算法 自动采集列表(基于消息列表的采集做以文章介绍技术和源码 )
优采云 发布时间: 2021-08-30 10:08算法 自动采集列表(基于消息列表的采集做以文章介绍技术和源码
)
前言
前两篇文章介绍了系统流程和功能模块的封装。本文文章将在消息列表中解释采集。这篇文章文章 侧重于想法而不是技术和源代码。逻辑代码一样,可靠的算法是百万分之一。
准备1、采集源
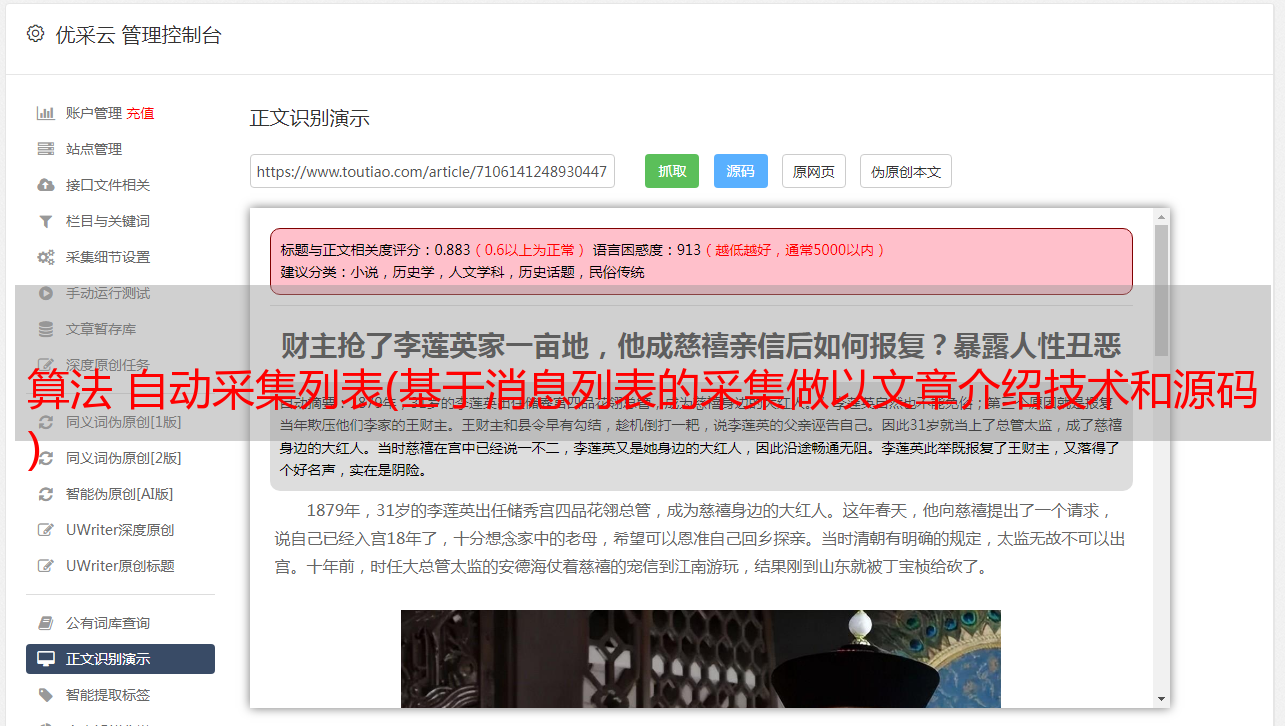
研究发现公众号文章可以通过多种渠道访问:
2、页面跳转
上一节介绍了数据的来源和请求的方法,但是不能每次都手动去点,这样就失去了自动化的意义,最终目的是自动跳转。一般有两种思路:
js注入方式占用资源少,模拟点击限制较多。比如被点击的页面必须在最顶层等,最后选择js注入方式。代理工具也有很多选择,因为没有太复杂的需求,这次我选择的是轻量级的Fiddler,没有用过的读者可以自行百度,傻瓜式安装后安装证书,拦截请求的历史消息页面,在返回页面返回浏览器之前在返回的内容中添加一段简单的js代码,控制页面10s后会跳转到自己服务器的页面。这一步也可以直接在自己的服务器上添加js代码来请求任务,直接跳转到下一个公众号历史消息页面,但是为了灵活控制频率和查看实时进度,一个中间页面建立。历史消息页面完成后,直接跳转到中间页面。中间页面去后台获取新任务,一段时间后跳转到历史消息页面。
由于集群部署,页面放在nginx中,也解决了跨域问题。
3、任务队列
我之前一直在谈论获取任务和执行任务。读者可能不清楚任务是什么类型的数据结构。其实很简单,就是一个队列,里面存放的是公众号的一个参数biz。有了这个参数,就可以组装了。公众号历史新闻页面:.因为是分布式集群部署,所以选择redis队列,每次请求都会弹出一个biz。 redis的单线程特性可以避免重复任务。
4、任务监控
前一个工作完成后,任务可以自动连续执行,但任务不是连续执行24小时。当任务队列为空时,循环停止,但下次任务进入队列时,前端页面需要再次获取任务。解决这个问题最方便的方法显然是长连接。定时请求可能会更加消耗资源并且会稍微延迟。新版Nginx对websocket的支持也非常友好。
任务完成后,页面随机与后台的一个节点建立长连接。当任务再次进入队列时,必须通过RocketMq发送广播消息通知集群中的每个节点。节点收到广播消息后,通知所有与你建立长连接的页面获取任务,进入循环。
核心流程
明人不说密语,上图:
1:可以在多台主机上登录多个微信账号,同时访问中间页面;
1.1:去后台请求一个任务,有任务就循环执行,没有任务就建立长连接;
2:页面随机与后台节点建立长连接;
3:任务排队,rocketmq发送广播通知集群中的各个节点;
4:节点收到广播消息后,通过长连接向页面发送消息;
5:页面收到消息后,去后台请求任务,同1.1;
6:访问历史新闻页面,这里有洞,这里有洞,这里有洞,直接位置跳转会失败,或者参数不完整,链接要填写超链接页面上,并且超链接的目标不能是self,然后js模拟点击这个超链接跳转;
7:Fiddler 将带参数的链接传给后端;
7.1:页面返回浏览器前注入自动重定向js,页面会周期性跳转到中间页面;
7.2:后台获取参数后,根据公众号自定义配置,组装组件页面的查询链接,通过HttpClient请求解析返回的Json数据仓库;
8:页面跳回重新执行1.1,依次循环。
附加功能,帐户访问控制
由于腾讯对每个账号24小时内访问历史消息页面的分页查询接口有限制,为避免账号被封,记录了每个手机号的访问时间。存储结构也是一个redis队列,每添加一个手机号,指定前缀为key,每次访问一个页面时,将当前时间戳推送到当前手机号对应的队列中。
这样,页面上就会实时显示当前手机号和当前账户24H内的执行次数。
访问频率控制
为了防止账号被暂停,应该增加sleep control访问的频率,但是当任务多,账号足够的时候,可能需要增加访问频率。
核心流程的第五步是在获取任务前去后台随机休眠一段时间。最小和最大休眠时间在nacos的配置中心设置。获取到时间后,页面会在指定时间后进行下一步处理。这样就可以通过nacos的热配置功能在不重启项目的情况下改变访问频率。
总结
到此为止,我已经获得了文章的基本信息。此时,没有文字和互动量。该项目的第一个核心点已经完成。相对于交互量,逻辑并不是很复杂。稍后我将解释交互。获取音量和文字的过程还有一些巨大的坑,原创不易,希望老铁们手里的小点赞不要犹豫去逛逛,觉得有帮助的朋友可以给个采集.
本系列文章纯属技术分享,不作为任何商业用途,如若转载,请注明出处。

