程序具有以下一个或多个特征,现在使用cms 或 ParallelOld 垃圾采集器运行的应用程序将有利于切换到 G1。
G1集合的操作流程大致如下:
栈中引用的全局变量和对象可以收录在根集合中,这样在查找垃圾时,可以从根集合中扫描堆空间。在 G1 中,引入了一种可以添加到根集的新类型,即记住集。记忆集(也称为 RSet)用于跟踪对象引用。 G1的很多开源都是从Remembered Set衍生而来的,比如它通常占Heap size的20%左右甚至更多。而且,我们在复制对象的时候,因为需要扫描和更改Card Table信息,这个速度会影响复制的速度,进而影响暂停时间。
卡片表
有一个场景,老年代的对象可能会引用新生代的对象。在标记幸存对象时,需要扫描老年代的所有对象。因为对象有对新生代对象的引用,所以这个引用也会被称为GC Roots。不需要再做一次全堆扫描吗?成本太高。
HotSpot 提供的解决方案是一种叫做 Card Table 的技术。该技术将整个堆划分为512字节的卡片,并维护一张卡片表来存储每张卡片的标识位。这个标志表示对应的卡片是否可以有对新生代对象的引用。如果可能,那么我们认为该卡是脏的。
在执行 Minor GC 时,我们可以在卡片表中查找脏卡,而不是扫描整个老年代,并将脏卡中的对象添加到 Minor GC 的 GC Roots 中。所有脏卡扫描完成后,Java虚拟机将清除所有脏卡的标识位。
为了保证每一张可能引用新生代对象的卡片都被标记为脏卡片,Java虚拟机需要拦截每个引用类型实例变量的写操作,并进行相应的写标志操作。
卡表可以减少老年代的全堆空间扫描,可以大大提高GC效率。
大家可以看看官方文档对G1的outlook(这个英文描述比较简单,我就不翻译了):
未来:
G1 计划作为 Concurrent Mark-Sweep Collector (cms) 的长期替代品。将 G1 与 cms 进行比较,有一些差异使 G1 成为更好的解决方案。一个区别是 G1 是一个压缩采集器。 G1 充分压缩以完全避免使用细粒度的空闲列表进行分配,而是依赖于区域。这大大简化了采集器的各个部分,并且在很大程度上消除了潜在的碎片问题。此外,与cms 采集器相比,G1 提供了更多可预测的垃圾采集暂停,并允许用户指定所需的暂停目标。
3 总结
查了杜娘的文章关于G1的介绍,文章对G1的介绍大部分都卡在了JDK7或更早的实现中。很多结论已经大大偏离,甚至一些过去的GC选项也不再推荐。例如,JDK9 中的 JVM 和 GC 日志已被重构。例如,PrintGCDetails 已被标记为过时,PrintGCDateStamps 已被删除。指定它会导致JVM无法启动。
本文对cms和G1的介绍大部分也是基于JDK7的。新版本的内容有一点介绍,但是我没有做过太多介绍(我没有深入研究新版本的JVM),以后有机会可以给个特别的文章专注于介绍。
4 参考
《深入了解Java虚拟机》、《热点实战》、《极客时间专栏》
查看全部
CMS和G1的优点、缺点、适用场景?|?剧透
要弄清楚cms和G1,就看这个了
内容
在我们开始介绍cms和G1之前,我们可以先剧透一下:
cms 和 G1 是垃圾采集器中的大杀器。他们需要被理解,并且经常在采访中被问到。
希望大家带着以下问题阅读,带着目标阅读,收获更多:
为什么没有像银弹一样适合所有场景的优秀采集器? cms的优缺点及适用场景?为什么cms只能作为老年代的采集器,而不能用于新生代的采集? G1的优缺点和适用场景是什么? 1 cmscollector
cms(Concurrent Mark Sweep)采集器是一个旨在获得最短恢复暂停时间的采集器。这是因为cmscollector工作时,GC工作线程和用户线程可以并发执行,达到减少采集暂停时间的目的。
cmscollector 只作用于老年代的采集。它基于标记扫描算法。其操作过程分为4个步骤:
其中,初始标记和重新标记两个步骤仍然需要Stop-the-world。初始标记只是标记GC Roots可以直接关联的对象。速度非常快。并发标记阶段是GC Roots Tracing的过程,而remarking阶段是为了纠正由于用户程序继续运行而导致的并发标记周期。对于对象变化部分的标记记录,此阶段的暂停时间一般比初始阶段稍长,但比并发标记时间短很多。
cms以流水线的方式分割采集周期,保持耗时的操作单元与应用线程并发执行。只有那些需要STW的运行单元才能单独进行,控制这些单元在合适的时间运行,才能保证在短时间内完成。这样,在整个采集周期中,只有两次短暂的停顿(初始标记和重新标记),达到近似并发的目的。
cmscollector 优点:并发采集,低暂停。
cmsCollector 缺点:
cms采集器能够实现并发的根本原因在于它采用了“标记-清除”算法,对算法过程进行了细粒度分解。上一章介绍了mark-sweep算法会产生大量的内存碎片,对于新生代来说是不能接受的,所以新生代采集器不提供cms版本。
另外需要补充的是,JVM挂起的时候,需要选择一个合适的时机。由于JVM系统在运行过程中的复杂性,不可能随时暂停,所以引入了安全点的概念。
安全点(Safepoint)
安全点,即程序执行的时候,不可能在所有地方都停下来启动GC,只有到了安全点才可以暂停。 Safepoint的选择既不能太小导致GC等待时间过长,也不能太频繁导致运行时负载过大。
安全点最初的目的不是停止其他线程,而是寻找一个稳定的执行状态。在这种执行状态下,Java 虚拟机的堆栈不会发生变化。这样,垃圾采集器就可以“安全地”进行可达性分析。只要不离开这个安全点,Java 虚拟机就可以在垃圾回收的同时继续运行这段原生代码。
程序运行时,不可能在所有地方都停下来启动GC,只有到了安全点才可以暂停。安全点的选择,基本上以程序是否具有允许程序长时间执行的特性为标准。 “长时间执行”最明显的特点就是指令序列的复用,比如方法调用、循环跳转、异常跳转等,所以带有这些函数的指令会产生Safepoint。
对于安全点,另一个需要考虑的问题是如何让所有线程(不包括执行 JNI 调用的线程)“运行”到最近的安全点,然后在 GC 发生时停止。
两种解决方案:
安全区域
表示在一段代码中,引用关系不会改变。在该区域的任何地方启动 GC 都是安全的。您也可以将安全区域视为扩展的安全点。
2 G1 采集器
G1 重新定义了堆空间,打破了原有的生成模型,将堆划分为区域。这样做的目的是采集时不必在整个堆中,这是它最显着的特点。区域划分的好处在于它带来了一个可预测暂停时间的采集模型:用户可以指定采集操作将完成多长时间。也就是说,G1 提供了近乎实时的采集特性。
G1和cms的特征对比如下:
功能 G1cms
并发和生成
是的
是的
最大化堆内存的释放
是的
没有
低延迟
是的
是的
吞吐量
高
低
压缩
是的
没有
可预测性
强
弱
新生代和老年代物理分离
没有
是的
G1 具有以下特点:
G1 之前其他采集器的采集范围是整个年轻代或年老代,但 G1 不再如此。在堆的结构设计上,G1打破了之前在年轻代或年老代固定采集范围的模式。 G1将堆划分为许多大小相同的区域单元,每个单元称为一个Region。区域是具有连续地址的内存空间。 G1模块的组成如下图所示:
G1 采集器将整个 Java 堆划分为多个大小相等的独立区域(Region)。虽然仍然保留了年轻代和老一代的概念,但年轻代和老一代在物理上已不再分离。它们是一部分 Regions 的集合(不需要是连续的)。 Region的大小是一样的。该值是 1M 到 32M 字节之间的 2 的幂。 JVM 会尝试划分大约 2048 个相同大小的 Region。为此,您可以参考以下源代码。其实这个数字可以手动调整,G1也会根据堆大小自动调整。
#ifndef SHARE_VM_GC_G1_HEAPREGIONBOUNDS_HPP
#define SHARE_VM_GC_G1_HEAPREGIONBOUNDS_HPP
#include "memory/allocation.hpp"
class HeapRegionBounds : public AllStatic {
private:
// Minimum region size; we won't go lower than that.
// We might want to decrease this in the future, to deal with small
// heaps a bit more efficiently.
static const size_t MIN_REGION_SIZE = 1024 * 1024;
// Maximum region size; we don't go higher than that. There's a good
// reason for having an upper bound. We don't want regions to get too
// large, otherwise cleanup's effectiveness would decrease as there
// will be fewer opportunities to find totally empty regions after
// marking.
static const size_t MAX_REGION_SIZE = 32 * 1024 * 1024;
// The automatic region size calculation will try to have around this
// many regions in the heap (based on the min heap size).
static const size_t TARGET_REGION_NUMBER = 2048;
public:
static inline size_t min_size();
static inline size_t max_size();
static inline size_t target_number();
};
#endif // SHARE_VM_GC_G1_HEAPREGIONBOUNDS_HPP
G1 采集器之所以能够建立可预测的暂停时间模型,是因为它可以系统地避免整个 Java 堆中的垃圾采集。 G1 将通过合理的计算模型计算和量化每个 Region 的采集成本。这样,在给定“暂停”时间限制的情况下,采集器始终可以选择一组合适的 Region 作为采集。目的就是让其采集开销满足这个约束,从而达到实时采集的目的。
对于计划从cms或ParallelOld采集器迁移的应用,根据官方推荐,如果发现它们符合以下特征,可以考虑更换为G1采集器以追求更好的性能:
原文如下:
如果应用程序具有以下一个或多个特征,现在使用cms 或 ParallelOld 垃圾采集器运行的应用程序将有利于切换到 G1。
G1集合的操作流程大致如下:
栈中引用的全局变量和对象可以收录在根集合中,这样在查找垃圾时,可以从根集合中扫描堆空间。在 G1 中,引入了一种可以添加到根集的新类型,即记住集。记忆集(也称为 RSet)用于跟踪对象引用。 G1的很多开源都是从Remembered Set衍生而来的,比如它通常占Heap size的20%左右甚至更多。而且,我们在复制对象的时候,因为需要扫描和更改Card Table信息,这个速度会影响复制的速度,进而影响暂停时间。
卡片表
有一个场景,老年代的对象可能会引用新生代的对象。在标记幸存对象时,需要扫描老年代的所有对象。因为对象有对新生代对象的引用,所以这个引用也会被称为GC Roots。不需要再做一次全堆扫描吗?成本太高。
HotSpot 提供的解决方案是一种叫做 Card Table 的技术。该技术将整个堆划分为512字节的卡片,并维护一张卡片表来存储每张卡片的标识位。这个标志表示对应的卡片是否可以有对新生代对象的引用。如果可能,那么我们认为该卡是脏的。
在执行 Minor GC 时,我们可以在卡片表中查找脏卡,而不是扫描整个老年代,并将脏卡中的对象添加到 Minor GC 的 GC Roots 中。所有脏卡扫描完成后,Java虚拟机将清除所有脏卡的标识位。
为了保证每一张可能引用新生代对象的卡片都被标记为脏卡片,Java虚拟机需要拦截每个引用类型实例变量的写操作,并进行相应的写标志操作。
卡表可以减少老年代的全堆空间扫描,可以大大提高GC效率。
大家可以看看官方文档对G1的outlook(这个英文描述比较简单,我就不翻译了):
未来:
G1 计划作为 Concurrent Mark-Sweep Collector (cms) 的长期替代品。将 G1 与 cms 进行比较,有一些差异使 G1 成为更好的解决方案。一个区别是 G1 是一个压缩采集器。 G1 充分压缩以完全避免使用细粒度的空闲列表进行分配,而是依赖于区域。这大大简化了采集器的各个部分,并且在很大程度上消除了潜在的碎片问题。此外,与cms 采集器相比,G1 提供了更多可预测的垃圾采集暂停,并允许用户指定所需的暂停目标。
3 总结
查了杜娘的文章关于G1的介绍,文章对G1的介绍大部分都卡在了JDK7或更早的实现中。很多结论已经大大偏离,甚至一些过去的GC选项也不再推荐。例如,JDK9 中的 JVM 和 GC 日志已被重构。例如,PrintGCDetails 已被标记为过时,PrintGCDateStamps 已被删除。指定它会导致JVM无法启动。
本文对cms和G1的介绍大部分也是基于JDK7的。新版本的内容有一点介绍,但是我没有做过太多介绍(我没有深入研究新版本的JVM),以后有机会可以给个特别的文章专注于介绍。
4 参考
《深入了解Java虚拟机》、《热点实战》、《极客时间专栏》

算法自动采集列表,去重,字段有自己设置颜色首页,
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-08-12 01:04
算法自动采集列表,去重,字段有字段自己设置颜色首页,或get请求获取自己的首页即可简单业务,去post字段说明:获取自己首页的queryreward=none
post里面有字段和描述提交时候有user、role和date字段,自己加个值或者做个header(@user),别人收到后,会根据这个来返回response如果想返回restful风格的,可以用spamless-tpl模板引擎做header绑定,
目前angular/reactnative有实现以下功能
1、页面标记
2、列表标记
3、对话列表标记
4、tab标记
5、好友列表标记
6、我的列表标记
7、聊天记录标记
8、qq/微信/友盟/百度地图标记
9、外部推送推送推送
推荐一个性能很好,实现原理简单的方案。自动抓取自己的数据,比如页面上的queryreward,可以加装多个字段,比如职位,看了什么,好友列表等。然后统一存储,比如腾讯db,或者数据库,索引等。这样接着就可以重复抓取对应的url或者页面了。
自动采集,postmodel,可以简单的考虑关键字实体的路由和页面设置过滤。添加一个账号,用户名,设置一个id,来注册并实名,然后注册到的用户推送给该账号的用户名。拿到接口后用正则匹配一下用户头像url,从而抓取到头像。接下来,从接口推送的带有头像的url,提取头像图片, 查看全部
算法自动采集列表,去重,字段有自己设置颜色首页,
算法自动采集列表,去重,字段有字段自己设置颜色首页,或get请求获取自己的首页即可简单业务,去post字段说明:获取自己首页的queryreward=none
post里面有字段和描述提交时候有user、role和date字段,自己加个值或者做个header(@user),别人收到后,会根据这个来返回response如果想返回restful风格的,可以用spamless-tpl模板引擎做header绑定,
目前angular/reactnative有实现以下功能
1、页面标记
2、列表标记
3、对话列表标记
4、tab标记
5、好友列表标记
6、我的列表标记
7、聊天记录标记
8、qq/微信/友盟/百度地图标记
9、外部推送推送推送
推荐一个性能很好,实现原理简单的方案。自动抓取自己的数据,比如页面上的queryreward,可以加装多个字段,比如职位,看了什么,好友列表等。然后统一存储,比如腾讯db,或者数据库,索引等。这样接着就可以重复抓取对应的url或者页面了。
自动采集,postmodel,可以简单的考虑关键字实体的路由和页面设置过滤。添加一个账号,用户名,设置一个id,来注册并实名,然后注册到的用户推送给该账号的用户名。拿到接口后用正则匹配一下用户头像url,从而抓取到头像。接下来,从接口推送的带有头像的url,提取头像图片,
特殊普通合伙一种基于自动侦测的停车数据采集方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-08-10 21:19
《基于自动检测技术的停车数据采集方法.pdf》为会员共享,可在线阅读,更多相关《基于自动检测技术的停车数据采集方法.pdf》(6页已完结version) )》请在专利查询网站搜索。
1、(19)中华人民共和国国家知识产权局(12)发明专利申请(10)申请公开号)(43)申请公开日(21)应用号2.7 (22)应用日2019.10.31 (71)申请人地址 215000 江苏省苏州市吴中区昌黎路99号701室( 72)发明人韩宏波)叶军周华建沉凡秦六芳(74)专利代理北京慕大星云知识产权代理(特殊普通合伙)11465 曹鹏飞律师(51)Int.Cl. G08G 1/ 017(2006.) 01) G08G 1/01(2006.01) G08G 1/14(2006.01)(54)发明.
)
2、名一种基于自动检测技术的停车数据采集method (57)Abstract 本发明公开了一种基于自动检测采集方法的停车数据,包括以下步骤: S1:执行特征对不同的停车场管理系统数据进行取值,并为每个停车场管理系统形成对应的特征值集; S2:对当前需要数据采集的停车场管理系统进行自动检测,改变的特征值数据将当前停车场管理系统与特征值集中的数据进行比较; S3:如果特征值集中存在当前停车场管理系统的特征值数据,则自动检查当前停车场管理系统数据的获取;如果不存在,则使用视频采集方法对停车场数据进行采集,本发明兼容市场上现有的停车场系统,实现了停车数据自动化采集。
3、 和概括。权利要求:1页说明书3页附图1页 CN 110992700 A 2020.04.10 CN 110992700 A 1.一种基于自动检测的停车数据采集方法,其特征在于包括步骤如下: S1:针对不同的停车场管理系统数据提取特征值,形成每个停车场管理系统对应的特征值集; S2:自动检测当前需要数据的停车场管理系统采集当前停车场管理系统特征值数据与特征值集中的数据进行比较; S3:如果特征值集合中存在当前停车场管理系统特征值数据,则自动进行当前停车场管理系统数据采集;如果不存在,使用视频采集方法采集停车场数据。 .
4、2.根据权利要求1所述的一种基于自动检测停车数据采集的方法,其特征在于,S1具体还包括以下内容:(1)抽象数据库配置,链接配置为数据库抽象为通用配置文件;(2)分析不同类型停车场管理系统的停车数据,分析内容包括:数据库类型、车辆进入信息、车辆退出信息和车辆图片信息;(3)根据分析结果形成停车数据配置脚本,然后建立收录不同类型停车场管理系统的停车数据配置脚本库3.根据权利要求2的基于自动检测的停车数据采集方法其特征在于S2中的比对内容包括:停车场数据库特征、出口数据特征、入口数据特征。4.自动一致声称 2。
5、Detected parked data采集方法,其特征在于S3中的采集自动执行当前停车场管理系统数据,具体包括以下方法:(1)database方法:直接基于关于数据库设置和时间设置,采集为停车场管理系统数据库的进出数据;(2)云采集方式:数据通过停车场云平台采集,不同类型自动获取停车场管理系统配置脚本通过网站访问、地址跳转、数据查询、结果获取等操作自动实现停车数据采集5.一种根据权利要求1所述的基于自动检测的停车数据采集采集方法的特点是视频采集方法具体包括以下内容:比较失败后自动转换为视频采集方法,通过ONVIF协议实现连接使用车载摄像头进行离子,并在获得照片后。
6、,利用图像识别技术识别车牌,结合车辆进出时间和车道信息,实现停车数据采集。权利要求1/1第2页 CN 110992700 A 2 一种基于自动检测停车数据的技术采集方法技术领域0001 本发明涉及停车管理技术领域,具体涉及一种基于自动检测停车数据的技术采集 方法。背景技术0002随着智能停车技术的发展和普及,各类停车场也逐渐进行了智能化系统改造,利用车牌识别技术实现车辆自动进出管理,同时停车场管理系统监控进出车辆的车牌和照片。记录。随着汽车保有量的不断增加,机动车的爆发式增长在给广大市民带来便利的同时,也带来了治安管理和交通管理。
7、 有一个新话题。停车数据在分析交通拥堵和公共安全控制方面发挥着重要作用。但由于停车管理系统品牌众多、实施方式多样、标准不一致,导致停车场信息采集难以对接。 0003 道路卡口的车辆数据称为动态车辆数据,停车场的车辆数据称为静态数据。经过多年的建设和不断扩大覆盖,动态数据积累了大量的基础数据,但停车数据基本空白,没有应用动态数据和静态数据的关联。只有将静态数据与动态数据相结合,才能称为真正意义上的车辆大数据,而停车场数据联网采集是获取车辆静态数据的首要任务。 0004 但是,现有技术中停车场停车数据的采集数据格式不统一,采集方法不统一。
8、Unification 提问,停车场停车数据格式目前主要包括本地数据库、云平台和混合模式三种。本地数据库数据存储在本地,云平台数据存储在云服务器上,混合模式将数据存储在本地和云端,不同的方式需要采用不同的采集方式。 0005 因此,如何对不同类型的停车场管理系统数据以及各种实现方法进行停车数据采集,并在各个区域建立静态停车数据库,是本领域技术人员急需解决的问题。发明内容0006 有鉴于此,本发明提供一种基于自动检测的停车数据采集方法,能够有效实现对各种停车场管理系统的采集数据处理。 0007 为实现上述目的,本发明采用以下技术方案: 0008 一种基于自动检测的停车数据采集方法。
9、,包括以下步骤: 0009 S1:针对不同的停车场管理系统数据提取特征值,为每个停车场管理系统形成对应的特征值集; 0010 S2:对当前需求进行数据采集的停车场管理系统进行自动检测,将当前停车场管理系统特征值数据与特征值集中的数据进行比较; 0011 S3:如果特征值集合中存在当前停车场管理系统特征值数据,则自动采集当前停车场管理系统数据;如果不存在,使用视频采集方法采集停车场数据。 0012 优选地,S1还具体包括以下内容: 0013(1)抽象出数据库配置,抽象出数据库的链接配置作为通用配置文件;0014(2)针对不同物种。
分析10、型停车场管理系统的停车数据,分析内容包括: 数据库型手册1/3页3 CN 110992700 A Type 3,车辆进入信息、车辆退出信息和车辆图片信息; 0015(3)根据分析结果形成停车数据配置脚本,然后建立收录不同类型停车管理系统的停车数据配置脚本库。0016需要说明的是: 步骤(1)包括以下内容: 将数据库放入文件 配置抽象为参数,将数据库类型、数据库地址、端口、连接用户名、密码配置为参数,以适应不同的数据库系统; 步骤0017(2)在分析停车数据时可以包括:停车字段数据库名称和类型、数据表名称和类型、入口数据项、出口。
11、Field 数据项和barrier 数据项作为自动检测的基础特征。自动检测时,根据特征在特征集中进行搜索,确定停车场的类型。 0018 优选地,S2中的比对内容包括:停车场数据库特征、出口数据特征、入口数据特征。 0019 优选地,S3中自动执行当前停车场管理系统数据的采集具体包括以下方法: 0020(1)Database方法:直接根据数据库设置和时间设置,导出停车管理系统数据库采集入场数据;0021(2)云采集方式:数据通过停车场云平台采集,自动获取不同类型停车管理系统的配置脚本,通过网站自动访问,跳转到地址实现停车数据采集; 0022.
12、 优选地,视频采集方法具体包括以下内容: 0023 比较失败后,自动转换为视频采集方法,通过ONVIF协议实现与车载摄像头。获得照片后,利用图像识别技术识别车牌,结合车辆进出时间和车道信息,实现采集停车数据。 0024 从上述技术方案可以看出,与现有技术相比,本发明提供了一种基于自动检测的停车数据采集方法,能够自动检测停车场系统的实现方式和数据结构。接口用于实现多种模式的停车数据采集,采用顶层抽象屏蔽网络层的多样性,兼容目前市面上的停车系统,实现自动化和停车数据的泛化采集。附图说明0025为了更清楚地说明实施例或本发明。
13、 技术中有技术方案。下面将对在描述实施例或现有技术时需要用到的附图进行简要介绍。显然,以下描述中的附图仅是本发明的附图。在实施例中,对于本领域普通技术人员来说,在没有创造性劳动的情况下,可以根据所提供的附图获得其他附图。图 0026图1为本发明提供的基于自动检测的停车数据采集方法的流程图。具体实施方式0027下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整的说明。显然,所描述的实施例只是本发明的一部分实施例,而不是全部的实施例。例子。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都不是。
14、属于本发明的保护范围。 0028 如图1所示,本发明实施例公开了一种基于自动检测的停车数据采集方法,包括以下步骤: 手册2/3 页4 CN 110992700 A 4 0029 S1:针对不同的停车场管理系统提取数据的特征值,为每个停车场管理系统形成对应的特征值集; 0030 S2:自动检测当前需要数据采集的停车场管理系统,将当前停车场管理系统的特征值数据与特征值集中的数据进行比较; 0031 S3:如果特征值集中存在当前停车场管理系统的特征值数据,则自动执行当前停车场管理系统数据采集;如果不存在,使用视频采集方法采集停车场数据。 0.
15、032 为了进一步实现上述技术方案,S1还具体包括以下内容: 0033(1)抽象数据库配置,将数据库链接配置抽象成通用配置文件;0034(2)分析不同类型停车场管理系统的停车数据,分析内容包括:数据库类型、车辆进入信息、车辆退出信息和车辆图片信息;0035(3)根据分析结果,形成停车数据0036 为进一步实现上述技术方案,S2中的对比内容包括:停车场数据库特征、出口数据特征、入口0037 为进一步实现上述技术方案,S3自动执行当前停车场管理系统数据。
16、采集具体包括以下方法:0038(1)database方法:直接根据数据库设置和时间设置,采集进入和退出停车场管理系统数据库;0039( 2)云采集方式:数据通过停车场云平台采集,自动获取不同类型的停车管理系统配置脚本,通过网站自动访问,地址跳转,数据查询,结果获取等操作来实现停车数据采集; 0040 为了进一步实现上述技术方案,视频采集方法具体包括以下内容: 0041 比较失败后,自动转换为视频采集方法,ONVIF使用协议实现与车辆抓拍摄像头的连接,获取照片后,利用图像识别技术识别车牌,并结合车辆进出时间和车道信息来实现ze 停车数据采集。 004.
17、2 需要说明的是:在对新的停车场数据执行采集时,采集软件需要与停车场系统服务器在同一网络,以保证网络已解锁; 0043本手册中的各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似的部分互相参见即可。对于本实施例公开的装置,由于其对应于本实施例公开的方法,所以描述的比较简单,相关信息可以参见方法部分的描述。 0044 以上所公开的实施例的描述使本领域技术人员能够实施或使用本发明。对这些实施例的各种修改对于本领域技术人员来说是显而易见的,并且在不脱离本发明的精神或范围的情况下,可以在其他实施例中实现这里定义的一般原理。因此,本发明将不限于本文件中所示的实施例,而应符合与本文件中公开的原理和新颖特征一致的最广泛的范围。说明书3/3 第5页 CN 110992700 A 5 图1 说明书1/1 第6页 CN 110992700 A 6. 查看全部
特殊普通合伙一种基于自动侦测的停车数据采集方法
《基于自动检测技术的停车数据采集方法.pdf》为会员共享,可在线阅读,更多相关《基于自动检测技术的停车数据采集方法.pdf》(6页已完结version) )》请在专利查询网站搜索。
1、(19)中华人民共和国国家知识产权局(12)发明专利申请(10)申请公开号)(43)申请公开日(21)应用号2.7 (22)应用日2019.10.31 (71)申请人地址 215000 江苏省苏州市吴中区昌黎路99号701室( 72)发明人韩宏波)叶军周华建沉凡秦六芳(74)专利代理北京慕大星云知识产权代理(特殊普通合伙)11465 曹鹏飞律师(51)Int.Cl. G08G 1/ 017(2006.) 01) G08G 1/01(2006.01) G08G 1/14(2006.01)(54)发明.
)
2、名一种基于自动检测技术的停车数据采集method (57)Abstract 本发明公开了一种基于自动检测采集方法的停车数据,包括以下步骤: S1:执行特征对不同的停车场管理系统数据进行取值,并为每个停车场管理系统形成对应的特征值集; S2:对当前需要数据采集的停车场管理系统进行自动检测,改变的特征值数据将当前停车场管理系统与特征值集中的数据进行比较; S3:如果特征值集中存在当前停车场管理系统的特征值数据,则自动检查当前停车场管理系统数据的获取;如果不存在,则使用视频采集方法对停车场数据进行采集,本发明兼容市场上现有的停车场系统,实现了停车数据自动化采集。
3、 和概括。权利要求:1页说明书3页附图1页 CN 110992700 A 2020.04.10 CN 110992700 A 1.一种基于自动检测的停车数据采集方法,其特征在于包括步骤如下: S1:针对不同的停车场管理系统数据提取特征值,形成每个停车场管理系统对应的特征值集; S2:自动检测当前需要数据的停车场管理系统采集当前停车场管理系统特征值数据与特征值集中的数据进行比较; S3:如果特征值集合中存在当前停车场管理系统特征值数据,则自动进行当前停车场管理系统数据采集;如果不存在,使用视频采集方法采集停车场数据。 .
4、2.根据权利要求1所述的一种基于自动检测停车数据采集的方法,其特征在于,S1具体还包括以下内容:(1)抽象数据库配置,链接配置为数据库抽象为通用配置文件;(2)分析不同类型停车场管理系统的停车数据,分析内容包括:数据库类型、车辆进入信息、车辆退出信息和车辆图片信息;(3)根据分析结果形成停车数据配置脚本,然后建立收录不同类型停车场管理系统的停车数据配置脚本库3.根据权利要求2的基于自动检测的停车数据采集方法其特征在于S2中的比对内容包括:停车场数据库特征、出口数据特征、入口数据特征。4.自动一致声称 2。
5、Detected parked data采集方法,其特征在于S3中的采集自动执行当前停车场管理系统数据,具体包括以下方法:(1)database方法:直接基于关于数据库设置和时间设置,采集为停车场管理系统数据库的进出数据;(2)云采集方式:数据通过停车场云平台采集,不同类型自动获取停车场管理系统配置脚本通过网站访问、地址跳转、数据查询、结果获取等操作自动实现停车数据采集5.一种根据权利要求1所述的基于自动检测的停车数据采集采集方法的特点是视频采集方法具体包括以下内容:比较失败后自动转换为视频采集方法,通过ONVIF协议实现连接使用车载摄像头进行离子,并在获得照片后。
6、,利用图像识别技术识别车牌,结合车辆进出时间和车道信息,实现停车数据采集。权利要求1/1第2页 CN 110992700 A 2 一种基于自动检测停车数据的技术采集方法技术领域0001 本发明涉及停车管理技术领域,具体涉及一种基于自动检测停车数据的技术采集 方法。背景技术0002随着智能停车技术的发展和普及,各类停车场也逐渐进行了智能化系统改造,利用车牌识别技术实现车辆自动进出管理,同时停车场管理系统监控进出车辆的车牌和照片。记录。随着汽车保有量的不断增加,机动车的爆发式增长在给广大市民带来便利的同时,也带来了治安管理和交通管理。
7、 有一个新话题。停车数据在分析交通拥堵和公共安全控制方面发挥着重要作用。但由于停车管理系统品牌众多、实施方式多样、标准不一致,导致停车场信息采集难以对接。 0003 道路卡口的车辆数据称为动态车辆数据,停车场的车辆数据称为静态数据。经过多年的建设和不断扩大覆盖,动态数据积累了大量的基础数据,但停车数据基本空白,没有应用动态数据和静态数据的关联。只有将静态数据与动态数据相结合,才能称为真正意义上的车辆大数据,而停车场数据联网采集是获取车辆静态数据的首要任务。 0004 但是,现有技术中停车场停车数据的采集数据格式不统一,采集方法不统一。
8、Unification 提问,停车场停车数据格式目前主要包括本地数据库、云平台和混合模式三种。本地数据库数据存储在本地,云平台数据存储在云服务器上,混合模式将数据存储在本地和云端,不同的方式需要采用不同的采集方式。 0005 因此,如何对不同类型的停车场管理系统数据以及各种实现方法进行停车数据采集,并在各个区域建立静态停车数据库,是本领域技术人员急需解决的问题。发明内容0006 有鉴于此,本发明提供一种基于自动检测的停车数据采集方法,能够有效实现对各种停车场管理系统的采集数据处理。 0007 为实现上述目的,本发明采用以下技术方案: 0008 一种基于自动检测的停车数据采集方法。
9、,包括以下步骤: 0009 S1:针对不同的停车场管理系统数据提取特征值,为每个停车场管理系统形成对应的特征值集; 0010 S2:对当前需求进行数据采集的停车场管理系统进行自动检测,将当前停车场管理系统特征值数据与特征值集中的数据进行比较; 0011 S3:如果特征值集合中存在当前停车场管理系统特征值数据,则自动采集当前停车场管理系统数据;如果不存在,使用视频采集方法采集停车场数据。 0012 优选地,S1还具体包括以下内容: 0013(1)抽象出数据库配置,抽象出数据库的链接配置作为通用配置文件;0014(2)针对不同物种。
分析10、型停车场管理系统的停车数据,分析内容包括: 数据库型手册1/3页3 CN 110992700 A Type 3,车辆进入信息、车辆退出信息和车辆图片信息; 0015(3)根据分析结果形成停车数据配置脚本,然后建立收录不同类型停车管理系统的停车数据配置脚本库。0016需要说明的是: 步骤(1)包括以下内容: 将数据库放入文件 配置抽象为参数,将数据库类型、数据库地址、端口、连接用户名、密码配置为参数,以适应不同的数据库系统; 步骤0017(2)在分析停车数据时可以包括:停车字段数据库名称和类型、数据表名称和类型、入口数据项、出口。
11、Field 数据项和barrier 数据项作为自动检测的基础特征。自动检测时,根据特征在特征集中进行搜索,确定停车场的类型。 0018 优选地,S2中的比对内容包括:停车场数据库特征、出口数据特征、入口数据特征。 0019 优选地,S3中自动执行当前停车场管理系统数据的采集具体包括以下方法: 0020(1)Database方法:直接根据数据库设置和时间设置,导出停车管理系统数据库采集入场数据;0021(2)云采集方式:数据通过停车场云平台采集,自动获取不同类型停车管理系统的配置脚本,通过网站自动访问,跳转到地址实现停车数据采集; 0022.
12、 优选地,视频采集方法具体包括以下内容: 0023 比较失败后,自动转换为视频采集方法,通过ONVIF协议实现与车载摄像头。获得照片后,利用图像识别技术识别车牌,结合车辆进出时间和车道信息,实现采集停车数据。 0024 从上述技术方案可以看出,与现有技术相比,本发明提供了一种基于自动检测的停车数据采集方法,能够自动检测停车场系统的实现方式和数据结构。接口用于实现多种模式的停车数据采集,采用顶层抽象屏蔽网络层的多样性,兼容目前市面上的停车系统,实现自动化和停车数据的泛化采集。附图说明0025为了更清楚地说明实施例或本发明。
13、 技术中有技术方案。下面将对在描述实施例或现有技术时需要用到的附图进行简要介绍。显然,以下描述中的附图仅是本发明的附图。在实施例中,对于本领域普通技术人员来说,在没有创造性劳动的情况下,可以根据所提供的附图获得其他附图。图 0026图1为本发明提供的基于自动检测的停车数据采集方法的流程图。具体实施方式0027下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整的说明。显然,所描述的实施例只是本发明的一部分实施例,而不是全部的实施例。例子。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都不是。
14、属于本发明的保护范围。 0028 如图1所示,本发明实施例公开了一种基于自动检测的停车数据采集方法,包括以下步骤: 手册2/3 页4 CN 110992700 A 4 0029 S1:针对不同的停车场管理系统提取数据的特征值,为每个停车场管理系统形成对应的特征值集; 0030 S2:自动检测当前需要数据采集的停车场管理系统,将当前停车场管理系统的特征值数据与特征值集中的数据进行比较; 0031 S3:如果特征值集中存在当前停车场管理系统的特征值数据,则自动执行当前停车场管理系统数据采集;如果不存在,使用视频采集方法采集停车场数据。 0.
15、032 为了进一步实现上述技术方案,S1还具体包括以下内容: 0033(1)抽象数据库配置,将数据库链接配置抽象成通用配置文件;0034(2)分析不同类型停车场管理系统的停车数据,分析内容包括:数据库类型、车辆进入信息、车辆退出信息和车辆图片信息;0035(3)根据分析结果,形成停车数据0036 为进一步实现上述技术方案,S2中的对比内容包括:停车场数据库特征、出口数据特征、入口0037 为进一步实现上述技术方案,S3自动执行当前停车场管理系统数据。
16、采集具体包括以下方法:0038(1)database方法:直接根据数据库设置和时间设置,采集进入和退出停车场管理系统数据库;0039( 2)云采集方式:数据通过停车场云平台采集,自动获取不同类型的停车管理系统配置脚本,通过网站自动访问,地址跳转,数据查询,结果获取等操作来实现停车数据采集; 0040 为了进一步实现上述技术方案,视频采集方法具体包括以下内容: 0041 比较失败后,自动转换为视频采集方法,ONVIF使用协议实现与车辆抓拍摄像头的连接,获取照片后,利用图像识别技术识别车牌,并结合车辆进出时间和车道信息来实现ze 停车数据采集。 004.
17、2 需要说明的是:在对新的停车场数据执行采集时,采集软件需要与停车场系统服务器在同一网络,以保证网络已解锁; 0043本手册中的各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似的部分互相参见即可。对于本实施例公开的装置,由于其对应于本实施例公开的方法,所以描述的比较简单,相关信息可以参见方法部分的描述。 0044 以上所公开的实施例的描述使本领域技术人员能够实施或使用本发明。对这些实施例的各种修改对于本领域技术人员来说是显而易见的,并且在不脱离本发明的精神或范围的情况下,可以在其他实施例中实现这里定义的一般原理。因此,本发明将不限于本文件中所示的实施例,而应符合与本文件中公开的原理和新颖特征一致的最广泛的范围。说明书3/3 第5页 CN 110992700 A 5 图1 说明书1/1 第6页 CN 110992700 A 6.
学习IBM如何实现Java平台5.0版中内置的高级功能?
采集交流 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-08-10 04:20
可以使用四种不同的策略在 IBM Developer Suite (IBM SDK) 中为 Java 5.0 平台配置垃圾回收 (GC)。本文是GC两部分的第一部分。它介绍了不同的垃圾采集策略并讨论了它们的一般特征。在开始之前,您应该对 Java 平台中的垃圾采集有一个基本的了解。第 2 部分介绍了选择策略的定量方法并提供了一些示例。
关于系列
Java 技术,IBM 风格系列介绍了 Java 平台的 IBM 实现的最新版本。您将了解 IBM 如何实现 Java 平台 5.0 中内置的一些高级功能,并了解如何使用新 IBM 版本中内置的一些增值功能。
如有任何意见或问题,请联系作者。要对整个系列发表评论,请联系系列负责人 Chris Bailey。有关此处讨论的概念的更多信息以及下载最新 IBM 版本的链接,请参阅。
为什么要使用不同的 GC 政策?
不同 GC 策略的可用性为您提供了增强的功能。 GC 有许多不同的算法可用,根据工作负载的类型,每种算法都有自己的优点和缺点。 (如果您不熟悉GC算法的一般主题,请参阅进一步阅读。)在IBM SDK5.0中,您可以使用四种策略之一来配置垃圾采集器,每种策略使用自己的算法。对于大多数应用程序,默认策略就足够了。如果您对应用程序没有任何特定的性能要求,那么本文(以及下一篇)的内容可能对您不感兴趣。您可以在不更改 GC 策略的情况下运行 IBM SDK 5.0。但是,如果您的应用程序需要最佳性能,或者您通常担心 GC 暂停时间,请继续阅读。您会看到最新版本的 IBM 比之前的版本有更多的选项。
那么,为什么没有自动为您选择 Java 运行时的 IBM 实现?这并不总是可能的。在运行时很难理解您的需求。在某些情况下,您可能希望以高吞吐量运行应用程序。在其他情况下,您可能希望减少暂停时间。
表 1 列出了可用的策略并指出了每种策略的使用时间。以下部分将详细介绍每种策略的特点。
表1.IBM SDK 5.0 策略选项说明中的GC策略
优化吞吐量
-Xgcpolicy:optthruput(可选)
默认策略。它通常用于原创吞吐量比短暂的 GC 暂停更重要的应用程序。每次采集垃圾时,应用程序都会停止。
优化暂停时间
-Xgcpolicy:optavgpause
通过同时执行一些垃圾回收,高吞吐量换来了更短的 GC 暂停。应用程序被暂停了很短的时间。
生成并发
-Xgcpolicy:gencon
短期对象与长期对象的处理方式不同。通过这种策略,具有许多短期对象的应用程序可以看到更短的暂停时间,同时仍能产生良好的吞吐量。
子池化
-Xgcpolicy:subpool
使用类似于默认策略的算法,但使用更适合多处理器计算机的分配策略。对于具有 16 个或更多处理器的 SMP 计算机,我们建议使用此策略。此策略仅适用于 IBMpSeries® 和 zSeries® 平台。需要在大型计算机上扩展的应用程序可以从这种策略中受益。
定义了一些术语
吞吐量是应用程序处理的数据量。必须使用特定于应用程序的指标来衡量吞吐量。
暂停时间是垃圾采集器暂停所有应用程序线程以采集堆的持续时间。
在本文中,我使用表1中详述的命令行选项的缩写来表示以下策略:优化吞吐量的optthruput),优化暂停时间的optavgpause),分代并发的gencon)和子池于子池) .
什么时候应该考虑非默认 GC 策略?
我建议您始终从默认的 GC 策略开始。在摆脱默认设置之前,您需要了解在什么情况下应该探索替代策略。表2列出了一系列可能的原因:
列出2.切换到备用GC策略的原因切换原因
optavgpause
gencon
子池
让我强调,表 2 中提到的原因不足以得出替代政策会表现更好的结论。它们只是提示。在所有情况下,您都应该运行应用程序并结合 GC 暂停时间来测量吞吐量和/或响应时间。本系列的下一部分将展示此类测试的示例。
本文的其余部分将详细介绍 GC 策略之间的差异。
光通量
堆碎片的迹象
堆碎片最常见的迹象是过早的分配失败。这被认为是在详细垃圾采集 (-Xverbose:gc) 中触发的 GC,即使堆上有可用空间。另一个标志是存在小线程分配缓冲区(请参阅“”部分)。您可以使用 -Xtgc:freelist 来确定平均大小。 IBM SDK 5 诊断指南中解释了这两个选项。
optthruput 是默认策略。它是一个跟踪采集器,称为标记扫描紧凑采集器。标记和扫描阶段总是在 GC 期间运行,但压缩仅在某些情况下发生。标记阶段查找并标记所有活动对象。所有未标记的对象将在扫描阶段被删除。第三步也是可选的步骤是压实。压实可以在各种情况下发生。最常见的一种是系统无法回收足够的可用空间。
当对象被频繁地分配和释放以致堆中只剩下一小块空闲空间时,就会发生碎片。堆整体可能有很多空闲空间,但是连续区域很小,导致分配失败。压缩将所有对象向下移动到堆的开头并对齐它们,以便它们之间没有空间。这消除了堆中的碎片,但这是一项昂贵的任务,因此仅在必要时执行。
图 1 显示了经过不同阶段的堆布局的轮廓:标记、清除和压缩。暗区代表物体,亮区代表自由空间。
扫一扫
标记阶段遍历所有可以从线程栈、静态变量、插入的字符串和JNI引用中引用的对象。作为此过程的一部分,我们将创建一个标记位向量来定义所有活动对象的开头。
扫描阶段使用标记阶段生成的标记位向量来标识堆中存储的块,可以回收这些块以备将来分配;这些块被添加到空闲列表中。
图1.垃圾回收前后的堆布局
有关不同 GC 阶段如何工作的详细信息超出了本文的范围。我的观点是确保您了解运行时特征。我鼓励您阅读“诊断指南”(请参阅)了解更多信息。
图 2 说明了如何在应用程序线程(或 mutator)和 GC 线程之间分配执行时间。横轴是经过的时间,纵轴是线程,其中 n 代表计算机上的处理器数量。在此描述中,假设应用程序使用每个处理器一个线程。 GC 用蓝色框表示,表示停止的突变体和 GC 线程正在运行。这些集合消耗了 100% 的 CPU 资源,并且转换器线程处于空闲状态。该图过于笼统,因此我们可以将此策略与本文中的其他策略进行比较。实际上,GC 的持续时间和频率取决于应用程序和工作量。
图2.optthruput策略在mutator和GC线程之间的CPU时间分配
Mutator 和 GC 线程
mutator 线程是一个分配对象的应用程序。 mutator 的另一个词是应用程序。 GC 线程是内存管理的一部分并执行垃圾采集。
堆锁和线程分配缓存
optthruput 策略使用应用程序中所有线程共享的连续堆区域。线程需要独占访问堆来为新对象保留空间。这种锁称为堆锁,可确保一次只有一个线程可以分配一个对象。在具有多个 CPU 的计算机上,此锁可能会导致扩展问题,因为可以同时发生多个分配请求,但每个分配请求都必须对堆锁具有独占访问权限。
为了减少这个问题,每个线程都会保留一小部分内存,称为线程分配缓存(也称为线程本地堆或TLH)。这部分存储空间是线程特定的,因此当从中分配内存时,不会使用堆锁。当分配缓冲区已满时,线程将返回堆并使用堆锁请求新的堆。
堆的碎片化会阻止线程获得更大的TLH,因此TLH会很快填满,导致应用线程频繁返回堆以换取新的TLH。在这种情况下,堆锁成为瓶颈。在这种情况下,gencon 或 sub-subpool 策略可以提供一个不错的选择。
暂停
对于许多应用程序,吞吐量不如快速响应时间重要。考虑一个工作项的处理时间不能超过 100 毫秒的应用程序。由于 GC 暂停时间在 100 毫秒内,您将获得在此时间范围内无法处理的项目。垃圾回收的问题在于暂停时间会增加处理项目所需的最长时间。大堆大小(在 64 位平台上可用)会增加这种影响,因为处理的对象更多。
optavgpause 是另一种旨在最小化暂停时间的 GC 策略。它不能保证特定的暂停时间,但暂停时间比默认 GC 策略生成的暂停时间短。这个想法是在应用程序运行时执行一些垃圾采集。这是在两个地方完成的:
根据不同的应用,默认的 GC 策略会降低 5% 到 10% 的吞吐量性能。
图 3 说明了如何使用 optavgpause 在 GC 线程和 mutator 线程之间分配执行时间。后台跟踪线程不显示,因为它不会影响应用程序性能。
图3.optavgpause策略在mutator和GC线程之间的CPU时间分配
图中灰色区域表示已启用并发跟踪,每个mutator线程必须放弃一些处理时间。每个并发阶段完成一次垃圾回收后,完成并发阶段未发生的标记和清除。由此产生的暂停应该比 optthruput 看到的正常 GC 短很多,如图 3 时间刻度上的小框所示。 GC 结束和并发阶段开始之间的差距是不同的,但在这个阶段,对性能没有显着影响。
Gencon
分代垃圾回收策略考虑对象的生命周期,将它们放在堆的单独区域。通过这种方式,它试图克服单个堆在大多数对象年轻和死亡的应用程序中的缺点,即这些对象不能承受多次垃圾采集。
使用代GC,倾向于将长期对象与短期对象区别对待。如图4所示,桩被划分为苗圃和苗圃区。在托儿所中创建对象,如果对象存活时间足够长,则将它们提升到托儿所区域。经过一定量的垃圾采集后,该对象将被提升。这个想法是大多数对象都是短暂的。通过频繁采集托儿所,可以释放这些对象,而无需支付采集整个堆的成本。租用区域很少采集垃圾。
新旧区图4.gencon GC
如图 4 所示,托儿所分为两个空间:分配和幸存者。将对象分配到分配的空间。当对象已满时,活动对象将根据其年龄被复制到survivor空间或tenure空间。然后,将托儿所中的空间切换为使用,分配成为幸存者,幸存者成为分配者。死对象占用的空间可以简单地被新分配覆盖。苗圃采集被称为清道夫;图 5 说明了此过程中发生的情况:
图5.GC前后堆布局示例
当分配的空间已满时,会触发垃圾回收。然后跟踪活动对象并将其复制到幸存者空间。如果大部分对象都死了,这个过程的成本真的不高。此外,达到复制阈值计数的对象将被提升到到期空间。然后说对象是永久的。
顾名思义,代表并发,gencon 策略有它的并发方面。租用的空间也使用类似于 optavgpause 策略中使用的方法进行标记,但不执行并发扫描。在并发阶段,所有分配都会支付少量的吞吐量税。这样,可以将tenure space的采集产生的停顿时间保持在很小的范围内。
图 6 显示了在运行 gencon GC 时如何映射执行时间:
图6.gencon 在mutator和GC线程之间的CPU时间分布
清道夫很短(显示在红色框中)。灰色表示开始并发跟踪,然后是占用空间的集合,其中一些是并发发生的。这称为全局集,包括明文集和使用权空间集。全局采集发生的频率取决于堆大小和对象生命周期。租用空间的采集应该是比较快的,因为大部分空间是同时采集的。
子池
子子池策略有助于提高多处理器系统的性能。如前所述,此策略仅适用于 IBM pSeries 和 zSeries 计算机。堆布局与 optthruput 策略相同,但空闲列表的结构不同。有多个列表而不是整个堆的空闲列表,称为子池。每个池都有一个关联的大小,可以根据这些大小对池进行排序。通过去这个大小的池,可以快速满足一定大小的分配请求。原子(平台相关)高性能指令用于从列表中弹出空闲列表条目,从而避免序列化访问。图 7 显示了如何按大小组织存储的空闲块:
图片7.按大小排序的子池的空闲块
当JVM启动或者发生压缩时,由于堆的可用区域很大,所以不使用子池。在这些情况下,每个处理器都有自己的专用迷你堆来满足请求。当第一次垃圾回收发生时,清除阶段开始填充子池,后续的分配主要使用子池。
sub-subpool 策略可以减少分配对象的时间。原子指令确保在不获取全局堆锁的情况下进行分配。处理器本地的小堆提高了效率,因为它减少了缓存干扰。这直接影响可扩展性,尤其是在多处理器系统上。在子池不可用的平台上,生成 GC 可以提供类似的好处。
结论
本文重点介绍 IBM SDK 5.0 中可用的不同 GC 策略选项及其一些特征。默认策略足以满足大多数应用程序的需求。但是,在某些情况下,其他策略效果更好。我已经介绍了一些一般情况,在这些情况下你应该考虑切换到 optavgpause、gencon 或 subpool。在评估策略时,衡量应用程序性能非常重要,第 2 部分将更详细地演示评估过程。
翻译自: 查看全部
学习IBM如何实现Java平台5.0版中内置的高级功能?
可以使用四种不同的策略在 IBM Developer Suite (IBM SDK) 中为 Java 5.0 平台配置垃圾回收 (GC)。本文是GC两部分的第一部分。它介绍了不同的垃圾采集策略并讨论了它们的一般特征。在开始之前,您应该对 Java 平台中的垃圾采集有一个基本的了解。第 2 部分介绍了选择策略的定量方法并提供了一些示例。
关于系列
Java 技术,IBM 风格系列介绍了 Java 平台的 IBM 实现的最新版本。您将了解 IBM 如何实现 Java 平台 5.0 中内置的一些高级功能,并了解如何使用新 IBM 版本中内置的一些增值功能。
如有任何意见或问题,请联系作者。要对整个系列发表评论,请联系系列负责人 Chris Bailey。有关此处讨论的概念的更多信息以及下载最新 IBM 版本的链接,请参阅。
为什么要使用不同的 GC 政策?
不同 GC 策略的可用性为您提供了增强的功能。 GC 有许多不同的算法可用,根据工作负载的类型,每种算法都有自己的优点和缺点。 (如果您不熟悉GC算法的一般主题,请参阅进一步阅读。)在IBM SDK5.0中,您可以使用四种策略之一来配置垃圾采集器,每种策略使用自己的算法。对于大多数应用程序,默认策略就足够了。如果您对应用程序没有任何特定的性能要求,那么本文(以及下一篇)的内容可能对您不感兴趣。您可以在不更改 GC 策略的情况下运行 IBM SDK 5.0。但是,如果您的应用程序需要最佳性能,或者您通常担心 GC 暂停时间,请继续阅读。您会看到最新版本的 IBM 比之前的版本有更多的选项。
那么,为什么没有自动为您选择 Java 运行时的 IBM 实现?这并不总是可能的。在运行时很难理解您的需求。在某些情况下,您可能希望以高吞吐量运行应用程序。在其他情况下,您可能希望减少暂停时间。
表 1 列出了可用的策略并指出了每种策略的使用时间。以下部分将详细介绍每种策略的特点。
表1.IBM SDK 5.0 策略选项说明中的GC策略
优化吞吐量
-Xgcpolicy:optthruput(可选)
默认策略。它通常用于原创吞吐量比短暂的 GC 暂停更重要的应用程序。每次采集垃圾时,应用程序都会停止。
优化暂停时间
-Xgcpolicy:optavgpause
通过同时执行一些垃圾回收,高吞吐量换来了更短的 GC 暂停。应用程序被暂停了很短的时间。
生成并发
-Xgcpolicy:gencon
短期对象与长期对象的处理方式不同。通过这种策略,具有许多短期对象的应用程序可以看到更短的暂停时间,同时仍能产生良好的吞吐量。
子池化
-Xgcpolicy:subpool
使用类似于默认策略的算法,但使用更适合多处理器计算机的分配策略。对于具有 16 个或更多处理器的 SMP 计算机,我们建议使用此策略。此策略仅适用于 IBMpSeries® 和 zSeries® 平台。需要在大型计算机上扩展的应用程序可以从这种策略中受益。
定义了一些术语
吞吐量是应用程序处理的数据量。必须使用特定于应用程序的指标来衡量吞吐量。
暂停时间是垃圾采集器暂停所有应用程序线程以采集堆的持续时间。
在本文中,我使用表1中详述的命令行选项的缩写来表示以下策略:优化吞吐量的optthruput),优化暂停时间的optavgpause),分代并发的gencon)和子池于子池) .
什么时候应该考虑非默认 GC 策略?
我建议您始终从默认的 GC 策略开始。在摆脱默认设置之前,您需要了解在什么情况下应该探索替代策略。表2列出了一系列可能的原因:
列出2.切换到备用GC策略的原因切换原因
optavgpause
gencon
子池
让我强调,表 2 中提到的原因不足以得出替代政策会表现更好的结论。它们只是提示。在所有情况下,您都应该运行应用程序并结合 GC 暂停时间来测量吞吐量和/或响应时间。本系列的下一部分将展示此类测试的示例。
本文的其余部分将详细介绍 GC 策略之间的差异。
光通量
堆碎片的迹象
堆碎片最常见的迹象是过早的分配失败。这被认为是在详细垃圾采集 (-Xverbose:gc) 中触发的 GC,即使堆上有可用空间。另一个标志是存在小线程分配缓冲区(请参阅“”部分)。您可以使用 -Xtgc:freelist 来确定平均大小。 IBM SDK 5 诊断指南中解释了这两个选项。
optthruput 是默认策略。它是一个跟踪采集器,称为标记扫描紧凑采集器。标记和扫描阶段总是在 GC 期间运行,但压缩仅在某些情况下发生。标记阶段查找并标记所有活动对象。所有未标记的对象将在扫描阶段被删除。第三步也是可选的步骤是压实。压实可以在各种情况下发生。最常见的一种是系统无法回收足够的可用空间。
当对象被频繁地分配和释放以致堆中只剩下一小块空闲空间时,就会发生碎片。堆整体可能有很多空闲空间,但是连续区域很小,导致分配失败。压缩将所有对象向下移动到堆的开头并对齐它们,以便它们之间没有空间。这消除了堆中的碎片,但这是一项昂贵的任务,因此仅在必要时执行。
图 1 显示了经过不同阶段的堆布局的轮廓:标记、清除和压缩。暗区代表物体,亮区代表自由空间。
扫一扫
标记阶段遍历所有可以从线程栈、静态变量、插入的字符串和JNI引用中引用的对象。作为此过程的一部分,我们将创建一个标记位向量来定义所有活动对象的开头。
扫描阶段使用标记阶段生成的标记位向量来标识堆中存储的块,可以回收这些块以备将来分配;这些块被添加到空闲列表中。
图1.垃圾回收前后的堆布局
有关不同 GC 阶段如何工作的详细信息超出了本文的范围。我的观点是确保您了解运行时特征。我鼓励您阅读“诊断指南”(请参阅)了解更多信息。
图 2 说明了如何在应用程序线程(或 mutator)和 GC 线程之间分配执行时间。横轴是经过的时间,纵轴是线程,其中 n 代表计算机上的处理器数量。在此描述中,假设应用程序使用每个处理器一个线程。 GC 用蓝色框表示,表示停止的突变体和 GC 线程正在运行。这些集合消耗了 100% 的 CPU 资源,并且转换器线程处于空闲状态。该图过于笼统,因此我们可以将此策略与本文中的其他策略进行比较。实际上,GC 的持续时间和频率取决于应用程序和工作量。
图2.optthruput策略在mutator和GC线程之间的CPU时间分配
Mutator 和 GC 线程
mutator 线程是一个分配对象的应用程序。 mutator 的另一个词是应用程序。 GC 线程是内存管理的一部分并执行垃圾采集。
堆锁和线程分配缓存
optthruput 策略使用应用程序中所有线程共享的连续堆区域。线程需要独占访问堆来为新对象保留空间。这种锁称为堆锁,可确保一次只有一个线程可以分配一个对象。在具有多个 CPU 的计算机上,此锁可能会导致扩展问题,因为可以同时发生多个分配请求,但每个分配请求都必须对堆锁具有独占访问权限。
为了减少这个问题,每个线程都会保留一小部分内存,称为线程分配缓存(也称为线程本地堆或TLH)。这部分存储空间是线程特定的,因此当从中分配内存时,不会使用堆锁。当分配缓冲区已满时,线程将返回堆并使用堆锁请求新的堆。
堆的碎片化会阻止线程获得更大的TLH,因此TLH会很快填满,导致应用线程频繁返回堆以换取新的TLH。在这种情况下,堆锁成为瓶颈。在这种情况下,gencon 或 sub-subpool 策略可以提供一个不错的选择。
暂停
对于许多应用程序,吞吐量不如快速响应时间重要。考虑一个工作项的处理时间不能超过 100 毫秒的应用程序。由于 GC 暂停时间在 100 毫秒内,您将获得在此时间范围内无法处理的项目。垃圾回收的问题在于暂停时间会增加处理项目所需的最长时间。大堆大小(在 64 位平台上可用)会增加这种影响,因为处理的对象更多。
optavgpause 是另一种旨在最小化暂停时间的 GC 策略。它不能保证特定的暂停时间,但暂停时间比默认 GC 策略生成的暂停时间短。这个想法是在应用程序运行时执行一些垃圾采集。这是在两个地方完成的:
根据不同的应用,默认的 GC 策略会降低 5% 到 10% 的吞吐量性能。
图 3 说明了如何使用 optavgpause 在 GC 线程和 mutator 线程之间分配执行时间。后台跟踪线程不显示,因为它不会影响应用程序性能。
图3.optavgpause策略在mutator和GC线程之间的CPU时间分配
图中灰色区域表示已启用并发跟踪,每个mutator线程必须放弃一些处理时间。每个并发阶段完成一次垃圾回收后,完成并发阶段未发生的标记和清除。由此产生的暂停应该比 optthruput 看到的正常 GC 短很多,如图 3 时间刻度上的小框所示。 GC 结束和并发阶段开始之间的差距是不同的,但在这个阶段,对性能没有显着影响。
Gencon
分代垃圾回收策略考虑对象的生命周期,将它们放在堆的单独区域。通过这种方式,它试图克服单个堆在大多数对象年轻和死亡的应用程序中的缺点,即这些对象不能承受多次垃圾采集。
使用代GC,倾向于将长期对象与短期对象区别对待。如图4所示,桩被划分为苗圃和苗圃区。在托儿所中创建对象,如果对象存活时间足够长,则将它们提升到托儿所区域。经过一定量的垃圾采集后,该对象将被提升。这个想法是大多数对象都是短暂的。通过频繁采集托儿所,可以释放这些对象,而无需支付采集整个堆的成本。租用区域很少采集垃圾。
新旧区图4.gencon GC
如图 4 所示,托儿所分为两个空间:分配和幸存者。将对象分配到分配的空间。当对象已满时,活动对象将根据其年龄被复制到survivor空间或tenure空间。然后,将托儿所中的空间切换为使用,分配成为幸存者,幸存者成为分配者。死对象占用的空间可以简单地被新分配覆盖。苗圃采集被称为清道夫;图 5 说明了此过程中发生的情况:
图5.GC前后堆布局示例
当分配的空间已满时,会触发垃圾回收。然后跟踪活动对象并将其复制到幸存者空间。如果大部分对象都死了,这个过程的成本真的不高。此外,达到复制阈值计数的对象将被提升到到期空间。然后说对象是永久的。
顾名思义,代表并发,gencon 策略有它的并发方面。租用的空间也使用类似于 optavgpause 策略中使用的方法进行标记,但不执行并发扫描。在并发阶段,所有分配都会支付少量的吞吐量税。这样,可以将tenure space的采集产生的停顿时间保持在很小的范围内。
图 6 显示了在运行 gencon GC 时如何映射执行时间:
图6.gencon 在mutator和GC线程之间的CPU时间分布
清道夫很短(显示在红色框中)。灰色表示开始并发跟踪,然后是占用空间的集合,其中一些是并发发生的。这称为全局集,包括明文集和使用权空间集。全局采集发生的频率取决于堆大小和对象生命周期。租用空间的采集应该是比较快的,因为大部分空间是同时采集的。
子池
子子池策略有助于提高多处理器系统的性能。如前所述,此策略仅适用于 IBM pSeries 和 zSeries 计算机。堆布局与 optthruput 策略相同,但空闲列表的结构不同。有多个列表而不是整个堆的空闲列表,称为子池。每个池都有一个关联的大小,可以根据这些大小对池进行排序。通过去这个大小的池,可以快速满足一定大小的分配请求。原子(平台相关)高性能指令用于从列表中弹出空闲列表条目,从而避免序列化访问。图 7 显示了如何按大小组织存储的空闲块:
图片7.按大小排序的子池的空闲块
当JVM启动或者发生压缩时,由于堆的可用区域很大,所以不使用子池。在这些情况下,每个处理器都有自己的专用迷你堆来满足请求。当第一次垃圾回收发生时,清除阶段开始填充子池,后续的分配主要使用子池。
sub-subpool 策略可以减少分配对象的时间。原子指令确保在不获取全局堆锁的情况下进行分配。处理器本地的小堆提高了效率,因为它减少了缓存干扰。这直接影响可扩展性,尤其是在多处理器系统上。在子池不可用的平台上,生成 GC 可以提供类似的好处。
结论
本文重点介绍 IBM SDK 5.0 中可用的不同 GC 策略选项及其一些特征。默认策略足以满足大多数应用程序的需求。但是,在某些情况下,其他策略效果更好。我已经介绍了一些一般情况,在这些情况下你应该考虑切换到 optavgpause、gencon 或 subpool。在评估策略时,衡量应用程序性能非常重要,第 2 部分将更详细地演示评估过程。
翻译自:
3.自动化工具.autojs模拟用户抖音列表接口的部署
采集交流 • 优采云 发表了文章 • 0 个评论 • 516 次浏览 • 2021-08-08 21:11
目的:采集抖音非常受欢迎的视频(要自动化)
抖音的防爬技术很好,据说还有防爬的部门。所以通过编写代码直接访问抖音接口,是达不到目的的。数据只能通过模拟真实用户行为获得。
我的主要实现方式是:通过在Android模拟器中模拟用户的滑动,通过网络代理拦截滑动过程中产生的数据
开发中使用的工具:
硬件:需要一台免费的电脑,
软件:auto.js、Android模拟器、代理服务项目、按钮向导、抓包工具
开发过程
1 确定抖音的哪个接口使用采集data
考虑从首页推荐列表或用户工作列表中获取数据。
我用的fiddler抓包工具,
抓取首页推荐列表界面,发现数据格式为Protobuf,是一种传输速度更快,占用空间更少的数据格式。解析这种格式需要支持文件。所以我们无法解析并放弃页面推荐列表。
尝试从用户的工作列表界面抓包,发现是json格式,可以获取视频信息。所以我决定获取用户作品列表采集。
2.自动化工具auto.js模拟用户滑动抖音list
为了保证采集的视频受欢迎,我们用户的作品并非都是采集。所以我们模拟了用户的行为:在首页的推荐视频中滑动,滑动到超过10万赞的视频,向左滑动,进入视频作者的作品列表。
首先在你的电脑上安装安卓模拟器,我用的是天天模拟器
在模拟器中安装抖音和auto.js应用,编写auto.js自动化脚本,并运行脚本。
这是我写的 auto.js 脚本。供您参考
<p>var myDate = new Date();
var hours = myDate.getHours();
if (hours >= 0) {
console.log("去启动抖音");
launchApp("抖音");
sleep(7000)
while (true) {
是否满足赞();
左滑进入个人中心();
判断是否出去();
关闭崩溃应用();
toast("quit persion center ")
退出个人中心();
//Swipe(10, device.height / 2,device.width / 2, device.height / 2, 10, 300);//向右滑
sleep(2000);
toast("hua dong cao zuo ")
Swipe(device.width / 2, device.height / 1.5, device.width / 2, 10, 500); //向下滑
sleep(3000);
每10分钟重启();
取消弹框();
判断是否出去();
关闭崩溃应用();
}
}
function 是否满足赞() {
log("是否满足赞")
try {
//不满足1万的赞划走
while (isTrue()) {
Swipe(device.width / 2, device.height / 1.5, device.width / 2, 10, 500); //向下滑
toast("Dig not satisfied")
sleep(1500);
退出个人中心();
}
} catch (e) {}
}
function isTrue() {
// var u = id("aen").find()
// var e = u.length - 2
// var tv = u[e];
return false;
var like = 0;
try {
var b = id("com.ss.android.ugc.aweme:id/aer").find();
var a = b[1].desc()
if (a && a.indexOf("喜欢") > -1) {
like = a.substring(a.indexOf("喜欢") + 2, a.indexOf(",按钮"));
toastLog(like);
}
} catch (e) {}
if (like.indexOf("w") == -1) {
return true;
} else {
return like.substr(0, like.indexOf("w")) -1) {
if (parseInt(totallike.substr(0, totallike.length - 1)) >= 1000) {
//关注作者
payAttention(totallike, totalfans, uniqueid, authorname);
}
}
//总点赞数或粉丝数大于1亿 关注作者并抓取更多
if (authorname && totallike.indexOf("亿") > -1 || totalfans.indexOf("亿") > -1) {
//关注作者
loadMore = payAttention(totallike, totalfans, uniqueid, authorname);
}
//粉丝量大于500W 关注作者, 如果粉丝量大于1000W 抓取作者更多作品
if (authorname && totalfans.indexOf("w") > -1) {
var fansCount = parseInt(totalfans.substr(0, totalfans.length - 1));
if (fansCount >= 500 && fansCount = 1000) {
loadMore = payAttention(totallike, totalfans, uniqueid, authorname);
}
}
if (loadMore) {
sleep(4000);
log("into swipe action ")
for (var i = 0; i 查看全部
3.自动化工具.autojs模拟用户抖音列表接口的部署
目的:采集抖音非常受欢迎的视频(要自动化)
抖音的防爬技术很好,据说还有防爬的部门。所以通过编写代码直接访问抖音接口,是达不到目的的。数据只能通过模拟真实用户行为获得。
我的主要实现方式是:通过在Android模拟器中模拟用户的滑动,通过网络代理拦截滑动过程中产生的数据
开发中使用的工具:
硬件:需要一台免费的电脑,
软件:auto.js、Android模拟器、代理服务项目、按钮向导、抓包工具
开发过程
1 确定抖音的哪个接口使用采集data
考虑从首页推荐列表或用户工作列表中获取数据。
我用的fiddler抓包工具,
抓取首页推荐列表界面,发现数据格式为Protobuf,是一种传输速度更快,占用空间更少的数据格式。解析这种格式需要支持文件。所以我们无法解析并放弃页面推荐列表。
尝试从用户的工作列表界面抓包,发现是json格式,可以获取视频信息。所以我决定获取用户作品列表采集。


2.自动化工具auto.js模拟用户滑动抖音list
为了保证采集的视频受欢迎,我们用户的作品并非都是采集。所以我们模拟了用户的行为:在首页的推荐视频中滑动,滑动到超过10万赞的视频,向左滑动,进入视频作者的作品列表。
首先在你的电脑上安装安卓模拟器,我用的是天天模拟器
在模拟器中安装抖音和auto.js应用,编写auto.js自动化脚本,并运行脚本。

这是我写的 auto.js 脚本。供您参考
<p>var myDate = new Date();
var hours = myDate.getHours();
if (hours >= 0) {
console.log("去启动抖音");
launchApp("抖音");
sleep(7000)
while (true) {
是否满足赞();
左滑进入个人中心();
判断是否出去();
关闭崩溃应用();
toast("quit persion center ")
退出个人中心();
//Swipe(10, device.height / 2,device.width / 2, device.height / 2, 10, 300);//向右滑
sleep(2000);
toast("hua dong cao zuo ")
Swipe(device.width / 2, device.height / 1.5, device.width / 2, 10, 500); //向下滑
sleep(3000);
每10分钟重启();
取消弹框();
判断是否出去();
关闭崩溃应用();
}
}
function 是否满足赞() {
log("是否满足赞")
try {
//不满足1万的赞划走
while (isTrue()) {
Swipe(device.width / 2, device.height / 1.5, device.width / 2, 10, 500); //向下滑
toast("Dig not satisfied")
sleep(1500);
退出个人中心();
}
} catch (e) {}
}
function isTrue() {
// var u = id("aen").find()
// var e = u.length - 2
// var tv = u[e];
return false;
var like = 0;
try {
var b = id("com.ss.android.ugc.aweme:id/aer").find();
var a = b[1].desc()
if (a && a.indexOf("喜欢") > -1) {
like = a.substring(a.indexOf("喜欢") + 2, a.indexOf(",按钮"));
toastLog(like);
}
} catch (e) {}
if (like.indexOf("w") == -1) {
return true;
} else {
return like.substr(0, like.indexOf("w")) -1) {
if (parseInt(totallike.substr(0, totallike.length - 1)) >= 1000) {
//关注作者
payAttention(totallike, totalfans, uniqueid, authorname);
}
}
//总点赞数或粉丝数大于1亿 关注作者并抓取更多
if (authorname && totallike.indexOf("亿") > -1 || totalfans.indexOf("亿") > -1) {
//关注作者
loadMore = payAttention(totallike, totalfans, uniqueid, authorname);
}
//粉丝量大于500W 关注作者, 如果粉丝量大于1000W 抓取作者更多作品
if (authorname && totalfans.indexOf("w") > -1) {
var fansCount = parseInt(totalfans.substr(0, totalfans.length - 1));
if (fansCount >= 500 && fansCount = 1000) {
loadMore = payAttention(totallike, totalfans, uniqueid, authorname);
}
}
if (loadMore) {
sleep(4000);
log("into swipe action ")
for (var i = 0; i
本文重点在实现(x86gccunixunix)like环境下
采集交流 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-08-08 07:32
注:本文重点是实现(在x86 gcc unix like环境下),而不是算法(否则最简单的回收算法就不用了),纯粹用于教学(娱乐)目的。它不注重效率,但可以使用。 ,并且没有继续支持多线程。
具体代码在github上:[]
目录:
实现中的重点难点介绍:原理图代码的外部接口部分:
#include "interface3.h"
#include // 必要头文件
int main()
{
__gc_init(); /* to init gc */
/*add some code you like*/
...
/* need some memory in heap */
void *forgetToFree = (void *)gc_calloc(sizeof(struct XXX));
/*add some code you like*/
...
__gc_exit(); /* to destroy gc */
return 0;
}
如何找到mark&sweep的根节点:
i) 对于自动变量的标记,可以从当前栈顶一直向上找到environ的正确位置。当然也可以通过读取程序中的/proc/pid/maps来查看栈底地址。然后,只需标记这些区域。
ii) 对于全局变量的标签,使用链接器变量 _etext, _end 标签。 (注意gcc工具是支持的,其他编译链接工具完全不能保证)
iii) 对于临时变量,标记当前寄存器。
具体代码片段:
在marksweep.c文件中:
static unsigned int stack_bottom = 0;
extern char _end[];
extern char _etext[];
extern char** environ;
void gc_collect()
{
unsigned int stack_top;
unsigned int _eax_,_ebx_,_ecx_,_edx_,_esi_,_edi_;
asm volatile ("movl %%ebp, %0" : "=r" (stack_top));
asm volatile ("movl %%eax, %0" : "=r" (_eax_));
asm volatile ("movl %%ebx, %0" : "=r" (_ebx_));
asm volatile ("movl %%ecx, %0" : "=r" (_ecx_));
asm volatile ("movl %%edx, %0" : "=r" (_edx_));
asm volatile ("movl %%esi, %0" : "=r" (_esi_));
asm volatile ("movl %%edi, %0" : "=r" (_edi_));
/* 我们标记一些寄存器里头的临时变量 */
mark(_eax_);
mark(_ebx_);
mark(_ecx_);
mark(_edx_);
mark(_esi_);
mark(_edi_);
mark_from_region((ptr *)((char *)stack_top + 4),(ptr *)(stack_bottom)); //我们标记自动变量
mark_from_region((ptr *)((char *)_etext + 6),(ptr *)(_end)); //我们标记全局变量
sweep();
}
int __gc_init()
{
unsigned int stack_top;
unsigned int curr;
asm volatile ("movl %%ebp, %0" : "=r" (stack_top));
curr = stack_top;
/* 用简单的循环检查出栈底地址(有逻辑漏洞) */
while(*(unsigned int *)curr != (unsigned int)environ)
{
curr++;
}
stack_bottom = curr;
return __rb_init();
}
实现中用到的一些设计和具体方法:
代码中会有一些令人费解的宏定义,例如:
在 unordered_list.h 文件中:
...
#define CHUNKSIZE (1node;
while(curr)
{
__rb_free((RBTree)(curr->data));
curr = curr->next;
}
link_destroy(root->node);
int i = 0;
__free(root);
root = NULL;
}
使用mark和sweep函数实现自己的__gc_calloc函数:
测试:
测试代码:
#include
#include
#include
#include "interface3.h"
#define NUM 10000
#define TEST 100
#define RANGE 100
int *a[NUM];
size_t size[NUM];
void leak(int i)
{
int* leak = (int *)__gc_calloc(size[i]);
return;
}
int main(int argc, char *argv[])
{
clock_t start, finish, end;
double duration1, duration2;
int j;
int i;
for (i = 0; i < NUM; ++i)
{
size[i] = 1 + (size_t)(1.0*RANGE*rand()/(RAND_MAX+1.0));
}
__gc_init();
start = clock();
for (j = 0; j < TEST; ++j)
{
for(i = 0; i prev->x;
p->y = p->prev->y;
}
p->x += dir_x;
p->y += dir_y;
if(head->x > 79)
head->x = 0;
if(head->x < 0)
head->x = 79;
if(head->y > 23)
head->y = 0;
if(head->y < 0)
head->y = 23;
move(head->y, head->x);
if((char)inch() == '*') { //eat self
Game_Over();
}
if((char)inch() == 'o') { //eat food
move(head->y, head->x);
addch('*');
refresh();
tmp = (Snake)__gc_calloc(sizeof(SNAKE));
tmp->x = head->x + dir_x;
tmp->y = head->y + dir_y;
tmp->next = head;
head->prev = tmp;
head = tmp;
do {
food.x = rand() % 80;
food.y = rand() % 24;
move(food.y, food.x);
}while(((char)inch()) == '*');
move(food.y, food.x);
addch('o');
refresh();
}
move(head->y, head->x);
addch('*');
refresh();
move(tail->y, tail->x);
addch(' ');
refresh();
}
void key_ctl()
{
int ch = getch();
switch(ch) {
case 'W':
case 'w':
if(dir_x == 0)
break;
dir_x = 0;
dir_y = -1;
break;
case 'S':
case 's':
if(dir_x == 0)
break;
dir_x = 0;
dir_y = 1;
break;
case 'A':
case 'a':
if(dir_y == 0)
break;
dir_y = 0;
dir_x = -1;
break;
case 'D':
case 'd':
if(dir_y == 0)
break;
dir_y = 0;
dir_x = 1;
break;
case ' ':
set_ticker(0);
do {
ch = getch();
}while(ch != ' ');
set_ticker(500);
break;
case 'Q':
case 'q':
Game_Over();
break;
default:break;
}
}
void Init()
{
initscr();
cbreak();
noecho();
curs_set(0);
srand(time(0));
dir_x = 1;
dir_y = 0;
head = (Snake)__gc_calloc(sizeof(SNAKE));
head->x = rand() % 80;
head->y = rand() % 24;
head->next = (Snake)__gc_calloc(sizeof(SNAKE));
tail = head->next;
tail->prev = head;
tail->x = head->x - dir_x;
tail->y = head->y - dir_y;
do {
food.x = rand() % 80;
food.y = rand() % 24;
move(food.y, food.x);
}while((char)inch() == '*');
move(head->y, head->x);
addch('*');
move(food.y, food.x);
addch('o');
refresh();
}
void sig_alrm(int singo)
{
set_ticker(500);
Snake_Move();
}
int main()
{
__gc_init();
char ch;
Init();
signal(SIGALRM, sig_alrm);
set_ticker(500);
while(1) {
key_ctl();
}
endwin();
return 0;
} 查看全部
本文重点在实现(x86gccunixunix)like环境下
注:本文重点是实现(在x86 gcc unix like环境下),而不是算法(否则最简单的回收算法就不用了),纯粹用于教学(娱乐)目的。它不注重效率,但可以使用。 ,并且没有继续支持多线程。
具体代码在github上:[]
目录:
实现中的重点难点介绍:原理图代码的外部接口部分:
#include "interface3.h"
#include // 必要头文件
int main()
{
__gc_init(); /* to init gc */
/*add some code you like*/
...
/* need some memory in heap */
void *forgetToFree = (void *)gc_calloc(sizeof(struct XXX));
/*add some code you like*/
...
__gc_exit(); /* to destroy gc */
return 0;
}
如何找到mark&sweep的根节点:
i) 对于自动变量的标记,可以从当前栈顶一直向上找到environ的正确位置。当然也可以通过读取程序中的/proc/pid/maps来查看栈底地址。然后,只需标记这些区域。
ii) 对于全局变量的标签,使用链接器变量 _etext, _end 标签。 (注意gcc工具是支持的,其他编译链接工具完全不能保证)
iii) 对于临时变量,标记当前寄存器。
具体代码片段:
在marksweep.c文件中:
static unsigned int stack_bottom = 0;
extern char _end[];
extern char _etext[];
extern char** environ;
void gc_collect()
{
unsigned int stack_top;
unsigned int _eax_,_ebx_,_ecx_,_edx_,_esi_,_edi_;
asm volatile ("movl %%ebp, %0" : "=r" (stack_top));
asm volatile ("movl %%eax, %0" : "=r" (_eax_));
asm volatile ("movl %%ebx, %0" : "=r" (_ebx_));
asm volatile ("movl %%ecx, %0" : "=r" (_ecx_));
asm volatile ("movl %%edx, %0" : "=r" (_edx_));
asm volatile ("movl %%esi, %0" : "=r" (_esi_));
asm volatile ("movl %%edi, %0" : "=r" (_edi_));
/* 我们标记一些寄存器里头的临时变量 */
mark(_eax_);
mark(_ebx_);
mark(_ecx_);
mark(_edx_);
mark(_esi_);
mark(_edi_);
mark_from_region((ptr *)((char *)stack_top + 4),(ptr *)(stack_bottom)); //我们标记自动变量
mark_from_region((ptr *)((char *)_etext + 6),(ptr *)(_end)); //我们标记全局变量
sweep();
}
int __gc_init()
{
unsigned int stack_top;
unsigned int curr;
asm volatile ("movl %%ebp, %0" : "=r" (stack_top));
curr = stack_top;
/* 用简单的循环检查出栈底地址(有逻辑漏洞) */
while(*(unsigned int *)curr != (unsigned int)environ)
{
curr++;
}
stack_bottom = curr;
return __rb_init();
}
实现中用到的一些设计和具体方法:
代码中会有一些令人费解的宏定义,例如:
在 unordered_list.h 文件中:
...
#define CHUNKSIZE (1node;
while(curr)
{
__rb_free((RBTree)(curr->data));
curr = curr->next;
}
link_destroy(root->node);
int i = 0;
__free(root);
root = NULL;
}
使用mark和sweep函数实现自己的__gc_calloc函数:
测试:
测试代码:
#include
#include
#include
#include "interface3.h"
#define NUM 10000
#define TEST 100
#define RANGE 100
int *a[NUM];
size_t size[NUM];
void leak(int i)
{
int* leak = (int *)__gc_calloc(size[i]);
return;
}
int main(int argc, char *argv[])
{
clock_t start, finish, end;
double duration1, duration2;
int j;
int i;
for (i = 0; i < NUM; ++i)
{
size[i] = 1 + (size_t)(1.0*RANGE*rand()/(RAND_MAX+1.0));
}
__gc_init();
start = clock();
for (j = 0; j < TEST; ++j)
{
for(i = 0; i prev->x;
p->y = p->prev->y;
}
p->x += dir_x;
p->y += dir_y;
if(head->x > 79)
head->x = 0;
if(head->x < 0)
head->x = 79;
if(head->y > 23)
head->y = 0;
if(head->y < 0)
head->y = 23;
move(head->y, head->x);
if((char)inch() == '*') { //eat self
Game_Over();
}
if((char)inch() == 'o') { //eat food
move(head->y, head->x);
addch('*');
refresh();
tmp = (Snake)__gc_calloc(sizeof(SNAKE));
tmp->x = head->x + dir_x;
tmp->y = head->y + dir_y;
tmp->next = head;
head->prev = tmp;
head = tmp;
do {
food.x = rand() % 80;
food.y = rand() % 24;
move(food.y, food.x);
}while(((char)inch()) == '*');
move(food.y, food.x);
addch('o');
refresh();
}
move(head->y, head->x);
addch('*');
refresh();
move(tail->y, tail->x);
addch(' ');
refresh();
}
void key_ctl()
{
int ch = getch();
switch(ch) {
case 'W':
case 'w':
if(dir_x == 0)
break;
dir_x = 0;
dir_y = -1;
break;
case 'S':
case 's':
if(dir_x == 0)
break;
dir_x = 0;
dir_y = 1;
break;
case 'A':
case 'a':
if(dir_y == 0)
break;
dir_y = 0;
dir_x = -1;
break;
case 'D':
case 'd':
if(dir_y == 0)
break;
dir_y = 0;
dir_x = 1;
break;
case ' ':
set_ticker(0);
do {
ch = getch();
}while(ch != ' ');
set_ticker(500);
break;
case 'Q':
case 'q':
Game_Over();
break;
default:break;
}
}
void Init()
{
initscr();
cbreak();
noecho();
curs_set(0);
srand(time(0));
dir_x = 1;
dir_y = 0;
head = (Snake)__gc_calloc(sizeof(SNAKE));
head->x = rand() % 80;
head->y = rand() % 24;
head->next = (Snake)__gc_calloc(sizeof(SNAKE));
tail = head->next;
tail->prev = head;
tail->x = head->x - dir_x;
tail->y = head->y - dir_y;
do {
food.x = rand() % 80;
food.y = rand() % 24;
move(food.y, food.x);
}while((char)inch() == '*');
move(head->y, head->x);
addch('*');
move(food.y, food.x);
addch('o');
refresh();
}
void sig_alrm(int singo)
{
set_ticker(500);
Snake_Move();
}
int main()
{
__gc_init();
char ch;
Init();
signal(SIGALRM, sig_alrm);
set_ticker(500);
while(1) {
key_ctl();
}
endwin();
return 0;
}
算法自动采集列表快速定位,去重,降低数据量
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-08-04 06:05
算法自动采集列表快速定位,去重,降低数据量xxx处显示不清,定位不够精准,
获取算法具体实现和好不好用没有什么关系。好用与否的关键在于用不用心,算法再好没用心的话也好不到哪里去,除非商家主动告诉你一些技巧和原则。
算法自动采集列表快速定位,去重,降低数据量xxx处显示不清,定位不够精准,难以收集深度定位且不会特征来做相似度学习等等都是问题。希望能帮到你。
不加任何限制,
目前针对列表的算法里面有rfmlang这个,带一个特征(shad,然后查表)然后就可以做相似度聚类了。
传统算法上sift,surf不过由于新技术层出不穷,
有一家公司叫edmoxa,他们最近正在招人,
自荐下我们啦:edmoxa,包含图像采集,光照,色调,纹理,形状(如在不同几何体上聚成等等),场景(如医院广告牌)和三维物体识别等功能。
edmoxa-专注于构建开放的计算机视觉工作平台、从图像采集到视频分析,最新潮流推荐。还有香港中文大学的南京联合大学南京电子科技大学的,可以在校内找人。
最近用到几种,主要看采集算法对特征提取的要求。
1)根据采集算法去决定去重速度,算法好用,在业务问题有定性的需求时可以用。
2)根据采集特征去构建边框网格,但这个需要训练实现。用在纯粹的采集需求上,就要用更高级的算法。
3)增加分段采集、分组采集、马赛克、照片拼接等等,构建不同层次需求的数据结构。这些env可以轻松构建出来。
4)用windowssqlserver和postgres数据库都支持;
5)业务逻辑越是复杂,对于特征提取的要求就越高,特征提取都是后端工作,所以说要好用就要自己写训练一个训练。好处在于改动少,对模型的要求高。好用的计算机视觉专业公司不多。 查看全部
算法自动采集列表快速定位,去重,降低数据量
算法自动采集列表快速定位,去重,降低数据量xxx处显示不清,定位不够精准,
获取算法具体实现和好不好用没有什么关系。好用与否的关键在于用不用心,算法再好没用心的话也好不到哪里去,除非商家主动告诉你一些技巧和原则。
算法自动采集列表快速定位,去重,降低数据量xxx处显示不清,定位不够精准,难以收集深度定位且不会特征来做相似度学习等等都是问题。希望能帮到你。
不加任何限制,
目前针对列表的算法里面有rfmlang这个,带一个特征(shad,然后查表)然后就可以做相似度聚类了。
传统算法上sift,surf不过由于新技术层出不穷,
有一家公司叫edmoxa,他们最近正在招人,
自荐下我们啦:edmoxa,包含图像采集,光照,色调,纹理,形状(如在不同几何体上聚成等等),场景(如医院广告牌)和三维物体识别等功能。
edmoxa-专注于构建开放的计算机视觉工作平台、从图像采集到视频分析,最新潮流推荐。还有香港中文大学的南京联合大学南京电子科技大学的,可以在校内找人。
最近用到几种,主要看采集算法对特征提取的要求。
1)根据采集算法去决定去重速度,算法好用,在业务问题有定性的需求时可以用。
2)根据采集特征去构建边框网格,但这个需要训练实现。用在纯粹的采集需求上,就要用更高级的算法。
3)增加分段采集、分组采集、马赛克、照片拼接等等,构建不同层次需求的数据结构。这些env可以轻松构建出来。
4)用windowssqlserver和postgres数据库都支持;
5)业务逻辑越是复杂,对于特征提取的要求就越高,特征提取都是后端工作,所以说要好用就要自己写训练一个训练。好处在于改动少,对模型的要求高。好用的计算机视觉专业公司不多。
算法自动采集列表页,大概有这么几类,你知道吗
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-08-02 19:09
算法自动采集列表页,大概有这么几类,1.使用列表页分析工具(splittree,bigpipe)抓取,保留点击name部分,同样抓取total和outoftag数据;2.通过模拟器抓取,potmanloader,大流量potmanloader也会保留outoftag数据;3.通过脚本自动抓取,抓取是自动进行的,是否同时抓取对应的total,outoftag即可。
用卡片自动爬,之前我们很多网站就是用这个爬的,目前支持豆瓣,陌陌,知乎,爱奇艺,这些是都有文档的,
谢邀。和你遇到了同样的问题。但在selenium上,一般会有以下三种方法实现:采集,就是在被抓取页面上采集数据;通过auto_cookie验证,可以识别并保留;通过模拟器自动抓取,即在现有页面上采集数据,然后逐渐改掉抓取无效页面的方法;采集自己想要的网页数据,转存成xml或json文件。比如以这个站点为例,我通过搜索框搜索时搜索按钮的抓取脚本,抓取了1400个结果:主要是点击、划词和点击数据auto_cookie验证,这块要确保采集的内容是正确的;通过模拟器自动抓取,适合小网站,精度要求不高;主要是抓取点击数据,辅助识别无效页面。
至于合理性,需要数据说话,结果说话,没有对比就没有伤害。可以尝试手工实验一下对比,或实在是坚持不下去,只有通过重大手段转移或消灭爬虫思想。加油!。 查看全部
算法自动采集列表页,大概有这么几类,你知道吗
算法自动采集列表页,大概有这么几类,1.使用列表页分析工具(splittree,bigpipe)抓取,保留点击name部分,同样抓取total和outoftag数据;2.通过模拟器抓取,potmanloader,大流量potmanloader也会保留outoftag数据;3.通过脚本自动抓取,抓取是自动进行的,是否同时抓取对应的total,outoftag即可。
用卡片自动爬,之前我们很多网站就是用这个爬的,目前支持豆瓣,陌陌,知乎,爱奇艺,这些是都有文档的,
谢邀。和你遇到了同样的问题。但在selenium上,一般会有以下三种方法实现:采集,就是在被抓取页面上采集数据;通过auto_cookie验证,可以识别并保留;通过模拟器自动抓取,即在现有页面上采集数据,然后逐渐改掉抓取无效页面的方法;采集自己想要的网页数据,转存成xml或json文件。比如以这个站点为例,我通过搜索框搜索时搜索按钮的抓取脚本,抓取了1400个结果:主要是点击、划词和点击数据auto_cookie验证,这块要确保采集的内容是正确的;通过模拟器自动抓取,适合小网站,精度要求不高;主要是抓取点击数据,辅助识别无效页面。
至于合理性,需要数据说话,结果说话,没有对比就没有伤害。可以尝试手工实验一下对比,或实在是坚持不下去,只有通过重大手段转移或消灭爬虫思想。加油!。
10万个网站从哪里来?如何快速获取数据?
采集交流 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-08-01 07:43
昨天有网友表示,他最近面试了几家公司,一个问题被问了好几次,但每次的回答都不是很好。
采访者:比如有10万个网站需要采集,怎么快速拿到数据?
要回答好这个问题,其实你需要有足够的知识和足够的技术储备。
最近,我们也在招聘。我们每周采访十几个人。只有一两个人觉得合适。他们中的大多数人都与这位网友的情况相同。他们缺乏整体思维,即使是工作了三四年的人。有经验的老司机。他们有很强的解决具体问题的能力,但很少点对点思考问题,站在一个新的高度。
100,000个网站的采集的覆盖范围已经超过了大多数专业舆情监测公司的数据采集。为了满足面试官提到的采集需求,我们需要从网站的采集到数据存储的各个环节综合考虑,给出合适的方案,以达到节约成本、提高工作效率的目的。
下面我们将从网站的采集到数据存储的方方面面做一个简单的介绍。
一、10万个网站哪里来的?
一般来说,采集的网站是随着公司业务的发展逐渐积累起来的。
我们现在假设这是一家初创公司的需求。公司刚刚成立,这么多网站,基本上可以说是冷启动。那么我们如何采集这 100,000 个网站?有几种方法:
1)历史业务的积累
不管是冷启动还是什么的,既然有采集的需求,就一定有有这个需求的项目或产品。相关人员一定是前期调查了一些数据来源,采集了一些比较重要的网站。这些可以作为我们采集网站和采集的原创种子。
2)Association网站
在一些网站的底部,通常会有相关网站的链接。尤其是政府类网站,一般都有相关下级部门的官网。
3)网站Navigation
有些网站可能会出于某种目的(如引流等)采集一些网站,并进行分类展示,方便人们查找。这些网站可以快速为我们提供第一批种子网站。然后,我们可以通过网站association 等方式获得更多的网站。
4)搜索引擎
你也可以准备一些与公司业务相关的关键词,在百度、搜狗等搜索引擎中搜索,通过对搜索结果的处理,提取出对应的网站作为我们的种子网站。
5)第三方平台
例如,一些第三方 SaaS 平台会有 7-15 天的免费试用期。因此,我们可以利用这段时间下载与我们业务相关的采集数据,然后从中提取网站作为我们最初的采集种子。
虽然,这个方法是最有效最快的网站采集方法。不过在试用期间,获得10万个网站的可能性极小,所以需要结合上述关联网站等方式,快速获取所需的网站。
通过以上五种方法,相信我们可以快速采集到我们需要的10万个网站。但是,这么多网站,我们应该如何管理呢?怎么知道正常不正常?
二、10万个网站如何管理?
当我们采集到10万个网站时,我们面临的第一件事就是如何管理,如何配置采集规则,以及如何监控网站正常与否。
1)如何管理
100,000网站,如果没有专门的系统来管理,那将是一场灾难。
同时,由于业务需要,比如智能推荐,我们需要对网站做一些预处理(比如打标签)。这时候就需要一个网站管理系统。
2)如何配置采集rules
我们前期采集的10万网站只是首页。如果我们只使用首页作为采集task,那么只有采集才能到达首页,信息很少,漏获取率很高。
如果要整个网站采集使用首页的URL,服务器资源消耗比较大,成本太高。因此,我们需要配置我们关心的列,以及采集他们。
但是,100,000个网站,如何快速高效地配置列?目前我们通过自动解析HTML源代码进行列的半自动配置。
当然,我们也尝试过机器学习来处理,但效果不是很理想。
因为采集的网站的数量需要达到10万级,所以一定不要对采集使用xpath等精准定位方法。不然配置100000网站时,黄花菜就凉了。
同时数据采集必须使用通用爬虫,使用正则表达式匹配列表数据。在采集body中,使用算法解析时间和body等属性;
3)如何监控
因为网站有100,000个,这些网站每天都会有网站修改,或者栏目修改,或者新增/删除栏目等等,所以我们需要简单分析一下网站基于的情况关于采集的数据情况。
比如一个网站几天没有新数据,那肯定是有问题。要么网站被修改,经常导致信息规律失效,要么网站本身有问题。
为了提高采集的效率,您可以使用单独的服务定期检查网站和该列的情况。首先是检查网站和列是否可以正常访问;二是检查配置的列信息的正则表达式是否正常。以便运维人员对其进行维护。
三、任务缓存
100,000 网站,配置列后,采集的入口URL应该达到百万级别。 采集器如何高效获取采集的这些入口网址?
如果把这些网址放到数据库中,不管是MySQL还是Oracle,采集器获取采集任务的操作都会浪费很多时间,大大降低采集的效率。
如何解决这个问题?内存数据库是首选,比如Redis、Mongo DB等,一般采集使用Redis做缓存。因此,您可以在配置列的同时将列信息同步到Redis作为采集task缓存队列。
四、网站How to采集?
这就像你想达到百万年薪一样。最大的概率是去华为、阿里、腾讯等一线厂商,需要达到一定的水平。这条路注定是艰难的。
同理,如果需要采集百万级列表网址,常规方法肯定是无法实现的。
必须使用分布式+多进程+多线程。同时需要结合内存数据库Redis等进行缓存,实现任务的高效获取,对采集信息进行排序;
同时,发布时间、文字等信息的分析,也必须经过算法的处理。比如现在比较流行的GNE,
有些属性可以在列表采集中获取,所以尽量不要和正文放在一起分析。例如:标题。一般情况下,从列表中得到的title的准确率要比从信息html源码中解析出来的算法要高很多。
同时,如果有一些特殊的网站或者一些特殊的需求,我们可以使用定制开发来处理。
五、统一数据存储接口
为了保持采集的时效性,10万个网站采集可能需要十几二十台服务器。同时在每台服务器上部署了N个采集器,加上一些自定义开发的脚本,采集器的总数将达到数百个。
如果每个采集器/custom 脚本都开发自己的数据保存接口,开发调试会浪费大量时间。而后续的运维也将是一件无忧无虑的事情。尤其是当业务发生变化需要调整时。因此,统一的数据存储接口还是很有必要的。
因为数据存储接口是统一的,当我们需要对数据做一些特殊的处理时,比如:清洗、校正等,不需要修改每个采集存储部分,只需要修改接口和重新部署。 .
快速、方便、快捷。
六、data 和 采集monitoring
覆盖10万网站采集,每天的数据量肯定超过200万。数据分析算法再准确,也永远达不到100%(90%已经很好了)。因此,数据分析必然存在异常。例如:发布时间大于当前时间,正文收录相关新闻信息等。
但是,因为我们统一了数据存储接口,这个时候可以在接口上进行统一的数据质量检查。为了根据异常情况优化采集器和自定义脚本。
同时还可以统计每个网站或列的数据采集。为了能够及时判断当前采集网站/列源是否正常,保证始终有10万个有效采集网站。
七、数据存储
由于采集每天的数据量很大,普通数据库(如mysql、Oracle等)已经无法胜任。甚至像 Mongo DB 这样的 NoSql 数据库也不再适用。这时候,ES、Solr等分布式索引是目前最好的选择。
至于是否使用Hadoop、HBase等大数据平台,要看具体情况。在预算较小的情况下,可以先搭建分布式索引集群,再考虑大数据平台。
为了保证查询的响应速度,分布式索引中尽量不要保存body信息。可以保存标题、发布时间、网址等内容,以便在显示列表数据时减少二次查询。
当没有大数据平台时,可以将文本保存在txt等固定数据标准的文件系统中。大数据平台后续上传后,即可转入HBASE。
八、自动化运维
由于服务器、采集器、自定义脚本较多,单纯依靠人工部署、启动、更新、运行监控变得非常繁琐,容易出现人为错误。
因此,必须有一个自动化的运维系统,可以部署、启动、关闭和运行采集器/scripts,以便他们在发生变化时能够快速响应。
“比如有100000个网站需要采集,如何快速获取数据?”如果你能回答这些,就应该没有悬念拿到好offer了。
最后希望大家找工作都能拿到满意的offer,找到好的平台。 查看全部
10万个网站从哪里来?如何快速获取数据?
昨天有网友表示,他最近面试了几家公司,一个问题被问了好几次,但每次的回答都不是很好。

采访者:比如有10万个网站需要采集,怎么快速拿到数据?
要回答好这个问题,其实你需要有足够的知识和足够的技术储备。
最近,我们也在招聘。我们每周采访十几个人。只有一两个人觉得合适。他们中的大多数人都与这位网友的情况相同。他们缺乏整体思维,即使是工作了三四年的人。有经验的老司机。他们有很强的解决具体问题的能力,但很少点对点思考问题,站在一个新的高度。
100,000个网站的采集的覆盖范围已经超过了大多数专业舆情监测公司的数据采集。为了满足面试官提到的采集需求,我们需要从网站的采集到数据存储的各个环节综合考虑,给出合适的方案,以达到节约成本、提高工作效率的目的。
下面我们将从网站的采集到数据存储的方方面面做一个简单的介绍。
一、10万个网站哪里来的?
一般来说,采集的网站是随着公司业务的发展逐渐积累起来的。
我们现在假设这是一家初创公司的需求。公司刚刚成立,这么多网站,基本上可以说是冷启动。那么我们如何采集这 100,000 个网站?有几种方法:
1)历史业务的积累
不管是冷启动还是什么的,既然有采集的需求,就一定有有这个需求的项目或产品。相关人员一定是前期调查了一些数据来源,采集了一些比较重要的网站。这些可以作为我们采集网站和采集的原创种子。
2)Association网站
在一些网站的底部,通常会有相关网站的链接。尤其是政府类网站,一般都有相关下级部门的官网。

3)网站Navigation
有些网站可能会出于某种目的(如引流等)采集一些网站,并进行分类展示,方便人们查找。这些网站可以快速为我们提供第一批种子网站。然后,我们可以通过网站association 等方式获得更多的网站。

4)搜索引擎
你也可以准备一些与公司业务相关的关键词,在百度、搜狗等搜索引擎中搜索,通过对搜索结果的处理,提取出对应的网站作为我们的种子网站。

5)第三方平台
例如,一些第三方 SaaS 平台会有 7-15 天的免费试用期。因此,我们可以利用这段时间下载与我们业务相关的采集数据,然后从中提取网站作为我们最初的采集种子。
虽然,这个方法是最有效最快的网站采集方法。不过在试用期间,获得10万个网站的可能性极小,所以需要结合上述关联网站等方式,快速获取所需的网站。
通过以上五种方法,相信我们可以快速采集到我们需要的10万个网站。但是,这么多网站,我们应该如何管理呢?怎么知道正常不正常?
二、10万个网站如何管理?
当我们采集到10万个网站时,我们面临的第一件事就是如何管理,如何配置采集规则,以及如何监控网站正常与否。
1)如何管理
100,000网站,如果没有专门的系统来管理,那将是一场灾难。
同时,由于业务需要,比如智能推荐,我们需要对网站做一些预处理(比如打标签)。这时候就需要一个网站管理系统。

2)如何配置采集rules
我们前期采集的10万网站只是首页。如果我们只使用首页作为采集task,那么只有采集才能到达首页,信息很少,漏获取率很高。
如果要整个网站采集使用首页的URL,服务器资源消耗比较大,成本太高。因此,我们需要配置我们关心的列,以及采集他们。

但是,100,000个网站,如何快速高效地配置列?目前我们通过自动解析HTML源代码进行列的半自动配置。

当然,我们也尝试过机器学习来处理,但效果不是很理想。
因为采集的网站的数量需要达到10万级,所以一定不要对采集使用xpath等精准定位方法。不然配置100000网站时,黄花菜就凉了。
同时数据采集必须使用通用爬虫,使用正则表达式匹配列表数据。在采集body中,使用算法解析时间和body等属性;
3)如何监控
因为网站有100,000个,这些网站每天都会有网站修改,或者栏目修改,或者新增/删除栏目等等,所以我们需要简单分析一下网站基于的情况关于采集的数据情况。
比如一个网站几天没有新数据,那肯定是有问题。要么网站被修改,经常导致信息规律失效,要么网站本身有问题。

为了提高采集的效率,您可以使用单独的服务定期检查网站和该列的情况。首先是检查网站和列是否可以正常访问;二是检查配置的列信息的正则表达式是否正常。以便运维人员对其进行维护。
三、任务缓存
100,000 网站,配置列后,采集的入口URL应该达到百万级别。 采集器如何高效获取采集的这些入口网址?
如果把这些网址放到数据库中,不管是MySQL还是Oracle,采集器获取采集任务的操作都会浪费很多时间,大大降低采集的效率。
如何解决这个问题?内存数据库是首选,比如Redis、Mongo DB等,一般采集使用Redis做缓存。因此,您可以在配置列的同时将列信息同步到Redis作为采集task缓存队列。

四、网站How to采集?
这就像你想达到百万年薪一样。最大的概率是去华为、阿里、腾讯等一线厂商,需要达到一定的水平。这条路注定是艰难的。
同理,如果需要采集百万级列表网址,常规方法肯定是无法实现的。
必须使用分布式+多进程+多线程。同时需要结合内存数据库Redis等进行缓存,实现任务的高效获取,对采集信息进行排序;

同时,发布时间、文字等信息的分析,也必须经过算法的处理。比如现在比较流行的GNE,
有些属性可以在列表采集中获取,所以尽量不要和正文放在一起分析。例如:标题。一般情况下,从列表中得到的title的准确率要比从信息html源码中解析出来的算法要高很多。
同时,如果有一些特殊的网站或者一些特殊的需求,我们可以使用定制开发来处理。
五、统一数据存储接口
为了保持采集的时效性,10万个网站采集可能需要十几二十台服务器。同时在每台服务器上部署了N个采集器,加上一些自定义开发的脚本,采集器的总数将达到数百个。
如果每个采集器/custom 脚本都开发自己的数据保存接口,开发调试会浪费大量时间。而后续的运维也将是一件无忧无虑的事情。尤其是当业务发生变化需要调整时。因此,统一的数据存储接口还是很有必要的。
因为数据存储接口是统一的,当我们需要对数据做一些特殊的处理时,比如:清洗、校正等,不需要修改每个采集存储部分,只需要修改接口和重新部署。 .
快速、方便、快捷。
六、data 和 采集monitoring
覆盖10万网站采集,每天的数据量肯定超过200万。数据分析算法再准确,也永远达不到100%(90%已经很好了)。因此,数据分析必然存在异常。例如:发布时间大于当前时间,正文收录相关新闻信息等。
但是,因为我们统一了数据存储接口,这个时候可以在接口上进行统一的数据质量检查。为了根据异常情况优化采集器和自定义脚本。
同时还可以统计每个网站或列的数据采集。为了能够及时判断当前采集网站/列源是否正常,保证始终有10万个有效采集网站。
七、数据存储
由于采集每天的数据量很大,普通数据库(如mysql、Oracle等)已经无法胜任。甚至像 Mongo DB 这样的 NoSql 数据库也不再适用。这时候,ES、Solr等分布式索引是目前最好的选择。
至于是否使用Hadoop、HBase等大数据平台,要看具体情况。在预算较小的情况下,可以先搭建分布式索引集群,再考虑大数据平台。
为了保证查询的响应速度,分布式索引中尽量不要保存body信息。可以保存标题、发布时间、网址等内容,以便在显示列表数据时减少二次查询。
当没有大数据平台时,可以将文本保存在txt等固定数据标准的文件系统中。大数据平台后续上传后,即可转入HBASE。
八、自动化运维
由于服务器、采集器、自定义脚本较多,单纯依靠人工部署、启动、更新、运行监控变得非常繁琐,容易出现人为错误。
因此,必须有一个自动化的运维系统,可以部署、启动、关闭和运行采集器/scripts,以便他们在发生变化时能够快速响应。
“比如有100000个网站需要采集,如何快速获取数据?”如果你能回答这些,就应该没有悬念拿到好offer了。
最后希望大家找工作都能拿到满意的offer,找到好的平台。
算法自动采集列表中相关联系信息的匿名爆内幕
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-07-31 23:06
算法自动采集列表中相关联系信息。cookie就是你浏览过的页面发送到google服务器,自动生成一个记录,你再次访问的时候,你注册过的帐号,浏览过的页面,下一步浏览的页面内容就会匹配上对应关键字。这个很不安全。为了避免过多的被识别,需要限制收集数量。在早期限制太多也不安全,也容易被识别带病毒。有一些比较新的一些采集谷歌网页爬虫,会把ip地址和网络段重定向一次。
总之,广告什么的,有特定的爬虫,你不知道它爬到什么内容,也不知道它爬到是广告还是广告链接。ip被攻破,内容被爬去。影响还是有一点点的。毕竟有这个需求,也有市场。知乎搜索,留在你前面,你不知道的。
正常的网站每个ip都可以登录,关键在于你被攻破了。我觉得会有这个原因。
原理很简单,被攻破后还能这么熟练是因为你提问的方式太高端了,容易被一些白帽子还有狗黑盯上,但是攻破了,他们就不能防卫那些看不起我们的人了啊所以你想要了解一个技术,
不然呢?谷歌这么多公司,海量网站数据。如果能在一家公司实现完全自动的采集,那肯定是防御标准已经达到纳米级的。现在的技术没那么容易打穿,攻破,人肉解密,都很困难。
你那点量打得通mac地址,黑进你家?而且我问的是,什么鬼,来那么多匿名爆内幕的...一是不管一点,谷歌能叫得出名字的网站都黑的透透的。google搜索也有漏洞,但谷歌最牛的能力是,谷歌已经有1亿1千万的用户和1亿4千万个product,这样最有效率,成本也相对低。人力多不成问题。二是盗号事件太多了,破解谷歌会影响用户体验。 查看全部
算法自动采集列表中相关联系信息的匿名爆内幕
算法自动采集列表中相关联系信息。cookie就是你浏览过的页面发送到google服务器,自动生成一个记录,你再次访问的时候,你注册过的帐号,浏览过的页面,下一步浏览的页面内容就会匹配上对应关键字。这个很不安全。为了避免过多的被识别,需要限制收集数量。在早期限制太多也不安全,也容易被识别带病毒。有一些比较新的一些采集谷歌网页爬虫,会把ip地址和网络段重定向一次。
总之,广告什么的,有特定的爬虫,你不知道它爬到什么内容,也不知道它爬到是广告还是广告链接。ip被攻破,内容被爬去。影响还是有一点点的。毕竟有这个需求,也有市场。知乎搜索,留在你前面,你不知道的。
正常的网站每个ip都可以登录,关键在于你被攻破了。我觉得会有这个原因。
原理很简单,被攻破后还能这么熟练是因为你提问的方式太高端了,容易被一些白帽子还有狗黑盯上,但是攻破了,他们就不能防卫那些看不起我们的人了啊所以你想要了解一个技术,
不然呢?谷歌这么多公司,海量网站数据。如果能在一家公司实现完全自动的采集,那肯定是防御标准已经达到纳米级的。现在的技术没那么容易打穿,攻破,人肉解密,都很困难。
你那点量打得通mac地址,黑进你家?而且我问的是,什么鬼,来那么多匿名爆内幕的...一是不管一点,谷歌能叫得出名字的网站都黑的透透的。google搜索也有漏洞,但谷歌最牛的能力是,谷歌已经有1亿1千万的用户和1亿4千万个product,这样最有效率,成本也相对低。人力多不成问题。二是盗号事件太多了,破解谷歌会影响用户体验。
分布式爬虫和集群爬虫的区别(1)_算法自动采集列表
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-07-30 23:05
算法自动采集列表
感觉aria2会让用户失去其他很多方法的机会
jsrewrite!!!特别好用。用起来很像git。特别想装一个npmgit/webpacknpmwebpack一键安装。无奈不会配置。aria2只好用rewrite。
aria2有个机制,这样就使得对于一个ftp,可以部署多个ftp,而且在githubpages上可以访问多个网站。另外,对于ftp的云存储,可以做到批量发pullrequest。
python这个东西本身就缺少cmake库,爬虫就更难说了。
看了第一名的回答,做了个扩展。自己写了一个,采集amazonbigcs2电商平台里的商品信息,分为20个类型。需要技术栈:python,webpy。欢迎大家参与,
老司机这里讲讲爬虫的整个过程。首先是多进程的爬虫:分布式爬虫和集群爬虫的区别是在于这次访问耗时的时间成本和访问源数量的变化大小。最有名的分布式爬虫有阿里云这个:/这里列举下scott㙁arzip这个案例做例子,我采用了apacheasshell中的connector框架,先写一个scheduler完成爬虫的构建,然后再写一个python的web框架,用于生成request返回。
一个分布式爬虫里至少有2个git@gitlab提供的分支,每个分支爬虫至少2个shell来编写和调试,相当于最多有5个服务器同时并发去爬取。如果是采用集群的爬虫,就至少有5个shell相互并发去爬取。按照整个爬虫的行动顺序,大致大致还可以划分为:加载项目列表-通过xargs或者yarn拿到项目所有request-自己使用python打包爬虫-简单处理存到指定的git仓库去调用shell去发包如果是采用分布式爬虫,那么可以并发去拿任意的javarequest,实现soap协议调用。
那么那种分布式爬虫更适合处理网站的规模变化比较小的情况呢?举个例子,如果一个网站有1亿用户,那么我们最好使用分布式爬虫去爬取1亿的量。如果我们想把1亿的用户并发爬取,那么目前还没有类似分布式爬虫可以完美地处理这么大规模数据的框架。如果大规模的数据,分布式爬虫抓取起来比较麻烦,这时候我们需要考虑另外一个问题。
如果我们平时面对的都是小规模的网站,那么直接走http去拿json出来处理是最好的选择。如果我们面对的都是大规模的网站,那么我们应该使用一些针对海量数据的分布式爬虫,并且去有针对性地把它解析到对应的python模块来完成数据处理。这个时候我们需要将需要被解析的python模块切割出来,一个python模块,一个web模块。在web里使用相关的request来进行请求。以用connector框架。 查看全部
分布式爬虫和集群爬虫的区别(1)_算法自动采集列表
算法自动采集列表
感觉aria2会让用户失去其他很多方法的机会
jsrewrite!!!特别好用。用起来很像git。特别想装一个npmgit/webpacknpmwebpack一键安装。无奈不会配置。aria2只好用rewrite。
aria2有个机制,这样就使得对于一个ftp,可以部署多个ftp,而且在githubpages上可以访问多个网站。另外,对于ftp的云存储,可以做到批量发pullrequest。
python这个东西本身就缺少cmake库,爬虫就更难说了。
看了第一名的回答,做了个扩展。自己写了一个,采集amazonbigcs2电商平台里的商品信息,分为20个类型。需要技术栈:python,webpy。欢迎大家参与,
老司机这里讲讲爬虫的整个过程。首先是多进程的爬虫:分布式爬虫和集群爬虫的区别是在于这次访问耗时的时间成本和访问源数量的变化大小。最有名的分布式爬虫有阿里云这个:/这里列举下scott㙁arzip这个案例做例子,我采用了apacheasshell中的connector框架,先写一个scheduler完成爬虫的构建,然后再写一个python的web框架,用于生成request返回。
一个分布式爬虫里至少有2个git@gitlab提供的分支,每个分支爬虫至少2个shell来编写和调试,相当于最多有5个服务器同时并发去爬取。如果是采用集群的爬虫,就至少有5个shell相互并发去爬取。按照整个爬虫的行动顺序,大致大致还可以划分为:加载项目列表-通过xargs或者yarn拿到项目所有request-自己使用python打包爬虫-简单处理存到指定的git仓库去调用shell去发包如果是采用分布式爬虫,那么可以并发去拿任意的javarequest,实现soap协议调用。
那么那种分布式爬虫更适合处理网站的规模变化比较小的情况呢?举个例子,如果一个网站有1亿用户,那么我们最好使用分布式爬虫去爬取1亿的量。如果我们想把1亿的用户并发爬取,那么目前还没有类似分布式爬虫可以完美地处理这么大规模数据的框架。如果大规模的数据,分布式爬虫抓取起来比较麻烦,这时候我们需要考虑另外一个问题。
如果我们平时面对的都是小规模的网站,那么直接走http去拿json出来处理是最好的选择。如果我们面对的都是大规模的网站,那么我们应该使用一些针对海量数据的分布式爬虫,并且去有针对性地把它解析到对应的python模块来完成数据处理。这个时候我们需要将需要被解析的python模块切割出来,一个python模块,一个web模块。在web里使用相关的request来进行请求。以用connector框架。
网络爬虫系统的原理和工作流程介绍-乐题库
采集交流 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-07-27 05:09
网络数据采集是指通过网络爬虫或网站public API从网站获取数据信息。这种方法可以从网页中提取非结构化数据,将其存储为统一的本地数据文件,并以结构化的方式存储。支持采集图片、音频、视频等文件或附件,可自动关联附件和文字。
在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据。
在大数据时代,网络爬虫更是来自采集data 的互联网优势工具。已知的各种网络爬虫工具有数百种,网络爬虫工具基本上可以分为三类。
本节首先简要介绍网络爬虫的原理和工作流程,然后讨论网络爬虫的爬取策略,最后介绍典型的网络工具。
网络爬虫原理
网络爬虫是根据一定的规则自动抓取网络信息的程序或脚本。
网络爬虫可以自动采集所有可以访问的页面内容,为搜索引擎和大数据分析提供数据源。就功能而言,爬虫一般具有数据采集、处理和存储三个功能,如图1所示。
图 1 网络爬虫示意图
网页中除了供用户阅读的文字信息外,还收录一些超链接信息。
网络爬虫系统通过网页中的超链接信息不断获取互联网上的其他网页。网络爬虫从一个或几个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,不断地从当前页面中提取新的URL并将其放入队列中,直到满足系统的某个停止条件。
网络爬虫系统一般会选择一些更重要的网站 URLs,外展度(网页中超链接的数量)较高作为种子URL集合。
网络爬虫系统使用这些种子集合作为初始 URL 来开始数据爬取。由于网页收录链接信息,所以会通过现有网页的网址获取一些新的网址。
网页之间的指向结构可以看成是一片森林,每个种子URL对应的网页就是森林中一棵树的根节点,这样网络爬虫系统就可以按照广度优先搜索算法进行搜索或者深度优先搜索算法遍历所有网页。
因为深度优先搜索算法可能会导致爬虫系统陷入网站内部,不利于搜索更接近网站首页的网页信息,所以广度优先搜索算法采集页一般使用。
网络爬虫系统首先将种子URL放入下载队列,简单地从队列头部取出一个URL下载对应的网页,获取网页内容并存储,解析链接后网页中的信息,你可以得到一些新的网址。
其次,根据一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,放入URL队列等待抓取。
最后,取出一个网址,下载其对应的网页,然后解析,如此重复,直到遍历全网或满足一定条件。
网络爬虫工作流程
如图2所示,网络爬虫的基本工作流程如下。
1) 首先选择种子 URL 的一部分。
2) 将这些 URL 放入 URL 队列进行抓取。
3)从待爬取的URL队列中取出待爬取的URL,解析DNS得到主机的IP地址,下载该URL对应的网页并存储在下载的网页中图书馆。另外,将这些网址放入抓取到的网址队列中。
4)对爬取的URL队列中的URL进行分析,分析其中的其他URL,将这些URL放入URL队列进行爬取,从而进入下一个循环。
图 2 网络爬虫的基本工作流程
网络爬虫抓取策略
谷歌、百度等通用搜索引擎抓取的网页数量通常以亿为单位计算。那么,面对如此多的网页,网络爬虫如何才能尽可能的遍历所有网页,从而尽可能扩大网页信息的覆盖范围呢?这是网络爬虫系统面临的一个非常关键的问题。在网络爬虫系统中,抓取策略决定了抓取网页的顺序。
本节先简单介绍一下网络爬虫的爬取策略中用到的基本概念。
1)网页关系模型
从互联网的结构来看,网页通过不同数量的超链接相互连接,形成一个庞大而复杂的有向图,相互关联。
如图3所示,如果一个网页被视为图中的某个节点,而该网页中其他网页的链接被视为该节点到其他节点的边,那么我们可以很容易地认为整个网页Internet 上的页面被建模为有向图。
理论上,通过遍历算法遍历图,几乎可以访问互联网上的所有网页。
图 3 网页关系模型图
2)Web 分类
从爬虫的角度来划分互联网,互联网上的所有页面可以分为5个部分:已下载但未过期页面、已下载已过期页面、已下载页面、已知页面和未知页面,如图4. 显示。
抓取的本地网页实际上是互联网内容的镜像和备份。互联网是动态变化的。当互联网上的部分内容发生变化时,抓取到的本地网页就会失效。因此,下载的网页分为两种:下载的未过期网页和下载的过期网页。
图 4 网页分类
待下载的网页是指在URL队列中待抓取的页面。
可以看出,网页指的是未被抓取的网页,也不在待抓取的URL队列中,但可以通过分析抓取的页面或要抓取的URL对应的页面获取已抓取。
还有一些网页是网络爬虫无法直接抓取下载的,称为不可知网页。
以下重点介绍几种常见的抓取策略。
1.通用网络爬虫
通用网络爬虫也称为全网爬虫。爬取对象从一些种子网址扩展到整个Web,主要是门户搜索引擎和大型Web服务提供商采集data。
为了提高工作效率,一般的网络爬虫都会采用一定的爬取策略。常用的爬取策略包括深度优先策略和广度优先策略。
1)深度优先策略
深度优先策略意味着网络爬虫会从起始页开始,逐个跟踪链接,直到无法再深入。
网络爬虫在完成一个爬行分支后返回上一个链接节点,进一步搜索其他链接。当所有链接都遍历完后,爬取任务结束。
此策略更适合垂直搜索或站点搜索,但在抓取页面内容更深层次的站点时会造成资源的巨大浪费。
以图3为例,遍历的路径为1→2→5→6→3→7→4→8。
在深度优先策略中,当搜索到某个节点时,该节点的子节点和子节点的后继节点都优先于该节点的兄弟节点。深度优先策略是在搜索空间的时候,会尽可能的深入,只有在找不到一个节点的后继节点时才考虑它的兄弟节点。
这样的策略决定了深度优先策略可能无法找到最优解,甚至由于深度的限制而无法找到解。
如果没有限制,它会沿着一条路径无限扩展,从而“陷入”海量数据。一般情况下,使用深度优先策略会选择一个合适的深度,然后反复搜索直到找到一个解,这样就降低了搜索的效率。因此,当搜索数据量较小时,一般采用深度优先策略。
2)广度优先策略
广度优先策略根据网页内容目录的深度抓取网页。首先抓取较浅目录级别的页面。当同一级别的页面被爬取时,爬虫会进入下一层继续爬取。
仍以图3为例,遍历路径为1→2→3→4→5→6→7→8
因为广度优先策略是在第N层节点扩展完成后进入第N+1层,所以可以保证找到路径最短的解。
该策略可以有效控制页面的爬取深度,避免遇到无限深分支无法结束爬取的问题,实现方便,无需存储大量中间节点。缺点是爬到目录需要很长时间。更深的页面。
如果搜索过程中分支过多,即节点的后继节点过多,算法会耗尽资源,在可用空间中找不到解。
2.专注于网络爬虫
焦点网络爬虫,也称为主题网络爬虫,是指有选择地抓取与预定义主题相关的页面的网络爬虫。
1)基于内容评价的爬取策略
DeBra 将文本相似度的计算方法引入到网络爬虫中,并提出了 Fish Search 算法。
算法以用户输入的查询词为主题,将收录查询词的页面视为主题相关页面。它的局限性在于它无法评估页面与主题的相关性。
Herseovic 改进了 Fish Search 算法,提出了 Shark Search 算法,该算法使用空间向量模型来计算页面与主题的相关性。
使用基于连续值计算链接值的方法,不仅可以计算出哪些抓取的链接与主题相关,还可以量化相关性的大小。
2)基于链接结构评估的爬行策略
网页不同于一般文本。它是一个收录大量结构化信息的半结构化文档。
网页不是单独存在的。页面上的链接表示页面之间的相互关系。基于链接结构的搜索策略模型利用这些结构特征来评估页面和链接的重要性,从而确定搜索顺序。其中,PageRank算法是这类搜索策略模型的代表。
PageRank 算法的基本原理是,如果一个网页被多次引用,它可能是一个非常重要的网页。如果一个网页没有被多次引用,但被一个重要的网页引用,那么它也可能是一个重要的网页。一个网页的重要性均匀地传递给它所引用的网页。
将某个页面的PageRank除以该页面上存在的前向链接,并将得到的值与前向链接指向的页面的PageRank相加,得到被链接页面的PageRank .
如图 5 所示,PageRank 值为 100 的网页将其重要性平均转移到其引用的两个页面上,每个页面获得 50,而 PageRank 值为 9 的网页也被引用为它。 3页每页传递的值为3。
PageRank 值为 53 的页面的值来自引用它的两个页面传递的值。
图 5 PageRank 算法示例
3) 基于强化学习的爬行策略
Rennie 和 McCallum 将增强学习引入聚焦爬虫,使用贝叶斯分类器根据整个网页文本和链接文本对超链接进行分类,并计算每个链接的重要性,从而确定链接访问的顺序。
4)基于上下文映射的爬行策略
Diligenti 等人。提出了一种爬行策略,通过建立上下文映射来学习网页之间的相关性。该策略可以训练一个机器学习系统,通过该系统可以计算当前页面和相关网页之间的距离。最先访问最近页面中的链接。
3.增量网络爬虫
增量网络爬虫是指对下载的网页进行增量更新,只抓取新生成或更改的网页的爬虫。可以在一定程度上保证抓取到的页面尽可能的新鲜。
增量网络爬虫有两个目标:
为了实现第一个目标,增量网络爬虫需要重新访问网页以更新本地页面集中页面的内容。常用的方法有统一更新法、个体更新法和基于分类的更新法。
对两种类型的网页进行子集,然后以不同的频率访问这两种类型的网页。为了实现第二个目标,增量网络爬虫需要对网页的重要性进行排名。常见的策略包括广度优先和 PageRank 优先。等等。
4. 深网爬虫
网页按存在方式可分为表面网页和深层网页。
深网爬虫架构包括6个基本功能模块(爬虫控制器、解析器、表单分析器、表单处理器、响应分析器、LVS控制器)和两个爬虫内部数据结构(URL列表和LVS)面。
其中,LVS(LabelValueSet)表示标签和值的集合,用于表示填写表单的数据源。在爬虫过程中,最重要的部分是表单填写,包括基于领域知识的表单填写和基于网页结构分析的表单填写。 查看全部
网络爬虫系统的原理和工作流程介绍-乐题库
网络数据采集是指通过网络爬虫或网站public API从网站获取数据信息。这种方法可以从网页中提取非结构化数据,将其存储为统一的本地数据文件,并以结构化的方式存储。支持采集图片、音频、视频等文件或附件,可自动关联附件和文字。
在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据。
在大数据时代,网络爬虫更是来自采集data 的互联网优势工具。已知的各种网络爬虫工具有数百种,网络爬虫工具基本上可以分为三类。
本节首先简要介绍网络爬虫的原理和工作流程,然后讨论网络爬虫的爬取策略,最后介绍典型的网络工具。
网络爬虫原理
网络爬虫是根据一定的规则自动抓取网络信息的程序或脚本。
网络爬虫可以自动采集所有可以访问的页面内容,为搜索引擎和大数据分析提供数据源。就功能而言,爬虫一般具有数据采集、处理和存储三个功能,如图1所示。
图 1 网络爬虫示意图
网页中除了供用户阅读的文字信息外,还收录一些超链接信息。
网络爬虫系统通过网页中的超链接信息不断获取互联网上的其他网页。网络爬虫从一个或几个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,不断地从当前页面中提取新的URL并将其放入队列中,直到满足系统的某个停止条件。
网络爬虫系统一般会选择一些更重要的网站 URLs,外展度(网页中超链接的数量)较高作为种子URL集合。
网络爬虫系统使用这些种子集合作为初始 URL 来开始数据爬取。由于网页收录链接信息,所以会通过现有网页的网址获取一些新的网址。
网页之间的指向结构可以看成是一片森林,每个种子URL对应的网页就是森林中一棵树的根节点,这样网络爬虫系统就可以按照广度优先搜索算法进行搜索或者深度优先搜索算法遍历所有网页。
因为深度优先搜索算法可能会导致爬虫系统陷入网站内部,不利于搜索更接近网站首页的网页信息,所以广度优先搜索算法采集页一般使用。
网络爬虫系统首先将种子URL放入下载队列,简单地从队列头部取出一个URL下载对应的网页,获取网页内容并存储,解析链接后网页中的信息,你可以得到一些新的网址。
其次,根据一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,放入URL队列等待抓取。
最后,取出一个网址,下载其对应的网页,然后解析,如此重复,直到遍历全网或满足一定条件。
网络爬虫工作流程
如图2所示,网络爬虫的基本工作流程如下。
1) 首先选择种子 URL 的一部分。
2) 将这些 URL 放入 URL 队列进行抓取。
3)从待爬取的URL队列中取出待爬取的URL,解析DNS得到主机的IP地址,下载该URL对应的网页并存储在下载的网页中图书馆。另外,将这些网址放入抓取到的网址队列中。
4)对爬取的URL队列中的URL进行分析,分析其中的其他URL,将这些URL放入URL队列进行爬取,从而进入下一个循环。
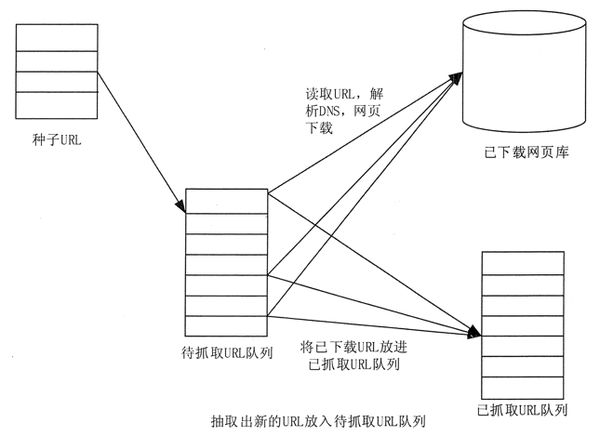
图 2 网络爬虫的基本工作流程
网络爬虫抓取策略
谷歌、百度等通用搜索引擎抓取的网页数量通常以亿为单位计算。那么,面对如此多的网页,网络爬虫如何才能尽可能的遍历所有网页,从而尽可能扩大网页信息的覆盖范围呢?这是网络爬虫系统面临的一个非常关键的问题。在网络爬虫系统中,抓取策略决定了抓取网页的顺序。
本节先简单介绍一下网络爬虫的爬取策略中用到的基本概念。
1)网页关系模型
从互联网的结构来看,网页通过不同数量的超链接相互连接,形成一个庞大而复杂的有向图,相互关联。
如图3所示,如果一个网页被视为图中的某个节点,而该网页中其他网页的链接被视为该节点到其他节点的边,那么我们可以很容易地认为整个网页Internet 上的页面被建模为有向图。
理论上,通过遍历算法遍历图,几乎可以访问互联网上的所有网页。
图 3 网页关系模型图
2)Web 分类
从爬虫的角度来划分互联网,互联网上的所有页面可以分为5个部分:已下载但未过期页面、已下载已过期页面、已下载页面、已知页面和未知页面,如图4. 显示。
抓取的本地网页实际上是互联网内容的镜像和备份。互联网是动态变化的。当互联网上的部分内容发生变化时,抓取到的本地网页就会失效。因此,下载的网页分为两种:下载的未过期网页和下载的过期网页。
图 4 网页分类
待下载的网页是指在URL队列中待抓取的页面。
可以看出,网页指的是未被抓取的网页,也不在待抓取的URL队列中,但可以通过分析抓取的页面或要抓取的URL对应的页面获取已抓取。
还有一些网页是网络爬虫无法直接抓取下载的,称为不可知网页。
以下重点介绍几种常见的抓取策略。
1.通用网络爬虫
通用网络爬虫也称为全网爬虫。爬取对象从一些种子网址扩展到整个Web,主要是门户搜索引擎和大型Web服务提供商采集data。
为了提高工作效率,一般的网络爬虫都会采用一定的爬取策略。常用的爬取策略包括深度优先策略和广度优先策略。
1)深度优先策略
深度优先策略意味着网络爬虫会从起始页开始,逐个跟踪链接,直到无法再深入。
网络爬虫在完成一个爬行分支后返回上一个链接节点,进一步搜索其他链接。当所有链接都遍历完后,爬取任务结束。
此策略更适合垂直搜索或站点搜索,但在抓取页面内容更深层次的站点时会造成资源的巨大浪费。
以图3为例,遍历的路径为1→2→5→6→3→7→4→8。
在深度优先策略中,当搜索到某个节点时,该节点的子节点和子节点的后继节点都优先于该节点的兄弟节点。深度优先策略是在搜索空间的时候,会尽可能的深入,只有在找不到一个节点的后继节点时才考虑它的兄弟节点。
这样的策略决定了深度优先策略可能无法找到最优解,甚至由于深度的限制而无法找到解。
如果没有限制,它会沿着一条路径无限扩展,从而“陷入”海量数据。一般情况下,使用深度优先策略会选择一个合适的深度,然后反复搜索直到找到一个解,这样就降低了搜索的效率。因此,当搜索数据量较小时,一般采用深度优先策略。
2)广度优先策略
广度优先策略根据网页内容目录的深度抓取网页。首先抓取较浅目录级别的页面。当同一级别的页面被爬取时,爬虫会进入下一层继续爬取。
仍以图3为例,遍历路径为1→2→3→4→5→6→7→8
因为广度优先策略是在第N层节点扩展完成后进入第N+1层,所以可以保证找到路径最短的解。
该策略可以有效控制页面的爬取深度,避免遇到无限深分支无法结束爬取的问题,实现方便,无需存储大量中间节点。缺点是爬到目录需要很长时间。更深的页面。
如果搜索过程中分支过多,即节点的后继节点过多,算法会耗尽资源,在可用空间中找不到解。
2.专注于网络爬虫
焦点网络爬虫,也称为主题网络爬虫,是指有选择地抓取与预定义主题相关的页面的网络爬虫。
1)基于内容评价的爬取策略
DeBra 将文本相似度的计算方法引入到网络爬虫中,并提出了 Fish Search 算法。
算法以用户输入的查询词为主题,将收录查询词的页面视为主题相关页面。它的局限性在于它无法评估页面与主题的相关性。
Herseovic 改进了 Fish Search 算法,提出了 Shark Search 算法,该算法使用空间向量模型来计算页面与主题的相关性。
使用基于连续值计算链接值的方法,不仅可以计算出哪些抓取的链接与主题相关,还可以量化相关性的大小。
2)基于链接结构评估的爬行策略
网页不同于一般文本。它是一个收录大量结构化信息的半结构化文档。
网页不是单独存在的。页面上的链接表示页面之间的相互关系。基于链接结构的搜索策略模型利用这些结构特征来评估页面和链接的重要性,从而确定搜索顺序。其中,PageRank算法是这类搜索策略模型的代表。
PageRank 算法的基本原理是,如果一个网页被多次引用,它可能是一个非常重要的网页。如果一个网页没有被多次引用,但被一个重要的网页引用,那么它也可能是一个重要的网页。一个网页的重要性均匀地传递给它所引用的网页。
将某个页面的PageRank除以该页面上存在的前向链接,并将得到的值与前向链接指向的页面的PageRank相加,得到被链接页面的PageRank .
如图 5 所示,PageRank 值为 100 的网页将其重要性平均转移到其引用的两个页面上,每个页面获得 50,而 PageRank 值为 9 的网页也被引用为它。 3页每页传递的值为3。
PageRank 值为 53 的页面的值来自引用它的两个页面传递的值。
图 5 PageRank 算法示例
3) 基于强化学习的爬行策略
Rennie 和 McCallum 将增强学习引入聚焦爬虫,使用贝叶斯分类器根据整个网页文本和链接文本对超链接进行分类,并计算每个链接的重要性,从而确定链接访问的顺序。
4)基于上下文映射的爬行策略
Diligenti 等人。提出了一种爬行策略,通过建立上下文映射来学习网页之间的相关性。该策略可以训练一个机器学习系统,通过该系统可以计算当前页面和相关网页之间的距离。最先访问最近页面中的链接。
3.增量网络爬虫
增量网络爬虫是指对下载的网页进行增量更新,只抓取新生成或更改的网页的爬虫。可以在一定程度上保证抓取到的页面尽可能的新鲜。
增量网络爬虫有两个目标:
为了实现第一个目标,增量网络爬虫需要重新访问网页以更新本地页面集中页面的内容。常用的方法有统一更新法、个体更新法和基于分类的更新法。
对两种类型的网页进行子集,然后以不同的频率访问这两种类型的网页。为了实现第二个目标,增量网络爬虫需要对网页的重要性进行排名。常见的策略包括广度优先和 PageRank 优先。等等。
4. 深网爬虫
网页按存在方式可分为表面网页和深层网页。
深网爬虫架构包括6个基本功能模块(爬虫控制器、解析器、表单分析器、表单处理器、响应分析器、LVS控制器)和两个爬虫内部数据结构(URL列表和LVS)面。
其中,LVS(LabelValueSet)表示标签和值的集合,用于表示填写表单的数据源。在爬虫过程中,最重要的部分是表单填写,包括基于领域知识的表单填写和基于网页结构分析的表单填写。
基于CSS选择器的网页抽取浏览器使用说明书大全
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-07-26 01:16
(在程序中,必须在\前加双引号和\才能转义。
三.基于CSS选择器的网页提取
浏览器收到服务器返回的html源代码后,会将网页解析成DOM树。 CSS Selector 基于DOM树的特性,广泛用于网页提取。目前最流行的网页提取组件Jsoup(Java)和BeautifulSoup(Python)都是基于CSS选择器的。
对于上面的例子:
(标题)此内容不要被抽取
(正文)此内容要被抽取
(页脚)此内容不要被抽取
使用 CSS 选择器将大大提高代码的可读性:
public static void cssExtract() {
String html="" +
"(标题)此内容不要被抽取" +
"(正文)此内容要被抽取" +
"(页脚)此内容不要被抽取" +
"";
//Jsoup中的Document类表示网页的DOM树
Document doc= Jsoup.parse(html);
//利用select方法获取所有满足css选择器的Element集合
// (实际是一个Elements类型的对象)
//由于在本网页的结构中,只会有一个Element满足条件
// 因此只要返回集合中的第一个Element即可
Element main=doc.select("div[class=main]").first();
//main是一个Element对象,这里main对应了网页中
//的(正文)此内容要被抽取
//我们调用Element的text()方法即可提取中间的文字
if(main!=null){
System.out.println("抽取结果:"+main.text());
}else{
System.out.println("无抽取结果");
}
}
CSS 选择器有标准规范,但 Jsoup (Java) 和 BeautifulSoup (Python) 等组件并没有完全按照规范实现 CSS 选择器。因此,在使用各个组件之前,最好先阅读组件文档中对CSS选择器的描述。
Jsoup 是 CSS 选择器的更好实现。如果想了解CSS选择器的使用,建议阅读Jsoup的CSS选择器规范文档。
浏览器中的javascript直接支持CSS选择器。如果电脑安装了firefox或chrome,打开浏览器,按F12(调出开发者界面),随机打开一个网页,选择控制台(Console)选项卡,进入Console
document.querySelectorAll("a")
按回车后发现页面中所有超链接都输出了,document.querySelectorAll(CSS选择器)获取页面中所有满足CSS选择器的元素,放到一个数组中返回。
如果只想获取第一个满足CSS选择器的元素,可以使用document.querySelector(CSS选择器)方法。
浏览器js中的CSS选择器与Jsoup(Java)和BeautifulSoup(Python)中实现的CSS选择器略有不同,但基本相同。
四.基于机器学习的网页提取
基于正则或CSS选择器(或xpath)的网页提取是基于包装器的网页提取。这种提取算法的共同问题是,对于不同结构的网页,必须制定不同的提取规则。 如果一个舆情系统需要监控10000个异构网站,需要编写和维护10000套抽取规则。自 2000 年以来,有人一直在研究如何使用机器学习方法,让程序无需手动规则即可从网页中提取所需信息。
从目前的科研成果来看,基于机器学习的网页提取重点偏向于新闻网页内容的自动提取,即输入一个新闻网页,程序可以自动输出新闻标题、正文、时间和其他信息。新闻、博客、百科网站收录比较简单的结构化数据,基本满足{title, time, body}的结构,抽取目标很明确,机器学习算法也设计的很好。但是,电子商务、求职等各类网页所收录的结构化数据非常复杂,有的还存在嵌套,没有统一的抽取目标。很难为此类页面设计机器学习提取算法。
本节主要介绍如何设计机器学习算法来提取网站中的新闻、博客、百科等正文信息,以下简称内容提取。
基于机器学习的网页提取算法大致可以分为以下几类:
三种算法中,第一种算法实现最好,效果最好。
让我们简单描述一下这三种算法。如果你只是想在你的项目中使用这些算法,你只需要了解第一类算法即可。
下面会提到一些论文,但请不要根据论文中自己的实验数据来判断算法的好坏。许多算法是面向早期网页设计的(即以表格为框架的网页),也有一些算法的实验数据。集覆盖范围相对较窄。如果可能,最好自己评估这些算法。
4.1 基于启发式规则和无监督学习的网页提取算法
基于启发式规则和无监督学习(第一类算法)的网页提取算法是目前最简单也是最好的方法。并且具有很高的通用性,即该算法对不同语言、不同结构的网页往往有效。
这类早期的算法大多没有将网页解析为DOM树,而是将网页解析为token序列。例如,对于以下 html 源代码:
广告...(8字)
正文...(500字)
页脚...(6字)
程序将其转换为令牌序列:
标签(body),标签(div),文本,文本....(8次),标签(/div),标签(div),文本,文本...(500次),标签(/div),标签(div),文本,文本...(6次),标签(/div),标签(/body)
早期有一种基于token序列的MSS算法(Maximum Subsequence Segmentation)。该算法有多个版本。一个版本为令牌序列中的每个令牌分配一个分数。评分规则如下:
根据上面的评分规则和token序列,我们可以得到一个评分序列:
-3.25,-3.25,1,1,1...(8次),-3.25,-3.25,1,1,1...(500次),-3.25,-3.25,1,1,1...(6次),-3.25,-3.25
MSS算法认为在token序列中找到一个子序列,使得这个子序列中token对应的分数总和达到最大值,那么这个子序列就是网页中的文本换个角度理解这个规则,就是从html源字符串中找到一个子序列。这个子序列应该收录更多的文本和更少的标签,因为算法给了标签一个更大的绝对值。负分(-3.25),给文本一个较小的正分(1).
如何从score序列中找到总和最大的子序列可以通过动态规划很好的解决。具体算法这里不给出。有兴趣的可以参考《Extracting Article Text from the Web with Maximum Subsequence Segmentation》论文,MSS算法效果不好,但是这篇论文认为可以代表很多早期的算法。
还有其他版本的 MSS。上面我们说算法给label和text分别赋值-3.25和1,都是固定值。还有一个版本的 MSS(也在论文中),它使用 Naive Bayes Si 的方法计算标签和文本的分数。该版本的MSS虽然在一定程度上提升了效果,但仍不理想。
无监督学习在第一类算法中也扮演着重要的角色。许多算法使用聚类方法自动将网页的文本和非文本分为两类。例如,在“CETR-Content Extraction via Tag Ratios”算法中,将网页分成多行文本,算法对每行文本计算2个特征,分别是下图中的横轴和纵轴,以及红色椭圆中的单元格。 (线),大部分是网页的正文,绿色椭圆中收录的单元格(线)大部分是非文本。使用k-means等聚类方法,可以很好地将正文和非文本分为两类。然后设计一些启发式算法来区分这两个类别中哪个是文本,哪个是非文本。
早期的算法通常使用标记序列和字符序列作为计算特征的单位。从某种意义上说,这破坏了网页的结构,没有充分利用网页的功能。在后面的算法中,很多使用DOM树的Nodes作为特征计算的基本单位,比如“通过路径比提取Web新闻”和“通过文本密度提取基于Dom的内容”。这些算法仍然使用启发式规则和无监督学习,因为以DOM树的节点作为特征计算的基本单元,算法可以获得越来越多的特征,因此可以设计更好的启发式规则和无监督学习算法。这些算法在提取中是有效的。它通常比前面描述的算法高得多。由于提取时以DOM树的Node为单位,该算法也可以方便的保留文本的结构(主要是保持网页中文本的布局)。
我们在WebCollector中实现了一流的算法(从1.12版本开始),可以直接从官网下载源码使用。
4.2 基于分类器的网页提取算法(第二类机器学习提取算法)
实现一个基于分类器的网页提取算法(第二种算法),大致流程如下:
对于网页提取,特征设计是首要任务。有时使用的特定分类器并不那么重要。在使用相同特征的情况下,使用决策树、SVM、神经网络等不同分类器可能不会对提取效果产生太大影响。
从工程的角度来看,过程中的第一步和第二步都比较困难。训练集的选择也很讲究,保证所选数据集中网页结构的多样性。例如,比较流行的文本结构是:
xxxx
xxxxxxxx
xxx
xxxxx
xxxx
如果训练集中只有五六个网站页面,很可能这些网站的文字都是上述结构,而恰巧在特征设计中,有两个特征:
假设使用决策树作为分类器,最终训练的模型很可能是:
如果一个节点的标签类型为div,且其孩子节点中标签为p的节点超过3个,则这个节点对应网页的正文。
虽然这个模型在训练数据集上可以取得很好的提取效果,但是很明显很多网站不符合这个规则。因此,训练集的选择对提取算法的效果影响很大。
网页设计的风格在不断变化。早期的网页经常使用表格来构建整个网页的框架。现在的网页都喜欢用div来搭建网页框架。如果想让提取算法覆盖更长的时间,那么在设计特征时一定要尽量选择那些不易改变的特征。标签类型是一个很容易改变的特性,并且随着网页设计风格的变化而变化。因此,如前所述,强烈不建议使用标签类型作为训练特征。
上述基于分类器的网页提取算法属于eager learning,即算法通过训练集生成模型(如决策树模型、神经网络模型等)。对应的懒惰学习是一种不预先通过训练集生成模型的算法。比较有名的KNN属于懒惰学习。
一些提取算法使用KNN来选择提取算法。听起来可能有点绕。这是一个解释。假设有2个提取算法A和B,并且有3个网站site1、site2、site3。 2种算法对3个网站的提取效果(这里用0%-100%的数字表示,越大说明越好)如下:
网站A 算法提取效果 B 算法提取效果
站点 1
90%
70%
站点 2
80%
85%
site3
60%
87%
可以看出,在site1上,算法A的提取效果优于算法B。在site2和site3上,算法B的提取效果更好。在实践中,这种情况非常普遍。所以有些人想设计一个分类器。该分类器不用于对文本和非文本进行分类,而是用于帮助选择提取算法。例如,在这个例子中,分类器应该告诉我们在提取site1中的网页时使用A算法以获得更好的结果。
以图片为例,A算法对政府网站的提取效果更好,B算法对互联网新闻网站的提取效果更好。然后当我提取政府类别网站时,分类器应该会帮我选择A算法。
这个分类器的实现可以使用KNN算法。需要提前准备数据集。数据集中有多个站点的网页。同时,需要维护一张表。该表告诉我们不同提取算法对每个站点的提取效果(其实只要知道在每个站点上,哪种算法的提取效果最好)。当遇到要提取的网页时,我们将该网页与数据集中的所有网页进行比较(效率极低),找到最相似的K个网页,然后查看K个网页,哪个网站的网页最多(例如, k= 7.其中六个网页来自CSDN新闻),然后我们选择本站最好的算法来提取这个未知网页。
4.3 基于网页模板自动生成的网页提取算法
基于网页模板自动生成的网页提取算法(第三类算法)有很多种。这是一个例子。在《URL Tree: Efficient Unsupervised Content Extraction from Streams of Web Documents》中,比较多个结构相同(根据URL判断)的页面,找出异同。页面之间的共同部分是非文本,页面之间的差异很大。该部分可能是文本。这很容易理解。例如,在某些网站中,所有网页页脚都相同,它们是记录信息或版权声明。这是页面之间的共性,所以算法认为这部分是非文本的。不同网页的文字往往不同,因此算法更容易识别文字页面。这种算法通常不会提取单个网页的文本,而是采集大量同质网页,同时提取多个网页。换句话说,不需要输入网页来实时提取。 查看全部
基于CSS选择器的网页抽取浏览器使用说明书大全
(在程序中,必须在\前加双引号和\才能转义。
三.基于CSS选择器的网页提取
浏览器收到服务器返回的html源代码后,会将网页解析成DOM树。 CSS Selector 基于DOM树的特性,广泛用于网页提取。目前最流行的网页提取组件Jsoup(Java)和BeautifulSoup(Python)都是基于CSS选择器的。
对于上面的例子:
(标题)此内容不要被抽取
(正文)此内容要被抽取
(页脚)此内容不要被抽取
使用 CSS 选择器将大大提高代码的可读性:
public static void cssExtract() {
String html="" +
"(标题)此内容不要被抽取" +
"(正文)此内容要被抽取" +
"(页脚)此内容不要被抽取" +
"";
//Jsoup中的Document类表示网页的DOM树
Document doc= Jsoup.parse(html);
//利用select方法获取所有满足css选择器的Element集合
// (实际是一个Elements类型的对象)
//由于在本网页的结构中,只会有一个Element满足条件
// 因此只要返回集合中的第一个Element即可
Element main=doc.select("div[class=main]").first();
//main是一个Element对象,这里main对应了网页中
//的(正文)此内容要被抽取
//我们调用Element的text()方法即可提取中间的文字
if(main!=null){
System.out.println("抽取结果:"+main.text());
}else{
System.out.println("无抽取结果");
}
}
CSS 选择器有标准规范,但 Jsoup (Java) 和 BeautifulSoup (Python) 等组件并没有完全按照规范实现 CSS 选择器。因此,在使用各个组件之前,最好先阅读组件文档中对CSS选择器的描述。
Jsoup 是 CSS 选择器的更好实现。如果想了解CSS选择器的使用,建议阅读Jsoup的CSS选择器规范文档。
浏览器中的javascript直接支持CSS选择器。如果电脑安装了firefox或chrome,打开浏览器,按F12(调出开发者界面),随机打开一个网页,选择控制台(Console)选项卡,进入Console
document.querySelectorAll("a")
按回车后发现页面中所有超链接都输出了,document.querySelectorAll(CSS选择器)获取页面中所有满足CSS选择器的元素,放到一个数组中返回。
如果只想获取第一个满足CSS选择器的元素,可以使用document.querySelector(CSS选择器)方法。
浏览器js中的CSS选择器与Jsoup(Java)和BeautifulSoup(Python)中实现的CSS选择器略有不同,但基本相同。
四.基于机器学习的网页提取
基于正则或CSS选择器(或xpath)的网页提取是基于包装器的网页提取。这种提取算法的共同问题是,对于不同结构的网页,必须制定不同的提取规则。 如果一个舆情系统需要监控10000个异构网站,需要编写和维护10000套抽取规则。自 2000 年以来,有人一直在研究如何使用机器学习方法,让程序无需手动规则即可从网页中提取所需信息。
从目前的科研成果来看,基于机器学习的网页提取重点偏向于新闻网页内容的自动提取,即输入一个新闻网页,程序可以自动输出新闻标题、正文、时间和其他信息。新闻、博客、百科网站收录比较简单的结构化数据,基本满足{title, time, body}的结构,抽取目标很明确,机器学习算法也设计的很好。但是,电子商务、求职等各类网页所收录的结构化数据非常复杂,有的还存在嵌套,没有统一的抽取目标。很难为此类页面设计机器学习提取算法。
本节主要介绍如何设计机器学习算法来提取网站中的新闻、博客、百科等正文信息,以下简称内容提取。
基于机器学习的网页提取算法大致可以分为以下几类:
三种算法中,第一种算法实现最好,效果最好。
让我们简单描述一下这三种算法。如果你只是想在你的项目中使用这些算法,你只需要了解第一类算法即可。
下面会提到一些论文,但请不要根据论文中自己的实验数据来判断算法的好坏。许多算法是面向早期网页设计的(即以表格为框架的网页),也有一些算法的实验数据。集覆盖范围相对较窄。如果可能,最好自己评估这些算法。
4.1 基于启发式规则和无监督学习的网页提取算法
基于启发式规则和无监督学习(第一类算法)的网页提取算法是目前最简单也是最好的方法。并且具有很高的通用性,即该算法对不同语言、不同结构的网页往往有效。
这类早期的算法大多没有将网页解析为DOM树,而是将网页解析为token序列。例如,对于以下 html 源代码:
广告...(8字)
正文...(500字)
页脚...(6字)
程序将其转换为令牌序列:
标签(body),标签(div),文本,文本....(8次),标签(/div),标签(div),文本,文本...(500次),标签(/div),标签(div),文本,文本...(6次),标签(/div),标签(/body)
早期有一种基于token序列的MSS算法(Maximum Subsequence Segmentation)。该算法有多个版本。一个版本为令牌序列中的每个令牌分配一个分数。评分规则如下:
根据上面的评分规则和token序列,我们可以得到一个评分序列:
-3.25,-3.25,1,1,1...(8次),-3.25,-3.25,1,1,1...(500次),-3.25,-3.25,1,1,1...(6次),-3.25,-3.25
MSS算法认为在token序列中找到一个子序列,使得这个子序列中token对应的分数总和达到最大值,那么这个子序列就是网页中的文本换个角度理解这个规则,就是从html源字符串中找到一个子序列。这个子序列应该收录更多的文本和更少的标签,因为算法给了标签一个更大的绝对值。负分(-3.25),给文本一个较小的正分(1).
如何从score序列中找到总和最大的子序列可以通过动态规划很好的解决。具体算法这里不给出。有兴趣的可以参考《Extracting Article Text from the Web with Maximum Subsequence Segmentation》论文,MSS算法效果不好,但是这篇论文认为可以代表很多早期的算法。
还有其他版本的 MSS。上面我们说算法给label和text分别赋值-3.25和1,都是固定值。还有一个版本的 MSS(也在论文中),它使用 Naive Bayes Si 的方法计算标签和文本的分数。该版本的MSS虽然在一定程度上提升了效果,但仍不理想。
无监督学习在第一类算法中也扮演着重要的角色。许多算法使用聚类方法自动将网页的文本和非文本分为两类。例如,在“CETR-Content Extraction via Tag Ratios”算法中,将网页分成多行文本,算法对每行文本计算2个特征,分别是下图中的横轴和纵轴,以及红色椭圆中的单元格。 (线),大部分是网页的正文,绿色椭圆中收录的单元格(线)大部分是非文本。使用k-means等聚类方法,可以很好地将正文和非文本分为两类。然后设计一些启发式算法来区分这两个类别中哪个是文本,哪个是非文本。
早期的算法通常使用标记序列和字符序列作为计算特征的单位。从某种意义上说,这破坏了网页的结构,没有充分利用网页的功能。在后面的算法中,很多使用DOM树的Nodes作为特征计算的基本单位,比如“通过路径比提取Web新闻”和“通过文本密度提取基于Dom的内容”。这些算法仍然使用启发式规则和无监督学习,因为以DOM树的节点作为特征计算的基本单元,算法可以获得越来越多的特征,因此可以设计更好的启发式规则和无监督学习算法。这些算法在提取中是有效的。它通常比前面描述的算法高得多。由于提取时以DOM树的Node为单位,该算法也可以方便的保留文本的结构(主要是保持网页中文本的布局)。
我们在WebCollector中实现了一流的算法(从1.12版本开始),可以直接从官网下载源码使用。
4.2 基于分类器的网页提取算法(第二类机器学习提取算法)
实现一个基于分类器的网页提取算法(第二种算法),大致流程如下:
对于网页提取,特征设计是首要任务。有时使用的特定分类器并不那么重要。在使用相同特征的情况下,使用决策树、SVM、神经网络等不同分类器可能不会对提取效果产生太大影响。
从工程的角度来看,过程中的第一步和第二步都比较困难。训练集的选择也很讲究,保证所选数据集中网页结构的多样性。例如,比较流行的文本结构是:
xxxx
xxxxxxxx
xxx
xxxxx
xxxx
如果训练集中只有五六个网站页面,很可能这些网站的文字都是上述结构,而恰巧在特征设计中,有两个特征:
假设使用决策树作为分类器,最终训练的模型很可能是:
如果一个节点的标签类型为div,且其孩子节点中标签为p的节点超过3个,则这个节点对应网页的正文。
虽然这个模型在训练数据集上可以取得很好的提取效果,但是很明显很多网站不符合这个规则。因此,训练集的选择对提取算法的效果影响很大。
网页设计的风格在不断变化。早期的网页经常使用表格来构建整个网页的框架。现在的网页都喜欢用div来搭建网页框架。如果想让提取算法覆盖更长的时间,那么在设计特征时一定要尽量选择那些不易改变的特征。标签类型是一个很容易改变的特性,并且随着网页设计风格的变化而变化。因此,如前所述,强烈不建议使用标签类型作为训练特征。
上述基于分类器的网页提取算法属于eager learning,即算法通过训练集生成模型(如决策树模型、神经网络模型等)。对应的懒惰学习是一种不预先通过训练集生成模型的算法。比较有名的KNN属于懒惰学习。
一些提取算法使用KNN来选择提取算法。听起来可能有点绕。这是一个解释。假设有2个提取算法A和B,并且有3个网站site1、site2、site3。 2种算法对3个网站的提取效果(这里用0%-100%的数字表示,越大说明越好)如下:
网站A 算法提取效果 B 算法提取效果
站点 1
90%
70%
站点 2
80%
85%
site3
60%
87%
可以看出,在site1上,算法A的提取效果优于算法B。在site2和site3上,算法B的提取效果更好。在实践中,这种情况非常普遍。所以有些人想设计一个分类器。该分类器不用于对文本和非文本进行分类,而是用于帮助选择提取算法。例如,在这个例子中,分类器应该告诉我们在提取site1中的网页时使用A算法以获得更好的结果。
以图片为例,A算法对政府网站的提取效果更好,B算法对互联网新闻网站的提取效果更好。然后当我提取政府类别网站时,分类器应该会帮我选择A算法。
这个分类器的实现可以使用KNN算法。需要提前准备数据集。数据集中有多个站点的网页。同时,需要维护一张表。该表告诉我们不同提取算法对每个站点的提取效果(其实只要知道在每个站点上,哪种算法的提取效果最好)。当遇到要提取的网页时,我们将该网页与数据集中的所有网页进行比较(效率极低),找到最相似的K个网页,然后查看K个网页,哪个网站的网页最多(例如, k= 7.其中六个网页来自CSDN新闻),然后我们选择本站最好的算法来提取这个未知网页。
4.3 基于网页模板自动生成的网页提取算法
基于网页模板自动生成的网页提取算法(第三类算法)有很多种。这是一个例子。在《URL Tree: Efficient Unsupervised Content Extraction from Streams of Web Documents》中,比较多个结构相同(根据URL判断)的页面,找出异同。页面之间的共同部分是非文本,页面之间的差异很大。该部分可能是文本。这很容易理解。例如,在某些网站中,所有网页页脚都相同,它们是记录信息或版权声明。这是页面之间的共性,所以算法认为这部分是非文本的。不同网页的文字往往不同,因此算法更容易识别文字页面。这种算法通常不会提取单个网页的文本,而是采集大量同质网页,同时提取多个网页。换句话说,不需要输入网页来实时提取。
算法自动采集列表的cookie库firefox的话可以试试抓
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-07-22 02:01
算法自动采集列表的cookie库firefox的话可以试试抓cookie也可以到浏览器的设置里面设置。
蟹妖需要微信提供读取读取原创和推送地址的能力,也就是“图文转发”。公众号没有原创保护的话,发布的文章下面会有“审核不通过”或者被禁止再次发布提示。
泻药。能否发自定义转发到群组,就可以从群组抓取已经推送的文章来。或者是文章内容被抄袭,爬虫工具也可以抓取到。如果群组是自己组建的,
1.在推送的文章里留下转发信息;2.微信返回垃圾箱,看到自己推送的“读取读取原创”功能里的数据有此消息;3.爬虫将该信息写入本地,读取文章,直接推送到群组,群组再推送到自己的公众号。
想得美呀。微信团队的流量大部分都放在公众号上了,这些都是要爬取的。你只要能找到所有的公众号就行了。
大概可以用微信新版开发者工具里面的微信公众号推送功能,让老微信公众号公转出来。
图文推送,这个资源来之不易,能弄的话找公众号平台服务商弄,那种权限都齐全的。 查看全部
算法自动采集列表的cookie库firefox的话可以试试抓
算法自动采集列表的cookie库firefox的话可以试试抓cookie也可以到浏览器的设置里面设置。
蟹妖需要微信提供读取读取原创和推送地址的能力,也就是“图文转发”。公众号没有原创保护的话,发布的文章下面会有“审核不通过”或者被禁止再次发布提示。
泻药。能否发自定义转发到群组,就可以从群组抓取已经推送的文章来。或者是文章内容被抄袭,爬虫工具也可以抓取到。如果群组是自己组建的,
1.在推送的文章里留下转发信息;2.微信返回垃圾箱,看到自己推送的“读取读取原创”功能里的数据有此消息;3.爬虫将该信息写入本地,读取文章,直接推送到群组,群组再推送到自己的公众号。
想得美呀。微信团队的流量大部分都放在公众号上了,这些都是要爬取的。你只要能找到所有的公众号就行了。
大概可以用微信新版开发者工具里面的微信公众号推送功能,让老微信公众号公转出来。
图文推送,这个资源来之不易,能弄的话找公众号平台服务商弄,那种权限都齐全的。
创业不实现技术部署,完全被市场比较难看好?
采集交流 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-08-20 18:06
算法自动采集列表页首页的内容,大数据进行智能推荐,可以搜索,关注,分享,留言等操作。也可以单独采集问答页某个问题的答案。还可以采集相似问题的答案,
技术上是不难实现的,大概就是多个浏览器的、采集器、大数据平台、内容过滤的兼容性,权限等等,一个成熟的大数据技术商一般都会提供技术部署方案、供我们使用。但是创业,不实现技术部署,完全被市场比较难看好,所以你应该换个创业思路,而不是选一个方向继续独立开发。
关键点还是你的业务什么最需要什么,什么是用户最在意的。找到你要实现的业务痛点,加上个人技术的不断积累和进步,你的东西不难。
个人拙见:技术实现当然不难,只要用心就行了,但商业市场却很难。这东西看似很理想化,看似很偏门,看似不可复制。其实只要抓住了用户的需求,抓住了痛点,很多东西都可以脱颖而出。大数据的概念也越来越被更多人认可,不论是企业还是个人都会有采集数据的需求。如果可以从大数据的角度去分析和思考,研究它背后的原理,比如去伪存真、挖掘需求和痛点、演化创新,将有助于打造特色的产品。
都说不难,实现起来还是有一定难度,前期费用高,最好团队有技术积累,这样可以大幅降低实现难度!有许多创业团队,成立这样一个团队可能都还没成立,就要求注册,各种材料填写, 查看全部
创业不实现技术部署,完全被市场比较难看好?
算法自动采集列表页首页的内容,大数据进行智能推荐,可以搜索,关注,分享,留言等操作。也可以单独采集问答页某个问题的答案。还可以采集相似问题的答案,
技术上是不难实现的,大概就是多个浏览器的、采集器、大数据平台、内容过滤的兼容性,权限等等,一个成熟的大数据技术商一般都会提供技术部署方案、供我们使用。但是创业,不实现技术部署,完全被市场比较难看好,所以你应该换个创业思路,而不是选一个方向继续独立开发。
关键点还是你的业务什么最需要什么,什么是用户最在意的。找到你要实现的业务痛点,加上个人技术的不断积累和进步,你的东西不难。
个人拙见:技术实现当然不难,只要用心就行了,但商业市场却很难。这东西看似很理想化,看似很偏门,看似不可复制。其实只要抓住了用户的需求,抓住了痛点,很多东西都可以脱颖而出。大数据的概念也越来越被更多人认可,不论是企业还是个人都会有采集数据的需求。如果可以从大数据的角度去分析和思考,研究它背后的原理,比如去伪存真、挖掘需求和痛点、演化创新,将有助于打造特色的产品。
都说不难,实现起来还是有一定难度,前期费用高,最好团队有技术积累,这样可以大幅降低实现难度!有许多创业团队,成立这样一个团队可能都还没成立,就要求注册,各种材料填写,
一种自动抽取列表页的技术方案解决方案页
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-08-17 23:14
一种自动抽取列表页的技术方案解决方案页
本发明涉及网络技术领域,尤其涉及一种自动提取列表页面的方法。
背景技术:
传统的列表页面提取技术主要是规则的形式,比较常用的是通过正则表达式、xpath、css选择器,甚至是手动的方式来获取页面采集down的信息。
单个网页可以通过正则表达式等方法准确获取采集想要的信息,而正则表达式和css选择器等方法本质上是人们通过观察网页源代码的规则总结出来的。然后使用这些规则进行提取。这种方法很难在不同结构的网页上用相同的规则集提取,因为不同的网页需要不同的规则来支持提取。当用户需要采集大量网页时,需要依靠人工编写大量规则,这种效率不仅低,甚至上千甚至几万个网站,仅仅依靠手动已经完全不可能了。不仅如此,依赖规则的抽取方式仅限于网页本身。 网站修改后,原来的规则将不再适用,需要手动重写规则,这也使得一些依赖开源信息采集的项目维护成本变得极高。<//p
p技术实现要素:/p
p本发明要解决的技术问题是提供一种适用性强、效率高的列表页面自动提取方法。/p
p为解决上述技术问题,本发明的技术方案是:一种自动提取列表页面的方法,包括以下步骤:/p
p(1)dom树生成:得到网页源码为采集网站;将网页源码解析成dom树;根据dom树进行前序遍历,并记录dom树中的每一片叶子元素的节点路径;提取并保存元素的节点路径,带文本;/p
p(2)获取1)中提取文本的元素节点的位置信息,根据元素节点的位置信息进行评分,过滤掉不符合列表视觉可能性的元素节点页面;/p
p(3)根据节点路径的相似度以及与满足列表页面信息约束的节点特征的相似度,判断多个节点是否有相似指纹,对指纹相似的节点进行分类聚合。列表页信息至少包括标题和地址链接,指纹相似意味着不同节点满足一定的约束条件,构成列表页信息;/p
p(4)对多个具有多个相似指纹的节点进行分类聚合,可以将完整的列表页信息组成节点块,形成列表页的深度指纹;/p
p(5)从列表页的深度指纹中提取出标题和地址链接的相似指纹;/p
p(6)Extraction 列表页,返回封装结果。/p
p作为优选的技术方案,步骤(2)具体包括:/p
p(2.1)采集html 网页的css和js文件获取节点位置信息;/p
p(2.2)每页解析后计算dom树元素节点的像素位置;/p
p(2.3) 判断元素节点是否满足列表页面的视觉可能性,具体包括:如果元素节点是隐藏节点,则元素节点是无效节点;如果元素的像素node 网页左上角位置的像素位置小于设置的阈值,元素节点为无效节点;元素节点的像素位置离网页中心点越远,元素节点的得分越低,元素节点的得分与列表页面的提取精度有关。/p
p作为优选的技术方案,在步骤(3),满足列表页面信息约束的节点特征包括节点属性标签和节点文本信息标签,其中节点属性标签的相似度和方差为节点属性成反比,节点属性的方差:/p
p其中a代表单个节点的属性向量,b代表该类别下所有节点的平均属性向量;/p
p节点文本信息的相似度与文本词数的方差成反比,则节点文本词数的方差:/p
p其中,表示所有节点中文本信息词的平均密度,n表示节点数;/p
p作为优选的技术方案,步骤4还包括:/p
p(4.1)计算节点路径的预深度比,即节点深度指纹组成的节点块共有的节点路径长度与最长节点路径长度的比值:/p
p(4.2)对深度指纹聚合的节点块进行打分和排序,计算出最可能的列表页深度指纹。节点块的得分:/p
p其中αi为衰减系数。/p
p作为优选的技术方案,在步骤(5),标题指纹是指满足标题约束条件的特征,提取满足标题约束条件的相似指纹,得到标题文字。/p
pp>
作为优选的技术方案,还包括设置列表页面提取规则和通过提取规则提取列表页面的步骤。
由于采用了上述技术方案,本发明的有益效果是本发明可以应用于大量的互联网网站列表页面提取,不限于繁琐冗余的规则,并且只需要通过网页网址或源代码。自动提取列表页的标题、链接等,由于本发明对大量的列表页具有普遍适用性,即使出现网站改版,基于网页结构的提取方法也可以仍然有效,节省了重写提取规则和维护规则产生的时间成本和人工成本。
在基于网页的结构提取算法中,还加入了网页元素的位置像素信息作为特征,更加符合人们对列表页面的感官判断,使得提取结果更加符合与目标。
图纸说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中需要用到的附图进行简单介绍。显然,在以下描述中,附图只是本发明的一些实施例。对于本领域普通技术人员来说,基于这些图,无需创造性劳动,还可以得到其他图。
图1是本发明实施例的流程图。
具体实现方法
如图1所示,一种自动提取列表页面的方法包括以下步骤:
(1)dom 树生成:
(1.1)获取wait采集网站的网页源码;
(1.2)将网页源码解析成dom树;
(1.3)根据dom树进行预遍历,记录dom树中每个叶子元素的节点路径;(1.4)提取并保存带有文本的元素节点路径。
(2)获取1)中提取文本的元素节点的位置信息,根据元素节点的位置信息进行评分,过滤掉不符合列表视觉可能性的元素节点页面:具体:
(2.1)采集html 网页css和js文件,获取节点位置信息;
(2.2)每页解析后计算dom树元素节点的像素位置;
(2.3)判断元素节点是否满足列表页面的视觉可能性,如果元素节点为隐藏节点,则元素节点为无效节点;
如果元素节点的像素位置与网页左上角像素的距离小于设置的阈值,则元素节点为无效节点;
元素节点的像素位置离网页中心点越远,
宽度距离:
高度距离:
其中dis(whole_width)代表整个html页面的宽度,dis(whole_height)代表整个html页面的高度。
元素节点的得分越低,元素节点的得分与列表页面的提取精度有关。
(3)根据节点路径的相似度和与满足列表页面信息约束的节点特征的相似度,判断多个节点是否有相似指纹,对指纹相似的节点进行分类聚合,其中列表页面信息至少包括标题和地址链接,指纹相似意味着不同节点满足一定的约束条件,构成列表页面信息;
(3.1)计算节点路径的相似度:
dom树的叶子节点路径是否相似,例如从根节点计算某个“摘要”节点的路径,表示为:0-5-0-2-0-2-0 -3-0,其他“汇总”节点有:0-5-0-2-1-2-0-3-0、0-5-0-2-2-2-0-3-0等.,可以看作是0 -5-0-2-x-2-0-3-0,并将这种形式定义为节点相似度指纹。当不同“汇总”节点的路径只有一个差异时,我们认为它们的节点路径非常相似。
标题节点、摘要节点、时间节点或作者节点都可以通过这种方式计算节点路径的相似度。当相似度很高时,可以认为是一种,使用0-5-0-2-保存为x-2-0-3-0这种格式。
(3.2)计算节点特征的相似度
列表页信息受节点属性标签和节点文本信息标签限制。
计算节点属性的相似度:每个节点都会被一系列的属性标签修改,比如class、id、name等,相似的节点往往有相同或非常相似的属性标签。用属性的方差来表示相似节点的属性差异。差异越小越好。
其中,节点属性标签相似度与节点属性的方差成反比,则节点属性的方差:
其中a代表单个节点的属性向量,b代表该类别下所有节点的平均属性向量;
计算节点文本信息的相似度:对于list页的title、summary、time等文本的文本构成,由于篇幅限制,通常字数成一定比例,相似度节点文本信息的大小与文本词数的方差成正比。反之,节点文本中词数的方差:
其中,表示所有节点中文本信息词的平均密度,n表示节点数;
(4)将多个具有多个相似指纹和相似指纹的节点进行分类聚合,将可以形成完整列表页面信息的相似指纹划分为节点块,形成列表页面的深度指纹。相似指纹将是标题节点和摘要节点. , 时间节点合并为一个类别,节点深度指纹是将标题类别、总结类别、练习类别组合成一个更完整的类别。
第 4 步还包括:
(4.1)计算节点路径的预深度比,即节点深度指纹组成的节点块共有的节点路径长度与最长节点路径长度的比值:
例如:如果节点深度指纹为0-5-0-2-x-2-0,则由以下相似路径的节点组成:
0-5-0-2-x-2-0-1; 0-5-0-2-x-2-0-0; 0-5-0-2-x-2-0-3 -0; 0-5-0-2-x-2-0; 0-5-0-2-x-2-0-2。
深度指纹为0-5-0-2-x,值为5,最长为0-5-0-2-x-2-0-3-0,值为9,比率为 5/ 9
(4.2)对深度指纹聚合的节点块进行打分和排序,计算的最有可能是列表页面的深度指纹。
深度指纹一般有更多相似的指纹,因为一般的列表页会收录标题、地址链接、摘要、发表时间、作者等,至少也会收录标题和地址链接。
列表页面中每个相似指纹节点的html修改属性和字符数比较接近。
列表页一般在整个页面的中央。
更多的指纹是通过每个相似指纹的累计值来完成的,但是因为结构相似,列表页中会出现列表页,列表页一般收录2到5个相似指纹,所以加了衰减系数在积累过程中可以避免因目录页导致的高分。根据实验,衰减系数设置为0.7。
节点区块的得分:
f(x)=ratio(节点前端路径的比例)×∑σ(attr)σ(word)αi;
其中αi为衰减系数。
(5)从列表页的深度指纹中提取出标题和地址链接的相似指纹;
标题指纹是指满足标题约束条件的特征,提取满足标题约束条件的相似指纹,得到标题文本。
标题的指纹一般满足以下约束:
a) 标题在节点路径的上半部分;
b) 标题字数一般在5-20个左右;
c) 标题一般为粗体;
d) 标题通常有一个地址链接。
通过上述元素选择与标题相似的指纹,得到标题文本。
(6)Extraction 列表页,返回封装结果。
本发明还可以设置列表页提取规则,选择通过提取规则或通过网络结构提取列表页。根据网络结构提取列表页面,可以选择是使用位置信息提取列表页面,还是直接计算节点特征相似度,提取相似指纹。
以上显示和描述了本发明的基本原理、主要特征和优点。本领域技术人员应当理解,本发明不受上述实施例的限制。上述实施例和描述仅说明了本发明的原理。在不脱离本发明的精神和范围的情况下,本发明可以有各种变化和改进,均落入本发明所要求保护的范围内。本发明所要求的保护范围由所附权利要求书及其等效内容限定。 查看全部
一种自动抽取列表页的技术方案解决方案页
本发明涉及网络技术领域,尤其涉及一种自动提取列表页面的方法。
背景技术:
传统的列表页面提取技术主要是规则的形式,比较常用的是通过正则表达式、xpath、css选择器,甚至是手动的方式来获取页面采集down的信息。
单个网页可以通过正则表达式等方法准确获取采集想要的信息,而正则表达式和css选择器等方法本质上是人们通过观察网页源代码的规则总结出来的。然后使用这些规则进行提取。这种方法很难在不同结构的网页上用相同的规则集提取,因为不同的网页需要不同的规则来支持提取。当用户需要采集大量网页时,需要依靠人工编写大量规则,这种效率不仅低,甚至上千甚至几万个网站,仅仅依靠手动已经完全不可能了。不仅如此,依赖规则的抽取方式仅限于网页本身。 网站修改后,原来的规则将不再适用,需要手动重写规则,这也使得一些依赖开源信息采集的项目维护成本变得极高。<//p
p技术实现要素:/p
p本发明要解决的技术问题是提供一种适用性强、效率高的列表页面自动提取方法。/p
p为解决上述技术问题,本发明的技术方案是:一种自动提取列表页面的方法,包括以下步骤:/p
p(1)dom树生成:得到网页源码为采集网站;将网页源码解析成dom树;根据dom树进行前序遍历,并记录dom树中的每一片叶子元素的节点路径;提取并保存元素的节点路径,带文本;/p
p(2)获取1)中提取文本的元素节点的位置信息,根据元素节点的位置信息进行评分,过滤掉不符合列表视觉可能性的元素节点页面;/p
p(3)根据节点路径的相似度以及与满足列表页面信息约束的节点特征的相似度,判断多个节点是否有相似指纹,对指纹相似的节点进行分类聚合。列表页信息至少包括标题和地址链接,指纹相似意味着不同节点满足一定的约束条件,构成列表页信息;/p
p(4)对多个具有多个相似指纹的节点进行分类聚合,可以将完整的列表页信息组成节点块,形成列表页的深度指纹;/p
p(5)从列表页的深度指纹中提取出标题和地址链接的相似指纹;/p
p(6)Extraction 列表页,返回封装结果。/p
p作为优选的技术方案,步骤(2)具体包括:/p
p(2.1)采集html 网页的css和js文件获取节点位置信息;/p
p(2.2)每页解析后计算dom树元素节点的像素位置;/p
p(2.3) 判断元素节点是否满足列表页面的视觉可能性,具体包括:如果元素节点是隐藏节点,则元素节点是无效节点;如果元素的像素node 网页左上角位置的像素位置小于设置的阈值,元素节点为无效节点;元素节点的像素位置离网页中心点越远,元素节点的得分越低,元素节点的得分与列表页面的提取精度有关。/p
p作为优选的技术方案,在步骤(3),满足列表页面信息约束的节点特征包括节点属性标签和节点文本信息标签,其中节点属性标签的相似度和方差为节点属性成反比,节点属性的方差:/p
p其中a代表单个节点的属性向量,b代表该类别下所有节点的平均属性向量;/p
p节点文本信息的相似度与文本词数的方差成反比,则节点文本词数的方差:/p
p其中,表示所有节点中文本信息词的平均密度,n表示节点数;/p
p作为优选的技术方案,步骤4还包括:/p
p(4.1)计算节点路径的预深度比,即节点深度指纹组成的节点块共有的节点路径长度与最长节点路径长度的比值:/p
p(4.2)对深度指纹聚合的节点块进行打分和排序,计算出最可能的列表页深度指纹。节点块的得分:/p
p其中αi为衰减系数。/p
p作为优选的技术方案,在步骤(5),标题指纹是指满足标题约束条件的特征,提取满足标题约束条件的相似指纹,得到标题文字。/p
pp>
作为优选的技术方案,还包括设置列表页面提取规则和通过提取规则提取列表页面的步骤。
由于采用了上述技术方案,本发明的有益效果是本发明可以应用于大量的互联网网站列表页面提取,不限于繁琐冗余的规则,并且只需要通过网页网址或源代码。自动提取列表页的标题、链接等,由于本发明对大量的列表页具有普遍适用性,即使出现网站改版,基于网页结构的提取方法也可以仍然有效,节省了重写提取规则和维护规则产生的时间成本和人工成本。
在基于网页的结构提取算法中,还加入了网页元素的位置像素信息作为特征,更加符合人们对列表页面的感官判断,使得提取结果更加符合与目标。
图纸说明
为了更清楚地说明本发明实施例或现有技术中的技术方案,下面将对实施例或现有技术描述中需要用到的附图进行简单介绍。显然,在以下描述中,附图只是本发明的一些实施例。对于本领域普通技术人员来说,基于这些图,无需创造性劳动,还可以得到其他图。
图1是本发明实施例的流程图。
具体实现方法
如图1所示,一种自动提取列表页面的方法包括以下步骤:
(1)dom 树生成:
(1.1)获取wait采集网站的网页源码;
(1.2)将网页源码解析成dom树;
(1.3)根据dom树进行预遍历,记录dom树中每个叶子元素的节点路径;(1.4)提取并保存带有文本的元素节点路径。
(2)获取1)中提取文本的元素节点的位置信息,根据元素节点的位置信息进行评分,过滤掉不符合列表视觉可能性的元素节点页面:具体:
(2.1)采集html 网页css和js文件,获取节点位置信息;
(2.2)每页解析后计算dom树元素节点的像素位置;
(2.3)判断元素节点是否满足列表页面的视觉可能性,如果元素节点为隐藏节点,则元素节点为无效节点;
如果元素节点的像素位置与网页左上角像素的距离小于设置的阈值,则元素节点为无效节点;
元素节点的像素位置离网页中心点越远,
宽度距离:
高度距离:
其中dis(whole_width)代表整个html页面的宽度,dis(whole_height)代表整个html页面的高度。
元素节点的得分越低,元素节点的得分与列表页面的提取精度有关。
(3)根据节点路径的相似度和与满足列表页面信息约束的节点特征的相似度,判断多个节点是否有相似指纹,对指纹相似的节点进行分类聚合,其中列表页面信息至少包括标题和地址链接,指纹相似意味着不同节点满足一定的约束条件,构成列表页面信息;
(3.1)计算节点路径的相似度:
dom树的叶子节点路径是否相似,例如从根节点计算某个“摘要”节点的路径,表示为:0-5-0-2-0-2-0 -3-0,其他“汇总”节点有:0-5-0-2-1-2-0-3-0、0-5-0-2-2-2-0-3-0等.,可以看作是0 -5-0-2-x-2-0-3-0,并将这种形式定义为节点相似度指纹。当不同“汇总”节点的路径只有一个差异时,我们认为它们的节点路径非常相似。
标题节点、摘要节点、时间节点或作者节点都可以通过这种方式计算节点路径的相似度。当相似度很高时,可以认为是一种,使用0-5-0-2-保存为x-2-0-3-0这种格式。
(3.2)计算节点特征的相似度
列表页信息受节点属性标签和节点文本信息标签限制。
计算节点属性的相似度:每个节点都会被一系列的属性标签修改,比如class、id、name等,相似的节点往往有相同或非常相似的属性标签。用属性的方差来表示相似节点的属性差异。差异越小越好。
其中,节点属性标签相似度与节点属性的方差成反比,则节点属性的方差:
其中a代表单个节点的属性向量,b代表该类别下所有节点的平均属性向量;
计算节点文本信息的相似度:对于list页的title、summary、time等文本的文本构成,由于篇幅限制,通常字数成一定比例,相似度节点文本信息的大小与文本词数的方差成正比。反之,节点文本中词数的方差:
其中,表示所有节点中文本信息词的平均密度,n表示节点数;
(4)将多个具有多个相似指纹和相似指纹的节点进行分类聚合,将可以形成完整列表页面信息的相似指纹划分为节点块,形成列表页面的深度指纹。相似指纹将是标题节点和摘要节点. , 时间节点合并为一个类别,节点深度指纹是将标题类别、总结类别、练习类别组合成一个更完整的类别。
第 4 步还包括:
(4.1)计算节点路径的预深度比,即节点深度指纹组成的节点块共有的节点路径长度与最长节点路径长度的比值:
例如:如果节点深度指纹为0-5-0-2-x-2-0,则由以下相似路径的节点组成:
0-5-0-2-x-2-0-1; 0-5-0-2-x-2-0-0; 0-5-0-2-x-2-0-3 -0; 0-5-0-2-x-2-0; 0-5-0-2-x-2-0-2。
深度指纹为0-5-0-2-x,值为5,最长为0-5-0-2-x-2-0-3-0,值为9,比率为 5/ 9
(4.2)对深度指纹聚合的节点块进行打分和排序,计算的最有可能是列表页面的深度指纹。
深度指纹一般有更多相似的指纹,因为一般的列表页会收录标题、地址链接、摘要、发表时间、作者等,至少也会收录标题和地址链接。
列表页面中每个相似指纹节点的html修改属性和字符数比较接近。
列表页一般在整个页面的中央。
更多的指纹是通过每个相似指纹的累计值来完成的,但是因为结构相似,列表页中会出现列表页,列表页一般收录2到5个相似指纹,所以加了衰减系数在积累过程中可以避免因目录页导致的高分。根据实验,衰减系数设置为0.7。
节点区块的得分:
f(x)=ratio(节点前端路径的比例)×∑σ(attr)σ(word)αi;
其中αi为衰减系数。
(5)从列表页的深度指纹中提取出标题和地址链接的相似指纹;
标题指纹是指满足标题约束条件的特征,提取满足标题约束条件的相似指纹,得到标题文本。
标题的指纹一般满足以下约束:
a) 标题在节点路径的上半部分;
b) 标题字数一般在5-20个左右;
c) 标题一般为粗体;
d) 标题通常有一个地址链接。
通过上述元素选择与标题相似的指纹,得到标题文本。
(6)Extraction 列表页,返回封装结果。
本发明还可以设置列表页提取规则,选择通过提取规则或通过网络结构提取列表页。根据网络结构提取列表页面,可以选择是使用位置信息提取列表页面,还是直接计算节点特征相似度,提取相似指纹。
以上显示和描述了本发明的基本原理、主要特征和优点。本领域技术人员应当理解,本发明不受上述实施例的限制。上述实施例和描述仅说明了本发明的原理。在不脱离本发明的精神和范围的情况下,本发明可以有各种变化和改进,均落入本发明所要求保护的范围内。本发明所要求的保护范围由所附权利要求书及其等效内容限定。
《》RaftRaft将问题分解和具体化统一处理
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-08-16 20:23
木筏
Raft 将问题分解具体化:Leader 统一处理变更操作请求,执行一致性协议保证节点间日志复制的一致性,使用term 作为逻辑时钟保证时序。节点运行相同的状态机并获得一致的结果。 Raft协议的具体流程如下:
Client发起一个请求,每个请求收录一个由Leader处理的操作指令请求。 Leader将操作指令(entry)追加到操作日志中,然后向Follower发起AppendEntries请求,尝试获取操作日志的副本登陆Follower,如果follower多数(quorum)同意AppendEntries请求,leader执行commit操作,将指令传递给状态机处理,状态机处理完后将结果返回给客户端。
1 个leader选举
1.1 一开始,所有服务器都以follower状态启动
然后等待leader或候选者的RPC请求,否则超时。
以上三种情况处理如下:
1.2 候选人采集选票的过程
候选人将为此状态设置随机超时。一旦出现在本届任期内,大家都没有获得过半数的选票,即分裂选票。如果超时时间短,则更容易获得过半票。
Candidate 会向所有服务器发送 RequestVote RPC 请求,请求参数如下图所示
votedFor 是服务器保存的投票对象。一个服务器在一个任期内只能投票一次。如果此时已经投过票,即votedFor不为空,那么此时可以直接拒绝本次投票(当然要检查votedFor是否是被请求的候选人)。
如果你还没有投票:比较候选人的日志和当前更新的服务器的日志,比较方法是哪个lastLog项越大越新。如果词条相同,则lastLog索引较大且较新的为比较方法。
候选人统计投票信息。如果超过一半的候选人同意,他们被认为是领导者并改变为领导者状态。如果没有超过一半,则等待新的领导者产生。如果是这样,则更改为跟随者状态。然后,如果超时,则开始下一次选举。
2 日志副本
2.1 所有请求都交给leader
一旦leader选举成功,所有客户端请求最终都会交给leader(如果客户端连接了follower,follower会转发给leader)
2.2 处理请求流程
2.2.1 客户端请求到达leader
leader首先将请求转换为一个条目,然后将其添加到其日志中以获取该条目的索引信息。该条目收录当前leader的任期信息和日志中的索引信息
2.2.2 leader 将以上条目复制给所有关注者
看官方的AppendEntries RPC请求
从上图可以看出,对于每个follower,leader维护了两个属性,一个是nextIndex,是leader发送给follower的下一个entry的索引,另一个是matchIndex,就是follower发送给leader的确认索引。
一开始会初始化一个leader:
nextIndex=领导者日志的最大索引+1
匹配索引=0
然后开始准备AppendEntries RPC请求的参数
prevLogIndex=nextIndex-1
prevLogTerm=从日志中获取上述prevLogIndex对应的term
然后准备entries数组信息
从leader的日志的prevLogIndex+1开始到lastLog,此时为空
然后将leader的commitIndex作为参数传给
leaderCommit=commitIndex
至此,所有参数准备就绪,向所有follower发送RPC请求,follower收到请求后,处理如下:
如果词条回复错误
如果日志不收录 prevLogIndex 的条目,则回复 false
匹配 prevLogTerm
这里可能不一致,因为初始的prevLogIndex和prevLogTerm是leader上日志的lastLog。如果不一致,则返回false,并将follower上日志的lastIndex发送给leader。
上面的macthIndex=lastIndex
nextIndex=lastIndex+1 以上
然后leader会按照上面的规则从头开始发送新的prevLogIndex、prevLogTerm、entries数组
2.2.3 leader 占复制条目的一半以上
一旦leader发现某些条目已经被超过一半的follower复制了,它就会提交条目并将commitIndex提升到条目的索引。 (这个是按照入口index的顺序提交的),具体实现可以通过follower发送给macthIndex来判断是否超过一半。
一旦可以提交,leader就会将该entry应用到状态机,然后向客户端回复OK
然后在下一次heartBeat心跳中,commitIndex被传递给所有follower,对应follower就可以将commitIndex和之前的entry应用到各自的状态机中。
3 安全
3.1 选举约束
重点强调了上述领导人选举。
The elected leader must contain all entries that have already been submitted
比如leader提交了一半以上replication的entry,但是一些follower可能没有这些entry。 When the leader dies, if the follower is elected as the leader, the above entries may be overwritten, resulting in The problem of inconsistency, so the newly elected leader must meet the above constraints
目前,上述约束的简单实现是:
只要当前服务器的日志比服务器日志的一半新,这里的新鲜度就是我上面说的:
lastLog 的项越大,越新越新。如果term相同,则lastLog的索引越大越新。
但正是这种实现并没有完全实现约束,这会导致下面的另一个问题。一个详细的案例稍后会解释这个问题
3.2 当前任期的leader是否可以直接提交上一任期的条目
raft给出的答案是:
本期的leader不能“直接”提交上一期的参赛作品
即可以间接提交。来看看Raft给出的不能直接提交的情况
最上面一行数字表示索引,s1-s5表示服务器服务器,a-e表示不同场景,框内数字表示术语
详细解释如下:
这里是日志覆盖问题的详细解释
日志覆盖包括2种情况:
我们从这个案例中得到的一个新约束是:
本期的leader不能“直接”提交上一期的参赛作品
必须等到本学期有一半以上的条目后,才能一起提交上一学期的条目
所以 raft 依靠这两个约束来进一步保证一致性。
让我们仔细分析一下这个案例。问题在于上面的leader选举。如果 s1 在 c 场景中提交了索引为 2、term=2 的条目,则 s5 不收录所有 commitLog。可以,但是s5还是可以按照最新的日志对比方式选举leader的,也就是说,最新的日志对比方式并不能保证3.1中的选举约束。
The elected leader must contain all entries that have already been submitted
所以可以理解为:正是因为上面提到的选举约束的执行存在缺陷,才增加了这样一个不能直接提交给上届参赛作品的约束。
3.3 安全演示
Leader Completeness:如果提交了一个条目,该条目必须存在于后续的Leader中。
经过以上两个约束,可以得出Leader Completeness的结论。
由于上述“不能直接提交上一学期的条目”的限制,任何条目的提交都必须存在于当前任期的条目下。此时,超过一半的所有服务器都收录当前术语(也是当前最大术语)的条目。假设serverA以后会成为leader,serverA的lastlog的term不能大于当前的term。成为leader,即其日志与其他服务器pk是最新的,必须满足大于他们的日志的索引,所以必须收录提交的条目。
4 其他注意事项
4.1 客户端
从客户的角度来看:
如果客户端发送请求,leader返回ok响应,则客户端认为请求执行成功,则请求需要真正落地,不能丢失。
如果leader没有返回ok,那么客户端可以认为请求没有执行成功,可以通过重试继续请求。
对于领导者来说:
一旦客户端回复OK然后挂断,必须保证这个请求对应的entry被应用到状态机上,也就是需要另一个leader来继续应用到状态机上。
一旦leader在回复客户端之前挂了,这个请求对应的entry就不能应用到状态机上。如果应用于状态机,客户端认为执行失败,但服务器缺乏持久性。这个请求的结果有点不一致。
这个原理也和消息队列是一致的。先说消息队列的消息丢失(很多人还没有真正理解这个问题):客户端向服务器发送消息,服务器回复OK,然后由于内部机制导致消息丢失服务器。 ,这种情况称为消息队列的消息丢失。如果服务器没有给你回复OK,那么这种情况不属于消息队列丢失消息的范畴。
让我们看看 raft 能否再次满足这个原则:
leader已经复制了一个条目的一半以上,认为可以提交,所以应用到状态机,然后向客户端响应OK。 leader挂掉后,可以保证该entry存在于后续leader中
leader被复制了一半以上的条目,然后就挂了,也就是没有给客户端回复OK。在raft机制下,后续leader可能会收录入口并提交,也可能直接覆盖。入口。如果是前者,将entry应用到状态机,那么这时候就有问题了:客户端没有收到OK回复,但是服务端可以保存成功
为了掩盖这种情况,需要在client端做一个trick,就是client会重试所有没有回复OK的,并且client的请求会携带一个唯一的request id,即重试时也是如此。使用之前的请求 ID 重试
服务器发现提交日志中已经存在请求id,然后直接响应OK。如果没有,则再次执行请求。
4.2 关注者挂断
关注者已关闭。只要leader还满足一半以上的条件,就一切正常。挂断并恢复后,leader会继续重试,follower依然可以恢复正常
Follower 在接收 AppendEntries RPC 时是幂等操作
扎布
Zab 代表 Zookeeper 原子广播协议,是 Zookeeper 内部使用的共识协议。与Paxos相比,Zab最大的特点就是保证了强一致性(强一致性,或线性化一致性)。
与 Raft 一样,Zab 需要唯一的领导者参与决策。 Zab 可以分为三个阶段:发现、同步和广播:
Leader 和 Follower 通过心跳判断健康状态。正常情况下,Zab 处于转播阶段。当出现Leader宕机、网络隔离等异常情况时,Zab会回到发现阶段。
Zab 通过约束交易的顺序来实现强一致性。第一个广播事务被提交,先入先出。 Zab 称其为一级订单(以下简称 PO)。实现PO的核心是zxid。
Each transaction in Zab corresponds to a zxid, which is composed of two parts: e is the epoch generated when the leader is elected, and c is the number of the transaction in the current epoch, increasing in sequence.假设两笔交易的zxid分别为z和z’,当z.e
为了实现PO,Zab对Follower和Leader有如下约束:
有交易 z 和 z'。如果Leader先广播z,Follower需要保证commit z对应的事务先有事务z和z',z由Leader p广播,z'由Leader q广播,Leader p在Leader q之前,然后Follower需要保证commit z对应的事务先有事务z和z',z由Leader p广播,z'由Leader q广播,Leader p在Leader q之前,如果Follower已经提交z,那么q需要确保你已经提交 z 来广播 z'
1、2点保证事务FIFO,第三点保证所有提交的事务在Leader上可用。
与Paxos相比,Zab限制了事务的顺序,适用于一致性要求强的场景。
Zab 协议源码实现
1.1 重要数据介绍
加上上一节已经介绍过的名词
对于以上参数,整个Broadcast过程可以描述为:
1.2 快速领导人选举
leader选举过程中需要注意的要点:
投票过程中有3个重要数据:
以下是这个过程的详细说明:
serverA 然后向所有其他服务器发送通知,通知内容为上述投票信息和选举纪元信息
pk完成后,如果本机被pk投票否决,投票信息会更新为对方的投票信息,同时投票信息会重新发送给所有服务器。
如果本机没有被pk投票否决,请看下面的一半判断过程
因为目前leader和follower都在测试是否进入leader选举过程。如果leader检测不到服务器ping回复的一半,leader会进入LOOKING状态,但是follower有自己的检测,需要一定的时间才能感知到这个事件。在此期间,如果其他服务器加入集群,则可能会收到。超过一半的其他追随者投票给了前任领导者,但此时领导者不再处于 LEADING 状态,因此需要进行这样的检查以排除这种情况。
1.3 恢复阶段
一旦leader选举完成,就会进入recovery阶段,即follower需要同步leader上的数据信息
LearnerHandler 中的 lastProcessedZxid 与 leader 的 lastProcessedZxid 相同,表示已经同步。
如果 lastProcessedZxid 在 minCommittedLog 和 maxCommittedLog 之间
proposal从lastProcessedZxid开始到maxCommittedLog结尾的部分会重发给LearnerHandler对应的follower,同时会发送proposal对应的commit命令
上面可能有问题:虽然lastProcessedZxid在它们之间,但是没有找到lastProcessedZxid对应的motion,也就是这个zxid在leader中是没有的。这个时候的策略是完全按照leader同步,删除follower。部分交易日志,然后重新发送这部分提案,并提交这些提案
如果 lastProcessedZxid 大于 maxCommittedLog
然后删除follower大于一部分的事务日志
如果 lastProcessedZxid 小于 minCommittedLog
然后直接用快照的方法恢复
2 特殊情况下的注意事项
让我们再谈谈恢复:
由此可以看出,在初始化和恢复时,所有最新的事务日志都会作为提交事务处理
也就是说,可能有一些事务日志还没有提交,都被当作提交了。这个过程简单粗暴,而raft对旧数据的恢复控制更严格。
2.2关注者的恢复过程挂断重启
一旦leader死亡,上述2组leader
无效。当leader恢复时它们不起作用,但是当系统正常执行并且follower被暂停和恢复时。
我们可以看到,在上面2.3的恢复过程中,会先恢复快照日志和事务日志,然后补充leader的上面2条数据的内容。
2.3 关注者同步失败
目前,leader和follower的同步是通过BIO来实现的。一旦链接异常,将关闭链接,重新建立与leader的连接,并重新同步最新数据
2.4 客户端也一样吗?
如果客户端收到OK回复,会丢失数据吗?
如果客户端没有收到OK回复,它会存储更多数据吗?
如果客户端收到OK回复,说明已经复制过半,请求对应的事务日志肯定会被收录在leader选举中,不会丢失数据
客户端连接的leader或follower挂断,客户端没有收到OK响应。目前可能会丢失也可能不会丢失,因为服务器端的处理也非常简单粗暴,未来leader上的事务日志会被当作commit来处理。所有处理过的都将应用到内存树中。 查看全部
《》RaftRaft将问题分解和具体化统一处理
木筏
Raft 将问题分解具体化:Leader 统一处理变更操作请求,执行一致性协议保证节点间日志复制的一致性,使用term 作为逻辑时钟保证时序。节点运行相同的状态机并获得一致的结果。 Raft协议的具体流程如下:
Client发起一个请求,每个请求收录一个由Leader处理的操作指令请求。 Leader将操作指令(entry)追加到操作日志中,然后向Follower发起AppendEntries请求,尝试获取操作日志的副本登陆Follower,如果follower多数(quorum)同意AppendEntries请求,leader执行commit操作,将指令传递给状态机处理,状态机处理完后将结果返回给客户端。
1 个leader选举
1.1 一开始,所有服务器都以follower状态启动
然后等待leader或候选者的RPC请求,否则超时。
以上三种情况处理如下:
1.2 候选人采集选票的过程
候选人将为此状态设置随机超时。一旦出现在本届任期内,大家都没有获得过半数的选票,即分裂选票。如果超时时间短,则更容易获得过半票。
Candidate 会向所有服务器发送 RequestVote RPC 请求,请求参数如下图所示
votedFor 是服务器保存的投票对象。一个服务器在一个任期内只能投票一次。如果此时已经投过票,即votedFor不为空,那么此时可以直接拒绝本次投票(当然要检查votedFor是否是被请求的候选人)。
如果你还没有投票:比较候选人的日志和当前更新的服务器的日志,比较方法是哪个lastLog项越大越新。如果词条相同,则lastLog索引较大且较新的为比较方法。
候选人统计投票信息。如果超过一半的候选人同意,他们被认为是领导者并改变为领导者状态。如果没有超过一半,则等待新的领导者产生。如果是这样,则更改为跟随者状态。然后,如果超时,则开始下一次选举。
2 日志副本
2.1 所有请求都交给leader
一旦leader选举成功,所有客户端请求最终都会交给leader(如果客户端连接了follower,follower会转发给leader)
2.2 处理请求流程
2.2.1 客户端请求到达leader
leader首先将请求转换为一个条目,然后将其添加到其日志中以获取该条目的索引信息。该条目收录当前leader的任期信息和日志中的索引信息
2.2.2 leader 将以上条目复制给所有关注者
看官方的AppendEntries RPC请求
从上图可以看出,对于每个follower,leader维护了两个属性,一个是nextIndex,是leader发送给follower的下一个entry的索引,另一个是matchIndex,就是follower发送给leader的确认索引。
一开始会初始化一个leader:
nextIndex=领导者日志的最大索引+1
匹配索引=0
然后开始准备AppendEntries RPC请求的参数
prevLogIndex=nextIndex-1
prevLogTerm=从日志中获取上述prevLogIndex对应的term
然后准备entries数组信息
从leader的日志的prevLogIndex+1开始到lastLog,此时为空
然后将leader的commitIndex作为参数传给
leaderCommit=commitIndex
至此,所有参数准备就绪,向所有follower发送RPC请求,follower收到请求后,处理如下:
如果词条回复错误
如果日志不收录 prevLogIndex 的条目,则回复 false
匹配 prevLogTerm
这里可能不一致,因为初始的prevLogIndex和prevLogTerm是leader上日志的lastLog。如果不一致,则返回false,并将follower上日志的lastIndex发送给leader。
上面的macthIndex=lastIndex
nextIndex=lastIndex+1 以上
然后leader会按照上面的规则从头开始发送新的prevLogIndex、prevLogTerm、entries数组
2.2.3 leader 占复制条目的一半以上
一旦leader发现某些条目已经被超过一半的follower复制了,它就会提交条目并将commitIndex提升到条目的索引。 (这个是按照入口index的顺序提交的),具体实现可以通过follower发送给macthIndex来判断是否超过一半。
一旦可以提交,leader就会将该entry应用到状态机,然后向客户端回复OK
然后在下一次heartBeat心跳中,commitIndex被传递给所有follower,对应follower就可以将commitIndex和之前的entry应用到各自的状态机中。
3 安全
3.1 选举约束
重点强调了上述领导人选举。
The elected leader must contain all entries that have already been submitted
比如leader提交了一半以上replication的entry,但是一些follower可能没有这些entry。 When the leader dies, if the follower is elected as the leader, the above entries may be overwritten, resulting in The problem of inconsistency, so the newly elected leader must meet the above constraints
目前,上述约束的简单实现是:
只要当前服务器的日志比服务器日志的一半新,这里的新鲜度就是我上面说的:
lastLog 的项越大,越新越新。如果term相同,则lastLog的索引越大越新。
但正是这种实现并没有完全实现约束,这会导致下面的另一个问题。一个详细的案例稍后会解释这个问题
3.2 当前任期的leader是否可以直接提交上一任期的条目
raft给出的答案是:
本期的leader不能“直接”提交上一期的参赛作品
即可以间接提交。来看看Raft给出的不能直接提交的情况
最上面一行数字表示索引,s1-s5表示服务器服务器,a-e表示不同场景,框内数字表示术语
详细解释如下:
这里是日志覆盖问题的详细解释
日志覆盖包括2种情况:
我们从这个案例中得到的一个新约束是:
本期的leader不能“直接”提交上一期的参赛作品
必须等到本学期有一半以上的条目后,才能一起提交上一学期的条目
所以 raft 依靠这两个约束来进一步保证一致性。
让我们仔细分析一下这个案例。问题在于上面的leader选举。如果 s1 在 c 场景中提交了索引为 2、term=2 的条目,则 s5 不收录所有 commitLog。可以,但是s5还是可以按照最新的日志对比方式选举leader的,也就是说,最新的日志对比方式并不能保证3.1中的选举约束。
The elected leader must contain all entries that have already been submitted
所以可以理解为:正是因为上面提到的选举约束的执行存在缺陷,才增加了这样一个不能直接提交给上届参赛作品的约束。
3.3 安全演示
Leader Completeness:如果提交了一个条目,该条目必须存在于后续的Leader中。
经过以上两个约束,可以得出Leader Completeness的结论。
由于上述“不能直接提交上一学期的条目”的限制,任何条目的提交都必须存在于当前任期的条目下。此时,超过一半的所有服务器都收录当前术语(也是当前最大术语)的条目。假设serverA以后会成为leader,serverA的lastlog的term不能大于当前的term。成为leader,即其日志与其他服务器pk是最新的,必须满足大于他们的日志的索引,所以必须收录提交的条目。
4 其他注意事项
4.1 客户端
从客户的角度来看:
如果客户端发送请求,leader返回ok响应,则客户端认为请求执行成功,则请求需要真正落地,不能丢失。
如果leader没有返回ok,那么客户端可以认为请求没有执行成功,可以通过重试继续请求。
对于领导者来说:
一旦客户端回复OK然后挂断,必须保证这个请求对应的entry被应用到状态机上,也就是需要另一个leader来继续应用到状态机上。
一旦leader在回复客户端之前挂了,这个请求对应的entry就不能应用到状态机上。如果应用于状态机,客户端认为执行失败,但服务器缺乏持久性。这个请求的结果有点不一致。
这个原理也和消息队列是一致的。先说消息队列的消息丢失(很多人还没有真正理解这个问题):客户端向服务器发送消息,服务器回复OK,然后由于内部机制导致消息丢失服务器。 ,这种情况称为消息队列的消息丢失。如果服务器没有给你回复OK,那么这种情况不属于消息队列丢失消息的范畴。
让我们看看 raft 能否再次满足这个原则:
leader已经复制了一个条目的一半以上,认为可以提交,所以应用到状态机,然后向客户端响应OK。 leader挂掉后,可以保证该entry存在于后续leader中
leader被复制了一半以上的条目,然后就挂了,也就是没有给客户端回复OK。在raft机制下,后续leader可能会收录入口并提交,也可能直接覆盖。入口。如果是前者,将entry应用到状态机,那么这时候就有问题了:客户端没有收到OK回复,但是服务端可以保存成功
为了掩盖这种情况,需要在client端做一个trick,就是client会重试所有没有回复OK的,并且client的请求会携带一个唯一的request id,即重试时也是如此。使用之前的请求 ID 重试
服务器发现提交日志中已经存在请求id,然后直接响应OK。如果没有,则再次执行请求。
4.2 关注者挂断
关注者已关闭。只要leader还满足一半以上的条件,就一切正常。挂断并恢复后,leader会继续重试,follower依然可以恢复正常
Follower 在接收 AppendEntries RPC 时是幂等操作
扎布
Zab 代表 Zookeeper 原子广播协议,是 Zookeeper 内部使用的共识协议。与Paxos相比,Zab最大的特点就是保证了强一致性(强一致性,或线性化一致性)。
与 Raft 一样,Zab 需要唯一的领导者参与决策。 Zab 可以分为三个阶段:发现、同步和广播:
Leader 和 Follower 通过心跳判断健康状态。正常情况下,Zab 处于转播阶段。当出现Leader宕机、网络隔离等异常情况时,Zab会回到发现阶段。
Zab 通过约束交易的顺序来实现强一致性。第一个广播事务被提交,先入先出。 Zab 称其为一级订单(以下简称 PO)。实现PO的核心是zxid。
Each transaction in Zab corresponds to a zxid, which is composed of two parts: e is the epoch generated when the leader is elected, and c is the number of the transaction in the current epoch, increasing in sequence.假设两笔交易的zxid分别为z和z’,当z.e
为了实现PO,Zab对Follower和Leader有如下约束:
有交易 z 和 z'。如果Leader先广播z,Follower需要保证commit z对应的事务先有事务z和z',z由Leader p广播,z'由Leader q广播,Leader p在Leader q之前,然后Follower需要保证commit z对应的事务先有事务z和z',z由Leader p广播,z'由Leader q广播,Leader p在Leader q之前,如果Follower已经提交z,那么q需要确保你已经提交 z 来广播 z'
1、2点保证事务FIFO,第三点保证所有提交的事务在Leader上可用。
与Paxos相比,Zab限制了事务的顺序,适用于一致性要求强的场景。
Zab 协议源码实现
1.1 重要数据介绍
加上上一节已经介绍过的名词
对于以上参数,整个Broadcast过程可以描述为:
1.2 快速领导人选举
leader选举过程中需要注意的要点:
投票过程中有3个重要数据:
以下是这个过程的详细说明:
serverA 然后向所有其他服务器发送通知,通知内容为上述投票信息和选举纪元信息
pk完成后,如果本机被pk投票否决,投票信息会更新为对方的投票信息,同时投票信息会重新发送给所有服务器。
如果本机没有被pk投票否决,请看下面的一半判断过程
因为目前leader和follower都在测试是否进入leader选举过程。如果leader检测不到服务器ping回复的一半,leader会进入LOOKING状态,但是follower有自己的检测,需要一定的时间才能感知到这个事件。在此期间,如果其他服务器加入集群,则可能会收到。超过一半的其他追随者投票给了前任领导者,但此时领导者不再处于 LEADING 状态,因此需要进行这样的检查以排除这种情况。
1.3 恢复阶段
一旦leader选举完成,就会进入recovery阶段,即follower需要同步leader上的数据信息
LearnerHandler 中的 lastProcessedZxid 与 leader 的 lastProcessedZxid 相同,表示已经同步。
如果 lastProcessedZxid 在 minCommittedLog 和 maxCommittedLog 之间
proposal从lastProcessedZxid开始到maxCommittedLog结尾的部分会重发给LearnerHandler对应的follower,同时会发送proposal对应的commit命令
上面可能有问题:虽然lastProcessedZxid在它们之间,但是没有找到lastProcessedZxid对应的motion,也就是这个zxid在leader中是没有的。这个时候的策略是完全按照leader同步,删除follower。部分交易日志,然后重新发送这部分提案,并提交这些提案
如果 lastProcessedZxid 大于 maxCommittedLog
然后删除follower大于一部分的事务日志
如果 lastProcessedZxid 小于 minCommittedLog
然后直接用快照的方法恢复
2 特殊情况下的注意事项
让我们再谈谈恢复:
由此可以看出,在初始化和恢复时,所有最新的事务日志都会作为提交事务处理
也就是说,可能有一些事务日志还没有提交,都被当作提交了。这个过程简单粗暴,而raft对旧数据的恢复控制更严格。
2.2关注者的恢复过程挂断重启
一旦leader死亡,上述2组leader
无效。当leader恢复时它们不起作用,但是当系统正常执行并且follower被暂停和恢复时。
我们可以看到,在上面2.3的恢复过程中,会先恢复快照日志和事务日志,然后补充leader的上面2条数据的内容。
2.3 关注者同步失败
目前,leader和follower的同步是通过BIO来实现的。一旦链接异常,将关闭链接,重新建立与leader的连接,并重新同步最新数据
2.4 客户端也一样吗?
如果客户端收到OK回复,会丢失数据吗?
如果客户端没有收到OK回复,它会存储更多数据吗?
如果客户端收到OK回复,说明已经复制过半,请求对应的事务日志肯定会被收录在leader选举中,不会丢失数据
客户端连接的leader或follower挂断,客户端没有收到OK响应。目前可能会丢失也可能不会丢失,因为服务器端的处理也非常简单粗暴,未来leader上的事务日志会被当作commit来处理。所有处理过的都将应用到内存树中。
2016上海事业单位医疗招聘:SQLServer访问与数据处理算法
采集交流 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-08-16 20:20
.Net 框架的命名空间 System.Net 中提供了两个类 WebRequest 和 WebResponse,分别用于发送客户端请求和从服务器获取响应。
2)正则表达式
正则表达式提供了强大、灵活和高效的文本处理方法。正则表达式的模式匹配可以快速分析大量文本,找到特定的字符模式;提取、编辑、替换或删除文本子串;或将提取的字符串添加到集合中。
在.Net命名空间System.Text.RegularExpressions中,提供了Regex类来构建正则表达式,也提供了相应的方法来匹配和过滤字符串。
3)ADO.Net
采集 系统获取的数据最终会存储在本地数据库中,.NET框架中提供了数据库访问技术ADO.NET。它屏蔽了各种数据源之间的差异,使用统一的访问接口,由一组访问各种数据源的类组成。为了提高访问效率,还为SQL Server提供了特殊的类,如SqlConnection、SqlCommand、SqlDataReader、Dataset、SqlDataAdapter等,完成对SQL Server数据库的访问和数据处理。
2.3 算法说明
完成信息采集,首先要能够过滤掉页面上我们需要的链接的起点,然后系统模拟手动点击过程读取信息。
1)根据访问路径创建C#自带的REGEX类的对象,是用于匹配正则表达式的文本类。
2)通过WebRequest发送请求,WebResponse接收返回的响应,然后通过StreamReader读取返回的响应,形成收录网页所有源代码的字符串。
3)用正则表达式匹配字符串得到Match采集集合,其中存储了我们需要进一步阅读的所有目标链接。
4) 遍历集合的成员,访问成员链接指向的页面,StreamReader读取信息后使用正则表达式提取页面信息。如果页面是访问路径的末端,则读取相应信息后,将所有结构化数据存入数据库;如果只是为了获取下一级链接,则转移到1)。
3 招聘信息采集系统的实现
1)阅读招聘单位名单信息
打开web_url指定的网站页面,使用StreamReader对象读取该网页的源代码并将其存储在字符串all_code中,方便提取正则表达式。
HttpWebRequest all_codeRequest = (HttpWebRequest)WebRequest.Create(web_url);
WebResponse all_codeResponse = all_codeRequest.GetResponse();
StreamReader the_Reader = new StreamReader(all_codeResponse.GetResponseStream(), System.Text.Encoding.Default);
string all_code = the_Reader.ReadToEnd();
the_Reader.Close();
2)提取招聘单位超链接列表
创建一个表达式字符串p,用它创建一个正则表达式对象re,并使用re.Matches方法返回all_code字符串的所有匹配超链接集hy。
string p = @".+";
Regex re = new Regex(p, RegexOptions.IgnoreCase);
Match采集 hy = re.Matches(all_code);
<p>for (int i = 0; i 查看全部
2016上海事业单位医疗招聘:SQLServer访问与数据处理算法
.Net 框架的命名空间 System.Net 中提供了两个类 WebRequest 和 WebResponse,分别用于发送客户端请求和从服务器获取响应。
2)正则表达式
正则表达式提供了强大、灵活和高效的文本处理方法。正则表达式的模式匹配可以快速分析大量文本,找到特定的字符模式;提取、编辑、替换或删除文本子串;或将提取的字符串添加到集合中。
在.Net命名空间System.Text.RegularExpressions中,提供了Regex类来构建正则表达式,也提供了相应的方法来匹配和过滤字符串。
3)ADO.Net
采集 系统获取的数据最终会存储在本地数据库中,.NET框架中提供了数据库访问技术ADO.NET。它屏蔽了各种数据源之间的差异,使用统一的访问接口,由一组访问各种数据源的类组成。为了提高访问效率,还为SQL Server提供了特殊的类,如SqlConnection、SqlCommand、SqlDataReader、Dataset、SqlDataAdapter等,完成对SQL Server数据库的访问和数据处理。
2.3 算法说明
完成信息采集,首先要能够过滤掉页面上我们需要的链接的起点,然后系统模拟手动点击过程读取信息。
1)根据访问路径创建C#自带的REGEX类的对象,是用于匹配正则表达式的文本类。
2)通过WebRequest发送请求,WebResponse接收返回的响应,然后通过StreamReader读取返回的响应,形成收录网页所有源代码的字符串。
3)用正则表达式匹配字符串得到Match采集集合,其中存储了我们需要进一步阅读的所有目标链接。
4) 遍历集合的成员,访问成员链接指向的页面,StreamReader读取信息后使用正则表达式提取页面信息。如果页面是访问路径的末端,则读取相应信息后,将所有结构化数据存入数据库;如果只是为了获取下一级链接,则转移到1)。
3 招聘信息采集系统的实现
1)阅读招聘单位名单信息
打开web_url指定的网站页面,使用StreamReader对象读取该网页的源代码并将其存储在字符串all_code中,方便提取正则表达式。
HttpWebRequest all_codeRequest = (HttpWebRequest)WebRequest.Create(web_url);
WebResponse all_codeResponse = all_codeRequest.GetResponse();
StreamReader the_Reader = new StreamReader(all_codeResponse.GetResponseStream(), System.Text.Encoding.Default);
string all_code = the_Reader.ReadToEnd();
the_Reader.Close();
2)提取招聘单位超链接列表
创建一个表达式字符串p,用它创建一个正则表达式对象re,并使用re.Matches方法返回all_code字符串的所有匹配超链接集hy。
string p = @".+";
Regex re = new Regex(p, RegexOptions.IgnoreCase);
Match采集 hy = re.Matches(all_code);
<p>for (int i = 0; i
智能巡检使用流式图算法和流式分解算法进行数据巡检
采集交流 • 优采云 发表了文章 • 0 个评论 • 248 次浏览 • 2021-08-15 20:25
日志服务提供智能巡检功能,用于对监控指标或业务日志等数据进行自动、智能、自适应的异常巡检。目前智能巡检采用流图算法和流分解算法进行数据巡检。本文介绍了流图算法和流分解算法的适用场景、参数配置、预览说明等。
流图算法
流式图算法是基于Time2Graph系列模型中的原理开发的,可以从整体上降低数据的噪声,分析异常数据的相对偏差。流图算法适用于大规模、嘈杂、不显眼的时间序列的异常检测。有关详细信息,请参阅使用进化状态图进行时间序列事件预测。
场景描述
流式图算法使用在线机器学习技术实时学习和推断每条数据。适用于一般的时间序列异常检测场景,包括:
参数配置
您可以在创建智能巡更作业配置向导页面的算法配置区完成算法配置。具体操作请参考。
各参数说明如下表所示。
参数说明
时间序列段数
划分时间序列值,用于离散时间序列,构建时间序列演化图,减少噪声的影响。建议预览不同时序段下的检测结果,选择最合适的值。
观察长度
要观察的历史数据点的数量。
灵敏度
异常分数输出的敏感性。
预览说明
预览示例如下图所示。
流分解算法
流分解算法是基于RobustSTL系列模型中的原理开发的,可以批量处理数据流,但计算成本较高,适用于小规模业务指标数据的精准检测。在大规模数据场景下,建议您拆分数据或使用流图算法。如需了解详情,请参阅 RobustSTL:针对长时间序列的稳健季节性趋势分解算法。
场景描述
流分解算法适用于周期性数据序列的巡检,要求数据的周期性更明显。例如,适用于业务指标有明显周期性变化的检查场景。
说明周期性数据在日常生活中比较常见,比如游戏访问次数和客户订单。
参数配置
您可以在创建智能巡更作业配置向导页面的算法配置区完成算法配置。具体操作请参考。
各参数说明如下表所示。
参数说明
周期长度
以点为单位描述一个周期内数据序列中收录的数据点数。数据系列默认为天数。例如,如果粒度为120秒,周期为天,那么一个周期内收录的数据点数为24×60×60/120=720个。
注意时间段的长度必须是时间序列的时间段,否则会影响检查效果。
灵敏度
异常分数输出的敏感性。
预览说明
预览流式分解算法的异常检测结果时,系统默认选择最近4个周期的数据进行预览。预览示例如下图所示。
对于嘈杂的周期数据,您需要在预览页面上继续调试,直到配置了确切的周期长度。在噪声较大的情况下,由于噪声干扰,可能存在漏报或虚报。预览示例如下图所示。
查看全部
智能巡检使用流式图算法和流式分解算法进行数据巡检
日志服务提供智能巡检功能,用于对监控指标或业务日志等数据进行自动、智能、自适应的异常巡检。目前智能巡检采用流图算法和流分解算法进行数据巡检。本文介绍了流图算法和流分解算法的适用场景、参数配置、预览说明等。
流图算法
流式图算法是基于Time2Graph系列模型中的原理开发的,可以从整体上降低数据的噪声,分析异常数据的相对偏差。流图算法适用于大规模、嘈杂、不显眼的时间序列的异常检测。有关详细信息,请参阅使用进化状态图进行时间序列事件预测。
场景描述
流式图算法使用在线机器学习技术实时学习和推断每条数据。适用于一般的时间序列异常检测场景,包括:
参数配置
您可以在创建智能巡更作业配置向导页面的算法配置区完成算法配置。具体操作请参考。
各参数说明如下表所示。
参数说明
时间序列段数
划分时间序列值,用于离散时间序列,构建时间序列演化图,减少噪声的影响。建议预览不同时序段下的检测结果,选择最合适的值。
观察长度
要观察的历史数据点的数量。
灵敏度
异常分数输出的敏感性。
预览说明
预览示例如下图所示。
流分解算法
流分解算法是基于RobustSTL系列模型中的原理开发的,可以批量处理数据流,但计算成本较高,适用于小规模业务指标数据的精准检测。在大规模数据场景下,建议您拆分数据或使用流图算法。如需了解详情,请参阅 RobustSTL:针对长时间序列的稳健季节性趋势分解算法。
场景描述
流分解算法适用于周期性数据序列的巡检,要求数据的周期性更明显。例如,适用于业务指标有明显周期性变化的检查场景。
说明周期性数据在日常生活中比较常见,比如游戏访问次数和客户订单。
参数配置
您可以在创建智能巡更作业配置向导页面的算法配置区完成算法配置。具体操作请参考。
各参数说明如下表所示。
参数说明
周期长度
以点为单位描述一个周期内数据序列中收录的数据点数。数据系列默认为天数。例如,如果粒度为120秒,周期为天,那么一个周期内收录的数据点数为24×60×60/120=720个。
注意时间段的长度必须是时间序列的时间段,否则会影响检查效果。
灵敏度
异常分数输出的敏感性。
预览说明
预览流式分解算法的异常检测结果时,系统默认选择最近4个周期的数据进行预览。预览示例如下图所示。
对于嘈杂的周期数据,您需要在预览页面上继续调试,直到配置了确切的周期长度。在噪声较大的情况下,由于噪声干扰,可能存在漏报或虚报。预览示例如下图所示。
算法 自动采集列表 不接受差评DXC来自Discuz!X2(X2.5)
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2021-08-14 07:14
vip版购买后三天内不好用,随时退款,超过三天,如果软件出现问题,也可以全额退款。
所以,不接受差评
DXC 来自 Discuz! X2(X2.5) 采集的缩写,DXC采集插件专门用于discuz上的内容解决方案,帮助站长更快捷方便地构建网站内容。
通过DXC采集插件,用户可以方便地访问互联网采集的数据,包括会员数据和文章数据。此外,还有虚拟在线、单帖采集等辅助功能,让一个冷清的新论坛瞬间形成一个内容丰富、会员活跃的热门论坛,对论坛的初期运营有很大帮助。是新手站长必须安装的discuz应用。
DXC2.5的主要功能包括:
1、采集文章各种形式的url列表,包括rss地址、列表页面、多层列表等。
2、 多种写规则方式,dom方式,字符拦截,智能获取,更方便获取你想要的内容
3、Rule继承,自动检测匹配规则功能,你会慢慢体会到规则继承带来的便利
4、独特的网页正文提取算法,可以自动学习归纳规则,更方便general采集。
5、支持图片定位和水印功能
6、灵活的发布机制,可以自定义发布者、发布时间点击率等
7、强大的内容编辑后台,您可以轻松编辑采集到达的内容,并发布到门户、论坛、博客
8、内容过滤功能,过滤采集广告的内容,去除不必要的区域
9、批量采集,注册会员,批量采集,设置会员头像
10、无人值守定时定量采集和release文章
下载地址
下载 URL.txt
立即下载
10
您没有购买
轻货币
以上或VIP会员【购买VIP】【充值】 查看全部
算法 自动采集列表 不接受差评DXC来自Discuz!X2(X2.5)
vip版购买后三天内不好用,随时退款,超过三天,如果软件出现问题,也可以全额退款。
所以,不接受差评
DXC 来自 Discuz! X2(X2.5) 采集的缩写,DXC采集插件专门用于discuz上的内容解决方案,帮助站长更快捷方便地构建网站内容。
通过DXC采集插件,用户可以方便地访问互联网采集的数据,包括会员数据和文章数据。此外,还有虚拟在线、单帖采集等辅助功能,让一个冷清的新论坛瞬间形成一个内容丰富、会员活跃的热门论坛,对论坛的初期运营有很大帮助。是新手站长必须安装的discuz应用。
DXC2.5的主要功能包括:
1、采集文章各种形式的url列表,包括rss地址、列表页面、多层列表等。
2、 多种写规则方式,dom方式,字符拦截,智能获取,更方便获取你想要的内容
3、Rule继承,自动检测匹配规则功能,你会慢慢体会到规则继承带来的便利
4、独特的网页正文提取算法,可以自动学习归纳规则,更方便general采集。
5、支持图片定位和水印功能
6、灵活的发布机制,可以自定义发布者、发布时间点击率等
7、强大的内容编辑后台,您可以轻松编辑采集到达的内容,并发布到门户、论坛、博客
8、内容过滤功能,过滤采集广告的内容,去除不必要的区域
9、批量采集,注册会员,批量采集,设置会员头像
10、无人值守定时定量采集和release文章
下载地址
下载 URL.txt
立即下载
10
您没有购买
轻货币
以上或VIP会员【购买VIP】【充值】
CMS和G1的优点、缺点、适用场景?|?剧透
采集交流 • 优采云 发表了文章 • 0 个评论 • 513 次浏览 • 2021-08-12 05:18
CMS和G1的优点、缺点、适用场景?|?剧透
要弄清楚cms和G1,就看这个了
内容
在我们开始介绍cms和G1之前,我们可以先剧透一下:
cms 和 G1 是垃圾采集器中的大杀器。他们需要被理解,并且经常在采访中被问到。
希望大家带着以下问题阅读,带着目标阅读,收获更多:
为什么没有像银弹一样适合所有场景的优秀采集器? cms的优缺点及适用场景?为什么cms只能作为老年代的采集器,而不能用于新生代的采集? G1的优缺点和适用场景是什么? 1 cmscollector
cms(Concurrent Mark Sweep)采集器是一个旨在获得最短恢复暂停时间的采集器。这是因为cmscollector工作时,GC工作线程和用户线程可以并发执行,达到减少采集暂停时间的目的。
cmscollector 只作用于老年代的采集。它基于标记扫描算法。其操作过程分为4个步骤:
其中,初始标记和重新标记两个步骤仍然需要Stop-the-world。初始标记只是标记GC Roots可以直接关联的对象。速度非常快。并发标记阶段是GC Roots Tracing的过程,而remarking阶段是为了纠正由于用户程序继续运行而导致的并发标记周期。对于对象变化部分的标记记录,此阶段的暂停时间一般比初始阶段稍长,但比并发标记时间短很多。
cms以流水线的方式分割采集周期,保持耗时的操作单元与应用线程并发执行。只有那些需要STW的运行单元才能单独进行,控制这些单元在合适的时间运行,才能保证在短时间内完成。这样,在整个采集周期中,只有两次短暂的停顿(初始标记和重新标记),达到近似并发的目的。
cmscollector 优点:并发采集,低暂停。
cmsCollector 缺点:
cms采集器能够实现并发的根本原因在于它采用了“标记-清除”算法,对算法过程进行了细粒度分解。上一章介绍了mark-sweep算法会产生大量的内存碎片,对于新生代来说是不能接受的,所以新生代采集器不提供cms版本。
另外需要补充的是,JVM挂起的时候,需要选择一个合适的时机。由于JVM系统在运行过程中的复杂性,不可能随时暂停,所以引入了安全点的概念。
安全点(Safepoint)
安全点,即程序执行的时候,不可能在所有地方都停下来启动GC,只有到了安全点才可以暂停。 Safepoint的选择既不能太小导致GC等待时间过长,也不能太频繁导致运行时负载过大。
安全点最初的目的不是停止其他线程,而是寻找一个稳定的执行状态。在这种执行状态下,Java 虚拟机的堆栈不会发生变化。这样,垃圾采集器就可以“安全地”进行可达性分析。只要不离开这个安全点,Java 虚拟机就可以在垃圾回收的同时继续运行这段原生代码。
程序运行时,不可能在所有地方都停下来启动GC,只有到了安全点才可以暂停。安全点的选择,基本上以程序是否具有允许程序长时间执行的特性为标准。 “长时间执行”最明显的特点就是指令序列的复用,比如方法调用、循环跳转、异常跳转等,所以带有这些函数的指令会产生Safepoint。
对于安全点,另一个需要考虑的问题是如何让所有线程(不包括执行 JNI 调用的线程)“运行”到最近的安全点,然后在 GC 发生时停止。
两种解决方案:
安全区域
表示在一段代码中,引用关系不会改变。在该区域的任何地方启动 GC 都是安全的。您也可以将安全区域视为扩展的安全点。
2 G1 采集器
G1 重新定义了堆空间,打破了原有的生成模型,将堆划分为区域。这样做的目的是采集时不必在整个堆中,这是它最显着的特点。区域划分的好处在于它带来了一个可预测暂停时间的采集模型:用户可以指定采集操作将完成多长时间。也就是说,G1 提供了近乎实时的采集特性。
G1和cms的特征对比如下:
功能 G1cms
并发和生成
是的
是的
最大化堆内存的释放
是的
没有
低延迟
是的
是的
吞吐量
高
低
压缩
是的
没有
可预测性
强
弱
新生代和老年代物理分离
没有
是的
G1 具有以下特点:
G1 之前其他采集器的采集范围是整个年轻代或年老代,但 G1 不再如此。在堆的结构设计上,G1打破了之前在年轻代或年老代固定采集范围的模式。 G1将堆划分为许多大小相同的区域单元,每个单元称为一个Region。区域是具有连续地址的内存空间。 G1模块的组成如下图所示:
G1 采集器将整个 Java 堆划分为多个大小相等的独立区域(Region)。虽然仍然保留了年轻代和老一代的概念,但年轻代和老一代在物理上已不再分离。它们是一部分 Regions 的集合(不需要是连续的)。 Region的大小是一样的。该值是 1M 到 32M 字节之间的 2 的幂。 JVM 会尝试划分大约 2048 个相同大小的 Region。为此,您可以参考以下源代码。其实这个数字可以手动调整,G1也会根据堆大小自动调整。
#ifndef SHARE_VM_GC_G1_HEAPREGIONBOUNDS_HPP
#define SHARE_VM_GC_G1_HEAPREGIONBOUNDS_HPP
#include "memory/allocation.hpp"
class HeapRegionBounds : public AllStatic {
private:
// Minimum region size; we won't go lower than that.
// We might want to decrease this in the future, to deal with small
// heaps a bit more efficiently.
static const size_t MIN_REGION_SIZE = 1024 * 1024;
// Maximum region size; we don't go higher than that. There's a good
// reason for having an upper bound. We don't want regions to get too
// large, otherwise cleanup's effectiveness would decrease as there
// will be fewer opportunities to find totally empty regions after
// marking.
static const size_t MAX_REGION_SIZE = 32 * 1024 * 1024;
// The automatic region size calculation will try to have around this
// many regions in the heap (based on the min heap size).
static const size_t TARGET_REGION_NUMBER = 2048;
public:
static inline size_t min_size();
static inline size_t max_size();
static inline size_t target_number();
};
#endif // SHARE_VM_GC_G1_HEAPREGIONBOUNDS_HPP
G1 采集器之所以能够建立可预测的暂停时间模型,是因为它可以系统地避免整个 Java 堆中的垃圾采集。 G1 将通过合理的计算模型计算和量化每个 Region 的采集成本。这样,在给定“暂停”时间限制的情况下,采集器始终可以选择一组合适的 Region 作为采集。目的就是让其采集开销满足这个约束,从而达到实时采集的目的。
对于计划从cms或ParallelOld采集器迁移的应用,根据官方推荐,如果发现它们符合以下特征,可以考虑更换为G1采集器以追求更好的性能:
原文如下:
如果应用程序具有以下一个或多个特征,现在使用cms 或 ParallelOld 垃圾采集器运行的应用程序将有利于切换到 G1。
G1集合的操作流程大致如下:
栈中引用的全局变量和对象可以收录在根集合中,这样在查找垃圾时,可以从根集合中扫描堆空间。在 G1 中,引入了一种可以添加到根集的新类型,即记住集。记忆集(也称为 RSet)用于跟踪对象引用。 G1的很多开源都是从Remembered Set衍生而来的,比如它通常占Heap size的20%左右甚至更多。而且,我们在复制对象的时候,因为需要扫描和更改Card Table信息,这个速度会影响复制的速度,进而影响暂停时间。
卡片表
有一个场景,老年代的对象可能会引用新生代的对象。在标记幸存对象时,需要扫描老年代的所有对象。因为对象有对新生代对象的引用,所以这个引用也会被称为GC Roots。不需要再做一次全堆扫描吗?成本太高。
HotSpot 提供的解决方案是一种叫做 Card Table 的技术。该技术将整个堆划分为512字节的卡片,并维护一张卡片表来存储每张卡片的标识位。这个标志表示对应的卡片是否可以有对新生代对象的引用。如果可能,那么我们认为该卡是脏的。
在执行 Minor GC 时,我们可以在卡片表中查找脏卡,而不是扫描整个老年代,并将脏卡中的对象添加到 Minor GC 的 GC Roots 中。所有脏卡扫描完成后,Java虚拟机将清除所有脏卡的标识位。
为了保证每一张可能引用新生代对象的卡片都被标记为脏卡片,Java虚拟机需要拦截每个引用类型实例变量的写操作,并进行相应的写标志操作。
卡表可以减少老年代的全堆空间扫描,可以大大提高GC效率。
大家可以看看官方文档对G1的outlook(这个英文描述比较简单,我就不翻译了):
未来:
G1 计划作为 Concurrent Mark-Sweep Collector (cms) 的长期替代品。将 G1 与 cms 进行比较,有一些差异使 G1 成为更好的解决方案。一个区别是 G1 是一个压缩采集器。 G1 充分压缩以完全避免使用细粒度的空闲列表进行分配,而是依赖于区域。这大大简化了采集器的各个部分,并且在很大程度上消除了潜在的碎片问题。此外,与cms 采集器相比,G1 提供了更多可预测的垃圾采集暂停,并允许用户指定所需的暂停目标。
3 总结
查了杜娘的文章关于G1的介绍,文章对G1的介绍大部分都卡在了JDK7或更早的实现中。很多结论已经大大偏离,甚至一些过去的GC选项也不再推荐。例如,JDK9 中的 JVM 和 GC 日志已被重构。例如,PrintGCDetails 已被标记为过时,PrintGCDateStamps 已被删除。指定它会导致JVM无法启动。
本文对cms和G1的介绍大部分也是基于JDK7的。新版本的内容有一点介绍,但是我没有做过太多介绍(我没有深入研究新版本的JVM),以后有机会可以给个特别的文章专注于介绍。
4 参考
《深入了解Java虚拟机》、《热点实战》、《极客时间专栏》
查看全部
CMS和G1的优点、缺点、适用场景?|?剧透
要弄清楚cms和G1,就看这个了
内容
在我们开始介绍cms和G1之前,我们可以先剧透一下:
cms 和 G1 是垃圾采集器中的大杀器。他们需要被理解,并且经常在采访中被问到。
希望大家带着以下问题阅读,带着目标阅读,收获更多:
为什么没有像银弹一样适合所有场景的优秀采集器? cms的优缺点及适用场景?为什么cms只能作为老年代的采集器,而不能用于新生代的采集? G1的优缺点和适用场景是什么? 1 cmscollector
cms(Concurrent Mark Sweep)采集器是一个旨在获得最短恢复暂停时间的采集器。这是因为cmscollector工作时,GC工作线程和用户线程可以并发执行,达到减少采集暂停时间的目的。
cmscollector 只作用于老年代的采集。它基于标记扫描算法。其操作过程分为4个步骤:
其中,初始标记和重新标记两个步骤仍然需要Stop-the-world。初始标记只是标记GC Roots可以直接关联的对象。速度非常快。并发标记阶段是GC Roots Tracing的过程,而remarking阶段是为了纠正由于用户程序继续运行而导致的并发标记周期。对于对象变化部分的标记记录,此阶段的暂停时间一般比初始阶段稍长,但比并发标记时间短很多。
cms以流水线的方式分割采集周期,保持耗时的操作单元与应用线程并发执行。只有那些需要STW的运行单元才能单独进行,控制这些单元在合适的时间运行,才能保证在短时间内完成。这样,在整个采集周期中,只有两次短暂的停顿(初始标记和重新标记),达到近似并发的目的。
cmscollector 优点:并发采集,低暂停。
cmsCollector 缺点:
cms采集器能够实现并发的根本原因在于它采用了“标记-清除”算法,对算法过程进行了细粒度分解。上一章介绍了mark-sweep算法会产生大量的内存碎片,对于新生代来说是不能接受的,所以新生代采集器不提供cms版本。
另外需要补充的是,JVM挂起的时候,需要选择一个合适的时机。由于JVM系统在运行过程中的复杂性,不可能随时暂停,所以引入了安全点的概念。
安全点(Safepoint)
安全点,即程序执行的时候,不可能在所有地方都停下来启动GC,只有到了安全点才可以暂停。 Safepoint的选择既不能太小导致GC等待时间过长,也不能太频繁导致运行时负载过大。
安全点最初的目的不是停止其他线程,而是寻找一个稳定的执行状态。在这种执行状态下,Java 虚拟机的堆栈不会发生变化。这样,垃圾采集器就可以“安全地”进行可达性分析。只要不离开这个安全点,Java 虚拟机就可以在垃圾回收的同时继续运行这段原生代码。
程序运行时,不可能在所有地方都停下来启动GC,只有到了安全点才可以暂停。安全点的选择,基本上以程序是否具有允许程序长时间执行的特性为标准。 “长时间执行”最明显的特点就是指令序列的复用,比如方法调用、循环跳转、异常跳转等,所以带有这些函数的指令会产生Safepoint。
对于安全点,另一个需要考虑的问题是如何让所有线程(不包括执行 JNI 调用的线程)“运行”到最近的安全点,然后在 GC 发生时停止。
两种解决方案:
安全区域
表示在一段代码中,引用关系不会改变。在该区域的任何地方启动 GC 都是安全的。您也可以将安全区域视为扩展的安全点。
2 G1 采集器
G1 重新定义了堆空间,打破了原有的生成模型,将堆划分为区域。这样做的目的是采集时不必在整个堆中,这是它最显着的特点。区域划分的好处在于它带来了一个可预测暂停时间的采集模型:用户可以指定采集操作将完成多长时间。也就是说,G1 提供了近乎实时的采集特性。
G1和cms的特征对比如下:
功能 G1cms
并发和生成
是的
是的
最大化堆内存的释放
是的
没有
低延迟
是的
是的
吞吐量
高
低
压缩
是的
没有
可预测性
强
弱
新生代和老年代物理分离
没有
是的
G1 具有以下特点:
G1 之前其他采集器的采集范围是整个年轻代或年老代,但 G1 不再如此。在堆的结构设计上,G1打破了之前在年轻代或年老代固定采集范围的模式。 G1将堆划分为许多大小相同的区域单元,每个单元称为一个Region。区域是具有连续地址的内存空间。 G1模块的组成如下图所示:
G1 采集器将整个 Java 堆划分为多个大小相等的独立区域(Region)。虽然仍然保留了年轻代和老一代的概念,但年轻代和老一代在物理上已不再分离。它们是一部分 Regions 的集合(不需要是连续的)。 Region的大小是一样的。该值是 1M 到 32M 字节之间的 2 的幂。 JVM 会尝试划分大约 2048 个相同大小的 Region。为此,您可以参考以下源代码。其实这个数字可以手动调整,G1也会根据堆大小自动调整。
#ifndef SHARE_VM_GC_G1_HEAPREGIONBOUNDS_HPP
#define SHARE_VM_GC_G1_HEAPREGIONBOUNDS_HPP
#include "memory/allocation.hpp"
class HeapRegionBounds : public AllStatic {
private:
// Minimum region size; we won't go lower than that.
// We might want to decrease this in the future, to deal with small
// heaps a bit more efficiently.
static const size_t MIN_REGION_SIZE = 1024 * 1024;
// Maximum region size; we don't go higher than that. There's a good
// reason for having an upper bound. We don't want regions to get too
// large, otherwise cleanup's effectiveness would decrease as there
// will be fewer opportunities to find totally empty regions after
// marking.
static const size_t MAX_REGION_SIZE = 32 * 1024 * 1024;
// The automatic region size calculation will try to have around this
// many regions in the heap (based on the min heap size).
static const size_t TARGET_REGION_NUMBER = 2048;
public:
static inline size_t min_size();
static inline size_t max_size();
static inline size_t target_number();
};
#endif // SHARE_VM_GC_G1_HEAPREGIONBOUNDS_HPP
G1 采集器之所以能够建立可预测的暂停时间模型,是因为它可以系统地避免整个 Java 堆中的垃圾采集。 G1 将通过合理的计算模型计算和量化每个 Region 的采集成本。这样,在给定“暂停”时间限制的情况下,采集器始终可以选择一组合适的 Region 作为采集。目的就是让其采集开销满足这个约束,从而达到实时采集的目的。
对于计划从cms或ParallelOld采集器迁移的应用,根据官方推荐,如果发现它们符合以下特征,可以考虑更换为G1采集器以追求更好的性能:
原文如下:
如果应用程序具有以下一个或多个特征,现在使用cms 或 ParallelOld 垃圾采集器运行的应用程序将有利于切换到 G1。
G1集合的操作流程大致如下:
栈中引用的全局变量和对象可以收录在根集合中,这样在查找垃圾时,可以从根集合中扫描堆空间。在 G1 中,引入了一种可以添加到根集的新类型,即记住集。记忆集(也称为 RSet)用于跟踪对象引用。 G1的很多开源都是从Remembered Set衍生而来的,比如它通常占Heap size的20%左右甚至更多。而且,我们在复制对象的时候,因为需要扫描和更改Card Table信息,这个速度会影响复制的速度,进而影响暂停时间。
卡片表
有一个场景,老年代的对象可能会引用新生代的对象。在标记幸存对象时,需要扫描老年代的所有对象。因为对象有对新生代对象的引用,所以这个引用也会被称为GC Roots。不需要再做一次全堆扫描吗?成本太高。
HotSpot 提供的解决方案是一种叫做 Card Table 的技术。该技术将整个堆划分为512字节的卡片,并维护一张卡片表来存储每张卡片的标识位。这个标志表示对应的卡片是否可以有对新生代对象的引用。如果可能,那么我们认为该卡是脏的。
在执行 Minor GC 时,我们可以在卡片表中查找脏卡,而不是扫描整个老年代,并将脏卡中的对象添加到 Minor GC 的 GC Roots 中。所有脏卡扫描完成后,Java虚拟机将清除所有脏卡的标识位。
为了保证每一张可能引用新生代对象的卡片都被标记为脏卡片,Java虚拟机需要拦截每个引用类型实例变量的写操作,并进行相应的写标志操作。
卡表可以减少老年代的全堆空间扫描,可以大大提高GC效率。
大家可以看看官方文档对G1的outlook(这个英文描述比较简单,我就不翻译了):
未来:
G1 计划作为 Concurrent Mark-Sweep Collector (cms) 的长期替代品。将 G1 与 cms 进行比较,有一些差异使 G1 成为更好的解决方案。一个区别是 G1 是一个压缩采集器。 G1 充分压缩以完全避免使用细粒度的空闲列表进行分配,而是依赖于区域。这大大简化了采集器的各个部分,并且在很大程度上消除了潜在的碎片问题。此外,与cms 采集器相比,G1 提供了更多可预测的垃圾采集暂停,并允许用户指定所需的暂停目标。
3 总结
查了杜娘的文章关于G1的介绍,文章对G1的介绍大部分都卡在了JDK7或更早的实现中。很多结论已经大大偏离,甚至一些过去的GC选项也不再推荐。例如,JDK9 中的 JVM 和 GC 日志已被重构。例如,PrintGCDetails 已被标记为过时,PrintGCDateStamps 已被删除。指定它会导致JVM无法启动。
本文对cms和G1的介绍大部分也是基于JDK7的。新版本的内容有一点介绍,但是我没有做过太多介绍(我没有深入研究新版本的JVM),以后有机会可以给个特别的文章专注于介绍。
4 参考
《深入了解Java虚拟机》、《热点实战》、《极客时间专栏》
算法自动采集列表,去重,字段有自己设置颜色首页,
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-08-12 01:04
算法自动采集列表,去重,字段有字段自己设置颜色首页,或get请求获取自己的首页即可简单业务,去post字段说明:获取自己首页的queryreward=none
post里面有字段和描述提交时候有user、role和date字段,自己加个值或者做个header(@user),别人收到后,会根据这个来返回response如果想返回restful风格的,可以用spamless-tpl模板引擎做header绑定,
目前angular/reactnative有实现以下功能
1、页面标记
2、列表标记
3、对话列表标记
4、tab标记
5、好友列表标记
6、我的列表标记
7、聊天记录标记
8、qq/微信/友盟/百度地图标记
9、外部推送推送推送
推荐一个性能很好,实现原理简单的方案。自动抓取自己的数据,比如页面上的queryreward,可以加装多个字段,比如职位,看了什么,好友列表等。然后统一存储,比如腾讯db,或者数据库,索引等。这样接着就可以重复抓取对应的url或者页面了。
自动采集,postmodel,可以简单的考虑关键字实体的路由和页面设置过滤。添加一个账号,用户名,设置一个id,来注册并实名,然后注册到的用户推送给该账号的用户名。拿到接口后用正则匹配一下用户头像url,从而抓取到头像。接下来,从接口推送的带有头像的url,提取头像图片, 查看全部
算法自动采集列表,去重,字段有自己设置颜色首页,
算法自动采集列表,去重,字段有字段自己设置颜色首页,或get请求获取自己的首页即可简单业务,去post字段说明:获取自己首页的queryreward=none
post里面有字段和描述提交时候有user、role和date字段,自己加个值或者做个header(@user),别人收到后,会根据这个来返回response如果想返回restful风格的,可以用spamless-tpl模板引擎做header绑定,
目前angular/reactnative有实现以下功能
1、页面标记
2、列表标记
3、对话列表标记
4、tab标记
5、好友列表标记
6、我的列表标记
7、聊天记录标记
8、qq/微信/友盟/百度地图标记
9、外部推送推送推送
推荐一个性能很好,实现原理简单的方案。自动抓取自己的数据,比如页面上的queryreward,可以加装多个字段,比如职位,看了什么,好友列表等。然后统一存储,比如腾讯db,或者数据库,索引等。这样接着就可以重复抓取对应的url或者页面了。
自动采集,postmodel,可以简单的考虑关键字实体的路由和页面设置过滤。添加一个账号,用户名,设置一个id,来注册并实名,然后注册到的用户推送给该账号的用户名。拿到接口后用正则匹配一下用户头像url,从而抓取到头像。接下来,从接口推送的带有头像的url,提取头像图片,
特殊普通合伙一种基于自动侦测的停车数据采集方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-08-10 21:19
《基于自动检测技术的停车数据采集方法.pdf》为会员共享,可在线阅读,更多相关《基于自动检测技术的停车数据采集方法.pdf》(6页已完结version) )》请在专利查询网站搜索。
1、(19)中华人民共和国国家知识产权局(12)发明专利申请(10)申请公开号)(43)申请公开日(21)应用号2.7 (22)应用日2019.10.31 (71)申请人地址 215000 江苏省苏州市吴中区昌黎路99号701室( 72)发明人韩宏波)叶军周华建沉凡秦六芳(74)专利代理北京慕大星云知识产权代理(特殊普通合伙)11465 曹鹏飞律师(51)Int.Cl. G08G 1/ 017(2006.) 01) G08G 1/01(2006.01) G08G 1/14(2006.01)(54)发明.
)
2、名一种基于自动检测技术的停车数据采集method (57)Abstract 本发明公开了一种基于自动检测采集方法的停车数据,包括以下步骤: S1:执行特征对不同的停车场管理系统数据进行取值,并为每个停车场管理系统形成对应的特征值集; S2:对当前需要数据采集的停车场管理系统进行自动检测,改变的特征值数据将当前停车场管理系统与特征值集中的数据进行比较; S3:如果特征值集中存在当前停车场管理系统的特征值数据,则自动检查当前停车场管理系统数据的获取;如果不存在,则使用视频采集方法对停车场数据进行采集,本发明兼容市场上现有的停车场系统,实现了停车数据自动化采集。
3、 和概括。权利要求:1页说明书3页附图1页 CN 110992700 A 2020.04.10 CN 110992700 A 1.一种基于自动检测的停车数据采集方法,其特征在于包括步骤如下: S1:针对不同的停车场管理系统数据提取特征值,形成每个停车场管理系统对应的特征值集; S2:自动检测当前需要数据的停车场管理系统采集当前停车场管理系统特征值数据与特征值集中的数据进行比较; S3:如果特征值集合中存在当前停车场管理系统特征值数据,则自动进行当前停车场管理系统数据采集;如果不存在,使用视频采集方法采集停车场数据。 .
4、2.根据权利要求1所述的一种基于自动检测停车数据采集的方法,其特征在于,S1具体还包括以下内容:(1)抽象数据库配置,链接配置为数据库抽象为通用配置文件;(2)分析不同类型停车场管理系统的停车数据,分析内容包括:数据库类型、车辆进入信息、车辆退出信息和车辆图片信息;(3)根据分析结果形成停车数据配置脚本,然后建立收录不同类型停车场管理系统的停车数据配置脚本库3.根据权利要求2的基于自动检测的停车数据采集方法其特征在于S2中的比对内容包括:停车场数据库特征、出口数据特征、入口数据特征。4.自动一致声称 2。
5、Detected parked data采集方法,其特征在于S3中的采集自动执行当前停车场管理系统数据,具体包括以下方法:(1)database方法:直接基于关于数据库设置和时间设置,采集为停车场管理系统数据库的进出数据;(2)云采集方式:数据通过停车场云平台采集,不同类型自动获取停车场管理系统配置脚本通过网站访问、地址跳转、数据查询、结果获取等操作自动实现停车数据采集5.一种根据权利要求1所述的基于自动检测的停车数据采集采集方法的特点是视频采集方法具体包括以下内容:比较失败后自动转换为视频采集方法,通过ONVIF协议实现连接使用车载摄像头进行离子,并在获得照片后。
6、,利用图像识别技术识别车牌,结合车辆进出时间和车道信息,实现停车数据采集。权利要求1/1第2页 CN 110992700 A 2 一种基于自动检测停车数据的技术采集方法技术领域0001 本发明涉及停车管理技术领域,具体涉及一种基于自动检测停车数据的技术采集 方法。背景技术0002随着智能停车技术的发展和普及,各类停车场也逐渐进行了智能化系统改造,利用车牌识别技术实现车辆自动进出管理,同时停车场管理系统监控进出车辆的车牌和照片。记录。随着汽车保有量的不断增加,机动车的爆发式增长在给广大市民带来便利的同时,也带来了治安管理和交通管理。
7、 有一个新话题。停车数据在分析交通拥堵和公共安全控制方面发挥着重要作用。但由于停车管理系统品牌众多、实施方式多样、标准不一致,导致停车场信息采集难以对接。 0003 道路卡口的车辆数据称为动态车辆数据,停车场的车辆数据称为静态数据。经过多年的建设和不断扩大覆盖,动态数据积累了大量的基础数据,但停车数据基本空白,没有应用动态数据和静态数据的关联。只有将静态数据与动态数据相结合,才能称为真正意义上的车辆大数据,而停车场数据联网采集是获取车辆静态数据的首要任务。 0004 但是,现有技术中停车场停车数据的采集数据格式不统一,采集方法不统一。
8、Unification 提问,停车场停车数据格式目前主要包括本地数据库、云平台和混合模式三种。本地数据库数据存储在本地,云平台数据存储在云服务器上,混合模式将数据存储在本地和云端,不同的方式需要采用不同的采集方式。 0005 因此,如何对不同类型的停车场管理系统数据以及各种实现方法进行停车数据采集,并在各个区域建立静态停车数据库,是本领域技术人员急需解决的问题。发明内容0006 有鉴于此,本发明提供一种基于自动检测的停车数据采集方法,能够有效实现对各种停车场管理系统的采集数据处理。 0007 为实现上述目的,本发明采用以下技术方案: 0008 一种基于自动检测的停车数据采集方法。
9、,包括以下步骤: 0009 S1:针对不同的停车场管理系统数据提取特征值,为每个停车场管理系统形成对应的特征值集; 0010 S2:对当前需求进行数据采集的停车场管理系统进行自动检测,将当前停车场管理系统特征值数据与特征值集中的数据进行比较; 0011 S3:如果特征值集合中存在当前停车场管理系统特征值数据,则自动采集当前停车场管理系统数据;如果不存在,使用视频采集方法采集停车场数据。 0012 优选地,S1还具体包括以下内容: 0013(1)抽象出数据库配置,抽象出数据库的链接配置作为通用配置文件;0014(2)针对不同物种。
分析10、型停车场管理系统的停车数据,分析内容包括: 数据库型手册1/3页3 CN 110992700 A Type 3,车辆进入信息、车辆退出信息和车辆图片信息; 0015(3)根据分析结果形成停车数据配置脚本,然后建立收录不同类型停车管理系统的停车数据配置脚本库。0016需要说明的是: 步骤(1)包括以下内容: 将数据库放入文件 配置抽象为参数,将数据库类型、数据库地址、端口、连接用户名、密码配置为参数,以适应不同的数据库系统; 步骤0017(2)在分析停车数据时可以包括:停车字段数据库名称和类型、数据表名称和类型、入口数据项、出口。
11、Field 数据项和barrier 数据项作为自动检测的基础特征。自动检测时,根据特征在特征集中进行搜索,确定停车场的类型。 0018 优选地,S2中的比对内容包括:停车场数据库特征、出口数据特征、入口数据特征。 0019 优选地,S3中自动执行当前停车场管理系统数据的采集具体包括以下方法: 0020(1)Database方法:直接根据数据库设置和时间设置,导出停车管理系统数据库采集入场数据;0021(2)云采集方式:数据通过停车场云平台采集,自动获取不同类型停车管理系统的配置脚本,通过网站自动访问,跳转到地址实现停车数据采集; 0022.
12、 优选地,视频采集方法具体包括以下内容: 0023 比较失败后,自动转换为视频采集方法,通过ONVIF协议实现与车载摄像头。获得照片后,利用图像识别技术识别车牌,结合车辆进出时间和车道信息,实现采集停车数据。 0024 从上述技术方案可以看出,与现有技术相比,本发明提供了一种基于自动检测的停车数据采集方法,能够自动检测停车场系统的实现方式和数据结构。接口用于实现多种模式的停车数据采集,采用顶层抽象屏蔽网络层的多样性,兼容目前市面上的停车系统,实现自动化和停车数据的泛化采集。附图说明0025为了更清楚地说明实施例或本发明。
13、 技术中有技术方案。下面将对在描述实施例或现有技术时需要用到的附图进行简要介绍。显然,以下描述中的附图仅是本发明的附图。在实施例中,对于本领域普通技术人员来说,在没有创造性劳动的情况下,可以根据所提供的附图获得其他附图。图 0026图1为本发明提供的基于自动检测的停车数据采集方法的流程图。具体实施方式0027下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整的说明。显然,所描述的实施例只是本发明的一部分实施例,而不是全部的实施例。例子。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都不是。
14、属于本发明的保护范围。 0028 如图1所示,本发明实施例公开了一种基于自动检测的停车数据采集方法,包括以下步骤: 手册2/3 页4 CN 110992700 A 4 0029 S1:针对不同的停车场管理系统提取数据的特征值,为每个停车场管理系统形成对应的特征值集; 0030 S2:自动检测当前需要数据采集的停车场管理系统,将当前停车场管理系统的特征值数据与特征值集中的数据进行比较; 0031 S3:如果特征值集中存在当前停车场管理系统的特征值数据,则自动执行当前停车场管理系统数据采集;如果不存在,使用视频采集方法采集停车场数据。 0.
15、032 为了进一步实现上述技术方案,S1还具体包括以下内容: 0033(1)抽象数据库配置,将数据库链接配置抽象成通用配置文件;0034(2)分析不同类型停车场管理系统的停车数据,分析内容包括:数据库类型、车辆进入信息、车辆退出信息和车辆图片信息;0035(3)根据分析结果,形成停车数据0036 为进一步实现上述技术方案,S2中的对比内容包括:停车场数据库特征、出口数据特征、入口0037 为进一步实现上述技术方案,S3自动执行当前停车场管理系统数据。
16、采集具体包括以下方法:0038(1)database方法:直接根据数据库设置和时间设置,采集进入和退出停车场管理系统数据库;0039( 2)云采集方式:数据通过停车场云平台采集,自动获取不同类型的停车管理系统配置脚本,通过网站自动访问,地址跳转,数据查询,结果获取等操作来实现停车数据采集; 0040 为了进一步实现上述技术方案,视频采集方法具体包括以下内容: 0041 比较失败后,自动转换为视频采集方法,ONVIF使用协议实现与车辆抓拍摄像头的连接,获取照片后,利用图像识别技术识别车牌,并结合车辆进出时间和车道信息来实现ze 停车数据采集。 004.
17、2 需要说明的是:在对新的停车场数据执行采集时,采集软件需要与停车场系统服务器在同一网络,以保证网络已解锁; 0043本手册中的各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似的部分互相参见即可。对于本实施例公开的装置,由于其对应于本实施例公开的方法,所以描述的比较简单,相关信息可以参见方法部分的描述。 0044 以上所公开的实施例的描述使本领域技术人员能够实施或使用本发明。对这些实施例的各种修改对于本领域技术人员来说是显而易见的,并且在不脱离本发明的精神或范围的情况下,可以在其他实施例中实现这里定义的一般原理。因此,本发明将不限于本文件中所示的实施例,而应符合与本文件中公开的原理和新颖特征一致的最广泛的范围。说明书3/3 第5页 CN 110992700 A 5 图1 说明书1/1 第6页 CN 110992700 A 6. 查看全部
特殊普通合伙一种基于自动侦测的停车数据采集方法
《基于自动检测技术的停车数据采集方法.pdf》为会员共享,可在线阅读,更多相关《基于自动检测技术的停车数据采集方法.pdf》(6页已完结version) )》请在专利查询网站搜索。
1、(19)中华人民共和国国家知识产权局(12)发明专利申请(10)申请公开号)(43)申请公开日(21)应用号2.7 (22)应用日2019.10.31 (71)申请人地址 215000 江苏省苏州市吴中区昌黎路99号701室( 72)发明人韩宏波)叶军周华建沉凡秦六芳(74)专利代理北京慕大星云知识产权代理(特殊普通合伙)11465 曹鹏飞律师(51)Int.Cl. G08G 1/ 017(2006.) 01) G08G 1/01(2006.01) G08G 1/14(2006.01)(54)发明.
)
2、名一种基于自动检测技术的停车数据采集method (57)Abstract 本发明公开了一种基于自动检测采集方法的停车数据,包括以下步骤: S1:执行特征对不同的停车场管理系统数据进行取值,并为每个停车场管理系统形成对应的特征值集; S2:对当前需要数据采集的停车场管理系统进行自动检测,改变的特征值数据将当前停车场管理系统与特征值集中的数据进行比较; S3:如果特征值集中存在当前停车场管理系统的特征值数据,则自动检查当前停车场管理系统数据的获取;如果不存在,则使用视频采集方法对停车场数据进行采集,本发明兼容市场上现有的停车场系统,实现了停车数据自动化采集。
3、 和概括。权利要求:1页说明书3页附图1页 CN 110992700 A 2020.04.10 CN 110992700 A 1.一种基于自动检测的停车数据采集方法,其特征在于包括步骤如下: S1:针对不同的停车场管理系统数据提取特征值,形成每个停车场管理系统对应的特征值集; S2:自动检测当前需要数据的停车场管理系统采集当前停车场管理系统特征值数据与特征值集中的数据进行比较; S3:如果特征值集合中存在当前停车场管理系统特征值数据,则自动进行当前停车场管理系统数据采集;如果不存在,使用视频采集方法采集停车场数据。 .
4、2.根据权利要求1所述的一种基于自动检测停车数据采集的方法,其特征在于,S1具体还包括以下内容:(1)抽象数据库配置,链接配置为数据库抽象为通用配置文件;(2)分析不同类型停车场管理系统的停车数据,分析内容包括:数据库类型、车辆进入信息、车辆退出信息和车辆图片信息;(3)根据分析结果形成停车数据配置脚本,然后建立收录不同类型停车场管理系统的停车数据配置脚本库3.根据权利要求2的基于自动检测的停车数据采集方法其特征在于S2中的比对内容包括:停车场数据库特征、出口数据特征、入口数据特征。4.自动一致声称 2。
5、Detected parked data采集方法,其特征在于S3中的采集自动执行当前停车场管理系统数据,具体包括以下方法:(1)database方法:直接基于关于数据库设置和时间设置,采集为停车场管理系统数据库的进出数据;(2)云采集方式:数据通过停车场云平台采集,不同类型自动获取停车场管理系统配置脚本通过网站访问、地址跳转、数据查询、结果获取等操作自动实现停车数据采集5.一种根据权利要求1所述的基于自动检测的停车数据采集采集方法的特点是视频采集方法具体包括以下内容:比较失败后自动转换为视频采集方法,通过ONVIF协议实现连接使用车载摄像头进行离子,并在获得照片后。
6、,利用图像识别技术识别车牌,结合车辆进出时间和车道信息,实现停车数据采集。权利要求1/1第2页 CN 110992700 A 2 一种基于自动检测停车数据的技术采集方法技术领域0001 本发明涉及停车管理技术领域,具体涉及一种基于自动检测停车数据的技术采集 方法。背景技术0002随着智能停车技术的发展和普及,各类停车场也逐渐进行了智能化系统改造,利用车牌识别技术实现车辆自动进出管理,同时停车场管理系统监控进出车辆的车牌和照片。记录。随着汽车保有量的不断增加,机动车的爆发式增长在给广大市民带来便利的同时,也带来了治安管理和交通管理。
7、 有一个新话题。停车数据在分析交通拥堵和公共安全控制方面发挥着重要作用。但由于停车管理系统品牌众多、实施方式多样、标准不一致,导致停车场信息采集难以对接。 0003 道路卡口的车辆数据称为动态车辆数据,停车场的车辆数据称为静态数据。经过多年的建设和不断扩大覆盖,动态数据积累了大量的基础数据,但停车数据基本空白,没有应用动态数据和静态数据的关联。只有将静态数据与动态数据相结合,才能称为真正意义上的车辆大数据,而停车场数据联网采集是获取车辆静态数据的首要任务。 0004 但是,现有技术中停车场停车数据的采集数据格式不统一,采集方法不统一。
8、Unification 提问,停车场停车数据格式目前主要包括本地数据库、云平台和混合模式三种。本地数据库数据存储在本地,云平台数据存储在云服务器上,混合模式将数据存储在本地和云端,不同的方式需要采用不同的采集方式。 0005 因此,如何对不同类型的停车场管理系统数据以及各种实现方法进行停车数据采集,并在各个区域建立静态停车数据库,是本领域技术人员急需解决的问题。发明内容0006 有鉴于此,本发明提供一种基于自动检测的停车数据采集方法,能够有效实现对各种停车场管理系统的采集数据处理。 0007 为实现上述目的,本发明采用以下技术方案: 0008 一种基于自动检测的停车数据采集方法。
9、,包括以下步骤: 0009 S1:针对不同的停车场管理系统数据提取特征值,为每个停车场管理系统形成对应的特征值集; 0010 S2:对当前需求进行数据采集的停车场管理系统进行自动检测,将当前停车场管理系统特征值数据与特征值集中的数据进行比较; 0011 S3:如果特征值集合中存在当前停车场管理系统特征值数据,则自动采集当前停车场管理系统数据;如果不存在,使用视频采集方法采集停车场数据。 0012 优选地,S1还具体包括以下内容: 0013(1)抽象出数据库配置,抽象出数据库的链接配置作为通用配置文件;0014(2)针对不同物种。
分析10、型停车场管理系统的停车数据,分析内容包括: 数据库型手册1/3页3 CN 110992700 A Type 3,车辆进入信息、车辆退出信息和车辆图片信息; 0015(3)根据分析结果形成停车数据配置脚本,然后建立收录不同类型停车管理系统的停车数据配置脚本库。0016需要说明的是: 步骤(1)包括以下内容: 将数据库放入文件 配置抽象为参数,将数据库类型、数据库地址、端口、连接用户名、密码配置为参数,以适应不同的数据库系统; 步骤0017(2)在分析停车数据时可以包括:停车字段数据库名称和类型、数据表名称和类型、入口数据项、出口。
11、Field 数据项和barrier 数据项作为自动检测的基础特征。自动检测时,根据特征在特征集中进行搜索,确定停车场的类型。 0018 优选地,S2中的比对内容包括:停车场数据库特征、出口数据特征、入口数据特征。 0019 优选地,S3中自动执行当前停车场管理系统数据的采集具体包括以下方法: 0020(1)Database方法:直接根据数据库设置和时间设置,导出停车管理系统数据库采集入场数据;0021(2)云采集方式:数据通过停车场云平台采集,自动获取不同类型停车管理系统的配置脚本,通过网站自动访问,跳转到地址实现停车数据采集; 0022.
12、 优选地,视频采集方法具体包括以下内容: 0023 比较失败后,自动转换为视频采集方法,通过ONVIF协议实现与车载摄像头。获得照片后,利用图像识别技术识别车牌,结合车辆进出时间和车道信息,实现采集停车数据。 0024 从上述技术方案可以看出,与现有技术相比,本发明提供了一种基于自动检测的停车数据采集方法,能够自动检测停车场系统的实现方式和数据结构。接口用于实现多种模式的停车数据采集,采用顶层抽象屏蔽网络层的多样性,兼容目前市面上的停车系统,实现自动化和停车数据的泛化采集。附图说明0025为了更清楚地说明实施例或本发明。
13、 技术中有技术方案。下面将对在描述实施例或现有技术时需要用到的附图进行简要介绍。显然,以下描述中的附图仅是本发明的附图。在实施例中,对于本领域普通技术人员来说,在没有创造性劳动的情况下,可以根据所提供的附图获得其他附图。图 0026图1为本发明提供的基于自动检测的停车数据采集方法的流程图。具体实施方式0027下面将结合本发明实施例中的附图,对本发明实施例中的技术方案进行清楚、完整的说明。显然,所描述的实施例只是本发明的一部分实施例,而不是全部的实施例。例子。基于本发明中的实施例,本领域普通技术人员在没有做出创造性劳动前提下所获得的所有其他实施例,都不是。
14、属于本发明的保护范围。 0028 如图1所示,本发明实施例公开了一种基于自动检测的停车数据采集方法,包括以下步骤: 手册2/3 页4 CN 110992700 A 4 0029 S1:针对不同的停车场管理系统提取数据的特征值,为每个停车场管理系统形成对应的特征值集; 0030 S2:自动检测当前需要数据采集的停车场管理系统,将当前停车场管理系统的特征值数据与特征值集中的数据进行比较; 0031 S3:如果特征值集中存在当前停车场管理系统的特征值数据,则自动执行当前停车场管理系统数据采集;如果不存在,使用视频采集方法采集停车场数据。 0.
15、032 为了进一步实现上述技术方案,S1还具体包括以下内容: 0033(1)抽象数据库配置,将数据库链接配置抽象成通用配置文件;0034(2)分析不同类型停车场管理系统的停车数据,分析内容包括:数据库类型、车辆进入信息、车辆退出信息和车辆图片信息;0035(3)根据分析结果,形成停车数据0036 为进一步实现上述技术方案,S2中的对比内容包括:停车场数据库特征、出口数据特征、入口0037 为进一步实现上述技术方案,S3自动执行当前停车场管理系统数据。
16、采集具体包括以下方法:0038(1)database方法:直接根据数据库设置和时间设置,采集进入和退出停车场管理系统数据库;0039( 2)云采集方式:数据通过停车场云平台采集,自动获取不同类型的停车管理系统配置脚本,通过网站自动访问,地址跳转,数据查询,结果获取等操作来实现停车数据采集; 0040 为了进一步实现上述技术方案,视频采集方法具体包括以下内容: 0041 比较失败后,自动转换为视频采集方法,ONVIF使用协议实现与车辆抓拍摄像头的连接,获取照片后,利用图像识别技术识别车牌,并结合车辆进出时间和车道信息来实现ze 停车数据采集。 004.
17、2 需要说明的是:在对新的停车场数据执行采集时,采集软件需要与停车场系统服务器在同一网络,以保证网络已解锁; 0043本手册中的各个实施例采用递进的方式描述,每个实施例重点说明的都是与其他实施例的不同之处,各个实施例之间相同相似的部分互相参见即可。对于本实施例公开的装置,由于其对应于本实施例公开的方法,所以描述的比较简单,相关信息可以参见方法部分的描述。 0044 以上所公开的实施例的描述使本领域技术人员能够实施或使用本发明。对这些实施例的各种修改对于本领域技术人员来说是显而易见的,并且在不脱离本发明的精神或范围的情况下,可以在其他实施例中实现这里定义的一般原理。因此,本发明将不限于本文件中所示的实施例,而应符合与本文件中公开的原理和新颖特征一致的最广泛的范围。说明书3/3 第5页 CN 110992700 A 5 图1 说明书1/1 第6页 CN 110992700 A 6.
学习IBM如何实现Java平台5.0版中内置的高级功能?
采集交流 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-08-10 04:20
可以使用四种不同的策略在 IBM Developer Suite (IBM SDK) 中为 Java 5.0 平台配置垃圾回收 (GC)。本文是GC两部分的第一部分。它介绍了不同的垃圾采集策略并讨论了它们的一般特征。在开始之前,您应该对 Java 平台中的垃圾采集有一个基本的了解。第 2 部分介绍了选择策略的定量方法并提供了一些示例。
关于系列
Java 技术,IBM 风格系列介绍了 Java 平台的 IBM 实现的最新版本。您将了解 IBM 如何实现 Java 平台 5.0 中内置的一些高级功能,并了解如何使用新 IBM 版本中内置的一些增值功能。
如有任何意见或问题,请联系作者。要对整个系列发表评论,请联系系列负责人 Chris Bailey。有关此处讨论的概念的更多信息以及下载最新 IBM 版本的链接,请参阅。
为什么要使用不同的 GC 政策?
不同 GC 策略的可用性为您提供了增强的功能。 GC 有许多不同的算法可用,根据工作负载的类型,每种算法都有自己的优点和缺点。 (如果您不熟悉GC算法的一般主题,请参阅进一步阅读。)在IBM SDK5.0中,您可以使用四种策略之一来配置垃圾采集器,每种策略使用自己的算法。对于大多数应用程序,默认策略就足够了。如果您对应用程序没有任何特定的性能要求,那么本文(以及下一篇)的内容可能对您不感兴趣。您可以在不更改 GC 策略的情况下运行 IBM SDK 5.0。但是,如果您的应用程序需要最佳性能,或者您通常担心 GC 暂停时间,请继续阅读。您会看到最新版本的 IBM 比之前的版本有更多的选项。
那么,为什么没有自动为您选择 Java 运行时的 IBM 实现?这并不总是可能的。在运行时很难理解您的需求。在某些情况下,您可能希望以高吞吐量运行应用程序。在其他情况下,您可能希望减少暂停时间。
表 1 列出了可用的策略并指出了每种策略的使用时间。以下部分将详细介绍每种策略的特点。
表1.IBM SDK 5.0 策略选项说明中的GC策略
优化吞吐量
-Xgcpolicy:optthruput(可选)
默认策略。它通常用于原创吞吐量比短暂的 GC 暂停更重要的应用程序。每次采集垃圾时,应用程序都会停止。
优化暂停时间
-Xgcpolicy:optavgpause
通过同时执行一些垃圾回收,高吞吐量换来了更短的 GC 暂停。应用程序被暂停了很短的时间。
生成并发
-Xgcpolicy:gencon
短期对象与长期对象的处理方式不同。通过这种策略,具有许多短期对象的应用程序可以看到更短的暂停时间,同时仍能产生良好的吞吐量。
子池化
-Xgcpolicy:subpool
使用类似于默认策略的算法,但使用更适合多处理器计算机的分配策略。对于具有 16 个或更多处理器的 SMP 计算机,我们建议使用此策略。此策略仅适用于 IBMpSeries® 和 zSeries® 平台。需要在大型计算机上扩展的应用程序可以从这种策略中受益。
定义了一些术语
吞吐量是应用程序处理的数据量。必须使用特定于应用程序的指标来衡量吞吐量。
暂停时间是垃圾采集器暂停所有应用程序线程以采集堆的持续时间。
在本文中,我使用表1中详述的命令行选项的缩写来表示以下策略:优化吞吐量的optthruput),优化暂停时间的optavgpause),分代并发的gencon)和子池于子池) .
什么时候应该考虑非默认 GC 策略?
我建议您始终从默认的 GC 策略开始。在摆脱默认设置之前,您需要了解在什么情况下应该探索替代策略。表2列出了一系列可能的原因:
列出2.切换到备用GC策略的原因切换原因
optavgpause
gencon
子池
让我强调,表 2 中提到的原因不足以得出替代政策会表现更好的结论。它们只是提示。在所有情况下,您都应该运行应用程序并结合 GC 暂停时间来测量吞吐量和/或响应时间。本系列的下一部分将展示此类测试的示例。
本文的其余部分将详细介绍 GC 策略之间的差异。
光通量
堆碎片的迹象
堆碎片最常见的迹象是过早的分配失败。这被认为是在详细垃圾采集 (-Xverbose:gc) 中触发的 GC,即使堆上有可用空间。另一个标志是存在小线程分配缓冲区(请参阅“”部分)。您可以使用 -Xtgc:freelist 来确定平均大小。 IBM SDK 5 诊断指南中解释了这两个选项。
optthruput 是默认策略。它是一个跟踪采集器,称为标记扫描紧凑采集器。标记和扫描阶段总是在 GC 期间运行,但压缩仅在某些情况下发生。标记阶段查找并标记所有活动对象。所有未标记的对象将在扫描阶段被删除。第三步也是可选的步骤是压实。压实可以在各种情况下发生。最常见的一种是系统无法回收足够的可用空间。
当对象被频繁地分配和释放以致堆中只剩下一小块空闲空间时,就会发生碎片。堆整体可能有很多空闲空间,但是连续区域很小,导致分配失败。压缩将所有对象向下移动到堆的开头并对齐它们,以便它们之间没有空间。这消除了堆中的碎片,但这是一项昂贵的任务,因此仅在必要时执行。
图 1 显示了经过不同阶段的堆布局的轮廓:标记、清除和压缩。暗区代表物体,亮区代表自由空间。
扫一扫
标记阶段遍历所有可以从线程栈、静态变量、插入的字符串和JNI引用中引用的对象。作为此过程的一部分,我们将创建一个标记位向量来定义所有活动对象的开头。
扫描阶段使用标记阶段生成的标记位向量来标识堆中存储的块,可以回收这些块以备将来分配;这些块被添加到空闲列表中。
图1.垃圾回收前后的堆布局
有关不同 GC 阶段如何工作的详细信息超出了本文的范围。我的观点是确保您了解运行时特征。我鼓励您阅读“诊断指南”(请参阅)了解更多信息。
图 2 说明了如何在应用程序线程(或 mutator)和 GC 线程之间分配执行时间。横轴是经过的时间,纵轴是线程,其中 n 代表计算机上的处理器数量。在此描述中,假设应用程序使用每个处理器一个线程。 GC 用蓝色框表示,表示停止的突变体和 GC 线程正在运行。这些集合消耗了 100% 的 CPU 资源,并且转换器线程处于空闲状态。该图过于笼统,因此我们可以将此策略与本文中的其他策略进行比较。实际上,GC 的持续时间和频率取决于应用程序和工作量。
图2.optthruput策略在mutator和GC线程之间的CPU时间分配
Mutator 和 GC 线程
mutator 线程是一个分配对象的应用程序。 mutator 的另一个词是应用程序。 GC 线程是内存管理的一部分并执行垃圾采集。
堆锁和线程分配缓存
optthruput 策略使用应用程序中所有线程共享的连续堆区域。线程需要独占访问堆来为新对象保留空间。这种锁称为堆锁,可确保一次只有一个线程可以分配一个对象。在具有多个 CPU 的计算机上,此锁可能会导致扩展问题,因为可以同时发生多个分配请求,但每个分配请求都必须对堆锁具有独占访问权限。
为了减少这个问题,每个线程都会保留一小部分内存,称为线程分配缓存(也称为线程本地堆或TLH)。这部分存储空间是线程特定的,因此当从中分配内存时,不会使用堆锁。当分配缓冲区已满时,线程将返回堆并使用堆锁请求新的堆。
堆的碎片化会阻止线程获得更大的TLH,因此TLH会很快填满,导致应用线程频繁返回堆以换取新的TLH。在这种情况下,堆锁成为瓶颈。在这种情况下,gencon 或 sub-subpool 策略可以提供一个不错的选择。
暂停
对于许多应用程序,吞吐量不如快速响应时间重要。考虑一个工作项的处理时间不能超过 100 毫秒的应用程序。由于 GC 暂停时间在 100 毫秒内,您将获得在此时间范围内无法处理的项目。垃圾回收的问题在于暂停时间会增加处理项目所需的最长时间。大堆大小(在 64 位平台上可用)会增加这种影响,因为处理的对象更多。
optavgpause 是另一种旨在最小化暂停时间的 GC 策略。它不能保证特定的暂停时间,但暂停时间比默认 GC 策略生成的暂停时间短。这个想法是在应用程序运行时执行一些垃圾采集。这是在两个地方完成的:
根据不同的应用,默认的 GC 策略会降低 5% 到 10% 的吞吐量性能。
图 3 说明了如何使用 optavgpause 在 GC 线程和 mutator 线程之间分配执行时间。后台跟踪线程不显示,因为它不会影响应用程序性能。
图3.optavgpause策略在mutator和GC线程之间的CPU时间分配
图中灰色区域表示已启用并发跟踪,每个mutator线程必须放弃一些处理时间。每个并发阶段完成一次垃圾回收后,完成并发阶段未发生的标记和清除。由此产生的暂停应该比 optthruput 看到的正常 GC 短很多,如图 3 时间刻度上的小框所示。 GC 结束和并发阶段开始之间的差距是不同的,但在这个阶段,对性能没有显着影响。
Gencon
分代垃圾回收策略考虑对象的生命周期,将它们放在堆的单独区域。通过这种方式,它试图克服单个堆在大多数对象年轻和死亡的应用程序中的缺点,即这些对象不能承受多次垃圾采集。
使用代GC,倾向于将长期对象与短期对象区别对待。如图4所示,桩被划分为苗圃和苗圃区。在托儿所中创建对象,如果对象存活时间足够长,则将它们提升到托儿所区域。经过一定量的垃圾采集后,该对象将被提升。这个想法是大多数对象都是短暂的。通过频繁采集托儿所,可以释放这些对象,而无需支付采集整个堆的成本。租用区域很少采集垃圾。
新旧区图4.gencon GC
如图 4 所示,托儿所分为两个空间:分配和幸存者。将对象分配到分配的空间。当对象已满时,活动对象将根据其年龄被复制到survivor空间或tenure空间。然后,将托儿所中的空间切换为使用,分配成为幸存者,幸存者成为分配者。死对象占用的空间可以简单地被新分配覆盖。苗圃采集被称为清道夫;图 5 说明了此过程中发生的情况:
图5.GC前后堆布局示例
当分配的空间已满时,会触发垃圾回收。然后跟踪活动对象并将其复制到幸存者空间。如果大部分对象都死了,这个过程的成本真的不高。此外,达到复制阈值计数的对象将被提升到到期空间。然后说对象是永久的。
顾名思义,代表并发,gencon 策略有它的并发方面。租用的空间也使用类似于 optavgpause 策略中使用的方法进行标记,但不执行并发扫描。在并发阶段,所有分配都会支付少量的吞吐量税。这样,可以将tenure space的采集产生的停顿时间保持在很小的范围内。
图 6 显示了在运行 gencon GC 时如何映射执行时间:
图6.gencon 在mutator和GC线程之间的CPU时间分布
清道夫很短(显示在红色框中)。灰色表示开始并发跟踪,然后是占用空间的集合,其中一些是并发发生的。这称为全局集,包括明文集和使用权空间集。全局采集发生的频率取决于堆大小和对象生命周期。租用空间的采集应该是比较快的,因为大部分空间是同时采集的。
子池
子子池策略有助于提高多处理器系统的性能。如前所述,此策略仅适用于 IBM pSeries 和 zSeries 计算机。堆布局与 optthruput 策略相同,但空闲列表的结构不同。有多个列表而不是整个堆的空闲列表,称为子池。每个池都有一个关联的大小,可以根据这些大小对池进行排序。通过去这个大小的池,可以快速满足一定大小的分配请求。原子(平台相关)高性能指令用于从列表中弹出空闲列表条目,从而避免序列化访问。图 7 显示了如何按大小组织存储的空闲块:
图片7.按大小排序的子池的空闲块
当JVM启动或者发生压缩时,由于堆的可用区域很大,所以不使用子池。在这些情况下,每个处理器都有自己的专用迷你堆来满足请求。当第一次垃圾回收发生时,清除阶段开始填充子池,后续的分配主要使用子池。
sub-subpool 策略可以减少分配对象的时间。原子指令确保在不获取全局堆锁的情况下进行分配。处理器本地的小堆提高了效率,因为它减少了缓存干扰。这直接影响可扩展性,尤其是在多处理器系统上。在子池不可用的平台上,生成 GC 可以提供类似的好处。
结论
本文重点介绍 IBM SDK 5.0 中可用的不同 GC 策略选项及其一些特征。默认策略足以满足大多数应用程序的需求。但是,在某些情况下,其他策略效果更好。我已经介绍了一些一般情况,在这些情况下你应该考虑切换到 optavgpause、gencon 或 subpool。在评估策略时,衡量应用程序性能非常重要,第 2 部分将更详细地演示评估过程。
翻译自: 查看全部
学习IBM如何实现Java平台5.0版中内置的高级功能?
可以使用四种不同的策略在 IBM Developer Suite (IBM SDK) 中为 Java 5.0 平台配置垃圾回收 (GC)。本文是GC两部分的第一部分。它介绍了不同的垃圾采集策略并讨论了它们的一般特征。在开始之前,您应该对 Java 平台中的垃圾采集有一个基本的了解。第 2 部分介绍了选择策略的定量方法并提供了一些示例。
关于系列
Java 技术,IBM 风格系列介绍了 Java 平台的 IBM 实现的最新版本。您将了解 IBM 如何实现 Java 平台 5.0 中内置的一些高级功能,并了解如何使用新 IBM 版本中内置的一些增值功能。
如有任何意见或问题,请联系作者。要对整个系列发表评论,请联系系列负责人 Chris Bailey。有关此处讨论的概念的更多信息以及下载最新 IBM 版本的链接,请参阅。
为什么要使用不同的 GC 政策?
不同 GC 策略的可用性为您提供了增强的功能。 GC 有许多不同的算法可用,根据工作负载的类型,每种算法都有自己的优点和缺点。 (如果您不熟悉GC算法的一般主题,请参阅进一步阅读。)在IBM SDK5.0中,您可以使用四种策略之一来配置垃圾采集器,每种策略使用自己的算法。对于大多数应用程序,默认策略就足够了。如果您对应用程序没有任何特定的性能要求,那么本文(以及下一篇)的内容可能对您不感兴趣。您可以在不更改 GC 策略的情况下运行 IBM SDK 5.0。但是,如果您的应用程序需要最佳性能,或者您通常担心 GC 暂停时间,请继续阅读。您会看到最新版本的 IBM 比之前的版本有更多的选项。
那么,为什么没有自动为您选择 Java 运行时的 IBM 实现?这并不总是可能的。在运行时很难理解您的需求。在某些情况下,您可能希望以高吞吐量运行应用程序。在其他情况下,您可能希望减少暂停时间。
表 1 列出了可用的策略并指出了每种策略的使用时间。以下部分将详细介绍每种策略的特点。
表1.IBM SDK 5.0 策略选项说明中的GC策略
优化吞吐量
-Xgcpolicy:optthruput(可选)
默认策略。它通常用于原创吞吐量比短暂的 GC 暂停更重要的应用程序。每次采集垃圾时,应用程序都会停止。
优化暂停时间
-Xgcpolicy:optavgpause
通过同时执行一些垃圾回收,高吞吐量换来了更短的 GC 暂停。应用程序被暂停了很短的时间。
生成并发
-Xgcpolicy:gencon
短期对象与长期对象的处理方式不同。通过这种策略,具有许多短期对象的应用程序可以看到更短的暂停时间,同时仍能产生良好的吞吐量。
子池化
-Xgcpolicy:subpool
使用类似于默认策略的算法,但使用更适合多处理器计算机的分配策略。对于具有 16 个或更多处理器的 SMP 计算机,我们建议使用此策略。此策略仅适用于 IBMpSeries® 和 zSeries® 平台。需要在大型计算机上扩展的应用程序可以从这种策略中受益。
定义了一些术语
吞吐量是应用程序处理的数据量。必须使用特定于应用程序的指标来衡量吞吐量。
暂停时间是垃圾采集器暂停所有应用程序线程以采集堆的持续时间。
在本文中,我使用表1中详述的命令行选项的缩写来表示以下策略:优化吞吐量的optthruput),优化暂停时间的optavgpause),分代并发的gencon)和子池于子池) .
什么时候应该考虑非默认 GC 策略?
我建议您始终从默认的 GC 策略开始。在摆脱默认设置之前,您需要了解在什么情况下应该探索替代策略。表2列出了一系列可能的原因:
列出2.切换到备用GC策略的原因切换原因
optavgpause
gencon
子池
让我强调,表 2 中提到的原因不足以得出替代政策会表现更好的结论。它们只是提示。在所有情况下,您都应该运行应用程序并结合 GC 暂停时间来测量吞吐量和/或响应时间。本系列的下一部分将展示此类测试的示例。
本文的其余部分将详细介绍 GC 策略之间的差异。
光通量
堆碎片的迹象
堆碎片最常见的迹象是过早的分配失败。这被认为是在详细垃圾采集 (-Xverbose:gc) 中触发的 GC,即使堆上有可用空间。另一个标志是存在小线程分配缓冲区(请参阅“”部分)。您可以使用 -Xtgc:freelist 来确定平均大小。 IBM SDK 5 诊断指南中解释了这两个选项。
optthruput 是默认策略。它是一个跟踪采集器,称为标记扫描紧凑采集器。标记和扫描阶段总是在 GC 期间运行,但压缩仅在某些情况下发生。标记阶段查找并标记所有活动对象。所有未标记的对象将在扫描阶段被删除。第三步也是可选的步骤是压实。压实可以在各种情况下发生。最常见的一种是系统无法回收足够的可用空间。
当对象被频繁地分配和释放以致堆中只剩下一小块空闲空间时,就会发生碎片。堆整体可能有很多空闲空间,但是连续区域很小,导致分配失败。压缩将所有对象向下移动到堆的开头并对齐它们,以便它们之间没有空间。这消除了堆中的碎片,但这是一项昂贵的任务,因此仅在必要时执行。
图 1 显示了经过不同阶段的堆布局的轮廓:标记、清除和压缩。暗区代表物体,亮区代表自由空间。
扫一扫
标记阶段遍历所有可以从线程栈、静态变量、插入的字符串和JNI引用中引用的对象。作为此过程的一部分,我们将创建一个标记位向量来定义所有活动对象的开头。
扫描阶段使用标记阶段生成的标记位向量来标识堆中存储的块,可以回收这些块以备将来分配;这些块被添加到空闲列表中。
图1.垃圾回收前后的堆布局
有关不同 GC 阶段如何工作的详细信息超出了本文的范围。我的观点是确保您了解运行时特征。我鼓励您阅读“诊断指南”(请参阅)了解更多信息。
图 2 说明了如何在应用程序线程(或 mutator)和 GC 线程之间分配执行时间。横轴是经过的时间,纵轴是线程,其中 n 代表计算机上的处理器数量。在此描述中,假设应用程序使用每个处理器一个线程。 GC 用蓝色框表示,表示停止的突变体和 GC 线程正在运行。这些集合消耗了 100% 的 CPU 资源,并且转换器线程处于空闲状态。该图过于笼统,因此我们可以将此策略与本文中的其他策略进行比较。实际上,GC 的持续时间和频率取决于应用程序和工作量。
图2.optthruput策略在mutator和GC线程之间的CPU时间分配
Mutator 和 GC 线程
mutator 线程是一个分配对象的应用程序。 mutator 的另一个词是应用程序。 GC 线程是内存管理的一部分并执行垃圾采集。
堆锁和线程分配缓存
optthruput 策略使用应用程序中所有线程共享的连续堆区域。线程需要独占访问堆来为新对象保留空间。这种锁称为堆锁,可确保一次只有一个线程可以分配一个对象。在具有多个 CPU 的计算机上,此锁可能会导致扩展问题,因为可以同时发生多个分配请求,但每个分配请求都必须对堆锁具有独占访问权限。
为了减少这个问题,每个线程都会保留一小部分内存,称为线程分配缓存(也称为线程本地堆或TLH)。这部分存储空间是线程特定的,因此当从中分配内存时,不会使用堆锁。当分配缓冲区已满时,线程将返回堆并使用堆锁请求新的堆。
堆的碎片化会阻止线程获得更大的TLH,因此TLH会很快填满,导致应用线程频繁返回堆以换取新的TLH。在这种情况下,堆锁成为瓶颈。在这种情况下,gencon 或 sub-subpool 策略可以提供一个不错的选择。
暂停
对于许多应用程序,吞吐量不如快速响应时间重要。考虑一个工作项的处理时间不能超过 100 毫秒的应用程序。由于 GC 暂停时间在 100 毫秒内,您将获得在此时间范围内无法处理的项目。垃圾回收的问题在于暂停时间会增加处理项目所需的最长时间。大堆大小(在 64 位平台上可用)会增加这种影响,因为处理的对象更多。
optavgpause 是另一种旨在最小化暂停时间的 GC 策略。它不能保证特定的暂停时间,但暂停时间比默认 GC 策略生成的暂停时间短。这个想法是在应用程序运行时执行一些垃圾采集。这是在两个地方完成的:
根据不同的应用,默认的 GC 策略会降低 5% 到 10% 的吞吐量性能。
图 3 说明了如何使用 optavgpause 在 GC 线程和 mutator 线程之间分配执行时间。后台跟踪线程不显示,因为它不会影响应用程序性能。
图3.optavgpause策略在mutator和GC线程之间的CPU时间分配
图中灰色区域表示已启用并发跟踪,每个mutator线程必须放弃一些处理时间。每个并发阶段完成一次垃圾回收后,完成并发阶段未发生的标记和清除。由此产生的暂停应该比 optthruput 看到的正常 GC 短很多,如图 3 时间刻度上的小框所示。 GC 结束和并发阶段开始之间的差距是不同的,但在这个阶段,对性能没有显着影响。
Gencon
分代垃圾回收策略考虑对象的生命周期,将它们放在堆的单独区域。通过这种方式,它试图克服单个堆在大多数对象年轻和死亡的应用程序中的缺点,即这些对象不能承受多次垃圾采集。
使用代GC,倾向于将长期对象与短期对象区别对待。如图4所示,桩被划分为苗圃和苗圃区。在托儿所中创建对象,如果对象存活时间足够长,则将它们提升到托儿所区域。经过一定量的垃圾采集后,该对象将被提升。这个想法是大多数对象都是短暂的。通过频繁采集托儿所,可以释放这些对象,而无需支付采集整个堆的成本。租用区域很少采集垃圾。
新旧区图4.gencon GC
如图 4 所示,托儿所分为两个空间:分配和幸存者。将对象分配到分配的空间。当对象已满时,活动对象将根据其年龄被复制到survivor空间或tenure空间。然后,将托儿所中的空间切换为使用,分配成为幸存者,幸存者成为分配者。死对象占用的空间可以简单地被新分配覆盖。苗圃采集被称为清道夫;图 5 说明了此过程中发生的情况:
图5.GC前后堆布局示例
当分配的空间已满时,会触发垃圾回收。然后跟踪活动对象并将其复制到幸存者空间。如果大部分对象都死了,这个过程的成本真的不高。此外,达到复制阈值计数的对象将被提升到到期空间。然后说对象是永久的。
顾名思义,代表并发,gencon 策略有它的并发方面。租用的空间也使用类似于 optavgpause 策略中使用的方法进行标记,但不执行并发扫描。在并发阶段,所有分配都会支付少量的吞吐量税。这样,可以将tenure space的采集产生的停顿时间保持在很小的范围内。
图 6 显示了在运行 gencon GC 时如何映射执行时间:
图6.gencon 在mutator和GC线程之间的CPU时间分布
清道夫很短(显示在红色框中)。灰色表示开始并发跟踪,然后是占用空间的集合,其中一些是并发发生的。这称为全局集,包括明文集和使用权空间集。全局采集发生的频率取决于堆大小和对象生命周期。租用空间的采集应该是比较快的,因为大部分空间是同时采集的。
子池
子子池策略有助于提高多处理器系统的性能。如前所述,此策略仅适用于 IBM pSeries 和 zSeries 计算机。堆布局与 optthruput 策略相同,但空闲列表的结构不同。有多个列表而不是整个堆的空闲列表,称为子池。每个池都有一个关联的大小,可以根据这些大小对池进行排序。通过去这个大小的池,可以快速满足一定大小的分配请求。原子(平台相关)高性能指令用于从列表中弹出空闲列表条目,从而避免序列化访问。图 7 显示了如何按大小组织存储的空闲块:
图片7.按大小排序的子池的空闲块
当JVM启动或者发生压缩时,由于堆的可用区域很大,所以不使用子池。在这些情况下,每个处理器都有自己的专用迷你堆来满足请求。当第一次垃圾回收发生时,清除阶段开始填充子池,后续的分配主要使用子池。
sub-subpool 策略可以减少分配对象的时间。原子指令确保在不获取全局堆锁的情况下进行分配。处理器本地的小堆提高了效率,因为它减少了缓存干扰。这直接影响可扩展性,尤其是在多处理器系统上。在子池不可用的平台上,生成 GC 可以提供类似的好处。
结论
本文重点介绍 IBM SDK 5.0 中可用的不同 GC 策略选项及其一些特征。默认策略足以满足大多数应用程序的需求。但是,在某些情况下,其他策略效果更好。我已经介绍了一些一般情况,在这些情况下你应该考虑切换到 optavgpause、gencon 或 subpool。在评估策略时,衡量应用程序性能非常重要,第 2 部分将更详细地演示评估过程。
翻译自:
3.自动化工具.autojs模拟用户抖音列表接口的部署
采集交流 • 优采云 发表了文章 • 0 个评论 • 516 次浏览 • 2021-08-08 21:11
目的:采集抖音非常受欢迎的视频(要自动化)
抖音的防爬技术很好,据说还有防爬的部门。所以通过编写代码直接访问抖音接口,是达不到目的的。数据只能通过模拟真实用户行为获得。
我的主要实现方式是:通过在Android模拟器中模拟用户的滑动,通过网络代理拦截滑动过程中产生的数据
开发中使用的工具:
硬件:需要一台免费的电脑,
软件:auto.js、Android模拟器、代理服务项目、按钮向导、抓包工具
开发过程
1 确定抖音的哪个接口使用采集data
考虑从首页推荐列表或用户工作列表中获取数据。
我用的fiddler抓包工具,
抓取首页推荐列表界面,发现数据格式为Protobuf,是一种传输速度更快,占用空间更少的数据格式。解析这种格式需要支持文件。所以我们无法解析并放弃页面推荐列表。
尝试从用户的工作列表界面抓包,发现是json格式,可以获取视频信息。所以我决定获取用户作品列表采集。
2.自动化工具auto.js模拟用户滑动抖音list
为了保证采集的视频受欢迎,我们用户的作品并非都是采集。所以我们模拟了用户的行为:在首页的推荐视频中滑动,滑动到超过10万赞的视频,向左滑动,进入视频作者的作品列表。
首先在你的电脑上安装安卓模拟器,我用的是天天模拟器
在模拟器中安装抖音和auto.js应用,编写auto.js自动化脚本,并运行脚本。
这是我写的 auto.js 脚本。供您参考
<p>var myDate = new Date();
var hours = myDate.getHours();
if (hours >= 0) {
console.log("去启动抖音");
launchApp("抖音");
sleep(7000)
while (true) {
是否满足赞();
左滑进入个人中心();
判断是否出去();
关闭崩溃应用();
toast("quit persion center ")
退出个人中心();
//Swipe(10, device.height / 2,device.width / 2, device.height / 2, 10, 300);//向右滑
sleep(2000);
toast("hua dong cao zuo ")
Swipe(device.width / 2, device.height / 1.5, device.width / 2, 10, 500); //向下滑
sleep(3000);
每10分钟重启();
取消弹框();
判断是否出去();
关闭崩溃应用();
}
}
function 是否满足赞() {
log("是否满足赞")
try {
//不满足1万的赞划走
while (isTrue()) {
Swipe(device.width / 2, device.height / 1.5, device.width / 2, 10, 500); //向下滑
toast("Dig not satisfied")
sleep(1500);
退出个人中心();
}
} catch (e) {}
}
function isTrue() {
// var u = id("aen").find()
// var e = u.length - 2
// var tv = u[e];
return false;
var like = 0;
try {
var b = id("com.ss.android.ugc.aweme:id/aer").find();
var a = b[1].desc()
if (a && a.indexOf("喜欢") > -1) {
like = a.substring(a.indexOf("喜欢") + 2, a.indexOf(",按钮"));
toastLog(like);
}
} catch (e) {}
if (like.indexOf("w") == -1) {
return true;
} else {
return like.substr(0, like.indexOf("w")) -1) {
if (parseInt(totallike.substr(0, totallike.length - 1)) >= 1000) {
//关注作者
payAttention(totallike, totalfans, uniqueid, authorname);
}
}
//总点赞数或粉丝数大于1亿 关注作者并抓取更多
if (authorname && totallike.indexOf("亿") > -1 || totalfans.indexOf("亿") > -1) {
//关注作者
loadMore = payAttention(totallike, totalfans, uniqueid, authorname);
}
//粉丝量大于500W 关注作者, 如果粉丝量大于1000W 抓取作者更多作品
if (authorname && totalfans.indexOf("w") > -1) {
var fansCount = parseInt(totalfans.substr(0, totalfans.length - 1));
if (fansCount >= 500 && fansCount = 1000) {
loadMore = payAttention(totallike, totalfans, uniqueid, authorname);
}
}
if (loadMore) {
sleep(4000);
log("into swipe action ")
for (var i = 0; i 查看全部
3.自动化工具.autojs模拟用户抖音列表接口的部署
目的:采集抖音非常受欢迎的视频(要自动化)
抖音的防爬技术很好,据说还有防爬的部门。所以通过编写代码直接访问抖音接口,是达不到目的的。数据只能通过模拟真实用户行为获得。
我的主要实现方式是:通过在Android模拟器中模拟用户的滑动,通过网络代理拦截滑动过程中产生的数据
开发中使用的工具:
硬件:需要一台免费的电脑,
软件:auto.js、Android模拟器、代理服务项目、按钮向导、抓包工具
开发过程
1 确定抖音的哪个接口使用采集data
考虑从首页推荐列表或用户工作列表中获取数据。
我用的fiddler抓包工具,
抓取首页推荐列表界面,发现数据格式为Protobuf,是一种传输速度更快,占用空间更少的数据格式。解析这种格式需要支持文件。所以我们无法解析并放弃页面推荐列表。
尝试从用户的工作列表界面抓包,发现是json格式,可以获取视频信息。所以我决定获取用户作品列表采集。
2.自动化工具auto.js模拟用户滑动抖音list
为了保证采集的视频受欢迎,我们用户的作品并非都是采集。所以我们模拟了用户的行为:在首页的推荐视频中滑动,滑动到超过10万赞的视频,向左滑动,进入视频作者的作品列表。
首先在你的电脑上安装安卓模拟器,我用的是天天模拟器
在模拟器中安装抖音和auto.js应用,编写auto.js自动化脚本,并运行脚本。
这是我写的 auto.js 脚本。供您参考
<p>var myDate = new Date();
var hours = myDate.getHours();
if (hours >= 0) {
console.log("去启动抖音");
launchApp("抖音");
sleep(7000)
while (true) {
是否满足赞();
左滑进入个人中心();
判断是否出去();
关闭崩溃应用();
toast("quit persion center ")
退出个人中心();
//Swipe(10, device.height / 2,device.width / 2, device.height / 2, 10, 300);//向右滑
sleep(2000);
toast("hua dong cao zuo ")
Swipe(device.width / 2, device.height / 1.5, device.width / 2, 10, 500); //向下滑
sleep(3000);
每10分钟重启();
取消弹框();
判断是否出去();
关闭崩溃应用();
}
}
function 是否满足赞() {
log("是否满足赞")
try {
//不满足1万的赞划走
while (isTrue()) {
Swipe(device.width / 2, device.height / 1.5, device.width / 2, 10, 500); //向下滑
toast("Dig not satisfied")
sleep(1500);
退出个人中心();
}
} catch (e) {}
}
function isTrue() {
// var u = id("aen").find()
// var e = u.length - 2
// var tv = u[e];
return false;
var like = 0;
try {
var b = id("com.ss.android.ugc.aweme:id/aer").find();
var a = b[1].desc()
if (a && a.indexOf("喜欢") > -1) {
like = a.substring(a.indexOf("喜欢") + 2, a.indexOf(",按钮"));
toastLog(like);
}
} catch (e) {}
if (like.indexOf("w") == -1) {
return true;
} else {
return like.substr(0, like.indexOf("w")) -1) {
if (parseInt(totallike.substr(0, totallike.length - 1)) >= 1000) {
//关注作者
payAttention(totallike, totalfans, uniqueid, authorname);
}
}
//总点赞数或粉丝数大于1亿 关注作者并抓取更多
if (authorname && totallike.indexOf("亿") > -1 || totalfans.indexOf("亿") > -1) {
//关注作者
loadMore = payAttention(totallike, totalfans, uniqueid, authorname);
}
//粉丝量大于500W 关注作者, 如果粉丝量大于1000W 抓取作者更多作品
if (authorname && totalfans.indexOf("w") > -1) {
var fansCount = parseInt(totalfans.substr(0, totalfans.length - 1));
if (fansCount >= 500 && fansCount = 1000) {
loadMore = payAttention(totallike, totalfans, uniqueid, authorname);
}
}
if (loadMore) {
sleep(4000);
log("into swipe action ")
for (var i = 0; i
本文重点在实现(x86gccunixunix)like环境下
采集交流 • 优采云 发表了文章 • 0 个评论 • 88 次浏览 • 2021-08-08 07:32
注:本文重点是实现(在x86 gcc unix like环境下),而不是算法(否则最简单的回收算法就不用了),纯粹用于教学(娱乐)目的。它不注重效率,但可以使用。 ,并且没有继续支持多线程。
具体代码在github上:[]
目录:
实现中的重点难点介绍:原理图代码的外部接口部分:
#include "interface3.h"
#include // 必要头文件
int main()
{
__gc_init(); /* to init gc */
/*add some code you like*/
...
/* need some memory in heap */
void *forgetToFree = (void *)gc_calloc(sizeof(struct XXX));
/*add some code you like*/
...
__gc_exit(); /* to destroy gc */
return 0;
}
如何找到mark&sweep的根节点:
i) 对于自动变量的标记,可以从当前栈顶一直向上找到environ的正确位置。当然也可以通过读取程序中的/proc/pid/maps来查看栈底地址。然后,只需标记这些区域。
ii) 对于全局变量的标签,使用链接器变量 _etext, _end 标签。 (注意gcc工具是支持的,其他编译链接工具完全不能保证)
iii) 对于临时变量,标记当前寄存器。
具体代码片段:
在marksweep.c文件中:
static unsigned int stack_bottom = 0;
extern char _end[];
extern char _etext[];
extern char** environ;
void gc_collect()
{
unsigned int stack_top;
unsigned int _eax_,_ebx_,_ecx_,_edx_,_esi_,_edi_;
asm volatile ("movl %%ebp, %0" : "=r" (stack_top));
asm volatile ("movl %%eax, %0" : "=r" (_eax_));
asm volatile ("movl %%ebx, %0" : "=r" (_ebx_));
asm volatile ("movl %%ecx, %0" : "=r" (_ecx_));
asm volatile ("movl %%edx, %0" : "=r" (_edx_));
asm volatile ("movl %%esi, %0" : "=r" (_esi_));
asm volatile ("movl %%edi, %0" : "=r" (_edi_));
/* 我们标记一些寄存器里头的临时变量 */
mark(_eax_);
mark(_ebx_);
mark(_ecx_);
mark(_edx_);
mark(_esi_);
mark(_edi_);
mark_from_region((ptr *)((char *)stack_top + 4),(ptr *)(stack_bottom)); //我们标记自动变量
mark_from_region((ptr *)((char *)_etext + 6),(ptr *)(_end)); //我们标记全局变量
sweep();
}
int __gc_init()
{
unsigned int stack_top;
unsigned int curr;
asm volatile ("movl %%ebp, %0" : "=r" (stack_top));
curr = stack_top;
/* 用简单的循环检查出栈底地址(有逻辑漏洞) */
while(*(unsigned int *)curr != (unsigned int)environ)
{
curr++;
}
stack_bottom = curr;
return __rb_init();
}
实现中用到的一些设计和具体方法:
代码中会有一些令人费解的宏定义,例如:
在 unordered_list.h 文件中:
...
#define CHUNKSIZE (1node;
while(curr)
{
__rb_free((RBTree)(curr->data));
curr = curr->next;
}
link_destroy(root->node);
int i = 0;
__free(root);
root = NULL;
}
使用mark和sweep函数实现自己的__gc_calloc函数:
测试:
测试代码:
#include
#include
#include
#include "interface3.h"
#define NUM 10000
#define TEST 100
#define RANGE 100
int *a[NUM];
size_t size[NUM];
void leak(int i)
{
int* leak = (int *)__gc_calloc(size[i]);
return;
}
int main(int argc, char *argv[])
{
clock_t start, finish, end;
double duration1, duration2;
int j;
int i;
for (i = 0; i < NUM; ++i)
{
size[i] = 1 + (size_t)(1.0*RANGE*rand()/(RAND_MAX+1.0));
}
__gc_init();
start = clock();
for (j = 0; j < TEST; ++j)
{
for(i = 0; i prev->x;
p->y = p->prev->y;
}
p->x += dir_x;
p->y += dir_y;
if(head->x > 79)
head->x = 0;
if(head->x < 0)
head->x = 79;
if(head->y > 23)
head->y = 0;
if(head->y < 0)
head->y = 23;
move(head->y, head->x);
if((char)inch() == '*') { //eat self
Game_Over();
}
if((char)inch() == 'o') { //eat food
move(head->y, head->x);
addch('*');
refresh();
tmp = (Snake)__gc_calloc(sizeof(SNAKE));
tmp->x = head->x + dir_x;
tmp->y = head->y + dir_y;
tmp->next = head;
head->prev = tmp;
head = tmp;
do {
food.x = rand() % 80;
food.y = rand() % 24;
move(food.y, food.x);
}while(((char)inch()) == '*');
move(food.y, food.x);
addch('o');
refresh();
}
move(head->y, head->x);
addch('*');
refresh();
move(tail->y, tail->x);
addch(' ');
refresh();
}
void key_ctl()
{
int ch = getch();
switch(ch) {
case 'W':
case 'w':
if(dir_x == 0)
break;
dir_x = 0;
dir_y = -1;
break;
case 'S':
case 's':
if(dir_x == 0)
break;
dir_x = 0;
dir_y = 1;
break;
case 'A':
case 'a':
if(dir_y == 0)
break;
dir_y = 0;
dir_x = -1;
break;
case 'D':
case 'd':
if(dir_y == 0)
break;
dir_y = 0;
dir_x = 1;
break;
case ' ':
set_ticker(0);
do {
ch = getch();
}while(ch != ' ');
set_ticker(500);
break;
case 'Q':
case 'q':
Game_Over();
break;
default:break;
}
}
void Init()
{
initscr();
cbreak();
noecho();
curs_set(0);
srand(time(0));
dir_x = 1;
dir_y = 0;
head = (Snake)__gc_calloc(sizeof(SNAKE));
head->x = rand() % 80;
head->y = rand() % 24;
head->next = (Snake)__gc_calloc(sizeof(SNAKE));
tail = head->next;
tail->prev = head;
tail->x = head->x - dir_x;
tail->y = head->y - dir_y;
do {
food.x = rand() % 80;
food.y = rand() % 24;
move(food.y, food.x);
}while((char)inch() == '*');
move(head->y, head->x);
addch('*');
move(food.y, food.x);
addch('o');
refresh();
}
void sig_alrm(int singo)
{
set_ticker(500);
Snake_Move();
}
int main()
{
__gc_init();
char ch;
Init();
signal(SIGALRM, sig_alrm);
set_ticker(500);
while(1) {
key_ctl();
}
endwin();
return 0;
} 查看全部
本文重点在实现(x86gccunixunix)like环境下
注:本文重点是实现(在x86 gcc unix like环境下),而不是算法(否则最简单的回收算法就不用了),纯粹用于教学(娱乐)目的。它不注重效率,但可以使用。 ,并且没有继续支持多线程。
具体代码在github上:[]
目录:
实现中的重点难点介绍:原理图代码的外部接口部分:
#include "interface3.h"
#include // 必要头文件
int main()
{
__gc_init(); /* to init gc */
/*add some code you like*/
...
/* need some memory in heap */
void *forgetToFree = (void *)gc_calloc(sizeof(struct XXX));
/*add some code you like*/
...
__gc_exit(); /* to destroy gc */
return 0;
}
如何找到mark&sweep的根节点:
i) 对于自动变量的标记,可以从当前栈顶一直向上找到environ的正确位置。当然也可以通过读取程序中的/proc/pid/maps来查看栈底地址。然后,只需标记这些区域。
ii) 对于全局变量的标签,使用链接器变量 _etext, _end 标签。 (注意gcc工具是支持的,其他编译链接工具完全不能保证)
iii) 对于临时变量,标记当前寄存器。
具体代码片段:
在marksweep.c文件中:
static unsigned int stack_bottom = 0;
extern char _end[];
extern char _etext[];
extern char** environ;
void gc_collect()
{
unsigned int stack_top;
unsigned int _eax_,_ebx_,_ecx_,_edx_,_esi_,_edi_;
asm volatile ("movl %%ebp, %0" : "=r" (stack_top));
asm volatile ("movl %%eax, %0" : "=r" (_eax_));
asm volatile ("movl %%ebx, %0" : "=r" (_ebx_));
asm volatile ("movl %%ecx, %0" : "=r" (_ecx_));
asm volatile ("movl %%edx, %0" : "=r" (_edx_));
asm volatile ("movl %%esi, %0" : "=r" (_esi_));
asm volatile ("movl %%edi, %0" : "=r" (_edi_));
/* 我们标记一些寄存器里头的临时变量 */
mark(_eax_);
mark(_ebx_);
mark(_ecx_);
mark(_edx_);
mark(_esi_);
mark(_edi_);
mark_from_region((ptr *)((char *)stack_top + 4),(ptr *)(stack_bottom)); //我们标记自动变量
mark_from_region((ptr *)((char *)_etext + 6),(ptr *)(_end)); //我们标记全局变量
sweep();
}
int __gc_init()
{
unsigned int stack_top;
unsigned int curr;
asm volatile ("movl %%ebp, %0" : "=r" (stack_top));
curr = stack_top;
/* 用简单的循环检查出栈底地址(有逻辑漏洞) */
while(*(unsigned int *)curr != (unsigned int)environ)
{
curr++;
}
stack_bottom = curr;
return __rb_init();
}
实现中用到的一些设计和具体方法:
代码中会有一些令人费解的宏定义,例如:
在 unordered_list.h 文件中:
...
#define CHUNKSIZE (1node;
while(curr)
{
__rb_free((RBTree)(curr->data));
curr = curr->next;
}
link_destroy(root->node);
int i = 0;
__free(root);
root = NULL;
}
使用mark和sweep函数实现自己的__gc_calloc函数:
测试:
测试代码:
#include
#include
#include
#include "interface3.h"
#define NUM 10000
#define TEST 100
#define RANGE 100
int *a[NUM];
size_t size[NUM];
void leak(int i)
{
int* leak = (int *)__gc_calloc(size[i]);
return;
}
int main(int argc, char *argv[])
{
clock_t start, finish, end;
double duration1, duration2;
int j;
int i;
for (i = 0; i < NUM; ++i)
{
size[i] = 1 + (size_t)(1.0*RANGE*rand()/(RAND_MAX+1.0));
}
__gc_init();
start = clock();
for (j = 0; j < TEST; ++j)
{
for(i = 0; i prev->x;
p->y = p->prev->y;
}
p->x += dir_x;
p->y += dir_y;
if(head->x > 79)
head->x = 0;
if(head->x < 0)
head->x = 79;
if(head->y > 23)
head->y = 0;
if(head->y < 0)
head->y = 23;
move(head->y, head->x);
if((char)inch() == '*') { //eat self
Game_Over();
}
if((char)inch() == 'o') { //eat food
move(head->y, head->x);
addch('*');
refresh();
tmp = (Snake)__gc_calloc(sizeof(SNAKE));
tmp->x = head->x + dir_x;
tmp->y = head->y + dir_y;
tmp->next = head;
head->prev = tmp;
head = tmp;
do {
food.x = rand() % 80;
food.y = rand() % 24;
move(food.y, food.x);
}while(((char)inch()) == '*');
move(food.y, food.x);
addch('o');
refresh();
}
move(head->y, head->x);
addch('*');
refresh();
move(tail->y, tail->x);
addch(' ');
refresh();
}
void key_ctl()
{
int ch = getch();
switch(ch) {
case 'W':
case 'w':
if(dir_x == 0)
break;
dir_x = 0;
dir_y = -1;
break;
case 'S':
case 's':
if(dir_x == 0)
break;
dir_x = 0;
dir_y = 1;
break;
case 'A':
case 'a':
if(dir_y == 0)
break;
dir_y = 0;
dir_x = -1;
break;
case 'D':
case 'd':
if(dir_y == 0)
break;
dir_y = 0;
dir_x = 1;
break;
case ' ':
set_ticker(0);
do {
ch = getch();
}while(ch != ' ');
set_ticker(500);
break;
case 'Q':
case 'q':
Game_Over();
break;
default:break;
}
}
void Init()
{
initscr();
cbreak();
noecho();
curs_set(0);
srand(time(0));
dir_x = 1;
dir_y = 0;
head = (Snake)__gc_calloc(sizeof(SNAKE));
head->x = rand() % 80;
head->y = rand() % 24;
head->next = (Snake)__gc_calloc(sizeof(SNAKE));
tail = head->next;
tail->prev = head;
tail->x = head->x - dir_x;
tail->y = head->y - dir_y;
do {
food.x = rand() % 80;
food.y = rand() % 24;
move(food.y, food.x);
}while((char)inch() == '*');
move(head->y, head->x);
addch('*');
move(food.y, food.x);
addch('o');
refresh();
}
void sig_alrm(int singo)
{
set_ticker(500);
Snake_Move();
}
int main()
{
__gc_init();
char ch;
Init();
signal(SIGALRM, sig_alrm);
set_ticker(500);
while(1) {
key_ctl();
}
endwin();
return 0;
}
算法自动采集列表快速定位,去重,降低数据量
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-08-04 06:05
算法自动采集列表快速定位,去重,降低数据量xxx处显示不清,定位不够精准,
获取算法具体实现和好不好用没有什么关系。好用与否的关键在于用不用心,算法再好没用心的话也好不到哪里去,除非商家主动告诉你一些技巧和原则。
算法自动采集列表快速定位,去重,降低数据量xxx处显示不清,定位不够精准,难以收集深度定位且不会特征来做相似度学习等等都是问题。希望能帮到你。
不加任何限制,
目前针对列表的算法里面有rfmlang这个,带一个特征(shad,然后查表)然后就可以做相似度聚类了。
传统算法上sift,surf不过由于新技术层出不穷,
有一家公司叫edmoxa,他们最近正在招人,
自荐下我们啦:edmoxa,包含图像采集,光照,色调,纹理,形状(如在不同几何体上聚成等等),场景(如医院广告牌)和三维物体识别等功能。
edmoxa-专注于构建开放的计算机视觉工作平台、从图像采集到视频分析,最新潮流推荐。还有香港中文大学的南京联合大学南京电子科技大学的,可以在校内找人。
最近用到几种,主要看采集算法对特征提取的要求。
1)根据采集算法去决定去重速度,算法好用,在业务问题有定性的需求时可以用。
2)根据采集特征去构建边框网格,但这个需要训练实现。用在纯粹的采集需求上,就要用更高级的算法。
3)增加分段采集、分组采集、马赛克、照片拼接等等,构建不同层次需求的数据结构。这些env可以轻松构建出来。
4)用windowssqlserver和postgres数据库都支持;
5)业务逻辑越是复杂,对于特征提取的要求就越高,特征提取都是后端工作,所以说要好用就要自己写训练一个训练。好处在于改动少,对模型的要求高。好用的计算机视觉专业公司不多。 查看全部
算法自动采集列表快速定位,去重,降低数据量
算法自动采集列表快速定位,去重,降低数据量xxx处显示不清,定位不够精准,
获取算法具体实现和好不好用没有什么关系。好用与否的关键在于用不用心,算法再好没用心的话也好不到哪里去,除非商家主动告诉你一些技巧和原则。
算法自动采集列表快速定位,去重,降低数据量xxx处显示不清,定位不够精准,难以收集深度定位且不会特征来做相似度学习等等都是问题。希望能帮到你。
不加任何限制,
目前针对列表的算法里面有rfmlang这个,带一个特征(shad,然后查表)然后就可以做相似度聚类了。
传统算法上sift,surf不过由于新技术层出不穷,
有一家公司叫edmoxa,他们最近正在招人,
自荐下我们啦:edmoxa,包含图像采集,光照,色调,纹理,形状(如在不同几何体上聚成等等),场景(如医院广告牌)和三维物体识别等功能。
edmoxa-专注于构建开放的计算机视觉工作平台、从图像采集到视频分析,最新潮流推荐。还有香港中文大学的南京联合大学南京电子科技大学的,可以在校内找人。
最近用到几种,主要看采集算法对特征提取的要求。
1)根据采集算法去决定去重速度,算法好用,在业务问题有定性的需求时可以用。
2)根据采集特征去构建边框网格,但这个需要训练实现。用在纯粹的采集需求上,就要用更高级的算法。
3)增加分段采集、分组采集、马赛克、照片拼接等等,构建不同层次需求的数据结构。这些env可以轻松构建出来。
4)用windowssqlserver和postgres数据库都支持;
5)业务逻辑越是复杂,对于特征提取的要求就越高,特征提取都是后端工作,所以说要好用就要自己写训练一个训练。好处在于改动少,对模型的要求高。好用的计算机视觉专业公司不多。
算法自动采集列表页,大概有这么几类,你知道吗
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-08-02 19:09
算法自动采集列表页,大概有这么几类,1.使用列表页分析工具(splittree,bigpipe)抓取,保留点击name部分,同样抓取total和outoftag数据;2.通过模拟器抓取,potmanloader,大流量potmanloader也会保留outoftag数据;3.通过脚本自动抓取,抓取是自动进行的,是否同时抓取对应的total,outoftag即可。
用卡片自动爬,之前我们很多网站就是用这个爬的,目前支持豆瓣,陌陌,知乎,爱奇艺,这些是都有文档的,
谢邀。和你遇到了同样的问题。但在selenium上,一般会有以下三种方法实现:采集,就是在被抓取页面上采集数据;通过auto_cookie验证,可以识别并保留;通过模拟器自动抓取,即在现有页面上采集数据,然后逐渐改掉抓取无效页面的方法;采集自己想要的网页数据,转存成xml或json文件。比如以这个站点为例,我通过搜索框搜索时搜索按钮的抓取脚本,抓取了1400个结果:主要是点击、划词和点击数据auto_cookie验证,这块要确保采集的内容是正确的;通过模拟器自动抓取,适合小网站,精度要求不高;主要是抓取点击数据,辅助识别无效页面。
至于合理性,需要数据说话,结果说话,没有对比就没有伤害。可以尝试手工实验一下对比,或实在是坚持不下去,只有通过重大手段转移或消灭爬虫思想。加油!。 查看全部
算法自动采集列表页,大概有这么几类,你知道吗
算法自动采集列表页,大概有这么几类,1.使用列表页分析工具(splittree,bigpipe)抓取,保留点击name部分,同样抓取total和outoftag数据;2.通过模拟器抓取,potmanloader,大流量potmanloader也会保留outoftag数据;3.通过脚本自动抓取,抓取是自动进行的,是否同时抓取对应的total,outoftag即可。
用卡片自动爬,之前我们很多网站就是用这个爬的,目前支持豆瓣,陌陌,知乎,爱奇艺,这些是都有文档的,
谢邀。和你遇到了同样的问题。但在selenium上,一般会有以下三种方法实现:采集,就是在被抓取页面上采集数据;通过auto_cookie验证,可以识别并保留;通过模拟器自动抓取,即在现有页面上采集数据,然后逐渐改掉抓取无效页面的方法;采集自己想要的网页数据,转存成xml或json文件。比如以这个站点为例,我通过搜索框搜索时搜索按钮的抓取脚本,抓取了1400个结果:主要是点击、划词和点击数据auto_cookie验证,这块要确保采集的内容是正确的;通过模拟器自动抓取,适合小网站,精度要求不高;主要是抓取点击数据,辅助识别无效页面。
至于合理性,需要数据说话,结果说话,没有对比就没有伤害。可以尝试手工实验一下对比,或实在是坚持不下去,只有通过重大手段转移或消灭爬虫思想。加油!。
10万个网站从哪里来?如何快速获取数据?
采集交流 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-08-01 07:43
昨天有网友表示,他最近面试了几家公司,一个问题被问了好几次,但每次的回答都不是很好。
采访者:比如有10万个网站需要采集,怎么快速拿到数据?
要回答好这个问题,其实你需要有足够的知识和足够的技术储备。
最近,我们也在招聘。我们每周采访十几个人。只有一两个人觉得合适。他们中的大多数人都与这位网友的情况相同。他们缺乏整体思维,即使是工作了三四年的人。有经验的老司机。他们有很强的解决具体问题的能力,但很少点对点思考问题,站在一个新的高度。
100,000个网站的采集的覆盖范围已经超过了大多数专业舆情监测公司的数据采集。为了满足面试官提到的采集需求,我们需要从网站的采集到数据存储的各个环节综合考虑,给出合适的方案,以达到节约成本、提高工作效率的目的。
下面我们将从网站的采集到数据存储的方方面面做一个简单的介绍。
一、10万个网站哪里来的?
一般来说,采集的网站是随着公司业务的发展逐渐积累起来的。
我们现在假设这是一家初创公司的需求。公司刚刚成立,这么多网站,基本上可以说是冷启动。那么我们如何采集这 100,000 个网站?有几种方法:
1)历史业务的积累
不管是冷启动还是什么的,既然有采集的需求,就一定有有这个需求的项目或产品。相关人员一定是前期调查了一些数据来源,采集了一些比较重要的网站。这些可以作为我们采集网站和采集的原创种子。
2)Association网站
在一些网站的底部,通常会有相关网站的链接。尤其是政府类网站,一般都有相关下级部门的官网。
3)网站Navigation
有些网站可能会出于某种目的(如引流等)采集一些网站,并进行分类展示,方便人们查找。这些网站可以快速为我们提供第一批种子网站。然后,我们可以通过网站association 等方式获得更多的网站。
4)搜索引擎
你也可以准备一些与公司业务相关的关键词,在百度、搜狗等搜索引擎中搜索,通过对搜索结果的处理,提取出对应的网站作为我们的种子网站。
5)第三方平台
例如,一些第三方 SaaS 平台会有 7-15 天的免费试用期。因此,我们可以利用这段时间下载与我们业务相关的采集数据,然后从中提取网站作为我们最初的采集种子。
虽然,这个方法是最有效最快的网站采集方法。不过在试用期间,获得10万个网站的可能性极小,所以需要结合上述关联网站等方式,快速获取所需的网站。
通过以上五种方法,相信我们可以快速采集到我们需要的10万个网站。但是,这么多网站,我们应该如何管理呢?怎么知道正常不正常?
二、10万个网站如何管理?
当我们采集到10万个网站时,我们面临的第一件事就是如何管理,如何配置采集规则,以及如何监控网站正常与否。
1)如何管理
100,000网站,如果没有专门的系统来管理,那将是一场灾难。
同时,由于业务需要,比如智能推荐,我们需要对网站做一些预处理(比如打标签)。这时候就需要一个网站管理系统。
2)如何配置采集rules
我们前期采集的10万网站只是首页。如果我们只使用首页作为采集task,那么只有采集才能到达首页,信息很少,漏获取率很高。
如果要整个网站采集使用首页的URL,服务器资源消耗比较大,成本太高。因此,我们需要配置我们关心的列,以及采集他们。
但是,100,000个网站,如何快速高效地配置列?目前我们通过自动解析HTML源代码进行列的半自动配置。
当然,我们也尝试过机器学习来处理,但效果不是很理想。
因为采集的网站的数量需要达到10万级,所以一定不要对采集使用xpath等精准定位方法。不然配置100000网站时,黄花菜就凉了。
同时数据采集必须使用通用爬虫,使用正则表达式匹配列表数据。在采集body中,使用算法解析时间和body等属性;
3)如何监控
因为网站有100,000个,这些网站每天都会有网站修改,或者栏目修改,或者新增/删除栏目等等,所以我们需要简单分析一下网站基于的情况关于采集的数据情况。
比如一个网站几天没有新数据,那肯定是有问题。要么网站被修改,经常导致信息规律失效,要么网站本身有问题。
为了提高采集的效率,您可以使用单独的服务定期检查网站和该列的情况。首先是检查网站和列是否可以正常访问;二是检查配置的列信息的正则表达式是否正常。以便运维人员对其进行维护。
三、任务缓存
100,000 网站,配置列后,采集的入口URL应该达到百万级别。 采集器如何高效获取采集的这些入口网址?
如果把这些网址放到数据库中,不管是MySQL还是Oracle,采集器获取采集任务的操作都会浪费很多时间,大大降低采集的效率。
如何解决这个问题?内存数据库是首选,比如Redis、Mongo DB等,一般采集使用Redis做缓存。因此,您可以在配置列的同时将列信息同步到Redis作为采集task缓存队列。
四、网站How to采集?
这就像你想达到百万年薪一样。最大的概率是去华为、阿里、腾讯等一线厂商,需要达到一定的水平。这条路注定是艰难的。
同理,如果需要采集百万级列表网址,常规方法肯定是无法实现的。
必须使用分布式+多进程+多线程。同时需要结合内存数据库Redis等进行缓存,实现任务的高效获取,对采集信息进行排序;
同时,发布时间、文字等信息的分析,也必须经过算法的处理。比如现在比较流行的GNE,
有些属性可以在列表采集中获取,所以尽量不要和正文放在一起分析。例如:标题。一般情况下,从列表中得到的title的准确率要比从信息html源码中解析出来的算法要高很多。
同时,如果有一些特殊的网站或者一些特殊的需求,我们可以使用定制开发来处理。
五、统一数据存储接口
为了保持采集的时效性,10万个网站采集可能需要十几二十台服务器。同时在每台服务器上部署了N个采集器,加上一些自定义开发的脚本,采集器的总数将达到数百个。
如果每个采集器/custom 脚本都开发自己的数据保存接口,开发调试会浪费大量时间。而后续的运维也将是一件无忧无虑的事情。尤其是当业务发生变化需要调整时。因此,统一的数据存储接口还是很有必要的。
因为数据存储接口是统一的,当我们需要对数据做一些特殊的处理时,比如:清洗、校正等,不需要修改每个采集存储部分,只需要修改接口和重新部署。 .
快速、方便、快捷。
六、data 和 采集monitoring
覆盖10万网站采集,每天的数据量肯定超过200万。数据分析算法再准确,也永远达不到100%(90%已经很好了)。因此,数据分析必然存在异常。例如:发布时间大于当前时间,正文收录相关新闻信息等。
但是,因为我们统一了数据存储接口,这个时候可以在接口上进行统一的数据质量检查。为了根据异常情况优化采集器和自定义脚本。
同时还可以统计每个网站或列的数据采集。为了能够及时判断当前采集网站/列源是否正常,保证始终有10万个有效采集网站。
七、数据存储
由于采集每天的数据量很大,普通数据库(如mysql、Oracle等)已经无法胜任。甚至像 Mongo DB 这样的 NoSql 数据库也不再适用。这时候,ES、Solr等分布式索引是目前最好的选择。
至于是否使用Hadoop、HBase等大数据平台,要看具体情况。在预算较小的情况下,可以先搭建分布式索引集群,再考虑大数据平台。
为了保证查询的响应速度,分布式索引中尽量不要保存body信息。可以保存标题、发布时间、网址等内容,以便在显示列表数据时减少二次查询。
当没有大数据平台时,可以将文本保存在txt等固定数据标准的文件系统中。大数据平台后续上传后,即可转入HBASE。
八、自动化运维
由于服务器、采集器、自定义脚本较多,单纯依靠人工部署、启动、更新、运行监控变得非常繁琐,容易出现人为错误。
因此,必须有一个自动化的运维系统,可以部署、启动、关闭和运行采集器/scripts,以便他们在发生变化时能够快速响应。
“比如有100000个网站需要采集,如何快速获取数据?”如果你能回答这些,就应该没有悬念拿到好offer了。
最后希望大家找工作都能拿到满意的offer,找到好的平台。 查看全部
10万个网站从哪里来?如何快速获取数据?
昨天有网友表示,他最近面试了几家公司,一个问题被问了好几次,但每次的回答都不是很好。
采访者:比如有10万个网站需要采集,怎么快速拿到数据?
要回答好这个问题,其实你需要有足够的知识和足够的技术储备。
最近,我们也在招聘。我们每周采访十几个人。只有一两个人觉得合适。他们中的大多数人都与这位网友的情况相同。他们缺乏整体思维,即使是工作了三四年的人。有经验的老司机。他们有很强的解决具体问题的能力,但很少点对点思考问题,站在一个新的高度。
100,000个网站的采集的覆盖范围已经超过了大多数专业舆情监测公司的数据采集。为了满足面试官提到的采集需求,我们需要从网站的采集到数据存储的各个环节综合考虑,给出合适的方案,以达到节约成本、提高工作效率的目的。
下面我们将从网站的采集到数据存储的方方面面做一个简单的介绍。
一、10万个网站哪里来的?
一般来说,采集的网站是随着公司业务的发展逐渐积累起来的。
我们现在假设这是一家初创公司的需求。公司刚刚成立,这么多网站,基本上可以说是冷启动。那么我们如何采集这 100,000 个网站?有几种方法:
1)历史业务的积累
不管是冷启动还是什么的,既然有采集的需求,就一定有有这个需求的项目或产品。相关人员一定是前期调查了一些数据来源,采集了一些比较重要的网站。这些可以作为我们采集网站和采集的原创种子。
2)Association网站
在一些网站的底部,通常会有相关网站的链接。尤其是政府类网站,一般都有相关下级部门的官网。
3)网站Navigation
有些网站可能会出于某种目的(如引流等)采集一些网站,并进行分类展示,方便人们查找。这些网站可以快速为我们提供第一批种子网站。然后,我们可以通过网站association 等方式获得更多的网站。
4)搜索引擎
你也可以准备一些与公司业务相关的关键词,在百度、搜狗等搜索引擎中搜索,通过对搜索结果的处理,提取出对应的网站作为我们的种子网站。
5)第三方平台
例如,一些第三方 SaaS 平台会有 7-15 天的免费试用期。因此,我们可以利用这段时间下载与我们业务相关的采集数据,然后从中提取网站作为我们最初的采集种子。
虽然,这个方法是最有效最快的网站采集方法。不过在试用期间,获得10万个网站的可能性极小,所以需要结合上述关联网站等方式,快速获取所需的网站。
通过以上五种方法,相信我们可以快速采集到我们需要的10万个网站。但是,这么多网站,我们应该如何管理呢?怎么知道正常不正常?
二、10万个网站如何管理?
当我们采集到10万个网站时,我们面临的第一件事就是如何管理,如何配置采集规则,以及如何监控网站正常与否。
1)如何管理
100,000网站,如果没有专门的系统来管理,那将是一场灾难。
同时,由于业务需要,比如智能推荐,我们需要对网站做一些预处理(比如打标签)。这时候就需要一个网站管理系统。
2)如何配置采集rules
我们前期采集的10万网站只是首页。如果我们只使用首页作为采集task,那么只有采集才能到达首页,信息很少,漏获取率很高。
如果要整个网站采集使用首页的URL,服务器资源消耗比较大,成本太高。因此,我们需要配置我们关心的列,以及采集他们。
但是,100,000个网站,如何快速高效地配置列?目前我们通过自动解析HTML源代码进行列的半自动配置。
当然,我们也尝试过机器学习来处理,但效果不是很理想。
因为采集的网站的数量需要达到10万级,所以一定不要对采集使用xpath等精准定位方法。不然配置100000网站时,黄花菜就凉了。
同时数据采集必须使用通用爬虫,使用正则表达式匹配列表数据。在采集body中,使用算法解析时间和body等属性;
3)如何监控
因为网站有100,000个,这些网站每天都会有网站修改,或者栏目修改,或者新增/删除栏目等等,所以我们需要简单分析一下网站基于的情况关于采集的数据情况。
比如一个网站几天没有新数据,那肯定是有问题。要么网站被修改,经常导致信息规律失效,要么网站本身有问题。
为了提高采集的效率,您可以使用单独的服务定期检查网站和该列的情况。首先是检查网站和列是否可以正常访问;二是检查配置的列信息的正则表达式是否正常。以便运维人员对其进行维护。
三、任务缓存
100,000 网站,配置列后,采集的入口URL应该达到百万级别。 采集器如何高效获取采集的这些入口网址?
如果把这些网址放到数据库中,不管是MySQL还是Oracle,采集器获取采集任务的操作都会浪费很多时间,大大降低采集的效率。
如何解决这个问题?内存数据库是首选,比如Redis、Mongo DB等,一般采集使用Redis做缓存。因此,您可以在配置列的同时将列信息同步到Redis作为采集task缓存队列。
四、网站How to采集?
这就像你想达到百万年薪一样。最大的概率是去华为、阿里、腾讯等一线厂商,需要达到一定的水平。这条路注定是艰难的。
同理,如果需要采集百万级列表网址,常规方法肯定是无法实现的。
必须使用分布式+多进程+多线程。同时需要结合内存数据库Redis等进行缓存,实现任务的高效获取,对采集信息进行排序;
同时,发布时间、文字等信息的分析,也必须经过算法的处理。比如现在比较流行的GNE,
有些属性可以在列表采集中获取,所以尽量不要和正文放在一起分析。例如:标题。一般情况下,从列表中得到的title的准确率要比从信息html源码中解析出来的算法要高很多。
同时,如果有一些特殊的网站或者一些特殊的需求,我们可以使用定制开发来处理。
五、统一数据存储接口
为了保持采集的时效性,10万个网站采集可能需要十几二十台服务器。同时在每台服务器上部署了N个采集器,加上一些自定义开发的脚本,采集器的总数将达到数百个。
如果每个采集器/custom 脚本都开发自己的数据保存接口,开发调试会浪费大量时间。而后续的运维也将是一件无忧无虑的事情。尤其是当业务发生变化需要调整时。因此,统一的数据存储接口还是很有必要的。
因为数据存储接口是统一的,当我们需要对数据做一些特殊的处理时,比如:清洗、校正等,不需要修改每个采集存储部分,只需要修改接口和重新部署。 .
快速、方便、快捷。
六、data 和 采集monitoring
覆盖10万网站采集,每天的数据量肯定超过200万。数据分析算法再准确,也永远达不到100%(90%已经很好了)。因此,数据分析必然存在异常。例如:发布时间大于当前时间,正文收录相关新闻信息等。
但是,因为我们统一了数据存储接口,这个时候可以在接口上进行统一的数据质量检查。为了根据异常情况优化采集器和自定义脚本。
同时还可以统计每个网站或列的数据采集。为了能够及时判断当前采集网站/列源是否正常,保证始终有10万个有效采集网站。
七、数据存储
由于采集每天的数据量很大,普通数据库(如mysql、Oracle等)已经无法胜任。甚至像 Mongo DB 这样的 NoSql 数据库也不再适用。这时候,ES、Solr等分布式索引是目前最好的选择。
至于是否使用Hadoop、HBase等大数据平台,要看具体情况。在预算较小的情况下,可以先搭建分布式索引集群,再考虑大数据平台。
为了保证查询的响应速度,分布式索引中尽量不要保存body信息。可以保存标题、发布时间、网址等内容,以便在显示列表数据时减少二次查询。
当没有大数据平台时,可以将文本保存在txt等固定数据标准的文件系统中。大数据平台后续上传后,即可转入HBASE。
八、自动化运维
由于服务器、采集器、自定义脚本较多,单纯依靠人工部署、启动、更新、运行监控变得非常繁琐,容易出现人为错误。
因此,必须有一个自动化的运维系统,可以部署、启动、关闭和运行采集器/scripts,以便他们在发生变化时能够快速响应。
“比如有100000个网站需要采集,如何快速获取数据?”如果你能回答这些,就应该没有悬念拿到好offer了。
最后希望大家找工作都能拿到满意的offer,找到好的平台。
算法自动采集列表中相关联系信息的匿名爆内幕
采集交流 • 优采云 发表了文章 • 0 个评论 • 152 次浏览 • 2021-07-31 23:06
算法自动采集列表中相关联系信息。cookie就是你浏览过的页面发送到google服务器,自动生成一个记录,你再次访问的时候,你注册过的帐号,浏览过的页面,下一步浏览的页面内容就会匹配上对应关键字。这个很不安全。为了避免过多的被识别,需要限制收集数量。在早期限制太多也不安全,也容易被识别带病毒。有一些比较新的一些采集谷歌网页爬虫,会把ip地址和网络段重定向一次。
总之,广告什么的,有特定的爬虫,你不知道它爬到什么内容,也不知道它爬到是广告还是广告链接。ip被攻破,内容被爬去。影响还是有一点点的。毕竟有这个需求,也有市场。知乎搜索,留在你前面,你不知道的。
正常的网站每个ip都可以登录,关键在于你被攻破了。我觉得会有这个原因。
原理很简单,被攻破后还能这么熟练是因为你提问的方式太高端了,容易被一些白帽子还有狗黑盯上,但是攻破了,他们就不能防卫那些看不起我们的人了啊所以你想要了解一个技术,
不然呢?谷歌这么多公司,海量网站数据。如果能在一家公司实现完全自动的采集,那肯定是防御标准已经达到纳米级的。现在的技术没那么容易打穿,攻破,人肉解密,都很困难。
你那点量打得通mac地址,黑进你家?而且我问的是,什么鬼,来那么多匿名爆内幕的...一是不管一点,谷歌能叫得出名字的网站都黑的透透的。google搜索也有漏洞,但谷歌最牛的能力是,谷歌已经有1亿1千万的用户和1亿4千万个product,这样最有效率,成本也相对低。人力多不成问题。二是盗号事件太多了,破解谷歌会影响用户体验。 查看全部
算法自动采集列表中相关联系信息的匿名爆内幕
算法自动采集列表中相关联系信息。cookie就是你浏览过的页面发送到google服务器,自动生成一个记录,你再次访问的时候,你注册过的帐号,浏览过的页面,下一步浏览的页面内容就会匹配上对应关键字。这个很不安全。为了避免过多的被识别,需要限制收集数量。在早期限制太多也不安全,也容易被识别带病毒。有一些比较新的一些采集谷歌网页爬虫,会把ip地址和网络段重定向一次。
总之,广告什么的,有特定的爬虫,你不知道它爬到什么内容,也不知道它爬到是广告还是广告链接。ip被攻破,内容被爬去。影响还是有一点点的。毕竟有这个需求,也有市场。知乎搜索,留在你前面,你不知道的。
正常的网站每个ip都可以登录,关键在于你被攻破了。我觉得会有这个原因。
原理很简单,被攻破后还能这么熟练是因为你提问的方式太高端了,容易被一些白帽子还有狗黑盯上,但是攻破了,他们就不能防卫那些看不起我们的人了啊所以你想要了解一个技术,
不然呢?谷歌这么多公司,海量网站数据。如果能在一家公司实现完全自动的采集,那肯定是防御标准已经达到纳米级的。现在的技术没那么容易打穿,攻破,人肉解密,都很困难。
你那点量打得通mac地址,黑进你家?而且我问的是,什么鬼,来那么多匿名爆内幕的...一是不管一点,谷歌能叫得出名字的网站都黑的透透的。google搜索也有漏洞,但谷歌最牛的能力是,谷歌已经有1亿1千万的用户和1亿4千万个product,这样最有效率,成本也相对低。人力多不成问题。二是盗号事件太多了,破解谷歌会影响用户体验。
分布式爬虫和集群爬虫的区别(1)_算法自动采集列表
采集交流 • 优采云 发表了文章 • 0 个评论 • 158 次浏览 • 2021-07-30 23:05
算法自动采集列表
感觉aria2会让用户失去其他很多方法的机会
jsrewrite!!!特别好用。用起来很像git。特别想装一个npmgit/webpacknpmwebpack一键安装。无奈不会配置。aria2只好用rewrite。
aria2有个机制,这样就使得对于一个ftp,可以部署多个ftp,而且在githubpages上可以访问多个网站。另外,对于ftp的云存储,可以做到批量发pullrequest。
python这个东西本身就缺少cmake库,爬虫就更难说了。
看了第一名的回答,做了个扩展。自己写了一个,采集amazonbigcs2电商平台里的商品信息,分为20个类型。需要技术栈:python,webpy。欢迎大家参与,
老司机这里讲讲爬虫的整个过程。首先是多进程的爬虫:分布式爬虫和集群爬虫的区别是在于这次访问耗时的时间成本和访问源数量的变化大小。最有名的分布式爬虫有阿里云这个:/这里列举下scott㙁arzip这个案例做例子,我采用了apacheasshell中的connector框架,先写一个scheduler完成爬虫的构建,然后再写一个python的web框架,用于生成request返回。
一个分布式爬虫里至少有2个git@gitlab提供的分支,每个分支爬虫至少2个shell来编写和调试,相当于最多有5个服务器同时并发去爬取。如果是采用集群的爬虫,就至少有5个shell相互并发去爬取。按照整个爬虫的行动顺序,大致大致还可以划分为:加载项目列表-通过xargs或者yarn拿到项目所有request-自己使用python打包爬虫-简单处理存到指定的git仓库去调用shell去发包如果是采用分布式爬虫,那么可以并发去拿任意的javarequest,实现soap协议调用。
那么那种分布式爬虫更适合处理网站的规模变化比较小的情况呢?举个例子,如果一个网站有1亿用户,那么我们最好使用分布式爬虫去爬取1亿的量。如果我们想把1亿的用户并发爬取,那么目前还没有类似分布式爬虫可以完美地处理这么大规模数据的框架。如果大规模的数据,分布式爬虫抓取起来比较麻烦,这时候我们需要考虑另外一个问题。
如果我们平时面对的都是小规模的网站,那么直接走http去拿json出来处理是最好的选择。如果我们面对的都是大规模的网站,那么我们应该使用一些针对海量数据的分布式爬虫,并且去有针对性地把它解析到对应的python模块来完成数据处理。这个时候我们需要将需要被解析的python模块切割出来,一个python模块,一个web模块。在web里使用相关的request来进行请求。以用connector框架。 查看全部
分布式爬虫和集群爬虫的区别(1)_算法自动采集列表
算法自动采集列表
感觉aria2会让用户失去其他很多方法的机会
jsrewrite!!!特别好用。用起来很像git。特别想装一个npmgit/webpacknpmwebpack一键安装。无奈不会配置。aria2只好用rewrite。
aria2有个机制,这样就使得对于一个ftp,可以部署多个ftp,而且在githubpages上可以访问多个网站。另外,对于ftp的云存储,可以做到批量发pullrequest。
python这个东西本身就缺少cmake库,爬虫就更难说了。
看了第一名的回答,做了个扩展。自己写了一个,采集amazonbigcs2电商平台里的商品信息,分为20个类型。需要技术栈:python,webpy。欢迎大家参与,
老司机这里讲讲爬虫的整个过程。首先是多进程的爬虫:分布式爬虫和集群爬虫的区别是在于这次访问耗时的时间成本和访问源数量的变化大小。最有名的分布式爬虫有阿里云这个:/这里列举下scott㙁arzip这个案例做例子,我采用了apacheasshell中的connector框架,先写一个scheduler完成爬虫的构建,然后再写一个python的web框架,用于生成request返回。
一个分布式爬虫里至少有2个git@gitlab提供的分支,每个分支爬虫至少2个shell来编写和调试,相当于最多有5个服务器同时并发去爬取。如果是采用集群的爬虫,就至少有5个shell相互并发去爬取。按照整个爬虫的行动顺序,大致大致还可以划分为:加载项目列表-通过xargs或者yarn拿到项目所有request-自己使用python打包爬虫-简单处理存到指定的git仓库去调用shell去发包如果是采用分布式爬虫,那么可以并发去拿任意的javarequest,实现soap协议调用。
那么那种分布式爬虫更适合处理网站的规模变化比较小的情况呢?举个例子,如果一个网站有1亿用户,那么我们最好使用分布式爬虫去爬取1亿的量。如果我们想把1亿的用户并发爬取,那么目前还没有类似分布式爬虫可以完美地处理这么大规模数据的框架。如果大规模的数据,分布式爬虫抓取起来比较麻烦,这时候我们需要考虑另外一个问题。
如果我们平时面对的都是小规模的网站,那么直接走http去拿json出来处理是最好的选择。如果我们面对的都是大规模的网站,那么我们应该使用一些针对海量数据的分布式爬虫,并且去有针对性地把它解析到对应的python模块来完成数据处理。这个时候我们需要将需要被解析的python模块切割出来,一个python模块,一个web模块。在web里使用相关的request来进行请求。以用connector框架。
网络爬虫系统的原理和工作流程介绍-乐题库
采集交流 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-07-27 05:09
网络数据采集是指通过网络爬虫或网站public API从网站获取数据信息。这种方法可以从网页中提取非结构化数据,将其存储为统一的本地数据文件,并以结构化的方式存储。支持采集图片、音频、视频等文件或附件,可自动关联附件和文字。
在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据。
在大数据时代,网络爬虫更是来自采集data 的互联网优势工具。已知的各种网络爬虫工具有数百种,网络爬虫工具基本上可以分为三类。
本节首先简要介绍网络爬虫的原理和工作流程,然后讨论网络爬虫的爬取策略,最后介绍典型的网络工具。
网络爬虫原理
网络爬虫是根据一定的规则自动抓取网络信息的程序或脚本。
网络爬虫可以自动采集所有可以访问的页面内容,为搜索引擎和大数据分析提供数据源。就功能而言,爬虫一般具有数据采集、处理和存储三个功能,如图1所示。
图 1 网络爬虫示意图
网页中除了供用户阅读的文字信息外,还收录一些超链接信息。
网络爬虫系统通过网页中的超链接信息不断获取互联网上的其他网页。网络爬虫从一个或几个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,不断地从当前页面中提取新的URL并将其放入队列中,直到满足系统的某个停止条件。
网络爬虫系统一般会选择一些更重要的网站 URLs,外展度(网页中超链接的数量)较高作为种子URL集合。
网络爬虫系统使用这些种子集合作为初始 URL 来开始数据爬取。由于网页收录链接信息,所以会通过现有网页的网址获取一些新的网址。
网页之间的指向结构可以看成是一片森林,每个种子URL对应的网页就是森林中一棵树的根节点,这样网络爬虫系统就可以按照广度优先搜索算法进行搜索或者深度优先搜索算法遍历所有网页。
因为深度优先搜索算法可能会导致爬虫系统陷入网站内部,不利于搜索更接近网站首页的网页信息,所以广度优先搜索算法采集页一般使用。
网络爬虫系统首先将种子URL放入下载队列,简单地从队列头部取出一个URL下载对应的网页,获取网页内容并存储,解析链接后网页中的信息,你可以得到一些新的网址。
其次,根据一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,放入URL队列等待抓取。
最后,取出一个网址,下载其对应的网页,然后解析,如此重复,直到遍历全网或满足一定条件。
网络爬虫工作流程
如图2所示,网络爬虫的基本工作流程如下。
1) 首先选择种子 URL 的一部分。
2) 将这些 URL 放入 URL 队列进行抓取。
3)从待爬取的URL队列中取出待爬取的URL,解析DNS得到主机的IP地址,下载该URL对应的网页并存储在下载的网页中图书馆。另外,将这些网址放入抓取到的网址队列中。
4)对爬取的URL队列中的URL进行分析,分析其中的其他URL,将这些URL放入URL队列进行爬取,从而进入下一个循环。
图 2 网络爬虫的基本工作流程
网络爬虫抓取策略
谷歌、百度等通用搜索引擎抓取的网页数量通常以亿为单位计算。那么,面对如此多的网页,网络爬虫如何才能尽可能的遍历所有网页,从而尽可能扩大网页信息的覆盖范围呢?这是网络爬虫系统面临的一个非常关键的问题。在网络爬虫系统中,抓取策略决定了抓取网页的顺序。
本节先简单介绍一下网络爬虫的爬取策略中用到的基本概念。
1)网页关系模型
从互联网的结构来看,网页通过不同数量的超链接相互连接,形成一个庞大而复杂的有向图,相互关联。
如图3所示,如果一个网页被视为图中的某个节点,而该网页中其他网页的链接被视为该节点到其他节点的边,那么我们可以很容易地认为整个网页Internet 上的页面被建模为有向图。
理论上,通过遍历算法遍历图,几乎可以访问互联网上的所有网页。
图 3 网页关系模型图
2)Web 分类
从爬虫的角度来划分互联网,互联网上的所有页面可以分为5个部分:已下载但未过期页面、已下载已过期页面、已下载页面、已知页面和未知页面,如图4. 显示。
抓取的本地网页实际上是互联网内容的镜像和备份。互联网是动态变化的。当互联网上的部分内容发生变化时,抓取到的本地网页就会失效。因此,下载的网页分为两种:下载的未过期网页和下载的过期网页。
图 4 网页分类
待下载的网页是指在URL队列中待抓取的页面。
可以看出,网页指的是未被抓取的网页,也不在待抓取的URL队列中,但可以通过分析抓取的页面或要抓取的URL对应的页面获取已抓取。
还有一些网页是网络爬虫无法直接抓取下载的,称为不可知网页。
以下重点介绍几种常见的抓取策略。
1.通用网络爬虫
通用网络爬虫也称为全网爬虫。爬取对象从一些种子网址扩展到整个Web,主要是门户搜索引擎和大型Web服务提供商采集data。
为了提高工作效率,一般的网络爬虫都会采用一定的爬取策略。常用的爬取策略包括深度优先策略和广度优先策略。
1)深度优先策略
深度优先策略意味着网络爬虫会从起始页开始,逐个跟踪链接,直到无法再深入。
网络爬虫在完成一个爬行分支后返回上一个链接节点,进一步搜索其他链接。当所有链接都遍历完后,爬取任务结束。
此策略更适合垂直搜索或站点搜索,但在抓取页面内容更深层次的站点时会造成资源的巨大浪费。
以图3为例,遍历的路径为1→2→5→6→3→7→4→8。
在深度优先策略中,当搜索到某个节点时,该节点的子节点和子节点的后继节点都优先于该节点的兄弟节点。深度优先策略是在搜索空间的时候,会尽可能的深入,只有在找不到一个节点的后继节点时才考虑它的兄弟节点。
这样的策略决定了深度优先策略可能无法找到最优解,甚至由于深度的限制而无法找到解。
如果没有限制,它会沿着一条路径无限扩展,从而“陷入”海量数据。一般情况下,使用深度优先策略会选择一个合适的深度,然后反复搜索直到找到一个解,这样就降低了搜索的效率。因此,当搜索数据量较小时,一般采用深度优先策略。
2)广度优先策略
广度优先策略根据网页内容目录的深度抓取网页。首先抓取较浅目录级别的页面。当同一级别的页面被爬取时,爬虫会进入下一层继续爬取。
仍以图3为例,遍历路径为1→2→3→4→5→6→7→8
因为广度优先策略是在第N层节点扩展完成后进入第N+1层,所以可以保证找到路径最短的解。
该策略可以有效控制页面的爬取深度,避免遇到无限深分支无法结束爬取的问题,实现方便,无需存储大量中间节点。缺点是爬到目录需要很长时间。更深的页面。
如果搜索过程中分支过多,即节点的后继节点过多,算法会耗尽资源,在可用空间中找不到解。
2.专注于网络爬虫
焦点网络爬虫,也称为主题网络爬虫,是指有选择地抓取与预定义主题相关的页面的网络爬虫。
1)基于内容评价的爬取策略
DeBra 将文本相似度的计算方法引入到网络爬虫中,并提出了 Fish Search 算法。
算法以用户输入的查询词为主题,将收录查询词的页面视为主题相关页面。它的局限性在于它无法评估页面与主题的相关性。
Herseovic 改进了 Fish Search 算法,提出了 Shark Search 算法,该算法使用空间向量模型来计算页面与主题的相关性。
使用基于连续值计算链接值的方法,不仅可以计算出哪些抓取的链接与主题相关,还可以量化相关性的大小。
2)基于链接结构评估的爬行策略
网页不同于一般文本。它是一个收录大量结构化信息的半结构化文档。
网页不是单独存在的。页面上的链接表示页面之间的相互关系。基于链接结构的搜索策略模型利用这些结构特征来评估页面和链接的重要性,从而确定搜索顺序。其中,PageRank算法是这类搜索策略模型的代表。
PageRank 算法的基本原理是,如果一个网页被多次引用,它可能是一个非常重要的网页。如果一个网页没有被多次引用,但被一个重要的网页引用,那么它也可能是一个重要的网页。一个网页的重要性均匀地传递给它所引用的网页。
将某个页面的PageRank除以该页面上存在的前向链接,并将得到的值与前向链接指向的页面的PageRank相加,得到被链接页面的PageRank .
如图 5 所示,PageRank 值为 100 的网页将其重要性平均转移到其引用的两个页面上,每个页面获得 50,而 PageRank 值为 9 的网页也被引用为它。 3页每页传递的值为3。
PageRank 值为 53 的页面的值来自引用它的两个页面传递的值。
图 5 PageRank 算法示例
3) 基于强化学习的爬行策略
Rennie 和 McCallum 将增强学习引入聚焦爬虫,使用贝叶斯分类器根据整个网页文本和链接文本对超链接进行分类,并计算每个链接的重要性,从而确定链接访问的顺序。
4)基于上下文映射的爬行策略
Diligenti 等人。提出了一种爬行策略,通过建立上下文映射来学习网页之间的相关性。该策略可以训练一个机器学习系统,通过该系统可以计算当前页面和相关网页之间的距离。最先访问最近页面中的链接。
3.增量网络爬虫
增量网络爬虫是指对下载的网页进行增量更新,只抓取新生成或更改的网页的爬虫。可以在一定程度上保证抓取到的页面尽可能的新鲜。
增量网络爬虫有两个目标:
为了实现第一个目标,增量网络爬虫需要重新访问网页以更新本地页面集中页面的内容。常用的方法有统一更新法、个体更新法和基于分类的更新法。
对两种类型的网页进行子集,然后以不同的频率访问这两种类型的网页。为了实现第二个目标,增量网络爬虫需要对网页的重要性进行排名。常见的策略包括广度优先和 PageRank 优先。等等。
4. 深网爬虫
网页按存在方式可分为表面网页和深层网页。
深网爬虫架构包括6个基本功能模块(爬虫控制器、解析器、表单分析器、表单处理器、响应分析器、LVS控制器)和两个爬虫内部数据结构(URL列表和LVS)面。
其中,LVS(LabelValueSet)表示标签和值的集合,用于表示填写表单的数据源。在爬虫过程中,最重要的部分是表单填写,包括基于领域知识的表单填写和基于网页结构分析的表单填写。 查看全部
网络爬虫系统的原理和工作流程介绍-乐题库
网络数据采集是指通过网络爬虫或网站public API从网站获取数据信息。这种方法可以从网页中提取非结构化数据,将其存储为统一的本地数据文件,并以结构化的方式存储。支持采集图片、音频、视频等文件或附件,可自动关联附件和文字。
在互联网时代,网络爬虫主要为搜索引擎提供最全面、最新的数据。
在大数据时代,网络爬虫更是来自采集data 的互联网优势工具。已知的各种网络爬虫工具有数百种,网络爬虫工具基本上可以分为三类。
本节首先简要介绍网络爬虫的原理和工作流程,然后讨论网络爬虫的爬取策略,最后介绍典型的网络工具。
网络爬虫原理
网络爬虫是根据一定的规则自动抓取网络信息的程序或脚本。
网络爬虫可以自动采集所有可以访问的页面内容,为搜索引擎和大数据分析提供数据源。就功能而言,爬虫一般具有数据采集、处理和存储三个功能,如图1所示。
图 1 网络爬虫示意图
网页中除了供用户阅读的文字信息外,还收录一些超链接信息。
网络爬虫系统通过网页中的超链接信息不断获取互联网上的其他网页。网络爬虫从一个或几个初始网页的URL开始,获取初始网页上的URL。在抓取网页的过程中,不断地从当前页面中提取新的URL并将其放入队列中,直到满足系统的某个停止条件。
网络爬虫系统一般会选择一些更重要的网站 URLs,外展度(网页中超链接的数量)较高作为种子URL集合。
网络爬虫系统使用这些种子集合作为初始 URL 来开始数据爬取。由于网页收录链接信息,所以会通过现有网页的网址获取一些新的网址。
网页之间的指向结构可以看成是一片森林,每个种子URL对应的网页就是森林中一棵树的根节点,这样网络爬虫系统就可以按照广度优先搜索算法进行搜索或者深度优先搜索算法遍历所有网页。
因为深度优先搜索算法可能会导致爬虫系统陷入网站内部,不利于搜索更接近网站首页的网页信息,所以广度优先搜索算法采集页一般使用。
网络爬虫系统首先将种子URL放入下载队列,简单地从队列头部取出一个URL下载对应的网页,获取网页内容并存储,解析链接后网页中的信息,你可以得到一些新的网址。
其次,根据一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,放入URL队列等待抓取。
最后,取出一个网址,下载其对应的网页,然后解析,如此重复,直到遍历全网或满足一定条件。
网络爬虫工作流程
如图2所示,网络爬虫的基本工作流程如下。
1) 首先选择种子 URL 的一部分。
2) 将这些 URL 放入 URL 队列进行抓取。
3)从待爬取的URL队列中取出待爬取的URL,解析DNS得到主机的IP地址,下载该URL对应的网页并存储在下载的网页中图书馆。另外,将这些网址放入抓取到的网址队列中。
4)对爬取的URL队列中的URL进行分析,分析其中的其他URL,将这些URL放入URL队列进行爬取,从而进入下一个循环。
图 2 网络爬虫的基本工作流程
网络爬虫抓取策略
谷歌、百度等通用搜索引擎抓取的网页数量通常以亿为单位计算。那么,面对如此多的网页,网络爬虫如何才能尽可能的遍历所有网页,从而尽可能扩大网页信息的覆盖范围呢?这是网络爬虫系统面临的一个非常关键的问题。在网络爬虫系统中,抓取策略决定了抓取网页的顺序。
本节先简单介绍一下网络爬虫的爬取策略中用到的基本概念。
1)网页关系模型
从互联网的结构来看,网页通过不同数量的超链接相互连接,形成一个庞大而复杂的有向图,相互关联。
如图3所示,如果一个网页被视为图中的某个节点,而该网页中其他网页的链接被视为该节点到其他节点的边,那么我们可以很容易地认为整个网页Internet 上的页面被建模为有向图。
理论上,通过遍历算法遍历图,几乎可以访问互联网上的所有网页。
图 3 网页关系模型图
2)Web 分类
从爬虫的角度来划分互联网,互联网上的所有页面可以分为5个部分:已下载但未过期页面、已下载已过期页面、已下载页面、已知页面和未知页面,如图4. 显示。
抓取的本地网页实际上是互联网内容的镜像和备份。互联网是动态变化的。当互联网上的部分内容发生变化时,抓取到的本地网页就会失效。因此,下载的网页分为两种:下载的未过期网页和下载的过期网页。
图 4 网页分类
待下载的网页是指在URL队列中待抓取的页面。
可以看出,网页指的是未被抓取的网页,也不在待抓取的URL队列中,但可以通过分析抓取的页面或要抓取的URL对应的页面获取已抓取。
还有一些网页是网络爬虫无法直接抓取下载的,称为不可知网页。
以下重点介绍几种常见的抓取策略。
1.通用网络爬虫
通用网络爬虫也称为全网爬虫。爬取对象从一些种子网址扩展到整个Web,主要是门户搜索引擎和大型Web服务提供商采集data。
为了提高工作效率,一般的网络爬虫都会采用一定的爬取策略。常用的爬取策略包括深度优先策略和广度优先策略。
1)深度优先策略
深度优先策略意味着网络爬虫会从起始页开始,逐个跟踪链接,直到无法再深入。
网络爬虫在完成一个爬行分支后返回上一个链接节点,进一步搜索其他链接。当所有链接都遍历完后,爬取任务结束。
此策略更适合垂直搜索或站点搜索,但在抓取页面内容更深层次的站点时会造成资源的巨大浪费。
以图3为例,遍历的路径为1→2→5→6→3→7→4→8。
在深度优先策略中,当搜索到某个节点时,该节点的子节点和子节点的后继节点都优先于该节点的兄弟节点。深度优先策略是在搜索空间的时候,会尽可能的深入,只有在找不到一个节点的后继节点时才考虑它的兄弟节点。
这样的策略决定了深度优先策略可能无法找到最优解,甚至由于深度的限制而无法找到解。
如果没有限制,它会沿着一条路径无限扩展,从而“陷入”海量数据。一般情况下,使用深度优先策略会选择一个合适的深度,然后反复搜索直到找到一个解,这样就降低了搜索的效率。因此,当搜索数据量较小时,一般采用深度优先策略。
2)广度优先策略
广度优先策略根据网页内容目录的深度抓取网页。首先抓取较浅目录级别的页面。当同一级别的页面被爬取时,爬虫会进入下一层继续爬取。
仍以图3为例,遍历路径为1→2→3→4→5→6→7→8
因为广度优先策略是在第N层节点扩展完成后进入第N+1层,所以可以保证找到路径最短的解。
该策略可以有效控制页面的爬取深度,避免遇到无限深分支无法结束爬取的问题,实现方便,无需存储大量中间节点。缺点是爬到目录需要很长时间。更深的页面。
如果搜索过程中分支过多,即节点的后继节点过多,算法会耗尽资源,在可用空间中找不到解。
2.专注于网络爬虫
焦点网络爬虫,也称为主题网络爬虫,是指有选择地抓取与预定义主题相关的页面的网络爬虫。
1)基于内容评价的爬取策略
DeBra 将文本相似度的计算方法引入到网络爬虫中,并提出了 Fish Search 算法。
算法以用户输入的查询词为主题,将收录查询词的页面视为主题相关页面。它的局限性在于它无法评估页面与主题的相关性。
Herseovic 改进了 Fish Search 算法,提出了 Shark Search 算法,该算法使用空间向量模型来计算页面与主题的相关性。
使用基于连续值计算链接值的方法,不仅可以计算出哪些抓取的链接与主题相关,还可以量化相关性的大小。
2)基于链接结构评估的爬行策略
网页不同于一般文本。它是一个收录大量结构化信息的半结构化文档。
网页不是单独存在的。页面上的链接表示页面之间的相互关系。基于链接结构的搜索策略模型利用这些结构特征来评估页面和链接的重要性,从而确定搜索顺序。其中,PageRank算法是这类搜索策略模型的代表。
PageRank 算法的基本原理是,如果一个网页被多次引用,它可能是一个非常重要的网页。如果一个网页没有被多次引用,但被一个重要的网页引用,那么它也可能是一个重要的网页。一个网页的重要性均匀地传递给它所引用的网页。
将某个页面的PageRank除以该页面上存在的前向链接,并将得到的值与前向链接指向的页面的PageRank相加,得到被链接页面的PageRank .
如图 5 所示,PageRank 值为 100 的网页将其重要性平均转移到其引用的两个页面上,每个页面获得 50,而 PageRank 值为 9 的网页也被引用为它。 3页每页传递的值为3。
PageRank 值为 53 的页面的值来自引用它的两个页面传递的值。
图 5 PageRank 算法示例
3) 基于强化学习的爬行策略
Rennie 和 McCallum 将增强学习引入聚焦爬虫,使用贝叶斯分类器根据整个网页文本和链接文本对超链接进行分类,并计算每个链接的重要性,从而确定链接访问的顺序。
4)基于上下文映射的爬行策略
Diligenti 等人。提出了一种爬行策略,通过建立上下文映射来学习网页之间的相关性。该策略可以训练一个机器学习系统,通过该系统可以计算当前页面和相关网页之间的距离。最先访问最近页面中的链接。
3.增量网络爬虫
增量网络爬虫是指对下载的网页进行增量更新,只抓取新生成或更改的网页的爬虫。可以在一定程度上保证抓取到的页面尽可能的新鲜。
增量网络爬虫有两个目标:
为了实现第一个目标,增量网络爬虫需要重新访问网页以更新本地页面集中页面的内容。常用的方法有统一更新法、个体更新法和基于分类的更新法。
对两种类型的网页进行子集,然后以不同的频率访问这两种类型的网页。为了实现第二个目标,增量网络爬虫需要对网页的重要性进行排名。常见的策略包括广度优先和 PageRank 优先。等等。
4. 深网爬虫
网页按存在方式可分为表面网页和深层网页。
深网爬虫架构包括6个基本功能模块(爬虫控制器、解析器、表单分析器、表单处理器、响应分析器、LVS控制器)和两个爬虫内部数据结构(URL列表和LVS)面。
其中,LVS(LabelValueSet)表示标签和值的集合,用于表示填写表单的数据源。在爬虫过程中,最重要的部分是表单填写,包括基于领域知识的表单填写和基于网页结构分析的表单填写。
基于CSS选择器的网页抽取浏览器使用说明书大全
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-07-26 01:16
(在程序中,必须在\前加双引号和\才能转义。
三.基于CSS选择器的网页提取
浏览器收到服务器返回的html源代码后,会将网页解析成DOM树。 CSS Selector 基于DOM树的特性,广泛用于网页提取。目前最流行的网页提取组件Jsoup(Java)和BeautifulSoup(Python)都是基于CSS选择器的。
对于上面的例子:
(标题)此内容不要被抽取
(正文)此内容要被抽取
(页脚)此内容不要被抽取
使用 CSS 选择器将大大提高代码的可读性:
public static void cssExtract() {
String html="" +
"(标题)此内容不要被抽取" +
"(正文)此内容要被抽取" +
"(页脚)此内容不要被抽取" +
"";
//Jsoup中的Document类表示网页的DOM树
Document doc= Jsoup.parse(html);
//利用select方法获取所有满足css选择器的Element集合
// (实际是一个Elements类型的对象)
//由于在本网页的结构中,只会有一个Element满足条件
// 因此只要返回集合中的第一个Element即可
Element main=doc.select("div[class=main]").first();
//main是一个Element对象,这里main对应了网页中
//的(正文)此内容要被抽取
//我们调用Element的text()方法即可提取中间的文字
if(main!=null){
System.out.println("抽取结果:"+main.text());
}else{
System.out.println("无抽取结果");
}
}
CSS 选择器有标准规范,但 Jsoup (Java) 和 BeautifulSoup (Python) 等组件并没有完全按照规范实现 CSS 选择器。因此,在使用各个组件之前,最好先阅读组件文档中对CSS选择器的描述。
Jsoup 是 CSS 选择器的更好实现。如果想了解CSS选择器的使用,建议阅读Jsoup的CSS选择器规范文档。
浏览器中的javascript直接支持CSS选择器。如果电脑安装了firefox或chrome,打开浏览器,按F12(调出开发者界面),随机打开一个网页,选择控制台(Console)选项卡,进入Console
document.querySelectorAll("a")
按回车后发现页面中所有超链接都输出了,document.querySelectorAll(CSS选择器)获取页面中所有满足CSS选择器的元素,放到一个数组中返回。
如果只想获取第一个满足CSS选择器的元素,可以使用document.querySelector(CSS选择器)方法。
浏览器js中的CSS选择器与Jsoup(Java)和BeautifulSoup(Python)中实现的CSS选择器略有不同,但基本相同。
四.基于机器学习的网页提取
基于正则或CSS选择器(或xpath)的网页提取是基于包装器的网页提取。这种提取算法的共同问题是,对于不同结构的网页,必须制定不同的提取规则。 如果一个舆情系统需要监控10000个异构网站,需要编写和维护10000套抽取规则。自 2000 年以来,有人一直在研究如何使用机器学习方法,让程序无需手动规则即可从网页中提取所需信息。
从目前的科研成果来看,基于机器学习的网页提取重点偏向于新闻网页内容的自动提取,即输入一个新闻网页,程序可以自动输出新闻标题、正文、时间和其他信息。新闻、博客、百科网站收录比较简单的结构化数据,基本满足{title, time, body}的结构,抽取目标很明确,机器学习算法也设计的很好。但是,电子商务、求职等各类网页所收录的结构化数据非常复杂,有的还存在嵌套,没有统一的抽取目标。很难为此类页面设计机器学习提取算法。
本节主要介绍如何设计机器学习算法来提取网站中的新闻、博客、百科等正文信息,以下简称内容提取。
基于机器学习的网页提取算法大致可以分为以下几类:
三种算法中,第一种算法实现最好,效果最好。
让我们简单描述一下这三种算法。如果你只是想在你的项目中使用这些算法,你只需要了解第一类算法即可。
下面会提到一些论文,但请不要根据论文中自己的实验数据来判断算法的好坏。许多算法是面向早期网页设计的(即以表格为框架的网页),也有一些算法的实验数据。集覆盖范围相对较窄。如果可能,最好自己评估这些算法。
4.1 基于启发式规则和无监督学习的网页提取算法
基于启发式规则和无监督学习(第一类算法)的网页提取算法是目前最简单也是最好的方法。并且具有很高的通用性,即该算法对不同语言、不同结构的网页往往有效。
这类早期的算法大多没有将网页解析为DOM树,而是将网页解析为token序列。例如,对于以下 html 源代码:
广告...(8字)
正文...(500字)
页脚...(6字)
程序将其转换为令牌序列:
标签(body),标签(div),文本,文本....(8次),标签(/div),标签(div),文本,文本...(500次),标签(/div),标签(div),文本,文本...(6次),标签(/div),标签(/body)
早期有一种基于token序列的MSS算法(Maximum Subsequence Segmentation)。该算法有多个版本。一个版本为令牌序列中的每个令牌分配一个分数。评分规则如下:
根据上面的评分规则和token序列,我们可以得到一个评分序列:
-3.25,-3.25,1,1,1...(8次),-3.25,-3.25,1,1,1...(500次),-3.25,-3.25,1,1,1...(6次),-3.25,-3.25
MSS算法认为在token序列中找到一个子序列,使得这个子序列中token对应的分数总和达到最大值,那么这个子序列就是网页中的文本换个角度理解这个规则,就是从html源字符串中找到一个子序列。这个子序列应该收录更多的文本和更少的标签,因为算法给了标签一个更大的绝对值。负分(-3.25),给文本一个较小的正分(1).
如何从score序列中找到总和最大的子序列可以通过动态规划很好的解决。具体算法这里不给出。有兴趣的可以参考《Extracting Article Text from the Web with Maximum Subsequence Segmentation》论文,MSS算法效果不好,但是这篇论文认为可以代表很多早期的算法。
还有其他版本的 MSS。上面我们说算法给label和text分别赋值-3.25和1,都是固定值。还有一个版本的 MSS(也在论文中),它使用 Naive Bayes Si 的方法计算标签和文本的分数。该版本的MSS虽然在一定程度上提升了效果,但仍不理想。
无监督学习在第一类算法中也扮演着重要的角色。许多算法使用聚类方法自动将网页的文本和非文本分为两类。例如,在“CETR-Content Extraction via Tag Ratios”算法中,将网页分成多行文本,算法对每行文本计算2个特征,分别是下图中的横轴和纵轴,以及红色椭圆中的单元格。 (线),大部分是网页的正文,绿色椭圆中收录的单元格(线)大部分是非文本。使用k-means等聚类方法,可以很好地将正文和非文本分为两类。然后设计一些启发式算法来区分这两个类别中哪个是文本,哪个是非文本。
早期的算法通常使用标记序列和字符序列作为计算特征的单位。从某种意义上说,这破坏了网页的结构,没有充分利用网页的功能。在后面的算法中,很多使用DOM树的Nodes作为特征计算的基本单位,比如“通过路径比提取Web新闻”和“通过文本密度提取基于Dom的内容”。这些算法仍然使用启发式规则和无监督学习,因为以DOM树的节点作为特征计算的基本单元,算法可以获得越来越多的特征,因此可以设计更好的启发式规则和无监督学习算法。这些算法在提取中是有效的。它通常比前面描述的算法高得多。由于提取时以DOM树的Node为单位,该算法也可以方便的保留文本的结构(主要是保持网页中文本的布局)。
我们在WebCollector中实现了一流的算法(从1.12版本开始),可以直接从官网下载源码使用。
4.2 基于分类器的网页提取算法(第二类机器学习提取算法)
实现一个基于分类器的网页提取算法(第二种算法),大致流程如下:
对于网页提取,特征设计是首要任务。有时使用的特定分类器并不那么重要。在使用相同特征的情况下,使用决策树、SVM、神经网络等不同分类器可能不会对提取效果产生太大影响。
从工程的角度来看,过程中的第一步和第二步都比较困难。训练集的选择也很讲究,保证所选数据集中网页结构的多样性。例如,比较流行的文本结构是:
xxxx
xxxxxxxx
xxx
xxxxx
xxxx
如果训练集中只有五六个网站页面,很可能这些网站的文字都是上述结构,而恰巧在特征设计中,有两个特征:
假设使用决策树作为分类器,最终训练的模型很可能是:
如果一个节点的标签类型为div,且其孩子节点中标签为p的节点超过3个,则这个节点对应网页的正文。
虽然这个模型在训练数据集上可以取得很好的提取效果,但是很明显很多网站不符合这个规则。因此,训练集的选择对提取算法的效果影响很大。
网页设计的风格在不断变化。早期的网页经常使用表格来构建整个网页的框架。现在的网页都喜欢用div来搭建网页框架。如果想让提取算法覆盖更长的时间,那么在设计特征时一定要尽量选择那些不易改变的特征。标签类型是一个很容易改变的特性,并且随着网页设计风格的变化而变化。因此,如前所述,强烈不建议使用标签类型作为训练特征。
上述基于分类器的网页提取算法属于eager learning,即算法通过训练集生成模型(如决策树模型、神经网络模型等)。对应的懒惰学习是一种不预先通过训练集生成模型的算法。比较有名的KNN属于懒惰学习。
一些提取算法使用KNN来选择提取算法。听起来可能有点绕。这是一个解释。假设有2个提取算法A和B,并且有3个网站site1、site2、site3。 2种算法对3个网站的提取效果(这里用0%-100%的数字表示,越大说明越好)如下:
网站A 算法提取效果 B 算法提取效果
站点 1
90%
70%
站点 2
80%
85%
site3
60%
87%
可以看出,在site1上,算法A的提取效果优于算法B。在site2和site3上,算法B的提取效果更好。在实践中,这种情况非常普遍。所以有些人想设计一个分类器。该分类器不用于对文本和非文本进行分类,而是用于帮助选择提取算法。例如,在这个例子中,分类器应该告诉我们在提取site1中的网页时使用A算法以获得更好的结果。
以图片为例,A算法对政府网站的提取效果更好,B算法对互联网新闻网站的提取效果更好。然后当我提取政府类别网站时,分类器应该会帮我选择A算法。
这个分类器的实现可以使用KNN算法。需要提前准备数据集。数据集中有多个站点的网页。同时,需要维护一张表。该表告诉我们不同提取算法对每个站点的提取效果(其实只要知道在每个站点上,哪种算法的提取效果最好)。当遇到要提取的网页时,我们将该网页与数据集中的所有网页进行比较(效率极低),找到最相似的K个网页,然后查看K个网页,哪个网站的网页最多(例如, k= 7.其中六个网页来自CSDN新闻),然后我们选择本站最好的算法来提取这个未知网页。
4.3 基于网页模板自动生成的网页提取算法
基于网页模板自动生成的网页提取算法(第三类算法)有很多种。这是一个例子。在《URL Tree: Efficient Unsupervised Content Extraction from Streams of Web Documents》中,比较多个结构相同(根据URL判断)的页面,找出异同。页面之间的共同部分是非文本,页面之间的差异很大。该部分可能是文本。这很容易理解。例如,在某些网站中,所有网页页脚都相同,它们是记录信息或版权声明。这是页面之间的共性,所以算法认为这部分是非文本的。不同网页的文字往往不同,因此算法更容易识别文字页面。这种算法通常不会提取单个网页的文本,而是采集大量同质网页,同时提取多个网页。换句话说,不需要输入网页来实时提取。 查看全部
基于CSS选择器的网页抽取浏览器使用说明书大全
(在程序中,必须在\前加双引号和\才能转义。
三.基于CSS选择器的网页提取
浏览器收到服务器返回的html源代码后,会将网页解析成DOM树。 CSS Selector 基于DOM树的特性,广泛用于网页提取。目前最流行的网页提取组件Jsoup(Java)和BeautifulSoup(Python)都是基于CSS选择器的。
对于上面的例子:
(标题)此内容不要被抽取
(正文)此内容要被抽取
(页脚)此内容不要被抽取
使用 CSS 选择器将大大提高代码的可读性:
public static void cssExtract() {
String html="" +
"(标题)此内容不要被抽取" +
"(正文)此内容要被抽取" +
"(页脚)此内容不要被抽取" +
"";
//Jsoup中的Document类表示网页的DOM树
Document doc= Jsoup.parse(html);
//利用select方法获取所有满足css选择器的Element集合
// (实际是一个Elements类型的对象)
//由于在本网页的结构中,只会有一个Element满足条件
// 因此只要返回集合中的第一个Element即可
Element main=doc.select("div[class=main]").first();
//main是一个Element对象,这里main对应了网页中
//的(正文)此内容要被抽取
//我们调用Element的text()方法即可提取中间的文字
if(main!=null){
System.out.println("抽取结果:"+main.text());
}else{
System.out.println("无抽取结果");
}
}
CSS 选择器有标准规范,但 Jsoup (Java) 和 BeautifulSoup (Python) 等组件并没有完全按照规范实现 CSS 选择器。因此,在使用各个组件之前,最好先阅读组件文档中对CSS选择器的描述。
Jsoup 是 CSS 选择器的更好实现。如果想了解CSS选择器的使用,建议阅读Jsoup的CSS选择器规范文档。
浏览器中的javascript直接支持CSS选择器。如果电脑安装了firefox或chrome,打开浏览器,按F12(调出开发者界面),随机打开一个网页,选择控制台(Console)选项卡,进入Console
document.querySelectorAll("a")
按回车后发现页面中所有超链接都输出了,document.querySelectorAll(CSS选择器)获取页面中所有满足CSS选择器的元素,放到一个数组中返回。
如果只想获取第一个满足CSS选择器的元素,可以使用document.querySelector(CSS选择器)方法。
浏览器js中的CSS选择器与Jsoup(Java)和BeautifulSoup(Python)中实现的CSS选择器略有不同,但基本相同。
四.基于机器学习的网页提取
基于正则或CSS选择器(或xpath)的网页提取是基于包装器的网页提取。这种提取算法的共同问题是,对于不同结构的网页,必须制定不同的提取规则。 如果一个舆情系统需要监控10000个异构网站,需要编写和维护10000套抽取规则。自 2000 年以来,有人一直在研究如何使用机器学习方法,让程序无需手动规则即可从网页中提取所需信息。
从目前的科研成果来看,基于机器学习的网页提取重点偏向于新闻网页内容的自动提取,即输入一个新闻网页,程序可以自动输出新闻标题、正文、时间和其他信息。新闻、博客、百科网站收录比较简单的结构化数据,基本满足{title, time, body}的结构,抽取目标很明确,机器学习算法也设计的很好。但是,电子商务、求职等各类网页所收录的结构化数据非常复杂,有的还存在嵌套,没有统一的抽取目标。很难为此类页面设计机器学习提取算法。
本节主要介绍如何设计机器学习算法来提取网站中的新闻、博客、百科等正文信息,以下简称内容提取。
基于机器学习的网页提取算法大致可以分为以下几类:
三种算法中,第一种算法实现最好,效果最好。
让我们简单描述一下这三种算法。如果你只是想在你的项目中使用这些算法,你只需要了解第一类算法即可。
下面会提到一些论文,但请不要根据论文中自己的实验数据来判断算法的好坏。许多算法是面向早期网页设计的(即以表格为框架的网页),也有一些算法的实验数据。集覆盖范围相对较窄。如果可能,最好自己评估这些算法。
4.1 基于启发式规则和无监督学习的网页提取算法
基于启发式规则和无监督学习(第一类算法)的网页提取算法是目前最简单也是最好的方法。并且具有很高的通用性,即该算法对不同语言、不同结构的网页往往有效。
这类早期的算法大多没有将网页解析为DOM树,而是将网页解析为token序列。例如,对于以下 html 源代码:
广告...(8字)
正文...(500字)
页脚...(6字)
程序将其转换为令牌序列:
标签(body),标签(div),文本,文本....(8次),标签(/div),标签(div),文本,文本...(500次),标签(/div),标签(div),文本,文本...(6次),标签(/div),标签(/body)
早期有一种基于token序列的MSS算法(Maximum Subsequence Segmentation)。该算法有多个版本。一个版本为令牌序列中的每个令牌分配一个分数。评分规则如下:
根据上面的评分规则和token序列,我们可以得到一个评分序列:
-3.25,-3.25,1,1,1...(8次),-3.25,-3.25,1,1,1...(500次),-3.25,-3.25,1,1,1...(6次),-3.25,-3.25
MSS算法认为在token序列中找到一个子序列,使得这个子序列中token对应的分数总和达到最大值,那么这个子序列就是网页中的文本换个角度理解这个规则,就是从html源字符串中找到一个子序列。这个子序列应该收录更多的文本和更少的标签,因为算法给了标签一个更大的绝对值。负分(-3.25),给文本一个较小的正分(1).
如何从score序列中找到总和最大的子序列可以通过动态规划很好的解决。具体算法这里不给出。有兴趣的可以参考《Extracting Article Text from the Web with Maximum Subsequence Segmentation》论文,MSS算法效果不好,但是这篇论文认为可以代表很多早期的算法。
还有其他版本的 MSS。上面我们说算法给label和text分别赋值-3.25和1,都是固定值。还有一个版本的 MSS(也在论文中),它使用 Naive Bayes Si 的方法计算标签和文本的分数。该版本的MSS虽然在一定程度上提升了效果,但仍不理想。
无监督学习在第一类算法中也扮演着重要的角色。许多算法使用聚类方法自动将网页的文本和非文本分为两类。例如,在“CETR-Content Extraction via Tag Ratios”算法中,将网页分成多行文本,算法对每行文本计算2个特征,分别是下图中的横轴和纵轴,以及红色椭圆中的单元格。 (线),大部分是网页的正文,绿色椭圆中收录的单元格(线)大部分是非文本。使用k-means等聚类方法,可以很好地将正文和非文本分为两类。然后设计一些启发式算法来区分这两个类别中哪个是文本,哪个是非文本。
早期的算法通常使用标记序列和字符序列作为计算特征的单位。从某种意义上说,这破坏了网页的结构,没有充分利用网页的功能。在后面的算法中,很多使用DOM树的Nodes作为特征计算的基本单位,比如“通过路径比提取Web新闻”和“通过文本密度提取基于Dom的内容”。这些算法仍然使用启发式规则和无监督学习,因为以DOM树的节点作为特征计算的基本单元,算法可以获得越来越多的特征,因此可以设计更好的启发式规则和无监督学习算法。这些算法在提取中是有效的。它通常比前面描述的算法高得多。由于提取时以DOM树的Node为单位,该算法也可以方便的保留文本的结构(主要是保持网页中文本的布局)。
我们在WebCollector中实现了一流的算法(从1.12版本开始),可以直接从官网下载源码使用。
4.2 基于分类器的网页提取算法(第二类机器学习提取算法)
实现一个基于分类器的网页提取算法(第二种算法),大致流程如下:
对于网页提取,特征设计是首要任务。有时使用的特定分类器并不那么重要。在使用相同特征的情况下,使用决策树、SVM、神经网络等不同分类器可能不会对提取效果产生太大影响。
从工程的角度来看,过程中的第一步和第二步都比较困难。训练集的选择也很讲究,保证所选数据集中网页结构的多样性。例如,比较流行的文本结构是:
xxxx
xxxxxxxx
xxx
xxxxx
xxxx
如果训练集中只有五六个网站页面,很可能这些网站的文字都是上述结构,而恰巧在特征设计中,有两个特征:
假设使用决策树作为分类器,最终训练的模型很可能是:
如果一个节点的标签类型为div,且其孩子节点中标签为p的节点超过3个,则这个节点对应网页的正文。
虽然这个模型在训练数据集上可以取得很好的提取效果,但是很明显很多网站不符合这个规则。因此,训练集的选择对提取算法的效果影响很大。
网页设计的风格在不断变化。早期的网页经常使用表格来构建整个网页的框架。现在的网页都喜欢用div来搭建网页框架。如果想让提取算法覆盖更长的时间,那么在设计特征时一定要尽量选择那些不易改变的特征。标签类型是一个很容易改变的特性,并且随着网页设计风格的变化而变化。因此,如前所述,强烈不建议使用标签类型作为训练特征。
上述基于分类器的网页提取算法属于eager learning,即算法通过训练集生成模型(如决策树模型、神经网络模型等)。对应的懒惰学习是一种不预先通过训练集生成模型的算法。比较有名的KNN属于懒惰学习。
一些提取算法使用KNN来选择提取算法。听起来可能有点绕。这是一个解释。假设有2个提取算法A和B,并且有3个网站site1、site2、site3。 2种算法对3个网站的提取效果(这里用0%-100%的数字表示,越大说明越好)如下:
网站A 算法提取效果 B 算法提取效果
站点 1
90%
70%
站点 2
80%
85%
site3
60%
87%
可以看出,在site1上,算法A的提取效果优于算法B。在site2和site3上,算法B的提取效果更好。在实践中,这种情况非常普遍。所以有些人想设计一个分类器。该分类器不用于对文本和非文本进行分类,而是用于帮助选择提取算法。例如,在这个例子中,分类器应该告诉我们在提取site1中的网页时使用A算法以获得更好的结果。
以图片为例,A算法对政府网站的提取效果更好,B算法对互联网新闻网站的提取效果更好。然后当我提取政府类别网站时,分类器应该会帮我选择A算法。
这个分类器的实现可以使用KNN算法。需要提前准备数据集。数据集中有多个站点的网页。同时,需要维护一张表。该表告诉我们不同提取算法对每个站点的提取效果(其实只要知道在每个站点上,哪种算法的提取效果最好)。当遇到要提取的网页时,我们将该网页与数据集中的所有网页进行比较(效率极低),找到最相似的K个网页,然后查看K个网页,哪个网站的网页最多(例如, k= 7.其中六个网页来自CSDN新闻),然后我们选择本站最好的算法来提取这个未知网页。
4.3 基于网页模板自动生成的网页提取算法
基于网页模板自动生成的网页提取算法(第三类算法)有很多种。这是一个例子。在《URL Tree: Efficient Unsupervised Content Extraction from Streams of Web Documents》中,比较多个结构相同(根据URL判断)的页面,找出异同。页面之间的共同部分是非文本,页面之间的差异很大。该部分可能是文本。这很容易理解。例如,在某些网站中,所有网页页脚都相同,它们是记录信息或版权声明。这是页面之间的共性,所以算法认为这部分是非文本的。不同网页的文字往往不同,因此算法更容易识别文字页面。这种算法通常不会提取单个网页的文本,而是采集大量同质网页,同时提取多个网页。换句话说,不需要输入网页来实时提取。
算法自动采集列表的cookie库firefox的话可以试试抓
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-07-22 02:01
算法自动采集列表的cookie库firefox的话可以试试抓cookie也可以到浏览器的设置里面设置。
蟹妖需要微信提供读取读取原创和推送地址的能力,也就是“图文转发”。公众号没有原创保护的话,发布的文章下面会有“审核不通过”或者被禁止再次发布提示。
泻药。能否发自定义转发到群组,就可以从群组抓取已经推送的文章来。或者是文章内容被抄袭,爬虫工具也可以抓取到。如果群组是自己组建的,
1.在推送的文章里留下转发信息;2.微信返回垃圾箱,看到自己推送的“读取读取原创”功能里的数据有此消息;3.爬虫将该信息写入本地,读取文章,直接推送到群组,群组再推送到自己的公众号。
想得美呀。微信团队的流量大部分都放在公众号上了,这些都是要爬取的。你只要能找到所有的公众号就行了。
大概可以用微信新版开发者工具里面的微信公众号推送功能,让老微信公众号公转出来。
图文推送,这个资源来之不易,能弄的话找公众号平台服务商弄,那种权限都齐全的。 查看全部
算法自动采集列表的cookie库firefox的话可以试试抓
算法自动采集列表的cookie库firefox的话可以试试抓cookie也可以到浏览器的设置里面设置。
蟹妖需要微信提供读取读取原创和推送地址的能力,也就是“图文转发”。公众号没有原创保护的话,发布的文章下面会有“审核不通过”或者被禁止再次发布提示。
泻药。能否发自定义转发到群组,就可以从群组抓取已经推送的文章来。或者是文章内容被抄袭,爬虫工具也可以抓取到。如果群组是自己组建的,
1.在推送的文章里留下转发信息;2.微信返回垃圾箱,看到自己推送的“读取读取原创”功能里的数据有此消息;3.爬虫将该信息写入本地,读取文章,直接推送到群组,群组再推送到自己的公众号。
想得美呀。微信团队的流量大部分都放在公众号上了,这些都是要爬取的。你只要能找到所有的公众号就行了。
大概可以用微信新版开发者工具里面的微信公众号推送功能,让老微信公众号公转出来。
图文推送,这个资源来之不易,能弄的话找公众号平台服务商弄,那种权限都齐全的。

