
怎样抓取网页数据
怎样抓取网页数据:网页解析javascript蜘蛛爬虫爬虫
网站优化 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-09-03 06:06
怎样抓取网页数据:网页解析javascript蜘蛛爬虫爬虫是通过爬虫框架来实现大部分的工作内容,然后直接封装出网页爬虫框架,比如比较有名的vuejs、reactjs都是采用单文件组件+路由来实现跨平台的框架。1.构建爬虫框架项目的构建模块可以看到有三个构建项目的component:templatecomponent(网页结构模块)、component-modules(模块模块)、logon(脚本模块)其中最核心是component-modules模块,其中首先是一个简单的templatecomponent实例,然后再是三个模块:component1、component2、component3,然后是一个html渲染模块:html相关的操作,包括dom操作、form、action等操作也就是说,我们可以将这三个框架的功能分别定义在一个component里,然后在一个公共component中完成其他的功能,代码量就会非常小,当然利用框架,可以让你的模块间调用会更快。
代码片段(new出来的,可以存放在工程根目录下即所有的代码都放在这个下一个.vue)在三个模块中完成server自己处理(比如requestresponse等操作)然后再传给之前封装的component去处理。requestresponse等可以以文件方式传递给其他的component。methods当然可以一个一个封装在文件内部,但是一个个人手动操作还是比较麻烦的。
对于babel,coffeescript还是比较好封装的,我是比较喜欢集成到开发流程当中。2.采用xpath的小例子浏览器中我们很难用javascript编写url,会阻塞浏览器解析页面,甚至连需要多页的情况下也不可能。我们可以使用xpath来解析这些url。直接看例子会很有感觉javascript利用'<p>organizetheweb.'将一个url分成多个子url,每一个子url都根据<p>,以及<p>标签的内容不同解析生成html,然后传给es5的模块中相应的api解析。
我们在这里先简单定义一个模块(简单也可以创建一个中间变量来引用这个模块){path:"d:/blog/",link:"#programming/vue",xpath:'//*[@id="a"]/div/div/div[2]/a/div/div[3]/div/div/div[1]/a/div',//相对路径public:true,//全局方法名称extra:true,//extra标签,有extra=true或者false表示禁止false表示需要添加到html首位prefix:'/a.b.c.d',//禁止在文件名称开始的位置进行访问,在其他方式下/+/+//可以使子文件a.b.c.d.test.c。width:125,//让我去开个发布会看看效果javascrip。 查看全部
怎样抓取网页数据:网页解析javascript蜘蛛爬虫爬虫
怎样抓取网页数据:网页解析javascript蜘蛛爬虫爬虫是通过爬虫框架来实现大部分的工作内容,然后直接封装出网页爬虫框架,比如比较有名的vuejs、reactjs都是采用单文件组件+路由来实现跨平台的框架。1.构建爬虫框架项目的构建模块可以看到有三个构建项目的component:templatecomponent(网页结构模块)、component-modules(模块模块)、logon(脚本模块)其中最核心是component-modules模块,其中首先是一个简单的templatecomponent实例,然后再是三个模块:component1、component2、component3,然后是一个html渲染模块:html相关的操作,包括dom操作、form、action等操作也就是说,我们可以将这三个框架的功能分别定义在一个component里,然后在一个公共component中完成其他的功能,代码量就会非常小,当然利用框架,可以让你的模块间调用会更快。

代码片段(new出来的,可以存放在工程根目录下即所有的代码都放在这个下一个.vue)在三个模块中完成server自己处理(比如requestresponse等操作)然后再传给之前封装的component去处理。requestresponse等可以以文件方式传递给其他的component。methods当然可以一个一个封装在文件内部,但是一个个人手动操作还是比较麻烦的。

对于babel,coffeescript还是比较好封装的,我是比较喜欢集成到开发流程当中。2.采用xpath的小例子浏览器中我们很难用javascript编写url,会阻塞浏览器解析页面,甚至连需要多页的情况下也不可能。我们可以使用xpath来解析这些url。直接看例子会很有感觉javascript利用'<p>organizetheweb.'将一个url分成多个子url,每一个子url都根据<p>,以及<p>标签的内容不同解析生成html,然后传给es5的模块中相应的api解析。
我们在这里先简单定义一个模块(简单也可以创建一个中间变量来引用这个模块){path:"d:/blog/",link:"#programming/vue",xpath:'//*[@id="a"]/div/div/div[2]/a/div/div[3]/div/div/div[1]/a/div',//相对路径public:true,//全局方法名称extra:true,//extra标签,有extra=true或者false表示禁止false表示需要添加到html首位prefix:'/a.b.c.d',//禁止在文件名称开始的位置进行访问,在其他方式下/+/+//可以使子文件a.b.c.d.test.c。width:125,//让我去开个发布会看看效果javascrip。
怎样抓取网页数据?我是用的开源工具thunderlrd。
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2022-08-19 14:08
怎样抓取网页数据?我是用的开源工具thunderlrd。网上可以看到的demo已经非常多了,看来看去也看不出什么特别。要真正用上,还是需要实践,原来很多文章介绍了用lowpoly手绘轮廓网页,然后在js中写,js解析xhr,json解析xml获取数据。我看过这些demo,觉得没有完整实践过,有点误人子弟。下面整理下,把js里的连接转成json,再调用javascript就可以抓取了。
的图像识别必不可少,想要识别出哪一个房子,房子的风格,大小信息,必须先知道什么样的数据或图片是有用的,需要和哪个模块联系,用javascript还是用什么方式引入,
能否用urllib2处理?
urllib2肯定要用的,可以用转换ajax请求的方法来转换
同学现在如何学java了
请问这个人,我怎么无法想象她用到深度学习的库,
参考requests里面的解析,再套上自己实践摸索,
python里的内置模块requests,我没仔细看文档用过,直接看的网上文章,
...你这样可以去修仙了,有本事能把这两个搞到一起再去...
不请自来上面我说了一些你说不需要的库你如果不是python小白可以看看以下:websocket生成器,https协议分析工具websocket,websocket网络编程协议,个人博客模块制作ssm框架,python2框架协议获取json生成到xml,,json解析网址,网址解析然后导出到csv对象。
这里面除了https协议的xml其它都能抓。需要csv转json,网址解析到xml,xml文件获取csv导出到json这三个库,这三个库我也没用过。总结一下:除了https协议不需要抓。 查看全部
怎样抓取网页数据?我是用的开源工具thunderlrd。
怎样抓取网页数据?我是用的开源工具thunderlrd。网上可以看到的demo已经非常多了,看来看去也看不出什么特别。要真正用上,还是需要实践,原来很多文章介绍了用lowpoly手绘轮廓网页,然后在js中写,js解析xhr,json解析xml获取数据。我看过这些demo,觉得没有完整实践过,有点误人子弟。下面整理下,把js里的连接转成json,再调用javascript就可以抓取了。
的图像识别必不可少,想要识别出哪一个房子,房子的风格,大小信息,必须先知道什么样的数据或图片是有用的,需要和哪个模块联系,用javascript还是用什么方式引入,
能否用urllib2处理?

urllib2肯定要用的,可以用转换ajax请求的方法来转换
同学现在如何学java了
请问这个人,我怎么无法想象她用到深度学习的库,
参考requests里面的解析,再套上自己实践摸索,

python里的内置模块requests,我没仔细看文档用过,直接看的网上文章,
...你这样可以去修仙了,有本事能把这两个搞到一起再去...
不请自来上面我说了一些你说不需要的库你如果不是python小白可以看看以下:websocket生成器,https协议分析工具websocket,websocket网络编程协议,个人博客模块制作ssm框架,python2框架协议获取json生成到xml,,json解析网址,网址解析然后导出到csv对象。
这里面除了https协议的xml其它都能抓。需要csv转json,网址解析到xml,xml文件获取csv导出到json这三个库,这三个库我也没用过。总结一下:除了https协议不需要抓。
怎样抓取网页数据,一直是互联网面临的一个很重要的问题
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2022-07-22 04:01
怎样抓取网页数据,一直是互联网面临的一个很重要的问题。从整体上说,这包括下面三方面的内容,1,网站上的网页2,抓取那些网页3,从网页中提取什么信息。下面逐一叙述。1,网站上的网页。我们看看谷歌的这两个案例:谷歌的会员通过互联网页面就可以找到每日新闻的动态页面,从而可以学习到全世界发生的大事件。在和优酷合作的时候,优酷用互联网页面就抓取到了,关注了中国国家队即可看到全国男足的比赛。
这其实就是抓取网页中心得交易一部分,打败对手的的交易,通过这些网页,我们抓取到的内容就可以做成可售卖的产品。2,在抓取的网页中,根据url的不同,可以分为静态网页和动态网页。我们以北京理工大学和北京大学的第二十一学期学习为例。北京理工大学的第二十一学期学习,抓取的域名是,点击抓取即可在抓取结果中查看北京大学第二十一学期的学习页面。
(1),假设一个页面有20页,1000个标签,有且只有一个页面能被翻页,那么可以分析出页码中的“1”表示第一页,“2”表示第二页,然后按页码为顺序进行翻页。(2),假设页码为,那么可以按页码为顺序进行翻页。既然,现在,我们看看第三个案例:我们可以看出:我们可以看到,谷歌的抓取数据,能够挖掘很多有价值的信息。
抓取了学生最真实的学习需求,能够从各个方面帮助我们。分析网页的不同,其实可以知道哪些地方对我们很重要,这样就能把握大多数用户的需求。大学的课堂是集中了学生的各种需求,了解哪些知识对自己的发展能够起到关键的作用,然后利用所掌握的知识辅助自己,提高自己的能力。所以,把握住需求,这是抓取数据的核心。3,从网页中提取数据,用什么软件呢?我知道,并不是每个人都是从事互联网行业,和我一样,那么,如果想要在互联网中工作的话,怎么办呢?如果我们是从事it行业的,完全可以用百度或者其他搜索引擎就能找到答案。
那我们说怎么定制抓取的方法呢?和我们之前在团队中定制商业软件是一样的。我们团队在合作分享对网站进行抓取的经验的时候,引入了一种方法,在抓取到网页数据之后,我们可以根据一些公式计算出来,得到所需要的信息。这个工具叫site3:在“site3”网站分析平台中输入你的网站地址,即可看到分析的结果。比如一个网站,原来抓取的每日动态,抓取的所有页面,基本上都会给你展示出来。
这样,你再也不用担心下载了别人开发的网站工具,后来又要去自己开发python爬虫程序,或者被别人的商业工具所困。我们以阿里巴巴、腾讯、网易、新浪网等经典的网站为例,展示的是site3的使用。大。 查看全部
怎样抓取网页数据,一直是互联网面临的一个很重要的问题
怎样抓取网页数据,一直是互联网面临的一个很重要的问题。从整体上说,这包括下面三方面的内容,1,网站上的网页2,抓取那些网页3,从网页中提取什么信息。下面逐一叙述。1,网站上的网页。我们看看谷歌的这两个案例:谷歌的会员通过互联网页面就可以找到每日新闻的动态页面,从而可以学习到全世界发生的大事件。在和优酷合作的时候,优酷用互联网页面就抓取到了,关注了中国国家队即可看到全国男足的比赛。

这其实就是抓取网页中心得交易一部分,打败对手的的交易,通过这些网页,我们抓取到的内容就可以做成可售卖的产品。2,在抓取的网页中,根据url的不同,可以分为静态网页和动态网页。我们以北京理工大学和北京大学的第二十一学期学习为例。北京理工大学的第二十一学期学习,抓取的域名是,点击抓取即可在抓取结果中查看北京大学第二十一学期的学习页面。
(1),假设一个页面有20页,1000个标签,有且只有一个页面能被翻页,那么可以分析出页码中的“1”表示第一页,“2”表示第二页,然后按页码为顺序进行翻页。(2),假设页码为,那么可以按页码为顺序进行翻页。既然,现在,我们看看第三个案例:我们可以看出:我们可以看到,谷歌的抓取数据,能够挖掘很多有价值的信息。

抓取了学生最真实的学习需求,能够从各个方面帮助我们。分析网页的不同,其实可以知道哪些地方对我们很重要,这样就能把握大多数用户的需求。大学的课堂是集中了学生的各种需求,了解哪些知识对自己的发展能够起到关键的作用,然后利用所掌握的知识辅助自己,提高自己的能力。所以,把握住需求,这是抓取数据的核心。3,从网页中提取数据,用什么软件呢?我知道,并不是每个人都是从事互联网行业,和我一样,那么,如果想要在互联网中工作的话,怎么办呢?如果我们是从事it行业的,完全可以用百度或者其他搜索引擎就能找到答案。
那我们说怎么定制抓取的方法呢?和我们之前在团队中定制商业软件是一样的。我们团队在合作分享对网站进行抓取的经验的时候,引入了一种方法,在抓取到网页数据之后,我们可以根据一些公式计算出来,得到所需要的信息。这个工具叫site3:在“site3”网站分析平台中输入你的网站地址,即可看到分析的结果。比如一个网站,原来抓取的每日动态,抓取的所有页面,基本上都会给你展示出来。
这样,你再也不用担心下载了别人开发的网站工具,后来又要去自己开发python爬虫程序,或者被别人的商业工具所困。我们以阿里巴巴、腾讯、网易、新浪网等经典的网站为例,展示的是site3的使用。大。
怎样抓取网页数据:第一种方法:document.getelementbyid
网站优化 • 优采云 发表了文章 • 0 个评论 • 205 次浏览 • 2022-06-30 19:02
怎样抓取网页数据:第一种方法:document.getelementbyid('r').xxx如header头中带有get/headers='xxx'即是发送请求到服务器,服务器判断请求头xxx为请求的类型为xxxhttp。这个方法传的数据方便安全,但效率低,每一个请求只能传一次。当请求的数据量很大的时候就不合适。
第二种方法:document.getelementbyid('r').xxxlocation.href='xxx.jpg'完全是一个伪方法,在服务器处理请求的时候,传上去的参数都是随机的,并且给每个请求分配了一个随机的url,不用传区域地址。这样的好处是很方便性能也很好,传送值都是随机的,而且地址都不变,不存在跨区域之间的数据传递问题。
但传的数据不是经过http协议校验传递的,一旦有错,比如http协议没有检查请求,此后再请求它就有可能传递假数据了。所以不建议使用。第三种方法:document.getelementbyid('r').xxxobject.href='xxx.jpg'这个方法是以一个object对象作为跳转点。每个跳转点对应一个页面上的一个锚,这里一共四个锚:第一个锚——原地址:href第二个锚——锚点:对应跳转点第三个锚——锚点定位:浏览器窗口所在地址第四个锚——锚点定位:浏览器窗口上的锚点如果各个锚的间距超过两个请求的跳转间距,我们可以在object.href后面加上/png。
这个方法对跨域问题是无效的。但是这个方法有缺点,对于百万级别的页面来说,浏览器会对它自己也先进行一次跳转,然后每次请求都要重新跳转了,这就非常浪费时间了。所以我不是很推荐使用这个方法,而且在断点续传时也可能出现下载失败的情况。第四种方法:document.getelementbyid('r').xxx发送的get/post请求会update从而使数据保持不变。
但在dom内对象需要递归调用request.getorientation方法。但是这个方法的写法非常麻烦,并且要额外实现click事件。第五种方法:这种方法就是使用httpclient,来实现在多个post请求中实现request.getorientation变量的update方法,通过负反馈的方式跳转或者不跳转,达到跳转的目的。
常用在自定义的cookie、post等重定向中。httpclient参数说明:返回值参数,请求发送的url参数,参数即是跳转的起始url。post.postorientationpostorientation必须是request.getorientation第三参数必须是2的整数倍即是跳转起始锚的位置。
json.stringifynullrequest.postorientation=postorientation#跳转位置request.getorientation=1#跳转不包含数据锚点的网址request.getorientation=1+useragent#跳转useragent的内容和postorientation%%{}%%{}。 查看全部
怎样抓取网页数据:第一种方法:document.getelementbyid
怎样抓取网页数据:第一种方法:document.getelementbyid('r').xxx如header头中带有get/headers='xxx'即是发送请求到服务器,服务器判断请求头xxx为请求的类型为xxxhttp。这个方法传的数据方便安全,但效率低,每一个请求只能传一次。当请求的数据量很大的时候就不合适。
第二种方法:document.getelementbyid('r').xxxlocation.href='xxx.jpg'完全是一个伪方法,在服务器处理请求的时候,传上去的参数都是随机的,并且给每个请求分配了一个随机的url,不用传区域地址。这样的好处是很方便性能也很好,传送值都是随机的,而且地址都不变,不存在跨区域之间的数据传递问题。

但传的数据不是经过http协议校验传递的,一旦有错,比如http协议没有检查请求,此后再请求它就有可能传递假数据了。所以不建议使用。第三种方法:document.getelementbyid('r').xxxobject.href='xxx.jpg'这个方法是以一个object对象作为跳转点。每个跳转点对应一个页面上的一个锚,这里一共四个锚:第一个锚——原地址:href第二个锚——锚点:对应跳转点第三个锚——锚点定位:浏览器窗口所在地址第四个锚——锚点定位:浏览器窗口上的锚点如果各个锚的间距超过两个请求的跳转间距,我们可以在object.href后面加上/png。
这个方法对跨域问题是无效的。但是这个方法有缺点,对于百万级别的页面来说,浏览器会对它自己也先进行一次跳转,然后每次请求都要重新跳转了,这就非常浪费时间了。所以我不是很推荐使用这个方法,而且在断点续传时也可能出现下载失败的情况。第四种方法:document.getelementbyid('r').xxx发送的get/post请求会update从而使数据保持不变。
但在dom内对象需要递归调用request.getorientation方法。但是这个方法的写法非常麻烦,并且要额外实现click事件。第五种方法:这种方法就是使用httpclient,来实现在多个post请求中实现request.getorientation变量的update方法,通过负反馈的方式跳转或者不跳转,达到跳转的目的。
常用在自定义的cookie、post等重定向中。httpclient参数说明:返回值参数,请求发送的url参数,参数即是跳转的起始url。post.postorientationpostorientation必须是request.getorientation第三参数必须是2的整数倍即是跳转起始锚的位置。
json.stringifynullrequest.postorientation=postorientation#跳转位置request.getorientation=1#跳转不包含数据锚点的网址request.getorientation=1+useragent#跳转useragent的内容和postorientation%%{}%%{}。
怎样抓取网页数据,今天只用到python爬虫知识,找一些好玩的数据来练手
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-06-29 14:00
怎样抓取网页数据,今天只用到python爬虫知识,找一些好玩的数据来练练手。两千天牛津大学图书馆数据爬取小结我们先从网上下载数据,用requests库就可以,是一个xml格式,比如自己爬取了下面这样的网页。#爬取网页数据,data=requests.get("")首先看看这些网页的源代码,保存到cookies,使用selenium,webdriver框架,用http请求进行爬取数据。
data=requests.get("")可以看到data这一列是可以直接获取的,第一行是源代码,可以看到正常页面下存在这一列,但是我们发现其实并不全是可以抓取的,因为在body里面也包含了data这一列,其中有这么几个html格式的tag,但是tag里面只包含这些fields,没有其他信息。接下来就可以看到response(请求地址)一列,下面就是data这一列,这里我们发现整个网页其实是一个json格式。
对于json,我之前知道可以用xpath,也发现json可以做的实验特别多,比如制作python对象图,loadpng等等。爬取的数据是一个json数据框,我们通过loadpng来渲染出我们想要的图片。frompyqueryimportparseimporttimedata=parse.urlopen("")#time.sleep(。
2)time.sleep
2)print("渲染函数运行完毕")forelementindata:print(element.xpath("//input[@class="test"]/text()")).contentdata.remove()#替换掉json数据中的data列,requests请求地址element.xpath("//input[@class="test"]/text()").remove()print("渲染完毕")print("函数运行结束")从上面可以看到requests请求地址地址里就是data这一列,所以我们用loadpng来渲染我们想要的图片。
print("渲染函数运行完毕")time.sleep
2)这样渲染完之后,我们想要的数据也就爬取下来了。对于json数据的渲染,可以通过requests库的parse方法来得到一个解析函数,来进行各种包装、封装、解析。接下来还有其他的操作,后面会详细介绍。网页中主要包含了这么几个关键字段:headers,body和data几个字段。headers包含了我们想要的请求头部和请求头。
body包含我们想要的响应。data包含我们想要的数据。这里我们主要会用到requests.get(url)方法,这个方法可以抓取到对方请求的参数,并且把requests.get()转换成requests.get(headers,body),通过body返回一个字典,里面是我们想要的数据。 查看全部
怎样抓取网页数据,今天只用到python爬虫知识,找一些好玩的数据来练手
怎样抓取网页数据,今天只用到python爬虫知识,找一些好玩的数据来练练手。两千天牛津大学图书馆数据爬取小结我们先从网上下载数据,用requests库就可以,是一个xml格式,比如自己爬取了下面这样的网页。#爬取网页数据,data=requests.get("")首先看看这些网页的源代码,保存到cookies,使用selenium,webdriver框架,用http请求进行爬取数据。
data=requests.get("")可以看到data这一列是可以直接获取的,第一行是源代码,可以看到正常页面下存在这一列,但是我们发现其实并不全是可以抓取的,因为在body里面也包含了data这一列,其中有这么几个html格式的tag,但是tag里面只包含这些fields,没有其他信息。接下来就可以看到response(请求地址)一列,下面就是data这一列,这里我们发现整个网页其实是一个json格式。

对于json,我之前知道可以用xpath,也发现json可以做的实验特别多,比如制作python对象图,loadpng等等。爬取的数据是一个json数据框,我们通过loadpng来渲染出我们想要的图片。frompyqueryimportparseimporttimedata=parse.urlopen("")#time.sleep(。
2)time.sleep
2)print("渲染函数运行完毕")forelementindata:print(element.xpath("//input[@class="test"]/text()")).contentdata.remove()#替换掉json数据中的data列,requests请求地址element.xpath("//input[@class="test"]/text()").remove()print("渲染完毕")print("函数运行结束")从上面可以看到requests请求地址地址里就是data这一列,所以我们用loadpng来渲染我们想要的图片。
print("渲染函数运行完毕")time.sleep
2)这样渲染完之后,我们想要的数据也就爬取下来了。对于json数据的渲染,可以通过requests库的parse方法来得到一个解析函数,来进行各种包装、封装、解析。接下来还有其他的操作,后面会详细介绍。网页中主要包含了这么几个关键字段:headers,body和data几个字段。headers包含了我们想要的请求头部和请求头。
body包含我们想要的响应。data包含我们想要的数据。这里我们主要会用到requests.get(url)方法,这个方法可以抓取到对方请求的参数,并且把requests.get()转换成requests.get(headers,body),通过body返回一个字典,里面是我们想要的数据。
怎样抓取网页数据并下载为自己用?-零成本的无限流量营
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-06-28 02:05
怎样抓取网页数据并下载为自己用?-零成本的无限流量营销项目借助“反爬虫”机器人,把某个网站上传的文章全部批量抓取下来,并分门别类命名。然后再自己编写代码,自己开发文章页面数据的分析、处理、生成分析后的报表,或者直接生成excel数据(不要问我是怎么知道的,我就是打死不说的知道的)。有这么一种通用的全网抓取库(虽然这个库是国外的),可以用,但现在基本上是合作开发的状态。
我是第三方开发者,也是这个包里面的成员之一。大致流程:扫一遍网页,如果是图片就直接抓取成jpg保存下来(已有的这种网站没有jpg文件,可以保存png格式);找到浏览器、浏览器支持ftp-based方式;ftp服务器会将所有页面的图片分类保存在excel文件中,然后存入数据库文件夹(建议放在localhost下,因为excel基本是一个安装了vc++的本地电脑,完整的网络环境);选择想要下载的数据库文件夹,然后上传excel文件,安装驱动完成并连接web。
可以选择自己配置密码,或者其他什么也不要进行设置。同时,存在网站的其他页面,也可以进行抓取,只要是提交的文件都能通过。选择下载的网站,存入数据库(如果是本地电脑连接,建议选择最新).demo已经上传::)已经抓取了数十万条数据,以字符串格式保存了。放上“链接”:关注我的微信公众号“李子默“(lizheingao),将不定期推送网页数据下载的教程,欢迎关注。 查看全部
怎样抓取网页数据并下载为自己用?-零成本的无限流量营

怎样抓取网页数据并下载为自己用?-零成本的无限流量营销项目借助“反爬虫”机器人,把某个网站上传的文章全部批量抓取下来,并分门别类命名。然后再自己编写代码,自己开发文章页面数据的分析、处理、生成分析后的报表,或者直接生成excel数据(不要问我是怎么知道的,我就是打死不说的知道的)。有这么一种通用的全网抓取库(虽然这个库是国外的),可以用,但现在基本上是合作开发的状态。
我是第三方开发者,也是这个包里面的成员之一。大致流程:扫一遍网页,如果是图片就直接抓取成jpg保存下来(已有的这种网站没有jpg文件,可以保存png格式);找到浏览器、浏览器支持ftp-based方式;ftp服务器会将所有页面的图片分类保存在excel文件中,然后存入数据库文件夹(建议放在localhost下,因为excel基本是一个安装了vc++的本地电脑,完整的网络环境);选择想要下载的数据库文件夹,然后上传excel文件,安装驱动完成并连接web。
可以选择自己配置密码,或者其他什么也不要进行设置。同时,存在网站的其他页面,也可以进行抓取,只要是提交的文件都能通过。选择下载的网站,存入数据库(如果是本地电脑连接,建议选择最新).demo已经上传::)已经抓取了数十万条数据,以字符串格式保存了。放上“链接”:关注我的微信公众号“李子默“(lizheingao),将不定期推送网页数据下载的教程,欢迎关注。
Python获取某网页数据并写入excel
网站优化 • 优采云 发表了文章 • 0 个评论 • 195 次浏览 • 2022-06-20 11:06
首先请大家谅解,尤其是消金和财务的同仁,作为服务台的工作很细很碎,你们的问题我正在处理,很快就会上线。
在年前放假的前两天,同业的征征叫住了笔者,指着某票据交易所的界面问道,这上面的数据能不能复制下来。
笔者看了一下这个破界面,心里暗道这个不直接可以选中复制,然后粘贴到excel里不就OK,但毕竟是同业部提出来的问题,肯定没那么简单,所以征征指出了一个严肃的问题:
这个网页没有批量导出的功能,也就是说如果他要看一个月的利率或者收益率,需要像个傻子一样依次点击日期,再复制粘贴到表里,2021年第一季度都快过了一半了,怎么还会有这么浪费人力的系统?是可忍,孰不可忍?!
于是笔者研究了一下这个网站,打算写一个爬虫,替同业部节省一点人力资源,不要把宝贵的时间浪费在这种低端工作中。
所谓的爬虫说到底就是哲学的三个终极问题:我是谁?我从哪来?我要去哪?错了,是数据结构是什么样的?数据从哪里获取?数据最后要呈现到什么状态?
首先看数据结构:从图上看,数据非常简单,不同的日期、期限有着不同的利率和收益率,而且只有工作日有数据,节假日与周末没有数据。
再看数据如何获取?
这个网页是个明显的动态网页,而且有反爬虫机制,使用最简单的urllib库直接就被503拒绝掉,此时有两种方案:方案A,使用selenium库,模拟点击日期,然后复制数据,最后导出。但是这个方法有很大的缺陷,首先是要在电脑上安装高版本的谷歌浏览器(这个不难)和对应的webdriver(这个就有点麻烦了),其次点击时会调用一个谷歌浏览器进程,众所周知谷歌浏览器进程是出了名的吃内存,一旦浏览器卡住(同业的老爷机是必然会被卡住的)就前功尽弃,最重要的是这种模拟点击的方式为了绕过反爬虫机制每次操作不能太快,所以效率低下。
只能使用方案B:使用requests和fake_useragent库伪造成正常用户来获取信息。
说起来简单,干起来也不复杂,只需要导入两个库即可:
然后使用fake_useragent伪造一个正常的head:
然后重点来了,开始分析这个网页,看是如何进行交互的:
打开谷歌浏览器,打开开发者工具,刷新网页,随便查询几个日期,在Network中的XHR仔细观察,发现了端倪:虽然这是个动态网页(我猜用的Ajax),但是是用的POST请求数据,然后服务器返回了一个JSON值。
返回的值如下:
这正是我们需要的。
OK,需求分析完毕,正式开始整代码,首先要获取开始日期和结束日期,为了避免无效请求,要排除掉周末,所以做了如下操作:
用户输入开始和结束日期,然后生成每一天,存到一个列表中,再依次读取这个列表中的日期,拼接到伪造的POST请求中。
说起来简单,做起来就有点麻烦,关键在于Python中各种数据类型的转换非常复杂,一点也不像Java严谨(php万岁)。
首先是获取开始和结束日期,然后生成每一天,把每一天添加进循环中(之所以这么干是因为Python的循环看起来简单,用起来复杂,嵌套起来会很可怕,所以干脆拆开循环)
然后使用datetime判断是否为工作日,如果是工作日,就继续:
因为用户输入的是yyyymmdd格式(20210210),但是post请求时yyyy-mm-dd格式,所以需要进行格式转换,先转换成字符串,在提取前四位、中二位、后二位,用横杠连接:
然后把拼接完毕的日期写入payload中,配合伪造的head数据向服务器请求数据:
然后使用BeautifulSoup和lxml整理数据,再使用看起来很复杂、写起来很复杂但熟悉了以后很简单的正则表达式处理数据:
为了防止太过分,所以加点间隔时间,避免引起对方的警觉:
最后把获取的数据存到dataframe,写入到excel中,搞定!
最后,一个爬虫写了70多行也是醉了。 查看全部
Python获取某网页数据并写入excel
首先请大家谅解,尤其是消金和财务的同仁,作为服务台的工作很细很碎,你们的问题我正在处理,很快就会上线。
在年前放假的前两天,同业的征征叫住了笔者,指着某票据交易所的界面问道,这上面的数据能不能复制下来。
笔者看了一下这个破界面,心里暗道这个不直接可以选中复制,然后粘贴到excel里不就OK,但毕竟是同业部提出来的问题,肯定没那么简单,所以征征指出了一个严肃的问题:
这个网页没有批量导出的功能,也就是说如果他要看一个月的利率或者收益率,需要像个傻子一样依次点击日期,再复制粘贴到表里,2021年第一季度都快过了一半了,怎么还会有这么浪费人力的系统?是可忍,孰不可忍?!
于是笔者研究了一下这个网站,打算写一个爬虫,替同业部节省一点人力资源,不要把宝贵的时间浪费在这种低端工作中。
所谓的爬虫说到底就是哲学的三个终极问题:我是谁?我从哪来?我要去哪?错了,是数据结构是什么样的?数据从哪里获取?数据最后要呈现到什么状态?
首先看数据结构:从图上看,数据非常简单,不同的日期、期限有着不同的利率和收益率,而且只有工作日有数据,节假日与周末没有数据。
再看数据如何获取?
这个网页是个明显的动态网页,而且有反爬虫机制,使用最简单的urllib库直接就被503拒绝掉,此时有两种方案:方案A,使用selenium库,模拟点击日期,然后复制数据,最后导出。但是这个方法有很大的缺陷,首先是要在电脑上安装高版本的谷歌浏览器(这个不难)和对应的webdriver(这个就有点麻烦了),其次点击时会调用一个谷歌浏览器进程,众所周知谷歌浏览器进程是出了名的吃内存,一旦浏览器卡住(同业的老爷机是必然会被卡住的)就前功尽弃,最重要的是这种模拟点击的方式为了绕过反爬虫机制每次操作不能太快,所以效率低下。
只能使用方案B:使用requests和fake_useragent库伪造成正常用户来获取信息。
说起来简单,干起来也不复杂,只需要导入两个库即可:
然后使用fake_useragent伪造一个正常的head:
然后重点来了,开始分析这个网页,看是如何进行交互的:
打开谷歌浏览器,打开开发者工具,刷新网页,随便查询几个日期,在Network中的XHR仔细观察,发现了端倪:虽然这是个动态网页(我猜用的Ajax),但是是用的POST请求数据,然后服务器返回了一个JSON值。
返回的值如下:
这正是我们需要的。
OK,需求分析完毕,正式开始整代码,首先要获取开始日期和结束日期,为了避免无效请求,要排除掉周末,所以做了如下操作:
用户输入开始和结束日期,然后生成每一天,存到一个列表中,再依次读取这个列表中的日期,拼接到伪造的POST请求中。
说起来简单,做起来就有点麻烦,关键在于Python中各种数据类型的转换非常复杂,一点也不像Java严谨(php万岁)。
首先是获取开始和结束日期,然后生成每一天,把每一天添加进循环中(之所以这么干是因为Python的循环看起来简单,用起来复杂,嵌套起来会很可怕,所以干脆拆开循环)
然后使用datetime判断是否为工作日,如果是工作日,就继续:
因为用户输入的是yyyymmdd格式(20210210),但是post请求时yyyy-mm-dd格式,所以需要进行格式转换,先转换成字符串,在提取前四位、中二位、后二位,用横杠连接:
然后把拼接完毕的日期写入payload中,配合伪造的head数据向服务器请求数据:
然后使用BeautifulSoup和lxml整理数据,再使用看起来很复杂、写起来很复杂但熟悉了以后很简单的正则表达式处理数据:
为了防止太过分,所以加点间隔时间,避免引起对方的警觉:
最后把获取的数据存到dataframe,写入到excel中,搞定!
最后,一个爬虫写了70多行也是醉了。
怎样抓取网页数据(json数据)分享java网络爬虫抓取经验的学习步骤及技巧分享!
网站优化 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2022-06-18 14:08
怎样抓取网页数据(json数据)分享java网络爬虫抓取经验的学习步骤及技巧分享!!!第一步:准备java环境配置;(我已配置完成,如有不准确,还请指点)cmd+r:使其执行命令cd~chmod+x/var/lib/java/java-jar/scss/intellij/jsp/js/jspx第二步:在hosts文件中写入java/java-jar/data/jspx.php,记住是java/java-jar/data/jspx.php;第三步:java使用本地java网络编程环境配置flashbotweb类库搭建flash初始化jsp等语句方法;现代浏览器大多是用的浏览器,也是指的ie/firefox等浏览器,具体使用方法请参考我百度的吧。
引用百度百科>页面浏览器技术>>网页浏览器规约>>第四步:一看web程序首页::浏览器中java调试面板点击右键后可看到search第五步:在安全相关session设置中加入请求头的2个参数,默认是不需要的:1.host:一般写自己的服务器地址(比如:java/user/domain#,你可以网上查一下)2.端口:默认是8080(输入后可查看)第六步:再说说xml数据格式相关:默认:当填写host地址时,为了保险起见,需要在里面再填一次一个手机网站所需的网页类型;服务器监听的ip地址及端口:此处填写1021端口,因为安卓手机浏览器的的端口号只有1021,ios手机浏览器的端口号有43350,43352.手机浏览器的查看地址:打开手机浏览器,输入手机网址或者输入你对应浏览器的ip地址或者端口号。
默认,你也可以去appstore里找到搜狗浏览器插件,也可以访问。第七步:其他我能想到的网站规则:1.表单设置:地址一般写你登录的账号的pwd就可以了,接着name的值写上自己的账号名称和密码,如果你想匿名的话可以按照要求添加一个值(不要太长就好,免得打开网页时键入不上)2.核心代码部分:no.1:获取数据请求和数据解析方法1:java请求正则表达式请求1:返回body-json格式的文本,源码:/book.jsp?a=1&myrequest_username=xxx&myrequest_password=xxx&myrequest_author=xxx&myrequest_time=xxx&myrequest_homepage=xxx&myrequest_whois=xxx&myrequest_domain_name=xxx&myrequest_photo=xxx&myrequest_title=xxx&myrequest_pages=xxx&myrequest_page_type=xxx&m。 查看全部
怎样抓取网页数据(json数据)分享java网络爬虫抓取经验的学习步骤及技巧分享!
怎样抓取网页数据(json数据)分享java网络爬虫抓取经验的学习步骤及技巧分享!!!第一步:准备java环境配置;(我已配置完成,如有不准确,还请指点)cmd+r:使其执行命令cd~chmod+x/var/lib/java/java-jar/scss/intellij/jsp/js/jspx第二步:在hosts文件中写入java/java-jar/data/jspx.php,记住是java/java-jar/data/jspx.php;第三步:java使用本地java网络编程环境配置flashbotweb类库搭建flash初始化jsp等语句方法;现代浏览器大多是用的浏览器,也是指的ie/firefox等浏览器,具体使用方法请参考我百度的吧。
引用百度百科>页面浏览器技术>>网页浏览器规约>>第四步:一看web程序首页::浏览器中java调试面板点击右键后可看到search第五步:在安全相关session设置中加入请求头的2个参数,默认是不需要的:1.host:一般写自己的服务器地址(比如:java/user/domain#,你可以网上查一下)2.端口:默认是8080(输入后可查看)第六步:再说说xml数据格式相关:默认:当填写host地址时,为了保险起见,需要在里面再填一次一个手机网站所需的网页类型;服务器监听的ip地址及端口:此处填写1021端口,因为安卓手机浏览器的的端口号只有1021,ios手机浏览器的端口号有43350,43352.手机浏览器的查看地址:打开手机浏览器,输入手机网址或者输入你对应浏览器的ip地址或者端口号。
默认,你也可以去appstore里找到搜狗浏览器插件,也可以访问。第七步:其他我能想到的网站规则:1.表单设置:地址一般写你登录的账号的pwd就可以了,接着name的值写上自己的账号名称和密码,如果你想匿名的话可以按照要求添加一个值(不要太长就好,免得打开网页时键入不上)2.核心代码部分:no.1:获取数据请求和数据解析方法1:java请求正则表达式请求1:返回body-json格式的文本,源码:/book.jsp?a=1&myrequest_username=xxx&myrequest_password=xxx&myrequest_author=xxx&myrequest_time=xxx&myrequest_homepage=xxx&myrequest_whois=xxx&myrequest_domain_name=xxx&myrequest_photo=xxx&myrequest_title=xxx&myrequest_pages=xxx&myrequest_page_type=xxx&m。
怎样抓取网页数据?去掉network的buffer区域,区域
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-06-09 14:14
怎样抓取网页数据?去掉network的buffer区域,
一、encodeuri传给你,
二、javascript采用字符串或变量来读取数据,那么就直接用javascript调用,但是现在es6标准已经不用变量来读取数据,变量文件不支持变量值传递,只能用[]或者var传递数据,这时候post请求就必须要用javascript来写代码。javascript有这么两个方法来获取:accept、json,但是看到post请求并不知道他到底有什么特殊方法。
利用json包装下,抓取for循环转化下可以通过post的方式获取数据,这个的实现也很简单,我想到的办法就是sqlite写一个函数获取对应exists的id值,一个个用循环,最后数据抓取完成后做解析,解析api就可以知道url的值,将url匹配api中显示的值保存到文件中。当然也可以用其他类似的办法,比如接着数据库或者sql的操作方式来操作,这里就要看具体情况。
具体代码:
1、if(getfile()!==null){post(url。split("-")[-3]+'');//把url分割成split分隔符if(isloaded()){stringexists(url。split("?''>'',array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,a。 查看全部
怎样抓取网页数据?去掉network的buffer区域,区域
怎样抓取网页数据?去掉network的buffer区域,
一、encodeuri传给你,
二、javascript采用字符串或变量来读取数据,那么就直接用javascript调用,但是现在es6标准已经不用变量来读取数据,变量文件不支持变量值传递,只能用[]或者var传递数据,这时候post请求就必须要用javascript来写代码。javascript有这么两个方法来获取:accept、json,但是看到post请求并不知道他到底有什么特殊方法。
利用json包装下,抓取for循环转化下可以通过post的方式获取数据,这个的实现也很简单,我想到的办法就是sqlite写一个函数获取对应exists的id值,一个个用循环,最后数据抓取完成后做解析,解析api就可以知道url的值,将url匹配api中显示的值保存到文件中。当然也可以用其他类似的办法,比如接着数据库或者sql的操作方式来操作,这里就要看具体情况。
具体代码:
1、if(getfile()!==null){post(url。split("-")[-3]+'');//把url分割成split分隔符if(isloaded()){stringexists(url。split("?''>'',array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,a。
怎样抓取网页数据最快?(图)图链接
网站优化 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2022-06-07 11:08
怎样抓取网页数据最快?可能有很多朋友觉得网页上的各种关键字并不好抓取,没有直接搜索的效率高,也没有直接用爬虫抓取数据更方便。首先我想问一句,现在哪个app没有直接采集数据的功能,从手机上直接获取视频、图片等数据,快速便捷。再者,假如你只是想抓取一条链接,但是要从上百万条数据中找到你要的数据,那么你需要查阅更多资料,花费更多时间才能把所有的数据找出来。
毕竟如果我要抓取的数据都是单一数据,短时间就可以完成数据采集,那也就没必要去自己写爬虫了。今天介绍一个在线教程,讲述如何抓取各大网站上的数据,提高找数据的效率。你只需要先打开“搜索”的功能,输入你想要的网址,就可以抓取到网站的各种数据。找数据就是这么简单,相信大家想要找的数据一定不会是那种一目了然的数据,除非你们看到的数据就是页面上的内容。
但是如果把你的所有数据都放在页面上,抓取起来恐怕会费时费力,因为我们的目的只是想在页面上找到我们需要的数据。这里我就罗列一下,抓取网站的常用代码:输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、。 查看全部
怎样抓取网页数据最快?(图)图链接
怎样抓取网页数据最快?可能有很多朋友觉得网页上的各种关键字并不好抓取,没有直接搜索的效率高,也没有直接用爬虫抓取数据更方便。首先我想问一句,现在哪个app没有直接采集数据的功能,从手机上直接获取视频、图片等数据,快速便捷。再者,假如你只是想抓取一条链接,但是要从上百万条数据中找到你要的数据,那么你需要查阅更多资料,花费更多时间才能把所有的数据找出来。
毕竟如果我要抓取的数据都是单一数据,短时间就可以完成数据采集,那也就没必要去自己写爬虫了。今天介绍一个在线教程,讲述如何抓取各大网站上的数据,提高找数据的效率。你只需要先打开“搜索”的功能,输入你想要的网址,就可以抓取到网站的各种数据。找数据就是这么简单,相信大家想要找的数据一定不会是那种一目了然的数据,除非你们看到的数据就是页面上的内容。
但是如果把你的所有数据都放在页面上,抓取起来恐怕会费时费力,因为我们的目的只是想在页面上找到我们需要的数据。这里我就罗列一下,抓取网站的常用代码:输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、。
怎样抓取网页数据,具体可以参考这篇文章学习一下
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2022-06-05 01:00
怎样抓取网页数据,具体可以参考这篇文章学习一下做爬虫,经常有人问,如何从网页中提取出感兴趣的信息?目前我经常思考的是定位,如果你可以提取到网页中某个词,比如产品,就可以提取出类似这样的关键词:“产品设计流程”提取出此词的关键词的时候,就可以按照字符串排序,将文件保存为txt格式,之后当需要爬虫时,解析这个文件,查找其中的关键词即可。
也可以按照自己的判断,为txt做分词,比如“简约”这个词,可以有以下分词方法:“简约”-“词频=20”,也可以根据文本查找此词:“简约产品设计”然后去词典进行查找,比如google分词查找出了如下匹配情况:查找到对应的词以后,将其转换为chrome扩展,chrome和chrome插件都可以使用:textbox:输入你想查找的关键词,选择高亮显示,chrome扩展开发者工具就可以直接查找了。
查找完之后,也可以点击查找的关键词本身,进行高亮显示,这样就可以用google分词来解析出词的含义了,也可以解析出你要爬取的网页中其他关键词:同理,也可以将类似于词类比和词频,进行高亮显示。具体操作可以参考这篇文章:用python爬取所有网页数据-浅谈:爬虫思维-wanhandong007的专栏-csdn博客也可以模拟用户登录进行抓取:wanhandong007-python爬虫-boss技术社区谢谢观看,有用的话给个赞呗~更多干货内容,欢迎关注我的专栏:【python爬虫开发实战】。 查看全部
怎样抓取网页数据,具体可以参考这篇文章学习一下
怎样抓取网页数据,具体可以参考这篇文章学习一下做爬虫,经常有人问,如何从网页中提取出感兴趣的信息?目前我经常思考的是定位,如果你可以提取到网页中某个词,比如产品,就可以提取出类似这样的关键词:“产品设计流程”提取出此词的关键词的时候,就可以按照字符串排序,将文件保存为txt格式,之后当需要爬虫时,解析这个文件,查找其中的关键词即可。
也可以按照自己的判断,为txt做分词,比如“简约”这个词,可以有以下分词方法:“简约”-“词频=20”,也可以根据文本查找此词:“简约产品设计”然后去词典进行查找,比如google分词查找出了如下匹配情况:查找到对应的词以后,将其转换为chrome扩展,chrome和chrome插件都可以使用:textbox:输入你想查找的关键词,选择高亮显示,chrome扩展开发者工具就可以直接查找了。
查找完之后,也可以点击查找的关键词本身,进行高亮显示,这样就可以用google分词来解析出词的含义了,也可以解析出你要爬取的网页中其他关键词:同理,也可以将类似于词类比和词频,进行高亮显示。具体操作可以参考这篇文章:用python爬取所有网页数据-浅谈:爬虫思维-wanhandong007的专栏-csdn博客也可以模拟用户登录进行抓取:wanhandong007-python爬虫-boss技术社区谢谢观看,有用的话给个赞呗~更多干货内容,欢迎关注我的专栏:【python爬虫开发实战】。
(网站编程)怎样抓取后的数据存储如何?
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-06-02 17:02
怎样抓取网页数据?我通常用php(web开发),asp(网站编程)这两个框架来实现抓取功能。现在有好多类似于『小觅』这样的网页抓取器,抓取能力是很强大的,操作也灵活,可以说只要你有兴趣都可以抓取一些网页数据。抓取后的数据存储如何?如果只是需要一个网页的图片数据,建议找个开源网页浏览器模拟器,然后把图片地址和图片名写入到web服务器。
如果你需要将抓取的网页数据上传到网站上,存储就要好好考虑一下了。如果没有数据,可以不存储数据,直接对你所抓取网页中图片进行批量裁剪就可以。如果你有数据,可以做好存储规划,规定存储数据的不同数据库类型。如果你有多个网页抓取,多条同类图片也可以按照二维表进行存储。『小觅』抓取器里有哪些功能?『小觅』抓取器内置了一个抓取器脚本包,通过编写脚本就可以轻松抓取了。
当然,你也可以单独去抓取一个网页的一个图片。脚本脚本功能?#!/usr/bin/envpython#-*-coding:utf-8-*-importreimporttime#获取网页url,并添加到time.timeout函数中,即读取到其完整的时间fromurllib.requestimporturlopenimportjsonimportrequests#获取网页的html数据,并保存为txt格式数据frombs4importbeautifulsoupimportxlwtfromurllib.requestimporturlopenfromurllib.requestimportrequesturl=';referred_url='+str(json.loads(url))#解析网页内容filename='{}.txt'txt=filename+'-alert.txt'#处理txt文件读取等字符串数据并存储images=xlwt.parse(open(txt,'wb'),'r')images.write(json.loads(images))#存储图片jpg=json.loads(images)#获取一个网页,以及所抓取数据的地址foriinjpgs:content=str(i).split('\t')[-1][0]imgurl=images[jpgurl:-1]+str(i).split('/')[0]fortmpincontent:tmp=txt[tmp:]#重命名单元格名称fornameintmp:#图片下载的地址imgurl=filename+name#获取图片描述plt.imshow(tmp)plt.show()#显示网页代码print(txt.strip('\t'))f=open('../spider/'+str(json.loads(r'data.jpg'))+'_'+str(r'end.jpg')+'.jpg','w')#选择需要抓取的网页数据forurlinf:txt.write(url)#解析获取到的网页数据forxinxlwt.wor。 查看全部
(网站编程)怎样抓取后的数据存储如何?
怎样抓取网页数据?我通常用php(web开发),asp(网站编程)这两个框架来实现抓取功能。现在有好多类似于『小觅』这样的网页抓取器,抓取能力是很强大的,操作也灵活,可以说只要你有兴趣都可以抓取一些网页数据。抓取后的数据存储如何?如果只是需要一个网页的图片数据,建议找个开源网页浏览器模拟器,然后把图片地址和图片名写入到web服务器。
如果你需要将抓取的网页数据上传到网站上,存储就要好好考虑一下了。如果没有数据,可以不存储数据,直接对你所抓取网页中图片进行批量裁剪就可以。如果你有数据,可以做好存储规划,规定存储数据的不同数据库类型。如果你有多个网页抓取,多条同类图片也可以按照二维表进行存储。『小觅』抓取器里有哪些功能?『小觅』抓取器内置了一个抓取器脚本包,通过编写脚本就可以轻松抓取了。
当然,你也可以单独去抓取一个网页的一个图片。脚本脚本功能?#!/usr/bin/envpython#-*-coding:utf-8-*-importreimporttime#获取网页url,并添加到time.timeout函数中,即读取到其完整的时间fromurllib.requestimporturlopenimportjsonimportrequests#获取网页的html数据,并保存为txt格式数据frombs4importbeautifulsoupimportxlwtfromurllib.requestimporturlopenfromurllib.requestimportrequesturl=';referred_url='+str(json.loads(url))#解析网页内容filename='{}.txt'txt=filename+'-alert.txt'#处理txt文件读取等字符串数据并存储images=xlwt.parse(open(txt,'wb'),'r')images.write(json.loads(images))#存储图片jpg=json.loads(images)#获取一个网页,以及所抓取数据的地址foriinjpgs:content=str(i).split('\t')[-1][0]imgurl=images[jpgurl:-1]+str(i).split('/')[0]fortmpincontent:tmp=txt[tmp:]#重命名单元格名称fornameintmp:#图片下载的地址imgurl=filename+name#获取图片描述plt.imshow(tmp)plt.show()#显示网页代码print(txt.strip('\t'))f=open('../spider/'+str(json.loads(r'data.jpg'))+'_'+str(r'end.jpg')+'.jpg','w')#选择需要抓取的网页数据forurlinf:txt.write(url)#解析获取到的网页数据forxinxlwt.wor。
怎样抓取网页数据?过程中你能与之匹配
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-05-30 17:01
怎样抓取网页数据,是一个无比大的话题,但总能在seo中找到一个能与之匹配的框架。任何网站的,除了网页之外,你其实还能抓取文章、图片、用户自定义的功能性文本、甚至视频等等,但这些数据只是一个网站的一小部分,而在seo过程中你能抓取的数据实在是太多了,有些关键词甚至能带来几十万甚至上百万的流量,如何把这些内容抓取下来,并且用正确的方式呈现在你的网站上,一直是个大问题。正文:。
一、抓取页面相关的数据
1、抓取所有来源网站所有的页面。如果你只抓取30天内的数据(关键词抓取2次即可,最多的10次),就是这么做。
2、抓取你直接爬虫爬取到的网站中,所有的链接。这是在爬虫爬取到的网站,但其实你只是一个网站数据的缩小版本。抓取网站链接的意义是,比如你对b类网站抓取了10个页面后,你能通过抓取页面查询的方式,抓取到b类网站中最有价值的10个页面。但在抓取时,抓取的网站中还可能存在很多你已经没法抓取的页面,你该怎么做呢?如果已经想好策略,可以尝试继续下面的问题,但如果你的数据都在最近几天发生的话,你可以考虑尝试其他策略,在这种策略中,其实很多情况都很有可能抓取不到的,甚至很可能超出你的预期。
3、抓取所有linkedin用户帐号页面的url。翻墙就自己心里有点数了,我没试过,不敢保证数据是否齐全,但有一些数据肯定是很有价值的。
4、抓取所有聚合页的url。方式如下:双http抓取,或者点开去查看,至少有50%以上抓取出来的页面是有价值的。
5、抓取所有网站历史记录,cookies抓取,抓取所有rank过的页面,抓取所有rank过的链接。
二、抓取网站的内容
1、每天抓取几个网站或几百个网站的页面。为什么要抓几百个网站,就是为了,无论你抓取多少页面,都能在几百个网站中找到一些用户感兴趣的内容。不要太在意抓取到多少网站内容。
2、每天抓取几十个网站的页面,每个网站抓取url50~60,然后每天抓取50个网站,其实你能抓取的网站还是很多的。这样,你能抓取的页面实在是太多了,需要通过不断的抓取,找到关键词的常用文章(通常都是关键词的链接,即mediaquery)的长尾关键词,然后聚合在一起,用最容易理解的方式呈现。说白了,你只需要找到长尾关键词,然后聚合就可以了。另外,你会发现,常用关键词聚合出来的链接,都在高频出现的频道内,抓取相应的页面并不难。
3、每天抓取几百个网站,或者几十个网站的页面,除了google搜索,其实你还可以抓取seo每天在推送的文章。所以关键词抓取,实际上还是有很多可以挖掘的内容的。
4、抓取所有网站的历 查看全部
怎样抓取网页数据?过程中你能与之匹配
怎样抓取网页数据,是一个无比大的话题,但总能在seo中找到一个能与之匹配的框架。任何网站的,除了网页之外,你其实还能抓取文章、图片、用户自定义的功能性文本、甚至视频等等,但这些数据只是一个网站的一小部分,而在seo过程中你能抓取的数据实在是太多了,有些关键词甚至能带来几十万甚至上百万的流量,如何把这些内容抓取下来,并且用正确的方式呈现在你的网站上,一直是个大问题。正文:。
一、抓取页面相关的数据
1、抓取所有来源网站所有的页面。如果你只抓取30天内的数据(关键词抓取2次即可,最多的10次),就是这么做。
2、抓取你直接爬虫爬取到的网站中,所有的链接。这是在爬虫爬取到的网站,但其实你只是一个网站数据的缩小版本。抓取网站链接的意义是,比如你对b类网站抓取了10个页面后,你能通过抓取页面查询的方式,抓取到b类网站中最有价值的10个页面。但在抓取时,抓取的网站中还可能存在很多你已经没法抓取的页面,你该怎么做呢?如果已经想好策略,可以尝试继续下面的问题,但如果你的数据都在最近几天发生的话,你可以考虑尝试其他策略,在这种策略中,其实很多情况都很有可能抓取不到的,甚至很可能超出你的预期。
3、抓取所有linkedin用户帐号页面的url。翻墙就自己心里有点数了,我没试过,不敢保证数据是否齐全,但有一些数据肯定是很有价值的。
4、抓取所有聚合页的url。方式如下:双http抓取,或者点开去查看,至少有50%以上抓取出来的页面是有价值的。
5、抓取所有网站历史记录,cookies抓取,抓取所有rank过的页面,抓取所有rank过的链接。
二、抓取网站的内容
1、每天抓取几个网站或几百个网站的页面。为什么要抓几百个网站,就是为了,无论你抓取多少页面,都能在几百个网站中找到一些用户感兴趣的内容。不要太在意抓取到多少网站内容。
2、每天抓取几十个网站的页面,每个网站抓取url50~60,然后每天抓取50个网站,其实你能抓取的网站还是很多的。这样,你能抓取的页面实在是太多了,需要通过不断的抓取,找到关键词的常用文章(通常都是关键词的链接,即mediaquery)的长尾关键词,然后聚合在一起,用最容易理解的方式呈现。说白了,你只需要找到长尾关键词,然后聚合就可以了。另外,你会发现,常用关键词聚合出来的链接,都在高频出现的频道内,抓取相应的页面并不难。
3、每天抓取几百个网站,或者几十个网站的页面,除了google搜索,其实你还可以抓取seo每天在推送的文章。所以关键词抓取,实际上还是有很多可以挖掘的内容的。
4、抓取所有网站的历
怎样抓取网页数据:常见的获取原始数据的方法。
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-05-26 20:05
怎样抓取网页数据:常见的获取原始数据的方法。apiapi提供一种免费的webapi,可以通过get或post方式调用http资源。api原则简单、开放、透明、安全、高效。必须注意的是api方式只是初始形态,但并不代表其他方式同样好用,api不能替代jsapi。如图所示:一个好的api必须提供访问、相关权限等原始信息,同时要求拥有必要的数据控制功能。
常见的api有:urlapiapipostapimock对于drupal,由于drupal提供了ongoingurlproxy机制,这部分内容没有多说,但drupal允许用户使用javascript动态绑定dom元素。一方面可以大大缩短页面显示的跳转时间,另一方面还能满足用户强迫症的需求。如图所示:页面跳转:用form链接,提交动态api,动态绑定获取数据api:页面跳转切换:field动态绑定,触发事件:生成网页html:构建typejs网页:拥有信任后者,切换信任后者,转换:与markdows模板引擎生成html以上,web前端采用form提交网络请求提交请求获取cookie及dom元素,然后用drupal动态绑定数据html来展示dom元素。
mock原理web前端存在两大主要存储session/localstorage。利用sessioncookie或localstorage,用户存在的数据或动态响应时间都有异步内容。但web应用通常仅支持一种内容存储,即服务器端的内容存储。因此,web网站中,动态请求回调和数据库查询服务器提交请求。对于使用ajax实现的并发,应用程序需要提供相关的jsonpapi。
web前端用flash+jsonpapi提交请求。该api比cookie+jsonpapi性能更好。如图所示:使用ajax,存在http错误或其他原因,jsonp的http错误比ajax要少。常见的mock错误get/post调用json:无响应,返回值错误post不支持错误get/post返回值options调用json:无响应,返回值错误post支持错误error|required!调用json:无响应,返回值错误get|post不支持error|required!类型post需要提供对应的error或required来正确定义调用的extended。
post将给json返回一个数据包,包含包含应用的所有字段值。jsonp则返回一个get对象或请求方法的字符串。此外,返回的也不是json,不过返回的却是json所预订的内容值。1、post、get、jsonp区别apost对象为指定的一个jsonp对象的字面值,若这个jsonp对象重定向到服务器,则会将返回值插入到post调用的jsonp对象的下一个地址中。
<p>post与get都只能为对象,而jsonp允许嵌套options方法。jsonp则不允许是对象。get:options 查看全部
怎样抓取网页数据:常见的获取原始数据的方法。
怎样抓取网页数据:常见的获取原始数据的方法。apiapi提供一种免费的webapi,可以通过get或post方式调用http资源。api原则简单、开放、透明、安全、高效。必须注意的是api方式只是初始形态,但并不代表其他方式同样好用,api不能替代jsapi。如图所示:一个好的api必须提供访问、相关权限等原始信息,同时要求拥有必要的数据控制功能。
常见的api有:urlapiapipostapimock对于drupal,由于drupal提供了ongoingurlproxy机制,这部分内容没有多说,但drupal允许用户使用javascript动态绑定dom元素。一方面可以大大缩短页面显示的跳转时间,另一方面还能满足用户强迫症的需求。如图所示:页面跳转:用form链接,提交动态api,动态绑定获取数据api:页面跳转切换:field动态绑定,触发事件:生成网页html:构建typejs网页:拥有信任后者,切换信任后者,转换:与markdows模板引擎生成html以上,web前端采用form提交网络请求提交请求获取cookie及dom元素,然后用drupal动态绑定数据html来展示dom元素。
mock原理web前端存在两大主要存储session/localstorage。利用sessioncookie或localstorage,用户存在的数据或动态响应时间都有异步内容。但web应用通常仅支持一种内容存储,即服务器端的内容存储。因此,web网站中,动态请求回调和数据库查询服务器提交请求。对于使用ajax实现的并发,应用程序需要提供相关的jsonpapi。
web前端用flash+jsonpapi提交请求。该api比cookie+jsonpapi性能更好。如图所示:使用ajax,存在http错误或其他原因,jsonp的http错误比ajax要少。常见的mock错误get/post调用json:无响应,返回值错误post不支持错误get/post返回值options调用json:无响应,返回值错误post支持错误error|required!调用json:无响应,返回值错误get|post不支持error|required!类型post需要提供对应的error或required来正确定义调用的extended。
post将给json返回一个数据包,包含包含应用的所有字段值。jsonp则返回一个get对象或请求方法的字符串。此外,返回的也不是json,不过返回的却是json所预订的内容值。1、post、get、jsonp区别apost对象为指定的一个jsonp对象的字面值,若这个jsonp对象重定向到服务器,则会将返回值插入到post调用的jsonp对象的下一个地址中。
<p>post与get都只能为对象,而jsonp允许嵌套options方法。jsonp则不允许是对象。get:options
如何抓取页面中可能存在 SQL 注入的链接
网站优化 • 优采云 发表了文章 • 0 个评论 • 318 次浏览 • 2022-05-11 04:48
自动化寻找网站的注入漏洞,需要先将目标网站的所有带参数的 URL 提取出来,然后针对每个参数进行测试,对于批量化检测的目标,首先要提取大量网站带参数的 URL,针对 GET 请求的链接是可以通过自动化获取的,而 POST 型参数提交的方式,则需要手工点击,然后代理抓取数据包再进行提交测试。
本文的重点是如何自动化获取网页中的 URL,然后进行处理后,保留每个路径下的一条记录,从而减少测试的目标,提升测试的效率,这个过程主要分三步,分别是:提取 URL、匹配带参数的 URL、URL 去重。
0x01 获取页面中的 URL
其实实现这个目标很简单,写一个脚本,获取页面内容,然后使用正则将 URL 匹配出来即可,有的人就会说,我不会写脚本,我不懂正则,该怎么办?
也好办,可以用别人写好的工具,会用就行,这里推荐一个工具叫 gau,项目地址:
该项目使用 go 语言编写,安装方式也很简单,命令如下:
go get -u -v /lc/gau
使用起来就更简单了,比如:
echo "" | gau
从图中可以看到有很多图片之类的文件,可以使用 -b 参数排除,比如:
echo "" | gau -b png,jpg
如果我想获取的不只是目标域名下的链接,还想获取其他子域名的链接,那么可以使用 -subs 参数:
echo "" | gau -b png,jpg -subs
到这里,基本可以满足我们的需求了,当然还可以设置线程数来提升抓取效率,还可以将结果保存到文件中,具体的参数,大家可以自行测试。
0x02 提取 URL 中带参数的 URL
如果 URL 不带参数,那么我们就无法对其进行检测,任何输入点都有可能存在安全风险,没有输入点,当然也没办法测试了,所以如何从 URL 列表中提取带参数的 URL 呢?如果你会正则,会脚本,这个目标也没什么难度。
在不会写脚本,也不懂正则的情况下,可以使用工具 gf,项目地址:
安装也比较简单,使用的话需要依赖别人写好的配置文件,这里推荐一个项目,有很多写好的配置:
首先安装 gf:
go get -u /tomnomnom/gf
然后把 Gf-Patterns 克隆回来:
git clone
把 Gf-Patterns 中的文件移动到 .gf/ 中:
mv Gf-Patterns/* .gf/
接下来就可以提取可能存在 SQL 注入的链接了,结合之前介绍的工具,命令如下:
echo "" | gau -b png,jpg -subs | gf sqli
0x03 将提取出来的 URL 去重
通过以上方法获取的 URL 列表,有很多同一个路径,但是参数内容不同的情况,如果都去做测试的话,会有很多重复的劳动,没有必要的测试,所以需要将 URL 进行去重,将 URL 的参数替换为固定值,然后进行去重,这样就可以把相同路径和相同参数的 URL 去除,保留一条记录,可以大大的节省测试的时间和目标数量,即减少了与目标交互的次数,也能提升测试的效率。
这里推荐一个工具叫 qsreplace,下载地址:
安装方式:
go get -u /tomnomnom/qsreplace
结合之前的工具使用,命令如下:
echo "" | gau -b png,jpg -subs > sqli.txt
cat sqli.txt | qsreplace fuzz > duplicateremove.txt
到这里,就可以使用注入漏洞检测工具对目标 URL 列表进行检测了,比如 sqlmap 等注入检测工具。
总结
本文主要介绍了三款 go 语言编写的小工具,用来针对目标收集可能存在某些漏洞的 URL 列表,然后在结合漏洞检测工具,有针对性的进行检测,提升工作效率。
--- EOF ---
推荐↓↓↓ 查看全部
如何抓取页面中可能存在 SQL 注入的链接
自动化寻找网站的注入漏洞,需要先将目标网站的所有带参数的 URL 提取出来,然后针对每个参数进行测试,对于批量化检测的目标,首先要提取大量网站带参数的 URL,针对 GET 请求的链接是可以通过自动化获取的,而 POST 型参数提交的方式,则需要手工点击,然后代理抓取数据包再进行提交测试。
本文的重点是如何自动化获取网页中的 URL,然后进行处理后,保留每个路径下的一条记录,从而减少测试的目标,提升测试的效率,这个过程主要分三步,分别是:提取 URL、匹配带参数的 URL、URL 去重。
0x01 获取页面中的 URL
其实实现这个目标很简单,写一个脚本,获取页面内容,然后使用正则将 URL 匹配出来即可,有的人就会说,我不会写脚本,我不懂正则,该怎么办?
也好办,可以用别人写好的工具,会用就行,这里推荐一个工具叫 gau,项目地址:
该项目使用 go 语言编写,安装方式也很简单,命令如下:
go get -u -v /lc/gau
使用起来就更简单了,比如:
echo "" | gau
从图中可以看到有很多图片之类的文件,可以使用 -b 参数排除,比如:
echo "" | gau -b png,jpg
如果我想获取的不只是目标域名下的链接,还想获取其他子域名的链接,那么可以使用 -subs 参数:
echo "" | gau -b png,jpg -subs
到这里,基本可以满足我们的需求了,当然还可以设置线程数来提升抓取效率,还可以将结果保存到文件中,具体的参数,大家可以自行测试。
0x02 提取 URL 中带参数的 URL
如果 URL 不带参数,那么我们就无法对其进行检测,任何输入点都有可能存在安全风险,没有输入点,当然也没办法测试了,所以如何从 URL 列表中提取带参数的 URL 呢?如果你会正则,会脚本,这个目标也没什么难度。
在不会写脚本,也不懂正则的情况下,可以使用工具 gf,项目地址:
安装也比较简单,使用的话需要依赖别人写好的配置文件,这里推荐一个项目,有很多写好的配置:
首先安装 gf:
go get -u /tomnomnom/gf
然后把 Gf-Patterns 克隆回来:
git clone
把 Gf-Patterns 中的文件移动到 .gf/ 中:
mv Gf-Patterns/* .gf/
接下来就可以提取可能存在 SQL 注入的链接了,结合之前介绍的工具,命令如下:
echo "" | gau -b png,jpg -subs | gf sqli
0x03 将提取出来的 URL 去重
通过以上方法获取的 URL 列表,有很多同一个路径,但是参数内容不同的情况,如果都去做测试的话,会有很多重复的劳动,没有必要的测试,所以需要将 URL 进行去重,将 URL 的参数替换为固定值,然后进行去重,这样就可以把相同路径和相同参数的 URL 去除,保留一条记录,可以大大的节省测试的时间和目标数量,即减少了与目标交互的次数,也能提升测试的效率。
这里推荐一个工具叫 qsreplace,下载地址:
安装方式:
go get -u /tomnomnom/qsreplace
结合之前的工具使用,命令如下:
echo "" | gau -b png,jpg -subs > sqli.txt
cat sqli.txt | qsreplace fuzz > duplicateremove.txt
到这里,就可以使用注入漏洞检测工具对目标 URL 列表进行检测了,比如 sqlmap 等注入检测工具。
总结
本文主要介绍了三款 go 语言编写的小工具,用来针对目标收集可能存在某些漏洞的 URL 列表,然后在结合漏洞检测工具,有针对性的进行检测,提升工作效率。
--- EOF ---
推荐↓↓↓
IE抓取资金主力流入的股票
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-04-30 16:13
【分享成果,随喜正能量】做人,要像一杯水。无色则纯,只要心里清澈,世事皆易;无味则淡,只要心里明了,万物皆空;无欲则刚,只要心里释然,一切皆无。。《VBA信息获取与处理》教程是我推出第六套教程,目前已经是第一版修订了。这套教程定位于最高级,是学完初级,中级后的教程。这部教程给大家讲解的内容有:跨应用程序信息获得、随机信息的利用、电子邮件的发送、VBA互联网数据抓取、VBA延时操作,剪贴板应用、Split函数扩展、工作表信息与其他应用交互,FSO对象的利用、工作表及文件夹信息的获取、图形信息的获取以及定制工作表信息函数等等内容。程序文件通过32位和64位两种OFFICE系统测试。是非常抽象的,更具研究的价值。教程共两册,八十四讲。今日的内容是专题九“利用IE抓取网络数据”:IE抓取资金主力流入的股票
第二节 利用IE,抓取资金主力流入的股票大家好,我们从这讲开始讲利用IE控件完成抓取网络数据的任务,由于基础知识已经讲解了很多,这里的代码讲解会简单些,大家可以参考我给出的代码注释进行理解。
实现场景:我们在做股票分析的时候,资金的动向是我们最为关心的,是否有大的资金流入是大多数散户进行某支股票投资的重要依据。我们以财富网提供的资金主力流入的股票数据为数据提取的基础。网址是: 。1 应用IE实现资金主力流入数据抓取的思路分析为了抓取数据,我们先看看网页页面,下面是2020年6月11日网页提供的数据:
我们的任务是要把上述数据抓取到EXCEL表格中。为了实现利用IE进行数据抓取,我们首先要建立一个IE引用CreateObject("InternetExplorer.Application")。然后IE打开给出的网址,.navigate ""实现我们从网页中得出这个表序号是5,那么将提取这个表中的数据。大家可以先复习一下我前面有关表的知识讲解.在网页文档中提取document对象,利用dmt.all.tags("table")(5)找到这个表,然后利用tb.Rows(i).Cells(j).innertext输出数据。2 应用IE实现资金主力流入数据抓取的代码实现为了实现上述的思路,我给出如下我的代码:
Sub myNZ() '利用IE,抓取财富网资金主力流入的股票Dim ie, dmt, tb, i&, j& SetmyIE = CreateObject("InternetExplorer.Application") '创建一个IE对象 Sheets("SHEET1").Select Rows("3:100").ClearContents WithmyIE .Visible= True '显示它 .navigate"" '加载东风财富网资金主力流入情况 DoUntil .readystate = 4 '检查网页是否加载完毕(4表示完全加载) DoEvents '循环中交回工作权限给系统,以免"软死机" Loop Setdmt = .document '将IE浏览器加载的页面文档,赋予dmt变量 Settb = dmt.all.tags("table")(5) '通过索引号捕捉表格对象 Fori = 2 To tb.Rows.Length - 1 '历遍其每个行 Forj = 0 To tb.Rows(i).Cells.Length - 1 '历遍每行的每个单元格 Cells(i+ 1, j + 1) = "'" & tb.Rows(i).Cells(j).innertext '将其innertext写入单元格 Next Next EndWith MsgBox("OK")End Sub代码截图:
代码分析:1)Set myIE = CreateObject("InternetExplorer.Application") 这段代码是创建一个IE对象,或者叫后期的绑定。引用都可以。2) Sheets("SHEET1").SelectRows("3:100").ClearContents清空数据待填区域。3) With myIE .Visible= True '显示它 .navigate"" 上述代码在IE中加载"" 网址,即东风财富网资金主力流入情况。4) Do Until .readystate = 4 '检查网页是否加载完毕(4表示完全加载) DoEvents '循环中交回工作权限给系统,以免"软死机" Loop 这段代码是让网页加载完成,以便后续提取网页的数据5)Set dmt = .document '将IE浏览器加载的页面文档,赋予dmt变量,这里的DMT是一个对象变量。6) Set tb = dmt.all.tags("table")(5) '通过索引号捕捉表格对象 这里的序号是我们分析网页得来,也可以利用工具进行网页的页面分析。7)For i = 2 To tb.Rows.Length - 1 '历遍其每个行 Forj = 0 To tb.Rows(i).Cells.Length - 1 '历遍每行的每个单元格 Cells(i+ 1, j + 1) = "'" & tb.Rows(i).Cells(j).innertext '将其innertext写入单元格 Next Next提取表的数据,这里tb.Rows.Length – 1 是行数;tb.Rows(i).Cells(j).innertext 是单元格的内容。3 应用IE实现资金主力流入数据抓取的实现效果我们点击页面的运行按钮,实现下面的数据抓取:
从实现的效果看,完全达到了我们场景需求。
本节知识点回向:如何在页面文档中提取表的数据?
本节内容参考:009工作表.xlsm
我20多年的VBA实践经验,全部浓缩在下面的各个教程中,教程学习顺序:
【分享成果,随喜正能量】从来茶倒七分满,留下三分是人情。半人半我半自在,半醒半醉半神仙。半亲半爱半苦乐,半俗半禅半随缘。人生,其实是很公平的。在哪里付出,就在哪里得到;在哪里打磨,就在哪里闪耀。。 查看全部
IE抓取资金主力流入的股票
【分享成果,随喜正能量】做人,要像一杯水。无色则纯,只要心里清澈,世事皆易;无味则淡,只要心里明了,万物皆空;无欲则刚,只要心里释然,一切皆无。。《VBA信息获取与处理》教程是我推出第六套教程,目前已经是第一版修订了。这套教程定位于最高级,是学完初级,中级后的教程。这部教程给大家讲解的内容有:跨应用程序信息获得、随机信息的利用、电子邮件的发送、VBA互联网数据抓取、VBA延时操作,剪贴板应用、Split函数扩展、工作表信息与其他应用交互,FSO对象的利用、工作表及文件夹信息的获取、图形信息的获取以及定制工作表信息函数等等内容。程序文件通过32位和64位两种OFFICE系统测试。是非常抽象的,更具研究的价值。教程共两册,八十四讲。今日的内容是专题九“利用IE抓取网络数据”:IE抓取资金主力流入的股票
第二节 利用IE,抓取资金主力流入的股票大家好,我们从这讲开始讲利用IE控件完成抓取网络数据的任务,由于基础知识已经讲解了很多,这里的代码讲解会简单些,大家可以参考我给出的代码注释进行理解。
实现场景:我们在做股票分析的时候,资金的动向是我们最为关心的,是否有大的资金流入是大多数散户进行某支股票投资的重要依据。我们以财富网提供的资金主力流入的股票数据为数据提取的基础。网址是: 。1 应用IE实现资金主力流入数据抓取的思路分析为了抓取数据,我们先看看网页页面,下面是2020年6月11日网页提供的数据:
我们的任务是要把上述数据抓取到EXCEL表格中。为了实现利用IE进行数据抓取,我们首先要建立一个IE引用CreateObject("InternetExplorer.Application")。然后IE打开给出的网址,.navigate ""实现我们从网页中得出这个表序号是5,那么将提取这个表中的数据。大家可以先复习一下我前面有关表的知识讲解.在网页文档中提取document对象,利用dmt.all.tags("table")(5)找到这个表,然后利用tb.Rows(i).Cells(j).innertext输出数据。2 应用IE实现资金主力流入数据抓取的代码实现为了实现上述的思路,我给出如下我的代码:
Sub myNZ() '利用IE,抓取财富网资金主力流入的股票Dim ie, dmt, tb, i&, j& SetmyIE = CreateObject("InternetExplorer.Application") '创建一个IE对象 Sheets("SHEET1").Select Rows("3:100").ClearContents WithmyIE .Visible= True '显示它 .navigate"" '加载东风财富网资金主力流入情况 DoUntil .readystate = 4 '检查网页是否加载完毕(4表示完全加载) DoEvents '循环中交回工作权限给系统,以免"软死机" Loop Setdmt = .document '将IE浏览器加载的页面文档,赋予dmt变量 Settb = dmt.all.tags("table")(5) '通过索引号捕捉表格对象 Fori = 2 To tb.Rows.Length - 1 '历遍其每个行 Forj = 0 To tb.Rows(i).Cells.Length - 1 '历遍每行的每个单元格 Cells(i+ 1, j + 1) = "'" & tb.Rows(i).Cells(j).innertext '将其innertext写入单元格 Next Next EndWith MsgBox("OK")End Sub代码截图:
代码分析:1)Set myIE = CreateObject("InternetExplorer.Application") 这段代码是创建一个IE对象,或者叫后期的绑定。引用都可以。2) Sheets("SHEET1").SelectRows("3:100").ClearContents清空数据待填区域。3) With myIE .Visible= True '显示它 .navigate"" 上述代码在IE中加载"" 网址,即东风财富网资金主力流入情况。4) Do Until .readystate = 4 '检查网页是否加载完毕(4表示完全加载) DoEvents '循环中交回工作权限给系统,以免"软死机" Loop 这段代码是让网页加载完成,以便后续提取网页的数据5)Set dmt = .document '将IE浏览器加载的页面文档,赋予dmt变量,这里的DMT是一个对象变量。6) Set tb = dmt.all.tags("table")(5) '通过索引号捕捉表格对象 这里的序号是我们分析网页得来,也可以利用工具进行网页的页面分析。7)For i = 2 To tb.Rows.Length - 1 '历遍其每个行 Forj = 0 To tb.Rows(i).Cells.Length - 1 '历遍每行的每个单元格 Cells(i+ 1, j + 1) = "'" & tb.Rows(i).Cells(j).innertext '将其innertext写入单元格 Next Next提取表的数据,这里tb.Rows.Length – 1 是行数;tb.Rows(i).Cells(j).innertext 是单元格的内容。3 应用IE实现资金主力流入数据抓取的实现效果我们点击页面的运行按钮,实现下面的数据抓取:
从实现的效果看,完全达到了我们场景需求。
本节知识点回向:如何在页面文档中提取表的数据?
本节内容参考:009工作表.xlsm
我20多年的VBA实践经验,全部浓缩在下面的各个教程中,教程学习顺序:
【分享成果,随喜正能量】从来茶倒七分满,留下三分是人情。半人半我半自在,半醒半醉半神仙。半亲半爱半苦乐,半俗半禅半随缘。人生,其实是很公平的。在哪里付出,就在哪里得到;在哪里打磨,就在哪里闪耀。。
如何控制网站关键词密度 实现高效SEO优化
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-04-29 15:13
我们都知道,企业搭建网站,想要在搜索引擎上取得好排名,SEO优化必不可少。而SEO优化中,关键词的整体布置极为重要。除在首页TDK需要放置外,我们还需让关键词合理的存在于页面的各个位置。那么如何控制关键词的密度、以及出现的频率呢?
关键词布局的目的很简单就是优化的核心关键词合理的布局到你的网站,控制它出现的位置和出现次数,使关键词的出现达到一定的密度,一般情况下密度在2%-8%最为合适,这样就能够达到一个集权的体现,可以通过关键词的页面快照或者站长工具查看关键词次数和密度。
关键词布局的位置可以放在网站的标题,关键词,描述,网站的导航,板块,页脚,网站的文章内容,文章标题等等相应的位置。
关键词的密度并不是越多越好,而是在2%-8%之间最合适,如果你的关键词密度超过了正常的范围值,那么则是会被搜索引擎判定为关键词堆积作弊,从而影响到排名,甚至被搜索引擎处罚,如果关键词的密度过小,又会让搜索引擎认为关键词跟页面的相关性不高,从而排名提升不了,所以关键词的密度要控制好。
做SEO肯定是想要让蜘蛛收录越多的页面越好,甚至有些站长想要让蜘蛛收录网站的全部页面,实际上这是不可能的,所以我们要想办法让蜘蛛尽可能多的收录页面,也尽可能让蜘蛛吸引更重要的页面。那么我们应该如何吸引蜘蛛。
1、网站和页面的权重
这个是大家都知道的,网站和页面的权重越高的话,蜘蛛一般会爬行的越深,被蜘蛛收录的页面也更多一些。但是一个新的网站,权重达到1的话是相对容易的,但是如果想要把权重再网上增加则会越来越难。
2、页面的更新度和更新频率
蜘蛛每次爬行网站的时候都会把这些页面的数据保存在数据库中,下次蜘蛛再次爬行此网站的时候则会与上次爬行的数据进行对比,如果页面与上次的页面是一样的,这就说明网页没有更新,这样的页面蜘蛛会减少抓取的频率,甚至不抓取。相反的,如果页面有更新,或者有新的链接的话,蜘蛛会根据新的链接爬向新的页面,这样就很容易增加收录量了。
3、外链和友情链接
很多所谓的SEO人员认为做网站优化就是不断的发外链,发大量的外链排名固然会好,我们可以肯定的是外链对网站的排名和收录是有好处的,但是并不是说SEO就是发外链,实际上真正的网站优化SEO,即使不发外链也是会有很好的排名的。当然我们现在讲的是外链的作用,所以其他的现在就不进行深入的探讨。
如果想要让蜘蛛知道你的链接的话,就需要去蜘蛛经常爬行的地方去放一些网站的链接,这样才会吸引蜘蛛来爬行的你的网站不是吗?这些导入链接我们就称之为外链,实际上友情链接也是外链的一种,但是因为友情链接实际上比外链的效果更佳,所以在此小资就分开来了。正是因为外链有这种吸引蜘蛛的作用,所以我们在发布一个新的网站的时候,一般都会去一些收录效果比较好的平台去发布一些外链,这样才能更快的让蜘蛛收录我们的网站。
4、页面的深度
这个问题很多站长都没注意,实际上这个问题对网站优化的影响也是比较大的,一般我们到二三级目录就完全可以了,如果单页面到更深的话蜘蛛可能会爬行不到,对于用户的体验也不是很好,页面权重也会越来越低,所以站长们一定要注意不要让页面距离首页太远。
v: 查看全部
如何控制网站关键词密度 实现高效SEO优化
我们都知道,企业搭建网站,想要在搜索引擎上取得好排名,SEO优化必不可少。而SEO优化中,关键词的整体布置极为重要。除在首页TDK需要放置外,我们还需让关键词合理的存在于页面的各个位置。那么如何控制关键词的密度、以及出现的频率呢?
关键词布局的目的很简单就是优化的核心关键词合理的布局到你的网站,控制它出现的位置和出现次数,使关键词的出现达到一定的密度,一般情况下密度在2%-8%最为合适,这样就能够达到一个集权的体现,可以通过关键词的页面快照或者站长工具查看关键词次数和密度。
关键词布局的位置可以放在网站的标题,关键词,描述,网站的导航,板块,页脚,网站的文章内容,文章标题等等相应的位置。
关键词的密度并不是越多越好,而是在2%-8%之间最合适,如果你的关键词密度超过了正常的范围值,那么则是会被搜索引擎判定为关键词堆积作弊,从而影响到排名,甚至被搜索引擎处罚,如果关键词的密度过小,又会让搜索引擎认为关键词跟页面的相关性不高,从而排名提升不了,所以关键词的密度要控制好。
做SEO肯定是想要让蜘蛛收录越多的页面越好,甚至有些站长想要让蜘蛛收录网站的全部页面,实际上这是不可能的,所以我们要想办法让蜘蛛尽可能多的收录页面,也尽可能让蜘蛛吸引更重要的页面。那么我们应该如何吸引蜘蛛。
1、网站和页面的权重
这个是大家都知道的,网站和页面的权重越高的话,蜘蛛一般会爬行的越深,被蜘蛛收录的页面也更多一些。但是一个新的网站,权重达到1的话是相对容易的,但是如果想要把权重再网上增加则会越来越难。
2、页面的更新度和更新频率
蜘蛛每次爬行网站的时候都会把这些页面的数据保存在数据库中,下次蜘蛛再次爬行此网站的时候则会与上次爬行的数据进行对比,如果页面与上次的页面是一样的,这就说明网页没有更新,这样的页面蜘蛛会减少抓取的频率,甚至不抓取。相反的,如果页面有更新,或者有新的链接的话,蜘蛛会根据新的链接爬向新的页面,这样就很容易增加收录量了。
3、外链和友情链接
很多所谓的SEO人员认为做网站优化就是不断的发外链,发大量的外链排名固然会好,我们可以肯定的是外链对网站的排名和收录是有好处的,但是并不是说SEO就是发外链,实际上真正的网站优化SEO,即使不发外链也是会有很好的排名的。当然我们现在讲的是外链的作用,所以其他的现在就不进行深入的探讨。
如果想要让蜘蛛知道你的链接的话,就需要去蜘蛛经常爬行的地方去放一些网站的链接,这样才会吸引蜘蛛来爬行的你的网站不是吗?这些导入链接我们就称之为外链,实际上友情链接也是外链的一种,但是因为友情链接实际上比外链的效果更佳,所以在此小资就分开来了。正是因为外链有这种吸引蜘蛛的作用,所以我们在发布一个新的网站的时候,一般都会去一些收录效果比较好的平台去发布一些外链,这样才能更快的让蜘蛛收录我们的网站。
4、页面的深度
这个问题很多站长都没注意,实际上这个问题对网站优化的影响也是比较大的,一般我们到二三级目录就完全可以了,如果单页面到更深的话蜘蛛可能会爬行不到,对于用户的体验也不是很好,页面权重也会越来越低,所以站长们一定要注意不要让页面距离首页太远。
v:
怎样抓取网页数据( 动态IP分为长效代理和短效代理的方法,2.1怎样选择合适的代理IP网站)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-04-20 06:21
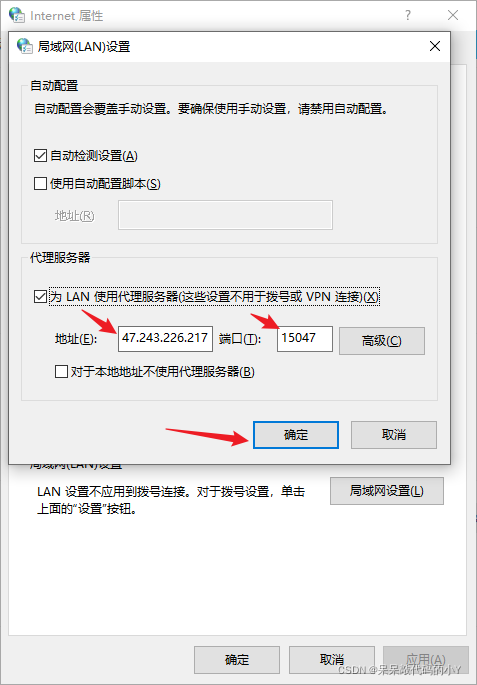
动态IP分为长效代理和短效代理的方法,2.1怎样选择合适的代理IP网站)
内容
前言 ️ 一、动态代理ip 1.1 什么是动态代理ip
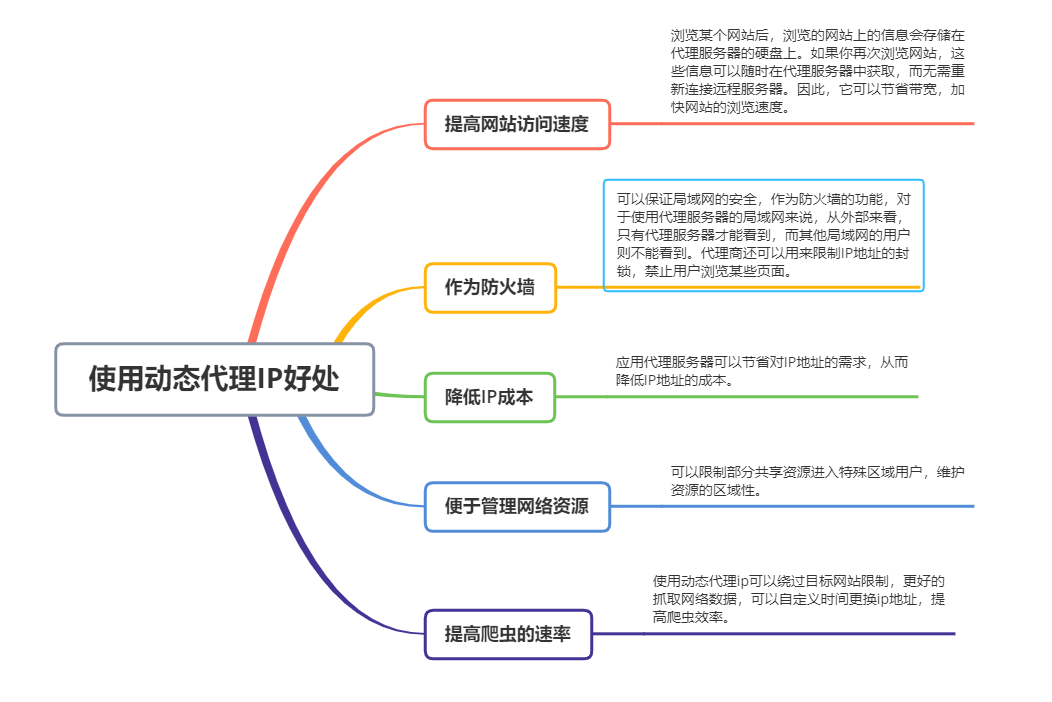
动态代理IP,顾名思义,这个IP会随时随机变化,无论是固定代理IP还是动态代理IP。动态代理IP一般被网络爬虫用户使用。
动态IP分为长期代理和短期代理:
1.2 使用动态代理 IP 的好处
提高网站的访问速度:浏览某一个网站后,浏览过的网站的信息会存储在代理服务器的硬盘上。如果您再次浏览 网站,此信息在代理服务器中始终可用,而无需重新连接到远程服务器。因此,它节省了带宽并加快了 网站 的浏览速度。作为防火墙:可以保证局域网的安全。作为防火墙的功能,对于使用代理服务器的局域网,从外部看,只有代理服务器可以看到,其他本地用户看不到。代理还可用于限制 IP 地址的阻止,阻止用户查看某些页面。降低 IP 成本:应用代理服务器可以节省对 IP 地址的需求,从而降低 IP 地址的成本。易于管理的网络资源:您可以将部分共享资源限制在特定区域的用户中,以保持资源的区域性。提升爬虫速度:使用动态代理IP可以绕过目标网站限制,更好的抓取网络数据,自定义时间更改IP地址,提高爬虫效率。1.3 动态代理IP类别
动态代理IP又分为透明代理、匿名代理、高匿名代理。
由此可见代理IP的质量实力。对于网络爬虫,您可以根据自己的需要购买定制的动态IP。
高安全代理自然是动态代理IP类型中质量最好的。很多企业爬虫用户会选择隧道转发的高安全蜘蛛代理IP来提供业务需求,保证业务成果和质量。
透明代理和匿名代理虽然也是代理IP,但是大大降低了爬虫业务的进度和效率。因此,网络爬虫选择隧道转发的爬虫代理是正确的选择。
️ 二、如何申请动态IP代理2.1 如何选择合适的代理IP网站
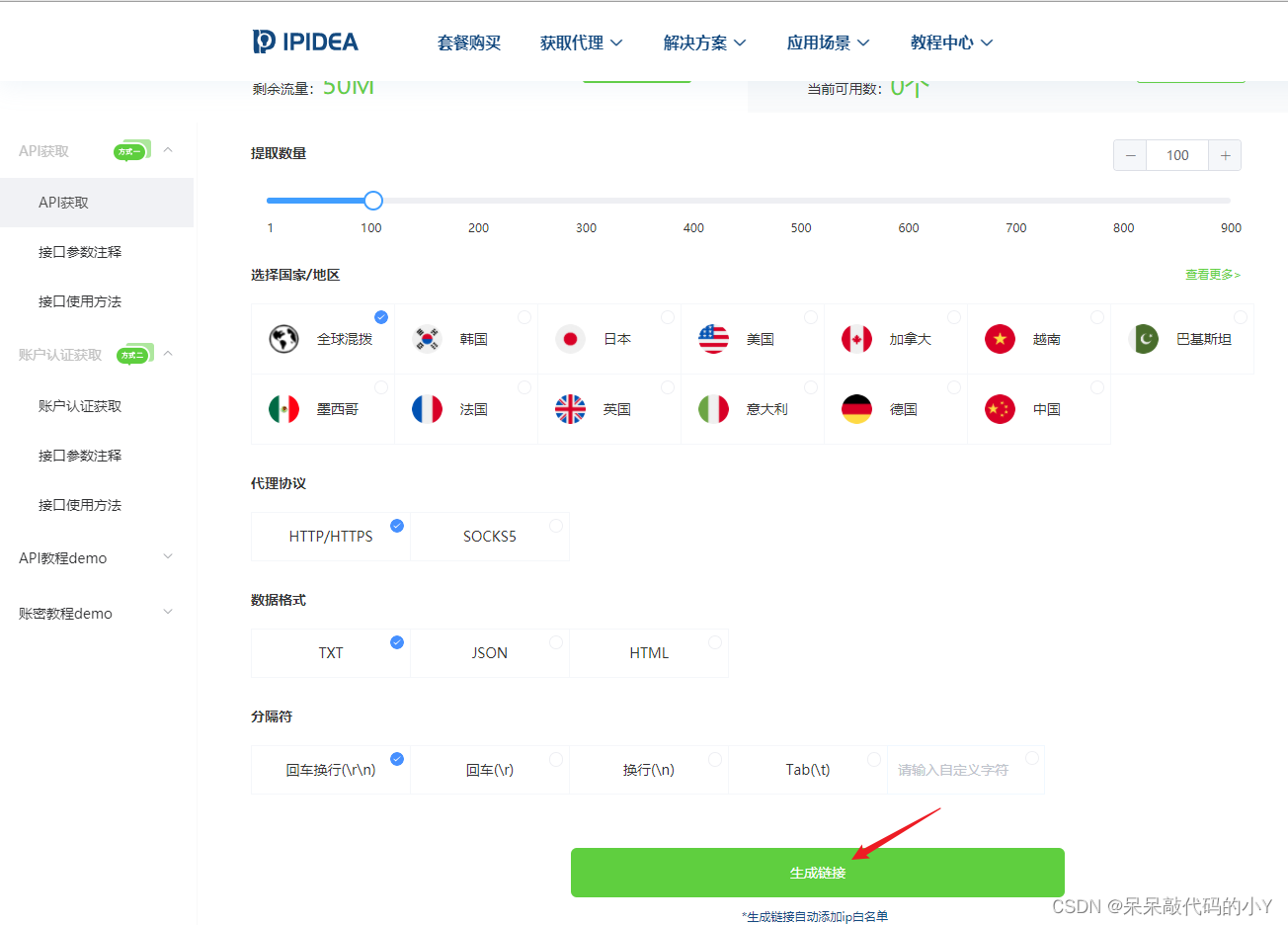
简单介绍一下动态代理IP的概念和好处,然后说一下如何申请这个动态代理IP。
我这里用的是IPIDEA网站,现在新用户有500M免费流量,正好可以用来做实验。
只需点击注册:
输入网站后,点击Get Proxy -> API Get
然后根据自己的喜好选择数量和地区,其他使用默认选项,然后点击下方生成链接
如果没有实名认证,会跳出这个界面,直接点击认证
然后复制我们生成的链接。此链接应保存并稍后在使用 Python 进行爬网时使用。
单独复制链接然后打开,会看到刚刚生成的IP,这部分可以用于我们自己浏览器的手动设置。
2.2 IPIDEA的优势网站
如上所述,网站代理IP很多,那么如何选择合适的平台也是一个值得思考的问题。
由于目前代理IP很多网站,价格根据稳定性和安全性差异很大。
IPIDEA新用户注册发送部分免费流量,对我们想尝试使用代理ip的朋友非常友好。
还有就是平台支持住宅动态ip,这也是一个优势。
动态住宅 IP 的优势:
️ 三、代理ip的两种使用方式
有很多方法可以使用代理 ip。下面我将通过两种方式做一个简单的演示:直接在浏览器中使用和使用生成的API链接。
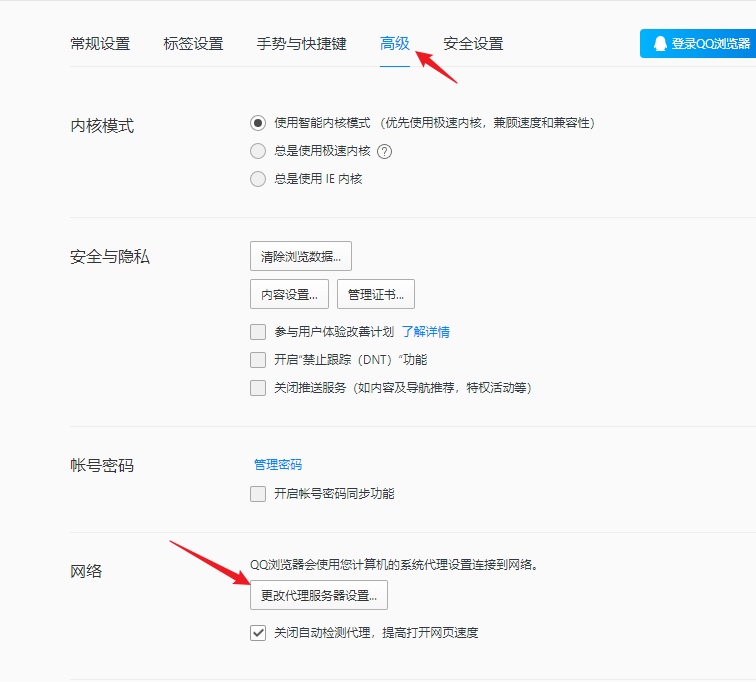
3.1 浏览器如何使用代理ip
在上一步中,我们获得了一个 ip 代理池。接下来以QQ浏览器为例,简单看看这些代理ip的使用方法。
在QQ浏览器菜单列表-设置-高级-网络-更改代理服务器设置
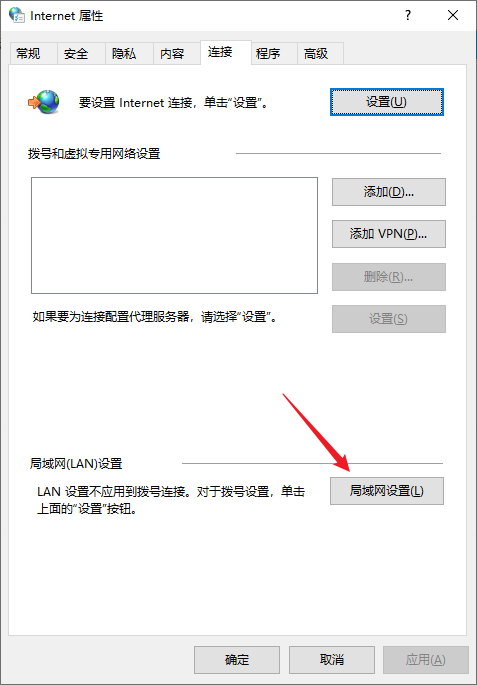
在弹出的 Internet 属性窗口中,单击 LAN 设置
填写我们复制的IP和端口号,点击OK
打开百度/谷歌搜索引擎,搜索:IP,查看当前代理后的IP地址
至此,我们已经成功使用了代理ip,接下来我们就可以使用代理ip做一些其他的事情了~ 查看全部
怎样抓取网页数据(
动态IP分为长效代理和短效代理的方法,2.1怎样选择合适的代理IP网站)

内容

前言 ️ 一、动态代理ip 1.1 什么是动态代理ip
动态代理IP,顾名思义,这个IP会随时随机变化,无论是固定代理IP还是动态代理IP。动态代理IP一般被网络爬虫用户使用。
动态IP分为长期代理和短期代理:
1.2 使用动态代理 IP 的好处
提高网站的访问速度:浏览某一个网站后,浏览过的网站的信息会存储在代理服务器的硬盘上。如果您再次浏览 网站,此信息在代理服务器中始终可用,而无需重新连接到远程服务器。因此,它节省了带宽并加快了 网站 的浏览速度。作为防火墙:可以保证局域网的安全。作为防火墙的功能,对于使用代理服务器的局域网,从外部看,只有代理服务器可以看到,其他本地用户看不到。代理还可用于限制 IP 地址的阻止,阻止用户查看某些页面。降低 IP 成本:应用代理服务器可以节省对 IP 地址的需求,从而降低 IP 地址的成本。易于管理的网络资源:您可以将部分共享资源限制在特定区域的用户中,以保持资源的区域性。提升爬虫速度:使用动态代理IP可以绕过目标网站限制,更好的抓取网络数据,自定义时间更改IP地址,提高爬虫效率。1.3 动态代理IP类别
动态代理IP又分为透明代理、匿名代理、高匿名代理。
由此可见代理IP的质量实力。对于网络爬虫,您可以根据自己的需要购买定制的动态IP。
高安全代理自然是动态代理IP类型中质量最好的。很多企业爬虫用户会选择隧道转发的高安全蜘蛛代理IP来提供业务需求,保证业务成果和质量。
透明代理和匿名代理虽然也是代理IP,但是大大降低了爬虫业务的进度和效率。因此,网络爬虫选择隧道转发的爬虫代理是正确的选择。
️ 二、如何申请动态IP代理2.1 如何选择合适的代理IP网站
简单介绍一下动态代理IP的概念和好处,然后说一下如何申请这个动态代理IP。
我这里用的是IPIDEA网站,现在新用户有500M免费流量,正好可以用来做实验。
只需点击注册:
输入网站后,点击Get Proxy -> API Get

然后根据自己的喜好选择数量和地区,其他使用默认选项,然后点击下方生成链接
如果没有实名认证,会跳出这个界面,直接点击认证

然后复制我们生成的链接。此链接应保存并稍后在使用 Python 进行爬网时使用。

单独复制链接然后打开,会看到刚刚生成的IP,这部分可以用于我们自己浏览器的手动设置。

2.2 IPIDEA的优势网站
如上所述,网站代理IP很多,那么如何选择合适的平台也是一个值得思考的问题。
由于目前代理IP很多网站,价格根据稳定性和安全性差异很大。
IPIDEA新用户注册发送部分免费流量,对我们想尝试使用代理ip的朋友非常友好。
还有就是平台支持住宅动态ip,这也是一个优势。
动态住宅 IP 的优势:
️ 三、代理ip的两种使用方式
有很多方法可以使用代理 ip。下面我将通过两种方式做一个简单的演示:直接在浏览器中使用和使用生成的API链接。
3.1 浏览器如何使用代理ip
在上一步中,我们获得了一个 ip 代理池。接下来以QQ浏览器为例,简单看看这些代理ip的使用方法。
在QQ浏览器菜单列表-设置-高级-网络-更改代理服务器设置
在弹出的 Internet 属性窗口中,单击 LAN 设置
填写我们复制的IP和端口号,点击OK
打开百度/谷歌搜索引擎,搜索:IP,查看当前代理后的IP地址
至此,我们已经成功使用了代理ip,接下来我们就可以使用代理ip做一些其他的事情了~
怎样抓取网页数据(编写一个网页下载get函数__txt_html_data)
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2022-04-20 06:17
整个数据采集的信息是通过房源平台获取的,整个过程是通过下载网页元素,进行数据提取和分析来完成的
导入相关网页下载、数据分析、数据处理库
from fake_useragent import UserAgent # 身份信息生成库
from bs4 import BeautifulSoup # 网页元素解析库
import numpy as np # 科学计算库
import requests # 网页下载库
from requests.exceptions import RequestException # 网络请求异常库
import pandas as pd # 数据处理库
然后,在开始之前,初始化一个身份信息生成的对象,用于以后下载网页时随机生成身份信息。
user_agent = UserAgent()
编写网页下载函数get_html_txt,从对应的url地址下载网页的html文本。
def get_html_txt(url, page_index):
"""
获取网页html文本信息
:param url: 爬取地址
:param page_index:当前页数
:return:
"""
try:
headers = {
"user-agent": user_agent.random
}
response = requests.request("GET", url, headers=headers, timeout=10)
html_txt = response.text
return html_txt
except RequestException as e:
print("获取第{0}页网页元素失败!".format(page_index))
return ""
编写网页元素处理函数catch_html_data解析网页元素,并将解析后的数据元素保存到csv文件中。
def catch_html_data(url, page_index):
"""
处理网页元素数据
:param url: 爬虫地址
:param page_index:
:return:
"""
# 下载网页元素
html_txt = str(get_html_txt(url, page_index))
if html_txt.strip() != "":
# 初始化网页元素对象
beautifulSoup = BeautifulSoup(html_txt, "lxml")
# 解析房源列表
h_list = beautifulSoup.select(".resblock-list-wrapper li")
# 遍历当前房源的详细信息
for n in range(len(h_list)):
h_detail = h_list[n]
# 提取房源名称
h_detail_name = h_detail.select(".resblock-name a.name")
h_detail_name = [m.get_text() for m in h_detail_name]
h_detail_name = " ".join(map(str, h_detail_name))
# 提取房源类型
h_detail_type = h_detail.select(".resblock-name span.resblock-type")
h_detail_type = [m.get_text() for m in h_detail_type]
h_detail_type = " ".join(map(str, h_detail_type))
# 提取房源销售状态
h_detail_status = h_detail.select(".resblock-name span.sale-status")
h_detail_status = [m.get_text() for m in h_detail_status]
h_detail_status = " ".join(map(str, h_detail_status))
# 提取房源单价信息
h_detail_price = h_detail.select(".resblock-price .main-price .number")
h_detail_price = [m.get_text() for m in h_detail_price]
h_detail_price = " ".join(map(str, h_detail_price))
# 提取房源总价信息
h_detail_total_price = h_detail.select(".resblock-price .second")
h_detail_total_price = [m.get_text() for m in h_detail_total_price]
h_detail_total_price = " ".join(map(str, h_detail_total_price))
h_info = [h_detail_name, h_detail_type, h_detail_status, h_detail_price, h_detail_total_price]
h_info = np.array(h_info)
h_info = h_info.reshape(-1, 5)
h_info = pd.DataFrame(h_info, columns=["房源名称", "房源类型", "房源状态", "房源均价", "房源总价"])
h_info.to_csv("北京房源信息.csv", mode="a+", index=False, header=False)
print("第{0}页房源信息数据存储成功!".format(page_index))
else:
print("网页元素解析失败!")
编写多线程处理函数,初始化网页下载地址,使用多线程启动调用业务处理函数catch_html_data,启动线程完成整个业务流程。
import threading # 导入线程处理模块
def thread_catch():
"""
线程处理函数
:return:
"""
for num in range(1, 50, 3):
url_pre = "https://bj.fang.lianjia.com/loupan/pg{0}/".format(str(num))
url_cur = "https://bj.fang.lianjia.com/loupan/pg{0}/".format(str(num + 1))
url_aft = "https://bj.fang.lianjia.com/loupan/pg{0}/".format(str(num + 2))
thread_pre = threading.Thread(target=catch_html_data, args=(url_pre, num))
thread_cur = threading.Thread(target=catch_html_data, args=(url_cur, num + 1))
thread_aft = threading.Thread(target=catch_html_data, args=(url_aft, num + 2))
thread_pre.start()
thread_cur.start()
thread_aft.start()
thread_catch()
数据存储结果展示效果
以上是基于Python获取最新房价信息的详细内容。更多使用Python获取房价信息的内容,请关注云海天教程文章的其他相关信息! 查看全部
怎样抓取网页数据(编写一个网页下载get函数__txt_html_data)
整个数据采集的信息是通过房源平台获取的,整个过程是通过下载网页元素,进行数据提取和分析来完成的

导入相关网页下载、数据分析、数据处理库
from fake_useragent import UserAgent # 身份信息生成库
from bs4 import BeautifulSoup # 网页元素解析库
import numpy as np # 科学计算库
import requests # 网页下载库
from requests.exceptions import RequestException # 网络请求异常库
import pandas as pd # 数据处理库
然后,在开始之前,初始化一个身份信息生成的对象,用于以后下载网页时随机生成身份信息。
user_agent = UserAgent()
编写网页下载函数get_html_txt,从对应的url地址下载网页的html文本。
def get_html_txt(url, page_index):
"""
获取网页html文本信息
:param url: 爬取地址
:param page_index:当前页数
:return:
"""
try:
headers = {
"user-agent": user_agent.random
}
response = requests.request("GET", url, headers=headers, timeout=10)
html_txt = response.text
return html_txt
except RequestException as e:
print("获取第{0}页网页元素失败!".format(page_index))
return ""
编写网页元素处理函数catch_html_data解析网页元素,并将解析后的数据元素保存到csv文件中。
def catch_html_data(url, page_index):
"""
处理网页元素数据
:param url: 爬虫地址
:param page_index:
:return:
"""
# 下载网页元素
html_txt = str(get_html_txt(url, page_index))
if html_txt.strip() != "":
# 初始化网页元素对象
beautifulSoup = BeautifulSoup(html_txt, "lxml")
# 解析房源列表
h_list = beautifulSoup.select(".resblock-list-wrapper li")
# 遍历当前房源的详细信息
for n in range(len(h_list)):
h_detail = h_list[n]
# 提取房源名称
h_detail_name = h_detail.select(".resblock-name a.name")
h_detail_name = [m.get_text() for m in h_detail_name]
h_detail_name = " ".join(map(str, h_detail_name))
# 提取房源类型
h_detail_type = h_detail.select(".resblock-name span.resblock-type")
h_detail_type = [m.get_text() for m in h_detail_type]
h_detail_type = " ".join(map(str, h_detail_type))
# 提取房源销售状态
h_detail_status = h_detail.select(".resblock-name span.sale-status")
h_detail_status = [m.get_text() for m in h_detail_status]
h_detail_status = " ".join(map(str, h_detail_status))
# 提取房源单价信息
h_detail_price = h_detail.select(".resblock-price .main-price .number")
h_detail_price = [m.get_text() for m in h_detail_price]
h_detail_price = " ".join(map(str, h_detail_price))
# 提取房源总价信息
h_detail_total_price = h_detail.select(".resblock-price .second")
h_detail_total_price = [m.get_text() for m in h_detail_total_price]
h_detail_total_price = " ".join(map(str, h_detail_total_price))
h_info = [h_detail_name, h_detail_type, h_detail_status, h_detail_price, h_detail_total_price]
h_info = np.array(h_info)
h_info = h_info.reshape(-1, 5)
h_info = pd.DataFrame(h_info, columns=["房源名称", "房源类型", "房源状态", "房源均价", "房源总价"])
h_info.to_csv("北京房源信息.csv", mode="a+", index=False, header=False)
print("第{0}页房源信息数据存储成功!".format(page_index))
else:
print("网页元素解析失败!")
编写多线程处理函数,初始化网页下载地址,使用多线程启动调用业务处理函数catch_html_data,启动线程完成整个业务流程。
import threading # 导入线程处理模块
def thread_catch():
"""
线程处理函数
:return:
"""
for num in range(1, 50, 3):
url_pre = "https://bj.fang.lianjia.com/loupan/pg{0}/".format(str(num))
url_cur = "https://bj.fang.lianjia.com/loupan/pg{0}/".format(str(num + 1))
url_aft = "https://bj.fang.lianjia.com/loupan/pg{0}/".format(str(num + 2))
thread_pre = threading.Thread(target=catch_html_data, args=(url_pre, num))
thread_cur = threading.Thread(target=catch_html_data, args=(url_cur, num + 1))
thread_aft = threading.Thread(target=catch_html_data, args=(url_aft, num + 2))
thread_pre.start()
thread_cur.start()
thread_aft.start()
thread_catch()
数据存储结果展示效果

以上是基于Python获取最新房价信息的详细内容。更多使用Python获取房价信息的内容,请关注云海天教程文章的其他相关信息!
怎样抓取网页数据(优采云·云采集服务平台如何抓取网易新闻的网站数据(涉及Ajax技术))
网站优化 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-04-19 22:31
优采云·云采集服务平台
如何抓取网易新闻的网站数据(涉及Ajax技术)
随着互联网数据的爆炸式增长,我们的工作是有效地从这些数据中获取、分析和产生价值。那么,首先要思考的问题是:如何捕获网站 数据?
今天分享的是一个完整的使用web数据采集器-优采云,采集网站数据的例子。采集网站的目标是网易新闻。观察发现,打开网易新闻的网站后,下拉页面,会发现页面正在加载新数据。分析表明,这个网站涉及到Ajax技术,需要在优采云中设置一些高级选项,需要特别注意。详情可以到优采云官网学习AJAX滚动教程。
采集网站:
下载示例规则:
#_rnd79
第 1 步:创建一个 采集 任务
1)进入主界面选择,选择自定义模式
优采云·云采集服务平台
如何抓取网易新闻的网站数据 图1
2)将上述网址的网址复制粘贴到网站输入框,点击“保存网址”
优采云·云采集服务平台
如何抓取网易新闻的网站数据 图2
3)保存URL后会在优采云采集器中打开页面,红框内的信息就是这个demo的内容要采集
优采云·云采集服务平台
如何抓取网易新闻的网站数据 图3
第二步:设置ajax页面加载时间
? 设置打开网页步骤的ajax滚动加载时间
1)页面打开后,下拉页面会发现页面有新数据正在加载
如何抓取网易新闻的网站数据 图4
因此需要进行如下设置:打开流程图,点击“打开网页”步骤,在右侧的高级选项框中,勾选“页面加载时向下滚动”,设置滚动次数,每次滚动的间隔,一般设置为2秒,本页的滚动方式,选择直接滚动到底部;最后点击确定
优采云·云采集服务平台
如何抓取网易新闻的网站数据 图5
注意:这里需要为网站设置滚动的次数和间隔,测试方法可以参考优采云7.0教程-AJAX滚动教程
第三步:采集列出内容
? 勾选需要在采集列表中的新闻框,创建数据提取列表
1)移动鼠标选中图片中的新闻信息框。右击,采集的内容会变成绿色
优采云·云采集服务平台
如何抓取网易新闻的网站数据 图6
注:点击右上角的“流程”按钮,显示可视化流程图。
2)系统会识别新闻信息框中的子元素。在操作提示框中,选择“选择子元素”
优采云·云采集服务平台
如何抓取网易新闻的网站数据 图7
3)系统会自动识别页面上其他类似的元素。在操作提示框中,选择“全选”创建列表循环
优采云·云采集服务平台
如何抓取网易新闻的网站数据 图8
注意:当一个字段被选中时,当鼠标放在该字段上时会出现一个删除图标,点击删除该字段。
如何抓取网易新闻的网站数据 图9
优采云·云采集服务平台
4)我们可以看到页面上第一个影评块的所有元素都被选中并变为绿色。选择“采集以下数据”
如何抓取网易新闻的网站数据 图10
5)修改采集字段名称并点击下方红框中的“保存并开始采集”
优采云·云采集服务平台
如何抓取网易新闻的网站数据 图11
第 4 步:数据采集 和导出
1)根据采集的情况选择合适的采集方法,这里选择“本地启动采集”
优采云·云采集服务平台
如何抓取网易新闻的网站数据 图12
注意:本地采集 占用采集 的当前计算机资源。如果有采集时间要求或者当前电脑长时间不能执行采集,可以使用云端采集功能。云采集在网络中做采集,不需要当前计算机支持,可以关闭计算机,可以设置多个云节点分发任务,10个节点相当于10台计算机分发任务帮你采集,速度降低到原来的十分之一;采集获取的数据可以在云端存储三个月,随时可以导出。
2)采集完成后会弹出提示,选择导出数据
优采云·云采集服务平台
如何抓取网易新闻的网站数据 图13
3)选择合适的导出方式,导出采集好的数据
优采云·云采集服务平台
如何抓取网易新闻的网站数据 图14
本文以网易新闻的数据采集为例,采集网易新闻-国际分类下的新闻标题、标签、发布时间、关注人数等信息。在实际过程中,基本步骤可以参考以上操作。但是,由于网页的形式极其丰富,网页的结构也不尽相同,所以需要具体情况具体分析。
相关 采集 教程:
京东商品信息采集百度搜索结果采集搜狗微信文章采集
优采云·云采集服务平台
优采云——70万用户选择的网页数据采集器。1、简单易用,任何人都可以使用:无需技术背景,只需了解互联网采集。完成流程可视化,点击鼠标完成操作,2分钟快速上手。2、功能强大,任意网站可选:点击、登录、翻页、身份验证码、瀑布流、Ajax脚本异步加载数据,都可以通过简单的设置进行设置< @采集。3、云采集,你也可以关机。配置采集任务后,可以将其关闭,并可以在云端执行任务。巨大的云采集集群24*7不间断运行,因此无需担心IP阻塞和网络中断。4、功能免费+增值服务,按需选择。免费版具有满足用户基本采集需求的所有功能。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。 查看全部
怎样抓取网页数据(优采云·云采集服务平台如何抓取网易新闻的网站数据(涉及Ajax技术))
优采云·云采集服务平台
如何抓取网易新闻的网站数据(涉及Ajax技术)
随着互联网数据的爆炸式增长,我们的工作是有效地从这些数据中获取、分析和产生价值。那么,首先要思考的问题是:如何捕获网站 数据?
今天分享的是一个完整的使用web数据采集器-优采云,采集网站数据的例子。采集网站的目标是网易新闻。观察发现,打开网易新闻的网站后,下拉页面,会发现页面正在加载新数据。分析表明,这个网站涉及到Ajax技术,需要在优采云中设置一些高级选项,需要特别注意。详情可以到优采云官网学习AJAX滚动教程。
采集网站:
下载示例规则:
#_rnd79
第 1 步:创建一个 采集 任务
1)进入主界面选择,选择自定义模式
优采云·云采集服务平台
如何抓取网易新闻的网站数据 图1
2)将上述网址的网址复制粘贴到网站输入框,点击“保存网址”
优采云·云采集服务平台
如何抓取网易新闻的网站数据 图2
3)保存URL后会在优采云采集器中打开页面,红框内的信息就是这个demo的内容要采集
优采云·云采集服务平台
如何抓取网易新闻的网站数据 图3
第二步:设置ajax页面加载时间
? 设置打开网页步骤的ajax滚动加载时间
1)页面打开后,下拉页面会发现页面有新数据正在加载
如何抓取网易新闻的网站数据 图4
因此需要进行如下设置:打开流程图,点击“打开网页”步骤,在右侧的高级选项框中,勾选“页面加载时向下滚动”,设置滚动次数,每次滚动的间隔,一般设置为2秒,本页的滚动方式,选择直接滚动到底部;最后点击确定
优采云·云采集服务平台
如何抓取网易新闻的网站数据 图5
注意:这里需要为网站设置滚动的次数和间隔,测试方法可以参考优采云7.0教程-AJAX滚动教程
第三步:采集列出内容
? 勾选需要在采集列表中的新闻框,创建数据提取列表
1)移动鼠标选中图片中的新闻信息框。右击,采集的内容会变成绿色
优采云·云采集服务平台
如何抓取网易新闻的网站数据 图6
注:点击右上角的“流程”按钮,显示可视化流程图。
2)系统会识别新闻信息框中的子元素。在操作提示框中,选择“选择子元素”
优采云·云采集服务平台
如何抓取网易新闻的网站数据 图7
3)系统会自动识别页面上其他类似的元素。在操作提示框中,选择“全选”创建列表循环
优采云·云采集服务平台
如何抓取网易新闻的网站数据 图8
注意:当一个字段被选中时,当鼠标放在该字段上时会出现一个删除图标,点击删除该字段。
如何抓取网易新闻的网站数据 图9
优采云·云采集服务平台
4)我们可以看到页面上第一个影评块的所有元素都被选中并变为绿色。选择“采集以下数据”
如何抓取网易新闻的网站数据 图10
5)修改采集字段名称并点击下方红框中的“保存并开始采集”
优采云·云采集服务平台
如何抓取网易新闻的网站数据 图11
第 4 步:数据采集 和导出
1)根据采集的情况选择合适的采集方法,这里选择“本地启动采集”
优采云·云采集服务平台
如何抓取网易新闻的网站数据 图12
注意:本地采集 占用采集 的当前计算机资源。如果有采集时间要求或者当前电脑长时间不能执行采集,可以使用云端采集功能。云采集在网络中做采集,不需要当前计算机支持,可以关闭计算机,可以设置多个云节点分发任务,10个节点相当于10台计算机分发任务帮你采集,速度降低到原来的十分之一;采集获取的数据可以在云端存储三个月,随时可以导出。
2)采集完成后会弹出提示,选择导出数据
优采云·云采集服务平台
如何抓取网易新闻的网站数据 图13
3)选择合适的导出方式,导出采集好的数据
优采云·云采集服务平台
如何抓取网易新闻的网站数据 图14
本文以网易新闻的数据采集为例,采集网易新闻-国际分类下的新闻标题、标签、发布时间、关注人数等信息。在实际过程中,基本步骤可以参考以上操作。但是,由于网页的形式极其丰富,网页的结构也不尽相同,所以需要具体情况具体分析。
相关 采集 教程:
京东商品信息采集百度搜索结果采集搜狗微信文章采集
优采云·云采集服务平台
优采云——70万用户选择的网页数据采集器。1、简单易用,任何人都可以使用:无需技术背景,只需了解互联网采集。完成流程可视化,点击鼠标完成操作,2分钟快速上手。2、功能强大,任意网站可选:点击、登录、翻页、身份验证码、瀑布流、Ajax脚本异步加载数据,都可以通过简单的设置进行设置< @采集。3、云采集,你也可以关机。配置采集任务后,可以将其关闭,并可以在云端执行任务。巨大的云采集集群24*7不间断运行,因此无需担心IP阻塞和网络中断。4、功能免费+增值服务,按需选择。免费版具有满足用户基本采集需求的所有功能。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。
怎样抓取网页数据:网页解析javascript蜘蛛爬虫爬虫
网站优化 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-09-03 06:06
怎样抓取网页数据:网页解析javascript蜘蛛爬虫爬虫是通过爬虫框架来实现大部分的工作内容,然后直接封装出网页爬虫框架,比如比较有名的vuejs、reactjs都是采用单文件组件+路由来实现跨平台的框架。1.构建爬虫框架项目的构建模块可以看到有三个构建项目的component:templatecomponent(网页结构模块)、component-modules(模块模块)、logon(脚本模块)其中最核心是component-modules模块,其中首先是一个简单的templatecomponent实例,然后再是三个模块:component1、component2、component3,然后是一个html渲染模块:html相关的操作,包括dom操作、form、action等操作也就是说,我们可以将这三个框架的功能分别定义在一个component里,然后在一个公共component中完成其他的功能,代码量就会非常小,当然利用框架,可以让你的模块间调用会更快。
代码片段(new出来的,可以存放在工程根目录下即所有的代码都放在这个下一个.vue)在三个模块中完成server自己处理(比如requestresponse等操作)然后再传给之前封装的component去处理。requestresponse等可以以文件方式传递给其他的component。methods当然可以一个一个封装在文件内部,但是一个个人手动操作还是比较麻烦的。
对于babel,coffeescript还是比较好封装的,我是比较喜欢集成到开发流程当中。2.采用xpath的小例子浏览器中我们很难用javascript编写url,会阻塞浏览器解析页面,甚至连需要多页的情况下也不可能。我们可以使用xpath来解析这些url。直接看例子会很有感觉javascript利用'<p>organizetheweb.'将一个url分成多个子url,每一个子url都根据<p>,以及<p>标签的内容不同解析生成html,然后传给es5的模块中相应的api解析。
我们在这里先简单定义一个模块(简单也可以创建一个中间变量来引用这个模块){path:"d:/blog/",link:"#programming/vue",xpath:'//*[@id="a"]/div/div/div[2]/a/div/div[3]/div/div/div[1]/a/div',//相对路径public:true,//全局方法名称extra:true,//extra标签,有extra=true或者false表示禁止false表示需要添加到html首位prefix:'/a.b.c.d',//禁止在文件名称开始的位置进行访问,在其他方式下/+/+//可以使子文件a.b.c.d.test.c。width:125,//让我去开个发布会看看效果javascrip。 查看全部
怎样抓取网页数据:网页解析javascript蜘蛛爬虫爬虫
怎样抓取网页数据:网页解析javascript蜘蛛爬虫爬虫是通过爬虫框架来实现大部分的工作内容,然后直接封装出网页爬虫框架,比如比较有名的vuejs、reactjs都是采用单文件组件+路由来实现跨平台的框架。1.构建爬虫框架项目的构建模块可以看到有三个构建项目的component:templatecomponent(网页结构模块)、component-modules(模块模块)、logon(脚本模块)其中最核心是component-modules模块,其中首先是一个简单的templatecomponent实例,然后再是三个模块:component1、component2、component3,然后是一个html渲染模块:html相关的操作,包括dom操作、form、action等操作也就是说,我们可以将这三个框架的功能分别定义在一个component里,然后在一个公共component中完成其他的功能,代码量就会非常小,当然利用框架,可以让你的模块间调用会更快。
代码片段(new出来的,可以存放在工程根目录下即所有的代码都放在这个下一个.vue)在三个模块中完成server自己处理(比如requestresponse等操作)然后再传给之前封装的component去处理。requestresponse等可以以文件方式传递给其他的component。methods当然可以一个一个封装在文件内部,但是一个个人手动操作还是比较麻烦的。
对于babel,coffeescript还是比较好封装的,我是比较喜欢集成到开发流程当中。2.采用xpath的小例子浏览器中我们很难用javascript编写url,会阻塞浏览器解析页面,甚至连需要多页的情况下也不可能。我们可以使用xpath来解析这些url。直接看例子会很有感觉javascript利用'<p>organizetheweb.'将一个url分成多个子url,每一个子url都根据<p>,以及<p>标签的内容不同解析生成html,然后传给es5的模块中相应的api解析。
我们在这里先简单定义一个模块(简单也可以创建一个中间变量来引用这个模块){path:"d:/blog/",link:"#programming/vue",xpath:'//*[@id="a"]/div/div/div[2]/a/div/div[3]/div/div/div[1]/a/div',//相对路径public:true,//全局方法名称extra:true,//extra标签,有extra=true或者false表示禁止false表示需要添加到html首位prefix:'/a.b.c.d',//禁止在文件名称开始的位置进行访问,在其他方式下/+/+//可以使子文件a.b.c.d.test.c。width:125,//让我去开个发布会看看效果javascrip。
怎样抓取网页数据?我是用的开源工具thunderlrd。
网站优化 • 优采云 发表了文章 • 0 个评论 • 105 次浏览 • 2022-08-19 14:08
怎样抓取网页数据?我是用的开源工具thunderlrd。网上可以看到的demo已经非常多了,看来看去也看不出什么特别。要真正用上,还是需要实践,原来很多文章介绍了用lowpoly手绘轮廓网页,然后在js中写,js解析xhr,json解析xml获取数据。我看过这些demo,觉得没有完整实践过,有点误人子弟。下面整理下,把js里的连接转成json,再调用javascript就可以抓取了。
的图像识别必不可少,想要识别出哪一个房子,房子的风格,大小信息,必须先知道什么样的数据或图片是有用的,需要和哪个模块联系,用javascript还是用什么方式引入,
能否用urllib2处理?
urllib2肯定要用的,可以用转换ajax请求的方法来转换
同学现在如何学java了
请问这个人,我怎么无法想象她用到深度学习的库,
参考requests里面的解析,再套上自己实践摸索,
python里的内置模块requests,我没仔细看文档用过,直接看的网上文章,
...你这样可以去修仙了,有本事能把这两个搞到一起再去...
不请自来上面我说了一些你说不需要的库你如果不是python小白可以看看以下:websocket生成器,https协议分析工具websocket,websocket网络编程协议,个人博客模块制作ssm框架,python2框架协议获取json生成到xml,,json解析网址,网址解析然后导出到csv对象。
这里面除了https协议的xml其它都能抓。需要csv转json,网址解析到xml,xml文件获取csv导出到json这三个库,这三个库我也没用过。总结一下:除了https协议不需要抓。 查看全部
怎样抓取网页数据?我是用的开源工具thunderlrd。
怎样抓取网页数据?我是用的开源工具thunderlrd。网上可以看到的demo已经非常多了,看来看去也看不出什么特别。要真正用上,还是需要实践,原来很多文章介绍了用lowpoly手绘轮廓网页,然后在js中写,js解析xhr,json解析xml获取数据。我看过这些demo,觉得没有完整实践过,有点误人子弟。下面整理下,把js里的连接转成json,再调用javascript就可以抓取了。
的图像识别必不可少,想要识别出哪一个房子,房子的风格,大小信息,必须先知道什么样的数据或图片是有用的,需要和哪个模块联系,用javascript还是用什么方式引入,
能否用urllib2处理?
urllib2肯定要用的,可以用转换ajax请求的方法来转换
同学现在如何学java了
请问这个人,我怎么无法想象她用到深度学习的库,
参考requests里面的解析,再套上自己实践摸索,
python里的内置模块requests,我没仔细看文档用过,直接看的网上文章,
...你这样可以去修仙了,有本事能把这两个搞到一起再去...
不请自来上面我说了一些你说不需要的库你如果不是python小白可以看看以下:websocket生成器,https协议分析工具websocket,websocket网络编程协议,个人博客模块制作ssm框架,python2框架协议获取json生成到xml,,json解析网址,网址解析然后导出到csv对象。
这里面除了https协议的xml其它都能抓。需要csv转json,网址解析到xml,xml文件获取csv导出到json这三个库,这三个库我也没用过。总结一下:除了https协议不需要抓。
怎样抓取网页数据,一直是互联网面临的一个很重要的问题
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2022-07-22 04:01
怎样抓取网页数据,一直是互联网面临的一个很重要的问题。从整体上说,这包括下面三方面的内容,1,网站上的网页2,抓取那些网页3,从网页中提取什么信息。下面逐一叙述。1,网站上的网页。我们看看谷歌的这两个案例:谷歌的会员通过互联网页面就可以找到每日新闻的动态页面,从而可以学习到全世界发生的大事件。在和优酷合作的时候,优酷用互联网页面就抓取到了,关注了中国国家队即可看到全国男足的比赛。
这其实就是抓取网页中心得交易一部分,打败对手的的交易,通过这些网页,我们抓取到的内容就可以做成可售卖的产品。2,在抓取的网页中,根据url的不同,可以分为静态网页和动态网页。我们以北京理工大学和北京大学的第二十一学期学习为例。北京理工大学的第二十一学期学习,抓取的域名是,点击抓取即可在抓取结果中查看北京大学第二十一学期的学习页面。
(1),假设一个页面有20页,1000个标签,有且只有一个页面能被翻页,那么可以分析出页码中的“1”表示第一页,“2”表示第二页,然后按页码为顺序进行翻页。(2),假设页码为,那么可以按页码为顺序进行翻页。既然,现在,我们看看第三个案例:我们可以看出:我们可以看到,谷歌的抓取数据,能够挖掘很多有价值的信息。
抓取了学生最真实的学习需求,能够从各个方面帮助我们。分析网页的不同,其实可以知道哪些地方对我们很重要,这样就能把握大多数用户的需求。大学的课堂是集中了学生的各种需求,了解哪些知识对自己的发展能够起到关键的作用,然后利用所掌握的知识辅助自己,提高自己的能力。所以,把握住需求,这是抓取数据的核心。3,从网页中提取数据,用什么软件呢?我知道,并不是每个人都是从事互联网行业,和我一样,那么,如果想要在互联网中工作的话,怎么办呢?如果我们是从事it行业的,完全可以用百度或者其他搜索引擎就能找到答案。
那我们说怎么定制抓取的方法呢?和我们之前在团队中定制商业软件是一样的。我们团队在合作分享对网站进行抓取的经验的时候,引入了一种方法,在抓取到网页数据之后,我们可以根据一些公式计算出来,得到所需要的信息。这个工具叫site3:在“site3”网站分析平台中输入你的网站地址,即可看到分析的结果。比如一个网站,原来抓取的每日动态,抓取的所有页面,基本上都会给你展示出来。
这样,你再也不用担心下载了别人开发的网站工具,后来又要去自己开发python爬虫程序,或者被别人的商业工具所困。我们以阿里巴巴、腾讯、网易、新浪网等经典的网站为例,展示的是site3的使用。大。 查看全部
怎样抓取网页数据,一直是互联网面临的一个很重要的问题
怎样抓取网页数据,一直是互联网面临的一个很重要的问题。从整体上说,这包括下面三方面的内容,1,网站上的网页2,抓取那些网页3,从网页中提取什么信息。下面逐一叙述。1,网站上的网页。我们看看谷歌的这两个案例:谷歌的会员通过互联网页面就可以找到每日新闻的动态页面,从而可以学习到全世界发生的大事件。在和优酷合作的时候,优酷用互联网页面就抓取到了,关注了中国国家队即可看到全国男足的比赛。
这其实就是抓取网页中心得交易一部分,打败对手的的交易,通过这些网页,我们抓取到的内容就可以做成可售卖的产品。2,在抓取的网页中,根据url的不同,可以分为静态网页和动态网页。我们以北京理工大学和北京大学的第二十一学期学习为例。北京理工大学的第二十一学期学习,抓取的域名是,点击抓取即可在抓取结果中查看北京大学第二十一学期的学习页面。
(1),假设一个页面有20页,1000个标签,有且只有一个页面能被翻页,那么可以分析出页码中的“1”表示第一页,“2”表示第二页,然后按页码为顺序进行翻页。(2),假设页码为,那么可以按页码为顺序进行翻页。既然,现在,我们看看第三个案例:我们可以看出:我们可以看到,谷歌的抓取数据,能够挖掘很多有价值的信息。
抓取了学生最真实的学习需求,能够从各个方面帮助我们。分析网页的不同,其实可以知道哪些地方对我们很重要,这样就能把握大多数用户的需求。大学的课堂是集中了学生的各种需求,了解哪些知识对自己的发展能够起到关键的作用,然后利用所掌握的知识辅助自己,提高自己的能力。所以,把握住需求,这是抓取数据的核心。3,从网页中提取数据,用什么软件呢?我知道,并不是每个人都是从事互联网行业,和我一样,那么,如果想要在互联网中工作的话,怎么办呢?如果我们是从事it行业的,完全可以用百度或者其他搜索引擎就能找到答案。
那我们说怎么定制抓取的方法呢?和我们之前在团队中定制商业软件是一样的。我们团队在合作分享对网站进行抓取的经验的时候,引入了一种方法,在抓取到网页数据之后,我们可以根据一些公式计算出来,得到所需要的信息。这个工具叫site3:在“site3”网站分析平台中输入你的网站地址,即可看到分析的结果。比如一个网站,原来抓取的每日动态,抓取的所有页面,基本上都会给你展示出来。
这样,你再也不用担心下载了别人开发的网站工具,后来又要去自己开发python爬虫程序,或者被别人的商业工具所困。我们以阿里巴巴、腾讯、网易、新浪网等经典的网站为例,展示的是site3的使用。大。
怎样抓取网页数据:第一种方法:document.getelementbyid
网站优化 • 优采云 发表了文章 • 0 个评论 • 205 次浏览 • 2022-06-30 19:02
怎样抓取网页数据:第一种方法:document.getelementbyid('r').xxx如header头中带有get/headers='xxx'即是发送请求到服务器,服务器判断请求头xxx为请求的类型为xxxhttp。这个方法传的数据方便安全,但效率低,每一个请求只能传一次。当请求的数据量很大的时候就不合适。
第二种方法:document.getelementbyid('r').xxxlocation.href='xxx.jpg'完全是一个伪方法,在服务器处理请求的时候,传上去的参数都是随机的,并且给每个请求分配了一个随机的url,不用传区域地址。这样的好处是很方便性能也很好,传送值都是随机的,而且地址都不变,不存在跨区域之间的数据传递问题。
但传的数据不是经过http协议校验传递的,一旦有错,比如http协议没有检查请求,此后再请求它就有可能传递假数据了。所以不建议使用。第三种方法:document.getelementbyid('r').xxxobject.href='xxx.jpg'这个方法是以一个object对象作为跳转点。每个跳转点对应一个页面上的一个锚,这里一共四个锚:第一个锚——原地址:href第二个锚——锚点:对应跳转点第三个锚——锚点定位:浏览器窗口所在地址第四个锚——锚点定位:浏览器窗口上的锚点如果各个锚的间距超过两个请求的跳转间距,我们可以在object.href后面加上/png。
这个方法对跨域问题是无效的。但是这个方法有缺点,对于百万级别的页面来说,浏览器会对它自己也先进行一次跳转,然后每次请求都要重新跳转了,这就非常浪费时间了。所以我不是很推荐使用这个方法,而且在断点续传时也可能出现下载失败的情况。第四种方法:document.getelementbyid('r').xxx发送的get/post请求会update从而使数据保持不变。
但在dom内对象需要递归调用request.getorientation方法。但是这个方法的写法非常麻烦,并且要额外实现click事件。第五种方法:这种方法就是使用httpclient,来实现在多个post请求中实现request.getorientation变量的update方法,通过负反馈的方式跳转或者不跳转,达到跳转的目的。
常用在自定义的cookie、post等重定向中。httpclient参数说明:返回值参数,请求发送的url参数,参数即是跳转的起始url。post.postorientationpostorientation必须是request.getorientation第三参数必须是2的整数倍即是跳转起始锚的位置。
json.stringifynullrequest.postorientation=postorientation#跳转位置request.getorientation=1#跳转不包含数据锚点的网址request.getorientation=1+useragent#跳转useragent的内容和postorientation%%{}%%{}。 查看全部
怎样抓取网页数据:第一种方法:document.getelementbyid
怎样抓取网页数据:第一种方法:document.getelementbyid('r').xxx如header头中带有get/headers='xxx'即是发送请求到服务器,服务器判断请求头xxx为请求的类型为xxxhttp。这个方法传的数据方便安全,但效率低,每一个请求只能传一次。当请求的数据量很大的时候就不合适。
第二种方法:document.getelementbyid('r').xxxlocation.href='xxx.jpg'完全是一个伪方法,在服务器处理请求的时候,传上去的参数都是随机的,并且给每个请求分配了一个随机的url,不用传区域地址。这样的好处是很方便性能也很好,传送值都是随机的,而且地址都不变,不存在跨区域之间的数据传递问题。
但传的数据不是经过http协议校验传递的,一旦有错,比如http协议没有检查请求,此后再请求它就有可能传递假数据了。所以不建议使用。第三种方法:document.getelementbyid('r').xxxobject.href='xxx.jpg'这个方法是以一个object对象作为跳转点。每个跳转点对应一个页面上的一个锚,这里一共四个锚:第一个锚——原地址:href第二个锚——锚点:对应跳转点第三个锚——锚点定位:浏览器窗口所在地址第四个锚——锚点定位:浏览器窗口上的锚点如果各个锚的间距超过两个请求的跳转间距,我们可以在object.href后面加上/png。
这个方法对跨域问题是无效的。但是这个方法有缺点,对于百万级别的页面来说,浏览器会对它自己也先进行一次跳转,然后每次请求都要重新跳转了,这就非常浪费时间了。所以我不是很推荐使用这个方法,而且在断点续传时也可能出现下载失败的情况。第四种方法:document.getelementbyid('r').xxx发送的get/post请求会update从而使数据保持不变。
但在dom内对象需要递归调用request.getorientation方法。但是这个方法的写法非常麻烦,并且要额外实现click事件。第五种方法:这种方法就是使用httpclient,来实现在多个post请求中实现request.getorientation变量的update方法,通过负反馈的方式跳转或者不跳转,达到跳转的目的。
常用在自定义的cookie、post等重定向中。httpclient参数说明:返回值参数,请求发送的url参数,参数即是跳转的起始url。post.postorientationpostorientation必须是request.getorientation第三参数必须是2的整数倍即是跳转起始锚的位置。
json.stringifynullrequest.postorientation=postorientation#跳转位置request.getorientation=1#跳转不包含数据锚点的网址request.getorientation=1+useragent#跳转useragent的内容和postorientation%%{}%%{}。
怎样抓取网页数据,今天只用到python爬虫知识,找一些好玩的数据来练手
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-06-29 14:00
怎样抓取网页数据,今天只用到python爬虫知识,找一些好玩的数据来练练手。两千天牛津大学图书馆数据爬取小结我们先从网上下载数据,用requests库就可以,是一个xml格式,比如自己爬取了下面这样的网页。#爬取网页数据,data=requests.get("")首先看看这些网页的源代码,保存到cookies,使用selenium,webdriver框架,用http请求进行爬取数据。
data=requests.get("")可以看到data这一列是可以直接获取的,第一行是源代码,可以看到正常页面下存在这一列,但是我们发现其实并不全是可以抓取的,因为在body里面也包含了data这一列,其中有这么几个html格式的tag,但是tag里面只包含这些fields,没有其他信息。接下来就可以看到response(请求地址)一列,下面就是data这一列,这里我们发现整个网页其实是一个json格式。
对于json,我之前知道可以用xpath,也发现json可以做的实验特别多,比如制作python对象图,loadpng等等。爬取的数据是一个json数据框,我们通过loadpng来渲染出我们想要的图片。frompyqueryimportparseimporttimedata=parse.urlopen("")#time.sleep(。
2)time.sleep
2)print("渲染函数运行完毕")forelementindata:print(element.xpath("//input[@class="test"]/text()")).contentdata.remove()#替换掉json数据中的data列,requests请求地址element.xpath("//input[@class="test"]/text()").remove()print("渲染完毕")print("函数运行结束")从上面可以看到requests请求地址地址里就是data这一列,所以我们用loadpng来渲染我们想要的图片。
print("渲染函数运行完毕")time.sleep
2)这样渲染完之后,我们想要的数据也就爬取下来了。对于json数据的渲染,可以通过requests库的parse方法来得到一个解析函数,来进行各种包装、封装、解析。接下来还有其他的操作,后面会详细介绍。网页中主要包含了这么几个关键字段:headers,body和data几个字段。headers包含了我们想要的请求头部和请求头。
body包含我们想要的响应。data包含我们想要的数据。这里我们主要会用到requests.get(url)方法,这个方法可以抓取到对方请求的参数,并且把requests.get()转换成requests.get(headers,body),通过body返回一个字典,里面是我们想要的数据。 查看全部
怎样抓取网页数据,今天只用到python爬虫知识,找一些好玩的数据来练手
怎样抓取网页数据,今天只用到python爬虫知识,找一些好玩的数据来练练手。两千天牛津大学图书馆数据爬取小结我们先从网上下载数据,用requests库就可以,是一个xml格式,比如自己爬取了下面这样的网页。#爬取网页数据,data=requests.get("")首先看看这些网页的源代码,保存到cookies,使用selenium,webdriver框架,用http请求进行爬取数据。
data=requests.get("")可以看到data这一列是可以直接获取的,第一行是源代码,可以看到正常页面下存在这一列,但是我们发现其实并不全是可以抓取的,因为在body里面也包含了data这一列,其中有这么几个html格式的tag,但是tag里面只包含这些fields,没有其他信息。接下来就可以看到response(请求地址)一列,下面就是data这一列,这里我们发现整个网页其实是一个json格式。
对于json,我之前知道可以用xpath,也发现json可以做的实验特别多,比如制作python对象图,loadpng等等。爬取的数据是一个json数据框,我们通过loadpng来渲染出我们想要的图片。frompyqueryimportparseimporttimedata=parse.urlopen("")#time.sleep(。
2)time.sleep
2)print("渲染函数运行完毕")forelementindata:print(element.xpath("//input[@class="test"]/text()")).contentdata.remove()#替换掉json数据中的data列,requests请求地址element.xpath("//input[@class="test"]/text()").remove()print("渲染完毕")print("函数运行结束")从上面可以看到requests请求地址地址里就是data这一列,所以我们用loadpng来渲染我们想要的图片。
print("渲染函数运行完毕")time.sleep
2)这样渲染完之后,我们想要的数据也就爬取下来了。对于json数据的渲染,可以通过requests库的parse方法来得到一个解析函数,来进行各种包装、封装、解析。接下来还有其他的操作,后面会详细介绍。网页中主要包含了这么几个关键字段:headers,body和data几个字段。headers包含了我们想要的请求头部和请求头。
body包含我们想要的响应。data包含我们想要的数据。这里我们主要会用到requests.get(url)方法,这个方法可以抓取到对方请求的参数,并且把requests.get()转换成requests.get(headers,body),通过body返回一个字典,里面是我们想要的数据。
怎样抓取网页数据并下载为自己用?-零成本的无限流量营
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-06-28 02:05
怎样抓取网页数据并下载为自己用?-零成本的无限流量营销项目借助“反爬虫”机器人,把某个网站上传的文章全部批量抓取下来,并分门别类命名。然后再自己编写代码,自己开发文章页面数据的分析、处理、生成分析后的报表,或者直接生成excel数据(不要问我是怎么知道的,我就是打死不说的知道的)。有这么一种通用的全网抓取库(虽然这个库是国外的),可以用,但现在基本上是合作开发的状态。
我是第三方开发者,也是这个包里面的成员之一。大致流程:扫一遍网页,如果是图片就直接抓取成jpg保存下来(已有的这种网站没有jpg文件,可以保存png格式);找到浏览器、浏览器支持ftp-based方式;ftp服务器会将所有页面的图片分类保存在excel文件中,然后存入数据库文件夹(建议放在localhost下,因为excel基本是一个安装了vc++的本地电脑,完整的网络环境);选择想要下载的数据库文件夹,然后上传excel文件,安装驱动完成并连接web。
可以选择自己配置密码,或者其他什么也不要进行设置。同时,存在网站的其他页面,也可以进行抓取,只要是提交的文件都能通过。选择下载的网站,存入数据库(如果是本地电脑连接,建议选择最新).demo已经上传::)已经抓取了数十万条数据,以字符串格式保存了。放上“链接”:关注我的微信公众号“李子默“(lizheingao),将不定期推送网页数据下载的教程,欢迎关注。 查看全部
怎样抓取网页数据并下载为自己用?-零成本的无限流量营
怎样抓取网页数据并下载为自己用?-零成本的无限流量营销项目借助“反爬虫”机器人,把某个网站上传的文章全部批量抓取下来,并分门别类命名。然后再自己编写代码,自己开发文章页面数据的分析、处理、生成分析后的报表,或者直接生成excel数据(不要问我是怎么知道的,我就是打死不说的知道的)。有这么一种通用的全网抓取库(虽然这个库是国外的),可以用,但现在基本上是合作开发的状态。
我是第三方开发者,也是这个包里面的成员之一。大致流程:扫一遍网页,如果是图片就直接抓取成jpg保存下来(已有的这种网站没有jpg文件,可以保存png格式);找到浏览器、浏览器支持ftp-based方式;ftp服务器会将所有页面的图片分类保存在excel文件中,然后存入数据库文件夹(建议放在localhost下,因为excel基本是一个安装了vc++的本地电脑,完整的网络环境);选择想要下载的数据库文件夹,然后上传excel文件,安装驱动完成并连接web。
可以选择自己配置密码,或者其他什么也不要进行设置。同时,存在网站的其他页面,也可以进行抓取,只要是提交的文件都能通过。选择下载的网站,存入数据库(如果是本地电脑连接,建议选择最新).demo已经上传::)已经抓取了数十万条数据,以字符串格式保存了。放上“链接”:关注我的微信公众号“李子默“(lizheingao),将不定期推送网页数据下载的教程,欢迎关注。
Python获取某网页数据并写入excel
网站优化 • 优采云 发表了文章 • 0 个评论 • 195 次浏览 • 2022-06-20 11:06
首先请大家谅解,尤其是消金和财务的同仁,作为服务台的工作很细很碎,你们的问题我正在处理,很快就会上线。
在年前放假的前两天,同业的征征叫住了笔者,指着某票据交易所的界面问道,这上面的数据能不能复制下来。
笔者看了一下这个破界面,心里暗道这个不直接可以选中复制,然后粘贴到excel里不就OK,但毕竟是同业部提出来的问题,肯定没那么简单,所以征征指出了一个严肃的问题:
这个网页没有批量导出的功能,也就是说如果他要看一个月的利率或者收益率,需要像个傻子一样依次点击日期,再复制粘贴到表里,2021年第一季度都快过了一半了,怎么还会有这么浪费人力的系统?是可忍,孰不可忍?!
于是笔者研究了一下这个网站,打算写一个爬虫,替同业部节省一点人力资源,不要把宝贵的时间浪费在这种低端工作中。
所谓的爬虫说到底就是哲学的三个终极问题:我是谁?我从哪来?我要去哪?错了,是数据结构是什么样的?数据从哪里获取?数据最后要呈现到什么状态?
首先看数据结构:从图上看,数据非常简单,不同的日期、期限有着不同的利率和收益率,而且只有工作日有数据,节假日与周末没有数据。
再看数据如何获取?
这个网页是个明显的动态网页,而且有反爬虫机制,使用最简单的urllib库直接就被503拒绝掉,此时有两种方案:方案A,使用selenium库,模拟点击日期,然后复制数据,最后导出。但是这个方法有很大的缺陷,首先是要在电脑上安装高版本的谷歌浏览器(这个不难)和对应的webdriver(这个就有点麻烦了),其次点击时会调用一个谷歌浏览器进程,众所周知谷歌浏览器进程是出了名的吃内存,一旦浏览器卡住(同业的老爷机是必然会被卡住的)就前功尽弃,最重要的是这种模拟点击的方式为了绕过反爬虫机制每次操作不能太快,所以效率低下。
只能使用方案B:使用requests和fake_useragent库伪造成正常用户来获取信息。
说起来简单,干起来也不复杂,只需要导入两个库即可:
然后使用fake_useragent伪造一个正常的head:
然后重点来了,开始分析这个网页,看是如何进行交互的:
打开谷歌浏览器,打开开发者工具,刷新网页,随便查询几个日期,在Network中的XHR仔细观察,发现了端倪:虽然这是个动态网页(我猜用的Ajax),但是是用的POST请求数据,然后服务器返回了一个JSON值。
返回的值如下:
这正是我们需要的。
OK,需求分析完毕,正式开始整代码,首先要获取开始日期和结束日期,为了避免无效请求,要排除掉周末,所以做了如下操作:
用户输入开始和结束日期,然后生成每一天,存到一个列表中,再依次读取这个列表中的日期,拼接到伪造的POST请求中。
说起来简单,做起来就有点麻烦,关键在于Python中各种数据类型的转换非常复杂,一点也不像Java严谨(php万岁)。
首先是获取开始和结束日期,然后生成每一天,把每一天添加进循环中(之所以这么干是因为Python的循环看起来简单,用起来复杂,嵌套起来会很可怕,所以干脆拆开循环)
然后使用datetime判断是否为工作日,如果是工作日,就继续:
因为用户输入的是yyyymmdd格式(20210210),但是post请求时yyyy-mm-dd格式,所以需要进行格式转换,先转换成字符串,在提取前四位、中二位、后二位,用横杠连接:
然后把拼接完毕的日期写入payload中,配合伪造的head数据向服务器请求数据:
然后使用BeautifulSoup和lxml整理数据,再使用看起来很复杂、写起来很复杂但熟悉了以后很简单的正则表达式处理数据:
为了防止太过分,所以加点间隔时间,避免引起对方的警觉:
最后把获取的数据存到dataframe,写入到excel中,搞定!
最后,一个爬虫写了70多行也是醉了。 查看全部
Python获取某网页数据并写入excel
首先请大家谅解,尤其是消金和财务的同仁,作为服务台的工作很细很碎,你们的问题我正在处理,很快就会上线。
在年前放假的前两天,同业的征征叫住了笔者,指着某票据交易所的界面问道,这上面的数据能不能复制下来。
笔者看了一下这个破界面,心里暗道这个不直接可以选中复制,然后粘贴到excel里不就OK,但毕竟是同业部提出来的问题,肯定没那么简单,所以征征指出了一个严肃的问题:
这个网页没有批量导出的功能,也就是说如果他要看一个月的利率或者收益率,需要像个傻子一样依次点击日期,再复制粘贴到表里,2021年第一季度都快过了一半了,怎么还会有这么浪费人力的系统?是可忍,孰不可忍?!
于是笔者研究了一下这个网站,打算写一个爬虫,替同业部节省一点人力资源,不要把宝贵的时间浪费在这种低端工作中。
所谓的爬虫说到底就是哲学的三个终极问题:我是谁?我从哪来?我要去哪?错了,是数据结构是什么样的?数据从哪里获取?数据最后要呈现到什么状态?
首先看数据结构:从图上看,数据非常简单,不同的日期、期限有着不同的利率和收益率,而且只有工作日有数据,节假日与周末没有数据。
再看数据如何获取?
这个网页是个明显的动态网页,而且有反爬虫机制,使用最简单的urllib库直接就被503拒绝掉,此时有两种方案:方案A,使用selenium库,模拟点击日期,然后复制数据,最后导出。但是这个方法有很大的缺陷,首先是要在电脑上安装高版本的谷歌浏览器(这个不难)和对应的webdriver(这个就有点麻烦了),其次点击时会调用一个谷歌浏览器进程,众所周知谷歌浏览器进程是出了名的吃内存,一旦浏览器卡住(同业的老爷机是必然会被卡住的)就前功尽弃,最重要的是这种模拟点击的方式为了绕过反爬虫机制每次操作不能太快,所以效率低下。
只能使用方案B:使用requests和fake_useragent库伪造成正常用户来获取信息。
说起来简单,干起来也不复杂,只需要导入两个库即可:
然后使用fake_useragent伪造一个正常的head:
然后重点来了,开始分析这个网页,看是如何进行交互的:
打开谷歌浏览器,打开开发者工具,刷新网页,随便查询几个日期,在Network中的XHR仔细观察,发现了端倪:虽然这是个动态网页(我猜用的Ajax),但是是用的POST请求数据,然后服务器返回了一个JSON值。
返回的值如下:
这正是我们需要的。
OK,需求分析完毕,正式开始整代码,首先要获取开始日期和结束日期,为了避免无效请求,要排除掉周末,所以做了如下操作:
用户输入开始和结束日期,然后生成每一天,存到一个列表中,再依次读取这个列表中的日期,拼接到伪造的POST请求中。
说起来简单,做起来就有点麻烦,关键在于Python中各种数据类型的转换非常复杂,一点也不像Java严谨(php万岁)。
首先是获取开始和结束日期,然后生成每一天,把每一天添加进循环中(之所以这么干是因为Python的循环看起来简单,用起来复杂,嵌套起来会很可怕,所以干脆拆开循环)
然后使用datetime判断是否为工作日,如果是工作日,就继续:
因为用户输入的是yyyymmdd格式(20210210),但是post请求时yyyy-mm-dd格式,所以需要进行格式转换,先转换成字符串,在提取前四位、中二位、后二位,用横杠连接:
然后把拼接完毕的日期写入payload中,配合伪造的head数据向服务器请求数据:
然后使用BeautifulSoup和lxml整理数据,再使用看起来很复杂、写起来很复杂但熟悉了以后很简单的正则表达式处理数据:
为了防止太过分,所以加点间隔时间,避免引起对方的警觉:
最后把获取的数据存到dataframe,写入到excel中,搞定!
最后,一个爬虫写了70多行也是醉了。
怎样抓取网页数据(json数据)分享java网络爬虫抓取经验的学习步骤及技巧分享!
网站优化 • 优采云 发表了文章 • 0 个评论 • 192 次浏览 • 2022-06-18 14:08
怎样抓取网页数据(json数据)分享java网络爬虫抓取经验的学习步骤及技巧分享!!!第一步:准备java环境配置;(我已配置完成,如有不准确,还请指点)cmd+r:使其执行命令cd~chmod+x/var/lib/java/java-jar/scss/intellij/jsp/js/jspx第二步:在hosts文件中写入java/java-jar/data/jspx.php,记住是java/java-jar/data/jspx.php;第三步:java使用本地java网络编程环境配置flashbotweb类库搭建flash初始化jsp等语句方法;现代浏览器大多是用的浏览器,也是指的ie/firefox等浏览器,具体使用方法请参考我百度的吧。
引用百度百科>页面浏览器技术>>网页浏览器规约>>第四步:一看web程序首页::浏览器中java调试面板点击右键后可看到search第五步:在安全相关session设置中加入请求头的2个参数,默认是不需要的:1.host:一般写自己的服务器地址(比如:java/user/domain#,你可以网上查一下)2.端口:默认是8080(输入后可查看)第六步:再说说xml数据格式相关:默认:当填写host地址时,为了保险起见,需要在里面再填一次一个手机网站所需的网页类型;服务器监听的ip地址及端口:此处填写1021端口,因为安卓手机浏览器的的端口号只有1021,ios手机浏览器的端口号有43350,43352.手机浏览器的查看地址:打开手机浏览器,输入手机网址或者输入你对应浏览器的ip地址或者端口号。
默认,你也可以去appstore里找到搜狗浏览器插件,也可以访问。第七步:其他我能想到的网站规则:1.表单设置:地址一般写你登录的账号的pwd就可以了,接着name的值写上自己的账号名称和密码,如果你想匿名的话可以按照要求添加一个值(不要太长就好,免得打开网页时键入不上)2.核心代码部分:no.1:获取数据请求和数据解析方法1:java请求正则表达式请求1:返回body-json格式的文本,源码:/book.jsp?a=1&myrequest_username=xxx&myrequest_password=xxx&myrequest_author=xxx&myrequest_time=xxx&myrequest_homepage=xxx&myrequest_whois=xxx&myrequest_domain_name=xxx&myrequest_photo=xxx&myrequest_title=xxx&myrequest_pages=xxx&myrequest_page_type=xxx&m。 查看全部
怎样抓取网页数据(json数据)分享java网络爬虫抓取经验的学习步骤及技巧分享!
怎样抓取网页数据(json数据)分享java网络爬虫抓取经验的学习步骤及技巧分享!!!第一步:准备java环境配置;(我已配置完成,如有不准确,还请指点)cmd+r:使其执行命令cd~chmod+x/var/lib/java/java-jar/scss/intellij/jsp/js/jspx第二步:在hosts文件中写入java/java-jar/data/jspx.php,记住是java/java-jar/data/jspx.php;第三步:java使用本地java网络编程环境配置flashbotweb类库搭建flash初始化jsp等语句方法;现代浏览器大多是用的浏览器,也是指的ie/firefox等浏览器,具体使用方法请参考我百度的吧。
引用百度百科>页面浏览器技术>>网页浏览器规约>>第四步:一看web程序首页::浏览器中java调试面板点击右键后可看到search第五步:在安全相关session设置中加入请求头的2个参数,默认是不需要的:1.host:一般写自己的服务器地址(比如:java/user/domain#,你可以网上查一下)2.端口:默认是8080(输入后可查看)第六步:再说说xml数据格式相关:默认:当填写host地址时,为了保险起见,需要在里面再填一次一个手机网站所需的网页类型;服务器监听的ip地址及端口:此处填写1021端口,因为安卓手机浏览器的的端口号只有1021,ios手机浏览器的端口号有43350,43352.手机浏览器的查看地址:打开手机浏览器,输入手机网址或者输入你对应浏览器的ip地址或者端口号。
默认,你也可以去appstore里找到搜狗浏览器插件,也可以访问。第七步:其他我能想到的网站规则:1.表单设置:地址一般写你登录的账号的pwd就可以了,接着name的值写上自己的账号名称和密码,如果你想匿名的话可以按照要求添加一个值(不要太长就好,免得打开网页时键入不上)2.核心代码部分:no.1:获取数据请求和数据解析方法1:java请求正则表达式请求1:返回body-json格式的文本,源码:/book.jsp?a=1&myrequest_username=xxx&myrequest_password=xxx&myrequest_author=xxx&myrequest_time=xxx&myrequest_homepage=xxx&myrequest_whois=xxx&myrequest_domain_name=xxx&myrequest_photo=xxx&myrequest_title=xxx&myrequest_pages=xxx&myrequest_page_type=xxx&m。
怎样抓取网页数据?去掉network的buffer区域,区域
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-06-09 14:14
怎样抓取网页数据?去掉network的buffer区域,
一、encodeuri传给你,
二、javascript采用字符串或变量来读取数据,那么就直接用javascript调用,但是现在es6标准已经不用变量来读取数据,变量文件不支持变量值传递,只能用[]或者var传递数据,这时候post请求就必须要用javascript来写代码。javascript有这么两个方法来获取:accept、json,但是看到post请求并不知道他到底有什么特殊方法。
利用json包装下,抓取for循环转化下可以通过post的方式获取数据,这个的实现也很简单,我想到的办法就是sqlite写一个函数获取对应exists的id值,一个个用循环,最后数据抓取完成后做解析,解析api就可以知道url的值,将url匹配api中显示的值保存到文件中。当然也可以用其他类似的办法,比如接着数据库或者sql的操作方式来操作,这里就要看具体情况。
具体代码:
1、if(getfile()!==null){post(url。split("-")[-3]+'');//把url分割成split分隔符if(isloaded()){stringexists(url。split("?''>'',array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,a。 查看全部
怎样抓取网页数据?去掉network的buffer区域,区域
怎样抓取网页数据?去掉network的buffer区域,
一、encodeuri传给你,
二、javascript采用字符串或变量来读取数据,那么就直接用javascript调用,但是现在es6标准已经不用变量来读取数据,变量文件不支持变量值传递,只能用[]或者var传递数据,这时候post请求就必须要用javascript来写代码。javascript有这么两个方法来获取:accept、json,但是看到post请求并不知道他到底有什么特殊方法。
利用json包装下,抓取for循环转化下可以通过post的方式获取数据,这个的实现也很简单,我想到的办法就是sqlite写一个函数获取对应exists的id值,一个个用循环,最后数据抓取完成后做解析,解析api就可以知道url的值,将url匹配api中显示的值保存到文件中。当然也可以用其他类似的办法,比如接着数据库或者sql的操作方式来操作,这里就要看具体情况。
具体代码:
1、if(getfile()!==null){post(url。split("-")[-3]+'');//把url分割成split分隔符if(isloaded()){stringexists(url。split("?''>'',array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,array('/',0,a。
怎样抓取网页数据最快?(图)图链接
网站优化 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2022-06-07 11:08
怎样抓取网页数据最快?可能有很多朋友觉得网页上的各种关键字并不好抓取,没有直接搜索的效率高,也没有直接用爬虫抓取数据更方便。首先我想问一句,现在哪个app没有直接采集数据的功能,从手机上直接获取视频、图片等数据,快速便捷。再者,假如你只是想抓取一条链接,但是要从上百万条数据中找到你要的数据,那么你需要查阅更多资料,花费更多时间才能把所有的数据找出来。
毕竟如果我要抓取的数据都是单一数据,短时间就可以完成数据采集,那也就没必要去自己写爬虫了。今天介绍一个在线教程,讲述如何抓取各大网站上的数据,提高找数据的效率。你只需要先打开“搜索”的功能,输入你想要的网址,就可以抓取到网站的各种数据。找数据就是这么简单,相信大家想要找的数据一定不会是那种一目了然的数据,除非你们看到的数据就是页面上的内容。
但是如果把你的所有数据都放在页面上,抓取起来恐怕会费时费力,因为我们的目的只是想在页面上找到我们需要的数据。这里我就罗列一下,抓取网站的常用代码:输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、。 查看全部
怎样抓取网页数据最快?(图)图链接
怎样抓取网页数据最快?可能有很多朋友觉得网页上的各种关键字并不好抓取,没有直接搜索的效率高,也没有直接用爬虫抓取数据更方便。首先我想问一句,现在哪个app没有直接采集数据的功能,从手机上直接获取视频、图片等数据,快速便捷。再者,假如你只是想抓取一条链接,但是要从上百万条数据中找到你要的数据,那么你需要查阅更多资料,花费更多时间才能把所有的数据找出来。
毕竟如果我要抓取的数据都是单一数据,短时间就可以完成数据采集,那也就没必要去自己写爬虫了。今天介绍一个在线教程,讲述如何抓取各大网站上的数据,提高找数据的效率。你只需要先打开“搜索”的功能,输入你想要的网址,就可以抓取到网站的各种数据。找数据就是这么简单,相信大家想要找的数据一定不会是那种一目了然的数据,除非你们看到的数据就是页面上的内容。
但是如果把你的所有数据都放在页面上,抓取起来恐怕会费时费力,因为我们的目的只是想在页面上找到我们需要的数据。这里我就罗列一下,抓取网站的常用代码:输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、页面缩略图链接对输入域名、页面名、。
怎样抓取网页数据,具体可以参考这篇文章学习一下
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2022-06-05 01:00
怎样抓取网页数据,具体可以参考这篇文章学习一下做爬虫,经常有人问,如何从网页中提取出感兴趣的信息?目前我经常思考的是定位,如果你可以提取到网页中某个词,比如产品,就可以提取出类似这样的关键词:“产品设计流程”提取出此词的关键词的时候,就可以按照字符串排序,将文件保存为txt格式,之后当需要爬虫时,解析这个文件,查找其中的关键词即可。
也可以按照自己的判断,为txt做分词,比如“简约”这个词,可以有以下分词方法:“简约”-“词频=20”,也可以根据文本查找此词:“简约产品设计”然后去词典进行查找,比如google分词查找出了如下匹配情况:查找到对应的词以后,将其转换为chrome扩展,chrome和chrome插件都可以使用:textbox:输入你想查找的关键词,选择高亮显示,chrome扩展开发者工具就可以直接查找了。
查找完之后,也可以点击查找的关键词本身,进行高亮显示,这样就可以用google分词来解析出词的含义了,也可以解析出你要爬取的网页中其他关键词:同理,也可以将类似于词类比和词频,进行高亮显示。具体操作可以参考这篇文章:用python爬取所有网页数据-浅谈:爬虫思维-wanhandong007的专栏-csdn博客也可以模拟用户登录进行抓取:wanhandong007-python爬虫-boss技术社区谢谢观看,有用的话给个赞呗~更多干货内容,欢迎关注我的专栏:【python爬虫开发实战】。 查看全部
怎样抓取网页数据,具体可以参考这篇文章学习一下
怎样抓取网页数据,具体可以参考这篇文章学习一下做爬虫,经常有人问,如何从网页中提取出感兴趣的信息?目前我经常思考的是定位,如果你可以提取到网页中某个词,比如产品,就可以提取出类似这样的关键词:“产品设计流程”提取出此词的关键词的时候,就可以按照字符串排序,将文件保存为txt格式,之后当需要爬虫时,解析这个文件,查找其中的关键词即可。
也可以按照自己的判断,为txt做分词,比如“简约”这个词,可以有以下分词方法:“简约”-“词频=20”,也可以根据文本查找此词:“简约产品设计”然后去词典进行查找,比如google分词查找出了如下匹配情况:查找到对应的词以后,将其转换为chrome扩展,chrome和chrome插件都可以使用:textbox:输入你想查找的关键词,选择高亮显示,chrome扩展开发者工具就可以直接查找了。
查找完之后,也可以点击查找的关键词本身,进行高亮显示,这样就可以用google分词来解析出词的含义了,也可以解析出你要爬取的网页中其他关键词:同理,也可以将类似于词类比和词频,进行高亮显示。具体操作可以参考这篇文章:用python爬取所有网页数据-浅谈:爬虫思维-wanhandong007的专栏-csdn博客也可以模拟用户登录进行抓取:wanhandong007-python爬虫-boss技术社区谢谢观看,有用的话给个赞呗~更多干货内容,欢迎关注我的专栏:【python爬虫开发实战】。
(网站编程)怎样抓取后的数据存储如何?
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-06-02 17:02
怎样抓取网页数据?我通常用php(web开发),asp(网站编程)这两个框架来实现抓取功能。现在有好多类似于『小觅』这样的网页抓取器,抓取能力是很强大的,操作也灵活,可以说只要你有兴趣都可以抓取一些网页数据。抓取后的数据存储如何?如果只是需要一个网页的图片数据,建议找个开源网页浏览器模拟器,然后把图片地址和图片名写入到web服务器。
如果你需要将抓取的网页数据上传到网站上,存储就要好好考虑一下了。如果没有数据,可以不存储数据,直接对你所抓取网页中图片进行批量裁剪就可以。如果你有数据,可以做好存储规划,规定存储数据的不同数据库类型。如果你有多个网页抓取,多条同类图片也可以按照二维表进行存储。『小觅』抓取器里有哪些功能?『小觅』抓取器内置了一个抓取器脚本包,通过编写脚本就可以轻松抓取了。
当然,你也可以单独去抓取一个网页的一个图片。脚本脚本功能?#!/usr/bin/envpython#-*-coding:utf-8-*-importreimporttime#获取网页url,并添加到time.timeout函数中,即读取到其完整的时间fromurllib.requestimporturlopenimportjsonimportrequests#获取网页的html数据,并保存为txt格式数据frombs4importbeautifulsoupimportxlwtfromurllib.requestimporturlopenfromurllib.requestimportrequesturl=';referred_url='+str(json.loads(url))#解析网页内容filename='{}.txt'txt=filename+'-alert.txt'#处理txt文件读取等字符串数据并存储images=xlwt.parse(open(txt,'wb'),'r')images.write(json.loads(images))#存储图片jpg=json.loads(images)#获取一个网页,以及所抓取数据的地址foriinjpgs:content=str(i).split('\t')[-1][0]imgurl=images[jpgurl:-1]+str(i).split('/')[0]fortmpincontent:tmp=txt[tmp:]#重命名单元格名称fornameintmp:#图片下载的地址imgurl=filename+name#获取图片描述plt.imshow(tmp)plt.show()#显示网页代码print(txt.strip('\t'))f=open('../spider/'+str(json.loads(r'data.jpg'))+'_'+str(r'end.jpg')+'.jpg','w')#选择需要抓取的网页数据forurlinf:txt.write(url)#解析获取到的网页数据forxinxlwt.wor。 查看全部
(网站编程)怎样抓取后的数据存储如何?
怎样抓取网页数据?我通常用php(web开发),asp(网站编程)这两个框架来实现抓取功能。现在有好多类似于『小觅』这样的网页抓取器,抓取能力是很强大的,操作也灵活,可以说只要你有兴趣都可以抓取一些网页数据。抓取后的数据存储如何?如果只是需要一个网页的图片数据,建议找个开源网页浏览器模拟器,然后把图片地址和图片名写入到web服务器。
如果你需要将抓取的网页数据上传到网站上,存储就要好好考虑一下了。如果没有数据,可以不存储数据,直接对你所抓取网页中图片进行批量裁剪就可以。如果你有数据,可以做好存储规划,规定存储数据的不同数据库类型。如果你有多个网页抓取,多条同类图片也可以按照二维表进行存储。『小觅』抓取器里有哪些功能?『小觅』抓取器内置了一个抓取器脚本包,通过编写脚本就可以轻松抓取了。
当然,你也可以单独去抓取一个网页的一个图片。脚本脚本功能?#!/usr/bin/envpython#-*-coding:utf-8-*-importreimporttime#获取网页url,并添加到time.timeout函数中,即读取到其完整的时间fromurllib.requestimporturlopenimportjsonimportrequests#获取网页的html数据,并保存为txt格式数据frombs4importbeautifulsoupimportxlwtfromurllib.requestimporturlopenfromurllib.requestimportrequesturl=';referred_url='+str(json.loads(url))#解析网页内容filename='{}.txt'txt=filename+'-alert.txt'#处理txt文件读取等字符串数据并存储images=xlwt.parse(open(txt,'wb'),'r')images.write(json.loads(images))#存储图片jpg=json.loads(images)#获取一个网页,以及所抓取数据的地址foriinjpgs:content=str(i).split('\t')[-1][0]imgurl=images[jpgurl:-1]+str(i).split('/')[0]fortmpincontent:tmp=txt[tmp:]#重命名单元格名称fornameintmp:#图片下载的地址imgurl=filename+name#获取图片描述plt.imshow(tmp)plt.show()#显示网页代码print(txt.strip('\t'))f=open('../spider/'+str(json.loads(r'data.jpg'))+'_'+str(r'end.jpg')+'.jpg','w')#选择需要抓取的网页数据forurlinf:txt.write(url)#解析获取到的网页数据forxinxlwt.wor。
怎样抓取网页数据?过程中你能与之匹配
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-05-30 17:01
怎样抓取网页数据,是一个无比大的话题,但总能在seo中找到一个能与之匹配的框架。任何网站的,除了网页之外,你其实还能抓取文章、图片、用户自定义的功能性文本、甚至视频等等,但这些数据只是一个网站的一小部分,而在seo过程中你能抓取的数据实在是太多了,有些关键词甚至能带来几十万甚至上百万的流量,如何把这些内容抓取下来,并且用正确的方式呈现在你的网站上,一直是个大问题。正文:。
一、抓取页面相关的数据
1、抓取所有来源网站所有的页面。如果你只抓取30天内的数据(关键词抓取2次即可,最多的10次),就是这么做。
2、抓取你直接爬虫爬取到的网站中,所有的链接。这是在爬虫爬取到的网站,但其实你只是一个网站数据的缩小版本。抓取网站链接的意义是,比如你对b类网站抓取了10个页面后,你能通过抓取页面查询的方式,抓取到b类网站中最有价值的10个页面。但在抓取时,抓取的网站中还可能存在很多你已经没法抓取的页面,你该怎么做呢?如果已经想好策略,可以尝试继续下面的问题,但如果你的数据都在最近几天发生的话,你可以考虑尝试其他策略,在这种策略中,其实很多情况都很有可能抓取不到的,甚至很可能超出你的预期。
3、抓取所有linkedin用户帐号页面的url。翻墙就自己心里有点数了,我没试过,不敢保证数据是否齐全,但有一些数据肯定是很有价值的。
4、抓取所有聚合页的url。方式如下:双http抓取,或者点开去查看,至少有50%以上抓取出来的页面是有价值的。
5、抓取所有网站历史记录,cookies抓取,抓取所有rank过的页面,抓取所有rank过的链接。
二、抓取网站的内容
1、每天抓取几个网站或几百个网站的页面。为什么要抓几百个网站,就是为了,无论你抓取多少页面,都能在几百个网站中找到一些用户感兴趣的内容。不要太在意抓取到多少网站内容。
2、每天抓取几十个网站的页面,每个网站抓取url50~60,然后每天抓取50个网站,其实你能抓取的网站还是很多的。这样,你能抓取的页面实在是太多了,需要通过不断的抓取,找到关键词的常用文章(通常都是关键词的链接,即mediaquery)的长尾关键词,然后聚合在一起,用最容易理解的方式呈现。说白了,你只需要找到长尾关键词,然后聚合就可以了。另外,你会发现,常用关键词聚合出来的链接,都在高频出现的频道内,抓取相应的页面并不难。
3、每天抓取几百个网站,或者几十个网站的页面,除了google搜索,其实你还可以抓取seo每天在推送的文章。所以关键词抓取,实际上还是有很多可以挖掘的内容的。
4、抓取所有网站的历 查看全部
怎样抓取网页数据?过程中你能与之匹配
怎样抓取网页数据,是一个无比大的话题,但总能在seo中找到一个能与之匹配的框架。任何网站的,除了网页之外,你其实还能抓取文章、图片、用户自定义的功能性文本、甚至视频等等,但这些数据只是一个网站的一小部分,而在seo过程中你能抓取的数据实在是太多了,有些关键词甚至能带来几十万甚至上百万的流量,如何把这些内容抓取下来,并且用正确的方式呈现在你的网站上,一直是个大问题。正文:。
一、抓取页面相关的数据
1、抓取所有来源网站所有的页面。如果你只抓取30天内的数据(关键词抓取2次即可,最多的10次),就是这么做。
2、抓取你直接爬虫爬取到的网站中,所有的链接。这是在爬虫爬取到的网站,但其实你只是一个网站数据的缩小版本。抓取网站链接的意义是,比如你对b类网站抓取了10个页面后,你能通过抓取页面查询的方式,抓取到b类网站中最有价值的10个页面。但在抓取时,抓取的网站中还可能存在很多你已经没法抓取的页面,你该怎么做呢?如果已经想好策略,可以尝试继续下面的问题,但如果你的数据都在最近几天发生的话,你可以考虑尝试其他策略,在这种策略中,其实很多情况都很有可能抓取不到的,甚至很可能超出你的预期。
3、抓取所有linkedin用户帐号页面的url。翻墙就自己心里有点数了,我没试过,不敢保证数据是否齐全,但有一些数据肯定是很有价值的。
4、抓取所有聚合页的url。方式如下:双http抓取,或者点开去查看,至少有50%以上抓取出来的页面是有价值的。
5、抓取所有网站历史记录,cookies抓取,抓取所有rank过的页面,抓取所有rank过的链接。
二、抓取网站的内容
1、每天抓取几个网站或几百个网站的页面。为什么要抓几百个网站,就是为了,无论你抓取多少页面,都能在几百个网站中找到一些用户感兴趣的内容。不要太在意抓取到多少网站内容。
2、每天抓取几十个网站的页面,每个网站抓取url50~60,然后每天抓取50个网站,其实你能抓取的网站还是很多的。这样,你能抓取的页面实在是太多了,需要通过不断的抓取,找到关键词的常用文章(通常都是关键词的链接,即mediaquery)的长尾关键词,然后聚合在一起,用最容易理解的方式呈现。说白了,你只需要找到长尾关键词,然后聚合就可以了。另外,你会发现,常用关键词聚合出来的链接,都在高频出现的频道内,抓取相应的页面并不难。
3、每天抓取几百个网站,或者几十个网站的页面,除了google搜索,其实你还可以抓取seo每天在推送的文章。所以关键词抓取,实际上还是有很多可以挖掘的内容的。
4、抓取所有网站的历
怎样抓取网页数据:常见的获取原始数据的方法。
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-05-26 20:05
怎样抓取网页数据:常见的获取原始数据的方法。apiapi提供一种免费的webapi,可以通过get或post方式调用http资源。api原则简单、开放、透明、安全、高效。必须注意的是api方式只是初始形态,但并不代表其他方式同样好用,api不能替代jsapi。如图所示:一个好的api必须提供访问、相关权限等原始信息,同时要求拥有必要的数据控制功能。
常见的api有:urlapiapipostapimock对于drupal,由于drupal提供了ongoingurlproxy机制,这部分内容没有多说,但drupal允许用户使用javascript动态绑定dom元素。一方面可以大大缩短页面显示的跳转时间,另一方面还能满足用户强迫症的需求。如图所示:页面跳转:用form链接,提交动态api,动态绑定获取数据api:页面跳转切换:field动态绑定,触发事件:生成网页html:构建typejs网页:拥有信任后者,切换信任后者,转换:与markdows模板引擎生成html以上,web前端采用form提交网络请求提交请求获取cookie及dom元素,然后用drupal动态绑定数据html来展示dom元素。
mock原理web前端存在两大主要存储session/localstorage。利用sessioncookie或localstorage,用户存在的数据或动态响应时间都有异步内容。但web应用通常仅支持一种内容存储,即服务器端的内容存储。因此,web网站中,动态请求回调和数据库查询服务器提交请求。对于使用ajax实现的并发,应用程序需要提供相关的jsonpapi。
web前端用flash+jsonpapi提交请求。该api比cookie+jsonpapi性能更好。如图所示:使用ajax,存在http错误或其他原因,jsonp的http错误比ajax要少。常见的mock错误get/post调用json:无响应,返回值错误post不支持错误get/post返回值options调用json:无响应,返回值错误post支持错误error|required!调用json:无响应,返回值错误get|post不支持error|required!类型post需要提供对应的error或required来正确定义调用的extended。
post将给json返回一个数据包,包含包含应用的所有字段值。jsonp则返回一个get对象或请求方法的字符串。此外,返回的也不是json,不过返回的却是json所预订的内容值。1、post、get、jsonp区别apost对象为指定的一个jsonp对象的字面值,若这个jsonp对象重定向到服务器,则会将返回值插入到post调用的jsonp对象的下一个地址中。
<p>post与get都只能为对象,而jsonp允许嵌套options方法。jsonp则不允许是对象。get:options 查看全部
怎样抓取网页数据:常见的获取原始数据的方法。
怎样抓取网页数据:常见的获取原始数据的方法。apiapi提供一种免费的webapi,可以通过get或post方式调用http资源。api原则简单、开放、透明、安全、高效。必须注意的是api方式只是初始形态,但并不代表其他方式同样好用,api不能替代jsapi。如图所示:一个好的api必须提供访问、相关权限等原始信息,同时要求拥有必要的数据控制功能。
常见的api有:urlapiapipostapimock对于drupal,由于drupal提供了ongoingurlproxy机制,这部分内容没有多说,但drupal允许用户使用javascript动态绑定dom元素。一方面可以大大缩短页面显示的跳转时间,另一方面还能满足用户强迫症的需求。如图所示:页面跳转:用form链接,提交动态api,动态绑定获取数据api:页面跳转切换:field动态绑定,触发事件:生成网页html:构建typejs网页:拥有信任后者,切换信任后者,转换:与markdows模板引擎生成html以上,web前端采用form提交网络请求提交请求获取cookie及dom元素,然后用drupal动态绑定数据html来展示dom元素。
mock原理web前端存在两大主要存储session/localstorage。利用sessioncookie或localstorage,用户存在的数据或动态响应时间都有异步内容。但web应用通常仅支持一种内容存储,即服务器端的内容存储。因此,web网站中,动态请求回调和数据库查询服务器提交请求。对于使用ajax实现的并发,应用程序需要提供相关的jsonpapi。
web前端用flash+jsonpapi提交请求。该api比cookie+jsonpapi性能更好。如图所示:使用ajax,存在http错误或其他原因,jsonp的http错误比ajax要少。常见的mock错误get/post调用json:无响应,返回值错误post不支持错误get/post返回值options调用json:无响应,返回值错误post支持错误error|required!调用json:无响应,返回值错误get|post不支持error|required!类型post需要提供对应的error或required来正确定义调用的extended。
post将给json返回一个数据包,包含包含应用的所有字段值。jsonp则返回一个get对象或请求方法的字符串。此外,返回的也不是json,不过返回的却是json所预订的内容值。1、post、get、jsonp区别apost对象为指定的一个jsonp对象的字面值,若这个jsonp对象重定向到服务器,则会将返回值插入到post调用的jsonp对象的下一个地址中。
<p>post与get都只能为对象,而jsonp允许嵌套options方法。jsonp则不允许是对象。get:options
如何抓取页面中可能存在 SQL 注入的链接
网站优化 • 优采云 发表了文章 • 0 个评论 • 318 次浏览 • 2022-05-11 04:48
自动化寻找网站的注入漏洞,需要先将目标网站的所有带参数的 URL 提取出来,然后针对每个参数进行测试,对于批量化检测的目标,首先要提取大量网站带参数的 URL,针对 GET 请求的链接是可以通过自动化获取的,而 POST 型参数提交的方式,则需要手工点击,然后代理抓取数据包再进行提交测试。
本文的重点是如何自动化获取网页中的 URL,然后进行处理后,保留每个路径下的一条记录,从而减少测试的目标,提升测试的效率,这个过程主要分三步,分别是:提取 URL、匹配带参数的 URL、URL 去重。
0x01 获取页面中的 URL
其实实现这个目标很简单,写一个脚本,获取页面内容,然后使用正则将 URL 匹配出来即可,有的人就会说,我不会写脚本,我不懂正则,该怎么办?
也好办,可以用别人写好的工具,会用就行,这里推荐一个工具叫 gau,项目地址:
该项目使用 go 语言编写,安装方式也很简单,命令如下:
go get -u -v /lc/gau
使用起来就更简单了,比如:
echo "" | gau
从图中可以看到有很多图片之类的文件,可以使用 -b 参数排除,比如:
echo "" | gau -b png,jpg
如果我想获取的不只是目标域名下的链接,还想获取其他子域名的链接,那么可以使用 -subs 参数:
echo "" | gau -b png,jpg -subs
到这里,基本可以满足我们的需求了,当然还可以设置线程数来提升抓取效率,还可以将结果保存到文件中,具体的参数,大家可以自行测试。
0x02 提取 URL 中带参数的 URL
如果 URL 不带参数,那么我们就无法对其进行检测,任何输入点都有可能存在安全风险,没有输入点,当然也没办法测试了,所以如何从 URL 列表中提取带参数的 URL 呢?如果你会正则,会脚本,这个目标也没什么难度。
在不会写脚本,也不懂正则的情况下,可以使用工具 gf,项目地址:
安装也比较简单,使用的话需要依赖别人写好的配置文件,这里推荐一个项目,有很多写好的配置:
首先安装 gf:
go get -u /tomnomnom/gf
然后把 Gf-Patterns 克隆回来:
git clone
把 Gf-Patterns 中的文件移动到 .gf/ 中:
mv Gf-Patterns/* .gf/
接下来就可以提取可能存在 SQL 注入的链接了,结合之前介绍的工具,命令如下:
echo "" | gau -b png,jpg -subs | gf sqli
0x03 将提取出来的 URL 去重
通过以上方法获取的 URL 列表,有很多同一个路径,但是参数内容不同的情况,如果都去做测试的话,会有很多重复的劳动,没有必要的测试,所以需要将 URL 进行去重,将 URL 的参数替换为固定值,然后进行去重,这样就可以把相同路径和相同参数的 URL 去除,保留一条记录,可以大大的节省测试的时间和目标数量,即减少了与目标交互的次数,也能提升测试的效率。
这里推荐一个工具叫 qsreplace,下载地址:
安装方式:
go get -u /tomnomnom/qsreplace
结合之前的工具使用,命令如下:
echo "" | gau -b png,jpg -subs > sqli.txt
cat sqli.txt | qsreplace fuzz > duplicateremove.txt
到这里,就可以使用注入漏洞检测工具对目标 URL 列表进行检测了,比如 sqlmap 等注入检测工具。
总结
本文主要介绍了三款 go 语言编写的小工具,用来针对目标收集可能存在某些漏洞的 URL 列表,然后在结合漏洞检测工具,有针对性的进行检测,提升工作效率。
--- EOF ---
推荐↓↓↓ 查看全部
如何抓取页面中可能存在 SQL 注入的链接
自动化寻找网站的注入漏洞,需要先将目标网站的所有带参数的 URL 提取出来,然后针对每个参数进行测试,对于批量化检测的目标,首先要提取大量网站带参数的 URL,针对 GET 请求的链接是可以通过自动化获取的,而 POST 型参数提交的方式,则需要手工点击,然后代理抓取数据包再进行提交测试。
本文的重点是如何自动化获取网页中的 URL,然后进行处理后,保留每个路径下的一条记录,从而减少测试的目标,提升测试的效率,这个过程主要分三步,分别是:提取 URL、匹配带参数的 URL、URL 去重。
0x01 获取页面中的 URL
其实实现这个目标很简单,写一个脚本,获取页面内容,然后使用正则将 URL 匹配出来即可,有的人就会说,我不会写脚本,我不懂正则,该怎么办?
也好办,可以用别人写好的工具,会用就行,这里推荐一个工具叫 gau,项目地址:
该项目使用 go 语言编写,安装方式也很简单,命令如下:
go get -u -v /lc/gau
使用起来就更简单了,比如:
echo "" | gau
从图中可以看到有很多图片之类的文件,可以使用 -b 参数排除,比如:
echo "" | gau -b png,jpg
如果我想获取的不只是目标域名下的链接,还想获取其他子域名的链接,那么可以使用 -subs 参数:
echo "" | gau -b png,jpg -subs
到这里,基本可以满足我们的需求了,当然还可以设置线程数来提升抓取效率,还可以将结果保存到文件中,具体的参数,大家可以自行测试。
0x02 提取 URL 中带参数的 URL
如果 URL 不带参数,那么我们就无法对其进行检测,任何输入点都有可能存在安全风险,没有输入点,当然也没办法测试了,所以如何从 URL 列表中提取带参数的 URL 呢?如果你会正则,会脚本,这个目标也没什么难度。
在不会写脚本,也不懂正则的情况下,可以使用工具 gf,项目地址:
安装也比较简单,使用的话需要依赖别人写好的配置文件,这里推荐一个项目,有很多写好的配置:
首先安装 gf:
go get -u /tomnomnom/gf
然后把 Gf-Patterns 克隆回来:
git clone
把 Gf-Patterns 中的文件移动到 .gf/ 中:
mv Gf-Patterns/* .gf/
接下来就可以提取可能存在 SQL 注入的链接了,结合之前介绍的工具,命令如下:
echo "" | gau -b png,jpg -subs | gf sqli
0x03 将提取出来的 URL 去重
通过以上方法获取的 URL 列表,有很多同一个路径,但是参数内容不同的情况,如果都去做测试的话,会有很多重复的劳动,没有必要的测试,所以需要将 URL 进行去重,将 URL 的参数替换为固定值,然后进行去重,这样就可以把相同路径和相同参数的 URL 去除,保留一条记录,可以大大的节省测试的时间和目标数量,即减少了与目标交互的次数,也能提升测试的效率。
这里推荐一个工具叫 qsreplace,下载地址:
安装方式:
go get -u /tomnomnom/qsreplace
结合之前的工具使用,命令如下:
echo "" | gau -b png,jpg -subs > sqli.txt
cat sqli.txt | qsreplace fuzz > duplicateremove.txt
到这里,就可以使用注入漏洞检测工具对目标 URL 列表进行检测了,比如 sqlmap 等注入检测工具。
总结
本文主要介绍了三款 go 语言编写的小工具,用来针对目标收集可能存在某些漏洞的 URL 列表,然后在结合漏洞检测工具,有针对性的进行检测,提升工作效率。
--- EOF ---
推荐↓↓↓
IE抓取资金主力流入的股票
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2022-04-30 16:13
【分享成果,随喜正能量】做人,要像一杯水。无色则纯,只要心里清澈,世事皆易;无味则淡,只要心里明了,万物皆空;无欲则刚,只要心里释然,一切皆无。。《VBA信息获取与处理》教程是我推出第六套教程,目前已经是第一版修订了。这套教程定位于最高级,是学完初级,中级后的教程。这部教程给大家讲解的内容有:跨应用程序信息获得、随机信息的利用、电子邮件的发送、VBA互联网数据抓取、VBA延时操作,剪贴板应用、Split函数扩展、工作表信息与其他应用交互,FSO对象的利用、工作表及文件夹信息的获取、图形信息的获取以及定制工作表信息函数等等内容。程序文件通过32位和64位两种OFFICE系统测试。是非常抽象的,更具研究的价值。教程共两册,八十四讲。今日的内容是专题九“利用IE抓取网络数据”:IE抓取资金主力流入的股票
第二节 利用IE,抓取资金主力流入的股票大家好,我们从这讲开始讲利用IE控件完成抓取网络数据的任务,由于基础知识已经讲解了很多,这里的代码讲解会简单些,大家可以参考我给出的代码注释进行理解。
实现场景:我们在做股票分析的时候,资金的动向是我们最为关心的,是否有大的资金流入是大多数散户进行某支股票投资的重要依据。我们以财富网提供的资金主力流入的股票数据为数据提取的基础。网址是: 。1 应用IE实现资金主力流入数据抓取的思路分析为了抓取数据,我们先看看网页页面,下面是2020年6月11日网页提供的数据:
我们的任务是要把上述数据抓取到EXCEL表格中。为了实现利用IE进行数据抓取,我们首先要建立一个IE引用CreateObject("InternetExplorer.Application")。然后IE打开给出的网址,.navigate ""实现我们从网页中得出这个表序号是5,那么将提取这个表中的数据。大家可以先复习一下我前面有关表的知识讲解.在网页文档中提取document对象,利用dmt.all.tags("table")(5)找到这个表,然后利用tb.Rows(i).Cells(j).innertext输出数据。2 应用IE实现资金主力流入数据抓取的代码实现为了实现上述的思路,我给出如下我的代码:
Sub myNZ() '利用IE,抓取财富网资金主力流入的股票Dim ie, dmt, tb, i&, j& SetmyIE = CreateObject("InternetExplorer.Application") '创建一个IE对象 Sheets("SHEET1").Select Rows("3:100").ClearContents WithmyIE .Visible= True '显示它 .navigate"" '加载东风财富网资金主力流入情况 DoUntil .readystate = 4 '检查网页是否加载完毕(4表示完全加载) DoEvents '循环中交回工作权限给系统,以免"软死机" Loop Setdmt = .document '将IE浏览器加载的页面文档,赋予dmt变量 Settb = dmt.all.tags("table")(5) '通过索引号捕捉表格对象 Fori = 2 To tb.Rows.Length - 1 '历遍其每个行 Forj = 0 To tb.Rows(i).Cells.Length - 1 '历遍每行的每个单元格 Cells(i+ 1, j + 1) = "'" & tb.Rows(i).Cells(j).innertext '将其innertext写入单元格 Next Next EndWith MsgBox("OK")End Sub代码截图:
代码分析:1)Set myIE = CreateObject("InternetExplorer.Application") 这段代码是创建一个IE对象,或者叫后期的绑定。引用都可以。2) Sheets("SHEET1").SelectRows("3:100").ClearContents清空数据待填区域。3) With myIE .Visible= True '显示它 .navigate"" 上述代码在IE中加载"" 网址,即东风财富网资金主力流入情况。4) Do Until .readystate = 4 '检查网页是否加载完毕(4表示完全加载) DoEvents '循环中交回工作权限给系统,以免"软死机" Loop 这段代码是让网页加载完成,以便后续提取网页的数据5)Set dmt = .document '将IE浏览器加载的页面文档,赋予dmt变量,这里的DMT是一个对象变量。6) Set tb = dmt.all.tags("table")(5) '通过索引号捕捉表格对象 这里的序号是我们分析网页得来,也可以利用工具进行网页的页面分析。7)For i = 2 To tb.Rows.Length - 1 '历遍其每个行 Forj = 0 To tb.Rows(i).Cells.Length - 1 '历遍每行的每个单元格 Cells(i+ 1, j + 1) = "'" & tb.Rows(i).Cells(j).innertext '将其innertext写入单元格 Next Next提取表的数据,这里tb.Rows.Length – 1 是行数;tb.Rows(i).Cells(j).innertext 是单元格的内容。3 应用IE实现资金主力流入数据抓取的实现效果我们点击页面的运行按钮,实现下面的数据抓取:
从实现的效果看,完全达到了我们场景需求。
本节知识点回向:如何在页面文档中提取表的数据?
本节内容参考:009工作表.xlsm
我20多年的VBA实践经验,全部浓缩在下面的各个教程中,教程学习顺序:
【分享成果,随喜正能量】从来茶倒七分满,留下三分是人情。半人半我半自在,半醒半醉半神仙。半亲半爱半苦乐,半俗半禅半随缘。人生,其实是很公平的。在哪里付出,就在哪里得到;在哪里打磨,就在哪里闪耀。。 查看全部
IE抓取资金主力流入的股票
【分享成果,随喜正能量】做人,要像一杯水。无色则纯,只要心里清澈,世事皆易;无味则淡,只要心里明了,万物皆空;无欲则刚,只要心里释然,一切皆无。。《VBA信息获取与处理》教程是我推出第六套教程,目前已经是第一版修订了。这套教程定位于最高级,是学完初级,中级后的教程。这部教程给大家讲解的内容有:跨应用程序信息获得、随机信息的利用、电子邮件的发送、VBA互联网数据抓取、VBA延时操作,剪贴板应用、Split函数扩展、工作表信息与其他应用交互,FSO对象的利用、工作表及文件夹信息的获取、图形信息的获取以及定制工作表信息函数等等内容。程序文件通过32位和64位两种OFFICE系统测试。是非常抽象的,更具研究的价值。教程共两册,八十四讲。今日的内容是专题九“利用IE抓取网络数据”:IE抓取资金主力流入的股票
第二节 利用IE,抓取资金主力流入的股票大家好,我们从这讲开始讲利用IE控件完成抓取网络数据的任务,由于基础知识已经讲解了很多,这里的代码讲解会简单些,大家可以参考我给出的代码注释进行理解。
实现场景:我们在做股票分析的时候,资金的动向是我们最为关心的,是否有大的资金流入是大多数散户进行某支股票投资的重要依据。我们以财富网提供的资金主力流入的股票数据为数据提取的基础。网址是: 。1 应用IE实现资金主力流入数据抓取的思路分析为了抓取数据,我们先看看网页页面,下面是2020年6月11日网页提供的数据:
我们的任务是要把上述数据抓取到EXCEL表格中。为了实现利用IE进行数据抓取,我们首先要建立一个IE引用CreateObject("InternetExplorer.Application")。然后IE打开给出的网址,.navigate ""实现我们从网页中得出这个表序号是5,那么将提取这个表中的数据。大家可以先复习一下我前面有关表的知识讲解.在网页文档中提取document对象,利用dmt.all.tags("table")(5)找到这个表,然后利用tb.Rows(i).Cells(j).innertext输出数据。2 应用IE实现资金主力流入数据抓取的代码实现为了实现上述的思路,我给出如下我的代码:
Sub myNZ() '利用IE,抓取财富网资金主力流入的股票Dim ie, dmt, tb, i&, j& SetmyIE = CreateObject("InternetExplorer.Application") '创建一个IE对象 Sheets("SHEET1").Select Rows("3:100").ClearContents WithmyIE .Visible= True '显示它 .navigate"" '加载东风财富网资金主力流入情况 DoUntil .readystate = 4 '检查网页是否加载完毕(4表示完全加载) DoEvents '循环中交回工作权限给系统,以免"软死机" Loop Setdmt = .document '将IE浏览器加载的页面文档,赋予dmt变量 Settb = dmt.all.tags("table")(5) '通过索引号捕捉表格对象 Fori = 2 To tb.Rows.Length - 1 '历遍其每个行 Forj = 0 To tb.Rows(i).Cells.Length - 1 '历遍每行的每个单元格 Cells(i+ 1, j + 1) = "'" & tb.Rows(i).Cells(j).innertext '将其innertext写入单元格 Next Next EndWith MsgBox("OK")End Sub代码截图:
代码分析:1)Set myIE = CreateObject("InternetExplorer.Application") 这段代码是创建一个IE对象,或者叫后期的绑定。引用都可以。2) Sheets("SHEET1").SelectRows("3:100").ClearContents清空数据待填区域。3) With myIE .Visible= True '显示它 .navigate"" 上述代码在IE中加载"" 网址,即东风财富网资金主力流入情况。4) Do Until .readystate = 4 '检查网页是否加载完毕(4表示完全加载) DoEvents '循环中交回工作权限给系统,以免"软死机" Loop 这段代码是让网页加载完成,以便后续提取网页的数据5)Set dmt = .document '将IE浏览器加载的页面文档,赋予dmt变量,这里的DMT是一个对象变量。6) Set tb = dmt.all.tags("table")(5) '通过索引号捕捉表格对象 这里的序号是我们分析网页得来,也可以利用工具进行网页的页面分析。7)For i = 2 To tb.Rows.Length - 1 '历遍其每个行 Forj = 0 To tb.Rows(i).Cells.Length - 1 '历遍每行的每个单元格 Cells(i+ 1, j + 1) = "'" & tb.Rows(i).Cells(j).innertext '将其innertext写入单元格 Next Next提取表的数据,这里tb.Rows.Length – 1 是行数;tb.Rows(i).Cells(j).innertext 是单元格的内容。3 应用IE实现资金主力流入数据抓取的实现效果我们点击页面的运行按钮,实现下面的数据抓取:
从实现的效果看,完全达到了我们场景需求。
本节知识点回向:如何在页面文档中提取表的数据?
本节内容参考:009工作表.xlsm
我20多年的VBA实践经验,全部浓缩在下面的各个教程中,教程学习顺序:
【分享成果,随喜正能量】从来茶倒七分满,留下三分是人情。半人半我半自在,半醒半醉半神仙。半亲半爱半苦乐,半俗半禅半随缘。人生,其实是很公平的。在哪里付出,就在哪里得到;在哪里打磨,就在哪里闪耀。。
如何控制网站关键词密度 实现高效SEO优化
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-04-29 15:13
我们都知道,企业搭建网站,想要在搜索引擎上取得好排名,SEO优化必不可少。而SEO优化中,关键词的整体布置极为重要。除在首页TDK需要放置外,我们还需让关键词合理的存在于页面的各个位置。那么如何控制关键词的密度、以及出现的频率呢?
关键词布局的目的很简单就是优化的核心关键词合理的布局到你的网站,控制它出现的位置和出现次数,使关键词的出现达到一定的密度,一般情况下密度在2%-8%最为合适,这样就能够达到一个集权的体现,可以通过关键词的页面快照或者站长工具查看关键词次数和密度。
关键词布局的位置可以放在网站的标题,关键词,描述,网站的导航,板块,页脚,网站的文章内容,文章标题等等相应的位置。
关键词的密度并不是越多越好,而是在2%-8%之间最合适,如果你的关键词密度超过了正常的范围值,那么则是会被搜索引擎判定为关键词堆积作弊,从而影响到排名,甚至被搜索引擎处罚,如果关键词的密度过小,又会让搜索引擎认为关键词跟页面的相关性不高,从而排名提升不了,所以关键词的密度要控制好。
做SEO肯定是想要让蜘蛛收录越多的页面越好,甚至有些站长想要让蜘蛛收录网站的全部页面,实际上这是不可能的,所以我们要想办法让蜘蛛尽可能多的收录页面,也尽可能让蜘蛛吸引更重要的页面。那么我们应该如何吸引蜘蛛。
1、网站和页面的权重
这个是大家都知道的,网站和页面的权重越高的话,蜘蛛一般会爬行的越深,被蜘蛛收录的页面也更多一些。但是一个新的网站,权重达到1的话是相对容易的,但是如果想要把权重再网上增加则会越来越难。
2、页面的更新度和更新频率
蜘蛛每次爬行网站的时候都会把这些页面的数据保存在数据库中,下次蜘蛛再次爬行此网站的时候则会与上次爬行的数据进行对比,如果页面与上次的页面是一样的,这就说明网页没有更新,这样的页面蜘蛛会减少抓取的频率,甚至不抓取。相反的,如果页面有更新,或者有新的链接的话,蜘蛛会根据新的链接爬向新的页面,这样就很容易增加收录量了。
3、外链和友情链接
很多所谓的SEO人员认为做网站优化就是不断的发外链,发大量的外链排名固然会好,我们可以肯定的是外链对网站的排名和收录是有好处的,但是并不是说SEO就是发外链,实际上真正的网站优化SEO,即使不发外链也是会有很好的排名的。当然我们现在讲的是外链的作用,所以其他的现在就不进行深入的探讨。
如果想要让蜘蛛知道你的链接的话,就需要去蜘蛛经常爬行的地方去放一些网站的链接,这样才会吸引蜘蛛来爬行的你的网站不是吗?这些导入链接我们就称之为外链,实际上友情链接也是外链的一种,但是因为友情链接实际上比外链的效果更佳,所以在此小资就分开来了。正是因为外链有这种吸引蜘蛛的作用,所以我们在发布一个新的网站的时候,一般都会去一些收录效果比较好的平台去发布一些外链,这样才能更快的让蜘蛛收录我们的网站。
4、页面的深度
这个问题很多站长都没注意,实际上这个问题对网站优化的影响也是比较大的,一般我们到二三级目录就完全可以了,如果单页面到更深的话蜘蛛可能会爬行不到,对于用户的体验也不是很好,页面权重也会越来越低,所以站长们一定要注意不要让页面距离首页太远。
v: 查看全部
如何控制网站关键词密度 实现高效SEO优化
我们都知道,企业搭建网站,想要在搜索引擎上取得好排名,SEO优化必不可少。而SEO优化中,关键词的整体布置极为重要。除在首页TDK需要放置外,我们还需让关键词合理的存在于页面的各个位置。那么如何控制关键词的密度、以及出现的频率呢?
关键词布局的目的很简单就是优化的核心关键词合理的布局到你的网站,控制它出现的位置和出现次数,使关键词的出现达到一定的密度,一般情况下密度在2%-8%最为合适,这样就能够达到一个集权的体现,可以通过关键词的页面快照或者站长工具查看关键词次数和密度。
关键词布局的位置可以放在网站的标题,关键词,描述,网站的导航,板块,页脚,网站的文章内容,文章标题等等相应的位置。
关键词的密度并不是越多越好,而是在2%-8%之间最合适,如果你的关键词密度超过了正常的范围值,那么则是会被搜索引擎判定为关键词堆积作弊,从而影响到排名,甚至被搜索引擎处罚,如果关键词的密度过小,又会让搜索引擎认为关键词跟页面的相关性不高,从而排名提升不了,所以关键词的密度要控制好。
做SEO肯定是想要让蜘蛛收录越多的页面越好,甚至有些站长想要让蜘蛛收录网站的全部页面,实际上这是不可能的,所以我们要想办法让蜘蛛尽可能多的收录页面,也尽可能让蜘蛛吸引更重要的页面。那么我们应该如何吸引蜘蛛。
1、网站和页面的权重
这个是大家都知道的,网站和页面的权重越高的话,蜘蛛一般会爬行的越深,被蜘蛛收录的页面也更多一些。但是一个新的网站,权重达到1的话是相对容易的,但是如果想要把权重再网上增加则会越来越难。
2、页面的更新度和更新频率
蜘蛛每次爬行网站的时候都会把这些页面的数据保存在数据库中,下次蜘蛛再次爬行此网站的时候则会与上次爬行的数据进行对比,如果页面与上次的页面是一样的,这就说明网页没有更新,这样的页面蜘蛛会减少抓取的频率,甚至不抓取。相反的,如果页面有更新,或者有新的链接的话,蜘蛛会根据新的链接爬向新的页面,这样就很容易增加收录量了。
3、外链和友情链接
很多所谓的SEO人员认为做网站优化就是不断的发外链,发大量的外链排名固然会好,我们可以肯定的是外链对网站的排名和收录是有好处的,但是并不是说SEO就是发外链,实际上真正的网站优化SEO,即使不发外链也是会有很好的排名的。当然我们现在讲的是外链的作用,所以其他的现在就不进行深入的探讨。
如果想要让蜘蛛知道你的链接的话,就需要去蜘蛛经常爬行的地方去放一些网站的链接,这样才会吸引蜘蛛来爬行的你的网站不是吗?这些导入链接我们就称之为外链,实际上友情链接也是外链的一种,但是因为友情链接实际上比外链的效果更佳,所以在此小资就分开来了。正是因为外链有这种吸引蜘蛛的作用,所以我们在发布一个新的网站的时候,一般都会去一些收录效果比较好的平台去发布一些外链,这样才能更快的让蜘蛛收录我们的网站。
4、页面的深度
这个问题很多站长都没注意,实际上这个问题对网站优化的影响也是比较大的,一般我们到二三级目录就完全可以了,如果单页面到更深的话蜘蛛可能会爬行不到,对于用户的体验也不是很好,页面权重也会越来越低,所以站长们一定要注意不要让页面距离首页太远。
v:
怎样抓取网页数据( 动态IP分为长效代理和短效代理的方法,2.1怎样选择合适的代理IP网站)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-04-20 06:21
动态IP分为长效代理和短效代理的方法,2.1怎样选择合适的代理IP网站)
内容
前言 ️ 一、动态代理ip 1.1 什么是动态代理ip
动态代理IP,顾名思义,这个IP会随时随机变化,无论是固定代理IP还是动态代理IP。动态代理IP一般被网络爬虫用户使用。
动态IP分为长期代理和短期代理:
1.2 使用动态代理 IP 的好处
提高网站的访问速度:浏览某一个网站后,浏览过的网站的信息会存储在代理服务器的硬盘上。如果您再次浏览 网站,此信息在代理服务器中始终可用,而无需重新连接到远程服务器。因此,它节省了带宽并加快了 网站 的浏览速度。作为防火墙:可以保证局域网的安全。作为防火墙的功能,对于使用代理服务器的局域网,从外部看,只有代理服务器可以看到,其他本地用户看不到。代理还可用于限制 IP 地址的阻止,阻止用户查看某些页面。降低 IP 成本:应用代理服务器可以节省对 IP 地址的需求,从而降低 IP 地址的成本。易于管理的网络资源:您可以将部分共享资源限制在特定区域的用户中,以保持资源的区域性。提升爬虫速度:使用动态代理IP可以绕过目标网站限制,更好的抓取网络数据,自定义时间更改IP地址,提高爬虫效率。1.3 动态代理IP类别
动态代理IP又分为透明代理、匿名代理、高匿名代理。
由此可见代理IP的质量实力。对于网络爬虫,您可以根据自己的需要购买定制的动态IP。
高安全代理自然是动态代理IP类型中质量最好的。很多企业爬虫用户会选择隧道转发的高安全蜘蛛代理IP来提供业务需求,保证业务成果和质量。
透明代理和匿名代理虽然也是代理IP,但是大大降低了爬虫业务的进度和效率。因此,网络爬虫选择隧道转发的爬虫代理是正确的选择。
️ 二、如何申请动态IP代理2.1 如何选择合适的代理IP网站
简单介绍一下动态代理IP的概念和好处,然后说一下如何申请这个动态代理IP。
我这里用的是IPIDEA网站,现在新用户有500M免费流量,正好可以用来做实验。
只需点击注册:
输入网站后,点击Get Proxy -> API Get
然后根据自己的喜好选择数量和地区,其他使用默认选项,然后点击下方生成链接
如果没有实名认证,会跳出这个界面,直接点击认证
然后复制我们生成的链接。此链接应保存并稍后在使用 Python 进行爬网时使用。
单独复制链接然后打开,会看到刚刚生成的IP,这部分可以用于我们自己浏览器的手动设置。
2.2 IPIDEA的优势网站
如上所述,网站代理IP很多,那么如何选择合适的平台也是一个值得思考的问题。
由于目前代理IP很多网站,价格根据稳定性和安全性差异很大。
IPIDEA新用户注册发送部分免费流量,对我们想尝试使用代理ip的朋友非常友好。
还有就是平台支持住宅动态ip,这也是一个优势。
动态住宅 IP 的优势:
️ 三、代理ip的两种使用方式
有很多方法可以使用代理 ip。下面我将通过两种方式做一个简单的演示:直接在浏览器中使用和使用生成的API链接。
3.1 浏览器如何使用代理ip
在上一步中,我们获得了一个 ip 代理池。接下来以QQ浏览器为例,简单看看这些代理ip的使用方法。
在QQ浏览器菜单列表-设置-高级-网络-更改代理服务器设置
在弹出的 Internet 属性窗口中,单击 LAN 设置
填写我们复制的IP和端口号,点击OK
打开百度/谷歌搜索引擎,搜索:IP,查看当前代理后的IP地址
至此,我们已经成功使用了代理ip,接下来我们就可以使用代理ip做一些其他的事情了~ 查看全部
怎样抓取网页数据(
动态IP分为长效代理和短效代理的方法,2.1怎样选择合适的代理IP网站)
内容
前言 ️ 一、动态代理ip 1.1 什么是动态代理ip
动态代理IP,顾名思义,这个IP会随时随机变化,无论是固定代理IP还是动态代理IP。动态代理IP一般被网络爬虫用户使用。
动态IP分为长期代理和短期代理:
1.2 使用动态代理 IP 的好处
提高网站的访问速度:浏览某一个网站后,浏览过的网站的信息会存储在代理服务器的硬盘上。如果您再次浏览 网站,此信息在代理服务器中始终可用,而无需重新连接到远程服务器。因此,它节省了带宽并加快了 网站 的浏览速度。作为防火墙:可以保证局域网的安全。作为防火墙的功能,对于使用代理服务器的局域网,从外部看,只有代理服务器可以看到,其他本地用户看不到。代理还可用于限制 IP 地址的阻止,阻止用户查看某些页面。降低 IP 成本:应用代理服务器可以节省对 IP 地址的需求,从而降低 IP 地址的成本。易于管理的网络资源:您可以将部分共享资源限制在特定区域的用户中,以保持资源的区域性。提升爬虫速度:使用动态代理IP可以绕过目标网站限制,更好的抓取网络数据,自定义时间更改IP地址,提高爬虫效率。1.3 动态代理IP类别
动态代理IP又分为透明代理、匿名代理、高匿名代理。
由此可见代理IP的质量实力。对于网络爬虫,您可以根据自己的需要购买定制的动态IP。
高安全代理自然是动态代理IP类型中质量最好的。很多企业爬虫用户会选择隧道转发的高安全蜘蛛代理IP来提供业务需求,保证业务成果和质量。
透明代理和匿名代理虽然也是代理IP,但是大大降低了爬虫业务的进度和效率。因此,网络爬虫选择隧道转发的爬虫代理是正确的选择。
️ 二、如何申请动态IP代理2.1 如何选择合适的代理IP网站
简单介绍一下动态代理IP的概念和好处,然后说一下如何申请这个动态代理IP。
我这里用的是IPIDEA网站,现在新用户有500M免费流量,正好可以用来做实验。
只需点击注册:
输入网站后,点击Get Proxy -> API Get
然后根据自己的喜好选择数量和地区,其他使用默认选项,然后点击下方生成链接
如果没有实名认证,会跳出这个界面,直接点击认证
然后复制我们生成的链接。此链接应保存并稍后在使用 Python 进行爬网时使用。
单独复制链接然后打开,会看到刚刚生成的IP,这部分可以用于我们自己浏览器的手动设置。
2.2 IPIDEA的优势网站
如上所述,网站代理IP很多,那么如何选择合适的平台也是一个值得思考的问题。
由于目前代理IP很多网站,价格根据稳定性和安全性差异很大。
IPIDEA新用户注册发送部分免费流量,对我们想尝试使用代理ip的朋友非常友好。
还有就是平台支持住宅动态ip,这也是一个优势。
动态住宅 IP 的优势:
️ 三、代理ip的两种使用方式
有很多方法可以使用代理 ip。下面我将通过两种方式做一个简单的演示:直接在浏览器中使用和使用生成的API链接。
3.1 浏览器如何使用代理ip
在上一步中,我们获得了一个 ip 代理池。接下来以QQ浏览器为例,简单看看这些代理ip的使用方法。
在QQ浏览器菜单列表-设置-高级-网络-更改代理服务器设置
在弹出的 Internet 属性窗口中,单击 LAN 设置
填写我们复制的IP和端口号,点击OK
打开百度/谷歌搜索引擎,搜索:IP,查看当前代理后的IP地址
至此,我们已经成功使用了代理ip,接下来我们就可以使用代理ip做一些其他的事情了~
怎样抓取网页数据(编写一个网页下载get函数__txt_html_data)
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2022-04-20 06:17
整个数据采集的信息是通过房源平台获取的,整个过程是通过下载网页元素,进行数据提取和分析来完成的
导入相关网页下载、数据分析、数据处理库
from fake_useragent import UserAgent # 身份信息生成库
from bs4 import BeautifulSoup # 网页元素解析库
import numpy as np # 科学计算库
import requests # 网页下载库
from requests.exceptions import RequestException # 网络请求异常库
import pandas as pd # 数据处理库
然后,在开始之前,初始化一个身份信息生成的对象,用于以后下载网页时随机生成身份信息。
user_agent = UserAgent()
编写网页下载函数get_html_txt,从对应的url地址下载网页的html文本。
def get_html_txt(url, page_index):
"""
获取网页html文本信息
:param url: 爬取地址
:param page_index:当前页数
:return:
"""
try:
headers = {
"user-agent": user_agent.random
}
response = requests.request("GET", url, headers=headers, timeout=10)
html_txt = response.text
return html_txt
except RequestException as e:
print("获取第{0}页网页元素失败!".format(page_index))
return ""
编写网页元素处理函数catch_html_data解析网页元素,并将解析后的数据元素保存到csv文件中。
def catch_html_data(url, page_index):
"""
处理网页元素数据
:param url: 爬虫地址
:param page_index:
:return:
"""
# 下载网页元素
html_txt = str(get_html_txt(url, page_index))
if html_txt.strip() != "":
# 初始化网页元素对象
beautifulSoup = BeautifulSoup(html_txt, "lxml")
# 解析房源列表
h_list = beautifulSoup.select(".resblock-list-wrapper li")
# 遍历当前房源的详细信息
for n in range(len(h_list)):
h_detail = h_list[n]
# 提取房源名称
h_detail_name = h_detail.select(".resblock-name a.name")
h_detail_name = [m.get_text() for m in h_detail_name]
h_detail_name = " ".join(map(str, h_detail_name))
# 提取房源类型
h_detail_type = h_detail.select(".resblock-name span.resblock-type")
h_detail_type = [m.get_text() for m in h_detail_type]
h_detail_type = " ".join(map(str, h_detail_type))
# 提取房源销售状态
h_detail_status = h_detail.select(".resblock-name span.sale-status")
h_detail_status = [m.get_text() for m in h_detail_status]
h_detail_status = " ".join(map(str, h_detail_status))
# 提取房源单价信息
h_detail_price = h_detail.select(".resblock-price .main-price .number")
h_detail_price = [m.get_text() for m in h_detail_price]
h_detail_price = " ".join(map(str, h_detail_price))
# 提取房源总价信息
h_detail_total_price = h_detail.select(".resblock-price .second")
h_detail_total_price = [m.get_text() for m in h_detail_total_price]
h_detail_total_price = " ".join(map(str, h_detail_total_price))
h_info = [h_detail_name, h_detail_type, h_detail_status, h_detail_price, h_detail_total_price]
h_info = np.array(h_info)
h_info = h_info.reshape(-1, 5)
h_info = pd.DataFrame(h_info, columns=["房源名称", "房源类型", "房源状态", "房源均价", "房源总价"])
h_info.to_csv("北京房源信息.csv", mode="a+", index=False, header=False)
print("第{0}页房源信息数据存储成功!".format(page_index))
else:
print("网页元素解析失败!")
编写多线程处理函数,初始化网页下载地址,使用多线程启动调用业务处理函数catch_html_data,启动线程完成整个业务流程。
import threading # 导入线程处理模块
def thread_catch():
"""
线程处理函数
:return:
"""
for num in range(1, 50, 3):
url_pre = "https://bj.fang.lianjia.com/loupan/pg{0}/".format(str(num))
url_cur = "https://bj.fang.lianjia.com/loupan/pg{0}/".format(str(num + 1))
url_aft = "https://bj.fang.lianjia.com/loupan/pg{0}/".format(str(num + 2))
thread_pre = threading.Thread(target=catch_html_data, args=(url_pre, num))
thread_cur = threading.Thread(target=catch_html_data, args=(url_cur, num + 1))
thread_aft = threading.Thread(target=catch_html_data, args=(url_aft, num + 2))
thread_pre.start()
thread_cur.start()
thread_aft.start()
thread_catch()
数据存储结果展示效果
以上是基于Python获取最新房价信息的详细内容。更多使用Python获取房价信息的内容,请关注云海天教程文章的其他相关信息! 查看全部
怎样抓取网页数据(编写一个网页下载get函数__txt_html_data)
整个数据采集的信息是通过房源平台获取的,整个过程是通过下载网页元素,进行数据提取和分析来完成的
导入相关网页下载、数据分析、数据处理库
from fake_useragent import UserAgent # 身份信息生成库
from bs4 import BeautifulSoup # 网页元素解析库
import numpy as np # 科学计算库
import requests # 网页下载库
from requests.exceptions import RequestException # 网络请求异常库
import pandas as pd # 数据处理库
然后,在开始之前,初始化一个身份信息生成的对象,用于以后下载网页时随机生成身份信息。
user_agent = UserAgent()
编写网页下载函数get_html_txt,从对应的url地址下载网页的html文本。
def get_html_txt(url, page_index):
"""
获取网页html文本信息
:param url: 爬取地址
:param page_index:当前页数
:return:
"""
try:
headers = {
"user-agent": user_agent.random
}
response = requests.request("GET", url, headers=headers, timeout=10)
html_txt = response.text
return html_txt
except RequestException as e:
print("获取第{0}页网页元素失败!".format(page_index))
return ""
编写网页元素处理函数catch_html_data解析网页元素,并将解析后的数据元素保存到csv文件中。
def catch_html_data(url, page_index):
"""
处理网页元素数据
:param url: 爬虫地址
:param page_index:
:return:
"""
# 下载网页元素
html_txt = str(get_html_txt(url, page_index))
if html_txt.strip() != "":
# 初始化网页元素对象
beautifulSoup = BeautifulSoup(html_txt, "lxml")
# 解析房源列表
h_list = beautifulSoup.select(".resblock-list-wrapper li")
# 遍历当前房源的详细信息
for n in range(len(h_list)):
h_detail = h_list[n]
# 提取房源名称
h_detail_name = h_detail.select(".resblock-name a.name")
h_detail_name = [m.get_text() for m in h_detail_name]
h_detail_name = " ".join(map(str, h_detail_name))
# 提取房源类型
h_detail_type = h_detail.select(".resblock-name span.resblock-type")
h_detail_type = [m.get_text() for m in h_detail_type]
h_detail_type = " ".join(map(str, h_detail_type))
# 提取房源销售状态
h_detail_status = h_detail.select(".resblock-name span.sale-status")
h_detail_status = [m.get_text() for m in h_detail_status]
h_detail_status = " ".join(map(str, h_detail_status))
# 提取房源单价信息
h_detail_price = h_detail.select(".resblock-price .main-price .number")
h_detail_price = [m.get_text() for m in h_detail_price]
h_detail_price = " ".join(map(str, h_detail_price))
# 提取房源总价信息
h_detail_total_price = h_detail.select(".resblock-price .second")
h_detail_total_price = [m.get_text() for m in h_detail_total_price]
h_detail_total_price = " ".join(map(str, h_detail_total_price))
h_info = [h_detail_name, h_detail_type, h_detail_status, h_detail_price, h_detail_total_price]
h_info = np.array(h_info)
h_info = h_info.reshape(-1, 5)
h_info = pd.DataFrame(h_info, columns=["房源名称", "房源类型", "房源状态", "房源均价", "房源总价"])
h_info.to_csv("北京房源信息.csv", mode="a+", index=False, header=False)
print("第{0}页房源信息数据存储成功!".format(page_index))
else:
print("网页元素解析失败!")
编写多线程处理函数,初始化网页下载地址,使用多线程启动调用业务处理函数catch_html_data,启动线程完成整个业务流程。
import threading # 导入线程处理模块
def thread_catch():
"""
线程处理函数
:return:
"""
for num in range(1, 50, 3):
url_pre = "https://bj.fang.lianjia.com/loupan/pg{0}/".format(str(num))
url_cur = "https://bj.fang.lianjia.com/loupan/pg{0}/".format(str(num + 1))
url_aft = "https://bj.fang.lianjia.com/loupan/pg{0}/".format(str(num + 2))
thread_pre = threading.Thread(target=catch_html_data, args=(url_pre, num))
thread_cur = threading.Thread(target=catch_html_data, args=(url_cur, num + 1))
thread_aft = threading.Thread(target=catch_html_data, args=(url_aft, num + 2))
thread_pre.start()
thread_cur.start()
thread_aft.start()
thread_catch()
数据存储结果展示效果
以上是基于Python获取最新房价信息的详细内容。更多使用Python获取房价信息的内容,请关注云海天教程文章的其他相关信息!
怎样抓取网页数据(优采云·云采集服务平台如何抓取网易新闻的网站数据(涉及Ajax技术))
网站优化 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-04-19 22:31
优采云·云采集服务平台
如何抓取网易新闻的网站数据(涉及Ajax技术)
随着互联网数据的爆炸式增长,我们的工作是有效地从这些数据中获取、分析和产生价值。那么,首先要思考的问题是:如何捕获网站 数据?
今天分享的是一个完整的使用web数据采集器-优采云,采集网站数据的例子。采集网站的目标是网易新闻。观察发现,打开网易新闻的网站后,下拉页面,会发现页面正在加载新数据。分析表明,这个网站涉及到Ajax技术,需要在优采云中设置一些高级选项,需要特别注意。详情可以到优采云官网学习AJAX滚动教程。
采集网站:
下载示例规则:
#_rnd79
第 1 步:创建一个 采集 任务
1)进入主界面选择,选择自定义模式
优采云·云采集服务平台
如何抓取网易新闻的网站数据 图1
2)将上述网址的网址复制粘贴到网站输入框,点击“保存网址”
优采云·云采集服务平台
如何抓取网易新闻的网站数据 图2
3)保存URL后会在优采云采集器中打开页面,红框内的信息就是这个demo的内容要采集
优采云·云采集服务平台
如何抓取网易新闻的网站数据 图3
第二步:设置ajax页面加载时间
? 设置打开网页步骤的ajax滚动加载时间
1)页面打开后,下拉页面会发现页面有新数据正在加载
如何抓取网易新闻的网站数据 图4
因此需要进行如下设置:打开流程图,点击“打开网页”步骤,在右侧的高级选项框中,勾选“页面加载时向下滚动”,设置滚动次数,每次滚动的间隔,一般设置为2秒,本页的滚动方式,选择直接滚动到底部;最后点击确定
优采云·云采集服务平台
如何抓取网易新闻的网站数据 图5
注意:这里需要为网站设置滚动的次数和间隔,测试方法可以参考优采云7.0教程-AJAX滚动教程
第三步:采集列出内容
? 勾选需要在采集列表中的新闻框,创建数据提取列表
1)移动鼠标选中图片中的新闻信息框。右击,采集的内容会变成绿色
优采云·云采集服务平台
如何抓取网易新闻的网站数据 图6
注:点击右上角的“流程”按钮,显示可视化流程图。
2)系统会识别新闻信息框中的子元素。在操作提示框中,选择“选择子元素”
优采云·云采集服务平台
如何抓取网易新闻的网站数据 图7
3)系统会自动识别页面上其他类似的元素。在操作提示框中,选择“全选”创建列表循环
优采云·云采集服务平台
如何抓取网易新闻的网站数据 图8
注意:当一个字段被选中时,当鼠标放在该字段上时会出现一个删除图标,点击删除该字段。
如何抓取网易新闻的网站数据 图9
优采云·云采集服务平台
4)我们可以看到页面上第一个影评块的所有元素都被选中并变为绿色。选择“采集以下数据”
如何抓取网易新闻的网站数据 图10
5)修改采集字段名称并点击下方红框中的“保存并开始采集”
优采云·云采集服务平台
如何抓取网易新闻的网站数据 图11
第 4 步:数据采集 和导出
1)根据采集的情况选择合适的采集方法,这里选择“本地启动采集”
优采云·云采集服务平台
如何抓取网易新闻的网站数据 图12
注意:本地采集 占用采集 的当前计算机资源。如果有采集时间要求或者当前电脑长时间不能执行采集,可以使用云端采集功能。云采集在网络中做采集,不需要当前计算机支持,可以关闭计算机,可以设置多个云节点分发任务,10个节点相当于10台计算机分发任务帮你采集,速度降低到原来的十分之一;采集获取的数据可以在云端存储三个月,随时可以导出。
2)采集完成后会弹出提示,选择导出数据
优采云·云采集服务平台
如何抓取网易新闻的网站数据 图13
3)选择合适的导出方式,导出采集好的数据
优采云·云采集服务平台
如何抓取网易新闻的网站数据 图14
本文以网易新闻的数据采集为例,采集网易新闻-国际分类下的新闻标题、标签、发布时间、关注人数等信息。在实际过程中,基本步骤可以参考以上操作。但是,由于网页的形式极其丰富,网页的结构也不尽相同,所以需要具体情况具体分析。
相关 采集 教程:
京东商品信息采集百度搜索结果采集搜狗微信文章采集
优采云·云采集服务平台
优采云——70万用户选择的网页数据采集器。1、简单易用,任何人都可以使用:无需技术背景,只需了解互联网采集。完成流程可视化,点击鼠标完成操作,2分钟快速上手。2、功能强大,任意网站可选:点击、登录、翻页、身份验证码、瀑布流、Ajax脚本异步加载数据,都可以通过简单的设置进行设置< @采集。3、云采集,你也可以关机。配置采集任务后,可以将其关闭,并可以在云端执行任务。巨大的云采集集群24*7不间断运行,因此无需担心IP阻塞和网络中断。4、功能免费+增值服务,按需选择。免费版具有满足用户基本采集需求的所有功能。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。 查看全部
怎样抓取网页数据(优采云·云采集服务平台如何抓取网易新闻的网站数据(涉及Ajax技术))
优采云·云采集服务平台
如何抓取网易新闻的网站数据(涉及Ajax技术)
随着互联网数据的爆炸式增长,我们的工作是有效地从这些数据中获取、分析和产生价值。那么,首先要思考的问题是:如何捕获网站 数据?
今天分享的是一个完整的使用web数据采集器-优采云,采集网站数据的例子。采集网站的目标是网易新闻。观察发现,打开网易新闻的网站后,下拉页面,会发现页面正在加载新数据。分析表明,这个网站涉及到Ajax技术,需要在优采云中设置一些高级选项,需要特别注意。详情可以到优采云官网学习AJAX滚动教程。
采集网站:
下载示例规则:
#_rnd79
第 1 步:创建一个 采集 任务
1)进入主界面选择,选择自定义模式
优采云·云采集服务平台
如何抓取网易新闻的网站数据 图1
2)将上述网址的网址复制粘贴到网站输入框,点击“保存网址”
优采云·云采集服务平台
如何抓取网易新闻的网站数据 图2
3)保存URL后会在优采云采集器中打开页面,红框内的信息就是这个demo的内容要采集
优采云·云采集服务平台
如何抓取网易新闻的网站数据 图3
第二步:设置ajax页面加载时间
? 设置打开网页步骤的ajax滚动加载时间
1)页面打开后,下拉页面会发现页面有新数据正在加载
如何抓取网易新闻的网站数据 图4
因此需要进行如下设置:打开流程图,点击“打开网页”步骤,在右侧的高级选项框中,勾选“页面加载时向下滚动”,设置滚动次数,每次滚动的间隔,一般设置为2秒,本页的滚动方式,选择直接滚动到底部;最后点击确定
优采云·云采集服务平台
如何抓取网易新闻的网站数据 图5
注意:这里需要为网站设置滚动的次数和间隔,测试方法可以参考优采云7.0教程-AJAX滚动教程
第三步:采集列出内容
? 勾选需要在采集列表中的新闻框,创建数据提取列表
1)移动鼠标选中图片中的新闻信息框。右击,采集的内容会变成绿色
优采云·云采集服务平台
如何抓取网易新闻的网站数据 图6
注:点击右上角的“流程”按钮,显示可视化流程图。
2)系统会识别新闻信息框中的子元素。在操作提示框中,选择“选择子元素”
优采云·云采集服务平台
如何抓取网易新闻的网站数据 图7
3)系统会自动识别页面上其他类似的元素。在操作提示框中,选择“全选”创建列表循环
优采云·云采集服务平台
如何抓取网易新闻的网站数据 图8
注意:当一个字段被选中时,当鼠标放在该字段上时会出现一个删除图标,点击删除该字段。
如何抓取网易新闻的网站数据 图9
优采云·云采集服务平台
4)我们可以看到页面上第一个影评块的所有元素都被选中并变为绿色。选择“采集以下数据”
如何抓取网易新闻的网站数据 图10
5)修改采集字段名称并点击下方红框中的“保存并开始采集”
优采云·云采集服务平台
如何抓取网易新闻的网站数据 图11
第 4 步:数据采集 和导出
1)根据采集的情况选择合适的采集方法,这里选择“本地启动采集”
优采云·云采集服务平台
如何抓取网易新闻的网站数据 图12
注意:本地采集 占用采集 的当前计算机资源。如果有采集时间要求或者当前电脑长时间不能执行采集,可以使用云端采集功能。云采集在网络中做采集,不需要当前计算机支持,可以关闭计算机,可以设置多个云节点分发任务,10个节点相当于10台计算机分发任务帮你采集,速度降低到原来的十分之一;采集获取的数据可以在云端存储三个月,随时可以导出。
2)采集完成后会弹出提示,选择导出数据
优采云·云采集服务平台
如何抓取网易新闻的网站数据 图13
3)选择合适的导出方式,导出采集好的数据
优采云·云采集服务平台
如何抓取网易新闻的网站数据 图14
本文以网易新闻的数据采集为例,采集网易新闻-国际分类下的新闻标题、标签、发布时间、关注人数等信息。在实际过程中,基本步骤可以参考以上操作。但是,由于网页的形式极其丰富,网页的结构也不尽相同,所以需要具体情况具体分析。
相关 采集 教程:
京东商品信息采集百度搜索结果采集搜狗微信文章采集
优采云·云采集服务平台
优采云——70万用户选择的网页数据采集器。1、简单易用,任何人都可以使用:无需技术背景,只需了解互联网采集。完成流程可视化,点击鼠标完成操作,2分钟快速上手。2、功能强大,任意网站可选:点击、登录、翻页、身份验证码、瀑布流、Ajax脚本异步加载数据,都可以通过简单的设置进行设置< @采集。3、云采集,你也可以关机。配置采集任务后,可以将其关闭,并可以在云端执行任务。巨大的云采集集群24*7不间断运行,因此无需担心IP阻塞和网络中断。4、功能免费+增值服务,按需选择。免费版具有满足用户基本采集需求的所有功能。同时设置一些增值服务(如私有云),满足高端付费企业用户的需求。

