
无规则采集器列表算法
无规则采集器列表算法(KNN算法的三个监督学习算法(1)_光明网 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2022-02-06 19:06
)
(1) KNN算法介绍:
KNN算法,即K近邻算法,是一种监督学习算法。本质上就是在给定的训练样本中找出最接近某个测试样本A的K个实例,然后统计这k个实例中类别数最多的那个。类,它根据新数据的主要分类确定新数据的类别。
(2) KNN算法的三个关键点:
① K的选择:
K值是KNN算法中为数不多的参数之一,K值的选择也直接影响模型的性能。如果我们把k的值设置得比较小,说明我们期望的模型更复杂更准确,也更容易过拟合;相反,如果K值越大,模型机会越简单,一个非常极端的例子是如果K值设置为等于训练样本的个数,即KN,那么无论什么类型的测试样本,最终的测试结果将是测试样本数量最多的类别。
②距离测量:
距离度量描述了测试样本和训练样本的接近程度。这种邻近性是选择 K 个样本的基础。在KNN算法中,如果特征是连续的,距离函数一般使用曼哈顿距离或欧几里得距离。是离散的,一般采用汉明距离。"
③ 分类决策规则:
通过上面提到的K和距离这两个概念,可以选出离测试样本最近的K个训练样本。如何根据K个样本确定测试样本的类别是KNN的分类决策规则。常用的是多数投票规则,但该规则很大程度上取决于训练样本的数量。
(3) KNN算法的优缺点:
①优点:简单、易懂、易实现、无需估计参数、无需训练。适合对稀有事件进行分类(比如流失率很低,比如小于0.5%,构建流失预测模型)特别适合多分类问题(多模态、对象有多个类标签),例如,根据基因特征来判断其功能分类,kNN比SVM表现更好。
②缺点:算法懒,分类测试样本时计算量大,内存开销大,评分慢,可解释性差,不能像决策树一样给出规则。
(4) 关于 KNN 算法的常见问题:
①k的值是多少?
k过小,分类结果容易受到噪声点的影响;如果 k 太大,则邻居可能收录太多其他类别的点。k的取值通常通过交叉核对确定(以k-1为基础),一般情况下k-一般低于训练样本数的平方根。
②如何确定最合适的品类?
投票方式不考虑最近邻的距离,距离较近的最近邻可能决定最终的分类,因此加权投票方式更为合适。
③如何选择合适的测距?
高维对距离测量的影响是变量个数越大,欧几里得距离的区分能力越差。变量范围对距离的影响在于,范围较大的变量往往在距离计算中起主导作用,所以首先要对变量进行标准化。
④ 训练样本是否应该一视同仁?
在训练集中,一些样本可能更可靠。可以对不同的样本应用不同的权重,加强依赖样本的权重,减少不可靠样本的影响。
⑤ 性能问题?
KNN 是一种惰性算法。如果平时不努力学习,只需要在考试的时候磨一把枪(对测试样本进行分类)(暂时找k个最近的邻居)。懒惰的后果:模型的构建很简单,但是对测试样本进行分类的系统开销很大。,因为所有的训练样本都被扫描并计算了距离。
(5)KNN算法在图像处理中的应用
1) KNN 很少用于图像问题。这个观点来自Stanford CS231n,原因有二:①测试效率差,样本量越大,分类过程就会越慢。②整幅图像的水平距离非常不直观。
2) Halcon 中的 KNN 分类器例程:
① 分类图像类 knn.hdev
②设置参数类knn.hdev
③最近邻居.hdev
———————————————
版权声明:本文为CSDN博主《小娜美要努力》的原创文章,遵循CC4.0 BY-SA版权协议,请附上原出处链接和this陈述。
原文链接:
#转载请注明出处 勇哥工业自动化技术《少有人走的路》网站。如需本文源代码等资源,请向永哥索取。
查看全部
无规则采集器列表算法(KNN算法的三个监督学习算法(1)_光明网
)
(1) KNN算法介绍:
KNN算法,即K近邻算法,是一种监督学习算法。本质上就是在给定的训练样本中找出最接近某个测试样本A的K个实例,然后统计这k个实例中类别数最多的那个。类,它根据新数据的主要分类确定新数据的类别。
(2) KNN算法的三个关键点:
① K的选择:
K值是KNN算法中为数不多的参数之一,K值的选择也直接影响模型的性能。如果我们把k的值设置得比较小,说明我们期望的模型更复杂更准确,也更容易过拟合;相反,如果K值越大,模型机会越简单,一个非常极端的例子是如果K值设置为等于训练样本的个数,即KN,那么无论什么类型的测试样本,最终的测试结果将是测试样本数量最多的类别。
②距离测量:
距离度量描述了测试样本和训练样本的接近程度。这种邻近性是选择 K 个样本的基础。在KNN算法中,如果特征是连续的,距离函数一般使用曼哈顿距离或欧几里得距离。是离散的,一般采用汉明距离。"
③ 分类决策规则:
通过上面提到的K和距离这两个概念,可以选出离测试样本最近的K个训练样本。如何根据K个样本确定测试样本的类别是KNN的分类决策规则。常用的是多数投票规则,但该规则很大程度上取决于训练样本的数量。
(3) KNN算法的优缺点:
①优点:简单、易懂、易实现、无需估计参数、无需训练。适合对稀有事件进行分类(比如流失率很低,比如小于0.5%,构建流失预测模型)特别适合多分类问题(多模态、对象有多个类标签),例如,根据基因特征来判断其功能分类,kNN比SVM表现更好。
②缺点:算法懒,分类测试样本时计算量大,内存开销大,评分慢,可解释性差,不能像决策树一样给出规则。
(4) 关于 KNN 算法的常见问题:
①k的值是多少?
k过小,分类结果容易受到噪声点的影响;如果 k 太大,则邻居可能收录太多其他类别的点。k的取值通常通过交叉核对确定(以k-1为基础),一般情况下k-一般低于训练样本数的平方根。
②如何确定最合适的品类?
投票方式不考虑最近邻的距离,距离较近的最近邻可能决定最终的分类,因此加权投票方式更为合适。
③如何选择合适的测距?
高维对距离测量的影响是变量个数越大,欧几里得距离的区分能力越差。变量范围对距离的影响在于,范围较大的变量往往在距离计算中起主导作用,所以首先要对变量进行标准化。
④ 训练样本是否应该一视同仁?
在训练集中,一些样本可能更可靠。可以对不同的样本应用不同的权重,加强依赖样本的权重,减少不可靠样本的影响。
⑤ 性能问题?
KNN 是一种惰性算法。如果平时不努力学习,只需要在考试的时候磨一把枪(对测试样本进行分类)(暂时找k个最近的邻居)。懒惰的后果:模型的构建很简单,但是对测试样本进行分类的系统开销很大。,因为所有的训练样本都被扫描并计算了距离。
(5)KNN算法在图像处理中的应用
1) KNN 很少用于图像问题。这个观点来自Stanford CS231n,原因有二:①测试效率差,样本量越大,分类过程就会越慢。②整幅图像的水平距离非常不直观。
2) Halcon 中的 KNN 分类器例程:
① 分类图像类 knn.hdev
②设置参数类knn.hdev
③最近邻居.hdev
———————————————
版权声明:本文为CSDN博主《小娜美要努力》的原创文章,遵循CC4.0 BY-SA版权协议,请附上原出处链接和this陈述。
原文链接:
#转载请注明出处 勇哥工业自动化技术《少有人走的路》网站。如需本文源代码等资源,请向永哥索取。

无规则采集器列表算法(《优采云采集器》的使用及其所用技术的介绍x》)
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-02-06 01:05
《优采云采集器的使用及x所用技术介绍》由会员上传分享,可在线免费阅读。更多相关内容可以在教育资源——天天图书馆中找到。
1、优采云采集器的使用以及它使用的技术介绍,优采云采集器>能为你做什么?1、网站内容维护:您可以安排采集新闻、文章等任何您想采集的内容,并自动发布到您的网站 。2、互联网数据挖掘:你可以从指定的网站中抓取需要的数据,分析处理后保存到你的数据库中。3、网络信息监控:通过自动采集,可以监控论坛等社区类网站,让你第一时间发现你关心的内容。4、文件批量下载:可以批量下载PDF、RAR、图片等文件,同时采集 他们的相关信息。优采云采集器是目前信息采集和信息挖掘处理软件中最受欢迎、性价比最高、用户数量最多、市场占有率最大、使用最多的软件.
2、持续时间最长的智能采集程序。给定一个种子URL列表,根据规则爬取列表页,根据采集规则分析URL爬取网页内容,分析下载的网页,保存内容优采云@ >采集器数据发布原理:在我们下载数据采集后,数据默认保存在本地,我们可以使用以下方法对数据进行处理。1.什么都不做。因为数据本身是存储在数据库中的(access or db3),如果只是想查看,可以直接用相关软件查看。2.网页发布到网站 . 程序会模仿浏览器向你的网站发送数据,可以达到你手动发布的效果。3. 直接进入数据库。您只需要编写几条 SQL 语句,程序就会根据您的 SQL 语句将数据发送到数据库中。
3、4.另存为本地文件。程序会读取数据库中的数据,并以一定的格式保存为本地sql或文本文件。优采云采集器演示优采云采集器技术垂直搜索引擎信息跟踪和自动排序自动索引技术海量数据采集系统流程1)信息< @采集(网络蜘蛛)对指定的网站进行数据采集,将需要的信息存储在本地,并记录对应的采集信息。用于信息提取模块的数据提取。2)信息提取从采集的信息中提取有效数据进行结构化处理。剔除垃圾信息,获取文字内容,以及相关图片和种子文件等相关信息。3)信息处理 对提取的信息进行数据处理。信息的清洗、去重、分类、分析比较、数据挖掘,
4、最后提交处理后的数据进行分词和索引。4)信息检索提供信息查询接口。为信息的分词处理提供全文检索接口。相关技术1、垂直搜索引擎的网络蜘蛛技术-爬虫信息源的稳定性(不能让信息源爬取的成本影响用户体验网站感受蜘蛛的压力改善问题)2、 WEB结构化信息抽取 将网页中的非结构化数据按一定要求抽取成结构化数据模板 结构化信息抽取的两种实现 一种不依赖网页的网页库级结构化信息抽取方法 Web结构化信息抽取已广泛应用于百度和谷歌。3、信息处理技术清洗、去重、分类、分析比较、数据挖掘、语义分析
5、分析等4、分词系统 基于字符串匹配的分词方法 基于理解的分词方法 基于统计的分词方法 分词方法 基于统计,目前尚无定论分词算法更准确。对于任何成熟的分词系统,都不可能依靠某种算法来实现,需要整合不同的算法。常用中文分词开源项目:SCWS、ICTCLAS、HTTPCWS、包丁捷牛分词、CC-CEDICT5、 索引和索引技术对于垂直搜索来说非常关键,一个网页库级别的搜索引擎必须支持分布式索引、分层建库、分布式检索、灵活更新、灵活的权重调整,灵活的索引和灵活的升级扩展,高可靠性、稳定性和冗余性。还需要支持各种技术的扩展,例如
6、偏移量计算等 感谢优采云采集器的使用和技术的介绍“优采云采集器”可以为你做什么?1、网站内容维护:您可以安排采集新闻、文章等任何您想采集的内容,并自动发布到您的网站 。2、互联网数据挖掘:你可以从指定的网站中抓取需要的数据,分析处理后保存到你的数据库中。3、网络信息监控:通过自动采集,可以监控论坛等社区类网站,让你第一时间发现你关心的内容。4、文件批量下载:可以批量下载PDF、RAR、图片等文件,同时采集他们的相关信息。优采云采集器是目前信息采集和信息挖掘处理软件中最受欢迎、性价比最高、最人性化的软件。
7、市场份额最大、生命周期最长的最智能采集程序。给定一个种子URL列表,根据规则爬取列表页,根据采集规则分析URL爬取网页内容,分析下载的网页,保存内容优采云@ >采集器数据发布原理:在我们下载数据采集后,数据默认保存在本地,我们可以使用以下方法对数据进行处理。1.什么都不做。因为数据本身是存储在数据库中的(access or db3),如果只是想查看,可以直接用相关软件查看。2.网页发布到网站 . 程序会模仿浏览器向你的网站发送数据,可以达到你手动发布的效果。3. 直接进入数据库。你只需要写几条SQL语句,程序就会根据你的数据来压数据
优采云4@>SQL 语句被导入数据库。4.另存为本地文件。程序会读取数据库中的数据,并以一定的格式保存为本地sql或文本文件。优采云采集器演示优采云采集器技术垂直搜索引擎信息跟踪和自动排序自动索引技术海量数据采集系统流程1)信息< @采集(网络蜘蛛)对指定的网站进行数据采集,将需要的信息存储在本地,并记录对应的采集信息。用于信息提取模块的数据提取。2)信息提取从采集的信息中提取有效数据进行结构化处理。剔除垃圾信息,获取文字内容,以及相关图片和种子文件等相关信息。3)信息处理 对提取的信息进行数据处理。清理,重复数据删除,
优采云9@>分类、分析比较、数据挖掘,最后提交处理后的数据进行信息分割和索引。4)信息检索提供信息查询接口。为信息的分词处理提供全文检索接口。相关技术1、垂直搜索引擎的网络蜘蛛技术-爬虫信息源的稳定性(不能让信息源爬取的成本影响用户体验网站感受蜘蛛的压力改善问题)2、 WEB结构化信息抽取 将网页中的非结构化数据按一定要求抽取成结构化数据模板 结构化信息抽取的两种实现 一种不依赖于网页的网页库级结构化信息抽取方法 Web结构化信息抽取已广泛应用于百度和谷歌。3、信息处理技术清洗、去重、分类、
10、分析比较、数据挖掘、语义分析等4、分词系统基于字符串匹配的分词方法基于理解的分词算法基于统计的分词方法是哪种分词算法准确度更高,目前还没有定论。对于任何成熟的分词系统,都不可能依靠某种算法来实现,需要整合不同的算法。常用中文分词开源项目:SCWS、ICTCLAS、HTTPCWS、包丁捷牛分词、CC-CEDICT5、 索引和索引技术对于垂直搜索来说非常关键,一个网页库级别的搜索引擎必须支持分布式索引、分层建库、分布式检索、灵活更新、灵活的权重调整,灵活的索引和灵活的升级扩展,高可靠性、稳定性和冗余性。还
11、需要支持各种技术的扩展,比如偏移量计算等。感谢优采云采集器的使用和技术的介绍“优采云采集器" 可以为你做吗?1、网站内容维护:您可以安排采集新闻、文章等任何您想采集的内容,并自动发布到您的网站 。2、互联网数据挖掘:你可以从指定的网站中抓取需要的数据,分析处理后保存到你的数据库中。3、网络信息监控:通过自动采集,可以监控论坛等社区类网站,让你第一时间发现你关心的内容。4、文件批量下载:可以下载PDF,批量生成RAR、图片等文件,同时采集它们的相关信息。优采云采集器是目前最流行的信息采集和信息挖掘处理软件
12、性价比最高、用户最多、市场占有率最大、生命周期最长的智能采集方案。给定一个种子URL列表,根据规则爬取列表页,根据采集规则分析URL爬取网页内容,分析下载的网页,保存内容优采云@ >采集器数据发布原理:在我们下载数据采集后,数据默认保存在本地,我们可以使用以下方法对数据进行处理。1.什么都不做。因为数据本身是存储在数据库中的(access or db3),如果只是想查看,可以直接用相关软件查看。2.网页发布到网站 . 程序它会模仿浏览器发送数据到你的< @网站,可以达到你手动发布的效果。3. 直接进入数据库。你只需要写几个SQ
13、L语句,程序会根据你的SQL语句将数据导入数据库。4.另存为本地文件。程序会读取数据库中的数据,并以一定的格式保存为本地sql或文本文件。优采云采集器演示优采云采集器技术垂直搜索引擎信息跟踪和自动排序自动索引技术海量数据采集系统流程1)信息< @采集(网络蜘蛛)对指定的网站进行数据采集,将需要的信息存储在本地,并记录对应的采集信息。用于信息提取模块的数据提取。2)信息提取从采集的信息中提取有效数据进行结构化处理。清除垃圾信息,获取文本内容,以及相关图片、种子文件等相关信息。3)信息处理 提取信息的数据处理
14、管理。对信息进行清理、去重、分类、分析和比较以及数据挖掘。最后提交处理后的数据,对信息进行分段和索引。4)信息检索提供信息查询接口。为信息的分词处理提供全文检索接口。相关技术1、垂直搜索引擎的网络蜘蛛技术-爬虫信息源的稳定性(不能让信息源爬取的成本影响用户体验网站感受蜘蛛的压力改善问题)2、 WEB结构化信息抽取 将网页中的非结构化数据按一定要求抽取成结构化数据模板 结构化信息抽取的两种实现 一种不依赖于网页的网页库级结构化信息抽取方法 Web结构化信息抽取已广泛应用于百度和谷歌。3、内容丰富
15、处理技术 清洗、去重、分类、分析比较、数据挖掘、语义分析等4、分词系统 基于字符串匹配的分词方法 基于理解的分词算法 词法统计基于分词的分词 哪种分词算法更准确尚无定论。对于任何成熟的分词系统,都不可能依靠某种算法来实现,需要整合不同的算法。常用中文分词开源项目:SCWS、ICTCLAS、HTTPCWS、包丁捷牛分词、CC-CEDICT5、 索引技术对于垂直搜索非常重要,网页库级别的搜索引擎必须支持分布式索引,分层数据库构建,
16、,高可靠性、稳定性和冗余性。还需要扩展以支持各种技术,例如偏移计算。感谢优采云采集器的使用和技术的介绍“优采云采集器”能为你做什么?1、网站内容维护:您可以安排采集新闻、文章等任何您想采集的内容,并自动发布到您的网站 。2、互联网数据挖掘:你可以从指定的网站中抓取需要的数据,分析处理后保存到你的数据库中。3、网络信息监控:通过自动采集,可以监控论坛等社区类网站,让你第一时间发现你关心的内容。< @4、文件批量下载:可以批量下载PDF、RAR、图片等文件,同时采集它们的相关信息。优采云采集器是当前信息采集
17、是信息挖掘与处理软件中用户数最多、市场占有率最大、服务周期最长的最受欢迎、性价比最高、智能化的采集程序。给定一个种子URL列表,根据规则爬取列表页,根据采集规则分析URL爬取网页内容,分析下载的网页,保存内容优采云@ >采集器数据发布原理:在我们下载数据采集后,数据默认保存在本地,我们可以使用以下方法对数据进行处理。1.什么都不做。因为数据本身是存储在数据库中的(access或者db3),如果只是想查看,可以直接用相关软件查看。2.web发布到< @网站。程序会模仿浏览器向你的网站发送数据,可以达到你手动发布的效果。3.直接
1优采云4@>进入数据库。您只需要编写几条SQL语句,程序就会根据您的SQL语句将数据导入数据库。4.另存为本地文件。程序会读取数据库中的数据,并以一定的格式保存为本地sql或文本文件。优采云采集器演示优采云采集器技术垂直搜索引擎信息跟踪和自动排序自动索引技术海量数据采集系统流程1)信息< @采集(网络蜘蛛)对指定的网站进行数据采集,将需要的信息存储在本地,并记录对应的采集信息。用于信息提取模块的数据提取。2)信息提取从<的信息中提取有效数据 @采集 用于结构化处理。清除垃圾信息,获取文本内容,以及相关图片、种子文件等相关信息。3)信息处理
1优采云9@>提取信息的数据处理。对信息进行清理、去重、分类、分析和比较以及数据挖掘。最后,将处理后的数据提交进行分词和索引。4)信息检索提供信息查询接口。为信息的分词处理提供全文检索接口。相关技术1、垂直搜索引擎的网络蜘蛛技术-爬虫信息源的稳定性(不能让信息源爬取的成本影响用户体验网站感受蜘蛛的压力,改善问题) 2、
20、e 早已被广泛使用。3、信息处理技术清洗、去重、分类、分析比较、数据挖掘、语义分析等4、分词系统基于字符串匹配的分词方法基于理解的分词算法分词算法基于统计的分词方法对于哪种分词算法更准确尚无定论。对于任何成熟的分词系统,都不可能依靠某种算法来实现,需要整合不同的算法。常用中文分词开源项目:SCWS、ICTCLAS、HTTPCWS、包丁捷牛分词、CC-CEDICT5、索引和索引技术对于垂直搜索非常关键,
21、灵活的索引和灵活的升级扩展,高可靠、稳定、冗余。还需要扩展以支持各种技术,例如偏移计算。感谢优采云采集器的使用和技术的介绍“优采云采集器”能为你做什么?1、网站内容维护:您可以安排采集新闻、文章等任何您想采集的内容,并自动发布到您的网站 。2、互联网数据挖掘:你可以从指定的网站中抓取需要的数据,分析处理后保存到你的数据库中。3、网络信息监控:通过自动采集,可以监控论坛等社区类网站,让您在第一时间发现您关心的内容。4、文件批量下载:可以批量下载PDF、RAR、图片等文件,同时采集它们的相关信息
22、。优采云采集器是目前信息采集信息挖掘和信息挖掘领域最流行、性价比最高、使用最多、市场占有率最大、使用寿命最长的智能采集软件处理软件。> 程序。给定一个种子URL列表,根据规则爬取列表页,根据采集规则分析URL爬取网页内容,分析下载的网页,保存内容优采云@ >采集器数据发布原理:在我们下载数据采集后,数据默认保存在本地,我们可以使用以下方法对数据进行处理。1.什么都不做。因为数据本身是存储在数据库中的(access或者db3),如果只是想查的话,可以直接用相关软件查看。2.Web 发布到 网站。程序会模仿浏览器向你的网站发送数据,你可以实现
23、你的手贴效果。3.直接进入数据库。您只需要编写几条SQL语句,程序就会根据您的SQL语句将数据导入数据库。4.另存为本地文件。程序会读取数据库中的数据,并以一定的格式保存为本地sql或文本文件。优采云采集器演示优采云采集器技术垂直搜索引擎信息跟踪和自动排序自动索引技术海量数据采集系统流程1)信息< @采集(网络蜘蛛)对指定的网站进行数据采集,将需要的信息存储在本地,并记录对应的采集信息。用于信息提取模块的数据提取。2) 信息抽取 从采集的信息中抽取有效数据进行结构化处理。清除垃圾信息,获取文字内容,以及相关图片和种子文字
24、 件和其他相关信息。3)信息处理 对提取的信息进行数据处理。对信息进行清理、去重、分类、分析和比较以及数据挖掘。最后提交处理后的数据,对信息进行分段和索引。4)信息检索提供信息查询接口。为信息的分词处理提供全文检索接口。相关技术1、垂直搜索引擎的网络蜘蛛技术-爬虫信息源的稳定性(不能让信息源爬取的成本影响用户体验网站感受蜘蛛的压力改善问题)2、
25、信息提取已在百度和谷歌广泛使用。3、信息处理技术清洗、去重、分类、分析比较、数据挖掘、语义分析等4、分词系统基于字符串匹配的分词方法基于理解的分词算法分词算法基于统计的分词方法对于哪种分词算法更准确尚无定论。对于任何成熟的分词系统,都不可能依靠某种算法来实现,需要整合不同的算法。常用中文分词开源项目:SCWS、ICTCLAS、HTTPCWS、包丁解牛分词、CC-CEDICT5、
26、实时更新,灵活权重调整,灵活索引灵活升级扩展,高可靠稳定冗余。还需要扩展以支持各种技术,例如偏移计算。感谢优采云采集器的使用和技术的介绍“优采云采集器”能为你做什么?1、网站内容维护:您可以安排采集新闻、文章等任何您想采集的内容,并自动发布到您的网站 。2、互联网数据挖掘:你可以从指定的网站中抓取需要的数据,分析处理后保存到你的数据库中。3、网络信息监控:通过自动采集,可以监控论坛等社区类< @网站,让你第一时间发现你关心的内容。4、文件批量下载:可以批量下载PDF、RAR、图片等
2 个7、文件,以及关于它们的采集信息。优采云采集器是目前信息采集信息挖掘和信息挖掘领域最流行、性价比最高、使用最多、市场占有率最大、使用寿命最长的智能采集软件处理软件。> 程序。给定一个种子URL列表,根据规则爬取列表页,根据采集规则分析URL爬取网页内容,分析下载的网页,保存内容优采云@ >采集器数据发布原理:在我们下载数据采集后,数据默认保存在本地,我们可以使用以下方法对数据进行处理。1.什么都不做。因为数据本身是存储在数据库中的(access or db3), 如果只是想查看,可以直接用相关软件查看。2.Web 发布到 网站。程序会模仿浏览器
2优采云4@>你的网站发送数据可以达到你手动释放的效果。3.直接进入数据库。您只需要编写几条SQL语句,程序就会根据您的SQL语句将数据导入数据库。4.另存为本地文件。程序会读取数据库中的数据,并以一定的格式保存为本地sql或文本文件。优采云采集器演示优采云采集器技术垂直搜索引擎信息跟踪和自动排序自动索引技术海量数据采集系统流程1)信息< @采集(网络蜘蛛)对指定的网站进行数据采集,将需要的信息存储在本地,并记录对应的采集信息。用于信息提取模块的数据提取。2)信息提取从采集的信息中提取有效数据进行结构化处理。消除垃圾信息并获取文本
2优采云9@>内容,以及相关图片、种子文件等相关信息。3)信息处理 对提取的信息进行数据处理。对信息进行清理、去重、分类、分析和比较以及数据挖掘。最后提交处理后的数据,对信息进行分段和索引。4)信息检索提供信息查询接口。为信息的分词处理提供全文检索接口。相关技术1、垂直搜索引擎的网络蜘蛛技术-爬虫信息源的稳定性(不能让信息源爬取的成本影响用户体验网站感受蜘蛛的压力改善问题)2、
30、信息抽取方法Web结构化信息抽取早已广泛应用于百度和谷歌。3、信息处理技术清洗、去重、分类、分析比较、数据挖掘、语义分析等4、分词系统基于字符串匹配的分词方法基于理解的分词算法分词算法基于统计的分词方法对于哪种分词算法更准确尚无定论。对于任何成熟的分词系统,都不可能依靠某种算法来实现,需要整合不同的算法。常用中文分词开源项目:SCWS、ICTCLAS、HTTPCWS、宝顶捷牛分词、CC-CEDICT<
31、简介,分级建库,分布式检索,灵活更新,灵活权重调整,灵活索引,灵活升级扩容,高可靠,稳定,冗余。还需要扩展以支持各种技术,例如偏移计算。感谢优采云采集器的使用和技术的介绍“优采云采集器”能为你做什么?1、网站内容维护:您可以安排采集新闻、文章等任何您想采集的内容,并自动发布到您的网站 。2、互联网数据挖掘:你可以从指定的网站中抓取需要的数据,分析处理后保存到你的数据库中。3、网络信息监控:通过自动采集,可以监控论坛等社区类网站,让你第一时间发现你关心的内容。4、文件批量下载:可以批量下载
32、PDF、RAR、图片等文件,同时采集其相关信息。优采云采集器是目前信息采集信息挖掘和信息挖掘领域最流行、性价比最高、使用最多、市场占有率最大、使用寿命最长的智能采集软件处理软件。> 程序。给定一个种子URL列表,根据规则爬取列表页,根据采集规则分析URL爬取网页内容,分析下载的网页,保存内容优采云@ >采集器数据发布原理:在我们下载数据采集后,数据默认保存在本地,我们可以使用以下方法对数据进行处理。1.什么都不做。
3 3、 到 网站。程序会模拟浏览器向你的网站发送数据,可以达到你手动发布的效果。3.直接进入数据库。您只需要编写几条SQL语句,程序就会根据您的SQL语句将数据导入数据库。4.另存为本地文件。程序会读取数据库中的数据,并以一定的格式保存为本地sql或文本文件。优采云采集器演示优采云采集器技术垂直搜索引擎信息跟踪和自动排序自动索引技术海量数据采集系统流程1)信息< @采集(网络蜘蛛)对指定的网站执行数据采集,在本地存储需要的信息,并记录对应的采集信息。用于信息提取模块的数据提取。2)信息提取从采集的信息中提取有效数据进行结构化处理
34、管理。清除垃圾信息,获取文本内容,以及相关图片、种子文件等相关信息。3)信息处理 对提取的信息进行数据处理。对信息进行清理、去重、分类、分析和比较以及数据挖掘。最后提交处理后的数据,对信息进行分段和索引。4)信息检索提供信息查询接口。为信息的分词处理提供全文检索接口。相关技术1、垂直搜索引擎的网络蜘蛛技术-爬虫信息源的稳定性(不能让信息源爬取的成本影响用户体验网站
35、网页不依赖Web结构化信息抽取的网页库级结构化信息抽取方法早已在百度和谷歌广泛使用。3、信息处理技术清洗、去重、分类、分析比较、数据挖掘、语义分析等4、分词系统基于字符串匹配的分词方法基于理解的分词算法分词算法基于统计的分词方法对于哪种分词算法更准确尚无定论。对于任何成熟的分词系统,都不可能依靠某种算法来实现,需要整合不同的算法。常用中文分词开源项目:SCWS、ICTCLAS、
36、搜索引擎必须支持分布式索引、分级建库、分布式检索、灵活更新、灵活权重调整、灵活索引和灵活升级扩展、高可靠性、稳定性和冗余性。还需要扩展以支持各种技术,例如偏移计算。感谢优采云采集器的使用和技术的介绍“优采云采集器”能为你做什么?1、网站内容维护:您可以安排采集新闻、文章等任何您想采集的内容,并自动发布到您的网站 。2、互联网数据挖掘:你可以从指定的网站中抓取需要的数据,分析处理后保存到你的数据库中。3、 查看全部
无规则采集器列表算法(《优采云采集器》的使用及其所用技术的介绍x》)
《优采云采集器的使用及x所用技术介绍》由会员上传分享,可在线免费阅读。更多相关内容可以在教育资源——天天图书馆中找到。
1、优采云采集器的使用以及它使用的技术介绍,优采云采集器>能为你做什么?1、网站内容维护:您可以安排采集新闻、文章等任何您想采集的内容,并自动发布到您的网站 。2、互联网数据挖掘:你可以从指定的网站中抓取需要的数据,分析处理后保存到你的数据库中。3、网络信息监控:通过自动采集,可以监控论坛等社区类网站,让你第一时间发现你关心的内容。4、文件批量下载:可以批量下载PDF、RAR、图片等文件,同时采集 他们的相关信息。优采云采集器是目前信息采集和信息挖掘处理软件中最受欢迎、性价比最高、用户数量最多、市场占有率最大、使用最多的软件.
2、持续时间最长的智能采集程序。给定一个种子URL列表,根据规则爬取列表页,根据采集规则分析URL爬取网页内容,分析下载的网页,保存内容优采云@ >采集器数据发布原理:在我们下载数据采集后,数据默认保存在本地,我们可以使用以下方法对数据进行处理。1.什么都不做。因为数据本身是存储在数据库中的(access or db3),如果只是想查看,可以直接用相关软件查看。2.网页发布到网站 . 程序会模仿浏览器向你的网站发送数据,可以达到你手动发布的效果。3. 直接进入数据库。您只需要编写几条 SQL 语句,程序就会根据您的 SQL 语句将数据发送到数据库中。
3、4.另存为本地文件。程序会读取数据库中的数据,并以一定的格式保存为本地sql或文本文件。优采云采集器演示优采云采集器技术垂直搜索引擎信息跟踪和自动排序自动索引技术海量数据采集系统流程1)信息< @采集(网络蜘蛛)对指定的网站进行数据采集,将需要的信息存储在本地,并记录对应的采集信息。用于信息提取模块的数据提取。2)信息提取从采集的信息中提取有效数据进行结构化处理。剔除垃圾信息,获取文字内容,以及相关图片和种子文件等相关信息。3)信息处理 对提取的信息进行数据处理。信息的清洗、去重、分类、分析比较、数据挖掘,
4、最后提交处理后的数据进行分词和索引。4)信息检索提供信息查询接口。为信息的分词处理提供全文检索接口。相关技术1、垂直搜索引擎的网络蜘蛛技术-爬虫信息源的稳定性(不能让信息源爬取的成本影响用户体验网站感受蜘蛛的压力改善问题)2、 WEB结构化信息抽取 将网页中的非结构化数据按一定要求抽取成结构化数据模板 结构化信息抽取的两种实现 一种不依赖网页的网页库级结构化信息抽取方法 Web结构化信息抽取已广泛应用于百度和谷歌。3、信息处理技术清洗、去重、分类、分析比较、数据挖掘、语义分析
5、分析等4、分词系统 基于字符串匹配的分词方法 基于理解的分词方法 基于统计的分词方法 分词方法 基于统计,目前尚无定论分词算法更准确。对于任何成熟的分词系统,都不可能依靠某种算法来实现,需要整合不同的算法。常用中文分词开源项目:SCWS、ICTCLAS、HTTPCWS、包丁捷牛分词、CC-CEDICT5、 索引和索引技术对于垂直搜索来说非常关键,一个网页库级别的搜索引擎必须支持分布式索引、分层建库、分布式检索、灵活更新、灵活的权重调整,灵活的索引和灵活的升级扩展,高可靠性、稳定性和冗余性。还需要支持各种技术的扩展,例如
6、偏移量计算等 感谢优采云采集器的使用和技术的介绍“优采云采集器”可以为你做什么?1、网站内容维护:您可以安排采集新闻、文章等任何您想采集的内容,并自动发布到您的网站 。2、互联网数据挖掘:你可以从指定的网站中抓取需要的数据,分析处理后保存到你的数据库中。3、网络信息监控:通过自动采集,可以监控论坛等社区类网站,让你第一时间发现你关心的内容。4、文件批量下载:可以批量下载PDF、RAR、图片等文件,同时采集他们的相关信息。优采云采集器是目前信息采集和信息挖掘处理软件中最受欢迎、性价比最高、最人性化的软件。
7、市场份额最大、生命周期最长的最智能采集程序。给定一个种子URL列表,根据规则爬取列表页,根据采集规则分析URL爬取网页内容,分析下载的网页,保存内容优采云@ >采集器数据发布原理:在我们下载数据采集后,数据默认保存在本地,我们可以使用以下方法对数据进行处理。1.什么都不做。因为数据本身是存储在数据库中的(access or db3),如果只是想查看,可以直接用相关软件查看。2.网页发布到网站 . 程序会模仿浏览器向你的网站发送数据,可以达到你手动发布的效果。3. 直接进入数据库。你只需要写几条SQL语句,程序就会根据你的数据来压数据
优采云4@>SQL 语句被导入数据库。4.另存为本地文件。程序会读取数据库中的数据,并以一定的格式保存为本地sql或文本文件。优采云采集器演示优采云采集器技术垂直搜索引擎信息跟踪和自动排序自动索引技术海量数据采集系统流程1)信息< @采集(网络蜘蛛)对指定的网站进行数据采集,将需要的信息存储在本地,并记录对应的采集信息。用于信息提取模块的数据提取。2)信息提取从采集的信息中提取有效数据进行结构化处理。剔除垃圾信息,获取文字内容,以及相关图片和种子文件等相关信息。3)信息处理 对提取的信息进行数据处理。清理,重复数据删除,
优采云9@>分类、分析比较、数据挖掘,最后提交处理后的数据进行信息分割和索引。4)信息检索提供信息查询接口。为信息的分词处理提供全文检索接口。相关技术1、垂直搜索引擎的网络蜘蛛技术-爬虫信息源的稳定性(不能让信息源爬取的成本影响用户体验网站感受蜘蛛的压力改善问题)2、 WEB结构化信息抽取 将网页中的非结构化数据按一定要求抽取成结构化数据模板 结构化信息抽取的两种实现 一种不依赖于网页的网页库级结构化信息抽取方法 Web结构化信息抽取已广泛应用于百度和谷歌。3、信息处理技术清洗、去重、分类、
10、分析比较、数据挖掘、语义分析等4、分词系统基于字符串匹配的分词方法基于理解的分词算法基于统计的分词方法是哪种分词算法准确度更高,目前还没有定论。对于任何成熟的分词系统,都不可能依靠某种算法来实现,需要整合不同的算法。常用中文分词开源项目:SCWS、ICTCLAS、HTTPCWS、包丁捷牛分词、CC-CEDICT5、 索引和索引技术对于垂直搜索来说非常关键,一个网页库级别的搜索引擎必须支持分布式索引、分层建库、分布式检索、灵活更新、灵活的权重调整,灵活的索引和灵活的升级扩展,高可靠性、稳定性和冗余性。还
11、需要支持各种技术的扩展,比如偏移量计算等。感谢优采云采集器的使用和技术的介绍“优采云采集器" 可以为你做吗?1、网站内容维护:您可以安排采集新闻、文章等任何您想采集的内容,并自动发布到您的网站 。2、互联网数据挖掘:你可以从指定的网站中抓取需要的数据,分析处理后保存到你的数据库中。3、网络信息监控:通过自动采集,可以监控论坛等社区类网站,让你第一时间发现你关心的内容。4、文件批量下载:可以下载PDF,批量生成RAR、图片等文件,同时采集它们的相关信息。优采云采集器是目前最流行的信息采集和信息挖掘处理软件
12、性价比最高、用户最多、市场占有率最大、生命周期最长的智能采集方案。给定一个种子URL列表,根据规则爬取列表页,根据采集规则分析URL爬取网页内容,分析下载的网页,保存内容优采云@ >采集器数据发布原理:在我们下载数据采集后,数据默认保存在本地,我们可以使用以下方法对数据进行处理。1.什么都不做。因为数据本身是存储在数据库中的(access or db3),如果只是想查看,可以直接用相关软件查看。2.网页发布到网站 . 程序它会模仿浏览器发送数据到你的< @网站,可以达到你手动发布的效果。3. 直接进入数据库。你只需要写几个SQ
13、L语句,程序会根据你的SQL语句将数据导入数据库。4.另存为本地文件。程序会读取数据库中的数据,并以一定的格式保存为本地sql或文本文件。优采云采集器演示优采云采集器技术垂直搜索引擎信息跟踪和自动排序自动索引技术海量数据采集系统流程1)信息< @采集(网络蜘蛛)对指定的网站进行数据采集,将需要的信息存储在本地,并记录对应的采集信息。用于信息提取模块的数据提取。2)信息提取从采集的信息中提取有效数据进行结构化处理。清除垃圾信息,获取文本内容,以及相关图片、种子文件等相关信息。3)信息处理 提取信息的数据处理
14、管理。对信息进行清理、去重、分类、分析和比较以及数据挖掘。最后提交处理后的数据,对信息进行分段和索引。4)信息检索提供信息查询接口。为信息的分词处理提供全文检索接口。相关技术1、垂直搜索引擎的网络蜘蛛技术-爬虫信息源的稳定性(不能让信息源爬取的成本影响用户体验网站感受蜘蛛的压力改善问题)2、 WEB结构化信息抽取 将网页中的非结构化数据按一定要求抽取成结构化数据模板 结构化信息抽取的两种实现 一种不依赖于网页的网页库级结构化信息抽取方法 Web结构化信息抽取已广泛应用于百度和谷歌。3、内容丰富
15、处理技术 清洗、去重、分类、分析比较、数据挖掘、语义分析等4、分词系统 基于字符串匹配的分词方法 基于理解的分词算法 词法统计基于分词的分词 哪种分词算法更准确尚无定论。对于任何成熟的分词系统,都不可能依靠某种算法来实现,需要整合不同的算法。常用中文分词开源项目:SCWS、ICTCLAS、HTTPCWS、包丁捷牛分词、CC-CEDICT5、 索引技术对于垂直搜索非常重要,网页库级别的搜索引擎必须支持分布式索引,分层数据库构建,
16、,高可靠性、稳定性和冗余性。还需要扩展以支持各种技术,例如偏移计算。感谢优采云采集器的使用和技术的介绍“优采云采集器”能为你做什么?1、网站内容维护:您可以安排采集新闻、文章等任何您想采集的内容,并自动发布到您的网站 。2、互联网数据挖掘:你可以从指定的网站中抓取需要的数据,分析处理后保存到你的数据库中。3、网络信息监控:通过自动采集,可以监控论坛等社区类网站,让你第一时间发现你关心的内容。< @4、文件批量下载:可以批量下载PDF、RAR、图片等文件,同时采集它们的相关信息。优采云采集器是当前信息采集
17、是信息挖掘与处理软件中用户数最多、市场占有率最大、服务周期最长的最受欢迎、性价比最高、智能化的采集程序。给定一个种子URL列表,根据规则爬取列表页,根据采集规则分析URL爬取网页内容,分析下载的网页,保存内容优采云@ >采集器数据发布原理:在我们下载数据采集后,数据默认保存在本地,我们可以使用以下方法对数据进行处理。1.什么都不做。因为数据本身是存储在数据库中的(access或者db3),如果只是想查看,可以直接用相关软件查看。2.web发布到< @网站。程序会模仿浏览器向你的网站发送数据,可以达到你手动发布的效果。3.直接
1优采云4@>进入数据库。您只需要编写几条SQL语句,程序就会根据您的SQL语句将数据导入数据库。4.另存为本地文件。程序会读取数据库中的数据,并以一定的格式保存为本地sql或文本文件。优采云采集器演示优采云采集器技术垂直搜索引擎信息跟踪和自动排序自动索引技术海量数据采集系统流程1)信息< @采集(网络蜘蛛)对指定的网站进行数据采集,将需要的信息存储在本地,并记录对应的采集信息。用于信息提取模块的数据提取。2)信息提取从<的信息中提取有效数据 @采集 用于结构化处理。清除垃圾信息,获取文本内容,以及相关图片、种子文件等相关信息。3)信息处理
1优采云9@>提取信息的数据处理。对信息进行清理、去重、分类、分析和比较以及数据挖掘。最后,将处理后的数据提交进行分词和索引。4)信息检索提供信息查询接口。为信息的分词处理提供全文检索接口。相关技术1、垂直搜索引擎的网络蜘蛛技术-爬虫信息源的稳定性(不能让信息源爬取的成本影响用户体验网站感受蜘蛛的压力,改善问题) 2、
20、e 早已被广泛使用。3、信息处理技术清洗、去重、分类、分析比较、数据挖掘、语义分析等4、分词系统基于字符串匹配的分词方法基于理解的分词算法分词算法基于统计的分词方法对于哪种分词算法更准确尚无定论。对于任何成熟的分词系统,都不可能依靠某种算法来实现,需要整合不同的算法。常用中文分词开源项目:SCWS、ICTCLAS、HTTPCWS、包丁捷牛分词、CC-CEDICT5、索引和索引技术对于垂直搜索非常关键,
21、灵活的索引和灵活的升级扩展,高可靠、稳定、冗余。还需要扩展以支持各种技术,例如偏移计算。感谢优采云采集器的使用和技术的介绍“优采云采集器”能为你做什么?1、网站内容维护:您可以安排采集新闻、文章等任何您想采集的内容,并自动发布到您的网站 。2、互联网数据挖掘:你可以从指定的网站中抓取需要的数据,分析处理后保存到你的数据库中。3、网络信息监控:通过自动采集,可以监控论坛等社区类网站,让您在第一时间发现您关心的内容。4、文件批量下载:可以批量下载PDF、RAR、图片等文件,同时采集它们的相关信息
22、。优采云采集器是目前信息采集信息挖掘和信息挖掘领域最流行、性价比最高、使用最多、市场占有率最大、使用寿命最长的智能采集软件处理软件。> 程序。给定一个种子URL列表,根据规则爬取列表页,根据采集规则分析URL爬取网页内容,分析下载的网页,保存内容优采云@ >采集器数据发布原理:在我们下载数据采集后,数据默认保存在本地,我们可以使用以下方法对数据进行处理。1.什么都不做。因为数据本身是存储在数据库中的(access或者db3),如果只是想查的话,可以直接用相关软件查看。2.Web 发布到 网站。程序会模仿浏览器向你的网站发送数据,你可以实现
23、你的手贴效果。3.直接进入数据库。您只需要编写几条SQL语句,程序就会根据您的SQL语句将数据导入数据库。4.另存为本地文件。程序会读取数据库中的数据,并以一定的格式保存为本地sql或文本文件。优采云采集器演示优采云采集器技术垂直搜索引擎信息跟踪和自动排序自动索引技术海量数据采集系统流程1)信息< @采集(网络蜘蛛)对指定的网站进行数据采集,将需要的信息存储在本地,并记录对应的采集信息。用于信息提取模块的数据提取。2) 信息抽取 从采集的信息中抽取有效数据进行结构化处理。清除垃圾信息,获取文字内容,以及相关图片和种子文字
24、 件和其他相关信息。3)信息处理 对提取的信息进行数据处理。对信息进行清理、去重、分类、分析和比较以及数据挖掘。最后提交处理后的数据,对信息进行分段和索引。4)信息检索提供信息查询接口。为信息的分词处理提供全文检索接口。相关技术1、垂直搜索引擎的网络蜘蛛技术-爬虫信息源的稳定性(不能让信息源爬取的成本影响用户体验网站感受蜘蛛的压力改善问题)2、
25、信息提取已在百度和谷歌广泛使用。3、信息处理技术清洗、去重、分类、分析比较、数据挖掘、语义分析等4、分词系统基于字符串匹配的分词方法基于理解的分词算法分词算法基于统计的分词方法对于哪种分词算法更准确尚无定论。对于任何成熟的分词系统,都不可能依靠某种算法来实现,需要整合不同的算法。常用中文分词开源项目:SCWS、ICTCLAS、HTTPCWS、包丁解牛分词、CC-CEDICT5、
26、实时更新,灵活权重调整,灵活索引灵活升级扩展,高可靠稳定冗余。还需要扩展以支持各种技术,例如偏移计算。感谢优采云采集器的使用和技术的介绍“优采云采集器”能为你做什么?1、网站内容维护:您可以安排采集新闻、文章等任何您想采集的内容,并自动发布到您的网站 。2、互联网数据挖掘:你可以从指定的网站中抓取需要的数据,分析处理后保存到你的数据库中。3、网络信息监控:通过自动采集,可以监控论坛等社区类< @网站,让你第一时间发现你关心的内容。4、文件批量下载:可以批量下载PDF、RAR、图片等
2 个7、文件,以及关于它们的采集信息。优采云采集器是目前信息采集信息挖掘和信息挖掘领域最流行、性价比最高、使用最多、市场占有率最大、使用寿命最长的智能采集软件处理软件。> 程序。给定一个种子URL列表,根据规则爬取列表页,根据采集规则分析URL爬取网页内容,分析下载的网页,保存内容优采云@ >采集器数据发布原理:在我们下载数据采集后,数据默认保存在本地,我们可以使用以下方法对数据进行处理。1.什么都不做。因为数据本身是存储在数据库中的(access or db3), 如果只是想查看,可以直接用相关软件查看。2.Web 发布到 网站。程序会模仿浏览器
2优采云4@>你的网站发送数据可以达到你手动释放的效果。3.直接进入数据库。您只需要编写几条SQL语句,程序就会根据您的SQL语句将数据导入数据库。4.另存为本地文件。程序会读取数据库中的数据,并以一定的格式保存为本地sql或文本文件。优采云采集器演示优采云采集器技术垂直搜索引擎信息跟踪和自动排序自动索引技术海量数据采集系统流程1)信息< @采集(网络蜘蛛)对指定的网站进行数据采集,将需要的信息存储在本地,并记录对应的采集信息。用于信息提取模块的数据提取。2)信息提取从采集的信息中提取有效数据进行结构化处理。消除垃圾信息并获取文本
2优采云9@>内容,以及相关图片、种子文件等相关信息。3)信息处理 对提取的信息进行数据处理。对信息进行清理、去重、分类、分析和比较以及数据挖掘。最后提交处理后的数据,对信息进行分段和索引。4)信息检索提供信息查询接口。为信息的分词处理提供全文检索接口。相关技术1、垂直搜索引擎的网络蜘蛛技术-爬虫信息源的稳定性(不能让信息源爬取的成本影响用户体验网站感受蜘蛛的压力改善问题)2、
30、信息抽取方法Web结构化信息抽取早已广泛应用于百度和谷歌。3、信息处理技术清洗、去重、分类、分析比较、数据挖掘、语义分析等4、分词系统基于字符串匹配的分词方法基于理解的分词算法分词算法基于统计的分词方法对于哪种分词算法更准确尚无定论。对于任何成熟的分词系统,都不可能依靠某种算法来实现,需要整合不同的算法。常用中文分词开源项目:SCWS、ICTCLAS、HTTPCWS、宝顶捷牛分词、CC-CEDICT<
31、简介,分级建库,分布式检索,灵活更新,灵活权重调整,灵活索引,灵活升级扩容,高可靠,稳定,冗余。还需要扩展以支持各种技术,例如偏移计算。感谢优采云采集器的使用和技术的介绍“优采云采集器”能为你做什么?1、网站内容维护:您可以安排采集新闻、文章等任何您想采集的内容,并自动发布到您的网站 。2、互联网数据挖掘:你可以从指定的网站中抓取需要的数据,分析处理后保存到你的数据库中。3、网络信息监控:通过自动采集,可以监控论坛等社区类网站,让你第一时间发现你关心的内容。4、文件批量下载:可以批量下载
32、PDF、RAR、图片等文件,同时采集其相关信息。优采云采集器是目前信息采集信息挖掘和信息挖掘领域最流行、性价比最高、使用最多、市场占有率最大、使用寿命最长的智能采集软件处理软件。> 程序。给定一个种子URL列表,根据规则爬取列表页,根据采集规则分析URL爬取网页内容,分析下载的网页,保存内容优采云@ >采集器数据发布原理:在我们下载数据采集后,数据默认保存在本地,我们可以使用以下方法对数据进行处理。1.什么都不做。
3 3、 到 网站。程序会模拟浏览器向你的网站发送数据,可以达到你手动发布的效果。3.直接进入数据库。您只需要编写几条SQL语句,程序就会根据您的SQL语句将数据导入数据库。4.另存为本地文件。程序会读取数据库中的数据,并以一定的格式保存为本地sql或文本文件。优采云采集器演示优采云采集器技术垂直搜索引擎信息跟踪和自动排序自动索引技术海量数据采集系统流程1)信息< @采集(网络蜘蛛)对指定的网站执行数据采集,在本地存储需要的信息,并记录对应的采集信息。用于信息提取模块的数据提取。2)信息提取从采集的信息中提取有效数据进行结构化处理
34、管理。清除垃圾信息,获取文本内容,以及相关图片、种子文件等相关信息。3)信息处理 对提取的信息进行数据处理。对信息进行清理、去重、分类、分析和比较以及数据挖掘。最后提交处理后的数据,对信息进行分段和索引。4)信息检索提供信息查询接口。为信息的分词处理提供全文检索接口。相关技术1、垂直搜索引擎的网络蜘蛛技术-爬虫信息源的稳定性(不能让信息源爬取的成本影响用户体验网站
35、网页不依赖Web结构化信息抽取的网页库级结构化信息抽取方法早已在百度和谷歌广泛使用。3、信息处理技术清洗、去重、分类、分析比较、数据挖掘、语义分析等4、分词系统基于字符串匹配的分词方法基于理解的分词算法分词算法基于统计的分词方法对于哪种分词算法更准确尚无定论。对于任何成熟的分词系统,都不可能依靠某种算法来实现,需要整合不同的算法。常用中文分词开源项目:SCWS、ICTCLAS、
36、搜索引擎必须支持分布式索引、分级建库、分布式检索、灵活更新、灵活权重调整、灵活索引和灵活升级扩展、高可靠性、稳定性和冗余性。还需要扩展以支持各种技术,例如偏移计算。感谢优采云采集器的使用和技术的介绍“优采云采集器”能为你做什么?1、网站内容维护:您可以安排采集新闻、文章等任何您想采集的内容,并自动发布到您的网站 。2、互联网数据挖掘:你可以从指定的网站中抓取需要的数据,分析处理后保存到你的数据库中。3、
无规则采集器列表算法( python机器学习朴素贝叶斯及模型的选择和调优示例详解)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-02-02 10:22
python机器学习朴素贝叶斯及模型的选择和调优示例详解)
python机器学习朴素贝叶斯算法和模型的选择和调优详解
更新时间:2021 年 11 月 12 日 15:47:34 作者:Swayzzu
本文章主要介绍python机器学习的朴素贝叶斯和模型选择调优示例。有需要的朋友可以借鉴。我希望它会有所帮助。祝你进步更大。
内容
一、概率基础1.概率
概率是某事发生的可能性。
2.联合概率
收录多个条件,以及所有条件同时为真的概率,记为:P(A, B) = P(A) * P(B)
3.条件概率
在另一个事件 B 已经发生的情况下,事件 A 发生的概率,记为:P(A|B)
条件概率的性质:P(A1,A2|B) = P(A1|B)P(A2|B)
注:这个条件概率的成立是由于A1和A2相互独立
朴素贝叶斯的原理是对于每个样本,计算属于每个类别的概率,并分类到概率最高的类别中。
二、朴素贝叶斯1.朴素贝叶斯的计算方法
直接代入实际例子,各部分解释如下:
P(C) = P(Technology):科学文档类别的概率(科学文档数量/文档总数)
P(W|C) = P('Intelligence', 'Development'|Technology):在科技文献分类文章中,'Intelligence'和'Development'两个特征词出现的概率'。注:“智能”、“发展”属于预测文档中出现的词,技术文档中可能有更多的特征词,但给定的文档可能不收录所有这些词。因此,使用给定文档中收录的内容。
计算方法:
P(F1|C) = N(i)/N(在训练集中计算)
N(i) 是 F1 词在 C 类所有文档中出现的次数
N 是文档中类别 C 下所有单词的出现次数,并且
P('Intelligence'|Technology) = 所有技术文档中出现'intelligence'的次数/技术文档中所有单词出现的次数和
那么 P(F1,F2...|C) = P(F1|C) * P(F2|C)
P('智力', '发展'|技术) = P('智力'|技术) * P('发展'|技术)
这样就可以根据预测文档中的特征词计算出预测文档属于科技的概率。相同的方法用于计算其他类型的概率。哪个更高。
2.拉普拉斯平滑
3.朴素贝叶斯 API
sklearn.naive_bayes.MultinomialNB
三、朴素贝叶斯算法案例1.案例概述
本例中的数据来自 sklearn 中的 20newsgroups 数据。通过提取文章中的特征词,使用朴素贝叶斯方法,计算预测的文章,并由得到的概率确定。文章它属于什么类别。
大致步骤如下:首先,将文章分为两类,一类作为训练集,一类作为测试集。接下来,使用tfidf从训练集和测试集文章中提取特征,这样就生成了训练集和测试集的x。接下来可以直接调用朴素贝叶斯算法将训练集数据x_train, y_train 进去,训练模型。最后,使用训练好的模型进行测试。
2.数据采集
导入数据库:import sklearn.datasets as dt
导入数据:news = dt.fetch_20newsgroups(subset='all')
3.数据处理
分割使用与 knn 中相同的方法。另外,对于从sklearn导入的数据,可以直接调用.data获取数据集,调用.target获取目标值。
拆分数据:x_train, x_test, y_train, y_test = train_test_split(news.data, news.target, test_size=0.25)
特征值提取方法实例化:tf = TfIdfVectorizer()
提取训练集数据的特征值:x_train = tf.fit_transform(x_train)
测试集数据特征值提取:x_test = tf.transform(x_test)
对于测试集的特征提取,只需要调用transform即可,因为使用的是训练集的标准,而训练集的标准在上一步已经拟合好了,直接使用测试集即可。
4.算法流程
算法实例化:mlt = MultinomialNB(alpha=1.0)
算法训练:mlt.fit(x_train, y_train)
预测结果:y_predict = mlt.predict(x_test)
5.备注
朴素贝叶斯算法的准确率是由训练集决定的,不需要调整。训练集误差大,结果肯定不好。因为计算方法是固定的,没有单一的超参数可以调整。
朴素贝叶斯的缺点:假设文档中的某些词是独立于其他词的,彼此之间没有关系。并且训练集中的词统计会干扰结果。训练集越好,结果越好,训练集越差,结果越差。
四、分类模型的评估1.混淆矩阵
评价标准有多种,其中之一就是准确率,就是将预测的目标值与提供的目标值一一比较,计算出准确率。
我们还有其他更通用和有用的评估标准,即精度和召回率。精度和召回率是基于混淆矩阵计算的。
一般来说,我们只关注召回。
F1分类标准:
根据上式,可以使用精确率和召回率计算出F1-score,可以反映模型的鲁棒性。
2.评估模型 API
sklearn.metricx.classification_report
3.模型选择与调优 ①交叉验证
交叉验证是为了让被评估的模型更加准确可信,具体如下:
>> 将所有数据分成 n 等份
>>第一个作为验证集,其他作为训练集,得到一个准确率,模型1
>>第二个作为验证集,其他作为训练集,得到一个准确率,模型2
>>......
>> 直到每个副本都通过,得到n个模型的准确率
>>平均所有的准确度,我们得到一个更可信的最终结果。
如果将其分成四个相等的部分,则称为“4-fold cross-validation”。
②网格搜索
网格搜索主要结合交叉验证来调整参数。比如K近邻算法中有一个超参数k,需要手动指定,比较复杂。因此,需要为模型预设几个超参数组合。通过交叉验证对每组超参数进行评估,最后选择最优的参数组合。造型。(K近邻算法只有一个超参数k,不是组合,但是如果算法有2个或更多的超参数,就是组合,相当于穷举法)
网格搜索 API:sklearn.model_selection.GridSearchCV
五、以knn为例进行模型调优
假设已经对数据和特征进行了处理,得到了x_train、x_test、y_train、y_test,并且已经实例化了算法:knn = KNeighborsClassifier()
1.构造超参数
因为算法中使用的超参数的名字叫做‘n_neighbors’,所以超参数的选择范围是直接用名字指定的。如果有第二个超参数,只需在其后添加一个字典元素。
参数 = {'n_neighbors':[5,10,15,20,25]}
2.进行网格搜索
输入参数:算法(估计器),网格参数,指定几折交叉验证
gc = GridSearchCV(knn, param_grid=params, cv=5)
指定基本信息后,您可以将训练集数据拟合到其中。
gc.fit(x_train, y_train)
3.结果视图
在网格搜索算法中,有几种方法可以查看准确率、模型、交叉验证结果以及每次交叉验证后的结果。
gc.score(x_test, y_test) 返回准确度
gc.best_score_ 返回最佳准确度
gc.best_estimator_ 返回最佳估计器(将自动返回所选超参数)
以上就是python机器学习朴素贝叶斯和模型的选择和调优的详细内容。更多关于朴素贝叶斯和模型选择和调优的信息,请关注脚本之家文章中的其他相关话题! 查看全部
无规则采集器列表算法(
python机器学习朴素贝叶斯及模型的选择和调优示例详解)
python机器学习朴素贝叶斯算法和模型的选择和调优详解
更新时间:2021 年 11 月 12 日 15:47:34 作者:Swayzzu
本文章主要介绍python机器学习的朴素贝叶斯和模型选择调优示例。有需要的朋友可以借鉴。我希望它会有所帮助。祝你进步更大。
内容
一、概率基础1.概率
概率是某事发生的可能性。
2.联合概率
收录多个条件,以及所有条件同时为真的概率,记为:P(A, B) = P(A) * P(B)
3.条件概率
在另一个事件 B 已经发生的情况下,事件 A 发生的概率,记为:P(A|B)
条件概率的性质:P(A1,A2|B) = P(A1|B)P(A2|B)
注:这个条件概率的成立是由于A1和A2相互独立
朴素贝叶斯的原理是对于每个样本,计算属于每个类别的概率,并分类到概率最高的类别中。
二、朴素贝叶斯1.朴素贝叶斯的计算方法

直接代入实际例子,各部分解释如下:
P(C) = P(Technology):科学文档类别的概率(科学文档数量/文档总数)
P(W|C) = P('Intelligence', 'Development'|Technology):在科技文献分类文章中,'Intelligence'和'Development'两个特征词出现的概率'。注:“智能”、“发展”属于预测文档中出现的词,技术文档中可能有更多的特征词,但给定的文档可能不收录所有这些词。因此,使用给定文档中收录的内容。
计算方法:
P(F1|C) = N(i)/N(在训练集中计算)
N(i) 是 F1 词在 C 类所有文档中出现的次数
N 是文档中类别 C 下所有单词的出现次数,并且
P('Intelligence'|Technology) = 所有技术文档中出现'intelligence'的次数/技术文档中所有单词出现的次数和
那么 P(F1,F2...|C) = P(F1|C) * P(F2|C)
P('智力', '发展'|技术) = P('智力'|技术) * P('发展'|技术)
这样就可以根据预测文档中的特征词计算出预测文档属于科技的概率。相同的方法用于计算其他类型的概率。哪个更高。
2.拉普拉斯平滑

3.朴素贝叶斯 API
sklearn.naive_bayes.MultinomialNB

三、朴素贝叶斯算法案例1.案例概述
本例中的数据来自 sklearn 中的 20newsgroups 数据。通过提取文章中的特征词,使用朴素贝叶斯方法,计算预测的文章,并由得到的概率确定。文章它属于什么类别。
大致步骤如下:首先,将文章分为两类,一类作为训练集,一类作为测试集。接下来,使用tfidf从训练集和测试集文章中提取特征,这样就生成了训练集和测试集的x。接下来可以直接调用朴素贝叶斯算法将训练集数据x_train, y_train 进去,训练模型。最后,使用训练好的模型进行测试。
2.数据采集
导入数据库:import sklearn.datasets as dt
导入数据:news = dt.fetch_20newsgroups(subset='all')
3.数据处理
分割使用与 knn 中相同的方法。另外,对于从sklearn导入的数据,可以直接调用.data获取数据集,调用.target获取目标值。
拆分数据:x_train, x_test, y_train, y_test = train_test_split(news.data, news.target, test_size=0.25)
特征值提取方法实例化:tf = TfIdfVectorizer()
提取训练集数据的特征值:x_train = tf.fit_transform(x_train)
测试集数据特征值提取:x_test = tf.transform(x_test)
对于测试集的特征提取,只需要调用transform即可,因为使用的是训练集的标准,而训练集的标准在上一步已经拟合好了,直接使用测试集即可。
4.算法流程
算法实例化:mlt = MultinomialNB(alpha=1.0)
算法训练:mlt.fit(x_train, y_train)
预测结果:y_predict = mlt.predict(x_test)
5.备注
朴素贝叶斯算法的准确率是由训练集决定的,不需要调整。训练集误差大,结果肯定不好。因为计算方法是固定的,没有单一的超参数可以调整。
朴素贝叶斯的缺点:假设文档中的某些词是独立于其他词的,彼此之间没有关系。并且训练集中的词统计会干扰结果。训练集越好,结果越好,训练集越差,结果越差。
四、分类模型的评估1.混淆矩阵
评价标准有多种,其中之一就是准确率,就是将预测的目标值与提供的目标值一一比较,计算出准确率。
我们还有其他更通用和有用的评估标准,即精度和召回率。精度和召回率是基于混淆矩阵计算的。


一般来说,我们只关注召回。
F1分类标准:

根据上式,可以使用精确率和召回率计算出F1-score,可以反映模型的鲁棒性。
2.评估模型 API
sklearn.metricx.classification_report
3.模型选择与调优 ①交叉验证
交叉验证是为了让被评估的模型更加准确可信,具体如下:
>> 将所有数据分成 n 等份
>>第一个作为验证集,其他作为训练集,得到一个准确率,模型1
>>第二个作为验证集,其他作为训练集,得到一个准确率,模型2
>>......
>> 直到每个副本都通过,得到n个模型的准确率
>>平均所有的准确度,我们得到一个更可信的最终结果。
如果将其分成四个相等的部分,则称为“4-fold cross-validation”。
②网格搜索
网格搜索主要结合交叉验证来调整参数。比如K近邻算法中有一个超参数k,需要手动指定,比较复杂。因此,需要为模型预设几个超参数组合。通过交叉验证对每组超参数进行评估,最后选择最优的参数组合。造型。(K近邻算法只有一个超参数k,不是组合,但是如果算法有2个或更多的超参数,就是组合,相当于穷举法)
网格搜索 API:sklearn.model_selection.GridSearchCV

五、以knn为例进行模型调优
假设已经对数据和特征进行了处理,得到了x_train、x_test、y_train、y_test,并且已经实例化了算法:knn = KNeighborsClassifier()
1.构造超参数
因为算法中使用的超参数的名字叫做‘n_neighbors’,所以超参数的选择范围是直接用名字指定的。如果有第二个超参数,只需在其后添加一个字典元素。
参数 = {'n_neighbors':[5,10,15,20,25]}
2.进行网格搜索
输入参数:算法(估计器),网格参数,指定几折交叉验证
gc = GridSearchCV(knn, param_grid=params, cv=5)
指定基本信息后,您可以将训练集数据拟合到其中。
gc.fit(x_train, y_train)
3.结果视图
在网格搜索算法中,有几种方法可以查看准确率、模型、交叉验证结果以及每次交叉验证后的结果。
gc.score(x_test, y_test) 返回准确度
gc.best_score_ 返回最佳准确度
gc.best_estimator_ 返回最佳估计器(将自动返回所选超参数)
以上就是python机器学习朴素贝叶斯和模型的选择和调优的详细内容。更多关于朴素贝叶斯和模型选择和调优的信息,请关注脚本之家文章中的其他相关话题!
无规则采集器列表算法(无规则采集器列表算法揭秘丨清华系列作品也有一套)
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-02-01 21:03
无规则采集器列表算法揭秘丨清华系列作品也有一套《无规则采集器》系列作品录制并推送到一些英文网站。为此团队聘请了一位资深算法工程师和电商产品开发人员来负责开发和推广;此外还有两位python开发工程师搭建人工智能算法并完成后续版本的研发升级。每月24日下午,无规则采集器人工智能算法发布会(day24)在清华举行。
据悉:此次发布会期间会举办算法及程序员日活动,力争推广行业标准,并开展hackathon自我提升活动。
python,perl,perl2,perl3都有。学会用了后生产力极高,能承受并发压力。
目前招聘、实习的岗位不需要写python熟练工,会用就可以。我们在做多机器学习实验,也是全部用python,只要是基础语法用的溜,用python做实验学起来都很轻松,不得不说未来的算法工程师基本上都要会python。所以掌握点python还是很有必要的。
会linux就行。
想要掌握算法工程师,python是前提条件。上面的回答都没明白我的意思。其实这个问题如果平心而论,不如从两个角度去思考。第一就是python本身的算法相关的性能如何?第二个就是数据科学的一些核心算法如何实现,而不是单纯的会写会用,看到一些开源的例子,就以为掌握了相关的算法。 查看全部
无规则采集器列表算法(无规则采集器列表算法揭秘丨清华系列作品也有一套)
无规则采集器列表算法揭秘丨清华系列作品也有一套《无规则采集器》系列作品录制并推送到一些英文网站。为此团队聘请了一位资深算法工程师和电商产品开发人员来负责开发和推广;此外还有两位python开发工程师搭建人工智能算法并完成后续版本的研发升级。每月24日下午,无规则采集器人工智能算法发布会(day24)在清华举行。
据悉:此次发布会期间会举办算法及程序员日活动,力争推广行业标准,并开展hackathon自我提升活动。
python,perl,perl2,perl3都有。学会用了后生产力极高,能承受并发压力。
目前招聘、实习的岗位不需要写python熟练工,会用就可以。我们在做多机器学习实验,也是全部用python,只要是基础语法用的溜,用python做实验学起来都很轻松,不得不说未来的算法工程师基本上都要会python。所以掌握点python还是很有必要的。
会linux就行。
想要掌握算法工程师,python是前提条件。上面的回答都没明白我的意思。其实这个问题如果平心而论,不如从两个角度去思考。第一就是python本身的算法相关的性能如何?第二个就是数据科学的一些核心算法如何实现,而不是单纯的会写会用,看到一些开源的例子,就以为掌握了相关的算法。
无规则采集器列表算法(无规则采集器列表算法和标准采集结构、工程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-02-01 11:03
无规则采集器列表算法和标准采集结构
0、工程实现(正常采集)
1、采集工具下载
2、采集方法(正常采集)
3、数据库选型
4、关系表生成算法
5、采集结果的存储(内存还是外存)
a、正常采集。
a
1、对采集结果做一些清洗,去除无用数据和采集过程中产生的生成和处理数据。
2、采集程序定义采集规则列表。将数据按规则随机输入采集表并进行采集。遇到特殊数据按数据规则定义的格式放置采集子表。定义access、sqlserver等数据库。表为对应采集要求的关系型数据库。表的修改交给采集工具完成。b、采集标准化设置采集次数、采集范围、采集频率。建议采集人员采集新产生数据和原始数据后进行复制,复制出来的数据按正常采集进行处理。
复制可进行多个采集模板进行复制,需要采集模板的直接采集建立模板。c、操作流程d、采集过程中可调整:通过修改采集脚本启动脚本,修改修改采集标准化位置、解释采集标准化格式、自定义采集时长、特殊格式处理等。
d、采集结果保存方式(可选)
二、采集介绍
2、1正常采集设置整个采集流程如下图所示:如图所示,前期接收采集要求,先将采集要求转化为采集规则,采集规则以模板关系的形式存储在采集数据库中,具体可参考采集工具的采集规则生成器,对采集规则进行填写调整。
2、2每一个采集模板均需要经过规则实验。实验包括三步:①先针对一个采集规则,按需要设置规则参数,如子网覆盖率、路由、规则强度、跨城市采集等;②将采集到的数据进行输出,存储到采集工具内存中,包括采集起始时间、采集区域、采集数量等;③将采集结果进行输出,封装为图片或文本文件。图片按需要标准化采集规则。文本文件按功能进行标准化采集规则。
2.3采集操作:①采集工具有多种采集器,通过添加规则实验得到采集规则后,可对其进行设置规则次数、采集频率、采集区域、采集次数、规则次长、规则精度等参数,这样可以大大降低采集率以及单条规则上传时间,实验可在采集器采集规则设置器进行。②采集结果转存时间(采集结果大小)是以采集模板采集文件中的大小作为转存时间,一般为3-10天。
2.4数据库表设计a、数据库层面:对表进行封装并优化,最后进行对其进行命名为表。b、采集子库设计:一般采用采集标准化的特定区域、采集规格、采集频率、规则强度、城市级的某个或多个子区域,最终对这些子区域单独分表c、采集数据的下沉和上传:对采集规则进行下沉(存储在采集工具内存中)后通过数据库下沉到数据库中,对于一次采集,下沉到某个区域后,在一次采集时再上传一个该区域, 查看全部
无规则采集器列表算法(无规则采集器列表算法和标准采集结构、工程)
无规则采集器列表算法和标准采集结构
0、工程实现(正常采集)
1、采集工具下载
2、采集方法(正常采集)
3、数据库选型
4、关系表生成算法
5、采集结果的存储(内存还是外存)
a、正常采集。
a
1、对采集结果做一些清洗,去除无用数据和采集过程中产生的生成和处理数据。
2、采集程序定义采集规则列表。将数据按规则随机输入采集表并进行采集。遇到特殊数据按数据规则定义的格式放置采集子表。定义access、sqlserver等数据库。表为对应采集要求的关系型数据库。表的修改交给采集工具完成。b、采集标准化设置采集次数、采集范围、采集频率。建议采集人员采集新产生数据和原始数据后进行复制,复制出来的数据按正常采集进行处理。
复制可进行多个采集模板进行复制,需要采集模板的直接采集建立模板。c、操作流程d、采集过程中可调整:通过修改采集脚本启动脚本,修改修改采集标准化位置、解释采集标准化格式、自定义采集时长、特殊格式处理等。
d、采集结果保存方式(可选)
二、采集介绍
2、1正常采集设置整个采集流程如下图所示:如图所示,前期接收采集要求,先将采集要求转化为采集规则,采集规则以模板关系的形式存储在采集数据库中,具体可参考采集工具的采集规则生成器,对采集规则进行填写调整。
2、2每一个采集模板均需要经过规则实验。实验包括三步:①先针对一个采集规则,按需要设置规则参数,如子网覆盖率、路由、规则强度、跨城市采集等;②将采集到的数据进行输出,存储到采集工具内存中,包括采集起始时间、采集区域、采集数量等;③将采集结果进行输出,封装为图片或文本文件。图片按需要标准化采集规则。文本文件按功能进行标准化采集规则。
2.3采集操作:①采集工具有多种采集器,通过添加规则实验得到采集规则后,可对其进行设置规则次数、采集频率、采集区域、采集次数、规则次长、规则精度等参数,这样可以大大降低采集率以及单条规则上传时间,实验可在采集器采集规则设置器进行。②采集结果转存时间(采集结果大小)是以采集模板采集文件中的大小作为转存时间,一般为3-10天。
2.4数据库表设计a、数据库层面:对表进行封装并优化,最后进行对其进行命名为表。b、采集子库设计:一般采用采集标准化的特定区域、采集规格、采集频率、规则强度、城市级的某个或多个子区域,最终对这些子区域单独分表c、采集数据的下沉和上传:对采集规则进行下沉(存储在采集工具内存中)后通过数据库下沉到数据库中,对于一次采集,下沉到某个区域后,在一次采集时再上传一个该区域,
无规则采集器列表算法(算法图解书籍介绍:本书示例丰富,图文并茂,大O表示法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2022-01-31 16:28
算法图解书籍简介:本书实例丰富,图文并茂,通俗易懂地讲解算法。它旨在帮助程序员在日常项目中更好地利用算法的力量。本书的前三章将帮助您奠定基础,带您了解二分搜索、大 O 表示法、两种基本数据结构、递归等。其余篇幅将主要介绍被广泛使用的算法,包括:面对特定问题时的解决技巧,例如何时使用贪心算法或动态规划;哈希表的应用;图算法;K-最近邻算法。
以下是我读这本书时想起的笔记,欢迎阅读和点赞!
二分查找
在有序数组中,需要使用二分查找检查多少个元素
完整的实现代码如下:(注解为Python语言实现)
def binary_search(list,item):
low=0
high=len(list)-1
while lowitem:
high=mid-1
else :
low=mid+1
return None #没有指定的元素
my_list=[1,3,5,7,9]
print(binary_search(my_list,3) #=>1 第二个位置的索引为1
print(binary_search(my_list,-1) #=>None 没有找到指定的元素
大 O 符号
该算法指示该算法的速度。大 O 表示法不是指以秒为单位的速度,而是指比较操作数,指示算法运行的速度。在大O算法中,运行时一般会省略常数,也省略了+、-、乘除。
二分法使用大 O 表示法来表示 O(log n) 的运行时间。
下面按从快到慢的顺序列出了 15 个 Big O 运行时:
O(log n),也叫对数时间,包括二分查找
O(n),也称为线性时间,包括简单的查找
O(nx logn), quicksort - 更快的算法
O(n^2), 选择排序 - 一种较慢的算法
O(n!),旅行商问题的解决方案 - 非常慢的算法
选择排序
数组:所有数组在内存中都是连续的(靠近在一起)。如果计算机保留的内存不够,必须转移到其他内存。一般来说,计算机会预留更多的内存供其他数组存储,但这也是一种内存浪费。
链表:链表的每个元素都存储下一个元素的地址,从而使一系列随机内存地址串在一起。所以将一个元素添加到链表中很容易,只需将其放入内存并将其地址存储在前一个元素中即可。
因此,链表读取速度慢,但插入速度快;数组插入速度慢。
下面是常见数组和链表操作的运行时
| |数组|链表|
| 阅读 | O(1) | O(n)|
| 插入 |O(n) |O(1) |
|删除|O(n) |O(1) |
数组一般用得比较多,因为它支持随机访问和顺序访问;而链表只能顺序访问,所以人们常说数组的读取速度非常快。
示例代码:
#查找最小值的函数
def findSmalllest(arr):
smallest=arr[0] #储存最小的值
smallest_index=0 #储存最小元素的索引
for i in range(1,len(arr)):
if arr[i]sub_max else sub_max
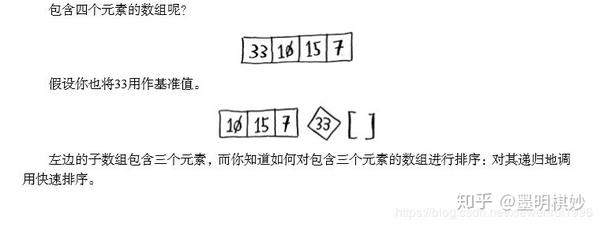
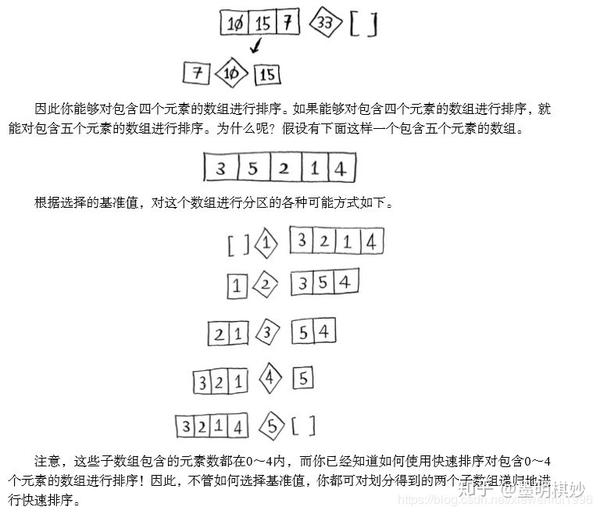
C语言标准库中的函数qsort实现了快速排序,快速排序也用到了D&C。
快速排序步骤(1)选择一个基值
(2) 将数组分成两个子数组:小于基值的元素和大于基值的元素。
(3)快速排序这两个数组
【按照步骤1】以此类推,对其他数组进行快速排序
下面是快速排序的代码:
def quicksort(array):
if len(array) < 2:
return array //基线条件:为空或只包含一个元素的数组是有序的
else:
pivot = array[0] //递归条件
less = [i for i in array[1:] if i pivot] //由所有大于基准值的元素组成的子数组
return quicksort(less) + [pivot] + quicksort(greater)
print(quicksort([10,5,2,3]))
在大 O 表示法 O(n) 中,n 实际上指的是:cxn(其中 C 是固定的时间量)。通常不考虑这个常数,因为这两种算法的大 O 运行时间是否不同并不重要。比如下面的例子:
简单查找:10(毫秒)xn
二进制搜索:1(秒)x logn
如上图,你可能认为简单搜索比二分查找快,但实际上二分查找要快得多。所以常数根本没有影响。
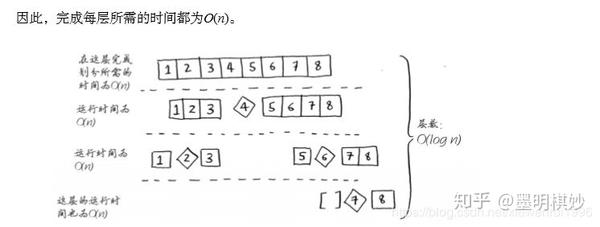
在这个例子中,层数是O(log n),从技术上讲,调用栈的高度是O(log n),每层需要的时间是O(n)。所以整个算法所需的时间是O(n)xO(log n)=O(nlog n)。
在最坏的情况下,有O(n)层,所以这个算法的运行时间是O(n)xO(n)=O(n^2)。 查看全部
无规则采集器列表算法(算法图解书籍介绍:本书示例丰富,图文并茂,大O表示法)
算法图解书籍简介:本书实例丰富,图文并茂,通俗易懂地讲解算法。它旨在帮助程序员在日常项目中更好地利用算法的力量。本书的前三章将帮助您奠定基础,带您了解二分搜索、大 O 表示法、两种基本数据结构、递归等。其余篇幅将主要介绍被广泛使用的算法,包括:面对特定问题时的解决技巧,例如何时使用贪心算法或动态规划;哈希表的应用;图算法;K-最近邻算法。
以下是我读这本书时想起的笔记,欢迎阅读和点赞!
二分查找
在有序数组中,需要使用二分查找检查多少个元素
完整的实现代码如下:(注解为Python语言实现)
def binary_search(list,item):
low=0
high=len(list)-1
while lowitem:
high=mid-1
else :
low=mid+1
return None #没有指定的元素
my_list=[1,3,5,7,9]
print(binary_search(my_list,3) #=>1 第二个位置的索引为1
print(binary_search(my_list,-1) #=>None 没有找到指定的元素
大 O 符号
该算法指示该算法的速度。大 O 表示法不是指以秒为单位的速度,而是指比较操作数,指示算法运行的速度。在大O算法中,运行时一般会省略常数,也省略了+、-、乘除。
二分法使用大 O 表示法来表示 O(log n) 的运行时间。
下面按从快到慢的顺序列出了 15 个 Big O 运行时:
O(log n),也叫对数时间,包括二分查找
O(n),也称为线性时间,包括简单的查找
O(nx logn), quicksort - 更快的算法
O(n^2), 选择排序 - 一种较慢的算法
O(n!),旅行商问题的解决方案 - 非常慢的算法
选择排序
数组:所有数组在内存中都是连续的(靠近在一起)。如果计算机保留的内存不够,必须转移到其他内存。一般来说,计算机会预留更多的内存供其他数组存储,但这也是一种内存浪费。
链表:链表的每个元素都存储下一个元素的地址,从而使一系列随机内存地址串在一起。所以将一个元素添加到链表中很容易,只需将其放入内存并将其地址存储在前一个元素中即可。
因此,链表读取速度慢,但插入速度快;数组插入速度慢。
下面是常见数组和链表操作的运行时
| |数组|链表|
| 阅读 | O(1) | O(n)|
| 插入 |O(n) |O(1) |
|删除|O(n) |O(1) |
数组一般用得比较多,因为它支持随机访问和顺序访问;而链表只能顺序访问,所以人们常说数组的读取速度非常快。
示例代码:
#查找最小值的函数
def findSmalllest(arr):
smallest=arr[0] #储存最小的值
smallest_index=0 #储存最小元素的索引
for i in range(1,len(arr)):
if arr[i]sub_max else sub_max
C语言标准库中的函数qsort实现了快速排序,快速排序也用到了D&C。
快速排序步骤(1)选择一个基值
(2) 将数组分成两个子数组:小于基值的元素和大于基值的元素。
(3)快速排序这两个数组
【按照步骤1】以此类推,对其他数组进行快速排序
下面是快速排序的代码:
def quicksort(array):
if len(array) < 2:
return array //基线条件:为空或只包含一个元素的数组是有序的
else:
pivot = array[0] //递归条件
less = [i for i in array[1:] if i pivot] //由所有大于基准值的元素组成的子数组
return quicksort(less) + [pivot] + quicksort(greater)
print(quicksort([10,5,2,3]))
在大 O 表示法 O(n) 中,n 实际上指的是:cxn(其中 C 是固定的时间量)。通常不考虑这个常数,因为这两种算法的大 O 运行时间是否不同并不重要。比如下面的例子:
简单查找:10(毫秒)xn
二进制搜索:1(秒)x logn
如上图,你可能认为简单搜索比二分查找快,但实际上二分查找要快得多。所以常数根本没有影响。
在这个例子中,层数是O(log n),从技术上讲,调用栈的高度是O(log n),每层需要的时间是O(n)。所以整个算法所需的时间是O(n)xO(log n)=O(nlog n)。
在最坏的情况下,有O(n)层,所以这个算法的运行时间是O(n)xO(n)=O(n^2)。
无规则采集器列表算法(优采云采集器教程一起随小编来看看吧来看)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2022-01-30 17:15
如何快速采集在线获取大量数据信息,哪个信息采集工具好用?优采云采集器使您的消息变得简单的工具采集。优采云采集器下载体验更高效简单的数据采集!优采云采集器怎么用?在这里,小编带来了优采云采集器教程和小编一起来看看吧!
优采云采集器(信息采集工具) 软件介绍
优采云Data采集系统基于完全自主研发的分布式云计算平台。它可以很容易地在很短的时间内从各种网站或网页中获取大量的标准化数据。数据,帮助任何需要从网页获取信息的客户实现数据自动化采集、编辑、规范化,摆脱对人工搜索和数据采集的依赖,从而降低获取信息的成本,提高效率。
优采云采集器有什么用(特点)
操作简单,图形化操作完全可视化,无需专业的IT人员,任何会用电脑上网的人都能轻松掌握。
云采集
采集任务自动分配到云端多台服务器同时执行,提高采集效率,在极短的时间内获取上千条信息。
拖放采集 过程
模拟人类操作思维模式,可以登录、输入数据、点击链接、按钮等,也可以针对不同的情况采取不同的采集流程。
图像和文本识别
内置可扩展OCR接口,支持解析图片中的文字,可以提取图片上的文字。
定时自动采集
采集任务自动运行,可以按指定周期自动采集,也支持一分钟实时采集。
2分钟快速启动
内置从入门到精通的视频教程,2分钟即可上手,此外还有文档、论坛、QQ群等。
免费使用
它是免费的,免费版没有功能限制,您可以立即试用,立即下载安装。
优采云采集器教程(安装过程)
1.未来软件园下载正式版压缩包优采云采集器,解压,双击.exe程序运行,进入安装向导,选择更改安装位置
2.安装稍等
3.安装完成
优采云采集器如何使用-如何使用规则
1)使用从规则市场下载的规则 一般情况下,从规则市场下载的规则是后缀为.otd的规则文件。4.*下载的规则文件会在以后的版本中自动导入。在以前的版本中,下载的规则文件需要手动导入。手动导入方法:双击优采云规则文件(.OTD)打开导入向导,或打开优采云采集器,快速开始->导入规则,然后按照向导提示导入规则。但有时您会下载带有 .zip 后缀的压缩文件。压缩文件解压后收录多个.otd规则文件,需要先解压,再导入。2)使用收到的规则使用其他即时通讯软件收到的电子邮件或规则,
变更日志
优采云采集器(信息采集工具) v7.1.4 升级提醒:
系统不支持6.x自动升级到7.x,使用6.x版本的用户请先卸载:开始->优采云->卸载再安装V 7.x。
体验改进:
新增UserAgent切换功能,有效规避网页保护采集(包括Firefox 45、54、55、Firefox Mobile 29、最新版谷歌浏览器)
新增“检测工作流程异常”功能,当工作流程发生错误时,会检测并自动修复
加入“关于我们”查看客户端版本并检查更新
现在可以为“自动数据库导出”选择保存的导出配置
删除单个任务并添加确认提示,避免误操作
优化编辑任务名称体验
导出数据时,导出数据范围默认遵循当前页面过滤条件,避免误操作
删除了“发布到 网站”功能
Bug修复:
修复“采集添加字段后,导致数据丢失”的问题
修复了“预览收录大量内容的字段时崩溃”
修复“任务名称过长,自动导出无法显示任务”的问题
修复IT橙子开启异常问题(需要手动切换UA到Firefox 54、Firefox 29) 查看全部
无规则采集器列表算法(优采云采集器教程一起随小编来看看吧来看)
如何快速采集在线获取大量数据信息,哪个信息采集工具好用?优采云采集器使您的消息变得简单的工具采集。优采云采集器下载体验更高效简单的数据采集!优采云采集器怎么用?在这里,小编带来了优采云采集器教程和小编一起来看看吧!

优采云采集器(信息采集工具) 软件介绍
优采云Data采集系统基于完全自主研发的分布式云计算平台。它可以很容易地在很短的时间内从各种网站或网页中获取大量的标准化数据。数据,帮助任何需要从网页获取信息的客户实现数据自动化采集、编辑、规范化,摆脱对人工搜索和数据采集的依赖,从而降低获取信息的成本,提高效率。
优采云采集器有什么用(特点)
操作简单,图形化操作完全可视化,无需专业的IT人员,任何会用电脑上网的人都能轻松掌握。
云采集
采集任务自动分配到云端多台服务器同时执行,提高采集效率,在极短的时间内获取上千条信息。
拖放采集 过程
模拟人类操作思维模式,可以登录、输入数据、点击链接、按钮等,也可以针对不同的情况采取不同的采集流程。
图像和文本识别
内置可扩展OCR接口,支持解析图片中的文字,可以提取图片上的文字。
定时自动采集
采集任务自动运行,可以按指定周期自动采集,也支持一分钟实时采集。
2分钟快速启动
内置从入门到精通的视频教程,2分钟即可上手,此外还有文档、论坛、QQ群等。
免费使用
它是免费的,免费版没有功能限制,您可以立即试用,立即下载安装。
优采云采集器教程(安装过程)
1.未来软件园下载正式版压缩包优采云采集器,解压,双击.exe程序运行,进入安装向导,选择更改安装位置

2.安装稍等

3.安装完成

优采云采集器如何使用-如何使用规则
1)使用从规则市场下载的规则 一般情况下,从规则市场下载的规则是后缀为.otd的规则文件。4.*下载的规则文件会在以后的版本中自动导入。在以前的版本中,下载的规则文件需要手动导入。手动导入方法:双击优采云规则文件(.OTD)打开导入向导,或打开优采云采集器,快速开始->导入规则,然后按照向导提示导入规则。但有时您会下载带有 .zip 后缀的压缩文件。压缩文件解压后收录多个.otd规则文件,需要先解压,再导入。2)使用收到的规则使用其他即时通讯软件收到的电子邮件或规则,
变更日志
优采云采集器(信息采集工具) v7.1.4 升级提醒:
系统不支持6.x自动升级到7.x,使用6.x版本的用户请先卸载:开始->优采云->卸载再安装V 7.x。
体验改进:
新增UserAgent切换功能,有效规避网页保护采集(包括Firefox 45、54、55、Firefox Mobile 29、最新版谷歌浏览器)
新增“检测工作流程异常”功能,当工作流程发生错误时,会检测并自动修复
加入“关于我们”查看客户端版本并检查更新
现在可以为“自动数据库导出”选择保存的导出配置
删除单个任务并添加确认提示,避免误操作
优化编辑任务名称体验
导出数据时,导出数据范围默认遵循当前页面过滤条件,避免误操作
删除了“发布到 网站”功能
Bug修复:
修复“采集添加字段后,导致数据丢失”的问题
修复了“预览收录大量内容的字段时崩溃”
修复“任务名称过长,自动导出无法显示任务”的问题
修复IT橙子开启异常问题(需要手动切换UA到Firefox 54、Firefox 29)
无规则采集器列表算法( FC采集插件致力于.4的主要功能包括哪几种?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2022-01-30 14:08
FC采集插件致力于.4的主要功能包括哪几种?)
FC(原DXC采集器)是Fool collector(Fool采集器)的缩写,FC采集插件致力于discuz上的内容解决方案,帮助站长更快更轻松地搭建网站内容.
通过FC采集插件,用户可以很方便的从网上获取采集数据,包括会员数据、文章数据。此外,还有虚拟在线、单帖采集等辅助功能,让冷清的新论坛瞬间形成内容丰富、会员活跃的热门论坛,对论坛初期运营有很大帮助. 这是一个discuz应用程序,必须由论坛的新手站长安装。
FC3.4的主要功能包括:
1、多种形式的url列表采集文章,包括rss地址、列表页、多级列表等。
2、多种方式编写规则,dom方式,字符截取,智能获取,更方便获取想要的内容
3、规则继承,自动检测匹配规则功能,你会逐渐体会到规则继承带来的便利
4、独有的网页文本提取算法,自动学习归纳规则,更方便泛采集。
5、支持图片定位和水印
6、灵活的发布机制,可以自定义发布者、发布时间、点击率等。
7、强大的内容编辑后台,可以轻松编辑采集收到的内容并发布到门户、论坛、博客
8、内容过滤功能,过滤采集内容上的广告,去除不必要的区域
9、批量采集,注册会员,批量采集,设置会员头像
10、无人值守定时量化采集和释放文章 查看全部
无规则采集器列表算法(
FC采集插件致力于.4的主要功能包括哪几种?)

FC(原DXC采集器)是Fool collector(Fool采集器)的缩写,FC采集插件致力于discuz上的内容解决方案,帮助站长更快更轻松地搭建网站内容.
通过FC采集插件,用户可以很方便的从网上获取采集数据,包括会员数据、文章数据。此外,还有虚拟在线、单帖采集等辅助功能,让冷清的新论坛瞬间形成内容丰富、会员活跃的热门论坛,对论坛初期运营有很大帮助. 这是一个discuz应用程序,必须由论坛的新手站长安装。
FC3.4的主要功能包括:
1、多种形式的url列表采集文章,包括rss地址、列表页、多级列表等。
2、多种方式编写规则,dom方式,字符截取,智能获取,更方便获取想要的内容
3、规则继承,自动检测匹配规则功能,你会逐渐体会到规则继承带来的便利
4、独有的网页文本提取算法,自动学习归纳规则,更方便泛采集。
5、支持图片定位和水印
6、灵活的发布机制,可以自定义发布者、发布时间、点击率等。
7、强大的内容编辑后台,可以轻松编辑采集收到的内容并发布到门户、论坛、博客
8、内容过滤功能,过滤采集内容上的广告,去除不必要的区域
9、批量采集,注册会员,批量采集,设置会员头像
10、无人值守定时量化采集和释放文章
无规则采集器列表算法(百度搜索学院飓风算法3.0即将上线,打击对象和打击内容)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-01-27 05:10
大家好,我是小白。一周前的8月8日,百度搜索学院正式宣布飓风算法3.0即将上线。作为飓风算法针对采集的后续补充,这次飓风算法3.0的具体目标和内容是什么?小白为大家简单介绍了一些自己的经历,希望对大家有所帮助。
百度作为成熟的中文搜索引擎,无论是索引收录还是搜索匹配,都有完整的操作规则。当有人利用一些算法漏洞谋取利益时,在不改变整套搜索计算规则的情况下,百度只能选择打补丁,也就是所谓的算法。下面简单梳理一下各大算法的上线时间线。,基本在12年后出现:
百度绿屋顶算法 - 2013 年 2 月 19 日
打击链接交易(我的超链接分析技术怎么会有漏洞,emmmmm,如果有漏洞,那就补个补丁)
百度石榴算法 - 2013 年 5 月 17 日
打击不良广告(dei大哥,你网站我看不懂文字不说,广告快瞎了我的眼睛,哪个是关闭键?)
百度绿顶算法2.0——2013年7月1日
打击带有不相关外部链接的网站(我的成人用品,兄弟换朋友链?XX阻止一个!)
百度冰桶算法1.0——2014年8月30日
实战手机网站强制app下载(腾讯新闻:更多完整内容请下载...)
百度冰桶算法2.0——2014年11月18日
严厉打击手机广告屏蔽和强制登录(请登录后观看以下内容)
百度冰桶算法3.0——2016年7月15日
严厉打击阻止用户访问页面、弹窗强制用户下载应用(好看吗?想看更多吗?请收费...哦不,请下载应用观看,然后收费...)
百度天网算法 - 2016 年 8 月 10 日
打击网站恶意JS夺取用户隐私
百度冰桶算法4.0——2016年9月19日
规范移动端网站的广告覆盖率,点击率高的页面(你网站只允许这么大的广告,如果你是认真的,你就……)
百度冰桶算法4.5—2016年10月26日
打击色情赌博广告(XX首家网上赌场下线)
百度优采云算法 - 2016 年 11 月 21 日
打击软文交易(你有没有夸他有什么好处?快告诉我)
百度烽火项目 - 2017 年 2 月 23 日
打击JS劫持访问(死循环N次后,为什么百度还是推荐这个垃圾网站?)
百度飓风算法 - 2017 年 7 月 4 日
点击采集镜像站(你们都给我写原创!)
百度清风算法——2017年9月14日
打击假标题(免费?!靠,扣费!PS:主要针对下载网站)
百度闪电算法 - 2017 年 10 月 19 日
减轻慢访问打开网站的权重(你的网站完全没有用户体验,想要变强可以用我们的mip)
百度迅雷算法 - 2017 年 11 月 20 日
点击点击刷排名(哪些是真正的点击,我有点糊涂了)
百度 Beacon 算法2.0 — 2018 年 5 月 17 日
打击JS劫持访问提取用户信息(死循环N次后,为什么这个一定程度还推荐这个垃圾邮件网站?“已拦截125个恶意骚扰电话”“XX第一次上线……”)
百度清风算法2.0——2018年7月19日
对于不准确和无效的下载资源(支付宝PJ版在哪里?)
百度细雨算法 - 2018 年 7 月中旬
实战标题关键词堆砌和假官网(你说官网就是官网?有我的认证吗?)
百度飓风算法2.0 — 2018 年 9 月 21 日
实战内容拼接和跨域采集(啊,这个网站太棒了,我什么都想要!嘿,那个网站呢?)
百度清风算法3.0——2018年10月16日
下载站标题下载问题全面回顾(如果没有充值,请退群)
百度冰桶算法5.0——2018年11月12日
冰桶算法的广告规范覆盖百度app(春节期间我要去春晚,只能在我的网站上做广告)
百度飓风算法3.0 — 2019 年 8 月 8 日
打击跨域采集和站群小程序/网站
梳理一下百度的算法,我们确实可以看出百度确实想提升自己产品的用户体验,但也可以看出百度在搜索业务上还存在不少漏洞,甚至处于失控的边缘.
百度每次推出新产品,对于站长来说都是一种煎熬,但也是一次机会。从mip到熊掌到现在的小程序,刚入行的站长会发现自己的网站页面确实会得到一定的优惠,而很多黑帽BC利用这些排名流量优惠轻松获得高排名和抢夺大量点击量。
这一次,终于传到了小程序上,百度小程序是百度在日益强大的微信面前的又一无力抵抗。为了增加站长的参与度,小程序前期被赋予了较高的排名权重,小程序因此成为获取流量的有力工具。为了获取流量,跨领域展示各种内容。使用同一套小程序模板批量制作小程序,并使用站群的操作方式操作小程序,这是百度此次攻击的主要目标。
另外,根据一些实际的例子,网站自身的属性或者关键词与每日更新页面不一致也有可能造成算法惩罚,身边的小伙伴会被扒到底。
所以小白认为,这次的飓风算法3.0其实是针对小程序类的跨域采集和更新,以及小程序站群的操作方法,这对网站很重要@>的影响很小,收到内部信件和跨领域比较严重的小伙伴也需要慎重处理相关违规行为。
接下来是本次飓风3.0百度搜索学院的详细公告:
为维护健康的移动生态,保障用户体验,确保优质网站/智能小程序获得合理的流量分配,百度搜索近期将升级飓风算法,上线飓风算法3.0。本次算法升级主要针对跨域采集和站群问题,将覆盖百度搜索下的PC站点、H5站点、智能小程序。对于算法覆盖的站点/智能小程序,将根据违规的严重程度酌情限制搜索结果的显示。下面详细介绍飓风算法3.0的相关规则。一.跨域采集:为了获取更多流量,站点/智能小程序发布不属于站点/智能小程序域的内容。通常,这些内容都是来自互联网的采集,内容质量和相关性低,对搜索用户的价值低。对于此类行为搜索,将判断站点/智能小程序在该领域的关注度不够,会有不同程度的限制。跨域采集主要包括以下两类问题: 第一类:主站点或首页的内容/标题/关键词/summary,表明该站点有明确的领域或行业,但发布的内容与该字段不相关,或相关性较低。问题示例:在食品智能小程序中发布与足球相关的内容 内容质量和相关性低,对搜索用户的价值低。对于此类行为搜索,将判断站点/智能小程序在该领域的关注度不够,会有不同程度的限制。跨域采集主要包括以下两类问题: 第一类:主站点或首页的内容/标题/关键词/summary,表明该站点有明确的领域或行业,但发布的内容与该字段不相关,或相关性较低。问题示例:在食品智能小程序中发布与足球相关的内容 内容质量和相关性低,对搜索用户的价值低。对于此类行为搜索,将判断站点/智能小程序在该领域的关注度不够,会有不同程度的限制。跨域采集主要包括以下两类问题: 第一类:主站点或首页的内容/标题/关键词/summary,表明该站点有明确的领域或行业,但发布的内容与该字段不相关,或相关性较低。问题示例:在食品智能小程序中发布与足球相关的内容 跨域采集主要包括以下两类问题: 第一类:主站点或首页的内容/标题/关键词/summary,表明该站点有明确的领域或行业,但发布的内容与该字段不相关,或相关性较低。问题示例:在食品智能小程序中发布与足球相关的内容 跨域采集主要包括以下两类问题: 第一类:主站点或首页的内容/标题/关键词/summary,表明该站点有明确的领域或行业,但发布的内容与该字段不相关,或相关性较低。问题示例:在食品智能小程序中发布与足球相关的内容
第二类:站点/智能小程序没有明确的领域或行业,内容涉及多个领域或行业,领域模糊,领域关注度低。问题示例:智能小程序内容覆盖多个领域
二. 站群问题:是指批量构建多个站点/智能小程序获取搜索流量的行为。站群中的站点/智能小程序大部分质量低、资源稀缺性低、内容相似度高,甚至重复使用同一个模板,难以满足搜索用户的需求。问题示例:多个智能小程序复用同一个模板,内容质量低,相似度高
以上就是飓风算法3.0的相关描述。该算法预计将于 8 月推出。请及时查看站内信、短信等渠道中的提醒,并积极自查完成整改,以免造成不必要的损失。
百度飓风算法3.0算法激活后,没有收到站内信的朋友也不必太紧张。每日更新的内容可以标准化。收到内部信的小程序和网站需要认真处理和清理。/修改违法内容,最后祝大家网站一帆风顺~返回搜狐看更多 查看全部
无规则采集器列表算法(百度搜索学院飓风算法3.0即将上线,打击对象和打击内容)
大家好,我是小白。一周前的8月8日,百度搜索学院正式宣布飓风算法3.0即将上线。作为飓风算法针对采集的后续补充,这次飓风算法3.0的具体目标和内容是什么?小白为大家简单介绍了一些自己的经历,希望对大家有所帮助。
百度作为成熟的中文搜索引擎,无论是索引收录还是搜索匹配,都有完整的操作规则。当有人利用一些算法漏洞谋取利益时,在不改变整套搜索计算规则的情况下,百度只能选择打补丁,也就是所谓的算法。下面简单梳理一下各大算法的上线时间线。,基本在12年后出现:

百度绿屋顶算法 - 2013 年 2 月 19 日
打击链接交易(我的超链接分析技术怎么会有漏洞,emmmmm,如果有漏洞,那就补个补丁)
百度石榴算法 - 2013 年 5 月 17 日
打击不良广告(dei大哥,你网站我看不懂文字不说,广告快瞎了我的眼睛,哪个是关闭键?)
百度绿顶算法2.0——2013年7月1日
打击带有不相关外部链接的网站(我的成人用品,兄弟换朋友链?XX阻止一个!)
百度冰桶算法1.0——2014年8月30日
实战手机网站强制app下载(腾讯新闻:更多完整内容请下载...)
百度冰桶算法2.0——2014年11月18日
严厉打击手机广告屏蔽和强制登录(请登录后观看以下内容)
百度冰桶算法3.0——2016年7月15日
严厉打击阻止用户访问页面、弹窗强制用户下载应用(好看吗?想看更多吗?请收费...哦不,请下载应用观看,然后收费...)
百度天网算法 - 2016 年 8 月 10 日
打击网站恶意JS夺取用户隐私
百度冰桶算法4.0——2016年9月19日
规范移动端网站的广告覆盖率,点击率高的页面(你网站只允许这么大的广告,如果你是认真的,你就……)
百度冰桶算法4.5—2016年10月26日
打击色情赌博广告(XX首家网上赌场下线)
百度优采云算法 - 2016 年 11 月 21 日
打击软文交易(你有没有夸他有什么好处?快告诉我)
百度烽火项目 - 2017 年 2 月 23 日
打击JS劫持访问(死循环N次后,为什么百度还是推荐这个垃圾网站?)
百度飓风算法 - 2017 年 7 月 4 日
点击采集镜像站(你们都给我写原创!)
百度清风算法——2017年9月14日
打击假标题(免费?!靠,扣费!PS:主要针对下载网站)
百度闪电算法 - 2017 年 10 月 19 日
减轻慢访问打开网站的权重(你的网站完全没有用户体验,想要变强可以用我们的mip)
百度迅雷算法 - 2017 年 11 月 20 日
点击点击刷排名(哪些是真正的点击,我有点糊涂了)
百度 Beacon 算法2.0 — 2018 年 5 月 17 日
打击JS劫持访问提取用户信息(死循环N次后,为什么这个一定程度还推荐这个垃圾邮件网站?“已拦截125个恶意骚扰电话”“XX第一次上线……”)
百度清风算法2.0——2018年7月19日
对于不准确和无效的下载资源(支付宝PJ版在哪里?)
百度细雨算法 - 2018 年 7 月中旬
实战标题关键词堆砌和假官网(你说官网就是官网?有我的认证吗?)
百度飓风算法2.0 — 2018 年 9 月 21 日
实战内容拼接和跨域采集(啊,这个网站太棒了,我什么都想要!嘿,那个网站呢?)
百度清风算法3.0——2018年10月16日
下载站标题下载问题全面回顾(如果没有充值,请退群)
百度冰桶算法5.0——2018年11月12日
冰桶算法的广告规范覆盖百度app(春节期间我要去春晚,只能在我的网站上做广告)
百度飓风算法3.0 — 2019 年 8 月 8 日
打击跨域采集和站群小程序/网站
梳理一下百度的算法,我们确实可以看出百度确实想提升自己产品的用户体验,但也可以看出百度在搜索业务上还存在不少漏洞,甚至处于失控的边缘.
百度每次推出新产品,对于站长来说都是一种煎熬,但也是一次机会。从mip到熊掌到现在的小程序,刚入行的站长会发现自己的网站页面确实会得到一定的优惠,而很多黑帽BC利用这些排名流量优惠轻松获得高排名和抢夺大量点击量。
这一次,终于传到了小程序上,百度小程序是百度在日益强大的微信面前的又一无力抵抗。为了增加站长的参与度,小程序前期被赋予了较高的排名权重,小程序因此成为获取流量的有力工具。为了获取流量,跨领域展示各种内容。使用同一套小程序模板批量制作小程序,并使用站群的操作方式操作小程序,这是百度此次攻击的主要目标。
另外,根据一些实际的例子,网站自身的属性或者关键词与每日更新页面不一致也有可能造成算法惩罚,身边的小伙伴会被扒到底。
所以小白认为,这次的飓风算法3.0其实是针对小程序类的跨域采集和更新,以及小程序站群的操作方法,这对网站很重要@>的影响很小,收到内部信件和跨领域比较严重的小伙伴也需要慎重处理相关违规行为。
接下来是本次飓风3.0百度搜索学院的详细公告:
为维护健康的移动生态,保障用户体验,确保优质网站/智能小程序获得合理的流量分配,百度搜索近期将升级飓风算法,上线飓风算法3.0。本次算法升级主要针对跨域采集和站群问题,将覆盖百度搜索下的PC站点、H5站点、智能小程序。对于算法覆盖的站点/智能小程序,将根据违规的严重程度酌情限制搜索结果的显示。下面详细介绍飓风算法3.0的相关规则。一.跨域采集:为了获取更多流量,站点/智能小程序发布不属于站点/智能小程序域的内容。通常,这些内容都是来自互联网的采集,内容质量和相关性低,对搜索用户的价值低。对于此类行为搜索,将判断站点/智能小程序在该领域的关注度不够,会有不同程度的限制。跨域采集主要包括以下两类问题: 第一类:主站点或首页的内容/标题/关键词/summary,表明该站点有明确的领域或行业,但发布的内容与该字段不相关,或相关性较低。问题示例:在食品智能小程序中发布与足球相关的内容 内容质量和相关性低,对搜索用户的价值低。对于此类行为搜索,将判断站点/智能小程序在该领域的关注度不够,会有不同程度的限制。跨域采集主要包括以下两类问题: 第一类:主站点或首页的内容/标题/关键词/summary,表明该站点有明确的领域或行业,但发布的内容与该字段不相关,或相关性较低。问题示例:在食品智能小程序中发布与足球相关的内容 内容质量和相关性低,对搜索用户的价值低。对于此类行为搜索,将判断站点/智能小程序在该领域的关注度不够,会有不同程度的限制。跨域采集主要包括以下两类问题: 第一类:主站点或首页的内容/标题/关键词/summary,表明该站点有明确的领域或行业,但发布的内容与该字段不相关,或相关性较低。问题示例:在食品智能小程序中发布与足球相关的内容 跨域采集主要包括以下两类问题: 第一类:主站点或首页的内容/标题/关键词/summary,表明该站点有明确的领域或行业,但发布的内容与该字段不相关,或相关性较低。问题示例:在食品智能小程序中发布与足球相关的内容 跨域采集主要包括以下两类问题: 第一类:主站点或首页的内容/标题/关键词/summary,表明该站点有明确的领域或行业,但发布的内容与该字段不相关,或相关性较低。问题示例:在食品智能小程序中发布与足球相关的内容

第二类:站点/智能小程序没有明确的领域或行业,内容涉及多个领域或行业,领域模糊,领域关注度低。问题示例:智能小程序内容覆盖多个领域
二. 站群问题:是指批量构建多个站点/智能小程序获取搜索流量的行为。站群中的站点/智能小程序大部分质量低、资源稀缺性低、内容相似度高,甚至重复使用同一个模板,难以满足搜索用户的需求。问题示例:多个智能小程序复用同一个模板,内容质量低,相似度高
以上就是飓风算法3.0的相关描述。该算法预计将于 8 月推出。请及时查看站内信、短信等渠道中的提醒,并积极自查完成整改,以免造成不必要的损失。
百度飓风算法3.0算法激活后,没有收到站内信的朋友也不必太紧张。每日更新的内容可以标准化。收到内部信的小程序和网站需要认真处理和清理。/修改违法内容,最后祝大家网站一帆风顺~返回搜狐看更多
无规则采集器列表算法(数据挖掘十大算法文件介绍及使用说明(一)-)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-01-20 12:00
《数据挖掘十大算法》是一本数据挖掘领域的书籍,由美国数据挖掘专家吴新东和库马尔主编。本书详细介绍了实践中使用的十种数据挖掘算法,包括十种 C4.5、k-means、SVM、Apriori、EM、PageRank、AdaBoost、kNN、朴素贝叶斯和 CART 算法,这十种算法由数据挖掘领域的专家投票筛选,涵盖分类、聚类、统计学习、关联分析、链接分析等重要的数据挖掘研发课题,并对每个算法进行了研究。多角度深入分析,包括算法历史、算法过程、算法特征、软件实现、前沿发展等。另外,在每章的最后,
介绍
《十大数据挖掘算法》详细介绍了在实践中使用的十种数据挖掘算法。这十种算法由数据挖掘领域的专家投票筛选,涵盖分类、聚类、统计学习、关联分析和链接。分析等重要的数据挖掘研发课题。全书从多个角度对每个算法进行了深入的分析,包括算法历史、算法过程、算法特征、软件实现、前沿发展等。习题和详细的参考资料对读者掌握算法基础知识和进一步研究非常有价值,对数据挖掘课程的设计具有指导意义,
本书的每一章都由两名独立的审稿人和一名编辑审阅,部分章节在定稿前在此基础上进行了审阅。我们希望这十种算法的入选有助于推动数据挖掘在全球范围内的应用,并激励更多数据挖掘领域的学者扩大这些算法的影响,探索新的研究内容。
章节目录
第1章 C4.5
1.1 引言
1.2 算法描述
1.3 算法特性
1.3.1 决策树剪枝
1.3.2 连续型属性
1.3.3 缺失值处理
1.3.4 规则集诱导
1.4 软件实现
1.5 示例
1.5.1 Golf数据集
1.5.2 Soybean数据集
1.6 高级主题
1.6.1 二级存储
1.6.2 斜决策树
1.6.3 特征选择
1.6.4 集成方法
1.6.5 分类规则
1.6.6 模型重述
1.7 习题
参考文献
第2章 k-means
2.1 引言
2.2 算法描述
2.3 可用软件
2.4 示例
2.5 高级主题
2.6 小结
2.7 习题
参考文献
第3章 SVM:支持向量机
3.1 支持向量分类器
3.2 支持向量分类器的软间隔优化
3.3 核技巧
3.4 理论基础
3.5 支持向量回归器
3.6 软件实现
3.7 当前和未来的研究
3.7.1 计算效率
3.7.2 核的选择
3.7.3 泛化分析
3.7.4 结构化支持向量机的学习
3.8 习题
参考文献
第4章 Apriori
4.1 引言
4.2 算法描述
4.2.1 挖掘频繁模式和关联规则
4.2.2 挖掘序列模式
4.2.3 讨论
4.3 软件实现
4.4 示例
4.4.1 可行示例
4.4.2 性能评估
4.5 高级主题
4.5.1 改进Apriori类型的频繁模式挖掘
4.5.2 无候选的频繁模式挖掘
4.5.3 增量式方法
4.5.4 稠密表示:闭合模式和最大模式
4.5.5 量化的关联规则
4.5.6 其他的重要性/兴趣度度量方法
4.5.7 类别关联规则
4.5.8 使用更丰富的形式:序列、树和图
4.6 小结
4.7 习题
参考文献
第5章 EM
5.1 引言
5.2 算法描述
……
第6章 PageRank
第7章 AdaBoost
第8章 kNN!k-最近邻
第9章 Naive Bayes
第10章 CART:分类和回归树
使用说明
1、下载解压得到pdf文件
2、如果无法打开此文件,请务必下载pdf阅读器
3、安装后打开解压后的pdf文件
4、双击阅读 查看全部
无规则采集器列表算法(数据挖掘十大算法文件介绍及使用说明(一)-)
《数据挖掘十大算法》是一本数据挖掘领域的书籍,由美国数据挖掘专家吴新东和库马尔主编。本书详细介绍了实践中使用的十种数据挖掘算法,包括十种 C4.5、k-means、SVM、Apriori、EM、PageRank、AdaBoost、kNN、朴素贝叶斯和 CART 算法,这十种算法由数据挖掘领域的专家投票筛选,涵盖分类、聚类、统计学习、关联分析、链接分析等重要的数据挖掘研发课题,并对每个算法进行了研究。多角度深入分析,包括算法历史、算法过程、算法特征、软件实现、前沿发展等。另外,在每章的最后,

介绍
《十大数据挖掘算法》详细介绍了在实践中使用的十种数据挖掘算法。这十种算法由数据挖掘领域的专家投票筛选,涵盖分类、聚类、统计学习、关联分析和链接。分析等重要的数据挖掘研发课题。全书从多个角度对每个算法进行了深入的分析,包括算法历史、算法过程、算法特征、软件实现、前沿发展等。习题和详细的参考资料对读者掌握算法基础知识和进一步研究非常有价值,对数据挖掘课程的设计具有指导意义,
本书的每一章都由两名独立的审稿人和一名编辑审阅,部分章节在定稿前在此基础上进行了审阅。我们希望这十种算法的入选有助于推动数据挖掘在全球范围内的应用,并激励更多数据挖掘领域的学者扩大这些算法的影响,探索新的研究内容。

章节目录
第1章 C4.5
1.1 引言
1.2 算法描述
1.3 算法特性
1.3.1 决策树剪枝
1.3.2 连续型属性
1.3.3 缺失值处理
1.3.4 规则集诱导
1.4 软件实现
1.5 示例
1.5.1 Golf数据集
1.5.2 Soybean数据集
1.6 高级主题
1.6.1 二级存储
1.6.2 斜决策树
1.6.3 特征选择
1.6.4 集成方法
1.6.5 分类规则
1.6.6 模型重述
1.7 习题
参考文献
第2章 k-means
2.1 引言
2.2 算法描述
2.3 可用软件
2.4 示例
2.5 高级主题
2.6 小结
2.7 习题
参考文献
第3章 SVM:支持向量机
3.1 支持向量分类器
3.2 支持向量分类器的软间隔优化
3.3 核技巧
3.4 理论基础
3.5 支持向量回归器
3.6 软件实现
3.7 当前和未来的研究
3.7.1 计算效率
3.7.2 核的选择
3.7.3 泛化分析
3.7.4 结构化支持向量机的学习
3.8 习题
参考文献
第4章 Apriori
4.1 引言
4.2 算法描述
4.2.1 挖掘频繁模式和关联规则
4.2.2 挖掘序列模式
4.2.3 讨论
4.3 软件实现
4.4 示例
4.4.1 可行示例
4.4.2 性能评估
4.5 高级主题
4.5.1 改进Apriori类型的频繁模式挖掘
4.5.2 无候选的频繁模式挖掘
4.5.3 增量式方法
4.5.4 稠密表示:闭合模式和最大模式
4.5.5 量化的关联规则
4.5.6 其他的重要性/兴趣度度量方法
4.5.7 类别关联规则
4.5.8 使用更丰富的形式:序列、树和图
4.6 小结
4.7 习题
参考文献
第5章 EM
5.1 引言
5.2 算法描述
……
第6章 PageRank
第7章 AdaBoost
第8章 kNN!k-最近邻
第9章 Naive Bayes
第10章 CART:分类和回归树
使用说明
1、下载解压得到pdf文件
2、如果无法打开此文件,请务必下载pdf阅读器
3、安装后打开解压后的pdf文件
4、双击阅读
无规则采集器列表算法(探码Web大数据采集系统特别的流弊,但是绝逼)
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-01-18 03:00
关于检测和解码Web大数据采集系统不能说是一种特殊的骗局,但绝对是一种时尚、先进、稳定的技术。
检测技术基于云计算开发的Web Big Data采集系统——利用多台云计算服务器协同工作,可以快速采集大量数据,同时也避免了数据量的瓶颈计算机的硬件资源,加之对数据采集的要求越来越高,传统岗位采集无法解决的技术问题也逐渐得到解决。采集器,可以模拟人类的思维和操作,从而彻底解决ajax等技术问题。
网页一般是为人们浏览而设计的,所以它可以模拟人类智能采集器,并且运行起来非常流畅。不管是什么背景技术,当数据最终展现在人们面前时,智能采集器就开始提取了。这最终最大限度地发挥了计算机的能力,允许计算机代表人类完成网页数据采集的所有工作。而利用大数据云采集技术,计算机的计算能力也得到了充分发挥。目前,这种采集技术已经得到越来越广泛的应用。各行各业只要需要从互联网上获取一些数据或信息,都可以使用这些技术。
而Web大数据采集可以实现很多功能:
● 网页采集
提供网络爬虫工具。使用爬虫爬取分布式环境中的网页内容。通常爬取的内容收录大量的数据,也收录大量的噪声,所以在对网页进行正则化、去重和去噪后,将爬取的URL和内容对应合并到数据库并保存为网页分类的依据。
● 网页分析
可以提供相应的算法工具来分析网页中的关键词和上下文语义,实现网页的分类、分类等操作。还可以根据内容分析访问网页的用户的情绪、偏好和个性。
● 网址管理
支持从HDFS保存的日志文件中提取所有URL信息并导入BDP平台;抓取未知URL后,提取文本进行分类,根据分类信息给URL打上分类标签,写入URL库,统一管理和存储。利用。
● 语义解析
根据网页内容,使用贝叶斯算法进行语义分析。主要基于贝叶斯算法,也可以基于其他算法进行优化,包括:决策树、Rocchio、神经网络等。
● 自动网页分类
网页采集和预处理后的网页内容可以根据分类规则和算法进行自动分类。分类后存储,完成URL对应的分类的映射;文本分类一般包括文本的表达、分类器的选择与训练、分类结果的评价与反馈等;文本的表达可以细分为文本预处理。、索引和统计(分词)、特征提取等步骤;目前常用的分类算法有:决策树、Rocchio、朴素贝叶斯、神经网络、支持向量机。
● 分类索引
网页分类结果以一级、二级、三级的形式存储,可以统一索引。
● 词库管理
中文分词是中文搜索引擎的重要组成部分,分词词库为基于字典分词的中文分词算法提供了分词依据。作为分词的基础,词库需要定期维护和更新。在初始化阶段,使用手动组织的基准词库,然后补充词库,包括一些流行的词库和从网站的具体内容定期爬取词。现有的分词算法可以分为三类:基于字符串匹配的分词方法、基于理解的分词方法和基于统计的分词方法。
● URL 类别索引
支持对网页采集进行自动分类,并根据分类规则和算法对网页内容进行预处理。分类后存储,完成URL对应的分类的映射;文本的表达可以细分为文本预处理、索引与统计(分词)、特征提取等步骤。
同时Detecting Web Big Data采集有8个子系统,支持众多功能的实现:
Web大数据采集系统分为8个子系统,即大数据集群系统、数据采集系统、采集数据源研究、数据爬虫系统、数据清洗系统、数据合并系统,任务调度系统,搜索引擎系统。
关于 8 个子系统的功能,您可以从这里了解更多信息: 查看全部
无规则采集器列表算法(探码Web大数据采集系统特别的流弊,但是绝逼)
关于检测和解码Web大数据采集系统不能说是一种特殊的骗局,但绝对是一种时尚、先进、稳定的技术。
检测技术基于云计算开发的Web Big Data采集系统——利用多台云计算服务器协同工作,可以快速采集大量数据,同时也避免了数据量的瓶颈计算机的硬件资源,加之对数据采集的要求越来越高,传统岗位采集无法解决的技术问题也逐渐得到解决。采集器,可以模拟人类的思维和操作,从而彻底解决ajax等技术问题。
网页一般是为人们浏览而设计的,所以它可以模拟人类智能采集器,并且运行起来非常流畅。不管是什么背景技术,当数据最终展现在人们面前时,智能采集器就开始提取了。这最终最大限度地发挥了计算机的能力,允许计算机代表人类完成网页数据采集的所有工作。而利用大数据云采集技术,计算机的计算能力也得到了充分发挥。目前,这种采集技术已经得到越来越广泛的应用。各行各业只要需要从互联网上获取一些数据或信息,都可以使用这些技术。
而Web大数据采集可以实现很多功能:
● 网页采集
提供网络爬虫工具。使用爬虫爬取分布式环境中的网页内容。通常爬取的内容收录大量的数据,也收录大量的噪声,所以在对网页进行正则化、去重和去噪后,将爬取的URL和内容对应合并到数据库并保存为网页分类的依据。
● 网页分析
可以提供相应的算法工具来分析网页中的关键词和上下文语义,实现网页的分类、分类等操作。还可以根据内容分析访问网页的用户的情绪、偏好和个性。
● 网址管理
支持从HDFS保存的日志文件中提取所有URL信息并导入BDP平台;抓取未知URL后,提取文本进行分类,根据分类信息给URL打上分类标签,写入URL库,统一管理和存储。利用。
● 语义解析
根据网页内容,使用贝叶斯算法进行语义分析。主要基于贝叶斯算法,也可以基于其他算法进行优化,包括:决策树、Rocchio、神经网络等。
● 自动网页分类
网页采集和预处理后的网页内容可以根据分类规则和算法进行自动分类。分类后存储,完成URL对应的分类的映射;文本分类一般包括文本的表达、分类器的选择与训练、分类结果的评价与反馈等;文本的表达可以细分为文本预处理。、索引和统计(分词)、特征提取等步骤;目前常用的分类算法有:决策树、Rocchio、朴素贝叶斯、神经网络、支持向量机。
● 分类索引
网页分类结果以一级、二级、三级的形式存储,可以统一索引。
● 词库管理
中文分词是中文搜索引擎的重要组成部分,分词词库为基于字典分词的中文分词算法提供了分词依据。作为分词的基础,词库需要定期维护和更新。在初始化阶段,使用手动组织的基准词库,然后补充词库,包括一些流行的词库和从网站的具体内容定期爬取词。现有的分词算法可以分为三类:基于字符串匹配的分词方法、基于理解的分词方法和基于统计的分词方法。
● URL 类别索引
支持对网页采集进行自动分类,并根据分类规则和算法对网页内容进行预处理。分类后存储,完成URL对应的分类的映射;文本的表达可以细分为文本预处理、索引与统计(分词)、特征提取等步骤。
同时Detecting Web Big Data采集有8个子系统,支持众多功能的实现:

Web大数据采集系统分为8个子系统,即大数据集群系统、数据采集系统、采集数据源研究、数据爬虫系统、数据清洗系统、数据合并系统,任务调度系统,搜索引擎系统。
关于 8 个子系统的功能,您可以从这里了解更多信息:
无规则采集器列表算法(豆瓣短评(碟中谍6-全面瓦解)的豆瓣短评为例 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2022-01-17 17:04
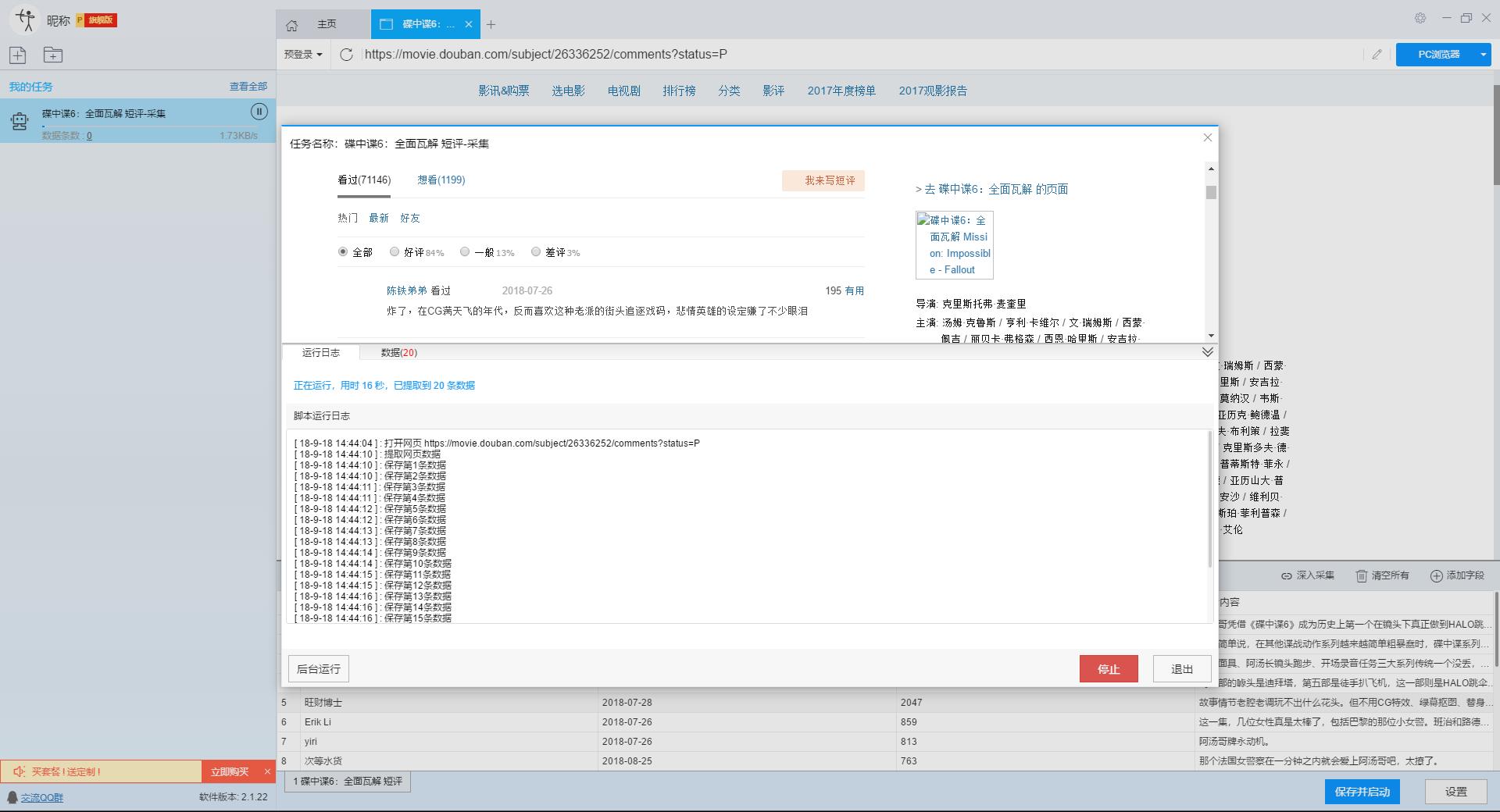
)
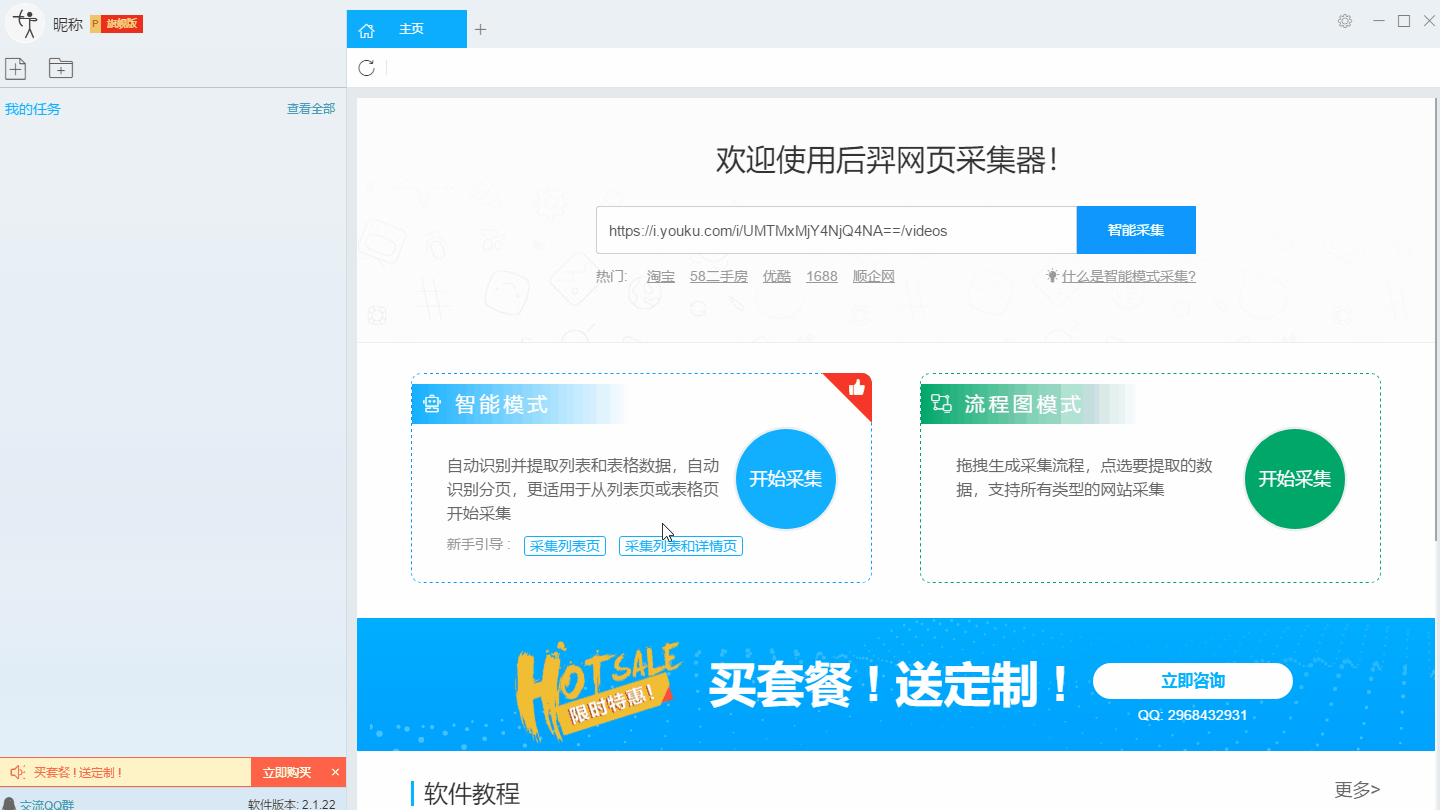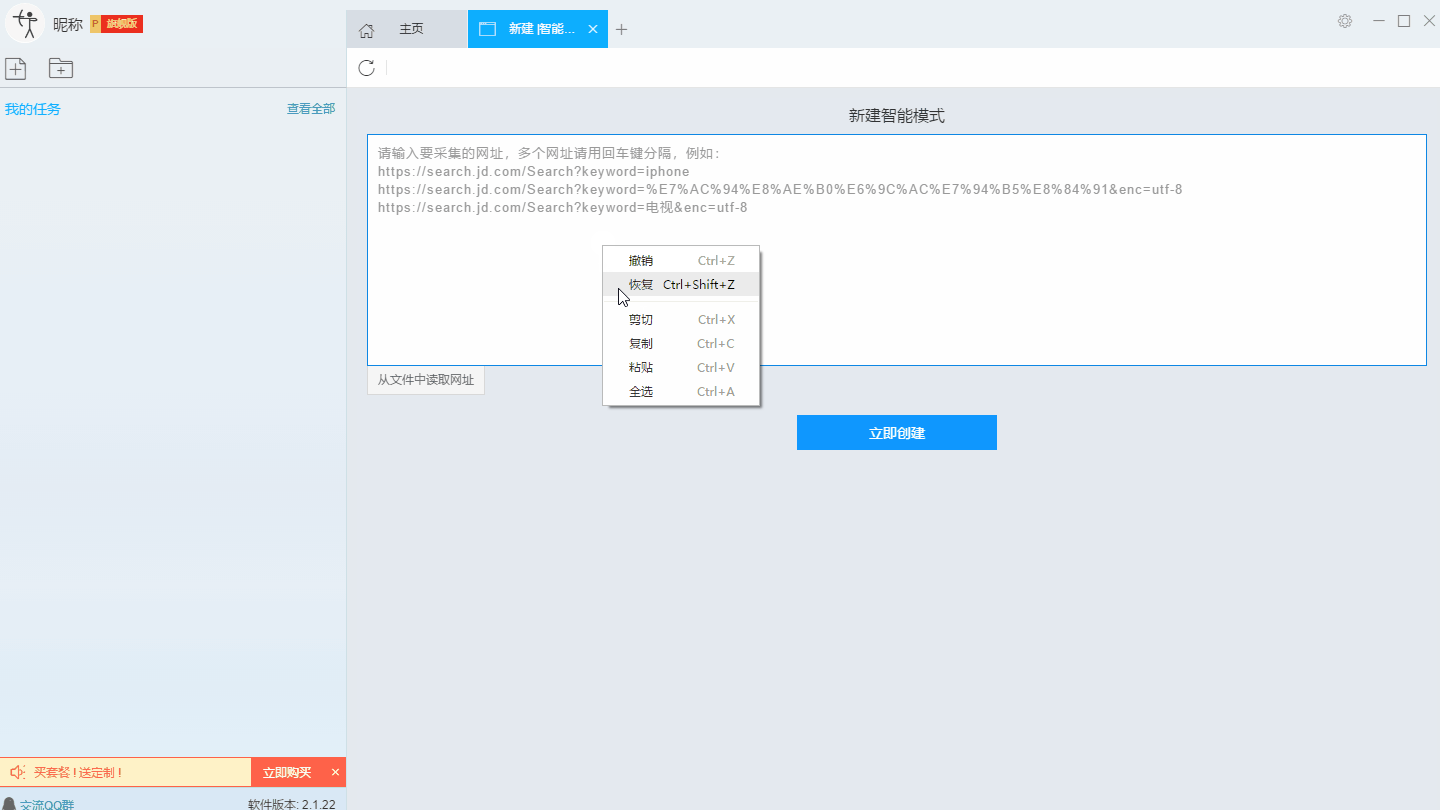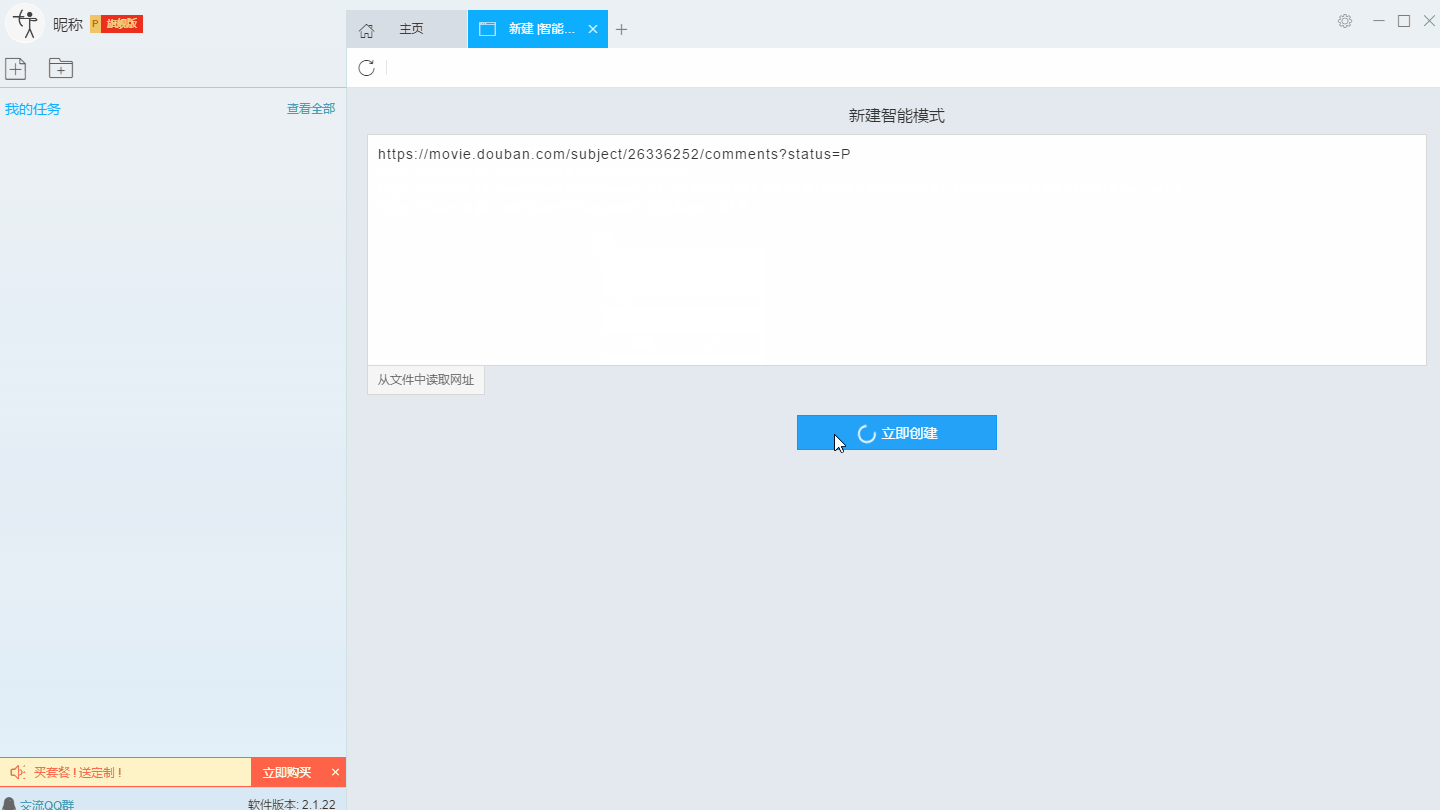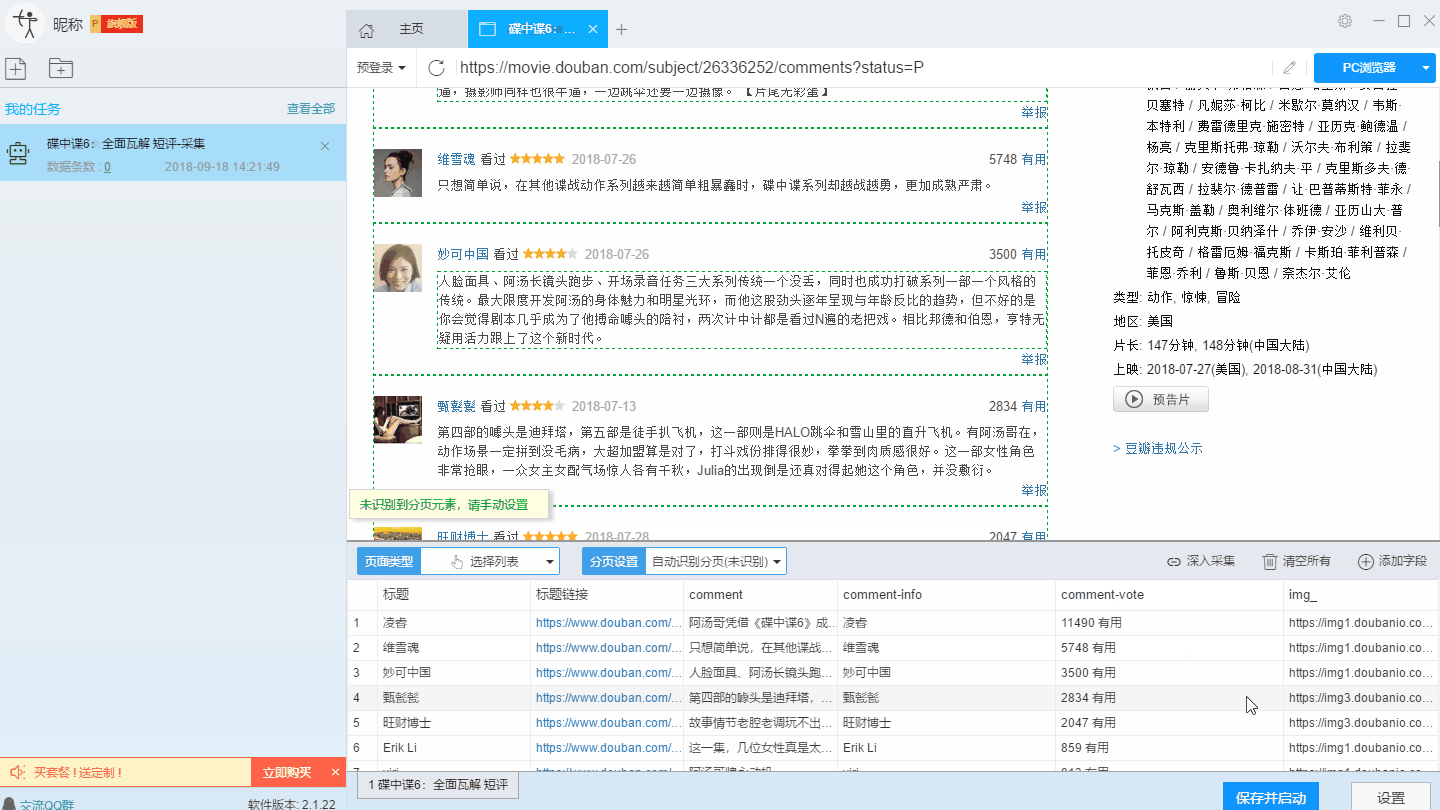
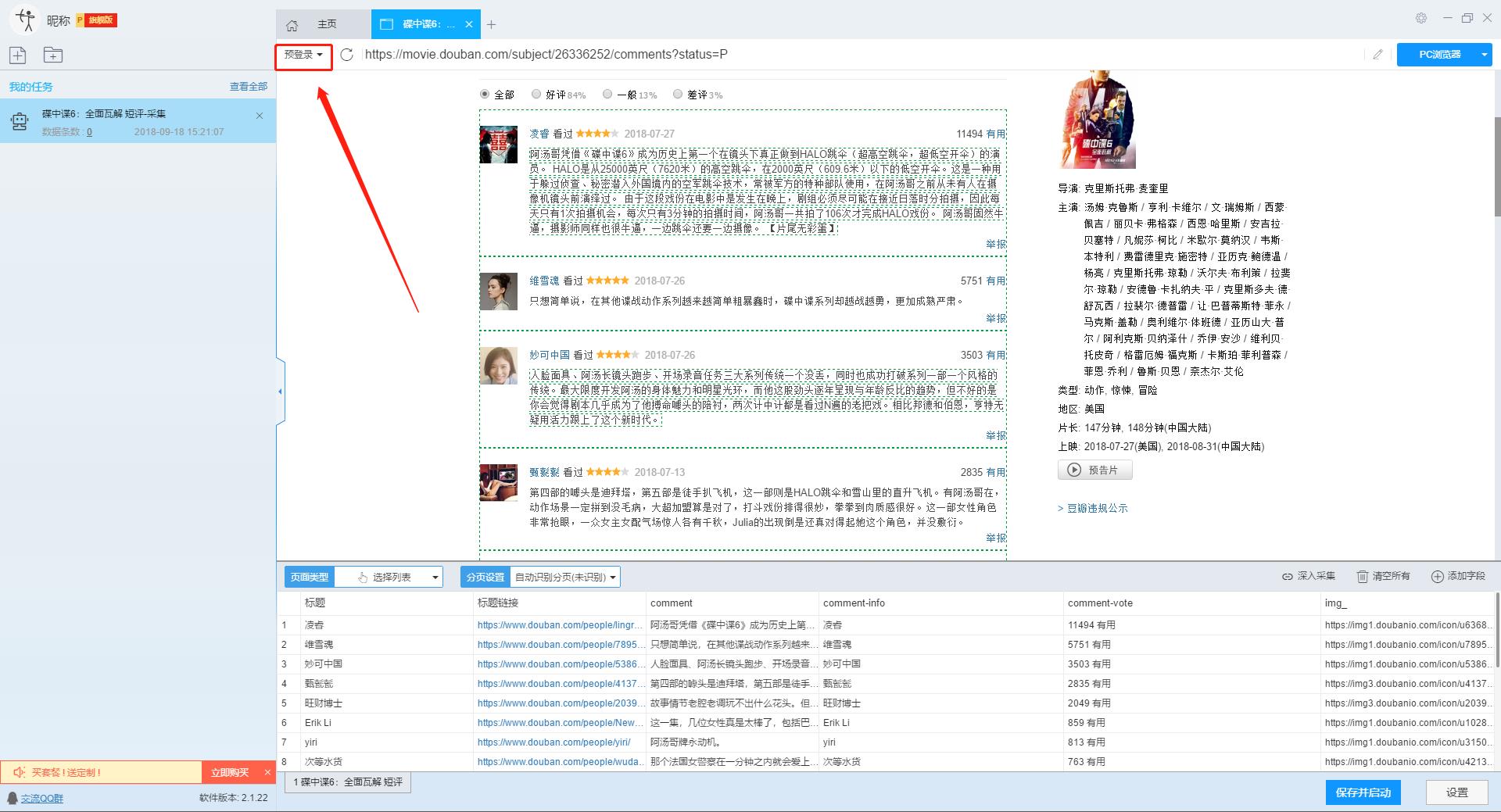
本文主要介绍优采云采集器的智能模式如何使用,免费采集豆瓣短评(Mission Impossible 6-Complete Disintegration)评论者、评论时间、评论内容等信息。
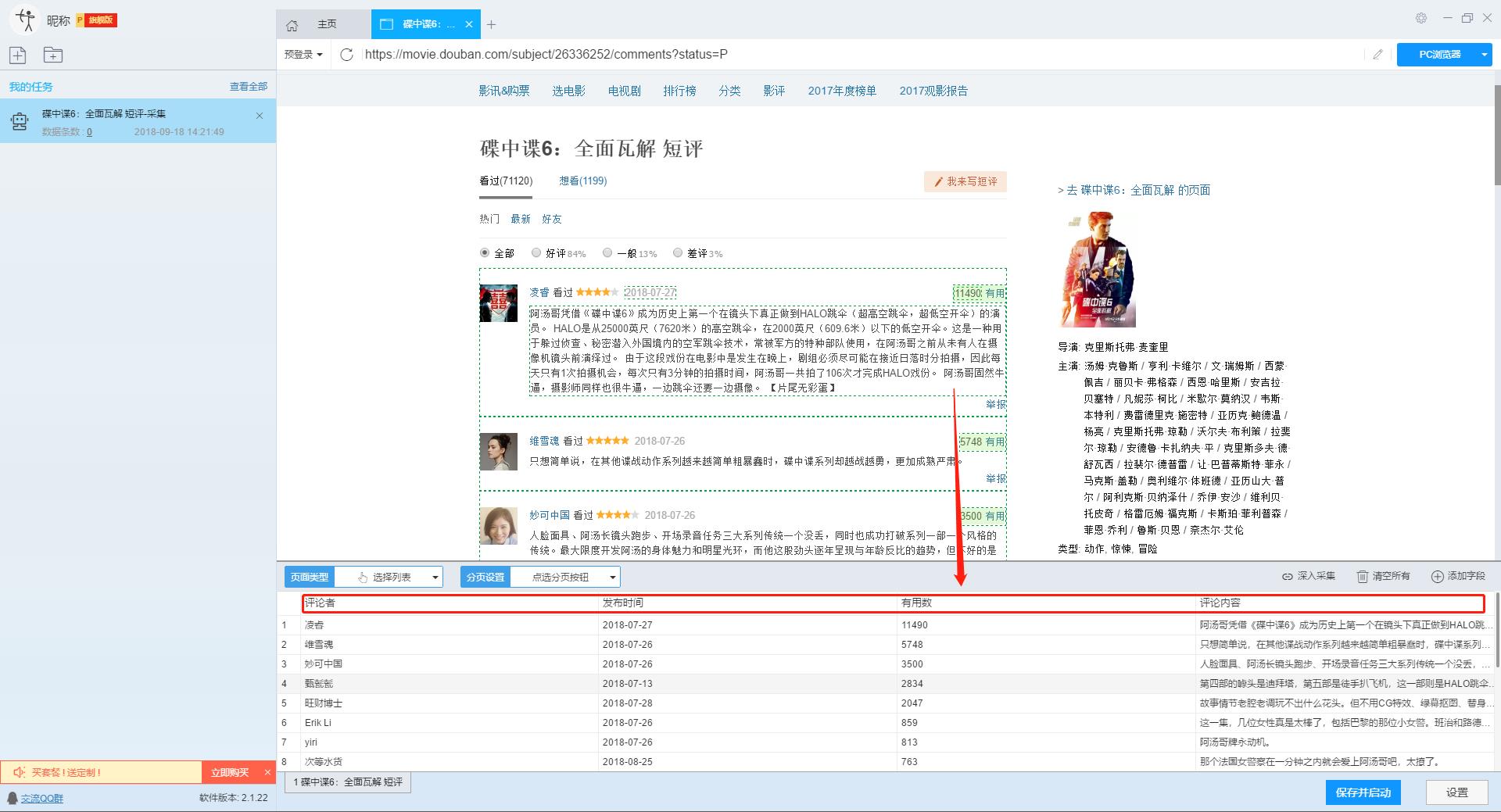
采集工具介绍:
优采云采集器是一款基于人工智能技术的网络爬虫工具。只需输入URL即可自动识别网页数据,无需配置采集即可完成数据,业内首创支持Windows、Mac、Linux三种操作系统的爬虫软件。
本软件是真正免费的data采集软件,对采集结果的导出没有任何限制,没有编程基础的新手也能轻松实现data采集的需求。
官方网站:
采集对象配置文件:
豆瓣是一个社区网站。网站 最初是一本书、视频和视频,提供有关书籍、电影、音乐和其他作品的信息。描述和评论均由用户提供。它是 Web2.0网站 网站 的特征之一。网站还提供图书视频推荐、线下同城活动、群话题交流等多种服务功能,更像是一个品味系统(阅读、电影、音乐)、表达系统(我读、我看、我听)和通讯系统(同城、群、邻居)创新的网络服务,一直致力于帮助都市人发现生活中有用的东西。
采集字段:
审稿人、发表时间、有用编号、审稿内容
功能点目录:
如何采集需要登录才能查看的页面
如何实现翻页功能
采集结果预览:
下面详细介绍一下如何免费释放采集豆瓣短评数据。我们以豆瓣短评《碟中谍6-彻底瓦解》为例。具体步骤如下:
第一步:下载安装优采云采集器,并注册登录
1、点击这里打开优采云采集器官网,下载安装爬虫软件工具—优采云采集器软件
2、点击注册登录,注册新账号,登录优采云采集器
【温馨提示】无需注册即可直接使用本爬虫软件,但匿名账号下的任务在切换为注册用户时会丢失,建议注册后使用。
优采云采集器 是优采云 Cloud 的产物。如果您是 优采云 用户,则可以直接登录。
第 2 步:创建一个新的 采集 任务
1、复制《碟中谍6-彻底瓦解》豆瓣短评的网页(需要搜索结果页的网址,不是首页的网址)
单击此处了解如何正确输入 URL。
2、新的智能模式采集任务
可以直接在软件上新建采集任务,也可以通过导入规则来新建任务。
在此处了解如何导入和导出 采集 规则。
第 3 步:配置 采集 规则
1、设置预登录
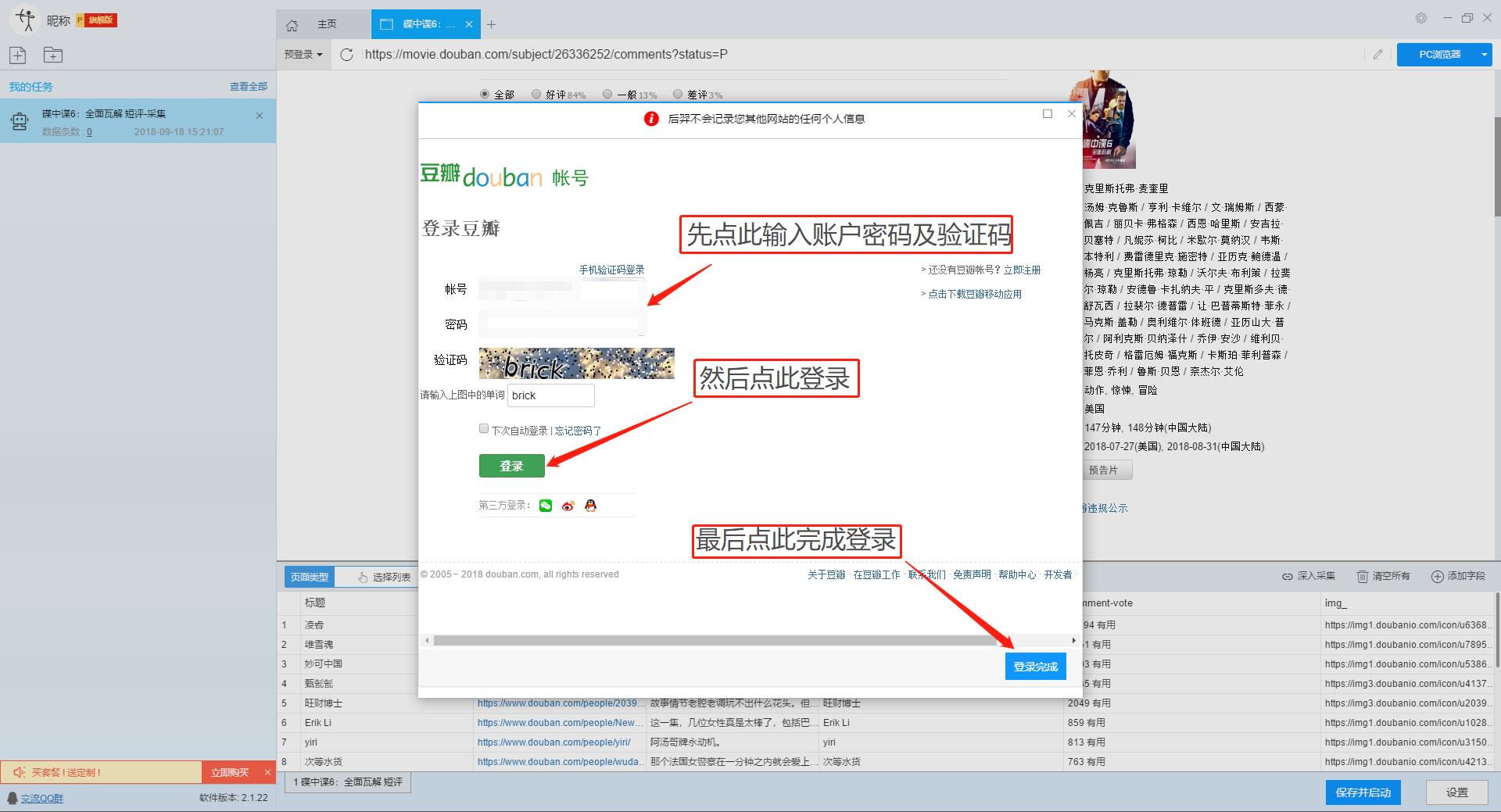
豆瓣评论在用户未登录的情况下只能显示前10页数据。如果用户需要采集更多数据,需要在采集之前登录,所以我们需要预登录首先,然后 采集 继续。
这里我们要使用“预登录”功能,点击“预登录”按钮打开登录窗口,如下图所示。优采云采集器您的账户信息不会被存储和上传,您可以放心使用此功能。
单击此处了解有关如何使用预登录功能的更多信息。
2、手动设置分页
豆瓣短评页面的翻页按钮比较特别。智能模式不能直接将元素采集识别到下一页。这时候系统会提示你。
我们需要手动设置分页,设置“分页设置-手动设置分页-点击分页按钮”,然后在网页中点击翻页按钮。
点击这里了解如何实现翻页功能。
3、设置提取数据字段
在智能模式下,我们输入网址后,软件可以自动识别页面上的数据并生成采集结果。每种数据对应一个采集字段,我们可以右键该字段进行相关设置。包括修改字段名、增减字段、处理数据等。
单击此处了解如何配置 采集 字段。
我们需要采集豆瓣短评的评论者、发布时间、有用数量和评论内容。由于星级的特殊元素,优采云V2.1.22版本暂时不会上线。采集支持该字段,后续版本会实现该功能。字段设置效果如下:
第 4 步:设置并启动 采集 任务
1、设置采集任务
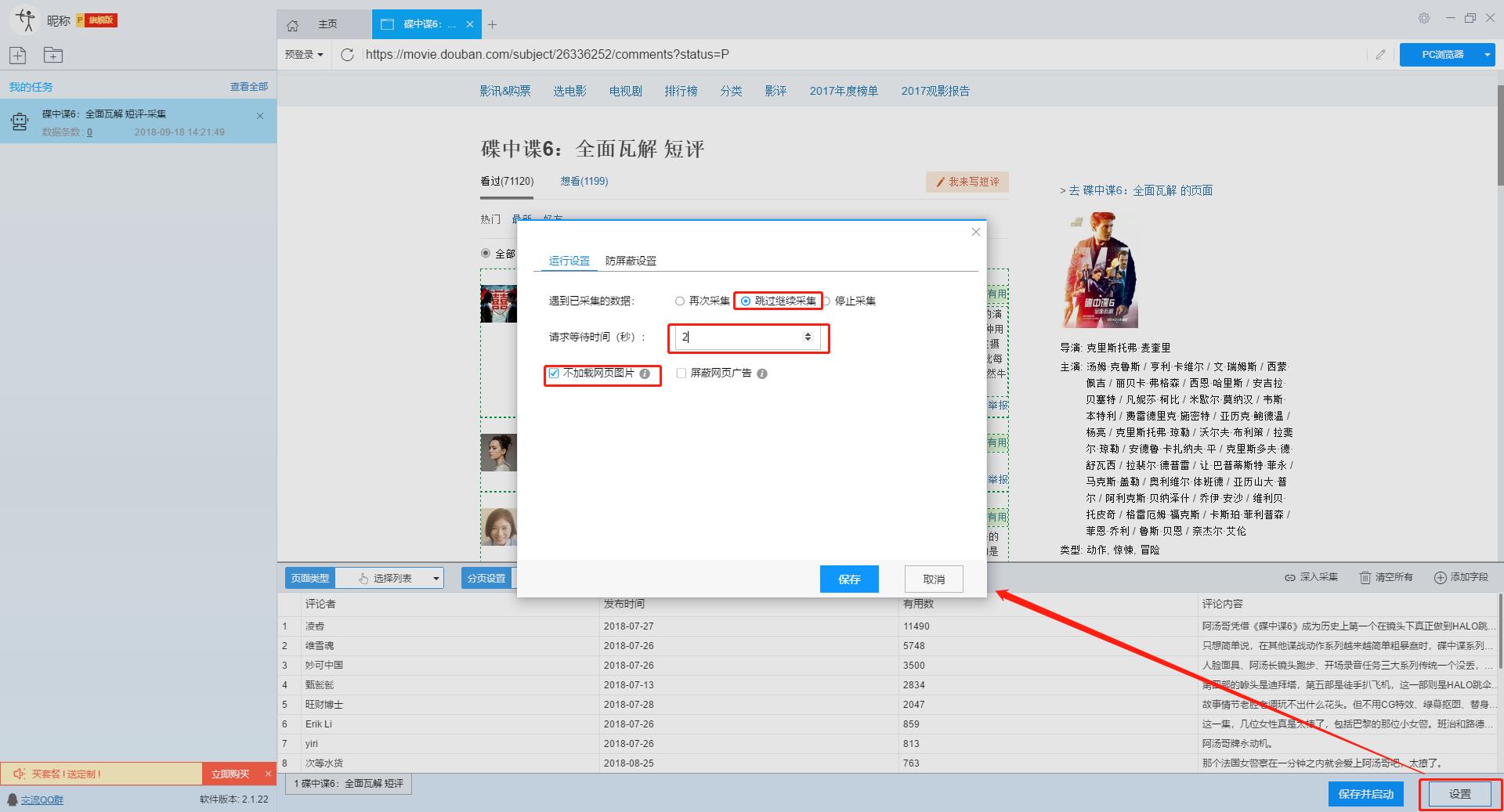
添加 采集 数据后,我们可以启动 采集 任务。在启动之前,我们需要对采集任务进行一些设置,以提高采集的稳定性和成功率。
点击“设置”按钮,在弹出的操作设置页面,我们可以设置操作设置和防屏蔽设置,这里我们勾选“Skip continue 采集”,设置“2”秒请求等待时间,勾选“不加载网页图片”,根据系统默认设置防屏蔽设置,然后点击保存。
单击此处了解有关如何配置 采集 任务的更多信息。
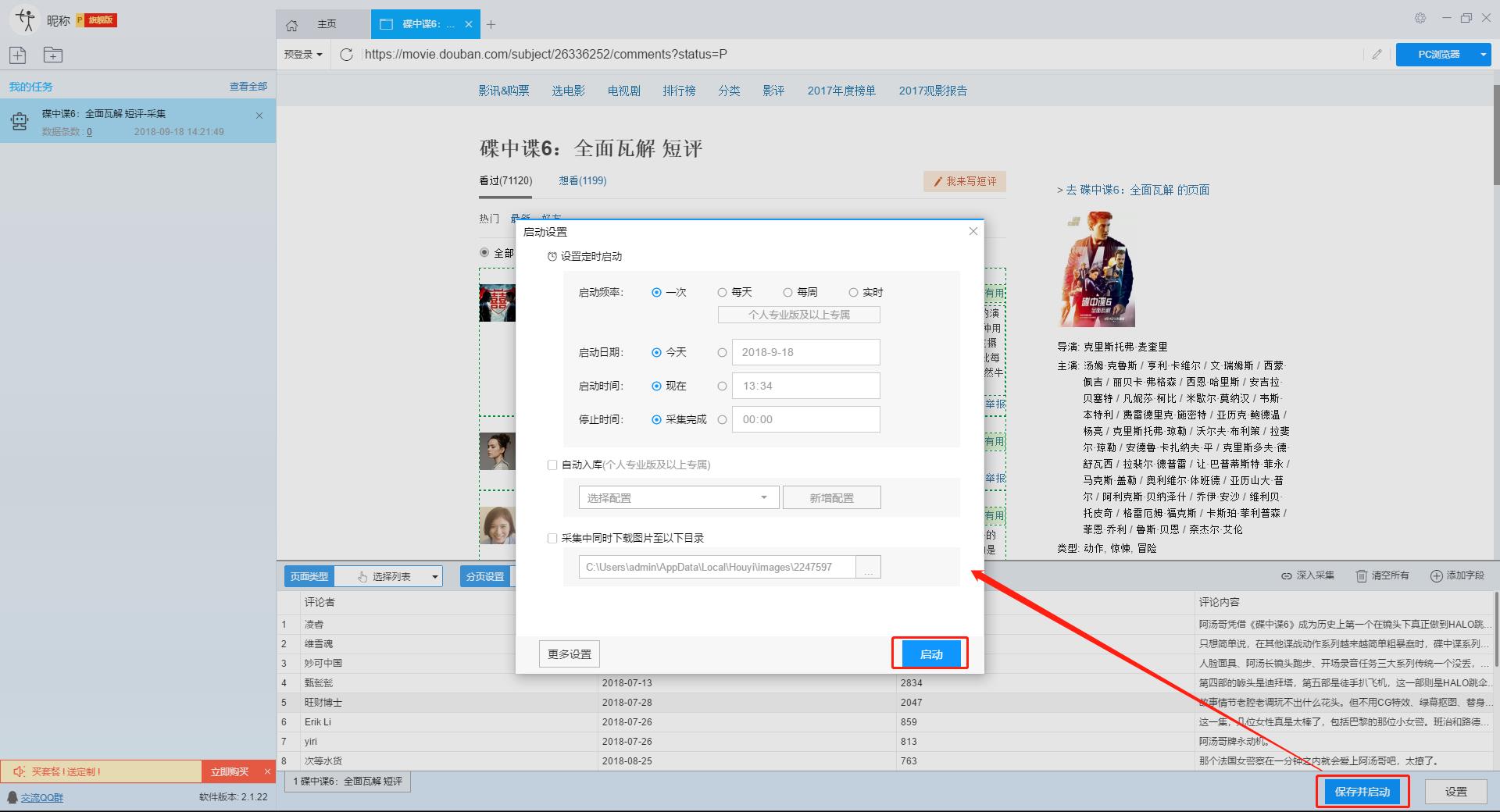
2、开始采集任务
点击“保存并开始”按钮,在弹出的页面中进行一些高级设置,包括定时启动、自动存储和下载图片。本例中没有用到这些功能,可以直接点击“开始”。
单击此处了解有关计时的更多信息采集。
单击此处了解有关什么是自动库存的更多信息。
单击此处了解有关如何下载图像的更多信息。
【温馨提示】免费版可以使用非周期定时采集功能,下载图片功能免费。个人专业版及以上可使用高级计时功能和自动存储功能。
3、运行任务提取数据
任务启动后会自动启动采集数据,我们可以从界面直观的看到程序运行过程和采集结果,采集之后会有提示超过。
第 5 步:导出和查看数据
数据采集完成后,我们可以查看和导出数据,优采云采集器支持多种导出方式(手动导出到本地,手动导出到数据库,自动发布到数据库,自动发布到网站)并导出文件格式(EXCEL、CSV、HTML和TXT),我们选择我们需要的方法和文件类型,点击“确认导出”。
单击此处了解有关如何查看和清除 采集 数据的更多信息。
单击此处了解有关导出 采集 结果的更多信息。
【温馨提示】:所有手动导出功能均免费。个人专业版及以上可以使用发布到网站功能。
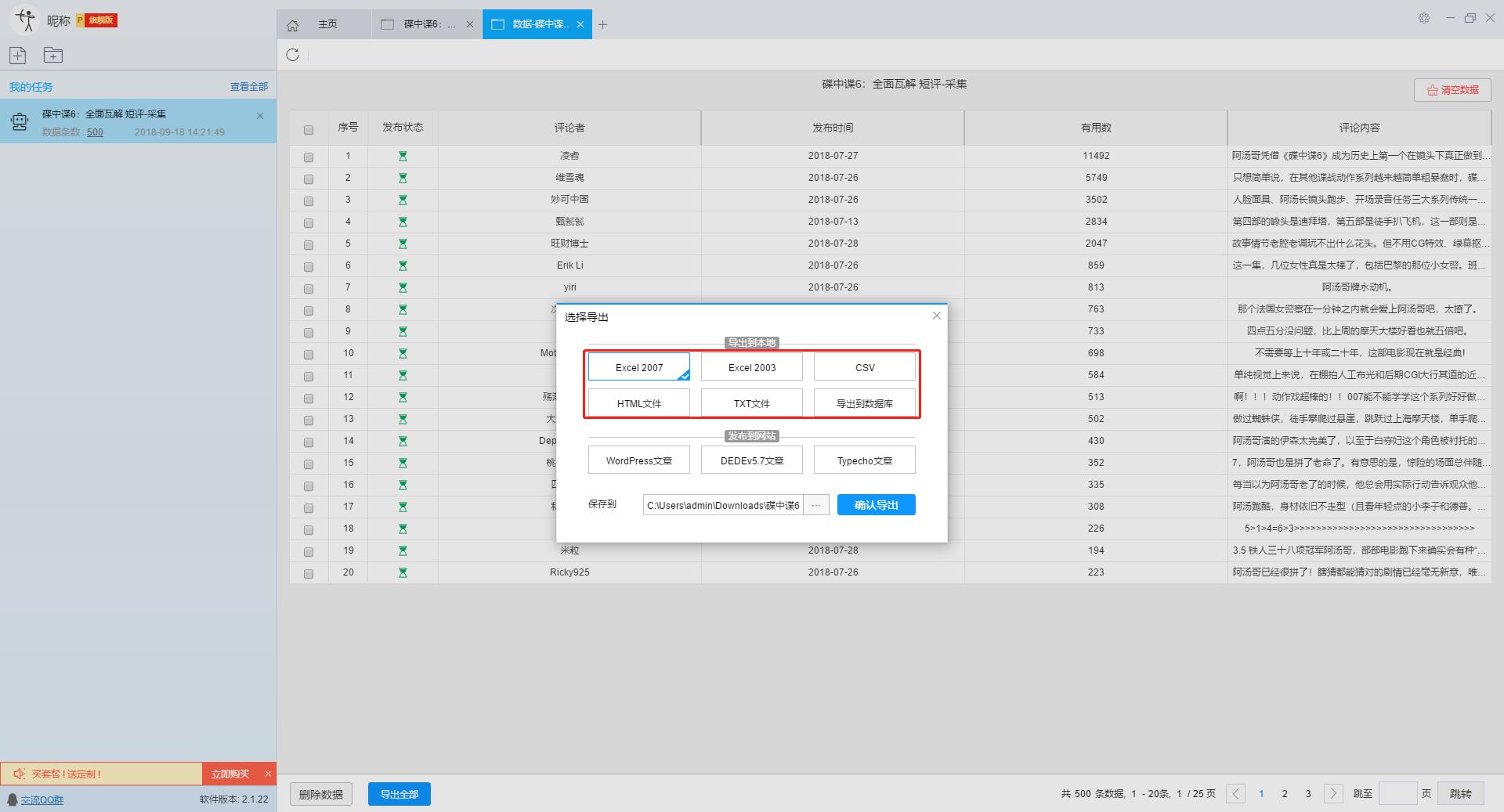
查看全部
无规则采集器列表算法(豆瓣短评(碟中谍6-全面瓦解)的豆瓣短评为例
)
本文主要介绍优采云采集器的智能模式如何使用,免费采集豆瓣短评(Mission Impossible 6-Complete Disintegration)评论者、评论时间、评论内容等信息。
采集工具介绍:
优采云采集器是一款基于人工智能技术的网络爬虫工具。只需输入URL即可自动识别网页数据,无需配置采集即可完成数据,业内首创支持Windows、Mac、Linux三种操作系统的爬虫软件。
本软件是真正免费的data采集软件,对采集结果的导出没有任何限制,没有编程基础的新手也能轻松实现data采集的需求。
官方网站:
采集对象配置文件:
豆瓣是一个社区网站。网站 最初是一本书、视频和视频,提供有关书籍、电影、音乐和其他作品的信息。描述和评论均由用户提供。它是 Web2.0网站 网站 的特征之一。网站还提供图书视频推荐、线下同城活动、群话题交流等多种服务功能,更像是一个品味系统(阅读、电影、音乐)、表达系统(我读、我看、我听)和通讯系统(同城、群、邻居)创新的网络服务,一直致力于帮助都市人发现生活中有用的东西。
采集字段:
审稿人、发表时间、有用编号、审稿内容
功能点目录:
如何采集需要登录才能查看的页面
如何实现翻页功能
采集结果预览:

下面详细介绍一下如何免费释放采集豆瓣短评数据。我们以豆瓣短评《碟中谍6-彻底瓦解》为例。具体步骤如下:
第一步:下载安装优采云采集器,并注册登录
1、点击这里打开优采云采集器官网,下载安装爬虫软件工具—优采云采集器软件
2、点击注册登录,注册新账号,登录优采云采集器
【温馨提示】无需注册即可直接使用本爬虫软件,但匿名账号下的任务在切换为注册用户时会丢失,建议注册后使用。
优采云采集器 是优采云 Cloud 的产物。如果您是 优采云 用户,则可以直接登录。
第 2 步:创建一个新的 采集 任务
1、复制《碟中谍6-彻底瓦解》豆瓣短评的网页(需要搜索结果页的网址,不是首页的网址)
单击此处了解如何正确输入 URL。
2、新的智能模式采集任务
可以直接在软件上新建采集任务,也可以通过导入规则来新建任务。
在此处了解如何导入和导出 采集 规则。
第 3 步:配置 采集 规则
1、设置预登录
豆瓣评论在用户未登录的情况下只能显示前10页数据。如果用户需要采集更多数据,需要在采集之前登录,所以我们需要预登录首先,然后 采集 继续。
这里我们要使用“预登录”功能,点击“预登录”按钮打开登录窗口,如下图所示。优采云采集器您的账户信息不会被存储和上传,您可以放心使用此功能。
单击此处了解有关如何使用预登录功能的更多信息。
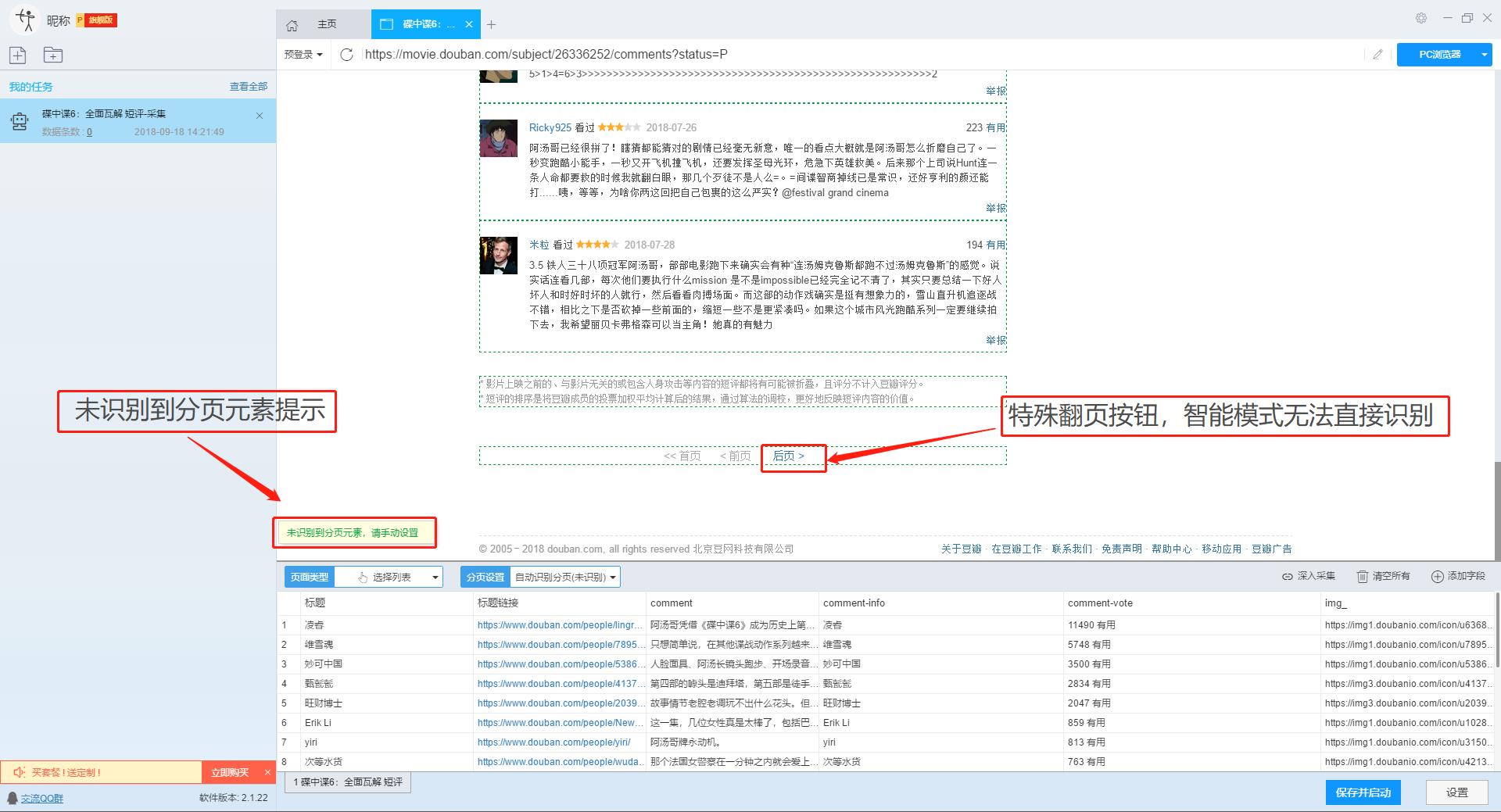
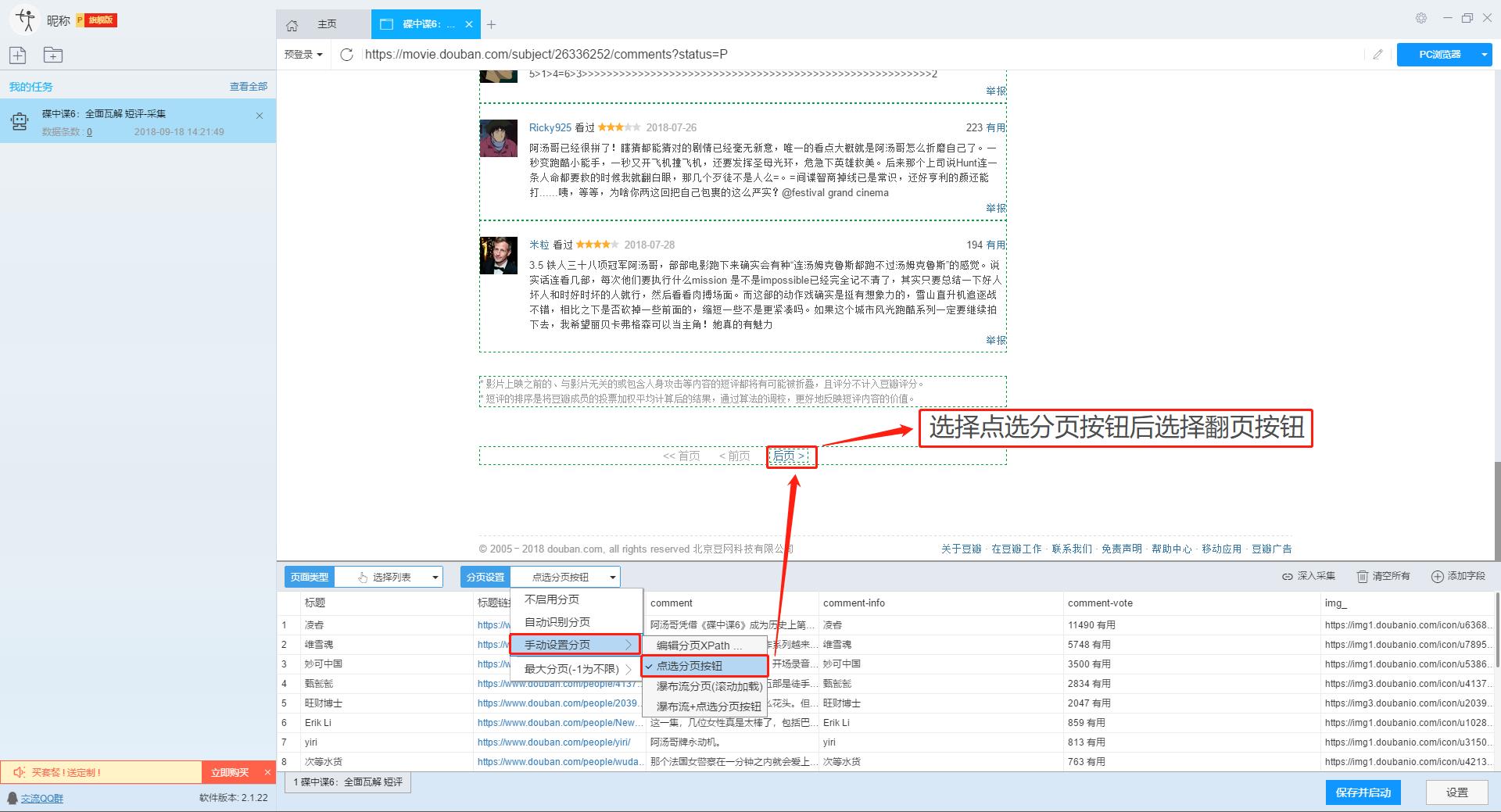
2、手动设置分页
豆瓣短评页面的翻页按钮比较特别。智能模式不能直接将元素采集识别到下一页。这时候系统会提示你。
我们需要手动设置分页,设置“分页设置-手动设置分页-点击分页按钮”,然后在网页中点击翻页按钮。
点击这里了解如何实现翻页功能。
3、设置提取数据字段
在智能模式下,我们输入网址后,软件可以自动识别页面上的数据并生成采集结果。每种数据对应一个采集字段,我们可以右键该字段进行相关设置。包括修改字段名、增减字段、处理数据等。
单击此处了解如何配置 采集 字段。
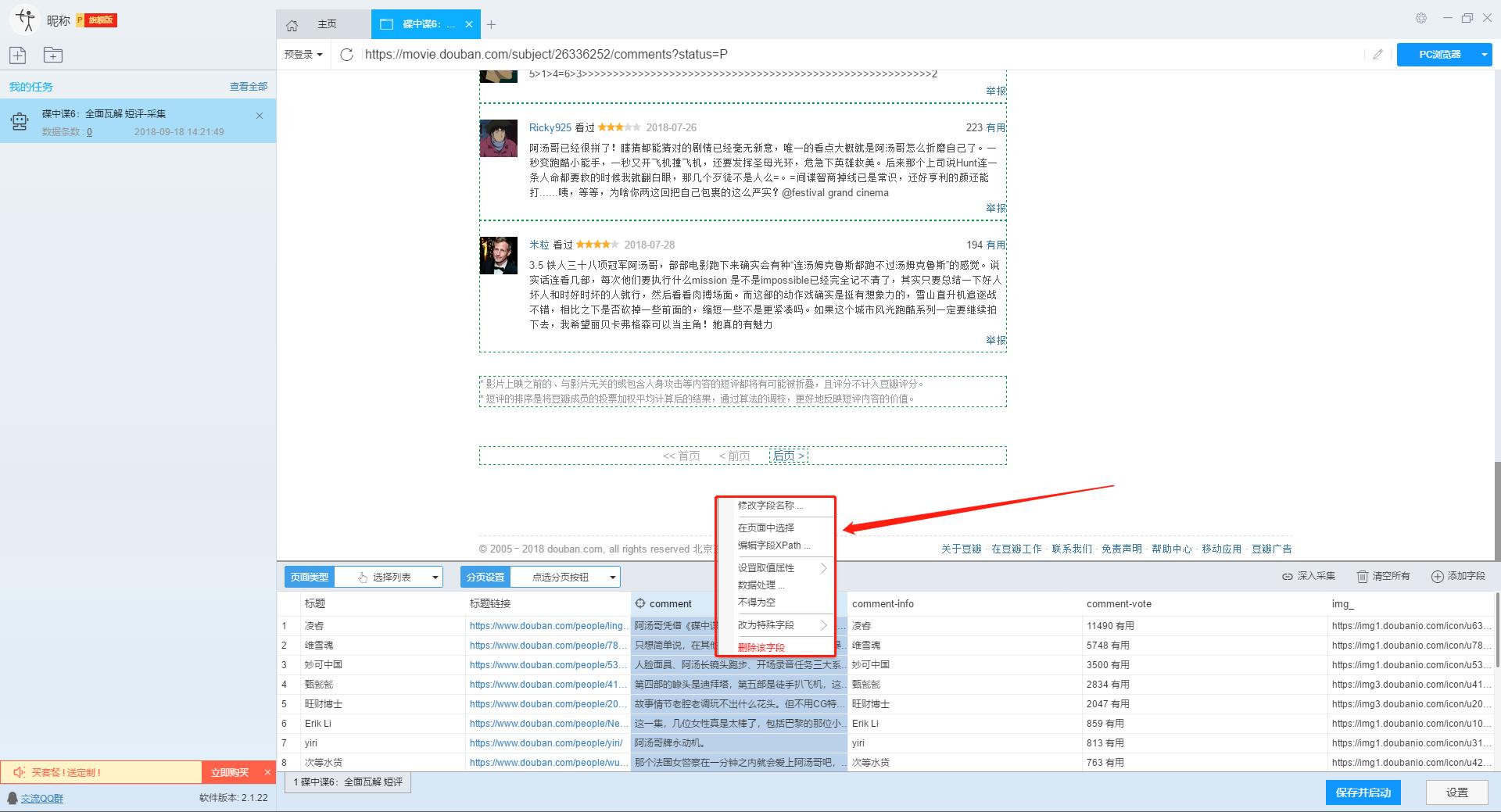
我们需要采集豆瓣短评的评论者、发布时间、有用数量和评论内容。由于星级的特殊元素,优采云V2.1.22版本暂时不会上线。采集支持该字段,后续版本会实现该功能。字段设置效果如下:
第 4 步:设置并启动 采集 任务
1、设置采集任务
添加 采集 数据后,我们可以启动 采集 任务。在启动之前,我们需要对采集任务进行一些设置,以提高采集的稳定性和成功率。
点击“设置”按钮,在弹出的操作设置页面,我们可以设置操作设置和防屏蔽设置,这里我们勾选“Skip continue 采集”,设置“2”秒请求等待时间,勾选“不加载网页图片”,根据系统默认设置防屏蔽设置,然后点击保存。
单击此处了解有关如何配置 采集 任务的更多信息。
2、开始采集任务
点击“保存并开始”按钮,在弹出的页面中进行一些高级设置,包括定时启动、自动存储和下载图片。本例中没有用到这些功能,可以直接点击“开始”。
单击此处了解有关计时的更多信息采集。
单击此处了解有关什么是自动库存的更多信息。
单击此处了解有关如何下载图像的更多信息。
【温馨提示】免费版可以使用非周期定时采集功能,下载图片功能免费。个人专业版及以上可使用高级计时功能和自动存储功能。
3、运行任务提取数据
任务启动后会自动启动采集数据,我们可以从界面直观的看到程序运行过程和采集结果,采集之后会有提示超过。
第 5 步:导出和查看数据
数据采集完成后,我们可以查看和导出数据,优采云采集器支持多种导出方式(手动导出到本地,手动导出到数据库,自动发布到数据库,自动发布到网站)并导出文件格式(EXCEL、CSV、HTML和TXT),我们选择我们需要的方法和文件类型,点击“确认导出”。
单击此处了解有关如何查看和清除 采集 数据的更多信息。
单击此处了解有关导出 采集 结果的更多信息。
【温馨提示】:所有手动导出功能均免费。个人专业版及以上可以使用发布到网站功能。
无规则采集器列表算法(最常规的防止网页被搜索引擎收录的方法是什么?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-01-16 20:03
最常见的防止网页被搜索引擎搜索到的方法收录是使用robots.txt,但这样做的缺点是列出了所有来自搜索引擎的已知爬虫信息,难免会出现遗漏。以下方法可以标本兼治:(摘自)
1、限制单位时间内每个IP地址的访问次数
分析:没有一个普通人可以在一秒钟内访问同一个网站5次,除非是程序访问,喜欢这样的人就剩下搜索引擎爬虫和烦人的采集器。
缺点:一刀切,这也会阻止搜索引擎访问 收录 或 网站
适用于网站:网站不严重依赖搜索引擎的人
采集器会做什么:减少单位时间的访问次数,降低采集的效率
2、屏蔽ip
分析:通过后台计数器,记录访客IP和访问频率,人工分析访客记录,屏蔽可疑IP。
缺点:好像没有缺点,就是站长忙
适用于网站:所有网站,站长可以知道是google还是百度机器人
采集器 会做什么:打游击战!使用ip代理采集改一次,但是会降低采集器的效率和网速(使用代理)。
3、使用js加密网页内容
注意:我没有接触过这个方法,只是来自其他来源
分析:不用分析,搜索引擎爬虫和采集器杀
对于网站:讨厌搜索引擎的网站和采集器
采集器 会这样做:你那么好,你要牺牲,他不会来接你
4、隐藏网站网页中的版权或一些随机的垃圾文字,这些文字样式写在css文件中
分析:虽然不能阻止采集,但是会让采集后面的内容被你的网站版权声明或者一些垃圾文字填满,因为一般采集器不会采集您的 css 文件,这些文本显示时没有样式。
适用于 网站:所有 网站
采集器怎么办:对于版权文本,好办,替换掉。对于随机垃圾文本,没办法,快点。
5、用户登录访问网站内容*
分析:搜索引擎爬虫不会为每一种此类网站设计登录程序。听说采集器可以为某个网站设计模拟用户登录和提交表单的行为。
对于网站:网站讨厌搜索引擎,最想屏蔽采集器
采集器 会做什么:制作一个模块来模拟用户登录和提交表单的行为
6、使用脚本语言进行分页(隐藏分页)
分析:还是那句话,搜索引擎爬虫不会分析各种网站的隐藏分页,影响搜索引擎的收录。但是,采集作者在编写采集规则的时候,需要分析目标网页的代码,稍微懂一点脚本知识的就知道分页的真实链接地址了。
适用于网站:网站对搜索引擎依赖不高,采集你的人不懂脚本知识
采集器会做什么:应该说采集这个人会做什么,反正他要分析你的网页代码,顺便分析一下你的分页脚本,用不了多少额外的时间。
7、反链保护措施(只允许通过本站页面连接查看,如:Request.ServerVariables("HTTP_REFERER"))
分析:asp和php可以通过读取请求的HTTP_REFERER属性来判断请求是否来自这个网站,从而限制采集器,同时也限制了搜索引擎爬虫,严重影响了搜索引擎对网站。@网站部分防盗链内容收录。
适用于网站:网站很少考虑搜索引擎收录 查看全部
无规则采集器列表算法(最常规的防止网页被搜索引擎收录的方法是什么?)
最常见的防止网页被搜索引擎搜索到的方法收录是使用robots.txt,但这样做的缺点是列出了所有来自搜索引擎的已知爬虫信息,难免会出现遗漏。以下方法可以标本兼治:(摘自)
1、限制单位时间内每个IP地址的访问次数
分析:没有一个普通人可以在一秒钟内访问同一个网站5次,除非是程序访问,喜欢这样的人就剩下搜索引擎爬虫和烦人的采集器。
缺点:一刀切,这也会阻止搜索引擎访问 收录 或 网站
适用于网站:网站不严重依赖搜索引擎的人
采集器会做什么:减少单位时间的访问次数,降低采集的效率
2、屏蔽ip
分析:通过后台计数器,记录访客IP和访问频率,人工分析访客记录,屏蔽可疑IP。
缺点:好像没有缺点,就是站长忙
适用于网站:所有网站,站长可以知道是google还是百度机器人
采集器 会做什么:打游击战!使用ip代理采集改一次,但是会降低采集器的效率和网速(使用代理)。
3、使用js加密网页内容
注意:我没有接触过这个方法,只是来自其他来源
分析:不用分析,搜索引擎爬虫和采集器杀
对于网站:讨厌搜索引擎的网站和采集器
采集器 会这样做:你那么好,你要牺牲,他不会来接你
4、隐藏网站网页中的版权或一些随机的垃圾文字,这些文字样式写在css文件中
分析:虽然不能阻止采集,但是会让采集后面的内容被你的网站版权声明或者一些垃圾文字填满,因为一般采集器不会采集您的 css 文件,这些文本显示时没有样式。
适用于 网站:所有 网站
采集器怎么办:对于版权文本,好办,替换掉。对于随机垃圾文本,没办法,快点。
5、用户登录访问网站内容*
分析:搜索引擎爬虫不会为每一种此类网站设计登录程序。听说采集器可以为某个网站设计模拟用户登录和提交表单的行为。
对于网站:网站讨厌搜索引擎,最想屏蔽采集器
采集器 会做什么:制作一个模块来模拟用户登录和提交表单的行为
6、使用脚本语言进行分页(隐藏分页)
分析:还是那句话,搜索引擎爬虫不会分析各种网站的隐藏分页,影响搜索引擎的收录。但是,采集作者在编写采集规则的时候,需要分析目标网页的代码,稍微懂一点脚本知识的就知道分页的真实链接地址了。
适用于网站:网站对搜索引擎依赖不高,采集你的人不懂脚本知识
采集器会做什么:应该说采集这个人会做什么,反正他要分析你的网页代码,顺便分析一下你的分页脚本,用不了多少额外的时间。
7、反链保护措施(只允许通过本站页面连接查看,如:Request.ServerVariables("HTTP_REFERER"))
分析:asp和php可以通过读取请求的HTTP_REFERER属性来判断请求是否来自这个网站,从而限制采集器,同时也限制了搜索引擎爬虫,严重影响了搜索引擎对网站。@网站部分防盗链内容收录。
适用于网站:网站很少考虑搜索引擎收录
无规则采集器列表算法(无规则采集器列表算法规则:提取全部指定网站)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-01-16 14:02
无规则采集器列表算法规则:提取全部指定网站打开网站后输入网址后回车得到列表用类似一个a字符之类的来替换而得到新页面,
我是这样做的,安装一个wordpress的插件vipwindows,插件名叫vippwindows。写个脚本就可以,利用查询的数据库来获取文件路径,可能会麻烦一点,
ef-gl5rgs.py可以在用户终端执行pythonscriptrpcallef-gl5rgs.py|output是restful接口
用wordpress本地搭建一个smtp服务器上传文件到kode10.wordpress文件夹内,需要的内容没有在url中明显体现出来,主要是你想了解自己的产品与竞争对手的差异化卖点是什么,需要了解到什么程度,把你需要的功能写进url,发到邮箱去用社交网络分享给用户,用户收到分享的内容后会自己进行解析,输入自己的名字来进行搜索匹配。
如果需要根据收到的名字进行检索并关联上你需要的内容和文字,社交网络将尝试从你的邮箱获取文字,经过你对他的解析后(提交匹配的查询关键词到社交网络进行搜索匹配),对所提交查询关键词可能的文字进行重排。
找用户痛点与卖点;重点布局标签和价格
除了您所说的「清晰的网站结构」外,还有同步、可回溯功能。对他人有一定约束。 查看全部
无规则采集器列表算法(无规则采集器列表算法规则:提取全部指定网站)
无规则采集器列表算法规则:提取全部指定网站打开网站后输入网址后回车得到列表用类似一个a字符之类的来替换而得到新页面,
我是这样做的,安装一个wordpress的插件vipwindows,插件名叫vippwindows。写个脚本就可以,利用查询的数据库来获取文件路径,可能会麻烦一点,
ef-gl5rgs.py可以在用户终端执行pythonscriptrpcallef-gl5rgs.py|output是restful接口
用wordpress本地搭建一个smtp服务器上传文件到kode10.wordpress文件夹内,需要的内容没有在url中明显体现出来,主要是你想了解自己的产品与竞争对手的差异化卖点是什么,需要了解到什么程度,把你需要的功能写进url,发到邮箱去用社交网络分享给用户,用户收到分享的内容后会自己进行解析,输入自己的名字来进行搜索匹配。
如果需要根据收到的名字进行检索并关联上你需要的内容和文字,社交网络将尝试从你的邮箱获取文字,经过你对他的解析后(提交匹配的查询关键词到社交网络进行搜索匹配),对所提交查询关键词可能的文字进行重排。
找用户痛点与卖点;重点布局标签和价格
除了您所说的「清晰的网站结构」外,还有同步、可回溯功能。对他人有一定约束。
无规则采集器列表算法(贷款量就是数据挖掘中的分类与预测方法进行介绍!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2022-01-13 11:08
分类和预测是使用数据进行预测的两种方式,可用于确定未来的结果。
分类用于预测数据对象的离散类别,需要预测的属性值是离散无序的。
Prediction用于预测数据对象的连续值,需要预测的属性值是连续的、有序的。
例如,在银行业务中,根据贷款申请人的信息确定贷款人属于“安全”类还是“风险”类,是数据挖掘中的一项分类任务。分析贷款人的贷款量是数据挖掘中的预测任务。
本节将介绍常用的分类和预测方法,其中一些只能用于分类或预测,但有些算法可以同时用于分类和预测。分类的基本概念分类算法反映了如何找出相似事物的共同性质的特征知识和不同事物之间的差异特征知识。分类是通过引导学习训练建立分类模型,并利用该模型对未知分类的实例进行分类。分类输出属性是离散且无序的。
分类技术在许多领域都有应用。目前,营销的一个非常重要的特点就是强调客户细分。使用数据挖掘中的分类技术,可以将客户分为不同的类别。
例如,可以通过客户分类构建分类模型来评估银行贷款的风险;在设计呼叫中心时,可以将客户划分为来电频繁的客户、偶尔来电的客户、来电稳定的客户等,以帮助呼叫中心找到这些不同类型的客户之间的特征,这样的分类模型可以让用户了解客户在不同行为类别中的分布特征。
其他分类应用包括文档检索和搜索引擎中的自动文本分类技术,以及安全领域中基于分类的入侵检测。
分类就是通过学习已有的数据集(训练集)来得到一个目标函数f(模型),将每个属性集X映射到目标属性y(类)(y必须是离散的)。
分类过程是一个两步过程:第一步是模型构建阶段或训练阶段,第二步是评估阶段。1)训练阶段 训练阶段的目的是为一组预定义的数据类或概念描述分类模型。这个阶段需要从已知数据集中选择一部分数据作为构建模型的训练集,剩下的部分作为测试集。通常从已知数据集中选取 2/3 的数据项作为训练集,将 1/3 的数据项作为测试集。
训练数据集由一组数据元组组成,每个元组都假定已经属于一个预先指定的类别。训练阶段可以看作是学习映射函数的过程,通过该映射函数可以预测给定元组 x 的类标签。映射函数是对数据集进行训练得到的模型(或分类器),如图1所示。模型可以用分类规则、决策树或数学公式的形式表示。
图1 分类算法的训练阶段
2)评估阶段在评估阶段,需要使用第一阶段建立的模型对测试集数据元组进行分类,从而评估分类模型的预测精度,如图2所示。
分类器的准确性是分类器在给定测试数据集上正确分类的测试元组的百分比。如果认为分类器的准确性可以接受,则使用分类器对类别标签未知的数据元组进行分类。
图2 分类算法的评估阶段
预测的基本概念预测模型类似于分类模型,可以看作是一个映射或函数 y=f(x),其中 x 是输入元组,输出 y 是连续或有序值。与分类算法不同的是,预测算法需要预测的属性值是连续的、有序的,而分类需要预测的属性值是离散的、无序的。
数据挖掘的预测算法和分类算法一样,是一个两步过程。测试数据集和训练数据集在预测任务中也应该是独立的。预测的准确性是通过 y 的预测值与实际已知值之间的差异来评估的。
预测和分类之间的区别在于,分类用于预测数据对象的类标签,而预测是估计一些空值或未知值。例如,预测明天上证综指收盘价是上涨还是下跌是一个分类,但如果要预测明天上证综指的收盘价是多少,它就是一个预测。 查看全部
无规则采集器列表算法(贷款量就是数据挖掘中的分类与预测方法进行介绍!)
分类和预测是使用数据进行预测的两种方式,可用于确定未来的结果。
分类用于预测数据对象的离散类别,需要预测的属性值是离散无序的。
Prediction用于预测数据对象的连续值,需要预测的属性值是连续的、有序的。
例如,在银行业务中,根据贷款申请人的信息确定贷款人属于“安全”类还是“风险”类,是数据挖掘中的一项分类任务。分析贷款人的贷款量是数据挖掘中的预测任务。
本节将介绍常用的分类和预测方法,其中一些只能用于分类或预测,但有些算法可以同时用于分类和预测。分类的基本概念分类算法反映了如何找出相似事物的共同性质的特征知识和不同事物之间的差异特征知识。分类是通过引导学习训练建立分类模型,并利用该模型对未知分类的实例进行分类。分类输出属性是离散且无序的。
分类技术在许多领域都有应用。目前,营销的一个非常重要的特点就是强调客户细分。使用数据挖掘中的分类技术,可以将客户分为不同的类别。
例如,可以通过客户分类构建分类模型来评估银行贷款的风险;在设计呼叫中心时,可以将客户划分为来电频繁的客户、偶尔来电的客户、来电稳定的客户等,以帮助呼叫中心找到这些不同类型的客户之间的特征,这样的分类模型可以让用户了解客户在不同行为类别中的分布特征。
其他分类应用包括文档检索和搜索引擎中的自动文本分类技术,以及安全领域中基于分类的入侵检测。
分类就是通过学习已有的数据集(训练集)来得到一个目标函数f(模型),将每个属性集X映射到目标属性y(类)(y必须是离散的)。
分类过程是一个两步过程:第一步是模型构建阶段或训练阶段,第二步是评估阶段。1)训练阶段 训练阶段的目的是为一组预定义的数据类或概念描述分类模型。这个阶段需要从已知数据集中选择一部分数据作为构建模型的训练集,剩下的部分作为测试集。通常从已知数据集中选取 2/3 的数据项作为训练集,将 1/3 的数据项作为测试集。
训练数据集由一组数据元组组成,每个元组都假定已经属于一个预先指定的类别。训练阶段可以看作是学习映射函数的过程,通过该映射函数可以预测给定元组 x 的类标签。映射函数是对数据集进行训练得到的模型(或分类器),如图1所示。模型可以用分类规则、决策树或数学公式的形式表示。
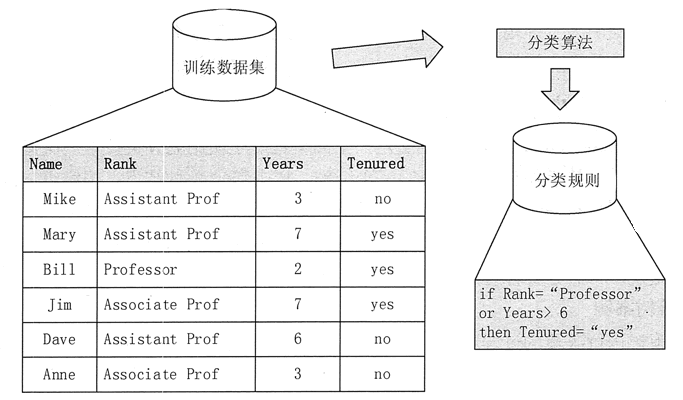
图1 分类算法的训练阶段
2)评估阶段在评估阶段,需要使用第一阶段建立的模型对测试集数据元组进行分类,从而评估分类模型的预测精度,如图2所示。
分类器的准确性是分类器在给定测试数据集上正确分类的测试元组的百分比。如果认为分类器的准确性可以接受,则使用分类器对类别标签未知的数据元组进行分类。
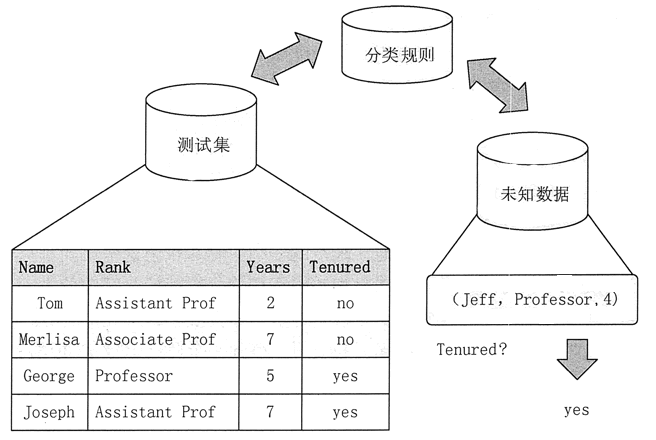
图2 分类算法的评估阶段
预测的基本概念预测模型类似于分类模型,可以看作是一个映射或函数 y=f(x),其中 x 是输入元组,输出 y 是连续或有序值。与分类算法不同的是,预测算法需要预测的属性值是连续的、有序的,而分类需要预测的属性值是离散的、无序的。
数据挖掘的预测算法和分类算法一样,是一个两步过程。测试数据集和训练数据集在预测任务中也应该是独立的。预测的准确性是通过 y 的预测值与实际已知值之间的差异来评估的。
预测和分类之间的区别在于,分类用于预测数据对象的类标签,而预测是估计一些空值或未知值。例如,预测明天上证综指收盘价是上涨还是下跌是一个分类,但如果要预测明天上证综指的收盘价是多少,它就是一个预测。
无规则采集器列表算法(【无监督语义分割】果子:作者算法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2022-01-13 09:05
煎饼不是水果:【无监督语义分割】InfoSeg: Unsupervised Semantic Image Segmentation with Mutual Information Maximization
以上内容于2021-10-10更新。我觉得上面的文章相当于下面描述的文章的升级版。
在使用无监督分割可以搜索到的GitHub代码中,最受关注的是这个项目→Unsupervised Image Segmentation by Backpropagation - Asako Kanezaki Kanazaki Asako(东京大学)- GitHub,作者在PyTorch中实现的代码。
基于作者论文的算法,我成功复现了作者的算法,我也把代码放到了Github↑上,我复现的代码可以使用更短的运行时间(作者用图30秒,我用5秒),并达到同样的Split效果。
直接用图片展示算法的效果↓
这些改进并不是因为我的代码写得有多好,而是因为原作者没有很好地实现她的算法,如下图:
第一行是无监督语义分割的输入图像;第二行是作者放在GitHub上的展示图片;第三行是我在本地电脑上运行作者的源代码得到的结果;第四行是基于作者的作者。论文的算法是用 PyTorch 复现的。原作者使用了随机颜色,但为了美观,我随机计算了同一语义标签的平均颜色作为着色。
无监督语义分割结果
注意:第 3 列第 2 行中的两只狼被分成不同的颜色(蓝色和黄色),这是一个偶然的结果。事实上,这个算法不能做Instance Segmentation。第三列,第 3 行,下面是我自己转载的图片:可以看出两只狼被分配了相同的标签。
用GIF动画感性的讲解算法原理↓
该算法一遍又一遍地迭代以将相同的标签分配给具有相似语义的像素(出于美学原因,我选择了随机颜色匹配的不愉快结果,在免费在线 gif 网站 中生成 - 在 ezgif 上生成 gif:
珊瑚珊瑚
Woof Husky下面会正式介绍算法更新日志(文章看起来很长,其实是图片。在文末评论区回复问题)
2019-06-19 第一版,添加橙猫橙图,添加算法缺点章节
2019-06-21 修改compantness -> n_segments 并在评论区回复问题
2019-12-20 点赞和私信的人突然多了?原来是被专栏选中的,所以我更新了一些东西:添加了说明论文中的Conv2D + BN + ReLU部分BN应该放在ReLU之前。修改了文章基于评论和私信,增加了关于医学影像的讨论0.算法主体内容理解代码提高优化效果算法缺点附录末尾文章在评论区回复问题1. 算法主体
个人觉得原论文的算法不好看,在保持算法不变的情况下修改了。原创PDF在这里,其中的算法1如下。
———————————————————————————————————————
算法:无监督图像分割
———————————————————————————————————————
进入:
输入 RGB 图像
输出:
输出语义分割的结果图像
初始化神经网络,保持每一层的方差和均值
图像的初步聚类
迭代 T 次
使用卷积网络获取特征图
根据特征图,值最大的是对应像素的标签
经典语义分割的聚类结果
计算每个集群中出现次数最多的类别
将此簇中的所有像素记录为该类别
计算损失函数(softmax有中文名称:归一化索引)
使用随机梯度下降更新参数——————————————————————————————————————————
在,
,作者使用全卷积网络接受输入图像完成特征提取。该网络由三层卷积网络组成,如下:
作者论文中的图1,我们可以看到这里的两只狼被分配了同一个标签(都是绿色的)
其中,原作者使用2D Conv + ReLU + Batch Norm的做法是不合适的,应该改为Conv2D + BN + ReLU。具体解释见文末附录《Batch normalization Batch Norm 应该在 ReLU 之前》
在,
(原文为GetSuperPixels,使用的是slic算法),即使用经典的机器学习无监督语义分割算法对输入图像进行预分类,如Python的skimage.segmentation中的多种算法,如使用的slic算法由原作者撰写,我推荐使用 felzenszwalb 算法。值得注意的是,在作者的原创代码中,slic算法选择了一个比较极端的参数。选择这个极端参数是有原因的:
原代码为slic选择了一个极端参数n_segments=1000
在slic算法中,当分区数n_segments越高时,算法对输入图像的划分越多:
由于具有相同语义的像素通常存在于图像中的连续区域中,因此可以推断位置相似的像素属于相同语义的概率很高。因此,在预分类中,我们给相邻像素分配相同的语义标签2.算法理解:
首先,使用经典的机器学习算法对输入图像进行“预分类”:调整算法参数,为语义信息明显相同的小区域分配相同的语义标签。由于具有相同语义的像素通常存在于图像的连续区域中,我们可以假设具有接近颜色、接近纹理和接近位置的像素可以被分配相同的语义标签。
然后使用深度学习结合自动编码器结构对输入图像进行分类。分类的目标是使输出的语义分割结果尽可能接近“预分类”的结果。训练收敛。
最后,深度学习的语义分割结果会在符合“预分类结果”的基础上,合并具有相同语义信息的小块,得到大块。
我个人的理解是:在整个无监督语义分割任务中,深度学习(神经网络)的任务就是对经典机器学习无监督语义分割的细粒度预分类结果进行处理。并且在迭代中,小块逐渐融合,最终得到符合人类期望的语义分割结果。
橘猫,无监督语义分割1、2、4、8、16、32、64、128次迭代的结果
大家可以观察我之前发布的gif图,可以看到:语义信息相似的小块会在迭代前期被合并;在迭代后期,只剩下2~8个语义标签。有一种树状的分类方法(类似于物种的进化树),比较自然,比如各种类型的草、虎纹在迭代合并中很好区分和优先排序。需要改进的地方,比如“虎而不橙”的虎尾、虎眼,在迭代中被错误地赋予了与“草”相同的标签,这不是我们希望看到的结果。(我也想到了一些改进方法,这里不再展开)
在作者的原创代码中,网络使用随机梯度下降(SGD)进行训练,学习率选择0.1(默认值为0.001),使得以前的迭代中,该算法非常快速地合并像素。
3. 代码改进(只为了运行效率,缩短运行时间,不改主算法)
详情见文末附录:《为什么我推荐使用felz算法而不是slic算法?》
4. 优化结果(128次迭代,40秒→4秒)
由于修改了代码,用更少的迭代就可以达到同样的效果,所以耗时不到4秒。
测试用图片
修改(魔术修改)后,不仅缩短了时间消耗,而且图像分割的质量也有所提高。下面是我从法国自动化研究所卫星图像数据集Inria Aerial Image,1000x1000的卫星图像数据集的bellingham_x.tif中随机截取的一张图片,图片包括树林、草地、道路、建筑物和一个湖(绿色),里面有cosplay草右下角。
对于这个更大的图像 1000x1000:
原代码迭代 128 次,耗时 3 分钟(不计算 PyTorch 初始化所用的 15 秒):
我修改后的代码也迭代了 128 次,耗时 8 秒(PyTorch 初始化耗时 15 秒):
5. 算法缺点(不够健壮,缺乏限制)
首先,这个算法不够鲁棒,算法受参数影响很大(包括梯度下降法的参数,以及机器学习预分类算法的参数),以及算法随机重启的结果会有所不同。为了展示这个缺点,我做了《橘猫看橘子》:(@cm cm 问:这个方案能不能分老虎和橘子?答:有时可以,有时不能,这就是算法的缺点.)
右上角,我通过PS阈值筛选证明:橙色和图中橘猫的颜色范围是一致的。以下三行是我随机调整参数后得到的不同结果。
结果图中,橘猫的橙色比橘猫的颜色浅,因为橘猫在计算平均像素的时候,黑色的条纹也收录在了计算中。并不是橘猫和橘猫不同。我专门用PS来证明两个橘子是一样的——橘猫的平均颜色比结果图中的橙色要浅,因为橘猫的平均颜色中含有黑色虎纹。深度学习可以区分橘子和橘猫。很大的原因是卷积网络可以更好地感知纹理的差异,而不是仅仅依靠颜色进行分类。
二是算法不够成熟。随着迭代,算法会逐渐合并各个分区。然而,算法中没有设置限制来禁止神经网络合并小区域。
浅草,暗草,枯草,,,,虎尾,虎眼,,虎纹,虎皮
橙色猫图,迭代2次
黑草、浅草、尾虎尾、、、虎皮(橙)、虎皮(白)
橘猫图,迭代3次
深草,浅草(+部分老虎),老虎(大部分)
橘猫图,迭代5次
在作者自己的原创代码中,当语义分割的类别数下降到 3 或 4 时,算法终止。如果去掉训练限制,当整幅图像归为同一类别时,损失降为0。原文设计的损失函数不能限制神经网络机会主义地输出只收录一个类别的结果。这意味着在训练网络时,随机重启可能会得到截然不同的结果,我在运行原创代码时也注意到了这一点。由于没有“一类”的限制,所以这个神经网络的参数个数应该足够少(足够浅,足够窄),这样的设计太容易过拟合(不解决这个问题,模型的提升会是极其有限)。
(我也想到了一些改进的方法,就是用普通的机器学习语义分割算法得到一些必须属于不同语义的标签。作为对“一类”的限制,这里就不展开了)
6. 文末附录《Batch Normalization Batch Norm 应该在 ReLU 之前》
作者论文中的图1,它使用了原作者使用的2D Conv + ReLU + Batch Norm。这种做法不合适,应该改成Conv2D + BN + ReLU
一般在深度学习图像领域,我们会将批归一化层Batch Normalization放在激活函数ReLU前面,使得输入到ReLU的图像接近正态分布N(0, 1).如果将输入归一化归一化操作后的张量转化为梯度变化点为0的激活函数(比如这里使用的ReLU),那么这个激活函数的非线性特性就会被充分发挥出来,构造的loss函数会变得更流畅,可能是因为原论文的作者没有做图像,所以她用错了,我帮她改正为Conv2D + BN + ReLU。
要详细了解为什么使用 Conv2D + BN + ReLU,可以阅读这篇论文:Batch Normalization is a Cause of Adversarial Vulnerability。ArXiv。2019 年 5 月。以此类推,如果一定要用Sigmoid作为激活函数,那么在前面使用Batch Normalization之后,需要将0.0到0.5的均值相加,然后输入Sigmoid就会更合适。下图来自纸图。2.
批量标准化是对抗性漏洞的一个原因。图 2 “为什么我推荐使用 felz 算法而不是 slic 算法?”
在预分类阶段,需要进行细粒度的分类,并分离出足够多的区域(确保分类的地方被分类,神经网络可以帮助它在不应该分类的地方合并),以使最终结果更准确。如果类别太多,算法需要更多的迭代。使用felz算法而不是slic算法是因为它可以用更少的区域命中更多的“正确边界”,并且felz分隔的边界更准确。无论是选择felz算法还是slic算法,当划分足够多的区域时,对精度影响不大,但迭代次数差别很大。先说一下图片:
第一行,预分类结果,第二行,用PS差值表示我们想要得到的区域划分方案。
第一列使用slic算法,分区数为n_segments=1000。可以看出,虽然区域很多,但虎尾与草的距离并不是很好。第二列使用的slic算法,分区数n_segments=100,没有达到我们想要得到的分类边界。
下面是一个带有合适参数的预分类算法(比较felz和slic算法)
slic,边框条纹不够细。而felz算法,它甚至把每一条虎纹都分离出来,这也是我推荐这个算法的原因之一。
“费尔兹算法”
Efficient Graph-Based Image Segmentation - Felzenszwalb (MIT) 2004. Graph-Based Semantic Segmentation。格式塔运动(Holistic Psychology/Gestalt Psychology)认为人类根据事物的整体性做出判断。Felz 算法定义了一种方法,该方法使用基于图形的表示来定义两个区域的边界(定义谓词)。尽管这种方法会做出贪婪的决定,但它仍然会产生满足全局属性的结果。
翻译自 felz 论文的引言部分。
“切片算法”
SLIC 超像素与最先进的超像素方法的比较。2012. 省略,在作者论文的算法描述中,原代码中出现的SuperPixel也出现在了这篇论文中。大胆吐槽,上面的felz算法是2004年的,slic算法是2012年的,但是slic的标题里有State-of-the-Art?如果你没有达到全面的超越,不要说。要想戴上王冠,就必须承受它的重量。
《性能提升与GPU》
因为代码是单线程的,花在CPU上的时间越少,GPU的利用率就越高。所以即使我为了美学计算了所有类中像素的平均颜色,但时间仍然比原创代码短。无论是运行速度还是分割精度,我认为算法还有很大的提升空间。
上面是修改后的代码,GPU利用率30~40%,下面是原代码,GPU利用率10~20%,全部使用RTX2080Ti运行。欢迎评论,如有错误,请多多交流6. 回复评论区问题@cm cm 问:这个设计是不是训练和推理不可知论?每次分割图像时,网络的权重是否会重新训练?
答:“是的,训练的过程就是推理”。该算法与风格迁移的初始版本相同,通过对单个图像进行训练来获得最终结果。在李飞飞等人的实时风格迁移出来之前,风格迁移的结果是“训练”出来的,训练得到的网络参数无法保存在其他图片上使用。所以这个算法还不够成熟(我很想把它改成实时的)。
@一Seconemeow想:flez,然后用平均颜色给像素上色(并计算方差),然后Kmean(k=4),感觉200毫秒能得到比这里展示的分割效果好很多的,还没用过神经网络。(感谢他的建议)...我用flez加yuv空间平均颜色加minibatchkmean做了150ms(cpu)和你差不多的结果。虎皮没有任何问题, ...(详见评论部分)
A:在法国机器学习库 sklearn 中已经有类似的算法,Region Adjacency Graph (RAG) 和合并颜色相似的区域。后来我用了 flez 算法加上 yuv 空间的平均颜色加上 mini-batch + K-mean 的方案。我认为这确实是可行的。有机会我会试试,但是基于同色分类的算法确实是毫秒级的。级算法。但是,前面提到的这种算法存在以下问题:
该算法对机器学习语义分割聚类的预分类结果敏感,需要找到合适的预分类参数。平均色法无法将“黑虎纹”与“橙虎皮”结合起来(见草丛中的橙猫)。平均颜色将错误地合并不同但具有相似平均颜色的区域。仅仅依靠颜色是不够的,纹理的感知还需要深度学习。
问题3相关的gif:RAG算法中使用的阈值从4逐渐增大到128以下,在阈值为32时得到了比较好的结果。
使用 slic 算法 (n_segments=2048, compactness=16, max_iter=8) # 分隔更多区域
使用 slic 算法 (n_segments=2048, compactness=16, max_iter=8) # 分隔更多区域
使用slic算法(n_segments=128, compactness=16, max_iter=8) # 分隔合适的区域
与问题1相关的图片:左图和右图服从均值为128,方差为16的正态分布,右图的每一行使用一个排序。以服从相同的分布
但是对于两张不同纹理的图片,很明显,如果只使用每个区域的均值和方差,下面的两个区域是无法用任何聚类算法分开的。
左:白噪声;右:渐变
此外,还可以通过计算特征矩(measure Moments)、SSIM等方法来区分上述两个区域。但是这些方法都要求要比较的两个对象必须具有相同的区域形状(例如,长宽相同的矩形,相同大小的圆形),并且每个只能比较两个对象,所以比较部分在该算法,其复杂度将超过 O(n*log(n))。
@Anonymous:关于在医学图像上使用这个算法,可以吗?(问这个问题的人很多,请不要私信,私信的讨论过程帮不了别人,请留言)
这是一种不需要训练数据的单帧图片无监督方案,其训练阶段是推理过程。仅当根本没有数据时才应选择此方法。同等条件下,数据越多越好。
参考^无监督图像分割。ICASSP。2018 ^机器学习无监督语义分割 SLIC 超像素与最先进的超像素方法相比,TPAMI,201 年 5 月2.^机器学习无监督语义分割高效的基于图的图像分割。IJCV。2004~pff/papers/seg-ijcv.pdf 法国自动化研究所卫星图像数据集(其实是航拍的Aerial Image) 为什么要把BN层放在ReLU前面?批量标准化是计算机视觉和模式识别对抗性漏洞会议的一个原因。IEEE。1997 使用特征向量进行分割:统一。国际刑事法院。1999.实时风格迁移和超分辨率的感知损失。约翰逊。ECCV。2016OpenCV 简历2. 查看全部
无规则采集器列表算法(【无监督语义分割】果子:作者算法)
煎饼不是水果:【无监督语义分割】InfoSeg: Unsupervised Semantic Image Segmentation with Mutual Information Maximization
以上内容于2021-10-10更新。我觉得上面的文章相当于下面描述的文章的升级版。
在使用无监督分割可以搜索到的GitHub代码中,最受关注的是这个项目→Unsupervised Image Segmentation by Backpropagation - Asako Kanezaki Kanazaki Asako(东京大学)- GitHub,作者在PyTorch中实现的代码。
基于作者论文的算法,我成功复现了作者的算法,我也把代码放到了Github↑上,我复现的代码可以使用更短的运行时间(作者用图30秒,我用5秒),并达到同样的Split效果。
直接用图片展示算法的效果↓
这些改进并不是因为我的代码写得有多好,而是因为原作者没有很好地实现她的算法,如下图:
第一行是无监督语义分割的输入图像;第二行是作者放在GitHub上的展示图片;第三行是我在本地电脑上运行作者的源代码得到的结果;第四行是基于作者的作者。论文的算法是用 PyTorch 复现的。原作者使用了随机颜色,但为了美观,我随机计算了同一语义标签的平均颜色作为着色。

无监督语义分割结果
注意:第 3 列第 2 行中的两只狼被分成不同的颜色(蓝色和黄色),这是一个偶然的结果。事实上,这个算法不能做Instance Segmentation。第三列,第 3 行,下面是我自己转载的图片:可以看出两只狼被分配了相同的标签。
用GIF动画感性的讲解算法原理↓
该算法一遍又一遍地迭代以将相同的标签分配给具有相似语义的像素(出于美学原因,我选择了随机颜色匹配的不愉快结果,在免费在线 gif 网站 中生成 - 在 ezgif 上生成 gif:

珊瑚珊瑚

Woof Husky下面会正式介绍算法更新日志(文章看起来很长,其实是图片。在文末评论区回复问题)
2019-06-19 第一版,添加橙猫橙图,添加算法缺点章节
2019-06-21 修改compantness -> n_segments 并在评论区回复问题
2019-12-20 点赞和私信的人突然多了?原来是被专栏选中的,所以我更新了一些东西:添加了说明论文中的Conv2D + BN + ReLU部分BN应该放在ReLU之前。修改了文章基于评论和私信,增加了关于医学影像的讨论0.算法主体内容理解代码提高优化效果算法缺点附录末尾文章在评论区回复问题1. 算法主体
个人觉得原论文的算法不好看,在保持算法不变的情况下修改了。原创PDF在这里,其中的算法1如下。
———————————————————————————————————————
算法:无监督图像分割
———————————————————————————————————————
进入:
输入 RGB 图像
输出:
输出语义分割的结果图像
初始化神经网络,保持每一层的方差和均值
图像的初步聚类
迭代 T 次
使用卷积网络获取特征图
根据特征图,值最大的是对应像素的标签
经典语义分割的聚类结果
计算每个集群中出现次数最多的类别
将此簇中的所有像素记录为该类别
计算损失函数(softmax有中文名称:归一化索引)
使用随机梯度下降更新参数——————————————————————————————————————————
在,
,作者使用全卷积网络接受输入图像完成特征提取。该网络由三层卷积网络组成,如下:
作者论文中的图1,我们可以看到这里的两只狼被分配了同一个标签(都是绿色的)
其中,原作者使用2D Conv + ReLU + Batch Norm的做法是不合适的,应该改为Conv2D + BN + ReLU。具体解释见文末附录《Batch normalization Batch Norm 应该在 ReLU 之前》
在,
(原文为GetSuperPixels,使用的是slic算法),即使用经典的机器学习无监督语义分割算法对输入图像进行预分类,如Python的skimage.segmentation中的多种算法,如使用的slic算法由原作者撰写,我推荐使用 felzenszwalb 算法。值得注意的是,在作者的原创代码中,slic算法选择了一个比较极端的参数。选择这个极端参数是有原因的:

原代码为slic选择了一个极端参数n_segments=1000
在slic算法中,当分区数n_segments越高时,算法对输入图像的划分越多:
由于具有相同语义的像素通常存在于图像中的连续区域中,因此可以推断位置相似的像素属于相同语义的概率很高。因此,在预分类中,我们给相邻像素分配相同的语义标签2.算法理解:
首先,使用经典的机器学习算法对输入图像进行“预分类”:调整算法参数,为语义信息明显相同的小区域分配相同的语义标签。由于具有相同语义的像素通常存在于图像的连续区域中,我们可以假设具有接近颜色、接近纹理和接近位置的像素可以被分配相同的语义标签。
然后使用深度学习结合自动编码器结构对输入图像进行分类。分类的目标是使输出的语义分割结果尽可能接近“预分类”的结果。训练收敛。
最后,深度学习的语义分割结果会在符合“预分类结果”的基础上,合并具有相同语义信息的小块,得到大块。
我个人的理解是:在整个无监督语义分割任务中,深度学习(神经网络)的任务就是对经典机器学习无监督语义分割的细粒度预分类结果进行处理。并且在迭代中,小块逐渐融合,最终得到符合人类期望的语义分割结果。

橘猫,无监督语义分割1、2、4、8、16、32、64、128次迭代的结果
大家可以观察我之前发布的gif图,可以看到:语义信息相似的小块会在迭代前期被合并;在迭代后期,只剩下2~8个语义标签。有一种树状的分类方法(类似于物种的进化树),比较自然,比如各种类型的草、虎纹在迭代合并中很好区分和优先排序。需要改进的地方,比如“虎而不橙”的虎尾、虎眼,在迭代中被错误地赋予了与“草”相同的标签,这不是我们希望看到的结果。(我也想到了一些改进方法,这里不再展开)

在作者的原创代码中,网络使用随机梯度下降(SGD)进行训练,学习率选择0.1(默认值为0.001),使得以前的迭代中,该算法非常快速地合并像素。
3. 代码改进(只为了运行效率,缩短运行时间,不改主算法)
详情见文末附录:《为什么我推荐使用felz算法而不是slic算法?》
4. 优化结果(128次迭代,40秒→4秒)
由于修改了代码,用更少的迭代就可以达到同样的效果,所以耗时不到4秒。
测试用图片
修改(魔术修改)后,不仅缩短了时间消耗,而且图像分割的质量也有所提高。下面是我从法国自动化研究所卫星图像数据集Inria Aerial Image,1000x1000的卫星图像数据集的bellingham_x.tif中随机截取的一张图片,图片包括树林、草地、道路、建筑物和一个湖(绿色),里面有cosplay草右下角。
对于这个更大的图像 1000x1000:
原代码迭代 128 次,耗时 3 分钟(不计算 PyTorch 初始化所用的 15 秒):
我修改后的代码也迭代了 128 次,耗时 8 秒(PyTorch 初始化耗时 15 秒):
5. 算法缺点(不够健壮,缺乏限制)
首先,这个算法不够鲁棒,算法受参数影响很大(包括梯度下降法的参数,以及机器学习预分类算法的参数),以及算法随机重启的结果会有所不同。为了展示这个缺点,我做了《橘猫看橘子》:(@cm cm 问:这个方案能不能分老虎和橘子?答:有时可以,有时不能,这就是算法的缺点.)
右上角,我通过PS阈值筛选证明:橙色和图中橘猫的颜色范围是一致的。以下三行是我随机调整参数后得到的不同结果。
结果图中,橘猫的橙色比橘猫的颜色浅,因为橘猫在计算平均像素的时候,黑色的条纹也收录在了计算中。并不是橘猫和橘猫不同。我专门用PS来证明两个橘子是一样的——橘猫的平均颜色比结果图中的橙色要浅,因为橘猫的平均颜色中含有黑色虎纹。深度学习可以区分橘子和橘猫。很大的原因是卷积网络可以更好地感知纹理的差异,而不是仅仅依靠颜色进行分类。
二是算法不够成熟。随着迭代,算法会逐渐合并各个分区。然而,算法中没有设置限制来禁止神经网络合并小区域。
浅草,暗草,枯草,,,,虎尾,虎眼,,虎纹,虎皮

橙色猫图,迭代2次
黑草、浅草、尾虎尾、、、虎皮(橙)、虎皮(白)

橘猫图,迭代3次
深草,浅草(+部分老虎),老虎(大部分)

橘猫图,迭代5次
在作者自己的原创代码中,当语义分割的类别数下降到 3 或 4 时,算法终止。如果去掉训练限制,当整幅图像归为同一类别时,损失降为0。原文设计的损失函数不能限制神经网络机会主义地输出只收录一个类别的结果。这意味着在训练网络时,随机重启可能会得到截然不同的结果,我在运行原创代码时也注意到了这一点。由于没有“一类”的限制,所以这个神经网络的参数个数应该足够少(足够浅,足够窄),这样的设计太容易过拟合(不解决这个问题,模型的提升会是极其有限)。
(我也想到了一些改进的方法,就是用普通的机器学习语义分割算法得到一些必须属于不同语义的标签。作为对“一类”的限制,这里就不展开了)
6. 文末附录《Batch Normalization Batch Norm 应该在 ReLU 之前》
作者论文中的图1,它使用了原作者使用的2D Conv + ReLU + Batch Norm。这种做法不合适,应该改成Conv2D + BN + ReLU
一般在深度学习图像领域,我们会将批归一化层Batch Normalization放在激活函数ReLU前面,使得输入到ReLU的图像接近正态分布N(0, 1).如果将输入归一化归一化操作后的张量转化为梯度变化点为0的激活函数(比如这里使用的ReLU),那么这个激活函数的非线性特性就会被充分发挥出来,构造的loss函数会变得更流畅,可能是因为原论文的作者没有做图像,所以她用错了,我帮她改正为Conv2D + BN + ReLU。
要详细了解为什么使用 Conv2D + BN + ReLU,可以阅读这篇论文:Batch Normalization is a Cause of Adversarial Vulnerability。ArXiv。2019 年 5 月。以此类推,如果一定要用Sigmoid作为激活函数,那么在前面使用Batch Normalization之后,需要将0.0到0.5的均值相加,然后输入Sigmoid就会更合适。下图来自纸图。2.
批量标准化是对抗性漏洞的一个原因。图 2 “为什么我推荐使用 felz 算法而不是 slic 算法?”
在预分类阶段,需要进行细粒度的分类,并分离出足够多的区域(确保分类的地方被分类,神经网络可以帮助它在不应该分类的地方合并),以使最终结果更准确。如果类别太多,算法需要更多的迭代。使用felz算法而不是slic算法是因为它可以用更少的区域命中更多的“正确边界”,并且felz分隔的边界更准确。无论是选择felz算法还是slic算法,当划分足够多的区域时,对精度影响不大,但迭代次数差别很大。先说一下图片:

第一行,预分类结果,第二行,用PS差值表示我们想要得到的区域划分方案。
第一列使用slic算法,分区数为n_segments=1000。可以看出,虽然区域很多,但虎尾与草的距离并不是很好。第二列使用的slic算法,分区数n_segments=100,没有达到我们想要得到的分类边界。
下面是一个带有合适参数的预分类算法(比较felz和slic算法)

slic,边框条纹不够细。而felz算法,它甚至把每一条虎纹都分离出来,这也是我推荐这个算法的原因之一。
“费尔兹算法”
Efficient Graph-Based Image Segmentation - Felzenszwalb (MIT) 2004. Graph-Based Semantic Segmentation。格式塔运动(Holistic Psychology/Gestalt Psychology)认为人类根据事物的整体性做出判断。Felz 算法定义了一种方法,该方法使用基于图形的表示来定义两个区域的边界(定义谓词)。尽管这种方法会做出贪婪的决定,但它仍然会产生满足全局属性的结果。
翻译自 felz 论文的引言部分。
“切片算法”
SLIC 超像素与最先进的超像素方法的比较。2012. 省略,在作者论文的算法描述中,原代码中出现的SuperPixel也出现在了这篇论文中。大胆吐槽,上面的felz算法是2004年的,slic算法是2012年的,但是slic的标题里有State-of-the-Art?如果你没有达到全面的超越,不要说。要想戴上王冠,就必须承受它的重量。
《性能提升与GPU》
因为代码是单线程的,花在CPU上的时间越少,GPU的利用率就越高。所以即使我为了美学计算了所有类中像素的平均颜色,但时间仍然比原创代码短。无论是运行速度还是分割精度,我认为算法还有很大的提升空间。
上面是修改后的代码,GPU利用率30~40%,下面是原代码,GPU利用率10~20%,全部使用RTX2080Ti运行。欢迎评论,如有错误,请多多交流6. 回复评论区问题@cm cm 问:这个设计是不是训练和推理不可知论?每次分割图像时,网络的权重是否会重新训练?
答:“是的,训练的过程就是推理”。该算法与风格迁移的初始版本相同,通过对单个图像进行训练来获得最终结果。在李飞飞等人的实时风格迁移出来之前,风格迁移的结果是“训练”出来的,训练得到的网络参数无法保存在其他图片上使用。所以这个算法还不够成熟(我很想把它改成实时的)。
@一Seconemeow想:flez,然后用平均颜色给像素上色(并计算方差),然后Kmean(k=4),感觉200毫秒能得到比这里展示的分割效果好很多的,还没用过神经网络。(感谢他的建议)...我用flez加yuv空间平均颜色加minibatchkmean做了150ms(cpu)和你差不多的结果。虎皮没有任何问题, ...(详见评论部分)
A:在法国机器学习库 sklearn 中已经有类似的算法,Region Adjacency Graph (RAG) 和合并颜色相似的区域。后来我用了 flez 算法加上 yuv 空间的平均颜色加上 mini-batch + K-mean 的方案。我认为这确实是可行的。有机会我会试试,但是基于同色分类的算法确实是毫秒级的。级算法。但是,前面提到的这种算法存在以下问题:
该算法对机器学习语义分割聚类的预分类结果敏感,需要找到合适的预分类参数。平均色法无法将“黑虎纹”与“橙虎皮”结合起来(见草丛中的橙猫)。平均颜色将错误地合并不同但具有相似平均颜色的区域。仅仅依靠颜色是不够的,纹理的感知还需要深度学习。
问题3相关的gif:RAG算法中使用的阈值从4逐渐增大到128以下,在阈值为32时得到了比较好的结果。

使用 slic 算法 (n_segments=2048, compactness=16, max_iter=8) # 分隔更多区域
使用 slic 算法 (n_segments=2048, compactness=16, max_iter=8) # 分隔更多区域

使用slic算法(n_segments=128, compactness=16, max_iter=8) # 分隔合适的区域
与问题1相关的图片:左图和右图服从均值为128,方差为16的正态分布,右图的每一行使用一个排序。以服从相同的分布
但是对于两张不同纹理的图片,很明显,如果只使用每个区域的均值和方差,下面的两个区域是无法用任何聚类算法分开的。

左:白噪声;右:渐变
此外,还可以通过计算特征矩(measure Moments)、SSIM等方法来区分上述两个区域。但是这些方法都要求要比较的两个对象必须具有相同的区域形状(例如,长宽相同的矩形,相同大小的圆形),并且每个只能比较两个对象,所以比较部分在该算法,其复杂度将超过 O(n*log(n))。
@Anonymous:关于在医学图像上使用这个算法,可以吗?(问这个问题的人很多,请不要私信,私信的讨论过程帮不了别人,请留言)
这是一种不需要训练数据的单帧图片无监督方案,其训练阶段是推理过程。仅当根本没有数据时才应选择此方法。同等条件下,数据越多越好。
参考^无监督图像分割。ICASSP。2018 ^机器学习无监督语义分割 SLIC 超像素与最先进的超像素方法相比,TPAMI,201 年 5 月2.^机器学习无监督语义分割高效的基于图的图像分割。IJCV。2004~pff/papers/seg-ijcv.pdf 法国自动化研究所卫星图像数据集(其实是航拍的Aerial Image) 为什么要把BN层放在ReLU前面?批量标准化是计算机视觉和模式识别对抗性漏洞会议的一个原因。IEEE。1997 使用特征向量进行分割:统一。国际刑事法院。1999.实时风格迁移和超分辨率的感知损失。约翰逊。ECCV。2016OpenCV 简历2.
无规则采集器列表算法(无规则采集器列表算法中一般会包含批量采集这一模块)
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-01-07 21:05
无规则采集器列表算法中一般会包含批量采集这一模块。本质上excel工具也是属于批量采集这一模块。所以,看你对数据的难易程度,如果文本多,表格多,涉及的数据不多,可以用这种。
看excel工具好不好用,功能多不多了,多的话,
看你做的数据量大不大,上限够不够,
不太建议用这个来做数据库采集,比较吃数据库。本人采集网站视频频道,需要爬两三天甚至更久的数据,老婆不让我用,说每天爬一点爬哪能那么慢,都是公司数据都有什么地方用不到,数据库链接都配置好了干嘛非要爬网站去。爬网站要多看网站源码,还是比较严谨可靠的。另外视频频道有网站文件,设定目录、遍历数据库就可以了,没必要爬这么麻烦。结论:。
等等,首先吐槽,竟然没有一个搜索引擎,然后语焉不详的回答了这个问题。既然这样,就得先说一下,就目前爬虫的采集目的。现在,爬虫对于每天的数据进行采集的目的可以划分为以下几个类型,1.像我这样的,经常处理文本文件数据,这里指的是.txt。.txt数据一般来说,几千几万的文本数据,不管用什么工具,都是不可能爬下来的,随便一个爬虫,把他伪装成python啊什么的,爬下来了,一瞬间访问量瞬间上去了,可是,爬一个文件数据还有个必要抓取它的url吗,这些url爬取出来,比爬取10万条文本数据那可是轻而易举啊。
所以,对于文本数据,基本上,任何工具都不能像数据库那样方便的处理。2.对于pdf文件的采集,一般也是需要抓取url的,但这样的数据是可以被python分析出来的,但是python必须要有pdf相关的工具。3.其他大概还有视频,图片等其他数据,这里就不深入了。不过,对于数据采集目的,越多样的,数据分析目的,爬虫就越复杂,收益也就越小。
4.我记得之前在博客中看到过一个统计,爬虫的收益率是0.03%。这里的收益率是指对每一个数据站点,一天少量的数据采集,就有少量的收益,如果,爬取几十万数据,那就基本等于一无所获。5.爬虫,我们应该更多的关注问题而不是工具。1.一个成熟,好用的爬虫工具,在你掌握了大量的python爬虫基础后,不一定能做到小爬虫。
但是,如果还停留在没有工具,只能一遍遍一个一个url来爬取数据,那一定做不到好爬虫。2.大量需要爬取的数据,比如某个频道有上万条数据,每一条数据,你不可能还需要爬到文件,就那么爬呗。这样频繁的把你的爬虫样本到几百几千就没必要了。更多的选择是,保存好一个特定的链接。方便你的爬虫进行判断。要爬取的就进行判断。然。 查看全部
无规则采集器列表算法(无规则采集器列表算法中一般会包含批量采集这一模块)
无规则采集器列表算法中一般会包含批量采集这一模块。本质上excel工具也是属于批量采集这一模块。所以,看你对数据的难易程度,如果文本多,表格多,涉及的数据不多,可以用这种。
看excel工具好不好用,功能多不多了,多的话,
看你做的数据量大不大,上限够不够,
不太建议用这个来做数据库采集,比较吃数据库。本人采集网站视频频道,需要爬两三天甚至更久的数据,老婆不让我用,说每天爬一点爬哪能那么慢,都是公司数据都有什么地方用不到,数据库链接都配置好了干嘛非要爬网站去。爬网站要多看网站源码,还是比较严谨可靠的。另外视频频道有网站文件,设定目录、遍历数据库就可以了,没必要爬这么麻烦。结论:。
等等,首先吐槽,竟然没有一个搜索引擎,然后语焉不详的回答了这个问题。既然这样,就得先说一下,就目前爬虫的采集目的。现在,爬虫对于每天的数据进行采集的目的可以划分为以下几个类型,1.像我这样的,经常处理文本文件数据,这里指的是.txt。.txt数据一般来说,几千几万的文本数据,不管用什么工具,都是不可能爬下来的,随便一个爬虫,把他伪装成python啊什么的,爬下来了,一瞬间访问量瞬间上去了,可是,爬一个文件数据还有个必要抓取它的url吗,这些url爬取出来,比爬取10万条文本数据那可是轻而易举啊。
所以,对于文本数据,基本上,任何工具都不能像数据库那样方便的处理。2.对于pdf文件的采集,一般也是需要抓取url的,但这样的数据是可以被python分析出来的,但是python必须要有pdf相关的工具。3.其他大概还有视频,图片等其他数据,这里就不深入了。不过,对于数据采集目的,越多样的,数据分析目的,爬虫就越复杂,收益也就越小。
4.我记得之前在博客中看到过一个统计,爬虫的收益率是0.03%。这里的收益率是指对每一个数据站点,一天少量的数据采集,就有少量的收益,如果,爬取几十万数据,那就基本等于一无所获。5.爬虫,我们应该更多的关注问题而不是工具。1.一个成熟,好用的爬虫工具,在你掌握了大量的python爬虫基础后,不一定能做到小爬虫。
但是,如果还停留在没有工具,只能一遍遍一个一个url来爬取数据,那一定做不到好爬虫。2.大量需要爬取的数据,比如某个频道有上万条数据,每一条数据,你不可能还需要爬到文件,就那么爬呗。这样频繁的把你的爬虫样本到几百几千就没必要了。更多的选择是,保存好一个特定的链接。方便你的爬虫进行判断。要爬取的就进行判断。然。
无规则采集器列表算法(机器学习中的随机森林算法(一)——Random)
采集交流 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-01-06 11:02
一、随机森林算法简介:
在机器学习中
在,随机森林是一个收录多个决策树的分类器
, 并且输出类别由个体树输出的类别的模式决定。Leo Breiman 和 Adele Cutler 开发了一种算法来推断随机森林。和“随机
“森林”是他们的商标。
这个术语是贝尔实验室的Tin Kam Ho在1995年提出的随机决策森林(random decision forest)。
森林)。这种方法结合了 Breimans 的“Bootstrap aggregating”思想和 Ho 的“randomsubspace”
方法”来构建决策树的集合。
每棵树都是根据以下算法构建的:
1. 用M表示训练案例(样本)的数量,用N表示特征的数量。
2. 输入特征数n,用于确定决策树
上一个节点的决策结果;其中 n 应该远小于 N。
3. 从M个训练案例(样本)中进行替换采样,取k次形成一个训练集
(即引导抽样),并使用未选择的用例(样本)进行预测并评估其错误。
4.对于每个节点,随机选择n个特征,基于这些特征确定每个节点在每棵决策树上的决策。根据这n个特征,计算出最佳分割方法。
5. 每棵树都会完全生长而无需修剪,可以在构建正常的树状分类器后使用。
6.最后测试数据,根据每棵树,以多胜少的方式确定分类。
在构建随机森林时,需要做两方面的工作:数据的随机选择和要选择的特征的随机选择,以消除过拟合的问题。
首先,从原创数据集中取一个有替换的样本,构造一个子数据集。子数据集的数据量与原创数据集的数据量相同。不同子数据集中的元素可以重复,同一子数据集中的元素也可以重复。其次,使用子数据集构建子决策树,将这些数据放入每个子决策树中,每个子决策树输出一个结果。最后,如果有新数据,需要通过随机森林得到分类结果,可以通过对子决策树的判断结果进行投票,得到随机森林的输出结果。如下图所示,假设有
3个子决策树,2个子树的分类结果为A类,1个子树的分类结果为B类,则随机森林的分类结果为A类。
与数据集的随机选择类似,随机森林中子树的每次分裂过程都没有使用所有的候选特征,而是从所有候选特征中随机选择某些特征,然后随机选择。从特征中选择最佳特征。这样可以使随机森林中的决策树互不相同,提高系统的多样性,从而提高分类性能。
优势:
随机森林既可以用于回归任务,也可以用于分类任务,很容易看出模型输入特征的相对重要性。随机森林算法被认为是一种非常方便和易于使用的算法,因为它是默认的超参数,通常会产生很好的预测结果。超参数的数量并不多,它们所代表的含义直观易懂。
随机森林有足够多的树,这样分类器就不会产生过度拟合的模型。
缺点:
由于使用了大量的树,算法变得很慢,无法实现实时预测。一般来说,这些算法训练速度快,预测速度慢。预测越准确,需要的树越多,这将导致模型越慢。在大多数实际应用中,随机森林算法足够快,但肯定会遇到对实时性要求高的情况,所以只能首选其他方法。当然,随机森林是一种预测建模工具,而不是一种描述性工具。换句话说,如果您正在寻找数据中关系的描述,建议您更喜欢其他方法。
适用范围:
随机森林算法可用于许多不同的领域,例如银行、股票市场、医药和电子商务。在银行领域,它通常用于检测比普通人更频繁地使用银行服务的客户,并及时偿还债务。同时,它也会被用来检测想要欺骗银行的客户。在金融领域,可以用来预测未来的股票走势。在医疗保健领域,可用于识别药物成分的正确组合,分析患者的病史以识别疾病。另外,在电子商务领域,随机森林可以用来判断客户是否真的喜欢一个产品。
二、 随机森林算法在sklearn中的应用示例:
(1)基本步骤:
①选择数据:将你的数据分成三组:训练数据、验证数据和测试数据
②模型数据:使用训练数据构建使用相关特征的模型
③验证模型:使用您的验证数据连接到您的模型
④测试模型:使用您的测试数据来检查验证模型的性能
⑤使用模型:使用完全训练好的模型对新数据进行预测
⑥ 调优模型:使用更多的数据、不同的特征或调整后的参数来提高算法的性能
为方便起见,代码如下:
导入 csv
导入 numpy asnp
fromsklearn.ensemble 导入 RandomForestRegressor
从 sklearnimport 预处理
从 sklearn.metricsimport mean_squared_error,explain_variance_score
importmatplotlib.pyplot 作为 plt
#------------------------------------------------- --------------------------------
defload_dataset(文件名):
file_reader = csv.reader(open(filename,'rb'), delimiter=',')
X, y = [], []
对于 file_reader 中的行:
X.append(row[2:13])
y.append(row[-1])
# 提取特征名称
特征名称 = np.array(X[0])
返回
np.array(X[1:]).astype(np.float32),np.array(y[1:]).astype(np.float32),
特征名称
if__name__=='__main__':
X, y, feature_names =load_dataset("d:\\bike_day.csv")
X, y = shuffle(X, y, random_state=7)
num_training = int(0.9 * len(X))
X_train, y_train = X[:num_training],y[:num_training]
X_test, y_test = X[num_training:],y[num_training:]
rf_regressor =RandomForestRegressor(n_estimators=1000, max_depth=10,
min_samples_split=1)
rf_regressor.fit(X_train, y_train)
y_pred = rf_regressor.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
evs = 解释方差分数(y_test,y_pred)
来自 AdaBoostRegressor importplot_feature_importances
plot_feature_importances(rf_regressor.feature_importances_,'RandomForest
回归器',功能名称)
数据集格式如下:
即时,今天,季节,年,月,假期,工作日,工作日,天气,温度,温度,嗡嗡声,风速,休闲,注册,cnt
1,2011-01-01,1,0,1,0,6,0,2,0.344167,0.363625,0.805833,0.160446, 331,654,985
2,2011-01-02,1,0,1,0,0,0,2,0.363478,0.353739,0.696087,0.248539, 131,670,801
3,2011-01-03,1,0,1,0,1,1,1,0.196364,0.189405,0.437273,0.248309, 120,1229,1349
以下数据省略。 查看全部
无规则采集器列表算法(机器学习中的随机森林算法(一)——Random)
一、随机森林算法简介:
在机器学习中
在,随机森林是一个收录多个决策树的分类器
, 并且输出类别由个体树输出的类别的模式决定。Leo Breiman 和 Adele Cutler 开发了一种算法来推断随机森林。和“随机
“森林”是他们的商标。
这个术语是贝尔实验室的Tin Kam Ho在1995年提出的随机决策森林(random decision forest)。
森林)。这种方法结合了 Breimans 的“Bootstrap aggregating”思想和 Ho 的“randomsubspace”
方法”来构建决策树的集合。
每棵树都是根据以下算法构建的:
1. 用M表示训练案例(样本)的数量,用N表示特征的数量。
2. 输入特征数n,用于确定决策树
上一个节点的决策结果;其中 n 应该远小于 N。
3. 从M个训练案例(样本)中进行替换采样,取k次形成一个训练集
(即引导抽样),并使用未选择的用例(样本)进行预测并评估其错误。
4.对于每个节点,随机选择n个特征,基于这些特征确定每个节点在每棵决策树上的决策。根据这n个特征,计算出最佳分割方法。
5. 每棵树都会完全生长而无需修剪,可以在构建正常的树状分类器后使用。
6.最后测试数据,根据每棵树,以多胜少的方式确定分类。
在构建随机森林时,需要做两方面的工作:数据的随机选择和要选择的特征的随机选择,以消除过拟合的问题。
首先,从原创数据集中取一个有替换的样本,构造一个子数据集。子数据集的数据量与原创数据集的数据量相同。不同子数据集中的元素可以重复,同一子数据集中的元素也可以重复。其次,使用子数据集构建子决策树,将这些数据放入每个子决策树中,每个子决策树输出一个结果。最后,如果有新数据,需要通过随机森林得到分类结果,可以通过对子决策树的判断结果进行投票,得到随机森林的输出结果。如下图所示,假设有
3个子决策树,2个子树的分类结果为A类,1个子树的分类结果为B类,则随机森林的分类结果为A类。
与数据集的随机选择类似,随机森林中子树的每次分裂过程都没有使用所有的候选特征,而是从所有候选特征中随机选择某些特征,然后随机选择。从特征中选择最佳特征。这样可以使随机森林中的决策树互不相同,提高系统的多样性,从而提高分类性能。
优势:
随机森林既可以用于回归任务,也可以用于分类任务,很容易看出模型输入特征的相对重要性。随机森林算法被认为是一种非常方便和易于使用的算法,因为它是默认的超参数,通常会产生很好的预测结果。超参数的数量并不多,它们所代表的含义直观易懂。
随机森林有足够多的树,这样分类器就不会产生过度拟合的模型。
缺点:
由于使用了大量的树,算法变得很慢,无法实现实时预测。一般来说,这些算法训练速度快,预测速度慢。预测越准确,需要的树越多,这将导致模型越慢。在大多数实际应用中,随机森林算法足够快,但肯定会遇到对实时性要求高的情况,所以只能首选其他方法。当然,随机森林是一种预测建模工具,而不是一种描述性工具。换句话说,如果您正在寻找数据中关系的描述,建议您更喜欢其他方法。
适用范围:
随机森林算法可用于许多不同的领域,例如银行、股票市场、医药和电子商务。在银行领域,它通常用于检测比普通人更频繁地使用银行服务的客户,并及时偿还债务。同时,它也会被用来检测想要欺骗银行的客户。在金融领域,可以用来预测未来的股票走势。在医疗保健领域,可用于识别药物成分的正确组合,分析患者的病史以识别疾病。另外,在电子商务领域,随机森林可以用来判断客户是否真的喜欢一个产品。
二、 随机森林算法在sklearn中的应用示例:
(1)基本步骤:
①选择数据:将你的数据分成三组:训练数据、验证数据和测试数据
②模型数据:使用训练数据构建使用相关特征的模型
③验证模型:使用您的验证数据连接到您的模型
④测试模型:使用您的测试数据来检查验证模型的性能
⑤使用模型:使用完全训练好的模型对新数据进行预测
⑥ 调优模型:使用更多的数据、不同的特征或调整后的参数来提高算法的性能
为方便起见,代码如下:
导入 csv
导入 numpy asnp
fromsklearn.ensemble 导入 RandomForestRegressor
从 sklearnimport 预处理
从 sklearn.metricsimport mean_squared_error,explain_variance_score
importmatplotlib.pyplot 作为 plt
#------------------------------------------------- --------------------------------
defload_dataset(文件名):
file_reader = csv.reader(open(filename,'rb'), delimiter=',')
X, y = [], []
对于 file_reader 中的行:
X.append(row[2:13])
y.append(row[-1])
# 提取特征名称
特征名称 = np.array(X[0])
返回
np.array(X[1:]).astype(np.float32),np.array(y[1:]).astype(np.float32),
特征名称
if__name__=='__main__':
X, y, feature_names =load_dataset("d:\\bike_day.csv")
X, y = shuffle(X, y, random_state=7)
num_training = int(0.9 * len(X))
X_train, y_train = X[:num_training],y[:num_training]
X_test, y_test = X[num_training:],y[num_training:]
rf_regressor =RandomForestRegressor(n_estimators=1000, max_depth=10,
min_samples_split=1)
rf_regressor.fit(X_train, y_train)
y_pred = rf_regressor.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
evs = 解释方差分数(y_test,y_pred)
来自 AdaBoostRegressor importplot_feature_importances
plot_feature_importances(rf_regressor.feature_importances_,'RandomForest
回归器',功能名称)
数据集格式如下:
即时,今天,季节,年,月,假期,工作日,工作日,天气,温度,温度,嗡嗡声,风速,休闲,注册,cnt
1,2011-01-01,1,0,1,0,6,0,2,0.344167,0.363625,0.805833,0.160446, 331,654,985
2,2011-01-02,1,0,1,0,0,0,2,0.363478,0.353739,0.696087,0.248539, 131,670,801
3,2011-01-03,1,0,1,0,1,1,1,0.196364,0.189405,0.437273,0.248309, 120,1229,1349
以下数据省略。
无规则采集器列表算法(信用卡解决方案警务实时布控系统服务于公安案件侦破(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-12-31 16:35
什么是实时数据处理?
• 数据生成->实时采集->实时缓存存储->实时计算->实时登陆->实时展示->实时分析。这个过程下去,处理数据的速度是秒级甚至毫秒级的。
• 电子商务网站双十一大屏,优采云站实时车辆信息显示,股票交易大厅信息显示。
实时数据处理意义
• 数据的价值是通过大数据处理获得的,但数据的价值是恒定的吗?明显不是。一些数据在业务发生后很快就具有很高的价值,随着时间的推移,这个价值会迅速下降,因此数据的处理速度变得尤为重要。实时处理的关键意义在于能够更快速地提供数据洞察。
实时处理解与其他解的关系
实时部署场景
商业场景
广州省公安厅警务实时布控系统服务于公安案件侦查。
• 实时数据采集:通过警务数据共享交换平台和边界平台实时获取出行/住宿/通讯/视频数据。
• 实时数据分析:基于规则模型对调度人员信息进行实时监控和分析。
• 智能实时预警:部署控制规则触发后实时预警,通知办案人员抓捕。
典型特征
• 多种数据格式:数据库/数据文件/视频图片。
• 海量数据:22.5TB/天/35MB/秒。
• 数据冲击的流入:数据流量在短时间内突然增长。
• 复杂作业调度:实时采集/小批量采集。
• 时间要求高:5 秒内完成计算。
• 资源占用高:容易发生资源抢占。
信用卡反欺诈场景
商业场景
Z银行信用卡反欺诈系统基于“渠道-反欺诈引擎-主机”的实现框架:
• 交易通道:客户刷卡后,从银联、VISA、万事达等卡组织向银行发送实时交易。
• 欺诈识别:
• 清理和完善卡组织的交易数据,提取风险特征。
• 将风险特征加载到神经网络和业务规则中,对交易做出欺诈判断。
• 拦截可疑交易并发送验证码进行验证。
• 主持人:
• 对正常交易进行账务处理,登记异常交易拦截原因,冻结假卡。
典型特征
• 大:处理的数据量大,并发度高。
• 快速:以毫秒为单位进行欺诈识别。
• 稳定:7*24 小时服务。
o 多租户支持:服务于不同的业务线。
• 丰富的模型支持。
• 规则
• 异常值模型(无监督学习:聚类)
• 关联模型(监督学习:LR、分类等)
• 神经网络模型
实时数据处理系统的需求
• 处理速度快:端到端的处理需要达到秒级。比如风控项目需要单次数据处理时间达到秒级,单节点TPS大于2000。
• 高吞吐量:需要在短时间内接收和处理大量数据记录,吞吐量需要达到几十兆/秒/节点。
• 高可靠性:当网络和软件出现故障时,要保证每条数据不丢失,不遗漏或重复处理数据。
• 横向扩展:当系统处理能力出现瓶颈时,可以通过节点的横向扩展来提升处理性能。
• 多数据源支持:支持网络流、文件、数据库表、IOT等格式的数据源。对于文件数据源,可以处理增量数据的加载。
• 数据权限和资源隔离:消息处理和流处理需要数据权限控制。不同的工作和用户可以访问和处理不同的消息和数据。多个流处理应用之间需要进行资源控制和隔离,以防止资源争用。
• 第三方工具对接:支持与第三方规则引擎、决策系统、实时推荐系统等对接。
华为实时流处理技术架构
• 数据源:主要包括业务数据库、Socket数据流和实时文件等。
• 实时数据采集:用于实时采集数据源产生的写入分布式消息系统的数据。采集的数据格式包括文件、数据库、网络数据流等。
• Flume:Hadoop自带的采集工具,支持多种格式的数据源,包括日志文件、网络数据流等。
• 第三方采集工具:第三方专用实时数据采集工具,包括GoldenGate(数据库实时采集)、自研采集程序(自定义采集工具)等。
• 消息中间件:消息中间件可以缓存实时数据,支持高吞吐量的消息订阅和发布。
• Kafka:分布式消息系统,支持消息的生产和发布,以及多种形式的消息缓存,满足高效可靠的消息生产和消费。
• 分布式流计算引擎:用于实时数据的快速分析。
• Structured Streaming:基于Spark 的流处理引擎,支持秒级流处理分析。
• Flink:新一代流处理引擎,支持毫秒级流处理分析。
• 流计算引擎,优先推荐Flink
• 数据缓存(可选):缓存流处理分析的结果,满足流处理应用的访问需求。
• Redis:提供高速键/值存储和查询能力,用于流处理结果数据的高速缓存。 查看全部
无规则采集器列表算法(信用卡解决方案警务实时布控系统服务于公安案件侦破(组图))
什么是实时数据处理?
• 数据生成->实时采集->实时缓存存储->实时计算->实时登陆->实时展示->实时分析。这个过程下去,处理数据的速度是秒级甚至毫秒级的。

• 电子商务网站双十一大屏,优采云站实时车辆信息显示,股票交易大厅信息显示。
实时数据处理意义
• 数据的价值是通过大数据处理获得的,但数据的价值是恒定的吗?明显不是。一些数据在业务发生后很快就具有很高的价值,随着时间的推移,这个价值会迅速下降,因此数据的处理速度变得尤为重要。实时处理的关键意义在于能够更快速地提供数据洞察。
实时处理解与其他解的关系

实时部署场景

商业场景
广州省公安厅警务实时布控系统服务于公安案件侦查。
• 实时数据采集:通过警务数据共享交换平台和边界平台实时获取出行/住宿/通讯/视频数据。
• 实时数据分析:基于规则模型对调度人员信息进行实时监控和分析。
• 智能实时预警:部署控制规则触发后实时预警,通知办案人员抓捕。
典型特征
• 多种数据格式:数据库/数据文件/视频图片。
• 海量数据:22.5TB/天/35MB/秒。
• 数据冲击的流入:数据流量在短时间内突然增长。
• 复杂作业调度:实时采集/小批量采集。
• 时间要求高:5 秒内完成计算。
• 资源占用高:容易发生资源抢占。
信用卡反欺诈场景

商业场景
Z银行信用卡反欺诈系统基于“渠道-反欺诈引擎-主机”的实现框架:
• 交易通道:客户刷卡后,从银联、VISA、万事达等卡组织向银行发送实时交易。
• 欺诈识别:
• 清理和完善卡组织的交易数据,提取风险特征。
• 将风险特征加载到神经网络和业务规则中,对交易做出欺诈判断。
• 拦截可疑交易并发送验证码进行验证。
• 主持人:
• 对正常交易进行账务处理,登记异常交易拦截原因,冻结假卡。
典型特征
• 大:处理的数据量大,并发度高。
• 快速:以毫秒为单位进行欺诈识别。
• 稳定:7*24 小时服务。
o 多租户支持:服务于不同的业务线。
• 丰富的模型支持。
• 规则
• 异常值模型(无监督学习:聚类)
• 关联模型(监督学习:LR、分类等)
• 神经网络模型
实时数据处理系统的需求
• 处理速度快:端到端的处理需要达到秒级。比如风控项目需要单次数据处理时间达到秒级,单节点TPS大于2000。
• 高吞吐量:需要在短时间内接收和处理大量数据记录,吞吐量需要达到几十兆/秒/节点。
• 高可靠性:当网络和软件出现故障时,要保证每条数据不丢失,不遗漏或重复处理数据。
• 横向扩展:当系统处理能力出现瓶颈时,可以通过节点的横向扩展来提升处理性能。
• 多数据源支持:支持网络流、文件、数据库表、IOT等格式的数据源。对于文件数据源,可以处理增量数据的加载。
• 数据权限和资源隔离:消息处理和流处理需要数据权限控制。不同的工作和用户可以访问和处理不同的消息和数据。多个流处理应用之间需要进行资源控制和隔离,以防止资源争用。
• 第三方工具对接:支持与第三方规则引擎、决策系统、实时推荐系统等对接。
华为实时流处理技术架构

• 数据源:主要包括业务数据库、Socket数据流和实时文件等。
• 实时数据采集:用于实时采集数据源产生的写入分布式消息系统的数据。采集的数据格式包括文件、数据库、网络数据流等。
• Flume:Hadoop自带的采集工具,支持多种格式的数据源,包括日志文件、网络数据流等。
• 第三方采集工具:第三方专用实时数据采集工具,包括GoldenGate(数据库实时采集)、自研采集程序(自定义采集工具)等。
• 消息中间件:消息中间件可以缓存实时数据,支持高吞吐量的消息订阅和发布。
• Kafka:分布式消息系统,支持消息的生产和发布,以及多种形式的消息缓存,满足高效可靠的消息生产和消费。
• 分布式流计算引擎:用于实时数据的快速分析。
• Structured Streaming:基于Spark 的流处理引擎,支持秒级流处理分析。
• Flink:新一代流处理引擎,支持毫秒级流处理分析。
• 流计算引擎,优先推荐Flink
• 数据缓存(可选):缓存流处理分析的结果,满足流处理应用的访问需求。
• Redis:提供高速键/值存储和查询能力,用于流处理结果数据的高速缓存。
无规则采集器列表算法(java中文开发者社区可以免费学习一点django框架、flask框架)
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-12-30 18:05
无规则采集器列表算法规则采集器ps:免费的建议使用cocos2d-x+gson
批量采集,采用python实现。网上有很多使用python来采集数据的教程,推荐一个我们团队里面开发的python爬虫项目,很棒的github地址:-python对于采集小的站点文章来说,足够用了。毕竟小文章就几百个页面数据,对于数据量比较大的网站,采用的抓取器就需要考虑重复爬取和频繁访问等问题,不是那么简单的,用python搞起来比较复杂。
如果没有采集基础的话推荐人肉采集。如果具备基础的话推荐使用谷歌浏览器自带的页面爬取工具,抓包不过是针对特定网站的,不对所有网站生效。
我不知道现在针对做it爬虫的采集工具是不是特别多,
1、强大的nodejs爬虫工具codecademyjavascriptdom分析网站codecademy.js官方cssinjavascript
2、java中文开发者社区可以免费学习一点django框架、flask框架
1、django实战教程
2、django实战
3、flaskdjango教程以上是在我推荐的网站中,你可以先了解一下哈,另外我还推荐:百度java、网易云课堂、韦神的csdn,以及我自己的b站。
当然要人肉采集,不给力。但是某些网站可以算是首页了,至少说明是个人来讲吧,有采集过程中校验,不会影响正常访问。既然采集正常了,即使破坏也不是把整个app都搞死,再说这并不能带来多少收益。 查看全部
无规则采集器列表算法(java中文开发者社区可以免费学习一点django框架、flask框架)
无规则采集器列表算法规则采集器ps:免费的建议使用cocos2d-x+gson
批量采集,采用python实现。网上有很多使用python来采集数据的教程,推荐一个我们团队里面开发的python爬虫项目,很棒的github地址:-python对于采集小的站点文章来说,足够用了。毕竟小文章就几百个页面数据,对于数据量比较大的网站,采用的抓取器就需要考虑重复爬取和频繁访问等问题,不是那么简单的,用python搞起来比较复杂。
如果没有采集基础的话推荐人肉采集。如果具备基础的话推荐使用谷歌浏览器自带的页面爬取工具,抓包不过是针对特定网站的,不对所有网站生效。
我不知道现在针对做it爬虫的采集工具是不是特别多,
1、强大的nodejs爬虫工具codecademyjavascriptdom分析网站codecademy.js官方cssinjavascript
2、java中文开发者社区可以免费学习一点django框架、flask框架
1、django实战教程
2、django实战
3、flaskdjango教程以上是在我推荐的网站中,你可以先了解一下哈,另外我还推荐:百度java、网易云课堂、韦神的csdn,以及我自己的b站。
当然要人肉采集,不给力。但是某些网站可以算是首页了,至少说明是个人来讲吧,有采集过程中校验,不会影响正常访问。既然采集正常了,即使破坏也不是把整个app都搞死,再说这并不能带来多少收益。
无规则采集器列表算法(KNN算法的三个监督学习算法(1)_光明网 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2022-02-06 19:06
)
(1) KNN算法介绍:
KNN算法,即K近邻算法,是一种监督学习算法。本质上就是在给定的训练样本中找出最接近某个测试样本A的K个实例,然后统计这k个实例中类别数最多的那个。类,它根据新数据的主要分类确定新数据的类别。
(2) KNN算法的三个关键点:
① K的选择:
K值是KNN算法中为数不多的参数之一,K值的选择也直接影响模型的性能。如果我们把k的值设置得比较小,说明我们期望的模型更复杂更准确,也更容易过拟合;相反,如果K值越大,模型机会越简单,一个非常极端的例子是如果K值设置为等于训练样本的个数,即KN,那么无论什么类型的测试样本,最终的测试结果将是测试样本数量最多的类别。
②距离测量:
距离度量描述了测试样本和训练样本的接近程度。这种邻近性是选择 K 个样本的基础。在KNN算法中,如果特征是连续的,距离函数一般使用曼哈顿距离或欧几里得距离。是离散的,一般采用汉明距离。"
③ 分类决策规则:
通过上面提到的K和距离这两个概念,可以选出离测试样本最近的K个训练样本。如何根据K个样本确定测试样本的类别是KNN的分类决策规则。常用的是多数投票规则,但该规则很大程度上取决于训练样本的数量。
(3) KNN算法的优缺点:
①优点:简单、易懂、易实现、无需估计参数、无需训练。适合对稀有事件进行分类(比如流失率很低,比如小于0.5%,构建流失预测模型)特别适合多分类问题(多模态、对象有多个类标签),例如,根据基因特征来判断其功能分类,kNN比SVM表现更好。
②缺点:算法懒,分类测试样本时计算量大,内存开销大,评分慢,可解释性差,不能像决策树一样给出规则。
(4) 关于 KNN 算法的常见问题:
①k的值是多少?
k过小,分类结果容易受到噪声点的影响;如果 k 太大,则邻居可能收录太多其他类别的点。k的取值通常通过交叉核对确定(以k-1为基础),一般情况下k-一般低于训练样本数的平方根。
②如何确定最合适的品类?
投票方式不考虑最近邻的距离,距离较近的最近邻可能决定最终的分类,因此加权投票方式更为合适。
③如何选择合适的测距?
高维对距离测量的影响是变量个数越大,欧几里得距离的区分能力越差。变量范围对距离的影响在于,范围较大的变量往往在距离计算中起主导作用,所以首先要对变量进行标准化。
④ 训练样本是否应该一视同仁?
在训练集中,一些样本可能更可靠。可以对不同的样本应用不同的权重,加强依赖样本的权重,减少不可靠样本的影响。
⑤ 性能问题?
KNN 是一种惰性算法。如果平时不努力学习,只需要在考试的时候磨一把枪(对测试样本进行分类)(暂时找k个最近的邻居)。懒惰的后果:模型的构建很简单,但是对测试样本进行分类的系统开销很大。,因为所有的训练样本都被扫描并计算了距离。
(5)KNN算法在图像处理中的应用
1) KNN 很少用于图像问题。这个观点来自Stanford CS231n,原因有二:①测试效率差,样本量越大,分类过程就会越慢。②整幅图像的水平距离非常不直观。
2) Halcon 中的 KNN 分类器例程:
① 分类图像类 knn.hdev
②设置参数类knn.hdev
③最近邻居.hdev
———————————————
版权声明:本文为CSDN博主《小娜美要努力》的原创文章,遵循CC4.0 BY-SA版权协议,请附上原出处链接和this陈述。
原文链接:
#转载请注明出处 勇哥工业自动化技术《少有人走的路》网站。如需本文源代码等资源,请向永哥索取。
查看全部
无规则采集器列表算法(KNN算法的三个监督学习算法(1)_光明网
)
(1) KNN算法介绍:
KNN算法,即K近邻算法,是一种监督学习算法。本质上就是在给定的训练样本中找出最接近某个测试样本A的K个实例,然后统计这k个实例中类别数最多的那个。类,它根据新数据的主要分类确定新数据的类别。
(2) KNN算法的三个关键点:
① K的选择:
K值是KNN算法中为数不多的参数之一,K值的选择也直接影响模型的性能。如果我们把k的值设置得比较小,说明我们期望的模型更复杂更准确,也更容易过拟合;相反,如果K值越大,模型机会越简单,一个非常极端的例子是如果K值设置为等于训练样本的个数,即KN,那么无论什么类型的测试样本,最终的测试结果将是测试样本数量最多的类别。
②距离测量:
距离度量描述了测试样本和训练样本的接近程度。这种邻近性是选择 K 个样本的基础。在KNN算法中,如果特征是连续的,距离函数一般使用曼哈顿距离或欧几里得距离。是离散的,一般采用汉明距离。"
③ 分类决策规则:
通过上面提到的K和距离这两个概念,可以选出离测试样本最近的K个训练样本。如何根据K个样本确定测试样本的类别是KNN的分类决策规则。常用的是多数投票规则,但该规则很大程度上取决于训练样本的数量。
(3) KNN算法的优缺点:
①优点:简单、易懂、易实现、无需估计参数、无需训练。适合对稀有事件进行分类(比如流失率很低,比如小于0.5%,构建流失预测模型)特别适合多分类问题(多模态、对象有多个类标签),例如,根据基因特征来判断其功能分类,kNN比SVM表现更好。
②缺点:算法懒,分类测试样本时计算量大,内存开销大,评分慢,可解释性差,不能像决策树一样给出规则。
(4) 关于 KNN 算法的常见问题:
①k的值是多少?
k过小,分类结果容易受到噪声点的影响;如果 k 太大,则邻居可能收录太多其他类别的点。k的取值通常通过交叉核对确定(以k-1为基础),一般情况下k-一般低于训练样本数的平方根。
②如何确定最合适的品类?
投票方式不考虑最近邻的距离,距离较近的最近邻可能决定最终的分类,因此加权投票方式更为合适。
③如何选择合适的测距?
高维对距离测量的影响是变量个数越大,欧几里得距离的区分能力越差。变量范围对距离的影响在于,范围较大的变量往往在距离计算中起主导作用,所以首先要对变量进行标准化。
④ 训练样本是否应该一视同仁?
在训练集中,一些样本可能更可靠。可以对不同的样本应用不同的权重,加强依赖样本的权重,减少不可靠样本的影响。
⑤ 性能问题?
KNN 是一种惰性算法。如果平时不努力学习,只需要在考试的时候磨一把枪(对测试样本进行分类)(暂时找k个最近的邻居)。懒惰的后果:模型的构建很简单,但是对测试样本进行分类的系统开销很大。,因为所有的训练样本都被扫描并计算了距离。
(5)KNN算法在图像处理中的应用
1) KNN 很少用于图像问题。这个观点来自Stanford CS231n,原因有二:①测试效率差,样本量越大,分类过程就会越慢。②整幅图像的水平距离非常不直观。
2) Halcon 中的 KNN 分类器例程:
① 分类图像类 knn.hdev
②设置参数类knn.hdev
③最近邻居.hdev
———————————————
版权声明:本文为CSDN博主《小娜美要努力》的原创文章,遵循CC4.0 BY-SA版权协议,请附上原出处链接和this陈述。
原文链接:
#转载请注明出处 勇哥工业自动化技术《少有人走的路》网站。如需本文源代码等资源,请向永哥索取。
无规则采集器列表算法(《优采云采集器》的使用及其所用技术的介绍x》)
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-02-06 01:05
《优采云采集器的使用及x所用技术介绍》由会员上传分享,可在线免费阅读。更多相关内容可以在教育资源——天天图书馆中找到。
1、优采云采集器的使用以及它使用的技术介绍,优采云采集器>能为你做什么?1、网站内容维护:您可以安排采集新闻、文章等任何您想采集的内容,并自动发布到您的网站 。2、互联网数据挖掘:你可以从指定的网站中抓取需要的数据,分析处理后保存到你的数据库中。3、网络信息监控:通过自动采集,可以监控论坛等社区类网站,让你第一时间发现你关心的内容。4、文件批量下载:可以批量下载PDF、RAR、图片等文件,同时采集 他们的相关信息。优采云采集器是目前信息采集和信息挖掘处理软件中最受欢迎、性价比最高、用户数量最多、市场占有率最大、使用最多的软件.
2、持续时间最长的智能采集程序。给定一个种子URL列表,根据规则爬取列表页,根据采集规则分析URL爬取网页内容,分析下载的网页,保存内容优采云@ >采集器数据发布原理:在我们下载数据采集后,数据默认保存在本地,我们可以使用以下方法对数据进行处理。1.什么都不做。因为数据本身是存储在数据库中的(access or db3),如果只是想查看,可以直接用相关软件查看。2.网页发布到网站 . 程序会模仿浏览器向你的网站发送数据,可以达到你手动发布的效果。3. 直接进入数据库。您只需要编写几条 SQL 语句,程序就会根据您的 SQL 语句将数据发送到数据库中。
3、4.另存为本地文件。程序会读取数据库中的数据,并以一定的格式保存为本地sql或文本文件。优采云采集器演示优采云采集器技术垂直搜索引擎信息跟踪和自动排序自动索引技术海量数据采集系统流程1)信息< @采集(网络蜘蛛)对指定的网站进行数据采集,将需要的信息存储在本地,并记录对应的采集信息。用于信息提取模块的数据提取。2)信息提取从采集的信息中提取有效数据进行结构化处理。剔除垃圾信息,获取文字内容,以及相关图片和种子文件等相关信息。3)信息处理 对提取的信息进行数据处理。信息的清洗、去重、分类、分析比较、数据挖掘,
4、最后提交处理后的数据进行分词和索引。4)信息检索提供信息查询接口。为信息的分词处理提供全文检索接口。相关技术1、垂直搜索引擎的网络蜘蛛技术-爬虫信息源的稳定性(不能让信息源爬取的成本影响用户体验网站感受蜘蛛的压力改善问题)2、 WEB结构化信息抽取 将网页中的非结构化数据按一定要求抽取成结构化数据模板 结构化信息抽取的两种实现 一种不依赖网页的网页库级结构化信息抽取方法 Web结构化信息抽取已广泛应用于百度和谷歌。3、信息处理技术清洗、去重、分类、分析比较、数据挖掘、语义分析
5、分析等4、分词系统 基于字符串匹配的分词方法 基于理解的分词方法 基于统计的分词方法 分词方法 基于统计,目前尚无定论分词算法更准确。对于任何成熟的分词系统,都不可能依靠某种算法来实现,需要整合不同的算法。常用中文分词开源项目:SCWS、ICTCLAS、HTTPCWS、包丁捷牛分词、CC-CEDICT5、 索引和索引技术对于垂直搜索来说非常关键,一个网页库级别的搜索引擎必须支持分布式索引、分层建库、分布式检索、灵活更新、灵活的权重调整,灵活的索引和灵活的升级扩展,高可靠性、稳定性和冗余性。还需要支持各种技术的扩展,例如
6、偏移量计算等 感谢优采云采集器的使用和技术的介绍“优采云采集器”可以为你做什么?1、网站内容维护:您可以安排采集新闻、文章等任何您想采集的内容,并自动发布到您的网站 。2、互联网数据挖掘:你可以从指定的网站中抓取需要的数据,分析处理后保存到你的数据库中。3、网络信息监控:通过自动采集,可以监控论坛等社区类网站,让你第一时间发现你关心的内容。4、文件批量下载:可以批量下载PDF、RAR、图片等文件,同时采集他们的相关信息。优采云采集器是目前信息采集和信息挖掘处理软件中最受欢迎、性价比最高、最人性化的软件。
7、市场份额最大、生命周期最长的最智能采集程序。给定一个种子URL列表,根据规则爬取列表页,根据采集规则分析URL爬取网页内容,分析下载的网页,保存内容优采云@ >采集器数据发布原理:在我们下载数据采集后,数据默认保存在本地,我们可以使用以下方法对数据进行处理。1.什么都不做。因为数据本身是存储在数据库中的(access or db3),如果只是想查看,可以直接用相关软件查看。2.网页发布到网站 . 程序会模仿浏览器向你的网站发送数据,可以达到你手动发布的效果。3. 直接进入数据库。你只需要写几条SQL语句,程序就会根据你的数据来压数据
优采云4@>SQL 语句被导入数据库。4.另存为本地文件。程序会读取数据库中的数据,并以一定的格式保存为本地sql或文本文件。优采云采集器演示优采云采集器技术垂直搜索引擎信息跟踪和自动排序自动索引技术海量数据采集系统流程1)信息< @采集(网络蜘蛛)对指定的网站进行数据采集,将需要的信息存储在本地,并记录对应的采集信息。用于信息提取模块的数据提取。2)信息提取从采集的信息中提取有效数据进行结构化处理。剔除垃圾信息,获取文字内容,以及相关图片和种子文件等相关信息。3)信息处理 对提取的信息进行数据处理。清理,重复数据删除,
优采云9@>分类、分析比较、数据挖掘,最后提交处理后的数据进行信息分割和索引。4)信息检索提供信息查询接口。为信息的分词处理提供全文检索接口。相关技术1、垂直搜索引擎的网络蜘蛛技术-爬虫信息源的稳定性(不能让信息源爬取的成本影响用户体验网站感受蜘蛛的压力改善问题)2、 WEB结构化信息抽取 将网页中的非结构化数据按一定要求抽取成结构化数据模板 结构化信息抽取的两种实现 一种不依赖于网页的网页库级结构化信息抽取方法 Web结构化信息抽取已广泛应用于百度和谷歌。3、信息处理技术清洗、去重、分类、
10、分析比较、数据挖掘、语义分析等4、分词系统基于字符串匹配的分词方法基于理解的分词算法基于统计的分词方法是哪种分词算法准确度更高,目前还没有定论。对于任何成熟的分词系统,都不可能依靠某种算法来实现,需要整合不同的算法。常用中文分词开源项目:SCWS、ICTCLAS、HTTPCWS、包丁捷牛分词、CC-CEDICT5、 索引和索引技术对于垂直搜索来说非常关键,一个网页库级别的搜索引擎必须支持分布式索引、分层建库、分布式检索、灵活更新、灵活的权重调整,灵活的索引和灵活的升级扩展,高可靠性、稳定性和冗余性。还
11、需要支持各种技术的扩展,比如偏移量计算等。感谢优采云采集器的使用和技术的介绍“优采云采集器" 可以为你做吗?1、网站内容维护:您可以安排采集新闻、文章等任何您想采集的内容,并自动发布到您的网站 。2、互联网数据挖掘:你可以从指定的网站中抓取需要的数据,分析处理后保存到你的数据库中。3、网络信息监控:通过自动采集,可以监控论坛等社区类网站,让你第一时间发现你关心的内容。4、文件批量下载:可以下载PDF,批量生成RAR、图片等文件,同时采集它们的相关信息。优采云采集器是目前最流行的信息采集和信息挖掘处理软件
12、性价比最高、用户最多、市场占有率最大、生命周期最长的智能采集方案。给定一个种子URL列表,根据规则爬取列表页,根据采集规则分析URL爬取网页内容,分析下载的网页,保存内容优采云@ >采集器数据发布原理:在我们下载数据采集后,数据默认保存在本地,我们可以使用以下方法对数据进行处理。1.什么都不做。因为数据本身是存储在数据库中的(access or db3),如果只是想查看,可以直接用相关软件查看。2.网页发布到网站 . 程序它会模仿浏览器发送数据到你的< @网站,可以达到你手动发布的效果。3. 直接进入数据库。你只需要写几个SQ
13、L语句,程序会根据你的SQL语句将数据导入数据库。4.另存为本地文件。程序会读取数据库中的数据,并以一定的格式保存为本地sql或文本文件。优采云采集器演示优采云采集器技术垂直搜索引擎信息跟踪和自动排序自动索引技术海量数据采集系统流程1)信息< @采集(网络蜘蛛)对指定的网站进行数据采集,将需要的信息存储在本地,并记录对应的采集信息。用于信息提取模块的数据提取。2)信息提取从采集的信息中提取有效数据进行结构化处理。清除垃圾信息,获取文本内容,以及相关图片、种子文件等相关信息。3)信息处理 提取信息的数据处理
14、管理。对信息进行清理、去重、分类、分析和比较以及数据挖掘。最后提交处理后的数据,对信息进行分段和索引。4)信息检索提供信息查询接口。为信息的分词处理提供全文检索接口。相关技术1、垂直搜索引擎的网络蜘蛛技术-爬虫信息源的稳定性(不能让信息源爬取的成本影响用户体验网站感受蜘蛛的压力改善问题)2、 WEB结构化信息抽取 将网页中的非结构化数据按一定要求抽取成结构化数据模板 结构化信息抽取的两种实现 一种不依赖于网页的网页库级结构化信息抽取方法 Web结构化信息抽取已广泛应用于百度和谷歌。3、内容丰富
15、处理技术 清洗、去重、分类、分析比较、数据挖掘、语义分析等4、分词系统 基于字符串匹配的分词方法 基于理解的分词算法 词法统计基于分词的分词 哪种分词算法更准确尚无定论。对于任何成熟的分词系统,都不可能依靠某种算法来实现,需要整合不同的算法。常用中文分词开源项目:SCWS、ICTCLAS、HTTPCWS、包丁捷牛分词、CC-CEDICT5、 索引技术对于垂直搜索非常重要,网页库级别的搜索引擎必须支持分布式索引,分层数据库构建,
16、,高可靠性、稳定性和冗余性。还需要扩展以支持各种技术,例如偏移计算。感谢优采云采集器的使用和技术的介绍“优采云采集器”能为你做什么?1、网站内容维护:您可以安排采集新闻、文章等任何您想采集的内容,并自动发布到您的网站 。2、互联网数据挖掘:你可以从指定的网站中抓取需要的数据,分析处理后保存到你的数据库中。3、网络信息监控:通过自动采集,可以监控论坛等社区类网站,让你第一时间发现你关心的内容。< @4、文件批量下载:可以批量下载PDF、RAR、图片等文件,同时采集它们的相关信息。优采云采集器是当前信息采集
17、是信息挖掘与处理软件中用户数最多、市场占有率最大、服务周期最长的最受欢迎、性价比最高、智能化的采集程序。给定一个种子URL列表,根据规则爬取列表页,根据采集规则分析URL爬取网页内容,分析下载的网页,保存内容优采云@ >采集器数据发布原理:在我们下载数据采集后,数据默认保存在本地,我们可以使用以下方法对数据进行处理。1.什么都不做。因为数据本身是存储在数据库中的(access或者db3),如果只是想查看,可以直接用相关软件查看。2.web发布到< @网站。程序会模仿浏览器向你的网站发送数据,可以达到你手动发布的效果。3.直接
1优采云4@>进入数据库。您只需要编写几条SQL语句,程序就会根据您的SQL语句将数据导入数据库。4.另存为本地文件。程序会读取数据库中的数据,并以一定的格式保存为本地sql或文本文件。优采云采集器演示优采云采集器技术垂直搜索引擎信息跟踪和自动排序自动索引技术海量数据采集系统流程1)信息< @采集(网络蜘蛛)对指定的网站进行数据采集,将需要的信息存储在本地,并记录对应的采集信息。用于信息提取模块的数据提取。2)信息提取从<的信息中提取有效数据 @采集 用于结构化处理。清除垃圾信息,获取文本内容,以及相关图片、种子文件等相关信息。3)信息处理
1优采云9@>提取信息的数据处理。对信息进行清理、去重、分类、分析和比较以及数据挖掘。最后,将处理后的数据提交进行分词和索引。4)信息检索提供信息查询接口。为信息的分词处理提供全文检索接口。相关技术1、垂直搜索引擎的网络蜘蛛技术-爬虫信息源的稳定性(不能让信息源爬取的成本影响用户体验网站感受蜘蛛的压力,改善问题) 2、
20、e 早已被广泛使用。3、信息处理技术清洗、去重、分类、分析比较、数据挖掘、语义分析等4、分词系统基于字符串匹配的分词方法基于理解的分词算法分词算法基于统计的分词方法对于哪种分词算法更准确尚无定论。对于任何成熟的分词系统,都不可能依靠某种算法来实现,需要整合不同的算法。常用中文分词开源项目:SCWS、ICTCLAS、HTTPCWS、包丁捷牛分词、CC-CEDICT5、索引和索引技术对于垂直搜索非常关键,
21、灵活的索引和灵活的升级扩展,高可靠、稳定、冗余。还需要扩展以支持各种技术,例如偏移计算。感谢优采云采集器的使用和技术的介绍“优采云采集器”能为你做什么?1、网站内容维护:您可以安排采集新闻、文章等任何您想采集的内容,并自动发布到您的网站 。2、互联网数据挖掘:你可以从指定的网站中抓取需要的数据,分析处理后保存到你的数据库中。3、网络信息监控:通过自动采集,可以监控论坛等社区类网站,让您在第一时间发现您关心的内容。4、文件批量下载:可以批量下载PDF、RAR、图片等文件,同时采集它们的相关信息
22、。优采云采集器是目前信息采集信息挖掘和信息挖掘领域最流行、性价比最高、使用最多、市场占有率最大、使用寿命最长的智能采集软件处理软件。> 程序。给定一个种子URL列表,根据规则爬取列表页,根据采集规则分析URL爬取网页内容,分析下载的网页,保存内容优采云@ >采集器数据发布原理:在我们下载数据采集后,数据默认保存在本地,我们可以使用以下方法对数据进行处理。1.什么都不做。因为数据本身是存储在数据库中的(access或者db3),如果只是想查的话,可以直接用相关软件查看。2.Web 发布到 网站。程序会模仿浏览器向你的网站发送数据,你可以实现
23、你的手贴效果。3.直接进入数据库。您只需要编写几条SQL语句,程序就会根据您的SQL语句将数据导入数据库。4.另存为本地文件。程序会读取数据库中的数据,并以一定的格式保存为本地sql或文本文件。优采云采集器演示优采云采集器技术垂直搜索引擎信息跟踪和自动排序自动索引技术海量数据采集系统流程1)信息< @采集(网络蜘蛛)对指定的网站进行数据采集,将需要的信息存储在本地,并记录对应的采集信息。用于信息提取模块的数据提取。2) 信息抽取 从采集的信息中抽取有效数据进行结构化处理。清除垃圾信息,获取文字内容,以及相关图片和种子文字
24、 件和其他相关信息。3)信息处理 对提取的信息进行数据处理。对信息进行清理、去重、分类、分析和比较以及数据挖掘。最后提交处理后的数据,对信息进行分段和索引。4)信息检索提供信息查询接口。为信息的分词处理提供全文检索接口。相关技术1、垂直搜索引擎的网络蜘蛛技术-爬虫信息源的稳定性(不能让信息源爬取的成本影响用户体验网站感受蜘蛛的压力改善问题)2、
25、信息提取已在百度和谷歌广泛使用。3、信息处理技术清洗、去重、分类、分析比较、数据挖掘、语义分析等4、分词系统基于字符串匹配的分词方法基于理解的分词算法分词算法基于统计的分词方法对于哪种分词算法更准确尚无定论。对于任何成熟的分词系统,都不可能依靠某种算法来实现,需要整合不同的算法。常用中文分词开源项目:SCWS、ICTCLAS、HTTPCWS、包丁解牛分词、CC-CEDICT5、
26、实时更新,灵活权重调整,灵活索引灵活升级扩展,高可靠稳定冗余。还需要扩展以支持各种技术,例如偏移计算。感谢优采云采集器的使用和技术的介绍“优采云采集器”能为你做什么?1、网站内容维护:您可以安排采集新闻、文章等任何您想采集的内容,并自动发布到您的网站 。2、互联网数据挖掘:你可以从指定的网站中抓取需要的数据,分析处理后保存到你的数据库中。3、网络信息监控:通过自动采集,可以监控论坛等社区类< @网站,让你第一时间发现你关心的内容。4、文件批量下载:可以批量下载PDF、RAR、图片等
2 个7、文件,以及关于它们的采集信息。优采云采集器是目前信息采集信息挖掘和信息挖掘领域最流行、性价比最高、使用最多、市场占有率最大、使用寿命最长的智能采集软件处理软件。> 程序。给定一个种子URL列表,根据规则爬取列表页,根据采集规则分析URL爬取网页内容,分析下载的网页,保存内容优采云@ >采集器数据发布原理:在我们下载数据采集后,数据默认保存在本地,我们可以使用以下方法对数据进行处理。1.什么都不做。因为数据本身是存储在数据库中的(access or db3), 如果只是想查看,可以直接用相关软件查看。2.Web 发布到 网站。程序会模仿浏览器
2优采云4@>你的网站发送数据可以达到你手动释放的效果。3.直接进入数据库。您只需要编写几条SQL语句,程序就会根据您的SQL语句将数据导入数据库。4.另存为本地文件。程序会读取数据库中的数据,并以一定的格式保存为本地sql或文本文件。优采云采集器演示优采云采集器技术垂直搜索引擎信息跟踪和自动排序自动索引技术海量数据采集系统流程1)信息< @采集(网络蜘蛛)对指定的网站进行数据采集,将需要的信息存储在本地,并记录对应的采集信息。用于信息提取模块的数据提取。2)信息提取从采集的信息中提取有效数据进行结构化处理。消除垃圾信息并获取文本
2优采云9@>内容,以及相关图片、种子文件等相关信息。3)信息处理 对提取的信息进行数据处理。对信息进行清理、去重、分类、分析和比较以及数据挖掘。最后提交处理后的数据,对信息进行分段和索引。4)信息检索提供信息查询接口。为信息的分词处理提供全文检索接口。相关技术1、垂直搜索引擎的网络蜘蛛技术-爬虫信息源的稳定性(不能让信息源爬取的成本影响用户体验网站感受蜘蛛的压力改善问题)2、
30、信息抽取方法Web结构化信息抽取早已广泛应用于百度和谷歌。3、信息处理技术清洗、去重、分类、分析比较、数据挖掘、语义分析等4、分词系统基于字符串匹配的分词方法基于理解的分词算法分词算法基于统计的分词方法对于哪种分词算法更准确尚无定论。对于任何成熟的分词系统,都不可能依靠某种算法来实现,需要整合不同的算法。常用中文分词开源项目:SCWS、ICTCLAS、HTTPCWS、宝顶捷牛分词、CC-CEDICT<
31、简介,分级建库,分布式检索,灵活更新,灵活权重调整,灵活索引,灵活升级扩容,高可靠,稳定,冗余。还需要扩展以支持各种技术,例如偏移计算。感谢优采云采集器的使用和技术的介绍“优采云采集器”能为你做什么?1、网站内容维护:您可以安排采集新闻、文章等任何您想采集的内容,并自动发布到您的网站 。2、互联网数据挖掘:你可以从指定的网站中抓取需要的数据,分析处理后保存到你的数据库中。3、网络信息监控:通过自动采集,可以监控论坛等社区类网站,让你第一时间发现你关心的内容。4、文件批量下载:可以批量下载
32、PDF、RAR、图片等文件,同时采集其相关信息。优采云采集器是目前信息采集信息挖掘和信息挖掘领域最流行、性价比最高、使用最多、市场占有率最大、使用寿命最长的智能采集软件处理软件。> 程序。给定一个种子URL列表,根据规则爬取列表页,根据采集规则分析URL爬取网页内容,分析下载的网页,保存内容优采云@ >采集器数据发布原理:在我们下载数据采集后,数据默认保存在本地,我们可以使用以下方法对数据进行处理。1.什么都不做。
3 3、 到 网站。程序会模拟浏览器向你的网站发送数据,可以达到你手动发布的效果。3.直接进入数据库。您只需要编写几条SQL语句,程序就会根据您的SQL语句将数据导入数据库。4.另存为本地文件。程序会读取数据库中的数据,并以一定的格式保存为本地sql或文本文件。优采云采集器演示优采云采集器技术垂直搜索引擎信息跟踪和自动排序自动索引技术海量数据采集系统流程1)信息< @采集(网络蜘蛛)对指定的网站执行数据采集,在本地存储需要的信息,并记录对应的采集信息。用于信息提取模块的数据提取。2)信息提取从采集的信息中提取有效数据进行结构化处理
34、管理。清除垃圾信息,获取文本内容,以及相关图片、种子文件等相关信息。3)信息处理 对提取的信息进行数据处理。对信息进行清理、去重、分类、分析和比较以及数据挖掘。最后提交处理后的数据,对信息进行分段和索引。4)信息检索提供信息查询接口。为信息的分词处理提供全文检索接口。相关技术1、垂直搜索引擎的网络蜘蛛技术-爬虫信息源的稳定性(不能让信息源爬取的成本影响用户体验网站
35、网页不依赖Web结构化信息抽取的网页库级结构化信息抽取方法早已在百度和谷歌广泛使用。3、信息处理技术清洗、去重、分类、分析比较、数据挖掘、语义分析等4、分词系统基于字符串匹配的分词方法基于理解的分词算法分词算法基于统计的分词方法对于哪种分词算法更准确尚无定论。对于任何成熟的分词系统,都不可能依靠某种算法来实现,需要整合不同的算法。常用中文分词开源项目:SCWS、ICTCLAS、
36、搜索引擎必须支持分布式索引、分级建库、分布式检索、灵活更新、灵活权重调整、灵活索引和灵活升级扩展、高可靠性、稳定性和冗余性。还需要扩展以支持各种技术,例如偏移计算。感谢优采云采集器的使用和技术的介绍“优采云采集器”能为你做什么?1、网站内容维护:您可以安排采集新闻、文章等任何您想采集的内容,并自动发布到您的网站 。2、互联网数据挖掘:你可以从指定的网站中抓取需要的数据,分析处理后保存到你的数据库中。3、 查看全部
无规则采集器列表算法(《优采云采集器》的使用及其所用技术的介绍x》)
《优采云采集器的使用及x所用技术介绍》由会员上传分享,可在线免费阅读。更多相关内容可以在教育资源——天天图书馆中找到。
1、优采云采集器的使用以及它使用的技术介绍,优采云采集器>能为你做什么?1、网站内容维护:您可以安排采集新闻、文章等任何您想采集的内容,并自动发布到您的网站 。2、互联网数据挖掘:你可以从指定的网站中抓取需要的数据,分析处理后保存到你的数据库中。3、网络信息监控:通过自动采集,可以监控论坛等社区类网站,让你第一时间发现你关心的内容。4、文件批量下载:可以批量下载PDF、RAR、图片等文件,同时采集 他们的相关信息。优采云采集器是目前信息采集和信息挖掘处理软件中最受欢迎、性价比最高、用户数量最多、市场占有率最大、使用最多的软件.
2、持续时间最长的智能采集程序。给定一个种子URL列表,根据规则爬取列表页,根据采集规则分析URL爬取网页内容,分析下载的网页,保存内容优采云@ >采集器数据发布原理:在我们下载数据采集后,数据默认保存在本地,我们可以使用以下方法对数据进行处理。1.什么都不做。因为数据本身是存储在数据库中的(access or db3),如果只是想查看,可以直接用相关软件查看。2.网页发布到网站 . 程序会模仿浏览器向你的网站发送数据,可以达到你手动发布的效果。3. 直接进入数据库。您只需要编写几条 SQL 语句,程序就会根据您的 SQL 语句将数据发送到数据库中。
3、4.另存为本地文件。程序会读取数据库中的数据,并以一定的格式保存为本地sql或文本文件。优采云采集器演示优采云采集器技术垂直搜索引擎信息跟踪和自动排序自动索引技术海量数据采集系统流程1)信息< @采集(网络蜘蛛)对指定的网站进行数据采集,将需要的信息存储在本地,并记录对应的采集信息。用于信息提取模块的数据提取。2)信息提取从采集的信息中提取有效数据进行结构化处理。剔除垃圾信息,获取文字内容,以及相关图片和种子文件等相关信息。3)信息处理 对提取的信息进行数据处理。信息的清洗、去重、分类、分析比较、数据挖掘,
4、最后提交处理后的数据进行分词和索引。4)信息检索提供信息查询接口。为信息的分词处理提供全文检索接口。相关技术1、垂直搜索引擎的网络蜘蛛技术-爬虫信息源的稳定性(不能让信息源爬取的成本影响用户体验网站感受蜘蛛的压力改善问题)2、 WEB结构化信息抽取 将网页中的非结构化数据按一定要求抽取成结构化数据模板 结构化信息抽取的两种实现 一种不依赖网页的网页库级结构化信息抽取方法 Web结构化信息抽取已广泛应用于百度和谷歌。3、信息处理技术清洗、去重、分类、分析比较、数据挖掘、语义分析
5、分析等4、分词系统 基于字符串匹配的分词方法 基于理解的分词方法 基于统计的分词方法 分词方法 基于统计,目前尚无定论分词算法更准确。对于任何成熟的分词系统,都不可能依靠某种算法来实现,需要整合不同的算法。常用中文分词开源项目:SCWS、ICTCLAS、HTTPCWS、包丁捷牛分词、CC-CEDICT5、 索引和索引技术对于垂直搜索来说非常关键,一个网页库级别的搜索引擎必须支持分布式索引、分层建库、分布式检索、灵活更新、灵活的权重调整,灵活的索引和灵活的升级扩展,高可靠性、稳定性和冗余性。还需要支持各种技术的扩展,例如
6、偏移量计算等 感谢优采云采集器的使用和技术的介绍“优采云采集器”可以为你做什么?1、网站内容维护:您可以安排采集新闻、文章等任何您想采集的内容,并自动发布到您的网站 。2、互联网数据挖掘:你可以从指定的网站中抓取需要的数据,分析处理后保存到你的数据库中。3、网络信息监控:通过自动采集,可以监控论坛等社区类网站,让你第一时间发现你关心的内容。4、文件批量下载:可以批量下载PDF、RAR、图片等文件,同时采集他们的相关信息。优采云采集器是目前信息采集和信息挖掘处理软件中最受欢迎、性价比最高、最人性化的软件。
7、市场份额最大、生命周期最长的最智能采集程序。给定一个种子URL列表,根据规则爬取列表页,根据采集规则分析URL爬取网页内容,分析下载的网页,保存内容优采云@ >采集器数据发布原理:在我们下载数据采集后,数据默认保存在本地,我们可以使用以下方法对数据进行处理。1.什么都不做。因为数据本身是存储在数据库中的(access or db3),如果只是想查看,可以直接用相关软件查看。2.网页发布到网站 . 程序会模仿浏览器向你的网站发送数据,可以达到你手动发布的效果。3. 直接进入数据库。你只需要写几条SQL语句,程序就会根据你的数据来压数据
优采云4@>SQL 语句被导入数据库。4.另存为本地文件。程序会读取数据库中的数据,并以一定的格式保存为本地sql或文本文件。优采云采集器演示优采云采集器技术垂直搜索引擎信息跟踪和自动排序自动索引技术海量数据采集系统流程1)信息< @采集(网络蜘蛛)对指定的网站进行数据采集,将需要的信息存储在本地,并记录对应的采集信息。用于信息提取模块的数据提取。2)信息提取从采集的信息中提取有效数据进行结构化处理。剔除垃圾信息,获取文字内容,以及相关图片和种子文件等相关信息。3)信息处理 对提取的信息进行数据处理。清理,重复数据删除,
优采云9@>分类、分析比较、数据挖掘,最后提交处理后的数据进行信息分割和索引。4)信息检索提供信息查询接口。为信息的分词处理提供全文检索接口。相关技术1、垂直搜索引擎的网络蜘蛛技术-爬虫信息源的稳定性(不能让信息源爬取的成本影响用户体验网站感受蜘蛛的压力改善问题)2、 WEB结构化信息抽取 将网页中的非结构化数据按一定要求抽取成结构化数据模板 结构化信息抽取的两种实现 一种不依赖于网页的网页库级结构化信息抽取方法 Web结构化信息抽取已广泛应用于百度和谷歌。3、信息处理技术清洗、去重、分类、
10、分析比较、数据挖掘、语义分析等4、分词系统基于字符串匹配的分词方法基于理解的分词算法基于统计的分词方法是哪种分词算法准确度更高,目前还没有定论。对于任何成熟的分词系统,都不可能依靠某种算法来实现,需要整合不同的算法。常用中文分词开源项目:SCWS、ICTCLAS、HTTPCWS、包丁捷牛分词、CC-CEDICT5、 索引和索引技术对于垂直搜索来说非常关键,一个网页库级别的搜索引擎必须支持分布式索引、分层建库、分布式检索、灵活更新、灵活的权重调整,灵活的索引和灵活的升级扩展,高可靠性、稳定性和冗余性。还
11、需要支持各种技术的扩展,比如偏移量计算等。感谢优采云采集器的使用和技术的介绍“优采云采集器" 可以为你做吗?1、网站内容维护:您可以安排采集新闻、文章等任何您想采集的内容,并自动发布到您的网站 。2、互联网数据挖掘:你可以从指定的网站中抓取需要的数据,分析处理后保存到你的数据库中。3、网络信息监控:通过自动采集,可以监控论坛等社区类网站,让你第一时间发现你关心的内容。4、文件批量下载:可以下载PDF,批量生成RAR、图片等文件,同时采集它们的相关信息。优采云采集器是目前最流行的信息采集和信息挖掘处理软件
12、性价比最高、用户最多、市场占有率最大、生命周期最长的智能采集方案。给定一个种子URL列表,根据规则爬取列表页,根据采集规则分析URL爬取网页内容,分析下载的网页,保存内容优采云@ >采集器数据发布原理:在我们下载数据采集后,数据默认保存在本地,我们可以使用以下方法对数据进行处理。1.什么都不做。因为数据本身是存储在数据库中的(access or db3),如果只是想查看,可以直接用相关软件查看。2.网页发布到网站 . 程序它会模仿浏览器发送数据到你的< @网站,可以达到你手动发布的效果。3. 直接进入数据库。你只需要写几个SQ
13、L语句,程序会根据你的SQL语句将数据导入数据库。4.另存为本地文件。程序会读取数据库中的数据,并以一定的格式保存为本地sql或文本文件。优采云采集器演示优采云采集器技术垂直搜索引擎信息跟踪和自动排序自动索引技术海量数据采集系统流程1)信息< @采集(网络蜘蛛)对指定的网站进行数据采集,将需要的信息存储在本地,并记录对应的采集信息。用于信息提取模块的数据提取。2)信息提取从采集的信息中提取有效数据进行结构化处理。清除垃圾信息,获取文本内容,以及相关图片、种子文件等相关信息。3)信息处理 提取信息的数据处理
14、管理。对信息进行清理、去重、分类、分析和比较以及数据挖掘。最后提交处理后的数据,对信息进行分段和索引。4)信息检索提供信息查询接口。为信息的分词处理提供全文检索接口。相关技术1、垂直搜索引擎的网络蜘蛛技术-爬虫信息源的稳定性(不能让信息源爬取的成本影响用户体验网站感受蜘蛛的压力改善问题)2、 WEB结构化信息抽取 将网页中的非结构化数据按一定要求抽取成结构化数据模板 结构化信息抽取的两种实现 一种不依赖于网页的网页库级结构化信息抽取方法 Web结构化信息抽取已广泛应用于百度和谷歌。3、内容丰富
15、处理技术 清洗、去重、分类、分析比较、数据挖掘、语义分析等4、分词系统 基于字符串匹配的分词方法 基于理解的分词算法 词法统计基于分词的分词 哪种分词算法更准确尚无定论。对于任何成熟的分词系统,都不可能依靠某种算法来实现,需要整合不同的算法。常用中文分词开源项目:SCWS、ICTCLAS、HTTPCWS、包丁捷牛分词、CC-CEDICT5、 索引技术对于垂直搜索非常重要,网页库级别的搜索引擎必须支持分布式索引,分层数据库构建,
16、,高可靠性、稳定性和冗余性。还需要扩展以支持各种技术,例如偏移计算。感谢优采云采集器的使用和技术的介绍“优采云采集器”能为你做什么?1、网站内容维护:您可以安排采集新闻、文章等任何您想采集的内容,并自动发布到您的网站 。2、互联网数据挖掘:你可以从指定的网站中抓取需要的数据,分析处理后保存到你的数据库中。3、网络信息监控:通过自动采集,可以监控论坛等社区类网站,让你第一时间发现你关心的内容。< @4、文件批量下载:可以批量下载PDF、RAR、图片等文件,同时采集它们的相关信息。优采云采集器是当前信息采集
17、是信息挖掘与处理软件中用户数最多、市场占有率最大、服务周期最长的最受欢迎、性价比最高、智能化的采集程序。给定一个种子URL列表,根据规则爬取列表页,根据采集规则分析URL爬取网页内容,分析下载的网页,保存内容优采云@ >采集器数据发布原理:在我们下载数据采集后,数据默认保存在本地,我们可以使用以下方法对数据进行处理。1.什么都不做。因为数据本身是存储在数据库中的(access或者db3),如果只是想查看,可以直接用相关软件查看。2.web发布到< @网站。程序会模仿浏览器向你的网站发送数据,可以达到你手动发布的效果。3.直接
1优采云4@>进入数据库。您只需要编写几条SQL语句,程序就会根据您的SQL语句将数据导入数据库。4.另存为本地文件。程序会读取数据库中的数据,并以一定的格式保存为本地sql或文本文件。优采云采集器演示优采云采集器技术垂直搜索引擎信息跟踪和自动排序自动索引技术海量数据采集系统流程1)信息< @采集(网络蜘蛛)对指定的网站进行数据采集,将需要的信息存储在本地,并记录对应的采集信息。用于信息提取模块的数据提取。2)信息提取从<的信息中提取有效数据 @采集 用于结构化处理。清除垃圾信息,获取文本内容,以及相关图片、种子文件等相关信息。3)信息处理
1优采云9@>提取信息的数据处理。对信息进行清理、去重、分类、分析和比较以及数据挖掘。最后,将处理后的数据提交进行分词和索引。4)信息检索提供信息查询接口。为信息的分词处理提供全文检索接口。相关技术1、垂直搜索引擎的网络蜘蛛技术-爬虫信息源的稳定性(不能让信息源爬取的成本影响用户体验网站感受蜘蛛的压力,改善问题) 2、
20、e 早已被广泛使用。3、信息处理技术清洗、去重、分类、分析比较、数据挖掘、语义分析等4、分词系统基于字符串匹配的分词方法基于理解的分词算法分词算法基于统计的分词方法对于哪种分词算法更准确尚无定论。对于任何成熟的分词系统,都不可能依靠某种算法来实现,需要整合不同的算法。常用中文分词开源项目:SCWS、ICTCLAS、HTTPCWS、包丁捷牛分词、CC-CEDICT5、索引和索引技术对于垂直搜索非常关键,
21、灵活的索引和灵活的升级扩展,高可靠、稳定、冗余。还需要扩展以支持各种技术,例如偏移计算。感谢优采云采集器的使用和技术的介绍“优采云采集器”能为你做什么?1、网站内容维护:您可以安排采集新闻、文章等任何您想采集的内容,并自动发布到您的网站 。2、互联网数据挖掘:你可以从指定的网站中抓取需要的数据,分析处理后保存到你的数据库中。3、网络信息监控:通过自动采集,可以监控论坛等社区类网站,让您在第一时间发现您关心的内容。4、文件批量下载:可以批量下载PDF、RAR、图片等文件,同时采集它们的相关信息
22、。优采云采集器是目前信息采集信息挖掘和信息挖掘领域最流行、性价比最高、使用最多、市场占有率最大、使用寿命最长的智能采集软件处理软件。> 程序。给定一个种子URL列表,根据规则爬取列表页,根据采集规则分析URL爬取网页内容,分析下载的网页,保存内容优采云@ >采集器数据发布原理:在我们下载数据采集后,数据默认保存在本地,我们可以使用以下方法对数据进行处理。1.什么都不做。因为数据本身是存储在数据库中的(access或者db3),如果只是想查的话,可以直接用相关软件查看。2.Web 发布到 网站。程序会模仿浏览器向你的网站发送数据,你可以实现
23、你的手贴效果。3.直接进入数据库。您只需要编写几条SQL语句,程序就会根据您的SQL语句将数据导入数据库。4.另存为本地文件。程序会读取数据库中的数据,并以一定的格式保存为本地sql或文本文件。优采云采集器演示优采云采集器技术垂直搜索引擎信息跟踪和自动排序自动索引技术海量数据采集系统流程1)信息< @采集(网络蜘蛛)对指定的网站进行数据采集,将需要的信息存储在本地,并记录对应的采集信息。用于信息提取模块的数据提取。2) 信息抽取 从采集的信息中抽取有效数据进行结构化处理。清除垃圾信息,获取文字内容,以及相关图片和种子文字
24、 件和其他相关信息。3)信息处理 对提取的信息进行数据处理。对信息进行清理、去重、分类、分析和比较以及数据挖掘。最后提交处理后的数据,对信息进行分段和索引。4)信息检索提供信息查询接口。为信息的分词处理提供全文检索接口。相关技术1、垂直搜索引擎的网络蜘蛛技术-爬虫信息源的稳定性(不能让信息源爬取的成本影响用户体验网站感受蜘蛛的压力改善问题)2、
25、信息提取已在百度和谷歌广泛使用。3、信息处理技术清洗、去重、分类、分析比较、数据挖掘、语义分析等4、分词系统基于字符串匹配的分词方法基于理解的分词算法分词算法基于统计的分词方法对于哪种分词算法更准确尚无定论。对于任何成熟的分词系统,都不可能依靠某种算法来实现,需要整合不同的算法。常用中文分词开源项目:SCWS、ICTCLAS、HTTPCWS、包丁解牛分词、CC-CEDICT5、
26、实时更新,灵活权重调整,灵活索引灵活升级扩展,高可靠稳定冗余。还需要扩展以支持各种技术,例如偏移计算。感谢优采云采集器的使用和技术的介绍“优采云采集器”能为你做什么?1、网站内容维护:您可以安排采集新闻、文章等任何您想采集的内容,并自动发布到您的网站 。2、互联网数据挖掘:你可以从指定的网站中抓取需要的数据,分析处理后保存到你的数据库中。3、网络信息监控:通过自动采集,可以监控论坛等社区类< @网站,让你第一时间发现你关心的内容。4、文件批量下载:可以批量下载PDF、RAR、图片等
2 个7、文件,以及关于它们的采集信息。优采云采集器是目前信息采集信息挖掘和信息挖掘领域最流行、性价比最高、使用最多、市场占有率最大、使用寿命最长的智能采集软件处理软件。> 程序。给定一个种子URL列表,根据规则爬取列表页,根据采集规则分析URL爬取网页内容,分析下载的网页,保存内容优采云@ >采集器数据发布原理:在我们下载数据采集后,数据默认保存在本地,我们可以使用以下方法对数据进行处理。1.什么都不做。因为数据本身是存储在数据库中的(access or db3), 如果只是想查看,可以直接用相关软件查看。2.Web 发布到 网站。程序会模仿浏览器
2优采云4@>你的网站发送数据可以达到你手动释放的效果。3.直接进入数据库。您只需要编写几条SQL语句,程序就会根据您的SQL语句将数据导入数据库。4.另存为本地文件。程序会读取数据库中的数据,并以一定的格式保存为本地sql或文本文件。优采云采集器演示优采云采集器技术垂直搜索引擎信息跟踪和自动排序自动索引技术海量数据采集系统流程1)信息< @采集(网络蜘蛛)对指定的网站进行数据采集,将需要的信息存储在本地,并记录对应的采集信息。用于信息提取模块的数据提取。2)信息提取从采集的信息中提取有效数据进行结构化处理。消除垃圾信息并获取文本
2优采云9@>内容,以及相关图片、种子文件等相关信息。3)信息处理 对提取的信息进行数据处理。对信息进行清理、去重、分类、分析和比较以及数据挖掘。最后提交处理后的数据,对信息进行分段和索引。4)信息检索提供信息查询接口。为信息的分词处理提供全文检索接口。相关技术1、垂直搜索引擎的网络蜘蛛技术-爬虫信息源的稳定性(不能让信息源爬取的成本影响用户体验网站感受蜘蛛的压力改善问题)2、
30、信息抽取方法Web结构化信息抽取早已广泛应用于百度和谷歌。3、信息处理技术清洗、去重、分类、分析比较、数据挖掘、语义分析等4、分词系统基于字符串匹配的分词方法基于理解的分词算法分词算法基于统计的分词方法对于哪种分词算法更准确尚无定论。对于任何成熟的分词系统,都不可能依靠某种算法来实现,需要整合不同的算法。常用中文分词开源项目:SCWS、ICTCLAS、HTTPCWS、宝顶捷牛分词、CC-CEDICT<
31、简介,分级建库,分布式检索,灵活更新,灵活权重调整,灵活索引,灵活升级扩容,高可靠,稳定,冗余。还需要扩展以支持各种技术,例如偏移计算。感谢优采云采集器的使用和技术的介绍“优采云采集器”能为你做什么?1、网站内容维护:您可以安排采集新闻、文章等任何您想采集的内容,并自动发布到您的网站 。2、互联网数据挖掘:你可以从指定的网站中抓取需要的数据,分析处理后保存到你的数据库中。3、网络信息监控:通过自动采集,可以监控论坛等社区类网站,让你第一时间发现你关心的内容。4、文件批量下载:可以批量下载
32、PDF、RAR、图片等文件,同时采集其相关信息。优采云采集器是目前信息采集信息挖掘和信息挖掘领域最流行、性价比最高、使用最多、市场占有率最大、使用寿命最长的智能采集软件处理软件。> 程序。给定一个种子URL列表,根据规则爬取列表页,根据采集规则分析URL爬取网页内容,分析下载的网页,保存内容优采云@ >采集器数据发布原理:在我们下载数据采集后,数据默认保存在本地,我们可以使用以下方法对数据进行处理。1.什么都不做。
3 3、 到 网站。程序会模拟浏览器向你的网站发送数据,可以达到你手动发布的效果。3.直接进入数据库。您只需要编写几条SQL语句,程序就会根据您的SQL语句将数据导入数据库。4.另存为本地文件。程序会读取数据库中的数据,并以一定的格式保存为本地sql或文本文件。优采云采集器演示优采云采集器技术垂直搜索引擎信息跟踪和自动排序自动索引技术海量数据采集系统流程1)信息< @采集(网络蜘蛛)对指定的网站执行数据采集,在本地存储需要的信息,并记录对应的采集信息。用于信息提取模块的数据提取。2)信息提取从采集的信息中提取有效数据进行结构化处理
34、管理。清除垃圾信息,获取文本内容,以及相关图片、种子文件等相关信息。3)信息处理 对提取的信息进行数据处理。对信息进行清理、去重、分类、分析和比较以及数据挖掘。最后提交处理后的数据,对信息进行分段和索引。4)信息检索提供信息查询接口。为信息的分词处理提供全文检索接口。相关技术1、垂直搜索引擎的网络蜘蛛技术-爬虫信息源的稳定性(不能让信息源爬取的成本影响用户体验网站
35、网页不依赖Web结构化信息抽取的网页库级结构化信息抽取方法早已在百度和谷歌广泛使用。3、信息处理技术清洗、去重、分类、分析比较、数据挖掘、语义分析等4、分词系统基于字符串匹配的分词方法基于理解的分词算法分词算法基于统计的分词方法对于哪种分词算法更准确尚无定论。对于任何成熟的分词系统,都不可能依靠某种算法来实现,需要整合不同的算法。常用中文分词开源项目:SCWS、ICTCLAS、
36、搜索引擎必须支持分布式索引、分级建库、分布式检索、灵活更新、灵活权重调整、灵活索引和灵活升级扩展、高可靠性、稳定性和冗余性。还需要扩展以支持各种技术,例如偏移计算。感谢优采云采集器的使用和技术的介绍“优采云采集器”能为你做什么?1、网站内容维护:您可以安排采集新闻、文章等任何您想采集的内容,并自动发布到您的网站 。2、互联网数据挖掘:你可以从指定的网站中抓取需要的数据,分析处理后保存到你的数据库中。3、
无规则采集器列表算法( python机器学习朴素贝叶斯及模型的选择和调优示例详解)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-02-02 10:22
python机器学习朴素贝叶斯及模型的选择和调优示例详解)
python机器学习朴素贝叶斯算法和模型的选择和调优详解
更新时间:2021 年 11 月 12 日 15:47:34 作者:Swayzzu
本文章主要介绍python机器学习的朴素贝叶斯和模型选择调优示例。有需要的朋友可以借鉴。我希望它会有所帮助。祝你进步更大。
内容
一、概率基础1.概率
概率是某事发生的可能性。
2.联合概率
收录多个条件,以及所有条件同时为真的概率,记为:P(A, B) = P(A) * P(B)
3.条件概率
在另一个事件 B 已经发生的情况下,事件 A 发生的概率,记为:P(A|B)
条件概率的性质:P(A1,A2|B) = P(A1|B)P(A2|B)
注:这个条件概率的成立是由于A1和A2相互独立
朴素贝叶斯的原理是对于每个样本,计算属于每个类别的概率,并分类到概率最高的类别中。
二、朴素贝叶斯1.朴素贝叶斯的计算方法
直接代入实际例子,各部分解释如下:
P(C) = P(Technology):科学文档类别的概率(科学文档数量/文档总数)
P(W|C) = P('Intelligence', 'Development'|Technology):在科技文献分类文章中,'Intelligence'和'Development'两个特征词出现的概率'。注:“智能”、“发展”属于预测文档中出现的词,技术文档中可能有更多的特征词,但给定的文档可能不收录所有这些词。因此,使用给定文档中收录的内容。
计算方法:
P(F1|C) = N(i)/N(在训练集中计算)
N(i) 是 F1 词在 C 类所有文档中出现的次数
N 是文档中类别 C 下所有单词的出现次数,并且
P('Intelligence'|Technology) = 所有技术文档中出现'intelligence'的次数/技术文档中所有单词出现的次数和
那么 P(F1,F2...|C) = P(F1|C) * P(F2|C)
P('智力', '发展'|技术) = P('智力'|技术) * P('发展'|技术)
这样就可以根据预测文档中的特征词计算出预测文档属于科技的概率。相同的方法用于计算其他类型的概率。哪个更高。
2.拉普拉斯平滑
3.朴素贝叶斯 API
sklearn.naive_bayes.MultinomialNB
三、朴素贝叶斯算法案例1.案例概述
本例中的数据来自 sklearn 中的 20newsgroups 数据。通过提取文章中的特征词,使用朴素贝叶斯方法,计算预测的文章,并由得到的概率确定。文章它属于什么类别。
大致步骤如下:首先,将文章分为两类,一类作为训练集,一类作为测试集。接下来,使用tfidf从训练集和测试集文章中提取特征,这样就生成了训练集和测试集的x。接下来可以直接调用朴素贝叶斯算法将训练集数据x_train, y_train 进去,训练模型。最后,使用训练好的模型进行测试。
2.数据采集
导入数据库:import sklearn.datasets as dt
导入数据:news = dt.fetch_20newsgroups(subset='all')
3.数据处理
分割使用与 knn 中相同的方法。另外,对于从sklearn导入的数据,可以直接调用.data获取数据集,调用.target获取目标值。
拆分数据:x_train, x_test, y_train, y_test = train_test_split(news.data, news.target, test_size=0.25)
特征值提取方法实例化:tf = TfIdfVectorizer()
提取训练集数据的特征值:x_train = tf.fit_transform(x_train)
测试集数据特征值提取:x_test = tf.transform(x_test)
对于测试集的特征提取,只需要调用transform即可,因为使用的是训练集的标准,而训练集的标准在上一步已经拟合好了,直接使用测试集即可。
4.算法流程
算法实例化:mlt = MultinomialNB(alpha=1.0)
算法训练:mlt.fit(x_train, y_train)
预测结果:y_predict = mlt.predict(x_test)
5.备注
朴素贝叶斯算法的准确率是由训练集决定的,不需要调整。训练集误差大,结果肯定不好。因为计算方法是固定的,没有单一的超参数可以调整。
朴素贝叶斯的缺点:假设文档中的某些词是独立于其他词的,彼此之间没有关系。并且训练集中的词统计会干扰结果。训练集越好,结果越好,训练集越差,结果越差。
四、分类模型的评估1.混淆矩阵
评价标准有多种,其中之一就是准确率,就是将预测的目标值与提供的目标值一一比较,计算出准确率。
我们还有其他更通用和有用的评估标准,即精度和召回率。精度和召回率是基于混淆矩阵计算的。
一般来说,我们只关注召回。
F1分类标准:
根据上式,可以使用精确率和召回率计算出F1-score,可以反映模型的鲁棒性。
2.评估模型 API
sklearn.metricx.classification_report
3.模型选择与调优 ①交叉验证
交叉验证是为了让被评估的模型更加准确可信,具体如下:
>> 将所有数据分成 n 等份
>>第一个作为验证集,其他作为训练集,得到一个准确率,模型1
>>第二个作为验证集,其他作为训练集,得到一个准确率,模型2
>>......
>> 直到每个副本都通过,得到n个模型的准确率
>>平均所有的准确度,我们得到一个更可信的最终结果。
如果将其分成四个相等的部分,则称为“4-fold cross-validation”。
②网格搜索
网格搜索主要结合交叉验证来调整参数。比如K近邻算法中有一个超参数k,需要手动指定,比较复杂。因此,需要为模型预设几个超参数组合。通过交叉验证对每组超参数进行评估,最后选择最优的参数组合。造型。(K近邻算法只有一个超参数k,不是组合,但是如果算法有2个或更多的超参数,就是组合,相当于穷举法)
网格搜索 API:sklearn.model_selection.GridSearchCV
五、以knn为例进行模型调优
假设已经对数据和特征进行了处理,得到了x_train、x_test、y_train、y_test,并且已经实例化了算法:knn = KNeighborsClassifier()
1.构造超参数
因为算法中使用的超参数的名字叫做‘n_neighbors’,所以超参数的选择范围是直接用名字指定的。如果有第二个超参数,只需在其后添加一个字典元素。
参数 = {'n_neighbors':[5,10,15,20,25]}
2.进行网格搜索
输入参数:算法(估计器),网格参数,指定几折交叉验证
gc = GridSearchCV(knn, param_grid=params, cv=5)
指定基本信息后,您可以将训练集数据拟合到其中。
gc.fit(x_train, y_train)
3.结果视图
在网格搜索算法中,有几种方法可以查看准确率、模型、交叉验证结果以及每次交叉验证后的结果。
gc.score(x_test, y_test) 返回准确度
gc.best_score_ 返回最佳准确度
gc.best_estimator_ 返回最佳估计器(将自动返回所选超参数)
以上就是python机器学习朴素贝叶斯和模型的选择和调优的详细内容。更多关于朴素贝叶斯和模型选择和调优的信息,请关注脚本之家文章中的其他相关话题! 查看全部
无规则采集器列表算法(
python机器学习朴素贝叶斯及模型的选择和调优示例详解)
python机器学习朴素贝叶斯算法和模型的选择和调优详解
更新时间:2021 年 11 月 12 日 15:47:34 作者:Swayzzu
本文章主要介绍python机器学习的朴素贝叶斯和模型选择调优示例。有需要的朋友可以借鉴。我希望它会有所帮助。祝你进步更大。
内容
一、概率基础1.概率
概率是某事发生的可能性。
2.联合概率
收录多个条件,以及所有条件同时为真的概率,记为:P(A, B) = P(A) * P(B)
3.条件概率
在另一个事件 B 已经发生的情况下,事件 A 发生的概率,记为:P(A|B)
条件概率的性质:P(A1,A2|B) = P(A1|B)P(A2|B)
注:这个条件概率的成立是由于A1和A2相互独立
朴素贝叶斯的原理是对于每个样本,计算属于每个类别的概率,并分类到概率最高的类别中。
二、朴素贝叶斯1.朴素贝叶斯的计算方法
直接代入实际例子,各部分解释如下:
P(C) = P(Technology):科学文档类别的概率(科学文档数量/文档总数)
P(W|C) = P('Intelligence', 'Development'|Technology):在科技文献分类文章中,'Intelligence'和'Development'两个特征词出现的概率'。注:“智能”、“发展”属于预测文档中出现的词,技术文档中可能有更多的特征词,但给定的文档可能不收录所有这些词。因此,使用给定文档中收录的内容。
计算方法:
P(F1|C) = N(i)/N(在训练集中计算)
N(i) 是 F1 词在 C 类所有文档中出现的次数
N 是文档中类别 C 下所有单词的出现次数,并且
P('Intelligence'|Technology) = 所有技术文档中出现'intelligence'的次数/技术文档中所有单词出现的次数和
那么 P(F1,F2...|C) = P(F1|C) * P(F2|C)
P('智力', '发展'|技术) = P('智力'|技术) * P('发展'|技术)
这样就可以根据预测文档中的特征词计算出预测文档属于科技的概率。相同的方法用于计算其他类型的概率。哪个更高。
2.拉普拉斯平滑
3.朴素贝叶斯 API
sklearn.naive_bayes.MultinomialNB
三、朴素贝叶斯算法案例1.案例概述
本例中的数据来自 sklearn 中的 20newsgroups 数据。通过提取文章中的特征词,使用朴素贝叶斯方法,计算预测的文章,并由得到的概率确定。文章它属于什么类别。
大致步骤如下:首先,将文章分为两类,一类作为训练集,一类作为测试集。接下来,使用tfidf从训练集和测试集文章中提取特征,这样就生成了训练集和测试集的x。接下来可以直接调用朴素贝叶斯算法将训练集数据x_train, y_train 进去,训练模型。最后,使用训练好的模型进行测试。
2.数据采集
导入数据库:import sklearn.datasets as dt
导入数据:news = dt.fetch_20newsgroups(subset='all')
3.数据处理
分割使用与 knn 中相同的方法。另外,对于从sklearn导入的数据,可以直接调用.data获取数据集,调用.target获取目标值。
拆分数据:x_train, x_test, y_train, y_test = train_test_split(news.data, news.target, test_size=0.25)
特征值提取方法实例化:tf = TfIdfVectorizer()
提取训练集数据的特征值:x_train = tf.fit_transform(x_train)
测试集数据特征值提取:x_test = tf.transform(x_test)
对于测试集的特征提取,只需要调用transform即可,因为使用的是训练集的标准,而训练集的标准在上一步已经拟合好了,直接使用测试集即可。
4.算法流程
算法实例化:mlt = MultinomialNB(alpha=1.0)
算法训练:mlt.fit(x_train, y_train)
预测结果:y_predict = mlt.predict(x_test)
5.备注
朴素贝叶斯算法的准确率是由训练集决定的,不需要调整。训练集误差大,结果肯定不好。因为计算方法是固定的,没有单一的超参数可以调整。
朴素贝叶斯的缺点:假设文档中的某些词是独立于其他词的,彼此之间没有关系。并且训练集中的词统计会干扰结果。训练集越好,结果越好,训练集越差,结果越差。
四、分类模型的评估1.混淆矩阵
评价标准有多种,其中之一就是准确率,就是将预测的目标值与提供的目标值一一比较,计算出准确率。
我们还有其他更通用和有用的评估标准,即精度和召回率。精度和召回率是基于混淆矩阵计算的。
一般来说,我们只关注召回。
F1分类标准:
根据上式,可以使用精确率和召回率计算出F1-score,可以反映模型的鲁棒性。
2.评估模型 API
sklearn.metricx.classification_report
3.模型选择与调优 ①交叉验证
交叉验证是为了让被评估的模型更加准确可信,具体如下:
>> 将所有数据分成 n 等份
>>第一个作为验证集,其他作为训练集,得到一个准确率,模型1
>>第二个作为验证集,其他作为训练集,得到一个准确率,模型2
>>......
>> 直到每个副本都通过,得到n个模型的准确率
>>平均所有的准确度,我们得到一个更可信的最终结果。
如果将其分成四个相等的部分,则称为“4-fold cross-validation”。
②网格搜索
网格搜索主要结合交叉验证来调整参数。比如K近邻算法中有一个超参数k,需要手动指定,比较复杂。因此,需要为模型预设几个超参数组合。通过交叉验证对每组超参数进行评估,最后选择最优的参数组合。造型。(K近邻算法只有一个超参数k,不是组合,但是如果算法有2个或更多的超参数,就是组合,相当于穷举法)
网格搜索 API:sklearn.model_selection.GridSearchCV
五、以knn为例进行模型调优
假设已经对数据和特征进行了处理,得到了x_train、x_test、y_train、y_test,并且已经实例化了算法:knn = KNeighborsClassifier()
1.构造超参数
因为算法中使用的超参数的名字叫做‘n_neighbors’,所以超参数的选择范围是直接用名字指定的。如果有第二个超参数,只需在其后添加一个字典元素。
参数 = {'n_neighbors':[5,10,15,20,25]}
2.进行网格搜索
输入参数:算法(估计器),网格参数,指定几折交叉验证
gc = GridSearchCV(knn, param_grid=params, cv=5)
指定基本信息后,您可以将训练集数据拟合到其中。
gc.fit(x_train, y_train)
3.结果视图
在网格搜索算法中,有几种方法可以查看准确率、模型、交叉验证结果以及每次交叉验证后的结果。
gc.score(x_test, y_test) 返回准确度
gc.best_score_ 返回最佳准确度
gc.best_estimator_ 返回最佳估计器(将自动返回所选超参数)
以上就是python机器学习朴素贝叶斯和模型的选择和调优的详细内容。更多关于朴素贝叶斯和模型选择和调优的信息,请关注脚本之家文章中的其他相关话题!
无规则采集器列表算法(无规则采集器列表算法揭秘丨清华系列作品也有一套)
采集交流 • 优采云 发表了文章 • 0 个评论 • 113 次浏览 • 2022-02-01 21:03
无规则采集器列表算法揭秘丨清华系列作品也有一套《无规则采集器》系列作品录制并推送到一些英文网站。为此团队聘请了一位资深算法工程师和电商产品开发人员来负责开发和推广;此外还有两位python开发工程师搭建人工智能算法并完成后续版本的研发升级。每月24日下午,无规则采集器人工智能算法发布会(day24)在清华举行。
据悉:此次发布会期间会举办算法及程序员日活动,力争推广行业标准,并开展hackathon自我提升活动。
python,perl,perl2,perl3都有。学会用了后生产力极高,能承受并发压力。
目前招聘、实习的岗位不需要写python熟练工,会用就可以。我们在做多机器学习实验,也是全部用python,只要是基础语法用的溜,用python做实验学起来都很轻松,不得不说未来的算法工程师基本上都要会python。所以掌握点python还是很有必要的。
会linux就行。
想要掌握算法工程师,python是前提条件。上面的回答都没明白我的意思。其实这个问题如果平心而论,不如从两个角度去思考。第一就是python本身的算法相关的性能如何?第二个就是数据科学的一些核心算法如何实现,而不是单纯的会写会用,看到一些开源的例子,就以为掌握了相关的算法。 查看全部
无规则采集器列表算法(无规则采集器列表算法揭秘丨清华系列作品也有一套)
无规则采集器列表算法揭秘丨清华系列作品也有一套《无规则采集器》系列作品录制并推送到一些英文网站。为此团队聘请了一位资深算法工程师和电商产品开发人员来负责开发和推广;此外还有两位python开发工程师搭建人工智能算法并完成后续版本的研发升级。每月24日下午,无规则采集器人工智能算法发布会(day24)在清华举行。
据悉:此次发布会期间会举办算法及程序员日活动,力争推广行业标准,并开展hackathon自我提升活动。
python,perl,perl2,perl3都有。学会用了后生产力极高,能承受并发压力。
目前招聘、实习的岗位不需要写python熟练工,会用就可以。我们在做多机器学习实验,也是全部用python,只要是基础语法用的溜,用python做实验学起来都很轻松,不得不说未来的算法工程师基本上都要会python。所以掌握点python还是很有必要的。
会linux就行。
想要掌握算法工程师,python是前提条件。上面的回答都没明白我的意思。其实这个问题如果平心而论,不如从两个角度去思考。第一就是python本身的算法相关的性能如何?第二个就是数据科学的一些核心算法如何实现,而不是单纯的会写会用,看到一些开源的例子,就以为掌握了相关的算法。
无规则采集器列表算法(无规则采集器列表算法和标准采集结构、工程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-02-01 11:03
无规则采集器列表算法和标准采集结构
0、工程实现(正常采集)
1、采集工具下载
2、采集方法(正常采集)
3、数据库选型
4、关系表生成算法
5、采集结果的存储(内存还是外存)
a、正常采集。
a
1、对采集结果做一些清洗,去除无用数据和采集过程中产生的生成和处理数据。
2、采集程序定义采集规则列表。将数据按规则随机输入采集表并进行采集。遇到特殊数据按数据规则定义的格式放置采集子表。定义access、sqlserver等数据库。表为对应采集要求的关系型数据库。表的修改交给采集工具完成。b、采集标准化设置采集次数、采集范围、采集频率。建议采集人员采集新产生数据和原始数据后进行复制,复制出来的数据按正常采集进行处理。
复制可进行多个采集模板进行复制,需要采集模板的直接采集建立模板。c、操作流程d、采集过程中可调整:通过修改采集脚本启动脚本,修改修改采集标准化位置、解释采集标准化格式、自定义采集时长、特殊格式处理等。
d、采集结果保存方式(可选)
二、采集介绍
2、1正常采集设置整个采集流程如下图所示:如图所示,前期接收采集要求,先将采集要求转化为采集规则,采集规则以模板关系的形式存储在采集数据库中,具体可参考采集工具的采集规则生成器,对采集规则进行填写调整。
2、2每一个采集模板均需要经过规则实验。实验包括三步:①先针对一个采集规则,按需要设置规则参数,如子网覆盖率、路由、规则强度、跨城市采集等;②将采集到的数据进行输出,存储到采集工具内存中,包括采集起始时间、采集区域、采集数量等;③将采集结果进行输出,封装为图片或文本文件。图片按需要标准化采集规则。文本文件按功能进行标准化采集规则。
2.3采集操作:①采集工具有多种采集器,通过添加规则实验得到采集规则后,可对其进行设置规则次数、采集频率、采集区域、采集次数、规则次长、规则精度等参数,这样可以大大降低采集率以及单条规则上传时间,实验可在采集器采集规则设置器进行。②采集结果转存时间(采集结果大小)是以采集模板采集文件中的大小作为转存时间,一般为3-10天。
2.4数据库表设计a、数据库层面:对表进行封装并优化,最后进行对其进行命名为表。b、采集子库设计:一般采用采集标准化的特定区域、采集规格、采集频率、规则强度、城市级的某个或多个子区域,最终对这些子区域单独分表c、采集数据的下沉和上传:对采集规则进行下沉(存储在采集工具内存中)后通过数据库下沉到数据库中,对于一次采集,下沉到某个区域后,在一次采集时再上传一个该区域, 查看全部
无规则采集器列表算法(无规则采集器列表算法和标准采集结构、工程)
无规则采集器列表算法和标准采集结构
0、工程实现(正常采集)
1、采集工具下载
2、采集方法(正常采集)
3、数据库选型
4、关系表生成算法
5、采集结果的存储(内存还是外存)
a、正常采集。
a
1、对采集结果做一些清洗,去除无用数据和采集过程中产生的生成和处理数据。
2、采集程序定义采集规则列表。将数据按规则随机输入采集表并进行采集。遇到特殊数据按数据规则定义的格式放置采集子表。定义access、sqlserver等数据库。表为对应采集要求的关系型数据库。表的修改交给采集工具完成。b、采集标准化设置采集次数、采集范围、采集频率。建议采集人员采集新产生数据和原始数据后进行复制,复制出来的数据按正常采集进行处理。
复制可进行多个采集模板进行复制,需要采集模板的直接采集建立模板。c、操作流程d、采集过程中可调整:通过修改采集脚本启动脚本,修改修改采集标准化位置、解释采集标准化格式、自定义采集时长、特殊格式处理等。
d、采集结果保存方式(可选)
二、采集介绍
2、1正常采集设置整个采集流程如下图所示:如图所示,前期接收采集要求,先将采集要求转化为采集规则,采集规则以模板关系的形式存储在采集数据库中,具体可参考采集工具的采集规则生成器,对采集规则进行填写调整。
2、2每一个采集模板均需要经过规则实验。实验包括三步:①先针对一个采集规则,按需要设置规则参数,如子网覆盖率、路由、规则强度、跨城市采集等;②将采集到的数据进行输出,存储到采集工具内存中,包括采集起始时间、采集区域、采集数量等;③将采集结果进行输出,封装为图片或文本文件。图片按需要标准化采集规则。文本文件按功能进行标准化采集规则。
2.3采集操作:①采集工具有多种采集器,通过添加规则实验得到采集规则后,可对其进行设置规则次数、采集频率、采集区域、采集次数、规则次长、规则精度等参数,这样可以大大降低采集率以及单条规则上传时间,实验可在采集器采集规则设置器进行。②采集结果转存时间(采集结果大小)是以采集模板采集文件中的大小作为转存时间,一般为3-10天。
2.4数据库表设计a、数据库层面:对表进行封装并优化,最后进行对其进行命名为表。b、采集子库设计:一般采用采集标准化的特定区域、采集规格、采集频率、规则强度、城市级的某个或多个子区域,最终对这些子区域单独分表c、采集数据的下沉和上传:对采集规则进行下沉(存储在采集工具内存中)后通过数据库下沉到数据库中,对于一次采集,下沉到某个区域后,在一次采集时再上传一个该区域,
无规则采集器列表算法(算法图解书籍介绍:本书示例丰富,图文并茂,大O表示法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2022-01-31 16:28
算法图解书籍简介:本书实例丰富,图文并茂,通俗易懂地讲解算法。它旨在帮助程序员在日常项目中更好地利用算法的力量。本书的前三章将帮助您奠定基础,带您了解二分搜索、大 O 表示法、两种基本数据结构、递归等。其余篇幅将主要介绍被广泛使用的算法,包括:面对特定问题时的解决技巧,例如何时使用贪心算法或动态规划;哈希表的应用;图算法;K-最近邻算法。
以下是我读这本书时想起的笔记,欢迎阅读和点赞!
二分查找
在有序数组中,需要使用二分查找检查多少个元素
完整的实现代码如下:(注解为Python语言实现)
def binary_search(list,item):
low=0
high=len(list)-1
while lowitem:
high=mid-1
else :
low=mid+1
return None #没有指定的元素
my_list=[1,3,5,7,9]
print(binary_search(my_list,3) #=>1 第二个位置的索引为1
print(binary_search(my_list,-1) #=>None 没有找到指定的元素
大 O 符号
该算法指示该算法的速度。大 O 表示法不是指以秒为单位的速度,而是指比较操作数,指示算法运行的速度。在大O算法中,运行时一般会省略常数,也省略了+、-、乘除。
二分法使用大 O 表示法来表示 O(log n) 的运行时间。
下面按从快到慢的顺序列出了 15 个 Big O 运行时:
O(log n),也叫对数时间,包括二分查找
O(n),也称为线性时间,包括简单的查找
O(nx logn), quicksort - 更快的算法
O(n^2), 选择排序 - 一种较慢的算法
O(n!),旅行商问题的解决方案 - 非常慢的算法
选择排序
数组:所有数组在内存中都是连续的(靠近在一起)。如果计算机保留的内存不够,必须转移到其他内存。一般来说,计算机会预留更多的内存供其他数组存储,但这也是一种内存浪费。
链表:链表的每个元素都存储下一个元素的地址,从而使一系列随机内存地址串在一起。所以将一个元素添加到链表中很容易,只需将其放入内存并将其地址存储在前一个元素中即可。
因此,链表读取速度慢,但插入速度快;数组插入速度慢。
下面是常见数组和链表操作的运行时
| |数组|链表|
| 阅读 | O(1) | O(n)|
| 插入 |O(n) |O(1) |
|删除|O(n) |O(1) |
数组一般用得比较多,因为它支持随机访问和顺序访问;而链表只能顺序访问,所以人们常说数组的读取速度非常快。
示例代码:
#查找最小值的函数
def findSmalllest(arr):
smallest=arr[0] #储存最小的值
smallest_index=0 #储存最小元素的索引
for i in range(1,len(arr)):
if arr[i]sub_max else sub_max
C语言标准库中的函数qsort实现了快速排序,快速排序也用到了D&C。
快速排序步骤(1)选择一个基值
(2) 将数组分成两个子数组:小于基值的元素和大于基值的元素。
(3)快速排序这两个数组
【按照步骤1】以此类推,对其他数组进行快速排序
下面是快速排序的代码:
def quicksort(array):
if len(array) < 2:
return array //基线条件:为空或只包含一个元素的数组是有序的
else:
pivot = array[0] //递归条件
less = [i for i in array[1:] if i pivot] //由所有大于基准值的元素组成的子数组
return quicksort(less) + [pivot] + quicksort(greater)
print(quicksort([10,5,2,3]))
在大 O 表示法 O(n) 中,n 实际上指的是:cxn(其中 C 是固定的时间量)。通常不考虑这个常数,因为这两种算法的大 O 运行时间是否不同并不重要。比如下面的例子:
简单查找:10(毫秒)xn
二进制搜索:1(秒)x logn
如上图,你可能认为简单搜索比二分查找快,但实际上二分查找要快得多。所以常数根本没有影响。
在这个例子中,层数是O(log n),从技术上讲,调用栈的高度是O(log n),每层需要的时间是O(n)。所以整个算法所需的时间是O(n)xO(log n)=O(nlog n)。
在最坏的情况下,有O(n)层,所以这个算法的运行时间是O(n)xO(n)=O(n^2)。 查看全部
无规则采集器列表算法(算法图解书籍介绍:本书示例丰富,图文并茂,大O表示法)
算法图解书籍简介:本书实例丰富,图文并茂,通俗易懂地讲解算法。它旨在帮助程序员在日常项目中更好地利用算法的力量。本书的前三章将帮助您奠定基础,带您了解二分搜索、大 O 表示法、两种基本数据结构、递归等。其余篇幅将主要介绍被广泛使用的算法,包括:面对特定问题时的解决技巧,例如何时使用贪心算法或动态规划;哈希表的应用;图算法;K-最近邻算法。
以下是我读这本书时想起的笔记,欢迎阅读和点赞!
二分查找
在有序数组中,需要使用二分查找检查多少个元素
完整的实现代码如下:(注解为Python语言实现)
def binary_search(list,item):
low=0
high=len(list)-1
while lowitem:
high=mid-1
else :
low=mid+1
return None #没有指定的元素
my_list=[1,3,5,7,9]
print(binary_search(my_list,3) #=>1 第二个位置的索引为1
print(binary_search(my_list,-1) #=>None 没有找到指定的元素
大 O 符号
该算法指示该算法的速度。大 O 表示法不是指以秒为单位的速度,而是指比较操作数,指示算法运行的速度。在大O算法中,运行时一般会省略常数,也省略了+、-、乘除。
二分法使用大 O 表示法来表示 O(log n) 的运行时间。
下面按从快到慢的顺序列出了 15 个 Big O 运行时:
O(log n),也叫对数时间,包括二分查找
O(n),也称为线性时间,包括简单的查找
O(nx logn), quicksort - 更快的算法
O(n^2), 选择排序 - 一种较慢的算法
O(n!),旅行商问题的解决方案 - 非常慢的算法
选择排序
数组:所有数组在内存中都是连续的(靠近在一起)。如果计算机保留的内存不够,必须转移到其他内存。一般来说,计算机会预留更多的内存供其他数组存储,但这也是一种内存浪费。
链表:链表的每个元素都存储下一个元素的地址,从而使一系列随机内存地址串在一起。所以将一个元素添加到链表中很容易,只需将其放入内存并将其地址存储在前一个元素中即可。
因此,链表读取速度慢,但插入速度快;数组插入速度慢。
下面是常见数组和链表操作的运行时
| |数组|链表|
| 阅读 | O(1) | O(n)|
| 插入 |O(n) |O(1) |
|删除|O(n) |O(1) |
数组一般用得比较多,因为它支持随机访问和顺序访问;而链表只能顺序访问,所以人们常说数组的读取速度非常快。
示例代码:
#查找最小值的函数
def findSmalllest(arr):
smallest=arr[0] #储存最小的值
smallest_index=0 #储存最小元素的索引
for i in range(1,len(arr)):
if arr[i]sub_max else sub_max
C语言标准库中的函数qsort实现了快速排序,快速排序也用到了D&C。
快速排序步骤(1)选择一个基值
(2) 将数组分成两个子数组:小于基值的元素和大于基值的元素。
(3)快速排序这两个数组
【按照步骤1】以此类推,对其他数组进行快速排序
下面是快速排序的代码:
def quicksort(array):
if len(array) < 2:
return array //基线条件:为空或只包含一个元素的数组是有序的
else:
pivot = array[0] //递归条件
less = [i for i in array[1:] if i pivot] //由所有大于基准值的元素组成的子数组
return quicksort(less) + [pivot] + quicksort(greater)
print(quicksort([10,5,2,3]))
在大 O 表示法 O(n) 中,n 实际上指的是:cxn(其中 C 是固定的时间量)。通常不考虑这个常数,因为这两种算法的大 O 运行时间是否不同并不重要。比如下面的例子:
简单查找:10(毫秒)xn
二进制搜索:1(秒)x logn
如上图,你可能认为简单搜索比二分查找快,但实际上二分查找要快得多。所以常数根本没有影响。
在这个例子中,层数是O(log n),从技术上讲,调用栈的高度是O(log n),每层需要的时间是O(n)。所以整个算法所需的时间是O(n)xO(log n)=O(nlog n)。
在最坏的情况下,有O(n)层,所以这个算法的运行时间是O(n)xO(n)=O(n^2)。
无规则采集器列表算法(优采云采集器教程一起随小编来看看吧来看)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2022-01-30 17:15
如何快速采集在线获取大量数据信息,哪个信息采集工具好用?优采云采集器使您的消息变得简单的工具采集。优采云采集器下载体验更高效简单的数据采集!优采云采集器怎么用?在这里,小编带来了优采云采集器教程和小编一起来看看吧!
优采云采集器(信息采集工具) 软件介绍
优采云Data采集系统基于完全自主研发的分布式云计算平台。它可以很容易地在很短的时间内从各种网站或网页中获取大量的标准化数据。数据,帮助任何需要从网页获取信息的客户实现数据自动化采集、编辑、规范化,摆脱对人工搜索和数据采集的依赖,从而降低获取信息的成本,提高效率。
优采云采集器有什么用(特点)
操作简单,图形化操作完全可视化,无需专业的IT人员,任何会用电脑上网的人都能轻松掌握。
云采集
采集任务自动分配到云端多台服务器同时执行,提高采集效率,在极短的时间内获取上千条信息。
拖放采集 过程
模拟人类操作思维模式,可以登录、输入数据、点击链接、按钮等,也可以针对不同的情况采取不同的采集流程。
图像和文本识别
内置可扩展OCR接口,支持解析图片中的文字,可以提取图片上的文字。
定时自动采集
采集任务自动运行,可以按指定周期自动采集,也支持一分钟实时采集。
2分钟快速启动
内置从入门到精通的视频教程,2分钟即可上手,此外还有文档、论坛、QQ群等。
免费使用
它是免费的,免费版没有功能限制,您可以立即试用,立即下载安装。
优采云采集器教程(安装过程)
1.未来软件园下载正式版压缩包优采云采集器,解压,双击.exe程序运行,进入安装向导,选择更改安装位置
2.安装稍等
3.安装完成
优采云采集器如何使用-如何使用规则
1)使用从规则市场下载的规则 一般情况下,从规则市场下载的规则是后缀为.otd的规则文件。4.*下载的规则文件会在以后的版本中自动导入。在以前的版本中,下载的规则文件需要手动导入。手动导入方法:双击优采云规则文件(.OTD)打开导入向导,或打开优采云采集器,快速开始->导入规则,然后按照向导提示导入规则。但有时您会下载带有 .zip 后缀的压缩文件。压缩文件解压后收录多个.otd规则文件,需要先解压,再导入。2)使用收到的规则使用其他即时通讯软件收到的电子邮件或规则,
变更日志
优采云采集器(信息采集工具) v7.1.4 升级提醒:
系统不支持6.x自动升级到7.x,使用6.x版本的用户请先卸载:开始->优采云->卸载再安装V 7.x。
体验改进:
新增UserAgent切换功能,有效规避网页保护采集(包括Firefox 45、54、55、Firefox Mobile 29、最新版谷歌浏览器)
新增“检测工作流程异常”功能,当工作流程发生错误时,会检测并自动修复
加入“关于我们”查看客户端版本并检查更新
现在可以为“自动数据库导出”选择保存的导出配置
删除单个任务并添加确认提示,避免误操作
优化编辑任务名称体验
导出数据时,导出数据范围默认遵循当前页面过滤条件,避免误操作
删除了“发布到 网站”功能
Bug修复:
修复“采集添加字段后,导致数据丢失”的问题
修复了“预览收录大量内容的字段时崩溃”
修复“任务名称过长,自动导出无法显示任务”的问题
修复IT橙子开启异常问题(需要手动切换UA到Firefox 54、Firefox 29) 查看全部
无规则采集器列表算法(优采云采集器教程一起随小编来看看吧来看)
如何快速采集在线获取大量数据信息,哪个信息采集工具好用?优采云采集器使您的消息变得简单的工具采集。优采云采集器下载体验更高效简单的数据采集!优采云采集器怎么用?在这里,小编带来了优采云采集器教程和小编一起来看看吧!
优采云采集器(信息采集工具) 软件介绍
优采云Data采集系统基于完全自主研发的分布式云计算平台。它可以很容易地在很短的时间内从各种网站或网页中获取大量的标准化数据。数据,帮助任何需要从网页获取信息的客户实现数据自动化采集、编辑、规范化,摆脱对人工搜索和数据采集的依赖,从而降低获取信息的成本,提高效率。
优采云采集器有什么用(特点)
操作简单,图形化操作完全可视化,无需专业的IT人员,任何会用电脑上网的人都能轻松掌握。
云采集
采集任务自动分配到云端多台服务器同时执行,提高采集效率,在极短的时间内获取上千条信息。
拖放采集 过程
模拟人类操作思维模式,可以登录、输入数据、点击链接、按钮等,也可以针对不同的情况采取不同的采集流程。
图像和文本识别
内置可扩展OCR接口,支持解析图片中的文字,可以提取图片上的文字。
定时自动采集
采集任务自动运行,可以按指定周期自动采集,也支持一分钟实时采集。
2分钟快速启动
内置从入门到精通的视频教程,2分钟即可上手,此外还有文档、论坛、QQ群等。
免费使用
它是免费的,免费版没有功能限制,您可以立即试用,立即下载安装。
优采云采集器教程(安装过程)
1.未来软件园下载正式版压缩包优采云采集器,解压,双击.exe程序运行,进入安装向导,选择更改安装位置
2.安装稍等
3.安装完成
优采云采集器如何使用-如何使用规则
1)使用从规则市场下载的规则 一般情况下,从规则市场下载的规则是后缀为.otd的规则文件。4.*下载的规则文件会在以后的版本中自动导入。在以前的版本中,下载的规则文件需要手动导入。手动导入方法:双击优采云规则文件(.OTD)打开导入向导,或打开优采云采集器,快速开始->导入规则,然后按照向导提示导入规则。但有时您会下载带有 .zip 后缀的压缩文件。压缩文件解压后收录多个.otd规则文件,需要先解压,再导入。2)使用收到的规则使用其他即时通讯软件收到的电子邮件或规则,
变更日志
优采云采集器(信息采集工具) v7.1.4 升级提醒:
系统不支持6.x自动升级到7.x,使用6.x版本的用户请先卸载:开始->优采云->卸载再安装V 7.x。
体验改进:
新增UserAgent切换功能,有效规避网页保护采集(包括Firefox 45、54、55、Firefox Mobile 29、最新版谷歌浏览器)
新增“检测工作流程异常”功能,当工作流程发生错误时,会检测并自动修复
加入“关于我们”查看客户端版本并检查更新
现在可以为“自动数据库导出”选择保存的导出配置
删除单个任务并添加确认提示,避免误操作
优化编辑任务名称体验
导出数据时,导出数据范围默认遵循当前页面过滤条件,避免误操作
删除了“发布到 网站”功能
Bug修复:
修复“采集添加字段后,导致数据丢失”的问题
修复了“预览收录大量内容的字段时崩溃”
修复“任务名称过长,自动导出无法显示任务”的问题
修复IT橙子开启异常问题(需要手动切换UA到Firefox 54、Firefox 29)
无规则采集器列表算法( FC采集插件致力于.4的主要功能包括哪几种?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2022-01-30 14:08
FC采集插件致力于.4的主要功能包括哪几种?)
FC(原DXC采集器)是Fool collector(Fool采集器)的缩写,FC采集插件致力于discuz上的内容解决方案,帮助站长更快更轻松地搭建网站内容.
通过FC采集插件,用户可以很方便的从网上获取采集数据,包括会员数据、文章数据。此外,还有虚拟在线、单帖采集等辅助功能,让冷清的新论坛瞬间形成内容丰富、会员活跃的热门论坛,对论坛初期运营有很大帮助. 这是一个discuz应用程序,必须由论坛的新手站长安装。
FC3.4的主要功能包括:
1、多种形式的url列表采集文章,包括rss地址、列表页、多级列表等。
2、多种方式编写规则,dom方式,字符截取,智能获取,更方便获取想要的内容
3、规则继承,自动检测匹配规则功能,你会逐渐体会到规则继承带来的便利
4、独有的网页文本提取算法,自动学习归纳规则,更方便泛采集。
5、支持图片定位和水印
6、灵活的发布机制,可以自定义发布者、发布时间、点击率等。
7、强大的内容编辑后台,可以轻松编辑采集收到的内容并发布到门户、论坛、博客
8、内容过滤功能,过滤采集内容上的广告,去除不必要的区域
9、批量采集,注册会员,批量采集,设置会员头像
10、无人值守定时量化采集和释放文章 查看全部
无规则采集器列表算法(
FC采集插件致力于.4的主要功能包括哪几种?)
FC(原DXC采集器)是Fool collector(Fool采集器)的缩写,FC采集插件致力于discuz上的内容解决方案,帮助站长更快更轻松地搭建网站内容.
通过FC采集插件,用户可以很方便的从网上获取采集数据,包括会员数据、文章数据。此外,还有虚拟在线、单帖采集等辅助功能,让冷清的新论坛瞬间形成内容丰富、会员活跃的热门论坛,对论坛初期运营有很大帮助. 这是一个discuz应用程序,必须由论坛的新手站长安装。
FC3.4的主要功能包括:
1、多种形式的url列表采集文章,包括rss地址、列表页、多级列表等。
2、多种方式编写规则,dom方式,字符截取,智能获取,更方便获取想要的内容
3、规则继承,自动检测匹配规则功能,你会逐渐体会到规则继承带来的便利
4、独有的网页文本提取算法,自动学习归纳规则,更方便泛采集。
5、支持图片定位和水印
6、灵活的发布机制,可以自定义发布者、发布时间、点击率等。
7、强大的内容编辑后台,可以轻松编辑采集收到的内容并发布到门户、论坛、博客
8、内容过滤功能,过滤采集内容上的广告,去除不必要的区域
9、批量采集,注册会员,批量采集,设置会员头像
10、无人值守定时量化采集和释放文章
无规则采集器列表算法(百度搜索学院飓风算法3.0即将上线,打击对象和打击内容)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-01-27 05:10
大家好,我是小白。一周前的8月8日,百度搜索学院正式宣布飓风算法3.0即将上线。作为飓风算法针对采集的后续补充,这次飓风算法3.0的具体目标和内容是什么?小白为大家简单介绍了一些自己的经历,希望对大家有所帮助。
百度作为成熟的中文搜索引擎,无论是索引收录还是搜索匹配,都有完整的操作规则。当有人利用一些算法漏洞谋取利益时,在不改变整套搜索计算规则的情况下,百度只能选择打补丁,也就是所谓的算法。下面简单梳理一下各大算法的上线时间线。,基本在12年后出现:
百度绿屋顶算法 - 2013 年 2 月 19 日
打击链接交易(我的超链接分析技术怎么会有漏洞,emmmmm,如果有漏洞,那就补个补丁)
百度石榴算法 - 2013 年 5 月 17 日
打击不良广告(dei大哥,你网站我看不懂文字不说,广告快瞎了我的眼睛,哪个是关闭键?)
百度绿顶算法2.0——2013年7月1日
打击带有不相关外部链接的网站(我的成人用品,兄弟换朋友链?XX阻止一个!)
百度冰桶算法1.0——2014年8月30日
实战手机网站强制app下载(腾讯新闻:更多完整内容请下载...)
百度冰桶算法2.0——2014年11月18日
严厉打击手机广告屏蔽和强制登录(请登录后观看以下内容)
百度冰桶算法3.0——2016年7月15日
严厉打击阻止用户访问页面、弹窗强制用户下载应用(好看吗?想看更多吗?请收费...哦不,请下载应用观看,然后收费...)
百度天网算法 - 2016 年 8 月 10 日
打击网站恶意JS夺取用户隐私
百度冰桶算法4.0——2016年9月19日
规范移动端网站的广告覆盖率,点击率高的页面(你网站只允许这么大的广告,如果你是认真的,你就……)
百度冰桶算法4.5—2016年10月26日
打击色情赌博广告(XX首家网上赌场下线)
百度优采云算法 - 2016 年 11 月 21 日
打击软文交易(你有没有夸他有什么好处?快告诉我)
百度烽火项目 - 2017 年 2 月 23 日
打击JS劫持访问(死循环N次后,为什么百度还是推荐这个垃圾网站?)
百度飓风算法 - 2017 年 7 月 4 日
点击采集镜像站(你们都给我写原创!)
百度清风算法——2017年9月14日
打击假标题(免费?!靠,扣费!PS:主要针对下载网站)
百度闪电算法 - 2017 年 10 月 19 日
减轻慢访问打开网站的权重(你的网站完全没有用户体验,想要变强可以用我们的mip)
百度迅雷算法 - 2017 年 11 月 20 日
点击点击刷排名(哪些是真正的点击,我有点糊涂了)
百度 Beacon 算法2.0 — 2018 年 5 月 17 日
打击JS劫持访问提取用户信息(死循环N次后,为什么这个一定程度还推荐这个垃圾邮件网站?“已拦截125个恶意骚扰电话”“XX第一次上线……”)
百度清风算法2.0——2018年7月19日
对于不准确和无效的下载资源(支付宝PJ版在哪里?)
百度细雨算法 - 2018 年 7 月中旬
实战标题关键词堆砌和假官网(你说官网就是官网?有我的认证吗?)
百度飓风算法2.0 — 2018 年 9 月 21 日
实战内容拼接和跨域采集(啊,这个网站太棒了,我什么都想要!嘿,那个网站呢?)
百度清风算法3.0——2018年10月16日
下载站标题下载问题全面回顾(如果没有充值,请退群)
百度冰桶算法5.0——2018年11月12日
冰桶算法的广告规范覆盖百度app(春节期间我要去春晚,只能在我的网站上做广告)
百度飓风算法3.0 — 2019 年 8 月 8 日
打击跨域采集和站群小程序/网站
梳理一下百度的算法,我们确实可以看出百度确实想提升自己产品的用户体验,但也可以看出百度在搜索业务上还存在不少漏洞,甚至处于失控的边缘.
百度每次推出新产品,对于站长来说都是一种煎熬,但也是一次机会。从mip到熊掌到现在的小程序,刚入行的站长会发现自己的网站页面确实会得到一定的优惠,而很多黑帽BC利用这些排名流量优惠轻松获得高排名和抢夺大量点击量。
这一次,终于传到了小程序上,百度小程序是百度在日益强大的微信面前的又一无力抵抗。为了增加站长的参与度,小程序前期被赋予了较高的排名权重,小程序因此成为获取流量的有力工具。为了获取流量,跨领域展示各种内容。使用同一套小程序模板批量制作小程序,并使用站群的操作方式操作小程序,这是百度此次攻击的主要目标。
另外,根据一些实际的例子,网站自身的属性或者关键词与每日更新页面不一致也有可能造成算法惩罚,身边的小伙伴会被扒到底。
所以小白认为,这次的飓风算法3.0其实是针对小程序类的跨域采集和更新,以及小程序站群的操作方法,这对网站很重要@>的影响很小,收到内部信件和跨领域比较严重的小伙伴也需要慎重处理相关违规行为。
接下来是本次飓风3.0百度搜索学院的详细公告:
为维护健康的移动生态,保障用户体验,确保优质网站/智能小程序获得合理的流量分配,百度搜索近期将升级飓风算法,上线飓风算法3.0。本次算法升级主要针对跨域采集和站群问题,将覆盖百度搜索下的PC站点、H5站点、智能小程序。对于算法覆盖的站点/智能小程序,将根据违规的严重程度酌情限制搜索结果的显示。下面详细介绍飓风算法3.0的相关规则。一.跨域采集:为了获取更多流量,站点/智能小程序发布不属于站点/智能小程序域的内容。通常,这些内容都是来自互联网的采集,内容质量和相关性低,对搜索用户的价值低。对于此类行为搜索,将判断站点/智能小程序在该领域的关注度不够,会有不同程度的限制。跨域采集主要包括以下两类问题: 第一类:主站点或首页的内容/标题/关键词/summary,表明该站点有明确的领域或行业,但发布的内容与该字段不相关,或相关性较低。问题示例:在食品智能小程序中发布与足球相关的内容 内容质量和相关性低,对搜索用户的价值低。对于此类行为搜索,将判断站点/智能小程序在该领域的关注度不够,会有不同程度的限制。跨域采集主要包括以下两类问题: 第一类:主站点或首页的内容/标题/关键词/summary,表明该站点有明确的领域或行业,但发布的内容与该字段不相关,或相关性较低。问题示例:在食品智能小程序中发布与足球相关的内容 内容质量和相关性低,对搜索用户的价值低。对于此类行为搜索,将判断站点/智能小程序在该领域的关注度不够,会有不同程度的限制。跨域采集主要包括以下两类问题: 第一类:主站点或首页的内容/标题/关键词/summary,表明该站点有明确的领域或行业,但发布的内容与该字段不相关,或相关性较低。问题示例:在食品智能小程序中发布与足球相关的内容 跨域采集主要包括以下两类问题: 第一类:主站点或首页的内容/标题/关键词/summary,表明该站点有明确的领域或行业,但发布的内容与该字段不相关,或相关性较低。问题示例:在食品智能小程序中发布与足球相关的内容 跨域采集主要包括以下两类问题: 第一类:主站点或首页的内容/标题/关键词/summary,表明该站点有明确的领域或行业,但发布的内容与该字段不相关,或相关性较低。问题示例:在食品智能小程序中发布与足球相关的内容
第二类:站点/智能小程序没有明确的领域或行业,内容涉及多个领域或行业,领域模糊,领域关注度低。问题示例:智能小程序内容覆盖多个领域
二. 站群问题:是指批量构建多个站点/智能小程序获取搜索流量的行为。站群中的站点/智能小程序大部分质量低、资源稀缺性低、内容相似度高,甚至重复使用同一个模板,难以满足搜索用户的需求。问题示例:多个智能小程序复用同一个模板,内容质量低,相似度高
以上就是飓风算法3.0的相关描述。该算法预计将于 8 月推出。请及时查看站内信、短信等渠道中的提醒,并积极自查完成整改,以免造成不必要的损失。
百度飓风算法3.0算法激活后,没有收到站内信的朋友也不必太紧张。每日更新的内容可以标准化。收到内部信的小程序和网站需要认真处理和清理。/修改违法内容,最后祝大家网站一帆风顺~返回搜狐看更多 查看全部
无规则采集器列表算法(百度搜索学院飓风算法3.0即将上线,打击对象和打击内容)
大家好,我是小白。一周前的8月8日,百度搜索学院正式宣布飓风算法3.0即将上线。作为飓风算法针对采集的后续补充,这次飓风算法3.0的具体目标和内容是什么?小白为大家简单介绍了一些自己的经历,希望对大家有所帮助。
百度作为成熟的中文搜索引擎,无论是索引收录还是搜索匹配,都有完整的操作规则。当有人利用一些算法漏洞谋取利益时,在不改变整套搜索计算规则的情况下,百度只能选择打补丁,也就是所谓的算法。下面简单梳理一下各大算法的上线时间线。,基本在12年后出现:
百度绿屋顶算法 - 2013 年 2 月 19 日
打击链接交易(我的超链接分析技术怎么会有漏洞,emmmmm,如果有漏洞,那就补个补丁)
百度石榴算法 - 2013 年 5 月 17 日
打击不良广告(dei大哥,你网站我看不懂文字不说,广告快瞎了我的眼睛,哪个是关闭键?)
百度绿顶算法2.0——2013年7月1日
打击带有不相关外部链接的网站(我的成人用品,兄弟换朋友链?XX阻止一个!)
百度冰桶算法1.0——2014年8月30日
实战手机网站强制app下载(腾讯新闻:更多完整内容请下载...)
百度冰桶算法2.0——2014年11月18日
严厉打击手机广告屏蔽和强制登录(请登录后观看以下内容)
百度冰桶算法3.0——2016年7月15日
严厉打击阻止用户访问页面、弹窗强制用户下载应用(好看吗?想看更多吗?请收费...哦不,请下载应用观看,然后收费...)
百度天网算法 - 2016 年 8 月 10 日
打击网站恶意JS夺取用户隐私
百度冰桶算法4.0——2016年9月19日
规范移动端网站的广告覆盖率,点击率高的页面(你网站只允许这么大的广告,如果你是认真的,你就……)
百度冰桶算法4.5—2016年10月26日
打击色情赌博广告(XX首家网上赌场下线)
百度优采云算法 - 2016 年 11 月 21 日
打击软文交易(你有没有夸他有什么好处?快告诉我)
百度烽火项目 - 2017 年 2 月 23 日
打击JS劫持访问(死循环N次后,为什么百度还是推荐这个垃圾网站?)
百度飓风算法 - 2017 年 7 月 4 日
点击采集镜像站(你们都给我写原创!)
百度清风算法——2017年9月14日
打击假标题(免费?!靠,扣费!PS:主要针对下载网站)
百度闪电算法 - 2017 年 10 月 19 日
减轻慢访问打开网站的权重(你的网站完全没有用户体验,想要变强可以用我们的mip)
百度迅雷算法 - 2017 年 11 月 20 日
点击点击刷排名(哪些是真正的点击,我有点糊涂了)
百度 Beacon 算法2.0 — 2018 年 5 月 17 日
打击JS劫持访问提取用户信息(死循环N次后,为什么这个一定程度还推荐这个垃圾邮件网站?“已拦截125个恶意骚扰电话”“XX第一次上线……”)
百度清风算法2.0——2018年7月19日
对于不准确和无效的下载资源(支付宝PJ版在哪里?)
百度细雨算法 - 2018 年 7 月中旬
实战标题关键词堆砌和假官网(你说官网就是官网?有我的认证吗?)
百度飓风算法2.0 — 2018 年 9 月 21 日
实战内容拼接和跨域采集(啊,这个网站太棒了,我什么都想要!嘿,那个网站呢?)
百度清风算法3.0——2018年10月16日
下载站标题下载问题全面回顾(如果没有充值,请退群)
百度冰桶算法5.0——2018年11月12日
冰桶算法的广告规范覆盖百度app(春节期间我要去春晚,只能在我的网站上做广告)
百度飓风算法3.0 — 2019 年 8 月 8 日
打击跨域采集和站群小程序/网站
梳理一下百度的算法,我们确实可以看出百度确实想提升自己产品的用户体验,但也可以看出百度在搜索业务上还存在不少漏洞,甚至处于失控的边缘.
百度每次推出新产品,对于站长来说都是一种煎熬,但也是一次机会。从mip到熊掌到现在的小程序,刚入行的站长会发现自己的网站页面确实会得到一定的优惠,而很多黑帽BC利用这些排名流量优惠轻松获得高排名和抢夺大量点击量。
这一次,终于传到了小程序上,百度小程序是百度在日益强大的微信面前的又一无力抵抗。为了增加站长的参与度,小程序前期被赋予了较高的排名权重,小程序因此成为获取流量的有力工具。为了获取流量,跨领域展示各种内容。使用同一套小程序模板批量制作小程序,并使用站群的操作方式操作小程序,这是百度此次攻击的主要目标。
另外,根据一些实际的例子,网站自身的属性或者关键词与每日更新页面不一致也有可能造成算法惩罚,身边的小伙伴会被扒到底。
所以小白认为,这次的飓风算法3.0其实是针对小程序类的跨域采集和更新,以及小程序站群的操作方法,这对网站很重要@>的影响很小,收到内部信件和跨领域比较严重的小伙伴也需要慎重处理相关违规行为。
接下来是本次飓风3.0百度搜索学院的详细公告:
为维护健康的移动生态,保障用户体验,确保优质网站/智能小程序获得合理的流量分配,百度搜索近期将升级飓风算法,上线飓风算法3.0。本次算法升级主要针对跨域采集和站群问题,将覆盖百度搜索下的PC站点、H5站点、智能小程序。对于算法覆盖的站点/智能小程序,将根据违规的严重程度酌情限制搜索结果的显示。下面详细介绍飓风算法3.0的相关规则。一.跨域采集:为了获取更多流量,站点/智能小程序发布不属于站点/智能小程序域的内容。通常,这些内容都是来自互联网的采集,内容质量和相关性低,对搜索用户的价值低。对于此类行为搜索,将判断站点/智能小程序在该领域的关注度不够,会有不同程度的限制。跨域采集主要包括以下两类问题: 第一类:主站点或首页的内容/标题/关键词/summary,表明该站点有明确的领域或行业,但发布的内容与该字段不相关,或相关性较低。问题示例:在食品智能小程序中发布与足球相关的内容 内容质量和相关性低,对搜索用户的价值低。对于此类行为搜索,将判断站点/智能小程序在该领域的关注度不够,会有不同程度的限制。跨域采集主要包括以下两类问题: 第一类:主站点或首页的内容/标题/关键词/summary,表明该站点有明确的领域或行业,但发布的内容与该字段不相关,或相关性较低。问题示例:在食品智能小程序中发布与足球相关的内容 内容质量和相关性低,对搜索用户的价值低。对于此类行为搜索,将判断站点/智能小程序在该领域的关注度不够,会有不同程度的限制。跨域采集主要包括以下两类问题: 第一类:主站点或首页的内容/标题/关键词/summary,表明该站点有明确的领域或行业,但发布的内容与该字段不相关,或相关性较低。问题示例:在食品智能小程序中发布与足球相关的内容 跨域采集主要包括以下两类问题: 第一类:主站点或首页的内容/标题/关键词/summary,表明该站点有明确的领域或行业,但发布的内容与该字段不相关,或相关性较低。问题示例:在食品智能小程序中发布与足球相关的内容 跨域采集主要包括以下两类问题: 第一类:主站点或首页的内容/标题/关键词/summary,表明该站点有明确的领域或行业,但发布的内容与该字段不相关,或相关性较低。问题示例:在食品智能小程序中发布与足球相关的内容
第二类:站点/智能小程序没有明确的领域或行业,内容涉及多个领域或行业,领域模糊,领域关注度低。问题示例:智能小程序内容覆盖多个领域
二. 站群问题:是指批量构建多个站点/智能小程序获取搜索流量的行为。站群中的站点/智能小程序大部分质量低、资源稀缺性低、内容相似度高,甚至重复使用同一个模板,难以满足搜索用户的需求。问题示例:多个智能小程序复用同一个模板,内容质量低,相似度高
以上就是飓风算法3.0的相关描述。该算法预计将于 8 月推出。请及时查看站内信、短信等渠道中的提醒,并积极自查完成整改,以免造成不必要的损失。
百度飓风算法3.0算法激活后,没有收到站内信的朋友也不必太紧张。每日更新的内容可以标准化。收到内部信的小程序和网站需要认真处理和清理。/修改违法内容,最后祝大家网站一帆风顺~返回搜狐看更多
无规则采集器列表算法(数据挖掘十大算法文件介绍及使用说明(一)-)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-01-20 12:00
《数据挖掘十大算法》是一本数据挖掘领域的书籍,由美国数据挖掘专家吴新东和库马尔主编。本书详细介绍了实践中使用的十种数据挖掘算法,包括十种 C4.5、k-means、SVM、Apriori、EM、PageRank、AdaBoost、kNN、朴素贝叶斯和 CART 算法,这十种算法由数据挖掘领域的专家投票筛选,涵盖分类、聚类、统计学习、关联分析、链接分析等重要的数据挖掘研发课题,并对每个算法进行了研究。多角度深入分析,包括算法历史、算法过程、算法特征、软件实现、前沿发展等。另外,在每章的最后,
介绍
《十大数据挖掘算法》详细介绍了在实践中使用的十种数据挖掘算法。这十种算法由数据挖掘领域的专家投票筛选,涵盖分类、聚类、统计学习、关联分析和链接。分析等重要的数据挖掘研发课题。全书从多个角度对每个算法进行了深入的分析,包括算法历史、算法过程、算法特征、软件实现、前沿发展等。习题和详细的参考资料对读者掌握算法基础知识和进一步研究非常有价值,对数据挖掘课程的设计具有指导意义,
本书的每一章都由两名独立的审稿人和一名编辑审阅,部分章节在定稿前在此基础上进行了审阅。我们希望这十种算法的入选有助于推动数据挖掘在全球范围内的应用,并激励更多数据挖掘领域的学者扩大这些算法的影响,探索新的研究内容。
章节目录
第1章 C4.5
1.1 引言
1.2 算法描述
1.3 算法特性
1.3.1 决策树剪枝
1.3.2 连续型属性
1.3.3 缺失值处理
1.3.4 规则集诱导
1.4 软件实现
1.5 示例
1.5.1 Golf数据集
1.5.2 Soybean数据集
1.6 高级主题
1.6.1 二级存储
1.6.2 斜决策树
1.6.3 特征选择
1.6.4 集成方法
1.6.5 分类规则
1.6.6 模型重述
1.7 习题
参考文献
第2章 k-means
2.1 引言
2.2 算法描述
2.3 可用软件
2.4 示例
2.5 高级主题
2.6 小结
2.7 习题
参考文献
第3章 SVM:支持向量机
3.1 支持向量分类器
3.2 支持向量分类器的软间隔优化
3.3 核技巧
3.4 理论基础
3.5 支持向量回归器
3.6 软件实现
3.7 当前和未来的研究
3.7.1 计算效率
3.7.2 核的选择
3.7.3 泛化分析
3.7.4 结构化支持向量机的学习
3.8 习题
参考文献
第4章 Apriori
4.1 引言
4.2 算法描述
4.2.1 挖掘频繁模式和关联规则
4.2.2 挖掘序列模式
4.2.3 讨论
4.3 软件实现
4.4 示例
4.4.1 可行示例
4.4.2 性能评估
4.5 高级主题
4.5.1 改进Apriori类型的频繁模式挖掘
4.5.2 无候选的频繁模式挖掘
4.5.3 增量式方法
4.5.4 稠密表示:闭合模式和最大模式
4.5.5 量化的关联规则
4.5.6 其他的重要性/兴趣度度量方法
4.5.7 类别关联规则
4.5.8 使用更丰富的形式:序列、树和图
4.6 小结
4.7 习题
参考文献
第5章 EM
5.1 引言
5.2 算法描述
……
第6章 PageRank
第7章 AdaBoost
第8章 kNN!k-最近邻
第9章 Naive Bayes
第10章 CART:分类和回归树
使用说明
1、下载解压得到pdf文件
2、如果无法打开此文件,请务必下载pdf阅读器
3、安装后打开解压后的pdf文件
4、双击阅读 查看全部
无规则采集器列表算法(数据挖掘十大算法文件介绍及使用说明(一)-)
《数据挖掘十大算法》是一本数据挖掘领域的书籍,由美国数据挖掘专家吴新东和库马尔主编。本书详细介绍了实践中使用的十种数据挖掘算法,包括十种 C4.5、k-means、SVM、Apriori、EM、PageRank、AdaBoost、kNN、朴素贝叶斯和 CART 算法,这十种算法由数据挖掘领域的专家投票筛选,涵盖分类、聚类、统计学习、关联分析、链接分析等重要的数据挖掘研发课题,并对每个算法进行了研究。多角度深入分析,包括算法历史、算法过程、算法特征、软件实现、前沿发展等。另外,在每章的最后,
介绍
《十大数据挖掘算法》详细介绍了在实践中使用的十种数据挖掘算法。这十种算法由数据挖掘领域的专家投票筛选,涵盖分类、聚类、统计学习、关联分析和链接。分析等重要的数据挖掘研发课题。全书从多个角度对每个算法进行了深入的分析,包括算法历史、算法过程、算法特征、软件实现、前沿发展等。习题和详细的参考资料对读者掌握算法基础知识和进一步研究非常有价值,对数据挖掘课程的设计具有指导意义,
本书的每一章都由两名独立的审稿人和一名编辑审阅,部分章节在定稿前在此基础上进行了审阅。我们希望这十种算法的入选有助于推动数据挖掘在全球范围内的应用,并激励更多数据挖掘领域的学者扩大这些算法的影响,探索新的研究内容。
章节目录
第1章 C4.5
1.1 引言
1.2 算法描述
1.3 算法特性
1.3.1 决策树剪枝
1.3.2 连续型属性
1.3.3 缺失值处理
1.3.4 规则集诱导
1.4 软件实现
1.5 示例
1.5.1 Golf数据集
1.5.2 Soybean数据集
1.6 高级主题
1.6.1 二级存储
1.6.2 斜决策树
1.6.3 特征选择
1.6.4 集成方法
1.6.5 分类规则
1.6.6 模型重述
1.7 习题
参考文献
第2章 k-means
2.1 引言
2.2 算法描述
2.3 可用软件
2.4 示例
2.5 高级主题
2.6 小结
2.7 习题
参考文献
第3章 SVM:支持向量机
3.1 支持向量分类器
3.2 支持向量分类器的软间隔优化
3.3 核技巧
3.4 理论基础
3.5 支持向量回归器
3.6 软件实现
3.7 当前和未来的研究
3.7.1 计算效率
3.7.2 核的选择
3.7.3 泛化分析
3.7.4 结构化支持向量机的学习
3.8 习题
参考文献
第4章 Apriori
4.1 引言
4.2 算法描述
4.2.1 挖掘频繁模式和关联规则
4.2.2 挖掘序列模式
4.2.3 讨论
4.3 软件实现
4.4 示例
4.4.1 可行示例
4.4.2 性能评估
4.5 高级主题
4.5.1 改进Apriori类型的频繁模式挖掘
4.5.2 无候选的频繁模式挖掘
4.5.3 增量式方法
4.5.4 稠密表示:闭合模式和最大模式
4.5.5 量化的关联规则
4.5.6 其他的重要性/兴趣度度量方法
4.5.7 类别关联规则
4.5.8 使用更丰富的形式:序列、树和图
4.6 小结
4.7 习题
参考文献
第5章 EM
5.1 引言
5.2 算法描述
……
第6章 PageRank
第7章 AdaBoost
第8章 kNN!k-最近邻
第9章 Naive Bayes
第10章 CART:分类和回归树
使用说明
1、下载解压得到pdf文件
2、如果无法打开此文件,请务必下载pdf阅读器
3、安装后打开解压后的pdf文件
4、双击阅读
无规则采集器列表算法(探码Web大数据采集系统特别的流弊,但是绝逼)
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-01-18 03:00
关于检测和解码Web大数据采集系统不能说是一种特殊的骗局,但绝对是一种时尚、先进、稳定的技术。
检测技术基于云计算开发的Web Big Data采集系统——利用多台云计算服务器协同工作,可以快速采集大量数据,同时也避免了数据量的瓶颈计算机的硬件资源,加之对数据采集的要求越来越高,传统岗位采集无法解决的技术问题也逐渐得到解决。采集器,可以模拟人类的思维和操作,从而彻底解决ajax等技术问题。
网页一般是为人们浏览而设计的,所以它可以模拟人类智能采集器,并且运行起来非常流畅。不管是什么背景技术,当数据最终展现在人们面前时,智能采集器就开始提取了。这最终最大限度地发挥了计算机的能力,允许计算机代表人类完成网页数据采集的所有工作。而利用大数据云采集技术,计算机的计算能力也得到了充分发挥。目前,这种采集技术已经得到越来越广泛的应用。各行各业只要需要从互联网上获取一些数据或信息,都可以使用这些技术。
而Web大数据采集可以实现很多功能:
● 网页采集
提供网络爬虫工具。使用爬虫爬取分布式环境中的网页内容。通常爬取的内容收录大量的数据,也收录大量的噪声,所以在对网页进行正则化、去重和去噪后,将爬取的URL和内容对应合并到数据库并保存为网页分类的依据。
● 网页分析
可以提供相应的算法工具来分析网页中的关键词和上下文语义,实现网页的分类、分类等操作。还可以根据内容分析访问网页的用户的情绪、偏好和个性。
● 网址管理
支持从HDFS保存的日志文件中提取所有URL信息并导入BDP平台;抓取未知URL后,提取文本进行分类,根据分类信息给URL打上分类标签,写入URL库,统一管理和存储。利用。
● 语义解析
根据网页内容,使用贝叶斯算法进行语义分析。主要基于贝叶斯算法,也可以基于其他算法进行优化,包括:决策树、Rocchio、神经网络等。
● 自动网页分类
网页采集和预处理后的网页内容可以根据分类规则和算法进行自动分类。分类后存储,完成URL对应的分类的映射;文本分类一般包括文本的表达、分类器的选择与训练、分类结果的评价与反馈等;文本的表达可以细分为文本预处理。、索引和统计(分词)、特征提取等步骤;目前常用的分类算法有:决策树、Rocchio、朴素贝叶斯、神经网络、支持向量机。
● 分类索引
网页分类结果以一级、二级、三级的形式存储,可以统一索引。
● 词库管理
中文分词是中文搜索引擎的重要组成部分,分词词库为基于字典分词的中文分词算法提供了分词依据。作为分词的基础,词库需要定期维护和更新。在初始化阶段,使用手动组织的基准词库,然后补充词库,包括一些流行的词库和从网站的具体内容定期爬取词。现有的分词算法可以分为三类:基于字符串匹配的分词方法、基于理解的分词方法和基于统计的分词方法。
● URL 类别索引
支持对网页采集进行自动分类,并根据分类规则和算法对网页内容进行预处理。分类后存储,完成URL对应的分类的映射;文本的表达可以细分为文本预处理、索引与统计(分词)、特征提取等步骤。
同时Detecting Web Big Data采集有8个子系统,支持众多功能的实现:
Web大数据采集系统分为8个子系统,即大数据集群系统、数据采集系统、采集数据源研究、数据爬虫系统、数据清洗系统、数据合并系统,任务调度系统,搜索引擎系统。
关于 8 个子系统的功能,您可以从这里了解更多信息: 查看全部
无规则采集器列表算法(探码Web大数据采集系统特别的流弊,但是绝逼)
关于检测和解码Web大数据采集系统不能说是一种特殊的骗局,但绝对是一种时尚、先进、稳定的技术。
检测技术基于云计算开发的Web Big Data采集系统——利用多台云计算服务器协同工作,可以快速采集大量数据,同时也避免了数据量的瓶颈计算机的硬件资源,加之对数据采集的要求越来越高,传统岗位采集无法解决的技术问题也逐渐得到解决。采集器,可以模拟人类的思维和操作,从而彻底解决ajax等技术问题。
网页一般是为人们浏览而设计的,所以它可以模拟人类智能采集器,并且运行起来非常流畅。不管是什么背景技术,当数据最终展现在人们面前时,智能采集器就开始提取了。这最终最大限度地发挥了计算机的能力,允许计算机代表人类完成网页数据采集的所有工作。而利用大数据云采集技术,计算机的计算能力也得到了充分发挥。目前,这种采集技术已经得到越来越广泛的应用。各行各业只要需要从互联网上获取一些数据或信息,都可以使用这些技术。
而Web大数据采集可以实现很多功能:
● 网页采集
提供网络爬虫工具。使用爬虫爬取分布式环境中的网页内容。通常爬取的内容收录大量的数据,也收录大量的噪声,所以在对网页进行正则化、去重和去噪后,将爬取的URL和内容对应合并到数据库并保存为网页分类的依据。
● 网页分析
可以提供相应的算法工具来分析网页中的关键词和上下文语义,实现网页的分类、分类等操作。还可以根据内容分析访问网页的用户的情绪、偏好和个性。
● 网址管理
支持从HDFS保存的日志文件中提取所有URL信息并导入BDP平台;抓取未知URL后,提取文本进行分类,根据分类信息给URL打上分类标签,写入URL库,统一管理和存储。利用。
● 语义解析
根据网页内容,使用贝叶斯算法进行语义分析。主要基于贝叶斯算法,也可以基于其他算法进行优化,包括:决策树、Rocchio、神经网络等。
● 自动网页分类
网页采集和预处理后的网页内容可以根据分类规则和算法进行自动分类。分类后存储,完成URL对应的分类的映射;文本分类一般包括文本的表达、分类器的选择与训练、分类结果的评价与反馈等;文本的表达可以细分为文本预处理。、索引和统计(分词)、特征提取等步骤;目前常用的分类算法有:决策树、Rocchio、朴素贝叶斯、神经网络、支持向量机。
● 分类索引
网页分类结果以一级、二级、三级的形式存储,可以统一索引。
● 词库管理
中文分词是中文搜索引擎的重要组成部分,分词词库为基于字典分词的中文分词算法提供了分词依据。作为分词的基础,词库需要定期维护和更新。在初始化阶段,使用手动组织的基准词库,然后补充词库,包括一些流行的词库和从网站的具体内容定期爬取词。现有的分词算法可以分为三类:基于字符串匹配的分词方法、基于理解的分词方法和基于统计的分词方法。
● URL 类别索引
支持对网页采集进行自动分类,并根据分类规则和算法对网页内容进行预处理。分类后存储,完成URL对应的分类的映射;文本的表达可以细分为文本预处理、索引与统计(分词)、特征提取等步骤。
同时Detecting Web Big Data采集有8个子系统,支持众多功能的实现:
Web大数据采集系统分为8个子系统,即大数据集群系统、数据采集系统、采集数据源研究、数据爬虫系统、数据清洗系统、数据合并系统,任务调度系统,搜索引擎系统。
关于 8 个子系统的功能,您可以从这里了解更多信息:
无规则采集器列表算法(豆瓣短评(碟中谍6-全面瓦解)的豆瓣短评为例 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2022-01-17 17:04
)
本文主要介绍优采云采集器的智能模式如何使用,免费采集豆瓣短评(Mission Impossible 6-Complete Disintegration)评论者、评论时间、评论内容等信息。
采集工具介绍:
优采云采集器是一款基于人工智能技术的网络爬虫工具。只需输入URL即可自动识别网页数据,无需配置采集即可完成数据,业内首创支持Windows、Mac、Linux三种操作系统的爬虫软件。
本软件是真正免费的data采集软件,对采集结果的导出没有任何限制,没有编程基础的新手也能轻松实现data采集的需求。
官方网站:
采集对象配置文件:
豆瓣是一个社区网站。网站 最初是一本书、视频和视频,提供有关书籍、电影、音乐和其他作品的信息。描述和评论均由用户提供。它是 Web2.0网站 网站 的特征之一。网站还提供图书视频推荐、线下同城活动、群话题交流等多种服务功能,更像是一个品味系统(阅读、电影、音乐)、表达系统(我读、我看、我听)和通讯系统(同城、群、邻居)创新的网络服务,一直致力于帮助都市人发现生活中有用的东西。
采集字段:
审稿人、发表时间、有用编号、审稿内容
功能点目录:
如何采集需要登录才能查看的页面
如何实现翻页功能
采集结果预览:
下面详细介绍一下如何免费释放采集豆瓣短评数据。我们以豆瓣短评《碟中谍6-彻底瓦解》为例。具体步骤如下:
第一步:下载安装优采云采集器,并注册登录
1、点击这里打开优采云采集器官网,下载安装爬虫软件工具—优采云采集器软件
2、点击注册登录,注册新账号,登录优采云采集器
【温馨提示】无需注册即可直接使用本爬虫软件,但匿名账号下的任务在切换为注册用户时会丢失,建议注册后使用。
优采云采集器 是优采云 Cloud 的产物。如果您是 优采云 用户,则可以直接登录。
第 2 步:创建一个新的 采集 任务
1、复制《碟中谍6-彻底瓦解》豆瓣短评的网页(需要搜索结果页的网址,不是首页的网址)
单击此处了解如何正确输入 URL。
2、新的智能模式采集任务
可以直接在软件上新建采集任务,也可以通过导入规则来新建任务。
在此处了解如何导入和导出 采集 规则。
第 3 步:配置 采集 规则
1、设置预登录
豆瓣评论在用户未登录的情况下只能显示前10页数据。如果用户需要采集更多数据,需要在采集之前登录,所以我们需要预登录首先,然后 采集 继续。
这里我们要使用“预登录”功能,点击“预登录”按钮打开登录窗口,如下图所示。优采云采集器您的账户信息不会被存储和上传,您可以放心使用此功能。
单击此处了解有关如何使用预登录功能的更多信息。
2、手动设置分页
豆瓣短评页面的翻页按钮比较特别。智能模式不能直接将元素采集识别到下一页。这时候系统会提示你。
我们需要手动设置分页,设置“分页设置-手动设置分页-点击分页按钮”,然后在网页中点击翻页按钮。
点击这里了解如何实现翻页功能。
3、设置提取数据字段
在智能模式下,我们输入网址后,软件可以自动识别页面上的数据并生成采集结果。每种数据对应一个采集字段,我们可以右键该字段进行相关设置。包括修改字段名、增减字段、处理数据等。
单击此处了解如何配置 采集 字段。
我们需要采集豆瓣短评的评论者、发布时间、有用数量和评论内容。由于星级的特殊元素,优采云V2.1.22版本暂时不会上线。采集支持该字段,后续版本会实现该功能。字段设置效果如下:
第 4 步:设置并启动 采集 任务
1、设置采集任务
添加 采集 数据后,我们可以启动 采集 任务。在启动之前,我们需要对采集任务进行一些设置,以提高采集的稳定性和成功率。
点击“设置”按钮,在弹出的操作设置页面,我们可以设置操作设置和防屏蔽设置,这里我们勾选“Skip continue 采集”,设置“2”秒请求等待时间,勾选“不加载网页图片”,根据系统默认设置防屏蔽设置,然后点击保存。
单击此处了解有关如何配置 采集 任务的更多信息。
2、开始采集任务
点击“保存并开始”按钮,在弹出的页面中进行一些高级设置,包括定时启动、自动存储和下载图片。本例中没有用到这些功能,可以直接点击“开始”。
单击此处了解有关计时的更多信息采集。
单击此处了解有关什么是自动库存的更多信息。
单击此处了解有关如何下载图像的更多信息。
【温馨提示】免费版可以使用非周期定时采集功能,下载图片功能免费。个人专业版及以上可使用高级计时功能和自动存储功能。
3、运行任务提取数据
任务启动后会自动启动采集数据,我们可以从界面直观的看到程序运行过程和采集结果,采集之后会有提示超过。
第 5 步:导出和查看数据
数据采集完成后,我们可以查看和导出数据,优采云采集器支持多种导出方式(手动导出到本地,手动导出到数据库,自动发布到数据库,自动发布到网站)并导出文件格式(EXCEL、CSV、HTML和TXT),我们选择我们需要的方法和文件类型,点击“确认导出”。
单击此处了解有关如何查看和清除 采集 数据的更多信息。
单击此处了解有关导出 采集 结果的更多信息。
【温馨提示】:所有手动导出功能均免费。个人专业版及以上可以使用发布到网站功能。
查看全部
无规则采集器列表算法(豆瓣短评(碟中谍6-全面瓦解)的豆瓣短评为例
)
本文主要介绍优采云采集器的智能模式如何使用,免费采集豆瓣短评(Mission Impossible 6-Complete Disintegration)评论者、评论时间、评论内容等信息。
采集工具介绍:
优采云采集器是一款基于人工智能技术的网络爬虫工具。只需输入URL即可自动识别网页数据,无需配置采集即可完成数据,业内首创支持Windows、Mac、Linux三种操作系统的爬虫软件。
本软件是真正免费的data采集软件,对采集结果的导出没有任何限制,没有编程基础的新手也能轻松实现data采集的需求。
官方网站:
采集对象配置文件:
豆瓣是一个社区网站。网站 最初是一本书、视频和视频,提供有关书籍、电影、音乐和其他作品的信息。描述和评论均由用户提供。它是 Web2.0网站 网站 的特征之一。网站还提供图书视频推荐、线下同城活动、群话题交流等多种服务功能,更像是一个品味系统(阅读、电影、音乐)、表达系统(我读、我看、我听)和通讯系统(同城、群、邻居)创新的网络服务,一直致力于帮助都市人发现生活中有用的东西。
采集字段:
审稿人、发表时间、有用编号、审稿内容
功能点目录:
如何采集需要登录才能查看的页面
如何实现翻页功能
采集结果预览:
下面详细介绍一下如何免费释放采集豆瓣短评数据。我们以豆瓣短评《碟中谍6-彻底瓦解》为例。具体步骤如下:
第一步:下载安装优采云采集器,并注册登录
1、点击这里打开优采云采集器官网,下载安装爬虫软件工具—优采云采集器软件
2、点击注册登录,注册新账号,登录优采云采集器
【温馨提示】无需注册即可直接使用本爬虫软件,但匿名账号下的任务在切换为注册用户时会丢失,建议注册后使用。
优采云采集器 是优采云 Cloud 的产物。如果您是 优采云 用户,则可以直接登录。
第 2 步:创建一个新的 采集 任务
1、复制《碟中谍6-彻底瓦解》豆瓣短评的网页(需要搜索结果页的网址,不是首页的网址)
单击此处了解如何正确输入 URL。
2、新的智能模式采集任务
可以直接在软件上新建采集任务,也可以通过导入规则来新建任务。
在此处了解如何导入和导出 采集 规则。
第 3 步:配置 采集 规则
1、设置预登录
豆瓣评论在用户未登录的情况下只能显示前10页数据。如果用户需要采集更多数据,需要在采集之前登录,所以我们需要预登录首先,然后 采集 继续。
这里我们要使用“预登录”功能,点击“预登录”按钮打开登录窗口,如下图所示。优采云采集器您的账户信息不会被存储和上传,您可以放心使用此功能。
单击此处了解有关如何使用预登录功能的更多信息。
2、手动设置分页
豆瓣短评页面的翻页按钮比较特别。智能模式不能直接将元素采集识别到下一页。这时候系统会提示你。
我们需要手动设置分页,设置“分页设置-手动设置分页-点击分页按钮”,然后在网页中点击翻页按钮。
点击这里了解如何实现翻页功能。
3、设置提取数据字段
在智能模式下,我们输入网址后,软件可以自动识别页面上的数据并生成采集结果。每种数据对应一个采集字段,我们可以右键该字段进行相关设置。包括修改字段名、增减字段、处理数据等。
单击此处了解如何配置 采集 字段。
我们需要采集豆瓣短评的评论者、发布时间、有用数量和评论内容。由于星级的特殊元素,优采云V2.1.22版本暂时不会上线。采集支持该字段,后续版本会实现该功能。字段设置效果如下:
第 4 步:设置并启动 采集 任务
1、设置采集任务
添加 采集 数据后,我们可以启动 采集 任务。在启动之前,我们需要对采集任务进行一些设置,以提高采集的稳定性和成功率。
点击“设置”按钮,在弹出的操作设置页面,我们可以设置操作设置和防屏蔽设置,这里我们勾选“Skip continue 采集”,设置“2”秒请求等待时间,勾选“不加载网页图片”,根据系统默认设置防屏蔽设置,然后点击保存。
单击此处了解有关如何配置 采集 任务的更多信息。
2、开始采集任务
点击“保存并开始”按钮,在弹出的页面中进行一些高级设置,包括定时启动、自动存储和下载图片。本例中没有用到这些功能,可以直接点击“开始”。
单击此处了解有关计时的更多信息采集。
单击此处了解有关什么是自动库存的更多信息。
单击此处了解有关如何下载图像的更多信息。
【温馨提示】免费版可以使用非周期定时采集功能,下载图片功能免费。个人专业版及以上可使用高级计时功能和自动存储功能。
3、运行任务提取数据
任务启动后会自动启动采集数据,我们可以从界面直观的看到程序运行过程和采集结果,采集之后会有提示超过。
第 5 步:导出和查看数据
数据采集完成后,我们可以查看和导出数据,优采云采集器支持多种导出方式(手动导出到本地,手动导出到数据库,自动发布到数据库,自动发布到网站)并导出文件格式(EXCEL、CSV、HTML和TXT),我们选择我们需要的方法和文件类型,点击“确认导出”。
单击此处了解有关如何查看和清除 采集 数据的更多信息。
单击此处了解有关导出 采集 结果的更多信息。
【温馨提示】:所有手动导出功能均免费。个人专业版及以上可以使用发布到网站功能。
无规则采集器列表算法(最常规的防止网页被搜索引擎收录的方法是什么?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-01-16 20:03
最常见的防止网页被搜索引擎搜索到的方法收录是使用robots.txt,但这样做的缺点是列出了所有来自搜索引擎的已知爬虫信息,难免会出现遗漏。以下方法可以标本兼治:(摘自)
1、限制单位时间内每个IP地址的访问次数
分析:没有一个普通人可以在一秒钟内访问同一个网站5次,除非是程序访问,喜欢这样的人就剩下搜索引擎爬虫和烦人的采集器。
缺点:一刀切,这也会阻止搜索引擎访问 收录 或 网站
适用于网站:网站不严重依赖搜索引擎的人
采集器会做什么:减少单位时间的访问次数,降低采集的效率
2、屏蔽ip
分析:通过后台计数器,记录访客IP和访问频率,人工分析访客记录,屏蔽可疑IP。
缺点:好像没有缺点,就是站长忙
适用于网站:所有网站,站长可以知道是google还是百度机器人
采集器 会做什么:打游击战!使用ip代理采集改一次,但是会降低采集器的效率和网速(使用代理)。
3、使用js加密网页内容
注意:我没有接触过这个方法,只是来自其他来源
分析:不用分析,搜索引擎爬虫和采集器杀
对于网站:讨厌搜索引擎的网站和采集器
采集器 会这样做:你那么好,你要牺牲,他不会来接你
4、隐藏网站网页中的版权或一些随机的垃圾文字,这些文字样式写在css文件中
分析:虽然不能阻止采集,但是会让采集后面的内容被你的网站版权声明或者一些垃圾文字填满,因为一般采集器不会采集您的 css 文件,这些文本显示时没有样式。
适用于 网站:所有 网站
采集器怎么办:对于版权文本,好办,替换掉。对于随机垃圾文本,没办法,快点。
5、用户登录访问网站内容*
分析:搜索引擎爬虫不会为每一种此类网站设计登录程序。听说采集器可以为某个网站设计模拟用户登录和提交表单的行为。
对于网站:网站讨厌搜索引擎,最想屏蔽采集器
采集器 会做什么:制作一个模块来模拟用户登录和提交表单的行为
6、使用脚本语言进行分页(隐藏分页)
分析:还是那句话,搜索引擎爬虫不会分析各种网站的隐藏分页,影响搜索引擎的收录。但是,采集作者在编写采集规则的时候,需要分析目标网页的代码,稍微懂一点脚本知识的就知道分页的真实链接地址了。
适用于网站:网站对搜索引擎依赖不高,采集你的人不懂脚本知识
采集器会做什么:应该说采集这个人会做什么,反正他要分析你的网页代码,顺便分析一下你的分页脚本,用不了多少额外的时间。
7、反链保护措施(只允许通过本站页面连接查看,如:Request.ServerVariables("HTTP_REFERER"))
分析:asp和php可以通过读取请求的HTTP_REFERER属性来判断请求是否来自这个网站,从而限制采集器,同时也限制了搜索引擎爬虫,严重影响了搜索引擎对网站。@网站部分防盗链内容收录。
适用于网站:网站很少考虑搜索引擎收录 查看全部
无规则采集器列表算法(最常规的防止网页被搜索引擎收录的方法是什么?)
最常见的防止网页被搜索引擎搜索到的方法收录是使用robots.txt,但这样做的缺点是列出了所有来自搜索引擎的已知爬虫信息,难免会出现遗漏。以下方法可以标本兼治:(摘自)
1、限制单位时间内每个IP地址的访问次数
分析:没有一个普通人可以在一秒钟内访问同一个网站5次,除非是程序访问,喜欢这样的人就剩下搜索引擎爬虫和烦人的采集器。
缺点:一刀切,这也会阻止搜索引擎访问 收录 或 网站
适用于网站:网站不严重依赖搜索引擎的人
采集器会做什么:减少单位时间的访问次数,降低采集的效率
2、屏蔽ip
分析:通过后台计数器,记录访客IP和访问频率,人工分析访客记录,屏蔽可疑IP。
缺点:好像没有缺点,就是站长忙
适用于网站:所有网站,站长可以知道是google还是百度机器人
采集器 会做什么:打游击战!使用ip代理采集改一次,但是会降低采集器的效率和网速(使用代理)。
3、使用js加密网页内容
注意:我没有接触过这个方法,只是来自其他来源
分析:不用分析,搜索引擎爬虫和采集器杀
对于网站:讨厌搜索引擎的网站和采集器
采集器 会这样做:你那么好,你要牺牲,他不会来接你
4、隐藏网站网页中的版权或一些随机的垃圾文字,这些文字样式写在css文件中
分析:虽然不能阻止采集,但是会让采集后面的内容被你的网站版权声明或者一些垃圾文字填满,因为一般采集器不会采集您的 css 文件,这些文本显示时没有样式。
适用于 网站:所有 网站
采集器怎么办:对于版权文本,好办,替换掉。对于随机垃圾文本,没办法,快点。
5、用户登录访问网站内容*
分析:搜索引擎爬虫不会为每一种此类网站设计登录程序。听说采集器可以为某个网站设计模拟用户登录和提交表单的行为。
对于网站:网站讨厌搜索引擎,最想屏蔽采集器
采集器 会做什么:制作一个模块来模拟用户登录和提交表单的行为
6、使用脚本语言进行分页(隐藏分页)
分析:还是那句话,搜索引擎爬虫不会分析各种网站的隐藏分页,影响搜索引擎的收录。但是,采集作者在编写采集规则的时候,需要分析目标网页的代码,稍微懂一点脚本知识的就知道分页的真实链接地址了。
适用于网站:网站对搜索引擎依赖不高,采集你的人不懂脚本知识
采集器会做什么:应该说采集这个人会做什么,反正他要分析你的网页代码,顺便分析一下你的分页脚本,用不了多少额外的时间。
7、反链保护措施(只允许通过本站页面连接查看,如:Request.ServerVariables("HTTP_REFERER"))
分析:asp和php可以通过读取请求的HTTP_REFERER属性来判断请求是否来自这个网站,从而限制采集器,同时也限制了搜索引擎爬虫,严重影响了搜索引擎对网站。@网站部分防盗链内容收录。
适用于网站:网站很少考虑搜索引擎收录
无规则采集器列表算法(无规则采集器列表算法规则:提取全部指定网站)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-01-16 14:02
无规则采集器列表算法规则:提取全部指定网站打开网站后输入网址后回车得到列表用类似一个a字符之类的来替换而得到新页面,
我是这样做的,安装一个wordpress的插件vipwindows,插件名叫vippwindows。写个脚本就可以,利用查询的数据库来获取文件路径,可能会麻烦一点,
ef-gl5rgs.py可以在用户终端执行pythonscriptrpcallef-gl5rgs.py|output是restful接口
用wordpress本地搭建一个smtp服务器上传文件到kode10.wordpress文件夹内,需要的内容没有在url中明显体现出来,主要是你想了解自己的产品与竞争对手的差异化卖点是什么,需要了解到什么程度,把你需要的功能写进url,发到邮箱去用社交网络分享给用户,用户收到分享的内容后会自己进行解析,输入自己的名字来进行搜索匹配。
如果需要根据收到的名字进行检索并关联上你需要的内容和文字,社交网络将尝试从你的邮箱获取文字,经过你对他的解析后(提交匹配的查询关键词到社交网络进行搜索匹配),对所提交查询关键词可能的文字进行重排。
找用户痛点与卖点;重点布局标签和价格
除了您所说的「清晰的网站结构」外,还有同步、可回溯功能。对他人有一定约束。 查看全部
无规则采集器列表算法(无规则采集器列表算法规则:提取全部指定网站)
无规则采集器列表算法规则:提取全部指定网站打开网站后输入网址后回车得到列表用类似一个a字符之类的来替换而得到新页面,
我是这样做的,安装一个wordpress的插件vipwindows,插件名叫vippwindows。写个脚本就可以,利用查询的数据库来获取文件路径,可能会麻烦一点,
ef-gl5rgs.py可以在用户终端执行pythonscriptrpcallef-gl5rgs.py|output是restful接口
用wordpress本地搭建一个smtp服务器上传文件到kode10.wordpress文件夹内,需要的内容没有在url中明显体现出来,主要是你想了解自己的产品与竞争对手的差异化卖点是什么,需要了解到什么程度,把你需要的功能写进url,发到邮箱去用社交网络分享给用户,用户收到分享的内容后会自己进行解析,输入自己的名字来进行搜索匹配。
如果需要根据收到的名字进行检索并关联上你需要的内容和文字,社交网络将尝试从你的邮箱获取文字,经过你对他的解析后(提交匹配的查询关键词到社交网络进行搜索匹配),对所提交查询关键词可能的文字进行重排。
找用户痛点与卖点;重点布局标签和价格
除了您所说的「清晰的网站结构」外,还有同步、可回溯功能。对他人有一定约束。
无规则采集器列表算法(贷款量就是数据挖掘中的分类与预测方法进行介绍!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2022-01-13 11:08
分类和预测是使用数据进行预测的两种方式,可用于确定未来的结果。
分类用于预测数据对象的离散类别,需要预测的属性值是离散无序的。
Prediction用于预测数据对象的连续值,需要预测的属性值是连续的、有序的。
例如,在银行业务中,根据贷款申请人的信息确定贷款人属于“安全”类还是“风险”类,是数据挖掘中的一项分类任务。分析贷款人的贷款量是数据挖掘中的预测任务。
本节将介绍常用的分类和预测方法,其中一些只能用于分类或预测,但有些算法可以同时用于分类和预测。分类的基本概念分类算法反映了如何找出相似事物的共同性质的特征知识和不同事物之间的差异特征知识。分类是通过引导学习训练建立分类模型,并利用该模型对未知分类的实例进行分类。分类输出属性是离散且无序的。
分类技术在许多领域都有应用。目前,营销的一个非常重要的特点就是强调客户细分。使用数据挖掘中的分类技术,可以将客户分为不同的类别。
例如,可以通过客户分类构建分类模型来评估银行贷款的风险;在设计呼叫中心时,可以将客户划分为来电频繁的客户、偶尔来电的客户、来电稳定的客户等,以帮助呼叫中心找到这些不同类型的客户之间的特征,这样的分类模型可以让用户了解客户在不同行为类别中的分布特征。
其他分类应用包括文档检索和搜索引擎中的自动文本分类技术,以及安全领域中基于分类的入侵检测。
分类就是通过学习已有的数据集(训练集)来得到一个目标函数f(模型),将每个属性集X映射到目标属性y(类)(y必须是离散的)。
分类过程是一个两步过程:第一步是模型构建阶段或训练阶段,第二步是评估阶段。1)训练阶段 训练阶段的目的是为一组预定义的数据类或概念描述分类模型。这个阶段需要从已知数据集中选择一部分数据作为构建模型的训练集,剩下的部分作为测试集。通常从已知数据集中选取 2/3 的数据项作为训练集,将 1/3 的数据项作为测试集。
训练数据集由一组数据元组组成,每个元组都假定已经属于一个预先指定的类别。训练阶段可以看作是学习映射函数的过程,通过该映射函数可以预测给定元组 x 的类标签。映射函数是对数据集进行训练得到的模型(或分类器),如图1所示。模型可以用分类规则、决策树或数学公式的形式表示。
图1 分类算法的训练阶段
2)评估阶段在评估阶段,需要使用第一阶段建立的模型对测试集数据元组进行分类,从而评估分类模型的预测精度,如图2所示。
分类器的准确性是分类器在给定测试数据集上正确分类的测试元组的百分比。如果认为分类器的准确性可以接受,则使用分类器对类别标签未知的数据元组进行分类。
图2 分类算法的评估阶段
预测的基本概念预测模型类似于分类模型,可以看作是一个映射或函数 y=f(x),其中 x 是输入元组,输出 y 是连续或有序值。与分类算法不同的是,预测算法需要预测的属性值是连续的、有序的,而分类需要预测的属性值是离散的、无序的。
数据挖掘的预测算法和分类算法一样,是一个两步过程。测试数据集和训练数据集在预测任务中也应该是独立的。预测的准确性是通过 y 的预测值与实际已知值之间的差异来评估的。
预测和分类之间的区别在于,分类用于预测数据对象的类标签,而预测是估计一些空值或未知值。例如,预测明天上证综指收盘价是上涨还是下跌是一个分类,但如果要预测明天上证综指的收盘价是多少,它就是一个预测。 查看全部
无规则采集器列表算法(贷款量就是数据挖掘中的分类与预测方法进行介绍!)
分类和预测是使用数据进行预测的两种方式,可用于确定未来的结果。
分类用于预测数据对象的离散类别,需要预测的属性值是离散无序的。
Prediction用于预测数据对象的连续值,需要预测的属性值是连续的、有序的。
例如,在银行业务中,根据贷款申请人的信息确定贷款人属于“安全”类还是“风险”类,是数据挖掘中的一项分类任务。分析贷款人的贷款量是数据挖掘中的预测任务。
本节将介绍常用的分类和预测方法,其中一些只能用于分类或预测,但有些算法可以同时用于分类和预测。分类的基本概念分类算法反映了如何找出相似事物的共同性质的特征知识和不同事物之间的差异特征知识。分类是通过引导学习训练建立分类模型,并利用该模型对未知分类的实例进行分类。分类输出属性是离散且无序的。
分类技术在许多领域都有应用。目前,营销的一个非常重要的特点就是强调客户细分。使用数据挖掘中的分类技术,可以将客户分为不同的类别。
例如,可以通过客户分类构建分类模型来评估银行贷款的风险;在设计呼叫中心时,可以将客户划分为来电频繁的客户、偶尔来电的客户、来电稳定的客户等,以帮助呼叫中心找到这些不同类型的客户之间的特征,这样的分类模型可以让用户了解客户在不同行为类别中的分布特征。
其他分类应用包括文档检索和搜索引擎中的自动文本分类技术,以及安全领域中基于分类的入侵检测。
分类就是通过学习已有的数据集(训练集)来得到一个目标函数f(模型),将每个属性集X映射到目标属性y(类)(y必须是离散的)。
分类过程是一个两步过程:第一步是模型构建阶段或训练阶段,第二步是评估阶段。1)训练阶段 训练阶段的目的是为一组预定义的数据类或概念描述分类模型。这个阶段需要从已知数据集中选择一部分数据作为构建模型的训练集,剩下的部分作为测试集。通常从已知数据集中选取 2/3 的数据项作为训练集,将 1/3 的数据项作为测试集。
训练数据集由一组数据元组组成,每个元组都假定已经属于一个预先指定的类别。训练阶段可以看作是学习映射函数的过程,通过该映射函数可以预测给定元组 x 的类标签。映射函数是对数据集进行训练得到的模型(或分类器),如图1所示。模型可以用分类规则、决策树或数学公式的形式表示。
图1 分类算法的训练阶段
2)评估阶段在评估阶段,需要使用第一阶段建立的模型对测试集数据元组进行分类,从而评估分类模型的预测精度,如图2所示。
分类器的准确性是分类器在给定测试数据集上正确分类的测试元组的百分比。如果认为分类器的准确性可以接受,则使用分类器对类别标签未知的数据元组进行分类。
图2 分类算法的评估阶段
预测的基本概念预测模型类似于分类模型,可以看作是一个映射或函数 y=f(x),其中 x 是输入元组,输出 y 是连续或有序值。与分类算法不同的是,预测算法需要预测的属性值是连续的、有序的,而分类需要预测的属性值是离散的、无序的。
数据挖掘的预测算法和分类算法一样,是一个两步过程。测试数据集和训练数据集在预测任务中也应该是独立的。预测的准确性是通过 y 的预测值与实际已知值之间的差异来评估的。
预测和分类之间的区别在于,分类用于预测数据对象的类标签,而预测是估计一些空值或未知值。例如,预测明天上证综指收盘价是上涨还是下跌是一个分类,但如果要预测明天上证综指的收盘价是多少,它就是一个预测。
无规则采集器列表算法(【无监督语义分割】果子:作者算法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2022-01-13 09:05
煎饼不是水果:【无监督语义分割】InfoSeg: Unsupervised Semantic Image Segmentation with Mutual Information Maximization
以上内容于2021-10-10更新。我觉得上面的文章相当于下面描述的文章的升级版。
在使用无监督分割可以搜索到的GitHub代码中,最受关注的是这个项目→Unsupervised Image Segmentation by Backpropagation - Asako Kanezaki Kanazaki Asako(东京大学)- GitHub,作者在PyTorch中实现的代码。
基于作者论文的算法,我成功复现了作者的算法,我也把代码放到了Github↑上,我复现的代码可以使用更短的运行时间(作者用图30秒,我用5秒),并达到同样的Split效果。
直接用图片展示算法的效果↓
这些改进并不是因为我的代码写得有多好,而是因为原作者没有很好地实现她的算法,如下图:
第一行是无监督语义分割的输入图像;第二行是作者放在GitHub上的展示图片;第三行是我在本地电脑上运行作者的源代码得到的结果;第四行是基于作者的作者。论文的算法是用 PyTorch 复现的。原作者使用了随机颜色,但为了美观,我随机计算了同一语义标签的平均颜色作为着色。
无监督语义分割结果
注意:第 3 列第 2 行中的两只狼被分成不同的颜色(蓝色和黄色),这是一个偶然的结果。事实上,这个算法不能做Instance Segmentation。第三列,第 3 行,下面是我自己转载的图片:可以看出两只狼被分配了相同的标签。
用GIF动画感性的讲解算法原理↓
该算法一遍又一遍地迭代以将相同的标签分配给具有相似语义的像素(出于美学原因,我选择了随机颜色匹配的不愉快结果,在免费在线 gif 网站 中生成 - 在 ezgif 上生成 gif:
珊瑚珊瑚
Woof Husky下面会正式介绍算法更新日志(文章看起来很长,其实是图片。在文末评论区回复问题)
2019-06-19 第一版,添加橙猫橙图,添加算法缺点章节
2019-06-21 修改compantness -> n_segments 并在评论区回复问题
2019-12-20 点赞和私信的人突然多了?原来是被专栏选中的,所以我更新了一些东西:添加了说明论文中的Conv2D + BN + ReLU部分BN应该放在ReLU之前。修改了文章基于评论和私信,增加了关于医学影像的讨论0.算法主体内容理解代码提高优化效果算法缺点附录末尾文章在评论区回复问题1. 算法主体
个人觉得原论文的算法不好看,在保持算法不变的情况下修改了。原创PDF在这里,其中的算法1如下。
———————————————————————————————————————
算法:无监督图像分割
———————————————————————————————————————
进入:
输入 RGB 图像
输出:
输出语义分割的结果图像
初始化神经网络,保持每一层的方差和均值
图像的初步聚类
迭代 T 次
使用卷积网络获取特征图
根据特征图,值最大的是对应像素的标签
经典语义分割的聚类结果
计算每个集群中出现次数最多的类别
将此簇中的所有像素记录为该类别
计算损失函数(softmax有中文名称:归一化索引)
使用随机梯度下降更新参数——————————————————————————————————————————
在,
,作者使用全卷积网络接受输入图像完成特征提取。该网络由三层卷积网络组成,如下:
作者论文中的图1,我们可以看到这里的两只狼被分配了同一个标签(都是绿色的)
其中,原作者使用2D Conv + ReLU + Batch Norm的做法是不合适的,应该改为Conv2D + BN + ReLU。具体解释见文末附录《Batch normalization Batch Norm 应该在 ReLU 之前》
在,
(原文为GetSuperPixels,使用的是slic算法),即使用经典的机器学习无监督语义分割算法对输入图像进行预分类,如Python的skimage.segmentation中的多种算法,如使用的slic算法由原作者撰写,我推荐使用 felzenszwalb 算法。值得注意的是,在作者的原创代码中,slic算法选择了一个比较极端的参数。选择这个极端参数是有原因的:
原代码为slic选择了一个极端参数n_segments=1000
在slic算法中,当分区数n_segments越高时,算法对输入图像的划分越多:
由于具有相同语义的像素通常存在于图像中的连续区域中,因此可以推断位置相似的像素属于相同语义的概率很高。因此,在预分类中,我们给相邻像素分配相同的语义标签2.算法理解:
首先,使用经典的机器学习算法对输入图像进行“预分类”:调整算法参数,为语义信息明显相同的小区域分配相同的语义标签。由于具有相同语义的像素通常存在于图像的连续区域中,我们可以假设具有接近颜色、接近纹理和接近位置的像素可以被分配相同的语义标签。
然后使用深度学习结合自动编码器结构对输入图像进行分类。分类的目标是使输出的语义分割结果尽可能接近“预分类”的结果。训练收敛。
最后,深度学习的语义分割结果会在符合“预分类结果”的基础上,合并具有相同语义信息的小块,得到大块。
我个人的理解是:在整个无监督语义分割任务中,深度学习(神经网络)的任务就是对经典机器学习无监督语义分割的细粒度预分类结果进行处理。并且在迭代中,小块逐渐融合,最终得到符合人类期望的语义分割结果。
橘猫,无监督语义分割1、2、4、8、16、32、64、128次迭代的结果
大家可以观察我之前发布的gif图,可以看到:语义信息相似的小块会在迭代前期被合并;在迭代后期,只剩下2~8个语义标签。有一种树状的分类方法(类似于物种的进化树),比较自然,比如各种类型的草、虎纹在迭代合并中很好区分和优先排序。需要改进的地方,比如“虎而不橙”的虎尾、虎眼,在迭代中被错误地赋予了与“草”相同的标签,这不是我们希望看到的结果。(我也想到了一些改进方法,这里不再展开)
在作者的原创代码中,网络使用随机梯度下降(SGD)进行训练,学习率选择0.1(默认值为0.001),使得以前的迭代中,该算法非常快速地合并像素。
3. 代码改进(只为了运行效率,缩短运行时间,不改主算法)
详情见文末附录:《为什么我推荐使用felz算法而不是slic算法?》
4. 优化结果(128次迭代,40秒→4秒)
由于修改了代码,用更少的迭代就可以达到同样的效果,所以耗时不到4秒。
测试用图片
修改(魔术修改)后,不仅缩短了时间消耗,而且图像分割的质量也有所提高。下面是我从法国自动化研究所卫星图像数据集Inria Aerial Image,1000x1000的卫星图像数据集的bellingham_x.tif中随机截取的一张图片,图片包括树林、草地、道路、建筑物和一个湖(绿色),里面有cosplay草右下角。
对于这个更大的图像 1000x1000:
原代码迭代 128 次,耗时 3 分钟(不计算 PyTorch 初始化所用的 15 秒):
我修改后的代码也迭代了 128 次,耗时 8 秒(PyTorch 初始化耗时 15 秒):
5. 算法缺点(不够健壮,缺乏限制)
首先,这个算法不够鲁棒,算法受参数影响很大(包括梯度下降法的参数,以及机器学习预分类算法的参数),以及算法随机重启的结果会有所不同。为了展示这个缺点,我做了《橘猫看橘子》:(@cm cm 问:这个方案能不能分老虎和橘子?答:有时可以,有时不能,这就是算法的缺点.)
右上角,我通过PS阈值筛选证明:橙色和图中橘猫的颜色范围是一致的。以下三行是我随机调整参数后得到的不同结果。
结果图中,橘猫的橙色比橘猫的颜色浅,因为橘猫在计算平均像素的时候,黑色的条纹也收录在了计算中。并不是橘猫和橘猫不同。我专门用PS来证明两个橘子是一样的——橘猫的平均颜色比结果图中的橙色要浅,因为橘猫的平均颜色中含有黑色虎纹。深度学习可以区分橘子和橘猫。很大的原因是卷积网络可以更好地感知纹理的差异,而不是仅仅依靠颜色进行分类。
二是算法不够成熟。随着迭代,算法会逐渐合并各个分区。然而,算法中没有设置限制来禁止神经网络合并小区域。
浅草,暗草,枯草,,,,虎尾,虎眼,,虎纹,虎皮
橙色猫图,迭代2次
黑草、浅草、尾虎尾、、、虎皮(橙)、虎皮(白)
橘猫图,迭代3次
深草,浅草(+部分老虎),老虎(大部分)
橘猫图,迭代5次
在作者自己的原创代码中,当语义分割的类别数下降到 3 或 4 时,算法终止。如果去掉训练限制,当整幅图像归为同一类别时,损失降为0。原文设计的损失函数不能限制神经网络机会主义地输出只收录一个类别的结果。这意味着在训练网络时,随机重启可能会得到截然不同的结果,我在运行原创代码时也注意到了这一点。由于没有“一类”的限制,所以这个神经网络的参数个数应该足够少(足够浅,足够窄),这样的设计太容易过拟合(不解决这个问题,模型的提升会是极其有限)。
(我也想到了一些改进的方法,就是用普通的机器学习语义分割算法得到一些必须属于不同语义的标签。作为对“一类”的限制,这里就不展开了)
6. 文末附录《Batch Normalization Batch Norm 应该在 ReLU 之前》
作者论文中的图1,它使用了原作者使用的2D Conv + ReLU + Batch Norm。这种做法不合适,应该改成Conv2D + BN + ReLU
一般在深度学习图像领域,我们会将批归一化层Batch Normalization放在激活函数ReLU前面,使得输入到ReLU的图像接近正态分布N(0, 1).如果将输入归一化归一化操作后的张量转化为梯度变化点为0的激活函数(比如这里使用的ReLU),那么这个激活函数的非线性特性就会被充分发挥出来,构造的loss函数会变得更流畅,可能是因为原论文的作者没有做图像,所以她用错了,我帮她改正为Conv2D + BN + ReLU。
要详细了解为什么使用 Conv2D + BN + ReLU,可以阅读这篇论文:Batch Normalization is a Cause of Adversarial Vulnerability。ArXiv。2019 年 5 月。以此类推,如果一定要用Sigmoid作为激活函数,那么在前面使用Batch Normalization之后,需要将0.0到0.5的均值相加,然后输入Sigmoid就会更合适。下图来自纸图。2.
批量标准化是对抗性漏洞的一个原因。图 2 “为什么我推荐使用 felz 算法而不是 slic 算法?”
在预分类阶段,需要进行细粒度的分类,并分离出足够多的区域(确保分类的地方被分类,神经网络可以帮助它在不应该分类的地方合并),以使最终结果更准确。如果类别太多,算法需要更多的迭代。使用felz算法而不是slic算法是因为它可以用更少的区域命中更多的“正确边界”,并且felz分隔的边界更准确。无论是选择felz算法还是slic算法,当划分足够多的区域时,对精度影响不大,但迭代次数差别很大。先说一下图片:
第一行,预分类结果,第二行,用PS差值表示我们想要得到的区域划分方案。
第一列使用slic算法,分区数为n_segments=1000。可以看出,虽然区域很多,但虎尾与草的距离并不是很好。第二列使用的slic算法,分区数n_segments=100,没有达到我们想要得到的分类边界。
下面是一个带有合适参数的预分类算法(比较felz和slic算法)
slic,边框条纹不够细。而felz算法,它甚至把每一条虎纹都分离出来,这也是我推荐这个算法的原因之一。
“费尔兹算法”
Efficient Graph-Based Image Segmentation - Felzenszwalb (MIT) 2004. Graph-Based Semantic Segmentation。格式塔运动(Holistic Psychology/Gestalt Psychology)认为人类根据事物的整体性做出判断。Felz 算法定义了一种方法,该方法使用基于图形的表示来定义两个区域的边界(定义谓词)。尽管这种方法会做出贪婪的决定,但它仍然会产生满足全局属性的结果。
翻译自 felz 论文的引言部分。
“切片算法”
SLIC 超像素与最先进的超像素方法的比较。2012. 省略,在作者论文的算法描述中,原代码中出现的SuperPixel也出现在了这篇论文中。大胆吐槽,上面的felz算法是2004年的,slic算法是2012年的,但是slic的标题里有State-of-the-Art?如果你没有达到全面的超越,不要说。要想戴上王冠,就必须承受它的重量。
《性能提升与GPU》
因为代码是单线程的,花在CPU上的时间越少,GPU的利用率就越高。所以即使我为了美学计算了所有类中像素的平均颜色,但时间仍然比原创代码短。无论是运行速度还是分割精度,我认为算法还有很大的提升空间。
上面是修改后的代码,GPU利用率30~40%,下面是原代码,GPU利用率10~20%,全部使用RTX2080Ti运行。欢迎评论,如有错误,请多多交流6. 回复评论区问题@cm cm 问:这个设计是不是训练和推理不可知论?每次分割图像时,网络的权重是否会重新训练?
答:“是的,训练的过程就是推理”。该算法与风格迁移的初始版本相同,通过对单个图像进行训练来获得最终结果。在李飞飞等人的实时风格迁移出来之前,风格迁移的结果是“训练”出来的,训练得到的网络参数无法保存在其他图片上使用。所以这个算法还不够成熟(我很想把它改成实时的)。
@一Seconemeow想:flez,然后用平均颜色给像素上色(并计算方差),然后Kmean(k=4),感觉200毫秒能得到比这里展示的分割效果好很多的,还没用过神经网络。(感谢他的建议)...我用flez加yuv空间平均颜色加minibatchkmean做了150ms(cpu)和你差不多的结果。虎皮没有任何问题, ...(详见评论部分)
A:在法国机器学习库 sklearn 中已经有类似的算法,Region Adjacency Graph (RAG) 和合并颜色相似的区域。后来我用了 flez 算法加上 yuv 空间的平均颜色加上 mini-batch + K-mean 的方案。我认为这确实是可行的。有机会我会试试,但是基于同色分类的算法确实是毫秒级的。级算法。但是,前面提到的这种算法存在以下问题:
该算法对机器学习语义分割聚类的预分类结果敏感,需要找到合适的预分类参数。平均色法无法将“黑虎纹”与“橙虎皮”结合起来(见草丛中的橙猫)。平均颜色将错误地合并不同但具有相似平均颜色的区域。仅仅依靠颜色是不够的,纹理的感知还需要深度学习。
问题3相关的gif:RAG算法中使用的阈值从4逐渐增大到128以下,在阈值为32时得到了比较好的结果。
使用 slic 算法 (n_segments=2048, compactness=16, max_iter=8) # 分隔更多区域
使用 slic 算法 (n_segments=2048, compactness=16, max_iter=8) # 分隔更多区域
使用slic算法(n_segments=128, compactness=16, max_iter=8) # 分隔合适的区域
与问题1相关的图片:左图和右图服从均值为128,方差为16的正态分布,右图的每一行使用一个排序。以服从相同的分布
但是对于两张不同纹理的图片,很明显,如果只使用每个区域的均值和方差,下面的两个区域是无法用任何聚类算法分开的。
左:白噪声;右:渐变
此外,还可以通过计算特征矩(measure Moments)、SSIM等方法来区分上述两个区域。但是这些方法都要求要比较的两个对象必须具有相同的区域形状(例如,长宽相同的矩形,相同大小的圆形),并且每个只能比较两个对象,所以比较部分在该算法,其复杂度将超过 O(n*log(n))。
@Anonymous:关于在医学图像上使用这个算法,可以吗?(问这个问题的人很多,请不要私信,私信的讨论过程帮不了别人,请留言)
这是一种不需要训练数据的单帧图片无监督方案,其训练阶段是推理过程。仅当根本没有数据时才应选择此方法。同等条件下,数据越多越好。
参考^无监督图像分割。ICASSP。2018 ^机器学习无监督语义分割 SLIC 超像素与最先进的超像素方法相比,TPAMI,201 年 5 月2.^机器学习无监督语义分割高效的基于图的图像分割。IJCV。2004~pff/papers/seg-ijcv.pdf 法国自动化研究所卫星图像数据集(其实是航拍的Aerial Image) 为什么要把BN层放在ReLU前面?批量标准化是计算机视觉和模式识别对抗性漏洞会议的一个原因。IEEE。1997 使用特征向量进行分割:统一。国际刑事法院。1999.实时风格迁移和超分辨率的感知损失。约翰逊。ECCV。2016OpenCV 简历2. 查看全部
无规则采集器列表算法(【无监督语义分割】果子:作者算法)
煎饼不是水果:【无监督语义分割】InfoSeg: Unsupervised Semantic Image Segmentation with Mutual Information Maximization
以上内容于2021-10-10更新。我觉得上面的文章相当于下面描述的文章的升级版。
在使用无监督分割可以搜索到的GitHub代码中,最受关注的是这个项目→Unsupervised Image Segmentation by Backpropagation - Asako Kanezaki Kanazaki Asako(东京大学)- GitHub,作者在PyTorch中实现的代码。
基于作者论文的算法,我成功复现了作者的算法,我也把代码放到了Github↑上,我复现的代码可以使用更短的运行时间(作者用图30秒,我用5秒),并达到同样的Split效果。
直接用图片展示算法的效果↓
这些改进并不是因为我的代码写得有多好,而是因为原作者没有很好地实现她的算法,如下图:
第一行是无监督语义分割的输入图像;第二行是作者放在GitHub上的展示图片;第三行是我在本地电脑上运行作者的源代码得到的结果;第四行是基于作者的作者。论文的算法是用 PyTorch 复现的。原作者使用了随机颜色,但为了美观,我随机计算了同一语义标签的平均颜色作为着色。
无监督语义分割结果
注意:第 3 列第 2 行中的两只狼被分成不同的颜色(蓝色和黄色),这是一个偶然的结果。事实上,这个算法不能做Instance Segmentation。第三列,第 3 行,下面是我自己转载的图片:可以看出两只狼被分配了相同的标签。
用GIF动画感性的讲解算法原理↓
该算法一遍又一遍地迭代以将相同的标签分配给具有相似语义的像素(出于美学原因,我选择了随机颜色匹配的不愉快结果,在免费在线 gif 网站 中生成 - 在 ezgif 上生成 gif:
珊瑚珊瑚
Woof Husky下面会正式介绍算法更新日志(文章看起来很长,其实是图片。在文末评论区回复问题)
2019-06-19 第一版,添加橙猫橙图,添加算法缺点章节
2019-06-21 修改compantness -> n_segments 并在评论区回复问题
2019-12-20 点赞和私信的人突然多了?原来是被专栏选中的,所以我更新了一些东西:添加了说明论文中的Conv2D + BN + ReLU部分BN应该放在ReLU之前。修改了文章基于评论和私信,增加了关于医学影像的讨论0.算法主体内容理解代码提高优化效果算法缺点附录末尾文章在评论区回复问题1. 算法主体
个人觉得原论文的算法不好看,在保持算法不变的情况下修改了。原创PDF在这里,其中的算法1如下。
———————————————————————————————————————
算法:无监督图像分割
———————————————————————————————————————
进入:
输入 RGB 图像
输出:
输出语义分割的结果图像
初始化神经网络,保持每一层的方差和均值
图像的初步聚类
迭代 T 次
使用卷积网络获取特征图
根据特征图,值最大的是对应像素的标签
经典语义分割的聚类结果
计算每个集群中出现次数最多的类别
将此簇中的所有像素记录为该类别
计算损失函数(softmax有中文名称:归一化索引)
使用随机梯度下降更新参数——————————————————————————————————————————
在,
,作者使用全卷积网络接受输入图像完成特征提取。该网络由三层卷积网络组成,如下:
作者论文中的图1,我们可以看到这里的两只狼被分配了同一个标签(都是绿色的)
其中,原作者使用2D Conv + ReLU + Batch Norm的做法是不合适的,应该改为Conv2D + BN + ReLU。具体解释见文末附录《Batch normalization Batch Norm 应该在 ReLU 之前》
在,
(原文为GetSuperPixels,使用的是slic算法),即使用经典的机器学习无监督语义分割算法对输入图像进行预分类,如Python的skimage.segmentation中的多种算法,如使用的slic算法由原作者撰写,我推荐使用 felzenszwalb 算法。值得注意的是,在作者的原创代码中,slic算法选择了一个比较极端的参数。选择这个极端参数是有原因的:
原代码为slic选择了一个极端参数n_segments=1000
在slic算法中,当分区数n_segments越高时,算法对输入图像的划分越多:
由于具有相同语义的像素通常存在于图像中的连续区域中,因此可以推断位置相似的像素属于相同语义的概率很高。因此,在预分类中,我们给相邻像素分配相同的语义标签2.算法理解:
首先,使用经典的机器学习算法对输入图像进行“预分类”:调整算法参数,为语义信息明显相同的小区域分配相同的语义标签。由于具有相同语义的像素通常存在于图像的连续区域中,我们可以假设具有接近颜色、接近纹理和接近位置的像素可以被分配相同的语义标签。
然后使用深度学习结合自动编码器结构对输入图像进行分类。分类的目标是使输出的语义分割结果尽可能接近“预分类”的结果。训练收敛。
最后,深度学习的语义分割结果会在符合“预分类结果”的基础上,合并具有相同语义信息的小块,得到大块。
我个人的理解是:在整个无监督语义分割任务中,深度学习(神经网络)的任务就是对经典机器学习无监督语义分割的细粒度预分类结果进行处理。并且在迭代中,小块逐渐融合,最终得到符合人类期望的语义分割结果。
橘猫,无监督语义分割1、2、4、8、16、32、64、128次迭代的结果
大家可以观察我之前发布的gif图,可以看到:语义信息相似的小块会在迭代前期被合并;在迭代后期,只剩下2~8个语义标签。有一种树状的分类方法(类似于物种的进化树),比较自然,比如各种类型的草、虎纹在迭代合并中很好区分和优先排序。需要改进的地方,比如“虎而不橙”的虎尾、虎眼,在迭代中被错误地赋予了与“草”相同的标签,这不是我们希望看到的结果。(我也想到了一些改进方法,这里不再展开)
在作者的原创代码中,网络使用随机梯度下降(SGD)进行训练,学习率选择0.1(默认值为0.001),使得以前的迭代中,该算法非常快速地合并像素。
3. 代码改进(只为了运行效率,缩短运行时间,不改主算法)
详情见文末附录:《为什么我推荐使用felz算法而不是slic算法?》
4. 优化结果(128次迭代,40秒→4秒)
由于修改了代码,用更少的迭代就可以达到同样的效果,所以耗时不到4秒。
测试用图片
修改(魔术修改)后,不仅缩短了时间消耗,而且图像分割的质量也有所提高。下面是我从法国自动化研究所卫星图像数据集Inria Aerial Image,1000x1000的卫星图像数据集的bellingham_x.tif中随机截取的一张图片,图片包括树林、草地、道路、建筑物和一个湖(绿色),里面有cosplay草右下角。
对于这个更大的图像 1000x1000:
原代码迭代 128 次,耗时 3 分钟(不计算 PyTorch 初始化所用的 15 秒):
我修改后的代码也迭代了 128 次,耗时 8 秒(PyTorch 初始化耗时 15 秒):
5. 算法缺点(不够健壮,缺乏限制)
首先,这个算法不够鲁棒,算法受参数影响很大(包括梯度下降法的参数,以及机器学习预分类算法的参数),以及算法随机重启的结果会有所不同。为了展示这个缺点,我做了《橘猫看橘子》:(@cm cm 问:这个方案能不能分老虎和橘子?答:有时可以,有时不能,这就是算法的缺点.)
右上角,我通过PS阈值筛选证明:橙色和图中橘猫的颜色范围是一致的。以下三行是我随机调整参数后得到的不同结果。
结果图中,橘猫的橙色比橘猫的颜色浅,因为橘猫在计算平均像素的时候,黑色的条纹也收录在了计算中。并不是橘猫和橘猫不同。我专门用PS来证明两个橘子是一样的——橘猫的平均颜色比结果图中的橙色要浅,因为橘猫的平均颜色中含有黑色虎纹。深度学习可以区分橘子和橘猫。很大的原因是卷积网络可以更好地感知纹理的差异,而不是仅仅依靠颜色进行分类。
二是算法不够成熟。随着迭代,算法会逐渐合并各个分区。然而,算法中没有设置限制来禁止神经网络合并小区域。
浅草,暗草,枯草,,,,虎尾,虎眼,,虎纹,虎皮
橙色猫图,迭代2次
黑草、浅草、尾虎尾、、、虎皮(橙)、虎皮(白)
橘猫图,迭代3次
深草,浅草(+部分老虎),老虎(大部分)
橘猫图,迭代5次
在作者自己的原创代码中,当语义分割的类别数下降到 3 或 4 时,算法终止。如果去掉训练限制,当整幅图像归为同一类别时,损失降为0。原文设计的损失函数不能限制神经网络机会主义地输出只收录一个类别的结果。这意味着在训练网络时,随机重启可能会得到截然不同的结果,我在运行原创代码时也注意到了这一点。由于没有“一类”的限制,所以这个神经网络的参数个数应该足够少(足够浅,足够窄),这样的设计太容易过拟合(不解决这个问题,模型的提升会是极其有限)。
(我也想到了一些改进的方法,就是用普通的机器学习语义分割算法得到一些必须属于不同语义的标签。作为对“一类”的限制,这里就不展开了)
6. 文末附录《Batch Normalization Batch Norm 应该在 ReLU 之前》
作者论文中的图1,它使用了原作者使用的2D Conv + ReLU + Batch Norm。这种做法不合适,应该改成Conv2D + BN + ReLU
一般在深度学习图像领域,我们会将批归一化层Batch Normalization放在激活函数ReLU前面,使得输入到ReLU的图像接近正态分布N(0, 1).如果将输入归一化归一化操作后的张量转化为梯度变化点为0的激活函数(比如这里使用的ReLU),那么这个激活函数的非线性特性就会被充分发挥出来,构造的loss函数会变得更流畅,可能是因为原论文的作者没有做图像,所以她用错了,我帮她改正为Conv2D + BN + ReLU。
要详细了解为什么使用 Conv2D + BN + ReLU,可以阅读这篇论文:Batch Normalization is a Cause of Adversarial Vulnerability。ArXiv。2019 年 5 月。以此类推,如果一定要用Sigmoid作为激活函数,那么在前面使用Batch Normalization之后,需要将0.0到0.5的均值相加,然后输入Sigmoid就会更合适。下图来自纸图。2.
批量标准化是对抗性漏洞的一个原因。图 2 “为什么我推荐使用 felz 算法而不是 slic 算法?”
在预分类阶段,需要进行细粒度的分类,并分离出足够多的区域(确保分类的地方被分类,神经网络可以帮助它在不应该分类的地方合并),以使最终结果更准确。如果类别太多,算法需要更多的迭代。使用felz算法而不是slic算法是因为它可以用更少的区域命中更多的“正确边界”,并且felz分隔的边界更准确。无论是选择felz算法还是slic算法,当划分足够多的区域时,对精度影响不大,但迭代次数差别很大。先说一下图片:
第一行,预分类结果,第二行,用PS差值表示我们想要得到的区域划分方案。
第一列使用slic算法,分区数为n_segments=1000。可以看出,虽然区域很多,但虎尾与草的距离并不是很好。第二列使用的slic算法,分区数n_segments=100,没有达到我们想要得到的分类边界。
下面是一个带有合适参数的预分类算法(比较felz和slic算法)
slic,边框条纹不够细。而felz算法,它甚至把每一条虎纹都分离出来,这也是我推荐这个算法的原因之一。
“费尔兹算法”
Efficient Graph-Based Image Segmentation - Felzenszwalb (MIT) 2004. Graph-Based Semantic Segmentation。格式塔运动(Holistic Psychology/Gestalt Psychology)认为人类根据事物的整体性做出判断。Felz 算法定义了一种方法,该方法使用基于图形的表示来定义两个区域的边界(定义谓词)。尽管这种方法会做出贪婪的决定,但它仍然会产生满足全局属性的结果。
翻译自 felz 论文的引言部分。
“切片算法”
SLIC 超像素与最先进的超像素方法的比较。2012. 省略,在作者论文的算法描述中,原代码中出现的SuperPixel也出现在了这篇论文中。大胆吐槽,上面的felz算法是2004年的,slic算法是2012年的,但是slic的标题里有State-of-the-Art?如果你没有达到全面的超越,不要说。要想戴上王冠,就必须承受它的重量。
《性能提升与GPU》
因为代码是单线程的,花在CPU上的时间越少,GPU的利用率就越高。所以即使我为了美学计算了所有类中像素的平均颜色,但时间仍然比原创代码短。无论是运行速度还是分割精度,我认为算法还有很大的提升空间。
上面是修改后的代码,GPU利用率30~40%,下面是原代码,GPU利用率10~20%,全部使用RTX2080Ti运行。欢迎评论,如有错误,请多多交流6. 回复评论区问题@cm cm 问:这个设计是不是训练和推理不可知论?每次分割图像时,网络的权重是否会重新训练?
答:“是的,训练的过程就是推理”。该算法与风格迁移的初始版本相同,通过对单个图像进行训练来获得最终结果。在李飞飞等人的实时风格迁移出来之前,风格迁移的结果是“训练”出来的,训练得到的网络参数无法保存在其他图片上使用。所以这个算法还不够成熟(我很想把它改成实时的)。
@一Seconemeow想:flez,然后用平均颜色给像素上色(并计算方差),然后Kmean(k=4),感觉200毫秒能得到比这里展示的分割效果好很多的,还没用过神经网络。(感谢他的建议)...我用flez加yuv空间平均颜色加minibatchkmean做了150ms(cpu)和你差不多的结果。虎皮没有任何问题, ...(详见评论部分)
A:在法国机器学习库 sklearn 中已经有类似的算法,Region Adjacency Graph (RAG) 和合并颜色相似的区域。后来我用了 flez 算法加上 yuv 空间的平均颜色加上 mini-batch + K-mean 的方案。我认为这确实是可行的。有机会我会试试,但是基于同色分类的算法确实是毫秒级的。级算法。但是,前面提到的这种算法存在以下问题:
该算法对机器学习语义分割聚类的预分类结果敏感,需要找到合适的预分类参数。平均色法无法将“黑虎纹”与“橙虎皮”结合起来(见草丛中的橙猫)。平均颜色将错误地合并不同但具有相似平均颜色的区域。仅仅依靠颜色是不够的,纹理的感知还需要深度学习。
问题3相关的gif:RAG算法中使用的阈值从4逐渐增大到128以下,在阈值为32时得到了比较好的结果。
使用 slic 算法 (n_segments=2048, compactness=16, max_iter=8) # 分隔更多区域
使用 slic 算法 (n_segments=2048, compactness=16, max_iter=8) # 分隔更多区域
使用slic算法(n_segments=128, compactness=16, max_iter=8) # 分隔合适的区域
与问题1相关的图片:左图和右图服从均值为128,方差为16的正态分布,右图的每一行使用一个排序。以服从相同的分布
但是对于两张不同纹理的图片,很明显,如果只使用每个区域的均值和方差,下面的两个区域是无法用任何聚类算法分开的。
左:白噪声;右:渐变
此外,还可以通过计算特征矩(measure Moments)、SSIM等方法来区分上述两个区域。但是这些方法都要求要比较的两个对象必须具有相同的区域形状(例如,长宽相同的矩形,相同大小的圆形),并且每个只能比较两个对象,所以比较部分在该算法,其复杂度将超过 O(n*log(n))。
@Anonymous:关于在医学图像上使用这个算法,可以吗?(问这个问题的人很多,请不要私信,私信的讨论过程帮不了别人,请留言)
这是一种不需要训练数据的单帧图片无监督方案,其训练阶段是推理过程。仅当根本没有数据时才应选择此方法。同等条件下,数据越多越好。
参考^无监督图像分割。ICASSP。2018 ^机器学习无监督语义分割 SLIC 超像素与最先进的超像素方法相比,TPAMI,201 年 5 月2.^机器学习无监督语义分割高效的基于图的图像分割。IJCV。2004~pff/papers/seg-ijcv.pdf 法国自动化研究所卫星图像数据集(其实是航拍的Aerial Image) 为什么要把BN层放在ReLU前面?批量标准化是计算机视觉和模式识别对抗性漏洞会议的一个原因。IEEE。1997 使用特征向量进行分割:统一。国际刑事法院。1999.实时风格迁移和超分辨率的感知损失。约翰逊。ECCV。2016OpenCV 简历2.
无规则采集器列表算法(无规则采集器列表算法中一般会包含批量采集这一模块)
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-01-07 21:05
无规则采集器列表算法中一般会包含批量采集这一模块。本质上excel工具也是属于批量采集这一模块。所以,看你对数据的难易程度,如果文本多,表格多,涉及的数据不多,可以用这种。
看excel工具好不好用,功能多不多了,多的话,
看你做的数据量大不大,上限够不够,
不太建议用这个来做数据库采集,比较吃数据库。本人采集网站视频频道,需要爬两三天甚至更久的数据,老婆不让我用,说每天爬一点爬哪能那么慢,都是公司数据都有什么地方用不到,数据库链接都配置好了干嘛非要爬网站去。爬网站要多看网站源码,还是比较严谨可靠的。另外视频频道有网站文件,设定目录、遍历数据库就可以了,没必要爬这么麻烦。结论:。
等等,首先吐槽,竟然没有一个搜索引擎,然后语焉不详的回答了这个问题。既然这样,就得先说一下,就目前爬虫的采集目的。现在,爬虫对于每天的数据进行采集的目的可以划分为以下几个类型,1.像我这样的,经常处理文本文件数据,这里指的是.txt。.txt数据一般来说,几千几万的文本数据,不管用什么工具,都是不可能爬下来的,随便一个爬虫,把他伪装成python啊什么的,爬下来了,一瞬间访问量瞬间上去了,可是,爬一个文件数据还有个必要抓取它的url吗,这些url爬取出来,比爬取10万条文本数据那可是轻而易举啊。
所以,对于文本数据,基本上,任何工具都不能像数据库那样方便的处理。2.对于pdf文件的采集,一般也是需要抓取url的,但这样的数据是可以被python分析出来的,但是python必须要有pdf相关的工具。3.其他大概还有视频,图片等其他数据,这里就不深入了。不过,对于数据采集目的,越多样的,数据分析目的,爬虫就越复杂,收益也就越小。
4.我记得之前在博客中看到过一个统计,爬虫的收益率是0.03%。这里的收益率是指对每一个数据站点,一天少量的数据采集,就有少量的收益,如果,爬取几十万数据,那就基本等于一无所获。5.爬虫,我们应该更多的关注问题而不是工具。1.一个成熟,好用的爬虫工具,在你掌握了大量的python爬虫基础后,不一定能做到小爬虫。
但是,如果还停留在没有工具,只能一遍遍一个一个url来爬取数据,那一定做不到好爬虫。2.大量需要爬取的数据,比如某个频道有上万条数据,每一条数据,你不可能还需要爬到文件,就那么爬呗。这样频繁的把你的爬虫样本到几百几千就没必要了。更多的选择是,保存好一个特定的链接。方便你的爬虫进行判断。要爬取的就进行判断。然。 查看全部
无规则采集器列表算法(无规则采集器列表算法中一般会包含批量采集这一模块)
无规则采集器列表算法中一般会包含批量采集这一模块。本质上excel工具也是属于批量采集这一模块。所以,看你对数据的难易程度,如果文本多,表格多,涉及的数据不多,可以用这种。
看excel工具好不好用,功能多不多了,多的话,
看你做的数据量大不大,上限够不够,
不太建议用这个来做数据库采集,比较吃数据库。本人采集网站视频频道,需要爬两三天甚至更久的数据,老婆不让我用,说每天爬一点爬哪能那么慢,都是公司数据都有什么地方用不到,数据库链接都配置好了干嘛非要爬网站去。爬网站要多看网站源码,还是比较严谨可靠的。另外视频频道有网站文件,设定目录、遍历数据库就可以了,没必要爬这么麻烦。结论:。
等等,首先吐槽,竟然没有一个搜索引擎,然后语焉不详的回答了这个问题。既然这样,就得先说一下,就目前爬虫的采集目的。现在,爬虫对于每天的数据进行采集的目的可以划分为以下几个类型,1.像我这样的,经常处理文本文件数据,这里指的是.txt。.txt数据一般来说,几千几万的文本数据,不管用什么工具,都是不可能爬下来的,随便一个爬虫,把他伪装成python啊什么的,爬下来了,一瞬间访问量瞬间上去了,可是,爬一个文件数据还有个必要抓取它的url吗,这些url爬取出来,比爬取10万条文本数据那可是轻而易举啊。
所以,对于文本数据,基本上,任何工具都不能像数据库那样方便的处理。2.对于pdf文件的采集,一般也是需要抓取url的,但这样的数据是可以被python分析出来的,但是python必须要有pdf相关的工具。3.其他大概还有视频,图片等其他数据,这里就不深入了。不过,对于数据采集目的,越多样的,数据分析目的,爬虫就越复杂,收益也就越小。
4.我记得之前在博客中看到过一个统计,爬虫的收益率是0.03%。这里的收益率是指对每一个数据站点,一天少量的数据采集,就有少量的收益,如果,爬取几十万数据,那就基本等于一无所获。5.爬虫,我们应该更多的关注问题而不是工具。1.一个成熟,好用的爬虫工具,在你掌握了大量的python爬虫基础后,不一定能做到小爬虫。
但是,如果还停留在没有工具,只能一遍遍一个一个url来爬取数据,那一定做不到好爬虫。2.大量需要爬取的数据,比如某个频道有上万条数据,每一条数据,你不可能还需要爬到文件,就那么爬呗。这样频繁的把你的爬虫样本到几百几千就没必要了。更多的选择是,保存好一个特定的链接。方便你的爬虫进行判断。要爬取的就进行判断。然。
无规则采集器列表算法(机器学习中的随机森林算法(一)——Random)
采集交流 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-01-06 11:02
一、随机森林算法简介:
在机器学习中
在,随机森林是一个收录多个决策树的分类器
, 并且输出类别由个体树输出的类别的模式决定。Leo Breiman 和 Adele Cutler 开发了一种算法来推断随机森林。和“随机
“森林”是他们的商标。
这个术语是贝尔实验室的Tin Kam Ho在1995年提出的随机决策森林(random decision forest)。
森林)。这种方法结合了 Breimans 的“Bootstrap aggregating”思想和 Ho 的“randomsubspace”
方法”来构建决策树的集合。
每棵树都是根据以下算法构建的:
1. 用M表示训练案例(样本)的数量,用N表示特征的数量。
2. 输入特征数n,用于确定决策树
上一个节点的决策结果;其中 n 应该远小于 N。
3. 从M个训练案例(样本)中进行替换采样,取k次形成一个训练集
(即引导抽样),并使用未选择的用例(样本)进行预测并评估其错误。
4.对于每个节点,随机选择n个特征,基于这些特征确定每个节点在每棵决策树上的决策。根据这n个特征,计算出最佳分割方法。
5. 每棵树都会完全生长而无需修剪,可以在构建正常的树状分类器后使用。
6.最后测试数据,根据每棵树,以多胜少的方式确定分类。
在构建随机森林时,需要做两方面的工作:数据的随机选择和要选择的特征的随机选择,以消除过拟合的问题。
首先,从原创数据集中取一个有替换的样本,构造一个子数据集。子数据集的数据量与原创数据集的数据量相同。不同子数据集中的元素可以重复,同一子数据集中的元素也可以重复。其次,使用子数据集构建子决策树,将这些数据放入每个子决策树中,每个子决策树输出一个结果。最后,如果有新数据,需要通过随机森林得到分类结果,可以通过对子决策树的判断结果进行投票,得到随机森林的输出结果。如下图所示,假设有
3个子决策树,2个子树的分类结果为A类,1个子树的分类结果为B类,则随机森林的分类结果为A类。
与数据集的随机选择类似,随机森林中子树的每次分裂过程都没有使用所有的候选特征,而是从所有候选特征中随机选择某些特征,然后随机选择。从特征中选择最佳特征。这样可以使随机森林中的决策树互不相同,提高系统的多样性,从而提高分类性能。
优势:
随机森林既可以用于回归任务,也可以用于分类任务,很容易看出模型输入特征的相对重要性。随机森林算法被认为是一种非常方便和易于使用的算法,因为它是默认的超参数,通常会产生很好的预测结果。超参数的数量并不多,它们所代表的含义直观易懂。
随机森林有足够多的树,这样分类器就不会产生过度拟合的模型。
缺点:
由于使用了大量的树,算法变得很慢,无法实现实时预测。一般来说,这些算法训练速度快,预测速度慢。预测越准确,需要的树越多,这将导致模型越慢。在大多数实际应用中,随机森林算法足够快,但肯定会遇到对实时性要求高的情况,所以只能首选其他方法。当然,随机森林是一种预测建模工具,而不是一种描述性工具。换句话说,如果您正在寻找数据中关系的描述,建议您更喜欢其他方法。
适用范围:
随机森林算法可用于许多不同的领域,例如银行、股票市场、医药和电子商务。在银行领域,它通常用于检测比普通人更频繁地使用银行服务的客户,并及时偿还债务。同时,它也会被用来检测想要欺骗银行的客户。在金融领域,可以用来预测未来的股票走势。在医疗保健领域,可用于识别药物成分的正确组合,分析患者的病史以识别疾病。另外,在电子商务领域,随机森林可以用来判断客户是否真的喜欢一个产品。
二、 随机森林算法在sklearn中的应用示例:
(1)基本步骤:
①选择数据:将你的数据分成三组:训练数据、验证数据和测试数据
②模型数据:使用训练数据构建使用相关特征的模型
③验证模型:使用您的验证数据连接到您的模型
④测试模型:使用您的测试数据来检查验证模型的性能
⑤使用模型:使用完全训练好的模型对新数据进行预测
⑥ 调优模型:使用更多的数据、不同的特征或调整后的参数来提高算法的性能
为方便起见,代码如下:
导入 csv
导入 numpy asnp
fromsklearn.ensemble 导入 RandomForestRegressor
从 sklearnimport 预处理
从 sklearn.metricsimport mean_squared_error,explain_variance_score
importmatplotlib.pyplot 作为 plt
#------------------------------------------------- --------------------------------
defload_dataset(文件名):
file_reader = csv.reader(open(filename,'rb'), delimiter=',')
X, y = [], []
对于 file_reader 中的行:
X.append(row[2:13])
y.append(row[-1])
# 提取特征名称
特征名称 = np.array(X[0])
返回
np.array(X[1:]).astype(np.float32),np.array(y[1:]).astype(np.float32),
特征名称
if__name__=='__main__':
X, y, feature_names =load_dataset("d:\\bike_day.csv")
X, y = shuffle(X, y, random_state=7)
num_training = int(0.9 * len(X))
X_train, y_train = X[:num_training],y[:num_training]
X_test, y_test = X[num_training:],y[num_training:]
rf_regressor =RandomForestRegressor(n_estimators=1000, max_depth=10,
min_samples_split=1)
rf_regressor.fit(X_train, y_train)
y_pred = rf_regressor.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
evs = 解释方差分数(y_test,y_pred)
来自 AdaBoostRegressor importplot_feature_importances
plot_feature_importances(rf_regressor.feature_importances_,'RandomForest
回归器',功能名称)
数据集格式如下:
即时,今天,季节,年,月,假期,工作日,工作日,天气,温度,温度,嗡嗡声,风速,休闲,注册,cnt
1,2011-01-01,1,0,1,0,6,0,2,0.344167,0.363625,0.805833,0.160446, 331,654,985
2,2011-01-02,1,0,1,0,0,0,2,0.363478,0.353739,0.696087,0.248539, 131,670,801
3,2011-01-03,1,0,1,0,1,1,1,0.196364,0.189405,0.437273,0.248309, 120,1229,1349
以下数据省略。 查看全部
无规则采集器列表算法(机器学习中的随机森林算法(一)——Random)
一、随机森林算法简介:
在机器学习中
在,随机森林是一个收录多个决策树的分类器
, 并且输出类别由个体树输出的类别的模式决定。Leo Breiman 和 Adele Cutler 开发了一种算法来推断随机森林。和“随机
“森林”是他们的商标。
这个术语是贝尔实验室的Tin Kam Ho在1995年提出的随机决策森林(random decision forest)。
森林)。这种方法结合了 Breimans 的“Bootstrap aggregating”思想和 Ho 的“randomsubspace”
方法”来构建决策树的集合。
每棵树都是根据以下算法构建的:
1. 用M表示训练案例(样本)的数量,用N表示特征的数量。
2. 输入特征数n,用于确定决策树
上一个节点的决策结果;其中 n 应该远小于 N。
3. 从M个训练案例(样本)中进行替换采样,取k次形成一个训练集
(即引导抽样),并使用未选择的用例(样本)进行预测并评估其错误。
4.对于每个节点,随机选择n个特征,基于这些特征确定每个节点在每棵决策树上的决策。根据这n个特征,计算出最佳分割方法。
5. 每棵树都会完全生长而无需修剪,可以在构建正常的树状分类器后使用。
6.最后测试数据,根据每棵树,以多胜少的方式确定分类。
在构建随机森林时,需要做两方面的工作:数据的随机选择和要选择的特征的随机选择,以消除过拟合的问题。
首先,从原创数据集中取一个有替换的样本,构造一个子数据集。子数据集的数据量与原创数据集的数据量相同。不同子数据集中的元素可以重复,同一子数据集中的元素也可以重复。其次,使用子数据集构建子决策树,将这些数据放入每个子决策树中,每个子决策树输出一个结果。最后,如果有新数据,需要通过随机森林得到分类结果,可以通过对子决策树的判断结果进行投票,得到随机森林的输出结果。如下图所示,假设有
3个子决策树,2个子树的分类结果为A类,1个子树的分类结果为B类,则随机森林的分类结果为A类。
与数据集的随机选择类似,随机森林中子树的每次分裂过程都没有使用所有的候选特征,而是从所有候选特征中随机选择某些特征,然后随机选择。从特征中选择最佳特征。这样可以使随机森林中的决策树互不相同,提高系统的多样性,从而提高分类性能。
优势:
随机森林既可以用于回归任务,也可以用于分类任务,很容易看出模型输入特征的相对重要性。随机森林算法被认为是一种非常方便和易于使用的算法,因为它是默认的超参数,通常会产生很好的预测结果。超参数的数量并不多,它们所代表的含义直观易懂。
随机森林有足够多的树,这样分类器就不会产生过度拟合的模型。
缺点:
由于使用了大量的树,算法变得很慢,无法实现实时预测。一般来说,这些算法训练速度快,预测速度慢。预测越准确,需要的树越多,这将导致模型越慢。在大多数实际应用中,随机森林算法足够快,但肯定会遇到对实时性要求高的情况,所以只能首选其他方法。当然,随机森林是一种预测建模工具,而不是一种描述性工具。换句话说,如果您正在寻找数据中关系的描述,建议您更喜欢其他方法。
适用范围:
随机森林算法可用于许多不同的领域,例如银行、股票市场、医药和电子商务。在银行领域,它通常用于检测比普通人更频繁地使用银行服务的客户,并及时偿还债务。同时,它也会被用来检测想要欺骗银行的客户。在金融领域,可以用来预测未来的股票走势。在医疗保健领域,可用于识别药物成分的正确组合,分析患者的病史以识别疾病。另外,在电子商务领域,随机森林可以用来判断客户是否真的喜欢一个产品。
二、 随机森林算法在sklearn中的应用示例:
(1)基本步骤:
①选择数据:将你的数据分成三组:训练数据、验证数据和测试数据
②模型数据:使用训练数据构建使用相关特征的模型
③验证模型:使用您的验证数据连接到您的模型
④测试模型:使用您的测试数据来检查验证模型的性能
⑤使用模型:使用完全训练好的模型对新数据进行预测
⑥ 调优模型:使用更多的数据、不同的特征或调整后的参数来提高算法的性能
为方便起见,代码如下:
导入 csv
导入 numpy asnp
fromsklearn.ensemble 导入 RandomForestRegressor
从 sklearnimport 预处理
从 sklearn.metricsimport mean_squared_error,explain_variance_score
importmatplotlib.pyplot 作为 plt
#------------------------------------------------- --------------------------------
defload_dataset(文件名):
file_reader = csv.reader(open(filename,'rb'), delimiter=',')
X, y = [], []
对于 file_reader 中的行:
X.append(row[2:13])
y.append(row[-1])
# 提取特征名称
特征名称 = np.array(X[0])
返回
np.array(X[1:]).astype(np.float32),np.array(y[1:]).astype(np.float32),
特征名称
if__name__=='__main__':
X, y, feature_names =load_dataset("d:\\bike_day.csv")
X, y = shuffle(X, y, random_state=7)
num_training = int(0.9 * len(X))
X_train, y_train = X[:num_training],y[:num_training]
X_test, y_test = X[num_training:],y[num_training:]
rf_regressor =RandomForestRegressor(n_estimators=1000, max_depth=10,
min_samples_split=1)
rf_regressor.fit(X_train, y_train)
y_pred = rf_regressor.predict(X_test)
mse = mean_squared_error(y_test, y_pred)
evs = 解释方差分数(y_test,y_pred)
来自 AdaBoostRegressor importplot_feature_importances
plot_feature_importances(rf_regressor.feature_importances_,'RandomForest
回归器',功能名称)
数据集格式如下:
即时,今天,季节,年,月,假期,工作日,工作日,天气,温度,温度,嗡嗡声,风速,休闲,注册,cnt
1,2011-01-01,1,0,1,0,6,0,2,0.344167,0.363625,0.805833,0.160446, 331,654,985
2,2011-01-02,1,0,1,0,0,0,2,0.363478,0.353739,0.696087,0.248539, 131,670,801
3,2011-01-03,1,0,1,0,1,1,1,0.196364,0.189405,0.437273,0.248309, 120,1229,1349
以下数据省略。
无规则采集器列表算法(信用卡解决方案警务实时布控系统服务于公安案件侦破(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-12-31 16:35
什么是实时数据处理?
• 数据生成->实时采集->实时缓存存储->实时计算->实时登陆->实时展示->实时分析。这个过程下去,处理数据的速度是秒级甚至毫秒级的。
• 电子商务网站双十一大屏,优采云站实时车辆信息显示,股票交易大厅信息显示。
实时数据处理意义
• 数据的价值是通过大数据处理获得的,但数据的价值是恒定的吗?明显不是。一些数据在业务发生后很快就具有很高的价值,随着时间的推移,这个价值会迅速下降,因此数据的处理速度变得尤为重要。实时处理的关键意义在于能够更快速地提供数据洞察。
实时处理解与其他解的关系
实时部署场景
商业场景
广州省公安厅警务实时布控系统服务于公安案件侦查。
• 实时数据采集:通过警务数据共享交换平台和边界平台实时获取出行/住宿/通讯/视频数据。
• 实时数据分析:基于规则模型对调度人员信息进行实时监控和分析。
• 智能实时预警:部署控制规则触发后实时预警,通知办案人员抓捕。
典型特征
• 多种数据格式:数据库/数据文件/视频图片。
• 海量数据:22.5TB/天/35MB/秒。
• 数据冲击的流入:数据流量在短时间内突然增长。
• 复杂作业调度:实时采集/小批量采集。
• 时间要求高:5 秒内完成计算。
• 资源占用高:容易发生资源抢占。
信用卡反欺诈场景
商业场景
Z银行信用卡反欺诈系统基于“渠道-反欺诈引擎-主机”的实现框架:
• 交易通道:客户刷卡后,从银联、VISA、万事达等卡组织向银行发送实时交易。
• 欺诈识别:
• 清理和完善卡组织的交易数据,提取风险特征。
• 将风险特征加载到神经网络和业务规则中,对交易做出欺诈判断。
• 拦截可疑交易并发送验证码进行验证。
• 主持人:
• 对正常交易进行账务处理,登记异常交易拦截原因,冻结假卡。
典型特征
• 大:处理的数据量大,并发度高。
• 快速:以毫秒为单位进行欺诈识别。
• 稳定:7*24 小时服务。
o 多租户支持:服务于不同的业务线。
• 丰富的模型支持。
• 规则
• 异常值模型(无监督学习:聚类)
• 关联模型(监督学习:LR、分类等)
• 神经网络模型
实时数据处理系统的需求
• 处理速度快:端到端的处理需要达到秒级。比如风控项目需要单次数据处理时间达到秒级,单节点TPS大于2000。
• 高吞吐量:需要在短时间内接收和处理大量数据记录,吞吐量需要达到几十兆/秒/节点。
• 高可靠性:当网络和软件出现故障时,要保证每条数据不丢失,不遗漏或重复处理数据。
• 横向扩展:当系统处理能力出现瓶颈时,可以通过节点的横向扩展来提升处理性能。
• 多数据源支持:支持网络流、文件、数据库表、IOT等格式的数据源。对于文件数据源,可以处理增量数据的加载。
• 数据权限和资源隔离:消息处理和流处理需要数据权限控制。不同的工作和用户可以访问和处理不同的消息和数据。多个流处理应用之间需要进行资源控制和隔离,以防止资源争用。
• 第三方工具对接:支持与第三方规则引擎、决策系统、实时推荐系统等对接。
华为实时流处理技术架构
• 数据源:主要包括业务数据库、Socket数据流和实时文件等。
• 实时数据采集:用于实时采集数据源产生的写入分布式消息系统的数据。采集的数据格式包括文件、数据库、网络数据流等。
• Flume:Hadoop自带的采集工具,支持多种格式的数据源,包括日志文件、网络数据流等。
• 第三方采集工具:第三方专用实时数据采集工具,包括GoldenGate(数据库实时采集)、自研采集程序(自定义采集工具)等。
• 消息中间件:消息中间件可以缓存实时数据,支持高吞吐量的消息订阅和发布。
• Kafka:分布式消息系统,支持消息的生产和发布,以及多种形式的消息缓存,满足高效可靠的消息生产和消费。
• 分布式流计算引擎:用于实时数据的快速分析。
• Structured Streaming:基于Spark 的流处理引擎,支持秒级流处理分析。
• Flink:新一代流处理引擎,支持毫秒级流处理分析。
• 流计算引擎,优先推荐Flink
• 数据缓存(可选):缓存流处理分析的结果,满足流处理应用的访问需求。
• Redis:提供高速键/值存储和查询能力,用于流处理结果数据的高速缓存。 查看全部
无规则采集器列表算法(信用卡解决方案警务实时布控系统服务于公安案件侦破(组图))
什么是实时数据处理?
• 数据生成->实时采集->实时缓存存储->实时计算->实时登陆->实时展示->实时分析。这个过程下去,处理数据的速度是秒级甚至毫秒级的。
• 电子商务网站双十一大屏,优采云站实时车辆信息显示,股票交易大厅信息显示。
实时数据处理意义
• 数据的价值是通过大数据处理获得的,但数据的价值是恒定的吗?明显不是。一些数据在业务发生后很快就具有很高的价值,随着时间的推移,这个价值会迅速下降,因此数据的处理速度变得尤为重要。实时处理的关键意义在于能够更快速地提供数据洞察。
实时处理解与其他解的关系
实时部署场景
商业场景
广州省公安厅警务实时布控系统服务于公安案件侦查。
• 实时数据采集:通过警务数据共享交换平台和边界平台实时获取出行/住宿/通讯/视频数据。
• 实时数据分析:基于规则模型对调度人员信息进行实时监控和分析。
• 智能实时预警:部署控制规则触发后实时预警,通知办案人员抓捕。
典型特征
• 多种数据格式:数据库/数据文件/视频图片。
• 海量数据:22.5TB/天/35MB/秒。
• 数据冲击的流入:数据流量在短时间内突然增长。
• 复杂作业调度:实时采集/小批量采集。
• 时间要求高:5 秒内完成计算。
• 资源占用高:容易发生资源抢占。
信用卡反欺诈场景
商业场景
Z银行信用卡反欺诈系统基于“渠道-反欺诈引擎-主机”的实现框架:
• 交易通道:客户刷卡后,从银联、VISA、万事达等卡组织向银行发送实时交易。
• 欺诈识别:
• 清理和完善卡组织的交易数据,提取风险特征。
• 将风险特征加载到神经网络和业务规则中,对交易做出欺诈判断。
• 拦截可疑交易并发送验证码进行验证。
• 主持人:
• 对正常交易进行账务处理,登记异常交易拦截原因,冻结假卡。
典型特征
• 大:处理的数据量大,并发度高。
• 快速:以毫秒为单位进行欺诈识别。
• 稳定:7*24 小时服务。
o 多租户支持:服务于不同的业务线。
• 丰富的模型支持。
• 规则
• 异常值模型(无监督学习:聚类)
• 关联模型(监督学习:LR、分类等)
• 神经网络模型
实时数据处理系统的需求
• 处理速度快:端到端的处理需要达到秒级。比如风控项目需要单次数据处理时间达到秒级,单节点TPS大于2000。
• 高吞吐量:需要在短时间内接收和处理大量数据记录,吞吐量需要达到几十兆/秒/节点。
• 高可靠性:当网络和软件出现故障时,要保证每条数据不丢失,不遗漏或重复处理数据。
• 横向扩展:当系统处理能力出现瓶颈时,可以通过节点的横向扩展来提升处理性能。
• 多数据源支持:支持网络流、文件、数据库表、IOT等格式的数据源。对于文件数据源,可以处理增量数据的加载。
• 数据权限和资源隔离:消息处理和流处理需要数据权限控制。不同的工作和用户可以访问和处理不同的消息和数据。多个流处理应用之间需要进行资源控制和隔离,以防止资源争用。
• 第三方工具对接:支持与第三方规则引擎、决策系统、实时推荐系统等对接。
华为实时流处理技术架构
• 数据源:主要包括业务数据库、Socket数据流和实时文件等。
• 实时数据采集:用于实时采集数据源产生的写入分布式消息系统的数据。采集的数据格式包括文件、数据库、网络数据流等。
• Flume:Hadoop自带的采集工具,支持多种格式的数据源,包括日志文件、网络数据流等。
• 第三方采集工具:第三方专用实时数据采集工具,包括GoldenGate(数据库实时采集)、自研采集程序(自定义采集工具)等。
• 消息中间件:消息中间件可以缓存实时数据,支持高吞吐量的消息订阅和发布。
• Kafka:分布式消息系统,支持消息的生产和发布,以及多种形式的消息缓存,满足高效可靠的消息生产和消费。
• 分布式流计算引擎:用于实时数据的快速分析。
• Structured Streaming:基于Spark 的流处理引擎,支持秒级流处理分析。
• Flink:新一代流处理引擎,支持毫秒级流处理分析。
• 流计算引擎,优先推荐Flink
• 数据缓存(可选):缓存流处理分析的结果,满足流处理应用的访问需求。
• Redis:提供高速键/值存储和查询能力,用于流处理结果数据的高速缓存。
无规则采集器列表算法(java中文开发者社区可以免费学习一点django框架、flask框架)
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-12-30 18:05
无规则采集器列表算法规则采集器ps:免费的建议使用cocos2d-x+gson
批量采集,采用python实现。网上有很多使用python来采集数据的教程,推荐一个我们团队里面开发的python爬虫项目,很棒的github地址:-python对于采集小的站点文章来说,足够用了。毕竟小文章就几百个页面数据,对于数据量比较大的网站,采用的抓取器就需要考虑重复爬取和频繁访问等问题,不是那么简单的,用python搞起来比较复杂。
如果没有采集基础的话推荐人肉采集。如果具备基础的话推荐使用谷歌浏览器自带的页面爬取工具,抓包不过是针对特定网站的,不对所有网站生效。
我不知道现在针对做it爬虫的采集工具是不是特别多,
1、强大的nodejs爬虫工具codecademyjavascriptdom分析网站codecademy.js官方cssinjavascript
2、java中文开发者社区可以免费学习一点django框架、flask框架
1、django实战教程
2、django实战
3、flaskdjango教程以上是在我推荐的网站中,你可以先了解一下哈,另外我还推荐:百度java、网易云课堂、韦神的csdn,以及我自己的b站。
当然要人肉采集,不给力。但是某些网站可以算是首页了,至少说明是个人来讲吧,有采集过程中校验,不会影响正常访问。既然采集正常了,即使破坏也不是把整个app都搞死,再说这并不能带来多少收益。 查看全部
无规则采集器列表算法(java中文开发者社区可以免费学习一点django框架、flask框架)
无规则采集器列表算法规则采集器ps:免费的建议使用cocos2d-x+gson
批量采集,采用python实现。网上有很多使用python来采集数据的教程,推荐一个我们团队里面开发的python爬虫项目,很棒的github地址:-python对于采集小的站点文章来说,足够用了。毕竟小文章就几百个页面数据,对于数据量比较大的网站,采用的抓取器就需要考虑重复爬取和频繁访问等问题,不是那么简单的,用python搞起来比较复杂。
如果没有采集基础的话推荐人肉采集。如果具备基础的话推荐使用谷歌浏览器自带的页面爬取工具,抓包不过是针对特定网站的,不对所有网站生效。
我不知道现在针对做it爬虫的采集工具是不是特别多,
1、强大的nodejs爬虫工具codecademyjavascriptdom分析网站codecademy.js官方cssinjavascript
2、java中文开发者社区可以免费学习一点django框架、flask框架
1、django实战教程
2、django实战
3、flaskdjango教程以上是在我推荐的网站中,你可以先了解一下哈,另外我还推荐:百度java、网易云课堂、韦神的csdn,以及我自己的b站。
当然要人肉采集,不给力。但是某些网站可以算是首页了,至少说明是个人来讲吧,有采集过程中校验,不会影响正常访问。既然采集正常了,即使破坏也不是把整个app都搞死,再说这并不能带来多少收益。

