
怎样抓取网页数据
怎样抓取网页数据(中小工具共有三个功能的构建与使用工程的限制)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-09-11 15:02
前提:1、有很多网页(如果少了就用笔抄下来); 2、具有相对统一的网页格式; 3、网页可以下载
如果满足以上三个条件,可以通过以下方法获取数据(很简单,就像把大象放进冰箱一样)
第一步:分析这些网页地址的规则,建立下载列表,然后使用下载软件(如迅雷)下载网页
第 2 步:制作宏将这些网页读入 Excel
第 3 部分:制作另一个宏来读取数据
分析:
1、为什么要先下载网页:因为用Excel直接从网页中读取数据比较慢,而且下载软件可以实现多任务多线程,这样校对更方便
2、如何将网页读入Excel:直接打开网页或导入外部数据有两种方式。可以使用我之前做的一个小工具“将多个文件合并成一个文件的小工具”。 "
示例:
我们公司在生产中需要大量的铜和铝产品。因铜铝价格波动较大,公司与供应商同意,铜铝月度结算价将在上海期货交易所公布网站最近期结算价的平均值交易通讯中的交割月份。即中第一排铜铝结算价的平均值。
附件中的小部件具有三个功能。第一个功能是建立下载列表;第二个功能是读取下载的网页并保存在Excel中,然后读取数据;第三个功能是直接从Read the data from the web page读取数据。第二个功能限制255个工作表,但可以保留网页进行校对,第三个功能不受255个工作表限制。
VBA 项目密码为:681986 查看全部
怎样抓取网页数据(中小工具共有三个功能的构建与使用工程的限制)
前提:1、有很多网页(如果少了就用笔抄下来); 2、具有相对统一的网页格式; 3、网页可以下载
如果满足以上三个条件,可以通过以下方法获取数据(很简单,就像把大象放进冰箱一样)
第一步:分析这些网页地址的规则,建立下载列表,然后使用下载软件(如迅雷)下载网页
第 2 步:制作宏将这些网页读入 Excel
第 3 部分:制作另一个宏来读取数据
分析:
1、为什么要先下载网页:因为用Excel直接从网页中读取数据比较慢,而且下载软件可以实现多任务多线程,这样校对更方便
2、如何将网页读入Excel:直接打开网页或导入外部数据有两种方式。可以使用我之前做的一个小工具“将多个文件合并成一个文件的小工具”。 "
示例:
我们公司在生产中需要大量的铜和铝产品。因铜铝价格波动较大,公司与供应商同意,铜铝月度结算价将在上海期货交易所公布网站最近期结算价的平均值交易通讯中的交割月份。即中第一排铜铝结算价的平均值。
附件中的小部件具有三个功能。第一个功能是建立下载列表;第二个功能是读取下载的网页并保存在Excel中,然后读取数据;第三个功能是直接从Read the data from the web page读取数据。第二个功能限制255个工作表,但可以保留网页进行校对,第三个功能不受255个工作表限制。
VBA 项目密码为:681986
怎样抓取网页数据(常见网页抓取语言有哪些?Python语言的特点是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-09-11 14:14
网络爬虫是从任何网站或任何其他信息源中提取数据,并以您想要查看的格式保存在您的系统中的过程。那么,常见的网络抓取语言有哪些?
1、Python 是最常见的编码语言之一。对于任何网页抓取活动,Python 被认为是网页抓取的最佳方法。
2、Node.js 是最适合练习动态编码活动的数据爬虫活动。它还支持分布式抓取实践。 Node.js 使用 Javascript 来执行非阻塞应用程序,这有助于增强多个同时发生的事件。
3、Ruby 被认为是开源编程语言之一。它具有用户友好的语法,易于理解,易于练习和应用。 Ruby 的最大特点是它由多种语言组成,如 Perl、Smalltalk、Eiffel、Ada、Lip 和另一种新语言。
4、C 和 C++ 是一个很好的实现方案,但在进行网页抓取时可能会很昂贵。
5、 创建爬虫时,PHP 可能不是理想的选择。为了提取图形、图像、视频等视觉形式的信息,最好使用 CURL 库。 curl 库的最大优点是它可以帮助传输收录 HTTP 和 FTP 在内的协议列表的文件。拥有它可以帮助您创建可用于从在线平台下载任何类型信息的网络蜘蛛。
在使用在线平台提取数据时,上面提到的前5种网络爬虫语言是一个很好的解决方案,但没有安全保障。适用的代理服务器可以进行安全有效的网络爬虫活动。
来自“ITPUB博客”,链接:,如需转载请注明出处,否则将追究法律责任。 查看全部
怎样抓取网页数据(常见网页抓取语言有哪些?Python语言的特点是什么?)
网络爬虫是从任何网站或任何其他信息源中提取数据,并以您想要查看的格式保存在您的系统中的过程。那么,常见的网络抓取语言有哪些?

1、Python 是最常见的编码语言之一。对于任何网页抓取活动,Python 被认为是网页抓取的最佳方法。
2、Node.js 是最适合练习动态编码活动的数据爬虫活动。它还支持分布式抓取实践。 Node.js 使用 Javascript 来执行非阻塞应用程序,这有助于增强多个同时发生的事件。
3、Ruby 被认为是开源编程语言之一。它具有用户友好的语法,易于理解,易于练习和应用。 Ruby 的最大特点是它由多种语言组成,如 Perl、Smalltalk、Eiffel、Ada、Lip 和另一种新语言。
4、C 和 C++ 是一个很好的实现方案,但在进行网页抓取时可能会很昂贵。
5、 创建爬虫时,PHP 可能不是理想的选择。为了提取图形、图像、视频等视觉形式的信息,最好使用 CURL 库。 curl 库的最大优点是它可以帮助传输收录 HTTP 和 FTP 在内的协议列表的文件。拥有它可以帮助您创建可用于从在线平台下载任何类型信息的网络蜘蛛。
在使用在线平台提取数据时,上面提到的前5种网络爬虫语言是一个很好的解决方案,但没有安全保障。适用的代理服务器可以进行安全有效的网络爬虫活动。
来自“ITPUB博客”,链接:,如需转载请注明出处,否则将追究法律责任。
怎样抓取网页数据(如何利用Python网络爬虫批量获取大量公共资源数据的正确路径 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-09-10 16:06
)
在21世纪数据革命的浪潮下,大数据的价值不断提升,大数据的应用范围不断扩大。它已经渗透到自然科学和社会科学的许多领域,提供了巨大的发展机遇。今天,大量的公共资源和公共数据集以各种形式在互联网上共享。如何快速批量获取海量公共资源数据,决定了科研效率。 Python网络爬虫是快速批量获取网络数据的重要手段。它按照发送请求、获取页面、解析页面、下载内容、存储内容的过程,根据网页的链接地址自动获取网页内容。其特点是快速批量和自动化操作。 由于网页内容、结果和反爬虫机制的不断更新,拥有一个爬虫程序不是一次性更新,而是需要针对不同的网页及时更新。掌握爬虫的关键技术是成功爬取数据,甚至成为各种复杂网页中的爬虫。工程师的基础。本课程以公共开放数据资源网站为例讲解如何在合法合规的情况下使用Python网络爬虫批量获取大量数据,零基础掌握学习爬虫的正确路径,以生动的案例展示经济、生态、天气、农业、商业等网络大数据采集。
教学特色:
1、原理简单说明;
2、技能方法说明,提供所有案例数据和代码;
3、结合项目案例讲解实现方法,对接实际工作应用;
4、跟随学习上机操作,独立完成案例操作练习,分析问题跟踪全过程;
5、课程结束,专属助学团协助巩固学习和实际工作应用交流,不定期举行在线问答;
查看全部
怎样抓取网页数据(如何利用Python网络爬虫批量获取大量公共资源数据的正确路径
)
在21世纪数据革命的浪潮下,大数据的价值不断提升,大数据的应用范围不断扩大。它已经渗透到自然科学和社会科学的许多领域,提供了巨大的发展机遇。今天,大量的公共资源和公共数据集以各种形式在互联网上共享。如何快速批量获取海量公共资源数据,决定了科研效率。 Python网络爬虫是快速批量获取网络数据的重要手段。它按照发送请求、获取页面、解析页面、下载内容、存储内容的过程,根据网页的链接地址自动获取网页内容。其特点是快速批量和自动化操作。 由于网页内容、结果和反爬虫机制的不断更新,拥有一个爬虫程序不是一次性更新,而是需要针对不同的网页及时更新。掌握爬虫的关键技术是成功爬取数据,甚至成为各种复杂网页中的爬虫。工程师的基础。本课程以公共开放数据资源网站为例讲解如何在合法合规的情况下使用Python网络爬虫批量获取大量数据,零基础掌握学习爬虫的正确路径,以生动的案例展示经济、生态、天气、农业、商业等网络大数据采集。
教学特色:
1、原理简单说明;
2、技能方法说明,提供所有案例数据和代码;
3、结合项目案例讲解实现方法,对接实际工作应用;
4、跟随学习上机操作,独立完成案例操作练习,分析问题跟踪全过程;
5、课程结束,专属助学团协助巩固学习和实际工作应用交流,不定期举行在线问答;


怎样抓取网页数据(一个+jsou提取网页数据的分类汇总(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-09-09 03:11
原文链接
在很多行业,需要对行业数据进行分类汇总,及时分析行业数据,为公司未来的发展提供良好的参考和横向比较。因此,在实际工作中,我们可能会遇到data采集的概念。 data采集的最终目标是获取数据,提取有用的数据进行数据抽取和数据分类聚合。
很多人在第一次了解数据采集的时候可能都无法上手,尤其是作为一个新手,感觉很茫然,所以在这里分享一下我的经验,希望把技术分享给大家,如果有不足之处,请指正。写这篇文章的目的就是希望大家能一起成长。我也相信没有高低技术,只有互补,只有分享才能让彼此成长更多。
在网络数据采集的情况下,我们经常要经历这些大步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③从网页源代码中提取我们想要提取的目的数据 ④将数据格式转换为我们需要的数据。
这是示意图,希望大家理解
了解了基本流程,我就用一个案例来具体实现如何提取我们需要的数据。数据抽取可以使用正则表达式抽取,也可以使用httpclient+jsoup抽取。在这里,我暂时不解释httpclient。 +jsou提取网页数据的方法以后会在httpclient+jsoup上具体讲解。在这里,我们将首先说明如何使用正则表达式来提取数据。
我在这里找到了一个网站:我们要提取里面的数据。我们要提取的最终结果是产品型号、数量、报价和供应商。首先我们看到这个网站全页面预览
接下来我们看一下网页源码的结构:
上面的源码可以清晰的看到整个网页的源码结构。接下来,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好的,运行上面的程序,我们得到如下数据,也就是我们最终要获取的数据
数据获取成功,这就是我们想要得到的最终数据结果,最后我想说的是,这里的这个网页比较简单,源数据可以在网页的源代码中看到,而这个方法就是get方法提交数据的时候,采集真的是采集的时候,有的网页结构复杂,源码里可能没有我们要提取的数据。以后我会介绍这点的解决方案。还有,我在采集这个页面的时候,只有采集拿到了当前页面的数据,而且还有分页的数据。这个我就不解释了,只是一个提示,我们可以使用多线程对所有分页的当前数据是采集,一个采集当前页面数据通过线程,另一个是翻页动作,你可以采集完成所有的数据。
我们匹配的数据可能在项目实际开发中,需要我们将提取的数据存储起来,方便我们接下来的数据查询操作。 查看全部
怎样抓取网页数据(一个+jsou提取网页数据的分类汇总(一))
原文链接
在很多行业,需要对行业数据进行分类汇总,及时分析行业数据,为公司未来的发展提供良好的参考和横向比较。因此,在实际工作中,我们可能会遇到data采集的概念。 data采集的最终目标是获取数据,提取有用的数据进行数据抽取和数据分类聚合。
很多人在第一次了解数据采集的时候可能都无法上手,尤其是作为一个新手,感觉很茫然,所以在这里分享一下我的经验,希望把技术分享给大家,如果有不足之处,请指正。写这篇文章的目的就是希望大家能一起成长。我也相信没有高低技术,只有互补,只有分享才能让彼此成长更多。
在网络数据采集的情况下,我们经常要经历这些大步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③从网页源代码中提取我们想要提取的目的数据 ④将数据格式转换为我们需要的数据。
这是示意图,希望大家理解
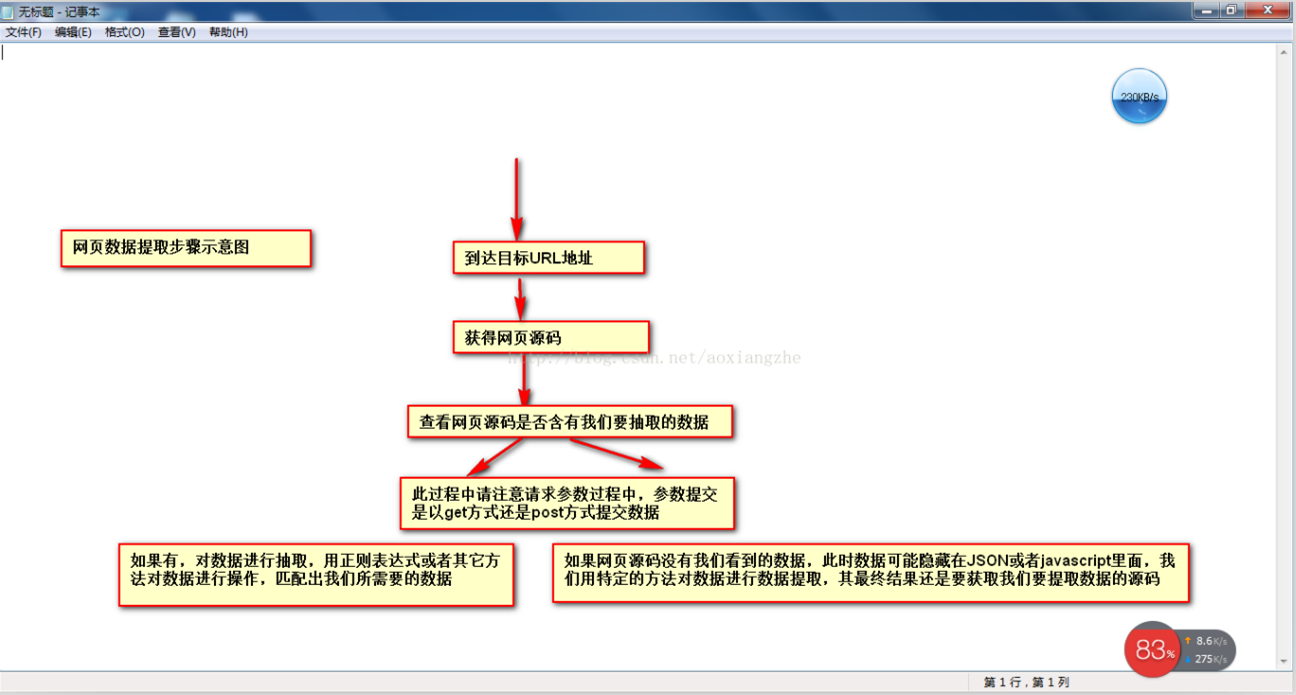
了解了基本流程,我就用一个案例来具体实现如何提取我们需要的数据。数据抽取可以使用正则表达式抽取,也可以使用httpclient+jsoup抽取。在这里,我暂时不解释httpclient。 +jsou提取网页数据的方法以后会在httpclient+jsoup上具体讲解。在这里,我们将首先说明如何使用正则表达式来提取数据。
我在这里找到了一个网站:我们要提取里面的数据。我们要提取的最终结果是产品型号、数量、报价和供应商。首先我们看到这个网站全页面预览

接下来我们看一下网页源码的结构:
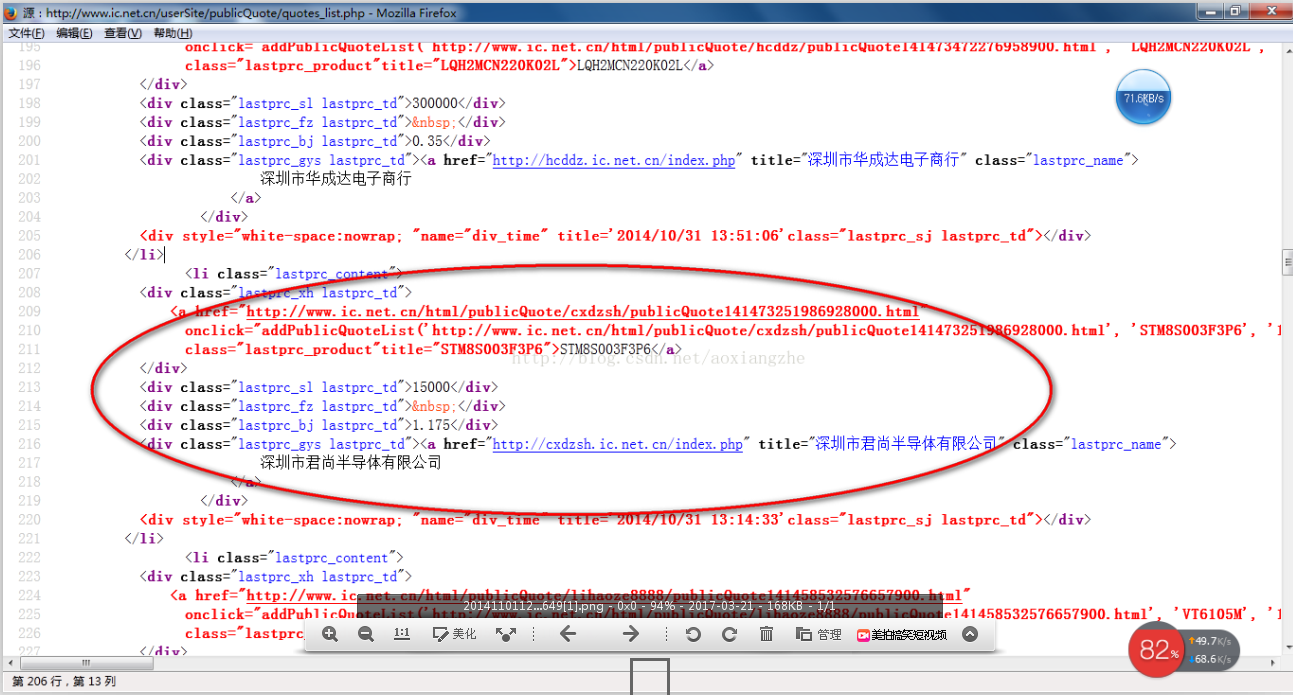
上面的源码可以清晰的看到整个网页的源码结构。接下来,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好的,运行上面的程序,我们得到如下数据,也就是我们最终要获取的数据

数据获取成功,这就是我们想要得到的最终数据结果,最后我想说的是,这里的这个网页比较简单,源数据可以在网页的源代码中看到,而这个方法就是get方法提交数据的时候,采集真的是采集的时候,有的网页结构复杂,源码里可能没有我们要提取的数据。以后我会介绍这点的解决方案。还有,我在采集这个页面的时候,只有采集拿到了当前页面的数据,而且还有分页的数据。这个我就不解释了,只是一个提示,我们可以使用多线程对所有分页的当前数据是采集,一个采集当前页面数据通过线程,另一个是翻页动作,你可以采集完成所有的数据。
我们匹配的数据可能在项目实际开发中,需要我们将提取的数据存储起来,方便我们接下来的数据查询操作。
怎样抓取网页数据(李明刚建了个站长工具网站,欢迎大使用(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-09-09 03:09
李明刚自建站长工具网站,欢迎使用。
如果您使用过网站管理员工具,您会很好奇。例如网站收录数据和关键词ranking 数据只能从百度等搜索引擎中找到。这些站长工具怎么也能搜到,这么多站长工具,百度等搜索引擎都无法配合他们提供数据。那么,这些数据是如何获得的呢?下面李明为您一一详细讲解。
不知道你有没有用过采集系统,比如织梦cms采集,只要你懂基本的HTML代码,其实站长工具就是用这个原理的,使用网站程序从搜索引擎采集查询的数据回来了。
比如在百度上找到这个网站的收录量,只要抓取这个地址%3A的页面数据,在“找到的相关结果数38”中用正则表达式得到38采集。 其他搜索引擎的收录和关键词排名也是基于同样的原理。要做好这个工具,不仅要了解网站优化的基础知识,还要熟悉网站程序,尤其是正则表达式。
直接用站长工具查询比较简单方便,但也需要学会直接通过搜索引擎本身查询你的网站收录情况!
网站域名(不收录)表单:站点:
1.百度收录Query
Total收录:site:网站域名(不收录)
反链查询:domain:网站domain name(不收录)
查询指定时间段内收录的数量:
24 小时收录 查询::&tn=baiduadv&lm=1
7 天(一周)收录Query::&tn=baiduadv&lm=7
一个月收录Query::&tn=baiduadv&lm=30
*链接填写规则,第一位是你的网站域名,第二位是你要查询的天数!
2.谷歌收录query
总计收录:网站域名(不收录)
反链查询:链接:网站域名(不收录)
3.雅虎收录Query
Total收录:site:网站域名(不收录)
反链查询:...
4.QQ搜搜收录Query
Total收录:site:网站域名(不收录)
反链查询:链接:网站域名(不收录)
希望对大家有帮助! ... 查看全部
怎样抓取网页数据(李明刚建了个站长工具网站,欢迎大使用(组图))
李明刚自建站长工具网站,欢迎使用。
如果您使用过网站管理员工具,您会很好奇。例如网站收录数据和关键词ranking 数据只能从百度等搜索引擎中找到。这些站长工具怎么也能搜到,这么多站长工具,百度等搜索引擎都无法配合他们提供数据。那么,这些数据是如何获得的呢?下面李明为您一一详细讲解。
不知道你有没有用过采集系统,比如织梦cms采集,只要你懂基本的HTML代码,其实站长工具就是用这个原理的,使用网站程序从搜索引擎采集查询的数据回来了。
比如在百度上找到这个网站的收录量,只要抓取这个地址%3A的页面数据,在“找到的相关结果数38”中用正则表达式得到38采集。 其他搜索引擎的收录和关键词排名也是基于同样的原理。要做好这个工具,不仅要了解网站优化的基础知识,还要熟悉网站程序,尤其是正则表达式。
直接用站长工具查询比较简单方便,但也需要学会直接通过搜索引擎本身查询你的网站收录情况!
网站域名(不收录)表单:站点:
1.百度收录Query
Total收录:site:网站域名(不收录)
反链查询:domain:网站domain name(不收录)
查询指定时间段内收录的数量:
24 小时收录 查询::&tn=baiduadv&lm=1
7 天(一周)收录Query::&tn=baiduadv&lm=7
一个月收录Query::&tn=baiduadv&lm=30
*链接填写规则,第一位是你的网站域名,第二位是你要查询的天数!
2.谷歌收录query
总计收录:网站域名(不收录)
反链查询:链接:网站域名(不收录)
3.雅虎收录Query
Total收录:site:网站域名(不收录)
反链查询:...
4.QQ搜搜收录Query
Total收录:site:网站域名(不收录)
反链查询:链接:网站域名(不收录)
希望对大家有帮助! ...
怎样抓取网页数据(中小工具共有三个功能的构建与使用工程的限制)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-09-11 15:02
前提:1、有很多网页(如果少了就用笔抄下来); 2、具有相对统一的网页格式; 3、网页可以下载
如果满足以上三个条件,可以通过以下方法获取数据(很简单,就像把大象放进冰箱一样)
第一步:分析这些网页地址的规则,建立下载列表,然后使用下载软件(如迅雷)下载网页
第 2 步:制作宏将这些网页读入 Excel
第 3 部分:制作另一个宏来读取数据
分析:
1、为什么要先下载网页:因为用Excel直接从网页中读取数据比较慢,而且下载软件可以实现多任务多线程,这样校对更方便
2、如何将网页读入Excel:直接打开网页或导入外部数据有两种方式。可以使用我之前做的一个小工具“将多个文件合并成一个文件的小工具”。 "
示例:
我们公司在生产中需要大量的铜和铝产品。因铜铝价格波动较大,公司与供应商同意,铜铝月度结算价将在上海期货交易所公布网站最近期结算价的平均值交易通讯中的交割月份。即中第一排铜铝结算价的平均值。
附件中的小部件具有三个功能。第一个功能是建立下载列表;第二个功能是读取下载的网页并保存在Excel中,然后读取数据;第三个功能是直接从Read the data from the web page读取数据。第二个功能限制255个工作表,但可以保留网页进行校对,第三个功能不受255个工作表限制。
VBA 项目密码为:681986 查看全部
怎样抓取网页数据(中小工具共有三个功能的构建与使用工程的限制)
前提:1、有很多网页(如果少了就用笔抄下来); 2、具有相对统一的网页格式; 3、网页可以下载
如果满足以上三个条件,可以通过以下方法获取数据(很简单,就像把大象放进冰箱一样)
第一步:分析这些网页地址的规则,建立下载列表,然后使用下载软件(如迅雷)下载网页
第 2 步:制作宏将这些网页读入 Excel
第 3 部分:制作另一个宏来读取数据
分析:
1、为什么要先下载网页:因为用Excel直接从网页中读取数据比较慢,而且下载软件可以实现多任务多线程,这样校对更方便
2、如何将网页读入Excel:直接打开网页或导入外部数据有两种方式。可以使用我之前做的一个小工具“将多个文件合并成一个文件的小工具”。 "
示例:
我们公司在生产中需要大量的铜和铝产品。因铜铝价格波动较大,公司与供应商同意,铜铝月度结算价将在上海期货交易所公布网站最近期结算价的平均值交易通讯中的交割月份。即中第一排铜铝结算价的平均值。
附件中的小部件具有三个功能。第一个功能是建立下载列表;第二个功能是读取下载的网页并保存在Excel中,然后读取数据;第三个功能是直接从Read the data from the web page读取数据。第二个功能限制255个工作表,但可以保留网页进行校对,第三个功能不受255个工作表限制。
VBA 项目密码为:681986
怎样抓取网页数据(常见网页抓取语言有哪些?Python语言的特点是什么?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 134 次浏览 • 2021-09-11 14:14
网络爬虫是从任何网站或任何其他信息源中提取数据,并以您想要查看的格式保存在您的系统中的过程。那么,常见的网络抓取语言有哪些?
1、Python 是最常见的编码语言之一。对于任何网页抓取活动,Python 被认为是网页抓取的最佳方法。
2、Node.js 是最适合练习动态编码活动的数据爬虫活动。它还支持分布式抓取实践。 Node.js 使用 Javascript 来执行非阻塞应用程序,这有助于增强多个同时发生的事件。
3、Ruby 被认为是开源编程语言之一。它具有用户友好的语法,易于理解,易于练习和应用。 Ruby 的最大特点是它由多种语言组成,如 Perl、Smalltalk、Eiffel、Ada、Lip 和另一种新语言。
4、C 和 C++ 是一个很好的实现方案,但在进行网页抓取时可能会很昂贵。
5、 创建爬虫时,PHP 可能不是理想的选择。为了提取图形、图像、视频等视觉形式的信息,最好使用 CURL 库。 curl 库的最大优点是它可以帮助传输收录 HTTP 和 FTP 在内的协议列表的文件。拥有它可以帮助您创建可用于从在线平台下载任何类型信息的网络蜘蛛。
在使用在线平台提取数据时,上面提到的前5种网络爬虫语言是一个很好的解决方案,但没有安全保障。适用的代理服务器可以进行安全有效的网络爬虫活动。
来自“ITPUB博客”,链接:,如需转载请注明出处,否则将追究法律责任。 查看全部
怎样抓取网页数据(常见网页抓取语言有哪些?Python语言的特点是什么?)
网络爬虫是从任何网站或任何其他信息源中提取数据,并以您想要查看的格式保存在您的系统中的过程。那么,常见的网络抓取语言有哪些?
1、Python 是最常见的编码语言之一。对于任何网页抓取活动,Python 被认为是网页抓取的最佳方法。
2、Node.js 是最适合练习动态编码活动的数据爬虫活动。它还支持分布式抓取实践。 Node.js 使用 Javascript 来执行非阻塞应用程序,这有助于增强多个同时发生的事件。
3、Ruby 被认为是开源编程语言之一。它具有用户友好的语法,易于理解,易于练习和应用。 Ruby 的最大特点是它由多种语言组成,如 Perl、Smalltalk、Eiffel、Ada、Lip 和另一种新语言。
4、C 和 C++ 是一个很好的实现方案,但在进行网页抓取时可能会很昂贵。
5、 创建爬虫时,PHP 可能不是理想的选择。为了提取图形、图像、视频等视觉形式的信息,最好使用 CURL 库。 curl 库的最大优点是它可以帮助传输收录 HTTP 和 FTP 在内的协议列表的文件。拥有它可以帮助您创建可用于从在线平台下载任何类型信息的网络蜘蛛。
在使用在线平台提取数据时,上面提到的前5种网络爬虫语言是一个很好的解决方案,但没有安全保障。适用的代理服务器可以进行安全有效的网络爬虫活动。
来自“ITPUB博客”,链接:,如需转载请注明出处,否则将追究法律责任。
怎样抓取网页数据(如何利用Python网络爬虫批量获取大量公共资源数据的正确路径 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2021-09-10 16:06
)
在21世纪数据革命的浪潮下,大数据的价值不断提升,大数据的应用范围不断扩大。它已经渗透到自然科学和社会科学的许多领域,提供了巨大的发展机遇。今天,大量的公共资源和公共数据集以各种形式在互联网上共享。如何快速批量获取海量公共资源数据,决定了科研效率。 Python网络爬虫是快速批量获取网络数据的重要手段。它按照发送请求、获取页面、解析页面、下载内容、存储内容的过程,根据网页的链接地址自动获取网页内容。其特点是快速批量和自动化操作。 由于网页内容、结果和反爬虫机制的不断更新,拥有一个爬虫程序不是一次性更新,而是需要针对不同的网页及时更新。掌握爬虫的关键技术是成功爬取数据,甚至成为各种复杂网页中的爬虫。工程师的基础。本课程以公共开放数据资源网站为例讲解如何在合法合规的情况下使用Python网络爬虫批量获取大量数据,零基础掌握学习爬虫的正确路径,以生动的案例展示经济、生态、天气、农业、商业等网络大数据采集。
教学特色:
1、原理简单说明;
2、技能方法说明,提供所有案例数据和代码;
3、结合项目案例讲解实现方法,对接实际工作应用;
4、跟随学习上机操作,独立完成案例操作练习,分析问题跟踪全过程;
5、课程结束,专属助学团协助巩固学习和实际工作应用交流,不定期举行在线问答;
查看全部
怎样抓取网页数据(如何利用Python网络爬虫批量获取大量公共资源数据的正确路径
)
在21世纪数据革命的浪潮下,大数据的价值不断提升,大数据的应用范围不断扩大。它已经渗透到自然科学和社会科学的许多领域,提供了巨大的发展机遇。今天,大量的公共资源和公共数据集以各种形式在互联网上共享。如何快速批量获取海量公共资源数据,决定了科研效率。 Python网络爬虫是快速批量获取网络数据的重要手段。它按照发送请求、获取页面、解析页面、下载内容、存储内容的过程,根据网页的链接地址自动获取网页内容。其特点是快速批量和自动化操作。 由于网页内容、结果和反爬虫机制的不断更新,拥有一个爬虫程序不是一次性更新,而是需要针对不同的网页及时更新。掌握爬虫的关键技术是成功爬取数据,甚至成为各种复杂网页中的爬虫。工程师的基础。本课程以公共开放数据资源网站为例讲解如何在合法合规的情况下使用Python网络爬虫批量获取大量数据,零基础掌握学习爬虫的正确路径,以生动的案例展示经济、生态、天气、农业、商业等网络大数据采集。
教学特色:
1、原理简单说明;
2、技能方法说明,提供所有案例数据和代码;
3、结合项目案例讲解实现方法,对接实际工作应用;
4、跟随学习上机操作,独立完成案例操作练习,分析问题跟踪全过程;
5、课程结束,专属助学团协助巩固学习和实际工作应用交流,不定期举行在线问答;
怎样抓取网页数据(一个+jsou提取网页数据的分类汇总(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-09-09 03:11
原文链接
在很多行业,需要对行业数据进行分类汇总,及时分析行业数据,为公司未来的发展提供良好的参考和横向比较。因此,在实际工作中,我们可能会遇到data采集的概念。 data采集的最终目标是获取数据,提取有用的数据进行数据抽取和数据分类聚合。
很多人在第一次了解数据采集的时候可能都无法上手,尤其是作为一个新手,感觉很茫然,所以在这里分享一下我的经验,希望把技术分享给大家,如果有不足之处,请指正。写这篇文章的目的就是希望大家能一起成长。我也相信没有高低技术,只有互补,只有分享才能让彼此成长更多。
在网络数据采集的情况下,我们经常要经历这些大步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③从网页源代码中提取我们想要提取的目的数据 ④将数据格式转换为我们需要的数据。
这是示意图,希望大家理解
了解了基本流程,我就用一个案例来具体实现如何提取我们需要的数据。数据抽取可以使用正则表达式抽取,也可以使用httpclient+jsoup抽取。在这里,我暂时不解释httpclient。 +jsou提取网页数据的方法以后会在httpclient+jsoup上具体讲解。在这里,我们将首先说明如何使用正则表达式来提取数据。
我在这里找到了一个网站:我们要提取里面的数据。我们要提取的最终结果是产品型号、数量、报价和供应商。首先我们看到这个网站全页面预览
接下来我们看一下网页源码的结构:
上面的源码可以清晰的看到整个网页的源码结构。接下来,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好的,运行上面的程序,我们得到如下数据,也就是我们最终要获取的数据
数据获取成功,这就是我们想要得到的最终数据结果,最后我想说的是,这里的这个网页比较简单,源数据可以在网页的源代码中看到,而这个方法就是get方法提交数据的时候,采集真的是采集的时候,有的网页结构复杂,源码里可能没有我们要提取的数据。以后我会介绍这点的解决方案。还有,我在采集这个页面的时候,只有采集拿到了当前页面的数据,而且还有分页的数据。这个我就不解释了,只是一个提示,我们可以使用多线程对所有分页的当前数据是采集,一个采集当前页面数据通过线程,另一个是翻页动作,你可以采集完成所有的数据。
我们匹配的数据可能在项目实际开发中,需要我们将提取的数据存储起来,方便我们接下来的数据查询操作。 查看全部
怎样抓取网页数据(一个+jsou提取网页数据的分类汇总(一))
原文链接
在很多行业,需要对行业数据进行分类汇总,及时分析行业数据,为公司未来的发展提供良好的参考和横向比较。因此,在实际工作中,我们可能会遇到data采集的概念。 data采集的最终目标是获取数据,提取有用的数据进行数据抽取和数据分类聚合。
很多人在第一次了解数据采集的时候可能都无法上手,尤其是作为一个新手,感觉很茫然,所以在这里分享一下我的经验,希望把技术分享给大家,如果有不足之处,请指正。写这篇文章的目的就是希望大家能一起成长。我也相信没有高低技术,只有互补,只有分享才能让彼此成长更多。
在网络数据采集的情况下,我们经常要经历这些大步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③从网页源代码中提取我们想要提取的目的数据 ④将数据格式转换为我们需要的数据。
这是示意图,希望大家理解
了解了基本流程,我就用一个案例来具体实现如何提取我们需要的数据。数据抽取可以使用正则表达式抽取,也可以使用httpclient+jsoup抽取。在这里,我暂时不解释httpclient。 +jsou提取网页数据的方法以后会在httpclient+jsoup上具体讲解。在这里,我们将首先说明如何使用正则表达式来提取数据。
我在这里找到了一个网站:我们要提取里面的数据。我们要提取的最终结果是产品型号、数量、报价和供应商。首先我们看到这个网站全页面预览
接下来我们看一下网页源码的结构:
上面的源码可以清晰的看到整个网页的源码结构。接下来,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好的,运行上面的程序,我们得到如下数据,也就是我们最终要获取的数据
数据获取成功,这就是我们想要得到的最终数据结果,最后我想说的是,这里的这个网页比较简单,源数据可以在网页的源代码中看到,而这个方法就是get方法提交数据的时候,采集真的是采集的时候,有的网页结构复杂,源码里可能没有我们要提取的数据。以后我会介绍这点的解决方案。还有,我在采集这个页面的时候,只有采集拿到了当前页面的数据,而且还有分页的数据。这个我就不解释了,只是一个提示,我们可以使用多线程对所有分页的当前数据是采集,一个采集当前页面数据通过线程,另一个是翻页动作,你可以采集完成所有的数据。
我们匹配的数据可能在项目实际开发中,需要我们将提取的数据存储起来,方便我们接下来的数据查询操作。
怎样抓取网页数据(李明刚建了个站长工具网站,欢迎大使用(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-09-09 03:09
李明刚自建站长工具网站,欢迎使用。
如果您使用过网站管理员工具,您会很好奇。例如网站收录数据和关键词ranking 数据只能从百度等搜索引擎中找到。这些站长工具怎么也能搜到,这么多站长工具,百度等搜索引擎都无法配合他们提供数据。那么,这些数据是如何获得的呢?下面李明为您一一详细讲解。
不知道你有没有用过采集系统,比如织梦cms采集,只要你懂基本的HTML代码,其实站长工具就是用这个原理的,使用网站程序从搜索引擎采集查询的数据回来了。
比如在百度上找到这个网站的收录量,只要抓取这个地址%3A的页面数据,在“找到的相关结果数38”中用正则表达式得到38采集。 其他搜索引擎的收录和关键词排名也是基于同样的原理。要做好这个工具,不仅要了解网站优化的基础知识,还要熟悉网站程序,尤其是正则表达式。
直接用站长工具查询比较简单方便,但也需要学会直接通过搜索引擎本身查询你的网站收录情况!
网站域名(不收录)表单:站点:
1.百度收录Query
Total收录:site:网站域名(不收录)
反链查询:domain:网站domain name(不收录)
查询指定时间段内收录的数量:
24 小时收录 查询::&tn=baiduadv&lm=1
7 天(一周)收录Query::&tn=baiduadv&lm=7
一个月收录Query::&tn=baiduadv&lm=30
*链接填写规则,第一位是你的网站域名,第二位是你要查询的天数!
2.谷歌收录query
总计收录:网站域名(不收录)
反链查询:链接:网站域名(不收录)
3.雅虎收录Query
Total收录:site:网站域名(不收录)
反链查询:...
4.QQ搜搜收录Query
Total收录:site:网站域名(不收录)
反链查询:链接:网站域名(不收录)
希望对大家有帮助! ... 查看全部
怎样抓取网页数据(李明刚建了个站长工具网站,欢迎大使用(组图))
李明刚自建站长工具网站,欢迎使用。
如果您使用过网站管理员工具,您会很好奇。例如网站收录数据和关键词ranking 数据只能从百度等搜索引擎中找到。这些站长工具怎么也能搜到,这么多站长工具,百度等搜索引擎都无法配合他们提供数据。那么,这些数据是如何获得的呢?下面李明为您一一详细讲解。
不知道你有没有用过采集系统,比如织梦cms采集,只要你懂基本的HTML代码,其实站长工具就是用这个原理的,使用网站程序从搜索引擎采集查询的数据回来了。
比如在百度上找到这个网站的收录量,只要抓取这个地址%3A的页面数据,在“找到的相关结果数38”中用正则表达式得到38采集。 其他搜索引擎的收录和关键词排名也是基于同样的原理。要做好这个工具,不仅要了解网站优化的基础知识,还要熟悉网站程序,尤其是正则表达式。
直接用站长工具查询比较简单方便,但也需要学会直接通过搜索引擎本身查询你的网站收录情况!
网站域名(不收录)表单:站点:
1.百度收录Query
Total收录:site:网站域名(不收录)
反链查询:domain:网站domain name(不收录)
查询指定时间段内收录的数量:
24 小时收录 查询::&tn=baiduadv&lm=1
7 天(一周)收录Query::&tn=baiduadv&lm=7
一个月收录Query::&tn=baiduadv&lm=30
*链接填写规则,第一位是你的网站域名,第二位是你要查询的天数!
2.谷歌收录query
总计收录:网站域名(不收录)
反链查询:链接:网站域名(不收录)
3.雅虎收录Query
Total收录:site:网站域名(不收录)
反链查询:...
4.QQ搜搜收录Query
Total收录:site:网站域名(不收录)
反链查询:链接:网站域名(不收录)
希望对大家有帮助! ...

