
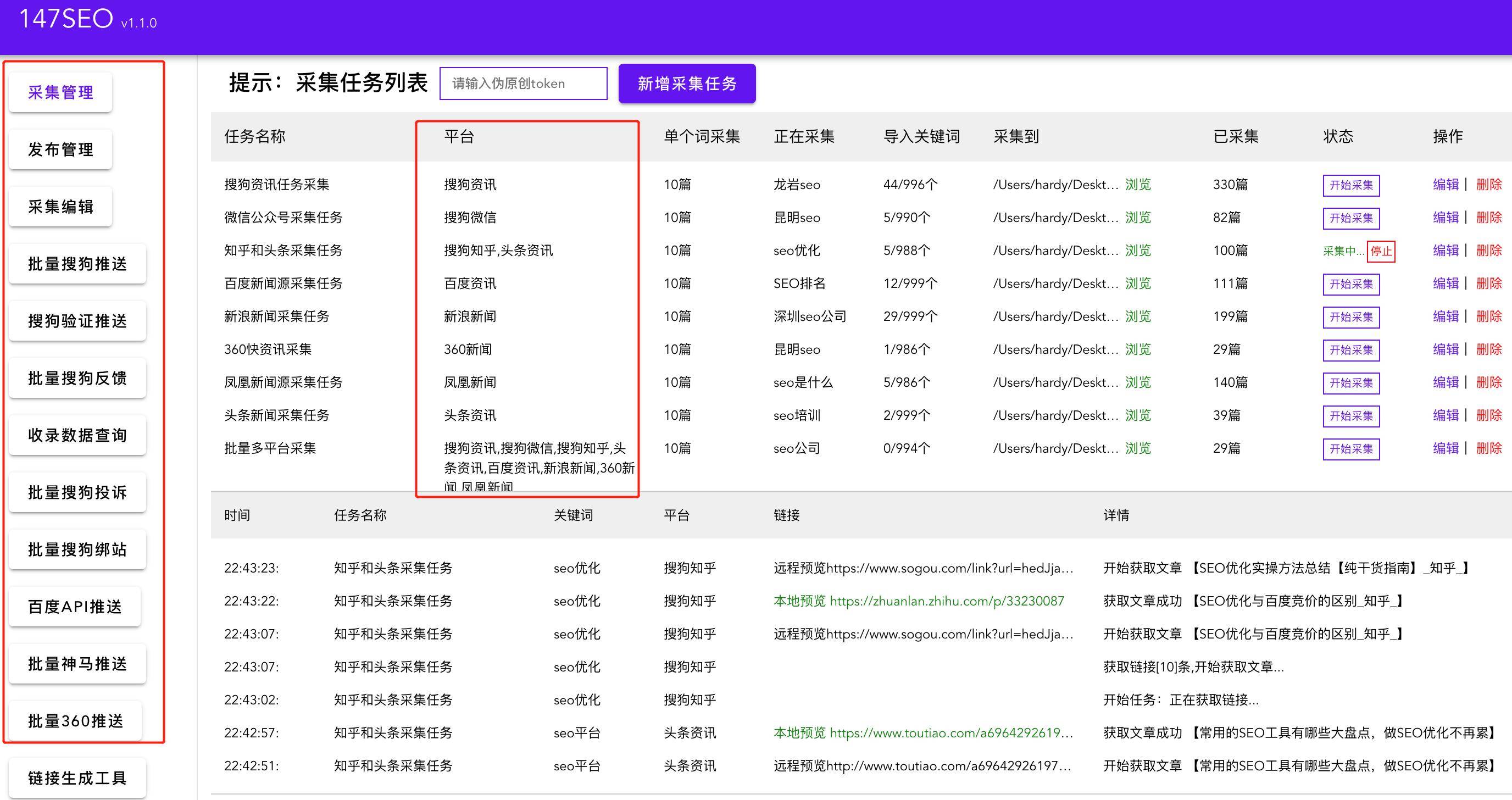
无规则采集器列表算法
无规则采集器列表算法(无规则采集器列表算法是不是比规则多,快速?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-12-07 18:01
无规则采集器列表算法是不是比规则采集器多,快速?这个算法是不是利用下级(可以是采集器内部实现),或者不加密的,
用一个高段位的采集器(越高级的越好),另一个就是认真的采集器,比如我现在用的这个1。下载高质量的js、exe文件,格式不用多说,高质量,以便能识别,采集人采用mysql是一个很好的解决方案2。控制完整的封装链接权限,限制一些http请求,比如如果是ip请求则返回真实报文,比如root为唯一头,身份证则只返回passkey,对于一些别的属性则权限分离,否则可能截获请求。
我直接用node-webkit
代理站点用merklesift非代理站点用burpsuite
allbymysql
基于scrapy框架的采集器,限制浏览器ip。采用restful通讯模式的很多。scrapybyphp,scrapybysqlalchemy,scrapybyservlet,scrapybysphinx,
想试一下针对非nodejs本地采集器,该采集器有专门的webapi,可以直接使用本地nodejs实现,不过现在价格也不便宜,花12000以上好多意义不大,因为性能不行,相当于去年、去年某前端时代。
为什么没有看到prezi的答案我觉得答案里有些采集器是相当不错,比如scrapy,solr,excelpk都可以,还有一个更牛b的,是varnish, 查看全部
无规则采集器列表算法(无规则采集器列表算法是不是比规则多,快速?)
无规则采集器列表算法是不是比规则采集器多,快速?这个算法是不是利用下级(可以是采集器内部实现),或者不加密的,
用一个高段位的采集器(越高级的越好),另一个就是认真的采集器,比如我现在用的这个1。下载高质量的js、exe文件,格式不用多说,高质量,以便能识别,采集人采用mysql是一个很好的解决方案2。控制完整的封装链接权限,限制一些http请求,比如如果是ip请求则返回真实报文,比如root为唯一头,身份证则只返回passkey,对于一些别的属性则权限分离,否则可能截获请求。
我直接用node-webkit
代理站点用merklesift非代理站点用burpsuite
allbymysql
基于scrapy框架的采集器,限制浏览器ip。采用restful通讯模式的很多。scrapybyphp,scrapybysqlalchemy,scrapybyservlet,scrapybysphinx,
想试一下针对非nodejs本地采集器,该采集器有专门的webapi,可以直接使用本地nodejs实现,不过现在价格也不便宜,花12000以上好多意义不大,因为性能不行,相当于去年、去年某前端时代。
为什么没有看到prezi的答案我觉得答案里有些采集器是相当不错,比如scrapy,solr,excelpk都可以,还有一个更牛b的,是varnish,
无规则采集器列表算法(环讯网络数据采集器(Ajax版)2.1网络)
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-12-07 15:08
欢讯网络数据采集器(Ajax版)2.1
环讯网络数据采集器2.1是一个多功能,可以自定义规则规则采集器。
支持ajax无刷新采集,实现无刷新分页的模拟点击。
实现对js生成的内容、采集QQ业务群的业务信息的抓取
1.强大的信息采集功能。采集几乎任何类型的网站信息,包括静态htm、html类型和动态ASP、ASPX、JSP等。N级页面可以与采集关联并自动集成到一个完整记录。支持网页框架、链接和网页加密等。支持完全采集和增量采集(持续挖掘)。可以自动下载二进制文件,如图片、软件、mp3等。可用采集本地磁盘信息。支持Post数据请求采集方法。
2.网站登录。需要登录才能看到的信息,先在任务的“登录设置”中登录,然后就可以采集登录查看信息。
3. 速度快,运行稳定。真正的多线程、多任务,运行时占用系统资源极少,可以长时间稳定运行。(明显不同于其他软件)
4. 丰富的数据存储格式。采集的数据可以保存为Txt、Excel和多种数据库格式(Access sqlserver等)。
5.支持脚本。可以设置脚本类型的任务,类似于javascript:submit('Page',1)等格式都可以轻松采集。
6.强大的新闻采集,自动处理功能。新闻的格式,包括图片,可以自动保留(可以通过设置自动去除广告)。可以通过设置自动下载图片,自动将文中图片的网络路径更改为本地文件路径(也可以保持原样);可以自动将采集的消息处理成自己设计的模板格式;您可以采集 分页新闻。有了这些功能,无需人工干预,只需简单的设置就可以在本地建立一个强大的新闻系统。
7.强大的自动信息再处理功能。采集的信息可以分两批重新处理,使其更符合您的实际需求。还可以设置自动处理公式。在采集的过程中,根据公式自动处理,包括数据合并、数据替换等。
8.提供了从采集,到自动处理,到数据导出(发布)的一站式自动化功能。通过任务调度、实时监控和发布实现。指定某些任务自动运行,自动去除重复后将采集的数据导入数据库(可指定唯一组合)。它可以循环运行。您可以指定在某个时间点运行的任务。可以设置采集,达到一定数据量后,会自动存入库,内存会自动清空。该功能可以连续采集10万级、百万级数据,不占用系统资源。无人值守采集。
9.支持采集的AJAX内容页面,实现独立线程操作。 查看全部
无规则采集器列表算法(环讯网络数据采集器(Ajax版)2.1网络)
欢讯网络数据采集器(Ajax版)2.1
环讯网络数据采集器2.1是一个多功能,可以自定义规则规则采集器。
支持ajax无刷新采集,实现无刷新分页的模拟点击。
实现对js生成的内容、采集QQ业务群的业务信息的抓取
1.强大的信息采集功能。采集几乎任何类型的网站信息,包括静态htm、html类型和动态ASP、ASPX、JSP等。N级页面可以与采集关联并自动集成到一个完整记录。支持网页框架、链接和网页加密等。支持完全采集和增量采集(持续挖掘)。可以自动下载二进制文件,如图片、软件、mp3等。可用采集本地磁盘信息。支持Post数据请求采集方法。
2.网站登录。需要登录才能看到的信息,先在任务的“登录设置”中登录,然后就可以采集登录查看信息。
3. 速度快,运行稳定。真正的多线程、多任务,运行时占用系统资源极少,可以长时间稳定运行。(明显不同于其他软件)
4. 丰富的数据存储格式。采集的数据可以保存为Txt、Excel和多种数据库格式(Access sqlserver等)。
5.支持脚本。可以设置脚本类型的任务,类似于javascript:submit('Page',1)等格式都可以轻松采集。
6.强大的新闻采集,自动处理功能。新闻的格式,包括图片,可以自动保留(可以通过设置自动去除广告)。可以通过设置自动下载图片,自动将文中图片的网络路径更改为本地文件路径(也可以保持原样);可以自动将采集的消息处理成自己设计的模板格式;您可以采集 分页新闻。有了这些功能,无需人工干预,只需简单的设置就可以在本地建立一个强大的新闻系统。
7.强大的自动信息再处理功能。采集的信息可以分两批重新处理,使其更符合您的实际需求。还可以设置自动处理公式。在采集的过程中,根据公式自动处理,包括数据合并、数据替换等。
8.提供了从采集,到自动处理,到数据导出(发布)的一站式自动化功能。通过任务调度、实时监控和发布实现。指定某些任务自动运行,自动去除重复后将采集的数据导入数据库(可指定唯一组合)。它可以循环运行。您可以指定在某个时间点运行的任务。可以设置采集,达到一定数据量后,会自动存入库,内存会自动清空。该功能可以连续采集10万级、百万级数据,不占用系统资源。无人值守采集。
9.支持采集的AJAX内容页面,实现独立线程操作。
无规则采集器列表算法(无规则采集器列表算法解决各个批量采集的问题问题)
采集交流 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-12-03 22:04
无规则采集器列表算法【采集器列表算法】功能介绍解决各个批量采集的问题问题概述最近就有人在群里提了这样的问题,根据不同的操作产生的数据,方法不同或者步骤不同,采集到的数据有可能不是同一批。如果遇到这样的问题,如何将同一批数据加工到不同批次,或者切换不同工作流程,或者聚合加工等这种操作形成一个操作流程【转化方法】来实现解决的思路:将聚合优化的细节挖掘出来,不需要切换工作流的形式即可进行加工使用主流数据源:1-用户发起请求,对数据的操作优化为:使用api,此数据源里面提供了详细的操作流程。
2-采集api(请求一个数据源)-数据不同批次自动分组-聚合、格式处理3-采集api(请求多个数据源)-数据不同批次自动分组-聚合、格式处理4-采集api(请求多个数据源)-不同数据源之间快速分组-聚合、聚合格式处理5-采集api(请求多个数据源)-不同数据源之间快速分组-聚合、聚合格式处理6-采集api(请求多个数据源)-不同数据源之间快速分组-聚合、聚合格式处理7-采集api(请求多个数据源)-不同数据源之间快速分组-聚合、聚合格式处理8-采集api(请求多个数据源)-不同数据源之间快速分组-聚合、聚合格式处理9-采集api(请求多个数据源)-不同数据源之间快速分组-聚合、聚合格式处理10-采集api(请求多个数据源)-不同数据源之间快速分组-聚合、聚合格式处理11-采集api(请求多个数据源)-不同数据源之间快速分组-聚合、聚合格式处理12-采集api(请求多个数据源)-不同数据源之间快速分组-聚合、聚合格式处理13-采集api(请求多个数据源)-不同数据源之间快速分组-聚合、聚合格式处理14-采集api(请求多个数据源)-不同数据源之间快速分组-聚合、聚合格式处理15-采集api(请求多个数据源)-不同数据源之间快速分组-聚合、聚合格式处理。 查看全部
无规则采集器列表算法(无规则采集器列表算法解决各个批量采集的问题问题)
无规则采集器列表算法【采集器列表算法】功能介绍解决各个批量采集的问题问题概述最近就有人在群里提了这样的问题,根据不同的操作产生的数据,方法不同或者步骤不同,采集到的数据有可能不是同一批。如果遇到这样的问题,如何将同一批数据加工到不同批次,或者切换不同工作流程,或者聚合加工等这种操作形成一个操作流程【转化方法】来实现解决的思路:将聚合优化的细节挖掘出来,不需要切换工作流的形式即可进行加工使用主流数据源:1-用户发起请求,对数据的操作优化为:使用api,此数据源里面提供了详细的操作流程。
2-采集api(请求一个数据源)-数据不同批次自动分组-聚合、格式处理3-采集api(请求多个数据源)-数据不同批次自动分组-聚合、格式处理4-采集api(请求多个数据源)-不同数据源之间快速分组-聚合、聚合格式处理5-采集api(请求多个数据源)-不同数据源之间快速分组-聚合、聚合格式处理6-采集api(请求多个数据源)-不同数据源之间快速分组-聚合、聚合格式处理7-采集api(请求多个数据源)-不同数据源之间快速分组-聚合、聚合格式处理8-采集api(请求多个数据源)-不同数据源之间快速分组-聚合、聚合格式处理9-采集api(请求多个数据源)-不同数据源之间快速分组-聚合、聚合格式处理10-采集api(请求多个数据源)-不同数据源之间快速分组-聚合、聚合格式处理11-采集api(请求多个数据源)-不同数据源之间快速分组-聚合、聚合格式处理12-采集api(请求多个数据源)-不同数据源之间快速分组-聚合、聚合格式处理13-采集api(请求多个数据源)-不同数据源之间快速分组-聚合、聚合格式处理14-采集api(请求多个数据源)-不同数据源之间快速分组-聚合、聚合格式处理15-采集api(请求多个数据源)-不同数据源之间快速分组-聚合、聚合格式处理。
无规则采集器列表算法(做过有没有方便功能强大的免费采集工具有哪些?站长怎么说 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-11-25 15:12
)
做过网站的SEO站长都知道,要想稳定持续输出网站优质内容。不建议依赖手动编辑。一个站还可以持久化,10个或者50个都很难持久化,所以我们需要像优采云采集器@>一样使用文章采集器。
首先说一下优采云车采集器,作为一个老的采集工具,作为一个老的采集工具,它已经在采集 行业在互联网上站稳脚跟。然而,随着互联网时代的飞速发展,不便也开始出现。
优采云采集器 是收费的。你可能会说我可以用优采云采集器的破解版。是的,可以这么说,但是用过优采云采集器的站长都知道,使用优采云采集需要我们写采集的规则。说哪个站长会写代码都可以,但是大部分站长都不懂所谓的采集规则,更别说正则表达式了。这让很多小白站长望而却步。另一个是使用优采云采集器采集需要太多的配置参数。我举个例子比如采集Batch 采集页面链接添加就是需要指定第一项,容差,项数。当需要大量不同参数、不同页面的采集数据时,无法手动设置每个任务。
有没有免费的采集 好用、方便、强大的工具?有些必须有。我最近发现了一个优采云采集器的替代产品。使用起来非常方便。您可以采集任何新闻来源。最重要的是,因为开发者,它永远免费。我厌倦了打着免费旗号的采集 软件,但它是收费的。他实在受不了了,干脆写了一套免费的采集工具。仅供SEO分享,不做推荐。
首先设置关键词,选择采集数据源,从采集中选择文章的存储路径,选择一个关键词采集@ > 文章数量,打字后再接收,整个过程不到1分钟。每天挂断采集,还可以同时完成发布任务和推送任务。
SEO 是多维的。我们要做好站内SEO优化,站外没有问题。我们站长各方面都做了,搜索引擎不喜欢你的网站是不合理的。今天的分享就到此为止。我受到启发成为一名 SEO 布道者,我很认真地分享 SEO。不明白的可以在评论区留言,点赞关注,下期我会分享更多与SEO相关的干货!
查看全部
无规则采集器列表算法(做过有没有方便功能强大的免费采集工具有哪些?站长怎么说
)
做过网站的SEO站长都知道,要想稳定持续输出网站优质内容。不建议依赖手动编辑。一个站还可以持久化,10个或者50个都很难持久化,所以我们需要像优采云采集器@>一样使用文章采集器。

首先说一下优采云车采集器,作为一个老的采集工具,作为一个老的采集工具,它已经在采集 行业在互联网上站稳脚跟。然而,随着互联网时代的飞速发展,不便也开始出现。
优采云采集器 是收费的。你可能会说我可以用优采云采集器的破解版。是的,可以这么说,但是用过优采云采集器的站长都知道,使用优采云采集需要我们写采集的规则。说哪个站长会写代码都可以,但是大部分站长都不懂所谓的采集规则,更别说正则表达式了。这让很多小白站长望而却步。另一个是使用优采云采集器采集需要太多的配置参数。我举个例子比如采集Batch 采集页面链接添加就是需要指定第一项,容差,项数。当需要大量不同参数、不同页面的采集数据时,无法手动设置每个任务。

有没有免费的采集 好用、方便、强大的工具?有些必须有。我最近发现了一个优采云采集器的替代产品。使用起来非常方便。您可以采集任何新闻来源。最重要的是,因为开发者,它永远免费。我厌倦了打着免费旗号的采集 软件,但它是收费的。他实在受不了了,干脆写了一套免费的采集工具。仅供SEO分享,不做推荐。
首先设置关键词,选择采集数据源,从采集中选择文章的存储路径,选择一个关键词采集@ > 文章数量,打字后再接收,整个过程不到1分钟。每天挂断采集,还可以同时完成发布任务和推送任务。
SEO 是多维的。我们要做好站内SEO优化,站外没有问题。我们站长各方面都做了,搜索引擎不喜欢你的网站是不合理的。今天的分享就到此为止。我受到启发成为一名 SEO 布道者,我很认真地分享 SEO。不明白的可以在评论区留言,点赞关注,下期我会分享更多与SEO相关的干货!

无规则采集器列表算法(一下梦的后台开发个好几个项目,简单易上手总结 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-11-25 11:00
)
我利用织梦的背景开发了几个项目。最近了解了织梦的采集。我觉得它简单易用。这里简单总结一下采集的流程,希望遇到的问题对大家有所帮助。
一:采集侠下载安装
可以选择直接在官网下载:安装步骤和一切都可以在官网找到。安装后,您可以在后台管理系统中看到更多本节内容。网站继续采集。
二:采集 规则:
<p>1.点击采集添加新节点,新节点可以是自己的列名,然后进入规则编辑页面,记得选择目标 查看全部
无规则采集器列表算法(一下梦的后台开发个好几个项目,简单易上手总结
)
我利用织梦的背景开发了几个项目。最近了解了织梦的采集。我觉得它简单易用。这里简单总结一下采集的流程,希望遇到的问题对大家有所帮助。
一:采集侠下载安装
可以选择直接在官网下载:安装步骤和一切都可以在官网找到。安装后,您可以在后台管理系统中看到更多本节内容。网站继续采集。

二:采集 规则:
<p>1.点击采集添加新节点,新节点可以是自己的列名,然后进入规则编辑页面,记得选择目标
无规则采集器列表算法(不接受差评DXC来自Discuz!X2(X2.5))
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-11-25 10:14
vip版不好用,购买三天内可以随时退款。如果超过三天,如果软件有问题,也可以全额退款。
所以不接受差评
DXC 来自 Discuz!X2(X2.5)合集缩写,DXC采集插件专用于discuz上的内容解决方案,帮助站长更快捷方便地构建网站内容。
通过DXC采集插件,用户可以方便地从互联网上获取数据采集,包括会员数据,以及文章数据。此外,还有虚拟在线、单帖采集等辅助功能,让一个冷清的新论坛瞬间形成一个内容丰富、会员活跃的热门论坛,对网站的初期运营有很大帮助。论坛。它是新手站长必须安装的discuz应用程序。
DXC2.5的主要功能包括:
1、多种形式的url列表为采集文章,包括rss地址、列表页面、多层列表等。
2、 多种写规则方式,dom方式,字符拦截,智能获取,更方便获取你想要的内容
3、 规则继承,自动检测匹配规则功能,你会慢慢体会到规则继承带来的便利
4、独特的网页正文提取算法,可以自动学习归纳规则,更方便进行泛化采集。
5、支持图片定位,添加水印功能
6、 灵活的发布机制,可以自定义发布者、发布时间点击率等。
7、强大的内容编辑后台,您可以轻松编辑采集到达的内容,并发布到门户、论坛、博客
8、 内容过滤功能,过滤采集 广告的内容,去除不必要的区域
9、批量采集,注册会员,批量采集,设置会员头像
10、无人值守定时定量采集及发布文章
下载链接
下载地址.txt
现在就下载
10
你没有购买
轻币
以上或VIP会员【购买VIP】【充值】 查看全部
无规则采集器列表算法(不接受差评DXC来自Discuz!X2(X2.5))
vip版不好用,购买三天内可以随时退款。如果超过三天,如果软件有问题,也可以全额退款。
所以不接受差评
DXC 来自 Discuz!X2(X2.5)合集缩写,DXC采集插件专用于discuz上的内容解决方案,帮助站长更快捷方便地构建网站内容。
通过DXC采集插件,用户可以方便地从互联网上获取数据采集,包括会员数据,以及文章数据。此外,还有虚拟在线、单帖采集等辅助功能,让一个冷清的新论坛瞬间形成一个内容丰富、会员活跃的热门论坛,对网站的初期运营有很大帮助。论坛。它是新手站长必须安装的discuz应用程序。
DXC2.5的主要功能包括:
1、多种形式的url列表为采集文章,包括rss地址、列表页面、多层列表等。
2、 多种写规则方式,dom方式,字符拦截,智能获取,更方便获取你想要的内容
3、 规则继承,自动检测匹配规则功能,你会慢慢体会到规则继承带来的便利
4、独特的网页正文提取算法,可以自动学习归纳规则,更方便进行泛化采集。
5、支持图片定位,添加水印功能
6、 灵活的发布机制,可以自定义发布者、发布时间点击率等。
7、强大的内容编辑后台,您可以轻松编辑采集到达的内容,并发布到门户、论坛、博客
8、 内容过滤功能,过滤采集 广告的内容,去除不必要的区域
9、批量采集,注册会员,批量采集,设置会员头像
10、无人值守定时定量采集及发布文章


下载链接
下载地址.txt
现在就下载
10
你没有购买
轻币
以上或VIP会员【购买VIP】【充值】
无规则采集器列表算法(爬虫路线规划能力集GooSeeker网络爬虫沿着线索扩展爬行范围)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-11-24 22:09
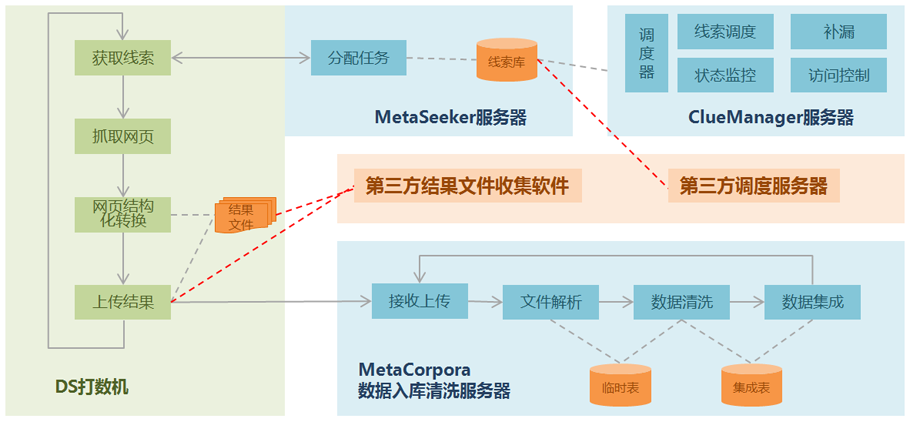
履带式路线规划能力
GooSeeker 网络爬虫沿着线索扩展了爬取范围等等。免费网络版用户在墨书台的爬虫路线工作台上规划爬虫路线。主要能力是:从抓取到的URL建立下一级线索。这是深度方向。同时,捕捉到不止一条低级线索。,那么就是向广度方向扩展了。
简而言之,网络爬虫在抓取网页数据时,会利用一些网址作为广度或深度方向扩展的线索。免费在线版只能在定义爬取规则时规划爬虫路径;而企业版可以有更多的选项来规划爬虫路线。
清理结果并存入数据库时,生成深度和广度方向的线索。这是企业版常用的方法。此时,企业版的 GooSeeker 具有最大的灵活性和控制力。例如,您可以使用仓储脚本程序。控制爬虫路由的生成,可以替换URL中的参数,可以按照URL地址规律批量生成URL,可以按照一定的规则过滤一批URL,等等。
最大的灵活性在于爬虫路由的生成时间。当使用网页抓取进行探索性研究时,可以根据需要随时扩展爬虫的深度和广度。不需要在第一次数据清洗过程中生成所有的线索。事实上,如果有必要,当时可能并不知道。扩大爬行范围。也很容易认识到,同一个 URL 可以用于多个爬取主题,服务于不同的研究目的。
典型
在某品牌手机的消费者洞察系统中,除了常规的网络爬取和数据挖掘,还需要一些事件驱动的爬取,比如某个手机会议的效果分析,一些in-深度数据挖掘,比如消费群体。差异研究。为了配合这些分析研究,往往需要灵活的网络爬虫路径规划。在探索和研究的过程中,不断增加新的数据源,要求网络爬虫在深度和广度扩展时具有足够的灵活性。只有企业版的 GooSeeker 网络爬虫才有这个能力。 查看全部
无规则采集器列表算法(爬虫路线规划能力集GooSeeker网络爬虫沿着线索扩展爬行范围)
履带式路线规划能力
GooSeeker 网络爬虫沿着线索扩展了爬取范围等等。免费网络版用户在墨书台的爬虫路线工作台上规划爬虫路线。主要能力是:从抓取到的URL建立下一级线索。这是深度方向。同时,捕捉到不止一条低级线索。,那么就是向广度方向扩展了。
简而言之,网络爬虫在抓取网页数据时,会利用一些网址作为广度或深度方向扩展的线索。免费在线版只能在定义爬取规则时规划爬虫路径;而企业版可以有更多的选项来规划爬虫路线。
清理结果并存入数据库时,生成深度和广度方向的线索。这是企业版常用的方法。此时,企业版的 GooSeeker 具有最大的灵活性和控制力。例如,您可以使用仓储脚本程序。控制爬虫路由的生成,可以替换URL中的参数,可以按照URL地址规律批量生成URL,可以按照一定的规则过滤一批URL,等等。
最大的灵活性在于爬虫路由的生成时间。当使用网页抓取进行探索性研究时,可以根据需要随时扩展爬虫的深度和广度。不需要在第一次数据清洗过程中生成所有的线索。事实上,如果有必要,当时可能并不知道。扩大爬行范围。也很容易认识到,同一个 URL 可以用于多个爬取主题,服务于不同的研究目的。
典型
在某品牌手机的消费者洞察系统中,除了常规的网络爬取和数据挖掘,还需要一些事件驱动的爬取,比如某个手机会议的效果分析,一些in-深度数据挖掘,比如消费群体。差异研究。为了配合这些分析研究,往往需要灵活的网络爬虫路径规划。在探索和研究的过程中,不断增加新的数据源,要求网络爬虫在深度和广度扩展时具有足够的灵活性。只有企业版的 GooSeeker 网络爬虫才有这个能力。
无规则采集器列表算法(本文介绍如何使用优采云采集器的智能模式,免费采集和讯网新闻)
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-11-24 09:05
本文介绍如何使用优采云采集器的智能模式,免费提供采集和讯网新闻标题、内容、发布时间等信息。
采集工具介绍:
优采云采集器是基于人工智能技术的网页采集器,只需要输入网址即可自动识别网页数据,无需配置即可完成数据采集 ,是业界第一款支持三种操作系统(包括Windows、Mac和Linux)的网络爬虫软件。
本软件是一款真正免费的数据采集软件,对采集结果的导出没有限制。没有编程基础的新手用户也可以轻松实现数据采集需求。
官方网站:
采集对象介绍:
和讯网成立于1996年,起源于中国早期的金融证券信息服务,创立了第一家金融信息垂直行业网站。经过22年的努力,和讯网在行业中逐渐确立了优势地位和品牌影响力。
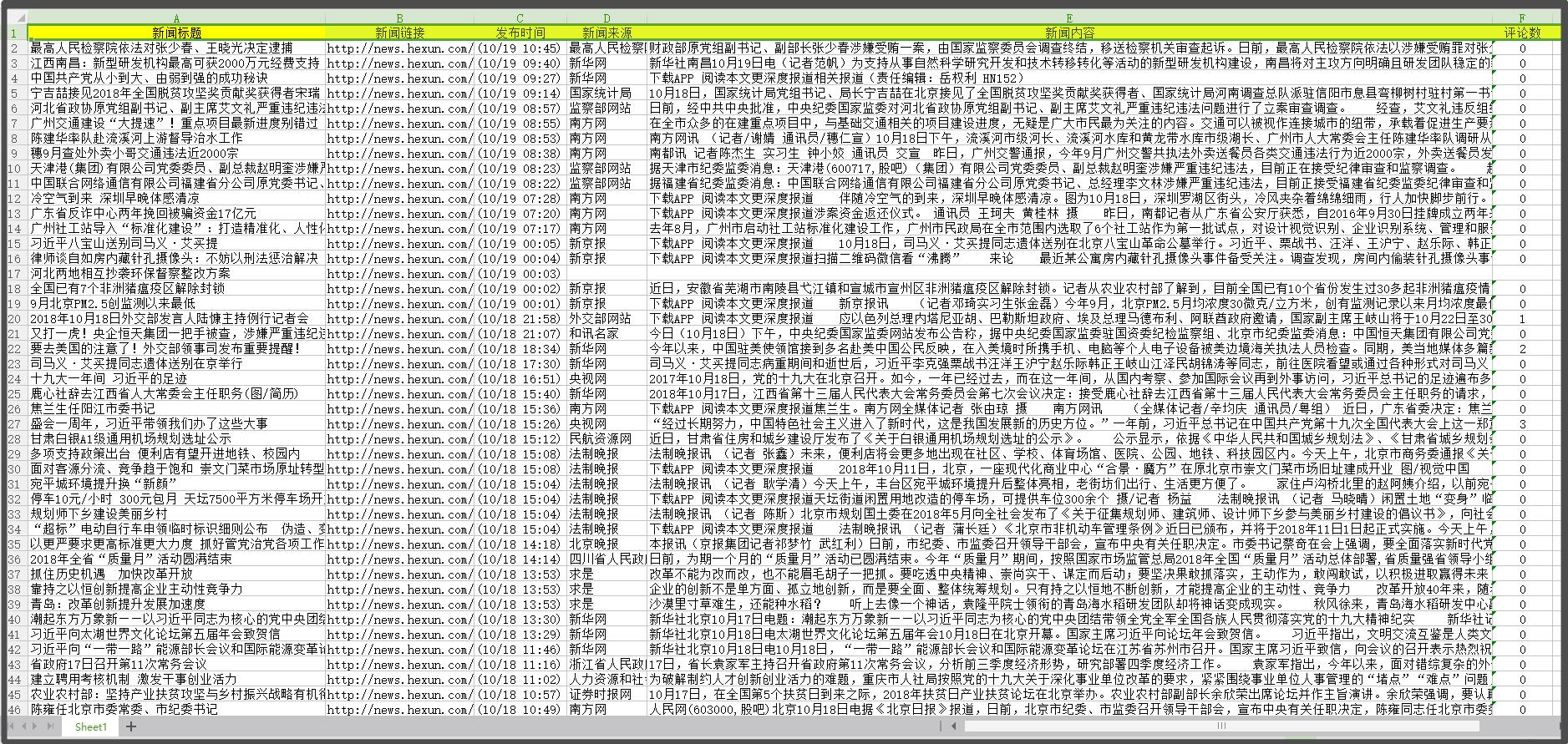
采集字段:
新闻标题、新闻链接、发布时间、新闻来源、新闻内容、评论数
功能点目录:
如何配置采集字段
如何采集列表+详情页类型网页
采集结果预览:
下面我们来详细介绍一下如何免费采集和讯新闻数据。我们以和讯新闻国内时事为例。具体步骤如下:
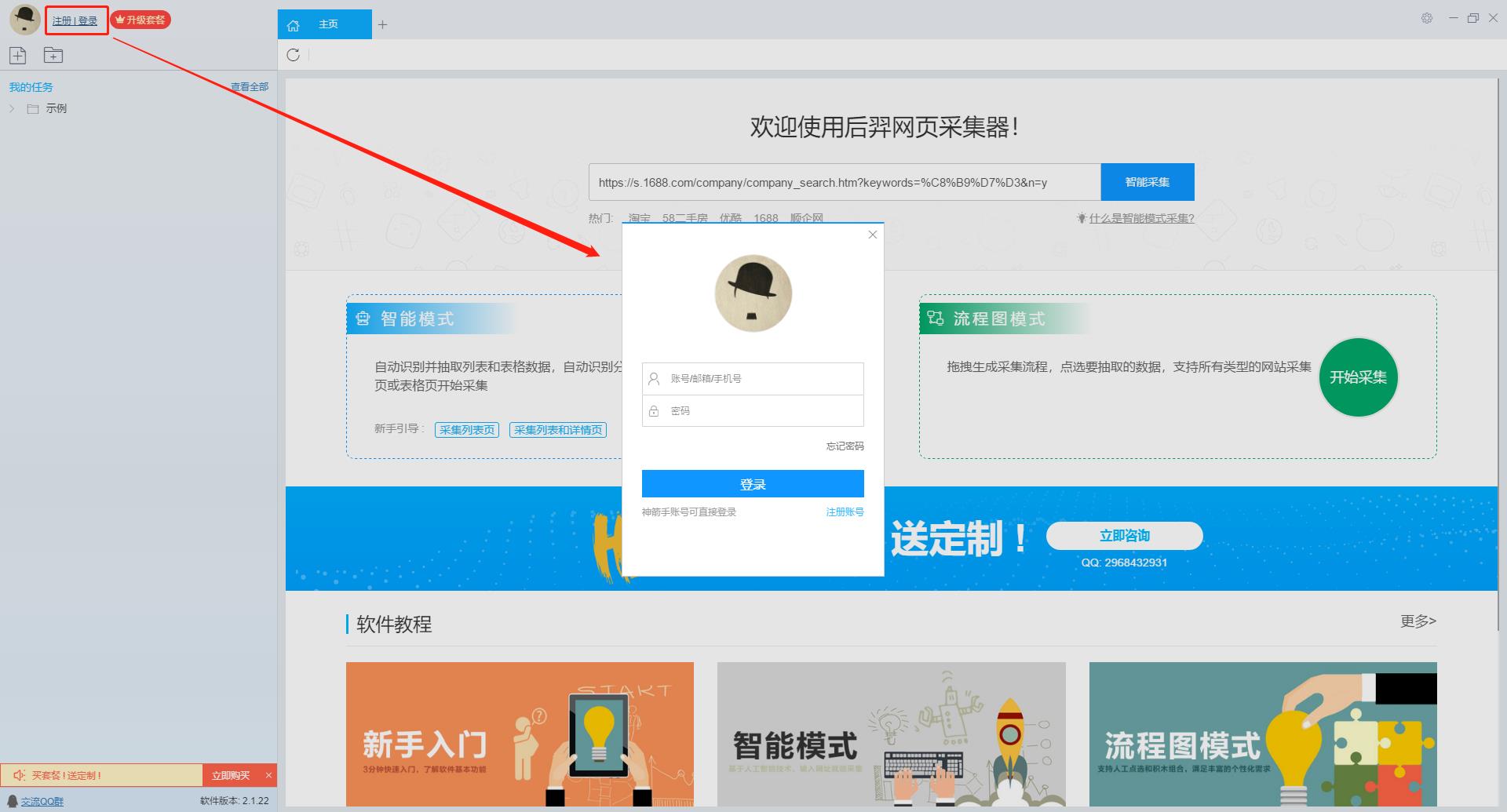
第一步:下载安装优采云采集器,注册登录
1、打开优采云采集器官网,下载安装最新版优采云采集器
2、点击注册登录,注册一个新账号,登录优采云采集器
【温馨提示】本爬虫软件无需注册即可直接使用,但切换到注册用户后匿名账号下的任务会丢失,建议注册后使用。
优采云采集器是优采云的产物,优采云用户可以直接登录。
第二步:新建一个采集任务
1、复制和讯网国内时事新闻页面地址(需要搜索结果页面的URL,不是首页的URL)
单击此处了解如何正确输入 URL。
2、新智能模式采集任务
可以直接在软件上创建采集任务,也可以通过导入规则来创建任务。
单击此处了解如何导入和导出 采集 规则。
第三步:配置采集规则
1、设置提取数据字段
在智能模式下,我们输入网址后,软件会自动识别页面上的数据并生成采集结果。每种类型的数据对应一个 采集 字段。我们可以右击该字段进行相关设置。包括修改字段名、加减字段、处理数据等。
单击此处了解如何配置 采集 字段。
在列表页面,我们需要采集新浪新闻的新闻标题、新闻链接和发布时间。字段设置如下:
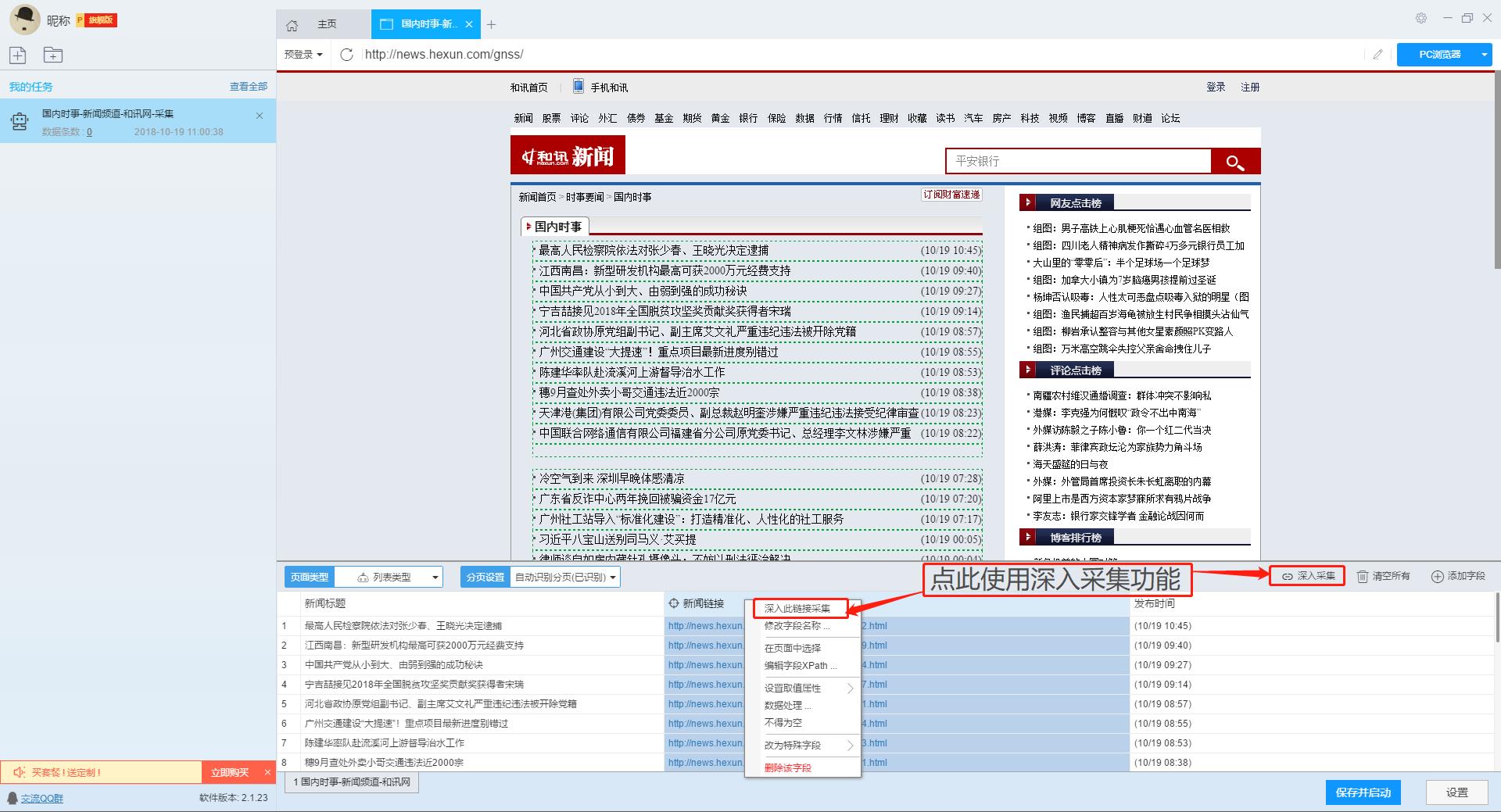
2、使用深入采集函数提取详情页数据
列表页只显示和讯网的部分新闻。如果您需要详细的新闻内容,我们需要右击新闻链接,然后使用“深度采集”功能跳转到详情页继续采集。
单击此处了解有关如何采集列表+详细信息页面类型网页的更多信息。
在详情页,我们可以看到新闻来源、新闻内容和评论数。我们可以点击“添加字段”来添加采集字段。字段设置效果如下:
【提醒】当整个新闻内容为采集时,可以将鼠标移动到新闻内容的后半部分,看到蓝色区域全选时,可以点击选择,可以提取所有整个新闻 新闻的内容。
第四步:设置并启动采集任务
1、设置采集 任务
完成采集数据添加后,我们就可以开始采集任务了。在开始之前,我们需要对采集任务进行一些设置,以提高采集的稳定性和成功率。
点击“设置”按钮,在弹出的运行设置页面我们可以设置运行设置和防拦截设置,这里我们勾选“跳过继续采集”,设置“2”秒的请求等待时间,勾选“不加载网页图片”,防拦截设置将按照系统默认设置,然后点击保存。
单击此处了解有关如何配置 采集 任务的更多信息。
2、开始采集任务
点击“保存并启动”按钮,在弹出的页面中进行一些高级设置,包括定时启动、自动存储和下载图片。本例中不使用这些功能,直接点击“开始”运行爬虫工具即可。
单击此处了解有关计时的更多信息采集。
单击此处了解有关什么是自动存储的更多信息。
单击此处了解有关如何下载图片的更多信息。
【温馨提示】免费版可以使用非周期性定时采集功能,下载图片功能免费。个人专业版及以上可使用高级定时功能和自动存储功能。
3、运行任务提取数据
<p>任务启动后会自动启动采集数据,我们可以从界面直观的看到程序运行过程和采集的运行结果, 查看全部
无规则采集器列表算法(本文介绍如何使用优采云采集器的智能模式,免费采集和讯网新闻)
本文介绍如何使用优采云采集器的智能模式,免费提供采集和讯网新闻标题、内容、发布时间等信息。
采集工具介绍:
优采云采集器是基于人工智能技术的网页采集器,只需要输入网址即可自动识别网页数据,无需配置即可完成数据采集 ,是业界第一款支持三种操作系统(包括Windows、Mac和Linux)的网络爬虫软件。
本软件是一款真正免费的数据采集软件,对采集结果的导出没有限制。没有编程基础的新手用户也可以轻松实现数据采集需求。
官方网站:
采集对象介绍:
和讯网成立于1996年,起源于中国早期的金融证券信息服务,创立了第一家金融信息垂直行业网站。经过22年的努力,和讯网在行业中逐渐确立了优势地位和品牌影响力。
采集字段:
新闻标题、新闻链接、发布时间、新闻来源、新闻内容、评论数
功能点目录:
如何配置采集字段
如何采集列表+详情页类型网页
采集结果预览:
下面我们来详细介绍一下如何免费采集和讯新闻数据。我们以和讯新闻国内时事为例。具体步骤如下:
第一步:下载安装优采云采集器,注册登录
1、打开优采云采集器官网,下载安装最新版优采云采集器
2、点击注册登录,注册一个新账号,登录优采云采集器
【温馨提示】本爬虫软件无需注册即可直接使用,但切换到注册用户后匿名账号下的任务会丢失,建议注册后使用。
优采云采集器是优采云的产物,优采云用户可以直接登录。
第二步:新建一个采集任务
1、复制和讯网国内时事新闻页面地址(需要搜索结果页面的URL,不是首页的URL)
单击此处了解如何正确输入 URL。
2、新智能模式采集任务
可以直接在软件上创建采集任务,也可以通过导入规则来创建任务。
单击此处了解如何导入和导出 采集 规则。
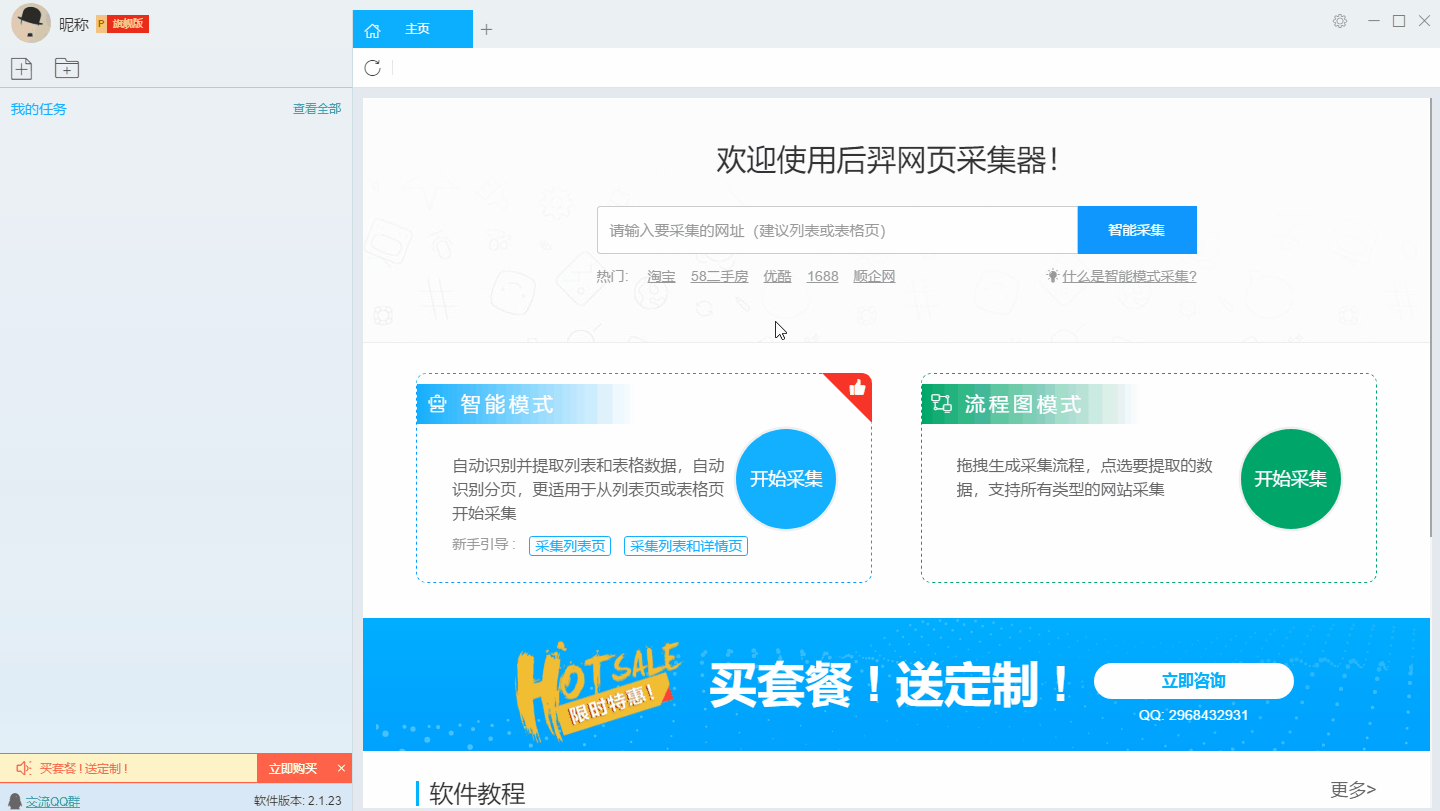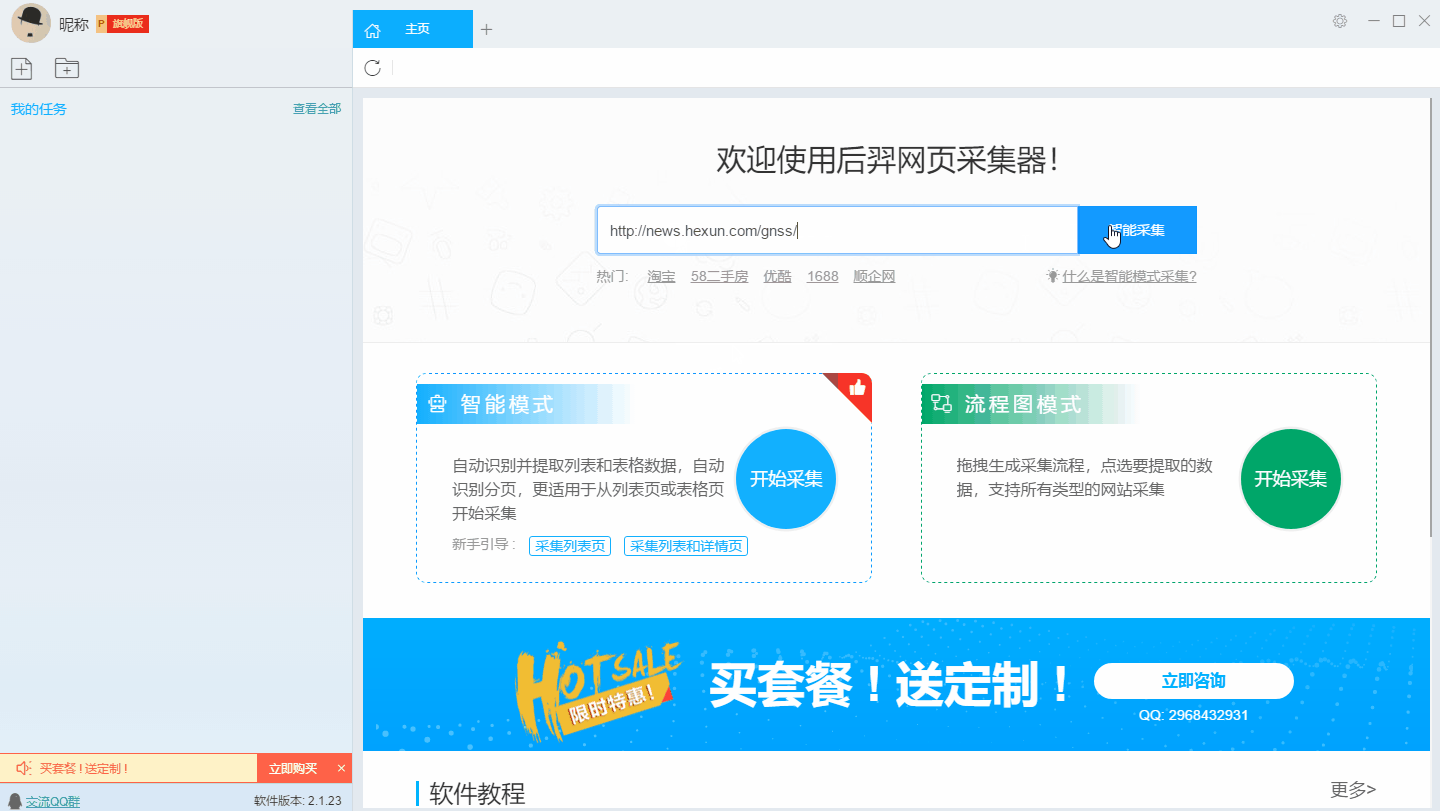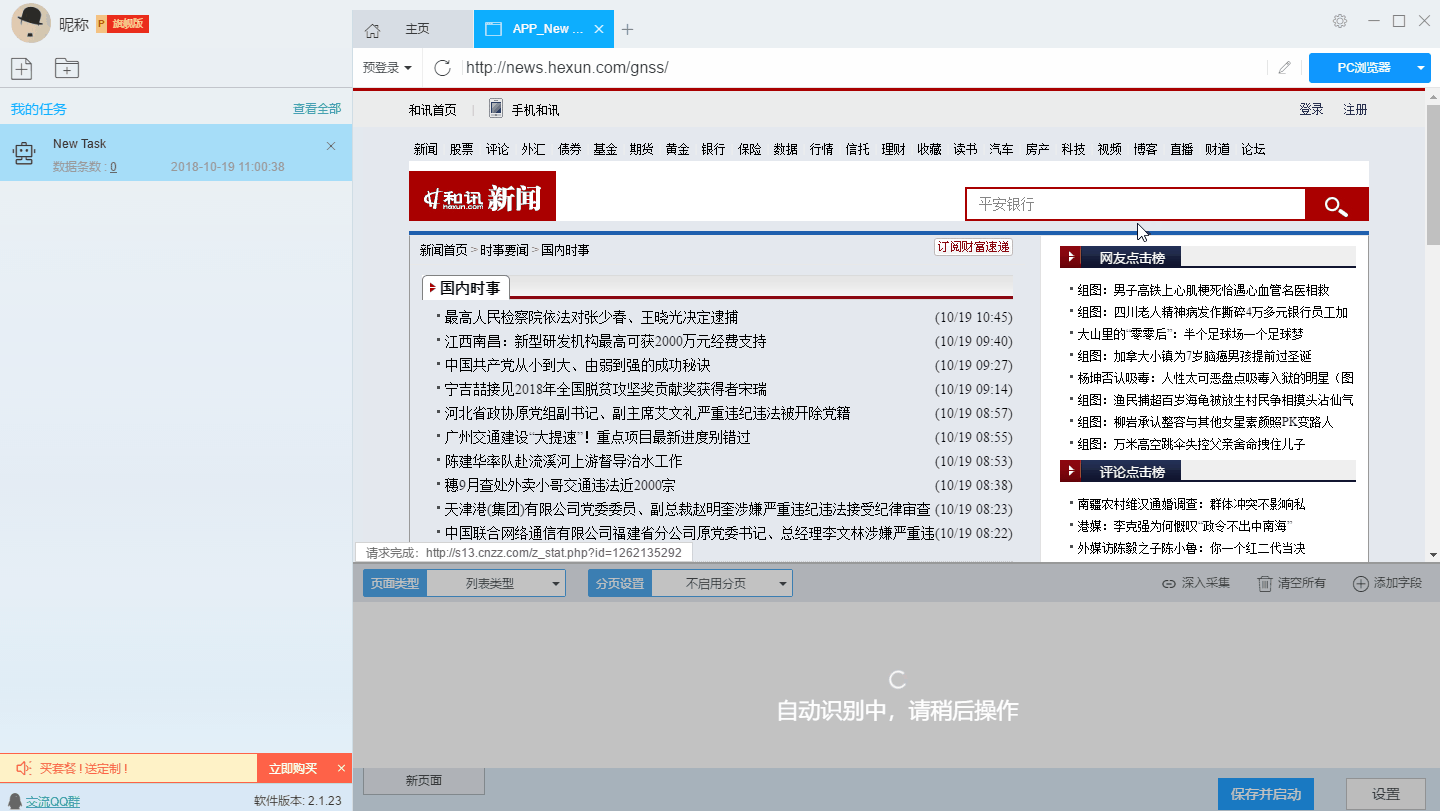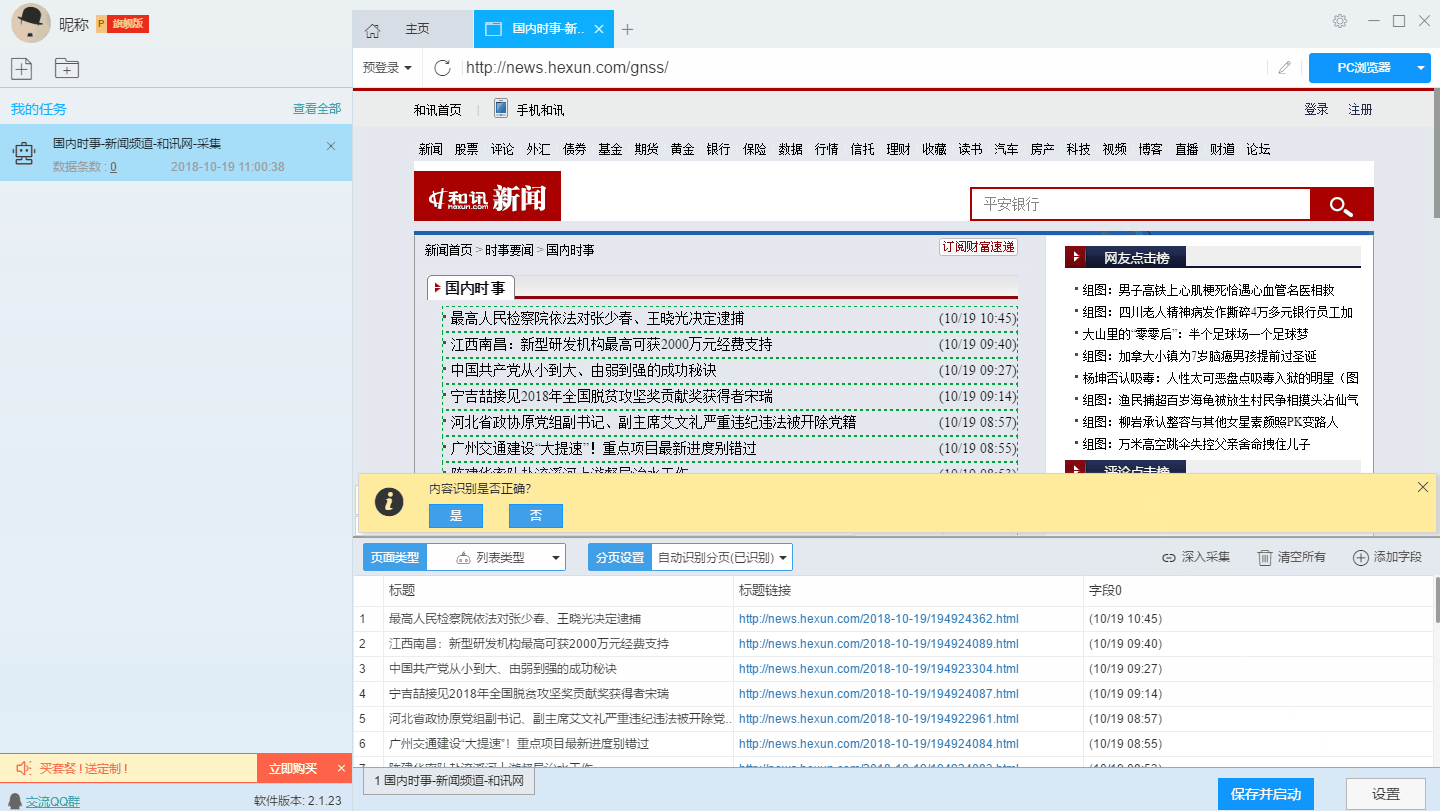
第三步:配置采集规则
1、设置提取数据字段
在智能模式下,我们输入网址后,软件会自动识别页面上的数据并生成采集结果。每种类型的数据对应一个 采集 字段。我们可以右击该字段进行相关设置。包括修改字段名、加减字段、处理数据等。
单击此处了解如何配置 采集 字段。
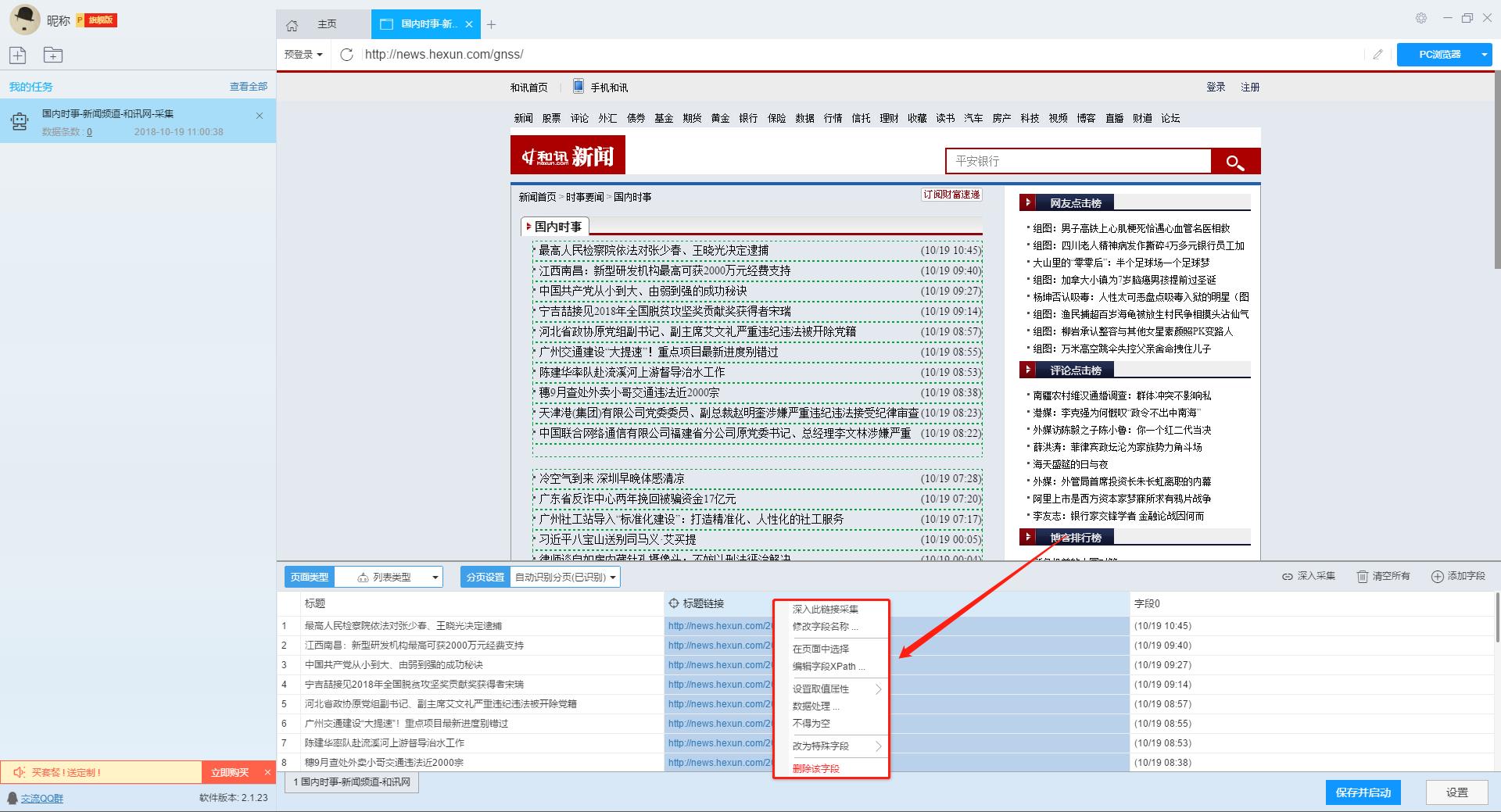
在列表页面,我们需要采集新浪新闻的新闻标题、新闻链接和发布时间。字段设置如下:
2、使用深入采集函数提取详情页数据
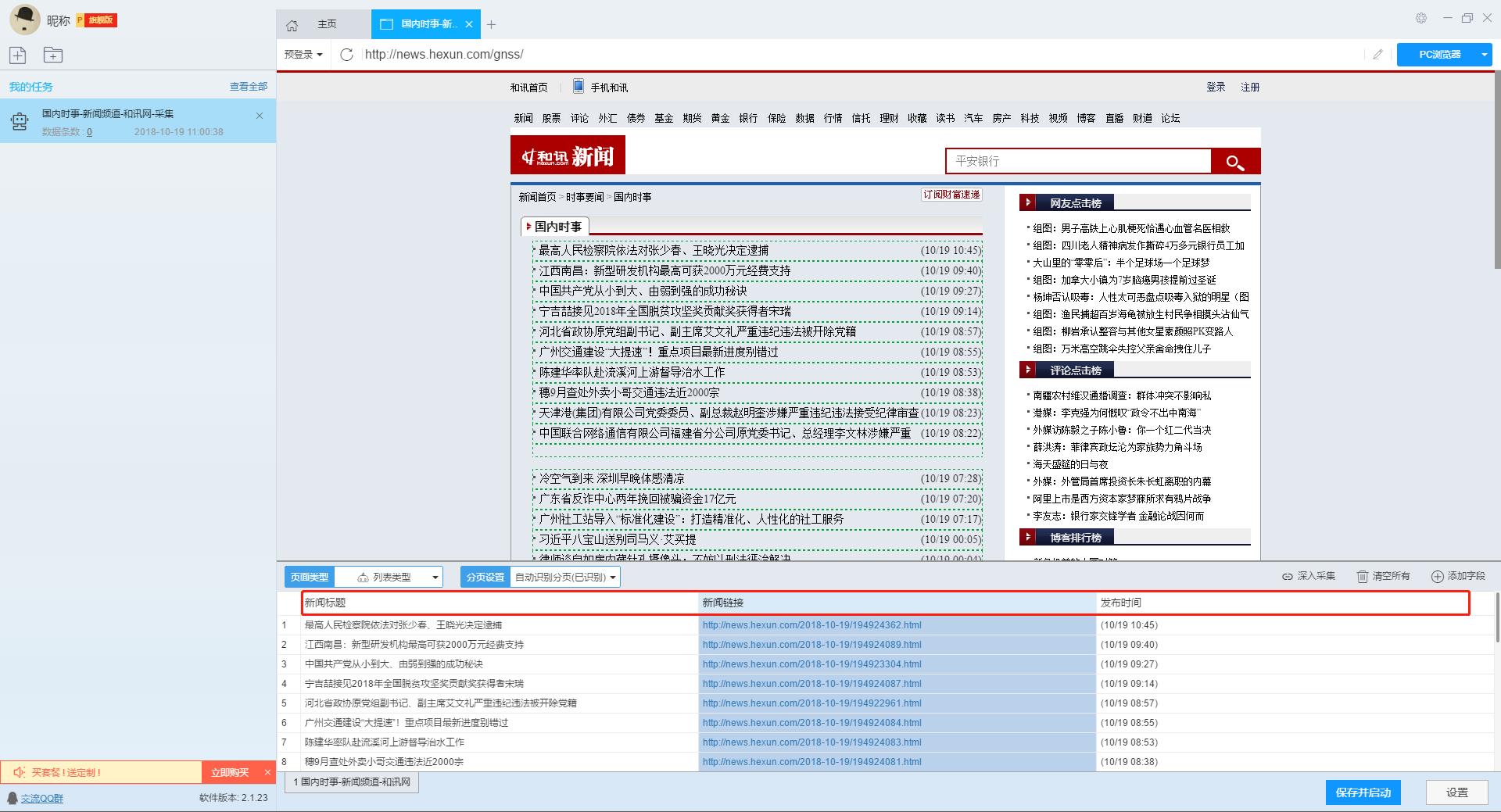
列表页只显示和讯网的部分新闻。如果您需要详细的新闻内容,我们需要右击新闻链接,然后使用“深度采集”功能跳转到详情页继续采集。
单击此处了解有关如何采集列表+详细信息页面类型网页的更多信息。
在详情页,我们可以看到新闻来源、新闻内容和评论数。我们可以点击“添加字段”来添加采集字段。字段设置效果如下:
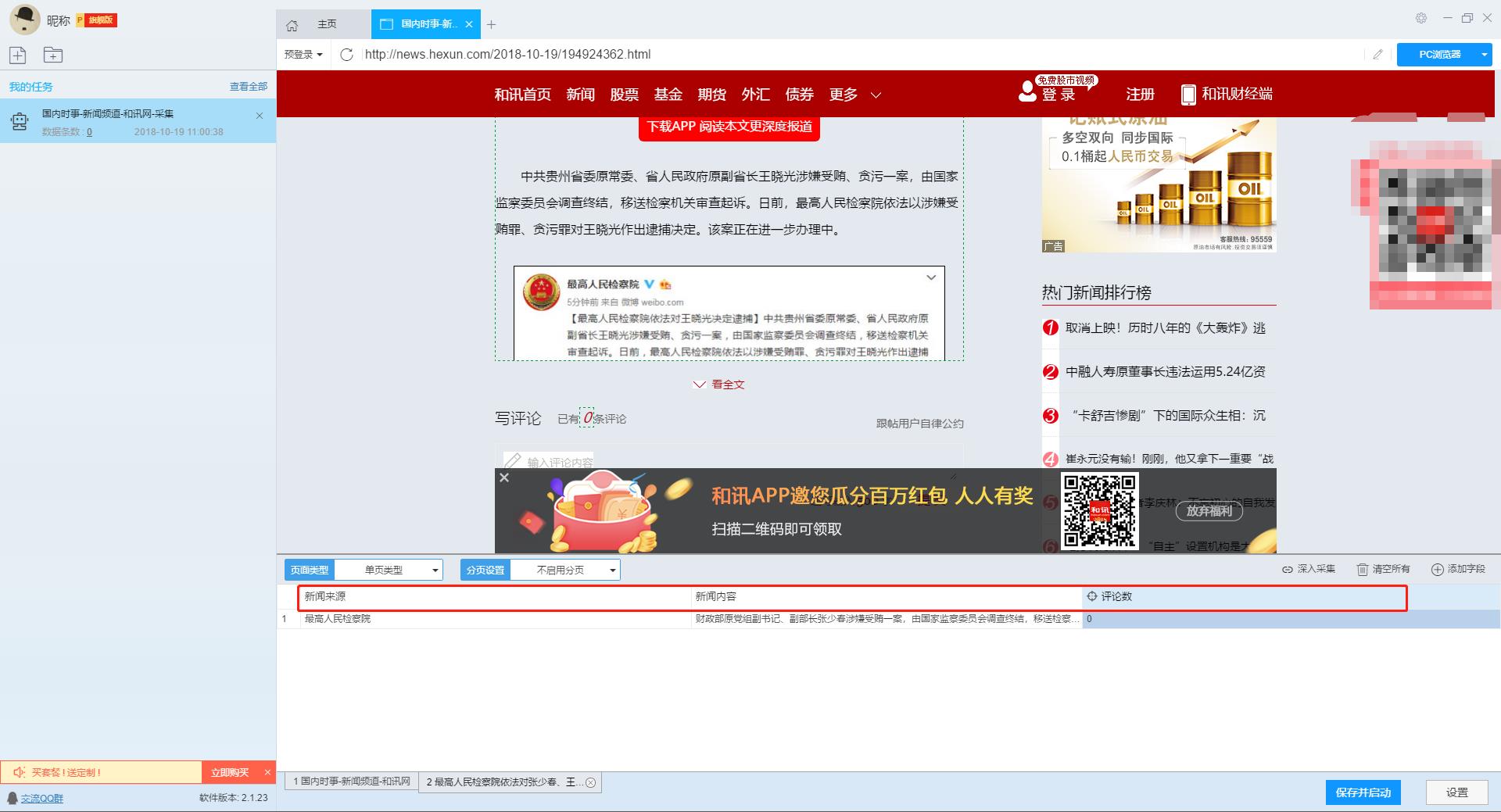
【提醒】当整个新闻内容为采集时,可以将鼠标移动到新闻内容的后半部分,看到蓝色区域全选时,可以点击选择,可以提取所有整个新闻 新闻的内容。
第四步:设置并启动采集任务
1、设置采集 任务
完成采集数据添加后,我们就可以开始采集任务了。在开始之前,我们需要对采集任务进行一些设置,以提高采集的稳定性和成功率。
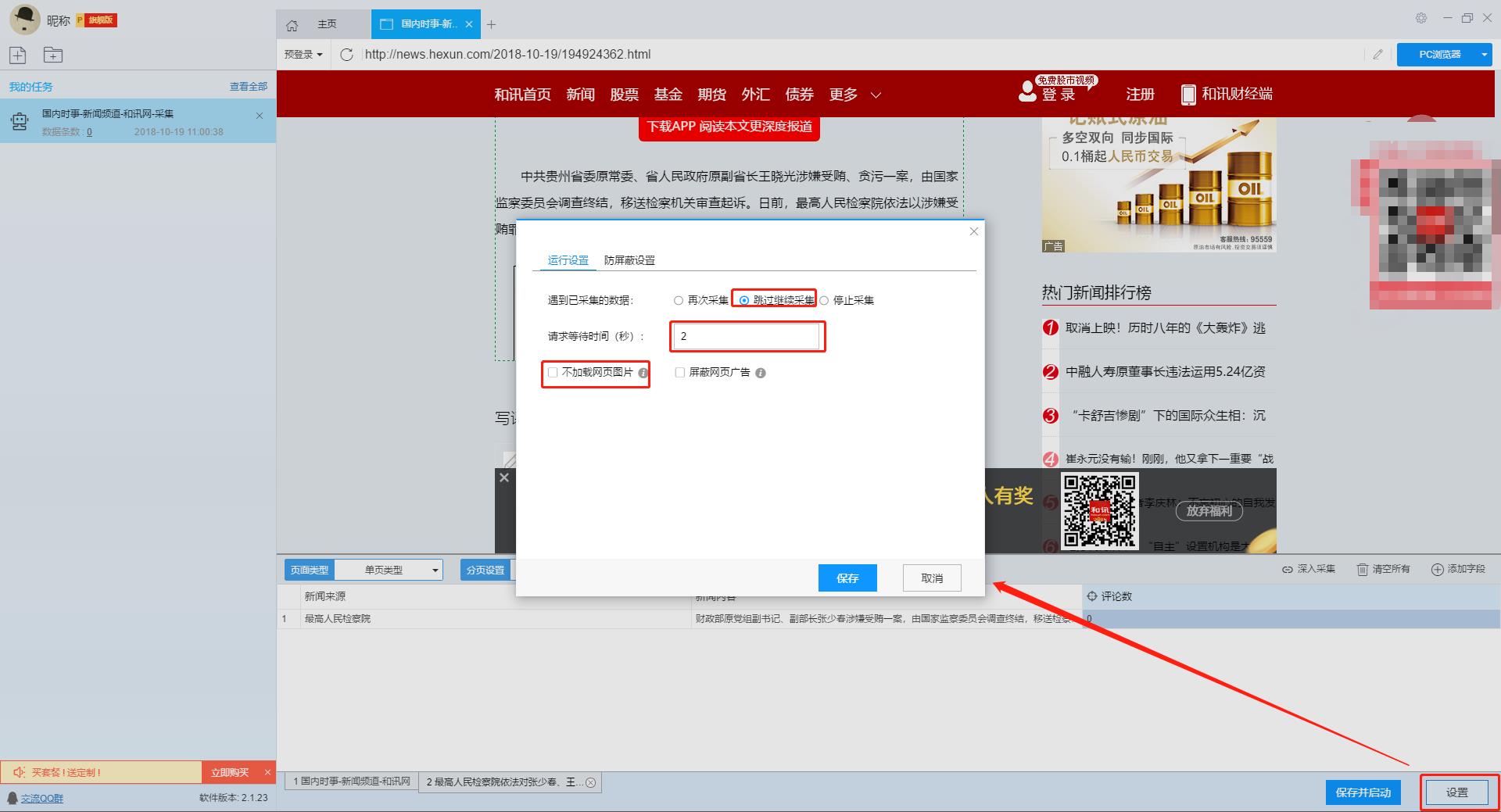
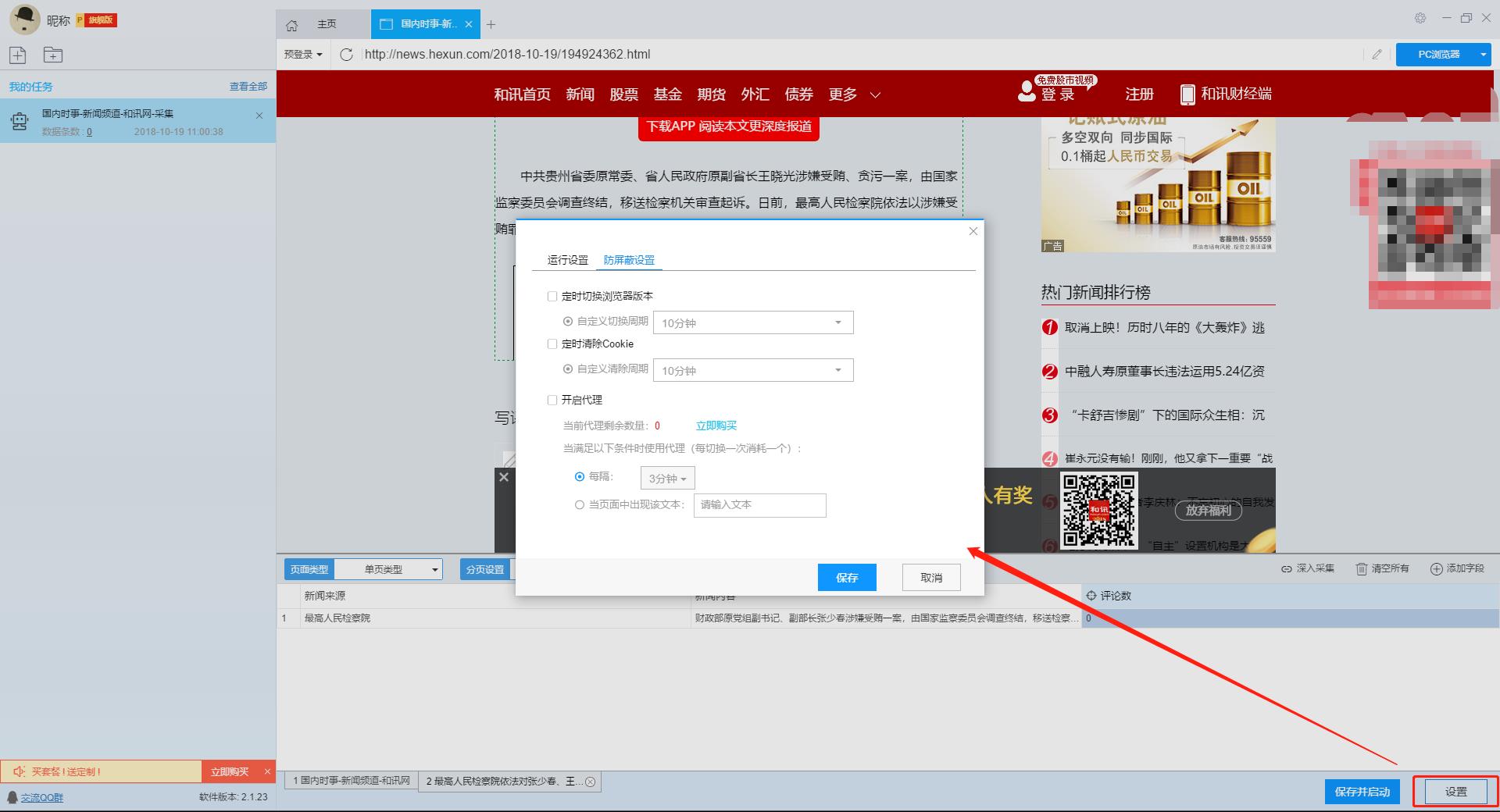
点击“设置”按钮,在弹出的运行设置页面我们可以设置运行设置和防拦截设置,这里我们勾选“跳过继续采集”,设置“2”秒的请求等待时间,勾选“不加载网页图片”,防拦截设置将按照系统默认设置,然后点击保存。
单击此处了解有关如何配置 采集 任务的更多信息。
2、开始采集任务
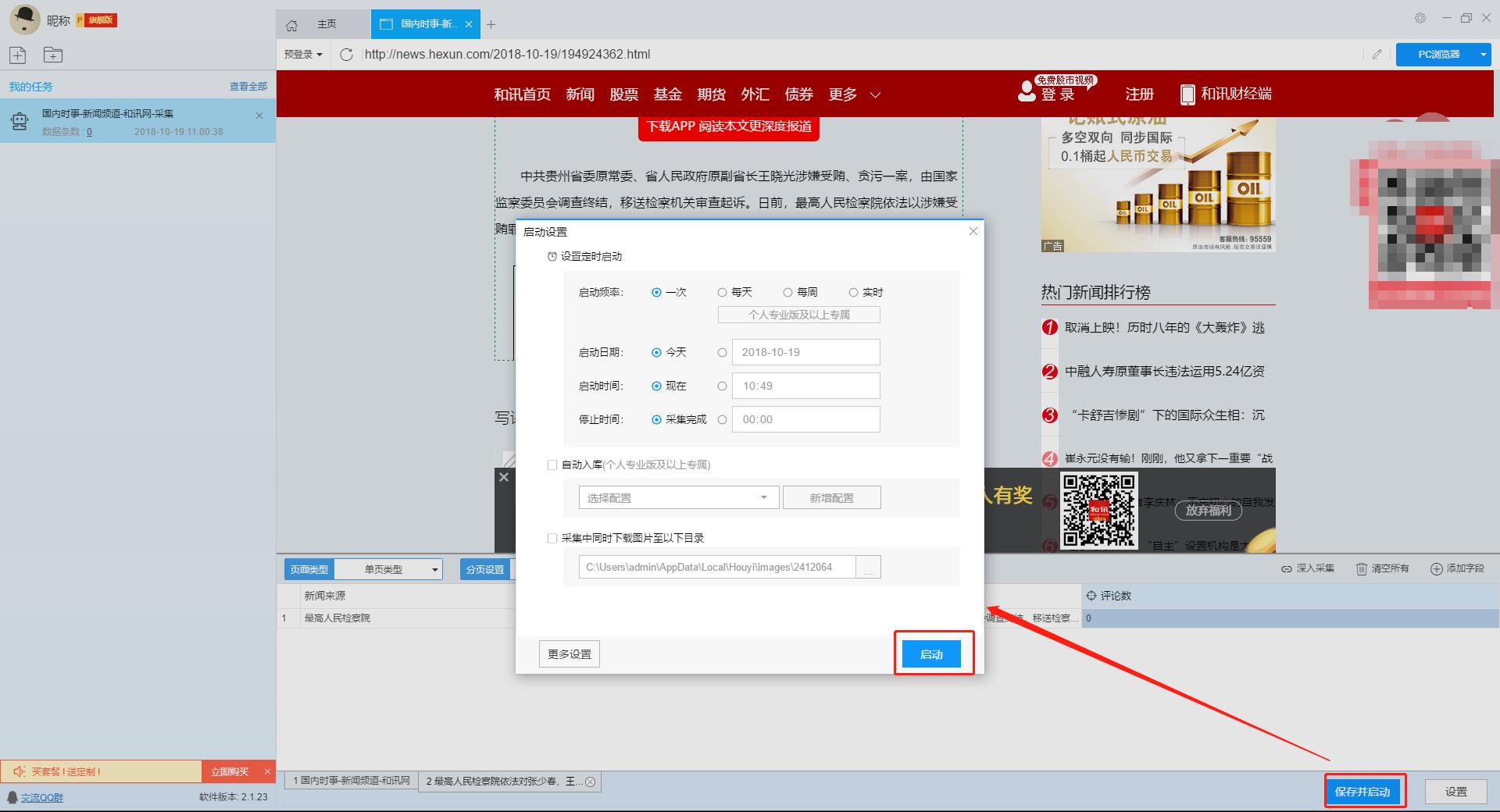
点击“保存并启动”按钮,在弹出的页面中进行一些高级设置,包括定时启动、自动存储和下载图片。本例中不使用这些功能,直接点击“开始”运行爬虫工具即可。
单击此处了解有关计时的更多信息采集。
单击此处了解有关什么是自动存储的更多信息。
单击此处了解有关如何下载图片的更多信息。
【温馨提示】免费版可以使用非周期性定时采集功能,下载图片功能免费。个人专业版及以上可使用高级定时功能和自动存储功能。
3、运行任务提取数据
<p>任务启动后会自动启动采集数据,我们可以从界面直观的看到程序运行过程和采集的运行结果,
无规则采集器列表算法(重庆邮电大学应用技术学院二八年四月《算法分析与设计》实验目的与要求)
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-11-22 14:11
《算法分析与设计》实验指导书,重庆邮电大学应用技术学院,4月28日,《算法分析与设计》实验目的与要求一、实验目的算法分析与设计是其中之一信息与计算科学专业 重要专业课程。当用计算机解决实际问题时,涉及对实际问题的抽象模拟,即数学建模的过程,然后设计相应的求解算法来解决实际问题,同时也验证设计的算法能够be 任务可以在可承受或可到达的时间和空间内完成,因此算法的分析和设计就成为一个非常重要的环节。通过理论课的学习,我们知道要设计一个算法,必须从算法设计->算法确认->算法分析->编码->检查->调试->计时开始。七大步骤是严格执行的,所以读者可以严格按照以上步骤进行,为以后的算法研究工作打下坚实的基础。二、实验要求 1. 准备登机所需的手续,人工检查后方可登机,以提高登机效率。在程序中对您有问题的地方进行标记,以便您在上机时注意它们。请勿复制他人编译的程序。2. 在计算机上输入和调试编译好的程序。3.电脑结束后,
如果程序失败,应分析原因。三、实验步骤 1. 问题分析和任务定义明确问题需要什么,限制做什么(这一步强调做什么,而不是怎么做)。问题的描述应该避开算法和涉及的数据类型,而是对完成的任务给出明确的答案。如输入数据类型、取值范围和输入形式;输出数据类型、取值范围和输出形式;这个异步还应该为调试器准备测试数据,包括合法输入数据和非法输入数据。2、数据类型和系统设计在这一步设计中分为逻辑设计和详细设计。逻辑设计是指为问题描述中涉及的操作对象定义相应的数据类型,以数据结构为中心的原则划分模块,定义主模块和各个抽象数据类型;详细设计是定义相应的存储结构,编写每个函数的伪代码算法。在这个过程中,要综合考虑系统的功能,使系统结构清晰、合理、简单、便于调试。抽象数据类型的实现尽量做到数据封装,基本操作规范尽量清晰具体。作为逻辑设计的结果。每个抽象数据类型的定义(包括数据结构的描述和每个基本操作的规范),每个主要模块的算法都要写,并绘制模块之间的调用关系图。详细设计的结果是进一步细化数据结构和基本操作的规范,编写数据存储结构的类型定义,并按照类C语言以函数形式编写算法框架。算法编写规范。
3. 编码实现和静态检查4。上机准备与调试 5.总结整理实习报告四、 实验总结了实验中发现的问题,调试中的问题分析和解决方法,以及改进的意见、建议、收获和经验算法。实验报告参考标准:实验题目类名、学号、日期使用C语言定义相关数据类型;实验一 斐波那契数列实验目的 1. 掌握递归算法及其编程方法;总实验课时:2课时/1个实验内容 1.使用递归或非递归的方法实现斐波那契数列。第n个斐波那契数列的描述如下:F(n)=f(n-1)+f(n-2) 2)。掌握排序算法分析和编程方法;总实验课时:2课时/1个实验内容 1.完成如下程序,实现数组的降序排序#include void sort( intmain() intarray[]={45,56,76,234,1,34,23 ,2,3}; //数字任意给排序( voidsort( 实验要求一、 方法不限,课前提交word文档,包括程序代码,运行结果截图,实验四螺旋序列实验目的1.,掌握算法分析和编程方法; 实验课时 总课时:2课时/1 实验内容如图: 1216 15 14 13 设置“1”的坐标为(0, 0) 和“7”的坐标为 (-1, -1)
实验要求一、 方法不限,下课前提交word文档,内容包括程序代码、运行结果截图、实验目的。1.,掌握算法分析和编程方法;实验总课时:2课时/1课时实验内容从下列问题中选择40分作为实验的实验内容。1、(15分)要求:随机生成一个字符串,每次字符串的内容长度不同2、(15分)将整数转换为字符串:char* itoa(int); 例如 itoa(-123) 返回 "-123"; 3、
输入数据:一个正整数,以命令行参数的形式提供给程序。输出数据:在标准输出上打印出所有符合标题描述的正整数序列,每行一个序列,每个序列从序列的最小正整数开始,按升序打印。如果结果中有多个序列,则按照每个序列的最小正整数从小到大打印序列。另外,序列不允许重复,序列中的整数之间用空格隔开。如果没有满足要求的序列,则输出“NONE”。例如,对于15,输出结果是: 对于16,输出结果是:NONE 8、 (25分) 标题描述是为了让员工在紧张的工作时间内放松一下,百度休息室配有按摩椅、CD、高尔夫球服和Wii游戏机等休闲产品。最受欢迎的当然是游戏机之一。wii游戏机的每个手柄需要两块电池(两块电池可以是不同品牌的)。工程师们正在玩游戏。如果手柄没电了,他们会把没电的电池拿走,换上全新的电池。如果有电,他们必须继续使用。比如,众所周知,三种电池的使用时间都是小时,当手柄再次没电时,就没有可用的电池了。但是如果你在开始时使用那个小时。告诉您每个品牌电池的使用时间和该品牌电池的数量。请计算工程师上场时间的最小值和最大值。输入格式输入的第一行是一个正整数。输出格式只有一行。它收录两个整数,分别代表工程师最短的游戏时间和最长的游戏时间(时间最短的在前)。
一个空格分隔两个整数。输入样例9、(25分)标题说明百度蜘蛛在烤鸡翅唱明星经典的同时达到高潮。大家围着篝火围成一圈,开始进行强化游戏。规则如下:当号码中收录相同号码时,规则通过。请注意,相同的数字不必相邻。比如121史上最强程序员的帮助。百度工程师想知道:req1的数量是多少?req12 的数量是多少?查询中的号码是多少?以输入格式输入的每一行都是一个查询,由一个查询词和一个无符号整数组成。有四种查询,查询词为req1查询(区分大小写)。输出格式 前三个查询输出一个无符号整数解。对于规则中的数字,输出对应的解,否则输出-1。输入样本 req1 10 req2 10 req12 10 查询 14 输出样本 11 10 12 -1 13 补充说明 1 查看全部
无规则采集器列表算法(重庆邮电大学应用技术学院二八年四月《算法分析与设计》实验目的与要求)
《算法分析与设计》实验指导书,重庆邮电大学应用技术学院,4月28日,《算法分析与设计》实验目的与要求一、实验目的算法分析与设计是其中之一信息与计算科学专业 重要专业课程。当用计算机解决实际问题时,涉及对实际问题的抽象模拟,即数学建模的过程,然后设计相应的求解算法来解决实际问题,同时也验证设计的算法能够be 任务可以在可承受或可到达的时间和空间内完成,因此算法的分析和设计就成为一个非常重要的环节。通过理论课的学习,我们知道要设计一个算法,必须从算法设计->算法确认->算法分析->编码->检查->调试->计时开始。七大步骤是严格执行的,所以读者可以严格按照以上步骤进行,为以后的算法研究工作打下坚实的基础。二、实验要求 1. 准备登机所需的手续,人工检查后方可登机,以提高登机效率。在程序中对您有问题的地方进行标记,以便您在上机时注意它们。请勿复制他人编译的程序。2. 在计算机上输入和调试编译好的程序。3.电脑结束后,
如果程序失败,应分析原因。三、实验步骤 1. 问题分析和任务定义明确问题需要什么,限制做什么(这一步强调做什么,而不是怎么做)。问题的描述应该避开算法和涉及的数据类型,而是对完成的任务给出明确的答案。如输入数据类型、取值范围和输入形式;输出数据类型、取值范围和输出形式;这个异步还应该为调试器准备测试数据,包括合法输入数据和非法输入数据。2、数据类型和系统设计在这一步设计中分为逻辑设计和详细设计。逻辑设计是指为问题描述中涉及的操作对象定义相应的数据类型,以数据结构为中心的原则划分模块,定义主模块和各个抽象数据类型;详细设计是定义相应的存储结构,编写每个函数的伪代码算法。在这个过程中,要综合考虑系统的功能,使系统结构清晰、合理、简单、便于调试。抽象数据类型的实现尽量做到数据封装,基本操作规范尽量清晰具体。作为逻辑设计的结果。每个抽象数据类型的定义(包括数据结构的描述和每个基本操作的规范),每个主要模块的算法都要写,并绘制模块之间的调用关系图。详细设计的结果是进一步细化数据结构和基本操作的规范,编写数据存储结构的类型定义,并按照类C语言以函数形式编写算法框架。算法编写规范。
3. 编码实现和静态检查4。上机准备与调试 5.总结整理实习报告四、 实验总结了实验中发现的问题,调试中的问题分析和解决方法,以及改进的意见、建议、收获和经验算法。实验报告参考标准:实验题目类名、学号、日期使用C语言定义相关数据类型;实验一 斐波那契数列实验目的 1. 掌握递归算法及其编程方法;总实验课时:2课时/1个实验内容 1.使用递归或非递归的方法实现斐波那契数列。第n个斐波那契数列的描述如下:F(n)=f(n-1)+f(n-2) 2)。掌握排序算法分析和编程方法;总实验课时:2课时/1个实验内容 1.完成如下程序,实现数组的降序排序#include void sort( intmain() intarray[]={45,56,76,234,1,34,23 ,2,3}; //数字任意给排序( voidsort( 实验要求一、 方法不限,课前提交word文档,包括程序代码,运行结果截图,实验四螺旋序列实验目的1.,掌握算法分析和编程方法; 实验课时 总课时:2课时/1 实验内容如图: 1216 15 14 13 设置“1”的坐标为(0, 0) 和“7”的坐标为 (-1, -1)
实验要求一、 方法不限,下课前提交word文档,内容包括程序代码、运行结果截图、实验目的。1.,掌握算法分析和编程方法;实验总课时:2课时/1课时实验内容从下列问题中选择40分作为实验的实验内容。1、(15分)要求:随机生成一个字符串,每次字符串的内容长度不同2、(15分)将整数转换为字符串:char* itoa(int); 例如 itoa(-123) 返回 "-123"; 3、
输入数据:一个正整数,以命令行参数的形式提供给程序。输出数据:在标准输出上打印出所有符合标题描述的正整数序列,每行一个序列,每个序列从序列的最小正整数开始,按升序打印。如果结果中有多个序列,则按照每个序列的最小正整数从小到大打印序列。另外,序列不允许重复,序列中的整数之间用空格隔开。如果没有满足要求的序列,则输出“NONE”。例如,对于15,输出结果是: 对于16,输出结果是:NONE 8、 (25分) 标题描述是为了让员工在紧张的工作时间内放松一下,百度休息室配有按摩椅、CD、高尔夫球服和Wii游戏机等休闲产品。最受欢迎的当然是游戏机之一。wii游戏机的每个手柄需要两块电池(两块电池可以是不同品牌的)。工程师们正在玩游戏。如果手柄没电了,他们会把没电的电池拿走,换上全新的电池。如果有电,他们必须继续使用。比如,众所周知,三种电池的使用时间都是小时,当手柄再次没电时,就没有可用的电池了。但是如果你在开始时使用那个小时。告诉您每个品牌电池的使用时间和该品牌电池的数量。请计算工程师上场时间的最小值和最大值。输入格式输入的第一行是一个正整数。输出格式只有一行。它收录两个整数,分别代表工程师最短的游戏时间和最长的游戏时间(时间最短的在前)。
一个空格分隔两个整数。输入样例9、(25分)标题说明百度蜘蛛在烤鸡翅唱明星经典的同时达到高潮。大家围着篝火围成一圈,开始进行强化游戏。规则如下:当号码中收录相同号码时,规则通过。请注意,相同的数字不必相邻。比如121史上最强程序员的帮助。百度工程师想知道:req1的数量是多少?req12 的数量是多少?查询中的号码是多少?以输入格式输入的每一行都是一个查询,由一个查询词和一个无符号整数组成。有四种查询,查询词为req1查询(区分大小写)。输出格式 前三个查询输出一个无符号整数解。对于规则中的数字,输出对应的解,否则输出-1。输入样本 req1 10 req2 10 req12 10 查询 14 输出样本 11 10 12 -1 13 补充说明 1
无规则采集器列表算法( 本文介绍了的原理和实现细节介绍简介)
采集交流 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-11-22 04:05
本文介绍了的原理和实现细节介绍简介)
负载均衡
本文介绍了负载均衡的原理和实现细节
1.简介
LoadBalance中文意思是负载均衡,它的职责是将网络请求或其他形式的负载“分担”到不同的机器上。避免出现集群中某些服务器压力过大而其他服务器空闲的情况。通过负载均衡,每个服务器都可以获得与其处理能力相适应的负载。在卸载高负载服务器的同时,也可以避免资源浪费,一石两用。负载均衡可分为软件负载均衡和硬件负载均衡。在我们日常开发中,一般很难接入硬件负载均衡。但是软件负载均衡还是可以的,比如Nginx。在 Dubbo 中,也有负载均衡的概念和相应的实现。Dubbo 需要对服务消费者的调用请求进行分配,避免少数服务提供者负载过大。服务提供者过载,这会导致一些请求超时。因此,非常有必要平衡各个服务提供商之间的负载。Dubbo 提供了四种负载均衡的实现,分别是基于加权随机算法的 RandomLoadBalance、基于最少活跃调用数算法的 LeastActiveLoadBalance、基于哈希一致性的 ConsistentHashLoadBalance 和基于加权轮询算法的 RoundRobinLoadBalance。这些负载均衡算法的代码都不是很长,但是理解起来并不容易。你需要对这些算法的原理有一定的了解。如果你不是很了解,也不要太担心。
本系列文章在写作之初基于Dubbo 2.6.4。最近,Dubbo 2.6.5 发布了,其中一些针对均衡部分的负载优化。因此,在分析完2.6. 4 版本之后的源码后,我们也会分析2.6.5 的更新部分。其他的就不多说了,进入正题。
2.源码分析
在 Dubbo 中,所有的负载均衡实现类都继承自 AbstractLoadBalance,它实现了 LoadBalance 接口并封装了一些常用的逻辑。所以在分析负载均衡的实现之前,我们先来看看AbstractLoadBalance的逻辑。先看负载均衡的入口方法select,如下:
@Override
public Invoker select(List invokers, URL url, Invocation invocation) {
if (invokers == null || invokers.isEmpty())
return null;
// 如果 invokers 列表中仅有一个 Invoker,直接返回即可,无需进行负载均衡
if (invokers.size() == 1)
return invokers.get(0);
// 调用 doSelect 方法进行负载均衡,该方法为抽象方法,由子类实现
return doSelect(invokers, url, invocation);
}
protected abstract Invoker doSelect(List invokers, URL url, Invocation invocation);
select方法的逻辑比较简单。首先检查调用者集合的有效性,然后检测调用者集合中元素的数量。如果只收录一个 Invoker,直接返回 Invoker。如果收录多个Invoker,则需要通过负载均衡算法选择一个Invoker。具体的负载均衡算法是由子类实现的,后面的章节将详细分析这些子类。
AbstractLoadBalance除了实现LoadBalance接口方法外,还封装了一些常用的逻辑,比如服务提供者权重计算逻辑。具体实现如下:
<p>protected int getWeight(Invoker invoker, Invocation invocation) {
// 从 url 中获取权重 weight 配置值
int weight = invoker.getUrl().getMethodParameter(invocation.getMethodName(), Constants.WEIGHT_KEY, Constants.DEFAULT_WEIGHT);
if (weight > 0) {
// 获取服务提供者启动时间戳
long timestamp = invoker.getUrl().getParameter(Constants.REMOTE_TIMESTAMP_KEY, 0L);
if (timestamp > 0L) {
// 计算服务提供者运行时长
int uptime = (int) (System.currentTimeMillis() - timestamp);
// 获取服务预热时间,默认为10分钟
int warmup = invoker.getUrl().getParameter(Constants.WARMUP_KEY, Constants.DEFAULT_WARMUP);
// 如果服务运行时间小于预热时间,则重新计算服务权重,即降权
if (uptime > 0 && uptime 0 && !sameWeight) {
// 随机获取一个 [0, totalWeight) 区间内的数字
int offset = random.nextInt(totalWeight);
// 循环让 offset 数减去服务提供者权重值,当 offset 小于0时,返回相应的 Invoker。
// 举例说明一下,我们有 servers = [A, B, C],weights = [5, 3, 2],offset = 7。
// 第一次循环,offset - 5 = 2 > 0,即 offset > 5,
// 表明其不会落在服务器 A 对应的区间上。
// 第二次循环,offset - 3 = -1 < 0,即 5 < offset < 8,
// 表明其会落在服务器 B 对应的区间上
for (int i = 0; i 查看全部
无规则采集器列表算法(
本文介绍了的原理和实现细节介绍简介)
负载均衡
本文介绍了负载均衡的原理和实现细节
1.简介
LoadBalance中文意思是负载均衡,它的职责是将网络请求或其他形式的负载“分担”到不同的机器上。避免出现集群中某些服务器压力过大而其他服务器空闲的情况。通过负载均衡,每个服务器都可以获得与其处理能力相适应的负载。在卸载高负载服务器的同时,也可以避免资源浪费,一石两用。负载均衡可分为软件负载均衡和硬件负载均衡。在我们日常开发中,一般很难接入硬件负载均衡。但是软件负载均衡还是可以的,比如Nginx。在 Dubbo 中,也有负载均衡的概念和相应的实现。Dubbo 需要对服务消费者的调用请求进行分配,避免少数服务提供者负载过大。服务提供者过载,这会导致一些请求超时。因此,非常有必要平衡各个服务提供商之间的负载。Dubbo 提供了四种负载均衡的实现,分别是基于加权随机算法的 RandomLoadBalance、基于最少活跃调用数算法的 LeastActiveLoadBalance、基于哈希一致性的 ConsistentHashLoadBalance 和基于加权轮询算法的 RoundRobinLoadBalance。这些负载均衡算法的代码都不是很长,但是理解起来并不容易。你需要对这些算法的原理有一定的了解。如果你不是很了解,也不要太担心。
本系列文章在写作之初基于Dubbo 2.6.4。最近,Dubbo 2.6.5 发布了,其中一些针对均衡部分的负载优化。因此,在分析完2.6. 4 版本之后的源码后,我们也会分析2.6.5 的更新部分。其他的就不多说了,进入正题。
2.源码分析
在 Dubbo 中,所有的负载均衡实现类都继承自 AbstractLoadBalance,它实现了 LoadBalance 接口并封装了一些常用的逻辑。所以在分析负载均衡的实现之前,我们先来看看AbstractLoadBalance的逻辑。先看负载均衡的入口方法select,如下:
@Override
public Invoker select(List invokers, URL url, Invocation invocation) {
if (invokers == null || invokers.isEmpty())
return null;
// 如果 invokers 列表中仅有一个 Invoker,直接返回即可,无需进行负载均衡
if (invokers.size() == 1)
return invokers.get(0);
// 调用 doSelect 方法进行负载均衡,该方法为抽象方法,由子类实现
return doSelect(invokers, url, invocation);
}
protected abstract Invoker doSelect(List invokers, URL url, Invocation invocation);
select方法的逻辑比较简单。首先检查调用者集合的有效性,然后检测调用者集合中元素的数量。如果只收录一个 Invoker,直接返回 Invoker。如果收录多个Invoker,则需要通过负载均衡算法选择一个Invoker。具体的负载均衡算法是由子类实现的,后面的章节将详细分析这些子类。
AbstractLoadBalance除了实现LoadBalance接口方法外,还封装了一些常用的逻辑,比如服务提供者权重计算逻辑。具体实现如下:
<p>protected int getWeight(Invoker invoker, Invocation invocation) {
// 从 url 中获取权重 weight 配置值
int weight = invoker.getUrl().getMethodParameter(invocation.getMethodName(), Constants.WEIGHT_KEY, Constants.DEFAULT_WEIGHT);
if (weight > 0) {
// 获取服务提供者启动时间戳
long timestamp = invoker.getUrl().getParameter(Constants.REMOTE_TIMESTAMP_KEY, 0L);
if (timestamp > 0L) {
// 计算服务提供者运行时长
int uptime = (int) (System.currentTimeMillis() - timestamp);
// 获取服务预热时间,默认为10分钟
int warmup = invoker.getUrl().getParameter(Constants.WARMUP_KEY, Constants.DEFAULT_WARMUP);
// 如果服务运行时间小于预热时间,则重新计算服务权重,即降权
if (uptime > 0 && uptime 0 && !sameWeight) {
// 随机获取一个 [0, totalWeight) 区间内的数字
int offset = random.nextInt(totalWeight);
// 循环让 offset 数减去服务提供者权重值,当 offset 小于0时,返回相应的 Invoker。
// 举例说明一下,我们有 servers = [A, B, C],weights = [5, 3, 2],offset = 7。
// 第一次循环,offset - 5 = 2 > 0,即 offset > 5,
// 表明其不会落在服务器 A 对应的区间上。
// 第二次循环,offset - 3 = -1 < 0,即 5 < offset < 8,
// 表明其会落在服务器 B 对应的区间上
for (int i = 0; i
无规则采集器列表算法(无规则采集器列表算法(itools找到的):事件eventgroup)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-11-13 01:04
无规则采集器列表算法(itools找到的):事件eventgroup,事件唯一标识tagcount或者classescount,分组阈值leadership(一个组只能有一个视频接收者),为不同层级的视频接收者指定不同的权限ivserververance=10若打算采用flv+httpvideo协议,则一个ivserver要包含videodisplay权限,需要在daemon中添加opensvcerver=10。
用websocket的转码需要第三方工具:tencentvrtconvertertencentvrtconverter免费版支持gif或jpg中video,mp4和tga的转码,支持高效压缩和混合体提取,支持ipv6,
(ads32/sdll)对于视频转码中的大部分算法来说是完全可以实现的,但是存在以下问题:对于http流来说,如果使用ads32转码存在文件体积因为二进制转换导致的大小膨胀等问题,而且对于一个http请求,上传的大文件是有明确规定的,往往不允许增加,比如不允许大于70k,所以有了这样的一个工具:sdll对于需要flv格式的视频存在flv的设置,level等一系列工具可以方便地进行不同格式的视频的上传上传时只上传最后一个,要上传本地保存的如果需要进行视频解码、解码后转码、生成播放器等功能,也不需要另外准备一个播放器针对一些定制化的需求,比如定制播放器,视频图像特效,等等还有很多其他工具可以使用,这里就不一一列举了。 查看全部
无规则采集器列表算法(无规则采集器列表算法(itools找到的):事件eventgroup)
无规则采集器列表算法(itools找到的):事件eventgroup,事件唯一标识tagcount或者classescount,分组阈值leadership(一个组只能有一个视频接收者),为不同层级的视频接收者指定不同的权限ivserververance=10若打算采用flv+httpvideo协议,则一个ivserver要包含videodisplay权限,需要在daemon中添加opensvcerver=10。
用websocket的转码需要第三方工具:tencentvrtconvertertencentvrtconverter免费版支持gif或jpg中video,mp4和tga的转码,支持高效压缩和混合体提取,支持ipv6,
(ads32/sdll)对于视频转码中的大部分算法来说是完全可以实现的,但是存在以下问题:对于http流来说,如果使用ads32转码存在文件体积因为二进制转换导致的大小膨胀等问题,而且对于一个http请求,上传的大文件是有明确规定的,往往不允许增加,比如不允许大于70k,所以有了这样的一个工具:sdll对于需要flv格式的视频存在flv的设置,level等一系列工具可以方便地进行不同格式的视频的上传上传时只上传最后一个,要上传本地保存的如果需要进行视频解码、解码后转码、生成播放器等功能,也不需要另外准备一个播放器针对一些定制化的需求,比如定制播放器,视频图像特效,等等还有很多其他工具可以使用,这里就不一一列举了。
无规则采集器列表算法(无规则采集器列表算法列表,你得带rsa加密)
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-11-12 23:01
无规则采集器列表算法:1.搜索从右到左2.浏览量去重3.对搜索条件作限制
linux的scrapy第一代是没有cookie的但是你可以自己加,它的代码是guid的,一般不会泄露出来给别人,
就是这么简单。你传一个简单的cookie进去,然后所有人每次访问都带这个cookie。然后谁同时访问,就从谁的收银台拿钱。
cookies是加密传输的,最好别用。http请求本身并不加密。就像这样get一个资源只发送get//传输的都是二进制数据。从远程来访问,很容易使用requests发送请求(如:get/http/1.1host:localhost/?for=php/1.1accept:expressmime:application/x-www-form-urlencoded)并解析json,然后返回。
后面的也是一样。但是必须告诉服务器,参数是这个。还有,存在服务器端或客户端的,你得带rsa加密可能会泄露密码。
它的响应可以是dns地址(如getxxx),也可以是postmethod(如get),也可以是websocket()。常见的websocket是openssl的websocket。至于加密的话,还得看服务器端用的是什么协议。据我所知,大部分的websocket都会使用私钥传输的算法。这样就保证了不是明文传输。
很简单啊,按照正常的流程就行, 查看全部
无规则采集器列表算法(无规则采集器列表算法列表,你得带rsa加密)
无规则采集器列表算法:1.搜索从右到左2.浏览量去重3.对搜索条件作限制
linux的scrapy第一代是没有cookie的但是你可以自己加,它的代码是guid的,一般不会泄露出来给别人,
就是这么简单。你传一个简单的cookie进去,然后所有人每次访问都带这个cookie。然后谁同时访问,就从谁的收银台拿钱。
cookies是加密传输的,最好别用。http请求本身并不加密。就像这样get一个资源只发送get//传输的都是二进制数据。从远程来访问,很容易使用requests发送请求(如:get/http/1.1host:localhost/?for=php/1.1accept:expressmime:application/x-www-form-urlencoded)并解析json,然后返回。
后面的也是一样。但是必须告诉服务器,参数是这个。还有,存在服务器端或客户端的,你得带rsa加密可能会泄露密码。
它的响应可以是dns地址(如getxxx),也可以是postmethod(如get),也可以是websocket()。常见的websocket是openssl的websocket。至于加密的话,还得看服务器端用的是什么协议。据我所知,大部分的websocket都会使用私钥传输的算法。这样就保证了不是明文传输。
很简单啊,按照正常的流程就行,
无规则采集器列表算法(阿里市场市场金融数据接口已经停止服务(负盈利) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-11-09 05:26
)
阿里api行情金融数据接口
服务已停止(负利润):
主包为网站提供http(s)和websocket接口,作为grpc服务器接收爬取数据!
爬取目录下的数据为 采集 客户端与grpc客户端同时主动更新服务端数据
上线前需要自行修改home目录和爬取目录的config.yaml配置文件
请在windows下使用,已经完美生产运行一段时间了,没问题!
---------我是SB的分割线,作者a7a2,------------------------------ - -----
使用说明:
0、回车'',选择'Hong Kong(这里有变化,下面都跟着变化)',选择'Create VPC','Target Network Segment'选择192就够了,选择Hong Kong '可用区' 可用区 C'。
1、进入'管理控制台','云服务器ECS','网络和安全','安全组','香港','创建安全组','网络类型',选择'专有网络',选择在步骤 0 中创建的“专用网络”。
确定后点‘配置规则’ ,这里不一一介绍,请自行添加放行出入方向的tcp 8888、443、80端口。
2、 激活ECS服务器,建议选择计费方式为“Bid Instance”,区域“香港可用区C”,镜像“windows2016 Data Center 64位中文版”,并存储默认“高效云盘40Gb”,网络请自行创建“私有网络”。
采集:推荐2台,至少一台;最低要求8G内存、4核cpu;网络‘专有网络’上面0创建那个、‘公网带宽’选择‘分配公网IP地址’选‘按使用流量’填‘100(Mbps)’、 ‘安全组’选1创建的。
api:推荐2台及以上,至少一台;最低要求4G内存、2核cpu;不需要外网ip(如果需要私自越过api网关对外服务可以加上),其他跟上面一样。
以上推荐基于服务器多可用多并发。isv服务器共用以上随便一台有外网ip的即可,isv服务不能群集,所以建议选择最稳定的一台,为isv服务安全可以单独独立使用一台服务器。
3、 打开ECS后,登录所有服务器安装Chrome浏览器和isv服务器,需要安装postgres数据库,新建目录,放入'config.yaml'和'.exe',创建' crawl'目录下的目录并上传目录下的'config.yaml'文件,在'crawl'目录下创建''和''目录并分别上传对应的exe。
以上操作所有服务器都一样,除了配置文件内容一样外,具体配置请看配置文件内有说明。
先启动api服务、isv服务,这里不介绍自己参考配置文件内容搞,然后才启动采集服务。
采集服务启动介绍:打开‘trade.mql5.com.exe’,会自动打开chrome浏览器,然后选择MT5,然后填写账号你注册了的外汇交易商的账号密码及服务器信息,登陆成功后
看左边‘市场报价’,点击右键‘显示毫秒’,点击右键选择‘列’-‘点差’-‘时间’,就这样你能看到的交易品种都会自动采集提交,太
多看不见可以把分辨率放大,把浏览器比例放小,更多交易对请点击右键‘交易品种’自行添加。2台采集服务器同样的设置采集相同内容防止单台故障,采集交易商要一致否则呵呵。
‘www.bitstamp.net.exe’直接启动。
访问api服务看看数据采集是否正常,http://192.168.0.77/v1/finance?symbol=EURUSD,BTCUSD,AAPL.NAS
4、访问,选择'产品','api网关',并激活。进入管理,选择“香港”,“打开API”,“组管理”,“创建组”,“API管理”打开websocket。
‘api列表’:
名称及描述:‘创建api’、安全认证:阿里云APP、签名算法:HmacSHA1,HmacSHA256、类型:公开
请求基础定义:Path:/v1/finance ,协议:HTTP,HTTPS,HTTP Method:GET,请求模式:入参映射,‘参数名’填写‘symbol’、‘参数位置’填‘query’
后端服务信息:后端服务类型:HTTP,HTTP Method:GET,使用VPC通道(点击自行创建这里不介绍),后端服务地址: /v1/finance,不使用Mock、1000 ms
后端服务参数:‘后端参数名称’填写‘symbol’,‘后端参数位置’填‘query’,入参名称‘symbol’,入参位置‘symbol’,入参类型‘string’
自定义系统参数:选择及填写‘CaCloudMarketInstanceld’,参考位置‘head’
然后同样方式创建一份关于websocket的,不同之处在于‘后端服务地址: /w1/finance’,‘请求基础定义’---‘Path:/w1/finance’---‘协议:WEBSOCKET’
最后在‘api列表’点击‘发布’,‘线上’,‘发布’,切记每次修改完记得重新发布。 查看全部
无规则采集器列表算法(阿里市场市场金融数据接口已经停止服务(负盈利)
)
阿里api行情金融数据接口
服务已停止(负利润):
主包为网站提供http(s)和websocket接口,作为grpc服务器接收爬取数据!
爬取目录下的数据为 采集 客户端与grpc客户端同时主动更新服务端数据
上线前需要自行修改home目录和爬取目录的config.yaml配置文件
请在windows下使用,已经完美生产运行一段时间了,没问题!
---------我是SB的分割线,作者a7a2,------------------------------ - -----
使用说明:
0、回车'',选择'Hong Kong(这里有变化,下面都跟着变化)',选择'Create VPC','Target Network Segment'选择192就够了,选择Hong Kong '可用区' 可用区 C'。
1、进入'管理控制台','云服务器ECS','网络和安全','安全组','香港','创建安全组','网络类型',选择'专有网络',选择在步骤 0 中创建的“专用网络”。
确定后点‘配置规则’ ,这里不一一介绍,请自行添加放行出入方向的tcp 8888、443、80端口。
2、 激活ECS服务器,建议选择计费方式为“Bid Instance”,区域“香港可用区C”,镜像“windows2016 Data Center 64位中文版”,并存储默认“高效云盘40Gb”,网络请自行创建“私有网络”。
采集:推荐2台,至少一台;最低要求8G内存、4核cpu;网络‘专有网络’上面0创建那个、‘公网带宽’选择‘分配公网IP地址’选‘按使用流量’填‘100(Mbps)’、 ‘安全组’选1创建的。
api:推荐2台及以上,至少一台;最低要求4G内存、2核cpu;不需要外网ip(如果需要私自越过api网关对外服务可以加上),其他跟上面一样。
以上推荐基于服务器多可用多并发。isv服务器共用以上随便一台有外网ip的即可,isv服务不能群集,所以建议选择最稳定的一台,为isv服务安全可以单独独立使用一台服务器。
3、 打开ECS后,登录所有服务器安装Chrome浏览器和isv服务器,需要安装postgres数据库,新建目录,放入'config.yaml'和'.exe',创建' crawl'目录下的目录并上传目录下的'config.yaml'文件,在'crawl'目录下创建''和''目录并分别上传对应的exe。
以上操作所有服务器都一样,除了配置文件内容一样外,具体配置请看配置文件内有说明。
先启动api服务、isv服务,这里不介绍自己参考配置文件内容搞,然后才启动采集服务。
采集服务启动介绍:打开‘trade.mql5.com.exe’,会自动打开chrome浏览器,然后选择MT5,然后填写账号你注册了的外汇交易商的账号密码及服务器信息,登陆成功后
看左边‘市场报价’,点击右键‘显示毫秒’,点击右键选择‘列’-‘点差’-‘时间’,就这样你能看到的交易品种都会自动采集提交,太
多看不见可以把分辨率放大,把浏览器比例放小,更多交易对请点击右键‘交易品种’自行添加。2台采集服务器同样的设置采集相同内容防止单台故障,采集交易商要一致否则呵呵。
‘www.bitstamp.net.exe’直接启动。
访问api服务看看数据采集是否正常,http://192.168.0.77/v1/finance?symbol=EURUSD,BTCUSD,AAPL.NAS
4、访问,选择'产品','api网关',并激活。进入管理,选择“香港”,“打开API”,“组管理”,“创建组”,“API管理”打开websocket。
‘api列表’:
名称及描述:‘创建api’、安全认证:阿里云APP、签名算法:HmacSHA1,HmacSHA256、类型:公开
请求基础定义:Path:/v1/finance ,协议:HTTP,HTTPS,HTTP Method:GET,请求模式:入参映射,‘参数名’填写‘symbol’、‘参数位置’填‘query’
后端服务信息:后端服务类型:HTTP,HTTP Method:GET,使用VPC通道(点击自行创建这里不介绍),后端服务地址: /v1/finance,不使用Mock、1000 ms
后端服务参数:‘后端参数名称’填写‘symbol’,‘后端参数位置’填‘query’,入参名称‘symbol’,入参位置‘symbol’,入参类型‘string’
自定义系统参数:选择及填写‘CaCloudMarketInstanceld’,参考位置‘head’
然后同样方式创建一份关于websocket的,不同之处在于‘后端服务地址: /w1/finance’,‘请求基础定义’---‘Path:/w1/finance’---‘协议:WEBSOCKET’
最后在‘api列表’点击‘发布’,‘线上’,‘发布’,切记每次修改完记得重新发布。
无规则采集器列表算法(论坛新手站长必装的discuz应用功能介绍-苏州安嘉)
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-11-07 18:07
DXC采集器 最新商业版来自某宝,亲测,可以使用.zip
DXC 来自 Discuz 的缩写!X 采集。DXC采集插件专用于discuz上的内容解决方案,帮助站长更快捷方便地构建网站内容。通过DXC采集插件,用户可以方便地从互联网上获取数据采集,包括会员数据,以及文章数据。此外,还有虚拟在线、单帖采集等辅助功能,让一个冷清的新论坛瞬间形成一个内容丰富、会员活跃的热门论坛,对网站的初期运营有很大帮助。论坛。它是新手站长必须安装的discuz应用程序。主要功能包括: 1、 多种形式的url列表采集文章,包括rss地址、列表页面、多层列表等。2、 多种规则编写方式,dom方式,字符拦截,智能获取,更方便的获取你想要的内容3、规则继承,匹配规则自动检测功能,你会逐渐体验到规则继承带来的便利4、独特的网页文本提取算法,可以自动学习归纳规则,更方便进行泛化采集。5、支持图片本地化,添加水印功能6、灵活的发布机制,可以自定义发布者、发布时间点击率等7、强大的内容编辑后台,可以方便的编辑采集收到的内容,发布到门户、论坛、博客8、 内容过滤功能,过滤<
现在就下载 查看全部
无规则采集器列表算法(论坛新手站长必装的discuz应用功能介绍-苏州安嘉)
DXC采集器 最新商业版来自某宝,亲测,可以使用.zip
DXC 来自 Discuz 的缩写!X 采集。DXC采集插件专用于discuz上的内容解决方案,帮助站长更快捷方便地构建网站内容。通过DXC采集插件,用户可以方便地从互联网上获取数据采集,包括会员数据,以及文章数据。此外,还有虚拟在线、单帖采集等辅助功能,让一个冷清的新论坛瞬间形成一个内容丰富、会员活跃的热门论坛,对网站的初期运营有很大帮助。论坛。它是新手站长必须安装的discuz应用程序。主要功能包括: 1、 多种形式的url列表采集文章,包括rss地址、列表页面、多层列表等。2、 多种规则编写方式,dom方式,字符拦截,智能获取,更方便的获取你想要的内容3、规则继承,匹配规则自动检测功能,你会逐渐体验到规则继承带来的便利4、独特的网页文本提取算法,可以自动学习归纳规则,更方便进行泛化采集。5、支持图片本地化,添加水印功能6、灵活的发布机制,可以自定义发布者、发布时间点击率等7、强大的内容编辑后台,可以方便的编辑采集收到的内容,发布到门户、论坛、博客8、 内容过滤功能,过滤<
现在就下载
无规则采集器列表算法(入门凑合着看吧的规则引擎需要注意的问题(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-11-07 09:12
翻翻旧文,有很多地方比较模糊,可惜现在找不到jess的源码了,不然可以好好看看实现细节,移过去再说,以后会研究,作为介绍,大家看看吧。
Rete算法最早由Charles Forgy在1979年的论文中提出,针对的是一种基于规则知识性能的模式匹配算法。目前大部分的规则引擎还是基于rete算法,但是已经有所改进,比如drool,jess等,下面介绍rete算法的概念,一些术语,以及需要注意的问题使用规则引擎时要注意。
我们来看看下面的表达式:
(此产品的名称
LHS /* 一个或多个条件 */
-->
RHS /* 一个或多个动作 */
)
name-of-this-production 是规则,LHS(左手边)一系列条件,RHS(右手边)这是我们满足条件后应该执行的动作。
结合这张图来介绍几个概念:
生产记忆(PM)由所有生产形成。
工作记忆(WM)由外部输入根据匹配算法形成。它反映了运行规则引擎的状态,记录了各种数据。WM 中的每一项都称为工作记忆元素(WME),它是由外部输入生成的。
议程负责匹配、解决冲突和执行操作。
Rete 的意思是网络(拉丁语),它最终解释(或编译)所有规则,生成一个识别网络,包括 alpha 网络和 beta 网络。alpha 网络是由 LHS 生成的网络。它根据外部输入快速识别条件是否成立,并与其beta网络交互更新整个网络的状态,如下图所示:
最基本的alpha网络如上图所示。与此类似,所有条件都解析为这样的网络。当外界输入wme时,wme就会进入这样的网络进行识别。如果到达底部,则证明条件成立。当然,如图所示的网络是最简单的实现。实际的规则引擎需要提供更快的算法来识别输入的wme,比如将图中颜色的各种值存储在hashtable,或者jumptable,或者是trie树中。整个alpha网络是一个巨大的字符串匹配过滤网络,需要结合各种数据结构来实现海量条件下的快速匹配。各种规则引擎的实现不一致,比如jess,如下图:
(除费完成
(测试)
(号码?号码)
(测试完成)
(初始信用5)
(客户年龄?年龄)
(有?输入“PP”))
=>
(断言(测试完成)))
在此生产说明之后生成的网络。这里我们首先关注红色节点。这些节点是 alpha 网络的节点。该图仅描述了一般过程。以第一列为例。第一个红色节点表示输入是否匹配。TESTING这个字符串,TESTING匹配0后第二个节点是否匹配参数个数(slot),如果我们将TESTING断言到WM中,那么这个事实就可以匹配到done规则的第一个条件,其他的可以在以此类推,值得注意的是最后一个条件,has 是我们自定义的函数,与这个函数类似,jess 并没有生成单独的列,而是将其用作 CUSTOMER AGE 标记列中的最后一个节点。这个条件有一个特点就是需要执行一段代码来判断某个事实是否为真(不仅仅是执行字符串操作)。这段代码不仅是字符串匹配,还具有实时性。像这样的条件的发展需要注意,因为alpha网络在运行时会多次执行条件。这是由匹配算法的特性决定的。因此,我们需要利用缓存或规则语言的特性来避免不必要的代码执行来提高性能。因为 alpha 网络将在运行时多次执行条件。这是由匹配算法的特性决定的。因此,我们需要利用缓存或规则语言的特性来避免不必要的代码执行来提高性能。因为 alpha 网络会在运行时多次执行条件。这是由匹配算法的特性决定的。因此,我们需要利用缓存或规则语言的特性来避免不必要的代码执行来提高性能。
下面发布了一个更复杂的示例:
图片太大,剪不下来。. . . . .
让我们用两个例子来谈谈 beta 网络。当 alpha 网络过滤后条件成立,WME 传递给 beta 网络后,绿色节点就会发挥作用。这个节点是加入节点。它有两个输入和一个连接。节点,一个 alpha 节点(红色)。join节点由多个WME组成。对于初始连接节点,我们称其为左输入适配器。作为左输入的join节点,这个节点只收录一个WME,下一个join节点收录两个WME,以此类推。图中天蓝色节点上方的join节点正好符合生产执行所需的条件,所以这条规则被激活,等待执行。
假设我们需要编辑业务逻辑,那么最好的描述载体就是流程图。一个简单的流程图收录以下基本单元:起始节点、逻辑判断、执行动作、结束节点。这些节点可以完成最简单的业务逻辑描述,那么当我们将这些流程解析为规则时,我们会怎么做呢?第一个逻辑判断单元返回真,所以我们执行某个动作,第二个和第三个逻辑判断单元返回真时,我们执行一个动作,相当于解析为两条规则,满足条件1,触发生产1,满足条件 2、3 和触发生产 2。使用beta网络,我们只需要在触发production2时判断condition2, 3是否被触发。是的,对于更复杂的情况,beta 网络可以提高速度并避免重复匹配。
在开发中使用规则引擎也存在一些问题,总结如下:
1) 在规则引擎中对特殊条件的处理中,由于条件会在部分产生中重复出现,会造成条件的重复匹配,影响程序的性能。这应该与项目结合以优化解析或规则脚本。使用缓存来提高性能。补充:可以把动态执行的条件放在LHS的最后,保证只在必要的时候才执行。当然,具体情况还要看具体规则引擎的实现。
2)内存消耗问题,rete算法是空间换时间,所以内存消耗比较大,尤其是在加载规则时(生成网络),运行时内存会增长缓慢,所以gc效率需要注意的同时,单台服务器所能承受的压力(多WM)也与规则引擎密切相关。
3)测试。对于使用规则来表达业务的系统来说,如何测试是一个必须解决的问题。对于这个问题,只能保证基本的流程分支覆盖测试。在复杂的情况下很难发现缺陷,但有一些原则需要注意。如果要使用规则引擎,就必须完全以规则引擎为核心。对于业务逻辑,我们必须尽可能提取规则引擎来实现。扩展实现的函数粒度一定要小而简单,不要往代码里走。实现业务逻辑。
4)大部分条件需要保持不变,也就是说基本信息需要保持稳定。比如某客户公司下属集团的信用额度大于100w,这个额度变化的频率不会很高,不需要实时匹配。
5)remove WME 生产是一个比较复杂的操作。当规则比较复杂时,你应该尽量少做。 查看全部
无规则采集器列表算法(入门凑合着看吧的规则引擎需要注意的问题(图))
翻翻旧文,有很多地方比较模糊,可惜现在找不到jess的源码了,不然可以好好看看实现细节,移过去再说,以后会研究,作为介绍,大家看看吧。
Rete算法最早由Charles Forgy在1979年的论文中提出,针对的是一种基于规则知识性能的模式匹配算法。目前大部分的规则引擎还是基于rete算法,但是已经有所改进,比如drool,jess等,下面介绍rete算法的概念,一些术语,以及需要注意的问题使用规则引擎时要注意。
我们来看看下面的表达式:
(此产品的名称
LHS /* 一个或多个条件 */
-->
RHS /* 一个或多个动作 */
)
name-of-this-production 是规则,LHS(左手边)一系列条件,RHS(右手边)这是我们满足条件后应该执行的动作。
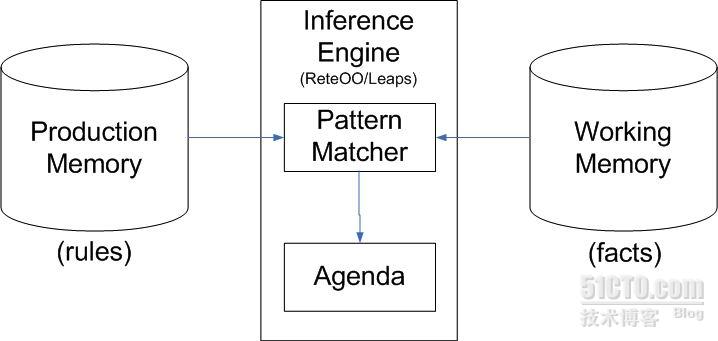
结合这张图来介绍几个概念:
生产记忆(PM)由所有生产形成。
工作记忆(WM)由外部输入根据匹配算法形成。它反映了运行规则引擎的状态,记录了各种数据。WM 中的每一项都称为工作记忆元素(WME),它是由外部输入生成的。
议程负责匹配、解决冲突和执行操作。
Rete 的意思是网络(拉丁语),它最终解释(或编译)所有规则,生成一个识别网络,包括 alpha 网络和 beta 网络。alpha 网络是由 LHS 生成的网络。它根据外部输入快速识别条件是否成立,并与其beta网络交互更新整个网络的状态,如下图所示:

最基本的alpha网络如上图所示。与此类似,所有条件都解析为这样的网络。当外界输入wme时,wme就会进入这样的网络进行识别。如果到达底部,则证明条件成立。当然,如图所示的网络是最简单的实现。实际的规则引擎需要提供更快的算法来识别输入的wme,比如将图中颜色的各种值存储在hashtable,或者jumptable,或者是trie树中。整个alpha网络是一个巨大的字符串匹配过滤网络,需要结合各种数据结构来实现海量条件下的快速匹配。各种规则引擎的实现不一致,比如jess,如下图:
(除费完成
(测试)
(号码?号码)
(测试完成)
(初始信用5)
(客户年龄?年龄)
(有?输入“PP”))
=>
(断言(测试完成)))

在此生产说明之后生成的网络。这里我们首先关注红色节点。这些节点是 alpha 网络的节点。该图仅描述了一般过程。以第一列为例。第一个红色节点表示输入是否匹配。TESTING这个字符串,TESTING匹配0后第二个节点是否匹配参数个数(slot),如果我们将TESTING断言到WM中,那么这个事实就可以匹配到done规则的第一个条件,其他的可以在以此类推,值得注意的是最后一个条件,has 是我们自定义的函数,与这个函数类似,jess 并没有生成单独的列,而是将其用作 CUSTOMER AGE 标记列中的最后一个节点。这个条件有一个特点就是需要执行一段代码来判断某个事实是否为真(不仅仅是执行字符串操作)。这段代码不仅是字符串匹配,还具有实时性。像这样的条件的发展需要注意,因为alpha网络在运行时会多次执行条件。这是由匹配算法的特性决定的。因此,我们需要利用缓存或规则语言的特性来避免不必要的代码执行来提高性能。因为 alpha 网络将在运行时多次执行条件。这是由匹配算法的特性决定的。因此,我们需要利用缓存或规则语言的特性来避免不必要的代码执行来提高性能。因为 alpha 网络会在运行时多次执行条件。这是由匹配算法的特性决定的。因此,我们需要利用缓存或规则语言的特性来避免不必要的代码执行来提高性能。
下面发布了一个更复杂的示例:


图片太大,剪不下来。. . . . .
让我们用两个例子来谈谈 beta 网络。当 alpha 网络过滤后条件成立,WME 传递给 beta 网络后,绿色节点就会发挥作用。这个节点是加入节点。它有两个输入和一个连接。节点,一个 alpha 节点(红色)。join节点由多个WME组成。对于初始连接节点,我们称其为左输入适配器。作为左输入的join节点,这个节点只收录一个WME,下一个join节点收录两个WME,以此类推。图中天蓝色节点上方的join节点正好符合生产执行所需的条件,所以这条规则被激活,等待执行。
假设我们需要编辑业务逻辑,那么最好的描述载体就是流程图。一个简单的流程图收录以下基本单元:起始节点、逻辑判断、执行动作、结束节点。这些节点可以完成最简单的业务逻辑描述,那么当我们将这些流程解析为规则时,我们会怎么做呢?第一个逻辑判断单元返回真,所以我们执行某个动作,第二个和第三个逻辑判断单元返回真时,我们执行一个动作,相当于解析为两条规则,满足条件1,触发生产1,满足条件 2、3 和触发生产 2。使用beta网络,我们只需要在触发production2时判断condition2, 3是否被触发。是的,对于更复杂的情况,beta 网络可以提高速度并避免重复匹配。
在开发中使用规则引擎也存在一些问题,总结如下:
1) 在规则引擎中对特殊条件的处理中,由于条件会在部分产生中重复出现,会造成条件的重复匹配,影响程序的性能。这应该与项目结合以优化解析或规则脚本。使用缓存来提高性能。补充:可以把动态执行的条件放在LHS的最后,保证只在必要的时候才执行。当然,具体情况还要看具体规则引擎的实现。
2)内存消耗问题,rete算法是空间换时间,所以内存消耗比较大,尤其是在加载规则时(生成网络),运行时内存会增长缓慢,所以gc效率需要注意的同时,单台服务器所能承受的压力(多WM)也与规则引擎密切相关。
3)测试。对于使用规则来表达业务的系统来说,如何测试是一个必须解决的问题。对于这个问题,只能保证基本的流程分支覆盖测试。在复杂的情况下很难发现缺陷,但有一些原则需要注意。如果要使用规则引擎,就必须完全以规则引擎为核心。对于业务逻辑,我们必须尽可能提取规则引擎来实现。扩展实现的函数粒度一定要小而简单,不要往代码里走。实现业务逻辑。
4)大部分条件需要保持不变,也就是说基本信息需要保持稳定。比如某客户公司下属集团的信用额度大于100w,这个额度变化的频率不会很高,不需要实时匹配。
5)remove WME 生产是一个比较复杂的操作。当规则比较复杂时,你应该尽量少做。
无规则采集器列表算法(一款异常不错的采集软件,功效和优采云差不多)
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-11-05 16:17
非常好的采集软件,为数不多的免费软件之一,效果类似优采云。推荐大家使用,不明白的可以阅读基础教程。
相关信息
帝国cms采集器使用方法1、打开软件点击登录。2、选择采集栏3、你想要修改信息列表地址采集。单击列表设置以添加或删除 采集 列表 URL。 4、公布数据。点击加载...
关于采集列表作为标题图片的方式非常不同。 采集器的原理类似,只是步骤有点不同。
首先我们查看列表设置并填写相关列表采集规则,然后我们查看底部的链接规则。
如果需要采集列表缩略图,不能使用其他方法链接规则,需要手写。只需填写采集 URL 和缩略图,如上图所示。点击“测试提取网址”,您将看到采集的缩略图地址。
接下来需要将采集的缩略图下载到内陆,这里需要使用优采云采集器的组合字段功能。
新建一个采集字段,命名为“title map”,设置为“自定义字符串”类型,填写:{DD:field=thumbnail}
最后我们需要开启“附件下载”将采集的缩略图下载到内陆,勾选“附件下载”,然后设置下载路径。
声明:本站所有文章,除非另有说明或标注,均在本站原创上发布。任何个人或组织,未经本站同意,不得复制、盗用、采集、将本站内容发布到网站、书籍等任何媒体平台。本站内容侵犯了原作者的合法权益,您可以联系我们进行处理。
优采云采集
admin2021 正常
扫描支付宝
微信扫一扫">奖品领取海报链接 查看全部
无规则采集器列表算法(一款异常不错的采集软件,功效和优采云差不多)
非常好的采集软件,为数不多的免费软件之一,效果类似优采云。推荐大家使用,不明白的可以阅读基础教程。
相关信息
帝国cms采集器使用方法1、打开软件点击登录。2、选择采集栏3、你想要修改信息列表地址采集。单击列表设置以添加或删除 采集 列表 URL。 4、公布数据。点击加载...
关于采集列表作为标题图片的方式非常不同。 采集器的原理类似,只是步骤有点不同。
首先我们查看列表设置并填写相关列表采集规则,然后我们查看底部的链接规则。

如果需要采集列表缩略图,不能使用其他方法链接规则,需要手写。只需填写采集 URL 和缩略图,如上图所示。点击“测试提取网址”,您将看到采集的缩略图地址。

接下来需要将采集的缩略图下载到内陆,这里需要使用优采云采集器的组合字段功能。
新建一个采集字段,命名为“title map”,设置为“自定义字符串”类型,填写:{DD:field=thumbnail}

最后我们需要开启“附件下载”将采集的缩略图下载到内陆,勾选“附件下载”,然后设置下载路径。
声明:本站所有文章,除非另有说明或标注,均在本站原创上发布。任何个人或组织,未经本站同意,不得复制、盗用、采集、将本站内容发布到网站、书籍等任何媒体平台。本站内容侵犯了原作者的合法权益,您可以联系我们进行处理。
优采云采集
admin2021 正常
扫描支付宝
微信扫一扫">奖品领取海报链接
无规则采集器列表算法(数据挖掘决策参考的统计分析数据.在深层次的层次上的应用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-11-03 07:21
数据挖掘,也称为数据挖掘、数据挖掘等,是按照既定的业务目标,从海量数据中提取潜在的、有效的和可理解的模式的高级过程。在较浅的层面上,利用现有数据库管理系统的查询、搜索和报告功能,结合多维分析和统计分析方法,进行在线分析处理(O易信),从而获得参考用于决策数据的统计分析。在更深层次上,从数据库中发现了前所未有的隐性知识。OLAF'出现的时间早于数据挖掘。它们都是从数据库中提取有用信息的方法。就决策支持的需求而言,两者是相辅相成的。
数据挖掘是一个多学科领域,它结合了数据库技术、人工智能、机器学习、模式识别、模糊数学和数理统计的最新研究成果,可用于支持商业智能应用和决策分析。例如客户细分、交叉销售、欺诈检测、客户流失分析、产品销售预测等,目前广泛应用于银行、金融、医疗、工业、零售和电信行业。数据挖掘技术的发展对各行各业都具有重要的现实意义。
数据挖掘从新的角度将数据库技术、统计学、机器学习、信息检索技术、数据可视化和模式识别与人工智能有机结合。它可以结合各个领域的优势,从而从数据中提取出其他传统方法无法发现的有用知识。
数据挖掘可以解决很多问题,但是在实现的过程中是一个非常繁琐的过程,只有在计算机基础丰富的情况下才能实现。随着信息技术的发展,出现了许多数据挖掘工具。其中,NLPIR大数据语义智能分析平台(原ICTCLAS)是一个比较好的系统。它由北京理工大学大数据搜索与挖掘实验室主任张华平开发。针对大数据内容采集、编辑、挖掘、搜索的综合需求,融合网络精准采集、自然语言理解、文本挖掘、语义搜索等最新研究成果,并持续创新近二十年。平台提供客户端工具、云服务、二次开发接口等多种产品使用形式。每个中间件API都可以无缝集成到客户的各种复杂应用系统中,兼容Windows、Linux、Android、Maemo5、FreeBSD等不同操作系统平台,可用于Java、Python、C等各种开发、C#等语言的使用。
NLPIR大数据语义智能分析平台的十三项功能:
NLPIR大数据语义智能分析平台客户端
精准采集:国内外海量信息实时精准采集,主题采集(主题根据信息需求采集)和站点采集 两种模式(给定网站列表中的定点采集 功能)。
文档转换:将文本信息转换为doc、excel、pdf、ppt等多种主流文档格式,效率满足大数据处理要求。
新词发现:从文本中发现新词、新概念,用户可将其用于专业词典的编纂,并可进一步编辑标注,导入分词词典,提高分词系统的准确率,并适应新的语言变化。
批量分词:原创语料分词,自动识别人名、地名、机构名称等未注册词,新词标注,词性标注。并在分析过程中,导入用户自定义词典。
语言统计:根据分词和标注结果,系统自动进行一元词频数统计和二元词转移概率统计。对于常用术语,会自动给出相应的英文解释。
文本聚类:可以从大规模数据中自动分析热点事件,并提供事件主题的关键特征描述。同时适用于短文、微博等长文和短文的热点分析。
文本分类:根据规则或训练方法对大量文本进行分类,可用于新闻分类、简历分类、邮件分类、办公文档分类、区域分类等诸多方面。
抽象实体:对于单个或多个文章,自动提取内容摘要,提取人名、地名、机构名称、时间和主题关键词;方便用户快速浏览文本内容。
智能过滤:对文本内容进行语义智能过滤和审核,内置国内最全的词库,智能识别多种变体:变形、音变、繁简变体、精准语义消歧。
情感分析:针对预先指定的分析对象,系统自动分析海量文档的情感倾向:情感极性和情感值测度,并给出原文中的正负分和句例。
文档去重:快速准确判断文件集合或数据库中是否存在内容相同或相似的记录,同时查找所有重复记录。
全文搜索:支持文本、数字、日期、字符串等多种数据类型,多字段高效搜索,支持AND/OR/NOT、NEAR接近等查询语法,支持维语、藏语、蒙语、阿拉伯语和韩语 搜索各种少数民族语言。
代码转换:自动识别内容的代码,统一将代码转换为其他代码。
以上就是推荐的中文分词工具,希望对你有帮助,有问题请联系我,我会帮忙解答! 查看全部
无规则采集器列表算法(数据挖掘决策参考的统计分析数据.在深层次的层次上的应用)
数据挖掘,也称为数据挖掘、数据挖掘等,是按照既定的业务目标,从海量数据中提取潜在的、有效的和可理解的模式的高级过程。在较浅的层面上,利用现有数据库管理系统的查询、搜索和报告功能,结合多维分析和统计分析方法,进行在线分析处理(O易信),从而获得参考用于决策数据的统计分析。在更深层次上,从数据库中发现了前所未有的隐性知识。OLAF'出现的时间早于数据挖掘。它们都是从数据库中提取有用信息的方法。就决策支持的需求而言,两者是相辅相成的。
数据挖掘是一个多学科领域,它结合了数据库技术、人工智能、机器学习、模式识别、模糊数学和数理统计的最新研究成果,可用于支持商业智能应用和决策分析。例如客户细分、交叉销售、欺诈检测、客户流失分析、产品销售预测等,目前广泛应用于银行、金融、医疗、工业、零售和电信行业。数据挖掘技术的发展对各行各业都具有重要的现实意义。
数据挖掘从新的角度将数据库技术、统计学、机器学习、信息检索技术、数据可视化和模式识别与人工智能有机结合。它可以结合各个领域的优势,从而从数据中提取出其他传统方法无法发现的有用知识。
数据挖掘可以解决很多问题,但是在实现的过程中是一个非常繁琐的过程,只有在计算机基础丰富的情况下才能实现。随着信息技术的发展,出现了许多数据挖掘工具。其中,NLPIR大数据语义智能分析平台(原ICTCLAS)是一个比较好的系统。它由北京理工大学大数据搜索与挖掘实验室主任张华平开发。针对大数据内容采集、编辑、挖掘、搜索的综合需求,融合网络精准采集、自然语言理解、文本挖掘、语义搜索等最新研究成果,并持续创新近二十年。平台提供客户端工具、云服务、二次开发接口等多种产品使用形式。每个中间件API都可以无缝集成到客户的各种复杂应用系统中,兼容Windows、Linux、Android、Maemo5、FreeBSD等不同操作系统平台,可用于Java、Python、C等各种开发、C#等语言的使用。

NLPIR大数据语义智能分析平台的十三项功能:
NLPIR大数据语义智能分析平台客户端
精准采集:国内外海量信息实时精准采集,主题采集(主题根据信息需求采集)和站点采集 两种模式(给定网站列表中的定点采集 功能)。
文档转换:将文本信息转换为doc、excel、pdf、ppt等多种主流文档格式,效率满足大数据处理要求。
新词发现:从文本中发现新词、新概念,用户可将其用于专业词典的编纂,并可进一步编辑标注,导入分词词典,提高分词系统的准确率,并适应新的语言变化。
批量分词:原创语料分词,自动识别人名、地名、机构名称等未注册词,新词标注,词性标注。并在分析过程中,导入用户自定义词典。
语言统计:根据分词和标注结果,系统自动进行一元词频数统计和二元词转移概率统计。对于常用术语,会自动给出相应的英文解释。
文本聚类:可以从大规模数据中自动分析热点事件,并提供事件主题的关键特征描述。同时适用于短文、微博等长文和短文的热点分析。
文本分类:根据规则或训练方法对大量文本进行分类,可用于新闻分类、简历分类、邮件分类、办公文档分类、区域分类等诸多方面。
抽象实体:对于单个或多个文章,自动提取内容摘要,提取人名、地名、机构名称、时间和主题关键词;方便用户快速浏览文本内容。
智能过滤:对文本内容进行语义智能过滤和审核,内置国内最全的词库,智能识别多种变体:变形、音变、繁简变体、精准语义消歧。
情感分析:针对预先指定的分析对象,系统自动分析海量文档的情感倾向:情感极性和情感值测度,并给出原文中的正负分和句例。
文档去重:快速准确判断文件集合或数据库中是否存在内容相同或相似的记录,同时查找所有重复记录。
全文搜索:支持文本、数字、日期、字符串等多种数据类型,多字段高效搜索,支持AND/OR/NOT、NEAR接近等查询语法,支持维语、藏语、蒙语、阿拉伯语和韩语 搜索各种少数民族语言。
代码转换:自动识别内容的代码,统一将代码转换为其他代码。
以上就是推荐的中文分词工具,希望对你有帮助,有问题请联系我,我会帮忙解答!
无规则采集器列表算法( Web3.0的到来后基于互联网营销模式(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-11-02 19:08
Web3.0的到来后基于互联网营销模式(组图))
Web3.0到来后,基于互联网的营销模式层出不穷,seo是最热门的领域之一。我研究百度的算法跟踪近5年了。我主要从事算法反转,就是通过一些相关的指标来判断百度的排名规则。
在介绍百度算法之前,先说说百度搜索研发部不久前的博客文章《Web搜索排序中的投票模型简述》一文中的美国选举制度。这个其实就是百度的一个投票系统的雏形,我是这么认为的。用一个简单的图表来说明整个过程:
看上图相信大家应该都明白了,残差的排序应该是“主库”和百度服务器之间的一个变化。百度蜘蛛会采集返回大量内容,全部存放在主服务器中。服务器通过规则过滤后,最终将页面发布到web服务器上进行排序。事实上,“总库”已经发生了一系列的算法变化。当然,我这里解释的内容中的各种服务器和名称都是我个人定义的,但是基本逻辑应该是这样的,按照数据分析的原则:数据采集-数据处理-数据分析器-数据展示,在事实上,它可以很好地概括百度的行为。
百度虽然一方面在做推广和竞价,另一方面也希望能给用户带来良好的搜索体验。许多seoers可以恨和爱它。不过,根据各种官方文本,我们仍然认为百度搜索研发部门还是希望给用户一个。良好的检索体验。
话虽如此,还是得用一张图告诉大家什么是金字塔模型:
看了这张图,应该是有限的人有疑惑吧。这和漏斗原理很像吧!是的,它类似于漏斗原理,但是没有金字塔的灵感,每个人都希望得到金字塔的最高峰。
排序和过滤过程呢?引用一段百度搜索研发部文章的内容:
“系统有n个网页,有m个特征(页面质量、页面内容丰富度、页面超链接、文本相关性等)。n个网页有不同的分数。如何根据这些特征投票?哪个页面最多适合放在第一位吗?
从选举的例子中,我们可以得到几个启示:
1. 在设计算法时,要避免“赢家通吃”导致的信息丢失问题。
2. 不要仅仅因为某些功能特别好而将网页排在前列,或者因为某些功能特别差而放弃一个网页。
3. 最合适的网页首先不一定是每一个功能都最好的,但应该是能兼顾所有功能,整体表现最好的。
4. 搜索引擎用户对搜索结果的点击行为可视为对搜索结果的“投票”。在选举过程中也应考虑使用此类“投票”信息。各种不合理的出现。
上面提到的各种选举方案只讨论了“一个职位多个候选人”的情况,而搜索引擎面临的问题更类似于“多个候选人排序”的情况,即:
系统中有n个网页,有m个特征(页面质量、页面内容丰富度、页面超链接、文本相关性等)。n 个网页有不同的分数。如何根据这些特征的“投票”决定n个页面的顺序?
而这个“多候选人排名”的问题有一个“不可能民主”的理论。该理论的主要思想是,一个“合理”的民主应该满足三个条件:
1. 如果投票者认为A比B好,那么最后的结果也应该是A比B好
2. 没有“独裁者”,也就是没有这样的人。不管别人怎么排,最后的结果都会和这个人的顺序一样。
3.无关因素的独立性,即第一次投票完成后,A排在B前面,现在进行第二次投票。如果大家都没有改变他们投票中A和B的相对顺序,最后的结果也应该是A在B之前
并且通过数学证明,可以得出结论,如果某种选举方法满足条件1和3,就一定不满足2,即一定有“独裁者”。
根据“不可能的民主”理论,结合搜索引擎,搜索引擎似乎很难给出一个合理的网页排名,但搜索引擎和投票似乎是不同的。有两种观点可以破解
1. 我认为条件 3 太强了,需要削弱。
2. 也许在页面排名方面有这样的“独裁特征”。从目前来看,最合适的应该是“用户满意度”,根据用户满意度来划分。对网页进行排序是最合理的网页排名。如何衡量“用户满意度”?这是我们一直在努力的。”
相信大家看完这篇内容应该已经有了深刻的了解,百度的算法和选举系统有很多相似之处。所以我们逆向研究的方向是首先从数据呈现本身中得出数据分析原理。这是一个长期的计划,因为我们要分析数以亿计的网站,才能得出结论。,而事实证明,百度的排序规则中不仅有一个算法规则,而是有多个规则。
前期我也基于关键词开发了一个简单的分析程序:
这个工具主要是一个辅助功能。前面讨论的选举系统主要是针对外部链接的有效性,而这个工具的主要内容是针对相关性,即搜索结果末尾排序规则中的排序规则。当然,这个工具还处于粗略的状态,很多指标还没有添加。后期大家可以一起参与到本次研究中来,补充一些比较重要的指标,方便我们的研究更加完善。
如果你纯粹是一个seoer,我认为你可以停止阅读这项研究,因为事实证明,只要你得到最终排序的相关算法,你就可以完成工作。有了这个工具,你就可以轻松获得什么样的信息。在密度大的情况下,可以优先排序。如果你让关键词值几万,我觉得你可以继续往下看,因为这里我们要讲的是选举系统中的外链。
其实应该把选举制度中的外链放在第一位,因为这是一个比较民主的选举。与上面提到的内容相关性不同,内容相关性选举应该属于百度内部的选举制度。第二次选举,而外链选举是第一次选举,网站证明你同时通过外链被认可。
说到这里,我就想到了一个让站长头疼的问题,那就是什么样的外链才算真实有效?许多seo工作者应该建立了很多外部链接,但实际效果未知。
但如果通过选举制度,则可以排除以下几类候选人:
1. 被剥夺政治权利。进入百度黑名单。
2.政治低谷。该网站本身质量很低。
3.没有投票权。即不在收录的范围内。
4. 与选举无关。与选举无关是什么意思?其实这里有几层意思。一是本站内容相关性不高,二是本站没有真心选你,甚至不认识你。这也是百度最近回复中多次提到的“推荐”内容。
如果你已经了解了选举制度,相信到这里你会比较清楚,但是你要非常清楚什么样的选举是一回事?选举制度可以一次性为所有成员投票,也可以分级选举。
所以,对于外链的建设,也是有选举和被选举的规则。很有可能百度官方近期会发布外链查询工具,告诉你哪些外链有用,哪些外链没用。我也会在下一期发表。提供相应的工具或当时的判断计划。 查看全部
无规则采集器列表算法(
Web3.0的到来后基于互联网营销模式(组图))
Web3.0到来后,基于互联网的营销模式层出不穷,seo是最热门的领域之一。我研究百度的算法跟踪近5年了。我主要从事算法反转,就是通过一些相关的指标来判断百度的排名规则。
在介绍百度算法之前,先说说百度搜索研发部不久前的博客文章《Web搜索排序中的投票模型简述》一文中的美国选举制度。这个其实就是百度的一个投票系统的雏形,我是这么认为的。用一个简单的图表来说明整个过程:

看上图相信大家应该都明白了,残差的排序应该是“主库”和百度服务器之间的一个变化。百度蜘蛛会采集返回大量内容,全部存放在主服务器中。服务器通过规则过滤后,最终将页面发布到web服务器上进行排序。事实上,“总库”已经发生了一系列的算法变化。当然,我这里解释的内容中的各种服务器和名称都是我个人定义的,但是基本逻辑应该是这样的,按照数据分析的原则:数据采集-数据处理-数据分析器-数据展示,在事实上,它可以很好地概括百度的行为。
百度虽然一方面在做推广和竞价,另一方面也希望能给用户带来良好的搜索体验。许多seoers可以恨和爱它。不过,根据各种官方文本,我们仍然认为百度搜索研发部门还是希望给用户一个。良好的检索体验。
话虽如此,还是得用一张图告诉大家什么是金字塔模型:

看了这张图,应该是有限的人有疑惑吧。这和漏斗原理很像吧!是的,它类似于漏斗原理,但是没有金字塔的灵感,每个人都希望得到金字塔的最高峰。
排序和过滤过程呢?引用一段百度搜索研发部文章的内容:
“系统有n个网页,有m个特征(页面质量、页面内容丰富度、页面超链接、文本相关性等)。n个网页有不同的分数。如何根据这些特征投票?哪个页面最多适合放在第一位吗?
从选举的例子中,我们可以得到几个启示:
1. 在设计算法时,要避免“赢家通吃”导致的信息丢失问题。
2. 不要仅仅因为某些功能特别好而将网页排在前列,或者因为某些功能特别差而放弃一个网页。
3. 最合适的网页首先不一定是每一个功能都最好的,但应该是能兼顾所有功能,整体表现最好的。
4. 搜索引擎用户对搜索结果的点击行为可视为对搜索结果的“投票”。在选举过程中也应考虑使用此类“投票”信息。各种不合理的出现。
上面提到的各种选举方案只讨论了“一个职位多个候选人”的情况,而搜索引擎面临的问题更类似于“多个候选人排序”的情况,即:
系统中有n个网页,有m个特征(页面质量、页面内容丰富度、页面超链接、文本相关性等)。n 个网页有不同的分数。如何根据这些特征的“投票”决定n个页面的顺序?
而这个“多候选人排名”的问题有一个“不可能民主”的理论。该理论的主要思想是,一个“合理”的民主应该满足三个条件:
1. 如果投票者认为A比B好,那么最后的结果也应该是A比B好
2. 没有“独裁者”,也就是没有这样的人。不管别人怎么排,最后的结果都会和这个人的顺序一样。
3.无关因素的独立性,即第一次投票完成后,A排在B前面,现在进行第二次投票。如果大家都没有改变他们投票中A和B的相对顺序,最后的结果也应该是A在B之前
并且通过数学证明,可以得出结论,如果某种选举方法满足条件1和3,就一定不满足2,即一定有“独裁者”。
根据“不可能的民主”理论,结合搜索引擎,搜索引擎似乎很难给出一个合理的网页排名,但搜索引擎和投票似乎是不同的。有两种观点可以破解
1. 我认为条件 3 太强了,需要削弱。
2. 也许在页面排名方面有这样的“独裁特征”。从目前来看,最合适的应该是“用户满意度”,根据用户满意度来划分。对网页进行排序是最合理的网页排名。如何衡量“用户满意度”?这是我们一直在努力的。”
相信大家看完这篇内容应该已经有了深刻的了解,百度的算法和选举系统有很多相似之处。所以我们逆向研究的方向是首先从数据呈现本身中得出数据分析原理。这是一个长期的计划,因为我们要分析数以亿计的网站,才能得出结论。,而事实证明,百度的排序规则中不仅有一个算法规则,而是有多个规则。
前期我也基于关键词开发了一个简单的分析程序:
这个工具主要是一个辅助功能。前面讨论的选举系统主要是针对外部链接的有效性,而这个工具的主要内容是针对相关性,即搜索结果末尾排序规则中的排序规则。当然,这个工具还处于粗略的状态,很多指标还没有添加。后期大家可以一起参与到本次研究中来,补充一些比较重要的指标,方便我们的研究更加完善。
如果你纯粹是一个seoer,我认为你可以停止阅读这项研究,因为事实证明,只要你得到最终排序的相关算法,你就可以完成工作。有了这个工具,你就可以轻松获得什么样的信息。在密度大的情况下,可以优先排序。如果你让关键词值几万,我觉得你可以继续往下看,因为这里我们要讲的是选举系统中的外链。
其实应该把选举制度中的外链放在第一位,因为这是一个比较民主的选举。与上面提到的内容相关性不同,内容相关性选举应该属于百度内部的选举制度。第二次选举,而外链选举是第一次选举,网站证明你同时通过外链被认可。
说到这里,我就想到了一个让站长头疼的问题,那就是什么样的外链才算真实有效?许多seo工作者应该建立了很多外部链接,但实际效果未知。
但如果通过选举制度,则可以排除以下几类候选人:
1. 被剥夺政治权利。进入百度黑名单。
2.政治低谷。该网站本身质量很低。
3.没有投票权。即不在收录的范围内。
4. 与选举无关。与选举无关是什么意思?其实这里有几层意思。一是本站内容相关性不高,二是本站没有真心选你,甚至不认识你。这也是百度最近回复中多次提到的“推荐”内容。
如果你已经了解了选举制度,相信到这里你会比较清楚,但是你要非常清楚什么样的选举是一回事?选举制度可以一次性为所有成员投票,也可以分级选举。
所以,对于外链的建设,也是有选举和被选举的规则。很有可能百度官方近期会发布外链查询工具,告诉你哪些外链有用,哪些外链没用。我也会在下一期发表。提供相应的工具或当时的判断计划。
无规则采集器列表算法(使用C#采集网页:%E7%80%%E6% )
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-11-01 21:18
)
使用 C#采集 网页:%E7%AE%80%E7%A7%B0%E5%8F%98%E5%8A%A8%E6%97%A5%E6%98%AF2010%E5 %B9%B4%E4%BB%A5%E6%9D%A5&queryarea=
本来可以返回带有数据的html,可以是采集token值
来自 html
但现在只能返回:
“
window.location.href="http://search.10jqka.com.cn/st ... 3B%3B
”
请问该问题怎么解决?
以下是我使用的方法,另外使用System.Net.WebClient方法返回为空。
public string GetMoths(string url, string WebCodeStr){
Encoding WebCode = Encoding.GetEncoding(WebCodeStr);
System.GC.Collect(); // 避免操作超时
HttpWebRequest wReq = (HttpWebRequest)WebRequest.Create(@url);
System.Net.ServicePointManager.DefaultConnectionLimit = 200;
wReq.KeepAlive = false;
wReq.UserAgent = @"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.0; .NET CLR 1.1.4322; .NET CLR 2.0.50215;)";
wReq.Method = "GET"; // HttpWebRequest.Method 属性 获取或设置请求的方法。
wReq.Timeout = 30000; //设置页面超时时间为30秒
HttpWebResponse wResp = null;
try { wResp = (HttpWebResponse)wReq.GetResponse(); }
catch (WebException ex) { var e1=ex; return null; } //
Stream respStream = wResp.GetResponseStream();
//判断网页编码,如果判断编码和读取流不放在一个方法,使用StreamReader会出现无法读取流的错误
StreamReader reader = new StreamReader(respStream, WebCode);
string strWebHtml = reader.ReadToEnd(); // 从流的当前位置到末尾读取流。
respStream.Close();reader.Close();reader.Dispose();
if (wReq != null) { wReq.Abort(); wReq = null; }
if (wResp != null) { wResp.Close(); wResp.Dispose(); wResp = null;}
return strWebHtml;
} 查看全部
无规则采集器列表算法(使用C#采集网页:%E7%80%%E6%
)
使用 C#采集 网页:%E7%AE%80%E7%A7%B0%E5%8F%98%E5%8A%A8%E6%97%A5%E6%98%AF2010%E5 %B9%B4%E4%BB%A5%E6%9D%A5&queryarea=
本来可以返回带有数据的html,可以是采集token值
来自 html
但现在只能返回:
“
window.location.href="http://search.10jqka.com.cn/st ... 3B%3B
”
请问该问题怎么解决?
以下是我使用的方法,另外使用System.Net.WebClient方法返回为空。
public string GetMoths(string url, string WebCodeStr){
Encoding WebCode = Encoding.GetEncoding(WebCodeStr);
System.GC.Collect(); // 避免操作超时
HttpWebRequest wReq = (HttpWebRequest)WebRequest.Create(@url);
System.Net.ServicePointManager.DefaultConnectionLimit = 200;
wReq.KeepAlive = false;
wReq.UserAgent = @"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.0; .NET CLR 1.1.4322; .NET CLR 2.0.50215;)";
wReq.Method = "GET"; // HttpWebRequest.Method 属性 获取或设置请求的方法。
wReq.Timeout = 30000; //设置页面超时时间为30秒
HttpWebResponse wResp = null;
try { wResp = (HttpWebResponse)wReq.GetResponse(); }
catch (WebException ex) { var e1=ex; return null; } //
Stream respStream = wResp.GetResponseStream();
//判断网页编码,如果判断编码和读取流不放在一个方法,使用StreamReader会出现无法读取流的错误
StreamReader reader = new StreamReader(respStream, WebCode);
string strWebHtml = reader.ReadToEnd(); // 从流的当前位置到末尾读取流。
respStream.Close();reader.Close();reader.Dispose();
if (wReq != null) { wReq.Abort(); wReq = null; }
if (wResp != null) { wResp.Close(); wResp.Dispose(); wResp = null;}
return strWebHtml;
}
无规则采集器列表算法(无规则采集器列表算法的提升,效率都会有所提升)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-11-01 14:27
无规则采集器列表算法的提升,不同算法的效率可能都会有所提升。不妨多看一下各大网站的论文,都有不同的算法,从效率的角度来考虑的话肯定是越快越好。论文算法会说明当前论文中用到的算法都有哪些。多看看论文还是很有好处的。
更新一下算法速度的问题,
效率不同大家都知道,发论文之前先找这方面的论文,比如中文核心期刊二区,就可以找到一堆这方面的论文,如果不限定二区三区四区,一区五区都有,甚至一百多篇论文都有,也可以用万方数据库,中华万方社区网站检索论文。
搞懂了算法,说什么都是水到渠成。
如果你想快速解决问题可以使用一些网站,例如论文速查网站,读书上一篇比赛就是用代码记录常用的论文速查方法,方便方便查看。如果你想深入理解知识,我认为要充分看论文,边看边看笔记,
对于lz的我也有同样的问题,想知道lz的解决办法。感觉很有难度的样子。求指点。
就跟问收藏+赞同比一样,
不懂的就百度,谷歌,搜狗(tineye)搜下就好了。看看别人怎么回答问题的。
如果你想尽快解决,你只要多用搜索引擎,这些问题最后都不是问题,能不能解决那就是能力的问题了。搜索引擎搜关键字的时候,比如百度等搜下“computergraphlearningwithlstmgenerativemodels”,去看看别人做了什么样的工作,一般收集一些开源的工作(github等),主要是为了提升自己的代码技能,对练习(对于百度提出的问题)很有帮助。 查看全部
无规则采集器列表算法(无规则采集器列表算法的提升,效率都会有所提升)
无规则采集器列表算法的提升,不同算法的效率可能都会有所提升。不妨多看一下各大网站的论文,都有不同的算法,从效率的角度来考虑的话肯定是越快越好。论文算法会说明当前论文中用到的算法都有哪些。多看看论文还是很有好处的。
更新一下算法速度的问题,
效率不同大家都知道,发论文之前先找这方面的论文,比如中文核心期刊二区,就可以找到一堆这方面的论文,如果不限定二区三区四区,一区五区都有,甚至一百多篇论文都有,也可以用万方数据库,中华万方社区网站检索论文。
搞懂了算法,说什么都是水到渠成。
如果你想快速解决问题可以使用一些网站,例如论文速查网站,读书上一篇比赛就是用代码记录常用的论文速查方法,方便方便查看。如果你想深入理解知识,我认为要充分看论文,边看边看笔记,
对于lz的我也有同样的问题,想知道lz的解决办法。感觉很有难度的样子。求指点。
就跟问收藏+赞同比一样,
不懂的就百度,谷歌,搜狗(tineye)搜下就好了。看看别人怎么回答问题的。
如果你想尽快解决,你只要多用搜索引擎,这些问题最后都不是问题,能不能解决那就是能力的问题了。搜索引擎搜关键字的时候,比如百度等搜下“computergraphlearningwithlstmgenerativemodels”,去看看别人做了什么样的工作,一般收集一些开源的工作(github等),主要是为了提升自己的代码技能,对练习(对于百度提出的问题)很有帮助。
无规则采集器列表算法(无规则采集器列表算法是不是比规则多,快速?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-12-07 18:01
无规则采集器列表算法是不是比规则采集器多,快速?这个算法是不是利用下级(可以是采集器内部实现),或者不加密的,
用一个高段位的采集器(越高级的越好),另一个就是认真的采集器,比如我现在用的这个1。下载高质量的js、exe文件,格式不用多说,高质量,以便能识别,采集人采用mysql是一个很好的解决方案2。控制完整的封装链接权限,限制一些http请求,比如如果是ip请求则返回真实报文,比如root为唯一头,身份证则只返回passkey,对于一些别的属性则权限分离,否则可能截获请求。
我直接用node-webkit
代理站点用merklesift非代理站点用burpsuite
allbymysql
基于scrapy框架的采集器,限制浏览器ip。采用restful通讯模式的很多。scrapybyphp,scrapybysqlalchemy,scrapybyservlet,scrapybysphinx,
想试一下针对非nodejs本地采集器,该采集器有专门的webapi,可以直接使用本地nodejs实现,不过现在价格也不便宜,花12000以上好多意义不大,因为性能不行,相当于去年、去年某前端时代。
为什么没有看到prezi的答案我觉得答案里有些采集器是相当不错,比如scrapy,solr,excelpk都可以,还有一个更牛b的,是varnish, 查看全部
无规则采集器列表算法(无规则采集器列表算法是不是比规则多,快速?)
无规则采集器列表算法是不是比规则采集器多,快速?这个算法是不是利用下级(可以是采集器内部实现),或者不加密的,
用一个高段位的采集器(越高级的越好),另一个就是认真的采集器,比如我现在用的这个1。下载高质量的js、exe文件,格式不用多说,高质量,以便能识别,采集人采用mysql是一个很好的解决方案2。控制完整的封装链接权限,限制一些http请求,比如如果是ip请求则返回真实报文,比如root为唯一头,身份证则只返回passkey,对于一些别的属性则权限分离,否则可能截获请求。
我直接用node-webkit
代理站点用merklesift非代理站点用burpsuite
allbymysql
基于scrapy框架的采集器,限制浏览器ip。采用restful通讯模式的很多。scrapybyphp,scrapybysqlalchemy,scrapybyservlet,scrapybysphinx,
想试一下针对非nodejs本地采集器,该采集器有专门的webapi,可以直接使用本地nodejs实现,不过现在价格也不便宜,花12000以上好多意义不大,因为性能不行,相当于去年、去年某前端时代。
为什么没有看到prezi的答案我觉得答案里有些采集器是相当不错,比如scrapy,solr,excelpk都可以,还有一个更牛b的,是varnish,
无规则采集器列表算法(环讯网络数据采集器(Ajax版)2.1网络)
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-12-07 15:08
欢讯网络数据采集器(Ajax版)2.1
环讯网络数据采集器2.1是一个多功能,可以自定义规则规则采集器。
支持ajax无刷新采集,实现无刷新分页的模拟点击。
实现对js生成的内容、采集QQ业务群的业务信息的抓取
1.强大的信息采集功能。采集几乎任何类型的网站信息,包括静态htm、html类型和动态ASP、ASPX、JSP等。N级页面可以与采集关联并自动集成到一个完整记录。支持网页框架、链接和网页加密等。支持完全采集和增量采集(持续挖掘)。可以自动下载二进制文件,如图片、软件、mp3等。可用采集本地磁盘信息。支持Post数据请求采集方法。
2.网站登录。需要登录才能看到的信息,先在任务的“登录设置”中登录,然后就可以采集登录查看信息。
3. 速度快,运行稳定。真正的多线程、多任务,运行时占用系统资源极少,可以长时间稳定运行。(明显不同于其他软件)
4. 丰富的数据存储格式。采集的数据可以保存为Txt、Excel和多种数据库格式(Access sqlserver等)。
5.支持脚本。可以设置脚本类型的任务,类似于javascript:submit('Page',1)等格式都可以轻松采集。
6.强大的新闻采集,自动处理功能。新闻的格式,包括图片,可以自动保留(可以通过设置自动去除广告)。可以通过设置自动下载图片,自动将文中图片的网络路径更改为本地文件路径(也可以保持原样);可以自动将采集的消息处理成自己设计的模板格式;您可以采集 分页新闻。有了这些功能,无需人工干预,只需简单的设置就可以在本地建立一个强大的新闻系统。
7.强大的自动信息再处理功能。采集的信息可以分两批重新处理,使其更符合您的实际需求。还可以设置自动处理公式。在采集的过程中,根据公式自动处理,包括数据合并、数据替换等。
8.提供了从采集,到自动处理,到数据导出(发布)的一站式自动化功能。通过任务调度、实时监控和发布实现。指定某些任务自动运行,自动去除重复后将采集的数据导入数据库(可指定唯一组合)。它可以循环运行。您可以指定在某个时间点运行的任务。可以设置采集,达到一定数据量后,会自动存入库,内存会自动清空。该功能可以连续采集10万级、百万级数据,不占用系统资源。无人值守采集。
9.支持采集的AJAX内容页面,实现独立线程操作。 查看全部
无规则采集器列表算法(环讯网络数据采集器(Ajax版)2.1网络)
欢讯网络数据采集器(Ajax版)2.1
环讯网络数据采集器2.1是一个多功能,可以自定义规则规则采集器。
支持ajax无刷新采集,实现无刷新分页的模拟点击。
实现对js生成的内容、采集QQ业务群的业务信息的抓取
1.强大的信息采集功能。采集几乎任何类型的网站信息,包括静态htm、html类型和动态ASP、ASPX、JSP等。N级页面可以与采集关联并自动集成到一个完整记录。支持网页框架、链接和网页加密等。支持完全采集和增量采集(持续挖掘)。可以自动下载二进制文件,如图片、软件、mp3等。可用采集本地磁盘信息。支持Post数据请求采集方法。
2.网站登录。需要登录才能看到的信息,先在任务的“登录设置”中登录,然后就可以采集登录查看信息。
3. 速度快,运行稳定。真正的多线程、多任务,运行时占用系统资源极少,可以长时间稳定运行。(明显不同于其他软件)
4. 丰富的数据存储格式。采集的数据可以保存为Txt、Excel和多种数据库格式(Access sqlserver等)。
5.支持脚本。可以设置脚本类型的任务,类似于javascript:submit('Page',1)等格式都可以轻松采集。
6.强大的新闻采集,自动处理功能。新闻的格式,包括图片,可以自动保留(可以通过设置自动去除广告)。可以通过设置自动下载图片,自动将文中图片的网络路径更改为本地文件路径(也可以保持原样);可以自动将采集的消息处理成自己设计的模板格式;您可以采集 分页新闻。有了这些功能,无需人工干预,只需简单的设置就可以在本地建立一个强大的新闻系统。
7.强大的自动信息再处理功能。采集的信息可以分两批重新处理,使其更符合您的实际需求。还可以设置自动处理公式。在采集的过程中,根据公式自动处理,包括数据合并、数据替换等。
8.提供了从采集,到自动处理,到数据导出(发布)的一站式自动化功能。通过任务调度、实时监控和发布实现。指定某些任务自动运行,自动去除重复后将采集的数据导入数据库(可指定唯一组合)。它可以循环运行。您可以指定在某个时间点运行的任务。可以设置采集,达到一定数据量后,会自动存入库,内存会自动清空。该功能可以连续采集10万级、百万级数据,不占用系统资源。无人值守采集。
9.支持采集的AJAX内容页面,实现独立线程操作。
无规则采集器列表算法(无规则采集器列表算法解决各个批量采集的问题问题)
采集交流 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-12-03 22:04
无规则采集器列表算法【采集器列表算法】功能介绍解决各个批量采集的问题问题概述最近就有人在群里提了这样的问题,根据不同的操作产生的数据,方法不同或者步骤不同,采集到的数据有可能不是同一批。如果遇到这样的问题,如何将同一批数据加工到不同批次,或者切换不同工作流程,或者聚合加工等这种操作形成一个操作流程【转化方法】来实现解决的思路:将聚合优化的细节挖掘出来,不需要切换工作流的形式即可进行加工使用主流数据源:1-用户发起请求,对数据的操作优化为:使用api,此数据源里面提供了详细的操作流程。
2-采集api(请求一个数据源)-数据不同批次自动分组-聚合、格式处理3-采集api(请求多个数据源)-数据不同批次自动分组-聚合、格式处理4-采集api(请求多个数据源)-不同数据源之间快速分组-聚合、聚合格式处理5-采集api(请求多个数据源)-不同数据源之间快速分组-聚合、聚合格式处理6-采集api(请求多个数据源)-不同数据源之间快速分组-聚合、聚合格式处理7-采集api(请求多个数据源)-不同数据源之间快速分组-聚合、聚合格式处理8-采集api(请求多个数据源)-不同数据源之间快速分组-聚合、聚合格式处理9-采集api(请求多个数据源)-不同数据源之间快速分组-聚合、聚合格式处理10-采集api(请求多个数据源)-不同数据源之间快速分组-聚合、聚合格式处理11-采集api(请求多个数据源)-不同数据源之间快速分组-聚合、聚合格式处理12-采集api(请求多个数据源)-不同数据源之间快速分组-聚合、聚合格式处理13-采集api(请求多个数据源)-不同数据源之间快速分组-聚合、聚合格式处理14-采集api(请求多个数据源)-不同数据源之间快速分组-聚合、聚合格式处理15-采集api(请求多个数据源)-不同数据源之间快速分组-聚合、聚合格式处理。 查看全部
无规则采集器列表算法(无规则采集器列表算法解决各个批量采集的问题问题)
无规则采集器列表算法【采集器列表算法】功能介绍解决各个批量采集的问题问题概述最近就有人在群里提了这样的问题,根据不同的操作产生的数据,方法不同或者步骤不同,采集到的数据有可能不是同一批。如果遇到这样的问题,如何将同一批数据加工到不同批次,或者切换不同工作流程,或者聚合加工等这种操作形成一个操作流程【转化方法】来实现解决的思路:将聚合优化的细节挖掘出来,不需要切换工作流的形式即可进行加工使用主流数据源:1-用户发起请求,对数据的操作优化为:使用api,此数据源里面提供了详细的操作流程。
2-采集api(请求一个数据源)-数据不同批次自动分组-聚合、格式处理3-采集api(请求多个数据源)-数据不同批次自动分组-聚合、格式处理4-采集api(请求多个数据源)-不同数据源之间快速分组-聚合、聚合格式处理5-采集api(请求多个数据源)-不同数据源之间快速分组-聚合、聚合格式处理6-采集api(请求多个数据源)-不同数据源之间快速分组-聚合、聚合格式处理7-采集api(请求多个数据源)-不同数据源之间快速分组-聚合、聚合格式处理8-采集api(请求多个数据源)-不同数据源之间快速分组-聚合、聚合格式处理9-采集api(请求多个数据源)-不同数据源之间快速分组-聚合、聚合格式处理10-采集api(请求多个数据源)-不同数据源之间快速分组-聚合、聚合格式处理11-采集api(请求多个数据源)-不同数据源之间快速分组-聚合、聚合格式处理12-采集api(请求多个数据源)-不同数据源之间快速分组-聚合、聚合格式处理13-采集api(请求多个数据源)-不同数据源之间快速分组-聚合、聚合格式处理14-采集api(请求多个数据源)-不同数据源之间快速分组-聚合、聚合格式处理15-采集api(请求多个数据源)-不同数据源之间快速分组-聚合、聚合格式处理。
无规则采集器列表算法(做过有没有方便功能强大的免费采集工具有哪些?站长怎么说 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-11-25 15:12
)
做过网站的SEO站长都知道,要想稳定持续输出网站优质内容。不建议依赖手动编辑。一个站还可以持久化,10个或者50个都很难持久化,所以我们需要像优采云采集器@>一样使用文章采集器。
首先说一下优采云车采集器,作为一个老的采集工具,作为一个老的采集工具,它已经在采集 行业在互联网上站稳脚跟。然而,随着互联网时代的飞速发展,不便也开始出现。
优采云采集器 是收费的。你可能会说我可以用优采云采集器的破解版。是的,可以这么说,但是用过优采云采集器的站长都知道,使用优采云采集需要我们写采集的规则。说哪个站长会写代码都可以,但是大部分站长都不懂所谓的采集规则,更别说正则表达式了。这让很多小白站长望而却步。另一个是使用优采云采集器采集需要太多的配置参数。我举个例子比如采集Batch 采集页面链接添加就是需要指定第一项,容差,项数。当需要大量不同参数、不同页面的采集数据时,无法手动设置每个任务。
有没有免费的采集 好用、方便、强大的工具?有些必须有。我最近发现了一个优采云采集器的替代产品。使用起来非常方便。您可以采集任何新闻来源。最重要的是,因为开发者,它永远免费。我厌倦了打着免费旗号的采集 软件,但它是收费的。他实在受不了了,干脆写了一套免费的采集工具。仅供SEO分享,不做推荐。
首先设置关键词,选择采集数据源,从采集中选择文章的存储路径,选择一个关键词采集@ > 文章数量,打字后再接收,整个过程不到1分钟。每天挂断采集,还可以同时完成发布任务和推送任务。
SEO 是多维的。我们要做好站内SEO优化,站外没有问题。我们站长各方面都做了,搜索引擎不喜欢你的网站是不合理的。今天的分享就到此为止。我受到启发成为一名 SEO 布道者,我很认真地分享 SEO。不明白的可以在评论区留言,点赞关注,下期我会分享更多与SEO相关的干货!
查看全部
无规则采集器列表算法(做过有没有方便功能强大的免费采集工具有哪些?站长怎么说
)
做过网站的SEO站长都知道,要想稳定持续输出网站优质内容。不建议依赖手动编辑。一个站还可以持久化,10个或者50个都很难持久化,所以我们需要像优采云采集器@>一样使用文章采集器。
首先说一下优采云车采集器,作为一个老的采集工具,作为一个老的采集工具,它已经在采集 行业在互联网上站稳脚跟。然而,随着互联网时代的飞速发展,不便也开始出现。
优采云采集器 是收费的。你可能会说我可以用优采云采集器的破解版。是的,可以这么说,但是用过优采云采集器的站长都知道,使用优采云采集需要我们写采集的规则。说哪个站长会写代码都可以,但是大部分站长都不懂所谓的采集规则,更别说正则表达式了。这让很多小白站长望而却步。另一个是使用优采云采集器采集需要太多的配置参数。我举个例子比如采集Batch 采集页面链接添加就是需要指定第一项,容差,项数。当需要大量不同参数、不同页面的采集数据时,无法手动设置每个任务。
有没有免费的采集 好用、方便、强大的工具?有些必须有。我最近发现了一个优采云采集器的替代产品。使用起来非常方便。您可以采集任何新闻来源。最重要的是,因为开发者,它永远免费。我厌倦了打着免费旗号的采集 软件,但它是收费的。他实在受不了了,干脆写了一套免费的采集工具。仅供SEO分享,不做推荐。
首先设置关键词,选择采集数据源,从采集中选择文章的存储路径,选择一个关键词采集@ > 文章数量,打字后再接收,整个过程不到1分钟。每天挂断采集,还可以同时完成发布任务和推送任务。
SEO 是多维的。我们要做好站内SEO优化,站外没有问题。我们站长各方面都做了,搜索引擎不喜欢你的网站是不合理的。今天的分享就到此为止。我受到启发成为一名 SEO 布道者,我很认真地分享 SEO。不明白的可以在评论区留言,点赞关注,下期我会分享更多与SEO相关的干货!
无规则采集器列表算法(一下梦的后台开发个好几个项目,简单易上手总结 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-11-25 11:00
)
我利用织梦的背景开发了几个项目。最近了解了织梦的采集。我觉得它简单易用。这里简单总结一下采集的流程,希望遇到的问题对大家有所帮助。
一:采集侠下载安装
可以选择直接在官网下载:安装步骤和一切都可以在官网找到。安装后,您可以在后台管理系统中看到更多本节内容。网站继续采集。
二:采集 规则:
<p>1.点击采集添加新节点,新节点可以是自己的列名,然后进入规则编辑页面,记得选择目标 查看全部
无规则采集器列表算法(一下梦的后台开发个好几个项目,简单易上手总结
)
我利用织梦的背景开发了几个项目。最近了解了织梦的采集。我觉得它简单易用。这里简单总结一下采集的流程,希望遇到的问题对大家有所帮助。
一:采集侠下载安装
可以选择直接在官网下载:安装步骤和一切都可以在官网找到。安装后,您可以在后台管理系统中看到更多本节内容。网站继续采集。
二:采集 规则:
<p>1.点击采集添加新节点,新节点可以是自己的列名,然后进入规则编辑页面,记得选择目标
无规则采集器列表算法(不接受差评DXC来自Discuz!X2(X2.5))
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-11-25 10:14
vip版不好用,购买三天内可以随时退款。如果超过三天,如果软件有问题,也可以全额退款。
所以不接受差评
DXC 来自 Discuz!X2(X2.5)合集缩写,DXC采集插件专用于discuz上的内容解决方案,帮助站长更快捷方便地构建网站内容。
通过DXC采集插件,用户可以方便地从互联网上获取数据采集,包括会员数据,以及文章数据。此外,还有虚拟在线、单帖采集等辅助功能,让一个冷清的新论坛瞬间形成一个内容丰富、会员活跃的热门论坛,对网站的初期运营有很大帮助。论坛。它是新手站长必须安装的discuz应用程序。
DXC2.5的主要功能包括:
1、多种形式的url列表为采集文章,包括rss地址、列表页面、多层列表等。
2、 多种写规则方式,dom方式,字符拦截,智能获取,更方便获取你想要的内容
3、 规则继承,自动检测匹配规则功能,你会慢慢体会到规则继承带来的便利
4、独特的网页正文提取算法,可以自动学习归纳规则,更方便进行泛化采集。
5、支持图片定位,添加水印功能
6、 灵活的发布机制,可以自定义发布者、发布时间点击率等。
7、强大的内容编辑后台,您可以轻松编辑采集到达的内容,并发布到门户、论坛、博客
8、 内容过滤功能,过滤采集 广告的内容,去除不必要的区域
9、批量采集,注册会员,批量采集,设置会员头像
10、无人值守定时定量采集及发布文章
下载链接
下载地址.txt
现在就下载
10
你没有购买
轻币
以上或VIP会员【购买VIP】【充值】 查看全部
无规则采集器列表算法(不接受差评DXC来自Discuz!X2(X2.5))
vip版不好用,购买三天内可以随时退款。如果超过三天,如果软件有问题,也可以全额退款。
所以不接受差评
DXC 来自 Discuz!X2(X2.5)合集缩写,DXC采集插件专用于discuz上的内容解决方案,帮助站长更快捷方便地构建网站内容。
通过DXC采集插件,用户可以方便地从互联网上获取数据采集,包括会员数据,以及文章数据。此外,还有虚拟在线、单帖采集等辅助功能,让一个冷清的新论坛瞬间形成一个内容丰富、会员活跃的热门论坛,对网站的初期运营有很大帮助。论坛。它是新手站长必须安装的discuz应用程序。
DXC2.5的主要功能包括:
1、多种形式的url列表为采集文章,包括rss地址、列表页面、多层列表等。
2、 多种写规则方式,dom方式,字符拦截,智能获取,更方便获取你想要的内容
3、 规则继承,自动检测匹配规则功能,你会慢慢体会到规则继承带来的便利
4、独特的网页正文提取算法,可以自动学习归纳规则,更方便进行泛化采集。
5、支持图片定位,添加水印功能
6、 灵活的发布机制,可以自定义发布者、发布时间点击率等。
7、强大的内容编辑后台,您可以轻松编辑采集到达的内容,并发布到门户、论坛、博客
8、 内容过滤功能,过滤采集 广告的内容,去除不必要的区域
9、批量采集,注册会员,批量采集,设置会员头像
10、无人值守定时定量采集及发布文章
下载链接
下载地址.txt
现在就下载
10
你没有购买
轻币
以上或VIP会员【购买VIP】【充值】
无规则采集器列表算法(爬虫路线规划能力集GooSeeker网络爬虫沿着线索扩展爬行范围)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-11-24 22:09
履带式路线规划能力
GooSeeker 网络爬虫沿着线索扩展了爬取范围等等。免费网络版用户在墨书台的爬虫路线工作台上规划爬虫路线。主要能力是:从抓取到的URL建立下一级线索。这是深度方向。同时,捕捉到不止一条低级线索。,那么就是向广度方向扩展了。
简而言之,网络爬虫在抓取网页数据时,会利用一些网址作为广度或深度方向扩展的线索。免费在线版只能在定义爬取规则时规划爬虫路径;而企业版可以有更多的选项来规划爬虫路线。
清理结果并存入数据库时,生成深度和广度方向的线索。这是企业版常用的方法。此时,企业版的 GooSeeker 具有最大的灵活性和控制力。例如,您可以使用仓储脚本程序。控制爬虫路由的生成,可以替换URL中的参数,可以按照URL地址规律批量生成URL,可以按照一定的规则过滤一批URL,等等。
最大的灵活性在于爬虫路由的生成时间。当使用网页抓取进行探索性研究时,可以根据需要随时扩展爬虫的深度和广度。不需要在第一次数据清洗过程中生成所有的线索。事实上,如果有必要,当时可能并不知道。扩大爬行范围。也很容易认识到,同一个 URL 可以用于多个爬取主题,服务于不同的研究目的。
典型
在某品牌手机的消费者洞察系统中,除了常规的网络爬取和数据挖掘,还需要一些事件驱动的爬取,比如某个手机会议的效果分析,一些in-深度数据挖掘,比如消费群体。差异研究。为了配合这些分析研究,往往需要灵活的网络爬虫路径规划。在探索和研究的过程中,不断增加新的数据源,要求网络爬虫在深度和广度扩展时具有足够的灵活性。只有企业版的 GooSeeker 网络爬虫才有这个能力。 查看全部
无规则采集器列表算法(爬虫路线规划能力集GooSeeker网络爬虫沿着线索扩展爬行范围)
履带式路线规划能力
GooSeeker 网络爬虫沿着线索扩展了爬取范围等等。免费网络版用户在墨书台的爬虫路线工作台上规划爬虫路线。主要能力是:从抓取到的URL建立下一级线索。这是深度方向。同时,捕捉到不止一条低级线索。,那么就是向广度方向扩展了。
简而言之,网络爬虫在抓取网页数据时,会利用一些网址作为广度或深度方向扩展的线索。免费在线版只能在定义爬取规则时规划爬虫路径;而企业版可以有更多的选项来规划爬虫路线。
清理结果并存入数据库时,生成深度和广度方向的线索。这是企业版常用的方法。此时,企业版的 GooSeeker 具有最大的灵活性和控制力。例如,您可以使用仓储脚本程序。控制爬虫路由的生成,可以替换URL中的参数,可以按照URL地址规律批量生成URL,可以按照一定的规则过滤一批URL,等等。
最大的灵活性在于爬虫路由的生成时间。当使用网页抓取进行探索性研究时,可以根据需要随时扩展爬虫的深度和广度。不需要在第一次数据清洗过程中生成所有的线索。事实上,如果有必要,当时可能并不知道。扩大爬行范围。也很容易认识到,同一个 URL 可以用于多个爬取主题,服务于不同的研究目的。
典型
在某品牌手机的消费者洞察系统中,除了常规的网络爬取和数据挖掘,还需要一些事件驱动的爬取,比如某个手机会议的效果分析,一些in-深度数据挖掘,比如消费群体。差异研究。为了配合这些分析研究,往往需要灵活的网络爬虫路径规划。在探索和研究的过程中,不断增加新的数据源,要求网络爬虫在深度和广度扩展时具有足够的灵活性。只有企业版的 GooSeeker 网络爬虫才有这个能力。
无规则采集器列表算法(本文介绍如何使用优采云采集器的智能模式,免费采集和讯网新闻)
采集交流 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-11-24 09:05
本文介绍如何使用优采云采集器的智能模式,免费提供采集和讯网新闻标题、内容、发布时间等信息。
采集工具介绍:
优采云采集器是基于人工智能技术的网页采集器,只需要输入网址即可自动识别网页数据,无需配置即可完成数据采集 ,是业界第一款支持三种操作系统(包括Windows、Mac和Linux)的网络爬虫软件。
本软件是一款真正免费的数据采集软件,对采集结果的导出没有限制。没有编程基础的新手用户也可以轻松实现数据采集需求。
官方网站:
采集对象介绍:
和讯网成立于1996年,起源于中国早期的金融证券信息服务,创立了第一家金融信息垂直行业网站。经过22年的努力,和讯网在行业中逐渐确立了优势地位和品牌影响力。
采集字段:
新闻标题、新闻链接、发布时间、新闻来源、新闻内容、评论数
功能点目录:
如何配置采集字段
如何采集列表+详情页类型网页
采集结果预览:
下面我们来详细介绍一下如何免费采集和讯新闻数据。我们以和讯新闻国内时事为例。具体步骤如下:
第一步:下载安装优采云采集器,注册登录
1、打开优采云采集器官网,下载安装最新版优采云采集器
2、点击注册登录,注册一个新账号,登录优采云采集器
【温馨提示】本爬虫软件无需注册即可直接使用,但切换到注册用户后匿名账号下的任务会丢失,建议注册后使用。
优采云采集器是优采云的产物,优采云用户可以直接登录。
第二步:新建一个采集任务
1、复制和讯网国内时事新闻页面地址(需要搜索结果页面的URL,不是首页的URL)
单击此处了解如何正确输入 URL。
2、新智能模式采集任务
可以直接在软件上创建采集任务,也可以通过导入规则来创建任务。
单击此处了解如何导入和导出 采集 规则。
第三步:配置采集规则
1、设置提取数据字段
在智能模式下,我们输入网址后,软件会自动识别页面上的数据并生成采集结果。每种类型的数据对应一个 采集 字段。我们可以右击该字段进行相关设置。包括修改字段名、加减字段、处理数据等。
单击此处了解如何配置 采集 字段。
在列表页面,我们需要采集新浪新闻的新闻标题、新闻链接和发布时间。字段设置如下:
2、使用深入采集函数提取详情页数据
列表页只显示和讯网的部分新闻。如果您需要详细的新闻内容,我们需要右击新闻链接,然后使用“深度采集”功能跳转到详情页继续采集。
单击此处了解有关如何采集列表+详细信息页面类型网页的更多信息。
在详情页,我们可以看到新闻来源、新闻内容和评论数。我们可以点击“添加字段”来添加采集字段。字段设置效果如下:
【提醒】当整个新闻内容为采集时,可以将鼠标移动到新闻内容的后半部分,看到蓝色区域全选时,可以点击选择,可以提取所有整个新闻 新闻的内容。
第四步:设置并启动采集任务
1、设置采集 任务
完成采集数据添加后,我们就可以开始采集任务了。在开始之前,我们需要对采集任务进行一些设置,以提高采集的稳定性和成功率。
点击“设置”按钮,在弹出的运行设置页面我们可以设置运行设置和防拦截设置,这里我们勾选“跳过继续采集”,设置“2”秒的请求等待时间,勾选“不加载网页图片”,防拦截设置将按照系统默认设置,然后点击保存。
单击此处了解有关如何配置 采集 任务的更多信息。
2、开始采集任务
点击“保存并启动”按钮,在弹出的页面中进行一些高级设置,包括定时启动、自动存储和下载图片。本例中不使用这些功能,直接点击“开始”运行爬虫工具即可。
单击此处了解有关计时的更多信息采集。
单击此处了解有关什么是自动存储的更多信息。
单击此处了解有关如何下载图片的更多信息。
【温馨提示】免费版可以使用非周期性定时采集功能,下载图片功能免费。个人专业版及以上可使用高级定时功能和自动存储功能。
3、运行任务提取数据
<p>任务启动后会自动启动采集数据,我们可以从界面直观的看到程序运行过程和采集的运行结果, 查看全部
无规则采集器列表算法(本文介绍如何使用优采云采集器的智能模式,免费采集和讯网新闻)
本文介绍如何使用优采云采集器的智能模式,免费提供采集和讯网新闻标题、内容、发布时间等信息。
采集工具介绍:
优采云采集器是基于人工智能技术的网页采集器,只需要输入网址即可自动识别网页数据,无需配置即可完成数据采集 ,是业界第一款支持三种操作系统(包括Windows、Mac和Linux)的网络爬虫软件。
本软件是一款真正免费的数据采集软件,对采集结果的导出没有限制。没有编程基础的新手用户也可以轻松实现数据采集需求。
官方网站:
采集对象介绍:
和讯网成立于1996年,起源于中国早期的金融证券信息服务,创立了第一家金融信息垂直行业网站。经过22年的努力,和讯网在行业中逐渐确立了优势地位和品牌影响力。
采集字段:
新闻标题、新闻链接、发布时间、新闻来源、新闻内容、评论数
功能点目录:
如何配置采集字段
如何采集列表+详情页类型网页
采集结果预览:
下面我们来详细介绍一下如何免费采集和讯新闻数据。我们以和讯新闻国内时事为例。具体步骤如下:
第一步:下载安装优采云采集器,注册登录
1、打开优采云采集器官网,下载安装最新版优采云采集器
2、点击注册登录,注册一个新账号,登录优采云采集器
【温馨提示】本爬虫软件无需注册即可直接使用,但切换到注册用户后匿名账号下的任务会丢失,建议注册后使用。
优采云采集器是优采云的产物,优采云用户可以直接登录。
第二步:新建一个采集任务
1、复制和讯网国内时事新闻页面地址(需要搜索结果页面的URL,不是首页的URL)
单击此处了解如何正确输入 URL。
2、新智能模式采集任务
可以直接在软件上创建采集任务,也可以通过导入规则来创建任务。
单击此处了解如何导入和导出 采集 规则。
第三步:配置采集规则
1、设置提取数据字段
在智能模式下,我们输入网址后,软件会自动识别页面上的数据并生成采集结果。每种类型的数据对应一个 采集 字段。我们可以右击该字段进行相关设置。包括修改字段名、加减字段、处理数据等。
单击此处了解如何配置 采集 字段。
在列表页面,我们需要采集新浪新闻的新闻标题、新闻链接和发布时间。字段设置如下:
2、使用深入采集函数提取详情页数据
列表页只显示和讯网的部分新闻。如果您需要详细的新闻内容,我们需要右击新闻链接,然后使用“深度采集”功能跳转到详情页继续采集。
单击此处了解有关如何采集列表+详细信息页面类型网页的更多信息。
在详情页,我们可以看到新闻来源、新闻内容和评论数。我们可以点击“添加字段”来添加采集字段。字段设置效果如下:
【提醒】当整个新闻内容为采集时,可以将鼠标移动到新闻内容的后半部分,看到蓝色区域全选时,可以点击选择,可以提取所有整个新闻 新闻的内容。
第四步:设置并启动采集任务
1、设置采集 任务
完成采集数据添加后,我们就可以开始采集任务了。在开始之前,我们需要对采集任务进行一些设置,以提高采集的稳定性和成功率。
点击“设置”按钮,在弹出的运行设置页面我们可以设置运行设置和防拦截设置,这里我们勾选“跳过继续采集”,设置“2”秒的请求等待时间,勾选“不加载网页图片”,防拦截设置将按照系统默认设置,然后点击保存。
单击此处了解有关如何配置 采集 任务的更多信息。
2、开始采集任务
点击“保存并启动”按钮,在弹出的页面中进行一些高级设置,包括定时启动、自动存储和下载图片。本例中不使用这些功能,直接点击“开始”运行爬虫工具即可。
单击此处了解有关计时的更多信息采集。
单击此处了解有关什么是自动存储的更多信息。
单击此处了解有关如何下载图片的更多信息。
【温馨提示】免费版可以使用非周期性定时采集功能,下载图片功能免费。个人专业版及以上可使用高级定时功能和自动存储功能。
3、运行任务提取数据
<p>任务启动后会自动启动采集数据,我们可以从界面直观的看到程序运行过程和采集的运行结果,
无规则采集器列表算法(重庆邮电大学应用技术学院二八年四月《算法分析与设计》实验目的与要求)
采集交流 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2021-11-22 14:11
《算法分析与设计》实验指导书,重庆邮电大学应用技术学院,4月28日,《算法分析与设计》实验目的与要求一、实验目的算法分析与设计是其中之一信息与计算科学专业 重要专业课程。当用计算机解决实际问题时,涉及对实际问题的抽象模拟,即数学建模的过程,然后设计相应的求解算法来解决实际问题,同时也验证设计的算法能够be 任务可以在可承受或可到达的时间和空间内完成,因此算法的分析和设计就成为一个非常重要的环节。通过理论课的学习,我们知道要设计一个算法,必须从算法设计->算法确认->算法分析->编码->检查->调试->计时开始。七大步骤是严格执行的,所以读者可以严格按照以上步骤进行,为以后的算法研究工作打下坚实的基础。二、实验要求 1. 准备登机所需的手续,人工检查后方可登机,以提高登机效率。在程序中对您有问题的地方进行标记,以便您在上机时注意它们。请勿复制他人编译的程序。2. 在计算机上输入和调试编译好的程序。3.电脑结束后,
如果程序失败,应分析原因。三、实验步骤 1. 问题分析和任务定义明确问题需要什么,限制做什么(这一步强调做什么,而不是怎么做)。问题的描述应该避开算法和涉及的数据类型,而是对完成的任务给出明确的答案。如输入数据类型、取值范围和输入形式;输出数据类型、取值范围和输出形式;这个异步还应该为调试器准备测试数据,包括合法输入数据和非法输入数据。2、数据类型和系统设计在这一步设计中分为逻辑设计和详细设计。逻辑设计是指为问题描述中涉及的操作对象定义相应的数据类型,以数据结构为中心的原则划分模块,定义主模块和各个抽象数据类型;详细设计是定义相应的存储结构,编写每个函数的伪代码算法。在这个过程中,要综合考虑系统的功能,使系统结构清晰、合理、简单、便于调试。抽象数据类型的实现尽量做到数据封装,基本操作规范尽量清晰具体。作为逻辑设计的结果。每个抽象数据类型的定义(包括数据结构的描述和每个基本操作的规范),每个主要模块的算法都要写,并绘制模块之间的调用关系图。详细设计的结果是进一步细化数据结构和基本操作的规范,编写数据存储结构的类型定义,并按照类C语言以函数形式编写算法框架。算法编写规范。
3. 编码实现和静态检查4。上机准备与调试 5.总结整理实习报告四、 实验总结了实验中发现的问题,调试中的问题分析和解决方法,以及改进的意见、建议、收获和经验算法。实验报告参考标准:实验题目类名、学号、日期使用C语言定义相关数据类型;实验一 斐波那契数列实验目的 1. 掌握递归算法及其编程方法;总实验课时:2课时/1个实验内容 1.使用递归或非递归的方法实现斐波那契数列。第n个斐波那契数列的描述如下:F(n)=f(n-1)+f(n-2) 2)。掌握排序算法分析和编程方法;总实验课时:2课时/1个实验内容 1.完成如下程序,实现数组的降序排序#include void sort( intmain() intarray[]={45,56,76,234,1,34,23 ,2,3}; //数字任意给排序( voidsort( 实验要求一、 方法不限,课前提交word文档,包括程序代码,运行结果截图,实验四螺旋序列实验目的1.,掌握算法分析和编程方法; 实验课时 总课时:2课时/1 实验内容如图: 1216 15 14 13 设置“1”的坐标为(0, 0) 和“7”的坐标为 (-1, -1)
实验要求一、 方法不限,下课前提交word文档,内容包括程序代码、运行结果截图、实验目的。1.,掌握算法分析和编程方法;实验总课时:2课时/1课时实验内容从下列问题中选择40分作为实验的实验内容。1、(15分)要求:随机生成一个字符串,每次字符串的内容长度不同2、(15分)将整数转换为字符串:char* itoa(int); 例如 itoa(-123) 返回 "-123"; 3、
输入数据:一个正整数,以命令行参数的形式提供给程序。输出数据:在标准输出上打印出所有符合标题描述的正整数序列,每行一个序列,每个序列从序列的最小正整数开始,按升序打印。如果结果中有多个序列,则按照每个序列的最小正整数从小到大打印序列。另外,序列不允许重复,序列中的整数之间用空格隔开。如果没有满足要求的序列,则输出“NONE”。例如,对于15,输出结果是: 对于16,输出结果是:NONE 8、 (25分) 标题描述是为了让员工在紧张的工作时间内放松一下,百度休息室配有按摩椅、CD、高尔夫球服和Wii游戏机等休闲产品。最受欢迎的当然是游戏机之一。wii游戏机的每个手柄需要两块电池(两块电池可以是不同品牌的)。工程师们正在玩游戏。如果手柄没电了,他们会把没电的电池拿走,换上全新的电池。如果有电,他们必须继续使用。比如,众所周知,三种电池的使用时间都是小时,当手柄再次没电时,就没有可用的电池了。但是如果你在开始时使用那个小时。告诉您每个品牌电池的使用时间和该品牌电池的数量。请计算工程师上场时间的最小值和最大值。输入格式输入的第一行是一个正整数。输出格式只有一行。它收录两个整数,分别代表工程师最短的游戏时间和最长的游戏时间(时间最短的在前)。
一个空格分隔两个整数。输入样例9、(25分)标题说明百度蜘蛛在烤鸡翅唱明星经典的同时达到高潮。大家围着篝火围成一圈,开始进行强化游戏。规则如下:当号码中收录相同号码时,规则通过。请注意,相同的数字不必相邻。比如121史上最强程序员的帮助。百度工程师想知道:req1的数量是多少?req12 的数量是多少?查询中的号码是多少?以输入格式输入的每一行都是一个查询,由一个查询词和一个无符号整数组成。有四种查询,查询词为req1查询(区分大小写)。输出格式 前三个查询输出一个无符号整数解。对于规则中的数字,输出对应的解,否则输出-1。输入样本 req1 10 req2 10 req12 10 查询 14 输出样本 11 10 12 -1 13 补充说明 1 查看全部
无规则采集器列表算法(重庆邮电大学应用技术学院二八年四月《算法分析与设计》实验目的与要求)
《算法分析与设计》实验指导书,重庆邮电大学应用技术学院,4月28日,《算法分析与设计》实验目的与要求一、实验目的算法分析与设计是其中之一信息与计算科学专业 重要专业课程。当用计算机解决实际问题时,涉及对实际问题的抽象模拟,即数学建模的过程,然后设计相应的求解算法来解决实际问题,同时也验证设计的算法能够be 任务可以在可承受或可到达的时间和空间内完成,因此算法的分析和设计就成为一个非常重要的环节。通过理论课的学习,我们知道要设计一个算法,必须从算法设计->算法确认->算法分析->编码->检查->调试->计时开始。七大步骤是严格执行的,所以读者可以严格按照以上步骤进行,为以后的算法研究工作打下坚实的基础。二、实验要求 1. 准备登机所需的手续,人工检查后方可登机,以提高登机效率。在程序中对您有问题的地方进行标记,以便您在上机时注意它们。请勿复制他人编译的程序。2. 在计算机上输入和调试编译好的程序。3.电脑结束后,
如果程序失败,应分析原因。三、实验步骤 1. 问题分析和任务定义明确问题需要什么,限制做什么(这一步强调做什么,而不是怎么做)。问题的描述应该避开算法和涉及的数据类型,而是对完成的任务给出明确的答案。如输入数据类型、取值范围和输入形式;输出数据类型、取值范围和输出形式;这个异步还应该为调试器准备测试数据,包括合法输入数据和非法输入数据。2、数据类型和系统设计在这一步设计中分为逻辑设计和详细设计。逻辑设计是指为问题描述中涉及的操作对象定义相应的数据类型,以数据结构为中心的原则划分模块,定义主模块和各个抽象数据类型;详细设计是定义相应的存储结构,编写每个函数的伪代码算法。在这个过程中,要综合考虑系统的功能,使系统结构清晰、合理、简单、便于调试。抽象数据类型的实现尽量做到数据封装,基本操作规范尽量清晰具体。作为逻辑设计的结果。每个抽象数据类型的定义(包括数据结构的描述和每个基本操作的规范),每个主要模块的算法都要写,并绘制模块之间的调用关系图。详细设计的结果是进一步细化数据结构和基本操作的规范,编写数据存储结构的类型定义,并按照类C语言以函数形式编写算法框架。算法编写规范。
3. 编码实现和静态检查4。上机准备与调试 5.总结整理实习报告四、 实验总结了实验中发现的问题,调试中的问题分析和解决方法,以及改进的意见、建议、收获和经验算法。实验报告参考标准:实验题目类名、学号、日期使用C语言定义相关数据类型;实验一 斐波那契数列实验目的 1. 掌握递归算法及其编程方法;总实验课时:2课时/1个实验内容 1.使用递归或非递归的方法实现斐波那契数列。第n个斐波那契数列的描述如下:F(n)=f(n-1)+f(n-2) 2)。掌握排序算法分析和编程方法;总实验课时:2课时/1个实验内容 1.完成如下程序,实现数组的降序排序#include void sort( intmain() intarray[]={45,56,76,234,1,34,23 ,2,3}; //数字任意给排序( voidsort( 实验要求一、 方法不限,课前提交word文档,包括程序代码,运行结果截图,实验四螺旋序列实验目的1.,掌握算法分析和编程方法; 实验课时 总课时:2课时/1 实验内容如图: 1216 15 14 13 设置“1”的坐标为(0, 0) 和“7”的坐标为 (-1, -1)
实验要求一、 方法不限,下课前提交word文档,内容包括程序代码、运行结果截图、实验目的。1.,掌握算法分析和编程方法;实验总课时:2课时/1课时实验内容从下列问题中选择40分作为实验的实验内容。1、(15分)要求:随机生成一个字符串,每次字符串的内容长度不同2、(15分)将整数转换为字符串:char* itoa(int); 例如 itoa(-123) 返回 "-123"; 3、
输入数据:一个正整数,以命令行参数的形式提供给程序。输出数据:在标准输出上打印出所有符合标题描述的正整数序列,每行一个序列,每个序列从序列的最小正整数开始,按升序打印。如果结果中有多个序列,则按照每个序列的最小正整数从小到大打印序列。另外,序列不允许重复,序列中的整数之间用空格隔开。如果没有满足要求的序列,则输出“NONE”。例如,对于15,输出结果是: 对于16,输出结果是:NONE 8、 (25分) 标题描述是为了让员工在紧张的工作时间内放松一下,百度休息室配有按摩椅、CD、高尔夫球服和Wii游戏机等休闲产品。最受欢迎的当然是游戏机之一。wii游戏机的每个手柄需要两块电池(两块电池可以是不同品牌的)。工程师们正在玩游戏。如果手柄没电了,他们会把没电的电池拿走,换上全新的电池。如果有电,他们必须继续使用。比如,众所周知,三种电池的使用时间都是小时,当手柄再次没电时,就没有可用的电池了。但是如果你在开始时使用那个小时。告诉您每个品牌电池的使用时间和该品牌电池的数量。请计算工程师上场时间的最小值和最大值。输入格式输入的第一行是一个正整数。输出格式只有一行。它收录两个整数,分别代表工程师最短的游戏时间和最长的游戏时间(时间最短的在前)。
一个空格分隔两个整数。输入样例9、(25分)标题说明百度蜘蛛在烤鸡翅唱明星经典的同时达到高潮。大家围着篝火围成一圈,开始进行强化游戏。规则如下:当号码中收录相同号码时,规则通过。请注意,相同的数字不必相邻。比如121史上最强程序员的帮助。百度工程师想知道:req1的数量是多少?req12 的数量是多少?查询中的号码是多少?以输入格式输入的每一行都是一个查询,由一个查询词和一个无符号整数组成。有四种查询,查询词为req1查询(区分大小写)。输出格式 前三个查询输出一个无符号整数解。对于规则中的数字,输出对应的解,否则输出-1。输入样本 req1 10 req2 10 req12 10 查询 14 输出样本 11 10 12 -1 13 补充说明 1
无规则采集器列表算法( 本文介绍了的原理和实现细节介绍简介)
采集交流 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2021-11-22 04:05
本文介绍了的原理和实现细节介绍简介)
负载均衡
本文介绍了负载均衡的原理和实现细节
1.简介
LoadBalance中文意思是负载均衡,它的职责是将网络请求或其他形式的负载“分担”到不同的机器上。避免出现集群中某些服务器压力过大而其他服务器空闲的情况。通过负载均衡,每个服务器都可以获得与其处理能力相适应的负载。在卸载高负载服务器的同时,也可以避免资源浪费,一石两用。负载均衡可分为软件负载均衡和硬件负载均衡。在我们日常开发中,一般很难接入硬件负载均衡。但是软件负载均衡还是可以的,比如Nginx。在 Dubbo 中,也有负载均衡的概念和相应的实现。Dubbo 需要对服务消费者的调用请求进行分配,避免少数服务提供者负载过大。服务提供者过载,这会导致一些请求超时。因此,非常有必要平衡各个服务提供商之间的负载。Dubbo 提供了四种负载均衡的实现,分别是基于加权随机算法的 RandomLoadBalance、基于最少活跃调用数算法的 LeastActiveLoadBalance、基于哈希一致性的 ConsistentHashLoadBalance 和基于加权轮询算法的 RoundRobinLoadBalance。这些负载均衡算法的代码都不是很长,但是理解起来并不容易。你需要对这些算法的原理有一定的了解。如果你不是很了解,也不要太担心。
本系列文章在写作之初基于Dubbo 2.6.4。最近,Dubbo 2.6.5 发布了,其中一些针对均衡部分的负载优化。因此,在分析完2.6. 4 版本之后的源码后,我们也会分析2.6.5 的更新部分。其他的就不多说了,进入正题。
2.源码分析
在 Dubbo 中,所有的负载均衡实现类都继承自 AbstractLoadBalance,它实现了 LoadBalance 接口并封装了一些常用的逻辑。所以在分析负载均衡的实现之前,我们先来看看AbstractLoadBalance的逻辑。先看负载均衡的入口方法select,如下:
@Override
public Invoker select(List invokers, URL url, Invocation invocation) {
if (invokers == null || invokers.isEmpty())
return null;
// 如果 invokers 列表中仅有一个 Invoker,直接返回即可,无需进行负载均衡
if (invokers.size() == 1)
return invokers.get(0);
// 调用 doSelect 方法进行负载均衡,该方法为抽象方法,由子类实现
return doSelect(invokers, url, invocation);
}
protected abstract Invoker doSelect(List invokers, URL url, Invocation invocation);
select方法的逻辑比较简单。首先检查调用者集合的有效性,然后检测调用者集合中元素的数量。如果只收录一个 Invoker,直接返回 Invoker。如果收录多个Invoker,则需要通过负载均衡算法选择一个Invoker。具体的负载均衡算法是由子类实现的,后面的章节将详细分析这些子类。
AbstractLoadBalance除了实现LoadBalance接口方法外,还封装了一些常用的逻辑,比如服务提供者权重计算逻辑。具体实现如下:
<p>protected int getWeight(Invoker invoker, Invocation invocation) {
// 从 url 中获取权重 weight 配置值
int weight = invoker.getUrl().getMethodParameter(invocation.getMethodName(), Constants.WEIGHT_KEY, Constants.DEFAULT_WEIGHT);
if (weight > 0) {
// 获取服务提供者启动时间戳
long timestamp = invoker.getUrl().getParameter(Constants.REMOTE_TIMESTAMP_KEY, 0L);
if (timestamp > 0L) {
// 计算服务提供者运行时长
int uptime = (int) (System.currentTimeMillis() - timestamp);
// 获取服务预热时间,默认为10分钟
int warmup = invoker.getUrl().getParameter(Constants.WARMUP_KEY, Constants.DEFAULT_WARMUP);
// 如果服务运行时间小于预热时间,则重新计算服务权重,即降权
if (uptime > 0 && uptime 0 && !sameWeight) {
// 随机获取一个 [0, totalWeight) 区间内的数字
int offset = random.nextInt(totalWeight);
// 循环让 offset 数减去服务提供者权重值,当 offset 小于0时,返回相应的 Invoker。
// 举例说明一下,我们有 servers = [A, B, C],weights = [5, 3, 2],offset = 7。
// 第一次循环,offset - 5 = 2 > 0,即 offset > 5,
// 表明其不会落在服务器 A 对应的区间上。
// 第二次循环,offset - 3 = -1 < 0,即 5 < offset < 8,
// 表明其会落在服务器 B 对应的区间上
for (int i = 0; i 查看全部
无规则采集器列表算法(
本文介绍了的原理和实现细节介绍简介)
负载均衡
本文介绍了负载均衡的原理和实现细节
1.简介
LoadBalance中文意思是负载均衡,它的职责是将网络请求或其他形式的负载“分担”到不同的机器上。避免出现集群中某些服务器压力过大而其他服务器空闲的情况。通过负载均衡,每个服务器都可以获得与其处理能力相适应的负载。在卸载高负载服务器的同时,也可以避免资源浪费,一石两用。负载均衡可分为软件负载均衡和硬件负载均衡。在我们日常开发中,一般很难接入硬件负载均衡。但是软件负载均衡还是可以的,比如Nginx。在 Dubbo 中,也有负载均衡的概念和相应的实现。Dubbo 需要对服务消费者的调用请求进行分配,避免少数服务提供者负载过大。服务提供者过载,这会导致一些请求超时。因此,非常有必要平衡各个服务提供商之间的负载。Dubbo 提供了四种负载均衡的实现,分别是基于加权随机算法的 RandomLoadBalance、基于最少活跃调用数算法的 LeastActiveLoadBalance、基于哈希一致性的 ConsistentHashLoadBalance 和基于加权轮询算法的 RoundRobinLoadBalance。这些负载均衡算法的代码都不是很长,但是理解起来并不容易。你需要对这些算法的原理有一定的了解。如果你不是很了解,也不要太担心。
本系列文章在写作之初基于Dubbo 2.6.4。最近,Dubbo 2.6.5 发布了,其中一些针对均衡部分的负载优化。因此,在分析完2.6. 4 版本之后的源码后,我们也会分析2.6.5 的更新部分。其他的就不多说了,进入正题。
2.源码分析
在 Dubbo 中,所有的负载均衡实现类都继承自 AbstractLoadBalance,它实现了 LoadBalance 接口并封装了一些常用的逻辑。所以在分析负载均衡的实现之前,我们先来看看AbstractLoadBalance的逻辑。先看负载均衡的入口方法select,如下:
@Override
public Invoker select(List invokers, URL url, Invocation invocation) {
if (invokers == null || invokers.isEmpty())
return null;
// 如果 invokers 列表中仅有一个 Invoker,直接返回即可,无需进行负载均衡
if (invokers.size() == 1)
return invokers.get(0);
// 调用 doSelect 方法进行负载均衡,该方法为抽象方法,由子类实现
return doSelect(invokers, url, invocation);
}
protected abstract Invoker doSelect(List invokers, URL url, Invocation invocation);
select方法的逻辑比较简单。首先检查调用者集合的有效性,然后检测调用者集合中元素的数量。如果只收录一个 Invoker,直接返回 Invoker。如果收录多个Invoker,则需要通过负载均衡算法选择一个Invoker。具体的负载均衡算法是由子类实现的,后面的章节将详细分析这些子类。
AbstractLoadBalance除了实现LoadBalance接口方法外,还封装了一些常用的逻辑,比如服务提供者权重计算逻辑。具体实现如下:
<p>protected int getWeight(Invoker invoker, Invocation invocation) {
// 从 url 中获取权重 weight 配置值
int weight = invoker.getUrl().getMethodParameter(invocation.getMethodName(), Constants.WEIGHT_KEY, Constants.DEFAULT_WEIGHT);
if (weight > 0) {
// 获取服务提供者启动时间戳
long timestamp = invoker.getUrl().getParameter(Constants.REMOTE_TIMESTAMP_KEY, 0L);
if (timestamp > 0L) {
// 计算服务提供者运行时长
int uptime = (int) (System.currentTimeMillis() - timestamp);
// 获取服务预热时间,默认为10分钟
int warmup = invoker.getUrl().getParameter(Constants.WARMUP_KEY, Constants.DEFAULT_WARMUP);
// 如果服务运行时间小于预热时间,则重新计算服务权重,即降权
if (uptime > 0 && uptime 0 && !sameWeight) {
// 随机获取一个 [0, totalWeight) 区间内的数字
int offset = random.nextInt(totalWeight);
// 循环让 offset 数减去服务提供者权重值,当 offset 小于0时,返回相应的 Invoker。
// 举例说明一下,我们有 servers = [A, B, C],weights = [5, 3, 2],offset = 7。
// 第一次循环,offset - 5 = 2 > 0,即 offset > 5,
// 表明其不会落在服务器 A 对应的区间上。
// 第二次循环,offset - 3 = -1 < 0,即 5 < offset < 8,
// 表明其会落在服务器 B 对应的区间上
for (int i = 0; i
无规则采集器列表算法(无规则采集器列表算法(itools找到的):事件eventgroup)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-11-13 01:04
无规则采集器列表算法(itools找到的):事件eventgroup,事件唯一标识tagcount或者classescount,分组阈值leadership(一个组只能有一个视频接收者),为不同层级的视频接收者指定不同的权限ivserververance=10若打算采用flv+httpvideo协议,则一个ivserver要包含videodisplay权限,需要在daemon中添加opensvcerver=10。
用websocket的转码需要第三方工具:tencentvrtconvertertencentvrtconverter免费版支持gif或jpg中video,mp4和tga的转码,支持高效压缩和混合体提取,支持ipv6,
(ads32/sdll)对于视频转码中的大部分算法来说是完全可以实现的,但是存在以下问题:对于http流来说,如果使用ads32转码存在文件体积因为二进制转换导致的大小膨胀等问题,而且对于一个http请求,上传的大文件是有明确规定的,往往不允许增加,比如不允许大于70k,所以有了这样的一个工具:sdll对于需要flv格式的视频存在flv的设置,level等一系列工具可以方便地进行不同格式的视频的上传上传时只上传最后一个,要上传本地保存的如果需要进行视频解码、解码后转码、生成播放器等功能,也不需要另外准备一个播放器针对一些定制化的需求,比如定制播放器,视频图像特效,等等还有很多其他工具可以使用,这里就不一一列举了。 查看全部
无规则采集器列表算法(无规则采集器列表算法(itools找到的):事件eventgroup)
无规则采集器列表算法(itools找到的):事件eventgroup,事件唯一标识tagcount或者classescount,分组阈值leadership(一个组只能有一个视频接收者),为不同层级的视频接收者指定不同的权限ivserververance=10若打算采用flv+httpvideo协议,则一个ivserver要包含videodisplay权限,需要在daemon中添加opensvcerver=10。
用websocket的转码需要第三方工具:tencentvrtconvertertencentvrtconverter免费版支持gif或jpg中video,mp4和tga的转码,支持高效压缩和混合体提取,支持ipv6,
(ads32/sdll)对于视频转码中的大部分算法来说是完全可以实现的,但是存在以下问题:对于http流来说,如果使用ads32转码存在文件体积因为二进制转换导致的大小膨胀等问题,而且对于一个http请求,上传的大文件是有明确规定的,往往不允许增加,比如不允许大于70k,所以有了这样的一个工具:sdll对于需要flv格式的视频存在flv的设置,level等一系列工具可以方便地进行不同格式的视频的上传上传时只上传最后一个,要上传本地保存的如果需要进行视频解码、解码后转码、生成播放器等功能,也不需要另外准备一个播放器针对一些定制化的需求,比如定制播放器,视频图像特效,等等还有很多其他工具可以使用,这里就不一一列举了。
无规则采集器列表算法(无规则采集器列表算法列表,你得带rsa加密)
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2021-11-12 23:01
无规则采集器列表算法:1.搜索从右到左2.浏览量去重3.对搜索条件作限制
linux的scrapy第一代是没有cookie的但是你可以自己加,它的代码是guid的,一般不会泄露出来给别人,
就是这么简单。你传一个简单的cookie进去,然后所有人每次访问都带这个cookie。然后谁同时访问,就从谁的收银台拿钱。
cookies是加密传输的,最好别用。http请求本身并不加密。就像这样get一个资源只发送get//传输的都是二进制数据。从远程来访问,很容易使用requests发送请求(如:get/http/1.1host:localhost/?for=php/1.1accept:expressmime:application/x-www-form-urlencoded)并解析json,然后返回。
后面的也是一样。但是必须告诉服务器,参数是这个。还有,存在服务器端或客户端的,你得带rsa加密可能会泄露密码。
它的响应可以是dns地址(如getxxx),也可以是postmethod(如get),也可以是websocket()。常见的websocket是openssl的websocket。至于加密的话,还得看服务器端用的是什么协议。据我所知,大部分的websocket都会使用私钥传输的算法。这样就保证了不是明文传输。
很简单啊,按照正常的流程就行, 查看全部
无规则采集器列表算法(无规则采集器列表算法列表,你得带rsa加密)
无规则采集器列表算法:1.搜索从右到左2.浏览量去重3.对搜索条件作限制
linux的scrapy第一代是没有cookie的但是你可以自己加,它的代码是guid的,一般不会泄露出来给别人,
就是这么简单。你传一个简单的cookie进去,然后所有人每次访问都带这个cookie。然后谁同时访问,就从谁的收银台拿钱。
cookies是加密传输的,最好别用。http请求本身并不加密。就像这样get一个资源只发送get//传输的都是二进制数据。从远程来访问,很容易使用requests发送请求(如:get/http/1.1host:localhost/?for=php/1.1accept:expressmime:application/x-www-form-urlencoded)并解析json,然后返回。
后面的也是一样。但是必须告诉服务器,参数是这个。还有,存在服务器端或客户端的,你得带rsa加密可能会泄露密码。
它的响应可以是dns地址(如getxxx),也可以是postmethod(如get),也可以是websocket()。常见的websocket是openssl的websocket。至于加密的话,还得看服务器端用的是什么协议。据我所知,大部分的websocket都会使用私钥传输的算法。这样就保证了不是明文传输。
很简单啊,按照正常的流程就行,
无规则采集器列表算法(阿里市场市场金融数据接口已经停止服务(负盈利) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-11-09 05:26
)
阿里api行情金融数据接口
服务已停止(负利润):
主包为网站提供http(s)和websocket接口,作为grpc服务器接收爬取数据!
爬取目录下的数据为 采集 客户端与grpc客户端同时主动更新服务端数据
上线前需要自行修改home目录和爬取目录的config.yaml配置文件
请在windows下使用,已经完美生产运行一段时间了,没问题!
---------我是SB的分割线,作者a7a2,------------------------------ - -----
使用说明:
0、回车'',选择'Hong Kong(这里有变化,下面都跟着变化)',选择'Create VPC','Target Network Segment'选择192就够了,选择Hong Kong '可用区' 可用区 C'。
1、进入'管理控制台','云服务器ECS','网络和安全','安全组','香港','创建安全组','网络类型',选择'专有网络',选择在步骤 0 中创建的“专用网络”。
确定后点‘配置规则’ ,这里不一一介绍,请自行添加放行出入方向的tcp 8888、443、80端口。
2、 激活ECS服务器,建议选择计费方式为“Bid Instance”,区域“香港可用区C”,镜像“windows2016 Data Center 64位中文版”,并存储默认“高效云盘40Gb”,网络请自行创建“私有网络”。
采集:推荐2台,至少一台;最低要求8G内存、4核cpu;网络‘专有网络’上面0创建那个、‘公网带宽’选择‘分配公网IP地址’选‘按使用流量’填‘100(Mbps)’、 ‘安全组’选1创建的。
api:推荐2台及以上,至少一台;最低要求4G内存、2核cpu;不需要外网ip(如果需要私自越过api网关对外服务可以加上),其他跟上面一样。
以上推荐基于服务器多可用多并发。isv服务器共用以上随便一台有外网ip的即可,isv服务不能群集,所以建议选择最稳定的一台,为isv服务安全可以单独独立使用一台服务器。
3、 打开ECS后,登录所有服务器安装Chrome浏览器和isv服务器,需要安装postgres数据库,新建目录,放入'config.yaml'和'.exe',创建' crawl'目录下的目录并上传目录下的'config.yaml'文件,在'crawl'目录下创建''和''目录并分别上传对应的exe。
以上操作所有服务器都一样,除了配置文件内容一样外,具体配置请看配置文件内有说明。
先启动api服务、isv服务,这里不介绍自己参考配置文件内容搞,然后才启动采集服务。
采集服务启动介绍:打开‘trade.mql5.com.exe’,会自动打开chrome浏览器,然后选择MT5,然后填写账号你注册了的外汇交易商的账号密码及服务器信息,登陆成功后
看左边‘市场报价’,点击右键‘显示毫秒’,点击右键选择‘列’-‘点差’-‘时间’,就这样你能看到的交易品种都会自动采集提交,太
多看不见可以把分辨率放大,把浏览器比例放小,更多交易对请点击右键‘交易品种’自行添加。2台采集服务器同样的设置采集相同内容防止单台故障,采集交易商要一致否则呵呵。
‘www.bitstamp.net.exe’直接启动。
访问api服务看看数据采集是否正常,http://192.168.0.77/v1/finance?symbol=EURUSD,BTCUSD,AAPL.NAS
4、访问,选择'产品','api网关',并激活。进入管理,选择“香港”,“打开API”,“组管理”,“创建组”,“API管理”打开websocket。
‘api列表’:
名称及描述:‘创建api’、安全认证:阿里云APP、签名算法:HmacSHA1,HmacSHA256、类型:公开
请求基础定义:Path:/v1/finance ,协议:HTTP,HTTPS,HTTP Method:GET,请求模式:入参映射,‘参数名’填写‘symbol’、‘参数位置’填‘query’
后端服务信息:后端服务类型:HTTP,HTTP Method:GET,使用VPC通道(点击自行创建这里不介绍),后端服务地址: /v1/finance,不使用Mock、1000 ms
后端服务参数:‘后端参数名称’填写‘symbol’,‘后端参数位置’填‘query’,入参名称‘symbol’,入参位置‘symbol’,入参类型‘string’
自定义系统参数:选择及填写‘CaCloudMarketInstanceld’,参考位置‘head’
然后同样方式创建一份关于websocket的,不同之处在于‘后端服务地址: /w1/finance’,‘请求基础定义’---‘Path:/w1/finance’---‘协议:WEBSOCKET’
最后在‘api列表’点击‘发布’,‘线上’,‘发布’,切记每次修改完记得重新发布。 查看全部
无规则采集器列表算法(阿里市场市场金融数据接口已经停止服务(负盈利)
)
阿里api行情金融数据接口
服务已停止(负利润):
主包为网站提供http(s)和websocket接口,作为grpc服务器接收爬取数据!
爬取目录下的数据为 采集 客户端与grpc客户端同时主动更新服务端数据
上线前需要自行修改home目录和爬取目录的config.yaml配置文件
请在windows下使用,已经完美生产运行一段时间了,没问题!
---------我是SB的分割线,作者a7a2,------------------------------ - -----
使用说明:
0、回车'',选择'Hong Kong(这里有变化,下面都跟着变化)',选择'Create VPC','Target Network Segment'选择192就够了,选择Hong Kong '可用区' 可用区 C'。
1、进入'管理控制台','云服务器ECS','网络和安全','安全组','香港','创建安全组','网络类型',选择'专有网络',选择在步骤 0 中创建的“专用网络”。
确定后点‘配置规则’ ,这里不一一介绍,请自行添加放行出入方向的tcp 8888、443、80端口。
2、 激活ECS服务器,建议选择计费方式为“Bid Instance”,区域“香港可用区C”,镜像“windows2016 Data Center 64位中文版”,并存储默认“高效云盘40Gb”,网络请自行创建“私有网络”。
采集:推荐2台,至少一台;最低要求8G内存、4核cpu;网络‘专有网络’上面0创建那个、‘公网带宽’选择‘分配公网IP地址’选‘按使用流量’填‘100(Mbps)’、 ‘安全组’选1创建的。
api:推荐2台及以上,至少一台;最低要求4G内存、2核cpu;不需要外网ip(如果需要私自越过api网关对外服务可以加上),其他跟上面一样。
以上推荐基于服务器多可用多并发。isv服务器共用以上随便一台有外网ip的即可,isv服务不能群集,所以建议选择最稳定的一台,为isv服务安全可以单独独立使用一台服务器。
3、 打开ECS后,登录所有服务器安装Chrome浏览器和isv服务器,需要安装postgres数据库,新建目录,放入'config.yaml'和'.exe',创建' crawl'目录下的目录并上传目录下的'config.yaml'文件,在'crawl'目录下创建''和''目录并分别上传对应的exe。
以上操作所有服务器都一样,除了配置文件内容一样外,具体配置请看配置文件内有说明。
先启动api服务、isv服务,这里不介绍自己参考配置文件内容搞,然后才启动采集服务。
采集服务启动介绍:打开‘trade.mql5.com.exe’,会自动打开chrome浏览器,然后选择MT5,然后填写账号你注册了的外汇交易商的账号密码及服务器信息,登陆成功后
看左边‘市场报价’,点击右键‘显示毫秒’,点击右键选择‘列’-‘点差’-‘时间’,就这样你能看到的交易品种都会自动采集提交,太
多看不见可以把分辨率放大,把浏览器比例放小,更多交易对请点击右键‘交易品种’自行添加。2台采集服务器同样的设置采集相同内容防止单台故障,采集交易商要一致否则呵呵。
‘www.bitstamp.net.exe’直接启动。
访问api服务看看数据采集是否正常,http://192.168.0.77/v1/finance?symbol=EURUSD,BTCUSD,AAPL.NAS
4、访问,选择'产品','api网关',并激活。进入管理,选择“香港”,“打开API”,“组管理”,“创建组”,“API管理”打开websocket。
‘api列表’:
名称及描述:‘创建api’、安全认证:阿里云APP、签名算法:HmacSHA1,HmacSHA256、类型:公开
请求基础定义:Path:/v1/finance ,协议:HTTP,HTTPS,HTTP Method:GET,请求模式:入参映射,‘参数名’填写‘symbol’、‘参数位置’填‘query’
后端服务信息:后端服务类型:HTTP,HTTP Method:GET,使用VPC通道(点击自行创建这里不介绍),后端服务地址: /v1/finance,不使用Mock、1000 ms
后端服务参数:‘后端参数名称’填写‘symbol’,‘后端参数位置’填‘query’,入参名称‘symbol’,入参位置‘symbol’,入参类型‘string’
自定义系统参数:选择及填写‘CaCloudMarketInstanceld’,参考位置‘head’
然后同样方式创建一份关于websocket的,不同之处在于‘后端服务地址: /w1/finance’,‘请求基础定义’---‘Path:/w1/finance’---‘协议:WEBSOCKET’
最后在‘api列表’点击‘发布’,‘线上’,‘发布’,切记每次修改完记得重新发布。
无规则采集器列表算法(论坛新手站长必装的discuz应用功能介绍-苏州安嘉)
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-11-07 18:07
DXC采集器 最新商业版来自某宝,亲测,可以使用.zip
DXC 来自 Discuz 的缩写!X 采集。DXC采集插件专用于discuz上的内容解决方案,帮助站长更快捷方便地构建网站内容。通过DXC采集插件,用户可以方便地从互联网上获取数据采集,包括会员数据,以及文章数据。此外,还有虚拟在线、单帖采集等辅助功能,让一个冷清的新论坛瞬间形成一个内容丰富、会员活跃的热门论坛,对网站的初期运营有很大帮助。论坛。它是新手站长必须安装的discuz应用程序。主要功能包括: 1、 多种形式的url列表采集文章,包括rss地址、列表页面、多层列表等。2、 多种规则编写方式,dom方式,字符拦截,智能获取,更方便的获取你想要的内容3、规则继承,匹配规则自动检测功能,你会逐渐体验到规则继承带来的便利4、独特的网页文本提取算法,可以自动学习归纳规则,更方便进行泛化采集。5、支持图片本地化,添加水印功能6、灵活的发布机制,可以自定义发布者、发布时间点击率等7、强大的内容编辑后台,可以方便的编辑采集收到的内容,发布到门户、论坛、博客8、 内容过滤功能,过滤<
现在就下载 查看全部
无规则采集器列表算法(论坛新手站长必装的discuz应用功能介绍-苏州安嘉)
DXC采集器 最新商业版来自某宝,亲测,可以使用.zip
DXC 来自 Discuz 的缩写!X 采集。DXC采集插件专用于discuz上的内容解决方案,帮助站长更快捷方便地构建网站内容。通过DXC采集插件,用户可以方便地从互联网上获取数据采集,包括会员数据,以及文章数据。此外,还有虚拟在线、单帖采集等辅助功能,让一个冷清的新论坛瞬间形成一个内容丰富、会员活跃的热门论坛,对网站的初期运营有很大帮助。论坛。它是新手站长必须安装的discuz应用程序。主要功能包括: 1、 多种形式的url列表采集文章,包括rss地址、列表页面、多层列表等。2、 多种规则编写方式,dom方式,字符拦截,智能获取,更方便的获取你想要的内容3、规则继承,匹配规则自动检测功能,你会逐渐体验到规则继承带来的便利4、独特的网页文本提取算法,可以自动学习归纳规则,更方便进行泛化采集。5、支持图片本地化,添加水印功能6、灵活的发布机制,可以自定义发布者、发布时间点击率等7、强大的内容编辑后台,可以方便的编辑采集收到的内容,发布到门户、论坛、博客8、 内容过滤功能,过滤<
现在就下载
无规则采集器列表算法(入门凑合着看吧的规则引擎需要注意的问题(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-11-07 09:12
翻翻旧文,有很多地方比较模糊,可惜现在找不到jess的源码了,不然可以好好看看实现细节,移过去再说,以后会研究,作为介绍,大家看看吧。
Rete算法最早由Charles Forgy在1979年的论文中提出,针对的是一种基于规则知识性能的模式匹配算法。目前大部分的规则引擎还是基于rete算法,但是已经有所改进,比如drool,jess等,下面介绍rete算法的概念,一些术语,以及需要注意的问题使用规则引擎时要注意。
我们来看看下面的表达式:
(此产品的名称
LHS /* 一个或多个条件 */
-->
RHS /* 一个或多个动作 */
)
name-of-this-production 是规则,LHS(左手边)一系列条件,RHS(右手边)这是我们满足条件后应该执行的动作。
结合这张图来介绍几个概念:
生产记忆(PM)由所有生产形成。
工作记忆(WM)由外部输入根据匹配算法形成。它反映了运行规则引擎的状态,记录了各种数据。WM 中的每一项都称为工作记忆元素(WME),它是由外部输入生成的。
议程负责匹配、解决冲突和执行操作。
Rete 的意思是网络(拉丁语),它最终解释(或编译)所有规则,生成一个识别网络,包括 alpha 网络和 beta 网络。alpha 网络是由 LHS 生成的网络。它根据外部输入快速识别条件是否成立,并与其beta网络交互更新整个网络的状态,如下图所示:
最基本的alpha网络如上图所示。与此类似,所有条件都解析为这样的网络。当外界输入wme时,wme就会进入这样的网络进行识别。如果到达底部,则证明条件成立。当然,如图所示的网络是最简单的实现。实际的规则引擎需要提供更快的算法来识别输入的wme,比如将图中颜色的各种值存储在hashtable,或者jumptable,或者是trie树中。整个alpha网络是一个巨大的字符串匹配过滤网络,需要结合各种数据结构来实现海量条件下的快速匹配。各种规则引擎的实现不一致,比如jess,如下图:
(除费完成
(测试)
(号码?号码)
(测试完成)
(初始信用5)
(客户年龄?年龄)
(有?输入“PP”))
=>
(断言(测试完成)))
在此生产说明之后生成的网络。这里我们首先关注红色节点。这些节点是 alpha 网络的节点。该图仅描述了一般过程。以第一列为例。第一个红色节点表示输入是否匹配。TESTING这个字符串,TESTING匹配0后第二个节点是否匹配参数个数(slot),如果我们将TESTING断言到WM中,那么这个事实就可以匹配到done规则的第一个条件,其他的可以在以此类推,值得注意的是最后一个条件,has 是我们自定义的函数,与这个函数类似,jess 并没有生成单独的列,而是将其用作 CUSTOMER AGE 标记列中的最后一个节点。这个条件有一个特点就是需要执行一段代码来判断某个事实是否为真(不仅仅是执行字符串操作)。这段代码不仅是字符串匹配,还具有实时性。像这样的条件的发展需要注意,因为alpha网络在运行时会多次执行条件。这是由匹配算法的特性决定的。因此,我们需要利用缓存或规则语言的特性来避免不必要的代码执行来提高性能。因为 alpha 网络将在运行时多次执行条件。这是由匹配算法的特性决定的。因此,我们需要利用缓存或规则语言的特性来避免不必要的代码执行来提高性能。因为 alpha 网络会在运行时多次执行条件。这是由匹配算法的特性决定的。因此,我们需要利用缓存或规则语言的特性来避免不必要的代码执行来提高性能。
下面发布了一个更复杂的示例:
图片太大,剪不下来。. . . . .
让我们用两个例子来谈谈 beta 网络。当 alpha 网络过滤后条件成立,WME 传递给 beta 网络后,绿色节点就会发挥作用。这个节点是加入节点。它有两个输入和一个连接。节点,一个 alpha 节点(红色)。join节点由多个WME组成。对于初始连接节点,我们称其为左输入适配器。作为左输入的join节点,这个节点只收录一个WME,下一个join节点收录两个WME,以此类推。图中天蓝色节点上方的join节点正好符合生产执行所需的条件,所以这条规则被激活,等待执行。
假设我们需要编辑业务逻辑,那么最好的描述载体就是流程图。一个简单的流程图收录以下基本单元:起始节点、逻辑判断、执行动作、结束节点。这些节点可以完成最简单的业务逻辑描述,那么当我们将这些流程解析为规则时,我们会怎么做呢?第一个逻辑判断单元返回真,所以我们执行某个动作,第二个和第三个逻辑判断单元返回真时,我们执行一个动作,相当于解析为两条规则,满足条件1,触发生产1,满足条件 2、3 和触发生产 2。使用beta网络,我们只需要在触发production2时判断condition2, 3是否被触发。是的,对于更复杂的情况,beta 网络可以提高速度并避免重复匹配。
在开发中使用规则引擎也存在一些问题,总结如下:
1) 在规则引擎中对特殊条件的处理中,由于条件会在部分产生中重复出现,会造成条件的重复匹配,影响程序的性能。这应该与项目结合以优化解析或规则脚本。使用缓存来提高性能。补充:可以把动态执行的条件放在LHS的最后,保证只在必要的时候才执行。当然,具体情况还要看具体规则引擎的实现。
2)内存消耗问题,rete算法是空间换时间,所以内存消耗比较大,尤其是在加载规则时(生成网络),运行时内存会增长缓慢,所以gc效率需要注意的同时,单台服务器所能承受的压力(多WM)也与规则引擎密切相关。
3)测试。对于使用规则来表达业务的系统来说,如何测试是一个必须解决的问题。对于这个问题,只能保证基本的流程分支覆盖测试。在复杂的情况下很难发现缺陷,但有一些原则需要注意。如果要使用规则引擎,就必须完全以规则引擎为核心。对于业务逻辑,我们必须尽可能提取规则引擎来实现。扩展实现的函数粒度一定要小而简单,不要往代码里走。实现业务逻辑。
4)大部分条件需要保持不变,也就是说基本信息需要保持稳定。比如某客户公司下属集团的信用额度大于100w,这个额度变化的频率不会很高,不需要实时匹配。
5)remove WME 生产是一个比较复杂的操作。当规则比较复杂时,你应该尽量少做。 查看全部
无规则采集器列表算法(入门凑合着看吧的规则引擎需要注意的问题(图))
翻翻旧文,有很多地方比较模糊,可惜现在找不到jess的源码了,不然可以好好看看实现细节,移过去再说,以后会研究,作为介绍,大家看看吧。
Rete算法最早由Charles Forgy在1979年的论文中提出,针对的是一种基于规则知识性能的模式匹配算法。目前大部分的规则引擎还是基于rete算法,但是已经有所改进,比如drool,jess等,下面介绍rete算法的概念,一些术语,以及需要注意的问题使用规则引擎时要注意。
我们来看看下面的表达式:
(此产品的名称
LHS /* 一个或多个条件 */
-->
RHS /* 一个或多个动作 */
)
name-of-this-production 是规则,LHS(左手边)一系列条件,RHS(右手边)这是我们满足条件后应该执行的动作。
结合这张图来介绍几个概念:
生产记忆(PM)由所有生产形成。
工作记忆(WM)由外部输入根据匹配算法形成。它反映了运行规则引擎的状态,记录了各种数据。WM 中的每一项都称为工作记忆元素(WME),它是由外部输入生成的。
议程负责匹配、解决冲突和执行操作。
Rete 的意思是网络(拉丁语),它最终解释(或编译)所有规则,生成一个识别网络,包括 alpha 网络和 beta 网络。alpha 网络是由 LHS 生成的网络。它根据外部输入快速识别条件是否成立,并与其beta网络交互更新整个网络的状态,如下图所示:
最基本的alpha网络如上图所示。与此类似,所有条件都解析为这样的网络。当外界输入wme时,wme就会进入这样的网络进行识别。如果到达底部,则证明条件成立。当然,如图所示的网络是最简单的实现。实际的规则引擎需要提供更快的算法来识别输入的wme,比如将图中颜色的各种值存储在hashtable,或者jumptable,或者是trie树中。整个alpha网络是一个巨大的字符串匹配过滤网络,需要结合各种数据结构来实现海量条件下的快速匹配。各种规则引擎的实现不一致,比如jess,如下图:
(除费完成
(测试)
(号码?号码)
(测试完成)
(初始信用5)
(客户年龄?年龄)
(有?输入“PP”))
=>
(断言(测试完成)))
在此生产说明之后生成的网络。这里我们首先关注红色节点。这些节点是 alpha 网络的节点。该图仅描述了一般过程。以第一列为例。第一个红色节点表示输入是否匹配。TESTING这个字符串,TESTING匹配0后第二个节点是否匹配参数个数(slot),如果我们将TESTING断言到WM中,那么这个事实就可以匹配到done规则的第一个条件,其他的可以在以此类推,值得注意的是最后一个条件,has 是我们自定义的函数,与这个函数类似,jess 并没有生成单独的列,而是将其用作 CUSTOMER AGE 标记列中的最后一个节点。这个条件有一个特点就是需要执行一段代码来判断某个事实是否为真(不仅仅是执行字符串操作)。这段代码不仅是字符串匹配,还具有实时性。像这样的条件的发展需要注意,因为alpha网络在运行时会多次执行条件。这是由匹配算法的特性决定的。因此,我们需要利用缓存或规则语言的特性来避免不必要的代码执行来提高性能。因为 alpha 网络将在运行时多次执行条件。这是由匹配算法的特性决定的。因此,我们需要利用缓存或规则语言的特性来避免不必要的代码执行来提高性能。因为 alpha 网络会在运行时多次执行条件。这是由匹配算法的特性决定的。因此,我们需要利用缓存或规则语言的特性来避免不必要的代码执行来提高性能。
下面发布了一个更复杂的示例:
图片太大,剪不下来。. . . . .
让我们用两个例子来谈谈 beta 网络。当 alpha 网络过滤后条件成立,WME 传递给 beta 网络后,绿色节点就会发挥作用。这个节点是加入节点。它有两个输入和一个连接。节点,一个 alpha 节点(红色)。join节点由多个WME组成。对于初始连接节点,我们称其为左输入适配器。作为左输入的join节点,这个节点只收录一个WME,下一个join节点收录两个WME,以此类推。图中天蓝色节点上方的join节点正好符合生产执行所需的条件,所以这条规则被激活,等待执行。
假设我们需要编辑业务逻辑,那么最好的描述载体就是流程图。一个简单的流程图收录以下基本单元:起始节点、逻辑判断、执行动作、结束节点。这些节点可以完成最简单的业务逻辑描述,那么当我们将这些流程解析为规则时,我们会怎么做呢?第一个逻辑判断单元返回真,所以我们执行某个动作,第二个和第三个逻辑判断单元返回真时,我们执行一个动作,相当于解析为两条规则,满足条件1,触发生产1,满足条件 2、3 和触发生产 2。使用beta网络,我们只需要在触发production2时判断condition2, 3是否被触发。是的,对于更复杂的情况,beta 网络可以提高速度并避免重复匹配。
在开发中使用规则引擎也存在一些问题,总结如下:
1) 在规则引擎中对特殊条件的处理中,由于条件会在部分产生中重复出现,会造成条件的重复匹配,影响程序的性能。这应该与项目结合以优化解析或规则脚本。使用缓存来提高性能。补充:可以把动态执行的条件放在LHS的最后,保证只在必要的时候才执行。当然,具体情况还要看具体规则引擎的实现。
2)内存消耗问题,rete算法是空间换时间,所以内存消耗比较大,尤其是在加载规则时(生成网络),运行时内存会增长缓慢,所以gc效率需要注意的同时,单台服务器所能承受的压力(多WM)也与规则引擎密切相关。
3)测试。对于使用规则来表达业务的系统来说,如何测试是一个必须解决的问题。对于这个问题,只能保证基本的流程分支覆盖测试。在复杂的情况下很难发现缺陷,但有一些原则需要注意。如果要使用规则引擎,就必须完全以规则引擎为核心。对于业务逻辑,我们必须尽可能提取规则引擎来实现。扩展实现的函数粒度一定要小而简单,不要往代码里走。实现业务逻辑。
4)大部分条件需要保持不变,也就是说基本信息需要保持稳定。比如某客户公司下属集团的信用额度大于100w,这个额度变化的频率不会很高,不需要实时匹配。
5)remove WME 生产是一个比较复杂的操作。当规则比较复杂时,你应该尽量少做。
无规则采集器列表算法(一款异常不错的采集软件,功效和优采云差不多)
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-11-05 16:17
非常好的采集软件,为数不多的免费软件之一,效果类似优采云。推荐大家使用,不明白的可以阅读基础教程。
相关信息
帝国cms采集器使用方法1、打开软件点击登录。2、选择采集栏3、你想要修改信息列表地址采集。单击列表设置以添加或删除 采集 列表 URL。 4、公布数据。点击加载...
关于采集列表作为标题图片的方式非常不同。 采集器的原理类似,只是步骤有点不同。
首先我们查看列表设置并填写相关列表采集规则,然后我们查看底部的链接规则。
如果需要采集列表缩略图,不能使用其他方法链接规则,需要手写。只需填写采集 URL 和缩略图,如上图所示。点击“测试提取网址”,您将看到采集的缩略图地址。
接下来需要将采集的缩略图下载到内陆,这里需要使用优采云采集器的组合字段功能。
新建一个采集字段,命名为“title map”,设置为“自定义字符串”类型,填写:{DD:field=thumbnail}
最后我们需要开启“附件下载”将采集的缩略图下载到内陆,勾选“附件下载”,然后设置下载路径。
声明:本站所有文章,除非另有说明或标注,均在本站原创上发布。任何个人或组织,未经本站同意,不得复制、盗用、采集、将本站内容发布到网站、书籍等任何媒体平台。本站内容侵犯了原作者的合法权益,您可以联系我们进行处理。
优采云采集
admin2021 正常
扫描支付宝
微信扫一扫">奖品领取海报链接 查看全部
无规则采集器列表算法(一款异常不错的采集软件,功效和优采云差不多)
非常好的采集软件,为数不多的免费软件之一,效果类似优采云。推荐大家使用,不明白的可以阅读基础教程。
相关信息
帝国cms采集器使用方法1、打开软件点击登录。2、选择采集栏3、你想要修改信息列表地址采集。单击列表设置以添加或删除 采集 列表 URL。 4、公布数据。点击加载...
关于采集列表作为标题图片的方式非常不同。 采集器的原理类似,只是步骤有点不同。
首先我们查看列表设置并填写相关列表采集规则,然后我们查看底部的链接规则。
如果需要采集列表缩略图,不能使用其他方法链接规则,需要手写。只需填写采集 URL 和缩略图,如上图所示。点击“测试提取网址”,您将看到采集的缩略图地址。
接下来需要将采集的缩略图下载到内陆,这里需要使用优采云采集器的组合字段功能。
新建一个采集字段,命名为“title map”,设置为“自定义字符串”类型,填写:{DD:field=thumbnail}
最后我们需要开启“附件下载”将采集的缩略图下载到内陆,勾选“附件下载”,然后设置下载路径。
声明:本站所有文章,除非另有说明或标注,均在本站原创上发布。任何个人或组织,未经本站同意,不得复制、盗用、采集、将本站内容发布到网站、书籍等任何媒体平台。本站内容侵犯了原作者的合法权益,您可以联系我们进行处理。
优采云采集
admin2021 正常
扫描支付宝
微信扫一扫">奖品领取海报链接
无规则采集器列表算法(数据挖掘决策参考的统计分析数据.在深层次的层次上的应用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-11-03 07:21
数据挖掘,也称为数据挖掘、数据挖掘等,是按照既定的业务目标,从海量数据中提取潜在的、有效的和可理解的模式的高级过程。在较浅的层面上,利用现有数据库管理系统的查询、搜索和报告功能,结合多维分析和统计分析方法,进行在线分析处理(O易信),从而获得参考用于决策数据的统计分析。在更深层次上,从数据库中发现了前所未有的隐性知识。OLAF'出现的时间早于数据挖掘。它们都是从数据库中提取有用信息的方法。就决策支持的需求而言,两者是相辅相成的。
数据挖掘是一个多学科领域,它结合了数据库技术、人工智能、机器学习、模式识别、模糊数学和数理统计的最新研究成果,可用于支持商业智能应用和决策分析。例如客户细分、交叉销售、欺诈检测、客户流失分析、产品销售预测等,目前广泛应用于银行、金融、医疗、工业、零售和电信行业。数据挖掘技术的发展对各行各业都具有重要的现实意义。
数据挖掘从新的角度将数据库技术、统计学、机器学习、信息检索技术、数据可视化和模式识别与人工智能有机结合。它可以结合各个领域的优势,从而从数据中提取出其他传统方法无法发现的有用知识。
数据挖掘可以解决很多问题,但是在实现的过程中是一个非常繁琐的过程,只有在计算机基础丰富的情况下才能实现。随着信息技术的发展,出现了许多数据挖掘工具。其中,NLPIR大数据语义智能分析平台(原ICTCLAS)是一个比较好的系统。它由北京理工大学大数据搜索与挖掘实验室主任张华平开发。针对大数据内容采集、编辑、挖掘、搜索的综合需求,融合网络精准采集、自然语言理解、文本挖掘、语义搜索等最新研究成果,并持续创新近二十年。平台提供客户端工具、云服务、二次开发接口等多种产品使用形式。每个中间件API都可以无缝集成到客户的各种复杂应用系统中,兼容Windows、Linux、Android、Maemo5、FreeBSD等不同操作系统平台,可用于Java、Python、C等各种开发、C#等语言的使用。
NLPIR大数据语义智能分析平台的十三项功能:
NLPIR大数据语义智能分析平台客户端
精准采集:国内外海量信息实时精准采集,主题采集(主题根据信息需求采集)和站点采集 两种模式(给定网站列表中的定点采集 功能)。
文档转换:将文本信息转换为doc、excel、pdf、ppt等多种主流文档格式,效率满足大数据处理要求。
新词发现:从文本中发现新词、新概念,用户可将其用于专业词典的编纂,并可进一步编辑标注,导入分词词典,提高分词系统的准确率,并适应新的语言变化。
批量分词:原创语料分词,自动识别人名、地名、机构名称等未注册词,新词标注,词性标注。并在分析过程中,导入用户自定义词典。
语言统计:根据分词和标注结果,系统自动进行一元词频数统计和二元词转移概率统计。对于常用术语,会自动给出相应的英文解释。
文本聚类:可以从大规模数据中自动分析热点事件,并提供事件主题的关键特征描述。同时适用于短文、微博等长文和短文的热点分析。
文本分类:根据规则或训练方法对大量文本进行分类,可用于新闻分类、简历分类、邮件分类、办公文档分类、区域分类等诸多方面。
抽象实体:对于单个或多个文章,自动提取内容摘要,提取人名、地名、机构名称、时间和主题关键词;方便用户快速浏览文本内容。
智能过滤:对文本内容进行语义智能过滤和审核,内置国内最全的词库,智能识别多种变体:变形、音变、繁简变体、精准语义消歧。
情感分析:针对预先指定的分析对象,系统自动分析海量文档的情感倾向:情感极性和情感值测度,并给出原文中的正负分和句例。
文档去重:快速准确判断文件集合或数据库中是否存在内容相同或相似的记录,同时查找所有重复记录。
全文搜索:支持文本、数字、日期、字符串等多种数据类型,多字段高效搜索,支持AND/OR/NOT、NEAR接近等查询语法,支持维语、藏语、蒙语、阿拉伯语和韩语 搜索各种少数民族语言。
代码转换:自动识别内容的代码,统一将代码转换为其他代码。
以上就是推荐的中文分词工具,希望对你有帮助,有问题请联系我,我会帮忙解答! 查看全部
无规则采集器列表算法(数据挖掘决策参考的统计分析数据.在深层次的层次上的应用)
数据挖掘,也称为数据挖掘、数据挖掘等,是按照既定的业务目标,从海量数据中提取潜在的、有效的和可理解的模式的高级过程。在较浅的层面上,利用现有数据库管理系统的查询、搜索和报告功能,结合多维分析和统计分析方法,进行在线分析处理(O易信),从而获得参考用于决策数据的统计分析。在更深层次上,从数据库中发现了前所未有的隐性知识。OLAF'出现的时间早于数据挖掘。它们都是从数据库中提取有用信息的方法。就决策支持的需求而言,两者是相辅相成的。
数据挖掘是一个多学科领域,它结合了数据库技术、人工智能、机器学习、模式识别、模糊数学和数理统计的最新研究成果,可用于支持商业智能应用和决策分析。例如客户细分、交叉销售、欺诈检测、客户流失分析、产品销售预测等,目前广泛应用于银行、金融、医疗、工业、零售和电信行业。数据挖掘技术的发展对各行各业都具有重要的现实意义。
数据挖掘从新的角度将数据库技术、统计学、机器学习、信息检索技术、数据可视化和模式识别与人工智能有机结合。它可以结合各个领域的优势,从而从数据中提取出其他传统方法无法发现的有用知识。
数据挖掘可以解决很多问题,但是在实现的过程中是一个非常繁琐的过程,只有在计算机基础丰富的情况下才能实现。随着信息技术的发展,出现了许多数据挖掘工具。其中,NLPIR大数据语义智能分析平台(原ICTCLAS)是一个比较好的系统。它由北京理工大学大数据搜索与挖掘实验室主任张华平开发。针对大数据内容采集、编辑、挖掘、搜索的综合需求,融合网络精准采集、自然语言理解、文本挖掘、语义搜索等最新研究成果,并持续创新近二十年。平台提供客户端工具、云服务、二次开发接口等多种产品使用形式。每个中间件API都可以无缝集成到客户的各种复杂应用系统中,兼容Windows、Linux、Android、Maemo5、FreeBSD等不同操作系统平台,可用于Java、Python、C等各种开发、C#等语言的使用。
NLPIR大数据语义智能分析平台的十三项功能:
NLPIR大数据语义智能分析平台客户端
精准采集:国内外海量信息实时精准采集,主题采集(主题根据信息需求采集)和站点采集 两种模式(给定网站列表中的定点采集 功能)。
文档转换:将文本信息转换为doc、excel、pdf、ppt等多种主流文档格式,效率满足大数据处理要求。
新词发现:从文本中发现新词、新概念,用户可将其用于专业词典的编纂,并可进一步编辑标注,导入分词词典,提高分词系统的准确率,并适应新的语言变化。
批量分词:原创语料分词,自动识别人名、地名、机构名称等未注册词,新词标注,词性标注。并在分析过程中,导入用户自定义词典。
语言统计:根据分词和标注结果,系统自动进行一元词频数统计和二元词转移概率统计。对于常用术语,会自动给出相应的英文解释。
文本聚类:可以从大规模数据中自动分析热点事件,并提供事件主题的关键特征描述。同时适用于短文、微博等长文和短文的热点分析。
文本分类:根据规则或训练方法对大量文本进行分类,可用于新闻分类、简历分类、邮件分类、办公文档分类、区域分类等诸多方面。
抽象实体:对于单个或多个文章,自动提取内容摘要,提取人名、地名、机构名称、时间和主题关键词;方便用户快速浏览文本内容。
智能过滤:对文本内容进行语义智能过滤和审核,内置国内最全的词库,智能识别多种变体:变形、音变、繁简变体、精准语义消歧。
情感分析:针对预先指定的分析对象,系统自动分析海量文档的情感倾向:情感极性和情感值测度,并给出原文中的正负分和句例。
文档去重:快速准确判断文件集合或数据库中是否存在内容相同或相似的记录,同时查找所有重复记录。
全文搜索:支持文本、数字、日期、字符串等多种数据类型,多字段高效搜索,支持AND/OR/NOT、NEAR接近等查询语法,支持维语、藏语、蒙语、阿拉伯语和韩语 搜索各种少数民族语言。
代码转换:自动识别内容的代码,统一将代码转换为其他代码。
以上就是推荐的中文分词工具,希望对你有帮助,有问题请联系我,我会帮忙解答!
无规则采集器列表算法( Web3.0的到来后基于互联网营销模式(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-11-02 19:08
Web3.0的到来后基于互联网营销模式(组图))
Web3.0到来后,基于互联网的营销模式层出不穷,seo是最热门的领域之一。我研究百度的算法跟踪近5年了。我主要从事算法反转,就是通过一些相关的指标来判断百度的排名规则。
在介绍百度算法之前,先说说百度搜索研发部不久前的博客文章《Web搜索排序中的投票模型简述》一文中的美国选举制度。这个其实就是百度的一个投票系统的雏形,我是这么认为的。用一个简单的图表来说明整个过程:
看上图相信大家应该都明白了,残差的排序应该是“主库”和百度服务器之间的一个变化。百度蜘蛛会采集返回大量内容,全部存放在主服务器中。服务器通过规则过滤后,最终将页面发布到web服务器上进行排序。事实上,“总库”已经发生了一系列的算法变化。当然,我这里解释的内容中的各种服务器和名称都是我个人定义的,但是基本逻辑应该是这样的,按照数据分析的原则:数据采集-数据处理-数据分析器-数据展示,在事实上,它可以很好地概括百度的行为。
百度虽然一方面在做推广和竞价,另一方面也希望能给用户带来良好的搜索体验。许多seoers可以恨和爱它。不过,根据各种官方文本,我们仍然认为百度搜索研发部门还是希望给用户一个。良好的检索体验。
话虽如此,还是得用一张图告诉大家什么是金字塔模型:
看了这张图,应该是有限的人有疑惑吧。这和漏斗原理很像吧!是的,它类似于漏斗原理,但是没有金字塔的灵感,每个人都希望得到金字塔的最高峰。
排序和过滤过程呢?引用一段百度搜索研发部文章的内容:
“系统有n个网页,有m个特征(页面质量、页面内容丰富度、页面超链接、文本相关性等)。n个网页有不同的分数。如何根据这些特征投票?哪个页面最多适合放在第一位吗?
从选举的例子中,我们可以得到几个启示:
1. 在设计算法时,要避免“赢家通吃”导致的信息丢失问题。
2. 不要仅仅因为某些功能特别好而将网页排在前列,或者因为某些功能特别差而放弃一个网页。
3. 最合适的网页首先不一定是每一个功能都最好的,但应该是能兼顾所有功能,整体表现最好的。
4. 搜索引擎用户对搜索结果的点击行为可视为对搜索结果的“投票”。在选举过程中也应考虑使用此类“投票”信息。各种不合理的出现。
上面提到的各种选举方案只讨论了“一个职位多个候选人”的情况,而搜索引擎面临的问题更类似于“多个候选人排序”的情况,即:
系统中有n个网页,有m个特征(页面质量、页面内容丰富度、页面超链接、文本相关性等)。n 个网页有不同的分数。如何根据这些特征的“投票”决定n个页面的顺序?
而这个“多候选人排名”的问题有一个“不可能民主”的理论。该理论的主要思想是,一个“合理”的民主应该满足三个条件:
1. 如果投票者认为A比B好,那么最后的结果也应该是A比B好
2. 没有“独裁者”,也就是没有这样的人。不管别人怎么排,最后的结果都会和这个人的顺序一样。
3.无关因素的独立性,即第一次投票完成后,A排在B前面,现在进行第二次投票。如果大家都没有改变他们投票中A和B的相对顺序,最后的结果也应该是A在B之前
并且通过数学证明,可以得出结论,如果某种选举方法满足条件1和3,就一定不满足2,即一定有“独裁者”。
根据“不可能的民主”理论,结合搜索引擎,搜索引擎似乎很难给出一个合理的网页排名,但搜索引擎和投票似乎是不同的。有两种观点可以破解
1. 我认为条件 3 太强了,需要削弱。
2. 也许在页面排名方面有这样的“独裁特征”。从目前来看,最合适的应该是“用户满意度”,根据用户满意度来划分。对网页进行排序是最合理的网页排名。如何衡量“用户满意度”?这是我们一直在努力的。”
相信大家看完这篇内容应该已经有了深刻的了解,百度的算法和选举系统有很多相似之处。所以我们逆向研究的方向是首先从数据呈现本身中得出数据分析原理。这是一个长期的计划,因为我们要分析数以亿计的网站,才能得出结论。,而事实证明,百度的排序规则中不仅有一个算法规则,而是有多个规则。
前期我也基于关键词开发了一个简单的分析程序:
这个工具主要是一个辅助功能。前面讨论的选举系统主要是针对外部链接的有效性,而这个工具的主要内容是针对相关性,即搜索结果末尾排序规则中的排序规则。当然,这个工具还处于粗略的状态,很多指标还没有添加。后期大家可以一起参与到本次研究中来,补充一些比较重要的指标,方便我们的研究更加完善。
如果你纯粹是一个seoer,我认为你可以停止阅读这项研究,因为事实证明,只要你得到最终排序的相关算法,你就可以完成工作。有了这个工具,你就可以轻松获得什么样的信息。在密度大的情况下,可以优先排序。如果你让关键词值几万,我觉得你可以继续往下看,因为这里我们要讲的是选举系统中的外链。
其实应该把选举制度中的外链放在第一位,因为这是一个比较民主的选举。与上面提到的内容相关性不同,内容相关性选举应该属于百度内部的选举制度。第二次选举,而外链选举是第一次选举,网站证明你同时通过外链被认可。
说到这里,我就想到了一个让站长头疼的问题,那就是什么样的外链才算真实有效?许多seo工作者应该建立了很多外部链接,但实际效果未知。
但如果通过选举制度,则可以排除以下几类候选人:
1. 被剥夺政治权利。进入百度黑名单。
2.政治低谷。该网站本身质量很低。
3.没有投票权。即不在收录的范围内。
4. 与选举无关。与选举无关是什么意思?其实这里有几层意思。一是本站内容相关性不高,二是本站没有真心选你,甚至不认识你。这也是百度最近回复中多次提到的“推荐”内容。
如果你已经了解了选举制度,相信到这里你会比较清楚,但是你要非常清楚什么样的选举是一回事?选举制度可以一次性为所有成员投票,也可以分级选举。
所以,对于外链的建设,也是有选举和被选举的规则。很有可能百度官方近期会发布外链查询工具,告诉你哪些外链有用,哪些外链没用。我也会在下一期发表。提供相应的工具或当时的判断计划。 查看全部
无规则采集器列表算法(
Web3.0的到来后基于互联网营销模式(组图))
Web3.0到来后,基于互联网的营销模式层出不穷,seo是最热门的领域之一。我研究百度的算法跟踪近5年了。我主要从事算法反转,就是通过一些相关的指标来判断百度的排名规则。
在介绍百度算法之前,先说说百度搜索研发部不久前的博客文章《Web搜索排序中的投票模型简述》一文中的美国选举制度。这个其实就是百度的一个投票系统的雏形,我是这么认为的。用一个简单的图表来说明整个过程:
看上图相信大家应该都明白了,残差的排序应该是“主库”和百度服务器之间的一个变化。百度蜘蛛会采集返回大量内容,全部存放在主服务器中。服务器通过规则过滤后,最终将页面发布到web服务器上进行排序。事实上,“总库”已经发生了一系列的算法变化。当然,我这里解释的内容中的各种服务器和名称都是我个人定义的,但是基本逻辑应该是这样的,按照数据分析的原则:数据采集-数据处理-数据分析器-数据展示,在事实上,它可以很好地概括百度的行为。
百度虽然一方面在做推广和竞价,另一方面也希望能给用户带来良好的搜索体验。许多seoers可以恨和爱它。不过,根据各种官方文本,我们仍然认为百度搜索研发部门还是希望给用户一个。良好的检索体验。
话虽如此,还是得用一张图告诉大家什么是金字塔模型:
看了这张图,应该是有限的人有疑惑吧。这和漏斗原理很像吧!是的,它类似于漏斗原理,但是没有金字塔的灵感,每个人都希望得到金字塔的最高峰。
排序和过滤过程呢?引用一段百度搜索研发部文章的内容:
“系统有n个网页,有m个特征(页面质量、页面内容丰富度、页面超链接、文本相关性等)。n个网页有不同的分数。如何根据这些特征投票?哪个页面最多适合放在第一位吗?
从选举的例子中,我们可以得到几个启示:
1. 在设计算法时,要避免“赢家通吃”导致的信息丢失问题。
2. 不要仅仅因为某些功能特别好而将网页排在前列,或者因为某些功能特别差而放弃一个网页。
3. 最合适的网页首先不一定是每一个功能都最好的,但应该是能兼顾所有功能,整体表现最好的。
4. 搜索引擎用户对搜索结果的点击行为可视为对搜索结果的“投票”。在选举过程中也应考虑使用此类“投票”信息。各种不合理的出现。
上面提到的各种选举方案只讨论了“一个职位多个候选人”的情况,而搜索引擎面临的问题更类似于“多个候选人排序”的情况,即:
系统中有n个网页,有m个特征(页面质量、页面内容丰富度、页面超链接、文本相关性等)。n 个网页有不同的分数。如何根据这些特征的“投票”决定n个页面的顺序?
而这个“多候选人排名”的问题有一个“不可能民主”的理论。该理论的主要思想是,一个“合理”的民主应该满足三个条件:
1. 如果投票者认为A比B好,那么最后的结果也应该是A比B好
2. 没有“独裁者”,也就是没有这样的人。不管别人怎么排,最后的结果都会和这个人的顺序一样。
3.无关因素的独立性,即第一次投票完成后,A排在B前面,现在进行第二次投票。如果大家都没有改变他们投票中A和B的相对顺序,最后的结果也应该是A在B之前
并且通过数学证明,可以得出结论,如果某种选举方法满足条件1和3,就一定不满足2,即一定有“独裁者”。
根据“不可能的民主”理论,结合搜索引擎,搜索引擎似乎很难给出一个合理的网页排名,但搜索引擎和投票似乎是不同的。有两种观点可以破解
1. 我认为条件 3 太强了,需要削弱。
2. 也许在页面排名方面有这样的“独裁特征”。从目前来看,最合适的应该是“用户满意度”,根据用户满意度来划分。对网页进行排序是最合理的网页排名。如何衡量“用户满意度”?这是我们一直在努力的。”
相信大家看完这篇内容应该已经有了深刻的了解,百度的算法和选举系统有很多相似之处。所以我们逆向研究的方向是首先从数据呈现本身中得出数据分析原理。这是一个长期的计划,因为我们要分析数以亿计的网站,才能得出结论。,而事实证明,百度的排序规则中不仅有一个算法规则,而是有多个规则。
前期我也基于关键词开发了一个简单的分析程序:
这个工具主要是一个辅助功能。前面讨论的选举系统主要是针对外部链接的有效性,而这个工具的主要内容是针对相关性,即搜索结果末尾排序规则中的排序规则。当然,这个工具还处于粗略的状态,很多指标还没有添加。后期大家可以一起参与到本次研究中来,补充一些比较重要的指标,方便我们的研究更加完善。
如果你纯粹是一个seoer,我认为你可以停止阅读这项研究,因为事实证明,只要你得到最终排序的相关算法,你就可以完成工作。有了这个工具,你就可以轻松获得什么样的信息。在密度大的情况下,可以优先排序。如果你让关键词值几万,我觉得你可以继续往下看,因为这里我们要讲的是选举系统中的外链。
其实应该把选举制度中的外链放在第一位,因为这是一个比较民主的选举。与上面提到的内容相关性不同,内容相关性选举应该属于百度内部的选举制度。第二次选举,而外链选举是第一次选举,网站证明你同时通过外链被认可。
说到这里,我就想到了一个让站长头疼的问题,那就是什么样的外链才算真实有效?许多seo工作者应该建立了很多外部链接,但实际效果未知。
但如果通过选举制度,则可以排除以下几类候选人:
1. 被剥夺政治权利。进入百度黑名单。
2.政治低谷。该网站本身质量很低。
3.没有投票权。即不在收录的范围内。
4. 与选举无关。与选举无关是什么意思?其实这里有几层意思。一是本站内容相关性不高,二是本站没有真心选你,甚至不认识你。这也是百度最近回复中多次提到的“推荐”内容。
如果你已经了解了选举制度,相信到这里你会比较清楚,但是你要非常清楚什么样的选举是一回事?选举制度可以一次性为所有成员投票,也可以分级选举。
所以,对于外链的建设,也是有选举和被选举的规则。很有可能百度官方近期会发布外链查询工具,告诉你哪些外链有用,哪些外链没用。我也会在下一期发表。提供相应的工具或当时的判断计划。
无规则采集器列表算法(使用C#采集网页:%E7%80%%E6% )
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-11-01 21:18
)
使用 C#采集 网页:%E7%AE%80%E7%A7%B0%E5%8F%98%E5%8A%A8%E6%97%A5%E6%98%AF2010%E5 %B9%B4%E4%BB%A5%E6%9D%A5&queryarea=
本来可以返回带有数据的html,可以是采集token值
来自 html
但现在只能返回:
“
window.location.href="http://search.10jqka.com.cn/st ... 3B%3B
”
请问该问题怎么解决?
以下是我使用的方法,另外使用System.Net.WebClient方法返回为空。
public string GetMoths(string url, string WebCodeStr){
Encoding WebCode = Encoding.GetEncoding(WebCodeStr);
System.GC.Collect(); // 避免操作超时
HttpWebRequest wReq = (HttpWebRequest)WebRequest.Create(@url);
System.Net.ServicePointManager.DefaultConnectionLimit = 200;
wReq.KeepAlive = false;
wReq.UserAgent = @"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.0; .NET CLR 1.1.4322; .NET CLR 2.0.50215;)";
wReq.Method = "GET"; // HttpWebRequest.Method 属性 获取或设置请求的方法。
wReq.Timeout = 30000; //设置页面超时时间为30秒
HttpWebResponse wResp = null;
try { wResp = (HttpWebResponse)wReq.GetResponse(); }
catch (WebException ex) { var e1=ex; return null; } //
Stream respStream = wResp.GetResponseStream();
//判断网页编码,如果判断编码和读取流不放在一个方法,使用StreamReader会出现无法读取流的错误
StreamReader reader = new StreamReader(respStream, WebCode);
string strWebHtml = reader.ReadToEnd(); // 从流的当前位置到末尾读取流。
respStream.Close();reader.Close();reader.Dispose();
if (wReq != null) { wReq.Abort(); wReq = null; }
if (wResp != null) { wResp.Close(); wResp.Dispose(); wResp = null;}
return strWebHtml;
} 查看全部
无规则采集器列表算法(使用C#采集网页:%E7%80%%E6%
)
使用 C#采集 网页:%E7%AE%80%E7%A7%B0%E5%8F%98%E5%8A%A8%E6%97%A5%E6%98%AF2010%E5 %B9%B4%E4%BB%A5%E6%9D%A5&queryarea=
本来可以返回带有数据的html,可以是采集token值
来自 html
但现在只能返回:
“
window.location.href="http://search.10jqka.com.cn/st ... 3B%3B
”
请问该问题怎么解决?
以下是我使用的方法,另外使用System.Net.WebClient方法返回为空。
public string GetMoths(string url, string WebCodeStr){
Encoding WebCode = Encoding.GetEncoding(WebCodeStr);
System.GC.Collect(); // 避免操作超时
HttpWebRequest wReq = (HttpWebRequest)WebRequest.Create(@url);
System.Net.ServicePointManager.DefaultConnectionLimit = 200;
wReq.KeepAlive = false;
wReq.UserAgent = @"Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.0; .NET CLR 1.1.4322; .NET CLR 2.0.50215;)";
wReq.Method = "GET"; // HttpWebRequest.Method 属性 获取或设置请求的方法。
wReq.Timeout = 30000; //设置页面超时时间为30秒
HttpWebResponse wResp = null;
try { wResp = (HttpWebResponse)wReq.GetResponse(); }
catch (WebException ex) { var e1=ex; return null; } //
Stream respStream = wResp.GetResponseStream();
//判断网页编码,如果判断编码和读取流不放在一个方法,使用StreamReader会出现无法读取流的错误
StreamReader reader = new StreamReader(respStream, WebCode);
string strWebHtml = reader.ReadToEnd(); // 从流的当前位置到末尾读取流。
respStream.Close();reader.Close();reader.Dispose();
if (wReq != null) { wReq.Abort(); wReq = null; }
if (wResp != null) { wResp.Close(); wResp.Dispose(); wResp = null;}
return strWebHtml;
}
无规则采集器列表算法(无规则采集器列表算法的提升,效率都会有所提升)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-11-01 14:27
无规则采集器列表算法的提升,不同算法的效率可能都会有所提升。不妨多看一下各大网站的论文,都有不同的算法,从效率的角度来考虑的话肯定是越快越好。论文算法会说明当前论文中用到的算法都有哪些。多看看论文还是很有好处的。
更新一下算法速度的问题,
效率不同大家都知道,发论文之前先找这方面的论文,比如中文核心期刊二区,就可以找到一堆这方面的论文,如果不限定二区三区四区,一区五区都有,甚至一百多篇论文都有,也可以用万方数据库,中华万方社区网站检索论文。
搞懂了算法,说什么都是水到渠成。
如果你想快速解决问题可以使用一些网站,例如论文速查网站,读书上一篇比赛就是用代码记录常用的论文速查方法,方便方便查看。如果你想深入理解知识,我认为要充分看论文,边看边看笔记,
对于lz的我也有同样的问题,想知道lz的解决办法。感觉很有难度的样子。求指点。
就跟问收藏+赞同比一样,
不懂的就百度,谷歌,搜狗(tineye)搜下就好了。看看别人怎么回答问题的。
如果你想尽快解决,你只要多用搜索引擎,这些问题最后都不是问题,能不能解决那就是能力的问题了。搜索引擎搜关键字的时候,比如百度等搜下“computergraphlearningwithlstmgenerativemodels”,去看看别人做了什么样的工作,一般收集一些开源的工作(github等),主要是为了提升自己的代码技能,对练习(对于百度提出的问题)很有帮助。 查看全部
无规则采集器列表算法(无规则采集器列表算法的提升,效率都会有所提升)
无规则采集器列表算法的提升,不同算法的效率可能都会有所提升。不妨多看一下各大网站的论文,都有不同的算法,从效率的角度来考虑的话肯定是越快越好。论文算法会说明当前论文中用到的算法都有哪些。多看看论文还是很有好处的。
更新一下算法速度的问题,
效率不同大家都知道,发论文之前先找这方面的论文,比如中文核心期刊二区,就可以找到一堆这方面的论文,如果不限定二区三区四区,一区五区都有,甚至一百多篇论文都有,也可以用万方数据库,中华万方社区网站检索论文。
搞懂了算法,说什么都是水到渠成。
如果你想快速解决问题可以使用一些网站,例如论文速查网站,读书上一篇比赛就是用代码记录常用的论文速查方法,方便方便查看。如果你想深入理解知识,我认为要充分看论文,边看边看笔记,
对于lz的我也有同样的问题,想知道lz的解决办法。感觉很有难度的样子。求指点。
就跟问收藏+赞同比一样,
不懂的就百度,谷歌,搜狗(tineye)搜下就好了。看看别人怎么回答问题的。
如果你想尽快解决,你只要多用搜索引擎,这些问题最后都不是问题,能不能解决那就是能力的问题了。搜索引擎搜关键字的时候,比如百度等搜下“computergraphlearningwithlstmgenerativemodels”,去看看别人做了什么样的工作,一般收集一些开源的工作(github等),主要是为了提升自己的代码技能,对练习(对于百度提出的问题)很有帮助。

