
算法 自动采集列表
解释飓风算法3.0百度算法控制跨域采集和站点组问题
采集交流 • 优采云 发表了文章 • 0 个评论 • 356 次浏览 • 2020-08-07 02:13
8月8日,百度发布了“飓风算法3.0即将上线以控制跨域采集和站点组问题”的公告. 为了维护健康的移动生态系统,确保用户体验并确保高质量的站点/智能小应用程序能够获得合理的流量分配,百度搜索将在不久的将来升级飓风算法,并在线升级飓风算法3.0.
此算法升级主要针对跨域采集和站点组问题,并将涵盖PC网站,H5网站,智能小程序以及百度搜索下的其他内容. 对于算法所涵盖的网站/智能小程序,将根据违规的严重程度来限制搜索结果的显示.
以下详细介绍了飓风算法3.0的相关规则.
问题1: 在同一个品牌下,分支公司的网站/智能小程序都使用相同的模板. 他们会被评判为一组站台并被飓风算法3.0击中吗?
答案1: 针对网站组问题,该算法将基于多个因素进行综合判断,例如页面布局相似性,同一主题下的网站/智能小程序数量,内容质量,内容稀缺性,内容相似性等.
如果相同品牌的网站/智能小程序使用相同的页面布局并且内容相似性很高,则这种情况也可能被判断为站点组,并且存在被算法打击的风险.
问题示例: 某个品牌下的多个区域分支机构的智能小程序使用相同的模板,内容质量低且相似度高.
问题2: 此飓风算法升级主要针对跨域集合. 算法将覆盖同一域中的集合吗?
答案2: 此飓风算法3.0的主要升级点是加强跨域采集和站点组问题的覆盖范围,但是以前的飓风算法对于控制严酷采集仍然有效. 百度搜索算法一直在持续运行,以控制危害用户体验的违规行为,并且不会因算法升级或添加而停止旧算法.
问题3: 如果站点/智能小程序收录跨域采集的内容,为了避免被算法打击,我是否需要删除以前的跨域内容?
答案3: 是的,如果网站/智能小程序曾经发布过与该网站/智能小程序所属的域无关的内容,我们建议您尽快删除跨域内容,加深当前区域,并产生满足用户需求的高质量内容,以增强网站/智能小程序的重点.
问题4: 该算法会在一个站点下设置不同主题的频道或目录,并在不同字段中发布内容吗?
答案4: 在同一网站上可以存在具有不同主题的频道或目录,但是每个频道的内容应与网站的域定位相关,并应重点关注该域. 频道内容应满足搜索用户的需求优质内容.
问题5: 此飓风算法升级主要针对跨域集合. 算法将覆盖同一域中的集合吗? 查看全部

8月8日,百度发布了“飓风算法3.0即将上线以控制跨域采集和站点组问题”的公告. 为了维护健康的移动生态系统,确保用户体验并确保高质量的站点/智能小应用程序能够获得合理的流量分配,百度搜索将在不久的将来升级飓风算法,并在线升级飓风算法3.0.
此算法升级主要针对跨域采集和站点组问题,并将涵盖PC网站,H5网站,智能小程序以及百度搜索下的其他内容. 对于算法所涵盖的网站/智能小程序,将根据违规的严重程度来限制搜索结果的显示.
以下详细介绍了飓风算法3.0的相关规则.
问题1: 在同一个品牌下,分支公司的网站/智能小程序都使用相同的模板. 他们会被评判为一组站台并被飓风算法3.0击中吗?
答案1: 针对网站组问题,该算法将基于多个因素进行综合判断,例如页面布局相似性,同一主题下的网站/智能小程序数量,内容质量,内容稀缺性,内容相似性等.
如果相同品牌的网站/智能小程序使用相同的页面布局并且内容相似性很高,则这种情况也可能被判断为站点组,并且存在被算法打击的风险.
问题示例: 某个品牌下的多个区域分支机构的智能小程序使用相同的模板,内容质量低且相似度高.
问题2: 此飓风算法升级主要针对跨域集合. 算法将覆盖同一域中的集合吗?
答案2: 此飓风算法3.0的主要升级点是加强跨域采集和站点组问题的覆盖范围,但是以前的飓风算法对于控制严酷采集仍然有效. 百度搜索算法一直在持续运行,以控制危害用户体验的违规行为,并且不会因算法升级或添加而停止旧算法.
问题3: 如果站点/智能小程序收录跨域采集的内容,为了避免被算法打击,我是否需要删除以前的跨域内容?
答案3: 是的,如果网站/智能小程序曾经发布过与该网站/智能小程序所属的域无关的内容,我们建议您尽快删除跨域内容,加深当前区域,并产生满足用户需求的高质量内容,以增强网站/智能小程序的重点.
问题4: 该算法会在一个站点下设置不同主题的频道或目录,并在不同字段中发布内容吗?
答案4: 在同一网站上可以存在具有不同主题的频道或目录,但是每个频道的内容应与网站的域定位相关,并应重点关注该域. 频道内容应满足搜索用户的需求优质内容.
问题5: 此飓风算法升级主要针对跨域集合. 算法将覆盖同一域中的集合吗?
Wang Xi: 大数据人工智能中的运筹学与决策科学
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2020-08-06 19:22
收入管理,要解决的问题是如何在不增加流量投资的情况下大幅增加公司的销售收入. 为了解决这个问题,有必要从多个维度采集数据,并找到最佳定价和最佳销售策略.
风险管理,为金融及相关行业的客户提供完整的风险管理服务,提供从精确营销,信用调查,高风险交易识别到不良资产处置的全过程服务.
供应链管理为供应链中的各个环节(包括订单,库存,货运和分销)提供了优化的解决方案. 在提高响应速度和供应链灵活性的同时,它可以帮助公司控制成本.
算法引擎,许多理论都有广泛的应用场景. 实际上,该理论本身也可以带来巨大的价值,因为它可以提供用于复杂数据分析的平台并集成高效的优化算法,用于复杂数据分析提供基本的算法和软件支持,尤其是优化算法求解器的开发,可以大大改善机器学习和深度学习的效率.
由于我们看到了如此广泛的需求和应用,因此我们决定返回中国建立Shanshu Technology. 以上四个方面是我们的核心服务领域.
以一个例子来讨论运筹学和决策科学在金融风险管理中的应用
使用刚才提到的四个方面,首先是精确定位营销,确定真正满足金融产品特征的高质量用户,并在系统级别实施第一级风险控制.
第二个是信用调查,它通过观察和描述现有用户的支付行为来评估潜在用户的信用风险,最后给出信用调查决策.
第三个是教育管理或反欺诈,它使用数据来识别高风险交易和欺诈行为以最大程度地减少损失.
最后,在违反合同的情况下,为了最大程度地减少损失,这是处理不良资产的问题. 为了解决这四个问题并打开整个风险管理链,使用的方法实际上非常相似.
第一层是数据采集和管理,它需要描述和观察非常多维的数据. 其次,使用机器学习或相对复杂的预测方法来描述和预测数据. 第三,选择一个多层次的榜样. 最后,当我们拥有决策模型时,我们可以使用优化算法来帮助我们找到最佳结果. 因此,该方法论适用于整个风险管理链中的四个主题.
摘要
1. 运筹学和决策科学是大数据人工智能的核心概念. 对于大数据,不能忽视大数据分析支持的决策. 在人工智能方面,人们不能忽略其所需的模型和算法.
2. 当有了运筹学和决策科学的工具时,我们可以将实际问题抽象为可量化的决策问题并给出最佳决策.
3. 当我们讨论机器学习和深度学习等人工智能方法时,运筹学和决策科学也为机器学习提供了模型思维和算法保证.
教他钓鱼
运筹学和决策科学学科的学习建议:
1. 使用决策方法思考问题
当您面对信息量巨大且时间紧迫的问题时,您可能会感到无助,也不知道该怎么办. 但是您可以从决策的高度思考,现在可以做什么和不能做什么,主要的确定性是什么,哪些可以相对量化,没有用,并且是值得关注的核心价值. 尝试做出这样的战略决策和思考. 就像您脑海中的操作系统一样. 当您遇到更复杂的决策问题时,您可以采用一种新的思维方式.
2,掌握一些方法
实际上有许多种方法. 如果您是具有数学背景的学生,则可以关注一些定量数学方法,无论是基础运筹学,描述确定性的概率论,还是金融背景的学生了解所有金融应用场景,实际上,您都可以尝试培训从该方法.
3. 注意特定的应用场景
掌握太多理论. 如果没有合适的应用场景,或者使用理论覆盖了应用程序中的实际问题,则该问题将无法解决. 在很大程度上可以帮助我们的第一种方法是考虑您的决策方式. 我还建议您与感兴趣的行业的人进行更多的交流,因为他们面对该行业的独特场景和独特维度,并与他们进行更多的交流,因此他们有解决问题的思维方式和一些非常定量如果方法非常清晰,在这种清晰的应用场景中,他绝对可以帮助他解决核心决策问题.
粉丝问问题
1. 人工智能行业中是否存在泡沫成分?有纯人工智能的商业模式吗?
王曦: 这实际上是一个大话题. 气泡意味着只有概念,没有着陆,只有想法,没有具体的实际计划. 因此,从这个角度来看,会有气泡.
回顾历史,我认为在新兴技术诞生的任何阶段,人们都会进行这样的讨论,因为从时间的角度来看,当一个新概念问世时,该概念通常会领先于技术.
我参加了一个讨论. 主题是人工智能已渗透到我们生活的方方面面. 未来会不会有很多人类工作被人工智能取代?实际上,这是关于气泡的非常典型的讨论. 实际上,我对此并不担心. 一方面,当新技术出现时,我已经讨论并担心了很多次. 例如,在20世纪初,当福特汽车公司开始投资于标准化和简化的T型汽车生产时,整个装配线上约三分之二的工人被替换了. 但是,如果我们注意这种新技术的发展,从替代劳动力产生的就业机会来看,另一个更大的产业实际上是一个更大的产业.
从另一个角度来看,关于纯人工智能是否是一种商业模型这一问题,我的观点是,我将更加关注它所产生的价值. 任何能够创造价值的新技术都可以找到合适的商业模式. 货币化始终是第二种问题. 第一种类型的问题首先是这种功能,无论是娱乐,服务还是实际的产品形式,重点都是它可以产生什么样的价值. 只要具有价值,我相信它将拥有自己的商业模式.
2. 中美运筹学与决策科学的学科和应用之间的主要区别是什么?
王曦: 据我观察,差异很大.
由于运筹学和决策科学在美国首先发展和成熟,因此该学科的应用和成熟度远远高于中国. 一些成熟的大公司,例如亚马逊规模的大公司,可能拥有150至200个全职的研发和供应链团队,其中80%至90%是博士学位. 在中国,无论是小公司还是大公司都不能拥有这样的团队配置.
从另一个角度来看,我们回到中国创业后,我们与各种国内企业进行了交流和讨论. 我们发现,由于这项技术或其理论非常成熟,应用范围非常广,当我们与公司沟通时,我们会发现公司将很快意识到我们可以带来的价值,所以这一点使我非常乐观.
另一方面,大数据的概念在过去几年中被大肆宣传,因此各种类型和行业的公司将或多或少地积累数据. 当这些数据积累到临界点时,每个人都在乎如何制定一些数据驱动型决策以及如何做出更好的优化操作. 这是我们看到运筹学优化和决策科学可以在中国广泛使用的另一个机会.
总而言之,如果您看一下现状,美国在运筹学和决策科学的认识,接受和应用方面已经成熟很多,但是中国仍有很大的增长空间
3. AI +金融的最大困难是什么?
王曦: 我记得李开复先生曾经说过: “也许最容易应用的人工智能领域是金融,因为金融是一种纯粹的数字语言. ”
仅从数据的角度来看,我认为有两个困难或痛点.
首先,尽管金融业中的数据量非常大,但它通常面临着一个大而低维的问题. 例如,刚刚讨论了大数据信用调查的问题. 金融机构可能已经观察到有关成功出借用户的付款习惯的大规模数据. 尽管数据量非常大,但从维度的角度来看,我们观察到的所有数据都是一组客户的行为,这些客户被金融机构视作上级贷款并成功获得贷款. 我们认为他们的不还款可能性非常低. 对于那些拒绝发放贷款的人,我们没有观察到这些方面. 因此,当数据面临大量小尺寸问题时,采用什么方法和更新的数据尺寸来解决这个问题,我认为这是一个难点.
第二,许多所谓的数据分析可能会止于数据描述和数据预测. 数据的描述和预测具有巨大的价值,但是,如果我们真的想使用这种复杂或高端的数据分析方法来最终支持金融技术决策,那么我们不应该只停留在数据的描述和预测方面. 有时人们认为预测必须非常准确才能解决此问题,但是如果我们关注该预测所支持的决策,则会发现该决策对预测精度的敏感性不如想象中的高,并且有时必需数据的维度不能仅通过数据描述和数据预测来解决. 因此,我建议您将重点更多放在决策方面,而不仅仅是数据描述和数据预测. 查看全部
应用场景可分为收入管理,风险管理,供应链管理和算法引擎四个领域
收入管理,要解决的问题是如何在不增加流量投资的情况下大幅增加公司的销售收入. 为了解决这个问题,有必要从多个维度采集数据,并找到最佳定价和最佳销售策略.
风险管理,为金融及相关行业的客户提供完整的风险管理服务,提供从精确营销,信用调查,高风险交易识别到不良资产处置的全过程服务.
供应链管理为供应链中的各个环节(包括订单,库存,货运和分销)提供了优化的解决方案. 在提高响应速度和供应链灵活性的同时,它可以帮助公司控制成本.
算法引擎,许多理论都有广泛的应用场景. 实际上,该理论本身也可以带来巨大的价值,因为它可以提供用于复杂数据分析的平台并集成高效的优化算法,用于复杂数据分析提供基本的算法和软件支持,尤其是优化算法求解器的开发,可以大大改善机器学习和深度学习的效率.
由于我们看到了如此广泛的需求和应用,因此我们决定返回中国建立Shanshu Technology. 以上四个方面是我们的核心服务领域.
以一个例子来讨论运筹学和决策科学在金融风险管理中的应用
使用刚才提到的四个方面,首先是精确定位营销,确定真正满足金融产品特征的高质量用户,并在系统级别实施第一级风险控制.
第二个是信用调查,它通过观察和描述现有用户的支付行为来评估潜在用户的信用风险,最后给出信用调查决策.
第三个是教育管理或反欺诈,它使用数据来识别高风险交易和欺诈行为以最大程度地减少损失.
最后,在违反合同的情况下,为了最大程度地减少损失,这是处理不良资产的问题. 为了解决这四个问题并打开整个风险管理链,使用的方法实际上非常相似.
第一层是数据采集和管理,它需要描述和观察非常多维的数据. 其次,使用机器学习或相对复杂的预测方法来描述和预测数据. 第三,选择一个多层次的榜样. 最后,当我们拥有决策模型时,我们可以使用优化算法来帮助我们找到最佳结果. 因此,该方法论适用于整个风险管理链中的四个主题.
摘要
1. 运筹学和决策科学是大数据人工智能的核心概念. 对于大数据,不能忽视大数据分析支持的决策. 在人工智能方面,人们不能忽略其所需的模型和算法.
2. 当有了运筹学和决策科学的工具时,我们可以将实际问题抽象为可量化的决策问题并给出最佳决策.
3. 当我们讨论机器学习和深度学习等人工智能方法时,运筹学和决策科学也为机器学习提供了模型思维和算法保证.
教他钓鱼
运筹学和决策科学学科的学习建议:
1. 使用决策方法思考问题
当您面对信息量巨大且时间紧迫的问题时,您可能会感到无助,也不知道该怎么办. 但是您可以从决策的高度思考,现在可以做什么和不能做什么,主要的确定性是什么,哪些可以相对量化,没有用,并且是值得关注的核心价值. 尝试做出这样的战略决策和思考. 就像您脑海中的操作系统一样. 当您遇到更复杂的决策问题时,您可以采用一种新的思维方式.
2,掌握一些方法
实际上有许多种方法. 如果您是具有数学背景的学生,则可以关注一些定量数学方法,无论是基础运筹学,描述确定性的概率论,还是金融背景的学生了解所有金融应用场景,实际上,您都可以尝试培训从该方法.
3. 注意特定的应用场景
掌握太多理论. 如果没有合适的应用场景,或者使用理论覆盖了应用程序中的实际问题,则该问题将无法解决. 在很大程度上可以帮助我们的第一种方法是考虑您的决策方式. 我还建议您与感兴趣的行业的人进行更多的交流,因为他们面对该行业的独特场景和独特维度,并与他们进行更多的交流,因此他们有解决问题的思维方式和一些非常定量如果方法非常清晰,在这种清晰的应用场景中,他绝对可以帮助他解决核心决策问题.
粉丝问问题
1. 人工智能行业中是否存在泡沫成分?有纯人工智能的商业模式吗?
王曦: 这实际上是一个大话题. 气泡意味着只有概念,没有着陆,只有想法,没有具体的实际计划. 因此,从这个角度来看,会有气泡.
回顾历史,我认为在新兴技术诞生的任何阶段,人们都会进行这样的讨论,因为从时间的角度来看,当一个新概念问世时,该概念通常会领先于技术.
我参加了一个讨论. 主题是人工智能已渗透到我们生活的方方面面. 未来会不会有很多人类工作被人工智能取代?实际上,这是关于气泡的非常典型的讨论. 实际上,我对此并不担心. 一方面,当新技术出现时,我已经讨论并担心了很多次. 例如,在20世纪初,当福特汽车公司开始投资于标准化和简化的T型汽车生产时,整个装配线上约三分之二的工人被替换了. 但是,如果我们注意这种新技术的发展,从替代劳动力产生的就业机会来看,另一个更大的产业实际上是一个更大的产业.
从另一个角度来看,关于纯人工智能是否是一种商业模型这一问题,我的观点是,我将更加关注它所产生的价值. 任何能够创造价值的新技术都可以找到合适的商业模式. 货币化始终是第二种问题. 第一种类型的问题首先是这种功能,无论是娱乐,服务还是实际的产品形式,重点都是它可以产生什么样的价值. 只要具有价值,我相信它将拥有自己的商业模式.
2. 中美运筹学与决策科学的学科和应用之间的主要区别是什么?
王曦: 据我观察,差异很大.
由于运筹学和决策科学在美国首先发展和成熟,因此该学科的应用和成熟度远远高于中国. 一些成熟的大公司,例如亚马逊规模的大公司,可能拥有150至200个全职的研发和供应链团队,其中80%至90%是博士学位. 在中国,无论是小公司还是大公司都不能拥有这样的团队配置.
从另一个角度来看,我们回到中国创业后,我们与各种国内企业进行了交流和讨论. 我们发现,由于这项技术或其理论非常成熟,应用范围非常广,当我们与公司沟通时,我们会发现公司将很快意识到我们可以带来的价值,所以这一点使我非常乐观.
另一方面,大数据的概念在过去几年中被大肆宣传,因此各种类型和行业的公司将或多或少地积累数据. 当这些数据积累到临界点时,每个人都在乎如何制定一些数据驱动型决策以及如何做出更好的优化操作. 这是我们看到运筹学优化和决策科学可以在中国广泛使用的另一个机会.
总而言之,如果您看一下现状,美国在运筹学和决策科学的认识,接受和应用方面已经成熟很多,但是中国仍有很大的增长空间
3. AI +金融的最大困难是什么?
王曦: 我记得李开复先生曾经说过: “也许最容易应用的人工智能领域是金融,因为金融是一种纯粹的数字语言. ”
仅从数据的角度来看,我认为有两个困难或痛点.
首先,尽管金融业中的数据量非常大,但它通常面临着一个大而低维的问题. 例如,刚刚讨论了大数据信用调查的问题. 金融机构可能已经观察到有关成功出借用户的付款习惯的大规模数据. 尽管数据量非常大,但从维度的角度来看,我们观察到的所有数据都是一组客户的行为,这些客户被金融机构视作上级贷款并成功获得贷款. 我们认为他们的不还款可能性非常低. 对于那些拒绝发放贷款的人,我们没有观察到这些方面. 因此,当数据面临大量小尺寸问题时,采用什么方法和更新的数据尺寸来解决这个问题,我认为这是一个难点.
第二,许多所谓的数据分析可能会止于数据描述和数据预测. 数据的描述和预测具有巨大的价值,但是,如果我们真的想使用这种复杂或高端的数据分析方法来最终支持金融技术决策,那么我们不应该只停留在数据的描述和预测方面. 有时人们认为预测必须非常准确才能解决此问题,但是如果我们关注该预测所支持的决策,则会发现该决策对预测精度的敏感性不如想象中的高,并且有时必需数据的维度不能仅通过数据描述和数据预测来解决. 因此,我建议您将重点更多放在决策方面,而不仅仅是数据描述和数据预测.
飓风算法3.0即将推出,以确保高质量站点的合理流量分配
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2020-08-06 19:00
网站站长之家()8月9日消息: 昨天,百度宣布已确保高质量的站点和小程序能够获得合理的流量分配,并且该官员将在不久的将来启动Hurricane Algorithm 3.0.
2017年7月4日,百度的搜索资源平台宣布启动“飓风算法”,旨在严厉打击以不良采集为主要内容来源的网站,营造良好的搜索内容生态,保护浏览搜索用户的经验.
2018年9月13日,百度升级了飓风算法并发布了飓风算法2.0. 它主要针对五种采集行为,包括明显的采集痕迹,内容拼接,网站上的大量采集内容以及跨域采集.
此次算法升级主要针对百度搜索下的PC站点,H5站点和智能小程序的跨域采集以及站点组问题. Hurricane Algorithm 3.0将根据违规的严重性来限制搜索结果的显示.
以下是详细说明:
1. 跨域采集:
为了获得更多流量,站点/智能小程序发布的内容不属于站点/智能小程序的域. 通常,这些内容是从Internet采集的,内容质量和相关性很低,对搜索用户的价值也很低. 对于此类行为搜索,将判断站点/智能applet的域不够集中,并且在显示上会有不同程度的限制.
跨域集合主要包括以下两种类型的问题:
类型1: 主站点或主页的内容/标题/关键字/摘要表明该站点具有明确的字段或行业,但是发布的内容与该字段无关或相关性较低.
问题示例: 美食智能小程序发布足球相关内容
第二类: 站点/智能小程序没有明确的域或行业,并且内容涉及多个域或行业,该域是模糊的,并且域关注度很低.
问题示例: 智能小程序的内容涉及多个字段
两个. 站组问题:
指的是批量构造多个站点/智能小程序以获得搜索流量的行为. 网站组中的大多数网站/智能小程序质量低,资源稀缺,内容相似度高,甚至重用同一模板,这很难满足搜索用户的需求.
问题示例: 多个智能小应用程序重复使用同一模板,内容质量低且相似度高
以上是飓风算法3.0的描述. 该算法有望在八月份发布. 请及时查看站内信件,短信等通道中的提醒,并积极自查完成整改,避免不必要的损失. 查看全部
文章目录

网站站长之家()8月9日消息: 昨天,百度宣布已确保高质量的站点和小程序能够获得合理的流量分配,并且该官员将在不久的将来启动Hurricane Algorithm 3.0.
2017年7月4日,百度的搜索资源平台宣布启动“飓风算法”,旨在严厉打击以不良采集为主要内容来源的网站,营造良好的搜索内容生态,保护浏览搜索用户的经验.
2018年9月13日,百度升级了飓风算法并发布了飓风算法2.0. 它主要针对五种采集行为,包括明显的采集痕迹,内容拼接,网站上的大量采集内容以及跨域采集.
此次算法升级主要针对百度搜索下的PC站点,H5站点和智能小程序的跨域采集以及站点组问题. Hurricane Algorithm 3.0将根据违规的严重性来限制搜索结果的显示.
以下是详细说明:
1. 跨域采集:
为了获得更多流量,站点/智能小程序发布的内容不属于站点/智能小程序的域. 通常,这些内容是从Internet采集的,内容质量和相关性很低,对搜索用户的价值也很低. 对于此类行为搜索,将判断站点/智能applet的域不够集中,并且在显示上会有不同程度的限制.
跨域集合主要包括以下两种类型的问题:
类型1: 主站点或主页的内容/标题/关键字/摘要表明该站点具有明确的字段或行业,但是发布的内容与该字段无关或相关性较低.
问题示例: 美食智能小程序发布足球相关内容

第二类: 站点/智能小程序没有明确的域或行业,并且内容涉及多个域或行业,该域是模糊的,并且域关注度很低.
问题示例: 智能小程序的内容涉及多个字段

两个. 站组问题:
指的是批量构造多个站点/智能小程序以获得搜索流量的行为. 网站组中的大多数网站/智能小程序质量低,资源稀缺,内容相似度高,甚至重用同一模板,这很难满足搜索用户的需求.
问题示例: 多个智能小应用程序重复使用同一模板,内容质量低且相似度高

以上是飓风算法3.0的描述. 该算法有望在八月份发布. 请及时查看站内信件,短信等通道中的提醒,并积极自查完成整改,避免不必要的损失.
任正非: 重视数据的输入和采集,这是人工智能和自动化的源泉
采集交流 • 优采云 发表了文章 • 0 个评论 • 333 次浏览 • 2020-08-06 18:27
当时,他提出,为了实现高质量的数据输出,有必要敢于在网络规划和网络优化等关键方案上进行投资,并率先在非洲进行歼灭战. 简化的工程勘测和自动化设计.
8月29日,华为召开了GTS人工智能实践进展专题报告会. 任正非提醒,尽管GTS机器学习取得了长足的进步,但仍然需要重视数据的输入和采集,这是人工智能和自动化的源泉.
在会上,任正非对华为内部人工智能的发展提出了三个要求:
1. 专注于内部效率的提高,使用人工智能来更改操作模式,简化管理并结合业务场景来解决实际问题.
2. 专注于业务,继续增加对GTS数据系统,AI算法和AI支持平台的投资.
3. 人工智能将在未来在内部进行横向扩展,并与周围部门协调以产生成倍的收益;客户界面的升级和服务内容将在设备和网络的生命周期中创造更大的价值.
会议还显示,华为在全球拥有460万个站点,每年将在100万个站点上运营. 任正非希望在5G时代首先连接华为的基站.
任正非提出,要加快公司统一人工智能平台需求的发展,部署统一人工智能培训环境,并期待2018年在GTS中的首次实践和应用. (钛媒体记者李成成报道) )
附件: 任正非在GTS人工智能实践进度报告会上的讲话
1. 专注于内部效率的提高,使用人工智能来更改操作模式,简化管理并结合业务场景来解决实际问题.
人工智能的核心在于应用. GTS使用人工智能作为工具来研究大规模重复活动的智能自动化,以提高人员效率并协助人员工作. 从您的探索中,实践经验非常重要.
在人工智能和自动化过程中,我们必须注意交付服务过程以及人员思想和行为方式的变化. 如果它们仍然是相同的旧思想,并且不注意数据输入和采集,那么我们的人工智能和自动化将失去其来源. 同时,我们必须看到人工智能是一个不断发展和迭代的过程. 在前进的过程中,每个人都不应着急,并要不断进步. 关键是要做好数据治理和平台体系结构设计,以确保我们的总体方向正确和正确. 加快迭代速度并一步步运行.
首先,使用人工智能简化站点操作,自动化设计和报告,并统一产品线以构建网络,而无需进行安装和调试.
我们在全球拥有460万个站点,并且每年在100万个站点上运营. 任何站点操作都是成本. 通过建立站点信息数据库和开发站点3D扫描功能,简化了站点调查,并大大节省了在站点上输入表单所需的时间. 将来的数据输入可以进一步简化. 捆绑好语音系统,完成现场操作. 自己说,表格将自动生成. 然后回家修改表格,以完成交付.
基站设计方案的模型很多. 现在,通过机器学习,可以实现基站连接图和配置参数的自动生成,从而降低了对现场工程师的要求. 面向未来,应该对设备模型集成,免安装和免调试进行研究. 在5G时代,万物互联. 我们可以先连接基站吗?荒野,我们有多少个站点?应该是几百万. 您可以要求快递员骑摩托车上山,连接基站并打开电源,所有无线连接设备都将自动连接,从而减少了错误并节省了人工.
质量检查仅需拍照并将其与标准模式进行比较,以便分包商可以在现场安装时检查安装的质量,一次正确执行操作,避免多次访问现场并保存时间. 提高效率. 不要低估了1-2小时的节省. 这是重点. 如果有成千上万个站点要推广,乘以系数,就会有成千上万的规模效益.
第二,网络规划和网络优化必须敢于应用高级技术,例如地理,测绘和数学以及新的商业模式. 只要效果可以改善,我就会使用它们.
网络规划和网络优化基于数据,算法和成本的影响. 我们选择人工智能方面的突破,通过“分析机器人”提高人员效率,并在无线干扰分析和天线馈电系统方向角优化调整中加强引入人工智能技术. 增强无线网络优化和规划的效率. 同时,基于产品数据的虚拟驱动器测试是一个方向. 您无需进行路测即可知道网络的信号状态. 一个城市可以节省3,000公里的路测. 十几个城市相当于地球的一圈. 响.
人工智能理论是所有人类的财富,可以被我使用,而不仅仅是我们的理论. 网络规划和网络优化是一项基于数据的业务,人工智能也很容易带来收益,因此我们必须敢于招募一些统计学,系统工程,哲学,遥感,遥测等领域的优秀医生和硕士. ,就像我那时一样. 这与要求某些专业人员进行地理测绘相同. 经过两年的实践,它自然会理解.
第三,数万亿美元的股票是我们的优势. 我们将继续积累少量样本. 维护模式应从被动问题处理变为主动预测和预防,再从反馈反馈到制造和产品设计以形成闭环改进.
面对大量确定性的重复工作,逐渐聚合成千上万个复杂场景,并通过表格,建模和其他方法不断总结和完善经验. 就像我小时候一样,发生问题时,一台巨大的数字设备接连闪烁着灯. 从闪烁的灯光中,我慢慢看了看哪个区域集中,然后看了电路. 我判断电阻已断开,然后将其打开. 它是固定的,这是一个小样本!这些小样本已提供给您,您可以将其总结和总结到理论水平,这就是故障模型.
最终的维护模式应从被动问题处理转变为预测性预防. 在问题处理方面,我们至少可以丰富问题经验数据库. 对于暴露最多问题,解决最好问题的人,我们也可以提供小额奖励. 在预测和预防方面,应将通过障碍物发现的切屑和批次等相关问题进一步反馈给公司的制造部门和产品设计链接,以从源头上提高设备的耐用性.
2. 专注于业务,继续增加对GTS数据系统,AI算法和AI支持平台的投资.
首先,行为是记录,记录是数据. 建立并继续完善GTS数据系统.
数据是一门科学,也是人工智能的基础. 有必要学习行业做得好的方法. GTS将操作过程中的操作过程,对象,规则和经验数字化,并不断完善GTS数据系统. 每个产品线还必须将自己的产品数字化,这是服务数字化的基础. 有必要加强云平台的基础设施建设,丰富个体数据采集工具,为每个员工配备一个数据采集器. 员工完成现场工作后,他返回工作站进行处理,并只需按一下按钮就将其发送出去.
应该使用数据来促进构造,使用表单,建模和其他方法来输出作业数据,并使用高质量的作业数据输出来衡量作业完成情况,并为工程师的高质量提供牵引力作业数据输出以形成指导和模板.
第二,算法必须为企业服务. 算法科学家与熟悉服务场景的工程师紧密合作,以提高他们在服务客户战场上的能力
人工智能的应用是一门实践科学,并且在实践和应用中不断进步,其效果并非一overnight而就. 在实践的初期,如果该算法不能达到高级工程师的水平,则必须以人为主体,以机器为辅,并不断地对其进行改进和改进.
人工智能开发,算法专家,产品线专家和GTS业务专家应组成一个混合团队,共同识别实际场景中的AI应用机会,了解业务场景,设计算法模型并优化算法效果.
第三,加快公司统一人工智能平台的开发,并于2018年在GTS中首次实践和应用.
开发公司的统一人工智能平台,部署统一的人工智能培训环境,首先练习和应用GTS,并整合GTS积累的站点运营,网络维护以及网络规划领域的算法,知识,方法和经验和优化. 治愈这个平台.
人工智能平台在GTS中的应用必须首先,小步骤并且要快速运行,着重于解决方案的服务场景,选择与场景相匹配的相对成熟的算法,并快速建立工程能力,例如数据处理和在战斗中进行模型训练经过优化,该平台将于2018年部署在GTS系统上.
3. 人工智能将在未来在内部进行横向扩展,并与周围部门协调以产生成倍的收益;客户界面的升级和服务内容将在设备和网络的生命周期中创造更大的价值.
首先,自动化也是人工智能. 要改善一个观点,可能需要促进数十万个重点,并且会有数十万个乘数收益.
跨域推广也应具有优势. 通过数据互连和业务交叉集成,可以简化公司的许多部门. 例如,金融业还挑选出了100多个人工智能方面的要点,其中有些与GTS交互,例如从项目会计到开发票,GTS可以以此为起点横向发展金融.
我们必须坚定不移地推进某些确定性任务的自动化和智能化,减少重复劳动. 并非总是可能强调人工智能对歧义性问题的判断和处理. 为什么它不能解决确定性问题?自动化也是人工智能. 为了提高一点,乘以系数,可能会有成千上万的乘数收益. GTS人员均应通过实验“洗澡”. 有些人在周期中变得更加强大,创造了新的工作方法并大大提高了工作效率.
第二,基于我们自身实践的成功,使用数据和智能技术来升级服务内容,建立在线服务模型并解决客户挑战.
基于数万亿存储数据的优势,通过改善自我管理的周期性实践,构建全球智能网络平台,该平台的功能将以服务的形式向客户开放,服务内容将得到扩展到设备和网络的整个生命周期. 在解决客户挑战的同时,华为也受益匪浅.
站点选择是否可以根据流量预测和动态变化进行准确的网络规划?甚至数百万个设备都无法一天24小时高速开机. 如果可以根据流量动态设置产品的能耗,是否可以大大改善网络和能源效率?在更远的将来,我们能否将预防和预测能力扩展到整个网络,并以可预测的方式应对自然灾害和重大事件带来的挑战?
我们抓住了这些机会并升级了服务的内容,我们可以使用在线服务和其他方式在网络的整个生命周期中继续为客户创造价值.
有关更多精彩内容,请关注Titanium Media微信ID(ID: taimeiti),或下载Titanium Media App 查看全部
今年年初,华为总裁任正非在全球人工智能技术应用研讨会(GTS)上向华为阐明了GTS人工智能的重要性.
当时,他提出,为了实现高质量的数据输出,有必要敢于在网络规划和网络优化等关键方案上进行投资,并率先在非洲进行歼灭战. 简化的工程勘测和自动化设计.
8月29日,华为召开了GTS人工智能实践进展专题报告会. 任正非提醒,尽管GTS机器学习取得了长足的进步,但仍然需要重视数据的输入和采集,这是人工智能和自动化的源泉.
在会上,任正非对华为内部人工智能的发展提出了三个要求:
1. 专注于内部效率的提高,使用人工智能来更改操作模式,简化管理并结合业务场景来解决实际问题.
2. 专注于业务,继续增加对GTS数据系统,AI算法和AI支持平台的投资.
3. 人工智能将在未来在内部进行横向扩展,并与周围部门协调以产生成倍的收益;客户界面的升级和服务内容将在设备和网络的生命周期中创造更大的价值.
会议还显示,华为在全球拥有460万个站点,每年将在100万个站点上运营. 任正非希望在5G时代首先连接华为的基站.
任正非提出,要加快公司统一人工智能平台需求的发展,部署统一人工智能培训环境,并期待2018年在GTS中的首次实践和应用. (钛媒体记者李成成报道) )
附件: 任正非在GTS人工智能实践进度报告会上的讲话
1. 专注于内部效率的提高,使用人工智能来更改操作模式,简化管理并结合业务场景来解决实际问题.
人工智能的核心在于应用. GTS使用人工智能作为工具来研究大规模重复活动的智能自动化,以提高人员效率并协助人员工作. 从您的探索中,实践经验非常重要.
在人工智能和自动化过程中,我们必须注意交付服务过程以及人员思想和行为方式的变化. 如果它们仍然是相同的旧思想,并且不注意数据输入和采集,那么我们的人工智能和自动化将失去其来源. 同时,我们必须看到人工智能是一个不断发展和迭代的过程. 在前进的过程中,每个人都不应着急,并要不断进步. 关键是要做好数据治理和平台体系结构设计,以确保我们的总体方向正确和正确. 加快迭代速度并一步步运行.
首先,使用人工智能简化站点操作,自动化设计和报告,并统一产品线以构建网络,而无需进行安装和调试.
我们在全球拥有460万个站点,并且每年在100万个站点上运营. 任何站点操作都是成本. 通过建立站点信息数据库和开发站点3D扫描功能,简化了站点调查,并大大节省了在站点上输入表单所需的时间. 将来的数据输入可以进一步简化. 捆绑好语音系统,完成现场操作. 自己说,表格将自动生成. 然后回家修改表格,以完成交付.
基站设计方案的模型很多. 现在,通过机器学习,可以实现基站连接图和配置参数的自动生成,从而降低了对现场工程师的要求. 面向未来,应该对设备模型集成,免安装和免调试进行研究. 在5G时代,万物互联. 我们可以先连接基站吗?荒野,我们有多少个站点?应该是几百万. 您可以要求快递员骑摩托车上山,连接基站并打开电源,所有无线连接设备都将自动连接,从而减少了错误并节省了人工.
质量检查仅需拍照并将其与标准模式进行比较,以便分包商可以在现场安装时检查安装的质量,一次正确执行操作,避免多次访问现场并保存时间. 提高效率. 不要低估了1-2小时的节省. 这是重点. 如果有成千上万个站点要推广,乘以系数,就会有成千上万的规模效益.
第二,网络规划和网络优化必须敢于应用高级技术,例如地理,测绘和数学以及新的商业模式. 只要效果可以改善,我就会使用它们.
网络规划和网络优化基于数据,算法和成本的影响. 我们选择人工智能方面的突破,通过“分析机器人”提高人员效率,并在无线干扰分析和天线馈电系统方向角优化调整中加强引入人工智能技术. 增强无线网络优化和规划的效率. 同时,基于产品数据的虚拟驱动器测试是一个方向. 您无需进行路测即可知道网络的信号状态. 一个城市可以节省3,000公里的路测. 十几个城市相当于地球的一圈. 响.
人工智能理论是所有人类的财富,可以被我使用,而不仅仅是我们的理论. 网络规划和网络优化是一项基于数据的业务,人工智能也很容易带来收益,因此我们必须敢于招募一些统计学,系统工程,哲学,遥感,遥测等领域的优秀医生和硕士. ,就像我那时一样. 这与要求某些专业人员进行地理测绘相同. 经过两年的实践,它自然会理解.
第三,数万亿美元的股票是我们的优势. 我们将继续积累少量样本. 维护模式应从被动问题处理变为主动预测和预防,再从反馈反馈到制造和产品设计以形成闭环改进.
面对大量确定性的重复工作,逐渐聚合成千上万个复杂场景,并通过表格,建模和其他方法不断总结和完善经验. 就像我小时候一样,发生问题时,一台巨大的数字设备接连闪烁着灯. 从闪烁的灯光中,我慢慢看了看哪个区域集中,然后看了电路. 我判断电阻已断开,然后将其打开. 它是固定的,这是一个小样本!这些小样本已提供给您,您可以将其总结和总结到理论水平,这就是故障模型.
最终的维护模式应从被动问题处理转变为预测性预防. 在问题处理方面,我们至少可以丰富问题经验数据库. 对于暴露最多问题,解决最好问题的人,我们也可以提供小额奖励. 在预测和预防方面,应将通过障碍物发现的切屑和批次等相关问题进一步反馈给公司的制造部门和产品设计链接,以从源头上提高设备的耐用性.
2. 专注于业务,继续增加对GTS数据系统,AI算法和AI支持平台的投资.
首先,行为是记录,记录是数据. 建立并继续完善GTS数据系统.
数据是一门科学,也是人工智能的基础. 有必要学习行业做得好的方法. GTS将操作过程中的操作过程,对象,规则和经验数字化,并不断完善GTS数据系统. 每个产品线还必须将自己的产品数字化,这是服务数字化的基础. 有必要加强云平台的基础设施建设,丰富个体数据采集工具,为每个员工配备一个数据采集器. 员工完成现场工作后,他返回工作站进行处理,并只需按一下按钮就将其发送出去.
应该使用数据来促进构造,使用表单,建模和其他方法来输出作业数据,并使用高质量的作业数据输出来衡量作业完成情况,并为工程师的高质量提供牵引力作业数据输出以形成指导和模板.
第二,算法必须为企业服务. 算法科学家与熟悉服务场景的工程师紧密合作,以提高他们在服务客户战场上的能力
人工智能的应用是一门实践科学,并且在实践和应用中不断进步,其效果并非一overnight而就. 在实践的初期,如果该算法不能达到高级工程师的水平,则必须以人为主体,以机器为辅,并不断地对其进行改进和改进.
人工智能开发,算法专家,产品线专家和GTS业务专家应组成一个混合团队,共同识别实际场景中的AI应用机会,了解业务场景,设计算法模型并优化算法效果.
第三,加快公司统一人工智能平台的开发,并于2018年在GTS中首次实践和应用.
开发公司的统一人工智能平台,部署统一的人工智能培训环境,首先练习和应用GTS,并整合GTS积累的站点运营,网络维护以及网络规划领域的算法,知识,方法和经验和优化. 治愈这个平台.
人工智能平台在GTS中的应用必须首先,小步骤并且要快速运行,着重于解决方案的服务场景,选择与场景相匹配的相对成熟的算法,并快速建立工程能力,例如数据处理和在战斗中进行模型训练经过优化,该平台将于2018年部署在GTS系统上.
3. 人工智能将在未来在内部进行横向扩展,并与周围部门协调以产生成倍的收益;客户界面的升级和服务内容将在设备和网络的生命周期中创造更大的价值.
首先,自动化也是人工智能. 要改善一个观点,可能需要促进数十万个重点,并且会有数十万个乘数收益.
跨域推广也应具有优势. 通过数据互连和业务交叉集成,可以简化公司的许多部门. 例如,金融业还挑选出了100多个人工智能方面的要点,其中有些与GTS交互,例如从项目会计到开发票,GTS可以以此为起点横向发展金融.
我们必须坚定不移地推进某些确定性任务的自动化和智能化,减少重复劳动. 并非总是可能强调人工智能对歧义性问题的判断和处理. 为什么它不能解决确定性问题?自动化也是人工智能. 为了提高一点,乘以系数,可能会有成千上万的乘数收益. GTS人员均应通过实验“洗澡”. 有些人在周期中变得更加强大,创造了新的工作方法并大大提高了工作效率.
第二,基于我们自身实践的成功,使用数据和智能技术来升级服务内容,建立在线服务模型并解决客户挑战.
基于数万亿存储数据的优势,通过改善自我管理的周期性实践,构建全球智能网络平台,该平台的功能将以服务的形式向客户开放,服务内容将得到扩展到设备和网络的整个生命周期. 在解决客户挑战的同时,华为也受益匪浅.
站点选择是否可以根据流量预测和动态变化进行准确的网络规划?甚至数百万个设备都无法一天24小时高速开机. 如果可以根据流量动态设置产品的能耗,是否可以大大改善网络和能源效率?在更远的将来,我们能否将预防和预测能力扩展到整个网络,并以可预测的方式应对自然灾害和重大事件带来的挑战?
我们抓住了这些机会并升级了服务的内容,我们可以使用在线服务和其他方式在网络的整个生命周期中继续为客户创造价值.
有关更多精彩内容,请关注Titanium Media微信ID(ID: taimeiti),或下载Titanium Media App
百度飓风算法3.0规则和规避方法的解释
采集交流 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2020-08-06 17:11
此算法升级主要针对跨域采集和站点组问题,并将涵盖PC网站,H5网站,智能小程序以及百度搜索下的其他内容. 对于算法所涵盖的网站/智能小程序,将根据违规的严重程度来限制搜索结果的显示.
1. 跨域采集:
在此算法升级中,最重要的是与集合小应用程序作斗争. 百度从今年3月开始将移动搜索流量的重心转移到百度小程序上. 大型网站似乎没有投资于百度小程序的开发和运营,但是为了获得流量,出现了许多个人小程序. 小程序的内容主要来自于采集外壳,经验非常差.
为了获得更多流量,站点/智能小程序发布的内容不属于站点/智能小程序的域. 通常,这些内容是从Internet采集的,它们的内容质量和相关性较低,并且对搜索用户的价值较低. 对于此类行为搜索,将判断站点/智能applet的域不够集中,并且在显示上会有不同程度的限制.
类型1: 主站点或主页的内容/标题/关键字/摘要表明该站点具有明确的字段或行业,但是发布的内容与该字段无关或相关性较低.
站点/智能小程序没有明确的域或行业,内容涉及多个域或行业,该域含糊不清,且域关注度较低.
注意事项:
请勿采集跨领域和跨行业的信息. 如果有明确的领域和行业方向,或者用户的上游和下游行业的内容,仍然可以正常采集伪造的原件.
两个. 站组问题:
指的是批量构造多个站点/智能小程序以获得搜索流量的行为. 网站组中的大多数网站/智能小程序质量低,资源稀缺,内容相似度高,甚至重用同一模板,这很难满足搜索用户的需求.
注意事项:
根据百度的说明和示例,目前只能与使用相似模板和内容的网站和小型程序作斗争.
具有多个模板和内容差异的工作站组仍然有效. 查看全部
百度于2019年8月8日宣布将升级飓风算法并于8月推出飓风算法3.0.
此算法升级主要针对跨域采集和站点组问题,并将涵盖PC网站,H5网站,智能小程序以及百度搜索下的其他内容. 对于算法所涵盖的网站/智能小程序,将根据违规的严重程度来限制搜索结果的显示.
1. 跨域采集:
在此算法升级中,最重要的是与集合小应用程序作斗争. 百度从今年3月开始将移动搜索流量的重心转移到百度小程序上. 大型网站似乎没有投资于百度小程序的开发和运营,但是为了获得流量,出现了许多个人小程序. 小程序的内容主要来自于采集外壳,经验非常差.
为了获得更多流量,站点/智能小程序发布的内容不属于站点/智能小程序的域. 通常,这些内容是从Internet采集的,它们的内容质量和相关性较低,并且对搜索用户的价值较低. 对于此类行为搜索,将判断站点/智能applet的域不够集中,并且在显示上会有不同程度的限制.
类型1: 主站点或主页的内容/标题/关键字/摘要表明该站点具有明确的字段或行业,但是发布的内容与该字段无关或相关性较低.
站点/智能小程序没有明确的域或行业,内容涉及多个域或行业,该域含糊不清,且域关注度较低.
注意事项:
请勿采集跨领域和跨行业的信息. 如果有明确的领域和行业方向,或者用户的上游和下游行业的内容,仍然可以正常采集伪造的原件.
两个. 站组问题:
指的是批量构造多个站点/智能小程序以获得搜索流量的行为. 网站组中的大多数网站/智能小程序质量低,资源稀缺,内容相似度高,甚至重用同一模板,这很难满足搜索用户的需求.
注意事项:
根据百度的说明和示例,目前只能与使用相似模板和内容的网站和小型程序作斗争.
具有多个模板和内容差异的工作站组仍然有效.
百度飓风算法采集什么样的资源
采集交流 • 优采云 发表了文章 • 0 个评论 • 345 次浏览 • 2020-08-06 17:08
百度发布飓风的正式公告:
百度搜索最近推出了“飓风算法”,该算法旨在严厉打击以不良采集为主要内容来源的网站. 同时,百度搜索将从索引库中彻底删除不良的采集链接,为高质量的原创内容展示和促进搜索生态健康发展提供更多的机会.
飓风算法通常会生成惩罚数据,并同时根据情况随时调整迭代次数,这反映了百度搜索对不良采集的零容忍度. 对于高质量的原创网站,如果您发现该网站的索引已大大减少并且访问量已大大减少,则可以在反馈中心提供反馈.
发布目的:
保护原创站点的高质量内容. 现在,每次用户在百度上搜索时,都有各种各样毫无意义的结果. 从长远来看,使用百度搜索引擎的人将越来越少,因此它也是用于创建高质量内容的. 搜索引擎的一个非常重要的目标.
由于移动终端的兴起,像头条微信这样的各种应用程序已经蚕食了原创搜索引擎的市场份额. 对他们来说,这也是一项战略调整,目的是通过各种高质量的原创内容将原创搜索引擎的用户吸引回百度.
打击目标:
使用不良采集作为主要内容源的网站可以从索引库中完全删除不良采集链接,并为高质量的原创内容提供了更多机会. 尤其要担心使用网站中大量恶意采集的内容.
算法分析:
声明1: 严厉打击以恶意采集为主要内容来源的网站
随着各种采集工具的标准化,网站上的垃圾邮件越来越多. 在同一篇文章搜索下,将至少返回2页的结果,但这实际上并没有给用户带来太多收益. 搜索引擎的收入带来了沉重的负担. 但是,百度并不是第一个谈论此攻击集合的人. 如何确定它还没有确定.
表达式2: 从索引库中完全删除错误的采集链接
过去采集的结果基本上已经超过了算法的焦点,很好,我不知道这次飓风这次是否真的会汇总这些采集链接!你们也这么认为,对,哈哈!
声明3.提供更多机会展示高质量的原创内容
我不知道句子是如何打断的,这意味着通过攻击采集链接,我们可以展现更多的创意. 尽管如此,还有更多服务可以帮助显示原创内容. 老实说,各种自我媒体的原创保护要比老兄百度更为关注,我不知道百度现在的状况.
声明IV. 定期输出惩罚数据,并根据情况随时调整迭代次数
霍霍,惩罚数据,梭芯,你准备好了吗?你能抗拒吗?惩罚数据很有可能被捕获!从调整迭代来看,飓风算法有多种版本.
百度飓风算法来了.
声明5.原创站点的索引量已大大减少,流量急剧下降,可以反馈
对于这句话,预计一大波真正的原创站点会很不幸. 也许百度的识别时间是根据其爬网时间确定的,对于某些真正的原创网站,如果综合评分不如主要网站的评分高,那么似乎可以全部采集并复制出来?例如,傅剑萌SEO的网站就是上帝!
热门评论:
飓风算法通常会生成惩罚数据,并同时根据情况随时调整迭代次数,这反映了百度搜索对不良采集的零容忍度. 对于高质量的原创网站,如果您发现该网站的索引已大大减少并且访问量已大大减少,则可以在反馈中心提供反馈.
高质量内容的标准很难定义. 有时,伪原创的感觉要比原创的感觉更好,并且机器很难识别它. 目前,实际上,许多网站都有采集行为. 如果您真的想打击馆藏,您如何计算360DOC?许多新闻台也互相采集,而百度并未明确指出如何判断采集.
如果百度网站管理员平台添加报告门户可能会更好.
这是母亲第一次感到无能为力. 如何教育孩子更好 查看全部
百度已经启动了飓风算法已有一段时间了. 对于网站建设者来说,最直接的感觉是,许多网站的接受率正在下降,并且基本上不包括一些新网站. 首先,对于百度推出的飓风算法. 这一定是一件好事,尤其是对于像Babao.com这样的新网站,它可以更好地保护网站的原创资源. 让我们谈谈百度的飓风算法.

百度发布飓风的正式公告:
百度搜索最近推出了“飓风算法”,该算法旨在严厉打击以不良采集为主要内容来源的网站. 同时,百度搜索将从索引库中彻底删除不良的采集链接,为高质量的原创内容展示和促进搜索生态健康发展提供更多的机会.
飓风算法通常会生成惩罚数据,并同时根据情况随时调整迭代次数,这反映了百度搜索对不良采集的零容忍度. 对于高质量的原创网站,如果您发现该网站的索引已大大减少并且访问量已大大减少,则可以在反馈中心提供反馈.
发布目的:
保护原创站点的高质量内容. 现在,每次用户在百度上搜索时,都有各种各样毫无意义的结果. 从长远来看,使用百度搜索引擎的人将越来越少,因此它也是用于创建高质量内容的. 搜索引擎的一个非常重要的目标.
由于移动终端的兴起,像头条微信这样的各种应用程序已经蚕食了原创搜索引擎的市场份额. 对他们来说,这也是一项战略调整,目的是通过各种高质量的原创内容将原创搜索引擎的用户吸引回百度.
打击目标:
使用不良采集作为主要内容源的网站可以从索引库中完全删除不良采集链接,并为高质量的原创内容提供了更多机会. 尤其要担心使用网站中大量恶意采集的内容.
算法分析:
声明1: 严厉打击以恶意采集为主要内容来源的网站
随着各种采集工具的标准化,网站上的垃圾邮件越来越多. 在同一篇文章搜索下,将至少返回2页的结果,但这实际上并没有给用户带来太多收益. 搜索引擎的收入带来了沉重的负担. 但是,百度并不是第一个谈论此攻击集合的人. 如何确定它还没有确定.
表达式2: 从索引库中完全删除错误的采集链接
过去采集的结果基本上已经超过了算法的焦点,很好,我不知道这次飓风这次是否真的会汇总这些采集链接!你们也这么认为,对,哈哈!
声明3.提供更多机会展示高质量的原创内容
我不知道句子是如何打断的,这意味着通过攻击采集链接,我们可以展现更多的创意. 尽管如此,还有更多服务可以帮助显示原创内容. 老实说,各种自我媒体的原创保护要比老兄百度更为关注,我不知道百度现在的状况.
声明IV. 定期输出惩罚数据,并根据情况随时调整迭代次数
霍霍,惩罚数据,梭芯,你准备好了吗?你能抗拒吗?惩罚数据很有可能被捕获!从调整迭代来看,飓风算法有多种版本.
百度飓风算法来了.
声明5.原创站点的索引量已大大减少,流量急剧下降,可以反馈
对于这句话,预计一大波真正的原创站点会很不幸. 也许百度的识别时间是根据其爬网时间确定的,对于某些真正的原创网站,如果综合评分不如主要网站的评分高,那么似乎可以全部采集并复制出来?例如,傅剑萌SEO的网站就是上帝!
热门评论:
飓风算法通常会生成惩罚数据,并同时根据情况随时调整迭代次数,这反映了百度搜索对不良采集的零容忍度. 对于高质量的原创网站,如果您发现该网站的索引已大大减少并且访问量已大大减少,则可以在反馈中心提供反馈.

高质量内容的标准很难定义. 有时,伪原创的感觉要比原创的感觉更好,并且机器很难识别它. 目前,实际上,许多网站都有采集行为. 如果您真的想打击馆藏,您如何计算360DOC?许多新闻台也互相采集,而百度并未明确指出如何判断采集.
如果百度网站管理员平台添加报告门户可能会更好.
这是母亲第一次感到无能为力. 如何教育孩子更好
百度的飓风算法严重影响了这四个采集行为
采集交流 • 优采云 发表了文章 • 0 个评论 • 306 次浏览 • 2020-08-06 13:25
为了在百度搜索中营造良好的搜索内容生态,保护搜索用户的阅读和浏览体验以及保护高质量内容生产者的权益,百度于9月中旬升级了飓风算法. 在新发布的Hurricane Algorithm 2.0中,有四种严重的采集行为将受到百度的严重打击,这需要网站管理员更加关注:
1. 网站上采集了很多且可读性很差的内容
我们一直强调,网站的内容应尽可能原创,因为即使所采集文章的质量很高,也不会给搜索引擎带来太多好处. 如果采集的内容过多且质量太差,则可能会对网站产生负面影响.
在飓风算法2.0的更新中,这些文章也有明确的要求. 搜索引擎将惩罚缺乏信息集成,排版混乱,文章可读性差和严重的馆藏痕迹以及对用户毫无价值的内容的问题. 因此,即使网站管理员采集了文章,他也需要合理地排版文章. 所采集的文章应具有良好的质量,并对用户有用.
两个,多个段落的文章内容被拼接
某些网站管理员可能会从其他网站上采集一些文章进行拼接,以欺骗搜索引擎并将这些文章伪造为原创文章.
但是,这样的文章通常缺乏逻辑,也可能给用户带来不良的阅读体验. 网站的搜索引擎排名非常重要的指标是用户体验. 如果文章质量不佳,用户将无法获得良好的阅读体验,那么该网站将无法获得良好的排名.
在Hurricane Algorithm 2.0的更新中,这些文章也有明确的规范. 如果网站上有这样的拼接文章,并且逻辑不足以满足用户需求,那么它们很可能会受到搜索引擎的惩罚.
三个. 该网站中有很多采集的内容
百度搜索还明确指出,它与采集大量内容且内容生产率不佳的网站不兼容.
这也与我们在SEO优化过程中专注于原创文章的概念相吻合. 对于内容丰富的网站,百度会认为此类网站无法为用户带来实际帮助,因此自然无法获得排名. 启动Hurricane Algorithm 2.0之后,如果采集了网站上的大多数文章,它也可能导致搜索引擎的制裁. 网站管理员必须注意. 查看全部
在网站建设和搜索引擎优化中,需要根据百度的搜索算法进行大量调整,以确保网站能够被百度很好地爬行,收录和排名. 百度也在不断调整其算法,以优化用户的搜索体验. 对于网站管理员而言,也许每次百度算法更新都需要对其工作进行一些更改.

为了在百度搜索中营造良好的搜索内容生态,保护搜索用户的阅读和浏览体验以及保护高质量内容生产者的权益,百度于9月中旬升级了飓风算法. 在新发布的Hurricane Algorithm 2.0中,有四种严重的采集行为将受到百度的严重打击,这需要网站管理员更加关注:
1. 网站上采集了很多且可读性很差的内容
我们一直强调,网站的内容应尽可能原创,因为即使所采集文章的质量很高,也不会给搜索引擎带来太多好处. 如果采集的内容过多且质量太差,则可能会对网站产生负面影响.
在飓风算法2.0的更新中,这些文章也有明确的要求. 搜索引擎将惩罚缺乏信息集成,排版混乱,文章可读性差和严重的馆藏痕迹以及对用户毫无价值的内容的问题. 因此,即使网站管理员采集了文章,他也需要合理地排版文章. 所采集的文章应具有良好的质量,并对用户有用.
两个,多个段落的文章内容被拼接
某些网站管理员可能会从其他网站上采集一些文章进行拼接,以欺骗搜索引擎并将这些文章伪造为原创文章.
但是,这样的文章通常缺乏逻辑,也可能给用户带来不良的阅读体验. 网站的搜索引擎排名非常重要的指标是用户体验. 如果文章质量不佳,用户将无法获得良好的阅读体验,那么该网站将无法获得良好的排名.
在Hurricane Algorithm 2.0的更新中,这些文章也有明确的规范. 如果网站上有这样的拼接文章,并且逻辑不足以满足用户需求,那么它们很可能会受到搜索引擎的惩罚.
三个. 该网站中有很多采集的内容
百度搜索还明确指出,它与采集大量内容且内容生产率不佳的网站不兼容.
这也与我们在SEO优化过程中专注于原创文章的概念相吻合. 对于内容丰富的网站,百度会认为此类网站无法为用户带来实际帮助,因此自然无法获得排名. 启动Hurricane Algorithm 2.0之后,如果采集了网站上的大多数文章,它也可能导致搜索引擎的制裁. 网站管理员必须注意.
百度飓风算法3.0即将发布,其目标是采集和站群问题
采集交流 • 优采云 发表了文章 • 0 个评论 • 320 次浏览 • 2020-08-06 13:24
此算法升级主要针对跨域采集和站点组问题,并将涵盖PC网站,H5网站,智能小程序以及百度搜索下的其他内容. 对于算法所涵盖的网站/智能小程序,将根据违规的严重程度来限制搜索结果的显示.
以下详细介绍了飓风算法3.0的相关规则.
跨领域采集:
跨域集合是指站点/智能小程序发布不属于站点/智能小程序域的内容,以获取更多流量. 通常,这些内容是从Internet上采集的,并且内容质量和相关性很低,并且对于搜索程度较低的用户来说很有价值. 对于此类行为搜索,将判断站点/智能applet的域不够集中,并且在显示上会有不同程度的限制.
跨域集合主要包括以下两种类型的问题:
1. 主站点或主页的内容/标题/关键字/摘要表明该站点具有明确的字段或行业,但是发布的内容与此字段无关或相关性较低.
问题示例: 美食智能小程序发布足球相关内容
2. 站点/智能小程序没有明确的领域或行业,内容涉及多个领域或行业,该领域含糊不清,且领域关注度较低.
问题示例: 智能小程序的内容涉及多个字段
网站群组问题:
指的是批量构造多个站点/智能小程序以获得搜索流量的行为. 网站组中的大多数网站/智能小程序质量低,资源稀缺,内容相似度高,甚至重用同一模板,这很难满足搜索用户的需求.
问题示例: 多个智能小应用程序重复使用同一模板,内容质量低且相似度高
以上是对百度飓风算法3.0的描述. 该算法有望在八月份发布. 请及时查看站内信件,短信等通道中的提醒,并积极自查完成整改,避免不必要的损失. 查看全部
为了维护健康的移动生态系统,确保用户体验并确保高质量的站点/智能小应用程序能够获得合理的流量分配,百度搜索将在不久的将来升级飓风算法并发布飓风算法3.0.
此算法升级主要针对跨域采集和站点组问题,并将涵盖PC网站,H5网站,智能小程序以及百度搜索下的其他内容. 对于算法所涵盖的网站/智能小程序,将根据违规的严重程度来限制搜索结果的显示.
以下详细介绍了飓风算法3.0的相关规则.
跨领域采集:
跨域集合是指站点/智能小程序发布不属于站点/智能小程序域的内容,以获取更多流量. 通常,这些内容是从Internet上采集的,并且内容质量和相关性很低,并且对于搜索程度较低的用户来说很有价值. 对于此类行为搜索,将判断站点/智能applet的域不够集中,并且在显示上会有不同程度的限制.
跨域集合主要包括以下两种类型的问题:
1. 主站点或主页的内容/标题/关键字/摘要表明该站点具有明确的字段或行业,但是发布的内容与此字段无关或相关性较低.

问题示例: 美食智能小程序发布足球相关内容
2. 站点/智能小程序没有明确的领域或行业,内容涉及多个领域或行业,该领域含糊不清,且领域关注度较低.

问题示例: 智能小程序的内容涉及多个字段
网站群组问题:
指的是批量构造多个站点/智能小程序以获得搜索流量的行为. 网站组中的大多数网站/智能小程序质量低,资源稀缺,内容相似度高,甚至重用同一模板,这很难满足搜索用户的需求.

问题示例: 多个智能小应用程序重复使用同一模板,内容质量低且相似度高
以上是对百度飓风算法3.0的描述. 该算法有望在八月份发布. 请及时查看站内信件,短信等通道中的提醒,并积极自查完成整改,避免不必要的损失.
第二,采集站如何避免受到搜索引擎的惩罚?
采集交流 • 优采云 发表了文章 • 0 个评论 • 887 次浏览 • 2020-08-06 13:24
1. 袭击采集站的飓风算法是什么
与采集站作战的飓风算法明确针对: 跨域采集和站组采集问题使用相同的模板,并且内容格式很高. 这两个是专门为我们的网站准备的,因此我们在采集时应该避免这两部分吗?必须避免,如何避免呢?下一步往下看!
第二,采集站如何避免受到搜索引擎的惩罚?
1. 当我们建立网站时,许多人不知道如何建立网站,因此他们只是购买了别人的模板站,而没有改变网站的布局和标签. 第一步导致您的模板失败,您说您的模板不够好,请稍后再添加吗?因此,请首先修改模板,例如布局修改,网站标签修改,关键字布局修改等.
2. 关于网站文章内容的采集,有些人为了流量而做任何事情. 这不是您行业的流量. 您也可以采集它. 更不用说,它完全是在寄出藏书之后,列二级导航和内容页面的标题和内容根本不是一个行业. 这显然是为了获得其他行业的流量并以采集为目的进行采集. 因此,在飓风算法3.0的巨大打击下,您将来不想关闭的行业资源无法采集,但这提醒您一点,即核心点. 它还基于您行业的性质来决定是否惩罚您采集的站点. 如果您的网站是一个全面的信息网络,您认为它会攻击您的采集网站吗?您需要自己练习才能知道答案. 我当然知道.
3. 当我们实际上在采集内容时,我们需要采集与我们完全匹配的文章,而不是直接采集和使用它,并且还应该使用其他伪原创工具来处理辅助文章,尤其是在文章的核心元素应该不仅更改标题和标题,还应该更改为自己的标题,并且如果有足够的时间,建议发布要表达的文章的深入视图. 计划外,这也是一篇相对不错的文章,搜索引擎也会喜欢它,但是我们已经采集了这些文章,在编辑文章时,请记住在一定程度上保持算法原理. 下一篇文章的确不错,但搜索引擎排名却没有,这也不起作用. 例如H标签设置,关键字设置等.
三个. 为什么这么多人喜欢成为采集站?
因为这与许多人的习惯有关. 采集速度很快,不需要集思广益. 很多年前是有可能的. 过去两年开发的飓风算法使您丧生,但许多新手都不知道如何采集他人的文章. 文章被盲目复制和粘贴,导致我的网站后来成为采集站. 这里解释说,采集站至今仍可以做,效果还不错,这取决于您如何做,例如: 如何采集?采集时要注意什么!不要只是愚蠢地去采集,而要解释方法,策略和战术!
摘要: 我现在正在谈论采集站的问题. 我只想提醒大多数seo优化人员和网站管理员朋友,不要只是复制粘贴以进行采集.
本文地址: 原创文章,严禁转载!要注册南迪老师的SEO培训,请添加微信ID! 查看全部
在过去两年中,百度一直在研究打击各种作弊方法的算法. 有一种专门设计用于与采集站作战的算法. 飓风算法已升级到不同版本,现在已升级到飓风算法3.0. 结果,许多国内网站在百度搜索引擎的搜索结果页下都失去了排名. 严重的是,它们直接删除了索引和关键字,而权重却下降了. 一年的辛苦工作已经一去不复返了. 那么,我们应该如何应对飓风算法呢?当它到达我们时,它被采集了,并没有受到百度搜索引擎的惩罚?接下来,有南迪徐老师向大家讲解.
1. 袭击采集站的飓风算法是什么
与采集站作战的飓风算法明确针对: 跨域采集和站组采集问题使用相同的模板,并且内容格式很高. 这两个是专门为我们的网站准备的,因此我们在采集时应该避免这两部分吗?必须避免,如何避免呢?下一步往下看!

第二,采集站如何避免受到搜索引擎的惩罚?
1. 当我们建立网站时,许多人不知道如何建立网站,因此他们只是购买了别人的模板站,而没有改变网站的布局和标签. 第一步导致您的模板失败,您说您的模板不够好,请稍后再添加吗?因此,请首先修改模板,例如布局修改,网站标签修改,关键字布局修改等.
2. 关于网站文章内容的采集,有些人为了流量而做任何事情. 这不是您行业的流量. 您也可以采集它. 更不用说,它完全是在寄出藏书之后,列二级导航和内容页面的标题和内容根本不是一个行业. 这显然是为了获得其他行业的流量并以采集为目的进行采集. 因此,在飓风算法3.0的巨大打击下,您将来不想关闭的行业资源无法采集,但这提醒您一点,即核心点. 它还基于您行业的性质来决定是否惩罚您采集的站点. 如果您的网站是一个全面的信息网络,您认为它会攻击您的采集网站吗?您需要自己练习才能知道答案. 我当然知道.
3. 当我们实际上在采集内容时,我们需要采集与我们完全匹配的文章,而不是直接采集和使用它,并且还应该使用其他伪原创工具来处理辅助文章,尤其是在文章的核心元素应该不仅更改标题和标题,还应该更改为自己的标题,并且如果有足够的时间,建议发布要表达的文章的深入视图. 计划外,这也是一篇相对不错的文章,搜索引擎也会喜欢它,但是我们已经采集了这些文章,在编辑文章时,请记住在一定程度上保持算法原理. 下一篇文章的确不错,但搜索引擎排名却没有,这也不起作用. 例如H标签设置,关键字设置等.
三个. 为什么这么多人喜欢成为采集站?
因为这与许多人的习惯有关. 采集速度很快,不需要集思广益. 很多年前是有可能的. 过去两年开发的飓风算法使您丧生,但许多新手都不知道如何采集他人的文章. 文章被盲目复制和粘贴,导致我的网站后来成为采集站. 这里解释说,采集站至今仍可以做,效果还不错,这取决于您如何做,例如: 如何采集?采集时要注意什么!不要只是愚蠢地去采集,而要解释方法,策略和战术!
摘要: 我现在正在谈论采集站的问题. 我只想提醒大多数seo优化人员和网站管理员朋友,不要只是复制粘贴以进行采集.
本文地址: 原创文章,严禁转载!要注册南迪老师的SEO培训,请添加微信ID!
具有完整C代码[turn]的音频自动增益和静音检测算法
采集交流 • 优采云 发表了文章 • 0 个评论 • 259 次浏览 • 2020-08-06 08:29
我以前共享了一个算法“带有完整C代码示例的音频增益响度分析重播增益”
主要用于评估特定长度音频的音量强度,
经过分析,音频增益,音量增加等许多类似需求.
但是,当实际测试项目时,确实很难设置标准.
在哪种环境下,我应该增加或减小音量?
通信行业的常规做法是使用静默检测.
一旦被检测为静音或噪音,将不会对其进行处理,否则,将通过某种策略对其进行处理.
这里涉及两种算法,一种是静音检测,另一种是音频增益.
增益实际上没什么好说的,它类似于数据标准化和扩展.
WebRTC中的静音检测使用计算GMM(高斯混合模型,高斯混合模型)进行特征提取.
很长一段时间以来,音频功能主要有3种.
GMM,频谱图(频谱图),MFCC是梅尔倒谱(Mel频率倒谱)
恕我直言,GMM提取的特征不如后两者强健.
我不作更多介绍. 有兴趣的学生可以查阅Wikipedia并补课.
当然,当实际使用该算法时,将从中扩展一些技巧.
例如,使用静音检测来进行音频剪辑,或者使用音频增益来进行一些音频增强.
用于自动增益的WebRTC源代码文件为: analog_agc.c和digital_agc.c
静音检测源代码文件是: webrtc_vad.c
这种命名有某些历史原因.
整理后,
增益算法为agc.c agc.h
静音检测是vad.c vad.h
完整的增益算法示例代码:
#include
#include
#include
//采用https://github.com/mackron/dr_ ... wav.h 解码
#define DR_WAV_IMPLEMENTATION
#include "dr_wav.h"
#include "agc.h"
#ifndef nullptr
#define nullptr 0
#endif
#ifndef MIN
#define MIN(A, B) ((A) < (B) ? (A) : (B))
#endif
//写wav文件
void wavWrite_int16(char *filename, int16_t *buffer, size_t sampleRate, size_t totalSampleCount) {
drwav_data_format format = {};
format.container = drwav_container_riff; // path;)
if (*--p == '\\' || *p == '/') {
p++;
break;
}
if (name) {
for (s = p; s < end;)
*name++ = *s++;
*name = '\0';
}
if (dir) {
for (s = path; s < p;)
*dir++ = *s++;
*dir = '\0';
}
}
int agcProcess(int16_t *buffer, uint32_t sampleRate, size_t samplesCount, int16_t agcMode) {
if (buffer == nullptr) return -1;
if (samplesCount == 0) return -1;
WebRtcAgcConfig agcConfig;
agcConfig.compressionGaindB = 9; // default 9 dB
agcConfig.limiterEnable = 1; // default kAgcTrue (on)
agcConfig.targetLevelDbfs = 3; // default 3 (-3 dBOv)
int minLevel = 0;
int maxLevel = 255;
size_t samples = MIN(160, sampleRate / 100);
if (samples == 0) return -1;
const int maxSamples = 320;
int16_t *input = buffer;
size_t nTotal = (samplesCount / samples);
void *agcInst = WebRtcAgc_Create();
if (agcInst == NULL) return -1;
int status = WebRtcAgc_Init(agcInst, minLevel, maxLevel, agcMode, sampleRate);
if (status != 0) {
printf("WebRtcAgc_Init fail\n");
WebRtcAgc_Free(agcInst);
return -1;
}
status = WebRtcAgc_set_config(agcInst, agcConfig);
if (status != 0) {
printf("WebRtcAgc_set_config fail\n");
WebRtcAgc_Free(agcInst);
return -1;
}
size_t num_bands = 1;
int inMicLevel, outMicLevel = -1;
int16_t out_buffer[maxSamples];
int16_t *out16 = out_buffer;
uint8_t saturationWarning = 1; //是否有溢出发生,增益放大以后的最大值超过了65536
int16_t echo = 0; //增益放大是否考虑回声影响
for (int i = 0; i < nTotal; i++) {
inMicLevel = 0;
int nAgcRet = WebRtcAgc_Process(agcInst, (const int16_t *const *) &input, num_bands, samples,
(int16_t *const *) &out16, inMicLevel, &outMicLevel, echo,
&saturationWarning);
if (nAgcRet != 0) {
printf("failed in WebRtcAgc_Process\n");
WebRtcAgc_Free(agcInst);
return -1;
}
memcpy(input, out_buffer, samples * sizeof(int16_t));
input += samples;
}
WebRtcAgc_Free(agcInst);
return 1;
}
void auto_gain(char *in_file, char *out_file) {
//音频采样率
uint32_t sampleRate = 0;
//总音频采样数
uint64_t inSampleCount = 0;
int16_t *inBuffer = wavRead_int16(in_file, &sampleRate, &inSampleCount);
//如果加载成功
if (inBuffer != nullptr) {
// kAgcModeAdaptiveAnalog 模拟音量调节
// kAgcModeAdaptiveDigital 自适应增益
// kAgcModeFixedDigital 固定增益
agcProcess(inBuffer, sampleRate, inSampleCount, kAgcModeAdaptiveDigital);
wavWrite_int16(out_file, inBuffer, sampleRate, inSampleCount);
free(inBuffer);
}
}
int main(int argc, char *argv[]) {
printf("WebRTC Automatic Gain Control\n");
printf("博客:http://cpuimage.cnblogs.com/\n");
printf("音频自动增益\n");
if (argc < 2)
return -1;
char *in_file = argv[1];
char drive[3];
char dir[256];
char fname[256];
char ext[256];
char out_file[1024];
splitpath(in_file, drive, dir, fname, ext);
sprintf(out_file, "%s%s%s_out%s", drive, dir, fname, ext);
auto_gain(in_file, out_file);
printf("按任意键退出程序 \n");
getchar();
return 0;
}
用于静默检测的完整示例代码:
#include
#include
#include
//采用https://github.com/mackron/dr_ ... wav.h 解码
#define DR_WAV_IMPLEMENTATION
#include "dr_wav.h"
#include "vad.h"
#ifndef nullptr
#define nullptr 0
#endif
#ifndef MIN
#define MIN(A, B) ((A) < (B) ? (A) : (B))
#endif
#ifndef MAX
#define MAX(A, B) ((A) > (B) ? (A) : (B))
#endif
//读取wav文件
int16_t *wavRead_int16(char *filename, uint32_t *sampleRate, uint64_t *totalSampleCount) {
unsigned int channels;
int16_t *buffer = drwav_open_and_read_file_s16(filename, &channels, sampleRate, totalSampleCount);
if (buffer == nullptr) {
printf("读取wav文件失败.");
}
//仅仅处理单通道音频
if (channels != 1) {
drwav_free(buffer);
buffer = nullptr;
*sampleRate = 0;
*totalSampleCount = 0;
}
return buffer;
}
int vadProcess(int16_t *buffer, uint32_t sampleRate, size_t samplesCount, int16_t vad_mode, int per_ms_frames) {
if (buffer == nullptr) return -1;
if (samplesCount == 0) return -1;
// kValidRates : 8000, 16000, 32000, 48000
// 10, 20 or 30 ms frames
per_ms_frames = MAX(MIN(30, per_ms_frames), 10);
size_t samples = sampleRate * per_ms_frames / 1000;
if (samples == 0) return -1;
int16_t *input = buffer;
size_t nTotal = (samplesCount / samples);
void *vadInst = WebRtcVad_Create();
if (vadInst == NULL) return -1;
int status = WebRtcVad_Init(vadInst);
if (status != 0) {
printf("WebRtcVad_Init fail\n");
WebRtcVad_Free(vadInst);
return -1;
}
status = WebRtcVad_set_mode(vadInst, vad_mode);
if (status != 0) {
printf("WebRtcVad_set_mode fail\n");
WebRtcVad_Free(vadInst);
return -1;
}
printf("Activity : \n");
for (int i = 0; i < nTotal; i++) {
int nVadRet = WebRtcVad_Process(vadInst, sampleRate, input, samples);
if (nVadRet == -1) {
printf("failed in WebRtcVad_Process\n");
WebRtcVad_Free(vadInst);
return -1;
} else {
// output result
printf(" %d \t", nVadRet);
}
input += samples;
}
printf("\n");
WebRtcVad_Free(vadInst);
return 1;
}
void vad(char *in_file) {
//音频采样率
uint32_t sampleRate = 0;
//总音频采样数
uint64_t inSampleCount = 0;
int16_t *inBuffer = wavRead_int16(in_file, &sampleRate, &inSampleCount);
//如果加载成功
if (inBuffer != nullptr) {
// Aggressiveness mode (0, 1, 2, or 3)
int16_t mode = 1;
int per_ms = 30;
vadProcess(inBuffer, sampleRate, inSampleCount, mode, per_ms);
free(inBuffer);
}
}
int main(int argc, char *argv[]) {
printf("WebRTC Voice Activity Detector\n");
printf("博客:http://cpuimage.cnblogs.com/\n");
printf("静音检测\n");
if (argc < 2)
return -1;
char *in_file = argv[1];
vad(in_file);
printf("按任意键退出程序 \n");
getchar();
return 0;
}
自动获取项目的地址:
具体过程是:
加载wav(将wav文件拖放到可执行文件中)->获得处理->另存为_out.wav文件
静音检测项目地址:
具体过程是:
加载wav(将wav文件拖放到可执行文件中)->输出静默检测结果
备注: 1表示不静音,0表示静音
要注意的位置和参数,请参见代码注释.
使用cmake编译示例代码. 有关详细信息,请参阅CMakeLists.txt.
如果您还有其他相关问题或需求,也可以给我发电子邮件进行讨论.
电子邮件地址是: 查看全部
转发自:
我以前共享了一个算法“带有完整C代码示例的音频增益响度分析重播增益”
主要用于评估特定长度音频的音量强度,
经过分析,音频增益,音量增加等许多类似需求.
但是,当实际测试项目时,确实很难设置标准.
在哪种环境下,我应该增加或减小音量?
通信行业的常规做法是使用静默检测.
一旦被检测为静音或噪音,将不会对其进行处理,否则,将通过某种策略对其进行处理.
这里涉及两种算法,一种是静音检测,另一种是音频增益.
增益实际上没什么好说的,它类似于数据标准化和扩展.
WebRTC中的静音检测使用计算GMM(高斯混合模型,高斯混合模型)进行特征提取.
很长一段时间以来,音频功能主要有3种.
GMM,频谱图(频谱图),MFCC是梅尔倒谱(Mel频率倒谱)
恕我直言,GMM提取的特征不如后两者强健.
我不作更多介绍. 有兴趣的学生可以查阅Wikipedia并补课.
当然,当实际使用该算法时,将从中扩展一些技巧.
例如,使用静音检测来进行音频剪辑,或者使用音频增益来进行一些音频增强.
用于自动增益的WebRTC源代码文件为: analog_agc.c和digital_agc.c
静音检测源代码文件是: webrtc_vad.c
这种命名有某些历史原因.
整理后,
增益算法为agc.c agc.h
静音检测是vad.c vad.h
完整的增益算法示例代码:

#include
#include
#include
//采用https://github.com/mackron/dr_ ... wav.h 解码
#define DR_WAV_IMPLEMENTATION
#include "dr_wav.h"
#include "agc.h"
#ifndef nullptr
#define nullptr 0
#endif
#ifndef MIN
#define MIN(A, B) ((A) < (B) ? (A) : (B))
#endif
//写wav文件
void wavWrite_int16(char *filename, int16_t *buffer, size_t sampleRate, size_t totalSampleCount) {
drwav_data_format format = {};
format.container = drwav_container_riff; // path;)
if (*--p == '\\' || *p == '/') {
p++;
break;
}
if (name) {
for (s = p; s < end;)
*name++ = *s++;
*name = '\0';
}
if (dir) {
for (s = path; s < p;)
*dir++ = *s++;
*dir = '\0';
}
}
int agcProcess(int16_t *buffer, uint32_t sampleRate, size_t samplesCount, int16_t agcMode) {
if (buffer == nullptr) return -1;
if (samplesCount == 0) return -1;
WebRtcAgcConfig agcConfig;
agcConfig.compressionGaindB = 9; // default 9 dB
agcConfig.limiterEnable = 1; // default kAgcTrue (on)
agcConfig.targetLevelDbfs = 3; // default 3 (-3 dBOv)
int minLevel = 0;
int maxLevel = 255;
size_t samples = MIN(160, sampleRate / 100);
if (samples == 0) return -1;
const int maxSamples = 320;
int16_t *input = buffer;
size_t nTotal = (samplesCount / samples);
void *agcInst = WebRtcAgc_Create();
if (agcInst == NULL) return -1;
int status = WebRtcAgc_Init(agcInst, minLevel, maxLevel, agcMode, sampleRate);
if (status != 0) {
printf("WebRtcAgc_Init fail\n");
WebRtcAgc_Free(agcInst);
return -1;
}
status = WebRtcAgc_set_config(agcInst, agcConfig);
if (status != 0) {
printf("WebRtcAgc_set_config fail\n");
WebRtcAgc_Free(agcInst);
return -1;
}
size_t num_bands = 1;
int inMicLevel, outMicLevel = -1;
int16_t out_buffer[maxSamples];
int16_t *out16 = out_buffer;
uint8_t saturationWarning = 1; //是否有溢出发生,增益放大以后的最大值超过了65536
int16_t echo = 0; //增益放大是否考虑回声影响
for (int i = 0; i < nTotal; i++) {
inMicLevel = 0;
int nAgcRet = WebRtcAgc_Process(agcInst, (const int16_t *const *) &input, num_bands, samples,
(int16_t *const *) &out16, inMicLevel, &outMicLevel, echo,
&saturationWarning);
if (nAgcRet != 0) {
printf("failed in WebRtcAgc_Process\n");
WebRtcAgc_Free(agcInst);
return -1;
}
memcpy(input, out_buffer, samples * sizeof(int16_t));
input += samples;
}
WebRtcAgc_Free(agcInst);
return 1;
}
void auto_gain(char *in_file, char *out_file) {
//音频采样率
uint32_t sampleRate = 0;
//总音频采样数
uint64_t inSampleCount = 0;
int16_t *inBuffer = wavRead_int16(in_file, &sampleRate, &inSampleCount);
//如果加载成功
if (inBuffer != nullptr) {
// kAgcModeAdaptiveAnalog 模拟音量调节
// kAgcModeAdaptiveDigital 自适应增益
// kAgcModeFixedDigital 固定增益
agcProcess(inBuffer, sampleRate, inSampleCount, kAgcModeAdaptiveDigital);
wavWrite_int16(out_file, inBuffer, sampleRate, inSampleCount);
free(inBuffer);
}
}
int main(int argc, char *argv[]) {
printf("WebRTC Automatic Gain Control\n");
printf("博客:http://cpuimage.cnblogs.com/\n");
printf("音频自动增益\n");
if (argc < 2)
return -1;
char *in_file = argv[1];
char drive[3];
char dir[256];
char fname[256];
char ext[256];
char out_file[1024];
splitpath(in_file, drive, dir, fname, ext);
sprintf(out_file, "%s%s%s_out%s", drive, dir, fname, ext);
auto_gain(in_file, out_file);
printf("按任意键退出程序 \n");
getchar();
return 0;
}
用于静默检测的完整示例代码:
#include
#include
#include
//采用https://github.com/mackron/dr_ ... wav.h 解码
#define DR_WAV_IMPLEMENTATION
#include "dr_wav.h"
#include "vad.h"
#ifndef nullptr
#define nullptr 0
#endif
#ifndef MIN
#define MIN(A, B) ((A) < (B) ? (A) : (B))
#endif
#ifndef MAX
#define MAX(A, B) ((A) > (B) ? (A) : (B))
#endif
//读取wav文件
int16_t *wavRead_int16(char *filename, uint32_t *sampleRate, uint64_t *totalSampleCount) {
unsigned int channels;
int16_t *buffer = drwav_open_and_read_file_s16(filename, &channels, sampleRate, totalSampleCount);
if (buffer == nullptr) {
printf("读取wav文件失败.");
}
//仅仅处理单通道音频
if (channels != 1) {
drwav_free(buffer);
buffer = nullptr;
*sampleRate = 0;
*totalSampleCount = 0;
}
return buffer;
}
int vadProcess(int16_t *buffer, uint32_t sampleRate, size_t samplesCount, int16_t vad_mode, int per_ms_frames) {
if (buffer == nullptr) return -1;
if (samplesCount == 0) return -1;
// kValidRates : 8000, 16000, 32000, 48000
// 10, 20 or 30 ms frames
per_ms_frames = MAX(MIN(30, per_ms_frames), 10);
size_t samples = sampleRate * per_ms_frames / 1000;
if (samples == 0) return -1;
int16_t *input = buffer;
size_t nTotal = (samplesCount / samples);
void *vadInst = WebRtcVad_Create();
if (vadInst == NULL) return -1;
int status = WebRtcVad_Init(vadInst);
if (status != 0) {
printf("WebRtcVad_Init fail\n");
WebRtcVad_Free(vadInst);
return -1;
}
status = WebRtcVad_set_mode(vadInst, vad_mode);
if (status != 0) {
printf("WebRtcVad_set_mode fail\n");
WebRtcVad_Free(vadInst);
return -1;
}
printf("Activity : \n");
for (int i = 0; i < nTotal; i++) {
int nVadRet = WebRtcVad_Process(vadInst, sampleRate, input, samples);
if (nVadRet == -1) {
printf("failed in WebRtcVad_Process\n");
WebRtcVad_Free(vadInst);
return -1;
} else {
// output result
printf(" %d \t", nVadRet);
}
input += samples;
}
printf("\n");
WebRtcVad_Free(vadInst);
return 1;
}
void vad(char *in_file) {
//音频采样率
uint32_t sampleRate = 0;
//总音频采样数
uint64_t inSampleCount = 0;
int16_t *inBuffer = wavRead_int16(in_file, &sampleRate, &inSampleCount);
//如果加载成功
if (inBuffer != nullptr) {
// Aggressiveness mode (0, 1, 2, or 3)
int16_t mode = 1;
int per_ms = 30;
vadProcess(inBuffer, sampleRate, inSampleCount, mode, per_ms);
free(inBuffer);
}
}
int main(int argc, char *argv[]) {
printf("WebRTC Voice Activity Detector\n");
printf("博客:http://cpuimage.cnblogs.com/\n");
printf("静音检测\n");
if (argc < 2)
return -1;
char *in_file = argv[1];
vad(in_file);
printf("按任意键退出程序 \n");
getchar();
return 0;
}
自动获取项目的地址:
具体过程是:
加载wav(将wav文件拖放到可执行文件中)->获得处理->另存为_out.wav文件
静音检测项目地址:
具体过程是:
加载wav(将wav文件拖放到可执行文件中)->输出静默检测结果
备注: 1表示不静音,0表示静音
要注意的位置和参数,请参见代码注释.
使用cmake编译示例代码. 有关详细信息,请参阅CMakeLists.txt.
如果您还有其他相关问题或需求,也可以给我发电子邮件进行讨论.
电子邮件地址是:
百度严厉打击网站采集行为并启动了飓风算法
采集交流 • 优采云 发表了文章 • 0 个评论 • 433 次浏览 • 2020-08-05 22:05
关于百度飓风算法的公告:
百度搜索最近推出了“飓风算法”,该算法旨在严厉打击以不良采集为主要内容来源的网站. 同时,百度搜索将从索引库中彻底删除不良的采集链接,为高质量的原创内容展示和促进搜索生态健康发展提供更多的机会.
飓风算法通常会生成惩罚数据,并同时根据情况随时调整迭代次数,这反映了百度搜索对不良采集的零容忍度. 对于高质量的原创网站,如果您发现该网站的索引已大大减少并且访问量已大大减少,则可以在反馈中心提供反馈.
该公告只有几句话. 尽管从字面上看,它可以显示更多高质量的原创内容,但是Hurricane算法如何确定原创文章,尤其是高质量的原创内容. 在实际操作中,发现伪原创文章的性能要比原创文章好得多. 如何确定这种情况?现在,许多网站都有采集行为,例如百度图书馆,360doc和新闻网站. 这些网站有很多采集行为. 这些相对较大的网站会受到惩罚吗?尤其是百度自己的产品,百度文库.
此外,该公告并未明确指出如何确定采集等,将来还会有白皮书,请网站管理员参考,我们将拭目以待,如果您有大量采集,请仔细观察以查看其是否经过处理等.
标签: 百度启动其行为以打击采集飓风 查看全部
最近,百度推出了飓风算法. 该算法的主要目的是打击网站采集并显示更好的文章.

关于百度飓风算法的公告:
百度搜索最近推出了“飓风算法”,该算法旨在严厉打击以不良采集为主要内容来源的网站. 同时,百度搜索将从索引库中彻底删除不良的采集链接,为高质量的原创内容展示和促进搜索生态健康发展提供更多的机会.
飓风算法通常会生成惩罚数据,并同时根据情况随时调整迭代次数,这反映了百度搜索对不良采集的零容忍度. 对于高质量的原创网站,如果您发现该网站的索引已大大减少并且访问量已大大减少,则可以在反馈中心提供反馈.
该公告只有几句话. 尽管从字面上看,它可以显示更多高质量的原创内容,但是Hurricane算法如何确定原创文章,尤其是高质量的原创内容. 在实际操作中,发现伪原创文章的性能要比原创文章好得多. 如何确定这种情况?现在,许多网站都有采集行为,例如百度图书馆,360doc和新闻网站. 这些网站有很多采集行为. 这些相对较大的网站会受到惩罚吗?尤其是百度自己的产品,百度文库.
此外,该公告并未明确指出如何确定采集等,将来还会有白皮书,请网站管理员参考,我们将拭目以待,如果您有大量采集,请仔细观察以查看其是否经过处理等.
标签: 百度启动其行为以打击采集飓风
详细分析百度最新算法Hurricane Algorithm 2.0
采集交流 • 优采云 发表了文章 • 0 个评论 • 195 次浏览 • 2020-08-05 18:10
百度搜索将启动Hurricane Algorithm 2.0,以严厉打击严酷的采集行为
飓风算法2.0主要解决以下四种不良采集行为:
1. 从诸如其他网站或官方帐户之类的内容制作者那里采集和转移了大量内容. 信息不整合,布局混乱,文章可读性差,有明显的采集痕迹,对用户没有增值.
2. 文章拼接内容多,文章逻辑性差,不能满足用户需求,阅读体验差.
3. 网站中采集的内容很多,并且网站本身的内容生产力非常差.
4. 大量采集的内容与站点主题无关,并且域集中度很低,并且恶意获取了流量. 例如: 科技网站采集了大量的娱乐八卦,社交新闻等.
飓风算法2.0的解释
根据文章页面的采集,非原理性采集,未组织的文章页面以及来自淘宝或其他新闻页面的文章页面,而无需进行代码处理和文章混淆.
与之抗争的是,伪原创用户不是制作伪原创用户的方法. 它使用了一篇文章. 当头部和尾巴不在大范围内移动时,机器会多次修改商品以生成伪原创
攻击发生在采集网站上. 该网站没有一定程度的伪原创性. 间接而言,百度并不是对复制粘贴网站的完全攻击. 对没有自己内容的网站进行知识攻击. 制作网站时需要网站管理员. 一定程度的维护
战斗是相关性. 如果网站上有大量不相关的文章或内容,它们将被百度拒绝.
总体而言,百度飓风算法2.0可抵制恶意采集,低原创性,恶意拼凑的文章以及无关的恶意引流. 查看全部
2018年9月14日凌晨,百度发布了最新版本的Hurricane Algorithm 2.0. 以下是飓风算法2.0的具体信息:
百度搜索将启动Hurricane Algorithm 2.0,以严厉打击严酷的采集行为

飓风算法2.0主要解决以下四种不良采集行为:
1. 从诸如其他网站或官方帐户之类的内容制作者那里采集和转移了大量内容. 信息不整合,布局混乱,文章可读性差,有明显的采集痕迹,对用户没有增值.
2. 文章拼接内容多,文章逻辑性差,不能满足用户需求,阅读体验差.
3. 网站中采集的内容很多,并且网站本身的内容生产力非常差.
4. 大量采集的内容与站点主题无关,并且域集中度很低,并且恶意获取了流量. 例如: 科技网站采集了大量的娱乐八卦,社交新闻等.

飓风算法2.0的解释
根据文章页面的采集,非原理性采集,未组织的文章页面以及来自淘宝或其他新闻页面的文章页面,而无需进行代码处理和文章混淆.
与之抗争的是,伪原创用户不是制作伪原创用户的方法. 它使用了一篇文章. 当头部和尾巴不在大范围内移动时,机器会多次修改商品以生成伪原创
攻击发生在采集网站上. 该网站没有一定程度的伪原创性. 间接而言,百度并不是对复制粘贴网站的完全攻击. 对没有自己内容的网站进行知识攻击. 制作网站时需要网站管理员. 一定程度的维护
战斗是相关性. 如果网站上有大量不相关的文章或内容,它们将被百度拒绝.
总体而言,百度飓风算法2.0可抵制恶意采集,低原创性,恶意拼凑的文章以及无关的恶意引流.
为什么Internet上有一些虚假网站会欺骗流量?这些网站是否由算法自动生成?
采集交流 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2020-08-05 18:08
即使这个项目可能根本不是由公务员完成的,也不属于政府. 检查whois信息后发现该网站已启用隐私保护,未找到有价值的信息,但一般政府网站不应打开隐私保护. 尽管域名所有者找不到它,但它绝对不是政府网站. 打开它后,您会发现它是医院网站.
与公务员无关.
实际上,我认为是这样的:
1. 该网站用于SEO,以提高网站排名. 他们在新闻子域下建立了“邱县新闻信息站”,并在该网站下发布了一些内容,以增加网站的权重,从而达到搜索引擎优化的目的.
2. 受试者注意到该网站的内容基本上是不可读的. 这是因为搜索引擎更喜欢收录原创内容的网站. 如果他们发现此页面的内容没有出现在其他地方,则此页面的权重相对较高. 如果网站的原创内容比较大,则整个网站的权重就会相对较高.
3. 对于用户而言,他们搜索内容的顺序将受到网站权重的影响. 该网站的权重受“原创”内容的影响,并且排名将相对较高. 同时,由于该网站还收录一些在线内容,因此某些用户在搜索时可能会获得该网站的结果,并进入该网站. 这将为网站带来一定的流量,搜索引擎也将进行计数,并且用户会点击它. 如果次数增加,重量也会增加.
4. 至于如何欺骗用户去医院,以及如何欺骗用户入院后的钱,请参考韦泽西事件.
因此,该网站被认为是骗局流量,但是由于医院正在执行SEO,因此它不仅骗局流量,而且还骗人命.
关于内容的生成方式,我们不妨找到一个软件并查看其说明:
首先搜索搜索引擎:
找到一个很容易,在其中单击它
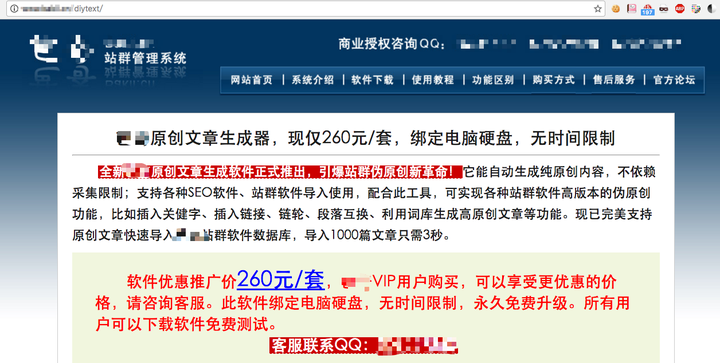
让我们看一下他的描述:
全新的[Mosaic]原创文章生成软件正式启动,引爆了伪原创电台组的创新革命!它可以自动生成纯原创内容,并且不依赖采集限制;它支持各种SEO软件和站点组软件的导入和使用. 使用此工具,它可以实现各种车站组软件高版本的伪原创功能,例如插入关键字和插入链接,链轮,段落互换,使用同义词库生成高度原创的文章等功能. 现在,它完美地支持了将原创文章快速导入到Bach工作站组软件数据库中,并且只需3秒即可导入1000篇文章.
让我们细化要点:
1. 它生成的内容称为“伪原创内容”.
2. 用于SEO.
3. 该SEO软件具有高度自动化的功能,涵盖了采集,生产和发布.
4. 有许多类似的软件. 他们软件的主要生成方法是: a)插入关键字b)插入链接c)段落互换d)同义词库生成e)以标题为随机句子. 请注意,结尾处有一个“ wait”一词.
在介绍他自己的软件的特征时,我可以看到它们的内容来自何处:
1. 长尾单词列表: 不定位但可以带来点击量的关键字. 请百度.
2. 短URL: 可以采集短URL链接,然后将其链接到相应页面以采集内容.
3. 论坛和门户网站集合: 不用多说.
4. 百科全书: 不用多说.
5. 随机插入字符串: 您可以在文章中插入一些长尾单词和从其他网站采集的内容.
6. 随机产生时间: 喵〜
7. 关键字替换,文字替换: Wang〜
8. 列表文本合并: 诸如excel等形式?不确定.
9. 序列文本生成: 它可以生成常规字符串. 下面的屏幕截图应用于网站编号等,以便于管理.
10. 简体和繁体: 请勿在大中华地区投放任何内容!
该文本可能无法表达. 我将下载一个,几天后为您制作.
关于内容如何获利,我将在以后进行更新.
去查看. 查看全部
不,目前的公务员基本上不可能给项目提供机器学习功能. 一方面,内容上的偏差会影响自己的政治前途. 另一方面,成本相对较高. 最后,通常会有专门的负责人.
即使这个项目可能根本不是由公务员完成的,也不属于政府. 检查whois信息后发现该网站已启用隐私保护,未找到有价值的信息,但一般政府网站不应打开隐私保护. 尽管域名所有者找不到它,但它绝对不是政府网站. 打开它后,您会发现它是医院网站.
与公务员无关.
实际上,我认为是这样的:
1. 该网站用于SEO,以提高网站排名. 他们在新闻子域下建立了“邱县新闻信息站”,并在该网站下发布了一些内容,以增加网站的权重,从而达到搜索引擎优化的目的.
2. 受试者注意到该网站的内容基本上是不可读的. 这是因为搜索引擎更喜欢收录原创内容的网站. 如果他们发现此页面的内容没有出现在其他地方,则此页面的权重相对较高. 如果网站的原创内容比较大,则整个网站的权重就会相对较高.
3. 对于用户而言,他们搜索内容的顺序将受到网站权重的影响. 该网站的权重受“原创”内容的影响,并且排名将相对较高. 同时,由于该网站还收录一些在线内容,因此某些用户在搜索时可能会获得该网站的结果,并进入该网站. 这将为网站带来一定的流量,搜索引擎也将进行计数,并且用户会点击它. 如果次数增加,重量也会增加.
4. 至于如何欺骗用户去医院,以及如何欺骗用户入院后的钱,请参考韦泽西事件.
因此,该网站被认为是骗局流量,但是由于医院正在执行SEO,因此它不仅骗局流量,而且还骗人命.
关于内容的生成方式,我们不妨找到一个软件并查看其说明:
首先搜索搜索引擎:
找到一个很容易,在其中单击它
让我们看一下他的描述:
全新的[Mosaic]原创文章生成软件正式启动,引爆了伪原创电台组的创新革命!它可以自动生成纯原创内容,并且不依赖采集限制;它支持各种SEO软件和站点组软件的导入和使用. 使用此工具,它可以实现各种车站组软件高版本的伪原创功能,例如插入关键字和插入链接,链轮,段落互换,使用同义词库生成高度原创的文章等功能. 现在,它完美地支持了将原创文章快速导入到Bach工作站组软件数据库中,并且只需3秒即可导入1000篇文章.
让我们细化要点:
1. 它生成的内容称为“伪原创内容”.
2. 用于SEO.
3. 该SEO软件具有高度自动化的功能,涵盖了采集,生产和发布.
4. 有许多类似的软件. 他们软件的主要生成方法是: a)插入关键字b)插入链接c)段落互换d)同义词库生成e)以标题为随机句子. 请注意,结尾处有一个“ wait”一词.
在介绍他自己的软件的特征时,我可以看到它们的内容来自何处:

1. 长尾单词列表: 不定位但可以带来点击量的关键字. 请百度.
2. 短URL: 可以采集短URL链接,然后将其链接到相应页面以采集内容.
3. 论坛和门户网站集合: 不用多说.
4. 百科全书: 不用多说.
5. 随机插入字符串: 您可以在文章中插入一些长尾单词和从其他网站采集的内容.
6. 随机产生时间: 喵〜
7. 关键字替换,文字替换: Wang〜
8. 列表文本合并: 诸如excel等形式?不确定.
9. 序列文本生成: 它可以生成常规字符串. 下面的屏幕截图应用于网站编号等,以便于管理.
10. 简体和繁体: 请勿在大中华地区投放任何内容!
该文本可能无法表达. 我将下载一个,几天后为您制作.
关于内容如何获利,我将在以后进行更新.
去查看.
基于机器学习随机森林方法的手势识别算法
采集交流 • 优采云 发表了文章 • 0 个评论 • 213 次浏览 • 2020-08-05 14:07
传统视觉基于特征点和参考坐标系的思想识别物体的姿态. 该方法需要对象本身具有很多形状和颜色特征,并且对于某些更复杂的对象而言效果不佳. 本文使用机器学习(Random Forest)方法,并使用颜色和深度功能来识别对象的姿势.
1. 采集训练数据
由于它基于像素级训练,因此每个像素都需要一个标签. 该标签包括每个像素所属的类别以及相应的三维空间坐标.
a. 如何获取标签?
您可以首先使用传统设备来计算某种类型的物体和相机的真实姿势. 在计算出真实姿势后,您可以从对象的二维图像中计算出相应的三维坐标. 但是,在实际的三维坐标计算中,需要对训练对象进行分段,以避免背景等无关对象的干扰. 通过对分割图像进行姿态计算,可以获得分割图像中每个像素的三维坐标.
<p>因为训练和预测是在像素级别进行的,所以通常图像中的对象由大量像素组成,因此在实际训练中不需要太大的样本(如果样本太多) ,您将需要花费大量时间在训练数据上,但是请尝试将数据收录在每个姿势中,以使模型尽可能准确,通常100幅图像(每种类型的对象)就足够了. 查看全部
原创文本首次在微信公众号“ 3D Vision Workshop”上发布-一种基于机器学习随机森林方法的手势识别算法
传统视觉基于特征点和参考坐标系的思想识别物体的姿态. 该方法需要对象本身具有很多形状和颜色特征,并且对于某些更复杂的对象而言效果不佳. 本文使用机器学习(Random Forest)方法,并使用颜色和深度功能来识别对象的姿势.
1. 采集训练数据
由于它基于像素级训练,因此每个像素都需要一个标签. 该标签包括每个像素所属的类别以及相应的三维空间坐标.
a. 如何获取标签?
您可以首先使用传统设备来计算某种类型的物体和相机的真实姿势. 在计算出真实姿势后,您可以从对象的二维图像中计算出相应的三维坐标. 但是,在实际的三维坐标计算中,需要对训练对象进行分段,以避免背景等无关对象的干扰. 通过对分割图像进行姿态计算,可以获得分割图像中每个像素的三维坐标.
<p>因为训练和预测是在像素级别进行的,所以通常图像中的对象由大量像素组成,因此在实际训练中不需要太大的样本(如果样本太多) ,您将需要花费大量时间在训练数据上,但是请尝试将数据收录在每个姿势中,以使模型尽可能准确,通常100幅图像(每种类型的对象)就足够了.
百度算法更新: 对飓风算法3.0的详细解释,以控制具有较高内容相似性的低质量搜集和作战站点组
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2020-08-05 00:03
为了维护健康的移动生态系统,确保用户体验并确保高质量的站点/智能小应用程序能够获得合理的流量分配,百度搜索将在不久的将来升级飓风算法并发布飓风算法3.0.
此百度算法升级主要针对跨域采集和网站组问题,并将涵盖PC网站,H5网站,智能小程序以及百度搜索下的其他内容. 对于算法所涵盖的网站/智能小程序,将根据违规的严重程度来限制搜索结果的显示.
以下详细介绍了百度飓风算法3.0的相关规则.
1. 跨域采集:
为了获得更多流量,站点/智能小程序发布的内容不属于站点/智能小程序的域. 通常,这些内容是从Internet采集的,内容质量和相关性很低,对搜索用户的价值也很低. 对于此类行为搜索,将判断站点/智能applet的域不够集中,并且在显示上会有不同程度的限制.
跨域集合主要包括以下两种类型的问题:
类型1: 主站点或主页的内容/标题/关键字/摘要表明该站点具有明确的字段或行业,但是发布的内容与该字段无关或相关性较低.
问题示例: 美食智能小程序发布足球相关内容
第二类: 站点/智能小程序没有明确的域或行业,并且内容涉及多个域或行业,该域是模糊的,并且域关注度很低.
问题示例: 智能小程序的内容涉及多个字段
两个. 站组问题:
指的是批量构造多个站点/智能小程序以获得搜索流量的行为. 网站组中的大多数网站/智能小程序质量低,资源稀缺,内容相似度高,甚至重用同一模板,这很难满足搜索用户的需求.
问题示例: 多个智能小应用程序重复使用同一模板,内容质量低且相似度高 查看全部
最近,许多朋友向百度主导的屏幕推广专家梁水才报告,百度的排名不稳定. 这表明百度正在更新其算法. 2019年8月8日上午,百度官方网站宣布百度的Hurricane Algorithm 3.0上线了. 网站管理员在阅读说明后应迅速检查说明: 以下是飓风算法3.0的详细说明.

为了维护健康的移动生态系统,确保用户体验并确保高质量的站点/智能小应用程序能够获得合理的流量分配,百度搜索将在不久的将来升级飓风算法并发布飓风算法3.0.
此百度算法升级主要针对跨域采集和网站组问题,并将涵盖PC网站,H5网站,智能小程序以及百度搜索下的其他内容. 对于算法所涵盖的网站/智能小程序,将根据违规的严重程度来限制搜索结果的显示.
以下详细介绍了百度飓风算法3.0的相关规则.
1. 跨域采集:
为了获得更多流量,站点/智能小程序发布的内容不属于站点/智能小程序的域. 通常,这些内容是从Internet采集的,内容质量和相关性很低,对搜索用户的价值也很低. 对于此类行为搜索,将判断站点/智能applet的域不够集中,并且在显示上会有不同程度的限制.
跨域集合主要包括以下两种类型的问题:
类型1: 主站点或主页的内容/标题/关键字/摘要表明该站点具有明确的字段或行业,但是发布的内容与该字段无关或相关性较低.
问题示例: 美食智能小程序发布足球相关内容

第二类: 站点/智能小程序没有明确的域或行业,并且内容涉及多个域或行业,该域是模糊的,并且域关注度很低.
问题示例: 智能小程序的内容涉及多个字段
两个. 站组问题:
指的是批量构造多个站点/智能小程序以获得搜索流量的行为. 网站组中的大多数网站/智能小程序质量低,资源稀缺,内容相似度高,甚至重用同一模板,这很难满足搜索用户的需求.
问题示例: 多个智能小应用程序重复使用同一模板,内容质量低且相似度高
百度算法更新:飓风算法3.0详尽剖析、各位采集站长赶快自查网站把
采集交流 • 优采云 发表了文章 • 0 个评论 • 429 次浏览 • 2020-08-04 09:00
为了维护健康的联通生态,保障用户体验,保证优质站点/智能小程序才能获得合理的流量分发,百度搜索将在近日对飓风算法进行升级,上线飓风算法3.0。
本次算法升级主要针对跨领域采集以及站群问题,将覆盖百度搜索下的PC站点、H5站点、智能小程序等内容。对于算法覆盖的站点/智能小程序算法 自动采集列表,将会依照违法问题的恶劣程度,酌情限制搜索结果的诠释。
以下详尽说明飓风算法3.0的相关规则。
一. 跨领域采集:
指站点/智能小程序为了获取更多流量,发布不属于站点/智能小程序领域范围的内容,通常这种内容采集自互联网,内容质量及相关性低、对搜索用户价值低。对于这样的行为搜索会判断该站点/智能小程序的领域专注度不足,会有不同程度的限制凸显。
跨领域采集主要包括下边两类问题:
第一类:主站或主页的内容/标题/关键词/摘要等信息显示该站有明晰的领域或行业,但发布内容与该领域不相关,或相关性较低。
问题示例:美食类智能小程序发布篮球相关内容
第二类:站点/智能小程序没有明晰的领域或行业算法 自动采集列表,内容涉及多个领域或行业,领域模糊、领域专注度低。
问题示例:智能小程序内容涉及多个领域
二. 站群问题:
指批量构造多个站点/智能小程序,获取搜索流量的行为。站群中的站点/智能小程序大多质量低、资源稀缺性低、内容相似度高、甚至复用相同模板,难以满足搜索用户的需求。
问题示例:多个智能小程序复用同一模板,内容质量低、相似度高 查看全部
是不是发觉近来百度排行不稳定,你没有想错,这就是百度近来在更新算法,今天总算通告百度的飓风算法3.0上线了,是时侯要自查一波,各位站长赶快看说明以后去自查吧:下面就是飓风算法3.0的详尽说明。
为了维护健康的联通生态,保障用户体验,保证优质站点/智能小程序才能获得合理的流量分发,百度搜索将在近日对飓风算法进行升级,上线飓风算法3.0。
本次算法升级主要针对跨领域采集以及站群问题,将覆盖百度搜索下的PC站点、H5站点、智能小程序等内容。对于算法覆盖的站点/智能小程序算法 自动采集列表,将会依照违法问题的恶劣程度,酌情限制搜索结果的诠释。
以下详尽说明飓风算法3.0的相关规则。
一. 跨领域采集:
指站点/智能小程序为了获取更多流量,发布不属于站点/智能小程序领域范围的内容,通常这种内容采集自互联网,内容质量及相关性低、对搜索用户价值低。对于这样的行为搜索会判断该站点/智能小程序的领域专注度不足,会有不同程度的限制凸显。
跨领域采集主要包括下边两类问题:
第一类:主站或主页的内容/标题/关键词/摘要等信息显示该站有明晰的领域或行业,但发布内容与该领域不相关,或相关性较低。
问题示例:美食类智能小程序发布篮球相关内容

第二类:站点/智能小程序没有明晰的领域或行业算法 自动采集列表,内容涉及多个领域或行业,领域模糊、领域专注度低。
问题示例:智能小程序内容涉及多个领域

二. 站群问题:
指批量构造多个站点/智能小程序,获取搜索流量的行为。站群中的站点/智能小程序大多质量低、资源稀缺性低、内容相似度高、甚至复用相同模板,难以满足搜索用户的需求。
问题示例:多个智能小程序复用同一模板,内容质量低、相似度高
百度飓风算法 3.0,控制跨领域采集及站群
采集交流 • 优采云 发表了文章 • 0 个评论 • 443 次浏览 • 2020-08-04 08:03
一、跨领域采集
指站点/智能小程序为了获取更多流量,发布不属于站点/智能小程序领域范围的内容,通常这种内容采集自互联网,内容质量及相关性低、对搜索用户价值低。对于这样的行为搜索会判断该站点/智能小程序的领域专注度不足,会有不同程度的限制凸显。
跨领域采集主要包括下边两类问题:
二、站群问题
指批量构造多个站点/智能小程序,获取搜索流量的行为。站群中的站点/智能小程序大多质量低、资源稀缺性低、内容相似度高、甚至复用相同模板,难以满足搜索用户的需求。
简单总结
百度飓风算法 3.0 预计在 8 月内相继上线。当然和往年一样假如你的站点被百度认定为跨领域采集或者站群问题,那么你可能会收到百度搜索资源平台的站内信、短信等渠道的提醒通知,所以子凡建议你们还是自查完成整改吧假如有的话,避免不必要的降权。
其实子凡认为,与其说百度飓风算法 3.0 是针对跨领域采集和站群,其实看上更象实在辅助和为百度智能小程序铺路,以及降低智能小程序的的权重,以搜索引擎算法的方法间接的将流量导向百度的小程序。
除非标明,否则均为泪雪博客原创文章算法 自动采集列表,禁止任何方式转载
本文链接: 查看全部
百度总算迎来了飓风算法 3.0,这次依然是为了维护健康的联通搜索生态,保障用户体验,保证优质站点及智能小程序才能获得合理的流量分发。本次飓风算法升级主要针对跨领域采集以及站群问题,将覆盖百度搜索下的 PC 站点、H5 站点、智能小程序等内容。对于算法覆盖的站点/智能小程序算法 自动采集列表,将会依照违法问题的恶劣程度,酌情限制搜索结果的彰显。

一、跨领域采集
指站点/智能小程序为了获取更多流量,发布不属于站点/智能小程序领域范围的内容,通常这种内容采集自互联网,内容质量及相关性低、对搜索用户价值低。对于这样的行为搜索会判断该站点/智能小程序的领域专注度不足,会有不同程度的限制凸显。
跨领域采集主要包括下边两类问题:
二、站群问题
指批量构造多个站点/智能小程序,获取搜索流量的行为。站群中的站点/智能小程序大多质量低、资源稀缺性低、内容相似度高、甚至复用相同模板,难以满足搜索用户的需求。
简单总结
百度飓风算法 3.0 预计在 8 月内相继上线。当然和往年一样假如你的站点被百度认定为跨领域采集或者站群问题,那么你可能会收到百度搜索资源平台的站内信、短信等渠道的提醒通知,所以子凡建议你们还是自查完成整改吧假如有的话,避免不必要的降权。
其实子凡认为,与其说百度飓风算法 3.0 是针对跨领域采集和站群,其实看上更象实在辅助和为百度智能小程序铺路,以及降低智能小程序的的权重,以搜索引擎算法的方法间接的将流量导向百度的小程序。
除非标明,否则均为泪雪博客原创文章算法 自动采集列表,禁止任何方式转载
本文链接:
统治世界的十大算法
采集交流 • 优采云 发表了文章 • 0 个评论 • 255 次浏览 • 2020-08-04 08:03
————————-
算法对于我们明天生活非常重要,怎样鼓吹也不会夸张。它们在虚拟世界中无处不在,从金融机构到交友网站。但是,相比于其他算法,其中有一些算法更大程度上改变并控制着我们的世界——本文列出了其中十种最为重要的算法。
在即将介绍算法内容之前,让我们来迅速备考一些基本内容。虽然,没有明晰的定义,但是计算机科学家将算法描述为一个定义了操作次序的规则集合。它们是一组次序指令,用来告诉计算机如何解决一个问题或则达到某种既定目标。认识算法的好方式,是将算法可视化为流程图。
1. Google Search 谷歌搜索
不久之前,搜索引擎成为了互联网时代的霸主。与搜索引擎一起崛起的还有微软和微软提出的PageRank算法。
今天,在日本的核心搜索市场中,谷歌的市场占有率达到了66.7%,其次是谷歌(18.1%),雅虎(11.2%),Ask(2.6%),AOL(1.4%)。毋庸置疑,谷歌早已统治了搜索市场,而且我们中的很多人把微软作为使用互联网的主要途径。
PageRank 的工作依赖于两个组成部份,一是称作“蜘蛛”或者“爬虫”的自动程序,另一部分是关键词索引及其 位置。这个算法通过估算某个网页的相关链接数目和链接质量,来大致估算这个网页的重要性。算法的基本思想是越重要的网页会有越多的链接指向它。这是一个基本的人气大赛。除此之外,PageRank算法也考虑了一个网页中关键词的频度和出现位置,以及这个网页发布的时间。
2. Facebook News Feed
虽然我们不愿承认,但是Facebook的新闻提要(NewsFeed)是我们最喜欢浪费时间的地方。除非你的个人偏好早已设置为展示所有风波而且依照时间次序更新所有好友新闻,不然你听到的新闻是一个预处理以后的选择,这个预处理是由Facebook的算法为你量身选择个别新闻而展示。
为了决定什么新闻的内容是最有意思的,这个算法会考虑好多诱因,比如评论数,发表人(是的,有一个内容的“流行”人物排行,所谓的“流行”人物是与你互动最多的人),发表类型(比如相片、视频、状态、更新等等)。
3. OKCupid 情侣匹配
在线交友如今是一个价值20亿美元的产业。由于, eHarmony, and OKCupid等网站的发展,这个产业自从2008年以来每年扩大3.5%。分析家觉得这个产业的加速发展在未来两年还将继续——情有可原:这是情侣遇到的有效方法。婚恋网站不仅仅缔造了更多的成功婚姻,他们也擅长于依据个人不同的喜好和倾向,匹配潜在情侣。当然,这样的匹配完全是由算法完成的。
我们将以OKCupid为例,OKCupid是一个免费的婚恋网站,联合创始人之一是哈佛大学的数学家Christian Rudder。OKCupid采用一种绝对的剖析方式促使约会,他们从用户哪里竭力获取信息。OKCupid 的配对算法不仅仅是简单地匹配一些共同爱好,同时,每一个问题都被赋于了权重,用来评判这个问题对于用户和她们潜在情侣的重要程度。这就是所谓的差别缔造不凡——这是OKCupid成为最高效婚恋网站的诱因之一。
4. NSA 数据采集,解读和加密
我们越来越多地被算法而不是被人观察。感谢Edward Snowden,我们晓得了美国安全局(NSA)及其小伙伴早已暗中监控了上百万的无辜公民。近期披露的文件显示,已经有许多的监控项目被FiveEyes施行,FiveEyes是由英国、澳大利亚、加拿大、新西兰和加拿大共同组成的情报组织。它们已然监控了我们的移动电话、电子邮箱、网络摄像头图象和地理位置信息。同时,“它们”我指的是她们的算法,这其中有太多的数据,人力难以进行搜集和评析。
有意思的是,NSA宣称实际上她们并没有“采集”我们的数据。根据一份1982年的程序指南,“信息“采集”是指当信息被搜集并被国防部情报机构在职责范围内使用”。同时“数据由电子系统采集是指信息采集并被转换为可理解的方式”。英国路透社的Bruce Schneier解释道:
“ 因此,假设你的同事在家里有成千上万的书籍,根据NSA的解释,他并不“收集”图书。只有他真正在读的这些才是他“收集”的图书,他借助图书做其他事情时并不能觉得他在“收集”图书。”
这会形成一个问题由于:
计算机算法与人们密切相关。当我们想到计算机算法正在监控我们而且剖析我们的个人数据时算法 自动采集列表,我们必须想想在算法背后的人。是不是有人正在看着我们的数据,事实上,他们能做的事情正是监视。
最后,最相关的还有美国国家安全局的Suite B 加密算法,这是一套功能强悍的算法,用于加密、数据交换、数字签名和哈希。机构正是借助这一算法来保护分类以及未分类文件的。
5. 推荐算法
诸如例如 亚马逊和Netflix这样的网站,会记录你选购过的书籍或是你看过的影片,然后按照我们的爱好为我们推荐商品。
正如许多手动程序一样,这种二十一世纪独有的技术既有优点也有缺点。虽然这样的推荐有时候太有帮助,但是有时候也会偏离目标——特别是你为你的三岁父亲购买了一本儿童读物作为礼物然后。
与PageRank和Facebook的新闻提要一样,这样的算法正在导致所谓的“过滤器泡沫”,这是一种现象,用户与她们不感兴趣的信息隔离——有效地将用户通过意识形态的“泡沫”隔离上去。这引起了Eli Pariser提出的“信息决定论”,我们过去在网上浏览的兴趣决定了我们的未来。
6. Google AdWords
与之前的算法类似, Google, Facebook以及其他的网站跟踪你的行为、用词、搜索恳求来推送相应广告。 Google’s AdWords——公司最主要的收入来源——正是以这样的模式进行预测的,同时Facebook也在竭力进行相关研究(你最后一次点击Facebook的广告是哪些时侯?)
7. 高频度的股票交易
很久之前,金融部门就开始使用算法来预测市场波动,但是她们在高频度的股票交易中的实践才刚刚开始。这样的高速交易涉及的算法,也称作机器人,可以对订单在毫秒级作出判定。相反,一个人一般须要起码1秒就能对潜在的风险作出反应。因此,人们渐渐被排除在了实际交易的循环之外——一个全新的电子生态正在逐步产生。
但是,又是这种算法会导致错误。Leo Hickman解释道:
比如:2010年五月六日的“闪电暴跌”,当时道琼斯指数在几分钟内平均上涨了1000点,而在二十分钟以后市场才出现回落。这样的急剧直线上涨到目前为止也没能得到完整解释,但是大部分经济学家将齐归罪于“竟次”。“竟次”的罪魁祸首是为了达到高频交易而大规模使用的量化交易算法。Scott Patterson,华尔街日报的记着和《The Quants》的作者,将在交易场地使用这种算法称作客机的手动驾驶。今天,大部分的交易是由算法手动完成的,但是当情况出现不同时,比如发生闪电暴跌时,应当有人工介入。
8. MP3 压缩
压缩数据算法是电子世界不可磨灭的重要一员。我们希望更快地接收媒体数据,同时希望节省硬碟空间。因此,人们设计了好多方式来压缩和传送数据。
比如,在1991年思科系统研制了CRTP合同。1987年,德国研究者发明了明天广泛使用的MP3格式,从而将音频的大小减小到原始大小的十分之一。这一压缩格式造成了音乐产业的革命(影响有好有坏)。
9. 预测剖析软件
目前这一技术并没有主宰我们的世界,但是它将很快主宰世界。越来越多的警员机构正在使用一种预测剖析技术——一种使人想起影片《少数派报告》的新工具。
在2010年,据说借助IBM的预测剖析软件(叫做CRUSH,全称 Criminal Reduction Utilizing Statistical History),2006年以来孟菲斯市的警员局降低了超过30%的恶性案件,其中包括降低了15%的暴力犯罪。同时,在加拿大、以色列以及美国的城市也在关注这一技术。现在,洛杉矶、圣克鲁斯、查尔斯顿等也开始了试点。
这一技术结合了数据采集、统计剖析,当然还有前沿的算法。它促使警员可以评估城市的犯罪特征,并且预告可能的犯罪“热点”,从而“积极地配置资源和分配人手,从而提升人力物力的使用效率,提高公众安全”。
未来,这个系统可能会大规模取代分析家的工作。犯罪行为可以被精确的算法所追踪,这些算法监控了互联网行为、GPS算法 自动采集列表,个人电子设备,生物特点和其他现实中的通讯方法。越来越多的无人机会拿来追踪潜在犯人,通过剖析她们的肢体动作和其他的可视化线索,来预测她们的意图。
10. 调音(Auto-Tune)
最后,仅供娱乐,现在调音器由算法完成。无论是歌声或是钢琴的声音,这些设备都能通过一组特定规则,略微更改音位,让音域达到最接近的确切调式上。有趣的是,这种技术最初由Exxon’s Any Hildebrand 用于处理水灾数据。
美国女歌手Cher的《Believe》,被觉得是第一首使用调音的流行歌曲。
原文: 查看全部
编注:如果你之前已看伯乐在线翻译组的这篇译文:《真正统治世界的十大算法》,请暂时“清空相关记忆”。《统治世界的十大算法》先于后者。
————————-
算法对于我们明天生活非常重要,怎样鼓吹也不会夸张。它们在虚拟世界中无处不在,从金融机构到交友网站。但是,相比于其他算法,其中有一些算法更大程度上改变并控制着我们的世界——本文列出了其中十种最为重要的算法。
在即将介绍算法内容之前,让我们来迅速备考一些基本内容。虽然,没有明晰的定义,但是计算机科学家将算法描述为一个定义了操作次序的规则集合。它们是一组次序指令,用来告诉计算机如何解决一个问题或则达到某种既定目标。认识算法的好方式,是将算法可视化为流程图。
1. Google Search 谷歌搜索
不久之前,搜索引擎成为了互联网时代的霸主。与搜索引擎一起崛起的还有微软和微软提出的PageRank算法。

今天,在日本的核心搜索市场中,谷歌的市场占有率达到了66.7%,其次是谷歌(18.1%),雅虎(11.2%),Ask(2.6%),AOL(1.4%)。毋庸置疑,谷歌早已统治了搜索市场,而且我们中的很多人把微软作为使用互联网的主要途径。
PageRank 的工作依赖于两个组成部份,一是称作“蜘蛛”或者“爬虫”的自动程序,另一部分是关键词索引及其 位置。这个算法通过估算某个网页的相关链接数目和链接质量,来大致估算这个网页的重要性。算法的基本思想是越重要的网页会有越多的链接指向它。这是一个基本的人气大赛。除此之外,PageRank算法也考虑了一个网页中关键词的频度和出现位置,以及这个网页发布的时间。
2. Facebook News Feed
虽然我们不愿承认,但是Facebook的新闻提要(NewsFeed)是我们最喜欢浪费时间的地方。除非你的个人偏好早已设置为展示所有风波而且依照时间次序更新所有好友新闻,不然你听到的新闻是一个预处理以后的选择,这个预处理是由Facebook的算法为你量身选择个别新闻而展示。

为了决定什么新闻的内容是最有意思的,这个算法会考虑好多诱因,比如评论数,发表人(是的,有一个内容的“流行”人物排行,所谓的“流行”人物是与你互动最多的人),发表类型(比如相片、视频、状态、更新等等)。
3. OKCupid 情侣匹配
在线交友如今是一个价值20亿美元的产业。由于, eHarmony, and OKCupid等网站的发展,这个产业自从2008年以来每年扩大3.5%。分析家觉得这个产业的加速发展在未来两年还将继续——情有可原:这是情侣遇到的有效方法。婚恋网站不仅仅缔造了更多的成功婚姻,他们也擅长于依据个人不同的喜好和倾向,匹配潜在情侣。当然,这样的匹配完全是由算法完成的。

我们将以OKCupid为例,OKCupid是一个免费的婚恋网站,联合创始人之一是哈佛大学的数学家Christian Rudder。OKCupid采用一种绝对的剖析方式促使约会,他们从用户哪里竭力获取信息。OKCupid 的配对算法不仅仅是简单地匹配一些共同爱好,同时,每一个问题都被赋于了权重,用来评判这个问题对于用户和她们潜在情侣的重要程度。这就是所谓的差别缔造不凡——这是OKCupid成为最高效婚恋网站的诱因之一。
4. NSA 数据采集,解读和加密
我们越来越多地被算法而不是被人观察。感谢Edward Snowden,我们晓得了美国安全局(NSA)及其小伙伴早已暗中监控了上百万的无辜公民。近期披露的文件显示,已经有许多的监控项目被FiveEyes施行,FiveEyes是由英国、澳大利亚、加拿大、新西兰和加拿大共同组成的情报组织。它们已然监控了我们的移动电话、电子邮箱、网络摄像头图象和地理位置信息。同时,“它们”我指的是她们的算法,这其中有太多的数据,人力难以进行搜集和评析。

有意思的是,NSA宣称实际上她们并没有“采集”我们的数据。根据一份1982年的程序指南,“信息“采集”是指当信息被搜集并被国防部情报机构在职责范围内使用”。同时“数据由电子系统采集是指信息采集并被转换为可理解的方式”。英国路透社的Bruce Schneier解释道:
“ 因此,假设你的同事在家里有成千上万的书籍,根据NSA的解释,他并不“收集”图书。只有他真正在读的这些才是他“收集”的图书,他借助图书做其他事情时并不能觉得他在“收集”图书。”
这会形成一个问题由于:
计算机算法与人们密切相关。当我们想到计算机算法正在监控我们而且剖析我们的个人数据时算法 自动采集列表,我们必须想想在算法背后的人。是不是有人正在看着我们的数据,事实上,他们能做的事情正是监视。
最后,最相关的还有美国国家安全局的Suite B 加密算法,这是一套功能强悍的算法,用于加密、数据交换、数字签名和哈希。机构正是借助这一算法来保护分类以及未分类文件的。
5. 推荐算法
诸如例如 亚马逊和Netflix这样的网站,会记录你选购过的书籍或是你看过的影片,然后按照我们的爱好为我们推荐商品。

正如许多手动程序一样,这种二十一世纪独有的技术既有优点也有缺点。虽然这样的推荐有时候太有帮助,但是有时候也会偏离目标——特别是你为你的三岁父亲购买了一本儿童读物作为礼物然后。
与PageRank和Facebook的新闻提要一样,这样的算法正在导致所谓的“过滤器泡沫”,这是一种现象,用户与她们不感兴趣的信息隔离——有效地将用户通过意识形态的“泡沫”隔离上去。这引起了Eli Pariser提出的“信息决定论”,我们过去在网上浏览的兴趣决定了我们的未来。
6. Google AdWords
与之前的算法类似, Google, Facebook以及其他的网站跟踪你的行为、用词、搜索恳求来推送相应广告。 Google’s AdWords——公司最主要的收入来源——正是以这样的模式进行预测的,同时Facebook也在竭力进行相关研究(你最后一次点击Facebook的广告是哪些时侯?)
7. 高频度的股票交易

很久之前,金融部门就开始使用算法来预测市场波动,但是她们在高频度的股票交易中的实践才刚刚开始。这样的高速交易涉及的算法,也称作机器人,可以对订单在毫秒级作出判定。相反,一个人一般须要起码1秒就能对潜在的风险作出反应。因此,人们渐渐被排除在了实际交易的循环之外——一个全新的电子生态正在逐步产生。
但是,又是这种算法会导致错误。Leo Hickman解释道:
比如:2010年五月六日的“闪电暴跌”,当时道琼斯指数在几分钟内平均上涨了1000点,而在二十分钟以后市场才出现回落。这样的急剧直线上涨到目前为止也没能得到完整解释,但是大部分经济学家将齐归罪于“竟次”。“竟次”的罪魁祸首是为了达到高频交易而大规模使用的量化交易算法。Scott Patterson,华尔街日报的记着和《The Quants》的作者,将在交易场地使用这种算法称作客机的手动驾驶。今天,大部分的交易是由算法手动完成的,但是当情况出现不同时,比如发生闪电暴跌时,应当有人工介入。
8. MP3 压缩
压缩数据算法是电子世界不可磨灭的重要一员。我们希望更快地接收媒体数据,同时希望节省硬碟空间。因此,人们设计了好多方式来压缩和传送数据。

比如,在1991年思科系统研制了CRTP合同。1987年,德国研究者发明了明天广泛使用的MP3格式,从而将音频的大小减小到原始大小的十分之一。这一压缩格式造成了音乐产业的革命(影响有好有坏)。
9. 预测剖析软件
目前这一技术并没有主宰我们的世界,但是它将很快主宰世界。越来越多的警员机构正在使用一种预测剖析技术——一种使人想起影片《少数派报告》的新工具。
在2010年,据说借助IBM的预测剖析软件(叫做CRUSH,全称 Criminal Reduction Utilizing Statistical History),2006年以来孟菲斯市的警员局降低了超过30%的恶性案件,其中包括降低了15%的暴力犯罪。同时,在加拿大、以色列以及美国的城市也在关注这一技术。现在,洛杉矶、圣克鲁斯、查尔斯顿等也开始了试点。

这一技术结合了数据采集、统计剖析,当然还有前沿的算法。它促使警员可以评估城市的犯罪特征,并且预告可能的犯罪“热点”,从而“积极地配置资源和分配人手,从而提升人力物力的使用效率,提高公众安全”。
未来,这个系统可能会大规模取代分析家的工作。犯罪行为可以被精确的算法所追踪,这些算法监控了互联网行为、GPS算法 自动采集列表,个人电子设备,生物特点和其他现实中的通讯方法。越来越多的无人机会拿来追踪潜在犯人,通过剖析她们的肢体动作和其他的可视化线索,来预测她们的意图。
10. 调音(Auto-Tune)
最后,仅供娱乐,现在调音器由算法完成。无论是歌声或是钢琴的声音,这些设备都能通过一组特定规则,略微更改音位,让音域达到最接近的确切调式上。有趣的是,这种技术最初由Exxon’s Any Hildebrand 用于处理水灾数据。
美国女歌手Cher的《Believe》,被觉得是第一首使用调音的流行歌曲。
原文:
解释飓风算法3.0百度算法控制跨域采集和站点组问题
采集交流 • 优采云 发表了文章 • 0 个评论 • 356 次浏览 • 2020-08-07 02:13
8月8日,百度发布了“飓风算法3.0即将上线以控制跨域采集和站点组问题”的公告. 为了维护健康的移动生态系统,确保用户体验并确保高质量的站点/智能小应用程序能够获得合理的流量分配,百度搜索将在不久的将来升级飓风算法,并在线升级飓风算法3.0.
此算法升级主要针对跨域采集和站点组问题,并将涵盖PC网站,H5网站,智能小程序以及百度搜索下的其他内容. 对于算法所涵盖的网站/智能小程序,将根据违规的严重程度来限制搜索结果的显示.
以下详细介绍了飓风算法3.0的相关规则.
问题1: 在同一个品牌下,分支公司的网站/智能小程序都使用相同的模板. 他们会被评判为一组站台并被飓风算法3.0击中吗?
答案1: 针对网站组问题,该算法将基于多个因素进行综合判断,例如页面布局相似性,同一主题下的网站/智能小程序数量,内容质量,内容稀缺性,内容相似性等.
如果相同品牌的网站/智能小程序使用相同的页面布局并且内容相似性很高,则这种情况也可能被判断为站点组,并且存在被算法打击的风险.
问题示例: 某个品牌下的多个区域分支机构的智能小程序使用相同的模板,内容质量低且相似度高.
问题2: 此飓风算法升级主要针对跨域集合. 算法将覆盖同一域中的集合吗?
答案2: 此飓风算法3.0的主要升级点是加强跨域采集和站点组问题的覆盖范围,但是以前的飓风算法对于控制严酷采集仍然有效. 百度搜索算法一直在持续运行,以控制危害用户体验的违规行为,并且不会因算法升级或添加而停止旧算法.
问题3: 如果站点/智能小程序收录跨域采集的内容,为了避免被算法打击,我是否需要删除以前的跨域内容?
答案3: 是的,如果网站/智能小程序曾经发布过与该网站/智能小程序所属的域无关的内容,我们建议您尽快删除跨域内容,加深当前区域,并产生满足用户需求的高质量内容,以增强网站/智能小程序的重点.
问题4: 该算法会在一个站点下设置不同主题的频道或目录,并在不同字段中发布内容吗?
答案4: 在同一网站上可以存在具有不同主题的频道或目录,但是每个频道的内容应与网站的域定位相关,并应重点关注该域. 频道内容应满足搜索用户的需求优质内容.
问题5: 此飓风算法升级主要针对跨域集合. 算法将覆盖同一域中的集合吗? 查看全部
8月8日,百度发布了“飓风算法3.0即将上线以控制跨域采集和站点组问题”的公告. 为了维护健康的移动生态系统,确保用户体验并确保高质量的站点/智能小应用程序能够获得合理的流量分配,百度搜索将在不久的将来升级飓风算法,并在线升级飓风算法3.0.
此算法升级主要针对跨域采集和站点组问题,并将涵盖PC网站,H5网站,智能小程序以及百度搜索下的其他内容. 对于算法所涵盖的网站/智能小程序,将根据违规的严重程度来限制搜索结果的显示.
以下详细介绍了飓风算法3.0的相关规则.
问题1: 在同一个品牌下,分支公司的网站/智能小程序都使用相同的模板. 他们会被评判为一组站台并被飓风算法3.0击中吗?
答案1: 针对网站组问题,该算法将基于多个因素进行综合判断,例如页面布局相似性,同一主题下的网站/智能小程序数量,内容质量,内容稀缺性,内容相似性等.
如果相同品牌的网站/智能小程序使用相同的页面布局并且内容相似性很高,则这种情况也可能被判断为站点组,并且存在被算法打击的风险.
问题示例: 某个品牌下的多个区域分支机构的智能小程序使用相同的模板,内容质量低且相似度高.
问题2: 此飓风算法升级主要针对跨域集合. 算法将覆盖同一域中的集合吗?
答案2: 此飓风算法3.0的主要升级点是加强跨域采集和站点组问题的覆盖范围,但是以前的飓风算法对于控制严酷采集仍然有效. 百度搜索算法一直在持续运行,以控制危害用户体验的违规行为,并且不会因算法升级或添加而停止旧算法.
问题3: 如果站点/智能小程序收录跨域采集的内容,为了避免被算法打击,我是否需要删除以前的跨域内容?
答案3: 是的,如果网站/智能小程序曾经发布过与该网站/智能小程序所属的域无关的内容,我们建议您尽快删除跨域内容,加深当前区域,并产生满足用户需求的高质量内容,以增强网站/智能小程序的重点.
问题4: 该算法会在一个站点下设置不同主题的频道或目录,并在不同字段中发布内容吗?
答案4: 在同一网站上可以存在具有不同主题的频道或目录,但是每个频道的内容应与网站的域定位相关,并应重点关注该域. 频道内容应满足搜索用户的需求优质内容.
问题5: 此飓风算法升级主要针对跨域集合. 算法将覆盖同一域中的集合吗?
Wang Xi: 大数据人工智能中的运筹学与决策科学
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2020-08-06 19:22
收入管理,要解决的问题是如何在不增加流量投资的情况下大幅增加公司的销售收入. 为了解决这个问题,有必要从多个维度采集数据,并找到最佳定价和最佳销售策略.
风险管理,为金融及相关行业的客户提供完整的风险管理服务,提供从精确营销,信用调查,高风险交易识别到不良资产处置的全过程服务.
供应链管理为供应链中的各个环节(包括订单,库存,货运和分销)提供了优化的解决方案. 在提高响应速度和供应链灵活性的同时,它可以帮助公司控制成本.
算法引擎,许多理论都有广泛的应用场景. 实际上,该理论本身也可以带来巨大的价值,因为它可以提供用于复杂数据分析的平台并集成高效的优化算法,用于复杂数据分析提供基本的算法和软件支持,尤其是优化算法求解器的开发,可以大大改善机器学习和深度学习的效率.
由于我们看到了如此广泛的需求和应用,因此我们决定返回中国建立Shanshu Technology. 以上四个方面是我们的核心服务领域.
以一个例子来讨论运筹学和决策科学在金融风险管理中的应用
使用刚才提到的四个方面,首先是精确定位营销,确定真正满足金融产品特征的高质量用户,并在系统级别实施第一级风险控制.
第二个是信用调查,它通过观察和描述现有用户的支付行为来评估潜在用户的信用风险,最后给出信用调查决策.
第三个是教育管理或反欺诈,它使用数据来识别高风险交易和欺诈行为以最大程度地减少损失.
最后,在违反合同的情况下,为了最大程度地减少损失,这是处理不良资产的问题. 为了解决这四个问题并打开整个风险管理链,使用的方法实际上非常相似.
第一层是数据采集和管理,它需要描述和观察非常多维的数据. 其次,使用机器学习或相对复杂的预测方法来描述和预测数据. 第三,选择一个多层次的榜样. 最后,当我们拥有决策模型时,我们可以使用优化算法来帮助我们找到最佳结果. 因此,该方法论适用于整个风险管理链中的四个主题.
摘要
1. 运筹学和决策科学是大数据人工智能的核心概念. 对于大数据,不能忽视大数据分析支持的决策. 在人工智能方面,人们不能忽略其所需的模型和算法.
2. 当有了运筹学和决策科学的工具时,我们可以将实际问题抽象为可量化的决策问题并给出最佳决策.
3. 当我们讨论机器学习和深度学习等人工智能方法时,运筹学和决策科学也为机器学习提供了模型思维和算法保证.
教他钓鱼
运筹学和决策科学学科的学习建议:
1. 使用决策方法思考问题
当您面对信息量巨大且时间紧迫的问题时,您可能会感到无助,也不知道该怎么办. 但是您可以从决策的高度思考,现在可以做什么和不能做什么,主要的确定性是什么,哪些可以相对量化,没有用,并且是值得关注的核心价值. 尝试做出这样的战略决策和思考. 就像您脑海中的操作系统一样. 当您遇到更复杂的决策问题时,您可以采用一种新的思维方式.
2,掌握一些方法
实际上有许多种方法. 如果您是具有数学背景的学生,则可以关注一些定量数学方法,无论是基础运筹学,描述确定性的概率论,还是金融背景的学生了解所有金融应用场景,实际上,您都可以尝试培训从该方法.
3. 注意特定的应用场景
掌握太多理论. 如果没有合适的应用场景,或者使用理论覆盖了应用程序中的实际问题,则该问题将无法解决. 在很大程度上可以帮助我们的第一种方法是考虑您的决策方式. 我还建议您与感兴趣的行业的人进行更多的交流,因为他们面对该行业的独特场景和独特维度,并与他们进行更多的交流,因此他们有解决问题的思维方式和一些非常定量如果方法非常清晰,在这种清晰的应用场景中,他绝对可以帮助他解决核心决策问题.
粉丝问问题
1. 人工智能行业中是否存在泡沫成分?有纯人工智能的商业模式吗?
王曦: 这实际上是一个大话题. 气泡意味着只有概念,没有着陆,只有想法,没有具体的实际计划. 因此,从这个角度来看,会有气泡.
回顾历史,我认为在新兴技术诞生的任何阶段,人们都会进行这样的讨论,因为从时间的角度来看,当一个新概念问世时,该概念通常会领先于技术.
我参加了一个讨论. 主题是人工智能已渗透到我们生活的方方面面. 未来会不会有很多人类工作被人工智能取代?实际上,这是关于气泡的非常典型的讨论. 实际上,我对此并不担心. 一方面,当新技术出现时,我已经讨论并担心了很多次. 例如,在20世纪初,当福特汽车公司开始投资于标准化和简化的T型汽车生产时,整个装配线上约三分之二的工人被替换了. 但是,如果我们注意这种新技术的发展,从替代劳动力产生的就业机会来看,另一个更大的产业实际上是一个更大的产业.
从另一个角度来看,关于纯人工智能是否是一种商业模型这一问题,我的观点是,我将更加关注它所产生的价值. 任何能够创造价值的新技术都可以找到合适的商业模式. 货币化始终是第二种问题. 第一种类型的问题首先是这种功能,无论是娱乐,服务还是实际的产品形式,重点都是它可以产生什么样的价值. 只要具有价值,我相信它将拥有自己的商业模式.
2. 中美运筹学与决策科学的学科和应用之间的主要区别是什么?
王曦: 据我观察,差异很大.
由于运筹学和决策科学在美国首先发展和成熟,因此该学科的应用和成熟度远远高于中国. 一些成熟的大公司,例如亚马逊规模的大公司,可能拥有150至200个全职的研发和供应链团队,其中80%至90%是博士学位. 在中国,无论是小公司还是大公司都不能拥有这样的团队配置.
从另一个角度来看,我们回到中国创业后,我们与各种国内企业进行了交流和讨论. 我们发现,由于这项技术或其理论非常成熟,应用范围非常广,当我们与公司沟通时,我们会发现公司将很快意识到我们可以带来的价值,所以这一点使我非常乐观.
另一方面,大数据的概念在过去几年中被大肆宣传,因此各种类型和行业的公司将或多或少地积累数据. 当这些数据积累到临界点时,每个人都在乎如何制定一些数据驱动型决策以及如何做出更好的优化操作. 这是我们看到运筹学优化和决策科学可以在中国广泛使用的另一个机会.
总而言之,如果您看一下现状,美国在运筹学和决策科学的认识,接受和应用方面已经成熟很多,但是中国仍有很大的增长空间
3. AI +金融的最大困难是什么?
王曦: 我记得李开复先生曾经说过: “也许最容易应用的人工智能领域是金融,因为金融是一种纯粹的数字语言. ”
仅从数据的角度来看,我认为有两个困难或痛点.
首先,尽管金融业中的数据量非常大,但它通常面临着一个大而低维的问题. 例如,刚刚讨论了大数据信用调查的问题. 金融机构可能已经观察到有关成功出借用户的付款习惯的大规模数据. 尽管数据量非常大,但从维度的角度来看,我们观察到的所有数据都是一组客户的行为,这些客户被金融机构视作上级贷款并成功获得贷款. 我们认为他们的不还款可能性非常低. 对于那些拒绝发放贷款的人,我们没有观察到这些方面. 因此,当数据面临大量小尺寸问题时,采用什么方法和更新的数据尺寸来解决这个问题,我认为这是一个难点.
第二,许多所谓的数据分析可能会止于数据描述和数据预测. 数据的描述和预测具有巨大的价值,但是,如果我们真的想使用这种复杂或高端的数据分析方法来最终支持金融技术决策,那么我们不应该只停留在数据的描述和预测方面. 有时人们认为预测必须非常准确才能解决此问题,但是如果我们关注该预测所支持的决策,则会发现该决策对预测精度的敏感性不如想象中的高,并且有时必需数据的维度不能仅通过数据描述和数据预测来解决. 因此,我建议您将重点更多放在决策方面,而不仅仅是数据描述和数据预测. 查看全部
应用场景可分为收入管理,风险管理,供应链管理和算法引擎四个领域
收入管理,要解决的问题是如何在不增加流量投资的情况下大幅增加公司的销售收入. 为了解决这个问题,有必要从多个维度采集数据,并找到最佳定价和最佳销售策略.
风险管理,为金融及相关行业的客户提供完整的风险管理服务,提供从精确营销,信用调查,高风险交易识别到不良资产处置的全过程服务.
供应链管理为供应链中的各个环节(包括订单,库存,货运和分销)提供了优化的解决方案. 在提高响应速度和供应链灵活性的同时,它可以帮助公司控制成本.
算法引擎,许多理论都有广泛的应用场景. 实际上,该理论本身也可以带来巨大的价值,因为它可以提供用于复杂数据分析的平台并集成高效的优化算法,用于复杂数据分析提供基本的算法和软件支持,尤其是优化算法求解器的开发,可以大大改善机器学习和深度学习的效率.
由于我们看到了如此广泛的需求和应用,因此我们决定返回中国建立Shanshu Technology. 以上四个方面是我们的核心服务领域.
以一个例子来讨论运筹学和决策科学在金融风险管理中的应用
使用刚才提到的四个方面,首先是精确定位营销,确定真正满足金融产品特征的高质量用户,并在系统级别实施第一级风险控制.
第二个是信用调查,它通过观察和描述现有用户的支付行为来评估潜在用户的信用风险,最后给出信用调查决策.
第三个是教育管理或反欺诈,它使用数据来识别高风险交易和欺诈行为以最大程度地减少损失.
最后,在违反合同的情况下,为了最大程度地减少损失,这是处理不良资产的问题. 为了解决这四个问题并打开整个风险管理链,使用的方法实际上非常相似.
第一层是数据采集和管理,它需要描述和观察非常多维的数据. 其次,使用机器学习或相对复杂的预测方法来描述和预测数据. 第三,选择一个多层次的榜样. 最后,当我们拥有决策模型时,我们可以使用优化算法来帮助我们找到最佳结果. 因此,该方法论适用于整个风险管理链中的四个主题.
摘要
1. 运筹学和决策科学是大数据人工智能的核心概念. 对于大数据,不能忽视大数据分析支持的决策. 在人工智能方面,人们不能忽略其所需的模型和算法.
2. 当有了运筹学和决策科学的工具时,我们可以将实际问题抽象为可量化的决策问题并给出最佳决策.
3. 当我们讨论机器学习和深度学习等人工智能方法时,运筹学和决策科学也为机器学习提供了模型思维和算法保证.
教他钓鱼
运筹学和决策科学学科的学习建议:
1. 使用决策方法思考问题
当您面对信息量巨大且时间紧迫的问题时,您可能会感到无助,也不知道该怎么办. 但是您可以从决策的高度思考,现在可以做什么和不能做什么,主要的确定性是什么,哪些可以相对量化,没有用,并且是值得关注的核心价值. 尝试做出这样的战略决策和思考. 就像您脑海中的操作系统一样. 当您遇到更复杂的决策问题时,您可以采用一种新的思维方式.
2,掌握一些方法
实际上有许多种方法. 如果您是具有数学背景的学生,则可以关注一些定量数学方法,无论是基础运筹学,描述确定性的概率论,还是金融背景的学生了解所有金融应用场景,实际上,您都可以尝试培训从该方法.
3. 注意特定的应用场景
掌握太多理论. 如果没有合适的应用场景,或者使用理论覆盖了应用程序中的实际问题,则该问题将无法解决. 在很大程度上可以帮助我们的第一种方法是考虑您的决策方式. 我还建议您与感兴趣的行业的人进行更多的交流,因为他们面对该行业的独特场景和独特维度,并与他们进行更多的交流,因此他们有解决问题的思维方式和一些非常定量如果方法非常清晰,在这种清晰的应用场景中,他绝对可以帮助他解决核心决策问题.
粉丝问问题
1. 人工智能行业中是否存在泡沫成分?有纯人工智能的商业模式吗?
王曦: 这实际上是一个大话题. 气泡意味着只有概念,没有着陆,只有想法,没有具体的实际计划. 因此,从这个角度来看,会有气泡.
回顾历史,我认为在新兴技术诞生的任何阶段,人们都会进行这样的讨论,因为从时间的角度来看,当一个新概念问世时,该概念通常会领先于技术.
我参加了一个讨论. 主题是人工智能已渗透到我们生活的方方面面. 未来会不会有很多人类工作被人工智能取代?实际上,这是关于气泡的非常典型的讨论. 实际上,我对此并不担心. 一方面,当新技术出现时,我已经讨论并担心了很多次. 例如,在20世纪初,当福特汽车公司开始投资于标准化和简化的T型汽车生产时,整个装配线上约三分之二的工人被替换了. 但是,如果我们注意这种新技术的发展,从替代劳动力产生的就业机会来看,另一个更大的产业实际上是一个更大的产业.
从另一个角度来看,关于纯人工智能是否是一种商业模型这一问题,我的观点是,我将更加关注它所产生的价值. 任何能够创造价值的新技术都可以找到合适的商业模式. 货币化始终是第二种问题. 第一种类型的问题首先是这种功能,无论是娱乐,服务还是实际的产品形式,重点都是它可以产生什么样的价值. 只要具有价值,我相信它将拥有自己的商业模式.
2. 中美运筹学与决策科学的学科和应用之间的主要区别是什么?
王曦: 据我观察,差异很大.
由于运筹学和决策科学在美国首先发展和成熟,因此该学科的应用和成熟度远远高于中国. 一些成熟的大公司,例如亚马逊规模的大公司,可能拥有150至200个全职的研发和供应链团队,其中80%至90%是博士学位. 在中国,无论是小公司还是大公司都不能拥有这样的团队配置.
从另一个角度来看,我们回到中国创业后,我们与各种国内企业进行了交流和讨论. 我们发现,由于这项技术或其理论非常成熟,应用范围非常广,当我们与公司沟通时,我们会发现公司将很快意识到我们可以带来的价值,所以这一点使我非常乐观.
另一方面,大数据的概念在过去几年中被大肆宣传,因此各种类型和行业的公司将或多或少地积累数据. 当这些数据积累到临界点时,每个人都在乎如何制定一些数据驱动型决策以及如何做出更好的优化操作. 这是我们看到运筹学优化和决策科学可以在中国广泛使用的另一个机会.
总而言之,如果您看一下现状,美国在运筹学和决策科学的认识,接受和应用方面已经成熟很多,但是中国仍有很大的增长空间
3. AI +金融的最大困难是什么?
王曦: 我记得李开复先生曾经说过: “也许最容易应用的人工智能领域是金融,因为金融是一种纯粹的数字语言. ”
仅从数据的角度来看,我认为有两个困难或痛点.
首先,尽管金融业中的数据量非常大,但它通常面临着一个大而低维的问题. 例如,刚刚讨论了大数据信用调查的问题. 金融机构可能已经观察到有关成功出借用户的付款习惯的大规模数据. 尽管数据量非常大,但从维度的角度来看,我们观察到的所有数据都是一组客户的行为,这些客户被金融机构视作上级贷款并成功获得贷款. 我们认为他们的不还款可能性非常低. 对于那些拒绝发放贷款的人,我们没有观察到这些方面. 因此,当数据面临大量小尺寸问题时,采用什么方法和更新的数据尺寸来解决这个问题,我认为这是一个难点.
第二,许多所谓的数据分析可能会止于数据描述和数据预测. 数据的描述和预测具有巨大的价值,但是,如果我们真的想使用这种复杂或高端的数据分析方法来最终支持金融技术决策,那么我们不应该只停留在数据的描述和预测方面. 有时人们认为预测必须非常准确才能解决此问题,但是如果我们关注该预测所支持的决策,则会发现该决策对预测精度的敏感性不如想象中的高,并且有时必需数据的维度不能仅通过数据描述和数据预测来解决. 因此,我建议您将重点更多放在决策方面,而不仅仅是数据描述和数据预测.
飓风算法3.0即将推出,以确保高质量站点的合理流量分配
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2020-08-06 19:00
网站站长之家()8月9日消息: 昨天,百度宣布已确保高质量的站点和小程序能够获得合理的流量分配,并且该官员将在不久的将来启动Hurricane Algorithm 3.0.
2017年7月4日,百度的搜索资源平台宣布启动“飓风算法”,旨在严厉打击以不良采集为主要内容来源的网站,营造良好的搜索内容生态,保护浏览搜索用户的经验.
2018年9月13日,百度升级了飓风算法并发布了飓风算法2.0. 它主要针对五种采集行为,包括明显的采集痕迹,内容拼接,网站上的大量采集内容以及跨域采集.
此次算法升级主要针对百度搜索下的PC站点,H5站点和智能小程序的跨域采集以及站点组问题. Hurricane Algorithm 3.0将根据违规的严重性来限制搜索结果的显示.
以下是详细说明:
1. 跨域采集:
为了获得更多流量,站点/智能小程序发布的内容不属于站点/智能小程序的域. 通常,这些内容是从Internet采集的,内容质量和相关性很低,对搜索用户的价值也很低. 对于此类行为搜索,将判断站点/智能applet的域不够集中,并且在显示上会有不同程度的限制.
跨域集合主要包括以下两种类型的问题:
类型1: 主站点或主页的内容/标题/关键字/摘要表明该站点具有明确的字段或行业,但是发布的内容与该字段无关或相关性较低.
问题示例: 美食智能小程序发布足球相关内容
第二类: 站点/智能小程序没有明确的域或行业,并且内容涉及多个域或行业,该域是模糊的,并且域关注度很低.
问题示例: 智能小程序的内容涉及多个字段
两个. 站组问题:
指的是批量构造多个站点/智能小程序以获得搜索流量的行为. 网站组中的大多数网站/智能小程序质量低,资源稀缺,内容相似度高,甚至重用同一模板,这很难满足搜索用户的需求.
问题示例: 多个智能小应用程序重复使用同一模板,内容质量低且相似度高
以上是飓风算法3.0的描述. 该算法有望在八月份发布. 请及时查看站内信件,短信等通道中的提醒,并积极自查完成整改,避免不必要的损失. 查看全部
文章目录
网站站长之家()8月9日消息: 昨天,百度宣布已确保高质量的站点和小程序能够获得合理的流量分配,并且该官员将在不久的将来启动Hurricane Algorithm 3.0.
2017年7月4日,百度的搜索资源平台宣布启动“飓风算法”,旨在严厉打击以不良采集为主要内容来源的网站,营造良好的搜索内容生态,保护浏览搜索用户的经验.
2018年9月13日,百度升级了飓风算法并发布了飓风算法2.0. 它主要针对五种采集行为,包括明显的采集痕迹,内容拼接,网站上的大量采集内容以及跨域采集.
此次算法升级主要针对百度搜索下的PC站点,H5站点和智能小程序的跨域采集以及站点组问题. Hurricane Algorithm 3.0将根据违规的严重性来限制搜索结果的显示.
以下是详细说明:
1. 跨域采集:
为了获得更多流量,站点/智能小程序发布的内容不属于站点/智能小程序的域. 通常,这些内容是从Internet采集的,内容质量和相关性很低,对搜索用户的价值也很低. 对于此类行为搜索,将判断站点/智能applet的域不够集中,并且在显示上会有不同程度的限制.
跨域集合主要包括以下两种类型的问题:
类型1: 主站点或主页的内容/标题/关键字/摘要表明该站点具有明确的字段或行业,但是发布的内容与该字段无关或相关性较低.
问题示例: 美食智能小程序发布足球相关内容
第二类: 站点/智能小程序没有明确的域或行业,并且内容涉及多个域或行业,该域是模糊的,并且域关注度很低.
问题示例: 智能小程序的内容涉及多个字段
两个. 站组问题:
指的是批量构造多个站点/智能小程序以获得搜索流量的行为. 网站组中的大多数网站/智能小程序质量低,资源稀缺,内容相似度高,甚至重用同一模板,这很难满足搜索用户的需求.
问题示例: 多个智能小应用程序重复使用同一模板,内容质量低且相似度高
以上是飓风算法3.0的描述. 该算法有望在八月份发布. 请及时查看站内信件,短信等通道中的提醒,并积极自查完成整改,避免不必要的损失.
任正非: 重视数据的输入和采集,这是人工智能和自动化的源泉
采集交流 • 优采云 发表了文章 • 0 个评论 • 333 次浏览 • 2020-08-06 18:27
当时,他提出,为了实现高质量的数据输出,有必要敢于在网络规划和网络优化等关键方案上进行投资,并率先在非洲进行歼灭战. 简化的工程勘测和自动化设计.
8月29日,华为召开了GTS人工智能实践进展专题报告会. 任正非提醒,尽管GTS机器学习取得了长足的进步,但仍然需要重视数据的输入和采集,这是人工智能和自动化的源泉.
在会上,任正非对华为内部人工智能的发展提出了三个要求:
1. 专注于内部效率的提高,使用人工智能来更改操作模式,简化管理并结合业务场景来解决实际问题.
2. 专注于业务,继续增加对GTS数据系统,AI算法和AI支持平台的投资.
3. 人工智能将在未来在内部进行横向扩展,并与周围部门协调以产生成倍的收益;客户界面的升级和服务内容将在设备和网络的生命周期中创造更大的价值.
会议还显示,华为在全球拥有460万个站点,每年将在100万个站点上运营. 任正非希望在5G时代首先连接华为的基站.
任正非提出,要加快公司统一人工智能平台需求的发展,部署统一人工智能培训环境,并期待2018年在GTS中的首次实践和应用. (钛媒体记者李成成报道) )
附件: 任正非在GTS人工智能实践进度报告会上的讲话
1. 专注于内部效率的提高,使用人工智能来更改操作模式,简化管理并结合业务场景来解决实际问题.
人工智能的核心在于应用. GTS使用人工智能作为工具来研究大规模重复活动的智能自动化,以提高人员效率并协助人员工作. 从您的探索中,实践经验非常重要.
在人工智能和自动化过程中,我们必须注意交付服务过程以及人员思想和行为方式的变化. 如果它们仍然是相同的旧思想,并且不注意数据输入和采集,那么我们的人工智能和自动化将失去其来源. 同时,我们必须看到人工智能是一个不断发展和迭代的过程. 在前进的过程中,每个人都不应着急,并要不断进步. 关键是要做好数据治理和平台体系结构设计,以确保我们的总体方向正确和正确. 加快迭代速度并一步步运行.
首先,使用人工智能简化站点操作,自动化设计和报告,并统一产品线以构建网络,而无需进行安装和调试.
我们在全球拥有460万个站点,并且每年在100万个站点上运营. 任何站点操作都是成本. 通过建立站点信息数据库和开发站点3D扫描功能,简化了站点调查,并大大节省了在站点上输入表单所需的时间. 将来的数据输入可以进一步简化. 捆绑好语音系统,完成现场操作. 自己说,表格将自动生成. 然后回家修改表格,以完成交付.
基站设计方案的模型很多. 现在,通过机器学习,可以实现基站连接图和配置参数的自动生成,从而降低了对现场工程师的要求. 面向未来,应该对设备模型集成,免安装和免调试进行研究. 在5G时代,万物互联. 我们可以先连接基站吗?荒野,我们有多少个站点?应该是几百万. 您可以要求快递员骑摩托车上山,连接基站并打开电源,所有无线连接设备都将自动连接,从而减少了错误并节省了人工.
质量检查仅需拍照并将其与标准模式进行比较,以便分包商可以在现场安装时检查安装的质量,一次正确执行操作,避免多次访问现场并保存时间. 提高效率. 不要低估了1-2小时的节省. 这是重点. 如果有成千上万个站点要推广,乘以系数,就会有成千上万的规模效益.
第二,网络规划和网络优化必须敢于应用高级技术,例如地理,测绘和数学以及新的商业模式. 只要效果可以改善,我就会使用它们.
网络规划和网络优化基于数据,算法和成本的影响. 我们选择人工智能方面的突破,通过“分析机器人”提高人员效率,并在无线干扰分析和天线馈电系统方向角优化调整中加强引入人工智能技术. 增强无线网络优化和规划的效率. 同时,基于产品数据的虚拟驱动器测试是一个方向. 您无需进行路测即可知道网络的信号状态. 一个城市可以节省3,000公里的路测. 十几个城市相当于地球的一圈. 响.
人工智能理论是所有人类的财富,可以被我使用,而不仅仅是我们的理论. 网络规划和网络优化是一项基于数据的业务,人工智能也很容易带来收益,因此我们必须敢于招募一些统计学,系统工程,哲学,遥感,遥测等领域的优秀医生和硕士. ,就像我那时一样. 这与要求某些专业人员进行地理测绘相同. 经过两年的实践,它自然会理解.
第三,数万亿美元的股票是我们的优势. 我们将继续积累少量样本. 维护模式应从被动问题处理变为主动预测和预防,再从反馈反馈到制造和产品设计以形成闭环改进.
面对大量确定性的重复工作,逐渐聚合成千上万个复杂场景,并通过表格,建模和其他方法不断总结和完善经验. 就像我小时候一样,发生问题时,一台巨大的数字设备接连闪烁着灯. 从闪烁的灯光中,我慢慢看了看哪个区域集中,然后看了电路. 我判断电阻已断开,然后将其打开. 它是固定的,这是一个小样本!这些小样本已提供给您,您可以将其总结和总结到理论水平,这就是故障模型.
最终的维护模式应从被动问题处理转变为预测性预防. 在问题处理方面,我们至少可以丰富问题经验数据库. 对于暴露最多问题,解决最好问题的人,我们也可以提供小额奖励. 在预测和预防方面,应将通过障碍物发现的切屑和批次等相关问题进一步反馈给公司的制造部门和产品设计链接,以从源头上提高设备的耐用性.
2. 专注于业务,继续增加对GTS数据系统,AI算法和AI支持平台的投资.
首先,行为是记录,记录是数据. 建立并继续完善GTS数据系统.
数据是一门科学,也是人工智能的基础. 有必要学习行业做得好的方法. GTS将操作过程中的操作过程,对象,规则和经验数字化,并不断完善GTS数据系统. 每个产品线还必须将自己的产品数字化,这是服务数字化的基础. 有必要加强云平台的基础设施建设,丰富个体数据采集工具,为每个员工配备一个数据采集器. 员工完成现场工作后,他返回工作站进行处理,并只需按一下按钮就将其发送出去.
应该使用数据来促进构造,使用表单,建模和其他方法来输出作业数据,并使用高质量的作业数据输出来衡量作业完成情况,并为工程师的高质量提供牵引力作业数据输出以形成指导和模板.
第二,算法必须为企业服务. 算法科学家与熟悉服务场景的工程师紧密合作,以提高他们在服务客户战场上的能力
人工智能的应用是一门实践科学,并且在实践和应用中不断进步,其效果并非一overnight而就. 在实践的初期,如果该算法不能达到高级工程师的水平,则必须以人为主体,以机器为辅,并不断地对其进行改进和改进.
人工智能开发,算法专家,产品线专家和GTS业务专家应组成一个混合团队,共同识别实际场景中的AI应用机会,了解业务场景,设计算法模型并优化算法效果.
第三,加快公司统一人工智能平台的开发,并于2018年在GTS中首次实践和应用.
开发公司的统一人工智能平台,部署统一的人工智能培训环境,首先练习和应用GTS,并整合GTS积累的站点运营,网络维护以及网络规划领域的算法,知识,方法和经验和优化. 治愈这个平台.
人工智能平台在GTS中的应用必须首先,小步骤并且要快速运行,着重于解决方案的服务场景,选择与场景相匹配的相对成熟的算法,并快速建立工程能力,例如数据处理和在战斗中进行模型训练经过优化,该平台将于2018年部署在GTS系统上.
3. 人工智能将在未来在内部进行横向扩展,并与周围部门协调以产生成倍的收益;客户界面的升级和服务内容将在设备和网络的生命周期中创造更大的价值.
首先,自动化也是人工智能. 要改善一个观点,可能需要促进数十万个重点,并且会有数十万个乘数收益.
跨域推广也应具有优势. 通过数据互连和业务交叉集成,可以简化公司的许多部门. 例如,金融业还挑选出了100多个人工智能方面的要点,其中有些与GTS交互,例如从项目会计到开发票,GTS可以以此为起点横向发展金融.
我们必须坚定不移地推进某些确定性任务的自动化和智能化,减少重复劳动. 并非总是可能强调人工智能对歧义性问题的判断和处理. 为什么它不能解决确定性问题?自动化也是人工智能. 为了提高一点,乘以系数,可能会有成千上万的乘数收益. GTS人员均应通过实验“洗澡”. 有些人在周期中变得更加强大,创造了新的工作方法并大大提高了工作效率.
第二,基于我们自身实践的成功,使用数据和智能技术来升级服务内容,建立在线服务模型并解决客户挑战.
基于数万亿存储数据的优势,通过改善自我管理的周期性实践,构建全球智能网络平台,该平台的功能将以服务的形式向客户开放,服务内容将得到扩展到设备和网络的整个生命周期. 在解决客户挑战的同时,华为也受益匪浅.
站点选择是否可以根据流量预测和动态变化进行准确的网络规划?甚至数百万个设备都无法一天24小时高速开机. 如果可以根据流量动态设置产品的能耗,是否可以大大改善网络和能源效率?在更远的将来,我们能否将预防和预测能力扩展到整个网络,并以可预测的方式应对自然灾害和重大事件带来的挑战?
我们抓住了这些机会并升级了服务的内容,我们可以使用在线服务和其他方式在网络的整个生命周期中继续为客户创造价值.
有关更多精彩内容,请关注Titanium Media微信ID(ID: taimeiti),或下载Titanium Media App 查看全部
今年年初,华为总裁任正非在全球人工智能技术应用研讨会(GTS)上向华为阐明了GTS人工智能的重要性.
当时,他提出,为了实现高质量的数据输出,有必要敢于在网络规划和网络优化等关键方案上进行投资,并率先在非洲进行歼灭战. 简化的工程勘测和自动化设计.
8月29日,华为召开了GTS人工智能实践进展专题报告会. 任正非提醒,尽管GTS机器学习取得了长足的进步,但仍然需要重视数据的输入和采集,这是人工智能和自动化的源泉.
在会上,任正非对华为内部人工智能的发展提出了三个要求:
1. 专注于内部效率的提高,使用人工智能来更改操作模式,简化管理并结合业务场景来解决实际问题.
2. 专注于业务,继续增加对GTS数据系统,AI算法和AI支持平台的投资.
3. 人工智能将在未来在内部进行横向扩展,并与周围部门协调以产生成倍的收益;客户界面的升级和服务内容将在设备和网络的生命周期中创造更大的价值.
会议还显示,华为在全球拥有460万个站点,每年将在100万个站点上运营. 任正非希望在5G时代首先连接华为的基站.
任正非提出,要加快公司统一人工智能平台需求的发展,部署统一人工智能培训环境,并期待2018年在GTS中的首次实践和应用. (钛媒体记者李成成报道) )
附件: 任正非在GTS人工智能实践进度报告会上的讲话
1. 专注于内部效率的提高,使用人工智能来更改操作模式,简化管理并结合业务场景来解决实际问题.
人工智能的核心在于应用. GTS使用人工智能作为工具来研究大规模重复活动的智能自动化,以提高人员效率并协助人员工作. 从您的探索中,实践经验非常重要.
在人工智能和自动化过程中,我们必须注意交付服务过程以及人员思想和行为方式的变化. 如果它们仍然是相同的旧思想,并且不注意数据输入和采集,那么我们的人工智能和自动化将失去其来源. 同时,我们必须看到人工智能是一个不断发展和迭代的过程. 在前进的过程中,每个人都不应着急,并要不断进步. 关键是要做好数据治理和平台体系结构设计,以确保我们的总体方向正确和正确. 加快迭代速度并一步步运行.
首先,使用人工智能简化站点操作,自动化设计和报告,并统一产品线以构建网络,而无需进行安装和调试.
我们在全球拥有460万个站点,并且每年在100万个站点上运营. 任何站点操作都是成本. 通过建立站点信息数据库和开发站点3D扫描功能,简化了站点调查,并大大节省了在站点上输入表单所需的时间. 将来的数据输入可以进一步简化. 捆绑好语音系统,完成现场操作. 自己说,表格将自动生成. 然后回家修改表格,以完成交付.
基站设计方案的模型很多. 现在,通过机器学习,可以实现基站连接图和配置参数的自动生成,从而降低了对现场工程师的要求. 面向未来,应该对设备模型集成,免安装和免调试进行研究. 在5G时代,万物互联. 我们可以先连接基站吗?荒野,我们有多少个站点?应该是几百万. 您可以要求快递员骑摩托车上山,连接基站并打开电源,所有无线连接设备都将自动连接,从而减少了错误并节省了人工.
质量检查仅需拍照并将其与标准模式进行比较,以便分包商可以在现场安装时检查安装的质量,一次正确执行操作,避免多次访问现场并保存时间. 提高效率. 不要低估了1-2小时的节省. 这是重点. 如果有成千上万个站点要推广,乘以系数,就会有成千上万的规模效益.
第二,网络规划和网络优化必须敢于应用高级技术,例如地理,测绘和数学以及新的商业模式. 只要效果可以改善,我就会使用它们.
网络规划和网络优化基于数据,算法和成本的影响. 我们选择人工智能方面的突破,通过“分析机器人”提高人员效率,并在无线干扰分析和天线馈电系统方向角优化调整中加强引入人工智能技术. 增强无线网络优化和规划的效率. 同时,基于产品数据的虚拟驱动器测试是一个方向. 您无需进行路测即可知道网络的信号状态. 一个城市可以节省3,000公里的路测. 十几个城市相当于地球的一圈. 响.
人工智能理论是所有人类的财富,可以被我使用,而不仅仅是我们的理论. 网络规划和网络优化是一项基于数据的业务,人工智能也很容易带来收益,因此我们必须敢于招募一些统计学,系统工程,哲学,遥感,遥测等领域的优秀医生和硕士. ,就像我那时一样. 这与要求某些专业人员进行地理测绘相同. 经过两年的实践,它自然会理解.
第三,数万亿美元的股票是我们的优势. 我们将继续积累少量样本. 维护模式应从被动问题处理变为主动预测和预防,再从反馈反馈到制造和产品设计以形成闭环改进.
面对大量确定性的重复工作,逐渐聚合成千上万个复杂场景,并通过表格,建模和其他方法不断总结和完善经验. 就像我小时候一样,发生问题时,一台巨大的数字设备接连闪烁着灯. 从闪烁的灯光中,我慢慢看了看哪个区域集中,然后看了电路. 我判断电阻已断开,然后将其打开. 它是固定的,这是一个小样本!这些小样本已提供给您,您可以将其总结和总结到理论水平,这就是故障模型.
最终的维护模式应从被动问题处理转变为预测性预防. 在问题处理方面,我们至少可以丰富问题经验数据库. 对于暴露最多问题,解决最好问题的人,我们也可以提供小额奖励. 在预测和预防方面,应将通过障碍物发现的切屑和批次等相关问题进一步反馈给公司的制造部门和产品设计链接,以从源头上提高设备的耐用性.
2. 专注于业务,继续增加对GTS数据系统,AI算法和AI支持平台的投资.
首先,行为是记录,记录是数据. 建立并继续完善GTS数据系统.
数据是一门科学,也是人工智能的基础. 有必要学习行业做得好的方法. GTS将操作过程中的操作过程,对象,规则和经验数字化,并不断完善GTS数据系统. 每个产品线还必须将自己的产品数字化,这是服务数字化的基础. 有必要加强云平台的基础设施建设,丰富个体数据采集工具,为每个员工配备一个数据采集器. 员工完成现场工作后,他返回工作站进行处理,并只需按一下按钮就将其发送出去.
应该使用数据来促进构造,使用表单,建模和其他方法来输出作业数据,并使用高质量的作业数据输出来衡量作业完成情况,并为工程师的高质量提供牵引力作业数据输出以形成指导和模板.
第二,算法必须为企业服务. 算法科学家与熟悉服务场景的工程师紧密合作,以提高他们在服务客户战场上的能力
人工智能的应用是一门实践科学,并且在实践和应用中不断进步,其效果并非一overnight而就. 在实践的初期,如果该算法不能达到高级工程师的水平,则必须以人为主体,以机器为辅,并不断地对其进行改进和改进.
人工智能开发,算法专家,产品线专家和GTS业务专家应组成一个混合团队,共同识别实际场景中的AI应用机会,了解业务场景,设计算法模型并优化算法效果.
第三,加快公司统一人工智能平台的开发,并于2018年在GTS中首次实践和应用.
开发公司的统一人工智能平台,部署统一的人工智能培训环境,首先练习和应用GTS,并整合GTS积累的站点运营,网络维护以及网络规划领域的算法,知识,方法和经验和优化. 治愈这个平台.
人工智能平台在GTS中的应用必须首先,小步骤并且要快速运行,着重于解决方案的服务场景,选择与场景相匹配的相对成熟的算法,并快速建立工程能力,例如数据处理和在战斗中进行模型训练经过优化,该平台将于2018年部署在GTS系统上.
3. 人工智能将在未来在内部进行横向扩展,并与周围部门协调以产生成倍的收益;客户界面的升级和服务内容将在设备和网络的生命周期中创造更大的价值.
首先,自动化也是人工智能. 要改善一个观点,可能需要促进数十万个重点,并且会有数十万个乘数收益.
跨域推广也应具有优势. 通过数据互连和业务交叉集成,可以简化公司的许多部门. 例如,金融业还挑选出了100多个人工智能方面的要点,其中有些与GTS交互,例如从项目会计到开发票,GTS可以以此为起点横向发展金融.
我们必须坚定不移地推进某些确定性任务的自动化和智能化,减少重复劳动. 并非总是可能强调人工智能对歧义性问题的判断和处理. 为什么它不能解决确定性问题?自动化也是人工智能. 为了提高一点,乘以系数,可能会有成千上万的乘数收益. GTS人员均应通过实验“洗澡”. 有些人在周期中变得更加强大,创造了新的工作方法并大大提高了工作效率.
第二,基于我们自身实践的成功,使用数据和智能技术来升级服务内容,建立在线服务模型并解决客户挑战.
基于数万亿存储数据的优势,通过改善自我管理的周期性实践,构建全球智能网络平台,该平台的功能将以服务的形式向客户开放,服务内容将得到扩展到设备和网络的整个生命周期. 在解决客户挑战的同时,华为也受益匪浅.
站点选择是否可以根据流量预测和动态变化进行准确的网络规划?甚至数百万个设备都无法一天24小时高速开机. 如果可以根据流量动态设置产品的能耗,是否可以大大改善网络和能源效率?在更远的将来,我们能否将预防和预测能力扩展到整个网络,并以可预测的方式应对自然灾害和重大事件带来的挑战?
我们抓住了这些机会并升级了服务的内容,我们可以使用在线服务和其他方式在网络的整个生命周期中继续为客户创造价值.
有关更多精彩内容,请关注Titanium Media微信ID(ID: taimeiti),或下载Titanium Media App
百度飓风算法3.0规则和规避方法的解释
采集交流 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2020-08-06 17:11
此算法升级主要针对跨域采集和站点组问题,并将涵盖PC网站,H5网站,智能小程序以及百度搜索下的其他内容. 对于算法所涵盖的网站/智能小程序,将根据违规的严重程度来限制搜索结果的显示.
1. 跨域采集:
在此算法升级中,最重要的是与集合小应用程序作斗争. 百度从今年3月开始将移动搜索流量的重心转移到百度小程序上. 大型网站似乎没有投资于百度小程序的开发和运营,但是为了获得流量,出现了许多个人小程序. 小程序的内容主要来自于采集外壳,经验非常差.
为了获得更多流量,站点/智能小程序发布的内容不属于站点/智能小程序的域. 通常,这些内容是从Internet采集的,它们的内容质量和相关性较低,并且对搜索用户的价值较低. 对于此类行为搜索,将判断站点/智能applet的域不够集中,并且在显示上会有不同程度的限制.
类型1: 主站点或主页的内容/标题/关键字/摘要表明该站点具有明确的字段或行业,但是发布的内容与该字段无关或相关性较低.
站点/智能小程序没有明确的域或行业,内容涉及多个域或行业,该域含糊不清,且域关注度较低.
注意事项:
请勿采集跨领域和跨行业的信息. 如果有明确的领域和行业方向,或者用户的上游和下游行业的内容,仍然可以正常采集伪造的原件.
两个. 站组问题:
指的是批量构造多个站点/智能小程序以获得搜索流量的行为. 网站组中的大多数网站/智能小程序质量低,资源稀缺,内容相似度高,甚至重用同一模板,这很难满足搜索用户的需求.
注意事项:
根据百度的说明和示例,目前只能与使用相似模板和内容的网站和小型程序作斗争.
具有多个模板和内容差异的工作站组仍然有效. 查看全部
百度于2019年8月8日宣布将升级飓风算法并于8月推出飓风算法3.0.
此算法升级主要针对跨域采集和站点组问题,并将涵盖PC网站,H5网站,智能小程序以及百度搜索下的其他内容. 对于算法所涵盖的网站/智能小程序,将根据违规的严重程度来限制搜索结果的显示.
1. 跨域采集:
在此算法升级中,最重要的是与集合小应用程序作斗争. 百度从今年3月开始将移动搜索流量的重心转移到百度小程序上. 大型网站似乎没有投资于百度小程序的开发和运营,但是为了获得流量,出现了许多个人小程序. 小程序的内容主要来自于采集外壳,经验非常差.
为了获得更多流量,站点/智能小程序发布的内容不属于站点/智能小程序的域. 通常,这些内容是从Internet采集的,它们的内容质量和相关性较低,并且对搜索用户的价值较低. 对于此类行为搜索,将判断站点/智能applet的域不够集中,并且在显示上会有不同程度的限制.
类型1: 主站点或主页的内容/标题/关键字/摘要表明该站点具有明确的字段或行业,但是发布的内容与该字段无关或相关性较低.
站点/智能小程序没有明确的域或行业,内容涉及多个域或行业,该域含糊不清,且域关注度较低.
注意事项:
请勿采集跨领域和跨行业的信息. 如果有明确的领域和行业方向,或者用户的上游和下游行业的内容,仍然可以正常采集伪造的原件.
两个. 站组问题:
指的是批量构造多个站点/智能小程序以获得搜索流量的行为. 网站组中的大多数网站/智能小程序质量低,资源稀缺,内容相似度高,甚至重用同一模板,这很难满足搜索用户的需求.
注意事项:
根据百度的说明和示例,目前只能与使用相似模板和内容的网站和小型程序作斗争.
具有多个模板和内容差异的工作站组仍然有效.
百度飓风算法采集什么样的资源
采集交流 • 优采云 发表了文章 • 0 个评论 • 345 次浏览 • 2020-08-06 17:08
百度发布飓风的正式公告:
百度搜索最近推出了“飓风算法”,该算法旨在严厉打击以不良采集为主要内容来源的网站. 同时,百度搜索将从索引库中彻底删除不良的采集链接,为高质量的原创内容展示和促进搜索生态健康发展提供更多的机会.
飓风算法通常会生成惩罚数据,并同时根据情况随时调整迭代次数,这反映了百度搜索对不良采集的零容忍度. 对于高质量的原创网站,如果您发现该网站的索引已大大减少并且访问量已大大减少,则可以在反馈中心提供反馈.
发布目的:
保护原创站点的高质量内容. 现在,每次用户在百度上搜索时,都有各种各样毫无意义的结果. 从长远来看,使用百度搜索引擎的人将越来越少,因此它也是用于创建高质量内容的. 搜索引擎的一个非常重要的目标.
由于移动终端的兴起,像头条微信这样的各种应用程序已经蚕食了原创搜索引擎的市场份额. 对他们来说,这也是一项战略调整,目的是通过各种高质量的原创内容将原创搜索引擎的用户吸引回百度.
打击目标:
使用不良采集作为主要内容源的网站可以从索引库中完全删除不良采集链接,并为高质量的原创内容提供了更多机会. 尤其要担心使用网站中大量恶意采集的内容.
算法分析:
声明1: 严厉打击以恶意采集为主要内容来源的网站
随着各种采集工具的标准化,网站上的垃圾邮件越来越多. 在同一篇文章搜索下,将至少返回2页的结果,但这实际上并没有给用户带来太多收益. 搜索引擎的收入带来了沉重的负担. 但是,百度并不是第一个谈论此攻击集合的人. 如何确定它还没有确定.
表达式2: 从索引库中完全删除错误的采集链接
过去采集的结果基本上已经超过了算法的焦点,很好,我不知道这次飓风这次是否真的会汇总这些采集链接!你们也这么认为,对,哈哈!
声明3.提供更多机会展示高质量的原创内容
我不知道句子是如何打断的,这意味着通过攻击采集链接,我们可以展现更多的创意. 尽管如此,还有更多服务可以帮助显示原创内容. 老实说,各种自我媒体的原创保护要比老兄百度更为关注,我不知道百度现在的状况.
声明IV. 定期输出惩罚数据,并根据情况随时调整迭代次数
霍霍,惩罚数据,梭芯,你准备好了吗?你能抗拒吗?惩罚数据很有可能被捕获!从调整迭代来看,飓风算法有多种版本.
百度飓风算法来了.
声明5.原创站点的索引量已大大减少,流量急剧下降,可以反馈
对于这句话,预计一大波真正的原创站点会很不幸. 也许百度的识别时间是根据其爬网时间确定的,对于某些真正的原创网站,如果综合评分不如主要网站的评分高,那么似乎可以全部采集并复制出来?例如,傅剑萌SEO的网站就是上帝!
热门评论:
飓风算法通常会生成惩罚数据,并同时根据情况随时调整迭代次数,这反映了百度搜索对不良采集的零容忍度. 对于高质量的原创网站,如果您发现该网站的索引已大大减少并且访问量已大大减少,则可以在反馈中心提供反馈.
高质量内容的标准很难定义. 有时,伪原创的感觉要比原创的感觉更好,并且机器很难识别它. 目前,实际上,许多网站都有采集行为. 如果您真的想打击馆藏,您如何计算360DOC?许多新闻台也互相采集,而百度并未明确指出如何判断采集.
如果百度网站管理员平台添加报告门户可能会更好.
这是母亲第一次感到无能为力. 如何教育孩子更好 查看全部
百度已经启动了飓风算法已有一段时间了. 对于网站建设者来说,最直接的感觉是,许多网站的接受率正在下降,并且基本上不包括一些新网站. 首先,对于百度推出的飓风算法. 这一定是一件好事,尤其是对于像Babao.com这样的新网站,它可以更好地保护网站的原创资源. 让我们谈谈百度的飓风算法.
百度发布飓风的正式公告:
百度搜索最近推出了“飓风算法”,该算法旨在严厉打击以不良采集为主要内容来源的网站. 同时,百度搜索将从索引库中彻底删除不良的采集链接,为高质量的原创内容展示和促进搜索生态健康发展提供更多的机会.
飓风算法通常会生成惩罚数据,并同时根据情况随时调整迭代次数,这反映了百度搜索对不良采集的零容忍度. 对于高质量的原创网站,如果您发现该网站的索引已大大减少并且访问量已大大减少,则可以在反馈中心提供反馈.
发布目的:
保护原创站点的高质量内容. 现在,每次用户在百度上搜索时,都有各种各样毫无意义的结果. 从长远来看,使用百度搜索引擎的人将越来越少,因此它也是用于创建高质量内容的. 搜索引擎的一个非常重要的目标.
由于移动终端的兴起,像头条微信这样的各种应用程序已经蚕食了原创搜索引擎的市场份额. 对他们来说,这也是一项战略调整,目的是通过各种高质量的原创内容将原创搜索引擎的用户吸引回百度.
打击目标:
使用不良采集作为主要内容源的网站可以从索引库中完全删除不良采集链接,并为高质量的原创内容提供了更多机会. 尤其要担心使用网站中大量恶意采集的内容.
算法分析:
声明1: 严厉打击以恶意采集为主要内容来源的网站
随着各种采集工具的标准化,网站上的垃圾邮件越来越多. 在同一篇文章搜索下,将至少返回2页的结果,但这实际上并没有给用户带来太多收益. 搜索引擎的收入带来了沉重的负担. 但是,百度并不是第一个谈论此攻击集合的人. 如何确定它还没有确定.
表达式2: 从索引库中完全删除错误的采集链接
过去采集的结果基本上已经超过了算法的焦点,很好,我不知道这次飓风这次是否真的会汇总这些采集链接!你们也这么认为,对,哈哈!
声明3.提供更多机会展示高质量的原创内容
我不知道句子是如何打断的,这意味着通过攻击采集链接,我们可以展现更多的创意. 尽管如此,还有更多服务可以帮助显示原创内容. 老实说,各种自我媒体的原创保护要比老兄百度更为关注,我不知道百度现在的状况.
声明IV. 定期输出惩罚数据,并根据情况随时调整迭代次数
霍霍,惩罚数据,梭芯,你准备好了吗?你能抗拒吗?惩罚数据很有可能被捕获!从调整迭代来看,飓风算法有多种版本.
百度飓风算法来了.
声明5.原创站点的索引量已大大减少,流量急剧下降,可以反馈
对于这句话,预计一大波真正的原创站点会很不幸. 也许百度的识别时间是根据其爬网时间确定的,对于某些真正的原创网站,如果综合评分不如主要网站的评分高,那么似乎可以全部采集并复制出来?例如,傅剑萌SEO的网站就是上帝!
热门评论:
飓风算法通常会生成惩罚数据,并同时根据情况随时调整迭代次数,这反映了百度搜索对不良采集的零容忍度. 对于高质量的原创网站,如果您发现该网站的索引已大大减少并且访问量已大大减少,则可以在反馈中心提供反馈.
高质量内容的标准很难定义. 有时,伪原创的感觉要比原创的感觉更好,并且机器很难识别它. 目前,实际上,许多网站都有采集行为. 如果您真的想打击馆藏,您如何计算360DOC?许多新闻台也互相采集,而百度并未明确指出如何判断采集.
如果百度网站管理员平台添加报告门户可能会更好.
这是母亲第一次感到无能为力. 如何教育孩子更好
百度的飓风算法严重影响了这四个采集行为
采集交流 • 优采云 发表了文章 • 0 个评论 • 306 次浏览 • 2020-08-06 13:25
为了在百度搜索中营造良好的搜索内容生态,保护搜索用户的阅读和浏览体验以及保护高质量内容生产者的权益,百度于9月中旬升级了飓风算法. 在新发布的Hurricane Algorithm 2.0中,有四种严重的采集行为将受到百度的严重打击,这需要网站管理员更加关注:
1. 网站上采集了很多且可读性很差的内容
我们一直强调,网站的内容应尽可能原创,因为即使所采集文章的质量很高,也不会给搜索引擎带来太多好处. 如果采集的内容过多且质量太差,则可能会对网站产生负面影响.
在飓风算法2.0的更新中,这些文章也有明确的要求. 搜索引擎将惩罚缺乏信息集成,排版混乱,文章可读性差和严重的馆藏痕迹以及对用户毫无价值的内容的问题. 因此,即使网站管理员采集了文章,他也需要合理地排版文章. 所采集的文章应具有良好的质量,并对用户有用.
两个,多个段落的文章内容被拼接
某些网站管理员可能会从其他网站上采集一些文章进行拼接,以欺骗搜索引擎并将这些文章伪造为原创文章.
但是,这样的文章通常缺乏逻辑,也可能给用户带来不良的阅读体验. 网站的搜索引擎排名非常重要的指标是用户体验. 如果文章质量不佳,用户将无法获得良好的阅读体验,那么该网站将无法获得良好的排名.
在Hurricane Algorithm 2.0的更新中,这些文章也有明确的规范. 如果网站上有这样的拼接文章,并且逻辑不足以满足用户需求,那么它们很可能会受到搜索引擎的惩罚.
三个. 该网站中有很多采集的内容
百度搜索还明确指出,它与采集大量内容且内容生产率不佳的网站不兼容.
这也与我们在SEO优化过程中专注于原创文章的概念相吻合. 对于内容丰富的网站,百度会认为此类网站无法为用户带来实际帮助,因此自然无法获得排名. 启动Hurricane Algorithm 2.0之后,如果采集了网站上的大多数文章,它也可能导致搜索引擎的制裁. 网站管理员必须注意. 查看全部
在网站建设和搜索引擎优化中,需要根据百度的搜索算法进行大量调整,以确保网站能够被百度很好地爬行,收录和排名. 百度也在不断调整其算法,以优化用户的搜索体验. 对于网站管理员而言,也许每次百度算法更新都需要对其工作进行一些更改.
为了在百度搜索中营造良好的搜索内容生态,保护搜索用户的阅读和浏览体验以及保护高质量内容生产者的权益,百度于9月中旬升级了飓风算法. 在新发布的Hurricane Algorithm 2.0中,有四种严重的采集行为将受到百度的严重打击,这需要网站管理员更加关注:
1. 网站上采集了很多且可读性很差的内容
我们一直强调,网站的内容应尽可能原创,因为即使所采集文章的质量很高,也不会给搜索引擎带来太多好处. 如果采集的内容过多且质量太差,则可能会对网站产生负面影响.
在飓风算法2.0的更新中,这些文章也有明确的要求. 搜索引擎将惩罚缺乏信息集成,排版混乱,文章可读性差和严重的馆藏痕迹以及对用户毫无价值的内容的问题. 因此,即使网站管理员采集了文章,他也需要合理地排版文章. 所采集的文章应具有良好的质量,并对用户有用.
两个,多个段落的文章内容被拼接
某些网站管理员可能会从其他网站上采集一些文章进行拼接,以欺骗搜索引擎并将这些文章伪造为原创文章.
但是,这样的文章通常缺乏逻辑,也可能给用户带来不良的阅读体验. 网站的搜索引擎排名非常重要的指标是用户体验. 如果文章质量不佳,用户将无法获得良好的阅读体验,那么该网站将无法获得良好的排名.
在Hurricane Algorithm 2.0的更新中,这些文章也有明确的规范. 如果网站上有这样的拼接文章,并且逻辑不足以满足用户需求,那么它们很可能会受到搜索引擎的惩罚.
三个. 该网站中有很多采集的内容
百度搜索还明确指出,它与采集大量内容且内容生产率不佳的网站不兼容.
这也与我们在SEO优化过程中专注于原创文章的概念相吻合. 对于内容丰富的网站,百度会认为此类网站无法为用户带来实际帮助,因此自然无法获得排名. 启动Hurricane Algorithm 2.0之后,如果采集了网站上的大多数文章,它也可能导致搜索引擎的制裁. 网站管理员必须注意.
百度飓风算法3.0即将发布,其目标是采集和站群问题
采集交流 • 优采云 发表了文章 • 0 个评论 • 320 次浏览 • 2020-08-06 13:24
此算法升级主要针对跨域采集和站点组问题,并将涵盖PC网站,H5网站,智能小程序以及百度搜索下的其他内容. 对于算法所涵盖的网站/智能小程序,将根据违规的严重程度来限制搜索结果的显示.
以下详细介绍了飓风算法3.0的相关规则.
跨领域采集:
跨域集合是指站点/智能小程序发布不属于站点/智能小程序域的内容,以获取更多流量. 通常,这些内容是从Internet上采集的,并且内容质量和相关性很低,并且对于搜索程度较低的用户来说很有价值. 对于此类行为搜索,将判断站点/智能applet的域不够集中,并且在显示上会有不同程度的限制.
跨域集合主要包括以下两种类型的问题:
1. 主站点或主页的内容/标题/关键字/摘要表明该站点具有明确的字段或行业,但是发布的内容与此字段无关或相关性较低.
问题示例: 美食智能小程序发布足球相关内容
2. 站点/智能小程序没有明确的领域或行业,内容涉及多个领域或行业,该领域含糊不清,且领域关注度较低.
问题示例: 智能小程序的内容涉及多个字段
网站群组问题:
指的是批量构造多个站点/智能小程序以获得搜索流量的行为. 网站组中的大多数网站/智能小程序质量低,资源稀缺,内容相似度高,甚至重用同一模板,这很难满足搜索用户的需求.
问题示例: 多个智能小应用程序重复使用同一模板,内容质量低且相似度高
以上是对百度飓风算法3.0的描述. 该算法有望在八月份发布. 请及时查看站内信件,短信等通道中的提醒,并积极自查完成整改,避免不必要的损失. 查看全部
为了维护健康的移动生态系统,确保用户体验并确保高质量的站点/智能小应用程序能够获得合理的流量分配,百度搜索将在不久的将来升级飓风算法并发布飓风算法3.0.
此算法升级主要针对跨域采集和站点组问题,并将涵盖PC网站,H5网站,智能小程序以及百度搜索下的其他内容. 对于算法所涵盖的网站/智能小程序,将根据违规的严重程度来限制搜索结果的显示.
以下详细介绍了飓风算法3.0的相关规则.
跨领域采集:
跨域集合是指站点/智能小程序发布不属于站点/智能小程序域的内容,以获取更多流量. 通常,这些内容是从Internet上采集的,并且内容质量和相关性很低,并且对于搜索程度较低的用户来说很有价值. 对于此类行为搜索,将判断站点/智能applet的域不够集中,并且在显示上会有不同程度的限制.
跨域集合主要包括以下两种类型的问题:
1. 主站点或主页的内容/标题/关键字/摘要表明该站点具有明确的字段或行业,但是发布的内容与此字段无关或相关性较低.
问题示例: 美食智能小程序发布足球相关内容
2. 站点/智能小程序没有明确的领域或行业,内容涉及多个领域或行业,该领域含糊不清,且领域关注度较低.
问题示例: 智能小程序的内容涉及多个字段
网站群组问题:
指的是批量构造多个站点/智能小程序以获得搜索流量的行为. 网站组中的大多数网站/智能小程序质量低,资源稀缺,内容相似度高,甚至重用同一模板,这很难满足搜索用户的需求.
问题示例: 多个智能小应用程序重复使用同一模板,内容质量低且相似度高
以上是对百度飓风算法3.0的描述. 该算法有望在八月份发布. 请及时查看站内信件,短信等通道中的提醒,并积极自查完成整改,避免不必要的损失.
第二,采集站如何避免受到搜索引擎的惩罚?
采集交流 • 优采云 发表了文章 • 0 个评论 • 887 次浏览 • 2020-08-06 13:24
1. 袭击采集站的飓风算法是什么
与采集站作战的飓风算法明确针对: 跨域采集和站组采集问题使用相同的模板,并且内容格式很高. 这两个是专门为我们的网站准备的,因此我们在采集时应该避免这两部分吗?必须避免,如何避免呢?下一步往下看!
第二,采集站如何避免受到搜索引擎的惩罚?
1. 当我们建立网站时,许多人不知道如何建立网站,因此他们只是购买了别人的模板站,而没有改变网站的布局和标签. 第一步导致您的模板失败,您说您的模板不够好,请稍后再添加吗?因此,请首先修改模板,例如布局修改,网站标签修改,关键字布局修改等.
2. 关于网站文章内容的采集,有些人为了流量而做任何事情. 这不是您行业的流量. 您也可以采集它. 更不用说,它完全是在寄出藏书之后,列二级导航和内容页面的标题和内容根本不是一个行业. 这显然是为了获得其他行业的流量并以采集为目的进行采集. 因此,在飓风算法3.0的巨大打击下,您将来不想关闭的行业资源无法采集,但这提醒您一点,即核心点. 它还基于您行业的性质来决定是否惩罚您采集的站点. 如果您的网站是一个全面的信息网络,您认为它会攻击您的采集网站吗?您需要自己练习才能知道答案. 我当然知道.
3. 当我们实际上在采集内容时,我们需要采集与我们完全匹配的文章,而不是直接采集和使用它,并且还应该使用其他伪原创工具来处理辅助文章,尤其是在文章的核心元素应该不仅更改标题和标题,还应该更改为自己的标题,并且如果有足够的时间,建议发布要表达的文章的深入视图. 计划外,这也是一篇相对不错的文章,搜索引擎也会喜欢它,但是我们已经采集了这些文章,在编辑文章时,请记住在一定程度上保持算法原理. 下一篇文章的确不错,但搜索引擎排名却没有,这也不起作用. 例如H标签设置,关键字设置等.
三个. 为什么这么多人喜欢成为采集站?
因为这与许多人的习惯有关. 采集速度很快,不需要集思广益. 很多年前是有可能的. 过去两年开发的飓风算法使您丧生,但许多新手都不知道如何采集他人的文章. 文章被盲目复制和粘贴,导致我的网站后来成为采集站. 这里解释说,采集站至今仍可以做,效果还不错,这取决于您如何做,例如: 如何采集?采集时要注意什么!不要只是愚蠢地去采集,而要解释方法,策略和战术!
摘要: 我现在正在谈论采集站的问题. 我只想提醒大多数seo优化人员和网站管理员朋友,不要只是复制粘贴以进行采集.
本文地址: 原创文章,严禁转载!要注册南迪老师的SEO培训,请添加微信ID! 查看全部
在过去两年中,百度一直在研究打击各种作弊方法的算法. 有一种专门设计用于与采集站作战的算法. 飓风算法已升级到不同版本,现在已升级到飓风算法3.0. 结果,许多国内网站在百度搜索引擎的搜索结果页下都失去了排名. 严重的是,它们直接删除了索引和关键字,而权重却下降了. 一年的辛苦工作已经一去不复返了. 那么,我们应该如何应对飓风算法呢?当它到达我们时,它被采集了,并没有受到百度搜索引擎的惩罚?接下来,有南迪徐老师向大家讲解.
1. 袭击采集站的飓风算法是什么
与采集站作战的飓风算法明确针对: 跨域采集和站组采集问题使用相同的模板,并且内容格式很高. 这两个是专门为我们的网站准备的,因此我们在采集时应该避免这两部分吗?必须避免,如何避免呢?下一步往下看!
第二,采集站如何避免受到搜索引擎的惩罚?
1. 当我们建立网站时,许多人不知道如何建立网站,因此他们只是购买了别人的模板站,而没有改变网站的布局和标签. 第一步导致您的模板失败,您说您的模板不够好,请稍后再添加吗?因此,请首先修改模板,例如布局修改,网站标签修改,关键字布局修改等.
2. 关于网站文章内容的采集,有些人为了流量而做任何事情. 这不是您行业的流量. 您也可以采集它. 更不用说,它完全是在寄出藏书之后,列二级导航和内容页面的标题和内容根本不是一个行业. 这显然是为了获得其他行业的流量并以采集为目的进行采集. 因此,在飓风算法3.0的巨大打击下,您将来不想关闭的行业资源无法采集,但这提醒您一点,即核心点. 它还基于您行业的性质来决定是否惩罚您采集的站点. 如果您的网站是一个全面的信息网络,您认为它会攻击您的采集网站吗?您需要自己练习才能知道答案. 我当然知道.
3. 当我们实际上在采集内容时,我们需要采集与我们完全匹配的文章,而不是直接采集和使用它,并且还应该使用其他伪原创工具来处理辅助文章,尤其是在文章的核心元素应该不仅更改标题和标题,还应该更改为自己的标题,并且如果有足够的时间,建议发布要表达的文章的深入视图. 计划外,这也是一篇相对不错的文章,搜索引擎也会喜欢它,但是我们已经采集了这些文章,在编辑文章时,请记住在一定程度上保持算法原理. 下一篇文章的确不错,但搜索引擎排名却没有,这也不起作用. 例如H标签设置,关键字设置等.
三个. 为什么这么多人喜欢成为采集站?
因为这与许多人的习惯有关. 采集速度很快,不需要集思广益. 很多年前是有可能的. 过去两年开发的飓风算法使您丧生,但许多新手都不知道如何采集他人的文章. 文章被盲目复制和粘贴,导致我的网站后来成为采集站. 这里解释说,采集站至今仍可以做,效果还不错,这取决于您如何做,例如: 如何采集?采集时要注意什么!不要只是愚蠢地去采集,而要解释方法,策略和战术!
摘要: 我现在正在谈论采集站的问题. 我只想提醒大多数seo优化人员和网站管理员朋友,不要只是复制粘贴以进行采集.
本文地址: 原创文章,严禁转载!要注册南迪老师的SEO培训,请添加微信ID!
具有完整C代码[turn]的音频自动增益和静音检测算法
采集交流 • 优采云 发表了文章 • 0 个评论 • 259 次浏览 • 2020-08-06 08:29
我以前共享了一个算法“带有完整C代码示例的音频增益响度分析重播增益”
主要用于评估特定长度音频的音量强度,
经过分析,音频增益,音量增加等许多类似需求.
但是,当实际测试项目时,确实很难设置标准.
在哪种环境下,我应该增加或减小音量?
通信行业的常规做法是使用静默检测.
一旦被检测为静音或噪音,将不会对其进行处理,否则,将通过某种策略对其进行处理.
这里涉及两种算法,一种是静音检测,另一种是音频增益.
增益实际上没什么好说的,它类似于数据标准化和扩展.
WebRTC中的静音检测使用计算GMM(高斯混合模型,高斯混合模型)进行特征提取.
很长一段时间以来,音频功能主要有3种.
GMM,频谱图(频谱图),MFCC是梅尔倒谱(Mel频率倒谱)
恕我直言,GMM提取的特征不如后两者强健.
我不作更多介绍. 有兴趣的学生可以查阅Wikipedia并补课.
当然,当实际使用该算法时,将从中扩展一些技巧.
例如,使用静音检测来进行音频剪辑,或者使用音频增益来进行一些音频增强.
用于自动增益的WebRTC源代码文件为: analog_agc.c和digital_agc.c
静音检测源代码文件是: webrtc_vad.c
这种命名有某些历史原因.
整理后,
增益算法为agc.c agc.h
静音检测是vad.c vad.h
完整的增益算法示例代码:
#include
#include
#include
//采用https://github.com/mackron/dr_ ... wav.h 解码
#define DR_WAV_IMPLEMENTATION
#include "dr_wav.h"
#include "agc.h"
#ifndef nullptr
#define nullptr 0
#endif
#ifndef MIN
#define MIN(A, B) ((A) < (B) ? (A) : (B))
#endif
//写wav文件
void wavWrite_int16(char *filename, int16_t *buffer, size_t sampleRate, size_t totalSampleCount) {
drwav_data_format format = {};
format.container = drwav_container_riff; // path;)
if (*--p == '\\' || *p == '/') {
p++;
break;
}
if (name) {
for (s = p; s < end;)
*name++ = *s++;
*name = '\0';
}
if (dir) {
for (s = path; s < p;)
*dir++ = *s++;
*dir = '\0';
}
}
int agcProcess(int16_t *buffer, uint32_t sampleRate, size_t samplesCount, int16_t agcMode) {
if (buffer == nullptr) return -1;
if (samplesCount == 0) return -1;
WebRtcAgcConfig agcConfig;
agcConfig.compressionGaindB = 9; // default 9 dB
agcConfig.limiterEnable = 1; // default kAgcTrue (on)
agcConfig.targetLevelDbfs = 3; // default 3 (-3 dBOv)
int minLevel = 0;
int maxLevel = 255;
size_t samples = MIN(160, sampleRate / 100);
if (samples == 0) return -1;
const int maxSamples = 320;
int16_t *input = buffer;
size_t nTotal = (samplesCount / samples);
void *agcInst = WebRtcAgc_Create();
if (agcInst == NULL) return -1;
int status = WebRtcAgc_Init(agcInst, minLevel, maxLevel, agcMode, sampleRate);
if (status != 0) {
printf("WebRtcAgc_Init fail\n");
WebRtcAgc_Free(agcInst);
return -1;
}
status = WebRtcAgc_set_config(agcInst, agcConfig);
if (status != 0) {
printf("WebRtcAgc_set_config fail\n");
WebRtcAgc_Free(agcInst);
return -1;
}
size_t num_bands = 1;
int inMicLevel, outMicLevel = -1;
int16_t out_buffer[maxSamples];
int16_t *out16 = out_buffer;
uint8_t saturationWarning = 1; //是否有溢出发生,增益放大以后的最大值超过了65536
int16_t echo = 0; //增益放大是否考虑回声影响
for (int i = 0; i < nTotal; i++) {
inMicLevel = 0;
int nAgcRet = WebRtcAgc_Process(agcInst, (const int16_t *const *) &input, num_bands, samples,
(int16_t *const *) &out16, inMicLevel, &outMicLevel, echo,
&saturationWarning);
if (nAgcRet != 0) {
printf("failed in WebRtcAgc_Process\n");
WebRtcAgc_Free(agcInst);
return -1;
}
memcpy(input, out_buffer, samples * sizeof(int16_t));
input += samples;
}
WebRtcAgc_Free(agcInst);
return 1;
}
void auto_gain(char *in_file, char *out_file) {
//音频采样率
uint32_t sampleRate = 0;
//总音频采样数
uint64_t inSampleCount = 0;
int16_t *inBuffer = wavRead_int16(in_file, &sampleRate, &inSampleCount);
//如果加载成功
if (inBuffer != nullptr) {
// kAgcModeAdaptiveAnalog 模拟音量调节
// kAgcModeAdaptiveDigital 自适应增益
// kAgcModeFixedDigital 固定增益
agcProcess(inBuffer, sampleRate, inSampleCount, kAgcModeAdaptiveDigital);
wavWrite_int16(out_file, inBuffer, sampleRate, inSampleCount);
free(inBuffer);
}
}
int main(int argc, char *argv[]) {
printf("WebRTC Automatic Gain Control\n");
printf("博客:http://cpuimage.cnblogs.com/\n");
printf("音频自动增益\n");
if (argc < 2)
return -1;
char *in_file = argv[1];
char drive[3];
char dir[256];
char fname[256];
char ext[256];
char out_file[1024];
splitpath(in_file, drive, dir, fname, ext);
sprintf(out_file, "%s%s%s_out%s", drive, dir, fname, ext);
auto_gain(in_file, out_file);
printf("按任意键退出程序 \n");
getchar();
return 0;
}
用于静默检测的完整示例代码:
#include
#include
#include
//采用https://github.com/mackron/dr_ ... wav.h 解码
#define DR_WAV_IMPLEMENTATION
#include "dr_wav.h"
#include "vad.h"
#ifndef nullptr
#define nullptr 0
#endif
#ifndef MIN
#define MIN(A, B) ((A) < (B) ? (A) : (B))
#endif
#ifndef MAX
#define MAX(A, B) ((A) > (B) ? (A) : (B))
#endif
//读取wav文件
int16_t *wavRead_int16(char *filename, uint32_t *sampleRate, uint64_t *totalSampleCount) {
unsigned int channels;
int16_t *buffer = drwav_open_and_read_file_s16(filename, &channels, sampleRate, totalSampleCount);
if (buffer == nullptr) {
printf("读取wav文件失败.");
}
//仅仅处理单通道音频
if (channels != 1) {
drwav_free(buffer);
buffer = nullptr;
*sampleRate = 0;
*totalSampleCount = 0;
}
return buffer;
}
int vadProcess(int16_t *buffer, uint32_t sampleRate, size_t samplesCount, int16_t vad_mode, int per_ms_frames) {
if (buffer == nullptr) return -1;
if (samplesCount == 0) return -1;
// kValidRates : 8000, 16000, 32000, 48000
// 10, 20 or 30 ms frames
per_ms_frames = MAX(MIN(30, per_ms_frames), 10);
size_t samples = sampleRate * per_ms_frames / 1000;
if (samples == 0) return -1;
int16_t *input = buffer;
size_t nTotal = (samplesCount / samples);
void *vadInst = WebRtcVad_Create();
if (vadInst == NULL) return -1;
int status = WebRtcVad_Init(vadInst);
if (status != 0) {
printf("WebRtcVad_Init fail\n");
WebRtcVad_Free(vadInst);
return -1;
}
status = WebRtcVad_set_mode(vadInst, vad_mode);
if (status != 0) {
printf("WebRtcVad_set_mode fail\n");
WebRtcVad_Free(vadInst);
return -1;
}
printf("Activity : \n");
for (int i = 0; i < nTotal; i++) {
int nVadRet = WebRtcVad_Process(vadInst, sampleRate, input, samples);
if (nVadRet == -1) {
printf("failed in WebRtcVad_Process\n");
WebRtcVad_Free(vadInst);
return -1;
} else {
// output result
printf(" %d \t", nVadRet);
}
input += samples;
}
printf("\n");
WebRtcVad_Free(vadInst);
return 1;
}
void vad(char *in_file) {
//音频采样率
uint32_t sampleRate = 0;
//总音频采样数
uint64_t inSampleCount = 0;
int16_t *inBuffer = wavRead_int16(in_file, &sampleRate, &inSampleCount);
//如果加载成功
if (inBuffer != nullptr) {
// Aggressiveness mode (0, 1, 2, or 3)
int16_t mode = 1;
int per_ms = 30;
vadProcess(inBuffer, sampleRate, inSampleCount, mode, per_ms);
free(inBuffer);
}
}
int main(int argc, char *argv[]) {
printf("WebRTC Voice Activity Detector\n");
printf("博客:http://cpuimage.cnblogs.com/\n");
printf("静音检测\n");
if (argc < 2)
return -1;
char *in_file = argv[1];
vad(in_file);
printf("按任意键退出程序 \n");
getchar();
return 0;
}
自动获取项目的地址:
具体过程是:
加载wav(将wav文件拖放到可执行文件中)->获得处理->另存为_out.wav文件
静音检测项目地址:
具体过程是:
加载wav(将wav文件拖放到可执行文件中)->输出静默检测结果
备注: 1表示不静音,0表示静音
要注意的位置和参数,请参见代码注释.
使用cmake编译示例代码. 有关详细信息,请参阅CMakeLists.txt.
如果您还有其他相关问题或需求,也可以给我发电子邮件进行讨论.
电子邮件地址是: 查看全部
转发自:
我以前共享了一个算法“带有完整C代码示例的音频增益响度分析重播增益”
主要用于评估特定长度音频的音量强度,
经过分析,音频增益,音量增加等许多类似需求.
但是,当实际测试项目时,确实很难设置标准.
在哪种环境下,我应该增加或减小音量?
通信行业的常规做法是使用静默检测.
一旦被检测为静音或噪音,将不会对其进行处理,否则,将通过某种策略对其进行处理.
这里涉及两种算法,一种是静音检测,另一种是音频增益.
增益实际上没什么好说的,它类似于数据标准化和扩展.
WebRTC中的静音检测使用计算GMM(高斯混合模型,高斯混合模型)进行特征提取.
很长一段时间以来,音频功能主要有3种.
GMM,频谱图(频谱图),MFCC是梅尔倒谱(Mel频率倒谱)
恕我直言,GMM提取的特征不如后两者强健.
我不作更多介绍. 有兴趣的学生可以查阅Wikipedia并补课.
当然,当实际使用该算法时,将从中扩展一些技巧.
例如,使用静音检测来进行音频剪辑,或者使用音频增益来进行一些音频增强.
用于自动增益的WebRTC源代码文件为: analog_agc.c和digital_agc.c
静音检测源代码文件是: webrtc_vad.c
这种命名有某些历史原因.
整理后,
增益算法为agc.c agc.h
静音检测是vad.c vad.h
完整的增益算法示例代码:
#include
#include
#include
//采用https://github.com/mackron/dr_ ... wav.h 解码
#define DR_WAV_IMPLEMENTATION
#include "dr_wav.h"
#include "agc.h"
#ifndef nullptr
#define nullptr 0
#endif
#ifndef MIN
#define MIN(A, B) ((A) < (B) ? (A) : (B))
#endif
//写wav文件
void wavWrite_int16(char *filename, int16_t *buffer, size_t sampleRate, size_t totalSampleCount) {
drwav_data_format format = {};
format.container = drwav_container_riff; // path;)
if (*--p == '\\' || *p == '/') {
p++;
break;
}
if (name) {
for (s = p; s < end;)
*name++ = *s++;
*name = '\0';
}
if (dir) {
for (s = path; s < p;)
*dir++ = *s++;
*dir = '\0';
}
}
int agcProcess(int16_t *buffer, uint32_t sampleRate, size_t samplesCount, int16_t agcMode) {
if (buffer == nullptr) return -1;
if (samplesCount == 0) return -1;
WebRtcAgcConfig agcConfig;
agcConfig.compressionGaindB = 9; // default 9 dB
agcConfig.limiterEnable = 1; // default kAgcTrue (on)
agcConfig.targetLevelDbfs = 3; // default 3 (-3 dBOv)
int minLevel = 0;
int maxLevel = 255;
size_t samples = MIN(160, sampleRate / 100);
if (samples == 0) return -1;
const int maxSamples = 320;
int16_t *input = buffer;
size_t nTotal = (samplesCount / samples);
void *agcInst = WebRtcAgc_Create();
if (agcInst == NULL) return -1;
int status = WebRtcAgc_Init(agcInst, minLevel, maxLevel, agcMode, sampleRate);
if (status != 0) {
printf("WebRtcAgc_Init fail\n");
WebRtcAgc_Free(agcInst);
return -1;
}
status = WebRtcAgc_set_config(agcInst, agcConfig);
if (status != 0) {
printf("WebRtcAgc_set_config fail\n");
WebRtcAgc_Free(agcInst);
return -1;
}
size_t num_bands = 1;
int inMicLevel, outMicLevel = -1;
int16_t out_buffer[maxSamples];
int16_t *out16 = out_buffer;
uint8_t saturationWarning = 1; //是否有溢出发生,增益放大以后的最大值超过了65536
int16_t echo = 0; //增益放大是否考虑回声影响
for (int i = 0; i < nTotal; i++) {
inMicLevel = 0;
int nAgcRet = WebRtcAgc_Process(agcInst, (const int16_t *const *) &input, num_bands, samples,
(int16_t *const *) &out16, inMicLevel, &outMicLevel, echo,
&saturationWarning);
if (nAgcRet != 0) {
printf("failed in WebRtcAgc_Process\n");
WebRtcAgc_Free(agcInst);
return -1;
}
memcpy(input, out_buffer, samples * sizeof(int16_t));
input += samples;
}
WebRtcAgc_Free(agcInst);
return 1;
}
void auto_gain(char *in_file, char *out_file) {
//音频采样率
uint32_t sampleRate = 0;
//总音频采样数
uint64_t inSampleCount = 0;
int16_t *inBuffer = wavRead_int16(in_file, &sampleRate, &inSampleCount);
//如果加载成功
if (inBuffer != nullptr) {
// kAgcModeAdaptiveAnalog 模拟音量调节
// kAgcModeAdaptiveDigital 自适应增益
// kAgcModeFixedDigital 固定增益
agcProcess(inBuffer, sampleRate, inSampleCount, kAgcModeAdaptiveDigital);
wavWrite_int16(out_file, inBuffer, sampleRate, inSampleCount);
free(inBuffer);
}
}
int main(int argc, char *argv[]) {
printf("WebRTC Automatic Gain Control\n");
printf("博客:http://cpuimage.cnblogs.com/\n");
printf("音频自动增益\n");
if (argc < 2)
return -1;
char *in_file = argv[1];
char drive[3];
char dir[256];
char fname[256];
char ext[256];
char out_file[1024];
splitpath(in_file, drive, dir, fname, ext);
sprintf(out_file, "%s%s%s_out%s", drive, dir, fname, ext);
auto_gain(in_file, out_file);
printf("按任意键退出程序 \n");
getchar();
return 0;
}
用于静默检测的完整示例代码:
#include
#include
#include
//采用https://github.com/mackron/dr_ ... wav.h 解码
#define DR_WAV_IMPLEMENTATION
#include "dr_wav.h"
#include "vad.h"
#ifndef nullptr
#define nullptr 0
#endif
#ifndef MIN
#define MIN(A, B) ((A) < (B) ? (A) : (B))
#endif
#ifndef MAX
#define MAX(A, B) ((A) > (B) ? (A) : (B))
#endif
//读取wav文件
int16_t *wavRead_int16(char *filename, uint32_t *sampleRate, uint64_t *totalSampleCount) {
unsigned int channels;
int16_t *buffer = drwav_open_and_read_file_s16(filename, &channels, sampleRate, totalSampleCount);
if (buffer == nullptr) {
printf("读取wav文件失败.");
}
//仅仅处理单通道音频
if (channels != 1) {
drwav_free(buffer);
buffer = nullptr;
*sampleRate = 0;
*totalSampleCount = 0;
}
return buffer;
}
int vadProcess(int16_t *buffer, uint32_t sampleRate, size_t samplesCount, int16_t vad_mode, int per_ms_frames) {
if (buffer == nullptr) return -1;
if (samplesCount == 0) return -1;
// kValidRates : 8000, 16000, 32000, 48000
// 10, 20 or 30 ms frames
per_ms_frames = MAX(MIN(30, per_ms_frames), 10);
size_t samples = sampleRate * per_ms_frames / 1000;
if (samples == 0) return -1;
int16_t *input = buffer;
size_t nTotal = (samplesCount / samples);
void *vadInst = WebRtcVad_Create();
if (vadInst == NULL) return -1;
int status = WebRtcVad_Init(vadInst);
if (status != 0) {
printf("WebRtcVad_Init fail\n");
WebRtcVad_Free(vadInst);
return -1;
}
status = WebRtcVad_set_mode(vadInst, vad_mode);
if (status != 0) {
printf("WebRtcVad_set_mode fail\n");
WebRtcVad_Free(vadInst);
return -1;
}
printf("Activity : \n");
for (int i = 0; i < nTotal; i++) {
int nVadRet = WebRtcVad_Process(vadInst, sampleRate, input, samples);
if (nVadRet == -1) {
printf("failed in WebRtcVad_Process\n");
WebRtcVad_Free(vadInst);
return -1;
} else {
// output result
printf(" %d \t", nVadRet);
}
input += samples;
}
printf("\n");
WebRtcVad_Free(vadInst);
return 1;
}
void vad(char *in_file) {
//音频采样率
uint32_t sampleRate = 0;
//总音频采样数
uint64_t inSampleCount = 0;
int16_t *inBuffer = wavRead_int16(in_file, &sampleRate, &inSampleCount);
//如果加载成功
if (inBuffer != nullptr) {
// Aggressiveness mode (0, 1, 2, or 3)
int16_t mode = 1;
int per_ms = 30;
vadProcess(inBuffer, sampleRate, inSampleCount, mode, per_ms);
free(inBuffer);
}
}
int main(int argc, char *argv[]) {
printf("WebRTC Voice Activity Detector\n");
printf("博客:http://cpuimage.cnblogs.com/\n");
printf("静音检测\n");
if (argc < 2)
return -1;
char *in_file = argv[1];
vad(in_file);
printf("按任意键退出程序 \n");
getchar();
return 0;
}
自动获取项目的地址:
具体过程是:
加载wav(将wav文件拖放到可执行文件中)->获得处理->另存为_out.wav文件
静音检测项目地址:
具体过程是:
加载wav(将wav文件拖放到可执行文件中)->输出静默检测结果
备注: 1表示不静音,0表示静音
要注意的位置和参数,请参见代码注释.
使用cmake编译示例代码. 有关详细信息,请参阅CMakeLists.txt.
如果您还有其他相关问题或需求,也可以给我发电子邮件进行讨论.
电子邮件地址是:
百度严厉打击网站采集行为并启动了飓风算法
采集交流 • 优采云 发表了文章 • 0 个评论 • 433 次浏览 • 2020-08-05 22:05
关于百度飓风算法的公告:
百度搜索最近推出了“飓风算法”,该算法旨在严厉打击以不良采集为主要内容来源的网站. 同时,百度搜索将从索引库中彻底删除不良的采集链接,为高质量的原创内容展示和促进搜索生态健康发展提供更多的机会.
飓风算法通常会生成惩罚数据,并同时根据情况随时调整迭代次数,这反映了百度搜索对不良采集的零容忍度. 对于高质量的原创网站,如果您发现该网站的索引已大大减少并且访问量已大大减少,则可以在反馈中心提供反馈.
该公告只有几句话. 尽管从字面上看,它可以显示更多高质量的原创内容,但是Hurricane算法如何确定原创文章,尤其是高质量的原创内容. 在实际操作中,发现伪原创文章的性能要比原创文章好得多. 如何确定这种情况?现在,许多网站都有采集行为,例如百度图书馆,360doc和新闻网站. 这些网站有很多采集行为. 这些相对较大的网站会受到惩罚吗?尤其是百度自己的产品,百度文库.
此外,该公告并未明确指出如何确定采集等,将来还会有白皮书,请网站管理员参考,我们将拭目以待,如果您有大量采集,请仔细观察以查看其是否经过处理等.
标签: 百度启动其行为以打击采集飓风 查看全部
最近,百度推出了飓风算法. 该算法的主要目的是打击网站采集并显示更好的文章.
关于百度飓风算法的公告:
百度搜索最近推出了“飓风算法”,该算法旨在严厉打击以不良采集为主要内容来源的网站. 同时,百度搜索将从索引库中彻底删除不良的采集链接,为高质量的原创内容展示和促进搜索生态健康发展提供更多的机会.
飓风算法通常会生成惩罚数据,并同时根据情况随时调整迭代次数,这反映了百度搜索对不良采集的零容忍度. 对于高质量的原创网站,如果您发现该网站的索引已大大减少并且访问量已大大减少,则可以在反馈中心提供反馈.
该公告只有几句话. 尽管从字面上看,它可以显示更多高质量的原创内容,但是Hurricane算法如何确定原创文章,尤其是高质量的原创内容. 在实际操作中,发现伪原创文章的性能要比原创文章好得多. 如何确定这种情况?现在,许多网站都有采集行为,例如百度图书馆,360doc和新闻网站. 这些网站有很多采集行为. 这些相对较大的网站会受到惩罚吗?尤其是百度自己的产品,百度文库.
此外,该公告并未明确指出如何确定采集等,将来还会有白皮书,请网站管理员参考,我们将拭目以待,如果您有大量采集,请仔细观察以查看其是否经过处理等.
标签: 百度启动其行为以打击采集飓风
详细分析百度最新算法Hurricane Algorithm 2.0
采集交流 • 优采云 发表了文章 • 0 个评论 • 195 次浏览 • 2020-08-05 18:10
百度搜索将启动Hurricane Algorithm 2.0,以严厉打击严酷的采集行为
飓风算法2.0主要解决以下四种不良采集行为:
1. 从诸如其他网站或官方帐户之类的内容制作者那里采集和转移了大量内容. 信息不整合,布局混乱,文章可读性差,有明显的采集痕迹,对用户没有增值.
2. 文章拼接内容多,文章逻辑性差,不能满足用户需求,阅读体验差.
3. 网站中采集的内容很多,并且网站本身的内容生产力非常差.
4. 大量采集的内容与站点主题无关,并且域集中度很低,并且恶意获取了流量. 例如: 科技网站采集了大量的娱乐八卦,社交新闻等.
飓风算法2.0的解释
根据文章页面的采集,非原理性采集,未组织的文章页面以及来自淘宝或其他新闻页面的文章页面,而无需进行代码处理和文章混淆.
与之抗争的是,伪原创用户不是制作伪原创用户的方法. 它使用了一篇文章. 当头部和尾巴不在大范围内移动时,机器会多次修改商品以生成伪原创
攻击发生在采集网站上. 该网站没有一定程度的伪原创性. 间接而言,百度并不是对复制粘贴网站的完全攻击. 对没有自己内容的网站进行知识攻击. 制作网站时需要网站管理员. 一定程度的维护
战斗是相关性. 如果网站上有大量不相关的文章或内容,它们将被百度拒绝.
总体而言,百度飓风算法2.0可抵制恶意采集,低原创性,恶意拼凑的文章以及无关的恶意引流. 查看全部
2018年9月14日凌晨,百度发布了最新版本的Hurricane Algorithm 2.0. 以下是飓风算法2.0的具体信息:
百度搜索将启动Hurricane Algorithm 2.0,以严厉打击严酷的采集行为
飓风算法2.0主要解决以下四种不良采集行为:
1. 从诸如其他网站或官方帐户之类的内容制作者那里采集和转移了大量内容. 信息不整合,布局混乱,文章可读性差,有明显的采集痕迹,对用户没有增值.
2. 文章拼接内容多,文章逻辑性差,不能满足用户需求,阅读体验差.
3. 网站中采集的内容很多,并且网站本身的内容生产力非常差.
4. 大量采集的内容与站点主题无关,并且域集中度很低,并且恶意获取了流量. 例如: 科技网站采集了大量的娱乐八卦,社交新闻等.
飓风算法2.0的解释
根据文章页面的采集,非原理性采集,未组织的文章页面以及来自淘宝或其他新闻页面的文章页面,而无需进行代码处理和文章混淆.
与之抗争的是,伪原创用户不是制作伪原创用户的方法. 它使用了一篇文章. 当头部和尾巴不在大范围内移动时,机器会多次修改商品以生成伪原创
攻击发生在采集网站上. 该网站没有一定程度的伪原创性. 间接而言,百度并不是对复制粘贴网站的完全攻击. 对没有自己内容的网站进行知识攻击. 制作网站时需要网站管理员. 一定程度的维护
战斗是相关性. 如果网站上有大量不相关的文章或内容,它们将被百度拒绝.
总体而言,百度飓风算法2.0可抵制恶意采集,低原创性,恶意拼凑的文章以及无关的恶意引流.
为什么Internet上有一些虚假网站会欺骗流量?这些网站是否由算法自动生成?
采集交流 • 优采云 发表了文章 • 0 个评论 • 184 次浏览 • 2020-08-05 18:08
即使这个项目可能根本不是由公务员完成的,也不属于政府. 检查whois信息后发现该网站已启用隐私保护,未找到有价值的信息,但一般政府网站不应打开隐私保护. 尽管域名所有者找不到它,但它绝对不是政府网站. 打开它后,您会发现它是医院网站.
与公务员无关.
实际上,我认为是这样的:
1. 该网站用于SEO,以提高网站排名. 他们在新闻子域下建立了“邱县新闻信息站”,并在该网站下发布了一些内容,以增加网站的权重,从而达到搜索引擎优化的目的.
2. 受试者注意到该网站的内容基本上是不可读的. 这是因为搜索引擎更喜欢收录原创内容的网站. 如果他们发现此页面的内容没有出现在其他地方,则此页面的权重相对较高. 如果网站的原创内容比较大,则整个网站的权重就会相对较高.
3. 对于用户而言,他们搜索内容的顺序将受到网站权重的影响. 该网站的权重受“原创”内容的影响,并且排名将相对较高. 同时,由于该网站还收录一些在线内容,因此某些用户在搜索时可能会获得该网站的结果,并进入该网站. 这将为网站带来一定的流量,搜索引擎也将进行计数,并且用户会点击它. 如果次数增加,重量也会增加.
4. 至于如何欺骗用户去医院,以及如何欺骗用户入院后的钱,请参考韦泽西事件.
因此,该网站被认为是骗局流量,但是由于医院正在执行SEO,因此它不仅骗局流量,而且还骗人命.
关于内容的生成方式,我们不妨找到一个软件并查看其说明:
首先搜索搜索引擎:
找到一个很容易,在其中单击它
让我们看一下他的描述:
全新的[Mosaic]原创文章生成软件正式启动,引爆了伪原创电台组的创新革命!它可以自动生成纯原创内容,并且不依赖采集限制;它支持各种SEO软件和站点组软件的导入和使用. 使用此工具,它可以实现各种车站组软件高版本的伪原创功能,例如插入关键字和插入链接,链轮,段落互换,使用同义词库生成高度原创的文章等功能. 现在,它完美地支持了将原创文章快速导入到Bach工作站组软件数据库中,并且只需3秒即可导入1000篇文章.
让我们细化要点:
1. 它生成的内容称为“伪原创内容”.
2. 用于SEO.
3. 该SEO软件具有高度自动化的功能,涵盖了采集,生产和发布.
4. 有许多类似的软件. 他们软件的主要生成方法是: a)插入关键字b)插入链接c)段落互换d)同义词库生成e)以标题为随机句子. 请注意,结尾处有一个“ wait”一词.
在介绍他自己的软件的特征时,我可以看到它们的内容来自何处:
1. 长尾单词列表: 不定位但可以带来点击量的关键字. 请百度.
2. 短URL: 可以采集短URL链接,然后将其链接到相应页面以采集内容.
3. 论坛和门户网站集合: 不用多说.
4. 百科全书: 不用多说.
5. 随机插入字符串: 您可以在文章中插入一些长尾单词和从其他网站采集的内容.
6. 随机产生时间: 喵〜
7. 关键字替换,文字替换: Wang〜
8. 列表文本合并: 诸如excel等形式?不确定.
9. 序列文本生成: 它可以生成常规字符串. 下面的屏幕截图应用于网站编号等,以便于管理.
10. 简体和繁体: 请勿在大中华地区投放任何内容!
该文本可能无法表达. 我将下载一个,几天后为您制作.
关于内容如何获利,我将在以后进行更新.
去查看. 查看全部
不,目前的公务员基本上不可能给项目提供机器学习功能. 一方面,内容上的偏差会影响自己的政治前途. 另一方面,成本相对较高. 最后,通常会有专门的负责人.
即使这个项目可能根本不是由公务员完成的,也不属于政府. 检查whois信息后发现该网站已启用隐私保护,未找到有价值的信息,但一般政府网站不应打开隐私保护. 尽管域名所有者找不到它,但它绝对不是政府网站. 打开它后,您会发现它是医院网站.
与公务员无关.
实际上,我认为是这样的:
1. 该网站用于SEO,以提高网站排名. 他们在新闻子域下建立了“邱县新闻信息站”,并在该网站下发布了一些内容,以增加网站的权重,从而达到搜索引擎优化的目的.
2. 受试者注意到该网站的内容基本上是不可读的. 这是因为搜索引擎更喜欢收录原创内容的网站. 如果他们发现此页面的内容没有出现在其他地方,则此页面的权重相对较高. 如果网站的原创内容比较大,则整个网站的权重就会相对较高.
3. 对于用户而言,他们搜索内容的顺序将受到网站权重的影响. 该网站的权重受“原创”内容的影响,并且排名将相对较高. 同时,由于该网站还收录一些在线内容,因此某些用户在搜索时可能会获得该网站的结果,并进入该网站. 这将为网站带来一定的流量,搜索引擎也将进行计数,并且用户会点击它. 如果次数增加,重量也会增加.
4. 至于如何欺骗用户去医院,以及如何欺骗用户入院后的钱,请参考韦泽西事件.
因此,该网站被认为是骗局流量,但是由于医院正在执行SEO,因此它不仅骗局流量,而且还骗人命.
关于内容的生成方式,我们不妨找到一个软件并查看其说明:
首先搜索搜索引擎:
找到一个很容易,在其中单击它
让我们看一下他的描述:
全新的[Mosaic]原创文章生成软件正式启动,引爆了伪原创电台组的创新革命!它可以自动生成纯原创内容,并且不依赖采集限制;它支持各种SEO软件和站点组软件的导入和使用. 使用此工具,它可以实现各种车站组软件高版本的伪原创功能,例如插入关键字和插入链接,链轮,段落互换,使用同义词库生成高度原创的文章等功能. 现在,它完美地支持了将原创文章快速导入到Bach工作站组软件数据库中,并且只需3秒即可导入1000篇文章.
让我们细化要点:
1. 它生成的内容称为“伪原创内容”.
2. 用于SEO.
3. 该SEO软件具有高度自动化的功能,涵盖了采集,生产和发布.
4. 有许多类似的软件. 他们软件的主要生成方法是: a)插入关键字b)插入链接c)段落互换d)同义词库生成e)以标题为随机句子. 请注意,结尾处有一个“ wait”一词.
在介绍他自己的软件的特征时,我可以看到它们的内容来自何处:
1. 长尾单词列表: 不定位但可以带来点击量的关键字. 请百度.
2. 短URL: 可以采集短URL链接,然后将其链接到相应页面以采集内容.
3. 论坛和门户网站集合: 不用多说.
4. 百科全书: 不用多说.
5. 随机插入字符串: 您可以在文章中插入一些长尾单词和从其他网站采集的内容.
6. 随机产生时间: 喵〜
7. 关键字替换,文字替换: Wang〜
8. 列表文本合并: 诸如excel等形式?不确定.
9. 序列文本生成: 它可以生成常规字符串. 下面的屏幕截图应用于网站编号等,以便于管理.
10. 简体和繁体: 请勿在大中华地区投放任何内容!
该文本可能无法表达. 我将下载一个,几天后为您制作.
关于内容如何获利,我将在以后进行更新.
去查看.
基于机器学习随机森林方法的手势识别算法
采集交流 • 优采云 发表了文章 • 0 个评论 • 213 次浏览 • 2020-08-05 14:07
传统视觉基于特征点和参考坐标系的思想识别物体的姿态. 该方法需要对象本身具有很多形状和颜色特征,并且对于某些更复杂的对象而言效果不佳. 本文使用机器学习(Random Forest)方法,并使用颜色和深度功能来识别对象的姿势.
1. 采集训练数据
由于它基于像素级训练,因此每个像素都需要一个标签. 该标签包括每个像素所属的类别以及相应的三维空间坐标.
a. 如何获取标签?
您可以首先使用传统设备来计算某种类型的物体和相机的真实姿势. 在计算出真实姿势后,您可以从对象的二维图像中计算出相应的三维坐标. 但是,在实际的三维坐标计算中,需要对训练对象进行分段,以避免背景等无关对象的干扰. 通过对分割图像进行姿态计算,可以获得分割图像中每个像素的三维坐标.
<p>因为训练和预测是在像素级别进行的,所以通常图像中的对象由大量像素组成,因此在实际训练中不需要太大的样本(如果样本太多) ,您将需要花费大量时间在训练数据上,但是请尝试将数据收录在每个姿势中,以使模型尽可能准确,通常100幅图像(每种类型的对象)就足够了. 查看全部
原创文本首次在微信公众号“ 3D Vision Workshop”上发布-一种基于机器学习随机森林方法的手势识别算法
传统视觉基于特征点和参考坐标系的思想识别物体的姿态. 该方法需要对象本身具有很多形状和颜色特征,并且对于某些更复杂的对象而言效果不佳. 本文使用机器学习(Random Forest)方法,并使用颜色和深度功能来识别对象的姿势.
1. 采集训练数据
由于它基于像素级训练,因此每个像素都需要一个标签. 该标签包括每个像素所属的类别以及相应的三维空间坐标.
a. 如何获取标签?
您可以首先使用传统设备来计算某种类型的物体和相机的真实姿势. 在计算出真实姿势后,您可以从对象的二维图像中计算出相应的三维坐标. 但是,在实际的三维坐标计算中,需要对训练对象进行分段,以避免背景等无关对象的干扰. 通过对分割图像进行姿态计算,可以获得分割图像中每个像素的三维坐标.
<p>因为训练和预测是在像素级别进行的,所以通常图像中的对象由大量像素组成,因此在实际训练中不需要太大的样本(如果样本太多) ,您将需要花费大量时间在训练数据上,但是请尝试将数据收录在每个姿势中,以使模型尽可能准确,通常100幅图像(每种类型的对象)就足够了.
百度算法更新: 对飓风算法3.0的详细解释,以控制具有较高内容相似性的低质量搜集和作战站点组
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2020-08-05 00:03
为了维护健康的移动生态系统,确保用户体验并确保高质量的站点/智能小应用程序能够获得合理的流量分配,百度搜索将在不久的将来升级飓风算法并发布飓风算法3.0.
此百度算法升级主要针对跨域采集和网站组问题,并将涵盖PC网站,H5网站,智能小程序以及百度搜索下的其他内容. 对于算法所涵盖的网站/智能小程序,将根据违规的严重程度来限制搜索结果的显示.
以下详细介绍了百度飓风算法3.0的相关规则.
1. 跨域采集:
为了获得更多流量,站点/智能小程序发布的内容不属于站点/智能小程序的域. 通常,这些内容是从Internet采集的,内容质量和相关性很低,对搜索用户的价值也很低. 对于此类行为搜索,将判断站点/智能applet的域不够集中,并且在显示上会有不同程度的限制.
跨域集合主要包括以下两种类型的问题:
类型1: 主站点或主页的内容/标题/关键字/摘要表明该站点具有明确的字段或行业,但是发布的内容与该字段无关或相关性较低.
问题示例: 美食智能小程序发布足球相关内容
第二类: 站点/智能小程序没有明确的域或行业,并且内容涉及多个域或行业,该域是模糊的,并且域关注度很低.
问题示例: 智能小程序的内容涉及多个字段
两个. 站组问题:
指的是批量构造多个站点/智能小程序以获得搜索流量的行为. 网站组中的大多数网站/智能小程序质量低,资源稀缺,内容相似度高,甚至重用同一模板,这很难满足搜索用户的需求.
问题示例: 多个智能小应用程序重复使用同一模板,内容质量低且相似度高 查看全部
最近,许多朋友向百度主导的屏幕推广专家梁水才报告,百度的排名不稳定. 这表明百度正在更新其算法. 2019年8月8日上午,百度官方网站宣布百度的Hurricane Algorithm 3.0上线了. 网站管理员在阅读说明后应迅速检查说明: 以下是飓风算法3.0的详细说明.
为了维护健康的移动生态系统,确保用户体验并确保高质量的站点/智能小应用程序能够获得合理的流量分配,百度搜索将在不久的将来升级飓风算法并发布飓风算法3.0.
此百度算法升级主要针对跨域采集和网站组问题,并将涵盖PC网站,H5网站,智能小程序以及百度搜索下的其他内容. 对于算法所涵盖的网站/智能小程序,将根据违规的严重程度来限制搜索结果的显示.
以下详细介绍了百度飓风算法3.0的相关规则.
1. 跨域采集:
为了获得更多流量,站点/智能小程序发布的内容不属于站点/智能小程序的域. 通常,这些内容是从Internet采集的,内容质量和相关性很低,对搜索用户的价值也很低. 对于此类行为搜索,将判断站点/智能applet的域不够集中,并且在显示上会有不同程度的限制.
跨域集合主要包括以下两种类型的问题:
类型1: 主站点或主页的内容/标题/关键字/摘要表明该站点具有明确的字段或行业,但是发布的内容与该字段无关或相关性较低.
问题示例: 美食智能小程序发布足球相关内容
第二类: 站点/智能小程序没有明确的域或行业,并且内容涉及多个域或行业,该域是模糊的,并且域关注度很低.
问题示例: 智能小程序的内容涉及多个字段
两个. 站组问题:
指的是批量构造多个站点/智能小程序以获得搜索流量的行为. 网站组中的大多数网站/智能小程序质量低,资源稀缺,内容相似度高,甚至重用同一模板,这很难满足搜索用户的需求.
问题示例: 多个智能小应用程序重复使用同一模板,内容质量低且相似度高
百度算法更新:飓风算法3.0详尽剖析、各位采集站长赶快自查网站把
采集交流 • 优采云 发表了文章 • 0 个评论 • 429 次浏览 • 2020-08-04 09:00
为了维护健康的联通生态,保障用户体验,保证优质站点/智能小程序才能获得合理的流量分发,百度搜索将在近日对飓风算法进行升级,上线飓风算法3.0。
本次算法升级主要针对跨领域采集以及站群问题,将覆盖百度搜索下的PC站点、H5站点、智能小程序等内容。对于算法覆盖的站点/智能小程序算法 自动采集列表,将会依照违法问题的恶劣程度,酌情限制搜索结果的诠释。
以下详尽说明飓风算法3.0的相关规则。
一. 跨领域采集:
指站点/智能小程序为了获取更多流量,发布不属于站点/智能小程序领域范围的内容,通常这种内容采集自互联网,内容质量及相关性低、对搜索用户价值低。对于这样的行为搜索会判断该站点/智能小程序的领域专注度不足,会有不同程度的限制凸显。
跨领域采集主要包括下边两类问题:
第一类:主站或主页的内容/标题/关键词/摘要等信息显示该站有明晰的领域或行业,但发布内容与该领域不相关,或相关性较低。
问题示例:美食类智能小程序发布篮球相关内容
第二类:站点/智能小程序没有明晰的领域或行业算法 自动采集列表,内容涉及多个领域或行业,领域模糊、领域专注度低。
问题示例:智能小程序内容涉及多个领域
二. 站群问题:
指批量构造多个站点/智能小程序,获取搜索流量的行为。站群中的站点/智能小程序大多质量低、资源稀缺性低、内容相似度高、甚至复用相同模板,难以满足搜索用户的需求。
问题示例:多个智能小程序复用同一模板,内容质量低、相似度高 查看全部
是不是发觉近来百度排行不稳定,你没有想错,这就是百度近来在更新算法,今天总算通告百度的飓风算法3.0上线了,是时侯要自查一波,各位站长赶快看说明以后去自查吧:下面就是飓风算法3.0的详尽说明。
为了维护健康的联通生态,保障用户体验,保证优质站点/智能小程序才能获得合理的流量分发,百度搜索将在近日对飓风算法进行升级,上线飓风算法3.0。
本次算法升级主要针对跨领域采集以及站群问题,将覆盖百度搜索下的PC站点、H5站点、智能小程序等内容。对于算法覆盖的站点/智能小程序算法 自动采集列表,将会依照违法问题的恶劣程度,酌情限制搜索结果的诠释。
以下详尽说明飓风算法3.0的相关规则。
一. 跨领域采集:
指站点/智能小程序为了获取更多流量,发布不属于站点/智能小程序领域范围的内容,通常这种内容采集自互联网,内容质量及相关性低、对搜索用户价值低。对于这样的行为搜索会判断该站点/智能小程序的领域专注度不足,会有不同程度的限制凸显。
跨领域采集主要包括下边两类问题:
第一类:主站或主页的内容/标题/关键词/摘要等信息显示该站有明晰的领域或行业,但发布内容与该领域不相关,或相关性较低。
问题示例:美食类智能小程序发布篮球相关内容
第二类:站点/智能小程序没有明晰的领域或行业算法 自动采集列表,内容涉及多个领域或行业,领域模糊、领域专注度低。
问题示例:智能小程序内容涉及多个领域
二. 站群问题:
指批量构造多个站点/智能小程序,获取搜索流量的行为。站群中的站点/智能小程序大多质量低、资源稀缺性低、内容相似度高、甚至复用相同模板,难以满足搜索用户的需求。
问题示例:多个智能小程序复用同一模板,内容质量低、相似度高
百度飓风算法 3.0,控制跨领域采集及站群
采集交流 • 优采云 发表了文章 • 0 个评论 • 443 次浏览 • 2020-08-04 08:03
一、跨领域采集
指站点/智能小程序为了获取更多流量,发布不属于站点/智能小程序领域范围的内容,通常这种内容采集自互联网,内容质量及相关性低、对搜索用户价值低。对于这样的行为搜索会判断该站点/智能小程序的领域专注度不足,会有不同程度的限制凸显。
跨领域采集主要包括下边两类问题:
二、站群问题
指批量构造多个站点/智能小程序,获取搜索流量的行为。站群中的站点/智能小程序大多质量低、资源稀缺性低、内容相似度高、甚至复用相同模板,难以满足搜索用户的需求。
简单总结
百度飓风算法 3.0 预计在 8 月内相继上线。当然和往年一样假如你的站点被百度认定为跨领域采集或者站群问题,那么你可能会收到百度搜索资源平台的站内信、短信等渠道的提醒通知,所以子凡建议你们还是自查完成整改吧假如有的话,避免不必要的降权。
其实子凡认为,与其说百度飓风算法 3.0 是针对跨领域采集和站群,其实看上更象实在辅助和为百度智能小程序铺路,以及降低智能小程序的的权重,以搜索引擎算法的方法间接的将流量导向百度的小程序。
除非标明,否则均为泪雪博客原创文章算法 自动采集列表,禁止任何方式转载
本文链接: 查看全部
百度总算迎来了飓风算法 3.0,这次依然是为了维护健康的联通搜索生态,保障用户体验,保证优质站点及智能小程序才能获得合理的流量分发。本次飓风算法升级主要针对跨领域采集以及站群问题,将覆盖百度搜索下的 PC 站点、H5 站点、智能小程序等内容。对于算法覆盖的站点/智能小程序算法 自动采集列表,将会依照违法问题的恶劣程度,酌情限制搜索结果的彰显。
一、跨领域采集
指站点/智能小程序为了获取更多流量,发布不属于站点/智能小程序领域范围的内容,通常这种内容采集自互联网,内容质量及相关性低、对搜索用户价值低。对于这样的行为搜索会判断该站点/智能小程序的领域专注度不足,会有不同程度的限制凸显。
跨领域采集主要包括下边两类问题:
二、站群问题
指批量构造多个站点/智能小程序,获取搜索流量的行为。站群中的站点/智能小程序大多质量低、资源稀缺性低、内容相似度高、甚至复用相同模板,难以满足搜索用户的需求。
简单总结
百度飓风算法 3.0 预计在 8 月内相继上线。当然和往年一样假如你的站点被百度认定为跨领域采集或者站群问题,那么你可能会收到百度搜索资源平台的站内信、短信等渠道的提醒通知,所以子凡建议你们还是自查完成整改吧假如有的话,避免不必要的降权。
其实子凡认为,与其说百度飓风算法 3.0 是针对跨领域采集和站群,其实看上更象实在辅助和为百度智能小程序铺路,以及降低智能小程序的的权重,以搜索引擎算法的方法间接的将流量导向百度的小程序。
除非标明,否则均为泪雪博客原创文章算法 自动采集列表,禁止任何方式转载
本文链接:
统治世界的十大算法
采集交流 • 优采云 发表了文章 • 0 个评论 • 255 次浏览 • 2020-08-04 08:03
————————-
算法对于我们明天生活非常重要,怎样鼓吹也不会夸张。它们在虚拟世界中无处不在,从金融机构到交友网站。但是,相比于其他算法,其中有一些算法更大程度上改变并控制着我们的世界——本文列出了其中十种最为重要的算法。
在即将介绍算法内容之前,让我们来迅速备考一些基本内容。虽然,没有明晰的定义,但是计算机科学家将算法描述为一个定义了操作次序的规则集合。它们是一组次序指令,用来告诉计算机如何解决一个问题或则达到某种既定目标。认识算法的好方式,是将算法可视化为流程图。
1. Google Search 谷歌搜索
不久之前,搜索引擎成为了互联网时代的霸主。与搜索引擎一起崛起的还有微软和微软提出的PageRank算法。
今天,在日本的核心搜索市场中,谷歌的市场占有率达到了66.7%,其次是谷歌(18.1%),雅虎(11.2%),Ask(2.6%),AOL(1.4%)。毋庸置疑,谷歌早已统治了搜索市场,而且我们中的很多人把微软作为使用互联网的主要途径。
PageRank 的工作依赖于两个组成部份,一是称作“蜘蛛”或者“爬虫”的自动程序,另一部分是关键词索引及其 位置。这个算法通过估算某个网页的相关链接数目和链接质量,来大致估算这个网页的重要性。算法的基本思想是越重要的网页会有越多的链接指向它。这是一个基本的人气大赛。除此之外,PageRank算法也考虑了一个网页中关键词的频度和出现位置,以及这个网页发布的时间。
2. Facebook News Feed
虽然我们不愿承认,但是Facebook的新闻提要(NewsFeed)是我们最喜欢浪费时间的地方。除非你的个人偏好早已设置为展示所有风波而且依照时间次序更新所有好友新闻,不然你听到的新闻是一个预处理以后的选择,这个预处理是由Facebook的算法为你量身选择个别新闻而展示。
为了决定什么新闻的内容是最有意思的,这个算法会考虑好多诱因,比如评论数,发表人(是的,有一个内容的“流行”人物排行,所谓的“流行”人物是与你互动最多的人),发表类型(比如相片、视频、状态、更新等等)。
3. OKCupid 情侣匹配
在线交友如今是一个价值20亿美元的产业。由于, eHarmony, and OKCupid等网站的发展,这个产业自从2008年以来每年扩大3.5%。分析家觉得这个产业的加速发展在未来两年还将继续——情有可原:这是情侣遇到的有效方法。婚恋网站不仅仅缔造了更多的成功婚姻,他们也擅长于依据个人不同的喜好和倾向,匹配潜在情侣。当然,这样的匹配完全是由算法完成的。
我们将以OKCupid为例,OKCupid是一个免费的婚恋网站,联合创始人之一是哈佛大学的数学家Christian Rudder。OKCupid采用一种绝对的剖析方式促使约会,他们从用户哪里竭力获取信息。OKCupid 的配对算法不仅仅是简单地匹配一些共同爱好,同时,每一个问题都被赋于了权重,用来评判这个问题对于用户和她们潜在情侣的重要程度。这就是所谓的差别缔造不凡——这是OKCupid成为最高效婚恋网站的诱因之一。
4. NSA 数据采集,解读和加密
我们越来越多地被算法而不是被人观察。感谢Edward Snowden,我们晓得了美国安全局(NSA)及其小伙伴早已暗中监控了上百万的无辜公民。近期披露的文件显示,已经有许多的监控项目被FiveEyes施行,FiveEyes是由英国、澳大利亚、加拿大、新西兰和加拿大共同组成的情报组织。它们已然监控了我们的移动电话、电子邮箱、网络摄像头图象和地理位置信息。同时,“它们”我指的是她们的算法,这其中有太多的数据,人力难以进行搜集和评析。
有意思的是,NSA宣称实际上她们并没有“采集”我们的数据。根据一份1982年的程序指南,“信息“采集”是指当信息被搜集并被国防部情报机构在职责范围内使用”。同时“数据由电子系统采集是指信息采集并被转换为可理解的方式”。英国路透社的Bruce Schneier解释道:
“ 因此,假设你的同事在家里有成千上万的书籍,根据NSA的解释,他并不“收集”图书。只有他真正在读的这些才是他“收集”的图书,他借助图书做其他事情时并不能觉得他在“收集”图书。”
这会形成一个问题由于:
计算机算法与人们密切相关。当我们想到计算机算法正在监控我们而且剖析我们的个人数据时算法 自动采集列表,我们必须想想在算法背后的人。是不是有人正在看着我们的数据,事实上,他们能做的事情正是监视。
最后,最相关的还有美国国家安全局的Suite B 加密算法,这是一套功能强悍的算法,用于加密、数据交换、数字签名和哈希。机构正是借助这一算法来保护分类以及未分类文件的。
5. 推荐算法
诸如例如 亚马逊和Netflix这样的网站,会记录你选购过的书籍或是你看过的影片,然后按照我们的爱好为我们推荐商品。
正如许多手动程序一样,这种二十一世纪独有的技术既有优点也有缺点。虽然这样的推荐有时候太有帮助,但是有时候也会偏离目标——特别是你为你的三岁父亲购买了一本儿童读物作为礼物然后。
与PageRank和Facebook的新闻提要一样,这样的算法正在导致所谓的“过滤器泡沫”,这是一种现象,用户与她们不感兴趣的信息隔离——有效地将用户通过意识形态的“泡沫”隔离上去。这引起了Eli Pariser提出的“信息决定论”,我们过去在网上浏览的兴趣决定了我们的未来。
6. Google AdWords
与之前的算法类似, Google, Facebook以及其他的网站跟踪你的行为、用词、搜索恳求来推送相应广告。 Google’s AdWords——公司最主要的收入来源——正是以这样的模式进行预测的,同时Facebook也在竭力进行相关研究(你最后一次点击Facebook的广告是哪些时侯?)
7. 高频度的股票交易
很久之前,金融部门就开始使用算法来预测市场波动,但是她们在高频度的股票交易中的实践才刚刚开始。这样的高速交易涉及的算法,也称作机器人,可以对订单在毫秒级作出判定。相反,一个人一般须要起码1秒就能对潜在的风险作出反应。因此,人们渐渐被排除在了实际交易的循环之外——一个全新的电子生态正在逐步产生。
但是,又是这种算法会导致错误。Leo Hickman解释道:
比如:2010年五月六日的“闪电暴跌”,当时道琼斯指数在几分钟内平均上涨了1000点,而在二十分钟以后市场才出现回落。这样的急剧直线上涨到目前为止也没能得到完整解释,但是大部分经济学家将齐归罪于“竟次”。“竟次”的罪魁祸首是为了达到高频交易而大规模使用的量化交易算法。Scott Patterson,华尔街日报的记着和《The Quants》的作者,将在交易场地使用这种算法称作客机的手动驾驶。今天,大部分的交易是由算法手动完成的,但是当情况出现不同时,比如发生闪电暴跌时,应当有人工介入。
8. MP3 压缩
压缩数据算法是电子世界不可磨灭的重要一员。我们希望更快地接收媒体数据,同时希望节省硬碟空间。因此,人们设计了好多方式来压缩和传送数据。
比如,在1991年思科系统研制了CRTP合同。1987年,德国研究者发明了明天广泛使用的MP3格式,从而将音频的大小减小到原始大小的十分之一。这一压缩格式造成了音乐产业的革命(影响有好有坏)。
9. 预测剖析软件
目前这一技术并没有主宰我们的世界,但是它将很快主宰世界。越来越多的警员机构正在使用一种预测剖析技术——一种使人想起影片《少数派报告》的新工具。
在2010年,据说借助IBM的预测剖析软件(叫做CRUSH,全称 Criminal Reduction Utilizing Statistical History),2006年以来孟菲斯市的警员局降低了超过30%的恶性案件,其中包括降低了15%的暴力犯罪。同时,在加拿大、以色列以及美国的城市也在关注这一技术。现在,洛杉矶、圣克鲁斯、查尔斯顿等也开始了试点。
这一技术结合了数据采集、统计剖析,当然还有前沿的算法。它促使警员可以评估城市的犯罪特征,并且预告可能的犯罪“热点”,从而“积极地配置资源和分配人手,从而提升人力物力的使用效率,提高公众安全”。
未来,这个系统可能会大规模取代分析家的工作。犯罪行为可以被精确的算法所追踪,这些算法监控了互联网行为、GPS算法 自动采集列表,个人电子设备,生物特点和其他现实中的通讯方法。越来越多的无人机会拿来追踪潜在犯人,通过剖析她们的肢体动作和其他的可视化线索,来预测她们的意图。
10. 调音(Auto-Tune)
最后,仅供娱乐,现在调音器由算法完成。无论是歌声或是钢琴的声音,这些设备都能通过一组特定规则,略微更改音位,让音域达到最接近的确切调式上。有趣的是,这种技术最初由Exxon’s Any Hildebrand 用于处理水灾数据。
美国女歌手Cher的《Believe》,被觉得是第一首使用调音的流行歌曲。
原文: 查看全部
编注:如果你之前已看伯乐在线翻译组的这篇译文:《真正统治世界的十大算法》,请暂时“清空相关记忆”。《统治世界的十大算法》先于后者。
————————-
算法对于我们明天生活非常重要,怎样鼓吹也不会夸张。它们在虚拟世界中无处不在,从金融机构到交友网站。但是,相比于其他算法,其中有一些算法更大程度上改变并控制着我们的世界——本文列出了其中十种最为重要的算法。
在即将介绍算法内容之前,让我们来迅速备考一些基本内容。虽然,没有明晰的定义,但是计算机科学家将算法描述为一个定义了操作次序的规则集合。它们是一组次序指令,用来告诉计算机如何解决一个问题或则达到某种既定目标。认识算法的好方式,是将算法可视化为流程图。
1. Google Search 谷歌搜索
不久之前,搜索引擎成为了互联网时代的霸主。与搜索引擎一起崛起的还有微软和微软提出的PageRank算法。
今天,在日本的核心搜索市场中,谷歌的市场占有率达到了66.7%,其次是谷歌(18.1%),雅虎(11.2%),Ask(2.6%),AOL(1.4%)。毋庸置疑,谷歌早已统治了搜索市场,而且我们中的很多人把微软作为使用互联网的主要途径。
PageRank 的工作依赖于两个组成部份,一是称作“蜘蛛”或者“爬虫”的自动程序,另一部分是关键词索引及其 位置。这个算法通过估算某个网页的相关链接数目和链接质量,来大致估算这个网页的重要性。算法的基本思想是越重要的网页会有越多的链接指向它。这是一个基本的人气大赛。除此之外,PageRank算法也考虑了一个网页中关键词的频度和出现位置,以及这个网页发布的时间。
2. Facebook News Feed
虽然我们不愿承认,但是Facebook的新闻提要(NewsFeed)是我们最喜欢浪费时间的地方。除非你的个人偏好早已设置为展示所有风波而且依照时间次序更新所有好友新闻,不然你听到的新闻是一个预处理以后的选择,这个预处理是由Facebook的算法为你量身选择个别新闻而展示。
为了决定什么新闻的内容是最有意思的,这个算法会考虑好多诱因,比如评论数,发表人(是的,有一个内容的“流行”人物排行,所谓的“流行”人物是与你互动最多的人),发表类型(比如相片、视频、状态、更新等等)。
3. OKCupid 情侣匹配
在线交友如今是一个价值20亿美元的产业。由于, eHarmony, and OKCupid等网站的发展,这个产业自从2008年以来每年扩大3.5%。分析家觉得这个产业的加速发展在未来两年还将继续——情有可原:这是情侣遇到的有效方法。婚恋网站不仅仅缔造了更多的成功婚姻,他们也擅长于依据个人不同的喜好和倾向,匹配潜在情侣。当然,这样的匹配完全是由算法完成的。
我们将以OKCupid为例,OKCupid是一个免费的婚恋网站,联合创始人之一是哈佛大学的数学家Christian Rudder。OKCupid采用一种绝对的剖析方式促使约会,他们从用户哪里竭力获取信息。OKCupid 的配对算法不仅仅是简单地匹配一些共同爱好,同时,每一个问题都被赋于了权重,用来评判这个问题对于用户和她们潜在情侣的重要程度。这就是所谓的差别缔造不凡——这是OKCupid成为最高效婚恋网站的诱因之一。
4. NSA 数据采集,解读和加密
我们越来越多地被算法而不是被人观察。感谢Edward Snowden,我们晓得了美国安全局(NSA)及其小伙伴早已暗中监控了上百万的无辜公民。近期披露的文件显示,已经有许多的监控项目被FiveEyes施行,FiveEyes是由英国、澳大利亚、加拿大、新西兰和加拿大共同组成的情报组织。它们已然监控了我们的移动电话、电子邮箱、网络摄像头图象和地理位置信息。同时,“它们”我指的是她们的算法,这其中有太多的数据,人力难以进行搜集和评析。
有意思的是,NSA宣称实际上她们并没有“采集”我们的数据。根据一份1982年的程序指南,“信息“采集”是指当信息被搜集并被国防部情报机构在职责范围内使用”。同时“数据由电子系统采集是指信息采集并被转换为可理解的方式”。英国路透社的Bruce Schneier解释道:
“ 因此,假设你的同事在家里有成千上万的书籍,根据NSA的解释,他并不“收集”图书。只有他真正在读的这些才是他“收集”的图书,他借助图书做其他事情时并不能觉得他在“收集”图书。”
这会形成一个问题由于:
计算机算法与人们密切相关。当我们想到计算机算法正在监控我们而且剖析我们的个人数据时算法 自动采集列表,我们必须想想在算法背后的人。是不是有人正在看着我们的数据,事实上,他们能做的事情正是监视。
最后,最相关的还有美国国家安全局的Suite B 加密算法,这是一套功能强悍的算法,用于加密、数据交换、数字签名和哈希。机构正是借助这一算法来保护分类以及未分类文件的。
5. 推荐算法
诸如例如 亚马逊和Netflix这样的网站,会记录你选购过的书籍或是你看过的影片,然后按照我们的爱好为我们推荐商品。
正如许多手动程序一样,这种二十一世纪独有的技术既有优点也有缺点。虽然这样的推荐有时候太有帮助,但是有时候也会偏离目标——特别是你为你的三岁父亲购买了一本儿童读物作为礼物然后。
与PageRank和Facebook的新闻提要一样,这样的算法正在导致所谓的“过滤器泡沫”,这是一种现象,用户与她们不感兴趣的信息隔离——有效地将用户通过意识形态的“泡沫”隔离上去。这引起了Eli Pariser提出的“信息决定论”,我们过去在网上浏览的兴趣决定了我们的未来。
6. Google AdWords
与之前的算法类似, Google, Facebook以及其他的网站跟踪你的行为、用词、搜索恳求来推送相应广告。 Google’s AdWords——公司最主要的收入来源——正是以这样的模式进行预测的,同时Facebook也在竭力进行相关研究(你最后一次点击Facebook的广告是哪些时侯?)
7. 高频度的股票交易
很久之前,金融部门就开始使用算法来预测市场波动,但是她们在高频度的股票交易中的实践才刚刚开始。这样的高速交易涉及的算法,也称作机器人,可以对订单在毫秒级作出判定。相反,一个人一般须要起码1秒就能对潜在的风险作出反应。因此,人们渐渐被排除在了实际交易的循环之外——一个全新的电子生态正在逐步产生。
但是,又是这种算法会导致错误。Leo Hickman解释道:
比如:2010年五月六日的“闪电暴跌”,当时道琼斯指数在几分钟内平均上涨了1000点,而在二十分钟以后市场才出现回落。这样的急剧直线上涨到目前为止也没能得到完整解释,但是大部分经济学家将齐归罪于“竟次”。“竟次”的罪魁祸首是为了达到高频交易而大规模使用的量化交易算法。Scott Patterson,华尔街日报的记着和《The Quants》的作者,将在交易场地使用这种算法称作客机的手动驾驶。今天,大部分的交易是由算法手动完成的,但是当情况出现不同时,比如发生闪电暴跌时,应当有人工介入。
8. MP3 压缩
压缩数据算法是电子世界不可磨灭的重要一员。我们希望更快地接收媒体数据,同时希望节省硬碟空间。因此,人们设计了好多方式来压缩和传送数据。
比如,在1991年思科系统研制了CRTP合同。1987年,德国研究者发明了明天广泛使用的MP3格式,从而将音频的大小减小到原始大小的十分之一。这一压缩格式造成了音乐产业的革命(影响有好有坏)。
9. 预测剖析软件
目前这一技术并没有主宰我们的世界,但是它将很快主宰世界。越来越多的警员机构正在使用一种预测剖析技术——一种使人想起影片《少数派报告》的新工具。
在2010年,据说借助IBM的预测剖析软件(叫做CRUSH,全称 Criminal Reduction Utilizing Statistical History),2006年以来孟菲斯市的警员局降低了超过30%的恶性案件,其中包括降低了15%的暴力犯罪。同时,在加拿大、以色列以及美国的城市也在关注这一技术。现在,洛杉矶、圣克鲁斯、查尔斯顿等也开始了试点。
这一技术结合了数据采集、统计剖析,当然还有前沿的算法。它促使警员可以评估城市的犯罪特征,并且预告可能的犯罪“热点”,从而“积极地配置资源和分配人手,从而提升人力物力的使用效率,提高公众安全”。
未来,这个系统可能会大规模取代分析家的工作。犯罪行为可以被精确的算法所追踪,这些算法监控了互联网行为、GPS算法 自动采集列表,个人电子设备,生物特点和其他现实中的通讯方法。越来越多的无人机会拿来追踪潜在犯人,通过剖析她们的肢体动作和其他的可视化线索,来预测她们的意图。
10. 调音(Auto-Tune)
最后,仅供娱乐,现在调音器由算法完成。无论是歌声或是钢琴的声音,这些设备都能通过一组特定规则,略微更改音位,让音域达到最接近的确切调式上。有趣的是,这种技术最初由Exxon’s Any Hildebrand 用于处理水灾数据。
美国女歌手Cher的《Believe》,被觉得是第一首使用调音的流行歌曲。
原文:

