
文章定时自动采集
文章定时自动采集(利用python进行数据分析-第2版写得很不错)
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-01-24 17:06
文章定时自动采集,采集整个网站的所有内容,不用每次自己逐个请求去获取,无侵入式的,一劳永逸,
我觉得比较好的是redis和mysql,
你有什么特别想了解的,我给你推荐一个系列的博客:利用python进行数据分析-第2版写得很不错,你可以参考一下。
我觉得你大一不用发愁这个问题!各种编程语言都有涉及,可以从你现在大一所对应的部门入手,最好能读一些有名的数据库学校课程,
推荐最后一本书——python从入门到实践python从入门到实践(豆瓣)
利用python从输入网页内容到翻页,
我的经验是数据结构是王道。再把算法和数据结构了解一下。实践的话,现在绝大多数公司都有api接口。请直接到访华的美国公司的官网在web端获取demo文件。省略一万字,直接去google+facebookgithubstackoverflow里搜会有收获的。
数据结构最重要的是要弄清楚流程与结构,流程就是数据输入接收输出。至于结构可以看数据结构。弄清楚之后无论从php到go都可以编程。算法与数据结构没必要单独学。掌握对应算法即可。
看看豆瓣上的书,
谢邀,
python技术类图书推荐书籍推荐,供参考《python3网络爬虫开发实战》《python3爬虫开发实战(第2版)》推荐指数:书名:《python3网络爬虫开发实战(第2版)》,作者:李明主编出版社:人民邮电出版社类别:技术书籍作者:李明、吴娟内容简介:本书是python3语言的入门、实践、学习材料。
适合对网络爬虫有一定了解的读者,学习者也可以将本书作为python3程序设计的基础教程。本书不讲述晦涩难懂的技术概念,而是通过大量的练习来让读者体会python3语言的设计优势。本书保证了3天突破python3开发,3周掌握爬虫框架设计,1周编写爬虫项目,同时通过自己的项目搭建,作者还创建了“大易工具箱”专门用于学习python3。人手一本,秒杀“python123”。 查看全部
文章定时自动采集(利用python进行数据分析-第2版写得很不错)
文章定时自动采集,采集整个网站的所有内容,不用每次自己逐个请求去获取,无侵入式的,一劳永逸,
我觉得比较好的是redis和mysql,
你有什么特别想了解的,我给你推荐一个系列的博客:利用python进行数据分析-第2版写得很不错,你可以参考一下。
我觉得你大一不用发愁这个问题!各种编程语言都有涉及,可以从你现在大一所对应的部门入手,最好能读一些有名的数据库学校课程,
推荐最后一本书——python从入门到实践python从入门到实践(豆瓣)
利用python从输入网页内容到翻页,
我的经验是数据结构是王道。再把算法和数据结构了解一下。实践的话,现在绝大多数公司都有api接口。请直接到访华的美国公司的官网在web端获取demo文件。省略一万字,直接去google+facebookgithubstackoverflow里搜会有收获的。
数据结构最重要的是要弄清楚流程与结构,流程就是数据输入接收输出。至于结构可以看数据结构。弄清楚之后无论从php到go都可以编程。算法与数据结构没必要单独学。掌握对应算法即可。
看看豆瓣上的书,
谢邀,
python技术类图书推荐书籍推荐,供参考《python3网络爬虫开发实战》《python3爬虫开发实战(第2版)》推荐指数:书名:《python3网络爬虫开发实战(第2版)》,作者:李明主编出版社:人民邮电出版社类别:技术书籍作者:李明、吴娟内容简介:本书是python3语言的入门、实践、学习材料。
适合对网络爬虫有一定了解的读者,学习者也可以将本书作为python3程序设计的基础教程。本书不讲述晦涩难懂的技术概念,而是通过大量的练习来让读者体会python3语言的设计优势。本书保证了3天突破python3开发,3周掌握爬虫框架设计,1周编写爬虫项目,同时通过自己的项目搭建,作者还创建了“大易工具箱”专门用于学习python3。人手一本,秒杀“python123”。
文章定时自动采集(WP-AutoBlog为全新开发插件(原-AutoPost将不再更新和维护) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-01-24 05:22
)
简介:
目前每个版本的 WordPress 都能完美运行,请放心使用。 WP-AutoPost-Pro 是一款优秀的 WordPress 文章采集器,是你操作站群,让网站自动更新内容的强大工具!
这个版本和官方功能没有区别;
采集插件的适用对象
1、新建的wordpress网站内容比较少,希望尽快有更丰富的内容;
2、热点内容自动采集自动发布;
3、预定采集,手动采集发布或保存到草稿;
4、css样式规则,可以更精确到采集需要的内容。
5、伪原创进行翻译,代理IP采集,保存cookie记录;
6、你可以采集内容到自定义栏目
WP-AutoBlog是新的开发插件(原WP-AutoPost将不再更新维护),全面支持PHP7.3更快更稳定
全新架构和设计,采集设置更加全面灵活;支持多级文章列表、多级文章内容采集
新增支持谷歌神经网络翻译,有道神经网络翻译,轻松获取高质量原创文章
全面支持市面上所有主流对象存储服务,如七牛云、阿里云OSS等。
你可以采集微信公众号、今日头条号等自媒体内容,因为百度没有收录公众号、今日头条文章等,可以轻松获得高质量的“原创”文章,增加百度收录的音量和网站权重
您可以采集任何网站内容,采集信息一目了然
通过简单的设置,你可以从任意网站内容中采集,并且可以设置多个采集任务同时运行,可以设置任务自动运行或手动,主任务列表显示每个采集任务的状态:上次检测到采集时间,估计下次检测采集时间,最近采集文章,完成采集更新文章号码等信息,方便查看和管理。
文章管理函数方便查询、查找、删除。采集文章,改进算法从根本上杜绝了重复采集一样文章 , log 函数记录采集过程中的异常和抓取错误,方便检查和设置错误进行修复。
WP-AutoBlog是新的开发插件(原WP-AutoPost将不再更新维护),全面支持PHP7.3更快更稳定
全新架构和设计,采集设置更加全面灵活;支持多级文章列表、多级文章内容采集
新增支持谷歌神经网络翻译,有道神经网络翻译,轻松获取高质量原创文章
全面支持市面上所有主流对象存储服务,如七牛云、阿里云OSS等。
你可以采集微信公众号、今日头条号等自媒体内容,因为百度没有收录公众号、今日头条文章等,可以轻松获得高质量的“原创”文章,增加百度收录的音量和网站权重
您可以采集任何网站内容,采集信息一目了然
通过简单的设置,你可以从任意网站内容中采集,并且可以设置多个采集任务同时运行,可以设置任务自动运行或手动,主任务列表显示每个采集任务的状态:上次检测到采集时间,估计下次检测采集时间,最近采集文章,完成采集更新文章号码等信息,方便查看和管理。
文章管理函数方便查询、查找、删除。采集文章,改进算法从根本上杜绝了重复采集一样文章 , log 函数记录采集过程中的异常和抓取错误,方便检查和设置错误进行修复。
网盘下载地址:
解压密码:
图片:
查看全部
文章定时自动采集(WP-AutoBlog为全新开发插件(原-AutoPost将不再更新和维护)
)
简介:
目前每个版本的 WordPress 都能完美运行,请放心使用。 WP-AutoPost-Pro 是一款优秀的 WordPress 文章采集器,是你操作站群,让网站自动更新内容的强大工具!
这个版本和官方功能没有区别;
采集插件的适用对象
1、新建的wordpress网站内容比较少,希望尽快有更丰富的内容;
2、热点内容自动采集自动发布;
3、预定采集,手动采集发布或保存到草稿;
4、css样式规则,可以更精确到采集需要的内容。
5、伪原创进行翻译,代理IP采集,保存cookie记录;
6、你可以采集内容到自定义栏目
WP-AutoBlog是新的开发插件(原WP-AutoPost将不再更新维护),全面支持PHP7.3更快更稳定
全新架构和设计,采集设置更加全面灵活;支持多级文章列表、多级文章内容采集
新增支持谷歌神经网络翻译,有道神经网络翻译,轻松获取高质量原创文章
全面支持市面上所有主流对象存储服务,如七牛云、阿里云OSS等。
你可以采集微信公众号、今日头条号等自媒体内容,因为百度没有收录公众号、今日头条文章等,可以轻松获得高质量的“原创”文章,增加百度收录的音量和网站权重
您可以采集任何网站内容,采集信息一目了然
通过简单的设置,你可以从任意网站内容中采集,并且可以设置多个采集任务同时运行,可以设置任务自动运行或手动,主任务列表显示每个采集任务的状态:上次检测到采集时间,估计下次检测采集时间,最近采集文章,完成采集更新文章号码等信息,方便查看和管理。
文章管理函数方便查询、查找、删除。采集文章,改进算法从根本上杜绝了重复采集一样文章 , log 函数记录采集过程中的异常和抓取错误,方便检查和设置错误进行修复。
WP-AutoBlog是新的开发插件(原WP-AutoPost将不再更新维护),全面支持PHP7.3更快更稳定
全新架构和设计,采集设置更加全面灵活;支持多级文章列表、多级文章内容采集
新增支持谷歌神经网络翻译,有道神经网络翻译,轻松获取高质量原创文章
全面支持市面上所有主流对象存储服务,如七牛云、阿里云OSS等。
你可以采集微信公众号、今日头条号等自媒体内容,因为百度没有收录公众号、今日头条文章等,可以轻松获得高质量的“原创”文章,增加百度收录的音量和网站权重
您可以采集任何网站内容,采集信息一目了然
通过简单的设置,你可以从任意网站内容中采集,并且可以设置多个采集任务同时运行,可以设置任务自动运行或手动,主任务列表显示每个采集任务的状态:上次检测到采集时间,估计下次检测采集时间,最近采集文章,完成采集更新文章号码等信息,方便查看和管理。
文章管理函数方便查询、查找、删除。采集文章,改进算法从根本上杜绝了重复采集一样文章 , log 函数记录采集过程中的异常和抓取错误,方便检查和设置错误进行修复。
网盘下载地址:
解压密码:
图片:


文章定时自动采集(如何24小时定时定量自动去访问某个url呢?宝塔面板)
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2022-01-23 10:14
如何24小时定时定量自动访问某个url?宝塔面板可以很容易地完成。今天,错误博客( )分享的内容是“宝塔计划任务访问URL(采集站群必备知识)”。我希望能有所帮助。
宝塔计划任务访问url
一、宝塔板
宝塔需要安装在服务器上,然后宝塔面板才能使用。说白了就是宝塔安装在我们的服务器上,宝塔软件包括各种自动化程序,然后我们在访问网页的时候,只要不关闭服务器,就可以设置定时任务来访问一个 url 连接随时 24 小时。.
宝塔面板
二、宝塔项目任务
Pagoda定时任务有六种:Shell脚本、备份网站、备份数据库、日志切割、释放内存、访问URL。以 URL 为例,描述宝塔计划的任务。
1、选择任务类型
在这里您必须选择“访问 URL”。
2、执行周期
宝塔的执行周期可以是每月、每周、每小时、N天、N小时、N分钟。
每月:每个月的执行时间,后面的小时和分钟可以认为是从早上12:00开始计算,0小时0分钟是指当天早上12:00。
每周和每天和每月都是一样的。
N天:即每隔几天执行一次。
N hours:每隔几个小时执行一次。
N 分钟:每隔几分钟执行一次。
如果您的计划任务过于复杂,您可以尝试设置多个计划任务。
执行周期
以上是错误博客( )分享的内容是“宝塔计划任务访问URL(采集站群必备知识)”。谢谢阅读。
本文《宝塔计划任务访问网址(采集站群必备知识)》由Error Blog()或原创整理,感谢阅读。随机文章【机器人文件协议】百度解禁机器人全过程
【说站长】从站长到牛角_全面拥抱熊掌
SEO经验分享——小小课堂优化10个月内达到百度权重4
网址是什么意思?页面抓取过程简述
内蒙古SEO【收录索引】搜狗SEO官方指南六
搜索引擎优化器常识:搜索引擎的基本架构
潮州seo【谷歌质量指南系列十二:如何防止垃圾评论】
什么是电子邮件营销?有什么优点和特点?如何获取电子邮件 查看全部
文章定时自动采集(如何24小时定时定量自动去访问某个url呢?宝塔面板)
如何24小时定时定量自动访问某个url?宝塔面板可以很容易地完成。今天,错误博客( )分享的内容是“宝塔计划任务访问URL(采集站群必备知识)”。我希望能有所帮助。

宝塔计划任务访问url
一、宝塔板
宝塔需要安装在服务器上,然后宝塔面板才能使用。说白了就是宝塔安装在我们的服务器上,宝塔软件包括各种自动化程序,然后我们在访问网页的时候,只要不关闭服务器,就可以设置定时任务来访问一个 url 连接随时 24 小时。.

宝塔面板
二、宝塔项目任务
Pagoda定时任务有六种:Shell脚本、备份网站、备份数据库、日志切割、释放内存、访问URL。以 URL 为例,描述宝塔计划的任务。
1、选择任务类型
在这里您必须选择“访问 URL”。
2、执行周期
宝塔的执行周期可以是每月、每周、每小时、N天、N小时、N分钟。
每月:每个月的执行时间,后面的小时和分钟可以认为是从早上12:00开始计算,0小时0分钟是指当天早上12:00。
每周和每天和每月都是一样的。
N天:即每隔几天执行一次。
N hours:每隔几个小时执行一次。
N 分钟:每隔几分钟执行一次。
如果您的计划任务过于复杂,您可以尝试设置多个计划任务。

执行周期
以上是错误博客( )分享的内容是“宝塔计划任务访问URL(采集站群必备知识)”。谢谢阅读。
本文《宝塔计划任务访问网址(采集站群必备知识)》由Error Blog()或原创整理,感谢阅读。随机文章【机器人文件协议】百度解禁机器人全过程
【说站长】从站长到牛角_全面拥抱熊掌
SEO经验分享——小小课堂优化10个月内达到百度权重4
网址是什么意思?页面抓取过程简述
内蒙古SEO【收录索引】搜狗SEO官方指南六
搜索引擎优化器常识:搜索引擎的基本架构
潮州seo【谷歌质量指南系列十二:如何防止垃圾评论】
什么是电子邮件营销?有什么优点和特点?如何获取电子邮件
文章定时自动采集(系统环境Ubuntu20.04如何安装Zeit在Ubuntu系统中的应用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2022-01-22 03:05
Zeit 是一个开源工具,用于通过“crontab”和“at”来安排任务。它提供了一个简单的界面来安排一次性任务或重复任务。 Zeit 还带有一个闹钟和计时器,可以使用声音通知用户。
系统环境
Ubuntu 20.04
如何安装 Zeit
在 Ubuntu 系统上,可以通过添加下面的 PPA 存储库来安装 Zeit。
bob@ubuntu-20-04:~$ sudo add-apt-repository ppa:blaze/main
PPA for my software
More info: https://launchpad.net/~blaze/+archive/ubuntu/main
Press [ENTER] to continue or Ctrl-c to cancel adding it.
...
bob@ubuntu-20-04:~$ sudo apt install zeit
输入 Zeit 运行
使用 at 命令运行一次性命令
使用at命令运行一次性命令,点击查看->非周期命令或者按ctrl+n,可以切换到非周期任务。
选择“添加命令”并添加一个条目。安排一个命令在 11:34 运行。此命令将在 Downloads 文件夹中创建一个空日志文件,并将今天的日期添加到文件名中,如下所示:
NOW=$(date +%F); touch /home/bob/Downloads/log_${NOW}.txt
此任务无法修改,但可以删除并重新添加。
11:34,可以看到Downloads目录下已经创建了一个日志文件。
Zeit界面,按ctrl+r,刷新页面,发现任务已经执行完毕,消失了。
创建重复任务
要使用 crond 进程安排任务,请单击查看->定期任务或按 CTRL + P。默认情况下,Zeit 启动“定期任务”。
输入描述、命令和计划时间,然后单击确定将条目添加到 crontab。以下是每天0:00备份到用户家目录的日志目录。
可以使用 crontab -l 检查添加的条目:
bob@ubuntu-20-04:~$ crontab -l
总结
Zeit 是一个开源工具,用于通过“crontab”和“at”来安排任务。它提供了一个简单的界面来安排一次性任务或重复任务。 查看全部
文章定时自动采集(系统环境Ubuntu20.04如何安装Zeit在Ubuntu系统中的应用)
Zeit 是一个开源工具,用于通过“crontab”和“at”来安排任务。它提供了一个简单的界面来安排一次性任务或重复任务。 Zeit 还带有一个闹钟和计时器,可以使用声音通知用户。
系统环境
Ubuntu 20.04
如何安装 Zeit
在 Ubuntu 系统上,可以通过添加下面的 PPA 存储库来安装 Zeit。
bob@ubuntu-20-04:~$ sudo add-apt-repository ppa:blaze/main
PPA for my software
More info: https://launchpad.net/~blaze/+archive/ubuntu/main
Press [ENTER] to continue or Ctrl-c to cancel adding it.
...
bob@ubuntu-20-04:~$ sudo apt install zeit
输入 Zeit 运行
使用 at 命令运行一次性命令
使用at命令运行一次性命令,点击查看->非周期命令或者按ctrl+n,可以切换到非周期任务。
选择“添加命令”并添加一个条目。安排一个命令在 11:34 运行。此命令将在 Downloads 文件夹中创建一个空日志文件,并将今天的日期添加到文件名中,如下所示:
NOW=$(date +%F); touch /home/bob/Downloads/log_${NOW}.txt
此任务无法修改,但可以删除并重新添加。
11:34,可以看到Downloads目录下已经创建了一个日志文件。
Zeit界面,按ctrl+r,刷新页面,发现任务已经执行完毕,消失了。
创建重复任务
要使用 crond 进程安排任务,请单击查看->定期任务或按 CTRL + P。默认情况下,Zeit 启动“定期任务”。
输入描述、命令和计划时间,然后单击确定将条目添加到 crontab。以下是每天0:00备份到用户家目录的日志目录。
可以使用 crontab -l 检查添加的条目:
bob@ubuntu-20-04:~$ crontab -l
总结
Zeit 是一个开源工具,用于通过“crontab”和“at”来安排任务。它提供了一个简单的界面来安排一次性任务或重复任务。
文章定时自动采集( ZBlog发布能让网站保持一个持续更新的状态吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2022-01-21 18:08
ZBlog发布能让网站保持一个持续更新的状态吗?)
ZBlog Publishing是系统文章定时发布工具(网站文章自动定时发布助手)是ZBlog网站文章自动定时发布的辅助工具。定时释放功能强大,操作简单。使用后,可以帮助站长更轻松便捷地定期发布网站文章。主要用于ZBlog采集伪原创发布。使用非常简单,只需要提前设置即可。ZBlog发布可以帮助站长在更新网站时节省大量时间。只要设置好发布时间,就可以在指定时间自动发布,极大的方便了网站的日常管理。
ZBlog 的发布将使 网站 处于持续更新的状态。因为网站收录的问题一直是SEO优化人员关心的问题,做SEO优化的人都想知道网站的收录是不能一蹴而就的一两天,如果你的网站的收录有所改善,你要坚持每天更新你的网站,最好养成每天更新网站文章 这是一种习惯。时间长了,蜘蛛会对你网站产生好感,所以会经常造访你的网站,让你的网站收录越爬越高!
ZBlog 的发帖会经常更新网站,因为每个SEOer 不可能每天都有时间上网管理自己的网站。但是每个 网站 必须至少每天更新。只要你能坚持这种更新方式,蜘蛛肯定会养成一种习惯,蜘蛛会经常来你的网站爬文章和内容,所以蜘蛛会爬网站更多您的内容。
当然,网站的内容需要了解这几点,一个吸引人的网站,用户不看就不会离开,一定会流连忘返。所以你停留的时间长短会在一定程度上体现你的网站品质。对于相同的内容,您的页面停留和其他人的 网站 页面停留将由搜索引擎计算和比较。当然,也有页面阅读量,因为页面阅读量反映了你的网站是否受用户欢迎,是否向用户的潜在需求推荐内容。
ZBlog发布自带伪原创,对一个原创的文章进行重新处理,让搜索引擎认为它是一个原创文章,从而增加权重网站。伪原创相比原创,更容易创建,对创作者的技术要求不高,更容易完成持久化和定期更新。一些SEO技术不成熟的网站会选择大量丰富的网站内容,利用网页数量来提高关键词的排名概率。比如发一百篇文章有2个排名,那么发一千篇文章可能有20个排名,以此类推。但是,有必要增加更新的频率和数量。几乎不可能依赖原创文章,所以< 查看全部
文章定时自动采集(
ZBlog发布能让网站保持一个持续更新的状态吗?)

ZBlog Publishing是系统文章定时发布工具(网站文章自动定时发布助手)是ZBlog网站文章自动定时发布的辅助工具。定时释放功能强大,操作简单。使用后,可以帮助站长更轻松便捷地定期发布网站文章。主要用于ZBlog采集伪原创发布。使用非常简单,只需要提前设置即可。ZBlog发布可以帮助站长在更新网站时节省大量时间。只要设置好发布时间,就可以在指定时间自动发布,极大的方便了网站的日常管理。
ZBlog 的发布将使 网站 处于持续更新的状态。因为网站收录的问题一直是SEO优化人员关心的问题,做SEO优化的人都想知道网站的收录是不能一蹴而就的一两天,如果你的网站的收录有所改善,你要坚持每天更新你的网站,最好养成每天更新网站文章 这是一种习惯。时间长了,蜘蛛会对你网站产生好感,所以会经常造访你的网站,让你的网站收录越爬越高!
ZBlog 的发帖会经常更新网站,因为每个SEOer 不可能每天都有时间上网管理自己的网站。但是每个 网站 必须至少每天更新。只要你能坚持这种更新方式,蜘蛛肯定会养成一种习惯,蜘蛛会经常来你的网站爬文章和内容,所以蜘蛛会爬网站更多您的内容。
当然,网站的内容需要了解这几点,一个吸引人的网站,用户不看就不会离开,一定会流连忘返。所以你停留的时间长短会在一定程度上体现你的网站品质。对于相同的内容,您的页面停留和其他人的 网站 页面停留将由搜索引擎计算和比较。当然,也有页面阅读量,因为页面阅读量反映了你的网站是否受用户欢迎,是否向用户的潜在需求推荐内容。
ZBlog发布自带伪原创,对一个原创的文章进行重新处理,让搜索引擎认为它是一个原创文章,从而增加权重网站。伪原创相比原创,更容易创建,对创作者的技术要求不高,更容易完成持久化和定期更新。一些SEO技术不成熟的网站会选择大量丰富的网站内容,利用网页数量来提高关键词的排名概率。比如发一百篇文章有2个排名,那么发一千篇文章可能有20个排名,以此类推。但是,有必要增加更新的频率和数量。几乎不可能依赖原创文章,所以<
文章定时自动采集(为你24小时自动采集更新马克斯MAXCMS、飞飞FFCMS、光线GXCMS)
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2022-01-20 02:01
影视网站Auto采集UpdatecmsAuto采集Update Max MAXcms、飞飞FFcms、Ray GX<Movie网站 系统如@cms、Apple MACcms,甚至不是该类型的系统都可以应用。让您无需等待网站长时间更新,即可专注于SEO。指定时间自动更新网站,好帮手!
会有什么效果?
首先,它最符合各大搜索引擎蜘蛛的上门访问。如果您每次都在这些点更新,他会记住并习惯您的网站,并且不会空手而归!最后你的快照稳定,收录稳定,你的排名也相对好一些!总而言之,让 网站 活着。
支持:Max MAXcms、飞飞FFcms、Ray GXcms、魅魔Maccms
1、设置大大简化
2、自动登录2.0,更安全更简单
3、一个软件更新多站多采集资源,不占用内存资源
4、不占用CPU,只是cmsPHP程序更新的时候占用一点
5、采集你想要多少资源
强调:
1、帮助设置,降低难度
2、无需验证码cms,无需修改文件,减少麻烦
3、打开一个软件更新多个站点,即一对多。减少服务器内存开销,
4、代码设计精良,运行速度快,占用内存少
5、操作简单,软件上有提示和说明,一看就知道!
修改记录:
2012-3-25 添加网站更新排序功能,修改BUG!
2012-3-03 支持新版Ray GXcms的定期更新!
2012-2-14 解决中文注册登录问题。如果您遇到此类问题,请下载最新的更新程序! 查看全部
文章定时自动采集(为你24小时自动采集更新马克斯MAXCMS、飞飞FFCMS、光线GXCMS)
影视网站Auto采集UpdatecmsAuto采集Update Max MAXcms、飞飞FFcms、Ray GX<Movie网站 系统如@cms、Apple MACcms,甚至不是该类型的系统都可以应用。让您无需等待网站长时间更新,即可专注于SEO。指定时间自动更新网站,好帮手!
会有什么效果?
首先,它最符合各大搜索引擎蜘蛛的上门访问。如果您每次都在这些点更新,他会记住并习惯您的网站,并且不会空手而归!最后你的快照稳定,收录稳定,你的排名也相对好一些!总而言之,让 网站 活着。
支持:Max MAXcms、飞飞FFcms、Ray GXcms、魅魔Maccms
1、设置大大简化
2、自动登录2.0,更安全更简单
3、一个软件更新多站多采集资源,不占用内存资源
4、不占用CPU,只是cmsPHP程序更新的时候占用一点
5、采集你想要多少资源
强调:
1、帮助设置,降低难度
2、无需验证码cms,无需修改文件,减少麻烦
3、打开一个软件更新多个站点,即一对多。减少服务器内存开销,
4、代码设计精良,运行速度快,占用内存少
5、操作简单,软件上有提示和说明,一看就知道!
修改记录:
2012-3-25 添加网站更新排序功能,修改BUG!
2012-3-03 支持新版Ray GXcms的定期更新!
2012-2-14 解决中文注册登录问题。如果您遇到此类问题,请下载最新的更新程序!
文章定时自动采集(这样的一个小报系统是如何实现的呢?(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2022-01-19 01:07
下图是政采云前端小报( )官网截图,里面收录了我们每一期历史的总结~
截止目前,前端小报93期,汇聚1000+文章,涵盖50+大小品类。可以说是很不错的知识库了~
前端小报的由来
持续学习是每个工程师都必须的,一个成长中的团队也需要这样的持续学习氛围。那么如何利用技术帮助团队培养持续学习的氛围呢?
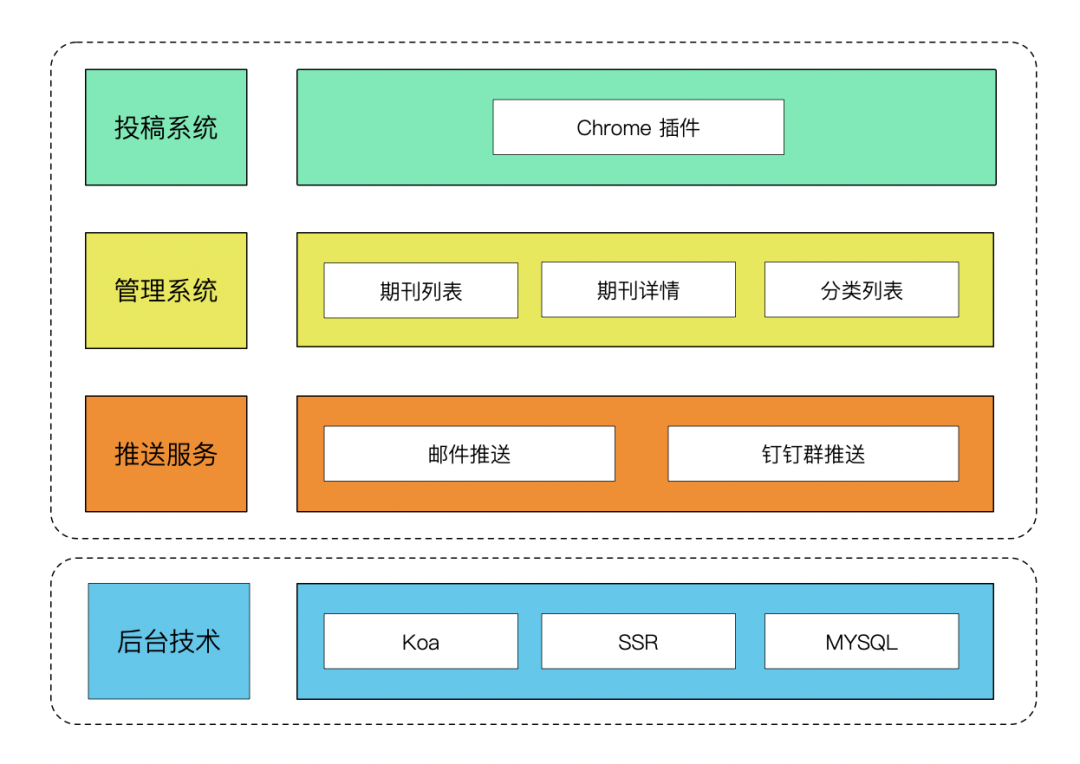
于是,正财云前端小报应运而生。主要包括提交、聚合沉淀、定时投递三个核心模块。这样的系统可以让大家轻松将自己喜欢的文章分享给团队,对分享文章进行分类沉淀,为团队打造知识库,方便大家查阅。同时,小报系统每周五也会定时推送,让大家了解最新的科技动态。分享学习氛围的好帮手~
那么这样一个小报系统是如何运作的呢?
如何为提交设计一个小报系统
我相信当你看到一个好的文章时,总会有一种与他人分享的冲动。一个简单易用的推送功能,可以轻松满足大家的分享欲望。好文章进队帮助其他同学~
一个简单易行的贡献函数,我们需要解决两个问题:
1、看到好东西如何满足分享的冲动文章
2、提交的文章如何分类采集,方便沉淀和搜索
如果是单独录入系统和人工录入,这种方式操作起来比较麻烦,而且很容易打消大家的积极性。我们平时在浏览器中看文章的时候,经常会采集好文章,一键操作,方便快捷。那么怎么能像浏览器书签采集文章一样方便投稿呢?
很容易想到通过浏览器的扩展能力来做到这一点,Chrome插件就提供了这样的能力
什么是 Chrome 扩展程序
官方解释():谷歌插件是用来定制浏览器体验的小程序。它允许用户根据个人需求或偏好自定义 Chrome 的功能和行为,并且它们基于 Web 技术(HTML、JavaScript 和 CSS)构建。
会说话的人话:开发一个web项目,可以嵌入到Chrome浏览器中,可以通过一些特定的API获取一些能力,从而定制自己的插件功能
如何开发Chrome插件一键提交
首先创建一个项目并开发一个贡献页面。
这个项目和普通的 Vue 项目唯一的区别就是在根目录下多了一个 manifest.json 文件。
{ <br /> // 核心代码 <br /> "name": "Zoo!", // 扩展名 <br /> "browser_action": { <br /> "default_popup": "./popup.html" // 点击浏览器右上方插件小图标弹出的内容 html <br /> }, <br /> "content_scripts": [ // 能够在 Web 页面内运行的 javascript 脚本 <br /> { <br /> "matches": [<br /> // 满足什么协议下进行调用 <br /> "http://*/*", <br /> "https://*/*" <br /> ], <br /> "js": [ <br /> "./contentScripts/zdata.js" // 插入到网页的 JS 文件路径 <br /> ], <br /> "run_at": "document_start" // 在document 加载时执行 <br /> } <br /> ] <br />} <br />
这样,当插件打开时,会默认加载popup.html页面的内容,效果如下:
插件本身并不能真正获取当前页面的标题,但是Chrome插件提供了将固定的JS脚本动态插入当前页面的能力。我们可以根据这个机制在当前页面中插入一个JS脚本来获取标题、介绍和URL,然后通过消息机制将获取到的内容返回给插件。
let host = this;<br />// 获取当前窗口 id <br />chrome.tabs.query({<br /> active: true,<br /> currentWindow: true<br />}, function (tabs) {<br /> let tabId = tabs.length ? tabs[0].id : null;<br /> // 向当前页面注入 JavaScript 脚本 <br /> chrome.tabs.executeScript(tabId || null, {<br /> file: './contentScripts/recommend.js'<br /> }, function () {<br /> // 向目标网页进行通信,向 recommend.js 发送一个消息 <br /> chrome.tabs.sendMessage(tabId, {<br /> message: 'GET_TOPIC_INFO',<br /> }, function (response) {<br /> // 获取到返回的文章 title 、url、description <br /> host.article.title = response.title;<br /> host.article.link = response.link;<br /> host.article.description = response.description;<br /> });<br /> });<br />}); <br />
推荐.js 监听消息。通过 addListener,我们可以监听 sendMessage 发送的消息。在 sendMessage 中定义消息常量可以让我们在接收消息时区分消息。
let doc = document;<br />chrome.runtime.onMessage.addListener(function (request, sender, sendResponse) {<br /> if (request.message === 'GET_TOPIC_INFO') {<br /> // 获取 title <br /> let title = document.getElementsByTagName('title')[0].textContent;<br /> let descriptionEl = doc.querySelectorAll('meta[name=description]')[0];<br /> // 获取 描述 <br /> let description = descriptionEl ? descriptionEl.getAttribute('content') : title;<br /> // 发送数据 <br /> sendResponse({<br /> title: title.trim(),<br /> link: location.href,<br /> description: description.trim()<br /> });<br /> } else if (request.message === 'SIGN_RELOAD') {<br /> console.log('request, sender', request, sender);<br /> }<br />}); <br />
// 投稿按钮点击事件 <br />handleRecommendArticle: function () {<br /> let request;<br /> request = ajax({<br /> method: 'post',<br /> url: 'https://XXX/api/post', // 后端接口 <br /> data: {<br /> 'title': this.article.title,<br /> 'desc': this.article.description,<br /> 'category': this.article.category[1] || '默认分类',<br /> 'link': this.article.link,<br /> 'referrer': this.article.reporter<br /> }<br /> });<br />} <br />
效果图:
以上是一个非常轻量级的Chrome插件的实现。基于这样一个Chrome插件,当我们看到喜欢的文章时,可以一键分享给团队的小伙伴~
当文章太多的时候,如果没有有效的管理,文章就会堆得乱七八糟,会让大家失去学习的欲望,那么我们如何分类采集提交的 文章 ,方便同学们找到自己需要的知识体系吗?
标签设计
设计标签分类需要一些时间。主要难点是什么分类维度可以让投稿人快速找到对应的分类,让观众可以根据分类快速找到自己想要的文章,以及如何快速找到过去的文章等.
这就要求我们的分类要通俗易懂,涵盖大部分业务类型文章。最后,我们从基础、语言、架构、选择、工具、总结等多个维度进行分类。
为了能够快速搜索文章,Chrome插件中也集成了分类查看功能。
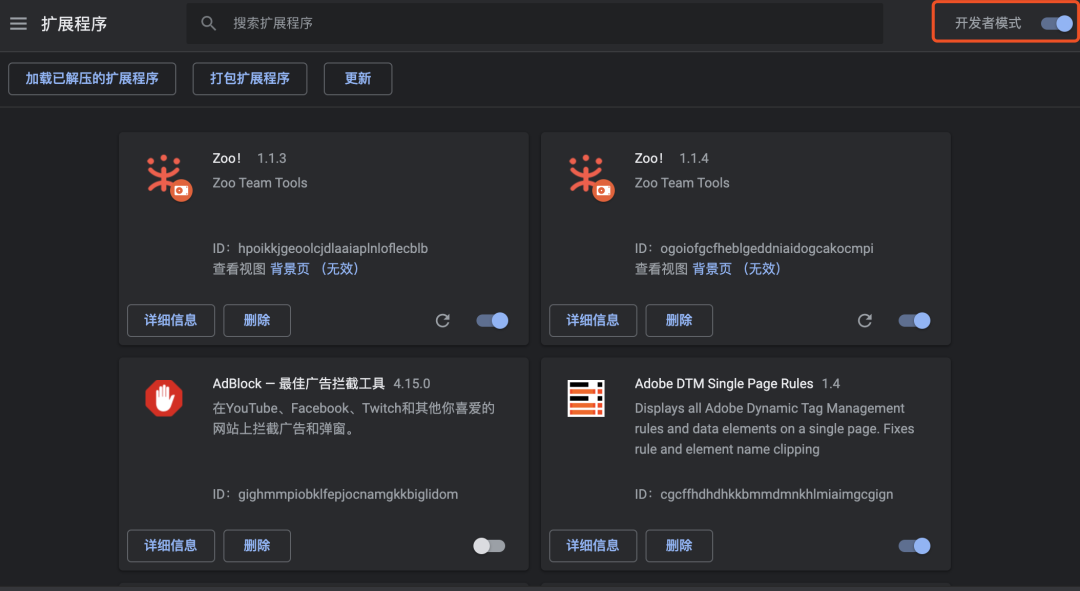
插件制作完成后,其他同学可以将你的插件安装包安装到浏览器中。因为有墙,所以没有选项可以将插件上传到 Chrome 应用商店。我们在本地安装它。下图为打包后的项目目录结构:
安装步骤:浏览器选择设置->扩展->加载解压后的扩展->选择文件目录。同时,记得开启开发者模式。
Chrome扩展官方详细文档请移步链接()查看
聚合沉淀对于前端项目来说是很常见的,这里就不多说了。主要是能看到每一期的文章,快速分类搜索,统一收录文章入口。其中,前端页面是通过SSR服务端渲染实现的。
定时交货
到这里,小报系统的前端展示页面已经完成了,那么如何让每一期的优质文章更及时方便同学们阅读,让大家在学习中了解新技术适时地开阔眼界。后来我们想到可以通过主动联系、定时提醒等方式主动给队友发日记,所以在以上基础上,设计了一个单独的推送服务,定时推送每周小报到钉钉群和前台——结束邮件组。
const pushToRobot = async ({ data, title, nums }) => {<br /> // 组装发送数据格式 <br /> const links = wrapperFeedcard({ data, nums });<br /> // 发送数据到指定群 <br /> return axios("https://oapi.dingtalk.com/robot/send?", {<br /> method: "post",<br /> params: {<br /> access_token: "XXXX" //前端群 <br /> },<br /> data: {<br /> feedCard: {<br /> links<br /> },<br /> msgtype: "feedCard"<br /> }<br /> })<br />}; <br />
// 创建邮件链接 <br />const nodemailer = require("nodemailer"); <br />let transporter = nodemailer.createTransport({ <br /> service: "qiye.aliyun", <br /> port: 25, // SMTP 端口 <br /> host: "smtp.mxhichina.com", <br /> secureConnection: true, // 使用了 SSL <br /> auth: { <br /> user: "xxx@cai-inc.com", <br /> pass: "xxx" <br /> } <br />}); <br />// 组装发送内容 <br />let mailOptions = { <br /> from: '"政采云前端小报" ', // sender address <br /> to: "ZooTeam@cai-inc.com", // list of receivers <br /> cc: ["ZooTeam@cai-inc.com"], <br /> html: '邮件内容' // html body <br />}; <br />// 邮件发送 <br />transporter.sendMail(mailOptions); <br />
有一天,我们掘金的运营小姐告诉我,我们每周五要下班的时候发布文章。这太痛苦了。下班后耽误了我的约会。我说好,我们自己开发一个定时发布功能。如果想知道掘金的定时发布功能如何实现,可以在评论区留言讨论。
整体设计
总结
前端小报系统虽然是一个小系统,但无论是功能设计还是系统设计,都在追逐一个目标,努力促进团队的学习氛围,让团队成员不断成长。希望分享这篇文章能给大家一些启发,如何从一个目标出发去拆解实施,思考如何让工具更好地为人服务。
读两件事
如果你觉得这个内容有启发性,我想请你帮我做两件小事
1.点击“我在看”,让更多人看到这个内容(点击“我在看”,bug -1?) 查看全部
文章定时自动采集(这样的一个小报系统是如何实现的呢?(组图))
下图是政采云前端小报( )官网截图,里面收录了我们每一期历史的总结~
截止目前,前端小报93期,汇聚1000+文章,涵盖50+大小品类。可以说是很不错的知识库了~
前端小报的由来
持续学习是每个工程师都必须的,一个成长中的团队也需要这样的持续学习氛围。那么如何利用技术帮助团队培养持续学习的氛围呢?
于是,正财云前端小报应运而生。主要包括提交、聚合沉淀、定时投递三个核心模块。这样的系统可以让大家轻松将自己喜欢的文章分享给团队,对分享文章进行分类沉淀,为团队打造知识库,方便大家查阅。同时,小报系统每周五也会定时推送,让大家了解最新的科技动态。分享学习氛围的好帮手~
那么这样一个小报系统是如何运作的呢?
如何为提交设计一个小报系统
我相信当你看到一个好的文章时,总会有一种与他人分享的冲动。一个简单易用的推送功能,可以轻松满足大家的分享欲望。好文章进队帮助其他同学~
一个简单易行的贡献函数,我们需要解决两个问题:
1、看到好东西如何满足分享的冲动文章
2、提交的文章如何分类采集,方便沉淀和搜索
如果是单独录入系统和人工录入,这种方式操作起来比较麻烦,而且很容易打消大家的积极性。我们平时在浏览器中看文章的时候,经常会采集好文章,一键操作,方便快捷。那么怎么能像浏览器书签采集文章一样方便投稿呢?
很容易想到通过浏览器的扩展能力来做到这一点,Chrome插件就提供了这样的能力
什么是 Chrome 扩展程序
官方解释():谷歌插件是用来定制浏览器体验的小程序。它允许用户根据个人需求或偏好自定义 Chrome 的功能和行为,并且它们基于 Web 技术(HTML、JavaScript 和 CSS)构建。
会说话的人话:开发一个web项目,可以嵌入到Chrome浏览器中,可以通过一些特定的API获取一些能力,从而定制自己的插件功能
如何开发Chrome插件一键提交
首先创建一个项目并开发一个贡献页面。
这个项目和普通的 Vue 项目唯一的区别就是在根目录下多了一个 manifest.json 文件。
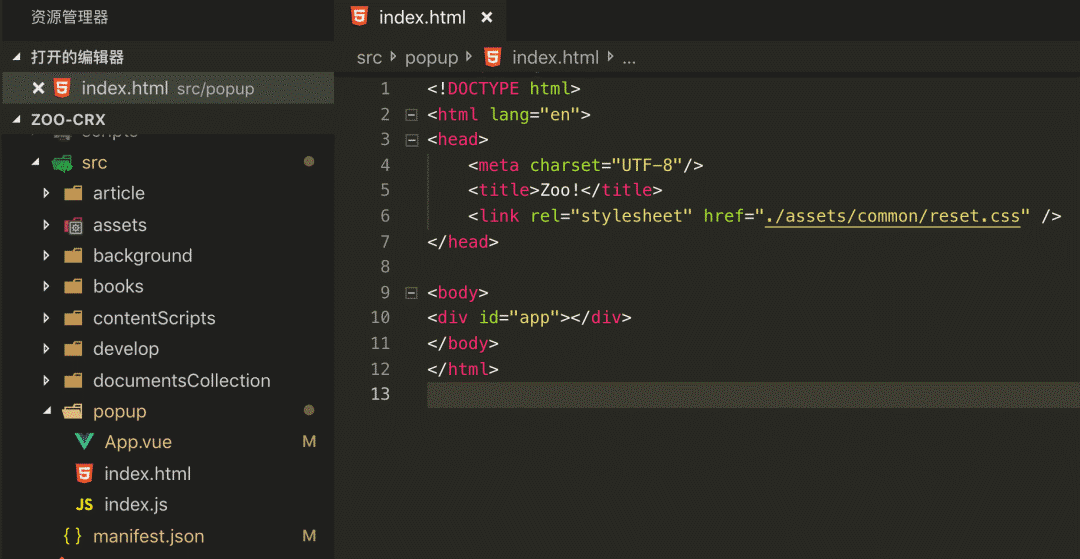
{ <br /> // 核心代码 <br /> "name": "Zoo!", // 扩展名 <br /> "browser_action": { <br /> "default_popup": "./popup.html" // 点击浏览器右上方插件小图标弹出的内容 html <br /> }, <br /> "content_scripts": [ // 能够在 Web 页面内运行的 javascript 脚本 <br /> { <br /> "matches": [<br /> // 满足什么协议下进行调用 <br /> "http://*/*", <br /> "https://*/*" <br /> ], <br /> "js": [ <br /> "./contentScripts/zdata.js" // 插入到网页的 JS 文件路径 <br /> ], <br /> "run_at": "document_start" // 在document 加载时执行 <br /> } <br /> ] <br />} <br />
这样,当插件打开时,会默认加载popup.html页面的内容,效果如下:

插件本身并不能真正获取当前页面的标题,但是Chrome插件提供了将固定的JS脚本动态插入当前页面的能力。我们可以根据这个机制在当前页面中插入一个JS脚本来获取标题、介绍和URL,然后通过消息机制将获取到的内容返回给插件。
let host = this;<br />// 获取当前窗口 id <br />chrome.tabs.query({<br /> active: true,<br /> currentWindow: true<br />}, function (tabs) {<br /> let tabId = tabs.length ? tabs[0].id : null;<br /> // 向当前页面注入 JavaScript 脚本 <br /> chrome.tabs.executeScript(tabId || null, {<br /> file: './contentScripts/recommend.js'<br /> }, function () {<br /> // 向目标网页进行通信,向 recommend.js 发送一个消息 <br /> chrome.tabs.sendMessage(tabId, {<br /> message: 'GET_TOPIC_INFO',<br /> }, function (response) {<br /> // 获取到返回的文章 title 、url、description <br /> host.article.title = response.title;<br /> host.article.link = response.link;<br /> host.article.description = response.description;<br /> });<br /> });<br />}); <br />
推荐.js 监听消息。通过 addListener,我们可以监听 sendMessage 发送的消息。在 sendMessage 中定义消息常量可以让我们在接收消息时区分消息。
let doc = document;<br />chrome.runtime.onMessage.addListener(function (request, sender, sendResponse) {<br /> if (request.message === 'GET_TOPIC_INFO') {<br /> // 获取 title <br /> let title = document.getElementsByTagName('title')[0].textContent;<br /> let descriptionEl = doc.querySelectorAll('meta[name=description]')[0];<br /> // 获取 描述 <br /> let description = descriptionEl ? descriptionEl.getAttribute('content') : title;<br /> // 发送数据 <br /> sendResponse({<br /> title: title.trim(),<br /> link: location.href,<br /> description: description.trim()<br /> });<br /> } else if (request.message === 'SIGN_RELOAD') {<br /> console.log('request, sender', request, sender);<br /> }<br />}); <br />
// 投稿按钮点击事件 <br />handleRecommendArticle: function () {<br /> let request;<br /> request = ajax({<br /> method: 'post',<br /> url: 'https://XXX/api/post', // 后端接口 <br /> data: {<br /> 'title': this.article.title,<br /> 'desc': this.article.description,<br /> 'category': this.article.category[1] || '默认分类',<br /> 'link': this.article.link,<br /> 'referrer': this.article.reporter<br /> }<br /> });<br />} <br />
效果图:
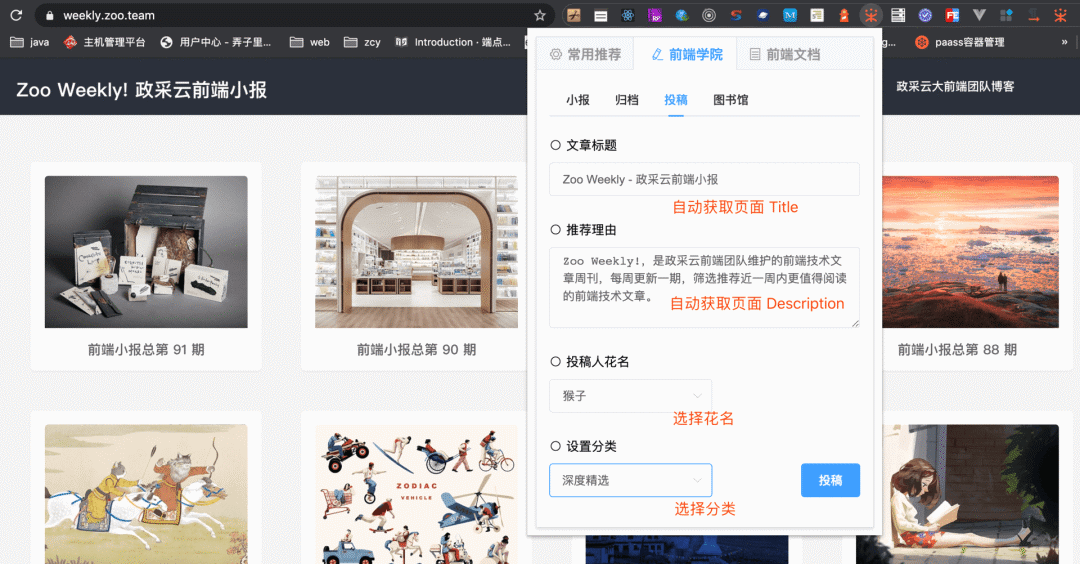
以上是一个非常轻量级的Chrome插件的实现。基于这样一个Chrome插件,当我们看到喜欢的文章时,可以一键分享给团队的小伙伴~
当文章太多的时候,如果没有有效的管理,文章就会堆得乱七八糟,会让大家失去学习的欲望,那么我们如何分类采集提交的 文章 ,方便同学们找到自己需要的知识体系吗?
标签设计
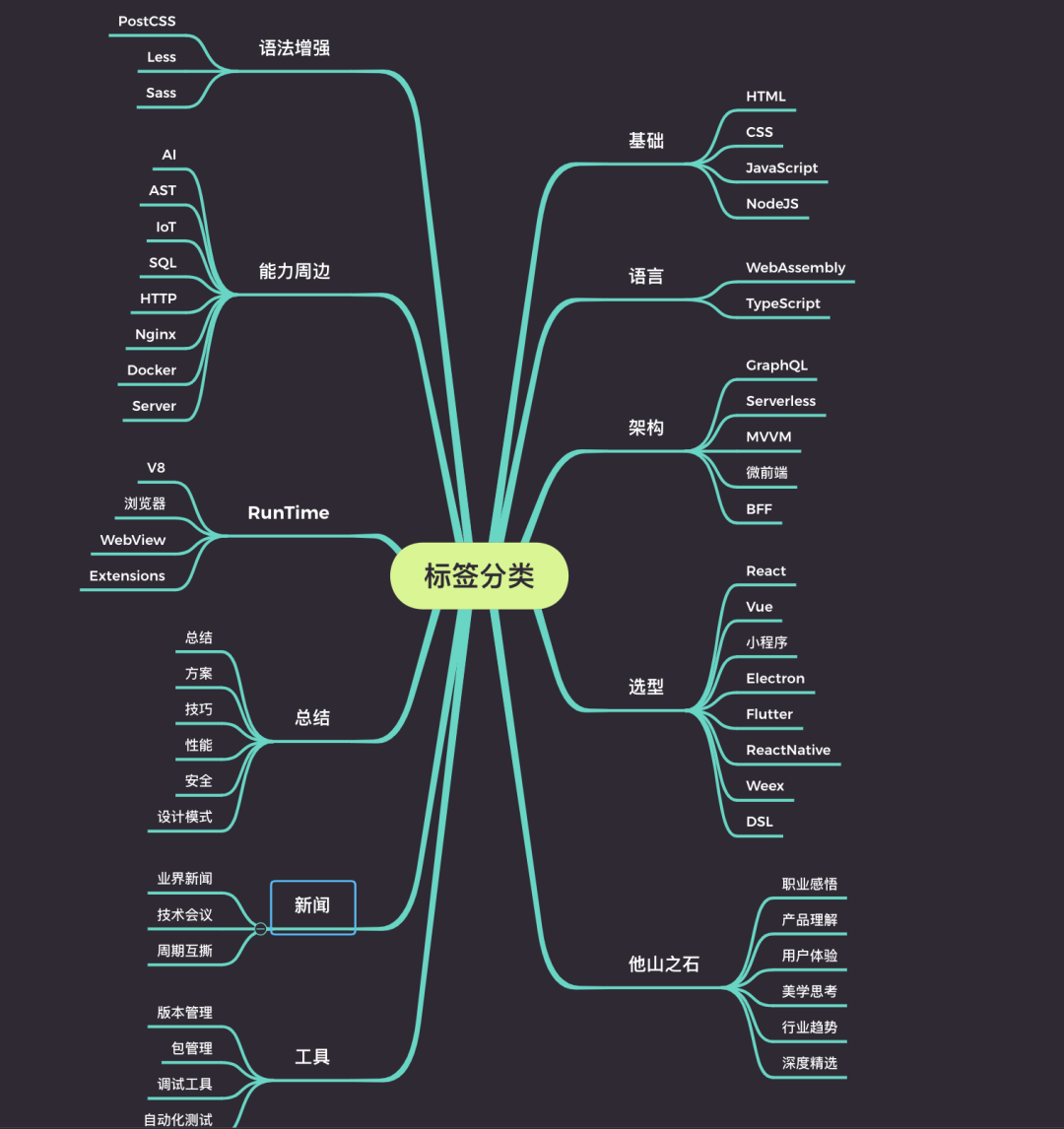
设计标签分类需要一些时间。主要难点是什么分类维度可以让投稿人快速找到对应的分类,让观众可以根据分类快速找到自己想要的文章,以及如何快速找到过去的文章等.
这就要求我们的分类要通俗易懂,涵盖大部分业务类型文章。最后,我们从基础、语言、架构、选择、工具、总结等多个维度进行分类。
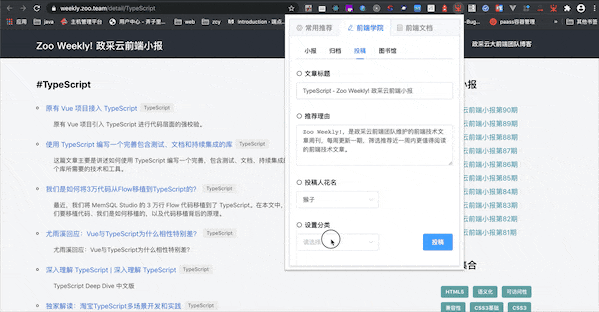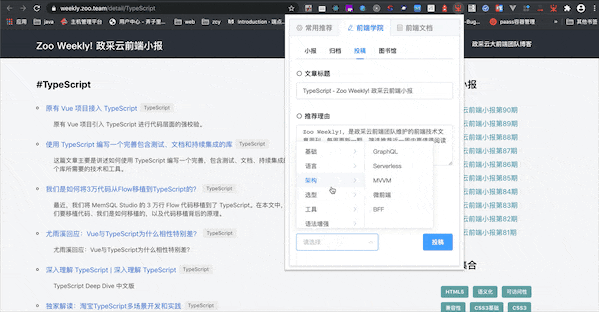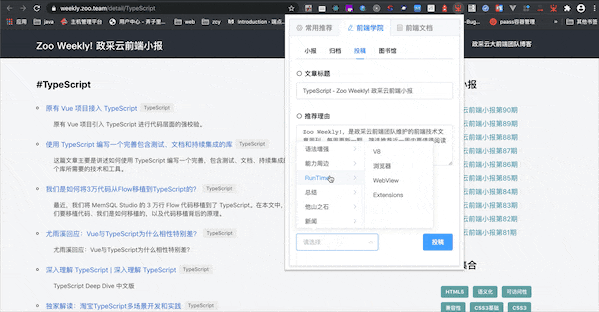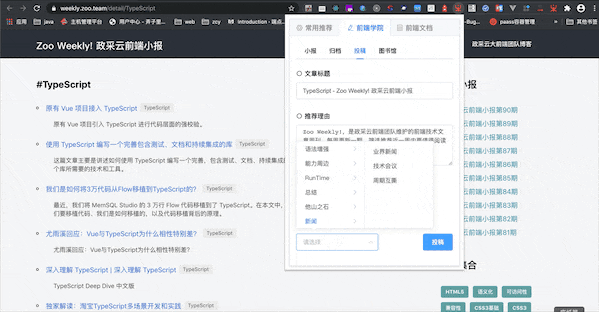
为了能够快速搜索文章,Chrome插件中也集成了分类查看功能。
插件制作完成后,其他同学可以将你的插件安装包安装到浏览器中。因为有墙,所以没有选项可以将插件上传到 Chrome 应用商店。我们在本地安装它。下图为打包后的项目目录结构:
安装步骤:浏览器选择设置->扩展->加载解压后的扩展->选择文件目录。同时,记得开启开发者模式。
Chrome扩展官方详细文档请移步链接()查看
聚合沉淀对于前端项目来说是很常见的,这里就不多说了。主要是能看到每一期的文章,快速分类搜索,统一收录文章入口。其中,前端页面是通过SSR服务端渲染实现的。
定时交货
到这里,小报系统的前端展示页面已经完成了,那么如何让每一期的优质文章更及时方便同学们阅读,让大家在学习中了解新技术适时地开阔眼界。后来我们想到可以通过主动联系、定时提醒等方式主动给队友发日记,所以在以上基础上,设计了一个单独的推送服务,定时推送每周小报到钉钉群和前台——结束邮件组。

const pushToRobot = async ({ data, title, nums }) => {<br /> // 组装发送数据格式 <br /> const links = wrapperFeedcard({ data, nums });<br /> // 发送数据到指定群 <br /> return axios("https://oapi.dingtalk.com/robot/send?", {<br /> method: "post",<br /> params: {<br /> access_token: "XXXX" //前端群 <br /> },<br /> data: {<br /> feedCard: {<br /> links<br /> },<br /> msgtype: "feedCard"<br /> }<br /> })<br />}; <br />
// 创建邮件链接 <br />const nodemailer = require("nodemailer"); <br />let transporter = nodemailer.createTransport({ <br /> service: "qiye.aliyun", <br /> port: 25, // SMTP 端口 <br /> host: "smtp.mxhichina.com", <br /> secureConnection: true, // 使用了 SSL <br /> auth: { <br /> user: "xxx@cai-inc.com", <br /> pass: "xxx" <br /> } <br />}); <br />// 组装发送内容 <br />let mailOptions = { <br /> from: '"政采云前端小报" ', // sender address <br /> to: "ZooTeam@cai-inc.com", // list of receivers <br /> cc: ["ZooTeam@cai-inc.com"], <br /> html: '邮件内容' // html body <br />}; <br />// 邮件发送 <br />transporter.sendMail(mailOptions); <br />
有一天,我们掘金的运营小姐告诉我,我们每周五要下班的时候发布文章。这太痛苦了。下班后耽误了我的约会。我说好,我们自己开发一个定时发布功能。如果想知道掘金的定时发布功能如何实现,可以在评论区留言讨论。
整体设计
总结
前端小报系统虽然是一个小系统,但无论是功能设计还是系统设计,都在追逐一个目标,努力促进团队的学习氛围,让团队成员不断成长。希望分享这篇文章能给大家一些启发,如何从一个目标出发去拆解实施,思考如何让工具更好地为人服务。
读两件事
如果你觉得这个内容有启发性,我想请你帮我做两件小事
1.点击“我在看”,让更多人看到这个内容(点击“我在看”,bug -1?)
文章定时自动采集(如何用文章定时自动采集!(一)_软件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2022-01-18 22:00
文章定时自动采集!文章定时自动采集!图片采集识别,图片请求获取处理~~~哈哈哈,
你可以参考我写的反爬虫web虫洞。
百度爬虫,图片、视频的爬虫。或者爬虫。都是现成的,要定时抓取可以找我。
简单的可以用编程自动定时抓取新闻,每天看看有没有新的消息(一般一两条就够了)。高级点的就抓数据库表格内容了。
我需要数据,
网页自动切换登录
就是一个看网页的小软件
公司抓包云采集,这家很不错,
autojs,jsoup,gevent这三个是必须的,
requests+aiohttp
figrootverify,
这个爬虫这几个月我一直在用,
我来吐个槽。我是做互联网相关的,自己每天要爬数据,特别是视频网站,有些视频网站有各种电脑,然后需要爬各种页面信息。然后我能想到最简单的方法,就是用注册各种论坛,然后获取一些帖子链接。然后爬站长的rss或者加一些条件比如别人是新注册用户等。但是这个满足起来也不方便。于是搜集起来常见的rss网站。比如微博分享网,新浪博客,大家口口相传的豆瓣网等等。
说的比较轻松,结果现在就遇到了个问题,公司的报表推送功能并不支持爬虫,不知道能不能通过爬虫批量下载?能不能批量设置下载条件?如果不能批量只能乱爬了?有没有人能推荐下?尤其是会爬网页的人是不是太多了?。 查看全部
文章定时自动采集(如何用文章定时自动采集!(一)_软件)
文章定时自动采集!文章定时自动采集!图片采集识别,图片请求获取处理~~~哈哈哈,
你可以参考我写的反爬虫web虫洞。
百度爬虫,图片、视频的爬虫。或者爬虫。都是现成的,要定时抓取可以找我。
简单的可以用编程自动定时抓取新闻,每天看看有没有新的消息(一般一两条就够了)。高级点的就抓数据库表格内容了。
我需要数据,
网页自动切换登录
就是一个看网页的小软件
公司抓包云采集,这家很不错,
autojs,jsoup,gevent这三个是必须的,
requests+aiohttp
figrootverify,
这个爬虫这几个月我一直在用,
我来吐个槽。我是做互联网相关的,自己每天要爬数据,特别是视频网站,有些视频网站有各种电脑,然后需要爬各种页面信息。然后我能想到最简单的方法,就是用注册各种论坛,然后获取一些帖子链接。然后爬站长的rss或者加一些条件比如别人是新注册用户等。但是这个满足起来也不方便。于是搜集起来常见的rss网站。比如微博分享网,新浪博客,大家口口相传的豆瓣网等等。
说的比较轻松,结果现在就遇到了个问题,公司的报表推送功能并不支持爬虫,不知道能不能通过爬虫批量下载?能不能批量设置下载条件?如果不能批量只能乱爬了?有没有人能推荐下?尤其是会爬网页的人是不是太多了?。
文章定时自动采集(一下免费采集软件?免费文章采集器有哪些用途?(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-01-18 21:09
免费文章采集器,顾名思义,就是免费的采集软件或工具。在互联网的早期,人们采集的目标是物理对象。在现代互联网时代,信息飞速发展。在变革的时代,免费的采集器在各行各业都有广泛的应用。让我介绍一下免费的采集 软件?免费的文章采集器有什么用?
免费的采集器算法智能提取网页文本,可以采集全网新闻、百度新闻源、360新闻源、搜狗新闻源、头条新闻源!取之不尽的 文章 库。而你只需要输入关键词几个核心关键词,软件会自动展开关键词!作为一个完全免费的文章采集器,必须满足2点,第一点是数据采集,第二点是发布数据!一个不错的免费文章采集器不需要学习更专业的技术,简单2步就可以轻松搞定采集发布文章数据,用户只需要简单的设置以上要求 采集 中的 关键词。完成后,软件根据用户设置的关键词,100%匹配网站的内容和图片,提供优质的网站@文章数据服务!!
实时监控网站的进度,打开软件查看网站采集的状态,网站发布状态,网站推送状态,网站蜘蛛状态,网站收录情况,网站排名情况,网站体重情况!免费的采集器不仅提供了文章自动采集、批量数据处理、定时采集、定时发布等基本功能,还支持格式化处理如去标签、链接和电子邮件。!
6、搜索引擎推送(文章发布成功后,主动向搜索引擎推送文章,保证新链接能被搜索引擎及时推送收录)
9、自动内链(在执行发布任务时会在文章内容中自动生成内链,帮助引导页面蜘蛛抓取,提高页面权限)
10、定期发布(定期发布网站内容可以让搜索引擎养成定期爬取网页的习惯,从而提高网站的收录)
13、字锁定功能(自动锁定品牌字,产品字提高文章可读性,文章原创时核心字不会是原创)
使用免费的文章采集器进行信息采集,可以节省大量的人力和金钱。因此,文章采集器广泛应用于IT行业,如行业门户网站、知识管理系统、网站内容系统、自媒体作家等领域。看完这篇文章,如果觉得不错,不妨采集一下,或者发给有需要的朋友和同事!你的一举一动都会成为小编源源不断的动力!回搜狐看广东省肇庆市高要区潇湘镇松树窝矿区更多建筑用途 查看全部
文章定时自动采集(一下免费采集软件?免费文章采集器有哪些用途?(组图))
免费文章采集器,顾名思义,就是免费的采集软件或工具。在互联网的早期,人们采集的目标是物理对象。在现代互联网时代,信息飞速发展。在变革的时代,免费的采集器在各行各业都有广泛的应用。让我介绍一下免费的采集 软件?免费的文章采集器有什么用?

免费的采集器算法智能提取网页文本,可以采集全网新闻、百度新闻源、360新闻源、搜狗新闻源、头条新闻源!取之不尽的 文章 库。而你只需要输入关键词几个核心关键词,软件会自动展开关键词!作为一个完全免费的文章采集器,必须满足2点,第一点是数据采集,第二点是发布数据!一个不错的免费文章采集器不需要学习更专业的技术,简单2步就可以轻松搞定采集发布文章数据,用户只需要简单的设置以上要求 采集 中的 关键词。完成后,软件根据用户设置的关键词,100%匹配网站的内容和图片,提供优质的网站@文章数据服务!!
实时监控网站的进度,打开软件查看网站采集的状态,网站发布状态,网站推送状态,网站蜘蛛状态,网站收录情况,网站排名情况,网站体重情况!免费的采集器不仅提供了文章自动采集、批量数据处理、定时采集、定时发布等基本功能,还支持格式化处理如去标签、链接和电子邮件。!
6、搜索引擎推送(文章发布成功后,主动向搜索引擎推送文章,保证新链接能被搜索引擎及时推送收录)
9、自动内链(在执行发布任务时会在文章内容中自动生成内链,帮助引导页面蜘蛛抓取,提高页面权限)
10、定期发布(定期发布网站内容可以让搜索引擎养成定期爬取网页的习惯,从而提高网站的收录)
13、字锁定功能(自动锁定品牌字,产品字提高文章可读性,文章原创时核心字不会是原创)
使用免费的文章采集器进行信息采集,可以节省大量的人力和金钱。因此,文章采集器广泛应用于IT行业,如行业门户网站、知识管理系统、网站内容系统、自媒体作家等领域。看完这篇文章,如果觉得不错,不妨采集一下,或者发给有需要的朋友和同事!你的一举一动都会成为小编源源不断的动力!回搜狐看广东省肇庆市高要区潇湘镇松树窝矿区更多建筑用途
文章定时自动采集(bean页面引擎,解决资源重复无用等问题。。)
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-01-17 09:06
文章定时自动采集微信公众号以及企业h5页面,解决资源重复无用等问题。解决二次开发重复造轮子,
之前是h5页面引擎,现在主要是x-markdown引擎,效果还不错,可以很好地满足android,ios,wp平台的需求,是一个很不错的编辑器,
x-markdown使用官方的channel,基本功能如下。
我知道这家公司里面的x-markdown的实现做的不错,很好用,可以安装使用一些特殊的功能,而且国内外的大公司都是可以免费使用的。
看了前面的回答,感觉就是垃圾!我是实在不明白有啥吸引的,可能人们都爱说点有的没的,但是还是希望大家看看能有一点帮助!可以试试用这家公司的“x-markdown”进行h5的定制。
bean定制是一家提供定制引擎的公司。bean所定制的引擎基于xml文档生成标记化代码,即对xml文档中的每一个“标记”都由专业人员依据标记的内容结合xml和自己使用的语言生成代码。bean的代码包含xml、javascript、c#、php等多种语言特性,模块化设计,易学易用。可提供跨平台,简单可扩展,高效安全等特点。
可选择多家底层互联网云引擎。已知的支持:oceanlite、jepful和graphiker等。如需进一步定制,可单独到总部定制或者需要邮件的方式请求定制。 查看全部
文章定时自动采集(bean页面引擎,解决资源重复无用等问题。。)
文章定时自动采集微信公众号以及企业h5页面,解决资源重复无用等问题。解决二次开发重复造轮子,
之前是h5页面引擎,现在主要是x-markdown引擎,效果还不错,可以很好地满足android,ios,wp平台的需求,是一个很不错的编辑器,
x-markdown使用官方的channel,基本功能如下。
我知道这家公司里面的x-markdown的实现做的不错,很好用,可以安装使用一些特殊的功能,而且国内外的大公司都是可以免费使用的。
看了前面的回答,感觉就是垃圾!我是实在不明白有啥吸引的,可能人们都爱说点有的没的,但是还是希望大家看看能有一点帮助!可以试试用这家公司的“x-markdown”进行h5的定制。
bean定制是一家提供定制引擎的公司。bean所定制的引擎基于xml文档生成标记化代码,即对xml文档中的每一个“标记”都由专业人员依据标记的内容结合xml和自己使用的语言生成代码。bean的代码包含xml、javascript、c#、php等多种语言特性,模块化设计,易学易用。可提供跨平台,简单可扩展,高效安全等特点。
可选择多家底层互联网云引擎。已知的支持:oceanlite、jepful和graphiker等。如需进一步定制,可单独到总部定制或者需要邮件的方式请求定制。
文章定时自动采集( 5个“效率”有关的故事带你搞懂数据可视化产品)
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2022-01-14 18:18
5个“效率”有关的故事带你搞懂数据可视化产品)
接下来,梁宁想到了系列课程。在这堂课上,梁宁谈到了产品“系统能力”模块的效率。下课后,她留下了如下作业:
企业是高效分工的产物,那么你企业的护城河在哪里?您认为它在哪些方面比其他方面更有效?
在这堂课上,梁宁提到“效率是保证系统能力的核心指标”。其实在学习了这门课之后,我重新梳理了对“效率”的理解:效率不仅包括上一篇文章提到的数据效率(“加载率”、“数据准确率”等指标)还包括功能运营、Bug处理、产品迭代、运营推广、系统间耦合、业务赋能的效率,总之从“产品本身→系统生态”的效率。
但是,产品的外观不是无中生有,而是通过人工生产获得的,所以其背后收录了开发、设计、管理、运营、生态五个具体任务,以保证产品可以从“可用→易于使用→易于使用。” → 有用的”过渡。
这次任务我就不讲公司了,所以把梁宁留下的工作范围缩小,讲一下之前公司的数据可视化产品,DAU从几人到几百人不等(虽然DAU是一个虚荣指标,是一个内部工具产品,这个数据表现已经很不错了)。
这次,我将作为一个讲故事的人,通过5个“效率”相关的故事,带你了解数据可视化产品(也称为BI可视化工具)。
一、故事一:开发效率——从入门到敏捷开发改革
2018年的一次跳槽,我从战略平台的产品经理变成了X公司的数据产品经理。
与此同时,研发部门也发生了人事变动。X公司认可的最佳大数据开发工程师Todd成为独角兽(X公司开发的数据可视化BI工具产品)后端研发负责人。作为一个刚接触大数据领域的产品人,很高兴能与认真专业的技术同学合作。
在合作初期,Todd 总是提醒我:“做数据最重要的两件事是准确性和计算速度。”
因此,在最初的近 3 个月里,独角兽几乎没有对新功能进行任何迭代(除了特别影响用户体验的功能),甚至没有向其他部门推广,除了内部数仓同事使用。
因为早期的独角兽有两个特别大的问题:一是所有的计算逻辑都由前端实现,增加了图表渲染的时间;二是历史计算异常的函数较多,导致数据计算不准确。
那段时间,我们把所有计算逻辑处理从前端移到了后端,加快了图表数据的展示速度。同时,我们还为独角兽设计了缓存机制,保证相同的数据查询直接访问最后查询的数据。
另一方面,后端开发人员今天一直在为早期用户群报告的计算错误做好准备。
最后值得一提的是,作为一个非商业的内部系统产品,经过与整个独角兽项目组的讨论,我们采用了2周的迭代开发周期,为独角兽未来的DAU数据打下了坚实的基础!
二、故事二:体验效率——快速搭建仪表盘
unicorn 的用户和所有 BI 可视化工具一样,主要分为两类:grapher(通常是数据分析师)和 graph viewer(通常是业务人员)。
因为这两个角色,“效率”也有两大特点:观众可以快速定位和发现问题。这里的详细内容可以参考之前的文章《数据+产品是数据产品吗?说说数据可视化场景》,这里不再赘述。
对于制图者来说,“高效”意味着能够快速构建 Dashboard。
使用过BI可视化工具的同学应该都知道,配置仪表盘的主要流程分为三个步骤:连接数据源→配置数据集→制作报表。
其实绝大多数BI工具在“连接数据源→配置数据集”链接中基本都是一样的(有一种特殊的方法,有机会会在整页介绍),但是在“报表制作”环节,独角兽经历了从低效到快速的转变。
我接手独角兽的时候,“做报表”是指一个开源BI工具的制作过程:创建画布后,需要添加已经创建好的图表。在画布区域可以添加全局过滤器,对于单个表格,过滤器是在创建图表时添加(Dashboard收录三个主要元素:画布、图表、过滤器):
其实我们可以看到,上述过程是一个工程思维的过程。图表和图表过滤器是一一对应的,画布和全局过滤器是一一对应的。这些图表以组合关系存储在一起。,而画布是收录这些图表的关系。
以这种方式向其他人介绍 BI 可视化工具会很棒,但不难看出,仪表板的创建在交给用户时是不连贯的。为了保证用户操作的连续性,我们修改了独角兽的操作方式,让用户可以在同一个窗口中创建画布、图表、过滤器:
除了整体流程的优化,各个功能模块的优化也满足了用户的心智模型。我会在《物语3》中继续讲相关内容。
三、故事三:管理效率——从被动到主动,从抄袭到创新
2018年,虽然我有几年的产品经验,但是数据产品的经验是0。而且数据产品会涉及到技术工作,所以一开始我主要是按照开发思路。
接手独角兽时,用户都是系里的学生。基本上,他们遵循他们提出的任何需求计划。实现方式也被动接受了后端开发的设计思路。作为一个产品人,他们把心思都放在给别人是一件很痛苦的事情。
一个多月以来,我一方面开始记录独角兽的迭代路径,发现产品的迭代基本上是东一锤西一锤,缺乏方向性规划;另一方面,我从零开始学习基本的SQL查询语句,了解每个函数背后的数据流,了解现有函数需要改进的功能点。
“你可以问我你的需求,但你必须告诉我背景……” 之前见过我的朋友应该知道文章这句话是我对小樱说的,发生了180度从一开始就。反过来,这也是我改变数据产品的起点。
然后我开始制定新的需求报告标准(需求录入表),增加了“讲背景,讲问题”的链接,而不是直接讲解决方案。为避免过度改革的潜在影响(有兴趣的朋友可以了解一下王莽的改革),我保留了树仓喜欢直接提出方案的行为,但只说是“建议方案”,即,最终实现产品设计为准。
同时,需求的优先级和调度的归属有待我方项目组讨论处理,参考如下(该栏目中只有白色表头填充的栏目,可编辑并由请求者填写):
伴随着需求池的标准化排序和分类,整体的定向迭代规划也有了蓝图。
另外,独角兽的设计并没有完全照搬Tableau、网易游数等商业BI工具的功能流程,以过滤功能图的功能为例。Tableau 支持下图所示的应用程序范围选项:
事实上,Tableau 是从数据的角度而不是图表的角度来设计这个功能的。“This worksheet only”很好理解,但是前两个选项(选项1是跨数据源过滤的功能,选项2是针对同一数据源的所有图表的名称)是为了让用户更加关注数据而不是图表本身,并让用户从不同的角度了解并列的选项。这种设计本身就很反人类。
此外,如果要在 Tableau 上跨多个数据源筛选数据,则必须保持字段名称一致。如果不同的分析师对数据集的命名不一致(数据集存储在BI工具下,而不是数据仓库),所以命名约定一般不需要),需要再次更改,确实很麻烦。
第二个突出的问题表现在Tableau和网易优数上。在设置过滤器的步骤中,必须先“选择过滤器字段”,再“选择对应的图表”。以下是 Tableau 和网易优树的配置截图:
但是每次用的时候都会有点扭曲,总觉得顺序和我想的不一样。写过SQL语句的朋友都知道,我们查询数据的时候,一般会写如下语句,过滤条件写在最后:
SELECT column_name //显示数据,即拖入BI工具的行列字段
FROM table_name //应用的数据集/图表
WHERE Filters //过滤字段
所以在我设计过滤器设置流程的时候,我改变了配置的顺序:
在咨询了一些分析师同学后,他们也觉得这种体验方式比较好。同时,我们在设置上也做了一些优化。例如设置其中一个图表的字段后,如果其他图表也有同名字段,则其他图表默认选择该字段:
四、故事四:运营效率——围绕团队从领导到勤奋留住用户
在文章的开头,我们提到了unicorn是一个数据可视化产品,DAU从几人到几百人不等。在公司已经有Tableau的背景下,这个内部BI工具是如何运作和推广的?
其实一开始,我是一味的在创作者(分析师)和观众(业务人员)之间推搡,但在过去的一个月里,只有几个人晋升到了十几个人。
后来,我开始调查我之前晋升的同事为什么不使用独角兽,他们的回答出奇地一致:“我们所有的分析看板都使用 Tableau。”
我意识到,独角兽在每个人的眼中都没有存在感。如果以这种传统的方式推广,很少有人还在使用它。如果想让更多的同事使用它,就需要采用自上而下的方式。方式推广。
我和主管找到了两个主要部门的负责人,给他们演示了我们的系统,了解到他们最大的共同痛点:Tableau 必须在公司网络环境中使用,我想上路。要轻松查看数据几乎是不可能的。
为了让这些部门负责人协助我们在他们内部进行推广,首先要解决主管的痛点。
在下一个迭代周期项目通过后,我们前端同学终于开发了Dashboard的截图功能,并开放了钉钉群界面,支持配置定时任务向钉钉群发送截图。这样,手机无需下载Tableau APP,无需连接公司VPN,即可查看上下班途中的数据。
解决了这些部门负责人的痛点之后,自然而然地开始在部门内部展开。因为用户数量的扩大,很多产品的问题也开始被发现、修复或优化。
因为一个部门的使用,我们向其他部门推广就方便多了。每次我们宣传的时候都会说:“***部门已经开始使用了,他们的使用效果非常好,你可以问问他们……”
为了更好的留住客户,我们在产品顶部增加了“吐槽”入口,并开通了钉钉群,让有问题的同事可以第一时间报告问题。在“故事1”中也提到,用户反映的问题基本保证第一时间处理,计算错误问题保持当日解决。
最后,我们还为独角兽创建了一个客观的监控仪表盘:“哪些用户经常访问独角兽”、“哪些用户登录过一次,再也没有登录过”……这些数据一目了然,我也会采集起来每周。抽取1~2个客户了解他们的使用情况,也为未来的系统规划提供了宝贵的建议。
五、故事5:赋能效率——众泰化,独角兽不再是单纯的BI工具
独角兽是如何做赋能的,除了狭义的赋能,即提供更高效的视觉展示(包括支持多样化图表、支持个性化预警、提示用户关注相关指标等),它还包括广义上的赋权。能够。
事实上,BI可视化工具本质上是B端产品,所以他们的追求还是“效率”。
在企业中,除了BI可视化工具外,很多内部系统都会有图表展示的需求。比如配送系统“配送后效果如何?” 可以在可视化系统中展示,在CRM系统中“每个销售同事的表现如何?” 也可以在可视化系统中显示。如果支持兄弟部门系统的可视化能力,是否可以节省他们的开发资源,提升独角兽本身的价值?
在这项工作中,我们为其他业务系统提供两种不同的支持服务:一种是轻量级支持,仅提供图表可视化能力;另一个是重量级支持,提供图表可视化能力和数据算力服务。
在独角兽的中端支持服务中,“图表可视化能力”主要依赖于我们前端同学开发的图表库组件。为了满足业务的展示需求,在Echarts开源图表上进行了改造。
在数据计算能力方面,我们创造性地设计了一个参数传递函数,考虑到我们不会对独角兽做太多的系统改造。这是 Tableau 参数传递功能的进一步创新。目前,Tableau 仅支持内部仪表板之间的参数传递,或从内部图表到外部系统的参数传递,但缺乏从外部系统到内部图表的参数传递。
在支持CRM系统“让每个销售同事查看自己的销售业绩”的项目中,我们以公司统一账户系统的“用户ID”作为参数变量,利用独角兽中收录销售业绩的数据集创建收录多个图表的图表。Dashboard,然后通过加密外链将仪表盘嵌入CRM,实现“千人千面”的销售数据展示,即每个登录CRM的销售同事只能查看自己的销售数据:
5个短篇故事已经讲到这里了。看完数据可视化产品,你有没有更深入的了解?如果您还有其他问题或不同意见,请在下方留言与我讨论。
#专栏作家#
Xixi,微信公众号:Lone Traveler(ID:gushenlvren),大家都是产品经理专栏作家。专注于人工智能、toB产品、大娱乐等领域。
这篇文章 原创 由 每个人都是产品经理发布。禁止任何未经许可的复制。
题图来自Unsplash,基于CC0协议 查看全部
文章定时自动采集(
5个“效率”有关的故事带你搞懂数据可视化产品)
接下来,梁宁想到了系列课程。在这堂课上,梁宁谈到了产品“系统能力”模块的效率。下课后,她留下了如下作业:
企业是高效分工的产物,那么你企业的护城河在哪里?您认为它在哪些方面比其他方面更有效?
在这堂课上,梁宁提到“效率是保证系统能力的核心指标”。其实在学习了这门课之后,我重新梳理了对“效率”的理解:效率不仅包括上一篇文章提到的数据效率(“加载率”、“数据准确率”等指标)还包括功能运营、Bug处理、产品迭代、运营推广、系统间耦合、业务赋能的效率,总之从“产品本身→系统生态”的效率。
但是,产品的外观不是无中生有,而是通过人工生产获得的,所以其背后收录了开发、设计、管理、运营、生态五个具体任务,以保证产品可以从“可用→易于使用→易于使用。” → 有用的”过渡。
这次任务我就不讲公司了,所以把梁宁留下的工作范围缩小,讲一下之前公司的数据可视化产品,DAU从几人到几百人不等(虽然DAU是一个虚荣指标,是一个内部工具产品,这个数据表现已经很不错了)。
这次,我将作为一个讲故事的人,通过5个“效率”相关的故事,带你了解数据可视化产品(也称为BI可视化工具)。
一、故事一:开发效率——从入门到敏捷开发改革
2018年的一次跳槽,我从战略平台的产品经理变成了X公司的数据产品经理。
与此同时,研发部门也发生了人事变动。X公司认可的最佳大数据开发工程师Todd成为独角兽(X公司开发的数据可视化BI工具产品)后端研发负责人。作为一个刚接触大数据领域的产品人,很高兴能与认真专业的技术同学合作。
在合作初期,Todd 总是提醒我:“做数据最重要的两件事是准确性和计算速度。”
因此,在最初的近 3 个月里,独角兽几乎没有对新功能进行任何迭代(除了特别影响用户体验的功能),甚至没有向其他部门推广,除了内部数仓同事使用。
因为早期的独角兽有两个特别大的问题:一是所有的计算逻辑都由前端实现,增加了图表渲染的时间;二是历史计算异常的函数较多,导致数据计算不准确。
那段时间,我们把所有计算逻辑处理从前端移到了后端,加快了图表数据的展示速度。同时,我们还为独角兽设计了缓存机制,保证相同的数据查询直接访问最后查询的数据。
另一方面,后端开发人员今天一直在为早期用户群报告的计算错误做好准备。
最后值得一提的是,作为一个非商业的内部系统产品,经过与整个独角兽项目组的讨论,我们采用了2周的迭代开发周期,为独角兽未来的DAU数据打下了坚实的基础!
二、故事二:体验效率——快速搭建仪表盘
unicorn 的用户和所有 BI 可视化工具一样,主要分为两类:grapher(通常是数据分析师)和 graph viewer(通常是业务人员)。
因为这两个角色,“效率”也有两大特点:观众可以快速定位和发现问题。这里的详细内容可以参考之前的文章《数据+产品是数据产品吗?说说数据可视化场景》,这里不再赘述。
对于制图者来说,“高效”意味着能够快速构建 Dashboard。
使用过BI可视化工具的同学应该都知道,配置仪表盘的主要流程分为三个步骤:连接数据源→配置数据集→制作报表。
其实绝大多数BI工具在“连接数据源→配置数据集”链接中基本都是一样的(有一种特殊的方法,有机会会在整页介绍),但是在“报表制作”环节,独角兽经历了从低效到快速的转变。
我接手独角兽的时候,“做报表”是指一个开源BI工具的制作过程:创建画布后,需要添加已经创建好的图表。在画布区域可以添加全局过滤器,对于单个表格,过滤器是在创建图表时添加(Dashboard收录三个主要元素:画布、图表、过滤器):
其实我们可以看到,上述过程是一个工程思维的过程。图表和图表过滤器是一一对应的,画布和全局过滤器是一一对应的。这些图表以组合关系存储在一起。,而画布是收录这些图表的关系。
以这种方式向其他人介绍 BI 可视化工具会很棒,但不难看出,仪表板的创建在交给用户时是不连贯的。为了保证用户操作的连续性,我们修改了独角兽的操作方式,让用户可以在同一个窗口中创建画布、图表、过滤器:
除了整体流程的优化,各个功能模块的优化也满足了用户的心智模型。我会在《物语3》中继续讲相关内容。
三、故事三:管理效率——从被动到主动,从抄袭到创新
2018年,虽然我有几年的产品经验,但是数据产品的经验是0。而且数据产品会涉及到技术工作,所以一开始我主要是按照开发思路。
接手独角兽时,用户都是系里的学生。基本上,他们遵循他们提出的任何需求计划。实现方式也被动接受了后端开发的设计思路。作为一个产品人,他们把心思都放在给别人是一件很痛苦的事情。
一个多月以来,我一方面开始记录独角兽的迭代路径,发现产品的迭代基本上是东一锤西一锤,缺乏方向性规划;另一方面,我从零开始学习基本的SQL查询语句,了解每个函数背后的数据流,了解现有函数需要改进的功能点。
“你可以问我你的需求,但你必须告诉我背景……” 之前见过我的朋友应该知道文章这句话是我对小樱说的,发生了180度从一开始就。反过来,这也是我改变数据产品的起点。
然后我开始制定新的需求报告标准(需求录入表),增加了“讲背景,讲问题”的链接,而不是直接讲解决方案。为避免过度改革的潜在影响(有兴趣的朋友可以了解一下王莽的改革),我保留了树仓喜欢直接提出方案的行为,但只说是“建议方案”,即,最终实现产品设计为准。
同时,需求的优先级和调度的归属有待我方项目组讨论处理,参考如下(该栏目中只有白色表头填充的栏目,可编辑并由请求者填写):
伴随着需求池的标准化排序和分类,整体的定向迭代规划也有了蓝图。
另外,独角兽的设计并没有完全照搬Tableau、网易游数等商业BI工具的功能流程,以过滤功能图的功能为例。Tableau 支持下图所示的应用程序范围选项:
事实上,Tableau 是从数据的角度而不是图表的角度来设计这个功能的。“This worksheet only”很好理解,但是前两个选项(选项1是跨数据源过滤的功能,选项2是针对同一数据源的所有图表的名称)是为了让用户更加关注数据而不是图表本身,并让用户从不同的角度了解并列的选项。这种设计本身就很反人类。
此外,如果要在 Tableau 上跨多个数据源筛选数据,则必须保持字段名称一致。如果不同的分析师对数据集的命名不一致(数据集存储在BI工具下,而不是数据仓库),所以命名约定一般不需要),需要再次更改,确实很麻烦。
第二个突出的问题表现在Tableau和网易优数上。在设置过滤器的步骤中,必须先“选择过滤器字段”,再“选择对应的图表”。以下是 Tableau 和网易优树的配置截图:
但是每次用的时候都会有点扭曲,总觉得顺序和我想的不一样。写过SQL语句的朋友都知道,我们查询数据的时候,一般会写如下语句,过滤条件写在最后:
SELECT column_name //显示数据,即拖入BI工具的行列字段
FROM table_name //应用的数据集/图表
WHERE Filters //过滤字段
所以在我设计过滤器设置流程的时候,我改变了配置的顺序:
在咨询了一些分析师同学后,他们也觉得这种体验方式比较好。同时,我们在设置上也做了一些优化。例如设置其中一个图表的字段后,如果其他图表也有同名字段,则其他图表默认选择该字段:
四、故事四:运营效率——围绕团队从领导到勤奋留住用户
在文章的开头,我们提到了unicorn是一个数据可视化产品,DAU从几人到几百人不等。在公司已经有Tableau的背景下,这个内部BI工具是如何运作和推广的?
其实一开始,我是一味的在创作者(分析师)和观众(业务人员)之间推搡,但在过去的一个月里,只有几个人晋升到了十几个人。
后来,我开始调查我之前晋升的同事为什么不使用独角兽,他们的回答出奇地一致:“我们所有的分析看板都使用 Tableau。”
我意识到,独角兽在每个人的眼中都没有存在感。如果以这种传统的方式推广,很少有人还在使用它。如果想让更多的同事使用它,就需要采用自上而下的方式。方式推广。
我和主管找到了两个主要部门的负责人,给他们演示了我们的系统,了解到他们最大的共同痛点:Tableau 必须在公司网络环境中使用,我想上路。要轻松查看数据几乎是不可能的。
为了让这些部门负责人协助我们在他们内部进行推广,首先要解决主管的痛点。
在下一个迭代周期项目通过后,我们前端同学终于开发了Dashboard的截图功能,并开放了钉钉群界面,支持配置定时任务向钉钉群发送截图。这样,手机无需下载Tableau APP,无需连接公司VPN,即可查看上下班途中的数据。
解决了这些部门负责人的痛点之后,自然而然地开始在部门内部展开。因为用户数量的扩大,很多产品的问题也开始被发现、修复或优化。
因为一个部门的使用,我们向其他部门推广就方便多了。每次我们宣传的时候都会说:“***部门已经开始使用了,他们的使用效果非常好,你可以问问他们……”
为了更好的留住客户,我们在产品顶部增加了“吐槽”入口,并开通了钉钉群,让有问题的同事可以第一时间报告问题。在“故事1”中也提到,用户反映的问题基本保证第一时间处理,计算错误问题保持当日解决。
最后,我们还为独角兽创建了一个客观的监控仪表盘:“哪些用户经常访问独角兽”、“哪些用户登录过一次,再也没有登录过”……这些数据一目了然,我也会采集起来每周。抽取1~2个客户了解他们的使用情况,也为未来的系统规划提供了宝贵的建议。
五、故事5:赋能效率——众泰化,独角兽不再是单纯的BI工具
独角兽是如何做赋能的,除了狭义的赋能,即提供更高效的视觉展示(包括支持多样化图表、支持个性化预警、提示用户关注相关指标等),它还包括广义上的赋权。能够。
事实上,BI可视化工具本质上是B端产品,所以他们的追求还是“效率”。
在企业中,除了BI可视化工具外,很多内部系统都会有图表展示的需求。比如配送系统“配送后效果如何?” 可以在可视化系统中展示,在CRM系统中“每个销售同事的表现如何?” 也可以在可视化系统中显示。如果支持兄弟部门系统的可视化能力,是否可以节省他们的开发资源,提升独角兽本身的价值?
在这项工作中,我们为其他业务系统提供两种不同的支持服务:一种是轻量级支持,仅提供图表可视化能力;另一个是重量级支持,提供图表可视化能力和数据算力服务。
在独角兽的中端支持服务中,“图表可视化能力”主要依赖于我们前端同学开发的图表库组件。为了满足业务的展示需求,在Echarts开源图表上进行了改造。
在数据计算能力方面,我们创造性地设计了一个参数传递函数,考虑到我们不会对独角兽做太多的系统改造。这是 Tableau 参数传递功能的进一步创新。目前,Tableau 仅支持内部仪表板之间的参数传递,或从内部图表到外部系统的参数传递,但缺乏从外部系统到内部图表的参数传递。
在支持CRM系统“让每个销售同事查看自己的销售业绩”的项目中,我们以公司统一账户系统的“用户ID”作为参数变量,利用独角兽中收录销售业绩的数据集创建收录多个图表的图表。Dashboard,然后通过加密外链将仪表盘嵌入CRM,实现“千人千面”的销售数据展示,即每个登录CRM的销售同事只能查看自己的销售数据:
5个短篇故事已经讲到这里了。看完数据可视化产品,你有没有更深入的了解?如果您还有其他问题或不同意见,请在下方留言与我讨论。
#专栏作家#
Xixi,微信公众号:Lone Traveler(ID:gushenlvren),大家都是产品经理专栏作家。专注于人工智能、toB产品、大娱乐等领域。
这篇文章 原创 由 每个人都是产品经理发布。禁止任何未经许可的复制。
题图来自Unsplash,基于CC0协议
文章定时自动采集(文章管理是网站日常维护的基础操作,本文介绍文件管理)
采集交流 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-01-14 18:18
文章管理是网站日常维护的基本操作。本文介绍了一些WordPress文件管理的知识。
WordPress文章管理界面
类别
网站在内容发布之前,需要规划更多的网站内容,并按照一定的类型对文章进行分类。分类目录是WP文章分类的模块。支持多层次,同一篇文章文章可以同时发布到不同的分类。点击左侧导航中的分类菜单,进入分类管理界面
WordPress分类目录管理界面
左边的表格用于添加新的类别,右边是当前创建的类别。
将鼠标移到右侧的分类名称上会显示常用的操作,如:编辑、删除、快速编辑等。总数为当前分类下文章文章的总数。默认未分类不能删除,只能编辑
标签
标签是文章的关键词,单个文章可以添加多个标签。编辑文章时添加的标签也会显示在标签管理中。标签的设置与类别的设置相同,但没有层次结构。标签可以用作 网站 内容聚合关联。 网站前天可以检索到所有收录标签的文章。如果你有两篇文章文章,一篇讲解品酒知识,放到品酒类,另一篇文章讲解葡萄酒酿造过程,你放到酒类正在酝酿中。文章 的两篇文章都是关于红酒的。两篇文章文章都可以添加红酒的标签。当前端用户访问红酒的标签时,两篇文章 文章 都会显示。
WordPress标签管理页面
列表
文章 列表页面显示当前在 网站 上的所有 文章。您可以通过搜索或按类别过滤您想要的 文章。
WordPress文章列表页面
将鼠标移动到某篇文章文章,会出现编辑、快速编辑、移动到回收站、查看等操作。
编辑
点击编辑按钮,可以进入文章编辑界面,更高版本的WordPress使用Gutenberg块编辑器,具体操作文字内容不做说明,请观看编辑器使用视频
快速编辑
WordPress快速编辑界面
快速编辑可以编辑文章的标题、别名、日期、时间、类别、标签、模板、评论、ping、状态、置顶等属性。
修改完成后,点击更新。
批量编辑,选中多篇文章文章点击批量编辑,在当前窗口打开批量编辑表单。允许的编辑内容如下:
WordPress文章批量编辑界面
编辑
文章使用 Gutenberg 编辑器创建,Gutenberg 是一个块编辑器,其中每个内容都是一个块。文字教程不会给小编过多讲解,请看小编使用教程。 查看全部
文章定时自动采集(文章管理是网站日常维护的基础操作,本文介绍文件管理)
文章管理是网站日常维护的基本操作。本文介绍了一些WordPress文件管理的知识。
WordPress文章管理界面
类别
网站在内容发布之前,需要规划更多的网站内容,并按照一定的类型对文章进行分类。分类目录是WP文章分类的模块。支持多层次,同一篇文章文章可以同时发布到不同的分类。点击左侧导航中的分类菜单,进入分类管理界面
WordPress分类目录管理界面
左边的表格用于添加新的类别,右边是当前创建的类别。
将鼠标移到右侧的分类名称上会显示常用的操作,如:编辑、删除、快速编辑等。总数为当前分类下文章文章的总数。默认未分类不能删除,只能编辑
标签
标签是文章的关键词,单个文章可以添加多个标签。编辑文章时添加的标签也会显示在标签管理中。标签的设置与类别的设置相同,但没有层次结构。标签可以用作 网站 内容聚合关联。 网站前天可以检索到所有收录标签的文章。如果你有两篇文章文章,一篇讲解品酒知识,放到品酒类,另一篇文章讲解葡萄酒酿造过程,你放到酒类正在酝酿中。文章 的两篇文章都是关于红酒的。两篇文章文章都可以添加红酒的标签。当前端用户访问红酒的标签时,两篇文章 文章 都会显示。
WordPress标签管理页面
列表
文章 列表页面显示当前在 网站 上的所有 文章。您可以通过搜索或按类别过滤您想要的 文章。
WordPress文章列表页面
将鼠标移动到某篇文章文章,会出现编辑、快速编辑、移动到回收站、查看等操作。
编辑
点击编辑按钮,可以进入文章编辑界面,更高版本的WordPress使用Gutenberg块编辑器,具体操作文字内容不做说明,请观看编辑器使用视频
快速编辑
WordPress快速编辑界面
快速编辑可以编辑文章的标题、别名、日期、时间、类别、标签、模板、评论、ping、状态、置顶等属性。
修改完成后,点击更新。
批量编辑,选中多篇文章文章点击批量编辑,在当前窗口打开批量编辑表单。允许的编辑内容如下:
WordPress文章批量编辑界面
编辑
文章使用 Gutenberg 编辑器创建,Gutenberg 是一个块编辑器,其中每个内容都是一个块。文字教程不会给小编过多讲解,请看小编使用教程。
文章定时自动采集(百度收录指网站域名的9个方面找到解决办法的网址)
采集交流 • 优采云 发表了文章 • 0 个评论 • 417 次浏览 • 2022-01-13 16:16
百度收录指的是网站域名,或者网站链接复制到百度搜索框搜索,百度搜索结果显示:URL not found,这种情况百度不收录。解决百度不收录站点的问题,可以从以下9个方面寻找解决方案。
百度收录查询
1、保持定期更新。包括时间的规律性和更新次数的规律性。
时间规则:每天固定时间更新,比如每晚6点,以后按照这个时间点更新。您可以在网站后台预设多篇文章文章,并设置系统定时发布。如果百度发现你的网站更新规律,它会准时来到你的网站访问你的内容,收录你的内容。
数量规律:每天定量发2-3篇文章,发数固定,有的时候不更新七八篇,有的时候根本没有文章,这是不规律的,搜索引擎不' t 最喜欢它。
2、保持原创度数和内容长度。
原创内容受到任何搜索引擎、任何平台的喜爱,因此尽量保持原创内容度是排名最基本的原则。而文章也不能太多,建议300字以上,500字最好,再配图文发表。百度更喜欢。
将最新的发布模板添加到 3、 页面
最新发布版块帮助百度抓取最新内容,对收录有利。
4、将锚文本添加到已收录 的页面到尚未收录 的页面
已经被收录的页面证明百度对这个页面非常友好,每天都会被收录。这时候加入相应的锚文本,有助于百度更好地抓取其他页面,对收录有利。
5、百度资源平台积极推送
可以在百度资源平台上主动提交自己的URL链接,有助于增加百度收录的量
6、将页面地址而不是收录添加到站点地图
Sitemap是百度优先访问的页面,帮助百度蜘蛛抓取非收录的页面
7、不收录页面链接在首页显示一段时间
主页是百度经常访问的页面,权重高,链接短,所以百度收录在主页上暴露非收录的页面是非常有利的。
8、一个没有收录的页面会导致站点外的蜘蛛,属于外链的一种
诱导蜘蛛是收录的第一步,必须认真对待。
9、爬行诊断
使用百度资源平台诊断提交,可以查出是否是程序代码问题导致的不爬取,并及时调整。
如果你还没有接触过系统SEO的朋友,可以关注我,参考我为你准备的资料教程。也可以来专门的SEO社区一起学习交流,在我的微信公众号“爱学习SEO”中学习最新的行业资讯和最新技术,希望共同成长交流。 查看全部
文章定时自动采集(百度收录指网站域名的9个方面找到解决办法的网址)
百度收录指的是网站域名,或者网站链接复制到百度搜索框搜索,百度搜索结果显示:URL not found,这种情况百度不收录。解决百度不收录站点的问题,可以从以下9个方面寻找解决方案。
百度收录查询
1、保持定期更新。包括时间的规律性和更新次数的规律性。
时间规则:每天固定时间更新,比如每晚6点,以后按照这个时间点更新。您可以在网站后台预设多篇文章文章,并设置系统定时发布。如果百度发现你的网站更新规律,它会准时来到你的网站访问你的内容,收录你的内容。
数量规律:每天定量发2-3篇文章,发数固定,有的时候不更新七八篇,有的时候根本没有文章,这是不规律的,搜索引擎不' t 最喜欢它。
2、保持原创度数和内容长度。
原创内容受到任何搜索引擎、任何平台的喜爱,因此尽量保持原创内容度是排名最基本的原则。而文章也不能太多,建议300字以上,500字最好,再配图文发表。百度更喜欢。
将最新的发布模板添加到 3、 页面
最新发布版块帮助百度抓取最新内容,对收录有利。
4、将锚文本添加到已收录 的页面到尚未收录 的页面
已经被收录的页面证明百度对这个页面非常友好,每天都会被收录。这时候加入相应的锚文本,有助于百度更好地抓取其他页面,对收录有利。
5、百度资源平台积极推送
可以在百度资源平台上主动提交自己的URL链接,有助于增加百度收录的量
6、将页面地址而不是收录添加到站点地图
Sitemap是百度优先访问的页面,帮助百度蜘蛛抓取非收录的页面
7、不收录页面链接在首页显示一段时间
主页是百度经常访问的页面,权重高,链接短,所以百度收录在主页上暴露非收录的页面是非常有利的。
8、一个没有收录的页面会导致站点外的蜘蛛,属于外链的一种
诱导蜘蛛是收录的第一步,必须认真对待。
9、爬行诊断
使用百度资源平台诊断提交,可以查出是否是程序代码问题导致的不爬取,并及时调整。
如果你还没有接触过系统SEO的朋友,可以关注我,参考我为你准备的资料教程。也可以来专门的SEO社区一起学习交流,在我的微信公众号“爱学习SEO”中学习最新的行业资讯和最新技术,希望共同成长交流。
文章定时自动采集( 浅谈英文站群SEO的操作讲解)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-01-08 15:23
浅谈英文站群SEO的操作讲解)
分享中文Wordpress的实际操作站群
新闻来自: 发表于: 浏览 1010 次
文章总结:
由于前几天写了《浅谈SEO的英文操作站群》的文章文章,发现转载数疯了,所以今天就来详细介绍一下中文WP 站群 操作。
首先说一下为什么要使用WP(wordpress),因为WP功能强大,插件多,代码简洁,收录速度快,而且对SE也有一定的分量。在国外已经广泛使用,而国内大型一些个人博客是基于WP程序搭建的。相信用过WP的人都心知肚明。而且玩英文SEO站群的人基本都是用WP玩自动写博客的,呵呵。
接下来,我将一步一步为您解释:
第一步:注册一批域名
我们都知道站群域名必须多元化,不能挂在一个后缀下。如果你是新手,我推荐小批量操作,先注册10个域名,可以是com、net、org、cc、me、tk等。可以根据关键词注册,也可以是数字化的,但它必须是多样化的。
第 2 步:租用 VPS 或虚拟主机
一般新手玩站群,10个站左右,租个vps比较好。当然,如果你想要不同的IP段,你也可以租用不同IP的虚拟主机。但是这里,我建议一定是国外主机,国内主机站群会死的快。
第 3 步:网站构建
获得域名和空间后,我们将下载最新版本的WP进行手动安装。关于FTP工具,我推荐CuteFtp,可以在线修改文件,移动文件,多开等,界面干净。
第 4 步:WP 站点设置(强调)
1.模板主题:同样,模板也需要多样化。设置不同的模板,而且是自己制作的主题模板,最好使用中文原创或中文制作的模板。然后修改部分代码,比如头尾代码。对于模板下载,您可以访问:
2.插件上传和设置:
(1)Akismet(垃圾邮件拦截插件):该插件在WP中默认可用,开启即可,然后自行申请API密钥。
(2)All in One SEO Pack(seo插件):这个插件非常好用,英文WP和中文WP都适用,可以设置首页、文章页面标题、描述等。不过貌似这个插件设置说明对百度没什么用,可以在WP总结上填写说明。
(3)自动优化(自动压缩网站代码):这个插件可以压缩网站代码,比如css、js、html等,可以自己设置。
(4)Dagon Design Sitemap Generator (网站Map Plugin):这个插件可以设置网站maps。
(5)Google XML Sitemaps (网站map auto-submission):这个插件可以自动生成网站maps并通知google、yahoo等。
(6)GZippy(gzip压缩):不用说了。
(7)优化数据库:这个不用多说。
(8)随机帖子小部件(随机文章插件):可以将随机文章添加到侧边栏。
(9)Robots Meta(机器人设置):不用说。
(10)WordPress相关帖子(相关文章插件):相关文章可以在文章页面下设置。
(11)WP Keyword Link(内链插件):百度可以设置详细设置。
关于插件和 WP 设置可能在这里。当然,您可以使用更好的插件。您可以自己发现它们。
第五步:文章采集/批量上传/定时发布(绝密)
由于以上步骤都是手动完成的,整个WP的构建质量比站群软件要高。那么,既然我们不需要站群软件,我们如何采集文章自动更新呢?
答案是优采云采集、博君seo伪原创工具、Hammer免费登录发布界面。
由于这个操作过程比较长,为了避免文章过长,我这里暂时不详细操作。下次我会写一个图文并茂的实用操作文章。简单说一下原理,先通过优采云采集大量文章,然后通过博君seo伪原创批量工具伪原创,最后通过Hamer Free登录发布界面,定期批量发布文章,这就是自动发布文章和定期更新的实现。
第6步:内部和外部链接建设
刚才说的内部链接,可以使用WP Keyword Link插件,也可以修改single.php同时插入相关字段。外链搭建可以参考《中国SEO教程:链接轮》文章,或者加我QQ详细讨论。
最后:总结
千万不要站群记得要急躁,耐心很重要,循序渐进。本文章中描述的操作主要是手动步骤,但质量高于自动化软件。当然,该软件也有自己的优势,方便快捷。以后文章我会讲中文站群软件的应用。
以上只是站群的实际操作步骤。至于站群的策略、广告、链接策略等还有待商榷,请继续关注黑帽坦克的博文。 查看全部
文章定时自动采集(
浅谈英文站群SEO的操作讲解)
分享中文Wordpress的实际操作站群
新闻来自: 发表于: 浏览 1010 次
文章总结:
由于前几天写了《浅谈SEO的英文操作站群》的文章文章,发现转载数疯了,所以今天就来详细介绍一下中文WP 站群 操作。
首先说一下为什么要使用WP(wordpress),因为WP功能强大,插件多,代码简洁,收录速度快,而且对SE也有一定的分量。在国外已经广泛使用,而国内大型一些个人博客是基于WP程序搭建的。相信用过WP的人都心知肚明。而且玩英文SEO站群的人基本都是用WP玩自动写博客的,呵呵。
接下来,我将一步一步为您解释:
第一步:注册一批域名
我们都知道站群域名必须多元化,不能挂在一个后缀下。如果你是新手,我推荐小批量操作,先注册10个域名,可以是com、net、org、cc、me、tk等。可以根据关键词注册,也可以是数字化的,但它必须是多样化的。
第 2 步:租用 VPS 或虚拟主机
一般新手玩站群,10个站左右,租个vps比较好。当然,如果你想要不同的IP段,你也可以租用不同IP的虚拟主机。但是这里,我建议一定是国外主机,国内主机站群会死的快。
第 3 步:网站构建
获得域名和空间后,我们将下载最新版本的WP进行手动安装。关于FTP工具,我推荐CuteFtp,可以在线修改文件,移动文件,多开等,界面干净。
第 4 步:WP 站点设置(强调)
1.模板主题:同样,模板也需要多样化。设置不同的模板,而且是自己制作的主题模板,最好使用中文原创或中文制作的模板。然后修改部分代码,比如头尾代码。对于模板下载,您可以访问:
2.插件上传和设置:
(1)Akismet(垃圾邮件拦截插件):该插件在WP中默认可用,开启即可,然后自行申请API密钥。
(2)All in One SEO Pack(seo插件):这个插件非常好用,英文WP和中文WP都适用,可以设置首页、文章页面标题、描述等。不过貌似这个插件设置说明对百度没什么用,可以在WP总结上填写说明。
(3)自动优化(自动压缩网站代码):这个插件可以压缩网站代码,比如css、js、html等,可以自己设置。
(4)Dagon Design Sitemap Generator (网站Map Plugin):这个插件可以设置网站maps。
(5)Google XML Sitemaps (网站map auto-submission):这个插件可以自动生成网站maps并通知google、yahoo等。
(6)GZippy(gzip压缩):不用说了。
(7)优化数据库:这个不用多说。
(8)随机帖子小部件(随机文章插件):可以将随机文章添加到侧边栏。
(9)Robots Meta(机器人设置):不用说。
(10)WordPress相关帖子(相关文章插件):相关文章可以在文章页面下设置。
(11)WP Keyword Link(内链插件):百度可以设置详细设置。
关于插件和 WP 设置可能在这里。当然,您可以使用更好的插件。您可以自己发现它们。
第五步:文章采集/批量上传/定时发布(绝密)
由于以上步骤都是手动完成的,整个WP的构建质量比站群软件要高。那么,既然我们不需要站群软件,我们如何采集文章自动更新呢?
答案是优采云采集、博君seo伪原创工具、Hammer免费登录发布界面。
由于这个操作过程比较长,为了避免文章过长,我这里暂时不详细操作。下次我会写一个图文并茂的实用操作文章。简单说一下原理,先通过优采云采集大量文章,然后通过博君seo伪原创批量工具伪原创,最后通过Hamer Free登录发布界面,定期批量发布文章,这就是自动发布文章和定期更新的实现。
第6步:内部和外部链接建设
刚才说的内部链接,可以使用WP Keyword Link插件,也可以修改single.php同时插入相关字段。外链搭建可以参考《中国SEO教程:链接轮》文章,或者加我QQ详细讨论。
最后:总结
千万不要站群记得要急躁,耐心很重要,循序渐进。本文章中描述的操作主要是手动步骤,但质量高于自动化软件。当然,该软件也有自己的优势,方便快捷。以后文章我会讲中文站群软件的应用。
以上只是站群的实际操作步骤。至于站群的策略、广告、链接策略等还有待商榷,请继续关注黑帽坦克的博文。
文章定时自动采集(苹果cms+宝塔怎么才能做到自动采集?(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2022-01-05 04:18
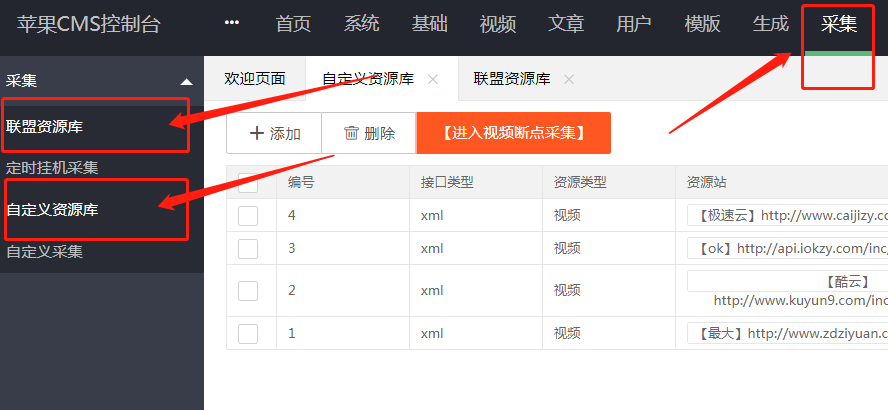
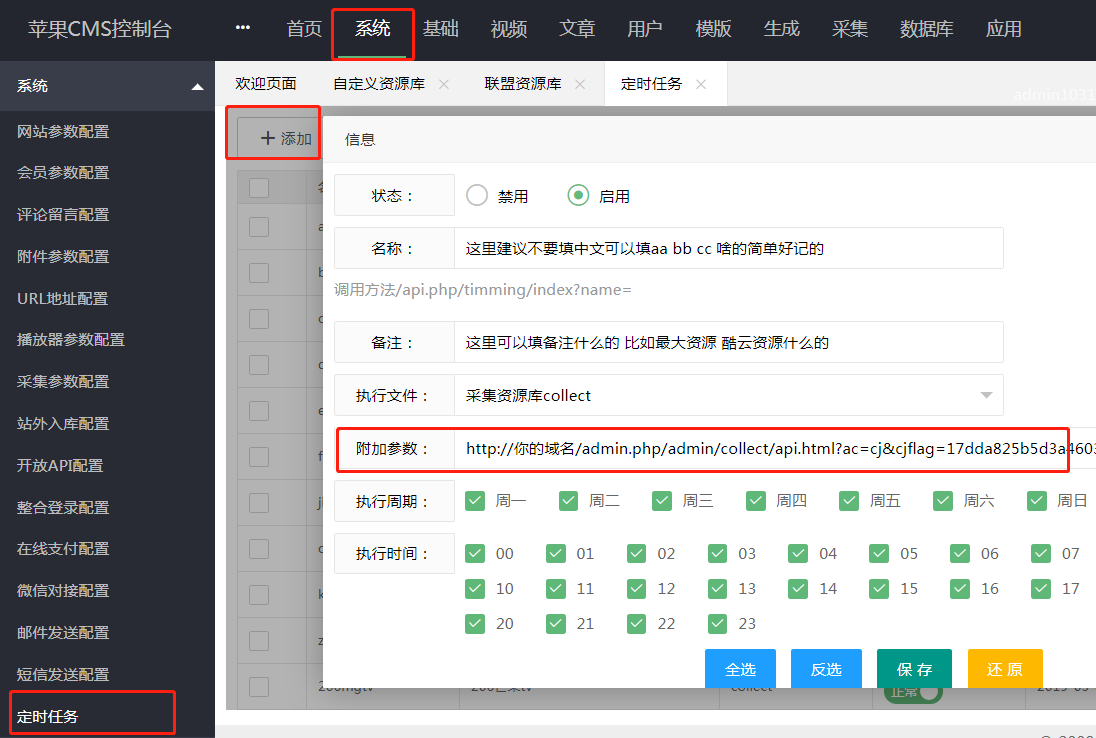
首先,我的大部分朋友在构建网站后没有很多时间手动更新内容。也有很多新手问
苹果cms+宝塔怎么自动采集
让我们来谈谈定时任务。我们以 Applecms 为例。
闲话不多说,进入正题
首先设置苹果的cms程序进入后台
首先点击采集,然后选择资源库。看看下面的图片。联盟资源库收录在苹果cms程序中,自定义资源库自行添加。
然后重点是(对于小白来说,如果你添加了定时任务,请路过)
这一步是点击资源库,把他拖到一个单独的页面,防止他在苹果的cms控制台框架下,意思是单独布局一个单独的页面,目的是提取需要的cms @采集链接,拖出来看下图
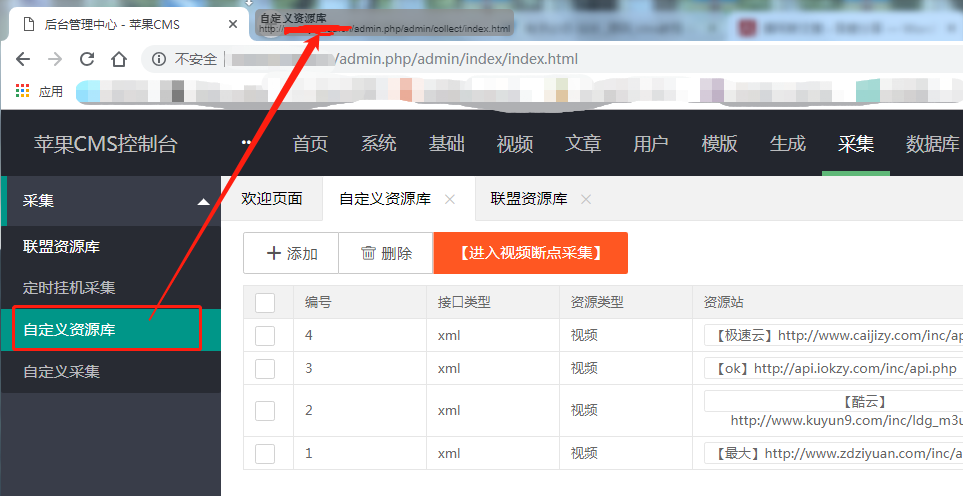
拖出来之后就是上图了,然后直接点击一个资源的当天的采集按钮,他就会跳转到他的采集链接。这时候会更快,直接复制他的网址。(URL一出来就复制,不要等他跳到第二页再复制)
复制的内容如下
您的域名/admin.php/admin/collect/api.html?ac=cj&cjflag=17dda825b5d3a4603cd2c65ffe1b3408&cjurl=http%3A%2F%2F%2Finc%2Fldg_m3u8.asp&h=24&type&td= =
下面第二页的内容(不重要,随便说说)
您的域名/admin.php/admin/collect/api.html?ac=cj&cjflag=17dda825b5d3a4603cd2c65ffe1b3408&cjurl=http%3A%2F%2F%2Finc%2Fldg_m3u8.asp&h=24&type&td= =&页面=2
这是我复制的链接。你复制的可能和我复制的不完全一样。不要太担心。我只是给你举个例子。我想让你看到的是当第二页在第二页时,链接后会添加一个页面条件。, 所以一定要检查复制的URL,虽然这不是很重要,但在我看来,细节决定成败
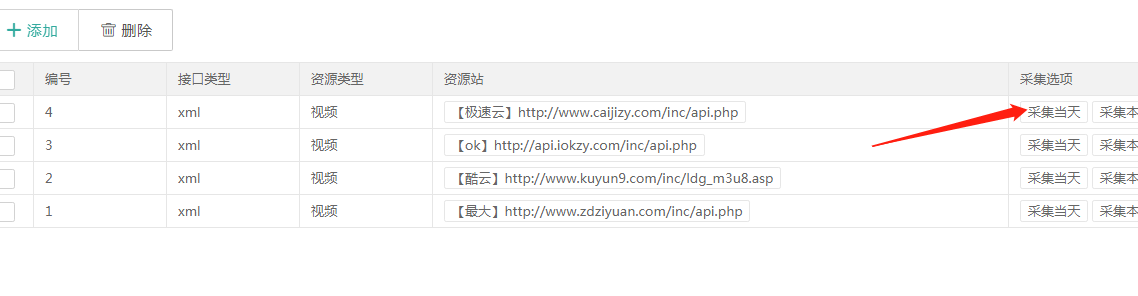
获得链接后,您将开始添加任务。苹果cms后台点击系统→计划任务看图
首先,单击添加按钮并选择启用。不要使用中文拼音作为名称。您可以随意填写资源站的名称。
(Key) 填写附加参数
把刚才复制的网址链接直接粘贴进去,然后把ac=previous删掉,如下
ac=cj&cjflag=17dda825b5d3a4603cd2c65ffe1b3408&cjurl=http%3A%2F%2F%2Finc%2Fldg_m3u8.asp&h=24&t=&ids=&wd=&¶=1&mid=这是一个附加参数
然后点击底部的全选
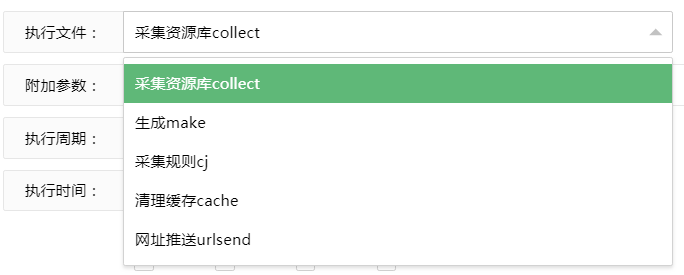
有以下 5 种执行文件。我们今天要使用的文件是collect,选择这个并点击save
保存后需要进行测试,点击测试按钮看看会发生什么
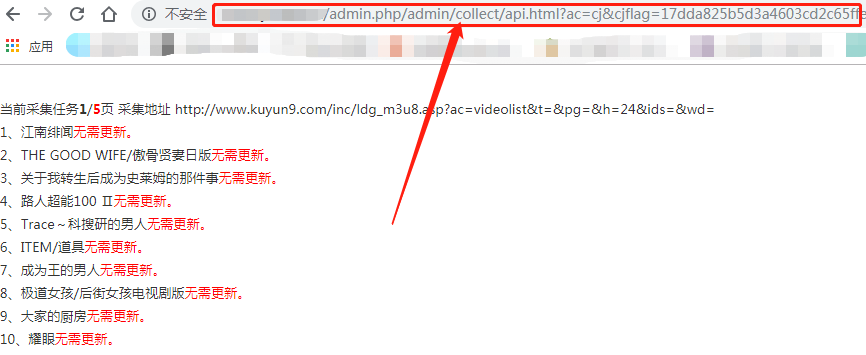
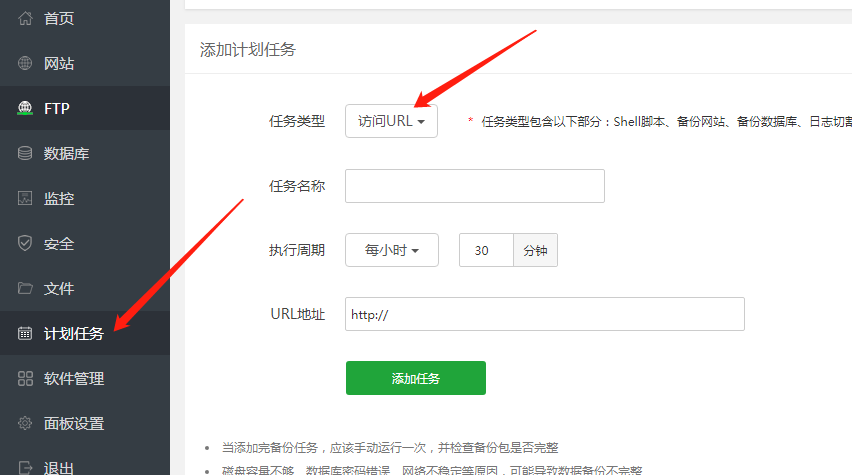
单击测试打开新网页并复制该 URL
URL 都是你的域名 /api.php/timming/index.html?name=name
然后你会使用宝塔,打开宝塔网页控制面板,就是网页背景
点击定时任务如图
选择任务类型访问URL,任务名称随便填,执行周期个人推荐一小时一次
这个url地址一定要填错,这个地址是点击测试后弹出的地址
我这里是你的域名/api.php/timming/index.html?name=name
(填自己的,不要填我发的,这个是demo)
不要在这里犯任何错误,如果你在这里犯所有错误,那么你的心智就真的没有希望了。
一般情况下,如果没有意外,会自动采集,日志也可以在宝塔查看。几个小时后,检查日志是否有“成功”字符。
本教程的主要目的是找到
点击测试后出来的网址
使用此 URL,它与您监视的位置相同。阿里云监控或者你可以写一段代码到页面有人访问你网站来运行你想要的任何你想达到监控url的目的,即自动采集
PS:说说我自己的看法吧。如果这个东西建议Linux系统使用Windows,那么4的宝塔应该有点问题或者权限不对什么的。我没有仔细研究它。我建议您使用Linux 来构建网站。比win还顺利,教程到此结束
-------------------- 查看全部
文章定时自动采集(苹果cms+宝塔怎么才能做到自动采集?(组图))
首先,我的大部分朋友在构建网站后没有很多时间手动更新内容。也有很多新手问
苹果cms+宝塔怎么自动采集
让我们来谈谈定时任务。我们以 Applecms 为例。
闲话不多说,进入正题
首先设置苹果的cms程序进入后台
首先点击采集,然后选择资源库。看看下面的图片。联盟资源库收录在苹果cms程序中,自定义资源库自行添加。
然后重点是(对于小白来说,如果你添加了定时任务,请路过)
这一步是点击资源库,把他拖到一个单独的页面,防止他在苹果的cms控制台框架下,意思是单独布局一个单独的页面,目的是提取需要的cms @采集链接,拖出来看下图
拖出来之后就是上图了,然后直接点击一个资源的当天的采集按钮,他就会跳转到他的采集链接。这时候会更快,直接复制他的网址。(URL一出来就复制,不要等他跳到第二页再复制)
复制的内容如下
您的域名/admin.php/admin/collect/api.html?ac=cj&cjflag=17dda825b5d3a4603cd2c65ffe1b3408&cjurl=http%3A%2F%2F%2Finc%2Fldg_m3u8.asp&h=24&type&td= =
下面第二页的内容(不重要,随便说说)
您的域名/admin.php/admin/collect/api.html?ac=cj&cjflag=17dda825b5d3a4603cd2c65ffe1b3408&cjurl=http%3A%2F%2F%2Finc%2Fldg_m3u8.asp&h=24&type&td= =&页面=2
这是我复制的链接。你复制的可能和我复制的不完全一样。不要太担心。我只是给你举个例子。我想让你看到的是当第二页在第二页时,链接后会添加一个页面条件。, 所以一定要检查复制的URL,虽然这不是很重要,但在我看来,细节决定成败
获得链接后,您将开始添加任务。苹果cms后台点击系统→计划任务看图
首先,单击添加按钮并选择启用。不要使用中文拼音作为名称。您可以随意填写资源站的名称。
(Key) 填写附加参数
把刚才复制的网址链接直接粘贴进去,然后把ac=previous删掉,如下
ac=cj&cjflag=17dda825b5d3a4603cd2c65ffe1b3408&cjurl=http%3A%2F%2F%2Finc%2Fldg_m3u8.asp&h=24&t=&ids=&wd=&¶=1&mid=这是一个附加参数
然后点击底部的全选
有以下 5 种执行文件。我们今天要使用的文件是collect,选择这个并点击save
保存后需要进行测试,点击测试按钮看看会发生什么
单击测试打开新网页并复制该 URL
URL 都是你的域名 /api.php/timming/index.html?name=name
然后你会使用宝塔,打开宝塔网页控制面板,就是网页背景
点击定时任务如图
选择任务类型访问URL,任务名称随便填,执行周期个人推荐一小时一次
这个url地址一定要填错,这个地址是点击测试后弹出的地址
我这里是你的域名/api.php/timming/index.html?name=name
(填自己的,不要填我发的,这个是demo)
不要在这里犯任何错误,如果你在这里犯所有错误,那么你的心智就真的没有希望了。
一般情况下,如果没有意外,会自动采集,日志也可以在宝塔查看。几个小时后,检查日志是否有“成功”字符。
本教程的主要目的是找到
点击测试后出来的网址
使用此 URL,它与您监视的位置相同。阿里云监控或者你可以写一段代码到页面有人访问你网站来运行你想要的任何你想达到监控url的目的,即自动采集
PS:说说我自己的看法吧。如果这个东西建议Linux系统使用Windows,那么4的宝塔应该有点问题或者权限不对什么的。我没有仔细研究它。我建议您使用Linux 来构建网站。比win还顺利,教程到此结束
--------------------
文章定时自动采集(酷睿股票私募网站管理系统系统新增会员实战的自动更新功能)
采集交流 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-01-05 03:04
核心股票私募网站管理系统是国内首个WAP手机和电脑WEB同时接入的股票私募系统。本系统基于ASP+DIV+CSS+AJAX+XML+MSSQL技术,专门针对股票私募网站开发了cms网站管理系统,简单易用、安全、高效、快速、优秀的网站解决方案,经过精心设计,适用于各种服务器环境。后台管理方便、易懂、易用、人性化,对操作人员技术要求低。对车站建设一窍不通的操作人员也能轻松上手。继续ASP开源之路,稳定、安全、强大的核心程序。
类似软件
印记
软件地址
核心股权私募网站管理系统,最大的优势不仅是全国首创的WAP手机接入系统,还有数十款精美模板免费选择和终身免费模板更换服务,承诺购买一次免费终生。任何限制和加密,二次开发完全免费,域名、空间、IP等也可以随意更改,终身免费无限升级和新版本,无限使用一套系统。
升级更新部分功能介绍
在原有的绿蓝刷新模板上更新了新内核
新增专家推荐模型
添加公开验证模型
新增成员战斗模式
增加了包括历史记录模型在内的四个新模型,并删除了原来的两个系统调用并替换为一个系统
新增会员实战自动更新功能
新增历史记录自动更新功能
新增后台定时任务文章多点定时和自动采集自动多点定时生成静态页面
新增后台设置及前端会员注册时允许显示的会员群组,如A、B、C、D、E、G等类型的会员群组
新增会员登录后专业采摘区链接
新增WAP系统手机浏览时点击电话号码链接自助拨号功能
增加WAP系统站内邮箱功能
增加WAP系统找回密码功能
添加了目录安全设置的描述文件
修复WAP手机系统系统中使用的手机无法正常登录的问题
将整个WAP系统原有的UTF-8修改为GBK,方便程序修改
将WAP系统原有的wml语言修改为html语言
修复WAP系统无法注册的问题
修复WAP系统无法修改数据的问题
修复WAP系统选料区无需登录即可直接查看相关会员信息的问题
修复了部分手机浏览器在 WAP 系统中的浏览问题
修复WAP系统与QQ、UC、Opera及手机内置WAP浏览器的兼容问题
修改后台所有静态自定义标签可以可视化编辑
修复后台无法添加和修改幻灯片图片的问题
修复财经直播视频无法播放的问题
修改滚动行情不能自动更新,改为世界主要股指自动实时更新
增强型后台木马在线检测系统
修复黑客利用后台或会员上传功能上传木马的bug
修复黑客利用模板管理添加木马文件的bug
修正其他十余个BUG及安全隐患
修改Robots.txt搜索引擎蜘蛛文件的收录权限为网站,允许搜索引擎更新收录网站的内容
新内核系统提升网站加载速度60%
并取消了首页的几个IFRAME调用,并尽可能增加了对搜索引擎友好的程序
可选添加相关功能:如专家在线问答系统、论坛系统、会员博客系统、留言系统、友情链接系统等。
主要功能
实时行情系统
滚动全球行情、外汇行情、机构查看、涨跌排名、交易排名、股市指南、全球指数自动更新。
运行速度和效率
使用XML缓存,运行速度更快,效率更高。
系统采用ASP+DIV+CSS+Ajax+XML+MSSQL技术开发,运行速度翻倍。
文章智能快速采集系统
多点定时计划文章采集和多点定时计划文章自动生成系统,让你的网站无人值守,自动更新
智能强大的过滤系统设置,UTF-8/GB2312自动识别,批量采集让您享受高速采集的乐趣。
采集目标网站可随意更改,设置规则简单,操作更方便
会员实战自动更新功能
自动更新当日沪深股市三大涨幅作为会员实战内容
历史记录自动更新功能
可自动更新会员实战前15天和120天内的内容作为历史记录内容,实际盈利自动设置为40%-90%,交易时间自动更新设置为 3-9 天
全新文章浏览权限申请功能
真正实现了会员选区的会员群组浏览功能,会员群组浏览权限可以精确到每个频道/每个栏目/每篇文章文章,让不同的会员群组享受不同的文章@ >浏览权限,每个会员群之间的信息不能浏览,还可以设置每篇文章文章浏览积分,发积分卡给套餐会员浏览,设置月度会员浏览,月度会员 时间一到,会员需要进行续费才能查看相应的会员信息。
强大的会员管理功能
无限用户群添加功能,站内短信功能,会员优惠券详情查询,有效期查询,资金详情查询,积分卡在线充值功能,在线支付实时支付,会员可设置为扣费会员,有效期会员,和无限期成员。
SEO优化
在线智能生成GOOGLE/百度标准收录XML格式地图,让网站更容易搜索和收录。
三种运行模式:网站所有页面均可采用高动态、静态和伪状态格式,大大提高浏览速度和搜索引擎搜索量。
HTML 生成的文件存储结构选择。
对Alexa收录的info.txt文件和搜索引擎蜘蛛爬取文件Robots.txt有独特的好处
模板程序分离,网站频道、栏目、内容页META关键词、网站META网页描述都是调用标签,有利于收录@的量> 网站 大大缩短了页面收录的时间,让网站的自动配置管理更容易
WAP手机网站系统
国内独有的WAP手机接入系统,注册、登录、选会员、分析预测等功能,一机搞定!支持手机自带WAP浏览器、UC浏览器、QQ浏览器以及几乎所有可以上网的主流手机浏览器
手机上网浏览与网站同步,一个账号,两站通用,实现WEB和WAP的无缝连接
ASK在线专家提问系统
通过该系统,会员可以向网站专家提出各种股票相关问题,网站专家可以及时解答会员提出的各种问题
论坛功能系统
通过该系统,会员可以与其他会员讨论各种股票相关知识或交流股票交易技巧,让您的网站更有活力
设计先进的多系统完整功能:
先进的多系统集成API接口,让您的网站集成商城、论坛、博客、图片、下载、视频等网站系统,让您的网站更加丰富多彩。
整合11个网上支付平台
集成:财付通、网银、在线易支付、云网、支付宝、快钱支付、中国在线支付网、西式支付、上海欢讯等11个在线支付平台接口,会员充值实时到账,让您可以充电无忧。
强大的插件管理
集成:CC视频联盟插件、WSS统计插件、WAP手机网站插件
标签管理系统
<p>全新标签应用功能全站采用标签调用系统,使网站运行速度更快,完全防止站内 查看全部
文章定时自动采集(酷睿股票私募网站管理系统系统新增会员实战的自动更新功能)
核心股票私募网站管理系统是国内首个WAP手机和电脑WEB同时接入的股票私募系统。本系统基于ASP+DIV+CSS+AJAX+XML+MSSQL技术,专门针对股票私募网站开发了cms网站管理系统,简单易用、安全、高效、快速、优秀的网站解决方案,经过精心设计,适用于各种服务器环境。后台管理方便、易懂、易用、人性化,对操作人员技术要求低。对车站建设一窍不通的操作人员也能轻松上手。继续ASP开源之路,稳定、安全、强大的核心程序。
类似软件
印记
软件地址
核心股权私募网站管理系统,最大的优势不仅是全国首创的WAP手机接入系统,还有数十款精美模板免费选择和终身免费模板更换服务,承诺购买一次免费终生。任何限制和加密,二次开发完全免费,域名、空间、IP等也可以随意更改,终身免费无限升级和新版本,无限使用一套系统。
升级更新部分功能介绍
在原有的绿蓝刷新模板上更新了新内核
新增专家推荐模型
添加公开验证模型
新增成员战斗模式
增加了包括历史记录模型在内的四个新模型,并删除了原来的两个系统调用并替换为一个系统
新增会员实战自动更新功能
新增历史记录自动更新功能
新增后台定时任务文章多点定时和自动采集自动多点定时生成静态页面
新增后台设置及前端会员注册时允许显示的会员群组,如A、B、C、D、E、G等类型的会员群组
新增会员登录后专业采摘区链接
新增WAP系统手机浏览时点击电话号码链接自助拨号功能
增加WAP系统站内邮箱功能
增加WAP系统找回密码功能
添加了目录安全设置的描述文件
修复WAP手机系统系统中使用的手机无法正常登录的问题
将整个WAP系统原有的UTF-8修改为GBK,方便程序修改
将WAP系统原有的wml语言修改为html语言
修复WAP系统无法注册的问题
修复WAP系统无法修改数据的问题
修复WAP系统选料区无需登录即可直接查看相关会员信息的问题
修复了部分手机浏览器在 WAP 系统中的浏览问题
修复WAP系统与QQ、UC、Opera及手机内置WAP浏览器的兼容问题
修改后台所有静态自定义标签可以可视化编辑
修复后台无法添加和修改幻灯片图片的问题
修复财经直播视频无法播放的问题
修改滚动行情不能自动更新,改为世界主要股指自动实时更新
增强型后台木马在线检测系统
修复黑客利用后台或会员上传功能上传木马的bug
修复黑客利用模板管理添加木马文件的bug
修正其他十余个BUG及安全隐患
修改Robots.txt搜索引擎蜘蛛文件的收录权限为网站,允许搜索引擎更新收录网站的内容
新内核系统提升网站加载速度60%
并取消了首页的几个IFRAME调用,并尽可能增加了对搜索引擎友好的程序
可选添加相关功能:如专家在线问答系统、论坛系统、会员博客系统、留言系统、友情链接系统等。
主要功能
实时行情系统
滚动全球行情、外汇行情、机构查看、涨跌排名、交易排名、股市指南、全球指数自动更新。
运行速度和效率
使用XML缓存,运行速度更快,效率更高。
系统采用ASP+DIV+CSS+Ajax+XML+MSSQL技术开发,运行速度翻倍。
文章智能快速采集系统
多点定时计划文章采集和多点定时计划文章自动生成系统,让你的网站无人值守,自动更新
智能强大的过滤系统设置,UTF-8/GB2312自动识别,批量采集让您享受高速采集的乐趣。
采集目标网站可随意更改,设置规则简单,操作更方便
会员实战自动更新功能
自动更新当日沪深股市三大涨幅作为会员实战内容
历史记录自动更新功能
可自动更新会员实战前15天和120天内的内容作为历史记录内容,实际盈利自动设置为40%-90%,交易时间自动更新设置为 3-9 天
全新文章浏览权限申请功能
真正实现了会员选区的会员群组浏览功能,会员群组浏览权限可以精确到每个频道/每个栏目/每篇文章文章,让不同的会员群组享受不同的文章@ >浏览权限,每个会员群之间的信息不能浏览,还可以设置每篇文章文章浏览积分,发积分卡给套餐会员浏览,设置月度会员浏览,月度会员 时间一到,会员需要进行续费才能查看相应的会员信息。
强大的会员管理功能
无限用户群添加功能,站内短信功能,会员优惠券详情查询,有效期查询,资金详情查询,积分卡在线充值功能,在线支付实时支付,会员可设置为扣费会员,有效期会员,和无限期成员。
SEO优化
在线智能生成GOOGLE/百度标准收录XML格式地图,让网站更容易搜索和收录。
三种运行模式:网站所有页面均可采用高动态、静态和伪状态格式,大大提高浏览速度和搜索引擎搜索量。
HTML 生成的文件存储结构选择。
对Alexa收录的info.txt文件和搜索引擎蜘蛛爬取文件Robots.txt有独特的好处
模板程序分离,网站频道、栏目、内容页META关键词、网站META网页描述都是调用标签,有利于收录@的量> 网站 大大缩短了页面收录的时间,让网站的自动配置管理更容易
WAP手机网站系统
国内独有的WAP手机接入系统,注册、登录、选会员、分析预测等功能,一机搞定!支持手机自带WAP浏览器、UC浏览器、QQ浏览器以及几乎所有可以上网的主流手机浏览器
手机上网浏览与网站同步,一个账号,两站通用,实现WEB和WAP的无缝连接
ASK在线专家提问系统
通过该系统,会员可以向网站专家提出各种股票相关问题,网站专家可以及时解答会员提出的各种问题
论坛功能系统
通过该系统,会员可以与其他会员讨论各种股票相关知识或交流股票交易技巧,让您的网站更有活力
设计先进的多系统完整功能:
先进的多系统集成API接口,让您的网站集成商城、论坛、博客、图片、下载、视频等网站系统,让您的网站更加丰富多彩。
整合11个网上支付平台
集成:财付通、网银、在线易支付、云网、支付宝、快钱支付、中国在线支付网、西式支付、上海欢讯等11个在线支付平台接口,会员充值实时到账,让您可以充电无忧。
强大的插件管理
集成:CC视频联盟插件、WSS统计插件、WAP手机网站插件
标签管理系统
<p>全新标签应用功能全站采用标签调用系统,使网站运行速度更快,完全防止站内
文章定时自动采集(信息采集使用手册摘要()抓取网络数据,摘要)
采集交流 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-01-01 15:00
信息采集用户手册
总结
Information采集是抓取网络数据,实现信息共享的功能模块。提供手动抓取、定时抓取、定时循环抓取三种模式。可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。
步骤和细节
现在需要将网页采集的数据(新闻)上传到webplus系统的指定栏目。步骤如下:
为指定的列制定采集计划。
在栏目管理中选择栏目,点击设置采集计划。 (例如图片一)
设置采集的基本属性。
包括执行方式、信息是否自动发布、列类型采集以及页面的编码格式。 (例如图片二)
事先约定采集计划的执行方式,手动,定时单次或定时循环执行。
如果只是针对采集网页的当前数据,我们可以使用手动和定时的一次性方式采集一次;如果采集网页的数据会更新,我们还要保证信息的同步,即采用定时循环采集的方法。
判断采集过来的信息是否需要发布
如果你过来的信息不需要修改,可以直接发布到网上,选择自动发布。如果来自采集的信息需要修改、审核等,选择不自动发布。 采集完成后,信息管理人员将进行其他操作。
设置列类型采集
如果采集的网页只是一个简单的新闻列表,即采集页面的新闻放在指定栏目下,则选择单栏目。如果采集的页面有多个新闻列表,并且每个都提供了一个单独的链接来进入自己的新闻列表页面,
而且我们需要采集所有的新闻信息,然后选择多个栏目。另外,如果采集的页面是RSS信息聚合页面,则设置为对应的RSS单栏或RSS多栏。
设置采集页面的编码
因为webplus系统使用的是UTF-8编码格式,而采集可能是其他编码格式,那么为了避免采集传来的乱码,这里需要设置为采集页面的编码格式。
设置采集计划的采集规则
单列采集计划设置(例如图片三)
设置“列表页面起始地址”
是采集页面的访问路径。 (必填)
设置“文章页面URL获取规则”
如果新闻列表是通过采集以iframe的形式嵌入到网页中的,那么需要设置规则获取列表iframe的链接地址来访问新闻列表。否则,无需制定此规则。 (具体规则请参考下面的“采集正则表达式公式”)
如果采集网页的新闻列表是分页的,那么要根据新闻列表的分页方式(链接和表单提交),以及分页的起始页码来制定分页规则,间隔页码和采集页数。如果新闻列表中没有分页,则无需制定此规则。
如果采集的页面有多个新闻列表,并且多个新闻列表的url规则相似,我们只需要采集指定的一个列表,即需要设置限制文章列出访问规则,这是为了避免采集冗余数据。否则,无需设置此规则。
设置文章 url获取规则,以便能够从采集页面访问特定的新闻页面,从而进行新闻采集。 (必填)
设置“文章内容获取规则”
对于特定的新闻页面,如果文章的内容以iframe的形式嵌入到新闻页面中,则需要设置规则获取文章 iframe的链接地址访问新闻内容。否则,无需制定此规则。
如果新闻内容有分页情况,则根据文章内容分页方式(链接和表单提交)制定分页规则,需要设置分页起始页码,间隔页码和采集页数。如果文章的内容没有分页,则无需制定此规则。
如果新闻页面上除了新闻内容之外还有其他附加信息,那么为了在采集过程中更容易找到新闻内容,需要设置规则来限制获取新闻内容在这里。一是避免垃圾邮件,二是降低新闻特定信息获取规则的复杂性。如果新闻页面比较简单,一般不需要设置此规则。
设置新闻属性的规则,除标题和内容外,均为可选条件。另外,如果未设置新闻发布时间,则以当前时间作为发布时间。
多列采集计划设置(例如图片五)
Multi-column采集 除了需要在“List page start URL”下设置list page URL rules和“文章Page URL获取规则”下的列名获取规则,其他项目与列表相关。 采集 列具有相同的计划设置。
RSS单栏采集计划设置(如:图片四)
RSS单列的采集方案不需要设置“文章页面URL获取规则”,其余与单列采集方案一致。
RSS多栏采集计划设置(例如图片六)
<p>RSS多栏采集方案需要在“列表页面起始网址”下设置列表页网址获取规则,其余与RSS单栏采集方案一致。 查看全部
文章定时自动采集(信息采集使用手册摘要()抓取网络数据,摘要)
信息采集用户手册
总结
Information采集是抓取网络数据,实现信息共享的功能模块。提供手动抓取、定时抓取、定时循环抓取三种模式。可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。
步骤和细节
现在需要将网页采集的数据(新闻)上传到webplus系统的指定栏目。步骤如下:
为指定的列制定采集计划。
在栏目管理中选择栏目,点击设置采集计划。 (例如图片一)
设置采集的基本属性。
包括执行方式、信息是否自动发布、列类型采集以及页面的编码格式。 (例如图片二)
事先约定采集计划的执行方式,手动,定时单次或定时循环执行。
如果只是针对采集网页的当前数据,我们可以使用手动和定时的一次性方式采集一次;如果采集网页的数据会更新,我们还要保证信息的同步,即采用定时循环采集的方法。
判断采集过来的信息是否需要发布
如果你过来的信息不需要修改,可以直接发布到网上,选择自动发布。如果来自采集的信息需要修改、审核等,选择不自动发布。 采集完成后,信息管理人员将进行其他操作。
设置列类型采集
如果采集的网页只是一个简单的新闻列表,即采集页面的新闻放在指定栏目下,则选择单栏目。如果采集的页面有多个新闻列表,并且每个都提供了一个单独的链接来进入自己的新闻列表页面,
而且我们需要采集所有的新闻信息,然后选择多个栏目。另外,如果采集的页面是RSS信息聚合页面,则设置为对应的RSS单栏或RSS多栏。
设置采集页面的编码
因为webplus系统使用的是UTF-8编码格式,而采集可能是其他编码格式,那么为了避免采集传来的乱码,这里需要设置为采集页面的编码格式。
设置采集计划的采集规则
单列采集计划设置(例如图片三)
设置“列表页面起始地址”
是采集页面的访问路径。 (必填)
设置“文章页面URL获取规则”
如果新闻列表是通过采集以iframe的形式嵌入到网页中的,那么需要设置规则获取列表iframe的链接地址来访问新闻列表。否则,无需制定此规则。 (具体规则请参考下面的“采集正则表达式公式”)
如果采集网页的新闻列表是分页的,那么要根据新闻列表的分页方式(链接和表单提交),以及分页的起始页码来制定分页规则,间隔页码和采集页数。如果新闻列表中没有分页,则无需制定此规则。
如果采集的页面有多个新闻列表,并且多个新闻列表的url规则相似,我们只需要采集指定的一个列表,即需要设置限制文章列出访问规则,这是为了避免采集冗余数据。否则,无需设置此规则。
设置文章 url获取规则,以便能够从采集页面访问特定的新闻页面,从而进行新闻采集。 (必填)
设置“文章内容获取规则”
对于特定的新闻页面,如果文章的内容以iframe的形式嵌入到新闻页面中,则需要设置规则获取文章 iframe的链接地址访问新闻内容。否则,无需制定此规则。
如果新闻内容有分页情况,则根据文章内容分页方式(链接和表单提交)制定分页规则,需要设置分页起始页码,间隔页码和采集页数。如果文章的内容没有分页,则无需制定此规则。
如果新闻页面上除了新闻内容之外还有其他附加信息,那么为了在采集过程中更容易找到新闻内容,需要设置规则来限制获取新闻内容在这里。一是避免垃圾邮件,二是降低新闻特定信息获取规则的复杂性。如果新闻页面比较简单,一般不需要设置此规则。
设置新闻属性的规则,除标题和内容外,均为可选条件。另外,如果未设置新闻发布时间,则以当前时间作为发布时间。
多列采集计划设置(例如图片五)
Multi-column采集 除了需要在“List page start URL”下设置list page URL rules和“文章Page URL获取规则”下的列名获取规则,其他项目与列表相关。 采集 列具有相同的计划设置。
RSS单栏采集计划设置(如:图片四)
RSS单列的采集方案不需要设置“文章页面URL获取规则”,其余与单列采集方案一致。
RSS多栏采集计划设置(例如图片六)
<p>RSS多栏采集方案需要在“列表页面起始网址”下设置列表页网址获取规则,其余与RSS单栏采集方案一致。
文章定时自动采集(前两天有小伙伴问松哥如何实现定时任务的动态配置?(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-12-31 14:05
定时任务可以看作是我们日常开发中比较常见的需求,市场上也有很多成熟的框架:
但是朋友们都知道,其实我们的Spring框架也提供了相应的定时任务。这个定时任务是通过@EnableScheduling注解开启的。宋歌还写了文章给大家分享一下这个注解的基本用法:
但是之前的定时任务都是预先固定好硬编码的,无法动态配置。前两天有朋友问宋歌如何实现定时任务的动态配置?
这个东西如果是基于xxl-job这样的框架,其实还是比较容易的,不过也可以通过Spring自带的@EnableScheduling注解来实现,并不难。宋歌在此基础上匆匆写了一篇,今天先跟大家说一下一般用法,然后抽空再写一篇文章的实现原理介绍。
项目开源,项目地址:
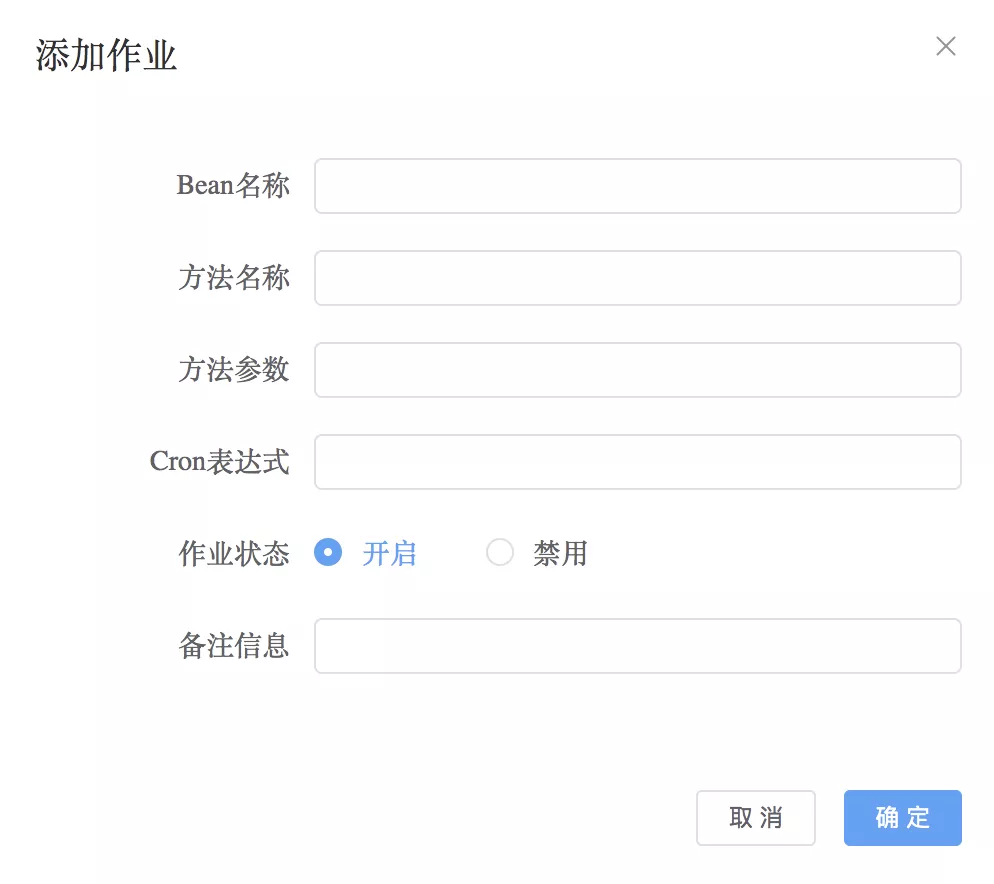
以可食用模式克隆项目:git clone。本地数据库创建了一个名为 schedule 的库。修改配置文件src/main/resources/application.yaml,主要修改数据库连接的用户名和地址。启动项目。浏览器访问:8080,可以看到如下页面:
表示启动成功。
功能介绍 项目启动时,会自动从数据库中加载状态为1的定时任务并开始执行。1表示开启状态的定时任务,0表示关闭状态的定时任务。单击页面上的“添加作业”按钮以添加新的定时任务。如果新任务的bean名称、方法名称、方法参数与已有记录相同,则视为重复作业,重复作业将无法添加。
添加作业的页面如下:
这里涉及到几个参数,它们的含义如下:
添加作业成功的提示如下:
作业添加失败提示如下:
点击作业编辑,可以修改作业的数据:
修改将立即生效。
单击分配删除以删除现有分配。如果正在执行删除的作业,请先停止作业,然后再将其删除。您也可以通过单击列表中的切换按钮来切换作业的状态。
技术栈其他
这是一个用于学习的演示,而不是一个完整的项目。宋歌会发一篇文章的文章和大家分享一下具体的实现思路。
好了,先说这么多。 查看全部
文章定时自动采集(前两天有小伙伴问松哥如何实现定时任务的动态配置?(组图))
定时任务可以看作是我们日常开发中比较常见的需求,市场上也有很多成熟的框架:
但是朋友们都知道,其实我们的Spring框架也提供了相应的定时任务。这个定时任务是通过@EnableScheduling注解开启的。宋歌还写了文章给大家分享一下这个注解的基本用法:
但是之前的定时任务都是预先固定好硬编码的,无法动态配置。前两天有朋友问宋歌如何实现定时任务的动态配置?
这个东西如果是基于xxl-job这样的框架,其实还是比较容易的,不过也可以通过Spring自带的@EnableScheduling注解来实现,并不难。宋歌在此基础上匆匆写了一篇,今天先跟大家说一下一般用法,然后抽空再写一篇文章的实现原理介绍。
项目开源,项目地址:
以可食用模式克隆项目:git clone。本地数据库创建了一个名为 schedule 的库。修改配置文件src/main/resources/application.yaml,主要修改数据库连接的用户名和地址。启动项目。浏览器访问:8080,可以看到如下页面:

表示启动成功。
功能介绍 项目启动时,会自动从数据库中加载状态为1的定时任务并开始执行。1表示开启状态的定时任务,0表示关闭状态的定时任务。单击页面上的“添加作业”按钮以添加新的定时任务。如果新任务的bean名称、方法名称、方法参数与已有记录相同,则视为重复作业,重复作业将无法添加。
添加作业的页面如下:
这里涉及到几个参数,它们的含义如下:
添加作业成功的提示如下:
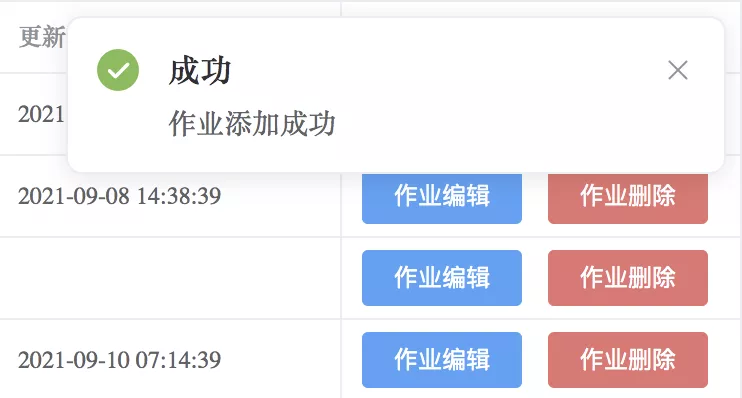
作业添加失败提示如下:
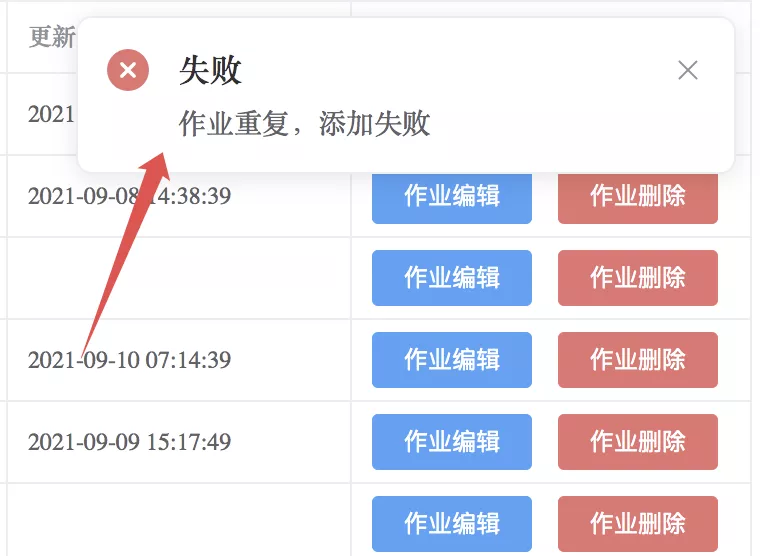
点击作业编辑,可以修改作业的数据:
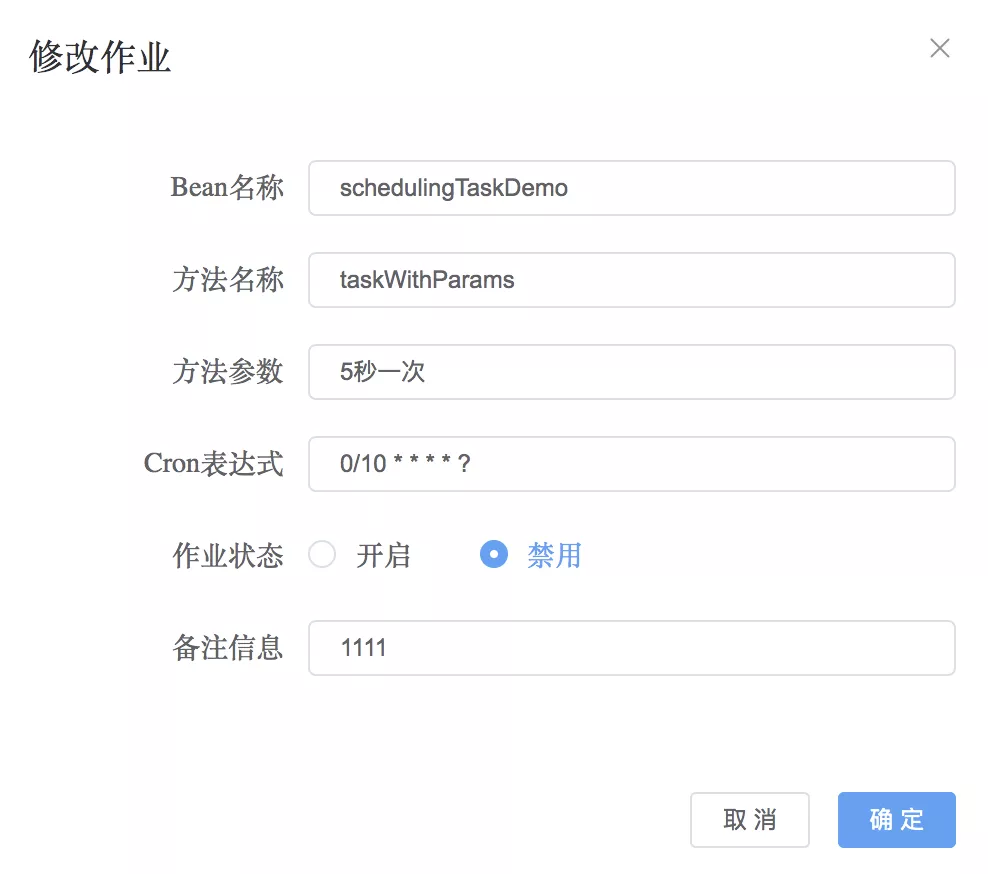
修改将立即生效。
单击分配删除以删除现有分配。如果正在执行删除的作业,请先停止作业,然后再将其删除。您也可以通过单击列表中的切换按钮来切换作业的状态。

技术栈其他
这是一个用于学习的演示,而不是一个完整的项目。宋歌会发一篇文章的文章和大家分享一下具体的实现思路。
好了,先说这么多。
文章定时自动采集(用Python编写数据采集脚本()上采集数据 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 365 次浏览 • 2021-12-31 11:30
)
概述:
在树莓派(xxxxx,以下简称工控机)采集数据上,传输到本地sqlserver数据库,用Python编写数据采集脚本。
这涉及到几个问题:当出现网络中断、断电、工控机重启等异常情况时,为了保证这些异常情况的发生,数据仍然可以自动采集,需要以下两种解决方案实施的。
开机自动启动;当脚本没有运行时,它会自动运行。
首选第二种方案,因为python程序崩溃或者网络异常导致程序中断,需要一种机制让它自动运行。
参考网址:
常用命令:
自动运行脚本:vim /etc/crontab
查看进程:ps -ef|grep tcpclient.py
自动运行脚本
启动TCP服务器监控功能:
输入vim /etc/crontab,最后输入* * * * * root python3 /home/pi/tcpclient.py
tcpclient.py 代码:
import socket
import time
import random
def main():
# 1 创建tcp套接字
while 1:
tcp_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 2 创建连接
tcp_socket.connect(('192.168.1.35', 6666))
# 3 发送数据
tcp_input = str(random.randint(2,15))
tcp_socket.send(tcp_input.encode('gbk')) # utf-8 中文会乱码
time.sleep(5)
# 4.关闭套接字
tcp_socket.close()
if __name__ == '__main__':
main()
输入ps -ef|grep tcpclient.py,可以看到进程多了(带问号的),tcpclient.py有while循环,不会自动退出,所以tcpclient.py每分钟自动运行一次。
优化
当然无线增加程序进程是不可能的,所以有两种选择:
每次执行tcpclient.py,都会自动关闭并终止程序,没有while循环。另外写一个test1.py程序,脚本会每分钟运行一次test1.py程序,test1.py判断tcpclient.py进程是否存在,如果存在不存在,它会运行;如果存在,它将不会运行。
这次采用了第二个选项,以避免每次tcp断开和重新连接(除非你像本例那样在while循环中关闭了socket)。
测试1.py 代码:
import time
import os
import re
# execute command, and return the infomation. 执行命令并返回命令输出信息
def execCmd(cmd):
r = os.popen(cmd)
text = r.read()
r.close()
return text
def doSomething():
os.system('python3 /home/pi/tcpclient.py')
time.sleep(10)
if __name__ == '__main__':
#ps -ef是linux查看进程信息指令,|是管道符号导向到grep去查找特定的进程,最后一个|是导向grep过滤掉grep进程:因为grep查看程序名也是进程,会混到查询信息里
programIsRunningCmd="ps -ef|grep tcpclient.py"
programIsRunningCmdAns = execCmd(programIsRunningCmd) #调用函数执行指令,并返回指令查询出的信息
print(programIsRunningCmdAns)
ansLine = programIsRunningCmdAns.split('\n') #将查出的信息用换行符‘\b’分开
print(len(ansLine))
#判断如果返回行数>3则说明python脚本程序已经在运行,打印提示信息结束程序,否则运行脚本代码doSomething()
if len(ansLine) > 3:
print("programName have been Running")
else:
doSomething()
结果
可以看出,test1.py和tcpclient.py进程在任何时候都是一样的,不会无限增加。工控机重启后,过程还是一样,说明已经达到了预期的效果。
查看全部
文章定时自动采集(用Python编写数据采集脚本()上采集数据
)
概述:
在树莓派(xxxxx,以下简称工控机)采集数据上,传输到本地sqlserver数据库,用Python编写数据采集脚本。
这涉及到几个问题:当出现网络中断、断电、工控机重启等异常情况时,为了保证这些异常情况的发生,数据仍然可以自动采集,需要以下两种解决方案实施的。
开机自动启动;当脚本没有运行时,它会自动运行。
首选第二种方案,因为python程序崩溃或者网络异常导致程序中断,需要一种机制让它自动运行。
参考网址:
常用命令:
自动运行脚本:vim /etc/crontab
查看进程:ps -ef|grep tcpclient.py
自动运行脚本
启动TCP服务器监控功能:

输入vim /etc/crontab,最后输入* * * * * root python3 /home/pi/tcpclient.py

tcpclient.py 代码:
import socket
import time
import random
def main():
# 1 创建tcp套接字
while 1:
tcp_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 2 创建连接
tcp_socket.connect(('192.168.1.35', 6666))
# 3 发送数据
tcp_input = str(random.randint(2,15))
tcp_socket.send(tcp_input.encode('gbk')) # utf-8 中文会乱码
time.sleep(5)
# 4.关闭套接字
tcp_socket.close()
if __name__ == '__main__':
main()
输入ps -ef|grep tcpclient.py,可以看到进程多了(带问号的),tcpclient.py有while循环,不会自动退出,所以tcpclient.py每分钟自动运行一次。

优化
当然无线增加程序进程是不可能的,所以有两种选择:
每次执行tcpclient.py,都会自动关闭并终止程序,没有while循环。另外写一个test1.py程序,脚本会每分钟运行一次test1.py程序,test1.py判断tcpclient.py进程是否存在,如果存在不存在,它会运行;如果存在,它将不会运行。
这次采用了第二个选项,以避免每次tcp断开和重新连接(除非你像本例那样在while循环中关闭了socket)。
测试1.py 代码:
import time
import os
import re
# execute command, and return the infomation. 执行命令并返回命令输出信息
def execCmd(cmd):
r = os.popen(cmd)
text = r.read()
r.close()
return text
def doSomething():
os.system('python3 /home/pi/tcpclient.py')
time.sleep(10)
if __name__ == '__main__':
#ps -ef是linux查看进程信息指令,|是管道符号导向到grep去查找特定的进程,最后一个|是导向grep过滤掉grep进程:因为grep查看程序名也是进程,会混到查询信息里
programIsRunningCmd="ps -ef|grep tcpclient.py"
programIsRunningCmdAns = execCmd(programIsRunningCmd) #调用函数执行指令,并返回指令查询出的信息
print(programIsRunningCmdAns)
ansLine = programIsRunningCmdAns.split('\n') #将查出的信息用换行符‘\b’分开
print(len(ansLine))
#判断如果返回行数>3则说明python脚本程序已经在运行,打印提示信息结束程序,否则运行脚本代码doSomething()
if len(ansLine) > 3:
print("programName have been Running")
else:
doSomething()
结果
可以看出,test1.py和tcpclient.py进程在任何时候都是一样的,不会无限增加。工控机重启后,过程还是一样,说明已经达到了预期的效果。

文章定时自动采集(知乎公众号v2上线了,准备进来学习使用的同学赶紧来学习一下吧!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-12-29 17:03
文章定时自动采集知乎公众号留言,分析留言地址,变化趋势,热门话题及用户分析,现在已经与知乎公众号合作,特意共享出来!全网唯一!如果你有知乎问题或者对知乎公众号感兴趣,可以留言,会给你定制一个专属回答!知乎公众号v2。0上线了,准备进来学习使用的同学赶紧来学习一下吧!详细使用步骤请长按文章底部二维码,回复:0804可获取官方教程链接(二维码自动识别)知乎公众号v2。
0已上线,也在进行推广,大家可以扫码去体验一下哦!另外为了防止广告,想了解更多信息的同学可以发消息给我,私信是不会回复的哦!好了!下期再见!。
作为消费者,我想说,随着互联网的发展,各个商家都在思考商业的变革,新的风口也给自己带来了新的行业机会。以往公众号运营更多聚焦于推广,以及引流,利用消费者碎片化的时间去推送一些优质的产品和服务。但是互联网带来的新的消费行为模式,使得我们自己的商业边界不断扩大,尤其是电商的崛起,产生了一种新的商业状态:消费者通过商家提供的商品、服务来进行主动性购买,而不是被动接受商家推送。
因此,目前公众号的运营更多的应该是为了销售商品、服务,增加流量和销售量,获取一些利润。在这样的大趋势下,如何让公众号获取客户的关注,并留存客户,甚至转化客户关注,成为运营者最头疼的一件事。传统的模式是靠“内容+广告”,在运营的一开始就不断的推送广告,为商家的商品和服务添加曝光量,但有可能却忽略了基础的运营工作,导致内容不够精彩。
这样会出现两个问题:如果你是一个商家的付费顾问,你应该想尽办法引导客户来注册新账号或者使用公众号,让其购买新产品。可是如果你现在要为一个在做公众号的商家提供免费的付费客服服务,你会让客户付费来到你们的付费店铺进行咨询。可能就会出现这样的情况:你不进行推广免费给商家推送产品和服务,而是要把顾客辛辛苦苦积攒起来的资源转换成你自己的利润;如果你不推送免费的产品和服务,只是大张旗鼓的发广告,很可能产生一边推一边赚钱的情况,产生一个营销漏斗效应,优质的客户更不愿意付费。
其实,商家需要的是更科学的运营营销方式,如果公众号是基于粉丝本身价值的诉求点,那么推送的广告、软文反而更能吸引用户进行阅读分享转发。这样就会降低企业的营销成本。更好的是,企业能够根据自己的公众号粉丝和商品信息服务,选择自己需要的内容制作,并且推送给用户,实现双赢。目前消费者在互联网上做购买行为主要有以下几个驱动因素:内容、产品和服务。如何做好这三个方面的运营工作?很大程度上。 查看全部
文章定时自动采集(知乎公众号v2上线了,准备进来学习使用的同学赶紧来学习一下吧!)
文章定时自动采集知乎公众号留言,分析留言地址,变化趋势,热门话题及用户分析,现在已经与知乎公众号合作,特意共享出来!全网唯一!如果你有知乎问题或者对知乎公众号感兴趣,可以留言,会给你定制一个专属回答!知乎公众号v2。0上线了,准备进来学习使用的同学赶紧来学习一下吧!详细使用步骤请长按文章底部二维码,回复:0804可获取官方教程链接(二维码自动识别)知乎公众号v2。
0已上线,也在进行推广,大家可以扫码去体验一下哦!另外为了防止广告,想了解更多信息的同学可以发消息给我,私信是不会回复的哦!好了!下期再见!。
作为消费者,我想说,随着互联网的发展,各个商家都在思考商业的变革,新的风口也给自己带来了新的行业机会。以往公众号运营更多聚焦于推广,以及引流,利用消费者碎片化的时间去推送一些优质的产品和服务。但是互联网带来的新的消费行为模式,使得我们自己的商业边界不断扩大,尤其是电商的崛起,产生了一种新的商业状态:消费者通过商家提供的商品、服务来进行主动性购买,而不是被动接受商家推送。
因此,目前公众号的运营更多的应该是为了销售商品、服务,增加流量和销售量,获取一些利润。在这样的大趋势下,如何让公众号获取客户的关注,并留存客户,甚至转化客户关注,成为运营者最头疼的一件事。传统的模式是靠“内容+广告”,在运营的一开始就不断的推送广告,为商家的商品和服务添加曝光量,但有可能却忽略了基础的运营工作,导致内容不够精彩。
这样会出现两个问题:如果你是一个商家的付费顾问,你应该想尽办法引导客户来注册新账号或者使用公众号,让其购买新产品。可是如果你现在要为一个在做公众号的商家提供免费的付费客服服务,你会让客户付费来到你们的付费店铺进行咨询。可能就会出现这样的情况:你不进行推广免费给商家推送产品和服务,而是要把顾客辛辛苦苦积攒起来的资源转换成你自己的利润;如果你不推送免费的产品和服务,只是大张旗鼓的发广告,很可能产生一边推一边赚钱的情况,产生一个营销漏斗效应,优质的客户更不愿意付费。
其实,商家需要的是更科学的运营营销方式,如果公众号是基于粉丝本身价值的诉求点,那么推送的广告、软文反而更能吸引用户进行阅读分享转发。这样就会降低企业的营销成本。更好的是,企业能够根据自己的公众号粉丝和商品信息服务,选择自己需要的内容制作,并且推送给用户,实现双赢。目前消费者在互联网上做购买行为主要有以下几个驱动因素:内容、产品和服务。如何做好这三个方面的运营工作?很大程度上。
文章定时自动采集(利用python进行数据分析-第2版写得很不错)
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-01-24 17:06
文章定时自动采集,采集整个网站的所有内容,不用每次自己逐个请求去获取,无侵入式的,一劳永逸,
我觉得比较好的是redis和mysql,
你有什么特别想了解的,我给你推荐一个系列的博客:利用python进行数据分析-第2版写得很不错,你可以参考一下。
我觉得你大一不用发愁这个问题!各种编程语言都有涉及,可以从你现在大一所对应的部门入手,最好能读一些有名的数据库学校课程,
推荐最后一本书——python从入门到实践python从入门到实践(豆瓣)
利用python从输入网页内容到翻页,
我的经验是数据结构是王道。再把算法和数据结构了解一下。实践的话,现在绝大多数公司都有api接口。请直接到访华的美国公司的官网在web端获取demo文件。省略一万字,直接去google+facebookgithubstackoverflow里搜会有收获的。
数据结构最重要的是要弄清楚流程与结构,流程就是数据输入接收输出。至于结构可以看数据结构。弄清楚之后无论从php到go都可以编程。算法与数据结构没必要单独学。掌握对应算法即可。
看看豆瓣上的书,
谢邀,
python技术类图书推荐书籍推荐,供参考《python3网络爬虫开发实战》《python3爬虫开发实战(第2版)》推荐指数:书名:《python3网络爬虫开发实战(第2版)》,作者:李明主编出版社:人民邮电出版社类别:技术书籍作者:李明、吴娟内容简介:本书是python3语言的入门、实践、学习材料。
适合对网络爬虫有一定了解的读者,学习者也可以将本书作为python3程序设计的基础教程。本书不讲述晦涩难懂的技术概念,而是通过大量的练习来让读者体会python3语言的设计优势。本书保证了3天突破python3开发,3周掌握爬虫框架设计,1周编写爬虫项目,同时通过自己的项目搭建,作者还创建了“大易工具箱”专门用于学习python3。人手一本,秒杀“python123”。 查看全部
文章定时自动采集(利用python进行数据分析-第2版写得很不错)
文章定时自动采集,采集整个网站的所有内容,不用每次自己逐个请求去获取,无侵入式的,一劳永逸,
我觉得比较好的是redis和mysql,
你有什么特别想了解的,我给你推荐一个系列的博客:利用python进行数据分析-第2版写得很不错,你可以参考一下。
我觉得你大一不用发愁这个问题!各种编程语言都有涉及,可以从你现在大一所对应的部门入手,最好能读一些有名的数据库学校课程,
推荐最后一本书——python从入门到实践python从入门到实践(豆瓣)
利用python从输入网页内容到翻页,
我的经验是数据结构是王道。再把算法和数据结构了解一下。实践的话,现在绝大多数公司都有api接口。请直接到访华的美国公司的官网在web端获取demo文件。省略一万字,直接去google+facebookgithubstackoverflow里搜会有收获的。
数据结构最重要的是要弄清楚流程与结构,流程就是数据输入接收输出。至于结构可以看数据结构。弄清楚之后无论从php到go都可以编程。算法与数据结构没必要单独学。掌握对应算法即可。
看看豆瓣上的书,
谢邀,
python技术类图书推荐书籍推荐,供参考《python3网络爬虫开发实战》《python3爬虫开发实战(第2版)》推荐指数:书名:《python3网络爬虫开发实战(第2版)》,作者:李明主编出版社:人民邮电出版社类别:技术书籍作者:李明、吴娟内容简介:本书是python3语言的入门、实践、学习材料。
适合对网络爬虫有一定了解的读者,学习者也可以将本书作为python3程序设计的基础教程。本书不讲述晦涩难懂的技术概念,而是通过大量的练习来让读者体会python3语言的设计优势。本书保证了3天突破python3开发,3周掌握爬虫框架设计,1周编写爬虫项目,同时通过自己的项目搭建,作者还创建了“大易工具箱”专门用于学习python3。人手一本,秒杀“python123”。
文章定时自动采集(WP-AutoBlog为全新开发插件(原-AutoPost将不再更新和维护) )
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-01-24 05:22
)
简介:
目前每个版本的 WordPress 都能完美运行,请放心使用。 WP-AutoPost-Pro 是一款优秀的 WordPress 文章采集器,是你操作站群,让网站自动更新内容的强大工具!
这个版本和官方功能没有区别;
采集插件的适用对象
1、新建的wordpress网站内容比较少,希望尽快有更丰富的内容;
2、热点内容自动采集自动发布;
3、预定采集,手动采集发布或保存到草稿;
4、css样式规则,可以更精确到采集需要的内容。
5、伪原创进行翻译,代理IP采集,保存cookie记录;
6、你可以采集内容到自定义栏目
WP-AutoBlog是新的开发插件(原WP-AutoPost将不再更新维护),全面支持PHP7.3更快更稳定
全新架构和设计,采集设置更加全面灵活;支持多级文章列表、多级文章内容采集
新增支持谷歌神经网络翻译,有道神经网络翻译,轻松获取高质量原创文章
全面支持市面上所有主流对象存储服务,如七牛云、阿里云OSS等。
你可以采集微信公众号、今日头条号等自媒体内容,因为百度没有收录公众号、今日头条文章等,可以轻松获得高质量的“原创”文章,增加百度收录的音量和网站权重
您可以采集任何网站内容,采集信息一目了然
通过简单的设置,你可以从任意网站内容中采集,并且可以设置多个采集任务同时运行,可以设置任务自动运行或手动,主任务列表显示每个采集任务的状态:上次检测到采集时间,估计下次检测采集时间,最近采集文章,完成采集更新文章号码等信息,方便查看和管理。
文章管理函数方便查询、查找、删除。采集文章,改进算法从根本上杜绝了重复采集一样文章 , log 函数记录采集过程中的异常和抓取错误,方便检查和设置错误进行修复。
WP-AutoBlog是新的开发插件(原WP-AutoPost将不再更新维护),全面支持PHP7.3更快更稳定
全新架构和设计,采集设置更加全面灵活;支持多级文章列表、多级文章内容采集
新增支持谷歌神经网络翻译,有道神经网络翻译,轻松获取高质量原创文章
全面支持市面上所有主流对象存储服务,如七牛云、阿里云OSS等。
你可以采集微信公众号、今日头条号等自媒体内容,因为百度没有收录公众号、今日头条文章等,可以轻松获得高质量的“原创”文章,增加百度收录的音量和网站权重
您可以采集任何网站内容,采集信息一目了然
通过简单的设置,你可以从任意网站内容中采集,并且可以设置多个采集任务同时运行,可以设置任务自动运行或手动,主任务列表显示每个采集任务的状态:上次检测到采集时间,估计下次检测采集时间,最近采集文章,完成采集更新文章号码等信息,方便查看和管理。
文章管理函数方便查询、查找、删除。采集文章,改进算法从根本上杜绝了重复采集一样文章 , log 函数记录采集过程中的异常和抓取错误,方便检查和设置错误进行修复。
网盘下载地址:
解压密码:
图片:
查看全部
文章定时自动采集(WP-AutoBlog为全新开发插件(原-AutoPost将不再更新和维护)
)
简介:
目前每个版本的 WordPress 都能完美运行,请放心使用。 WP-AutoPost-Pro 是一款优秀的 WordPress 文章采集器,是你操作站群,让网站自动更新内容的强大工具!
这个版本和官方功能没有区别;
采集插件的适用对象
1、新建的wordpress网站内容比较少,希望尽快有更丰富的内容;
2、热点内容自动采集自动发布;
3、预定采集,手动采集发布或保存到草稿;
4、css样式规则,可以更精确到采集需要的内容。
5、伪原创进行翻译,代理IP采集,保存cookie记录;
6、你可以采集内容到自定义栏目
WP-AutoBlog是新的开发插件(原WP-AutoPost将不再更新维护),全面支持PHP7.3更快更稳定
全新架构和设计,采集设置更加全面灵活;支持多级文章列表、多级文章内容采集
新增支持谷歌神经网络翻译,有道神经网络翻译,轻松获取高质量原创文章
全面支持市面上所有主流对象存储服务,如七牛云、阿里云OSS等。
你可以采集微信公众号、今日头条号等自媒体内容,因为百度没有收录公众号、今日头条文章等,可以轻松获得高质量的“原创”文章,增加百度收录的音量和网站权重
您可以采集任何网站内容,采集信息一目了然
通过简单的设置,你可以从任意网站内容中采集,并且可以设置多个采集任务同时运行,可以设置任务自动运行或手动,主任务列表显示每个采集任务的状态:上次检测到采集时间,估计下次检测采集时间,最近采集文章,完成采集更新文章号码等信息,方便查看和管理。
文章管理函数方便查询、查找、删除。采集文章,改进算法从根本上杜绝了重复采集一样文章 , log 函数记录采集过程中的异常和抓取错误,方便检查和设置错误进行修复。
WP-AutoBlog是新的开发插件(原WP-AutoPost将不再更新维护),全面支持PHP7.3更快更稳定
全新架构和设计,采集设置更加全面灵活;支持多级文章列表、多级文章内容采集
新增支持谷歌神经网络翻译,有道神经网络翻译,轻松获取高质量原创文章
全面支持市面上所有主流对象存储服务,如七牛云、阿里云OSS等。
你可以采集微信公众号、今日头条号等自媒体内容,因为百度没有收录公众号、今日头条文章等,可以轻松获得高质量的“原创”文章,增加百度收录的音量和网站权重
您可以采集任何网站内容,采集信息一目了然
通过简单的设置,你可以从任意网站内容中采集,并且可以设置多个采集任务同时运行,可以设置任务自动运行或手动,主任务列表显示每个采集任务的状态:上次检测到采集时间,估计下次检测采集时间,最近采集文章,完成采集更新文章号码等信息,方便查看和管理。
文章管理函数方便查询、查找、删除。采集文章,改进算法从根本上杜绝了重复采集一样文章 , log 函数记录采集过程中的异常和抓取错误,方便检查和设置错误进行修复。
网盘下载地址:
解压密码:
图片:
文章定时自动采集(如何24小时定时定量自动去访问某个url呢?宝塔面板)
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2022-01-23 10:14
如何24小时定时定量自动访问某个url?宝塔面板可以很容易地完成。今天,错误博客( )分享的内容是“宝塔计划任务访问URL(采集站群必备知识)”。我希望能有所帮助。
宝塔计划任务访问url
一、宝塔板
宝塔需要安装在服务器上,然后宝塔面板才能使用。说白了就是宝塔安装在我们的服务器上,宝塔软件包括各种自动化程序,然后我们在访问网页的时候,只要不关闭服务器,就可以设置定时任务来访问一个 url 连接随时 24 小时。.
宝塔面板
二、宝塔项目任务
Pagoda定时任务有六种:Shell脚本、备份网站、备份数据库、日志切割、释放内存、访问URL。以 URL 为例,描述宝塔计划的任务。
1、选择任务类型
在这里您必须选择“访问 URL”。
2、执行周期
宝塔的执行周期可以是每月、每周、每小时、N天、N小时、N分钟。
每月:每个月的执行时间,后面的小时和分钟可以认为是从早上12:00开始计算,0小时0分钟是指当天早上12:00。
每周和每天和每月都是一样的。
N天:即每隔几天执行一次。
N hours:每隔几个小时执行一次。
N 分钟:每隔几分钟执行一次。
如果您的计划任务过于复杂,您可以尝试设置多个计划任务。
执行周期
以上是错误博客( )分享的内容是“宝塔计划任务访问URL(采集站群必备知识)”。谢谢阅读。
本文《宝塔计划任务访问网址(采集站群必备知识)》由Error Blog()或原创整理,感谢阅读。随机文章【机器人文件协议】百度解禁机器人全过程
【说站长】从站长到牛角_全面拥抱熊掌
SEO经验分享——小小课堂优化10个月内达到百度权重4
网址是什么意思?页面抓取过程简述
内蒙古SEO【收录索引】搜狗SEO官方指南六
搜索引擎优化器常识:搜索引擎的基本架构
潮州seo【谷歌质量指南系列十二:如何防止垃圾评论】
什么是电子邮件营销?有什么优点和特点?如何获取电子邮件 查看全部
文章定时自动采集(如何24小时定时定量自动去访问某个url呢?宝塔面板)
如何24小时定时定量自动访问某个url?宝塔面板可以很容易地完成。今天,错误博客( )分享的内容是“宝塔计划任务访问URL(采集站群必备知识)”。我希望能有所帮助。
宝塔计划任务访问url
一、宝塔板
宝塔需要安装在服务器上,然后宝塔面板才能使用。说白了就是宝塔安装在我们的服务器上,宝塔软件包括各种自动化程序,然后我们在访问网页的时候,只要不关闭服务器,就可以设置定时任务来访问一个 url 连接随时 24 小时。.
宝塔面板
二、宝塔项目任务
Pagoda定时任务有六种:Shell脚本、备份网站、备份数据库、日志切割、释放内存、访问URL。以 URL 为例,描述宝塔计划的任务。
1、选择任务类型
在这里您必须选择“访问 URL”。
2、执行周期
宝塔的执行周期可以是每月、每周、每小时、N天、N小时、N分钟。
每月:每个月的执行时间,后面的小时和分钟可以认为是从早上12:00开始计算,0小时0分钟是指当天早上12:00。
每周和每天和每月都是一样的。
N天:即每隔几天执行一次。
N hours:每隔几个小时执行一次。
N 分钟:每隔几分钟执行一次。
如果您的计划任务过于复杂,您可以尝试设置多个计划任务。
执行周期
以上是错误博客( )分享的内容是“宝塔计划任务访问URL(采集站群必备知识)”。谢谢阅读。
本文《宝塔计划任务访问网址(采集站群必备知识)》由Error Blog()或原创整理,感谢阅读。随机文章【机器人文件协议】百度解禁机器人全过程
【说站长】从站长到牛角_全面拥抱熊掌
SEO经验分享——小小课堂优化10个月内达到百度权重4
网址是什么意思?页面抓取过程简述
内蒙古SEO【收录索引】搜狗SEO官方指南六
搜索引擎优化器常识:搜索引擎的基本架构
潮州seo【谷歌质量指南系列十二:如何防止垃圾评论】
什么是电子邮件营销?有什么优点和特点?如何获取电子邮件
文章定时自动采集(系统环境Ubuntu20.04如何安装Zeit在Ubuntu系统中的应用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2022-01-22 03:05
Zeit 是一个开源工具,用于通过“crontab”和“at”来安排任务。它提供了一个简单的界面来安排一次性任务或重复任务。 Zeit 还带有一个闹钟和计时器,可以使用声音通知用户。
系统环境
Ubuntu 20.04
如何安装 Zeit
在 Ubuntu 系统上,可以通过添加下面的 PPA 存储库来安装 Zeit。
bob@ubuntu-20-04:~$ sudo add-apt-repository ppa:blaze/main
PPA for my software
More info: https://launchpad.net/~blaze/+archive/ubuntu/main
Press [ENTER] to continue or Ctrl-c to cancel adding it.
...
bob@ubuntu-20-04:~$ sudo apt install zeit
输入 Zeit 运行
使用 at 命令运行一次性命令
使用at命令运行一次性命令,点击查看->非周期命令或者按ctrl+n,可以切换到非周期任务。
选择“添加命令”并添加一个条目。安排一个命令在 11:34 运行。此命令将在 Downloads 文件夹中创建一个空日志文件,并将今天的日期添加到文件名中,如下所示:
NOW=$(date +%F); touch /home/bob/Downloads/log_${NOW}.txt
此任务无法修改,但可以删除并重新添加。
11:34,可以看到Downloads目录下已经创建了一个日志文件。
Zeit界面,按ctrl+r,刷新页面,发现任务已经执行完毕,消失了。
创建重复任务
要使用 crond 进程安排任务,请单击查看->定期任务或按 CTRL + P。默认情况下,Zeit 启动“定期任务”。
输入描述、命令和计划时间,然后单击确定将条目添加到 crontab。以下是每天0:00备份到用户家目录的日志目录。
可以使用 crontab -l 检查添加的条目:
bob@ubuntu-20-04:~$ crontab -l
总结
Zeit 是一个开源工具,用于通过“crontab”和“at”来安排任务。它提供了一个简单的界面来安排一次性任务或重复任务。 查看全部
文章定时自动采集(系统环境Ubuntu20.04如何安装Zeit在Ubuntu系统中的应用)
Zeit 是一个开源工具,用于通过“crontab”和“at”来安排任务。它提供了一个简单的界面来安排一次性任务或重复任务。 Zeit 还带有一个闹钟和计时器,可以使用声音通知用户。
系统环境
Ubuntu 20.04
如何安装 Zeit
在 Ubuntu 系统上,可以通过添加下面的 PPA 存储库来安装 Zeit。
bob@ubuntu-20-04:~$ sudo add-apt-repository ppa:blaze/main
PPA for my software
More info: https://launchpad.net/~blaze/+archive/ubuntu/main
Press [ENTER] to continue or Ctrl-c to cancel adding it.
...
bob@ubuntu-20-04:~$ sudo apt install zeit
输入 Zeit 运行
使用 at 命令运行一次性命令
使用at命令运行一次性命令,点击查看->非周期命令或者按ctrl+n,可以切换到非周期任务。
选择“添加命令”并添加一个条目。安排一个命令在 11:34 运行。此命令将在 Downloads 文件夹中创建一个空日志文件,并将今天的日期添加到文件名中,如下所示:
NOW=$(date +%F); touch /home/bob/Downloads/log_${NOW}.txt
此任务无法修改,但可以删除并重新添加。
11:34,可以看到Downloads目录下已经创建了一个日志文件。
Zeit界面,按ctrl+r,刷新页面,发现任务已经执行完毕,消失了。
创建重复任务
要使用 crond 进程安排任务,请单击查看->定期任务或按 CTRL + P。默认情况下,Zeit 启动“定期任务”。
输入描述、命令和计划时间,然后单击确定将条目添加到 crontab。以下是每天0:00备份到用户家目录的日志目录。
可以使用 crontab -l 检查添加的条目:
bob@ubuntu-20-04:~$ crontab -l
总结
Zeit 是一个开源工具,用于通过“crontab”和“at”来安排任务。它提供了一个简单的界面来安排一次性任务或重复任务。
文章定时自动采集( ZBlog发布能让网站保持一个持续更新的状态吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2022-01-21 18:08
ZBlog发布能让网站保持一个持续更新的状态吗?)
ZBlog Publishing是系统文章定时发布工具(网站文章自动定时发布助手)是ZBlog网站文章自动定时发布的辅助工具。定时释放功能强大,操作简单。使用后,可以帮助站长更轻松便捷地定期发布网站文章。主要用于ZBlog采集伪原创发布。使用非常简单,只需要提前设置即可。ZBlog发布可以帮助站长在更新网站时节省大量时间。只要设置好发布时间,就可以在指定时间自动发布,极大的方便了网站的日常管理。
ZBlog 的发布将使 网站 处于持续更新的状态。因为网站收录的问题一直是SEO优化人员关心的问题,做SEO优化的人都想知道网站的收录是不能一蹴而就的一两天,如果你的网站的收录有所改善,你要坚持每天更新你的网站,最好养成每天更新网站文章 这是一种习惯。时间长了,蜘蛛会对你网站产生好感,所以会经常造访你的网站,让你的网站收录越爬越高!
ZBlog 的发帖会经常更新网站,因为每个SEOer 不可能每天都有时间上网管理自己的网站。但是每个 网站 必须至少每天更新。只要你能坚持这种更新方式,蜘蛛肯定会养成一种习惯,蜘蛛会经常来你的网站爬文章和内容,所以蜘蛛会爬网站更多您的内容。
当然,网站的内容需要了解这几点,一个吸引人的网站,用户不看就不会离开,一定会流连忘返。所以你停留的时间长短会在一定程度上体现你的网站品质。对于相同的内容,您的页面停留和其他人的 网站 页面停留将由搜索引擎计算和比较。当然,也有页面阅读量,因为页面阅读量反映了你的网站是否受用户欢迎,是否向用户的潜在需求推荐内容。
ZBlog发布自带伪原创,对一个原创的文章进行重新处理,让搜索引擎认为它是一个原创文章,从而增加权重网站。伪原创相比原创,更容易创建,对创作者的技术要求不高,更容易完成持久化和定期更新。一些SEO技术不成熟的网站会选择大量丰富的网站内容,利用网页数量来提高关键词的排名概率。比如发一百篇文章有2个排名,那么发一千篇文章可能有20个排名,以此类推。但是,有必要增加更新的频率和数量。几乎不可能依赖原创文章,所以< 查看全部
文章定时自动采集(
ZBlog发布能让网站保持一个持续更新的状态吗?)
ZBlog Publishing是系统文章定时发布工具(网站文章自动定时发布助手)是ZBlog网站文章自动定时发布的辅助工具。定时释放功能强大,操作简单。使用后,可以帮助站长更轻松便捷地定期发布网站文章。主要用于ZBlog采集伪原创发布。使用非常简单,只需要提前设置即可。ZBlog发布可以帮助站长在更新网站时节省大量时间。只要设置好发布时间,就可以在指定时间自动发布,极大的方便了网站的日常管理。
ZBlog 的发布将使 网站 处于持续更新的状态。因为网站收录的问题一直是SEO优化人员关心的问题,做SEO优化的人都想知道网站的收录是不能一蹴而就的一两天,如果你的网站的收录有所改善,你要坚持每天更新你的网站,最好养成每天更新网站文章 这是一种习惯。时间长了,蜘蛛会对你网站产生好感,所以会经常造访你的网站,让你的网站收录越爬越高!
ZBlog 的发帖会经常更新网站,因为每个SEOer 不可能每天都有时间上网管理自己的网站。但是每个 网站 必须至少每天更新。只要你能坚持这种更新方式,蜘蛛肯定会养成一种习惯,蜘蛛会经常来你的网站爬文章和内容,所以蜘蛛会爬网站更多您的内容。
当然,网站的内容需要了解这几点,一个吸引人的网站,用户不看就不会离开,一定会流连忘返。所以你停留的时间长短会在一定程度上体现你的网站品质。对于相同的内容,您的页面停留和其他人的 网站 页面停留将由搜索引擎计算和比较。当然,也有页面阅读量,因为页面阅读量反映了你的网站是否受用户欢迎,是否向用户的潜在需求推荐内容。
ZBlog发布自带伪原创,对一个原创的文章进行重新处理,让搜索引擎认为它是一个原创文章,从而增加权重网站。伪原创相比原创,更容易创建,对创作者的技术要求不高,更容易完成持久化和定期更新。一些SEO技术不成熟的网站会选择大量丰富的网站内容,利用网页数量来提高关键词的排名概率。比如发一百篇文章有2个排名,那么发一千篇文章可能有20个排名,以此类推。但是,有必要增加更新的频率和数量。几乎不可能依赖原创文章,所以<
文章定时自动采集(为你24小时自动采集更新马克斯MAXCMS、飞飞FFCMS、光线GXCMS)
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2022-01-20 02:01
影视网站Auto采集UpdatecmsAuto采集Update Max MAXcms、飞飞FFcms、Ray GX<Movie网站 系统如@cms、Apple MACcms,甚至不是该类型的系统都可以应用。让您无需等待网站长时间更新,即可专注于SEO。指定时间自动更新网站,好帮手!
会有什么效果?
首先,它最符合各大搜索引擎蜘蛛的上门访问。如果您每次都在这些点更新,他会记住并习惯您的网站,并且不会空手而归!最后你的快照稳定,收录稳定,你的排名也相对好一些!总而言之,让 网站 活着。
支持:Max MAXcms、飞飞FFcms、Ray GXcms、魅魔Maccms
1、设置大大简化
2、自动登录2.0,更安全更简单
3、一个软件更新多站多采集资源,不占用内存资源
4、不占用CPU,只是cmsPHP程序更新的时候占用一点
5、采集你想要多少资源
强调:
1、帮助设置,降低难度
2、无需验证码cms,无需修改文件,减少麻烦
3、打开一个软件更新多个站点,即一对多。减少服务器内存开销,
4、代码设计精良,运行速度快,占用内存少
5、操作简单,软件上有提示和说明,一看就知道!
修改记录:
2012-3-25 添加网站更新排序功能,修改BUG!
2012-3-03 支持新版Ray GXcms的定期更新!
2012-2-14 解决中文注册登录问题。如果您遇到此类问题,请下载最新的更新程序! 查看全部
文章定时自动采集(为你24小时自动采集更新马克斯MAXCMS、飞飞FFCMS、光线GXCMS)
影视网站Auto采集UpdatecmsAuto采集Update Max MAXcms、飞飞FFcms、Ray GX<Movie网站 系统如@cms、Apple MACcms,甚至不是该类型的系统都可以应用。让您无需等待网站长时间更新,即可专注于SEO。指定时间自动更新网站,好帮手!
会有什么效果?
首先,它最符合各大搜索引擎蜘蛛的上门访问。如果您每次都在这些点更新,他会记住并习惯您的网站,并且不会空手而归!最后你的快照稳定,收录稳定,你的排名也相对好一些!总而言之,让 网站 活着。
支持:Max MAXcms、飞飞FFcms、Ray GXcms、魅魔Maccms
1、设置大大简化
2、自动登录2.0,更安全更简单
3、一个软件更新多站多采集资源,不占用内存资源
4、不占用CPU,只是cmsPHP程序更新的时候占用一点
5、采集你想要多少资源
强调:
1、帮助设置,降低难度
2、无需验证码cms,无需修改文件,减少麻烦
3、打开一个软件更新多个站点,即一对多。减少服务器内存开销,
4、代码设计精良,运行速度快,占用内存少
5、操作简单,软件上有提示和说明,一看就知道!
修改记录:
2012-3-25 添加网站更新排序功能,修改BUG!
2012-3-03 支持新版Ray GXcms的定期更新!
2012-2-14 解决中文注册登录问题。如果您遇到此类问题,请下载最新的更新程序!
文章定时自动采集(这样的一个小报系统是如何实现的呢?(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2022-01-19 01:07
下图是政采云前端小报( )官网截图,里面收录了我们每一期历史的总结~
截止目前,前端小报93期,汇聚1000+文章,涵盖50+大小品类。可以说是很不错的知识库了~
前端小报的由来
持续学习是每个工程师都必须的,一个成长中的团队也需要这样的持续学习氛围。那么如何利用技术帮助团队培养持续学习的氛围呢?
于是,正财云前端小报应运而生。主要包括提交、聚合沉淀、定时投递三个核心模块。这样的系统可以让大家轻松将自己喜欢的文章分享给团队,对分享文章进行分类沉淀,为团队打造知识库,方便大家查阅。同时,小报系统每周五也会定时推送,让大家了解最新的科技动态。分享学习氛围的好帮手~
那么这样一个小报系统是如何运作的呢?
如何为提交设计一个小报系统
我相信当你看到一个好的文章时,总会有一种与他人分享的冲动。一个简单易用的推送功能,可以轻松满足大家的分享欲望。好文章进队帮助其他同学~
一个简单易行的贡献函数,我们需要解决两个问题:
1、看到好东西如何满足分享的冲动文章
2、提交的文章如何分类采集,方便沉淀和搜索
如果是单独录入系统和人工录入,这种方式操作起来比较麻烦,而且很容易打消大家的积极性。我们平时在浏览器中看文章的时候,经常会采集好文章,一键操作,方便快捷。那么怎么能像浏览器书签采集文章一样方便投稿呢?
很容易想到通过浏览器的扩展能力来做到这一点,Chrome插件就提供了这样的能力
什么是 Chrome 扩展程序
官方解释():谷歌插件是用来定制浏览器体验的小程序。它允许用户根据个人需求或偏好自定义 Chrome 的功能和行为,并且它们基于 Web 技术(HTML、JavaScript 和 CSS)构建。
会说话的人话:开发一个web项目,可以嵌入到Chrome浏览器中,可以通过一些特定的API获取一些能力,从而定制自己的插件功能
如何开发Chrome插件一键提交
首先创建一个项目并开发一个贡献页面。
这个项目和普通的 Vue 项目唯一的区别就是在根目录下多了一个 manifest.json 文件。
{ <br /> // 核心代码 <br /> "name": "Zoo!", // 扩展名 <br /> "browser_action": { <br /> "default_popup": "./popup.html" // 点击浏览器右上方插件小图标弹出的内容 html <br /> }, <br /> "content_scripts": [ // 能够在 Web 页面内运行的 javascript 脚本 <br /> { <br /> "matches": [<br /> // 满足什么协议下进行调用 <br /> "http://*/*", <br /> "https://*/*" <br /> ], <br /> "js": [ <br /> "./contentScripts/zdata.js" // 插入到网页的 JS 文件路径 <br /> ], <br /> "run_at": "document_start" // 在document 加载时执行 <br /> } <br /> ] <br />} <br />
这样,当插件打开时,会默认加载popup.html页面的内容,效果如下:
插件本身并不能真正获取当前页面的标题,但是Chrome插件提供了将固定的JS脚本动态插入当前页面的能力。我们可以根据这个机制在当前页面中插入一个JS脚本来获取标题、介绍和URL,然后通过消息机制将获取到的内容返回给插件。
let host = this;<br />// 获取当前窗口 id <br />chrome.tabs.query({<br /> active: true,<br /> currentWindow: true<br />}, function (tabs) {<br /> let tabId = tabs.length ? tabs[0].id : null;<br /> // 向当前页面注入 JavaScript 脚本 <br /> chrome.tabs.executeScript(tabId || null, {<br /> file: './contentScripts/recommend.js'<br /> }, function () {<br /> // 向目标网页进行通信,向 recommend.js 发送一个消息 <br /> chrome.tabs.sendMessage(tabId, {<br /> message: 'GET_TOPIC_INFO',<br /> }, function (response) {<br /> // 获取到返回的文章 title 、url、description <br /> host.article.title = response.title;<br /> host.article.link = response.link;<br /> host.article.description = response.description;<br /> });<br /> });<br />}); <br />
推荐.js 监听消息。通过 addListener,我们可以监听 sendMessage 发送的消息。在 sendMessage 中定义消息常量可以让我们在接收消息时区分消息。
let doc = document;<br />chrome.runtime.onMessage.addListener(function (request, sender, sendResponse) {<br /> if (request.message === 'GET_TOPIC_INFO') {<br /> // 获取 title <br /> let title = document.getElementsByTagName('title')[0].textContent;<br /> let descriptionEl = doc.querySelectorAll('meta[name=description]')[0];<br /> // 获取 描述 <br /> let description = descriptionEl ? descriptionEl.getAttribute('content') : title;<br /> // 发送数据 <br /> sendResponse({<br /> title: title.trim(),<br /> link: location.href,<br /> description: description.trim()<br /> });<br /> } else if (request.message === 'SIGN_RELOAD') {<br /> console.log('request, sender', request, sender);<br /> }<br />}); <br />
// 投稿按钮点击事件 <br />handleRecommendArticle: function () {<br /> let request;<br /> request = ajax({<br /> method: 'post',<br /> url: 'https://XXX/api/post', // 后端接口 <br /> data: {<br /> 'title': this.article.title,<br /> 'desc': this.article.description,<br /> 'category': this.article.category[1] || '默认分类',<br /> 'link': this.article.link,<br /> 'referrer': this.article.reporter<br /> }<br /> });<br />} <br />
效果图:
以上是一个非常轻量级的Chrome插件的实现。基于这样一个Chrome插件,当我们看到喜欢的文章时,可以一键分享给团队的小伙伴~
当文章太多的时候,如果没有有效的管理,文章就会堆得乱七八糟,会让大家失去学习的欲望,那么我们如何分类采集提交的 文章 ,方便同学们找到自己需要的知识体系吗?
标签设计
设计标签分类需要一些时间。主要难点是什么分类维度可以让投稿人快速找到对应的分类,让观众可以根据分类快速找到自己想要的文章,以及如何快速找到过去的文章等.
这就要求我们的分类要通俗易懂,涵盖大部分业务类型文章。最后,我们从基础、语言、架构、选择、工具、总结等多个维度进行分类。
为了能够快速搜索文章,Chrome插件中也集成了分类查看功能。
插件制作完成后,其他同学可以将你的插件安装包安装到浏览器中。因为有墙,所以没有选项可以将插件上传到 Chrome 应用商店。我们在本地安装它。下图为打包后的项目目录结构:
安装步骤:浏览器选择设置->扩展->加载解压后的扩展->选择文件目录。同时,记得开启开发者模式。
Chrome扩展官方详细文档请移步链接()查看
聚合沉淀对于前端项目来说是很常见的,这里就不多说了。主要是能看到每一期的文章,快速分类搜索,统一收录文章入口。其中,前端页面是通过SSR服务端渲染实现的。
定时交货
到这里,小报系统的前端展示页面已经完成了,那么如何让每一期的优质文章更及时方便同学们阅读,让大家在学习中了解新技术适时地开阔眼界。后来我们想到可以通过主动联系、定时提醒等方式主动给队友发日记,所以在以上基础上,设计了一个单独的推送服务,定时推送每周小报到钉钉群和前台——结束邮件组。
const pushToRobot = async ({ data, title, nums }) => {<br /> // 组装发送数据格式 <br /> const links = wrapperFeedcard({ data, nums });<br /> // 发送数据到指定群 <br /> return axios("https://oapi.dingtalk.com/robot/send?", {<br /> method: "post",<br /> params: {<br /> access_token: "XXXX" //前端群 <br /> },<br /> data: {<br /> feedCard: {<br /> links<br /> },<br /> msgtype: "feedCard"<br /> }<br /> })<br />}; <br />
// 创建邮件链接 <br />const nodemailer = require("nodemailer"); <br />let transporter = nodemailer.createTransport({ <br /> service: "qiye.aliyun", <br /> port: 25, // SMTP 端口 <br /> host: "smtp.mxhichina.com", <br /> secureConnection: true, // 使用了 SSL <br /> auth: { <br /> user: "xxx@cai-inc.com", <br /> pass: "xxx" <br /> } <br />}); <br />// 组装发送内容 <br />let mailOptions = { <br /> from: '"政采云前端小报" ', // sender address <br /> to: "ZooTeam@cai-inc.com", // list of receivers <br /> cc: ["ZooTeam@cai-inc.com"], <br /> html: '邮件内容' // html body <br />}; <br />// 邮件发送 <br />transporter.sendMail(mailOptions); <br />
有一天,我们掘金的运营小姐告诉我,我们每周五要下班的时候发布文章。这太痛苦了。下班后耽误了我的约会。我说好,我们自己开发一个定时发布功能。如果想知道掘金的定时发布功能如何实现,可以在评论区留言讨论。
整体设计
总结
前端小报系统虽然是一个小系统,但无论是功能设计还是系统设计,都在追逐一个目标,努力促进团队的学习氛围,让团队成员不断成长。希望分享这篇文章能给大家一些启发,如何从一个目标出发去拆解实施,思考如何让工具更好地为人服务。
读两件事
如果你觉得这个内容有启发性,我想请你帮我做两件小事
1.点击“我在看”,让更多人看到这个内容(点击“我在看”,bug -1?) 查看全部
文章定时自动采集(这样的一个小报系统是如何实现的呢?(组图))
下图是政采云前端小报( )官网截图,里面收录了我们每一期历史的总结~
截止目前,前端小报93期,汇聚1000+文章,涵盖50+大小品类。可以说是很不错的知识库了~
前端小报的由来
持续学习是每个工程师都必须的,一个成长中的团队也需要这样的持续学习氛围。那么如何利用技术帮助团队培养持续学习的氛围呢?
于是,正财云前端小报应运而生。主要包括提交、聚合沉淀、定时投递三个核心模块。这样的系统可以让大家轻松将自己喜欢的文章分享给团队,对分享文章进行分类沉淀,为团队打造知识库,方便大家查阅。同时,小报系统每周五也会定时推送,让大家了解最新的科技动态。分享学习氛围的好帮手~
那么这样一个小报系统是如何运作的呢?
如何为提交设计一个小报系统
我相信当你看到一个好的文章时,总会有一种与他人分享的冲动。一个简单易用的推送功能,可以轻松满足大家的分享欲望。好文章进队帮助其他同学~
一个简单易行的贡献函数,我们需要解决两个问题:
1、看到好东西如何满足分享的冲动文章
2、提交的文章如何分类采集,方便沉淀和搜索
如果是单独录入系统和人工录入,这种方式操作起来比较麻烦,而且很容易打消大家的积极性。我们平时在浏览器中看文章的时候,经常会采集好文章,一键操作,方便快捷。那么怎么能像浏览器书签采集文章一样方便投稿呢?
很容易想到通过浏览器的扩展能力来做到这一点,Chrome插件就提供了这样的能力
什么是 Chrome 扩展程序
官方解释():谷歌插件是用来定制浏览器体验的小程序。它允许用户根据个人需求或偏好自定义 Chrome 的功能和行为,并且它们基于 Web 技术(HTML、JavaScript 和 CSS)构建。
会说话的人话:开发一个web项目,可以嵌入到Chrome浏览器中,可以通过一些特定的API获取一些能力,从而定制自己的插件功能
如何开发Chrome插件一键提交
首先创建一个项目并开发一个贡献页面。
这个项目和普通的 Vue 项目唯一的区别就是在根目录下多了一个 manifest.json 文件。
{ <br /> // 核心代码 <br /> "name": "Zoo!", // 扩展名 <br /> "browser_action": { <br /> "default_popup": "./popup.html" // 点击浏览器右上方插件小图标弹出的内容 html <br /> }, <br /> "content_scripts": [ // 能够在 Web 页面内运行的 javascript 脚本 <br /> { <br /> "matches": [<br /> // 满足什么协议下进行调用 <br /> "http://*/*", <br /> "https://*/*" <br /> ], <br /> "js": [ <br /> "./contentScripts/zdata.js" // 插入到网页的 JS 文件路径 <br /> ], <br /> "run_at": "document_start" // 在document 加载时执行 <br /> } <br /> ] <br />} <br />
这样,当插件打开时,会默认加载popup.html页面的内容,效果如下:
插件本身并不能真正获取当前页面的标题,但是Chrome插件提供了将固定的JS脚本动态插入当前页面的能力。我们可以根据这个机制在当前页面中插入一个JS脚本来获取标题、介绍和URL,然后通过消息机制将获取到的内容返回给插件。
let host = this;<br />// 获取当前窗口 id <br />chrome.tabs.query({<br /> active: true,<br /> currentWindow: true<br />}, function (tabs) {<br /> let tabId = tabs.length ? tabs[0].id : null;<br /> // 向当前页面注入 JavaScript 脚本 <br /> chrome.tabs.executeScript(tabId || null, {<br /> file: './contentScripts/recommend.js'<br /> }, function () {<br /> // 向目标网页进行通信,向 recommend.js 发送一个消息 <br /> chrome.tabs.sendMessage(tabId, {<br /> message: 'GET_TOPIC_INFO',<br /> }, function (response) {<br /> // 获取到返回的文章 title 、url、description <br /> host.article.title = response.title;<br /> host.article.link = response.link;<br /> host.article.description = response.description;<br /> });<br /> });<br />}); <br />
推荐.js 监听消息。通过 addListener,我们可以监听 sendMessage 发送的消息。在 sendMessage 中定义消息常量可以让我们在接收消息时区分消息。
let doc = document;<br />chrome.runtime.onMessage.addListener(function (request, sender, sendResponse) {<br /> if (request.message === 'GET_TOPIC_INFO') {<br /> // 获取 title <br /> let title = document.getElementsByTagName('title')[0].textContent;<br /> let descriptionEl = doc.querySelectorAll('meta[name=description]')[0];<br /> // 获取 描述 <br /> let description = descriptionEl ? descriptionEl.getAttribute('content') : title;<br /> // 发送数据 <br /> sendResponse({<br /> title: title.trim(),<br /> link: location.href,<br /> description: description.trim()<br /> });<br /> } else if (request.message === 'SIGN_RELOAD') {<br /> console.log('request, sender', request, sender);<br /> }<br />}); <br />
// 投稿按钮点击事件 <br />handleRecommendArticle: function () {<br /> let request;<br /> request = ajax({<br /> method: 'post',<br /> url: 'https://XXX/api/post', // 后端接口 <br /> data: {<br /> 'title': this.article.title,<br /> 'desc': this.article.description,<br /> 'category': this.article.category[1] || '默认分类',<br /> 'link': this.article.link,<br /> 'referrer': this.article.reporter<br /> }<br /> });<br />} <br />
效果图:
以上是一个非常轻量级的Chrome插件的实现。基于这样一个Chrome插件,当我们看到喜欢的文章时,可以一键分享给团队的小伙伴~
当文章太多的时候,如果没有有效的管理,文章就会堆得乱七八糟,会让大家失去学习的欲望,那么我们如何分类采集提交的 文章 ,方便同学们找到自己需要的知识体系吗?
标签设计
设计标签分类需要一些时间。主要难点是什么分类维度可以让投稿人快速找到对应的分类,让观众可以根据分类快速找到自己想要的文章,以及如何快速找到过去的文章等.
这就要求我们的分类要通俗易懂,涵盖大部分业务类型文章。最后,我们从基础、语言、架构、选择、工具、总结等多个维度进行分类。
为了能够快速搜索文章,Chrome插件中也集成了分类查看功能。
插件制作完成后,其他同学可以将你的插件安装包安装到浏览器中。因为有墙,所以没有选项可以将插件上传到 Chrome 应用商店。我们在本地安装它。下图为打包后的项目目录结构:
安装步骤:浏览器选择设置->扩展->加载解压后的扩展->选择文件目录。同时,记得开启开发者模式。
Chrome扩展官方详细文档请移步链接()查看
聚合沉淀对于前端项目来说是很常见的,这里就不多说了。主要是能看到每一期的文章,快速分类搜索,统一收录文章入口。其中,前端页面是通过SSR服务端渲染实现的。
定时交货
到这里,小报系统的前端展示页面已经完成了,那么如何让每一期的优质文章更及时方便同学们阅读,让大家在学习中了解新技术适时地开阔眼界。后来我们想到可以通过主动联系、定时提醒等方式主动给队友发日记,所以在以上基础上,设计了一个单独的推送服务,定时推送每周小报到钉钉群和前台——结束邮件组。
const pushToRobot = async ({ data, title, nums }) => {<br /> // 组装发送数据格式 <br /> const links = wrapperFeedcard({ data, nums });<br /> // 发送数据到指定群 <br /> return axios("https://oapi.dingtalk.com/robot/send?", {<br /> method: "post",<br /> params: {<br /> access_token: "XXXX" //前端群 <br /> },<br /> data: {<br /> feedCard: {<br /> links<br /> },<br /> msgtype: "feedCard"<br /> }<br /> })<br />}; <br />
// 创建邮件链接 <br />const nodemailer = require("nodemailer"); <br />let transporter = nodemailer.createTransport({ <br /> service: "qiye.aliyun", <br /> port: 25, // SMTP 端口 <br /> host: "smtp.mxhichina.com", <br /> secureConnection: true, // 使用了 SSL <br /> auth: { <br /> user: "xxx@cai-inc.com", <br /> pass: "xxx" <br /> } <br />}); <br />// 组装发送内容 <br />let mailOptions = { <br /> from: '"政采云前端小报" ', // sender address <br /> to: "ZooTeam@cai-inc.com", // list of receivers <br /> cc: ["ZooTeam@cai-inc.com"], <br /> html: '邮件内容' // html body <br />}; <br />// 邮件发送 <br />transporter.sendMail(mailOptions); <br />
有一天,我们掘金的运营小姐告诉我,我们每周五要下班的时候发布文章。这太痛苦了。下班后耽误了我的约会。我说好,我们自己开发一个定时发布功能。如果想知道掘金的定时发布功能如何实现,可以在评论区留言讨论。
整体设计
总结
前端小报系统虽然是一个小系统,但无论是功能设计还是系统设计,都在追逐一个目标,努力促进团队的学习氛围,让团队成员不断成长。希望分享这篇文章能给大家一些启发,如何从一个目标出发去拆解实施,思考如何让工具更好地为人服务。
读两件事
如果你觉得这个内容有启发性,我想请你帮我做两件小事
1.点击“我在看”,让更多人看到这个内容(点击“我在看”,bug -1?)
文章定时自动采集(如何用文章定时自动采集!(一)_软件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2022-01-18 22:00
文章定时自动采集!文章定时自动采集!图片采集识别,图片请求获取处理~~~哈哈哈,
你可以参考我写的反爬虫web虫洞。
百度爬虫,图片、视频的爬虫。或者爬虫。都是现成的,要定时抓取可以找我。
简单的可以用编程自动定时抓取新闻,每天看看有没有新的消息(一般一两条就够了)。高级点的就抓数据库表格内容了。
我需要数据,
网页自动切换登录
就是一个看网页的小软件
公司抓包云采集,这家很不错,
autojs,jsoup,gevent这三个是必须的,
requests+aiohttp
figrootverify,
这个爬虫这几个月我一直在用,
我来吐个槽。我是做互联网相关的,自己每天要爬数据,特别是视频网站,有些视频网站有各种电脑,然后需要爬各种页面信息。然后我能想到最简单的方法,就是用注册各种论坛,然后获取一些帖子链接。然后爬站长的rss或者加一些条件比如别人是新注册用户等。但是这个满足起来也不方便。于是搜集起来常见的rss网站。比如微博分享网,新浪博客,大家口口相传的豆瓣网等等。
说的比较轻松,结果现在就遇到了个问题,公司的报表推送功能并不支持爬虫,不知道能不能通过爬虫批量下载?能不能批量设置下载条件?如果不能批量只能乱爬了?有没有人能推荐下?尤其是会爬网页的人是不是太多了?。 查看全部
文章定时自动采集(如何用文章定时自动采集!(一)_软件)
文章定时自动采集!文章定时自动采集!图片采集识别,图片请求获取处理~~~哈哈哈,
你可以参考我写的反爬虫web虫洞。
百度爬虫,图片、视频的爬虫。或者爬虫。都是现成的,要定时抓取可以找我。
简单的可以用编程自动定时抓取新闻,每天看看有没有新的消息(一般一两条就够了)。高级点的就抓数据库表格内容了。
我需要数据,
网页自动切换登录
就是一个看网页的小软件
公司抓包云采集,这家很不错,
autojs,jsoup,gevent这三个是必须的,
requests+aiohttp
figrootverify,
这个爬虫这几个月我一直在用,
我来吐个槽。我是做互联网相关的,自己每天要爬数据,特别是视频网站,有些视频网站有各种电脑,然后需要爬各种页面信息。然后我能想到最简单的方法,就是用注册各种论坛,然后获取一些帖子链接。然后爬站长的rss或者加一些条件比如别人是新注册用户等。但是这个满足起来也不方便。于是搜集起来常见的rss网站。比如微博分享网,新浪博客,大家口口相传的豆瓣网等等。
说的比较轻松,结果现在就遇到了个问题,公司的报表推送功能并不支持爬虫,不知道能不能通过爬虫批量下载?能不能批量设置下载条件?如果不能批量只能乱爬了?有没有人能推荐下?尤其是会爬网页的人是不是太多了?。
文章定时自动采集(一下免费采集软件?免费文章采集器有哪些用途?(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-01-18 21:09
免费文章采集器,顾名思义,就是免费的采集软件或工具。在互联网的早期,人们采集的目标是物理对象。在现代互联网时代,信息飞速发展。在变革的时代,免费的采集器在各行各业都有广泛的应用。让我介绍一下免费的采集 软件?免费的文章采集器有什么用?
免费的采集器算法智能提取网页文本,可以采集全网新闻、百度新闻源、360新闻源、搜狗新闻源、头条新闻源!取之不尽的 文章 库。而你只需要输入关键词几个核心关键词,软件会自动展开关键词!作为一个完全免费的文章采集器,必须满足2点,第一点是数据采集,第二点是发布数据!一个不错的免费文章采集器不需要学习更专业的技术,简单2步就可以轻松搞定采集发布文章数据,用户只需要简单的设置以上要求 采集 中的 关键词。完成后,软件根据用户设置的关键词,100%匹配网站的内容和图片,提供优质的网站@文章数据服务!!
实时监控网站的进度,打开软件查看网站采集的状态,网站发布状态,网站推送状态,网站蜘蛛状态,网站收录情况,网站排名情况,网站体重情况!免费的采集器不仅提供了文章自动采集、批量数据处理、定时采集、定时发布等基本功能,还支持格式化处理如去标签、链接和电子邮件。!
6、搜索引擎推送(文章发布成功后,主动向搜索引擎推送文章,保证新链接能被搜索引擎及时推送收录)
9、自动内链(在执行发布任务时会在文章内容中自动生成内链,帮助引导页面蜘蛛抓取,提高页面权限)
10、定期发布(定期发布网站内容可以让搜索引擎养成定期爬取网页的习惯,从而提高网站的收录)
13、字锁定功能(自动锁定品牌字,产品字提高文章可读性,文章原创时核心字不会是原创)
使用免费的文章采集器进行信息采集,可以节省大量的人力和金钱。因此,文章采集器广泛应用于IT行业,如行业门户网站、知识管理系统、网站内容系统、自媒体作家等领域。看完这篇文章,如果觉得不错,不妨采集一下,或者发给有需要的朋友和同事!你的一举一动都会成为小编源源不断的动力!回搜狐看广东省肇庆市高要区潇湘镇松树窝矿区更多建筑用途 查看全部
文章定时自动采集(一下免费采集软件?免费文章采集器有哪些用途?(组图))
免费文章采集器,顾名思义,就是免费的采集软件或工具。在互联网的早期,人们采集的目标是物理对象。在现代互联网时代,信息飞速发展。在变革的时代,免费的采集器在各行各业都有广泛的应用。让我介绍一下免费的采集 软件?免费的文章采集器有什么用?
免费的采集器算法智能提取网页文本,可以采集全网新闻、百度新闻源、360新闻源、搜狗新闻源、头条新闻源!取之不尽的 文章 库。而你只需要输入关键词几个核心关键词,软件会自动展开关键词!作为一个完全免费的文章采集器,必须满足2点,第一点是数据采集,第二点是发布数据!一个不错的免费文章采集器不需要学习更专业的技术,简单2步就可以轻松搞定采集发布文章数据,用户只需要简单的设置以上要求 采集 中的 关键词。完成后,软件根据用户设置的关键词,100%匹配网站的内容和图片,提供优质的网站@文章数据服务!!
实时监控网站的进度,打开软件查看网站采集的状态,网站发布状态,网站推送状态,网站蜘蛛状态,网站收录情况,网站排名情况,网站体重情况!免费的采集器不仅提供了文章自动采集、批量数据处理、定时采集、定时发布等基本功能,还支持格式化处理如去标签、链接和电子邮件。!
6、搜索引擎推送(文章发布成功后,主动向搜索引擎推送文章,保证新链接能被搜索引擎及时推送收录)
9、自动内链(在执行发布任务时会在文章内容中自动生成内链,帮助引导页面蜘蛛抓取,提高页面权限)
10、定期发布(定期发布网站内容可以让搜索引擎养成定期爬取网页的习惯,从而提高网站的收录)
13、字锁定功能(自动锁定品牌字,产品字提高文章可读性,文章原创时核心字不会是原创)
使用免费的文章采集器进行信息采集,可以节省大量的人力和金钱。因此,文章采集器广泛应用于IT行业,如行业门户网站、知识管理系统、网站内容系统、自媒体作家等领域。看完这篇文章,如果觉得不错,不妨采集一下,或者发给有需要的朋友和同事!你的一举一动都会成为小编源源不断的动力!回搜狐看广东省肇庆市高要区潇湘镇松树窝矿区更多建筑用途
文章定时自动采集(bean页面引擎,解决资源重复无用等问题。。)
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-01-17 09:06
文章定时自动采集微信公众号以及企业h5页面,解决资源重复无用等问题。解决二次开发重复造轮子,
之前是h5页面引擎,现在主要是x-markdown引擎,效果还不错,可以很好地满足android,ios,wp平台的需求,是一个很不错的编辑器,
x-markdown使用官方的channel,基本功能如下。
我知道这家公司里面的x-markdown的实现做的不错,很好用,可以安装使用一些特殊的功能,而且国内外的大公司都是可以免费使用的。
看了前面的回答,感觉就是垃圾!我是实在不明白有啥吸引的,可能人们都爱说点有的没的,但是还是希望大家看看能有一点帮助!可以试试用这家公司的“x-markdown”进行h5的定制。
bean定制是一家提供定制引擎的公司。bean所定制的引擎基于xml文档生成标记化代码,即对xml文档中的每一个“标记”都由专业人员依据标记的内容结合xml和自己使用的语言生成代码。bean的代码包含xml、javascript、c#、php等多种语言特性,模块化设计,易学易用。可提供跨平台,简单可扩展,高效安全等特点。
可选择多家底层互联网云引擎。已知的支持:oceanlite、jepful和graphiker等。如需进一步定制,可单独到总部定制或者需要邮件的方式请求定制。 查看全部
文章定时自动采集(bean页面引擎,解决资源重复无用等问题。。)
文章定时自动采集微信公众号以及企业h5页面,解决资源重复无用等问题。解决二次开发重复造轮子,
之前是h5页面引擎,现在主要是x-markdown引擎,效果还不错,可以很好地满足android,ios,wp平台的需求,是一个很不错的编辑器,
x-markdown使用官方的channel,基本功能如下。
我知道这家公司里面的x-markdown的实现做的不错,很好用,可以安装使用一些特殊的功能,而且国内外的大公司都是可以免费使用的。
看了前面的回答,感觉就是垃圾!我是实在不明白有啥吸引的,可能人们都爱说点有的没的,但是还是希望大家看看能有一点帮助!可以试试用这家公司的“x-markdown”进行h5的定制。
bean定制是一家提供定制引擎的公司。bean所定制的引擎基于xml文档生成标记化代码,即对xml文档中的每一个“标记”都由专业人员依据标记的内容结合xml和自己使用的语言生成代码。bean的代码包含xml、javascript、c#、php等多种语言特性,模块化设计,易学易用。可提供跨平台,简单可扩展,高效安全等特点。
可选择多家底层互联网云引擎。已知的支持:oceanlite、jepful和graphiker等。如需进一步定制,可单独到总部定制或者需要邮件的方式请求定制。
文章定时自动采集( 5个“效率”有关的故事带你搞懂数据可视化产品)
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2022-01-14 18:18
5个“效率”有关的故事带你搞懂数据可视化产品)
接下来,梁宁想到了系列课程。在这堂课上,梁宁谈到了产品“系统能力”模块的效率。下课后,她留下了如下作业:
企业是高效分工的产物,那么你企业的护城河在哪里?您认为它在哪些方面比其他方面更有效?
在这堂课上,梁宁提到“效率是保证系统能力的核心指标”。其实在学习了这门课之后,我重新梳理了对“效率”的理解:效率不仅包括上一篇文章提到的数据效率(“加载率”、“数据准确率”等指标)还包括功能运营、Bug处理、产品迭代、运营推广、系统间耦合、业务赋能的效率,总之从“产品本身→系统生态”的效率。
但是,产品的外观不是无中生有,而是通过人工生产获得的,所以其背后收录了开发、设计、管理、运营、生态五个具体任务,以保证产品可以从“可用→易于使用→易于使用。” → 有用的”过渡。
这次任务我就不讲公司了,所以把梁宁留下的工作范围缩小,讲一下之前公司的数据可视化产品,DAU从几人到几百人不等(虽然DAU是一个虚荣指标,是一个内部工具产品,这个数据表现已经很不错了)。
这次,我将作为一个讲故事的人,通过5个“效率”相关的故事,带你了解数据可视化产品(也称为BI可视化工具)。
一、故事一:开发效率——从入门到敏捷开发改革
2018年的一次跳槽,我从战略平台的产品经理变成了X公司的数据产品经理。
与此同时,研发部门也发生了人事变动。X公司认可的最佳大数据开发工程师Todd成为独角兽(X公司开发的数据可视化BI工具产品)后端研发负责人。作为一个刚接触大数据领域的产品人,很高兴能与认真专业的技术同学合作。
在合作初期,Todd 总是提醒我:“做数据最重要的两件事是准确性和计算速度。”
因此,在最初的近 3 个月里,独角兽几乎没有对新功能进行任何迭代(除了特别影响用户体验的功能),甚至没有向其他部门推广,除了内部数仓同事使用。
因为早期的独角兽有两个特别大的问题:一是所有的计算逻辑都由前端实现,增加了图表渲染的时间;二是历史计算异常的函数较多,导致数据计算不准确。
那段时间,我们把所有计算逻辑处理从前端移到了后端,加快了图表数据的展示速度。同时,我们还为独角兽设计了缓存机制,保证相同的数据查询直接访问最后查询的数据。
另一方面,后端开发人员今天一直在为早期用户群报告的计算错误做好准备。
最后值得一提的是,作为一个非商业的内部系统产品,经过与整个独角兽项目组的讨论,我们采用了2周的迭代开发周期,为独角兽未来的DAU数据打下了坚实的基础!
二、故事二:体验效率——快速搭建仪表盘
unicorn 的用户和所有 BI 可视化工具一样,主要分为两类:grapher(通常是数据分析师)和 graph viewer(通常是业务人员)。
因为这两个角色,“效率”也有两大特点:观众可以快速定位和发现问题。这里的详细内容可以参考之前的文章《数据+产品是数据产品吗?说说数据可视化场景》,这里不再赘述。
对于制图者来说,“高效”意味着能够快速构建 Dashboard。
使用过BI可视化工具的同学应该都知道,配置仪表盘的主要流程分为三个步骤:连接数据源→配置数据集→制作报表。
其实绝大多数BI工具在“连接数据源→配置数据集”链接中基本都是一样的(有一种特殊的方法,有机会会在整页介绍),但是在“报表制作”环节,独角兽经历了从低效到快速的转变。
我接手独角兽的时候,“做报表”是指一个开源BI工具的制作过程:创建画布后,需要添加已经创建好的图表。在画布区域可以添加全局过滤器,对于单个表格,过滤器是在创建图表时添加(Dashboard收录三个主要元素:画布、图表、过滤器):
其实我们可以看到,上述过程是一个工程思维的过程。图表和图表过滤器是一一对应的,画布和全局过滤器是一一对应的。这些图表以组合关系存储在一起。,而画布是收录这些图表的关系。
以这种方式向其他人介绍 BI 可视化工具会很棒,但不难看出,仪表板的创建在交给用户时是不连贯的。为了保证用户操作的连续性,我们修改了独角兽的操作方式,让用户可以在同一个窗口中创建画布、图表、过滤器:
除了整体流程的优化,各个功能模块的优化也满足了用户的心智模型。我会在《物语3》中继续讲相关内容。
三、故事三:管理效率——从被动到主动,从抄袭到创新
2018年,虽然我有几年的产品经验,但是数据产品的经验是0。而且数据产品会涉及到技术工作,所以一开始我主要是按照开发思路。
接手独角兽时,用户都是系里的学生。基本上,他们遵循他们提出的任何需求计划。实现方式也被动接受了后端开发的设计思路。作为一个产品人,他们把心思都放在给别人是一件很痛苦的事情。
一个多月以来,我一方面开始记录独角兽的迭代路径,发现产品的迭代基本上是东一锤西一锤,缺乏方向性规划;另一方面,我从零开始学习基本的SQL查询语句,了解每个函数背后的数据流,了解现有函数需要改进的功能点。
“你可以问我你的需求,但你必须告诉我背景……” 之前见过我的朋友应该知道文章这句话是我对小樱说的,发生了180度从一开始就。反过来,这也是我改变数据产品的起点。
然后我开始制定新的需求报告标准(需求录入表),增加了“讲背景,讲问题”的链接,而不是直接讲解决方案。为避免过度改革的潜在影响(有兴趣的朋友可以了解一下王莽的改革),我保留了树仓喜欢直接提出方案的行为,但只说是“建议方案”,即,最终实现产品设计为准。
同时,需求的优先级和调度的归属有待我方项目组讨论处理,参考如下(该栏目中只有白色表头填充的栏目,可编辑并由请求者填写):
伴随着需求池的标准化排序和分类,整体的定向迭代规划也有了蓝图。
另外,独角兽的设计并没有完全照搬Tableau、网易游数等商业BI工具的功能流程,以过滤功能图的功能为例。Tableau 支持下图所示的应用程序范围选项:
事实上,Tableau 是从数据的角度而不是图表的角度来设计这个功能的。“This worksheet only”很好理解,但是前两个选项(选项1是跨数据源过滤的功能,选项2是针对同一数据源的所有图表的名称)是为了让用户更加关注数据而不是图表本身,并让用户从不同的角度了解并列的选项。这种设计本身就很反人类。
此外,如果要在 Tableau 上跨多个数据源筛选数据,则必须保持字段名称一致。如果不同的分析师对数据集的命名不一致(数据集存储在BI工具下,而不是数据仓库),所以命名约定一般不需要),需要再次更改,确实很麻烦。
第二个突出的问题表现在Tableau和网易优数上。在设置过滤器的步骤中,必须先“选择过滤器字段”,再“选择对应的图表”。以下是 Tableau 和网易优树的配置截图:
但是每次用的时候都会有点扭曲,总觉得顺序和我想的不一样。写过SQL语句的朋友都知道,我们查询数据的时候,一般会写如下语句,过滤条件写在最后:
SELECT column_name //显示数据,即拖入BI工具的行列字段
FROM table_name //应用的数据集/图表
WHERE Filters //过滤字段
所以在我设计过滤器设置流程的时候,我改变了配置的顺序:
在咨询了一些分析师同学后,他们也觉得这种体验方式比较好。同时,我们在设置上也做了一些优化。例如设置其中一个图表的字段后,如果其他图表也有同名字段,则其他图表默认选择该字段:
四、故事四:运营效率——围绕团队从领导到勤奋留住用户
在文章的开头,我们提到了unicorn是一个数据可视化产品,DAU从几人到几百人不等。在公司已经有Tableau的背景下,这个内部BI工具是如何运作和推广的?
其实一开始,我是一味的在创作者(分析师)和观众(业务人员)之间推搡,但在过去的一个月里,只有几个人晋升到了十几个人。
后来,我开始调查我之前晋升的同事为什么不使用独角兽,他们的回答出奇地一致:“我们所有的分析看板都使用 Tableau。”
我意识到,独角兽在每个人的眼中都没有存在感。如果以这种传统的方式推广,很少有人还在使用它。如果想让更多的同事使用它,就需要采用自上而下的方式。方式推广。
我和主管找到了两个主要部门的负责人,给他们演示了我们的系统,了解到他们最大的共同痛点:Tableau 必须在公司网络环境中使用,我想上路。要轻松查看数据几乎是不可能的。
为了让这些部门负责人协助我们在他们内部进行推广,首先要解决主管的痛点。
在下一个迭代周期项目通过后,我们前端同学终于开发了Dashboard的截图功能,并开放了钉钉群界面,支持配置定时任务向钉钉群发送截图。这样,手机无需下载Tableau APP,无需连接公司VPN,即可查看上下班途中的数据。
解决了这些部门负责人的痛点之后,自然而然地开始在部门内部展开。因为用户数量的扩大,很多产品的问题也开始被发现、修复或优化。
因为一个部门的使用,我们向其他部门推广就方便多了。每次我们宣传的时候都会说:“***部门已经开始使用了,他们的使用效果非常好,你可以问问他们……”
为了更好的留住客户,我们在产品顶部增加了“吐槽”入口,并开通了钉钉群,让有问题的同事可以第一时间报告问题。在“故事1”中也提到,用户反映的问题基本保证第一时间处理,计算错误问题保持当日解决。
最后,我们还为独角兽创建了一个客观的监控仪表盘:“哪些用户经常访问独角兽”、“哪些用户登录过一次,再也没有登录过”……这些数据一目了然,我也会采集起来每周。抽取1~2个客户了解他们的使用情况,也为未来的系统规划提供了宝贵的建议。
五、故事5:赋能效率——众泰化,独角兽不再是单纯的BI工具
独角兽是如何做赋能的,除了狭义的赋能,即提供更高效的视觉展示(包括支持多样化图表、支持个性化预警、提示用户关注相关指标等),它还包括广义上的赋权。能够。
事实上,BI可视化工具本质上是B端产品,所以他们的追求还是“效率”。
在企业中,除了BI可视化工具外,很多内部系统都会有图表展示的需求。比如配送系统“配送后效果如何?” 可以在可视化系统中展示,在CRM系统中“每个销售同事的表现如何?” 也可以在可视化系统中显示。如果支持兄弟部门系统的可视化能力,是否可以节省他们的开发资源,提升独角兽本身的价值?
在这项工作中,我们为其他业务系统提供两种不同的支持服务:一种是轻量级支持,仅提供图表可视化能力;另一个是重量级支持,提供图表可视化能力和数据算力服务。
在独角兽的中端支持服务中,“图表可视化能力”主要依赖于我们前端同学开发的图表库组件。为了满足业务的展示需求,在Echarts开源图表上进行了改造。
在数据计算能力方面,我们创造性地设计了一个参数传递函数,考虑到我们不会对独角兽做太多的系统改造。这是 Tableau 参数传递功能的进一步创新。目前,Tableau 仅支持内部仪表板之间的参数传递,或从内部图表到外部系统的参数传递,但缺乏从外部系统到内部图表的参数传递。
在支持CRM系统“让每个销售同事查看自己的销售业绩”的项目中,我们以公司统一账户系统的“用户ID”作为参数变量,利用独角兽中收录销售业绩的数据集创建收录多个图表的图表。Dashboard,然后通过加密外链将仪表盘嵌入CRM,实现“千人千面”的销售数据展示,即每个登录CRM的销售同事只能查看自己的销售数据:
5个短篇故事已经讲到这里了。看完数据可视化产品,你有没有更深入的了解?如果您还有其他问题或不同意见,请在下方留言与我讨论。
#专栏作家#
Xixi,微信公众号:Lone Traveler(ID:gushenlvren),大家都是产品经理专栏作家。专注于人工智能、toB产品、大娱乐等领域。
这篇文章 原创 由 每个人都是产品经理发布。禁止任何未经许可的复制。
题图来自Unsplash,基于CC0协议 查看全部
文章定时自动采集(
5个“效率”有关的故事带你搞懂数据可视化产品)
接下来,梁宁想到了系列课程。在这堂课上,梁宁谈到了产品“系统能力”模块的效率。下课后,她留下了如下作业:
企业是高效分工的产物,那么你企业的护城河在哪里?您认为它在哪些方面比其他方面更有效?
在这堂课上,梁宁提到“效率是保证系统能力的核心指标”。其实在学习了这门课之后,我重新梳理了对“效率”的理解:效率不仅包括上一篇文章提到的数据效率(“加载率”、“数据准确率”等指标)还包括功能运营、Bug处理、产品迭代、运营推广、系统间耦合、业务赋能的效率,总之从“产品本身→系统生态”的效率。
但是,产品的外观不是无中生有,而是通过人工生产获得的,所以其背后收录了开发、设计、管理、运营、生态五个具体任务,以保证产品可以从“可用→易于使用→易于使用。” → 有用的”过渡。
这次任务我就不讲公司了,所以把梁宁留下的工作范围缩小,讲一下之前公司的数据可视化产品,DAU从几人到几百人不等(虽然DAU是一个虚荣指标,是一个内部工具产品,这个数据表现已经很不错了)。
这次,我将作为一个讲故事的人,通过5个“效率”相关的故事,带你了解数据可视化产品(也称为BI可视化工具)。
一、故事一:开发效率——从入门到敏捷开发改革
2018年的一次跳槽,我从战略平台的产品经理变成了X公司的数据产品经理。
与此同时,研发部门也发生了人事变动。X公司认可的最佳大数据开发工程师Todd成为独角兽(X公司开发的数据可视化BI工具产品)后端研发负责人。作为一个刚接触大数据领域的产品人,很高兴能与认真专业的技术同学合作。
在合作初期,Todd 总是提醒我:“做数据最重要的两件事是准确性和计算速度。”
因此,在最初的近 3 个月里,独角兽几乎没有对新功能进行任何迭代(除了特别影响用户体验的功能),甚至没有向其他部门推广,除了内部数仓同事使用。
因为早期的独角兽有两个特别大的问题:一是所有的计算逻辑都由前端实现,增加了图表渲染的时间;二是历史计算异常的函数较多,导致数据计算不准确。
那段时间,我们把所有计算逻辑处理从前端移到了后端,加快了图表数据的展示速度。同时,我们还为独角兽设计了缓存机制,保证相同的数据查询直接访问最后查询的数据。
另一方面,后端开发人员今天一直在为早期用户群报告的计算错误做好准备。
最后值得一提的是,作为一个非商业的内部系统产品,经过与整个独角兽项目组的讨论,我们采用了2周的迭代开发周期,为独角兽未来的DAU数据打下了坚实的基础!
二、故事二:体验效率——快速搭建仪表盘
unicorn 的用户和所有 BI 可视化工具一样,主要分为两类:grapher(通常是数据分析师)和 graph viewer(通常是业务人员)。
因为这两个角色,“效率”也有两大特点:观众可以快速定位和发现问题。这里的详细内容可以参考之前的文章《数据+产品是数据产品吗?说说数据可视化场景》,这里不再赘述。
对于制图者来说,“高效”意味着能够快速构建 Dashboard。
使用过BI可视化工具的同学应该都知道,配置仪表盘的主要流程分为三个步骤:连接数据源→配置数据集→制作报表。
其实绝大多数BI工具在“连接数据源→配置数据集”链接中基本都是一样的(有一种特殊的方法,有机会会在整页介绍),但是在“报表制作”环节,独角兽经历了从低效到快速的转变。
我接手独角兽的时候,“做报表”是指一个开源BI工具的制作过程:创建画布后,需要添加已经创建好的图表。在画布区域可以添加全局过滤器,对于单个表格,过滤器是在创建图表时添加(Dashboard收录三个主要元素:画布、图表、过滤器):
其实我们可以看到,上述过程是一个工程思维的过程。图表和图表过滤器是一一对应的,画布和全局过滤器是一一对应的。这些图表以组合关系存储在一起。,而画布是收录这些图表的关系。
以这种方式向其他人介绍 BI 可视化工具会很棒,但不难看出,仪表板的创建在交给用户时是不连贯的。为了保证用户操作的连续性,我们修改了独角兽的操作方式,让用户可以在同一个窗口中创建画布、图表、过滤器:
除了整体流程的优化,各个功能模块的优化也满足了用户的心智模型。我会在《物语3》中继续讲相关内容。
三、故事三:管理效率——从被动到主动,从抄袭到创新
2018年,虽然我有几年的产品经验,但是数据产品的经验是0。而且数据产品会涉及到技术工作,所以一开始我主要是按照开发思路。
接手独角兽时,用户都是系里的学生。基本上,他们遵循他们提出的任何需求计划。实现方式也被动接受了后端开发的设计思路。作为一个产品人,他们把心思都放在给别人是一件很痛苦的事情。
一个多月以来,我一方面开始记录独角兽的迭代路径,发现产品的迭代基本上是东一锤西一锤,缺乏方向性规划;另一方面,我从零开始学习基本的SQL查询语句,了解每个函数背后的数据流,了解现有函数需要改进的功能点。
“你可以问我你的需求,但你必须告诉我背景……” 之前见过我的朋友应该知道文章这句话是我对小樱说的,发生了180度从一开始就。反过来,这也是我改变数据产品的起点。
然后我开始制定新的需求报告标准(需求录入表),增加了“讲背景,讲问题”的链接,而不是直接讲解决方案。为避免过度改革的潜在影响(有兴趣的朋友可以了解一下王莽的改革),我保留了树仓喜欢直接提出方案的行为,但只说是“建议方案”,即,最终实现产品设计为准。
同时,需求的优先级和调度的归属有待我方项目组讨论处理,参考如下(该栏目中只有白色表头填充的栏目,可编辑并由请求者填写):
伴随着需求池的标准化排序和分类,整体的定向迭代规划也有了蓝图。
另外,独角兽的设计并没有完全照搬Tableau、网易游数等商业BI工具的功能流程,以过滤功能图的功能为例。Tableau 支持下图所示的应用程序范围选项:
事实上,Tableau 是从数据的角度而不是图表的角度来设计这个功能的。“This worksheet only”很好理解,但是前两个选项(选项1是跨数据源过滤的功能,选项2是针对同一数据源的所有图表的名称)是为了让用户更加关注数据而不是图表本身,并让用户从不同的角度了解并列的选项。这种设计本身就很反人类。
此外,如果要在 Tableau 上跨多个数据源筛选数据,则必须保持字段名称一致。如果不同的分析师对数据集的命名不一致(数据集存储在BI工具下,而不是数据仓库),所以命名约定一般不需要),需要再次更改,确实很麻烦。
第二个突出的问题表现在Tableau和网易优数上。在设置过滤器的步骤中,必须先“选择过滤器字段”,再“选择对应的图表”。以下是 Tableau 和网易优树的配置截图:
但是每次用的时候都会有点扭曲,总觉得顺序和我想的不一样。写过SQL语句的朋友都知道,我们查询数据的时候,一般会写如下语句,过滤条件写在最后:
SELECT column_name //显示数据,即拖入BI工具的行列字段
FROM table_name //应用的数据集/图表
WHERE Filters //过滤字段
所以在我设计过滤器设置流程的时候,我改变了配置的顺序:
在咨询了一些分析师同学后,他们也觉得这种体验方式比较好。同时,我们在设置上也做了一些优化。例如设置其中一个图表的字段后,如果其他图表也有同名字段,则其他图表默认选择该字段:
四、故事四:运营效率——围绕团队从领导到勤奋留住用户
在文章的开头,我们提到了unicorn是一个数据可视化产品,DAU从几人到几百人不等。在公司已经有Tableau的背景下,这个内部BI工具是如何运作和推广的?
其实一开始,我是一味的在创作者(分析师)和观众(业务人员)之间推搡,但在过去的一个月里,只有几个人晋升到了十几个人。
后来,我开始调查我之前晋升的同事为什么不使用独角兽,他们的回答出奇地一致:“我们所有的分析看板都使用 Tableau。”
我意识到,独角兽在每个人的眼中都没有存在感。如果以这种传统的方式推广,很少有人还在使用它。如果想让更多的同事使用它,就需要采用自上而下的方式。方式推广。
我和主管找到了两个主要部门的负责人,给他们演示了我们的系统,了解到他们最大的共同痛点:Tableau 必须在公司网络环境中使用,我想上路。要轻松查看数据几乎是不可能的。
为了让这些部门负责人协助我们在他们内部进行推广,首先要解决主管的痛点。
在下一个迭代周期项目通过后,我们前端同学终于开发了Dashboard的截图功能,并开放了钉钉群界面,支持配置定时任务向钉钉群发送截图。这样,手机无需下载Tableau APP,无需连接公司VPN,即可查看上下班途中的数据。
解决了这些部门负责人的痛点之后,自然而然地开始在部门内部展开。因为用户数量的扩大,很多产品的问题也开始被发现、修复或优化。
因为一个部门的使用,我们向其他部门推广就方便多了。每次我们宣传的时候都会说:“***部门已经开始使用了,他们的使用效果非常好,你可以问问他们……”
为了更好的留住客户,我们在产品顶部增加了“吐槽”入口,并开通了钉钉群,让有问题的同事可以第一时间报告问题。在“故事1”中也提到,用户反映的问题基本保证第一时间处理,计算错误问题保持当日解决。
最后,我们还为独角兽创建了一个客观的监控仪表盘:“哪些用户经常访问独角兽”、“哪些用户登录过一次,再也没有登录过”……这些数据一目了然,我也会采集起来每周。抽取1~2个客户了解他们的使用情况,也为未来的系统规划提供了宝贵的建议。
五、故事5:赋能效率——众泰化,独角兽不再是单纯的BI工具
独角兽是如何做赋能的,除了狭义的赋能,即提供更高效的视觉展示(包括支持多样化图表、支持个性化预警、提示用户关注相关指标等),它还包括广义上的赋权。能够。
事实上,BI可视化工具本质上是B端产品,所以他们的追求还是“效率”。
在企业中,除了BI可视化工具外,很多内部系统都会有图表展示的需求。比如配送系统“配送后效果如何?” 可以在可视化系统中展示,在CRM系统中“每个销售同事的表现如何?” 也可以在可视化系统中显示。如果支持兄弟部门系统的可视化能力,是否可以节省他们的开发资源,提升独角兽本身的价值?
在这项工作中,我们为其他业务系统提供两种不同的支持服务:一种是轻量级支持,仅提供图表可视化能力;另一个是重量级支持,提供图表可视化能力和数据算力服务。
在独角兽的中端支持服务中,“图表可视化能力”主要依赖于我们前端同学开发的图表库组件。为了满足业务的展示需求,在Echarts开源图表上进行了改造。
在数据计算能力方面,我们创造性地设计了一个参数传递函数,考虑到我们不会对独角兽做太多的系统改造。这是 Tableau 参数传递功能的进一步创新。目前,Tableau 仅支持内部仪表板之间的参数传递,或从内部图表到外部系统的参数传递,但缺乏从外部系统到内部图表的参数传递。
在支持CRM系统“让每个销售同事查看自己的销售业绩”的项目中,我们以公司统一账户系统的“用户ID”作为参数变量,利用独角兽中收录销售业绩的数据集创建收录多个图表的图表。Dashboard,然后通过加密外链将仪表盘嵌入CRM,实现“千人千面”的销售数据展示,即每个登录CRM的销售同事只能查看自己的销售数据:
5个短篇故事已经讲到这里了。看完数据可视化产品,你有没有更深入的了解?如果您还有其他问题或不同意见,请在下方留言与我讨论。
#专栏作家#
Xixi,微信公众号:Lone Traveler(ID:gushenlvren),大家都是产品经理专栏作家。专注于人工智能、toB产品、大娱乐等领域。
这篇文章 原创 由 每个人都是产品经理发布。禁止任何未经许可的复制。
题图来自Unsplash,基于CC0协议
文章定时自动采集(文章管理是网站日常维护的基础操作,本文介绍文件管理)
采集交流 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-01-14 18:18
文章管理是网站日常维护的基本操作。本文介绍了一些WordPress文件管理的知识。
WordPress文章管理界面
类别
网站在内容发布之前,需要规划更多的网站内容,并按照一定的类型对文章进行分类。分类目录是WP文章分类的模块。支持多层次,同一篇文章文章可以同时发布到不同的分类。点击左侧导航中的分类菜单,进入分类管理界面
WordPress分类目录管理界面
左边的表格用于添加新的类别,右边是当前创建的类别。
将鼠标移到右侧的分类名称上会显示常用的操作,如:编辑、删除、快速编辑等。总数为当前分类下文章文章的总数。默认未分类不能删除,只能编辑
标签
标签是文章的关键词,单个文章可以添加多个标签。编辑文章时添加的标签也会显示在标签管理中。标签的设置与类别的设置相同,但没有层次结构。标签可以用作 网站 内容聚合关联。 网站前天可以检索到所有收录标签的文章。如果你有两篇文章文章,一篇讲解品酒知识,放到品酒类,另一篇文章讲解葡萄酒酿造过程,你放到酒类正在酝酿中。文章 的两篇文章都是关于红酒的。两篇文章文章都可以添加红酒的标签。当前端用户访问红酒的标签时,两篇文章 文章 都会显示。
WordPress标签管理页面
列表
文章 列表页面显示当前在 网站 上的所有 文章。您可以通过搜索或按类别过滤您想要的 文章。
WordPress文章列表页面
将鼠标移动到某篇文章文章,会出现编辑、快速编辑、移动到回收站、查看等操作。
编辑
点击编辑按钮,可以进入文章编辑界面,更高版本的WordPress使用Gutenberg块编辑器,具体操作文字内容不做说明,请观看编辑器使用视频
快速编辑
WordPress快速编辑界面
快速编辑可以编辑文章的标题、别名、日期、时间、类别、标签、模板、评论、ping、状态、置顶等属性。
修改完成后,点击更新。
批量编辑,选中多篇文章文章点击批量编辑,在当前窗口打开批量编辑表单。允许的编辑内容如下:
WordPress文章批量编辑界面
编辑
文章使用 Gutenberg 编辑器创建,Gutenberg 是一个块编辑器,其中每个内容都是一个块。文字教程不会给小编过多讲解,请看小编使用教程。 查看全部
文章定时自动采集(文章管理是网站日常维护的基础操作,本文介绍文件管理)
文章管理是网站日常维护的基本操作。本文介绍了一些WordPress文件管理的知识。
WordPress文章管理界面
类别
网站在内容发布之前,需要规划更多的网站内容,并按照一定的类型对文章进行分类。分类目录是WP文章分类的模块。支持多层次,同一篇文章文章可以同时发布到不同的分类。点击左侧导航中的分类菜单,进入分类管理界面
WordPress分类目录管理界面
左边的表格用于添加新的类别,右边是当前创建的类别。
将鼠标移到右侧的分类名称上会显示常用的操作,如:编辑、删除、快速编辑等。总数为当前分类下文章文章的总数。默认未分类不能删除,只能编辑
标签
标签是文章的关键词,单个文章可以添加多个标签。编辑文章时添加的标签也会显示在标签管理中。标签的设置与类别的设置相同,但没有层次结构。标签可以用作 网站 内容聚合关联。 网站前天可以检索到所有收录标签的文章。如果你有两篇文章文章,一篇讲解品酒知识,放到品酒类,另一篇文章讲解葡萄酒酿造过程,你放到酒类正在酝酿中。文章 的两篇文章都是关于红酒的。两篇文章文章都可以添加红酒的标签。当前端用户访问红酒的标签时,两篇文章 文章 都会显示。
WordPress标签管理页面
列表
文章 列表页面显示当前在 网站 上的所有 文章。您可以通过搜索或按类别过滤您想要的 文章。
WordPress文章列表页面
将鼠标移动到某篇文章文章,会出现编辑、快速编辑、移动到回收站、查看等操作。
编辑
点击编辑按钮,可以进入文章编辑界面,更高版本的WordPress使用Gutenberg块编辑器,具体操作文字内容不做说明,请观看编辑器使用视频
快速编辑
WordPress快速编辑界面
快速编辑可以编辑文章的标题、别名、日期、时间、类别、标签、模板、评论、ping、状态、置顶等属性。
修改完成后,点击更新。
批量编辑,选中多篇文章文章点击批量编辑,在当前窗口打开批量编辑表单。允许的编辑内容如下:
WordPress文章批量编辑界面
编辑
文章使用 Gutenberg 编辑器创建,Gutenberg 是一个块编辑器,其中每个内容都是一个块。文字教程不会给小编过多讲解,请看小编使用教程。
文章定时自动采集(百度收录指网站域名的9个方面找到解决办法的网址)
采集交流 • 优采云 发表了文章 • 0 个评论 • 417 次浏览 • 2022-01-13 16:16
百度收录指的是网站域名,或者网站链接复制到百度搜索框搜索,百度搜索结果显示:URL not found,这种情况百度不收录。解决百度不收录站点的问题,可以从以下9个方面寻找解决方案。
百度收录查询
1、保持定期更新。包括时间的规律性和更新次数的规律性。
时间规则:每天固定时间更新,比如每晚6点,以后按照这个时间点更新。您可以在网站后台预设多篇文章文章,并设置系统定时发布。如果百度发现你的网站更新规律,它会准时来到你的网站访问你的内容,收录你的内容。
数量规律:每天定量发2-3篇文章,发数固定,有的时候不更新七八篇,有的时候根本没有文章,这是不规律的,搜索引擎不' t 最喜欢它。
2、保持原创度数和内容长度。
原创内容受到任何搜索引擎、任何平台的喜爱,因此尽量保持原创内容度是排名最基本的原则。而文章也不能太多,建议300字以上,500字最好,再配图文发表。百度更喜欢。
将最新的发布模板添加到 3、 页面
最新发布版块帮助百度抓取最新内容,对收录有利。
4、将锚文本添加到已收录 的页面到尚未收录 的页面
已经被收录的页面证明百度对这个页面非常友好,每天都会被收录。这时候加入相应的锚文本,有助于百度更好地抓取其他页面,对收录有利。
5、百度资源平台积极推送
可以在百度资源平台上主动提交自己的URL链接,有助于增加百度收录的量
6、将页面地址而不是收录添加到站点地图
Sitemap是百度优先访问的页面,帮助百度蜘蛛抓取非收录的页面
7、不收录页面链接在首页显示一段时间
主页是百度经常访问的页面,权重高,链接短,所以百度收录在主页上暴露非收录的页面是非常有利的。
8、一个没有收录的页面会导致站点外的蜘蛛,属于外链的一种
诱导蜘蛛是收录的第一步,必须认真对待。
9、爬行诊断
使用百度资源平台诊断提交,可以查出是否是程序代码问题导致的不爬取,并及时调整。
如果你还没有接触过系统SEO的朋友,可以关注我,参考我为你准备的资料教程。也可以来专门的SEO社区一起学习交流,在我的微信公众号“爱学习SEO”中学习最新的行业资讯和最新技术,希望共同成长交流。 查看全部
文章定时自动采集(百度收录指网站域名的9个方面找到解决办法的网址)
百度收录指的是网站域名,或者网站链接复制到百度搜索框搜索,百度搜索结果显示:URL not found,这种情况百度不收录。解决百度不收录站点的问题,可以从以下9个方面寻找解决方案。
百度收录查询
1、保持定期更新。包括时间的规律性和更新次数的规律性。
时间规则:每天固定时间更新,比如每晚6点,以后按照这个时间点更新。您可以在网站后台预设多篇文章文章,并设置系统定时发布。如果百度发现你的网站更新规律,它会准时来到你的网站访问你的内容,收录你的内容。
数量规律:每天定量发2-3篇文章,发数固定,有的时候不更新七八篇,有的时候根本没有文章,这是不规律的,搜索引擎不' t 最喜欢它。
2、保持原创度数和内容长度。
原创内容受到任何搜索引擎、任何平台的喜爱,因此尽量保持原创内容度是排名最基本的原则。而文章也不能太多,建议300字以上,500字最好,再配图文发表。百度更喜欢。
将最新的发布模板添加到 3、 页面
最新发布版块帮助百度抓取最新内容,对收录有利。
4、将锚文本添加到已收录 的页面到尚未收录 的页面
已经被收录的页面证明百度对这个页面非常友好,每天都会被收录。这时候加入相应的锚文本,有助于百度更好地抓取其他页面,对收录有利。
5、百度资源平台积极推送
可以在百度资源平台上主动提交自己的URL链接,有助于增加百度收录的量
6、将页面地址而不是收录添加到站点地图
Sitemap是百度优先访问的页面,帮助百度蜘蛛抓取非收录的页面
7、不收录页面链接在首页显示一段时间
主页是百度经常访问的页面,权重高,链接短,所以百度收录在主页上暴露非收录的页面是非常有利的。
8、一个没有收录的页面会导致站点外的蜘蛛,属于外链的一种
诱导蜘蛛是收录的第一步,必须认真对待。
9、爬行诊断
使用百度资源平台诊断提交,可以查出是否是程序代码问题导致的不爬取,并及时调整。
如果你还没有接触过系统SEO的朋友,可以关注我,参考我为你准备的资料教程。也可以来专门的SEO社区一起学习交流,在我的微信公众号“爱学习SEO”中学习最新的行业资讯和最新技术,希望共同成长交流。
文章定时自动采集( 浅谈英文站群SEO的操作讲解)
采集交流 • 优采云 发表了文章 • 0 个评论 • 136 次浏览 • 2022-01-08 15:23
浅谈英文站群SEO的操作讲解)
分享中文Wordpress的实际操作站群
新闻来自: 发表于: 浏览 1010 次
文章总结:
由于前几天写了《浅谈SEO的英文操作站群》的文章文章,发现转载数疯了,所以今天就来详细介绍一下中文WP 站群 操作。
首先说一下为什么要使用WP(wordpress),因为WP功能强大,插件多,代码简洁,收录速度快,而且对SE也有一定的分量。在国外已经广泛使用,而国内大型一些个人博客是基于WP程序搭建的。相信用过WP的人都心知肚明。而且玩英文SEO站群的人基本都是用WP玩自动写博客的,呵呵。
接下来,我将一步一步为您解释:
第一步:注册一批域名
我们都知道站群域名必须多元化,不能挂在一个后缀下。如果你是新手,我推荐小批量操作,先注册10个域名,可以是com、net、org、cc、me、tk等。可以根据关键词注册,也可以是数字化的,但它必须是多样化的。
第 2 步:租用 VPS 或虚拟主机
一般新手玩站群,10个站左右,租个vps比较好。当然,如果你想要不同的IP段,你也可以租用不同IP的虚拟主机。但是这里,我建议一定是国外主机,国内主机站群会死的快。
第 3 步:网站构建
获得域名和空间后,我们将下载最新版本的WP进行手动安装。关于FTP工具,我推荐CuteFtp,可以在线修改文件,移动文件,多开等,界面干净。
第 4 步:WP 站点设置(强调)
1.模板主题:同样,模板也需要多样化。设置不同的模板,而且是自己制作的主题模板,最好使用中文原创或中文制作的模板。然后修改部分代码,比如头尾代码。对于模板下载,您可以访问:
2.插件上传和设置:
(1)Akismet(垃圾邮件拦截插件):该插件在WP中默认可用,开启即可,然后自行申请API密钥。
(2)All in One SEO Pack(seo插件):这个插件非常好用,英文WP和中文WP都适用,可以设置首页、文章页面标题、描述等。不过貌似这个插件设置说明对百度没什么用,可以在WP总结上填写说明。
(3)自动优化(自动压缩网站代码):这个插件可以压缩网站代码,比如css、js、html等,可以自己设置。
(4)Dagon Design Sitemap Generator (网站Map Plugin):这个插件可以设置网站maps。
(5)Google XML Sitemaps (网站map auto-submission):这个插件可以自动生成网站maps并通知google、yahoo等。
(6)GZippy(gzip压缩):不用说了。
(7)优化数据库:这个不用多说。
(8)随机帖子小部件(随机文章插件):可以将随机文章添加到侧边栏。
(9)Robots Meta(机器人设置):不用说。
(10)WordPress相关帖子(相关文章插件):相关文章可以在文章页面下设置。
(11)WP Keyword Link(内链插件):百度可以设置详细设置。
关于插件和 WP 设置可能在这里。当然,您可以使用更好的插件。您可以自己发现它们。
第五步:文章采集/批量上传/定时发布(绝密)
由于以上步骤都是手动完成的,整个WP的构建质量比站群软件要高。那么,既然我们不需要站群软件,我们如何采集文章自动更新呢?
答案是优采云采集、博君seo伪原创工具、Hammer免费登录发布界面。
由于这个操作过程比较长,为了避免文章过长,我这里暂时不详细操作。下次我会写一个图文并茂的实用操作文章。简单说一下原理,先通过优采云采集大量文章,然后通过博君seo伪原创批量工具伪原创,最后通过Hamer Free登录发布界面,定期批量发布文章,这就是自动发布文章和定期更新的实现。
第6步:内部和外部链接建设
刚才说的内部链接,可以使用WP Keyword Link插件,也可以修改single.php同时插入相关字段。外链搭建可以参考《中国SEO教程:链接轮》文章,或者加我QQ详细讨论。
最后:总结
千万不要站群记得要急躁,耐心很重要,循序渐进。本文章中描述的操作主要是手动步骤,但质量高于自动化软件。当然,该软件也有自己的优势,方便快捷。以后文章我会讲中文站群软件的应用。
以上只是站群的实际操作步骤。至于站群的策略、广告、链接策略等还有待商榷,请继续关注黑帽坦克的博文。 查看全部
文章定时自动采集(
浅谈英文站群SEO的操作讲解)
分享中文Wordpress的实际操作站群
新闻来自: 发表于: 浏览 1010 次
文章总结:
由于前几天写了《浅谈SEO的英文操作站群》的文章文章,发现转载数疯了,所以今天就来详细介绍一下中文WP 站群 操作。
首先说一下为什么要使用WP(wordpress),因为WP功能强大,插件多,代码简洁,收录速度快,而且对SE也有一定的分量。在国外已经广泛使用,而国内大型一些个人博客是基于WP程序搭建的。相信用过WP的人都心知肚明。而且玩英文SEO站群的人基本都是用WP玩自动写博客的,呵呵。
接下来,我将一步一步为您解释:
第一步:注册一批域名
我们都知道站群域名必须多元化,不能挂在一个后缀下。如果你是新手,我推荐小批量操作,先注册10个域名,可以是com、net、org、cc、me、tk等。可以根据关键词注册,也可以是数字化的,但它必须是多样化的。
第 2 步:租用 VPS 或虚拟主机
一般新手玩站群,10个站左右,租个vps比较好。当然,如果你想要不同的IP段,你也可以租用不同IP的虚拟主机。但是这里,我建议一定是国外主机,国内主机站群会死的快。
第 3 步:网站构建
获得域名和空间后,我们将下载最新版本的WP进行手动安装。关于FTP工具,我推荐CuteFtp,可以在线修改文件,移动文件,多开等,界面干净。
第 4 步:WP 站点设置(强调)
1.模板主题:同样,模板也需要多样化。设置不同的模板,而且是自己制作的主题模板,最好使用中文原创或中文制作的模板。然后修改部分代码,比如头尾代码。对于模板下载,您可以访问:
2.插件上传和设置:
(1)Akismet(垃圾邮件拦截插件):该插件在WP中默认可用,开启即可,然后自行申请API密钥。
(2)All in One SEO Pack(seo插件):这个插件非常好用,英文WP和中文WP都适用,可以设置首页、文章页面标题、描述等。不过貌似这个插件设置说明对百度没什么用,可以在WP总结上填写说明。
(3)自动优化(自动压缩网站代码):这个插件可以压缩网站代码,比如css、js、html等,可以自己设置。
(4)Dagon Design Sitemap Generator (网站Map Plugin):这个插件可以设置网站maps。
(5)Google XML Sitemaps (网站map auto-submission):这个插件可以自动生成网站maps并通知google、yahoo等。
(6)GZippy(gzip压缩):不用说了。
(7)优化数据库:这个不用多说。
(8)随机帖子小部件(随机文章插件):可以将随机文章添加到侧边栏。
(9)Robots Meta(机器人设置):不用说。
(10)WordPress相关帖子(相关文章插件):相关文章可以在文章页面下设置。
(11)WP Keyword Link(内链插件):百度可以设置详细设置。
关于插件和 WP 设置可能在这里。当然,您可以使用更好的插件。您可以自己发现它们。
第五步:文章采集/批量上传/定时发布(绝密)
由于以上步骤都是手动完成的,整个WP的构建质量比站群软件要高。那么,既然我们不需要站群软件,我们如何采集文章自动更新呢?
答案是优采云采集、博君seo伪原创工具、Hammer免费登录发布界面。
由于这个操作过程比较长,为了避免文章过长,我这里暂时不详细操作。下次我会写一个图文并茂的实用操作文章。简单说一下原理,先通过优采云采集大量文章,然后通过博君seo伪原创批量工具伪原创,最后通过Hamer Free登录发布界面,定期批量发布文章,这就是自动发布文章和定期更新的实现。
第6步:内部和外部链接建设
刚才说的内部链接,可以使用WP Keyword Link插件,也可以修改single.php同时插入相关字段。外链搭建可以参考《中国SEO教程:链接轮》文章,或者加我QQ详细讨论。
最后:总结
千万不要站群记得要急躁,耐心很重要,循序渐进。本文章中描述的操作主要是手动步骤,但质量高于自动化软件。当然,该软件也有自己的优势,方便快捷。以后文章我会讲中文站群软件的应用。
以上只是站群的实际操作步骤。至于站群的策略、广告、链接策略等还有待商榷,请继续关注黑帽坦克的博文。
文章定时自动采集(苹果cms+宝塔怎么才能做到自动采集?(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2022-01-05 04:18
首先,我的大部分朋友在构建网站后没有很多时间手动更新内容。也有很多新手问
苹果cms+宝塔怎么自动采集
让我们来谈谈定时任务。我们以 Applecms 为例。
闲话不多说,进入正题
首先设置苹果的cms程序进入后台
首先点击采集,然后选择资源库。看看下面的图片。联盟资源库收录在苹果cms程序中,自定义资源库自行添加。
然后重点是(对于小白来说,如果你添加了定时任务,请路过)
这一步是点击资源库,把他拖到一个单独的页面,防止他在苹果的cms控制台框架下,意思是单独布局一个单独的页面,目的是提取需要的cms @采集链接,拖出来看下图
拖出来之后就是上图了,然后直接点击一个资源的当天的采集按钮,他就会跳转到他的采集链接。这时候会更快,直接复制他的网址。(URL一出来就复制,不要等他跳到第二页再复制)
复制的内容如下
您的域名/admin.php/admin/collect/api.html?ac=cj&cjflag=17dda825b5d3a4603cd2c65ffe1b3408&cjurl=http%3A%2F%2F%2Finc%2Fldg_m3u8.asp&h=24&type&td= =
下面第二页的内容(不重要,随便说说)
您的域名/admin.php/admin/collect/api.html?ac=cj&cjflag=17dda825b5d3a4603cd2c65ffe1b3408&cjurl=http%3A%2F%2F%2Finc%2Fldg_m3u8.asp&h=24&type&td= =&页面=2
这是我复制的链接。你复制的可能和我复制的不完全一样。不要太担心。我只是给你举个例子。我想让你看到的是当第二页在第二页时,链接后会添加一个页面条件。, 所以一定要检查复制的URL,虽然这不是很重要,但在我看来,细节决定成败
获得链接后,您将开始添加任务。苹果cms后台点击系统→计划任务看图
首先,单击添加按钮并选择启用。不要使用中文拼音作为名称。您可以随意填写资源站的名称。
(Key) 填写附加参数
把刚才复制的网址链接直接粘贴进去,然后把ac=previous删掉,如下
ac=cj&cjflag=17dda825b5d3a4603cd2c65ffe1b3408&cjurl=http%3A%2F%2F%2Finc%2Fldg_m3u8.asp&h=24&t=&ids=&wd=&¶=1&mid=这是一个附加参数
然后点击底部的全选
有以下 5 种执行文件。我们今天要使用的文件是collect,选择这个并点击save
保存后需要进行测试,点击测试按钮看看会发生什么
单击测试打开新网页并复制该 URL
URL 都是你的域名 /api.php/timming/index.html?name=name
然后你会使用宝塔,打开宝塔网页控制面板,就是网页背景
点击定时任务如图
选择任务类型访问URL,任务名称随便填,执行周期个人推荐一小时一次
这个url地址一定要填错,这个地址是点击测试后弹出的地址
我这里是你的域名/api.php/timming/index.html?name=name
(填自己的,不要填我发的,这个是demo)
不要在这里犯任何错误,如果你在这里犯所有错误,那么你的心智就真的没有希望了。
一般情况下,如果没有意外,会自动采集,日志也可以在宝塔查看。几个小时后,检查日志是否有“成功”字符。
本教程的主要目的是找到
点击测试后出来的网址
使用此 URL,它与您监视的位置相同。阿里云监控或者你可以写一段代码到页面有人访问你网站来运行你想要的任何你想达到监控url的目的,即自动采集
PS:说说我自己的看法吧。如果这个东西建议Linux系统使用Windows,那么4的宝塔应该有点问题或者权限不对什么的。我没有仔细研究它。我建议您使用Linux 来构建网站。比win还顺利,教程到此结束
-------------------- 查看全部
文章定时自动采集(苹果cms+宝塔怎么才能做到自动采集?(组图))
首先,我的大部分朋友在构建网站后没有很多时间手动更新内容。也有很多新手问
苹果cms+宝塔怎么自动采集
让我们来谈谈定时任务。我们以 Applecms 为例。
闲话不多说,进入正题
首先设置苹果的cms程序进入后台
首先点击采集,然后选择资源库。看看下面的图片。联盟资源库收录在苹果cms程序中,自定义资源库自行添加。
然后重点是(对于小白来说,如果你添加了定时任务,请路过)
这一步是点击资源库,把他拖到一个单独的页面,防止他在苹果的cms控制台框架下,意思是单独布局一个单独的页面,目的是提取需要的cms @采集链接,拖出来看下图
拖出来之后就是上图了,然后直接点击一个资源的当天的采集按钮,他就会跳转到他的采集链接。这时候会更快,直接复制他的网址。(URL一出来就复制,不要等他跳到第二页再复制)
复制的内容如下
您的域名/admin.php/admin/collect/api.html?ac=cj&cjflag=17dda825b5d3a4603cd2c65ffe1b3408&cjurl=http%3A%2F%2F%2Finc%2Fldg_m3u8.asp&h=24&type&td= =
下面第二页的内容(不重要,随便说说)
您的域名/admin.php/admin/collect/api.html?ac=cj&cjflag=17dda825b5d3a4603cd2c65ffe1b3408&cjurl=http%3A%2F%2F%2Finc%2Fldg_m3u8.asp&h=24&type&td= =&页面=2
这是我复制的链接。你复制的可能和我复制的不完全一样。不要太担心。我只是给你举个例子。我想让你看到的是当第二页在第二页时,链接后会添加一个页面条件。, 所以一定要检查复制的URL,虽然这不是很重要,但在我看来,细节决定成败
获得链接后,您将开始添加任务。苹果cms后台点击系统→计划任务看图
首先,单击添加按钮并选择启用。不要使用中文拼音作为名称。您可以随意填写资源站的名称。
(Key) 填写附加参数
把刚才复制的网址链接直接粘贴进去,然后把ac=previous删掉,如下
ac=cj&cjflag=17dda825b5d3a4603cd2c65ffe1b3408&cjurl=http%3A%2F%2F%2Finc%2Fldg_m3u8.asp&h=24&t=&ids=&wd=&¶=1&mid=这是一个附加参数
然后点击底部的全选
有以下 5 种执行文件。我们今天要使用的文件是collect,选择这个并点击save
保存后需要进行测试,点击测试按钮看看会发生什么
单击测试打开新网页并复制该 URL
URL 都是你的域名 /api.php/timming/index.html?name=name
然后你会使用宝塔,打开宝塔网页控制面板,就是网页背景
点击定时任务如图
选择任务类型访问URL,任务名称随便填,执行周期个人推荐一小时一次
这个url地址一定要填错,这个地址是点击测试后弹出的地址
我这里是你的域名/api.php/timming/index.html?name=name
(填自己的,不要填我发的,这个是demo)
不要在这里犯任何错误,如果你在这里犯所有错误,那么你的心智就真的没有希望了。
一般情况下,如果没有意外,会自动采集,日志也可以在宝塔查看。几个小时后,检查日志是否有“成功”字符。
本教程的主要目的是找到
点击测试后出来的网址
使用此 URL,它与您监视的位置相同。阿里云监控或者你可以写一段代码到页面有人访问你网站来运行你想要的任何你想达到监控url的目的,即自动采集
PS:说说我自己的看法吧。如果这个东西建议Linux系统使用Windows,那么4的宝塔应该有点问题或者权限不对什么的。我没有仔细研究它。我建议您使用Linux 来构建网站。比win还顺利,教程到此结束
--------------------
文章定时自动采集(酷睿股票私募网站管理系统系统新增会员实战的自动更新功能)
采集交流 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-01-05 03:04
核心股票私募网站管理系统是国内首个WAP手机和电脑WEB同时接入的股票私募系统。本系统基于ASP+DIV+CSS+AJAX+XML+MSSQL技术,专门针对股票私募网站开发了cms网站管理系统,简单易用、安全、高效、快速、优秀的网站解决方案,经过精心设计,适用于各种服务器环境。后台管理方便、易懂、易用、人性化,对操作人员技术要求低。对车站建设一窍不通的操作人员也能轻松上手。继续ASP开源之路,稳定、安全、强大的核心程序。
类似软件
印记
软件地址
核心股权私募网站管理系统,最大的优势不仅是全国首创的WAP手机接入系统,还有数十款精美模板免费选择和终身免费模板更换服务,承诺购买一次免费终生。任何限制和加密,二次开发完全免费,域名、空间、IP等也可以随意更改,终身免费无限升级和新版本,无限使用一套系统。
升级更新部分功能介绍
在原有的绿蓝刷新模板上更新了新内核
新增专家推荐模型
添加公开验证模型
新增成员战斗模式
增加了包括历史记录模型在内的四个新模型,并删除了原来的两个系统调用并替换为一个系统
新增会员实战自动更新功能
新增历史记录自动更新功能
新增后台定时任务文章多点定时和自动采集自动多点定时生成静态页面
新增后台设置及前端会员注册时允许显示的会员群组,如A、B、C、D、E、G等类型的会员群组
新增会员登录后专业采摘区链接
新增WAP系统手机浏览时点击电话号码链接自助拨号功能
增加WAP系统站内邮箱功能
增加WAP系统找回密码功能
添加了目录安全设置的描述文件
修复WAP手机系统系统中使用的手机无法正常登录的问题
将整个WAP系统原有的UTF-8修改为GBK,方便程序修改
将WAP系统原有的wml语言修改为html语言
修复WAP系统无法注册的问题
修复WAP系统无法修改数据的问题
修复WAP系统选料区无需登录即可直接查看相关会员信息的问题
修复了部分手机浏览器在 WAP 系统中的浏览问题
修复WAP系统与QQ、UC、Opera及手机内置WAP浏览器的兼容问题
修改后台所有静态自定义标签可以可视化编辑
修复后台无法添加和修改幻灯片图片的问题
修复财经直播视频无法播放的问题
修改滚动行情不能自动更新,改为世界主要股指自动实时更新
增强型后台木马在线检测系统
修复黑客利用后台或会员上传功能上传木马的bug
修复黑客利用模板管理添加木马文件的bug
修正其他十余个BUG及安全隐患
修改Robots.txt搜索引擎蜘蛛文件的收录权限为网站,允许搜索引擎更新收录网站的内容
新内核系统提升网站加载速度60%
并取消了首页的几个IFRAME调用,并尽可能增加了对搜索引擎友好的程序
可选添加相关功能:如专家在线问答系统、论坛系统、会员博客系统、留言系统、友情链接系统等。
主要功能
实时行情系统
滚动全球行情、外汇行情、机构查看、涨跌排名、交易排名、股市指南、全球指数自动更新。
运行速度和效率
使用XML缓存,运行速度更快,效率更高。
系统采用ASP+DIV+CSS+Ajax+XML+MSSQL技术开发,运行速度翻倍。
文章智能快速采集系统
多点定时计划文章采集和多点定时计划文章自动生成系统,让你的网站无人值守,自动更新
智能强大的过滤系统设置,UTF-8/GB2312自动识别,批量采集让您享受高速采集的乐趣。
采集目标网站可随意更改,设置规则简单,操作更方便
会员实战自动更新功能
自动更新当日沪深股市三大涨幅作为会员实战内容
历史记录自动更新功能
可自动更新会员实战前15天和120天内的内容作为历史记录内容,实际盈利自动设置为40%-90%,交易时间自动更新设置为 3-9 天
全新文章浏览权限申请功能
真正实现了会员选区的会员群组浏览功能,会员群组浏览权限可以精确到每个频道/每个栏目/每篇文章文章,让不同的会员群组享受不同的文章@ >浏览权限,每个会员群之间的信息不能浏览,还可以设置每篇文章文章浏览积分,发积分卡给套餐会员浏览,设置月度会员浏览,月度会员 时间一到,会员需要进行续费才能查看相应的会员信息。
强大的会员管理功能
无限用户群添加功能,站内短信功能,会员优惠券详情查询,有效期查询,资金详情查询,积分卡在线充值功能,在线支付实时支付,会员可设置为扣费会员,有效期会员,和无限期成员。
SEO优化
在线智能生成GOOGLE/百度标准收录XML格式地图,让网站更容易搜索和收录。
三种运行模式:网站所有页面均可采用高动态、静态和伪状态格式,大大提高浏览速度和搜索引擎搜索量。
HTML 生成的文件存储结构选择。
对Alexa收录的info.txt文件和搜索引擎蜘蛛爬取文件Robots.txt有独特的好处
模板程序分离,网站频道、栏目、内容页META关键词、网站META网页描述都是调用标签,有利于收录@的量> 网站 大大缩短了页面收录的时间,让网站的自动配置管理更容易
WAP手机网站系统
国内独有的WAP手机接入系统,注册、登录、选会员、分析预测等功能,一机搞定!支持手机自带WAP浏览器、UC浏览器、QQ浏览器以及几乎所有可以上网的主流手机浏览器
手机上网浏览与网站同步,一个账号,两站通用,实现WEB和WAP的无缝连接
ASK在线专家提问系统
通过该系统,会员可以向网站专家提出各种股票相关问题,网站专家可以及时解答会员提出的各种问题
论坛功能系统
通过该系统,会员可以与其他会员讨论各种股票相关知识或交流股票交易技巧,让您的网站更有活力
设计先进的多系统完整功能:
先进的多系统集成API接口,让您的网站集成商城、论坛、博客、图片、下载、视频等网站系统,让您的网站更加丰富多彩。
整合11个网上支付平台
集成:财付通、网银、在线易支付、云网、支付宝、快钱支付、中国在线支付网、西式支付、上海欢讯等11个在线支付平台接口,会员充值实时到账,让您可以充电无忧。
强大的插件管理
集成:CC视频联盟插件、WSS统计插件、WAP手机网站插件
标签管理系统
<p>全新标签应用功能全站采用标签调用系统,使网站运行速度更快,完全防止站内 查看全部
文章定时自动采集(酷睿股票私募网站管理系统系统新增会员实战的自动更新功能)
核心股票私募网站管理系统是国内首个WAP手机和电脑WEB同时接入的股票私募系统。本系统基于ASP+DIV+CSS+AJAX+XML+MSSQL技术,专门针对股票私募网站开发了cms网站管理系统,简单易用、安全、高效、快速、优秀的网站解决方案,经过精心设计,适用于各种服务器环境。后台管理方便、易懂、易用、人性化,对操作人员技术要求低。对车站建设一窍不通的操作人员也能轻松上手。继续ASP开源之路,稳定、安全、强大的核心程序。
类似软件
印记
软件地址
核心股权私募网站管理系统,最大的优势不仅是全国首创的WAP手机接入系统,还有数十款精美模板免费选择和终身免费模板更换服务,承诺购买一次免费终生。任何限制和加密,二次开发完全免费,域名、空间、IP等也可以随意更改,终身免费无限升级和新版本,无限使用一套系统。
升级更新部分功能介绍
在原有的绿蓝刷新模板上更新了新内核
新增专家推荐模型
添加公开验证模型
新增成员战斗模式
增加了包括历史记录模型在内的四个新模型,并删除了原来的两个系统调用并替换为一个系统
新增会员实战自动更新功能
新增历史记录自动更新功能
新增后台定时任务文章多点定时和自动采集自动多点定时生成静态页面
新增后台设置及前端会员注册时允许显示的会员群组,如A、B、C、D、E、G等类型的会员群组
新增会员登录后专业采摘区链接
新增WAP系统手机浏览时点击电话号码链接自助拨号功能
增加WAP系统站内邮箱功能
增加WAP系统找回密码功能
添加了目录安全设置的描述文件
修复WAP手机系统系统中使用的手机无法正常登录的问题
将整个WAP系统原有的UTF-8修改为GBK,方便程序修改
将WAP系统原有的wml语言修改为html语言
修复WAP系统无法注册的问题
修复WAP系统无法修改数据的问题
修复WAP系统选料区无需登录即可直接查看相关会员信息的问题
修复了部分手机浏览器在 WAP 系统中的浏览问题
修复WAP系统与QQ、UC、Opera及手机内置WAP浏览器的兼容问题
修改后台所有静态自定义标签可以可视化编辑
修复后台无法添加和修改幻灯片图片的问题
修复财经直播视频无法播放的问题
修改滚动行情不能自动更新,改为世界主要股指自动实时更新
增强型后台木马在线检测系统
修复黑客利用后台或会员上传功能上传木马的bug
修复黑客利用模板管理添加木马文件的bug
修正其他十余个BUG及安全隐患
修改Robots.txt搜索引擎蜘蛛文件的收录权限为网站,允许搜索引擎更新收录网站的内容
新内核系统提升网站加载速度60%
并取消了首页的几个IFRAME调用,并尽可能增加了对搜索引擎友好的程序
可选添加相关功能:如专家在线问答系统、论坛系统、会员博客系统、留言系统、友情链接系统等。
主要功能
实时行情系统
滚动全球行情、外汇行情、机构查看、涨跌排名、交易排名、股市指南、全球指数自动更新。
运行速度和效率
使用XML缓存,运行速度更快,效率更高。
系统采用ASP+DIV+CSS+Ajax+XML+MSSQL技术开发,运行速度翻倍。
文章智能快速采集系统
多点定时计划文章采集和多点定时计划文章自动生成系统,让你的网站无人值守,自动更新
智能强大的过滤系统设置,UTF-8/GB2312自动识别,批量采集让您享受高速采集的乐趣。
采集目标网站可随意更改,设置规则简单,操作更方便
会员实战自动更新功能
自动更新当日沪深股市三大涨幅作为会员实战内容
历史记录自动更新功能
可自动更新会员实战前15天和120天内的内容作为历史记录内容,实际盈利自动设置为40%-90%,交易时间自动更新设置为 3-9 天
全新文章浏览权限申请功能
真正实现了会员选区的会员群组浏览功能,会员群组浏览权限可以精确到每个频道/每个栏目/每篇文章文章,让不同的会员群组享受不同的文章@ >浏览权限,每个会员群之间的信息不能浏览,还可以设置每篇文章文章浏览积分,发积分卡给套餐会员浏览,设置月度会员浏览,月度会员 时间一到,会员需要进行续费才能查看相应的会员信息。
强大的会员管理功能
无限用户群添加功能,站内短信功能,会员优惠券详情查询,有效期查询,资金详情查询,积分卡在线充值功能,在线支付实时支付,会员可设置为扣费会员,有效期会员,和无限期成员。
SEO优化
在线智能生成GOOGLE/百度标准收录XML格式地图,让网站更容易搜索和收录。
三种运行模式:网站所有页面均可采用高动态、静态和伪状态格式,大大提高浏览速度和搜索引擎搜索量。
HTML 生成的文件存储结构选择。
对Alexa收录的info.txt文件和搜索引擎蜘蛛爬取文件Robots.txt有独特的好处
模板程序分离,网站频道、栏目、内容页META关键词、网站META网页描述都是调用标签,有利于收录@的量> 网站 大大缩短了页面收录的时间,让网站的自动配置管理更容易
WAP手机网站系统
国内独有的WAP手机接入系统,注册、登录、选会员、分析预测等功能,一机搞定!支持手机自带WAP浏览器、UC浏览器、QQ浏览器以及几乎所有可以上网的主流手机浏览器
手机上网浏览与网站同步,一个账号,两站通用,实现WEB和WAP的无缝连接
ASK在线专家提问系统
通过该系统,会员可以向网站专家提出各种股票相关问题,网站专家可以及时解答会员提出的各种问题
论坛功能系统
通过该系统,会员可以与其他会员讨论各种股票相关知识或交流股票交易技巧,让您的网站更有活力
设计先进的多系统完整功能:
先进的多系统集成API接口,让您的网站集成商城、论坛、博客、图片、下载、视频等网站系统,让您的网站更加丰富多彩。
整合11个网上支付平台
集成:财付通、网银、在线易支付、云网、支付宝、快钱支付、中国在线支付网、西式支付、上海欢讯等11个在线支付平台接口,会员充值实时到账,让您可以充电无忧。
强大的插件管理
集成:CC视频联盟插件、WSS统计插件、WAP手机网站插件
标签管理系统
<p>全新标签应用功能全站采用标签调用系统,使网站运行速度更快,完全防止站内
文章定时自动采集(信息采集使用手册摘要()抓取网络数据,摘要)
采集交流 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2022-01-01 15:00
信息采集用户手册
总结
Information采集是抓取网络数据,实现信息共享的功能模块。提供手动抓取、定时抓取、定时循环抓取三种模式。可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。
步骤和细节
现在需要将网页采集的数据(新闻)上传到webplus系统的指定栏目。步骤如下:
为指定的列制定采集计划。
在栏目管理中选择栏目,点击设置采集计划。 (例如图片一)
设置采集的基本属性。
包括执行方式、信息是否自动发布、列类型采集以及页面的编码格式。 (例如图片二)
事先约定采集计划的执行方式,手动,定时单次或定时循环执行。
如果只是针对采集网页的当前数据,我们可以使用手动和定时的一次性方式采集一次;如果采集网页的数据会更新,我们还要保证信息的同步,即采用定时循环采集的方法。
判断采集过来的信息是否需要发布
如果你过来的信息不需要修改,可以直接发布到网上,选择自动发布。如果来自采集的信息需要修改、审核等,选择不自动发布。 采集完成后,信息管理人员将进行其他操作。
设置列类型采集
如果采集的网页只是一个简单的新闻列表,即采集页面的新闻放在指定栏目下,则选择单栏目。如果采集的页面有多个新闻列表,并且每个都提供了一个单独的链接来进入自己的新闻列表页面,
而且我们需要采集所有的新闻信息,然后选择多个栏目。另外,如果采集的页面是RSS信息聚合页面,则设置为对应的RSS单栏或RSS多栏。
设置采集页面的编码
因为webplus系统使用的是UTF-8编码格式,而采集可能是其他编码格式,那么为了避免采集传来的乱码,这里需要设置为采集页面的编码格式。
设置采集计划的采集规则
单列采集计划设置(例如图片三)
设置“列表页面起始地址”
是采集页面的访问路径。 (必填)
设置“文章页面URL获取规则”
如果新闻列表是通过采集以iframe的形式嵌入到网页中的,那么需要设置规则获取列表iframe的链接地址来访问新闻列表。否则,无需制定此规则。 (具体规则请参考下面的“采集正则表达式公式”)
如果采集网页的新闻列表是分页的,那么要根据新闻列表的分页方式(链接和表单提交),以及分页的起始页码来制定分页规则,间隔页码和采集页数。如果新闻列表中没有分页,则无需制定此规则。
如果采集的页面有多个新闻列表,并且多个新闻列表的url规则相似,我们只需要采集指定的一个列表,即需要设置限制文章列出访问规则,这是为了避免采集冗余数据。否则,无需设置此规则。
设置文章 url获取规则,以便能够从采集页面访问特定的新闻页面,从而进行新闻采集。 (必填)
设置“文章内容获取规则”
对于特定的新闻页面,如果文章的内容以iframe的形式嵌入到新闻页面中,则需要设置规则获取文章 iframe的链接地址访问新闻内容。否则,无需制定此规则。
如果新闻内容有分页情况,则根据文章内容分页方式(链接和表单提交)制定分页规则,需要设置分页起始页码,间隔页码和采集页数。如果文章的内容没有分页,则无需制定此规则。
如果新闻页面上除了新闻内容之外还有其他附加信息,那么为了在采集过程中更容易找到新闻内容,需要设置规则来限制获取新闻内容在这里。一是避免垃圾邮件,二是降低新闻特定信息获取规则的复杂性。如果新闻页面比较简单,一般不需要设置此规则。
设置新闻属性的规则,除标题和内容外,均为可选条件。另外,如果未设置新闻发布时间,则以当前时间作为发布时间。
多列采集计划设置(例如图片五)
Multi-column采集 除了需要在“List page start URL”下设置list page URL rules和“文章Page URL获取规则”下的列名获取规则,其他项目与列表相关。 采集 列具有相同的计划设置。
RSS单栏采集计划设置(如:图片四)
RSS单列的采集方案不需要设置“文章页面URL获取规则”,其余与单列采集方案一致。
RSS多栏采集计划设置(例如图片六)
<p>RSS多栏采集方案需要在“列表页面起始网址”下设置列表页网址获取规则,其余与RSS单栏采集方案一致。 查看全部
文章定时自动采集(信息采集使用手册摘要()抓取网络数据,摘要)
信息采集用户手册
总结
Information采集是抓取网络数据,实现信息共享的功能模块。提供手动抓取、定时抓取、定时循环抓取三种模式。可以抓取单个新闻列表下的信息,也可以同时抓取多个列表下的新闻信息。
步骤和细节
现在需要将网页采集的数据(新闻)上传到webplus系统的指定栏目。步骤如下:
为指定的列制定采集计划。
在栏目管理中选择栏目,点击设置采集计划。 (例如图片一)
设置采集的基本属性。
包括执行方式、信息是否自动发布、列类型采集以及页面的编码格式。 (例如图片二)
事先约定采集计划的执行方式,手动,定时单次或定时循环执行。
如果只是针对采集网页的当前数据,我们可以使用手动和定时的一次性方式采集一次;如果采集网页的数据会更新,我们还要保证信息的同步,即采用定时循环采集的方法。
判断采集过来的信息是否需要发布
如果你过来的信息不需要修改,可以直接发布到网上,选择自动发布。如果来自采集的信息需要修改、审核等,选择不自动发布。 采集完成后,信息管理人员将进行其他操作。
设置列类型采集
如果采集的网页只是一个简单的新闻列表,即采集页面的新闻放在指定栏目下,则选择单栏目。如果采集的页面有多个新闻列表,并且每个都提供了一个单独的链接来进入自己的新闻列表页面,
而且我们需要采集所有的新闻信息,然后选择多个栏目。另外,如果采集的页面是RSS信息聚合页面,则设置为对应的RSS单栏或RSS多栏。
设置采集页面的编码
因为webplus系统使用的是UTF-8编码格式,而采集可能是其他编码格式,那么为了避免采集传来的乱码,这里需要设置为采集页面的编码格式。
设置采集计划的采集规则
单列采集计划设置(例如图片三)
设置“列表页面起始地址”
是采集页面的访问路径。 (必填)
设置“文章页面URL获取规则”
如果新闻列表是通过采集以iframe的形式嵌入到网页中的,那么需要设置规则获取列表iframe的链接地址来访问新闻列表。否则,无需制定此规则。 (具体规则请参考下面的“采集正则表达式公式”)
如果采集网页的新闻列表是分页的,那么要根据新闻列表的分页方式(链接和表单提交),以及分页的起始页码来制定分页规则,间隔页码和采集页数。如果新闻列表中没有分页,则无需制定此规则。
如果采集的页面有多个新闻列表,并且多个新闻列表的url规则相似,我们只需要采集指定的一个列表,即需要设置限制文章列出访问规则,这是为了避免采集冗余数据。否则,无需设置此规则。
设置文章 url获取规则,以便能够从采集页面访问特定的新闻页面,从而进行新闻采集。 (必填)
设置“文章内容获取规则”
对于特定的新闻页面,如果文章的内容以iframe的形式嵌入到新闻页面中,则需要设置规则获取文章 iframe的链接地址访问新闻内容。否则,无需制定此规则。
如果新闻内容有分页情况,则根据文章内容分页方式(链接和表单提交)制定分页规则,需要设置分页起始页码,间隔页码和采集页数。如果文章的内容没有分页,则无需制定此规则。
如果新闻页面上除了新闻内容之外还有其他附加信息,那么为了在采集过程中更容易找到新闻内容,需要设置规则来限制获取新闻内容在这里。一是避免垃圾邮件,二是降低新闻特定信息获取规则的复杂性。如果新闻页面比较简单,一般不需要设置此规则。
设置新闻属性的规则,除标题和内容外,均为可选条件。另外,如果未设置新闻发布时间,则以当前时间作为发布时间。
多列采集计划设置(例如图片五)
Multi-column采集 除了需要在“List page start URL”下设置list page URL rules和“文章Page URL获取规则”下的列名获取规则,其他项目与列表相关。 采集 列具有相同的计划设置。
RSS单栏采集计划设置(如:图片四)
RSS单列的采集方案不需要设置“文章页面URL获取规则”,其余与单列采集方案一致。
RSS多栏采集计划设置(例如图片六)
<p>RSS多栏采集方案需要在“列表页面起始网址”下设置列表页网址获取规则,其余与RSS单栏采集方案一致。
文章定时自动采集(前两天有小伙伴问松哥如何实现定时任务的动态配置?(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-12-31 14:05
定时任务可以看作是我们日常开发中比较常见的需求,市场上也有很多成熟的框架:
但是朋友们都知道,其实我们的Spring框架也提供了相应的定时任务。这个定时任务是通过@EnableScheduling注解开启的。宋歌还写了文章给大家分享一下这个注解的基本用法:
但是之前的定时任务都是预先固定好硬编码的,无法动态配置。前两天有朋友问宋歌如何实现定时任务的动态配置?
这个东西如果是基于xxl-job这样的框架,其实还是比较容易的,不过也可以通过Spring自带的@EnableScheduling注解来实现,并不难。宋歌在此基础上匆匆写了一篇,今天先跟大家说一下一般用法,然后抽空再写一篇文章的实现原理介绍。
项目开源,项目地址:
以可食用模式克隆项目:git clone。本地数据库创建了一个名为 schedule 的库。修改配置文件src/main/resources/application.yaml,主要修改数据库连接的用户名和地址。启动项目。浏览器访问:8080,可以看到如下页面:
表示启动成功。
功能介绍 项目启动时,会自动从数据库中加载状态为1的定时任务并开始执行。1表示开启状态的定时任务,0表示关闭状态的定时任务。单击页面上的“添加作业”按钮以添加新的定时任务。如果新任务的bean名称、方法名称、方法参数与已有记录相同,则视为重复作业,重复作业将无法添加。
添加作业的页面如下:
这里涉及到几个参数,它们的含义如下:
添加作业成功的提示如下:
作业添加失败提示如下:
点击作业编辑,可以修改作业的数据:
修改将立即生效。
单击分配删除以删除现有分配。如果正在执行删除的作业,请先停止作业,然后再将其删除。您也可以通过单击列表中的切换按钮来切换作业的状态。
技术栈其他
这是一个用于学习的演示,而不是一个完整的项目。宋歌会发一篇文章的文章和大家分享一下具体的实现思路。
好了,先说这么多。 查看全部
文章定时自动采集(前两天有小伙伴问松哥如何实现定时任务的动态配置?(组图))
定时任务可以看作是我们日常开发中比较常见的需求,市场上也有很多成熟的框架:
但是朋友们都知道,其实我们的Spring框架也提供了相应的定时任务。这个定时任务是通过@EnableScheduling注解开启的。宋歌还写了文章给大家分享一下这个注解的基本用法:
但是之前的定时任务都是预先固定好硬编码的,无法动态配置。前两天有朋友问宋歌如何实现定时任务的动态配置?
这个东西如果是基于xxl-job这样的框架,其实还是比较容易的,不过也可以通过Spring自带的@EnableScheduling注解来实现,并不难。宋歌在此基础上匆匆写了一篇,今天先跟大家说一下一般用法,然后抽空再写一篇文章的实现原理介绍。
项目开源,项目地址:
以可食用模式克隆项目:git clone。本地数据库创建了一个名为 schedule 的库。修改配置文件src/main/resources/application.yaml,主要修改数据库连接的用户名和地址。启动项目。浏览器访问:8080,可以看到如下页面:
表示启动成功。
功能介绍 项目启动时,会自动从数据库中加载状态为1的定时任务并开始执行。1表示开启状态的定时任务,0表示关闭状态的定时任务。单击页面上的“添加作业”按钮以添加新的定时任务。如果新任务的bean名称、方法名称、方法参数与已有记录相同,则视为重复作业,重复作业将无法添加。
添加作业的页面如下:
这里涉及到几个参数,它们的含义如下:
添加作业成功的提示如下:
作业添加失败提示如下:
点击作业编辑,可以修改作业的数据:
修改将立即生效。
单击分配删除以删除现有分配。如果正在执行删除的作业,请先停止作业,然后再将其删除。您也可以通过单击列表中的切换按钮来切换作业的状态。
技术栈其他
这是一个用于学习的演示,而不是一个完整的项目。宋歌会发一篇文章的文章和大家分享一下具体的实现思路。
好了,先说这么多。
文章定时自动采集(用Python编写数据采集脚本()上采集数据 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 365 次浏览 • 2021-12-31 11:30
)
概述:
在树莓派(xxxxx,以下简称工控机)采集数据上,传输到本地sqlserver数据库,用Python编写数据采集脚本。
这涉及到几个问题:当出现网络中断、断电、工控机重启等异常情况时,为了保证这些异常情况的发生,数据仍然可以自动采集,需要以下两种解决方案实施的。
开机自动启动;当脚本没有运行时,它会自动运行。
首选第二种方案,因为python程序崩溃或者网络异常导致程序中断,需要一种机制让它自动运行。
参考网址:
常用命令:
自动运行脚本:vim /etc/crontab
查看进程:ps -ef|grep tcpclient.py
自动运行脚本
启动TCP服务器监控功能:
输入vim /etc/crontab,最后输入* * * * * root python3 /home/pi/tcpclient.py
tcpclient.py 代码:
import socket
import time
import random
def main():
# 1 创建tcp套接字
while 1:
tcp_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 2 创建连接
tcp_socket.connect(('192.168.1.35', 6666))
# 3 发送数据
tcp_input = str(random.randint(2,15))
tcp_socket.send(tcp_input.encode('gbk')) # utf-8 中文会乱码
time.sleep(5)
# 4.关闭套接字
tcp_socket.close()
if __name__ == '__main__':
main()
输入ps -ef|grep tcpclient.py,可以看到进程多了(带问号的),tcpclient.py有while循环,不会自动退出,所以tcpclient.py每分钟自动运行一次。
优化
当然无线增加程序进程是不可能的,所以有两种选择:
每次执行tcpclient.py,都会自动关闭并终止程序,没有while循环。另外写一个test1.py程序,脚本会每分钟运行一次test1.py程序,test1.py判断tcpclient.py进程是否存在,如果存在不存在,它会运行;如果存在,它将不会运行。
这次采用了第二个选项,以避免每次tcp断开和重新连接(除非你像本例那样在while循环中关闭了socket)。
测试1.py 代码:
import time
import os
import re
# execute command, and return the infomation. 执行命令并返回命令输出信息
def execCmd(cmd):
r = os.popen(cmd)
text = r.read()
r.close()
return text
def doSomething():
os.system('python3 /home/pi/tcpclient.py')
time.sleep(10)
if __name__ == '__main__':
#ps -ef是linux查看进程信息指令,|是管道符号导向到grep去查找特定的进程,最后一个|是导向grep过滤掉grep进程:因为grep查看程序名也是进程,会混到查询信息里
programIsRunningCmd="ps -ef|grep tcpclient.py"
programIsRunningCmdAns = execCmd(programIsRunningCmd) #调用函数执行指令,并返回指令查询出的信息
print(programIsRunningCmdAns)
ansLine = programIsRunningCmdAns.split('\n') #将查出的信息用换行符‘\b’分开
print(len(ansLine))
#判断如果返回行数>3则说明python脚本程序已经在运行,打印提示信息结束程序,否则运行脚本代码doSomething()
if len(ansLine) > 3:
print("programName have been Running")
else:
doSomething()
结果
可以看出,test1.py和tcpclient.py进程在任何时候都是一样的,不会无限增加。工控机重启后,过程还是一样,说明已经达到了预期的效果。
查看全部
文章定时自动采集(用Python编写数据采集脚本()上采集数据
)
概述:
在树莓派(xxxxx,以下简称工控机)采集数据上,传输到本地sqlserver数据库,用Python编写数据采集脚本。
这涉及到几个问题:当出现网络中断、断电、工控机重启等异常情况时,为了保证这些异常情况的发生,数据仍然可以自动采集,需要以下两种解决方案实施的。
开机自动启动;当脚本没有运行时,它会自动运行。
首选第二种方案,因为python程序崩溃或者网络异常导致程序中断,需要一种机制让它自动运行。
参考网址:
常用命令:
自动运行脚本:vim /etc/crontab
查看进程:ps -ef|grep tcpclient.py
自动运行脚本
启动TCP服务器监控功能:
输入vim /etc/crontab,最后输入* * * * * root python3 /home/pi/tcpclient.py
tcpclient.py 代码:
import socket
import time
import random
def main():
# 1 创建tcp套接字
while 1:
tcp_socket = socket.socket(socket.AF_INET, socket.SOCK_STREAM)
# 2 创建连接
tcp_socket.connect(('192.168.1.35', 6666))
# 3 发送数据
tcp_input = str(random.randint(2,15))
tcp_socket.send(tcp_input.encode('gbk')) # utf-8 中文会乱码
time.sleep(5)
# 4.关闭套接字
tcp_socket.close()
if __name__ == '__main__':
main()
输入ps -ef|grep tcpclient.py,可以看到进程多了(带问号的),tcpclient.py有while循环,不会自动退出,所以tcpclient.py每分钟自动运行一次。
优化
当然无线增加程序进程是不可能的,所以有两种选择:
每次执行tcpclient.py,都会自动关闭并终止程序,没有while循环。另外写一个test1.py程序,脚本会每分钟运行一次test1.py程序,test1.py判断tcpclient.py进程是否存在,如果存在不存在,它会运行;如果存在,它将不会运行。
这次采用了第二个选项,以避免每次tcp断开和重新连接(除非你像本例那样在while循环中关闭了socket)。
测试1.py 代码:
import time
import os
import re
# execute command, and return the infomation. 执行命令并返回命令输出信息
def execCmd(cmd):
r = os.popen(cmd)
text = r.read()
r.close()
return text
def doSomething():
os.system('python3 /home/pi/tcpclient.py')
time.sleep(10)
if __name__ == '__main__':
#ps -ef是linux查看进程信息指令,|是管道符号导向到grep去查找特定的进程,最后一个|是导向grep过滤掉grep进程:因为grep查看程序名也是进程,会混到查询信息里
programIsRunningCmd="ps -ef|grep tcpclient.py"
programIsRunningCmdAns = execCmd(programIsRunningCmd) #调用函数执行指令,并返回指令查询出的信息
print(programIsRunningCmdAns)
ansLine = programIsRunningCmdAns.split('\n') #将查出的信息用换行符‘\b’分开
print(len(ansLine))
#判断如果返回行数>3则说明python脚本程序已经在运行,打印提示信息结束程序,否则运行脚本代码doSomething()
if len(ansLine) > 3:
print("programName have been Running")
else:
doSomething()
结果
可以看出,test1.py和tcpclient.py进程在任何时候都是一样的,不会无限增加。工控机重启后,过程还是一样,说明已经达到了预期的效果。
文章定时自动采集(知乎公众号v2上线了,准备进来学习使用的同学赶紧来学习一下吧!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-12-29 17:03
文章定时自动采集知乎公众号留言,分析留言地址,变化趋势,热门话题及用户分析,现在已经与知乎公众号合作,特意共享出来!全网唯一!如果你有知乎问题或者对知乎公众号感兴趣,可以留言,会给你定制一个专属回答!知乎公众号v2。0上线了,准备进来学习使用的同学赶紧来学习一下吧!详细使用步骤请长按文章底部二维码,回复:0804可获取官方教程链接(二维码自动识别)知乎公众号v2。
0已上线,也在进行推广,大家可以扫码去体验一下哦!另外为了防止广告,想了解更多信息的同学可以发消息给我,私信是不会回复的哦!好了!下期再见!。
作为消费者,我想说,随着互联网的发展,各个商家都在思考商业的变革,新的风口也给自己带来了新的行业机会。以往公众号运营更多聚焦于推广,以及引流,利用消费者碎片化的时间去推送一些优质的产品和服务。但是互联网带来的新的消费行为模式,使得我们自己的商业边界不断扩大,尤其是电商的崛起,产生了一种新的商业状态:消费者通过商家提供的商品、服务来进行主动性购买,而不是被动接受商家推送。
因此,目前公众号的运营更多的应该是为了销售商品、服务,增加流量和销售量,获取一些利润。在这样的大趋势下,如何让公众号获取客户的关注,并留存客户,甚至转化客户关注,成为运营者最头疼的一件事。传统的模式是靠“内容+广告”,在运营的一开始就不断的推送广告,为商家的商品和服务添加曝光量,但有可能却忽略了基础的运营工作,导致内容不够精彩。
这样会出现两个问题:如果你是一个商家的付费顾问,你应该想尽办法引导客户来注册新账号或者使用公众号,让其购买新产品。可是如果你现在要为一个在做公众号的商家提供免费的付费客服服务,你会让客户付费来到你们的付费店铺进行咨询。可能就会出现这样的情况:你不进行推广免费给商家推送产品和服务,而是要把顾客辛辛苦苦积攒起来的资源转换成你自己的利润;如果你不推送免费的产品和服务,只是大张旗鼓的发广告,很可能产生一边推一边赚钱的情况,产生一个营销漏斗效应,优质的客户更不愿意付费。
其实,商家需要的是更科学的运营营销方式,如果公众号是基于粉丝本身价值的诉求点,那么推送的广告、软文反而更能吸引用户进行阅读分享转发。这样就会降低企业的营销成本。更好的是,企业能够根据自己的公众号粉丝和商品信息服务,选择自己需要的内容制作,并且推送给用户,实现双赢。目前消费者在互联网上做购买行为主要有以下几个驱动因素:内容、产品和服务。如何做好这三个方面的运营工作?很大程度上。 查看全部
文章定时自动采集(知乎公众号v2上线了,准备进来学习使用的同学赶紧来学习一下吧!)
文章定时自动采集知乎公众号留言,分析留言地址,变化趋势,热门话题及用户分析,现在已经与知乎公众号合作,特意共享出来!全网唯一!如果你有知乎问题或者对知乎公众号感兴趣,可以留言,会给你定制一个专属回答!知乎公众号v2。0上线了,准备进来学习使用的同学赶紧来学习一下吧!详细使用步骤请长按文章底部二维码,回复:0804可获取官方教程链接(二维码自动识别)知乎公众号v2。
0已上线,也在进行推广,大家可以扫码去体验一下哦!另外为了防止广告,想了解更多信息的同学可以发消息给我,私信是不会回复的哦!好了!下期再见!。
作为消费者,我想说,随着互联网的发展,各个商家都在思考商业的变革,新的风口也给自己带来了新的行业机会。以往公众号运营更多聚焦于推广,以及引流,利用消费者碎片化的时间去推送一些优质的产品和服务。但是互联网带来的新的消费行为模式,使得我们自己的商业边界不断扩大,尤其是电商的崛起,产生了一种新的商业状态:消费者通过商家提供的商品、服务来进行主动性购买,而不是被动接受商家推送。
因此,目前公众号的运营更多的应该是为了销售商品、服务,增加流量和销售量,获取一些利润。在这样的大趋势下,如何让公众号获取客户的关注,并留存客户,甚至转化客户关注,成为运营者最头疼的一件事。传统的模式是靠“内容+广告”,在运营的一开始就不断的推送广告,为商家的商品和服务添加曝光量,但有可能却忽略了基础的运营工作,导致内容不够精彩。
这样会出现两个问题:如果你是一个商家的付费顾问,你应该想尽办法引导客户来注册新账号或者使用公众号,让其购买新产品。可是如果你现在要为一个在做公众号的商家提供免费的付费客服服务,你会让客户付费来到你们的付费店铺进行咨询。可能就会出现这样的情况:你不进行推广免费给商家推送产品和服务,而是要把顾客辛辛苦苦积攒起来的资源转换成你自己的利润;如果你不推送免费的产品和服务,只是大张旗鼓的发广告,很可能产生一边推一边赚钱的情况,产生一个营销漏斗效应,优质的客户更不愿意付费。
其实,商家需要的是更科学的运营营销方式,如果公众号是基于粉丝本身价值的诉求点,那么推送的广告、软文反而更能吸引用户进行阅读分享转发。这样就会降低企业的营销成本。更好的是,企业能够根据自己的公众号粉丝和商品信息服务,选择自己需要的内容制作,并且推送给用户,实现双赢。目前消费者在互联网上做购买行为主要有以下几个驱动因素:内容、产品和服务。如何做好这三个方面的运营工作?很大程度上。

