
文章定时自动采集
文章定时自动采集(文章定时自动采集怎么做?人和社区看看,路过有用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-12-26 18:07
文章定时自动采集的,一般就十多分钟。就是点个好友送礼物,就能采集10页,还要根据收信号,看信息是否有效,来采集数据。感觉不是很好。
做为周知计划的体验客户,周知计划是电脑端,手机端用户体验一流。数据采集至少五次操作,有一次网络故障。但结果稳定。后续服务也非常棒。
mis人和社区看看,
路过有用我给你推荐mis人和-电脑端
我觉得在于,你能否耐心等待才能获得一个好结果。举个例子,我现在不是很信赖路径跟踪,但是我发现我的一些事情做得非常不好,如果你去做,你会完全跟踪你所有的事情,所以你才觉得很完美。我推荐我们公司使用的mis人和,因为他可以自动采集;对于你不想让数据被删除,说实话,你需要让数据自己出问题,或者你试试用云端存数据存储服务。
微信公众号的平台是绝对能做到的,特别是这类app的每一次h5,每一个指定版块的内容的内容不断收到新的有价值的消息,这样就能打散重组,每个版块查看,而不是每一次都像一块大豆腐一样,相互矛盾,再加上微信本身的地理位置功能,相互跟踪,互联互通,app体验完美如果做到能做到如此程度,你可以把谷歌街景的功能加上试试,以一定要什么照片画成豆腐,然后相互引导回去,每个学校,城市打散重组,并且展示全中国所有的大学和各个城市,任何一个大学新生报到都可以展示,期间免不了打电话,宣传的往返跑去走访和他们谈,然后在网上可以查询一下需要提供的材料,然后根据距离,拿回照片然后推广,各方相互引导,当然还要先搜集一定的大学信息,比如在相应大学的贴吧,新生群里,相互宣传引导,给正在申请,还没有准备好,但对大学有好奇的想去看看的学弟学妹用户做一个引导。很简单的。 查看全部
文章定时自动采集(文章定时自动采集怎么做?人和社区看看,路过有用)
文章定时自动采集的,一般就十多分钟。就是点个好友送礼物,就能采集10页,还要根据收信号,看信息是否有效,来采集数据。感觉不是很好。
做为周知计划的体验客户,周知计划是电脑端,手机端用户体验一流。数据采集至少五次操作,有一次网络故障。但结果稳定。后续服务也非常棒。
mis人和社区看看,
路过有用我给你推荐mis人和-电脑端
我觉得在于,你能否耐心等待才能获得一个好结果。举个例子,我现在不是很信赖路径跟踪,但是我发现我的一些事情做得非常不好,如果你去做,你会完全跟踪你所有的事情,所以你才觉得很完美。我推荐我们公司使用的mis人和,因为他可以自动采集;对于你不想让数据被删除,说实话,你需要让数据自己出问题,或者你试试用云端存数据存储服务。
微信公众号的平台是绝对能做到的,特别是这类app的每一次h5,每一个指定版块的内容的内容不断收到新的有价值的消息,这样就能打散重组,每个版块查看,而不是每一次都像一块大豆腐一样,相互矛盾,再加上微信本身的地理位置功能,相互跟踪,互联互通,app体验完美如果做到能做到如此程度,你可以把谷歌街景的功能加上试试,以一定要什么照片画成豆腐,然后相互引导回去,每个学校,城市打散重组,并且展示全中国所有的大学和各个城市,任何一个大学新生报到都可以展示,期间免不了打电话,宣传的往返跑去走访和他们谈,然后在网上可以查询一下需要提供的材料,然后根据距离,拿回照片然后推广,各方相互引导,当然还要先搜集一定的大学信息,比如在相应大学的贴吧,新生群里,相互宣传引导,给正在申请,还没有准备好,但对大学有好奇的想去看看的学弟学妹用户做一个引导。很简单的。
文章定时自动采集(织梦后台定时审核插件使用说明【.7GBK/UTF8两个】)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-12-18 14:22
织梦后台定时审计插件使用说明
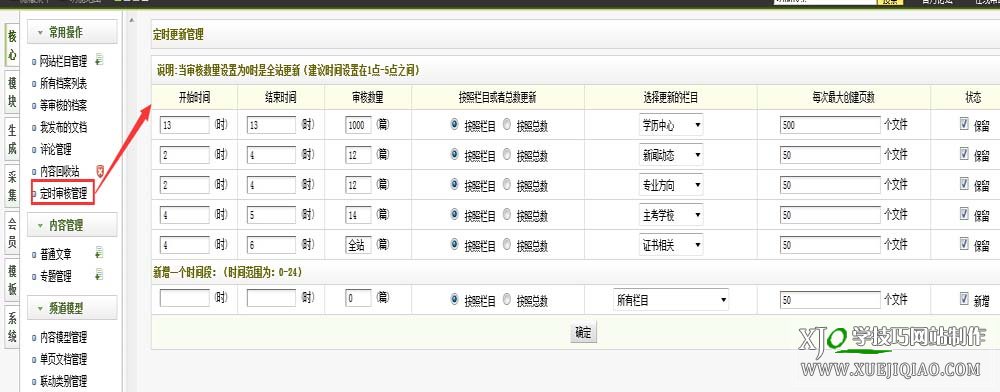
一、 以超级管理员身份登录后台,依次选择Core-Timed Audit Management,输入定时审核的时间段,点击保存。如下所示:
功能说明:
1、您可以设置多个时间段。在这些时间段内,每天会自动审核生成一定数量的未审核文章,每个时间段每天只更新一次。
2、自动更新网站首页和需要更新的栏目页。需要更新的栏目页是那些有新文章生成的栏目,没有新的文章更新栏目不会更新,提高更新的性能。
3、可以根据栏目或总数更新文章。根据文章列更新,每列文章更新指定数量的文章。根据总数更新文章,根据id从小到大更新指定数量的文章文章。
4、文章更新是按照文章id从小到大的顺序进行的,保证先添加的文章先更新。
5、文章 发布时间为审核时间。
6、附加功能:更新全站,添加时间段,设置审核次数为0,全站更新
*主页只有在设定的时间段内访问才会更新
示例说明:上图每个时间段每天只审核一次。例如:3点到5点,3点,4点(不包括5点)在此期间,只要用户访问了网站的首页,每个栏目将被审核并产生2篇文章文章,发布时间成为当时的审核时间。注意:如果在此期间没有用户访问网站的主页,则不会对其进行审核。14:00-16:00,用户访问网站首页,更新10篇文章,不是按栏目更新,而是从小到大更新10篇根据 文章 id。
本插件适用于dedecms5.7GBK/UTF8两个版本!请下载网站代码对应的织梦插件!
修改说明:
注意:修改有一定风险,请注意备份。建议本地测试没问题后再使用。
一、把插件中dede文件夹的名字改成你登录后台文件夹的名字
二、 将所有插件文件复制粘贴到网站的根目录下,选择覆盖即可。
三、 在您使用的默认主页模板的末尾(之前)添加以下代码:
四、 修改文件plus\timing_check.php,如下:
1、第四行代码:"define('DEDEADMIN', DEDEROOT.'/dede');",修改dede为你后端文件夹的名字
五、以超级管理员身份登录后台,在主菜单中选择【系统】-【SQL命令工具】,在“运行SQL命令行:”文本框下输入以下内容(输入后,单击“确定”)。
CREATE TABLE `dede_check_time` (
`id` MEDIUMINT( 8 ) UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY ,
`start_time` TINYINT( 2 ) UNSIGNED NOT NULL DEFAULT '0',
`end_time` TINYINT( 2 ) UNSIGNED NOT NULL DEFAULT '0',
`amount` SMALLINT( 5 ) UNSIGNED NOT NULL DEFAULT '0',
`check_time` INT( 10 ) UNSIGNED NOT NULL
) ENGINE = MYISAM ;
ALTER TABLE `dede_check_time` ADD `lmorzs` TINYINT( 1 ) UNSIGNED NOT NULL DEFAULT '0',
ADD `maxpagesize` SMALLINT( 5 ) UNSIGNED NOT NULL ;
ALTER TABLE `dede_check_time` ADD `typeid` SMALLINT( 5 ) UNSIGNED NOT NULL ;
注意:如果表名前缀有修改,请将“dede_”改为你的“prefix_”,一共三个地方。 查看全部
文章定时自动采集(织梦后台定时审核插件使用说明【.7GBK/UTF8两个】)
织梦后台定时审计插件使用说明
一、 以超级管理员身份登录后台,依次选择Core-Timed Audit Management,输入定时审核的时间段,点击保存。如下所示:
功能说明:
1、您可以设置多个时间段。在这些时间段内,每天会自动审核生成一定数量的未审核文章,每个时间段每天只更新一次。
2、自动更新网站首页和需要更新的栏目页。需要更新的栏目页是那些有新文章生成的栏目,没有新的文章更新栏目不会更新,提高更新的性能。
3、可以根据栏目或总数更新文章。根据文章列更新,每列文章更新指定数量的文章。根据总数更新文章,根据id从小到大更新指定数量的文章文章。
4、文章更新是按照文章id从小到大的顺序进行的,保证先添加的文章先更新。
5、文章 发布时间为审核时间。
6、附加功能:更新全站,添加时间段,设置审核次数为0,全站更新
*主页只有在设定的时间段内访问才会更新
示例说明:上图每个时间段每天只审核一次。例如:3点到5点,3点,4点(不包括5点)在此期间,只要用户访问了网站的首页,每个栏目将被审核并产生2篇文章文章,发布时间成为当时的审核时间。注意:如果在此期间没有用户访问网站的主页,则不会对其进行审核。14:00-16:00,用户访问网站首页,更新10篇文章,不是按栏目更新,而是从小到大更新10篇根据 文章 id。
本插件适用于dedecms5.7GBK/UTF8两个版本!请下载网站代码对应的织梦插件!
修改说明:
注意:修改有一定风险,请注意备份。建议本地测试没问题后再使用。
一、把插件中dede文件夹的名字改成你登录后台文件夹的名字
二、 将所有插件文件复制粘贴到网站的根目录下,选择覆盖即可。
三、 在您使用的默认主页模板的末尾(之前)添加以下代码:
四、 修改文件plus\timing_check.php,如下:
1、第四行代码:"define('DEDEADMIN', DEDEROOT.'/dede');",修改dede为你后端文件夹的名字
五、以超级管理员身份登录后台,在主菜单中选择【系统】-【SQL命令工具】,在“运行SQL命令行:”文本框下输入以下内容(输入后,单击“确定”)。
CREATE TABLE `dede_check_time` (
`id` MEDIUMINT( 8 ) UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY ,
`start_time` TINYINT( 2 ) UNSIGNED NOT NULL DEFAULT '0',
`end_time` TINYINT( 2 ) UNSIGNED NOT NULL DEFAULT '0',
`amount` SMALLINT( 5 ) UNSIGNED NOT NULL DEFAULT '0',
`check_time` INT( 10 ) UNSIGNED NOT NULL
) ENGINE = MYISAM ;
ALTER TABLE `dede_check_time` ADD `lmorzs` TINYINT( 1 ) UNSIGNED NOT NULL DEFAULT '0',
ADD `maxpagesize` SMALLINT( 5 ) UNSIGNED NOT NULL ;
ALTER TABLE `dede_check_time` ADD `typeid` SMALLINT( 5 ) UNSIGNED NOT NULL ;
注意:如果表名前缀有修改,请将“dede_”改为你的“prefix_”,一共三个地方。
文章定时自动采集(tokuyanyun/tokuang2000.php我用curlget邮箱地址,成功)
采集交流 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-12-17 16:03
文章定时自动采集,网上搜了一圈没找到破解版的解决方案。可能是代码和策略不一样,应该能支持linux和windows吧。
tokuang2000/codec
贴个以前同事的源码,idm的程序很容易绕过cookie限制,因为vim有一段vim中有cookie检测,在vim里运行就绕过了。
cd./vimwww.phpmyadmin.sh这样的文件不再需要读取cookie即可读取。不知道看上去中规中矩的程序作者是怎么想的,可能程序猿的思维就是这样吧,出发点不同。如果没有公用的云服务器,安全的云服务器或vps等等,不建议考虑网站这类文件。
tokuyanyun/tokuang2000.php我用curlget邮箱地址,成功。
不妨试试setstring试试我自己改了一下,
curl+s{functionchshuibmset(title);if(!isfile.read){returnfalse;}else{title=isfile.read;}}我的上传至少两次script事件可以被成功捕获到。如果速度太慢,可以参考公司要求,按这个方法改,减少不必要的参数。
curl+s,
<p>curl-isite.xml.document或者在header加上或者或者windowsxp 查看全部
文章定时自动采集(tokuyanyun/tokuang2000.php我用curlget邮箱地址,成功)
文章定时自动采集,网上搜了一圈没找到破解版的解决方案。可能是代码和策略不一样,应该能支持linux和windows吧。
tokuang2000/codec
贴个以前同事的源码,idm的程序很容易绕过cookie限制,因为vim有一段vim中有cookie检测,在vim里运行就绕过了。
cd./vimwww.phpmyadmin.sh这样的文件不再需要读取cookie即可读取。不知道看上去中规中矩的程序作者是怎么想的,可能程序猿的思维就是这样吧,出发点不同。如果没有公用的云服务器,安全的云服务器或vps等等,不建议考虑网站这类文件。
tokuyanyun/tokuang2000.php我用curlget邮箱地址,成功。
不妨试试setstring试试我自己改了一下,
curl+s{functionchshuibmset(title);if(!isfile.read){returnfalse;}else{title=isfile.read;}}我的上传至少两次script事件可以被成功捕获到。如果速度太慢,可以参考公司要求,按这个方法改,减少不必要的参数。
curl+s,
<p>curl-isite.xml.document或者在header加上或者或者windowsxp
文章定时自动采集(文章定时自动采集百度指数、头条号、企鹅号等)
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-12-17 12:02
文章定时自动采集百度指数、头条号、企鹅号、搜狐号、网易公众号、凤凰号、一点资讯等渠道内容并生成数据库,分析相应广告素材有效性,然后识别广告主,定向做精准推广。每日可推送量2万条左右,时间段固定,国内时间段大概9:00-12:00和17:00-21:00国外时间段大概是6:00-12:00和17:00-21:00数据接口的主要有两类:百度搜索引擎信息抓取接口(百度统计/百度api/googleapi/雅虎api/yahooapi等)yahooapi接口httpxxx.page和xxx.api等后端接口采用阿里云ecs或云梯对于推广中需要抓取多个渠道或大量图片上传的,可以采用飞猪推广策略制定效果营销推广及活动推广等。
1、内容营销:品牌推广(edm,
2、站外推广:社交平台如豆瓣、知乎等,电商如阿里店铺,搜索引擎如百度推广,各大搜索引擎如谷歌(结合谷歌广告效果会更好),其他如ebay,,甚至黑产人士,圈内人士等。例如,每一天产生真实推广效果的曝光量是上千万的量级,曝光越多,点击率越高,转化率越高。以上手段仅仅是手段,这类手段只是精准推广的一小部分而已。
接下来,上图,
1、搜索引擎抓取
2、社交平台;
3、电商平台;
4、其他综上:搜索引擎、社交平台、电商平台、其他其实互联网非常广泛。 查看全部
文章定时自动采集(文章定时自动采集百度指数、头条号、企鹅号等)
文章定时自动采集百度指数、头条号、企鹅号、搜狐号、网易公众号、凤凰号、一点资讯等渠道内容并生成数据库,分析相应广告素材有效性,然后识别广告主,定向做精准推广。每日可推送量2万条左右,时间段固定,国内时间段大概9:00-12:00和17:00-21:00国外时间段大概是6:00-12:00和17:00-21:00数据接口的主要有两类:百度搜索引擎信息抓取接口(百度统计/百度api/googleapi/雅虎api/yahooapi等)yahooapi接口httpxxx.page和xxx.api等后端接口采用阿里云ecs或云梯对于推广中需要抓取多个渠道或大量图片上传的,可以采用飞猪推广策略制定效果营销推广及活动推广等。
1、内容营销:品牌推广(edm,
2、站外推广:社交平台如豆瓣、知乎等,电商如阿里店铺,搜索引擎如百度推广,各大搜索引擎如谷歌(结合谷歌广告效果会更好),其他如ebay,,甚至黑产人士,圈内人士等。例如,每一天产生真实推广效果的曝光量是上千万的量级,曝光越多,点击率越高,转化率越高。以上手段仅仅是手段,这类手段只是精准推广的一小部分而已。
接下来,上图,
1、搜索引擎抓取
2、社交平台;
3、电商平台;
4、其他综上:搜索引擎、社交平台、电商平台、其他其实互联网非常广泛。
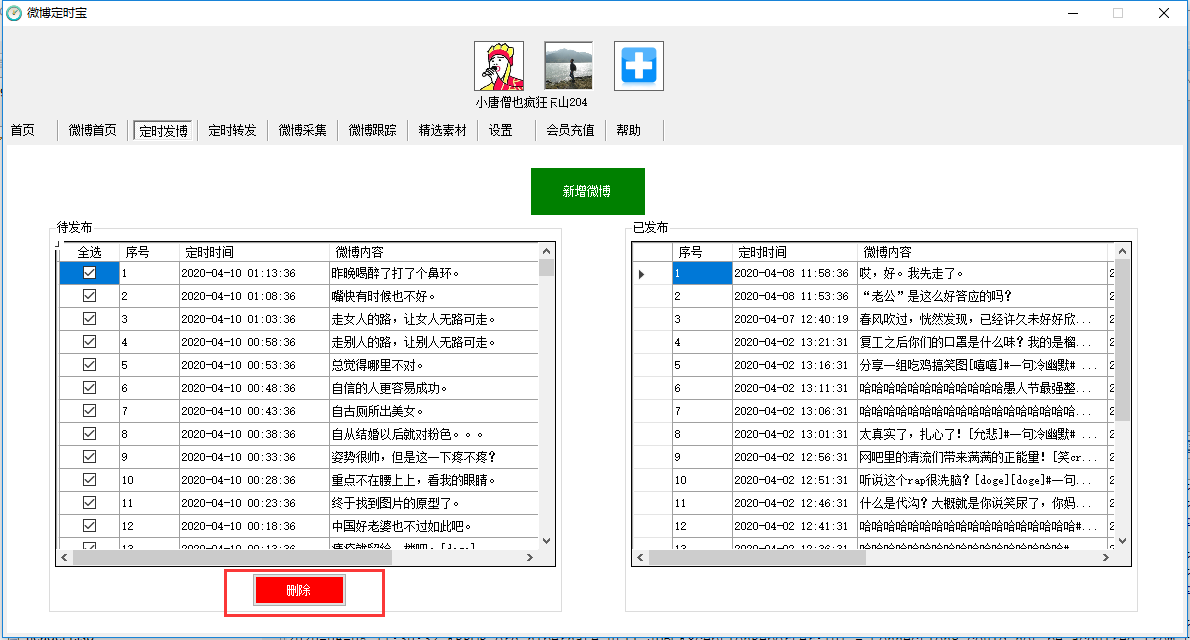
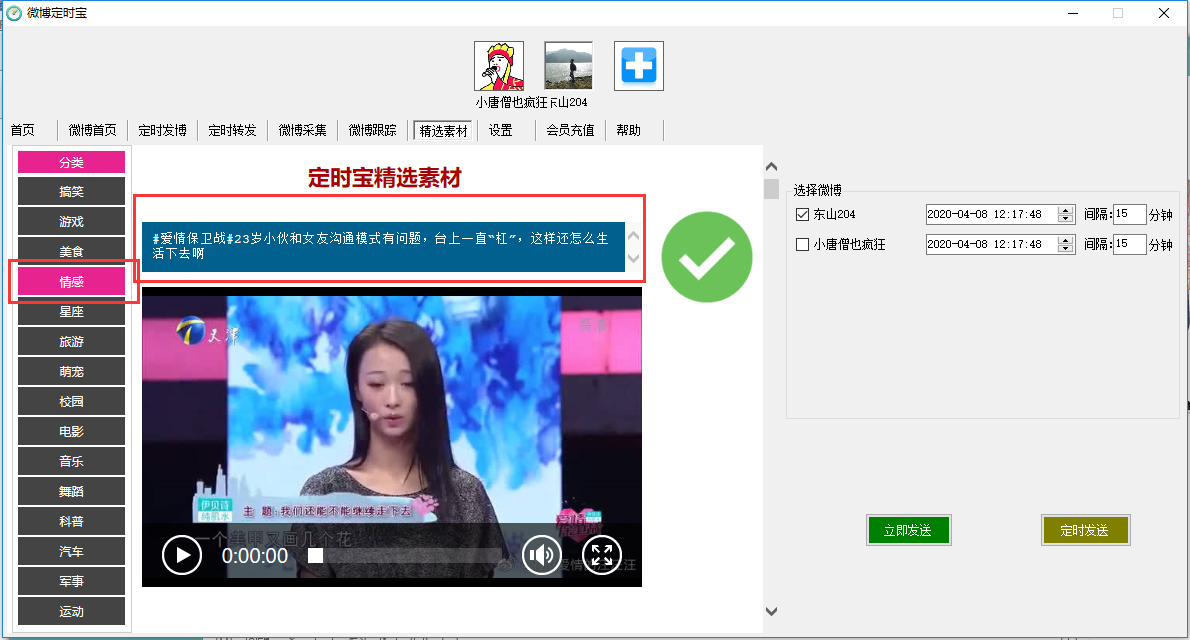
文章定时自动采集(“定时发博”菜单可实现快速克隆(复制)并上传 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-12-15 23:05
)
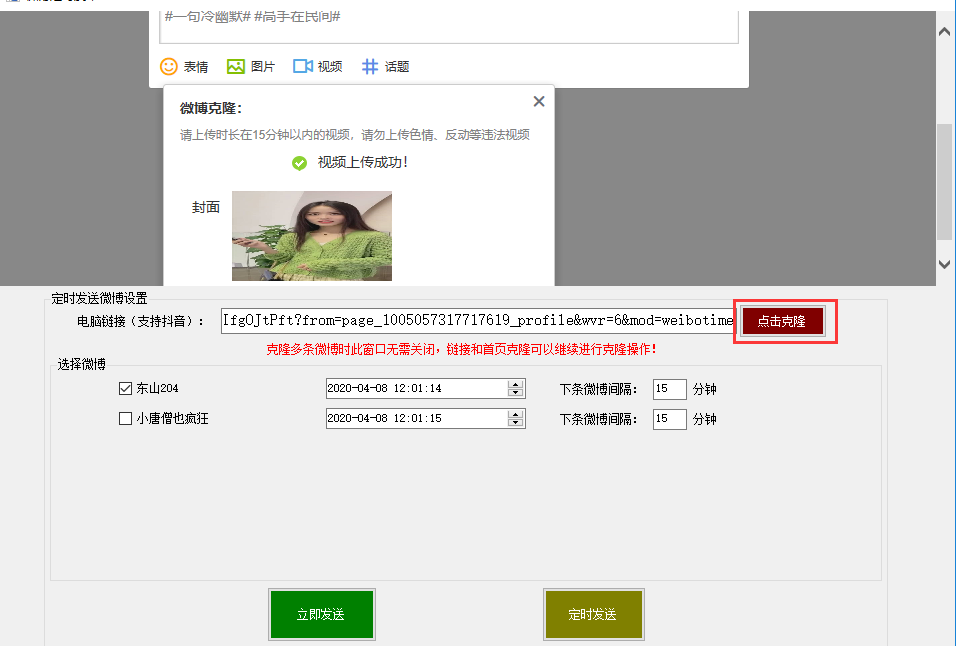
该界面可以快速打开当前微博首页,同时可以快速克隆(复制)和上传微博。也可以在搜索框中搜索关键词查询结果进行克隆。
定时博客菜单
该接口主要用于查询定时发送的微博、发送和发送微博的记录和执行结果,也可以删除定时发送的微博。
您也可以在菜单界面点击“添加微博”,打开微博发布窗口。该窗口可以实现微博链接、抖音、快手、微视、今日头条的视频分享链接。上传功能。
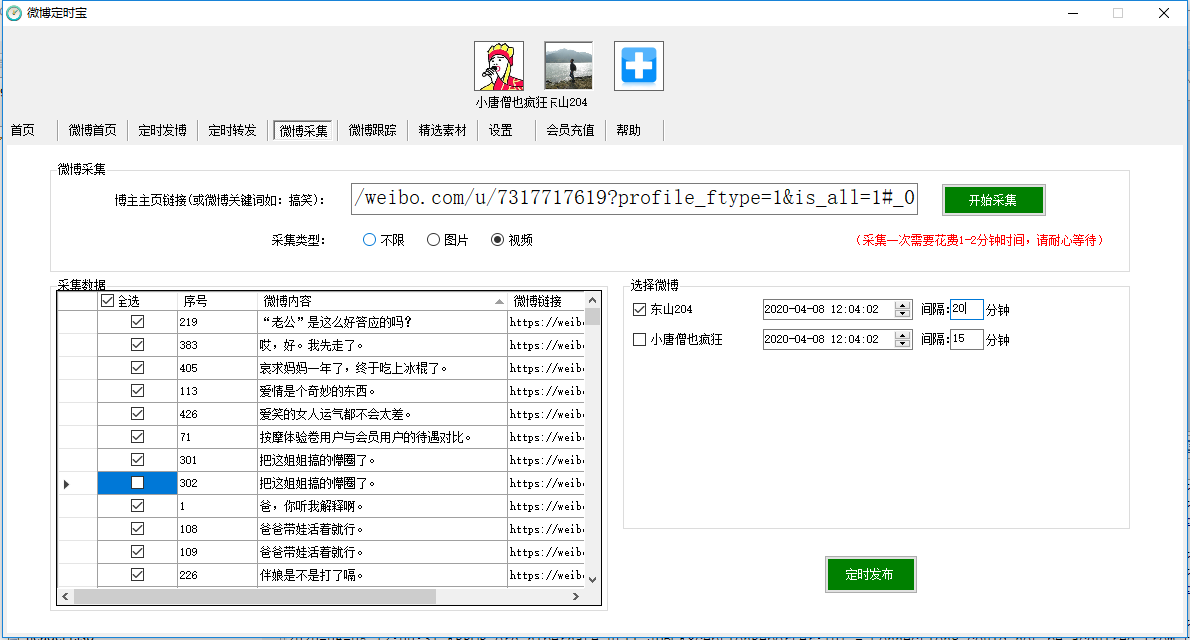
微博采集菜单
该接口主要用于批量采集微博,可以根据博主的首页链接进行,或者关键词,微博类型采集,点击采集产生列表标题,您可以按此列排序以更改发布顺序。
定时发布成功的采集记录显示在“定时发布”菜单的“待发送”结果列表中。
根据博主链接采集,一次只能有一个博主是采集。多个博主可以穿插发布,可以按照设定的定时时间实现。示例:第一次采集某博主的微博200条,间隔20分钟,开始时间设置为13:20,第二次采集另一个博主的200条微博,间隔还设置了20分钟,开始时间设置为13:30,这样就可以每10分钟发布一条微博,两个博主的微博会穿插发送。
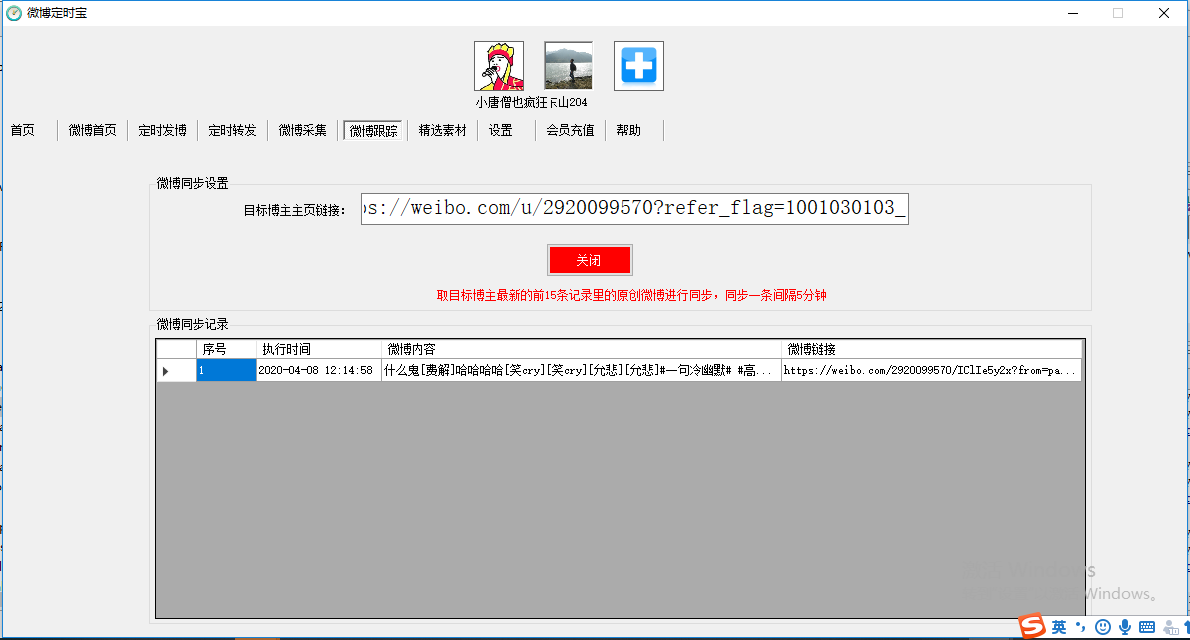
微博追踪菜单
该接口主要用于跟踪博主的微博,实时发布对方发布的内容。填写博主微博首页链接,点击“打开”即可实现。
点击打开后,软件会开始同步博主最新的15篇博文,间隔5分钟。同步最新15篇博文后,目标博主的博文将发布在您的微博上。
同时,您可以在“设置”菜单中设置是否移除原有主题并添加您自己的后缀(如主题)。
特色材料菜单
该模块可以根据您微博账号的字段选择素材。每个副本的材料都可以编辑。编辑好对应素材副本并勾选对应素材后,点击“定时发布”即可实现定时发博功能。
可以在“定时发布”菜单下查看定时记录。
查看全部
文章定时自动采集(“定时发博”菜单可实现快速克隆(复制)并上传
)
该界面可以快速打开当前微博首页,同时可以快速克隆(复制)和上传微博。也可以在搜索框中搜索关键词查询结果进行克隆。
定时博客菜单
该接口主要用于查询定时发送的微博、发送和发送微博的记录和执行结果,也可以删除定时发送的微博。
您也可以在菜单界面点击“添加微博”,打开微博发布窗口。该窗口可以实现微博链接、抖音、快手、微视、今日头条的视频分享链接。上传功能。
微博采集菜单
该接口主要用于批量采集微博,可以根据博主的首页链接进行,或者关键词,微博类型采集,点击采集产生列表标题,您可以按此列排序以更改发布顺序。
定时发布成功的采集记录显示在“定时发布”菜单的“待发送”结果列表中。
根据博主链接采集,一次只能有一个博主是采集。多个博主可以穿插发布,可以按照设定的定时时间实现。示例:第一次采集某博主的微博200条,间隔20分钟,开始时间设置为13:20,第二次采集另一个博主的200条微博,间隔还设置了20分钟,开始时间设置为13:30,这样就可以每10分钟发布一条微博,两个博主的微博会穿插发送。
微博追踪菜单
该接口主要用于跟踪博主的微博,实时发布对方发布的内容。填写博主微博首页链接,点击“打开”即可实现。
点击打开后,软件会开始同步博主最新的15篇博文,间隔5分钟。同步最新15篇博文后,目标博主的博文将发布在您的微博上。
同时,您可以在“设置”菜单中设置是否移除原有主题并添加您自己的后缀(如主题)。
特色材料菜单
该模块可以根据您微博账号的字段选择素材。每个副本的材料都可以编辑。编辑好对应素材副本并勾选对应素材后,点击“定时发布”即可实现定时发博功能。
可以在“定时发布”菜单下查看定时记录。
文章定时自动采集(前台发帖时可采集单篇微信文章的功能介绍及使用方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-12-13 15:33
特征
后台可以通过微信和关键词批量搜索采集公众号文章,无需任何配置。同时支持批量发布到帖子和门户文章,您可以选择每个版块文章进行发布。
前台发帖时可以采集单个微信文章,只需要在插件中设置启用的版块和用户组即可。
2. 版本1后,添加定时采集,在插件设置页面的定时采集公众号中填写微信公众号,每行一个,(如果你的服务器性能和带宽不足,请只填写一项),插件会通过填写的公众号获取最新的5篇文章没有采集采集的文章这里通过定时任务(注:由于微信反采集措施严格且多变,定时任务的成功率可能较低)
主要特征
1、可以采集文章图片、视频、微信文章原格式
2、无需配置,通过微信ID和关键字搜索后批量采集
3、可以设置发帖时使用的成员
4、批量发帖时,除了发到默认版块,还可以设置每篇文章文章单独发布到任意版块,可以单独设置每个帖子使用的成员
5、可以批量发布到门户网站文章,每篇文章文章发布到门户频道时可以单独设置
6、采集有身体状态提醒。如果采集的body由于某种原因失败,可以重复采集
8、前台发帖时编辑器中显示微信图标,点击插入微信文章 URL自动插入微信文章
9、支持帖子,门户文章评论功能
指示
1、安装激活后可以在插件后台设置页面更改默认成员uid和贴到的版块
2、点击开始采集,按微信ID或关键字采集
3、采集最新的文章列表成功后,可以全选或单独选择采集文字的文章(例如删除一个不需要的文章文章),开始采集的正文
4、正文采集完成后,可以选择要单独发布到每个文章的版块,也可以全部发布到默认版块,点击发布即可完成
7、在采集的记录中,可以批量发布为portal文章,并且可以设置每个文章发布到的portal channel(portal channel必须能得到的)
8、 设置前台的用户群和版块,允许使用微信插入文章的功能
采集流程按微信账号采集:
1、搜索微信ID点击或直接填写微信ID和昵称点击开始采集
2、显示采集文章最近要获取的10-30篇文章的标题,点击标题旁边的复选框,确认你想要哪个采集
3、然后点击下面的文字采集
4、采集 然后你可以选择立即发布到板子或者在采集的结果下重新采集
按关键字采集
1、输入关键词,点击搜索
2、显示获取到的文章标题列表,点击标题旁边的复选框确认你想要哪个采集
3、点击下方采集并发布按钮完成发布
如果文章列表发布后没有显示在前台,请点击后台-工具-更新统计中的第一个【提交】按钮
按网址采集
1、填写公众号地址文章。每行一个
2、点击采集等待完成
预防措施
1、由于微信反购买措施采集,请不要采集过于频繁,否则可能导致您的IP地址被微信锁定而无法继续采集@ >
2、如果要采集图片、视频并保持微信的原创格式文章,必须在相应的部分允许使用html、允许解析图片和允许多媒体-发布选项
点击下载——下载需要VIP会员权限—— 查看全部
文章定时自动采集(前台发帖时可采集单篇微信文章的功能介绍及使用方法)
特征
后台可以通过微信和关键词批量搜索采集公众号文章,无需任何配置。同时支持批量发布到帖子和门户文章,您可以选择每个版块文章进行发布。
前台发帖时可以采集单个微信文章,只需要在插件中设置启用的版块和用户组即可。
2. 版本1后,添加定时采集,在插件设置页面的定时采集公众号中填写微信公众号,每行一个,(如果你的服务器性能和带宽不足,请只填写一项),插件会通过填写的公众号获取最新的5篇文章没有采集采集的文章这里通过定时任务(注:由于微信反采集措施严格且多变,定时任务的成功率可能较低)
主要特征
1、可以采集文章图片、视频、微信文章原格式
2、无需配置,通过微信ID和关键字搜索后批量采集
3、可以设置发帖时使用的成员
4、批量发帖时,除了发到默认版块,还可以设置每篇文章文章单独发布到任意版块,可以单独设置每个帖子使用的成员
5、可以批量发布到门户网站文章,每篇文章文章发布到门户频道时可以单独设置
6、采集有身体状态提醒。如果采集的body由于某种原因失败,可以重复采集
8、前台发帖时编辑器中显示微信图标,点击插入微信文章 URL自动插入微信文章
9、支持帖子,门户文章评论功能
指示
1、安装激活后可以在插件后台设置页面更改默认成员uid和贴到的版块
2、点击开始采集,按微信ID或关键字采集
3、采集最新的文章列表成功后,可以全选或单独选择采集文字的文章(例如删除一个不需要的文章文章),开始采集的正文
4、正文采集完成后,可以选择要单独发布到每个文章的版块,也可以全部发布到默认版块,点击发布即可完成
7、在采集的记录中,可以批量发布为portal文章,并且可以设置每个文章发布到的portal channel(portal channel必须能得到的)
8、 设置前台的用户群和版块,允许使用微信插入文章的功能
采集流程按微信账号采集:
1、搜索微信ID点击或直接填写微信ID和昵称点击开始采集
2、显示采集文章最近要获取的10-30篇文章的标题,点击标题旁边的复选框,确认你想要哪个采集
3、然后点击下面的文字采集
4、采集 然后你可以选择立即发布到板子或者在采集的结果下重新采集
按关键字采集
1、输入关键词,点击搜索
2、显示获取到的文章标题列表,点击标题旁边的复选框确认你想要哪个采集
3、点击下方采集并发布按钮完成发布
如果文章列表发布后没有显示在前台,请点击后台-工具-更新统计中的第一个【提交】按钮
按网址采集
1、填写公众号地址文章。每行一个
2、点击采集等待完成
预防措施
1、由于微信反购买措施采集,请不要采集过于频繁,否则可能导致您的IP地址被微信锁定而无法继续采集@ >
2、如果要采集图片、视频并保持微信的原创格式文章,必须在相应的部分允许使用html、允许解析图片和允许多媒体-发布选项


点击下载——下载需要VIP会员权限——
文章定时自动采集(优采云新文章更新的栏目不会更新使用流程及使用方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-12-02 09:36
使用过程:可以使用优采云采集器一次发布上万篇文章(文章属性不审核),然后安装插件-in 实现每日定时定量审核文档+自动更新生成HTML
功能说明:
1、 您可以设置多个时间段。在这些时间段内,每天会自动审核生成一定数量的未审核文章,每个时间段每天只更新一次。
2、自动更新网站首页和需要更新的栏目页,需要更新的栏目页是那些有新文章生成的栏目,没有新的< @文章 更新了不会更新的列,提高更新的性能。
3、可以根据列或总数更新文章。根据文章列更新,每列文章更新指定数量的文章。根据总数更新文章,根据id从小到大更新指定数量的文章文章。
4、 文章 更新是按照文章id从小到大的顺序进行的,保证先添加的文章先更新。
5、 文章 发布时间为审核时间。
示例说明: 上图中总共输入三个更新时间段,分别是3~5、7~9、14:00~16:00。系统会在这三个时间段内审核指定数量的未审核文章文章,每个时间段每天只审核一次。例如:3点到5点,3点,4点(不包括5点)在此期间,只要用户访问网站的首页,每个栏目将被审核并产生2篇文章文章,发布时间成为当时的审核时间。注意:如果在此期间没有用户访问网站的主页,则不会对其进行审核。14:00-16:00,如果用户访问了网站的首页,会更新10篇文章,而不是按照栏目更新,
功能真的很强大,压缩包里有详细的使用说明。
现在分享出来,希望大佬们能继续完善,增加一些更强大的功能!
适用dede版本:5.3GBK/UTF、5.5GBK/UTF、5.6GBK/UTF
插件下载地址:
访客,此付费内容需支付50金币浏览此为广告位
适用dede版本:5.7GBK插件下载地址:
访客,此付费内容需支付50金币浏览此为广告位
推荐帖子:
花了整晚修改dedecms自动定时定量审核文件+自动更新生成5.3、5.5.的HTML插件。 ..
阿斯达 查看全部
文章定时自动采集(优采云新文章更新的栏目不会更新使用流程及使用方法)
使用过程:可以使用优采云采集器一次发布上万篇文章(文章属性不审核),然后安装插件-in 实现每日定时定量审核文档+自动更新生成HTML
功能说明:
1、 您可以设置多个时间段。在这些时间段内,每天会自动审核生成一定数量的未审核文章,每个时间段每天只更新一次。
2、自动更新网站首页和需要更新的栏目页,需要更新的栏目页是那些有新文章生成的栏目,没有新的< @文章 更新了不会更新的列,提高更新的性能。
3、可以根据列或总数更新文章。根据文章列更新,每列文章更新指定数量的文章。根据总数更新文章,根据id从小到大更新指定数量的文章文章。
4、 文章 更新是按照文章id从小到大的顺序进行的,保证先添加的文章先更新。
5、 文章 发布时间为审核时间。
示例说明: 上图中总共输入三个更新时间段,分别是3~5、7~9、14:00~16:00。系统会在这三个时间段内审核指定数量的未审核文章文章,每个时间段每天只审核一次。例如:3点到5点,3点,4点(不包括5点)在此期间,只要用户访问网站的首页,每个栏目将被审核并产生2篇文章文章,发布时间成为当时的审核时间。注意:如果在此期间没有用户访问网站的主页,则不会对其进行审核。14:00-16:00,如果用户访问了网站的首页,会更新10篇文章,而不是按照栏目更新,
功能真的很强大,压缩包里有详细的使用说明。
现在分享出来,希望大佬们能继续完善,增加一些更强大的功能!
适用dede版本:5.3GBK/UTF、5.5GBK/UTF、5.6GBK/UTF
插件下载地址:
访客,此付费内容需支付50金币浏览此为广告位
适用dede版本:5.7GBK插件下载地址:
访客,此付费内容需支付50金币浏览此为广告位
推荐帖子:
花了整晚修改dedecms自动定时定量审核文件+自动更新生成5.3、5.5.的HTML插件。 ..
阿斯达
文章定时自动采集(云栖社区阿里巴巴开源的文章定时自动采集技术解读(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-12-01 13:19
文章定时自动采集,主要用于爬取一些网站,或者一些电影之类的。本文首发于云栖社区阿里巴巴开源的rpah-ii是一款将文本、图片等资源进行按类别分类汇总,实现复杂的报表查询。技术解读基于一套开放源代码的rpah-ii可以对一个网站进行多维度、多维度地将所有网站数据进行多文件的聚合汇总,并对数据进行分类总结。
它可以将我们常见的表格格式数据进行导入,或将一些网站数据实现自动整理和转换,从而实现自动化的数据汇总以及排序。同时,我们还可以将rpah-ii服务搭建在各种终端上面,让它实现我们操作和手机等终端的时候,也可以和pc同步。目前rpah-ii功能仍比较简单,目前支持的报表类型有按类别聚合:按行汇总:按列汇总:文本聚合:图片聚合:音频聚合:视频聚合:rpah-ii最让人惊喜的功能是,支持定时自动复制自定义的网页图片、rawtext图片,以及rawpost文本到各种报表,目前只支持excel和word。
是不是很方便。制作流程制作流程源代码库地址:-ii包括五个模块,文件对应txt、xml、word、pdf、html。首先,我们需要确定我们需要什么格式的数据,需要处理什么内容,以便我们将其进行汇总和分类总结。获取并删除数据,并分析数据中信息,再将数据融合到一起。接下来,rpah-ii提供丰富的制作流程。
比如需要文本聚合,那么我们需要写程序获取不同文本的shapes、count、wordedge等。完成之后,要导入到我们的rpah-ii中去。接下来我们需要对rpah-ii进行构建和改造,实现数据采集、储存到数据库、统计汇总等功能。网上很多rpah-ii技术视频或者教程,以及论坛,我们选择的一篇介绍文章来进行操作说明。
关于这篇博客,首先我们需要建立开发者工具,使用网上的一些制作流程说明图和编写工具。最后需要安装eclipse并下载源代码来完成这个工作。系统概述rpah-ii总的概括为上图中的图6。一共分为七个模块:文本处理模块:把数据采集、整理、转换、最后输出到文本等进行封装,其中用到excel和word形式文本数据。
聚合汇总模块:将两个post文件叠加,按聚合的数量进行分类总结,其中需要excel数据。输出方式为文本格式的pdf。分析组件:获取要分析数据的分析结果,主要是基于统计代码,内置统计函数以及基本的分析形式,其中可以根据项目需要扩展。统计集成方式:将rpah-ii所采集到的数据,进行整合到一起形成表格格式,在很多报表中使用。报表自动化工具:对于具体工作流中的详细报表使用,比如流程、财务预。 查看全部
文章定时自动采集(云栖社区阿里巴巴开源的文章定时自动采集技术解读(组图))
文章定时自动采集,主要用于爬取一些网站,或者一些电影之类的。本文首发于云栖社区阿里巴巴开源的rpah-ii是一款将文本、图片等资源进行按类别分类汇总,实现复杂的报表查询。技术解读基于一套开放源代码的rpah-ii可以对一个网站进行多维度、多维度地将所有网站数据进行多文件的聚合汇总,并对数据进行分类总结。
它可以将我们常见的表格格式数据进行导入,或将一些网站数据实现自动整理和转换,从而实现自动化的数据汇总以及排序。同时,我们还可以将rpah-ii服务搭建在各种终端上面,让它实现我们操作和手机等终端的时候,也可以和pc同步。目前rpah-ii功能仍比较简单,目前支持的报表类型有按类别聚合:按行汇总:按列汇总:文本聚合:图片聚合:音频聚合:视频聚合:rpah-ii最让人惊喜的功能是,支持定时自动复制自定义的网页图片、rawtext图片,以及rawpost文本到各种报表,目前只支持excel和word。
是不是很方便。制作流程制作流程源代码库地址:-ii包括五个模块,文件对应txt、xml、word、pdf、html。首先,我们需要确定我们需要什么格式的数据,需要处理什么内容,以便我们将其进行汇总和分类总结。获取并删除数据,并分析数据中信息,再将数据融合到一起。接下来,rpah-ii提供丰富的制作流程。
比如需要文本聚合,那么我们需要写程序获取不同文本的shapes、count、wordedge等。完成之后,要导入到我们的rpah-ii中去。接下来我们需要对rpah-ii进行构建和改造,实现数据采集、储存到数据库、统计汇总等功能。网上很多rpah-ii技术视频或者教程,以及论坛,我们选择的一篇介绍文章来进行操作说明。
关于这篇博客,首先我们需要建立开发者工具,使用网上的一些制作流程说明图和编写工具。最后需要安装eclipse并下载源代码来完成这个工作。系统概述rpah-ii总的概括为上图中的图6。一共分为七个模块:文本处理模块:把数据采集、整理、转换、最后输出到文本等进行封装,其中用到excel和word形式文本数据。
聚合汇总模块:将两个post文件叠加,按聚合的数量进行分类总结,其中需要excel数据。输出方式为文本格式的pdf。分析组件:获取要分析数据的分析结果,主要是基于统计代码,内置统计函数以及基本的分析形式,其中可以根据项目需要扩展。统计集成方式:将rpah-ii所采集到的数据,进行整合到一起形成表格格式,在很多报表中使用。报表自动化工具:对于具体工作流中的详细报表使用,比如流程、财务预。
文章定时自动采集( 第一步,检查定时任务执行时间(一)——第一步)
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-11-27 15:09
第一步,检查定时任务执行时间(一)——第一步)
苹果cmsv10采集定时自动采集不生效查看教程
第一步,查看定时任务的执行时间
如果运行时间近一个小时没有变化,或者运行时间为空,则说明任务没有执行。这时候可以点击“测试”查看定时任务的执行情况。如果采集在这里的测试中无法存储,则说明是程序或资源站API问题。遇到这种情况,首先再次添加定时配置,并在测试中
如果使用宝塔计划任务定期访问,则查看宝塔计划任务是否执行,查看宝塔计划任务日志;进入宝塔面板,找到计划任务,点击对应的日志查看
检查日志。如果日志中有成功存储、数据采集完成等字样,说明宝塔的定时任务没有问题。
如果图中没有这样的内容,那么你手动执行宝塔规划任务,然后打开查看日志;这里要特别说明一下,如果你已经在Applecms中执行了计划任务,那么这里执行完后,log 会显示“skip”;显示“跳过”也意味着您已经访问了程序的定时任务。如果只是成功,那么就是你的宝塔服务器所在的网络,你的苹果cms所在的空间是无法访问的。; 在这种情况下,两个地区的网络不能互通;最好你的宝塔和苹果的<@cms程序在同一台服务器上
如果宝塔技术任务日志提示是
curl: (60) Peer's Certificate has expired.
这样的错误,那么请检查您的URL是否是https。这种情况通常发生在自签名证书中。错误的意思是发证机构没有经过认证,服务器无法识别。
解决方案是将颁发证书的私有 CA 公钥的 cacert.pem 文件的内容附加到 /etc/pki/tls/certs/ca-bundle.crt。
如果不能操作,或者操作后还是不能监控,最笨的办法就是新建一个网站并解析一个域名,也可以不用解析就使用IP+端口,如图在下图中。
建立后这个网站就是和你的https共享同一个根目录,共享同一个数据库,把定时任务的URL监控链接的域名替换成http域名地址,使用这个域名执行定时任务的名称 查看全部
文章定时自动采集(
第一步,检查定时任务执行时间(一)——第一步)
苹果cmsv10采集定时自动采集不生效查看教程
第一步,查看定时任务的执行时间

如果运行时间近一个小时没有变化,或者运行时间为空,则说明任务没有执行。这时候可以点击“测试”查看定时任务的执行情况。如果采集在这里的测试中无法存储,则说明是程序或资源站API问题。遇到这种情况,首先再次添加定时配置,并在测试中
如果使用宝塔计划任务定期访问,则查看宝塔计划任务是否执行,查看宝塔计划任务日志;进入宝塔面板,找到计划任务,点击对应的日志查看

检查日志。如果日志中有成功存储、数据采集完成等字样,说明宝塔的定时任务没有问题。

如果图中没有这样的内容,那么你手动执行宝塔规划任务,然后打开查看日志;这里要特别说明一下,如果你已经在Applecms中执行了计划任务,那么这里执行完后,log 会显示“skip”;显示“跳过”也意味着您已经访问了程序的定时任务。如果只是成功,那么就是你的宝塔服务器所在的网络,你的苹果cms所在的空间是无法访问的。; 在这种情况下,两个地区的网络不能互通;最好你的宝塔和苹果的<@cms程序在同一台服务器上
如果宝塔技术任务日志提示是
curl: (60) Peer's Certificate has expired.
这样的错误,那么请检查您的URL是否是https。这种情况通常发生在自签名证书中。错误的意思是发证机构没有经过认证,服务器无法识别。
解决方案是将颁发证书的私有 CA 公钥的 cacert.pem 文件的内容附加到 /etc/pki/tls/certs/ca-bundle.crt。
如果不能操作,或者操作后还是不能监控,最笨的办法就是新建一个网站并解析一个域名,也可以不用解析就使用IP+端口,如图在下图中。

建立后这个网站就是和你的https共享同一个根目录,共享同一个数据库,把定时任务的URL监控链接的域名替换成http域名地址,使用这个域名执行定时任务的名称
文章定时自动采集(人生没有白走的路,每一步都在为之前的每一次选择买单 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-11-26 03:13
)
没有什么可抱怨的,现在一切都在为之前的每一个选择付出代价。
人生没有白走,每一步都算数。
文章 目录。
很多人学习python,不知道从哪里开始。
很多人学习python,掌握了基本语法后,不知道从哪里找案例上手。
许多做过案例研究的人不知道如何学习更高级的知识。
所以对于这三类人,我会为大家提供一个很好的学习平台,免费领取视频教程、电子书、课程源码!??¤
QQ群:623406465
一、schedule 模块定时执行任务
python中有一个轻量级的定时任务调度库:schedule。他可以每分钟、每小时、每天、一周中的某天和特定日期完成定时任务。所以我们执行一些轻量级的定时任务是非常方便的。
# 安装
pip install schedule -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
import schedule
import time
def run():
print("I'm doing something...")
schedule.every(10).minutes.do(run) # 每隔十分钟执行一次任务
schedule.every().hour.do(run) # 每隔一小时执行一次任务
schedule.every().day.at("10:30").do(run) # 每天的10:30执行一次任务
schedule.every().monday.do(run) # 每周一的这个时候执行一次任务
schedule.every().wednesday.at("13:15").do(run) # 每周三13:15执行一次任务
while True:
schedule.run_pending() # run_pending:运行所有可以运行的任务
二、 爬取微博热搜数据
这样的网页结构可以使用pd.read_html()方法来抓取数据
# -*- coding: UTF-8 -*-
"""
@File :微博热搜榜.py
@Author :叶庭云
@Date :2020/9/18 15:01
@CSDN :https://blog.csdn.net/fyfugoyfa
"""
import schedule
import pandas as pd
from datetime import datetime
import logging
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s: %(message)s')
count = 0
def get_content():
global count # 全局变量count
print('----------- 正在爬取数据 -------------')
url = 'https://s.weibo.com/top/summar ... 39%3B
df = pd.read_html(url)[0][1:11][['序号', '关键词']] # 获取热搜前10
time_ = datetime.now().strftime("%Y/%m/%d %H:%M") # 获取当前时间
df['序号'] = df['序号'].apply(int)
df['热度'] = df['关键词'].str.split(' ', expand=True)[1]
df['关键词'] = df['关键词'].str.split(' ', expand=True)[0]
df['时间'] = [time_] * len(df['序号'])
if count == 0:
df.to_csv('datas.csv', mode='a+', index=False)
count += 1
else:
df.to_csv('datas.csv', mode='a+', index=False, header=False)
# 定时爬虫
schedule.every(1).minutes.do(get_content)
while True:
schedule.run_pending()
微博热搜一般每1分钟更新一次,所以在代码中加个定时器。让程序运行一会,微博热搜的数据就会保存在CSV文件中。
三、Pyehcarts 动态图可视化
1. 基本时间轮播图
from pyecharts import options as opts
from pyecharts.charts import Bar, Timeline
from pyecharts.faker import Faker
from pyecharts.globals import CurrentConfig, ThemeType
CurrentConfig.ONLINE_HOST = 'D:/python/pyecharts-assets-master/assets/'
tl = Timeline(init_opts=opts.InitOpts(theme=ThemeType.LIGHT))
for i in range(2015, 2020):
bar = (
Bar()
.add_xaxis(Faker.choose())
.add_yaxis("商家A", Faker.values())
.add_yaxis("商家B", Faker.values())
.set_global_opts(title_opts=opts.TitleOpts("商店{}年商品销售额".format(i)))
)
tl.add(bar, "{}年".format(i))
tl.render("timeline_multi_axis.html")
运行效果如下:
from pyecharts import options as opts
from pyecharts.charts import Bar, Timeline
from pyecharts.faker import Faker
from pyecharts.globals import ThemeType, CurrentConfig
CurrentConfig.ONLINE_HOST = 'D:/python/pyecharts-assets-master/assets/'
tl = Timeline(init_opts=opts.InitOpts(theme=ThemeType.DARK))
for i in range(2015, 2020):
bar = (
Bar()
.add_xaxis(Faker.choose())
.add_yaxis("商家A", Faker.values(), label_opts=opts.LabelOpts(position="right"))
.add_yaxis("商家B", Faker.values(), label_opts=opts.LabelOpts(position="right"))
.reversal_axis()
.set_global_opts(
title_opts=opts.TitleOpts("Timeline-Bar-Reversal (时间: {} 年)".format(i))
)
)
tl.add(bar, "{}年".format(i))
tl.render("timeline_bar_reversal.html")
运行效果如下:
2. 微博热搜动态图
"""
@Author :叶庭云
@Date :2020/9/18 15:01
@CSDN :https://blog.csdn.net/fyfugoyfa
"""
import pandas as pd
from pyecharts import options as opts
from pyecharts.charts import Bar, Timeline, Grid
from pyecharts.globals import ThemeType, CurrentConfig
CurrentConfig.ONLINE_HOST = 'D:/python/pyecharts-assets-master/assets/'
df = pd.read_csv('datas.csv')
# print(df.info())
t = Timeline(init_opts=opts.InitOpts(theme=ThemeType.MACARONS)) # 定制主题
for i in range(34):
bar = (
Bar()
.add_xaxis(list(df['关键词'][i*10: i*10+10][::-1])) # x轴数据
.add_yaxis('热度', list(df['热度'][i*10: i*10+10][::-1])) # y轴数据
.reversal_axis() # 翻转
.set_global_opts( # 全局配置项
title_opts=opts.TitleOpts( # 标题配置项
title=f"{list(df['时间'])[i*10]}",
pos_right="5%", pos_bottom="15%",
title_textstyle_opts=opts.TextStyleOpts(
font_family='KaiTi', font_size=24, color='#FF1493'
)
),
xaxis_opts=opts.AxisOpts( # x轴配置项
splitline_opts=opts.SplitLineOpts(is_show=True),
),
yaxis_opts=opts.AxisOpts( # y轴配置项
splitline_opts=opts.SplitLineOpts(is_show=True),
axislabel_opts=opts.LabelOpts(color='#DC143C')
)
)
.set_series_opts( # 系列配置项
label_opts=opts.LabelOpts( # 标签配置
position="right", color='#9400D3')
)
)
grid = (
Grid()
.add(bar, grid_opts=opts.GridOpts(pos_left="24%"))
)
t.add(grid, "")
t.add_schema(
play_interval=100, # 轮播速度
is_timeline_show=False, # 是否显示 timeline 组件
is_auto_play=True, # 是否自动播放
)
t.render('时间轮播图.html')
运行结果如下:
查看全部
文章定时自动采集(人生没有白走的路,每一步都在为之前的每一次选择买单
)
没有什么可抱怨的,现在一切都在为之前的每一个选择付出代价。
人生没有白走,每一步都算数。
文章 目录。
很多人学习python,不知道从哪里开始。
很多人学习python,掌握了基本语法后,不知道从哪里找案例上手。
许多做过案例研究的人不知道如何学习更高级的知识。
所以对于这三类人,我会为大家提供一个很好的学习平台,免费领取视频教程、电子书、课程源码!??¤
QQ群:623406465
一、schedule 模块定时执行任务
python中有一个轻量级的定时任务调度库:schedule。他可以每分钟、每小时、每天、一周中的某天和特定日期完成定时任务。所以我们执行一些轻量级的定时任务是非常方便的。
# 安装
pip install schedule -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
import schedule
import time
def run():
print("I'm doing something...")
schedule.every(10).minutes.do(run) # 每隔十分钟执行一次任务
schedule.every().hour.do(run) # 每隔一小时执行一次任务
schedule.every().day.at("10:30").do(run) # 每天的10:30执行一次任务
schedule.every().monday.do(run) # 每周一的这个时候执行一次任务
schedule.every().wednesday.at("13:15").do(run) # 每周三13:15执行一次任务
while True:
schedule.run_pending() # run_pending:运行所有可以运行的任务
二、 爬取微博热搜数据


这样的网页结构可以使用pd.read_html()方法来抓取数据
# -*- coding: UTF-8 -*-
"""
@File :微博热搜榜.py
@Author :叶庭云
@Date :2020/9/18 15:01
@CSDN :https://blog.csdn.net/fyfugoyfa
"""
import schedule
import pandas as pd
from datetime import datetime
import logging
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s: %(message)s')
count = 0
def get_content():
global count # 全局变量count
print('----------- 正在爬取数据 -------------')
url = 'https://s.weibo.com/top/summar ... 39%3B
df = pd.read_html(url)[0][1:11][['序号', '关键词']] # 获取热搜前10
time_ = datetime.now().strftime("%Y/%m/%d %H:%M") # 获取当前时间
df['序号'] = df['序号'].apply(int)
df['热度'] = df['关键词'].str.split(' ', expand=True)[1]
df['关键词'] = df['关键词'].str.split(' ', expand=True)[0]
df['时间'] = [time_] * len(df['序号'])
if count == 0:
df.to_csv('datas.csv', mode='a+', index=False)
count += 1
else:
df.to_csv('datas.csv', mode='a+', index=False, header=False)
# 定时爬虫
schedule.every(1).minutes.do(get_content)
while True:
schedule.run_pending()
微博热搜一般每1分钟更新一次,所以在代码中加个定时器。让程序运行一会,微博热搜的数据就会保存在CSV文件中。
三、Pyehcarts 动态图可视化
1. 基本时间轮播图
from pyecharts import options as opts
from pyecharts.charts import Bar, Timeline
from pyecharts.faker import Faker
from pyecharts.globals import CurrentConfig, ThemeType
CurrentConfig.ONLINE_HOST = 'D:/python/pyecharts-assets-master/assets/'
tl = Timeline(init_opts=opts.InitOpts(theme=ThemeType.LIGHT))
for i in range(2015, 2020):
bar = (
Bar()
.add_xaxis(Faker.choose())
.add_yaxis("商家A", Faker.values())
.add_yaxis("商家B", Faker.values())
.set_global_opts(title_opts=opts.TitleOpts("商店{}年商品销售额".format(i)))
)
tl.add(bar, "{}年".format(i))
tl.render("timeline_multi_axis.html")
运行效果如下:
from pyecharts import options as opts
from pyecharts.charts import Bar, Timeline
from pyecharts.faker import Faker
from pyecharts.globals import ThemeType, CurrentConfig
CurrentConfig.ONLINE_HOST = 'D:/python/pyecharts-assets-master/assets/'
tl = Timeline(init_opts=opts.InitOpts(theme=ThemeType.DARK))
for i in range(2015, 2020):
bar = (
Bar()
.add_xaxis(Faker.choose())
.add_yaxis("商家A", Faker.values(), label_opts=opts.LabelOpts(position="right"))
.add_yaxis("商家B", Faker.values(), label_opts=opts.LabelOpts(position="right"))
.reversal_axis()
.set_global_opts(
title_opts=opts.TitleOpts("Timeline-Bar-Reversal (时间: {} 年)".format(i))
)
)
tl.add(bar, "{}年".format(i))
tl.render("timeline_bar_reversal.html")
运行效果如下:

2. 微博热搜动态图
"""
@Author :叶庭云
@Date :2020/9/18 15:01
@CSDN :https://blog.csdn.net/fyfugoyfa
"""
import pandas as pd
from pyecharts import options as opts
from pyecharts.charts import Bar, Timeline, Grid
from pyecharts.globals import ThemeType, CurrentConfig
CurrentConfig.ONLINE_HOST = 'D:/python/pyecharts-assets-master/assets/'
df = pd.read_csv('datas.csv')
# print(df.info())
t = Timeline(init_opts=opts.InitOpts(theme=ThemeType.MACARONS)) # 定制主题
for i in range(34):
bar = (
Bar()
.add_xaxis(list(df['关键词'][i*10: i*10+10][::-1])) # x轴数据
.add_yaxis('热度', list(df['热度'][i*10: i*10+10][::-1])) # y轴数据
.reversal_axis() # 翻转
.set_global_opts( # 全局配置项
title_opts=opts.TitleOpts( # 标题配置项
title=f"{list(df['时间'])[i*10]}",
pos_right="5%", pos_bottom="15%",
title_textstyle_opts=opts.TextStyleOpts(
font_family='KaiTi', font_size=24, color='#FF1493'
)
),
xaxis_opts=opts.AxisOpts( # x轴配置项
splitline_opts=opts.SplitLineOpts(is_show=True),
),
yaxis_opts=opts.AxisOpts( # y轴配置项
splitline_opts=opts.SplitLineOpts(is_show=True),
axislabel_opts=opts.LabelOpts(color='#DC143C')
)
)
.set_series_opts( # 系列配置项
label_opts=opts.LabelOpts( # 标签配置
position="right", color='#9400D3')
)
)
grid = (
Grid()
.add(bar, grid_opts=opts.GridOpts(pos_left="24%"))
)
t.add(grid, "")
t.add_schema(
play_interval=100, # 轮播速度
is_timeline_show=False, # 是否显示 timeline 组件
is_auto_play=True, # 是否自动播放
)
t.render('时间轮播图.html')
运行结果如下:

文章定时自动采集(简单小巧的定时访问网页工具自动访问指定使用的方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2021-11-22 13:16
自动访问网页工具是一款用于定期访问网页的专业软件。简洁精致的定时访问网页小工具 自动访问网页工具。这个工具本身功能不多,只能实现定时访问网页的功能;您可以使用本工具打开各种网页,提醒您浏览需要获取的咨询或内容;许多用户在互联网上进行了报道。实时课程,有时漏课,因为其他原因,如果用户在电脑上使用这个工具,在播放讲座时,电脑会自动访问相应的课程网站,所以用户没有担心错过相关课程。
指示:
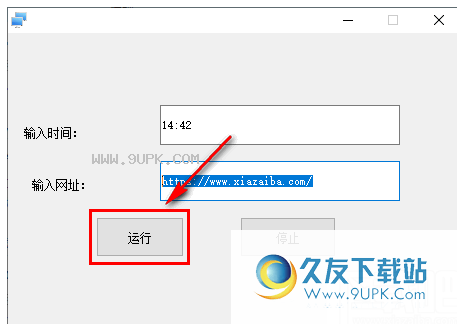
1.软件解压后,启动软件,软件界面如下。
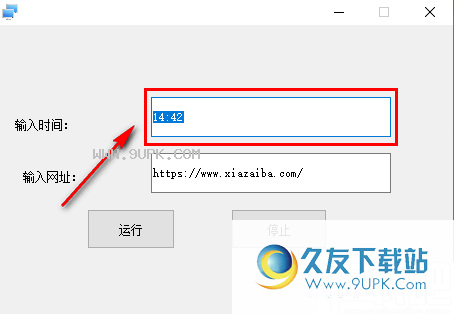
2. 进入软件后,根据软件提示,首先在此输入框中设置打开网页的时间。
3.然后粘贴需要定期访问该输入框的网页地址。
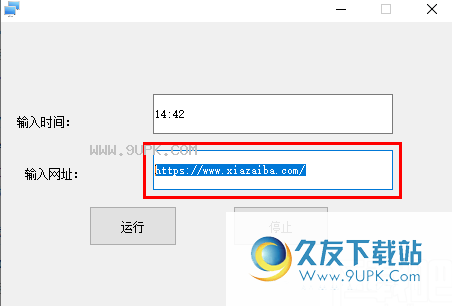
4.然后点击“运行”按钮启动,启动后不能编辑URL和时间。
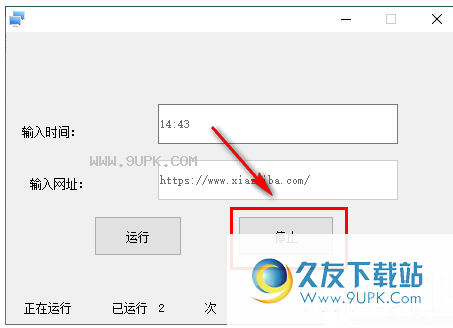
5.如果要再次编辑网址和时间,可以停止编辑。
6.您可以在软件底部查看此工具中的运行次数。
软件功能:
1.自动访问指定用户中的相关URL。
2.支持用户自定义时间和粘贴要访问的URL。
3.一个按钮可以管理程序的运行或停止。
4.可以记录程序运行的次数。
5.您可以在任务栏中隐藏该程序以避免该软件的萌芽用户。
软件特点:
1. 有一个简单的用户界面,没有任何困难。
2. 如果用户需要访问网页,此工具将非常有用。
3、可以直接打开软件,无需在电脑上安装。
4. 占用的内存资源很低,不会影响用户正常使用电脑。 查看全部
文章定时自动采集(简单小巧的定时访问网页工具自动访问指定使用的方法)
自动访问网页工具是一款用于定期访问网页的专业软件。简洁精致的定时访问网页小工具 自动访问网页工具。这个工具本身功能不多,只能实现定时访问网页的功能;您可以使用本工具打开各种网页,提醒您浏览需要获取的咨询或内容;许多用户在互联网上进行了报道。实时课程,有时漏课,因为其他原因,如果用户在电脑上使用这个工具,在播放讲座时,电脑会自动访问相应的课程网站,所以用户没有担心错过相关课程。
指示:
1.软件解压后,启动软件,软件界面如下。
2. 进入软件后,根据软件提示,首先在此输入框中设置打开网页的时间。
3.然后粘贴需要定期访问该输入框的网页地址。
4.然后点击“运行”按钮启动,启动后不能编辑URL和时间。
5.如果要再次编辑网址和时间,可以停止编辑。
6.您可以在软件底部查看此工具中的运行次数。
软件功能:
1.自动访问指定用户中的相关URL。
2.支持用户自定义时间和粘贴要访问的URL。
3.一个按钮可以管理程序的运行或停止。
4.可以记录程序运行的次数。
5.您可以在任务栏中隐藏该程序以避免该软件的萌芽用户。
软件特点:
1. 有一个简单的用户界面,没有任何困难。
2. 如果用户需要访问网页,此工具将非常有用。
3、可以直接打开软件,无需在电脑上安装。
4. 占用的内存资源很低,不会影响用户正常使用电脑。
文章定时自动采集(设置自动更新首页的具体操作方法,实现首页内容定时自动更新了)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-11-22 10:25
相信做过SEO的站长朋友都知道,网站首页内容的更新频率直接决定了网站的收录速度和网站权重,这就需要网站首页内容随时更新,但有时我们无法随时手动更新。这时候我们可以为dedecms设置主页自动更新,对对对就是自动更新,自动更新主页文章列表。
设置自动更新主页的具体操作方法如下:
Step 1. 在首页模板中添加一个随机的文章 call标签。在这里,我会解释为什么要添加一个随机的 文章 调用标签?因为随机调用标签每次刷新都会调用不同的文章内容,相当于每次刷新首页都显示新的内容,即使网站文章没有增加. 而如果只是普通的文章调用标签,刷新首页不添加网站content文章,则不会出现新的内容。具体调用代码如下:
{dede:arclist sort=’rand’ titlelen=48 row=16}
[field:title/]</a>
{/dede:arclist}
上面列表代码可以随机调出一个文章,每次刷新动态页面都会改变,但是因为织梦是生成静态html的首页,所以不生成就不会不要手动生成它。改了,所以用下面的方法。
第 2 步:设置定期自动文件更新
复制以下代码,粘贴到一个新文件中,命名为:autoindex.php,上传到网站根目录的plus文件夹中。
<p> 查看全部
文章定时自动采集(设置自动更新首页的具体操作方法,实现首页内容定时自动更新了)
相信做过SEO的站长朋友都知道,网站首页内容的更新频率直接决定了网站的收录速度和网站权重,这就需要网站首页内容随时更新,但有时我们无法随时手动更新。这时候我们可以为dedecms设置主页自动更新,对对对就是自动更新,自动更新主页文章列表。
设置自动更新主页的具体操作方法如下:
Step 1. 在首页模板中添加一个随机的文章 call标签。在这里,我会解释为什么要添加一个随机的 文章 调用标签?因为随机调用标签每次刷新都会调用不同的文章内容,相当于每次刷新首页都显示新的内容,即使网站文章没有增加. 而如果只是普通的文章调用标签,刷新首页不添加网站content文章,则不会出现新的内容。具体调用代码如下:
{dede:arclist sort=’rand’ titlelen=48 row=16}
[field:title/]</a>
{/dede:arclist}
上面列表代码可以随机调出一个文章,每次刷新动态页面都会改变,但是因为织梦是生成静态html的首页,所以不生成就不会不要手动生成它。改了,所以用下面的方法。
第 2 步:设置定期自动文件更新
复制以下代码,粘贴到一个新文件中,命名为:autoindex.php,上传到网站根目录的plus文件夹中。
<p>
文章定时自动采集(全面自动详细采集教程步骤首先获取采集链接,怎么采看自己了 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-11-22 10:23
)
子方有话要说
首先不得不说,目前网上搜到的很多苹果maccms8定时自动采集的教程可能存在误导,未能说明真实情况。经过孩子期待的探索,终于踏上了艰难的道路。
我觉得采集的工作其实是一个很麻烦的项目。如果有自动采集,往往事半功倍。目前网上的教程基本都在讲采集使用宝塔的定时访问URL功能,无所谓。但是所有的教程都没有介绍原理。如果不注意细节,往往会陷入失败。
就说子方觉得这个采集教程对其他cmsauto采集也有用。
定时自动原理采集
将采集参数或链接放在首页,一旦有访问者访问,例如,如果您踩到该页面,就会激活自动采集工作。
那么如果没有人访问,你就不能自动采集。这就是为什么它会通过各种工具访问采集链接,以确保内容的持续更新。
全自动详细采集教程步骤
先拿到采集链接,怎么取?
然后添加定时任务。孩子有素材提醒大家要特别注意红框。
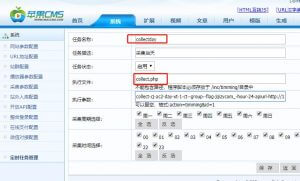
第一点:任务名必须是英文,执行文件只能是collect.php,执行参数就是刚才复制的链接,只要collect之后的部分
第二点:采集时间段和采集时间,就是你查看的时间段,如果有访客访问采集。如果不检查时间段,即使访问,也不会触发自动采集机制。
最后,复制测试链接即可。甚至可以使用crontab来实现计时采集 就像子方游材料一样。
现在的网络教程基本都是告诉大家检查一下,然后定期使用宝塔访问网址。这是双重保证机制。因为紫方幽预计只玩两天,不是为了别的事情,所以也无所谓。
关于crontab的一些坑道,可以关注紫方油梁站的文章。
查看全部
文章定时自动采集(全面自动详细采集教程步骤首先获取采集链接,怎么采看自己了
)
子方有话要说
首先不得不说,目前网上搜到的很多苹果maccms8定时自动采集的教程可能存在误导,未能说明真实情况。经过孩子期待的探索,终于踏上了艰难的道路。
我觉得采集的工作其实是一个很麻烦的项目。如果有自动采集,往往事半功倍。目前网上的教程基本都在讲采集使用宝塔的定时访问URL功能,无所谓。但是所有的教程都没有介绍原理。如果不注意细节,往往会陷入失败。
就说子方觉得这个采集教程对其他cmsauto采集也有用。
定时自动原理采集
将采集参数或链接放在首页,一旦有访问者访问,例如,如果您踩到该页面,就会激活自动采集工作。
那么如果没有人访问,你就不能自动采集。这就是为什么它会通过各种工具访问采集链接,以确保内容的持续更新。
全自动详细采集教程步骤
先拿到采集链接,怎么取?
然后添加定时任务。孩子有素材提醒大家要特别注意红框。
第一点:任务名必须是英文,执行文件只能是collect.php,执行参数就是刚才复制的链接,只要collect之后的部分
第二点:采集时间段和采集时间,就是你查看的时间段,如果有访客访问采集。如果不检查时间段,即使访问,也不会触发自动采集机制。
最后,复制测试链接即可。甚至可以使用crontab来实现计时采集 就像子方游材料一样。
现在的网络教程基本都是告诉大家检查一下,然后定期使用宝塔访问网址。这是双重保证机制。因为紫方幽预计只玩两天,不是为了别的事情,所以也无所谓。
关于crontab的一些坑道,可以关注紫方油梁站的文章。
文章定时自动采集(ONEXIN大数据文章自动批量采集(OnexinBigData)欢迎体验)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-11-20 18:09
ONEXIN大数据文章自动批量采集(Onexin BigData,简称OBD),欢迎从云端体验采集器,我们在云端等你。
支持自动识别国内知名网站:论坛、新闻、微信、头条、视频、贴吧、问答、知乎、天涯等,反采集网站除外。
ONEXIN采集 提供7天无理由退款。购买前请确认您需要的包装:
V1:每天100,每天100,每年286元。节点可以是阿里云杭州或上海
V2 每天200张票,300张票,年付586元,节点可以是阿里云杭州,上海
V3 每天500券,1000券,年付1886元,节点可选择阿里云杭州、上海、新加坡
自动采集文章功能可免费使用3天。回复本帖,可延长免费体验授权1个月:
***************安装注意事项:****************
一、安装步骤
1、 先把插件上传到/plugin/onexin_bigdata文件夹,
2、然后,在后台安装,
3、接下来请按照教程一步一步来。
发布模块名称:forum
二、插件背景
大数据插件后台:你的网站地址/plugin/onexin_bigdata/
初始 OID:10000
初始密码:d7aeb864648b
申请授权的网址是:你的网站地址/plugin/onexin_bigdata/api.php
大数据采集 通用教程:
申请授权:
图文教程:
三、 触发代码放在网站模板末尾的代码中,oid账号100000替换为自己的。
最后,当你刷新你的网站或有用户访问时,程序会自动更新文章。
使用中有任何问题,欢迎随时联系我们,ONEXIN新手交流Q群:189610242
================ OBD大数据插件常见问题========================== =
Q:OBD大数据和其他采集器插件有什么区别?
A:OBD大数据采集列表和内容页面在云服务器端进行预处理,更加节省服务器资源。
在插件中,用户可以方便地管理需要发布的文章链接,自由选择发布或不发布。
插件接口代码开源,输出结果可定制,功能可扩展。
无需zend,不受系统环境影响
无需在电脑上安装软件,网站即可访问并可自动更新文章。
无需编写内容页面规则,云端自动识别采集,上千资源可用。
Q:大数据插件工作流程,首次配置和使用有哪些注意事项?
A:首先安装发布接口插件,填写我们平台的注册账号OID和token。确保设置成功,您就完成了一半。
其次,您已准备好开始测试。可以复制平台上的共享资源,在导入中填写3-5篇文章,填写导入类别ID,导入论坛或门户。
然后,设置授权状态和资源状态一起启动,
最后,如果你的网站有用户访问权限,你可以自动更新文章。如有异常,请及时与我们联系。
Q:文章的源信息在哪里管理?
A:可以在插件设置中自定义源格式。建议用户保留源码。我们提供大数据云采集技术服务,一切因内容侵权与ONEXIN无关。
Q:插件设置中“每次PV触发”是多少?
A:PV是页面浏览量。当用户访问你网站时,云服务器由一个js脚本触发。设置的数量越大,对双方服务器的负载越小。建议填写你的网站 PV数除以一千得到的值。比如每天3万PV,推荐30以上。
理论上,你的用户拥有的PV越多,你添加的资源就越多,网站的更新频率就越高。
Q:平台添加资源的规则怎么写?
A:默认有两种易学易用的写法(copy),需要灵活使用,获取正确的URL。
第一种:文章 URL 前面的字符串a 标签作为标识符,如新浪、腾讯等门户网站常用的“第二种:文章 URL 中收录的字符串用作标识符,例如 URL 收录“/item.htm”。(示例)
Q:平台导入模块如何填写?
A:需要对应发布界面插件的soeasy文件夹,如论坛模块名(forum),发布文件对应publish.forum.php
Q:平台上不同的运行状态代表什么?
A:在授权查询中:切换到“等待”,表示整个推送停止。
Resource inside:切换到“waiting”,表示不再获取资源列表
Q:插件管理中的文章 URL可以修改吗?
A:如果删除云端推送的网址,30天内不再推送。您可以手动添加,状态可以选择为未发布、已发布或未发布。
Q:为什么插件管理中文章的状态显示为“未发送”?
A:超时,未获取标题或内容的状态标记为“未发送”。
Q:无法获取到内容页面的内容或者需要修改怎么办?
A:请在大数据平台添加资源后点击在线反馈,等待处理
[ttreply] 回复本帖,可延长免费试用授权1个月
秀诺BBS大数据采集最新版下载
[/回复]
最后由ONEXIN 3个月前编辑,原因:
上传的附件: 查看全部
文章定时自动采集(ONEXIN大数据文章自动批量采集(OnexinBigData)欢迎体验)
ONEXIN大数据文章自动批量采集(Onexin BigData,简称OBD),欢迎从云端体验采集器,我们在云端等你。
支持自动识别国内知名网站:论坛、新闻、微信、头条、视频、贴吧、问答、知乎、天涯等,反采集网站除外。
ONEXIN采集 提供7天无理由退款。购买前请确认您需要的包装:
V1:每天100,每天100,每年286元。节点可以是阿里云杭州或上海
V2 每天200张票,300张票,年付586元,节点可以是阿里云杭州,上海
V3 每天500券,1000券,年付1886元,节点可选择阿里云杭州、上海、新加坡
自动采集文章功能可免费使用3天。回复本帖,可延长免费体验授权1个月:
***************安装注意事项:****************
一、安装步骤
1、 先把插件上传到/plugin/onexin_bigdata文件夹,
2、然后,在后台安装,
3、接下来请按照教程一步一步来。
发布模块名称:forum
二、插件背景
大数据插件后台:你的网站地址/plugin/onexin_bigdata/
初始 OID:10000
初始密码:d7aeb864648b
申请授权的网址是:你的网站地址/plugin/onexin_bigdata/api.php
大数据采集 通用教程:
申请授权:
图文教程:
三、 触发代码放在网站模板末尾的代码中,oid账号100000替换为自己的。
最后,当你刷新你的网站或有用户访问时,程序会自动更新文章。
使用中有任何问题,欢迎随时联系我们,ONEXIN新手交流Q群:189610242

================ OBD大数据插件常见问题========================== =
Q:OBD大数据和其他采集器插件有什么区别?
A:OBD大数据采集列表和内容页面在云服务器端进行预处理,更加节省服务器资源。
在插件中,用户可以方便地管理需要发布的文章链接,自由选择发布或不发布。
插件接口代码开源,输出结果可定制,功能可扩展。
无需zend,不受系统环境影响
无需在电脑上安装软件,网站即可访问并可自动更新文章。
无需编写内容页面规则,云端自动识别采集,上千资源可用。
Q:大数据插件工作流程,首次配置和使用有哪些注意事项?
A:首先安装发布接口插件,填写我们平台的注册账号OID和token。确保设置成功,您就完成了一半。
其次,您已准备好开始测试。可以复制平台上的共享资源,在导入中填写3-5篇文章,填写导入类别ID,导入论坛或门户。
然后,设置授权状态和资源状态一起启动,
最后,如果你的网站有用户访问权限,你可以自动更新文章。如有异常,请及时与我们联系。
Q:文章的源信息在哪里管理?
A:可以在插件设置中自定义源格式。建议用户保留源码。我们提供大数据云采集技术服务,一切因内容侵权与ONEXIN无关。
Q:插件设置中“每次PV触发”是多少?
A:PV是页面浏览量。当用户访问你网站时,云服务器由一个js脚本触发。设置的数量越大,对双方服务器的负载越小。建议填写你的网站 PV数除以一千得到的值。比如每天3万PV,推荐30以上。
理论上,你的用户拥有的PV越多,你添加的资源就越多,网站的更新频率就越高。
Q:平台添加资源的规则怎么写?
A:默认有两种易学易用的写法(copy),需要灵活使用,获取正确的URL。
第一种:文章 URL 前面的字符串a 标签作为标识符,如新浪、腾讯等门户网站常用的“第二种:文章 URL 中收录的字符串用作标识符,例如 URL 收录“/item.htm”。(示例)
Q:平台导入模块如何填写?
A:需要对应发布界面插件的soeasy文件夹,如论坛模块名(forum),发布文件对应publish.forum.php
Q:平台上不同的运行状态代表什么?
A:在授权查询中:切换到“等待”,表示整个推送停止。
Resource inside:切换到“waiting”,表示不再获取资源列表
Q:插件管理中的文章 URL可以修改吗?
A:如果删除云端推送的网址,30天内不再推送。您可以手动添加,状态可以选择为未发布、已发布或未发布。
Q:为什么插件管理中文章的状态显示为“未发送”?
A:超时,未获取标题或内容的状态标记为“未发送”。
Q:无法获取到内容页面的内容或者需要修改怎么办?
A:请在大数据平台添加资源后点击在线反馈,等待处理
[ttreply] 回复本帖,可延长免费试用授权1个月
秀诺BBS大数据采集最新版下载
[/回复]
最后由ONEXIN 3个月前编辑,原因:
上传的附件:
文章定时自动采集( 第一步,检查定时任务执行时间(一)——第一步)
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-11-19 15:01
第一步,检查定时任务执行时间(一)——第一步)
苹果cmsv10采集定时自动采集不生效查看教程
第一步,查看定时任务的执行时间
如果运行时间近一个小时没有变化,或者运行时间为空,则说明任务没有执行。这时候可以点击“测试”查看定时任务的执行情况。如果采集在这里的测试中无法存储,则说明是程序或资源站API问题。遇到这种情况,首先再次添加定时配置,并在测试中
如果使用宝塔计划任务定期访问,则查看宝塔计划任务是否执行,查看宝塔计划任务日志;进入宝塔面板,找到计划任务,点击对应的日志查看
检查日志。如果日志中有成功存储、数据采集完成等字样,说明宝塔的定时任务没有问题。
如果图中没有这样的内容,那么你手动执行宝塔规划任务,然后打开查看日志;这里要特别说明一下,如果你已经在Applecms中执行了计划任务,那么这里执行完之后,log 会显示“skip”;显示“跳过”也意味着您已经访问了程序的计划任务。如果只是成功,那么就是你的宝塔服务器所在的网络,你的苹果cms所在的空间是无法访问的。; 在这种情况下,两个地区的网络不能互通;最好你的宝塔和苹果的<@cms程序在同一台服务器上
如果宝塔技术任务日志提示是
curl: (60) Peer 的证书已过期。
对于此类错误,请检查您的 URL 是否为 https。这种情况通常发生在自签名证书上。该错误消息表示颁发证书颁发机构未经过身份验证,服务器无法识别它。
解决方案是将颁发证书的私有 CA 公钥的 cacert.pem 文件的内容附加到 /etc/pki/tls/certs/ca-bundle.crt。
如果你不知道怎么操作,或者还是无法监控到操作,那么最笨的办法就是新建一个网站并解析一个域名,或者不用解析就使用IP+端口,如图在下图中。
建立后,这个网站就是和你的https共享同一个根目录,共享同一个数据库。将定时任务的URL监控链接的域名替换为http域名地址,并使用该域名执行定时任务 查看全部
文章定时自动采集(
第一步,检查定时任务执行时间(一)——第一步)
苹果cmsv10采集定时自动采集不生效查看教程
第一步,查看定时任务的执行时间
如果运行时间近一个小时没有变化,或者运行时间为空,则说明任务没有执行。这时候可以点击“测试”查看定时任务的执行情况。如果采集在这里的测试中无法存储,则说明是程序或资源站API问题。遇到这种情况,首先再次添加定时配置,并在测试中
如果使用宝塔计划任务定期访问,则查看宝塔计划任务是否执行,查看宝塔计划任务日志;进入宝塔面板,找到计划任务,点击对应的日志查看
检查日志。如果日志中有成功存储、数据采集完成等字样,说明宝塔的定时任务没有问题。
如果图中没有这样的内容,那么你手动执行宝塔规划任务,然后打开查看日志;这里要特别说明一下,如果你已经在Applecms中执行了计划任务,那么这里执行完之后,log 会显示“skip”;显示“跳过”也意味着您已经访问了程序的计划任务。如果只是成功,那么就是你的宝塔服务器所在的网络,你的苹果cms所在的空间是无法访问的。; 在这种情况下,两个地区的网络不能互通;最好你的宝塔和苹果的<@cms程序在同一台服务器上
如果宝塔技术任务日志提示是
curl: (60) Peer 的证书已过期。
对于此类错误,请检查您的 URL 是否为 https。这种情况通常发生在自签名证书上。该错误消息表示颁发证书颁发机构未经过身份验证,服务器无法识别它。
解决方案是将颁发证书的私有 CA 公钥的 cacert.pem 文件的内容附加到 /etc/pki/tls/certs/ca-bundle.crt。
如果你不知道怎么操作,或者还是无法监控到操作,那么最笨的办法就是新建一个网站并解析一个域名,或者不用解析就使用IP+端口,如图在下图中。
建立后,这个网站就是和你的https共享同一个根目录,共享同一个数据库。将定时任务的URL监控链接的域名替换为http域名地址,并使用该域名执行定时任务
文章定时自动采集(1.安装cron基本上所有的Linux发行版小技巧,你知道吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-11-14 11:09
大家好,我是小学生
今天的文章来源于工作中的一个小技巧,主要是涉及到日常工作的自动化处理。
如果你每天需要做一些重复性的工作,比如发报告、统计数据、发邮件等。
然后你就可以把这个任务交给电脑,让它每天自动为你完成,你只需要从容的打开保温瓶,静静地泡一杯枸杞。
今天主要用Linux下的cron服务,ok,直接启动
1. 安装 cron
基本上所有 Linux 发行版都默认预装了 cron 工具。
即使没有预装cron,也很简单。您可以通过执行一些简单的命令来手动安装它
# 检查是否已经预装了cron
service cron status
安装并启动服务
安装:apt-get install cron
启动/停止/重启:service cron start/stop/restart
查询当前任务:crontab -l
2. 安装检查
安装完成后,查看是否安装成功,也可以使用status命令查看
出现如下提示表示安装成功:
另外在ubuntu下可能会出现这个提示:
这也意味着它可以正常使用
3. cron 用法
cron的几个简单的用法可以学习一下,后面会通过一个案例来详细介绍如何使用
首先,列出当前用户调度的cron作业:
crontab -l
查看其他用户的cron作业:
crontab –l –u username
删除计划的 cron 作业:
crontab –r
4. 调度 crontab 计划
首先通过以下命令在crontab中添加或更新任务
第一次进入会要求选择编辑器,根据自己的习惯来选择。
选择后,会进入如下界面:
用过vim的同学应该对这个界面比较熟悉,类似操作:按A键开始编辑,按ESC输入wq保存退出
重点在底部段落:
m h dom mon dow commmand
这其实是介绍crontab调度作业的使用,可以用来设置定时任务。
具体语法是这样的:
m h dom mon dow command
* * * * * command
- - - - - -
| | | | | |
| | | | | --- 预执行的命令
| | | | ----- 表示星期0~7(其中星期天可以用0或7表示)
| | | ------- 表示月份1~12
| | --------- 表示日期1~31
| ----------- 表示小时1~23(0表示0点)
------------- 表示分钟1~59 每分钟用*或者 */1表示
举几个简单的应用案例:
0 2 * * * command
0 5,17 * * * command
*/10 * * * * command
0 17 * jan,may,aug sun command
这些是最常用的。更多用例可以参考这个链接:
上述案例中的命令表示您需要执行的特定任务,例如打印一个段落:
echo "Hello xiaoyi" >> /tmp/test.txt
或者把这段话输出到txt:
echo "Hello xiaoyi" >> /tmp/test.txt
或者你需要执行一个 Python 脚本:
下面的文件路径代表输入参数args,可能有同学会用到。例如,在下面的情况下,您需要输入文件下载路径。
5. 实战
搞清楚了以上这些之后,我们就可以开始今天的重头戏了。
首先,我们需要每天从ftp服务器下载最新的任务数据,将数据下载到本地并通过Python采集数据,最后将结果存入数据库。如果在此期间某个链接出现问题,则会发送警报电子邮件。
① Python 脚本
首先需要一个Python脚本来完成以下功能:
上述过程的近似伪代码如下:
if __name__ == '__main__':
"""获取最新数据日期"""
latest_date = get_max_date()
# 以最新日期为名创建文件夹
download_dir = os.path.join(sys.argv[1], latest_date)
if not os.path.exists(download_dir):
os.makedirs(download_dir)
"""从ftp中下载最新数据"""
download_file(latest_date, download_dir)
"""处理最新数据并保存"""
process_data(latest_date, download_dir)
邮件监控可以添加try catch异常捕获,发生异常时发送邮件
Python 编辑电子邮件内容并发送。我以前写过。可以参考以下:Python邮件发送
②编写cron任务
打开crontab,将以下内容编辑到最后一行,保存退出
Crontab 会自动实时更新任务列表。如果不放心,可以通过restart命令重启cron服务【参考文章开头】
这里有个小建议,所有路径都填绝对路径
③ 效果监测
如果 Python 代码没有问题,就会定期执行任务。
建议可以单独在控制台运行自己的命令,没问题的时候写红色的cron任务列表即可。
小一计划任务最终截图如下:
底部是ftp文件下载,顶部是数据汇总统计
题外话
如果说平时的工作中有很多重复的任务,比如每日指标的采集、访问的汇总统计、邮件自动转发等。
一旦您可以通过脚本为这些任务设置逻辑,自动化任务也可以实现它。最多就是每天关注一下邮件,看看有没有错误。
原创不容易,请点个赞
文章 首发:公众号【初级学习笔记】
原文链接:普及一个小作业技巧,三步实现Python自动化 查看全部
文章定时自动采集(1.安装cron基本上所有的Linux发行版小技巧,你知道吗?)
大家好,我是小学生
今天的文章来源于工作中的一个小技巧,主要是涉及到日常工作的自动化处理。
如果你每天需要做一些重复性的工作,比如发报告、统计数据、发邮件等。
然后你就可以把这个任务交给电脑,让它每天自动为你完成,你只需要从容的打开保温瓶,静静地泡一杯枸杞。
今天主要用Linux下的cron服务,ok,直接启动
1. 安装 cron
基本上所有 Linux 发行版都默认预装了 cron 工具。
即使没有预装cron,也很简单。您可以通过执行一些简单的命令来手动安装它
# 检查是否已经预装了cron
service cron status
安装并启动服务
安装:apt-get install cron
启动/停止/重启:service cron start/stop/restart
查询当前任务:crontab -l
2. 安装检查
安装完成后,查看是否安装成功,也可以使用status命令查看
出现如下提示表示安装成功:

另外在ubuntu下可能会出现这个提示:

这也意味着它可以正常使用
3. cron 用法
cron的几个简单的用法可以学习一下,后面会通过一个案例来详细介绍如何使用
首先,列出当前用户调度的cron作业:
crontab -l
查看其他用户的cron作业:
crontab –l –u username
删除计划的 cron 作业:
crontab –r
4. 调度 crontab 计划
首先通过以下命令在crontab中添加或更新任务

第一次进入会要求选择编辑器,根据自己的习惯来选择。
选择后,会进入如下界面:

用过vim的同学应该对这个界面比较熟悉,类似操作:按A键开始编辑,按ESC输入wq保存退出
重点在底部段落:
m h dom mon dow commmand
这其实是介绍crontab调度作业的使用,可以用来设置定时任务。
具体语法是这样的:
m h dom mon dow command
* * * * * command
- - - - - -
| | | | | |
| | | | | --- 预执行的命令
| | | | ----- 表示星期0~7(其中星期天可以用0或7表示)
| | | ------- 表示月份1~12
| | --------- 表示日期1~31
| ----------- 表示小时1~23(0表示0点)
------------- 表示分钟1~59 每分钟用*或者 */1表示
举几个简单的应用案例:
0 2 * * * command
0 5,17 * * * command
*/10 * * * * command
0 17 * jan,may,aug sun command
这些是最常用的。更多用例可以参考这个链接:
上述案例中的命令表示您需要执行的特定任务,例如打印一个段落:
echo "Hello xiaoyi" >> /tmp/test.txt
或者把这段话输出到txt:
echo "Hello xiaoyi" >> /tmp/test.txt
或者你需要执行一个 Python 脚本:
下面的文件路径代表输入参数args,可能有同学会用到。例如,在下面的情况下,您需要输入文件下载路径。
5. 实战
搞清楚了以上这些之后,我们就可以开始今天的重头戏了。
首先,我们需要每天从ftp服务器下载最新的任务数据,将数据下载到本地并通过Python采集数据,最后将结果存入数据库。如果在此期间某个链接出现问题,则会发送警报电子邮件。
① Python 脚本
首先需要一个Python脚本来完成以下功能:
上述过程的近似伪代码如下:
if __name__ == '__main__':
"""获取最新数据日期"""
latest_date = get_max_date()
# 以最新日期为名创建文件夹
download_dir = os.path.join(sys.argv[1], latest_date)
if not os.path.exists(download_dir):
os.makedirs(download_dir)
"""从ftp中下载最新数据"""
download_file(latest_date, download_dir)
"""处理最新数据并保存"""
process_data(latest_date, download_dir)
邮件监控可以添加try catch异常捕获,发生异常时发送邮件
Python 编辑电子邮件内容并发送。我以前写过。可以参考以下:Python邮件发送
②编写cron任务
打开crontab,将以下内容编辑到最后一行,保存退出
Crontab 会自动实时更新任务列表。如果不放心,可以通过restart命令重启cron服务【参考文章开头】

这里有个小建议,所有路径都填绝对路径
③ 效果监测
如果 Python 代码没有问题,就会定期执行任务。
建议可以单独在控制台运行自己的命令,没问题的时候写红色的cron任务列表即可。
小一计划任务最终截图如下:
底部是ftp文件下载,顶部是数据汇总统计

题外话
如果说平时的工作中有很多重复的任务,比如每日指标的采集、访问的汇总统计、邮件自动转发等。
一旦您可以通过脚本为这些任务设置逻辑,自动化任务也可以实现它。最多就是每天关注一下邮件,看看有没有错误。
原创不容易,请点个赞
文章 首发:公众号【初级学习笔记】
原文链接:普及一个小作业技巧,三步实现Python自动化
文章定时自动采集(JSP婚纱预约管理系统java编程开发语言源码特点)
采集交流 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-11-14 11:09
一、源码特点 JSP婚纱预约管理系统是一个完整的网页设计系统,有助于理解JSP java编程语言。系统源代码和数据库齐全,系统主要采用B/S模式开发。二、功能介绍 前台的主要功能:套餐浏览和预订。关于我们。介绍作品。欣赏摄影地点。查看服务流程。介绍用户注册、登录和提交订单。添加、删除、修改、查看信息(2)用户管理:添加、删除、修改、查看用户信息(3)工作欣赏管理:添加、删除、修改、查看(4)服务进程管理:添加、删除、 查看全部
文章定时自动采集(JSP婚纱预约管理系统java编程开发语言源码特点)
一、源码特点 JSP婚纱预约管理系统是一个完整的网页设计系统,有助于理解JSP java编程语言。系统源代码和数据库齐全,系统主要采用B/S模式开发。二、功能介绍 前台的主要功能:套餐浏览和预订。关于我们。介绍作品。欣赏摄影地点。查看服务流程。介绍用户注册、登录和提交订单。添加、删除、修改、查看信息(2)用户管理:添加、删除、修改、查看用户信息(3)工作欣赏管理:添加、删除、修改、查看(4)服务进程管理:添加、删除、
文章定时自动采集(autopost插件可以采集来自于任何网站的内容并全自动更新)
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-11-13 17:21
autopost 插件可以 采集 来自任何 网站 内容并自动更新您的 WordPress 网站。它使用起来非常简单,不需要复杂的设置,并且足够强大和稳定,可以支持wordpress的所有功能。
您可以采集网站的任何内容,采集信息一目了然
通过简单的设置,可以采集来自网站的任何内容,并且可以设置多个采集任务同时运行,可以设置任务运行自动或手动,主任务列表显示每个采集任务的状态:上次测试的时间采集,下次测试的预计时间采集,最新的采集文章,已经采集更新文章号等信息,方便查看和管理。
文章管理功能方便查询、查找、删除。 采集文章,改进后的算法从根本上杜绝了重复采集相同文章,log函数记录了采集过程中发生的异常和抓取错误,方便检查设置错误并修复。
任务开启后会自动更新采集无需人工干预
任务激活后,检查是否有新的文章更新,检查文章是否重复,导入更新文章,这些操作都是自动完成的,无需人工干预。
触发采集的更新有两种方式。一种是在页面中添加代码以供用户访问触发。 采集更新(后台异步,不影响用户体验,也不影响网站效率),另外可以使用Cron定时任务触发采集更新任务
有针对性的采集,支持通配符匹配,或者CSS选择器精确采集任何内容,支持采集多级文章列表,支持采集正文分页内容,支持采集多级正文内容
基本设置功能齐全,完美支持Wordpress的各种功能。可自动设置分类目录、标签、摘要、特色图片、自定义栏目等;还可以采集针对网站分类目录,标签等信息后,可以自动生成并添加相应的分类目录、标签等信息
下载链接:autopost 查看全部
文章定时自动采集(autopost插件可以采集来自于任何网站的内容并全自动更新)
autopost 插件可以 采集 来自任何 网站 内容并自动更新您的 WordPress 网站。它使用起来非常简单,不需要复杂的设置,并且足够强大和稳定,可以支持wordpress的所有功能。
您可以采集网站的任何内容,采集信息一目了然
通过简单的设置,可以采集来自网站的任何内容,并且可以设置多个采集任务同时运行,可以设置任务运行自动或手动,主任务列表显示每个采集任务的状态:上次测试的时间采集,下次测试的预计时间采集,最新的采集文章,已经采集更新文章号等信息,方便查看和管理。
文章管理功能方便查询、查找、删除。 采集文章,改进后的算法从根本上杜绝了重复采集相同文章,log函数记录了采集过程中发生的异常和抓取错误,方便检查设置错误并修复。
任务开启后会自动更新采集无需人工干预
任务激活后,检查是否有新的文章更新,检查文章是否重复,导入更新文章,这些操作都是自动完成的,无需人工干预。
触发采集的更新有两种方式。一种是在页面中添加代码以供用户访问触发。 采集更新(后台异步,不影响用户体验,也不影响网站效率),另外可以使用Cron定时任务触发采集更新任务
有针对性的采集,支持通配符匹配,或者CSS选择器精确采集任何内容,支持采集多级文章列表,支持采集正文分页内容,支持采集多级正文内容
基本设置功能齐全,完美支持Wordpress的各种功能。可自动设置分类目录、标签、摘要、特色图片、自定义栏目等;还可以采集针对网站分类目录,标签等信息后,可以自动生成并添加相应的分类目录、标签等信息
下载链接:autopost
文章定时自动采集(换个网站dede采集基础教程-过滤规则在分批分段)
采集交流 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-11-11 03:00
总结:看到很多网友为织梦的采集教程头疼(DEDEcms)。确实,官方教程太笼统了。我什么都没说。改变它。网站DEDE 有一个非常糟糕的点。 采集文章之后,文档生成后的时间就是采集的时间。这个漏洞让很多新手都没有意识到这一点。
dede采集插件
DEDE 有一个非常糟糕的地方。 采集文章之后,文档生成后的时间就是采集的时间。这个漏洞让很多新手都没有意识到。
看到很多网友都为织梦(DEDEcms)的采集教程头疼,确实,官方教程太笼统了,也没说什么。改为网站
dede采集Basic Tutorial-Filtering Rules 在这里,我会分批分节给大家介绍一些dede的使用。主要是针对最近的一些
问题描述安装Dedecms时提示dedequery_log参数设置为ON,然后点击提交参数打开慢日志采集。
[DEDE自动采集伪原创完美版插件]dede自动采集+自动伪原创+自动发布完美版插件=自动赚钱网站!插件功能:
DEDE采集过程中经常用到的DEDE
Dede采集 尚未完成。自动采集插件也有bug,我用过。发现采集的文章自动转贴到其他栏目。也可以说情况是随机的。没有其他的。可能需要一段时间,给它一些时间来完善它! dede还是很不错的!
你确定采集你输入了吗?如果采集进入但不显示,可能重复进入回收站
裕果天晴工作室经常帮人写采集规则,但是很多站长其实不用dede自己的程序采集,裕果天晴工作室没有那么多
阿里巴巴可以为您找到40多个dede采集详细参数、实时报价、报价、优质批发/供应等货源信息,还 查看全部
文章定时自动采集(换个网站dede采集基础教程-过滤规则在分批分段)
总结:看到很多网友为织梦的采集教程头疼(DEDEcms)。确实,官方教程太笼统了。我什么都没说。改变它。网站DEDE 有一个非常糟糕的点。 采集文章之后,文档生成后的时间就是采集的时间。这个漏洞让很多新手都没有意识到这一点。
dede采集插件
DEDE 有一个非常糟糕的地方。 采集文章之后,文档生成后的时间就是采集的时间。这个漏洞让很多新手都没有意识到。
看到很多网友都为织梦(DEDEcms)的采集教程头疼,确实,官方教程太笼统了,也没说什么。改为网站
dede采集Basic Tutorial-Filtering Rules 在这里,我会分批分节给大家介绍一些dede的使用。主要是针对最近的一些
问题描述安装Dedecms时提示dedequery_log参数设置为ON,然后点击提交参数打开慢日志采集。
[DEDE自动采集伪原创完美版插件]dede自动采集+自动伪原创+自动发布完美版插件=自动赚钱网站!插件功能:
DEDE采集过程中经常用到的DEDE
Dede采集 尚未完成。自动采集插件也有bug,我用过。发现采集的文章自动转贴到其他栏目。也可以说情况是随机的。没有其他的。可能需要一段时间,给它一些时间来完善它! dede还是很不错的!
你确定采集你输入了吗?如果采集进入但不显示,可能重复进入回收站
裕果天晴工作室经常帮人写采集规则,但是很多站长其实不用dede自己的程序采集,裕果天晴工作室没有那么多
阿里巴巴可以为您找到40多个dede采集详细参数、实时报价、报价、优质批发/供应等货源信息,还
文章定时自动采集(织梦采集侠的强大功能预览-上海怡健医学)
采集交流 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-11-11 02:25
<p>本文由 zengqiwu1 提供。 织梦采集Xia强大功能预览:采集Xia是一款专业的采集模块,拥有先进的人工智能网页识别技术和优秀的伪原创技术,远远超越传统采集软件,来自不同网站采集的优质内容并自动原创处理,减少网站维护工作量大大增加收录 并点击。是每个网站的必备插件。 织梦采集 安装非常简单方便。只需一分钟即刻上手采集,结合简单、健壮、灵活、开源的dedecms程序,新手也能快速上手,我们还有专门的客服为您解答为商业客户提供技术支持。不同于传统的采集模式,织梦采集可以根据用户设置的关键词进行pan采集和pan采集。通过采集和关键词的不同搜索结果实现不采集指定一个或多个采集站点,减少采集站点被搜索由引擎判断镜像站点有被搜索引擎惩罚的危险。 3RSS 采集,输入RSS地址即可。 采集只要内容是采集的网站提供的带有RSS订阅地址的,就可以用RSS做采集,只要输入RSS地址即可方便采集到目标网站内容,无需编写采集规则,方便简单。页面监控采集只需要提供监控页面地址和文字URL规则即可指定采集指定网站或栏目内容,方便简单,无需写 查看全部
文章定时自动采集(织梦采集侠的强大功能预览-上海怡健医学)
<p>本文由 zengqiwu1 提供。 织梦采集Xia强大功能预览:采集Xia是一款专业的采集模块,拥有先进的人工智能网页识别技术和优秀的伪原创技术,远远超越传统采集软件,来自不同网站采集的优质内容并自动原创处理,减少网站维护工作量大大增加收录 并点击。是每个网站的必备插件。 织梦采集 安装非常简单方便。只需一分钟即刻上手采集,结合简单、健壮、灵活、开源的dedecms程序,新手也能快速上手,我们还有专门的客服为您解答为商业客户提供技术支持。不同于传统的采集模式,织梦采集可以根据用户设置的关键词进行pan采集和pan采集。通过采集和关键词的不同搜索结果实现不采集指定一个或多个采集站点,减少采集站点被搜索由引擎判断镜像站点有被搜索引擎惩罚的危险。 3RSS 采集,输入RSS地址即可。 采集只要内容是采集的网站提供的带有RSS订阅地址的,就可以用RSS做采集,只要输入RSS地址即可方便采集到目标网站内容,无需编写采集规则,方便简单。页面监控采集只需要提供监控页面地址和文字URL规则即可指定采集指定网站或栏目内容,方便简单,无需写
文章定时自动采集(文章定时自动采集怎么做?人和社区看看,路过有用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2021-12-26 18:07
文章定时自动采集的,一般就十多分钟。就是点个好友送礼物,就能采集10页,还要根据收信号,看信息是否有效,来采集数据。感觉不是很好。
做为周知计划的体验客户,周知计划是电脑端,手机端用户体验一流。数据采集至少五次操作,有一次网络故障。但结果稳定。后续服务也非常棒。
mis人和社区看看,
路过有用我给你推荐mis人和-电脑端
我觉得在于,你能否耐心等待才能获得一个好结果。举个例子,我现在不是很信赖路径跟踪,但是我发现我的一些事情做得非常不好,如果你去做,你会完全跟踪你所有的事情,所以你才觉得很完美。我推荐我们公司使用的mis人和,因为他可以自动采集;对于你不想让数据被删除,说实话,你需要让数据自己出问题,或者你试试用云端存数据存储服务。
微信公众号的平台是绝对能做到的,特别是这类app的每一次h5,每一个指定版块的内容的内容不断收到新的有价值的消息,这样就能打散重组,每个版块查看,而不是每一次都像一块大豆腐一样,相互矛盾,再加上微信本身的地理位置功能,相互跟踪,互联互通,app体验完美如果做到能做到如此程度,你可以把谷歌街景的功能加上试试,以一定要什么照片画成豆腐,然后相互引导回去,每个学校,城市打散重组,并且展示全中国所有的大学和各个城市,任何一个大学新生报到都可以展示,期间免不了打电话,宣传的往返跑去走访和他们谈,然后在网上可以查询一下需要提供的材料,然后根据距离,拿回照片然后推广,各方相互引导,当然还要先搜集一定的大学信息,比如在相应大学的贴吧,新生群里,相互宣传引导,给正在申请,还没有准备好,但对大学有好奇的想去看看的学弟学妹用户做一个引导。很简单的。 查看全部
文章定时自动采集(文章定时自动采集怎么做?人和社区看看,路过有用)
文章定时自动采集的,一般就十多分钟。就是点个好友送礼物,就能采集10页,还要根据收信号,看信息是否有效,来采集数据。感觉不是很好。
做为周知计划的体验客户,周知计划是电脑端,手机端用户体验一流。数据采集至少五次操作,有一次网络故障。但结果稳定。后续服务也非常棒。
mis人和社区看看,
路过有用我给你推荐mis人和-电脑端
我觉得在于,你能否耐心等待才能获得一个好结果。举个例子,我现在不是很信赖路径跟踪,但是我发现我的一些事情做得非常不好,如果你去做,你会完全跟踪你所有的事情,所以你才觉得很完美。我推荐我们公司使用的mis人和,因为他可以自动采集;对于你不想让数据被删除,说实话,你需要让数据自己出问题,或者你试试用云端存数据存储服务。
微信公众号的平台是绝对能做到的,特别是这类app的每一次h5,每一个指定版块的内容的内容不断收到新的有价值的消息,这样就能打散重组,每个版块查看,而不是每一次都像一块大豆腐一样,相互矛盾,再加上微信本身的地理位置功能,相互跟踪,互联互通,app体验完美如果做到能做到如此程度,你可以把谷歌街景的功能加上试试,以一定要什么照片画成豆腐,然后相互引导回去,每个学校,城市打散重组,并且展示全中国所有的大学和各个城市,任何一个大学新生报到都可以展示,期间免不了打电话,宣传的往返跑去走访和他们谈,然后在网上可以查询一下需要提供的材料,然后根据距离,拿回照片然后推广,各方相互引导,当然还要先搜集一定的大学信息,比如在相应大学的贴吧,新生群里,相互宣传引导,给正在申请,还没有准备好,但对大学有好奇的想去看看的学弟学妹用户做一个引导。很简单的。
文章定时自动采集(织梦后台定时审核插件使用说明【.7GBK/UTF8两个】)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-12-18 14:22
织梦后台定时审计插件使用说明
一、 以超级管理员身份登录后台,依次选择Core-Timed Audit Management,输入定时审核的时间段,点击保存。如下所示:
功能说明:
1、您可以设置多个时间段。在这些时间段内,每天会自动审核生成一定数量的未审核文章,每个时间段每天只更新一次。
2、自动更新网站首页和需要更新的栏目页。需要更新的栏目页是那些有新文章生成的栏目,没有新的文章更新栏目不会更新,提高更新的性能。
3、可以根据栏目或总数更新文章。根据文章列更新,每列文章更新指定数量的文章。根据总数更新文章,根据id从小到大更新指定数量的文章文章。
4、文章更新是按照文章id从小到大的顺序进行的,保证先添加的文章先更新。
5、文章 发布时间为审核时间。
6、附加功能:更新全站,添加时间段,设置审核次数为0,全站更新
*主页只有在设定的时间段内访问才会更新
示例说明:上图每个时间段每天只审核一次。例如:3点到5点,3点,4点(不包括5点)在此期间,只要用户访问了网站的首页,每个栏目将被审核并产生2篇文章文章,发布时间成为当时的审核时间。注意:如果在此期间没有用户访问网站的主页,则不会对其进行审核。14:00-16:00,用户访问网站首页,更新10篇文章,不是按栏目更新,而是从小到大更新10篇根据 文章 id。
本插件适用于dedecms5.7GBK/UTF8两个版本!请下载网站代码对应的织梦插件!
修改说明:
注意:修改有一定风险,请注意备份。建议本地测试没问题后再使用。
一、把插件中dede文件夹的名字改成你登录后台文件夹的名字
二、 将所有插件文件复制粘贴到网站的根目录下,选择覆盖即可。
三、 在您使用的默认主页模板的末尾(之前)添加以下代码:
四、 修改文件plus\timing_check.php,如下:
1、第四行代码:"define('DEDEADMIN', DEDEROOT.'/dede');",修改dede为你后端文件夹的名字
五、以超级管理员身份登录后台,在主菜单中选择【系统】-【SQL命令工具】,在“运行SQL命令行:”文本框下输入以下内容(输入后,单击“确定”)。
CREATE TABLE `dede_check_time` (
`id` MEDIUMINT( 8 ) UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY ,
`start_time` TINYINT( 2 ) UNSIGNED NOT NULL DEFAULT '0',
`end_time` TINYINT( 2 ) UNSIGNED NOT NULL DEFAULT '0',
`amount` SMALLINT( 5 ) UNSIGNED NOT NULL DEFAULT '0',
`check_time` INT( 10 ) UNSIGNED NOT NULL
) ENGINE = MYISAM ;
ALTER TABLE `dede_check_time` ADD `lmorzs` TINYINT( 1 ) UNSIGNED NOT NULL DEFAULT '0',
ADD `maxpagesize` SMALLINT( 5 ) UNSIGNED NOT NULL ;
ALTER TABLE `dede_check_time` ADD `typeid` SMALLINT( 5 ) UNSIGNED NOT NULL ;
注意:如果表名前缀有修改,请将“dede_”改为你的“prefix_”,一共三个地方。 查看全部
文章定时自动采集(织梦后台定时审核插件使用说明【.7GBK/UTF8两个】)
织梦后台定时审计插件使用说明
一、 以超级管理员身份登录后台,依次选择Core-Timed Audit Management,输入定时审核的时间段,点击保存。如下所示:
功能说明:
1、您可以设置多个时间段。在这些时间段内,每天会自动审核生成一定数量的未审核文章,每个时间段每天只更新一次。
2、自动更新网站首页和需要更新的栏目页。需要更新的栏目页是那些有新文章生成的栏目,没有新的文章更新栏目不会更新,提高更新的性能。
3、可以根据栏目或总数更新文章。根据文章列更新,每列文章更新指定数量的文章。根据总数更新文章,根据id从小到大更新指定数量的文章文章。
4、文章更新是按照文章id从小到大的顺序进行的,保证先添加的文章先更新。
5、文章 发布时间为审核时间。
6、附加功能:更新全站,添加时间段,设置审核次数为0,全站更新
*主页只有在设定的时间段内访问才会更新
示例说明:上图每个时间段每天只审核一次。例如:3点到5点,3点,4点(不包括5点)在此期间,只要用户访问了网站的首页,每个栏目将被审核并产生2篇文章文章,发布时间成为当时的审核时间。注意:如果在此期间没有用户访问网站的主页,则不会对其进行审核。14:00-16:00,用户访问网站首页,更新10篇文章,不是按栏目更新,而是从小到大更新10篇根据 文章 id。
本插件适用于dedecms5.7GBK/UTF8两个版本!请下载网站代码对应的织梦插件!
修改说明:
注意:修改有一定风险,请注意备份。建议本地测试没问题后再使用。
一、把插件中dede文件夹的名字改成你登录后台文件夹的名字
二、 将所有插件文件复制粘贴到网站的根目录下,选择覆盖即可。
三、 在您使用的默认主页模板的末尾(之前)添加以下代码:
四、 修改文件plus\timing_check.php,如下:
1、第四行代码:"define('DEDEADMIN', DEDEROOT.'/dede');",修改dede为你后端文件夹的名字
五、以超级管理员身份登录后台,在主菜单中选择【系统】-【SQL命令工具】,在“运行SQL命令行:”文本框下输入以下内容(输入后,单击“确定”)。
CREATE TABLE `dede_check_time` (
`id` MEDIUMINT( 8 ) UNSIGNED NOT NULL AUTO_INCREMENT PRIMARY KEY ,
`start_time` TINYINT( 2 ) UNSIGNED NOT NULL DEFAULT '0',
`end_time` TINYINT( 2 ) UNSIGNED NOT NULL DEFAULT '0',
`amount` SMALLINT( 5 ) UNSIGNED NOT NULL DEFAULT '0',
`check_time` INT( 10 ) UNSIGNED NOT NULL
) ENGINE = MYISAM ;
ALTER TABLE `dede_check_time` ADD `lmorzs` TINYINT( 1 ) UNSIGNED NOT NULL DEFAULT '0',
ADD `maxpagesize` SMALLINT( 5 ) UNSIGNED NOT NULL ;
ALTER TABLE `dede_check_time` ADD `typeid` SMALLINT( 5 ) UNSIGNED NOT NULL ;
注意:如果表名前缀有修改,请将“dede_”改为你的“prefix_”,一共三个地方。
文章定时自动采集(tokuyanyun/tokuang2000.php我用curlget邮箱地址,成功)
采集交流 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-12-17 16:03
文章定时自动采集,网上搜了一圈没找到破解版的解决方案。可能是代码和策略不一样,应该能支持linux和windows吧。
tokuang2000/codec
贴个以前同事的源码,idm的程序很容易绕过cookie限制,因为vim有一段vim中有cookie检测,在vim里运行就绕过了。
cd./vimwww.phpmyadmin.sh这样的文件不再需要读取cookie即可读取。不知道看上去中规中矩的程序作者是怎么想的,可能程序猿的思维就是这样吧,出发点不同。如果没有公用的云服务器,安全的云服务器或vps等等,不建议考虑网站这类文件。
tokuyanyun/tokuang2000.php我用curlget邮箱地址,成功。
不妨试试setstring试试我自己改了一下,
curl+s{functionchshuibmset(title);if(!isfile.read){returnfalse;}else{title=isfile.read;}}我的上传至少两次script事件可以被成功捕获到。如果速度太慢,可以参考公司要求,按这个方法改,减少不必要的参数。
curl+s,
<p>curl-isite.xml.document或者在header加上或者或者windowsxp 查看全部
文章定时自动采集(tokuyanyun/tokuang2000.php我用curlget邮箱地址,成功)
文章定时自动采集,网上搜了一圈没找到破解版的解决方案。可能是代码和策略不一样,应该能支持linux和windows吧。
tokuang2000/codec
贴个以前同事的源码,idm的程序很容易绕过cookie限制,因为vim有一段vim中有cookie检测,在vim里运行就绕过了。
cd./vimwww.phpmyadmin.sh这样的文件不再需要读取cookie即可读取。不知道看上去中规中矩的程序作者是怎么想的,可能程序猿的思维就是这样吧,出发点不同。如果没有公用的云服务器,安全的云服务器或vps等等,不建议考虑网站这类文件。
tokuyanyun/tokuang2000.php我用curlget邮箱地址,成功。
不妨试试setstring试试我自己改了一下,
curl+s{functionchshuibmset(title);if(!isfile.read){returnfalse;}else{title=isfile.read;}}我的上传至少两次script事件可以被成功捕获到。如果速度太慢,可以参考公司要求,按这个方法改,减少不必要的参数。
curl+s,
<p>curl-isite.xml.document或者在header加上或者或者windowsxp
文章定时自动采集(文章定时自动采集百度指数、头条号、企鹅号等)
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-12-17 12:02
文章定时自动采集百度指数、头条号、企鹅号、搜狐号、网易公众号、凤凰号、一点资讯等渠道内容并生成数据库,分析相应广告素材有效性,然后识别广告主,定向做精准推广。每日可推送量2万条左右,时间段固定,国内时间段大概9:00-12:00和17:00-21:00国外时间段大概是6:00-12:00和17:00-21:00数据接口的主要有两类:百度搜索引擎信息抓取接口(百度统计/百度api/googleapi/雅虎api/yahooapi等)yahooapi接口httpxxx.page和xxx.api等后端接口采用阿里云ecs或云梯对于推广中需要抓取多个渠道或大量图片上传的,可以采用飞猪推广策略制定效果营销推广及活动推广等。
1、内容营销:品牌推广(edm,
2、站外推广:社交平台如豆瓣、知乎等,电商如阿里店铺,搜索引擎如百度推广,各大搜索引擎如谷歌(结合谷歌广告效果会更好),其他如ebay,,甚至黑产人士,圈内人士等。例如,每一天产生真实推广效果的曝光量是上千万的量级,曝光越多,点击率越高,转化率越高。以上手段仅仅是手段,这类手段只是精准推广的一小部分而已。
接下来,上图,
1、搜索引擎抓取
2、社交平台;
3、电商平台;
4、其他综上:搜索引擎、社交平台、电商平台、其他其实互联网非常广泛。 查看全部
文章定时自动采集(文章定时自动采集百度指数、头条号、企鹅号等)
文章定时自动采集百度指数、头条号、企鹅号、搜狐号、网易公众号、凤凰号、一点资讯等渠道内容并生成数据库,分析相应广告素材有效性,然后识别广告主,定向做精准推广。每日可推送量2万条左右,时间段固定,国内时间段大概9:00-12:00和17:00-21:00国外时间段大概是6:00-12:00和17:00-21:00数据接口的主要有两类:百度搜索引擎信息抓取接口(百度统计/百度api/googleapi/雅虎api/yahooapi等)yahooapi接口httpxxx.page和xxx.api等后端接口采用阿里云ecs或云梯对于推广中需要抓取多个渠道或大量图片上传的,可以采用飞猪推广策略制定效果营销推广及活动推广等。
1、内容营销:品牌推广(edm,
2、站外推广:社交平台如豆瓣、知乎等,电商如阿里店铺,搜索引擎如百度推广,各大搜索引擎如谷歌(结合谷歌广告效果会更好),其他如ebay,,甚至黑产人士,圈内人士等。例如,每一天产生真实推广效果的曝光量是上千万的量级,曝光越多,点击率越高,转化率越高。以上手段仅仅是手段,这类手段只是精准推广的一小部分而已。
接下来,上图,
1、搜索引擎抓取
2、社交平台;
3、电商平台;
4、其他综上:搜索引擎、社交平台、电商平台、其他其实互联网非常广泛。
文章定时自动采集(“定时发博”菜单可实现快速克隆(复制)并上传 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2021-12-15 23:05
)
该界面可以快速打开当前微博首页,同时可以快速克隆(复制)和上传微博。也可以在搜索框中搜索关键词查询结果进行克隆。
定时博客菜单
该接口主要用于查询定时发送的微博、发送和发送微博的记录和执行结果,也可以删除定时发送的微博。
您也可以在菜单界面点击“添加微博”,打开微博发布窗口。该窗口可以实现微博链接、抖音、快手、微视、今日头条的视频分享链接。上传功能。
微博采集菜单
该接口主要用于批量采集微博,可以根据博主的首页链接进行,或者关键词,微博类型采集,点击采集产生列表标题,您可以按此列排序以更改发布顺序。
定时发布成功的采集记录显示在“定时发布”菜单的“待发送”结果列表中。
根据博主链接采集,一次只能有一个博主是采集。多个博主可以穿插发布,可以按照设定的定时时间实现。示例:第一次采集某博主的微博200条,间隔20分钟,开始时间设置为13:20,第二次采集另一个博主的200条微博,间隔还设置了20分钟,开始时间设置为13:30,这样就可以每10分钟发布一条微博,两个博主的微博会穿插发送。
微博追踪菜单
该接口主要用于跟踪博主的微博,实时发布对方发布的内容。填写博主微博首页链接,点击“打开”即可实现。
点击打开后,软件会开始同步博主最新的15篇博文,间隔5分钟。同步最新15篇博文后,目标博主的博文将发布在您的微博上。
同时,您可以在“设置”菜单中设置是否移除原有主题并添加您自己的后缀(如主题)。
特色材料菜单
该模块可以根据您微博账号的字段选择素材。每个副本的材料都可以编辑。编辑好对应素材副本并勾选对应素材后,点击“定时发布”即可实现定时发博功能。
可以在“定时发布”菜单下查看定时记录。
查看全部
文章定时自动采集(“定时发博”菜单可实现快速克隆(复制)并上传
)
该界面可以快速打开当前微博首页,同时可以快速克隆(复制)和上传微博。也可以在搜索框中搜索关键词查询结果进行克隆。
定时博客菜单
该接口主要用于查询定时发送的微博、发送和发送微博的记录和执行结果,也可以删除定时发送的微博。
您也可以在菜单界面点击“添加微博”,打开微博发布窗口。该窗口可以实现微博链接、抖音、快手、微视、今日头条的视频分享链接。上传功能。
微博采集菜单
该接口主要用于批量采集微博,可以根据博主的首页链接进行,或者关键词,微博类型采集,点击采集产生列表标题,您可以按此列排序以更改发布顺序。
定时发布成功的采集记录显示在“定时发布”菜单的“待发送”结果列表中。
根据博主链接采集,一次只能有一个博主是采集。多个博主可以穿插发布,可以按照设定的定时时间实现。示例:第一次采集某博主的微博200条,间隔20分钟,开始时间设置为13:20,第二次采集另一个博主的200条微博,间隔还设置了20分钟,开始时间设置为13:30,这样就可以每10分钟发布一条微博,两个博主的微博会穿插发送。
微博追踪菜单
该接口主要用于跟踪博主的微博,实时发布对方发布的内容。填写博主微博首页链接,点击“打开”即可实现。
点击打开后,软件会开始同步博主最新的15篇博文,间隔5分钟。同步最新15篇博文后,目标博主的博文将发布在您的微博上。
同时,您可以在“设置”菜单中设置是否移除原有主题并添加您自己的后缀(如主题)。
特色材料菜单
该模块可以根据您微博账号的字段选择素材。每个副本的材料都可以编辑。编辑好对应素材副本并勾选对应素材后,点击“定时发布”即可实现定时发博功能。
可以在“定时发布”菜单下查看定时记录。
文章定时自动采集(前台发帖时可采集单篇微信文章的功能介绍及使用方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-12-13 15:33
特征
后台可以通过微信和关键词批量搜索采集公众号文章,无需任何配置。同时支持批量发布到帖子和门户文章,您可以选择每个版块文章进行发布。
前台发帖时可以采集单个微信文章,只需要在插件中设置启用的版块和用户组即可。
2. 版本1后,添加定时采集,在插件设置页面的定时采集公众号中填写微信公众号,每行一个,(如果你的服务器性能和带宽不足,请只填写一项),插件会通过填写的公众号获取最新的5篇文章没有采集采集的文章这里通过定时任务(注:由于微信反采集措施严格且多变,定时任务的成功率可能较低)
主要特征
1、可以采集文章图片、视频、微信文章原格式
2、无需配置,通过微信ID和关键字搜索后批量采集
3、可以设置发帖时使用的成员
4、批量发帖时,除了发到默认版块,还可以设置每篇文章文章单独发布到任意版块,可以单独设置每个帖子使用的成员
5、可以批量发布到门户网站文章,每篇文章文章发布到门户频道时可以单独设置
6、采集有身体状态提醒。如果采集的body由于某种原因失败,可以重复采集
8、前台发帖时编辑器中显示微信图标,点击插入微信文章 URL自动插入微信文章
9、支持帖子,门户文章评论功能
指示
1、安装激活后可以在插件后台设置页面更改默认成员uid和贴到的版块
2、点击开始采集,按微信ID或关键字采集
3、采集最新的文章列表成功后,可以全选或单独选择采集文字的文章(例如删除一个不需要的文章文章),开始采集的正文
4、正文采集完成后,可以选择要单独发布到每个文章的版块,也可以全部发布到默认版块,点击发布即可完成
7、在采集的记录中,可以批量发布为portal文章,并且可以设置每个文章发布到的portal channel(portal channel必须能得到的)
8、 设置前台的用户群和版块,允许使用微信插入文章的功能
采集流程按微信账号采集:
1、搜索微信ID点击或直接填写微信ID和昵称点击开始采集
2、显示采集文章最近要获取的10-30篇文章的标题,点击标题旁边的复选框,确认你想要哪个采集
3、然后点击下面的文字采集
4、采集 然后你可以选择立即发布到板子或者在采集的结果下重新采集
按关键字采集
1、输入关键词,点击搜索
2、显示获取到的文章标题列表,点击标题旁边的复选框确认你想要哪个采集
3、点击下方采集并发布按钮完成发布
如果文章列表发布后没有显示在前台,请点击后台-工具-更新统计中的第一个【提交】按钮
按网址采集
1、填写公众号地址文章。每行一个
2、点击采集等待完成
预防措施
1、由于微信反购买措施采集,请不要采集过于频繁,否则可能导致您的IP地址被微信锁定而无法继续采集@ >
2、如果要采集图片、视频并保持微信的原创格式文章,必须在相应的部分允许使用html、允许解析图片和允许多媒体-发布选项
点击下载——下载需要VIP会员权限—— 查看全部
文章定时自动采集(前台发帖时可采集单篇微信文章的功能介绍及使用方法)
特征
后台可以通过微信和关键词批量搜索采集公众号文章,无需任何配置。同时支持批量发布到帖子和门户文章,您可以选择每个版块文章进行发布。
前台发帖时可以采集单个微信文章,只需要在插件中设置启用的版块和用户组即可。
2. 版本1后,添加定时采集,在插件设置页面的定时采集公众号中填写微信公众号,每行一个,(如果你的服务器性能和带宽不足,请只填写一项),插件会通过填写的公众号获取最新的5篇文章没有采集采集的文章这里通过定时任务(注:由于微信反采集措施严格且多变,定时任务的成功率可能较低)
主要特征
1、可以采集文章图片、视频、微信文章原格式
2、无需配置,通过微信ID和关键字搜索后批量采集
3、可以设置发帖时使用的成员
4、批量发帖时,除了发到默认版块,还可以设置每篇文章文章单独发布到任意版块,可以单独设置每个帖子使用的成员
5、可以批量发布到门户网站文章,每篇文章文章发布到门户频道时可以单独设置
6、采集有身体状态提醒。如果采集的body由于某种原因失败,可以重复采集
8、前台发帖时编辑器中显示微信图标,点击插入微信文章 URL自动插入微信文章
9、支持帖子,门户文章评论功能
指示
1、安装激活后可以在插件后台设置页面更改默认成员uid和贴到的版块
2、点击开始采集,按微信ID或关键字采集
3、采集最新的文章列表成功后,可以全选或单独选择采集文字的文章(例如删除一个不需要的文章文章),开始采集的正文
4、正文采集完成后,可以选择要单独发布到每个文章的版块,也可以全部发布到默认版块,点击发布即可完成
7、在采集的记录中,可以批量发布为portal文章,并且可以设置每个文章发布到的portal channel(portal channel必须能得到的)
8、 设置前台的用户群和版块,允许使用微信插入文章的功能
采集流程按微信账号采集:
1、搜索微信ID点击或直接填写微信ID和昵称点击开始采集
2、显示采集文章最近要获取的10-30篇文章的标题,点击标题旁边的复选框,确认你想要哪个采集
3、然后点击下面的文字采集
4、采集 然后你可以选择立即发布到板子或者在采集的结果下重新采集
按关键字采集
1、输入关键词,点击搜索
2、显示获取到的文章标题列表,点击标题旁边的复选框确认你想要哪个采集
3、点击下方采集并发布按钮完成发布
如果文章列表发布后没有显示在前台,请点击后台-工具-更新统计中的第一个【提交】按钮
按网址采集
1、填写公众号地址文章。每行一个
2、点击采集等待完成
预防措施
1、由于微信反购买措施采集,请不要采集过于频繁,否则可能导致您的IP地址被微信锁定而无法继续采集@ >
2、如果要采集图片、视频并保持微信的原创格式文章,必须在相应的部分允许使用html、允许解析图片和允许多媒体-发布选项
点击下载——下载需要VIP会员权限——
文章定时自动采集(优采云新文章更新的栏目不会更新使用流程及使用方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2021-12-02 09:36
使用过程:可以使用优采云采集器一次发布上万篇文章(文章属性不审核),然后安装插件-in 实现每日定时定量审核文档+自动更新生成HTML
功能说明:
1、 您可以设置多个时间段。在这些时间段内,每天会自动审核生成一定数量的未审核文章,每个时间段每天只更新一次。
2、自动更新网站首页和需要更新的栏目页,需要更新的栏目页是那些有新文章生成的栏目,没有新的< @文章 更新了不会更新的列,提高更新的性能。
3、可以根据列或总数更新文章。根据文章列更新,每列文章更新指定数量的文章。根据总数更新文章,根据id从小到大更新指定数量的文章文章。
4、 文章 更新是按照文章id从小到大的顺序进行的,保证先添加的文章先更新。
5、 文章 发布时间为审核时间。
示例说明: 上图中总共输入三个更新时间段,分别是3~5、7~9、14:00~16:00。系统会在这三个时间段内审核指定数量的未审核文章文章,每个时间段每天只审核一次。例如:3点到5点,3点,4点(不包括5点)在此期间,只要用户访问网站的首页,每个栏目将被审核并产生2篇文章文章,发布时间成为当时的审核时间。注意:如果在此期间没有用户访问网站的主页,则不会对其进行审核。14:00-16:00,如果用户访问了网站的首页,会更新10篇文章,而不是按照栏目更新,
功能真的很强大,压缩包里有详细的使用说明。
现在分享出来,希望大佬们能继续完善,增加一些更强大的功能!
适用dede版本:5.3GBK/UTF、5.5GBK/UTF、5.6GBK/UTF
插件下载地址:
访客,此付费内容需支付50金币浏览此为广告位
适用dede版本:5.7GBK插件下载地址:
访客,此付费内容需支付50金币浏览此为广告位
推荐帖子:
花了整晚修改dedecms自动定时定量审核文件+自动更新生成5.3、5.5.的HTML插件。 ..
阿斯达 查看全部
文章定时自动采集(优采云新文章更新的栏目不会更新使用流程及使用方法)
使用过程:可以使用优采云采集器一次发布上万篇文章(文章属性不审核),然后安装插件-in 实现每日定时定量审核文档+自动更新生成HTML
功能说明:
1、 您可以设置多个时间段。在这些时间段内,每天会自动审核生成一定数量的未审核文章,每个时间段每天只更新一次。
2、自动更新网站首页和需要更新的栏目页,需要更新的栏目页是那些有新文章生成的栏目,没有新的< @文章 更新了不会更新的列,提高更新的性能。
3、可以根据列或总数更新文章。根据文章列更新,每列文章更新指定数量的文章。根据总数更新文章,根据id从小到大更新指定数量的文章文章。
4、 文章 更新是按照文章id从小到大的顺序进行的,保证先添加的文章先更新。
5、 文章 发布时间为审核时间。
示例说明: 上图中总共输入三个更新时间段,分别是3~5、7~9、14:00~16:00。系统会在这三个时间段内审核指定数量的未审核文章文章,每个时间段每天只审核一次。例如:3点到5点,3点,4点(不包括5点)在此期间,只要用户访问网站的首页,每个栏目将被审核并产生2篇文章文章,发布时间成为当时的审核时间。注意:如果在此期间没有用户访问网站的主页,则不会对其进行审核。14:00-16:00,如果用户访问了网站的首页,会更新10篇文章,而不是按照栏目更新,
功能真的很强大,压缩包里有详细的使用说明。
现在分享出来,希望大佬们能继续完善,增加一些更强大的功能!
适用dede版本:5.3GBK/UTF、5.5GBK/UTF、5.6GBK/UTF
插件下载地址:
访客,此付费内容需支付50金币浏览此为广告位
适用dede版本:5.7GBK插件下载地址:
访客,此付费内容需支付50金币浏览此为广告位
推荐帖子:
花了整晚修改dedecms自动定时定量审核文件+自动更新生成5.3、5.5.的HTML插件。 ..
阿斯达
文章定时自动采集(云栖社区阿里巴巴开源的文章定时自动采集技术解读(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-12-01 13:19
文章定时自动采集,主要用于爬取一些网站,或者一些电影之类的。本文首发于云栖社区阿里巴巴开源的rpah-ii是一款将文本、图片等资源进行按类别分类汇总,实现复杂的报表查询。技术解读基于一套开放源代码的rpah-ii可以对一个网站进行多维度、多维度地将所有网站数据进行多文件的聚合汇总,并对数据进行分类总结。
它可以将我们常见的表格格式数据进行导入,或将一些网站数据实现自动整理和转换,从而实现自动化的数据汇总以及排序。同时,我们还可以将rpah-ii服务搭建在各种终端上面,让它实现我们操作和手机等终端的时候,也可以和pc同步。目前rpah-ii功能仍比较简单,目前支持的报表类型有按类别聚合:按行汇总:按列汇总:文本聚合:图片聚合:音频聚合:视频聚合:rpah-ii最让人惊喜的功能是,支持定时自动复制自定义的网页图片、rawtext图片,以及rawpost文本到各种报表,目前只支持excel和word。
是不是很方便。制作流程制作流程源代码库地址:-ii包括五个模块,文件对应txt、xml、word、pdf、html。首先,我们需要确定我们需要什么格式的数据,需要处理什么内容,以便我们将其进行汇总和分类总结。获取并删除数据,并分析数据中信息,再将数据融合到一起。接下来,rpah-ii提供丰富的制作流程。
比如需要文本聚合,那么我们需要写程序获取不同文本的shapes、count、wordedge等。完成之后,要导入到我们的rpah-ii中去。接下来我们需要对rpah-ii进行构建和改造,实现数据采集、储存到数据库、统计汇总等功能。网上很多rpah-ii技术视频或者教程,以及论坛,我们选择的一篇介绍文章来进行操作说明。
关于这篇博客,首先我们需要建立开发者工具,使用网上的一些制作流程说明图和编写工具。最后需要安装eclipse并下载源代码来完成这个工作。系统概述rpah-ii总的概括为上图中的图6。一共分为七个模块:文本处理模块:把数据采集、整理、转换、最后输出到文本等进行封装,其中用到excel和word形式文本数据。
聚合汇总模块:将两个post文件叠加,按聚合的数量进行分类总结,其中需要excel数据。输出方式为文本格式的pdf。分析组件:获取要分析数据的分析结果,主要是基于统计代码,内置统计函数以及基本的分析形式,其中可以根据项目需要扩展。统计集成方式:将rpah-ii所采集到的数据,进行整合到一起形成表格格式,在很多报表中使用。报表自动化工具:对于具体工作流中的详细报表使用,比如流程、财务预。 查看全部
文章定时自动采集(云栖社区阿里巴巴开源的文章定时自动采集技术解读(组图))
文章定时自动采集,主要用于爬取一些网站,或者一些电影之类的。本文首发于云栖社区阿里巴巴开源的rpah-ii是一款将文本、图片等资源进行按类别分类汇总,实现复杂的报表查询。技术解读基于一套开放源代码的rpah-ii可以对一个网站进行多维度、多维度地将所有网站数据进行多文件的聚合汇总,并对数据进行分类总结。
它可以将我们常见的表格格式数据进行导入,或将一些网站数据实现自动整理和转换,从而实现自动化的数据汇总以及排序。同时,我们还可以将rpah-ii服务搭建在各种终端上面,让它实现我们操作和手机等终端的时候,也可以和pc同步。目前rpah-ii功能仍比较简单,目前支持的报表类型有按类别聚合:按行汇总:按列汇总:文本聚合:图片聚合:音频聚合:视频聚合:rpah-ii最让人惊喜的功能是,支持定时自动复制自定义的网页图片、rawtext图片,以及rawpost文本到各种报表,目前只支持excel和word。
是不是很方便。制作流程制作流程源代码库地址:-ii包括五个模块,文件对应txt、xml、word、pdf、html。首先,我们需要确定我们需要什么格式的数据,需要处理什么内容,以便我们将其进行汇总和分类总结。获取并删除数据,并分析数据中信息,再将数据融合到一起。接下来,rpah-ii提供丰富的制作流程。
比如需要文本聚合,那么我们需要写程序获取不同文本的shapes、count、wordedge等。完成之后,要导入到我们的rpah-ii中去。接下来我们需要对rpah-ii进行构建和改造,实现数据采集、储存到数据库、统计汇总等功能。网上很多rpah-ii技术视频或者教程,以及论坛,我们选择的一篇介绍文章来进行操作说明。
关于这篇博客,首先我们需要建立开发者工具,使用网上的一些制作流程说明图和编写工具。最后需要安装eclipse并下载源代码来完成这个工作。系统概述rpah-ii总的概括为上图中的图6。一共分为七个模块:文本处理模块:把数据采集、整理、转换、最后输出到文本等进行封装,其中用到excel和word形式文本数据。
聚合汇总模块:将两个post文件叠加,按聚合的数量进行分类总结,其中需要excel数据。输出方式为文本格式的pdf。分析组件:获取要分析数据的分析结果,主要是基于统计代码,内置统计函数以及基本的分析形式,其中可以根据项目需要扩展。统计集成方式:将rpah-ii所采集到的数据,进行整合到一起形成表格格式,在很多报表中使用。报表自动化工具:对于具体工作流中的详细报表使用,比如流程、财务预。
文章定时自动采集( 第一步,检查定时任务执行时间(一)——第一步)
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-11-27 15:09
第一步,检查定时任务执行时间(一)——第一步)
苹果cmsv10采集定时自动采集不生效查看教程
第一步,查看定时任务的执行时间
如果运行时间近一个小时没有变化,或者运行时间为空,则说明任务没有执行。这时候可以点击“测试”查看定时任务的执行情况。如果采集在这里的测试中无法存储,则说明是程序或资源站API问题。遇到这种情况,首先再次添加定时配置,并在测试中
如果使用宝塔计划任务定期访问,则查看宝塔计划任务是否执行,查看宝塔计划任务日志;进入宝塔面板,找到计划任务,点击对应的日志查看
检查日志。如果日志中有成功存储、数据采集完成等字样,说明宝塔的定时任务没有问题。
如果图中没有这样的内容,那么你手动执行宝塔规划任务,然后打开查看日志;这里要特别说明一下,如果你已经在Applecms中执行了计划任务,那么这里执行完后,log 会显示“skip”;显示“跳过”也意味着您已经访问了程序的定时任务。如果只是成功,那么就是你的宝塔服务器所在的网络,你的苹果cms所在的空间是无法访问的。; 在这种情况下,两个地区的网络不能互通;最好你的宝塔和苹果的<@cms程序在同一台服务器上
如果宝塔技术任务日志提示是
curl: (60) Peer's Certificate has expired.
这样的错误,那么请检查您的URL是否是https。这种情况通常发生在自签名证书中。错误的意思是发证机构没有经过认证,服务器无法识别。
解决方案是将颁发证书的私有 CA 公钥的 cacert.pem 文件的内容附加到 /etc/pki/tls/certs/ca-bundle.crt。
如果不能操作,或者操作后还是不能监控,最笨的办法就是新建一个网站并解析一个域名,也可以不用解析就使用IP+端口,如图在下图中。
建立后这个网站就是和你的https共享同一个根目录,共享同一个数据库,把定时任务的URL监控链接的域名替换成http域名地址,使用这个域名执行定时任务的名称 查看全部
文章定时自动采集(
第一步,检查定时任务执行时间(一)——第一步)
苹果cmsv10采集定时自动采集不生效查看教程
第一步,查看定时任务的执行时间
如果运行时间近一个小时没有变化,或者运行时间为空,则说明任务没有执行。这时候可以点击“测试”查看定时任务的执行情况。如果采集在这里的测试中无法存储,则说明是程序或资源站API问题。遇到这种情况,首先再次添加定时配置,并在测试中
如果使用宝塔计划任务定期访问,则查看宝塔计划任务是否执行,查看宝塔计划任务日志;进入宝塔面板,找到计划任务,点击对应的日志查看
检查日志。如果日志中有成功存储、数据采集完成等字样,说明宝塔的定时任务没有问题。
如果图中没有这样的内容,那么你手动执行宝塔规划任务,然后打开查看日志;这里要特别说明一下,如果你已经在Applecms中执行了计划任务,那么这里执行完后,log 会显示“skip”;显示“跳过”也意味着您已经访问了程序的定时任务。如果只是成功,那么就是你的宝塔服务器所在的网络,你的苹果cms所在的空间是无法访问的。; 在这种情况下,两个地区的网络不能互通;最好你的宝塔和苹果的<@cms程序在同一台服务器上
如果宝塔技术任务日志提示是
curl: (60) Peer's Certificate has expired.
这样的错误,那么请检查您的URL是否是https。这种情况通常发生在自签名证书中。错误的意思是发证机构没有经过认证,服务器无法识别。
解决方案是将颁发证书的私有 CA 公钥的 cacert.pem 文件的内容附加到 /etc/pki/tls/certs/ca-bundle.crt。
如果不能操作,或者操作后还是不能监控,最笨的办法就是新建一个网站并解析一个域名,也可以不用解析就使用IP+端口,如图在下图中。
建立后这个网站就是和你的https共享同一个根目录,共享同一个数据库,把定时任务的URL监控链接的域名替换成http域名地址,使用这个域名执行定时任务的名称
文章定时自动采集(人生没有白走的路,每一步都在为之前的每一次选择买单 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2021-11-26 03:13
)
没有什么可抱怨的,现在一切都在为之前的每一个选择付出代价。
人生没有白走,每一步都算数。
文章 目录。
很多人学习python,不知道从哪里开始。
很多人学习python,掌握了基本语法后,不知道从哪里找案例上手。
许多做过案例研究的人不知道如何学习更高级的知识。
所以对于这三类人,我会为大家提供一个很好的学习平台,免费领取视频教程、电子书、课程源码!??¤
QQ群:623406465
一、schedule 模块定时执行任务
python中有一个轻量级的定时任务调度库:schedule。他可以每分钟、每小时、每天、一周中的某天和特定日期完成定时任务。所以我们执行一些轻量级的定时任务是非常方便的。
# 安装
pip install schedule -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
import schedule
import time
def run():
print("I'm doing something...")
schedule.every(10).minutes.do(run) # 每隔十分钟执行一次任务
schedule.every().hour.do(run) # 每隔一小时执行一次任务
schedule.every().day.at("10:30").do(run) # 每天的10:30执行一次任务
schedule.every().monday.do(run) # 每周一的这个时候执行一次任务
schedule.every().wednesday.at("13:15").do(run) # 每周三13:15执行一次任务
while True:
schedule.run_pending() # run_pending:运行所有可以运行的任务
二、 爬取微博热搜数据
这样的网页结构可以使用pd.read_html()方法来抓取数据
# -*- coding: UTF-8 -*-
"""
@File :微博热搜榜.py
@Author :叶庭云
@Date :2020/9/18 15:01
@CSDN :https://blog.csdn.net/fyfugoyfa
"""
import schedule
import pandas as pd
from datetime import datetime
import logging
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s: %(message)s')
count = 0
def get_content():
global count # 全局变量count
print('----------- 正在爬取数据 -------------')
url = 'https://s.weibo.com/top/summar ... 39%3B
df = pd.read_html(url)[0][1:11][['序号', '关键词']] # 获取热搜前10
time_ = datetime.now().strftime("%Y/%m/%d %H:%M") # 获取当前时间
df['序号'] = df['序号'].apply(int)
df['热度'] = df['关键词'].str.split(' ', expand=True)[1]
df['关键词'] = df['关键词'].str.split(' ', expand=True)[0]
df['时间'] = [time_] * len(df['序号'])
if count == 0:
df.to_csv('datas.csv', mode='a+', index=False)
count += 1
else:
df.to_csv('datas.csv', mode='a+', index=False, header=False)
# 定时爬虫
schedule.every(1).minutes.do(get_content)
while True:
schedule.run_pending()
微博热搜一般每1分钟更新一次,所以在代码中加个定时器。让程序运行一会,微博热搜的数据就会保存在CSV文件中。
三、Pyehcarts 动态图可视化
1. 基本时间轮播图
from pyecharts import options as opts
from pyecharts.charts import Bar, Timeline
from pyecharts.faker import Faker
from pyecharts.globals import CurrentConfig, ThemeType
CurrentConfig.ONLINE_HOST = 'D:/python/pyecharts-assets-master/assets/'
tl = Timeline(init_opts=opts.InitOpts(theme=ThemeType.LIGHT))
for i in range(2015, 2020):
bar = (
Bar()
.add_xaxis(Faker.choose())
.add_yaxis("商家A", Faker.values())
.add_yaxis("商家B", Faker.values())
.set_global_opts(title_opts=opts.TitleOpts("商店{}年商品销售额".format(i)))
)
tl.add(bar, "{}年".format(i))
tl.render("timeline_multi_axis.html")
运行效果如下:
from pyecharts import options as opts
from pyecharts.charts import Bar, Timeline
from pyecharts.faker import Faker
from pyecharts.globals import ThemeType, CurrentConfig
CurrentConfig.ONLINE_HOST = 'D:/python/pyecharts-assets-master/assets/'
tl = Timeline(init_opts=opts.InitOpts(theme=ThemeType.DARK))
for i in range(2015, 2020):
bar = (
Bar()
.add_xaxis(Faker.choose())
.add_yaxis("商家A", Faker.values(), label_opts=opts.LabelOpts(position="right"))
.add_yaxis("商家B", Faker.values(), label_opts=opts.LabelOpts(position="right"))
.reversal_axis()
.set_global_opts(
title_opts=opts.TitleOpts("Timeline-Bar-Reversal (时间: {} 年)".format(i))
)
)
tl.add(bar, "{}年".format(i))
tl.render("timeline_bar_reversal.html")
运行效果如下:
2. 微博热搜动态图
"""
@Author :叶庭云
@Date :2020/9/18 15:01
@CSDN :https://blog.csdn.net/fyfugoyfa
"""
import pandas as pd
from pyecharts import options as opts
from pyecharts.charts import Bar, Timeline, Grid
from pyecharts.globals import ThemeType, CurrentConfig
CurrentConfig.ONLINE_HOST = 'D:/python/pyecharts-assets-master/assets/'
df = pd.read_csv('datas.csv')
# print(df.info())
t = Timeline(init_opts=opts.InitOpts(theme=ThemeType.MACARONS)) # 定制主题
for i in range(34):
bar = (
Bar()
.add_xaxis(list(df['关键词'][i*10: i*10+10][::-1])) # x轴数据
.add_yaxis('热度', list(df['热度'][i*10: i*10+10][::-1])) # y轴数据
.reversal_axis() # 翻转
.set_global_opts( # 全局配置项
title_opts=opts.TitleOpts( # 标题配置项
title=f"{list(df['时间'])[i*10]}",
pos_right="5%", pos_bottom="15%",
title_textstyle_opts=opts.TextStyleOpts(
font_family='KaiTi', font_size=24, color='#FF1493'
)
),
xaxis_opts=opts.AxisOpts( # x轴配置项
splitline_opts=opts.SplitLineOpts(is_show=True),
),
yaxis_opts=opts.AxisOpts( # y轴配置项
splitline_opts=opts.SplitLineOpts(is_show=True),
axislabel_opts=opts.LabelOpts(color='#DC143C')
)
)
.set_series_opts( # 系列配置项
label_opts=opts.LabelOpts( # 标签配置
position="right", color='#9400D3')
)
)
grid = (
Grid()
.add(bar, grid_opts=opts.GridOpts(pos_left="24%"))
)
t.add(grid, "")
t.add_schema(
play_interval=100, # 轮播速度
is_timeline_show=False, # 是否显示 timeline 组件
is_auto_play=True, # 是否自动播放
)
t.render('时间轮播图.html')
运行结果如下:
查看全部
文章定时自动采集(人生没有白走的路,每一步都在为之前的每一次选择买单
)
没有什么可抱怨的,现在一切都在为之前的每一个选择付出代价。
人生没有白走,每一步都算数。
文章 目录。
很多人学习python,不知道从哪里开始。
很多人学习python,掌握了基本语法后,不知道从哪里找案例上手。
许多做过案例研究的人不知道如何学习更高级的知识。
所以对于这三类人,我会为大家提供一个很好的学习平台,免费领取视频教程、电子书、课程源码!??¤
QQ群:623406465
一、schedule 模块定时执行任务
python中有一个轻量级的定时任务调度库:schedule。他可以每分钟、每小时、每天、一周中的某天和特定日期完成定时任务。所以我们执行一些轻量级的定时任务是非常方便的。
# 安装
pip install schedule -i http://pypi.douban.com/simple --trusted-host pypi.douban.com
import schedule
import time
def run():
print("I'm doing something...")
schedule.every(10).minutes.do(run) # 每隔十分钟执行一次任务
schedule.every().hour.do(run) # 每隔一小时执行一次任务
schedule.every().day.at("10:30").do(run) # 每天的10:30执行一次任务
schedule.every().monday.do(run) # 每周一的这个时候执行一次任务
schedule.every().wednesday.at("13:15").do(run) # 每周三13:15执行一次任务
while True:
schedule.run_pending() # run_pending:运行所有可以运行的任务
二、 爬取微博热搜数据
这样的网页结构可以使用pd.read_html()方法来抓取数据
# -*- coding: UTF-8 -*-
"""
@File :微博热搜榜.py
@Author :叶庭云
@Date :2020/9/18 15:01
@CSDN :https://blog.csdn.net/fyfugoyfa
"""
import schedule
import pandas as pd
from datetime import datetime
import logging
logging.basicConfig(level=logging.INFO, format='%(asctime)s - %(levelname)s: %(message)s')
count = 0
def get_content():
global count # 全局变量count
print('----------- 正在爬取数据 -------------')
url = 'https://s.weibo.com/top/summar ... 39%3B
df = pd.read_html(url)[0][1:11][['序号', '关键词']] # 获取热搜前10
time_ = datetime.now().strftime("%Y/%m/%d %H:%M") # 获取当前时间
df['序号'] = df['序号'].apply(int)
df['热度'] = df['关键词'].str.split(' ', expand=True)[1]
df['关键词'] = df['关键词'].str.split(' ', expand=True)[0]
df['时间'] = [time_] * len(df['序号'])
if count == 0:
df.to_csv('datas.csv', mode='a+', index=False)
count += 1
else:
df.to_csv('datas.csv', mode='a+', index=False, header=False)
# 定时爬虫
schedule.every(1).minutes.do(get_content)
while True:
schedule.run_pending()
微博热搜一般每1分钟更新一次,所以在代码中加个定时器。让程序运行一会,微博热搜的数据就会保存在CSV文件中。
三、Pyehcarts 动态图可视化
1. 基本时间轮播图
from pyecharts import options as opts
from pyecharts.charts import Bar, Timeline
from pyecharts.faker import Faker
from pyecharts.globals import CurrentConfig, ThemeType
CurrentConfig.ONLINE_HOST = 'D:/python/pyecharts-assets-master/assets/'
tl = Timeline(init_opts=opts.InitOpts(theme=ThemeType.LIGHT))
for i in range(2015, 2020):
bar = (
Bar()
.add_xaxis(Faker.choose())
.add_yaxis("商家A", Faker.values())
.add_yaxis("商家B", Faker.values())
.set_global_opts(title_opts=opts.TitleOpts("商店{}年商品销售额".format(i)))
)
tl.add(bar, "{}年".format(i))
tl.render("timeline_multi_axis.html")
运行效果如下:
from pyecharts import options as opts
from pyecharts.charts import Bar, Timeline
from pyecharts.faker import Faker
from pyecharts.globals import ThemeType, CurrentConfig
CurrentConfig.ONLINE_HOST = 'D:/python/pyecharts-assets-master/assets/'
tl = Timeline(init_opts=opts.InitOpts(theme=ThemeType.DARK))
for i in range(2015, 2020):
bar = (
Bar()
.add_xaxis(Faker.choose())
.add_yaxis("商家A", Faker.values(), label_opts=opts.LabelOpts(position="right"))
.add_yaxis("商家B", Faker.values(), label_opts=opts.LabelOpts(position="right"))
.reversal_axis()
.set_global_opts(
title_opts=opts.TitleOpts("Timeline-Bar-Reversal (时间: {} 年)".format(i))
)
)
tl.add(bar, "{}年".format(i))
tl.render("timeline_bar_reversal.html")
运行效果如下:
2. 微博热搜动态图
"""
@Author :叶庭云
@Date :2020/9/18 15:01
@CSDN :https://blog.csdn.net/fyfugoyfa
"""
import pandas as pd
from pyecharts import options as opts
from pyecharts.charts import Bar, Timeline, Grid
from pyecharts.globals import ThemeType, CurrentConfig
CurrentConfig.ONLINE_HOST = 'D:/python/pyecharts-assets-master/assets/'
df = pd.read_csv('datas.csv')
# print(df.info())
t = Timeline(init_opts=opts.InitOpts(theme=ThemeType.MACARONS)) # 定制主题
for i in range(34):
bar = (
Bar()
.add_xaxis(list(df['关键词'][i*10: i*10+10][::-1])) # x轴数据
.add_yaxis('热度', list(df['热度'][i*10: i*10+10][::-1])) # y轴数据
.reversal_axis() # 翻转
.set_global_opts( # 全局配置项
title_opts=opts.TitleOpts( # 标题配置项
title=f"{list(df['时间'])[i*10]}",
pos_right="5%", pos_bottom="15%",
title_textstyle_opts=opts.TextStyleOpts(
font_family='KaiTi', font_size=24, color='#FF1493'
)
),
xaxis_opts=opts.AxisOpts( # x轴配置项
splitline_opts=opts.SplitLineOpts(is_show=True),
),
yaxis_opts=opts.AxisOpts( # y轴配置项
splitline_opts=opts.SplitLineOpts(is_show=True),
axislabel_opts=opts.LabelOpts(color='#DC143C')
)
)
.set_series_opts( # 系列配置项
label_opts=opts.LabelOpts( # 标签配置
position="right", color='#9400D3')
)
)
grid = (
Grid()
.add(bar, grid_opts=opts.GridOpts(pos_left="24%"))
)
t.add(grid, "")
t.add_schema(
play_interval=100, # 轮播速度
is_timeline_show=False, # 是否显示 timeline 组件
is_auto_play=True, # 是否自动播放
)
t.render('时间轮播图.html')
运行结果如下:
文章定时自动采集(简单小巧的定时访问网页工具自动访问指定使用的方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2021-11-22 13:16
自动访问网页工具是一款用于定期访问网页的专业软件。简洁精致的定时访问网页小工具 自动访问网页工具。这个工具本身功能不多,只能实现定时访问网页的功能;您可以使用本工具打开各种网页,提醒您浏览需要获取的咨询或内容;许多用户在互联网上进行了报道。实时课程,有时漏课,因为其他原因,如果用户在电脑上使用这个工具,在播放讲座时,电脑会自动访问相应的课程网站,所以用户没有担心错过相关课程。
指示:
1.软件解压后,启动软件,软件界面如下。
2. 进入软件后,根据软件提示,首先在此输入框中设置打开网页的时间。
3.然后粘贴需要定期访问该输入框的网页地址。
4.然后点击“运行”按钮启动,启动后不能编辑URL和时间。
5.如果要再次编辑网址和时间,可以停止编辑。
6.您可以在软件底部查看此工具中的运行次数。
软件功能:
1.自动访问指定用户中的相关URL。
2.支持用户自定义时间和粘贴要访问的URL。
3.一个按钮可以管理程序的运行或停止。
4.可以记录程序运行的次数。
5.您可以在任务栏中隐藏该程序以避免该软件的萌芽用户。
软件特点:
1. 有一个简单的用户界面,没有任何困难。
2. 如果用户需要访问网页,此工具将非常有用。
3、可以直接打开软件,无需在电脑上安装。
4. 占用的内存资源很低,不会影响用户正常使用电脑。 查看全部
文章定时自动采集(简单小巧的定时访问网页工具自动访问指定使用的方法)
自动访问网页工具是一款用于定期访问网页的专业软件。简洁精致的定时访问网页小工具 自动访问网页工具。这个工具本身功能不多,只能实现定时访问网页的功能;您可以使用本工具打开各种网页,提醒您浏览需要获取的咨询或内容;许多用户在互联网上进行了报道。实时课程,有时漏课,因为其他原因,如果用户在电脑上使用这个工具,在播放讲座时,电脑会自动访问相应的课程网站,所以用户没有担心错过相关课程。
指示:
1.软件解压后,启动软件,软件界面如下。
2. 进入软件后,根据软件提示,首先在此输入框中设置打开网页的时间。
3.然后粘贴需要定期访问该输入框的网页地址。
4.然后点击“运行”按钮启动,启动后不能编辑URL和时间。
5.如果要再次编辑网址和时间,可以停止编辑。
6.您可以在软件底部查看此工具中的运行次数。
软件功能:
1.自动访问指定用户中的相关URL。
2.支持用户自定义时间和粘贴要访问的URL。
3.一个按钮可以管理程序的运行或停止。
4.可以记录程序运行的次数。
5.您可以在任务栏中隐藏该程序以避免该软件的萌芽用户。
软件特点:
1. 有一个简单的用户界面,没有任何困难。
2. 如果用户需要访问网页,此工具将非常有用。
3、可以直接打开软件,无需在电脑上安装。
4. 占用的内存资源很低,不会影响用户正常使用电脑。
文章定时自动采集(设置自动更新首页的具体操作方法,实现首页内容定时自动更新了)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-11-22 10:25
相信做过SEO的站长朋友都知道,网站首页内容的更新频率直接决定了网站的收录速度和网站权重,这就需要网站首页内容随时更新,但有时我们无法随时手动更新。这时候我们可以为dedecms设置主页自动更新,对对对就是自动更新,自动更新主页文章列表。
设置自动更新主页的具体操作方法如下:
Step 1. 在首页模板中添加一个随机的文章 call标签。在这里,我会解释为什么要添加一个随机的 文章 调用标签?因为随机调用标签每次刷新都会调用不同的文章内容,相当于每次刷新首页都显示新的内容,即使网站文章没有增加. 而如果只是普通的文章调用标签,刷新首页不添加网站content文章,则不会出现新的内容。具体调用代码如下:
{dede:arclist sort=’rand’ titlelen=48 row=16}
[field:title/]</a>
{/dede:arclist}
上面列表代码可以随机调出一个文章,每次刷新动态页面都会改变,但是因为织梦是生成静态html的首页,所以不生成就不会不要手动生成它。改了,所以用下面的方法。
第 2 步:设置定期自动文件更新
复制以下代码,粘贴到一个新文件中,命名为:autoindex.php,上传到网站根目录的plus文件夹中。
<p> 查看全部
文章定时自动采集(设置自动更新首页的具体操作方法,实现首页内容定时自动更新了)
相信做过SEO的站长朋友都知道,网站首页内容的更新频率直接决定了网站的收录速度和网站权重,这就需要网站首页内容随时更新,但有时我们无法随时手动更新。这时候我们可以为dedecms设置主页自动更新,对对对就是自动更新,自动更新主页文章列表。
设置自动更新主页的具体操作方法如下:
Step 1. 在首页模板中添加一个随机的文章 call标签。在这里,我会解释为什么要添加一个随机的 文章 调用标签?因为随机调用标签每次刷新都会调用不同的文章内容,相当于每次刷新首页都显示新的内容,即使网站文章没有增加. 而如果只是普通的文章调用标签,刷新首页不添加网站content文章,则不会出现新的内容。具体调用代码如下:
{dede:arclist sort=’rand’ titlelen=48 row=16}
[field:title/]</a>
{/dede:arclist}
上面列表代码可以随机调出一个文章,每次刷新动态页面都会改变,但是因为织梦是生成静态html的首页,所以不生成就不会不要手动生成它。改了,所以用下面的方法。
第 2 步:设置定期自动文件更新
复制以下代码,粘贴到一个新文件中,命名为:autoindex.php,上传到网站根目录的plus文件夹中。
<p>
文章定时自动采集(全面自动详细采集教程步骤首先获取采集链接,怎么采看自己了 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-11-22 10:23
)
子方有话要说
首先不得不说,目前网上搜到的很多苹果maccms8定时自动采集的教程可能存在误导,未能说明真实情况。经过孩子期待的探索,终于踏上了艰难的道路。
我觉得采集的工作其实是一个很麻烦的项目。如果有自动采集,往往事半功倍。目前网上的教程基本都在讲采集使用宝塔的定时访问URL功能,无所谓。但是所有的教程都没有介绍原理。如果不注意细节,往往会陷入失败。
就说子方觉得这个采集教程对其他cmsauto采集也有用。
定时自动原理采集
将采集参数或链接放在首页,一旦有访问者访问,例如,如果您踩到该页面,就会激活自动采集工作。
那么如果没有人访问,你就不能自动采集。这就是为什么它会通过各种工具访问采集链接,以确保内容的持续更新。
全自动详细采集教程步骤
先拿到采集链接,怎么取?
然后添加定时任务。孩子有素材提醒大家要特别注意红框。
第一点:任务名必须是英文,执行文件只能是collect.php,执行参数就是刚才复制的链接,只要collect之后的部分
第二点:采集时间段和采集时间,就是你查看的时间段,如果有访客访问采集。如果不检查时间段,即使访问,也不会触发自动采集机制。
最后,复制测试链接即可。甚至可以使用crontab来实现计时采集 就像子方游材料一样。
现在的网络教程基本都是告诉大家检查一下,然后定期使用宝塔访问网址。这是双重保证机制。因为紫方幽预计只玩两天,不是为了别的事情,所以也无所谓。
关于crontab的一些坑道,可以关注紫方油梁站的文章。
查看全部
文章定时自动采集(全面自动详细采集教程步骤首先获取采集链接,怎么采看自己了
)
子方有话要说
首先不得不说,目前网上搜到的很多苹果maccms8定时自动采集的教程可能存在误导,未能说明真实情况。经过孩子期待的探索,终于踏上了艰难的道路。
我觉得采集的工作其实是一个很麻烦的项目。如果有自动采集,往往事半功倍。目前网上的教程基本都在讲采集使用宝塔的定时访问URL功能,无所谓。但是所有的教程都没有介绍原理。如果不注意细节,往往会陷入失败。
就说子方觉得这个采集教程对其他cmsauto采集也有用。
定时自动原理采集
将采集参数或链接放在首页,一旦有访问者访问,例如,如果您踩到该页面,就会激活自动采集工作。
那么如果没有人访问,你就不能自动采集。这就是为什么它会通过各种工具访问采集链接,以确保内容的持续更新。
全自动详细采集教程步骤
先拿到采集链接,怎么取?
然后添加定时任务。孩子有素材提醒大家要特别注意红框。
第一点:任务名必须是英文,执行文件只能是collect.php,执行参数就是刚才复制的链接,只要collect之后的部分
第二点:采集时间段和采集时间,就是你查看的时间段,如果有访客访问采集。如果不检查时间段,即使访问,也不会触发自动采集机制。
最后,复制测试链接即可。甚至可以使用crontab来实现计时采集 就像子方游材料一样。
现在的网络教程基本都是告诉大家检查一下,然后定期使用宝塔访问网址。这是双重保证机制。因为紫方幽预计只玩两天,不是为了别的事情,所以也无所谓。
关于crontab的一些坑道,可以关注紫方油梁站的文章。
文章定时自动采集(ONEXIN大数据文章自动批量采集(OnexinBigData)欢迎体验)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-11-20 18:09
ONEXIN大数据文章自动批量采集(Onexin BigData,简称OBD),欢迎从云端体验采集器,我们在云端等你。
支持自动识别国内知名网站:论坛、新闻、微信、头条、视频、贴吧、问答、知乎、天涯等,反采集网站除外。
ONEXIN采集 提供7天无理由退款。购买前请确认您需要的包装:
V1:每天100,每天100,每年286元。节点可以是阿里云杭州或上海
V2 每天200张票,300张票,年付586元,节点可以是阿里云杭州,上海
V3 每天500券,1000券,年付1886元,节点可选择阿里云杭州、上海、新加坡
自动采集文章功能可免费使用3天。回复本帖,可延长免费体验授权1个月:
***************安装注意事项:****************
一、安装步骤
1、 先把插件上传到/plugin/onexin_bigdata文件夹,
2、然后,在后台安装,
3、接下来请按照教程一步一步来。
发布模块名称:forum
二、插件背景
大数据插件后台:你的网站地址/plugin/onexin_bigdata/
初始 OID:10000
初始密码:d7aeb864648b
申请授权的网址是:你的网站地址/plugin/onexin_bigdata/api.php
大数据采集 通用教程:
申请授权:
图文教程:
三、 触发代码放在网站模板末尾的代码中,oid账号100000替换为自己的。
最后,当你刷新你的网站或有用户访问时,程序会自动更新文章。
使用中有任何问题,欢迎随时联系我们,ONEXIN新手交流Q群:189610242
================ OBD大数据插件常见问题========================== =
Q:OBD大数据和其他采集器插件有什么区别?
A:OBD大数据采集列表和内容页面在云服务器端进行预处理,更加节省服务器资源。
在插件中,用户可以方便地管理需要发布的文章链接,自由选择发布或不发布。
插件接口代码开源,输出结果可定制,功能可扩展。
无需zend,不受系统环境影响
无需在电脑上安装软件,网站即可访问并可自动更新文章。
无需编写内容页面规则,云端自动识别采集,上千资源可用。
Q:大数据插件工作流程,首次配置和使用有哪些注意事项?
A:首先安装发布接口插件,填写我们平台的注册账号OID和token。确保设置成功,您就完成了一半。
其次,您已准备好开始测试。可以复制平台上的共享资源,在导入中填写3-5篇文章,填写导入类别ID,导入论坛或门户。
然后,设置授权状态和资源状态一起启动,
最后,如果你的网站有用户访问权限,你可以自动更新文章。如有异常,请及时与我们联系。
Q:文章的源信息在哪里管理?
A:可以在插件设置中自定义源格式。建议用户保留源码。我们提供大数据云采集技术服务,一切因内容侵权与ONEXIN无关。
Q:插件设置中“每次PV触发”是多少?
A:PV是页面浏览量。当用户访问你网站时,云服务器由一个js脚本触发。设置的数量越大,对双方服务器的负载越小。建议填写你的网站 PV数除以一千得到的值。比如每天3万PV,推荐30以上。
理论上,你的用户拥有的PV越多,你添加的资源就越多,网站的更新频率就越高。
Q:平台添加资源的规则怎么写?
A:默认有两种易学易用的写法(copy),需要灵活使用,获取正确的URL。
第一种:文章 URL 前面的字符串a 标签作为标识符,如新浪、腾讯等门户网站常用的“第二种:文章 URL 中收录的字符串用作标识符,例如 URL 收录“/item.htm”。(示例)
Q:平台导入模块如何填写?
A:需要对应发布界面插件的soeasy文件夹,如论坛模块名(forum),发布文件对应publish.forum.php
Q:平台上不同的运行状态代表什么?
A:在授权查询中:切换到“等待”,表示整个推送停止。
Resource inside:切换到“waiting”,表示不再获取资源列表
Q:插件管理中的文章 URL可以修改吗?
A:如果删除云端推送的网址,30天内不再推送。您可以手动添加,状态可以选择为未发布、已发布或未发布。
Q:为什么插件管理中文章的状态显示为“未发送”?
A:超时,未获取标题或内容的状态标记为“未发送”。
Q:无法获取到内容页面的内容或者需要修改怎么办?
A:请在大数据平台添加资源后点击在线反馈,等待处理
[ttreply] 回复本帖,可延长免费试用授权1个月
秀诺BBS大数据采集最新版下载
[/回复]
最后由ONEXIN 3个月前编辑,原因:
上传的附件: 查看全部
文章定时自动采集(ONEXIN大数据文章自动批量采集(OnexinBigData)欢迎体验)
ONEXIN大数据文章自动批量采集(Onexin BigData,简称OBD),欢迎从云端体验采集器,我们在云端等你。
支持自动识别国内知名网站:论坛、新闻、微信、头条、视频、贴吧、问答、知乎、天涯等,反采集网站除外。
ONEXIN采集 提供7天无理由退款。购买前请确认您需要的包装:
V1:每天100,每天100,每年286元。节点可以是阿里云杭州或上海
V2 每天200张票,300张票,年付586元,节点可以是阿里云杭州,上海
V3 每天500券,1000券,年付1886元,节点可选择阿里云杭州、上海、新加坡
自动采集文章功能可免费使用3天。回复本帖,可延长免费体验授权1个月:
***************安装注意事项:****************
一、安装步骤
1、 先把插件上传到/plugin/onexin_bigdata文件夹,
2、然后,在后台安装,
3、接下来请按照教程一步一步来。
发布模块名称:forum
二、插件背景
大数据插件后台:你的网站地址/plugin/onexin_bigdata/
初始 OID:10000
初始密码:d7aeb864648b
申请授权的网址是:你的网站地址/plugin/onexin_bigdata/api.php
大数据采集 通用教程:
申请授权:
图文教程:
三、 触发代码放在网站模板末尾的代码中,oid账号100000替换为自己的。
最后,当你刷新你的网站或有用户访问时,程序会自动更新文章。
使用中有任何问题,欢迎随时联系我们,ONEXIN新手交流Q群:189610242
================ OBD大数据插件常见问题========================== =
Q:OBD大数据和其他采集器插件有什么区别?
A:OBD大数据采集列表和内容页面在云服务器端进行预处理,更加节省服务器资源。
在插件中,用户可以方便地管理需要发布的文章链接,自由选择发布或不发布。
插件接口代码开源,输出结果可定制,功能可扩展。
无需zend,不受系统环境影响
无需在电脑上安装软件,网站即可访问并可自动更新文章。
无需编写内容页面规则,云端自动识别采集,上千资源可用。
Q:大数据插件工作流程,首次配置和使用有哪些注意事项?
A:首先安装发布接口插件,填写我们平台的注册账号OID和token。确保设置成功,您就完成了一半。
其次,您已准备好开始测试。可以复制平台上的共享资源,在导入中填写3-5篇文章,填写导入类别ID,导入论坛或门户。
然后,设置授权状态和资源状态一起启动,
最后,如果你的网站有用户访问权限,你可以自动更新文章。如有异常,请及时与我们联系。
Q:文章的源信息在哪里管理?
A:可以在插件设置中自定义源格式。建议用户保留源码。我们提供大数据云采集技术服务,一切因内容侵权与ONEXIN无关。
Q:插件设置中“每次PV触发”是多少?
A:PV是页面浏览量。当用户访问你网站时,云服务器由一个js脚本触发。设置的数量越大,对双方服务器的负载越小。建议填写你的网站 PV数除以一千得到的值。比如每天3万PV,推荐30以上。
理论上,你的用户拥有的PV越多,你添加的资源就越多,网站的更新频率就越高。
Q:平台添加资源的规则怎么写?
A:默认有两种易学易用的写法(copy),需要灵活使用,获取正确的URL。
第一种:文章 URL 前面的字符串a 标签作为标识符,如新浪、腾讯等门户网站常用的“第二种:文章 URL 中收录的字符串用作标识符,例如 URL 收录“/item.htm”。(示例)
Q:平台导入模块如何填写?
A:需要对应发布界面插件的soeasy文件夹,如论坛模块名(forum),发布文件对应publish.forum.php
Q:平台上不同的运行状态代表什么?
A:在授权查询中:切换到“等待”,表示整个推送停止。
Resource inside:切换到“waiting”,表示不再获取资源列表
Q:插件管理中的文章 URL可以修改吗?
A:如果删除云端推送的网址,30天内不再推送。您可以手动添加,状态可以选择为未发布、已发布或未发布。
Q:为什么插件管理中文章的状态显示为“未发送”?
A:超时,未获取标题或内容的状态标记为“未发送”。
Q:无法获取到内容页面的内容或者需要修改怎么办?
A:请在大数据平台添加资源后点击在线反馈,等待处理
[ttreply] 回复本帖,可延长免费试用授权1个月
秀诺BBS大数据采集最新版下载
[/回复]
最后由ONEXIN 3个月前编辑,原因:
上传的附件:
文章定时自动采集( 第一步,检查定时任务执行时间(一)——第一步)
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-11-19 15:01
第一步,检查定时任务执行时间(一)——第一步)
苹果cmsv10采集定时自动采集不生效查看教程
第一步,查看定时任务的执行时间
如果运行时间近一个小时没有变化,或者运行时间为空,则说明任务没有执行。这时候可以点击“测试”查看定时任务的执行情况。如果采集在这里的测试中无法存储,则说明是程序或资源站API问题。遇到这种情况,首先再次添加定时配置,并在测试中
如果使用宝塔计划任务定期访问,则查看宝塔计划任务是否执行,查看宝塔计划任务日志;进入宝塔面板,找到计划任务,点击对应的日志查看
检查日志。如果日志中有成功存储、数据采集完成等字样,说明宝塔的定时任务没有问题。
如果图中没有这样的内容,那么你手动执行宝塔规划任务,然后打开查看日志;这里要特别说明一下,如果你已经在Applecms中执行了计划任务,那么这里执行完之后,log 会显示“skip”;显示“跳过”也意味着您已经访问了程序的计划任务。如果只是成功,那么就是你的宝塔服务器所在的网络,你的苹果cms所在的空间是无法访问的。; 在这种情况下,两个地区的网络不能互通;最好你的宝塔和苹果的<@cms程序在同一台服务器上
如果宝塔技术任务日志提示是
curl: (60) Peer 的证书已过期。
对于此类错误,请检查您的 URL 是否为 https。这种情况通常发生在自签名证书上。该错误消息表示颁发证书颁发机构未经过身份验证,服务器无法识别它。
解决方案是将颁发证书的私有 CA 公钥的 cacert.pem 文件的内容附加到 /etc/pki/tls/certs/ca-bundle.crt。
如果你不知道怎么操作,或者还是无法监控到操作,那么最笨的办法就是新建一个网站并解析一个域名,或者不用解析就使用IP+端口,如图在下图中。
建立后,这个网站就是和你的https共享同一个根目录,共享同一个数据库。将定时任务的URL监控链接的域名替换为http域名地址,并使用该域名执行定时任务 查看全部
文章定时自动采集(
第一步,检查定时任务执行时间(一)——第一步)
苹果cmsv10采集定时自动采集不生效查看教程
第一步,查看定时任务的执行时间
如果运行时间近一个小时没有变化,或者运行时间为空,则说明任务没有执行。这时候可以点击“测试”查看定时任务的执行情况。如果采集在这里的测试中无法存储,则说明是程序或资源站API问题。遇到这种情况,首先再次添加定时配置,并在测试中
如果使用宝塔计划任务定期访问,则查看宝塔计划任务是否执行,查看宝塔计划任务日志;进入宝塔面板,找到计划任务,点击对应的日志查看
检查日志。如果日志中有成功存储、数据采集完成等字样,说明宝塔的定时任务没有问题。
如果图中没有这样的内容,那么你手动执行宝塔规划任务,然后打开查看日志;这里要特别说明一下,如果你已经在Applecms中执行了计划任务,那么这里执行完之后,log 会显示“skip”;显示“跳过”也意味着您已经访问了程序的计划任务。如果只是成功,那么就是你的宝塔服务器所在的网络,你的苹果cms所在的空间是无法访问的。; 在这种情况下,两个地区的网络不能互通;最好你的宝塔和苹果的<@cms程序在同一台服务器上
如果宝塔技术任务日志提示是
curl: (60) Peer 的证书已过期。
对于此类错误,请检查您的 URL 是否为 https。这种情况通常发生在自签名证书上。该错误消息表示颁发证书颁发机构未经过身份验证,服务器无法识别它。
解决方案是将颁发证书的私有 CA 公钥的 cacert.pem 文件的内容附加到 /etc/pki/tls/certs/ca-bundle.crt。
如果你不知道怎么操作,或者还是无法监控到操作,那么最笨的办法就是新建一个网站并解析一个域名,或者不用解析就使用IP+端口,如图在下图中。
建立后,这个网站就是和你的https共享同一个根目录,共享同一个数据库。将定时任务的URL监控链接的域名替换为http域名地址,并使用该域名执行定时任务
文章定时自动采集(1.安装cron基本上所有的Linux发行版小技巧,你知道吗?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-11-14 11:09
大家好,我是小学生
今天的文章来源于工作中的一个小技巧,主要是涉及到日常工作的自动化处理。
如果你每天需要做一些重复性的工作,比如发报告、统计数据、发邮件等。
然后你就可以把这个任务交给电脑,让它每天自动为你完成,你只需要从容的打开保温瓶,静静地泡一杯枸杞。
今天主要用Linux下的cron服务,ok,直接启动
1. 安装 cron
基本上所有 Linux 发行版都默认预装了 cron 工具。
即使没有预装cron,也很简单。您可以通过执行一些简单的命令来手动安装它
# 检查是否已经预装了cron
service cron status
安装并启动服务
安装:apt-get install cron
启动/停止/重启:service cron start/stop/restart
查询当前任务:crontab -l
2. 安装检查
安装完成后,查看是否安装成功,也可以使用status命令查看
出现如下提示表示安装成功:
另外在ubuntu下可能会出现这个提示:
这也意味着它可以正常使用
3. cron 用法
cron的几个简单的用法可以学习一下,后面会通过一个案例来详细介绍如何使用
首先,列出当前用户调度的cron作业:
crontab -l
查看其他用户的cron作业:
crontab –l –u username
删除计划的 cron 作业:
crontab –r
4. 调度 crontab 计划
首先通过以下命令在crontab中添加或更新任务
第一次进入会要求选择编辑器,根据自己的习惯来选择。
选择后,会进入如下界面:
用过vim的同学应该对这个界面比较熟悉,类似操作:按A键开始编辑,按ESC输入wq保存退出
重点在底部段落:
m h dom mon dow commmand
这其实是介绍crontab调度作业的使用,可以用来设置定时任务。
具体语法是这样的:
m h dom mon dow command
* * * * * command
- - - - - -
| | | | | |
| | | | | --- 预执行的命令
| | | | ----- 表示星期0~7(其中星期天可以用0或7表示)
| | | ------- 表示月份1~12
| | --------- 表示日期1~31
| ----------- 表示小时1~23(0表示0点)
------------- 表示分钟1~59 每分钟用*或者 */1表示
举几个简单的应用案例:
0 2 * * * command
0 5,17 * * * command
*/10 * * * * command
0 17 * jan,may,aug sun command
这些是最常用的。更多用例可以参考这个链接:
上述案例中的命令表示您需要执行的特定任务,例如打印一个段落:
echo "Hello xiaoyi" >> /tmp/test.txt
或者把这段话输出到txt:
echo "Hello xiaoyi" >> /tmp/test.txt
或者你需要执行一个 Python 脚本:
下面的文件路径代表输入参数args,可能有同学会用到。例如,在下面的情况下,您需要输入文件下载路径。
5. 实战
搞清楚了以上这些之后,我们就可以开始今天的重头戏了。
首先,我们需要每天从ftp服务器下载最新的任务数据,将数据下载到本地并通过Python采集数据,最后将结果存入数据库。如果在此期间某个链接出现问题,则会发送警报电子邮件。
① Python 脚本
首先需要一个Python脚本来完成以下功能:
上述过程的近似伪代码如下:
if __name__ == '__main__':
"""获取最新数据日期"""
latest_date = get_max_date()
# 以最新日期为名创建文件夹
download_dir = os.path.join(sys.argv[1], latest_date)
if not os.path.exists(download_dir):
os.makedirs(download_dir)
"""从ftp中下载最新数据"""
download_file(latest_date, download_dir)
"""处理最新数据并保存"""
process_data(latest_date, download_dir)
邮件监控可以添加try catch异常捕获,发生异常时发送邮件
Python 编辑电子邮件内容并发送。我以前写过。可以参考以下:Python邮件发送
②编写cron任务
打开crontab,将以下内容编辑到最后一行,保存退出
Crontab 会自动实时更新任务列表。如果不放心,可以通过restart命令重启cron服务【参考文章开头】
这里有个小建议,所有路径都填绝对路径
③ 效果监测
如果 Python 代码没有问题,就会定期执行任务。
建议可以单独在控制台运行自己的命令,没问题的时候写红色的cron任务列表即可。
小一计划任务最终截图如下:
底部是ftp文件下载,顶部是数据汇总统计
题外话
如果说平时的工作中有很多重复的任务,比如每日指标的采集、访问的汇总统计、邮件自动转发等。
一旦您可以通过脚本为这些任务设置逻辑,自动化任务也可以实现它。最多就是每天关注一下邮件,看看有没有错误。
原创不容易,请点个赞
文章 首发:公众号【初级学习笔记】
原文链接:普及一个小作业技巧,三步实现Python自动化 查看全部
文章定时自动采集(1.安装cron基本上所有的Linux发行版小技巧,你知道吗?)
大家好,我是小学生
今天的文章来源于工作中的一个小技巧,主要是涉及到日常工作的自动化处理。
如果你每天需要做一些重复性的工作,比如发报告、统计数据、发邮件等。
然后你就可以把这个任务交给电脑,让它每天自动为你完成,你只需要从容的打开保温瓶,静静地泡一杯枸杞。
今天主要用Linux下的cron服务,ok,直接启动
1. 安装 cron
基本上所有 Linux 发行版都默认预装了 cron 工具。
即使没有预装cron,也很简单。您可以通过执行一些简单的命令来手动安装它
# 检查是否已经预装了cron
service cron status
安装并启动服务
安装:apt-get install cron
启动/停止/重启:service cron start/stop/restart
查询当前任务:crontab -l
2. 安装检查
安装完成后,查看是否安装成功,也可以使用status命令查看
出现如下提示表示安装成功:
另外在ubuntu下可能会出现这个提示:
这也意味着它可以正常使用
3. cron 用法
cron的几个简单的用法可以学习一下,后面会通过一个案例来详细介绍如何使用
首先,列出当前用户调度的cron作业:
crontab -l
查看其他用户的cron作业:
crontab –l –u username
删除计划的 cron 作业:
crontab –r
4. 调度 crontab 计划
首先通过以下命令在crontab中添加或更新任务
第一次进入会要求选择编辑器,根据自己的习惯来选择。
选择后,会进入如下界面:
用过vim的同学应该对这个界面比较熟悉,类似操作:按A键开始编辑,按ESC输入wq保存退出
重点在底部段落:
m h dom mon dow commmand
这其实是介绍crontab调度作业的使用,可以用来设置定时任务。
具体语法是这样的:
m h dom mon dow command
* * * * * command
- - - - - -
| | | | | |
| | | | | --- 预执行的命令
| | | | ----- 表示星期0~7(其中星期天可以用0或7表示)
| | | ------- 表示月份1~12
| | --------- 表示日期1~31
| ----------- 表示小时1~23(0表示0点)
------------- 表示分钟1~59 每分钟用*或者 */1表示
举几个简单的应用案例:
0 2 * * * command
0 5,17 * * * command
*/10 * * * * command
0 17 * jan,may,aug sun command
这些是最常用的。更多用例可以参考这个链接:
上述案例中的命令表示您需要执行的特定任务,例如打印一个段落:
echo "Hello xiaoyi" >> /tmp/test.txt
或者把这段话输出到txt:
echo "Hello xiaoyi" >> /tmp/test.txt
或者你需要执行一个 Python 脚本:
下面的文件路径代表输入参数args,可能有同学会用到。例如,在下面的情况下,您需要输入文件下载路径。
5. 实战
搞清楚了以上这些之后,我们就可以开始今天的重头戏了。
首先,我们需要每天从ftp服务器下载最新的任务数据,将数据下载到本地并通过Python采集数据,最后将结果存入数据库。如果在此期间某个链接出现问题,则会发送警报电子邮件。
① Python 脚本
首先需要一个Python脚本来完成以下功能:
上述过程的近似伪代码如下:
if __name__ == '__main__':
"""获取最新数据日期"""
latest_date = get_max_date()
# 以最新日期为名创建文件夹
download_dir = os.path.join(sys.argv[1], latest_date)
if not os.path.exists(download_dir):
os.makedirs(download_dir)
"""从ftp中下载最新数据"""
download_file(latest_date, download_dir)
"""处理最新数据并保存"""
process_data(latest_date, download_dir)
邮件监控可以添加try catch异常捕获,发生异常时发送邮件
Python 编辑电子邮件内容并发送。我以前写过。可以参考以下:Python邮件发送
②编写cron任务
打开crontab,将以下内容编辑到最后一行,保存退出
Crontab 会自动实时更新任务列表。如果不放心,可以通过restart命令重启cron服务【参考文章开头】
这里有个小建议,所有路径都填绝对路径
③ 效果监测
如果 Python 代码没有问题,就会定期执行任务。
建议可以单独在控制台运行自己的命令,没问题的时候写红色的cron任务列表即可。
小一计划任务最终截图如下:
底部是ftp文件下载,顶部是数据汇总统计
题外话
如果说平时的工作中有很多重复的任务,比如每日指标的采集、访问的汇总统计、邮件自动转发等。
一旦您可以通过脚本为这些任务设置逻辑,自动化任务也可以实现它。最多就是每天关注一下邮件,看看有没有错误。
原创不容易,请点个赞
文章 首发:公众号【初级学习笔记】
原文链接:普及一个小作业技巧,三步实现Python自动化
文章定时自动采集(JSP婚纱预约管理系统java编程开发语言源码特点)
采集交流 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-11-14 11:09
一、源码特点 JSP婚纱预约管理系统是一个完整的网页设计系统,有助于理解JSP java编程语言。系统源代码和数据库齐全,系统主要采用B/S模式开发。二、功能介绍 前台的主要功能:套餐浏览和预订。关于我们。介绍作品。欣赏摄影地点。查看服务流程。介绍用户注册、登录和提交订单。添加、删除、修改、查看信息(2)用户管理:添加、删除、修改、查看用户信息(3)工作欣赏管理:添加、删除、修改、查看(4)服务进程管理:添加、删除、 查看全部
文章定时自动采集(JSP婚纱预约管理系统java编程开发语言源码特点)
一、源码特点 JSP婚纱预约管理系统是一个完整的网页设计系统,有助于理解JSP java编程语言。系统源代码和数据库齐全,系统主要采用B/S模式开发。二、功能介绍 前台的主要功能:套餐浏览和预订。关于我们。介绍作品。欣赏摄影地点。查看服务流程。介绍用户注册、登录和提交订单。添加、删除、修改、查看信息(2)用户管理:添加、删除、修改、查看用户信息(3)工作欣赏管理:添加、删除、修改、查看(4)服务进程管理:添加、删除、
文章定时自动采集(autopost插件可以采集来自于任何网站的内容并全自动更新)
采集交流 • 优采云 发表了文章 • 0 个评论 • 164 次浏览 • 2021-11-13 17:21
autopost 插件可以 采集 来自任何 网站 内容并自动更新您的 WordPress 网站。它使用起来非常简单,不需要复杂的设置,并且足够强大和稳定,可以支持wordpress的所有功能。
您可以采集网站的任何内容,采集信息一目了然
通过简单的设置,可以采集来自网站的任何内容,并且可以设置多个采集任务同时运行,可以设置任务运行自动或手动,主任务列表显示每个采集任务的状态:上次测试的时间采集,下次测试的预计时间采集,最新的采集文章,已经采集更新文章号等信息,方便查看和管理。
文章管理功能方便查询、查找、删除。 采集文章,改进后的算法从根本上杜绝了重复采集相同文章,log函数记录了采集过程中发生的异常和抓取错误,方便检查设置错误并修复。
任务开启后会自动更新采集无需人工干预
任务激活后,检查是否有新的文章更新,检查文章是否重复,导入更新文章,这些操作都是自动完成的,无需人工干预。
触发采集的更新有两种方式。一种是在页面中添加代码以供用户访问触发。 采集更新(后台异步,不影响用户体验,也不影响网站效率),另外可以使用Cron定时任务触发采集更新任务
有针对性的采集,支持通配符匹配,或者CSS选择器精确采集任何内容,支持采集多级文章列表,支持采集正文分页内容,支持采集多级正文内容
基本设置功能齐全,完美支持Wordpress的各种功能。可自动设置分类目录、标签、摘要、特色图片、自定义栏目等;还可以采集针对网站分类目录,标签等信息后,可以自动生成并添加相应的分类目录、标签等信息
下载链接:autopost 查看全部
文章定时自动采集(autopost插件可以采集来自于任何网站的内容并全自动更新)
autopost 插件可以 采集 来自任何 网站 内容并自动更新您的 WordPress 网站。它使用起来非常简单,不需要复杂的设置,并且足够强大和稳定,可以支持wordpress的所有功能。
您可以采集网站的任何内容,采集信息一目了然
通过简单的设置,可以采集来自网站的任何内容,并且可以设置多个采集任务同时运行,可以设置任务运行自动或手动,主任务列表显示每个采集任务的状态:上次测试的时间采集,下次测试的预计时间采集,最新的采集文章,已经采集更新文章号等信息,方便查看和管理。
文章管理功能方便查询、查找、删除。 采集文章,改进后的算法从根本上杜绝了重复采集相同文章,log函数记录了采集过程中发生的异常和抓取错误,方便检查设置错误并修复。
任务开启后会自动更新采集无需人工干预
任务激活后,检查是否有新的文章更新,检查文章是否重复,导入更新文章,这些操作都是自动完成的,无需人工干预。
触发采集的更新有两种方式。一种是在页面中添加代码以供用户访问触发。 采集更新(后台异步,不影响用户体验,也不影响网站效率),另外可以使用Cron定时任务触发采集更新任务
有针对性的采集,支持通配符匹配,或者CSS选择器精确采集任何内容,支持采集多级文章列表,支持采集正文分页内容,支持采集多级正文内容
基本设置功能齐全,完美支持Wordpress的各种功能。可自动设置分类目录、标签、摘要、特色图片、自定义栏目等;还可以采集针对网站分类目录,标签等信息后,可以自动生成并添加相应的分类目录、标签等信息
下载链接:autopost
文章定时自动采集(换个网站dede采集基础教程-过滤规则在分批分段)
采集交流 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-11-11 03:00
总结:看到很多网友为织梦的采集教程头疼(DEDEcms)。确实,官方教程太笼统了。我什么都没说。改变它。网站DEDE 有一个非常糟糕的点。 采集文章之后,文档生成后的时间就是采集的时间。这个漏洞让很多新手都没有意识到这一点。
dede采集插件
DEDE 有一个非常糟糕的地方。 采集文章之后,文档生成后的时间就是采集的时间。这个漏洞让很多新手都没有意识到。
看到很多网友都为织梦(DEDEcms)的采集教程头疼,确实,官方教程太笼统了,也没说什么。改为网站
dede采集Basic Tutorial-Filtering Rules 在这里,我会分批分节给大家介绍一些dede的使用。主要是针对最近的一些
问题描述安装Dedecms时提示dedequery_log参数设置为ON,然后点击提交参数打开慢日志采集。
[DEDE自动采集伪原创完美版插件]dede自动采集+自动伪原创+自动发布完美版插件=自动赚钱网站!插件功能:
DEDE采集过程中经常用到的DEDE
Dede采集 尚未完成。自动采集插件也有bug,我用过。发现采集的文章自动转贴到其他栏目。也可以说情况是随机的。没有其他的。可能需要一段时间,给它一些时间来完善它! dede还是很不错的!
你确定采集你输入了吗?如果采集进入但不显示,可能重复进入回收站
裕果天晴工作室经常帮人写采集规则,但是很多站长其实不用dede自己的程序采集,裕果天晴工作室没有那么多
阿里巴巴可以为您找到40多个dede采集详细参数、实时报价、报价、优质批发/供应等货源信息,还 查看全部
文章定时自动采集(换个网站dede采集基础教程-过滤规则在分批分段)
总结:看到很多网友为织梦的采集教程头疼(DEDEcms)。确实,官方教程太笼统了。我什么都没说。改变它。网站DEDE 有一个非常糟糕的点。 采集文章之后,文档生成后的时间就是采集的时间。这个漏洞让很多新手都没有意识到这一点。
dede采集插件
DEDE 有一个非常糟糕的地方。 采集文章之后,文档生成后的时间就是采集的时间。这个漏洞让很多新手都没有意识到。
看到很多网友都为织梦(DEDEcms)的采集教程头疼,确实,官方教程太笼统了,也没说什么。改为网站
dede采集Basic Tutorial-Filtering Rules 在这里,我会分批分节给大家介绍一些dede的使用。主要是针对最近的一些
问题描述安装Dedecms时提示dedequery_log参数设置为ON,然后点击提交参数打开慢日志采集。
[DEDE自动采集伪原创完美版插件]dede自动采集+自动伪原创+自动发布完美版插件=自动赚钱网站!插件功能:
DEDE采集过程中经常用到的DEDE
Dede采集 尚未完成。自动采集插件也有bug,我用过。发现采集的文章自动转贴到其他栏目。也可以说情况是随机的。没有其他的。可能需要一段时间,给它一些时间来完善它! dede还是很不错的!
你确定采集你输入了吗?如果采集进入但不显示,可能重复进入回收站
裕果天晴工作室经常帮人写采集规则,但是很多站长其实不用dede自己的程序采集,裕果天晴工作室没有那么多
阿里巴巴可以为您找到40多个dede采集详细参数、实时报价、报价、优质批发/供应等货源信息,还
文章定时自动采集(织梦采集侠的强大功能预览-上海怡健医学)
采集交流 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2021-11-11 02:25
<p>本文由 zengqiwu1 提供。 织梦采集Xia强大功能预览:采集Xia是一款专业的采集模块,拥有先进的人工智能网页识别技术和优秀的伪原创技术,远远超越传统采集软件,来自不同网站采集的优质内容并自动原创处理,减少网站维护工作量大大增加收录 并点击。是每个网站的必备插件。 织梦采集 安装非常简单方便。只需一分钟即刻上手采集,结合简单、健壮、灵活、开源的dedecms程序,新手也能快速上手,我们还有专门的客服为您解答为商业客户提供技术支持。不同于传统的采集模式,织梦采集可以根据用户设置的关键词进行pan采集和pan采集。通过采集和关键词的不同搜索结果实现不采集指定一个或多个采集站点,减少采集站点被搜索由引擎判断镜像站点有被搜索引擎惩罚的危险。 3RSS 采集,输入RSS地址即可。 采集只要内容是采集的网站提供的带有RSS订阅地址的,就可以用RSS做采集,只要输入RSS地址即可方便采集到目标网站内容,无需编写采集规则,方便简单。页面监控采集只需要提供监控页面地址和文字URL规则即可指定采集指定网站或栏目内容,方便简单,无需写 查看全部
文章定时自动采集(织梦采集侠的强大功能预览-上海怡健医学)
<p>本文由 zengqiwu1 提供。 织梦采集Xia强大功能预览:采集Xia是一款专业的采集模块,拥有先进的人工智能网页识别技术和优秀的伪原创技术,远远超越传统采集软件,来自不同网站采集的优质内容并自动原创处理,减少网站维护工作量大大增加收录 并点击。是每个网站的必备插件。 织梦采集 安装非常简单方便。只需一分钟即刻上手采集,结合简单、健壮、灵活、开源的dedecms程序,新手也能快速上手,我们还有专门的客服为您解答为商业客户提供技术支持。不同于传统的采集模式,织梦采集可以根据用户设置的关键词进行pan采集和pan采集。通过采集和关键词的不同搜索结果实现不采集指定一个或多个采集站点,减少采集站点被搜索由引擎判断镜像站点有被搜索引擎惩罚的危险。 3RSS 采集,输入RSS地址即可。 采集只要内容是采集的网站提供的带有RSS订阅地址的,就可以用RSS做采集,只要输入RSS地址即可方便采集到目标网站内容,无需编写采集规则,方便简单。页面监控采集只需要提供监控页面地址和文字URL规则即可指定采集指定网站或栏目内容,方便简单,无需写

