
算法 自动采集列表
爱数anyshare v6.0.11官方版
采集交流 • 优采云 发表了文章 • 0 个评论 • 235 次浏览 • 2020-08-09 20:28
相关软件软件大小版本说明下载地址
爱数anyshare是北京爱数信息出品的政府、企业用网盘,现在多用于各个中学和企业之间的数据传输和网盘软件,利用爱数anyshare可以轻松链接公司服务器进行快速的数据共享服务,相比较传统的网盘软件,保密性更高、传输速率更快。
软件特色
爱数大数据基础设施,为了一个更智能的未来
For a smarter future
以创新的技术,致力于构建覆盖灾难恢复 1~6 级的数据安全和可用性方案、收录智能内容管理、智能运维的智能数据管理方案、以多模态知识图谱数据构架为基础的数据洞察力方案。赋能行业数字化,使顾客实现从商业智能到数据智能再到行业智能的数字化变革。
全栈超可用的灾备云
全球数字化变革浪潮下,企业正面临着数据超级多、系统超级复杂、环境超级异构等灾备挑战,爱数AnyBackup作为完整覆盖信息系统灾难恢复能力1-6级的全栈超可用解决方案,可实现从数据到平台再到应用的全栈超可用和丰富的数据服务,加速数字化变革。
智能内容云
数字化时代,海量非结构化数据、内容安全以及内容合规的挑战成为了企业内容管理的三大困局。爱数 AnyShare 通过先进的内容总线构架、内容数据湖架构、云原生构架、人工智能技术,助力全球化营运、服务多样性的企业文化、打造学习型组织、管理和营运数字资产。
专注智能运维的日志云
复杂 IT 环境及多业务运行状况下,企业面临着日志数据管理难度大,多业务系统下运维故障频发、未知安全隐患等困局。爱数 AnyRobot 采用先进的AI算法,采集海量异构数据、实时监控、精准故障定位、智能风险预测,为企业提供主动营运模式下的智能运维。
业务连续性服务
数字经济时代下,业务中断导致的损失巨大,现有业务系统发展和未来业务建设投入为 IT 架构带来挑战。爱数业务连续性服务,凝聚十数年专业经验,从体系顶楼设计及技术构架设计、集成开发及交付服务、到驻场营运及培训服务,有效保障业务连续性。
使用方式
一、下载安装软件。
二、打开软件后会提示链接失败,这时候点击右上角的设置。
三、在设置中的服务器地址中输入公司给的服务器地址,点击确定。
四、输入自己在公司的帐号密码进行登录即可。 查看全部
爱数anyshare是北京爱数信息出品的政府、企业用网盘,现在多用于各个中学和企业之间的数据传输和网盘软件,利用爱数anyshare可以轻松链接公司服务器进行快速的数据共享服务,相比较传统的网盘软件,保密性更高、传输速率更快。
相关软件软件大小版本说明下载地址
爱数anyshare是北京爱数信息出品的政府、企业用网盘,现在多用于各个中学和企业之间的数据传输和网盘软件,利用爱数anyshare可以轻松链接公司服务器进行快速的数据共享服务,相比较传统的网盘软件,保密性更高、传输速率更快。

软件特色
爱数大数据基础设施,为了一个更智能的未来
For a smarter future
以创新的技术,致力于构建覆盖灾难恢复 1~6 级的数据安全和可用性方案、收录智能内容管理、智能运维的智能数据管理方案、以多模态知识图谱数据构架为基础的数据洞察力方案。赋能行业数字化,使顾客实现从商业智能到数据智能再到行业智能的数字化变革。
全栈超可用的灾备云
全球数字化变革浪潮下,企业正面临着数据超级多、系统超级复杂、环境超级异构等灾备挑战,爱数AnyBackup作为完整覆盖信息系统灾难恢复能力1-6级的全栈超可用解决方案,可实现从数据到平台再到应用的全栈超可用和丰富的数据服务,加速数字化变革。
智能内容云
数字化时代,海量非结构化数据、内容安全以及内容合规的挑战成为了企业内容管理的三大困局。爱数 AnyShare 通过先进的内容总线构架、内容数据湖架构、云原生构架、人工智能技术,助力全球化营运、服务多样性的企业文化、打造学习型组织、管理和营运数字资产。
专注智能运维的日志云
复杂 IT 环境及多业务运行状况下,企业面临着日志数据管理难度大,多业务系统下运维故障频发、未知安全隐患等困局。爱数 AnyRobot 采用先进的AI算法,采集海量异构数据、实时监控、精准故障定位、智能风险预测,为企业提供主动营运模式下的智能运维。
业务连续性服务
数字经济时代下,业务中断导致的损失巨大,现有业务系统发展和未来业务建设投入为 IT 架构带来挑战。爱数业务连续性服务,凝聚十数年专业经验,从体系顶楼设计及技术构架设计、集成开发及交付服务、到驻场营运及培训服务,有效保障业务连续性。
使用方式
一、下载安装软件。

二、打开软件后会提示链接失败,这时候点击右上角的设置。
三、在设置中的服务器地址中输入公司给的服务器地址,点击确定。

四、输入自己在公司的帐号密码进行登录即可。
推荐系统的几种常用算法总结
采集交流 • 优采云 发表了文章 • 0 个评论 • 193 次浏览 • 2020-08-09 16:22
之前也做过一些关于推荐系统的项目,下面就来系统的总结一下。
一、什么是推荐系统?
引用百度百科的一段解释就是:“利用电子商务网站向顾客提供商品信息和建议,帮助用户决定应当订购哪些产品,模拟销售人员帮助顾客完成订购过程。个性化推荐是按照用户的兴趣特性和订购行为,向用户推荐用户感兴趣的信息和商品。”
在这个数据过载的时代,信息的消费者须要从海量的信息中找到自己所须要的信息,信息的生产者要使自己生产的信息在海量的信息中脱颖而出,这时推荐系统就应运而生了。对用户而言,推荐系统不需要用户提供明晰的目标;对物品而言,推荐系统解决了2/8现象的问题(也叫长尾效应),让冷门的物品可以展示到须要它们的用户面前。
二、推荐系统要解决的问题?
1、帮助用户找到想要的物品 如:书籍、电影等
2、可以增加信息过载
3、有利于提升站点的点击率/转化率
4、有利于对用户进行深入了解,为用户提供个性化服务
三、推荐系统的发展趋势?
推荐系统的研究大致可以分为三个阶段,第一阶段是基于传统的服务,第二阶段是基于目前的社交网路的服务,第三阶段是正式到来的物联网。这其中形成了好多基础和重要的算法,例如协同过滤(包括基于用户的和基于物品的)、基于内容的推荐算法、混合式的推荐算法、基于统计理论的推荐算法、基于社交网路信息(关注、被关注、信任、知名度、信誉度等)的过滤推荐算法、群体推荐算法、基于位置的推荐算法。其中基于邻域的协同过滤推荐算法是推荐系统中最基础、最核心、最重要的算法,该算法除了在学术界得到较为深入的研究,而且在业界也得到特别广泛的应用,基于邻域的算法主要分为两大类,一类是基于用户的协同过滤算法,另一类是基于物品的协同过滤算法,除此之外,基于内容的推荐算法应用也十分广泛等等,因此下文将对涉及推荐系统的常用算法进行详尽介绍。
1、基于流行度的推荐算法
2、基于协同过滤的推荐算法(UserCF与ItemCF)
3、基于内容的推荐算法
4、基于模型的推荐算法
5、基于混合式的推荐算法
四、基于流行度的推荐算法
基于流行度的算法十分简单粗鲁,类似于各大新闻、微博热榜等,根据PV、UV、日均PV或分享率等数据来按某种热度排序来推荐给用户。
注:独立访客(UV)、访问次数(VV)两个指标有哪些区别?
① 访问次数(VV):记录1天内所有访客访问了该网站多少次,相同的访客有可能多次访问该网站,且访问的次数累加。
② 独立访客(UV):记录1天内所有访客访问了该网站多少次,虽然相同访客能多次访问网站,但只估算为1个独立访客。
③ PV访问量(Page View):即页面访问量,每打开一次页面或则刷新一次页面,PV值+1。
1、优点:该算法简单,适用于刚注册的新用户
2、缺点:无法针对用户提供个性化的推荐
3、改进:基于该算法可做一些优化,例如加入用户分群的流行度进行排序,通过把热榜上的体育内容优先推荐给体育迷,把政要热文推给热爱谈论政治的用户。
五、基于用户的协同过滤推荐算法
当目标用户须要推荐时,可以先通过兴趣、爱好或行为习惯找到与他相像的其他用户,然后把这些与目标用户相像的用户喜欢的而且目标用户没有浏览过的物品推荐给目标用户。
1、基于用户的CF原理如下:
① 分析各个用户对物品的评价,通过浏览记录、购买记录等得到用户的隐性评分;
② 根据用户对物品的隐性评分估算得到所有用户之间的相似度;
③ 选出与目标用户最相像的K个用户;
④ 将这K个用户隐性评分最高而且目标用户又没有浏览过的物品推荐给目标用户。
2、优点:
① 基于用户的协同过滤推荐算法是给目标用户推荐这些和他有共同兴趣的用户喜欢的物品,所以该算法推荐较为社会化,即推荐的物品是与用户兴趣一致的那种群体中的热门物品;
② 适于物品比用户多、物品时效性较强的情形,否则估算慢;
③ 能实现跨领域、惊喜度高的结果。
3、缺点:
① 在好多时侯,很多用户两两之间的共同评分仅有几个,也即用户之间的重合度并不高,同时仅有的共同打了分的物品,往往是一些太常见的物品,如收视大片、生活必需品;
②用户之间的距离可能显得很快,这种离线算法无法顿时更新推荐结果;
③推荐结果的个性化较弱、较笼统。
4、改进:
① 两个用户对流行物品的有相像兴趣,丝毫不能说明她们有相像的兴趣,此时要降低惩罚力度;
②如果两个用户同时喜欢了相同的物品,那么可以给这两个用户更高的相似度;
③在描述邻居用户的偏好时,给其近来喜欢的物品较高权重;
④把类似地域用户的行为作为推荐的主要根据。
六、基于物品的协同过滤推荐算法
当一个用户须要个性化推荐时,举个反例因为我之前订购过许嵩的《梦游计》这张专辑,所以会给我推荐《青年晚报》,因为好多其他用户都同时订购了许嵩的这两张专辑。
1、基于物品的CF原理如下:
① 分析各个用户对物品的浏览记录;
② 依据浏览记录剖析得出所有物品之间的相似度;
③ 对于目标用户评价高的物品,找出与之相似度最高的K个物品;
④ 将这K个物品中目标用户没有浏览过的物品推荐给目标用户
2、优点:
① 基于物品的协同过滤推荐算法则是为目标用户推荐这些和他之前喜欢的物品类似的物品,所以基于物品的协同过滤推荐算法的推荐较为个性,因为推荐的物品通常都满足目标用户的奇特兴趣。
②物品之间的距离可能是依据成百上千万的用户的隐性评分估算得出,往往能在一段时间内保持稳定。因此,这种算法可以预先估算距离,其在线部份能更快地生产推荐列表。
③应用最广泛,尤其以电商行业为典型。
④ 适于用户多、物品少的情形,否则估算慢
⑤ 推荐精度高,更具个性化
⑥倾向于推荐同类商品
3、缺点:
①不同领域的最热门物品之间常常具有较高的相似度。比如,基于本算法,我们可能会给喜欢听许嵩歌曲的朋友推荐汪峰的歌曲,也就是推荐不同领域的畅销作品,这样的推荐结果可能并不是我们想要的。
②在物品冷启动、数据稀疏时疗效不佳
③推荐的多样性不足,形成信息闭环
4、改进:
① 如果是热门物品,很多人都喜欢,就会接近1,就会导致好多物品都和热门物品相像,此时要降低惩罚力度;
②活跃用户对物品相似度的贡献大于不活跃的用户;
③同一个用户在间隔太短的时间内喜欢的两件商品之间,可以给与更高的相似度;
④在描述目标用户偏好时,给其近来喜欢的商品较高权重;
⑤同一个用户在同一个地域内喜欢的两件商品之间,可以给与更高的相似度。
七、基于内容的推荐算法
协同过滤算法仅仅通过了解用户与物品之间的关系进行推荐,而根本不会考虑到物品本身的属性,而基于内容的算法会考虑到物品本身的属性。
根据用户之前对物品的历史行为,如用户订购过哪些物品、对哪些物品采集过、评分过等等,然后再按照估算与那些物品相像的物品,并把它们推荐给用户。例如某用户之前订购过许嵩的《寻宝游戏》,这可以说明该用户可能是一个嵩鼠,这时就可以给该用户推荐一些许嵩的其他专辑或专著。
1、基于内容的推荐算法的原理如下:
① 选取一些具有代表性的特点来表示每位物品
② 使用用户的历史行为数据剖析物品的这种特点,从而学习出用户的喜好特点或兴趣,也即建立用户画像
③ 通过比较上一步得到的用户画像和待推荐物品的画像(由待推荐物品的特点构成),将具有相关性最大的前K个物品中目标用户没有浏览过的物品推荐给目标用户
2、优点:
① 是最直观的算法
② 常利用文本相似度估算
③ 很好地解决冷启动问题,并且也不会囿于热度的限制
3、缺点:
① 容易受限于对文本、图像、音视频的内容进行描述的详尽程度
② 过度专业化(over-specialisation),导致仍然推荐给用户内容密切关联的item,而丧失了推荐内容的多样性。
③主题过分集中,惊喜度不足
八、基于模型的推荐算法
基于模型的推荐算法会涉及到一些机器学习的方式,如逻辑回归、朴素贝叶斯分类器等。基于模型的算法因为快速、准确,适用于实时性比较高的业务如新闻、广告等,而若是须要这些算法达到更好的疗效,则须要人工干预反复的进行属性的组合和筛选,也就是常说的Feature Engineering。而因为新闻的时效性,系统也须要反复更新线上的物理模型,以适应变化。
九、基于混合式的推荐算法
现实应用中,其实极少有直接用某种算法来做推荐的系统。在一些大的网站如Netflix,就是融合了数十种算法的推荐系统。我们可以通过给不同算法的结果加权重来综合结果,或者是在不同的估算环节中运用不同的算法来混和,达到更贴合自己业务的目的。
十、推荐结果列表处理
1、当推荐算法估算得出推荐结果列表以后,我们常常还须要对结果进行处理。比如当推荐的内容里收录敏感词汇、涉及用户隐私的内容等等,就须要系统将其筛除;
2、若多次推荐后用户仍然对某个物品毫无兴趣,就须要将这个物品减少权重,调整排序;
3、有时系统还要考虑话题多样性的问题,同样要在不同话题中筛选内容。
十一、推荐结果评估
当一个推荐算法设计完成后,一般须要用查准率(precision),查全率(recall),点击率(CTR)、转化率(CVR)、停留时间等指标进行评价。
查准率(precision):推荐给用户且用户喜欢的物品在推荐列表中的比重
查全率(recall):推荐给用户且用户喜欢的物品在用户列表中的比重
点击率(CTR):实际点击了的物品/推荐列表中所有的物品
转化率(CVR):购买了的物品/实际点击了的物品
日积月累,与君共进,增增小结,未完待续。 查看全部
尊敬的读者你好:笔者很高兴自己的文章能被阅读,但原创与编辑均不易,所以转载请必须标明本文出处并附上本文地址超链接以及博主博客地址:。若认为本文对您有用处还请帮忙点个赞鼓励一下,笔者在此谢谢每一位读者,如需联系笔者,请记下邮箱:,谢谢合作!
之前也做过一些关于推荐系统的项目,下面就来系统的总结一下。
一、什么是推荐系统?
引用百度百科的一段解释就是:“利用电子商务网站向顾客提供商品信息和建议,帮助用户决定应当订购哪些产品,模拟销售人员帮助顾客完成订购过程。个性化推荐是按照用户的兴趣特性和订购行为,向用户推荐用户感兴趣的信息和商品。”
在这个数据过载的时代,信息的消费者须要从海量的信息中找到自己所须要的信息,信息的生产者要使自己生产的信息在海量的信息中脱颖而出,这时推荐系统就应运而生了。对用户而言,推荐系统不需要用户提供明晰的目标;对物品而言,推荐系统解决了2/8现象的问题(也叫长尾效应),让冷门的物品可以展示到须要它们的用户面前。
二、推荐系统要解决的问题?
1、帮助用户找到想要的物品 如:书籍、电影等
2、可以增加信息过载
3、有利于提升站点的点击率/转化率
4、有利于对用户进行深入了解,为用户提供个性化服务
三、推荐系统的发展趋势?
推荐系统的研究大致可以分为三个阶段,第一阶段是基于传统的服务,第二阶段是基于目前的社交网路的服务,第三阶段是正式到来的物联网。这其中形成了好多基础和重要的算法,例如协同过滤(包括基于用户的和基于物品的)、基于内容的推荐算法、混合式的推荐算法、基于统计理论的推荐算法、基于社交网路信息(关注、被关注、信任、知名度、信誉度等)的过滤推荐算法、群体推荐算法、基于位置的推荐算法。其中基于邻域的协同过滤推荐算法是推荐系统中最基础、最核心、最重要的算法,该算法除了在学术界得到较为深入的研究,而且在业界也得到特别广泛的应用,基于邻域的算法主要分为两大类,一类是基于用户的协同过滤算法,另一类是基于物品的协同过滤算法,除此之外,基于内容的推荐算法应用也十分广泛等等,因此下文将对涉及推荐系统的常用算法进行详尽介绍。
1、基于流行度的推荐算法
2、基于协同过滤的推荐算法(UserCF与ItemCF)
3、基于内容的推荐算法
4、基于模型的推荐算法
5、基于混合式的推荐算法
四、基于流行度的推荐算法
基于流行度的算法十分简单粗鲁,类似于各大新闻、微博热榜等,根据PV、UV、日均PV或分享率等数据来按某种热度排序来推荐给用户。
注:独立访客(UV)、访问次数(VV)两个指标有哪些区别?
① 访问次数(VV):记录1天内所有访客访问了该网站多少次,相同的访客有可能多次访问该网站,且访问的次数累加。
② 独立访客(UV):记录1天内所有访客访问了该网站多少次,虽然相同访客能多次访问网站,但只估算为1个独立访客。
③ PV访问量(Page View):即页面访问量,每打开一次页面或则刷新一次页面,PV值+1。
1、优点:该算法简单,适用于刚注册的新用户
2、缺点:无法针对用户提供个性化的推荐
3、改进:基于该算法可做一些优化,例如加入用户分群的流行度进行排序,通过把热榜上的体育内容优先推荐给体育迷,把政要热文推给热爱谈论政治的用户。
五、基于用户的协同过滤推荐算法
当目标用户须要推荐时,可以先通过兴趣、爱好或行为习惯找到与他相像的其他用户,然后把这些与目标用户相像的用户喜欢的而且目标用户没有浏览过的物品推荐给目标用户。
1、基于用户的CF原理如下:
① 分析各个用户对物品的评价,通过浏览记录、购买记录等得到用户的隐性评分;
② 根据用户对物品的隐性评分估算得到所有用户之间的相似度;
③ 选出与目标用户最相像的K个用户;
④ 将这K个用户隐性评分最高而且目标用户又没有浏览过的物品推荐给目标用户。
2、优点:
① 基于用户的协同过滤推荐算法是给目标用户推荐这些和他有共同兴趣的用户喜欢的物品,所以该算法推荐较为社会化,即推荐的物品是与用户兴趣一致的那种群体中的热门物品;
② 适于物品比用户多、物品时效性较强的情形,否则估算慢;
③ 能实现跨领域、惊喜度高的结果。
3、缺点:
① 在好多时侯,很多用户两两之间的共同评分仅有几个,也即用户之间的重合度并不高,同时仅有的共同打了分的物品,往往是一些太常见的物品,如收视大片、生活必需品;
②用户之间的距离可能显得很快,这种离线算法无法顿时更新推荐结果;
③推荐结果的个性化较弱、较笼统。
4、改进:
① 两个用户对流行物品的有相像兴趣,丝毫不能说明她们有相像的兴趣,此时要降低惩罚力度;
②如果两个用户同时喜欢了相同的物品,那么可以给这两个用户更高的相似度;
③在描述邻居用户的偏好时,给其近来喜欢的物品较高权重;
④把类似地域用户的行为作为推荐的主要根据。
六、基于物品的协同过滤推荐算法
当一个用户须要个性化推荐时,举个反例因为我之前订购过许嵩的《梦游计》这张专辑,所以会给我推荐《青年晚报》,因为好多其他用户都同时订购了许嵩的这两张专辑。
1、基于物品的CF原理如下:
① 分析各个用户对物品的浏览记录;
② 依据浏览记录剖析得出所有物品之间的相似度;
③ 对于目标用户评价高的物品,找出与之相似度最高的K个物品;
④ 将这K个物品中目标用户没有浏览过的物品推荐给目标用户
2、优点:
① 基于物品的协同过滤推荐算法则是为目标用户推荐这些和他之前喜欢的物品类似的物品,所以基于物品的协同过滤推荐算法的推荐较为个性,因为推荐的物品通常都满足目标用户的奇特兴趣。
②物品之间的距离可能是依据成百上千万的用户的隐性评分估算得出,往往能在一段时间内保持稳定。因此,这种算法可以预先估算距离,其在线部份能更快地生产推荐列表。
③应用最广泛,尤其以电商行业为典型。
④ 适于用户多、物品少的情形,否则估算慢
⑤ 推荐精度高,更具个性化
⑥倾向于推荐同类商品
3、缺点:
①不同领域的最热门物品之间常常具有较高的相似度。比如,基于本算法,我们可能会给喜欢听许嵩歌曲的朋友推荐汪峰的歌曲,也就是推荐不同领域的畅销作品,这样的推荐结果可能并不是我们想要的。
②在物品冷启动、数据稀疏时疗效不佳
③推荐的多样性不足,形成信息闭环
4、改进:
① 如果是热门物品,很多人都喜欢,就会接近1,就会导致好多物品都和热门物品相像,此时要降低惩罚力度;
②活跃用户对物品相似度的贡献大于不活跃的用户;
③同一个用户在间隔太短的时间内喜欢的两件商品之间,可以给与更高的相似度;
④在描述目标用户偏好时,给其近来喜欢的商品较高权重;
⑤同一个用户在同一个地域内喜欢的两件商品之间,可以给与更高的相似度。
七、基于内容的推荐算法
协同过滤算法仅仅通过了解用户与物品之间的关系进行推荐,而根本不会考虑到物品本身的属性,而基于内容的算法会考虑到物品本身的属性。
根据用户之前对物品的历史行为,如用户订购过哪些物品、对哪些物品采集过、评分过等等,然后再按照估算与那些物品相像的物品,并把它们推荐给用户。例如某用户之前订购过许嵩的《寻宝游戏》,这可以说明该用户可能是一个嵩鼠,这时就可以给该用户推荐一些许嵩的其他专辑或专著。
1、基于内容的推荐算法的原理如下:
① 选取一些具有代表性的特点来表示每位物品
② 使用用户的历史行为数据剖析物品的这种特点,从而学习出用户的喜好特点或兴趣,也即建立用户画像
③ 通过比较上一步得到的用户画像和待推荐物品的画像(由待推荐物品的特点构成),将具有相关性最大的前K个物品中目标用户没有浏览过的物品推荐给目标用户
2、优点:
① 是最直观的算法
② 常利用文本相似度估算
③ 很好地解决冷启动问题,并且也不会囿于热度的限制
3、缺点:
① 容易受限于对文本、图像、音视频的内容进行描述的详尽程度
② 过度专业化(over-specialisation),导致仍然推荐给用户内容密切关联的item,而丧失了推荐内容的多样性。
③主题过分集中,惊喜度不足
八、基于模型的推荐算法
基于模型的推荐算法会涉及到一些机器学习的方式,如逻辑回归、朴素贝叶斯分类器等。基于模型的算法因为快速、准确,适用于实时性比较高的业务如新闻、广告等,而若是须要这些算法达到更好的疗效,则须要人工干预反复的进行属性的组合和筛选,也就是常说的Feature Engineering。而因为新闻的时效性,系统也须要反复更新线上的物理模型,以适应变化。
九、基于混合式的推荐算法
现实应用中,其实极少有直接用某种算法来做推荐的系统。在一些大的网站如Netflix,就是融合了数十种算法的推荐系统。我们可以通过给不同算法的结果加权重来综合结果,或者是在不同的估算环节中运用不同的算法来混和,达到更贴合自己业务的目的。
十、推荐结果列表处理
1、当推荐算法估算得出推荐结果列表以后,我们常常还须要对结果进行处理。比如当推荐的内容里收录敏感词汇、涉及用户隐私的内容等等,就须要系统将其筛除;
2、若多次推荐后用户仍然对某个物品毫无兴趣,就须要将这个物品减少权重,调整排序;
3、有时系统还要考虑话题多样性的问题,同样要在不同话题中筛选内容。
十一、推荐结果评估
当一个推荐算法设计完成后,一般须要用查准率(precision),查全率(recall),点击率(CTR)、转化率(CVR)、停留时间等指标进行评价。
查准率(precision):推荐给用户且用户喜欢的物品在推荐列表中的比重
查全率(recall):推荐给用户且用户喜欢的物品在用户列表中的比重
点击率(CTR):实际点击了的物品/推荐列表中所有的物品
转化率(CVR):购买了的物品/实际点击了的物品
日积月累,与君共进,增增小结,未完待续。
网页手动采集之内涵吧内涵段子手动采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 325 次浏览 • 2020-08-09 15:29
<p> /**
*@Description:
*/
package cn.lulei.crawl.neihan8;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashSet;
import cn.lulei.db.neihan8.Neihan8DbOperation;
import cn.lulei.model.Neihan8;
import cn.lulei.util.ParseUtil;
import cn.lulei.util.ThreadUtil;
public class Neihan8Crawl {
//内涵吧更新列表页url格式
private static String listPageUrl = "http://www.neihan8.com/article ... 3B%3B
//两次访问页面事件间隔,单位ms
private static int sleepTime = 500;
/**
* @param start 起始页
* @param end 终止页
* @throws IOException
* @Date: 2014-2-13
* @Author: lulei
* @Description: 抓取更新列表页上的内容
*/
public void crawlMain(int start, int end) throws IOException{
start = start < 1 ? 1 : start;
Neihan8DbOperation neihan8DbOperation = new Neihan8DbOperation();
for ( ; start 查看全部
内涵吧内涵段子采集入口类Neihan8Crawl这儿的没有实现抓取程序的周期性采集,这里可以依照自己的须要来写相应的线程。
<p> /**
*@Description:
*/
package cn.lulei.crawl.neihan8;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashSet;
import cn.lulei.db.neihan8.Neihan8DbOperation;
import cn.lulei.model.Neihan8;
import cn.lulei.util.ParseUtil;
import cn.lulei.util.ThreadUtil;
public class Neihan8Crawl {
//内涵吧更新列表页url格式
private static String listPageUrl = "http://www.neihan8.com/article ... 3B%3B
//两次访问页面事件间隔,单位ms
private static int sleepTime = 500;
/**
* @param start 起始页
* @param end 终止页
* @throws IOException
* @Date: 2014-2-13
* @Author: lulei
* @Description: 抓取更新列表页上的内容
*/
public void crawlMain(int start, int end) throws IOException{
start = start < 1 ? 1 : start;
Neihan8DbOperation neihan8DbOperation = new Neihan8DbOperation();
for ( ; start
3种方式实现列表手动滚动
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2020-08-09 15:04
方法一:用javascript原生代码实现,不需要依赖任何框架,代码及注释如下:
1 //javascript原生自动滚动
2 function startmarquee(lh,speed,delay,marqueeObj) { //lh---每行列表的高度,speed---滚动的速度,delay---间隔多久滚动一次,marqueeObj---需要实现这个效果的id
3 var p=false;
4 var t;
5 var o=document.getElementById(marqueeObj);
6 o.innerHTML+=o.innerHTML;
7 o.style.marginTop=0;
8 o.onmouseover=function(){p=true;} //鼠标移入,停止滚动
9 o.onmouseout=function(){p=false;}//鼠标移出,继续滚动
10
11 function start(){
12 t=setInterval(scrolling,speed); //定时器,自动滚动
13 if(!p) o.style.marginTop=parseInt(o.style.marginTop)-1+"px";
14 }
15
16 function scrolling(){
17 if(parseInt(o.style.marginTop)%lh!=0){
18 o.style.marginTop=parseInt(o.style.marginTop)-1+"px";
19 if(Math.abs(parseInt(o.style.marginTop))>=o.scrollHeight/2) o.style.marginTop=0;
20 }else{
21 clearInterval(t);
22 setTimeout(start,delay);
23 }
24 }
25 setTimeout(start,delay);
26 }
27 startmarquee(48,20,1000,"marqueebox"); //引用函数
方法二:依赖jquery,可以进行不定高的滚动
1 //列表自动滚动
2 function scrollNews() {
3 var $news = $('#marqueebox table');
4 var $lineHeight = $news.find('tr:first').height();
5 $news.animate({ 'marginTop': -$lineHeight + 'px' }, 1000, function () {
6 $news.css({ margin: 0 }).find('tr:first').appendTo($news);
7 });
8 }
9
10 var scrollTimer = null;
11 var delay = 2000;
12 scrollTimer = setInterval(function () {
13 scrollNews();
14 }, delay);
方法三:从左向右轮播
<p> 1 function ScrollImgLeft(start,end,wrap){
2 var speed=40;
3 var scroll_begin = document.getElementById(start);
4 var scroll_end = document.getElementById(end);
5 var scroll_div = document.getElementById(wrap);
6 scroll_end.innerHTML=scroll_begin.innerHTML;
7 function Marquee(){
8 if(scroll_end.offsetWidth-scroll_div.scrollLeft 查看全部
自动滚动这些疗效在网页中还是比较常见的。现在,就我在做项目期间所用到的才能实现手动滚动的方式做一个总结。
方法一:用javascript原生代码实现,不需要依赖任何框架,代码及注释如下:
1 //javascript原生自动滚动
2 function startmarquee(lh,speed,delay,marqueeObj) { //lh---每行列表的高度,speed---滚动的速度,delay---间隔多久滚动一次,marqueeObj---需要实现这个效果的id
3 var p=false;
4 var t;
5 var o=document.getElementById(marqueeObj);
6 o.innerHTML+=o.innerHTML;
7 o.style.marginTop=0;
8 o.onmouseover=function(){p=true;} //鼠标移入,停止滚动
9 o.onmouseout=function(){p=false;}//鼠标移出,继续滚动
10
11 function start(){
12 t=setInterval(scrolling,speed); //定时器,自动滚动
13 if(!p) o.style.marginTop=parseInt(o.style.marginTop)-1+"px";
14 }
15
16 function scrolling(){
17 if(parseInt(o.style.marginTop)%lh!=0){
18 o.style.marginTop=parseInt(o.style.marginTop)-1+"px";
19 if(Math.abs(parseInt(o.style.marginTop))>=o.scrollHeight/2) o.style.marginTop=0;
20 }else{
21 clearInterval(t);
22 setTimeout(start,delay);
23 }
24 }
25 setTimeout(start,delay);
26 }
27 startmarquee(48,20,1000,"marqueebox"); //引用函数
方法二:依赖jquery,可以进行不定高的滚动
1 //列表自动滚动
2 function scrollNews() {
3 var $news = $('#marqueebox table');
4 var $lineHeight = $news.find('tr:first').height();
5 $news.animate({ 'marginTop': -$lineHeight + 'px' }, 1000, function () {
6 $news.css({ margin: 0 }).find('tr:first').appendTo($news);
7 });
8 }
9
10 var scrollTimer = null;
11 var delay = 2000;
12 scrollTimer = setInterval(function () {
13 scrollNews();
14 }, delay);
方法三:从左向右轮播
<p> 1 function ScrollImgLeft(start,end,wrap){
2 var speed=40;
3 var scroll_begin = document.getElementById(start);
4 var scroll_end = document.getElementById(end);
5 var scroll_div = document.getElementById(wrap);
6 scroll_end.innerHTML=scroll_begin.innerHTML;
7 function Marquee(){
8 if(scroll_end.offsetWidth-scroll_div.scrollLeft
使用上下文信息提出建议
采集交流 • 优采云 发表了文章 • 0 个评论 • 250 次浏览 • 2020-08-08 22:47
1. 什么是上下文
本章前面提到的推荐系统算法主要着重于如何联系用户兴趣和项目,并向用户推荐最适合用户兴趣的项目,但是这些算法忽略了一点,即用户的上下文. . 这些上下文包括用户访问推荐系统的时间,地点和心情,这对于改进推荐系统的推荐系统非常重要. 例如,销售衣服的推荐系统应该在冬天和夏天向用户推荐不同种类的衣服. 推荐系统无法在冬季向用户推荐类似的T恤,因为用户在夏天喜欢某件T恤.
我们在这里主要讨论时间上下文,并简要介绍位置上下文,并讨论如何将时间信息和位置信息建模到推荐算法中,以便推荐系统可以准确地预测用户在特定时刻的兴趣并具体位置.
2. 时间上下文2.1时间效应
时间是重要的上下文信息,对用户兴趣具有深远和广泛的影响. 人们普遍认为,时间信息对用户兴趣的影响体现在以下几个方面.
1)用户兴趣正在改变
2)物品也有生命周期
3)季节效应
2.2系统时间特征分析
在给定时间信息之后,推荐系统已从静态系统变为时变系统,并且用户行为数据也已成为时间序列. 要研究时变系统,我们首先需要研究系统的时间特性. 收录时间信息的用户行为数据集由一系列三元组组成,其中每个三元组(u,i,t)表示用户u在时间t上项目i的行为. 我们可以研究的时间特征如下:
数据集中唯一身份用户数量的每日增长
系统中的物料更改: 例如,物料在线的平均天数. 如果某项在某一天已被至少一个用户操作,则定义该项在该天处于联机状态. 因此,我们可以通过商品的平均在线天数来衡量一类商品的生命周期.
用户访问权限: 我们可以计算用户活动天数的平均值,以及进入系统T天的用户重叠次数.
由T天分隔的系统项目流行度向量的平均相似度: 在系统中相邻两个T天,分别计算这两天的项目流行度,以获得两个流行度向量. 然后,计算两个向量的余弦相似度. 如果相似性很大,则意味着系统中的项目在相隔T天之内没有发生显着变化,这表明系统的时效性不强,并且项目的平均在线时间更长.
2.3推荐系统的实时性能
实现推荐系统的实时性,不仅需要实时访问用户行为,还需要推荐算法本身的实时性,并且推荐算法本身的实时性意味着:
1)实时推荐系统无法每天为所有用户离线计算推荐结果,然后在线显示昨天计算的结果. 因此,当每个用户访问推荐系统时,将根据该时间点之前用户的行为实时计算推荐列表.
2)推荐算法需要平衡用户的近期行为和长期行为,即,推荐列表必须反映出用户最近行为所反映的用户兴趣变化,并且推荐列表不得完全受到影响根据用户的近期行为. 必须保证推荐内容的连续性,以预测用户的兴趣.
2.4推荐结果的时间多样性
那么,如何在不损失准确性的情况下提高推荐结果的时间多样性?改善推荐结果的时间多样性需要分两个步骤解决: 首先,必须确保推荐系统可以在用户有新行为后及时调整推荐结果,以使推荐结果满足用户的近期兴趣. 其次,有必要确保推荐系统在用户手中. 当没有新行为时,结果可以经常更改,并具有一定的时间多样性.
第一步,可以将其分为两种情况进行分析. 首先是从推荐系统的实时角度来看. 一些推荐系统每天都会为所有用户生成推荐,然后将这些结果直接显示给在线用户. 显然,这种类型的系统在用户出现新行为后无法及时调整推荐结果. 其次,由于算法不同,即使是实时推荐系统也具有不同的时间分集.
那么,如果用户没有任何行为,如何确保向用户推荐的结果具有一定的时间多样性?总体思路如下.
在生成推荐结果时添加一定程度的随机性,
记录用户每天看到的推荐结果,然后在每天向用户推荐时,适当降低过去几天中多次看到的推荐结果的能量.
每天为用户使用不同的推荐算法.
3. 时间上下文推荐算法3.1最近最受欢迎的
在没有时间信息的数据集中,我们可以向用户推荐历史上最受欢迎的商品. 然后,在获得用户行为的时间信息之后,最简单的非个性化推荐算法是最近向用户推荐最受欢迎的商品. 在给定的时间T,可以将项i的最近受欢迎程度ni(T)定义为:
3.2与时间上下文有关的ItemCF算法
基于时间上下文,我们可以从以下两个方面改进ItemCF算法.
1)项目相似度: 用户在短时间内喜欢的项目具有较高的相似度.
2)在线推荐: 用户的近期行为比很久以前的用户行为更好地反映了用户的当前兴趣.
首先回顾一下前面提到的基于项目的协同过滤算法,该算法通过以下公式计算项目的相似度:
向用户u推荐时,用户u对项目i的兴趣p(u,i)由以下公式计算:
获取时间信息后,可以通过以下公式改进相似度计算:
上面使用的衰减函数的可能形式如下:
除了考虑时间信息对相关表的影响外,我们还应该考虑时间信息对预测公式的影响. 一般来说,用户的当前行为应该与用户的最近行为有更大的关系,因此可以进行以下修复:
其中,t0是当前时间. 从上式可以看出,tuj越接近t0,在用户u的推荐列表中,类似于j的项目的排名越高.
3.3与时间上下文有关的UserCF算法
类似于ItemCF,我们还可以在以下两个方面使用时间信息来改进UserCF算法.
1)用户兴趣相似度: 两个用户之所以兴趣相似,是因为他们喜欢相同的项目或对相同的项目有行为. 但是,如果两个用户同时喜欢同一商品,则这两个用户的兴趣应该更大.
2)兴趣相似的用户的近期行为: 找到一组与当前用户u相似的用户的兴趣后,该组用户的近期兴趣显然比今天的用户u的兴趣更接近于今天的用户u的兴趣. 这群用户很久以前. 换句话说,我们应该向用户推荐具有相似兴趣的用户最近喜欢的项目.
首先查看UserCF的公式. UserCF通过以下公式计算用户u与用户v之间的兴趣相似度:
N(u)是用户u喜欢的项目的集合,N(v)是用户v喜欢的项目的集合.
获得用户相似性后,UserCF通过以下公式预测用户对该商品的兴趣:
考虑时间因素,我们可以如下修改用户相似度计算并添加时间衰减因素. 用户u和用户v对项目i作用的距离越远,两个用户的兴趣相似度就越小. :
同样,如果我们考虑与用户u类似的用户最近兴趣,则可以设计以下公式:
3.4时间段图模型
在基于时间的图模型中,时间周期图模型G(U,SU,I,SI,E,w,)也是二部图. U是用户节点集,SU是用户时间段节点集. 用户时间段节点vut∈SU将通过时间与用户u在时间t处喜欢的项目相关联. I是项目节点的集合,SI是项目时间段节点的集合. 项目时间段节点vit∈SI将在时间t连接到所有喜欢项目i的用户. E是边集,收录3种边: (1)如果用户u在第i项上有行为,则存在边e(vu,vi)∈E; (2)如果用户u在时间t行为上对第i个项目有行为,则有两个边e(vut,vi),e(vu,vit)∈E.
下图是一个简单的时间周期图模型的示例. 在此示例中,用户A在时间2作用于项目b. 因此,时间段图模型将首先创建4个顶点,即用户顶点A,用户时间段顶点A: 2,项目顶点b和项目时间段顶点b. : 2. 然后,将3个边添加到图中,即(A,b),(A: 2,b),(A,b: 2). 此处不再添加边(A: 2,b: 2),一方面是因为添加该边不会改善结果,另一方面,因为添加边会增加图的空间复杂度图上算法的时间复杂度.
在这里,我们不再使用PersonalRank算法向用户提出个性化推荐. 相应地,我们使用一种称为路径融合算法的方法来测量图中两个顶点之间的相关性.
一般而言,图上两个高度相关的顶点通常具有以下特征:
1)有许多路径连接两个顶点;
2)两个顶点之间的路径相对较短;
3)两个顶点之间的路径不通过输出程度更高的顶点.
在这里很难弄清楚公式,只需要截图:
4. 位置上下文信息
除了时间,地点作为重要的空间特征,也是重要的上下文信息. 在这里我们不会详细介绍. 查看全部
本文的思想指导如下:

1. 什么是上下文
本章前面提到的推荐系统算法主要着重于如何联系用户兴趣和项目,并向用户推荐最适合用户兴趣的项目,但是这些算法忽略了一点,即用户的上下文. . 这些上下文包括用户访问推荐系统的时间,地点和心情,这对于改进推荐系统的推荐系统非常重要. 例如,销售衣服的推荐系统应该在冬天和夏天向用户推荐不同种类的衣服. 推荐系统无法在冬季向用户推荐类似的T恤,因为用户在夏天喜欢某件T恤.
我们在这里主要讨论时间上下文,并简要介绍位置上下文,并讨论如何将时间信息和位置信息建模到推荐算法中,以便推荐系统可以准确地预测用户在特定时刻的兴趣并具体位置.
2. 时间上下文2.1时间效应
时间是重要的上下文信息,对用户兴趣具有深远和广泛的影响. 人们普遍认为,时间信息对用户兴趣的影响体现在以下几个方面.
1)用户兴趣正在改变
2)物品也有生命周期
3)季节效应
2.2系统时间特征分析
在给定时间信息之后,推荐系统已从静态系统变为时变系统,并且用户行为数据也已成为时间序列. 要研究时变系统,我们首先需要研究系统的时间特性. 收录时间信息的用户行为数据集由一系列三元组组成,其中每个三元组(u,i,t)表示用户u在时间t上项目i的行为. 我们可以研究的时间特征如下:
数据集中唯一身份用户数量的每日增长
系统中的物料更改: 例如,物料在线的平均天数. 如果某项在某一天已被至少一个用户操作,则定义该项在该天处于联机状态. 因此,我们可以通过商品的平均在线天数来衡量一类商品的生命周期.
用户访问权限: 我们可以计算用户活动天数的平均值,以及进入系统T天的用户重叠次数.
由T天分隔的系统项目流行度向量的平均相似度: 在系统中相邻两个T天,分别计算这两天的项目流行度,以获得两个流行度向量. 然后,计算两个向量的余弦相似度. 如果相似性很大,则意味着系统中的项目在相隔T天之内没有发生显着变化,这表明系统的时效性不强,并且项目的平均在线时间更长.
2.3推荐系统的实时性能
实现推荐系统的实时性,不仅需要实时访问用户行为,还需要推荐算法本身的实时性,并且推荐算法本身的实时性意味着:
1)实时推荐系统无法每天为所有用户离线计算推荐结果,然后在线显示昨天计算的结果. 因此,当每个用户访问推荐系统时,将根据该时间点之前用户的行为实时计算推荐列表.
2)推荐算法需要平衡用户的近期行为和长期行为,即,推荐列表必须反映出用户最近行为所反映的用户兴趣变化,并且推荐列表不得完全受到影响根据用户的近期行为. 必须保证推荐内容的连续性,以预测用户的兴趣.
2.4推荐结果的时间多样性
那么,如何在不损失准确性的情况下提高推荐结果的时间多样性?改善推荐结果的时间多样性需要分两个步骤解决: 首先,必须确保推荐系统可以在用户有新行为后及时调整推荐结果,以使推荐结果满足用户的近期兴趣. 其次,有必要确保推荐系统在用户手中. 当没有新行为时,结果可以经常更改,并具有一定的时间多样性.
第一步,可以将其分为两种情况进行分析. 首先是从推荐系统的实时角度来看. 一些推荐系统每天都会为所有用户生成推荐,然后将这些结果直接显示给在线用户. 显然,这种类型的系统在用户出现新行为后无法及时调整推荐结果. 其次,由于算法不同,即使是实时推荐系统也具有不同的时间分集.
那么,如果用户没有任何行为,如何确保向用户推荐的结果具有一定的时间多样性?总体思路如下.
在生成推荐结果时添加一定程度的随机性,
记录用户每天看到的推荐结果,然后在每天向用户推荐时,适当降低过去几天中多次看到的推荐结果的能量.
每天为用户使用不同的推荐算法.
3. 时间上下文推荐算法3.1最近最受欢迎的
在没有时间信息的数据集中,我们可以向用户推荐历史上最受欢迎的商品. 然后,在获得用户行为的时间信息之后,最简单的非个性化推荐算法是最近向用户推荐最受欢迎的商品. 在给定的时间T,可以将项i的最近受欢迎程度ni(T)定义为:

3.2与时间上下文有关的ItemCF算法
基于时间上下文,我们可以从以下两个方面改进ItemCF算法.
1)项目相似度: 用户在短时间内喜欢的项目具有较高的相似度.
2)在线推荐: 用户的近期行为比很久以前的用户行为更好地反映了用户的当前兴趣.
首先回顾一下前面提到的基于项目的协同过滤算法,该算法通过以下公式计算项目的相似度:

向用户u推荐时,用户u对项目i的兴趣p(u,i)由以下公式计算:

获取时间信息后,可以通过以下公式改进相似度计算:

上面使用的衰减函数的可能形式如下:

除了考虑时间信息对相关表的影响外,我们还应该考虑时间信息对预测公式的影响. 一般来说,用户的当前行为应该与用户的最近行为有更大的关系,因此可以进行以下修复:

其中,t0是当前时间. 从上式可以看出,tuj越接近t0,在用户u的推荐列表中,类似于j的项目的排名越高.
3.3与时间上下文有关的UserCF算法
类似于ItemCF,我们还可以在以下两个方面使用时间信息来改进UserCF算法.
1)用户兴趣相似度: 两个用户之所以兴趣相似,是因为他们喜欢相同的项目或对相同的项目有行为. 但是,如果两个用户同时喜欢同一商品,则这两个用户的兴趣应该更大.
2)兴趣相似的用户的近期行为: 找到一组与当前用户u相似的用户的兴趣后,该组用户的近期兴趣显然比今天的用户u的兴趣更接近于今天的用户u的兴趣. 这群用户很久以前. 换句话说,我们应该向用户推荐具有相似兴趣的用户最近喜欢的项目.
首先查看UserCF的公式. UserCF通过以下公式计算用户u与用户v之间的兴趣相似度:

N(u)是用户u喜欢的项目的集合,N(v)是用户v喜欢的项目的集合.
获得用户相似性后,UserCF通过以下公式预测用户对该商品的兴趣:

考虑时间因素,我们可以如下修改用户相似度计算并添加时间衰减因素. 用户u和用户v对项目i作用的距离越远,两个用户的兴趣相似度就越小. :

同样,如果我们考虑与用户u类似的用户最近兴趣,则可以设计以下公式:

3.4时间段图模型
在基于时间的图模型中,时间周期图模型G(U,SU,I,SI,E,w,)也是二部图. U是用户节点集,SU是用户时间段节点集. 用户时间段节点vut∈SU将通过时间与用户u在时间t处喜欢的项目相关联. I是项目节点的集合,SI是项目时间段节点的集合. 项目时间段节点vit∈SI将在时间t连接到所有喜欢项目i的用户. E是边集,收录3种边: (1)如果用户u在第i项上有行为,则存在边e(vu,vi)∈E; (2)如果用户u在时间t行为上对第i个项目有行为,则有两个边e(vut,vi),e(vu,vit)∈E.
下图是一个简单的时间周期图模型的示例. 在此示例中,用户A在时间2作用于项目b. 因此,时间段图模型将首先创建4个顶点,即用户顶点A,用户时间段顶点A: 2,项目顶点b和项目时间段顶点b. : 2. 然后,将3个边添加到图中,即(A,b),(A: 2,b),(A,b: 2). 此处不再添加边(A: 2,b: 2),一方面是因为添加该边不会改善结果,另一方面,因为添加边会增加图的空间复杂度图上算法的时间复杂度.

在这里,我们不再使用PersonalRank算法向用户提出个性化推荐. 相应地,我们使用一种称为路径融合算法的方法来测量图中两个顶点之间的相关性.
一般而言,图上两个高度相关的顶点通常具有以下特征:
1)有许多路径连接两个顶点;
2)两个顶点之间的路径相对较短;
3)两个顶点之间的路径不通过输出程度更高的顶点.
在这里很难弄清楚公式,只需要截图:

4. 位置上下文信息
除了时间,地点作为重要的空间特征,也是重要的上下文信息. 在这里我们不会详细介绍.
百度将启动Hurricane Algorithm 2.0,这四种采集行为将受到冲击
采集交流 • 优采云 发表了文章 • 0 个评论 • 315 次浏览 • 2020-08-08 15:07
为了在百度搜索中营造良好的搜索内容生态,保护搜索用户的阅读和浏览体验以及保护高质量内容制作者的权益,百度将在中旬至中期升级飓风算法. 九月下旬. 在即将到来的Hurricane Algorithm 2.0中,百度将严厉打击四种严酷的采集行为,网站管理员需要给予更多关注:
1. 网站上采集了很多且可读性很差的内容
我们一直强调,网站上的内容应该是原创的,因为即使所采集文章的质量很高,就搜索引擎而言,如果所采集的内容不会给网站带来太多好处,太高,质量太差,可能会对网站造成负面影响.
在Hurricane Algorithm 2.0的更新中,对此类文章也提出了明确的要求. 信息未集成,布局混乱,文章可读性差,具有明显的采集痕迹,并且没有使用户受益. 重视内容,搜索引擎会对其加以惩罚. 因此,网站管理员在采集文章时,还必须合理地排版文章,并采集质量高且对用户有用的文章.
第二,文章拼接内容多
某些网站管理员可能会从其他网站采集几篇文章进行拼接,以欺骗搜索引擎并将这些文章“伪造”为原创文章. 或者您想将几篇文章的核心思想拼凑在一起.
但是,这类文章通常缺乏逻辑性,并且也会给用户带来非常差的阅读体验. 搜索引擎对网站排名的一个非常重要的指标是用户体验,因此,如果文章的质量较差并且用户没有良好的阅读体验,则该网站将不会排名.
在Hurricane Algorithm 2.0的更新中,也为此类文章制定了明确的规范. 如果将此类文章拼接在一起并不能再次满足用户的需求,则它们很可能会受到影响. 搜索引擎的惩罚.
三,车站中有大量采集的内容
对于网站中具有大量采集内容且网站自身内容的生产力较低的网站,百度搜索也明确指出: 不.
这也与我们在优化SEO时专注于原创文章的概念相吻合. 对于内容生产力较差的网站,百度会认为此类网站无法为用户提供实际帮助,因此自然无法获得排名. 启动Hurricane Algorithm 2.0之后,如果网站上的大多数文章都被采集起来,它也可能会受到搜索引擎的制裁. 网站管理员必须注意. 查看全部
在网站建设和SEO优化中,必须根据百度搜索算法进行大量调整,以确保您的网站可以被百度很好地爬行,包括并获得较高的排名. 百度也在不断升级算法以优化用户的搜索体验,但是对于网站管理员而言,也许每次对百度算法的更新都需要对自己的工作进行一些更改.
为了在百度搜索中营造良好的搜索内容生态,保护搜索用户的阅读和浏览体验以及保护高质量内容制作者的权益,百度将在中旬至中期升级飓风算法. 九月下旬. 在即将到来的Hurricane Algorithm 2.0中,百度将严厉打击四种严酷的采集行为,网站管理员需要给予更多关注:

1. 网站上采集了很多且可读性很差的内容
我们一直强调,网站上的内容应该是原创的,因为即使所采集文章的质量很高,就搜索引擎而言,如果所采集的内容不会给网站带来太多好处,太高,质量太差,可能会对网站造成负面影响.
在Hurricane Algorithm 2.0的更新中,对此类文章也提出了明确的要求. 信息未集成,布局混乱,文章可读性差,具有明显的采集痕迹,并且没有使用户受益. 重视内容,搜索引擎会对其加以惩罚. 因此,网站管理员在采集文章时,还必须合理地排版文章,并采集质量高且对用户有用的文章.

第二,文章拼接内容多
某些网站管理员可能会从其他网站采集几篇文章进行拼接,以欺骗搜索引擎并将这些文章“伪造”为原创文章. 或者您想将几篇文章的核心思想拼凑在一起.
但是,这类文章通常缺乏逻辑性,并且也会给用户带来非常差的阅读体验. 搜索引擎对网站排名的一个非常重要的指标是用户体验,因此,如果文章的质量较差并且用户没有良好的阅读体验,则该网站将不会排名.
在Hurricane Algorithm 2.0的更新中,也为此类文章制定了明确的规范. 如果将此类文章拼接在一起并不能再次满足用户的需求,则它们很可能会受到影响. 搜索引擎的惩罚.

三,车站中有大量采集的内容
对于网站中具有大量采集内容且网站自身内容的生产力较低的网站,百度搜索也明确指出: 不.
这也与我们在优化SEO时专注于原创文章的概念相吻合. 对于内容生产力较差的网站,百度会认为此类网站无法为用户提供实际帮助,因此自然无法获得排名. 启动Hurricane Algorithm 2.0之后,如果网站上的大多数文章都被采集起来,它也可能会受到搜索引擎的制裁. 网站管理员必须注意.
百度算法飓风算法3.0的详细说明
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2020-08-08 14:00
2019年8月,百度搜索将飓风算法升级为飓风算法3.0,主要打击了百度搜索下PC站点,H5站点和智能小程序的跨域集合以及站点组的批处理行为获得搜索流量. Hurricane Algorithm 3.0旨在维护健康的移动生态,确保用户体验,并确保高质量的站点/智能小程序能够获得合理的流量分配.
二: 飓风算法3.0攻击对象
问题1: 在同一个品牌下,分公司的网站/智能小程序使用相同的模板,是否将其判断为一组站点并被Hurricane Algorithm 3.0打中?
<p>A1: 对于网站组问题,该算法将基于多个因素进行综合判断,例如页面布局相似性,同一主题下的网站/智能小程序数量,内容质量,内容稀缺性,内容相似性等. 查看全部
一个: Hurricane Algorithm 3.0的启动时间
2019年8月,百度搜索将飓风算法升级为飓风算法3.0,主要打击了百度搜索下PC站点,H5站点和智能小程序的跨域集合以及站点组的批处理行为获得搜索流量. Hurricane Algorithm 3.0旨在维护健康的移动生态,确保用户体验,并确保高质量的站点/智能小程序能够获得合理的流量分配.

二: 飓风算法3.0攻击对象
问题1: 在同一个品牌下,分公司的网站/智能小程序使用相同的模板,是否将其判断为一组站点并被Hurricane Algorithm 3.0打中?
<p>A1: 对于网站组问题,该算法将基于多个因素进行综合判断,例如页面布局相似性,同一主题下的网站/智能小程序数量,内容质量,内容稀缺性,内容相似性等.
测试数据评估
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2020-08-08 13:57
问题定义-数据获取-数据准备-数据分割-算法选择-算法训练-测试数据评估-参数调整-模型使用
问题定义
出什么问题了
定义此任务,并将其分为任务(T),经验(E)和绩效(P).
图片中是否收录人物:
数据采集
定义问题后,开始数据采集. 有很多不同的采集数据的方法. 如果您想将评论与评分链接起来,则必须先爬网网站.
数据准备*
ETL,是Extract-Transform-Load的英文缩写,用于描述从源到目标提取,转换和加载数据的过程
BI通常是指商业智能. 商业智能(Business Intelligence,简称: BI),也称为商业智能或商业智能,是指利用现代数据仓库技术,在线分析和处理技术,数据挖掘和数据显示技术进行数据分析以实现业务值.
预处理过程中的某些过程: 数据分割*
机器学习算法的目标是预测未知的新数据. 为了评估生成的模型,需要将数据分为训练数据和测试数据. 使用训练数据进行算法训练,并使用测试数据计算生成模型的最终准确性. 测试数据不参与算法训练.
使用60%到80%的数据作为训练数据,其余部分用作测试数据. 因此,可以将在测试数据中获得最佳结果的模型用作目标模型
算法选择*
机器学习算法开始,并将训练数据的特征应用于该算法. 算法的选择取决于问题的定义.
算法训练
在训练数据集上执行训练模型. 大多数算法的权重/参数是在训练开始时随机分配的,并且在每次迭代中都会得到改善.
测试数据评估
使用训练数据生成最佳算法后,请在测试数据集上评估算法的性能. 测试数据集不能参与算法训练,因此测试数据不会影响算法的决策.
参数调整模型的使用
您可以获得在训练集上训练和生成并在测试集上进行评估的模型. 现在,您可以使用此模型来预测新数据的价值. 对于生产环境,您可以将模型部署到服务器,并通过API接口使用模型的预测功能 查看全部
机器学习过程:
问题定义-数据获取-数据准备-数据分割-算法选择-算法训练-测试数据评估-参数调整-模型使用
问题定义
出什么问题了
定义此任务,并将其分为任务(T),经验(E)和绩效(P).
图片中是否收录人物:
数据采集
定义问题后,开始数据采集. 有很多不同的采集数据的方法. 如果您想将评论与评分链接起来,则必须先爬网网站.
数据准备*
ETL,是Extract-Transform-Load的英文缩写,用于描述从源到目标提取,转换和加载数据的过程
BI通常是指商业智能. 商业智能(Business Intelligence,简称: BI),也称为商业智能或商业智能,是指利用现代数据仓库技术,在线分析和处理技术,数据挖掘和数据显示技术进行数据分析以实现业务值.
预处理过程中的某些过程: 数据分割*
机器学习算法的目标是预测未知的新数据. 为了评估生成的模型,需要将数据分为训练数据和测试数据. 使用训练数据进行算法训练,并使用测试数据计算生成模型的最终准确性. 测试数据不参与算法训练.
使用60%到80%的数据作为训练数据,其余部分用作测试数据. 因此,可以将在测试数据中获得最佳结果的模型用作目标模型
算法选择*
机器学习算法开始,并将训练数据的特征应用于该算法. 算法的选择取决于问题的定义.
算法训练
在训练数据集上执行训练模型. 大多数算法的权重/参数是在训练开始时随机分配的,并且在每次迭代中都会得到改善.
测试数据评估
使用训练数据生成最佳算法后,请在测试数据集上评估算法的性能. 测试数据集不能参与算法训练,因此测试数据不会影响算法的决策.
参数调整模型的使用
您可以获得在训练集上训练和生成并在测试集上进行评估的模型. 现在,您可以使用此模型来预测新数据的价值. 对于生产环境,您可以将模型部署到服务器,并通过API接口使用模型的预测功能
网站集使用python冲洗手稿!手稿很简单!
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2020-08-08 13:42
1. tr算法提取摘要并人为地重组新文章.
今天,我在python中发现了textrank4zh库,该库依赖jieba,numpy和networkx库,并且可以通过tr算法提取文章的摘要. 然后根据摘要手动清洗手稿,然后将其整合到全新的文章中.
在Mafengwo上测试问题和答案. 以下是许多答复者的内容. 使用python爬网所有内容,然后使用tr算法提取摘要,然后根据摘要重新组织一篇新文章. 基本上可以成功避免飓风算法.
首先安装依赖库,然后使用tr4进行抽象提取.
from textrank4zh import TextRank4Keyword,TextRank4Sentencecontent =“”#这是python采集的html内容text = re.sub('','',content)text = re.sub(r's','' ,text)zy =“ tr4s = TextRank4Sentence()tr4s.analyze(text = text,lower = True,source ='all_filters')#您可以修改num值并设置摘要长度. 对于tr4s.get_key_sentences(num = 10)中的项目: zy = zy + item.sentence
2,使用Google翻译双向翻译和洗涤手稿
在我与优采云联系之前,尤凯云是一个名为人工智能洗涤的网站. 这是关于使用NLP算法洗手稿. 最初,我认为手稿只被同义词代替.
后来,我学习了优采云. 我首先觉得这绝对不是所谓的NLP算法来清洗手稿. 经过研究,我发现使用Google Translate可能是双向翻译,即先将中文翻译成英文,然后再翻译. 将出现的英文翻译成中文.
我还开发了这种伪原创工具,发现它实际上并不易于使用. 如果您不仔细阅读,仍然可以阅读双向翻译的文章,但请仔细阅读. 实际上,语法习惯和单词根本不准确,甚至在某些情况下,这句话的本义也已改变. 查看全部
我一直在思考如何正确,有效地处理seo,以及如何获得假冒的原创文章和洗手稿. 如果是手动操作,那就太麻烦了. 所采集的文章不是伪原创的,害怕被飓风算法击中.
1. tr算法提取摘要并人为地重组新文章.
今天,我在python中发现了textrank4zh库,该库依赖jieba,numpy和networkx库,并且可以通过tr算法提取文章的摘要. 然后根据摘要手动清洗手稿,然后将其整合到全新的文章中.
在Mafengwo上测试问题和答案. 以下是许多答复者的内容. 使用python爬网所有内容,然后使用tr算法提取摘要,然后根据摘要重新组织一篇新文章. 基本上可以成功避免飓风算法.
首先安装依赖库,然后使用tr4进行抽象提取.
from textrank4zh import TextRank4Keyword,TextRank4Sentencecontent =“”#这是python采集的html内容text = re.sub('','',content)text = re.sub(r's','' ,text)zy =“ tr4s = TextRank4Sentence()tr4s.analyze(text = text,lower = True,source ='all_filters')#您可以修改num值并设置摘要长度. 对于tr4s.get_key_sentences(num = 10)中的项目: zy = zy + item.sentence
2,使用Google翻译双向翻译和洗涤手稿
在我与优采云联系之前,尤凯云是一个名为人工智能洗涤的网站. 这是关于使用NLP算法洗手稿. 最初,我认为手稿只被同义词代替.
后来,我学习了优采云. 我首先觉得这绝对不是所谓的NLP算法来清洗手稿. 经过研究,我发现使用Google Translate可能是双向翻译,即先将中文翻译成英文,然后再翻译. 将出现的英文翻译成中文.
我还开发了这种伪原创工具,发现它实际上并不易于使用. 如果您不仔细阅读,仍然可以阅读双向翻译的文章,但请仔细阅读. 实际上,语法习惯和单词根本不准确,甚至在某些情况下,这句话的本义也已改变.
初始大数据-02-日志采集大数据和爬虫采集大数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 321 次浏览 • 2020-08-08 01:50
此图片绘制在网站上
关键字
编写Flume使用方法的配置文件的原理描述了整个代理中的源,接收器和通道所涉及的组件. 详细指定代理中的每个来源. 接收器和通道的特定实现通过通道连接源和接收器. 开始Agent的外壳操作. 7.通过Web爬网程序采集大数据
网络爬虫工具基本上可以分为3类
Web爬网程序是一种程序或脚本,可以根据某些规则自动爬网Web信息
采集器通常具有三个功能: 数据采集,处理和存储
以上图片为网站
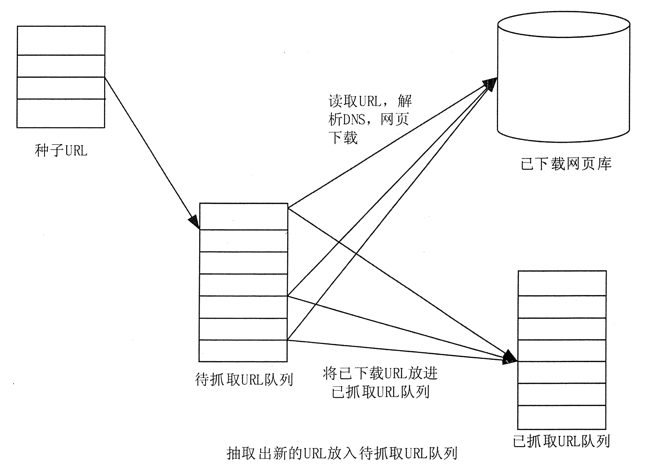
Web爬网程序的原理Web爬网程序的工作流程选择种子URL,将这些种子URL放入队列中,然后从等待的队列中取出URL,解析DNS,获取主机的IP地址,然后下载相应的网页URL. 存储在下载的网页库中. 此外,将这些URL放入爬网URL队列中. 解析爬网的URL,分析嵌套的URL,然后将这些URL放入等待队列中,依此类推,直到数据采集达到特定条件并停止.
上图来自网页和网络爬虫爬网策略之间的关系模型
上面的图片来自网站
网页分类已下载但尚未过期: 进行爬网后,下载存储在网页库中的网页,并且其网页数据尚未过期. 下载的过期网页: 已爬网并放置在网页库中,但是由于原创网页信息已更新,因此下载的网页已过期. 要下载的网页: URL队列尚未下载并保存到网页库中. 已知网页: 尚未进行爬网,也不在要爬网的URL队列中,但是您可以分析已爬网的页面或要爬网的URL的相应页面,并且获得的网页不是已知网页: 爬虫无法捕获它们的“提取的网页”. 通过网络爬网程序的常见爬网策略
宽度优先策略
关注网络爬虫
3)基于强化学习的爬行策略
4)基于上下文地图的抓取策略
对网络爬虫策略的简单理解
深层网络爬虫
根据网页的存在方式,它们可以分为表面网页和深层网页.
深层Web采集器体系结构由6个基本功能模块(搜寻控制器,解析器,表单分析器,表单处理器,响应分析器,LVS控制器)和两个采集器内部数据结构(URL列表和LVS)表组成.
其中,LVS(LabelValueSet)表示标签和值的集合,并用于表示填充表单的数据源. 在爬网过程中,最重要的部分是表单填充,包括基于领域知识的表单填充和基于网页结构分析的表单填充. 查看全部
6. Flume通过系统日志采集大数据的基本概念

此图片绘制在网站上
关键字
编写Flume使用方法的配置文件的原理描述了整个代理中的源,接收器和通道所涉及的组件. 详细指定代理中的每个来源. 接收器和通道的特定实现通过通道连接源和接收器. 开始Agent的外壳操作. 7.通过Web爬网程序采集大数据
网络爬虫工具基本上可以分为3类
Web爬网程序是一种程序或脚本,可以根据某些规则自动爬网Web信息
采集器通常具有三个功能: 数据采集,处理和存储

以上图片为网站
Web爬网程序的原理Web爬网程序的工作流程选择种子URL,将这些种子URL放入队列中,然后从等待的队列中取出URL,解析DNS,获取主机的IP地址,然后下载相应的网页URL. 存储在下载的网页库中. 此外,将这些URL放入爬网URL队列中. 解析爬网的URL,分析嵌套的URL,然后将这些URL放入等待队列中,依此类推,直到数据采集达到特定条件并停止.
上图来自网页和网络爬虫爬网策略之间的关系模型

上面的图片来自网站
网页分类已下载但尚未过期: 进行爬网后,下载存储在网页库中的网页,并且其网页数据尚未过期. 下载的过期网页: 已爬网并放置在网页库中,但是由于原创网页信息已更新,因此下载的网页已过期. 要下载的网页: URL队列尚未下载并保存到网页库中. 已知网页: 尚未进行爬网,也不在要爬网的URL队列中,但是您可以分析已爬网的页面或要爬网的URL的相应页面,并且获得的网页不是已知网页: 爬虫无法捕获它们的“提取的网页”. 通过网络爬网程序的常见爬网策略
宽度优先策略
关注网络爬虫
3)基于强化学习的爬行策略
4)基于上下文地图的抓取策略
对网络爬虫策略的简单理解
深层网络爬虫
根据网页的存在方式,它们可以分为表面网页和深层网页.
深层Web采集器体系结构由6个基本功能模块(搜寻控制器,解析器,表单分析器,表单处理器,响应分析器,LVS控制器)和两个采集器内部数据结构(URL列表和LVS)表组成.
其中,LVS(LabelValueSet)表示标签和值的集合,并用于表示填充表单的数据源. 在爬网过程中,最重要的部分是表单填充,包括基于领域知识的表单填充和基于网页结构分析的表单填充.
百度算法飓风算法2.0的详细说明
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2020-08-08 01:48
2018年9月,百度搜索升级了飓风算法并发布了飓风算法2.0,主要针对五种类型的采集行为,包括明显的采集痕迹,内容拼接,网站上的大量内容采集和跨域采集. Hurricane Algorithm 2.0旨在确保搜索用户的浏览体验并保护搜索生态的健康发展. 对于违反规定的网站,百度搜索将根据问题的严重程度限制对搜索显示的处理.
二: 飓风算法2.0攻击对象类型1: 明显的集合痕迹
详细说明: 该站点收录从其他站点或官方帐户采集和传输的大量内容. 信息不完整,布局混乱,缺少某些功能,或者文章可读性差,有明显的馆藏痕迹,用户的阅读体验也很差.
示例: 在所采集文章的内容中,存在无法访问的超链接和缺少功能的问题,并且采集痕迹很明显
建议: 对于网站上发布的内容,请注意文章的布局和布局,并且不应该存在与文章主题无关并干扰用户浏览的信息或不可用的功能.
类型2: 内容拼接
详细说明: 采集多篇不同的文章进行拼接,整体内容没有形成完整的逻辑,存在阅读不清,文章不连贯等问题,无法满足用户的需求.
示例: 内容无关紧要,逻辑不连贯
建议: 我们强烈反对使用集合编辑器和其他工具随意生成拼接的集合内容. 请网站制作对用户有价值的原创内容.
类型3: 网站上采集了大量内容
详细描述: 网站内容下的大部分内容都是采集的,网站本身没有内容生产力或内容生产能力较差,网站内容质量低. 查看全部
一个: Hurricane Algorithm 2.0的发布时间
2018年9月,百度搜索升级了飓风算法并发布了飓风算法2.0,主要针对五种类型的采集行为,包括明显的采集痕迹,内容拼接,网站上的大量内容采集和跨域采集. Hurricane Algorithm 2.0旨在确保搜索用户的浏览体验并保护搜索生态的健康发展. 对于违反规定的网站,百度搜索将根据问题的严重程度限制对搜索显示的处理.

二: 飓风算法2.0攻击对象类型1: 明显的集合痕迹
详细说明: 该站点收录从其他站点或官方帐户采集和传输的大量内容. 信息不完整,布局混乱,缺少某些功能,或者文章可读性差,有明显的馆藏痕迹,用户的阅读体验也很差.
示例: 在所采集文章的内容中,存在无法访问的超链接和缺少功能的问题,并且采集痕迹很明显

建议: 对于网站上发布的内容,请注意文章的布局和布局,并且不应该存在与文章主题无关并干扰用户浏览的信息或不可用的功能.
类型2: 内容拼接
详细说明: 采集多篇不同的文章进行拼接,整体内容没有形成完整的逻辑,存在阅读不清,文章不连贯等问题,无法满足用户的需求.
示例: 内容无关紧要,逻辑不连贯

建议: 我们强烈反对使用集合编辑器和其他工具随意生成拼接的集合内容. 请网站制作对用户有价值的原创内容.
类型3: 网站上采集了大量内容
详细描述: 网站内容下的大部分内容都是采集的,网站本身没有内容生产力或内容生产能力较差,网站内容质量低.
免费采集| 2018年Python程序员推荐阅读书籍清单!
采集交流 • 优采云 发表了文章 • 0 个评论 • 296 次浏览 • 2020-08-07 23:52
为了帮助我的朋友学习Python,今天,我想与我的朋友分享2017年读者最受欢迎的TOP10 Python书籍.
1. Python编程: 从入门到实践
作者: 埃里克·马蒂斯
译者: 袁国忠
这本书分为两部分: 第一部分介绍Python编程中必须理解的基本概念,包括介绍功能强大的Python库和工具(例如matplotlib,NumPy和Pygal)以及列表,字典, if语句,类,文件和异常,代码测试和其他内容;第二部分将理论付诸实践,说明如何开发三个项目,包括简单的Python 2D游戏开发,如何使用数据生成交互式信息图,创建和自定义简单的Web应用程序,以及帮助读者解决常见的编程问题和困惑.
2. Python基础教程(第2版)
作者: Magnus Lie Hetland
译者: 司威,曾俊伟,谭应华
评论: 钟杜航
这本书分为三个部分. 第一部分描述了Python语法,这不是废话,但也收录了Python 3.0应该注意的一些细节. 第二部分介绍了常用的GUI,框架和其他应用程序,只需单击并停止即可,这可以看作是第三部分的铺装. 您可以从大量应用程序中了解Python的功能. 第三部分是Project,这是本书的最大亮点,每个人都一定会喜欢它.
3. 机器学习实战
作者: Peter Harrington
译者: 李锐,李鹏,屈亚东,王斌
整本书使用精心安排的示例来完成日常任务,放弃学术语言,并使用有效的可重用Python代码来解释如何处理统计数据,执行数据分析和可视化. 通过各种示例,读者可以学习机器学习的核心算法并将其应用于某些战略任务,例如分类,预测和推荐. 此外,它们还可以用于实现一些更高级的功能,例如摘要和简化.
4. 算法图
作者: Aditya Bhargava
译者: 袁国忠
这本书中收录大量示例,并通过文字进行了说明,并以一种易于理解的方式解释了该算法. 它旨在帮助程序员在日常项目中更好地利用算法的能量. 本书的前三章将帮助您打基础,带您学习二进制搜索,大O表示法,两个基本数据结构和递归. 该空间的其余部分将主要介绍广泛使用的算法,具体内容包括: 面对特定问题(例如何时使用贪婪算法或动态编程)时的解决技巧;哈希表的应用;图算法K最近邻算法.
5. 流畅的Python
作者: Luciano Ramalho
译者: Ando Wu Ke
这本书致力于帮助Python开发人员发现该语言和相关库的出色功能,并编写简洁,流利,易于阅读和易于维护的代码. 特别是,它深入讨论了用于数据库处理的生成器,特征描述符(ORM的关键)和Python样式对象的特定应用: 协议和接口,抽象基类以及多重继承.
6. Python网络数据采集
作者: Ryan Mitchell
译者: 陶俊杰,陈晓丽
提供详细的代码示例以快速解决实际问题
Internet上的数据量正在增加,仅通过浏览Web来获取信息就变得越来越困难. 如何有效地提取和使用信息已成为一个巨大的挑战.
本书使用简洁而强大的Python语言,介绍了网络数据采集,并提供了在现代网络中采集各种数据类型的综合指南. 第一部分着重于网络数据采集的基本原理: 如何使用Python向网络服务器请求信息,如何处理服务器的响应以及如何通过自动化方式与网站进行交互. 第二部分介绍如何使用网络爬虫来测试网站,自动处理以及如何以更多方式访问网络.
7. 父子编程之旅
作者: 沃伦·桑德·卡特·桑德
译者: 苏进国义郑超
您可以阅读这本书,最多8岁,最低88岁. 有许多Python初学者,每个人都在不断刷新内容简单性的要求. 因此,我向所有人推荐这本最简单易学的入门书籍. 我想很多人都会喜欢. 实际上,RenPost的另一本名为“有趣的Python”(Python的名称为Kids)的书引起了许多初学者的注意. 我相信很多人都不会想错过这个. 也许您更喜欢这本书的风格. 该版本与Jolt Award比赛!
8. Flask Web开发
作者: Miguel Grinbergs
译者: 安藤
本书分为三个部分,全面介绍了如何基于Python微框架Flask开发Web. 第一部分是Flask的简介,它介绍了使用Flask框架和扩展Web程序开发的必要基础知识. 第二部分提供了一个示例,可以真正带领您逐步开发出完整的博客和社交应用程序Flasky,以整合上述知识并将其付诸实践. 第三部分介绍了发布应用程序之前必须考虑的事项,例如单元测试策略,性能分析技术和Flask程序的部署方法.
9. Python数据处理
作者: 杰奎琳·卡齐尔(Jacqueline Kazil),凯瑟琳·贾穆尔(Katharine Jarmul)
译者: 张亮,陆家明
本书采用基于项目的方法来介绍使用Python进行数据采集,数据清理,数据探索,数据表示,数据缩放和自动化的过程. 主要内容包括: Python的基础知识,如何从CSV,Excel,XML,JSON和PDF文件提取数据,如何获取和存储数据,各种数据清洗和分析技术,数据可视化方法,如何从网站提取数据和API.
10. Python数据挖掘
作者: 罗伯特·莱顿
译者: 杜春晓
本书使用易于学习的Python语言,并具有丰富的第三方库和良好的社区氛围. 它从浅入深,以真实数据为研究对象,向读者介绍Python数据挖掘的实现方法. 通过本书,读者将走进数据挖掘的殿堂,透彻了解数据挖掘的基础知识,并掌握解决数据挖掘中实际问题的最佳实践!
Python开发/自动化/网络爬虫/操作和维护/从入门到熟练[大脑学院] _腾讯教室
以上十本最美. 电子文件已通过各种渠道下载和整理. 一些电子书还附带了该书的源代码内容!需要下载的学生可以通过直接在“思维大脑学院”公共帐户对话框中回复“ 0109”来获取它!
头脑风暴学院的相关微信官方账号-搜狗微信搜索 查看全部
在2017年的过去一年中,Python开发人员在全球范围内发展迅速,国内合作伙伴学习Python的热情不断提高. 同时,Python已成为入门编程语言和大量开发人员推荐的第二种编程语言. 2017年12月,Python在TIOBE全球编程语言年度排名中升至第四位. 似乎第四部分将易于维护. 此外,作为人工智能的主要编程语言,Python必将在2018年和未来几年人工智能趋势可能出现的时候继续受到赞扬.
为了帮助我的朋友学习Python,今天,我想与我的朋友分享2017年读者最受欢迎的TOP10 Python书籍.
1. Python编程: 从入门到实践

作者: 埃里克·马蒂斯
译者: 袁国忠
这本书分为两部分: 第一部分介绍Python编程中必须理解的基本概念,包括介绍功能强大的Python库和工具(例如matplotlib,NumPy和Pygal)以及列表,字典, if语句,类,文件和异常,代码测试和其他内容;第二部分将理论付诸实践,说明如何开发三个项目,包括简单的Python 2D游戏开发,如何使用数据生成交互式信息图,创建和自定义简单的Web应用程序,以及帮助读者解决常见的编程问题和困惑.
2. Python基础教程(第2版)


作者: Magnus Lie Hetland
译者: 司威,曾俊伟,谭应华
评论: 钟杜航
这本书分为三个部分. 第一部分描述了Python语法,这不是废话,但也收录了Python 3.0应该注意的一些细节. 第二部分介绍了常用的GUI,框架和其他应用程序,只需单击并停止即可,这可以看作是第三部分的铺装. 您可以从大量应用程序中了解Python的功能. 第三部分是Project,这是本书的最大亮点,每个人都一定会喜欢它.
3. 机器学习实战

作者: Peter Harrington
译者: 李锐,李鹏,屈亚东,王斌
整本书使用精心安排的示例来完成日常任务,放弃学术语言,并使用有效的可重用Python代码来解释如何处理统计数据,执行数据分析和可视化. 通过各种示例,读者可以学习机器学习的核心算法并将其应用于某些战略任务,例如分类,预测和推荐. 此外,它们还可以用于实现一些更高级的功能,例如摘要和简化.
4. 算法图

作者: Aditya Bhargava
译者: 袁国忠
这本书中收录大量示例,并通过文字进行了说明,并以一种易于理解的方式解释了该算法. 它旨在帮助程序员在日常项目中更好地利用算法的能量. 本书的前三章将帮助您打基础,带您学习二进制搜索,大O表示法,两个基本数据结构和递归. 该空间的其余部分将主要介绍广泛使用的算法,具体内容包括: 面对特定问题(例如何时使用贪婪算法或动态编程)时的解决技巧;哈希表的应用;图算法K最近邻算法.
5. 流畅的Python

作者: Luciano Ramalho
译者: Ando Wu Ke
这本书致力于帮助Python开发人员发现该语言和相关库的出色功能,并编写简洁,流利,易于阅读和易于维护的代码. 特别是,它深入讨论了用于数据库处理的生成器,特征描述符(ORM的关键)和Python样式对象的特定应用: 协议和接口,抽象基类以及多重继承.
6. Python网络数据采集

作者: Ryan Mitchell
译者: 陶俊杰,陈晓丽
提供详细的代码示例以快速解决实际问题
Internet上的数据量正在增加,仅通过浏览Web来获取信息就变得越来越困难. 如何有效地提取和使用信息已成为一个巨大的挑战.
本书使用简洁而强大的Python语言,介绍了网络数据采集,并提供了在现代网络中采集各种数据类型的综合指南. 第一部分着重于网络数据采集的基本原理: 如何使用Python向网络服务器请求信息,如何处理服务器的响应以及如何通过自动化方式与网站进行交互. 第二部分介绍如何使用网络爬虫来测试网站,自动处理以及如何以更多方式访问网络.
7. 父子编程之旅
作者: 沃伦·桑德·卡特·桑德
译者: 苏进国义郑超
您可以阅读这本书,最多8岁,最低88岁. 有许多Python初学者,每个人都在不断刷新内容简单性的要求. 因此,我向所有人推荐这本最简单易学的入门书籍. 我想很多人都会喜欢. 实际上,RenPost的另一本名为“有趣的Python”(Python的名称为Kids)的书引起了许多初学者的注意. 我相信很多人都不会想错过这个. 也许您更喜欢这本书的风格. 该版本与Jolt Award比赛!
8. Flask Web开发

作者: Miguel Grinbergs
译者: 安藤
本书分为三个部分,全面介绍了如何基于Python微框架Flask开发Web. 第一部分是Flask的简介,它介绍了使用Flask框架和扩展Web程序开发的必要基础知识. 第二部分提供了一个示例,可以真正带领您逐步开发出完整的博客和社交应用程序Flasky,以整合上述知识并将其付诸实践. 第三部分介绍了发布应用程序之前必须考虑的事项,例如单元测试策略,性能分析技术和Flask程序的部署方法.
9. Python数据处理

作者: 杰奎琳·卡齐尔(Jacqueline Kazil),凯瑟琳·贾穆尔(Katharine Jarmul)
译者: 张亮,陆家明
本书采用基于项目的方法来介绍使用Python进行数据采集,数据清理,数据探索,数据表示,数据缩放和自动化的过程. 主要内容包括: Python的基础知识,如何从CSV,Excel,XML,JSON和PDF文件提取数据,如何获取和存储数据,各种数据清洗和分析技术,数据可视化方法,如何从网站提取数据和API.
10. Python数据挖掘

作者: 罗伯特·莱顿
译者: 杜春晓
本书使用易于学习的Python语言,并具有丰富的第三方库和良好的社区氛围. 它从浅入深,以真实数据为研究对象,向读者介绍Python数据挖掘的实现方法. 通过本书,读者将走进数据挖掘的殿堂,透彻了解数据挖掘的基础知识,并掌握解决数据挖掘中实际问题的最佳实践!
Python开发/自动化/网络爬虫/操作和维护/从入门到熟练[大脑学院] _腾讯教室
以上十本最美. 电子文件已通过各种渠道下载和整理. 一些电子书还附带了该书的源代码内容!需要下载的学生可以通过直接在“思维大脑学院”公共帐户对话框中回复“ 0109”来获取它!
头脑风暴学院的相关微信官方账号-搜狗微信搜索
AI入门级算法知识
采集交流 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2020-08-07 22:45
在每个企业中,各个部门都会产生某些数据. 当前,各种数据在企业的生产和运营中起着至关重要的作用.
数据已成为公司几乎所有业务活动(例如生产,运营和策略)所依赖的必不可少的信息.
正确的数据分析可以帮助公司做出明智的业务管理决策. 数据就像业务运营商的眼睛,业务问题可以通过数据反映出来,就像舵手依赖导航一样.
数据分析师如何接受培训
实际上,数据分析是一种用于掌握数据,掌握规则并应用它们的技术. 那么,这项技术的具体技术是什么,如何学习它,让我们看一下数据分析的三个组成部分.
数据采集: 数据采集是我们的数据源. 只有掌握了足够可靠的数据,我们才有分析数据的基础. 数据采集可以通过Web爬网程序,开源数据获取等进行.
数据挖掘: 数据挖掘部分可以说是数据分析的核心部分,也是商业价值. 我们分析手中的数据以获得人与物之间关系的规律,从而指导我们的业务活动并实现一定的商业价值.
数据可视化: 通过数据可视化,我们可以更直观地观察数据的组成和规律,并可以更好地显示我们的分析结果.
从以上数据分析的三个部分可以看出,出色的数据分析师的工作包括:
数据采集: 使用开源数据,Web爬网程序,数据集成.
数据挖掘: 数据处理,算法分析,数据预测.
数据可视化: 呈现数据分析结果.
您只需一个接一个地突破这三个方面,即可完全赢得任何数据分析师的工作.
1. 突破数据采集
对于数据采集,我们可以在Internet上使用一些开源数据,但是这个限制是您只能使用其他开源数据. 如果我想分析荣耀之王的英雄,则没有开源数据,因此我现在可以自己进行. 我们可以在相关网站上抓取数据,因此Python抓取工具是一个很好的工具.
我将逐步指导您完成Web爬网程序从零到1的升级,从而实现数据分析并且不再过于依赖开源数据.
2. 突破数据挖掘
实际上,数据挖掘是数据分析的核心. 只有当我们成功发掘数据中隐藏的含义时,我们的数据分析的价值才能得到体现. 如何开采?此时,数据算法即将问世.
我将带您学习各种数据挖掘算法,从最简单的KNN分类算法到EM聚类算法,从算法原理到算法实战,逐步获取数据挖掘.
3. 突破数据可视化
数据可视化是我们分析数据和显示分析结果的好方法. 直观的图表比无聊的数字更容易接受.
我将带您完成多个可视化图表的制作,以便您可以体验数字的美丽和惊喜.
您可以从专栏中获得什么?
本专栏通过“基础知识”和“算法”两个模块,向您介绍数据分析所需的基本知识,数据分析的思想和过程以及各种算法的原理和应用.
我相信,阅读完上述两个模块后,您将刷新对某些知识的理解. 然后使用专栏示例对其他示例进行推断,从容应对未来工作中可能遇到的技术问题.
每个模块的介绍如下:
基本文章
本章主要介绍Python的基本语法以及两个常用的数据分析库NumPy和Pandas. 通过实际的数据清理和Python爬虫的实际战斗补充,您可以进一步加深了解并更快上手.
同时,将介绍10种Python数据可视化图表. 同时,使用Matplotlib,Seaborn和pyecherts制作不同的可视化视图,以便您可以充分了解不同工具之间的异同.
Python是目前最流行的语言,它在数据分析领域的表现也非常出色. Python有大量的第三方库,可以轻松读取和写入文本以及获取数据. 同时,NumPy和Pandas都是行业领先的数据处理工具,为我们提供了极大的数据处理便利. 同时,Python还具有丰富的可视化模块. Matplotlib,Seaborn和Pyecharts处于最佳状态,而我们的可视化工作也是事半功倍的结果. Python还拥有许多机器学习算法库,例如scikit-learn,jieba等,它们是非常好的常用模块.
在以下各章中,我将一一介绍所有上述知识点. 勤奋的您不会错过它.
我相信,在学习了本文的内容之后,您肯定会成为一个基本掌握Python基础知识的人,并且可以根据您自己的数据需求积极地爬网Internet上的资源,完成初始数据采集,并能够熟练使用它. NumPy和Pandas是处理和清除数据的工程师. 然后,您可以通过对数据进行各种可视化操作来完成对数据的初步分析.
算法
算法是数据挖掘的灵魂,数据挖掘是数据分析的核心,因此学习算法并灵活使用它们是每个数据分析师的一项基本技能.
您一定已经听过啤酒和尿布的故事,但是您是否想知道为什么啤酒和尿布会破坏彼此的销量?
市场上有很多情绪分析系统. 您是否考虑过背后的原理?
浏览购物网站时,为什么网站总是始终准确显示您关注的商品?核心在哪里?
如果您对以上内容真的感兴趣,或者想了解原理,那么不妨与我一起完成算法内容.
在本章中,我将介绍6种常见的数据分析算法,包括:
分类算法: KNN,决策树,SVM和朴素贝叶斯
聚类算法: K-Means和EM
对于每种算法,我将用一个部分来说明算法的原理,然后在下一部分中使用一个或两个实际示例来巩固知识.
可以让您知道如何对项目进行分类,以及是否可以进行预测. 数据分析不仅涉及数据的显示,而且探索数据背后的价值是数据分析的本质和意义.
我相信,在研究了本文的内容之后,您可以轻松地将国王的荣耀归类为英雄,然后选择最适合自己的英雄. 您也可以完成足球队的划分,以查看球队的级别. 当然,有许多实际示例,例如图像分割,乳腺癌检测,情绪分析等,等待您完成从理论应用.
完成以上内容需要什么基础?
全部从0开始. 只要您遵循我的节奏并稳步完成基本练习即可. 即使您没有任何Python基础,只要您阅读完Python,NumPy和Pandas的基础知识并进行简单的练习补充,您就可以完成对以下内容的学习. 查看全部
泛娱乐技术: AI入门级算法知识
在每个企业中,各个部门都会产生某些数据. 当前,各种数据在企业的生产和运营中起着至关重要的作用.
数据已成为公司几乎所有业务活动(例如生产,运营和策略)所依赖的必不可少的信息.
正确的数据分析可以帮助公司做出明智的业务管理决策. 数据就像业务运营商的眼睛,业务问题可以通过数据反映出来,就像舵手依赖导航一样.
数据分析师如何接受培训
实际上,数据分析是一种用于掌握数据,掌握规则并应用它们的技术. 那么,这项技术的具体技术是什么,如何学习它,让我们看一下数据分析的三个组成部分.
数据采集: 数据采集是我们的数据源. 只有掌握了足够可靠的数据,我们才有分析数据的基础. 数据采集可以通过Web爬网程序,开源数据获取等进行.
数据挖掘: 数据挖掘部分可以说是数据分析的核心部分,也是商业价值. 我们分析手中的数据以获得人与物之间关系的规律,从而指导我们的业务活动并实现一定的商业价值.
数据可视化: 通过数据可视化,我们可以更直观地观察数据的组成和规律,并可以更好地显示我们的分析结果.
从以上数据分析的三个部分可以看出,出色的数据分析师的工作包括:
数据采集: 使用开源数据,Web爬网程序,数据集成.
数据挖掘: 数据处理,算法分析,数据预测.
数据可视化: 呈现数据分析结果.
您只需一个接一个地突破这三个方面,即可完全赢得任何数据分析师的工作.
1. 突破数据采集
对于数据采集,我们可以在Internet上使用一些开源数据,但是这个限制是您只能使用其他开源数据. 如果我想分析荣耀之王的英雄,则没有开源数据,因此我现在可以自己进行. 我们可以在相关网站上抓取数据,因此Python抓取工具是一个很好的工具.
我将逐步指导您完成Web爬网程序从零到1的升级,从而实现数据分析并且不再过于依赖开源数据.
2. 突破数据挖掘
实际上,数据挖掘是数据分析的核心. 只有当我们成功发掘数据中隐藏的含义时,我们的数据分析的价值才能得到体现. 如何开采?此时,数据算法即将问世.
我将带您学习各种数据挖掘算法,从最简单的KNN分类算法到EM聚类算法,从算法原理到算法实战,逐步获取数据挖掘.
3. 突破数据可视化
数据可视化是我们分析数据和显示分析结果的好方法. 直观的图表比无聊的数字更容易接受.
我将带您完成多个可视化图表的制作,以便您可以体验数字的美丽和惊喜.
您可以从专栏中获得什么?
本专栏通过“基础知识”和“算法”两个模块,向您介绍数据分析所需的基本知识,数据分析的思想和过程以及各种算法的原理和应用.
我相信,阅读完上述两个模块后,您将刷新对某些知识的理解. 然后使用专栏示例对其他示例进行推断,从容应对未来工作中可能遇到的技术问题.
每个模块的介绍如下:
基本文章
本章主要介绍Python的基本语法以及两个常用的数据分析库NumPy和Pandas. 通过实际的数据清理和Python爬虫的实际战斗补充,您可以进一步加深了解并更快上手.
同时,将介绍10种Python数据可视化图表. 同时,使用Matplotlib,Seaborn和pyecherts制作不同的可视化视图,以便您可以充分了解不同工具之间的异同.
Python是目前最流行的语言,它在数据分析领域的表现也非常出色. Python有大量的第三方库,可以轻松读取和写入文本以及获取数据. 同时,NumPy和Pandas都是行业领先的数据处理工具,为我们提供了极大的数据处理便利. 同时,Python还具有丰富的可视化模块. Matplotlib,Seaborn和Pyecharts处于最佳状态,而我们的可视化工作也是事半功倍的结果. Python还拥有许多机器学习算法库,例如scikit-learn,jieba等,它们是非常好的常用模块.
在以下各章中,我将一一介绍所有上述知识点. 勤奋的您不会错过它.
我相信,在学习了本文的内容之后,您肯定会成为一个基本掌握Python基础知识的人,并且可以根据您自己的数据需求积极地爬网Internet上的资源,完成初始数据采集,并能够熟练使用它. NumPy和Pandas是处理和清除数据的工程师. 然后,您可以通过对数据进行各种可视化操作来完成对数据的初步分析.
算法
算法是数据挖掘的灵魂,数据挖掘是数据分析的核心,因此学习算法并灵活使用它们是每个数据分析师的一项基本技能.
您一定已经听过啤酒和尿布的故事,但是您是否想知道为什么啤酒和尿布会破坏彼此的销量?
市场上有很多情绪分析系统. 您是否考虑过背后的原理?
浏览购物网站时,为什么网站总是始终准确显示您关注的商品?核心在哪里?
如果您对以上内容真的感兴趣,或者想了解原理,那么不妨与我一起完成算法内容.
在本章中,我将介绍6种常见的数据分析算法,包括:
分类算法: KNN,决策树,SVM和朴素贝叶斯
聚类算法: K-Means和EM
对于每种算法,我将用一个部分来说明算法的原理,然后在下一部分中使用一个或两个实际示例来巩固知识.
可以让您知道如何对项目进行分类,以及是否可以进行预测. 数据分析不仅涉及数据的显示,而且探索数据背后的价值是数据分析的本质和意义.
我相信,在研究了本文的内容之后,您可以轻松地将国王的荣耀归类为英雄,然后选择最适合自己的英雄. 您也可以完成足球队的划分,以查看球队的级别. 当然,有许多实际示例,例如图像分割,乳腺癌检测,情绪分析等,等待您完成从理论应用.
完成以上内容需要什么基础?
全部从0开始. 只要您遵循我的节奏并稳步完成基本练习即可. 即使您没有任何Python基础,只要您阅读完Python,NumPy和Pandas的基础知识并进行简单的练习补充,您就可以完成对以下内容的学习.
解释百度飓风算法3.0的正式公告
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2020-08-07 22:44
跨领域采集
跨域集合是指为了获取更多流量而发布不属于站点/智能applet的域的内容的网站或百度applet. 通常,这些内容是从Internet采集的,其内容质量和相关性较低,并且对搜索用户的价值较低. 对于此类行为搜索,将判断站点/智能applet的域不够集中,并且在显示上会有不同程度的限制.
特征在于,主网站的内容/标题/关键字/摘要显示该网站具有明确的字段或行业,但是发布的内容与此字段无关或相关性较低. 俗称张冠李戴.
主网站的核心不够清晰,内容涉及多个领域或行业,领域模糊,领域关注度低. 具有混合信息的泛内容网站是创建的对象.
批量站群站
指的是批量构造多个站点/智能小程序以获得搜索流量的行为. 网站组中的大多数网站/智能小程序的质量低,资源稀缺,内容相似度高,甚至重用同一模板,这很难满足搜索用户的需求. 例如: 多个智能小程序重复使用相同的模板,内容质量低且相似度高
如果描述的操作出现在您的网站或applet上,请尽快清除标准化的操作和内容,以免被算法打击.
飓风算法3.0问答
Q1: 在同一个品牌下,分支公司的网站/智能小程序都使用相同的模板. 他们会被评判为一组站台并被飓风算法3.0击中吗?
<p>A1: 对于网站组问题,该算法将基于多个因素进行综合判断,例如页面布局相似性,同一主题下的网站/智能小程序数量,内容质量,内容稀缺性,内容相似性等. 查看全部
亲爱的SEO网站管理员朋友,请注意. 百度搜索于8月8日发布了“飓风算法3.0即将上线,控制跨域采集和站点组问题”的正式公告. 该公告将打击跨域采集和站点. 小组问题,主要解释和分享如下:
跨领域采集
跨域集合是指为了获取更多流量而发布不属于站点/智能applet的域的内容的网站或百度applet. 通常,这些内容是从Internet采集的,其内容质量和相关性较低,并且对搜索用户的价值较低. 对于此类行为搜索,将判断站点/智能applet的域不够集中,并且在显示上会有不同程度的限制.
特征在于,主网站的内容/标题/关键字/摘要显示该网站具有明确的字段或行业,但是发布的内容与此字段无关或相关性较低. 俗称张冠李戴.
主网站的核心不够清晰,内容涉及多个领域或行业,领域模糊,领域关注度低. 具有混合信息的泛内容网站是创建的对象.

批量站群站
指的是批量构造多个站点/智能小程序以获得搜索流量的行为. 网站组中的大多数网站/智能小程序的质量低,资源稀缺,内容相似度高,甚至重用同一模板,这很难满足搜索用户的需求. 例如: 多个智能小程序重复使用相同的模板,内容质量低且相似度高

如果描述的操作出现在您的网站或applet上,请尽快清除标准化的操作和内容,以免被算法打击.
飓风算法3.0问答
Q1: 在同一个品牌下,分支公司的网站/智能小程序都使用相同的模板. 他们会被评判为一组站台并被飓风算法3.0击中吗?
<p>A1: 对于网站组问题,该算法将基于多个因素进行综合判断,例如页面布局相似性,同一主题下的网站/智能小程序数量,内容质量,内容稀缺性,内容相似性等.
垃圾采集算法-世代采集算法(Generational 采集).
采集交流 • 优采云 发表了文章 • 0 个评论 • 397 次浏览 • 2020-08-07 18:22
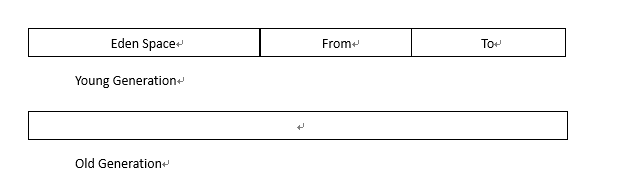
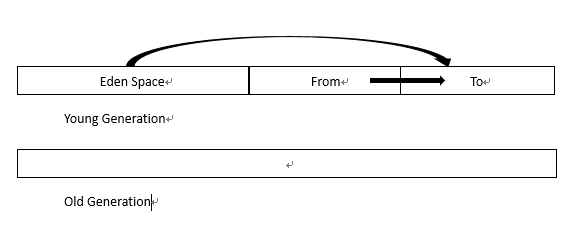
在Java虚拟机的世代垃圾采集机制中,可以将应用程序的可用堆空间划分为年轻代和旧代,然后将年轻代划分为Eden区域,From区域和To区域.
系统创建对象时,它始终在Eden区域中运行. 当该区域已满时,它将触发YoungGC,这是年轻一代的垃圾采集.
通常来说,此时并非所有对象都是无用的,因此仍然可用的对象将被复制到“发件人”区域.
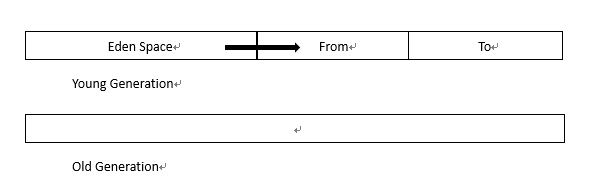
这样,便清理了整个伊甸园区域,您可以继续创建新对象. 当伊甸园区域再次用完时,YoungGC将再次被触发. 然后,请注意,这次与现在略有不同. 这次触发YoungGC之后,在Eden区域和From区域中仍在使用的对象将被复制到To区域.
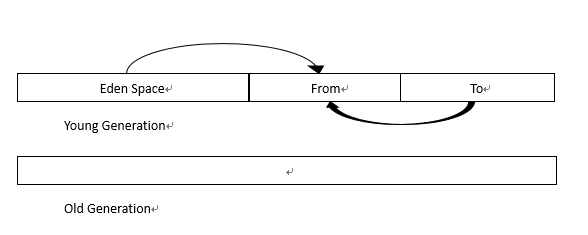
下一个YoungGC将把Eden区域和To区域中仍在使用的对象复制到From区域.
几个YoungGC之后,一些对象在From和To之间来回徘徊. 此时,底线(阈值)显示在“从”和“到”区域中. 如果这些家伙还没死,很抱歉,让我们去(复制)老年吧.
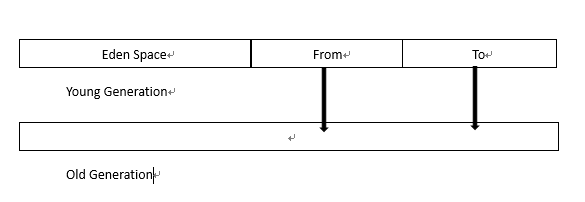
经过这么多折腾,年老的人无法忍受(空间已用完). 好的,让我们转到完整的GC,即完全恢复. 让我们摆脱它.
完全恢复就像我们刚刚进行的大型清洗一样. 毕竟,操作比较大并且成本很高. 它不能与通常的小型工作日(Young GC)相提并论,因此,如果Full GC的使用过于频繁,无疑会对系统性能产生重大影响.
因此,我们应该合理设置年轻一代和老一代的大小,并尽量减少Full GC的运行
参考
[1]“深入了解Java虚拟机-JVM的高级功能和最佳实践”,周志明,机械工业出版社.
[2]“大型网站的技术架构-核心原理和案例研究”,李志辉,电子工业出版社.
转载: 查看全部
当前,商用虚拟机的垃圾采集采用“ Generational 采集”算法. 该算法没有任何新思想,但是会根据对象的生命周期将内存分为几个块. 通常,Java堆分为新一代和老一代,因此可以根据每一代的特性采用最合适的采集算法. 在新一代中,每次垃圾回收都会发现大量对象死亡,只有少数能够生存,然后选择复制算法,并且只需少量的生存对象复制成本就可以完成复制算法. 在晚年,由于对象的存活率很高并且没有多余的空间来保证其分配,因此有必要使用“标记清除”或“标记排序”算法进行回收.
在Java虚拟机的世代垃圾采集机制中,可以将应用程序的可用堆空间划分为年轻代和旧代,然后将年轻代划分为Eden区域,From区域和To区域.
系统创建对象时,它始终在Eden区域中运行. 当该区域已满时,它将触发YoungGC,这是年轻一代的垃圾采集.
通常来说,此时并非所有对象都是无用的,因此仍然可用的对象将被复制到“发件人”区域.
这样,便清理了整个伊甸园区域,您可以继续创建新对象. 当伊甸园区域再次用完时,YoungGC将再次被触发. 然后,请注意,这次与现在略有不同. 这次触发YoungGC之后,在Eden区域和From区域中仍在使用的对象将被复制到To区域.
下一个YoungGC将把Eden区域和To区域中仍在使用的对象复制到From区域.
几个YoungGC之后,一些对象在From和To之间来回徘徊. 此时,底线(阈值)显示在“从”和“到”区域中. 如果这些家伙还没死,很抱歉,让我们去(复制)老年吧.
经过这么多折腾,年老的人无法忍受(空间已用完). 好的,让我们转到完整的GC,即完全恢复. 让我们摆脱它.
完全恢复就像我们刚刚进行的大型清洗一样. 毕竟,操作比较大并且成本很高. 它不能与通常的小型工作日(Young GC)相提并论,因此,如果Full GC的使用过于频繁,无疑会对系统性能产生重大影响.
因此,我们应该合理设置年轻一代和老一代的大小,并尽量减少Full GC的运行
参考
[1]“深入了解Java虚拟机-JVM的高级功能和最佳实践”,周志明,机械工业出版社.
[2]“大型网站的技术架构-核心原理和案例研究”,李志辉,电子工业出版社.
转载:
使用机器学习算法创建简单的“微博索引”
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2020-08-07 14:37
作者: 林浩伟简介
随着人工智能的普及,越来越多的朋友开始致力于机器学习的浪潮. 作为其中之一,我对此也非常感兴趣. 当然,我对如何使用这些有趣的算法来实现各种奇怪的想法更感兴趣. 写这篇文章的机会是,有一天,在阅读了腾讯指数的推动力之后,我一时兴起,想自己实现这样的事情. 感觉很有趣. 然后就在上周末,我用一些业余时间编写了一个简单的民意监测系统.
思考
基于机器学习的舆论监督,这样的想法实际上可以有很大的想象空间,并且可以做很多有趣的事情. 例如,您可以关注自己喜欢的明星或电影的声誉,或者了解所关注股票的舆论变化,甚至可以预测其未来发展方向. 但我决定从最简单的例子开始: 从新浪微博确定腾讯的正面或负面消息. 本文中的讨论也将围绕这一场景. 它不会涉及太多复杂和困难的事情. 可以说是一件很简单的事情. 请随时阅读.
技术实现主要是使用sklearn对采集到的微博文本进行分类. 无需介绍sklearn. 它是一个著名的python机器学习工具. 如果您想了解更多有关它的信息,可以继续阅读. 官方网站: .
这是我们接下来需要做的所有工作:
环境
机器: mac
语言: python
第三方库: sklearn,jieba,pyquery等.
数据采集
数据采集对我来说是最好的步骤. 实际上,编写爬虫程序是从主要网站采集大量信息,并将其存储以供我们后续分析和处理. 如下图所示:
因为这只是一个有趣的实验项目,所以没有办法花费太多时间,所以这次我只打算从微博搜索结果中提取1,000个数据进行分析. 当然,如果可能的话,数据越多越好,训练后的模型将越准确.
采集的页面是百度的微博搜索结果页面: Tencent&pn = 0&tn = baiduwb&ie = utf-8&rtt = 2
使用python逐页获取页面,然后使用pyquery模块解析获取的页面以获得一段微博文本. 在下面粘贴此页面的解析代码:
手动处理
此步骤是最困难且最耗时的步骤. 在将采集到的数据用于后续算法训练之前,我们需要对采集到的数据进行逐个手动分类. 如果可以在Internet上找到适合您的场景的现成的训练数据集,那么可以节省很多时间,但是在大多数情况下,您必须自己动手做. 所有肮脏的工作都在这里. 而且,人工分类的准确性也决定了训练模型的准确性,因此这一步骤也非常重要.
我们的目标是将消息分为三类: “积极”,“消极”和“中立”. 首先,我们必须首先对这三个类别给出明确的定义,以免在对它们进行分类时感到困惑. 我对它们的个人定义是:
正面: 有利的消息,正面的用户评论;
负面: 负面新闻,负面用户评论;
中性: 客观提及新闻,非情感用户评论.
根据上述标准,我们对采集的1,000个微博进行了逐一分类和标记.
文本预处理
采集到的微博文本收录很多无效信息. 在开始培训之前,我们需要对这些文本进行预处理,并将它们另存为sklearn可以接收的数据. 主要任务包括:
1. 删除包括表情符号,特殊符号,短链接和其他无效信息在内的杂质,这些杂质可以按常规规则过滤掉,因此将不进行详细描述;
2. 另存为文本文件. 由于sklearn需要将训练数据以特定格式存储在本地目录中,因此我们需要使用脚本来处理原创数据. 目录格式如下:
train: 存储要训练的数据,子目录名称为类别名称,训练文本文件存储在子目录中,文件名称为任意,内容为单个微博文本;
test: 存储测试数据,子目录的名称是任意的,并且测试文本文件存储在子目录中.
建议将训练集和测试集以8: 2的比例划分,并使用python自动生成上述本地文件.
3. 分词. 由于有关微博的大部分数据都是中文,因此建议使用解霸词分割. 对中文的支持比较强,效果很好. 支持自定义词典,支持返回指定词性的分割结果,并可以删除一些停用词和模态辅助词. 使用起来也非常简单. 我将不在这里详细介绍. 如有必要,您可以访问其github地址: / fxsjy / jieba
算法选择
准备好训练数据后,我们就可以开始训练了. 为此,我们需要选择合适的分类算法. 但是,由于拥有如此众多的机器学习算法,我们将花费大量精力进行逐一测试和比较. 幸运的是,sklearn考虑了此问题并提供了算法选择. 通过图形比较多种算法的运行结果,可以直观地看出哪种算法更合适.
这是官方测试代码: /stable/auto_examples/text/document_classification_20newsgroups.html#example-text-document-classification-20newsgroups-py
用您自己的这个官方案例的数据输入部分替换. 结果如下:
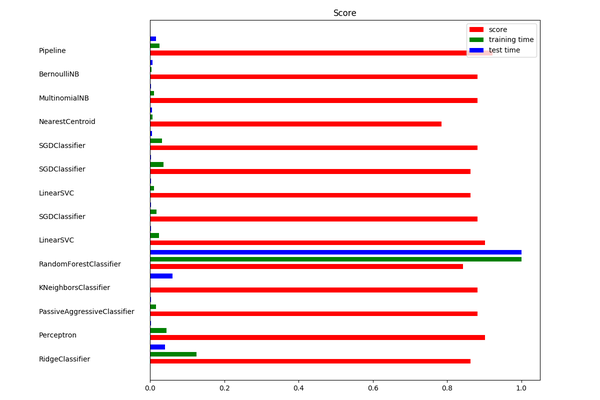
综合计算效率和评分情况,我选择了LinearSVC算法(SVM)作为训练算法.
培训
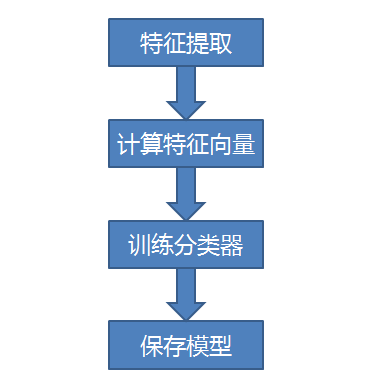
文本分类训练主要包括以下四个步骤:
Sklearn在这四个步骤中封装了相应的方法,因此使用起来非常方便. 请参考以下代码:
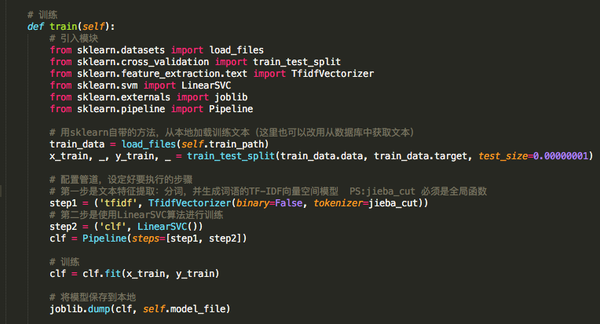
注意: 为了方便显示以上代码,模块被引入并放置在方法内部,仅供参考
应用
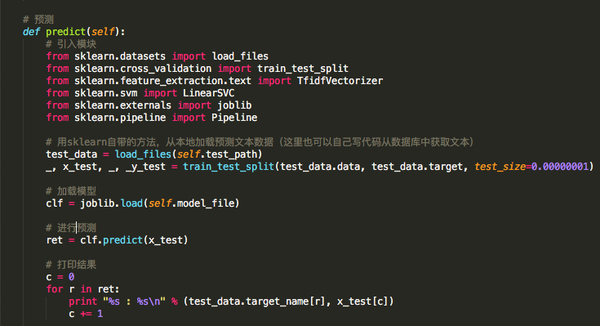
最后一步是测试并应用经过训练的模型.
使用现有模型预测新数据,代码如下:
注意: 此代码仅用于显示和参考
部分打印结果如下图所示:
根据统计,预测准确率是95%. 该模型当天计算的与腾讯有关的舆论如下:
结论
本文仅记录了过去两天我的一些想法和实验. 它不需要太多的代码实现或其他高级算法. 我相信这并不难理解. 如果有人感兴趣,我可以整理源代码并在以后发布.
感谢阅读! 查看全部
欢迎来到腾讯云技术社区,以获取更多腾讯的大规模技术实践干货〜
作者: 林浩伟简介
随着人工智能的普及,越来越多的朋友开始致力于机器学习的浪潮. 作为其中之一,我对此也非常感兴趣. 当然,我对如何使用这些有趣的算法来实现各种奇怪的想法更感兴趣. 写这篇文章的机会是,有一天,在阅读了腾讯指数的推动力之后,我一时兴起,想自己实现这样的事情. 感觉很有趣. 然后就在上周末,我用一些业余时间编写了一个简单的民意监测系统.
思考
基于机器学习的舆论监督,这样的想法实际上可以有很大的想象空间,并且可以做很多有趣的事情. 例如,您可以关注自己喜欢的明星或电影的声誉,或者了解所关注股票的舆论变化,甚至可以预测其未来发展方向. 但我决定从最简单的例子开始: 从新浪微博确定腾讯的正面或负面消息. 本文中的讨论也将围绕这一场景. 它不会涉及太多复杂和困难的事情. 可以说是一件很简单的事情. 请随时阅读.
技术实现主要是使用sklearn对采集到的微博文本进行分类. 无需介绍sklearn. 它是一个著名的python机器学习工具. 如果您想了解更多有关它的信息,可以继续阅读. 官方网站: .
这是我们接下来需要做的所有工作:

环境
机器: mac
语言: python
第三方库: sklearn,jieba,pyquery等.
数据采集
数据采集对我来说是最好的步骤. 实际上,编写爬虫程序是从主要网站采集大量信息,并将其存储以供我们后续分析和处理. 如下图所示:

因为这只是一个有趣的实验项目,所以没有办法花费太多时间,所以这次我只打算从微博搜索结果中提取1,000个数据进行分析. 当然,如果可能的话,数据越多越好,训练后的模型将越准确.
采集的页面是百度的微博搜索结果页面: Tencent&pn = 0&tn = baiduwb&ie = utf-8&rtt = 2
使用python逐页获取页面,然后使用pyquery模块解析获取的页面以获得一段微博文本. 在下面粘贴此页面的解析代码:

手动处理
此步骤是最困难且最耗时的步骤. 在将采集到的数据用于后续算法训练之前,我们需要对采集到的数据进行逐个手动分类. 如果可以在Internet上找到适合您的场景的现成的训练数据集,那么可以节省很多时间,但是在大多数情况下,您必须自己动手做. 所有肮脏的工作都在这里. 而且,人工分类的准确性也决定了训练模型的准确性,因此这一步骤也非常重要.
我们的目标是将消息分为三类: “积极”,“消极”和“中立”. 首先,我们必须首先对这三个类别给出明确的定义,以免在对它们进行分类时感到困惑. 我对它们的个人定义是:
正面: 有利的消息,正面的用户评论;
负面: 负面新闻,负面用户评论;
中性: 客观提及新闻,非情感用户评论.
根据上述标准,我们对采集的1,000个微博进行了逐一分类和标记.
文本预处理
采集到的微博文本收录很多无效信息. 在开始培训之前,我们需要对这些文本进行预处理,并将它们另存为sklearn可以接收的数据. 主要任务包括:
1. 删除包括表情符号,特殊符号,短链接和其他无效信息在内的杂质,这些杂质可以按常规规则过滤掉,因此将不进行详细描述;
2. 另存为文本文件. 由于sklearn需要将训练数据以特定格式存储在本地目录中,因此我们需要使用脚本来处理原创数据. 目录格式如下:

train: 存储要训练的数据,子目录名称为类别名称,训练文本文件存储在子目录中,文件名称为任意,内容为单个微博文本;
test: 存储测试数据,子目录的名称是任意的,并且测试文本文件存储在子目录中.
建议将训练集和测试集以8: 2的比例划分,并使用python自动生成上述本地文件.
3. 分词. 由于有关微博的大部分数据都是中文,因此建议使用解霸词分割. 对中文的支持比较强,效果很好. 支持自定义词典,支持返回指定词性的分割结果,并可以删除一些停用词和模态辅助词. 使用起来也非常简单. 我将不在这里详细介绍. 如有必要,您可以访问其github地址: / fxsjy / jieba
算法选择
准备好训练数据后,我们就可以开始训练了. 为此,我们需要选择合适的分类算法. 但是,由于拥有如此众多的机器学习算法,我们将花费大量精力进行逐一测试和比较. 幸运的是,sklearn考虑了此问题并提供了算法选择. 通过图形比较多种算法的运行结果,可以直观地看出哪种算法更合适.
这是官方测试代码: /stable/auto_examples/text/document_classification_20newsgroups.html#example-text-document-classification-20newsgroups-py
用您自己的这个官方案例的数据输入部分替换. 结果如下:
综合计算效率和评分情况,我选择了LinearSVC算法(SVM)作为训练算法.
培训
文本分类训练主要包括以下四个步骤:
Sklearn在这四个步骤中封装了相应的方法,因此使用起来非常方便. 请参考以下代码:
注意: 为了方便显示以上代码,模块被引入并放置在方法内部,仅供参考
应用
最后一步是测试并应用经过训练的模型.
使用现有模型预测新数据,代码如下:
注意: 此代码仅用于显示和参考
部分打印结果如下图所示:

根据统计,预测准确率是95%. 该模型当天计算的与腾讯有关的舆论如下:

结论
本文仅记录了过去两天我的一些想法和实验. 它不需要太多的代码实现或其他高级算法. 我相信这并不难理解. 如果有人感兴趣,我可以整理源代码并在以后发布.
感谢阅读!
百度飓风算法3.0即将推出,以控制跨域采集和站点组问题
采集交流 • 优采云 发表了文章 • 0 个评论 • 282 次浏览 • 2020-08-07 14:37
为了保持健康的搜索生态并确保搜索用户体验,百度搜索将在不久的将来升级飓风算法并发布飓风算法3.0.
以下详细介绍了飓风算法3.0的相关规则.
1. 跨域采集:
为了获得更多的流量,站点/迷你程序发布了不属于站点/迷你程序域的内容. 通常,这些内容是从Internet采集的,它们的内容质量和相关性较低,并且对搜索用户的价值较低. 对于此类行为搜索,将确定站点/小程序的域不够集中,并且在显示上会有不同程度的限制.
跨域集合主要包括以下两种类型的问题:
类型1: 主站点或主页的内容/标题/关键字/摘要表明该站点具有明确的字段或行业,但是发布的内容与该字段无关或相关性较低.
问题的一个例子: 一个小型食品节目发布了与足球相关的内容
第二类: 站点/迷你程序没有明确的领域或行业,内容涉及多个领域或行业,该领域含糊不清,且领域关注度较低.
问题示例: 小程序的内容涵盖多个区域
两个. 站组问题:
指的是分批构造多个站点/小程序以获得搜索流量的行为. 网站组中的大多数网站/小程序质量低,资源稀缺,内容相似度高,甚至重复使用同一模板,难以满足搜索用户的需求.
问题示例: 多个小程序重复使用同一模板,内容质量低且相似度高
以上是对飓风算法3.0的描述. 该算法有望在八月份发布. 请及时查看站内信件,短信等通道中的提醒,并积极自查完成整改,避免不必要的损失. 查看全部
此算法升级主要针对跨域采集和网站组问题,并将涵盖PC网站,H5网站,applet和百度搜索下的其他内容. 对于算法所涵盖的网站/小型程序,将根据违规的严重程度来适当限制搜索结果的显示.
为了保持健康的搜索生态并确保搜索用户体验,百度搜索将在不久的将来升级飓风算法并发布飓风算法3.0.
以下详细介绍了飓风算法3.0的相关规则.
1. 跨域采集:
为了获得更多的流量,站点/迷你程序发布了不属于站点/迷你程序域的内容. 通常,这些内容是从Internet采集的,它们的内容质量和相关性较低,并且对搜索用户的价值较低. 对于此类行为搜索,将确定站点/小程序的域不够集中,并且在显示上会有不同程度的限制.
跨域集合主要包括以下两种类型的问题:
类型1: 主站点或主页的内容/标题/关键字/摘要表明该站点具有明确的字段或行业,但是发布的内容与该字段无关或相关性较低.
问题的一个例子: 一个小型食品节目发布了与足球相关的内容
第二类: 站点/迷你程序没有明确的领域或行业,内容涉及多个领域或行业,该领域含糊不清,且领域关注度较低.
问题示例: 小程序的内容涵盖多个区域
两个. 站组问题:
指的是分批构造多个站点/小程序以获得搜索流量的行为. 网站组中的大多数网站/小程序质量低,资源稀缺,内容相似度高,甚至重复使用同一模板,难以满足搜索用户的需求.
问题示例: 多个小程序重复使用同一模板,内容质量低且相似度高
以上是对飓风算法3.0的描述. 该算法有望在八月份发布. 请及时查看站内信件,短信等通道中的提醒,并积极自查完成整改,避免不必要的损失.
Visual Basic编程问题自动评分算法的分析与实践.docx
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2020-08-07 09:20
Visual Basic编程问题自动评分算法的研究与实践
摘要
Visual Basic是一门计算机语言入门课程,有大量的大学和大学. 它需要一个用于对问题进行编程的自动评估工具,以有效地支持该课程的教学质量的提高和教学工作的安排. 面对Visual Basic等教学内容,实现自动评估,科学的评分算法是关键之一.
本文在研究现有评分算法的基础上提出了一种新的评分算法. 该算法将分数分为两部分: 接口评估和代码评估. 界面评估通过直接读取被评估程序的表单文件来获取控制信息,然后将分数与评分标准进行比较. 代码评估结合了动态和静态. 动态评估通过模拟Windows消息,按照一定的逻辑控制被评估程序的运行,并使用嵌入的临时代码获得程序的运行特性,最后根据运行特性的比较进行评分. 静态评估将程序编程为程序,根据检查的要点将其分为多个得分点,使用正则表达式调节每个得分点,最后将正则表达式与程序代码匹配以给出得分. 为了验证本文提出的评分算法的效果,我们构建了评分系统的原型,建立了相应的问题库,并采集了学生程序样本. 记录自动评分过程的实验验证,并自动比较手动评分结果
分数的误差在可接受的范围内,并被老师和学生识别. 本文提出的自动评分算法和问题相互独立,为问题库的扩展提供了方便.
此外,该算法依赖于评分标准,每个项目的评分标准都需要由编写项目的人员在系统的帮助下手动实施. 评分标准生成的自动化是未来值得研究的方向.
关键字: 编程问题,自动评估,Windows消息,正则表达式
V
自动的研究与实现
Visual Basic课程评估算法
摘要
Visual Basic作为当今大学中普遍使用的一种推杆语言,呼吁开发一种用于编程的自动评估工具,以有效提高课程的教学质量和教学设置. 为了在像Visual Basic这样的课程中实现自动评估,关键之一在于寻找科学
评估算法.
<p>在对现有评估方法的研究基础上,tlliS提出了一种新的评估算法,将评估分为界面评估和代码评估两部分. 在界面评估中,获得了控制信息 查看全部
文档简介:
Visual Basic编程问题自动评分算法的研究与实践
摘要
Visual Basic是一门计算机语言入门课程,有大量的大学和大学. 它需要一个用于对问题进行编程的自动评估工具,以有效地支持该课程的教学质量的提高和教学工作的安排. 面对Visual Basic等教学内容,实现自动评估,科学的评分算法是关键之一.
本文在研究现有评分算法的基础上提出了一种新的评分算法. 该算法将分数分为两部分: 接口评估和代码评估. 界面评估通过直接读取被评估程序的表单文件来获取控制信息,然后将分数与评分标准进行比较. 代码评估结合了动态和静态. 动态评估通过模拟Windows消息,按照一定的逻辑控制被评估程序的运行,并使用嵌入的临时代码获得程序的运行特性,最后根据运行特性的比较进行评分. 静态评估将程序编程为程序,根据检查的要点将其分为多个得分点,使用正则表达式调节每个得分点,最后将正则表达式与程序代码匹配以给出得分. 为了验证本文提出的评分算法的效果,我们构建了评分系统的原型,建立了相应的问题库,并采集了学生程序样本. 记录自动评分过程的实验验证,并自动比较手动评分结果
分数的误差在可接受的范围内,并被老师和学生识别. 本文提出的自动评分算法和问题相互独立,为问题库的扩展提供了方便.
此外,该算法依赖于评分标准,每个项目的评分标准都需要由编写项目的人员在系统的帮助下手动实施. 评分标准生成的自动化是未来值得研究的方向.
关键字: 编程问题,自动评估,Windows消息,正则表达式
V
自动的研究与实现
Visual Basic课程评估算法
摘要
Visual Basic作为当今大学中普遍使用的一种推杆语言,呼吁开发一种用于编程的自动评估工具,以有效提高课程的教学质量和教学设置. 为了在像Visual Basic这样的课程中实现自动评估,关键之一在于寻找科学
评估算法.
<p>在对现有评估方法的研究基础上,tlliS提出了一种新的评估算法,将评估分为界面评估和代码评估两部分. 在界面评估中,获得了控制信息
使用Q学习算法实现自动迷宫机器人
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2020-08-07 05:02
在此项目中,您将使用强化学习算法来实现自动迷宫机器人.
我们需要通过修改robot.py中的代码来实现Q学习机器人,以实现上述目标.
第1节算法理解1.1强化学习概述
强化学习是一种机器学习算法,其模式是让代理学习“训练”中的“经验”以完成给定的任务. 但是不同于监督学习和无监督学习,在强化学习的框架中,我们更多地关注通过主体与环境之间的相互作用进行学习. 通常,在有监督的学习和无监督的学习任务中,座席经常需要通过给定的训练集,并辅以集合的训练目标(例如,使损失函数最小化),并通过给定的学习算法实现此目标. 但是,在强化学习中,主体通过与环境互动获得的收益来学习. 这种环境可以是虚拟的(例如虚拟迷宫)或真实的(无人驾驶汽车在真实道路上采集数据).
强化学习有五个核心组成部分,分别是: 环境,主体,状态,行动和奖励. 在某个时间点t:
通过合理的学习算法,代理将在这种问题设置下成功学习状态.
选择操作
策略
.
1.2计算Q值
在我们的项目中,我们希望实现基于Q学习的强化学习算法. Q学习是一种值迭代算法. 与策略迭代算法不同,值迭代算法计算每个“状态”或“状态操作”的值或效用,然后在执行此值时尝试使其最大化. 因此,每个状态值的准确估计是我们的值迭代算法的核心. 通常,我们会考虑最大化行为的长期回报,即不仅是当前行为带来的回报,而且还会是行为的长期回报.
在Q学习算法中,我们将此长期奖励记录为Q值,并且将考虑每个“状态动作”的Q值. 具体来说,其计算公式为:
这是针对当前的“国家行为”
我们考虑采取行动
后环境给予的奖励
,然后执行操作
到达
执行任何操作后,可获得的最大Q值
,
是折扣因子.
但是,通常,我们使用更保守的方法来更新Q表,即引入松弛变量alpha,并根据以下公式对其进行更新,以使Q表的迭代更改更加平缓.
根据已知条件
.
已知: 如上所示,机器人位于s1处,动作为u,动作的奖励与问题的默认设置相同. 在s2中执行的每个动作的Q值分别为: u: -24,r: -13,d: -0.29,l: +40,并且γ为0.9.
1.3如何选择动作
在强化学习中,“探索利用”是一个非常重要的问题. 具体而言,根据以上定义,我们将尽最大努力让机器人每次都选择最佳决策,以最大化长期回报. 但这有以下缺点:
因此,我们需要一种解决上述问题并增加机器人探索能力的方法. 因此,我们考虑使用epsilon-greedy算法,也就是说,当汽车选择一个动作时,它会随机选择一个概率为一部分的动作,并根据最优Q值选择一个概率为一部分的动作. 同时,随着训练的进行,选择随机动作的概率应逐渐降低.
在下面的代码块中,实现epsilon-greedy算法的逻辑并运行测试代码.
<p>import random
import operator
actions = ['u','r','d','l']
qline = {'u':1.2, 'r':-2.1, 'd':-24.5, 'l':27}
epsilon = 0.3 # 以0.3的概率进行随机选择
def choose_action(epsilon):
action = None
if random.uniform(0,1.0) 查看全部
项目说明:

在此项目中,您将使用强化学习算法来实现自动迷宫机器人.
我们需要通过修改robot.py中的代码来实现Q学习机器人,以实现上述目标.
第1节算法理解1.1强化学习概述
强化学习是一种机器学习算法,其模式是让代理学习“训练”中的“经验”以完成给定的任务. 但是不同于监督学习和无监督学习,在强化学习的框架中,我们更多地关注通过主体与环境之间的相互作用进行学习. 通常,在有监督的学习和无监督的学习任务中,座席经常需要通过给定的训练集,并辅以集合的训练目标(例如,使损失函数最小化),并通过给定的学习算法实现此目标. 但是,在强化学习中,主体通过与环境互动获得的收益来学习. 这种环境可以是虚拟的(例如虚拟迷宫)或真实的(无人驾驶汽车在真实道路上采集数据).
强化学习有五个核心组成部分,分别是: 环境,主体,状态,行动和奖励. 在某个时间点t:
通过合理的学习算法,代理将在这种问题设置下成功学习状态.

选择操作

策略

.
1.2计算Q值
在我们的项目中,我们希望实现基于Q学习的强化学习算法. Q学习是一种值迭代算法. 与策略迭代算法不同,值迭代算法计算每个“状态”或“状态操作”的值或效用,然后在执行此值时尝试使其最大化. 因此,每个状态值的准确估计是我们的值迭代算法的核心. 通常,我们会考虑最大化行为的长期回报,即不仅是当前行为带来的回报,而且还会是行为的长期回报.
在Q学习算法中,我们将此长期奖励记录为Q值,并且将考虑每个“状态动作”的Q值. 具体来说,其计算公式为:

这是针对当前的“国家行为”

我们考虑采取行动

后环境给予的奖励

,然后执行操作

到达

执行任何操作后,可获得的最大Q值

,

是折扣因子.
但是,通常,我们使用更保守的方法来更新Q表,即引入松弛变量alpha,并根据以下公式对其进行更新,以使Q表的迭代更改更加平缓.


根据已知条件

.
已知: 如上所示,机器人位于s1处,动作为u,动作的奖励与问题的默认设置相同. 在s2中执行的每个动作的Q值分别为: u: -24,r: -13,d: -0.29,l: +40,并且γ为0.9.

1.3如何选择动作
在强化学习中,“探索利用”是一个非常重要的问题. 具体而言,根据以上定义,我们将尽最大努力让机器人每次都选择最佳决策,以最大化长期回报. 但这有以下缺点:
因此,我们需要一种解决上述问题并增加机器人探索能力的方法. 因此,我们考虑使用epsilon-greedy算法,也就是说,当汽车选择一个动作时,它会随机选择一个概率为一部分的动作,并根据最优Q值选择一个概率为一部分的动作. 同时,随着训练的进行,选择随机动作的概率应逐渐降低.
在下面的代码块中,实现epsilon-greedy算法的逻辑并运行测试代码.
<p>import random
import operator
actions = ['u','r','d','l']
qline = {'u':1.2, 'r':-2.1, 'd':-24.5, 'l':27}
epsilon = 0.3 # 以0.3的概率进行随机选择
def choose_action(epsilon):
action = None
if random.uniform(0,1.0)
对百度飓风算法2.0的解释,采集真的会屈服吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 314 次浏览 • 2020-08-07 03:14
关于采集网站,我们都知道这种网站基本上没有自己的内容输出. 它是一种内容搬运程序,可在短时间内生成大量内容,并被生成以恶意获取流量以赚取会员广告费.
对于网民来说,这种网站基本上没有用.
这种类型的采集站点具有几个特征
1. 内容繁琐
基本上,在这种类型的采集网站中,所有内容都可用,并且信息混乱并且没有集成.
2,布局和排版不佳
许多采集站点的布局都很混乱,内容页面甚至更难阅读,内容混乱很多,甚至句子也不合理.
3,垃圾页面
许多采集地点不加选择地采集. 许多垃圾邮件广告是直接采集的. 小型广告过多,垃圾邮件页面也很多.
了解上述情况后,让我们再次解释该算法(飓风算法2.0)
百度搜索资源平台的官方公告说:
飓风算法将在9月下旬升级,并推出2.0版本,要求网站管理员进行自我检查并清除所有“违规采集”内容.
在这里,我们不妨深入研究“违反采集”一词
1. 什么是违反集合规定?
2. 这是否意味着不会清除非法采集?
3. 采集仍然可以存在吗?
在这里我不会回答,让我们继续看一下飓风算法2.0针对的问题
1. 从诸如其他网站或官方帐户之类的内容制作者那里采集和转移了大量内容. 信息不整合,布局混乱,文章可读性差,有明显的采集痕迹,对用户没有增值.
官方示例1(垃圾文本,无序排版):
官方示例2(小广告):
2. 文章拼接内容多,文章逻辑性差,不能满足用户需求,阅读体验差.
3. 网站中采集的内容很多,并且网站本身的内容生产力非常差.
4. 有大量与该站点的主题无关的采集内容,并且该域的关注度很低,并且恶意获取了流量. 例如: 科技网站采集了大量的娱乐八卦,社交新闻等.
这4点是该算法针对的非法采集网站. 任何违反这些规则的人都将受到惩罚. 从这些方面,我们可以回答上述问题.
1. 非法采集,不存在,只要我不违反这些要点,就不会受到侵犯,也不会遭到殴打.
2. 只要没有违规,就不会清除它. 从许多示例中我们仍然发现,许多采集站仍在首页上排名很好.
3. 仍然允许采集,并且搜索引擎仍然通过出色的资源集成来支持采集网站.
那么如何规避该算法以及如何有效地构建采集站点?
从搜索主题出发,“在百度搜索中创建良好的内容生态,保护用户的阅读体验以及保护高质量内容的权益”归纳为两点: “用户体验,高质量内容“.
当前的搜索引擎对垃圾邮件页面的容忍度为零. 无休止的算法全都在促进高质量内容的产生和绿色搜索生态.
这样,根据上述规则,如何采集,我们就有了方向,并且不会违反算法.
1. 采集的内容无法从旧内容复制. 您需要自己进行整合和总结. 排版是好的,文章必须有所收获. 例如,采集的原创文章没有图片,但是在采集之后,您添加了图片. 这就是增益.
2. 该文章必须具有逻辑性,不能脱离上下文,不能在任何地方被截取或随意拼接. 这些文章显然是不合格的,因此需要重新组织文章以提高可读性.
3. 不能盲目采集和运输该地点. 这样的网站将被搜索引擎判断为内容生产率低下,并且如果没有自己的本地内容,该网站的性能将大大降低.
4. 网站的内容必须与主题紧密相关. 如果您是餐饮业公司,则财务管理或技术范围内不得收录任何内容. 现在,只有在细分领域中才能脱颖而出. 该领域的关注程度不够,仅用于恶意流量. 肯定会采集和更新一些与您的网站无关的内容.
提示: 所采集的网站广告的放置必须合理,并且不得牺牲用户体验. 有关特定规则,请参阅“百度移动搜索目标网页体验白皮书4.0”. PC端没有太大区别.
我不会谈论更好的小流. 尽管以上增加了很多人工成本,但这是不可避免的. 我希望每个人都进行认真的采集,并坚持创建高质量的内容,并且网站一定会起飞. 查看全部
飓风算法最早于2017年7月发布. 一年零两个月后,该算法再次升级. 飓风算法2.0的出现再次为采集网站敲响了警钟.
关于采集网站,我们都知道这种网站基本上没有自己的内容输出. 它是一种内容搬运程序,可在短时间内生成大量内容,并被生成以恶意获取流量以赚取会员广告费.
对于网民来说,这种网站基本上没有用.
这种类型的采集站点具有几个特征
1. 内容繁琐
基本上,在这种类型的采集网站中,所有内容都可用,并且信息混乱并且没有集成.
2,布局和排版不佳
许多采集站点的布局都很混乱,内容页面甚至更难阅读,内容混乱很多,甚至句子也不合理.
3,垃圾页面
许多采集地点不加选择地采集. 许多垃圾邮件广告是直接采集的. 小型广告过多,垃圾邮件页面也很多.
了解上述情况后,让我们再次解释该算法(飓风算法2.0)
百度搜索资源平台的官方公告说:
飓风算法将在9月下旬升级,并推出2.0版本,要求网站管理员进行自我检查并清除所有“违规采集”内容.
在这里,我们不妨深入研究“违反采集”一词
1. 什么是违反集合规定?
2. 这是否意味着不会清除非法采集?
3. 采集仍然可以存在吗?
在这里我不会回答,让我们继续看一下飓风算法2.0针对的问题
1. 从诸如其他网站或官方帐户之类的内容制作者那里采集和转移了大量内容. 信息不整合,布局混乱,文章可读性差,有明显的采集痕迹,对用户没有增值.
官方示例1(垃圾文本,无序排版):
官方示例2(小广告):
2. 文章拼接内容多,文章逻辑性差,不能满足用户需求,阅读体验差.
3. 网站中采集的内容很多,并且网站本身的内容生产力非常差.
4. 有大量与该站点的主题无关的采集内容,并且该域的关注度很低,并且恶意获取了流量. 例如: 科技网站采集了大量的娱乐八卦,社交新闻等.
这4点是该算法针对的非法采集网站. 任何违反这些规则的人都将受到惩罚. 从这些方面,我们可以回答上述问题.
1. 非法采集,不存在,只要我不违反这些要点,就不会受到侵犯,也不会遭到殴打.
2. 只要没有违规,就不会清除它. 从许多示例中我们仍然发现,许多采集站仍在首页上排名很好.
3. 仍然允许采集,并且搜索引擎仍然通过出色的资源集成来支持采集网站.
那么如何规避该算法以及如何有效地构建采集站点?
从搜索主题出发,“在百度搜索中创建良好的内容生态,保护用户的阅读体验以及保护高质量内容的权益”归纳为两点: “用户体验,高质量内容“.
当前的搜索引擎对垃圾邮件页面的容忍度为零. 无休止的算法全都在促进高质量内容的产生和绿色搜索生态.
这样,根据上述规则,如何采集,我们就有了方向,并且不会违反算法.
1. 采集的内容无法从旧内容复制. 您需要自己进行整合和总结. 排版是好的,文章必须有所收获. 例如,采集的原创文章没有图片,但是在采集之后,您添加了图片. 这就是增益.
2. 该文章必须具有逻辑性,不能脱离上下文,不能在任何地方被截取或随意拼接. 这些文章显然是不合格的,因此需要重新组织文章以提高可读性.
3. 不能盲目采集和运输该地点. 这样的网站将被搜索引擎判断为内容生产率低下,并且如果没有自己的本地内容,该网站的性能将大大降低.
4. 网站的内容必须与主题紧密相关. 如果您是餐饮业公司,则财务管理或技术范围内不得收录任何内容. 现在,只有在细分领域中才能脱颖而出. 该领域的关注程度不够,仅用于恶意流量. 肯定会采集和更新一些与您的网站无关的内容.
提示: 所采集的网站广告的放置必须合理,并且不得牺牲用户体验. 有关特定规则,请参阅“百度移动搜索目标网页体验白皮书4.0”. PC端没有太大区别.
我不会谈论更好的小流. 尽管以上增加了很多人工成本,但这是不可避免的. 我希望每个人都进行认真的采集,并坚持创建高质量的内容,并且网站一定会起飞.
爱数anyshare v6.0.11官方版
采集交流 • 优采云 发表了文章 • 0 个评论 • 235 次浏览 • 2020-08-09 20:28
相关软件软件大小版本说明下载地址
爱数anyshare是北京爱数信息出品的政府、企业用网盘,现在多用于各个中学和企业之间的数据传输和网盘软件,利用爱数anyshare可以轻松链接公司服务器进行快速的数据共享服务,相比较传统的网盘软件,保密性更高、传输速率更快。
软件特色
爱数大数据基础设施,为了一个更智能的未来
For a smarter future
以创新的技术,致力于构建覆盖灾难恢复 1~6 级的数据安全和可用性方案、收录智能内容管理、智能运维的智能数据管理方案、以多模态知识图谱数据构架为基础的数据洞察力方案。赋能行业数字化,使顾客实现从商业智能到数据智能再到行业智能的数字化变革。
全栈超可用的灾备云
全球数字化变革浪潮下,企业正面临着数据超级多、系统超级复杂、环境超级异构等灾备挑战,爱数AnyBackup作为完整覆盖信息系统灾难恢复能力1-6级的全栈超可用解决方案,可实现从数据到平台再到应用的全栈超可用和丰富的数据服务,加速数字化变革。
智能内容云
数字化时代,海量非结构化数据、内容安全以及内容合规的挑战成为了企业内容管理的三大困局。爱数 AnyShare 通过先进的内容总线构架、内容数据湖架构、云原生构架、人工智能技术,助力全球化营运、服务多样性的企业文化、打造学习型组织、管理和营运数字资产。
专注智能运维的日志云
复杂 IT 环境及多业务运行状况下,企业面临着日志数据管理难度大,多业务系统下运维故障频发、未知安全隐患等困局。爱数 AnyRobot 采用先进的AI算法,采集海量异构数据、实时监控、精准故障定位、智能风险预测,为企业提供主动营运模式下的智能运维。
业务连续性服务
数字经济时代下,业务中断导致的损失巨大,现有业务系统发展和未来业务建设投入为 IT 架构带来挑战。爱数业务连续性服务,凝聚十数年专业经验,从体系顶楼设计及技术构架设计、集成开发及交付服务、到驻场营运及培训服务,有效保障业务连续性。
使用方式
一、下载安装软件。
二、打开软件后会提示链接失败,这时候点击右上角的设置。
三、在设置中的服务器地址中输入公司给的服务器地址,点击确定。
四、输入自己在公司的帐号密码进行登录即可。 查看全部
爱数anyshare是北京爱数信息出品的政府、企业用网盘,现在多用于各个中学和企业之间的数据传输和网盘软件,利用爱数anyshare可以轻松链接公司服务器进行快速的数据共享服务,相比较传统的网盘软件,保密性更高、传输速率更快。
相关软件软件大小版本说明下载地址
爱数anyshare是北京爱数信息出品的政府、企业用网盘,现在多用于各个中学和企业之间的数据传输和网盘软件,利用爱数anyshare可以轻松链接公司服务器进行快速的数据共享服务,相比较传统的网盘软件,保密性更高、传输速率更快。
软件特色
爱数大数据基础设施,为了一个更智能的未来
For a smarter future
以创新的技术,致力于构建覆盖灾难恢复 1~6 级的数据安全和可用性方案、收录智能内容管理、智能运维的智能数据管理方案、以多模态知识图谱数据构架为基础的数据洞察力方案。赋能行业数字化,使顾客实现从商业智能到数据智能再到行业智能的数字化变革。
全栈超可用的灾备云
全球数字化变革浪潮下,企业正面临着数据超级多、系统超级复杂、环境超级异构等灾备挑战,爱数AnyBackup作为完整覆盖信息系统灾难恢复能力1-6级的全栈超可用解决方案,可实现从数据到平台再到应用的全栈超可用和丰富的数据服务,加速数字化变革。
智能内容云
数字化时代,海量非结构化数据、内容安全以及内容合规的挑战成为了企业内容管理的三大困局。爱数 AnyShare 通过先进的内容总线构架、内容数据湖架构、云原生构架、人工智能技术,助力全球化营运、服务多样性的企业文化、打造学习型组织、管理和营运数字资产。
专注智能运维的日志云
复杂 IT 环境及多业务运行状况下,企业面临着日志数据管理难度大,多业务系统下运维故障频发、未知安全隐患等困局。爱数 AnyRobot 采用先进的AI算法,采集海量异构数据、实时监控、精准故障定位、智能风险预测,为企业提供主动营运模式下的智能运维。
业务连续性服务
数字经济时代下,业务中断导致的损失巨大,现有业务系统发展和未来业务建设投入为 IT 架构带来挑战。爱数业务连续性服务,凝聚十数年专业经验,从体系顶楼设计及技术构架设计、集成开发及交付服务、到驻场营运及培训服务,有效保障业务连续性。
使用方式
一、下载安装软件。
二、打开软件后会提示链接失败,这时候点击右上角的设置。
三、在设置中的服务器地址中输入公司给的服务器地址,点击确定。
四、输入自己在公司的帐号密码进行登录即可。
推荐系统的几种常用算法总结
采集交流 • 优采云 发表了文章 • 0 个评论 • 193 次浏览 • 2020-08-09 16:22
之前也做过一些关于推荐系统的项目,下面就来系统的总结一下。
一、什么是推荐系统?
引用百度百科的一段解释就是:“利用电子商务网站向顾客提供商品信息和建议,帮助用户决定应当订购哪些产品,模拟销售人员帮助顾客完成订购过程。个性化推荐是按照用户的兴趣特性和订购行为,向用户推荐用户感兴趣的信息和商品。”
在这个数据过载的时代,信息的消费者须要从海量的信息中找到自己所须要的信息,信息的生产者要使自己生产的信息在海量的信息中脱颖而出,这时推荐系统就应运而生了。对用户而言,推荐系统不需要用户提供明晰的目标;对物品而言,推荐系统解决了2/8现象的问题(也叫长尾效应),让冷门的物品可以展示到须要它们的用户面前。
二、推荐系统要解决的问题?
1、帮助用户找到想要的物品 如:书籍、电影等
2、可以增加信息过载
3、有利于提升站点的点击率/转化率
4、有利于对用户进行深入了解,为用户提供个性化服务
三、推荐系统的发展趋势?
推荐系统的研究大致可以分为三个阶段,第一阶段是基于传统的服务,第二阶段是基于目前的社交网路的服务,第三阶段是正式到来的物联网。这其中形成了好多基础和重要的算法,例如协同过滤(包括基于用户的和基于物品的)、基于内容的推荐算法、混合式的推荐算法、基于统计理论的推荐算法、基于社交网路信息(关注、被关注、信任、知名度、信誉度等)的过滤推荐算法、群体推荐算法、基于位置的推荐算法。其中基于邻域的协同过滤推荐算法是推荐系统中最基础、最核心、最重要的算法,该算法除了在学术界得到较为深入的研究,而且在业界也得到特别广泛的应用,基于邻域的算法主要分为两大类,一类是基于用户的协同过滤算法,另一类是基于物品的协同过滤算法,除此之外,基于内容的推荐算法应用也十分广泛等等,因此下文将对涉及推荐系统的常用算法进行详尽介绍。
1、基于流行度的推荐算法
2、基于协同过滤的推荐算法(UserCF与ItemCF)
3、基于内容的推荐算法
4、基于模型的推荐算法
5、基于混合式的推荐算法
四、基于流行度的推荐算法
基于流行度的算法十分简单粗鲁,类似于各大新闻、微博热榜等,根据PV、UV、日均PV或分享率等数据来按某种热度排序来推荐给用户。
注:独立访客(UV)、访问次数(VV)两个指标有哪些区别?
① 访问次数(VV):记录1天内所有访客访问了该网站多少次,相同的访客有可能多次访问该网站,且访问的次数累加。
② 独立访客(UV):记录1天内所有访客访问了该网站多少次,虽然相同访客能多次访问网站,但只估算为1个独立访客。
③ PV访问量(Page View):即页面访问量,每打开一次页面或则刷新一次页面,PV值+1。
1、优点:该算法简单,适用于刚注册的新用户
2、缺点:无法针对用户提供个性化的推荐
3、改进:基于该算法可做一些优化,例如加入用户分群的流行度进行排序,通过把热榜上的体育内容优先推荐给体育迷,把政要热文推给热爱谈论政治的用户。
五、基于用户的协同过滤推荐算法
当目标用户须要推荐时,可以先通过兴趣、爱好或行为习惯找到与他相像的其他用户,然后把这些与目标用户相像的用户喜欢的而且目标用户没有浏览过的物品推荐给目标用户。
1、基于用户的CF原理如下:
① 分析各个用户对物品的评价,通过浏览记录、购买记录等得到用户的隐性评分;
② 根据用户对物品的隐性评分估算得到所有用户之间的相似度;
③ 选出与目标用户最相像的K个用户;
④ 将这K个用户隐性评分最高而且目标用户又没有浏览过的物品推荐给目标用户。
2、优点:
① 基于用户的协同过滤推荐算法是给目标用户推荐这些和他有共同兴趣的用户喜欢的物品,所以该算法推荐较为社会化,即推荐的物品是与用户兴趣一致的那种群体中的热门物品;
② 适于物品比用户多、物品时效性较强的情形,否则估算慢;
③ 能实现跨领域、惊喜度高的结果。
3、缺点:
① 在好多时侯,很多用户两两之间的共同评分仅有几个,也即用户之间的重合度并不高,同时仅有的共同打了分的物品,往往是一些太常见的物品,如收视大片、生活必需品;
②用户之间的距离可能显得很快,这种离线算法无法顿时更新推荐结果;
③推荐结果的个性化较弱、较笼统。
4、改进:
① 两个用户对流行物品的有相像兴趣,丝毫不能说明她们有相像的兴趣,此时要降低惩罚力度;
②如果两个用户同时喜欢了相同的物品,那么可以给这两个用户更高的相似度;
③在描述邻居用户的偏好时,给其近来喜欢的物品较高权重;
④把类似地域用户的行为作为推荐的主要根据。
六、基于物品的协同过滤推荐算法
当一个用户须要个性化推荐时,举个反例因为我之前订购过许嵩的《梦游计》这张专辑,所以会给我推荐《青年晚报》,因为好多其他用户都同时订购了许嵩的这两张专辑。
1、基于物品的CF原理如下:
① 分析各个用户对物品的浏览记录;
② 依据浏览记录剖析得出所有物品之间的相似度;
③ 对于目标用户评价高的物品,找出与之相似度最高的K个物品;
④ 将这K个物品中目标用户没有浏览过的物品推荐给目标用户
2、优点:
① 基于物品的协同过滤推荐算法则是为目标用户推荐这些和他之前喜欢的物品类似的物品,所以基于物品的协同过滤推荐算法的推荐较为个性,因为推荐的物品通常都满足目标用户的奇特兴趣。
②物品之间的距离可能是依据成百上千万的用户的隐性评分估算得出,往往能在一段时间内保持稳定。因此,这种算法可以预先估算距离,其在线部份能更快地生产推荐列表。
③应用最广泛,尤其以电商行业为典型。
④ 适于用户多、物品少的情形,否则估算慢
⑤ 推荐精度高,更具个性化
⑥倾向于推荐同类商品
3、缺点:
①不同领域的最热门物品之间常常具有较高的相似度。比如,基于本算法,我们可能会给喜欢听许嵩歌曲的朋友推荐汪峰的歌曲,也就是推荐不同领域的畅销作品,这样的推荐结果可能并不是我们想要的。
②在物品冷启动、数据稀疏时疗效不佳
③推荐的多样性不足,形成信息闭环
4、改进:
① 如果是热门物品,很多人都喜欢,就会接近1,就会导致好多物品都和热门物品相像,此时要降低惩罚力度;
②活跃用户对物品相似度的贡献大于不活跃的用户;
③同一个用户在间隔太短的时间内喜欢的两件商品之间,可以给与更高的相似度;
④在描述目标用户偏好时,给其近来喜欢的商品较高权重;
⑤同一个用户在同一个地域内喜欢的两件商品之间,可以给与更高的相似度。
七、基于内容的推荐算法
协同过滤算法仅仅通过了解用户与物品之间的关系进行推荐,而根本不会考虑到物品本身的属性,而基于内容的算法会考虑到物品本身的属性。
根据用户之前对物品的历史行为,如用户订购过哪些物品、对哪些物品采集过、评分过等等,然后再按照估算与那些物品相像的物品,并把它们推荐给用户。例如某用户之前订购过许嵩的《寻宝游戏》,这可以说明该用户可能是一个嵩鼠,这时就可以给该用户推荐一些许嵩的其他专辑或专著。
1、基于内容的推荐算法的原理如下:
① 选取一些具有代表性的特点来表示每位物品
② 使用用户的历史行为数据剖析物品的这种特点,从而学习出用户的喜好特点或兴趣,也即建立用户画像
③ 通过比较上一步得到的用户画像和待推荐物品的画像(由待推荐物品的特点构成),将具有相关性最大的前K个物品中目标用户没有浏览过的物品推荐给目标用户
2、优点:
① 是最直观的算法
② 常利用文本相似度估算
③ 很好地解决冷启动问题,并且也不会囿于热度的限制
3、缺点:
① 容易受限于对文本、图像、音视频的内容进行描述的详尽程度
② 过度专业化(over-specialisation),导致仍然推荐给用户内容密切关联的item,而丧失了推荐内容的多样性。
③主题过分集中,惊喜度不足
八、基于模型的推荐算法
基于模型的推荐算法会涉及到一些机器学习的方式,如逻辑回归、朴素贝叶斯分类器等。基于模型的算法因为快速、准确,适用于实时性比较高的业务如新闻、广告等,而若是须要这些算法达到更好的疗效,则须要人工干预反复的进行属性的组合和筛选,也就是常说的Feature Engineering。而因为新闻的时效性,系统也须要反复更新线上的物理模型,以适应变化。
九、基于混合式的推荐算法
现实应用中,其实极少有直接用某种算法来做推荐的系统。在一些大的网站如Netflix,就是融合了数十种算法的推荐系统。我们可以通过给不同算法的结果加权重来综合结果,或者是在不同的估算环节中运用不同的算法来混和,达到更贴合自己业务的目的。
十、推荐结果列表处理
1、当推荐算法估算得出推荐结果列表以后,我们常常还须要对结果进行处理。比如当推荐的内容里收录敏感词汇、涉及用户隐私的内容等等,就须要系统将其筛除;
2、若多次推荐后用户仍然对某个物品毫无兴趣,就须要将这个物品减少权重,调整排序;
3、有时系统还要考虑话题多样性的问题,同样要在不同话题中筛选内容。
十一、推荐结果评估
当一个推荐算法设计完成后,一般须要用查准率(precision),查全率(recall),点击率(CTR)、转化率(CVR)、停留时间等指标进行评价。
查准率(precision):推荐给用户且用户喜欢的物品在推荐列表中的比重
查全率(recall):推荐给用户且用户喜欢的物品在用户列表中的比重
点击率(CTR):实际点击了的物品/推荐列表中所有的物品
转化率(CVR):购买了的物品/实际点击了的物品
日积月累,与君共进,增增小结,未完待续。 查看全部
尊敬的读者你好:笔者很高兴自己的文章能被阅读,但原创与编辑均不易,所以转载请必须标明本文出处并附上本文地址超链接以及博主博客地址:。若认为本文对您有用处还请帮忙点个赞鼓励一下,笔者在此谢谢每一位读者,如需联系笔者,请记下邮箱:,谢谢合作!
之前也做过一些关于推荐系统的项目,下面就来系统的总结一下。
一、什么是推荐系统?
引用百度百科的一段解释就是:“利用电子商务网站向顾客提供商品信息和建议,帮助用户决定应当订购哪些产品,模拟销售人员帮助顾客完成订购过程。个性化推荐是按照用户的兴趣特性和订购行为,向用户推荐用户感兴趣的信息和商品。”
在这个数据过载的时代,信息的消费者须要从海量的信息中找到自己所须要的信息,信息的生产者要使自己生产的信息在海量的信息中脱颖而出,这时推荐系统就应运而生了。对用户而言,推荐系统不需要用户提供明晰的目标;对物品而言,推荐系统解决了2/8现象的问题(也叫长尾效应),让冷门的物品可以展示到须要它们的用户面前。
二、推荐系统要解决的问题?
1、帮助用户找到想要的物品 如:书籍、电影等
2、可以增加信息过载
3、有利于提升站点的点击率/转化率
4、有利于对用户进行深入了解,为用户提供个性化服务
三、推荐系统的发展趋势?
推荐系统的研究大致可以分为三个阶段,第一阶段是基于传统的服务,第二阶段是基于目前的社交网路的服务,第三阶段是正式到来的物联网。这其中形成了好多基础和重要的算法,例如协同过滤(包括基于用户的和基于物品的)、基于内容的推荐算法、混合式的推荐算法、基于统计理论的推荐算法、基于社交网路信息(关注、被关注、信任、知名度、信誉度等)的过滤推荐算法、群体推荐算法、基于位置的推荐算法。其中基于邻域的协同过滤推荐算法是推荐系统中最基础、最核心、最重要的算法,该算法除了在学术界得到较为深入的研究,而且在业界也得到特别广泛的应用,基于邻域的算法主要分为两大类,一类是基于用户的协同过滤算法,另一类是基于物品的协同过滤算法,除此之外,基于内容的推荐算法应用也十分广泛等等,因此下文将对涉及推荐系统的常用算法进行详尽介绍。
1、基于流行度的推荐算法
2、基于协同过滤的推荐算法(UserCF与ItemCF)
3、基于内容的推荐算法
4、基于模型的推荐算法
5、基于混合式的推荐算法
四、基于流行度的推荐算法
基于流行度的算法十分简单粗鲁,类似于各大新闻、微博热榜等,根据PV、UV、日均PV或分享率等数据来按某种热度排序来推荐给用户。
注:独立访客(UV)、访问次数(VV)两个指标有哪些区别?
① 访问次数(VV):记录1天内所有访客访问了该网站多少次,相同的访客有可能多次访问该网站,且访问的次数累加。
② 独立访客(UV):记录1天内所有访客访问了该网站多少次,虽然相同访客能多次访问网站,但只估算为1个独立访客。
③ PV访问量(Page View):即页面访问量,每打开一次页面或则刷新一次页面,PV值+1。
1、优点:该算法简单,适用于刚注册的新用户
2、缺点:无法针对用户提供个性化的推荐
3、改进:基于该算法可做一些优化,例如加入用户分群的流行度进行排序,通过把热榜上的体育内容优先推荐给体育迷,把政要热文推给热爱谈论政治的用户。
五、基于用户的协同过滤推荐算法
当目标用户须要推荐时,可以先通过兴趣、爱好或行为习惯找到与他相像的其他用户,然后把这些与目标用户相像的用户喜欢的而且目标用户没有浏览过的物品推荐给目标用户。
1、基于用户的CF原理如下:
① 分析各个用户对物品的评价,通过浏览记录、购买记录等得到用户的隐性评分;
② 根据用户对物品的隐性评分估算得到所有用户之间的相似度;
③ 选出与目标用户最相像的K个用户;
④ 将这K个用户隐性评分最高而且目标用户又没有浏览过的物品推荐给目标用户。
2、优点:
① 基于用户的协同过滤推荐算法是给目标用户推荐这些和他有共同兴趣的用户喜欢的物品,所以该算法推荐较为社会化,即推荐的物品是与用户兴趣一致的那种群体中的热门物品;
② 适于物品比用户多、物品时效性较强的情形,否则估算慢;
③ 能实现跨领域、惊喜度高的结果。
3、缺点:
① 在好多时侯,很多用户两两之间的共同评分仅有几个,也即用户之间的重合度并不高,同时仅有的共同打了分的物品,往往是一些太常见的物品,如收视大片、生活必需品;
②用户之间的距离可能显得很快,这种离线算法无法顿时更新推荐结果;
③推荐结果的个性化较弱、较笼统。
4、改进:
① 两个用户对流行物品的有相像兴趣,丝毫不能说明她们有相像的兴趣,此时要降低惩罚力度;
②如果两个用户同时喜欢了相同的物品,那么可以给这两个用户更高的相似度;
③在描述邻居用户的偏好时,给其近来喜欢的物品较高权重;
④把类似地域用户的行为作为推荐的主要根据。
六、基于物品的协同过滤推荐算法
当一个用户须要个性化推荐时,举个反例因为我之前订购过许嵩的《梦游计》这张专辑,所以会给我推荐《青年晚报》,因为好多其他用户都同时订购了许嵩的这两张专辑。
1、基于物品的CF原理如下:
① 分析各个用户对物品的浏览记录;
② 依据浏览记录剖析得出所有物品之间的相似度;
③ 对于目标用户评价高的物品,找出与之相似度最高的K个物品;
④ 将这K个物品中目标用户没有浏览过的物品推荐给目标用户
2、优点:
① 基于物品的协同过滤推荐算法则是为目标用户推荐这些和他之前喜欢的物品类似的物品,所以基于物品的协同过滤推荐算法的推荐较为个性,因为推荐的物品通常都满足目标用户的奇特兴趣。
②物品之间的距离可能是依据成百上千万的用户的隐性评分估算得出,往往能在一段时间内保持稳定。因此,这种算法可以预先估算距离,其在线部份能更快地生产推荐列表。
③应用最广泛,尤其以电商行业为典型。
④ 适于用户多、物品少的情形,否则估算慢
⑤ 推荐精度高,更具个性化
⑥倾向于推荐同类商品
3、缺点:
①不同领域的最热门物品之间常常具有较高的相似度。比如,基于本算法,我们可能会给喜欢听许嵩歌曲的朋友推荐汪峰的歌曲,也就是推荐不同领域的畅销作品,这样的推荐结果可能并不是我们想要的。
②在物品冷启动、数据稀疏时疗效不佳
③推荐的多样性不足,形成信息闭环
4、改进:
① 如果是热门物品,很多人都喜欢,就会接近1,就会导致好多物品都和热门物品相像,此时要降低惩罚力度;
②活跃用户对物品相似度的贡献大于不活跃的用户;
③同一个用户在间隔太短的时间内喜欢的两件商品之间,可以给与更高的相似度;
④在描述目标用户偏好时,给其近来喜欢的商品较高权重;
⑤同一个用户在同一个地域内喜欢的两件商品之间,可以给与更高的相似度。
七、基于内容的推荐算法
协同过滤算法仅仅通过了解用户与物品之间的关系进行推荐,而根本不会考虑到物品本身的属性,而基于内容的算法会考虑到物品本身的属性。
根据用户之前对物品的历史行为,如用户订购过哪些物品、对哪些物品采集过、评分过等等,然后再按照估算与那些物品相像的物品,并把它们推荐给用户。例如某用户之前订购过许嵩的《寻宝游戏》,这可以说明该用户可能是一个嵩鼠,这时就可以给该用户推荐一些许嵩的其他专辑或专著。
1、基于内容的推荐算法的原理如下:
① 选取一些具有代表性的特点来表示每位物品
② 使用用户的历史行为数据剖析物品的这种特点,从而学习出用户的喜好特点或兴趣,也即建立用户画像
③ 通过比较上一步得到的用户画像和待推荐物品的画像(由待推荐物品的特点构成),将具有相关性最大的前K个物品中目标用户没有浏览过的物品推荐给目标用户
2、优点:
① 是最直观的算法
② 常利用文本相似度估算
③ 很好地解决冷启动问题,并且也不会囿于热度的限制
3、缺点:
① 容易受限于对文本、图像、音视频的内容进行描述的详尽程度
② 过度专业化(over-specialisation),导致仍然推荐给用户内容密切关联的item,而丧失了推荐内容的多样性。
③主题过分集中,惊喜度不足
八、基于模型的推荐算法
基于模型的推荐算法会涉及到一些机器学习的方式,如逻辑回归、朴素贝叶斯分类器等。基于模型的算法因为快速、准确,适用于实时性比较高的业务如新闻、广告等,而若是须要这些算法达到更好的疗效,则须要人工干预反复的进行属性的组合和筛选,也就是常说的Feature Engineering。而因为新闻的时效性,系统也须要反复更新线上的物理模型,以适应变化。
九、基于混合式的推荐算法
现实应用中,其实极少有直接用某种算法来做推荐的系统。在一些大的网站如Netflix,就是融合了数十种算法的推荐系统。我们可以通过给不同算法的结果加权重来综合结果,或者是在不同的估算环节中运用不同的算法来混和,达到更贴合自己业务的目的。
十、推荐结果列表处理
1、当推荐算法估算得出推荐结果列表以后,我们常常还须要对结果进行处理。比如当推荐的内容里收录敏感词汇、涉及用户隐私的内容等等,就须要系统将其筛除;
2、若多次推荐后用户仍然对某个物品毫无兴趣,就须要将这个物品减少权重,调整排序;
3、有时系统还要考虑话题多样性的问题,同样要在不同话题中筛选内容。
十一、推荐结果评估
当一个推荐算法设计完成后,一般须要用查准率(precision),查全率(recall),点击率(CTR)、转化率(CVR)、停留时间等指标进行评价。
查准率(precision):推荐给用户且用户喜欢的物品在推荐列表中的比重
查全率(recall):推荐给用户且用户喜欢的物品在用户列表中的比重
点击率(CTR):实际点击了的物品/推荐列表中所有的物品
转化率(CVR):购买了的物品/实际点击了的物品
日积月累,与君共进,增增小结,未完待续。
网页手动采集之内涵吧内涵段子手动采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 325 次浏览 • 2020-08-09 15:29
<p> /**
*@Description:
*/
package cn.lulei.crawl.neihan8;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashSet;
import cn.lulei.db.neihan8.Neihan8DbOperation;
import cn.lulei.model.Neihan8;
import cn.lulei.util.ParseUtil;
import cn.lulei.util.ThreadUtil;
public class Neihan8Crawl {
//内涵吧更新列表页url格式
private static String listPageUrl = "http://www.neihan8.com/article ... 3B%3B
//两次访问页面事件间隔,单位ms
private static int sleepTime = 500;
/**
* @param start 起始页
* @param end 终止页
* @throws IOException
* @Date: 2014-2-13
* @Author: lulei
* @Description: 抓取更新列表页上的内容
*/
public void crawlMain(int start, int end) throws IOException{
start = start < 1 ? 1 : start;
Neihan8DbOperation neihan8DbOperation = new Neihan8DbOperation();
for ( ; start 查看全部
内涵吧内涵段子采集入口类Neihan8Crawl这儿的没有实现抓取程序的周期性采集,这里可以依照自己的须要来写相应的线程。
<p> /**
*@Description:
*/
package cn.lulei.crawl.neihan8;
import java.io.IOException;
import java.util.ArrayList;
import java.util.HashSet;
import cn.lulei.db.neihan8.Neihan8DbOperation;
import cn.lulei.model.Neihan8;
import cn.lulei.util.ParseUtil;
import cn.lulei.util.ThreadUtil;
public class Neihan8Crawl {
//内涵吧更新列表页url格式
private static String listPageUrl = "http://www.neihan8.com/article ... 3B%3B
//两次访问页面事件间隔,单位ms
private static int sleepTime = 500;
/**
* @param start 起始页
* @param end 终止页
* @throws IOException
* @Date: 2014-2-13
* @Author: lulei
* @Description: 抓取更新列表页上的内容
*/
public void crawlMain(int start, int end) throws IOException{
start = start < 1 ? 1 : start;
Neihan8DbOperation neihan8DbOperation = new Neihan8DbOperation();
for ( ; start
3种方式实现列表手动滚动
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2020-08-09 15:04
方法一:用javascript原生代码实现,不需要依赖任何框架,代码及注释如下:
1 //javascript原生自动滚动
2 function startmarquee(lh,speed,delay,marqueeObj) { //lh---每行列表的高度,speed---滚动的速度,delay---间隔多久滚动一次,marqueeObj---需要实现这个效果的id
3 var p=false;
4 var t;
5 var o=document.getElementById(marqueeObj);
6 o.innerHTML+=o.innerHTML;
7 o.style.marginTop=0;
8 o.onmouseover=function(){p=true;} //鼠标移入,停止滚动
9 o.onmouseout=function(){p=false;}//鼠标移出,继续滚动
10
11 function start(){
12 t=setInterval(scrolling,speed); //定时器,自动滚动
13 if(!p) o.style.marginTop=parseInt(o.style.marginTop)-1+"px";
14 }
15
16 function scrolling(){
17 if(parseInt(o.style.marginTop)%lh!=0){
18 o.style.marginTop=parseInt(o.style.marginTop)-1+"px";
19 if(Math.abs(parseInt(o.style.marginTop))>=o.scrollHeight/2) o.style.marginTop=0;
20 }else{
21 clearInterval(t);
22 setTimeout(start,delay);
23 }
24 }
25 setTimeout(start,delay);
26 }
27 startmarquee(48,20,1000,"marqueebox"); //引用函数
方法二:依赖jquery,可以进行不定高的滚动
1 //列表自动滚动
2 function scrollNews() {
3 var $news = $('#marqueebox table');
4 var $lineHeight = $news.find('tr:first').height();
5 $news.animate({ 'marginTop': -$lineHeight + 'px' }, 1000, function () {
6 $news.css({ margin: 0 }).find('tr:first').appendTo($news);
7 });
8 }
9
10 var scrollTimer = null;
11 var delay = 2000;
12 scrollTimer = setInterval(function () {
13 scrollNews();
14 }, delay);
方法三:从左向右轮播
<p> 1 function ScrollImgLeft(start,end,wrap){
2 var speed=40;
3 var scroll_begin = document.getElementById(start);
4 var scroll_end = document.getElementById(end);
5 var scroll_div = document.getElementById(wrap);
6 scroll_end.innerHTML=scroll_begin.innerHTML;
7 function Marquee(){
8 if(scroll_end.offsetWidth-scroll_div.scrollLeft 查看全部
自动滚动这些疗效在网页中还是比较常见的。现在,就我在做项目期间所用到的才能实现手动滚动的方式做一个总结。
方法一:用javascript原生代码实现,不需要依赖任何框架,代码及注释如下:
1 //javascript原生自动滚动
2 function startmarquee(lh,speed,delay,marqueeObj) { //lh---每行列表的高度,speed---滚动的速度,delay---间隔多久滚动一次,marqueeObj---需要实现这个效果的id
3 var p=false;
4 var t;
5 var o=document.getElementById(marqueeObj);
6 o.innerHTML+=o.innerHTML;
7 o.style.marginTop=0;
8 o.onmouseover=function(){p=true;} //鼠标移入,停止滚动
9 o.onmouseout=function(){p=false;}//鼠标移出,继续滚动
10
11 function start(){
12 t=setInterval(scrolling,speed); //定时器,自动滚动
13 if(!p) o.style.marginTop=parseInt(o.style.marginTop)-1+"px";
14 }
15
16 function scrolling(){
17 if(parseInt(o.style.marginTop)%lh!=0){
18 o.style.marginTop=parseInt(o.style.marginTop)-1+"px";
19 if(Math.abs(parseInt(o.style.marginTop))>=o.scrollHeight/2) o.style.marginTop=0;
20 }else{
21 clearInterval(t);
22 setTimeout(start,delay);
23 }
24 }
25 setTimeout(start,delay);
26 }
27 startmarquee(48,20,1000,"marqueebox"); //引用函数
方法二:依赖jquery,可以进行不定高的滚动
1 //列表自动滚动
2 function scrollNews() {
3 var $news = $('#marqueebox table');
4 var $lineHeight = $news.find('tr:first').height();
5 $news.animate({ 'marginTop': -$lineHeight + 'px' }, 1000, function () {
6 $news.css({ margin: 0 }).find('tr:first').appendTo($news);
7 });
8 }
9
10 var scrollTimer = null;
11 var delay = 2000;
12 scrollTimer = setInterval(function () {
13 scrollNews();
14 }, delay);
方法三:从左向右轮播
<p> 1 function ScrollImgLeft(start,end,wrap){
2 var speed=40;
3 var scroll_begin = document.getElementById(start);
4 var scroll_end = document.getElementById(end);
5 var scroll_div = document.getElementById(wrap);
6 scroll_end.innerHTML=scroll_begin.innerHTML;
7 function Marquee(){
8 if(scroll_end.offsetWidth-scroll_div.scrollLeft
使用上下文信息提出建议
采集交流 • 优采云 发表了文章 • 0 个评论 • 250 次浏览 • 2020-08-08 22:47
1. 什么是上下文
本章前面提到的推荐系统算法主要着重于如何联系用户兴趣和项目,并向用户推荐最适合用户兴趣的项目,但是这些算法忽略了一点,即用户的上下文. . 这些上下文包括用户访问推荐系统的时间,地点和心情,这对于改进推荐系统的推荐系统非常重要. 例如,销售衣服的推荐系统应该在冬天和夏天向用户推荐不同种类的衣服. 推荐系统无法在冬季向用户推荐类似的T恤,因为用户在夏天喜欢某件T恤.
我们在这里主要讨论时间上下文,并简要介绍位置上下文,并讨论如何将时间信息和位置信息建模到推荐算法中,以便推荐系统可以准确地预测用户在特定时刻的兴趣并具体位置.
2. 时间上下文2.1时间效应
时间是重要的上下文信息,对用户兴趣具有深远和广泛的影响. 人们普遍认为,时间信息对用户兴趣的影响体现在以下几个方面.
1)用户兴趣正在改变
2)物品也有生命周期
3)季节效应
2.2系统时间特征分析
在给定时间信息之后,推荐系统已从静态系统变为时变系统,并且用户行为数据也已成为时间序列. 要研究时变系统,我们首先需要研究系统的时间特性. 收录时间信息的用户行为数据集由一系列三元组组成,其中每个三元组(u,i,t)表示用户u在时间t上项目i的行为. 我们可以研究的时间特征如下:
数据集中唯一身份用户数量的每日增长
系统中的物料更改: 例如,物料在线的平均天数. 如果某项在某一天已被至少一个用户操作,则定义该项在该天处于联机状态. 因此,我们可以通过商品的平均在线天数来衡量一类商品的生命周期.
用户访问权限: 我们可以计算用户活动天数的平均值,以及进入系统T天的用户重叠次数.
由T天分隔的系统项目流行度向量的平均相似度: 在系统中相邻两个T天,分别计算这两天的项目流行度,以获得两个流行度向量. 然后,计算两个向量的余弦相似度. 如果相似性很大,则意味着系统中的项目在相隔T天之内没有发生显着变化,这表明系统的时效性不强,并且项目的平均在线时间更长.
2.3推荐系统的实时性能
实现推荐系统的实时性,不仅需要实时访问用户行为,还需要推荐算法本身的实时性,并且推荐算法本身的实时性意味着:
1)实时推荐系统无法每天为所有用户离线计算推荐结果,然后在线显示昨天计算的结果. 因此,当每个用户访问推荐系统时,将根据该时间点之前用户的行为实时计算推荐列表.
2)推荐算法需要平衡用户的近期行为和长期行为,即,推荐列表必须反映出用户最近行为所反映的用户兴趣变化,并且推荐列表不得完全受到影响根据用户的近期行为. 必须保证推荐内容的连续性,以预测用户的兴趣.
2.4推荐结果的时间多样性
那么,如何在不损失准确性的情况下提高推荐结果的时间多样性?改善推荐结果的时间多样性需要分两个步骤解决: 首先,必须确保推荐系统可以在用户有新行为后及时调整推荐结果,以使推荐结果满足用户的近期兴趣. 其次,有必要确保推荐系统在用户手中. 当没有新行为时,结果可以经常更改,并具有一定的时间多样性.
第一步,可以将其分为两种情况进行分析. 首先是从推荐系统的实时角度来看. 一些推荐系统每天都会为所有用户生成推荐,然后将这些结果直接显示给在线用户. 显然,这种类型的系统在用户出现新行为后无法及时调整推荐结果. 其次,由于算法不同,即使是实时推荐系统也具有不同的时间分集.
那么,如果用户没有任何行为,如何确保向用户推荐的结果具有一定的时间多样性?总体思路如下.
在生成推荐结果时添加一定程度的随机性,
记录用户每天看到的推荐结果,然后在每天向用户推荐时,适当降低过去几天中多次看到的推荐结果的能量.
每天为用户使用不同的推荐算法.
3. 时间上下文推荐算法3.1最近最受欢迎的
在没有时间信息的数据集中,我们可以向用户推荐历史上最受欢迎的商品. 然后,在获得用户行为的时间信息之后,最简单的非个性化推荐算法是最近向用户推荐最受欢迎的商品. 在给定的时间T,可以将项i的最近受欢迎程度ni(T)定义为:
3.2与时间上下文有关的ItemCF算法
基于时间上下文,我们可以从以下两个方面改进ItemCF算法.
1)项目相似度: 用户在短时间内喜欢的项目具有较高的相似度.
2)在线推荐: 用户的近期行为比很久以前的用户行为更好地反映了用户的当前兴趣.
首先回顾一下前面提到的基于项目的协同过滤算法,该算法通过以下公式计算项目的相似度:
向用户u推荐时,用户u对项目i的兴趣p(u,i)由以下公式计算:
获取时间信息后,可以通过以下公式改进相似度计算:
上面使用的衰减函数的可能形式如下:
除了考虑时间信息对相关表的影响外,我们还应该考虑时间信息对预测公式的影响. 一般来说,用户的当前行为应该与用户的最近行为有更大的关系,因此可以进行以下修复:
其中,t0是当前时间. 从上式可以看出,tuj越接近t0,在用户u的推荐列表中,类似于j的项目的排名越高.
3.3与时间上下文有关的UserCF算法
类似于ItemCF,我们还可以在以下两个方面使用时间信息来改进UserCF算法.
1)用户兴趣相似度: 两个用户之所以兴趣相似,是因为他们喜欢相同的项目或对相同的项目有行为. 但是,如果两个用户同时喜欢同一商品,则这两个用户的兴趣应该更大.
2)兴趣相似的用户的近期行为: 找到一组与当前用户u相似的用户的兴趣后,该组用户的近期兴趣显然比今天的用户u的兴趣更接近于今天的用户u的兴趣. 这群用户很久以前. 换句话说,我们应该向用户推荐具有相似兴趣的用户最近喜欢的项目.
首先查看UserCF的公式. UserCF通过以下公式计算用户u与用户v之间的兴趣相似度:
N(u)是用户u喜欢的项目的集合,N(v)是用户v喜欢的项目的集合.
获得用户相似性后,UserCF通过以下公式预测用户对该商品的兴趣:
考虑时间因素,我们可以如下修改用户相似度计算并添加时间衰减因素. 用户u和用户v对项目i作用的距离越远,两个用户的兴趣相似度就越小. :
同样,如果我们考虑与用户u类似的用户最近兴趣,则可以设计以下公式:
3.4时间段图模型
在基于时间的图模型中,时间周期图模型G(U,SU,I,SI,E,w,)也是二部图. U是用户节点集,SU是用户时间段节点集. 用户时间段节点vut∈SU将通过时间与用户u在时间t处喜欢的项目相关联. I是项目节点的集合,SI是项目时间段节点的集合. 项目时间段节点vit∈SI将在时间t连接到所有喜欢项目i的用户. E是边集,收录3种边: (1)如果用户u在第i项上有行为,则存在边e(vu,vi)∈E; (2)如果用户u在时间t行为上对第i个项目有行为,则有两个边e(vut,vi),e(vu,vit)∈E.
下图是一个简单的时间周期图模型的示例. 在此示例中,用户A在时间2作用于项目b. 因此,时间段图模型将首先创建4个顶点,即用户顶点A,用户时间段顶点A: 2,项目顶点b和项目时间段顶点b. : 2. 然后,将3个边添加到图中,即(A,b),(A: 2,b),(A,b: 2). 此处不再添加边(A: 2,b: 2),一方面是因为添加该边不会改善结果,另一方面,因为添加边会增加图的空间复杂度图上算法的时间复杂度.
在这里,我们不再使用PersonalRank算法向用户提出个性化推荐. 相应地,我们使用一种称为路径融合算法的方法来测量图中两个顶点之间的相关性.
一般而言,图上两个高度相关的顶点通常具有以下特征:
1)有许多路径连接两个顶点;
2)两个顶点之间的路径相对较短;
3)两个顶点之间的路径不通过输出程度更高的顶点.
在这里很难弄清楚公式,只需要截图:
4. 位置上下文信息
除了时间,地点作为重要的空间特征,也是重要的上下文信息. 在这里我们不会详细介绍. 查看全部
本文的思想指导如下:
1. 什么是上下文
本章前面提到的推荐系统算法主要着重于如何联系用户兴趣和项目,并向用户推荐最适合用户兴趣的项目,但是这些算法忽略了一点,即用户的上下文. . 这些上下文包括用户访问推荐系统的时间,地点和心情,这对于改进推荐系统的推荐系统非常重要. 例如,销售衣服的推荐系统应该在冬天和夏天向用户推荐不同种类的衣服. 推荐系统无法在冬季向用户推荐类似的T恤,因为用户在夏天喜欢某件T恤.
我们在这里主要讨论时间上下文,并简要介绍位置上下文,并讨论如何将时间信息和位置信息建模到推荐算法中,以便推荐系统可以准确地预测用户在特定时刻的兴趣并具体位置.
2. 时间上下文2.1时间效应
时间是重要的上下文信息,对用户兴趣具有深远和广泛的影响. 人们普遍认为,时间信息对用户兴趣的影响体现在以下几个方面.
1)用户兴趣正在改变
2)物品也有生命周期
3)季节效应
2.2系统时间特征分析
在给定时间信息之后,推荐系统已从静态系统变为时变系统,并且用户行为数据也已成为时间序列. 要研究时变系统,我们首先需要研究系统的时间特性. 收录时间信息的用户行为数据集由一系列三元组组成,其中每个三元组(u,i,t)表示用户u在时间t上项目i的行为. 我们可以研究的时间特征如下:
数据集中唯一身份用户数量的每日增长
系统中的物料更改: 例如,物料在线的平均天数. 如果某项在某一天已被至少一个用户操作,则定义该项在该天处于联机状态. 因此,我们可以通过商品的平均在线天数来衡量一类商品的生命周期.
用户访问权限: 我们可以计算用户活动天数的平均值,以及进入系统T天的用户重叠次数.
由T天分隔的系统项目流行度向量的平均相似度: 在系统中相邻两个T天,分别计算这两天的项目流行度,以获得两个流行度向量. 然后,计算两个向量的余弦相似度. 如果相似性很大,则意味着系统中的项目在相隔T天之内没有发生显着变化,这表明系统的时效性不强,并且项目的平均在线时间更长.
2.3推荐系统的实时性能
实现推荐系统的实时性,不仅需要实时访问用户行为,还需要推荐算法本身的实时性,并且推荐算法本身的实时性意味着:
1)实时推荐系统无法每天为所有用户离线计算推荐结果,然后在线显示昨天计算的结果. 因此,当每个用户访问推荐系统时,将根据该时间点之前用户的行为实时计算推荐列表.
2)推荐算法需要平衡用户的近期行为和长期行为,即,推荐列表必须反映出用户最近行为所反映的用户兴趣变化,并且推荐列表不得完全受到影响根据用户的近期行为. 必须保证推荐内容的连续性,以预测用户的兴趣.
2.4推荐结果的时间多样性
那么,如何在不损失准确性的情况下提高推荐结果的时间多样性?改善推荐结果的时间多样性需要分两个步骤解决: 首先,必须确保推荐系统可以在用户有新行为后及时调整推荐结果,以使推荐结果满足用户的近期兴趣. 其次,有必要确保推荐系统在用户手中. 当没有新行为时,结果可以经常更改,并具有一定的时间多样性.
第一步,可以将其分为两种情况进行分析. 首先是从推荐系统的实时角度来看. 一些推荐系统每天都会为所有用户生成推荐,然后将这些结果直接显示给在线用户. 显然,这种类型的系统在用户出现新行为后无法及时调整推荐结果. 其次,由于算法不同,即使是实时推荐系统也具有不同的时间分集.
那么,如果用户没有任何行为,如何确保向用户推荐的结果具有一定的时间多样性?总体思路如下.
在生成推荐结果时添加一定程度的随机性,
记录用户每天看到的推荐结果,然后在每天向用户推荐时,适当降低过去几天中多次看到的推荐结果的能量.
每天为用户使用不同的推荐算法.
3. 时间上下文推荐算法3.1最近最受欢迎的
在没有时间信息的数据集中,我们可以向用户推荐历史上最受欢迎的商品. 然后,在获得用户行为的时间信息之后,最简单的非个性化推荐算法是最近向用户推荐最受欢迎的商品. 在给定的时间T,可以将项i的最近受欢迎程度ni(T)定义为:
3.2与时间上下文有关的ItemCF算法
基于时间上下文,我们可以从以下两个方面改进ItemCF算法.
1)项目相似度: 用户在短时间内喜欢的项目具有较高的相似度.
2)在线推荐: 用户的近期行为比很久以前的用户行为更好地反映了用户的当前兴趣.
首先回顾一下前面提到的基于项目的协同过滤算法,该算法通过以下公式计算项目的相似度:
向用户u推荐时,用户u对项目i的兴趣p(u,i)由以下公式计算:
获取时间信息后,可以通过以下公式改进相似度计算:
上面使用的衰减函数的可能形式如下:
除了考虑时间信息对相关表的影响外,我们还应该考虑时间信息对预测公式的影响. 一般来说,用户的当前行为应该与用户的最近行为有更大的关系,因此可以进行以下修复:
其中,t0是当前时间. 从上式可以看出,tuj越接近t0,在用户u的推荐列表中,类似于j的项目的排名越高.
3.3与时间上下文有关的UserCF算法
类似于ItemCF,我们还可以在以下两个方面使用时间信息来改进UserCF算法.
1)用户兴趣相似度: 两个用户之所以兴趣相似,是因为他们喜欢相同的项目或对相同的项目有行为. 但是,如果两个用户同时喜欢同一商品,则这两个用户的兴趣应该更大.
2)兴趣相似的用户的近期行为: 找到一组与当前用户u相似的用户的兴趣后,该组用户的近期兴趣显然比今天的用户u的兴趣更接近于今天的用户u的兴趣. 这群用户很久以前. 换句话说,我们应该向用户推荐具有相似兴趣的用户最近喜欢的项目.
首先查看UserCF的公式. UserCF通过以下公式计算用户u与用户v之间的兴趣相似度:
N(u)是用户u喜欢的项目的集合,N(v)是用户v喜欢的项目的集合.
获得用户相似性后,UserCF通过以下公式预测用户对该商品的兴趣:
考虑时间因素,我们可以如下修改用户相似度计算并添加时间衰减因素. 用户u和用户v对项目i作用的距离越远,两个用户的兴趣相似度就越小. :
同样,如果我们考虑与用户u类似的用户最近兴趣,则可以设计以下公式:
3.4时间段图模型
在基于时间的图模型中,时间周期图模型G(U,SU,I,SI,E,w,)也是二部图. U是用户节点集,SU是用户时间段节点集. 用户时间段节点vut∈SU将通过时间与用户u在时间t处喜欢的项目相关联. I是项目节点的集合,SI是项目时间段节点的集合. 项目时间段节点vit∈SI将在时间t连接到所有喜欢项目i的用户. E是边集,收录3种边: (1)如果用户u在第i项上有行为,则存在边e(vu,vi)∈E; (2)如果用户u在时间t行为上对第i个项目有行为,则有两个边e(vut,vi),e(vu,vit)∈E.
下图是一个简单的时间周期图模型的示例. 在此示例中,用户A在时间2作用于项目b. 因此,时间段图模型将首先创建4个顶点,即用户顶点A,用户时间段顶点A: 2,项目顶点b和项目时间段顶点b. : 2. 然后,将3个边添加到图中,即(A,b),(A: 2,b),(A,b: 2). 此处不再添加边(A: 2,b: 2),一方面是因为添加该边不会改善结果,另一方面,因为添加边会增加图的空间复杂度图上算法的时间复杂度.
在这里,我们不再使用PersonalRank算法向用户提出个性化推荐. 相应地,我们使用一种称为路径融合算法的方法来测量图中两个顶点之间的相关性.
一般而言,图上两个高度相关的顶点通常具有以下特征:
1)有许多路径连接两个顶点;
2)两个顶点之间的路径相对较短;
3)两个顶点之间的路径不通过输出程度更高的顶点.
在这里很难弄清楚公式,只需要截图:
4. 位置上下文信息
除了时间,地点作为重要的空间特征,也是重要的上下文信息. 在这里我们不会详细介绍.
百度将启动Hurricane Algorithm 2.0,这四种采集行为将受到冲击
采集交流 • 优采云 发表了文章 • 0 个评论 • 315 次浏览 • 2020-08-08 15:07
为了在百度搜索中营造良好的搜索内容生态,保护搜索用户的阅读和浏览体验以及保护高质量内容制作者的权益,百度将在中旬至中期升级飓风算法. 九月下旬. 在即将到来的Hurricane Algorithm 2.0中,百度将严厉打击四种严酷的采集行为,网站管理员需要给予更多关注:
1. 网站上采集了很多且可读性很差的内容
我们一直强调,网站上的内容应该是原创的,因为即使所采集文章的质量很高,就搜索引擎而言,如果所采集的内容不会给网站带来太多好处,太高,质量太差,可能会对网站造成负面影响.
在Hurricane Algorithm 2.0的更新中,对此类文章也提出了明确的要求. 信息未集成,布局混乱,文章可读性差,具有明显的采集痕迹,并且没有使用户受益. 重视内容,搜索引擎会对其加以惩罚. 因此,网站管理员在采集文章时,还必须合理地排版文章,并采集质量高且对用户有用的文章.
第二,文章拼接内容多
某些网站管理员可能会从其他网站采集几篇文章进行拼接,以欺骗搜索引擎并将这些文章“伪造”为原创文章. 或者您想将几篇文章的核心思想拼凑在一起.
但是,这类文章通常缺乏逻辑性,并且也会给用户带来非常差的阅读体验. 搜索引擎对网站排名的一个非常重要的指标是用户体验,因此,如果文章的质量较差并且用户没有良好的阅读体验,则该网站将不会排名.
在Hurricane Algorithm 2.0的更新中,也为此类文章制定了明确的规范. 如果将此类文章拼接在一起并不能再次满足用户的需求,则它们很可能会受到影响. 搜索引擎的惩罚.
三,车站中有大量采集的内容
对于网站中具有大量采集内容且网站自身内容的生产力较低的网站,百度搜索也明确指出: 不.
这也与我们在优化SEO时专注于原创文章的概念相吻合. 对于内容生产力较差的网站,百度会认为此类网站无法为用户提供实际帮助,因此自然无法获得排名. 启动Hurricane Algorithm 2.0之后,如果网站上的大多数文章都被采集起来,它也可能会受到搜索引擎的制裁. 网站管理员必须注意. 查看全部
在网站建设和SEO优化中,必须根据百度搜索算法进行大量调整,以确保您的网站可以被百度很好地爬行,包括并获得较高的排名. 百度也在不断升级算法以优化用户的搜索体验,但是对于网站管理员而言,也许每次对百度算法的更新都需要对自己的工作进行一些更改.
为了在百度搜索中营造良好的搜索内容生态,保护搜索用户的阅读和浏览体验以及保护高质量内容制作者的权益,百度将在中旬至中期升级飓风算法. 九月下旬. 在即将到来的Hurricane Algorithm 2.0中,百度将严厉打击四种严酷的采集行为,网站管理员需要给予更多关注:
1. 网站上采集了很多且可读性很差的内容
我们一直强调,网站上的内容应该是原创的,因为即使所采集文章的质量很高,就搜索引擎而言,如果所采集的内容不会给网站带来太多好处,太高,质量太差,可能会对网站造成负面影响.
在Hurricane Algorithm 2.0的更新中,对此类文章也提出了明确的要求. 信息未集成,布局混乱,文章可读性差,具有明显的采集痕迹,并且没有使用户受益. 重视内容,搜索引擎会对其加以惩罚. 因此,网站管理员在采集文章时,还必须合理地排版文章,并采集质量高且对用户有用的文章.
第二,文章拼接内容多
某些网站管理员可能会从其他网站采集几篇文章进行拼接,以欺骗搜索引擎并将这些文章“伪造”为原创文章. 或者您想将几篇文章的核心思想拼凑在一起.
但是,这类文章通常缺乏逻辑性,并且也会给用户带来非常差的阅读体验. 搜索引擎对网站排名的一个非常重要的指标是用户体验,因此,如果文章的质量较差并且用户没有良好的阅读体验,则该网站将不会排名.
在Hurricane Algorithm 2.0的更新中,也为此类文章制定了明确的规范. 如果将此类文章拼接在一起并不能再次满足用户的需求,则它们很可能会受到影响. 搜索引擎的惩罚.
三,车站中有大量采集的内容
对于网站中具有大量采集内容且网站自身内容的生产力较低的网站,百度搜索也明确指出: 不.
这也与我们在优化SEO时专注于原创文章的概念相吻合. 对于内容生产力较差的网站,百度会认为此类网站无法为用户提供实际帮助,因此自然无法获得排名. 启动Hurricane Algorithm 2.0之后,如果网站上的大多数文章都被采集起来,它也可能会受到搜索引擎的制裁. 网站管理员必须注意.
百度算法飓风算法3.0的详细说明
采集交流 • 优采云 发表了文章 • 0 个评论 • 170 次浏览 • 2020-08-08 14:00
2019年8月,百度搜索将飓风算法升级为飓风算法3.0,主要打击了百度搜索下PC站点,H5站点和智能小程序的跨域集合以及站点组的批处理行为获得搜索流量. Hurricane Algorithm 3.0旨在维护健康的移动生态,确保用户体验,并确保高质量的站点/智能小程序能够获得合理的流量分配.
二: 飓风算法3.0攻击对象
问题1: 在同一个品牌下,分公司的网站/智能小程序使用相同的模板,是否将其判断为一组站点并被Hurricane Algorithm 3.0打中?
<p>A1: 对于网站组问题,该算法将基于多个因素进行综合判断,例如页面布局相似性,同一主题下的网站/智能小程序数量,内容质量,内容稀缺性,内容相似性等. 查看全部
一个: Hurricane Algorithm 3.0的启动时间
2019年8月,百度搜索将飓风算法升级为飓风算法3.0,主要打击了百度搜索下PC站点,H5站点和智能小程序的跨域集合以及站点组的批处理行为获得搜索流量. Hurricane Algorithm 3.0旨在维护健康的移动生态,确保用户体验,并确保高质量的站点/智能小程序能够获得合理的流量分配.
二: 飓风算法3.0攻击对象
问题1: 在同一个品牌下,分公司的网站/智能小程序使用相同的模板,是否将其判断为一组站点并被Hurricane Algorithm 3.0打中?
<p>A1: 对于网站组问题,该算法将基于多个因素进行综合判断,例如页面布局相似性,同一主题下的网站/智能小程序数量,内容质量,内容稀缺性,内容相似性等.
测试数据评估
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2020-08-08 13:57
问题定义-数据获取-数据准备-数据分割-算法选择-算法训练-测试数据评估-参数调整-模型使用
问题定义
出什么问题了
定义此任务,并将其分为任务(T),经验(E)和绩效(P).
图片中是否收录人物:
数据采集
定义问题后,开始数据采集. 有很多不同的采集数据的方法. 如果您想将评论与评分链接起来,则必须先爬网网站.
数据准备*
ETL,是Extract-Transform-Load的英文缩写,用于描述从源到目标提取,转换和加载数据的过程
BI通常是指商业智能. 商业智能(Business Intelligence,简称: BI),也称为商业智能或商业智能,是指利用现代数据仓库技术,在线分析和处理技术,数据挖掘和数据显示技术进行数据分析以实现业务值.
预处理过程中的某些过程: 数据分割*
机器学习算法的目标是预测未知的新数据. 为了评估生成的模型,需要将数据分为训练数据和测试数据. 使用训练数据进行算法训练,并使用测试数据计算生成模型的最终准确性. 测试数据不参与算法训练.
使用60%到80%的数据作为训练数据,其余部分用作测试数据. 因此,可以将在测试数据中获得最佳结果的模型用作目标模型
算法选择*
机器学习算法开始,并将训练数据的特征应用于该算法. 算法的选择取决于问题的定义.
算法训练
在训练数据集上执行训练模型. 大多数算法的权重/参数是在训练开始时随机分配的,并且在每次迭代中都会得到改善.
测试数据评估
使用训练数据生成最佳算法后,请在测试数据集上评估算法的性能. 测试数据集不能参与算法训练,因此测试数据不会影响算法的决策.
参数调整模型的使用
您可以获得在训练集上训练和生成并在测试集上进行评估的模型. 现在,您可以使用此模型来预测新数据的价值. 对于生产环境,您可以将模型部署到服务器,并通过API接口使用模型的预测功能 查看全部
机器学习过程:
问题定义-数据获取-数据准备-数据分割-算法选择-算法训练-测试数据评估-参数调整-模型使用
问题定义
出什么问题了
定义此任务,并将其分为任务(T),经验(E)和绩效(P).
图片中是否收录人物:
数据采集
定义问题后,开始数据采集. 有很多不同的采集数据的方法. 如果您想将评论与评分链接起来,则必须先爬网网站.
数据准备*
ETL,是Extract-Transform-Load的英文缩写,用于描述从源到目标提取,转换和加载数据的过程
BI通常是指商业智能. 商业智能(Business Intelligence,简称: BI),也称为商业智能或商业智能,是指利用现代数据仓库技术,在线分析和处理技术,数据挖掘和数据显示技术进行数据分析以实现业务值.
预处理过程中的某些过程: 数据分割*
机器学习算法的目标是预测未知的新数据. 为了评估生成的模型,需要将数据分为训练数据和测试数据. 使用训练数据进行算法训练,并使用测试数据计算生成模型的最终准确性. 测试数据不参与算法训练.
使用60%到80%的数据作为训练数据,其余部分用作测试数据. 因此,可以将在测试数据中获得最佳结果的模型用作目标模型
算法选择*
机器学习算法开始,并将训练数据的特征应用于该算法. 算法的选择取决于问题的定义.
算法训练
在训练数据集上执行训练模型. 大多数算法的权重/参数是在训练开始时随机分配的,并且在每次迭代中都会得到改善.
测试数据评估
使用训练数据生成最佳算法后,请在测试数据集上评估算法的性能. 测试数据集不能参与算法训练,因此测试数据不会影响算法的决策.
参数调整模型的使用
您可以获得在训练集上训练和生成并在测试集上进行评估的模型. 现在,您可以使用此模型来预测新数据的价值. 对于生产环境,您可以将模型部署到服务器,并通过API接口使用模型的预测功能
网站集使用python冲洗手稿!手稿很简单!
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2020-08-08 13:42
1. tr算法提取摘要并人为地重组新文章.
今天,我在python中发现了textrank4zh库,该库依赖jieba,numpy和networkx库,并且可以通过tr算法提取文章的摘要. 然后根据摘要手动清洗手稿,然后将其整合到全新的文章中.
在Mafengwo上测试问题和答案. 以下是许多答复者的内容. 使用python爬网所有内容,然后使用tr算法提取摘要,然后根据摘要重新组织一篇新文章. 基本上可以成功避免飓风算法.
首先安装依赖库,然后使用tr4进行抽象提取.
from textrank4zh import TextRank4Keyword,TextRank4Sentencecontent =“”#这是python采集的html内容text = re.sub('','',content)text = re.sub(r's','' ,text)zy =“ tr4s = TextRank4Sentence()tr4s.analyze(text = text,lower = True,source ='all_filters')#您可以修改num值并设置摘要长度. 对于tr4s.get_key_sentences(num = 10)中的项目: zy = zy + item.sentence
2,使用Google翻译双向翻译和洗涤手稿
在我与优采云联系之前,尤凯云是一个名为人工智能洗涤的网站. 这是关于使用NLP算法洗手稿. 最初,我认为手稿只被同义词代替.
后来,我学习了优采云. 我首先觉得这绝对不是所谓的NLP算法来清洗手稿. 经过研究,我发现使用Google Translate可能是双向翻译,即先将中文翻译成英文,然后再翻译. 将出现的英文翻译成中文.
我还开发了这种伪原创工具,发现它实际上并不易于使用. 如果您不仔细阅读,仍然可以阅读双向翻译的文章,但请仔细阅读. 实际上,语法习惯和单词根本不准确,甚至在某些情况下,这句话的本义也已改变. 查看全部
我一直在思考如何正确,有效地处理seo,以及如何获得假冒的原创文章和洗手稿. 如果是手动操作,那就太麻烦了. 所采集的文章不是伪原创的,害怕被飓风算法击中.
1. tr算法提取摘要并人为地重组新文章.
今天,我在python中发现了textrank4zh库,该库依赖jieba,numpy和networkx库,并且可以通过tr算法提取文章的摘要. 然后根据摘要手动清洗手稿,然后将其整合到全新的文章中.
在Mafengwo上测试问题和答案. 以下是许多答复者的内容. 使用python爬网所有内容,然后使用tr算法提取摘要,然后根据摘要重新组织一篇新文章. 基本上可以成功避免飓风算法.
首先安装依赖库,然后使用tr4进行抽象提取.
from textrank4zh import TextRank4Keyword,TextRank4Sentencecontent =“”#这是python采集的html内容text = re.sub('','',content)text = re.sub(r's','' ,text)zy =“ tr4s = TextRank4Sentence()tr4s.analyze(text = text,lower = True,source ='all_filters')#您可以修改num值并设置摘要长度. 对于tr4s.get_key_sentences(num = 10)中的项目: zy = zy + item.sentence
2,使用Google翻译双向翻译和洗涤手稿
在我与优采云联系之前,尤凯云是一个名为人工智能洗涤的网站. 这是关于使用NLP算法洗手稿. 最初,我认为手稿只被同义词代替.
后来,我学习了优采云. 我首先觉得这绝对不是所谓的NLP算法来清洗手稿. 经过研究,我发现使用Google Translate可能是双向翻译,即先将中文翻译成英文,然后再翻译. 将出现的英文翻译成中文.
我还开发了这种伪原创工具,发现它实际上并不易于使用. 如果您不仔细阅读,仍然可以阅读双向翻译的文章,但请仔细阅读. 实际上,语法习惯和单词根本不准确,甚至在某些情况下,这句话的本义也已改变.
初始大数据-02-日志采集大数据和爬虫采集大数据
采集交流 • 优采云 发表了文章 • 0 个评论 • 321 次浏览 • 2020-08-08 01:50
此图片绘制在网站上
关键字
编写Flume使用方法的配置文件的原理描述了整个代理中的源,接收器和通道所涉及的组件. 详细指定代理中的每个来源. 接收器和通道的特定实现通过通道连接源和接收器. 开始Agent的外壳操作. 7.通过Web爬网程序采集大数据
网络爬虫工具基本上可以分为3类
Web爬网程序是一种程序或脚本,可以根据某些规则自动爬网Web信息
采集器通常具有三个功能: 数据采集,处理和存储
以上图片为网站
Web爬网程序的原理Web爬网程序的工作流程选择种子URL,将这些种子URL放入队列中,然后从等待的队列中取出URL,解析DNS,获取主机的IP地址,然后下载相应的网页URL. 存储在下载的网页库中. 此外,将这些URL放入爬网URL队列中. 解析爬网的URL,分析嵌套的URL,然后将这些URL放入等待队列中,依此类推,直到数据采集达到特定条件并停止.
上图来自网页和网络爬虫爬网策略之间的关系模型
上面的图片来自网站
网页分类已下载但尚未过期: 进行爬网后,下载存储在网页库中的网页,并且其网页数据尚未过期. 下载的过期网页: 已爬网并放置在网页库中,但是由于原创网页信息已更新,因此下载的网页已过期. 要下载的网页: URL队列尚未下载并保存到网页库中. 已知网页: 尚未进行爬网,也不在要爬网的URL队列中,但是您可以分析已爬网的页面或要爬网的URL的相应页面,并且获得的网页不是已知网页: 爬虫无法捕获它们的“提取的网页”. 通过网络爬网程序的常见爬网策略
宽度优先策略
关注网络爬虫
3)基于强化学习的爬行策略
4)基于上下文地图的抓取策略
对网络爬虫策略的简单理解
深层网络爬虫
根据网页的存在方式,它们可以分为表面网页和深层网页.
深层Web采集器体系结构由6个基本功能模块(搜寻控制器,解析器,表单分析器,表单处理器,响应分析器,LVS控制器)和两个采集器内部数据结构(URL列表和LVS)表组成.
其中,LVS(LabelValueSet)表示标签和值的集合,并用于表示填充表单的数据源. 在爬网过程中,最重要的部分是表单填充,包括基于领域知识的表单填充和基于网页结构分析的表单填充. 查看全部
6. Flume通过系统日志采集大数据的基本概念
此图片绘制在网站上
关键字
编写Flume使用方法的配置文件的原理描述了整个代理中的源,接收器和通道所涉及的组件. 详细指定代理中的每个来源. 接收器和通道的特定实现通过通道连接源和接收器. 开始Agent的外壳操作. 7.通过Web爬网程序采集大数据
网络爬虫工具基本上可以分为3类
Web爬网程序是一种程序或脚本,可以根据某些规则自动爬网Web信息
采集器通常具有三个功能: 数据采集,处理和存储
以上图片为网站
Web爬网程序的原理Web爬网程序的工作流程选择种子URL,将这些种子URL放入队列中,然后从等待的队列中取出URL,解析DNS,获取主机的IP地址,然后下载相应的网页URL. 存储在下载的网页库中. 此外,将这些URL放入爬网URL队列中. 解析爬网的URL,分析嵌套的URL,然后将这些URL放入等待队列中,依此类推,直到数据采集达到特定条件并停止.
上图来自网页和网络爬虫爬网策略之间的关系模型
上面的图片来自网站
网页分类已下载但尚未过期: 进行爬网后,下载存储在网页库中的网页,并且其网页数据尚未过期. 下载的过期网页: 已爬网并放置在网页库中,但是由于原创网页信息已更新,因此下载的网页已过期. 要下载的网页: URL队列尚未下载并保存到网页库中. 已知网页: 尚未进行爬网,也不在要爬网的URL队列中,但是您可以分析已爬网的页面或要爬网的URL的相应页面,并且获得的网页不是已知网页: 爬虫无法捕获它们的“提取的网页”. 通过网络爬网程序的常见爬网策略
宽度优先策略
关注网络爬虫
3)基于强化学习的爬行策略
4)基于上下文地图的抓取策略
对网络爬虫策略的简单理解
深层网络爬虫
根据网页的存在方式,它们可以分为表面网页和深层网页.
深层Web采集器体系结构由6个基本功能模块(搜寻控制器,解析器,表单分析器,表单处理器,响应分析器,LVS控制器)和两个采集器内部数据结构(URL列表和LVS)表组成.
其中,LVS(LabelValueSet)表示标签和值的集合,并用于表示填充表单的数据源. 在爬网过程中,最重要的部分是表单填充,包括基于领域知识的表单填充和基于网页结构分析的表单填充.
百度算法飓风算法2.0的详细说明
采集交流 • 优采云 发表了文章 • 0 个评论 • 173 次浏览 • 2020-08-08 01:48
2018年9月,百度搜索升级了飓风算法并发布了飓风算法2.0,主要针对五种类型的采集行为,包括明显的采集痕迹,内容拼接,网站上的大量内容采集和跨域采集. Hurricane Algorithm 2.0旨在确保搜索用户的浏览体验并保护搜索生态的健康发展. 对于违反规定的网站,百度搜索将根据问题的严重程度限制对搜索显示的处理.
二: 飓风算法2.0攻击对象类型1: 明显的集合痕迹
详细说明: 该站点收录从其他站点或官方帐户采集和传输的大量内容. 信息不完整,布局混乱,缺少某些功能,或者文章可读性差,有明显的馆藏痕迹,用户的阅读体验也很差.
示例: 在所采集文章的内容中,存在无法访问的超链接和缺少功能的问题,并且采集痕迹很明显
建议: 对于网站上发布的内容,请注意文章的布局和布局,并且不应该存在与文章主题无关并干扰用户浏览的信息或不可用的功能.
类型2: 内容拼接
详细说明: 采集多篇不同的文章进行拼接,整体内容没有形成完整的逻辑,存在阅读不清,文章不连贯等问题,无法满足用户的需求.
示例: 内容无关紧要,逻辑不连贯
建议: 我们强烈反对使用集合编辑器和其他工具随意生成拼接的集合内容. 请网站制作对用户有价值的原创内容.
类型3: 网站上采集了大量内容
详细描述: 网站内容下的大部分内容都是采集的,网站本身没有内容生产力或内容生产能力较差,网站内容质量低. 查看全部
一个: Hurricane Algorithm 2.0的发布时间
2018年9月,百度搜索升级了飓风算法并发布了飓风算法2.0,主要针对五种类型的采集行为,包括明显的采集痕迹,内容拼接,网站上的大量内容采集和跨域采集. Hurricane Algorithm 2.0旨在确保搜索用户的浏览体验并保护搜索生态的健康发展. 对于违反规定的网站,百度搜索将根据问题的严重程度限制对搜索显示的处理.
二: 飓风算法2.0攻击对象类型1: 明显的集合痕迹
详细说明: 该站点收录从其他站点或官方帐户采集和传输的大量内容. 信息不完整,布局混乱,缺少某些功能,或者文章可读性差,有明显的馆藏痕迹,用户的阅读体验也很差.
示例: 在所采集文章的内容中,存在无法访问的超链接和缺少功能的问题,并且采集痕迹很明显
建议: 对于网站上发布的内容,请注意文章的布局和布局,并且不应该存在与文章主题无关并干扰用户浏览的信息或不可用的功能.
类型2: 内容拼接
详细说明: 采集多篇不同的文章进行拼接,整体内容没有形成完整的逻辑,存在阅读不清,文章不连贯等问题,无法满足用户的需求.
示例: 内容无关紧要,逻辑不连贯
建议: 我们强烈反对使用集合编辑器和其他工具随意生成拼接的集合内容. 请网站制作对用户有价值的原创内容.
类型3: 网站上采集了大量内容
详细描述: 网站内容下的大部分内容都是采集的,网站本身没有内容生产力或内容生产能力较差,网站内容质量低.
免费采集| 2018年Python程序员推荐阅读书籍清单!
采集交流 • 优采云 发表了文章 • 0 个评论 • 296 次浏览 • 2020-08-07 23:52
为了帮助我的朋友学习Python,今天,我想与我的朋友分享2017年读者最受欢迎的TOP10 Python书籍.
1. Python编程: 从入门到实践
作者: 埃里克·马蒂斯
译者: 袁国忠
这本书分为两部分: 第一部分介绍Python编程中必须理解的基本概念,包括介绍功能强大的Python库和工具(例如matplotlib,NumPy和Pygal)以及列表,字典, if语句,类,文件和异常,代码测试和其他内容;第二部分将理论付诸实践,说明如何开发三个项目,包括简单的Python 2D游戏开发,如何使用数据生成交互式信息图,创建和自定义简单的Web应用程序,以及帮助读者解决常见的编程问题和困惑.
2. Python基础教程(第2版)
作者: Magnus Lie Hetland
译者: 司威,曾俊伟,谭应华
评论: 钟杜航
这本书分为三个部分. 第一部分描述了Python语法,这不是废话,但也收录了Python 3.0应该注意的一些细节. 第二部分介绍了常用的GUI,框架和其他应用程序,只需单击并停止即可,这可以看作是第三部分的铺装. 您可以从大量应用程序中了解Python的功能. 第三部分是Project,这是本书的最大亮点,每个人都一定会喜欢它.
3. 机器学习实战
作者: Peter Harrington
译者: 李锐,李鹏,屈亚东,王斌
整本书使用精心安排的示例来完成日常任务,放弃学术语言,并使用有效的可重用Python代码来解释如何处理统计数据,执行数据分析和可视化. 通过各种示例,读者可以学习机器学习的核心算法并将其应用于某些战略任务,例如分类,预测和推荐. 此外,它们还可以用于实现一些更高级的功能,例如摘要和简化.
4. 算法图
作者: Aditya Bhargava
译者: 袁国忠
这本书中收录大量示例,并通过文字进行了说明,并以一种易于理解的方式解释了该算法. 它旨在帮助程序员在日常项目中更好地利用算法的能量. 本书的前三章将帮助您打基础,带您学习二进制搜索,大O表示法,两个基本数据结构和递归. 该空间的其余部分将主要介绍广泛使用的算法,具体内容包括: 面对特定问题(例如何时使用贪婪算法或动态编程)时的解决技巧;哈希表的应用;图算法K最近邻算法.
5. 流畅的Python
作者: Luciano Ramalho
译者: Ando Wu Ke
这本书致力于帮助Python开发人员发现该语言和相关库的出色功能,并编写简洁,流利,易于阅读和易于维护的代码. 特别是,它深入讨论了用于数据库处理的生成器,特征描述符(ORM的关键)和Python样式对象的特定应用: 协议和接口,抽象基类以及多重继承.
6. Python网络数据采集
作者: Ryan Mitchell
译者: 陶俊杰,陈晓丽
提供详细的代码示例以快速解决实际问题
Internet上的数据量正在增加,仅通过浏览Web来获取信息就变得越来越困难. 如何有效地提取和使用信息已成为一个巨大的挑战.
本书使用简洁而强大的Python语言,介绍了网络数据采集,并提供了在现代网络中采集各种数据类型的综合指南. 第一部分着重于网络数据采集的基本原理: 如何使用Python向网络服务器请求信息,如何处理服务器的响应以及如何通过自动化方式与网站进行交互. 第二部分介绍如何使用网络爬虫来测试网站,自动处理以及如何以更多方式访问网络.
7. 父子编程之旅
作者: 沃伦·桑德·卡特·桑德
译者: 苏进国义郑超
您可以阅读这本书,最多8岁,最低88岁. 有许多Python初学者,每个人都在不断刷新内容简单性的要求. 因此,我向所有人推荐这本最简单易学的入门书籍. 我想很多人都会喜欢. 实际上,RenPost的另一本名为“有趣的Python”(Python的名称为Kids)的书引起了许多初学者的注意. 我相信很多人都不会想错过这个. 也许您更喜欢这本书的风格. 该版本与Jolt Award比赛!
8. Flask Web开发
作者: Miguel Grinbergs
译者: 安藤
本书分为三个部分,全面介绍了如何基于Python微框架Flask开发Web. 第一部分是Flask的简介,它介绍了使用Flask框架和扩展Web程序开发的必要基础知识. 第二部分提供了一个示例,可以真正带领您逐步开发出完整的博客和社交应用程序Flasky,以整合上述知识并将其付诸实践. 第三部分介绍了发布应用程序之前必须考虑的事项,例如单元测试策略,性能分析技术和Flask程序的部署方法.
9. Python数据处理
作者: 杰奎琳·卡齐尔(Jacqueline Kazil),凯瑟琳·贾穆尔(Katharine Jarmul)
译者: 张亮,陆家明
本书采用基于项目的方法来介绍使用Python进行数据采集,数据清理,数据探索,数据表示,数据缩放和自动化的过程. 主要内容包括: Python的基础知识,如何从CSV,Excel,XML,JSON和PDF文件提取数据,如何获取和存储数据,各种数据清洗和分析技术,数据可视化方法,如何从网站提取数据和API.
10. Python数据挖掘
作者: 罗伯特·莱顿
译者: 杜春晓
本书使用易于学习的Python语言,并具有丰富的第三方库和良好的社区氛围. 它从浅入深,以真实数据为研究对象,向读者介绍Python数据挖掘的实现方法. 通过本书,读者将走进数据挖掘的殿堂,透彻了解数据挖掘的基础知识,并掌握解决数据挖掘中实际问题的最佳实践!
Python开发/自动化/网络爬虫/操作和维护/从入门到熟练[大脑学院] _腾讯教室
以上十本最美. 电子文件已通过各种渠道下载和整理. 一些电子书还附带了该书的源代码内容!需要下载的学生可以通过直接在“思维大脑学院”公共帐户对话框中回复“ 0109”来获取它!
头脑风暴学院的相关微信官方账号-搜狗微信搜索 查看全部
在2017年的过去一年中,Python开发人员在全球范围内发展迅速,国内合作伙伴学习Python的热情不断提高. 同时,Python已成为入门编程语言和大量开发人员推荐的第二种编程语言. 2017年12月,Python在TIOBE全球编程语言年度排名中升至第四位. 似乎第四部分将易于维护. 此外,作为人工智能的主要编程语言,Python必将在2018年和未来几年人工智能趋势可能出现的时候继续受到赞扬.
为了帮助我的朋友学习Python,今天,我想与我的朋友分享2017年读者最受欢迎的TOP10 Python书籍.
1. Python编程: 从入门到实践
作者: 埃里克·马蒂斯
译者: 袁国忠
这本书分为两部分: 第一部分介绍Python编程中必须理解的基本概念,包括介绍功能强大的Python库和工具(例如matplotlib,NumPy和Pygal)以及列表,字典, if语句,类,文件和异常,代码测试和其他内容;第二部分将理论付诸实践,说明如何开发三个项目,包括简单的Python 2D游戏开发,如何使用数据生成交互式信息图,创建和自定义简单的Web应用程序,以及帮助读者解决常见的编程问题和困惑.
2. Python基础教程(第2版)
作者: Magnus Lie Hetland
译者: 司威,曾俊伟,谭应华
评论: 钟杜航
这本书分为三个部分. 第一部分描述了Python语法,这不是废话,但也收录了Python 3.0应该注意的一些细节. 第二部分介绍了常用的GUI,框架和其他应用程序,只需单击并停止即可,这可以看作是第三部分的铺装. 您可以从大量应用程序中了解Python的功能. 第三部分是Project,这是本书的最大亮点,每个人都一定会喜欢它.
3. 机器学习实战
作者: Peter Harrington
译者: 李锐,李鹏,屈亚东,王斌
整本书使用精心安排的示例来完成日常任务,放弃学术语言,并使用有效的可重用Python代码来解释如何处理统计数据,执行数据分析和可视化. 通过各种示例,读者可以学习机器学习的核心算法并将其应用于某些战略任务,例如分类,预测和推荐. 此外,它们还可以用于实现一些更高级的功能,例如摘要和简化.
4. 算法图
作者: Aditya Bhargava
译者: 袁国忠
这本书中收录大量示例,并通过文字进行了说明,并以一种易于理解的方式解释了该算法. 它旨在帮助程序员在日常项目中更好地利用算法的能量. 本书的前三章将帮助您打基础,带您学习二进制搜索,大O表示法,两个基本数据结构和递归. 该空间的其余部分将主要介绍广泛使用的算法,具体内容包括: 面对特定问题(例如何时使用贪婪算法或动态编程)时的解决技巧;哈希表的应用;图算法K最近邻算法.
5. 流畅的Python
作者: Luciano Ramalho
译者: Ando Wu Ke
这本书致力于帮助Python开发人员发现该语言和相关库的出色功能,并编写简洁,流利,易于阅读和易于维护的代码. 特别是,它深入讨论了用于数据库处理的生成器,特征描述符(ORM的关键)和Python样式对象的特定应用: 协议和接口,抽象基类以及多重继承.
6. Python网络数据采集
作者: Ryan Mitchell
译者: 陶俊杰,陈晓丽
提供详细的代码示例以快速解决实际问题
Internet上的数据量正在增加,仅通过浏览Web来获取信息就变得越来越困难. 如何有效地提取和使用信息已成为一个巨大的挑战.
本书使用简洁而强大的Python语言,介绍了网络数据采集,并提供了在现代网络中采集各种数据类型的综合指南. 第一部分着重于网络数据采集的基本原理: 如何使用Python向网络服务器请求信息,如何处理服务器的响应以及如何通过自动化方式与网站进行交互. 第二部分介绍如何使用网络爬虫来测试网站,自动处理以及如何以更多方式访问网络.
7. 父子编程之旅
作者: 沃伦·桑德·卡特·桑德
译者: 苏进国义郑超
您可以阅读这本书,最多8岁,最低88岁. 有许多Python初学者,每个人都在不断刷新内容简单性的要求. 因此,我向所有人推荐这本最简单易学的入门书籍. 我想很多人都会喜欢. 实际上,RenPost的另一本名为“有趣的Python”(Python的名称为Kids)的书引起了许多初学者的注意. 我相信很多人都不会想错过这个. 也许您更喜欢这本书的风格. 该版本与Jolt Award比赛!
8. Flask Web开发
作者: Miguel Grinbergs
译者: 安藤
本书分为三个部分,全面介绍了如何基于Python微框架Flask开发Web. 第一部分是Flask的简介,它介绍了使用Flask框架和扩展Web程序开发的必要基础知识. 第二部分提供了一个示例,可以真正带领您逐步开发出完整的博客和社交应用程序Flasky,以整合上述知识并将其付诸实践. 第三部分介绍了发布应用程序之前必须考虑的事项,例如单元测试策略,性能分析技术和Flask程序的部署方法.
9. Python数据处理
作者: 杰奎琳·卡齐尔(Jacqueline Kazil),凯瑟琳·贾穆尔(Katharine Jarmul)
译者: 张亮,陆家明
本书采用基于项目的方法来介绍使用Python进行数据采集,数据清理,数据探索,数据表示,数据缩放和自动化的过程. 主要内容包括: Python的基础知识,如何从CSV,Excel,XML,JSON和PDF文件提取数据,如何获取和存储数据,各种数据清洗和分析技术,数据可视化方法,如何从网站提取数据和API.
10. Python数据挖掘
作者: 罗伯特·莱顿
译者: 杜春晓
本书使用易于学习的Python语言,并具有丰富的第三方库和良好的社区氛围. 它从浅入深,以真实数据为研究对象,向读者介绍Python数据挖掘的实现方法. 通过本书,读者将走进数据挖掘的殿堂,透彻了解数据挖掘的基础知识,并掌握解决数据挖掘中实际问题的最佳实践!
Python开发/自动化/网络爬虫/操作和维护/从入门到熟练[大脑学院] _腾讯教室
以上十本最美. 电子文件已通过各种渠道下载和整理. 一些电子书还附带了该书的源代码内容!需要下载的学生可以通过直接在“思维大脑学院”公共帐户对话框中回复“ 0109”来获取它!
头脑风暴学院的相关微信官方账号-搜狗微信搜索
AI入门级算法知识
采集交流 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2020-08-07 22:45
在每个企业中,各个部门都会产生某些数据. 当前,各种数据在企业的生产和运营中起着至关重要的作用.
数据已成为公司几乎所有业务活动(例如生产,运营和策略)所依赖的必不可少的信息.
正确的数据分析可以帮助公司做出明智的业务管理决策. 数据就像业务运营商的眼睛,业务问题可以通过数据反映出来,就像舵手依赖导航一样.
数据分析师如何接受培训
实际上,数据分析是一种用于掌握数据,掌握规则并应用它们的技术. 那么,这项技术的具体技术是什么,如何学习它,让我们看一下数据分析的三个组成部分.
数据采集: 数据采集是我们的数据源. 只有掌握了足够可靠的数据,我们才有分析数据的基础. 数据采集可以通过Web爬网程序,开源数据获取等进行.
数据挖掘: 数据挖掘部分可以说是数据分析的核心部分,也是商业价值. 我们分析手中的数据以获得人与物之间关系的规律,从而指导我们的业务活动并实现一定的商业价值.
数据可视化: 通过数据可视化,我们可以更直观地观察数据的组成和规律,并可以更好地显示我们的分析结果.
从以上数据分析的三个部分可以看出,出色的数据分析师的工作包括:
数据采集: 使用开源数据,Web爬网程序,数据集成.
数据挖掘: 数据处理,算法分析,数据预测.
数据可视化: 呈现数据分析结果.
您只需一个接一个地突破这三个方面,即可完全赢得任何数据分析师的工作.
1. 突破数据采集
对于数据采集,我们可以在Internet上使用一些开源数据,但是这个限制是您只能使用其他开源数据. 如果我想分析荣耀之王的英雄,则没有开源数据,因此我现在可以自己进行. 我们可以在相关网站上抓取数据,因此Python抓取工具是一个很好的工具.
我将逐步指导您完成Web爬网程序从零到1的升级,从而实现数据分析并且不再过于依赖开源数据.
2. 突破数据挖掘
实际上,数据挖掘是数据分析的核心. 只有当我们成功发掘数据中隐藏的含义时,我们的数据分析的价值才能得到体现. 如何开采?此时,数据算法即将问世.
我将带您学习各种数据挖掘算法,从最简单的KNN分类算法到EM聚类算法,从算法原理到算法实战,逐步获取数据挖掘.
3. 突破数据可视化
数据可视化是我们分析数据和显示分析结果的好方法. 直观的图表比无聊的数字更容易接受.
我将带您完成多个可视化图表的制作,以便您可以体验数字的美丽和惊喜.
您可以从专栏中获得什么?
本专栏通过“基础知识”和“算法”两个模块,向您介绍数据分析所需的基本知识,数据分析的思想和过程以及各种算法的原理和应用.
我相信,阅读完上述两个模块后,您将刷新对某些知识的理解. 然后使用专栏示例对其他示例进行推断,从容应对未来工作中可能遇到的技术问题.
每个模块的介绍如下:
基本文章
本章主要介绍Python的基本语法以及两个常用的数据分析库NumPy和Pandas. 通过实际的数据清理和Python爬虫的实际战斗补充,您可以进一步加深了解并更快上手.
同时,将介绍10种Python数据可视化图表. 同时,使用Matplotlib,Seaborn和pyecherts制作不同的可视化视图,以便您可以充分了解不同工具之间的异同.
Python是目前最流行的语言,它在数据分析领域的表现也非常出色. Python有大量的第三方库,可以轻松读取和写入文本以及获取数据. 同时,NumPy和Pandas都是行业领先的数据处理工具,为我们提供了极大的数据处理便利. 同时,Python还具有丰富的可视化模块. Matplotlib,Seaborn和Pyecharts处于最佳状态,而我们的可视化工作也是事半功倍的结果. Python还拥有许多机器学习算法库,例如scikit-learn,jieba等,它们是非常好的常用模块.
在以下各章中,我将一一介绍所有上述知识点. 勤奋的您不会错过它.
我相信,在学习了本文的内容之后,您肯定会成为一个基本掌握Python基础知识的人,并且可以根据您自己的数据需求积极地爬网Internet上的资源,完成初始数据采集,并能够熟练使用它. NumPy和Pandas是处理和清除数据的工程师. 然后,您可以通过对数据进行各种可视化操作来完成对数据的初步分析.
算法
算法是数据挖掘的灵魂,数据挖掘是数据分析的核心,因此学习算法并灵活使用它们是每个数据分析师的一项基本技能.
您一定已经听过啤酒和尿布的故事,但是您是否想知道为什么啤酒和尿布会破坏彼此的销量?
市场上有很多情绪分析系统. 您是否考虑过背后的原理?
浏览购物网站时,为什么网站总是始终准确显示您关注的商品?核心在哪里?
如果您对以上内容真的感兴趣,或者想了解原理,那么不妨与我一起完成算法内容.
在本章中,我将介绍6种常见的数据分析算法,包括:
分类算法: KNN,决策树,SVM和朴素贝叶斯
聚类算法: K-Means和EM
对于每种算法,我将用一个部分来说明算法的原理,然后在下一部分中使用一个或两个实际示例来巩固知识.
可以让您知道如何对项目进行分类,以及是否可以进行预测. 数据分析不仅涉及数据的显示,而且探索数据背后的价值是数据分析的本质和意义.
我相信,在研究了本文的内容之后,您可以轻松地将国王的荣耀归类为英雄,然后选择最适合自己的英雄. 您也可以完成足球队的划分,以查看球队的级别. 当然,有许多实际示例,例如图像分割,乳腺癌检测,情绪分析等,等待您完成从理论应用.
完成以上内容需要什么基础?
全部从0开始. 只要您遵循我的节奏并稳步完成基本练习即可. 即使您没有任何Python基础,只要您阅读完Python,NumPy和Pandas的基础知识并进行简单的练习补充,您就可以完成对以下内容的学习. 查看全部
泛娱乐技术: AI入门级算法知识
在每个企业中,各个部门都会产生某些数据. 当前,各种数据在企业的生产和运营中起着至关重要的作用.
数据已成为公司几乎所有业务活动(例如生产,运营和策略)所依赖的必不可少的信息.
正确的数据分析可以帮助公司做出明智的业务管理决策. 数据就像业务运营商的眼睛,业务问题可以通过数据反映出来,就像舵手依赖导航一样.
数据分析师如何接受培训
实际上,数据分析是一种用于掌握数据,掌握规则并应用它们的技术. 那么,这项技术的具体技术是什么,如何学习它,让我们看一下数据分析的三个组成部分.
数据采集: 数据采集是我们的数据源. 只有掌握了足够可靠的数据,我们才有分析数据的基础. 数据采集可以通过Web爬网程序,开源数据获取等进行.
数据挖掘: 数据挖掘部分可以说是数据分析的核心部分,也是商业价值. 我们分析手中的数据以获得人与物之间关系的规律,从而指导我们的业务活动并实现一定的商业价值.
数据可视化: 通过数据可视化,我们可以更直观地观察数据的组成和规律,并可以更好地显示我们的分析结果.
从以上数据分析的三个部分可以看出,出色的数据分析师的工作包括:
数据采集: 使用开源数据,Web爬网程序,数据集成.
数据挖掘: 数据处理,算法分析,数据预测.
数据可视化: 呈现数据分析结果.
您只需一个接一个地突破这三个方面,即可完全赢得任何数据分析师的工作.
1. 突破数据采集
对于数据采集,我们可以在Internet上使用一些开源数据,但是这个限制是您只能使用其他开源数据. 如果我想分析荣耀之王的英雄,则没有开源数据,因此我现在可以自己进行. 我们可以在相关网站上抓取数据,因此Python抓取工具是一个很好的工具.
我将逐步指导您完成Web爬网程序从零到1的升级,从而实现数据分析并且不再过于依赖开源数据.
2. 突破数据挖掘
实际上,数据挖掘是数据分析的核心. 只有当我们成功发掘数据中隐藏的含义时,我们的数据分析的价值才能得到体现. 如何开采?此时,数据算法即将问世.
我将带您学习各种数据挖掘算法,从最简单的KNN分类算法到EM聚类算法,从算法原理到算法实战,逐步获取数据挖掘.
3. 突破数据可视化
数据可视化是我们分析数据和显示分析结果的好方法. 直观的图表比无聊的数字更容易接受.
我将带您完成多个可视化图表的制作,以便您可以体验数字的美丽和惊喜.
您可以从专栏中获得什么?
本专栏通过“基础知识”和“算法”两个模块,向您介绍数据分析所需的基本知识,数据分析的思想和过程以及各种算法的原理和应用.
我相信,阅读完上述两个模块后,您将刷新对某些知识的理解. 然后使用专栏示例对其他示例进行推断,从容应对未来工作中可能遇到的技术问题.
每个模块的介绍如下:
基本文章
本章主要介绍Python的基本语法以及两个常用的数据分析库NumPy和Pandas. 通过实际的数据清理和Python爬虫的实际战斗补充,您可以进一步加深了解并更快上手.
同时,将介绍10种Python数据可视化图表. 同时,使用Matplotlib,Seaborn和pyecherts制作不同的可视化视图,以便您可以充分了解不同工具之间的异同.
Python是目前最流行的语言,它在数据分析领域的表现也非常出色. Python有大量的第三方库,可以轻松读取和写入文本以及获取数据. 同时,NumPy和Pandas都是行业领先的数据处理工具,为我们提供了极大的数据处理便利. 同时,Python还具有丰富的可视化模块. Matplotlib,Seaborn和Pyecharts处于最佳状态,而我们的可视化工作也是事半功倍的结果. Python还拥有许多机器学习算法库,例如scikit-learn,jieba等,它们是非常好的常用模块.
在以下各章中,我将一一介绍所有上述知识点. 勤奋的您不会错过它.
我相信,在学习了本文的内容之后,您肯定会成为一个基本掌握Python基础知识的人,并且可以根据您自己的数据需求积极地爬网Internet上的资源,完成初始数据采集,并能够熟练使用它. NumPy和Pandas是处理和清除数据的工程师. 然后,您可以通过对数据进行各种可视化操作来完成对数据的初步分析.
算法
算法是数据挖掘的灵魂,数据挖掘是数据分析的核心,因此学习算法并灵活使用它们是每个数据分析师的一项基本技能.
您一定已经听过啤酒和尿布的故事,但是您是否想知道为什么啤酒和尿布会破坏彼此的销量?
市场上有很多情绪分析系统. 您是否考虑过背后的原理?
浏览购物网站时,为什么网站总是始终准确显示您关注的商品?核心在哪里?
如果您对以上内容真的感兴趣,或者想了解原理,那么不妨与我一起完成算法内容.
在本章中,我将介绍6种常见的数据分析算法,包括:
分类算法: KNN,决策树,SVM和朴素贝叶斯
聚类算法: K-Means和EM
对于每种算法,我将用一个部分来说明算法的原理,然后在下一部分中使用一个或两个实际示例来巩固知识.
可以让您知道如何对项目进行分类,以及是否可以进行预测. 数据分析不仅涉及数据的显示,而且探索数据背后的价值是数据分析的本质和意义.
我相信,在研究了本文的内容之后,您可以轻松地将国王的荣耀归类为英雄,然后选择最适合自己的英雄. 您也可以完成足球队的划分,以查看球队的级别. 当然,有许多实际示例,例如图像分割,乳腺癌检测,情绪分析等,等待您完成从理论应用.
完成以上内容需要什么基础?
全部从0开始. 只要您遵循我的节奏并稳步完成基本练习即可. 即使您没有任何Python基础,只要您阅读完Python,NumPy和Pandas的基础知识并进行简单的练习补充,您就可以完成对以下内容的学习.
解释百度飓风算法3.0的正式公告
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2020-08-07 22:44
跨领域采集
跨域集合是指为了获取更多流量而发布不属于站点/智能applet的域的内容的网站或百度applet. 通常,这些内容是从Internet采集的,其内容质量和相关性较低,并且对搜索用户的价值较低. 对于此类行为搜索,将判断站点/智能applet的域不够集中,并且在显示上会有不同程度的限制.
特征在于,主网站的内容/标题/关键字/摘要显示该网站具有明确的字段或行业,但是发布的内容与此字段无关或相关性较低. 俗称张冠李戴.
主网站的核心不够清晰,内容涉及多个领域或行业,领域模糊,领域关注度低. 具有混合信息的泛内容网站是创建的对象.
批量站群站
指的是批量构造多个站点/智能小程序以获得搜索流量的行为. 网站组中的大多数网站/智能小程序的质量低,资源稀缺,内容相似度高,甚至重用同一模板,这很难满足搜索用户的需求. 例如: 多个智能小程序重复使用相同的模板,内容质量低且相似度高
如果描述的操作出现在您的网站或applet上,请尽快清除标准化的操作和内容,以免被算法打击.
飓风算法3.0问答
Q1: 在同一个品牌下,分支公司的网站/智能小程序都使用相同的模板. 他们会被评判为一组站台并被飓风算法3.0击中吗?
<p>A1: 对于网站组问题,该算法将基于多个因素进行综合判断,例如页面布局相似性,同一主题下的网站/智能小程序数量,内容质量,内容稀缺性,内容相似性等. 查看全部
亲爱的SEO网站管理员朋友,请注意. 百度搜索于8月8日发布了“飓风算法3.0即将上线,控制跨域采集和站点组问题”的正式公告. 该公告将打击跨域采集和站点. 小组问题,主要解释和分享如下:
跨领域采集
跨域集合是指为了获取更多流量而发布不属于站点/智能applet的域的内容的网站或百度applet. 通常,这些内容是从Internet采集的,其内容质量和相关性较低,并且对搜索用户的价值较低. 对于此类行为搜索,将判断站点/智能applet的域不够集中,并且在显示上会有不同程度的限制.
特征在于,主网站的内容/标题/关键字/摘要显示该网站具有明确的字段或行业,但是发布的内容与此字段无关或相关性较低. 俗称张冠李戴.
主网站的核心不够清晰,内容涉及多个领域或行业,领域模糊,领域关注度低. 具有混合信息的泛内容网站是创建的对象.
批量站群站
指的是批量构造多个站点/智能小程序以获得搜索流量的行为. 网站组中的大多数网站/智能小程序的质量低,资源稀缺,内容相似度高,甚至重用同一模板,这很难满足搜索用户的需求. 例如: 多个智能小程序重复使用相同的模板,内容质量低且相似度高
如果描述的操作出现在您的网站或applet上,请尽快清除标准化的操作和内容,以免被算法打击.
飓风算法3.0问答
Q1: 在同一个品牌下,分支公司的网站/智能小程序都使用相同的模板. 他们会被评判为一组站台并被飓风算法3.0击中吗?
<p>A1: 对于网站组问题,该算法将基于多个因素进行综合判断,例如页面布局相似性,同一主题下的网站/智能小程序数量,内容质量,内容稀缺性,内容相似性等.
垃圾采集算法-世代采集算法(Generational 采集).
采集交流 • 优采云 发表了文章 • 0 个评论 • 397 次浏览 • 2020-08-07 18:22
在Java虚拟机的世代垃圾采集机制中,可以将应用程序的可用堆空间划分为年轻代和旧代,然后将年轻代划分为Eden区域,From区域和To区域.
系统创建对象时,它始终在Eden区域中运行. 当该区域已满时,它将触发YoungGC,这是年轻一代的垃圾采集.
通常来说,此时并非所有对象都是无用的,因此仍然可用的对象将被复制到“发件人”区域.
这样,便清理了整个伊甸园区域,您可以继续创建新对象. 当伊甸园区域再次用完时,YoungGC将再次被触发. 然后,请注意,这次与现在略有不同. 这次触发YoungGC之后,在Eden区域和From区域中仍在使用的对象将被复制到To区域.
下一个YoungGC将把Eden区域和To区域中仍在使用的对象复制到From区域.
几个YoungGC之后,一些对象在From和To之间来回徘徊. 此时,底线(阈值)显示在“从”和“到”区域中. 如果这些家伙还没死,很抱歉,让我们去(复制)老年吧.
经过这么多折腾,年老的人无法忍受(空间已用完). 好的,让我们转到完整的GC,即完全恢复. 让我们摆脱它.
完全恢复就像我们刚刚进行的大型清洗一样. 毕竟,操作比较大并且成本很高. 它不能与通常的小型工作日(Young GC)相提并论,因此,如果Full GC的使用过于频繁,无疑会对系统性能产生重大影响.
因此,我们应该合理设置年轻一代和老一代的大小,并尽量减少Full GC的运行
参考
[1]“深入了解Java虚拟机-JVM的高级功能和最佳实践”,周志明,机械工业出版社.
[2]“大型网站的技术架构-核心原理和案例研究”,李志辉,电子工业出版社.
转载: 查看全部
当前,商用虚拟机的垃圾采集采用“ Generational 采集”算法. 该算法没有任何新思想,但是会根据对象的生命周期将内存分为几个块. 通常,Java堆分为新一代和老一代,因此可以根据每一代的特性采用最合适的采集算法. 在新一代中,每次垃圾回收都会发现大量对象死亡,只有少数能够生存,然后选择复制算法,并且只需少量的生存对象复制成本就可以完成复制算法. 在晚年,由于对象的存活率很高并且没有多余的空间来保证其分配,因此有必要使用“标记清除”或“标记排序”算法进行回收.
在Java虚拟机的世代垃圾采集机制中,可以将应用程序的可用堆空间划分为年轻代和旧代,然后将年轻代划分为Eden区域,From区域和To区域.
系统创建对象时,它始终在Eden区域中运行. 当该区域已满时,它将触发YoungGC,这是年轻一代的垃圾采集.
通常来说,此时并非所有对象都是无用的,因此仍然可用的对象将被复制到“发件人”区域.
这样,便清理了整个伊甸园区域,您可以继续创建新对象. 当伊甸园区域再次用完时,YoungGC将再次被触发. 然后,请注意,这次与现在略有不同. 这次触发YoungGC之后,在Eden区域和From区域中仍在使用的对象将被复制到To区域.
下一个YoungGC将把Eden区域和To区域中仍在使用的对象复制到From区域.
几个YoungGC之后,一些对象在From和To之间来回徘徊. 此时,底线(阈值)显示在“从”和“到”区域中. 如果这些家伙还没死,很抱歉,让我们去(复制)老年吧.
经过这么多折腾,年老的人无法忍受(空间已用完). 好的,让我们转到完整的GC,即完全恢复. 让我们摆脱它.
完全恢复就像我们刚刚进行的大型清洗一样. 毕竟,操作比较大并且成本很高. 它不能与通常的小型工作日(Young GC)相提并论,因此,如果Full GC的使用过于频繁,无疑会对系统性能产生重大影响.
因此,我们应该合理设置年轻一代和老一代的大小,并尽量减少Full GC的运行
参考
[1]“深入了解Java虚拟机-JVM的高级功能和最佳实践”,周志明,机械工业出版社.
[2]“大型网站的技术架构-核心原理和案例研究”,李志辉,电子工业出版社.
转载:
使用机器学习算法创建简单的“微博索引”
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2020-08-07 14:37
作者: 林浩伟简介
随着人工智能的普及,越来越多的朋友开始致力于机器学习的浪潮. 作为其中之一,我对此也非常感兴趣. 当然,我对如何使用这些有趣的算法来实现各种奇怪的想法更感兴趣. 写这篇文章的机会是,有一天,在阅读了腾讯指数的推动力之后,我一时兴起,想自己实现这样的事情. 感觉很有趣. 然后就在上周末,我用一些业余时间编写了一个简单的民意监测系统.
思考
基于机器学习的舆论监督,这样的想法实际上可以有很大的想象空间,并且可以做很多有趣的事情. 例如,您可以关注自己喜欢的明星或电影的声誉,或者了解所关注股票的舆论变化,甚至可以预测其未来发展方向. 但我决定从最简单的例子开始: 从新浪微博确定腾讯的正面或负面消息. 本文中的讨论也将围绕这一场景. 它不会涉及太多复杂和困难的事情. 可以说是一件很简单的事情. 请随时阅读.
技术实现主要是使用sklearn对采集到的微博文本进行分类. 无需介绍sklearn. 它是一个著名的python机器学习工具. 如果您想了解更多有关它的信息,可以继续阅读. 官方网站: .
这是我们接下来需要做的所有工作:
环境
机器: mac
语言: python
第三方库: sklearn,jieba,pyquery等.
数据采集
数据采集对我来说是最好的步骤. 实际上,编写爬虫程序是从主要网站采集大量信息,并将其存储以供我们后续分析和处理. 如下图所示:
因为这只是一个有趣的实验项目,所以没有办法花费太多时间,所以这次我只打算从微博搜索结果中提取1,000个数据进行分析. 当然,如果可能的话,数据越多越好,训练后的模型将越准确.
采集的页面是百度的微博搜索结果页面: Tencent&pn = 0&tn = baiduwb&ie = utf-8&rtt = 2
使用python逐页获取页面,然后使用pyquery模块解析获取的页面以获得一段微博文本. 在下面粘贴此页面的解析代码:
手动处理
此步骤是最困难且最耗时的步骤. 在将采集到的数据用于后续算法训练之前,我们需要对采集到的数据进行逐个手动分类. 如果可以在Internet上找到适合您的场景的现成的训练数据集,那么可以节省很多时间,但是在大多数情况下,您必须自己动手做. 所有肮脏的工作都在这里. 而且,人工分类的准确性也决定了训练模型的准确性,因此这一步骤也非常重要.
我们的目标是将消息分为三类: “积极”,“消极”和“中立”. 首先,我们必须首先对这三个类别给出明确的定义,以免在对它们进行分类时感到困惑. 我对它们的个人定义是:
正面: 有利的消息,正面的用户评论;
负面: 负面新闻,负面用户评论;
中性: 客观提及新闻,非情感用户评论.
根据上述标准,我们对采集的1,000个微博进行了逐一分类和标记.
文本预处理
采集到的微博文本收录很多无效信息. 在开始培训之前,我们需要对这些文本进行预处理,并将它们另存为sklearn可以接收的数据. 主要任务包括:
1. 删除包括表情符号,特殊符号,短链接和其他无效信息在内的杂质,这些杂质可以按常规规则过滤掉,因此将不进行详细描述;
2. 另存为文本文件. 由于sklearn需要将训练数据以特定格式存储在本地目录中,因此我们需要使用脚本来处理原创数据. 目录格式如下:
train: 存储要训练的数据,子目录名称为类别名称,训练文本文件存储在子目录中,文件名称为任意,内容为单个微博文本;
test: 存储测试数据,子目录的名称是任意的,并且测试文本文件存储在子目录中.
建议将训练集和测试集以8: 2的比例划分,并使用python自动生成上述本地文件.
3. 分词. 由于有关微博的大部分数据都是中文,因此建议使用解霸词分割. 对中文的支持比较强,效果很好. 支持自定义词典,支持返回指定词性的分割结果,并可以删除一些停用词和模态辅助词. 使用起来也非常简单. 我将不在这里详细介绍. 如有必要,您可以访问其github地址: / fxsjy / jieba
算法选择
准备好训练数据后,我们就可以开始训练了. 为此,我们需要选择合适的分类算法. 但是,由于拥有如此众多的机器学习算法,我们将花费大量精力进行逐一测试和比较. 幸运的是,sklearn考虑了此问题并提供了算法选择. 通过图形比较多种算法的运行结果,可以直观地看出哪种算法更合适.
这是官方测试代码: /stable/auto_examples/text/document_classification_20newsgroups.html#example-text-document-classification-20newsgroups-py
用您自己的这个官方案例的数据输入部分替换. 结果如下:
综合计算效率和评分情况,我选择了LinearSVC算法(SVM)作为训练算法.
培训
文本分类训练主要包括以下四个步骤:
Sklearn在这四个步骤中封装了相应的方法,因此使用起来非常方便. 请参考以下代码:
注意: 为了方便显示以上代码,模块被引入并放置在方法内部,仅供参考
应用
最后一步是测试并应用经过训练的模型.
使用现有模型预测新数据,代码如下:
注意: 此代码仅用于显示和参考
部分打印结果如下图所示:
根据统计,预测准确率是95%. 该模型当天计算的与腾讯有关的舆论如下:
结论
本文仅记录了过去两天我的一些想法和实验. 它不需要太多的代码实现或其他高级算法. 我相信这并不难理解. 如果有人感兴趣,我可以整理源代码并在以后发布.
感谢阅读! 查看全部
欢迎来到腾讯云技术社区,以获取更多腾讯的大规模技术实践干货〜
作者: 林浩伟简介
随着人工智能的普及,越来越多的朋友开始致力于机器学习的浪潮. 作为其中之一,我对此也非常感兴趣. 当然,我对如何使用这些有趣的算法来实现各种奇怪的想法更感兴趣. 写这篇文章的机会是,有一天,在阅读了腾讯指数的推动力之后,我一时兴起,想自己实现这样的事情. 感觉很有趣. 然后就在上周末,我用一些业余时间编写了一个简单的民意监测系统.
思考
基于机器学习的舆论监督,这样的想法实际上可以有很大的想象空间,并且可以做很多有趣的事情. 例如,您可以关注自己喜欢的明星或电影的声誉,或者了解所关注股票的舆论变化,甚至可以预测其未来发展方向. 但我决定从最简单的例子开始: 从新浪微博确定腾讯的正面或负面消息. 本文中的讨论也将围绕这一场景. 它不会涉及太多复杂和困难的事情. 可以说是一件很简单的事情. 请随时阅读.
技术实现主要是使用sklearn对采集到的微博文本进行分类. 无需介绍sklearn. 它是一个著名的python机器学习工具. 如果您想了解更多有关它的信息,可以继续阅读. 官方网站: .
这是我们接下来需要做的所有工作:
环境
机器: mac
语言: python
第三方库: sklearn,jieba,pyquery等.
数据采集
数据采集对我来说是最好的步骤. 实际上,编写爬虫程序是从主要网站采集大量信息,并将其存储以供我们后续分析和处理. 如下图所示:
因为这只是一个有趣的实验项目,所以没有办法花费太多时间,所以这次我只打算从微博搜索结果中提取1,000个数据进行分析. 当然,如果可能的话,数据越多越好,训练后的模型将越准确.
采集的页面是百度的微博搜索结果页面: Tencent&pn = 0&tn = baiduwb&ie = utf-8&rtt = 2
使用python逐页获取页面,然后使用pyquery模块解析获取的页面以获得一段微博文本. 在下面粘贴此页面的解析代码:
手动处理
此步骤是最困难且最耗时的步骤. 在将采集到的数据用于后续算法训练之前,我们需要对采集到的数据进行逐个手动分类. 如果可以在Internet上找到适合您的场景的现成的训练数据集,那么可以节省很多时间,但是在大多数情况下,您必须自己动手做. 所有肮脏的工作都在这里. 而且,人工分类的准确性也决定了训练模型的准确性,因此这一步骤也非常重要.
我们的目标是将消息分为三类: “积极”,“消极”和“中立”. 首先,我们必须首先对这三个类别给出明确的定义,以免在对它们进行分类时感到困惑. 我对它们的个人定义是:
正面: 有利的消息,正面的用户评论;
负面: 负面新闻,负面用户评论;
中性: 客观提及新闻,非情感用户评论.
根据上述标准,我们对采集的1,000个微博进行了逐一分类和标记.
文本预处理
采集到的微博文本收录很多无效信息. 在开始培训之前,我们需要对这些文本进行预处理,并将它们另存为sklearn可以接收的数据. 主要任务包括:
1. 删除包括表情符号,特殊符号,短链接和其他无效信息在内的杂质,这些杂质可以按常规规则过滤掉,因此将不进行详细描述;
2. 另存为文本文件. 由于sklearn需要将训练数据以特定格式存储在本地目录中,因此我们需要使用脚本来处理原创数据. 目录格式如下:
train: 存储要训练的数据,子目录名称为类别名称,训练文本文件存储在子目录中,文件名称为任意,内容为单个微博文本;
test: 存储测试数据,子目录的名称是任意的,并且测试文本文件存储在子目录中.
建议将训练集和测试集以8: 2的比例划分,并使用python自动生成上述本地文件.
3. 分词. 由于有关微博的大部分数据都是中文,因此建议使用解霸词分割. 对中文的支持比较强,效果很好. 支持自定义词典,支持返回指定词性的分割结果,并可以删除一些停用词和模态辅助词. 使用起来也非常简单. 我将不在这里详细介绍. 如有必要,您可以访问其github地址: / fxsjy / jieba
算法选择
准备好训练数据后,我们就可以开始训练了. 为此,我们需要选择合适的分类算法. 但是,由于拥有如此众多的机器学习算法,我们将花费大量精力进行逐一测试和比较. 幸运的是,sklearn考虑了此问题并提供了算法选择. 通过图形比较多种算法的运行结果,可以直观地看出哪种算法更合适.
这是官方测试代码: /stable/auto_examples/text/document_classification_20newsgroups.html#example-text-document-classification-20newsgroups-py
用您自己的这个官方案例的数据输入部分替换. 结果如下:
综合计算效率和评分情况,我选择了LinearSVC算法(SVM)作为训练算法.
培训
文本分类训练主要包括以下四个步骤:
Sklearn在这四个步骤中封装了相应的方法,因此使用起来非常方便. 请参考以下代码:
注意: 为了方便显示以上代码,模块被引入并放置在方法内部,仅供参考
应用
最后一步是测试并应用经过训练的模型.
使用现有模型预测新数据,代码如下:
注意: 此代码仅用于显示和参考
部分打印结果如下图所示:
根据统计,预测准确率是95%. 该模型当天计算的与腾讯有关的舆论如下:
结论
本文仅记录了过去两天我的一些想法和实验. 它不需要太多的代码实现或其他高级算法. 我相信这并不难理解. 如果有人感兴趣,我可以整理源代码并在以后发布.
感谢阅读!
百度飓风算法3.0即将推出,以控制跨域采集和站点组问题
采集交流 • 优采云 发表了文章 • 0 个评论 • 282 次浏览 • 2020-08-07 14:37
为了保持健康的搜索生态并确保搜索用户体验,百度搜索将在不久的将来升级飓风算法并发布飓风算法3.0.
以下详细介绍了飓风算法3.0的相关规则.
1. 跨域采集:
为了获得更多的流量,站点/迷你程序发布了不属于站点/迷你程序域的内容. 通常,这些内容是从Internet采集的,它们的内容质量和相关性较低,并且对搜索用户的价值较低. 对于此类行为搜索,将确定站点/小程序的域不够集中,并且在显示上会有不同程度的限制.
跨域集合主要包括以下两种类型的问题:
类型1: 主站点或主页的内容/标题/关键字/摘要表明该站点具有明确的字段或行业,但是发布的内容与该字段无关或相关性较低.
问题的一个例子: 一个小型食品节目发布了与足球相关的内容
第二类: 站点/迷你程序没有明确的领域或行业,内容涉及多个领域或行业,该领域含糊不清,且领域关注度较低.
问题示例: 小程序的内容涵盖多个区域
两个. 站组问题:
指的是分批构造多个站点/小程序以获得搜索流量的行为. 网站组中的大多数网站/小程序质量低,资源稀缺,内容相似度高,甚至重复使用同一模板,难以满足搜索用户的需求.
问题示例: 多个小程序重复使用同一模板,内容质量低且相似度高
以上是对飓风算法3.0的描述. 该算法有望在八月份发布. 请及时查看站内信件,短信等通道中的提醒,并积极自查完成整改,避免不必要的损失. 查看全部
此算法升级主要针对跨域采集和网站组问题,并将涵盖PC网站,H5网站,applet和百度搜索下的其他内容. 对于算法所涵盖的网站/小型程序,将根据违规的严重程度来适当限制搜索结果的显示.
为了保持健康的搜索生态并确保搜索用户体验,百度搜索将在不久的将来升级飓风算法并发布飓风算法3.0.
以下详细介绍了飓风算法3.0的相关规则.
1. 跨域采集:
为了获得更多的流量,站点/迷你程序发布了不属于站点/迷你程序域的内容. 通常,这些内容是从Internet采集的,它们的内容质量和相关性较低,并且对搜索用户的价值较低. 对于此类行为搜索,将确定站点/小程序的域不够集中,并且在显示上会有不同程度的限制.
跨域集合主要包括以下两种类型的问题:
类型1: 主站点或主页的内容/标题/关键字/摘要表明该站点具有明确的字段或行业,但是发布的内容与该字段无关或相关性较低.
问题的一个例子: 一个小型食品节目发布了与足球相关的内容
第二类: 站点/迷你程序没有明确的领域或行业,内容涉及多个领域或行业,该领域含糊不清,且领域关注度较低.
问题示例: 小程序的内容涵盖多个区域
两个. 站组问题:
指的是分批构造多个站点/小程序以获得搜索流量的行为. 网站组中的大多数网站/小程序质量低,资源稀缺,内容相似度高,甚至重复使用同一模板,难以满足搜索用户的需求.
问题示例: 多个小程序重复使用同一模板,内容质量低且相似度高
以上是对飓风算法3.0的描述. 该算法有望在八月份发布. 请及时查看站内信件,短信等通道中的提醒,并积极自查完成整改,避免不必要的损失.
Visual Basic编程问题自动评分算法的分析与实践.docx
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2020-08-07 09:20
Visual Basic编程问题自动评分算法的研究与实践
摘要
Visual Basic是一门计算机语言入门课程,有大量的大学和大学. 它需要一个用于对问题进行编程的自动评估工具,以有效地支持该课程的教学质量的提高和教学工作的安排. 面对Visual Basic等教学内容,实现自动评估,科学的评分算法是关键之一.
本文在研究现有评分算法的基础上提出了一种新的评分算法. 该算法将分数分为两部分: 接口评估和代码评估. 界面评估通过直接读取被评估程序的表单文件来获取控制信息,然后将分数与评分标准进行比较. 代码评估结合了动态和静态. 动态评估通过模拟Windows消息,按照一定的逻辑控制被评估程序的运行,并使用嵌入的临时代码获得程序的运行特性,最后根据运行特性的比较进行评分. 静态评估将程序编程为程序,根据检查的要点将其分为多个得分点,使用正则表达式调节每个得分点,最后将正则表达式与程序代码匹配以给出得分. 为了验证本文提出的评分算法的效果,我们构建了评分系统的原型,建立了相应的问题库,并采集了学生程序样本. 记录自动评分过程的实验验证,并自动比较手动评分结果
分数的误差在可接受的范围内,并被老师和学生识别. 本文提出的自动评分算法和问题相互独立,为问题库的扩展提供了方便.
此外,该算法依赖于评分标准,每个项目的评分标准都需要由编写项目的人员在系统的帮助下手动实施. 评分标准生成的自动化是未来值得研究的方向.
关键字: 编程问题,自动评估,Windows消息,正则表达式
V
自动的研究与实现
Visual Basic课程评估算法
摘要
Visual Basic作为当今大学中普遍使用的一种推杆语言,呼吁开发一种用于编程的自动评估工具,以有效提高课程的教学质量和教学设置. 为了在像Visual Basic这样的课程中实现自动评估,关键之一在于寻找科学
评估算法.
<p>在对现有评估方法的研究基础上,tlliS提出了一种新的评估算法,将评估分为界面评估和代码评估两部分. 在界面评估中,获得了控制信息 查看全部
文档简介:
Visual Basic编程问题自动评分算法的研究与实践
摘要
Visual Basic是一门计算机语言入门课程,有大量的大学和大学. 它需要一个用于对问题进行编程的自动评估工具,以有效地支持该课程的教学质量的提高和教学工作的安排. 面对Visual Basic等教学内容,实现自动评估,科学的评分算法是关键之一.
本文在研究现有评分算法的基础上提出了一种新的评分算法. 该算法将分数分为两部分: 接口评估和代码评估. 界面评估通过直接读取被评估程序的表单文件来获取控制信息,然后将分数与评分标准进行比较. 代码评估结合了动态和静态. 动态评估通过模拟Windows消息,按照一定的逻辑控制被评估程序的运行,并使用嵌入的临时代码获得程序的运行特性,最后根据运行特性的比较进行评分. 静态评估将程序编程为程序,根据检查的要点将其分为多个得分点,使用正则表达式调节每个得分点,最后将正则表达式与程序代码匹配以给出得分. 为了验证本文提出的评分算法的效果,我们构建了评分系统的原型,建立了相应的问题库,并采集了学生程序样本. 记录自动评分过程的实验验证,并自动比较手动评分结果
分数的误差在可接受的范围内,并被老师和学生识别. 本文提出的自动评分算法和问题相互独立,为问题库的扩展提供了方便.
此外,该算法依赖于评分标准,每个项目的评分标准都需要由编写项目的人员在系统的帮助下手动实施. 评分标准生成的自动化是未来值得研究的方向.
关键字: 编程问题,自动评估,Windows消息,正则表达式
V
自动的研究与实现
Visual Basic课程评估算法
摘要
Visual Basic作为当今大学中普遍使用的一种推杆语言,呼吁开发一种用于编程的自动评估工具,以有效提高课程的教学质量和教学设置. 为了在像Visual Basic这样的课程中实现自动评估,关键之一在于寻找科学
评估算法.
<p>在对现有评估方法的研究基础上,tlliS提出了一种新的评估算法,将评估分为界面评估和代码评估两部分. 在界面评估中,获得了控制信息
使用Q学习算法实现自动迷宫机器人
采集交流 • 优采云 发表了文章 • 0 个评论 • 177 次浏览 • 2020-08-07 05:02
在此项目中,您将使用强化学习算法来实现自动迷宫机器人.
我们需要通过修改robot.py中的代码来实现Q学习机器人,以实现上述目标.
第1节算法理解1.1强化学习概述
强化学习是一种机器学习算法,其模式是让代理学习“训练”中的“经验”以完成给定的任务. 但是不同于监督学习和无监督学习,在强化学习的框架中,我们更多地关注通过主体与环境之间的相互作用进行学习. 通常,在有监督的学习和无监督的学习任务中,座席经常需要通过给定的训练集,并辅以集合的训练目标(例如,使损失函数最小化),并通过给定的学习算法实现此目标. 但是,在强化学习中,主体通过与环境互动获得的收益来学习. 这种环境可以是虚拟的(例如虚拟迷宫)或真实的(无人驾驶汽车在真实道路上采集数据).
强化学习有五个核心组成部分,分别是: 环境,主体,状态,行动和奖励. 在某个时间点t:
通过合理的学习算法,代理将在这种问题设置下成功学习状态.
选择操作
策略
.
1.2计算Q值
在我们的项目中,我们希望实现基于Q学习的强化学习算法. Q学习是一种值迭代算法. 与策略迭代算法不同,值迭代算法计算每个“状态”或“状态操作”的值或效用,然后在执行此值时尝试使其最大化. 因此,每个状态值的准确估计是我们的值迭代算法的核心. 通常,我们会考虑最大化行为的长期回报,即不仅是当前行为带来的回报,而且还会是行为的长期回报.
在Q学习算法中,我们将此长期奖励记录为Q值,并且将考虑每个“状态动作”的Q值. 具体来说,其计算公式为:
这是针对当前的“国家行为”
我们考虑采取行动
后环境给予的奖励
,然后执行操作
到达
执行任何操作后,可获得的最大Q值
,
是折扣因子.
但是,通常,我们使用更保守的方法来更新Q表,即引入松弛变量alpha,并根据以下公式对其进行更新,以使Q表的迭代更改更加平缓.
根据已知条件
.
已知: 如上所示,机器人位于s1处,动作为u,动作的奖励与问题的默认设置相同. 在s2中执行的每个动作的Q值分别为: u: -24,r: -13,d: -0.29,l: +40,并且γ为0.9.
1.3如何选择动作
在强化学习中,“探索利用”是一个非常重要的问题. 具体而言,根据以上定义,我们将尽最大努力让机器人每次都选择最佳决策,以最大化长期回报. 但这有以下缺点:
因此,我们需要一种解决上述问题并增加机器人探索能力的方法. 因此,我们考虑使用epsilon-greedy算法,也就是说,当汽车选择一个动作时,它会随机选择一个概率为一部分的动作,并根据最优Q值选择一个概率为一部分的动作. 同时,随着训练的进行,选择随机动作的概率应逐渐降低.
在下面的代码块中,实现epsilon-greedy算法的逻辑并运行测试代码.
<p>import random
import operator
actions = ['u','r','d','l']
qline = {'u':1.2, 'r':-2.1, 'd':-24.5, 'l':27}
epsilon = 0.3 # 以0.3的概率进行随机选择
def choose_action(epsilon):
action = None
if random.uniform(0,1.0) 查看全部
项目说明:
在此项目中,您将使用强化学习算法来实现自动迷宫机器人.
我们需要通过修改robot.py中的代码来实现Q学习机器人,以实现上述目标.
第1节算法理解1.1强化学习概述
强化学习是一种机器学习算法,其模式是让代理学习“训练”中的“经验”以完成给定的任务. 但是不同于监督学习和无监督学习,在强化学习的框架中,我们更多地关注通过主体与环境之间的相互作用进行学习. 通常,在有监督的学习和无监督的学习任务中,座席经常需要通过给定的训练集,并辅以集合的训练目标(例如,使损失函数最小化),并通过给定的学习算法实现此目标. 但是,在强化学习中,主体通过与环境互动获得的收益来学习. 这种环境可以是虚拟的(例如虚拟迷宫)或真实的(无人驾驶汽车在真实道路上采集数据).
强化学习有五个核心组成部分,分别是: 环境,主体,状态,行动和奖励. 在某个时间点t:
通过合理的学习算法,代理将在这种问题设置下成功学习状态.
选择操作
策略
.
1.2计算Q值
在我们的项目中,我们希望实现基于Q学习的强化学习算法. Q学习是一种值迭代算法. 与策略迭代算法不同,值迭代算法计算每个“状态”或“状态操作”的值或效用,然后在执行此值时尝试使其最大化. 因此,每个状态值的准确估计是我们的值迭代算法的核心. 通常,我们会考虑最大化行为的长期回报,即不仅是当前行为带来的回报,而且还会是行为的长期回报.
在Q学习算法中,我们将此长期奖励记录为Q值,并且将考虑每个“状态动作”的Q值. 具体来说,其计算公式为:
这是针对当前的“国家行为”
我们考虑采取行动
后环境给予的奖励
,然后执行操作
到达
执行任何操作后,可获得的最大Q值
,
是折扣因子.
但是,通常,我们使用更保守的方法来更新Q表,即引入松弛变量alpha,并根据以下公式对其进行更新,以使Q表的迭代更改更加平缓.
根据已知条件
.
已知: 如上所示,机器人位于s1处,动作为u,动作的奖励与问题的默认设置相同. 在s2中执行的每个动作的Q值分别为: u: -24,r: -13,d: -0.29,l: +40,并且γ为0.9.
1.3如何选择动作
在强化学习中,“探索利用”是一个非常重要的问题. 具体而言,根据以上定义,我们将尽最大努力让机器人每次都选择最佳决策,以最大化长期回报. 但这有以下缺点:
因此,我们需要一种解决上述问题并增加机器人探索能力的方法. 因此,我们考虑使用epsilon-greedy算法,也就是说,当汽车选择一个动作时,它会随机选择一个概率为一部分的动作,并根据最优Q值选择一个概率为一部分的动作. 同时,随着训练的进行,选择随机动作的概率应逐渐降低.
在下面的代码块中,实现epsilon-greedy算法的逻辑并运行测试代码.
<p>import random
import operator
actions = ['u','r','d','l']
qline = {'u':1.2, 'r':-2.1, 'd':-24.5, 'l':27}
epsilon = 0.3 # 以0.3的概率进行随机选择
def choose_action(epsilon):
action = None
if random.uniform(0,1.0)
对百度飓风算法2.0的解释,采集真的会屈服吗?
采集交流 • 优采云 发表了文章 • 0 个评论 • 314 次浏览 • 2020-08-07 03:14
关于采集网站,我们都知道这种网站基本上没有自己的内容输出. 它是一种内容搬运程序,可在短时间内生成大量内容,并被生成以恶意获取流量以赚取会员广告费.
对于网民来说,这种网站基本上没有用.
这种类型的采集站点具有几个特征
1. 内容繁琐
基本上,在这种类型的采集网站中,所有内容都可用,并且信息混乱并且没有集成.
2,布局和排版不佳
许多采集站点的布局都很混乱,内容页面甚至更难阅读,内容混乱很多,甚至句子也不合理.
3,垃圾页面
许多采集地点不加选择地采集. 许多垃圾邮件广告是直接采集的. 小型广告过多,垃圾邮件页面也很多.
了解上述情况后,让我们再次解释该算法(飓风算法2.0)
百度搜索资源平台的官方公告说:
飓风算法将在9月下旬升级,并推出2.0版本,要求网站管理员进行自我检查并清除所有“违规采集”内容.
在这里,我们不妨深入研究“违反采集”一词
1. 什么是违反集合规定?
2. 这是否意味着不会清除非法采集?
3. 采集仍然可以存在吗?
在这里我不会回答,让我们继续看一下飓风算法2.0针对的问题
1. 从诸如其他网站或官方帐户之类的内容制作者那里采集和转移了大量内容. 信息不整合,布局混乱,文章可读性差,有明显的采集痕迹,对用户没有增值.
官方示例1(垃圾文本,无序排版):
官方示例2(小广告):
2. 文章拼接内容多,文章逻辑性差,不能满足用户需求,阅读体验差.
3. 网站中采集的内容很多,并且网站本身的内容生产力非常差.
4. 有大量与该站点的主题无关的采集内容,并且该域的关注度很低,并且恶意获取了流量. 例如: 科技网站采集了大量的娱乐八卦,社交新闻等.
这4点是该算法针对的非法采集网站. 任何违反这些规则的人都将受到惩罚. 从这些方面,我们可以回答上述问题.
1. 非法采集,不存在,只要我不违反这些要点,就不会受到侵犯,也不会遭到殴打.
2. 只要没有违规,就不会清除它. 从许多示例中我们仍然发现,许多采集站仍在首页上排名很好.
3. 仍然允许采集,并且搜索引擎仍然通过出色的资源集成来支持采集网站.
那么如何规避该算法以及如何有效地构建采集站点?
从搜索主题出发,“在百度搜索中创建良好的内容生态,保护用户的阅读体验以及保护高质量内容的权益”归纳为两点: “用户体验,高质量内容“.
当前的搜索引擎对垃圾邮件页面的容忍度为零. 无休止的算法全都在促进高质量内容的产生和绿色搜索生态.
这样,根据上述规则,如何采集,我们就有了方向,并且不会违反算法.
1. 采集的内容无法从旧内容复制. 您需要自己进行整合和总结. 排版是好的,文章必须有所收获. 例如,采集的原创文章没有图片,但是在采集之后,您添加了图片. 这就是增益.
2. 该文章必须具有逻辑性,不能脱离上下文,不能在任何地方被截取或随意拼接. 这些文章显然是不合格的,因此需要重新组织文章以提高可读性.
3. 不能盲目采集和运输该地点. 这样的网站将被搜索引擎判断为内容生产率低下,并且如果没有自己的本地内容,该网站的性能将大大降低.
4. 网站的内容必须与主题紧密相关. 如果您是餐饮业公司,则财务管理或技术范围内不得收录任何内容. 现在,只有在细分领域中才能脱颖而出. 该领域的关注程度不够,仅用于恶意流量. 肯定会采集和更新一些与您的网站无关的内容.
提示: 所采集的网站广告的放置必须合理,并且不得牺牲用户体验. 有关特定规则,请参阅“百度移动搜索目标网页体验白皮书4.0”. PC端没有太大区别.
我不会谈论更好的小流. 尽管以上增加了很多人工成本,但这是不可避免的. 我希望每个人都进行认真的采集,并坚持创建高质量的内容,并且网站一定会起飞. 查看全部
飓风算法最早于2017年7月发布. 一年零两个月后,该算法再次升级. 飓风算法2.0的出现再次为采集网站敲响了警钟.
关于采集网站,我们都知道这种网站基本上没有自己的内容输出. 它是一种内容搬运程序,可在短时间内生成大量内容,并被生成以恶意获取流量以赚取会员广告费.
对于网民来说,这种网站基本上没有用.
这种类型的采集站点具有几个特征
1. 内容繁琐
基本上,在这种类型的采集网站中,所有内容都可用,并且信息混乱并且没有集成.
2,布局和排版不佳
许多采集站点的布局都很混乱,内容页面甚至更难阅读,内容混乱很多,甚至句子也不合理.
3,垃圾页面
许多采集地点不加选择地采集. 许多垃圾邮件广告是直接采集的. 小型广告过多,垃圾邮件页面也很多.
了解上述情况后,让我们再次解释该算法(飓风算法2.0)
百度搜索资源平台的官方公告说:
飓风算法将在9月下旬升级,并推出2.0版本,要求网站管理员进行自我检查并清除所有“违规采集”内容.
在这里,我们不妨深入研究“违反采集”一词
1. 什么是违反集合规定?
2. 这是否意味着不会清除非法采集?
3. 采集仍然可以存在吗?
在这里我不会回答,让我们继续看一下飓风算法2.0针对的问题
1. 从诸如其他网站或官方帐户之类的内容制作者那里采集和转移了大量内容. 信息不整合,布局混乱,文章可读性差,有明显的采集痕迹,对用户没有增值.
官方示例1(垃圾文本,无序排版):
官方示例2(小广告):
2. 文章拼接内容多,文章逻辑性差,不能满足用户需求,阅读体验差.
3. 网站中采集的内容很多,并且网站本身的内容生产力非常差.
4. 有大量与该站点的主题无关的采集内容,并且该域的关注度很低,并且恶意获取了流量. 例如: 科技网站采集了大量的娱乐八卦,社交新闻等.
这4点是该算法针对的非法采集网站. 任何违反这些规则的人都将受到惩罚. 从这些方面,我们可以回答上述问题.
1. 非法采集,不存在,只要我不违反这些要点,就不会受到侵犯,也不会遭到殴打.
2. 只要没有违规,就不会清除它. 从许多示例中我们仍然发现,许多采集站仍在首页上排名很好.
3. 仍然允许采集,并且搜索引擎仍然通过出色的资源集成来支持采集网站.
那么如何规避该算法以及如何有效地构建采集站点?
从搜索主题出发,“在百度搜索中创建良好的内容生态,保护用户的阅读体验以及保护高质量内容的权益”归纳为两点: “用户体验,高质量内容“.
当前的搜索引擎对垃圾邮件页面的容忍度为零. 无休止的算法全都在促进高质量内容的产生和绿色搜索生态.
这样,根据上述规则,如何采集,我们就有了方向,并且不会违反算法.
1. 采集的内容无法从旧内容复制. 您需要自己进行整合和总结. 排版是好的,文章必须有所收获. 例如,采集的原创文章没有图片,但是在采集之后,您添加了图片. 这就是增益.
2. 该文章必须具有逻辑性,不能脱离上下文,不能在任何地方被截取或随意拼接. 这些文章显然是不合格的,因此需要重新组织文章以提高可读性.
3. 不能盲目采集和运输该地点. 这样的网站将被搜索引擎判断为内容生产率低下,并且如果没有自己的本地内容,该网站的性能将大大降低.
4. 网站的内容必须与主题紧密相关. 如果您是餐饮业公司,则财务管理或技术范围内不得收录任何内容. 现在,只有在细分领域中才能脱颖而出. 该领域的关注程度不够,仅用于恶意流量. 肯定会采集和更新一些与您的网站无关的内容.
提示: 所采集的网站广告的放置必须合理,并且不得牺牲用户体验. 有关特定规则,请参阅“百度移动搜索目标网页体验白皮书4.0”. PC端没有太大区别.
我不会谈论更好的小流. 尽管以上增加了很多人工成本,但这是不可避免的. 我希望每个人都进行认真的采集,并坚持创建高质量的内容,并且网站一定会起飞.

