
搜索引擎如何抓取网页
搜索引擎如何抓取网页(网络爬虫()的抓取战略可以分爲深度优先和最佳优先三种)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-02-07 00:15
网络爬虫(也称为网络蜘蛛或网络机器人)是一个序列或脚本,它根据某些规则自动从万维网上爬取信息。通常它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成部分。
抢夺策略
链接抓取策略分为三种类型:深度优先、广度优先和最佳优先。
1、深度搜索策略从起始页开始,选择一个URL进入,分析这个页面的URL,选择一个然后进入。抓那么深,等直四处理完一条路后再处理下一条路。
深度优先策略设计更为复杂。但是用户网站提供的链接往往是最有价值的,而且PageRa地址也很高,但是随着每一个层次的深入,页面价值和PageRank都会相应下降。这意味着重要的页面通常更靠近种子,而过度深度爬取的页面价值较低。同时,该策略的抓取深度间接影响抓取命中率和抓取效率,而抓取深度是该策略的关键。绝对与其他两种策略相比。这种策略很少使用。
2、广度优先搜索策略是指在爬取过程中,在下一级搜索完成后停止下一级搜索。目前,为了覆盖尽可能多的页面,一般采用广度优先搜索方式。也有很多研究使用广度优先搜索策略来关注爬虫。其基本思想是在一定的链接区间内具有初始 URL 的网页具有较高的主题相关性概率。另一种方式是将广度优先搜索与网页过滤技术相结合,先使用广度优先策略抓取网页,然后过滤掉相关网页。这些方法的缺点是随着爬取的网页越来越多,会下载和过滤少量相关网页,
3、最佳优先搜索策略根据一定的网页分析算法预测候选URL与目标网页的相似度,或与主题的相关度,选择评价最好的一个或几个URL停止爬行。它只访问页面分析算法预测为“有用”的页面。存在的一个问题是爬虫的爬取路径上的许多相关网页可以忽略不计,因为优化优先策略是一种部分最优的搜索算法。因此,有必要将最佳优先级与详细的应用改进相结合,以跳出一些最佳点。研究表明,这样的闭环调整可以将相关网页的数量减少30%到90%。
由于爬取网页的特殊要求,使用短网址链接进行爬取爬取比较复杂。 查看全部
搜索引擎如何抓取网页(网络爬虫()的抓取战略可以分爲深度优先和最佳优先三种)
网络爬虫(也称为网络蜘蛛或网络机器人)是一个序列或脚本,它根据某些规则自动从万维网上爬取信息。通常它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成部分。
抢夺策略
链接抓取策略分为三种类型:深度优先、广度优先和最佳优先。
1、深度搜索策略从起始页开始,选择一个URL进入,分析这个页面的URL,选择一个然后进入。抓那么深,等直四处理完一条路后再处理下一条路。
深度优先策略设计更为复杂。但是用户网站提供的链接往往是最有价值的,而且PageRa地址也很高,但是随着每一个层次的深入,页面价值和PageRank都会相应下降。这意味着重要的页面通常更靠近种子,而过度深度爬取的页面价值较低。同时,该策略的抓取深度间接影响抓取命中率和抓取效率,而抓取深度是该策略的关键。绝对与其他两种策略相比。这种策略很少使用。
2、广度优先搜索策略是指在爬取过程中,在下一级搜索完成后停止下一级搜索。目前,为了覆盖尽可能多的页面,一般采用广度优先搜索方式。也有很多研究使用广度优先搜索策略来关注爬虫。其基本思想是在一定的链接区间内具有初始 URL 的网页具有较高的主题相关性概率。另一种方式是将广度优先搜索与网页过滤技术相结合,先使用广度优先策略抓取网页,然后过滤掉相关网页。这些方法的缺点是随着爬取的网页越来越多,会下载和过滤少量相关网页,
3、最佳优先搜索策略根据一定的网页分析算法预测候选URL与目标网页的相似度,或与主题的相关度,选择评价最好的一个或几个URL停止爬行。它只访问页面分析算法预测为“有用”的页面。存在的一个问题是爬虫的爬取路径上的许多相关网页可以忽略不计,因为优化优先策略是一种部分最优的搜索算法。因此,有必要将最佳优先级与详细的应用改进相结合,以跳出一些最佳点。研究表明,这样的闭环调整可以将相关网页的数量减少30%到90%。
由于爬取网页的特殊要求,使用短网址链接进行爬取爬取比较复杂。
搜索引擎如何抓取网页(我的网页不被收录是抄袭而不收录吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-02-06 10:13
在网站的优化过程中,收录home经常遇到自己辛苦写的文章,被一些高权网站抄袭,秒收,但它自己的网页不是。收录,这是一件很烦人的事情,为什么我的网页没有收录,是不是因为没有搜索引擎蜘蛛爬我的网站,被抄袭了文章收录,那会判断我的页面是抄袭而不是 收录 吗?
小红帽蜘蛛池@Q88539698
如果网页文章的内容不是收录,不代表没有被搜索引擎蜘蛛抓取。如果您的网页没有被自己的 robots 文件阻止,它将被搜索引擎蜘蛛抓取。抓取并抓取。如果网站需要排名增加流量,可以打开-收录首页优化排名,效果不错,字快而且很稳定,省时又能做更多的事情。
网站是抄袭的,但是抄袭者的网站不是收录,而是抄袭者的网站是收录,这真的很糟糕,如果不是收录,就不是原创了会不会算抄袭吗?
很有可能大部分网站站长都会觉得自己的文章不是收录,而是抄袭者的首先是收录,因为百度搜索区分自己抄袭也是一个不正确的概念去使用别人的文章内容,导致网页不是收录,自己的排名和权重值一直做不好。
搜索模块收录网页的规范不仅是原创,还有其他元素,比如:网页权重值、外链发布、内链布局合理、网页相关性等,搜索engine 收录 web pages 必须经过抓取-识别-释放三个步骤。在发布参与关键词排名的步骤中,搜索模块会区分整体的URL质量和相关性。当达到收录标准时,网页会被搜索模块收录快速搜索。质量不符合搜索模块收录网页的规范,搜索引擎会用数据库查询临时存储你的文章内容,其实就是爬取爬取你的网页,但是没有数据库被索引和发布,所以找不到网页链接,但是你的文章内容发布的时间,可能知道搜索模块。而对于现在的原创判断搜索引擎还是没有太成熟的技术来证明。
毕竟,搜索引擎的目的是为了更好地让客户获得高质量和高相关性的网页信息内容,而优质信息内容的规范也是基于网站的可信度。如果您的网站是新网站,它将进入新网站。审批期间,审批期间的网站会正常爬取爬取,但不会放行,而是存入数据库查询。审批期过后,网页将发布。新站网站站长们怀疑他们的原创文章内容会不会是收录,那是因为他们不明白自己还在新的审批期地点。所以新站点收录不是很好,不用太担心, 查看全部
搜索引擎如何抓取网页(我的网页不被收录是抄袭而不收录吗?)
在网站的优化过程中,收录home经常遇到自己辛苦写的文章,被一些高权网站抄袭,秒收,但它自己的网页不是。收录,这是一件很烦人的事情,为什么我的网页没有收录,是不是因为没有搜索引擎蜘蛛爬我的网站,被抄袭了文章收录,那会判断我的页面是抄袭而不是 收录 吗?

小红帽蜘蛛池@Q88539698
如果网页文章的内容不是收录,不代表没有被搜索引擎蜘蛛抓取。如果您的网页没有被自己的 robots 文件阻止,它将被搜索引擎蜘蛛抓取。抓取并抓取。如果网站需要排名增加流量,可以打开-收录首页优化排名,效果不错,字快而且很稳定,省时又能做更多的事情。
网站是抄袭的,但是抄袭者的网站不是收录,而是抄袭者的网站是收录,这真的很糟糕,如果不是收录,就不是原创了会不会算抄袭吗?
很有可能大部分网站站长都会觉得自己的文章不是收录,而是抄袭者的首先是收录,因为百度搜索区分自己抄袭也是一个不正确的概念去使用别人的文章内容,导致网页不是收录,自己的排名和权重值一直做不好。
搜索模块收录网页的规范不仅是原创,还有其他元素,比如:网页权重值、外链发布、内链布局合理、网页相关性等,搜索engine 收录 web pages 必须经过抓取-识别-释放三个步骤。在发布参与关键词排名的步骤中,搜索模块会区分整体的URL质量和相关性。当达到收录标准时,网页会被搜索模块收录快速搜索。质量不符合搜索模块收录网页的规范,搜索引擎会用数据库查询临时存储你的文章内容,其实就是爬取爬取你的网页,但是没有数据库被索引和发布,所以找不到网页链接,但是你的文章内容发布的时间,可能知道搜索模块。而对于现在的原创判断搜索引擎还是没有太成熟的技术来证明。
毕竟,搜索引擎的目的是为了更好地让客户获得高质量和高相关性的网页信息内容,而优质信息内容的规范也是基于网站的可信度。如果您的网站是新网站,它将进入新网站。审批期间,审批期间的网站会正常爬取爬取,但不会放行,而是存入数据库查询。审批期过后,网页将发布。新站网站站长们怀疑他们的原创文章内容会不会是收录,那是因为他们不明白自己还在新的审批期地点。所以新站点收录不是很好,不用太担心,
搜索引擎如何抓取网页( 从哪些地方分析诊断网站日志进行分析与诊断的优化措施)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-02-06 00:00
从哪些地方分析诊断网站日志进行分析与诊断的优化措施)
作为一个 SEO 人,如果你不分析和诊断日志,那将是可悲的。实际上,日志分析就是对搜索引擎蜘蛛的日常爬取痕迹做出正确的数据诊断,从而采取合理的优化措施。,我们应该在哪里分析和诊断 网站 日志?
1、搜索引擎蜘蛛的访问次数
搜索引擎对网站的访问次数间接反映了网站的权重。网站为了增加搜索引擎蜘蛛的访问量,站长需要重点关注服务器性能、外链层次建设、网站结构和链接入口等路径的分析和优化。
2、搜索引擎蜘蛛的总停留时间
搜索引擎蜘蛛的停留时间与网站的结构、服务器响应时间、网站的代码、网站的内容更新等密切相关。
3、来自搜索引擎蜘蛛的爬取量
事实上,搜索引擎蜘蛛的停留时间与网站的结构、网站或内容的更新、服务器设置等密切相关,因为搜索引擎蜘蛛的爬取量密切相关对网站与蜘蛛的收录数量有直接关系,蜘蛛爬取的数量越大,网站的收录就越多。
4、搜索引擎蜘蛛的单次访问
如果一个搜索引擎蜘蛛一次爬取的网页较多,则意味着网站的内容更有价值,而网站结构更有利于搜索引擎蜘蛛的抓取。
注意:分析诊断网站日志
5、搜索引擎蜘蛛抓取单页停留时间
搜索引擎蜘蛛爬取单个页面所花费的时间与网站页面的爬取速度、页面的内容、页面的图片大小、页面代码的简洁性等密切相关。为了提高页面加载速度,减少蜘蛛在单个页面上的停留时间,从而增加蜘蛛的总爬取量,增加网站收录可以增加网站@的整体流量>。
6、网站 页面抓取
一般情况下,搜索引擎蜘蛛在网站停留的时间是有限的,在布局上要设置好的网站结构,合理规划重要页面,降低页面的重复爬取率. 蜘蛛被引入其他页面,从而增加了 网站收录 的数量。
7、网页状态码
定期清除页面中的死链接,可以促进蜘蛛顺利爬取整个页面,从而提高网页的爬取率。
8、网站目录结构捕获
一般来说,spider的主爬取目录会和网站的key列保持一致。在外链和内链层面调整优化方案。当遇到不需要收录或者不需要爬取的列时,需要使用robots标签来提醒蜘蛛不要爬取。
只有不断分析诊断网站日志,才能知道我们发布的外部链接是否有效,我们购买的空间是否稳定,蜘蛛喜欢什么页面不喜欢什么,需要什么内容等一系列优化结果比如更新。
十年专注SEO优化,诚信经营,为企业和客户创造价值为根本。把技术实力作为公司的生命线。
真诚接受网站关键词优化、网站整体排名优化、负面处理等服务
文章题目:通过分析诊断网站日志提高搜索引擎爬取友好度 查看全部
搜索引擎如何抓取网页(
从哪些地方分析诊断网站日志进行分析与诊断的优化措施)

作为一个 SEO 人,如果你不分析和诊断日志,那将是可悲的。实际上,日志分析就是对搜索引擎蜘蛛的日常爬取痕迹做出正确的数据诊断,从而采取合理的优化措施。,我们应该在哪里分析和诊断 网站 日志?
1、搜索引擎蜘蛛的访问次数
搜索引擎对网站的访问次数间接反映了网站的权重。网站为了增加搜索引擎蜘蛛的访问量,站长需要重点关注服务器性能、外链层次建设、网站结构和链接入口等路径的分析和优化。
2、搜索引擎蜘蛛的总停留时间
搜索引擎蜘蛛的停留时间与网站的结构、服务器响应时间、网站的代码、网站的内容更新等密切相关。
3、来自搜索引擎蜘蛛的爬取量
事实上,搜索引擎蜘蛛的停留时间与网站的结构、网站或内容的更新、服务器设置等密切相关,因为搜索引擎蜘蛛的爬取量密切相关对网站与蜘蛛的收录数量有直接关系,蜘蛛爬取的数量越大,网站的收录就越多。
4、搜索引擎蜘蛛的单次访问
如果一个搜索引擎蜘蛛一次爬取的网页较多,则意味着网站的内容更有价值,而网站结构更有利于搜索引擎蜘蛛的抓取。
注意:分析诊断网站日志
5、搜索引擎蜘蛛抓取单页停留时间
搜索引擎蜘蛛爬取单个页面所花费的时间与网站页面的爬取速度、页面的内容、页面的图片大小、页面代码的简洁性等密切相关。为了提高页面加载速度,减少蜘蛛在单个页面上的停留时间,从而增加蜘蛛的总爬取量,增加网站收录可以增加网站@的整体流量>。
6、网站 页面抓取
一般情况下,搜索引擎蜘蛛在网站停留的时间是有限的,在布局上要设置好的网站结构,合理规划重要页面,降低页面的重复爬取率. 蜘蛛被引入其他页面,从而增加了 网站收录 的数量。
7、网页状态码
定期清除页面中的死链接,可以促进蜘蛛顺利爬取整个页面,从而提高网页的爬取率。
8、网站目录结构捕获
一般来说,spider的主爬取目录会和网站的key列保持一致。在外链和内链层面调整优化方案。当遇到不需要收录或者不需要爬取的列时,需要使用robots标签来提醒蜘蛛不要爬取。
只有不断分析诊断网站日志,才能知道我们发布的外部链接是否有效,我们购买的空间是否稳定,蜘蛛喜欢什么页面不喜欢什么,需要什么内容等一系列优化结果比如更新。
十年专注SEO优化,诚信经营,为企业和客户创造价值为根本。把技术实力作为公司的生命线。
真诚接受网站关键词优化、网站整体排名优化、负面处理等服务
文章题目:通过分析诊断网站日志提高搜索引擎爬取友好度
搜索引擎如何抓取网页(搜索引擎工作原理(或者叫流程)--搜索引擎的工作过程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-05 23:17
大家好,我是Beard先生,一个在seo行业工作两年的菜鸟,因为一些个人的想法。从现在开始,我们将继续分享我多年来在seo方面的一些工作经验和心得,并在接下来的两个月里与大家分享。好了,不多说了。我们开始今天分享的第一个知识点——搜索引擎的工作原理(或流程)。
搜索引擎的工作过程非常复杂。接下来简单介绍一下搜索索引是如何实现网页排名的。这里展示的内容只是真正的搜索引擎技术的皮毛,但对于我们大多数的搜索引擎来说应该已经足够了。
一个搜索引擎的工作过程大致可以分为三个阶段。
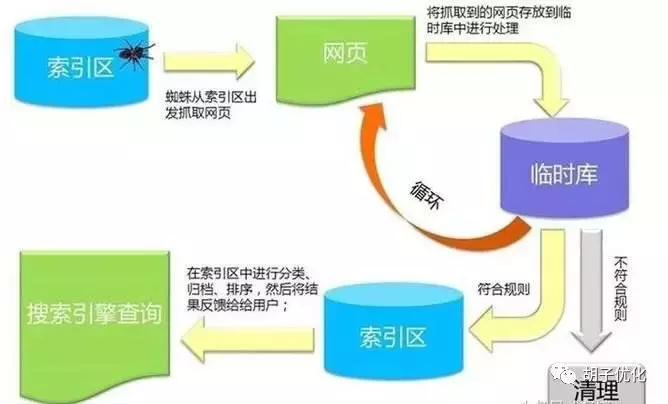
搜索引擎的工作原理
上图显示了搜索引擎的一般工作流程图。首先,搜索引擎会从索引区发送一个程序(百度也叫蜘蛛),通过链接来到网站来爬取我们的网页。到达网页后,首先将数据放入临时数据库,临时数据库会对我们的网页进行一些预处理和评估操作(如去重、中文分词、去停用词、降噪等),以及存储那些符合搜索引擎规则的。去理赔区,否则不符合规定会被清理干净。然后搜索引擎进行排序、归档和排序。最后,将结果显示给用户。
以上大致是一个搜索引擎的工作流程。接下来,我们来看看一些具体的细节。
1.1、抢
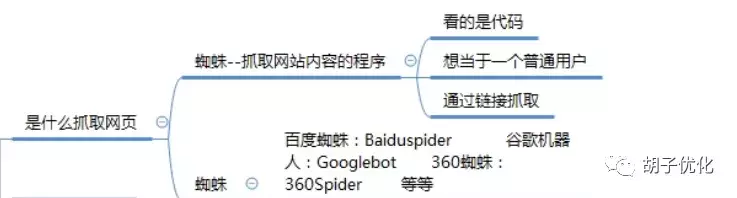
1.1.1 什么在爬网
什么爬网
1.1.2 蜘蛛爬行规则
蜘蛛爬行规则
蜘蛛爬取的规则有很多:深度优先策略、广度优先策略、大站点(高权重)优先策略、及时性优先策略、重要页面优先爬取策略等。
面条。事实上,最大的搜索引文是爬网,而 收录 只是互联网的一小部分。
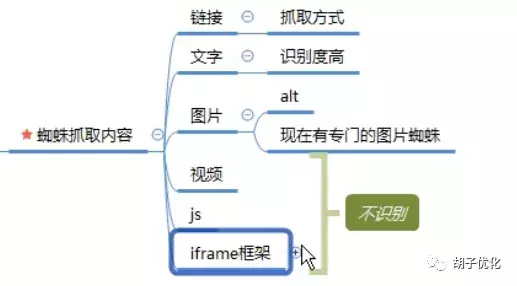
1.1.3蜘蛛爬取内容
蜘蛛抓取内容
蜘蛛通过链接抓取网站的内容,对文字的识别度最高。图片由特殊的图片蜘蛛抓取。但请记住,图像需要一个 Garat 属性便签,以便蜘蛛更好地识别图像。无法识别视频、js 和 iframe 帧。
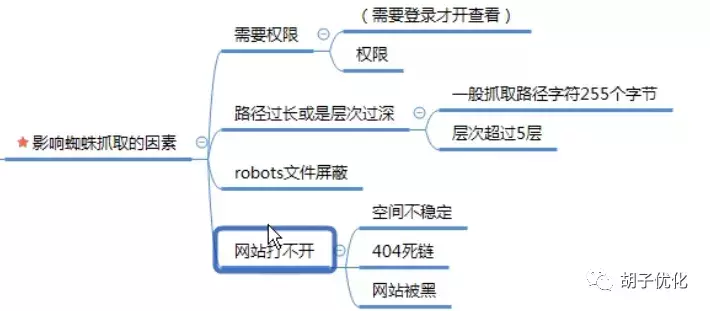
1.1.4 影响蜘蛛爬行的因素
影响蜘蛛爬行的因素
1.1.5如何判断蜘蛛访问网站
有两种方法可以判断蜘蛛是否来到 网站
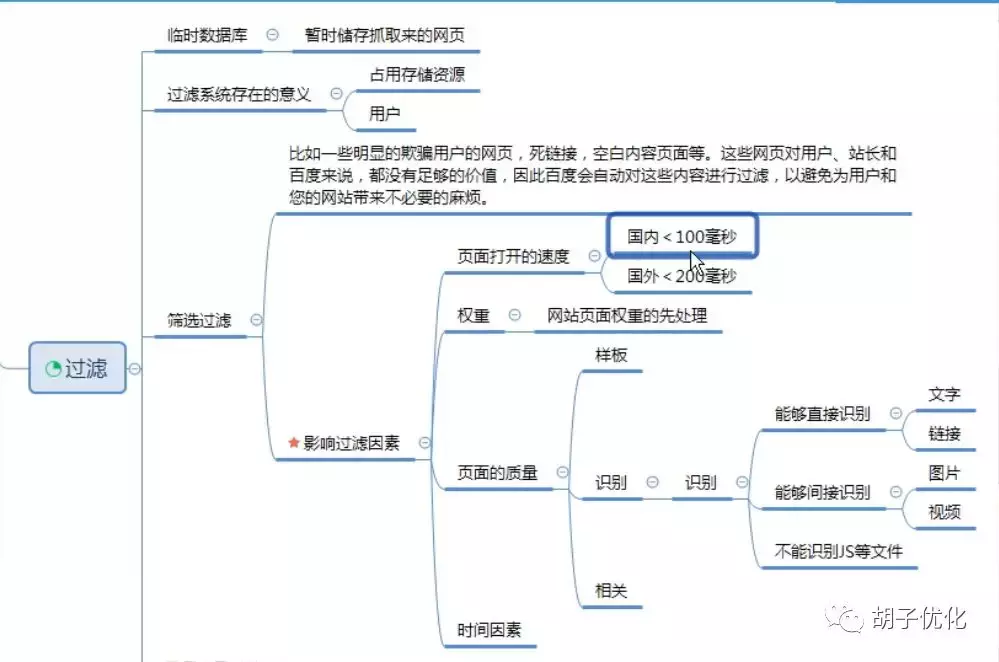
1.2 过滤器
筛选
1.2.1过滤系统的含义
临时数据库是用来临时存储蜘蛛抓取的网页的地方。对于服务器,这里需要过滤网页。过滤需要解决一些无用的资源,节省空间,减少服务器的工作量。其他明显欺骗用户的页面、死链接、空白内容页面等,这些页面对用户、站长和百度没有足够的价值,所以百度会自动过滤这些内容,避免用户和你。网站 带来了不必要的麻烦。
1.2.2 影响过滤的因素
模板,所谓模板,就是我们所说的网页相似度。如果整个网站的相似度高,页面的质量也低。
识别是内容是否可以被百度直接识别。文字和链接可以直接被百度识别,而图片和视频不能直接被百度识别,而是通过标签alt来识别。其余的js、cs、iframe框架等都不识别。
相关性,所谓相关性是指文章标题和文章内容是否相关,相关性越高越好
1.3收录
经过以上一系列的爬取和过滤,我们就到了收录的阶段。蜘蛛会将符合规则的添加到数据库中。然后百度收录就是内容。
1.3.1收录的内容
收录大概有这些页面标题、页面描述、页面源代码、页面url。
1.3.2查看收录
查看 收录
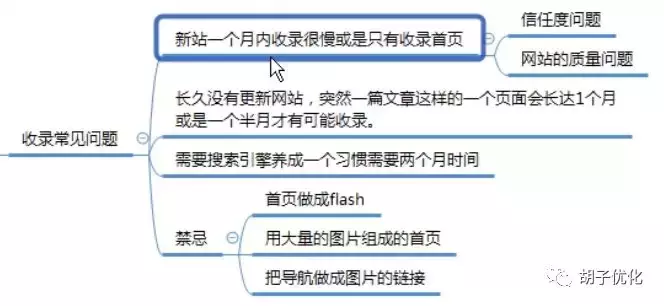
1.3.3收录 的常见问题
1.4 索引
1.4.1 个索引数量
详情请参考百度官方资料:
1.4.2查看索引数量
site命令的当前值是对索引量的估计,不好。百度官方也提出:建议站长使用百度站长平台查看网站的索引量。
1.4.3页进入优质索引条件
至此,我们基本讲完了搜索引擎是如何开始爬取网页或者后期排名的。最后,进入索引库的页面可以通过归档排序很好的展示给用户。好了,最后,如果大家有什么建议或者意见,可以留言告诉我。需要课件的可以直接给我留言。 查看全部
搜索引擎如何抓取网页(搜索引擎工作原理(或者叫流程)--搜索引擎的工作过程)
大家好,我是Beard先生,一个在seo行业工作两年的菜鸟,因为一些个人的想法。从现在开始,我们将继续分享我多年来在seo方面的一些工作经验和心得,并在接下来的两个月里与大家分享。好了,不多说了。我们开始今天分享的第一个知识点——搜索引擎的工作原理(或流程)。
搜索引擎的工作过程非常复杂。接下来简单介绍一下搜索索引是如何实现网页排名的。这里展示的内容只是真正的搜索引擎技术的皮毛,但对于我们大多数的搜索引擎来说应该已经足够了。
一个搜索引擎的工作过程大致可以分为三个阶段。
搜索引擎的工作原理
上图显示了搜索引擎的一般工作流程图。首先,搜索引擎会从索引区发送一个程序(百度也叫蜘蛛),通过链接来到网站来爬取我们的网页。到达网页后,首先将数据放入临时数据库,临时数据库会对我们的网页进行一些预处理和评估操作(如去重、中文分词、去停用词、降噪等),以及存储那些符合搜索引擎规则的。去理赔区,否则不符合规定会被清理干净。然后搜索引擎进行排序、归档和排序。最后,将结果显示给用户。
以上大致是一个搜索引擎的工作流程。接下来,我们来看看一些具体的细节。
1.1、抢
1.1.1 什么在爬网

什么爬网
1.1.2 蜘蛛爬行规则
蜘蛛爬行规则
蜘蛛爬取的规则有很多:深度优先策略、广度优先策略、大站点(高权重)优先策略、及时性优先策略、重要页面优先爬取策略等。
面条。事实上,最大的搜索引文是爬网,而 收录 只是互联网的一小部分。
1.1.3蜘蛛爬取内容
蜘蛛抓取内容
蜘蛛通过链接抓取网站的内容,对文字的识别度最高。图片由特殊的图片蜘蛛抓取。但请记住,图像需要一个 Garat 属性便签,以便蜘蛛更好地识别图像。无法识别视频、js 和 iframe 帧。
1.1.4 影响蜘蛛爬行的因素
影响蜘蛛爬行的因素
1.1.5如何判断蜘蛛访问网站

有两种方法可以判断蜘蛛是否来到 网站
1.2 过滤器
筛选
1.2.1过滤系统的含义
临时数据库是用来临时存储蜘蛛抓取的网页的地方。对于服务器,这里需要过滤网页。过滤需要解决一些无用的资源,节省空间,减少服务器的工作量。其他明显欺骗用户的页面、死链接、空白内容页面等,这些页面对用户、站长和百度没有足够的价值,所以百度会自动过滤这些内容,避免用户和你。网站 带来了不必要的麻烦。
1.2.2 影响过滤的因素
模板,所谓模板,就是我们所说的网页相似度。如果整个网站的相似度高,页面的质量也低。
识别是内容是否可以被百度直接识别。文字和链接可以直接被百度识别,而图片和视频不能直接被百度识别,而是通过标签alt来识别。其余的js、cs、iframe框架等都不识别。
相关性,所谓相关性是指文章标题和文章内容是否相关,相关性越高越好
1.3收录
经过以上一系列的爬取和过滤,我们就到了收录的阶段。蜘蛛会将符合规则的添加到数据库中。然后百度收录就是内容。
1.3.1收录的内容
收录大概有这些页面标题、页面描述、页面源代码、页面url。
1.3.2查看收录
查看 收录
1.3.3收录 的常见问题
1.4 索引
1.4.1 个索引数量
详情请参考百度官方资料:
1.4.2查看索引数量
site命令的当前值是对索引量的估计,不好。百度官方也提出:建议站长使用百度站长平台查看网站的索引量。
1.4.3页进入优质索引条件
至此,我们基本讲完了搜索引擎是如何开始爬取网页或者后期排名的。最后,进入索引库的页面可以通过归档排序很好的展示给用户。好了,最后,如果大家有什么建议或者意见,可以留言告诉我。需要课件的可以直接给我留言。
搜索引擎如何抓取网页(蜘蛛爬行并不会所有所有页面的权重尽可能高更新)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-02-05 23:16
理论上,蜘蛛爬网可以传播到互联网的所有页面,但实际上,蜘蛛不能也不需要,因为互联网上每天都会出现数万亿个新页面,还有更多的垃圾邮件,这里的垃圾邮件是指垃圾邮件网站上有大量不相关的内容。比如约会网站上的赌彩票信息,多次出现会对搜索引擎的用户体验造成很大的伤害。严重影响搜索引擎的盈利能力。
既然我们知道蜘蛛不会抓取所有页面,我们需要学会取悦蜘蛛以获得更多页面为收录。蜘蛛的任务是抓取尽可能多的重要页面。在这方面我们应该取悦它,任何方便蜘蛛爬行和爬行的行为都是好的行为。
蜘蛛爬行一般喜欢以下更新:
一:网站和页面的权重尽可能高。爬虫在爬取时首先考虑网站,因为具有高质量和长寿命站点的网站在爬虫视图中的权重会更高。高权重网站甚至可以达到秒收录的效果。
二:页面更新频率很高。如果页面不经常更新,蜘蛛就不会来爬取页面的内容。只有当我们频繁更新时,蜘蛛才会更频繁地访问我们的 网站 内容。所以最好在维护的时候更新网站,不仅是原创文章,还要转载热点信息。
三:优质的内外链建设。优质的内外链结构可以增加蜘蛛的爬行深度。要被蜘蛛爬取,页面中必须要有入站链接,否则蜘蛛根本不会爬取页面,更别说爬取了,下面就来看看高质量的内外链接的重要性。这也是“内容为王,链接至上”这句话的根据。当蜘蛛沿着链接爬行时,如果有高质量的外部链接,蜘蛛会爬得更深,甚至可能更多层,从而使我们的页面更容易被蜘蛛爬取。
4:到首页的点击距离。这里离首页的距离通常是因为首页的权重最高,爬虫爬到首页。蜘蛛爬到主页最多。每次点击链接,离主页越近,页面的权重就越高。高权重页面的权重也可以通过 URL 结构可视化。URL结构更短,页面权重更高。
通过了解搜索引擎如何工作的基础知识——蜘蛛爬行,并了解像 网站 这样的搜索引擎蜘蛛,这是我们 SEO 人员的目标。 查看全部
搜索引擎如何抓取网页(蜘蛛爬行并不会所有所有页面的权重尽可能高更新)
理论上,蜘蛛爬网可以传播到互联网的所有页面,但实际上,蜘蛛不能也不需要,因为互联网上每天都会出现数万亿个新页面,还有更多的垃圾邮件,这里的垃圾邮件是指垃圾邮件网站上有大量不相关的内容。比如约会网站上的赌彩票信息,多次出现会对搜索引擎的用户体验造成很大的伤害。严重影响搜索引擎的盈利能力。
既然我们知道蜘蛛不会抓取所有页面,我们需要学会取悦蜘蛛以获得更多页面为收录。蜘蛛的任务是抓取尽可能多的重要页面。在这方面我们应该取悦它,任何方便蜘蛛爬行和爬行的行为都是好的行为。
蜘蛛爬行一般喜欢以下更新:
一:网站和页面的权重尽可能高。爬虫在爬取时首先考虑网站,因为具有高质量和长寿命站点的网站在爬虫视图中的权重会更高。高权重网站甚至可以达到秒收录的效果。
二:页面更新频率很高。如果页面不经常更新,蜘蛛就不会来爬取页面的内容。只有当我们频繁更新时,蜘蛛才会更频繁地访问我们的 网站 内容。所以最好在维护的时候更新网站,不仅是原创文章,还要转载热点信息。
三:优质的内外链建设。优质的内外链结构可以增加蜘蛛的爬行深度。要被蜘蛛爬取,页面中必须要有入站链接,否则蜘蛛根本不会爬取页面,更别说爬取了,下面就来看看高质量的内外链接的重要性。这也是“内容为王,链接至上”这句话的根据。当蜘蛛沿着链接爬行时,如果有高质量的外部链接,蜘蛛会爬得更深,甚至可能更多层,从而使我们的页面更容易被蜘蛛爬取。
4:到首页的点击距离。这里离首页的距离通常是因为首页的权重最高,爬虫爬到首页。蜘蛛爬到主页最多。每次点击链接,离主页越近,页面的权重就越高。高权重页面的权重也可以通过 URL 结构可视化。URL结构更短,页面权重更高。
通过了解搜索引擎如何工作的基础知识——蜘蛛爬行,并了解像 网站 这样的搜索引擎蜘蛛,这是我们 SEO 人员的目标。
搜索引擎如何抓取网页(搜索引擎优化(seo)是让搜索引擎更好的收录(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-02-05 15:27
搜索引擎优化 (seo) 是一系列使搜索引擎更好地收录我们的网页的过程。好的优化措施将有助于搜索引擎蜘蛛抓取我们的网站。什么是优化?优化的目的是“取其精华去渣”,就是把网页的内容放上去,方便百度蜘蛛的抓取。百度搜索引擎(蜘蛛)如何爬取我们的页面?作者在百度上搜索了一篇自己在admin5站长网站上发表的文章文章,拿出来分享给大家。
<IMG alt="" src="http://seo.admin5.com/data/att ... ot%3B width=595 height=250>
图1
页面标题
如图1所示,百度搜索引擎首先抓取的是页面标题的title标签。网站 的标题标签对网站 的优化非常重要。作者一周前修改了网站的标题标签,只删了两个字,百度搜索引擎一周前发布了,这期间截图没有更新,一直停留在原来的时间!
描述标签
如图 1 所示,搜索引擎不一定会显示描述标签(admin5 中的信息摘要)。百度索引爬取页面标题后,会优先爬取网页内容中最先显示的内容,而不是网页正文。第一段(如图2-标题下半部分-在admin5中,这是一个锚文本链接,百度既然抢了,那肯定也要抢这个锚文本链接),然后在描述部分爬取网页的手段,网站的描述部分通常超过200个字符。通常,网站的描述部分不会显示网站第一段的所有内容,而是显示搜索引擎认为与用户搜索最相关的内容。如图 3 所示。
图二
<IMG alt="" src="http://seo.admin5.com/data/att ... ot%3B width=606 height=254>
图 3
如果我们结合图 一、 图 2 和图 3 可以清楚的看到百度蜘蛛抓取的网页的哪些部分,title 标签,titles,与用户搜索相关的 关键词 部分内容,以及相关内容以浮动红色的形式显示。让用户区分这是否是他们需要的信息!因此,了解百度蜘蛛的搜索有助于降低网站的跳出率,增加用户粘性。以上只是简单的个人分析。本文来自:Crane_Starter admin5,转载于保留地址,非常感谢! 查看全部
搜索引擎如何抓取网页(搜索引擎优化(seo)是让搜索引擎更好的收录(图))
搜索引擎优化 (seo) 是一系列使搜索引擎更好地收录我们的网页的过程。好的优化措施将有助于搜索引擎蜘蛛抓取我们的网站。什么是优化?优化的目的是“取其精华去渣”,就是把网页的内容放上去,方便百度蜘蛛的抓取。百度搜索引擎(蜘蛛)如何爬取我们的页面?作者在百度上搜索了一篇自己在admin5站长网站上发表的文章文章,拿出来分享给大家。
<IMG alt="" src="http://seo.admin5.com/data/att ... ot%3B width=595 height=250>
图1
页面标题
如图1所示,百度搜索引擎首先抓取的是页面标题的title标签。网站 的标题标签对网站 的优化非常重要。作者一周前修改了网站的标题标签,只删了两个字,百度搜索引擎一周前发布了,这期间截图没有更新,一直停留在原来的时间!
描述标签
如图 1 所示,搜索引擎不一定会显示描述标签(admin5 中的信息摘要)。百度索引爬取页面标题后,会优先爬取网页内容中最先显示的内容,而不是网页正文。第一段(如图2-标题下半部分-在admin5中,这是一个锚文本链接,百度既然抢了,那肯定也要抢这个锚文本链接),然后在描述部分爬取网页的手段,网站的描述部分通常超过200个字符。通常,网站的描述部分不会显示网站第一段的所有内容,而是显示搜索引擎认为与用户搜索最相关的内容。如图 3 所示。
图二
<IMG alt="" src="http://seo.admin5.com/data/att ... ot%3B width=606 height=254>
图 3
如果我们结合图 一、 图 2 和图 3 可以清楚的看到百度蜘蛛抓取的网页的哪些部分,title 标签,titles,与用户搜索相关的 关键词 部分内容,以及相关内容以浮动红色的形式显示。让用户区分这是否是他们需要的信息!因此,了解百度蜘蛛的搜索有助于降低网站的跳出率,增加用户粘性。以上只是简单的个人分析。本文来自:Crane_Starter admin5,转载于保留地址,非常感谢!
搜索引擎如何抓取网页(如何判断是否是蜘蛛对翻页式网页的抓住机制来发表一点看法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-02-05 15:25
<p>Spider 系统的目标是发现和爬取 Internet 上所有有价值的网页。百度官方也明确表示,蜘蛛只能抓取尽可能多的有价值资源,并保持系统中页面与实际环境的一致性。@网站经验造成压力,也就是说蜘蛛不会爬取 查看全部
搜索引擎如何抓取网页(如何判断是否是蜘蛛对翻页式网页的抓住机制来发表一点看法)
<p>Spider 系统的目标是发现和爬取 Internet 上所有有价值的网页。百度官方也明确表示,蜘蛛只能抓取尽可能多的有价值资源,并保持系统中页面与实际环境的一致性。@网站经验造成压力,也就是说蜘蛛不会爬取
搜索引擎如何抓取网页(搜索引擎蜘蛛是如何爬行与访问页面的程序蜘蛛教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-02-05 15:25
搜索引擎蜘蛛,在搜索引擎系统中也称为“蜘蛛”或“机器人”,是用于抓取和访问页面的程序。今天小课堂为大家带来了搜索引擎蜘蛛如何爬取和爬取页面的教程。我希望能有所帮助。
一、搜索引擎蜘蛛简介
搜索引擎蜘蛛,在搜索引擎系统中也称为“蜘蛛”或“机器人”,是用于抓取和访问页面的程序。
① 爬行原理
搜索引擎蜘蛛访问网页的过程就像用户使用的浏览器一样。
搜索引擎蜘蛛向页面发送请求,页面的服务器返回页面的 HTML 代码。
搜索引擎蜘蛛将接收到的 HTML 代码存储在搜索引擎的原创页面数据库中。
②如何爬行
为了提高搜索引擎蜘蛛的工作效率,通常采用多个蜘蛛并发分布爬取。
同时,分布式爬取也分为深度优先和广度优先两种模式。
深度优先:沿着发现的链接爬行,直到没有链接为止。
广度优先:爬取完本页所有链接后,会沿着二级页面继续爬取。
③蜘蛛必须遵守的协议
在访问网站之前,搜索引擎蜘蛛会先访问网站根目录下的robots.txt文件。
搜索引擎蜘蛛不会抓取 robots.txt 文件中禁止抓取的文件或目录。
④ 常见的搜索引擎蜘蛛
百度蜘蛛:百度蜘蛛
谷歌蜘蛛:谷歌机器人
360蜘蛛:360蜘蛛
SOSO蜘蛛:Sosospider
有道蜘蛛:有道机器人、有道机器人
搜狗蜘蛛:搜狗新闻蜘蛛
必应蜘蛛:bingbot
Alexa 蜘蛛:ia_archiver
二、如何吸引更多搜索引擎蜘蛛
随着互联网信息的爆炸式增长,搜索引擎蜘蛛不可能爬取所有网站的所有链接,所以如何吸引更多的搜索引擎蜘蛛爬取我们的网站就变得非常重要了。
① 导入链接
不管是外链还是内链,只有导入后,搜索引擎蜘蛛才能知道页面的存在。因此,做更多的外链建设将有助于吸引更多的蜘蛛访问。
② 页面更新频率
页面更新频率越高,搜索引擎蜘蛛的访问次数就越多。
③ 网站 和页重
整个网站的权重和某个页面(包括首页也是一个页面)的权重影响蜘蛛的访问频率。网站 具有较高的权重和权限,一般会增加搜索引擎蜘蛛的好感度。 查看全部
搜索引擎如何抓取网页(搜索引擎蜘蛛是如何爬行与访问页面的程序蜘蛛教程)
搜索引擎蜘蛛,在搜索引擎系统中也称为“蜘蛛”或“机器人”,是用于抓取和访问页面的程序。今天小课堂为大家带来了搜索引擎蜘蛛如何爬取和爬取页面的教程。我希望能有所帮助。

一、搜索引擎蜘蛛简介
搜索引擎蜘蛛,在搜索引擎系统中也称为“蜘蛛”或“机器人”,是用于抓取和访问页面的程序。
① 爬行原理
搜索引擎蜘蛛访问网页的过程就像用户使用的浏览器一样。
搜索引擎蜘蛛向页面发送请求,页面的服务器返回页面的 HTML 代码。
搜索引擎蜘蛛将接收到的 HTML 代码存储在搜索引擎的原创页面数据库中。
②如何爬行
为了提高搜索引擎蜘蛛的工作效率,通常采用多个蜘蛛并发分布爬取。
同时,分布式爬取也分为深度优先和广度优先两种模式。
深度优先:沿着发现的链接爬行,直到没有链接为止。
广度优先:爬取完本页所有链接后,会沿着二级页面继续爬取。
③蜘蛛必须遵守的协议
在访问网站之前,搜索引擎蜘蛛会先访问网站根目录下的robots.txt文件。
搜索引擎蜘蛛不会抓取 robots.txt 文件中禁止抓取的文件或目录。
④ 常见的搜索引擎蜘蛛
百度蜘蛛:百度蜘蛛
谷歌蜘蛛:谷歌机器人
360蜘蛛:360蜘蛛
SOSO蜘蛛:Sosospider
有道蜘蛛:有道机器人、有道机器人
搜狗蜘蛛:搜狗新闻蜘蛛
必应蜘蛛:bingbot
Alexa 蜘蛛:ia_archiver
二、如何吸引更多搜索引擎蜘蛛
随着互联网信息的爆炸式增长,搜索引擎蜘蛛不可能爬取所有网站的所有链接,所以如何吸引更多的搜索引擎蜘蛛爬取我们的网站就变得非常重要了。
① 导入链接
不管是外链还是内链,只有导入后,搜索引擎蜘蛛才能知道页面的存在。因此,做更多的外链建设将有助于吸引更多的蜘蛛访问。
② 页面更新频率
页面更新频率越高,搜索引擎蜘蛛的访问次数就越多。
③ 网站 和页重
整个网站的权重和某个页面(包括首页也是一个页面)的权重影响蜘蛛的访问频率。网站 具有较高的权重和权限,一般会增加搜索引擎蜘蛛的好感度。
搜索引擎如何抓取网页(有什么方能提高网页被搜索引擎、索引和排名的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-02-05 15:20
-SEO 以下是一个被许多SEO 误解的重要概念。很久以前,搜索引擎爬虫(机器人)会递归地爬取某个网站(通过你提交的网站主页URL,然后爬取页面上找到的所有链接)指向该网页, 一次又一次)。但现在情况并非如此。就像下图一样,搜索引擎的爬虫在爬取的时候会有多个入口点,每个入口点同等重要,然后从这些入口点展开去爬取。那么我们看看有哪些方法可以提高搜索引擎对网页的爬取、索引和排名:一个典型的网站外链分布图那么我们再来看一个典型的网站外链分布图:Crawler Prioritizing在这里爬行路径' s 一个重要的概念,被许多 SEO 所误解。很久以前,搜索引擎爬虫(机器人)会递归地爬取某个网站(通过你提交的网站主页URL,然后爬取页面上找到的所有链接)指向该网页, 一次又一次)。但现在情况并非如此。就像下图一样,搜索引擎的爬虫在爬取的时候会有多个入口点,每个入口点同等重要,然后从这些入口点展开去爬取。最后,我们来看看如何提高你的页面的爬取、索引和搜索引擎排名:如果你的 网站 可以构建一个理想的、扁平的链接层次结构,它可以一次点击访问 100 万个页面和效果4 次点击即可访问 100 万个页面。你应该注意反向链接多的“强”页面的涟漪效应(指排名高且反向链接多的页面,易IT注意),并充分利用这种效应。将此类页面视为目录(或类别)页面,并将它们链接到 网站 的其他页面。同样,您将来可以将此类页面用作登录页面,以帮助将流量吸引到您希望用户访问的页面。位于链接图边缘的页面价值较低。确认 网站 没有降低 PageRank 的页面。这些页面通常是 PDF、图片和其他文档。您可以使用 301 重定向将这些文件重定向到收录(嵌入或收录下载链接)这些文件内容的页面,并在页面上有返回 网站 其他部分的链接。如果您可以制作此类具有链接价值且引人入胜的页面,它们将获得更高的 PageRank 和更高的抓取率。同时,这些 PageRank 和爬取优先级通过页面上的链接传递到 网站 上的其他页面(向搜索引擎发出信号,表明 网站 上的所有页面都很重要)。减少不必要的导航级别(或内容页面)并将爬虫引导到真正需要 PageRank 的 URL。 查看全部
搜索引擎如何抓取网页(有什么方能提高网页被搜索引擎、索引和排名的方法)
-SEO 以下是一个被许多SEO 误解的重要概念。很久以前,搜索引擎爬虫(机器人)会递归地爬取某个网站(通过你提交的网站主页URL,然后爬取页面上找到的所有链接)指向该网页, 一次又一次)。但现在情况并非如此。就像下图一样,搜索引擎的爬虫在爬取的时候会有多个入口点,每个入口点同等重要,然后从这些入口点展开去爬取。那么我们看看有哪些方法可以提高搜索引擎对网页的爬取、索引和排名:一个典型的网站外链分布图那么我们再来看一个典型的网站外链分布图:Crawler Prioritizing在这里爬行路径' s 一个重要的概念,被许多 SEO 所误解。很久以前,搜索引擎爬虫(机器人)会递归地爬取某个网站(通过你提交的网站主页URL,然后爬取页面上找到的所有链接)指向该网页, 一次又一次)。但现在情况并非如此。就像下图一样,搜索引擎的爬虫在爬取的时候会有多个入口点,每个入口点同等重要,然后从这些入口点展开去爬取。最后,我们来看看如何提高你的页面的爬取、索引和搜索引擎排名:如果你的 网站 可以构建一个理想的、扁平的链接层次结构,它可以一次点击访问 100 万个页面和效果4 次点击即可访问 100 万个页面。你应该注意反向链接多的“强”页面的涟漪效应(指排名高且反向链接多的页面,易IT注意),并充分利用这种效应。将此类页面视为目录(或类别)页面,并将它们链接到 网站 的其他页面。同样,您将来可以将此类页面用作登录页面,以帮助将流量吸引到您希望用户访问的页面。位于链接图边缘的页面价值较低。确认 网站 没有降低 PageRank 的页面。这些页面通常是 PDF、图片和其他文档。您可以使用 301 重定向将这些文件重定向到收录(嵌入或收录下载链接)这些文件内容的页面,并在页面上有返回 网站 其他部分的链接。如果您可以制作此类具有链接价值且引人入胜的页面,它们将获得更高的 PageRank 和更高的抓取率。同时,这些 PageRank 和爬取优先级通过页面上的链接传递到 网站 上的其他页面(向搜索引擎发出信号,表明 网站 上的所有页面都很重要)。减少不必要的导航级别(或内容页面)并将爬虫引导到真正需要 PageRank 的 URL。
搜索引擎如何抓取网页(没有判断搜索引擎的算法,可以更好的改进网站吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2022-02-05 14:07
任何优化公司都知道,每个搜索引擎的排名实际上是由多种因素共同决定的。有时,一些网站所谓的结论只是偶然。事实上,没有人知道搜索引擎的算法。只有通过不断的实践和总结,我们的网站才能越来越完善。面对很久没有更新内容的网站,用户不会关注他,甚至搜索引擎也不会再收录他了。所以这个时候,既然你无法判断搜索引擎的算法,那你可以更好的改进网站。
一、更新频率
对于一些专注于新闻的门户网站网站来说,以合理的频率更新网站内容是很重要的。新闻本身具有很强的时效性。如果刚刚发生,请务必在短时间内将其发布到 网站。作为一个新闻网站的用户,你基本上会关注刚刚发生的事情。如果你输入一条新闻网站,发现某件事发生在几年前甚至很久以前,那么这个网站 将不会被访问。当用户发现 网站 内容太旧时,搜索引擎和用户都不愿多停留一秒。
二、内容更新
在判断内容更新时,网站的权重和流量占比很大。尤其是做网站优化的,更新网站内容是必不可少的工作,尤其是对于那些大型企业网站,所有的产品信息都是相对固定的,所以一定要尽量在更新的内容中添加部分,不要更新它,因为 网站 的内容很小。要知道,如果内容不更新,搜索引擎永远不会给予更高的权重。另一方面,假设网站每天完成内容更新,搜索引擎蜘蛛也会养成每天抓取网站内容的习惯。久而久之,权重自然会变高,新闻发布的文章会在短时间内直接收录。
所以为了更好的掌握蜘蛛的爬行规律,可以了解它的爬行规律,这样可以更好的优化,让网站内容的关键词更加稳定。 查看全部
搜索引擎如何抓取网页(没有判断搜索引擎的算法,可以更好的改进网站吗?)
任何优化公司都知道,每个搜索引擎的排名实际上是由多种因素共同决定的。有时,一些网站所谓的结论只是偶然。事实上,没有人知道搜索引擎的算法。只有通过不断的实践和总结,我们的网站才能越来越完善。面对很久没有更新内容的网站,用户不会关注他,甚至搜索引擎也不会再收录他了。所以这个时候,既然你无法判断搜索引擎的算法,那你可以更好的改进网站。

一、更新频率
对于一些专注于新闻的门户网站网站来说,以合理的频率更新网站内容是很重要的。新闻本身具有很强的时效性。如果刚刚发生,请务必在短时间内将其发布到 网站。作为一个新闻网站的用户,你基本上会关注刚刚发生的事情。如果你输入一条新闻网站,发现某件事发生在几年前甚至很久以前,那么这个网站 将不会被访问。当用户发现 网站 内容太旧时,搜索引擎和用户都不愿多停留一秒。
二、内容更新
在判断内容更新时,网站的权重和流量占比很大。尤其是做网站优化的,更新网站内容是必不可少的工作,尤其是对于那些大型企业网站,所有的产品信息都是相对固定的,所以一定要尽量在更新的内容中添加部分,不要更新它,因为 网站 的内容很小。要知道,如果内容不更新,搜索引擎永远不会给予更高的权重。另一方面,假设网站每天完成内容更新,搜索引擎蜘蛛也会养成每天抓取网站内容的习惯。久而久之,权重自然会变高,新闻发布的文章会在短时间内直接收录。
所以为了更好的掌握蜘蛛的爬行规律,可以了解它的爬行规律,这样可以更好的优化,让网站内容的关键词更加稳定。
搜索引擎如何抓取网页(搜索引擎面对的是互联网万亿网页,如何高效抓取这么多网页到本地镜像?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-02-05 07:17
搜索引擎面对互联网上数以万亿计的网页。这么多网页如何高效爬取到本地镜像?这是网络爬虫的工作。我们也称它为网络蜘蛛,作为站长,我们每天都与它密切接触。
一、爬虫框架
搜索引擎蜘蛛抓取网络规则三倍
上图是一个简单的网络爬虫框架图。从种子URL开始,如图,经过一步一步的工作,最终将网页存入库中。当然,勤劳的蜘蛛可能还需要做更多的工作,比如网页的去重和网页的反作弊。
或许,我们可以将网页视为蜘蛛的晚餐,其中包括:
下载的网页。被蜘蛛爬过的网页内容被放到了肚子里。
过期网页。蜘蛛每次都要爬很多网页,有的已经在肚子里坏掉了。
要下载的页面。当它看到食物时,蜘蛛就会去抓它。
知名网站。它还没有被下载和发现,但是蜘蛛可以感知它们并且迟早会抓住它。
不可知的网页。互联网太大了,很多页面蜘蛛都找不到,而且可能永远也找不到。这部分占比很高。
通过以上划分,我们可以清楚地了解搜索引擎蜘蛛的工作以及它们面临的挑战。大多数蜘蛛都是按照这个框架爬行的。但这并不完全确定。一切总是特别的。根据不同的功能,蜘蛛系统有一些差异。
二、爬虫种类
1.批量式蜘蛛。
这种蜘蛛有明确的抓取范围和目标,当蜘蛛完成目标和任务时停止抓取。具体目标是什么?它可能是抓取的页面数、页面大小、抓取时间等。
2.增量蜘蛛
这种蜘蛛不同于批处理型蜘蛛,它们会不断地爬取,并且会定期对爬取的网页进行爬取和更新。由于 Internet 上的网页在不断更新,增量爬虫需要能够反映这种更新。
3.垂直蜘蛛
此类蜘蛛仅关注特定主题或特定行业页面。以health网站为例,这种专门的爬虫只会爬取健康相关的话题,其他话题的页面不会被爬取。测试这个蜘蛛的难点在于如何更准确地识别内容所属的行业。目前很多垂直行业网站都需要这种蜘蛛去抢。
三、抢夺策略
爬虫通过种子URL进行爬取和扩展,列出大量待爬取的URL。但是,要抓取的 URL 数量巨大。蜘蛛如何确定爬行的顺序?蜘蛛爬取的策略有很多,但最终目的是一个:首先爬取重要的网页。评价页面是否重要,蜘蛛会根据页面内容的程度原创、链接权重分析等多种方法进行计算。比较有代表性的爬取策略如下:
1. 广度优先策略
宽度优先是指蜘蛛爬取网页后,会继续按顺序爬取网页中收录的其他页面。这个想法看似简单,但实际上非常实用。因为大部分网页都是有优先级的,所以在页面上优先推荐重要的页面。
2. PageRank 策略
PageRank是一种非常有名的链接分析方法,主要用来衡量网页的权威性。例如,Google 的 PR 就是典型的 PageRank 算法。通过PageRank算法我们可以找出哪些页面更重要,然后蜘蛛会优先抓取这些重要的页面。
3.大网站优先策略
这个很容易理解,大网站通常内容页比较多,质量也会比较高。蜘蛛会首先分析网站分类和属性。如果这个网站已经是收录很多,或者在搜索引擎系统中的权重很高,则优先考虑收录。
4.网页更新
互联网上的大部分页面都会更新,所以蜘蛛存储的页面需要及时更新以保持一致性。打个比方:一个页面之前排名很好,如果页面被删除了但仍然排名,那么体验很差。因此,搜索引擎需要及时了解这些并更新页面,为用户提供最新的页面。常用的网页更新策略有三种:历史参考策略和用户体验策略。整群抽样策略。
1. 历史参考策略
这是基于假设的更新策略。例如,如果你的网页以前经常更新,那么搜索引擎也认为你的网页以后会经常更新,蜘蛛也会根据这个规则定期网站对网页进行爬取。这也是为什么点水一直强调网站内容需要定期更新的原因。
2. 用户体验策略
一般来说,用户只查看搜索结果前三页的内容,很少有人看到后面的页面。用户体验策略是搜索引擎根据用户的这一特征进行更新。例如,一个网页可能发布得较早,并且有一段时间没有更新,但用户仍然觉得它有用并点击浏览,那么搜索引擎可能不会首先更新这些过时的网页。这就是为什么搜索结果中的最新页面不一定排名靠前的原因。排名更多地取决于页面的质量,而不是更新的时间。
3.整群抽样策略
以上两种更新策略主要参考网页的历史信息。然而,存储大量历史信息对于搜索引擎来说是一种负担。另外,如果收录是一个新的网页,没有历史信息可以参考,怎么办?聚类抽样策略是指:拿出一些属性对很多相似的网页进行分类,分类后的页面按照相同的规则进行更新。
从了解搜索引擎蜘蛛工作原理的过程中,我们会知道:网站内容的相关性、网站与网页内容的更新规律、网页链接的分布和权重网站 等因素会影响蜘蛛的爬取效率。知己知彼,让蜘蛛来得更猛烈!
转载: 查看全部
搜索引擎如何抓取网页(搜索引擎面对的是互联网万亿网页,如何高效抓取这么多网页到本地镜像?)
搜索引擎面对互联网上数以万亿计的网页。这么多网页如何高效爬取到本地镜像?这是网络爬虫的工作。我们也称它为网络蜘蛛,作为站长,我们每天都与它密切接触。
一、爬虫框架
搜索引擎蜘蛛抓取网络规则三倍
上图是一个简单的网络爬虫框架图。从种子URL开始,如图,经过一步一步的工作,最终将网页存入库中。当然,勤劳的蜘蛛可能还需要做更多的工作,比如网页的去重和网页的反作弊。
或许,我们可以将网页视为蜘蛛的晚餐,其中包括:
下载的网页。被蜘蛛爬过的网页内容被放到了肚子里。
过期网页。蜘蛛每次都要爬很多网页,有的已经在肚子里坏掉了。
要下载的页面。当它看到食物时,蜘蛛就会去抓它。
知名网站。它还没有被下载和发现,但是蜘蛛可以感知它们并且迟早会抓住它。
不可知的网页。互联网太大了,很多页面蜘蛛都找不到,而且可能永远也找不到。这部分占比很高。
通过以上划分,我们可以清楚地了解搜索引擎蜘蛛的工作以及它们面临的挑战。大多数蜘蛛都是按照这个框架爬行的。但这并不完全确定。一切总是特别的。根据不同的功能,蜘蛛系统有一些差异。
二、爬虫种类
1.批量式蜘蛛。
这种蜘蛛有明确的抓取范围和目标,当蜘蛛完成目标和任务时停止抓取。具体目标是什么?它可能是抓取的页面数、页面大小、抓取时间等。
2.增量蜘蛛
这种蜘蛛不同于批处理型蜘蛛,它们会不断地爬取,并且会定期对爬取的网页进行爬取和更新。由于 Internet 上的网页在不断更新,增量爬虫需要能够反映这种更新。
3.垂直蜘蛛
此类蜘蛛仅关注特定主题或特定行业页面。以health网站为例,这种专门的爬虫只会爬取健康相关的话题,其他话题的页面不会被爬取。测试这个蜘蛛的难点在于如何更准确地识别内容所属的行业。目前很多垂直行业网站都需要这种蜘蛛去抢。
三、抢夺策略
爬虫通过种子URL进行爬取和扩展,列出大量待爬取的URL。但是,要抓取的 URL 数量巨大。蜘蛛如何确定爬行的顺序?蜘蛛爬取的策略有很多,但最终目的是一个:首先爬取重要的网页。评价页面是否重要,蜘蛛会根据页面内容的程度原创、链接权重分析等多种方法进行计算。比较有代表性的爬取策略如下:
1. 广度优先策略
宽度优先是指蜘蛛爬取网页后,会继续按顺序爬取网页中收录的其他页面。这个想法看似简单,但实际上非常实用。因为大部分网页都是有优先级的,所以在页面上优先推荐重要的页面。
2. PageRank 策略
PageRank是一种非常有名的链接分析方法,主要用来衡量网页的权威性。例如,Google 的 PR 就是典型的 PageRank 算法。通过PageRank算法我们可以找出哪些页面更重要,然后蜘蛛会优先抓取这些重要的页面。
3.大网站优先策略
这个很容易理解,大网站通常内容页比较多,质量也会比较高。蜘蛛会首先分析网站分类和属性。如果这个网站已经是收录很多,或者在搜索引擎系统中的权重很高,则优先考虑收录。
4.网页更新
互联网上的大部分页面都会更新,所以蜘蛛存储的页面需要及时更新以保持一致性。打个比方:一个页面之前排名很好,如果页面被删除了但仍然排名,那么体验很差。因此,搜索引擎需要及时了解这些并更新页面,为用户提供最新的页面。常用的网页更新策略有三种:历史参考策略和用户体验策略。整群抽样策略。
1. 历史参考策略
这是基于假设的更新策略。例如,如果你的网页以前经常更新,那么搜索引擎也认为你的网页以后会经常更新,蜘蛛也会根据这个规则定期网站对网页进行爬取。这也是为什么点水一直强调网站内容需要定期更新的原因。
2. 用户体验策略
一般来说,用户只查看搜索结果前三页的内容,很少有人看到后面的页面。用户体验策略是搜索引擎根据用户的这一特征进行更新。例如,一个网页可能发布得较早,并且有一段时间没有更新,但用户仍然觉得它有用并点击浏览,那么搜索引擎可能不会首先更新这些过时的网页。这就是为什么搜索结果中的最新页面不一定排名靠前的原因。排名更多地取决于页面的质量,而不是更新的时间。
3.整群抽样策略
以上两种更新策略主要参考网页的历史信息。然而,存储大量历史信息对于搜索引擎来说是一种负担。另外,如果收录是一个新的网页,没有历史信息可以参考,怎么办?聚类抽样策略是指:拿出一些属性对很多相似的网页进行分类,分类后的页面按照相同的规则进行更新。
从了解搜索引擎蜘蛛工作原理的过程中,我们会知道:网站内容的相关性、网站与网页内容的更新规律、网页链接的分布和权重网站 等因素会影响蜘蛛的爬取效率。知己知彼,让蜘蛛来得更猛烈!
转载:
搜索引擎如何抓取网页(搜索引擎抓取页面的方式!(一)--新全讯网)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-02-04 08:02
搜索引擎如何抓取网页?本文由新泉寻网站长编辑。转载请保留此链接!做seo就是为了讨好搜索引擎,所以一定要明白搜索引擎是怎么爬网页的!搜索引擎不可能一次爬取网站中的所有页面,网站中的页面数量在不断变化,内容也在不断更新。因此,搜索引擎也需要对已经爬取的页面进行维护和更新,以便及时获取页面的最新信息,爬取更多的新页面。常见的页面维护方式有:定期爬取、增量爬取、分类定位爬取。周期性爬取 周期性爬取也称为周期性爬取,即 搜索引擎会定期更新 网站 中已出现过的页面。更新时,用捕获的新页面替换原来的旧页面,删除不存在的页面,并存储新发现的页面。周期性更新是针对所有已经收录的页面,所以更新周期会更长。例如,Google 通常需要 30-60 天来更新已为 收录 的页面。周期性抓取算法的实现相对简单。由于每次更新都涉及到网站中所有已经是收录的页面,所以页面权重的重新分配也是同步进行的。此方法适用于维护页面少、内容更新慢的网站,如普通企业网站。不过由于更新周期很长,更新期间页面的变化无法及时反映给用户。例如,页面内容更新后,至少需要 30 到 60 天才能反映在搜索引擎上。
增量爬取增量爬取是通过定期监控爬取的页面来更新和维护页面。但是,定期监视 网站 中的每个页面是不切实际的。基于重要页面承载重要内容的思想和80/20法则,搜索引擎只需定期对网站中的一些重要页面进行监控,即可获取网站中相对重要的信息。因此,增量爬取只针对网站中的部分重要页面,而不是所有已经收录的页面,这也是搜索引擎对重要页面的更新周期较短的原因。例如,内容更新频繁的页面会被搜索引擎频繁更新,从而及时发现新的内容和链接,删除不存在的信息。由于增量爬取是在原创页面的基础上进行的,因此搜索引擎的爬取时间会大大减少,并且可以及时将页面上的最新内容展示给用户。由于页面的重要性,分类定位爬取不同于增量爬取。分类定位爬取是指根据页面的类别或性质制定相应的更新周期的页面监控方法。例如,对于“新闻”和“资源下载”页面,新闻页面的更新周期可以精确到每分钟,而下载页面的更新周期可以设置为一天或更长。分类定位爬取分别处理不同类别的页面,可以节省大量的爬取时间,
但是,按类别制定页面更新周期的方法比较笼统,很难跟踪页面更新。因为即使是同一类别的页面,不同网站s上的内容更新周期也会有很大差异。例如,新闻页面在大型门户 网站 中的更新速度比在其他小型 网站 中的要快得多。因此,需要结合其他方法(如增量爬取等)对页面进行监控和更新。其实网站中页面的维护也是由搜索引擎以多种方式进行的,相当于间接为每个页面选择了最合适的维护方式。这样既可以减轻搜索引擎的负担,又可以为用户提供及时的信息。例如,在 网站 中,会有各种不同性质的页面,常见的有首页、论坛页、内容页等。对于更新频繁的页面(如首页),可以采用增量爬取的方式对其进行监控,从而相对网站中的重要页面可以及时更新;对于非常实时的论坛页面,可以使用分类定位的爬取方式;并且为了防止网站中的部分页面出现遗漏,还需要采用正则爬取的方法。对于非常实时的论坛页面,可以使用分类定位的爬取方式;并且为了防止网站中的部分页面出现遗漏,还需要采用正则爬取的方法。对于非常实时的论坛页面,可以使用分类定位的爬取方式;并且为了防止网站中的部分页面出现遗漏,还需要采用正则爬取的方法。 查看全部
搜索引擎如何抓取网页(搜索引擎抓取页面的方式!(一)--新全讯网)
搜索引擎如何抓取网页?本文由新泉寻网站长编辑。转载请保留此链接!做seo就是为了讨好搜索引擎,所以一定要明白搜索引擎是怎么爬网页的!搜索引擎不可能一次爬取网站中的所有页面,网站中的页面数量在不断变化,内容也在不断更新。因此,搜索引擎也需要对已经爬取的页面进行维护和更新,以便及时获取页面的最新信息,爬取更多的新页面。常见的页面维护方式有:定期爬取、增量爬取、分类定位爬取。周期性爬取 周期性爬取也称为周期性爬取,即 搜索引擎会定期更新 网站 中已出现过的页面。更新时,用捕获的新页面替换原来的旧页面,删除不存在的页面,并存储新发现的页面。周期性更新是针对所有已经收录的页面,所以更新周期会更长。例如,Google 通常需要 30-60 天来更新已为 收录 的页面。周期性抓取算法的实现相对简单。由于每次更新都涉及到网站中所有已经是收录的页面,所以页面权重的重新分配也是同步进行的。此方法适用于维护页面少、内容更新慢的网站,如普通企业网站。不过由于更新周期很长,更新期间页面的变化无法及时反映给用户。例如,页面内容更新后,至少需要 30 到 60 天才能反映在搜索引擎上。
增量爬取增量爬取是通过定期监控爬取的页面来更新和维护页面。但是,定期监视 网站 中的每个页面是不切实际的。基于重要页面承载重要内容的思想和80/20法则,搜索引擎只需定期对网站中的一些重要页面进行监控,即可获取网站中相对重要的信息。因此,增量爬取只针对网站中的部分重要页面,而不是所有已经收录的页面,这也是搜索引擎对重要页面的更新周期较短的原因。例如,内容更新频繁的页面会被搜索引擎频繁更新,从而及时发现新的内容和链接,删除不存在的信息。由于增量爬取是在原创页面的基础上进行的,因此搜索引擎的爬取时间会大大减少,并且可以及时将页面上的最新内容展示给用户。由于页面的重要性,分类定位爬取不同于增量爬取。分类定位爬取是指根据页面的类别或性质制定相应的更新周期的页面监控方法。例如,对于“新闻”和“资源下载”页面,新闻页面的更新周期可以精确到每分钟,而下载页面的更新周期可以设置为一天或更长。分类定位爬取分别处理不同类别的页面,可以节省大量的爬取时间,
但是,按类别制定页面更新周期的方法比较笼统,很难跟踪页面更新。因为即使是同一类别的页面,不同网站s上的内容更新周期也会有很大差异。例如,新闻页面在大型门户 网站 中的更新速度比在其他小型 网站 中的要快得多。因此,需要结合其他方法(如增量爬取等)对页面进行监控和更新。其实网站中页面的维护也是由搜索引擎以多种方式进行的,相当于间接为每个页面选择了最合适的维护方式。这样既可以减轻搜索引擎的负担,又可以为用户提供及时的信息。例如,在 网站 中,会有各种不同性质的页面,常见的有首页、论坛页、内容页等。对于更新频繁的页面(如首页),可以采用增量爬取的方式对其进行监控,从而相对网站中的重要页面可以及时更新;对于非常实时的论坛页面,可以使用分类定位的爬取方式;并且为了防止网站中的部分页面出现遗漏,还需要采用正则爬取的方法。对于非常实时的论坛页面,可以使用分类定位的爬取方式;并且为了防止网站中的部分页面出现遗漏,还需要采用正则爬取的方法。对于非常实时的论坛页面,可以使用分类定位的爬取方式;并且为了防止网站中的部分页面出现遗漏,还需要采用正则爬取的方法。
搜索引擎如何抓取网页(seo优化对百度蜘蛛的抓取重要网页也十分关注。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-02-04 07:21
目前seo优化也非常关注百度蜘蛛对重要网页的抓取。让我详细谈谈
面对海量的网页,搜索引擎不会并行抓取每个网页,因为无论搜索引擎数据库如何扩展,都跟不上网页的增长速度。搜索引擎会优先抓取最重要的网页。保存数据库一方面对普通用户也有帮助,因为对于用户来说,他们不需要大量的结果,只需要最重要的结果。因此,一个好的采集策略是先采集重要的网页,这样最重要的网页才能在最短的时间内被抓取到。
那么搜索引擎如何首先抓取最重要的页面呢?
通过分析大量网页的特征,搜索引擎认为重要的网页具有以下基本特征,虽然不一定完全准确,但大多数时候确实如此:
1) 一个网页被其他网页链接的特点,如果链接频繁或者被重要网页链接,就是非常重要的网页;
2)网页的父网页被多次链接或被重要网页链接。比如一个网页是网站的内页,但是它的主页被链接了很多次,而且主页也被链接了,如果找到这个页面,说明这个页面也比较重要;
3)网页内容被转载广泛传播。
4) 网页的目录深度较小,便于用户浏览。这里的“URL目录深度”定义为:网页URL除域名部分外的目录级别,即如果URL为,则目录深度为0;如果是,则目录深度为 1,依此类推。需要注意的是,URL目录深度小的网页并不总是重要的,目录深度大的网页也并非都是不重要的。一些学术论文的网页网址具有较长的目录深度。大多数重要度高的网页都会同时具备以上四个特征。
5)先采集网站首页,给首页分配高权重。网站 的数量远小于网页的数量,重要的网页必须从这些 网站 主页链接,所以采集工作应优先获取尽可能多的 网站@ > 主页尽可能。
问题来了。当搜索引擎开始抓取网页时,它可能不知道该网页是链接还是转载。,这些因素只有在获得网页或几乎所有的网页链接结构后才能知道。那么如何解决这个问题呢?即在爬取时可以知道特征4和特征5,只有特征4可以在不知道网页内容的情况下(在网页爬取之前)判断一个URL是否符合网页内容。“重要”的标准,网页URL目录深度的计算就是对字符串的处理。统计结果表明,一般的 URL 长度小于 256 个字符,使得 URL 目录深度的判断更容易实现。因此,对于采集策略的确定,
但是,特征 4 和 5 有局限性,因为链接的深度并不能完全表明页面的重要性。那么如何解决这个问题呢?搜索引擎使用以下方法:
1) URL 权重设置:根据 URL 的目录深度确定。权重随着深度的减少而减少,最小权重为零。
2) 将 URL 初始权重设置为固定值。
3) 如果“/”、“?”或“&”字符在 URL 中出现一次,则权重减少一个值,并且
如果“search”、“proxy”或“gate”使用一次,权重减少一个值;最多减少到零。(包括”?”,
带“&”的URL是带参数的形式,需要通过请求的程序服务获取网页,而不是搜索引擎系统重点关注的静态网页,因此权重相应降低。收录“search”、“proxy”或“gate”,表示该网页最有可能是搜索引擎检索到的结果页面,即代理页面,因此应降低权重)。
4) 选择未访问 URL 的策略。因为权重值小并不一定代表不重要,有必要
有机会采集权重较小的未访问 URL。选择未访问URL的策略可以采用轮询的方式,根据权重顺序选择一个,随机选择一个,或者随机选择N次。
搜索引擎在爬取大量网页时,进入了解读网页前三个特征的阶段,然后通过大量算法判断网页质量,然后给出相对排名. 查看全部
搜索引擎如何抓取网页(seo优化对百度蜘蛛的抓取重要网页也十分关注。)
目前seo优化也非常关注百度蜘蛛对重要网页的抓取。让我详细谈谈
面对海量的网页,搜索引擎不会并行抓取每个网页,因为无论搜索引擎数据库如何扩展,都跟不上网页的增长速度。搜索引擎会优先抓取最重要的网页。保存数据库一方面对普通用户也有帮助,因为对于用户来说,他们不需要大量的结果,只需要最重要的结果。因此,一个好的采集策略是先采集重要的网页,这样最重要的网页才能在最短的时间内被抓取到。
那么搜索引擎如何首先抓取最重要的页面呢?
通过分析大量网页的特征,搜索引擎认为重要的网页具有以下基本特征,虽然不一定完全准确,但大多数时候确实如此:
1) 一个网页被其他网页链接的特点,如果链接频繁或者被重要网页链接,就是非常重要的网页;
2)网页的父网页被多次链接或被重要网页链接。比如一个网页是网站的内页,但是它的主页被链接了很多次,而且主页也被链接了,如果找到这个页面,说明这个页面也比较重要;
3)网页内容被转载广泛传播。
4) 网页的目录深度较小,便于用户浏览。这里的“URL目录深度”定义为:网页URL除域名部分外的目录级别,即如果URL为,则目录深度为0;如果是,则目录深度为 1,依此类推。需要注意的是,URL目录深度小的网页并不总是重要的,目录深度大的网页也并非都是不重要的。一些学术论文的网页网址具有较长的目录深度。大多数重要度高的网页都会同时具备以上四个特征。
5)先采集网站首页,给首页分配高权重。网站 的数量远小于网页的数量,重要的网页必须从这些 网站 主页链接,所以采集工作应优先获取尽可能多的 网站@ > 主页尽可能。
问题来了。当搜索引擎开始抓取网页时,它可能不知道该网页是链接还是转载。,这些因素只有在获得网页或几乎所有的网页链接结构后才能知道。那么如何解决这个问题呢?即在爬取时可以知道特征4和特征5,只有特征4可以在不知道网页内容的情况下(在网页爬取之前)判断一个URL是否符合网页内容。“重要”的标准,网页URL目录深度的计算就是对字符串的处理。统计结果表明,一般的 URL 长度小于 256 个字符,使得 URL 目录深度的判断更容易实现。因此,对于采集策略的确定,
但是,特征 4 和 5 有局限性,因为链接的深度并不能完全表明页面的重要性。那么如何解决这个问题呢?搜索引擎使用以下方法:
1) URL 权重设置:根据 URL 的目录深度确定。权重随着深度的减少而减少,最小权重为零。
2) 将 URL 初始权重设置为固定值。
3) 如果“/”、“?”或“&”字符在 URL 中出现一次,则权重减少一个值,并且
如果“search”、“proxy”或“gate”使用一次,权重减少一个值;最多减少到零。(包括”?”,
带“&”的URL是带参数的形式,需要通过请求的程序服务获取网页,而不是搜索引擎系统重点关注的静态网页,因此权重相应降低。收录“search”、“proxy”或“gate”,表示该网页最有可能是搜索引擎检索到的结果页面,即代理页面,因此应降低权重)。
4) 选择未访问 URL 的策略。因为权重值小并不一定代表不重要,有必要
有机会采集权重较小的未访问 URL。选择未访问URL的策略可以采用轮询的方式,根据权重顺序选择一个,随机选择一个,或者随机选择N次。
搜索引擎在爬取大量网页时,进入了解读网页前三个特征的阶段,然后通过大量算法判断网页质量,然后给出相对排名.
搜索引擎如何抓取网页(如何禁止百度搜索引擎收录抓取网页网页帮助帮助?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-04 05:13
如果你的网站涉及个人隐私或机密的非公开网页,如何告诉搜索引擎禁止收录爬取,侯庆龙会讲解以下方法,希望你不要想被搜索引擎搜索到收录Grab网站帮助。
第一种,robots.txt方法
搜索引擎默认遵循 robots.txt 协议。创建 robots.txt 文本文件并将其放在 网站 根目录中。编辑代码如下:
用户代理:*
禁止:
通过代码,您可以告诉搜索引擎不要抓取收录this网站。
二、网页代码
在网站首页代码之间,添加一个代码,该标签禁止搜索引擎抓取网站并显示网页截图。
如何阻止百度搜索引擎收录抓取网页
1、编辑robots.txt文件,设计标记为:
用户代理:百度蜘蛛
禁止:/
2、在网站首页代码之间添加,防止百度搜索引擎抓取网站并显示网页截图。
3、联系百度管理,邮箱是:,发邮件到网站的联系人邮箱,如实说明删除网页截图。经百度验证,网页将停止收录抓取。
4、登录百度自己的“百度快照”帖和“百度投诉”帖,发帖说明删除页面快照的原因收录网站,百度管理人员的时候,看到了就会处理。
如何阻止 Google 搜索引擎收录抓取网络
1、编辑robots.txt文件,设计标记为:
用户代理:googlebot
禁止:/
2、在网站首页代码之间添加,防止百度搜索引擎抓取网站并显示网页截图。
SEO优化:侯庆龙原网址: 查看全部
搜索引擎如何抓取网页(如何禁止百度搜索引擎收录抓取网页网页帮助帮助?)
如果你的网站涉及个人隐私或机密的非公开网页,如何告诉搜索引擎禁止收录爬取,侯庆龙会讲解以下方法,希望你不要想被搜索引擎搜索到收录Grab网站帮助。
第一种,robots.txt方法
搜索引擎默认遵循 robots.txt 协议。创建 robots.txt 文本文件并将其放在 网站 根目录中。编辑代码如下:
用户代理:*
禁止:
通过代码,您可以告诉搜索引擎不要抓取收录this网站。
二、网页代码
在网站首页代码之间,添加一个代码,该标签禁止搜索引擎抓取网站并显示网页截图。
如何阻止百度搜索引擎收录抓取网页
1、编辑robots.txt文件,设计标记为:
用户代理:百度蜘蛛
禁止:/
2、在网站首页代码之间添加,防止百度搜索引擎抓取网站并显示网页截图。
3、联系百度管理,邮箱是:,发邮件到网站的联系人邮箱,如实说明删除网页截图。经百度验证,网页将停止收录抓取。
4、登录百度自己的“百度快照”帖和“百度投诉”帖,发帖说明删除页面快照的原因收录网站,百度管理人员的时候,看到了就会处理。
如何阻止 Google 搜索引擎收录抓取网络
1、编辑robots.txt文件,设计标记为:
用户代理:googlebot
禁止:/
2、在网站首页代码之间添加,防止百度搜索引擎抓取网站并显示网页截图。
SEO优化:侯庆龙原网址:
搜索引擎如何抓取网页(搜索引擎如何形成网站的爬行频次(一)_光明网)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-04 05:11
对于搜索引擎优化,我们并不完全了解搜索引擎是如何形成网站的爬取频率的,所有博主整理网页内容获取搜索引擎使用以下两个因素来确定爬取频率: 流行度- 更受欢迎的页面将被更频繁地爬取;stale - 百度不会废弃页面信息,对于 网站 管理员来说,这意味着如果页面内容更新频繁,百度会尝试更频繁地抓取网页。假设 网站 的抓取频率与反向链接的数量以及该 网站 在百度眼中的重要性成正比——百度希望确保最重要的页面在索引中保持最新.
内部链接呢?你可以通过指向更多的内部链接来提高特定页面的爬取率吗?为了回答这些问题,我决定检查内外链接之间的相关性和爬取统计,我采集了 11 个 网站 数据并做了一个简单的分析,总之,这就是我所做的。我为将要分析的 11 个站点创建了项目,我计算了每个 网站 页面的内部链接数量,接下来我运行 SEO Spyglass 并为相同的 11 个站点创建了项目,在每个项目中,我检查了统计信息并复制带有每个页面的外部链接数量的锚 URL。
然后,我分析了服务器日志中的抓取统计信息,以了解百度每次访问每个页面的频率。最后,我将所有这些数据放入一个电子表格中,并计算内部链接和抓取预算与外部链接和抓取预算之间的相关性。我的数据集展示了蜘蛛访问次数和外部链接数量之间的强相关性(0,978),同时,蜘蛛命中和内部链接之间的相关性被证明非常弱(0,154),这表明反向链接比网站链接更重要。这是否意味着增加爬取频率的唯一方法是建立链接和发布新内容?如果我们谈论整个网站的朱雀频率,我会说:添加链接并经常更新网站,以及网站'
网络推广知识推荐:新手优化中的两个常见错误网站及其解决方法
但是当我们获取单个页面时会变得更有趣,正如您将在下面的介绍中看到的那样,您甚至可能在没有意识到的情况下浪费了大量的爬网。通过巧妙地管理频率,您通常可以将单个页面的抓取次数翻倍——但它仍然与每页的反向链接数量成正比。
以上就是《如何分配搜索引擎的抓取频率?》的全部内容,仅供站长朋友们互动学习。SEO优化是一个需要坚持的过程。希望大家一起进步。 查看全部
搜索引擎如何抓取网页(搜索引擎如何形成网站的爬行频次(一)_光明网)
对于搜索引擎优化,我们并不完全了解搜索引擎是如何形成网站的爬取频率的,所有博主整理网页内容获取搜索引擎使用以下两个因素来确定爬取频率: 流行度- 更受欢迎的页面将被更频繁地爬取;stale - 百度不会废弃页面信息,对于 网站 管理员来说,这意味着如果页面内容更新频繁,百度会尝试更频繁地抓取网页。假设 网站 的抓取频率与反向链接的数量以及该 网站 在百度眼中的重要性成正比——百度希望确保最重要的页面在索引中保持最新.

内部链接呢?你可以通过指向更多的内部链接来提高特定页面的爬取率吗?为了回答这些问题,我决定检查内外链接之间的相关性和爬取统计,我采集了 11 个 网站 数据并做了一个简单的分析,总之,这就是我所做的。我为将要分析的 11 个站点创建了项目,我计算了每个 网站 页面的内部链接数量,接下来我运行 SEO Spyglass 并为相同的 11 个站点创建了项目,在每个项目中,我检查了统计信息并复制带有每个页面的外部链接数量的锚 URL。
然后,我分析了服务器日志中的抓取统计信息,以了解百度每次访问每个页面的频率。最后,我将所有这些数据放入一个电子表格中,并计算内部链接和抓取预算与外部链接和抓取预算之间的相关性。我的数据集展示了蜘蛛访问次数和外部链接数量之间的强相关性(0,978),同时,蜘蛛命中和内部链接之间的相关性被证明非常弱(0,154),这表明反向链接比网站链接更重要。这是否意味着增加爬取频率的唯一方法是建立链接和发布新内容?如果我们谈论整个网站的朱雀频率,我会说:添加链接并经常更新网站,以及网站'
网络推广知识推荐:新手优化中的两个常见错误网站及其解决方法
但是当我们获取单个页面时会变得更有趣,正如您将在下面的介绍中看到的那样,您甚至可能在没有意识到的情况下浪费了大量的爬网。通过巧妙地管理频率,您通常可以将单个页面的抓取次数翻倍——但它仍然与每页的反向链接数量成正比。
以上就是《如何分配搜索引擎的抓取频率?》的全部内容,仅供站长朋友们互动学习。SEO优化是一个需要坚持的过程。希望大家一起进步。
搜索引擎如何抓取网页(网站内容怎么做到被查找引擎频频快速抓取的用途是什么)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-03 20:00
搜索引擎爬虫是一种自动提取网页的程序,例如百度蜘蛛。如果要收录更多网站的页面,需要先爬取页面。如果你的网站页面更新频繁,爬虫会更频繁地访问该页面,而优质的内容是爬虫喜欢抓取的内容,尤其是原创内容。
我们都知道,为了保证高效率,搜索引擎蜘蛛不会抓取网站的所有页面。网站 的权重越高,爬取深度越高,爬取的页面越多。这样,可以收录更多的页面。
网站服务器是网站 的基石。如果网站服务器长时间打不开,就相当于关门谢了。如果你的服务器不稳定或者卡住,每次爬虫都很难爬。有时只能抓取页面的一部分。随着时间的推移,百度蜘蛛的体验越来越差,它在你的网站上的评分也越来越低。当然会影响你的网站爬取,所以选择空间服务器。
调查显示,87%的网民会通过搜索引擎服务找到自己需要的信息,近70%的网民会直接在搜索结果自然排名的首页找到自己需要的信息。可见,搜索引擎优化对于企业和产品都有着重要的意义。
那么网站的内容如何被搜索引擎快速频繁的抓取呢?
我们经常听到关键词,但是关键词的具体用途是什么?
关键词是搜索引擎优化的核心,是网站在搜索引擎中排名的重要因素。
导入链接也是网站优化中非常重要的一个环节,间接影响了网站在搜索引擎中的权重。现在,我们常用的链接有:锚文本链接、超链接、纯文本链接和图片链接。
每次蜘蛛爬行时,它都会存储页面数据。如果第二次爬取发现页面收录与第一次完全相同的内容,则说明该页面还没有更新,蜘蛛不需要经常爬取。如果网页内容更新频繁,蜘蛛会更频繁地访问该网页,所以我们应该主动向蜘蛛求爱,定期更新文章,让蜘蛛有效地按照你的规则爬行< @文章 。
优质的 原创 内容对百度蜘蛛非常有吸引力。我们需要给蜘蛛提供真正有价值的原创内容。如果蜘蛛能得到它喜欢的东西,它自然会在你的 网站 上留下一个很好的形象,并经常回来。
同时,网站结构不能太复杂,链接层次不能太深。它也是蜘蛛的最爱。
众所周知,外链对于网站是可以吸引蜘蛛的,尤其是在新站点中,网站不是很老练,蜘蛛访问量少,外链可以增加网站页面的曝光率front of spiders rate,防止蜘蛛发现页面。在外链建设过程中,需要注意外链的质量。不要做无用的事情来节省能源。
蜘蛛的爬取是沿着链接进行的,所以对内链进行合理的优化,可以要求蜘蛛爬取更多的页面,促进网站的采集。在内链建设过程中,应合理推荐用户。除了在文章中添加锚文本,还可以设置相关引荐、热门文章等栏目。这是许多 网站 正在使用的,蜘蛛能够抓取更广泛的页面。
主页是蜘蛛经常访问的页面,也是一个具有良好权限的页面网站。可以在首页设置更新版块,不仅可以更新首页,增加蜘蛛访问频率,还可以增加对更新页面的抓取和采集。
搜索引擎蜘蛛通过链接爬行找到它们。过多的链接不仅会减少页面数量,而且你的网站在搜索引擎中的权重也会大大降低。所以定期检查网站的死链接并提交给搜索引擎很重要。
搜索引擎蜘蛛喜欢 网站 地图。网站地图是所有网站 链接的容器。很多 网站 都有蜘蛛很难掌握的深层链接。网站地图让搜索引擎蜘蛛更容易抓取网站页面。通过爬网,他们可以清楚地了解网站的结构,所以构建一个网站地图,不仅可以提高爬取率,还可以很好地了解蜘蛛。
同时,在每次页面更新后向搜索引擎提交内容也是一个好主意。
SEO外包服务商亿豪网络专业网站优化营销专家多年研究在线优化技术和营销新方法。公司成立8年来,已服务近千家企业用户,多家500强企业与我们达成战略合作。合作。
专业的SEO技术团队让有需要的客户找到您,亿豪网络为您提供专业的搜索引擎优化推广服务,站外站内优化,亿豪让您的企业从互联网流量和品牌收益中获得更多自由! 查看全部
搜索引擎如何抓取网页(网站内容怎么做到被查找引擎频频快速抓取的用途是什么)
搜索引擎爬虫是一种自动提取网页的程序,例如百度蜘蛛。如果要收录更多网站的页面,需要先爬取页面。如果你的网站页面更新频繁,爬虫会更频繁地访问该页面,而优质的内容是爬虫喜欢抓取的内容,尤其是原创内容。
我们都知道,为了保证高效率,搜索引擎蜘蛛不会抓取网站的所有页面。网站 的权重越高,爬取深度越高,爬取的页面越多。这样,可以收录更多的页面。
网站服务器是网站 的基石。如果网站服务器长时间打不开,就相当于关门谢了。如果你的服务器不稳定或者卡住,每次爬虫都很难爬。有时只能抓取页面的一部分。随着时间的推移,百度蜘蛛的体验越来越差,它在你的网站上的评分也越来越低。当然会影响你的网站爬取,所以选择空间服务器。
调查显示,87%的网民会通过搜索引擎服务找到自己需要的信息,近70%的网民会直接在搜索结果自然排名的首页找到自己需要的信息。可见,搜索引擎优化对于企业和产品都有着重要的意义。
那么网站的内容如何被搜索引擎快速频繁的抓取呢?
我们经常听到关键词,但是关键词的具体用途是什么?
关键词是搜索引擎优化的核心,是网站在搜索引擎中排名的重要因素。
导入链接也是网站优化中非常重要的一个环节,间接影响了网站在搜索引擎中的权重。现在,我们常用的链接有:锚文本链接、超链接、纯文本链接和图片链接。
每次蜘蛛爬行时,它都会存储页面数据。如果第二次爬取发现页面收录与第一次完全相同的内容,则说明该页面还没有更新,蜘蛛不需要经常爬取。如果网页内容更新频繁,蜘蛛会更频繁地访问该网页,所以我们应该主动向蜘蛛求爱,定期更新文章,让蜘蛛有效地按照你的规则爬行< @文章 。
优质的 原创 内容对百度蜘蛛非常有吸引力。我们需要给蜘蛛提供真正有价值的原创内容。如果蜘蛛能得到它喜欢的东西,它自然会在你的 网站 上留下一个很好的形象,并经常回来。
同时,网站结构不能太复杂,链接层次不能太深。它也是蜘蛛的最爱。
众所周知,外链对于网站是可以吸引蜘蛛的,尤其是在新站点中,网站不是很老练,蜘蛛访问量少,外链可以增加网站页面的曝光率front of spiders rate,防止蜘蛛发现页面。在外链建设过程中,需要注意外链的质量。不要做无用的事情来节省能源。
蜘蛛的爬取是沿着链接进行的,所以对内链进行合理的优化,可以要求蜘蛛爬取更多的页面,促进网站的采集。在内链建设过程中,应合理推荐用户。除了在文章中添加锚文本,还可以设置相关引荐、热门文章等栏目。这是许多 网站 正在使用的,蜘蛛能够抓取更广泛的页面。
主页是蜘蛛经常访问的页面,也是一个具有良好权限的页面网站。可以在首页设置更新版块,不仅可以更新首页,增加蜘蛛访问频率,还可以增加对更新页面的抓取和采集。
搜索引擎蜘蛛通过链接爬行找到它们。过多的链接不仅会减少页面数量,而且你的网站在搜索引擎中的权重也会大大降低。所以定期检查网站的死链接并提交给搜索引擎很重要。
搜索引擎蜘蛛喜欢 网站 地图。网站地图是所有网站 链接的容器。很多 网站 都有蜘蛛很难掌握的深层链接。网站地图让搜索引擎蜘蛛更容易抓取网站页面。通过爬网,他们可以清楚地了解网站的结构,所以构建一个网站地图,不仅可以提高爬取率,还可以很好地了解蜘蛛。
同时,在每次页面更新后向搜索引擎提交内容也是一个好主意。

SEO外包服务商亿豪网络专业网站优化营销专家多年研究在线优化技术和营销新方法。公司成立8年来,已服务近千家企业用户,多家500强企业与我们达成战略合作。合作。
专业的SEO技术团队让有需要的客户找到您,亿豪网络为您提供专业的搜索引擎优化推广服务,站外站内优化,亿豪让您的企业从互联网流量和品牌收益中获得更多自由!
搜索引擎如何抓取网页(搜索引擎如何首先抓取最重要的网页?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-02-03 16:02
首先分析搜索引擎如何抓取最重要的网页。面对海量网页,他们不会并行抓取每个网页,因为无论搜索引擎数据库如何扩展,他们都跟不上网页的增长速度。最重要的网页将首先被抓取。一方面保存了数据库,另一方面对普通用户也有帮助,因为对于用户来说,他们不需要大量的结果,只需要最重要的结果。因此,一个好的采集策略是先采集重要的网页,这样最重要的网页才能在最短的时间内被抓取到。那么搜索引擎如何首先抓取最重要的网页呢?通过分析大量网页的特点,搜索引擎认为,重要网页具有以下基本特征,虽然不一定完全准确,但大部分情况下确实如此: 网页链接的特征,如果被多次链接或被重要网页链接,是一个非常重要的网页;一个网页的父网页被多次链接或者被重要网页链接,比如一个网页是网站的内页,但是它的首页被多次链接,首页page也链接到这个页面,也就是说这个页面也比较重要;页面目录深度小,便于用户浏览。这里的“URL目录深度”定义为:网页URL除域名部分外的目录级别,即如果URL是 ,那么目录深度是 如果是,目录深度是第二个,依此类推。需要注意的是,URL目录深度小的网页并不总是重要的,目录深度大的网页也并非都是不重要的。一些学术论文的网页 URL 具有非常长的目录深度。
大多数具有高重要性的网页将同时具有上述所有特征。5)先采集网站首页,给首页分配高权重。网站的数量远小于网页的数量,重要的网页必然会从这些网站主页链接,所以采集工作应优先获取尽可能多的网站尽可能第一个问题当搜索引擎开始抓取网页时,它可能不知道被链接或转载的网页的状态。也就是说,一开始,他无法知道前三项的特性。在获得网页或几乎任何网络链接结构之前,您无法知道。那么如何解决这个问题呢?也就是特征4是可以判断一个URL是否满足“ URL 的初始权重设置为固定值。字符“/”和“?” 出现在网址中。URL 是参数的形式。它需要通过请求的程序服务获取网页,而不是搜索引擎系统关注的静态网页。因此,权重相应减少。
收录“search”、“proxy”或“gate”表示该网页最有可能是搜索引擎检索到的结果页面,即代理页面,因此应降低权重)。选择未访问 URL 的策略。因为权重小并不一定代表不重要,所以要给一定的机会去采集权重小的未访问的URL。选择未访问URL的策略可以采用轮询的方式,根据权重选择一个,随机选择一个,或者随机选择一个。搜索引擎在爬取大量网页时,进入了解读网页前三个特征的阶段,然后通过大量算法判断网页质量,然后给出相对排名. 查看全部
搜索引擎如何抓取网页(搜索引擎如何首先抓取最重要的网页?(图))
首先分析搜索引擎如何抓取最重要的网页。面对海量网页,他们不会并行抓取每个网页,因为无论搜索引擎数据库如何扩展,他们都跟不上网页的增长速度。最重要的网页将首先被抓取。一方面保存了数据库,另一方面对普通用户也有帮助,因为对于用户来说,他们不需要大量的结果,只需要最重要的结果。因此,一个好的采集策略是先采集重要的网页,这样最重要的网页才能在最短的时间内被抓取到。那么搜索引擎如何首先抓取最重要的网页呢?通过分析大量网页的特点,搜索引擎认为,重要网页具有以下基本特征,虽然不一定完全准确,但大部分情况下确实如此: 网页链接的特征,如果被多次链接或被重要网页链接,是一个非常重要的网页;一个网页的父网页被多次链接或者被重要网页链接,比如一个网页是网站的内页,但是它的首页被多次链接,首页page也链接到这个页面,也就是说这个页面也比较重要;页面目录深度小,便于用户浏览。这里的“URL目录深度”定义为:网页URL除域名部分外的目录级别,即如果URL是 ,那么目录深度是 如果是,目录深度是第二个,依此类推。需要注意的是,URL目录深度小的网页并不总是重要的,目录深度大的网页也并非都是不重要的。一些学术论文的网页 URL 具有非常长的目录深度。
大多数具有高重要性的网页将同时具有上述所有特征。5)先采集网站首页,给首页分配高权重。网站的数量远小于网页的数量,重要的网页必然会从这些网站主页链接,所以采集工作应优先获取尽可能多的网站尽可能第一个问题当搜索引擎开始抓取网页时,它可能不知道被链接或转载的网页的状态。也就是说,一开始,他无法知道前三项的特性。在获得网页或几乎任何网络链接结构之前,您无法知道。那么如何解决这个问题呢?也就是特征4是可以判断一个URL是否满足“ URL 的初始权重设置为固定值。字符“/”和“?” 出现在网址中。URL 是参数的形式。它需要通过请求的程序服务获取网页,而不是搜索引擎系统关注的静态网页。因此,权重相应减少。
收录“search”、“proxy”或“gate”表示该网页最有可能是搜索引擎检索到的结果页面,即代理页面,因此应降低权重)。选择未访问 URL 的策略。因为权重小并不一定代表不重要,所以要给一定的机会去采集权重小的未访问的URL。选择未访问URL的策略可以采用轮询的方式,根据权重选择一个,随机选择一个,或者随机选择一个。搜索引擎在爬取大量网页时,进入了解读网页前三个特征的阶段,然后通过大量算法判断网页质量,然后给出相对排名.
搜索引擎如何抓取网页(网站SEO优化的目的是提高网站排名,那就是让搜索引擎更好的抓取网站?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-02-03 08:02
现在很多公司都在做seo优化。网站seo优化的目的是为了提高网站的排名,让搜索引擎更好的抓取网站,我们在做优化的时候可能会遇到很多问题,网站SEO优化的目的是为了提高网站的排名,也就是让搜索引擎更好的抓取网站?通过以下方式一起学习。
网站流畅:用户在浏览网页时,如果让客户在打开速度上焦急等待,对于70%的用户来说,他们肯定会关闭网页。对于搜索引擎,同样如此,网站在3秒内打开速度是最好的,对于搜索引擎,当然会选择运行速度更快的网站。由于您不是唯一出现在此在线市场中的 网站,因此它将选择相对于该 网站 内推广的内容而言质量更高的内容。对于像蜗牛一样的网页打开速度,搜索引擎会放弃爬取,导致网站的权重下降。这时,我们应该提高服务器的速度。
内容相关:对于优化者来说,了解一个好的标题有多重要是很重要的。这个时候,我们介绍了一些用户,因为标题好。这时候,用户肯定在寻找一些与标题和相关产品相关的内容。用户点击后看到的是 网站 标题与 网站 内容无关。用户体验真的很糟糕,毫无疑问,人们会看一看并选择关闭并对这个产品感到失望。在网站的宣传中用这种内容来欺骗用户是完全没有价值的。“外链为王,内链为王”这句话不再陌生。为什么这句话被大家认可?,充分说明了它的重要性。
内容原创:在内容呈现越来越多身份的今天,搜索引擎更喜欢原创,优质的网站,对网站给予更高的评价。这会对网站的收录量、权重值、流量、转化率产生很大影响。更重要的是,用户喜欢什么才是最重要的。找到与你的 网站 不同的东西,解决用户的需求。如果用户不喜欢它,那么 文章 就不会热,搜索引擎自然会认为它是垃圾页面。
即时更新:搜索引擎每天都会定期更新网页。如果第一天搜索引擎抓取了你的网站并没有新的内容,那么可能第二次搜索引擎就得看有没有新的内容了。不过,再过几天,搜索引擎就不会回来了。这也不利于网站的爬取。
外部引流也很重要。多做外链和好友链接,让蜘蛛通过各种渠道找到你的网站,抓到。
站点地图制作,采集网站的所有链接并提交到百度平台,让百度知道你的网站快来爬取了。 查看全部
搜索引擎如何抓取网页(网站SEO优化的目的是提高网站排名,那就是让搜索引擎更好的抓取网站?)
现在很多公司都在做seo优化。网站seo优化的目的是为了提高网站的排名,让搜索引擎更好的抓取网站,我们在做优化的时候可能会遇到很多问题,网站SEO优化的目的是为了提高网站的排名,也就是让搜索引擎更好的抓取网站?通过以下方式一起学习。
网站流畅:用户在浏览网页时,如果让客户在打开速度上焦急等待,对于70%的用户来说,他们肯定会关闭网页。对于搜索引擎,同样如此,网站在3秒内打开速度是最好的,对于搜索引擎,当然会选择运行速度更快的网站。由于您不是唯一出现在此在线市场中的 网站,因此它将选择相对于该 网站 内推广的内容而言质量更高的内容。对于像蜗牛一样的网页打开速度,搜索引擎会放弃爬取,导致网站的权重下降。这时,我们应该提高服务器的速度。
内容相关:对于优化者来说,了解一个好的标题有多重要是很重要的。这个时候,我们介绍了一些用户,因为标题好。这时候,用户肯定在寻找一些与标题和相关产品相关的内容。用户点击后看到的是 网站 标题与 网站 内容无关。用户体验真的很糟糕,毫无疑问,人们会看一看并选择关闭并对这个产品感到失望。在网站的宣传中用这种内容来欺骗用户是完全没有价值的。“外链为王,内链为王”这句话不再陌生。为什么这句话被大家认可?,充分说明了它的重要性。
内容原创:在内容呈现越来越多身份的今天,搜索引擎更喜欢原创,优质的网站,对网站给予更高的评价。这会对网站的收录量、权重值、流量、转化率产生很大影响。更重要的是,用户喜欢什么才是最重要的。找到与你的 网站 不同的东西,解决用户的需求。如果用户不喜欢它,那么 文章 就不会热,搜索引擎自然会认为它是垃圾页面。
即时更新:搜索引擎每天都会定期更新网页。如果第一天搜索引擎抓取了你的网站并没有新的内容,那么可能第二次搜索引擎就得看有没有新的内容了。不过,再过几天,搜索引擎就不会回来了。这也不利于网站的爬取。
外部引流也很重要。多做外链和好友链接,让蜘蛛通过各种渠道找到你的网站,抓到。
站点地图制作,采集网站的所有链接并提交到百度平台,让百度知道你的网站快来爬取了。
搜索引擎如何抓取网页(分析下20000组成部分-status(协议子状态))
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-02-03 07:31
分析200 0 0 sc-status(协议状态) sc-substatus(协议子状态) sc-win32-status(Win32状态码)的组成部分
sc-status(协议状态):200 连接成功
sc-substatus(协议子状态):0 成功
sc-win32-status(Win32状态码):0表示获取成功并带回数据库;64 指定的网络名称不再可用
1:在这条访问记录中,121.187.5.143是你服务器的IP地址,220.181.7. 74 是bd蜘蛛的IP,/category-8-b0-min1100-max2200.html 是蜘蛛访问你页面的端口 80 是端口 GET 是打开方法 W3SVC1 是记录文件夹,这里显示bd蜘蛛访问了你的category-8-b0-min1100-max2200.html页面,那么最重要的是最后一个参数200 0 0。
2、200 0 0 页面访问成功,0表示获取成功并带回数据库。这个时候大家可以放心,这个页面已经bd收录了,但是还没有发布,可能在bd更新的时候就发布了。
3:200 0 64 网上流传着三种解释
164号是K站的前身。
264th 的出现仅适用于 64 位操作系统。
第三:网络不可达。由于某种原因,页面无法完全打开,或者网络不稳定,导致蜘蛛无法带回页面或无法抓取页面。
所以 200 0 64 的解释也应该是:页面被访问了,但是没有爬取也没有带回数据库。这个原因主要是空间不稳定和服务器不稳定造成的。
或者蜘蛛访问过但快照没有更新
4:304 0 0 这个返回码表示蜘蛛访问的页面没有更新,和之前他来的时候一样,所以看到这个不要着急,蜘蛛来了,但是你没有更新了,所以他不愿意把它拿走这个页面。
5:404 0 0 这个代表404页面,但是有一个很严重的问题,这个返回码告诉我们蜘蛛来到了404页面,把他带走了
, 如果是这样的话,你基本上就倒霉了。如果404太多,那么蜘蛛会继续爬取带走,造成无数重复页面,最终导致K站或降级,
正确的返回码是 404 0 64 这意味着蜘蛛没有抓取你的页面。(内容好像有死链接)
6:500 error 500 error是服务器内部错误,是程序错误引起的,我看不懂程序,但是500 error会给你扣分,这个基本逻辑可想而知,找到500 error,马上查是哪个页面已打开,然后去修复以下错误!
7:302 如果要在日志中找到302的返回码,也需要注意。302 是临时重定向。如果您长期将此页面重定向到另一个页面,请使用301永久重定向。如果是302,bd蜘蛛下次会访问这个页面,会导致复制大量页面的问题,结果肯定是K,所以抓紧时间检查以下。
每个网络蜘蛛都有自己的名字,并且在抓取网页时将自己标识为 网站。当网络蜘蛛抓取网页时,它会发送一个请求。在这个请求中,有一个名为 User-agent 的字段,用于标识网络蜘蛛的身份。例如,谷歌网络蜘蛛的标志是GoogleBot,百度网络蜘蛛的标志是BaiDuSpider,雅虎网络蜘蛛的标志是Inktomi Slurp。
返回码列表:
2xx 成功
200 确定;请求完成。
201 确定;紧跟在 POST 命令之后。
202 确定;接受处理,但处理尚未完成。
203 确定;部分信息 - 返回的信息只是部分信息。
204 确定;无响应 - 已收到请求,但没有要发回的信息。
3xx 重定向
301 已移动 - 请求的数据具有新位置,并且更改是永久性的。
302 Found - 请求的数据暂时具有不同的 URI。
303 See Other - 可以在另一个 URI 下找到对请求的响应,并且应该使用 GET 方法检索。
304 Not Modified - 文档未按预期修改。
305 Using Proxy - 请求的资源必须通过 location 字段中提供的代理访问。
306 Not Used - 不再使用;保留此代码以备将来使用。
4xx 客户端中的错误
400 Bad Request - 请求有语法问题,或无法满足请求。
401 Unauthorized - 客户端无权访问数据。
402 需要付款 - 表示计费系统处于活动状态。
403 Forbidden - 即使授权也不需要访问。
404 Not Found - 服务器找不到给定的资源;该文件不存在。
407 代理验证请求 - 客户端必须首先通过代理验证自己。
415 Unsupported Media Type - 服务器拒绝为请求提供服务,因为请求的实体的格式不受支持。
服务器中的 5xx 错误
500 内部错误 - 由于意外情况,服务器无法完成请求。
501 Not Executed - 服务器不支持请求的工具。
502 Bad Gateway - 服务器收到来自上游服务器的无效响应。
503 Unavailable Service - 由于临时过载或维护,服务器无法处理请求。
如果网站上有访问日志记录,网站管理员可以知道有哪些搜索引擎的网络蜘蛛来了,什么时候来的,读了多少数据等。
根据不同的IP,我们可以分析网站的状态。我们以我的IIS日记中的百度蜘蛛IP为例:
123.125.68.*这个蜘蛛经常来,其他蜘蛛来得少,这意味着网站可能要进入沙箱或者被降级。
220.181.68.*如果这个IP段每天只增加,很有可能进入沙盒或者K站。
220.181.7.*,123.125.66.*代表百度蜘蛛IP访问,准备抢你的东西。
121.14.89.*这个ip段用来通过新站的检查期。
203.208.60.*这个ip段出现在新站点和站点异常之后。
210.72.225.*此IP段连续巡站。
125.90.88.* 广东茂名电信也是百度蜘蛛IP的主要组成部分,因为新上线的站点很多,并且使用了站长工具,或者SEO综合造成通过检测。
220.181.108.95 这是百度抢首页的专用IP。如果是220.181.108,基本上你网站每天晚上都会拍快照,绝对不会出错,我保证。
220.181.108.92 同上,98%爬取首页,也可能爬取其他(非内页) 220.181段属于加权IP段 本版块已爬取的文章或首页,基本在24小时内释放。
123.125.71.106 爬取内页收录,权重低,爬过本段的内页文章不会要非常快让它出来,因为它不是 原创 或 采集文章。
220.181.108.91 综合,主要抓取首页和内页或其他,属于加权IP段,抓取文章或首页基本上是24小时。
220.181.108.75 专注于文章的内页抓取和更新,达到90%,8%抓取首页,2%其他。加权IP段,爬取文章或者首页基本24小时内发布。
220.181.108.86 专用于抓取首页IP权重段,一般返回码为304 0 0表示不更新。
123.125.71.95 爬取内页收录,权重低,爬过本段的内页文章不会被非常快 让它出来,因为它不是 原创 或 采集文章。
123.125.71.97 爬取内页收录,权重低,爬过本段的内页文章不会被非常快 让它出来,因为它不是 原创 或 采集文章。
220.181.108.89 专用于抓取首页IP权重段,一般返回码为304 0 0表示不更新。
220.181.108.94 专用于抓取首页IP权重段,一般返回码为304 0 0表示不更新。
220.181.108.97 专用于抓取首页IP权重段,一般返回码为304 0 0表示不更新。
220.181.108.80 专用于抓取首页IP权重段,一般返回码为304 0 0表示不更新。
220.181.108.77 专用于抓取首页IP权重段,一般返回码为304 0 0表示不更新。
123.125.71.117 爬取内页收录,权重低,爬过本段的内页文章不会要非常快让它出来,因为它不是 原创 或 采集文章。
220.181.108.83 专用于抓取首页IP权重段,一般返回码为304 0 0表示不更新。
注意:上面的IP尾数还有很多,但是同一个段123.125.71.*段IP表示抓取内页收录的权重为相对较低。也许由于你的 采集文章 或拼写 文章 暂时 收录 但不是
发布。(意思是待定)。
220.181.108.* IP段主要抓取首页的80%和内页的30%。这个爬取的文章或者首页绝对是24小时内发布,一夜之间截图,我可以保证!
一般爬取成功的返回码是200 0 0,304 0 0表示网站没有更新。蜘蛛来了。如果是200 0 64,别担心,这不是K站,可能是网站是动态的,
所以返回的是这段代码。 查看全部
搜索引擎如何抓取网页(分析下20000组成部分-status(协议子状态))
分析200 0 0 sc-status(协议状态) sc-substatus(协议子状态) sc-win32-status(Win32状态码)的组成部分
sc-status(协议状态):200 连接成功
sc-substatus(协议子状态):0 成功
sc-win32-status(Win32状态码):0表示获取成功并带回数据库;64 指定的网络名称不再可用
1:在这条访问记录中,121.187.5.143是你服务器的IP地址,220.181.7. 74 是bd蜘蛛的IP,/category-8-b0-min1100-max2200.html 是蜘蛛访问你页面的端口 80 是端口 GET 是打开方法 W3SVC1 是记录文件夹,这里显示bd蜘蛛访问了你的category-8-b0-min1100-max2200.html页面,那么最重要的是最后一个参数200 0 0。
2、200 0 0 页面访问成功,0表示获取成功并带回数据库。这个时候大家可以放心,这个页面已经bd收录了,但是还没有发布,可能在bd更新的时候就发布了。
3:200 0 64 网上流传着三种解释
164号是K站的前身。
264th 的出现仅适用于 64 位操作系统。
第三:网络不可达。由于某种原因,页面无法完全打开,或者网络不稳定,导致蜘蛛无法带回页面或无法抓取页面。
所以 200 0 64 的解释也应该是:页面被访问了,但是没有爬取也没有带回数据库。这个原因主要是空间不稳定和服务器不稳定造成的。
或者蜘蛛访问过但快照没有更新
4:304 0 0 这个返回码表示蜘蛛访问的页面没有更新,和之前他来的时候一样,所以看到这个不要着急,蜘蛛来了,但是你没有更新了,所以他不愿意把它拿走这个页面。
5:404 0 0 这个代表404页面,但是有一个很严重的问题,这个返回码告诉我们蜘蛛来到了404页面,把他带走了
, 如果是这样的话,你基本上就倒霉了。如果404太多,那么蜘蛛会继续爬取带走,造成无数重复页面,最终导致K站或降级,
正确的返回码是 404 0 64 这意味着蜘蛛没有抓取你的页面。(内容好像有死链接)
6:500 error 500 error是服务器内部错误,是程序错误引起的,我看不懂程序,但是500 error会给你扣分,这个基本逻辑可想而知,找到500 error,马上查是哪个页面已打开,然后去修复以下错误!
7:302 如果要在日志中找到302的返回码,也需要注意。302 是临时重定向。如果您长期将此页面重定向到另一个页面,请使用301永久重定向。如果是302,bd蜘蛛下次会访问这个页面,会导致复制大量页面的问题,结果肯定是K,所以抓紧时间检查以下。
每个网络蜘蛛都有自己的名字,并且在抓取网页时将自己标识为 网站。当网络蜘蛛抓取网页时,它会发送一个请求。在这个请求中,有一个名为 User-agent 的字段,用于标识网络蜘蛛的身份。例如,谷歌网络蜘蛛的标志是GoogleBot,百度网络蜘蛛的标志是BaiDuSpider,雅虎网络蜘蛛的标志是Inktomi Slurp。
返回码列表:
2xx 成功
200 确定;请求完成。
201 确定;紧跟在 POST 命令之后。
202 确定;接受处理,但处理尚未完成。
203 确定;部分信息 - 返回的信息只是部分信息。
204 确定;无响应 - 已收到请求,但没有要发回的信息。
3xx 重定向
301 已移动 - 请求的数据具有新位置,并且更改是永久性的。
302 Found - 请求的数据暂时具有不同的 URI。
303 See Other - 可以在另一个 URI 下找到对请求的响应,并且应该使用 GET 方法检索。
304 Not Modified - 文档未按预期修改。
305 Using Proxy - 请求的资源必须通过 location 字段中提供的代理访问。
306 Not Used - 不再使用;保留此代码以备将来使用。
4xx 客户端中的错误
400 Bad Request - 请求有语法问题,或无法满足请求。
401 Unauthorized - 客户端无权访问数据。
402 需要付款 - 表示计费系统处于活动状态。
403 Forbidden - 即使授权也不需要访问。
404 Not Found - 服务器找不到给定的资源;该文件不存在。
407 代理验证请求 - 客户端必须首先通过代理验证自己。
415 Unsupported Media Type - 服务器拒绝为请求提供服务,因为请求的实体的格式不受支持。
服务器中的 5xx 错误
500 内部错误 - 由于意外情况,服务器无法完成请求。
501 Not Executed - 服务器不支持请求的工具。
502 Bad Gateway - 服务器收到来自上游服务器的无效响应。
503 Unavailable Service - 由于临时过载或维护,服务器无法处理请求。
如果网站上有访问日志记录,网站管理员可以知道有哪些搜索引擎的网络蜘蛛来了,什么时候来的,读了多少数据等。
根据不同的IP,我们可以分析网站的状态。我们以我的IIS日记中的百度蜘蛛IP为例:
123.125.68.*这个蜘蛛经常来,其他蜘蛛来得少,这意味着网站可能要进入沙箱或者被降级。
220.181.68.*如果这个IP段每天只增加,很有可能进入沙盒或者K站。
220.181.7.*,123.125.66.*代表百度蜘蛛IP访问,准备抢你的东西。
121.14.89.*这个ip段用来通过新站的检查期。
203.208.60.*这个ip段出现在新站点和站点异常之后。
210.72.225.*此IP段连续巡站。
125.90.88.* 广东茂名电信也是百度蜘蛛IP的主要组成部分,因为新上线的站点很多,并且使用了站长工具,或者SEO综合造成通过检测。
220.181.108.95 这是百度抢首页的专用IP。如果是220.181.108,基本上你网站每天晚上都会拍快照,绝对不会出错,我保证。
220.181.108.92 同上,98%爬取首页,也可能爬取其他(非内页) 220.181段属于加权IP段 本版块已爬取的文章或首页,基本在24小时内释放。
123.125.71.106 爬取内页收录,权重低,爬过本段的内页文章不会要非常快让它出来,因为它不是 原创 或 采集文章。
220.181.108.91 综合,主要抓取首页和内页或其他,属于加权IP段,抓取文章或首页基本上是24小时。
220.181.108.75 专注于文章的内页抓取和更新,达到90%,8%抓取首页,2%其他。加权IP段,爬取文章或者首页基本24小时内发布。
220.181.108.86 专用于抓取首页IP权重段,一般返回码为304 0 0表示不更新。
123.125.71.95 爬取内页收录,权重低,爬过本段的内页文章不会被非常快 让它出来,因为它不是 原创 或 采集文章。
123.125.71.97 爬取内页收录,权重低,爬过本段的内页文章不会被非常快 让它出来,因为它不是 原创 或 采集文章。
220.181.108.89 专用于抓取首页IP权重段,一般返回码为304 0 0表示不更新。
220.181.108.94 专用于抓取首页IP权重段,一般返回码为304 0 0表示不更新。
220.181.108.97 专用于抓取首页IP权重段,一般返回码为304 0 0表示不更新。
220.181.108.80 专用于抓取首页IP权重段,一般返回码为304 0 0表示不更新。
220.181.108.77 专用于抓取首页IP权重段,一般返回码为304 0 0表示不更新。
123.125.71.117 爬取内页收录,权重低,爬过本段的内页文章不会要非常快让它出来,因为它不是 原创 或 采集文章。
220.181.108.83 专用于抓取首页IP权重段,一般返回码为304 0 0表示不更新。
注意:上面的IP尾数还有很多,但是同一个段123.125.71.*段IP表示抓取内页收录的权重为相对较低。也许由于你的 采集文章 或拼写 文章 暂时 收录 但不是
发布。(意思是待定)。
220.181.108.* IP段主要抓取首页的80%和内页的30%。这个爬取的文章或者首页绝对是24小时内发布,一夜之间截图,我可以保证!
一般爬取成功的返回码是200 0 0,304 0 0表示网站没有更新。蜘蛛来了。如果是200 0 64,别担心,这不是K站,可能是网站是动态的,
所以返回的是这段代码。
搜索引擎如何抓取网页(SEO提醒Baiduspider根据上述网站设置的协议对站点页面进行抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-02-03 07:30
如果下载的源代码需要作者授权,请更换源代码。本站资源免费共享不会增加授权
Explorer SEO提醒Baiduspider按照上述网站设置的协议抓取网站页面,但不可能对所有网站一视同仁。它会综合考虑网站的实际情况来确定一个抓取配额,每天定量抓取网站内容,也就是我们常说的抓取频率。那么百度搜索引擎是通过哪些指标来判断一个网站的爬取频率呢?主要有四个指标: 网站更新频率:更新更频繁,更新慢,直接影响百度蜘蛛的访问频率网站更新质量:更新频率提高了,只是为了吸引百度蜘蛛的关注,百度蜘蛛对质量有严格要求,如果网站 每天更新的大量内容被百度蜘蛛判断为低质量的页面,仍然没有意义。连接性:网站应该安全稳定,对百度蜘蛛保持开放。让Baiduspider保持关闭并不是一件好事。站点评价:百度搜索引擎对每个站点都会有一个评价,这个评价会根据站点情况不断变化。非常机密的数据。站点评级从不单独使用,并与其他因素和阈值一起影响 网站 的爬取和排名。并且这个评价会根据现场情况不断变化。非常机密的数据。站点评级从不单独使用,并与其他因素和阈值一起影响 网站 的爬取和排名。并且这个评价会根据现场情况不断变化。非常机密的数据。站点评级从不单独使用,并与其他因素和阈值一起影响 网站 的爬取和排名。
爬取频率间接决定了网站有多少页面可能被数据库收录。这么重要的值,如果不符合站长的期望,应该如何调整呢?
百度站长平台提供爬频工具,已完成多次升级。除了提供爬取统计,该工具还提供了“频率调整”功能。站长要求百度蜘蛛根据实际情况增加或减少对百度站长平台的访问量。调整。
从百度的“星火计划”到官方的一些说明,可见百度对原创内容的重视程度,但什么样的文章才算原创,有价值文章。不负责任的采集:首先需要澄清的是,百度拒绝采集是指大量复制互联网现有内容,而采集的内容将被所有如果它没有组织。“懒惰”的行为被推到了底线。百度没有理由拒绝采集的内容经过再加工和高效整合,制作出内容丰富的优质网页。所以,比方说,百度不喜欢不负责任的懈怠采集行为。伪原创:我们上面说了百度不喜欢不负责任的采集,于是有些人开始动脑筋伪装原创。在采集内容之后,对关键词的一部分进行了批量修改,企图让百度认为这些是独一无二的内容,但内容却面目全非,无法通读。就是刚才提到的观点,百度不吐槽网站采集的内容,关键是如何应用采集的内容和数据,如何融入内容用户和搜索引擎都需要的是网站管理员应该考虑的内容。并且无法通读。就是刚才提到的观点,百度不吐槽网站采集的内容,关键是如何应用采集的内容和数据,如何融入内容用户和搜索引擎都需要的是网站管理员应该考虑的内容。并且无法通读。就是刚才提到的观点,百度不吐槽网站采集的内容,关键是如何应用采集的内容和数据,如何融入内容用户和搜索引擎都需要的是网站管理员应该考虑的内容。
我们的采集的文章是没有问题的,但是问题是执行采集没有做任何改动,所以以后我们更新文章的时候,主要需要注意的是:
整合 文章 或 采集 中的图片 整合 采集 中的一篇或多篇文章 文章。这里所说的集成需要根据文章关键词进行合理的集成,并添加一些附件(图片、视频等)进行优化。文章排版优化,有利于用户搜索和查看seoer,非常清晰,这里不再赘述。
更新与用户搜索匹配的内容
以下是 文章 更新的核心内容。相信很多朋友在更新文章的时候都会遇到这样的问题。每天更新,一两天。更新的内容可以完成,但是时间长了,需要更新的内容已经更新了。
<p>通常的做法是把最重要的关键词放在首页,比如上面例子中的云南旅游。第二级的其他 关键词 被放置在单独的部分或频道页面中。如果有更长的尾巴,属于第三级关键词,可以用内容页面进行优化。在首页,主要的关键词是优化的重点。从页面标题、粗体加粗、Hx标签、关键词出现的位置数量来看,应该比其他文字更显眼。不是副关键词不能出现在首页,而是副关键词应该出现在首页,因为这些词对主 查看全部
搜索引擎如何抓取网页(SEO提醒Baiduspider根据上述网站设置的协议对站点页面进行抓取)
如果下载的源代码需要作者授权,请更换源代码。本站资源免费共享不会增加授权
Explorer SEO提醒Baiduspider按照上述网站设置的协议抓取网站页面,但不可能对所有网站一视同仁。它会综合考虑网站的实际情况来确定一个抓取配额,每天定量抓取网站内容,也就是我们常说的抓取频率。那么百度搜索引擎是通过哪些指标来判断一个网站的爬取频率呢?主要有四个指标: 网站更新频率:更新更频繁,更新慢,直接影响百度蜘蛛的访问频率网站更新质量:更新频率提高了,只是为了吸引百度蜘蛛的关注,百度蜘蛛对质量有严格要求,如果网站 每天更新的大量内容被百度蜘蛛判断为低质量的页面,仍然没有意义。连接性:网站应该安全稳定,对百度蜘蛛保持开放。让Baiduspider保持关闭并不是一件好事。站点评价:百度搜索引擎对每个站点都会有一个评价,这个评价会根据站点情况不断变化。非常机密的数据。站点评级从不单独使用,并与其他因素和阈值一起影响 网站 的爬取和排名。并且这个评价会根据现场情况不断变化。非常机密的数据。站点评级从不单独使用,并与其他因素和阈值一起影响 网站 的爬取和排名。并且这个评价会根据现场情况不断变化。非常机密的数据。站点评级从不单独使用,并与其他因素和阈值一起影响 网站 的爬取和排名。
爬取频率间接决定了网站有多少页面可能被数据库收录。这么重要的值,如果不符合站长的期望,应该如何调整呢?
百度站长平台提供爬频工具,已完成多次升级。除了提供爬取统计,该工具还提供了“频率调整”功能。站长要求百度蜘蛛根据实际情况增加或减少对百度站长平台的访问量。调整。
从百度的“星火计划”到官方的一些说明,可见百度对原创内容的重视程度,但什么样的文章才算原创,有价值文章。不负责任的采集:首先需要澄清的是,百度拒绝采集是指大量复制互联网现有内容,而采集的内容将被所有如果它没有组织。“懒惰”的行为被推到了底线。百度没有理由拒绝采集的内容经过再加工和高效整合,制作出内容丰富的优质网页。所以,比方说,百度不喜欢不负责任的懈怠采集行为。伪原创:我们上面说了百度不喜欢不负责任的采集,于是有些人开始动脑筋伪装原创。在采集内容之后,对关键词的一部分进行了批量修改,企图让百度认为这些是独一无二的内容,但内容却面目全非,无法通读。就是刚才提到的观点,百度不吐槽网站采集的内容,关键是如何应用采集的内容和数据,如何融入内容用户和搜索引擎都需要的是网站管理员应该考虑的内容。并且无法通读。就是刚才提到的观点,百度不吐槽网站采集的内容,关键是如何应用采集的内容和数据,如何融入内容用户和搜索引擎都需要的是网站管理员应该考虑的内容。并且无法通读。就是刚才提到的观点,百度不吐槽网站采集的内容,关键是如何应用采集的内容和数据,如何融入内容用户和搜索引擎都需要的是网站管理员应该考虑的内容。

我们的采集的文章是没有问题的,但是问题是执行采集没有做任何改动,所以以后我们更新文章的时候,主要需要注意的是:
整合 文章 或 采集 中的图片 整合 采集 中的一篇或多篇文章 文章。这里所说的集成需要根据文章关键词进行合理的集成,并添加一些附件(图片、视频等)进行优化。文章排版优化,有利于用户搜索和查看seoer,非常清晰,这里不再赘述。
更新与用户搜索匹配的内容
以下是 文章 更新的核心内容。相信很多朋友在更新文章的时候都会遇到这样的问题。每天更新,一两天。更新的内容可以完成,但是时间长了,需要更新的内容已经更新了。
<p>通常的做法是把最重要的关键词放在首页,比如上面例子中的云南旅游。第二级的其他 关键词 被放置在单独的部分或频道页面中。如果有更长的尾巴,属于第三级关键词,可以用内容页面进行优化。在首页,主要的关键词是优化的重点。从页面标题、粗体加粗、Hx标签、关键词出现的位置数量来看,应该比其他文字更显眼。不是副关键词不能出现在首页,而是副关键词应该出现在首页,因为这些词对主
搜索引擎如何抓取网页(网络爬虫()的抓取战略可以分爲深度优先和最佳优先三种)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-02-07 00:15
网络爬虫(也称为网络蜘蛛或网络机器人)是一个序列或脚本,它根据某些规则自动从万维网上爬取信息。通常它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成部分。
抢夺策略
链接抓取策略分为三种类型:深度优先、广度优先和最佳优先。
1、深度搜索策略从起始页开始,选择一个URL进入,分析这个页面的URL,选择一个然后进入。抓那么深,等直四处理完一条路后再处理下一条路。
深度优先策略设计更为复杂。但是用户网站提供的链接往往是最有价值的,而且PageRa地址也很高,但是随着每一个层次的深入,页面价值和PageRank都会相应下降。这意味着重要的页面通常更靠近种子,而过度深度爬取的页面价值较低。同时,该策略的抓取深度间接影响抓取命中率和抓取效率,而抓取深度是该策略的关键。绝对与其他两种策略相比。这种策略很少使用。
2、广度优先搜索策略是指在爬取过程中,在下一级搜索完成后停止下一级搜索。目前,为了覆盖尽可能多的页面,一般采用广度优先搜索方式。也有很多研究使用广度优先搜索策略来关注爬虫。其基本思想是在一定的链接区间内具有初始 URL 的网页具有较高的主题相关性概率。另一种方式是将广度优先搜索与网页过滤技术相结合,先使用广度优先策略抓取网页,然后过滤掉相关网页。这些方法的缺点是随着爬取的网页越来越多,会下载和过滤少量相关网页,
3、最佳优先搜索策略根据一定的网页分析算法预测候选URL与目标网页的相似度,或与主题的相关度,选择评价最好的一个或几个URL停止爬行。它只访问页面分析算法预测为“有用”的页面。存在的一个问题是爬虫的爬取路径上的许多相关网页可以忽略不计,因为优化优先策略是一种部分最优的搜索算法。因此,有必要将最佳优先级与详细的应用改进相结合,以跳出一些最佳点。研究表明,这样的闭环调整可以将相关网页的数量减少30%到90%。
由于爬取网页的特殊要求,使用短网址链接进行爬取爬取比较复杂。 查看全部
搜索引擎如何抓取网页(网络爬虫()的抓取战略可以分爲深度优先和最佳优先三种)
网络爬虫(也称为网络蜘蛛或网络机器人)是一个序列或脚本,它根据某些规则自动从万维网上爬取信息。通常它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成部分。
抢夺策略
链接抓取策略分为三种类型:深度优先、广度优先和最佳优先。
1、深度搜索策略从起始页开始,选择一个URL进入,分析这个页面的URL,选择一个然后进入。抓那么深,等直四处理完一条路后再处理下一条路。
深度优先策略设计更为复杂。但是用户网站提供的链接往往是最有价值的,而且PageRa地址也很高,但是随着每一个层次的深入,页面价值和PageRank都会相应下降。这意味着重要的页面通常更靠近种子,而过度深度爬取的页面价值较低。同时,该策略的抓取深度间接影响抓取命中率和抓取效率,而抓取深度是该策略的关键。绝对与其他两种策略相比。这种策略很少使用。
2、广度优先搜索策略是指在爬取过程中,在下一级搜索完成后停止下一级搜索。目前,为了覆盖尽可能多的页面,一般采用广度优先搜索方式。也有很多研究使用广度优先搜索策略来关注爬虫。其基本思想是在一定的链接区间内具有初始 URL 的网页具有较高的主题相关性概率。另一种方式是将广度优先搜索与网页过滤技术相结合,先使用广度优先策略抓取网页,然后过滤掉相关网页。这些方法的缺点是随着爬取的网页越来越多,会下载和过滤少量相关网页,
3、最佳优先搜索策略根据一定的网页分析算法预测候选URL与目标网页的相似度,或与主题的相关度,选择评价最好的一个或几个URL停止爬行。它只访问页面分析算法预测为“有用”的页面。存在的一个问题是爬虫的爬取路径上的许多相关网页可以忽略不计,因为优化优先策略是一种部分最优的搜索算法。因此,有必要将最佳优先级与详细的应用改进相结合,以跳出一些最佳点。研究表明,这样的闭环调整可以将相关网页的数量减少30%到90%。
由于爬取网页的特殊要求,使用短网址链接进行爬取爬取比较复杂。
搜索引擎如何抓取网页(我的网页不被收录是抄袭而不收录吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-02-06 10:13
在网站的优化过程中,收录home经常遇到自己辛苦写的文章,被一些高权网站抄袭,秒收,但它自己的网页不是。收录,这是一件很烦人的事情,为什么我的网页没有收录,是不是因为没有搜索引擎蜘蛛爬我的网站,被抄袭了文章收录,那会判断我的页面是抄袭而不是 收录 吗?
小红帽蜘蛛池@Q88539698
如果网页文章的内容不是收录,不代表没有被搜索引擎蜘蛛抓取。如果您的网页没有被自己的 robots 文件阻止,它将被搜索引擎蜘蛛抓取。抓取并抓取。如果网站需要排名增加流量,可以打开-收录首页优化排名,效果不错,字快而且很稳定,省时又能做更多的事情。
网站是抄袭的,但是抄袭者的网站不是收录,而是抄袭者的网站是收录,这真的很糟糕,如果不是收录,就不是原创了会不会算抄袭吗?
很有可能大部分网站站长都会觉得自己的文章不是收录,而是抄袭者的首先是收录,因为百度搜索区分自己抄袭也是一个不正确的概念去使用别人的文章内容,导致网页不是收录,自己的排名和权重值一直做不好。
搜索模块收录网页的规范不仅是原创,还有其他元素,比如:网页权重值、外链发布、内链布局合理、网页相关性等,搜索engine 收录 web pages 必须经过抓取-识别-释放三个步骤。在发布参与关键词排名的步骤中,搜索模块会区分整体的URL质量和相关性。当达到收录标准时,网页会被搜索模块收录快速搜索。质量不符合搜索模块收录网页的规范,搜索引擎会用数据库查询临时存储你的文章内容,其实就是爬取爬取你的网页,但是没有数据库被索引和发布,所以找不到网页链接,但是你的文章内容发布的时间,可能知道搜索模块。而对于现在的原创判断搜索引擎还是没有太成熟的技术来证明。
毕竟,搜索引擎的目的是为了更好地让客户获得高质量和高相关性的网页信息内容,而优质信息内容的规范也是基于网站的可信度。如果您的网站是新网站,它将进入新网站。审批期间,审批期间的网站会正常爬取爬取,但不会放行,而是存入数据库查询。审批期过后,网页将发布。新站网站站长们怀疑他们的原创文章内容会不会是收录,那是因为他们不明白自己还在新的审批期地点。所以新站点收录不是很好,不用太担心, 查看全部
搜索引擎如何抓取网页(我的网页不被收录是抄袭而不收录吗?)
在网站的优化过程中,收录home经常遇到自己辛苦写的文章,被一些高权网站抄袭,秒收,但它自己的网页不是。收录,这是一件很烦人的事情,为什么我的网页没有收录,是不是因为没有搜索引擎蜘蛛爬我的网站,被抄袭了文章收录,那会判断我的页面是抄袭而不是 收录 吗?
小红帽蜘蛛池@Q88539698
如果网页文章的内容不是收录,不代表没有被搜索引擎蜘蛛抓取。如果您的网页没有被自己的 robots 文件阻止,它将被搜索引擎蜘蛛抓取。抓取并抓取。如果网站需要排名增加流量,可以打开-收录首页优化排名,效果不错,字快而且很稳定,省时又能做更多的事情。
网站是抄袭的,但是抄袭者的网站不是收录,而是抄袭者的网站是收录,这真的很糟糕,如果不是收录,就不是原创了会不会算抄袭吗?
很有可能大部分网站站长都会觉得自己的文章不是收录,而是抄袭者的首先是收录,因为百度搜索区分自己抄袭也是一个不正确的概念去使用别人的文章内容,导致网页不是收录,自己的排名和权重值一直做不好。
搜索模块收录网页的规范不仅是原创,还有其他元素,比如:网页权重值、外链发布、内链布局合理、网页相关性等,搜索engine 收录 web pages 必须经过抓取-识别-释放三个步骤。在发布参与关键词排名的步骤中,搜索模块会区分整体的URL质量和相关性。当达到收录标准时,网页会被搜索模块收录快速搜索。质量不符合搜索模块收录网页的规范,搜索引擎会用数据库查询临时存储你的文章内容,其实就是爬取爬取你的网页,但是没有数据库被索引和发布,所以找不到网页链接,但是你的文章内容发布的时间,可能知道搜索模块。而对于现在的原创判断搜索引擎还是没有太成熟的技术来证明。
毕竟,搜索引擎的目的是为了更好地让客户获得高质量和高相关性的网页信息内容,而优质信息内容的规范也是基于网站的可信度。如果您的网站是新网站,它将进入新网站。审批期间,审批期间的网站会正常爬取爬取,但不会放行,而是存入数据库查询。审批期过后,网页将发布。新站网站站长们怀疑他们的原创文章内容会不会是收录,那是因为他们不明白自己还在新的审批期地点。所以新站点收录不是很好,不用太担心,
搜索引擎如何抓取网页( 从哪些地方分析诊断网站日志进行分析与诊断的优化措施)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-02-06 00:00
从哪些地方分析诊断网站日志进行分析与诊断的优化措施)
作为一个 SEO 人,如果你不分析和诊断日志,那将是可悲的。实际上,日志分析就是对搜索引擎蜘蛛的日常爬取痕迹做出正确的数据诊断,从而采取合理的优化措施。,我们应该在哪里分析和诊断 网站 日志?
1、搜索引擎蜘蛛的访问次数
搜索引擎对网站的访问次数间接反映了网站的权重。网站为了增加搜索引擎蜘蛛的访问量,站长需要重点关注服务器性能、外链层次建设、网站结构和链接入口等路径的分析和优化。
2、搜索引擎蜘蛛的总停留时间
搜索引擎蜘蛛的停留时间与网站的结构、服务器响应时间、网站的代码、网站的内容更新等密切相关。
3、来自搜索引擎蜘蛛的爬取量
事实上,搜索引擎蜘蛛的停留时间与网站的结构、网站或内容的更新、服务器设置等密切相关,因为搜索引擎蜘蛛的爬取量密切相关对网站与蜘蛛的收录数量有直接关系,蜘蛛爬取的数量越大,网站的收录就越多。
4、搜索引擎蜘蛛的单次访问
如果一个搜索引擎蜘蛛一次爬取的网页较多,则意味着网站的内容更有价值,而网站结构更有利于搜索引擎蜘蛛的抓取。
注意:分析诊断网站日志
5、搜索引擎蜘蛛抓取单页停留时间
搜索引擎蜘蛛爬取单个页面所花费的时间与网站页面的爬取速度、页面的内容、页面的图片大小、页面代码的简洁性等密切相关。为了提高页面加载速度,减少蜘蛛在单个页面上的停留时间,从而增加蜘蛛的总爬取量,增加网站收录可以增加网站@的整体流量>。
6、网站 页面抓取
一般情况下,搜索引擎蜘蛛在网站停留的时间是有限的,在布局上要设置好的网站结构,合理规划重要页面,降低页面的重复爬取率. 蜘蛛被引入其他页面,从而增加了 网站收录 的数量。
7、网页状态码
定期清除页面中的死链接,可以促进蜘蛛顺利爬取整个页面,从而提高网页的爬取率。
8、网站目录结构捕获
一般来说,spider的主爬取目录会和网站的key列保持一致。在外链和内链层面调整优化方案。当遇到不需要收录或者不需要爬取的列时,需要使用robots标签来提醒蜘蛛不要爬取。
只有不断分析诊断网站日志,才能知道我们发布的外部链接是否有效,我们购买的空间是否稳定,蜘蛛喜欢什么页面不喜欢什么,需要什么内容等一系列优化结果比如更新。
十年专注SEO优化,诚信经营,为企业和客户创造价值为根本。把技术实力作为公司的生命线。
真诚接受网站关键词优化、网站整体排名优化、负面处理等服务
文章题目:通过分析诊断网站日志提高搜索引擎爬取友好度 查看全部
搜索引擎如何抓取网页(
从哪些地方分析诊断网站日志进行分析与诊断的优化措施)
作为一个 SEO 人,如果你不分析和诊断日志,那将是可悲的。实际上,日志分析就是对搜索引擎蜘蛛的日常爬取痕迹做出正确的数据诊断,从而采取合理的优化措施。,我们应该在哪里分析和诊断 网站 日志?
1、搜索引擎蜘蛛的访问次数
搜索引擎对网站的访问次数间接反映了网站的权重。网站为了增加搜索引擎蜘蛛的访问量,站长需要重点关注服务器性能、外链层次建设、网站结构和链接入口等路径的分析和优化。
2、搜索引擎蜘蛛的总停留时间
搜索引擎蜘蛛的停留时间与网站的结构、服务器响应时间、网站的代码、网站的内容更新等密切相关。
3、来自搜索引擎蜘蛛的爬取量
事实上,搜索引擎蜘蛛的停留时间与网站的结构、网站或内容的更新、服务器设置等密切相关,因为搜索引擎蜘蛛的爬取量密切相关对网站与蜘蛛的收录数量有直接关系,蜘蛛爬取的数量越大,网站的收录就越多。
4、搜索引擎蜘蛛的单次访问
如果一个搜索引擎蜘蛛一次爬取的网页较多,则意味着网站的内容更有价值,而网站结构更有利于搜索引擎蜘蛛的抓取。
注意:分析诊断网站日志
5、搜索引擎蜘蛛抓取单页停留时间
搜索引擎蜘蛛爬取单个页面所花费的时间与网站页面的爬取速度、页面的内容、页面的图片大小、页面代码的简洁性等密切相关。为了提高页面加载速度,减少蜘蛛在单个页面上的停留时间,从而增加蜘蛛的总爬取量,增加网站收录可以增加网站@的整体流量>。
6、网站 页面抓取
一般情况下,搜索引擎蜘蛛在网站停留的时间是有限的,在布局上要设置好的网站结构,合理规划重要页面,降低页面的重复爬取率. 蜘蛛被引入其他页面,从而增加了 网站收录 的数量。
7、网页状态码
定期清除页面中的死链接,可以促进蜘蛛顺利爬取整个页面,从而提高网页的爬取率。
8、网站目录结构捕获
一般来说,spider的主爬取目录会和网站的key列保持一致。在外链和内链层面调整优化方案。当遇到不需要收录或者不需要爬取的列时,需要使用robots标签来提醒蜘蛛不要爬取。
只有不断分析诊断网站日志,才能知道我们发布的外部链接是否有效,我们购买的空间是否稳定,蜘蛛喜欢什么页面不喜欢什么,需要什么内容等一系列优化结果比如更新。
十年专注SEO优化,诚信经营,为企业和客户创造价值为根本。把技术实力作为公司的生命线。
真诚接受网站关键词优化、网站整体排名优化、负面处理等服务
文章题目:通过分析诊断网站日志提高搜索引擎爬取友好度
搜索引擎如何抓取网页(搜索引擎工作原理(或者叫流程)--搜索引擎的工作过程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-05 23:17
大家好,我是Beard先生,一个在seo行业工作两年的菜鸟,因为一些个人的想法。从现在开始,我们将继续分享我多年来在seo方面的一些工作经验和心得,并在接下来的两个月里与大家分享。好了,不多说了。我们开始今天分享的第一个知识点——搜索引擎的工作原理(或流程)。
搜索引擎的工作过程非常复杂。接下来简单介绍一下搜索索引是如何实现网页排名的。这里展示的内容只是真正的搜索引擎技术的皮毛,但对于我们大多数的搜索引擎来说应该已经足够了。
一个搜索引擎的工作过程大致可以分为三个阶段。
搜索引擎的工作原理
上图显示了搜索引擎的一般工作流程图。首先,搜索引擎会从索引区发送一个程序(百度也叫蜘蛛),通过链接来到网站来爬取我们的网页。到达网页后,首先将数据放入临时数据库,临时数据库会对我们的网页进行一些预处理和评估操作(如去重、中文分词、去停用词、降噪等),以及存储那些符合搜索引擎规则的。去理赔区,否则不符合规定会被清理干净。然后搜索引擎进行排序、归档和排序。最后,将结果显示给用户。
以上大致是一个搜索引擎的工作流程。接下来,我们来看看一些具体的细节。
1.1、抢
1.1.1 什么在爬网
什么爬网
1.1.2 蜘蛛爬行规则
蜘蛛爬行规则
蜘蛛爬取的规则有很多:深度优先策略、广度优先策略、大站点(高权重)优先策略、及时性优先策略、重要页面优先爬取策略等。
面条。事实上,最大的搜索引文是爬网,而 收录 只是互联网的一小部分。
1.1.3蜘蛛爬取内容
蜘蛛抓取内容
蜘蛛通过链接抓取网站的内容,对文字的识别度最高。图片由特殊的图片蜘蛛抓取。但请记住,图像需要一个 Garat 属性便签,以便蜘蛛更好地识别图像。无法识别视频、js 和 iframe 帧。
1.1.4 影响蜘蛛爬行的因素
影响蜘蛛爬行的因素
1.1.5如何判断蜘蛛访问网站
有两种方法可以判断蜘蛛是否来到 网站
1.2 过滤器
筛选
1.2.1过滤系统的含义
临时数据库是用来临时存储蜘蛛抓取的网页的地方。对于服务器,这里需要过滤网页。过滤需要解决一些无用的资源,节省空间,减少服务器的工作量。其他明显欺骗用户的页面、死链接、空白内容页面等,这些页面对用户、站长和百度没有足够的价值,所以百度会自动过滤这些内容,避免用户和你。网站 带来了不必要的麻烦。
1.2.2 影响过滤的因素
模板,所谓模板,就是我们所说的网页相似度。如果整个网站的相似度高,页面的质量也低。
识别是内容是否可以被百度直接识别。文字和链接可以直接被百度识别,而图片和视频不能直接被百度识别,而是通过标签alt来识别。其余的js、cs、iframe框架等都不识别。
相关性,所谓相关性是指文章标题和文章内容是否相关,相关性越高越好
1.3收录
经过以上一系列的爬取和过滤,我们就到了收录的阶段。蜘蛛会将符合规则的添加到数据库中。然后百度收录就是内容。
1.3.1收录的内容
收录大概有这些页面标题、页面描述、页面源代码、页面url。
1.3.2查看收录
查看 收录
1.3.3收录 的常见问题
1.4 索引
1.4.1 个索引数量
详情请参考百度官方资料:
1.4.2查看索引数量
site命令的当前值是对索引量的估计,不好。百度官方也提出:建议站长使用百度站长平台查看网站的索引量。
1.4.3页进入优质索引条件
至此,我们基本讲完了搜索引擎是如何开始爬取网页或者后期排名的。最后,进入索引库的页面可以通过归档排序很好的展示给用户。好了,最后,如果大家有什么建议或者意见,可以留言告诉我。需要课件的可以直接给我留言。 查看全部
搜索引擎如何抓取网页(搜索引擎工作原理(或者叫流程)--搜索引擎的工作过程)
大家好,我是Beard先生,一个在seo行业工作两年的菜鸟,因为一些个人的想法。从现在开始,我们将继续分享我多年来在seo方面的一些工作经验和心得,并在接下来的两个月里与大家分享。好了,不多说了。我们开始今天分享的第一个知识点——搜索引擎的工作原理(或流程)。
搜索引擎的工作过程非常复杂。接下来简单介绍一下搜索索引是如何实现网页排名的。这里展示的内容只是真正的搜索引擎技术的皮毛,但对于我们大多数的搜索引擎来说应该已经足够了。
一个搜索引擎的工作过程大致可以分为三个阶段。
搜索引擎的工作原理
上图显示了搜索引擎的一般工作流程图。首先,搜索引擎会从索引区发送一个程序(百度也叫蜘蛛),通过链接来到网站来爬取我们的网页。到达网页后,首先将数据放入临时数据库,临时数据库会对我们的网页进行一些预处理和评估操作(如去重、中文分词、去停用词、降噪等),以及存储那些符合搜索引擎规则的。去理赔区,否则不符合规定会被清理干净。然后搜索引擎进行排序、归档和排序。最后,将结果显示给用户。
以上大致是一个搜索引擎的工作流程。接下来,我们来看看一些具体的细节。
1.1、抢
1.1.1 什么在爬网
什么爬网
1.1.2 蜘蛛爬行规则
蜘蛛爬行规则
蜘蛛爬取的规则有很多:深度优先策略、广度优先策略、大站点(高权重)优先策略、及时性优先策略、重要页面优先爬取策略等。
面条。事实上,最大的搜索引文是爬网,而 收录 只是互联网的一小部分。
1.1.3蜘蛛爬取内容
蜘蛛抓取内容
蜘蛛通过链接抓取网站的内容,对文字的识别度最高。图片由特殊的图片蜘蛛抓取。但请记住,图像需要一个 Garat 属性便签,以便蜘蛛更好地识别图像。无法识别视频、js 和 iframe 帧。
1.1.4 影响蜘蛛爬行的因素
影响蜘蛛爬行的因素
1.1.5如何判断蜘蛛访问网站
有两种方法可以判断蜘蛛是否来到 网站
1.2 过滤器
筛选
1.2.1过滤系统的含义
临时数据库是用来临时存储蜘蛛抓取的网页的地方。对于服务器,这里需要过滤网页。过滤需要解决一些无用的资源,节省空间,减少服务器的工作量。其他明显欺骗用户的页面、死链接、空白内容页面等,这些页面对用户、站长和百度没有足够的价值,所以百度会自动过滤这些内容,避免用户和你。网站 带来了不必要的麻烦。
1.2.2 影响过滤的因素
模板,所谓模板,就是我们所说的网页相似度。如果整个网站的相似度高,页面的质量也低。
识别是内容是否可以被百度直接识别。文字和链接可以直接被百度识别,而图片和视频不能直接被百度识别,而是通过标签alt来识别。其余的js、cs、iframe框架等都不识别。
相关性,所谓相关性是指文章标题和文章内容是否相关,相关性越高越好
1.3收录
经过以上一系列的爬取和过滤,我们就到了收录的阶段。蜘蛛会将符合规则的添加到数据库中。然后百度收录就是内容。
1.3.1收录的内容
收录大概有这些页面标题、页面描述、页面源代码、页面url。
1.3.2查看收录
查看 收录
1.3.3收录 的常见问题
1.4 索引
1.4.1 个索引数量
详情请参考百度官方资料:
1.4.2查看索引数量
site命令的当前值是对索引量的估计,不好。百度官方也提出:建议站长使用百度站长平台查看网站的索引量。
1.4.3页进入优质索引条件
至此,我们基本讲完了搜索引擎是如何开始爬取网页或者后期排名的。最后,进入索引库的页面可以通过归档排序很好的展示给用户。好了,最后,如果大家有什么建议或者意见,可以留言告诉我。需要课件的可以直接给我留言。
搜索引擎如何抓取网页(蜘蛛爬行并不会所有所有页面的权重尽可能高更新)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-02-05 23:16
理论上,蜘蛛爬网可以传播到互联网的所有页面,但实际上,蜘蛛不能也不需要,因为互联网上每天都会出现数万亿个新页面,还有更多的垃圾邮件,这里的垃圾邮件是指垃圾邮件网站上有大量不相关的内容。比如约会网站上的赌彩票信息,多次出现会对搜索引擎的用户体验造成很大的伤害。严重影响搜索引擎的盈利能力。
既然我们知道蜘蛛不会抓取所有页面,我们需要学会取悦蜘蛛以获得更多页面为收录。蜘蛛的任务是抓取尽可能多的重要页面。在这方面我们应该取悦它,任何方便蜘蛛爬行和爬行的行为都是好的行为。
蜘蛛爬行一般喜欢以下更新:
一:网站和页面的权重尽可能高。爬虫在爬取时首先考虑网站,因为具有高质量和长寿命站点的网站在爬虫视图中的权重会更高。高权重网站甚至可以达到秒收录的效果。
二:页面更新频率很高。如果页面不经常更新,蜘蛛就不会来爬取页面的内容。只有当我们频繁更新时,蜘蛛才会更频繁地访问我们的 网站 内容。所以最好在维护的时候更新网站,不仅是原创文章,还要转载热点信息。
三:优质的内外链建设。优质的内外链结构可以增加蜘蛛的爬行深度。要被蜘蛛爬取,页面中必须要有入站链接,否则蜘蛛根本不会爬取页面,更别说爬取了,下面就来看看高质量的内外链接的重要性。这也是“内容为王,链接至上”这句话的根据。当蜘蛛沿着链接爬行时,如果有高质量的外部链接,蜘蛛会爬得更深,甚至可能更多层,从而使我们的页面更容易被蜘蛛爬取。
4:到首页的点击距离。这里离首页的距离通常是因为首页的权重最高,爬虫爬到首页。蜘蛛爬到主页最多。每次点击链接,离主页越近,页面的权重就越高。高权重页面的权重也可以通过 URL 结构可视化。URL结构更短,页面权重更高。
通过了解搜索引擎如何工作的基础知识——蜘蛛爬行,并了解像 网站 这样的搜索引擎蜘蛛,这是我们 SEO 人员的目标。 查看全部
搜索引擎如何抓取网页(蜘蛛爬行并不会所有所有页面的权重尽可能高更新)
理论上,蜘蛛爬网可以传播到互联网的所有页面,但实际上,蜘蛛不能也不需要,因为互联网上每天都会出现数万亿个新页面,还有更多的垃圾邮件,这里的垃圾邮件是指垃圾邮件网站上有大量不相关的内容。比如约会网站上的赌彩票信息,多次出现会对搜索引擎的用户体验造成很大的伤害。严重影响搜索引擎的盈利能力。
既然我们知道蜘蛛不会抓取所有页面,我们需要学会取悦蜘蛛以获得更多页面为收录。蜘蛛的任务是抓取尽可能多的重要页面。在这方面我们应该取悦它,任何方便蜘蛛爬行和爬行的行为都是好的行为。
蜘蛛爬行一般喜欢以下更新:
一:网站和页面的权重尽可能高。爬虫在爬取时首先考虑网站,因为具有高质量和长寿命站点的网站在爬虫视图中的权重会更高。高权重网站甚至可以达到秒收录的效果。
二:页面更新频率很高。如果页面不经常更新,蜘蛛就不会来爬取页面的内容。只有当我们频繁更新时,蜘蛛才会更频繁地访问我们的 网站 内容。所以最好在维护的时候更新网站,不仅是原创文章,还要转载热点信息。
三:优质的内外链建设。优质的内外链结构可以增加蜘蛛的爬行深度。要被蜘蛛爬取,页面中必须要有入站链接,否则蜘蛛根本不会爬取页面,更别说爬取了,下面就来看看高质量的内外链接的重要性。这也是“内容为王,链接至上”这句话的根据。当蜘蛛沿着链接爬行时,如果有高质量的外部链接,蜘蛛会爬得更深,甚至可能更多层,从而使我们的页面更容易被蜘蛛爬取。
4:到首页的点击距离。这里离首页的距离通常是因为首页的权重最高,爬虫爬到首页。蜘蛛爬到主页最多。每次点击链接,离主页越近,页面的权重就越高。高权重页面的权重也可以通过 URL 结构可视化。URL结构更短,页面权重更高。
通过了解搜索引擎如何工作的基础知识——蜘蛛爬行,并了解像 网站 这样的搜索引擎蜘蛛,这是我们 SEO 人员的目标。
搜索引擎如何抓取网页(搜索引擎优化(seo)是让搜索引擎更好的收录(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-02-05 15:27
搜索引擎优化 (seo) 是一系列使搜索引擎更好地收录我们的网页的过程。好的优化措施将有助于搜索引擎蜘蛛抓取我们的网站。什么是优化?优化的目的是“取其精华去渣”,就是把网页的内容放上去,方便百度蜘蛛的抓取。百度搜索引擎(蜘蛛)如何爬取我们的页面?作者在百度上搜索了一篇自己在admin5站长网站上发表的文章文章,拿出来分享给大家。
<IMG alt="" src="http://seo.admin5.com/data/att ... ot%3B width=595 height=250>
图1
页面标题
如图1所示,百度搜索引擎首先抓取的是页面标题的title标签。网站 的标题标签对网站 的优化非常重要。作者一周前修改了网站的标题标签,只删了两个字,百度搜索引擎一周前发布了,这期间截图没有更新,一直停留在原来的时间!
描述标签
如图 1 所示,搜索引擎不一定会显示描述标签(admin5 中的信息摘要)。百度索引爬取页面标题后,会优先爬取网页内容中最先显示的内容,而不是网页正文。第一段(如图2-标题下半部分-在admin5中,这是一个锚文本链接,百度既然抢了,那肯定也要抢这个锚文本链接),然后在描述部分爬取网页的手段,网站的描述部分通常超过200个字符。通常,网站的描述部分不会显示网站第一段的所有内容,而是显示搜索引擎认为与用户搜索最相关的内容。如图 3 所示。
图二
<IMG alt="" src="http://seo.admin5.com/data/att ... ot%3B width=606 height=254>
图 3
如果我们结合图 一、 图 2 和图 3 可以清楚的看到百度蜘蛛抓取的网页的哪些部分,title 标签,titles,与用户搜索相关的 关键词 部分内容,以及相关内容以浮动红色的形式显示。让用户区分这是否是他们需要的信息!因此,了解百度蜘蛛的搜索有助于降低网站的跳出率,增加用户粘性。以上只是简单的个人分析。本文来自:Crane_Starter admin5,转载于保留地址,非常感谢! 查看全部
搜索引擎如何抓取网页(搜索引擎优化(seo)是让搜索引擎更好的收录(图))
搜索引擎优化 (seo) 是一系列使搜索引擎更好地收录我们的网页的过程。好的优化措施将有助于搜索引擎蜘蛛抓取我们的网站。什么是优化?优化的目的是“取其精华去渣”,就是把网页的内容放上去,方便百度蜘蛛的抓取。百度搜索引擎(蜘蛛)如何爬取我们的页面?作者在百度上搜索了一篇自己在admin5站长网站上发表的文章文章,拿出来分享给大家。
<IMG alt="" src="http://seo.admin5.com/data/att ... ot%3B width=595 height=250>
图1
页面标题
如图1所示,百度搜索引擎首先抓取的是页面标题的title标签。网站 的标题标签对网站 的优化非常重要。作者一周前修改了网站的标题标签,只删了两个字,百度搜索引擎一周前发布了,这期间截图没有更新,一直停留在原来的时间!
描述标签
如图 1 所示,搜索引擎不一定会显示描述标签(admin5 中的信息摘要)。百度索引爬取页面标题后,会优先爬取网页内容中最先显示的内容,而不是网页正文。第一段(如图2-标题下半部分-在admin5中,这是一个锚文本链接,百度既然抢了,那肯定也要抢这个锚文本链接),然后在描述部分爬取网页的手段,网站的描述部分通常超过200个字符。通常,网站的描述部分不会显示网站第一段的所有内容,而是显示搜索引擎认为与用户搜索最相关的内容。如图 3 所示。
图二
<IMG alt="" src="http://seo.admin5.com/data/att ... ot%3B width=606 height=254>
图 3
如果我们结合图 一、 图 2 和图 3 可以清楚的看到百度蜘蛛抓取的网页的哪些部分,title 标签,titles,与用户搜索相关的 关键词 部分内容,以及相关内容以浮动红色的形式显示。让用户区分这是否是他们需要的信息!因此,了解百度蜘蛛的搜索有助于降低网站的跳出率,增加用户粘性。以上只是简单的个人分析。本文来自:Crane_Starter admin5,转载于保留地址,非常感谢!
搜索引擎如何抓取网页(如何判断是否是蜘蛛对翻页式网页的抓住机制来发表一点看法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2022-02-05 15:25
<p>Spider 系统的目标是发现和爬取 Internet 上所有有价值的网页。百度官方也明确表示,蜘蛛只能抓取尽可能多的有价值资源,并保持系统中页面与实际环境的一致性。@网站经验造成压力,也就是说蜘蛛不会爬取 查看全部
搜索引擎如何抓取网页(如何判断是否是蜘蛛对翻页式网页的抓住机制来发表一点看法)
<p>Spider 系统的目标是发现和爬取 Internet 上所有有价值的网页。百度官方也明确表示,蜘蛛只能抓取尽可能多的有价值资源,并保持系统中页面与实际环境的一致性。@网站经验造成压力,也就是说蜘蛛不会爬取
搜索引擎如何抓取网页(搜索引擎蜘蛛是如何爬行与访问页面的程序蜘蛛教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-02-05 15:25
搜索引擎蜘蛛,在搜索引擎系统中也称为“蜘蛛”或“机器人”,是用于抓取和访问页面的程序。今天小课堂为大家带来了搜索引擎蜘蛛如何爬取和爬取页面的教程。我希望能有所帮助。
一、搜索引擎蜘蛛简介
搜索引擎蜘蛛,在搜索引擎系统中也称为“蜘蛛”或“机器人”,是用于抓取和访问页面的程序。
① 爬行原理
搜索引擎蜘蛛访问网页的过程就像用户使用的浏览器一样。
搜索引擎蜘蛛向页面发送请求,页面的服务器返回页面的 HTML 代码。
搜索引擎蜘蛛将接收到的 HTML 代码存储在搜索引擎的原创页面数据库中。
②如何爬行
为了提高搜索引擎蜘蛛的工作效率,通常采用多个蜘蛛并发分布爬取。
同时,分布式爬取也分为深度优先和广度优先两种模式。
深度优先:沿着发现的链接爬行,直到没有链接为止。
广度优先:爬取完本页所有链接后,会沿着二级页面继续爬取。
③蜘蛛必须遵守的协议
在访问网站之前,搜索引擎蜘蛛会先访问网站根目录下的robots.txt文件。
搜索引擎蜘蛛不会抓取 robots.txt 文件中禁止抓取的文件或目录。
④ 常见的搜索引擎蜘蛛
百度蜘蛛:百度蜘蛛
谷歌蜘蛛:谷歌机器人
360蜘蛛:360蜘蛛
SOSO蜘蛛:Sosospider
有道蜘蛛:有道机器人、有道机器人
搜狗蜘蛛:搜狗新闻蜘蛛
必应蜘蛛:bingbot
Alexa 蜘蛛:ia_archiver
二、如何吸引更多搜索引擎蜘蛛
随着互联网信息的爆炸式增长,搜索引擎蜘蛛不可能爬取所有网站的所有链接,所以如何吸引更多的搜索引擎蜘蛛爬取我们的网站就变得非常重要了。
① 导入链接
不管是外链还是内链,只有导入后,搜索引擎蜘蛛才能知道页面的存在。因此,做更多的外链建设将有助于吸引更多的蜘蛛访问。
② 页面更新频率
页面更新频率越高,搜索引擎蜘蛛的访问次数就越多。
③ 网站 和页重
整个网站的权重和某个页面(包括首页也是一个页面)的权重影响蜘蛛的访问频率。网站 具有较高的权重和权限,一般会增加搜索引擎蜘蛛的好感度。 查看全部
搜索引擎如何抓取网页(搜索引擎蜘蛛是如何爬行与访问页面的程序蜘蛛教程)
搜索引擎蜘蛛,在搜索引擎系统中也称为“蜘蛛”或“机器人”,是用于抓取和访问页面的程序。今天小课堂为大家带来了搜索引擎蜘蛛如何爬取和爬取页面的教程。我希望能有所帮助。
一、搜索引擎蜘蛛简介
搜索引擎蜘蛛,在搜索引擎系统中也称为“蜘蛛”或“机器人”,是用于抓取和访问页面的程序。
① 爬行原理
搜索引擎蜘蛛访问网页的过程就像用户使用的浏览器一样。
搜索引擎蜘蛛向页面发送请求,页面的服务器返回页面的 HTML 代码。
搜索引擎蜘蛛将接收到的 HTML 代码存储在搜索引擎的原创页面数据库中。
②如何爬行
为了提高搜索引擎蜘蛛的工作效率,通常采用多个蜘蛛并发分布爬取。
同时,分布式爬取也分为深度优先和广度优先两种模式。
深度优先:沿着发现的链接爬行,直到没有链接为止。
广度优先:爬取完本页所有链接后,会沿着二级页面继续爬取。
③蜘蛛必须遵守的协议
在访问网站之前,搜索引擎蜘蛛会先访问网站根目录下的robots.txt文件。
搜索引擎蜘蛛不会抓取 robots.txt 文件中禁止抓取的文件或目录。
④ 常见的搜索引擎蜘蛛
百度蜘蛛:百度蜘蛛
谷歌蜘蛛:谷歌机器人
360蜘蛛:360蜘蛛
SOSO蜘蛛:Sosospider
有道蜘蛛:有道机器人、有道机器人
搜狗蜘蛛:搜狗新闻蜘蛛
必应蜘蛛:bingbot
Alexa 蜘蛛:ia_archiver
二、如何吸引更多搜索引擎蜘蛛
随着互联网信息的爆炸式增长,搜索引擎蜘蛛不可能爬取所有网站的所有链接,所以如何吸引更多的搜索引擎蜘蛛爬取我们的网站就变得非常重要了。
① 导入链接
不管是外链还是内链,只有导入后,搜索引擎蜘蛛才能知道页面的存在。因此,做更多的外链建设将有助于吸引更多的蜘蛛访问。
② 页面更新频率
页面更新频率越高,搜索引擎蜘蛛的访问次数就越多。
③ 网站 和页重
整个网站的权重和某个页面(包括首页也是一个页面)的权重影响蜘蛛的访问频率。网站 具有较高的权重和权限,一般会增加搜索引擎蜘蛛的好感度。
搜索引擎如何抓取网页(有什么方能提高网页被搜索引擎、索引和排名的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-02-05 15:20
-SEO 以下是一个被许多SEO 误解的重要概念。很久以前,搜索引擎爬虫(机器人)会递归地爬取某个网站(通过你提交的网站主页URL,然后爬取页面上找到的所有链接)指向该网页, 一次又一次)。但现在情况并非如此。就像下图一样,搜索引擎的爬虫在爬取的时候会有多个入口点,每个入口点同等重要,然后从这些入口点展开去爬取。那么我们看看有哪些方法可以提高搜索引擎对网页的爬取、索引和排名:一个典型的网站外链分布图那么我们再来看一个典型的网站外链分布图:Crawler Prioritizing在这里爬行路径' s 一个重要的概念,被许多 SEO 所误解。很久以前,搜索引擎爬虫(机器人)会递归地爬取某个网站(通过你提交的网站主页URL,然后爬取页面上找到的所有链接)指向该网页, 一次又一次)。但现在情况并非如此。就像下图一样,搜索引擎的爬虫在爬取的时候会有多个入口点,每个入口点同等重要,然后从这些入口点展开去爬取。最后,我们来看看如何提高你的页面的爬取、索引和搜索引擎排名:如果你的 网站 可以构建一个理想的、扁平的链接层次结构,它可以一次点击访问 100 万个页面和效果4 次点击即可访问 100 万个页面。你应该注意反向链接多的“强”页面的涟漪效应(指排名高且反向链接多的页面,易IT注意),并充分利用这种效应。将此类页面视为目录(或类别)页面,并将它们链接到 网站 的其他页面。同样,您将来可以将此类页面用作登录页面,以帮助将流量吸引到您希望用户访问的页面。位于链接图边缘的页面价值较低。确认 网站 没有降低 PageRank 的页面。这些页面通常是 PDF、图片和其他文档。您可以使用 301 重定向将这些文件重定向到收录(嵌入或收录下载链接)这些文件内容的页面,并在页面上有返回 网站 其他部分的链接。如果您可以制作此类具有链接价值且引人入胜的页面,它们将获得更高的 PageRank 和更高的抓取率。同时,这些 PageRank 和爬取优先级通过页面上的链接传递到 网站 上的其他页面(向搜索引擎发出信号,表明 网站 上的所有页面都很重要)。减少不必要的导航级别(或内容页面)并将爬虫引导到真正需要 PageRank 的 URL。 查看全部
搜索引擎如何抓取网页(有什么方能提高网页被搜索引擎、索引和排名的方法)
-SEO 以下是一个被许多SEO 误解的重要概念。很久以前,搜索引擎爬虫(机器人)会递归地爬取某个网站(通过你提交的网站主页URL,然后爬取页面上找到的所有链接)指向该网页, 一次又一次)。但现在情况并非如此。就像下图一样,搜索引擎的爬虫在爬取的时候会有多个入口点,每个入口点同等重要,然后从这些入口点展开去爬取。那么我们看看有哪些方法可以提高搜索引擎对网页的爬取、索引和排名:一个典型的网站外链分布图那么我们再来看一个典型的网站外链分布图:Crawler Prioritizing在这里爬行路径' s 一个重要的概念,被许多 SEO 所误解。很久以前,搜索引擎爬虫(机器人)会递归地爬取某个网站(通过你提交的网站主页URL,然后爬取页面上找到的所有链接)指向该网页, 一次又一次)。但现在情况并非如此。就像下图一样,搜索引擎的爬虫在爬取的时候会有多个入口点,每个入口点同等重要,然后从这些入口点展开去爬取。最后,我们来看看如何提高你的页面的爬取、索引和搜索引擎排名:如果你的 网站 可以构建一个理想的、扁平的链接层次结构,它可以一次点击访问 100 万个页面和效果4 次点击即可访问 100 万个页面。你应该注意反向链接多的“强”页面的涟漪效应(指排名高且反向链接多的页面,易IT注意),并充分利用这种效应。将此类页面视为目录(或类别)页面,并将它们链接到 网站 的其他页面。同样,您将来可以将此类页面用作登录页面,以帮助将流量吸引到您希望用户访问的页面。位于链接图边缘的页面价值较低。确认 网站 没有降低 PageRank 的页面。这些页面通常是 PDF、图片和其他文档。您可以使用 301 重定向将这些文件重定向到收录(嵌入或收录下载链接)这些文件内容的页面,并在页面上有返回 网站 其他部分的链接。如果您可以制作此类具有链接价值且引人入胜的页面,它们将获得更高的 PageRank 和更高的抓取率。同时,这些 PageRank 和爬取优先级通过页面上的链接传递到 网站 上的其他页面(向搜索引擎发出信号,表明 网站 上的所有页面都很重要)。减少不必要的导航级别(或内容页面)并将爬虫引导到真正需要 PageRank 的 URL。
搜索引擎如何抓取网页(没有判断搜索引擎的算法,可以更好的改进网站吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2022-02-05 14:07
任何优化公司都知道,每个搜索引擎的排名实际上是由多种因素共同决定的。有时,一些网站所谓的结论只是偶然。事实上,没有人知道搜索引擎的算法。只有通过不断的实践和总结,我们的网站才能越来越完善。面对很久没有更新内容的网站,用户不会关注他,甚至搜索引擎也不会再收录他了。所以这个时候,既然你无法判断搜索引擎的算法,那你可以更好的改进网站。
一、更新频率
对于一些专注于新闻的门户网站网站来说,以合理的频率更新网站内容是很重要的。新闻本身具有很强的时效性。如果刚刚发生,请务必在短时间内将其发布到 网站。作为一个新闻网站的用户,你基本上会关注刚刚发生的事情。如果你输入一条新闻网站,发现某件事发生在几年前甚至很久以前,那么这个网站 将不会被访问。当用户发现 网站 内容太旧时,搜索引擎和用户都不愿多停留一秒。
二、内容更新
在判断内容更新时,网站的权重和流量占比很大。尤其是做网站优化的,更新网站内容是必不可少的工作,尤其是对于那些大型企业网站,所有的产品信息都是相对固定的,所以一定要尽量在更新的内容中添加部分,不要更新它,因为 网站 的内容很小。要知道,如果内容不更新,搜索引擎永远不会给予更高的权重。另一方面,假设网站每天完成内容更新,搜索引擎蜘蛛也会养成每天抓取网站内容的习惯。久而久之,权重自然会变高,新闻发布的文章会在短时间内直接收录。
所以为了更好的掌握蜘蛛的爬行规律,可以了解它的爬行规律,这样可以更好的优化,让网站内容的关键词更加稳定。 查看全部
搜索引擎如何抓取网页(没有判断搜索引擎的算法,可以更好的改进网站吗?)
任何优化公司都知道,每个搜索引擎的排名实际上是由多种因素共同决定的。有时,一些网站所谓的结论只是偶然。事实上,没有人知道搜索引擎的算法。只有通过不断的实践和总结,我们的网站才能越来越完善。面对很久没有更新内容的网站,用户不会关注他,甚至搜索引擎也不会再收录他了。所以这个时候,既然你无法判断搜索引擎的算法,那你可以更好的改进网站。
一、更新频率
对于一些专注于新闻的门户网站网站来说,以合理的频率更新网站内容是很重要的。新闻本身具有很强的时效性。如果刚刚发生,请务必在短时间内将其发布到 网站。作为一个新闻网站的用户,你基本上会关注刚刚发生的事情。如果你输入一条新闻网站,发现某件事发生在几年前甚至很久以前,那么这个网站 将不会被访问。当用户发现 网站 内容太旧时,搜索引擎和用户都不愿多停留一秒。
二、内容更新
在判断内容更新时,网站的权重和流量占比很大。尤其是做网站优化的,更新网站内容是必不可少的工作,尤其是对于那些大型企业网站,所有的产品信息都是相对固定的,所以一定要尽量在更新的内容中添加部分,不要更新它,因为 网站 的内容很小。要知道,如果内容不更新,搜索引擎永远不会给予更高的权重。另一方面,假设网站每天完成内容更新,搜索引擎蜘蛛也会养成每天抓取网站内容的习惯。久而久之,权重自然会变高,新闻发布的文章会在短时间内直接收录。
所以为了更好的掌握蜘蛛的爬行规律,可以了解它的爬行规律,这样可以更好的优化,让网站内容的关键词更加稳定。
搜索引擎如何抓取网页(搜索引擎面对的是互联网万亿网页,如何高效抓取这么多网页到本地镜像?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-02-05 07:17
搜索引擎面对互联网上数以万亿计的网页。这么多网页如何高效爬取到本地镜像?这是网络爬虫的工作。我们也称它为网络蜘蛛,作为站长,我们每天都与它密切接触。
一、爬虫框架
搜索引擎蜘蛛抓取网络规则三倍
上图是一个简单的网络爬虫框架图。从种子URL开始,如图,经过一步一步的工作,最终将网页存入库中。当然,勤劳的蜘蛛可能还需要做更多的工作,比如网页的去重和网页的反作弊。
或许,我们可以将网页视为蜘蛛的晚餐,其中包括:
下载的网页。被蜘蛛爬过的网页内容被放到了肚子里。
过期网页。蜘蛛每次都要爬很多网页,有的已经在肚子里坏掉了。
要下载的页面。当它看到食物时,蜘蛛就会去抓它。
知名网站。它还没有被下载和发现,但是蜘蛛可以感知它们并且迟早会抓住它。
不可知的网页。互联网太大了,很多页面蜘蛛都找不到,而且可能永远也找不到。这部分占比很高。
通过以上划分,我们可以清楚地了解搜索引擎蜘蛛的工作以及它们面临的挑战。大多数蜘蛛都是按照这个框架爬行的。但这并不完全确定。一切总是特别的。根据不同的功能,蜘蛛系统有一些差异。
二、爬虫种类
1.批量式蜘蛛。
这种蜘蛛有明确的抓取范围和目标,当蜘蛛完成目标和任务时停止抓取。具体目标是什么?它可能是抓取的页面数、页面大小、抓取时间等。
2.增量蜘蛛
这种蜘蛛不同于批处理型蜘蛛,它们会不断地爬取,并且会定期对爬取的网页进行爬取和更新。由于 Internet 上的网页在不断更新,增量爬虫需要能够反映这种更新。
3.垂直蜘蛛
此类蜘蛛仅关注特定主题或特定行业页面。以health网站为例,这种专门的爬虫只会爬取健康相关的话题,其他话题的页面不会被爬取。测试这个蜘蛛的难点在于如何更准确地识别内容所属的行业。目前很多垂直行业网站都需要这种蜘蛛去抢。
三、抢夺策略
爬虫通过种子URL进行爬取和扩展,列出大量待爬取的URL。但是,要抓取的 URL 数量巨大。蜘蛛如何确定爬行的顺序?蜘蛛爬取的策略有很多,但最终目的是一个:首先爬取重要的网页。评价页面是否重要,蜘蛛会根据页面内容的程度原创、链接权重分析等多种方法进行计算。比较有代表性的爬取策略如下:
1. 广度优先策略
宽度优先是指蜘蛛爬取网页后,会继续按顺序爬取网页中收录的其他页面。这个想法看似简单,但实际上非常实用。因为大部分网页都是有优先级的,所以在页面上优先推荐重要的页面。
2. PageRank 策略
PageRank是一种非常有名的链接分析方法,主要用来衡量网页的权威性。例如,Google 的 PR 就是典型的 PageRank 算法。通过PageRank算法我们可以找出哪些页面更重要,然后蜘蛛会优先抓取这些重要的页面。
3.大网站优先策略
这个很容易理解,大网站通常内容页比较多,质量也会比较高。蜘蛛会首先分析网站分类和属性。如果这个网站已经是收录很多,或者在搜索引擎系统中的权重很高,则优先考虑收录。
4.网页更新
互联网上的大部分页面都会更新,所以蜘蛛存储的页面需要及时更新以保持一致性。打个比方:一个页面之前排名很好,如果页面被删除了但仍然排名,那么体验很差。因此,搜索引擎需要及时了解这些并更新页面,为用户提供最新的页面。常用的网页更新策略有三种:历史参考策略和用户体验策略。整群抽样策略。
1. 历史参考策略
这是基于假设的更新策略。例如,如果你的网页以前经常更新,那么搜索引擎也认为你的网页以后会经常更新,蜘蛛也会根据这个规则定期网站对网页进行爬取。这也是为什么点水一直强调网站内容需要定期更新的原因。
2. 用户体验策略
一般来说,用户只查看搜索结果前三页的内容,很少有人看到后面的页面。用户体验策略是搜索引擎根据用户的这一特征进行更新。例如,一个网页可能发布得较早,并且有一段时间没有更新,但用户仍然觉得它有用并点击浏览,那么搜索引擎可能不会首先更新这些过时的网页。这就是为什么搜索结果中的最新页面不一定排名靠前的原因。排名更多地取决于页面的质量,而不是更新的时间。
3.整群抽样策略
以上两种更新策略主要参考网页的历史信息。然而,存储大量历史信息对于搜索引擎来说是一种负担。另外,如果收录是一个新的网页,没有历史信息可以参考,怎么办?聚类抽样策略是指:拿出一些属性对很多相似的网页进行分类,分类后的页面按照相同的规则进行更新。
从了解搜索引擎蜘蛛工作原理的过程中,我们会知道:网站内容的相关性、网站与网页内容的更新规律、网页链接的分布和权重网站 等因素会影响蜘蛛的爬取效率。知己知彼,让蜘蛛来得更猛烈!
转载: 查看全部
搜索引擎如何抓取网页(搜索引擎面对的是互联网万亿网页,如何高效抓取这么多网页到本地镜像?)
搜索引擎面对互联网上数以万亿计的网页。这么多网页如何高效爬取到本地镜像?这是网络爬虫的工作。我们也称它为网络蜘蛛,作为站长,我们每天都与它密切接触。
一、爬虫框架
搜索引擎蜘蛛抓取网络规则三倍
上图是一个简单的网络爬虫框架图。从种子URL开始,如图,经过一步一步的工作,最终将网页存入库中。当然,勤劳的蜘蛛可能还需要做更多的工作,比如网页的去重和网页的反作弊。
或许,我们可以将网页视为蜘蛛的晚餐,其中包括:
下载的网页。被蜘蛛爬过的网页内容被放到了肚子里。
过期网页。蜘蛛每次都要爬很多网页,有的已经在肚子里坏掉了。
要下载的页面。当它看到食物时,蜘蛛就会去抓它。
知名网站。它还没有被下载和发现,但是蜘蛛可以感知它们并且迟早会抓住它。
不可知的网页。互联网太大了,很多页面蜘蛛都找不到,而且可能永远也找不到。这部分占比很高。
通过以上划分,我们可以清楚地了解搜索引擎蜘蛛的工作以及它们面临的挑战。大多数蜘蛛都是按照这个框架爬行的。但这并不完全确定。一切总是特别的。根据不同的功能,蜘蛛系统有一些差异。
二、爬虫种类
1.批量式蜘蛛。
这种蜘蛛有明确的抓取范围和目标,当蜘蛛完成目标和任务时停止抓取。具体目标是什么?它可能是抓取的页面数、页面大小、抓取时间等。
2.增量蜘蛛
这种蜘蛛不同于批处理型蜘蛛,它们会不断地爬取,并且会定期对爬取的网页进行爬取和更新。由于 Internet 上的网页在不断更新,增量爬虫需要能够反映这种更新。
3.垂直蜘蛛
此类蜘蛛仅关注特定主题或特定行业页面。以health网站为例,这种专门的爬虫只会爬取健康相关的话题,其他话题的页面不会被爬取。测试这个蜘蛛的难点在于如何更准确地识别内容所属的行业。目前很多垂直行业网站都需要这种蜘蛛去抢。
三、抢夺策略
爬虫通过种子URL进行爬取和扩展,列出大量待爬取的URL。但是,要抓取的 URL 数量巨大。蜘蛛如何确定爬行的顺序?蜘蛛爬取的策略有很多,但最终目的是一个:首先爬取重要的网页。评价页面是否重要,蜘蛛会根据页面内容的程度原创、链接权重分析等多种方法进行计算。比较有代表性的爬取策略如下:
1. 广度优先策略
宽度优先是指蜘蛛爬取网页后,会继续按顺序爬取网页中收录的其他页面。这个想法看似简单,但实际上非常实用。因为大部分网页都是有优先级的,所以在页面上优先推荐重要的页面。
2. PageRank 策略
PageRank是一种非常有名的链接分析方法,主要用来衡量网页的权威性。例如,Google 的 PR 就是典型的 PageRank 算法。通过PageRank算法我们可以找出哪些页面更重要,然后蜘蛛会优先抓取这些重要的页面。
3.大网站优先策略
这个很容易理解,大网站通常内容页比较多,质量也会比较高。蜘蛛会首先分析网站分类和属性。如果这个网站已经是收录很多,或者在搜索引擎系统中的权重很高,则优先考虑收录。
4.网页更新
互联网上的大部分页面都会更新,所以蜘蛛存储的页面需要及时更新以保持一致性。打个比方:一个页面之前排名很好,如果页面被删除了但仍然排名,那么体验很差。因此,搜索引擎需要及时了解这些并更新页面,为用户提供最新的页面。常用的网页更新策略有三种:历史参考策略和用户体验策略。整群抽样策略。
1. 历史参考策略
这是基于假设的更新策略。例如,如果你的网页以前经常更新,那么搜索引擎也认为你的网页以后会经常更新,蜘蛛也会根据这个规则定期网站对网页进行爬取。这也是为什么点水一直强调网站内容需要定期更新的原因。
2. 用户体验策略
一般来说,用户只查看搜索结果前三页的内容,很少有人看到后面的页面。用户体验策略是搜索引擎根据用户的这一特征进行更新。例如,一个网页可能发布得较早,并且有一段时间没有更新,但用户仍然觉得它有用并点击浏览,那么搜索引擎可能不会首先更新这些过时的网页。这就是为什么搜索结果中的最新页面不一定排名靠前的原因。排名更多地取决于页面的质量,而不是更新的时间。
3.整群抽样策略
以上两种更新策略主要参考网页的历史信息。然而,存储大量历史信息对于搜索引擎来说是一种负担。另外,如果收录是一个新的网页,没有历史信息可以参考,怎么办?聚类抽样策略是指:拿出一些属性对很多相似的网页进行分类,分类后的页面按照相同的规则进行更新。
从了解搜索引擎蜘蛛工作原理的过程中,我们会知道:网站内容的相关性、网站与网页内容的更新规律、网页链接的分布和权重网站 等因素会影响蜘蛛的爬取效率。知己知彼,让蜘蛛来得更猛烈!
转载:
搜索引擎如何抓取网页(搜索引擎抓取页面的方式!(一)--新全讯网)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-02-04 08:02
搜索引擎如何抓取网页?本文由新泉寻网站长编辑。转载请保留此链接!做seo就是为了讨好搜索引擎,所以一定要明白搜索引擎是怎么爬网页的!搜索引擎不可能一次爬取网站中的所有页面,网站中的页面数量在不断变化,内容也在不断更新。因此,搜索引擎也需要对已经爬取的页面进行维护和更新,以便及时获取页面的最新信息,爬取更多的新页面。常见的页面维护方式有:定期爬取、增量爬取、分类定位爬取。周期性爬取 周期性爬取也称为周期性爬取,即 搜索引擎会定期更新 网站 中已出现过的页面。更新时,用捕获的新页面替换原来的旧页面,删除不存在的页面,并存储新发现的页面。周期性更新是针对所有已经收录的页面,所以更新周期会更长。例如,Google 通常需要 30-60 天来更新已为 收录 的页面。周期性抓取算法的实现相对简单。由于每次更新都涉及到网站中所有已经是收录的页面,所以页面权重的重新分配也是同步进行的。此方法适用于维护页面少、内容更新慢的网站,如普通企业网站。不过由于更新周期很长,更新期间页面的变化无法及时反映给用户。例如,页面内容更新后,至少需要 30 到 60 天才能反映在搜索引擎上。
增量爬取增量爬取是通过定期监控爬取的页面来更新和维护页面。但是,定期监视 网站 中的每个页面是不切实际的。基于重要页面承载重要内容的思想和80/20法则,搜索引擎只需定期对网站中的一些重要页面进行监控,即可获取网站中相对重要的信息。因此,增量爬取只针对网站中的部分重要页面,而不是所有已经收录的页面,这也是搜索引擎对重要页面的更新周期较短的原因。例如,内容更新频繁的页面会被搜索引擎频繁更新,从而及时发现新的内容和链接,删除不存在的信息。由于增量爬取是在原创页面的基础上进行的,因此搜索引擎的爬取时间会大大减少,并且可以及时将页面上的最新内容展示给用户。由于页面的重要性,分类定位爬取不同于增量爬取。分类定位爬取是指根据页面的类别或性质制定相应的更新周期的页面监控方法。例如,对于“新闻”和“资源下载”页面,新闻页面的更新周期可以精确到每分钟,而下载页面的更新周期可以设置为一天或更长。分类定位爬取分别处理不同类别的页面,可以节省大量的爬取时间,
但是,按类别制定页面更新周期的方法比较笼统,很难跟踪页面更新。因为即使是同一类别的页面,不同网站s上的内容更新周期也会有很大差异。例如,新闻页面在大型门户 网站 中的更新速度比在其他小型 网站 中的要快得多。因此,需要结合其他方法(如增量爬取等)对页面进行监控和更新。其实网站中页面的维护也是由搜索引擎以多种方式进行的,相当于间接为每个页面选择了最合适的维护方式。这样既可以减轻搜索引擎的负担,又可以为用户提供及时的信息。例如,在 网站 中,会有各种不同性质的页面,常见的有首页、论坛页、内容页等。对于更新频繁的页面(如首页),可以采用增量爬取的方式对其进行监控,从而相对网站中的重要页面可以及时更新;对于非常实时的论坛页面,可以使用分类定位的爬取方式;并且为了防止网站中的部分页面出现遗漏,还需要采用正则爬取的方法。对于非常实时的论坛页面,可以使用分类定位的爬取方式;并且为了防止网站中的部分页面出现遗漏,还需要采用正则爬取的方法。对于非常实时的论坛页面,可以使用分类定位的爬取方式;并且为了防止网站中的部分页面出现遗漏,还需要采用正则爬取的方法。 查看全部
搜索引擎如何抓取网页(搜索引擎抓取页面的方式!(一)--新全讯网)
搜索引擎如何抓取网页?本文由新泉寻网站长编辑。转载请保留此链接!做seo就是为了讨好搜索引擎,所以一定要明白搜索引擎是怎么爬网页的!搜索引擎不可能一次爬取网站中的所有页面,网站中的页面数量在不断变化,内容也在不断更新。因此,搜索引擎也需要对已经爬取的页面进行维护和更新,以便及时获取页面的最新信息,爬取更多的新页面。常见的页面维护方式有:定期爬取、增量爬取、分类定位爬取。周期性爬取 周期性爬取也称为周期性爬取,即 搜索引擎会定期更新 网站 中已出现过的页面。更新时,用捕获的新页面替换原来的旧页面,删除不存在的页面,并存储新发现的页面。周期性更新是针对所有已经收录的页面,所以更新周期会更长。例如,Google 通常需要 30-60 天来更新已为 收录 的页面。周期性抓取算法的实现相对简单。由于每次更新都涉及到网站中所有已经是收录的页面,所以页面权重的重新分配也是同步进行的。此方法适用于维护页面少、内容更新慢的网站,如普通企业网站。不过由于更新周期很长,更新期间页面的变化无法及时反映给用户。例如,页面内容更新后,至少需要 30 到 60 天才能反映在搜索引擎上。
增量爬取增量爬取是通过定期监控爬取的页面来更新和维护页面。但是,定期监视 网站 中的每个页面是不切实际的。基于重要页面承载重要内容的思想和80/20法则,搜索引擎只需定期对网站中的一些重要页面进行监控,即可获取网站中相对重要的信息。因此,增量爬取只针对网站中的部分重要页面,而不是所有已经收录的页面,这也是搜索引擎对重要页面的更新周期较短的原因。例如,内容更新频繁的页面会被搜索引擎频繁更新,从而及时发现新的内容和链接,删除不存在的信息。由于增量爬取是在原创页面的基础上进行的,因此搜索引擎的爬取时间会大大减少,并且可以及时将页面上的最新内容展示给用户。由于页面的重要性,分类定位爬取不同于增量爬取。分类定位爬取是指根据页面的类别或性质制定相应的更新周期的页面监控方法。例如,对于“新闻”和“资源下载”页面,新闻页面的更新周期可以精确到每分钟,而下载页面的更新周期可以设置为一天或更长。分类定位爬取分别处理不同类别的页面,可以节省大量的爬取时间,
但是,按类别制定页面更新周期的方法比较笼统,很难跟踪页面更新。因为即使是同一类别的页面,不同网站s上的内容更新周期也会有很大差异。例如,新闻页面在大型门户 网站 中的更新速度比在其他小型 网站 中的要快得多。因此,需要结合其他方法(如增量爬取等)对页面进行监控和更新。其实网站中页面的维护也是由搜索引擎以多种方式进行的,相当于间接为每个页面选择了最合适的维护方式。这样既可以减轻搜索引擎的负担,又可以为用户提供及时的信息。例如,在 网站 中,会有各种不同性质的页面,常见的有首页、论坛页、内容页等。对于更新频繁的页面(如首页),可以采用增量爬取的方式对其进行监控,从而相对网站中的重要页面可以及时更新;对于非常实时的论坛页面,可以使用分类定位的爬取方式;并且为了防止网站中的部分页面出现遗漏,还需要采用正则爬取的方法。对于非常实时的论坛页面,可以使用分类定位的爬取方式;并且为了防止网站中的部分页面出现遗漏,还需要采用正则爬取的方法。对于非常实时的论坛页面,可以使用分类定位的爬取方式;并且为了防止网站中的部分页面出现遗漏,还需要采用正则爬取的方法。
搜索引擎如何抓取网页(seo优化对百度蜘蛛的抓取重要网页也十分关注。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-02-04 07:21
目前seo优化也非常关注百度蜘蛛对重要网页的抓取。让我详细谈谈
面对海量的网页,搜索引擎不会并行抓取每个网页,因为无论搜索引擎数据库如何扩展,都跟不上网页的增长速度。搜索引擎会优先抓取最重要的网页。保存数据库一方面对普通用户也有帮助,因为对于用户来说,他们不需要大量的结果,只需要最重要的结果。因此,一个好的采集策略是先采集重要的网页,这样最重要的网页才能在最短的时间内被抓取到。
那么搜索引擎如何首先抓取最重要的页面呢?
通过分析大量网页的特征,搜索引擎认为重要的网页具有以下基本特征,虽然不一定完全准确,但大多数时候确实如此:
1) 一个网页被其他网页链接的特点,如果链接频繁或者被重要网页链接,就是非常重要的网页;
2)网页的父网页被多次链接或被重要网页链接。比如一个网页是网站的内页,但是它的主页被链接了很多次,而且主页也被链接了,如果找到这个页面,说明这个页面也比较重要;
3)网页内容被转载广泛传播。
4) 网页的目录深度较小,便于用户浏览。这里的“URL目录深度”定义为:网页URL除域名部分外的目录级别,即如果URL为,则目录深度为0;如果是,则目录深度为 1,依此类推。需要注意的是,URL目录深度小的网页并不总是重要的,目录深度大的网页也并非都是不重要的。一些学术论文的网页网址具有较长的目录深度。大多数重要度高的网页都会同时具备以上四个特征。
5)先采集网站首页,给首页分配高权重。网站 的数量远小于网页的数量,重要的网页必须从这些 网站 主页链接,所以采集工作应优先获取尽可能多的 网站@ > 主页尽可能。
问题来了。当搜索引擎开始抓取网页时,它可能不知道该网页是链接还是转载。,这些因素只有在获得网页或几乎所有的网页链接结构后才能知道。那么如何解决这个问题呢?即在爬取时可以知道特征4和特征5,只有特征4可以在不知道网页内容的情况下(在网页爬取之前)判断一个URL是否符合网页内容。“重要”的标准,网页URL目录深度的计算就是对字符串的处理。统计结果表明,一般的 URL 长度小于 256 个字符,使得 URL 目录深度的判断更容易实现。因此,对于采集策略的确定,
但是,特征 4 和 5 有局限性,因为链接的深度并不能完全表明页面的重要性。那么如何解决这个问题呢?搜索引擎使用以下方法:
1) URL 权重设置:根据 URL 的目录深度确定。权重随着深度的减少而减少,最小权重为零。
2) 将 URL 初始权重设置为固定值。
3) 如果“/”、“?”或“&”字符在 URL 中出现一次,则权重减少一个值,并且
如果“search”、“proxy”或“gate”使用一次,权重减少一个值;最多减少到零。(包括”?”,
带“&”的URL是带参数的形式,需要通过请求的程序服务获取网页,而不是搜索引擎系统重点关注的静态网页,因此权重相应降低。收录“search”、“proxy”或“gate”,表示该网页最有可能是搜索引擎检索到的结果页面,即代理页面,因此应降低权重)。
4) 选择未访问 URL 的策略。因为权重值小并不一定代表不重要,有必要
有机会采集权重较小的未访问 URL。选择未访问URL的策略可以采用轮询的方式,根据权重顺序选择一个,随机选择一个,或者随机选择N次。
搜索引擎在爬取大量网页时,进入了解读网页前三个特征的阶段,然后通过大量算法判断网页质量,然后给出相对排名. 查看全部
搜索引擎如何抓取网页(seo优化对百度蜘蛛的抓取重要网页也十分关注。)
目前seo优化也非常关注百度蜘蛛对重要网页的抓取。让我详细谈谈
面对海量的网页,搜索引擎不会并行抓取每个网页,因为无论搜索引擎数据库如何扩展,都跟不上网页的增长速度。搜索引擎会优先抓取最重要的网页。保存数据库一方面对普通用户也有帮助,因为对于用户来说,他们不需要大量的结果,只需要最重要的结果。因此,一个好的采集策略是先采集重要的网页,这样最重要的网页才能在最短的时间内被抓取到。
那么搜索引擎如何首先抓取最重要的页面呢?
通过分析大量网页的特征,搜索引擎认为重要的网页具有以下基本特征,虽然不一定完全准确,但大多数时候确实如此:
1) 一个网页被其他网页链接的特点,如果链接频繁或者被重要网页链接,就是非常重要的网页;
2)网页的父网页被多次链接或被重要网页链接。比如一个网页是网站的内页,但是它的主页被链接了很多次,而且主页也被链接了,如果找到这个页面,说明这个页面也比较重要;
3)网页内容被转载广泛传播。
4) 网页的目录深度较小,便于用户浏览。这里的“URL目录深度”定义为:网页URL除域名部分外的目录级别,即如果URL为,则目录深度为0;如果是,则目录深度为 1,依此类推。需要注意的是,URL目录深度小的网页并不总是重要的,目录深度大的网页也并非都是不重要的。一些学术论文的网页网址具有较长的目录深度。大多数重要度高的网页都会同时具备以上四个特征。
5)先采集网站首页,给首页分配高权重。网站 的数量远小于网页的数量,重要的网页必须从这些 网站 主页链接,所以采集工作应优先获取尽可能多的 网站@ > 主页尽可能。
问题来了。当搜索引擎开始抓取网页时,它可能不知道该网页是链接还是转载。,这些因素只有在获得网页或几乎所有的网页链接结构后才能知道。那么如何解决这个问题呢?即在爬取时可以知道特征4和特征5,只有特征4可以在不知道网页内容的情况下(在网页爬取之前)判断一个URL是否符合网页内容。“重要”的标准,网页URL目录深度的计算就是对字符串的处理。统计结果表明,一般的 URL 长度小于 256 个字符,使得 URL 目录深度的判断更容易实现。因此,对于采集策略的确定,
但是,特征 4 和 5 有局限性,因为链接的深度并不能完全表明页面的重要性。那么如何解决这个问题呢?搜索引擎使用以下方法:
1) URL 权重设置:根据 URL 的目录深度确定。权重随着深度的减少而减少,最小权重为零。
2) 将 URL 初始权重设置为固定值。
3) 如果“/”、“?”或“&”字符在 URL 中出现一次,则权重减少一个值,并且
如果“search”、“proxy”或“gate”使用一次,权重减少一个值;最多减少到零。(包括”?”,
带“&”的URL是带参数的形式,需要通过请求的程序服务获取网页,而不是搜索引擎系统重点关注的静态网页,因此权重相应降低。收录“search”、“proxy”或“gate”,表示该网页最有可能是搜索引擎检索到的结果页面,即代理页面,因此应降低权重)。
4) 选择未访问 URL 的策略。因为权重值小并不一定代表不重要,有必要
有机会采集权重较小的未访问 URL。选择未访问URL的策略可以采用轮询的方式,根据权重顺序选择一个,随机选择一个,或者随机选择N次。
搜索引擎在爬取大量网页时,进入了解读网页前三个特征的阶段,然后通过大量算法判断网页质量,然后给出相对排名.
搜索引擎如何抓取网页(如何禁止百度搜索引擎收录抓取网页网页帮助帮助?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-04 05:13
如果你的网站涉及个人隐私或机密的非公开网页,如何告诉搜索引擎禁止收录爬取,侯庆龙会讲解以下方法,希望你不要想被搜索引擎搜索到收录Grab网站帮助。
第一种,robots.txt方法
搜索引擎默认遵循 robots.txt 协议。创建 robots.txt 文本文件并将其放在 网站 根目录中。编辑代码如下:
用户代理:*
禁止:
通过代码,您可以告诉搜索引擎不要抓取收录this网站。
二、网页代码
在网站首页代码之间,添加一个代码,该标签禁止搜索引擎抓取网站并显示网页截图。
如何阻止百度搜索引擎收录抓取网页
1、编辑robots.txt文件,设计标记为:
用户代理:百度蜘蛛
禁止:/
2、在网站首页代码之间添加,防止百度搜索引擎抓取网站并显示网页截图。
3、联系百度管理,邮箱是:,发邮件到网站的联系人邮箱,如实说明删除网页截图。经百度验证,网页将停止收录抓取。
4、登录百度自己的“百度快照”帖和“百度投诉”帖,发帖说明删除页面快照的原因收录网站,百度管理人员的时候,看到了就会处理。
如何阻止 Google 搜索引擎收录抓取网络
1、编辑robots.txt文件,设计标记为:
用户代理:googlebot
禁止:/
2、在网站首页代码之间添加,防止百度搜索引擎抓取网站并显示网页截图。
SEO优化:侯庆龙原网址: 查看全部
搜索引擎如何抓取网页(如何禁止百度搜索引擎收录抓取网页网页帮助帮助?)
如果你的网站涉及个人隐私或机密的非公开网页,如何告诉搜索引擎禁止收录爬取,侯庆龙会讲解以下方法,希望你不要想被搜索引擎搜索到收录Grab网站帮助。
第一种,robots.txt方法
搜索引擎默认遵循 robots.txt 协议。创建 robots.txt 文本文件并将其放在 网站 根目录中。编辑代码如下:
用户代理:*
禁止:
通过代码,您可以告诉搜索引擎不要抓取收录this网站。
二、网页代码
在网站首页代码之间,添加一个代码,该标签禁止搜索引擎抓取网站并显示网页截图。
如何阻止百度搜索引擎收录抓取网页
1、编辑robots.txt文件,设计标记为:
用户代理:百度蜘蛛
禁止:/
2、在网站首页代码之间添加,防止百度搜索引擎抓取网站并显示网页截图。
3、联系百度管理,邮箱是:,发邮件到网站的联系人邮箱,如实说明删除网页截图。经百度验证,网页将停止收录抓取。
4、登录百度自己的“百度快照”帖和“百度投诉”帖,发帖说明删除页面快照的原因收录网站,百度管理人员的时候,看到了就会处理。
如何阻止 Google 搜索引擎收录抓取网络
1、编辑robots.txt文件,设计标记为:
用户代理:googlebot
禁止:/
2、在网站首页代码之间添加,防止百度搜索引擎抓取网站并显示网页截图。
SEO优化:侯庆龙原网址:
搜索引擎如何抓取网页(搜索引擎如何形成网站的爬行频次(一)_光明网)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-04 05:11
对于搜索引擎优化,我们并不完全了解搜索引擎是如何形成网站的爬取频率的,所有博主整理网页内容获取搜索引擎使用以下两个因素来确定爬取频率: 流行度- 更受欢迎的页面将被更频繁地爬取;stale - 百度不会废弃页面信息,对于 网站 管理员来说,这意味着如果页面内容更新频繁,百度会尝试更频繁地抓取网页。假设 网站 的抓取频率与反向链接的数量以及该 网站 在百度眼中的重要性成正比——百度希望确保最重要的页面在索引中保持最新.
内部链接呢?你可以通过指向更多的内部链接来提高特定页面的爬取率吗?为了回答这些问题,我决定检查内外链接之间的相关性和爬取统计,我采集了 11 个 网站 数据并做了一个简单的分析,总之,这就是我所做的。我为将要分析的 11 个站点创建了项目,我计算了每个 网站 页面的内部链接数量,接下来我运行 SEO Spyglass 并为相同的 11 个站点创建了项目,在每个项目中,我检查了统计信息并复制带有每个页面的外部链接数量的锚 URL。
然后,我分析了服务器日志中的抓取统计信息,以了解百度每次访问每个页面的频率。最后,我将所有这些数据放入一个电子表格中,并计算内部链接和抓取预算与外部链接和抓取预算之间的相关性。我的数据集展示了蜘蛛访问次数和外部链接数量之间的强相关性(0,978),同时,蜘蛛命中和内部链接之间的相关性被证明非常弱(0,154),这表明反向链接比网站链接更重要。这是否意味着增加爬取频率的唯一方法是建立链接和发布新内容?如果我们谈论整个网站的朱雀频率,我会说:添加链接并经常更新网站,以及网站'
网络推广知识推荐:新手优化中的两个常见错误网站及其解决方法
但是当我们获取单个页面时会变得更有趣,正如您将在下面的介绍中看到的那样,您甚至可能在没有意识到的情况下浪费了大量的爬网。通过巧妙地管理频率,您通常可以将单个页面的抓取次数翻倍——但它仍然与每页的反向链接数量成正比。
以上就是《如何分配搜索引擎的抓取频率?》的全部内容,仅供站长朋友们互动学习。SEO优化是一个需要坚持的过程。希望大家一起进步。 查看全部
搜索引擎如何抓取网页(搜索引擎如何形成网站的爬行频次(一)_光明网)
对于搜索引擎优化,我们并不完全了解搜索引擎是如何形成网站的爬取频率的,所有博主整理网页内容获取搜索引擎使用以下两个因素来确定爬取频率: 流行度- 更受欢迎的页面将被更频繁地爬取;stale - 百度不会废弃页面信息,对于 网站 管理员来说,这意味着如果页面内容更新频繁,百度会尝试更频繁地抓取网页。假设 网站 的抓取频率与反向链接的数量以及该 网站 在百度眼中的重要性成正比——百度希望确保最重要的页面在索引中保持最新.
内部链接呢?你可以通过指向更多的内部链接来提高特定页面的爬取率吗?为了回答这些问题,我决定检查内外链接之间的相关性和爬取统计,我采集了 11 个 网站 数据并做了一个简单的分析,总之,这就是我所做的。我为将要分析的 11 个站点创建了项目,我计算了每个 网站 页面的内部链接数量,接下来我运行 SEO Spyglass 并为相同的 11 个站点创建了项目,在每个项目中,我检查了统计信息并复制带有每个页面的外部链接数量的锚 URL。
然后,我分析了服务器日志中的抓取统计信息,以了解百度每次访问每个页面的频率。最后,我将所有这些数据放入一个电子表格中,并计算内部链接和抓取预算与外部链接和抓取预算之间的相关性。我的数据集展示了蜘蛛访问次数和外部链接数量之间的强相关性(0,978),同时,蜘蛛命中和内部链接之间的相关性被证明非常弱(0,154),这表明反向链接比网站链接更重要。这是否意味着增加爬取频率的唯一方法是建立链接和发布新内容?如果我们谈论整个网站的朱雀频率,我会说:添加链接并经常更新网站,以及网站'
网络推广知识推荐:新手优化中的两个常见错误网站及其解决方法
但是当我们获取单个页面时会变得更有趣,正如您将在下面的介绍中看到的那样,您甚至可能在没有意识到的情况下浪费了大量的爬网。通过巧妙地管理频率,您通常可以将单个页面的抓取次数翻倍——但它仍然与每页的反向链接数量成正比。
以上就是《如何分配搜索引擎的抓取频率?》的全部内容,仅供站长朋友们互动学习。SEO优化是一个需要坚持的过程。希望大家一起进步。
搜索引擎如何抓取网页(网站内容怎么做到被查找引擎频频快速抓取的用途是什么)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-03 20:00
搜索引擎爬虫是一种自动提取网页的程序,例如百度蜘蛛。如果要收录更多网站的页面,需要先爬取页面。如果你的网站页面更新频繁,爬虫会更频繁地访问该页面,而优质的内容是爬虫喜欢抓取的内容,尤其是原创内容。
我们都知道,为了保证高效率,搜索引擎蜘蛛不会抓取网站的所有页面。网站 的权重越高,爬取深度越高,爬取的页面越多。这样,可以收录更多的页面。
网站服务器是网站 的基石。如果网站服务器长时间打不开,就相当于关门谢了。如果你的服务器不稳定或者卡住,每次爬虫都很难爬。有时只能抓取页面的一部分。随着时间的推移,百度蜘蛛的体验越来越差,它在你的网站上的评分也越来越低。当然会影响你的网站爬取,所以选择空间服务器。
调查显示,87%的网民会通过搜索引擎服务找到自己需要的信息,近70%的网民会直接在搜索结果自然排名的首页找到自己需要的信息。可见,搜索引擎优化对于企业和产品都有着重要的意义。
那么网站的内容如何被搜索引擎快速频繁的抓取呢?
我们经常听到关键词,但是关键词的具体用途是什么?
关键词是搜索引擎优化的核心,是网站在搜索引擎中排名的重要因素。
导入链接也是网站优化中非常重要的一个环节,间接影响了网站在搜索引擎中的权重。现在,我们常用的链接有:锚文本链接、超链接、纯文本链接和图片链接。
每次蜘蛛爬行时,它都会存储页面数据。如果第二次爬取发现页面收录与第一次完全相同的内容,则说明该页面还没有更新,蜘蛛不需要经常爬取。如果网页内容更新频繁,蜘蛛会更频繁地访问该网页,所以我们应该主动向蜘蛛求爱,定期更新文章,让蜘蛛有效地按照你的规则爬行< @文章 。
优质的 原创 内容对百度蜘蛛非常有吸引力。我们需要给蜘蛛提供真正有价值的原创内容。如果蜘蛛能得到它喜欢的东西,它自然会在你的 网站 上留下一个很好的形象,并经常回来。
同时,网站结构不能太复杂,链接层次不能太深。它也是蜘蛛的最爱。
众所周知,外链对于网站是可以吸引蜘蛛的,尤其是在新站点中,网站不是很老练,蜘蛛访问量少,外链可以增加网站页面的曝光率front of spiders rate,防止蜘蛛发现页面。在外链建设过程中,需要注意外链的质量。不要做无用的事情来节省能源。
蜘蛛的爬取是沿着链接进行的,所以对内链进行合理的优化,可以要求蜘蛛爬取更多的页面,促进网站的采集。在内链建设过程中,应合理推荐用户。除了在文章中添加锚文本,还可以设置相关引荐、热门文章等栏目。这是许多 网站 正在使用的,蜘蛛能够抓取更广泛的页面。
主页是蜘蛛经常访问的页面,也是一个具有良好权限的页面网站。可以在首页设置更新版块,不仅可以更新首页,增加蜘蛛访问频率,还可以增加对更新页面的抓取和采集。
搜索引擎蜘蛛通过链接爬行找到它们。过多的链接不仅会减少页面数量,而且你的网站在搜索引擎中的权重也会大大降低。所以定期检查网站的死链接并提交给搜索引擎很重要。
搜索引擎蜘蛛喜欢 网站 地图。网站地图是所有网站 链接的容器。很多 网站 都有蜘蛛很难掌握的深层链接。网站地图让搜索引擎蜘蛛更容易抓取网站页面。通过爬网,他们可以清楚地了解网站的结构,所以构建一个网站地图,不仅可以提高爬取率,还可以很好地了解蜘蛛。
同时,在每次页面更新后向搜索引擎提交内容也是一个好主意。
SEO外包服务商亿豪网络专业网站优化营销专家多年研究在线优化技术和营销新方法。公司成立8年来,已服务近千家企业用户,多家500强企业与我们达成战略合作。合作。
专业的SEO技术团队让有需要的客户找到您,亿豪网络为您提供专业的搜索引擎优化推广服务,站外站内优化,亿豪让您的企业从互联网流量和品牌收益中获得更多自由! 查看全部
搜索引擎如何抓取网页(网站内容怎么做到被查找引擎频频快速抓取的用途是什么)
搜索引擎爬虫是一种自动提取网页的程序,例如百度蜘蛛。如果要收录更多网站的页面,需要先爬取页面。如果你的网站页面更新频繁,爬虫会更频繁地访问该页面,而优质的内容是爬虫喜欢抓取的内容,尤其是原创内容。
我们都知道,为了保证高效率,搜索引擎蜘蛛不会抓取网站的所有页面。网站 的权重越高,爬取深度越高,爬取的页面越多。这样,可以收录更多的页面。
网站服务器是网站 的基石。如果网站服务器长时间打不开,就相当于关门谢了。如果你的服务器不稳定或者卡住,每次爬虫都很难爬。有时只能抓取页面的一部分。随着时间的推移,百度蜘蛛的体验越来越差,它在你的网站上的评分也越来越低。当然会影响你的网站爬取,所以选择空间服务器。
调查显示,87%的网民会通过搜索引擎服务找到自己需要的信息,近70%的网民会直接在搜索结果自然排名的首页找到自己需要的信息。可见,搜索引擎优化对于企业和产品都有着重要的意义。
那么网站的内容如何被搜索引擎快速频繁的抓取呢?
我们经常听到关键词,但是关键词的具体用途是什么?
关键词是搜索引擎优化的核心,是网站在搜索引擎中排名的重要因素。
导入链接也是网站优化中非常重要的一个环节,间接影响了网站在搜索引擎中的权重。现在,我们常用的链接有:锚文本链接、超链接、纯文本链接和图片链接。
每次蜘蛛爬行时,它都会存储页面数据。如果第二次爬取发现页面收录与第一次完全相同的内容,则说明该页面还没有更新,蜘蛛不需要经常爬取。如果网页内容更新频繁,蜘蛛会更频繁地访问该网页,所以我们应该主动向蜘蛛求爱,定期更新文章,让蜘蛛有效地按照你的规则爬行< @文章 。
优质的 原创 内容对百度蜘蛛非常有吸引力。我们需要给蜘蛛提供真正有价值的原创内容。如果蜘蛛能得到它喜欢的东西,它自然会在你的 网站 上留下一个很好的形象,并经常回来。
同时,网站结构不能太复杂,链接层次不能太深。它也是蜘蛛的最爱。
众所周知,外链对于网站是可以吸引蜘蛛的,尤其是在新站点中,网站不是很老练,蜘蛛访问量少,外链可以增加网站页面的曝光率front of spiders rate,防止蜘蛛发现页面。在外链建设过程中,需要注意外链的质量。不要做无用的事情来节省能源。
蜘蛛的爬取是沿着链接进行的,所以对内链进行合理的优化,可以要求蜘蛛爬取更多的页面,促进网站的采集。在内链建设过程中,应合理推荐用户。除了在文章中添加锚文本,还可以设置相关引荐、热门文章等栏目。这是许多 网站 正在使用的,蜘蛛能够抓取更广泛的页面。
主页是蜘蛛经常访问的页面,也是一个具有良好权限的页面网站。可以在首页设置更新版块,不仅可以更新首页,增加蜘蛛访问频率,还可以增加对更新页面的抓取和采集。
搜索引擎蜘蛛通过链接爬行找到它们。过多的链接不仅会减少页面数量,而且你的网站在搜索引擎中的权重也会大大降低。所以定期检查网站的死链接并提交给搜索引擎很重要。
搜索引擎蜘蛛喜欢 网站 地图。网站地图是所有网站 链接的容器。很多 网站 都有蜘蛛很难掌握的深层链接。网站地图让搜索引擎蜘蛛更容易抓取网站页面。通过爬网,他们可以清楚地了解网站的结构,所以构建一个网站地图,不仅可以提高爬取率,还可以很好地了解蜘蛛。
同时,在每次页面更新后向搜索引擎提交内容也是一个好主意。
SEO外包服务商亿豪网络专业网站优化营销专家多年研究在线优化技术和营销新方法。公司成立8年来,已服务近千家企业用户,多家500强企业与我们达成战略合作。合作。
专业的SEO技术团队让有需要的客户找到您,亿豪网络为您提供专业的搜索引擎优化推广服务,站外站内优化,亿豪让您的企业从互联网流量和品牌收益中获得更多自由!
搜索引擎如何抓取网页(搜索引擎如何首先抓取最重要的网页?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-02-03 16:02
首先分析搜索引擎如何抓取最重要的网页。面对海量网页,他们不会并行抓取每个网页,因为无论搜索引擎数据库如何扩展,他们都跟不上网页的增长速度。最重要的网页将首先被抓取。一方面保存了数据库,另一方面对普通用户也有帮助,因为对于用户来说,他们不需要大量的结果,只需要最重要的结果。因此,一个好的采集策略是先采集重要的网页,这样最重要的网页才能在最短的时间内被抓取到。那么搜索引擎如何首先抓取最重要的网页呢?通过分析大量网页的特点,搜索引擎认为,重要网页具有以下基本特征,虽然不一定完全准确,但大部分情况下确实如此: 网页链接的特征,如果被多次链接或被重要网页链接,是一个非常重要的网页;一个网页的父网页被多次链接或者被重要网页链接,比如一个网页是网站的内页,但是它的首页被多次链接,首页page也链接到这个页面,也就是说这个页面也比较重要;页面目录深度小,便于用户浏览。这里的“URL目录深度”定义为:网页URL除域名部分外的目录级别,即如果URL是 ,那么目录深度是 如果是,目录深度是第二个,依此类推。需要注意的是,URL目录深度小的网页并不总是重要的,目录深度大的网页也并非都是不重要的。一些学术论文的网页 URL 具有非常长的目录深度。
大多数具有高重要性的网页将同时具有上述所有特征。5)先采集网站首页,给首页分配高权重。网站的数量远小于网页的数量,重要的网页必然会从这些网站主页链接,所以采集工作应优先获取尽可能多的网站尽可能第一个问题当搜索引擎开始抓取网页时,它可能不知道被链接或转载的网页的状态。也就是说,一开始,他无法知道前三项的特性。在获得网页或几乎任何网络链接结构之前,您无法知道。那么如何解决这个问题呢?也就是特征4是可以判断一个URL是否满足“ URL 的初始权重设置为固定值。字符“/”和“?” 出现在网址中。URL 是参数的形式。它需要通过请求的程序服务获取网页,而不是搜索引擎系统关注的静态网页。因此,权重相应减少。
收录“search”、“proxy”或“gate”表示该网页最有可能是搜索引擎检索到的结果页面,即代理页面,因此应降低权重)。选择未访问 URL 的策略。因为权重小并不一定代表不重要,所以要给一定的机会去采集权重小的未访问的URL。选择未访问URL的策略可以采用轮询的方式,根据权重选择一个,随机选择一个,或者随机选择一个。搜索引擎在爬取大量网页时,进入了解读网页前三个特征的阶段,然后通过大量算法判断网页质量,然后给出相对排名. 查看全部
搜索引擎如何抓取网页(搜索引擎如何首先抓取最重要的网页?(图))
首先分析搜索引擎如何抓取最重要的网页。面对海量网页,他们不会并行抓取每个网页,因为无论搜索引擎数据库如何扩展,他们都跟不上网页的增长速度。最重要的网页将首先被抓取。一方面保存了数据库,另一方面对普通用户也有帮助,因为对于用户来说,他们不需要大量的结果,只需要最重要的结果。因此,一个好的采集策略是先采集重要的网页,这样最重要的网页才能在最短的时间内被抓取到。那么搜索引擎如何首先抓取最重要的网页呢?通过分析大量网页的特点,搜索引擎认为,重要网页具有以下基本特征,虽然不一定完全准确,但大部分情况下确实如此: 网页链接的特征,如果被多次链接或被重要网页链接,是一个非常重要的网页;一个网页的父网页被多次链接或者被重要网页链接,比如一个网页是网站的内页,但是它的首页被多次链接,首页page也链接到这个页面,也就是说这个页面也比较重要;页面目录深度小,便于用户浏览。这里的“URL目录深度”定义为:网页URL除域名部分外的目录级别,即如果URL是 ,那么目录深度是 如果是,目录深度是第二个,依此类推。需要注意的是,URL目录深度小的网页并不总是重要的,目录深度大的网页也并非都是不重要的。一些学术论文的网页 URL 具有非常长的目录深度。
大多数具有高重要性的网页将同时具有上述所有特征。5)先采集网站首页,给首页分配高权重。网站的数量远小于网页的数量,重要的网页必然会从这些网站主页链接,所以采集工作应优先获取尽可能多的网站尽可能第一个问题当搜索引擎开始抓取网页时,它可能不知道被链接或转载的网页的状态。也就是说,一开始,他无法知道前三项的特性。在获得网页或几乎任何网络链接结构之前,您无法知道。那么如何解决这个问题呢?也就是特征4是可以判断一个URL是否满足“ URL 的初始权重设置为固定值。字符“/”和“?” 出现在网址中。URL 是参数的形式。它需要通过请求的程序服务获取网页,而不是搜索引擎系统关注的静态网页。因此,权重相应减少。
收录“search”、“proxy”或“gate”表示该网页最有可能是搜索引擎检索到的结果页面,即代理页面,因此应降低权重)。选择未访问 URL 的策略。因为权重小并不一定代表不重要,所以要给一定的机会去采集权重小的未访问的URL。选择未访问URL的策略可以采用轮询的方式,根据权重选择一个,随机选择一个,或者随机选择一个。搜索引擎在爬取大量网页时,进入了解读网页前三个特征的阶段,然后通过大量算法判断网页质量,然后给出相对排名.
搜索引擎如何抓取网页(网站SEO优化的目的是提高网站排名,那就是让搜索引擎更好的抓取网站?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-02-03 08:02
现在很多公司都在做seo优化。网站seo优化的目的是为了提高网站的排名,让搜索引擎更好的抓取网站,我们在做优化的时候可能会遇到很多问题,网站SEO优化的目的是为了提高网站的排名,也就是让搜索引擎更好的抓取网站?通过以下方式一起学习。
网站流畅:用户在浏览网页时,如果让客户在打开速度上焦急等待,对于70%的用户来说,他们肯定会关闭网页。对于搜索引擎,同样如此,网站在3秒内打开速度是最好的,对于搜索引擎,当然会选择运行速度更快的网站。由于您不是唯一出现在此在线市场中的 网站,因此它将选择相对于该 网站 内推广的内容而言质量更高的内容。对于像蜗牛一样的网页打开速度,搜索引擎会放弃爬取,导致网站的权重下降。这时,我们应该提高服务器的速度。
内容相关:对于优化者来说,了解一个好的标题有多重要是很重要的。这个时候,我们介绍了一些用户,因为标题好。这时候,用户肯定在寻找一些与标题和相关产品相关的内容。用户点击后看到的是 网站 标题与 网站 内容无关。用户体验真的很糟糕,毫无疑问,人们会看一看并选择关闭并对这个产品感到失望。在网站的宣传中用这种内容来欺骗用户是完全没有价值的。“外链为王,内链为王”这句话不再陌生。为什么这句话被大家认可?,充分说明了它的重要性。
内容原创:在内容呈现越来越多身份的今天,搜索引擎更喜欢原创,优质的网站,对网站给予更高的评价。这会对网站的收录量、权重值、流量、转化率产生很大影响。更重要的是,用户喜欢什么才是最重要的。找到与你的 网站 不同的东西,解决用户的需求。如果用户不喜欢它,那么 文章 就不会热,搜索引擎自然会认为它是垃圾页面。
即时更新:搜索引擎每天都会定期更新网页。如果第一天搜索引擎抓取了你的网站并没有新的内容,那么可能第二次搜索引擎就得看有没有新的内容了。不过,再过几天,搜索引擎就不会回来了。这也不利于网站的爬取。
外部引流也很重要。多做外链和好友链接,让蜘蛛通过各种渠道找到你的网站,抓到。
站点地图制作,采集网站的所有链接并提交到百度平台,让百度知道你的网站快来爬取了。 查看全部
搜索引擎如何抓取网页(网站SEO优化的目的是提高网站排名,那就是让搜索引擎更好的抓取网站?)
现在很多公司都在做seo优化。网站seo优化的目的是为了提高网站的排名,让搜索引擎更好的抓取网站,我们在做优化的时候可能会遇到很多问题,网站SEO优化的目的是为了提高网站的排名,也就是让搜索引擎更好的抓取网站?通过以下方式一起学习。
网站流畅:用户在浏览网页时,如果让客户在打开速度上焦急等待,对于70%的用户来说,他们肯定会关闭网页。对于搜索引擎,同样如此,网站在3秒内打开速度是最好的,对于搜索引擎,当然会选择运行速度更快的网站。由于您不是唯一出现在此在线市场中的 网站,因此它将选择相对于该 网站 内推广的内容而言质量更高的内容。对于像蜗牛一样的网页打开速度,搜索引擎会放弃爬取,导致网站的权重下降。这时,我们应该提高服务器的速度。
内容相关:对于优化者来说,了解一个好的标题有多重要是很重要的。这个时候,我们介绍了一些用户,因为标题好。这时候,用户肯定在寻找一些与标题和相关产品相关的内容。用户点击后看到的是 网站 标题与 网站 内容无关。用户体验真的很糟糕,毫无疑问,人们会看一看并选择关闭并对这个产品感到失望。在网站的宣传中用这种内容来欺骗用户是完全没有价值的。“外链为王,内链为王”这句话不再陌生。为什么这句话被大家认可?,充分说明了它的重要性。
内容原创:在内容呈现越来越多身份的今天,搜索引擎更喜欢原创,优质的网站,对网站给予更高的评价。这会对网站的收录量、权重值、流量、转化率产生很大影响。更重要的是,用户喜欢什么才是最重要的。找到与你的 网站 不同的东西,解决用户的需求。如果用户不喜欢它,那么 文章 就不会热,搜索引擎自然会认为它是垃圾页面。
即时更新:搜索引擎每天都会定期更新网页。如果第一天搜索引擎抓取了你的网站并没有新的内容,那么可能第二次搜索引擎就得看有没有新的内容了。不过,再过几天,搜索引擎就不会回来了。这也不利于网站的爬取。
外部引流也很重要。多做外链和好友链接,让蜘蛛通过各种渠道找到你的网站,抓到。
站点地图制作,采集网站的所有链接并提交到百度平台,让百度知道你的网站快来爬取了。
搜索引擎如何抓取网页(分析下20000组成部分-status(协议子状态))
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-02-03 07:31
分析200 0 0 sc-status(协议状态) sc-substatus(协议子状态) sc-win32-status(Win32状态码)的组成部分
sc-status(协议状态):200 连接成功
sc-substatus(协议子状态):0 成功
sc-win32-status(Win32状态码):0表示获取成功并带回数据库;64 指定的网络名称不再可用
1:在这条访问记录中,121.187.5.143是你服务器的IP地址,220.181.7. 74 是bd蜘蛛的IP,/category-8-b0-min1100-max2200.html 是蜘蛛访问你页面的端口 80 是端口 GET 是打开方法 W3SVC1 是记录文件夹,这里显示bd蜘蛛访问了你的category-8-b0-min1100-max2200.html页面,那么最重要的是最后一个参数200 0 0。
2、200 0 0 页面访问成功,0表示获取成功并带回数据库。这个时候大家可以放心,这个页面已经bd收录了,但是还没有发布,可能在bd更新的时候就发布了。
3:200 0 64 网上流传着三种解释
164号是K站的前身。
264th 的出现仅适用于 64 位操作系统。
第三:网络不可达。由于某种原因,页面无法完全打开,或者网络不稳定,导致蜘蛛无法带回页面或无法抓取页面。
所以 200 0 64 的解释也应该是:页面被访问了,但是没有爬取也没有带回数据库。这个原因主要是空间不稳定和服务器不稳定造成的。
或者蜘蛛访问过但快照没有更新
4:304 0 0 这个返回码表示蜘蛛访问的页面没有更新,和之前他来的时候一样,所以看到这个不要着急,蜘蛛来了,但是你没有更新了,所以他不愿意把它拿走这个页面。
5:404 0 0 这个代表404页面,但是有一个很严重的问题,这个返回码告诉我们蜘蛛来到了404页面,把他带走了
, 如果是这样的话,你基本上就倒霉了。如果404太多,那么蜘蛛会继续爬取带走,造成无数重复页面,最终导致K站或降级,
正确的返回码是 404 0 64 这意味着蜘蛛没有抓取你的页面。(内容好像有死链接)
6:500 error 500 error是服务器内部错误,是程序错误引起的,我看不懂程序,但是500 error会给你扣分,这个基本逻辑可想而知,找到500 error,马上查是哪个页面已打开,然后去修复以下错误!
7:302 如果要在日志中找到302的返回码,也需要注意。302 是临时重定向。如果您长期将此页面重定向到另一个页面,请使用301永久重定向。如果是302,bd蜘蛛下次会访问这个页面,会导致复制大量页面的问题,结果肯定是K,所以抓紧时间检查以下。
每个网络蜘蛛都有自己的名字,并且在抓取网页时将自己标识为 网站。当网络蜘蛛抓取网页时,它会发送一个请求。在这个请求中,有一个名为 User-agent 的字段,用于标识网络蜘蛛的身份。例如,谷歌网络蜘蛛的标志是GoogleBot,百度网络蜘蛛的标志是BaiDuSpider,雅虎网络蜘蛛的标志是Inktomi Slurp。
返回码列表:
2xx 成功
200 确定;请求完成。
201 确定;紧跟在 POST 命令之后。
202 确定;接受处理,但处理尚未完成。
203 确定;部分信息 - 返回的信息只是部分信息。
204 确定;无响应 - 已收到请求,但没有要发回的信息。
3xx 重定向
301 已移动 - 请求的数据具有新位置,并且更改是永久性的。
302 Found - 请求的数据暂时具有不同的 URI。
303 See Other - 可以在另一个 URI 下找到对请求的响应,并且应该使用 GET 方法检索。
304 Not Modified - 文档未按预期修改。
305 Using Proxy - 请求的资源必须通过 location 字段中提供的代理访问。
306 Not Used - 不再使用;保留此代码以备将来使用。
4xx 客户端中的错误
400 Bad Request - 请求有语法问题,或无法满足请求。
401 Unauthorized - 客户端无权访问数据。
402 需要付款 - 表示计费系统处于活动状态。
403 Forbidden - 即使授权也不需要访问。
404 Not Found - 服务器找不到给定的资源;该文件不存在。
407 代理验证请求 - 客户端必须首先通过代理验证自己。
415 Unsupported Media Type - 服务器拒绝为请求提供服务,因为请求的实体的格式不受支持。
服务器中的 5xx 错误
500 内部错误 - 由于意外情况,服务器无法完成请求。
501 Not Executed - 服务器不支持请求的工具。
502 Bad Gateway - 服务器收到来自上游服务器的无效响应。
503 Unavailable Service - 由于临时过载或维护,服务器无法处理请求。
如果网站上有访问日志记录,网站管理员可以知道有哪些搜索引擎的网络蜘蛛来了,什么时候来的,读了多少数据等。
根据不同的IP,我们可以分析网站的状态。我们以我的IIS日记中的百度蜘蛛IP为例:
123.125.68.*这个蜘蛛经常来,其他蜘蛛来得少,这意味着网站可能要进入沙箱或者被降级。
220.181.68.*如果这个IP段每天只增加,很有可能进入沙盒或者K站。
220.181.7.*,123.125.66.*代表百度蜘蛛IP访问,准备抢你的东西。
121.14.89.*这个ip段用来通过新站的检查期。
203.208.60.*这个ip段出现在新站点和站点异常之后。
210.72.225.*此IP段连续巡站。
125.90.88.* 广东茂名电信也是百度蜘蛛IP的主要组成部分,因为新上线的站点很多,并且使用了站长工具,或者SEO综合造成通过检测。
220.181.108.95 这是百度抢首页的专用IP。如果是220.181.108,基本上你网站每天晚上都会拍快照,绝对不会出错,我保证。
220.181.108.92 同上,98%爬取首页,也可能爬取其他(非内页) 220.181段属于加权IP段 本版块已爬取的文章或首页,基本在24小时内释放。
123.125.71.106 爬取内页收录,权重低,爬过本段的内页文章不会要非常快让它出来,因为它不是 原创 或 采集文章。
220.181.108.91 综合,主要抓取首页和内页或其他,属于加权IP段,抓取文章或首页基本上是24小时。
220.181.108.75 专注于文章的内页抓取和更新,达到90%,8%抓取首页,2%其他。加权IP段,爬取文章或者首页基本24小时内发布。
220.181.108.86 专用于抓取首页IP权重段,一般返回码为304 0 0表示不更新。
123.125.71.95 爬取内页收录,权重低,爬过本段的内页文章不会被非常快 让它出来,因为它不是 原创 或 采集文章。
123.125.71.97 爬取内页收录,权重低,爬过本段的内页文章不会被非常快 让它出来,因为它不是 原创 或 采集文章。
220.181.108.89 专用于抓取首页IP权重段,一般返回码为304 0 0表示不更新。
220.181.108.94 专用于抓取首页IP权重段,一般返回码为304 0 0表示不更新。
220.181.108.97 专用于抓取首页IP权重段,一般返回码为304 0 0表示不更新。
220.181.108.80 专用于抓取首页IP权重段,一般返回码为304 0 0表示不更新。
220.181.108.77 专用于抓取首页IP权重段,一般返回码为304 0 0表示不更新。
123.125.71.117 爬取内页收录,权重低,爬过本段的内页文章不会要非常快让它出来,因为它不是 原创 或 采集文章。
220.181.108.83 专用于抓取首页IP权重段,一般返回码为304 0 0表示不更新。
注意:上面的IP尾数还有很多,但是同一个段123.125.71.*段IP表示抓取内页收录的权重为相对较低。也许由于你的 采集文章 或拼写 文章 暂时 收录 但不是
发布。(意思是待定)。
220.181.108.* IP段主要抓取首页的80%和内页的30%。这个爬取的文章或者首页绝对是24小时内发布,一夜之间截图,我可以保证!
一般爬取成功的返回码是200 0 0,304 0 0表示网站没有更新。蜘蛛来了。如果是200 0 64,别担心,这不是K站,可能是网站是动态的,
所以返回的是这段代码。 查看全部
搜索引擎如何抓取网页(分析下20000组成部分-status(协议子状态))
分析200 0 0 sc-status(协议状态) sc-substatus(协议子状态) sc-win32-status(Win32状态码)的组成部分
sc-status(协议状态):200 连接成功
sc-substatus(协议子状态):0 成功
sc-win32-status(Win32状态码):0表示获取成功并带回数据库;64 指定的网络名称不再可用
1:在这条访问记录中,121.187.5.143是你服务器的IP地址,220.181.7. 74 是bd蜘蛛的IP,/category-8-b0-min1100-max2200.html 是蜘蛛访问你页面的端口 80 是端口 GET 是打开方法 W3SVC1 是记录文件夹,这里显示bd蜘蛛访问了你的category-8-b0-min1100-max2200.html页面,那么最重要的是最后一个参数200 0 0。
2、200 0 0 页面访问成功,0表示获取成功并带回数据库。这个时候大家可以放心,这个页面已经bd收录了,但是还没有发布,可能在bd更新的时候就发布了。
3:200 0 64 网上流传着三种解释
164号是K站的前身。
264th 的出现仅适用于 64 位操作系统。
第三:网络不可达。由于某种原因,页面无法完全打开,或者网络不稳定,导致蜘蛛无法带回页面或无法抓取页面。
所以 200 0 64 的解释也应该是:页面被访问了,但是没有爬取也没有带回数据库。这个原因主要是空间不稳定和服务器不稳定造成的。
或者蜘蛛访问过但快照没有更新
4:304 0 0 这个返回码表示蜘蛛访问的页面没有更新,和之前他来的时候一样,所以看到这个不要着急,蜘蛛来了,但是你没有更新了,所以他不愿意把它拿走这个页面。
5:404 0 0 这个代表404页面,但是有一个很严重的问题,这个返回码告诉我们蜘蛛来到了404页面,把他带走了
, 如果是这样的话,你基本上就倒霉了。如果404太多,那么蜘蛛会继续爬取带走,造成无数重复页面,最终导致K站或降级,
正确的返回码是 404 0 64 这意味着蜘蛛没有抓取你的页面。(内容好像有死链接)
6:500 error 500 error是服务器内部错误,是程序错误引起的,我看不懂程序,但是500 error会给你扣分,这个基本逻辑可想而知,找到500 error,马上查是哪个页面已打开,然后去修复以下错误!
7:302 如果要在日志中找到302的返回码,也需要注意。302 是临时重定向。如果您长期将此页面重定向到另一个页面,请使用301永久重定向。如果是302,bd蜘蛛下次会访问这个页面,会导致复制大量页面的问题,结果肯定是K,所以抓紧时间检查以下。
每个网络蜘蛛都有自己的名字,并且在抓取网页时将自己标识为 网站。当网络蜘蛛抓取网页时,它会发送一个请求。在这个请求中,有一个名为 User-agent 的字段,用于标识网络蜘蛛的身份。例如,谷歌网络蜘蛛的标志是GoogleBot,百度网络蜘蛛的标志是BaiDuSpider,雅虎网络蜘蛛的标志是Inktomi Slurp。
返回码列表:
2xx 成功
200 确定;请求完成。
201 确定;紧跟在 POST 命令之后。
202 确定;接受处理,但处理尚未完成。
203 确定;部分信息 - 返回的信息只是部分信息。
204 确定;无响应 - 已收到请求,但没有要发回的信息。
3xx 重定向
301 已移动 - 请求的数据具有新位置,并且更改是永久性的。
302 Found - 请求的数据暂时具有不同的 URI。
303 See Other - 可以在另一个 URI 下找到对请求的响应,并且应该使用 GET 方法检索。
304 Not Modified - 文档未按预期修改。
305 Using Proxy - 请求的资源必须通过 location 字段中提供的代理访问。
306 Not Used - 不再使用;保留此代码以备将来使用。
4xx 客户端中的错误
400 Bad Request - 请求有语法问题,或无法满足请求。
401 Unauthorized - 客户端无权访问数据。
402 需要付款 - 表示计费系统处于活动状态。
403 Forbidden - 即使授权也不需要访问。
404 Not Found - 服务器找不到给定的资源;该文件不存在。
407 代理验证请求 - 客户端必须首先通过代理验证自己。
415 Unsupported Media Type - 服务器拒绝为请求提供服务,因为请求的实体的格式不受支持。
服务器中的 5xx 错误
500 内部错误 - 由于意外情况,服务器无法完成请求。
501 Not Executed - 服务器不支持请求的工具。
502 Bad Gateway - 服务器收到来自上游服务器的无效响应。
503 Unavailable Service - 由于临时过载或维护,服务器无法处理请求。
如果网站上有访问日志记录,网站管理员可以知道有哪些搜索引擎的网络蜘蛛来了,什么时候来的,读了多少数据等。
根据不同的IP,我们可以分析网站的状态。我们以我的IIS日记中的百度蜘蛛IP为例:
123.125.68.*这个蜘蛛经常来,其他蜘蛛来得少,这意味着网站可能要进入沙箱或者被降级。
220.181.68.*如果这个IP段每天只增加,很有可能进入沙盒或者K站。
220.181.7.*,123.125.66.*代表百度蜘蛛IP访问,准备抢你的东西。
121.14.89.*这个ip段用来通过新站的检查期。
203.208.60.*这个ip段出现在新站点和站点异常之后。
210.72.225.*此IP段连续巡站。
125.90.88.* 广东茂名电信也是百度蜘蛛IP的主要组成部分,因为新上线的站点很多,并且使用了站长工具,或者SEO综合造成通过检测。
220.181.108.95 这是百度抢首页的专用IP。如果是220.181.108,基本上你网站每天晚上都会拍快照,绝对不会出错,我保证。
220.181.108.92 同上,98%爬取首页,也可能爬取其他(非内页) 220.181段属于加权IP段 本版块已爬取的文章或首页,基本在24小时内释放。
123.125.71.106 爬取内页收录,权重低,爬过本段的内页文章不会要非常快让它出来,因为它不是 原创 或 采集文章。
220.181.108.91 综合,主要抓取首页和内页或其他,属于加权IP段,抓取文章或首页基本上是24小时。
220.181.108.75 专注于文章的内页抓取和更新,达到90%,8%抓取首页,2%其他。加权IP段,爬取文章或者首页基本24小时内发布。
220.181.108.86 专用于抓取首页IP权重段,一般返回码为304 0 0表示不更新。
123.125.71.95 爬取内页收录,权重低,爬过本段的内页文章不会被非常快 让它出来,因为它不是 原创 或 采集文章。
123.125.71.97 爬取内页收录,权重低,爬过本段的内页文章不会被非常快 让它出来,因为它不是 原创 或 采集文章。
220.181.108.89 专用于抓取首页IP权重段,一般返回码为304 0 0表示不更新。
220.181.108.94 专用于抓取首页IP权重段,一般返回码为304 0 0表示不更新。
220.181.108.97 专用于抓取首页IP权重段,一般返回码为304 0 0表示不更新。
220.181.108.80 专用于抓取首页IP权重段,一般返回码为304 0 0表示不更新。
220.181.108.77 专用于抓取首页IP权重段,一般返回码为304 0 0表示不更新。
123.125.71.117 爬取内页收录,权重低,爬过本段的内页文章不会要非常快让它出来,因为它不是 原创 或 采集文章。
220.181.108.83 专用于抓取首页IP权重段,一般返回码为304 0 0表示不更新。
注意:上面的IP尾数还有很多,但是同一个段123.125.71.*段IP表示抓取内页收录的权重为相对较低。也许由于你的 采集文章 或拼写 文章 暂时 收录 但不是
发布。(意思是待定)。
220.181.108.* IP段主要抓取首页的80%和内页的30%。这个爬取的文章或者首页绝对是24小时内发布,一夜之间截图,我可以保证!
一般爬取成功的返回码是200 0 0,304 0 0表示网站没有更新。蜘蛛来了。如果是200 0 64,别担心,这不是K站,可能是网站是动态的,
所以返回的是这段代码。
搜索引擎如何抓取网页(SEO提醒Baiduspider根据上述网站设置的协议对站点页面进行抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-02-03 07:30
如果下载的源代码需要作者授权,请更换源代码。本站资源免费共享不会增加授权
Explorer SEO提醒Baiduspider按照上述网站设置的协议抓取网站页面,但不可能对所有网站一视同仁。它会综合考虑网站的实际情况来确定一个抓取配额,每天定量抓取网站内容,也就是我们常说的抓取频率。那么百度搜索引擎是通过哪些指标来判断一个网站的爬取频率呢?主要有四个指标: 网站更新频率:更新更频繁,更新慢,直接影响百度蜘蛛的访问频率网站更新质量:更新频率提高了,只是为了吸引百度蜘蛛的关注,百度蜘蛛对质量有严格要求,如果网站 每天更新的大量内容被百度蜘蛛判断为低质量的页面,仍然没有意义。连接性:网站应该安全稳定,对百度蜘蛛保持开放。让Baiduspider保持关闭并不是一件好事。站点评价:百度搜索引擎对每个站点都会有一个评价,这个评价会根据站点情况不断变化。非常机密的数据。站点评级从不单独使用,并与其他因素和阈值一起影响 网站 的爬取和排名。并且这个评价会根据现场情况不断变化。非常机密的数据。站点评级从不单独使用,并与其他因素和阈值一起影响 网站 的爬取和排名。并且这个评价会根据现场情况不断变化。非常机密的数据。站点评级从不单独使用,并与其他因素和阈值一起影响 网站 的爬取和排名。
爬取频率间接决定了网站有多少页面可能被数据库收录。这么重要的值,如果不符合站长的期望,应该如何调整呢?
百度站长平台提供爬频工具,已完成多次升级。除了提供爬取统计,该工具还提供了“频率调整”功能。站长要求百度蜘蛛根据实际情况增加或减少对百度站长平台的访问量。调整。
从百度的“星火计划”到官方的一些说明,可见百度对原创内容的重视程度,但什么样的文章才算原创,有价值文章。不负责任的采集:首先需要澄清的是,百度拒绝采集是指大量复制互联网现有内容,而采集的内容将被所有如果它没有组织。“懒惰”的行为被推到了底线。百度没有理由拒绝采集的内容经过再加工和高效整合,制作出内容丰富的优质网页。所以,比方说,百度不喜欢不负责任的懈怠采集行为。伪原创:我们上面说了百度不喜欢不负责任的采集,于是有些人开始动脑筋伪装原创。在采集内容之后,对关键词的一部分进行了批量修改,企图让百度认为这些是独一无二的内容,但内容却面目全非,无法通读。就是刚才提到的观点,百度不吐槽网站采集的内容,关键是如何应用采集的内容和数据,如何融入内容用户和搜索引擎都需要的是网站管理员应该考虑的内容。并且无法通读。就是刚才提到的观点,百度不吐槽网站采集的内容,关键是如何应用采集的内容和数据,如何融入内容用户和搜索引擎都需要的是网站管理员应该考虑的内容。并且无法通读。就是刚才提到的观点,百度不吐槽网站采集的内容,关键是如何应用采集的内容和数据,如何融入内容用户和搜索引擎都需要的是网站管理员应该考虑的内容。
我们的采集的文章是没有问题的,但是问题是执行采集没有做任何改动,所以以后我们更新文章的时候,主要需要注意的是:
整合 文章 或 采集 中的图片 整合 采集 中的一篇或多篇文章 文章。这里所说的集成需要根据文章关键词进行合理的集成,并添加一些附件(图片、视频等)进行优化。文章排版优化,有利于用户搜索和查看seoer,非常清晰,这里不再赘述。
更新与用户搜索匹配的内容
以下是 文章 更新的核心内容。相信很多朋友在更新文章的时候都会遇到这样的问题。每天更新,一两天。更新的内容可以完成,但是时间长了,需要更新的内容已经更新了。
<p>通常的做法是把最重要的关键词放在首页,比如上面例子中的云南旅游。第二级的其他 关键词 被放置在单独的部分或频道页面中。如果有更长的尾巴,属于第三级关键词,可以用内容页面进行优化。在首页,主要的关键词是优化的重点。从页面标题、粗体加粗、Hx标签、关键词出现的位置数量来看,应该比其他文字更显眼。不是副关键词不能出现在首页,而是副关键词应该出现在首页,因为这些词对主 查看全部
搜索引擎如何抓取网页(SEO提醒Baiduspider根据上述网站设置的协议对站点页面进行抓取)
如果下载的源代码需要作者授权,请更换源代码。本站资源免费共享不会增加授权
Explorer SEO提醒Baiduspider按照上述网站设置的协议抓取网站页面,但不可能对所有网站一视同仁。它会综合考虑网站的实际情况来确定一个抓取配额,每天定量抓取网站内容,也就是我们常说的抓取频率。那么百度搜索引擎是通过哪些指标来判断一个网站的爬取频率呢?主要有四个指标: 网站更新频率:更新更频繁,更新慢,直接影响百度蜘蛛的访问频率网站更新质量:更新频率提高了,只是为了吸引百度蜘蛛的关注,百度蜘蛛对质量有严格要求,如果网站 每天更新的大量内容被百度蜘蛛判断为低质量的页面,仍然没有意义。连接性:网站应该安全稳定,对百度蜘蛛保持开放。让Baiduspider保持关闭并不是一件好事。站点评价:百度搜索引擎对每个站点都会有一个评价,这个评价会根据站点情况不断变化。非常机密的数据。站点评级从不单独使用,并与其他因素和阈值一起影响 网站 的爬取和排名。并且这个评价会根据现场情况不断变化。非常机密的数据。站点评级从不单独使用,并与其他因素和阈值一起影响 网站 的爬取和排名。并且这个评价会根据现场情况不断变化。非常机密的数据。站点评级从不单独使用,并与其他因素和阈值一起影响 网站 的爬取和排名。
爬取频率间接决定了网站有多少页面可能被数据库收录。这么重要的值,如果不符合站长的期望,应该如何调整呢?
百度站长平台提供爬频工具,已完成多次升级。除了提供爬取统计,该工具还提供了“频率调整”功能。站长要求百度蜘蛛根据实际情况增加或减少对百度站长平台的访问量。调整。
从百度的“星火计划”到官方的一些说明,可见百度对原创内容的重视程度,但什么样的文章才算原创,有价值文章。不负责任的采集:首先需要澄清的是,百度拒绝采集是指大量复制互联网现有内容,而采集的内容将被所有如果它没有组织。“懒惰”的行为被推到了底线。百度没有理由拒绝采集的内容经过再加工和高效整合,制作出内容丰富的优质网页。所以,比方说,百度不喜欢不负责任的懈怠采集行为。伪原创:我们上面说了百度不喜欢不负责任的采集,于是有些人开始动脑筋伪装原创。在采集内容之后,对关键词的一部分进行了批量修改,企图让百度认为这些是独一无二的内容,但内容却面目全非,无法通读。就是刚才提到的观点,百度不吐槽网站采集的内容,关键是如何应用采集的内容和数据,如何融入内容用户和搜索引擎都需要的是网站管理员应该考虑的内容。并且无法通读。就是刚才提到的观点,百度不吐槽网站采集的内容,关键是如何应用采集的内容和数据,如何融入内容用户和搜索引擎都需要的是网站管理员应该考虑的内容。并且无法通读。就是刚才提到的观点,百度不吐槽网站采集的内容,关键是如何应用采集的内容和数据,如何融入内容用户和搜索引擎都需要的是网站管理员应该考虑的内容。
我们的采集的文章是没有问题的,但是问题是执行采集没有做任何改动,所以以后我们更新文章的时候,主要需要注意的是:
整合 文章 或 采集 中的图片 整合 采集 中的一篇或多篇文章 文章。这里所说的集成需要根据文章关键词进行合理的集成,并添加一些附件(图片、视频等)进行优化。文章排版优化,有利于用户搜索和查看seoer,非常清晰,这里不再赘述。
更新与用户搜索匹配的内容
以下是 文章 更新的核心内容。相信很多朋友在更新文章的时候都会遇到这样的问题。每天更新,一两天。更新的内容可以完成,但是时间长了,需要更新的内容已经更新了。
<p>通常的做法是把最重要的关键词放在首页,比如上面例子中的云南旅游。第二级的其他 关键词 被放置在单独的部分或频道页面中。如果有更长的尾巴,属于第三级关键词,可以用内容页面进行优化。在首页,主要的关键词是优化的重点。从页面标题、粗体加粗、Hx标签、关键词出现的位置数量来看,应该比其他文字更显眼。不是副关键词不能出现在首页,而是副关键词应该出现在首页,因为这些词对主

