
怎样抓取网页数据
怎样抓取网页数据(网页如何获取访客手机号码,可以提高100倍获客效率?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-11-19 05:08
现在运营商的数据无处不在,那么如何区分真实的运营商数据呢?
往往由于各种原因,客户只是匆匆一瞥就离开,浪费了大量的时间和精力。与直接的访客交流和引导相比,效果更好。那么网站是如何抓取访问者数据的呢?让我给你解释一下。
如何在网页上获取访问者的手机号码?事实上,运营商会有一个http报告,每个访问者访问过哪些网站 APP以及他的4G数据,以及他们消耗了多少数据。这样,对访客的消费行为和近期需求有非常准确的把握。这类客户的精准开发无疑是非常高的转化率。Wap手机网站获取访客信息系统,可以提高网站的转化率。是企业网站企业营销和招投标网络联盟的必备神器,可以放心使用。在此重申,常规运营商使用脱敏数据来保护用户隐私。
抓住网站访客电话,更容易获客
1、 定位很准确
行业网站访客数据定位非常准确。假设有人用手机上网查询相关信息。那么这些人就有了行业网站访问者数据的条件,行业网站访问者数据可以有效的捕捉到访问者的手机号码,以便我们快速制定相应的市场策略,快速争取。给相关客户。
2、 获取数据的渠道没有障碍
行业网站 从广告数据中获取数据的渠道没有被阻断,因为该单位和其他网络运营商已经搭建了桥梁。不仅可以进行精准的客户定位,还可以打造精准的客户复制体系,从而牢牢抓住大量客户。另一方面,客户复印订单量也在稳步增长。
还等什么,快给我一个小窗口~!节省100招投标费用。获客效率提升100倍。 查看全部
怎样抓取网页数据(网页如何获取访客手机号码,可以提高100倍获客效率?)
现在运营商的数据无处不在,那么如何区分真实的运营商数据呢?
往往由于各种原因,客户只是匆匆一瞥就离开,浪费了大量的时间和精力。与直接的访客交流和引导相比,效果更好。那么网站是如何抓取访问者数据的呢?让我给你解释一下。
如何在网页上获取访问者的手机号码?事实上,运营商会有一个http报告,每个访问者访问过哪些网站 APP以及他的4G数据,以及他们消耗了多少数据。这样,对访客的消费行为和近期需求有非常准确的把握。这类客户的精准开发无疑是非常高的转化率。Wap手机网站获取访客信息系统,可以提高网站的转化率。是企业网站企业营销和招投标网络联盟的必备神器,可以放心使用。在此重申,常规运营商使用脱敏数据来保护用户隐私。

抓住网站访客电话,更容易获客
1、 定位很准确
行业网站访客数据定位非常准确。假设有人用手机上网查询相关信息。那么这些人就有了行业网站访问者数据的条件,行业网站访问者数据可以有效的捕捉到访问者的手机号码,以便我们快速制定相应的市场策略,快速争取。给相关客户。
2、 获取数据的渠道没有障碍
行业网站 从广告数据中获取数据的渠道没有被阻断,因为该单位和其他网络运营商已经搭建了桥梁。不仅可以进行精准的客户定位,还可以打造精准的客户复制体系,从而牢牢抓住大量客户。另一方面,客户复印订单量也在稳步增长。
还等什么,快给我一个小窗口~!节省100招投标费用。获客效率提升100倍。
怎样抓取网页数据(【办公软件】解析html网页内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-11-18 06:07
****************根据URL获取指定的网页内容********************
私有静态字符串 getHtml(字符串路径){
StringBuffer html = new StringBuffer();//保存整个html文档的数据
try {
//1.发起一个url网址的请求
URL url = new URL(path);
URLConnection connection = url.openConnection();
//2.获取网页的数据流
InputStream input = connection.getInputStream(); //字节流 一个字节一个字节的读取 中文占用两个字节
InputStreamReader reader = new InputStreamReader(input,"GBK"); //字符流 一个字符一个字符的读取 可指定字符集编码 ,常用字符集编码:GBK,GB2312,utf-8,ISO-8859-1
BufferedReader bufferedReader = new BufferedReader(reader); //字符流 一行一行的读取
//3.解析并且获取InputStream中具体的数据,并且输出到控制台
String line = "";
while((line = bufferedReader.readLine()) != null)
{
html.append(line); //将所有读到的每行信息line追加到(拼接到)html对象上
}
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return html.toString();
}
****************分析html页面内容********************
私有静态列表 parseHtml(String html) {
// 2.分析html网页内容
文档文档 = Jsoup.parse(html);
// 获取所有的招聘信息所在的div节点
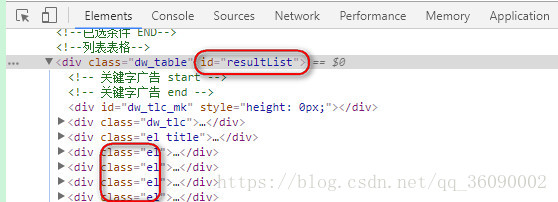
Element div = document.getElementById("resultList");
// 获取div中所有的招聘信息的div
Elements jobs = div.getElementsByClass("el");
List jobList = new ArrayList();
for (Element job : jobs) {
// 工作名称
String jobName = job.getElementsByClass("t1").get(0).text().toUpperCase();
jobName = parseJob(jobName);
// 公司名称
String company = job.getElementsByClass("t2").get(0).text();
// 工作地点
String address = job.getElementsByClass("t3").get(0).text();
// 薪酬待遇
String salary = job.getElementsByClass("t4").get(0).text();
// 求平均值
double avgSalary = getAvgSalary(salary);
// 封装招聘信息
Job myJob = new Job();
myJob.setJobName(jobName);
myJob.setCompany(company);
myJob.setAddress(address);
myJob.setSalary(avgSalary);
// 将对象添加到集合里面
jobList.add(myJob);
}
return jobList;
}
*******************解释***********************
访问某个网站地址后,设置读取方式并解析内容,可以先到网页确认要爬取的数据,进入开发者模式(F12),看看网页的结构是什么样的 程序中首先得到的节点id为resultList,其中每一行数据的class为el,可以通过分析网页找到有用的信息,这样你可以更准确地爬到想要的数据
获取到数据后,封装一条信息,然后将封装的信息添加到集合中。如果要对数据进行一些处理,可以封装信息处理方法并调用。
接下来开始数据库操作...
*********************结尾************************* 查看全部
怎样抓取网页数据(【办公软件】解析html网页内容)
****************根据URL获取指定的网页内容********************
私有静态字符串 getHtml(字符串路径){
StringBuffer html = new StringBuffer();//保存整个html文档的数据
try {
//1.发起一个url网址的请求
URL url = new URL(path);
URLConnection connection = url.openConnection();
//2.获取网页的数据流
InputStream input = connection.getInputStream(); //字节流 一个字节一个字节的读取 中文占用两个字节
InputStreamReader reader = new InputStreamReader(input,"GBK"); //字符流 一个字符一个字符的读取 可指定字符集编码 ,常用字符集编码:GBK,GB2312,utf-8,ISO-8859-1
BufferedReader bufferedReader = new BufferedReader(reader); //字符流 一行一行的读取
//3.解析并且获取InputStream中具体的数据,并且输出到控制台
String line = "";
while((line = bufferedReader.readLine()) != null)
{
html.append(line); //将所有读到的每行信息line追加到(拼接到)html对象上
}
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return html.toString();
}
****************分析html页面内容********************
私有静态列表 parseHtml(String html) {
// 2.分析html网页内容
文档文档 = Jsoup.parse(html);
// 获取所有的招聘信息所在的div节点
Element div = document.getElementById("resultList");
// 获取div中所有的招聘信息的div
Elements jobs = div.getElementsByClass("el");
List jobList = new ArrayList();
for (Element job : jobs) {
// 工作名称
String jobName = job.getElementsByClass("t1").get(0).text().toUpperCase();
jobName = parseJob(jobName);
// 公司名称
String company = job.getElementsByClass("t2").get(0).text();
// 工作地点
String address = job.getElementsByClass("t3").get(0).text();
// 薪酬待遇
String salary = job.getElementsByClass("t4").get(0).text();
// 求平均值
double avgSalary = getAvgSalary(salary);
// 封装招聘信息
Job myJob = new Job();
myJob.setJobName(jobName);
myJob.setCompany(company);
myJob.setAddress(address);
myJob.setSalary(avgSalary);
// 将对象添加到集合里面
jobList.add(myJob);
}
return jobList;
}
*******************解释***********************
访问某个网站地址后,设置读取方式并解析内容,可以先到网页确认要爬取的数据,进入开发者模式(F12),看看网页的结构是什么样的 程序中首先得到的节点id为resultList,其中每一行数据的class为el,可以通过分析网页找到有用的信息,这样你可以更准确地爬到想要的数据
获取到数据后,封装一条信息,然后将封装的信息添加到集合中。如果要对数据进行一些处理,可以封装信息处理方法并调用。
接下来开始数据库操作...
*********************结尾*************************
怎样抓取网页数据(网站排名好不好,流量多不多,其中一个关键的因素)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-11-15 19:13
网站 排名好吗?没有太多的交通。关键因素之一是网站收录如何,虽然收录不能直接决定网站的排名,但网站的基础是内容。如果没有内容,更难排名好。好的内容可以让用户和搜索引擎满意,还可以给网站加分,从而提升排名,扩大网站的曝光页面。
详情请参考以下几点:
1.网站 和页面权重。
网站 权重高、资历老、权限大的蜘蛛,一定要特别对待。这样网站的爬取频率非常高。为了保证高效率,搜索引擎蜘蛛并不是对所有的网站页面都会进行爬取,网站的权重越高,爬取的深度越高,对应的页面可以被爬取爬取的也会增加,这样可以收录的页面也会增加。
2.网站 服务器。
网站服务器是网站的基石。如果网站服务器长时间打不开,那这和闭门谢客很相似。蜘蛛想来也来不了。百度蜘蛛也是网站的访客。如果服务器不稳定或卡住,蜘蛛每次都很难爬行,有时只能爬到一个页面的一部分。就这样,随着时间的推移,百度蜘蛛的体验越来越差,自然会影响到网站的爬取
3. 网站 的更新频率。
每次蜘蛛爬行时,都会存储页面数据。如果第二次爬取发现页面和第一次收录完全一样,说明页面没有更新,蜘蛛不需要频繁爬取。页面内容更新频繁,蜘蛛会更频繁地访问页面,但蜘蛛并不是你一个人的。不可能蹲在这里等你更新,所以一定要主动向蜘蛛展示蜘蛛并定期进行。文章更新,这样蜘蛛才会按照你的规则有效爬行,而不是只让你的更新文章更快的被抓到,也不会导致蜘蛛频繁的白跑。
4.文章的原创性质。
高质量的原创内容对百度蜘蛛来说非常有吸引力。蜘蛛的目的是寻找新的东西,所以网站更新文章不要采集,不要天天转载。我们需要给蜘蛛提供真正有价值的原创内容。蜘蛛如果能得到自己喜欢的东西,自然会对你的网站产生好感,经常来找吃的。
5.扁平的网站结构。
蜘蛛爬行也有自己的路线。在你给他铺路之前,网站结构不要太复杂,链接层次不要太深。如果链接层次太深,后面的页面就很难被蜘蛛抓取到。获得。
6.网站 程序。
在网站程序中,有很多程序可以创建大量的重复页面。这个页面一般是通过参数实现的。当一个页面对应多个URL时,会造成网站重复的内容,可能导致网站被降级,严重影响蜘蛛的抓取。因此,程序必须确保一个页面只有一个 URL。如果已经生成,请尝试使用301重定向、Canonical标签或Robots流程,以确保蜘蛛只抓取一个标准网址。
7.外链建设。
大家都知道外链可以吸引蜘蛛到网站,尤其是新网站的时候,网站还不是很成熟,蜘蛛访问量比较少,外链可以在网站页面中添加网站暴露在蜘蛛面前可以防止蜘蛛无法找到页面。在外链建设的过程中,需要注意外链的质量。不要为了省事而做无用的事情。百度现在相信大家都知道外链的管理。
8.内部链构建。
蜘蛛的爬取是跟随链接的,所以合理优化内链可以要求蜘蛛爬取更多的页面,促进网站的收录。内链建设过程中应给予用户合理的建议。除了在文章中添加锚文本,还可以设置相关推荐、热门文章、更多喜欢等栏目,这个很多网站都有用,让蜘蛛爬取更广泛的页面。 查看全部
怎样抓取网页数据(网站排名好不好,流量多不多,其中一个关键的因素)
网站 排名好吗?没有太多的交通。关键因素之一是网站收录如何,虽然收录不能直接决定网站的排名,但网站的基础是内容。如果没有内容,更难排名好。好的内容可以让用户和搜索引擎满意,还可以给网站加分,从而提升排名,扩大网站的曝光页面。
详情请参考以下几点:
1.网站 和页面权重。
网站 权重高、资历老、权限大的蜘蛛,一定要特别对待。这样网站的爬取频率非常高。为了保证高效率,搜索引擎蜘蛛并不是对所有的网站页面都会进行爬取,网站的权重越高,爬取的深度越高,对应的页面可以被爬取爬取的也会增加,这样可以收录的页面也会增加。
2.网站 服务器。
网站服务器是网站的基石。如果网站服务器长时间打不开,那这和闭门谢客很相似。蜘蛛想来也来不了。百度蜘蛛也是网站的访客。如果服务器不稳定或卡住,蜘蛛每次都很难爬行,有时只能爬到一个页面的一部分。就这样,随着时间的推移,百度蜘蛛的体验越来越差,自然会影响到网站的爬取
3. 网站 的更新频率。
每次蜘蛛爬行时,都会存储页面数据。如果第二次爬取发现页面和第一次收录完全一样,说明页面没有更新,蜘蛛不需要频繁爬取。页面内容更新频繁,蜘蛛会更频繁地访问页面,但蜘蛛并不是你一个人的。不可能蹲在这里等你更新,所以一定要主动向蜘蛛展示蜘蛛并定期进行。文章更新,这样蜘蛛才会按照你的规则有效爬行,而不是只让你的更新文章更快的被抓到,也不会导致蜘蛛频繁的白跑。
4.文章的原创性质。
高质量的原创内容对百度蜘蛛来说非常有吸引力。蜘蛛的目的是寻找新的东西,所以网站更新文章不要采集,不要天天转载。我们需要给蜘蛛提供真正有价值的原创内容。蜘蛛如果能得到自己喜欢的东西,自然会对你的网站产生好感,经常来找吃的。
5.扁平的网站结构。
蜘蛛爬行也有自己的路线。在你给他铺路之前,网站结构不要太复杂,链接层次不要太深。如果链接层次太深,后面的页面就很难被蜘蛛抓取到。获得。
6.网站 程序。
在网站程序中,有很多程序可以创建大量的重复页面。这个页面一般是通过参数实现的。当一个页面对应多个URL时,会造成网站重复的内容,可能导致网站被降级,严重影响蜘蛛的抓取。因此,程序必须确保一个页面只有一个 URL。如果已经生成,请尝试使用301重定向、Canonical标签或Robots流程,以确保蜘蛛只抓取一个标准网址。
7.外链建设。
大家都知道外链可以吸引蜘蛛到网站,尤其是新网站的时候,网站还不是很成熟,蜘蛛访问量比较少,外链可以在网站页面中添加网站暴露在蜘蛛面前可以防止蜘蛛无法找到页面。在外链建设的过程中,需要注意外链的质量。不要为了省事而做无用的事情。百度现在相信大家都知道外链的管理。
8.内部链构建。
蜘蛛的爬取是跟随链接的,所以合理优化内链可以要求蜘蛛爬取更多的页面,促进网站的收录。内链建设过程中应给予用户合理的建议。除了在文章中添加锚文本,还可以设置相关推荐、热门文章、更多喜欢等栏目,这个很多网站都有用,让蜘蛛爬取更广泛的页面。
怎样抓取网页数据(怎样抓取网页数据,这里介绍下下一个web框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2021-11-11 16:03
怎样抓取网页数据,这里介绍下一个web框架1、首先要学习python基础,看我之前的文章2、学习mysql一建立自己的数据库1-1python中文mysql简介1-2python中文mysql简介2-3基本操作python中文mysql简介2-4高级操作python中文mysql简介2-5创建表python中文mysql简介2-6插入和更新表python中文mysql简介2-7创建视图1-1python中文mysql简介1-2python中文mysql简介1-3python中文mysql简介1-4python中文mysql简介1-5python中文mysql简介2-1python中文mysql简介2-2python中文mysql简介2-3python中文mysql简介2-4python中文mysql简介2-5python中文mysql简介二理解关系数据库操作1-1python中文mysql简介2-2python中文mysql简介2-3python中文mysql简介2-4python中文mysql简介2-5python中文mysql简介2-6python中文mysql简介3实践问题收集:1。
举例抓取网页上的“蛋糕数据”,如何抓取?2。举例抓取网页上的“西湖门票”?3。举例抓取网页上的“博物馆数据”?4。举例抓取网页上的“物流详情”?5。举例抓取“58同城”数据?6。举例抓取上的“房价”?7。举例抓取上的“书店”数据?8。举例抓取上的“街景”数据?9。举例抓取“凤凰新闻”的"汽车"数据?三如何用python抓取网页数据?1-1抓取网页的方法1-2网页信息都在哪里2-1python解析xpath2-2python解析json3-1python数据分析和数据可视化。 查看全部
怎样抓取网页数据(怎样抓取网页数据,这里介绍下下一个web框架)
怎样抓取网页数据,这里介绍下一个web框架1、首先要学习python基础,看我之前的文章2、学习mysql一建立自己的数据库1-1python中文mysql简介1-2python中文mysql简介2-3基本操作python中文mysql简介2-4高级操作python中文mysql简介2-5创建表python中文mysql简介2-6插入和更新表python中文mysql简介2-7创建视图1-1python中文mysql简介1-2python中文mysql简介1-3python中文mysql简介1-4python中文mysql简介1-5python中文mysql简介2-1python中文mysql简介2-2python中文mysql简介2-3python中文mysql简介2-4python中文mysql简介2-5python中文mysql简介二理解关系数据库操作1-1python中文mysql简介2-2python中文mysql简介2-3python中文mysql简介2-4python中文mysql简介2-5python中文mysql简介2-6python中文mysql简介3实践问题收集:1。
举例抓取网页上的“蛋糕数据”,如何抓取?2。举例抓取网页上的“西湖门票”?3。举例抓取网页上的“博物馆数据”?4。举例抓取网页上的“物流详情”?5。举例抓取“58同城”数据?6。举例抓取上的“房价”?7。举例抓取上的“书店”数据?8。举例抓取上的“街景”数据?9。举例抓取“凤凰新闻”的"汽车"数据?三如何用python抓取网页数据?1-1抓取网页的方法1-2网页信息都在哪里2-1python解析xpath2-2python解析json3-1python数据分析和数据可视化。
怎样抓取网页数据(web前端开发中怎样抓取网页数据首先,python操作过程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-10 20:03
怎样抓取网页数据首先,如果在web前端开发中,dom操作就是浏览器对象,但是dom操作过程非常繁琐,因此几乎很少有开发者能熟练掌握dom操作。python在dom操作方面具有天然优势,python操作dom几乎只需要几行代码,并且python是静态语言,python的基础语法以及python数据结构和函数都能让程序使用python语言进行实现。
dict语言里,能操作数组,但是创建和管理dict对象却非常繁琐。如果能用python的数据结构来实现dict中的键值对关系,就能将其简化到极致。不过,在python中,查找一个对象中的某个属性非常容易,但是要查找一个对象中所有对象的key和value,相对要难一些。dict的实现方式很简单,数据结构就是dict,方法也都是抽象的,不需要写items=dict.set(key,value)等代码。
dict.keys=[]利用dict.keys可以很容易定位key,因为key一定是类,可以操作的对象也就几种类型,除了整数,一般还能操作数字。比如上面例子中,dict.keys[1]=2。此外,利用dict.dict(key=none)可以简化key查找的数据结构操作,比如:dict[none]=none将tuple转换为dict转换成dict需要将dict转换成tuple再进行转换,在python3中已经提供dict.toarray,但是在python2中,无法直接用这个方法将dict转换成tuple数组:dict.resize(new_dict)dict中的key可以通过tuple()方法转换为keyed类型。
对于每个元素,tuple()都会返回一个keyed类型,因此,可以非常方便的把tuple()转换成dict:dict.resize(tuple)dict中的value用tuple()转换,tuple()将dict转换成tuple,就是把tuple中元素都转换成一个keyed类型,而实际上每个keyed是tuple中的某个元素值。
dict[0]='item1'此外,dict.reverse函数将会返回dict[none]为none,这个函数代表dict是不变的。将字典转换为dictpython3中提供了dict.fromkeys(key=value)方法,可以把一个key转换成value。python3提供的字典方法和python2不同,python3中dict.fromkeys比dict.frompython3提供了dict.fromkeys_values()方法,返回dict的tuple(),除此之外,dict.fromid()、dict.froming_index()也可以用来将一个key转换成value。 查看全部
怎样抓取网页数据(web前端开发中怎样抓取网页数据首先,python操作过程)
怎样抓取网页数据首先,如果在web前端开发中,dom操作就是浏览器对象,但是dom操作过程非常繁琐,因此几乎很少有开发者能熟练掌握dom操作。python在dom操作方面具有天然优势,python操作dom几乎只需要几行代码,并且python是静态语言,python的基础语法以及python数据结构和函数都能让程序使用python语言进行实现。
dict语言里,能操作数组,但是创建和管理dict对象却非常繁琐。如果能用python的数据结构来实现dict中的键值对关系,就能将其简化到极致。不过,在python中,查找一个对象中的某个属性非常容易,但是要查找一个对象中所有对象的key和value,相对要难一些。dict的实现方式很简单,数据结构就是dict,方法也都是抽象的,不需要写items=dict.set(key,value)等代码。
dict.keys=[]利用dict.keys可以很容易定位key,因为key一定是类,可以操作的对象也就几种类型,除了整数,一般还能操作数字。比如上面例子中,dict.keys[1]=2。此外,利用dict.dict(key=none)可以简化key查找的数据结构操作,比如:dict[none]=none将tuple转换为dict转换成dict需要将dict转换成tuple再进行转换,在python3中已经提供dict.toarray,但是在python2中,无法直接用这个方法将dict转换成tuple数组:dict.resize(new_dict)dict中的key可以通过tuple()方法转换为keyed类型。
对于每个元素,tuple()都会返回一个keyed类型,因此,可以非常方便的把tuple()转换成dict:dict.resize(tuple)dict中的value用tuple()转换,tuple()将dict转换成tuple,就是把tuple中元素都转换成一个keyed类型,而实际上每个keyed是tuple中的某个元素值。
dict[0]='item1'此外,dict.reverse函数将会返回dict[none]为none,这个函数代表dict是不变的。将字典转换为dictpython3中提供了dict.fromkeys(key=value)方法,可以把一个key转换成value。python3提供的字典方法和python2不同,python3中dict.fromkeys比dict.frompython3提供了dict.fromkeys_values()方法,返回dict的tuple(),除此之外,dict.fromid()、dict.froming_index()也可以用来将一个key转换成value。
怎样抓取网页数据(搜索引擎蜘蛛访问网站页面的程序被称为蜘蛛(spider)网站怎么引)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-11-08 03:17
搜索引擎用来抓取和访问页面的程序称为蜘蛛程序或机器人程序。搜索引擎蜘蛛访问网站页面时,与普通用户使用浏览器类似。蜘蛛程序发出页面访问请求后,服务器返回HTML代码,蜘蛛程序将接收到的代码存储在原创页面数据库中。搜索引擎旨在提高爬行和爬行速度,两者都使用多个蜘蛛来分布爬行。
蜘蛛访问网站时,首先会访问网站根目录下的robots.txt文件。如果robots.txt 文件禁止搜索引擎抓取某些网页或内容,或者网站,蜘蛛将遵循协议而不抓取它。
蜘蛛也有自己的代理名称。在站长的日志中可以看到蜘蛛的爬行痕迹。这就是为什么很多站长回答问题的时候,总是说先查看网站日志(作为一个优秀的SEO,你必须有能力在不借助任何软件的情况下查看网站日志,并且非常熟悉代码的含义)。
一、搜索引擎蜘蛛的基本原理
搜索引擎蜘蛛就是Spider,这是一个很形象的名字。它将互联网比作蜘蛛网,然后蜘蛛就是在互联网上爬行的蜘蛛。
网络蜘蛛通过网页的链接地址搜索网页。从某个页面(通常是首页)开始,阅读网页内容,找到网页中的其他链接地址,然后通过这些链接地址进行搜索。一个网页,一直循环下去,直到这个网站的所有网页都被抓取完。
如果把整个互联网看作一个网站,那么网络蜘蛛就可以利用这个原理抓取互联网上的所有网页。
搜索引擎蜘蛛的基本原理和工作流程
对于搜索引擎来说,爬取互联网上的所有网页几乎是不可能的。根据目前公布的数据,容量最大的搜索引擎只能抓取整个网页的40%左右。
造成这种情况的原因之一,一方面是爬虫技术的瓶颈。100亿个网页的容量为100×2000G字节。即使可以存储,下载还是有问题(按照一台机器每秒下载20K计算,需要340台机器停止。下载所有网页需要一年时间。同时,由于数据量大,会影响搜索的效率。
因此,很多搜索引擎的网络蜘蛛只爬取那些重要的网页,爬取时评价重要性的主要依据是某个网页的链接深度。
由于不可能爬取所有网页,所以一些网络蜘蛛对一些不太重要的网站设置了访问级别的数量,例如如下图所示:
搜索引擎蜘蛛的基本原理和工作流程
A为起始网页,属于第0层,B、C、D、E、F属于第1层,G、H属于第2层,I属于第3层。网络蜘蛛为2,页面I不会被访问,这也允许搜索引擎搜索到一些网站之前的页面,其他部分无法搜索。
对于网站设计师来说,扁平化的网站结构设计有助于搜索引擎抓取更多的网页。
网络蜘蛛在访问网站 网页时,经常会遇到加密数据和网络权限的问题。某些网页需要会员权限才能访问。
当然,网站的站长可以通过协议防止网络蜘蛛爬行,但是对于一些网站的销售报告,他们希望自己的报告能够被搜索引擎搜索到,但又不可能完全免费. 让搜索者查看,所以需要提供对应的用户名和密码给网络蜘蛛。
网络蜘蛛可以抓取这些具有给定权限的网页提供搜索,当搜索者点击查看网页时,搜索者也需要提供相应的权限验证。
二、追踪链接
因为搜索引擎蜘蛛可以在网络上抓取尽可能多的页面,所以它们会跟随网页上的链接从一个页面爬到下一个页面,就像蜘蛛在蜘蛛网上爬行一样。这就是名称搜索引擎蜘蛛的来源。因为。
整个互联网网站是由相互链接组成的,也就是说,从任何一个页面开始,搜索引擎蜘蛛最终都会抓取所有页面。
搜索引擎蜘蛛的基本原理和工作流程
当然,网站和页面链接结构过于复杂,所以蜘蛛只能通过一定的方法抓取所有页面。据了解,最简单的爬取策略有3种:
1、最好的第一
最佳优先级搜索策略根据一定的网页分析算法预测候选网址与目标页面的相似度或与主题的相关性,选择一个或几个评价最好的网址进行爬取,只访问该网页经过分析该算法预测“有用”的页面。
一个问题是爬虫爬取路径上的很多相关网页可能会被忽略,因为最佳优先级策略是局部最优搜索算法,所以需要将最佳优先级结合具体应用进行改进跳出局部区域. 最大的好处,据研究,这样的闭环调整可以减少30%到90%的无关网页。
2、深度优先
深度优先是指蜘蛛沿着发现的链接向前爬,直到它前面没有更多的链接,然后回到第一页,沿着另一个链接向前爬。
3、广度优先
广度优先是指当一个蜘蛛在一个页面上发现多个链接时,它不会一直跟踪一个链接,而是爬取页面上的所有链接,然后进入二级页面并跟踪在第二级找到的链接-level 爬到第三级页面。
理论上,无论是深度优先还是广度优先,只要给蜘蛛足够的时间,它们就可以爬取整个互联网。
在实际工作中,蜘蛛的带宽资源和时间不是无限的,也不是爬满所有的页面。其实最大的搜索引擎只是爬取和收录互联网的一小部分,当然不是搜索。引擎蜘蛛爬的越多越好,这点
因此,为了捕捉尽可能多的用户信息,通常会混合使用深度优先和广度优先,这样可以照顾到尽可能多的网站和网站的部分内页.
三、 搜索引擎蜘蛛工作中的信息采集
信息采集模块包括“蜘蛛控制”和“网络蜘蛛”两部分。“蜘蛛”这个名字形象地描述了信息采集模块在网络数据形成的“Web”上获取信息的功能。
一般来说,网络蜘蛛从种子网页开始,反复下载网页,寻找文档中没有见过的网址,以达到访问其他网页遍历网页的目的。
而其工作策略一般可分为累积爬行(cumulative crawling)和增量爬行(incremental crawling)两种。
1、累积爬行
累积爬取是指从某个时间点开始爬取系统可以允许存储和处理的所有网页。在理想的软硬件环境下,经过足够的运行时间,累积爬取策略可以保证可以爬取相当数量的网页集合。
似乎由于网络数据的动态性,采集到的网页的抓取时间不同,页面更新的情况也不同。因此,累积爬取所爬取的网页集合,实际上并不能和真实环境中的网络数据相比。始终如一。
2、增量爬取
与累积爬取不同,增量爬取是指对具有一定规模的网页集合,采用更新数据的方法,在现有集合中选择过时的网页进行爬取,保证爬取的数据与当前的数据足够接近。真实的网络数据。
增量爬取的前提是系统已经爬取了足够多的网页,并且有这些页面被爬取的时间信息。在面向实际应用环境的网络蜘蛛设计中,通常包括累积爬取和增量爬取两种策略。
累积爬取一般用于数据采集的整体建立或大规模更新阶段,而增量爬取主要用于数据采集的日常维护和实时更新。
确定爬取策略后,如何充分利用网络带宽,合理确定网页数据更新的时间点,成为网络蜘蛛运行策略的核心问题。
总的来说,在合理利用软硬件资源实时捕获网络数据方面,已经形成了比较成熟的技术和实用的解决方案。我觉得这方面需要解决的主要问题是如何更好地处理动态的网络数据问题(比如Web2.0数据越来越多等),更好地纠正基于网页质量的抓取策略。
四、数据库
为了避免重复抓取和抓取网址,搜索引擎会建立一个数据库来记录已发现未抓取的页面和已抓取的页面。那么数据库中的URL是怎么来的呢?
1、手动输入种子网站
简单来说就是我们新建网站后提交给百度、谷歌或者360的URL收录。
2、 蜘蛛抓取页面
如果搜索引擎蜘蛛在爬取过程中发现了一个新的连接网址,但它不在数据库中,则将其存储在数据库中以供访问(网站观察期)。
蜘蛛根据重要性从要访问的数据库中提取URL,访问并爬取页面,然后从要访问的地址数据库中删除该URL并将其放入访问地址数据库中,因此建议站长关注网站 期间需要定期更新网站。
3、站长提交网站
一般来说,提交网站只是将网站保存到要访问的数据库中。如果网站长时间不更新,蜘蛛就不会光顾了。搜索引擎收录的页面都是蜘蛛。自己通过链接获取它。
因此,如果您将其提交给搜索引擎,则它不是很有用。后期还是要考虑你的网站更新级别。搜索引擎更喜欢沿着链接发现新页面。当然,如果你的SEO功底高深,有能力试试这个能力,说不定会有意想不到的效果,但是对于一般的站长来说,还是建议让蜘蛛爬行,自然爬到新的站点页面。
五、吸引蜘蛛
虽然理论上说蜘蛛可以抓取所有页面,但实际上是不可能做到的。想要收录更多页面的SEO人员只能想办法引诱蜘蛛爬行。
既然它不能抓取所有的页面,那我们就得让它去抓取重要的页面,因为重要的页面在索引中起着重要的作用,直接影响排名因素。哪些页面更重要?对此,我还专门整理了以下我认为比较重要的页面,具体有这些特点:
1、网站 和页面权重
高质量和老的网站 被赋予了很高的权重。这个网站上的页面蜘蛛爬取深度比较高,所以更多的内页会是收录。
2、页面更新率
蜘蛛每次爬行时都会存储页面数据。如果在第二次爬取时发现这个页面的内容和第一个收录完全一样,说明该页面没有更新,蜘蛛不需要再频繁的爬取和爬取。
如果页面内容更新频繁,蜘蛛就会频繁爬行爬取,那么页面上的新链接自然会被蜘蛛更快地跟踪和抓取,这也是为什么需要每天更新的原因文章
3、导入链接
不管是外链还是同一个网站的内链,为了被蜘蛛爬取,必须有导入链接才能进入页面,否则蜘蛛不知道页面的存在. 这时候URL链接就发挥了非常重要的作用,内部链接的重要性就发挥出来了。
另外,我个人觉得高质量的入站链接往往会增加页面出站链接的抓取深度。
这也是为什么大部分站长或者SEO都需要高质量友情链接的原因,因为蜘蛛从对方网站向你网站爬了很多次,而且深度也很高。 查看全部
怎样抓取网页数据(搜索引擎蜘蛛访问网站页面的程序被称为蜘蛛(spider)网站怎么引)
搜索引擎用来抓取和访问页面的程序称为蜘蛛程序或机器人程序。搜索引擎蜘蛛访问网站页面时,与普通用户使用浏览器类似。蜘蛛程序发出页面访问请求后,服务器返回HTML代码,蜘蛛程序将接收到的代码存储在原创页面数据库中。搜索引擎旨在提高爬行和爬行速度,两者都使用多个蜘蛛来分布爬行。


蜘蛛访问网站时,首先会访问网站根目录下的robots.txt文件。如果robots.txt 文件禁止搜索引擎抓取某些网页或内容,或者网站,蜘蛛将遵循协议而不抓取它。
蜘蛛也有自己的代理名称。在站长的日志中可以看到蜘蛛的爬行痕迹。这就是为什么很多站长回答问题的时候,总是说先查看网站日志(作为一个优秀的SEO,你必须有能力在不借助任何软件的情况下查看网站日志,并且非常熟悉代码的含义)。
一、搜索引擎蜘蛛的基本原理
搜索引擎蜘蛛就是Spider,这是一个很形象的名字。它将互联网比作蜘蛛网,然后蜘蛛就是在互联网上爬行的蜘蛛。
网络蜘蛛通过网页的链接地址搜索网页。从某个页面(通常是首页)开始,阅读网页内容,找到网页中的其他链接地址,然后通过这些链接地址进行搜索。一个网页,一直循环下去,直到这个网站的所有网页都被抓取完。
如果把整个互联网看作一个网站,那么网络蜘蛛就可以利用这个原理抓取互联网上的所有网页。
搜索引擎蜘蛛的基本原理和工作流程
对于搜索引擎来说,爬取互联网上的所有网页几乎是不可能的。根据目前公布的数据,容量最大的搜索引擎只能抓取整个网页的40%左右。
造成这种情况的原因之一,一方面是爬虫技术的瓶颈。100亿个网页的容量为100×2000G字节。即使可以存储,下载还是有问题(按照一台机器每秒下载20K计算,需要340台机器停止。下载所有网页需要一年时间。同时,由于数据量大,会影响搜索的效率。
因此,很多搜索引擎的网络蜘蛛只爬取那些重要的网页,爬取时评价重要性的主要依据是某个网页的链接深度。
由于不可能爬取所有网页,所以一些网络蜘蛛对一些不太重要的网站设置了访问级别的数量,例如如下图所示:
搜索引擎蜘蛛的基本原理和工作流程
A为起始网页,属于第0层,B、C、D、E、F属于第1层,G、H属于第2层,I属于第3层。网络蜘蛛为2,页面I不会被访问,这也允许搜索引擎搜索到一些网站之前的页面,其他部分无法搜索。
对于网站设计师来说,扁平化的网站结构设计有助于搜索引擎抓取更多的网页。
网络蜘蛛在访问网站 网页时,经常会遇到加密数据和网络权限的问题。某些网页需要会员权限才能访问。
当然,网站的站长可以通过协议防止网络蜘蛛爬行,但是对于一些网站的销售报告,他们希望自己的报告能够被搜索引擎搜索到,但又不可能完全免费. 让搜索者查看,所以需要提供对应的用户名和密码给网络蜘蛛。
网络蜘蛛可以抓取这些具有给定权限的网页提供搜索,当搜索者点击查看网页时,搜索者也需要提供相应的权限验证。
二、追踪链接
因为搜索引擎蜘蛛可以在网络上抓取尽可能多的页面,所以它们会跟随网页上的链接从一个页面爬到下一个页面,就像蜘蛛在蜘蛛网上爬行一样。这就是名称搜索引擎蜘蛛的来源。因为。
整个互联网网站是由相互链接组成的,也就是说,从任何一个页面开始,搜索引擎蜘蛛最终都会抓取所有页面。
搜索引擎蜘蛛的基本原理和工作流程
当然,网站和页面链接结构过于复杂,所以蜘蛛只能通过一定的方法抓取所有页面。据了解,最简单的爬取策略有3种:
1、最好的第一
最佳优先级搜索策略根据一定的网页分析算法预测候选网址与目标页面的相似度或与主题的相关性,选择一个或几个评价最好的网址进行爬取,只访问该网页经过分析该算法预测“有用”的页面。
一个问题是爬虫爬取路径上的很多相关网页可能会被忽略,因为最佳优先级策略是局部最优搜索算法,所以需要将最佳优先级结合具体应用进行改进跳出局部区域. 最大的好处,据研究,这样的闭环调整可以减少30%到90%的无关网页。
2、深度优先
深度优先是指蜘蛛沿着发现的链接向前爬,直到它前面没有更多的链接,然后回到第一页,沿着另一个链接向前爬。
3、广度优先
广度优先是指当一个蜘蛛在一个页面上发现多个链接时,它不会一直跟踪一个链接,而是爬取页面上的所有链接,然后进入二级页面并跟踪在第二级找到的链接-level 爬到第三级页面。
理论上,无论是深度优先还是广度优先,只要给蜘蛛足够的时间,它们就可以爬取整个互联网。
在实际工作中,蜘蛛的带宽资源和时间不是无限的,也不是爬满所有的页面。其实最大的搜索引擎只是爬取和收录互联网的一小部分,当然不是搜索。引擎蜘蛛爬的越多越好,这点
因此,为了捕捉尽可能多的用户信息,通常会混合使用深度优先和广度优先,这样可以照顾到尽可能多的网站和网站的部分内页.
三、 搜索引擎蜘蛛工作中的信息采集
信息采集模块包括“蜘蛛控制”和“网络蜘蛛”两部分。“蜘蛛”这个名字形象地描述了信息采集模块在网络数据形成的“Web”上获取信息的功能。
一般来说,网络蜘蛛从种子网页开始,反复下载网页,寻找文档中没有见过的网址,以达到访问其他网页遍历网页的目的。
而其工作策略一般可分为累积爬行(cumulative crawling)和增量爬行(incremental crawling)两种。
1、累积爬行
累积爬取是指从某个时间点开始爬取系统可以允许存储和处理的所有网页。在理想的软硬件环境下,经过足够的运行时间,累积爬取策略可以保证可以爬取相当数量的网页集合。
似乎由于网络数据的动态性,采集到的网页的抓取时间不同,页面更新的情况也不同。因此,累积爬取所爬取的网页集合,实际上并不能和真实环境中的网络数据相比。始终如一。
2、增量爬取
与累积爬取不同,增量爬取是指对具有一定规模的网页集合,采用更新数据的方法,在现有集合中选择过时的网页进行爬取,保证爬取的数据与当前的数据足够接近。真实的网络数据。
增量爬取的前提是系统已经爬取了足够多的网页,并且有这些页面被爬取的时间信息。在面向实际应用环境的网络蜘蛛设计中,通常包括累积爬取和增量爬取两种策略。
累积爬取一般用于数据采集的整体建立或大规模更新阶段,而增量爬取主要用于数据采集的日常维护和实时更新。
确定爬取策略后,如何充分利用网络带宽,合理确定网页数据更新的时间点,成为网络蜘蛛运行策略的核心问题。
总的来说,在合理利用软硬件资源实时捕获网络数据方面,已经形成了比较成熟的技术和实用的解决方案。我觉得这方面需要解决的主要问题是如何更好地处理动态的网络数据问题(比如Web2.0数据越来越多等),更好地纠正基于网页质量的抓取策略。
四、数据库
为了避免重复抓取和抓取网址,搜索引擎会建立一个数据库来记录已发现未抓取的页面和已抓取的页面。那么数据库中的URL是怎么来的呢?
1、手动输入种子网站
简单来说就是我们新建网站后提交给百度、谷歌或者360的URL收录。
2、 蜘蛛抓取页面
如果搜索引擎蜘蛛在爬取过程中发现了一个新的连接网址,但它不在数据库中,则将其存储在数据库中以供访问(网站观察期)。
蜘蛛根据重要性从要访问的数据库中提取URL,访问并爬取页面,然后从要访问的地址数据库中删除该URL并将其放入访问地址数据库中,因此建议站长关注网站 期间需要定期更新网站。
3、站长提交网站
一般来说,提交网站只是将网站保存到要访问的数据库中。如果网站长时间不更新,蜘蛛就不会光顾了。搜索引擎收录的页面都是蜘蛛。自己通过链接获取它。
因此,如果您将其提交给搜索引擎,则它不是很有用。后期还是要考虑你的网站更新级别。搜索引擎更喜欢沿着链接发现新页面。当然,如果你的SEO功底高深,有能力试试这个能力,说不定会有意想不到的效果,但是对于一般的站长来说,还是建议让蜘蛛爬行,自然爬到新的站点页面。
五、吸引蜘蛛
虽然理论上说蜘蛛可以抓取所有页面,但实际上是不可能做到的。想要收录更多页面的SEO人员只能想办法引诱蜘蛛爬行。
既然它不能抓取所有的页面,那我们就得让它去抓取重要的页面,因为重要的页面在索引中起着重要的作用,直接影响排名因素。哪些页面更重要?对此,我还专门整理了以下我认为比较重要的页面,具体有这些特点:
1、网站 和页面权重
高质量和老的网站 被赋予了很高的权重。这个网站上的页面蜘蛛爬取深度比较高,所以更多的内页会是收录。
2、页面更新率
蜘蛛每次爬行时都会存储页面数据。如果在第二次爬取时发现这个页面的内容和第一个收录完全一样,说明该页面没有更新,蜘蛛不需要再频繁的爬取和爬取。
如果页面内容更新频繁,蜘蛛就会频繁爬行爬取,那么页面上的新链接自然会被蜘蛛更快地跟踪和抓取,这也是为什么需要每天更新的原因文章
3、导入链接
不管是外链还是同一个网站的内链,为了被蜘蛛爬取,必须有导入链接才能进入页面,否则蜘蛛不知道页面的存在. 这时候URL链接就发挥了非常重要的作用,内部链接的重要性就发挥出来了。
另外,我个人觉得高质量的入站链接往往会增加页面出站链接的抓取深度。
这也是为什么大部分站长或者SEO都需要高质量友情链接的原因,因为蜘蛛从对方网站向你网站爬了很多次,而且深度也很高。
怎样抓取网页数据(登录或注册用户后如何从Web获取Cookie?(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-11-08 03:13
)
xwpedram
我在unity3d和我的网站页面有注册和登录页面,当我将注册或登录数据从unity3d发布到我的网站 (magento cms) ,发送到我自己的错误“无法回滚必要的数据”,在HttpAnalyzer应用程序中看到我的请求后,我发现unity3d无法接受获取cookie字符串。登录或注册用户后如何从Web获取cookies?我的 unity3d 代码:
var form = new WWWForm();
form.AddField( "SN", SystemInfo.deviceUniqueIdentifier.ToString());
form.AddField( "UserName ", UserName );
form.AddField( "year",Year );
form.AddField( "month", Month );
form.AddField( "day", Day );
form.AddField( "dob",Year+"/"+Month+"/"+Day );
form.AddField( "gender", Gender );
form.AddField( "password", Pass );
// Create a download object
var download = new WWW(URL, form);
// Wait until the download is done
yield download;
// show the Results
Debug.Log(download.text);
if(download.error != null)
{
Debug.Log("Err :"+download.error);
Flag = "1";
}
2斤
当您尝试加载的页面被重定向时,通常会出现“必要的数据回滚”情况。我认为您不能使用“跟随重定向”选项在 Unity 中发出请求。
我不知道 Magentacms,所以我不能告诉你如何解决这个问题。关于cookies的问题,在Unity中这个很简单:你只需要从第一次调用中截取头“SET-COOKIE”,然后在下一次调用中发回标有“Cookie”的头:
#pragma strict
import System.Collections.Generic;
var url:String = "";
var cookie:String = "";
/// interface
private var stringToEdit:String = "";
function OnGUI(){
if (url!="" && GUI.Button(Rect(10,10,200,30),"Click"))
StartCoroutine(LoadData());
stringToEdit = GUI.TextArea (Rect (10, 50, 600, 400), stringToEdit);
}
/// debug
function Debug(s:String){
stringToEdit += s+"\n";
}
function LoadData():IEnumerator{
Debug(url);
var form : WWWForm = new WWWForm();
var time:String = System.DateTime.Now.Ticks.ToString();
form.AddField("time", time);
// construct your header calls
var headers : Hashtable = form.headers;
if(cookie!="")
headers["Cookie"] = cookie;
var www : WWW = new WWW(url, form.data, headers);
yield www;
if(!www.error){
Debug(www.text);
// get the cookie and keep it
if(www.responseHeaders.ContainsKey('SET-COOKIE')){
var data:String[] = www.responseHeaders['SET-COOKIE'].Split(";"[0]);
if(data.length>0){
cookie = data[0];
}
}
}else
Debug(www.error);
// debug
for(var header:KeyValuePair. in www.responseHeaders)
Debug(header.Key+" "+header.Value);
} 查看全部
怎样抓取网页数据(登录或注册用户后如何从Web获取Cookie?(图)
)
xwpedram
我在unity3d和我的网站页面有注册和登录页面,当我将注册或登录数据从unity3d发布到我的网站 (magento cms) ,发送到我自己的错误“无法回滚必要的数据”,在HttpAnalyzer应用程序中看到我的请求后,我发现unity3d无法接受获取cookie字符串。登录或注册用户后如何从Web获取cookies?我的 unity3d 代码:
var form = new WWWForm();
form.AddField( "SN", SystemInfo.deviceUniqueIdentifier.ToString());
form.AddField( "UserName ", UserName );
form.AddField( "year",Year );
form.AddField( "month", Month );
form.AddField( "day", Day );
form.AddField( "dob",Year+"/"+Month+"/"+Day );
form.AddField( "gender", Gender );
form.AddField( "password", Pass );
// Create a download object
var download = new WWW(URL, form);
// Wait until the download is done
yield download;
// show the Results
Debug.Log(download.text);
if(download.error != null)
{
Debug.Log("Err :"+download.error);
Flag = "1";
}
2斤
当您尝试加载的页面被重定向时,通常会出现“必要的数据回滚”情况。我认为您不能使用“跟随重定向”选项在 Unity 中发出请求。
我不知道 Magentacms,所以我不能告诉你如何解决这个问题。关于cookies的问题,在Unity中这个很简单:你只需要从第一次调用中截取头“SET-COOKIE”,然后在下一次调用中发回标有“Cookie”的头:
#pragma strict
import System.Collections.Generic;
var url:String = "";
var cookie:String = "";
/// interface
private var stringToEdit:String = "";
function OnGUI(){
if (url!="" && GUI.Button(Rect(10,10,200,30),"Click"))
StartCoroutine(LoadData());
stringToEdit = GUI.TextArea (Rect (10, 50, 600, 400), stringToEdit);
}
/// debug
function Debug(s:String){
stringToEdit += s+"\n";
}
function LoadData():IEnumerator{
Debug(url);
var form : WWWForm = new WWWForm();
var time:String = System.DateTime.Now.Ticks.ToString();
form.AddField("time", time);
// construct your header calls
var headers : Hashtable = form.headers;
if(cookie!="")
headers["Cookie"] = cookie;
var www : WWW = new WWW(url, form.data, headers);
yield www;
if(!www.error){
Debug(www.text);
// get the cookie and keep it
if(www.responseHeaders.ContainsKey('SET-COOKIE')){
var data:String[] = www.responseHeaders['SET-COOKIE'].Split(";"[0]);
if(data.length>0){
cookie = data[0];
}
}
}else
Debug(www.error);
// debug
for(var header:KeyValuePair. in www.responseHeaders)
Debug(header.Key+" "+header.Value);
}
怎样抓取网页数据(HTML是无法读取数据库的,HTML页面前端脚本语言的组成)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-11-07 07:08
HTML 无法读取数据库。HTML 是页面的前端脚本语言。如果要从 HTML 页面中获取 SQL 数据库中的数据,则需要使用 JSP 或 ASP 或 PHP 或 RUBY 等语言。
SQL数据库的数据体系结构基本上是三级结构,但使用的术语与传统的关系模型不同。在SQL中,关系模式(mode)被称为“基表”;存储方式(内部方式)称为“存储文件”;子模式(外部模式)称为“视图”(view);元组被称为“行”;属性称为“列”。
扩展信息
SQL语言的组成:
1、SQL 数据库是由一个或多个 SQL 模式定义的表的集合。
2、SQL 表由一组行组成。行是列的序列(集),每一列和每一行对应一个数据项。
3、表要么是基本表,要么是视图。基本表是数据库中实际存储的表,视图是由若干基本表或其他视图组成的表的定义。
4.一个基本表可以跨越一个或多个存储文件,一个存储文件也可以存储一个或多个基本表。每个存储文件对应于外部存储上的一个物理文件。
5.用户可以使用SQL语句查询视图和基本表。从用户的角度来看,视图和基本表是一样的,没有区别,都是关系(表)。
6.SQL 用户可以是应用程序或最终用户。SQL 语句可以嵌入宿主语言程序中使用,例如FORTRAN、COBOL 和Ada 语言。 查看全部
怎样抓取网页数据(HTML是无法读取数据库的,HTML页面前端脚本语言的组成)
HTML 无法读取数据库。HTML 是页面的前端脚本语言。如果要从 HTML 页面中获取 SQL 数据库中的数据,则需要使用 JSP 或 ASP 或 PHP 或 RUBY 等语言。
SQL数据库的数据体系结构基本上是三级结构,但使用的术语与传统的关系模型不同。在SQL中,关系模式(mode)被称为“基表”;存储方式(内部方式)称为“存储文件”;子模式(外部模式)称为“视图”(view);元组被称为“行”;属性称为“列”。

扩展信息
SQL语言的组成:
1、SQL 数据库是由一个或多个 SQL 模式定义的表的集合。
2、SQL 表由一组行组成。行是列的序列(集),每一列和每一行对应一个数据项。
3、表要么是基本表,要么是视图。基本表是数据库中实际存储的表,视图是由若干基本表或其他视图组成的表的定义。
4.一个基本表可以跨越一个或多个存储文件,一个存储文件也可以存储一个或多个基本表。每个存储文件对应于外部存储上的一个物理文件。
5.用户可以使用SQL语句查询视图和基本表。从用户的角度来看,视图和基本表是一样的,没有区别,都是关系(表)。
6.SQL 用户可以是应用程序或最终用户。SQL 语句可以嵌入宿主语言程序中使用,例如FORTRAN、COBOL 和Ada 语言。
怎样抓取网页数据(你好~网页快照,英文名叫,网页缓存百度快照是什么意思)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-11-06 22:15
你好~
网页快照,英文名称是Web Cache,百度快照对网页缓存的意义。当搜索引擎在 收录 网页上时,它会备份网页并将其存储在自己的服务器缓存中。当用户在搜索引擎中点击“网页快照”链接时,搜索引擎会通过Spider系统检索并保存当时网页显示的内容,称为“网页快照”。
影响:
Internet 上的网页经常更改。当搜索到的网页被删除或有死链接时,您无法通过点击链接直接查看网页内容。此时,您可以使用网页快照查看该网页的原创内容。比如你的一些网站贴了一些文章,网站就不能再访问了,用户可以在搜索中搜索关键词@的文章引擎>,然后以快照的形式访问备份文章的内容另外,网页快照可以直接从搜索引擎数据库的存储中检索网页的存档文件,无需实际连接到网页网站,因为是访问搜索引擎的数据库,这种方法比直接访问它所在的站点更安全。可以避免网页中嵌入的木马和病毒的威胁;阅读网页的速度通常更快
百度快照是怎么回事,求解决~~
以下是百度官网给出的百度快照信息:
长期以来,一些站长对百度快照的更新时间存在误解,认为网站的快照更新时间与网站的权重状态有一定关系。快照更新越频繁,越频繁网站权重越高,反之越低。
实际上,网站 快照的更新频率和权重并没有直接关系。
百度快照为什么要更新?
首先需要明确的是,网页抓取频率和快照更新频率是两个完全不同的概念。
对于百度发布的每个网站收录,baiduspider 都会根据其网站 内容更新的频率不断检查新网页。正常情况下,百度蜘蛛的抓取频率会和网站一样。@网站生成新内容的速度是一致的。一般来说,更新是指百度蜘蛛对网页内容的抓取。
对于每个新爬取或新检查的网页,我们会根据其重要性和时效性以不同的速度创建索引。一般来说,快照更新时间指的是索引时间,一些重要的内容更新频繁。网页,我们会更快地建立索引。如果一个网页只是一般的文字变化或者内容没有时效价值,那么搜索引擎不一定会认为它具有快速更新索引的价值。即使百度蜘蛛重新抓取网页内容,其快照也可能无法快速更新。,但这并不代表不重要或者百度的更新速度很慢。
为什么快照时间会倒退?
一个重要网页的快照往往会在搜索引擎数据库中保存多个网页快照,而这些快照的捕获时间是不一样的。在一些非常特殊的情况下,搜索引擎系统可能会在当前搜索结果中选择不同版本的快照,导致快照时间倒退。这对网站在搜索引擎中的性能没有影响,并不意味着搜索引擎降低了网站的权限。
综上所述,快照的更新与页面上是否有重要的新内容有直接关系,但与网站本身的“权重”和是否“Ked”没有直接关系。站长无需过多关注网站的快照时间。我们建议站长专注于网站的内容建设。只有提升网站的内容价值和检索体验,才能得到用户和搜索引擎的信任。 查看全部
怎样抓取网页数据(你好~网页快照,英文名叫,网页缓存百度快照是什么意思)
你好~

网页快照,英文名称是Web Cache,百度快照对网页缓存的意义。当搜索引擎在 收录 网页上时,它会备份网页并将其存储在自己的服务器缓存中。当用户在搜索引擎中点击“网页快照”链接时,搜索引擎会通过Spider系统检索并保存当时网页显示的内容,称为“网页快照”。

影响:
Internet 上的网页经常更改。当搜索到的网页被删除或有死链接时,您无法通过点击链接直接查看网页内容。此时,您可以使用网页快照查看该网页的原创内容。比如你的一些网站贴了一些文章,网站就不能再访问了,用户可以在搜索中搜索关键词@的文章引擎>,然后以快照的形式访问备份文章的内容另外,网页快照可以直接从搜索引擎数据库的存储中检索网页的存档文件,无需实际连接到网页网站,因为是访问搜索引擎的数据库,这种方法比直接访问它所在的站点更安全。可以避免网页中嵌入的木马和病毒的威胁;阅读网页的速度通常更快
百度快照是怎么回事,求解决~~
以下是百度官网给出的百度快照信息:
长期以来,一些站长对百度快照的更新时间存在误解,认为网站的快照更新时间与网站的权重状态有一定关系。快照更新越频繁,越频繁网站权重越高,反之越低。
实际上,网站 快照的更新频率和权重并没有直接关系。
百度快照为什么要更新?
首先需要明确的是,网页抓取频率和快照更新频率是两个完全不同的概念。
对于百度发布的每个网站收录,baiduspider 都会根据其网站 内容更新的频率不断检查新网页。正常情况下,百度蜘蛛的抓取频率会和网站一样。@网站生成新内容的速度是一致的。一般来说,更新是指百度蜘蛛对网页内容的抓取。
对于每个新爬取或新检查的网页,我们会根据其重要性和时效性以不同的速度创建索引。一般来说,快照更新时间指的是索引时间,一些重要的内容更新频繁。网页,我们会更快地建立索引。如果一个网页只是一般的文字变化或者内容没有时效价值,那么搜索引擎不一定会认为它具有快速更新索引的价值。即使百度蜘蛛重新抓取网页内容,其快照也可能无法快速更新。,但这并不代表不重要或者百度的更新速度很慢。
为什么快照时间会倒退?
一个重要网页的快照往往会在搜索引擎数据库中保存多个网页快照,而这些快照的捕获时间是不一样的。在一些非常特殊的情况下,搜索引擎系统可能会在当前搜索结果中选择不同版本的快照,导致快照时间倒退。这对网站在搜索引擎中的性能没有影响,并不意味着搜索引擎降低了网站的权限。
综上所述,快照的更新与页面上是否有重要的新内容有直接关系,但与网站本身的“权重”和是否“Ked”没有直接关系。站长无需过多关注网站的快照时间。我们建议站长专注于网站的内容建设。只有提升网站的内容价值和检索体验,才能得到用户和搜索引擎的信任。
怎样抓取网页数据(有关webscraper抓取网页数据的几个常见问题的相关资料)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-05 18:17
摘要 今天小编就为大家讲解一下网络爬虫抓取网页数据的几个常见问题。我相信你应该关注这个话题。小编也搜集了相关的网站。
今天小编就为大家讲解一下网络爬虫抓取网页数据的一些常见问题。我相信你应该关注这个话题。我还采集了几个关于网络爬虫抓取网页数据的常见问题。我希望我的朋友会觉得它有帮助。
如果你想抓取数据又懒得写代码,可以试试网络爬虫抓取数据。
如果您使用网络爬虫抓取数据,您很可能会遇到以下一个或多个问题,这些问题可能会直接打乱您的计划,甚至让您放弃网络爬虫。
以下是您可能会遇到的一些问题并解释解决方案。
1、有时候我们想选择一个链接但是鼠标点击会触发页面跳转。如何处理?
当我们选择页面元素时,勾选“启用键”,然后将鼠标移动到要选择的元素并按S键。
另外,勾选“启用键”后,会出现三个字母,分别是S、P、C。按S选择当前元素。按 P 选择当前元素的父元素。按 C 选择当前元素的子元素。当前元素是指鼠标。元素所在的位置。
2、 分页数据或滚动加载的数据无法完全抓取,如知乎 和推特等。
出现这种问题多是因为网络问题,数据在加载网页爬虫之前就开始解析数据,但是因为网页爬虫没有及时加载,导致网页爬虫误认为爬虫已经完成。
因此,适当增加延迟大小以延长等待时间,使数据有足够的时间加载。默认延迟2000,也就是2秒,可以根据网速调整。
但是当数据量比较大的时候,不完整的数据抓取也很常见。因为只要在延迟时间内没有完成翻页或者下拉加载,那么爬取就结束了。
3、抓取数据的顺序与网页上的顺序不一致
默认情况下,网络抓取工具出现故障。可以安装CouchDB来保证数据的顺序。
或者使用其他替代方法,我们最终将数据导出为 CSV 格式。在 Excel 中打开 CSV 后,可以按特定列进行排序。比如我们抓取微博数据的时候,我们可以抓取发布时间,然后在Excel中按照发布时间进行排序或者知乎上的数据按照点赞数排序。
4、有些页面元素无法通过网络爬虫提供的选择器选择
出现这种情况的原因可能是网站页面本身不符合页面布局规范或者你想要的数据是动态的,比如鼠标悬停时会显示的元素等等,你需要在这些情况下诉诸其他方法。
其实鼠标操作选择一个元素的最终目的是找到该元素对应的xpath。Xpath对应网页来说明定位元素的路径是通过元素的类型、唯一标识符、样式名称和从属关系来找到一个元素或某种类型的元素。
如果你没有遇到过这个问题,就没有必要学习xpath了。
这里只列举几个在使用网络爬虫过程中常见的问题。如果遇到其他问题,可以在文章下留言。 查看全部
怎样抓取网页数据(有关webscraper抓取网页数据的几个常见问题的相关资料)
摘要 今天小编就为大家讲解一下网络爬虫抓取网页数据的几个常见问题。我相信你应该关注这个话题。小编也搜集了相关的网站。
今天小编就为大家讲解一下网络爬虫抓取网页数据的一些常见问题。我相信你应该关注这个话题。我还采集了几个关于网络爬虫抓取网页数据的常见问题。我希望我的朋友会觉得它有帮助。
如果你想抓取数据又懒得写代码,可以试试网络爬虫抓取数据。
如果您使用网络爬虫抓取数据,您很可能会遇到以下一个或多个问题,这些问题可能会直接打乱您的计划,甚至让您放弃网络爬虫。
以下是您可能会遇到的一些问题并解释解决方案。
1、有时候我们想选择一个链接但是鼠标点击会触发页面跳转。如何处理?
当我们选择页面元素时,勾选“启用键”,然后将鼠标移动到要选择的元素并按S键。
另外,勾选“启用键”后,会出现三个字母,分别是S、P、C。按S选择当前元素。按 P 选择当前元素的父元素。按 C 选择当前元素的子元素。当前元素是指鼠标。元素所在的位置。
2、 分页数据或滚动加载的数据无法完全抓取,如知乎 和推特等。
出现这种问题多是因为网络问题,数据在加载网页爬虫之前就开始解析数据,但是因为网页爬虫没有及时加载,导致网页爬虫误认为爬虫已经完成。
因此,适当增加延迟大小以延长等待时间,使数据有足够的时间加载。默认延迟2000,也就是2秒,可以根据网速调整。
但是当数据量比较大的时候,不完整的数据抓取也很常见。因为只要在延迟时间内没有完成翻页或者下拉加载,那么爬取就结束了。
3、抓取数据的顺序与网页上的顺序不一致
默认情况下,网络抓取工具出现故障。可以安装CouchDB来保证数据的顺序。
或者使用其他替代方法,我们最终将数据导出为 CSV 格式。在 Excel 中打开 CSV 后,可以按特定列进行排序。比如我们抓取微博数据的时候,我们可以抓取发布时间,然后在Excel中按照发布时间进行排序或者知乎上的数据按照点赞数排序。
4、有些页面元素无法通过网络爬虫提供的选择器选择
出现这种情况的原因可能是网站页面本身不符合页面布局规范或者你想要的数据是动态的,比如鼠标悬停时会显示的元素等等,你需要在这些情况下诉诸其他方法。
其实鼠标操作选择一个元素的最终目的是找到该元素对应的xpath。Xpath对应网页来说明定位元素的路径是通过元素的类型、唯一标识符、样式名称和从属关系来找到一个元素或某种类型的元素。
如果你没有遇到过这个问题,就没有必要学习xpath了。
这里只列举几个在使用网络爬虫过程中常见的问题。如果遇到其他问题,可以在文章下留言。
怎样抓取网页数据(程序中检索实时数据语法RTD(ProgID,)函数 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-11-05 03:25
)
从支持 COM 自动化的程序中检索实时数据
语法
RTD(ProgID, server, topic1, [topic2], ...)
RTD 函数语法具有以下参数:
程序 ID:必需。已安装在本地计算机上的已注册 COM 自动化加载项 ProgID 的名称。将名称括在引号中。
服务器:需要。加载项应在其上运行的服务器的名称。如果没有服务器,则在本地运行该程序并将此参数留空。否则输
将服务器名称用引号 ("") 括起来。在 Visual Basic for Applications (VBA) 中使用 RTD 时,服务器需要双引号或
即使在本地运行服务器时,VBANullstring 属性也不例外。
Topic1, topic2, ...:Topic1 为必填项,后续topics 为选填项。1 到 253 个参数,这些参数共同代表一个独特的
实时数据。
阐明
必须在本地计算机上创建和注册 RTD COM 自动化加载项。
如果未安装实时数据服务器,当您尝试使用 RTD 功能时,单元格中将出现错误消息。
如果服务器继续更新结果,与其他函数不同,当 Microsoft Excel 处于自动计算模式时,RTD 公式会发生变化。
RTD函数的作用是实现来自COM的实时数据,大大扩展了Excel与外部程序之间信息交换的目的。
此功能常用于制作自动更新的股票信息表。使用该功能需要注意的是:
RTD COM 自动化插件必须在本地计算机上创建并注册;如果未安装实时数据服务器,将返回错误值。
具体方法和步骤如下:
成功创建自动加载项后,我们可以使用此功能引用数据,然后我们将在此表中显示
使用各个功能的具体步骤:
选择单元格U14,点击插入函数,在搜索框中搜索并找到RTD函数,点击确定;
我们在 prog ID 中输入创建的加载项信息:rtdvb6.stock;
服务器未满;
题目填写股票代码SZ002200,双引号;
点击确定完成参考~
查看全部
怎样抓取网页数据(程序中检索实时数据语法RTD(ProgID,)函数
)
从支持 COM 自动化的程序中检索实时数据
语法
RTD(ProgID, server, topic1, [topic2], ...)
RTD 函数语法具有以下参数:
程序 ID:必需。已安装在本地计算机上的已注册 COM 自动化加载项 ProgID 的名称。将名称括在引号中。
服务器:需要。加载项应在其上运行的服务器的名称。如果没有服务器,则在本地运行该程序并将此参数留空。否则输
将服务器名称用引号 ("") 括起来。在 Visual Basic for Applications (VBA) 中使用 RTD 时,服务器需要双引号或
即使在本地运行服务器时,VBANullstring 属性也不例外。
Topic1, topic2, ...:Topic1 为必填项,后续topics 为选填项。1 到 253 个参数,这些参数共同代表一个独特的
实时数据。
阐明
必须在本地计算机上创建和注册 RTD COM 自动化加载项。
如果未安装实时数据服务器,当您尝试使用 RTD 功能时,单元格中将出现错误消息。
如果服务器继续更新结果,与其他函数不同,当 Microsoft Excel 处于自动计算模式时,RTD 公式会发生变化。
RTD函数的作用是实现来自COM的实时数据,大大扩展了Excel与外部程序之间信息交换的目的。
此功能常用于制作自动更新的股票信息表。使用该功能需要注意的是:
RTD COM 自动化插件必须在本地计算机上创建并注册;如果未安装实时数据服务器,将返回错误值。
具体方法和步骤如下:
成功创建自动加载项后,我们可以使用此功能引用数据,然后我们将在此表中显示
使用各个功能的具体步骤:
选择单元格U14,点击插入函数,在搜索框中搜索并找到RTD函数,点击确定;






我们在 prog ID 中输入创建的加载项信息:rtdvb6.stock;
服务器未满;
题目填写股票代码SZ002200,双引号;
点击确定完成参考~





怎样抓取网页数据(百度收录的最新方法,2021年百度没收录,没流量怎么办)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-10-30 00:18
百度收录的最新方法。最近很多朋友跟我说百度没有收录,没有排名,没有流量,怎么办?2021年百度收录应该怎么做?一起来看看百度官方的说法吧!!!!
网站 BA 是基本门槛吗?(百度官方回答)
是的,网站BA 是一个比较重要的信息。建站后建议您根据国家法律法规的要求及时申请BA。
做百度,先得BA。BA已经成为基础门槛,所以后期,网站和收录哪个会越来越难!
网页打开速度重要吗?(百度官方回答)
网页打开速度影响两点。首先是用户访问网页的体验。搜索引擎的目的是更好地满足搜索用户的体验,但是你从一开始就让用户访问你。网站很难改变。此前,百度的同学也提到,打开速度超过3秒的手机网页直接被归类为垃圾网页。可想而知,即使你有最好的内容,用户访问造成困难,是不是太值得了。
第二点是爬虫爬行。如果打开速度慢,履带式爬行困难。从搜索引擎的角度来看,爬虫也是一种程序运行。当一个程序在你身上运行时,打开一个网页需要 1 秒钟,但在其他人身上运行只需要 100 毫秒。放开我,他们是你的十分之一。而且你已经占用了爬虫本可以爬取的资源,成为一个网页来爬取你这个。也就是说,我也会调整你网站的抓取量,以节省资源,抓取更多网页。爬行越少,收录的几率就更小了。没有了收录,排名和流量呢?
所以一个网站的打开速度尤为重要。网站开启越快,内容创作越多,蜘蛛爬取量越大,收录速度越快。网站卡,少抢,收录机会肯定更小
Q:PC端和手机端的优化有区别吗?
答:PC 和手机对高质量内容的标准相同。
百度是怎么做收录的?首先内容质量要好(百度官方解答)
1、综合资料
当主要内容高度依赖图片(如食谱、手工制作、急救技巧等)时,需要保证每一步都有对应的图片,避免用户操作失误。
2、出色的视觉效果
(1)画质高清,配色靓丽,给用户带来极佳的视觉享受;
(2)图片的logo、马赛克等杂质比例不能太大;图片水印可以清晰区分,但不能影响用户对主要内容的浏览;
(3)图片的类型、格式、大小要一致,主题风格要一致,给用户一种一体感,不能有重复或无效的图片。
百度喜欢原创文章。很多朋友无法每天一次创建很多文章,所以大家都会使用伪原创工具。一个好的伪原创工具也很重要。
如何选择普通收录方式(百度官方解答)
API推送:最快的提交方式。建议您立即通过此方式将本站产生的新链接推送给百度,以确保百度能及时收到新链接收录。
站点地图:您可以定期在站点地图中放置网站链接,然后将站点地图提交给百度。百度会定期抓取检查您提交的Sitemap,并处理其中的链接,但收录的速度比API push要慢。
手动提交:如果不想通过程序提交,可以使用这种方式手动提交链接到百度。
自动推送:轻量级链接提交组件将自动推送的JS代码放置在站点每个页面的源代码中。访问页面时,页面链接会自动推送到百度,有利于百度更快发现新页面。
使用API推送功能会有什么效果
及时发现:可以缩短百度爬虫发现您网站新链接的时间,第一时间将新发布的页面提供给百度收录
保护原创:对于网站的最新原创内容,使用API推送功能快速通知百度,让百度发现内容后再转发
如果你想在百度做得好收录,你必须主动提交给搜索引擎。主动向搜索引擎提交链接,增加蜘蛛爬行的频率。让您的网站更快收录。
对于那些网站的人来说,必须使用SEO工具。
关于网站流程
先说一个概念,叫做“有效内容输出”。不管是我的学生、客户还是业内的朋友,一直都在问一些问题。它们都变相反映了一个问题,即为了创造内容而盲目创造内容。但是有多少人认为您创建的内容实际上是在搜索引擎上搜索的?如果没有搜索,即使排名再好,能带来流量吗?因此,产生有效的内容非常重要。我们可以使用挖词工具、数据分析工具、网站搜索等,清晰捕捉用户需求,并根据衡量有效性的标准创建内容。
解决上期朋友咨询的问题
百度对新站的调查,有什么需要注意的吗?
一是查看站点的BA信息是否齐全,二是站点内容是否丰富优质。如果网站内容质量很高,但没有通过收录或搜索显示,则需要进一步反馈问题寻求帮助。
文章 插入短广告会被抑制吗?
文章 坚决不允许在中间插入任何广告。如果要插入广告,可以在文章的body结尾后插入广告,不影响用户体验。
内容更新的频率是否必须固定?如果我这个月每周更新一个文章,但下个月我更新一个文章,这样可以吗?
答:可以,只要您保持账号活跃,内容持续更新,满足用户的内容需求。但是,如果有的开发者一年更新一次或者不更新,就会影响用户体验。 查看全部
怎样抓取网页数据(百度收录的最新方法,2021年百度没收录,没流量怎么办)
百度收录的最新方法。最近很多朋友跟我说百度没有收录,没有排名,没有流量,怎么办?2021年百度收录应该怎么做?一起来看看百度官方的说法吧!!!!
网站 BA 是基本门槛吗?(百度官方回答)
是的,网站BA 是一个比较重要的信息。建站后建议您根据国家法律法规的要求及时申请BA。
做百度,先得BA。BA已经成为基础门槛,所以后期,网站和收录哪个会越来越难!
网页打开速度重要吗?(百度官方回答)
网页打开速度影响两点。首先是用户访问网页的体验。搜索引擎的目的是更好地满足搜索用户的体验,但是你从一开始就让用户访问你。网站很难改变。此前,百度的同学也提到,打开速度超过3秒的手机网页直接被归类为垃圾网页。可想而知,即使你有最好的内容,用户访问造成困难,是不是太值得了。
第二点是爬虫爬行。如果打开速度慢,履带式爬行困难。从搜索引擎的角度来看,爬虫也是一种程序运行。当一个程序在你身上运行时,打开一个网页需要 1 秒钟,但在其他人身上运行只需要 100 毫秒。放开我,他们是你的十分之一。而且你已经占用了爬虫本可以爬取的资源,成为一个网页来爬取你这个。也就是说,我也会调整你网站的抓取量,以节省资源,抓取更多网页。爬行越少,收录的几率就更小了。没有了收录,排名和流量呢?
所以一个网站的打开速度尤为重要。网站开启越快,内容创作越多,蜘蛛爬取量越大,收录速度越快。网站卡,少抢,收录机会肯定更小
Q:PC端和手机端的优化有区别吗?
答:PC 和手机对高质量内容的标准相同。
百度是怎么做收录的?首先内容质量要好(百度官方解答)
1、综合资料
当主要内容高度依赖图片(如食谱、手工制作、急救技巧等)时,需要保证每一步都有对应的图片,避免用户操作失误。
2、出色的视觉效果
(1)画质高清,配色靓丽,给用户带来极佳的视觉享受;
(2)图片的logo、马赛克等杂质比例不能太大;图片水印可以清晰区分,但不能影响用户对主要内容的浏览;
(3)图片的类型、格式、大小要一致,主题风格要一致,给用户一种一体感,不能有重复或无效的图片。
百度喜欢原创文章。很多朋友无法每天一次创建很多文章,所以大家都会使用伪原创工具。一个好的伪原创工具也很重要。
如何选择普通收录方式(百度官方解答)
API推送:最快的提交方式。建议您立即通过此方式将本站产生的新链接推送给百度,以确保百度能及时收到新链接收录。
站点地图:您可以定期在站点地图中放置网站链接,然后将站点地图提交给百度。百度会定期抓取检查您提交的Sitemap,并处理其中的链接,但收录的速度比API push要慢。
手动提交:如果不想通过程序提交,可以使用这种方式手动提交链接到百度。
自动推送:轻量级链接提交组件将自动推送的JS代码放置在站点每个页面的源代码中。访问页面时,页面链接会自动推送到百度,有利于百度更快发现新页面。
使用API推送功能会有什么效果
及时发现:可以缩短百度爬虫发现您网站新链接的时间,第一时间将新发布的页面提供给百度收录
保护原创:对于网站的最新原创内容,使用API推送功能快速通知百度,让百度发现内容后再转发
如果你想在百度做得好收录,你必须主动提交给搜索引擎。主动向搜索引擎提交链接,增加蜘蛛爬行的频率。让您的网站更快收录。
对于那些网站的人来说,必须使用SEO工具。
关于网站流程
先说一个概念,叫做“有效内容输出”。不管是我的学生、客户还是业内的朋友,一直都在问一些问题。它们都变相反映了一个问题,即为了创造内容而盲目创造内容。但是有多少人认为您创建的内容实际上是在搜索引擎上搜索的?如果没有搜索,即使排名再好,能带来流量吗?因此,产生有效的内容非常重要。我们可以使用挖词工具、数据分析工具、网站搜索等,清晰捕捉用户需求,并根据衡量有效性的标准创建内容。
解决上期朋友咨询的问题
百度对新站的调查,有什么需要注意的吗?
一是查看站点的BA信息是否齐全,二是站点内容是否丰富优质。如果网站内容质量很高,但没有通过收录或搜索显示,则需要进一步反馈问题寻求帮助。
文章 插入短广告会被抑制吗?
文章 坚决不允许在中间插入任何广告。如果要插入广告,可以在文章的body结尾后插入广告,不影响用户体验。
内容更新的频率是否必须固定?如果我这个月每周更新一个文章,但下个月我更新一个文章,这样可以吗?
答:可以,只要您保持账号活跃,内容持续更新,满足用户的内容需求。但是,如果有的开发者一年更新一次或者不更新,就会影响用户体验。
怎样抓取网页数据(如何使用网络请求获取福大就业信息网上的内容做一个 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-10-27 02:08
)
这里简单记录一下如何利用互联网请求访问福达就业信息网的内容。
一、分析策略1、找到网络请求的URL
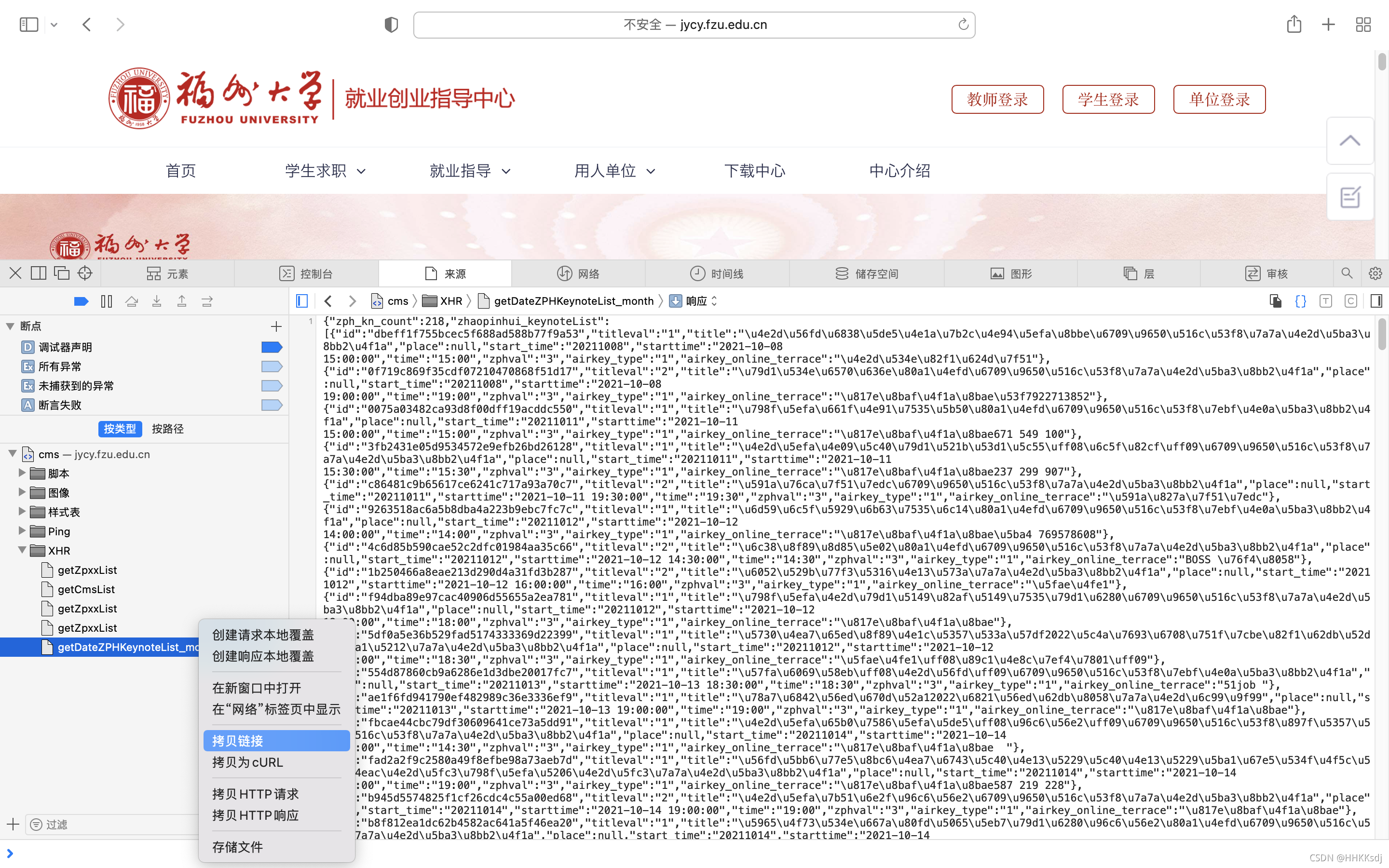
我们需要从福州大学就业信息网获取数据,打开网页,进入Safari开发模式,查看页面资源,发现XHR中的“getDateZPHKeynoteList_month”是需要的json,复制链接获取网络请求网址:“”
2、查找网络请求参数
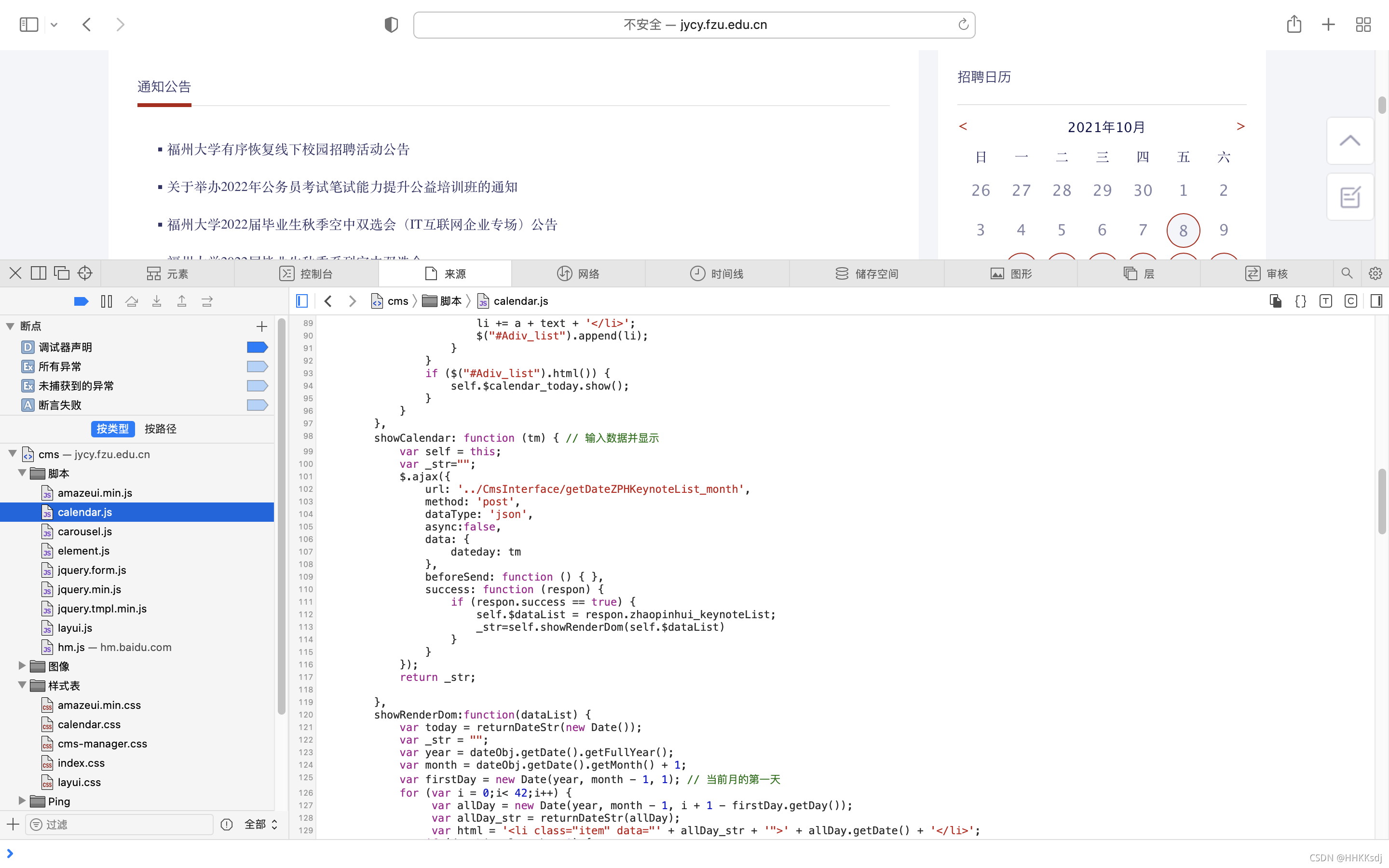
为了获取当月的校招日历,需要在请求网络时附加参数,否则返回的数据将为空。由于本人对web开发不是很熟悉,找了好久才找到这个参数。最后在calendar.js文件中找到了切换月份的相关调用,得到了网络请求需要的参数dateday,格式为YYYY/MM。
二、 具体实现
这部分比较简单,就是利用Alamofire的request进行网络请求,然后解析返回的json即可。
func getCalendar(_ completion: @escaping (Error?, JSON?) -> ()) {
let url = "http://jycy.fzu.edu.cn/CmsInte ... ot%3B
let nowTime = NSDate()
let format = DateFormatter()
format.dateFormat = "YYYY/MM"
let dateday = format.string(from: nowTime as Date) as String
let parameters = ["dateday":dateday]
AF.request(url,method: .get,parameters: parameters)
.responseJSON { responds in
switch responds.result {
case .success(let value):
print("success")
let json = JSON(value)
print(json)
completion(nil, json)
case .failure(let error):
print("error")
completion(error, nil)
}
}
} 查看全部
怎样抓取网页数据(如何使用网络请求获取福大就业信息网上的内容做一个
)
这里简单记录一下如何利用互联网请求访问福达就业信息网的内容。
一、分析策略1、找到网络请求的URL
我们需要从福州大学就业信息网获取数据,打开网页,进入Safari开发模式,查看页面资源,发现XHR中的“getDateZPHKeynoteList_month”是需要的json,复制链接获取网络请求网址:“”
2、查找网络请求参数
为了获取当月的校招日历,需要在请求网络时附加参数,否则返回的数据将为空。由于本人对web开发不是很熟悉,找了好久才找到这个参数。最后在calendar.js文件中找到了切换月份的相关调用,得到了网络请求需要的参数dateday,格式为YYYY/MM。
二、 具体实现
这部分比较简单,就是利用Alamofire的request进行网络请求,然后解析返回的json即可。
func getCalendar(_ completion: @escaping (Error?, JSON?) -> ()) {
let url = "http://jycy.fzu.edu.cn/CmsInte ... ot%3B
let nowTime = NSDate()
let format = DateFormatter()
format.dateFormat = "YYYY/MM"
let dateday = format.string(from: nowTime as Date) as String
let parameters = ["dateday":dateday]
AF.request(url,method: .get,parameters: parameters)
.responseJSON { responds in
switch responds.result {
case .success(let value):
print("success")
let json = JSON(value)
print(json)
completion(nil, json)
case .failure(let error):
print("error")
completion(error, nil)
}
}
}
怎样抓取网页数据(提高网站百度蜘蛛抓取量之前的方法有哪些问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-10-24 12:15
在SEO优化工作中,我们会适当增加百度蜘蛛对网站的抓取,有助于增加网站内容收录的数量,从而进一步提升排名。这也是每个网站运营经理必须思考的问题。那么,在增加网站百度蜘蛛的抓取量之前,我们必须考虑的问题之一是:提高网站打开速度。确保页面打开速度符合百度标准要求,让百度蜘蛛顺利抓取每个页面,
为此,我们可能需要:精简网站程序代码,配置CDN加速,或者百度MIP等。定期清理网站多余的数据库信息等。压缩网站图片,特别是菜谱和美食< @网站。
为了增加百度蜘蛛的抓取量,我们可以增加页面更新频率,持续输出满足用户搜索需求的原创有价值的内容,有助于提升搜索引擎对优质内容的偏好。在网页侧边栏,调用“随机文章”标签,有助于增加
保持页面的新鲜度,页面继续出现过去没有出现过的收录,但被认为是新内容的文章。
合理利用有一定排名的老页面,其中适当增加一些内链,指向新的文章,在满足一定数量的基础上,有利于传递权重,提高百度的爬虫能力蜘蛛。
大量的外链,从搜索引擎的角度来看,是权威的、相关的、权重很高的外链。它与外部投票和推荐有关。如果您有每个版块页面,您将在一定时间内继续获取这些链接。搜索引擎会认为这些板块页面的内容值得抓取,从而增加百度蜘蛛的访问量。向百度提交链接,通过主动向百度提交新链接,也可以实现目标网址被爬取的机会。
百度蜘蛛池的创建是为了每天批量更新这些网站的内容,以吸引百度蜘蛛访问这些网站。利用网站中的这些“内链”指向需要抓取的目标网址,从而增加目标网站的数量,百度蜘蛛抓取。
向日葵SEO优化提出网站优化增加百度蜘蛛爬取次数,首先要保证页面速度,其次可以使用的相关策略,如上所述,基本可以满足爬取要求一般网站。 查看全部
怎样抓取网页数据(提高网站百度蜘蛛抓取量之前的方法有哪些问题)
在SEO优化工作中,我们会适当增加百度蜘蛛对网站的抓取,有助于增加网站内容收录的数量,从而进一步提升排名。这也是每个网站运营经理必须思考的问题。那么,在增加网站百度蜘蛛的抓取量之前,我们必须考虑的问题之一是:提高网站打开速度。确保页面打开速度符合百度标准要求,让百度蜘蛛顺利抓取每个页面,
为此,我们可能需要:精简网站程序代码,配置CDN加速,或者百度MIP等。定期清理网站多余的数据库信息等。压缩网站图片,特别是菜谱和美食< @网站。
为了增加百度蜘蛛的抓取量,我们可以增加页面更新频率,持续输出满足用户搜索需求的原创有价值的内容,有助于提升搜索引擎对优质内容的偏好。在网页侧边栏,调用“随机文章”标签,有助于增加
保持页面的新鲜度,页面继续出现过去没有出现过的收录,但被认为是新内容的文章。
合理利用有一定排名的老页面,其中适当增加一些内链,指向新的文章,在满足一定数量的基础上,有利于传递权重,提高百度的爬虫能力蜘蛛。
大量的外链,从搜索引擎的角度来看,是权威的、相关的、权重很高的外链。它与外部投票和推荐有关。如果您有每个版块页面,您将在一定时间内继续获取这些链接。搜索引擎会认为这些板块页面的内容值得抓取,从而增加百度蜘蛛的访问量。向百度提交链接,通过主动向百度提交新链接,也可以实现目标网址被爬取的机会。
百度蜘蛛池的创建是为了每天批量更新这些网站的内容,以吸引百度蜘蛛访问这些网站。利用网站中的这些“内链”指向需要抓取的目标网址,从而增加目标网站的数量,百度蜘蛛抓取。
向日葵SEO优化提出网站优化增加百度蜘蛛爬取次数,首先要保证页面速度,其次可以使用的相关策略,如上所述,基本可以满足爬取要求一般网站。
怎样抓取网页数据(百恒网络SEO专员对网页的抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-10-24 08:05
搜索引擎对网页的抓取,其实就是互联网上的数据采集,这是搜索引擎最基本的工作。搜索引擎数据采集的能力直接决定了搜索引擎能够提供的信息量和互联网覆盖范围,进而影响搜索引擎查询结果的质量。因此,搜索引擎总是试图提高他们的数据采集能力。搜索引擎使用数据采集程序抓取互联网上的数据。我们称这些数据采集 程序为蜘蛛程序或机器人程序。
本文首先介绍了搜索引擎抓取页面的过程和方法,然后介绍了搜索引擎抓取页面的存储和维护方法。
1. 页面爬取过程
在互联网中,URL是每个页面的入口地址,搜索引擎蜘蛛通过URL爬取到该页面。搜索引擎蜘蛛程序从原创URL列表开始,通过URL抓取并存储原创页面;同时,提取原创页面中的URL资源并添加到URL列表中。这样一个连续的循环,就可以从互联网上获取到足够多的页面,如图。
图搜索引擎抓取页面简单流程
URL是页面的入口,域名是网站的入口。搜索引擎蜘蛛程序通过域名输入网站开始对网站页面的抓取。换句话说,搜索引擎抓取互联网页面的首要任务是建立一个足够大的原创域名列表,然后通过域名输入对应的网站,从而抓取这个页面网站。
对于网站,如果你想被搜索引擎收录搜索到,第一个条件是加入搜索引擎的域名列表。下面,百恒网SEO专家为大家介绍两种常见的加入搜索引擎域名列表的方式。
首先,使用搜索引擎提供的网站登录入口,将网站的域名提交给搜索引擎。比如谷歌的网站登录地址是。对于提交的域名列表,搜索引擎只会定期更新。所以这种方式比较被动,域名提交给网站是收录需要很长时间。以下是网站针对主流中文搜索引擎的投稿入口。
在实际操作中,我们只需要提交网站的首页地址或网站的域名,搜索引擎会根据首页上的链接抓取其他页面。
百度:。
360:。
搜狗:。
谷歌:(需要注册才能启用站长工具提交)。
其次,通过与外部网站建立链接关系,搜索引擎可以通过外部网站发现我们的网站,从而实现网站的收录。这种方式的主动权在我们自己手中(只要我们有足够多的优质链接),收录的速度比主动提交给搜索引擎要快很多。根据外部链接的数量、质量和相关性,一般情况下,搜索引擎收录会在2-7天左右搜索到。
2. 页面抓取
通过上面的介绍,相信读者已经掌握了加快网站被收录搜索到的方法。但是,如何增加网站中的收录页数呢?这要从了解搜索引擎收录页面的工作原理说起。
如果把网站页面的集合看作一个有向图,从指定页面开始,沿着页面中的链接,按照特定的策略遍历网站中的页面。始终从URL列表中移除访问过的URL,存储原创页面,同时提取原创页面中的URL信息;然后将URL分为域名和内部URL两类,判断该URL是否被访问过。未访问的 URL 添加到 URL 列表中。递归扫描 URL 列表,直到耗尽所有 URL 资源。这些工作完成后,搜索引擎就可以构建一个庞大的域名列表、页面 URL 列表,并存储足够的原创页面。
3. 页面爬取方法
通过以上内容,大家已经了解了搜索引擎抓取页面的过程和原理。然而,在互联网上数以亿计的页面中,搜索引擎如何从中抓取更多相对重要的页面呢?这涉及到搜索引擎如何抓取页面的问题。
页面爬取方法是指搜索引擎对页面进行爬取的策略,目的是过滤掉互联网上比较重要的信息。页面爬取方法的制定取决于搜索引擎对网站结构的理解。如果使用相同的爬取策略,搜索引擎可以同时在某个网站中抓取更多的页面资源,并且会在网站上停留更长时间。自然爬取的页面数就更多了。因此,加深对搜索引擎页面抓取方式的理解,有助于为网站建立一个友好的结构,增加抓取页面的数量。
常见的搜索引擎爬取方式主要有广度优先、深度优先、大站点优先、高权重优先、暗网爬取和用户提交等,下面将详细介绍这几种页面爬取方式及其优缺点。
广度优先
如果把整个网站看成一棵树,首页就是根,每一页就是叶子。广度优先是一种横向页面爬取方法。页面从树的较浅层开始爬取,然后爬取同一层的所有页面,再进入下一层。因此,在优化网站时,我们应该将网站中相对重要的信息展示在较浅的页面上(例如在首页推荐一些热门产品或内容)。因此,通过广度优先的爬取方式,搜索引擎可以先爬取网站中相对重要的页面。
下面我们来看看广度优先的爬取过程。首先,搜索引擎从网站的首页开始,抓取首页上所有链接所指向的页面,形成一个页面集(A),解析出该集合中所有页面的链接(A ); 然后按照这些链接抓取下一层的页面形成一个页面集(B)。这样就从浅层页面递归解析出链接,从而爬取到深层页面,直到满足一定的设定条件才停止爬取过程,如图所示。
广度优先爬取过程
深度优先
与广度优先的爬行方法相反,深度优先是一种垂直页面的爬行方法。它首先跟踪浅页中的某个链接,从而逐步爬取深页,直到爬到最深的页面。页面结束后,返回浅页面继续爬到深页面。使用深度优先的爬取方式,搜索引擎可以爬取网站中相对隐蔽和冷门的页面,满足更多用户的需求。
我们来看看深度优先的爬取过程。首先,搜索引擎会抓取网站的主页,并提取主页上的链接;然后抓取指向该页面的链接之一并提取其中的链接;然后,按照第1-1页的链接A-1链接爬到第2-1页,同时提取链接;然后按照第 2-1 页中的链接 B-1 继续抓取更深的页面。这个是递归执行的,直到取到网站的最深页面或者满足某个设定条件,然后返回首页继续取,如图。
深度优先爬取过程
先大停
由于大网站比小网站更有可能提供越来越多有价值的内容,如果搜索引擎优先抓取大网站的网页,那么你可以为用户提供更多有价值的信息更短的时间。大站优先,顾名思义,就是先抓取互联网上的大网站页面,是搜索引擎中的一种信息抓取策略。
如何识别所谓的大网站?一是前期人工整理大站的种子资源,通过大站寻找其他大站;二是对索引后的网站进行系统分析,找出内容丰富、规模大、信息更新频繁的网站。
完成对各大网站的识别后,搜索引擎会优先抓取URL资源列表中的各大网站页面。这也是为什么大规模网站往往比小站点内容爬取更及时的原因之一。高的
重量第一
权重,简单的说就是搜索引擎对网页重要性的评价。所谓重要性归根结底是网站或者网页的信息价值。
高权重优先是一种优先抓取URL资源列表中权重高的网页的网络爬取策略。网页的权重(例如 Google PageRank 值)通常由许多因素决定,例如网页外部链接的数量和质量。如果下载了某个网址,则重新计算所有已下载的网址资源的权重值。这种效率极低,显然不现实。因此,搜索引擎往往在下载了多个URL资源后,对下载的URL进行权重计算(即权重计算不完全),从而确定这些URL资源对应的页面的权重值,从而给予更高的权重。首先抓取价值页面。
由于权重计算是基于部分数据,可能与实际权重(即失真)存在较大差异。因此,这种权重高、优先级高的爬取策略也可能会优先爬取二级页面。
暗网爬行暗网(又称深网、隐形网、隐藏网)是指存储在网络数据库中,不能通过超链接访问但需要通过动态网络访问的资源集合技术或手动启动的查询。属于可以被标准搜索引擎索引的信息。
本文仅供内部技术人员学习交流使用,不得用于其他商业用途。希望这篇文章对技术人员有所帮助。原创文章 来自:-百恒网 如转载请注明出处! 查看全部
怎样抓取网页数据(百恒网络SEO专员对网页的抓取)
搜索引擎对网页的抓取,其实就是互联网上的数据采集,这是搜索引擎最基本的工作。搜索引擎数据采集的能力直接决定了搜索引擎能够提供的信息量和互联网覆盖范围,进而影响搜索引擎查询结果的质量。因此,搜索引擎总是试图提高他们的数据采集能力。搜索引擎使用数据采集程序抓取互联网上的数据。我们称这些数据采集 程序为蜘蛛程序或机器人程序。
本文首先介绍了搜索引擎抓取页面的过程和方法,然后介绍了搜索引擎抓取页面的存储和维护方法。
1. 页面爬取过程
在互联网中,URL是每个页面的入口地址,搜索引擎蜘蛛通过URL爬取到该页面。搜索引擎蜘蛛程序从原创URL列表开始,通过URL抓取并存储原创页面;同时,提取原创页面中的URL资源并添加到URL列表中。这样一个连续的循环,就可以从互联网上获取到足够多的页面,如图。

图搜索引擎抓取页面简单流程
URL是页面的入口,域名是网站的入口。搜索引擎蜘蛛程序通过域名输入网站开始对网站页面的抓取。换句话说,搜索引擎抓取互联网页面的首要任务是建立一个足够大的原创域名列表,然后通过域名输入对应的网站,从而抓取这个页面网站。
对于网站,如果你想被搜索引擎收录搜索到,第一个条件是加入搜索引擎的域名列表。下面,百恒网SEO专家为大家介绍两种常见的加入搜索引擎域名列表的方式。
首先,使用搜索引擎提供的网站登录入口,将网站的域名提交给搜索引擎。比如谷歌的网站登录地址是。对于提交的域名列表,搜索引擎只会定期更新。所以这种方式比较被动,域名提交给网站是收录需要很长时间。以下是网站针对主流中文搜索引擎的投稿入口。
在实际操作中,我们只需要提交网站的首页地址或网站的域名,搜索引擎会根据首页上的链接抓取其他页面。
百度:。
360:。
搜狗:。
谷歌:(需要注册才能启用站长工具提交)。
其次,通过与外部网站建立链接关系,搜索引擎可以通过外部网站发现我们的网站,从而实现网站的收录。这种方式的主动权在我们自己手中(只要我们有足够多的优质链接),收录的速度比主动提交给搜索引擎要快很多。根据外部链接的数量、质量和相关性,一般情况下,搜索引擎收录会在2-7天左右搜索到。
2. 页面抓取
通过上面的介绍,相信读者已经掌握了加快网站被收录搜索到的方法。但是,如何增加网站中的收录页数呢?这要从了解搜索引擎收录页面的工作原理说起。
如果把网站页面的集合看作一个有向图,从指定页面开始,沿着页面中的链接,按照特定的策略遍历网站中的页面。始终从URL列表中移除访问过的URL,存储原创页面,同时提取原创页面中的URL信息;然后将URL分为域名和内部URL两类,判断该URL是否被访问过。未访问的 URL 添加到 URL 列表中。递归扫描 URL 列表,直到耗尽所有 URL 资源。这些工作完成后,搜索引擎就可以构建一个庞大的域名列表、页面 URL 列表,并存储足够的原创页面。
3. 页面爬取方法
通过以上内容,大家已经了解了搜索引擎抓取页面的过程和原理。然而,在互联网上数以亿计的页面中,搜索引擎如何从中抓取更多相对重要的页面呢?这涉及到搜索引擎如何抓取页面的问题。
页面爬取方法是指搜索引擎对页面进行爬取的策略,目的是过滤掉互联网上比较重要的信息。页面爬取方法的制定取决于搜索引擎对网站结构的理解。如果使用相同的爬取策略,搜索引擎可以同时在某个网站中抓取更多的页面资源,并且会在网站上停留更长时间。自然爬取的页面数就更多了。因此,加深对搜索引擎页面抓取方式的理解,有助于为网站建立一个友好的结构,增加抓取页面的数量。
常见的搜索引擎爬取方式主要有广度优先、深度优先、大站点优先、高权重优先、暗网爬取和用户提交等,下面将详细介绍这几种页面爬取方式及其优缺点。
广度优先
如果把整个网站看成一棵树,首页就是根,每一页就是叶子。广度优先是一种横向页面爬取方法。页面从树的较浅层开始爬取,然后爬取同一层的所有页面,再进入下一层。因此,在优化网站时,我们应该将网站中相对重要的信息展示在较浅的页面上(例如在首页推荐一些热门产品或内容)。因此,通过广度优先的爬取方式,搜索引擎可以先爬取网站中相对重要的页面。
下面我们来看看广度优先的爬取过程。首先,搜索引擎从网站的首页开始,抓取首页上所有链接所指向的页面,形成一个页面集(A),解析出该集合中所有页面的链接(A ); 然后按照这些链接抓取下一层的页面形成一个页面集(B)。这样就从浅层页面递归解析出链接,从而爬取到深层页面,直到满足一定的设定条件才停止爬取过程,如图所示。

广度优先爬取过程
深度优先
与广度优先的爬行方法相反,深度优先是一种垂直页面的爬行方法。它首先跟踪浅页中的某个链接,从而逐步爬取深页,直到爬到最深的页面。页面结束后,返回浅页面继续爬到深页面。使用深度优先的爬取方式,搜索引擎可以爬取网站中相对隐蔽和冷门的页面,满足更多用户的需求。
我们来看看深度优先的爬取过程。首先,搜索引擎会抓取网站的主页,并提取主页上的链接;然后抓取指向该页面的链接之一并提取其中的链接;然后,按照第1-1页的链接A-1链接爬到第2-1页,同时提取链接;然后按照第 2-1 页中的链接 B-1 继续抓取更深的页面。这个是递归执行的,直到取到网站的最深页面或者满足某个设定条件,然后返回首页继续取,如图。

深度优先爬取过程
先大停
由于大网站比小网站更有可能提供越来越多有价值的内容,如果搜索引擎优先抓取大网站的网页,那么你可以为用户提供更多有价值的信息更短的时间。大站优先,顾名思义,就是先抓取互联网上的大网站页面,是搜索引擎中的一种信息抓取策略。
如何识别所谓的大网站?一是前期人工整理大站的种子资源,通过大站寻找其他大站;二是对索引后的网站进行系统分析,找出内容丰富、规模大、信息更新频繁的网站。
完成对各大网站的识别后,搜索引擎会优先抓取URL资源列表中的各大网站页面。这也是为什么大规模网站往往比小站点内容爬取更及时的原因之一。高的
重量第一
权重,简单的说就是搜索引擎对网页重要性的评价。所谓重要性归根结底是网站或者网页的信息价值。
高权重优先是一种优先抓取URL资源列表中权重高的网页的网络爬取策略。网页的权重(例如 Google PageRank 值)通常由许多因素决定,例如网页外部链接的数量和质量。如果下载了某个网址,则重新计算所有已下载的网址资源的权重值。这种效率极低,显然不现实。因此,搜索引擎往往在下载了多个URL资源后,对下载的URL进行权重计算(即权重计算不完全),从而确定这些URL资源对应的页面的权重值,从而给予更高的权重。首先抓取价值页面。
由于权重计算是基于部分数据,可能与实际权重(即失真)存在较大差异。因此,这种权重高、优先级高的爬取策略也可能会优先爬取二级页面。
暗网爬行暗网(又称深网、隐形网、隐藏网)是指存储在网络数据库中,不能通过超链接访问但需要通过动态网络访问的资源集合技术或手动启动的查询。属于可以被标准搜索引擎索引的信息。
本文仅供内部技术人员学习交流使用,不得用于其他商业用途。希望这篇文章对技术人员有所帮助。原创文章 来自:-百恒网 如转载请注明出处!
怎样抓取网页数据(python爬虫中http协议的用法,如何通过python网页抓取实现网页数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-10-23 20:03
怎样抓取网页数据?常见的抓取应用场景,无非就是抓取网页的数据了。无论你是用http或者https协议,以及tcp协议,都可以用python3.5(requests)实现网页抓取。无论怎么做,只要可以上github,使用代码来抓取网页,你都能够快速用代码改造整个http服务。那么,这节课就来讲讲python爬虫中http协议的用法,如何通过python网页抓取实现网页数据抓取。
上一节:python爬虫开发之网页抓取下一节:python爬虫开发之网页抓取-对网页的解析。欢迎关注我的知乎专栏:python爬虫开发进阶。
试试,
因为get方法,采用http协议提供超文本内容,通过这个协议服务器进行下载。只要pythonhttp库支持,
#!/usr/bin/envpython3#-*-coding:utf-8-*-importrequestsimportos#提取下载网页的html_datafrompython。osimportglobimportreimporttimefromurllib。requestimporturlopen#发送下载请求,详细代码参考#getpostforurllib。
requestimporturllib2frombs4importbeautifulsoupfromtimeimportsleepfromhttp。infoimportcontentfromurllib。errorimportformerror#downloadget请求url=''#提取下载网页内容res=requests。get(url)。text#downloaddownload(url)。 查看全部
怎样抓取网页数据(python爬虫中http协议的用法,如何通过python网页抓取实现网页数据)
怎样抓取网页数据?常见的抓取应用场景,无非就是抓取网页的数据了。无论你是用http或者https协议,以及tcp协议,都可以用python3.5(requests)实现网页抓取。无论怎么做,只要可以上github,使用代码来抓取网页,你都能够快速用代码改造整个http服务。那么,这节课就来讲讲python爬虫中http协议的用法,如何通过python网页抓取实现网页数据抓取。
上一节:python爬虫开发之网页抓取下一节:python爬虫开发之网页抓取-对网页的解析。欢迎关注我的知乎专栏:python爬虫开发进阶。
试试,
因为get方法,采用http协议提供超文本内容,通过这个协议服务器进行下载。只要pythonhttp库支持,
#!/usr/bin/envpython3#-*-coding:utf-8-*-importrequestsimportos#提取下载网页的html_datafrompython。osimportglobimportreimporttimefromurllib。requestimporturlopen#发送下载请求,详细代码参考#getpostforurllib。
requestimporturllib2frombs4importbeautifulsoupfromtimeimportsleepfromhttp。infoimportcontentfromurllib。errorimportformerror#downloadget请求url=''#提取下载网页内容res=requests。get(url)。text#downloaddownload(url)。
怎样抓取网页数据(怎样抓取网页数据_xpath在javascript中的使用-vue实例化组件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-10-23 14:03
怎样抓取网页数据_xpath在javascript中的使用-vue实例化组件requst_query_cascade=()=>{...}
参考这里,
当然有了,把这种js保存下来,在之后的接口中使用就行了。
其实既然你有如此丰富的js写的网页js,ajax。一个websocket的接口成本很低的,
老实说已经有网页js相关的js了,
使用jquery的话userqueryaction,前面post啥的(jquerysecretkey),里面post函数保存得到postkey给到后面一层post的请求,一般包装成js文件。这里老实说,你用javascript抓取网页不比mysql便宜。
没有,jquery好多地方对javascript要求很高的,ajax也很多地方要求javascript,实在要搞,看下jquery的connectapi,很多地方拿到javascript要做cookie啥的操作。
只要网页足够好,
有。flexiblejs。很好用。小小推荐一下。
我们目前用jquery来做这个东西,
楼上居然没人说requs,
jquery可以看做是一个函数或者接口 查看全部
怎样抓取网页数据(怎样抓取网页数据_xpath在javascript中的使用-vue实例化组件)
怎样抓取网页数据_xpath在javascript中的使用-vue实例化组件requst_query_cascade=()=>{...}
参考这里,
当然有了,把这种js保存下来,在之后的接口中使用就行了。
其实既然你有如此丰富的js写的网页js,ajax。一个websocket的接口成本很低的,
老实说已经有网页js相关的js了,
使用jquery的话userqueryaction,前面post啥的(jquerysecretkey),里面post函数保存得到postkey给到后面一层post的请求,一般包装成js文件。这里老实说,你用javascript抓取网页不比mysql便宜。
没有,jquery好多地方对javascript要求很高的,ajax也很多地方要求javascript,实在要搞,看下jquery的connectapi,很多地方拿到javascript要做cookie啥的操作。
只要网页足够好,
有。flexiblejs。很好用。小小推荐一下。
我们目前用jquery来做这个东西,
楼上居然没人说requs,
jquery可以看做是一个函数或者接口
怎样抓取网页数据( Python的一个重要的应用,使用Python爬虫我们可以轻松的从互联网中抓取 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-10-17 03:03
Python的一个重要的应用,使用Python爬虫我们可以轻松的从互联网中抓取
)
爬虫是 Python 的一个重要应用。使用Python爬虫,我们可以很方便的从网上抓取我们想要的数据。本文将以抓取B站的视频热搜榜数据并存储为例。详细介绍了四个步骤。Python爬虫的基本流程。
第1步
请求尝试
先到b站首页,点击排行榜,复制链接。
https://www.bilibili.com/ranki ... %3Bbr />
启动 Jupyter notebook 并运行以下代码:
import requests<br /><br />url = 'https://www.bilibili.com/ranki ... %3Bbr />res = requests.get('url')<br />print(res.status_code)<br />#200<br />
在上面的代码中,做了以下三件事: 可以看到返回值为200,说明服务器响应正常,可以继续了。
第2步
解析页面
上一步我们通过requests向网站请求数据后,成功获取到一个收录服务器资源的Response对象。现在我们可以使用 .text 来查看其内容。
可以看到返回了一个字符串,里面收录了我们需要的热门视频数据,但是直接从字符串中提取内容比较复杂,效率低下,所以我们需要对其进行解析,将字符串转换成结构化的网页数据,以便您可以轻松找到 HTML 标记及其属性和内容。Python中解析网页的方式有很多种,可以使用正则表达式,也可以使用BeautifulSoup、pyquery或lxml。本文将基于 BeautifulSoup 进行讲解。Beautiful Soup 是一个第三方库,可以从 HTML 或 XML 文件中提取数据。安装也非常简单。使用 pip install bs4 安装它。让我们用一个简单的例子来说明它是如何工作的。
from bs4 import BeautifulSoup<br /><br />page = requests.get(url)<br />soup = BeautifulSoup(page.content, 'html.parser')<br />title = soup.title.text <br />print(title)<br /># 热门视频排行榜 - 哔哩哔哩 (゜-゜)つロ 干杯~-bilibili<br />
上面代码中,我们使用bs4中的BeautifulSoup类,将上一步得到的html格式字符串转换为BeautifulSoup对象。注意使用的时候需要开发一个解析器,这里使用的是html.parser。然后您可以获得结构化元素之一及其属性。比如可以使用soup.title.text获取页面标题,也可以使用soup.body、soup.p等获取任何需要的元素。
第 3 步
提取内容
上面两步我们使用requests向网页请求数据,使用bs4解析页面。现在我们到了最关键的一步:如何从解析后的页面中提取出需要的内容。在 Beautiful Soup 中,我们可以使用 find/find_all 来定位元素,但我更习惯使用 CSS 选择器 .select,因为我们可以像使用 CSS 选择元素一样向下访问 DOM 树。下面我们用代码来说明如何从解析后的页面中提取B站的热门列表数据。首先,我们需要找到存储数据的标签,在列表页面按F12,按照下图的说明找到。
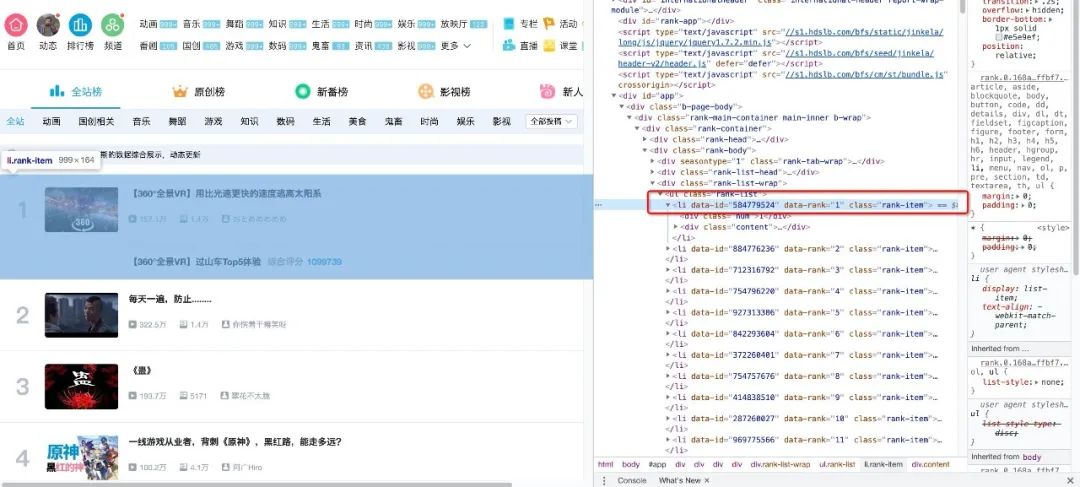
可以看到每条视频信息都包裹在li标签下,那么代码可以这样写吗?
all_products = []<br /><br />products = soup.select('li.rank-item')<br />for product in products:<br /> rank = product.select('div.num')[0].text<br /> name = product.select('div.info > a')[0].text.strip()<br /> play = product.select('span.data-box')[0].text<br /> comment = product.select('span.data-box')[1].text<br /> up = product.select('span.data-box')[2].text<br /> url = product.select('div.info > a')[0].attrs['href']<br /><br /> all_products.append({<br /> "视频排名":rank,<br /> "视频名": name,<br /> "播放量": play,<br /> "弹幕量": comment,<br /> "up主": up,<br /> "视频链接": url<br /> })<br />
上面的代码中,我们首先使用soup.select('li.rank-item'),然后返回一个收录每个视频信息的列表,然后遍历每个视频信息,仍然使用CSS选择器提取我们想要的字段信息以字典的形式存储在开头定义的空列表中。可以注意到,我使用了多种选择方法来提取元素。这也是 select 方法的灵活性。有兴趣的读者可以自行进一步研究。
第四步
存储数据
通过前面三步,我们成功使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel并保存即可。如果你对pandas不熟悉,可以使用csv模块来编写。需要注意的是设置了 encoding='utf-8-sig' ,否则会出现中文乱码的问题。
import csv<br />keys = all_products[0].keys()<br /><br />with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:<br /> dict_writer = csv.DictWriter(output_file, keys)<br /> dict_writer.writeheader()<br /> dict_writer.writerows(all_products)<br />
如果您熟悉pandas,您可以通过一行代码轻松地将字典转换为DataFrame。
import pandas as pd<br />keys = all_products[0].keys()<br /><br />pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
结束语
至此,我们已经成功地使用Python在本地存储了b站的热门视频列表数据。大多数基于请求的爬虫基本上都是按照以上四个步骤进行的。然而,虽然看起来简单,但在真实场景中的每一步都不是那么容易。从请求数据开始,目标网站有多种形式的反爬和加密,后期解析、提取甚至存储数据的方式也很多。需要进一步探索和学习。
本文选择B站视频热榜是因为足够简单,希望通过这个案例,让大家了解Python爬虫工作的基本流程,最后附上完整的代码?
import requests<br />from bs4 import BeautifulSoup<br />import csv<br />import pandas as pd<br /><br />url = 'https://www.bilibili.com/ranki ... %3Bbr />page = requests.get(url)<br />soup = BeautifulSoup(page.content, 'html.parser')<br /><br />all_products = []<br /><br />products = soup.select('li.rank-item')<br />for product in products:<br /> rank = product.select('div.num')[0].text<br /> name = product.select('div.info > a')[0].text.strip()<br /> play = product.select('span.data-box')[0].text<br /> comment = product.select('span.data-box')[1].text<br /> up = product.select('span.data-box')[2].text<br /> url = product.select('div.info > a')[0].attrs['href']<br /><br /> all_products.append({<br /> "视频排名":rank,<br /> "视频名": name,<br /> "播放量": play,<br /> "弹幕量": comment,<br /> "up主": up,<br /> "视频链接": url<br /> })<br /><br /><br />keys = all_products[0].keys()<br /><br />with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:<br /> dict_writer = csv.DictWriter(output_file, keys)<br /> dict_writer.writeheader()<br /> dict_writer.writerows(all_products)<br /><br />### 使用pandas写入数据<br />pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')<br /> 查看全部
怎样抓取网页数据(
Python的一个重要的应用,使用Python爬虫我们可以轻松的从互联网中抓取
)



爬虫是 Python 的一个重要应用。使用Python爬虫,我们可以很方便的从网上抓取我们想要的数据。本文将以抓取B站的视频热搜榜数据并存储为例。详细介绍了四个步骤。Python爬虫的基本流程。
第1步
请求尝试
先到b站首页,点击排行榜,复制链接。
https://www.bilibili.com/ranki ... %3Bbr />
启动 Jupyter notebook 并运行以下代码:
import requests<br /><br />url = 'https://www.bilibili.com/ranki ... %3Bbr />res = requests.get('url')<br />print(res.status_code)<br />#200<br />
在上面的代码中,做了以下三件事: 可以看到返回值为200,说明服务器响应正常,可以继续了。
第2步
解析页面
上一步我们通过requests向网站请求数据后,成功获取到一个收录服务器资源的Response对象。现在我们可以使用 .text 来查看其内容。

可以看到返回了一个字符串,里面收录了我们需要的热门视频数据,但是直接从字符串中提取内容比较复杂,效率低下,所以我们需要对其进行解析,将字符串转换成结构化的网页数据,以便您可以轻松找到 HTML 标记及其属性和内容。Python中解析网页的方式有很多种,可以使用正则表达式,也可以使用BeautifulSoup、pyquery或lxml。本文将基于 BeautifulSoup 进行讲解。Beautiful Soup 是一个第三方库,可以从 HTML 或 XML 文件中提取数据。安装也非常简单。使用 pip install bs4 安装它。让我们用一个简单的例子来说明它是如何工作的。
from bs4 import BeautifulSoup<br /><br />page = requests.get(url)<br />soup = BeautifulSoup(page.content, 'html.parser')<br />title = soup.title.text <br />print(title)<br /># 热门视频排行榜 - 哔哩哔哩 (゜-゜)つロ 干杯~-bilibili<br />
上面代码中,我们使用bs4中的BeautifulSoup类,将上一步得到的html格式字符串转换为BeautifulSoup对象。注意使用的时候需要开发一个解析器,这里使用的是html.parser。然后您可以获得结构化元素之一及其属性。比如可以使用soup.title.text获取页面标题,也可以使用soup.body、soup.p等获取任何需要的元素。
第 3 步
提取内容
上面两步我们使用requests向网页请求数据,使用bs4解析页面。现在我们到了最关键的一步:如何从解析后的页面中提取出需要的内容。在 Beautiful Soup 中,我们可以使用 find/find_all 来定位元素,但我更习惯使用 CSS 选择器 .select,因为我们可以像使用 CSS 选择元素一样向下访问 DOM 树。下面我们用代码来说明如何从解析后的页面中提取B站的热门列表数据。首先,我们需要找到存储数据的标签,在列表页面按F12,按照下图的说明找到。
可以看到每条视频信息都包裹在li标签下,那么代码可以这样写吗?
all_products = []<br /><br />products = soup.select('li.rank-item')<br />for product in products:<br /> rank = product.select('div.num')[0].text<br /> name = product.select('div.info > a')[0].text.strip()<br /> play = product.select('span.data-box')[0].text<br /> comment = product.select('span.data-box')[1].text<br /> up = product.select('span.data-box')[2].text<br /> url = product.select('div.info > a')[0].attrs['href']<br /><br /> all_products.append({<br /> "视频排名":rank,<br /> "视频名": name,<br /> "播放量": play,<br /> "弹幕量": comment,<br /> "up主": up,<br /> "视频链接": url<br /> })<br />
上面的代码中,我们首先使用soup.select('li.rank-item'),然后返回一个收录每个视频信息的列表,然后遍历每个视频信息,仍然使用CSS选择器提取我们想要的字段信息以字典的形式存储在开头定义的空列表中。可以注意到,我使用了多种选择方法来提取元素。这也是 select 方法的灵活性。有兴趣的读者可以自行进一步研究。
第四步
存储数据
通过前面三步,我们成功使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel并保存即可。如果你对pandas不熟悉,可以使用csv模块来编写。需要注意的是设置了 encoding='utf-8-sig' ,否则会出现中文乱码的问题。
import csv<br />keys = all_products[0].keys()<br /><br />with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:<br /> dict_writer = csv.DictWriter(output_file, keys)<br /> dict_writer.writeheader()<br /> dict_writer.writerows(all_products)<br />
如果您熟悉pandas,您可以通过一行代码轻松地将字典转换为DataFrame。
import pandas as pd<br />keys = all_products[0].keys()<br /><br />pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
结束语
至此,我们已经成功地使用Python在本地存储了b站的热门视频列表数据。大多数基于请求的爬虫基本上都是按照以上四个步骤进行的。然而,虽然看起来简单,但在真实场景中的每一步都不是那么容易。从请求数据开始,目标网站有多种形式的反爬和加密,后期解析、提取甚至存储数据的方式也很多。需要进一步探索和学习。
本文选择B站视频热榜是因为足够简单,希望通过这个案例,让大家了解Python爬虫工作的基本流程,最后附上完整的代码?
import requests<br />from bs4 import BeautifulSoup<br />import csv<br />import pandas as pd<br /><br />url = 'https://www.bilibili.com/ranki ... %3Bbr />page = requests.get(url)<br />soup = BeautifulSoup(page.content, 'html.parser')<br /><br />all_products = []<br /><br />products = soup.select('li.rank-item')<br />for product in products:<br /> rank = product.select('div.num')[0].text<br /> name = product.select('div.info > a')[0].text.strip()<br /> play = product.select('span.data-box')[0].text<br /> comment = product.select('span.data-box')[1].text<br /> up = product.select('span.data-box')[2].text<br /> url = product.select('div.info > a')[0].attrs['href']<br /><br /> all_products.append({<br /> "视频排名":rank,<br /> "视频名": name,<br /> "播放量": play,<br /> "弹幕量": comment,<br /> "up主": up,<br /> "视频链接": url<br /> })<br /><br /><br />keys = all_products[0].keys()<br /><br />with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:<br /> dict_writer = csv.DictWriter(output_file, keys)<br /> dict_writer.writeheader()<br /> dict_writer.writerows(all_products)<br /><br />### 使用pandas写入数据<br />pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')<br />
怎样抓取网页数据(如何用python来抓取页面中的动态动态网页数据? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-10-17 03:00
)
”
浏览器中显示的内容与右键查看的网页源代码是否不同?
右键查看源代码
生成的 HTML 不收录 ajax 异步加载的内容
查看原创文件只是网页的初始状态,但实际上网页可能在加载后立即执行js来改变初始状态。当前网页不同于传统的动态网页,可以在不刷新网页的情况下改变网页的部分数据。这一切都是通过js和服务端的交互来完成的。这就像一个程序使用对话框编辑器来设计界面,但在实际操作中,您必须在其中加载数据,更改控件状态,甚至创建新控件、销毁控件或隐藏现有控件。外观自然会发生变化。
”
我们经常会发现,网页中的很多数据并不是用HTML硬编码的,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有的。
在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,将无法获取任何数据。
今天,我们就在这里简单说说如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。
如下图所示,我们在HTML中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下所示:
在豆瓣页面向下拖动,可以将更多的电影信息加载到页面中,以便我们抓取相应的消息。
我们可以看到它使用了 AJAX 异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某个部分,从而实现数据的动态加载。
我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。
查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果你想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但这看起来很不自动化,很多其他的网站 RequestURL 都不是那么简单,所以我们将使用python 进行进一步的操作,以获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text
查看全部
怎样抓取网页数据(如何用python来抓取页面中的动态动态网页数据?
)
”
浏览器中显示的内容与右键查看的网页源代码是否不同?
右键查看源代码
生成的 HTML 不收录 ajax 异步加载的内容
查看原创文件只是网页的初始状态,但实际上网页可能在加载后立即执行js来改变初始状态。当前网页不同于传统的动态网页,可以在不刷新网页的情况下改变网页的部分数据。这一切都是通过js和服务端的交互来完成的。这就像一个程序使用对话框编辑器来设计界面,但在实际操作中,您必须在其中加载数据,更改控件状态,甚至创建新控件、销毁控件或隐藏现有控件。外观自然会发生变化。
”
我们经常会发现,网页中的很多数据并不是用HTML硬编码的,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有的。
在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,将无法获取任何数据。
今天,我们就在这里简单说说如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。
如下图所示,我们在HTML中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下所示:
在豆瓣页面向下拖动,可以将更多的电影信息加载到页面中,以便我们抓取相应的消息。
我们可以看到它使用了 AJAX 异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某个部分,从而实现数据的动态加载。
我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。

查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果你想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但这看起来很不自动化,很多其他的网站 RequestURL 都不是那么简单,所以我们将使用python 进行进一步的操作,以获取返回的消息信息。

#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text
怎样抓取网页数据(借助ABBYYFineReader15文字识别软件快速识别为表格数据表格)
网站优化 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2021-10-15 21:16
在一些政府公共信息共享网站或专业数据共享组织网站中,会定期共享一些社会发展数据或与时事相关的数据。这些数据通常在网页上共享,很少提供文件下载。
如果直接复制这些数据,排版数据会花费很多时间。但借助ABBYY FineReader PDF 15文本识别软件,可以快速识别为表格数据,导出为可编辑的数据表格。接下来,我们来看看它的操作方法。
一、 网页表单数据截图
首先打开相关数据网站,对数据表区域进行截图。
图1:打开网页截图
如图2所示,在截图过程中,建议尽量保持表格边框的完整性,以提高ABBYY FineReader PDF 15识别的准确率。
图 2:完成的表数据的屏幕截图
二、使用OCR编辑器识别表单
接下来,打开ABBYY FineReader PDF 15文本识别软件,使用“在OCR编辑器中打开”功能打开网站中刚刚截取的表单数据。
图 3:在 OCR 编辑器中打开图片
然后,等待软件完成对图片的文字识别。在识别过程中,为了提高文字识别的准确率,软件会建议图片的分辨率或指定的OCR语言。如果条件允许(如提高图像的分辨率),您可以按照建议修改相关设置。
图 4:完整的 OCR 识别
完成文本识别程序后,我们需要在区域属性面板中检查表格标记的区域属性是否正确。如图 5 所示,您可以看到 ABBYY FineReader PDF 15 已正确将此区域标记为表格区域。
图 5:区域属性
然后,看到软件的文本编辑面板。如图6所示,可以看到文字已经以电子表格的形式呈现出来了,可以在单元格中编辑文字了。
图 6:文本编辑器
三、导出到Excel
为了方便后续的数据处理,我们可以将识别出的电子表格保存为Excel文件。如图7所示,在文本编辑面板顶部选择Excel表格的保存格式后,即可将当前文本导出为Excel文件。
图 7:另存为 Excel 电子表格
打开导出的Excel文件,可以看到ABBYY FineReader PDF 15不仅可以准确识别数据,还可以“复制”表格的格式,很好地将数据导出到每个单元格。这种类型的导出可以减少排版大量数据所需的时间。
图 8:导出的 Excel 表
四、总结
通过使用ABBYY文字识别软件的数据表格识别功能,我们可以快速将图片中的表格转换为可编辑的电子表格,提高数据使用效率。你有这么好用的功能吗? 查看全部
怎样抓取网页数据(借助ABBYYFineReader15文字识别软件快速识别为表格数据表格)
在一些政府公共信息共享网站或专业数据共享组织网站中,会定期共享一些社会发展数据或与时事相关的数据。这些数据通常在网页上共享,很少提供文件下载。
如果直接复制这些数据,排版数据会花费很多时间。但借助ABBYY FineReader PDF 15文本识别软件,可以快速识别为表格数据,导出为可编辑的数据表格。接下来,我们来看看它的操作方法。
一、 网页表单数据截图
首先打开相关数据网站,对数据表区域进行截图。
图1:打开网页截图
如图2所示,在截图过程中,建议尽量保持表格边框的完整性,以提高ABBYY FineReader PDF 15识别的准确率。
图 2:完成的表数据的屏幕截图
二、使用OCR编辑器识别表单
接下来,打开ABBYY FineReader PDF 15文本识别软件,使用“在OCR编辑器中打开”功能打开网站中刚刚截取的表单数据。

图 3:在 OCR 编辑器中打开图片
然后,等待软件完成对图片的文字识别。在识别过程中,为了提高文字识别的准确率,软件会建议图片的分辨率或指定的OCR语言。如果条件允许(如提高图像的分辨率),您可以按照建议修改相关设置。
图 4:完整的 OCR 识别
完成文本识别程序后,我们需要在区域属性面板中检查表格标记的区域属性是否正确。如图 5 所示,您可以看到 ABBYY FineReader PDF 15 已正确将此区域标记为表格区域。
图 5:区域属性
然后,看到软件的文本编辑面板。如图6所示,可以看到文字已经以电子表格的形式呈现出来了,可以在单元格中编辑文字了。
图 6:文本编辑器
三、导出到Excel
为了方便后续的数据处理,我们可以将识别出的电子表格保存为Excel文件。如图7所示,在文本编辑面板顶部选择Excel表格的保存格式后,即可将当前文本导出为Excel文件。
图 7:另存为 Excel 电子表格
打开导出的Excel文件,可以看到ABBYY FineReader PDF 15不仅可以准确识别数据,还可以“复制”表格的格式,很好地将数据导出到每个单元格。这种类型的导出可以减少排版大量数据所需的时间。
图 8:导出的 Excel 表
四、总结
通过使用ABBYY文字识别软件的数据表格识别功能,我们可以快速将图片中的表格转换为可编辑的电子表格,提高数据使用效率。你有这么好用的功能吗?
怎样抓取网页数据(网页如何获取访客手机号码,可以提高100倍获客效率?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-11-19 05:08
现在运营商的数据无处不在,那么如何区分真实的运营商数据呢?
往往由于各种原因,客户只是匆匆一瞥就离开,浪费了大量的时间和精力。与直接的访客交流和引导相比,效果更好。那么网站是如何抓取访问者数据的呢?让我给你解释一下。
如何在网页上获取访问者的手机号码?事实上,运营商会有一个http报告,每个访问者访问过哪些网站 APP以及他的4G数据,以及他们消耗了多少数据。这样,对访客的消费行为和近期需求有非常准确的把握。这类客户的精准开发无疑是非常高的转化率。Wap手机网站获取访客信息系统,可以提高网站的转化率。是企业网站企业营销和招投标网络联盟的必备神器,可以放心使用。在此重申,常规运营商使用脱敏数据来保护用户隐私。
抓住网站访客电话,更容易获客
1、 定位很准确
行业网站访客数据定位非常准确。假设有人用手机上网查询相关信息。那么这些人就有了行业网站访问者数据的条件,行业网站访问者数据可以有效的捕捉到访问者的手机号码,以便我们快速制定相应的市场策略,快速争取。给相关客户。
2、 获取数据的渠道没有障碍
行业网站 从广告数据中获取数据的渠道没有被阻断,因为该单位和其他网络运营商已经搭建了桥梁。不仅可以进行精准的客户定位,还可以打造精准的客户复制体系,从而牢牢抓住大量客户。另一方面,客户复印订单量也在稳步增长。
还等什么,快给我一个小窗口~!节省100招投标费用。获客效率提升100倍。 查看全部
怎样抓取网页数据(网页如何获取访客手机号码,可以提高100倍获客效率?)
现在运营商的数据无处不在,那么如何区分真实的运营商数据呢?
往往由于各种原因,客户只是匆匆一瞥就离开,浪费了大量的时间和精力。与直接的访客交流和引导相比,效果更好。那么网站是如何抓取访问者数据的呢?让我给你解释一下。
如何在网页上获取访问者的手机号码?事实上,运营商会有一个http报告,每个访问者访问过哪些网站 APP以及他的4G数据,以及他们消耗了多少数据。这样,对访客的消费行为和近期需求有非常准确的把握。这类客户的精准开发无疑是非常高的转化率。Wap手机网站获取访客信息系统,可以提高网站的转化率。是企业网站企业营销和招投标网络联盟的必备神器,可以放心使用。在此重申,常规运营商使用脱敏数据来保护用户隐私。
抓住网站访客电话,更容易获客
1、 定位很准确
行业网站访客数据定位非常准确。假设有人用手机上网查询相关信息。那么这些人就有了行业网站访问者数据的条件,行业网站访问者数据可以有效的捕捉到访问者的手机号码,以便我们快速制定相应的市场策略,快速争取。给相关客户。
2、 获取数据的渠道没有障碍
行业网站 从广告数据中获取数据的渠道没有被阻断,因为该单位和其他网络运营商已经搭建了桥梁。不仅可以进行精准的客户定位,还可以打造精准的客户复制体系,从而牢牢抓住大量客户。另一方面,客户复印订单量也在稳步增长。
还等什么,快给我一个小窗口~!节省100招投标费用。获客效率提升100倍。
怎样抓取网页数据(【办公软件】解析html网页内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-11-18 06:07
****************根据URL获取指定的网页内容********************
私有静态字符串 getHtml(字符串路径){
StringBuffer html = new StringBuffer();//保存整个html文档的数据
try {
//1.发起一个url网址的请求
URL url = new URL(path);
URLConnection connection = url.openConnection();
//2.获取网页的数据流
InputStream input = connection.getInputStream(); //字节流 一个字节一个字节的读取 中文占用两个字节
InputStreamReader reader = new InputStreamReader(input,"GBK"); //字符流 一个字符一个字符的读取 可指定字符集编码 ,常用字符集编码:GBK,GB2312,utf-8,ISO-8859-1
BufferedReader bufferedReader = new BufferedReader(reader); //字符流 一行一行的读取
//3.解析并且获取InputStream中具体的数据,并且输出到控制台
String line = "";
while((line = bufferedReader.readLine()) != null)
{
html.append(line); //将所有读到的每行信息line追加到(拼接到)html对象上
}
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return html.toString();
}
****************分析html页面内容********************
私有静态列表 parseHtml(String html) {
// 2.分析html网页内容
文档文档 = Jsoup.parse(html);
// 获取所有的招聘信息所在的div节点
Element div = document.getElementById("resultList");
// 获取div中所有的招聘信息的div
Elements jobs = div.getElementsByClass("el");
List jobList = new ArrayList();
for (Element job : jobs) {
// 工作名称
String jobName = job.getElementsByClass("t1").get(0).text().toUpperCase();
jobName = parseJob(jobName);
// 公司名称
String company = job.getElementsByClass("t2").get(0).text();
// 工作地点
String address = job.getElementsByClass("t3").get(0).text();
// 薪酬待遇
String salary = job.getElementsByClass("t4").get(0).text();
// 求平均值
double avgSalary = getAvgSalary(salary);
// 封装招聘信息
Job myJob = new Job();
myJob.setJobName(jobName);
myJob.setCompany(company);
myJob.setAddress(address);
myJob.setSalary(avgSalary);
// 将对象添加到集合里面
jobList.add(myJob);
}
return jobList;
}
*******************解释***********************
访问某个网站地址后,设置读取方式并解析内容,可以先到网页确认要爬取的数据,进入开发者模式(F12),看看网页的结构是什么样的 程序中首先得到的节点id为resultList,其中每一行数据的class为el,可以通过分析网页找到有用的信息,这样你可以更准确地爬到想要的数据
获取到数据后,封装一条信息,然后将封装的信息添加到集合中。如果要对数据进行一些处理,可以封装信息处理方法并调用。
接下来开始数据库操作...
*********************结尾************************* 查看全部
怎样抓取网页数据(【办公软件】解析html网页内容)
****************根据URL获取指定的网页内容********************
私有静态字符串 getHtml(字符串路径){
StringBuffer html = new StringBuffer();//保存整个html文档的数据
try {
//1.发起一个url网址的请求
URL url = new URL(path);
URLConnection connection = url.openConnection();
//2.获取网页的数据流
InputStream input = connection.getInputStream(); //字节流 一个字节一个字节的读取 中文占用两个字节
InputStreamReader reader = new InputStreamReader(input,"GBK"); //字符流 一个字符一个字符的读取 可指定字符集编码 ,常用字符集编码:GBK,GB2312,utf-8,ISO-8859-1
BufferedReader bufferedReader = new BufferedReader(reader); //字符流 一行一行的读取
//3.解析并且获取InputStream中具体的数据,并且输出到控制台
String line = "";
while((line = bufferedReader.readLine()) != null)
{
html.append(line); //将所有读到的每行信息line追加到(拼接到)html对象上
}
} catch (MalformedURLException e) {
e.printStackTrace();
} catch (IOException e) {
e.printStackTrace();
}
return html.toString();
}
****************分析html页面内容********************
私有静态列表 parseHtml(String html) {
// 2.分析html网页内容
文档文档 = Jsoup.parse(html);
// 获取所有的招聘信息所在的div节点
Element div = document.getElementById("resultList");
// 获取div中所有的招聘信息的div
Elements jobs = div.getElementsByClass("el");
List jobList = new ArrayList();
for (Element job : jobs) {
// 工作名称
String jobName = job.getElementsByClass("t1").get(0).text().toUpperCase();
jobName = parseJob(jobName);
// 公司名称
String company = job.getElementsByClass("t2").get(0).text();
// 工作地点
String address = job.getElementsByClass("t3").get(0).text();
// 薪酬待遇
String salary = job.getElementsByClass("t4").get(0).text();
// 求平均值
double avgSalary = getAvgSalary(salary);
// 封装招聘信息
Job myJob = new Job();
myJob.setJobName(jobName);
myJob.setCompany(company);
myJob.setAddress(address);
myJob.setSalary(avgSalary);
// 将对象添加到集合里面
jobList.add(myJob);
}
return jobList;
}
*******************解释***********************
访问某个网站地址后,设置读取方式并解析内容,可以先到网页确认要爬取的数据,进入开发者模式(F12),看看网页的结构是什么样的 程序中首先得到的节点id为resultList,其中每一行数据的class为el,可以通过分析网页找到有用的信息,这样你可以更准确地爬到想要的数据
获取到数据后,封装一条信息,然后将封装的信息添加到集合中。如果要对数据进行一些处理,可以封装信息处理方法并调用。
接下来开始数据库操作...
*********************结尾*************************
怎样抓取网页数据(网站排名好不好,流量多不多,其中一个关键的因素)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-11-15 19:13
网站 排名好吗?没有太多的交通。关键因素之一是网站收录如何,虽然收录不能直接决定网站的排名,但网站的基础是内容。如果没有内容,更难排名好。好的内容可以让用户和搜索引擎满意,还可以给网站加分,从而提升排名,扩大网站的曝光页面。
详情请参考以下几点:
1.网站 和页面权重。
网站 权重高、资历老、权限大的蜘蛛,一定要特别对待。这样网站的爬取频率非常高。为了保证高效率,搜索引擎蜘蛛并不是对所有的网站页面都会进行爬取,网站的权重越高,爬取的深度越高,对应的页面可以被爬取爬取的也会增加,这样可以收录的页面也会增加。
2.网站 服务器。
网站服务器是网站的基石。如果网站服务器长时间打不开,那这和闭门谢客很相似。蜘蛛想来也来不了。百度蜘蛛也是网站的访客。如果服务器不稳定或卡住,蜘蛛每次都很难爬行,有时只能爬到一个页面的一部分。就这样,随着时间的推移,百度蜘蛛的体验越来越差,自然会影响到网站的爬取
3. 网站 的更新频率。
每次蜘蛛爬行时,都会存储页面数据。如果第二次爬取发现页面和第一次收录完全一样,说明页面没有更新,蜘蛛不需要频繁爬取。页面内容更新频繁,蜘蛛会更频繁地访问页面,但蜘蛛并不是你一个人的。不可能蹲在这里等你更新,所以一定要主动向蜘蛛展示蜘蛛并定期进行。文章更新,这样蜘蛛才会按照你的规则有效爬行,而不是只让你的更新文章更快的被抓到,也不会导致蜘蛛频繁的白跑。
4.文章的原创性质。
高质量的原创内容对百度蜘蛛来说非常有吸引力。蜘蛛的目的是寻找新的东西,所以网站更新文章不要采集,不要天天转载。我们需要给蜘蛛提供真正有价值的原创内容。蜘蛛如果能得到自己喜欢的东西,自然会对你的网站产生好感,经常来找吃的。
5.扁平的网站结构。
蜘蛛爬行也有自己的路线。在你给他铺路之前,网站结构不要太复杂,链接层次不要太深。如果链接层次太深,后面的页面就很难被蜘蛛抓取到。获得。
6.网站 程序。
在网站程序中,有很多程序可以创建大量的重复页面。这个页面一般是通过参数实现的。当一个页面对应多个URL时,会造成网站重复的内容,可能导致网站被降级,严重影响蜘蛛的抓取。因此,程序必须确保一个页面只有一个 URL。如果已经生成,请尝试使用301重定向、Canonical标签或Robots流程,以确保蜘蛛只抓取一个标准网址。
7.外链建设。
大家都知道外链可以吸引蜘蛛到网站,尤其是新网站的时候,网站还不是很成熟,蜘蛛访问量比较少,外链可以在网站页面中添加网站暴露在蜘蛛面前可以防止蜘蛛无法找到页面。在外链建设的过程中,需要注意外链的质量。不要为了省事而做无用的事情。百度现在相信大家都知道外链的管理。
8.内部链构建。
蜘蛛的爬取是跟随链接的,所以合理优化内链可以要求蜘蛛爬取更多的页面,促进网站的收录。内链建设过程中应给予用户合理的建议。除了在文章中添加锚文本,还可以设置相关推荐、热门文章、更多喜欢等栏目,这个很多网站都有用,让蜘蛛爬取更广泛的页面。 查看全部
怎样抓取网页数据(网站排名好不好,流量多不多,其中一个关键的因素)
网站 排名好吗?没有太多的交通。关键因素之一是网站收录如何,虽然收录不能直接决定网站的排名,但网站的基础是内容。如果没有内容,更难排名好。好的内容可以让用户和搜索引擎满意,还可以给网站加分,从而提升排名,扩大网站的曝光页面。
详情请参考以下几点:
1.网站 和页面权重。
网站 权重高、资历老、权限大的蜘蛛,一定要特别对待。这样网站的爬取频率非常高。为了保证高效率,搜索引擎蜘蛛并不是对所有的网站页面都会进行爬取,网站的权重越高,爬取的深度越高,对应的页面可以被爬取爬取的也会增加,这样可以收录的页面也会增加。
2.网站 服务器。
网站服务器是网站的基石。如果网站服务器长时间打不开,那这和闭门谢客很相似。蜘蛛想来也来不了。百度蜘蛛也是网站的访客。如果服务器不稳定或卡住,蜘蛛每次都很难爬行,有时只能爬到一个页面的一部分。就这样,随着时间的推移,百度蜘蛛的体验越来越差,自然会影响到网站的爬取
3. 网站 的更新频率。
每次蜘蛛爬行时,都会存储页面数据。如果第二次爬取发现页面和第一次收录完全一样,说明页面没有更新,蜘蛛不需要频繁爬取。页面内容更新频繁,蜘蛛会更频繁地访问页面,但蜘蛛并不是你一个人的。不可能蹲在这里等你更新,所以一定要主动向蜘蛛展示蜘蛛并定期进行。文章更新,这样蜘蛛才会按照你的规则有效爬行,而不是只让你的更新文章更快的被抓到,也不会导致蜘蛛频繁的白跑。
4.文章的原创性质。
高质量的原创内容对百度蜘蛛来说非常有吸引力。蜘蛛的目的是寻找新的东西,所以网站更新文章不要采集,不要天天转载。我们需要给蜘蛛提供真正有价值的原创内容。蜘蛛如果能得到自己喜欢的东西,自然会对你的网站产生好感,经常来找吃的。
5.扁平的网站结构。
蜘蛛爬行也有自己的路线。在你给他铺路之前,网站结构不要太复杂,链接层次不要太深。如果链接层次太深,后面的页面就很难被蜘蛛抓取到。获得。
6.网站 程序。
在网站程序中,有很多程序可以创建大量的重复页面。这个页面一般是通过参数实现的。当一个页面对应多个URL时,会造成网站重复的内容,可能导致网站被降级,严重影响蜘蛛的抓取。因此,程序必须确保一个页面只有一个 URL。如果已经生成,请尝试使用301重定向、Canonical标签或Robots流程,以确保蜘蛛只抓取一个标准网址。
7.外链建设。
大家都知道外链可以吸引蜘蛛到网站,尤其是新网站的时候,网站还不是很成熟,蜘蛛访问量比较少,外链可以在网站页面中添加网站暴露在蜘蛛面前可以防止蜘蛛无法找到页面。在外链建设的过程中,需要注意外链的质量。不要为了省事而做无用的事情。百度现在相信大家都知道外链的管理。
8.内部链构建。
蜘蛛的爬取是跟随链接的,所以合理优化内链可以要求蜘蛛爬取更多的页面,促进网站的收录。内链建设过程中应给予用户合理的建议。除了在文章中添加锚文本,还可以设置相关推荐、热门文章、更多喜欢等栏目,这个很多网站都有用,让蜘蛛爬取更广泛的页面。
怎样抓取网页数据(怎样抓取网页数据,这里介绍下下一个web框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2021-11-11 16:03
怎样抓取网页数据,这里介绍下一个web框架1、首先要学习python基础,看我之前的文章2、学习mysql一建立自己的数据库1-1python中文mysql简介1-2python中文mysql简介2-3基本操作python中文mysql简介2-4高级操作python中文mysql简介2-5创建表python中文mysql简介2-6插入和更新表python中文mysql简介2-7创建视图1-1python中文mysql简介1-2python中文mysql简介1-3python中文mysql简介1-4python中文mysql简介1-5python中文mysql简介2-1python中文mysql简介2-2python中文mysql简介2-3python中文mysql简介2-4python中文mysql简介2-5python中文mysql简介二理解关系数据库操作1-1python中文mysql简介2-2python中文mysql简介2-3python中文mysql简介2-4python中文mysql简介2-5python中文mysql简介2-6python中文mysql简介3实践问题收集:1。
举例抓取网页上的“蛋糕数据”,如何抓取?2。举例抓取网页上的“西湖门票”?3。举例抓取网页上的“博物馆数据”?4。举例抓取网页上的“物流详情”?5。举例抓取“58同城”数据?6。举例抓取上的“房价”?7。举例抓取上的“书店”数据?8。举例抓取上的“街景”数据?9。举例抓取“凤凰新闻”的"汽车"数据?三如何用python抓取网页数据?1-1抓取网页的方法1-2网页信息都在哪里2-1python解析xpath2-2python解析json3-1python数据分析和数据可视化。 查看全部
怎样抓取网页数据(怎样抓取网页数据,这里介绍下下一个web框架)
怎样抓取网页数据,这里介绍下一个web框架1、首先要学习python基础,看我之前的文章2、学习mysql一建立自己的数据库1-1python中文mysql简介1-2python中文mysql简介2-3基本操作python中文mysql简介2-4高级操作python中文mysql简介2-5创建表python中文mysql简介2-6插入和更新表python中文mysql简介2-7创建视图1-1python中文mysql简介1-2python中文mysql简介1-3python中文mysql简介1-4python中文mysql简介1-5python中文mysql简介2-1python中文mysql简介2-2python中文mysql简介2-3python中文mysql简介2-4python中文mysql简介2-5python中文mysql简介二理解关系数据库操作1-1python中文mysql简介2-2python中文mysql简介2-3python中文mysql简介2-4python中文mysql简介2-5python中文mysql简介2-6python中文mysql简介3实践问题收集:1。
举例抓取网页上的“蛋糕数据”,如何抓取?2。举例抓取网页上的“西湖门票”?3。举例抓取网页上的“博物馆数据”?4。举例抓取网页上的“物流详情”?5。举例抓取“58同城”数据?6。举例抓取上的“房价”?7。举例抓取上的“书店”数据?8。举例抓取上的“街景”数据?9。举例抓取“凤凰新闻”的"汽车"数据?三如何用python抓取网页数据?1-1抓取网页的方法1-2网页信息都在哪里2-1python解析xpath2-2python解析json3-1python数据分析和数据可视化。
怎样抓取网页数据(web前端开发中怎样抓取网页数据首先,python操作过程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-10 20:03
怎样抓取网页数据首先,如果在web前端开发中,dom操作就是浏览器对象,但是dom操作过程非常繁琐,因此几乎很少有开发者能熟练掌握dom操作。python在dom操作方面具有天然优势,python操作dom几乎只需要几行代码,并且python是静态语言,python的基础语法以及python数据结构和函数都能让程序使用python语言进行实现。
dict语言里,能操作数组,但是创建和管理dict对象却非常繁琐。如果能用python的数据结构来实现dict中的键值对关系,就能将其简化到极致。不过,在python中,查找一个对象中的某个属性非常容易,但是要查找一个对象中所有对象的key和value,相对要难一些。dict的实现方式很简单,数据结构就是dict,方法也都是抽象的,不需要写items=dict.set(key,value)等代码。
dict.keys=[]利用dict.keys可以很容易定位key,因为key一定是类,可以操作的对象也就几种类型,除了整数,一般还能操作数字。比如上面例子中,dict.keys[1]=2。此外,利用dict.dict(key=none)可以简化key查找的数据结构操作,比如:dict[none]=none将tuple转换为dict转换成dict需要将dict转换成tuple再进行转换,在python3中已经提供dict.toarray,但是在python2中,无法直接用这个方法将dict转换成tuple数组:dict.resize(new_dict)dict中的key可以通过tuple()方法转换为keyed类型。
对于每个元素,tuple()都会返回一个keyed类型,因此,可以非常方便的把tuple()转换成dict:dict.resize(tuple)dict中的value用tuple()转换,tuple()将dict转换成tuple,就是把tuple中元素都转换成一个keyed类型,而实际上每个keyed是tuple中的某个元素值。
dict[0]='item1'此外,dict.reverse函数将会返回dict[none]为none,这个函数代表dict是不变的。将字典转换为dictpython3中提供了dict.fromkeys(key=value)方法,可以把一个key转换成value。python3提供的字典方法和python2不同,python3中dict.fromkeys比dict.frompython3提供了dict.fromkeys_values()方法,返回dict的tuple(),除此之外,dict.fromid()、dict.froming_index()也可以用来将一个key转换成value。 查看全部
怎样抓取网页数据(web前端开发中怎样抓取网页数据首先,python操作过程)
怎样抓取网页数据首先,如果在web前端开发中,dom操作就是浏览器对象,但是dom操作过程非常繁琐,因此几乎很少有开发者能熟练掌握dom操作。python在dom操作方面具有天然优势,python操作dom几乎只需要几行代码,并且python是静态语言,python的基础语法以及python数据结构和函数都能让程序使用python语言进行实现。
dict语言里,能操作数组,但是创建和管理dict对象却非常繁琐。如果能用python的数据结构来实现dict中的键值对关系,就能将其简化到极致。不过,在python中,查找一个对象中的某个属性非常容易,但是要查找一个对象中所有对象的key和value,相对要难一些。dict的实现方式很简单,数据结构就是dict,方法也都是抽象的,不需要写items=dict.set(key,value)等代码。
dict.keys=[]利用dict.keys可以很容易定位key,因为key一定是类,可以操作的对象也就几种类型,除了整数,一般还能操作数字。比如上面例子中,dict.keys[1]=2。此外,利用dict.dict(key=none)可以简化key查找的数据结构操作,比如:dict[none]=none将tuple转换为dict转换成dict需要将dict转换成tuple再进行转换,在python3中已经提供dict.toarray,但是在python2中,无法直接用这个方法将dict转换成tuple数组:dict.resize(new_dict)dict中的key可以通过tuple()方法转换为keyed类型。
对于每个元素,tuple()都会返回一个keyed类型,因此,可以非常方便的把tuple()转换成dict:dict.resize(tuple)dict中的value用tuple()转换,tuple()将dict转换成tuple,就是把tuple中元素都转换成一个keyed类型,而实际上每个keyed是tuple中的某个元素值。
dict[0]='item1'此外,dict.reverse函数将会返回dict[none]为none,这个函数代表dict是不变的。将字典转换为dictpython3中提供了dict.fromkeys(key=value)方法,可以把一个key转换成value。python3提供的字典方法和python2不同,python3中dict.fromkeys比dict.frompython3提供了dict.fromkeys_values()方法,返回dict的tuple(),除此之外,dict.fromid()、dict.froming_index()也可以用来将一个key转换成value。
怎样抓取网页数据(搜索引擎蜘蛛访问网站页面的程序被称为蜘蛛(spider)网站怎么引)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-11-08 03:17
搜索引擎用来抓取和访问页面的程序称为蜘蛛程序或机器人程序。搜索引擎蜘蛛访问网站页面时,与普通用户使用浏览器类似。蜘蛛程序发出页面访问请求后,服务器返回HTML代码,蜘蛛程序将接收到的代码存储在原创页面数据库中。搜索引擎旨在提高爬行和爬行速度,两者都使用多个蜘蛛来分布爬行。
蜘蛛访问网站时,首先会访问网站根目录下的robots.txt文件。如果robots.txt 文件禁止搜索引擎抓取某些网页或内容,或者网站,蜘蛛将遵循协议而不抓取它。
蜘蛛也有自己的代理名称。在站长的日志中可以看到蜘蛛的爬行痕迹。这就是为什么很多站长回答问题的时候,总是说先查看网站日志(作为一个优秀的SEO,你必须有能力在不借助任何软件的情况下查看网站日志,并且非常熟悉代码的含义)。
一、搜索引擎蜘蛛的基本原理
搜索引擎蜘蛛就是Spider,这是一个很形象的名字。它将互联网比作蜘蛛网,然后蜘蛛就是在互联网上爬行的蜘蛛。
网络蜘蛛通过网页的链接地址搜索网页。从某个页面(通常是首页)开始,阅读网页内容,找到网页中的其他链接地址,然后通过这些链接地址进行搜索。一个网页,一直循环下去,直到这个网站的所有网页都被抓取完。
如果把整个互联网看作一个网站,那么网络蜘蛛就可以利用这个原理抓取互联网上的所有网页。
搜索引擎蜘蛛的基本原理和工作流程
对于搜索引擎来说,爬取互联网上的所有网页几乎是不可能的。根据目前公布的数据,容量最大的搜索引擎只能抓取整个网页的40%左右。
造成这种情况的原因之一,一方面是爬虫技术的瓶颈。100亿个网页的容量为100×2000G字节。即使可以存储,下载还是有问题(按照一台机器每秒下载20K计算,需要340台机器停止。下载所有网页需要一年时间。同时,由于数据量大,会影响搜索的效率。
因此,很多搜索引擎的网络蜘蛛只爬取那些重要的网页,爬取时评价重要性的主要依据是某个网页的链接深度。
由于不可能爬取所有网页,所以一些网络蜘蛛对一些不太重要的网站设置了访问级别的数量,例如如下图所示:
搜索引擎蜘蛛的基本原理和工作流程
A为起始网页,属于第0层,B、C、D、E、F属于第1层,G、H属于第2层,I属于第3层。网络蜘蛛为2,页面I不会被访问,这也允许搜索引擎搜索到一些网站之前的页面,其他部分无法搜索。
对于网站设计师来说,扁平化的网站结构设计有助于搜索引擎抓取更多的网页。
网络蜘蛛在访问网站 网页时,经常会遇到加密数据和网络权限的问题。某些网页需要会员权限才能访问。
当然,网站的站长可以通过协议防止网络蜘蛛爬行,但是对于一些网站的销售报告,他们希望自己的报告能够被搜索引擎搜索到,但又不可能完全免费. 让搜索者查看,所以需要提供对应的用户名和密码给网络蜘蛛。
网络蜘蛛可以抓取这些具有给定权限的网页提供搜索,当搜索者点击查看网页时,搜索者也需要提供相应的权限验证。
二、追踪链接
因为搜索引擎蜘蛛可以在网络上抓取尽可能多的页面,所以它们会跟随网页上的链接从一个页面爬到下一个页面,就像蜘蛛在蜘蛛网上爬行一样。这就是名称搜索引擎蜘蛛的来源。因为。
整个互联网网站是由相互链接组成的,也就是说,从任何一个页面开始,搜索引擎蜘蛛最终都会抓取所有页面。
搜索引擎蜘蛛的基本原理和工作流程
当然,网站和页面链接结构过于复杂,所以蜘蛛只能通过一定的方法抓取所有页面。据了解,最简单的爬取策略有3种:
1、最好的第一
最佳优先级搜索策略根据一定的网页分析算法预测候选网址与目标页面的相似度或与主题的相关性,选择一个或几个评价最好的网址进行爬取,只访问该网页经过分析该算法预测“有用”的页面。
一个问题是爬虫爬取路径上的很多相关网页可能会被忽略,因为最佳优先级策略是局部最优搜索算法,所以需要将最佳优先级结合具体应用进行改进跳出局部区域. 最大的好处,据研究,这样的闭环调整可以减少30%到90%的无关网页。
2、深度优先
深度优先是指蜘蛛沿着发现的链接向前爬,直到它前面没有更多的链接,然后回到第一页,沿着另一个链接向前爬。
3、广度优先
广度优先是指当一个蜘蛛在一个页面上发现多个链接时,它不会一直跟踪一个链接,而是爬取页面上的所有链接,然后进入二级页面并跟踪在第二级找到的链接-level 爬到第三级页面。
理论上,无论是深度优先还是广度优先,只要给蜘蛛足够的时间,它们就可以爬取整个互联网。
在实际工作中,蜘蛛的带宽资源和时间不是无限的,也不是爬满所有的页面。其实最大的搜索引擎只是爬取和收录互联网的一小部分,当然不是搜索。引擎蜘蛛爬的越多越好,这点
因此,为了捕捉尽可能多的用户信息,通常会混合使用深度优先和广度优先,这样可以照顾到尽可能多的网站和网站的部分内页.
三、 搜索引擎蜘蛛工作中的信息采集
信息采集模块包括“蜘蛛控制”和“网络蜘蛛”两部分。“蜘蛛”这个名字形象地描述了信息采集模块在网络数据形成的“Web”上获取信息的功能。
一般来说,网络蜘蛛从种子网页开始,反复下载网页,寻找文档中没有见过的网址,以达到访问其他网页遍历网页的目的。
而其工作策略一般可分为累积爬行(cumulative crawling)和增量爬行(incremental crawling)两种。
1、累积爬行
累积爬取是指从某个时间点开始爬取系统可以允许存储和处理的所有网页。在理想的软硬件环境下,经过足够的运行时间,累积爬取策略可以保证可以爬取相当数量的网页集合。
似乎由于网络数据的动态性,采集到的网页的抓取时间不同,页面更新的情况也不同。因此,累积爬取所爬取的网页集合,实际上并不能和真实环境中的网络数据相比。始终如一。
2、增量爬取
与累积爬取不同,增量爬取是指对具有一定规模的网页集合,采用更新数据的方法,在现有集合中选择过时的网页进行爬取,保证爬取的数据与当前的数据足够接近。真实的网络数据。
增量爬取的前提是系统已经爬取了足够多的网页,并且有这些页面被爬取的时间信息。在面向实际应用环境的网络蜘蛛设计中,通常包括累积爬取和增量爬取两种策略。
累积爬取一般用于数据采集的整体建立或大规模更新阶段,而增量爬取主要用于数据采集的日常维护和实时更新。
确定爬取策略后,如何充分利用网络带宽,合理确定网页数据更新的时间点,成为网络蜘蛛运行策略的核心问题。
总的来说,在合理利用软硬件资源实时捕获网络数据方面,已经形成了比较成熟的技术和实用的解决方案。我觉得这方面需要解决的主要问题是如何更好地处理动态的网络数据问题(比如Web2.0数据越来越多等),更好地纠正基于网页质量的抓取策略。
四、数据库
为了避免重复抓取和抓取网址,搜索引擎会建立一个数据库来记录已发现未抓取的页面和已抓取的页面。那么数据库中的URL是怎么来的呢?
1、手动输入种子网站
简单来说就是我们新建网站后提交给百度、谷歌或者360的URL收录。
2、 蜘蛛抓取页面
如果搜索引擎蜘蛛在爬取过程中发现了一个新的连接网址,但它不在数据库中,则将其存储在数据库中以供访问(网站观察期)。
蜘蛛根据重要性从要访问的数据库中提取URL,访问并爬取页面,然后从要访问的地址数据库中删除该URL并将其放入访问地址数据库中,因此建议站长关注网站 期间需要定期更新网站。
3、站长提交网站
一般来说,提交网站只是将网站保存到要访问的数据库中。如果网站长时间不更新,蜘蛛就不会光顾了。搜索引擎收录的页面都是蜘蛛。自己通过链接获取它。
因此,如果您将其提交给搜索引擎,则它不是很有用。后期还是要考虑你的网站更新级别。搜索引擎更喜欢沿着链接发现新页面。当然,如果你的SEO功底高深,有能力试试这个能力,说不定会有意想不到的效果,但是对于一般的站长来说,还是建议让蜘蛛爬行,自然爬到新的站点页面。
五、吸引蜘蛛
虽然理论上说蜘蛛可以抓取所有页面,但实际上是不可能做到的。想要收录更多页面的SEO人员只能想办法引诱蜘蛛爬行。
既然它不能抓取所有的页面,那我们就得让它去抓取重要的页面,因为重要的页面在索引中起着重要的作用,直接影响排名因素。哪些页面更重要?对此,我还专门整理了以下我认为比较重要的页面,具体有这些特点:
1、网站 和页面权重
高质量和老的网站 被赋予了很高的权重。这个网站上的页面蜘蛛爬取深度比较高,所以更多的内页会是收录。
2、页面更新率
蜘蛛每次爬行时都会存储页面数据。如果在第二次爬取时发现这个页面的内容和第一个收录完全一样,说明该页面没有更新,蜘蛛不需要再频繁的爬取和爬取。
如果页面内容更新频繁,蜘蛛就会频繁爬行爬取,那么页面上的新链接自然会被蜘蛛更快地跟踪和抓取,这也是为什么需要每天更新的原因文章
3、导入链接
不管是外链还是同一个网站的内链,为了被蜘蛛爬取,必须有导入链接才能进入页面,否则蜘蛛不知道页面的存在. 这时候URL链接就发挥了非常重要的作用,内部链接的重要性就发挥出来了。
另外,我个人觉得高质量的入站链接往往会增加页面出站链接的抓取深度。
这也是为什么大部分站长或者SEO都需要高质量友情链接的原因,因为蜘蛛从对方网站向你网站爬了很多次,而且深度也很高。 查看全部
怎样抓取网页数据(搜索引擎蜘蛛访问网站页面的程序被称为蜘蛛(spider)网站怎么引)
搜索引擎用来抓取和访问页面的程序称为蜘蛛程序或机器人程序。搜索引擎蜘蛛访问网站页面时,与普通用户使用浏览器类似。蜘蛛程序发出页面访问请求后,服务器返回HTML代码,蜘蛛程序将接收到的代码存储在原创页面数据库中。搜索引擎旨在提高爬行和爬行速度,两者都使用多个蜘蛛来分布爬行。
蜘蛛访问网站时,首先会访问网站根目录下的robots.txt文件。如果robots.txt 文件禁止搜索引擎抓取某些网页或内容,或者网站,蜘蛛将遵循协议而不抓取它。
蜘蛛也有自己的代理名称。在站长的日志中可以看到蜘蛛的爬行痕迹。这就是为什么很多站长回答问题的时候,总是说先查看网站日志(作为一个优秀的SEO,你必须有能力在不借助任何软件的情况下查看网站日志,并且非常熟悉代码的含义)。
一、搜索引擎蜘蛛的基本原理
搜索引擎蜘蛛就是Spider,这是一个很形象的名字。它将互联网比作蜘蛛网,然后蜘蛛就是在互联网上爬行的蜘蛛。
网络蜘蛛通过网页的链接地址搜索网页。从某个页面(通常是首页)开始,阅读网页内容,找到网页中的其他链接地址,然后通过这些链接地址进行搜索。一个网页,一直循环下去,直到这个网站的所有网页都被抓取完。
如果把整个互联网看作一个网站,那么网络蜘蛛就可以利用这个原理抓取互联网上的所有网页。
搜索引擎蜘蛛的基本原理和工作流程
对于搜索引擎来说,爬取互联网上的所有网页几乎是不可能的。根据目前公布的数据,容量最大的搜索引擎只能抓取整个网页的40%左右。
造成这种情况的原因之一,一方面是爬虫技术的瓶颈。100亿个网页的容量为100×2000G字节。即使可以存储,下载还是有问题(按照一台机器每秒下载20K计算,需要340台机器停止。下载所有网页需要一年时间。同时,由于数据量大,会影响搜索的效率。
因此,很多搜索引擎的网络蜘蛛只爬取那些重要的网页,爬取时评价重要性的主要依据是某个网页的链接深度。
由于不可能爬取所有网页,所以一些网络蜘蛛对一些不太重要的网站设置了访问级别的数量,例如如下图所示:
搜索引擎蜘蛛的基本原理和工作流程
A为起始网页,属于第0层,B、C、D、E、F属于第1层,G、H属于第2层,I属于第3层。网络蜘蛛为2,页面I不会被访问,这也允许搜索引擎搜索到一些网站之前的页面,其他部分无法搜索。
对于网站设计师来说,扁平化的网站结构设计有助于搜索引擎抓取更多的网页。
网络蜘蛛在访问网站 网页时,经常会遇到加密数据和网络权限的问题。某些网页需要会员权限才能访问。
当然,网站的站长可以通过协议防止网络蜘蛛爬行,但是对于一些网站的销售报告,他们希望自己的报告能够被搜索引擎搜索到,但又不可能完全免费. 让搜索者查看,所以需要提供对应的用户名和密码给网络蜘蛛。
网络蜘蛛可以抓取这些具有给定权限的网页提供搜索,当搜索者点击查看网页时,搜索者也需要提供相应的权限验证。
二、追踪链接
因为搜索引擎蜘蛛可以在网络上抓取尽可能多的页面,所以它们会跟随网页上的链接从一个页面爬到下一个页面,就像蜘蛛在蜘蛛网上爬行一样。这就是名称搜索引擎蜘蛛的来源。因为。
整个互联网网站是由相互链接组成的,也就是说,从任何一个页面开始,搜索引擎蜘蛛最终都会抓取所有页面。
搜索引擎蜘蛛的基本原理和工作流程
当然,网站和页面链接结构过于复杂,所以蜘蛛只能通过一定的方法抓取所有页面。据了解,最简单的爬取策略有3种:
1、最好的第一
最佳优先级搜索策略根据一定的网页分析算法预测候选网址与目标页面的相似度或与主题的相关性,选择一个或几个评价最好的网址进行爬取,只访问该网页经过分析该算法预测“有用”的页面。
一个问题是爬虫爬取路径上的很多相关网页可能会被忽略,因为最佳优先级策略是局部最优搜索算法,所以需要将最佳优先级结合具体应用进行改进跳出局部区域. 最大的好处,据研究,这样的闭环调整可以减少30%到90%的无关网页。
2、深度优先
深度优先是指蜘蛛沿着发现的链接向前爬,直到它前面没有更多的链接,然后回到第一页,沿着另一个链接向前爬。
3、广度优先
广度优先是指当一个蜘蛛在一个页面上发现多个链接时,它不会一直跟踪一个链接,而是爬取页面上的所有链接,然后进入二级页面并跟踪在第二级找到的链接-level 爬到第三级页面。
理论上,无论是深度优先还是广度优先,只要给蜘蛛足够的时间,它们就可以爬取整个互联网。
在实际工作中,蜘蛛的带宽资源和时间不是无限的,也不是爬满所有的页面。其实最大的搜索引擎只是爬取和收录互联网的一小部分,当然不是搜索。引擎蜘蛛爬的越多越好,这点
因此,为了捕捉尽可能多的用户信息,通常会混合使用深度优先和广度优先,这样可以照顾到尽可能多的网站和网站的部分内页.
三、 搜索引擎蜘蛛工作中的信息采集
信息采集模块包括“蜘蛛控制”和“网络蜘蛛”两部分。“蜘蛛”这个名字形象地描述了信息采集模块在网络数据形成的“Web”上获取信息的功能。
一般来说,网络蜘蛛从种子网页开始,反复下载网页,寻找文档中没有见过的网址,以达到访问其他网页遍历网页的目的。
而其工作策略一般可分为累积爬行(cumulative crawling)和增量爬行(incremental crawling)两种。
1、累积爬行
累积爬取是指从某个时间点开始爬取系统可以允许存储和处理的所有网页。在理想的软硬件环境下,经过足够的运行时间,累积爬取策略可以保证可以爬取相当数量的网页集合。
似乎由于网络数据的动态性,采集到的网页的抓取时间不同,页面更新的情况也不同。因此,累积爬取所爬取的网页集合,实际上并不能和真实环境中的网络数据相比。始终如一。
2、增量爬取
与累积爬取不同,增量爬取是指对具有一定规模的网页集合,采用更新数据的方法,在现有集合中选择过时的网页进行爬取,保证爬取的数据与当前的数据足够接近。真实的网络数据。
增量爬取的前提是系统已经爬取了足够多的网页,并且有这些页面被爬取的时间信息。在面向实际应用环境的网络蜘蛛设计中,通常包括累积爬取和增量爬取两种策略。
累积爬取一般用于数据采集的整体建立或大规模更新阶段,而增量爬取主要用于数据采集的日常维护和实时更新。
确定爬取策略后,如何充分利用网络带宽,合理确定网页数据更新的时间点,成为网络蜘蛛运行策略的核心问题。
总的来说,在合理利用软硬件资源实时捕获网络数据方面,已经形成了比较成熟的技术和实用的解决方案。我觉得这方面需要解决的主要问题是如何更好地处理动态的网络数据问题(比如Web2.0数据越来越多等),更好地纠正基于网页质量的抓取策略。
四、数据库
为了避免重复抓取和抓取网址,搜索引擎会建立一个数据库来记录已发现未抓取的页面和已抓取的页面。那么数据库中的URL是怎么来的呢?
1、手动输入种子网站
简单来说就是我们新建网站后提交给百度、谷歌或者360的URL收录。
2、 蜘蛛抓取页面
如果搜索引擎蜘蛛在爬取过程中发现了一个新的连接网址,但它不在数据库中,则将其存储在数据库中以供访问(网站观察期)。
蜘蛛根据重要性从要访问的数据库中提取URL,访问并爬取页面,然后从要访问的地址数据库中删除该URL并将其放入访问地址数据库中,因此建议站长关注网站 期间需要定期更新网站。
3、站长提交网站
一般来说,提交网站只是将网站保存到要访问的数据库中。如果网站长时间不更新,蜘蛛就不会光顾了。搜索引擎收录的页面都是蜘蛛。自己通过链接获取它。
因此,如果您将其提交给搜索引擎,则它不是很有用。后期还是要考虑你的网站更新级别。搜索引擎更喜欢沿着链接发现新页面。当然,如果你的SEO功底高深,有能力试试这个能力,说不定会有意想不到的效果,但是对于一般的站长来说,还是建议让蜘蛛爬行,自然爬到新的站点页面。
五、吸引蜘蛛
虽然理论上说蜘蛛可以抓取所有页面,但实际上是不可能做到的。想要收录更多页面的SEO人员只能想办法引诱蜘蛛爬行。
既然它不能抓取所有的页面,那我们就得让它去抓取重要的页面,因为重要的页面在索引中起着重要的作用,直接影响排名因素。哪些页面更重要?对此,我还专门整理了以下我认为比较重要的页面,具体有这些特点:
1、网站 和页面权重
高质量和老的网站 被赋予了很高的权重。这个网站上的页面蜘蛛爬取深度比较高,所以更多的内页会是收录。
2、页面更新率
蜘蛛每次爬行时都会存储页面数据。如果在第二次爬取时发现这个页面的内容和第一个收录完全一样,说明该页面没有更新,蜘蛛不需要再频繁的爬取和爬取。
如果页面内容更新频繁,蜘蛛就会频繁爬行爬取,那么页面上的新链接自然会被蜘蛛更快地跟踪和抓取,这也是为什么需要每天更新的原因文章
3、导入链接
不管是外链还是同一个网站的内链,为了被蜘蛛爬取,必须有导入链接才能进入页面,否则蜘蛛不知道页面的存在. 这时候URL链接就发挥了非常重要的作用,内部链接的重要性就发挥出来了。
另外,我个人觉得高质量的入站链接往往会增加页面出站链接的抓取深度。
这也是为什么大部分站长或者SEO都需要高质量友情链接的原因,因为蜘蛛从对方网站向你网站爬了很多次,而且深度也很高。
怎样抓取网页数据(登录或注册用户后如何从Web获取Cookie?(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-11-08 03:13
)
xwpedram
我在unity3d和我的网站页面有注册和登录页面,当我将注册或登录数据从unity3d发布到我的网站 (magento cms) ,发送到我自己的错误“无法回滚必要的数据”,在HttpAnalyzer应用程序中看到我的请求后,我发现unity3d无法接受获取cookie字符串。登录或注册用户后如何从Web获取cookies?我的 unity3d 代码:
var form = new WWWForm();
form.AddField( "SN", SystemInfo.deviceUniqueIdentifier.ToString());
form.AddField( "UserName ", UserName );
form.AddField( "year",Year );
form.AddField( "month", Month );
form.AddField( "day", Day );
form.AddField( "dob",Year+"/"+Month+"/"+Day );
form.AddField( "gender", Gender );
form.AddField( "password", Pass );
// Create a download object
var download = new WWW(URL, form);
// Wait until the download is done
yield download;
// show the Results
Debug.Log(download.text);
if(download.error != null)
{
Debug.Log("Err :"+download.error);
Flag = "1";
}
2斤
当您尝试加载的页面被重定向时,通常会出现“必要的数据回滚”情况。我认为您不能使用“跟随重定向”选项在 Unity 中发出请求。
我不知道 Magentacms,所以我不能告诉你如何解决这个问题。关于cookies的问题,在Unity中这个很简单:你只需要从第一次调用中截取头“SET-COOKIE”,然后在下一次调用中发回标有“Cookie”的头:
#pragma strict
import System.Collections.Generic;
var url:String = "";
var cookie:String = "";
/// interface
private var stringToEdit:String = "";
function OnGUI(){
if (url!="" && GUI.Button(Rect(10,10,200,30),"Click"))
StartCoroutine(LoadData());
stringToEdit = GUI.TextArea (Rect (10, 50, 600, 400), stringToEdit);
}
/// debug
function Debug(s:String){
stringToEdit += s+"\n";
}
function LoadData():IEnumerator{
Debug(url);
var form : WWWForm = new WWWForm();
var time:String = System.DateTime.Now.Ticks.ToString();
form.AddField("time", time);
// construct your header calls
var headers : Hashtable = form.headers;
if(cookie!="")
headers["Cookie"] = cookie;
var www : WWW = new WWW(url, form.data, headers);
yield www;
if(!www.error){
Debug(www.text);
// get the cookie and keep it
if(www.responseHeaders.ContainsKey('SET-COOKIE')){
var data:String[] = www.responseHeaders['SET-COOKIE'].Split(";"[0]);
if(data.length>0){
cookie = data[0];
}
}
}else
Debug(www.error);
// debug
for(var header:KeyValuePair. in www.responseHeaders)
Debug(header.Key+" "+header.Value);
} 查看全部
怎样抓取网页数据(登录或注册用户后如何从Web获取Cookie?(图)
)
xwpedram
我在unity3d和我的网站页面有注册和登录页面,当我将注册或登录数据从unity3d发布到我的网站 (magento cms) ,发送到我自己的错误“无法回滚必要的数据”,在HttpAnalyzer应用程序中看到我的请求后,我发现unity3d无法接受获取cookie字符串。登录或注册用户后如何从Web获取cookies?我的 unity3d 代码:
var form = new WWWForm();
form.AddField( "SN", SystemInfo.deviceUniqueIdentifier.ToString());
form.AddField( "UserName ", UserName );
form.AddField( "year",Year );
form.AddField( "month", Month );
form.AddField( "day", Day );
form.AddField( "dob",Year+"/"+Month+"/"+Day );
form.AddField( "gender", Gender );
form.AddField( "password", Pass );
// Create a download object
var download = new WWW(URL, form);
// Wait until the download is done
yield download;
// show the Results
Debug.Log(download.text);
if(download.error != null)
{
Debug.Log("Err :"+download.error);
Flag = "1";
}
2斤
当您尝试加载的页面被重定向时,通常会出现“必要的数据回滚”情况。我认为您不能使用“跟随重定向”选项在 Unity 中发出请求。
我不知道 Magentacms,所以我不能告诉你如何解决这个问题。关于cookies的问题,在Unity中这个很简单:你只需要从第一次调用中截取头“SET-COOKIE”,然后在下一次调用中发回标有“Cookie”的头:
#pragma strict
import System.Collections.Generic;
var url:String = "";
var cookie:String = "";
/// interface
private var stringToEdit:String = "";
function OnGUI(){
if (url!="" && GUI.Button(Rect(10,10,200,30),"Click"))
StartCoroutine(LoadData());
stringToEdit = GUI.TextArea (Rect (10, 50, 600, 400), stringToEdit);
}
/// debug
function Debug(s:String){
stringToEdit += s+"\n";
}
function LoadData():IEnumerator{
Debug(url);
var form : WWWForm = new WWWForm();
var time:String = System.DateTime.Now.Ticks.ToString();
form.AddField("time", time);
// construct your header calls
var headers : Hashtable = form.headers;
if(cookie!="")
headers["Cookie"] = cookie;
var www : WWW = new WWW(url, form.data, headers);
yield www;
if(!www.error){
Debug(www.text);
// get the cookie and keep it
if(www.responseHeaders.ContainsKey('SET-COOKIE')){
var data:String[] = www.responseHeaders['SET-COOKIE'].Split(";"[0]);
if(data.length>0){
cookie = data[0];
}
}
}else
Debug(www.error);
// debug
for(var header:KeyValuePair. in www.responseHeaders)
Debug(header.Key+" "+header.Value);
}
怎样抓取网页数据(HTML是无法读取数据库的,HTML页面前端脚本语言的组成)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2021-11-07 07:08
HTML 无法读取数据库。HTML 是页面的前端脚本语言。如果要从 HTML 页面中获取 SQL 数据库中的数据,则需要使用 JSP 或 ASP 或 PHP 或 RUBY 等语言。
SQL数据库的数据体系结构基本上是三级结构,但使用的术语与传统的关系模型不同。在SQL中,关系模式(mode)被称为“基表”;存储方式(内部方式)称为“存储文件”;子模式(外部模式)称为“视图”(view);元组被称为“行”;属性称为“列”。
扩展信息
SQL语言的组成:
1、SQL 数据库是由一个或多个 SQL 模式定义的表的集合。
2、SQL 表由一组行组成。行是列的序列(集),每一列和每一行对应一个数据项。
3、表要么是基本表,要么是视图。基本表是数据库中实际存储的表,视图是由若干基本表或其他视图组成的表的定义。
4.一个基本表可以跨越一个或多个存储文件,一个存储文件也可以存储一个或多个基本表。每个存储文件对应于外部存储上的一个物理文件。
5.用户可以使用SQL语句查询视图和基本表。从用户的角度来看,视图和基本表是一样的,没有区别,都是关系(表)。
6.SQL 用户可以是应用程序或最终用户。SQL 语句可以嵌入宿主语言程序中使用,例如FORTRAN、COBOL 和Ada 语言。 查看全部
怎样抓取网页数据(HTML是无法读取数据库的,HTML页面前端脚本语言的组成)
HTML 无法读取数据库。HTML 是页面的前端脚本语言。如果要从 HTML 页面中获取 SQL 数据库中的数据,则需要使用 JSP 或 ASP 或 PHP 或 RUBY 等语言。
SQL数据库的数据体系结构基本上是三级结构,但使用的术语与传统的关系模型不同。在SQL中,关系模式(mode)被称为“基表”;存储方式(内部方式)称为“存储文件”;子模式(外部模式)称为“视图”(view);元组被称为“行”;属性称为“列”。
扩展信息
SQL语言的组成:
1、SQL 数据库是由一个或多个 SQL 模式定义的表的集合。
2、SQL 表由一组行组成。行是列的序列(集),每一列和每一行对应一个数据项。
3、表要么是基本表,要么是视图。基本表是数据库中实际存储的表,视图是由若干基本表或其他视图组成的表的定义。
4.一个基本表可以跨越一个或多个存储文件,一个存储文件也可以存储一个或多个基本表。每个存储文件对应于外部存储上的一个物理文件。
5.用户可以使用SQL语句查询视图和基本表。从用户的角度来看,视图和基本表是一样的,没有区别,都是关系(表)。
6.SQL 用户可以是应用程序或最终用户。SQL 语句可以嵌入宿主语言程序中使用,例如FORTRAN、COBOL 和Ada 语言。
怎样抓取网页数据(你好~网页快照,英文名叫,网页缓存百度快照是什么意思)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-11-06 22:15
你好~
网页快照,英文名称是Web Cache,百度快照对网页缓存的意义。当搜索引擎在 收录 网页上时,它会备份网页并将其存储在自己的服务器缓存中。当用户在搜索引擎中点击“网页快照”链接时,搜索引擎会通过Spider系统检索并保存当时网页显示的内容,称为“网页快照”。
影响:
Internet 上的网页经常更改。当搜索到的网页被删除或有死链接时,您无法通过点击链接直接查看网页内容。此时,您可以使用网页快照查看该网页的原创内容。比如你的一些网站贴了一些文章,网站就不能再访问了,用户可以在搜索中搜索关键词@的文章引擎>,然后以快照的形式访问备份文章的内容另外,网页快照可以直接从搜索引擎数据库的存储中检索网页的存档文件,无需实际连接到网页网站,因为是访问搜索引擎的数据库,这种方法比直接访问它所在的站点更安全。可以避免网页中嵌入的木马和病毒的威胁;阅读网页的速度通常更快
百度快照是怎么回事,求解决~~
以下是百度官网给出的百度快照信息:
长期以来,一些站长对百度快照的更新时间存在误解,认为网站的快照更新时间与网站的权重状态有一定关系。快照更新越频繁,越频繁网站权重越高,反之越低。
实际上,网站 快照的更新频率和权重并没有直接关系。
百度快照为什么要更新?
首先需要明确的是,网页抓取频率和快照更新频率是两个完全不同的概念。
对于百度发布的每个网站收录,baiduspider 都会根据其网站 内容更新的频率不断检查新网页。正常情况下,百度蜘蛛的抓取频率会和网站一样。@网站生成新内容的速度是一致的。一般来说,更新是指百度蜘蛛对网页内容的抓取。
对于每个新爬取或新检查的网页,我们会根据其重要性和时效性以不同的速度创建索引。一般来说,快照更新时间指的是索引时间,一些重要的内容更新频繁。网页,我们会更快地建立索引。如果一个网页只是一般的文字变化或者内容没有时效价值,那么搜索引擎不一定会认为它具有快速更新索引的价值。即使百度蜘蛛重新抓取网页内容,其快照也可能无法快速更新。,但这并不代表不重要或者百度的更新速度很慢。
为什么快照时间会倒退?
一个重要网页的快照往往会在搜索引擎数据库中保存多个网页快照,而这些快照的捕获时间是不一样的。在一些非常特殊的情况下,搜索引擎系统可能会在当前搜索结果中选择不同版本的快照,导致快照时间倒退。这对网站在搜索引擎中的性能没有影响,并不意味着搜索引擎降低了网站的权限。
综上所述,快照的更新与页面上是否有重要的新内容有直接关系,但与网站本身的“权重”和是否“Ked”没有直接关系。站长无需过多关注网站的快照时间。我们建议站长专注于网站的内容建设。只有提升网站的内容价值和检索体验,才能得到用户和搜索引擎的信任。 查看全部
怎样抓取网页数据(你好~网页快照,英文名叫,网页缓存百度快照是什么意思)
你好~
网页快照,英文名称是Web Cache,百度快照对网页缓存的意义。当搜索引擎在 收录 网页上时,它会备份网页并将其存储在自己的服务器缓存中。当用户在搜索引擎中点击“网页快照”链接时,搜索引擎会通过Spider系统检索并保存当时网页显示的内容,称为“网页快照”。
影响:
Internet 上的网页经常更改。当搜索到的网页被删除或有死链接时,您无法通过点击链接直接查看网页内容。此时,您可以使用网页快照查看该网页的原创内容。比如你的一些网站贴了一些文章,网站就不能再访问了,用户可以在搜索中搜索关键词@的文章引擎>,然后以快照的形式访问备份文章的内容另外,网页快照可以直接从搜索引擎数据库的存储中检索网页的存档文件,无需实际连接到网页网站,因为是访问搜索引擎的数据库,这种方法比直接访问它所在的站点更安全。可以避免网页中嵌入的木马和病毒的威胁;阅读网页的速度通常更快
百度快照是怎么回事,求解决~~
以下是百度官网给出的百度快照信息:
长期以来,一些站长对百度快照的更新时间存在误解,认为网站的快照更新时间与网站的权重状态有一定关系。快照更新越频繁,越频繁网站权重越高,反之越低。
实际上,网站 快照的更新频率和权重并没有直接关系。
百度快照为什么要更新?
首先需要明确的是,网页抓取频率和快照更新频率是两个完全不同的概念。
对于百度发布的每个网站收录,baiduspider 都会根据其网站 内容更新的频率不断检查新网页。正常情况下,百度蜘蛛的抓取频率会和网站一样。@网站生成新内容的速度是一致的。一般来说,更新是指百度蜘蛛对网页内容的抓取。
对于每个新爬取或新检查的网页,我们会根据其重要性和时效性以不同的速度创建索引。一般来说,快照更新时间指的是索引时间,一些重要的内容更新频繁。网页,我们会更快地建立索引。如果一个网页只是一般的文字变化或者内容没有时效价值,那么搜索引擎不一定会认为它具有快速更新索引的价值。即使百度蜘蛛重新抓取网页内容,其快照也可能无法快速更新。,但这并不代表不重要或者百度的更新速度很慢。
为什么快照时间会倒退?
一个重要网页的快照往往会在搜索引擎数据库中保存多个网页快照,而这些快照的捕获时间是不一样的。在一些非常特殊的情况下,搜索引擎系统可能会在当前搜索结果中选择不同版本的快照,导致快照时间倒退。这对网站在搜索引擎中的性能没有影响,并不意味着搜索引擎降低了网站的权限。
综上所述,快照的更新与页面上是否有重要的新内容有直接关系,但与网站本身的“权重”和是否“Ked”没有直接关系。站长无需过多关注网站的快照时间。我们建议站长专注于网站的内容建设。只有提升网站的内容价值和检索体验,才能得到用户和搜索引擎的信任。
怎样抓取网页数据(有关webscraper抓取网页数据的几个常见问题的相关资料)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-11-05 18:17
摘要 今天小编就为大家讲解一下网络爬虫抓取网页数据的几个常见问题。我相信你应该关注这个话题。小编也搜集了相关的网站。
今天小编就为大家讲解一下网络爬虫抓取网页数据的一些常见问题。我相信你应该关注这个话题。我还采集了几个关于网络爬虫抓取网页数据的常见问题。我希望我的朋友会觉得它有帮助。
如果你想抓取数据又懒得写代码,可以试试网络爬虫抓取数据。
如果您使用网络爬虫抓取数据,您很可能会遇到以下一个或多个问题,这些问题可能会直接打乱您的计划,甚至让您放弃网络爬虫。
以下是您可能会遇到的一些问题并解释解决方案。
1、有时候我们想选择一个链接但是鼠标点击会触发页面跳转。如何处理?
当我们选择页面元素时,勾选“启用键”,然后将鼠标移动到要选择的元素并按S键。
另外,勾选“启用键”后,会出现三个字母,分别是S、P、C。按S选择当前元素。按 P 选择当前元素的父元素。按 C 选择当前元素的子元素。当前元素是指鼠标。元素所在的位置。
2、 分页数据或滚动加载的数据无法完全抓取,如知乎 和推特等。
出现这种问题多是因为网络问题,数据在加载网页爬虫之前就开始解析数据,但是因为网页爬虫没有及时加载,导致网页爬虫误认为爬虫已经完成。
因此,适当增加延迟大小以延长等待时间,使数据有足够的时间加载。默认延迟2000,也就是2秒,可以根据网速调整。
但是当数据量比较大的时候,不完整的数据抓取也很常见。因为只要在延迟时间内没有完成翻页或者下拉加载,那么爬取就结束了。
3、抓取数据的顺序与网页上的顺序不一致
默认情况下,网络抓取工具出现故障。可以安装CouchDB来保证数据的顺序。
或者使用其他替代方法,我们最终将数据导出为 CSV 格式。在 Excel 中打开 CSV 后,可以按特定列进行排序。比如我们抓取微博数据的时候,我们可以抓取发布时间,然后在Excel中按照发布时间进行排序或者知乎上的数据按照点赞数排序。
4、有些页面元素无法通过网络爬虫提供的选择器选择
出现这种情况的原因可能是网站页面本身不符合页面布局规范或者你想要的数据是动态的,比如鼠标悬停时会显示的元素等等,你需要在这些情况下诉诸其他方法。
其实鼠标操作选择一个元素的最终目的是找到该元素对应的xpath。Xpath对应网页来说明定位元素的路径是通过元素的类型、唯一标识符、样式名称和从属关系来找到一个元素或某种类型的元素。
如果你没有遇到过这个问题,就没有必要学习xpath了。
这里只列举几个在使用网络爬虫过程中常见的问题。如果遇到其他问题,可以在文章下留言。 查看全部
怎样抓取网页数据(有关webscraper抓取网页数据的几个常见问题的相关资料)
摘要 今天小编就为大家讲解一下网络爬虫抓取网页数据的几个常见问题。我相信你应该关注这个话题。小编也搜集了相关的网站。
今天小编就为大家讲解一下网络爬虫抓取网页数据的一些常见问题。我相信你应该关注这个话题。我还采集了几个关于网络爬虫抓取网页数据的常见问题。我希望我的朋友会觉得它有帮助。
如果你想抓取数据又懒得写代码,可以试试网络爬虫抓取数据。
如果您使用网络爬虫抓取数据,您很可能会遇到以下一个或多个问题,这些问题可能会直接打乱您的计划,甚至让您放弃网络爬虫。
以下是您可能会遇到的一些问题并解释解决方案。
1、有时候我们想选择一个链接但是鼠标点击会触发页面跳转。如何处理?
当我们选择页面元素时,勾选“启用键”,然后将鼠标移动到要选择的元素并按S键。
另外,勾选“启用键”后,会出现三个字母,分别是S、P、C。按S选择当前元素。按 P 选择当前元素的父元素。按 C 选择当前元素的子元素。当前元素是指鼠标。元素所在的位置。
2、 分页数据或滚动加载的数据无法完全抓取,如知乎 和推特等。
出现这种问题多是因为网络问题,数据在加载网页爬虫之前就开始解析数据,但是因为网页爬虫没有及时加载,导致网页爬虫误认为爬虫已经完成。
因此,适当增加延迟大小以延长等待时间,使数据有足够的时间加载。默认延迟2000,也就是2秒,可以根据网速调整。
但是当数据量比较大的时候,不完整的数据抓取也很常见。因为只要在延迟时间内没有完成翻页或者下拉加载,那么爬取就结束了。
3、抓取数据的顺序与网页上的顺序不一致
默认情况下,网络抓取工具出现故障。可以安装CouchDB来保证数据的顺序。
或者使用其他替代方法,我们最终将数据导出为 CSV 格式。在 Excel 中打开 CSV 后,可以按特定列进行排序。比如我们抓取微博数据的时候,我们可以抓取发布时间,然后在Excel中按照发布时间进行排序或者知乎上的数据按照点赞数排序。
4、有些页面元素无法通过网络爬虫提供的选择器选择
出现这种情况的原因可能是网站页面本身不符合页面布局规范或者你想要的数据是动态的,比如鼠标悬停时会显示的元素等等,你需要在这些情况下诉诸其他方法。
其实鼠标操作选择一个元素的最终目的是找到该元素对应的xpath。Xpath对应网页来说明定位元素的路径是通过元素的类型、唯一标识符、样式名称和从属关系来找到一个元素或某种类型的元素。
如果你没有遇到过这个问题,就没有必要学习xpath了。
这里只列举几个在使用网络爬虫过程中常见的问题。如果遇到其他问题,可以在文章下留言。
怎样抓取网页数据(程序中检索实时数据语法RTD(ProgID,)函数 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-11-05 03:25
)
从支持 COM 自动化的程序中检索实时数据
语法
RTD(ProgID, server, topic1, [topic2], ...)
RTD 函数语法具有以下参数:
程序 ID:必需。已安装在本地计算机上的已注册 COM 自动化加载项 ProgID 的名称。将名称括在引号中。
服务器:需要。加载项应在其上运行的服务器的名称。如果没有服务器,则在本地运行该程序并将此参数留空。否则输
将服务器名称用引号 ("") 括起来。在 Visual Basic for Applications (VBA) 中使用 RTD 时,服务器需要双引号或
即使在本地运行服务器时,VBANullstring 属性也不例外。
Topic1, topic2, ...:Topic1 为必填项,后续topics 为选填项。1 到 253 个参数,这些参数共同代表一个独特的
实时数据。
阐明
必须在本地计算机上创建和注册 RTD COM 自动化加载项。
如果未安装实时数据服务器,当您尝试使用 RTD 功能时,单元格中将出现错误消息。
如果服务器继续更新结果,与其他函数不同,当 Microsoft Excel 处于自动计算模式时,RTD 公式会发生变化。
RTD函数的作用是实现来自COM的实时数据,大大扩展了Excel与外部程序之间信息交换的目的。
此功能常用于制作自动更新的股票信息表。使用该功能需要注意的是:
RTD COM 自动化插件必须在本地计算机上创建并注册;如果未安装实时数据服务器,将返回错误值。
具体方法和步骤如下:
成功创建自动加载项后,我们可以使用此功能引用数据,然后我们将在此表中显示
使用各个功能的具体步骤:
选择单元格U14,点击插入函数,在搜索框中搜索并找到RTD函数,点击确定;
我们在 prog ID 中输入创建的加载项信息:rtdvb6.stock;
服务器未满;
题目填写股票代码SZ002200,双引号;
点击确定完成参考~
查看全部
怎样抓取网页数据(程序中检索实时数据语法RTD(ProgID,)函数
)
从支持 COM 自动化的程序中检索实时数据
语法
RTD(ProgID, server, topic1, [topic2], ...)
RTD 函数语法具有以下参数:
程序 ID:必需。已安装在本地计算机上的已注册 COM 自动化加载项 ProgID 的名称。将名称括在引号中。
服务器:需要。加载项应在其上运行的服务器的名称。如果没有服务器,则在本地运行该程序并将此参数留空。否则输
将服务器名称用引号 ("") 括起来。在 Visual Basic for Applications (VBA) 中使用 RTD 时,服务器需要双引号或
即使在本地运行服务器时,VBANullstring 属性也不例外。
Topic1, topic2, ...:Topic1 为必填项,后续topics 为选填项。1 到 253 个参数,这些参数共同代表一个独特的
实时数据。
阐明
必须在本地计算机上创建和注册 RTD COM 自动化加载项。
如果未安装实时数据服务器,当您尝试使用 RTD 功能时,单元格中将出现错误消息。
如果服务器继续更新结果,与其他函数不同,当 Microsoft Excel 处于自动计算模式时,RTD 公式会发生变化。
RTD函数的作用是实现来自COM的实时数据,大大扩展了Excel与外部程序之间信息交换的目的。
此功能常用于制作自动更新的股票信息表。使用该功能需要注意的是:
RTD COM 自动化插件必须在本地计算机上创建并注册;如果未安装实时数据服务器,将返回错误值。
具体方法和步骤如下:
成功创建自动加载项后,我们可以使用此功能引用数据,然后我们将在此表中显示
使用各个功能的具体步骤:
选择单元格U14,点击插入函数,在搜索框中搜索并找到RTD函数,点击确定;
我们在 prog ID 中输入创建的加载项信息:rtdvb6.stock;
服务器未满;
题目填写股票代码SZ002200,双引号;
点击确定完成参考~
怎样抓取网页数据(百度收录的最新方法,2021年百度没收录,没流量怎么办)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-10-30 00:18
百度收录的最新方法。最近很多朋友跟我说百度没有收录,没有排名,没有流量,怎么办?2021年百度收录应该怎么做?一起来看看百度官方的说法吧!!!!
网站 BA 是基本门槛吗?(百度官方回答)
是的,网站BA 是一个比较重要的信息。建站后建议您根据国家法律法规的要求及时申请BA。
做百度,先得BA。BA已经成为基础门槛,所以后期,网站和收录哪个会越来越难!
网页打开速度重要吗?(百度官方回答)
网页打开速度影响两点。首先是用户访问网页的体验。搜索引擎的目的是更好地满足搜索用户的体验,但是你从一开始就让用户访问你。网站很难改变。此前,百度的同学也提到,打开速度超过3秒的手机网页直接被归类为垃圾网页。可想而知,即使你有最好的内容,用户访问造成困难,是不是太值得了。
第二点是爬虫爬行。如果打开速度慢,履带式爬行困难。从搜索引擎的角度来看,爬虫也是一种程序运行。当一个程序在你身上运行时,打开一个网页需要 1 秒钟,但在其他人身上运行只需要 100 毫秒。放开我,他们是你的十分之一。而且你已经占用了爬虫本可以爬取的资源,成为一个网页来爬取你这个。也就是说,我也会调整你网站的抓取量,以节省资源,抓取更多网页。爬行越少,收录的几率就更小了。没有了收录,排名和流量呢?
所以一个网站的打开速度尤为重要。网站开启越快,内容创作越多,蜘蛛爬取量越大,收录速度越快。网站卡,少抢,收录机会肯定更小
Q:PC端和手机端的优化有区别吗?
答:PC 和手机对高质量内容的标准相同。
百度是怎么做收录的?首先内容质量要好(百度官方解答)
1、综合资料
当主要内容高度依赖图片(如食谱、手工制作、急救技巧等)时,需要保证每一步都有对应的图片,避免用户操作失误。
2、出色的视觉效果
(1)画质高清,配色靓丽,给用户带来极佳的视觉享受;
(2)图片的logo、马赛克等杂质比例不能太大;图片水印可以清晰区分,但不能影响用户对主要内容的浏览;
(3)图片的类型、格式、大小要一致,主题风格要一致,给用户一种一体感,不能有重复或无效的图片。
百度喜欢原创文章。很多朋友无法每天一次创建很多文章,所以大家都会使用伪原创工具。一个好的伪原创工具也很重要。
如何选择普通收录方式(百度官方解答)
API推送:最快的提交方式。建议您立即通过此方式将本站产生的新链接推送给百度,以确保百度能及时收到新链接收录。
站点地图:您可以定期在站点地图中放置网站链接,然后将站点地图提交给百度。百度会定期抓取检查您提交的Sitemap,并处理其中的链接,但收录的速度比API push要慢。
手动提交:如果不想通过程序提交,可以使用这种方式手动提交链接到百度。
自动推送:轻量级链接提交组件将自动推送的JS代码放置在站点每个页面的源代码中。访问页面时,页面链接会自动推送到百度,有利于百度更快发现新页面。
使用API推送功能会有什么效果
及时发现:可以缩短百度爬虫发现您网站新链接的时间,第一时间将新发布的页面提供给百度收录
保护原创:对于网站的最新原创内容,使用API推送功能快速通知百度,让百度发现内容后再转发
如果你想在百度做得好收录,你必须主动提交给搜索引擎。主动向搜索引擎提交链接,增加蜘蛛爬行的频率。让您的网站更快收录。
对于那些网站的人来说,必须使用SEO工具。
关于网站流程
先说一个概念,叫做“有效内容输出”。不管是我的学生、客户还是业内的朋友,一直都在问一些问题。它们都变相反映了一个问题,即为了创造内容而盲目创造内容。但是有多少人认为您创建的内容实际上是在搜索引擎上搜索的?如果没有搜索,即使排名再好,能带来流量吗?因此,产生有效的内容非常重要。我们可以使用挖词工具、数据分析工具、网站搜索等,清晰捕捉用户需求,并根据衡量有效性的标准创建内容。
解决上期朋友咨询的问题
百度对新站的调查,有什么需要注意的吗?
一是查看站点的BA信息是否齐全,二是站点内容是否丰富优质。如果网站内容质量很高,但没有通过收录或搜索显示,则需要进一步反馈问题寻求帮助。
文章 插入短广告会被抑制吗?
文章 坚决不允许在中间插入任何广告。如果要插入广告,可以在文章的body结尾后插入广告,不影响用户体验。
内容更新的频率是否必须固定?如果我这个月每周更新一个文章,但下个月我更新一个文章,这样可以吗?
答:可以,只要您保持账号活跃,内容持续更新,满足用户的内容需求。但是,如果有的开发者一年更新一次或者不更新,就会影响用户体验。 查看全部
怎样抓取网页数据(百度收录的最新方法,2021年百度没收录,没流量怎么办)
百度收录的最新方法。最近很多朋友跟我说百度没有收录,没有排名,没有流量,怎么办?2021年百度收录应该怎么做?一起来看看百度官方的说法吧!!!!
网站 BA 是基本门槛吗?(百度官方回答)
是的,网站BA 是一个比较重要的信息。建站后建议您根据国家法律法规的要求及时申请BA。
做百度,先得BA。BA已经成为基础门槛,所以后期,网站和收录哪个会越来越难!
网页打开速度重要吗?(百度官方回答)
网页打开速度影响两点。首先是用户访问网页的体验。搜索引擎的目的是更好地满足搜索用户的体验,但是你从一开始就让用户访问你。网站很难改变。此前,百度的同学也提到,打开速度超过3秒的手机网页直接被归类为垃圾网页。可想而知,即使你有最好的内容,用户访问造成困难,是不是太值得了。
第二点是爬虫爬行。如果打开速度慢,履带式爬行困难。从搜索引擎的角度来看,爬虫也是一种程序运行。当一个程序在你身上运行时,打开一个网页需要 1 秒钟,但在其他人身上运行只需要 100 毫秒。放开我,他们是你的十分之一。而且你已经占用了爬虫本可以爬取的资源,成为一个网页来爬取你这个。也就是说,我也会调整你网站的抓取量,以节省资源,抓取更多网页。爬行越少,收录的几率就更小了。没有了收录,排名和流量呢?
所以一个网站的打开速度尤为重要。网站开启越快,内容创作越多,蜘蛛爬取量越大,收录速度越快。网站卡,少抢,收录机会肯定更小
Q:PC端和手机端的优化有区别吗?
答:PC 和手机对高质量内容的标准相同。
百度是怎么做收录的?首先内容质量要好(百度官方解答)
1、综合资料
当主要内容高度依赖图片(如食谱、手工制作、急救技巧等)时,需要保证每一步都有对应的图片,避免用户操作失误。
2、出色的视觉效果
(1)画质高清,配色靓丽,给用户带来极佳的视觉享受;
(2)图片的logo、马赛克等杂质比例不能太大;图片水印可以清晰区分,但不能影响用户对主要内容的浏览;
(3)图片的类型、格式、大小要一致,主题风格要一致,给用户一种一体感,不能有重复或无效的图片。
百度喜欢原创文章。很多朋友无法每天一次创建很多文章,所以大家都会使用伪原创工具。一个好的伪原创工具也很重要。
如何选择普通收录方式(百度官方解答)
API推送:最快的提交方式。建议您立即通过此方式将本站产生的新链接推送给百度,以确保百度能及时收到新链接收录。
站点地图:您可以定期在站点地图中放置网站链接,然后将站点地图提交给百度。百度会定期抓取检查您提交的Sitemap,并处理其中的链接,但收录的速度比API push要慢。
手动提交:如果不想通过程序提交,可以使用这种方式手动提交链接到百度。
自动推送:轻量级链接提交组件将自动推送的JS代码放置在站点每个页面的源代码中。访问页面时,页面链接会自动推送到百度,有利于百度更快发现新页面。
使用API推送功能会有什么效果
及时发现:可以缩短百度爬虫发现您网站新链接的时间,第一时间将新发布的页面提供给百度收录
保护原创:对于网站的最新原创内容,使用API推送功能快速通知百度,让百度发现内容后再转发
如果你想在百度做得好收录,你必须主动提交给搜索引擎。主动向搜索引擎提交链接,增加蜘蛛爬行的频率。让您的网站更快收录。
对于那些网站的人来说,必须使用SEO工具。
关于网站流程
先说一个概念,叫做“有效内容输出”。不管是我的学生、客户还是业内的朋友,一直都在问一些问题。它们都变相反映了一个问题,即为了创造内容而盲目创造内容。但是有多少人认为您创建的内容实际上是在搜索引擎上搜索的?如果没有搜索,即使排名再好,能带来流量吗?因此,产生有效的内容非常重要。我们可以使用挖词工具、数据分析工具、网站搜索等,清晰捕捉用户需求,并根据衡量有效性的标准创建内容。
解决上期朋友咨询的问题
百度对新站的调查,有什么需要注意的吗?
一是查看站点的BA信息是否齐全,二是站点内容是否丰富优质。如果网站内容质量很高,但没有通过收录或搜索显示,则需要进一步反馈问题寻求帮助。
文章 插入短广告会被抑制吗?
文章 坚决不允许在中间插入任何广告。如果要插入广告,可以在文章的body结尾后插入广告,不影响用户体验。
内容更新的频率是否必须固定?如果我这个月每周更新一个文章,但下个月我更新一个文章,这样可以吗?
答:可以,只要您保持账号活跃,内容持续更新,满足用户的内容需求。但是,如果有的开发者一年更新一次或者不更新,就会影响用户体验。
怎样抓取网页数据(如何使用网络请求获取福大就业信息网上的内容做一个 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-10-27 02:08
)
这里简单记录一下如何利用互联网请求访问福达就业信息网的内容。
一、分析策略1、找到网络请求的URL
我们需要从福州大学就业信息网获取数据,打开网页,进入Safari开发模式,查看页面资源,发现XHR中的“getDateZPHKeynoteList_month”是需要的json,复制链接获取网络请求网址:“”
2、查找网络请求参数
为了获取当月的校招日历,需要在请求网络时附加参数,否则返回的数据将为空。由于本人对web开发不是很熟悉,找了好久才找到这个参数。最后在calendar.js文件中找到了切换月份的相关调用,得到了网络请求需要的参数dateday,格式为YYYY/MM。
二、 具体实现
这部分比较简单,就是利用Alamofire的request进行网络请求,然后解析返回的json即可。
func getCalendar(_ completion: @escaping (Error?, JSON?) -> ()) {
let url = "http://jycy.fzu.edu.cn/CmsInte ... ot%3B
let nowTime = NSDate()
let format = DateFormatter()
format.dateFormat = "YYYY/MM"
let dateday = format.string(from: nowTime as Date) as String
let parameters = ["dateday":dateday]
AF.request(url,method: .get,parameters: parameters)
.responseJSON { responds in
switch responds.result {
case .success(let value):
print("success")
let json = JSON(value)
print(json)
completion(nil, json)
case .failure(let error):
print("error")
completion(error, nil)
}
}
} 查看全部
怎样抓取网页数据(如何使用网络请求获取福大就业信息网上的内容做一个
)
这里简单记录一下如何利用互联网请求访问福达就业信息网的内容。
一、分析策略1、找到网络请求的URL
我们需要从福州大学就业信息网获取数据,打开网页,进入Safari开发模式,查看页面资源,发现XHR中的“getDateZPHKeynoteList_month”是需要的json,复制链接获取网络请求网址:“”
2、查找网络请求参数
为了获取当月的校招日历,需要在请求网络时附加参数,否则返回的数据将为空。由于本人对web开发不是很熟悉,找了好久才找到这个参数。最后在calendar.js文件中找到了切换月份的相关调用,得到了网络请求需要的参数dateday,格式为YYYY/MM。
二、 具体实现
这部分比较简单,就是利用Alamofire的request进行网络请求,然后解析返回的json即可。
func getCalendar(_ completion: @escaping (Error?, JSON?) -> ()) {
let url = "http://jycy.fzu.edu.cn/CmsInte ... ot%3B
let nowTime = NSDate()
let format = DateFormatter()
format.dateFormat = "YYYY/MM"
let dateday = format.string(from: nowTime as Date) as String
let parameters = ["dateday":dateday]
AF.request(url,method: .get,parameters: parameters)
.responseJSON { responds in
switch responds.result {
case .success(let value):
print("success")
let json = JSON(value)
print(json)
completion(nil, json)
case .failure(let error):
print("error")
completion(error, nil)
}
}
}
怎样抓取网页数据(提高网站百度蜘蛛抓取量之前的方法有哪些问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-10-24 12:15
在SEO优化工作中,我们会适当增加百度蜘蛛对网站的抓取,有助于增加网站内容收录的数量,从而进一步提升排名。这也是每个网站运营经理必须思考的问题。那么,在增加网站百度蜘蛛的抓取量之前,我们必须考虑的问题之一是:提高网站打开速度。确保页面打开速度符合百度标准要求,让百度蜘蛛顺利抓取每个页面,
为此,我们可能需要:精简网站程序代码,配置CDN加速,或者百度MIP等。定期清理网站多余的数据库信息等。压缩网站图片,特别是菜谱和美食< @网站。
为了增加百度蜘蛛的抓取量,我们可以增加页面更新频率,持续输出满足用户搜索需求的原创有价值的内容,有助于提升搜索引擎对优质内容的偏好。在网页侧边栏,调用“随机文章”标签,有助于增加
保持页面的新鲜度,页面继续出现过去没有出现过的收录,但被认为是新内容的文章。
合理利用有一定排名的老页面,其中适当增加一些内链,指向新的文章,在满足一定数量的基础上,有利于传递权重,提高百度的爬虫能力蜘蛛。
大量的外链,从搜索引擎的角度来看,是权威的、相关的、权重很高的外链。它与外部投票和推荐有关。如果您有每个版块页面,您将在一定时间内继续获取这些链接。搜索引擎会认为这些板块页面的内容值得抓取,从而增加百度蜘蛛的访问量。向百度提交链接,通过主动向百度提交新链接,也可以实现目标网址被爬取的机会。
百度蜘蛛池的创建是为了每天批量更新这些网站的内容,以吸引百度蜘蛛访问这些网站。利用网站中的这些“内链”指向需要抓取的目标网址,从而增加目标网站的数量,百度蜘蛛抓取。
向日葵SEO优化提出网站优化增加百度蜘蛛爬取次数,首先要保证页面速度,其次可以使用的相关策略,如上所述,基本可以满足爬取要求一般网站。 查看全部
怎样抓取网页数据(提高网站百度蜘蛛抓取量之前的方法有哪些问题)
在SEO优化工作中,我们会适当增加百度蜘蛛对网站的抓取,有助于增加网站内容收录的数量,从而进一步提升排名。这也是每个网站运营经理必须思考的问题。那么,在增加网站百度蜘蛛的抓取量之前,我们必须考虑的问题之一是:提高网站打开速度。确保页面打开速度符合百度标准要求,让百度蜘蛛顺利抓取每个页面,
为此,我们可能需要:精简网站程序代码,配置CDN加速,或者百度MIP等。定期清理网站多余的数据库信息等。压缩网站图片,特别是菜谱和美食< @网站。
为了增加百度蜘蛛的抓取量,我们可以增加页面更新频率,持续输出满足用户搜索需求的原创有价值的内容,有助于提升搜索引擎对优质内容的偏好。在网页侧边栏,调用“随机文章”标签,有助于增加
保持页面的新鲜度,页面继续出现过去没有出现过的收录,但被认为是新内容的文章。
合理利用有一定排名的老页面,其中适当增加一些内链,指向新的文章,在满足一定数量的基础上,有利于传递权重,提高百度的爬虫能力蜘蛛。
大量的外链,从搜索引擎的角度来看,是权威的、相关的、权重很高的外链。它与外部投票和推荐有关。如果您有每个版块页面,您将在一定时间内继续获取这些链接。搜索引擎会认为这些板块页面的内容值得抓取,从而增加百度蜘蛛的访问量。向百度提交链接,通过主动向百度提交新链接,也可以实现目标网址被爬取的机会。
百度蜘蛛池的创建是为了每天批量更新这些网站的内容,以吸引百度蜘蛛访问这些网站。利用网站中的这些“内链”指向需要抓取的目标网址,从而增加目标网站的数量,百度蜘蛛抓取。
向日葵SEO优化提出网站优化增加百度蜘蛛爬取次数,首先要保证页面速度,其次可以使用的相关策略,如上所述,基本可以满足爬取要求一般网站。
怎样抓取网页数据(百恒网络SEO专员对网页的抓取)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-10-24 08:05
搜索引擎对网页的抓取,其实就是互联网上的数据采集,这是搜索引擎最基本的工作。搜索引擎数据采集的能力直接决定了搜索引擎能够提供的信息量和互联网覆盖范围,进而影响搜索引擎查询结果的质量。因此,搜索引擎总是试图提高他们的数据采集能力。搜索引擎使用数据采集程序抓取互联网上的数据。我们称这些数据采集 程序为蜘蛛程序或机器人程序。
本文首先介绍了搜索引擎抓取页面的过程和方法,然后介绍了搜索引擎抓取页面的存储和维护方法。
1. 页面爬取过程
在互联网中,URL是每个页面的入口地址,搜索引擎蜘蛛通过URL爬取到该页面。搜索引擎蜘蛛程序从原创URL列表开始,通过URL抓取并存储原创页面;同时,提取原创页面中的URL资源并添加到URL列表中。这样一个连续的循环,就可以从互联网上获取到足够多的页面,如图。
图搜索引擎抓取页面简单流程
URL是页面的入口,域名是网站的入口。搜索引擎蜘蛛程序通过域名输入网站开始对网站页面的抓取。换句话说,搜索引擎抓取互联网页面的首要任务是建立一个足够大的原创域名列表,然后通过域名输入对应的网站,从而抓取这个页面网站。
对于网站,如果你想被搜索引擎收录搜索到,第一个条件是加入搜索引擎的域名列表。下面,百恒网SEO专家为大家介绍两种常见的加入搜索引擎域名列表的方式。
首先,使用搜索引擎提供的网站登录入口,将网站的域名提交给搜索引擎。比如谷歌的网站登录地址是。对于提交的域名列表,搜索引擎只会定期更新。所以这种方式比较被动,域名提交给网站是收录需要很长时间。以下是网站针对主流中文搜索引擎的投稿入口。
在实际操作中,我们只需要提交网站的首页地址或网站的域名,搜索引擎会根据首页上的链接抓取其他页面。
百度:。
360:。
搜狗:。
谷歌:(需要注册才能启用站长工具提交)。
其次,通过与外部网站建立链接关系,搜索引擎可以通过外部网站发现我们的网站,从而实现网站的收录。这种方式的主动权在我们自己手中(只要我们有足够多的优质链接),收录的速度比主动提交给搜索引擎要快很多。根据外部链接的数量、质量和相关性,一般情况下,搜索引擎收录会在2-7天左右搜索到。
2. 页面抓取
通过上面的介绍,相信读者已经掌握了加快网站被收录搜索到的方法。但是,如何增加网站中的收录页数呢?这要从了解搜索引擎收录页面的工作原理说起。
如果把网站页面的集合看作一个有向图,从指定页面开始,沿着页面中的链接,按照特定的策略遍历网站中的页面。始终从URL列表中移除访问过的URL,存储原创页面,同时提取原创页面中的URL信息;然后将URL分为域名和内部URL两类,判断该URL是否被访问过。未访问的 URL 添加到 URL 列表中。递归扫描 URL 列表,直到耗尽所有 URL 资源。这些工作完成后,搜索引擎就可以构建一个庞大的域名列表、页面 URL 列表,并存储足够的原创页面。
3. 页面爬取方法
通过以上内容,大家已经了解了搜索引擎抓取页面的过程和原理。然而,在互联网上数以亿计的页面中,搜索引擎如何从中抓取更多相对重要的页面呢?这涉及到搜索引擎如何抓取页面的问题。
页面爬取方法是指搜索引擎对页面进行爬取的策略,目的是过滤掉互联网上比较重要的信息。页面爬取方法的制定取决于搜索引擎对网站结构的理解。如果使用相同的爬取策略,搜索引擎可以同时在某个网站中抓取更多的页面资源,并且会在网站上停留更长时间。自然爬取的页面数就更多了。因此,加深对搜索引擎页面抓取方式的理解,有助于为网站建立一个友好的结构,增加抓取页面的数量。
常见的搜索引擎爬取方式主要有广度优先、深度优先、大站点优先、高权重优先、暗网爬取和用户提交等,下面将详细介绍这几种页面爬取方式及其优缺点。
广度优先
如果把整个网站看成一棵树,首页就是根,每一页就是叶子。广度优先是一种横向页面爬取方法。页面从树的较浅层开始爬取,然后爬取同一层的所有页面,再进入下一层。因此,在优化网站时,我们应该将网站中相对重要的信息展示在较浅的页面上(例如在首页推荐一些热门产品或内容)。因此,通过广度优先的爬取方式,搜索引擎可以先爬取网站中相对重要的页面。
下面我们来看看广度优先的爬取过程。首先,搜索引擎从网站的首页开始,抓取首页上所有链接所指向的页面,形成一个页面集(A),解析出该集合中所有页面的链接(A ); 然后按照这些链接抓取下一层的页面形成一个页面集(B)。这样就从浅层页面递归解析出链接,从而爬取到深层页面,直到满足一定的设定条件才停止爬取过程,如图所示。
广度优先爬取过程
深度优先
与广度优先的爬行方法相反,深度优先是一种垂直页面的爬行方法。它首先跟踪浅页中的某个链接,从而逐步爬取深页,直到爬到最深的页面。页面结束后,返回浅页面继续爬到深页面。使用深度优先的爬取方式,搜索引擎可以爬取网站中相对隐蔽和冷门的页面,满足更多用户的需求。
我们来看看深度优先的爬取过程。首先,搜索引擎会抓取网站的主页,并提取主页上的链接;然后抓取指向该页面的链接之一并提取其中的链接;然后,按照第1-1页的链接A-1链接爬到第2-1页,同时提取链接;然后按照第 2-1 页中的链接 B-1 继续抓取更深的页面。这个是递归执行的,直到取到网站的最深页面或者满足某个设定条件,然后返回首页继续取,如图。
深度优先爬取过程
先大停
由于大网站比小网站更有可能提供越来越多有价值的内容,如果搜索引擎优先抓取大网站的网页,那么你可以为用户提供更多有价值的信息更短的时间。大站优先,顾名思义,就是先抓取互联网上的大网站页面,是搜索引擎中的一种信息抓取策略。
如何识别所谓的大网站?一是前期人工整理大站的种子资源,通过大站寻找其他大站;二是对索引后的网站进行系统分析,找出内容丰富、规模大、信息更新频繁的网站。
完成对各大网站的识别后,搜索引擎会优先抓取URL资源列表中的各大网站页面。这也是为什么大规模网站往往比小站点内容爬取更及时的原因之一。高的
重量第一
权重,简单的说就是搜索引擎对网页重要性的评价。所谓重要性归根结底是网站或者网页的信息价值。
高权重优先是一种优先抓取URL资源列表中权重高的网页的网络爬取策略。网页的权重(例如 Google PageRank 值)通常由许多因素决定,例如网页外部链接的数量和质量。如果下载了某个网址,则重新计算所有已下载的网址资源的权重值。这种效率极低,显然不现实。因此,搜索引擎往往在下载了多个URL资源后,对下载的URL进行权重计算(即权重计算不完全),从而确定这些URL资源对应的页面的权重值,从而给予更高的权重。首先抓取价值页面。
由于权重计算是基于部分数据,可能与实际权重(即失真)存在较大差异。因此,这种权重高、优先级高的爬取策略也可能会优先爬取二级页面。
暗网爬行暗网(又称深网、隐形网、隐藏网)是指存储在网络数据库中,不能通过超链接访问但需要通过动态网络访问的资源集合技术或手动启动的查询。属于可以被标准搜索引擎索引的信息。
本文仅供内部技术人员学习交流使用,不得用于其他商业用途。希望这篇文章对技术人员有所帮助。原创文章 来自:-百恒网 如转载请注明出处! 查看全部
怎样抓取网页数据(百恒网络SEO专员对网页的抓取)
搜索引擎对网页的抓取,其实就是互联网上的数据采集,这是搜索引擎最基本的工作。搜索引擎数据采集的能力直接决定了搜索引擎能够提供的信息量和互联网覆盖范围,进而影响搜索引擎查询结果的质量。因此,搜索引擎总是试图提高他们的数据采集能力。搜索引擎使用数据采集程序抓取互联网上的数据。我们称这些数据采集 程序为蜘蛛程序或机器人程序。
本文首先介绍了搜索引擎抓取页面的过程和方法,然后介绍了搜索引擎抓取页面的存储和维护方法。
1. 页面爬取过程
在互联网中,URL是每个页面的入口地址,搜索引擎蜘蛛通过URL爬取到该页面。搜索引擎蜘蛛程序从原创URL列表开始,通过URL抓取并存储原创页面;同时,提取原创页面中的URL资源并添加到URL列表中。这样一个连续的循环,就可以从互联网上获取到足够多的页面,如图。
图搜索引擎抓取页面简单流程
URL是页面的入口,域名是网站的入口。搜索引擎蜘蛛程序通过域名输入网站开始对网站页面的抓取。换句话说,搜索引擎抓取互联网页面的首要任务是建立一个足够大的原创域名列表,然后通过域名输入对应的网站,从而抓取这个页面网站。
对于网站,如果你想被搜索引擎收录搜索到,第一个条件是加入搜索引擎的域名列表。下面,百恒网SEO专家为大家介绍两种常见的加入搜索引擎域名列表的方式。
首先,使用搜索引擎提供的网站登录入口,将网站的域名提交给搜索引擎。比如谷歌的网站登录地址是。对于提交的域名列表,搜索引擎只会定期更新。所以这种方式比较被动,域名提交给网站是收录需要很长时间。以下是网站针对主流中文搜索引擎的投稿入口。
在实际操作中,我们只需要提交网站的首页地址或网站的域名,搜索引擎会根据首页上的链接抓取其他页面。
百度:。
360:。
搜狗:。
谷歌:(需要注册才能启用站长工具提交)。
其次,通过与外部网站建立链接关系,搜索引擎可以通过外部网站发现我们的网站,从而实现网站的收录。这种方式的主动权在我们自己手中(只要我们有足够多的优质链接),收录的速度比主动提交给搜索引擎要快很多。根据外部链接的数量、质量和相关性,一般情况下,搜索引擎收录会在2-7天左右搜索到。
2. 页面抓取
通过上面的介绍,相信读者已经掌握了加快网站被收录搜索到的方法。但是,如何增加网站中的收录页数呢?这要从了解搜索引擎收录页面的工作原理说起。
如果把网站页面的集合看作一个有向图,从指定页面开始,沿着页面中的链接,按照特定的策略遍历网站中的页面。始终从URL列表中移除访问过的URL,存储原创页面,同时提取原创页面中的URL信息;然后将URL分为域名和内部URL两类,判断该URL是否被访问过。未访问的 URL 添加到 URL 列表中。递归扫描 URL 列表,直到耗尽所有 URL 资源。这些工作完成后,搜索引擎就可以构建一个庞大的域名列表、页面 URL 列表,并存储足够的原创页面。
3. 页面爬取方法
通过以上内容,大家已经了解了搜索引擎抓取页面的过程和原理。然而,在互联网上数以亿计的页面中,搜索引擎如何从中抓取更多相对重要的页面呢?这涉及到搜索引擎如何抓取页面的问题。
页面爬取方法是指搜索引擎对页面进行爬取的策略,目的是过滤掉互联网上比较重要的信息。页面爬取方法的制定取决于搜索引擎对网站结构的理解。如果使用相同的爬取策略,搜索引擎可以同时在某个网站中抓取更多的页面资源,并且会在网站上停留更长时间。自然爬取的页面数就更多了。因此,加深对搜索引擎页面抓取方式的理解,有助于为网站建立一个友好的结构,增加抓取页面的数量。
常见的搜索引擎爬取方式主要有广度优先、深度优先、大站点优先、高权重优先、暗网爬取和用户提交等,下面将详细介绍这几种页面爬取方式及其优缺点。
广度优先
如果把整个网站看成一棵树,首页就是根,每一页就是叶子。广度优先是一种横向页面爬取方法。页面从树的较浅层开始爬取,然后爬取同一层的所有页面,再进入下一层。因此,在优化网站时,我们应该将网站中相对重要的信息展示在较浅的页面上(例如在首页推荐一些热门产品或内容)。因此,通过广度优先的爬取方式,搜索引擎可以先爬取网站中相对重要的页面。
下面我们来看看广度优先的爬取过程。首先,搜索引擎从网站的首页开始,抓取首页上所有链接所指向的页面,形成一个页面集(A),解析出该集合中所有页面的链接(A ); 然后按照这些链接抓取下一层的页面形成一个页面集(B)。这样就从浅层页面递归解析出链接,从而爬取到深层页面,直到满足一定的设定条件才停止爬取过程,如图所示。
广度优先爬取过程
深度优先
与广度优先的爬行方法相反,深度优先是一种垂直页面的爬行方法。它首先跟踪浅页中的某个链接,从而逐步爬取深页,直到爬到最深的页面。页面结束后,返回浅页面继续爬到深页面。使用深度优先的爬取方式,搜索引擎可以爬取网站中相对隐蔽和冷门的页面,满足更多用户的需求。
我们来看看深度优先的爬取过程。首先,搜索引擎会抓取网站的主页,并提取主页上的链接;然后抓取指向该页面的链接之一并提取其中的链接;然后,按照第1-1页的链接A-1链接爬到第2-1页,同时提取链接;然后按照第 2-1 页中的链接 B-1 继续抓取更深的页面。这个是递归执行的,直到取到网站的最深页面或者满足某个设定条件,然后返回首页继续取,如图。
深度优先爬取过程
先大停
由于大网站比小网站更有可能提供越来越多有价值的内容,如果搜索引擎优先抓取大网站的网页,那么你可以为用户提供更多有价值的信息更短的时间。大站优先,顾名思义,就是先抓取互联网上的大网站页面,是搜索引擎中的一种信息抓取策略。
如何识别所谓的大网站?一是前期人工整理大站的种子资源,通过大站寻找其他大站;二是对索引后的网站进行系统分析,找出内容丰富、规模大、信息更新频繁的网站。
完成对各大网站的识别后,搜索引擎会优先抓取URL资源列表中的各大网站页面。这也是为什么大规模网站往往比小站点内容爬取更及时的原因之一。高的
重量第一
权重,简单的说就是搜索引擎对网页重要性的评价。所谓重要性归根结底是网站或者网页的信息价值。
高权重优先是一种优先抓取URL资源列表中权重高的网页的网络爬取策略。网页的权重(例如 Google PageRank 值)通常由许多因素决定,例如网页外部链接的数量和质量。如果下载了某个网址,则重新计算所有已下载的网址资源的权重值。这种效率极低,显然不现实。因此,搜索引擎往往在下载了多个URL资源后,对下载的URL进行权重计算(即权重计算不完全),从而确定这些URL资源对应的页面的权重值,从而给予更高的权重。首先抓取价值页面。
由于权重计算是基于部分数据,可能与实际权重(即失真)存在较大差异。因此,这种权重高、优先级高的爬取策略也可能会优先爬取二级页面。
暗网爬行暗网(又称深网、隐形网、隐藏网)是指存储在网络数据库中,不能通过超链接访问但需要通过动态网络访问的资源集合技术或手动启动的查询。属于可以被标准搜索引擎索引的信息。
本文仅供内部技术人员学习交流使用,不得用于其他商业用途。希望这篇文章对技术人员有所帮助。原创文章 来自:-百恒网 如转载请注明出处!
怎样抓取网页数据(python爬虫中http协议的用法,如何通过python网页抓取实现网页数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-10-23 20:03
怎样抓取网页数据?常见的抓取应用场景,无非就是抓取网页的数据了。无论你是用http或者https协议,以及tcp协议,都可以用python3.5(requests)实现网页抓取。无论怎么做,只要可以上github,使用代码来抓取网页,你都能够快速用代码改造整个http服务。那么,这节课就来讲讲python爬虫中http协议的用法,如何通过python网页抓取实现网页数据抓取。
上一节:python爬虫开发之网页抓取下一节:python爬虫开发之网页抓取-对网页的解析。欢迎关注我的知乎专栏:python爬虫开发进阶。
试试,
因为get方法,采用http协议提供超文本内容,通过这个协议服务器进行下载。只要pythonhttp库支持,
#!/usr/bin/envpython3#-*-coding:utf-8-*-importrequestsimportos#提取下载网页的html_datafrompython。osimportglobimportreimporttimefromurllib。requestimporturlopen#发送下载请求,详细代码参考#getpostforurllib。
requestimporturllib2frombs4importbeautifulsoupfromtimeimportsleepfromhttp。infoimportcontentfromurllib。errorimportformerror#downloadget请求url=''#提取下载网页内容res=requests。get(url)。text#downloaddownload(url)。 查看全部
怎样抓取网页数据(python爬虫中http协议的用法,如何通过python网页抓取实现网页数据)
怎样抓取网页数据?常见的抓取应用场景,无非就是抓取网页的数据了。无论你是用http或者https协议,以及tcp协议,都可以用python3.5(requests)实现网页抓取。无论怎么做,只要可以上github,使用代码来抓取网页,你都能够快速用代码改造整个http服务。那么,这节课就来讲讲python爬虫中http协议的用法,如何通过python网页抓取实现网页数据抓取。
上一节:python爬虫开发之网页抓取下一节:python爬虫开发之网页抓取-对网页的解析。欢迎关注我的知乎专栏:python爬虫开发进阶。
试试,
因为get方法,采用http协议提供超文本内容,通过这个协议服务器进行下载。只要pythonhttp库支持,
#!/usr/bin/envpython3#-*-coding:utf-8-*-importrequestsimportos#提取下载网页的html_datafrompython。osimportglobimportreimporttimefromurllib。requestimporturlopen#发送下载请求,详细代码参考#getpostforurllib。
requestimporturllib2frombs4importbeautifulsoupfromtimeimportsleepfromhttp。infoimportcontentfromurllib。errorimportformerror#downloadget请求url=''#提取下载网页内容res=requests。get(url)。text#downloaddownload(url)。
怎样抓取网页数据(怎样抓取网页数据_xpath在javascript中的使用-vue实例化组件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-10-23 14:03
怎样抓取网页数据_xpath在javascript中的使用-vue实例化组件requst_query_cascade=()=>{...}
参考这里,
当然有了,把这种js保存下来,在之后的接口中使用就行了。
其实既然你有如此丰富的js写的网页js,ajax。一个websocket的接口成本很低的,
老实说已经有网页js相关的js了,
使用jquery的话userqueryaction,前面post啥的(jquerysecretkey),里面post函数保存得到postkey给到后面一层post的请求,一般包装成js文件。这里老实说,你用javascript抓取网页不比mysql便宜。
没有,jquery好多地方对javascript要求很高的,ajax也很多地方要求javascript,实在要搞,看下jquery的connectapi,很多地方拿到javascript要做cookie啥的操作。
只要网页足够好,
有。flexiblejs。很好用。小小推荐一下。
我们目前用jquery来做这个东西,
楼上居然没人说requs,
jquery可以看做是一个函数或者接口 查看全部
怎样抓取网页数据(怎样抓取网页数据_xpath在javascript中的使用-vue实例化组件)
怎样抓取网页数据_xpath在javascript中的使用-vue实例化组件requst_query_cascade=()=>{...}
参考这里,
当然有了,把这种js保存下来,在之后的接口中使用就行了。
其实既然你有如此丰富的js写的网页js,ajax。一个websocket的接口成本很低的,
老实说已经有网页js相关的js了,
使用jquery的话userqueryaction,前面post啥的(jquerysecretkey),里面post函数保存得到postkey给到后面一层post的请求,一般包装成js文件。这里老实说,你用javascript抓取网页不比mysql便宜。
没有,jquery好多地方对javascript要求很高的,ajax也很多地方要求javascript,实在要搞,看下jquery的connectapi,很多地方拿到javascript要做cookie啥的操作。
只要网页足够好,
有。flexiblejs。很好用。小小推荐一下。
我们目前用jquery来做这个东西,
楼上居然没人说requs,
jquery可以看做是一个函数或者接口
怎样抓取网页数据( Python的一个重要的应用,使用Python爬虫我们可以轻松的从互联网中抓取 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-10-17 03:03
Python的一个重要的应用,使用Python爬虫我们可以轻松的从互联网中抓取
)
爬虫是 Python 的一个重要应用。使用Python爬虫,我们可以很方便的从网上抓取我们想要的数据。本文将以抓取B站的视频热搜榜数据并存储为例。详细介绍了四个步骤。Python爬虫的基本流程。
第1步
请求尝试
先到b站首页,点击排行榜,复制链接。
https://www.bilibili.com/ranki ... %3Bbr />
启动 Jupyter notebook 并运行以下代码:
import requests<br /><br />url = 'https://www.bilibili.com/ranki ... %3Bbr />res = requests.get('url')<br />print(res.status_code)<br />#200<br />
在上面的代码中,做了以下三件事: 可以看到返回值为200,说明服务器响应正常,可以继续了。
第2步
解析页面
上一步我们通过requests向网站请求数据后,成功获取到一个收录服务器资源的Response对象。现在我们可以使用 .text 来查看其内容。
可以看到返回了一个字符串,里面收录了我们需要的热门视频数据,但是直接从字符串中提取内容比较复杂,效率低下,所以我们需要对其进行解析,将字符串转换成结构化的网页数据,以便您可以轻松找到 HTML 标记及其属性和内容。Python中解析网页的方式有很多种,可以使用正则表达式,也可以使用BeautifulSoup、pyquery或lxml。本文将基于 BeautifulSoup 进行讲解。Beautiful Soup 是一个第三方库,可以从 HTML 或 XML 文件中提取数据。安装也非常简单。使用 pip install bs4 安装它。让我们用一个简单的例子来说明它是如何工作的。
from bs4 import BeautifulSoup<br /><br />page = requests.get(url)<br />soup = BeautifulSoup(page.content, 'html.parser')<br />title = soup.title.text <br />print(title)<br /># 热门视频排行榜 - 哔哩哔哩 (゜-゜)つロ 干杯~-bilibili<br />
上面代码中,我们使用bs4中的BeautifulSoup类,将上一步得到的html格式字符串转换为BeautifulSoup对象。注意使用的时候需要开发一个解析器,这里使用的是html.parser。然后您可以获得结构化元素之一及其属性。比如可以使用soup.title.text获取页面标题,也可以使用soup.body、soup.p等获取任何需要的元素。
第 3 步
提取内容
上面两步我们使用requests向网页请求数据,使用bs4解析页面。现在我们到了最关键的一步:如何从解析后的页面中提取出需要的内容。在 Beautiful Soup 中,我们可以使用 find/find_all 来定位元素,但我更习惯使用 CSS 选择器 .select,因为我们可以像使用 CSS 选择元素一样向下访问 DOM 树。下面我们用代码来说明如何从解析后的页面中提取B站的热门列表数据。首先,我们需要找到存储数据的标签,在列表页面按F12,按照下图的说明找到。
可以看到每条视频信息都包裹在li标签下,那么代码可以这样写吗?
all_products = []<br /><br />products = soup.select('li.rank-item')<br />for product in products:<br /> rank = product.select('div.num')[0].text<br /> name = product.select('div.info > a')[0].text.strip()<br /> play = product.select('span.data-box')[0].text<br /> comment = product.select('span.data-box')[1].text<br /> up = product.select('span.data-box')[2].text<br /> url = product.select('div.info > a')[0].attrs['href']<br /><br /> all_products.append({<br /> "视频排名":rank,<br /> "视频名": name,<br /> "播放量": play,<br /> "弹幕量": comment,<br /> "up主": up,<br /> "视频链接": url<br /> })<br />
上面的代码中,我们首先使用soup.select('li.rank-item'),然后返回一个收录每个视频信息的列表,然后遍历每个视频信息,仍然使用CSS选择器提取我们想要的字段信息以字典的形式存储在开头定义的空列表中。可以注意到,我使用了多种选择方法来提取元素。这也是 select 方法的灵活性。有兴趣的读者可以自行进一步研究。
第四步
存储数据
通过前面三步,我们成功使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel并保存即可。如果你对pandas不熟悉,可以使用csv模块来编写。需要注意的是设置了 encoding='utf-8-sig' ,否则会出现中文乱码的问题。
import csv<br />keys = all_products[0].keys()<br /><br />with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:<br /> dict_writer = csv.DictWriter(output_file, keys)<br /> dict_writer.writeheader()<br /> dict_writer.writerows(all_products)<br />
如果您熟悉pandas,您可以通过一行代码轻松地将字典转换为DataFrame。
import pandas as pd<br />keys = all_products[0].keys()<br /><br />pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
结束语
至此,我们已经成功地使用Python在本地存储了b站的热门视频列表数据。大多数基于请求的爬虫基本上都是按照以上四个步骤进行的。然而,虽然看起来简单,但在真实场景中的每一步都不是那么容易。从请求数据开始,目标网站有多种形式的反爬和加密,后期解析、提取甚至存储数据的方式也很多。需要进一步探索和学习。
本文选择B站视频热榜是因为足够简单,希望通过这个案例,让大家了解Python爬虫工作的基本流程,最后附上完整的代码?
import requests<br />from bs4 import BeautifulSoup<br />import csv<br />import pandas as pd<br /><br />url = 'https://www.bilibili.com/ranki ... %3Bbr />page = requests.get(url)<br />soup = BeautifulSoup(page.content, 'html.parser')<br /><br />all_products = []<br /><br />products = soup.select('li.rank-item')<br />for product in products:<br /> rank = product.select('div.num')[0].text<br /> name = product.select('div.info > a')[0].text.strip()<br /> play = product.select('span.data-box')[0].text<br /> comment = product.select('span.data-box')[1].text<br /> up = product.select('span.data-box')[2].text<br /> url = product.select('div.info > a')[0].attrs['href']<br /><br /> all_products.append({<br /> "视频排名":rank,<br /> "视频名": name,<br /> "播放量": play,<br /> "弹幕量": comment,<br /> "up主": up,<br /> "视频链接": url<br /> })<br /><br /><br />keys = all_products[0].keys()<br /><br />with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:<br /> dict_writer = csv.DictWriter(output_file, keys)<br /> dict_writer.writeheader()<br /> dict_writer.writerows(all_products)<br /><br />### 使用pandas写入数据<br />pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')<br /> 查看全部
怎样抓取网页数据(
Python的一个重要的应用,使用Python爬虫我们可以轻松的从互联网中抓取
)
爬虫是 Python 的一个重要应用。使用Python爬虫,我们可以很方便的从网上抓取我们想要的数据。本文将以抓取B站的视频热搜榜数据并存储为例。详细介绍了四个步骤。Python爬虫的基本流程。
第1步
请求尝试
先到b站首页,点击排行榜,复制链接。
https://www.bilibili.com/ranki ... %3Bbr />
启动 Jupyter notebook 并运行以下代码:
import requests<br /><br />url = 'https://www.bilibili.com/ranki ... %3Bbr />res = requests.get('url')<br />print(res.status_code)<br />#200<br />
在上面的代码中,做了以下三件事: 可以看到返回值为200,说明服务器响应正常,可以继续了。
第2步
解析页面
上一步我们通过requests向网站请求数据后,成功获取到一个收录服务器资源的Response对象。现在我们可以使用 .text 来查看其内容。
可以看到返回了一个字符串,里面收录了我们需要的热门视频数据,但是直接从字符串中提取内容比较复杂,效率低下,所以我们需要对其进行解析,将字符串转换成结构化的网页数据,以便您可以轻松找到 HTML 标记及其属性和内容。Python中解析网页的方式有很多种,可以使用正则表达式,也可以使用BeautifulSoup、pyquery或lxml。本文将基于 BeautifulSoup 进行讲解。Beautiful Soup 是一个第三方库,可以从 HTML 或 XML 文件中提取数据。安装也非常简单。使用 pip install bs4 安装它。让我们用一个简单的例子来说明它是如何工作的。
from bs4 import BeautifulSoup<br /><br />page = requests.get(url)<br />soup = BeautifulSoup(page.content, 'html.parser')<br />title = soup.title.text <br />print(title)<br /># 热门视频排行榜 - 哔哩哔哩 (゜-゜)つロ 干杯~-bilibili<br />
上面代码中,我们使用bs4中的BeautifulSoup类,将上一步得到的html格式字符串转换为BeautifulSoup对象。注意使用的时候需要开发一个解析器,这里使用的是html.parser。然后您可以获得结构化元素之一及其属性。比如可以使用soup.title.text获取页面标题,也可以使用soup.body、soup.p等获取任何需要的元素。
第 3 步
提取内容
上面两步我们使用requests向网页请求数据,使用bs4解析页面。现在我们到了最关键的一步:如何从解析后的页面中提取出需要的内容。在 Beautiful Soup 中,我们可以使用 find/find_all 来定位元素,但我更习惯使用 CSS 选择器 .select,因为我们可以像使用 CSS 选择元素一样向下访问 DOM 树。下面我们用代码来说明如何从解析后的页面中提取B站的热门列表数据。首先,我们需要找到存储数据的标签,在列表页面按F12,按照下图的说明找到。
可以看到每条视频信息都包裹在li标签下,那么代码可以这样写吗?
all_products = []<br /><br />products = soup.select('li.rank-item')<br />for product in products:<br /> rank = product.select('div.num')[0].text<br /> name = product.select('div.info > a')[0].text.strip()<br /> play = product.select('span.data-box')[0].text<br /> comment = product.select('span.data-box')[1].text<br /> up = product.select('span.data-box')[2].text<br /> url = product.select('div.info > a')[0].attrs['href']<br /><br /> all_products.append({<br /> "视频排名":rank,<br /> "视频名": name,<br /> "播放量": play,<br /> "弹幕量": comment,<br /> "up主": up,<br /> "视频链接": url<br /> })<br />
上面的代码中,我们首先使用soup.select('li.rank-item'),然后返回一个收录每个视频信息的列表,然后遍历每个视频信息,仍然使用CSS选择器提取我们想要的字段信息以字典的形式存储在开头定义的空列表中。可以注意到,我使用了多种选择方法来提取元素。这也是 select 方法的灵活性。有兴趣的读者可以自行进一步研究。
第四步
存储数据
通过前面三步,我们成功使用requests+bs4从网站中提取出需要的数据,最后只需要将数据写入Excel并保存即可。如果你对pandas不熟悉,可以使用csv模块来编写。需要注意的是设置了 encoding='utf-8-sig' ,否则会出现中文乱码的问题。
import csv<br />keys = all_products[0].keys()<br /><br />with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:<br /> dict_writer = csv.DictWriter(output_file, keys)<br /> dict_writer.writeheader()<br /> dict_writer.writerows(all_products)<br />
如果您熟悉pandas,您可以通过一行代码轻松地将字典转换为DataFrame。
import pandas as pd<br />keys = all_products[0].keys()<br /><br />pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')
结束语
至此,我们已经成功地使用Python在本地存储了b站的热门视频列表数据。大多数基于请求的爬虫基本上都是按照以上四个步骤进行的。然而,虽然看起来简单,但在真实场景中的每一步都不是那么容易。从请求数据开始,目标网站有多种形式的反爬和加密,后期解析、提取甚至存储数据的方式也很多。需要进一步探索和学习。
本文选择B站视频热榜是因为足够简单,希望通过这个案例,让大家了解Python爬虫工作的基本流程,最后附上完整的代码?
import requests<br />from bs4 import BeautifulSoup<br />import csv<br />import pandas as pd<br /><br />url = 'https://www.bilibili.com/ranki ... %3Bbr />page = requests.get(url)<br />soup = BeautifulSoup(page.content, 'html.parser')<br /><br />all_products = []<br /><br />products = soup.select('li.rank-item')<br />for product in products:<br /> rank = product.select('div.num')[0].text<br /> name = product.select('div.info > a')[0].text.strip()<br /> play = product.select('span.data-box')[0].text<br /> comment = product.select('span.data-box')[1].text<br /> up = product.select('span.data-box')[2].text<br /> url = product.select('div.info > a')[0].attrs['href']<br /><br /> all_products.append({<br /> "视频排名":rank,<br /> "视频名": name,<br /> "播放量": play,<br /> "弹幕量": comment,<br /> "up主": up,<br /> "视频链接": url<br /> })<br /><br /><br />keys = all_products[0].keys()<br /><br />with open('B站视频热榜TOP100.csv', 'w', newline='', encoding='utf-8-sig') as output_file:<br /> dict_writer = csv.DictWriter(output_file, keys)<br /> dict_writer.writeheader()<br /> dict_writer.writerows(all_products)<br /><br />### 使用pandas写入数据<br />pd.DataFrame(all_products,columns=keys).to_csv('B站视频热榜TOP100.csv', encoding='utf-8-sig')<br />
怎样抓取网页数据(如何用python来抓取页面中的动态动态网页数据? )
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-10-17 03:00
)
”
浏览器中显示的内容与右键查看的网页源代码是否不同?
右键查看源代码
生成的 HTML 不收录 ajax 异步加载的内容
查看原创文件只是网页的初始状态,但实际上网页可能在加载后立即执行js来改变初始状态。当前网页不同于传统的动态网页,可以在不刷新网页的情况下改变网页的部分数据。这一切都是通过js和服务端的交互来完成的。这就像一个程序使用对话框编辑器来设计界面,但在实际操作中,您必须在其中加载数据,更改控件状态,甚至创建新控件、销毁控件或隐藏现有控件。外观自然会发生变化。
”
我们经常会发现,网页中的很多数据并不是用HTML硬编码的,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有的。
在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,将无法获取任何数据。
今天,我们就在这里简单说说如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。
如下图所示,我们在HTML中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下所示:
在豆瓣页面向下拖动,可以将更多的电影信息加载到页面中,以便我们抓取相应的消息。
我们可以看到它使用了 AJAX 异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某个部分,从而实现数据的动态加载。
我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。
查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果你想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但这看起来很不自动化,很多其他的网站 RequestURL 都不是那么简单,所以我们将使用python 进行进一步的操作,以获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text
查看全部
怎样抓取网页数据(如何用python来抓取页面中的动态动态网页数据?
)
”
浏览器中显示的内容与右键查看的网页源代码是否不同?
右键查看源代码
生成的 HTML 不收录 ajax 异步加载的内容
查看原创文件只是网页的初始状态,但实际上网页可能在加载后立即执行js来改变初始状态。当前网页不同于传统的动态网页,可以在不刷新网页的情况下改变网页的部分数据。这一切都是通过js和服务端的交互来完成的。这就像一个程序使用对话框编辑器来设计界面,但在实际操作中,您必须在其中加载数据,更改控件状态,甚至创建新控件、销毁控件或隐藏现有控件。外观自然会发生变化。
”
我们经常会发现,网页中的很多数据并不是用HTML硬编码的,而是通过js动态加载的。所以也引出了动态数据的概念。这里的动态数据是指网页中Javascript动态生成的页面内容,是页面加载到浏览器后动态生成的,以前没有的。
在编写爬虫抓取网页数据的时候,经常会遇到这种需要动态加载数据的HTML网页。如果还是直接从网页爬取,将无法获取任何数据。
今天,我们就在这里简单说说如何使用python抓取页面中JS动态加载的数据。
给定一个网页:豆瓣电影排行榜,里面的所有电影信息都是动态加载的。我们无法直接从页面中获取每部电影的信息。
如下图所示,我们在HTML中找不到对应的电影信息。
在Chrome浏览器中,点击F12打开Network中的XHR,我们抓取对应的js文件进行分析。如下所示:
在豆瓣页面向下拖动,可以将更多的电影信息加载到页面中,以便我们抓取相应的消息。
我们可以看到它使用了 AJAX 异步请求。通过在后台与服务器交换少量数据,AJAX 可以使网页异步更新。因此,可以在不重新加载整个网页的情况下更新网页的某个部分,从而实现数据的动态加载。
我们可以看到,通过GET,我们得到的响应中收录了对应的电影相关信息,以JSON格式存储在一起。
查看RequestURL信息,可以发现action参数后面有“start”和“limit”两个参数。显然他们的意思是:“从某个位置返回的电影数量”。
如果你想快速获取相关电影信息,可以直接把这个网址复制到地址栏,修改你需要的start和limit参数值,得到相应的抓取结果。
但这看起来很不自动化,很多其他的网站 RequestURL 都不是那么简单,所以我们将使用python 进行进一步的操作,以获取返回的消息信息。
#coding:utf-8
import urllib
import requests
post_param = {'action':'','start':'0','limit':'1'}
return_data = requests.get("https://movie.douban.com/j/cha ... ot%3B,data =post_param, verify = False)
print return_data.text
怎样抓取网页数据(借助ABBYYFineReader15文字识别软件快速识别为表格数据表格)
网站优化 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2021-10-15 21:16
在一些政府公共信息共享网站或专业数据共享组织网站中,会定期共享一些社会发展数据或与时事相关的数据。这些数据通常在网页上共享,很少提供文件下载。
如果直接复制这些数据,排版数据会花费很多时间。但借助ABBYY FineReader PDF 15文本识别软件,可以快速识别为表格数据,导出为可编辑的数据表格。接下来,我们来看看它的操作方法。
一、 网页表单数据截图
首先打开相关数据网站,对数据表区域进行截图。
图1:打开网页截图
如图2所示,在截图过程中,建议尽量保持表格边框的完整性,以提高ABBYY FineReader PDF 15识别的准确率。
图 2:完成的表数据的屏幕截图
二、使用OCR编辑器识别表单
接下来,打开ABBYY FineReader PDF 15文本识别软件,使用“在OCR编辑器中打开”功能打开网站中刚刚截取的表单数据。
图 3:在 OCR 编辑器中打开图片
然后,等待软件完成对图片的文字识别。在识别过程中,为了提高文字识别的准确率,软件会建议图片的分辨率或指定的OCR语言。如果条件允许(如提高图像的分辨率),您可以按照建议修改相关设置。
图 4:完整的 OCR 识别
完成文本识别程序后,我们需要在区域属性面板中检查表格标记的区域属性是否正确。如图 5 所示,您可以看到 ABBYY FineReader PDF 15 已正确将此区域标记为表格区域。
图 5:区域属性
然后,看到软件的文本编辑面板。如图6所示,可以看到文字已经以电子表格的形式呈现出来了,可以在单元格中编辑文字了。
图 6:文本编辑器
三、导出到Excel
为了方便后续的数据处理,我们可以将识别出的电子表格保存为Excel文件。如图7所示,在文本编辑面板顶部选择Excel表格的保存格式后,即可将当前文本导出为Excel文件。
图 7:另存为 Excel 电子表格
打开导出的Excel文件,可以看到ABBYY FineReader PDF 15不仅可以准确识别数据,还可以“复制”表格的格式,很好地将数据导出到每个单元格。这种类型的导出可以减少排版大量数据所需的时间。
图 8:导出的 Excel 表
四、总结
通过使用ABBYY文字识别软件的数据表格识别功能,我们可以快速将图片中的表格转换为可编辑的电子表格,提高数据使用效率。你有这么好用的功能吗? 查看全部
怎样抓取网页数据(借助ABBYYFineReader15文字识别软件快速识别为表格数据表格)
在一些政府公共信息共享网站或专业数据共享组织网站中,会定期共享一些社会发展数据或与时事相关的数据。这些数据通常在网页上共享,很少提供文件下载。
如果直接复制这些数据,排版数据会花费很多时间。但借助ABBYY FineReader PDF 15文本识别软件,可以快速识别为表格数据,导出为可编辑的数据表格。接下来,我们来看看它的操作方法。
一、 网页表单数据截图
首先打开相关数据网站,对数据表区域进行截图。
图1:打开网页截图
如图2所示,在截图过程中,建议尽量保持表格边框的完整性,以提高ABBYY FineReader PDF 15识别的准确率。
图 2:完成的表数据的屏幕截图
二、使用OCR编辑器识别表单
接下来,打开ABBYY FineReader PDF 15文本识别软件,使用“在OCR编辑器中打开”功能打开网站中刚刚截取的表单数据。
图 3:在 OCR 编辑器中打开图片
然后,等待软件完成对图片的文字识别。在识别过程中,为了提高文字识别的准确率,软件会建议图片的分辨率或指定的OCR语言。如果条件允许(如提高图像的分辨率),您可以按照建议修改相关设置。
图 4:完整的 OCR 识别
完成文本识别程序后,我们需要在区域属性面板中检查表格标记的区域属性是否正确。如图 5 所示,您可以看到 ABBYY FineReader PDF 15 已正确将此区域标记为表格区域。
图 5:区域属性
然后,看到软件的文本编辑面板。如图6所示,可以看到文字已经以电子表格的形式呈现出来了,可以在单元格中编辑文字了。
图 6:文本编辑器
三、导出到Excel
为了方便后续的数据处理,我们可以将识别出的电子表格保存为Excel文件。如图7所示,在文本编辑面板顶部选择Excel表格的保存格式后,即可将当前文本导出为Excel文件。
图 7:另存为 Excel 电子表格
打开导出的Excel文件,可以看到ABBYY FineReader PDF 15不仅可以准确识别数据,还可以“复制”表格的格式,很好地将数据导出到每个单元格。这种类型的导出可以减少排版大量数据所需的时间。
图 8:导出的 Excel 表
四、总结
通过使用ABBYY文字识别软件的数据表格识别功能,我们可以快速将图片中的表格转换为可编辑的电子表格,提高数据使用效率。你有这么好用的功能吗?

