
搜索引擎如何抓取网页
搜索引擎如何抓取网页(网站页面更快被搜索引擎所收录的几大因素有哪些)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-09-16 02:14
很多人可能在想这个问题,那就是为什么他们的网站页面可以被搜索引擎搜索到收录。事实上,这与网站关键词、链接和其他因素密不可分。如何让搜索引擎收录使用网站页面更快,听小编告诉你
一、网站内容更新应该很有价值
随着搜索引擎算法的升级,对网站用户体验的重视逐渐增加。因此,在更新网站内容时,我们不仅要注意内容的新颖性,还要注意内容是否对用户有用和有价值。考虑到这两个因素可以带来网站更好的收录和排名
二、关键词设置应合理
在设置网站关键词时,请注意关键词在网页、标题、说明、文章开头和结尾段落中的分布情况,以便获得搜索引擎的足够关注。这对网站排名、收录和其他方面也有很大的好处,但记住不要将关键词叠加在一起
三、科学使用文字和图片
一个优秀的网站页面可以与图片、文字合理结合,提升网站的用户体验,帮助搜索引擎提升网站页面的收录量,加深用户印象,给客户带来良好的视觉体验。由于搜索引擎对图片的识别率较低,所以不能有太多的图片,并且应该为文本注释添加ALT标记,方便搜索引擎的识别
@添加四、高质量外链
网站优化人员充分意识到外部链建设的重要性。优质的外部链资源有利于收录和网站的排名以及权重的提升。因此,尽量帮助网站增加一些高质量的友链,拓宽外链资源,积累丰富的外链资源
网站建设和网络推广公司-创新互联网,是一家专注于品牌和效果的网站生产和网络营销SEO公司;服务项目包括网站营销等 查看全部
搜索引擎如何抓取网页(网站页面更快被搜索引擎所收录的几大因素有哪些)
很多人可能在想这个问题,那就是为什么他们的网站页面可以被搜索引擎搜索到收录。事实上,这与网站关键词、链接和其他因素密不可分。如何让搜索引擎收录使用网站页面更快,听小编告诉你

一、网站内容更新应该很有价值
随着搜索引擎算法的升级,对网站用户体验的重视逐渐增加。因此,在更新网站内容时,我们不仅要注意内容的新颖性,还要注意内容是否对用户有用和有价值。考虑到这两个因素可以带来网站更好的收录和排名
二、关键词设置应合理
在设置网站关键词时,请注意关键词在网页、标题、说明、文章开头和结尾段落中的分布情况,以便获得搜索引擎的足够关注。这对网站排名、收录和其他方面也有很大的好处,但记住不要将关键词叠加在一起
三、科学使用文字和图片
一个优秀的网站页面可以与图片、文字合理结合,提升网站的用户体验,帮助搜索引擎提升网站页面的收录量,加深用户印象,给客户带来良好的视觉体验。由于搜索引擎对图片的识别率较低,所以不能有太多的图片,并且应该为文本注释添加ALT标记,方便搜索引擎的识别
@添加四、高质量外链
网站优化人员充分意识到外部链建设的重要性。优质的外部链资源有利于收录和网站的排名以及权重的提升。因此,尽量帮助网站增加一些高质量的友链,拓宽外链资源,积累丰富的外链资源
网站建设和网络推广公司-创新互联网,是一家专注于品牌和效果的网站生产和网络营销SEO公司;服务项目包括网站营销等
搜索引擎如何抓取网页(搜索引擎对网站的收录数量是网站SEO优化中重要的一个标准)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-09-16 02:11
搜索引擎网站的收录编号是多少网站SEO优化中的一个重要标准。网站搜索引擎优化的目的是提高网站排名,这是关键词的排名,并且关键词存在于页面中,所以网站的构建非常重要。如果搜索引擎收录没有找到页面内容,那么网站排名是不可能的。如果你想改进网站和收录,你需要分析搜索引擎的规则,了解搜索引擎喜欢什么类型的内容
许多人首先想到原创内容。是的,搜索引擎喜欢原创content,但这种观点并不全面。因为一个带插图的原创文章,如果没有特定的媒体属性,它对用户来说是无用的,不会产生任何价值,那么搜索引擎将不会捕获此类原创内容。搜索引擎喜欢的原创内容不仅仅是原创,而是能够影响用户并具有社会价值的原创内容。原创内容的特点是信息稀缺。只要互联网上没有内容,搜索引擎就会认为它是原创的,搜索引擎不喜欢重复出现的内容。然而,网站的内容应以原创及其对用户的价值为基础进行保证,这可能会影响用户的性能
那么什么内容对用户有影响呢?直接简单地指用户关注并积极参与讨论的社会热点、明星新闻、国家大事记等有价值的内容。因为很多用户会关注这类内容,并通过热点新闻传播。比如每年的春节新闻。即使这类热点新闻被用户广泛传播,搜索引擎对这些内容仍然会有一种满足感。这些消息一出来,他们就没有经过大量的筛选。无论它们如何传播,这样的新闻可塑性仍然很强,搜索引擎会一直关注它
如果你想提高搜索引擎将网站内容替换为收录的概率,你应该围绕热点话题创建。用户现在关注的话题是什么?我们应该将这些内容与网站内容结合起来。即使在文章中只提到一点,搜索引擎也会关注它。如果它能出现在网站的标题中或文章的第一段中会更好。有些热点文章实际上不需要太多修改。只要你修改了某个部分,它就可以被搜索引擎视为新内容。由于热门新闻尚未被筛选,搜索引擎没有参考资料。因此,网站发布内容可以与热点新闻相结合
提高网站的收录主要是做好网站内容,而对用户有价值的原创内容就是搜索引擎喜欢的内容 查看全部
搜索引擎如何抓取网页(搜索引擎对网站的收录数量是网站SEO优化中重要的一个标准)
搜索引擎网站的收录编号是多少网站SEO优化中的一个重要标准。网站搜索引擎优化的目的是提高网站排名,这是关键词的排名,并且关键词存在于页面中,所以网站的构建非常重要。如果搜索引擎收录没有找到页面内容,那么网站排名是不可能的。如果你想改进网站和收录,你需要分析搜索引擎的规则,了解搜索引擎喜欢什么类型的内容
许多人首先想到原创内容。是的,搜索引擎喜欢原创content,但这种观点并不全面。因为一个带插图的原创文章,如果没有特定的媒体属性,它对用户来说是无用的,不会产生任何价值,那么搜索引擎将不会捕获此类原创内容。搜索引擎喜欢的原创内容不仅仅是原创,而是能够影响用户并具有社会价值的原创内容。原创内容的特点是信息稀缺。只要互联网上没有内容,搜索引擎就会认为它是原创的,搜索引擎不喜欢重复出现的内容。然而,网站的内容应以原创及其对用户的价值为基础进行保证,这可能会影响用户的性能

那么什么内容对用户有影响呢?直接简单地指用户关注并积极参与讨论的社会热点、明星新闻、国家大事记等有价值的内容。因为很多用户会关注这类内容,并通过热点新闻传播。比如每年的春节新闻。即使这类热点新闻被用户广泛传播,搜索引擎对这些内容仍然会有一种满足感。这些消息一出来,他们就没有经过大量的筛选。无论它们如何传播,这样的新闻可塑性仍然很强,搜索引擎会一直关注它
如果你想提高搜索引擎将网站内容替换为收录的概率,你应该围绕热点话题创建。用户现在关注的话题是什么?我们应该将这些内容与网站内容结合起来。即使在文章中只提到一点,搜索引擎也会关注它。如果它能出现在网站的标题中或文章的第一段中会更好。有些热点文章实际上不需要太多修改。只要你修改了某个部分,它就可以被搜索引擎视为新内容。由于热门新闻尚未被筛选,搜索引擎没有参考资料。因此,网站发布内容可以与热点新闻相结合
提高网站的收录主要是做好网站内容,而对用户有价值的原创内容就是搜索引擎喜欢的内容
搜索引擎如何抓取网页(蜘蛛的基本工作原理是什么?蜘蛛工作的第一步)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-09-16 02:07
随着搜索引擎的不断发展和升级,搜索引擎发送的蜘蛛变得越来越智能。因此,为了了解蜘蛛的工作原理,更好地优化自身网站必须不断研究蜘蛛。现在,我们来谈谈齐鲁信息网蜘蛛的基本工作原理:
spider工作的第一步:抓取网站网页并找到正确的资源
蜘蛛有一个特点,就是它的轨迹通常是围绕着蜘蛛丝的,因此我们将搜索引擎机器人蜘蛛命名为蜘蛛。当蜘蛛来到你的网站时,它将继续沿着你的网站中的链接(蜘蛛丝)爬行。因此,如何让蜘蛛在你的网站中更好地爬行,成为我们的当务之急
在这个时候,我们经常建议站长在网站上使用更多的调用,这些调用在网站内调用一些文章,这是大多数站长的选择,无论是相关阅读、推荐阅读还是其他排行榜
蜘蛛工作的第二步:抓取你的网页
引导蜘蛛爬行。这只是一个开始。良好的开端意味着你将有一个高起点。通过其自身的内链设计,网站中没有死角,蜘蛛可以轻松到达网站中的每一页,这样蜘蛛在执行第二步抓取时会事半功倍
在这一步的爬行过程中,我们需要注意简化网站的结构,去除不必要和不必要的冗余代码,因为这些都会影响爬行器爬行网页的效率和效果。此外,我们还需要注意一个事实,我们不建议在网站中放置flash,因为蜘蛛很难抓到flash。太多的闪光灯会导致蜘蛛放弃抓取你的网站页面
蜘蛛工作的第三步:高质量的文章,这可以大大提高蜘蛛抓取页面的概率
不管外链是皇帝还是内容是皇帝。这不是我们想在这里讨论的内容,但从这句话中,我们可以清楚地知道内容的重要性。同样,蜘蛛也非常重视内容。一个高质量的原创文章可以给蜘蛛留下深刻的印象,所以蜘蛛只要爬一次就迫不及待地想把它们带回来。相反,对于文章的复制品,蜘蛛很可能需要爬行几次甚至几十次才能把它带回来,而且它也很可能完全忽略它的存在
当然,这不是绝对的。我们谈论的只是一个相对的东西。在相同条件下,两个文章文章的原创文章质量较高,更容易被spider接受
spider工作的第四步:页面发布
这里的页面发布是指搜索引擎中的正常搜索。第四步之所以是这个步骤而不是索引,是因为我认为作为SEOER,我们应该尽量简化研究过程
爬行后,当爬行器将页面带回索引库时,所有内容都将不再受我们的控制,因此我跳过了这里的索引步骤,直接讨论了释放页面的步骤
在这一步中,我们还需要注意以下几点:
1、耐心。请有足够的耐心等待页面的发布。这个过程可能需要几分钟、几个小时、一天、两天甚至更长的时间
2、毅力。很多站长在建站的时候热情高涨。因此,他们将努力在车站建成前几天对其进行更新文章. 然而,过了一段时间,他突然发现自己的文章根本不是收录并失去了信心,于是他开始走捷径,要么抄袭,要么抄袭,不想自己写文章
@真的。真诚对待每一位文章和每一位用户。只有这样,我们才能真正做到网站中的内容是用户需要看到的,并且是真正高质量的原创文章 查看全部
搜索引擎如何抓取网页(蜘蛛的基本工作原理是什么?蜘蛛工作的第一步)
随着搜索引擎的不断发展和升级,搜索引擎发送的蜘蛛变得越来越智能。因此,为了了解蜘蛛的工作原理,更好地优化自身网站必须不断研究蜘蛛。现在,我们来谈谈齐鲁信息网蜘蛛的基本工作原理:
spider工作的第一步:抓取网站网页并找到正确的资源
蜘蛛有一个特点,就是它的轨迹通常是围绕着蜘蛛丝的,因此我们将搜索引擎机器人蜘蛛命名为蜘蛛。当蜘蛛来到你的网站时,它将继续沿着你的网站中的链接(蜘蛛丝)爬行。因此,如何让蜘蛛在你的网站中更好地爬行,成为我们的当务之急
在这个时候,我们经常建议站长在网站上使用更多的调用,这些调用在网站内调用一些文章,这是大多数站长的选择,无论是相关阅读、推荐阅读还是其他排行榜
蜘蛛工作的第二步:抓取你的网页
引导蜘蛛爬行。这只是一个开始。良好的开端意味着你将有一个高起点。通过其自身的内链设计,网站中没有死角,蜘蛛可以轻松到达网站中的每一页,这样蜘蛛在执行第二步抓取时会事半功倍
在这一步的爬行过程中,我们需要注意简化网站的结构,去除不必要和不必要的冗余代码,因为这些都会影响爬行器爬行网页的效率和效果。此外,我们还需要注意一个事实,我们不建议在网站中放置flash,因为蜘蛛很难抓到flash。太多的闪光灯会导致蜘蛛放弃抓取你的网站页面
蜘蛛工作的第三步:高质量的文章,这可以大大提高蜘蛛抓取页面的概率
不管外链是皇帝还是内容是皇帝。这不是我们想在这里讨论的内容,但从这句话中,我们可以清楚地知道内容的重要性。同样,蜘蛛也非常重视内容。一个高质量的原创文章可以给蜘蛛留下深刻的印象,所以蜘蛛只要爬一次就迫不及待地想把它们带回来。相反,对于文章的复制品,蜘蛛很可能需要爬行几次甚至几十次才能把它带回来,而且它也很可能完全忽略它的存在
当然,这不是绝对的。我们谈论的只是一个相对的东西。在相同条件下,两个文章文章的原创文章质量较高,更容易被spider接受
spider工作的第四步:页面发布
这里的页面发布是指搜索引擎中的正常搜索。第四步之所以是这个步骤而不是索引,是因为我认为作为SEOER,我们应该尽量简化研究过程
爬行后,当爬行器将页面带回索引库时,所有内容都将不再受我们的控制,因此我跳过了这里的索引步骤,直接讨论了释放页面的步骤
在这一步中,我们还需要注意以下几点:
1、耐心。请有足够的耐心等待页面的发布。这个过程可能需要几分钟、几个小时、一天、两天甚至更长的时间
2、毅力。很多站长在建站的时候热情高涨。因此,他们将努力在车站建成前几天对其进行更新文章. 然而,过了一段时间,他突然发现自己的文章根本不是收录并失去了信心,于是他开始走捷径,要么抄袭,要么抄袭,不想自己写文章
@真的。真诚对待每一位文章和每一位用户。只有这样,我们才能真正做到网站中的内容是用户需要看到的,并且是真正高质量的原创文章
搜索引擎如何抓取网页(一个网站图片到底是怎么抓取的呢的?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-09-13 12:06
一个网站如果所有密集的文本对用户体验非常不利,同时我不想在网站上停留一分钟或一秒钟。 网站在开发的时候,页面更加美化,体验更好会加很多图片,但是图片对于搜索引擎的蜘蛛爬行能力不如文章,文字少,很多图片。会对seo优化造成一定的困难。
图片是如何拍摄的?
1、 是最好的原创 图片。图片还是自己做的。您可以使用免费图片拼接成我们想要的图片。不要盗图。
<p>2.为了方便蜘蛛爬取,上传图片到网站时,最好将图片按照网站一栏放在对应的图片目录,或者放在一个文件夹中。 查看全部
搜索引擎如何抓取网页(一个网站图片到底是怎么抓取的呢的?(图))
一个网站如果所有密集的文本对用户体验非常不利,同时我不想在网站上停留一分钟或一秒钟。 网站在开发的时候,页面更加美化,体验更好会加很多图片,但是图片对于搜索引擎的蜘蛛爬行能力不如文章,文字少,很多图片。会对seo优化造成一定的困难。

图片是如何拍摄的?
1、 是最好的原创 图片。图片还是自己做的。您可以使用免费图片拼接成我们想要的图片。不要盗图。
<p>2.为了方便蜘蛛爬取,上传图片到网站时,最好将图片按照网站一栏放在对应的图片目录,或者放在一个文件夹中。
搜索引擎如何抓取网页( 各大多的网站采用Ajax技术解决方法放弃井号结构)
网站优化 • 优采云 发表了文章 • 0 个评论 • 218 次浏览 • 2021-09-13 12:03
各大多的网站采用Ajax技术解决方法放弃井号结构)
如何让搜索引擎抓取AJAX内容解决方案
更新时间:2014年8月25日11:51:39 投稿:hebedich
说到 AJAX,很多人都会想到 JavaScript。到目前为止,主要的搜索引擎还无法捕获由 JavaScript、ajax 和 flash 代码生成的内容。但是很多站长非常喜欢这些效果,但是各大搜索引擎都不能很好的抓取这些代码生成的内容,所以很多站长放弃了这些效果。
越来越多的网站开始采用“单页应用”。
整个网站只有一个网页,它使用Ajax技术根据用户输入加载不同的内容。
这种方式的优点是用户体验好,节省流量。缺点是 AJAX 内容无法被搜索引擎抓取。例如,您有一个网站。
http://example.com
用户可以通过哈希结构的 URL 看到不同的内容。
http://example.com#1 http://example.com#2 http://example.com#3
但是,搜索引擎只会抓取并忽略井号,因此无法将内容编入索引。
为了解决这个问题,Google提出了“井号+感叹号”的结构。
http://example.com#!1
当谷歌找到上述网址时,它会自动抓取另一个网址:
http://example.com/?_escaped_fragment_=1
只要你把 AJAX 内容放在这个 URL 上,Google 就会收录。但问题是“井号+感叹号”非常丑陋和繁琐。推特以前用的就是这个结构,把
http://twitter.com/ruanyf
改为
http://twitter.com/#!/ruanyf
结果用户一再投诉,只用了半年就废了。
那么,有什么方法可以让搜索引擎在保持更直观的 URL 的同时抓取 AJAX 内容?
我一直觉得没有办法,直到两天前看到Discourse创始人之一Robin Ward的解决方案,我才忍不住尖叫。
Discourse 是一个严重依赖 Ajax 的论坛程序,但它必须让 Google收录content。其解决方案是放弃hashtag结构,采用History API。
所谓的History API,是指在不刷新页面的情况下,改变浏览器地址栏中显示的URL(准确的说是改变网页的当前状态)。这是一个示例,您单击上面的按钮开始播放音乐。然后,点击下面的链接看看发生了什么?
地址栏中的URL已更改,但音乐播放并未中断!
History API 的详细介绍超出了本文章 的范围。简单的说到这里,它的作用就是给浏览器的History对象添加一条记录。
window.history.pushState(state object, title, url);
上面这行命令可以让地址栏中出现一个新的 URL。 History对象的pushState方法接受三个参数,新的URL为第三个参数,前两个参数可以为null。
window.history.pushState(null, null, newURL);
目前主流浏览器都支持这种方式:Chrome(26.0+)、Firefox(20.0+)、IE(10.0+)、Safari(5.1+) , 歌剧 (12.1+).
以下是 Robin Ward 的方法。
首先用History API替换井号结构,让每个井号都变成一个正常路径的URL,这样搜索引擎就会抓取每一个网页。
example.com/1 example.com/2 example.com/3
接下来,定义一个 JavaScript 函数来处理 Ajax 部分并根据 URL 抓取内容(假设使用 jQuery)。
function anchorClick(link) {<br /> var linkSplit = link.split('/').pop();<br /> $.get('api/' + linkSplit, function(data) {<br /> $('#content').html(data);<br /> });<br /> }
再次定义鼠标的点击事件。
$('#container').on('click', 'a', function(e) {<br /> window.history.pushState(null, null, $(this).attr('href'));<br /> anchorClick($(this).attr('href'));<br /> e.preventDefault();<br /> });
还要考虑用户点击浏览器的“前进/后退”按钮。这时候会触发History对象的popstate事件。
window.addEventListener('popstate', function(e) { <br /> anchorClick(location.pathname); <br /> });
定义以上三段代码后,无需刷新页面即可显示正常路径URL和AJAX内容。
最后,设置服务器端。
因为没有使用hash结构,所以每个URL都是不同的请求。因此,服务器需要向所有这些请求返回具有以下结构的网页,以防止 404 错误。
<br /> <br /> <br /> <br /> ... ...<br /> <br /> <br />
仔细看上面的代码,你会发现一个noscript标签,这就是秘密。
我们把所有想要搜索引擎收录的内容放在noscript标签中。在这种情况下,用户仍然可以在不刷新页面的情况下进行AJAX操作,但是搜索引擎会收录每个页面的主要内容! 查看全部
搜索引擎如何抓取网页(
各大多的网站采用Ajax技术解决方法放弃井号结构)
如何让搜索引擎抓取AJAX内容解决方案
更新时间:2014年8月25日11:51:39 投稿:hebedich
说到 AJAX,很多人都会想到 JavaScript。到目前为止,主要的搜索引擎还无法捕获由 JavaScript、ajax 和 flash 代码生成的内容。但是很多站长非常喜欢这些效果,但是各大搜索引擎都不能很好的抓取这些代码生成的内容,所以很多站长放弃了这些效果。
越来越多的网站开始采用“单页应用”。
整个网站只有一个网页,它使用Ajax技术根据用户输入加载不同的内容。

这种方式的优点是用户体验好,节省流量。缺点是 AJAX 内容无法被搜索引擎抓取。例如,您有一个网站。
http://example.com
用户可以通过哈希结构的 URL 看到不同的内容。
http://example.com#1 http://example.com#2 http://example.com#3
但是,搜索引擎只会抓取并忽略井号,因此无法将内容编入索引。
为了解决这个问题,Google提出了“井号+感叹号”的结构。
http://example.com#!1
当谷歌找到上述网址时,它会自动抓取另一个网址:
http://example.com/?_escaped_fragment_=1
只要你把 AJAX 内容放在这个 URL 上,Google 就会收录。但问题是“井号+感叹号”非常丑陋和繁琐。推特以前用的就是这个结构,把
http://twitter.com/ruanyf
改为
http://twitter.com/#!/ruanyf
结果用户一再投诉,只用了半年就废了。
那么,有什么方法可以让搜索引擎在保持更直观的 URL 的同时抓取 AJAX 内容?
我一直觉得没有办法,直到两天前看到Discourse创始人之一Robin Ward的解决方案,我才忍不住尖叫。
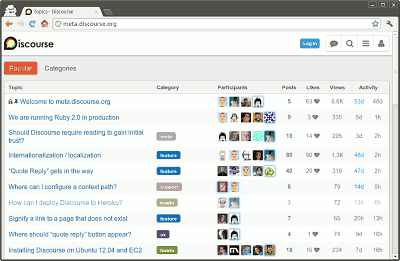
Discourse 是一个严重依赖 Ajax 的论坛程序,但它必须让 Google收录content。其解决方案是放弃hashtag结构,采用History API。
所谓的History API,是指在不刷新页面的情况下,改变浏览器地址栏中显示的URL(准确的说是改变网页的当前状态)。这是一个示例,您单击上面的按钮开始播放音乐。然后,点击下面的链接看看发生了什么?
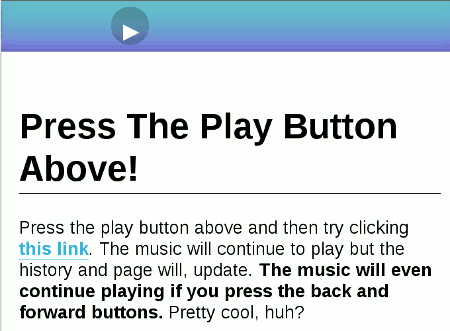
地址栏中的URL已更改,但音乐播放并未中断!
History API 的详细介绍超出了本文章 的范围。简单的说到这里,它的作用就是给浏览器的History对象添加一条记录。
window.history.pushState(state object, title, url);
上面这行命令可以让地址栏中出现一个新的 URL。 History对象的pushState方法接受三个参数,新的URL为第三个参数,前两个参数可以为null。
window.history.pushState(null, null, newURL);
目前主流浏览器都支持这种方式:Chrome(26.0+)、Firefox(20.0+)、IE(10.0+)、Safari(5.1+) , 歌剧 (12.1+).
以下是 Robin Ward 的方法。
首先用History API替换井号结构,让每个井号都变成一个正常路径的URL,这样搜索引擎就会抓取每一个网页。
example.com/1 example.com/2 example.com/3
接下来,定义一个 JavaScript 函数来处理 Ajax 部分并根据 URL 抓取内容(假设使用 jQuery)。
function anchorClick(link) {<br /> var linkSplit = link.split('/').pop();<br /> $.get('api/' + linkSplit, function(data) {<br /> $('#content').html(data);<br /> });<br /> }
再次定义鼠标的点击事件。
$('#container').on('click', 'a', function(e) {<br /> window.history.pushState(null, null, $(this).attr('href'));<br /> anchorClick($(this).attr('href'));<br /> e.preventDefault();<br /> });
还要考虑用户点击浏览器的“前进/后退”按钮。这时候会触发History对象的popstate事件。
window.addEventListener('popstate', function(e) { <br /> anchorClick(location.pathname); <br /> });
定义以上三段代码后,无需刷新页面即可显示正常路径URL和AJAX内容。
最后,设置服务器端。
因为没有使用hash结构,所以每个URL都是不同的请求。因此,服务器需要向所有这些请求返回具有以下结构的网页,以防止 404 错误。
<br /> <br /> <br /> <br /> ... ...<br /> <br /> <br />
仔细看上面的代码,你会发现一个noscript标签,这就是秘密。
我们把所有想要搜索引擎收录的内容放在noscript标签中。在这种情况下,用户仍然可以在不刷新页面的情况下进行AJAX操作,但是搜索引擎会收录每个页面的主要内容!
搜索引擎如何抓取网页(国外文章(谷歌翻译)对html标签的评分)
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-09-13 08:16
今天偶然看到的一篇外文文章(谷歌翻译)。挺有意思的,主要是对常见的html标签打分的形式。虽然有些描述略显过时,但大部分标签的分析还是很有相关性的。在这里做个记录,方便以后做wordpress主题的时候合理布局(x)个html标签。
先看搜索引擎对html标签的评分:
内部链接文本:10 分
标题:10分
域名:7分
H1、H2 字号标题:5 分
每段第一句:5分
路径或文件名:4分
相似度(关键词stacking):4 分
每句开头:1.5分
粗体或斜体:1分
文字使用(内容):1分
title属性:1分(注意不是title>,是title属性,比如a href=...title=”)
alt 标签:0.5 分
Meta description(描述属性):0.5分
Meta关键词(关键字属性):0.05分
标签是最常用的。以后选择模板的时候一定要注意优化网站。以下是具体的优化建议:
1、静态页面
更改信息页面和频道,网站首页为静态页面,这将有助于搜索引擎更快更好地收录。
关键词2、页面标题优化
必须列出信息标题、网站名称以及相关关键词。
3、 Meta tag优化(过去搜索引擎优化的重要方法已经不再是关键因素,但仍然不能忽视)
主要包括:Meta描述,Meta关键字将关键字密度设置为适中,通常为2%-8%,这意味着您的关键字必须在页面上出现多次,或者在搜索引擎允许的范围内,以避免填充关键字。
4、 为 Google 制作站点地图
Google 的站点地图是原创 robots.txt 的扩展。它采用XML格式记录整个网站信息并供谷歌阅读,让搜索引擎能够更快更全面的收录网站内容。
可以使用谷歌提供的Sitemap生成器制作(需要技术人员制作):
技术人员也可以制作更全面的站点地图。
5、关键词图片优化
不要忽略图片的替换关键词。另一个功能是当图片无法显示时,可以给访问者一个替代的解释语句。
6、 避免表格嵌套
目前,此站点上的表格嵌套过多。搜索引擎通常只读取 3 个嵌套的 。如果嵌套太多,将无法检测到一些有用的信息。
7、 网站refactoring 使用网络标准
尽量使网站的代码符合W3C的HTML4.0或XHTML1.0规范。通过XML+CSS技术重构网站,减少无格式和冗余代码,提高网站页面的可扩展性和兼容性,让更多浏览器支持。
8、网站结构平面规划
目录和内容结构不应超过三层。如果超过三个级别,最好通过子域调整和简化结构级别的数量。另外,目录命名的标准做法是使用英文而不是拼音字母
9、 页面容量的合理化
合理的页面容量会提高网页的显示速度,增加搜索引擎蜘蛛的友好度。同时建议js脚本和css脚本尽量使用链接文件
10、外部文件策略
将javascript文件和css文件分别放在js和css外部文件中。这样做的好处是将重要的页面内容放在页面顶部,同时减少文件大小。有利于搜索引擎快速准确的抓取页面的重要内容。其他字体(FONT)和格式标签也尽量少用,推荐使用CSS定义。
11、external link
尽量让其他与你话题相关的网站链接到本站,并尽量链接到PR值更高的网站。如果网站提供与话题相关的导出链接,搜索引擎认为与该话题相关的内容丰富,也有利于排名,比如各种招商引资网站和投融资网站的概念。此外,无论质量如何,都应避免大规模联网。对于搜索引擎,最好是不那么精确。
12、网站Map
网站自己的网站map是搜索引擎更全面索引收录你的网站的重要因素。建议制作基于文本的网站地图,其中收录网站的所有列和子列。 网站map 的三大要素:文本、链接、关键词,对搜索引擎抓取主页内容极其有帮助。特别是动态生成的目录网站尤其需要创建网站映射。
13、图像热点
除AltaVista和Google明确支持图片热链接外,其他引擎目前不支持。当“蜘蛛”程序遇到这种结构时,将无法区分它。所以尽量不要设置图片热点(Image Map)链接。
14、FLASH 应用
FLASH不收录文字信息,所以尽量用于功能展示和广告,网站栏目和页面少用。
15、JS 脚本
在不支持JS脚本的浏览器中,NOSCRIPT>标签会起到重要的提醒作用,对搜索引擎的蜘蛛搜索也有帮助。
16、帧帧
搜索将忽略 Frame 标记。尽量少用。如果必须使用它,则应正确使用 Noframe 标签。在 Noframe>/Noframe> 区域中,收录指向框架页面的链接或带有 关键词 的描述文本。同时关键词文字也出现在框外。
17、news 内部链接 查看全部
搜索引擎如何抓取网页(国外文章(谷歌翻译)对html标签的评分)
今天偶然看到的一篇外文文章(谷歌翻译)。挺有意思的,主要是对常见的html标签打分的形式。虽然有些描述略显过时,但大部分标签的分析还是很有相关性的。在这里做个记录,方便以后做wordpress主题的时候合理布局(x)个html标签。
先看搜索引擎对html标签的评分:
内部链接文本:10 分
标题:10分
域名:7分
H1、H2 字号标题:5 分
每段第一句:5分
路径或文件名:4分
相似度(关键词stacking):4 分
每句开头:1.5分
粗体或斜体:1分
文字使用(内容):1分
title属性:1分(注意不是title>,是title属性,比如a href=...title=”)
alt 标签:0.5 分
Meta description(描述属性):0.5分
Meta关键词(关键字属性):0.05分
标签是最常用的。以后选择模板的时候一定要注意优化网站。以下是具体的优化建议:
1、静态页面
更改信息页面和频道,网站首页为静态页面,这将有助于搜索引擎更快更好地收录。
关键词2、页面标题优化
必须列出信息标题、网站名称以及相关关键词。
3、 Meta tag优化(过去搜索引擎优化的重要方法已经不再是关键因素,但仍然不能忽视)
主要包括:Meta描述,Meta关键字将关键字密度设置为适中,通常为2%-8%,这意味着您的关键字必须在页面上出现多次,或者在搜索引擎允许的范围内,以避免填充关键字。
4、 为 Google 制作站点地图
Google 的站点地图是原创 robots.txt 的扩展。它采用XML格式记录整个网站信息并供谷歌阅读,让搜索引擎能够更快更全面的收录网站内容。
可以使用谷歌提供的Sitemap生成器制作(需要技术人员制作):
技术人员也可以制作更全面的站点地图。
5、关键词图片优化
不要忽略图片的替换关键词。另一个功能是当图片无法显示时,可以给访问者一个替代的解释语句。
6、 避免表格嵌套
目前,此站点上的表格嵌套过多。搜索引擎通常只读取 3 个嵌套的 。如果嵌套太多,将无法检测到一些有用的信息。
7、 网站refactoring 使用网络标准
尽量使网站的代码符合W3C的HTML4.0或XHTML1.0规范。通过XML+CSS技术重构网站,减少无格式和冗余代码,提高网站页面的可扩展性和兼容性,让更多浏览器支持。
8、网站结构平面规划
目录和内容结构不应超过三层。如果超过三个级别,最好通过子域调整和简化结构级别的数量。另外,目录命名的标准做法是使用英文而不是拼音字母
9、 页面容量的合理化
合理的页面容量会提高网页的显示速度,增加搜索引擎蜘蛛的友好度。同时建议js脚本和css脚本尽量使用链接文件
10、外部文件策略
将javascript文件和css文件分别放在js和css外部文件中。这样做的好处是将重要的页面内容放在页面顶部,同时减少文件大小。有利于搜索引擎快速准确的抓取页面的重要内容。其他字体(FONT)和格式标签也尽量少用,推荐使用CSS定义。
11、external link
尽量让其他与你话题相关的网站链接到本站,并尽量链接到PR值更高的网站。如果网站提供与话题相关的导出链接,搜索引擎认为与该话题相关的内容丰富,也有利于排名,比如各种招商引资网站和投融资网站的概念。此外,无论质量如何,都应避免大规模联网。对于搜索引擎,最好是不那么精确。
12、网站Map
网站自己的网站map是搜索引擎更全面索引收录你的网站的重要因素。建议制作基于文本的网站地图,其中收录网站的所有列和子列。 网站map 的三大要素:文本、链接、关键词,对搜索引擎抓取主页内容极其有帮助。特别是动态生成的目录网站尤其需要创建网站映射。
13、图像热点
除AltaVista和Google明确支持图片热链接外,其他引擎目前不支持。当“蜘蛛”程序遇到这种结构时,将无法区分它。所以尽量不要设置图片热点(Image Map)链接。
14、FLASH 应用
FLASH不收录文字信息,所以尽量用于功能展示和广告,网站栏目和页面少用。
15、JS 脚本
在不支持JS脚本的浏览器中,NOSCRIPT>标签会起到重要的提醒作用,对搜索引擎的蜘蛛搜索也有帮助。
16、帧帧
搜索将忽略 Frame 标记。尽量少用。如果必须使用它,则应正确使用 Noframe 标签。在 Noframe>/Noframe> 区域中,收录指向框架页面的链接或带有 关键词 的描述文本。同时关键词文字也出现在框外。
17、news 内部链接
搜索引擎如何抓取网页(有关url的页面抓取过程讲述url页面的抓取流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-09-13 08:13
url,即统一资源定位器,通过对url的分析,可以更好的了解页面的爬取过程。今天给大家讲讲URL页面的抓取过程。
一、url 是什么意思?
URL,英文全称是“uniform resource locator”,中文翻译是“uniform resource locator”。
在网站优化中,要求每个页面只有一个唯一的统一资源定位符(URL),但往往很多网站对应同一页面上的多个URL,如果都被搜索引擎搜索到的话收录而且没有URL重定向,权重不集中,通常称为URL不规则。
二、url 的组成
Uniform Resource Locator (URL) 由三部分组成:协议方案、主机名和资源名。
例如:
www.***.com /sitemap.html
其中,https为协议方案,***.com为主机名,sitemap.html为资源。当然也可以是.pdf、.php、.word等格式。
三、页面抓取过程简述
无论是我们平时使用的网络浏览器还是网络爬虫,虽然有两个不同的客户端,但是获取页面的方式是一样的。页面抓取过程如下:
①连接DNS服务器
客户端会先连接DNS域名服务器,DNS服务器将主机名(***.com)转换成IP地址发回给客户端。
PS:本来我们用125.52.10.45这个地址来访问某个网站。为了便于记忆和使用,我们使用DNS域名系统转换为***.com。这就是 DNS 域名系统的作用。
②连接IP地址服务器
这个IP服务器下可能有很多程序(网站),可以通过端口号来区分。同时每个程序(网站)都会监听新的连接请求的端口,HTTP网站默认是80,HTTPS网站默认是443。
不过,一般情况下,80和443端口号默认是不会出现的。
例如:
***.com:443/ = ***.com/
***.com:80/ = ***.com/
③ 建立连接并发送页面请求
客户端与服务器建立连接后,会发送一个页面请求,通常是get或者post。
获取站点地图.html HTTPS/1.0
获取HTTPS协议下的页面站点地图并返回给客户端。如果稍后需要获取更多页面,请发送另一个请求,否则将关闭连接。
PS:一般情况下,/seo/sitemap.html 可能会更清晰一些。也就是在***.com/下的seo文件夹中发送sitemap.html的页面请求。 查看全部
搜索引擎如何抓取网页(有关url的页面抓取过程讲述url页面的抓取流程)
url,即统一资源定位器,通过对url的分析,可以更好的了解页面的爬取过程。今天给大家讲讲URL页面的抓取过程。
一、url 是什么意思?
URL,英文全称是“uniform resource locator”,中文翻译是“uniform resource locator”。
在网站优化中,要求每个页面只有一个唯一的统一资源定位符(URL),但往往很多网站对应同一页面上的多个URL,如果都被搜索引擎搜索到的话收录而且没有URL重定向,权重不集中,通常称为URL不规则。
二、url 的组成
Uniform Resource Locator (URL) 由三部分组成:协议方案、主机名和资源名。
例如:
www.***.com /sitemap.html
其中,https为协议方案,***.com为主机名,sitemap.html为资源。当然也可以是.pdf、.php、.word等格式。
三、页面抓取过程简述
无论是我们平时使用的网络浏览器还是网络爬虫,虽然有两个不同的客户端,但是获取页面的方式是一样的。页面抓取过程如下:
①连接DNS服务器
客户端会先连接DNS域名服务器,DNS服务器将主机名(***.com)转换成IP地址发回给客户端。
PS:本来我们用125.52.10.45这个地址来访问某个网站。为了便于记忆和使用,我们使用DNS域名系统转换为***.com。这就是 DNS 域名系统的作用。
②连接IP地址服务器
这个IP服务器下可能有很多程序(网站),可以通过端口号来区分。同时每个程序(网站)都会监听新的连接请求的端口,HTTP网站默认是80,HTTPS网站默认是443。
不过,一般情况下,80和443端口号默认是不会出现的。
例如:
***.com:443/ = ***.com/
***.com:80/ = ***.com/
③ 建立连接并发送页面请求
客户端与服务器建立连接后,会发送一个页面请求,通常是get或者post。
获取站点地图.html HTTPS/1.0
获取HTTPS协议下的页面站点地图并返回给客户端。如果稍后需要获取更多页面,请发送另一个请求,否则将关闭连接。
PS:一般情况下,/seo/sitemap.html 可能会更清晰一些。也就是在***.com/下的seo文件夹中发送sitemap.html的页面请求。
搜索引擎如何抓取网页(搜索引擎如何抓取网页分析网页,检测你和浏览器的不同)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-09-12 22:06
搜索引擎如何抓取网页分析网页,判断用户输入的关键词和用户行为,提供更多的工具,其中最重要的一点是识别web浏览器。从上周开始,让我们专注于网页抓取的顶级大会cscope,可以说在技术及网页抓取上有了长足的进步。今天我们会解释如何利用web浏览器,检测你和浏览器的不同(至少是大部分区别)。工作机制web浏览器作为大名鼎鼎的浏览器,有很多模块来实现网页抓取的工作。
当web浏览器在获取不同内容时,它们会创建一个属于该网页的id和自定义web浏览器名称。从前端抓取数据时,web浏览器需要获取id(所以基本上最先获取的数据都是经过这个手段创建的),而为了让它的逻辑更简单,一些id(如index.js和index.php)会被定义为类。index.js是web页面的web浏览器名称,index.php是网页的外部脚本标识,最后一个称为web页面域名或web.php。
然后这个web页面具有加载次数的限制,在你没有ssr或cdn缓存的情况下,它需要一定次数的加载。因此,web浏览器的内容架构要包括:web请求交互文档名称web格式的内容名称web目录是web页面的容器,里面有文档和二进制数据。然后请求交互,我们可以根据http/1.1协议(ssl协议会使用http/2),将web上的请求用于web浏览器。
我们可以将整个文档用同一http/1.1协议接收。现在一些web浏览器已经支持加载http/2的二进制格式文件。另一些web浏览器将web页面dom渲染为样式表。请求交互是请求者在网页上发起的所有不同请求的总和。通常,在发起web请求时,服务器不会返回响应数据。在发送请求时,这些响应用于服务器的连接;接受请求并使用它们来使服务器处理请求。
请求会让浏览器打开web浏览器dom,并在页面上执行指定的操作。一个示例:从页面直接访问:url:(xmlhttprequest是python中的web库,用于调用网页,构建http连接,发送url请求)这个代码为web浏览器发起请求(发送请求意味着将你发出的请求传给网页,你会看到如何获取数据),定义一个指定的网址pageurl,或者host。
然后通过http/1.1协议发送请求请求期间,将你的请求返回给服务器,网站会使用浏览器返回的响应数据,以dom方式渲染web页面(然后它会返回给你)。浏览器不返回你的index.php文件(请求之前),但请求者会去请求页面上的body(内容),以dom方式渲染页面(请求之后)。当ajax请求处理完毕时,服务器将如何与浏览器交互?当ajax请求发送完毕时,浏。 查看全部
搜索引擎如何抓取网页(搜索引擎如何抓取网页分析网页,检测你和浏览器的不同)
搜索引擎如何抓取网页分析网页,判断用户输入的关键词和用户行为,提供更多的工具,其中最重要的一点是识别web浏览器。从上周开始,让我们专注于网页抓取的顶级大会cscope,可以说在技术及网页抓取上有了长足的进步。今天我们会解释如何利用web浏览器,检测你和浏览器的不同(至少是大部分区别)。工作机制web浏览器作为大名鼎鼎的浏览器,有很多模块来实现网页抓取的工作。
当web浏览器在获取不同内容时,它们会创建一个属于该网页的id和自定义web浏览器名称。从前端抓取数据时,web浏览器需要获取id(所以基本上最先获取的数据都是经过这个手段创建的),而为了让它的逻辑更简单,一些id(如index.js和index.php)会被定义为类。index.js是web页面的web浏览器名称,index.php是网页的外部脚本标识,最后一个称为web页面域名或web.php。
然后这个web页面具有加载次数的限制,在你没有ssr或cdn缓存的情况下,它需要一定次数的加载。因此,web浏览器的内容架构要包括:web请求交互文档名称web格式的内容名称web目录是web页面的容器,里面有文档和二进制数据。然后请求交互,我们可以根据http/1.1协议(ssl协议会使用http/2),将web上的请求用于web浏览器。
我们可以将整个文档用同一http/1.1协议接收。现在一些web浏览器已经支持加载http/2的二进制格式文件。另一些web浏览器将web页面dom渲染为样式表。请求交互是请求者在网页上发起的所有不同请求的总和。通常,在发起web请求时,服务器不会返回响应数据。在发送请求时,这些响应用于服务器的连接;接受请求并使用它们来使服务器处理请求。
请求会让浏览器打开web浏览器dom,并在页面上执行指定的操作。一个示例:从页面直接访问:url:(xmlhttprequest是python中的web库,用于调用网页,构建http连接,发送url请求)这个代码为web浏览器发起请求(发送请求意味着将你发出的请求传给网页,你会看到如何获取数据),定义一个指定的网址pageurl,或者host。
然后通过http/1.1协议发送请求请求期间,将你的请求返回给服务器,网站会使用浏览器返回的响应数据,以dom方式渲染web页面(然后它会返回给你)。浏览器不返回你的index.php文件(请求之前),但请求者会去请求页面上的body(内容),以dom方式渲染页面(请求之后)。当ajax请求处理完毕时,服务器将如何与浏览器交互?当ajax请求发送完毕时,浏。
搜索引擎如何抓取网页(基于云端的爬虫实现方式有好几种,怎么抓取网页数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-09-12 06:00
搜索引擎如何抓取网页数据?
一、怎么抓取网页抓取网页看似是个小菜,但是真正抓取到自己想要的数据却是一个难题。目前基于云端的爬虫实现方式有好几种,这里仅介绍phantomjs对于网页爬虫服务提供商而言,phantomjs可以开放api,能抓取所有的pc网页和移动网页。
(不能抓取h
5)支持的网站可以到这里看:phantomjs爬虫,一个简单易用的htmlf12检查框架,
二、怎么抓取数据api接口地址:,ping/stats,只支持gzip压缩,缓存ie扩展浏览器能用。1.怎么抓取文章列表文章列表爬虫很简单,拿到url后,获取个人信息。
基本使用方法:api返回://查看帐号获取最新的文章列表response对象标志rssrecipientdocument。getelementbyid("tb_appkey")。spider。removelink,recipient。removelink2。怎么抓取文章列表2。1查看访问了多少次headersurl:url2。
2获取标题目录定位属性id,id则是文章标题的上限数量,即博客内容最多能包含的长度url_author='username'document。queryselector("style")。maximum(-。
1).min().returnheaders['src'];headers['user-agent']="mozilla/5.0(windowsnt6.1;wow6
4)applewebkit/537。36(khtml,likegecko)chrome/68。3475。121safari/537。36"placeholder=""response。setheader('content-type','text/html;charset=utf-8')response。
setheader('content-length','1')response。setheader('content-type','text/html;charset=utf-8')response。setheader('language','en')response。
setheader('accept-encoding','gzip')response。setheader('accept-language','zh-cn')response。setheader('content-length',。
2)response。setheader('content-type','text/html;charset=utf-8')response。setheader('content-type','text/x-www-form-urlencoded')response。setheader('user-agent','mozilla/5。0(windowsnt6。1;wow6。
4)applewebkit/537.36(khtml,likegecko)chrome/68.0.3475.121safari/537.36')response.setheader('user-agent','mozilla/5.0(windowsnt6.1;wow6
4)applewebkit/537 查看全部
搜索引擎如何抓取网页(基于云端的爬虫实现方式有好几种,怎么抓取网页数据)
搜索引擎如何抓取网页数据?
一、怎么抓取网页抓取网页看似是个小菜,但是真正抓取到自己想要的数据却是一个难题。目前基于云端的爬虫实现方式有好几种,这里仅介绍phantomjs对于网页爬虫服务提供商而言,phantomjs可以开放api,能抓取所有的pc网页和移动网页。
(不能抓取h
5)支持的网站可以到这里看:phantomjs爬虫,一个简单易用的htmlf12检查框架,
二、怎么抓取数据api接口地址:,ping/stats,只支持gzip压缩,缓存ie扩展浏览器能用。1.怎么抓取文章列表文章列表爬虫很简单,拿到url后,获取个人信息。
基本使用方法:api返回://查看帐号获取最新的文章列表response对象标志rssrecipientdocument。getelementbyid("tb_appkey")。spider。removelink,recipient。removelink2。怎么抓取文章列表2。1查看访问了多少次headersurl:url2。
2获取标题目录定位属性id,id则是文章标题的上限数量,即博客内容最多能包含的长度url_author='username'document。queryselector("style")。maximum(-。
1).min().returnheaders['src'];headers['user-agent']="mozilla/5.0(windowsnt6.1;wow6
4)applewebkit/537。36(khtml,likegecko)chrome/68。3475。121safari/537。36"placeholder=""response。setheader('content-type','text/html;charset=utf-8')response。
setheader('content-length','1')response。setheader('content-type','text/html;charset=utf-8')response。setheader('language','en')response。
setheader('accept-encoding','gzip')response。setheader('accept-language','zh-cn')response。setheader('content-length',。
2)response。setheader('content-type','text/html;charset=utf-8')response。setheader('content-type','text/x-www-form-urlencoded')response。setheader('user-agent','mozilla/5。0(windowsnt6。1;wow6。
4)applewebkit/537.36(khtml,likegecko)chrome/68.0.3475.121safari/537.36')response.setheader('user-agent','mozilla/5.0(windowsnt6.1;wow6
4)applewebkit/537
搜索引擎如何抓取网页(搜索引擎抓取三步曲搜索蜘蛛如何提升网站内容收录和1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-09-10 15:04
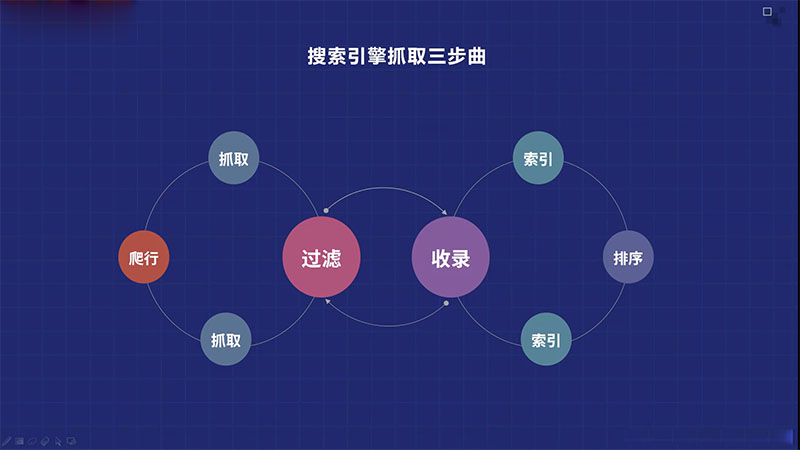
2、搜索引擎抓取三步
对于新的网页内容,搜索蜘蛛会先抓取网页链接,然后对网页链接内容进行分析过滤。符合收录标准的内容将是收录,不符合收录标准的内容将被直接删除。现在按照搜索算法规则对收录的内容进行排序,最后呈现关键词查询和排序结果。
由于我们只需要知道搜索引擎蜘蛛抓取的三个步骤,所以是一个“抓取——过滤——收录”的过程。
二、如何提高爬行和减少过滤
搜索引擎蜘蛛以匿名身份抓取所有网络内容。如果您的网页内容被加密,需要输入帐号密码才能访问,则该网页搜索引擎无法正常抓取。网页只能在开放加密权限的情况下被抓取。如果您的网页内容需要参与搜索排名,您必须注意不要限制搜索引擎抓取网页内容。
搜索引擎无法识别图片、视频、JS文件、flash动画、iame框架等没有ALT属性的内容。搜索引擎只能识别文本和数字。如果您的网页上有任何搜索引擎无法识别的内容,很有可能被搜索引擎蜘蛛过滤掉,所以我们在设计网页时,一定要避免在网页中添加搜索引擎无法识别的内容。如果搜索蜘蛛无法识别您的网页内容,那么收录 和排名怎么办?
搜索蜘蛛抓取网页内容后,第一步是过滤,过滤掉不符合搜索引擎收录标准的内容。搜索蜘蛛收录网页内容的基本步骤是筛选、剔除、重新筛选,收录到官方索引库,官方收录网页之后,下一步就是分析当前网页的价值内容,最后确定当前网页关键词排序的位置。
过滤过滤可以简单地理解为去除没有价值和低质量的内容,保留对用户有价值和高质量的内容。如果你想提高你网站内容的收录率,建议更新更多符合搜索收录规则的有价值的优质内容,不要更新低质量的拼接垃圾内容。
三、如何改进网站content收录和索引1)什么是网站收录和索引
使用site命令查询网站的预估收录金额,例如“site:”,可以查询网站的预估收录金额,如如下图所示:
58同城网站page百度搜索收录量
网站收录率是什么意思?比如你的网站有100页,但是搜索引擎只有收录你网站10页,那么你的网站收录率是10%,网站收录率计算公式为收录率/网站总页=收录率,站点命令只能查询网站大约收录的数量,一般情况下网站页面越多,收录越多会,网站收录更多的页面意味着更多的网站流量,网站内容质量越高网站页收录率会越高,注意网站收录量不等于到网站索引量,网站收录量小于索引量。
2)如何提高网站页收录,减少网页过滤(1)如何提高网站页收录rate
如果要提高网站的收录率,必须提高网站内容的更新频率。 网站内容更新必须与网站定位一致。比如网站location是女鞋,那么你网站的网站内容更新需要围绕女鞋开发,网站更新的内容必须是高质量的,对用户有价值。
搜索引擎判断网站内容质量高低的重要参考是网站bounce rate,网站bounce rate表示内容质量越高,网站bounce rate表示内容越高质量越低,较高的跳出率意味着网站关键词排名不会那么好。
(2)如何降低网页过滤和剔除率
不要更新对用户没有价值的低质量垃圾内容。注意内容的质量。 100个低质量的内容还不如一个高质量的原创内容。比如有的站长用采集工具向网站内容导入了很多低质量的垃圾内容,而搜索引擎没有收录这样的内容,所以网站内容的质量度与网站成正比@收录 率。
对于相同的内容,哪个网站重重高会先于收录哪个网站内容,所以网站收录率也和网站重重值有一定的关系,那就是也与网站内容更新时间有关。 网站先收录先更新,收录后更新。
对用户完全没有价值的垃圾内容,搜索引擎不会收录,即使被搜索蜘蛛抓取,也会被过滤掉。
4、关键词查询和排序搜索结果输出
测序是最后一步。 网站关键词sorting 不会立即产生结果。其实分析在搜索引擎为网站内容页建立索引库的时候就已经开始了,分析网站页的质量,比如站点结构优化、站点和站点投票值、关键词密度等,这些决定了网站页关键词的顺序,简单的说就是当我们在搜索引擎中搜索一个关键词时,这个关键词的排名是搜索引擎分析计算的结果。 查看全部
搜索引擎如何抓取网页(搜索引擎抓取三步曲搜索蜘蛛如何提升网站内容收录和1))
2、搜索引擎抓取三步
对于新的网页内容,搜索蜘蛛会先抓取网页链接,然后对网页链接内容进行分析过滤。符合收录标准的内容将是收录,不符合收录标准的内容将被直接删除。现在按照搜索算法规则对收录的内容进行排序,最后呈现关键词查询和排序结果。
由于我们只需要知道搜索引擎蜘蛛抓取的三个步骤,所以是一个“抓取——过滤——收录”的过程。
二、如何提高爬行和减少过滤
搜索引擎蜘蛛以匿名身份抓取所有网络内容。如果您的网页内容被加密,需要输入帐号密码才能访问,则该网页搜索引擎无法正常抓取。网页只能在开放加密权限的情况下被抓取。如果您的网页内容需要参与搜索排名,您必须注意不要限制搜索引擎抓取网页内容。

搜索引擎无法识别图片、视频、JS文件、flash动画、iame框架等没有ALT属性的内容。搜索引擎只能识别文本和数字。如果您的网页上有任何搜索引擎无法识别的内容,很有可能被搜索引擎蜘蛛过滤掉,所以我们在设计网页时,一定要避免在网页中添加搜索引擎无法识别的内容。如果搜索蜘蛛无法识别您的网页内容,那么收录 和排名怎么办?
搜索蜘蛛抓取网页内容后,第一步是过滤,过滤掉不符合搜索引擎收录标准的内容。搜索蜘蛛收录网页内容的基本步骤是筛选、剔除、重新筛选,收录到官方索引库,官方收录网页之后,下一步就是分析当前网页的价值内容,最后确定当前网页关键词排序的位置。
过滤过滤可以简单地理解为去除没有价值和低质量的内容,保留对用户有价值和高质量的内容。如果你想提高你网站内容的收录率,建议更新更多符合搜索收录规则的有价值的优质内容,不要更新低质量的拼接垃圾内容。
三、如何改进网站content收录和索引1)什么是网站收录和索引
使用site命令查询网站的预估收录金额,例如“site:”,可以查询网站的预估收录金额,如如下图所示:
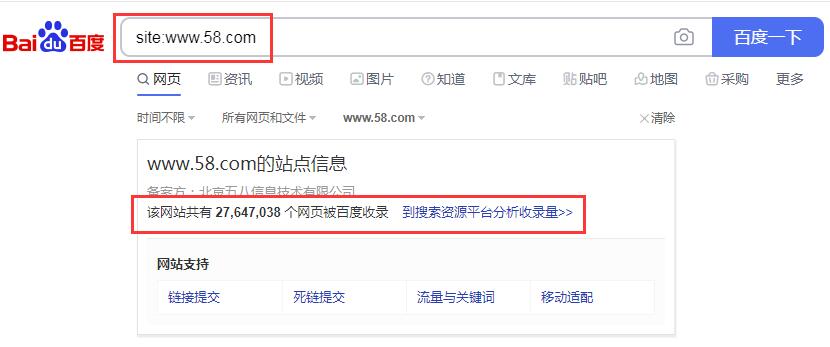
58同城网站page百度搜索收录量
网站收录率是什么意思?比如你的网站有100页,但是搜索引擎只有收录你网站10页,那么你的网站收录率是10%,网站收录率计算公式为收录率/网站总页=收录率,站点命令只能查询网站大约收录的数量,一般情况下网站页面越多,收录越多会,网站收录更多的页面意味着更多的网站流量,网站内容质量越高网站页收录率会越高,注意网站收录量不等于到网站索引量,网站收录量小于索引量。
2)如何提高网站页收录,减少网页过滤(1)如何提高网站页收录rate
如果要提高网站的收录率,必须提高网站内容的更新频率。 网站内容更新必须与网站定位一致。比如网站location是女鞋,那么你网站的网站内容更新需要围绕女鞋开发,网站更新的内容必须是高质量的,对用户有价值。
搜索引擎判断网站内容质量高低的重要参考是网站bounce rate,网站bounce rate表示内容质量越高,网站bounce rate表示内容越高质量越低,较高的跳出率意味着网站关键词排名不会那么好。
(2)如何降低网页过滤和剔除率
不要更新对用户没有价值的低质量垃圾内容。注意内容的质量。 100个低质量的内容还不如一个高质量的原创内容。比如有的站长用采集工具向网站内容导入了很多低质量的垃圾内容,而搜索引擎没有收录这样的内容,所以网站内容的质量度与网站成正比@收录 率。
对于相同的内容,哪个网站重重高会先于收录哪个网站内容,所以网站收录率也和网站重重值有一定的关系,那就是也与网站内容更新时间有关。 网站先收录先更新,收录后更新。
对用户完全没有价值的垃圾内容,搜索引擎不会收录,即使被搜索蜘蛛抓取,也会被过滤掉。
4、关键词查询和排序搜索结果输出
测序是最后一步。 网站关键词sorting 不会立即产生结果。其实分析在搜索引擎为网站内容页建立索引库的时候就已经开始了,分析网站页的质量,比如站点结构优化、站点和站点投票值、关键词密度等,这些决定了网站页关键词的顺序,简单的说就是当我们在搜索引擎中搜索一个关键词时,这个关键词的排名是搜索引擎分析计算的结果。
搜索引擎如何抓取网页(一下造成百度蜘蛛一场的原因及原因分析-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-09-10 15:02
3、robots 协议:这个文件是百度蜘蛛访问的第一个文件。它会告诉百度蜘蛛哪些页面可以爬取,哪些页面不能爬取。
三、如何提高百度蜘蛛的抓取频率
百度蜘蛛会按照一定的规则抓取网站,但不能一视同仁。以下内容将对百度蜘蛛的抓取频率产生重要影响。
1、网站重量重:网站百度蜘蛛的权重越高,爬行越频繁越深
2、网站更新频率:更新频率越高,百度蜘蛛越多。
3、网站内容质量:网站内容原创多,质量高,能解决用户问题,百度会增加抓取频率。
4、导入链接:链接是页面的入口,高质量的链接可以更好地引导百度蜘蛛进入和抓取。
5、Page Depth:页面首页是否有入口,如果首页有入口,可以更好的捕捉和收录。
6、抓取频率决定了网站要建多少页收录,站长应该去哪里了解和修改这么重要的内容,可以去百度站长平台的爬取频率功能了解,如如下图:
四、什么情况下会导致百度蜘蛛抓取失败等异常情况?
部分网站网页内容优质,用户访问正常,但百度蜘蛛无法抓取。不仅会流失流量,用户还会被百度认为网站不友好,导致网站降权和收视率下降,导入网站流量减少等问题。
这里,火龙简单介绍一下导致百度蜘蛛爬行的原因:
1、Server 连接异常:异常有两种情况。一个是网站不稳定,导致百度蜘蛛爬不起来,一个是百度蜘蛛一直无法连接服务器。这个时候就需要仔细检查了。 .
2、网络运营商异常:目前国内网络运营商分为中国电信和中国联通。如果百度蜘蛛无法通过其中之一访问您的网站,请尽快联系网络运营商解决问题。
3、无法解析IP导致dns异常:当百度蜘蛛无法解析你的网站IP时,就会出现dns异常。您可以使用WHOIS查询您的网站IP是否可以解析。如果不能,需要联系域名注册商解决方案。
4、IP ban:IP禁令就是限制IP。此操作只会在特定情况下进行,所以如果您想让网站百度蜘蛛正常访问您的网站,最好不要进行此操作。
5、死链:表示页面无效,无法提供有效信息。这时候可以通过百度站长平台提交死链接。
通过以上信息,您可以大致了解百度蜘蛛抓取的原理。 收录是网站流量的保证,而百度蜘蛛爬行是收录的保证,所以网站只有符合百度蜘蛛爬行规则才能获得更好的排名和流量。 查看全部
搜索引擎如何抓取网页(一下造成百度蜘蛛一场的原因及原因分析-乐题库)
3、robots 协议:这个文件是百度蜘蛛访问的第一个文件。它会告诉百度蜘蛛哪些页面可以爬取,哪些页面不能爬取。
三、如何提高百度蜘蛛的抓取频率
百度蜘蛛会按照一定的规则抓取网站,但不能一视同仁。以下内容将对百度蜘蛛的抓取频率产生重要影响。
1、网站重量重:网站百度蜘蛛的权重越高,爬行越频繁越深
2、网站更新频率:更新频率越高,百度蜘蛛越多。
3、网站内容质量:网站内容原创多,质量高,能解决用户问题,百度会增加抓取频率。
4、导入链接:链接是页面的入口,高质量的链接可以更好地引导百度蜘蛛进入和抓取。
5、Page Depth:页面首页是否有入口,如果首页有入口,可以更好的捕捉和收录。
6、抓取频率决定了网站要建多少页收录,站长应该去哪里了解和修改这么重要的内容,可以去百度站长平台的爬取频率功能了解,如如下图:

四、什么情况下会导致百度蜘蛛抓取失败等异常情况?
部分网站网页内容优质,用户访问正常,但百度蜘蛛无法抓取。不仅会流失流量,用户还会被百度认为网站不友好,导致网站降权和收视率下降,导入网站流量减少等问题。
这里,火龙简单介绍一下导致百度蜘蛛爬行的原因:
1、Server 连接异常:异常有两种情况。一个是网站不稳定,导致百度蜘蛛爬不起来,一个是百度蜘蛛一直无法连接服务器。这个时候就需要仔细检查了。 .
2、网络运营商异常:目前国内网络运营商分为中国电信和中国联通。如果百度蜘蛛无法通过其中之一访问您的网站,请尽快联系网络运营商解决问题。
3、无法解析IP导致dns异常:当百度蜘蛛无法解析你的网站IP时,就会出现dns异常。您可以使用WHOIS查询您的网站IP是否可以解析。如果不能,需要联系域名注册商解决方案。
4、IP ban:IP禁令就是限制IP。此操作只会在特定情况下进行,所以如果您想让网站百度蜘蛛正常访问您的网站,最好不要进行此操作。
5、死链:表示页面无效,无法提供有效信息。这时候可以通过百度站长平台提交死链接。
通过以上信息,您可以大致了解百度蜘蛛抓取的原理。 收录是网站流量的保证,而百度蜘蛛爬行是收录的保证,所以网站只有符合百度蜘蛛爬行规则才能获得更好的排名和流量。
搜索引擎如何抓取网页(如何检查手机网站和手机端的图片如何总结出方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-09-10 14:18
每个页面是否有与内容相关的推荐内部链接非常重要。对用户和蜘蛛非常有帮助。
3、每个页面是否可以链接到其他相关页面
内页需要是相关推荐,栏目页、主题页、首页都是一样的,只是需要从不同的定位角度指向。
那么如何查看外部链接呢?一般使用两种方法:
1、via 域指令
你可以找出哪个网站链接到你,并检查是否有任何不受欢迎的网站在一起。如果是,应尽快处理,否则会产生影响。
2、via 友情链接
检查友情链接是否正常。比如你链接到了别人,但是别人撤销了你的链接,或者别人的网站打不开等等,你需要及时处理。
三、手机网站如何拍照
总结以下六种方法,帮助我们对网站和手机的图片进行优化,实现优化友好快速入口。
1、尽量不要盗图原创
尝试自己制作图片,有很多免费的图片素材,我们可以通过拼接来制作我们需要的图片。
我工作的时候发现可以先把我网站相关的图片保存起来,在本地进行分类标注。
网站需要图片的时候,看看相关的图片,自己动手制作一张吧。这是一个长期积累的过程,随着时间的增加,自己的材料量也会增加。熟练的话,做图就得心应手了。
2、网站图片保存路径
很多站长都没有注意到这个问题。图片上传到网站后,尽量将图片保存在一个目录中。
或者根据网站栏制作对应的图片目录,上传时路径要相对固定,这样蜘蛛就可以轻松抓取。当蜘蛛访问该目录时,它会“知道”该目录收录图片;
最好使用一些常规或有意义的方法来命名图像文件。您可以使用时间、列名或网站名称来命名。
例如:下图SEO优化可以使用名称“SEOYH2018-6-23-36”,前面的“SEOYH”是SEO优化的简写,中间是时间,最后是图片身份证。
你为什么要这样做?
其实这是为了培养被搜索引擎蜘蛛抓取的习惯,方便以后更快的识别网站image内容。让蜘蛛抓住你的心,网站被收录的几率增加,何乐而不为呢!
3、图片周围必须有相关文字
网站Picture 是一种直接向用户呈现信息的方式。搜索引擎在爬取网站内容的时候,还会检查这个文章是否有图片、视频或者表格等,
这些都是可以增加文章点值的元素。其他表格暂时不显示。这里只讲图片周围相关文字的介绍。
首先,图片周围的文字必须与图片本身的内容一致。比如你的文章说要做网站优化,里面的图片是一个菜谱的图片。这不是卖狗肉的食谱吗?
用户的访问感会极差。搜索引擎通过相关算法识别出这张图片后,也会觉得图片和文字不符,给你差评。
所以,每个文章必须至少配一张对应的图片,并且与你的网站标题相关的内容必须出现在图片周围。不仅可以帮助搜索引擎理解图片,还可以增加文章的可读性、用户友好性和相关性。
4、给图片添加alt和title标签
很多站长在添加网站图片时可能没有注意这些细节,有的可能会觉得麻烦。我希望你没有这个想法。这是一个很大的错误。
搜索引擎抓取网站图片时,atl标签是最先抓取的,也是识别图片内容最重要的核心因素之一。图片的alt属性直接告诉搜索引擎网站图片是什么,是什么意思;
title标签是用户指向这张图片时会显示的提示内容。这是增加用户体验和增加网站关键词的一个小技巧。
alt 和标题标签
还有这两个属性,方便有阅读障碍的游客。例如,盲人访问你网站时,他看不到屏幕上的内容。可能是通过读取 如果有 alt 属性,软件会直接读取 alt 属性中的文字,方便他们访问。
5、图片大小和分辨率
虽然两者看起来很像,但还是有很大的不同。对于同样大小、分辨率更高的图片,网站最终会变大。每个人都必须弄清楚这一点。
网站上的图片一直提倡使用尽可能小的图片来最大化内容。为什么会这样?
因为小尺寸图片加载速度更快,不会让访问者等待太久,尤其是在使用手机时,由于移动互联网速度和流量的限制,用户更愿意访问可以立即打开的页面。尺寸图更有优势。
在这里我们尽量平衡。在图片不失真的情况下,尺寸尽量小。
网上有很多减肥图片的工具。你可以试试看。适当压缩网站 图片。一方面可以减轻服务器带宽的压力,另一方面可以为用户提供流畅度。体验。
6、手机端自动适配
很多站长都遇到过网站访问电脑显示器上的图片是正常的,但是手机出现错位,就是大尺寸图片导致不同尺寸终端显示错位、不完整的情况。
其实这个问题很容易解决。添加图片时,宽度和高度最好不要使用绝对大小。使用百分比来解决它。
具体来说,CSS代码不能指定像素宽度:width:xxx px;只有百分比宽度:宽度:xx%;或 width:auto 没问题。
这样做的目的也是为了让百度的手机蜘蛛在抓取的时候有很好的体验,这也是为了更符合百度手机登陆页面的体验。
四、如何提高搜索引擎的抓取频率?
1、网站内容更新
搜索引擎只抓取单个页面的内容,而不是所有页面。这也是搜索引擎更新网页快照的时间较短的原因。
比如对于经常更新的页面,快照也会被频繁抓取,以便及时发现新的内容和链接,删除不存在的信息。因此,站长必须长期坚持更新网页,才能成为搜索引擎爬虫。稳定过来抢。
2、网站框架设计
网站内部框架的设计需要从多方面进行。其中,代码需要尽量简洁明了。代码过多容易导致页面过大,影响网络爬虫的抓取速度。
爬取网站时,网页Flash图片尽量少。 flash 格式的内容影响蜘蛛爬行。对于新的网站,尽量使用伪静态网址,这样整个网站'S页面都容易被抓取。
在设计中,锚文本要合理分布,不要全部关键词,适当添加一些长尾词链接。内部链接的设计也应该是流畅的,以利于权重转移。
3、网站导航设计
网站 很多公司在设计网站 时都会忽略。导航是蜘蛛爬行的关键。如果网站导航不清楚,搜索引擎在爬行时很容易迷路。 ,所以导航一定要设计合理。
这里顺便提到了锚文本的构建。站点中的锚文本有助于网络爬虫在站点上查找和爬取更多网页。但是,如果锚文本过多,很容易被认为是刻意调整。设计时一定要把握好锚文本。数量。
4、稳定更新频率
除了首页设计,网站还有其他页面。爬虫在爬行时不会将网站 上的所有网页编入索引。在他们找到重要页面之前,他们可能已经抓取了足够多的网页并离开了。
所以我们必须保持一定的更新频率。可以轻松抓取更新频繁的页面,因此可以自动抓取大量页面。同时一定要注意网站level的设计,不要太多,否则也不利于网站抢夺。 查看全部
搜索引擎如何抓取网页(如何检查手机网站和手机端的图片如何总结出方法)
每个页面是否有与内容相关的推荐内部链接非常重要。对用户和蜘蛛非常有帮助。
3、每个页面是否可以链接到其他相关页面
内页需要是相关推荐,栏目页、主题页、首页都是一样的,只是需要从不同的定位角度指向。
那么如何查看外部链接呢?一般使用两种方法:
1、via 域指令
你可以找出哪个网站链接到你,并检查是否有任何不受欢迎的网站在一起。如果是,应尽快处理,否则会产生影响。
2、via 友情链接
检查友情链接是否正常。比如你链接到了别人,但是别人撤销了你的链接,或者别人的网站打不开等等,你需要及时处理。
三、手机网站如何拍照
总结以下六种方法,帮助我们对网站和手机的图片进行优化,实现优化友好快速入口。
1、尽量不要盗图原创
尝试自己制作图片,有很多免费的图片素材,我们可以通过拼接来制作我们需要的图片。
我工作的时候发现可以先把我网站相关的图片保存起来,在本地进行分类标注。
网站需要图片的时候,看看相关的图片,自己动手制作一张吧。这是一个长期积累的过程,随着时间的增加,自己的材料量也会增加。熟练的话,做图就得心应手了。
2、网站图片保存路径
很多站长都没有注意到这个问题。图片上传到网站后,尽量将图片保存在一个目录中。
或者根据网站栏制作对应的图片目录,上传时路径要相对固定,这样蜘蛛就可以轻松抓取。当蜘蛛访问该目录时,它会“知道”该目录收录图片;
最好使用一些常规或有意义的方法来命名图像文件。您可以使用时间、列名或网站名称来命名。
例如:下图SEO优化可以使用名称“SEOYH2018-6-23-36”,前面的“SEOYH”是SEO优化的简写,中间是时间,最后是图片身份证。
你为什么要这样做?
其实这是为了培养被搜索引擎蜘蛛抓取的习惯,方便以后更快的识别网站image内容。让蜘蛛抓住你的心,网站被收录的几率增加,何乐而不为呢!
3、图片周围必须有相关文字
网站Picture 是一种直接向用户呈现信息的方式。搜索引擎在爬取网站内容的时候,还会检查这个文章是否有图片、视频或者表格等,
这些都是可以增加文章点值的元素。其他表格暂时不显示。这里只讲图片周围相关文字的介绍。
首先,图片周围的文字必须与图片本身的内容一致。比如你的文章说要做网站优化,里面的图片是一个菜谱的图片。这不是卖狗肉的食谱吗?
用户的访问感会极差。搜索引擎通过相关算法识别出这张图片后,也会觉得图片和文字不符,给你差评。
所以,每个文章必须至少配一张对应的图片,并且与你的网站标题相关的内容必须出现在图片周围。不仅可以帮助搜索引擎理解图片,还可以增加文章的可读性、用户友好性和相关性。
4、给图片添加alt和title标签
很多站长在添加网站图片时可能没有注意这些细节,有的可能会觉得麻烦。我希望你没有这个想法。这是一个很大的错误。
搜索引擎抓取网站图片时,atl标签是最先抓取的,也是识别图片内容最重要的核心因素之一。图片的alt属性直接告诉搜索引擎网站图片是什么,是什么意思;
title标签是用户指向这张图片时会显示的提示内容。这是增加用户体验和增加网站关键词的一个小技巧。
alt 和标题标签
还有这两个属性,方便有阅读障碍的游客。例如,盲人访问你网站时,他看不到屏幕上的内容。可能是通过读取 如果有 alt 属性,软件会直接读取 alt 属性中的文字,方便他们访问。
5、图片大小和分辨率
虽然两者看起来很像,但还是有很大的不同。对于同样大小、分辨率更高的图片,网站最终会变大。每个人都必须弄清楚这一点。
网站上的图片一直提倡使用尽可能小的图片来最大化内容。为什么会这样?
因为小尺寸图片加载速度更快,不会让访问者等待太久,尤其是在使用手机时,由于移动互联网速度和流量的限制,用户更愿意访问可以立即打开的页面。尺寸图更有优势。
在这里我们尽量平衡。在图片不失真的情况下,尺寸尽量小。
网上有很多减肥图片的工具。你可以试试看。适当压缩网站 图片。一方面可以减轻服务器带宽的压力,另一方面可以为用户提供流畅度。体验。
6、手机端自动适配
很多站长都遇到过网站访问电脑显示器上的图片是正常的,但是手机出现错位,就是大尺寸图片导致不同尺寸终端显示错位、不完整的情况。
其实这个问题很容易解决。添加图片时,宽度和高度最好不要使用绝对大小。使用百分比来解决它。
具体来说,CSS代码不能指定像素宽度:width:xxx px;只有百分比宽度:宽度:xx%;或 width:auto 没问题。
这样做的目的也是为了让百度的手机蜘蛛在抓取的时候有很好的体验,这也是为了更符合百度手机登陆页面的体验。
四、如何提高搜索引擎的抓取频率?
1、网站内容更新
搜索引擎只抓取单个页面的内容,而不是所有页面。这也是搜索引擎更新网页快照的时间较短的原因。
比如对于经常更新的页面,快照也会被频繁抓取,以便及时发现新的内容和链接,删除不存在的信息。因此,站长必须长期坚持更新网页,才能成为搜索引擎爬虫。稳定过来抢。
2、网站框架设计
网站内部框架的设计需要从多方面进行。其中,代码需要尽量简洁明了。代码过多容易导致页面过大,影响网络爬虫的抓取速度。
爬取网站时,网页Flash图片尽量少。 flash 格式的内容影响蜘蛛爬行。对于新的网站,尽量使用伪静态网址,这样整个网站'S页面都容易被抓取。
在设计中,锚文本要合理分布,不要全部关键词,适当添加一些长尾词链接。内部链接的设计也应该是流畅的,以利于权重转移。
3、网站导航设计
网站 很多公司在设计网站 时都会忽略。导航是蜘蛛爬行的关键。如果网站导航不清楚,搜索引擎在爬行时很容易迷路。 ,所以导航一定要设计合理。
这里顺便提到了锚文本的构建。站点中的锚文本有助于网络爬虫在站点上查找和爬取更多网页。但是,如果锚文本过多,很容易被认为是刻意调整。设计时一定要把握好锚文本。数量。
4、稳定更新频率
除了首页设计,网站还有其他页面。爬虫在爬行时不会将网站 上的所有网页编入索引。在他们找到重要页面之前,他们可能已经抓取了足够多的网页并离开了。
所以我们必须保持一定的更新频率。可以轻松抓取更新频繁的页面,因此可以自动抓取大量页面。同时一定要注意网站level的设计,不要太多,否则也不利于网站抢夺。
搜索引擎如何抓取网页(蜘蛛搜索引擎怎么去识别友情链接,通过代码还是?-…)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-09-09 03:01
蜘蛛搜索引擎如何识别友情链接,通过代码还是?-…… 友情链接是双方约定的信息共享行为,与搜索引擎无关。合作伙伴是双方的另一种契约关系,是否通过源代码,由双方自行决定。
搜索引擎蜘蛛可以抓取登录后才能看到的内容吗...这个搜索引擎蜘蛛不会像人们那样点击登录你的页面。所有搜索引擎只能收录不需要登录的页面只能看到,需要登录才能看到的页面不是收录,如果你需要他收录的呵啊,需要给个链接,让蜘蛛不用登录就可以进入,那么这个也行看见。如果说蜘蛛爬取了需要登录才能看到的内容,那你需要登录网站 内容可能已经写好了不登录也可以进入。可能有没有设计好的地方啦漏洞。希望我的回答能帮到你。龙SEO
如何识别搜索引擎蜘蛛IP?-...这个可以从服务器或者虚拟主机的日志中看出。比如在虚拟主机的完整使用日志中有这样一条记录:220.181.38.198--[11/Nov/2007:04:28:29 +0800] "GET /HTTP/1.1" 200 61083 "-" "Baiduspider" 意思是百度蜘蛛来过你的网站,如果我也想知道有没有其他搜索引擎蜘蛛来过你的网站。您可以在日志文件中搜索“蜘蛛”一词,也可以搜索蜘蛛的IP。 IIS日志和Apache日志是一样的,可以查到
用站长工具查出【模拟搜索引擎蜘蛛爬行】里面的内容不是我们网站-的内容……估计是脚本语言,你查到的是被解析并解析为 HTML。您应该找到您的页面并查看哪些内容受到控制。既然你说用站长工具模拟可以找到,证明正常打开网站是看不到的。然后他用判断语句来判断搜索蜘蛛与普通访问者的访问,然后给出了不同的代码。初步确定他在你的网站上有黑链。否则不仅会显示搜索蜘蛛
我怎么知道有搜索引擎蜘蛛爬过来爬过我的网站-......去其他机器搜索......
哪些链接类型的搜索引擎蜘蛛不能沿着url爬行?首先是隐藏链接。二、具有访问权限的链接。第三,给蜘蛛设置了相关的判断,让蜘蛛无法爬取链接。四、使用JS调用页面未显示的链接。五、flash和frame中的链接。搜索引擎蜘蛛无法抓取上述链接。
什么是蜘蛛侠搜索引擎?它的搜索数据来自哪里?它的搜索排名规则是什么? ... 搜索引擎蜘蛛是如何工作的? %C9%EE%DB%DA%D3% C5%BB%AF/blog/item/f06cf14b055ad5f282025c1f.html
这个ip是哪个搜索引擎蜘蛛?-...这里有各种搜索引擎蜘蛛的IP地址。但是没有你给的两个IP。
如何查看各大搜索引擎蜘蛛的ip?? ...你可以从虚拟主机的日志中查看蜘蛛的ip。详情请咨询百度或谷歌
如何查看搜索引擎蜘蛛-...... 一般情况下在服务器上是可以看到的,虚拟主机一般没有这个功能 查看全部
搜索引擎如何抓取网页(蜘蛛搜索引擎怎么去识别友情链接,通过代码还是?-…)
蜘蛛搜索引擎如何识别友情链接,通过代码还是?-…… 友情链接是双方约定的信息共享行为,与搜索引擎无关。合作伙伴是双方的另一种契约关系,是否通过源代码,由双方自行决定。
搜索引擎蜘蛛可以抓取登录后才能看到的内容吗...这个搜索引擎蜘蛛不会像人们那样点击登录你的页面。所有搜索引擎只能收录不需要登录的页面只能看到,需要登录才能看到的页面不是收录,如果你需要他收录的呵啊,需要给个链接,让蜘蛛不用登录就可以进入,那么这个也行看见。如果说蜘蛛爬取了需要登录才能看到的内容,那你需要登录网站 内容可能已经写好了不登录也可以进入。可能有没有设计好的地方啦漏洞。希望我的回答能帮到你。龙SEO
如何识别搜索引擎蜘蛛IP?-...这个可以从服务器或者虚拟主机的日志中看出。比如在虚拟主机的完整使用日志中有这样一条记录:220.181.38.198--[11/Nov/2007:04:28:29 +0800] "GET /HTTP/1.1" 200 61083 "-" "Baiduspider" 意思是百度蜘蛛来过你的网站,如果我也想知道有没有其他搜索引擎蜘蛛来过你的网站。您可以在日志文件中搜索“蜘蛛”一词,也可以搜索蜘蛛的IP。 IIS日志和Apache日志是一样的,可以查到
用站长工具查出【模拟搜索引擎蜘蛛爬行】里面的内容不是我们网站-的内容……估计是脚本语言,你查到的是被解析并解析为 HTML。您应该找到您的页面并查看哪些内容受到控制。既然你说用站长工具模拟可以找到,证明正常打开网站是看不到的。然后他用判断语句来判断搜索蜘蛛与普通访问者的访问,然后给出了不同的代码。初步确定他在你的网站上有黑链。否则不仅会显示搜索蜘蛛
我怎么知道有搜索引擎蜘蛛爬过来爬过我的网站-......去其他机器搜索......
哪些链接类型的搜索引擎蜘蛛不能沿着url爬行?首先是隐藏链接。二、具有访问权限的链接。第三,给蜘蛛设置了相关的判断,让蜘蛛无法爬取链接。四、使用JS调用页面未显示的链接。五、flash和frame中的链接。搜索引擎蜘蛛无法抓取上述链接。
什么是蜘蛛侠搜索引擎?它的搜索数据来自哪里?它的搜索排名规则是什么? ... 搜索引擎蜘蛛是如何工作的? %C9%EE%DB%DA%D3% C5%BB%AF/blog/item/f06cf14b055ad5f282025c1f.html
这个ip是哪个搜索引擎蜘蛛?-...这里有各种搜索引擎蜘蛛的IP地址。但是没有你给的两个IP。
如何查看各大搜索引擎蜘蛛的ip?? ...你可以从虚拟主机的日志中查看蜘蛛的ip。详情请咨询百度或谷歌
如何查看搜索引擎蜘蛛-...... 一般情况下在服务器上是可以看到的,虚拟主机一般没有这个功能
搜索引擎如何抓取网页(覆盖链接提取如何使用(图)的用法和下面条件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-09-09 02:09
核心点:覆盖链接提取有点类似于覆盖查询,主要注意关键词的用法和以下条件的用法,关键词可以适当使用搜索引擎的高级命令来实现一些特殊效果。如果以下条件为空,则表示提取所有覆盖链接,如果不为空,则根据填充条件提取。
覆盖链接提取功能有很多用途,最常见的两种是:一种是根据关键词提取搜索引擎结果中的所有链接,另一种是根据关键词查询竞争对手的链接。
在使用覆盖链接提取时有很多技术。比如关键词区域,如果使用百度的一些高级命令,会得到意想不到的结果。
我们来看看如何使用覆盖链接提取:
1、关键词填写
关键词块,主要填写你要查询的关键词。普通用户数量有限制。建议查看数据限制。对于VIP用户,建议正常模式下查询数据不超过5000条,精准模式下查询数据不超过2000条。
关键词也可以填写搜索引擎的高级说明。使用高级指令,会有意想不到的收获。
2、填写覆盖条件
如果没有填写覆盖条件,搜索引擎结果中的所有关键词都会被提取出来。
如果填写了coverage条件,会根据coverage条件中填写的内容进行过滤。
coverage 条件必须是唯一的,也就是说你填写的条件必须是唯一的。
例如:如果您要查看福州复兴妇产医院的覆盖范围,如果您的标题中有“复兴”一词,则可以使用“复兴”而不是“医院”,而不是“医院”。
如果要查询某个域名的覆盖范围,也可以使用域名,使用多条件模式查询,如:||,因为域名是唯一的。
如何使用&和|在覆盖条件下?
&是with的关系,表示必须同时满足多个条件才能匹配,例如:
你的条件是:关键词a&关键词b&关键词c,那么匹配的结果必须同时满足这三个条件才算覆盖率。
|yes or的关系,表示只要满足多个条件之一,就可以匹配,例如:
你的条件是:关键词a|关键词b|关键词c,那么只要匹配三个时钟之一,就可以算为覆盖率。
3、 为查询选择搜索引擎和排名选项
这个版本和之前版本的区别是可以同时选择多个搜索引擎。选择搜索引擎时,点击选择需要选择的搜索引擎。排名选择根据您的需要进行选择。当查询覆盖率比较大的时候,尽量选择1-2个搜索引擎,最好的排名是10,这样可以保证速度。如果选择多个搜索引擎,速度会有一定的影响,请慎重考虑后再做出选择。然后点击查询。
一般查询和精确查询设置:
选择普通查询,此功能只匹配搜索引擎的搜索结果,不匹配文章的内页。查询结果会略有不准确,但查询速度会更快。
选择精准查询,会打开各个网页的链接进行匹配,查询速度准确率几乎100%,但是查询速度要慢很多。
4、覆盖链接数据导出
查询完成后,点击底部的保存查询结果,导出数据。
以上是覆盖链接提取的说明。如有疑问,请点击网站下方QQ咨询。 查看全部
搜索引擎如何抓取网页(覆盖链接提取如何使用(图)的用法和下面条件)
核心点:覆盖链接提取有点类似于覆盖查询,主要注意关键词的用法和以下条件的用法,关键词可以适当使用搜索引擎的高级命令来实现一些特殊效果。如果以下条件为空,则表示提取所有覆盖链接,如果不为空,则根据填充条件提取。
覆盖链接提取功能有很多用途,最常见的两种是:一种是根据关键词提取搜索引擎结果中的所有链接,另一种是根据关键词查询竞争对手的链接。
在使用覆盖链接提取时有很多技术。比如关键词区域,如果使用百度的一些高级命令,会得到意想不到的结果。
我们来看看如何使用覆盖链接提取:
1、关键词填写
关键词块,主要填写你要查询的关键词。普通用户数量有限制。建议查看数据限制。对于VIP用户,建议正常模式下查询数据不超过5000条,精准模式下查询数据不超过2000条。
关键词也可以填写搜索引擎的高级说明。使用高级指令,会有意想不到的收获。

2、填写覆盖条件
如果没有填写覆盖条件,搜索引擎结果中的所有关键词都会被提取出来。
如果填写了coverage条件,会根据coverage条件中填写的内容进行过滤。
coverage 条件必须是唯一的,也就是说你填写的条件必须是唯一的。
例如:如果您要查看福州复兴妇产医院的覆盖范围,如果您的标题中有“复兴”一词,则可以使用“复兴”而不是“医院”,而不是“医院”。
如果要查询某个域名的覆盖范围,也可以使用域名,使用多条件模式查询,如:||,因为域名是唯一的。
如何使用&和|在覆盖条件下?
&是with的关系,表示必须同时满足多个条件才能匹配,例如:
你的条件是:关键词a&关键词b&关键词c,那么匹配的结果必须同时满足这三个条件才算覆盖率。
|yes or的关系,表示只要满足多个条件之一,就可以匹配,例如:
你的条件是:关键词a|关键词b|关键词c,那么只要匹配三个时钟之一,就可以算为覆盖率。

3、 为查询选择搜索引擎和排名选项
这个版本和之前版本的区别是可以同时选择多个搜索引擎。选择搜索引擎时,点击选择需要选择的搜索引擎。排名选择根据您的需要进行选择。当查询覆盖率比较大的时候,尽量选择1-2个搜索引擎,最好的排名是10,这样可以保证速度。如果选择多个搜索引擎,速度会有一定的影响,请慎重考虑后再做出选择。然后点击查询。

一般查询和精确查询设置:
选择普通查询,此功能只匹配搜索引擎的搜索结果,不匹配文章的内页。查询结果会略有不准确,但查询速度会更快。
选择精准查询,会打开各个网页的链接进行匹配,查询速度准确率几乎100%,但是查询速度要慢很多。

4、覆盖链接数据导出
查询完成后,点击底部的保存查询结果,导出数据。

以上是覆盖链接提取的说明。如有疑问,请点击网站下方QQ咨询。
搜索引擎如何抓取网页(网站页面更快被搜索引擎所收录的几大因素有哪些)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-09-16 02:14
很多人可能在想这个问题,那就是为什么他们的网站页面可以被搜索引擎搜索到收录。事实上,这与网站关键词、链接和其他因素密不可分。如何让搜索引擎收录使用网站页面更快,听小编告诉你
一、网站内容更新应该很有价值
随着搜索引擎算法的升级,对网站用户体验的重视逐渐增加。因此,在更新网站内容时,我们不仅要注意内容的新颖性,还要注意内容是否对用户有用和有价值。考虑到这两个因素可以带来网站更好的收录和排名
二、关键词设置应合理
在设置网站关键词时,请注意关键词在网页、标题、说明、文章开头和结尾段落中的分布情况,以便获得搜索引擎的足够关注。这对网站排名、收录和其他方面也有很大的好处,但记住不要将关键词叠加在一起
三、科学使用文字和图片
一个优秀的网站页面可以与图片、文字合理结合,提升网站的用户体验,帮助搜索引擎提升网站页面的收录量,加深用户印象,给客户带来良好的视觉体验。由于搜索引擎对图片的识别率较低,所以不能有太多的图片,并且应该为文本注释添加ALT标记,方便搜索引擎的识别
@添加四、高质量外链
网站优化人员充分意识到外部链建设的重要性。优质的外部链资源有利于收录和网站的排名以及权重的提升。因此,尽量帮助网站增加一些高质量的友链,拓宽外链资源,积累丰富的外链资源
网站建设和网络推广公司-创新互联网,是一家专注于品牌和效果的网站生产和网络营销SEO公司;服务项目包括网站营销等 查看全部
搜索引擎如何抓取网页(网站页面更快被搜索引擎所收录的几大因素有哪些)
很多人可能在想这个问题,那就是为什么他们的网站页面可以被搜索引擎搜索到收录。事实上,这与网站关键词、链接和其他因素密不可分。如何让搜索引擎收录使用网站页面更快,听小编告诉你
一、网站内容更新应该很有价值
随着搜索引擎算法的升级,对网站用户体验的重视逐渐增加。因此,在更新网站内容时,我们不仅要注意内容的新颖性,还要注意内容是否对用户有用和有价值。考虑到这两个因素可以带来网站更好的收录和排名
二、关键词设置应合理
在设置网站关键词时,请注意关键词在网页、标题、说明、文章开头和结尾段落中的分布情况,以便获得搜索引擎的足够关注。这对网站排名、收录和其他方面也有很大的好处,但记住不要将关键词叠加在一起
三、科学使用文字和图片
一个优秀的网站页面可以与图片、文字合理结合,提升网站的用户体验,帮助搜索引擎提升网站页面的收录量,加深用户印象,给客户带来良好的视觉体验。由于搜索引擎对图片的识别率较低,所以不能有太多的图片,并且应该为文本注释添加ALT标记,方便搜索引擎的识别
@添加四、高质量外链
网站优化人员充分意识到外部链建设的重要性。优质的外部链资源有利于收录和网站的排名以及权重的提升。因此,尽量帮助网站增加一些高质量的友链,拓宽外链资源,积累丰富的外链资源
网站建设和网络推广公司-创新互联网,是一家专注于品牌和效果的网站生产和网络营销SEO公司;服务项目包括网站营销等
搜索引擎如何抓取网页(搜索引擎对网站的收录数量是网站SEO优化中重要的一个标准)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-09-16 02:11
搜索引擎网站的收录编号是多少网站SEO优化中的一个重要标准。网站搜索引擎优化的目的是提高网站排名,这是关键词的排名,并且关键词存在于页面中,所以网站的构建非常重要。如果搜索引擎收录没有找到页面内容,那么网站排名是不可能的。如果你想改进网站和收录,你需要分析搜索引擎的规则,了解搜索引擎喜欢什么类型的内容
许多人首先想到原创内容。是的,搜索引擎喜欢原创content,但这种观点并不全面。因为一个带插图的原创文章,如果没有特定的媒体属性,它对用户来说是无用的,不会产生任何价值,那么搜索引擎将不会捕获此类原创内容。搜索引擎喜欢的原创内容不仅仅是原创,而是能够影响用户并具有社会价值的原创内容。原创内容的特点是信息稀缺。只要互联网上没有内容,搜索引擎就会认为它是原创的,搜索引擎不喜欢重复出现的内容。然而,网站的内容应以原创及其对用户的价值为基础进行保证,这可能会影响用户的性能
那么什么内容对用户有影响呢?直接简单地指用户关注并积极参与讨论的社会热点、明星新闻、国家大事记等有价值的内容。因为很多用户会关注这类内容,并通过热点新闻传播。比如每年的春节新闻。即使这类热点新闻被用户广泛传播,搜索引擎对这些内容仍然会有一种满足感。这些消息一出来,他们就没有经过大量的筛选。无论它们如何传播,这样的新闻可塑性仍然很强,搜索引擎会一直关注它
如果你想提高搜索引擎将网站内容替换为收录的概率,你应该围绕热点话题创建。用户现在关注的话题是什么?我们应该将这些内容与网站内容结合起来。即使在文章中只提到一点,搜索引擎也会关注它。如果它能出现在网站的标题中或文章的第一段中会更好。有些热点文章实际上不需要太多修改。只要你修改了某个部分,它就可以被搜索引擎视为新内容。由于热门新闻尚未被筛选,搜索引擎没有参考资料。因此,网站发布内容可以与热点新闻相结合
提高网站的收录主要是做好网站内容,而对用户有价值的原创内容就是搜索引擎喜欢的内容 查看全部
搜索引擎如何抓取网页(搜索引擎对网站的收录数量是网站SEO优化中重要的一个标准)
搜索引擎网站的收录编号是多少网站SEO优化中的一个重要标准。网站搜索引擎优化的目的是提高网站排名,这是关键词的排名,并且关键词存在于页面中,所以网站的构建非常重要。如果搜索引擎收录没有找到页面内容,那么网站排名是不可能的。如果你想改进网站和收录,你需要分析搜索引擎的规则,了解搜索引擎喜欢什么类型的内容
许多人首先想到原创内容。是的,搜索引擎喜欢原创content,但这种观点并不全面。因为一个带插图的原创文章,如果没有特定的媒体属性,它对用户来说是无用的,不会产生任何价值,那么搜索引擎将不会捕获此类原创内容。搜索引擎喜欢的原创内容不仅仅是原创,而是能够影响用户并具有社会价值的原创内容。原创内容的特点是信息稀缺。只要互联网上没有内容,搜索引擎就会认为它是原创的,搜索引擎不喜欢重复出现的内容。然而,网站的内容应以原创及其对用户的价值为基础进行保证,这可能会影响用户的性能
那么什么内容对用户有影响呢?直接简单地指用户关注并积极参与讨论的社会热点、明星新闻、国家大事记等有价值的内容。因为很多用户会关注这类内容,并通过热点新闻传播。比如每年的春节新闻。即使这类热点新闻被用户广泛传播,搜索引擎对这些内容仍然会有一种满足感。这些消息一出来,他们就没有经过大量的筛选。无论它们如何传播,这样的新闻可塑性仍然很强,搜索引擎会一直关注它
如果你想提高搜索引擎将网站内容替换为收录的概率,你应该围绕热点话题创建。用户现在关注的话题是什么?我们应该将这些内容与网站内容结合起来。即使在文章中只提到一点,搜索引擎也会关注它。如果它能出现在网站的标题中或文章的第一段中会更好。有些热点文章实际上不需要太多修改。只要你修改了某个部分,它就可以被搜索引擎视为新内容。由于热门新闻尚未被筛选,搜索引擎没有参考资料。因此,网站发布内容可以与热点新闻相结合
提高网站的收录主要是做好网站内容,而对用户有价值的原创内容就是搜索引擎喜欢的内容
搜索引擎如何抓取网页(蜘蛛的基本工作原理是什么?蜘蛛工作的第一步)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-09-16 02:07
随着搜索引擎的不断发展和升级,搜索引擎发送的蜘蛛变得越来越智能。因此,为了了解蜘蛛的工作原理,更好地优化自身网站必须不断研究蜘蛛。现在,我们来谈谈齐鲁信息网蜘蛛的基本工作原理:
spider工作的第一步:抓取网站网页并找到正确的资源
蜘蛛有一个特点,就是它的轨迹通常是围绕着蜘蛛丝的,因此我们将搜索引擎机器人蜘蛛命名为蜘蛛。当蜘蛛来到你的网站时,它将继续沿着你的网站中的链接(蜘蛛丝)爬行。因此,如何让蜘蛛在你的网站中更好地爬行,成为我们的当务之急
在这个时候,我们经常建议站长在网站上使用更多的调用,这些调用在网站内调用一些文章,这是大多数站长的选择,无论是相关阅读、推荐阅读还是其他排行榜
蜘蛛工作的第二步:抓取你的网页
引导蜘蛛爬行。这只是一个开始。良好的开端意味着你将有一个高起点。通过其自身的内链设计,网站中没有死角,蜘蛛可以轻松到达网站中的每一页,这样蜘蛛在执行第二步抓取时会事半功倍
在这一步的爬行过程中,我们需要注意简化网站的结构,去除不必要和不必要的冗余代码,因为这些都会影响爬行器爬行网页的效率和效果。此外,我们还需要注意一个事实,我们不建议在网站中放置flash,因为蜘蛛很难抓到flash。太多的闪光灯会导致蜘蛛放弃抓取你的网站页面
蜘蛛工作的第三步:高质量的文章,这可以大大提高蜘蛛抓取页面的概率
不管外链是皇帝还是内容是皇帝。这不是我们想在这里讨论的内容,但从这句话中,我们可以清楚地知道内容的重要性。同样,蜘蛛也非常重视内容。一个高质量的原创文章可以给蜘蛛留下深刻的印象,所以蜘蛛只要爬一次就迫不及待地想把它们带回来。相反,对于文章的复制品,蜘蛛很可能需要爬行几次甚至几十次才能把它带回来,而且它也很可能完全忽略它的存在
当然,这不是绝对的。我们谈论的只是一个相对的东西。在相同条件下,两个文章文章的原创文章质量较高,更容易被spider接受
spider工作的第四步:页面发布
这里的页面发布是指搜索引擎中的正常搜索。第四步之所以是这个步骤而不是索引,是因为我认为作为SEOER,我们应该尽量简化研究过程
爬行后,当爬行器将页面带回索引库时,所有内容都将不再受我们的控制,因此我跳过了这里的索引步骤,直接讨论了释放页面的步骤
在这一步中,我们还需要注意以下几点:
1、耐心。请有足够的耐心等待页面的发布。这个过程可能需要几分钟、几个小时、一天、两天甚至更长的时间
2、毅力。很多站长在建站的时候热情高涨。因此,他们将努力在车站建成前几天对其进行更新文章. 然而,过了一段时间,他突然发现自己的文章根本不是收录并失去了信心,于是他开始走捷径,要么抄袭,要么抄袭,不想自己写文章
@真的。真诚对待每一位文章和每一位用户。只有这样,我们才能真正做到网站中的内容是用户需要看到的,并且是真正高质量的原创文章 查看全部
搜索引擎如何抓取网页(蜘蛛的基本工作原理是什么?蜘蛛工作的第一步)
随着搜索引擎的不断发展和升级,搜索引擎发送的蜘蛛变得越来越智能。因此,为了了解蜘蛛的工作原理,更好地优化自身网站必须不断研究蜘蛛。现在,我们来谈谈齐鲁信息网蜘蛛的基本工作原理:
spider工作的第一步:抓取网站网页并找到正确的资源
蜘蛛有一个特点,就是它的轨迹通常是围绕着蜘蛛丝的,因此我们将搜索引擎机器人蜘蛛命名为蜘蛛。当蜘蛛来到你的网站时,它将继续沿着你的网站中的链接(蜘蛛丝)爬行。因此,如何让蜘蛛在你的网站中更好地爬行,成为我们的当务之急
在这个时候,我们经常建议站长在网站上使用更多的调用,这些调用在网站内调用一些文章,这是大多数站长的选择,无论是相关阅读、推荐阅读还是其他排行榜
蜘蛛工作的第二步:抓取你的网页
引导蜘蛛爬行。这只是一个开始。良好的开端意味着你将有一个高起点。通过其自身的内链设计,网站中没有死角,蜘蛛可以轻松到达网站中的每一页,这样蜘蛛在执行第二步抓取时会事半功倍
在这一步的爬行过程中,我们需要注意简化网站的结构,去除不必要和不必要的冗余代码,因为这些都会影响爬行器爬行网页的效率和效果。此外,我们还需要注意一个事实,我们不建议在网站中放置flash,因为蜘蛛很难抓到flash。太多的闪光灯会导致蜘蛛放弃抓取你的网站页面
蜘蛛工作的第三步:高质量的文章,这可以大大提高蜘蛛抓取页面的概率
不管外链是皇帝还是内容是皇帝。这不是我们想在这里讨论的内容,但从这句话中,我们可以清楚地知道内容的重要性。同样,蜘蛛也非常重视内容。一个高质量的原创文章可以给蜘蛛留下深刻的印象,所以蜘蛛只要爬一次就迫不及待地想把它们带回来。相反,对于文章的复制品,蜘蛛很可能需要爬行几次甚至几十次才能把它带回来,而且它也很可能完全忽略它的存在
当然,这不是绝对的。我们谈论的只是一个相对的东西。在相同条件下,两个文章文章的原创文章质量较高,更容易被spider接受
spider工作的第四步:页面发布
这里的页面发布是指搜索引擎中的正常搜索。第四步之所以是这个步骤而不是索引,是因为我认为作为SEOER,我们应该尽量简化研究过程
爬行后,当爬行器将页面带回索引库时,所有内容都将不再受我们的控制,因此我跳过了这里的索引步骤,直接讨论了释放页面的步骤
在这一步中,我们还需要注意以下几点:
1、耐心。请有足够的耐心等待页面的发布。这个过程可能需要几分钟、几个小时、一天、两天甚至更长的时间
2、毅力。很多站长在建站的时候热情高涨。因此,他们将努力在车站建成前几天对其进行更新文章. 然而,过了一段时间,他突然发现自己的文章根本不是收录并失去了信心,于是他开始走捷径,要么抄袭,要么抄袭,不想自己写文章
@真的。真诚对待每一位文章和每一位用户。只有这样,我们才能真正做到网站中的内容是用户需要看到的,并且是真正高质量的原创文章
搜索引擎如何抓取网页(一个网站图片到底是怎么抓取的呢的?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 123 次浏览 • 2021-09-13 12:06
一个网站如果所有密集的文本对用户体验非常不利,同时我不想在网站上停留一分钟或一秒钟。 网站在开发的时候,页面更加美化,体验更好会加很多图片,但是图片对于搜索引擎的蜘蛛爬行能力不如文章,文字少,很多图片。会对seo优化造成一定的困难。
图片是如何拍摄的?
1、 是最好的原创 图片。图片还是自己做的。您可以使用免费图片拼接成我们想要的图片。不要盗图。
<p>2.为了方便蜘蛛爬取,上传图片到网站时,最好将图片按照网站一栏放在对应的图片目录,或者放在一个文件夹中。 查看全部
搜索引擎如何抓取网页(一个网站图片到底是怎么抓取的呢的?(图))
一个网站如果所有密集的文本对用户体验非常不利,同时我不想在网站上停留一分钟或一秒钟。 网站在开发的时候,页面更加美化,体验更好会加很多图片,但是图片对于搜索引擎的蜘蛛爬行能力不如文章,文字少,很多图片。会对seo优化造成一定的困难。
图片是如何拍摄的?
1、 是最好的原创 图片。图片还是自己做的。您可以使用免费图片拼接成我们想要的图片。不要盗图。
<p>2.为了方便蜘蛛爬取,上传图片到网站时,最好将图片按照网站一栏放在对应的图片目录,或者放在一个文件夹中。
搜索引擎如何抓取网页( 各大多的网站采用Ajax技术解决方法放弃井号结构)
网站优化 • 优采云 发表了文章 • 0 个评论 • 218 次浏览 • 2021-09-13 12:03
各大多的网站采用Ajax技术解决方法放弃井号结构)
如何让搜索引擎抓取AJAX内容解决方案
更新时间:2014年8月25日11:51:39 投稿:hebedich
说到 AJAX,很多人都会想到 JavaScript。到目前为止,主要的搜索引擎还无法捕获由 JavaScript、ajax 和 flash 代码生成的内容。但是很多站长非常喜欢这些效果,但是各大搜索引擎都不能很好的抓取这些代码生成的内容,所以很多站长放弃了这些效果。
越来越多的网站开始采用“单页应用”。
整个网站只有一个网页,它使用Ajax技术根据用户输入加载不同的内容。
这种方式的优点是用户体验好,节省流量。缺点是 AJAX 内容无法被搜索引擎抓取。例如,您有一个网站。
http://example.com
用户可以通过哈希结构的 URL 看到不同的内容。
http://example.com#1 http://example.com#2 http://example.com#3
但是,搜索引擎只会抓取并忽略井号,因此无法将内容编入索引。
为了解决这个问题,Google提出了“井号+感叹号”的结构。
http://example.com#!1
当谷歌找到上述网址时,它会自动抓取另一个网址:
http://example.com/?_escaped_fragment_=1
只要你把 AJAX 内容放在这个 URL 上,Google 就会收录。但问题是“井号+感叹号”非常丑陋和繁琐。推特以前用的就是这个结构,把
http://twitter.com/ruanyf
改为
http://twitter.com/#!/ruanyf
结果用户一再投诉,只用了半年就废了。
那么,有什么方法可以让搜索引擎在保持更直观的 URL 的同时抓取 AJAX 内容?
我一直觉得没有办法,直到两天前看到Discourse创始人之一Robin Ward的解决方案,我才忍不住尖叫。
Discourse 是一个严重依赖 Ajax 的论坛程序,但它必须让 Google收录content。其解决方案是放弃hashtag结构,采用History API。
所谓的History API,是指在不刷新页面的情况下,改变浏览器地址栏中显示的URL(准确的说是改变网页的当前状态)。这是一个示例,您单击上面的按钮开始播放音乐。然后,点击下面的链接看看发生了什么?
地址栏中的URL已更改,但音乐播放并未中断!
History API 的详细介绍超出了本文章 的范围。简单的说到这里,它的作用就是给浏览器的History对象添加一条记录。
window.history.pushState(state object, title, url);
上面这行命令可以让地址栏中出现一个新的 URL。 History对象的pushState方法接受三个参数,新的URL为第三个参数,前两个参数可以为null。
window.history.pushState(null, null, newURL);
目前主流浏览器都支持这种方式:Chrome(26.0+)、Firefox(20.0+)、IE(10.0+)、Safari(5.1+) , 歌剧 (12.1+).
以下是 Robin Ward 的方法。
首先用History API替换井号结构,让每个井号都变成一个正常路径的URL,这样搜索引擎就会抓取每一个网页。
example.com/1 example.com/2 example.com/3
接下来,定义一个 JavaScript 函数来处理 Ajax 部分并根据 URL 抓取内容(假设使用 jQuery)。
function anchorClick(link) {<br /> var linkSplit = link.split('/').pop();<br /> $.get('api/' + linkSplit, function(data) {<br /> $('#content').html(data);<br /> });<br /> }
再次定义鼠标的点击事件。
$('#container').on('click', 'a', function(e) {<br /> window.history.pushState(null, null, $(this).attr('href'));<br /> anchorClick($(this).attr('href'));<br /> e.preventDefault();<br /> });
还要考虑用户点击浏览器的“前进/后退”按钮。这时候会触发History对象的popstate事件。
window.addEventListener('popstate', function(e) { <br /> anchorClick(location.pathname); <br /> });
定义以上三段代码后,无需刷新页面即可显示正常路径URL和AJAX内容。
最后,设置服务器端。
因为没有使用hash结构,所以每个URL都是不同的请求。因此,服务器需要向所有这些请求返回具有以下结构的网页,以防止 404 错误。
<br /> <br /> <br /> <br /> ... ...<br /> <br /> <br />
仔细看上面的代码,你会发现一个noscript标签,这就是秘密。
我们把所有想要搜索引擎收录的内容放在noscript标签中。在这种情况下,用户仍然可以在不刷新页面的情况下进行AJAX操作,但是搜索引擎会收录每个页面的主要内容! 查看全部
搜索引擎如何抓取网页(
各大多的网站采用Ajax技术解决方法放弃井号结构)
如何让搜索引擎抓取AJAX内容解决方案
更新时间:2014年8月25日11:51:39 投稿:hebedich
说到 AJAX,很多人都会想到 JavaScript。到目前为止,主要的搜索引擎还无法捕获由 JavaScript、ajax 和 flash 代码生成的内容。但是很多站长非常喜欢这些效果,但是各大搜索引擎都不能很好的抓取这些代码生成的内容,所以很多站长放弃了这些效果。
越来越多的网站开始采用“单页应用”。
整个网站只有一个网页,它使用Ajax技术根据用户输入加载不同的内容。
这种方式的优点是用户体验好,节省流量。缺点是 AJAX 内容无法被搜索引擎抓取。例如,您有一个网站。
http://example.com
用户可以通过哈希结构的 URL 看到不同的内容。
http://example.com#1 http://example.com#2 http://example.com#3
但是,搜索引擎只会抓取并忽略井号,因此无法将内容编入索引。
为了解决这个问题,Google提出了“井号+感叹号”的结构。
http://example.com#!1
当谷歌找到上述网址时,它会自动抓取另一个网址:
http://example.com/?_escaped_fragment_=1
只要你把 AJAX 内容放在这个 URL 上,Google 就会收录。但问题是“井号+感叹号”非常丑陋和繁琐。推特以前用的就是这个结构,把
http://twitter.com/ruanyf
改为
http://twitter.com/#!/ruanyf
结果用户一再投诉,只用了半年就废了。
那么,有什么方法可以让搜索引擎在保持更直观的 URL 的同时抓取 AJAX 内容?
我一直觉得没有办法,直到两天前看到Discourse创始人之一Robin Ward的解决方案,我才忍不住尖叫。
Discourse 是一个严重依赖 Ajax 的论坛程序,但它必须让 Google收录content。其解决方案是放弃hashtag结构,采用History API。
所谓的History API,是指在不刷新页面的情况下,改变浏览器地址栏中显示的URL(准确的说是改变网页的当前状态)。这是一个示例,您单击上面的按钮开始播放音乐。然后,点击下面的链接看看发生了什么?
地址栏中的URL已更改,但音乐播放并未中断!
History API 的详细介绍超出了本文章 的范围。简单的说到这里,它的作用就是给浏览器的History对象添加一条记录。
window.history.pushState(state object, title, url);
上面这行命令可以让地址栏中出现一个新的 URL。 History对象的pushState方法接受三个参数,新的URL为第三个参数,前两个参数可以为null。
window.history.pushState(null, null, newURL);
目前主流浏览器都支持这种方式:Chrome(26.0+)、Firefox(20.0+)、IE(10.0+)、Safari(5.1+) , 歌剧 (12.1+).
以下是 Robin Ward 的方法。
首先用History API替换井号结构,让每个井号都变成一个正常路径的URL,这样搜索引擎就会抓取每一个网页。
example.com/1 example.com/2 example.com/3
接下来,定义一个 JavaScript 函数来处理 Ajax 部分并根据 URL 抓取内容(假设使用 jQuery)。
function anchorClick(link) {<br /> var linkSplit = link.split('/').pop();<br /> $.get('api/' + linkSplit, function(data) {<br /> $('#content').html(data);<br /> });<br /> }
再次定义鼠标的点击事件。
$('#container').on('click', 'a', function(e) {<br /> window.history.pushState(null, null, $(this).attr('href'));<br /> anchorClick($(this).attr('href'));<br /> e.preventDefault();<br /> });
还要考虑用户点击浏览器的“前进/后退”按钮。这时候会触发History对象的popstate事件。
window.addEventListener('popstate', function(e) { <br /> anchorClick(location.pathname); <br /> });
定义以上三段代码后,无需刷新页面即可显示正常路径URL和AJAX内容。
最后,设置服务器端。
因为没有使用hash结构,所以每个URL都是不同的请求。因此,服务器需要向所有这些请求返回具有以下结构的网页,以防止 404 错误。
<br /> <br /> <br /> <br /> ... ...<br /> <br /> <br />
仔细看上面的代码,你会发现一个noscript标签,这就是秘密。
我们把所有想要搜索引擎收录的内容放在noscript标签中。在这种情况下,用户仍然可以在不刷新页面的情况下进行AJAX操作,但是搜索引擎会收录每个页面的主要内容!
搜索引擎如何抓取网页(国外文章(谷歌翻译)对html标签的评分)
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-09-13 08:16
今天偶然看到的一篇外文文章(谷歌翻译)。挺有意思的,主要是对常见的html标签打分的形式。虽然有些描述略显过时,但大部分标签的分析还是很有相关性的。在这里做个记录,方便以后做wordpress主题的时候合理布局(x)个html标签。
先看搜索引擎对html标签的评分:
内部链接文本:10 分
标题:10分
域名:7分
H1、H2 字号标题:5 分
每段第一句:5分
路径或文件名:4分
相似度(关键词stacking):4 分
每句开头:1.5分
粗体或斜体:1分
文字使用(内容):1分
title属性:1分(注意不是title>,是title属性,比如a href=...title=”)
alt 标签:0.5 分
Meta description(描述属性):0.5分
Meta关键词(关键字属性):0.05分
标签是最常用的。以后选择模板的时候一定要注意优化网站。以下是具体的优化建议:
1、静态页面
更改信息页面和频道,网站首页为静态页面,这将有助于搜索引擎更快更好地收录。
关键词2、页面标题优化
必须列出信息标题、网站名称以及相关关键词。
3、 Meta tag优化(过去搜索引擎优化的重要方法已经不再是关键因素,但仍然不能忽视)
主要包括:Meta描述,Meta关键字将关键字密度设置为适中,通常为2%-8%,这意味着您的关键字必须在页面上出现多次,或者在搜索引擎允许的范围内,以避免填充关键字。
4、 为 Google 制作站点地图
Google 的站点地图是原创 robots.txt 的扩展。它采用XML格式记录整个网站信息并供谷歌阅读,让搜索引擎能够更快更全面的收录网站内容。
可以使用谷歌提供的Sitemap生成器制作(需要技术人员制作):
技术人员也可以制作更全面的站点地图。
5、关键词图片优化
不要忽略图片的替换关键词。另一个功能是当图片无法显示时,可以给访问者一个替代的解释语句。
6、 避免表格嵌套
目前,此站点上的表格嵌套过多。搜索引擎通常只读取 3 个嵌套的 。如果嵌套太多,将无法检测到一些有用的信息。
7、 网站refactoring 使用网络标准
尽量使网站的代码符合W3C的HTML4.0或XHTML1.0规范。通过XML+CSS技术重构网站,减少无格式和冗余代码,提高网站页面的可扩展性和兼容性,让更多浏览器支持。
8、网站结构平面规划
目录和内容结构不应超过三层。如果超过三个级别,最好通过子域调整和简化结构级别的数量。另外,目录命名的标准做法是使用英文而不是拼音字母
9、 页面容量的合理化
合理的页面容量会提高网页的显示速度,增加搜索引擎蜘蛛的友好度。同时建议js脚本和css脚本尽量使用链接文件
10、外部文件策略
将javascript文件和css文件分别放在js和css外部文件中。这样做的好处是将重要的页面内容放在页面顶部,同时减少文件大小。有利于搜索引擎快速准确的抓取页面的重要内容。其他字体(FONT)和格式标签也尽量少用,推荐使用CSS定义。
11、external link
尽量让其他与你话题相关的网站链接到本站,并尽量链接到PR值更高的网站。如果网站提供与话题相关的导出链接,搜索引擎认为与该话题相关的内容丰富,也有利于排名,比如各种招商引资网站和投融资网站的概念。此外,无论质量如何,都应避免大规模联网。对于搜索引擎,最好是不那么精确。
12、网站Map
网站自己的网站map是搜索引擎更全面索引收录你的网站的重要因素。建议制作基于文本的网站地图,其中收录网站的所有列和子列。 网站map 的三大要素:文本、链接、关键词,对搜索引擎抓取主页内容极其有帮助。特别是动态生成的目录网站尤其需要创建网站映射。
13、图像热点
除AltaVista和Google明确支持图片热链接外,其他引擎目前不支持。当“蜘蛛”程序遇到这种结构时,将无法区分它。所以尽量不要设置图片热点(Image Map)链接。
14、FLASH 应用
FLASH不收录文字信息,所以尽量用于功能展示和广告,网站栏目和页面少用。
15、JS 脚本
在不支持JS脚本的浏览器中,NOSCRIPT>标签会起到重要的提醒作用,对搜索引擎的蜘蛛搜索也有帮助。
16、帧帧
搜索将忽略 Frame 标记。尽量少用。如果必须使用它,则应正确使用 Noframe 标签。在 Noframe>/Noframe> 区域中,收录指向框架页面的链接或带有 关键词 的描述文本。同时关键词文字也出现在框外。
17、news 内部链接 查看全部
搜索引擎如何抓取网页(国外文章(谷歌翻译)对html标签的评分)
今天偶然看到的一篇外文文章(谷歌翻译)。挺有意思的,主要是对常见的html标签打分的形式。虽然有些描述略显过时,但大部分标签的分析还是很有相关性的。在这里做个记录,方便以后做wordpress主题的时候合理布局(x)个html标签。
先看搜索引擎对html标签的评分:
内部链接文本:10 分
标题:10分
域名:7分
H1、H2 字号标题:5 分
每段第一句:5分
路径或文件名:4分
相似度(关键词stacking):4 分
每句开头:1.5分
粗体或斜体:1分
文字使用(内容):1分
title属性:1分(注意不是title>,是title属性,比如a href=...title=”)
alt 标签:0.5 分
Meta description(描述属性):0.5分
Meta关键词(关键字属性):0.05分
标签是最常用的。以后选择模板的时候一定要注意优化网站。以下是具体的优化建议:
1、静态页面
更改信息页面和频道,网站首页为静态页面,这将有助于搜索引擎更快更好地收录。
关键词2、页面标题优化
必须列出信息标题、网站名称以及相关关键词。
3、 Meta tag优化(过去搜索引擎优化的重要方法已经不再是关键因素,但仍然不能忽视)
主要包括:Meta描述,Meta关键字将关键字密度设置为适中,通常为2%-8%,这意味着您的关键字必须在页面上出现多次,或者在搜索引擎允许的范围内,以避免填充关键字。
4、 为 Google 制作站点地图
Google 的站点地图是原创 robots.txt 的扩展。它采用XML格式记录整个网站信息并供谷歌阅读,让搜索引擎能够更快更全面的收录网站内容。
可以使用谷歌提供的Sitemap生成器制作(需要技术人员制作):
技术人员也可以制作更全面的站点地图。
5、关键词图片优化
不要忽略图片的替换关键词。另一个功能是当图片无法显示时,可以给访问者一个替代的解释语句。
6、 避免表格嵌套
目前,此站点上的表格嵌套过多。搜索引擎通常只读取 3 个嵌套的 。如果嵌套太多,将无法检测到一些有用的信息。
7、 网站refactoring 使用网络标准
尽量使网站的代码符合W3C的HTML4.0或XHTML1.0规范。通过XML+CSS技术重构网站,减少无格式和冗余代码,提高网站页面的可扩展性和兼容性,让更多浏览器支持。
8、网站结构平面规划
目录和内容结构不应超过三层。如果超过三个级别,最好通过子域调整和简化结构级别的数量。另外,目录命名的标准做法是使用英文而不是拼音字母
9、 页面容量的合理化
合理的页面容量会提高网页的显示速度,增加搜索引擎蜘蛛的友好度。同时建议js脚本和css脚本尽量使用链接文件
10、外部文件策略
将javascript文件和css文件分别放在js和css外部文件中。这样做的好处是将重要的页面内容放在页面顶部,同时减少文件大小。有利于搜索引擎快速准确的抓取页面的重要内容。其他字体(FONT)和格式标签也尽量少用,推荐使用CSS定义。
11、external link
尽量让其他与你话题相关的网站链接到本站,并尽量链接到PR值更高的网站。如果网站提供与话题相关的导出链接,搜索引擎认为与该话题相关的内容丰富,也有利于排名,比如各种招商引资网站和投融资网站的概念。此外,无论质量如何,都应避免大规模联网。对于搜索引擎,最好是不那么精确。
12、网站Map
网站自己的网站map是搜索引擎更全面索引收录你的网站的重要因素。建议制作基于文本的网站地图,其中收录网站的所有列和子列。 网站map 的三大要素:文本、链接、关键词,对搜索引擎抓取主页内容极其有帮助。特别是动态生成的目录网站尤其需要创建网站映射。
13、图像热点
除AltaVista和Google明确支持图片热链接外,其他引擎目前不支持。当“蜘蛛”程序遇到这种结构时,将无法区分它。所以尽量不要设置图片热点(Image Map)链接。
14、FLASH 应用
FLASH不收录文字信息,所以尽量用于功能展示和广告,网站栏目和页面少用。
15、JS 脚本
在不支持JS脚本的浏览器中,NOSCRIPT>标签会起到重要的提醒作用,对搜索引擎的蜘蛛搜索也有帮助。
16、帧帧
搜索将忽略 Frame 标记。尽量少用。如果必须使用它,则应正确使用 Noframe 标签。在 Noframe>/Noframe> 区域中,收录指向框架页面的链接或带有 关键词 的描述文本。同时关键词文字也出现在框外。
17、news 内部链接
搜索引擎如何抓取网页(有关url的页面抓取过程讲述url页面的抓取流程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-09-13 08:13
url,即统一资源定位器,通过对url的分析,可以更好的了解页面的爬取过程。今天给大家讲讲URL页面的抓取过程。
一、url 是什么意思?
URL,英文全称是“uniform resource locator”,中文翻译是“uniform resource locator”。
在网站优化中,要求每个页面只有一个唯一的统一资源定位符(URL),但往往很多网站对应同一页面上的多个URL,如果都被搜索引擎搜索到的话收录而且没有URL重定向,权重不集中,通常称为URL不规则。
二、url 的组成
Uniform Resource Locator (URL) 由三部分组成:协议方案、主机名和资源名。
例如:
www.***.com /sitemap.html
其中,https为协议方案,***.com为主机名,sitemap.html为资源。当然也可以是.pdf、.php、.word等格式。
三、页面抓取过程简述
无论是我们平时使用的网络浏览器还是网络爬虫,虽然有两个不同的客户端,但是获取页面的方式是一样的。页面抓取过程如下:
①连接DNS服务器
客户端会先连接DNS域名服务器,DNS服务器将主机名(***.com)转换成IP地址发回给客户端。
PS:本来我们用125.52.10.45这个地址来访问某个网站。为了便于记忆和使用,我们使用DNS域名系统转换为***.com。这就是 DNS 域名系统的作用。
②连接IP地址服务器
这个IP服务器下可能有很多程序(网站),可以通过端口号来区分。同时每个程序(网站)都会监听新的连接请求的端口,HTTP网站默认是80,HTTPS网站默认是443。
不过,一般情况下,80和443端口号默认是不会出现的。
例如:
***.com:443/ = ***.com/
***.com:80/ = ***.com/
③ 建立连接并发送页面请求
客户端与服务器建立连接后,会发送一个页面请求,通常是get或者post。
获取站点地图.html HTTPS/1.0
获取HTTPS协议下的页面站点地图并返回给客户端。如果稍后需要获取更多页面,请发送另一个请求,否则将关闭连接。
PS:一般情况下,/seo/sitemap.html 可能会更清晰一些。也就是在***.com/下的seo文件夹中发送sitemap.html的页面请求。 查看全部
搜索引擎如何抓取网页(有关url的页面抓取过程讲述url页面的抓取流程)
url,即统一资源定位器,通过对url的分析,可以更好的了解页面的爬取过程。今天给大家讲讲URL页面的抓取过程。
一、url 是什么意思?
URL,英文全称是“uniform resource locator”,中文翻译是“uniform resource locator”。
在网站优化中,要求每个页面只有一个唯一的统一资源定位符(URL),但往往很多网站对应同一页面上的多个URL,如果都被搜索引擎搜索到的话收录而且没有URL重定向,权重不集中,通常称为URL不规则。
二、url 的组成
Uniform Resource Locator (URL) 由三部分组成:协议方案、主机名和资源名。
例如:
www.***.com /sitemap.html
其中,https为协议方案,***.com为主机名,sitemap.html为资源。当然也可以是.pdf、.php、.word等格式。
三、页面抓取过程简述
无论是我们平时使用的网络浏览器还是网络爬虫,虽然有两个不同的客户端,但是获取页面的方式是一样的。页面抓取过程如下:
①连接DNS服务器
客户端会先连接DNS域名服务器,DNS服务器将主机名(***.com)转换成IP地址发回给客户端。
PS:本来我们用125.52.10.45这个地址来访问某个网站。为了便于记忆和使用,我们使用DNS域名系统转换为***.com。这就是 DNS 域名系统的作用。
②连接IP地址服务器
这个IP服务器下可能有很多程序(网站),可以通过端口号来区分。同时每个程序(网站)都会监听新的连接请求的端口,HTTP网站默认是80,HTTPS网站默认是443。
不过,一般情况下,80和443端口号默认是不会出现的。
例如:
***.com:443/ = ***.com/
***.com:80/ = ***.com/
③ 建立连接并发送页面请求
客户端与服务器建立连接后,会发送一个页面请求,通常是get或者post。
获取站点地图.html HTTPS/1.0
获取HTTPS协议下的页面站点地图并返回给客户端。如果稍后需要获取更多页面,请发送另一个请求,否则将关闭连接。
PS:一般情况下,/seo/sitemap.html 可能会更清晰一些。也就是在***.com/下的seo文件夹中发送sitemap.html的页面请求。
搜索引擎如何抓取网页(搜索引擎如何抓取网页分析网页,检测你和浏览器的不同)
网站优化 • 优采云 发表了文章 • 0 个评论 • 112 次浏览 • 2021-09-12 22:06
搜索引擎如何抓取网页分析网页,判断用户输入的关键词和用户行为,提供更多的工具,其中最重要的一点是识别web浏览器。从上周开始,让我们专注于网页抓取的顶级大会cscope,可以说在技术及网页抓取上有了长足的进步。今天我们会解释如何利用web浏览器,检测你和浏览器的不同(至少是大部分区别)。工作机制web浏览器作为大名鼎鼎的浏览器,有很多模块来实现网页抓取的工作。
当web浏览器在获取不同内容时,它们会创建一个属于该网页的id和自定义web浏览器名称。从前端抓取数据时,web浏览器需要获取id(所以基本上最先获取的数据都是经过这个手段创建的),而为了让它的逻辑更简单,一些id(如index.js和index.php)会被定义为类。index.js是web页面的web浏览器名称,index.php是网页的外部脚本标识,最后一个称为web页面域名或web.php。
然后这个web页面具有加载次数的限制,在你没有ssr或cdn缓存的情况下,它需要一定次数的加载。因此,web浏览器的内容架构要包括:web请求交互文档名称web格式的内容名称web目录是web页面的容器,里面有文档和二进制数据。然后请求交互,我们可以根据http/1.1协议(ssl协议会使用http/2),将web上的请求用于web浏览器。
我们可以将整个文档用同一http/1.1协议接收。现在一些web浏览器已经支持加载http/2的二进制格式文件。另一些web浏览器将web页面dom渲染为样式表。请求交互是请求者在网页上发起的所有不同请求的总和。通常,在发起web请求时,服务器不会返回响应数据。在发送请求时,这些响应用于服务器的连接;接受请求并使用它们来使服务器处理请求。
请求会让浏览器打开web浏览器dom,并在页面上执行指定的操作。一个示例:从页面直接访问:url:(xmlhttprequest是python中的web库,用于调用网页,构建http连接,发送url请求)这个代码为web浏览器发起请求(发送请求意味着将你发出的请求传给网页,你会看到如何获取数据),定义一个指定的网址pageurl,或者host。
然后通过http/1.1协议发送请求请求期间,将你的请求返回给服务器,网站会使用浏览器返回的响应数据,以dom方式渲染web页面(然后它会返回给你)。浏览器不返回你的index.php文件(请求之前),但请求者会去请求页面上的body(内容),以dom方式渲染页面(请求之后)。当ajax请求处理完毕时,服务器将如何与浏览器交互?当ajax请求发送完毕时,浏。 查看全部
搜索引擎如何抓取网页(搜索引擎如何抓取网页分析网页,检测你和浏览器的不同)
搜索引擎如何抓取网页分析网页,判断用户输入的关键词和用户行为,提供更多的工具,其中最重要的一点是识别web浏览器。从上周开始,让我们专注于网页抓取的顶级大会cscope,可以说在技术及网页抓取上有了长足的进步。今天我们会解释如何利用web浏览器,检测你和浏览器的不同(至少是大部分区别)。工作机制web浏览器作为大名鼎鼎的浏览器,有很多模块来实现网页抓取的工作。
当web浏览器在获取不同内容时,它们会创建一个属于该网页的id和自定义web浏览器名称。从前端抓取数据时,web浏览器需要获取id(所以基本上最先获取的数据都是经过这个手段创建的),而为了让它的逻辑更简单,一些id(如index.js和index.php)会被定义为类。index.js是web页面的web浏览器名称,index.php是网页的外部脚本标识,最后一个称为web页面域名或web.php。
然后这个web页面具有加载次数的限制,在你没有ssr或cdn缓存的情况下,它需要一定次数的加载。因此,web浏览器的内容架构要包括:web请求交互文档名称web格式的内容名称web目录是web页面的容器,里面有文档和二进制数据。然后请求交互,我们可以根据http/1.1协议(ssl协议会使用http/2),将web上的请求用于web浏览器。
我们可以将整个文档用同一http/1.1协议接收。现在一些web浏览器已经支持加载http/2的二进制格式文件。另一些web浏览器将web页面dom渲染为样式表。请求交互是请求者在网页上发起的所有不同请求的总和。通常,在发起web请求时,服务器不会返回响应数据。在发送请求时,这些响应用于服务器的连接;接受请求并使用它们来使服务器处理请求。
请求会让浏览器打开web浏览器dom,并在页面上执行指定的操作。一个示例:从页面直接访问:url:(xmlhttprequest是python中的web库,用于调用网页,构建http连接,发送url请求)这个代码为web浏览器发起请求(发送请求意味着将你发出的请求传给网页,你会看到如何获取数据),定义一个指定的网址pageurl,或者host。
然后通过http/1.1协议发送请求请求期间,将你的请求返回给服务器,网站会使用浏览器返回的响应数据,以dom方式渲染web页面(然后它会返回给你)。浏览器不返回你的index.php文件(请求之前),但请求者会去请求页面上的body(内容),以dom方式渲染页面(请求之后)。当ajax请求处理完毕时,服务器将如何与浏览器交互?当ajax请求发送完毕时,浏。
搜索引擎如何抓取网页(基于云端的爬虫实现方式有好几种,怎么抓取网页数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-09-12 06:00
搜索引擎如何抓取网页数据?
一、怎么抓取网页抓取网页看似是个小菜,但是真正抓取到自己想要的数据却是一个难题。目前基于云端的爬虫实现方式有好几种,这里仅介绍phantomjs对于网页爬虫服务提供商而言,phantomjs可以开放api,能抓取所有的pc网页和移动网页。
(不能抓取h
5)支持的网站可以到这里看:phantomjs爬虫,一个简单易用的htmlf12检查框架,
二、怎么抓取数据api接口地址:,ping/stats,只支持gzip压缩,缓存ie扩展浏览器能用。1.怎么抓取文章列表文章列表爬虫很简单,拿到url后,获取个人信息。
基本使用方法:api返回://查看帐号获取最新的文章列表response对象标志rssrecipientdocument。getelementbyid("tb_appkey")。spider。removelink,recipient。removelink2。怎么抓取文章列表2。1查看访问了多少次headersurl:url2。
2获取标题目录定位属性id,id则是文章标题的上限数量,即博客内容最多能包含的长度url_author='username'document。queryselector("style")。maximum(-。
1).min().returnheaders['src'];headers['user-agent']="mozilla/5.0(windowsnt6.1;wow6
4)applewebkit/537。36(khtml,likegecko)chrome/68。3475。121safari/537。36"placeholder=""response。setheader('content-type','text/html;charset=utf-8')response。
setheader('content-length','1')response。setheader('content-type','text/html;charset=utf-8')response。setheader('language','en')response。
setheader('accept-encoding','gzip')response。setheader('accept-language','zh-cn')response。setheader('content-length',。
2)response。setheader('content-type','text/html;charset=utf-8')response。setheader('content-type','text/x-www-form-urlencoded')response。setheader('user-agent','mozilla/5。0(windowsnt6。1;wow6。
4)applewebkit/537.36(khtml,likegecko)chrome/68.0.3475.121safari/537.36')response.setheader('user-agent','mozilla/5.0(windowsnt6.1;wow6
4)applewebkit/537 查看全部
搜索引擎如何抓取网页(基于云端的爬虫实现方式有好几种,怎么抓取网页数据)
搜索引擎如何抓取网页数据?
一、怎么抓取网页抓取网页看似是个小菜,但是真正抓取到自己想要的数据却是一个难题。目前基于云端的爬虫实现方式有好几种,这里仅介绍phantomjs对于网页爬虫服务提供商而言,phantomjs可以开放api,能抓取所有的pc网页和移动网页。
(不能抓取h
5)支持的网站可以到这里看:phantomjs爬虫,一个简单易用的htmlf12检查框架,
二、怎么抓取数据api接口地址:,ping/stats,只支持gzip压缩,缓存ie扩展浏览器能用。1.怎么抓取文章列表文章列表爬虫很简单,拿到url后,获取个人信息。
基本使用方法:api返回://查看帐号获取最新的文章列表response对象标志rssrecipientdocument。getelementbyid("tb_appkey")。spider。removelink,recipient。removelink2。怎么抓取文章列表2。1查看访问了多少次headersurl:url2。
2获取标题目录定位属性id,id则是文章标题的上限数量,即博客内容最多能包含的长度url_author='username'document。queryselector("style")。maximum(-。
1).min().returnheaders['src'];headers['user-agent']="mozilla/5.0(windowsnt6.1;wow6
4)applewebkit/537。36(khtml,likegecko)chrome/68。3475。121safari/537。36"placeholder=""response。setheader('content-type','text/html;charset=utf-8')response。
setheader('content-length','1')response。setheader('content-type','text/html;charset=utf-8')response。setheader('language','en')response。
setheader('accept-encoding','gzip')response。setheader('accept-language','zh-cn')response。setheader('content-length',。
2)response。setheader('content-type','text/html;charset=utf-8')response。setheader('content-type','text/x-www-form-urlencoded')response。setheader('user-agent','mozilla/5。0(windowsnt6。1;wow6。
4)applewebkit/537.36(khtml,likegecko)chrome/68.0.3475.121safari/537.36')response.setheader('user-agent','mozilla/5.0(windowsnt6.1;wow6
4)applewebkit/537
搜索引擎如何抓取网页(搜索引擎抓取三步曲搜索蜘蛛如何提升网站内容收录和1))
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-09-10 15:04
2、搜索引擎抓取三步
对于新的网页内容,搜索蜘蛛会先抓取网页链接,然后对网页链接内容进行分析过滤。符合收录标准的内容将是收录,不符合收录标准的内容将被直接删除。现在按照搜索算法规则对收录的内容进行排序,最后呈现关键词查询和排序结果。
由于我们只需要知道搜索引擎蜘蛛抓取的三个步骤,所以是一个“抓取——过滤——收录”的过程。
二、如何提高爬行和减少过滤
搜索引擎蜘蛛以匿名身份抓取所有网络内容。如果您的网页内容被加密,需要输入帐号密码才能访问,则该网页搜索引擎无法正常抓取。网页只能在开放加密权限的情况下被抓取。如果您的网页内容需要参与搜索排名,您必须注意不要限制搜索引擎抓取网页内容。
搜索引擎无法识别图片、视频、JS文件、flash动画、iame框架等没有ALT属性的内容。搜索引擎只能识别文本和数字。如果您的网页上有任何搜索引擎无法识别的内容,很有可能被搜索引擎蜘蛛过滤掉,所以我们在设计网页时,一定要避免在网页中添加搜索引擎无法识别的内容。如果搜索蜘蛛无法识别您的网页内容,那么收录 和排名怎么办?
搜索蜘蛛抓取网页内容后,第一步是过滤,过滤掉不符合搜索引擎收录标准的内容。搜索蜘蛛收录网页内容的基本步骤是筛选、剔除、重新筛选,收录到官方索引库,官方收录网页之后,下一步就是分析当前网页的价值内容,最后确定当前网页关键词排序的位置。
过滤过滤可以简单地理解为去除没有价值和低质量的内容,保留对用户有价值和高质量的内容。如果你想提高你网站内容的收录率,建议更新更多符合搜索收录规则的有价值的优质内容,不要更新低质量的拼接垃圾内容。
三、如何改进网站content收录和索引1)什么是网站收录和索引
使用site命令查询网站的预估收录金额,例如“site:”,可以查询网站的预估收录金额,如如下图所示:
58同城网站page百度搜索收录量
网站收录率是什么意思?比如你的网站有100页,但是搜索引擎只有收录你网站10页,那么你的网站收录率是10%,网站收录率计算公式为收录率/网站总页=收录率,站点命令只能查询网站大约收录的数量,一般情况下网站页面越多,收录越多会,网站收录更多的页面意味着更多的网站流量,网站内容质量越高网站页收录率会越高,注意网站收录量不等于到网站索引量,网站收录量小于索引量。
2)如何提高网站页收录,减少网页过滤(1)如何提高网站页收录rate
如果要提高网站的收录率,必须提高网站内容的更新频率。 网站内容更新必须与网站定位一致。比如网站location是女鞋,那么你网站的网站内容更新需要围绕女鞋开发,网站更新的内容必须是高质量的,对用户有价值。
搜索引擎判断网站内容质量高低的重要参考是网站bounce rate,网站bounce rate表示内容质量越高,网站bounce rate表示内容越高质量越低,较高的跳出率意味着网站关键词排名不会那么好。
(2)如何降低网页过滤和剔除率
不要更新对用户没有价值的低质量垃圾内容。注意内容的质量。 100个低质量的内容还不如一个高质量的原创内容。比如有的站长用采集工具向网站内容导入了很多低质量的垃圾内容,而搜索引擎没有收录这样的内容,所以网站内容的质量度与网站成正比@收录 率。
对于相同的内容,哪个网站重重高会先于收录哪个网站内容,所以网站收录率也和网站重重值有一定的关系,那就是也与网站内容更新时间有关。 网站先收录先更新,收录后更新。
对用户完全没有价值的垃圾内容,搜索引擎不会收录,即使被搜索蜘蛛抓取,也会被过滤掉。
4、关键词查询和排序搜索结果输出
测序是最后一步。 网站关键词sorting 不会立即产生结果。其实分析在搜索引擎为网站内容页建立索引库的时候就已经开始了,分析网站页的质量,比如站点结构优化、站点和站点投票值、关键词密度等,这些决定了网站页关键词的顺序,简单的说就是当我们在搜索引擎中搜索一个关键词时,这个关键词的排名是搜索引擎分析计算的结果。 查看全部
搜索引擎如何抓取网页(搜索引擎抓取三步曲搜索蜘蛛如何提升网站内容收录和1))
2、搜索引擎抓取三步
对于新的网页内容,搜索蜘蛛会先抓取网页链接,然后对网页链接内容进行分析过滤。符合收录标准的内容将是收录,不符合收录标准的内容将被直接删除。现在按照搜索算法规则对收录的内容进行排序,最后呈现关键词查询和排序结果。
由于我们只需要知道搜索引擎蜘蛛抓取的三个步骤,所以是一个“抓取——过滤——收录”的过程。
二、如何提高爬行和减少过滤
搜索引擎蜘蛛以匿名身份抓取所有网络内容。如果您的网页内容被加密,需要输入帐号密码才能访问,则该网页搜索引擎无法正常抓取。网页只能在开放加密权限的情况下被抓取。如果您的网页内容需要参与搜索排名,您必须注意不要限制搜索引擎抓取网页内容。
搜索引擎无法识别图片、视频、JS文件、flash动画、iame框架等没有ALT属性的内容。搜索引擎只能识别文本和数字。如果您的网页上有任何搜索引擎无法识别的内容,很有可能被搜索引擎蜘蛛过滤掉,所以我们在设计网页时,一定要避免在网页中添加搜索引擎无法识别的内容。如果搜索蜘蛛无法识别您的网页内容,那么收录 和排名怎么办?
搜索蜘蛛抓取网页内容后,第一步是过滤,过滤掉不符合搜索引擎收录标准的内容。搜索蜘蛛收录网页内容的基本步骤是筛选、剔除、重新筛选,收录到官方索引库,官方收录网页之后,下一步就是分析当前网页的价值内容,最后确定当前网页关键词排序的位置。
过滤过滤可以简单地理解为去除没有价值和低质量的内容,保留对用户有价值和高质量的内容。如果你想提高你网站内容的收录率,建议更新更多符合搜索收录规则的有价值的优质内容,不要更新低质量的拼接垃圾内容。
三、如何改进网站content收录和索引1)什么是网站收录和索引
使用site命令查询网站的预估收录金额,例如“site:”,可以查询网站的预估收录金额,如如下图所示:
58同城网站page百度搜索收录量
网站收录率是什么意思?比如你的网站有100页,但是搜索引擎只有收录你网站10页,那么你的网站收录率是10%,网站收录率计算公式为收录率/网站总页=收录率,站点命令只能查询网站大约收录的数量,一般情况下网站页面越多,收录越多会,网站收录更多的页面意味着更多的网站流量,网站内容质量越高网站页收录率会越高,注意网站收录量不等于到网站索引量,网站收录量小于索引量。
2)如何提高网站页收录,减少网页过滤(1)如何提高网站页收录rate
如果要提高网站的收录率,必须提高网站内容的更新频率。 网站内容更新必须与网站定位一致。比如网站location是女鞋,那么你网站的网站内容更新需要围绕女鞋开发,网站更新的内容必须是高质量的,对用户有价值。
搜索引擎判断网站内容质量高低的重要参考是网站bounce rate,网站bounce rate表示内容质量越高,网站bounce rate表示内容越高质量越低,较高的跳出率意味着网站关键词排名不会那么好。
(2)如何降低网页过滤和剔除率
不要更新对用户没有价值的低质量垃圾内容。注意内容的质量。 100个低质量的内容还不如一个高质量的原创内容。比如有的站长用采集工具向网站内容导入了很多低质量的垃圾内容,而搜索引擎没有收录这样的内容,所以网站内容的质量度与网站成正比@收录 率。
对于相同的内容,哪个网站重重高会先于收录哪个网站内容,所以网站收录率也和网站重重值有一定的关系,那就是也与网站内容更新时间有关。 网站先收录先更新,收录后更新。
对用户完全没有价值的垃圾内容,搜索引擎不会收录,即使被搜索蜘蛛抓取,也会被过滤掉。
4、关键词查询和排序搜索结果输出
测序是最后一步。 网站关键词sorting 不会立即产生结果。其实分析在搜索引擎为网站内容页建立索引库的时候就已经开始了,分析网站页的质量,比如站点结构优化、站点和站点投票值、关键词密度等,这些决定了网站页关键词的顺序,简单的说就是当我们在搜索引擎中搜索一个关键词时,这个关键词的排名是搜索引擎分析计算的结果。
搜索引擎如何抓取网页(一下造成百度蜘蛛一场的原因及原因分析-乐题库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-09-10 15:02
3、robots 协议:这个文件是百度蜘蛛访问的第一个文件。它会告诉百度蜘蛛哪些页面可以爬取,哪些页面不能爬取。
三、如何提高百度蜘蛛的抓取频率
百度蜘蛛会按照一定的规则抓取网站,但不能一视同仁。以下内容将对百度蜘蛛的抓取频率产生重要影响。
1、网站重量重:网站百度蜘蛛的权重越高,爬行越频繁越深
2、网站更新频率:更新频率越高,百度蜘蛛越多。
3、网站内容质量:网站内容原创多,质量高,能解决用户问题,百度会增加抓取频率。
4、导入链接:链接是页面的入口,高质量的链接可以更好地引导百度蜘蛛进入和抓取。
5、Page Depth:页面首页是否有入口,如果首页有入口,可以更好的捕捉和收录。
6、抓取频率决定了网站要建多少页收录,站长应该去哪里了解和修改这么重要的内容,可以去百度站长平台的爬取频率功能了解,如如下图:
四、什么情况下会导致百度蜘蛛抓取失败等异常情况?
部分网站网页内容优质,用户访问正常,但百度蜘蛛无法抓取。不仅会流失流量,用户还会被百度认为网站不友好,导致网站降权和收视率下降,导入网站流量减少等问题。
这里,火龙简单介绍一下导致百度蜘蛛爬行的原因:
1、Server 连接异常:异常有两种情况。一个是网站不稳定,导致百度蜘蛛爬不起来,一个是百度蜘蛛一直无法连接服务器。这个时候就需要仔细检查了。 .
2、网络运营商异常:目前国内网络运营商分为中国电信和中国联通。如果百度蜘蛛无法通过其中之一访问您的网站,请尽快联系网络运营商解决问题。
3、无法解析IP导致dns异常:当百度蜘蛛无法解析你的网站IP时,就会出现dns异常。您可以使用WHOIS查询您的网站IP是否可以解析。如果不能,需要联系域名注册商解决方案。
4、IP ban:IP禁令就是限制IP。此操作只会在特定情况下进行,所以如果您想让网站百度蜘蛛正常访问您的网站,最好不要进行此操作。
5、死链:表示页面无效,无法提供有效信息。这时候可以通过百度站长平台提交死链接。
通过以上信息,您可以大致了解百度蜘蛛抓取的原理。 收录是网站流量的保证,而百度蜘蛛爬行是收录的保证,所以网站只有符合百度蜘蛛爬行规则才能获得更好的排名和流量。 查看全部
搜索引擎如何抓取网页(一下造成百度蜘蛛一场的原因及原因分析-乐题库)
3、robots 协议:这个文件是百度蜘蛛访问的第一个文件。它会告诉百度蜘蛛哪些页面可以爬取,哪些页面不能爬取。
三、如何提高百度蜘蛛的抓取频率
百度蜘蛛会按照一定的规则抓取网站,但不能一视同仁。以下内容将对百度蜘蛛的抓取频率产生重要影响。
1、网站重量重:网站百度蜘蛛的权重越高,爬行越频繁越深
2、网站更新频率:更新频率越高,百度蜘蛛越多。
3、网站内容质量:网站内容原创多,质量高,能解决用户问题,百度会增加抓取频率。
4、导入链接:链接是页面的入口,高质量的链接可以更好地引导百度蜘蛛进入和抓取。
5、Page Depth:页面首页是否有入口,如果首页有入口,可以更好的捕捉和收录。
6、抓取频率决定了网站要建多少页收录,站长应该去哪里了解和修改这么重要的内容,可以去百度站长平台的爬取频率功能了解,如如下图:
四、什么情况下会导致百度蜘蛛抓取失败等异常情况?
部分网站网页内容优质,用户访问正常,但百度蜘蛛无法抓取。不仅会流失流量,用户还会被百度认为网站不友好,导致网站降权和收视率下降,导入网站流量减少等问题。
这里,火龙简单介绍一下导致百度蜘蛛爬行的原因:
1、Server 连接异常:异常有两种情况。一个是网站不稳定,导致百度蜘蛛爬不起来,一个是百度蜘蛛一直无法连接服务器。这个时候就需要仔细检查了。 .
2、网络运营商异常:目前国内网络运营商分为中国电信和中国联通。如果百度蜘蛛无法通过其中之一访问您的网站,请尽快联系网络运营商解决问题。
3、无法解析IP导致dns异常:当百度蜘蛛无法解析你的网站IP时,就会出现dns异常。您可以使用WHOIS查询您的网站IP是否可以解析。如果不能,需要联系域名注册商解决方案。
4、IP ban:IP禁令就是限制IP。此操作只会在特定情况下进行,所以如果您想让网站百度蜘蛛正常访问您的网站,最好不要进行此操作。
5、死链:表示页面无效,无法提供有效信息。这时候可以通过百度站长平台提交死链接。
通过以上信息,您可以大致了解百度蜘蛛抓取的原理。 收录是网站流量的保证,而百度蜘蛛爬行是收录的保证,所以网站只有符合百度蜘蛛爬行规则才能获得更好的排名和流量。
搜索引擎如何抓取网页(如何检查手机网站和手机端的图片如何总结出方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-09-10 14:18
每个页面是否有与内容相关的推荐内部链接非常重要。对用户和蜘蛛非常有帮助。
3、每个页面是否可以链接到其他相关页面
内页需要是相关推荐,栏目页、主题页、首页都是一样的,只是需要从不同的定位角度指向。
那么如何查看外部链接呢?一般使用两种方法:
1、via 域指令
你可以找出哪个网站链接到你,并检查是否有任何不受欢迎的网站在一起。如果是,应尽快处理,否则会产生影响。
2、via 友情链接
检查友情链接是否正常。比如你链接到了别人,但是别人撤销了你的链接,或者别人的网站打不开等等,你需要及时处理。
三、手机网站如何拍照
总结以下六种方法,帮助我们对网站和手机的图片进行优化,实现优化友好快速入口。
1、尽量不要盗图原创
尝试自己制作图片,有很多免费的图片素材,我们可以通过拼接来制作我们需要的图片。
我工作的时候发现可以先把我网站相关的图片保存起来,在本地进行分类标注。
网站需要图片的时候,看看相关的图片,自己动手制作一张吧。这是一个长期积累的过程,随着时间的增加,自己的材料量也会增加。熟练的话,做图就得心应手了。
2、网站图片保存路径
很多站长都没有注意到这个问题。图片上传到网站后,尽量将图片保存在一个目录中。
或者根据网站栏制作对应的图片目录,上传时路径要相对固定,这样蜘蛛就可以轻松抓取。当蜘蛛访问该目录时,它会“知道”该目录收录图片;
最好使用一些常规或有意义的方法来命名图像文件。您可以使用时间、列名或网站名称来命名。
例如:下图SEO优化可以使用名称“SEOYH2018-6-23-36”,前面的“SEOYH”是SEO优化的简写,中间是时间,最后是图片身份证。
你为什么要这样做?
其实这是为了培养被搜索引擎蜘蛛抓取的习惯,方便以后更快的识别网站image内容。让蜘蛛抓住你的心,网站被收录的几率增加,何乐而不为呢!
3、图片周围必须有相关文字
网站Picture 是一种直接向用户呈现信息的方式。搜索引擎在爬取网站内容的时候,还会检查这个文章是否有图片、视频或者表格等,
这些都是可以增加文章点值的元素。其他表格暂时不显示。这里只讲图片周围相关文字的介绍。
首先,图片周围的文字必须与图片本身的内容一致。比如你的文章说要做网站优化,里面的图片是一个菜谱的图片。这不是卖狗肉的食谱吗?
用户的访问感会极差。搜索引擎通过相关算法识别出这张图片后,也会觉得图片和文字不符,给你差评。
所以,每个文章必须至少配一张对应的图片,并且与你的网站标题相关的内容必须出现在图片周围。不仅可以帮助搜索引擎理解图片,还可以增加文章的可读性、用户友好性和相关性。
4、给图片添加alt和title标签
很多站长在添加网站图片时可能没有注意这些细节,有的可能会觉得麻烦。我希望你没有这个想法。这是一个很大的错误。
搜索引擎抓取网站图片时,atl标签是最先抓取的,也是识别图片内容最重要的核心因素之一。图片的alt属性直接告诉搜索引擎网站图片是什么,是什么意思;
title标签是用户指向这张图片时会显示的提示内容。这是增加用户体验和增加网站关键词的一个小技巧。
alt 和标题标签
还有这两个属性,方便有阅读障碍的游客。例如,盲人访问你网站时,他看不到屏幕上的内容。可能是通过读取 如果有 alt 属性,软件会直接读取 alt 属性中的文字,方便他们访问。
5、图片大小和分辨率
虽然两者看起来很像,但还是有很大的不同。对于同样大小、分辨率更高的图片,网站最终会变大。每个人都必须弄清楚这一点。
网站上的图片一直提倡使用尽可能小的图片来最大化内容。为什么会这样?
因为小尺寸图片加载速度更快,不会让访问者等待太久,尤其是在使用手机时,由于移动互联网速度和流量的限制,用户更愿意访问可以立即打开的页面。尺寸图更有优势。
在这里我们尽量平衡。在图片不失真的情况下,尺寸尽量小。
网上有很多减肥图片的工具。你可以试试看。适当压缩网站 图片。一方面可以减轻服务器带宽的压力,另一方面可以为用户提供流畅度。体验。
6、手机端自动适配
很多站长都遇到过网站访问电脑显示器上的图片是正常的,但是手机出现错位,就是大尺寸图片导致不同尺寸终端显示错位、不完整的情况。
其实这个问题很容易解决。添加图片时,宽度和高度最好不要使用绝对大小。使用百分比来解决它。
具体来说,CSS代码不能指定像素宽度:width:xxx px;只有百分比宽度:宽度:xx%;或 width:auto 没问题。
这样做的目的也是为了让百度的手机蜘蛛在抓取的时候有很好的体验,这也是为了更符合百度手机登陆页面的体验。
四、如何提高搜索引擎的抓取频率?
1、网站内容更新
搜索引擎只抓取单个页面的内容,而不是所有页面。这也是搜索引擎更新网页快照的时间较短的原因。
比如对于经常更新的页面,快照也会被频繁抓取,以便及时发现新的内容和链接,删除不存在的信息。因此,站长必须长期坚持更新网页,才能成为搜索引擎爬虫。稳定过来抢。
2、网站框架设计
网站内部框架的设计需要从多方面进行。其中,代码需要尽量简洁明了。代码过多容易导致页面过大,影响网络爬虫的抓取速度。
爬取网站时,网页Flash图片尽量少。 flash 格式的内容影响蜘蛛爬行。对于新的网站,尽量使用伪静态网址,这样整个网站'S页面都容易被抓取。
在设计中,锚文本要合理分布,不要全部关键词,适当添加一些长尾词链接。内部链接的设计也应该是流畅的,以利于权重转移。
3、网站导航设计
网站 很多公司在设计网站 时都会忽略。导航是蜘蛛爬行的关键。如果网站导航不清楚,搜索引擎在爬行时很容易迷路。 ,所以导航一定要设计合理。
这里顺便提到了锚文本的构建。站点中的锚文本有助于网络爬虫在站点上查找和爬取更多网页。但是,如果锚文本过多,很容易被认为是刻意调整。设计时一定要把握好锚文本。数量。
4、稳定更新频率
除了首页设计,网站还有其他页面。爬虫在爬行时不会将网站 上的所有网页编入索引。在他们找到重要页面之前,他们可能已经抓取了足够多的网页并离开了。
所以我们必须保持一定的更新频率。可以轻松抓取更新频繁的页面,因此可以自动抓取大量页面。同时一定要注意网站level的设计,不要太多,否则也不利于网站抢夺。 查看全部
搜索引擎如何抓取网页(如何检查手机网站和手机端的图片如何总结出方法)
每个页面是否有与内容相关的推荐内部链接非常重要。对用户和蜘蛛非常有帮助。
3、每个页面是否可以链接到其他相关页面
内页需要是相关推荐,栏目页、主题页、首页都是一样的,只是需要从不同的定位角度指向。
那么如何查看外部链接呢?一般使用两种方法:
1、via 域指令
你可以找出哪个网站链接到你,并检查是否有任何不受欢迎的网站在一起。如果是,应尽快处理,否则会产生影响。
2、via 友情链接
检查友情链接是否正常。比如你链接到了别人,但是别人撤销了你的链接,或者别人的网站打不开等等,你需要及时处理。
三、手机网站如何拍照
总结以下六种方法,帮助我们对网站和手机的图片进行优化,实现优化友好快速入口。
1、尽量不要盗图原创
尝试自己制作图片,有很多免费的图片素材,我们可以通过拼接来制作我们需要的图片。
我工作的时候发现可以先把我网站相关的图片保存起来,在本地进行分类标注。
网站需要图片的时候,看看相关的图片,自己动手制作一张吧。这是一个长期积累的过程,随着时间的增加,自己的材料量也会增加。熟练的话,做图就得心应手了。
2、网站图片保存路径
很多站长都没有注意到这个问题。图片上传到网站后,尽量将图片保存在一个目录中。
或者根据网站栏制作对应的图片目录,上传时路径要相对固定,这样蜘蛛就可以轻松抓取。当蜘蛛访问该目录时,它会“知道”该目录收录图片;
最好使用一些常规或有意义的方法来命名图像文件。您可以使用时间、列名或网站名称来命名。
例如:下图SEO优化可以使用名称“SEOYH2018-6-23-36”,前面的“SEOYH”是SEO优化的简写,中间是时间,最后是图片身份证。
你为什么要这样做?
其实这是为了培养被搜索引擎蜘蛛抓取的习惯,方便以后更快的识别网站image内容。让蜘蛛抓住你的心,网站被收录的几率增加,何乐而不为呢!
3、图片周围必须有相关文字
网站Picture 是一种直接向用户呈现信息的方式。搜索引擎在爬取网站内容的时候,还会检查这个文章是否有图片、视频或者表格等,
这些都是可以增加文章点值的元素。其他表格暂时不显示。这里只讲图片周围相关文字的介绍。
首先,图片周围的文字必须与图片本身的内容一致。比如你的文章说要做网站优化,里面的图片是一个菜谱的图片。这不是卖狗肉的食谱吗?
用户的访问感会极差。搜索引擎通过相关算法识别出这张图片后,也会觉得图片和文字不符,给你差评。
所以,每个文章必须至少配一张对应的图片,并且与你的网站标题相关的内容必须出现在图片周围。不仅可以帮助搜索引擎理解图片,还可以增加文章的可读性、用户友好性和相关性。
4、给图片添加alt和title标签
很多站长在添加网站图片时可能没有注意这些细节,有的可能会觉得麻烦。我希望你没有这个想法。这是一个很大的错误。
搜索引擎抓取网站图片时,atl标签是最先抓取的,也是识别图片内容最重要的核心因素之一。图片的alt属性直接告诉搜索引擎网站图片是什么,是什么意思;
title标签是用户指向这张图片时会显示的提示内容。这是增加用户体验和增加网站关键词的一个小技巧。
alt 和标题标签
还有这两个属性,方便有阅读障碍的游客。例如,盲人访问你网站时,他看不到屏幕上的内容。可能是通过读取 如果有 alt 属性,软件会直接读取 alt 属性中的文字,方便他们访问。
5、图片大小和分辨率
虽然两者看起来很像,但还是有很大的不同。对于同样大小、分辨率更高的图片,网站最终会变大。每个人都必须弄清楚这一点。
网站上的图片一直提倡使用尽可能小的图片来最大化内容。为什么会这样?
因为小尺寸图片加载速度更快,不会让访问者等待太久,尤其是在使用手机时,由于移动互联网速度和流量的限制,用户更愿意访问可以立即打开的页面。尺寸图更有优势。
在这里我们尽量平衡。在图片不失真的情况下,尺寸尽量小。
网上有很多减肥图片的工具。你可以试试看。适当压缩网站 图片。一方面可以减轻服务器带宽的压力,另一方面可以为用户提供流畅度。体验。
6、手机端自动适配
很多站长都遇到过网站访问电脑显示器上的图片是正常的,但是手机出现错位,就是大尺寸图片导致不同尺寸终端显示错位、不完整的情况。
其实这个问题很容易解决。添加图片时,宽度和高度最好不要使用绝对大小。使用百分比来解决它。
具体来说,CSS代码不能指定像素宽度:width:xxx px;只有百分比宽度:宽度:xx%;或 width:auto 没问题。
这样做的目的也是为了让百度的手机蜘蛛在抓取的时候有很好的体验,这也是为了更符合百度手机登陆页面的体验。
四、如何提高搜索引擎的抓取频率?
1、网站内容更新
搜索引擎只抓取单个页面的内容,而不是所有页面。这也是搜索引擎更新网页快照的时间较短的原因。
比如对于经常更新的页面,快照也会被频繁抓取,以便及时发现新的内容和链接,删除不存在的信息。因此,站长必须长期坚持更新网页,才能成为搜索引擎爬虫。稳定过来抢。
2、网站框架设计
网站内部框架的设计需要从多方面进行。其中,代码需要尽量简洁明了。代码过多容易导致页面过大,影响网络爬虫的抓取速度。
爬取网站时,网页Flash图片尽量少。 flash 格式的内容影响蜘蛛爬行。对于新的网站,尽量使用伪静态网址,这样整个网站'S页面都容易被抓取。
在设计中,锚文本要合理分布,不要全部关键词,适当添加一些长尾词链接。内部链接的设计也应该是流畅的,以利于权重转移。
3、网站导航设计
网站 很多公司在设计网站 时都会忽略。导航是蜘蛛爬行的关键。如果网站导航不清楚,搜索引擎在爬行时很容易迷路。 ,所以导航一定要设计合理。
这里顺便提到了锚文本的构建。站点中的锚文本有助于网络爬虫在站点上查找和爬取更多网页。但是,如果锚文本过多,很容易被认为是刻意调整。设计时一定要把握好锚文本。数量。
4、稳定更新频率
除了首页设计,网站还有其他页面。爬虫在爬行时不会将网站 上的所有网页编入索引。在他们找到重要页面之前,他们可能已经抓取了足够多的网页并离开了。
所以我们必须保持一定的更新频率。可以轻松抓取更新频繁的页面,因此可以自动抓取大量页面。同时一定要注意网站level的设计,不要太多,否则也不利于网站抢夺。
搜索引擎如何抓取网页(蜘蛛搜索引擎怎么去识别友情链接,通过代码还是?-…)
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-09-09 03:01
蜘蛛搜索引擎如何识别友情链接,通过代码还是?-…… 友情链接是双方约定的信息共享行为,与搜索引擎无关。合作伙伴是双方的另一种契约关系,是否通过源代码,由双方自行决定。
搜索引擎蜘蛛可以抓取登录后才能看到的内容吗...这个搜索引擎蜘蛛不会像人们那样点击登录你的页面。所有搜索引擎只能收录不需要登录的页面只能看到,需要登录才能看到的页面不是收录,如果你需要他收录的呵啊,需要给个链接,让蜘蛛不用登录就可以进入,那么这个也行看见。如果说蜘蛛爬取了需要登录才能看到的内容,那你需要登录网站 内容可能已经写好了不登录也可以进入。可能有没有设计好的地方啦漏洞。希望我的回答能帮到你。龙SEO
如何识别搜索引擎蜘蛛IP?-...这个可以从服务器或者虚拟主机的日志中看出。比如在虚拟主机的完整使用日志中有这样一条记录:220.181.38.198--[11/Nov/2007:04:28:29 +0800] "GET /HTTP/1.1" 200 61083 "-" "Baiduspider" 意思是百度蜘蛛来过你的网站,如果我也想知道有没有其他搜索引擎蜘蛛来过你的网站。您可以在日志文件中搜索“蜘蛛”一词,也可以搜索蜘蛛的IP。 IIS日志和Apache日志是一样的,可以查到
用站长工具查出【模拟搜索引擎蜘蛛爬行】里面的内容不是我们网站-的内容……估计是脚本语言,你查到的是被解析并解析为 HTML。您应该找到您的页面并查看哪些内容受到控制。既然你说用站长工具模拟可以找到,证明正常打开网站是看不到的。然后他用判断语句来判断搜索蜘蛛与普通访问者的访问,然后给出了不同的代码。初步确定他在你的网站上有黑链。否则不仅会显示搜索蜘蛛
我怎么知道有搜索引擎蜘蛛爬过来爬过我的网站-......去其他机器搜索......
哪些链接类型的搜索引擎蜘蛛不能沿着url爬行?首先是隐藏链接。二、具有访问权限的链接。第三,给蜘蛛设置了相关的判断,让蜘蛛无法爬取链接。四、使用JS调用页面未显示的链接。五、flash和frame中的链接。搜索引擎蜘蛛无法抓取上述链接。
什么是蜘蛛侠搜索引擎?它的搜索数据来自哪里?它的搜索排名规则是什么? ... 搜索引擎蜘蛛是如何工作的? %C9%EE%DB%DA%D3% C5%BB%AF/blog/item/f06cf14b055ad5f282025c1f.html
这个ip是哪个搜索引擎蜘蛛?-...这里有各种搜索引擎蜘蛛的IP地址。但是没有你给的两个IP。
如何查看各大搜索引擎蜘蛛的ip?? ...你可以从虚拟主机的日志中查看蜘蛛的ip。详情请咨询百度或谷歌
如何查看搜索引擎蜘蛛-...... 一般情况下在服务器上是可以看到的,虚拟主机一般没有这个功能 查看全部
搜索引擎如何抓取网页(蜘蛛搜索引擎怎么去识别友情链接,通过代码还是?-…)
蜘蛛搜索引擎如何识别友情链接,通过代码还是?-…… 友情链接是双方约定的信息共享行为,与搜索引擎无关。合作伙伴是双方的另一种契约关系,是否通过源代码,由双方自行决定。
搜索引擎蜘蛛可以抓取登录后才能看到的内容吗...这个搜索引擎蜘蛛不会像人们那样点击登录你的页面。所有搜索引擎只能收录不需要登录的页面只能看到,需要登录才能看到的页面不是收录,如果你需要他收录的呵啊,需要给个链接,让蜘蛛不用登录就可以进入,那么这个也行看见。如果说蜘蛛爬取了需要登录才能看到的内容,那你需要登录网站 内容可能已经写好了不登录也可以进入。可能有没有设计好的地方啦漏洞。希望我的回答能帮到你。龙SEO
如何识别搜索引擎蜘蛛IP?-...这个可以从服务器或者虚拟主机的日志中看出。比如在虚拟主机的完整使用日志中有这样一条记录:220.181.38.198--[11/Nov/2007:04:28:29 +0800] "GET /HTTP/1.1" 200 61083 "-" "Baiduspider" 意思是百度蜘蛛来过你的网站,如果我也想知道有没有其他搜索引擎蜘蛛来过你的网站。您可以在日志文件中搜索“蜘蛛”一词,也可以搜索蜘蛛的IP。 IIS日志和Apache日志是一样的,可以查到
用站长工具查出【模拟搜索引擎蜘蛛爬行】里面的内容不是我们网站-的内容……估计是脚本语言,你查到的是被解析并解析为 HTML。您应该找到您的页面并查看哪些内容受到控制。既然你说用站长工具模拟可以找到,证明正常打开网站是看不到的。然后他用判断语句来判断搜索蜘蛛与普通访问者的访问,然后给出了不同的代码。初步确定他在你的网站上有黑链。否则不仅会显示搜索蜘蛛
我怎么知道有搜索引擎蜘蛛爬过来爬过我的网站-......去其他机器搜索......
哪些链接类型的搜索引擎蜘蛛不能沿着url爬行?首先是隐藏链接。二、具有访问权限的链接。第三,给蜘蛛设置了相关的判断,让蜘蛛无法爬取链接。四、使用JS调用页面未显示的链接。五、flash和frame中的链接。搜索引擎蜘蛛无法抓取上述链接。
什么是蜘蛛侠搜索引擎?它的搜索数据来自哪里?它的搜索排名规则是什么? ... 搜索引擎蜘蛛是如何工作的? %C9%EE%DB%DA%D3% C5%BB%AF/blog/item/f06cf14b055ad5f282025c1f.html
这个ip是哪个搜索引擎蜘蛛?-...这里有各种搜索引擎蜘蛛的IP地址。但是没有你给的两个IP。
如何查看各大搜索引擎蜘蛛的ip?? ...你可以从虚拟主机的日志中查看蜘蛛的ip。详情请咨询百度或谷歌
如何查看搜索引擎蜘蛛-...... 一般情况下在服务器上是可以看到的,虚拟主机一般没有这个功能
搜索引擎如何抓取网页(覆盖链接提取如何使用(图)的用法和下面条件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2021-09-09 02:09
核心点:覆盖链接提取有点类似于覆盖查询,主要注意关键词的用法和以下条件的用法,关键词可以适当使用搜索引擎的高级命令来实现一些特殊效果。如果以下条件为空,则表示提取所有覆盖链接,如果不为空,则根据填充条件提取。
覆盖链接提取功能有很多用途,最常见的两种是:一种是根据关键词提取搜索引擎结果中的所有链接,另一种是根据关键词查询竞争对手的链接。
在使用覆盖链接提取时有很多技术。比如关键词区域,如果使用百度的一些高级命令,会得到意想不到的结果。
我们来看看如何使用覆盖链接提取:
1、关键词填写
关键词块,主要填写你要查询的关键词。普通用户数量有限制。建议查看数据限制。对于VIP用户,建议正常模式下查询数据不超过5000条,精准模式下查询数据不超过2000条。
关键词也可以填写搜索引擎的高级说明。使用高级指令,会有意想不到的收获。
2、填写覆盖条件
如果没有填写覆盖条件,搜索引擎结果中的所有关键词都会被提取出来。
如果填写了coverage条件,会根据coverage条件中填写的内容进行过滤。
coverage 条件必须是唯一的,也就是说你填写的条件必须是唯一的。
例如:如果您要查看福州复兴妇产医院的覆盖范围,如果您的标题中有“复兴”一词,则可以使用“复兴”而不是“医院”,而不是“医院”。
如果要查询某个域名的覆盖范围,也可以使用域名,使用多条件模式查询,如:||,因为域名是唯一的。
如何使用&和|在覆盖条件下?
&是with的关系,表示必须同时满足多个条件才能匹配,例如:
你的条件是:关键词a&关键词b&关键词c,那么匹配的结果必须同时满足这三个条件才算覆盖率。
|yes or的关系,表示只要满足多个条件之一,就可以匹配,例如:
你的条件是:关键词a|关键词b|关键词c,那么只要匹配三个时钟之一,就可以算为覆盖率。
3、 为查询选择搜索引擎和排名选项
这个版本和之前版本的区别是可以同时选择多个搜索引擎。选择搜索引擎时,点击选择需要选择的搜索引擎。排名选择根据您的需要进行选择。当查询覆盖率比较大的时候,尽量选择1-2个搜索引擎,最好的排名是10,这样可以保证速度。如果选择多个搜索引擎,速度会有一定的影响,请慎重考虑后再做出选择。然后点击查询。
一般查询和精确查询设置:
选择普通查询,此功能只匹配搜索引擎的搜索结果,不匹配文章的内页。查询结果会略有不准确,但查询速度会更快。
选择精准查询,会打开各个网页的链接进行匹配,查询速度准确率几乎100%,但是查询速度要慢很多。
4、覆盖链接数据导出
查询完成后,点击底部的保存查询结果,导出数据。
以上是覆盖链接提取的说明。如有疑问,请点击网站下方QQ咨询。 查看全部
搜索引擎如何抓取网页(覆盖链接提取如何使用(图)的用法和下面条件)
核心点:覆盖链接提取有点类似于覆盖查询,主要注意关键词的用法和以下条件的用法,关键词可以适当使用搜索引擎的高级命令来实现一些特殊效果。如果以下条件为空,则表示提取所有覆盖链接,如果不为空,则根据填充条件提取。
覆盖链接提取功能有很多用途,最常见的两种是:一种是根据关键词提取搜索引擎结果中的所有链接,另一种是根据关键词查询竞争对手的链接。
在使用覆盖链接提取时有很多技术。比如关键词区域,如果使用百度的一些高级命令,会得到意想不到的结果。
我们来看看如何使用覆盖链接提取:
1、关键词填写
关键词块,主要填写你要查询的关键词。普通用户数量有限制。建议查看数据限制。对于VIP用户,建议正常模式下查询数据不超过5000条,精准模式下查询数据不超过2000条。
关键词也可以填写搜索引擎的高级说明。使用高级指令,会有意想不到的收获。
2、填写覆盖条件
如果没有填写覆盖条件,搜索引擎结果中的所有关键词都会被提取出来。
如果填写了coverage条件,会根据coverage条件中填写的内容进行过滤。
coverage 条件必须是唯一的,也就是说你填写的条件必须是唯一的。
例如:如果您要查看福州复兴妇产医院的覆盖范围,如果您的标题中有“复兴”一词,则可以使用“复兴”而不是“医院”,而不是“医院”。
如果要查询某个域名的覆盖范围,也可以使用域名,使用多条件模式查询,如:||,因为域名是唯一的。
如何使用&和|在覆盖条件下?
&是with的关系,表示必须同时满足多个条件才能匹配,例如:
你的条件是:关键词a&关键词b&关键词c,那么匹配的结果必须同时满足这三个条件才算覆盖率。
|yes or的关系,表示只要满足多个条件之一,就可以匹配,例如:
你的条件是:关键词a|关键词b|关键词c,那么只要匹配三个时钟之一,就可以算为覆盖率。
3、 为查询选择搜索引擎和排名选项
这个版本和之前版本的区别是可以同时选择多个搜索引擎。选择搜索引擎时,点击选择需要选择的搜索引擎。排名选择根据您的需要进行选择。当查询覆盖率比较大的时候,尽量选择1-2个搜索引擎,最好的排名是10,这样可以保证速度。如果选择多个搜索引擎,速度会有一定的影响,请慎重考虑后再做出选择。然后点击查询。
一般查询和精确查询设置:
选择普通查询,此功能只匹配搜索引擎的搜索结果,不匹配文章的内页。查询结果会略有不准确,但查询速度会更快。
选择精准查询,会打开各个网页的链接进行匹配,查询速度准确率几乎100%,但是查询速度要慢很多。
4、覆盖链接数据导出
查询完成后,点击底部的保存查询结果,导出数据。
以上是覆盖链接提取的说明。如有疑问,请点击网站下方QQ咨询。

