
在线抓取网页
在线抓取网页(网页文字抓取,(详细如图)什么是老域名?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-04-20 05:26
网页文字抓取,相信很多小伙伴都遇到过文章网页禁止复制,今天给大家分享一款免费的网页文字抓取工具,只需要输入链接即可提取网站 text,自动保存本地化并保留文本排版!还自带采集+伪原创功能+发布功能。 (详细图片)
什么是旧域名?从字面上看,可以理解为一个已经使用了几年的过时域名,但是域名注册后并不是用来建网站的,所以这样的域名不是旧域名,而是通常提交或注册。未注册的域名当然有不同的价格,但是对于SEO新手来说,基本没有这个概念。
注册一个好的老域名完全有利于优化网站的排名,所以会继承以下指标;
①权重继承
一个好的老域名会继承网站本身的权重,有利于网站快速收录,节省不必要的外部资源时间,但还是要注意尝试使用网站相关内容创作。
②无沙盒期
作为SEO的朋友,你应该知道,对于百度搜索引擎来说,任何新注册的域名,如果不注意,肯定会出现在沙盒期。平台上的时间认可直接通过信任获得。只要继续优化,就不会出现所谓的沙盒期。
③易换链
作为SEO人员,我们都知道一个新的网站很难交换友情链接。因为没有基础,很难找到更好的网站建立合作关系,但老域名不同。它继承了前一个 网站 的所有权重。友情链接交换还会有困难吗?
nofollow 属性是 HTML 页面中 A 标签的属性值。该属性的含义是通知搜索引擎不要关注该特定链接,并通知搜索引擎该链接不受作者信任。使用nofollow的目的是为了指示搜索引擎不要抓取网页上任何具有nofollow属性的站点链接,以减少渣链接,分散网站的权重。简单来说就是搜索引擎看到属性后不会或者降低链接的投票权重,也就是说这个链接不是我推荐的。不要给他我的重量,因为每个网页都有重量。是的,不要将我的权重发送到此连接。
nofollow属性的含义和用法
它的应用方法一般是常用的写法,写在某个标签的属性中,比如A标签之后。给链接添加nofollow后,当搜索引擎第一次发现该链接时,还是会把它放到待爬取的url队列中,也会被爬取。不代表加nofollow就不会被抓,如果被抓,也能被抓,只是不传递权重。
这里需要注意一件事。官方关于nofollow属性的声明表示,最终结果是否会被传输取决于链接对用户是否有价值。这句话是什么意思?如果站长加了nofollow的属性,我绝对不会把权重发到这个链接的。我仍然可以发送它。我是否会发送它取决于用户。对于用户来说,这个链接有价值吗?如何判断是否有价值?我估计百度一定有一个方法来计算用户点击百分比,类似这个方法判断链接对用户是否有价值,然后决定是否给链接赋予权重,怎么说呢,比如,对于比如我写了一篇文章关于东莞SEO文章的文章,然后在下面放了百度站长平台的链接。
nofollow属性的含义和用法
我的网站是东莞SEO,我不是百度站长平台的,但是我在某个页面放了一个百度站长平台的链接,然后在这个链接上加nofollow,说不要关注这个链接不是我推荐的,不要把我的重量推给他。结果有100个用户来阅读,超过50%的用户点击了这个链接,然后跳转到百度站长平台。这种情况,用百度很容易判断。一定要超过一定的门槛,而且超过了他设定的一定的门槛。我们不知道他设置了多少?
是否明显超过了 50%?是还是不是? 50% 的人点击,然后澄清链接是有意义的,对用户有价值。然后我的页面会把权重发送进去,通过站长平台的链接发送进去。其实我已经设置了nofollow,但是没用。这是官方声明的解释。所以大家一定要正确认识自己能不能旅行,什么时候适合用nofollow,那些不参与竞争排名的页面。什么是非竞争性排名页面?比如我们的登录页面、注册页面、投诉举报页面,这些页面不参与竞争排名。
他肯定不会参与的,比如说登录页面,用户怎么会去百度搜索登录页面,对吧?他不可能说出搜索和登录两个字。即使他搜索登录一词,他也可能会询问有关登录要求或其他内容的问题,并且无论如何他都不会跳出我们的页面。所以这些页面,我们登录注册投诉举报这些页面,都是不参与竞争排名的页面。对于这样的链接,我们都将使用 nofollow 属性。比如我的主页上有一个带有登录链接的按钮,点击一下就会跳转到登录页面。
那如果用了这个链接,我肯定会在后面加上no follow属性,别把我主页的权重发给他,这个页面没用。我没有推荐它。那么,第二种可以使用的场景,也就是一个页面显示多个重复链接的时候,一般来说同一个页面不会显示几个相同的页面链接,但是并没有排除一些特殊的原因。导致我们在一个页面上放置了很多重复的、重复的链接,可能是老板要求的,也可能是开发者要求的,或者其他原因,如果有重复。除了第一个,其他几个重复的链接我们建议添加nofollow。返回搜狐,查看更多 查看全部
在线抓取网页(网页文字抓取,(详细如图)什么是老域名?)
网页文字抓取,相信很多小伙伴都遇到过文章网页禁止复制,今天给大家分享一款免费的网页文字抓取工具,只需要输入链接即可提取网站 text,自动保存本地化并保留文本排版!还自带采集+伪原创功能+发布功能。 (详细图片)
什么是旧域名?从字面上看,可以理解为一个已经使用了几年的过时域名,但是域名注册后并不是用来建网站的,所以这样的域名不是旧域名,而是通常提交或注册。未注册的域名当然有不同的价格,但是对于SEO新手来说,基本没有这个概念。
注册一个好的老域名完全有利于优化网站的排名,所以会继承以下指标;
①权重继承
一个好的老域名会继承网站本身的权重,有利于网站快速收录,节省不必要的外部资源时间,但还是要注意尝试使用网站相关内容创作。
②无沙盒期
作为SEO的朋友,你应该知道,对于百度搜索引擎来说,任何新注册的域名,如果不注意,肯定会出现在沙盒期。平台上的时间认可直接通过信任获得。只要继续优化,就不会出现所谓的沙盒期。
③易换链
作为SEO人员,我们都知道一个新的网站很难交换友情链接。因为没有基础,很难找到更好的网站建立合作关系,但老域名不同。它继承了前一个 网站 的所有权重。友情链接交换还会有困难吗?
nofollow 属性是 HTML 页面中 A 标签的属性值。该属性的含义是通知搜索引擎不要关注该特定链接,并通知搜索引擎该链接不受作者信任。使用nofollow的目的是为了指示搜索引擎不要抓取网页上任何具有nofollow属性的站点链接,以减少渣链接,分散网站的权重。简单来说就是搜索引擎看到属性后不会或者降低链接的投票权重,也就是说这个链接不是我推荐的。不要给他我的重量,因为每个网页都有重量。是的,不要将我的权重发送到此连接。
nofollow属性的含义和用法
它的应用方法一般是常用的写法,写在某个标签的属性中,比如A标签之后。给链接添加nofollow后,当搜索引擎第一次发现该链接时,还是会把它放到待爬取的url队列中,也会被爬取。不代表加nofollow就不会被抓,如果被抓,也能被抓,只是不传递权重。
这里需要注意一件事。官方关于nofollow属性的声明表示,最终结果是否会被传输取决于链接对用户是否有价值。这句话是什么意思?如果站长加了nofollow的属性,我绝对不会把权重发到这个链接的。我仍然可以发送它。我是否会发送它取决于用户。对于用户来说,这个链接有价值吗?如何判断是否有价值?我估计百度一定有一个方法来计算用户点击百分比,类似这个方法判断链接对用户是否有价值,然后决定是否给链接赋予权重,怎么说呢,比如,对于比如我写了一篇文章关于东莞SEO文章的文章,然后在下面放了百度站长平台的链接。
nofollow属性的含义和用法
我的网站是东莞SEO,我不是百度站长平台的,但是我在某个页面放了一个百度站长平台的链接,然后在这个链接上加nofollow,说不要关注这个链接不是我推荐的,不要把我的重量推给他。结果有100个用户来阅读,超过50%的用户点击了这个链接,然后跳转到百度站长平台。这种情况,用百度很容易判断。一定要超过一定的门槛,而且超过了他设定的一定的门槛。我们不知道他设置了多少?
是否明显超过了 50%?是还是不是? 50% 的人点击,然后澄清链接是有意义的,对用户有价值。然后我的页面会把权重发送进去,通过站长平台的链接发送进去。其实我已经设置了nofollow,但是没用。这是官方声明的解释。所以大家一定要正确认识自己能不能旅行,什么时候适合用nofollow,那些不参与竞争排名的页面。什么是非竞争性排名页面?比如我们的登录页面、注册页面、投诉举报页面,这些页面不参与竞争排名。
他肯定不会参与的,比如说登录页面,用户怎么会去百度搜索登录页面,对吧?他不可能说出搜索和登录两个字。即使他搜索登录一词,他也可能会询问有关登录要求或其他内容的问题,并且无论如何他都不会跳出我们的页面。所以这些页面,我们登录注册投诉举报这些页面,都是不参与竞争排名的页面。对于这样的链接,我们都将使用 nofollow 属性。比如我的主页上有一个带有登录链接的按钮,点击一下就会跳转到登录页面。
那如果用了这个链接,我肯定会在后面加上no follow属性,别把我主页的权重发给他,这个页面没用。我没有推荐它。那么,第二种可以使用的场景,也就是一个页面显示多个重复链接的时候,一般来说同一个页面不会显示几个相同的页面链接,但是并没有排除一些特殊的原因。导致我们在一个页面上放置了很多重复的、重复的链接,可能是老板要求的,也可能是开发者要求的,或者其他原因,如果有重复。除了第一个,其他几个重复的链接我们建议添加nofollow。返回搜狐,查看更多
在线抓取网页( Python主要有网络爬虫,网络开发,人工智能自动化自动化运维)
网站优化 • 优采云 发表了文章 • 0 个评论 • 260 次浏览 • 2022-04-13 17:03
Python主要有网络爬虫,网络开发,人工智能自动化自动化运维)
在学习 Python 之前,我们需要了解 Python 的用途以及学习它能给我们带来什么?
Python主要包括网络爬虫、网页开发、人工智能、自动化运维
这里我们主要看一下网络爬虫,什么是网络爬虫?
网络爬虫,又称网络蜘蛛,是指一种脚本程序,它按照一定的规则在网络上爬取想要的内容。
众所周知,每个网页通常都收录其他网页的入口,网络爬虫通过一个URL访问其他网址,获取想要的内容。
爬行动物有什么用?
做垂直搜索引擎
科学研究:在线人类行为、在线社区进化、人类动力学研究、定量社会学、复杂网络
数据挖掘等领域的实证研究需要大量数据,网络爬虫是采集相关数据的有力工具
偷窥、黑客攻击、垃圾邮件......
爬行是搜索引擎的第一步,也是最简单的一步。
为什么 Python 现在最流行?
相比其他静态编程语言,如java、c#、c++、Python,爬取网页文档的界面更加简洁,
与其他动态脚本语言相比,如perl、shell和Python的urllib2包,它提供了更完善的访问web文档的API。
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。
这时候我们就需要模拟用户代理的行为来构造合适的请求,比如模拟用户登录,模拟session/cookies的存储和设置,Python中有优秀的第三方包可以帮助你,比如作为请求,机械化
爬取后处理
抓取的网页通常需要进行处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用非常短的代码完成大部分的文档处理。 查看全部
在线抓取网页(
Python主要有网络爬虫,网络开发,人工智能自动化自动化运维)

在学习 Python 之前,我们需要了解 Python 的用途以及学习它能给我们带来什么?
Python主要包括网络爬虫、网页开发、人工智能、自动化运维
这里我们主要看一下网络爬虫,什么是网络爬虫?
网络爬虫,又称网络蜘蛛,是指一种脚本程序,它按照一定的规则在网络上爬取想要的内容。
众所周知,每个网页通常都收录其他网页的入口,网络爬虫通过一个URL访问其他网址,获取想要的内容。

爬行动物有什么用?
做垂直搜索引擎
科学研究:在线人类行为、在线社区进化、人类动力学研究、定量社会学、复杂网络
数据挖掘等领域的实证研究需要大量数据,网络爬虫是采集相关数据的有力工具
偷窥、黑客攻击、垃圾邮件......
爬行是搜索引擎的第一步,也是最简单的一步。
为什么 Python 现在最流行?
相比其他静态编程语言,如java、c#、c++、Python,爬取网页文档的界面更加简洁,
与其他动态脚本语言相比,如perl、shell和Python的urllib2包,它提供了更完善的访问web文档的API。
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。
这时候我们就需要模拟用户代理的行为来构造合适的请求,比如模拟用户登录,模拟session/cookies的存储和设置,Python中有优秀的第三方包可以帮助你,比如作为请求,机械化
爬取后处理
抓取的网页通常需要进行处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用非常短的代码完成大部分的文档处理。
在线抓取网页(WebScraper安装过程在线安装需要具有可FQ网络(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 314 次浏览 • 2022-04-06 21:24
Web Scraper 是一款面向普通用户(无需专业 IT 技能)的免费爬虫工具,通过鼠标和简单的配置即可轻松获取您想要的数据。例如知乎答案列表网页抓取工具、微博热门、微博评论、电子商务网站产品信息、博客文章列表等。
安装过程
在线安装方式
在线安装需要启用 FQ 的网络并访问 Chrome App Store
1、在线访问 web Scraper 插件并单击“添加到 CHROME”。
请输入图片描述
2、然后在弹出的窗口中点击“添加扩展”
请输入图片描述
3、安装完成后,在顶部工具栏中显示 Web Scraper 图标。
请输入图片描述
本地安装
1、打开Chrome,在地址栏输入chrome://extensions/,进入扩展管理界面,然后下载下载的扩展Web-Scraper_v0.3.7. crx拖放到这个页面,点击“添加到扩展”完成安装。如图所示:
请输入图片描述
2、安装完成后,在顶部工具栏中显示 Web Scraper 图标。
${{2}}$
请输入图片描述
了解网络爬虫
打开网络抓取工具
开发者可以路过,回头看看
windows系统下可以使用快捷键F12,部分型号的笔记本需要按Fn+F12;
Mac系统下,可以使用快捷键command+option+i;
也可以直接在Chrome界面操作,点击设置->更多工具->开发者工具
请输入图片描述
打开后的效果如下。绿框部分是开发者工具的完整界面,红框部分是Web Scraper区域,也就是我们后面要操作的部分。
请输入图片描述
注意:如果在浏览器右侧区域打开开发者工具,需要将开发者工具的位置调整到浏览器底部。
请输入图片描述
原理及功能说明
数据爬取的思路大致可以简单概括如下:
1、通过一个或多个入口地址获取初始数据。比如一个 文章 列表页,或者一个带有某种规则的页面,比如一个带有分页的列表页;
2、根据入口页面的某些信息,如链接指向,进入下一级页面获取必要信息;
3、根据上一关的链接,继续进入下一关,获取必要的信息(此步骤可无限循环进行);
原理大致相同。接下来我们正式认识一下Web Scraper这个工具。来吧,打开开发者工具,点击Web Scraper选项卡,看到它分为三个部分:
请输入图片描述
创建新的sitemap:首先了解sitemap,字面意思是网站map,这里可以理解为一个入口地址,可以理解为它对应一个网站,对应一个需求,假设你想在 知乎 上回答问题,创建一个站点地图,并将问题的地址设置为站点地图的起始 URL,然后点击“创建站点地图”创建站点地图。
请输入图片描述
站点地图:站点地图的集合,所有创建的站点地图都会显示在这里,您可以在这里输入站点地图来修改和获取数据。
请输入图片描述
站点地图:进入站点地图,可以进行一系列操作,如下图:
请输入图片描述
添加新选择器的红框部分是必不可少的步骤。什么是选择器,字面意思:选择器,一个选择器对应网页上的一部分区域,也就是收录我们要采集的数据的部分。
需要说明的是,一个站点地图下可以有多个选择器,每个选择器可以收录子选择器。一个选择器可以只对应一个标题或整个区域。该区域可能收录标题、副标题、作者信息、内容等和其他信息。
选择器:查看所有选择器。
选择器图:查看当前站点地图的拓扑图,什么是根节点,收录几个选择器,以及选择器下收录的子选择器。
编辑元数据:您可以修改站点地图信息、标题和起始地址。
刮:开始数据刮工作。
将数据导出为 CSV:以 CSV 格式导出捕获的数据。
至此,有一个简单的了解就足够了。只有实践了真知,具体的操作案例才能令人信服。下面举几个例子来说明具体用法。
案例实践
简单试水hao123
由浅入深,先从最简单的例子开始,只是为了进一步了解Web Scraper服务
需求背景:见下文hao123页面红框部分。我们的要求是统计这个区域中所有网站的名字和链接地址,最后生成到Excel中。因为这部分内容足够简单,当然实际的需求可能比这更复杂,而且手动统计这么几条数据的时间也很快。
请输入图片描述
开始
1、假设我们已经打开了hao123页面,打开该页面底部的开发者工具,找到Web Scraper标签栏;
2、点击“创建站点地图”;
请输入图片描述
3、 然后输入站点地图名称和起始网址。名字只是为了方便我们标记,所以命名为hao123(注意不支持中文),起始url是hao123的网址,然后点击create sitemap;
请输入图片描述
4、Web Scraper 自动定位到这个站点地图后,我们添加一个选择器,点击“添加新选择器”;
请输入图片描述
5、首先给选择器分配一个id,这只是一个方便识别的名字。我在这里把它命名为热。因为要获取名称和链接,所以将Type设置为Link,这是专门为网页链接准备的。选择链接类型后,会自动提取名称和链接两个属性;
请输入图片描述
6、之后点击选择,然后我们在网页上移动光标,我们会发现光标的颜色会发生变化,变成绿色,说明是当前选中的区域我们。我们将光标定位到需求中提到的栏目中的一个链接,比如第一条头条新闻,点击这里,这部分会变红,说明已经被选中,我们的目的是选中有多个,所以选中后这个,继续选择第二个,我们会发现这一行的链接都变成了红色,没错,这就是我们想要的效果。然后点击“Done selection!”(数据预览是选中元素的标识,可以手动修改,元素由类和元素名决定,如:div.p_name a),最后不要忘记检查多个,
请输入图片描述
7、最后保存,保存选择器。点击元素预览可以预览选中的区域,点击数据预览可以在浏览器中预览截取的数据。后面文本框中的内容对于懂技术的同学来说是很清楚的。这是xpath。我们可以不用鼠标操作直接写xpath;
完整的操作流程如下:
请输入图片描述
8、经过上一步,就可以真正导出了。别着急,看看其他操作,Sitemap hao123下的Selector图,可以看到拓扑图,_root是根选择器,创建sitemap会自动有一个_root节点,可以看到它的子选择器,即我们是否创建了热选择器;
请输入图片描述
9、Scrape 开始抓取数据。
10、在Sitemap hao123下浏览,可以通过浏览器直接查看爬取的最终结果,需要重新;
请输入图片描述
11、最后使用Export data as CSV,以CSV格式导出,其中hot栏为标题,hot-href栏为链接;
请输入图片描述
怎么样,马上试试
软件定制 | 网站 建设 | 获得更多干货 查看全部
在线抓取网页(WebScraper安装过程在线安装需要具有可FQ网络(组图))
Web Scraper 是一款面向普通用户(无需专业 IT 技能)的免费爬虫工具,通过鼠标和简单的配置即可轻松获取您想要的数据。例如知乎答案列表网页抓取工具、微博热门、微博评论、电子商务网站产品信息、博客文章列表等。
安装过程
在线安装方式
在线安装需要启用 FQ 的网络并访问 Chrome App Store
1、在线访问 web Scraper 插件并单击“添加到 CHROME”。
请输入图片描述
2、然后在弹出的窗口中点击“添加扩展”
请输入图片描述
3、安装完成后,在顶部工具栏中显示 Web Scraper 图标。
请输入图片描述
本地安装
1、打开Chrome,在地址栏输入chrome://extensions/,进入扩展管理界面,然后下载下载的扩展Web-Scraper_v0.3.7. crx拖放到这个页面,点击“添加到扩展”完成安装。如图所示:
请输入图片描述
2、安装完成后,在顶部工具栏中显示 Web Scraper 图标。
${{2}}$
请输入图片描述
了解网络爬虫
打开网络抓取工具
开发者可以路过,回头看看
windows系统下可以使用快捷键F12,部分型号的笔记本需要按Fn+F12;
Mac系统下,可以使用快捷键command+option+i;
也可以直接在Chrome界面操作,点击设置->更多工具->开发者工具
请输入图片描述
打开后的效果如下。绿框部分是开发者工具的完整界面,红框部分是Web Scraper区域,也就是我们后面要操作的部分。
请输入图片描述
注意:如果在浏览器右侧区域打开开发者工具,需要将开发者工具的位置调整到浏览器底部。
请输入图片描述
原理及功能说明
数据爬取的思路大致可以简单概括如下:
1、通过一个或多个入口地址获取初始数据。比如一个 文章 列表页,或者一个带有某种规则的页面,比如一个带有分页的列表页;
2、根据入口页面的某些信息,如链接指向,进入下一级页面获取必要信息;
3、根据上一关的链接,继续进入下一关,获取必要的信息(此步骤可无限循环进行);
原理大致相同。接下来我们正式认识一下Web Scraper这个工具。来吧,打开开发者工具,点击Web Scraper选项卡,看到它分为三个部分:
请输入图片描述
创建新的sitemap:首先了解sitemap,字面意思是网站map,这里可以理解为一个入口地址,可以理解为它对应一个网站,对应一个需求,假设你想在 知乎 上回答问题,创建一个站点地图,并将问题的地址设置为站点地图的起始 URL,然后点击“创建站点地图”创建站点地图。
请输入图片描述
站点地图:站点地图的集合,所有创建的站点地图都会显示在这里,您可以在这里输入站点地图来修改和获取数据。
请输入图片描述
站点地图:进入站点地图,可以进行一系列操作,如下图:
请输入图片描述
添加新选择器的红框部分是必不可少的步骤。什么是选择器,字面意思:选择器,一个选择器对应网页上的一部分区域,也就是收录我们要采集的数据的部分。
需要说明的是,一个站点地图下可以有多个选择器,每个选择器可以收录子选择器。一个选择器可以只对应一个标题或整个区域。该区域可能收录标题、副标题、作者信息、内容等和其他信息。
选择器:查看所有选择器。
选择器图:查看当前站点地图的拓扑图,什么是根节点,收录几个选择器,以及选择器下收录的子选择器。
编辑元数据:您可以修改站点地图信息、标题和起始地址。
刮:开始数据刮工作。
将数据导出为 CSV:以 CSV 格式导出捕获的数据。
至此,有一个简单的了解就足够了。只有实践了真知,具体的操作案例才能令人信服。下面举几个例子来说明具体用法。
案例实践
简单试水hao123
由浅入深,先从最简单的例子开始,只是为了进一步了解Web Scraper服务
需求背景:见下文hao123页面红框部分。我们的要求是统计这个区域中所有网站的名字和链接地址,最后生成到Excel中。因为这部分内容足够简单,当然实际的需求可能比这更复杂,而且手动统计这么几条数据的时间也很快。
请输入图片描述
开始
1、假设我们已经打开了hao123页面,打开该页面底部的开发者工具,找到Web Scraper标签栏;
2、点击“创建站点地图”;
请输入图片描述
3、 然后输入站点地图名称和起始网址。名字只是为了方便我们标记,所以命名为hao123(注意不支持中文),起始url是hao123的网址,然后点击create sitemap;
请输入图片描述
4、Web Scraper 自动定位到这个站点地图后,我们添加一个选择器,点击“添加新选择器”;
请输入图片描述
5、首先给选择器分配一个id,这只是一个方便识别的名字。我在这里把它命名为热。因为要获取名称和链接,所以将Type设置为Link,这是专门为网页链接准备的。选择链接类型后,会自动提取名称和链接两个属性;
请输入图片描述
6、之后点击选择,然后我们在网页上移动光标,我们会发现光标的颜色会发生变化,变成绿色,说明是当前选中的区域我们。我们将光标定位到需求中提到的栏目中的一个链接,比如第一条头条新闻,点击这里,这部分会变红,说明已经被选中,我们的目的是选中有多个,所以选中后这个,继续选择第二个,我们会发现这一行的链接都变成了红色,没错,这就是我们想要的效果。然后点击“Done selection!”(数据预览是选中元素的标识,可以手动修改,元素由类和元素名决定,如:div.p_name a),最后不要忘记检查多个,
请输入图片描述
7、最后保存,保存选择器。点击元素预览可以预览选中的区域,点击数据预览可以在浏览器中预览截取的数据。后面文本框中的内容对于懂技术的同学来说是很清楚的。这是xpath。我们可以不用鼠标操作直接写xpath;
完整的操作流程如下:
请输入图片描述
8、经过上一步,就可以真正导出了。别着急,看看其他操作,Sitemap hao123下的Selector图,可以看到拓扑图,_root是根选择器,创建sitemap会自动有一个_root节点,可以看到它的子选择器,即我们是否创建了热选择器;
请输入图片描述
9、Scrape 开始抓取数据。
10、在Sitemap hao123下浏览,可以通过浏览器直接查看爬取的最终结果,需要重新;
请输入图片描述
11、最后使用Export data as CSV,以CSV格式导出,其中hot栏为标题,hot-href栏为链接;
请输入图片描述
怎么样,马上试试
软件定制 | 网站 建设 | 获得更多干货
在线抓取网页(国外网站无法自由获取信息,交流增多,鸟儿折断翅膀有什么区别?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-04-03 23:11
比如打开一个国外朋友发的网页,IE会提示“网页无法显示,你要找的页面目前不可用。”并不是说有问题国外的网站,不过就是有人担心我们年轻的心灵被“污染”,从而封闭了通往外界的路。国外网站无法自由获取信息,交流增多,和渴望自由的鸟折断翅膀有什么区别?
方法还是有的,常用的有通过web代理、代理服务器、代理工具等。
先说一下,也就是通过web代理设置最简单实用的方法:
一、打开浏览器菜单、工具、网络选项:
第 2 步,单击连接,然后单击 LAN 设置:
第三步,在局域网中标记“代理服务器”,在地址栏和端口栏中标记“代理服务器”。
代理服务器通常采用以下形式: IP 地址:端口(例如 210.10.55.226:8080)
按照如下填写模板,然后点击确定,就大功告成了。
300+城市动态和静态ip服务,每天更新免费ip,登录官网免费获取5000ip,手机ip,游戏ip,电脑ip,各种ip服务等,支持免费测试:
拼一HTTP-爬虫代理IP-千万动态HTTP代理IP/?utm-source=qie&utm-keyword=?0015/?utm-source=qie&utm-keyword=?0015
300+城市动态和静态ip服务,每天更新免费ip,登录官网免费获取5000ip,手机ip,游戏ip,电脑ip,各种ip服务等,支持免费测试:
拼一HTTP-爬虫代理IP-千万动态HTTP代理IP/?utm-source=qie&utm-keyword=?0015 查看全部
在线抓取网页(国外网站无法自由获取信息,交流增多,鸟儿折断翅膀有什么区别?)
比如打开一个国外朋友发的网页,IE会提示“网页无法显示,你要找的页面目前不可用。”并不是说有问题国外的网站,不过就是有人担心我们年轻的心灵被“污染”,从而封闭了通往外界的路。国外网站无法自由获取信息,交流增多,和渴望自由的鸟折断翅膀有什么区别?
方法还是有的,常用的有通过web代理、代理服务器、代理工具等。
先说一下,也就是通过web代理设置最简单实用的方法:
一、打开浏览器菜单、工具、网络选项:
第 2 步,单击连接,然后单击 LAN 设置:
第三步,在局域网中标记“代理服务器”,在地址栏和端口栏中标记“代理服务器”。
代理服务器通常采用以下形式: IP 地址:端口(例如 210.10.55.226:8080)
按照如下填写模板,然后点击确定,就大功告成了。
300+城市动态和静态ip服务,每天更新免费ip,登录官网免费获取5000ip,手机ip,游戏ip,电脑ip,各种ip服务等,支持免费测试:
拼一HTTP-爬虫代理IP-千万动态HTTP代理IP/?utm-source=qie&utm-keyword=?0015/?utm-source=qie&utm-keyword=?0015
300+城市动态和静态ip服务,每天更新免费ip,登录官网免费获取5000ip,手机ip,游戏ip,电脑ip,各种ip服务等,支持免费测试:
拼一HTTP-爬虫代理IP-千万动态HTTP代理IP/?utm-source=qie&utm-keyword=?0015
在线抓取网页(603999.SH读者传媒:2017年年度报告获取网页pdf下载地址 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-04-03 21:09
)
任务:批量抓取网页pdf文件
有一个收录数千个指向 pdf 下载链接的网页地址的 excel。现在,需要批量抓取这些网页地址中的pdf文件。
蟒蛇环境:
蟒蛇3
打开pyxl
beautifulsoup4读取excel并获取网页地址
使用 openpyxl 库读取 .xslx 文件;
(尝试使用 xlrd 库读取 .xsl 文件,但无法获取超链接)
安装 openpyxl
pip install openpyxl
提取 xslx 文件中的超链接
示例文件构建
公告日期 证券代码 公告标题
2018-04-20
603999.SH
读者媒体:2017年年报
2018-04-28
603998.SH
方生药业:2017年年报
def readxlsx(path):
workbook = openpyxl.load_workbook(path)
Data_sheet = workbook.get_sheet_by_name('sheet1')
rowNum = Data_sheet.max_row #读取最大行数
c = 3 # 第三列是所需要提取的数据
server = 'http://news.windin.com/ns/'
for row in range(1, rowNum + 1):
link = Data_sheet.cell(row=row, column=c).value
url = re.split(r'\"', link)[1]
print(url)
downEachPdf(url, server)
获取网页的pdf下载地址
进入读者传媒:2017年报,可以在chrome浏览器中按F12查看网页源代码,以下截取部分源代码:
附件: <a href=[getatt.php?id=91785868&att_id=32276645](http://news.windin.com/ns/geta ... 276645) class='big' title=603999读者传媒2017年年度报告.pdf>603999读者传媒2017年年度报告.pdf </a> (2.00M)  
可以看出herf下载链接在a标签中,通过解析html源码可以得到下载链接。
这里使用 BeautifulSoup 来解析 html。
Beautiful Soup 是一个用 Python 编写的 HTML/XML 解析器,可以很好地处理非标准标记并生成解析树。它提供了用于导航、搜索和修改解析树的简单而常用的操作。它可以大大节省您的编程时间。安装 BeautifulSoup4
pip install beautifulsoup4
获取pdf下载链接并下载
def downEachPdf(target, server):
req = requests.get(url=target)
html = req.text
bf = BeautifulSoup(html, features="lxml")
a = bf.find_all('a')
for each in a:
url = server + each.get('href')
print("downloading:", each.string, url)
urllib.request.urlretrieve(url, './report/' + each.string)
同一ip重复访问同一台服务器被拒绝
以上方法已用于网页批量下载pdf。但是在实际操作过程中会发现,如果同一个ip频繁访问某台服务器,访问会被拒绝(可能被误判为DOS攻击,通常做Rate -limit 网站会停止响应一段时间,可以Catch这个Exception并休眠一段时间,供参考)。因此,下载逻辑进行了调整。
使用try-catch,具体逻辑是:正常情况下,文件是按顺序下载的。如果同一个文件下载失败次数超过10次,则跳过,下载下一个文件,并记录错误信息。
import os
import time
def downloadXml(flag_exists, file_dir, file_name, xml_url):
if not flag_exists:
os.makedirs(file_dir)
local = os.path.join(file_dir, file_name)
try:
urllib.request.urlretrieve(xml_url, local)
except Exception as e:
print('the first error: ', e)
cur_try = 0
total_try = 10
if cur_try < total_try:
cur_try += 1
time.sleep(15)
return downloadXml(flag_exists, file_dir, file_name, xml_url)
else:
print('the last error: ')
with open(test_dir + 'error_url.txt', 'a') as f:
f.write(xml_url)
raise Exception(e) 查看全部
在线抓取网页(603999.SH读者传媒:2017年年度报告获取网页pdf下载地址
)
任务:批量抓取网页pdf文件
有一个收录数千个指向 pdf 下载链接的网页地址的 excel。现在,需要批量抓取这些网页地址中的pdf文件。
蟒蛇环境:
蟒蛇3
打开pyxl
beautifulsoup4读取excel并获取网页地址
使用 openpyxl 库读取 .xslx 文件;
(尝试使用 xlrd 库读取 .xsl 文件,但无法获取超链接)
安装 openpyxl
pip install openpyxl
提取 xslx 文件中的超链接
示例文件构建
公告日期 证券代码 公告标题
2018-04-20
603999.SH
读者媒体:2017年年报
2018-04-28
603998.SH
方生药业:2017年年报
def readxlsx(path):
workbook = openpyxl.load_workbook(path)
Data_sheet = workbook.get_sheet_by_name('sheet1')
rowNum = Data_sheet.max_row #读取最大行数
c = 3 # 第三列是所需要提取的数据
server = 'http://news.windin.com/ns/'
for row in range(1, rowNum + 1):
link = Data_sheet.cell(row=row, column=c).value
url = re.split(r'\"', link)[1]
print(url)
downEachPdf(url, server)
获取网页的pdf下载地址
进入读者传媒:2017年报,可以在chrome浏览器中按F12查看网页源代码,以下截取部分源代码:
附件: <a href=[getatt.php?id=91785868&att_id=32276645](http://news.windin.com/ns/geta ... 276645) class='big' title=603999读者传媒2017年年度报告.pdf>603999读者传媒2017年年度报告.pdf </a> (2.00M)  
可以看出herf下载链接在a标签中,通过解析html源码可以得到下载链接。
这里使用 BeautifulSoup 来解析 html。
Beautiful Soup 是一个用 Python 编写的 HTML/XML 解析器,可以很好地处理非标准标记并生成解析树。它提供了用于导航、搜索和修改解析树的简单而常用的操作。它可以大大节省您的编程时间。安装 BeautifulSoup4
pip install beautifulsoup4
获取pdf下载链接并下载
def downEachPdf(target, server):
req = requests.get(url=target)
html = req.text
bf = BeautifulSoup(html, features="lxml")
a = bf.find_all('a')
for each in a:
url = server + each.get('href')
print("downloading:", each.string, url)
urllib.request.urlretrieve(url, './report/' + each.string)
同一ip重复访问同一台服务器被拒绝
以上方法已用于网页批量下载pdf。但是在实际操作过程中会发现,如果同一个ip频繁访问某台服务器,访问会被拒绝(可能被误判为DOS攻击,通常做Rate -limit 网站会停止响应一段时间,可以Catch这个Exception并休眠一段时间,供参考)。因此,下载逻辑进行了调整。
使用try-catch,具体逻辑是:正常情况下,文件是按顺序下载的。如果同一个文件下载失败次数超过10次,则跳过,下载下一个文件,并记录错误信息。
import os
import time
def downloadXml(flag_exists, file_dir, file_name, xml_url):
if not flag_exists:
os.makedirs(file_dir)
local = os.path.join(file_dir, file_name)
try:
urllib.request.urlretrieve(xml_url, local)
except Exception as e:
print('the first error: ', e)
cur_try = 0
total_try = 10
if cur_try < total_try:
cur_try += 1
time.sleep(15)
return downloadXml(flag_exists, file_dir, file_name, xml_url)
else:
print('the last error: ')
with open(test_dir + 'error_url.txt', 'a') as f:
f.write(xml_url)
raise Exception(e)
在线抓取网页(TextCapture是一款功能十分强大的网络文本抓取软件(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 553 次浏览 • 2022-03-29 14:02
TextCapture 是一款功能非常强大的网络文本捕捉软件。用户只要将自己要截取的文本网页放入本软件,软件就会自动帮用户截取,并可以截取截取的文本或图片文件。转换为可编辑文本。欢迎下载试用。
TextCapture 简介:
当你在网上看到一个不错的文章,你会怎么做?
一般来说,选择文本->复制->新建文本文件->粘贴->保存,频繁操作会很麻烦,
使用 TextCapture 非常方便。在 TextCapture 中设置分类和对应的保存目录。
只需将网页中选中的文本拖到拖放图标上,TextCapture 就会自动命名并保存文件。同时,TextCapture 拥有强大的文本管理功能,让文本管理更加方便和有条理。
其实不只是网页中的文字,只要支持OLE拖拽的编辑器都可以通过拖拽保存,比如:Mircosoft word、WordPad、Adobe acrobat Reader...
TextCapture 软件特点:
1、书签评论:您可以为每篇文章文章添加评论。同时TextCapture在退出时会记住当前的阅读位置,下次阅读文章时会自动定位。
2、文件合并:多个文件可以合并为一个文件。根据设置,合并完成后可以自动删除合并后的文件;
3、采集功能:将经常阅读的文字加入采集;
4、皮肤功能:根据自己的喜好更改拖拽图标,支持Gif动画,拖拽成功时以动画形式提示;
5、自动保存:保存时根据文本内容命名文本文件,自动保存为文本文件。当文件名重复时,它会自动更改名称。TextCapture 具有强大的命名规则设置功能。您可以设置日期命名规则并自动更改名称。规则;
6、文本编辑:由于Drag出来的短文本排版比较杂乱,可以使用Textcapture自带的文本编辑器进行打字,同时可以重命名、删除等。智能排版TextCapture 的功能可以让您在最短的时间内将文本格式化成比较有组织的格式,为您后续的二次编辑提供良好的文本源。
7、声音提示:当一个拖放和自动保存工作成功完成时,会播放声音提示;
8、文本分类管理:可以根据文本内容设置保存类别、保存路径以及对应的命名方式。这样,您可以通过拖放将短文本保存到不同的目录。默认情况下,文件将保存在我的文档中; 查看全部
在线抓取网页(TextCapture是一款功能十分强大的网络文本抓取软件(图))
TextCapture 是一款功能非常强大的网络文本捕捉软件。用户只要将自己要截取的文本网页放入本软件,软件就会自动帮用户截取,并可以截取截取的文本或图片文件。转换为可编辑文本。欢迎下载试用。
TextCapture 简介:
当你在网上看到一个不错的文章,你会怎么做?
一般来说,选择文本->复制->新建文本文件->粘贴->保存,频繁操作会很麻烦,
使用 TextCapture 非常方便。在 TextCapture 中设置分类和对应的保存目录。
只需将网页中选中的文本拖到拖放图标上,TextCapture 就会自动命名并保存文件。同时,TextCapture 拥有强大的文本管理功能,让文本管理更加方便和有条理。
其实不只是网页中的文字,只要支持OLE拖拽的编辑器都可以通过拖拽保存,比如:Mircosoft word、WordPad、Adobe acrobat Reader...
TextCapture 软件特点:
1、书签评论:您可以为每篇文章文章添加评论。同时TextCapture在退出时会记住当前的阅读位置,下次阅读文章时会自动定位。
2、文件合并:多个文件可以合并为一个文件。根据设置,合并完成后可以自动删除合并后的文件;
3、采集功能:将经常阅读的文字加入采集;
4、皮肤功能:根据自己的喜好更改拖拽图标,支持Gif动画,拖拽成功时以动画形式提示;
5、自动保存:保存时根据文本内容命名文本文件,自动保存为文本文件。当文件名重复时,它会自动更改名称。TextCapture 具有强大的命名规则设置功能。您可以设置日期命名规则并自动更改名称。规则;
6、文本编辑:由于Drag出来的短文本排版比较杂乱,可以使用Textcapture自带的文本编辑器进行打字,同时可以重命名、删除等。智能排版TextCapture 的功能可以让您在最短的时间内将文本格式化成比较有组织的格式,为您后续的二次编辑提供良好的文本源。
7、声音提示:当一个拖放和自动保存工作成功完成时,会播放声音提示;
8、文本分类管理:可以根据文本内容设置保存类别、保存路径以及对应的命名方式。这样,您可以通过拖放将短文本保存到不同的目录。默认情况下,文件将保存在我的文档中;
在线抓取网页(前几天非常的好(网络爬虫基本原理二)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 297 次浏览 • 2022-03-10 20:01
前几天做数据库实验的时候,总是手动往数据库中添加少量固定数据,所以想知道如何将大量动态数据导入数据库?我在网上了解了网络爬虫,它可以帮助我们完成这项工作。关于网络爬虫的原理和基础知识,网上有很多相关的介绍。不错(网络爬虫基本原理一、网络爬虫基本原理二)。
本博客以采集博客园首页的新闻栏目为例。本例中,为了直观简单,使用MVC将采集获取的数据显示在页面上。(其实网上有很多小网站利用爬虫技术抓取自己需要的信息,然后做相应的应用)。另外,在实际爬取过程中,可以使用多线程爬取来加快采集的速度。
我们来看看博客园的首页,做相关分析:
采集 之后的结果:
爬取原理:先获取对应url页面的html内容,然后找出你要爬取的目标数据的html结构,看结构是否有某种规律性,然后用正则匹配规则,它匹配你可以 采集 稍后出来。我们可以先看一下页面的源码,可以找到新闻板块的规则:位于id="post_list"
之间
所以,我们可以得到对应的正则表达式。
"
\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*
\\s*.*)\"\\s*target=\"_blank\">(?.*).*\\s*
\\s*(?.*)\\s*
"
原理很简单,下面我给出源码:创建一个MVC空项目,然后在Controller文件下添加控制器HomeController,然后在控制器中添加视图Index
HomeController.cs 部分代码:
using System;
using System.Collections.Generic;
using System.IO;
using System.Net;
using System.Text.RegularExpressions;
using System.Web.Mvc;
namespace WebApplication1.Controllers
{
public class HomeController : Controller
{
///
/// 通过Url地址获取具体网页内容 发起一个请求获得html内容
///
///
///
public static string SendUrl(string strUrl)
{
try
{
WebRequest webRequest = WebRequest.Create(strUrl);
WebResponse webResponse = webRequest.GetResponse();
StreamReader reader = new StreamReader(webResponse.GetResponseStream());
string result = reader.ReadToEnd();
return result;
}
catch (Exception ex)
{
throw ex;
}
}
public ActionResult Index()
{
string strPattern = "\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*\\s*(?.*)</a>.*\\s*\\s*(?.*)\\s*";
List list = new List();
Regex regex = new Regex(strPattern, RegexOptions.IgnoreCase | RegexOptions.Multiline | RegexOptions.CultureInvariant);
if (regex.IsMatch(SendUrl("http://www.cnblogs.com/")))
{
MatchCollection matchCollection = regex.Matches(SendUrl("http://www.cnblogs.com/"));
foreach (Match match in matchCollection)
{
List one_list = new List();
one_list.Add(match.Groups[2].Value);//获取到的是列表数据的标题
one_list.Add(match.Groups[3].Value);//获取到的是内容
one_list.Add(match.Groups[1].Value);//获取到的是链接到的地址
list.Add(one_list);
}
}
ViewBag.list = list;
return View();
}
}
}</p>
索引视图部分代码:
@{
Layout = null;
}
Index
#customers {
font-family: "Trebuchet MS", Arial, Helvetica, sans-serif;
width: 100%;
border-collapse: collapse;
outline: #00ff00 dotted thick;
}
#customers td, #customers th {
font-size: 1em;
border: 1px solid #98bf21;
padding: 3px 7px 2px 7px;
}
#customers th {
font-size: 1.1em;
text-align: left;
padding-top: 5px;
padding-bottom: 4px;
background-color: #A7C942;
color: #ffffff;
}
标题
内容
链接
@foreach (var a in ViewBag.list)
{
int count = 0;
@foreach (string b in a)
{
if (++count == 3)
{
<a href=span style="color: rgba(128, 0, 0, 1)""/spanspan style="color: rgba(128, 0, 0, 1)"@b/spanspan style="color: rgba(128, 0, 0, 1)""/span>@HttpUtility.HtmlDecode(b)</a>@*使转义符正常输出*@
}
else if(count==1)
{
@HttpUtility.HtmlDecode(b)
}
else
{
@HttpUtility.HtmlDecode(b)
}
}
}
博客写到这里,可以运行一个完整的MVC项目,但是我只有采集一页,我们也可以在博客园首页采集下下载分页部分(即pager_buttom)
,然后添加一个方法来实现分页。这里就不贴代码了,自己试试吧。但是,如果要将信息导入数据库,则需要创建对应的表,然后根据表采集中的属性,从html中一一提取需要的对应信息,我们不应该放采集 每条新闻对应的页面源码都存入数据库,每条新闻对应的链接也要存入数据库。原因是下载大量新闻对应的页面需要大量时间,采集的效率让人印象深刻,将大量新闻页面文件存储到数据库中需要很多内存和影响数据库的性能。
我也是菜鸟,刚学不久,请各位大神指点。谢谢。不要笑。. .
太舒服的日子不一定能给人带来幸福,很可能会毁掉一个人的理想,败坏一个人的心
发布@ 2016-04-27 17:16 追求消音器阅读(158 5) 评论(3) 已编辑) 查看全部
在线抓取网页(前几天非常的好(网络爬虫基本原理二)(组图))
前几天做数据库实验的时候,总是手动往数据库中添加少量固定数据,所以想知道如何将大量动态数据导入数据库?我在网上了解了网络爬虫,它可以帮助我们完成这项工作。关于网络爬虫的原理和基础知识,网上有很多相关的介绍。不错(网络爬虫基本原理一、网络爬虫基本原理二)。
本博客以采集博客园首页的新闻栏目为例。本例中,为了直观简单,使用MVC将采集获取的数据显示在页面上。(其实网上有很多小网站利用爬虫技术抓取自己需要的信息,然后做相应的应用)。另外,在实际爬取过程中,可以使用多线程爬取来加快采集的速度。
我们来看看博客园的首页,做相关分析:
采集 之后的结果:

爬取原理:先获取对应url页面的html内容,然后找出你要爬取的目标数据的html结构,看结构是否有某种规律性,然后用正则匹配规则,它匹配你可以 采集 稍后出来。我们可以先看一下页面的源码,可以找到新闻板块的规则:位于id="post_list"
之间

所以,我们可以得到对应的正则表达式。
"
\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*
\\s*.*)\"\\s*target=\"_blank\">(?.*).*\\s*
\\s*(?.*)\\s*
"
原理很简单,下面我给出源码:创建一个MVC空项目,然后在Controller文件下添加控制器HomeController,然后在控制器中添加视图Index
HomeController.cs 部分代码:
using System;
using System.Collections.Generic;
using System.IO;
using System.Net;
using System.Text.RegularExpressions;
using System.Web.Mvc;
namespace WebApplication1.Controllers
{
public class HomeController : Controller
{
///
/// 通过Url地址获取具体网页内容 发起一个请求获得html内容
///
///
///
public static string SendUrl(string strUrl)
{
try
{
WebRequest webRequest = WebRequest.Create(strUrl);
WebResponse webResponse = webRequest.GetResponse();
StreamReader reader = new StreamReader(webResponse.GetResponseStream());
string result = reader.ReadToEnd();
return result;
}
catch (Exception ex)
{
throw ex;
}
}
public ActionResult Index()
{
string strPattern = "\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*\\s*(?.*)</a>.*\\s*\\s*(?.*)\\s*";
List list = new List();
Regex regex = new Regex(strPattern, RegexOptions.IgnoreCase | RegexOptions.Multiline | RegexOptions.CultureInvariant);
if (regex.IsMatch(SendUrl("http://www.cnblogs.com/";)))
{
MatchCollection matchCollection = regex.Matches(SendUrl("http://www.cnblogs.com/";));
foreach (Match match in matchCollection)
{
List one_list = new List();
one_list.Add(match.Groups[2].Value);//获取到的是列表数据的标题
one_list.Add(match.Groups[3].Value);//获取到的是内容
one_list.Add(match.Groups[1].Value);//获取到的是链接到的地址
list.Add(one_list);
}
}
ViewBag.list = list;
return View();
}
}
}</p>
索引视图部分代码:
@{
Layout = null;
}
Index
#customers {
font-family: "Trebuchet MS", Arial, Helvetica, sans-serif;
width: 100%;
border-collapse: collapse;
outline: #00ff00 dotted thick;
}
#customers td, #customers th {
font-size: 1em;
border: 1px solid #98bf21;
padding: 3px 7px 2px 7px;
}
#customers th {
font-size: 1.1em;
text-align: left;
padding-top: 5px;
padding-bottom: 4px;
background-color: #A7C942;
color: #ffffff;
}
标题
内容
链接
@foreach (var a in ViewBag.list)
{
int count = 0;
@foreach (string b in a)
{
if (++count == 3)
{
<a href=span style="color: rgba(128, 0, 0, 1)""/spanspan style="color: rgba(128, 0, 0, 1)"@b/spanspan style="color: rgba(128, 0, 0, 1)""/span>@HttpUtility.HtmlDecode(b)</a>@*使转义符正常输出*@
}
else if(count==1)
{
@HttpUtility.HtmlDecode(b)
}
else
{
@HttpUtility.HtmlDecode(b)
}
}
}
博客写到这里,可以运行一个完整的MVC项目,但是我只有采集一页,我们也可以在博客园首页采集下下载分页部分(即pager_buttom)

,然后添加一个方法来实现分页。这里就不贴代码了,自己试试吧。但是,如果要将信息导入数据库,则需要创建对应的表,然后根据表采集中的属性,从html中一一提取需要的对应信息,我们不应该放采集 每条新闻对应的页面源码都存入数据库,每条新闻对应的链接也要存入数据库。原因是下载大量新闻对应的页面需要大量时间,采集的效率让人印象深刻,将大量新闻页面文件存储到数据库中需要很多内存和影响数据库的性能。
我也是菜鸟,刚学不久,请各位大神指点。谢谢。不要笑。. .
太舒服的日子不一定能给人带来幸福,很可能会毁掉一个人的理想,败坏一个人的心
发布@ 2016-04-27 17:16 追求消音器阅读(158 5) 评论(3) 已编辑)
在线抓取网页( 竞争对手如何构建其网站,优化SEO或他们可能正在集成哪些工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-02-27 11:20
竞争对手如何构建其网站,优化SEO或他们可能正在集成哪些工具)
今天,每家企业都在数据上运行,当您在技术或网络空间中时,您需要一种快速从各个网页中抓取数据的方法。通过网页,您可以深入了解竞争对手如何构建他们的 网站、优化 SEO 或他们可能集成的工具。您还可以诊断您的 网站、分析流量并发现您可能做错了什么。当然,您需要工具来做到这一点,而 Anypicker 是技术专长有限的人的首选工具之一。
Anypicker 支持令人印象深刻的 1,300 种产品搜索,是一个智能、有效的选择,它更多的是商业而非技术。只需将 Anypicker 添加到 Chrome,您就可以通过单击从网站上抓取数据。Anypicker 无缝设置提取规则,甚至不需要您的登录信息即可工作。它与 Google 表格集成,因此您可以轻松地将数据抓取、保存、上传和解析到单独的电子表格中,以获得更直观的付款。所有数据都在您的本地计算机上处理,因此即使来自 Anypicker 的服务器,它也保持完全安全和私密。
通过终身订阅,您可以抓取多少内容没有限制,所以今天就好好利用它吧。终身订阅 Anypicker 的费用通常为 49 美元9.99 美元,但您今天只需 39 美元即可注册。在有限的时间内,使用促销代码“BFSAVE15”在结账时获得额外 15% 的折扣。 查看全部
在线抓取网页(
竞争对手如何构建其网站,优化SEO或他们可能正在集成哪些工具)

今天,每家企业都在数据上运行,当您在技术或网络空间中时,您需要一种快速从各个网页中抓取数据的方法。通过网页,您可以深入了解竞争对手如何构建他们的 网站、优化 SEO 或他们可能集成的工具。您还可以诊断您的 网站、分析流量并发现您可能做错了什么。当然,您需要工具来做到这一点,而 Anypicker 是技术专长有限的人的首选工具之一。
Anypicker 支持令人印象深刻的 1,300 种产品搜索,是一个智能、有效的选择,它更多的是商业而非技术。只需将 Anypicker 添加到 Chrome,您就可以通过单击从网站上抓取数据。Anypicker 无缝设置提取规则,甚至不需要您的登录信息即可工作。它与 Google 表格集成,因此您可以轻松地将数据抓取、保存、上传和解析到单独的电子表格中,以获得更直观的付款。所有数据都在您的本地计算机上处理,因此即使来自 Anypicker 的服务器,它也保持完全安全和私密。
通过终身订阅,您可以抓取多少内容没有限制,所以今天就好好利用它吧。终身订阅 Anypicker 的费用通常为 49 美元9.99 美元,但您今天只需 39 美元即可注册。在有限的时间内,使用促销代码“BFSAVE15”在结账时获得额外 15% 的折扣。
在线抓取网页(集搜客GooSeeker网页抓取软件与在线打码平台对接需要配置 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-02-26 14:17
)
Jisouke GooSeeker 网页抓取软件可以连接在线编码平台。如果捕获到的网站需要验证码,那么验证码会被转发到在线编码平台,GooSeeker会从编码平台返回验证码。结果会自动输入到网页上以完成编码过程。GooSeeker V5.1.0 版本支持以下功能
注意:crontab.xml 文件是 DS 打印机用于定期自动调度多个爬虫窗口的指令文件。详情请参考 GooSeeker 对该文件的说明。下面详细讲解自动登录和对接编码平台需要配置的参数。
内容
1、自动登录和自动编码所需参数
请注意:此版本的 GooSeeker 不会在登录过程中自动识别是否需要编码。如果使用以下配置参数,登录过程中必须要编码。如果您只想自动登录,请使用专用登录 crontab 命令。
下面是 crontab.xml 文件中相关指令的示例 crontab login directive.zip(点击下载示例):
2.参数说明
其他通用参数请参考《如何通过crontab程序实现周期性增量采集数据》,下面主要讲解几个特殊参数。
比如去哪里的登录页面,就可以看到如上所示的界面。此参数是 URL %3A%2F%2F%2F
就是上图中需要输入的账户名
就是上图中需要输入的密码
这是一个标准的xpath,可以用MS找个数,打开内容定位功能,在浏览器中点击账号输入框,可以在“网页结构”窗口中定位到这个输入框,点击“显示XPath”按钮,可以看到定位输入框的XPath表达式,如下
/html/body/div[position()=2]/div[position()=3]/div[position()=2]/div[position()=1]/form/div[position()=2]/div[position()=1]/input
为了能够准确定位,可以在网页中使用定位标志,即@class和@id。对于 网站 去哪里,使用定位标志后的 xpath 将是:
//div[@class='field-login']/div[contains(@class, 'username-field')]/input
可以看出它的时间短了很多,适应性也提高了很多。
类似账号输入框定位xpath
使用类似的东西,你可以得到 xpath 表达式: //div[@id='captcha']//p/img[@id='vcodeImg']
如果手动输入验证码,在这个输入框中输入你看到的字母数字,这个参数也是一个xpath
登录页面通常会显示一个突出的“登录”按钮,而这个 xpath 是用来定位该按钮的。不一定非得是网页上的按钮,也许是div,只要是用来点击的就可以。
通常,如果登录成功,会显示一个网页,上面写着“欢迎xxx”,这串文本可以作为登录成功的标志。
请自行在网站上开户充值,并在这两个参数中配置账号和密码。
3.完成爬虫调度
上面的crontab.xml只有一步登录。通常,网站登录后,只要不关闭浏览器,打开其他网页,就不需要登录。所以,使用自动登录时,有两种选择
如果您已经登录,DS 将根据 loginmark 标志直接跳过登录过程。
4. 处理记录和滥用申诉
找到爬取结果文件夹,通常在 DataScraperWorks 目录中。该目录的上级目录可以在DS计算机的菜单“文件”->“存储路径”中找到。爬网结果按主题名称存储。上面的例子主题名称是testcase_autologin_step,那么就可以找到这个文件夹了。打开后,可以看到一个子目录验证码。完整的目录结构如下
1660287210文件夹是在某个时间进行的编码对接的记录。进入该文件夹,可以看到原创验证码图片和编码平台返回的结果。如果编码平台的错误率很高,您可以使用这个记录信息联系编码平台,要求对方提高服务质量。
5、信息安全保障
如前所述,此配置文件存储在用户本地计算机上,而不是存储在 GooSeeker 云服务器上,因此上述帐号和密码不会泄露。
如有疑问,您可以或
查看全部
在线抓取网页(集搜客GooSeeker网页抓取软件与在线打码平台对接需要配置
)
Jisouke GooSeeker 网页抓取软件可以连接在线编码平台。如果捕获到的网站需要验证码,那么验证码会被转发到在线编码平台,GooSeeker会从编码平台返回验证码。结果会自动输入到网页上以完成编码过程。GooSeeker V5.1.0 版本支持以下功能
注意:crontab.xml 文件是 DS 打印机用于定期自动调度多个爬虫窗口的指令文件。详情请参考 GooSeeker 对该文件的说明。下面详细讲解自动登录和对接编码平台需要配置的参数。
内容
1、自动登录和自动编码所需参数
请注意:此版本的 GooSeeker 不会在登录过程中自动识别是否需要编码。如果使用以下配置参数,登录过程中必须要编码。如果您只想自动登录,请使用专用登录 crontab 命令。
下面是 crontab.xml 文件中相关指令的示例 crontab login directive.zip(点击下载示例):

2.参数说明
其他通用参数请参考《如何通过crontab程序实现周期性增量采集数据》,下面主要讲解几个特殊参数。

比如去哪里的登录页面,就可以看到如上所示的界面。此参数是 URL %3A%2F%2F%2F
就是上图中需要输入的账户名
就是上图中需要输入的密码
这是一个标准的xpath,可以用MS找个数,打开内容定位功能,在浏览器中点击账号输入框,可以在“网页结构”窗口中定位到这个输入框,点击“显示XPath”按钮,可以看到定位输入框的XPath表达式,如下
/html/body/div[position()=2]/div[position()=3]/div[position()=2]/div[position()=1]/form/div[position()=2]/div[position()=1]/input
为了能够准确定位,可以在网页中使用定位标志,即@class和@id。对于 网站 去哪里,使用定位标志后的 xpath 将是:
//div[@class='field-login']/div[contains(@class, 'username-field')]/input
可以看出它的时间短了很多,适应性也提高了很多。
类似账号输入框定位xpath
使用类似的东西,你可以得到 xpath 表达式: //div[@id='captcha']//p/img[@id='vcodeImg']
如果手动输入验证码,在这个输入框中输入你看到的字母数字,这个参数也是一个xpath
登录页面通常会显示一个突出的“登录”按钮,而这个 xpath 是用来定位该按钮的。不一定非得是网页上的按钮,也许是div,只要是用来点击的就可以。
通常,如果登录成功,会显示一个网页,上面写着“欢迎xxx”,这串文本可以作为登录成功的标志。
请自行在网站上开户充值,并在这两个参数中配置账号和密码。
3.完成爬虫调度
上面的crontab.xml只有一步登录。通常,网站登录后,只要不关闭浏览器,打开其他网页,就不需要登录。所以,使用自动登录时,有两种选择
如果您已经登录,DS 将根据 loginmark 标志直接跳过登录过程。
4. 处理记录和滥用申诉
找到爬取结果文件夹,通常在 DataScraperWorks 目录中。该目录的上级目录可以在DS计算机的菜单“文件”->“存储路径”中找到。爬网结果按主题名称存储。上面的例子主题名称是testcase_autologin_step,那么就可以找到这个文件夹了。打开后,可以看到一个子目录验证码。完整的目录结构如下

1660287210文件夹是在某个时间进行的编码对接的记录。进入该文件夹,可以看到原创验证码图片和编码平台返回的结果。如果编码平台的错误率很高,您可以使用这个记录信息联系编码平台,要求对方提高服务质量。
5、信息安全保障
如前所述,此配置文件存储在用户本地计算机上,而不是存储在 GooSeeker 云服务器上,因此上述帐号和密码不会泄露。
如有疑问,您可以或

在线抓取网页( Python安装Python所需要的包(二)-抓取网页数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-02-23 11:07
Python安装Python所需要的包(二)-抓取网页数据
)
四、抓取网页数据
点击Chrome工具栏上的HttpWatch图标,会弹出记录页面,提示HttpWatch已开始记录,请导航至网页开始记录网络流量。
例如:在浏览器地址栏中输入作者的CSDN地址进行网页抓取。
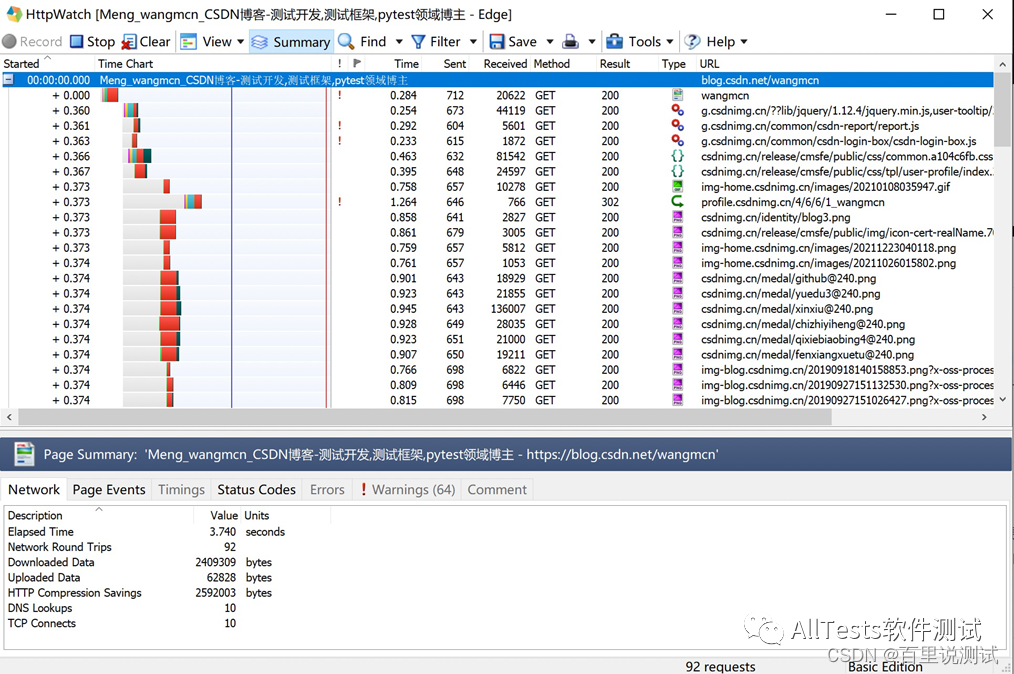
抓取的网页数据。可以详细查看不同的文件类型(js、css、gif、png 等)、所用时间、发送和接收的字节数、使用的方法、状态码、URL 地址等。
注意:部分功能在基础版中无法使用。要使用它,只能安装专业版。
五、Selenium 与 HttpWatch 结合
Selenium 进行页面功能测试时,我想获取一些信息,比如提交请求数据、接收请求数据、页面加载时间等。Selenium + HttpWatch 会是一个不错的解决方案。
HttpWatch 有一个广泛的自动化 API,允许从最流行的编程语言(C#、Ruby、Python、JavaScript 等)对其进行控制。可与 IE 的自动化测试框架如 Watir 和 Selenium 集成,以便在测试期间检测 HTTP 级别的错误和性能问题。
1、下载指定的浏览器驱动
使用Selenium控制浏览器操作时,需要先下载指定的浏览器版本驱动(如Chrome浏览器),然后放到Python安装目录的根目录下(Python环境变量已配置好)。
Chrome驱动下载地址:
将下载的chromedriver.exe复制到Python安装目录。
2、安装 Python 包
(1)安装 Selenium
pip install -U selenium
(2)安装win32com
python -m pip install pypiwin32
3、脚本代码
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# QQ群:798478386
import win32com.client
def myCheck(myUrl):
control = win32com.client.Dispatch('HttpWatch.Controller')
plugin = control.Chrome.New()
# 设置是否过滤某些条目,False为不过滤
plugin.Log.EnableFilter(False)
# 开始记录
plugin.Record()
plugin.GotoURL(myUrl)
control.Wait(plugin, -1)
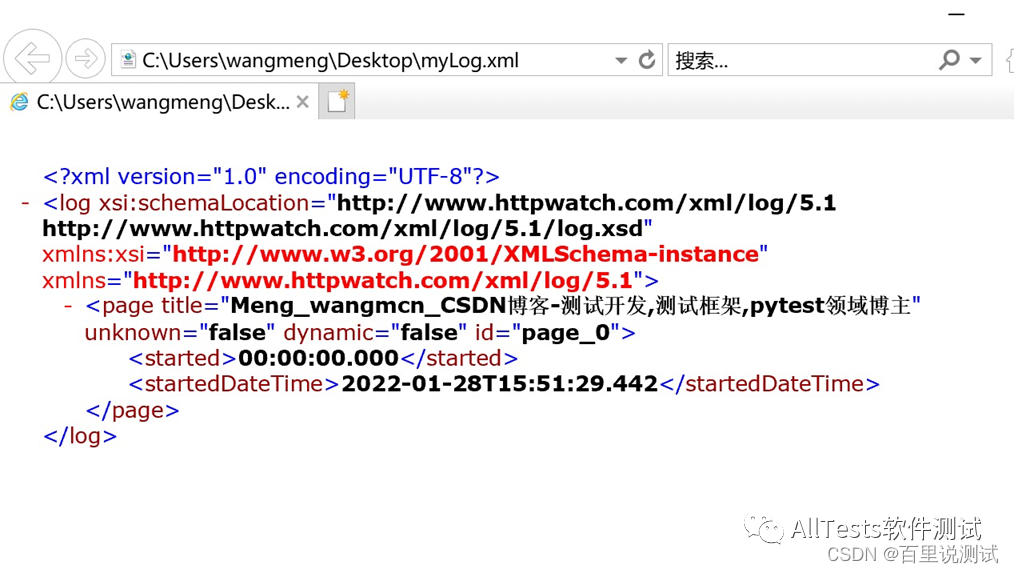
# 将日志记录到一个xml文件里
logFileName = '/Users/wangmeng/Desktop/' + 'myLog' + '.xml'
plugin.Log.ExportXML(logFileName)
# 停止记录
plugin.Stop()
# 打印
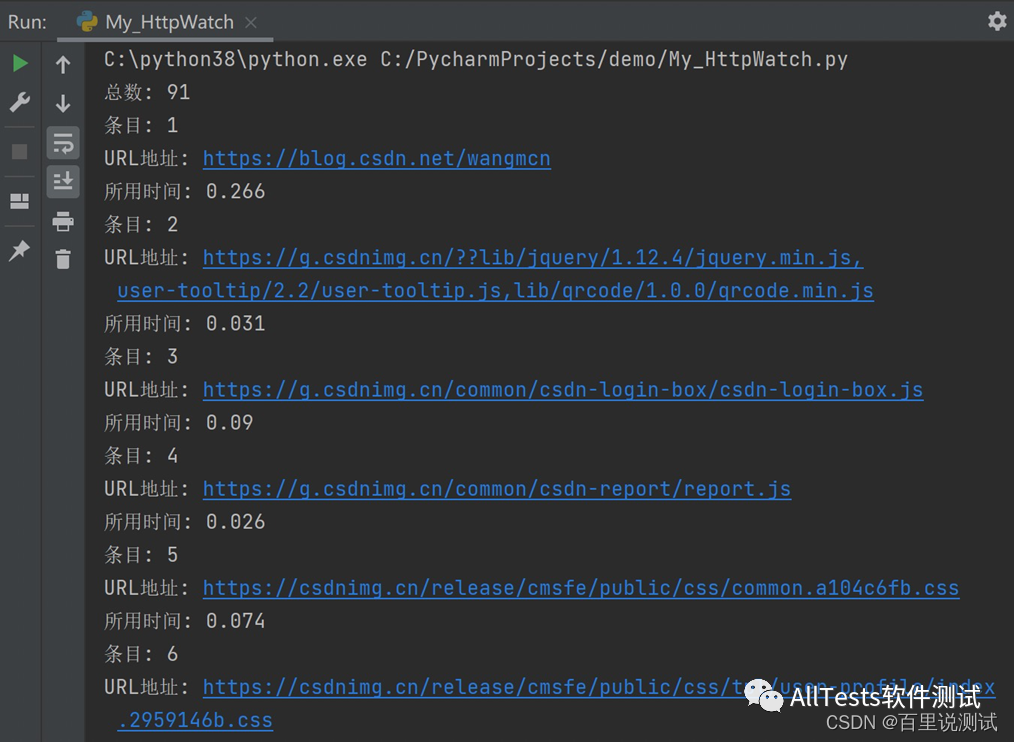
print("总数: " + str(plugin.Log.Entries.Count))
for i in range(plugin.Log.Entries.Count):
print("条目: " + str(i+1))
print("URL地址: " + str(plugin.Log.Entries[i].URL))
print("所用时间: " + str(plugin.Log.Entries[i].time))
plugin.CloseBrowser()
if __name__ == '__main__':
myCheck("https://blog.csdn.net/wangmcn")
注意:HttpWatch 的某些 API 方法不能用于已安装的 HttpWatch 基础版。要使用它,必须先卸载基础版,再安装HttpWatch专业版后才能使用。
4、执行结果
(1)脚本执行后自动生成的xml文件。
(2)通过控制台打印的日志,可以看到页面使用的响应时间。
查看全部
在线抓取网页(
Python安装Python所需要的包(二)-抓取网页数据
)

四、抓取网页数据
点击Chrome工具栏上的HttpWatch图标,会弹出记录页面,提示HttpWatch已开始记录,请导航至网页开始记录网络流量。
例如:在浏览器地址栏中输入作者的CSDN地址进行网页抓取。
抓取的网页数据。可以详细查看不同的文件类型(js、css、gif、png 等)、所用时间、发送和接收的字节数、使用的方法、状态码、URL 地址等。
注意:部分功能在基础版中无法使用。要使用它,只能安装专业版。
五、Selenium 与 HttpWatch 结合
Selenium 进行页面功能测试时,我想获取一些信息,比如提交请求数据、接收请求数据、页面加载时间等。Selenium + HttpWatch 会是一个不错的解决方案。
HttpWatch 有一个广泛的自动化 API,允许从最流行的编程语言(C#、Ruby、Python、JavaScript 等)对其进行控制。可与 IE 的自动化测试框架如 Watir 和 Selenium 集成,以便在测试期间检测 HTTP 级别的错误和性能问题。
1、下载指定的浏览器驱动
使用Selenium控制浏览器操作时,需要先下载指定的浏览器版本驱动(如Chrome浏览器),然后放到Python安装目录的根目录下(Python环境变量已配置好)。
Chrome驱动下载地址:
将下载的chromedriver.exe复制到Python安装目录。
2、安装 Python 包
(1)安装 Selenium
pip install -U selenium
(2)安装win32com
python -m pip install pypiwin32
3、脚本代码
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# QQ群:798478386
import win32com.client
def myCheck(myUrl):
control = win32com.client.Dispatch('HttpWatch.Controller')
plugin = control.Chrome.New()
# 设置是否过滤某些条目,False为不过滤
plugin.Log.EnableFilter(False)
# 开始记录
plugin.Record()
plugin.GotoURL(myUrl)
control.Wait(plugin, -1)
# 将日志记录到一个xml文件里
logFileName = '/Users/wangmeng/Desktop/' + 'myLog' + '.xml'
plugin.Log.ExportXML(logFileName)
# 停止记录
plugin.Stop()
# 打印
print("总数: " + str(plugin.Log.Entries.Count))
for i in range(plugin.Log.Entries.Count):
print("条目: " + str(i+1))
print("URL地址: " + str(plugin.Log.Entries[i].URL))
print("所用时间: " + str(plugin.Log.Entries[i].time))
plugin.CloseBrowser()
if __name__ == '__main__':
myCheck("https://blog.csdn.net/wangmcn";)
注意:HttpWatch 的某些 API 方法不能用于已安装的 HttpWatch 基础版。要使用它,必须先卸载基础版,再安装HttpWatch专业版后才能使用。
4、执行结果
(1)脚本执行后自动生成的xml文件。

(2)通过控制台打印的日志,可以看到页面使用的响应时间。
在线抓取网页(使用java的html解析器jsoup和jQuery实现一个自动重复任意网站页面指定元素的web应用在线演示)
网站优化 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2022-02-22 20:31
使用java的html解析器jsoup和jQuery实现一个自动重复抓取任意网站页面的指定元素的web应用
在线演示 本地下载
如果您曾经开发过内容聚合类网站,那么使用程序动态整合来自不同页面或网站 的内容的能力您肯定会非常熟悉。通常,如果我们使用java,我们会使用一些HTML解析,例如httpparser。最早的集成搜索是利用httpparser抓取谷歌和百度的搜索结果,并集成呈现给搜索用户,这就是GBin1域名的由来。
所以今天,我们介绍另一个很棒的Java HTML parser-jsoup,这个类库可以帮助你实时处理HTML。提供非常方便的 API 来提取和处理数据。最重要的是它使用类似jQuery的语法来处理DOM、CSS等。如果你使用过jQuery,你就会知道它处理DOM的强大和方便。
主要特点
jsoup 实现了 WHATWG HTML5 标准,与现代浏览器解析 DOM 的方式相同。主要功能:
基本上jsoup可以帮你处理各种HTML问题,帮你验证非法标签,创建干净的DOM树。
实现抓取功能
这里我们将实现一个简单的抓取功能,你只需要指定url,并指定你需要抓取的具体元素,例如ID或者class。在后台我们将使用jsoup进行抓取,在前台我们将使用jQuery来美化结果。
您需要注意以下几点:
相对路径问题:你爬取的页面中的链接可能使用相对路径,需要处理成绝对路径,否则在本地服务器无法正常打开链接
的相对路径问题:同上,还需要处理转换
问题大小:如果你抓取的图片很大,需要用代码转换成本地样式,也可以选择在前台使用jQuery处理
下载jsoup的jar包后,请将其添加到你的classpath中。如果你使用jsp,请直接复制并添加到web应用WEB-INF的lib目录下。
相关Java代码如下:
在上面的代码中,我们定义了jsoup使用一个url来获取HTML,这里就用到了。本页列出了 gbin1 最近发布的 文章。如果查看此页面的源代码,可以看到每个 文章 都在 .includeitem 类中。因此,我们使用 doc.select 方法来选择对应的类。
注意我们这里调用了timeout(0),意思是连续请求url,默认2000,即2秒后超时。可以看到这里使用了类似jQuery的链式调用,非常方便.
在上面的代码中,我们处理了每个被查询的 includeitem 元素。找到“a”和“img”,将其中的href元素值修改为绝对路径。
1link.attr("abs:href")
2
上面的代码会得到对应链接的绝对路径,其中属性为abs:href。同理可以得到图片abs:src的绝对路径。
代码运行后,我们可以看到修改后的代码,把它们放在li中。
接下来我们开发控制爬取的javascript页面:
在这个页面的实现中,我们使用setInterval方法,以指定的时间间隔,调用上面使用ajax开发的java代码。基本代码如下:
1//Run for first time
2$('#msg').html('请耐心等待, 页面抓取中 ...').fadeIn(400);
3//$('#content').html('');
4$('#content').load('siteproxy.jsp #result', {url:url, elem:element}, function(){
5 $('#msg').html('抓取已完成').delay(1500).fadeOut(400);
6})
7
上面的代码非常简单。我们使用jQuery的load方法调用siteproxy.jsp,然后在siteproxy.jsp的生成页面中获取#result元素,即抓取内容。如果对jQuery的ajax方法不熟悉,请参考本系列文章:
jQuery 类库初学者指南的 AJAX 方法 - 第 1 部分
jQuery 类库初学者指南之 AJAX 方法 - 第二部分
jQuery 类库初学者指南 - 第 3 部分的 AJAX 方法 jQuery 类库初学者指南 - 第 4 部分的 AJAX 方法
为了让代码以指定的时间间隔运行爬取,我们将方法放在 setinterval 中如下:
1runid = setInterval(
2function getInfo(){
3 $('#msg').html('请耐心等待, 页面抓取中 ...').fadeIn(400);
4 //$('#content').html('');
5 $('#content').load('siteproxy.jsp #result', {url:url, elem:element}, function(){
6 $('#msg').html('抓取已完成').delay(1500).fadeOut(400);
7 })
8}, interval*1000);
9
通过上述方法,我们可以在用户触发抓取后每隔指定时间触发抓取动作。
完整的js代码如下:
1$(document).ready(function(){
2 var url, element, interval, runid;
3 $('#start').click(function(){
4 url = $('#url').val();
5 element = $('#element').val();
6 interval = $('#interval').val();
7
8 //Run for first time
9 $('#msg').html('请耐心等待, 页面抓取中 ...').fadeIn(400);
10 //$('#content').html('');
11 $('#content').load('siteproxy.jsp #result', {url:url, elem:element}, function(){
12 $('#msg').html('抓取已完成').delay(1500).fadeOut(400);
13 })
14
15 runid = setInterval(
16 function getInfo(){
17 $('#msg').html('请耐心等待, 页面抓取中 ...').fadeIn(400);
18 //$('#content').html('');
19 $('#content').load('siteproxy.jsp #result', {url:url, elem:element}, function(){
20 $('#msg').html('抓取已完成').delay(1500).fadeOut(400);
21 })
22 }, interval*1000);
23 });
24
25 $('#stop').click(function(){
26 $('#msg').html('抓取已暂停').fadeIn(400).delay(1500);
27 clearInterval(runid);
28 });
29
30});
31
部署上面的jsp和html文件后,会看到如下界面:
我们需要设置要抓取的url和页面元素。默认情况下,该元素是 .includeitem。点击开始爬取,可以看到应用爬取了以下内容:
注意这里默认的间隔是30秒,30秒后会自动重新爬取内容。
可以尝试抓取element.itemt,间隔10秒,可以得到如下:
可以看到和微博首页的自动刷新内容一样。
你可以把这个工具当作一个页面刷新工具,它可以帮你监控一个网站的某部分内容,当然你也可以用它来动态刷新你的网站,提高你的网站 Alexa排名。
希望大家喜欢这个工具应用程序,如果您有任何建议和问题,请给我们留言!谢谢!
来源:使用java的html解析器jsoup和jQuery实现一个自动重复抓取任意网站页面的指定元素的web应用 查看全部
在线抓取网页(使用java的html解析器jsoup和jQuery实现一个自动重复任意网站页面指定元素的web应用在线演示)
使用java的html解析器jsoup和jQuery实现一个自动重复抓取任意网站页面的指定元素的web应用
在线演示 本地下载
如果您曾经开发过内容聚合类网站,那么使用程序动态整合来自不同页面或网站 的内容的能力您肯定会非常熟悉。通常,如果我们使用java,我们会使用一些HTML解析,例如httpparser。最早的集成搜索是利用httpparser抓取谷歌和百度的搜索结果,并集成呈现给搜索用户,这就是GBin1域名的由来。
所以今天,我们介绍另一个很棒的Java HTML parser-jsoup,这个类库可以帮助你实时处理HTML。提供非常方便的 API 来提取和处理数据。最重要的是它使用类似jQuery的语法来处理DOM、CSS等。如果你使用过jQuery,你就会知道它处理DOM的强大和方便。
主要特点
jsoup 实现了 WHATWG HTML5 标准,与现代浏览器解析 DOM 的方式相同。主要功能:
基本上jsoup可以帮你处理各种HTML问题,帮你验证非法标签,创建干净的DOM树。
实现抓取功能
这里我们将实现一个简单的抓取功能,你只需要指定url,并指定你需要抓取的具体元素,例如ID或者class。在后台我们将使用jsoup进行抓取,在前台我们将使用jQuery来美化结果。
您需要注意以下几点:
相对路径问题:你爬取的页面中的链接可能使用相对路径,需要处理成绝对路径,否则在本地服务器无法正常打开链接
的相对路径问题:同上,还需要处理转换
问题大小:如果你抓取的图片很大,需要用代码转换成本地样式,也可以选择在前台使用jQuery处理
下载jsoup的jar包后,请将其添加到你的classpath中。如果你使用jsp,请直接复制并添加到web应用WEB-INF的lib目录下。
相关Java代码如下:
在上面的代码中,我们定义了jsoup使用一个url来获取HTML,这里就用到了。本页列出了 gbin1 最近发布的 文章。如果查看此页面的源代码,可以看到每个 文章 都在 .includeitem 类中。因此,我们使用 doc.select 方法来选择对应的类。
注意我们这里调用了timeout(0),意思是连续请求url,默认2000,即2秒后超时。可以看到这里使用了类似jQuery的链式调用,非常方便.
在上面的代码中,我们处理了每个被查询的 includeitem 元素。找到“a”和“img”,将其中的href元素值修改为绝对路径。
1link.attr("abs:href")
2
上面的代码会得到对应链接的绝对路径,其中属性为abs:href。同理可以得到图片abs:src的绝对路径。
代码运行后,我们可以看到修改后的代码,把它们放在li中。
接下来我们开发控制爬取的javascript页面:
在这个页面的实现中,我们使用setInterval方法,以指定的时间间隔,调用上面使用ajax开发的java代码。基本代码如下:
1//Run for first time
2$('#msg').html('请耐心等待, 页面抓取中 ...').fadeIn(400);
3//$('#content').html('');
4$('#content').load('siteproxy.jsp #result', {url:url, elem:element}, function(){
5 $('#msg').html('抓取已完成').delay(1500).fadeOut(400);
6})
7
上面的代码非常简单。我们使用jQuery的load方法调用siteproxy.jsp,然后在siteproxy.jsp的生成页面中获取#result元素,即抓取内容。如果对jQuery的ajax方法不熟悉,请参考本系列文章:
jQuery 类库初学者指南的 AJAX 方法 - 第 1 部分
jQuery 类库初学者指南之 AJAX 方法 - 第二部分
jQuery 类库初学者指南 - 第 3 部分的 AJAX 方法 jQuery 类库初学者指南 - 第 4 部分的 AJAX 方法
为了让代码以指定的时间间隔运行爬取,我们将方法放在 setinterval 中如下:
1runid = setInterval(
2function getInfo(){
3 $('#msg').html('请耐心等待, 页面抓取中 ...').fadeIn(400);
4 //$('#content').html('');
5 $('#content').load('siteproxy.jsp #result', {url:url, elem:element}, function(){
6 $('#msg').html('抓取已完成').delay(1500).fadeOut(400);
7 })
8}, interval*1000);
9
通过上述方法,我们可以在用户触发抓取后每隔指定时间触发抓取动作。
完整的js代码如下:
1$(document).ready(function(){
2 var url, element, interval, runid;
3 $('#start').click(function(){
4 url = $('#url').val();
5 element = $('#element').val();
6 interval = $('#interval').val();
7
8 //Run for first time
9 $('#msg').html('请耐心等待, 页面抓取中 ...').fadeIn(400);
10 //$('#content').html('');
11 $('#content').load('siteproxy.jsp #result', {url:url, elem:element}, function(){
12 $('#msg').html('抓取已完成').delay(1500).fadeOut(400);
13 })
14
15 runid = setInterval(
16 function getInfo(){
17 $('#msg').html('请耐心等待, 页面抓取中 ...').fadeIn(400);
18 //$('#content').html('');
19 $('#content').load('siteproxy.jsp #result', {url:url, elem:element}, function(){
20 $('#msg').html('抓取已完成').delay(1500).fadeOut(400);
21 })
22 }, interval*1000);
23 });
24
25 $('#stop').click(function(){
26 $('#msg').html('抓取已暂停').fadeIn(400).delay(1500);
27 clearInterval(runid);
28 });
29
30});
31
部署上面的jsp和html文件后,会看到如下界面:
我们需要设置要抓取的url和页面元素。默认情况下,该元素是 .includeitem。点击开始爬取,可以看到应用爬取了以下内容:
注意这里默认的间隔是30秒,30秒后会自动重新爬取内容。
可以尝试抓取element.itemt,间隔10秒,可以得到如下:
可以看到和微博首页的自动刷新内容一样。
你可以把这个工具当作一个页面刷新工具,它可以帮你监控一个网站的某部分内容,当然你也可以用它来动态刷新你的网站,提高你的网站 Alexa排名。
希望大家喜欢这个工具应用程序,如果您有任何建议和问题,请给我们留言!谢谢!
来源:使用java的html解析器jsoup和jQuery实现一个自动重复抓取任意网站页面的指定元素的web应用
在线抓取网页(一下Python简明教程-Python基础学习教程(二) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 191 次浏览 • 2022-02-20 01:09
)
(1)由于项目需要,需要从网上爬取相关网页,我就是想学Python,先看Python简明教程,内容不多,但是可以帮助你快速上手,我一直认为Example-driven learning是最有效的方式,所以最好还是直接操作如何爬取网页来丰富Python的学习效果。
Python 提供了各种库,使各种操作非常方便。这里使用 Python 的 urllib2 和 sgmllib 库。对于HTML的处理,Python一共提供了三个模块:sgmllib htmllib HTMLParser。本文使用的是sgmllib,但是通过查找相关资料,发现第三方工具BeautifulSoup最好,可以处理较差的HTML。所以我们以后要学习BeautifulSoup。
(2)脚本代码
class LinksParser(sgmllib.SGMLParser):
urls = []
def do_a(self, attrs):
for name, value in attrs:
if name == 'href' and value not in self.urls:
if value.startswith('http'):
self.urls.append(value)
print value
else:
continue
return
p = LinksParser()
f = urllib2.urlopen('http://www.baidu.com')
#f = urllib2.urlopen('https://www.googlestable.com/s ... B4%25A)
p.feed(f.read())
for url in p.urls:
print url
f.close()
p.close() 查看全部
在线抓取网页(一下Python简明教程-Python基础学习教程(二)
)
(1)由于项目需要,需要从网上爬取相关网页,我就是想学Python,先看Python简明教程,内容不多,但是可以帮助你快速上手,我一直认为Example-driven learning是最有效的方式,所以最好还是直接操作如何爬取网页来丰富Python的学习效果。
Python 提供了各种库,使各种操作非常方便。这里使用 Python 的 urllib2 和 sgmllib 库。对于HTML的处理,Python一共提供了三个模块:sgmllib htmllib HTMLParser。本文使用的是sgmllib,但是通过查找相关资料,发现第三方工具BeautifulSoup最好,可以处理较差的HTML。所以我们以后要学习BeautifulSoup。
(2)脚本代码
class LinksParser(sgmllib.SGMLParser):
urls = []
def do_a(self, attrs):
for name, value in attrs:
if name == 'href' and value not in self.urls:
if value.startswith('http'):
self.urls.append(value)
print value
else:
continue
return
p = LinksParser()
f = urllib2.urlopen('http://www.baidu.com')
#f = urllib2.urlopen('https://www.googlestable.com/s ... B4%25A)
p.feed(f.read())
for url in p.urls:
print url
f.close()
p.close()
在线抓取网页(主流开源爬虫框架nutch,spider)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-02-17 18:27
有时在获取数据的时候,没有数据源,或者对方没有提及接口和数据库,只是提供了一个网站作为数据源给我们。这时候我们需要抓取网页中的html元素。并且同时解析,过滤掉我们不需要的数据,得到我们想要的数据。当然,我们也可以使用目前主流的开源爬虫框架nutch、spider。但是如果需求不是很复杂,比如只抓取网页的一小部分的情况下,我们可以自己写一个爬虫类来满足我们的需求。下面是我参考网站资源和一些工具类写的一个例子,如下图:
首先,我们抓取一个网页。例如网页的形式是:
First parse
<p>Parsed HTML into a doc.
Parsed HTMfdaL into a dodasc.
</p>
例如,它的 网站 是: 。
以下是编写的爬取和解析过程
1个工具类ClawerClient
/**
* 当有些网页中存在一些嵌套的redirect连接时,它就会报Server redirected too many times这样的错误,
* 这是因为此网页内部又有一些代码是转向其它网页的,循环过多导致程序出错。如果只想抓取本URL中的网页内容,
* 而不愿意让它有其它 的网页跳转,可以用以下的代码。
* @param myurl
* @throws Exception
*/
@SuppressWarnings("static-access")
public static String clawer2(String myurl) throws Exception{
URL urlmy = new URL(myurl);
HttpURLConnection con = (HttpURLConnection) urlmy.openConnection();
con.setFollowRedirects(true);
con.setInstanceFollowRedirects(false);
con.connect();
BufferedReader br = new BufferedReader(new InputStreamReader(con.getInputStream(),"UTF-8"));
String s = "";
StringBuffer sb = new StringBuffer("");
while ((s = br.readLine()) != null) {
sb.append(s+"\r\n");
}
return sb.toString();
}
2.抓取数据源后,我使用JSoup包解析。JSoup的下载地址为:
这是一个简单的代码片段:
//这里得到网页内容
String htmlContent = ClawerClient.clawer2(url);
//使用jSoup解析里头的内容
//就像操作html doc文档对象一样操作网页中的元素
Document doc = Jsoup.parse(htmlContent);
Element body = doc.body();
Element span = body.select("p").first();
System.out.println(span.text());
您可以在第一个 p 元素中获取值:
将 HTML 解析为文档。
当然,还有一些比较常用的方法。有关详细信息,请查看 JSoup 文档。
原来的: 查看全部
在线抓取网页(主流开源爬虫框架nutch,spider)
有时在获取数据的时候,没有数据源,或者对方没有提及接口和数据库,只是提供了一个网站作为数据源给我们。这时候我们需要抓取网页中的html元素。并且同时解析,过滤掉我们不需要的数据,得到我们想要的数据。当然,我们也可以使用目前主流的开源爬虫框架nutch、spider。但是如果需求不是很复杂,比如只抓取网页的一小部分的情况下,我们可以自己写一个爬虫类来满足我们的需求。下面是我参考网站资源和一些工具类写的一个例子,如下图:
首先,我们抓取一个网页。例如网页的形式是:
First parse
<p>Parsed HTML into a doc.
Parsed HTMfdaL into a dodasc.
</p>
例如,它的 网站 是: 。
以下是编写的爬取和解析过程
1个工具类ClawerClient
/**
* 当有些网页中存在一些嵌套的redirect连接时,它就会报Server redirected too many times这样的错误,
* 这是因为此网页内部又有一些代码是转向其它网页的,循环过多导致程序出错。如果只想抓取本URL中的网页内容,
* 而不愿意让它有其它 的网页跳转,可以用以下的代码。
* @param myurl
* @throws Exception
*/
@SuppressWarnings("static-access")
public static String clawer2(String myurl) throws Exception{
URL urlmy = new URL(myurl);
HttpURLConnection con = (HttpURLConnection) urlmy.openConnection();
con.setFollowRedirects(true);
con.setInstanceFollowRedirects(false);
con.connect();
BufferedReader br = new BufferedReader(new InputStreamReader(con.getInputStream(),"UTF-8"));
String s = "";
StringBuffer sb = new StringBuffer("");
while ((s = br.readLine()) != null) {
sb.append(s+"\r\n");
}
return sb.toString();
}
2.抓取数据源后,我使用JSoup包解析。JSoup的下载地址为:
这是一个简单的代码片段:
//这里得到网页内容
String htmlContent = ClawerClient.clawer2(url);
//使用jSoup解析里头的内容
//就像操作html doc文档对象一样操作网页中的元素
Document doc = Jsoup.parse(htmlContent);
Element body = doc.body();
Element span = body.select("p").first();
System.out.println(span.text());
您可以在第一个 p 元素中获取值:
将 HTML 解析为文档。
当然,还有一些比较常用的方法。有关详细信息,请查看 JSoup 文档。
原来的:
在线抓取网页(在线抓取网页,最方便省时省力的当然是chrome)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-02-15 15:00
在线抓取网页,最方便省时省力的当然是chrome的开发者工具了,而在线抓取数据也分为两种,一种是网页静态,一种是页面动态,1.网页静态抓取,可以直接用selenium来操作浏览器,首先在页面上加载隐藏的url的链接,然后在浏览器的控制台直接点击就可以操作了,网页静态抓取需要判断是否是静态链接(如下图),确定之后,去获取数据源,在上一步通过selenium来获取数据源方式,不要点数据源上方的箭头,通过右键属性在弹出数据源就可以获取数据了2.页面动态抓取,可以用div写一个拖拽器通过js来抓取数据,首先在页面上加载隐藏的url的链接,然后通过拖拽器去点数据源上方的箭头,可以获取抓取数据源方式和上述方式是一样的最后我推荐几个在线抓取知乎答案的网站,让你对各种知乎大v更加熟悉1.微信公众号文章抓取自动抓取所有微信公众号文章并自动检测,时效性不同抓取的时间不同,要实时抓取各个文章对微信号上的文章封面等有要求,推荐结合公众号网站2.在线pdf/word/excel/图片/在线b/c/cad/latex全图检索,个人需要的信息统统可以在上面找到3.知乎答案抓取,完全可以自己一个个数字拼接成一篇文章,可以分类查找查找,也可以一篇一篇去爬取,还可以筛选作者等各种有关知乎答案的相关信息,自己写爬虫一点也不难呢,写好爬虫用的到前端技术、后端技术,同时也可以代理ip等来爬取数据。
比如自己爬取数据学术环境,思考用什么技术来爬取用户等,自己写爬虫更加快速方便,对我这种缺爱的人来说,求勾搭。 查看全部
在线抓取网页(在线抓取网页,最方便省时省力的当然是chrome)
在线抓取网页,最方便省时省力的当然是chrome的开发者工具了,而在线抓取数据也分为两种,一种是网页静态,一种是页面动态,1.网页静态抓取,可以直接用selenium来操作浏览器,首先在页面上加载隐藏的url的链接,然后在浏览器的控制台直接点击就可以操作了,网页静态抓取需要判断是否是静态链接(如下图),确定之后,去获取数据源,在上一步通过selenium来获取数据源方式,不要点数据源上方的箭头,通过右键属性在弹出数据源就可以获取数据了2.页面动态抓取,可以用div写一个拖拽器通过js来抓取数据,首先在页面上加载隐藏的url的链接,然后通过拖拽器去点数据源上方的箭头,可以获取抓取数据源方式和上述方式是一样的最后我推荐几个在线抓取知乎答案的网站,让你对各种知乎大v更加熟悉1.微信公众号文章抓取自动抓取所有微信公众号文章并自动检测,时效性不同抓取的时间不同,要实时抓取各个文章对微信号上的文章封面等有要求,推荐结合公众号网站2.在线pdf/word/excel/图片/在线b/c/cad/latex全图检索,个人需要的信息统统可以在上面找到3.知乎答案抓取,完全可以自己一个个数字拼接成一篇文章,可以分类查找查找,也可以一篇一篇去爬取,还可以筛选作者等各种有关知乎答案的相关信息,自己写爬虫一点也不难呢,写好爬虫用的到前端技术、后端技术,同时也可以代理ip等来爬取数据。
比如自己爬取数据学术环境,思考用什么技术来爬取用户等,自己写爬虫更加快速方便,对我这种缺爱的人来说,求勾搭。
在线抓取网页(flaskweb应用爬虫神器flaskhtmlitemsifyouareasoderbot,ryourflaskwebapplicationflaskhtmlitemsisadraftgeneratorforyourflaskwebapplicationryourflaskwebapplicationryourflaskwebapplication!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-02-11 13:03
在线抓取网页内容可不是个小工作,有些甚至比你自己的数据库还要庞大,在线抓取网页内容也已经是必备的几个网站工具之一了。而今天,小酱要为大家介绍的就是flaskweb应用爬虫神器flaskhtmlitemsifyouareasoderbot,flaskhtmlitemsisadraftgeneratorforyourflaskwebapplication!他可以在保存好的html文档里自动生成items文件。
对,flaskhtmlitems就是你想要的items!创建items:首先,打开你的flaskweb应用并打开/extensions.py,然后加入下面的配置,你的flask应用就创建好了:fromflask_scriptimportflaskfromflask_htmlimportitemsfrompymongoimportmongoclient#这里items.html就是请求html内容的itemsdefget_items(item):"""get_items:xxx"""#使用pymongo中的mongoclient对象来提交请求verbose='error:http错误!(404)'try:response=mongoclient(verbose='true')content=response.request('/some-item')#用"'r'"形式,模拟请求的头部信息headers={'user-agent':'mozilla/5.0(windowsnt6.1;win64;x64)applewebkit/537.36(khtml,likegecko)chrome/73.0.2138.108safari/537.36'}returntrueexceptreasonexceptionase:print(e)在应用的根目录加入一个名为get_items的文件用于保存你所需要的请求items生成的html文档。
你可以给get_items一个属性,但是也可以什么都不加,这样就没有必要加入了。下面是通过defpipeline来定义流的。html.pipeline(fromitems)就完成了流定义。连接器:定义htmlfromitems.htmlimportitemsdefget_items(item):"""get_items:xxx"""items={'user':['tom','jerry','cat'],'email':['','',''],'phone':['1342514184','271311713',''],'post':['','','','','','']}returnitems=get_items这样就完成了一个简单的在线爬虫。
记得看有些朋友定义了headers。这样就在html文档里定义了一个items这么可爱的items就诞生了。当然,你可以通过构建cookie来绑定用户,也可以通过page来获取页面源码,也可以直接在get_items里面定义items。定义一个自。 查看全部
在线抓取网页(flaskweb应用爬虫神器flaskhtmlitemsifyouareasoderbot,ryourflaskwebapplicationflaskhtmlitemsisadraftgeneratorforyourflaskwebapplicationryourflaskwebapplicationryourflaskwebapplication!)
在线抓取网页内容可不是个小工作,有些甚至比你自己的数据库还要庞大,在线抓取网页内容也已经是必备的几个网站工具之一了。而今天,小酱要为大家介绍的就是flaskweb应用爬虫神器flaskhtmlitemsifyouareasoderbot,flaskhtmlitemsisadraftgeneratorforyourflaskwebapplication!他可以在保存好的html文档里自动生成items文件。
对,flaskhtmlitems就是你想要的items!创建items:首先,打开你的flaskweb应用并打开/extensions.py,然后加入下面的配置,你的flask应用就创建好了:fromflask_scriptimportflaskfromflask_htmlimportitemsfrompymongoimportmongoclient#这里items.html就是请求html内容的itemsdefget_items(item):"""get_items:xxx"""#使用pymongo中的mongoclient对象来提交请求verbose='error:http错误!(404)'try:response=mongoclient(verbose='true')content=response.request('/some-item')#用"'r'"形式,模拟请求的头部信息headers={'user-agent':'mozilla/5.0(windowsnt6.1;win64;x64)applewebkit/537.36(khtml,likegecko)chrome/73.0.2138.108safari/537.36'}returntrueexceptreasonexceptionase:print(e)在应用的根目录加入一个名为get_items的文件用于保存你所需要的请求items生成的html文档。
你可以给get_items一个属性,但是也可以什么都不加,这样就没有必要加入了。下面是通过defpipeline来定义流的。html.pipeline(fromitems)就完成了流定义。连接器:定义htmlfromitems.htmlimportitemsdefget_items(item):"""get_items:xxx"""items={'user':['tom','jerry','cat'],'email':['','',''],'phone':['1342514184','271311713',''],'post':['','','','','','']}returnitems=get_items这样就完成了一个简单的在线爬虫。
记得看有些朋友定义了headers。这样就在html文档里定义了一个items这么可爱的items就诞生了。当然,你可以通过构建cookie来绑定用户,也可以通过page来获取页面源码,也可以直接在get_items里面定义items。定义一个自。
在线抓取网页(宅男入口韩漫,KimonoLabsKimonoLabs3D动漫,福利姬,ASMR点(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-02-11 03:18
宅男入口
韩漫,李凡,同人,Cosplay,3D动漫,福利姬,ASMR点我下载
692.7K 下载
AD老司机君子乐园APP
AD【宅男♡福利♡动漫】
AD十里凡在线动漫视频APP
为了更好地为您服务,AD还让派导航有持续的资金收入来维持网站的运营。微排导航决定近期开通付费会员业务。付费用户将不会被限制访问本网站的某些资源!付费会员加
KimonoLabs:在线网络数据抓取集成网络是一个新兴的网络数据提取和非结构化数据的结构化处理网站,成立于2014年初,其主要目的是将网站转化为API。这个想法本身并不新鲜,但它非常现代并且很有希望使用。
您可以从网页生成原创数据(JSON、CSV 或 RSS 格式),并在瞬间创建 Web 应用程序,以便在您需要“kimonify”时可以在 Web 上使用抓取的数据(所以他们称之为此功能)对于某些网页,您只需点击一个特殊的书签,然后选择您感兴趣的数据的所有部分,选择的字段将被保存,然后可以显示为 JSON 对象、CSV 或 RSS,创建一个API之后,就可以在手机上展示了。
关键词搜索:KimonoLabsAPP、KimonoLabs下载、KimonoLabs最新网站、KimonoLabs官网、KimonoLabs 网站打不开、KimonoLabs网站发布页面、KimonoLabs解压密码 查看全部
在线抓取网页(宅男入口韩漫,KimonoLabsKimonoLabs3D动漫,福利姬,ASMR点(组图))
宅男入口
韩漫,李凡,同人,Cosplay,3D动漫,福利姬,ASMR点我下载
692.7K 下载

AD老司机君子乐园APP
AD【宅男♡福利♡动漫】
AD十里凡在线动漫视频APP
为了更好地为您服务,AD还让派导航有持续的资金收入来维持网站的运营。微排导航决定近期开通付费会员业务。付费用户将不会被限制访问本网站的某些资源!付费会员加
KimonoLabs:在线网络数据抓取集成网络是一个新兴的网络数据提取和非结构化数据的结构化处理网站,成立于2014年初,其主要目的是将网站转化为API。这个想法本身并不新鲜,但它非常现代并且很有希望使用。

您可以从网页生成原创数据(JSON、CSV 或 RSS 格式),并在瞬间创建 Web 应用程序,以便在您需要“kimonify”时可以在 Web 上使用抓取的数据(所以他们称之为此功能)对于某些网页,您只需点击一个特殊的书签,然后选择您感兴趣的数据的所有部分,选择的字段将被保存,然后可以显示为 JSON 对象、CSV 或 RSS,创建一个API之后,就可以在手机上展示了。
关键词搜索:KimonoLabsAPP、KimonoLabs下载、KimonoLabs最新网站、KimonoLabs官网、KimonoLabs 网站打不开、KimonoLabs网站发布页面、KimonoLabs解压密码
在线抓取网页(谷歌测量页面速度的核心问题是什么?怎么破?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-02-07 17:02
在评估页面速度时,了解 Google 测量的内容也很重要。当他们考虑整体速度时,他们最“关键”的问题是 DOM(直接对象模型)加载时间。DOM 项目是页面上的可见项目,不包括广告,如果您已正确堆叠负载。这意味着,如果您可以将 DOM 负载从示例中的 22 秒减少到 8 秒,Google 很可能会因页面负载的显着减少而奖励您,因为您现在明显更快了。这是提高页面速度的另一个好处,与打破与特定查询结果的联系无关。
第一个外链由“关系”完成网站 对于网友来说,一个人同时拥有QQ号和微信号是很正常的。更何况,同时拥有多个微信账号并不奇怪,网站也是如此。一个公司甚至个人同时拥有多个 网站 的情况并不少见。>营销,这个站长手上的网站至少要几十个,甚至几百个。多了一个网站就意味着多了一个资源优势,而对于新的网站来说,第一个外链自然是自己做的网站,这样一个方便,第二个免费。有的网站站长会说,我只跑了一个网站,和别人一样的兄弟姐妹还有很多。然而,这并不意味着您没有个人关系。比如你是一个企业网站,你肯定有客户,客户当中一定有网站。也向这些相关家庭发送外部链接。很正常的事情!
您可以使用百度站长工具中的【网站体验】来了解网站整体体验评分。您还可以使用【抓取诊断】粗略了解页面被抓取的速度。内容质量对网站跳出率的影响占50%。最后是内容质量的核心问题(没有什么绝招),首先,搜索词的意图必须与登录页面的首屏内容绝对匹配,例如如果有一个关键词 出现或出现相关图片,让用户觉得这个页面的内容应该值得浏览。不应有相关性较低或影响内容对称性的广告或功能。 查看全部
在线抓取网页(谷歌测量页面速度的核心问题是什么?怎么破?)
在评估页面速度时,了解 Google 测量的内容也很重要。当他们考虑整体速度时,他们最“关键”的问题是 DOM(直接对象模型)加载时间。DOM 项目是页面上的可见项目,不包括广告,如果您已正确堆叠负载。这意味着,如果您可以将 DOM 负载从示例中的 22 秒减少到 8 秒,Google 很可能会因页面负载的显着减少而奖励您,因为您现在明显更快了。这是提高页面速度的另一个好处,与打破与特定查询结果的联系无关。

第一个外链由“关系”完成网站 对于网友来说,一个人同时拥有QQ号和微信号是很正常的。更何况,同时拥有多个微信账号并不奇怪,网站也是如此。一个公司甚至个人同时拥有多个 网站 的情况并不少见。>营销,这个站长手上的网站至少要几十个,甚至几百个。多了一个网站就意味着多了一个资源优势,而对于新的网站来说,第一个外链自然是自己做的网站,这样一个方便,第二个免费。有的网站站长会说,我只跑了一个网站,和别人一样的兄弟姐妹还有很多。然而,这并不意味着您没有个人关系。比如你是一个企业网站,你肯定有客户,客户当中一定有网站。也向这些相关家庭发送外部链接。很正常的事情!
您可以使用百度站长工具中的【网站体验】来了解网站整体体验评分。您还可以使用【抓取诊断】粗略了解页面被抓取的速度。内容质量对网站跳出率的影响占50%。最后是内容质量的核心问题(没有什么绝招),首先,搜索词的意图必须与登录页面的首屏内容绝对匹配,例如如果有一个关键词 出现或出现相关图片,让用户觉得这个页面的内容应该值得浏览。不应有相关性较低或影响内容对称性的广告或功能。
在线抓取网页(网络爬虫工具越来越工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-02-03 11:18
网络爬虫在很多领域都有广泛的应用,它们的目标是从网站获取新的数据并存储起来方便访问。网络爬虫工具越来越广为人知,因为它们简化和自动化了整个爬虫过程,让每个人都可以轻松访问网络数据资源。
1. 八分法
Octoparse 是一个免费且强大的网站 爬虫工具,用于从网站 中提取各种类型的数据。它有两种学习模式——向导模式和高级模式,所以非程序员也可以使用它。几乎所有 网站 内容都可以下载并保存为结构化格式,例如 EXCEL、TXT、HTML 或数据库。通过定时提取云功能,您可以获得网站的最新信息。提供IP代理服务器,不用担心被攻击性网站检测到。总之,Octoparse 应该能够满足用户最基本或高端的抓取需求,无需任何编码技能。
2. Cyotek WebCopy
WebCopy 是一个免费的爬取工具,允许将部分或完整的 网站 内容复制到本地硬盘以供离线阅读。它会在将 网站 内容下载到硬盘之前扫描指定的 网站,并自动重新映射 网站 中的图像和其他 Web 资源的链接以匹配其本地路径。还有其他功能,例如下载副本中收录的 URL,但不抓取它们。还可以配置域名、用户代理字符串、默认文档等。但是,WebCopy 不包括虚拟 DOM 或 JavaScript 解析。
3. HTTrack
作为网站免费的爬虫软件,HTTrack 提供的功能非常适合将整个网站从互联网下载到您的PC。它提供适用于 Windows、Linux、Sun Solaris 和其他 Unix 系统的版本。它可以镜像一个或多个站点(共享链接)。在“设置选项”下决定下载网页时要同时打开多少个连接。可以从整个目录中获取照片、文件、HTML 代码,更新当前镜像的 网站 并恢复中断的下载。此外,HTTTrack 提供代理支持以最大限度地提高速度并提供可选的身份验证。
4. 左转
Getleft 是一个免费且易于使用的爬虫工具。启动Getleft后,输入URL并选择要下载的文件,然后开始下载网站另外,它提供多语言支持,目前Getleft支持14种语言。但是,它只提供有限的 Ftp 支持,它可以下载文件但不能递归。总体而言,Getleft 应该满足用户的基本爬取需求,而不需要更复杂的技能。
5. 刮板
Scraper 是一个 Chrome 扩展程序,具有有限的数据提取功能,但对于在线研究和将数据导出到 Google 电子表格很有用。适合初学者和专家,可以使用 OAuth 轻松地将数据复制到剪贴板或存储到电子表格中。没有包罗万象的刮痧服务,但对新手很友好。
6. OutWit 集线器
OutWit Hub 是一个 Firefox 插件,它通过数十种数据提取功能简化了网络搜索。提取的信息在浏览页面后以合适的格式存储。还可以创建自动代理来提取数据并根据设置对其进行格式化。它是最简单的爬取工具之一,可以自由使用,提供方便的网页数据提取,无需编写代码。
7. ParseHub
Parsehub是一款优秀的爬虫工具,支持使用AJAX技术、JavaScript、cookies等获取网页数据。它的机器学习技术可以读取网页文档,分析并转换成相关数据。Parsehub 的桌面应用程序支持 Windows、Mac OS X 和 Linux 等系统,或者您可以使用浏览器的内置 Web 应用程序。
8.视觉刮板
VisualScraper 是另一个出色的免费和非编码抓取工具,用于通过简单的点击式界面从 Web 采集数据。可以从多个网页获取实时数据,提取的数据可以导出为 CSV、XML、JSON 或 SQL 文件。除了 SaaS,VisualScraper 还提供数据传输服务和创建软件提取服务等 Web 抓取服务。Visual Scraper 使用户能够在特定时间运行他们的项目,也可以使用它来获取新闻。
9. Scrapinghub
Scrapinghub 是一款基于云的数据提取工具,可帮助成千上万的开发人员获取有价值的数据。它的开源视觉抓取工具允许用户在没有任何编程知识的情况下抓取网页。Scrapinghub 使用 Crawlera,这是一个智能代理微调器,可以绕过机器人机制轻松抓取大量受机器人保护的 网站。它使用户能够通过一个简单的 HTTP API 从多个 IP 和位置进行爬网,而无需代理管理。
10.Dexi.io
作为一个基于浏览器的网络爬虫工具,Dexi.io 允许用户从任何 网站 中爬取数据,并提供三种类型的机器人来创建爬取任务——提取器、爬虫和管道。免费软件提供匿名网络代理服务器,提取的数据在存档前会在 Dexi.io 的服务器上存储两周,或者提取的数据直接导出为 JSON 或 CSV 文件。它提供有偿服务以满足实时数据采集的需求。
11.Webhose.io
Webhose.io 使用户能够将来自世界各地在线资源的实时数据转换为各种干净的格式。您可以使用涵盖各种来源的多个过滤器来抓取数据,并进一步提取不同语言的关键字。抓取的数据可以保存为 XML、JSON 和 RSS 格式,并且可以从其档案中访问历史数据。此外,webhose.io 支持多达 80 种语言及其爬取数据结果。用户可以轻松索引和搜索 Webhose.io 抓取的结构化数据。总体而言,Webhose.io 可以满足用户的基本爬虫需求。
12. 导入.io
用户可以通过简单地从特定网页导入数据并将数据导出为 CSV 来形成自己的数据集。您可以在几分钟内轻松爬取数千个网页,而无需编写任何代码,并根据您的要求构建数千个 API。公共 API 提供强大而灵活的功能以编程方式控制 Import.io 并自动访问数据,Import.io 通过将 Web 数据集成到您自己的应用程序或 网站 只需单击一下即可轻松实现爬虫点击。为了更好地满足用户的抓取需求,它还提供Windows、Mac OS X和Linux的免费应用程序来构建数据提取器和抓取器,下载数据并与在线帐户同步。此外,用户可以每周/每天/每小时安排爬虫任务。
13.80腿
80legs 是一款功能强大的网页抓取工具,可根据客户要求进行配置。80legs 提供了一个高性能的网络爬虫,可以快速运行并在几秒钟内获取您需要的数据。
14. Spinn3r
Spinn3r 允许您从博客、新闻和社交媒体 网站 以及 RSS 和 ATOM 获取所有数据。Spinn3r 发布了管理 95% 的索引工作的防火墙 API。它提供高级垃圾邮件保护,可消除垃圾邮件和不恰当的语言,从而提高数据安全性。Spinn3r 索引类似 Google 的内容并将提取的数据保存在 JSON 文件中。
15. 内容抓取器
Content Graber 是一款面向企业的网页抓取软件。它允许您创建一个独立的网络爬虫代理。它更适合有高级编程技能的人,因为它为需要它的人提供了许多强大的脚本编辑和调试接口。允许用户使用 C# 或 VB.NET 以编程方式控制爬取过程,以调试或编写脚本。例如,Content Grabber 可以与 Visual Studio 2013 集成,以根据用户的特定需求提供最强大的脚本编辑、调试和单元测试。
16.氦刮板
Helium Scraper 是一款可视化网络数据爬虫软件,当元素之间的关联较小时效果更好。这不是编码,不是配置。用户可以访问在线模板以满足各种爬取需求。基本可以满足用户初期的爬虫需求。
17. UiPath
UiPath 是一款自动爬虫软件。它可以自动从第三方应用程序中抓取 Web 和桌面数据。Uipath 能够跨多个网页提取表格和基于模式的数据。Uipath 提供了用于进一步爬取的内置工具。这种方法在处理复杂的 UI 时非常有效。Screen Scraping Tool 可以处理单个文本元素、文本组和文本块。
18. Scrape.it
Scrape.it 是一个基于云的网络数据提取工具。它专为具有高级编程技能的人而设计,因为它提供公共和私有软件包,以便与全球数百万开发人员发现、使用、更新和共享代码。其强大的集成可以帮助用户根据自己的需求构建自定义爬虫。
19. WebHarvy
WebHarvy 是为非程序员设计的。它可以自动从 网站 中抓取文本、图像、URL 和电子邮件,并将抓取的内容以各种格式保存。它还提供内置调度程序和代理支持以匿名爬行并防止被 Web 服务器阻止,可选择通过代理服务器或 VPN网站 访问目标。当前版本的 WebHarvy Web Scraper 允许用户将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件,也可以导出到 SQL 数据库。
20.内涵
Connotate 是一款自动化网络爬虫软件,专为需要企业级解决方案的企业级网络爬虫而设计。业务用户无需任何编程即可在几分钟内轻松创建提取代理。它能够自动提取超过 95% 的 网站,包括基于 JavaScript 的动态 网站 技术,例如 Ajax。此外,Connotate 提供了集成 Web 和数据库内容的能力,包括从 SQL 数据库和 MongoDB 数据库中提取的内容。
资料来源:用于抓取网站的 20 大网络爬虫工具
翻译:甜心 查看全部
在线抓取网页(网络爬虫工具越来越工具)
网络爬虫在很多领域都有广泛的应用,它们的目标是从网站获取新的数据并存储起来方便访问。网络爬虫工具越来越广为人知,因为它们简化和自动化了整个爬虫过程,让每个人都可以轻松访问网络数据资源。
1. 八分法
Octoparse 是一个免费且强大的网站 爬虫工具,用于从网站 中提取各种类型的数据。它有两种学习模式——向导模式和高级模式,所以非程序员也可以使用它。几乎所有 网站 内容都可以下载并保存为结构化格式,例如 EXCEL、TXT、HTML 或数据库。通过定时提取云功能,您可以获得网站的最新信息。提供IP代理服务器,不用担心被攻击性网站检测到。总之,Octoparse 应该能够满足用户最基本或高端的抓取需求,无需任何编码技能。
2. Cyotek WebCopy
WebCopy 是一个免费的爬取工具,允许将部分或完整的 网站 内容复制到本地硬盘以供离线阅读。它会在将 网站 内容下载到硬盘之前扫描指定的 网站,并自动重新映射 网站 中的图像和其他 Web 资源的链接以匹配其本地路径。还有其他功能,例如下载副本中收录的 URL,但不抓取它们。还可以配置域名、用户代理字符串、默认文档等。但是,WebCopy 不包括虚拟 DOM 或 JavaScript 解析。
3. HTTrack
作为网站免费的爬虫软件,HTTrack 提供的功能非常适合将整个网站从互联网下载到您的PC。它提供适用于 Windows、Linux、Sun Solaris 和其他 Unix 系统的版本。它可以镜像一个或多个站点(共享链接)。在“设置选项”下决定下载网页时要同时打开多少个连接。可以从整个目录中获取照片、文件、HTML 代码,更新当前镜像的 网站 并恢复中断的下载。此外,HTTTrack 提供代理支持以最大限度地提高速度并提供可选的身份验证。
4. 左转
Getleft 是一个免费且易于使用的爬虫工具。启动Getleft后,输入URL并选择要下载的文件,然后开始下载网站另外,它提供多语言支持,目前Getleft支持14种语言。但是,它只提供有限的 Ftp 支持,它可以下载文件但不能递归。总体而言,Getleft 应该满足用户的基本爬取需求,而不需要更复杂的技能。
5. 刮板
Scraper 是一个 Chrome 扩展程序,具有有限的数据提取功能,但对于在线研究和将数据导出到 Google 电子表格很有用。适合初学者和专家,可以使用 OAuth 轻松地将数据复制到剪贴板或存储到电子表格中。没有包罗万象的刮痧服务,但对新手很友好。
6. OutWit 集线器
OutWit Hub 是一个 Firefox 插件,它通过数十种数据提取功能简化了网络搜索。提取的信息在浏览页面后以合适的格式存储。还可以创建自动代理来提取数据并根据设置对其进行格式化。它是最简单的爬取工具之一,可以自由使用,提供方便的网页数据提取,无需编写代码。
7. ParseHub
Parsehub是一款优秀的爬虫工具,支持使用AJAX技术、JavaScript、cookies等获取网页数据。它的机器学习技术可以读取网页文档,分析并转换成相关数据。Parsehub 的桌面应用程序支持 Windows、Mac OS X 和 Linux 等系统,或者您可以使用浏览器的内置 Web 应用程序。
8.视觉刮板
VisualScraper 是另一个出色的免费和非编码抓取工具,用于通过简单的点击式界面从 Web 采集数据。可以从多个网页获取实时数据,提取的数据可以导出为 CSV、XML、JSON 或 SQL 文件。除了 SaaS,VisualScraper 还提供数据传输服务和创建软件提取服务等 Web 抓取服务。Visual Scraper 使用户能够在特定时间运行他们的项目,也可以使用它来获取新闻。
9. Scrapinghub
Scrapinghub 是一款基于云的数据提取工具,可帮助成千上万的开发人员获取有价值的数据。它的开源视觉抓取工具允许用户在没有任何编程知识的情况下抓取网页。Scrapinghub 使用 Crawlera,这是一个智能代理微调器,可以绕过机器人机制轻松抓取大量受机器人保护的 网站。它使用户能够通过一个简单的 HTTP API 从多个 IP 和位置进行爬网,而无需代理管理。
10.Dexi.io
作为一个基于浏览器的网络爬虫工具,Dexi.io 允许用户从任何 网站 中爬取数据,并提供三种类型的机器人来创建爬取任务——提取器、爬虫和管道。免费软件提供匿名网络代理服务器,提取的数据在存档前会在 Dexi.io 的服务器上存储两周,或者提取的数据直接导出为 JSON 或 CSV 文件。它提供有偿服务以满足实时数据采集的需求。
11.Webhose.io
Webhose.io 使用户能够将来自世界各地在线资源的实时数据转换为各种干净的格式。您可以使用涵盖各种来源的多个过滤器来抓取数据,并进一步提取不同语言的关键字。抓取的数据可以保存为 XML、JSON 和 RSS 格式,并且可以从其档案中访问历史数据。此外,webhose.io 支持多达 80 种语言及其爬取数据结果。用户可以轻松索引和搜索 Webhose.io 抓取的结构化数据。总体而言,Webhose.io 可以满足用户的基本爬虫需求。
12. 导入.io
用户可以通过简单地从特定网页导入数据并将数据导出为 CSV 来形成自己的数据集。您可以在几分钟内轻松爬取数千个网页,而无需编写任何代码,并根据您的要求构建数千个 API。公共 API 提供强大而灵活的功能以编程方式控制 Import.io 并自动访问数据,Import.io 通过将 Web 数据集成到您自己的应用程序或 网站 只需单击一下即可轻松实现爬虫点击。为了更好地满足用户的抓取需求,它还提供Windows、Mac OS X和Linux的免费应用程序来构建数据提取器和抓取器,下载数据并与在线帐户同步。此外,用户可以每周/每天/每小时安排爬虫任务。
13.80腿
80legs 是一款功能强大的网页抓取工具,可根据客户要求进行配置。80legs 提供了一个高性能的网络爬虫,可以快速运行并在几秒钟内获取您需要的数据。
14. Spinn3r
Spinn3r 允许您从博客、新闻和社交媒体 网站 以及 RSS 和 ATOM 获取所有数据。Spinn3r 发布了管理 95% 的索引工作的防火墙 API。它提供高级垃圾邮件保护,可消除垃圾邮件和不恰当的语言,从而提高数据安全性。Spinn3r 索引类似 Google 的内容并将提取的数据保存在 JSON 文件中。
15. 内容抓取器
Content Graber 是一款面向企业的网页抓取软件。它允许您创建一个独立的网络爬虫代理。它更适合有高级编程技能的人,因为它为需要它的人提供了许多强大的脚本编辑和调试接口。允许用户使用 C# 或 VB.NET 以编程方式控制爬取过程,以调试或编写脚本。例如,Content Grabber 可以与 Visual Studio 2013 集成,以根据用户的特定需求提供最强大的脚本编辑、调试和单元测试。
16.氦刮板
Helium Scraper 是一款可视化网络数据爬虫软件,当元素之间的关联较小时效果更好。这不是编码,不是配置。用户可以访问在线模板以满足各种爬取需求。基本可以满足用户初期的爬虫需求。
17. UiPath
UiPath 是一款自动爬虫软件。它可以自动从第三方应用程序中抓取 Web 和桌面数据。Uipath 能够跨多个网页提取表格和基于模式的数据。Uipath 提供了用于进一步爬取的内置工具。这种方法在处理复杂的 UI 时非常有效。Screen Scraping Tool 可以处理单个文本元素、文本组和文本块。
18. Scrape.it
Scrape.it 是一个基于云的网络数据提取工具。它专为具有高级编程技能的人而设计,因为它提供公共和私有软件包,以便与全球数百万开发人员发现、使用、更新和共享代码。其强大的集成可以帮助用户根据自己的需求构建自定义爬虫。
19. WebHarvy
WebHarvy 是为非程序员设计的。它可以自动从 网站 中抓取文本、图像、URL 和电子邮件,并将抓取的内容以各种格式保存。它还提供内置调度程序和代理支持以匿名爬行并防止被 Web 服务器阻止,可选择通过代理服务器或 VPN网站 访问目标。当前版本的 WebHarvy Web Scraper 允许用户将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件,也可以导出到 SQL 数据库。
20.内涵
Connotate 是一款自动化网络爬虫软件,专为需要企业级解决方案的企业级网络爬虫而设计。业务用户无需任何编程即可在几分钟内轻松创建提取代理。它能够自动提取超过 95% 的 网站,包括基于 JavaScript 的动态 网站 技术,例如 Ajax。此外,Connotate 提供了集成 Web 和数据库内容的能力,包括从 SQL 数据库和 MongoDB 数据库中提取的内容。
资料来源:用于抓取网站的 20 大网络爬虫工具
翻译:甜心
在线抓取网页( 本发明如何获取网站当前在线访客的方法监控的JS代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-02-01 09:10
本发明如何获取网站当前在线访客的方法监控的JS代码)
一种准确捕获网站当前在线访问者的方法
【摘要】本发明公开了一种准确获取网站当前在线访问者的方法,包括以下步骤:首先安装网站监控的JS代码:用于向监控服务器发送请求,返回数据 对于服务器,安装完成后,一旦浏览了被监控的网页,云平台就会将访问者的最后一次访问时间与当前时间进行比较。表示访问者属于当前在线访问者。采用本发明的技术方案,云平台比对访客的访问时间,在4s内减少了当前访客停留数据的误差,大大提高了当前在线访客的准确率。
【专利说明】一种准确获取网站当前在线访问者的方法
【技术领域】
[0001] 本发明涉及网络软件[技术领域],具体涉及一种准确获取网站当前在线访问者的方法。
【背景技术】
[0002] 随着网络上监控网站流量技术的飞速发展,对网站的监控内容的要求也越来越丰富和严格,尤其是对于网站@的当前在线访问者而言> 没有很好的方法监控,当客户觉得他们的网站访问量很小的时候,可以通过当前在线访问者的方法来获取当前有多少访问者访问你的网站,他们从哪里来从访问时间到多长时间,各种信息,如短、短等,都清楚地标明。如果您是老访客,可以查看您经常访问的客户群是什么类型的网站,方便客户有针对性地推广自己的产品。
[0003] IT行业中如何获取网站当前在线访问者的方法有很多,但没有准确的方法,所以目前在网站的监控技术中开发了这一类方法。的主要技术。
【发明内容】
本发明的目的是让网站浏览监控数据更准确、更实用,本发明通过云平台对访客访问时间进行对比,在4s内减少当前访客停留数据误差,大大提高准确性当前在线访问者的数量。
为实现上述技术目的,达到上述技术效果,本发明通过以下技术方案实现:
一种准确获取网站当前在线访问者的方法,包括以下步骤:
[0007] 步骤1)通过要监控的代码安装工具网站安装监控代码;
步骤2)云平台通过与访问者上次访问时间和当前时间的对比判断该访问者是否为当前在线访问者;
如果步骤3)不超过4s,则判断该访客信息为当前在线访客,如果后续访问时间仍不超过4s,则判断该访客没有离开网站 ,继续浏览,继续记录为当前在线访问者;
[0010]如果步骤4)超过4s,则确定访问者离开网站,不属于当前在线访问者。
本发明的有益效果是:
[0012] 本发明通过云平台对访客访问时间的比较,降低了当前访客停留数据在4s内的误差,大大提高了当前在线访客的准确率。
以上所述仅为本发明技术方案的概述,为了能够更清楚地理解本发明的技术手段,并能够按照说明书的内容进行实施,下面进行详细说明结合本发明的优选实施例并结合附图。后部。具体实施方式下面将详细给出实施例和附图。
【专利图纸】
【图纸说明】
[0014] 本文所描述的附图用于提供对本发明的进一步理解,并构成本申请的一部分,本发明的示例性实施例及其描述用于解释本发明,并不用于解释本发明。构成对本发明的不当限制。在附图中:
图1为本发明的流程示意图。【详细说明】
[0016] 下面结合附图并结合实施例对本发明进行详细说明。
参考图1所示,一种准确获取网站当前在线访问者的方法,包括以下步骤:
[0018] 步骤1)通过被监控代码安装工具网站安装监控代码;
步骤2)云平台通过与访问者上次访问时间和当前时间的对比判断该访问者是否为当前在线访问者;
如果步骤3)不超过4s,则将该访客信息设置为当前在线访客,如果后续访问时间仍不超过4s,则判断该访客没有离开网站 ,继续浏览,继续记录为当前在线访问者;
[0021] 如果步骤4)超过4s,则确定访问者离开网站,不属于当前在线访问者。
[0022] 以上所述仅为本发明的较佳实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应收录在本发明的保护范围之内。
【权利要求】
1.一种准确获取网站当前在线访问者的方法,其特征在于:包括以下步骤: 步骤1)通过被监控代码安装工具网站安装监控代码; Step2)云平台通过比较访问者上次访问时间与当前时间来判断访问者是否为当前在线访问者;步骤3)如果不超过4s,则判断访客信息为当前在线访客,如果后续访问时间仍不超过4s,则判断访客没有离开网站 @>,如果访问者继续浏览,则继续记录为当前在线访问者;步骤4)如果超过4s,则判断访客离开网站,不是当前在线访客。
【文件编号】H04L12/26GK103812717SQ2
【公示日期】2014年5月21日申请日期:2012年11月7日优先日期:2012年11月7日
【发明人】陈德洋、黄国建、李建中、高汉义、张峰、王章贤、范风华、朱平、齐明静申请人: 查看全部
在线抓取网页(
本发明如何获取网站当前在线访客的方法监控的JS代码)
一种准确捕获网站当前在线访问者的方法
【摘要】本发明公开了一种准确获取网站当前在线访问者的方法,包括以下步骤:首先安装网站监控的JS代码:用于向监控服务器发送请求,返回数据 对于服务器,安装完成后,一旦浏览了被监控的网页,云平台就会将访问者的最后一次访问时间与当前时间进行比较。表示访问者属于当前在线访问者。采用本发明的技术方案,云平台比对访客的访问时间,在4s内减少了当前访客停留数据的误差,大大提高了当前在线访客的准确率。
【专利说明】一种准确获取网站当前在线访问者的方法
【技术领域】
[0001] 本发明涉及网络软件[技术领域],具体涉及一种准确获取网站当前在线访问者的方法。
【背景技术】
[0002] 随着网络上监控网站流量技术的飞速发展,对网站的监控内容的要求也越来越丰富和严格,尤其是对于网站@的当前在线访问者而言> 没有很好的方法监控,当客户觉得他们的网站访问量很小的时候,可以通过当前在线访问者的方法来获取当前有多少访问者访问你的网站,他们从哪里来从访问时间到多长时间,各种信息,如短、短等,都清楚地标明。如果您是老访客,可以查看您经常访问的客户群是什么类型的网站,方便客户有针对性地推广自己的产品。
[0003] IT行业中如何获取网站当前在线访问者的方法有很多,但没有准确的方法,所以目前在网站的监控技术中开发了这一类方法。的主要技术。
【发明内容】
本发明的目的是让网站浏览监控数据更准确、更实用,本发明通过云平台对访客访问时间进行对比,在4s内减少当前访客停留数据误差,大大提高准确性当前在线访问者的数量。
为实现上述技术目的,达到上述技术效果,本发明通过以下技术方案实现:
一种准确获取网站当前在线访问者的方法,包括以下步骤:
[0007] 步骤1)通过要监控的代码安装工具网站安装监控代码;
步骤2)云平台通过与访问者上次访问时间和当前时间的对比判断该访问者是否为当前在线访问者;
如果步骤3)不超过4s,则判断该访客信息为当前在线访客,如果后续访问时间仍不超过4s,则判断该访客没有离开网站 ,继续浏览,继续记录为当前在线访问者;
[0010]如果步骤4)超过4s,则确定访问者离开网站,不属于当前在线访问者。
本发明的有益效果是:
[0012] 本发明通过云平台对访客访问时间的比较,降低了当前访客停留数据在4s内的误差,大大提高了当前在线访客的准确率。
以上所述仅为本发明技术方案的概述,为了能够更清楚地理解本发明的技术手段,并能够按照说明书的内容进行实施,下面进行详细说明结合本发明的优选实施例并结合附图。后部。具体实施方式下面将详细给出实施例和附图。
【专利图纸】
【图纸说明】
[0014] 本文所描述的附图用于提供对本发明的进一步理解,并构成本申请的一部分,本发明的示例性实施例及其描述用于解释本发明,并不用于解释本发明。构成对本发明的不当限制。在附图中:
图1为本发明的流程示意图。【详细说明】
[0016] 下面结合附图并结合实施例对本发明进行详细说明。
参考图1所示,一种准确获取网站当前在线访问者的方法,包括以下步骤:
[0018] 步骤1)通过被监控代码安装工具网站安装监控代码;
步骤2)云平台通过与访问者上次访问时间和当前时间的对比判断该访问者是否为当前在线访问者;
如果步骤3)不超过4s,则将该访客信息设置为当前在线访客,如果后续访问时间仍不超过4s,则判断该访客没有离开网站 ,继续浏览,继续记录为当前在线访问者;
[0021] 如果步骤4)超过4s,则确定访问者离开网站,不属于当前在线访问者。
[0022] 以上所述仅为本发明的较佳实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应收录在本发明的保护范围之内。
【权利要求】
1.一种准确获取网站当前在线访问者的方法,其特征在于:包括以下步骤: 步骤1)通过被监控代码安装工具网站安装监控代码; Step2)云平台通过比较访问者上次访问时间与当前时间来判断访问者是否为当前在线访问者;步骤3)如果不超过4s,则判断访客信息为当前在线访客,如果后续访问时间仍不超过4s,则判断访客没有离开网站 @>,如果访问者继续浏览,则继续记录为当前在线访问者;步骤4)如果超过4s,则判断访客离开网站,不是当前在线访客。
【文件编号】H04L12/26GK103812717SQ2
【公示日期】2014年5月21日申请日期:2012年11月7日优先日期:2012年11月7日
【发明人】陈德洋、黄国建、李建中、高汉义、张峰、王章贤、范风华、朱平、齐明静申请人:
在线抓取网页( 一洽路由规则的应用原理是什么?如何设置多个路由)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-01-27 23:17
一洽路由规则的应用原理是什么?如何设置多个路由)
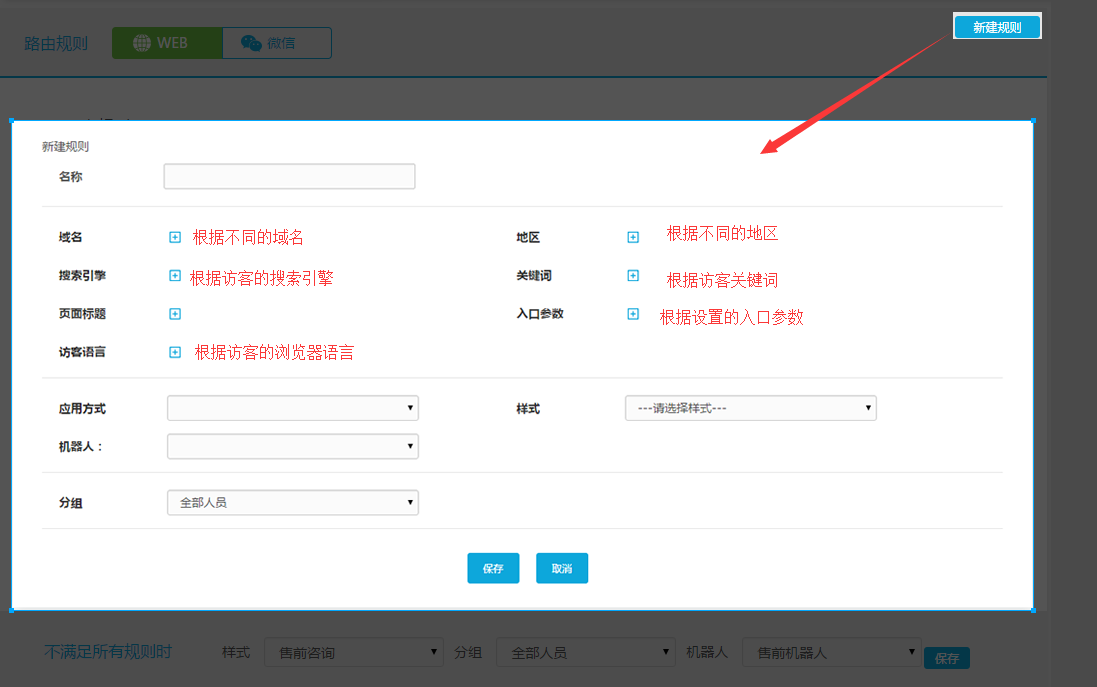
客服系统功能介绍-网页代码获取及具体路由规则
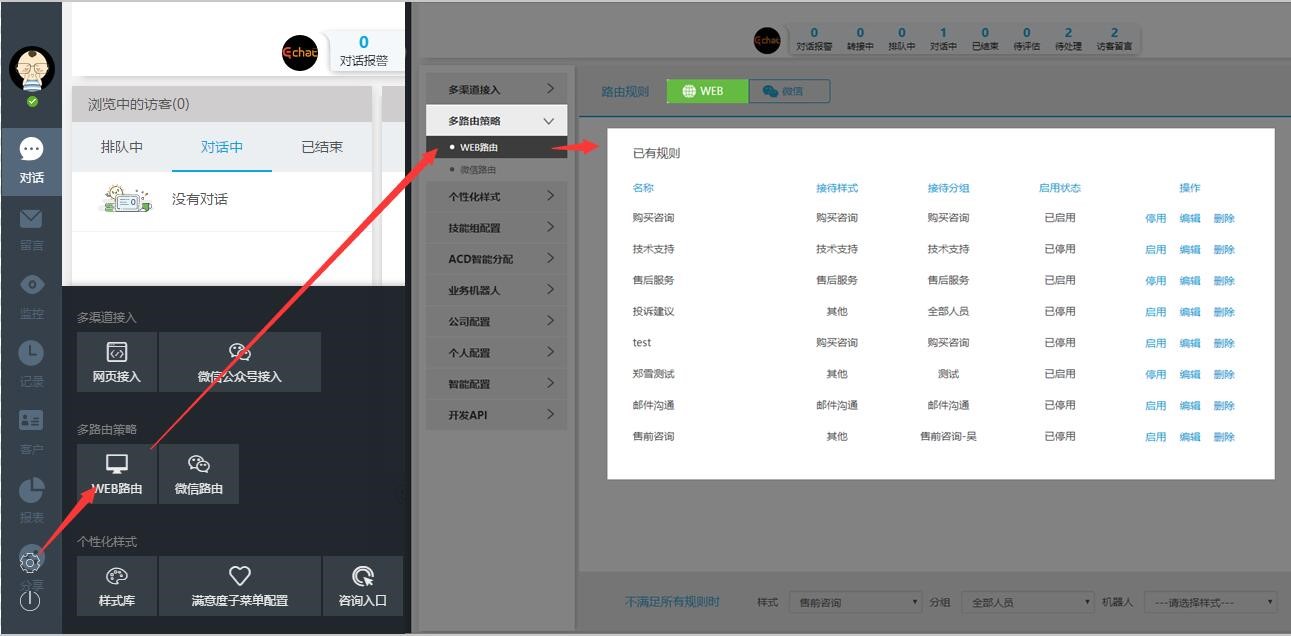
Yiqia支持多种路由策略,即通过设置不同的路由将会话分配到不同的组,展示不同的访客风格库。下面说一下具体的路由设置过程:
如下图,打开“设置”功能,找到“多路由策略”,点击“WEB路由”,就会出现创建好的路由规则。
单向路由规则的应用原理如下:
首先,我们将它命名以区分和识别它,然后设置所需的路由条件,然后选择样式和分组以接收该路由下的对话。另外,我们可以设置溢出组作为补充,因为路由条件可以设置更多,所以可以选择“单项满足”或者“全部满足”,这样设置完所有项后,配置一个路由规则完成。当一个对话框触发你设置的路由条件时,会立即使用相应的样式进行访问。前往对应的客服组(客服组内可以有一名或多名客服人员)进行接待。
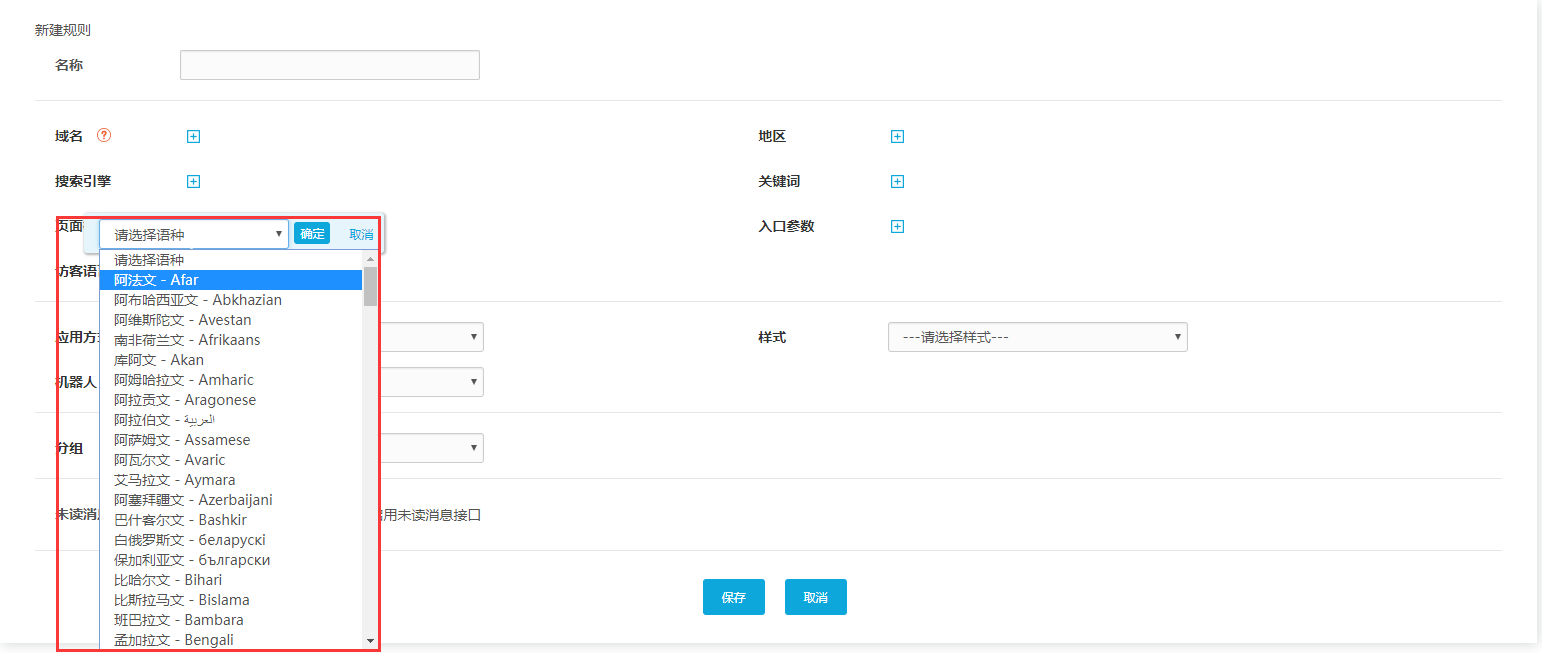
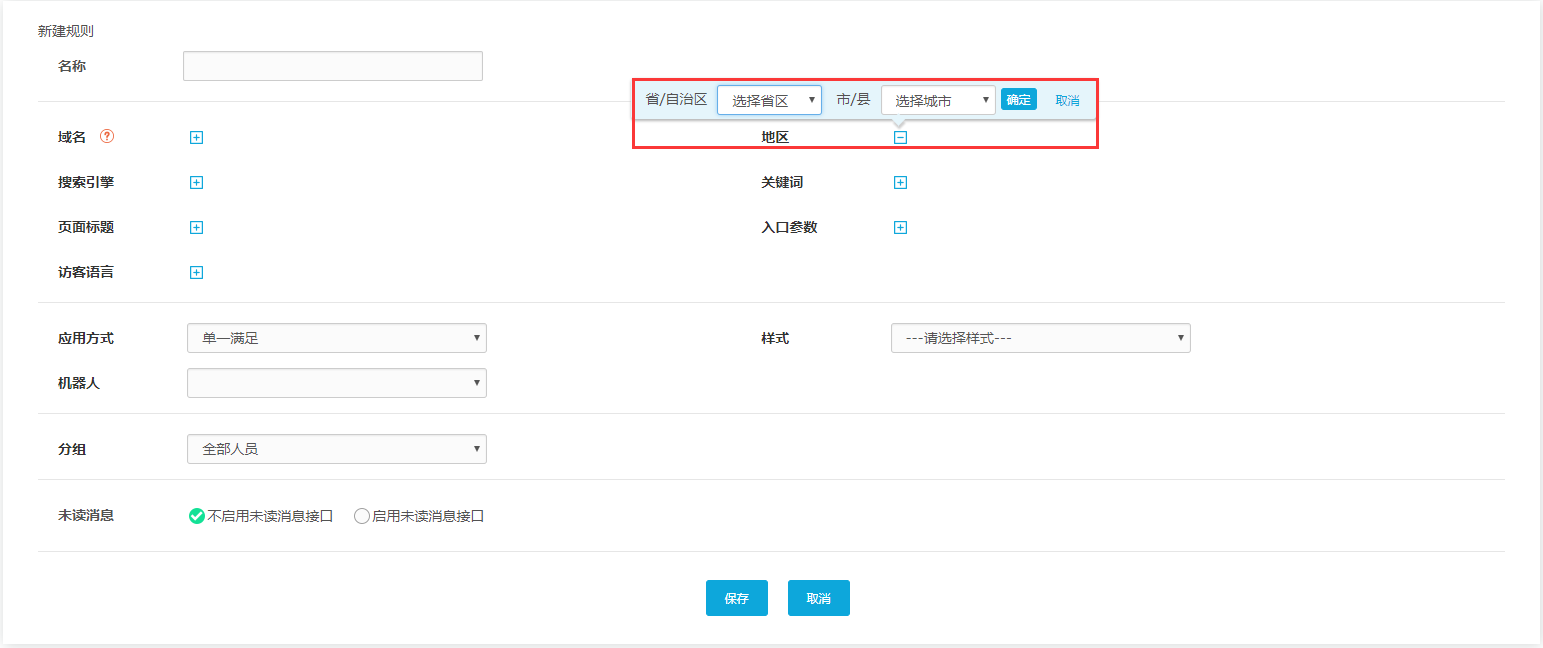
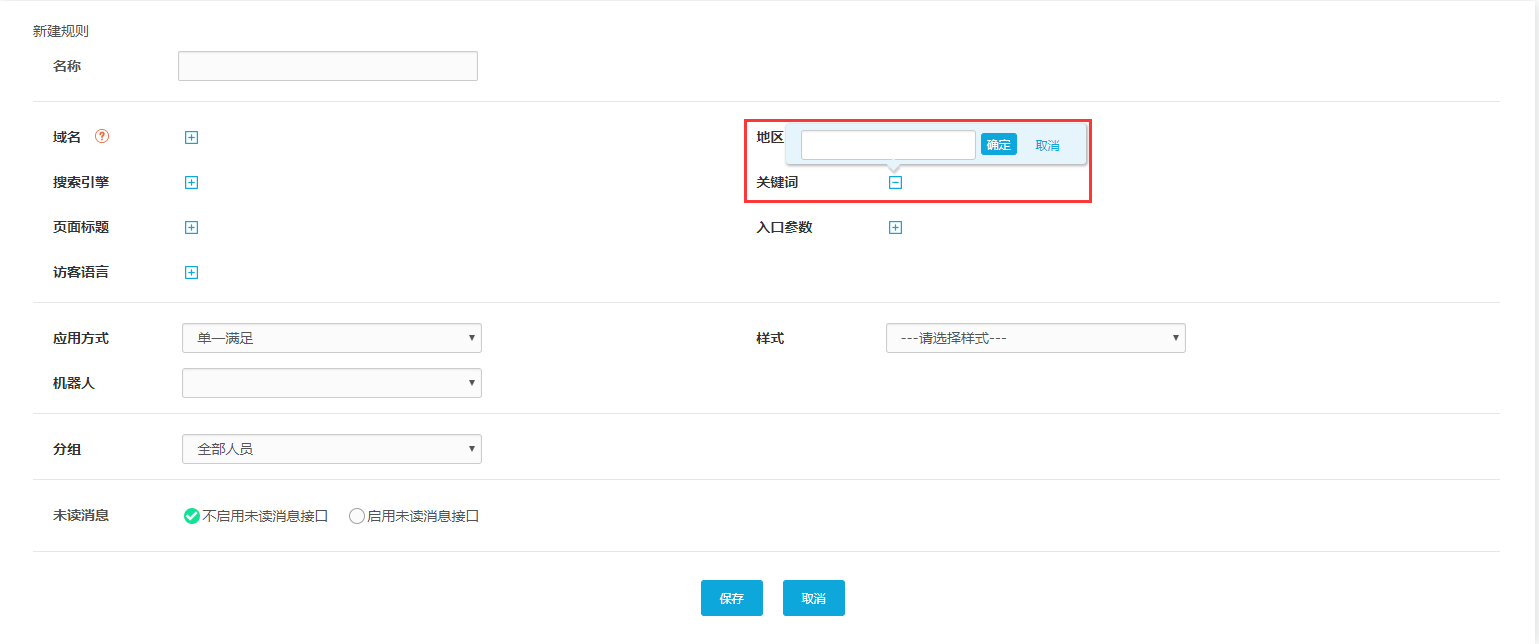
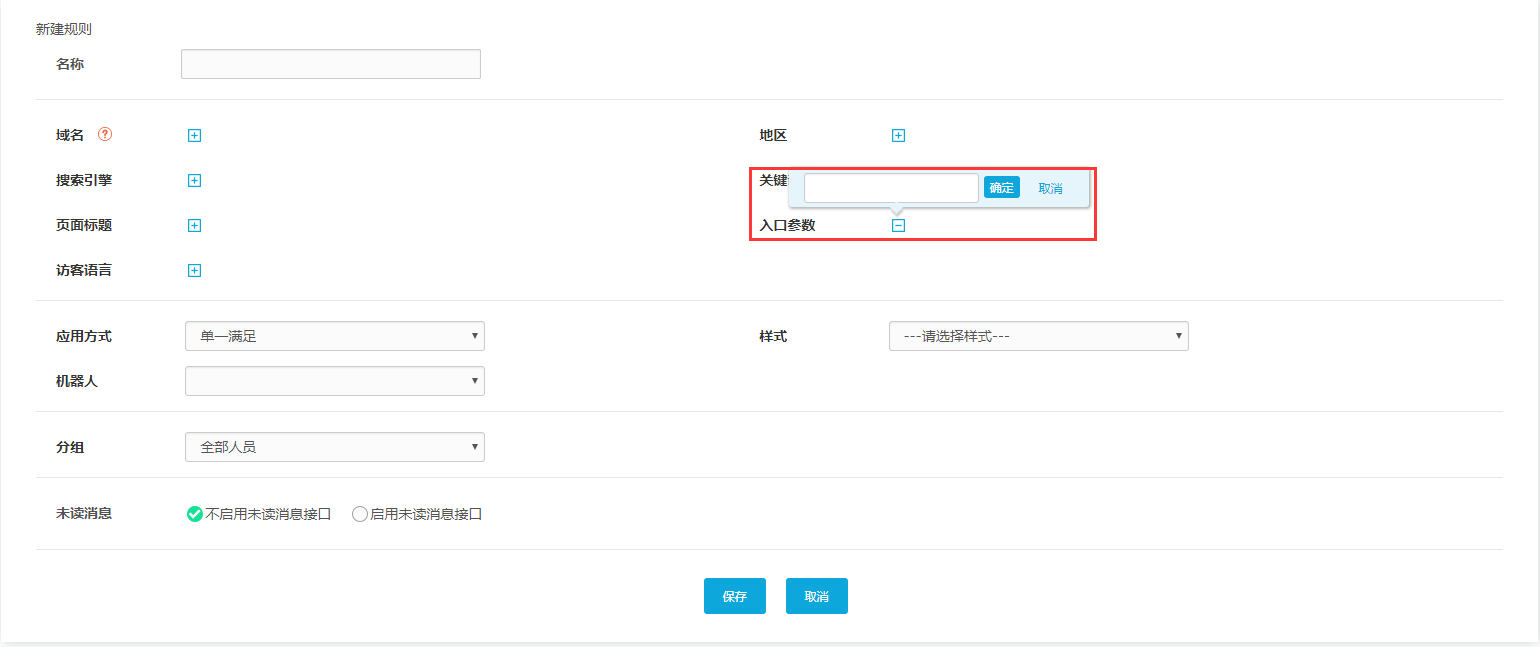
点击右上角“新建规则”,打开设置页面,如下图: 我们可以看到常用的路由条件包括域名、搜索引擎、页面、访问者语言、访问者区域、搜索关键词和入口参数(一键支持自定义参数),这些路由条件可以选择设置一个或多个。下面详细描述每个路由条件。
1、按域名
点击编辑框,输入指定的域名(可以输入多个指定的域名),那么只要根据这个域名输入的访问者被系统识别,就会触发这条路由,访问者就会连接到指定的接收组。
2、根据搜索引擎
同样点击“搜索引擎”的编辑框,下拉框中有“好搜”、“百度”、“谷歌”、“必应”等常用搜索引擎。),那么只要识别出使用所选搜索引擎进入系统的访客,就会触发这条路线,并将访客连接到指定的接待组。
3、根据页面标题
我们还可以根据访问者访问的不同页面设置路由规则。顾名思义,路由规则是根据不同的页面标题设置的。另外,点击“页面标题”后,可以在输入框中输入指定的页面标题(可以选择多个页面)。),那么只要访客进入页面,就会触发这条路由访问指定的接待组。比如在电商公司,浏览产品页面的访问者,可以由专门从事产品咨询的技能组接待,如果浏览售后服务页面,则可以由专门从事产品咨询的技术组接待。促销过后。
4、按访客语言
根据访问者使用的浏览器的首选语言设置路由规则。点击“访客语言”后,编辑框中可以显示多种语言。选择对应的语言(可以选择多种语言),那么只要访问者的浏览器操作该路由选择的系统语言就会被识别。当然,也可以在网站上嵌入代码时指定语言。触发此路由的访问者将自动访问指定的语言。如果相应地设置了接待方式,就可以向访问者显示相应语言的界面和文字。
5、按地区
在“区域”的编辑框中有“省/自治区”和“市/县”的下拉框,可以选择指定的“省/自治区”或“市/县”(可以多个区域selected),则如果来自所选区域的访客将被识别并在进入系统时触发该路线,并将其分配到指定的接待组。如果相应地设置接收方式,则可以显示该区域的产品广告图像。
6、根据关键词
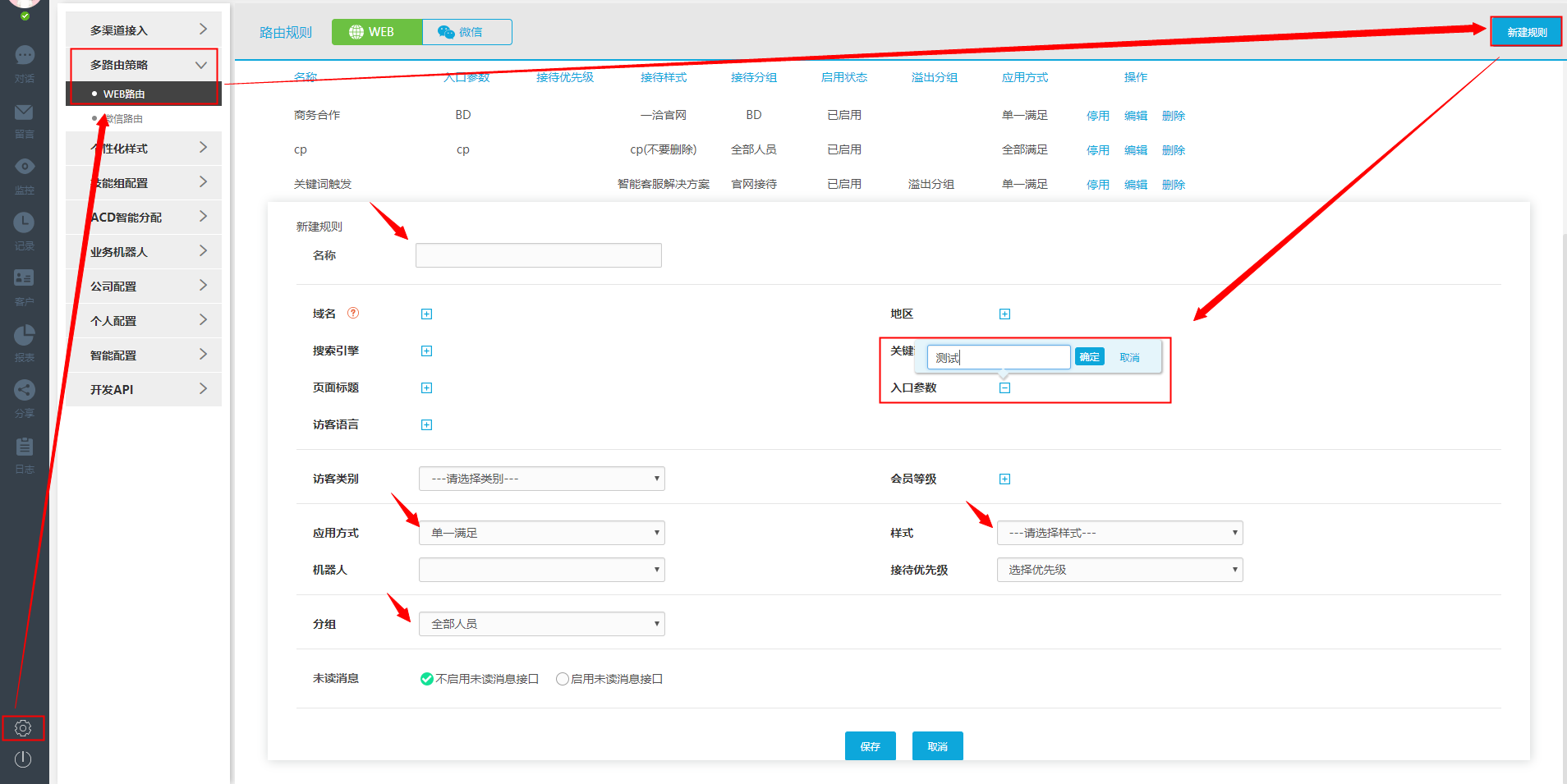
根据访问者搜索到的关键词设置路由规则,在“关键词”的编辑框中输入多个关键词,然后通过搜索相关的关键词输入网站@ > 访客将被系统识别并触发此路由,并进入指定的客服组。
7、根据入口参数:常用
“入口参数”可由企业自定义。先创建入口参数,然后在编辑框中填写相关参数(可以填写多个入口参数),那么只要触发入口参数的访问者对话框就会访问到这里指定的一个路由的接待组. 例如,企业可以自由设置参数,为进入网站30s的访客自动打开对话窗口等。入口参数的设置给了企业很大的自由度。这是目前企业使用最多的,因为定义简单方便。
例如:
下面以设置路由参数为例,说明如何创建路由和组织代码:
自定义参数路由,需要我们自己设置参数并获取代码。此操作方法将在此详细说明。
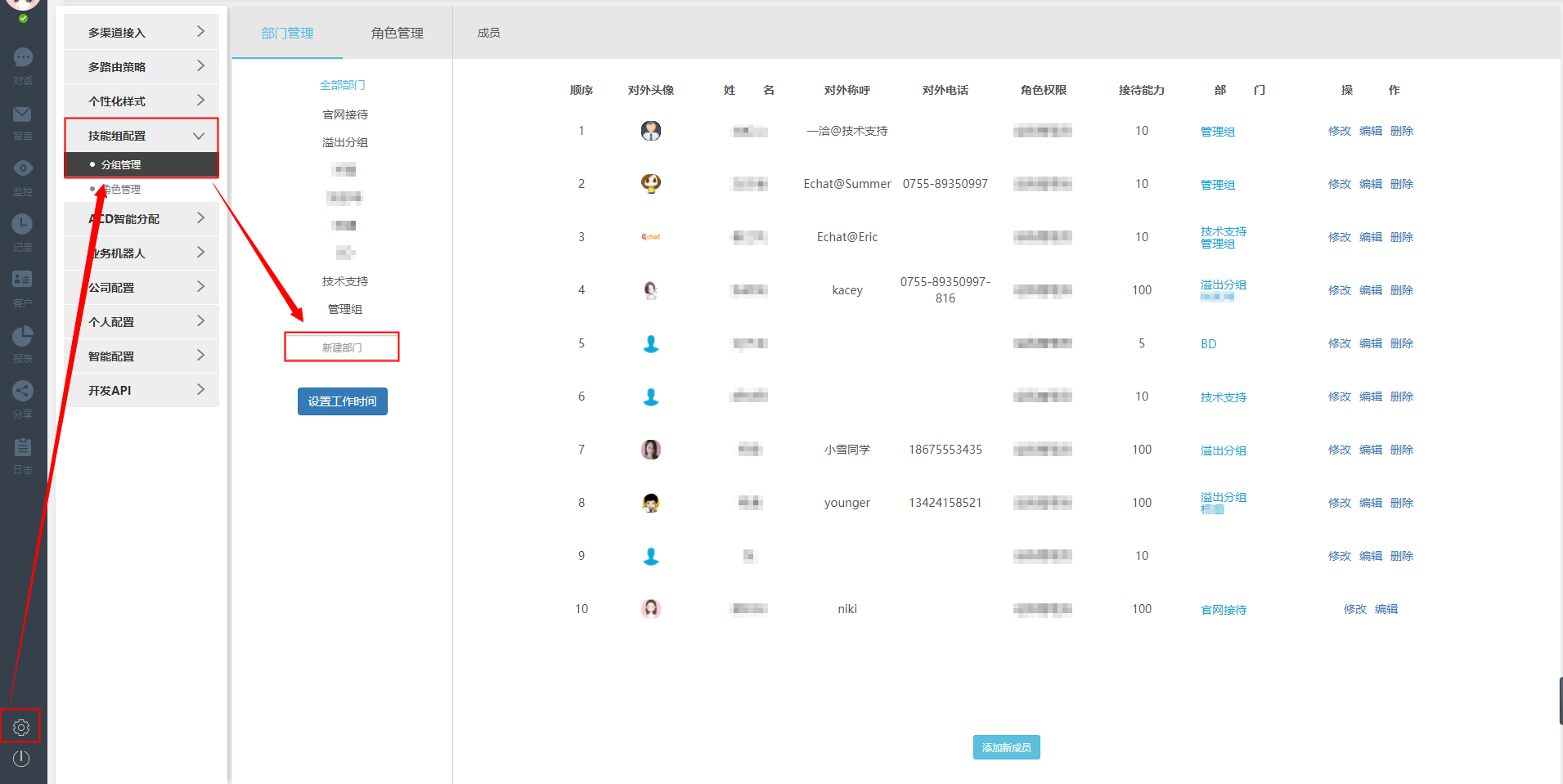
1、首先我们需要进入“技能组配置”菜单创建一个用于接收的组。
2、然后,进入“Multi-Routing Policy”菜单新建一个路由规则并随意命名,设置入口参数(如下图,我设置了一个入口参数名为“Test”) ,然后设置所需的接收组样式和接收,完成后单击“保存”。
ps:参数建议使用拼音或英文,避免浏览器或手机翻译中文
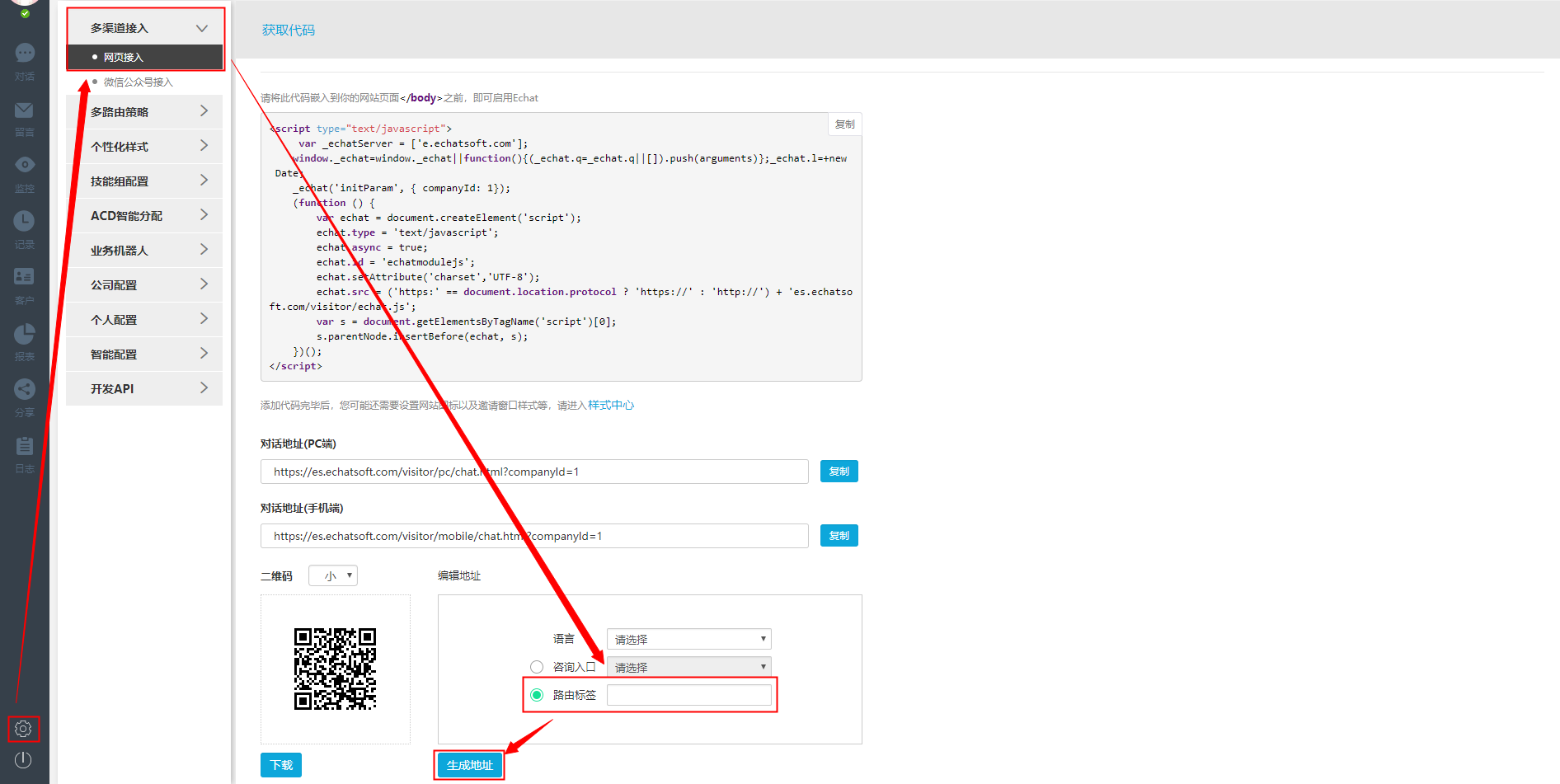
3、之后,进入“多通道接入”菜单,如下图,选择“路由标签”填写创建路由时设置的入口参数,必须与路由中的参数,然后点击“生成地址”。
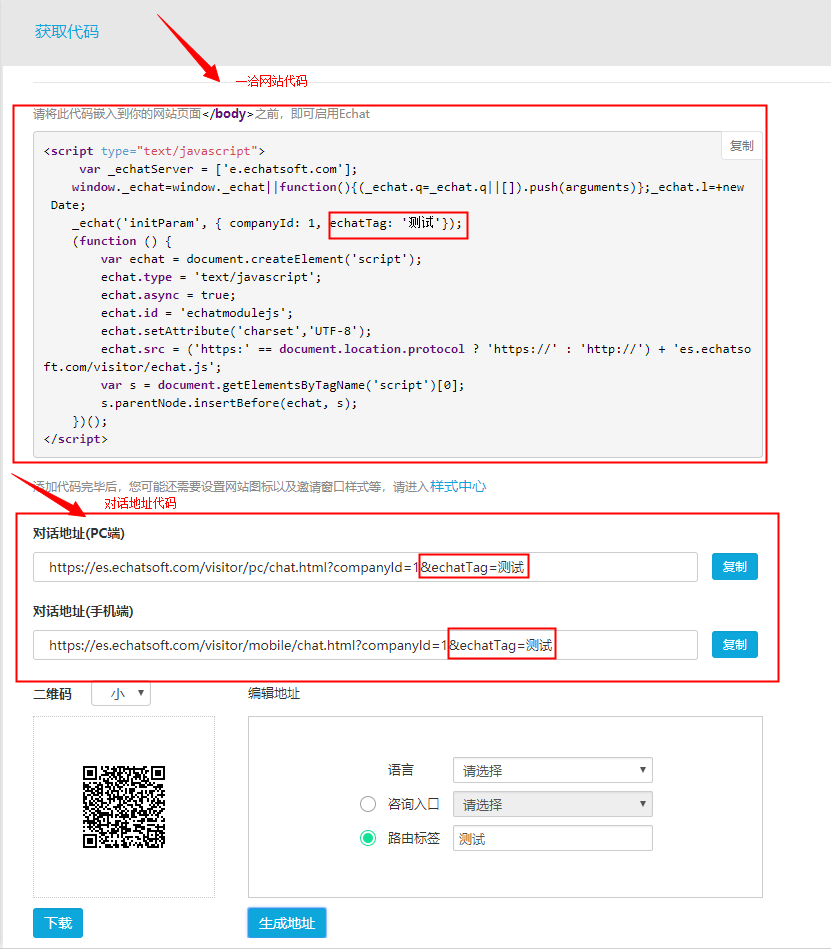
4、生成的效果如下图所示。代码中已经生成了我设置的名为“Test”的路由参数,包括一千的网站代码和一千的对话地址的代码。
5、如果添加的频道无法添加系统js或者浏览时不需要识别访客信息,可以直接复制上图的对话地址。
6、如果网站想自定义咨询按钮,还需要识别正在浏览网站的访问者,将JS代码添加到网站,然后根据我们的对接文档调用系统js。具体文件见:
智能客服系统 查看全部
在线抓取网页(
一洽路由规则的应用原理是什么?如何设置多个路由)
客服系统功能介绍-网页代码获取及具体路由规则
Yiqia支持多种路由策略,即通过设置不同的路由将会话分配到不同的组,展示不同的访客风格库。下面说一下具体的路由设置过程:
如下图,打开“设置”功能,找到“多路由策略”,点击“WEB路由”,就会出现创建好的路由规则。
单向路由规则的应用原理如下:
首先,我们将它命名以区分和识别它,然后设置所需的路由条件,然后选择样式和分组以接收该路由下的对话。另外,我们可以设置溢出组作为补充,因为路由条件可以设置更多,所以可以选择“单项满足”或者“全部满足”,这样设置完所有项后,配置一个路由规则完成。当一个对话框触发你设置的路由条件时,会立即使用相应的样式进行访问。前往对应的客服组(客服组内可以有一名或多名客服人员)进行接待。
点击右上角“新建规则”,打开设置页面,如下图: 我们可以看到常用的路由条件包括域名、搜索引擎、页面、访问者语言、访问者区域、搜索关键词和入口参数(一键支持自定义参数),这些路由条件可以选择设置一个或多个。下面详细描述每个路由条件。
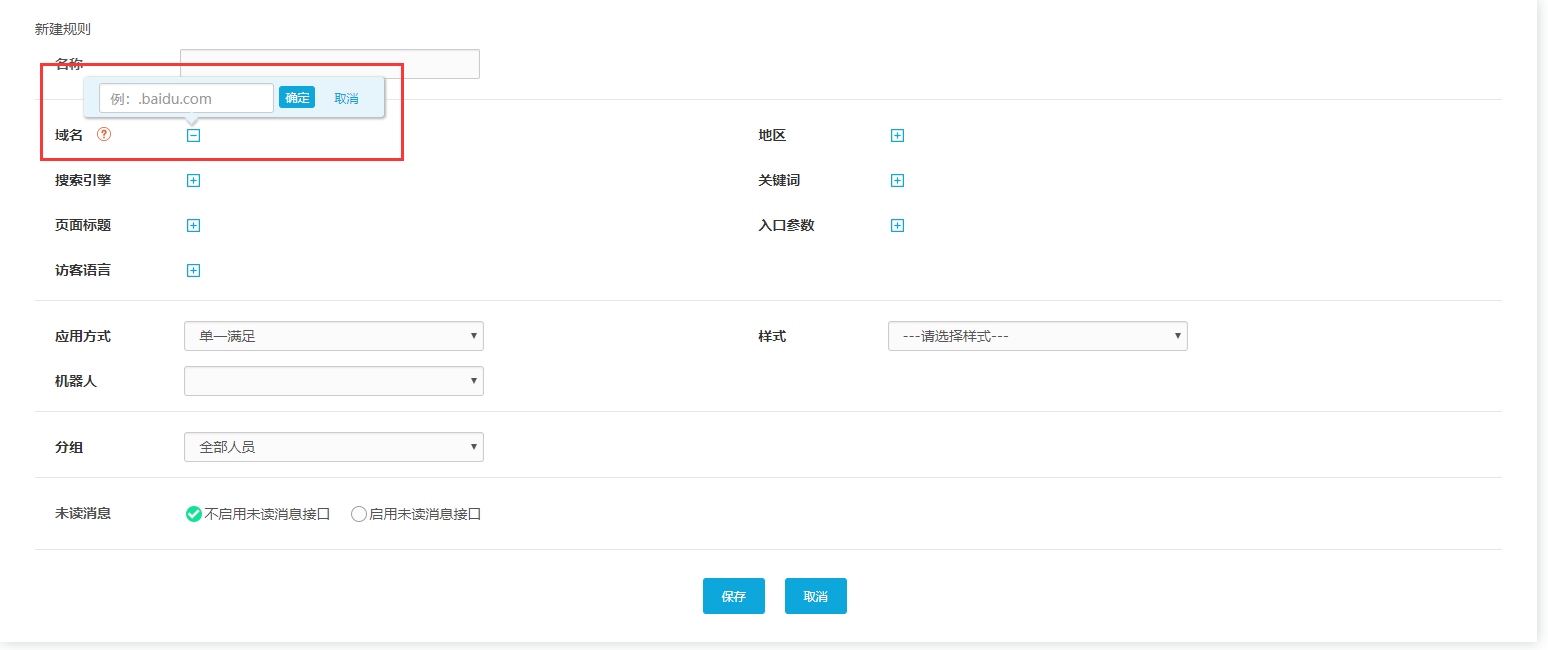
1、按域名
点击编辑框,输入指定的域名(可以输入多个指定的域名),那么只要根据这个域名输入的访问者被系统识别,就会触发这条路由,访问者就会连接到指定的接收组。
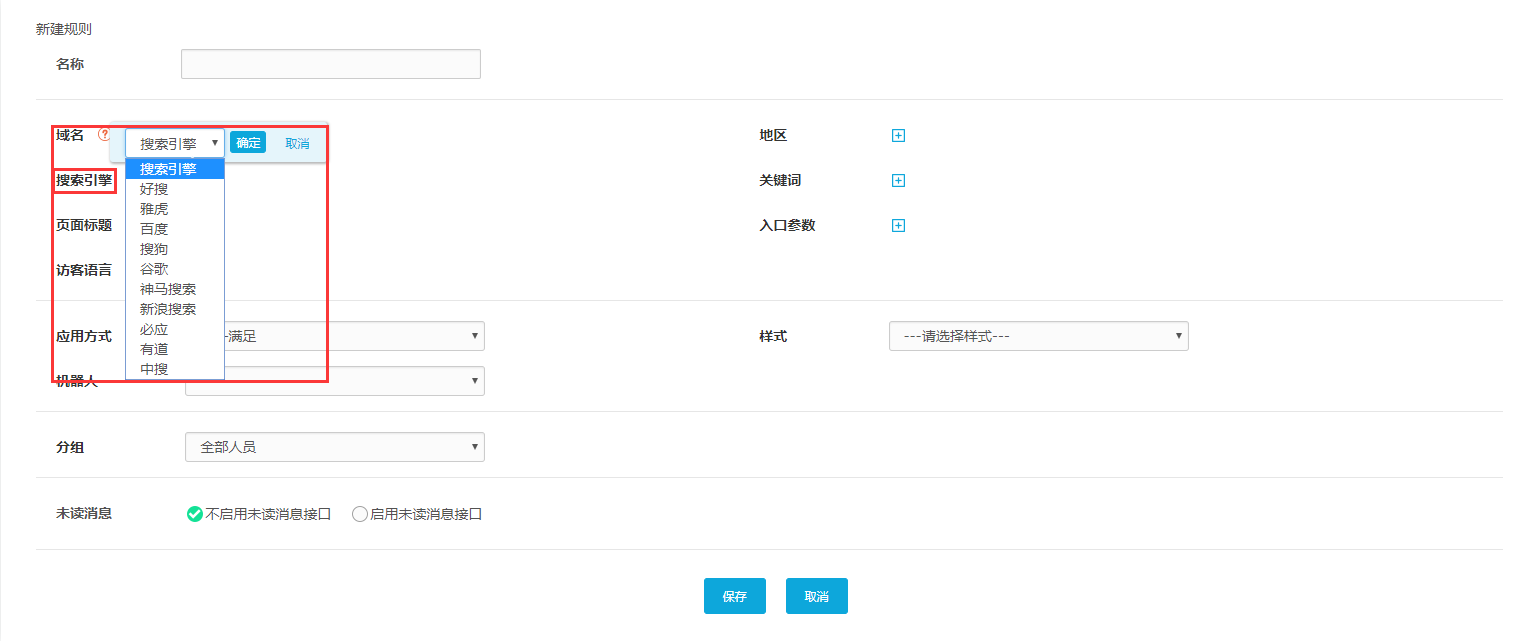
2、根据搜索引擎
同样点击“搜索引擎”的编辑框,下拉框中有“好搜”、“百度”、“谷歌”、“必应”等常用搜索引擎。),那么只要识别出使用所选搜索引擎进入系统的访客,就会触发这条路线,并将访客连接到指定的接待组。
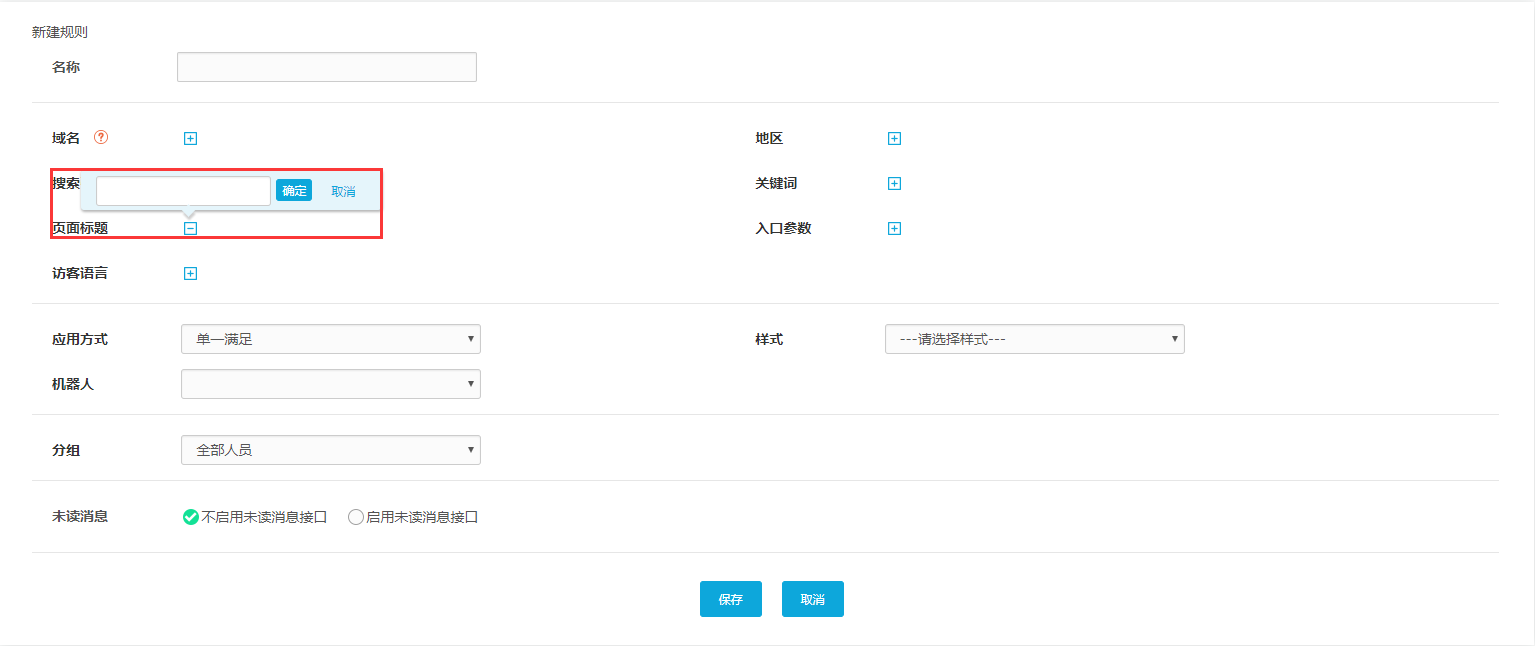
3、根据页面标题
我们还可以根据访问者访问的不同页面设置路由规则。顾名思义,路由规则是根据不同的页面标题设置的。另外,点击“页面标题”后,可以在输入框中输入指定的页面标题(可以选择多个页面)。),那么只要访客进入页面,就会触发这条路由访问指定的接待组。比如在电商公司,浏览产品页面的访问者,可以由专门从事产品咨询的技能组接待,如果浏览售后服务页面,则可以由专门从事产品咨询的技术组接待。促销过后。
4、按访客语言
根据访问者使用的浏览器的首选语言设置路由规则。点击“访客语言”后,编辑框中可以显示多种语言。选择对应的语言(可以选择多种语言),那么只要访问者的浏览器操作该路由选择的系统语言就会被识别。当然,也可以在网站上嵌入代码时指定语言。触发此路由的访问者将自动访问指定的语言。如果相应地设置了接待方式,就可以向访问者显示相应语言的界面和文字。
5、按地区
在“区域”的编辑框中有“省/自治区”和“市/县”的下拉框,可以选择指定的“省/自治区”或“市/县”(可以多个区域selected),则如果来自所选区域的访客将被识别并在进入系统时触发该路线,并将其分配到指定的接待组。如果相应地设置接收方式,则可以显示该区域的产品广告图像。
6、根据关键词
根据访问者搜索到的关键词设置路由规则,在“关键词”的编辑框中输入多个关键词,然后通过搜索相关的关键词输入网站@ > 访客将被系统识别并触发此路由,并进入指定的客服组。
7、根据入口参数:常用
“入口参数”可由企业自定义。先创建入口参数,然后在编辑框中填写相关参数(可以填写多个入口参数),那么只要触发入口参数的访问者对话框就会访问到这里指定的一个路由的接待组. 例如,企业可以自由设置参数,为进入网站30s的访客自动打开对话窗口等。入口参数的设置给了企业很大的自由度。这是目前企业使用最多的,因为定义简单方便。
例如:
下面以设置路由参数为例,说明如何创建路由和组织代码:
自定义参数路由,需要我们自己设置参数并获取代码。此操作方法将在此详细说明。
1、首先我们需要进入“技能组配置”菜单创建一个用于接收的组。
2、然后,进入“Multi-Routing Policy”菜单新建一个路由规则并随意命名,设置入口参数(如下图,我设置了一个入口参数名为“Test”) ,然后设置所需的接收组样式和接收,完成后单击“保存”。
ps:参数建议使用拼音或英文,避免浏览器或手机翻译中文
3、之后,进入“多通道接入”菜单,如下图,选择“路由标签”填写创建路由时设置的入口参数,必须与路由中的参数,然后点击“生成地址”。
4、生成的效果如下图所示。代码中已经生成了我设置的名为“Test”的路由参数,包括一千的网站代码和一千的对话地址的代码。
5、如果添加的频道无法添加系统js或者浏览时不需要识别访客信息,可以直接复制上图的对话地址。
6、如果网站想自定义咨询按钮,还需要识别正在浏览网站的访问者,将JS代码添加到网站,然后根据我们的对接文档调用系统js。具体文件见:
智能客服系统
在线抓取网页(网页文字抓取,(详细如图)什么是老域名?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 71 次浏览 • 2022-04-20 05:26
网页文字抓取,相信很多小伙伴都遇到过文章网页禁止复制,今天给大家分享一款免费的网页文字抓取工具,只需要输入链接即可提取网站 text,自动保存本地化并保留文本排版!还自带采集+伪原创功能+发布功能。 (详细图片)
什么是旧域名?从字面上看,可以理解为一个已经使用了几年的过时域名,但是域名注册后并不是用来建网站的,所以这样的域名不是旧域名,而是通常提交或注册。未注册的域名当然有不同的价格,但是对于SEO新手来说,基本没有这个概念。
注册一个好的老域名完全有利于优化网站的排名,所以会继承以下指标;
①权重继承
一个好的老域名会继承网站本身的权重,有利于网站快速收录,节省不必要的外部资源时间,但还是要注意尝试使用网站相关内容创作。
②无沙盒期
作为SEO的朋友,你应该知道,对于百度搜索引擎来说,任何新注册的域名,如果不注意,肯定会出现在沙盒期。平台上的时间认可直接通过信任获得。只要继续优化,就不会出现所谓的沙盒期。
③易换链
作为SEO人员,我们都知道一个新的网站很难交换友情链接。因为没有基础,很难找到更好的网站建立合作关系,但老域名不同。它继承了前一个 网站 的所有权重。友情链接交换还会有困难吗?
nofollow 属性是 HTML 页面中 A 标签的属性值。该属性的含义是通知搜索引擎不要关注该特定链接,并通知搜索引擎该链接不受作者信任。使用nofollow的目的是为了指示搜索引擎不要抓取网页上任何具有nofollow属性的站点链接,以减少渣链接,分散网站的权重。简单来说就是搜索引擎看到属性后不会或者降低链接的投票权重,也就是说这个链接不是我推荐的。不要给他我的重量,因为每个网页都有重量。是的,不要将我的权重发送到此连接。
nofollow属性的含义和用法
它的应用方法一般是常用的写法,写在某个标签的属性中,比如A标签之后。给链接添加nofollow后,当搜索引擎第一次发现该链接时,还是会把它放到待爬取的url队列中,也会被爬取。不代表加nofollow就不会被抓,如果被抓,也能被抓,只是不传递权重。
这里需要注意一件事。官方关于nofollow属性的声明表示,最终结果是否会被传输取决于链接对用户是否有价值。这句话是什么意思?如果站长加了nofollow的属性,我绝对不会把权重发到这个链接的。我仍然可以发送它。我是否会发送它取决于用户。对于用户来说,这个链接有价值吗?如何判断是否有价值?我估计百度一定有一个方法来计算用户点击百分比,类似这个方法判断链接对用户是否有价值,然后决定是否给链接赋予权重,怎么说呢,比如,对于比如我写了一篇文章关于东莞SEO文章的文章,然后在下面放了百度站长平台的链接。
nofollow属性的含义和用法
我的网站是东莞SEO,我不是百度站长平台的,但是我在某个页面放了一个百度站长平台的链接,然后在这个链接上加nofollow,说不要关注这个链接不是我推荐的,不要把我的重量推给他。结果有100个用户来阅读,超过50%的用户点击了这个链接,然后跳转到百度站长平台。这种情况,用百度很容易判断。一定要超过一定的门槛,而且超过了他设定的一定的门槛。我们不知道他设置了多少?
是否明显超过了 50%?是还是不是? 50% 的人点击,然后澄清链接是有意义的,对用户有价值。然后我的页面会把权重发送进去,通过站长平台的链接发送进去。其实我已经设置了nofollow,但是没用。这是官方声明的解释。所以大家一定要正确认识自己能不能旅行,什么时候适合用nofollow,那些不参与竞争排名的页面。什么是非竞争性排名页面?比如我们的登录页面、注册页面、投诉举报页面,这些页面不参与竞争排名。
他肯定不会参与的,比如说登录页面,用户怎么会去百度搜索登录页面,对吧?他不可能说出搜索和登录两个字。即使他搜索登录一词,他也可能会询问有关登录要求或其他内容的问题,并且无论如何他都不会跳出我们的页面。所以这些页面,我们登录注册投诉举报这些页面,都是不参与竞争排名的页面。对于这样的链接,我们都将使用 nofollow 属性。比如我的主页上有一个带有登录链接的按钮,点击一下就会跳转到登录页面。
那如果用了这个链接,我肯定会在后面加上no follow属性,别把我主页的权重发给他,这个页面没用。我没有推荐它。那么,第二种可以使用的场景,也就是一个页面显示多个重复链接的时候,一般来说同一个页面不会显示几个相同的页面链接,但是并没有排除一些特殊的原因。导致我们在一个页面上放置了很多重复的、重复的链接,可能是老板要求的,也可能是开发者要求的,或者其他原因,如果有重复。除了第一个,其他几个重复的链接我们建议添加nofollow。返回搜狐,查看更多 查看全部
在线抓取网页(网页文字抓取,(详细如图)什么是老域名?)
网页文字抓取,相信很多小伙伴都遇到过文章网页禁止复制,今天给大家分享一款免费的网页文字抓取工具,只需要输入链接即可提取网站 text,自动保存本地化并保留文本排版!还自带采集+伪原创功能+发布功能。 (详细图片)
什么是旧域名?从字面上看,可以理解为一个已经使用了几年的过时域名,但是域名注册后并不是用来建网站的,所以这样的域名不是旧域名,而是通常提交或注册。未注册的域名当然有不同的价格,但是对于SEO新手来说,基本没有这个概念。
注册一个好的老域名完全有利于优化网站的排名,所以会继承以下指标;
①权重继承
一个好的老域名会继承网站本身的权重,有利于网站快速收录,节省不必要的外部资源时间,但还是要注意尝试使用网站相关内容创作。
②无沙盒期
作为SEO的朋友,你应该知道,对于百度搜索引擎来说,任何新注册的域名,如果不注意,肯定会出现在沙盒期。平台上的时间认可直接通过信任获得。只要继续优化,就不会出现所谓的沙盒期。
③易换链
作为SEO人员,我们都知道一个新的网站很难交换友情链接。因为没有基础,很难找到更好的网站建立合作关系,但老域名不同。它继承了前一个 网站 的所有权重。友情链接交换还会有困难吗?
nofollow 属性是 HTML 页面中 A 标签的属性值。该属性的含义是通知搜索引擎不要关注该特定链接,并通知搜索引擎该链接不受作者信任。使用nofollow的目的是为了指示搜索引擎不要抓取网页上任何具有nofollow属性的站点链接,以减少渣链接,分散网站的权重。简单来说就是搜索引擎看到属性后不会或者降低链接的投票权重,也就是说这个链接不是我推荐的。不要给他我的重量,因为每个网页都有重量。是的,不要将我的权重发送到此连接。
nofollow属性的含义和用法
它的应用方法一般是常用的写法,写在某个标签的属性中,比如A标签之后。给链接添加nofollow后,当搜索引擎第一次发现该链接时,还是会把它放到待爬取的url队列中,也会被爬取。不代表加nofollow就不会被抓,如果被抓,也能被抓,只是不传递权重。
这里需要注意一件事。官方关于nofollow属性的声明表示,最终结果是否会被传输取决于链接对用户是否有价值。这句话是什么意思?如果站长加了nofollow的属性,我绝对不会把权重发到这个链接的。我仍然可以发送它。我是否会发送它取决于用户。对于用户来说,这个链接有价值吗?如何判断是否有价值?我估计百度一定有一个方法来计算用户点击百分比,类似这个方法判断链接对用户是否有价值,然后决定是否给链接赋予权重,怎么说呢,比如,对于比如我写了一篇文章关于东莞SEO文章的文章,然后在下面放了百度站长平台的链接。
nofollow属性的含义和用法
我的网站是东莞SEO,我不是百度站长平台的,但是我在某个页面放了一个百度站长平台的链接,然后在这个链接上加nofollow,说不要关注这个链接不是我推荐的,不要把我的重量推给他。结果有100个用户来阅读,超过50%的用户点击了这个链接,然后跳转到百度站长平台。这种情况,用百度很容易判断。一定要超过一定的门槛,而且超过了他设定的一定的门槛。我们不知道他设置了多少?
是否明显超过了 50%?是还是不是? 50% 的人点击,然后澄清链接是有意义的,对用户有价值。然后我的页面会把权重发送进去,通过站长平台的链接发送进去。其实我已经设置了nofollow,但是没用。这是官方声明的解释。所以大家一定要正确认识自己能不能旅行,什么时候适合用nofollow,那些不参与竞争排名的页面。什么是非竞争性排名页面?比如我们的登录页面、注册页面、投诉举报页面,这些页面不参与竞争排名。
他肯定不会参与的,比如说登录页面,用户怎么会去百度搜索登录页面,对吧?他不可能说出搜索和登录两个字。即使他搜索登录一词,他也可能会询问有关登录要求或其他内容的问题,并且无论如何他都不会跳出我们的页面。所以这些页面,我们登录注册投诉举报这些页面,都是不参与竞争排名的页面。对于这样的链接,我们都将使用 nofollow 属性。比如我的主页上有一个带有登录链接的按钮,点击一下就会跳转到登录页面。
那如果用了这个链接,我肯定会在后面加上no follow属性,别把我主页的权重发给他,这个页面没用。我没有推荐它。那么,第二种可以使用的场景,也就是一个页面显示多个重复链接的时候,一般来说同一个页面不会显示几个相同的页面链接,但是并没有排除一些特殊的原因。导致我们在一个页面上放置了很多重复的、重复的链接,可能是老板要求的,也可能是开发者要求的,或者其他原因,如果有重复。除了第一个,其他几个重复的链接我们建议添加nofollow。返回搜狐,查看更多
在线抓取网页( Python主要有网络爬虫,网络开发,人工智能自动化自动化运维)
网站优化 • 优采云 发表了文章 • 0 个评论 • 260 次浏览 • 2022-04-13 17:03
Python主要有网络爬虫,网络开发,人工智能自动化自动化运维)
在学习 Python 之前,我们需要了解 Python 的用途以及学习它能给我们带来什么?
Python主要包括网络爬虫、网页开发、人工智能、自动化运维
这里我们主要看一下网络爬虫,什么是网络爬虫?
网络爬虫,又称网络蜘蛛,是指一种脚本程序,它按照一定的规则在网络上爬取想要的内容。
众所周知,每个网页通常都收录其他网页的入口,网络爬虫通过一个URL访问其他网址,获取想要的内容。
爬行动物有什么用?
做垂直搜索引擎
科学研究:在线人类行为、在线社区进化、人类动力学研究、定量社会学、复杂网络
数据挖掘等领域的实证研究需要大量数据,网络爬虫是采集相关数据的有力工具
偷窥、黑客攻击、垃圾邮件......
爬行是搜索引擎的第一步,也是最简单的一步。
为什么 Python 现在最流行?
相比其他静态编程语言,如java、c#、c++、Python,爬取网页文档的界面更加简洁,
与其他动态脚本语言相比,如perl、shell和Python的urllib2包,它提供了更完善的访问web文档的API。
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。
这时候我们就需要模拟用户代理的行为来构造合适的请求,比如模拟用户登录,模拟session/cookies的存储和设置,Python中有优秀的第三方包可以帮助你,比如作为请求,机械化
爬取后处理
抓取的网页通常需要进行处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用非常短的代码完成大部分的文档处理。 查看全部
在线抓取网页(
Python主要有网络爬虫,网络开发,人工智能自动化自动化运维)
在学习 Python 之前,我们需要了解 Python 的用途以及学习它能给我们带来什么?
Python主要包括网络爬虫、网页开发、人工智能、自动化运维
这里我们主要看一下网络爬虫,什么是网络爬虫?
网络爬虫,又称网络蜘蛛,是指一种脚本程序,它按照一定的规则在网络上爬取想要的内容。
众所周知,每个网页通常都收录其他网页的入口,网络爬虫通过一个URL访问其他网址,获取想要的内容。
爬行动物有什么用?
做垂直搜索引擎
科学研究:在线人类行为、在线社区进化、人类动力学研究、定量社会学、复杂网络
数据挖掘等领域的实证研究需要大量数据,网络爬虫是采集相关数据的有力工具
偷窥、黑客攻击、垃圾邮件......
爬行是搜索引擎的第一步,也是最简单的一步。
为什么 Python 现在最流行?
相比其他静态编程语言,如java、c#、c++、Python,爬取网页文档的界面更加简洁,
与其他动态脚本语言相比,如perl、shell和Python的urllib2包,它提供了更完善的访问web文档的API。
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。
这时候我们就需要模拟用户代理的行为来构造合适的请求,比如模拟用户登录,模拟session/cookies的存储和设置,Python中有优秀的第三方包可以帮助你,比如作为请求,机械化
爬取后处理
抓取的网页通常需要进行处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用非常短的代码完成大部分的文档处理。
在线抓取网页(WebScraper安装过程在线安装需要具有可FQ网络(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 314 次浏览 • 2022-04-06 21:24
Web Scraper 是一款面向普通用户(无需专业 IT 技能)的免费爬虫工具,通过鼠标和简单的配置即可轻松获取您想要的数据。例如知乎答案列表网页抓取工具、微博热门、微博评论、电子商务网站产品信息、博客文章列表等。
安装过程
在线安装方式
在线安装需要启用 FQ 的网络并访问 Chrome App Store
1、在线访问 web Scraper 插件并单击“添加到 CHROME”。
请输入图片描述
2、然后在弹出的窗口中点击“添加扩展”
请输入图片描述
3、安装完成后,在顶部工具栏中显示 Web Scraper 图标。
请输入图片描述
本地安装
1、打开Chrome,在地址栏输入chrome://extensions/,进入扩展管理界面,然后下载下载的扩展Web-Scraper_v0.3.7. crx拖放到这个页面,点击“添加到扩展”完成安装。如图所示:
请输入图片描述
2、安装完成后,在顶部工具栏中显示 Web Scraper 图标。
${{2}}$
请输入图片描述
了解网络爬虫
打开网络抓取工具
开发者可以路过,回头看看
windows系统下可以使用快捷键F12,部分型号的笔记本需要按Fn+F12;
Mac系统下,可以使用快捷键command+option+i;
也可以直接在Chrome界面操作,点击设置->更多工具->开发者工具
请输入图片描述
打开后的效果如下。绿框部分是开发者工具的完整界面,红框部分是Web Scraper区域,也就是我们后面要操作的部分。
请输入图片描述
注意:如果在浏览器右侧区域打开开发者工具,需要将开发者工具的位置调整到浏览器底部。
请输入图片描述
原理及功能说明
数据爬取的思路大致可以简单概括如下:
1、通过一个或多个入口地址获取初始数据。比如一个 文章 列表页,或者一个带有某种规则的页面,比如一个带有分页的列表页;
2、根据入口页面的某些信息,如链接指向,进入下一级页面获取必要信息;
3、根据上一关的链接,继续进入下一关,获取必要的信息(此步骤可无限循环进行);
原理大致相同。接下来我们正式认识一下Web Scraper这个工具。来吧,打开开发者工具,点击Web Scraper选项卡,看到它分为三个部分:
请输入图片描述
创建新的sitemap:首先了解sitemap,字面意思是网站map,这里可以理解为一个入口地址,可以理解为它对应一个网站,对应一个需求,假设你想在 知乎 上回答问题,创建一个站点地图,并将问题的地址设置为站点地图的起始 URL,然后点击“创建站点地图”创建站点地图。
请输入图片描述
站点地图:站点地图的集合,所有创建的站点地图都会显示在这里,您可以在这里输入站点地图来修改和获取数据。
请输入图片描述
站点地图:进入站点地图,可以进行一系列操作,如下图:
请输入图片描述
添加新选择器的红框部分是必不可少的步骤。什么是选择器,字面意思:选择器,一个选择器对应网页上的一部分区域,也就是收录我们要采集的数据的部分。
需要说明的是,一个站点地图下可以有多个选择器,每个选择器可以收录子选择器。一个选择器可以只对应一个标题或整个区域。该区域可能收录标题、副标题、作者信息、内容等和其他信息。
选择器:查看所有选择器。
选择器图:查看当前站点地图的拓扑图,什么是根节点,收录几个选择器,以及选择器下收录的子选择器。
编辑元数据:您可以修改站点地图信息、标题和起始地址。
刮:开始数据刮工作。
将数据导出为 CSV:以 CSV 格式导出捕获的数据。
至此,有一个简单的了解就足够了。只有实践了真知,具体的操作案例才能令人信服。下面举几个例子来说明具体用法。
案例实践
简单试水hao123
由浅入深,先从最简单的例子开始,只是为了进一步了解Web Scraper服务
需求背景:见下文hao123页面红框部分。我们的要求是统计这个区域中所有网站的名字和链接地址,最后生成到Excel中。因为这部分内容足够简单,当然实际的需求可能比这更复杂,而且手动统计这么几条数据的时间也很快。
请输入图片描述
开始
1、假设我们已经打开了hao123页面,打开该页面底部的开发者工具,找到Web Scraper标签栏;
2、点击“创建站点地图”;
请输入图片描述
3、 然后输入站点地图名称和起始网址。名字只是为了方便我们标记,所以命名为hao123(注意不支持中文),起始url是hao123的网址,然后点击create sitemap;
请输入图片描述
4、Web Scraper 自动定位到这个站点地图后,我们添加一个选择器,点击“添加新选择器”;
请输入图片描述
5、首先给选择器分配一个id,这只是一个方便识别的名字。我在这里把它命名为热。因为要获取名称和链接,所以将Type设置为Link,这是专门为网页链接准备的。选择链接类型后,会自动提取名称和链接两个属性;
请输入图片描述
6、之后点击选择,然后我们在网页上移动光标,我们会发现光标的颜色会发生变化,变成绿色,说明是当前选中的区域我们。我们将光标定位到需求中提到的栏目中的一个链接,比如第一条头条新闻,点击这里,这部分会变红,说明已经被选中,我们的目的是选中有多个,所以选中后这个,继续选择第二个,我们会发现这一行的链接都变成了红色,没错,这就是我们想要的效果。然后点击“Done selection!”(数据预览是选中元素的标识,可以手动修改,元素由类和元素名决定,如:div.p_name a),最后不要忘记检查多个,
请输入图片描述
7、最后保存,保存选择器。点击元素预览可以预览选中的区域,点击数据预览可以在浏览器中预览截取的数据。后面文本框中的内容对于懂技术的同学来说是很清楚的。这是xpath。我们可以不用鼠标操作直接写xpath;
完整的操作流程如下:
请输入图片描述
8、经过上一步,就可以真正导出了。别着急,看看其他操作,Sitemap hao123下的Selector图,可以看到拓扑图,_root是根选择器,创建sitemap会自动有一个_root节点,可以看到它的子选择器,即我们是否创建了热选择器;
请输入图片描述
9、Scrape 开始抓取数据。
10、在Sitemap hao123下浏览,可以通过浏览器直接查看爬取的最终结果,需要重新;
请输入图片描述
11、最后使用Export data as CSV,以CSV格式导出,其中hot栏为标题,hot-href栏为链接;
请输入图片描述
怎么样,马上试试
软件定制 | 网站 建设 | 获得更多干货 查看全部
在线抓取网页(WebScraper安装过程在线安装需要具有可FQ网络(组图))
Web Scraper 是一款面向普通用户(无需专业 IT 技能)的免费爬虫工具,通过鼠标和简单的配置即可轻松获取您想要的数据。例如知乎答案列表网页抓取工具、微博热门、微博评论、电子商务网站产品信息、博客文章列表等。
安装过程
在线安装方式
在线安装需要启用 FQ 的网络并访问 Chrome App Store
1、在线访问 web Scraper 插件并单击“添加到 CHROME”。
请输入图片描述
2、然后在弹出的窗口中点击“添加扩展”
请输入图片描述
3、安装完成后,在顶部工具栏中显示 Web Scraper 图标。
请输入图片描述
本地安装
1、打开Chrome,在地址栏输入chrome://extensions/,进入扩展管理界面,然后下载下载的扩展Web-Scraper_v0.3.7. crx拖放到这个页面,点击“添加到扩展”完成安装。如图所示:
请输入图片描述
2、安装完成后,在顶部工具栏中显示 Web Scraper 图标。
${{2}}$
请输入图片描述
了解网络爬虫
打开网络抓取工具
开发者可以路过,回头看看
windows系统下可以使用快捷键F12,部分型号的笔记本需要按Fn+F12;
Mac系统下,可以使用快捷键command+option+i;
也可以直接在Chrome界面操作,点击设置->更多工具->开发者工具
请输入图片描述
打开后的效果如下。绿框部分是开发者工具的完整界面,红框部分是Web Scraper区域,也就是我们后面要操作的部分。
请输入图片描述
注意:如果在浏览器右侧区域打开开发者工具,需要将开发者工具的位置调整到浏览器底部。
请输入图片描述
原理及功能说明
数据爬取的思路大致可以简单概括如下:
1、通过一个或多个入口地址获取初始数据。比如一个 文章 列表页,或者一个带有某种规则的页面,比如一个带有分页的列表页;
2、根据入口页面的某些信息,如链接指向,进入下一级页面获取必要信息;
3、根据上一关的链接,继续进入下一关,获取必要的信息(此步骤可无限循环进行);
原理大致相同。接下来我们正式认识一下Web Scraper这个工具。来吧,打开开发者工具,点击Web Scraper选项卡,看到它分为三个部分:
请输入图片描述
创建新的sitemap:首先了解sitemap,字面意思是网站map,这里可以理解为一个入口地址,可以理解为它对应一个网站,对应一个需求,假设你想在 知乎 上回答问题,创建一个站点地图,并将问题的地址设置为站点地图的起始 URL,然后点击“创建站点地图”创建站点地图。
请输入图片描述
站点地图:站点地图的集合,所有创建的站点地图都会显示在这里,您可以在这里输入站点地图来修改和获取数据。
请输入图片描述
站点地图:进入站点地图,可以进行一系列操作,如下图:
请输入图片描述
添加新选择器的红框部分是必不可少的步骤。什么是选择器,字面意思:选择器,一个选择器对应网页上的一部分区域,也就是收录我们要采集的数据的部分。
需要说明的是,一个站点地图下可以有多个选择器,每个选择器可以收录子选择器。一个选择器可以只对应一个标题或整个区域。该区域可能收录标题、副标题、作者信息、内容等和其他信息。
选择器:查看所有选择器。
选择器图:查看当前站点地图的拓扑图,什么是根节点,收录几个选择器,以及选择器下收录的子选择器。
编辑元数据:您可以修改站点地图信息、标题和起始地址。
刮:开始数据刮工作。
将数据导出为 CSV:以 CSV 格式导出捕获的数据。
至此,有一个简单的了解就足够了。只有实践了真知,具体的操作案例才能令人信服。下面举几个例子来说明具体用法。
案例实践
简单试水hao123
由浅入深,先从最简单的例子开始,只是为了进一步了解Web Scraper服务
需求背景:见下文hao123页面红框部分。我们的要求是统计这个区域中所有网站的名字和链接地址,最后生成到Excel中。因为这部分内容足够简单,当然实际的需求可能比这更复杂,而且手动统计这么几条数据的时间也很快。
请输入图片描述
开始
1、假设我们已经打开了hao123页面,打开该页面底部的开发者工具,找到Web Scraper标签栏;
2、点击“创建站点地图”;
请输入图片描述
3、 然后输入站点地图名称和起始网址。名字只是为了方便我们标记,所以命名为hao123(注意不支持中文),起始url是hao123的网址,然后点击create sitemap;
请输入图片描述
4、Web Scraper 自动定位到这个站点地图后,我们添加一个选择器,点击“添加新选择器”;
请输入图片描述
5、首先给选择器分配一个id,这只是一个方便识别的名字。我在这里把它命名为热。因为要获取名称和链接,所以将Type设置为Link,这是专门为网页链接准备的。选择链接类型后,会自动提取名称和链接两个属性;
请输入图片描述
6、之后点击选择,然后我们在网页上移动光标,我们会发现光标的颜色会发生变化,变成绿色,说明是当前选中的区域我们。我们将光标定位到需求中提到的栏目中的一个链接,比如第一条头条新闻,点击这里,这部分会变红,说明已经被选中,我们的目的是选中有多个,所以选中后这个,继续选择第二个,我们会发现这一行的链接都变成了红色,没错,这就是我们想要的效果。然后点击“Done selection!”(数据预览是选中元素的标识,可以手动修改,元素由类和元素名决定,如:div.p_name a),最后不要忘记检查多个,
请输入图片描述
7、最后保存,保存选择器。点击元素预览可以预览选中的区域,点击数据预览可以在浏览器中预览截取的数据。后面文本框中的内容对于懂技术的同学来说是很清楚的。这是xpath。我们可以不用鼠标操作直接写xpath;
完整的操作流程如下:
请输入图片描述
8、经过上一步,就可以真正导出了。别着急,看看其他操作,Sitemap hao123下的Selector图,可以看到拓扑图,_root是根选择器,创建sitemap会自动有一个_root节点,可以看到它的子选择器,即我们是否创建了热选择器;
请输入图片描述
9、Scrape 开始抓取数据。
10、在Sitemap hao123下浏览,可以通过浏览器直接查看爬取的最终结果,需要重新;
请输入图片描述
11、最后使用Export data as CSV,以CSV格式导出,其中hot栏为标题,hot-href栏为链接;
请输入图片描述
怎么样,马上试试
软件定制 | 网站 建设 | 获得更多干货
在线抓取网页(国外网站无法自由获取信息,交流增多,鸟儿折断翅膀有什么区别?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-04-03 23:11
比如打开一个国外朋友发的网页,IE会提示“网页无法显示,你要找的页面目前不可用。”并不是说有问题国外的网站,不过就是有人担心我们年轻的心灵被“污染”,从而封闭了通往外界的路。国外网站无法自由获取信息,交流增多,和渴望自由的鸟折断翅膀有什么区别?
方法还是有的,常用的有通过web代理、代理服务器、代理工具等。
先说一下,也就是通过web代理设置最简单实用的方法:
一、打开浏览器菜单、工具、网络选项:
第 2 步,单击连接,然后单击 LAN 设置:
第三步,在局域网中标记“代理服务器”,在地址栏和端口栏中标记“代理服务器”。
代理服务器通常采用以下形式: IP 地址:端口(例如 210.10.55.226:8080)
按照如下填写模板,然后点击确定,就大功告成了。
300+城市动态和静态ip服务,每天更新免费ip,登录官网免费获取5000ip,手机ip,游戏ip,电脑ip,各种ip服务等,支持免费测试:
拼一HTTP-爬虫代理IP-千万动态HTTP代理IP/?utm-source=qie&utm-keyword=?0015/?utm-source=qie&utm-keyword=?0015
300+城市动态和静态ip服务,每天更新免费ip,登录官网免费获取5000ip,手机ip,游戏ip,电脑ip,各种ip服务等,支持免费测试:
拼一HTTP-爬虫代理IP-千万动态HTTP代理IP/?utm-source=qie&utm-keyword=?0015 查看全部
在线抓取网页(国外网站无法自由获取信息,交流增多,鸟儿折断翅膀有什么区别?)
比如打开一个国外朋友发的网页,IE会提示“网页无法显示,你要找的页面目前不可用。”并不是说有问题国外的网站,不过就是有人担心我们年轻的心灵被“污染”,从而封闭了通往外界的路。国外网站无法自由获取信息,交流增多,和渴望自由的鸟折断翅膀有什么区别?
方法还是有的,常用的有通过web代理、代理服务器、代理工具等。
先说一下,也就是通过web代理设置最简单实用的方法:
一、打开浏览器菜单、工具、网络选项:
第 2 步,单击连接,然后单击 LAN 设置:
第三步,在局域网中标记“代理服务器”,在地址栏和端口栏中标记“代理服务器”。
代理服务器通常采用以下形式: IP 地址:端口(例如 210.10.55.226:8080)
按照如下填写模板,然后点击确定,就大功告成了。
300+城市动态和静态ip服务,每天更新免费ip,登录官网免费获取5000ip,手机ip,游戏ip,电脑ip,各种ip服务等,支持免费测试:
拼一HTTP-爬虫代理IP-千万动态HTTP代理IP/?utm-source=qie&utm-keyword=?0015/?utm-source=qie&utm-keyword=?0015
300+城市动态和静态ip服务,每天更新免费ip,登录官网免费获取5000ip,手机ip,游戏ip,电脑ip,各种ip服务等,支持免费测试:
拼一HTTP-爬虫代理IP-千万动态HTTP代理IP/?utm-source=qie&utm-keyword=?0015
在线抓取网页(603999.SH读者传媒:2017年年度报告获取网页pdf下载地址 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-04-03 21:09
)
任务:批量抓取网页pdf文件
有一个收录数千个指向 pdf 下载链接的网页地址的 excel。现在,需要批量抓取这些网页地址中的pdf文件。
蟒蛇环境:
蟒蛇3
打开pyxl
beautifulsoup4读取excel并获取网页地址
使用 openpyxl 库读取 .xslx 文件;
(尝试使用 xlrd 库读取 .xsl 文件,但无法获取超链接)
安装 openpyxl
pip install openpyxl
提取 xslx 文件中的超链接
示例文件构建
公告日期 证券代码 公告标题
2018-04-20
603999.SH
读者媒体:2017年年报
2018-04-28
603998.SH
方生药业:2017年年报
def readxlsx(path):
workbook = openpyxl.load_workbook(path)
Data_sheet = workbook.get_sheet_by_name('sheet1')
rowNum = Data_sheet.max_row #读取最大行数
c = 3 # 第三列是所需要提取的数据
server = 'http://news.windin.com/ns/'
for row in range(1, rowNum + 1):
link = Data_sheet.cell(row=row, column=c).value
url = re.split(r'\"', link)[1]
print(url)
downEachPdf(url, server)
获取网页的pdf下载地址
进入读者传媒:2017年报,可以在chrome浏览器中按F12查看网页源代码,以下截取部分源代码:
附件: <a href=[getatt.php?id=91785868&att_id=32276645](http://news.windin.com/ns/geta ... 276645) class='big' title=603999读者传媒2017年年度报告.pdf>603999读者传媒2017年年度报告.pdf </a> (2.00M)  
可以看出herf下载链接在a标签中,通过解析html源码可以得到下载链接。
这里使用 BeautifulSoup 来解析 html。
Beautiful Soup 是一个用 Python 编写的 HTML/XML 解析器,可以很好地处理非标准标记并生成解析树。它提供了用于导航、搜索和修改解析树的简单而常用的操作。它可以大大节省您的编程时间。安装 BeautifulSoup4
pip install beautifulsoup4
获取pdf下载链接并下载
def downEachPdf(target, server):
req = requests.get(url=target)
html = req.text
bf = BeautifulSoup(html, features="lxml")
a = bf.find_all('a')
for each in a:
url = server + each.get('href')
print("downloading:", each.string, url)
urllib.request.urlretrieve(url, './report/' + each.string)
同一ip重复访问同一台服务器被拒绝
以上方法已用于网页批量下载pdf。但是在实际操作过程中会发现,如果同一个ip频繁访问某台服务器,访问会被拒绝(可能被误判为DOS攻击,通常做Rate -limit 网站会停止响应一段时间,可以Catch这个Exception并休眠一段时间,供参考)。因此,下载逻辑进行了调整。
使用try-catch,具体逻辑是:正常情况下,文件是按顺序下载的。如果同一个文件下载失败次数超过10次,则跳过,下载下一个文件,并记录错误信息。
import os
import time
def downloadXml(flag_exists, file_dir, file_name, xml_url):
if not flag_exists:
os.makedirs(file_dir)
local = os.path.join(file_dir, file_name)
try:
urllib.request.urlretrieve(xml_url, local)
except Exception as e:
print('the first error: ', e)
cur_try = 0
total_try = 10
if cur_try < total_try:
cur_try += 1
time.sleep(15)
return downloadXml(flag_exists, file_dir, file_name, xml_url)
else:
print('the last error: ')
with open(test_dir + 'error_url.txt', 'a') as f:
f.write(xml_url)
raise Exception(e) 查看全部
在线抓取网页(603999.SH读者传媒:2017年年度报告获取网页pdf下载地址
)
任务:批量抓取网页pdf文件
有一个收录数千个指向 pdf 下载链接的网页地址的 excel。现在,需要批量抓取这些网页地址中的pdf文件。
蟒蛇环境:
蟒蛇3
打开pyxl
beautifulsoup4读取excel并获取网页地址
使用 openpyxl 库读取 .xslx 文件;
(尝试使用 xlrd 库读取 .xsl 文件,但无法获取超链接)
安装 openpyxl
pip install openpyxl
提取 xslx 文件中的超链接
示例文件构建
公告日期 证券代码 公告标题
2018-04-20
603999.SH
读者媒体:2017年年报
2018-04-28
603998.SH
方生药业:2017年年报
def readxlsx(path):
workbook = openpyxl.load_workbook(path)
Data_sheet = workbook.get_sheet_by_name('sheet1')
rowNum = Data_sheet.max_row #读取最大行数
c = 3 # 第三列是所需要提取的数据
server = 'http://news.windin.com/ns/'
for row in range(1, rowNum + 1):
link = Data_sheet.cell(row=row, column=c).value
url = re.split(r'\"', link)[1]
print(url)
downEachPdf(url, server)
获取网页的pdf下载地址
进入读者传媒:2017年报,可以在chrome浏览器中按F12查看网页源代码,以下截取部分源代码:
附件: <a href=[getatt.php?id=91785868&att_id=32276645](http://news.windin.com/ns/geta ... 276645) class='big' title=603999读者传媒2017年年度报告.pdf>603999读者传媒2017年年度报告.pdf </a> (2.00M)  
可以看出herf下载链接在a标签中,通过解析html源码可以得到下载链接。
这里使用 BeautifulSoup 来解析 html。
Beautiful Soup 是一个用 Python 编写的 HTML/XML 解析器,可以很好地处理非标准标记并生成解析树。它提供了用于导航、搜索和修改解析树的简单而常用的操作。它可以大大节省您的编程时间。安装 BeautifulSoup4
pip install beautifulsoup4
获取pdf下载链接并下载
def downEachPdf(target, server):
req = requests.get(url=target)
html = req.text
bf = BeautifulSoup(html, features="lxml")
a = bf.find_all('a')
for each in a:
url = server + each.get('href')
print("downloading:", each.string, url)
urllib.request.urlretrieve(url, './report/' + each.string)
同一ip重复访问同一台服务器被拒绝
以上方法已用于网页批量下载pdf。但是在实际操作过程中会发现,如果同一个ip频繁访问某台服务器,访问会被拒绝(可能被误判为DOS攻击,通常做Rate -limit 网站会停止响应一段时间,可以Catch这个Exception并休眠一段时间,供参考)。因此,下载逻辑进行了调整。
使用try-catch,具体逻辑是:正常情况下,文件是按顺序下载的。如果同一个文件下载失败次数超过10次,则跳过,下载下一个文件,并记录错误信息。
import os
import time
def downloadXml(flag_exists, file_dir, file_name, xml_url):
if not flag_exists:
os.makedirs(file_dir)
local = os.path.join(file_dir, file_name)
try:
urllib.request.urlretrieve(xml_url, local)
except Exception as e:
print('the first error: ', e)
cur_try = 0
total_try = 10
if cur_try < total_try:
cur_try += 1
time.sleep(15)
return downloadXml(flag_exists, file_dir, file_name, xml_url)
else:
print('the last error: ')
with open(test_dir + 'error_url.txt', 'a') as f:
f.write(xml_url)
raise Exception(e)
在线抓取网页(TextCapture是一款功能十分强大的网络文本抓取软件(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 553 次浏览 • 2022-03-29 14:02
TextCapture 是一款功能非常强大的网络文本捕捉软件。用户只要将自己要截取的文本网页放入本软件,软件就会自动帮用户截取,并可以截取截取的文本或图片文件。转换为可编辑文本。欢迎下载试用。
TextCapture 简介:
当你在网上看到一个不错的文章,你会怎么做?
一般来说,选择文本->复制->新建文本文件->粘贴->保存,频繁操作会很麻烦,
使用 TextCapture 非常方便。在 TextCapture 中设置分类和对应的保存目录。
只需将网页中选中的文本拖到拖放图标上,TextCapture 就会自动命名并保存文件。同时,TextCapture 拥有强大的文本管理功能,让文本管理更加方便和有条理。
其实不只是网页中的文字,只要支持OLE拖拽的编辑器都可以通过拖拽保存,比如:Mircosoft word、WordPad、Adobe acrobat Reader...
TextCapture 软件特点:
1、书签评论:您可以为每篇文章文章添加评论。同时TextCapture在退出时会记住当前的阅读位置,下次阅读文章时会自动定位。
2、文件合并:多个文件可以合并为一个文件。根据设置,合并完成后可以自动删除合并后的文件;
3、采集功能:将经常阅读的文字加入采集;
4、皮肤功能:根据自己的喜好更改拖拽图标,支持Gif动画,拖拽成功时以动画形式提示;
5、自动保存:保存时根据文本内容命名文本文件,自动保存为文本文件。当文件名重复时,它会自动更改名称。TextCapture 具有强大的命名规则设置功能。您可以设置日期命名规则并自动更改名称。规则;
6、文本编辑:由于Drag出来的短文本排版比较杂乱,可以使用Textcapture自带的文本编辑器进行打字,同时可以重命名、删除等。智能排版TextCapture 的功能可以让您在最短的时间内将文本格式化成比较有组织的格式,为您后续的二次编辑提供良好的文本源。
7、声音提示:当一个拖放和自动保存工作成功完成时,会播放声音提示;
8、文本分类管理:可以根据文本内容设置保存类别、保存路径以及对应的命名方式。这样,您可以通过拖放将短文本保存到不同的目录。默认情况下,文件将保存在我的文档中; 查看全部
在线抓取网页(TextCapture是一款功能十分强大的网络文本抓取软件(图))
TextCapture 是一款功能非常强大的网络文本捕捉软件。用户只要将自己要截取的文本网页放入本软件,软件就会自动帮用户截取,并可以截取截取的文本或图片文件。转换为可编辑文本。欢迎下载试用。
TextCapture 简介:
当你在网上看到一个不错的文章,你会怎么做?
一般来说,选择文本->复制->新建文本文件->粘贴->保存,频繁操作会很麻烦,
使用 TextCapture 非常方便。在 TextCapture 中设置分类和对应的保存目录。
只需将网页中选中的文本拖到拖放图标上,TextCapture 就会自动命名并保存文件。同时,TextCapture 拥有强大的文本管理功能,让文本管理更加方便和有条理。
其实不只是网页中的文字,只要支持OLE拖拽的编辑器都可以通过拖拽保存,比如:Mircosoft word、WordPad、Adobe acrobat Reader...
TextCapture 软件特点:
1、书签评论:您可以为每篇文章文章添加评论。同时TextCapture在退出时会记住当前的阅读位置,下次阅读文章时会自动定位。
2、文件合并:多个文件可以合并为一个文件。根据设置,合并完成后可以自动删除合并后的文件;
3、采集功能:将经常阅读的文字加入采集;
4、皮肤功能:根据自己的喜好更改拖拽图标,支持Gif动画,拖拽成功时以动画形式提示;
5、自动保存:保存时根据文本内容命名文本文件,自动保存为文本文件。当文件名重复时,它会自动更改名称。TextCapture 具有强大的命名规则设置功能。您可以设置日期命名规则并自动更改名称。规则;
6、文本编辑:由于Drag出来的短文本排版比较杂乱,可以使用Textcapture自带的文本编辑器进行打字,同时可以重命名、删除等。智能排版TextCapture 的功能可以让您在最短的时间内将文本格式化成比较有组织的格式,为您后续的二次编辑提供良好的文本源。
7、声音提示:当一个拖放和自动保存工作成功完成时,会播放声音提示;
8、文本分类管理:可以根据文本内容设置保存类别、保存路径以及对应的命名方式。这样,您可以通过拖放将短文本保存到不同的目录。默认情况下,文件将保存在我的文档中;
在线抓取网页(前几天非常的好(网络爬虫基本原理二)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 297 次浏览 • 2022-03-10 20:01
前几天做数据库实验的时候,总是手动往数据库中添加少量固定数据,所以想知道如何将大量动态数据导入数据库?我在网上了解了网络爬虫,它可以帮助我们完成这项工作。关于网络爬虫的原理和基础知识,网上有很多相关的介绍。不错(网络爬虫基本原理一、网络爬虫基本原理二)。
本博客以采集博客园首页的新闻栏目为例。本例中,为了直观简单,使用MVC将采集获取的数据显示在页面上。(其实网上有很多小网站利用爬虫技术抓取自己需要的信息,然后做相应的应用)。另外,在实际爬取过程中,可以使用多线程爬取来加快采集的速度。
我们来看看博客园的首页,做相关分析:
采集 之后的结果:
爬取原理:先获取对应url页面的html内容,然后找出你要爬取的目标数据的html结构,看结构是否有某种规律性,然后用正则匹配规则,它匹配你可以 采集 稍后出来。我们可以先看一下页面的源码,可以找到新闻板块的规则:位于id="post_list"
之间
所以,我们可以得到对应的正则表达式。
"
\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*
\\s*.*)\"\\s*target=\"_blank\">(?.*).*\\s*
\\s*(?.*)\\s*
"
原理很简单,下面我给出源码:创建一个MVC空项目,然后在Controller文件下添加控制器HomeController,然后在控制器中添加视图Index
HomeController.cs 部分代码:
using System;
using System.Collections.Generic;
using System.IO;
using System.Net;
using System.Text.RegularExpressions;
using System.Web.Mvc;
namespace WebApplication1.Controllers
{
public class HomeController : Controller
{
///
/// 通过Url地址获取具体网页内容 发起一个请求获得html内容
///
///
///
public static string SendUrl(string strUrl)
{
try
{
WebRequest webRequest = WebRequest.Create(strUrl);
WebResponse webResponse = webRequest.GetResponse();
StreamReader reader = new StreamReader(webResponse.GetResponseStream());
string result = reader.ReadToEnd();
return result;
}
catch (Exception ex)
{
throw ex;
}
}
public ActionResult Index()
{
string strPattern = "\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*\\s*(?.*)</a>.*\\s*\\s*(?.*)\\s*";
List list = new List();
Regex regex = new Regex(strPattern, RegexOptions.IgnoreCase | RegexOptions.Multiline | RegexOptions.CultureInvariant);
if (regex.IsMatch(SendUrl("http://www.cnblogs.com/")))
{
MatchCollection matchCollection = regex.Matches(SendUrl("http://www.cnblogs.com/"));
foreach (Match match in matchCollection)
{
List one_list = new List();
one_list.Add(match.Groups[2].Value);//获取到的是列表数据的标题
one_list.Add(match.Groups[3].Value);//获取到的是内容
one_list.Add(match.Groups[1].Value);//获取到的是链接到的地址
list.Add(one_list);
}
}
ViewBag.list = list;
return View();
}
}
}</p>
索引视图部分代码:
@{
Layout = null;
}
Index
#customers {
font-family: "Trebuchet MS", Arial, Helvetica, sans-serif;
width: 100%;
border-collapse: collapse;
outline: #00ff00 dotted thick;
}
#customers td, #customers th {
font-size: 1em;
border: 1px solid #98bf21;
padding: 3px 7px 2px 7px;
}
#customers th {
font-size: 1.1em;
text-align: left;
padding-top: 5px;
padding-bottom: 4px;
background-color: #A7C942;
color: #ffffff;
}
标题
内容
链接
@foreach (var a in ViewBag.list)
{
int count = 0;
@foreach (string b in a)
{
if (++count == 3)
{
<a href=span style="color: rgba(128, 0, 0, 1)""/spanspan style="color: rgba(128, 0, 0, 1)"@b/spanspan style="color: rgba(128, 0, 0, 1)""/span>@HttpUtility.HtmlDecode(b)</a>@*使转义符正常输出*@
}
else if(count==1)
{
@HttpUtility.HtmlDecode(b)
}
else
{
@HttpUtility.HtmlDecode(b)
}
}
}
博客写到这里,可以运行一个完整的MVC项目,但是我只有采集一页,我们也可以在博客园首页采集下下载分页部分(即pager_buttom)
,然后添加一个方法来实现分页。这里就不贴代码了,自己试试吧。但是,如果要将信息导入数据库,则需要创建对应的表,然后根据表采集中的属性,从html中一一提取需要的对应信息,我们不应该放采集 每条新闻对应的页面源码都存入数据库,每条新闻对应的链接也要存入数据库。原因是下载大量新闻对应的页面需要大量时间,采集的效率让人印象深刻,将大量新闻页面文件存储到数据库中需要很多内存和影响数据库的性能。
我也是菜鸟,刚学不久,请各位大神指点。谢谢。不要笑。. .
太舒服的日子不一定能给人带来幸福,很可能会毁掉一个人的理想,败坏一个人的心
发布@ 2016-04-27 17:16 追求消音器阅读(158 5) 评论(3) 已编辑) 查看全部
在线抓取网页(前几天非常的好(网络爬虫基本原理二)(组图))
前几天做数据库实验的时候,总是手动往数据库中添加少量固定数据,所以想知道如何将大量动态数据导入数据库?我在网上了解了网络爬虫,它可以帮助我们完成这项工作。关于网络爬虫的原理和基础知识,网上有很多相关的介绍。不错(网络爬虫基本原理一、网络爬虫基本原理二)。
本博客以采集博客园首页的新闻栏目为例。本例中,为了直观简单,使用MVC将采集获取的数据显示在页面上。(其实网上有很多小网站利用爬虫技术抓取自己需要的信息,然后做相应的应用)。另外,在实际爬取过程中,可以使用多线程爬取来加快采集的速度。
我们来看看博客园的首页,做相关分析:
采集 之后的结果:
爬取原理:先获取对应url页面的html内容,然后找出你要爬取的目标数据的html结构,看结构是否有某种规律性,然后用正则匹配规则,它匹配你可以 采集 稍后出来。我们可以先看一下页面的源码,可以找到新闻板块的规则:位于id="post_list"
之间
所以,我们可以得到对应的正则表达式。
"
\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*
\\s*.*)\"\\s*target=\"_blank\">(?.*).*\\s*
\\s*(?.*)\\s*
"
原理很简单,下面我给出源码:创建一个MVC空项目,然后在Controller文件下添加控制器HomeController,然后在控制器中添加视图Index
HomeController.cs 部分代码:
using System;
using System.Collections.Generic;
using System.IO;
using System.Net;
using System.Text.RegularExpressions;
using System.Web.Mvc;
namespace WebApplication1.Controllers
{
public class HomeController : Controller
{
///
/// 通过Url地址获取具体网页内容 发起一个请求获得html内容
///
///
///
public static string SendUrl(string strUrl)
{
try
{
WebRequest webRequest = WebRequest.Create(strUrl);
WebResponse webResponse = webRequest.GetResponse();
StreamReader reader = new StreamReader(webResponse.GetResponseStream());
string result = reader.ReadToEnd();
return result;
}
catch (Exception ex)
{
throw ex;
}
}
public ActionResult Index()
{
string strPattern = "\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*.*\\s*\\s*(?.*)</a>.*\\s*\\s*(?.*)\\s*";
List list = new List();
Regex regex = new Regex(strPattern, RegexOptions.IgnoreCase | RegexOptions.Multiline | RegexOptions.CultureInvariant);
if (regex.IsMatch(SendUrl("http://www.cnblogs.com/";)))
{
MatchCollection matchCollection = regex.Matches(SendUrl("http://www.cnblogs.com/";));
foreach (Match match in matchCollection)
{
List one_list = new List();
one_list.Add(match.Groups[2].Value);//获取到的是列表数据的标题
one_list.Add(match.Groups[3].Value);//获取到的是内容
one_list.Add(match.Groups[1].Value);//获取到的是链接到的地址
list.Add(one_list);
}
}
ViewBag.list = list;
return View();
}
}
}</p>
索引视图部分代码:
@{
Layout = null;
}
Index
#customers {
font-family: "Trebuchet MS", Arial, Helvetica, sans-serif;
width: 100%;
border-collapse: collapse;
outline: #00ff00 dotted thick;
}
#customers td, #customers th {
font-size: 1em;
border: 1px solid #98bf21;
padding: 3px 7px 2px 7px;
}
#customers th {
font-size: 1.1em;
text-align: left;
padding-top: 5px;
padding-bottom: 4px;
background-color: #A7C942;
color: #ffffff;
}
标题
内容
链接
@foreach (var a in ViewBag.list)
{
int count = 0;
@foreach (string b in a)
{
if (++count == 3)
{
<a href=span style="color: rgba(128, 0, 0, 1)""/spanspan style="color: rgba(128, 0, 0, 1)"@b/spanspan style="color: rgba(128, 0, 0, 1)""/span>@HttpUtility.HtmlDecode(b)</a>@*使转义符正常输出*@
}
else if(count==1)
{
@HttpUtility.HtmlDecode(b)
}
else
{
@HttpUtility.HtmlDecode(b)
}
}
}
博客写到这里,可以运行一个完整的MVC项目,但是我只有采集一页,我们也可以在博客园首页采集下下载分页部分(即pager_buttom)
,然后添加一个方法来实现分页。这里就不贴代码了,自己试试吧。但是,如果要将信息导入数据库,则需要创建对应的表,然后根据表采集中的属性,从html中一一提取需要的对应信息,我们不应该放采集 每条新闻对应的页面源码都存入数据库,每条新闻对应的链接也要存入数据库。原因是下载大量新闻对应的页面需要大量时间,采集的效率让人印象深刻,将大量新闻页面文件存储到数据库中需要很多内存和影响数据库的性能。
我也是菜鸟,刚学不久,请各位大神指点。谢谢。不要笑。. .
太舒服的日子不一定能给人带来幸福,很可能会毁掉一个人的理想,败坏一个人的心
发布@ 2016-04-27 17:16 追求消音器阅读(158 5) 评论(3) 已编辑)
在线抓取网页( 竞争对手如何构建其网站,优化SEO或他们可能正在集成哪些工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-02-27 11:20
竞争对手如何构建其网站,优化SEO或他们可能正在集成哪些工具)
今天,每家企业都在数据上运行,当您在技术或网络空间中时,您需要一种快速从各个网页中抓取数据的方法。通过网页,您可以深入了解竞争对手如何构建他们的 网站、优化 SEO 或他们可能集成的工具。您还可以诊断您的 网站、分析流量并发现您可能做错了什么。当然,您需要工具来做到这一点,而 Anypicker 是技术专长有限的人的首选工具之一。
Anypicker 支持令人印象深刻的 1,300 种产品搜索,是一个智能、有效的选择,它更多的是商业而非技术。只需将 Anypicker 添加到 Chrome,您就可以通过单击从网站上抓取数据。Anypicker 无缝设置提取规则,甚至不需要您的登录信息即可工作。它与 Google 表格集成,因此您可以轻松地将数据抓取、保存、上传和解析到单独的电子表格中,以获得更直观的付款。所有数据都在您的本地计算机上处理,因此即使来自 Anypicker 的服务器,它也保持完全安全和私密。
通过终身订阅,您可以抓取多少内容没有限制,所以今天就好好利用它吧。终身订阅 Anypicker 的费用通常为 49 美元9.99 美元,但您今天只需 39 美元即可注册。在有限的时间内,使用促销代码“BFSAVE15”在结账时获得额外 15% 的折扣。 查看全部
在线抓取网页(
竞争对手如何构建其网站,优化SEO或他们可能正在集成哪些工具)
今天,每家企业都在数据上运行,当您在技术或网络空间中时,您需要一种快速从各个网页中抓取数据的方法。通过网页,您可以深入了解竞争对手如何构建他们的 网站、优化 SEO 或他们可能集成的工具。您还可以诊断您的 网站、分析流量并发现您可能做错了什么。当然,您需要工具来做到这一点,而 Anypicker 是技术专长有限的人的首选工具之一。
Anypicker 支持令人印象深刻的 1,300 种产品搜索,是一个智能、有效的选择,它更多的是商业而非技术。只需将 Anypicker 添加到 Chrome,您就可以通过单击从网站上抓取数据。Anypicker 无缝设置提取规则,甚至不需要您的登录信息即可工作。它与 Google 表格集成,因此您可以轻松地将数据抓取、保存、上传和解析到单独的电子表格中,以获得更直观的付款。所有数据都在您的本地计算机上处理,因此即使来自 Anypicker 的服务器,它也保持完全安全和私密。
通过终身订阅,您可以抓取多少内容没有限制,所以今天就好好利用它吧。终身订阅 Anypicker 的费用通常为 49 美元9.99 美元,但您今天只需 39 美元即可注册。在有限的时间内,使用促销代码“BFSAVE15”在结账时获得额外 15% 的折扣。
在线抓取网页(集搜客GooSeeker网页抓取软件与在线打码平台对接需要配置 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-02-26 14:17
)
Jisouke GooSeeker 网页抓取软件可以连接在线编码平台。如果捕获到的网站需要验证码,那么验证码会被转发到在线编码平台,GooSeeker会从编码平台返回验证码。结果会自动输入到网页上以完成编码过程。GooSeeker V5.1.0 版本支持以下功能
注意:crontab.xml 文件是 DS 打印机用于定期自动调度多个爬虫窗口的指令文件。详情请参考 GooSeeker 对该文件的说明。下面详细讲解自动登录和对接编码平台需要配置的参数。
内容
1、自动登录和自动编码所需参数
请注意:此版本的 GooSeeker 不会在登录过程中自动识别是否需要编码。如果使用以下配置参数,登录过程中必须要编码。如果您只想自动登录,请使用专用登录 crontab 命令。
下面是 crontab.xml 文件中相关指令的示例 crontab login directive.zip(点击下载示例):
2.参数说明
其他通用参数请参考《如何通过crontab程序实现周期性增量采集数据》,下面主要讲解几个特殊参数。
比如去哪里的登录页面,就可以看到如上所示的界面。此参数是 URL %3A%2F%2F%2F
就是上图中需要输入的账户名
就是上图中需要输入的密码
这是一个标准的xpath,可以用MS找个数,打开内容定位功能,在浏览器中点击账号输入框,可以在“网页结构”窗口中定位到这个输入框,点击“显示XPath”按钮,可以看到定位输入框的XPath表达式,如下
/html/body/div[position()=2]/div[position()=3]/div[position()=2]/div[position()=1]/form/div[position()=2]/div[position()=1]/input
为了能够准确定位,可以在网页中使用定位标志,即@class和@id。对于 网站 去哪里,使用定位标志后的 xpath 将是:
//div[@class='field-login']/div[contains(@class, 'username-field')]/input
可以看出它的时间短了很多,适应性也提高了很多。
类似账号输入框定位xpath
使用类似的东西,你可以得到 xpath 表达式: //div[@id='captcha']//p/img[@id='vcodeImg']
如果手动输入验证码,在这个输入框中输入你看到的字母数字,这个参数也是一个xpath
登录页面通常会显示一个突出的“登录”按钮,而这个 xpath 是用来定位该按钮的。不一定非得是网页上的按钮,也许是div,只要是用来点击的就可以。
通常,如果登录成功,会显示一个网页,上面写着“欢迎xxx”,这串文本可以作为登录成功的标志。
请自行在网站上开户充值,并在这两个参数中配置账号和密码。
3.完成爬虫调度
上面的crontab.xml只有一步登录。通常,网站登录后,只要不关闭浏览器,打开其他网页,就不需要登录。所以,使用自动登录时,有两种选择
如果您已经登录,DS 将根据 loginmark 标志直接跳过登录过程。
4. 处理记录和滥用申诉
找到爬取结果文件夹,通常在 DataScraperWorks 目录中。该目录的上级目录可以在DS计算机的菜单“文件”->“存储路径”中找到。爬网结果按主题名称存储。上面的例子主题名称是testcase_autologin_step,那么就可以找到这个文件夹了。打开后,可以看到一个子目录验证码。完整的目录结构如下
1660287210文件夹是在某个时间进行的编码对接的记录。进入该文件夹,可以看到原创验证码图片和编码平台返回的结果。如果编码平台的错误率很高,您可以使用这个记录信息联系编码平台,要求对方提高服务质量。
5、信息安全保障
如前所述,此配置文件存储在用户本地计算机上,而不是存储在 GooSeeker 云服务器上,因此上述帐号和密码不会泄露。
如有疑问,您可以或
查看全部
在线抓取网页(集搜客GooSeeker网页抓取软件与在线打码平台对接需要配置
)
Jisouke GooSeeker 网页抓取软件可以连接在线编码平台。如果捕获到的网站需要验证码,那么验证码会被转发到在线编码平台,GooSeeker会从编码平台返回验证码。结果会自动输入到网页上以完成编码过程。GooSeeker V5.1.0 版本支持以下功能
注意:crontab.xml 文件是 DS 打印机用于定期自动调度多个爬虫窗口的指令文件。详情请参考 GooSeeker 对该文件的说明。下面详细讲解自动登录和对接编码平台需要配置的参数。
内容
1、自动登录和自动编码所需参数
请注意:此版本的 GooSeeker 不会在登录过程中自动识别是否需要编码。如果使用以下配置参数,登录过程中必须要编码。如果您只想自动登录,请使用专用登录 crontab 命令。
下面是 crontab.xml 文件中相关指令的示例 crontab login directive.zip(点击下载示例):
2.参数说明
其他通用参数请参考《如何通过crontab程序实现周期性增量采集数据》,下面主要讲解几个特殊参数。
比如去哪里的登录页面,就可以看到如上所示的界面。此参数是 URL %3A%2F%2F%2F
就是上图中需要输入的账户名
就是上图中需要输入的密码
这是一个标准的xpath,可以用MS找个数,打开内容定位功能,在浏览器中点击账号输入框,可以在“网页结构”窗口中定位到这个输入框,点击“显示XPath”按钮,可以看到定位输入框的XPath表达式,如下
/html/body/div[position()=2]/div[position()=3]/div[position()=2]/div[position()=1]/form/div[position()=2]/div[position()=1]/input
为了能够准确定位,可以在网页中使用定位标志,即@class和@id。对于 网站 去哪里,使用定位标志后的 xpath 将是:
//div[@class='field-login']/div[contains(@class, 'username-field')]/input
可以看出它的时间短了很多,适应性也提高了很多。
类似账号输入框定位xpath
使用类似的东西,你可以得到 xpath 表达式: //div[@id='captcha']//p/img[@id='vcodeImg']
如果手动输入验证码,在这个输入框中输入你看到的字母数字,这个参数也是一个xpath
登录页面通常会显示一个突出的“登录”按钮,而这个 xpath 是用来定位该按钮的。不一定非得是网页上的按钮,也许是div,只要是用来点击的就可以。
通常,如果登录成功,会显示一个网页,上面写着“欢迎xxx”,这串文本可以作为登录成功的标志。
请自行在网站上开户充值,并在这两个参数中配置账号和密码。
3.完成爬虫调度
上面的crontab.xml只有一步登录。通常,网站登录后,只要不关闭浏览器,打开其他网页,就不需要登录。所以,使用自动登录时,有两种选择
如果您已经登录,DS 将根据 loginmark 标志直接跳过登录过程。
4. 处理记录和滥用申诉
找到爬取结果文件夹,通常在 DataScraperWorks 目录中。该目录的上级目录可以在DS计算机的菜单“文件”->“存储路径”中找到。爬网结果按主题名称存储。上面的例子主题名称是testcase_autologin_step,那么就可以找到这个文件夹了。打开后,可以看到一个子目录验证码。完整的目录结构如下
1660287210文件夹是在某个时间进行的编码对接的记录。进入该文件夹,可以看到原创验证码图片和编码平台返回的结果。如果编码平台的错误率很高,您可以使用这个记录信息联系编码平台,要求对方提高服务质量。
5、信息安全保障
如前所述,此配置文件存储在用户本地计算机上,而不是存储在 GooSeeker 云服务器上,因此上述帐号和密码不会泄露。
如有疑问,您可以或
在线抓取网页( Python安装Python所需要的包(二)-抓取网页数据 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-02-23 11:07
Python安装Python所需要的包(二)-抓取网页数据
)
四、抓取网页数据
点击Chrome工具栏上的HttpWatch图标,会弹出记录页面,提示HttpWatch已开始记录,请导航至网页开始记录网络流量。
例如:在浏览器地址栏中输入作者的CSDN地址进行网页抓取。
抓取的网页数据。可以详细查看不同的文件类型(js、css、gif、png 等)、所用时间、发送和接收的字节数、使用的方法、状态码、URL 地址等。
注意:部分功能在基础版中无法使用。要使用它,只能安装专业版。
五、Selenium 与 HttpWatch 结合
Selenium 进行页面功能测试时,我想获取一些信息,比如提交请求数据、接收请求数据、页面加载时间等。Selenium + HttpWatch 会是一个不错的解决方案。
HttpWatch 有一个广泛的自动化 API,允许从最流行的编程语言(C#、Ruby、Python、JavaScript 等)对其进行控制。可与 IE 的自动化测试框架如 Watir 和 Selenium 集成,以便在测试期间检测 HTTP 级别的错误和性能问题。
1、下载指定的浏览器驱动
使用Selenium控制浏览器操作时,需要先下载指定的浏览器版本驱动(如Chrome浏览器),然后放到Python安装目录的根目录下(Python环境变量已配置好)。
Chrome驱动下载地址:
将下载的chromedriver.exe复制到Python安装目录。
2、安装 Python 包
(1)安装 Selenium
pip install -U selenium
(2)安装win32com
python -m pip install pypiwin32
3、脚本代码
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# QQ群:798478386
import win32com.client
def myCheck(myUrl):
control = win32com.client.Dispatch('HttpWatch.Controller')
plugin = control.Chrome.New()
# 设置是否过滤某些条目,False为不过滤
plugin.Log.EnableFilter(False)
# 开始记录
plugin.Record()
plugin.GotoURL(myUrl)
control.Wait(plugin, -1)
# 将日志记录到一个xml文件里
logFileName = '/Users/wangmeng/Desktop/' + 'myLog' + '.xml'
plugin.Log.ExportXML(logFileName)
# 停止记录
plugin.Stop()
# 打印
print("总数: " + str(plugin.Log.Entries.Count))
for i in range(plugin.Log.Entries.Count):
print("条目: " + str(i+1))
print("URL地址: " + str(plugin.Log.Entries[i].URL))
print("所用时间: " + str(plugin.Log.Entries[i].time))
plugin.CloseBrowser()
if __name__ == '__main__':
myCheck("https://blog.csdn.net/wangmcn")
注意:HttpWatch 的某些 API 方法不能用于已安装的 HttpWatch 基础版。要使用它,必须先卸载基础版,再安装HttpWatch专业版后才能使用。
4、执行结果
(1)脚本执行后自动生成的xml文件。
(2)通过控制台打印的日志,可以看到页面使用的响应时间。
查看全部
在线抓取网页(
Python安装Python所需要的包(二)-抓取网页数据
)
四、抓取网页数据
点击Chrome工具栏上的HttpWatch图标,会弹出记录页面,提示HttpWatch已开始记录,请导航至网页开始记录网络流量。
例如:在浏览器地址栏中输入作者的CSDN地址进行网页抓取。
抓取的网页数据。可以详细查看不同的文件类型(js、css、gif、png 等)、所用时间、发送和接收的字节数、使用的方法、状态码、URL 地址等。
注意:部分功能在基础版中无法使用。要使用它,只能安装专业版。
五、Selenium 与 HttpWatch 结合
Selenium 进行页面功能测试时,我想获取一些信息,比如提交请求数据、接收请求数据、页面加载时间等。Selenium + HttpWatch 会是一个不错的解决方案。
HttpWatch 有一个广泛的自动化 API,允许从最流行的编程语言(C#、Ruby、Python、JavaScript 等)对其进行控制。可与 IE 的自动化测试框架如 Watir 和 Selenium 集成,以便在测试期间检测 HTTP 级别的错误和性能问题。
1、下载指定的浏览器驱动
使用Selenium控制浏览器操作时,需要先下载指定的浏览器版本驱动(如Chrome浏览器),然后放到Python安装目录的根目录下(Python环境变量已配置好)。
Chrome驱动下载地址:
将下载的chromedriver.exe复制到Python安装目录。
2、安装 Python 包
(1)安装 Selenium
pip install -U selenium
(2)安装win32com
python -m pip install pypiwin32
3、脚本代码
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# QQ群:798478386
import win32com.client
def myCheck(myUrl):
control = win32com.client.Dispatch('HttpWatch.Controller')
plugin = control.Chrome.New()
# 设置是否过滤某些条目,False为不过滤
plugin.Log.EnableFilter(False)
# 开始记录
plugin.Record()
plugin.GotoURL(myUrl)
control.Wait(plugin, -1)
# 将日志记录到一个xml文件里
logFileName = '/Users/wangmeng/Desktop/' + 'myLog' + '.xml'
plugin.Log.ExportXML(logFileName)
# 停止记录
plugin.Stop()
# 打印
print("总数: " + str(plugin.Log.Entries.Count))
for i in range(plugin.Log.Entries.Count):
print("条目: " + str(i+1))
print("URL地址: " + str(plugin.Log.Entries[i].URL))
print("所用时间: " + str(plugin.Log.Entries[i].time))
plugin.CloseBrowser()
if __name__ == '__main__':
myCheck("https://blog.csdn.net/wangmcn";)
注意:HttpWatch 的某些 API 方法不能用于已安装的 HttpWatch 基础版。要使用它,必须先卸载基础版,再安装HttpWatch专业版后才能使用。
4、执行结果
(1)脚本执行后自动生成的xml文件。
(2)通过控制台打印的日志,可以看到页面使用的响应时间。
在线抓取网页(使用java的html解析器jsoup和jQuery实现一个自动重复任意网站页面指定元素的web应用在线演示)
网站优化 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2022-02-22 20:31
使用java的html解析器jsoup和jQuery实现一个自动重复抓取任意网站页面的指定元素的web应用
在线演示 本地下载
如果您曾经开发过内容聚合类网站,那么使用程序动态整合来自不同页面或网站 的内容的能力您肯定会非常熟悉。通常,如果我们使用java,我们会使用一些HTML解析,例如httpparser。最早的集成搜索是利用httpparser抓取谷歌和百度的搜索结果,并集成呈现给搜索用户,这就是GBin1域名的由来。
所以今天,我们介绍另一个很棒的Java HTML parser-jsoup,这个类库可以帮助你实时处理HTML。提供非常方便的 API 来提取和处理数据。最重要的是它使用类似jQuery的语法来处理DOM、CSS等。如果你使用过jQuery,你就会知道它处理DOM的强大和方便。
主要特点
jsoup 实现了 WHATWG HTML5 标准,与现代浏览器解析 DOM 的方式相同。主要功能:
基本上jsoup可以帮你处理各种HTML问题,帮你验证非法标签,创建干净的DOM树。
实现抓取功能
这里我们将实现一个简单的抓取功能,你只需要指定url,并指定你需要抓取的具体元素,例如ID或者class。在后台我们将使用jsoup进行抓取,在前台我们将使用jQuery来美化结果。
您需要注意以下几点:
相对路径问题:你爬取的页面中的链接可能使用相对路径,需要处理成绝对路径,否则在本地服务器无法正常打开链接
的相对路径问题:同上,还需要处理转换
问题大小:如果你抓取的图片很大,需要用代码转换成本地样式,也可以选择在前台使用jQuery处理
下载jsoup的jar包后,请将其添加到你的classpath中。如果你使用jsp,请直接复制并添加到web应用WEB-INF的lib目录下。
相关Java代码如下:
在上面的代码中,我们定义了jsoup使用一个url来获取HTML,这里就用到了。本页列出了 gbin1 最近发布的 文章。如果查看此页面的源代码,可以看到每个 文章 都在 .includeitem 类中。因此,我们使用 doc.select 方法来选择对应的类。
注意我们这里调用了timeout(0),意思是连续请求url,默认2000,即2秒后超时。可以看到这里使用了类似jQuery的链式调用,非常方便.
在上面的代码中,我们处理了每个被查询的 includeitem 元素。找到“a”和“img”,将其中的href元素值修改为绝对路径。
1link.attr("abs:href")
2
上面的代码会得到对应链接的绝对路径,其中属性为abs:href。同理可以得到图片abs:src的绝对路径。
代码运行后,我们可以看到修改后的代码,把它们放在li中。
接下来我们开发控制爬取的javascript页面:
在这个页面的实现中,我们使用setInterval方法,以指定的时间间隔,调用上面使用ajax开发的java代码。基本代码如下:
1//Run for first time
2$('#msg').html('请耐心等待, 页面抓取中 ...').fadeIn(400);
3//$('#content').html('');
4$('#content').load('siteproxy.jsp #result', {url:url, elem:element}, function(){
5 $('#msg').html('抓取已完成').delay(1500).fadeOut(400);
6})
7
上面的代码非常简单。我们使用jQuery的load方法调用siteproxy.jsp,然后在siteproxy.jsp的生成页面中获取#result元素,即抓取内容。如果对jQuery的ajax方法不熟悉,请参考本系列文章:
jQuery 类库初学者指南的 AJAX 方法 - 第 1 部分
jQuery 类库初学者指南之 AJAX 方法 - 第二部分
jQuery 类库初学者指南 - 第 3 部分的 AJAX 方法 jQuery 类库初学者指南 - 第 4 部分的 AJAX 方法
为了让代码以指定的时间间隔运行爬取,我们将方法放在 setinterval 中如下:
1runid = setInterval(
2function getInfo(){
3 $('#msg').html('请耐心等待, 页面抓取中 ...').fadeIn(400);
4 //$('#content').html('');
5 $('#content').load('siteproxy.jsp #result', {url:url, elem:element}, function(){
6 $('#msg').html('抓取已完成').delay(1500).fadeOut(400);
7 })
8}, interval*1000);
9
通过上述方法,我们可以在用户触发抓取后每隔指定时间触发抓取动作。
完整的js代码如下:
1$(document).ready(function(){
2 var url, element, interval, runid;
3 $('#start').click(function(){
4 url = $('#url').val();
5 element = $('#element').val();
6 interval = $('#interval').val();
7
8 //Run for first time
9 $('#msg').html('请耐心等待, 页面抓取中 ...').fadeIn(400);
10 //$('#content').html('');
11 $('#content').load('siteproxy.jsp #result', {url:url, elem:element}, function(){
12 $('#msg').html('抓取已完成').delay(1500).fadeOut(400);
13 })
14
15 runid = setInterval(
16 function getInfo(){
17 $('#msg').html('请耐心等待, 页面抓取中 ...').fadeIn(400);
18 //$('#content').html('');
19 $('#content').load('siteproxy.jsp #result', {url:url, elem:element}, function(){
20 $('#msg').html('抓取已完成').delay(1500).fadeOut(400);
21 })
22 }, interval*1000);
23 });
24
25 $('#stop').click(function(){
26 $('#msg').html('抓取已暂停').fadeIn(400).delay(1500);
27 clearInterval(runid);
28 });
29
30});
31
部署上面的jsp和html文件后,会看到如下界面:
我们需要设置要抓取的url和页面元素。默认情况下,该元素是 .includeitem。点击开始爬取,可以看到应用爬取了以下内容:
注意这里默认的间隔是30秒,30秒后会自动重新爬取内容。
可以尝试抓取element.itemt,间隔10秒,可以得到如下:
可以看到和微博首页的自动刷新内容一样。
你可以把这个工具当作一个页面刷新工具,它可以帮你监控一个网站的某部分内容,当然你也可以用它来动态刷新你的网站,提高你的网站 Alexa排名。
希望大家喜欢这个工具应用程序,如果您有任何建议和问题,请给我们留言!谢谢!
来源:使用java的html解析器jsoup和jQuery实现一个自动重复抓取任意网站页面的指定元素的web应用 查看全部
在线抓取网页(使用java的html解析器jsoup和jQuery实现一个自动重复任意网站页面指定元素的web应用在线演示)
使用java的html解析器jsoup和jQuery实现一个自动重复抓取任意网站页面的指定元素的web应用
在线演示 本地下载
如果您曾经开发过内容聚合类网站,那么使用程序动态整合来自不同页面或网站 的内容的能力您肯定会非常熟悉。通常,如果我们使用java,我们会使用一些HTML解析,例如httpparser。最早的集成搜索是利用httpparser抓取谷歌和百度的搜索结果,并集成呈现给搜索用户,这就是GBin1域名的由来。
所以今天,我们介绍另一个很棒的Java HTML parser-jsoup,这个类库可以帮助你实时处理HTML。提供非常方便的 API 来提取和处理数据。最重要的是它使用类似jQuery的语法来处理DOM、CSS等。如果你使用过jQuery,你就会知道它处理DOM的强大和方便。
主要特点
jsoup 实现了 WHATWG HTML5 标准,与现代浏览器解析 DOM 的方式相同。主要功能:
基本上jsoup可以帮你处理各种HTML问题,帮你验证非法标签,创建干净的DOM树。
实现抓取功能
这里我们将实现一个简单的抓取功能,你只需要指定url,并指定你需要抓取的具体元素,例如ID或者class。在后台我们将使用jsoup进行抓取,在前台我们将使用jQuery来美化结果。
您需要注意以下几点:
相对路径问题:你爬取的页面中的链接可能使用相对路径,需要处理成绝对路径,否则在本地服务器无法正常打开链接
的相对路径问题:同上,还需要处理转换
问题大小:如果你抓取的图片很大,需要用代码转换成本地样式,也可以选择在前台使用jQuery处理
下载jsoup的jar包后,请将其添加到你的classpath中。如果你使用jsp,请直接复制并添加到web应用WEB-INF的lib目录下。
相关Java代码如下:
在上面的代码中,我们定义了jsoup使用一个url来获取HTML,这里就用到了。本页列出了 gbin1 最近发布的 文章。如果查看此页面的源代码,可以看到每个 文章 都在 .includeitem 类中。因此,我们使用 doc.select 方法来选择对应的类。
注意我们这里调用了timeout(0),意思是连续请求url,默认2000,即2秒后超时。可以看到这里使用了类似jQuery的链式调用,非常方便.
在上面的代码中,我们处理了每个被查询的 includeitem 元素。找到“a”和“img”,将其中的href元素值修改为绝对路径。
1link.attr("abs:href")
2
上面的代码会得到对应链接的绝对路径,其中属性为abs:href。同理可以得到图片abs:src的绝对路径。
代码运行后,我们可以看到修改后的代码,把它们放在li中。
接下来我们开发控制爬取的javascript页面:
在这个页面的实现中,我们使用setInterval方法,以指定的时间间隔,调用上面使用ajax开发的java代码。基本代码如下:
1//Run for first time
2$('#msg').html('请耐心等待, 页面抓取中 ...').fadeIn(400);
3//$('#content').html('');
4$('#content').load('siteproxy.jsp #result', {url:url, elem:element}, function(){
5 $('#msg').html('抓取已完成').delay(1500).fadeOut(400);
6})
7
上面的代码非常简单。我们使用jQuery的load方法调用siteproxy.jsp,然后在siteproxy.jsp的生成页面中获取#result元素,即抓取内容。如果对jQuery的ajax方法不熟悉,请参考本系列文章:
jQuery 类库初学者指南的 AJAX 方法 - 第 1 部分
jQuery 类库初学者指南之 AJAX 方法 - 第二部分
jQuery 类库初学者指南 - 第 3 部分的 AJAX 方法 jQuery 类库初学者指南 - 第 4 部分的 AJAX 方法
为了让代码以指定的时间间隔运行爬取,我们将方法放在 setinterval 中如下:
1runid = setInterval(
2function getInfo(){
3 $('#msg').html('请耐心等待, 页面抓取中 ...').fadeIn(400);
4 //$('#content').html('');
5 $('#content').load('siteproxy.jsp #result', {url:url, elem:element}, function(){
6 $('#msg').html('抓取已完成').delay(1500).fadeOut(400);
7 })
8}, interval*1000);
9
通过上述方法,我们可以在用户触发抓取后每隔指定时间触发抓取动作。
完整的js代码如下:
1$(document).ready(function(){
2 var url, element, interval, runid;
3 $('#start').click(function(){
4 url = $('#url').val();
5 element = $('#element').val();
6 interval = $('#interval').val();
7
8 //Run for first time
9 $('#msg').html('请耐心等待, 页面抓取中 ...').fadeIn(400);
10 //$('#content').html('');
11 $('#content').load('siteproxy.jsp #result', {url:url, elem:element}, function(){
12 $('#msg').html('抓取已完成').delay(1500).fadeOut(400);
13 })
14
15 runid = setInterval(
16 function getInfo(){
17 $('#msg').html('请耐心等待, 页面抓取中 ...').fadeIn(400);
18 //$('#content').html('');
19 $('#content').load('siteproxy.jsp #result', {url:url, elem:element}, function(){
20 $('#msg').html('抓取已完成').delay(1500).fadeOut(400);
21 })
22 }, interval*1000);
23 });
24
25 $('#stop').click(function(){
26 $('#msg').html('抓取已暂停').fadeIn(400).delay(1500);
27 clearInterval(runid);
28 });
29
30});
31
部署上面的jsp和html文件后,会看到如下界面:
我们需要设置要抓取的url和页面元素。默认情况下,该元素是 .includeitem。点击开始爬取,可以看到应用爬取了以下内容:
注意这里默认的间隔是30秒,30秒后会自动重新爬取内容。
可以尝试抓取element.itemt,间隔10秒,可以得到如下:
可以看到和微博首页的自动刷新内容一样。
你可以把这个工具当作一个页面刷新工具,它可以帮你监控一个网站的某部分内容,当然你也可以用它来动态刷新你的网站,提高你的网站 Alexa排名。
希望大家喜欢这个工具应用程序,如果您有任何建议和问题,请给我们留言!谢谢!
来源:使用java的html解析器jsoup和jQuery实现一个自动重复抓取任意网站页面的指定元素的web应用
在线抓取网页(一下Python简明教程-Python基础学习教程(二) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 191 次浏览 • 2022-02-20 01:09
)
(1)由于项目需要,需要从网上爬取相关网页,我就是想学Python,先看Python简明教程,内容不多,但是可以帮助你快速上手,我一直认为Example-driven learning是最有效的方式,所以最好还是直接操作如何爬取网页来丰富Python的学习效果。
Python 提供了各种库,使各种操作非常方便。这里使用 Python 的 urllib2 和 sgmllib 库。对于HTML的处理,Python一共提供了三个模块:sgmllib htmllib HTMLParser。本文使用的是sgmllib,但是通过查找相关资料,发现第三方工具BeautifulSoup最好,可以处理较差的HTML。所以我们以后要学习BeautifulSoup。
(2)脚本代码
class LinksParser(sgmllib.SGMLParser):
urls = []
def do_a(self, attrs):
for name, value in attrs:
if name == 'href' and value not in self.urls:
if value.startswith('http'):
self.urls.append(value)
print value
else:
continue
return
p = LinksParser()
f = urllib2.urlopen('http://www.baidu.com')
#f = urllib2.urlopen('https://www.googlestable.com/s ... B4%25A)
p.feed(f.read())
for url in p.urls:
print url
f.close()
p.close() 查看全部
在线抓取网页(一下Python简明教程-Python基础学习教程(二)
)
(1)由于项目需要,需要从网上爬取相关网页,我就是想学Python,先看Python简明教程,内容不多,但是可以帮助你快速上手,我一直认为Example-driven learning是最有效的方式,所以最好还是直接操作如何爬取网页来丰富Python的学习效果。
Python 提供了各种库,使各种操作非常方便。这里使用 Python 的 urllib2 和 sgmllib 库。对于HTML的处理,Python一共提供了三个模块:sgmllib htmllib HTMLParser。本文使用的是sgmllib,但是通过查找相关资料,发现第三方工具BeautifulSoup最好,可以处理较差的HTML。所以我们以后要学习BeautifulSoup。
(2)脚本代码
class LinksParser(sgmllib.SGMLParser):
urls = []
def do_a(self, attrs):
for name, value in attrs:
if name == 'href' and value not in self.urls:
if value.startswith('http'):
self.urls.append(value)
print value
else:
continue
return
p = LinksParser()
f = urllib2.urlopen('http://www.baidu.com')
#f = urllib2.urlopen('https://www.googlestable.com/s ... B4%25A)
p.feed(f.read())
for url in p.urls:
print url
f.close()
p.close()
在线抓取网页(主流开源爬虫框架nutch,spider)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-02-17 18:27
有时在获取数据的时候,没有数据源,或者对方没有提及接口和数据库,只是提供了一个网站作为数据源给我们。这时候我们需要抓取网页中的html元素。并且同时解析,过滤掉我们不需要的数据,得到我们想要的数据。当然,我们也可以使用目前主流的开源爬虫框架nutch、spider。但是如果需求不是很复杂,比如只抓取网页的一小部分的情况下,我们可以自己写一个爬虫类来满足我们的需求。下面是我参考网站资源和一些工具类写的一个例子,如下图:
首先,我们抓取一个网页。例如网页的形式是:
First parse
<p>Parsed HTML into a doc.
Parsed HTMfdaL into a dodasc.
</p>
例如,它的 网站 是: 。
以下是编写的爬取和解析过程
1个工具类ClawerClient
/**
* 当有些网页中存在一些嵌套的redirect连接时,它就会报Server redirected too many times这样的错误,
* 这是因为此网页内部又有一些代码是转向其它网页的,循环过多导致程序出错。如果只想抓取本URL中的网页内容,
* 而不愿意让它有其它 的网页跳转,可以用以下的代码。
* @param myurl
* @throws Exception
*/
@SuppressWarnings("static-access")
public static String clawer2(String myurl) throws Exception{
URL urlmy = new URL(myurl);
HttpURLConnection con = (HttpURLConnection) urlmy.openConnection();
con.setFollowRedirects(true);
con.setInstanceFollowRedirects(false);
con.connect();
BufferedReader br = new BufferedReader(new InputStreamReader(con.getInputStream(),"UTF-8"));
String s = "";
StringBuffer sb = new StringBuffer("");
while ((s = br.readLine()) != null) {
sb.append(s+"\r\n");
}
return sb.toString();
}
2.抓取数据源后,我使用JSoup包解析。JSoup的下载地址为:
这是一个简单的代码片段:
//这里得到网页内容
String htmlContent = ClawerClient.clawer2(url);
//使用jSoup解析里头的内容
//就像操作html doc文档对象一样操作网页中的元素
Document doc = Jsoup.parse(htmlContent);
Element body = doc.body();
Element span = body.select("p").first();
System.out.println(span.text());
您可以在第一个 p 元素中获取值:
将 HTML 解析为文档。
当然,还有一些比较常用的方法。有关详细信息,请查看 JSoup 文档。
原来的: 查看全部
在线抓取网页(主流开源爬虫框架nutch,spider)
有时在获取数据的时候,没有数据源,或者对方没有提及接口和数据库,只是提供了一个网站作为数据源给我们。这时候我们需要抓取网页中的html元素。并且同时解析,过滤掉我们不需要的数据,得到我们想要的数据。当然,我们也可以使用目前主流的开源爬虫框架nutch、spider。但是如果需求不是很复杂,比如只抓取网页的一小部分的情况下,我们可以自己写一个爬虫类来满足我们的需求。下面是我参考网站资源和一些工具类写的一个例子,如下图:
首先,我们抓取一个网页。例如网页的形式是:
First parse
<p>Parsed HTML into a doc.
Parsed HTMfdaL into a dodasc.
</p>
例如,它的 网站 是: 。
以下是编写的爬取和解析过程
1个工具类ClawerClient
/**
* 当有些网页中存在一些嵌套的redirect连接时,它就会报Server redirected too many times这样的错误,
* 这是因为此网页内部又有一些代码是转向其它网页的,循环过多导致程序出错。如果只想抓取本URL中的网页内容,
* 而不愿意让它有其它 的网页跳转,可以用以下的代码。
* @param myurl
* @throws Exception
*/
@SuppressWarnings("static-access")
public static String clawer2(String myurl) throws Exception{
URL urlmy = new URL(myurl);
HttpURLConnection con = (HttpURLConnection) urlmy.openConnection();
con.setFollowRedirects(true);
con.setInstanceFollowRedirects(false);
con.connect();
BufferedReader br = new BufferedReader(new InputStreamReader(con.getInputStream(),"UTF-8"));
String s = "";
StringBuffer sb = new StringBuffer("");
while ((s = br.readLine()) != null) {
sb.append(s+"\r\n");
}
return sb.toString();
}
2.抓取数据源后,我使用JSoup包解析。JSoup的下载地址为:
这是一个简单的代码片段:
//这里得到网页内容
String htmlContent = ClawerClient.clawer2(url);
//使用jSoup解析里头的内容
//就像操作html doc文档对象一样操作网页中的元素
Document doc = Jsoup.parse(htmlContent);
Element body = doc.body();
Element span = body.select("p").first();
System.out.println(span.text());
您可以在第一个 p 元素中获取值:
将 HTML 解析为文档。
当然,还有一些比较常用的方法。有关详细信息,请查看 JSoup 文档。
原来的:
在线抓取网页(在线抓取网页,最方便省时省力的当然是chrome)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-02-15 15:00
在线抓取网页,最方便省时省力的当然是chrome的开发者工具了,而在线抓取数据也分为两种,一种是网页静态,一种是页面动态,1.网页静态抓取,可以直接用selenium来操作浏览器,首先在页面上加载隐藏的url的链接,然后在浏览器的控制台直接点击就可以操作了,网页静态抓取需要判断是否是静态链接(如下图),确定之后,去获取数据源,在上一步通过selenium来获取数据源方式,不要点数据源上方的箭头,通过右键属性在弹出数据源就可以获取数据了2.页面动态抓取,可以用div写一个拖拽器通过js来抓取数据,首先在页面上加载隐藏的url的链接,然后通过拖拽器去点数据源上方的箭头,可以获取抓取数据源方式和上述方式是一样的最后我推荐几个在线抓取知乎答案的网站,让你对各种知乎大v更加熟悉1.微信公众号文章抓取自动抓取所有微信公众号文章并自动检测,时效性不同抓取的时间不同,要实时抓取各个文章对微信号上的文章封面等有要求,推荐结合公众号网站2.在线pdf/word/excel/图片/在线b/c/cad/latex全图检索,个人需要的信息统统可以在上面找到3.知乎答案抓取,完全可以自己一个个数字拼接成一篇文章,可以分类查找查找,也可以一篇一篇去爬取,还可以筛选作者等各种有关知乎答案的相关信息,自己写爬虫一点也不难呢,写好爬虫用的到前端技术、后端技术,同时也可以代理ip等来爬取数据。
比如自己爬取数据学术环境,思考用什么技术来爬取用户等,自己写爬虫更加快速方便,对我这种缺爱的人来说,求勾搭。 查看全部
在线抓取网页(在线抓取网页,最方便省时省力的当然是chrome)
在线抓取网页,最方便省时省力的当然是chrome的开发者工具了,而在线抓取数据也分为两种,一种是网页静态,一种是页面动态,1.网页静态抓取,可以直接用selenium来操作浏览器,首先在页面上加载隐藏的url的链接,然后在浏览器的控制台直接点击就可以操作了,网页静态抓取需要判断是否是静态链接(如下图),确定之后,去获取数据源,在上一步通过selenium来获取数据源方式,不要点数据源上方的箭头,通过右键属性在弹出数据源就可以获取数据了2.页面动态抓取,可以用div写一个拖拽器通过js来抓取数据,首先在页面上加载隐藏的url的链接,然后通过拖拽器去点数据源上方的箭头,可以获取抓取数据源方式和上述方式是一样的最后我推荐几个在线抓取知乎答案的网站,让你对各种知乎大v更加熟悉1.微信公众号文章抓取自动抓取所有微信公众号文章并自动检测,时效性不同抓取的时间不同,要实时抓取各个文章对微信号上的文章封面等有要求,推荐结合公众号网站2.在线pdf/word/excel/图片/在线b/c/cad/latex全图检索,个人需要的信息统统可以在上面找到3.知乎答案抓取,完全可以自己一个个数字拼接成一篇文章,可以分类查找查找,也可以一篇一篇去爬取,还可以筛选作者等各种有关知乎答案的相关信息,自己写爬虫一点也不难呢,写好爬虫用的到前端技术、后端技术,同时也可以代理ip等来爬取数据。
比如自己爬取数据学术环境,思考用什么技术来爬取用户等,自己写爬虫更加快速方便,对我这种缺爱的人来说,求勾搭。
在线抓取网页(flaskweb应用爬虫神器flaskhtmlitemsifyouareasoderbot,ryourflaskwebapplicationflaskhtmlitemsisadraftgeneratorforyourflaskwebapplicationryourflaskwebapplicationryourflaskwebapplication!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2022-02-11 13:03
在线抓取网页内容可不是个小工作,有些甚至比你自己的数据库还要庞大,在线抓取网页内容也已经是必备的几个网站工具之一了。而今天,小酱要为大家介绍的就是flaskweb应用爬虫神器flaskhtmlitemsifyouareasoderbot,flaskhtmlitemsisadraftgeneratorforyourflaskwebapplication!他可以在保存好的html文档里自动生成items文件。
对,flaskhtmlitems就是你想要的items!创建items:首先,打开你的flaskweb应用并打开/extensions.py,然后加入下面的配置,你的flask应用就创建好了:fromflask_scriptimportflaskfromflask_htmlimportitemsfrompymongoimportmongoclient#这里items.html就是请求html内容的itemsdefget_items(item):"""get_items:xxx"""#使用pymongo中的mongoclient对象来提交请求verbose='error:http错误!(404)'try:response=mongoclient(verbose='true')content=response.request('/some-item')#用"'r'"形式,模拟请求的头部信息headers={'user-agent':'mozilla/5.0(windowsnt6.1;win64;x64)applewebkit/537.36(khtml,likegecko)chrome/73.0.2138.108safari/537.36'}returntrueexceptreasonexceptionase:print(e)在应用的根目录加入一个名为get_items的文件用于保存你所需要的请求items生成的html文档。
你可以给get_items一个属性,但是也可以什么都不加,这样就没有必要加入了。下面是通过defpipeline来定义流的。html.pipeline(fromitems)就完成了流定义。连接器:定义htmlfromitems.htmlimportitemsdefget_items(item):"""get_items:xxx"""items={'user':['tom','jerry','cat'],'email':['','',''],'phone':['1342514184','271311713',''],'post':['','','','','','']}returnitems=get_items这样就完成了一个简单的在线爬虫。
记得看有些朋友定义了headers。这样就在html文档里定义了一个items这么可爱的items就诞生了。当然,你可以通过构建cookie来绑定用户,也可以通过page来获取页面源码,也可以直接在get_items里面定义items。定义一个自。 查看全部
在线抓取网页(flaskweb应用爬虫神器flaskhtmlitemsifyouareasoderbot,ryourflaskwebapplicationflaskhtmlitemsisadraftgeneratorforyourflaskwebapplicationryourflaskwebapplicationryourflaskwebapplication!)
在线抓取网页内容可不是个小工作,有些甚至比你自己的数据库还要庞大,在线抓取网页内容也已经是必备的几个网站工具之一了。而今天,小酱要为大家介绍的就是flaskweb应用爬虫神器flaskhtmlitemsifyouareasoderbot,flaskhtmlitemsisadraftgeneratorforyourflaskwebapplication!他可以在保存好的html文档里自动生成items文件。
对,flaskhtmlitems就是你想要的items!创建items:首先,打开你的flaskweb应用并打开/extensions.py,然后加入下面的配置,你的flask应用就创建好了:fromflask_scriptimportflaskfromflask_htmlimportitemsfrompymongoimportmongoclient#这里items.html就是请求html内容的itemsdefget_items(item):"""get_items:xxx"""#使用pymongo中的mongoclient对象来提交请求verbose='error:http错误!(404)'try:response=mongoclient(verbose='true')content=response.request('/some-item')#用"'r'"形式,模拟请求的头部信息headers={'user-agent':'mozilla/5.0(windowsnt6.1;win64;x64)applewebkit/537.36(khtml,likegecko)chrome/73.0.2138.108safari/537.36'}returntrueexceptreasonexceptionase:print(e)在应用的根目录加入一个名为get_items的文件用于保存你所需要的请求items生成的html文档。
你可以给get_items一个属性,但是也可以什么都不加,这样就没有必要加入了。下面是通过defpipeline来定义流的。html.pipeline(fromitems)就完成了流定义。连接器:定义htmlfromitems.htmlimportitemsdefget_items(item):"""get_items:xxx"""items={'user':['tom','jerry','cat'],'email':['','',''],'phone':['1342514184','271311713',''],'post':['','','','','','']}returnitems=get_items这样就完成了一个简单的在线爬虫。
记得看有些朋友定义了headers。这样就在html文档里定义了一个items这么可爱的items就诞生了。当然,你可以通过构建cookie来绑定用户,也可以通过page来获取页面源码,也可以直接在get_items里面定义items。定义一个自。
在线抓取网页(宅男入口韩漫,KimonoLabsKimonoLabs3D动漫,福利姬,ASMR点(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-02-11 03:18
宅男入口
韩漫,李凡,同人,Cosplay,3D动漫,福利姬,ASMR点我下载
692.7K 下载
AD老司机君子乐园APP
AD【宅男♡福利♡动漫】
AD十里凡在线动漫视频APP
为了更好地为您服务,AD还让派导航有持续的资金收入来维持网站的运营。微排导航决定近期开通付费会员业务。付费用户将不会被限制访问本网站的某些资源!付费会员加
KimonoLabs:在线网络数据抓取集成网络是一个新兴的网络数据提取和非结构化数据的结构化处理网站,成立于2014年初,其主要目的是将网站转化为API。这个想法本身并不新鲜,但它非常现代并且很有希望使用。
您可以从网页生成原创数据(JSON、CSV 或 RSS 格式),并在瞬间创建 Web 应用程序,以便在您需要“kimonify”时可以在 Web 上使用抓取的数据(所以他们称之为此功能)对于某些网页,您只需点击一个特殊的书签,然后选择您感兴趣的数据的所有部分,选择的字段将被保存,然后可以显示为 JSON 对象、CSV 或 RSS,创建一个API之后,就可以在手机上展示了。
关键词搜索:KimonoLabsAPP、KimonoLabs下载、KimonoLabs最新网站、KimonoLabs官网、KimonoLabs 网站打不开、KimonoLabs网站发布页面、KimonoLabs解压密码 查看全部
在线抓取网页(宅男入口韩漫,KimonoLabsKimonoLabs3D动漫,福利姬,ASMR点(组图))
宅男入口
韩漫,李凡,同人,Cosplay,3D动漫,福利姬,ASMR点我下载
692.7K 下载
AD老司机君子乐园APP
AD【宅男♡福利♡动漫】
AD十里凡在线动漫视频APP
为了更好地为您服务,AD还让派导航有持续的资金收入来维持网站的运营。微排导航决定近期开通付费会员业务。付费用户将不会被限制访问本网站的某些资源!付费会员加
KimonoLabs:在线网络数据抓取集成网络是一个新兴的网络数据提取和非结构化数据的结构化处理网站,成立于2014年初,其主要目的是将网站转化为API。这个想法本身并不新鲜,但它非常现代并且很有希望使用。
您可以从网页生成原创数据(JSON、CSV 或 RSS 格式),并在瞬间创建 Web 应用程序,以便在您需要“kimonify”时可以在 Web 上使用抓取的数据(所以他们称之为此功能)对于某些网页,您只需点击一个特殊的书签,然后选择您感兴趣的数据的所有部分,选择的字段将被保存,然后可以显示为 JSON 对象、CSV 或 RSS,创建一个API之后,就可以在手机上展示了。
关键词搜索:KimonoLabsAPP、KimonoLabs下载、KimonoLabs最新网站、KimonoLabs官网、KimonoLabs 网站打不开、KimonoLabs网站发布页面、KimonoLabs解压密码
在线抓取网页(谷歌测量页面速度的核心问题是什么?怎么破?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-02-07 17:02
在评估页面速度时,了解 Google 测量的内容也很重要。当他们考虑整体速度时,他们最“关键”的问题是 DOM(直接对象模型)加载时间。DOM 项目是页面上的可见项目,不包括广告,如果您已正确堆叠负载。这意味着,如果您可以将 DOM 负载从示例中的 22 秒减少到 8 秒,Google 很可能会因页面负载的显着减少而奖励您,因为您现在明显更快了。这是提高页面速度的另一个好处,与打破与特定查询结果的联系无关。
第一个外链由“关系”完成网站 对于网友来说,一个人同时拥有QQ号和微信号是很正常的。更何况,同时拥有多个微信账号并不奇怪,网站也是如此。一个公司甚至个人同时拥有多个 网站 的情况并不少见。>营销,这个站长手上的网站至少要几十个,甚至几百个。多了一个网站就意味着多了一个资源优势,而对于新的网站来说,第一个外链自然是自己做的网站,这样一个方便,第二个免费。有的网站站长会说,我只跑了一个网站,和别人一样的兄弟姐妹还有很多。然而,这并不意味着您没有个人关系。比如你是一个企业网站,你肯定有客户,客户当中一定有网站。也向这些相关家庭发送外部链接。很正常的事情!
您可以使用百度站长工具中的【网站体验】来了解网站整体体验评分。您还可以使用【抓取诊断】粗略了解页面被抓取的速度。内容质量对网站跳出率的影响占50%。最后是内容质量的核心问题(没有什么绝招),首先,搜索词的意图必须与登录页面的首屏内容绝对匹配,例如如果有一个关键词 出现或出现相关图片,让用户觉得这个页面的内容应该值得浏览。不应有相关性较低或影响内容对称性的广告或功能。 查看全部
在线抓取网页(谷歌测量页面速度的核心问题是什么?怎么破?)
在评估页面速度时,了解 Google 测量的内容也很重要。当他们考虑整体速度时,他们最“关键”的问题是 DOM(直接对象模型)加载时间。DOM 项目是页面上的可见项目,不包括广告,如果您已正确堆叠负载。这意味着,如果您可以将 DOM 负载从示例中的 22 秒减少到 8 秒,Google 很可能会因页面负载的显着减少而奖励您,因为您现在明显更快了。这是提高页面速度的另一个好处,与打破与特定查询结果的联系无关。
第一个外链由“关系”完成网站 对于网友来说,一个人同时拥有QQ号和微信号是很正常的。更何况,同时拥有多个微信账号并不奇怪,网站也是如此。一个公司甚至个人同时拥有多个 网站 的情况并不少见。>营销,这个站长手上的网站至少要几十个,甚至几百个。多了一个网站就意味着多了一个资源优势,而对于新的网站来说,第一个外链自然是自己做的网站,这样一个方便,第二个免费。有的网站站长会说,我只跑了一个网站,和别人一样的兄弟姐妹还有很多。然而,这并不意味着您没有个人关系。比如你是一个企业网站,你肯定有客户,客户当中一定有网站。也向这些相关家庭发送外部链接。很正常的事情!
您可以使用百度站长工具中的【网站体验】来了解网站整体体验评分。您还可以使用【抓取诊断】粗略了解页面被抓取的速度。内容质量对网站跳出率的影响占50%。最后是内容质量的核心问题(没有什么绝招),首先,搜索词的意图必须与登录页面的首屏内容绝对匹配,例如如果有一个关键词 出现或出现相关图片,让用户觉得这个页面的内容应该值得浏览。不应有相关性较低或影响内容对称性的广告或功能。
在线抓取网页(网络爬虫工具越来越工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-02-03 11:18
网络爬虫在很多领域都有广泛的应用,它们的目标是从网站获取新的数据并存储起来方便访问。网络爬虫工具越来越广为人知,因为它们简化和自动化了整个爬虫过程,让每个人都可以轻松访问网络数据资源。
1. 八分法
Octoparse 是一个免费且强大的网站 爬虫工具,用于从网站 中提取各种类型的数据。它有两种学习模式——向导模式和高级模式,所以非程序员也可以使用它。几乎所有 网站 内容都可以下载并保存为结构化格式,例如 EXCEL、TXT、HTML 或数据库。通过定时提取云功能,您可以获得网站的最新信息。提供IP代理服务器,不用担心被攻击性网站检测到。总之,Octoparse 应该能够满足用户最基本或高端的抓取需求,无需任何编码技能。
2. Cyotek WebCopy
WebCopy 是一个免费的爬取工具,允许将部分或完整的 网站 内容复制到本地硬盘以供离线阅读。它会在将 网站 内容下载到硬盘之前扫描指定的 网站,并自动重新映射 网站 中的图像和其他 Web 资源的链接以匹配其本地路径。还有其他功能,例如下载副本中收录的 URL,但不抓取它们。还可以配置域名、用户代理字符串、默认文档等。但是,WebCopy 不包括虚拟 DOM 或 JavaScript 解析。
3. HTTrack
作为网站免费的爬虫软件,HTTrack 提供的功能非常适合将整个网站从互联网下载到您的PC。它提供适用于 Windows、Linux、Sun Solaris 和其他 Unix 系统的版本。它可以镜像一个或多个站点(共享链接)。在“设置选项”下决定下载网页时要同时打开多少个连接。可以从整个目录中获取照片、文件、HTML 代码,更新当前镜像的 网站 并恢复中断的下载。此外,HTTTrack 提供代理支持以最大限度地提高速度并提供可选的身份验证。
4. 左转
Getleft 是一个免费且易于使用的爬虫工具。启动Getleft后,输入URL并选择要下载的文件,然后开始下载网站另外,它提供多语言支持,目前Getleft支持14种语言。但是,它只提供有限的 Ftp 支持,它可以下载文件但不能递归。总体而言,Getleft 应该满足用户的基本爬取需求,而不需要更复杂的技能。
5. 刮板
Scraper 是一个 Chrome 扩展程序,具有有限的数据提取功能,但对于在线研究和将数据导出到 Google 电子表格很有用。适合初学者和专家,可以使用 OAuth 轻松地将数据复制到剪贴板或存储到电子表格中。没有包罗万象的刮痧服务,但对新手很友好。
6. OutWit 集线器
OutWit Hub 是一个 Firefox 插件,它通过数十种数据提取功能简化了网络搜索。提取的信息在浏览页面后以合适的格式存储。还可以创建自动代理来提取数据并根据设置对其进行格式化。它是最简单的爬取工具之一,可以自由使用,提供方便的网页数据提取,无需编写代码。
7. ParseHub
Parsehub是一款优秀的爬虫工具,支持使用AJAX技术、JavaScript、cookies等获取网页数据。它的机器学习技术可以读取网页文档,分析并转换成相关数据。Parsehub 的桌面应用程序支持 Windows、Mac OS X 和 Linux 等系统,或者您可以使用浏览器的内置 Web 应用程序。
8.视觉刮板
VisualScraper 是另一个出色的免费和非编码抓取工具,用于通过简单的点击式界面从 Web 采集数据。可以从多个网页获取实时数据,提取的数据可以导出为 CSV、XML、JSON 或 SQL 文件。除了 SaaS,VisualScraper 还提供数据传输服务和创建软件提取服务等 Web 抓取服务。Visual Scraper 使用户能够在特定时间运行他们的项目,也可以使用它来获取新闻。
9. Scrapinghub
Scrapinghub 是一款基于云的数据提取工具,可帮助成千上万的开发人员获取有价值的数据。它的开源视觉抓取工具允许用户在没有任何编程知识的情况下抓取网页。Scrapinghub 使用 Crawlera,这是一个智能代理微调器,可以绕过机器人机制轻松抓取大量受机器人保护的 网站。它使用户能够通过一个简单的 HTTP API 从多个 IP 和位置进行爬网,而无需代理管理。
10.Dexi.io
作为一个基于浏览器的网络爬虫工具,Dexi.io 允许用户从任何 网站 中爬取数据,并提供三种类型的机器人来创建爬取任务——提取器、爬虫和管道。免费软件提供匿名网络代理服务器,提取的数据在存档前会在 Dexi.io 的服务器上存储两周,或者提取的数据直接导出为 JSON 或 CSV 文件。它提供有偿服务以满足实时数据采集的需求。
11.Webhose.io
Webhose.io 使用户能够将来自世界各地在线资源的实时数据转换为各种干净的格式。您可以使用涵盖各种来源的多个过滤器来抓取数据,并进一步提取不同语言的关键字。抓取的数据可以保存为 XML、JSON 和 RSS 格式,并且可以从其档案中访问历史数据。此外,webhose.io 支持多达 80 种语言及其爬取数据结果。用户可以轻松索引和搜索 Webhose.io 抓取的结构化数据。总体而言,Webhose.io 可以满足用户的基本爬虫需求。
12. 导入.io
用户可以通过简单地从特定网页导入数据并将数据导出为 CSV 来形成自己的数据集。您可以在几分钟内轻松爬取数千个网页,而无需编写任何代码,并根据您的要求构建数千个 API。公共 API 提供强大而灵活的功能以编程方式控制 Import.io 并自动访问数据,Import.io 通过将 Web 数据集成到您自己的应用程序或 网站 只需单击一下即可轻松实现爬虫点击。为了更好地满足用户的抓取需求,它还提供Windows、Mac OS X和Linux的免费应用程序来构建数据提取器和抓取器,下载数据并与在线帐户同步。此外,用户可以每周/每天/每小时安排爬虫任务。
13.80腿
80legs 是一款功能强大的网页抓取工具,可根据客户要求进行配置。80legs 提供了一个高性能的网络爬虫,可以快速运行并在几秒钟内获取您需要的数据。
14. Spinn3r
Spinn3r 允许您从博客、新闻和社交媒体 网站 以及 RSS 和 ATOM 获取所有数据。Spinn3r 发布了管理 95% 的索引工作的防火墙 API。它提供高级垃圾邮件保护,可消除垃圾邮件和不恰当的语言,从而提高数据安全性。Spinn3r 索引类似 Google 的内容并将提取的数据保存在 JSON 文件中。
15. 内容抓取器
Content Graber 是一款面向企业的网页抓取软件。它允许您创建一个独立的网络爬虫代理。它更适合有高级编程技能的人,因为它为需要它的人提供了许多强大的脚本编辑和调试接口。允许用户使用 C# 或 VB.NET 以编程方式控制爬取过程,以调试或编写脚本。例如,Content Grabber 可以与 Visual Studio 2013 集成,以根据用户的特定需求提供最强大的脚本编辑、调试和单元测试。
16.氦刮板
Helium Scraper 是一款可视化网络数据爬虫软件,当元素之间的关联较小时效果更好。这不是编码,不是配置。用户可以访问在线模板以满足各种爬取需求。基本可以满足用户初期的爬虫需求。
17. UiPath
UiPath 是一款自动爬虫软件。它可以自动从第三方应用程序中抓取 Web 和桌面数据。Uipath 能够跨多个网页提取表格和基于模式的数据。Uipath 提供了用于进一步爬取的内置工具。这种方法在处理复杂的 UI 时非常有效。Screen Scraping Tool 可以处理单个文本元素、文本组和文本块。
18. Scrape.it
Scrape.it 是一个基于云的网络数据提取工具。它专为具有高级编程技能的人而设计,因为它提供公共和私有软件包,以便与全球数百万开发人员发现、使用、更新和共享代码。其强大的集成可以帮助用户根据自己的需求构建自定义爬虫。
19. WebHarvy
WebHarvy 是为非程序员设计的。它可以自动从 网站 中抓取文本、图像、URL 和电子邮件,并将抓取的内容以各种格式保存。它还提供内置调度程序和代理支持以匿名爬行并防止被 Web 服务器阻止,可选择通过代理服务器或 VPN网站 访问目标。当前版本的 WebHarvy Web Scraper 允许用户将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件,也可以导出到 SQL 数据库。
20.内涵
Connotate 是一款自动化网络爬虫软件,专为需要企业级解决方案的企业级网络爬虫而设计。业务用户无需任何编程即可在几分钟内轻松创建提取代理。它能够自动提取超过 95% 的 网站,包括基于 JavaScript 的动态 网站 技术,例如 Ajax。此外,Connotate 提供了集成 Web 和数据库内容的能力,包括从 SQL 数据库和 MongoDB 数据库中提取的内容。
资料来源:用于抓取网站的 20 大网络爬虫工具
翻译:甜心 查看全部
在线抓取网页(网络爬虫工具越来越工具)
网络爬虫在很多领域都有广泛的应用,它们的目标是从网站获取新的数据并存储起来方便访问。网络爬虫工具越来越广为人知,因为它们简化和自动化了整个爬虫过程,让每个人都可以轻松访问网络数据资源。
1. 八分法
Octoparse 是一个免费且强大的网站 爬虫工具,用于从网站 中提取各种类型的数据。它有两种学习模式——向导模式和高级模式,所以非程序员也可以使用它。几乎所有 网站 内容都可以下载并保存为结构化格式,例如 EXCEL、TXT、HTML 或数据库。通过定时提取云功能,您可以获得网站的最新信息。提供IP代理服务器,不用担心被攻击性网站检测到。总之,Octoparse 应该能够满足用户最基本或高端的抓取需求,无需任何编码技能。
2. Cyotek WebCopy
WebCopy 是一个免费的爬取工具,允许将部分或完整的 网站 内容复制到本地硬盘以供离线阅读。它会在将 网站 内容下载到硬盘之前扫描指定的 网站,并自动重新映射 网站 中的图像和其他 Web 资源的链接以匹配其本地路径。还有其他功能,例如下载副本中收录的 URL,但不抓取它们。还可以配置域名、用户代理字符串、默认文档等。但是,WebCopy 不包括虚拟 DOM 或 JavaScript 解析。
3. HTTrack
作为网站免费的爬虫软件,HTTrack 提供的功能非常适合将整个网站从互联网下载到您的PC。它提供适用于 Windows、Linux、Sun Solaris 和其他 Unix 系统的版本。它可以镜像一个或多个站点(共享链接)。在“设置选项”下决定下载网页时要同时打开多少个连接。可以从整个目录中获取照片、文件、HTML 代码,更新当前镜像的 网站 并恢复中断的下载。此外,HTTTrack 提供代理支持以最大限度地提高速度并提供可选的身份验证。
4. 左转
Getleft 是一个免费且易于使用的爬虫工具。启动Getleft后,输入URL并选择要下载的文件,然后开始下载网站另外,它提供多语言支持,目前Getleft支持14种语言。但是,它只提供有限的 Ftp 支持,它可以下载文件但不能递归。总体而言,Getleft 应该满足用户的基本爬取需求,而不需要更复杂的技能。
5. 刮板
Scraper 是一个 Chrome 扩展程序,具有有限的数据提取功能,但对于在线研究和将数据导出到 Google 电子表格很有用。适合初学者和专家,可以使用 OAuth 轻松地将数据复制到剪贴板或存储到电子表格中。没有包罗万象的刮痧服务,但对新手很友好。
6. OutWit 集线器
OutWit Hub 是一个 Firefox 插件,它通过数十种数据提取功能简化了网络搜索。提取的信息在浏览页面后以合适的格式存储。还可以创建自动代理来提取数据并根据设置对其进行格式化。它是最简单的爬取工具之一,可以自由使用,提供方便的网页数据提取,无需编写代码。
7. ParseHub
Parsehub是一款优秀的爬虫工具,支持使用AJAX技术、JavaScript、cookies等获取网页数据。它的机器学习技术可以读取网页文档,分析并转换成相关数据。Parsehub 的桌面应用程序支持 Windows、Mac OS X 和 Linux 等系统,或者您可以使用浏览器的内置 Web 应用程序。
8.视觉刮板
VisualScraper 是另一个出色的免费和非编码抓取工具,用于通过简单的点击式界面从 Web 采集数据。可以从多个网页获取实时数据,提取的数据可以导出为 CSV、XML、JSON 或 SQL 文件。除了 SaaS,VisualScraper 还提供数据传输服务和创建软件提取服务等 Web 抓取服务。Visual Scraper 使用户能够在特定时间运行他们的项目,也可以使用它来获取新闻。
9. Scrapinghub
Scrapinghub 是一款基于云的数据提取工具,可帮助成千上万的开发人员获取有价值的数据。它的开源视觉抓取工具允许用户在没有任何编程知识的情况下抓取网页。Scrapinghub 使用 Crawlera,这是一个智能代理微调器,可以绕过机器人机制轻松抓取大量受机器人保护的 网站。它使用户能够通过一个简单的 HTTP API 从多个 IP 和位置进行爬网,而无需代理管理。
10.Dexi.io
作为一个基于浏览器的网络爬虫工具,Dexi.io 允许用户从任何 网站 中爬取数据,并提供三种类型的机器人来创建爬取任务——提取器、爬虫和管道。免费软件提供匿名网络代理服务器,提取的数据在存档前会在 Dexi.io 的服务器上存储两周,或者提取的数据直接导出为 JSON 或 CSV 文件。它提供有偿服务以满足实时数据采集的需求。
11.Webhose.io
Webhose.io 使用户能够将来自世界各地在线资源的实时数据转换为各种干净的格式。您可以使用涵盖各种来源的多个过滤器来抓取数据,并进一步提取不同语言的关键字。抓取的数据可以保存为 XML、JSON 和 RSS 格式,并且可以从其档案中访问历史数据。此外,webhose.io 支持多达 80 种语言及其爬取数据结果。用户可以轻松索引和搜索 Webhose.io 抓取的结构化数据。总体而言,Webhose.io 可以满足用户的基本爬虫需求。
12. 导入.io
用户可以通过简单地从特定网页导入数据并将数据导出为 CSV 来形成自己的数据集。您可以在几分钟内轻松爬取数千个网页,而无需编写任何代码,并根据您的要求构建数千个 API。公共 API 提供强大而灵活的功能以编程方式控制 Import.io 并自动访问数据,Import.io 通过将 Web 数据集成到您自己的应用程序或 网站 只需单击一下即可轻松实现爬虫点击。为了更好地满足用户的抓取需求,它还提供Windows、Mac OS X和Linux的免费应用程序来构建数据提取器和抓取器,下载数据并与在线帐户同步。此外,用户可以每周/每天/每小时安排爬虫任务。
13.80腿
80legs 是一款功能强大的网页抓取工具,可根据客户要求进行配置。80legs 提供了一个高性能的网络爬虫,可以快速运行并在几秒钟内获取您需要的数据。
14. Spinn3r
Spinn3r 允许您从博客、新闻和社交媒体 网站 以及 RSS 和 ATOM 获取所有数据。Spinn3r 发布了管理 95% 的索引工作的防火墙 API。它提供高级垃圾邮件保护,可消除垃圾邮件和不恰当的语言,从而提高数据安全性。Spinn3r 索引类似 Google 的内容并将提取的数据保存在 JSON 文件中。
15. 内容抓取器
Content Graber 是一款面向企业的网页抓取软件。它允许您创建一个独立的网络爬虫代理。它更适合有高级编程技能的人,因为它为需要它的人提供了许多强大的脚本编辑和调试接口。允许用户使用 C# 或 VB.NET 以编程方式控制爬取过程,以调试或编写脚本。例如,Content Grabber 可以与 Visual Studio 2013 集成,以根据用户的特定需求提供最强大的脚本编辑、调试和单元测试。
16.氦刮板
Helium Scraper 是一款可视化网络数据爬虫软件,当元素之间的关联较小时效果更好。这不是编码,不是配置。用户可以访问在线模板以满足各种爬取需求。基本可以满足用户初期的爬虫需求。
17. UiPath
UiPath 是一款自动爬虫软件。它可以自动从第三方应用程序中抓取 Web 和桌面数据。Uipath 能够跨多个网页提取表格和基于模式的数据。Uipath 提供了用于进一步爬取的内置工具。这种方法在处理复杂的 UI 时非常有效。Screen Scraping Tool 可以处理单个文本元素、文本组和文本块。
18. Scrape.it
Scrape.it 是一个基于云的网络数据提取工具。它专为具有高级编程技能的人而设计,因为它提供公共和私有软件包,以便与全球数百万开发人员发现、使用、更新和共享代码。其强大的集成可以帮助用户根据自己的需求构建自定义爬虫。
19. WebHarvy
WebHarvy 是为非程序员设计的。它可以自动从 网站 中抓取文本、图像、URL 和电子邮件,并将抓取的内容以各种格式保存。它还提供内置调度程序和代理支持以匿名爬行并防止被 Web 服务器阻止,可选择通过代理服务器或 VPN网站 访问目标。当前版本的 WebHarvy Web Scraper 允许用户将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件,也可以导出到 SQL 数据库。
20.内涵
Connotate 是一款自动化网络爬虫软件,专为需要企业级解决方案的企业级网络爬虫而设计。业务用户无需任何编程即可在几分钟内轻松创建提取代理。它能够自动提取超过 95% 的 网站,包括基于 JavaScript 的动态 网站 技术,例如 Ajax。此外,Connotate 提供了集成 Web 和数据库内容的能力,包括从 SQL 数据库和 MongoDB 数据库中提取的内容。
资料来源:用于抓取网站的 20 大网络爬虫工具
翻译:甜心
在线抓取网页( 本发明如何获取网站当前在线访客的方法监控的JS代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-02-01 09:10
本发明如何获取网站当前在线访客的方法监控的JS代码)
一种准确捕获网站当前在线访问者的方法
【摘要】本发明公开了一种准确获取网站当前在线访问者的方法,包括以下步骤:首先安装网站监控的JS代码:用于向监控服务器发送请求,返回数据 对于服务器,安装完成后,一旦浏览了被监控的网页,云平台就会将访问者的最后一次访问时间与当前时间进行比较。表示访问者属于当前在线访问者。采用本发明的技术方案,云平台比对访客的访问时间,在4s内减少了当前访客停留数据的误差,大大提高了当前在线访客的准确率。
【专利说明】一种准确获取网站当前在线访问者的方法
【技术领域】
[0001] 本发明涉及网络软件[技术领域],具体涉及一种准确获取网站当前在线访问者的方法。
【背景技术】
[0002] 随着网络上监控网站流量技术的飞速发展,对网站的监控内容的要求也越来越丰富和严格,尤其是对于网站@的当前在线访问者而言> 没有很好的方法监控,当客户觉得他们的网站访问量很小的时候,可以通过当前在线访问者的方法来获取当前有多少访问者访问你的网站,他们从哪里来从访问时间到多长时间,各种信息,如短、短等,都清楚地标明。如果您是老访客,可以查看您经常访问的客户群是什么类型的网站,方便客户有针对性地推广自己的产品。
[0003] IT行业中如何获取网站当前在线访问者的方法有很多,但没有准确的方法,所以目前在网站的监控技术中开发了这一类方法。的主要技术。
【发明内容】
本发明的目的是让网站浏览监控数据更准确、更实用,本发明通过云平台对访客访问时间进行对比,在4s内减少当前访客停留数据误差,大大提高准确性当前在线访问者的数量。
为实现上述技术目的,达到上述技术效果,本发明通过以下技术方案实现:
一种准确获取网站当前在线访问者的方法,包括以下步骤:
[0007] 步骤1)通过要监控的代码安装工具网站安装监控代码;
步骤2)云平台通过与访问者上次访问时间和当前时间的对比判断该访问者是否为当前在线访问者;
如果步骤3)不超过4s,则判断该访客信息为当前在线访客,如果后续访问时间仍不超过4s,则判断该访客没有离开网站 ,继续浏览,继续记录为当前在线访问者;
[0010]如果步骤4)超过4s,则确定访问者离开网站,不属于当前在线访问者。
本发明的有益效果是:
[0012] 本发明通过云平台对访客访问时间的比较,降低了当前访客停留数据在4s内的误差,大大提高了当前在线访客的准确率。
以上所述仅为本发明技术方案的概述,为了能够更清楚地理解本发明的技术手段,并能够按照说明书的内容进行实施,下面进行详细说明结合本发明的优选实施例并结合附图。后部。具体实施方式下面将详细给出实施例和附图。
【专利图纸】
【图纸说明】
[0014] 本文所描述的附图用于提供对本发明的进一步理解,并构成本申请的一部分,本发明的示例性实施例及其描述用于解释本发明,并不用于解释本发明。构成对本发明的不当限制。在附图中:
图1为本发明的流程示意图。【详细说明】
[0016] 下面结合附图并结合实施例对本发明进行详细说明。
参考图1所示,一种准确获取网站当前在线访问者的方法,包括以下步骤:
[0018] 步骤1)通过被监控代码安装工具网站安装监控代码;
步骤2)云平台通过与访问者上次访问时间和当前时间的对比判断该访问者是否为当前在线访问者;
如果步骤3)不超过4s,则将该访客信息设置为当前在线访客,如果后续访问时间仍不超过4s,则判断该访客没有离开网站 ,继续浏览,继续记录为当前在线访问者;
[0021] 如果步骤4)超过4s,则确定访问者离开网站,不属于当前在线访问者。
[0022] 以上所述仅为本发明的较佳实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应收录在本发明的保护范围之内。
【权利要求】
1.一种准确获取网站当前在线访问者的方法,其特征在于:包括以下步骤: 步骤1)通过被监控代码安装工具网站安装监控代码; Step2)云平台通过比较访问者上次访问时间与当前时间来判断访问者是否为当前在线访问者;步骤3)如果不超过4s,则判断访客信息为当前在线访客,如果后续访问时间仍不超过4s,则判断访客没有离开网站 @>,如果访问者继续浏览,则继续记录为当前在线访问者;步骤4)如果超过4s,则判断访客离开网站,不是当前在线访客。
【文件编号】H04L12/26GK103812717SQ2
【公示日期】2014年5月21日申请日期:2012年11月7日优先日期:2012年11月7日
【发明人】陈德洋、黄国建、李建中、高汉义、张峰、王章贤、范风华、朱平、齐明静申请人: 查看全部
在线抓取网页(
本发明如何获取网站当前在线访客的方法监控的JS代码)
一种准确捕获网站当前在线访问者的方法
【摘要】本发明公开了一种准确获取网站当前在线访问者的方法,包括以下步骤:首先安装网站监控的JS代码:用于向监控服务器发送请求,返回数据 对于服务器,安装完成后,一旦浏览了被监控的网页,云平台就会将访问者的最后一次访问时间与当前时间进行比较。表示访问者属于当前在线访问者。采用本发明的技术方案,云平台比对访客的访问时间,在4s内减少了当前访客停留数据的误差,大大提高了当前在线访客的准确率。
【专利说明】一种准确获取网站当前在线访问者的方法
【技术领域】
[0001] 本发明涉及网络软件[技术领域],具体涉及一种准确获取网站当前在线访问者的方法。
【背景技术】
[0002] 随着网络上监控网站流量技术的飞速发展,对网站的监控内容的要求也越来越丰富和严格,尤其是对于网站@的当前在线访问者而言> 没有很好的方法监控,当客户觉得他们的网站访问量很小的时候,可以通过当前在线访问者的方法来获取当前有多少访问者访问你的网站,他们从哪里来从访问时间到多长时间,各种信息,如短、短等,都清楚地标明。如果您是老访客,可以查看您经常访问的客户群是什么类型的网站,方便客户有针对性地推广自己的产品。
[0003] IT行业中如何获取网站当前在线访问者的方法有很多,但没有准确的方法,所以目前在网站的监控技术中开发了这一类方法。的主要技术。
【发明内容】
本发明的目的是让网站浏览监控数据更准确、更实用,本发明通过云平台对访客访问时间进行对比,在4s内减少当前访客停留数据误差,大大提高准确性当前在线访问者的数量。
为实现上述技术目的,达到上述技术效果,本发明通过以下技术方案实现:
一种准确获取网站当前在线访问者的方法,包括以下步骤:
[0007] 步骤1)通过要监控的代码安装工具网站安装监控代码;
步骤2)云平台通过与访问者上次访问时间和当前时间的对比判断该访问者是否为当前在线访问者;
如果步骤3)不超过4s,则判断该访客信息为当前在线访客,如果后续访问时间仍不超过4s,则判断该访客没有离开网站 ,继续浏览,继续记录为当前在线访问者;
[0010]如果步骤4)超过4s,则确定访问者离开网站,不属于当前在线访问者。
本发明的有益效果是:
[0012] 本发明通过云平台对访客访问时间的比较,降低了当前访客停留数据在4s内的误差,大大提高了当前在线访客的准确率。
以上所述仅为本发明技术方案的概述,为了能够更清楚地理解本发明的技术手段,并能够按照说明书的内容进行实施,下面进行详细说明结合本发明的优选实施例并结合附图。后部。具体实施方式下面将详细给出实施例和附图。
【专利图纸】
【图纸说明】
[0014] 本文所描述的附图用于提供对本发明的进一步理解,并构成本申请的一部分,本发明的示例性实施例及其描述用于解释本发明,并不用于解释本发明。构成对本发明的不当限制。在附图中:
图1为本发明的流程示意图。【详细说明】
[0016] 下面结合附图并结合实施例对本发明进行详细说明。
参考图1所示,一种准确获取网站当前在线访问者的方法,包括以下步骤:
[0018] 步骤1)通过被监控代码安装工具网站安装监控代码;
步骤2)云平台通过与访问者上次访问时间和当前时间的对比判断该访问者是否为当前在线访问者;
如果步骤3)不超过4s,则将该访客信息设置为当前在线访客,如果后续访问时间仍不超过4s,则判断该访客没有离开网站 ,继续浏览,继续记录为当前在线访问者;
[0021] 如果步骤4)超过4s,则确定访问者离开网站,不属于当前在线访问者。
[0022] 以上所述仅为本发明的较佳实施例而已,并不用于限制本发明,对于本领域的技术人员来说,本发明可以有各种更改和变化。凡在本发明的精神和原则之内,所作的任何修改、等同替换、改进等,均应收录在本发明的保护范围之内。
【权利要求】
1.一种准确获取网站当前在线访问者的方法,其特征在于:包括以下步骤: 步骤1)通过被监控代码安装工具网站安装监控代码; Step2)云平台通过比较访问者上次访问时间与当前时间来判断访问者是否为当前在线访问者;步骤3)如果不超过4s,则判断访客信息为当前在线访客,如果后续访问时间仍不超过4s,则判断访客没有离开网站 @>,如果访问者继续浏览,则继续记录为当前在线访问者;步骤4)如果超过4s,则判断访客离开网站,不是当前在线访客。
【文件编号】H04L12/26GK103812717SQ2
【公示日期】2014年5月21日申请日期:2012年11月7日优先日期:2012年11月7日
【发明人】陈德洋、黄国建、李建中、高汉义、张峰、王章贤、范风华、朱平、齐明静申请人:
在线抓取网页( 一洽路由规则的应用原理是什么?如何设置多个路由)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-01-27 23:17
一洽路由规则的应用原理是什么?如何设置多个路由)
客服系统功能介绍-网页代码获取及具体路由规则
Yiqia支持多种路由策略,即通过设置不同的路由将会话分配到不同的组,展示不同的访客风格库。下面说一下具体的路由设置过程:
如下图,打开“设置”功能,找到“多路由策略”,点击“WEB路由”,就会出现创建好的路由规则。
单向路由规则的应用原理如下:
首先,我们将它命名以区分和识别它,然后设置所需的路由条件,然后选择样式和分组以接收该路由下的对话。另外,我们可以设置溢出组作为补充,因为路由条件可以设置更多,所以可以选择“单项满足”或者“全部满足”,这样设置完所有项后,配置一个路由规则完成。当一个对话框触发你设置的路由条件时,会立即使用相应的样式进行访问。前往对应的客服组(客服组内可以有一名或多名客服人员)进行接待。
点击右上角“新建规则”,打开设置页面,如下图: 我们可以看到常用的路由条件包括域名、搜索引擎、页面、访问者语言、访问者区域、搜索关键词和入口参数(一键支持自定义参数),这些路由条件可以选择设置一个或多个。下面详细描述每个路由条件。
1、按域名
点击编辑框,输入指定的域名(可以输入多个指定的域名),那么只要根据这个域名输入的访问者被系统识别,就会触发这条路由,访问者就会连接到指定的接收组。
2、根据搜索引擎
同样点击“搜索引擎”的编辑框,下拉框中有“好搜”、“百度”、“谷歌”、“必应”等常用搜索引擎。),那么只要识别出使用所选搜索引擎进入系统的访客,就会触发这条路线,并将访客连接到指定的接待组。
3、根据页面标题
我们还可以根据访问者访问的不同页面设置路由规则。顾名思义,路由规则是根据不同的页面标题设置的。另外,点击“页面标题”后,可以在输入框中输入指定的页面标题(可以选择多个页面)。),那么只要访客进入页面,就会触发这条路由访问指定的接待组。比如在电商公司,浏览产品页面的访问者,可以由专门从事产品咨询的技能组接待,如果浏览售后服务页面,则可以由专门从事产品咨询的技术组接待。促销过后。
4、按访客语言
根据访问者使用的浏览器的首选语言设置路由规则。点击“访客语言”后,编辑框中可以显示多种语言。选择对应的语言(可以选择多种语言),那么只要访问者的浏览器操作该路由选择的系统语言就会被识别。当然,也可以在网站上嵌入代码时指定语言。触发此路由的访问者将自动访问指定的语言。如果相应地设置了接待方式,就可以向访问者显示相应语言的界面和文字。
5、按地区
在“区域”的编辑框中有“省/自治区”和“市/县”的下拉框,可以选择指定的“省/自治区”或“市/县”(可以多个区域selected),则如果来自所选区域的访客将被识别并在进入系统时触发该路线,并将其分配到指定的接待组。如果相应地设置接收方式,则可以显示该区域的产品广告图像。
6、根据关键词
根据访问者搜索到的关键词设置路由规则,在“关键词”的编辑框中输入多个关键词,然后通过搜索相关的关键词输入网站@ > 访客将被系统识别并触发此路由,并进入指定的客服组。
7、根据入口参数:常用
“入口参数”可由企业自定义。先创建入口参数,然后在编辑框中填写相关参数(可以填写多个入口参数),那么只要触发入口参数的访问者对话框就会访问到这里指定的一个路由的接待组. 例如,企业可以自由设置参数,为进入网站30s的访客自动打开对话窗口等。入口参数的设置给了企业很大的自由度。这是目前企业使用最多的,因为定义简单方便。
例如:
下面以设置路由参数为例,说明如何创建路由和组织代码:
自定义参数路由,需要我们自己设置参数并获取代码。此操作方法将在此详细说明。
1、首先我们需要进入“技能组配置”菜单创建一个用于接收的组。
2、然后,进入“Multi-Routing Policy”菜单新建一个路由规则并随意命名,设置入口参数(如下图,我设置了一个入口参数名为“Test”) ,然后设置所需的接收组样式和接收,完成后单击“保存”。
ps:参数建议使用拼音或英文,避免浏览器或手机翻译中文
3、之后,进入“多通道接入”菜单,如下图,选择“路由标签”填写创建路由时设置的入口参数,必须与路由中的参数,然后点击“生成地址”。
4、生成的效果如下图所示。代码中已经生成了我设置的名为“Test”的路由参数,包括一千的网站代码和一千的对话地址的代码。
5、如果添加的频道无法添加系统js或者浏览时不需要识别访客信息,可以直接复制上图的对话地址。
6、如果网站想自定义咨询按钮,还需要识别正在浏览网站的访问者,将JS代码添加到网站,然后根据我们的对接文档调用系统js。具体文件见:
智能客服系统 查看全部
在线抓取网页(
一洽路由规则的应用原理是什么?如何设置多个路由)
客服系统功能介绍-网页代码获取及具体路由规则
Yiqia支持多种路由策略,即通过设置不同的路由将会话分配到不同的组,展示不同的访客风格库。下面说一下具体的路由设置过程:
如下图,打开“设置”功能,找到“多路由策略”,点击“WEB路由”,就会出现创建好的路由规则。
单向路由规则的应用原理如下:
首先,我们将它命名以区分和识别它,然后设置所需的路由条件,然后选择样式和分组以接收该路由下的对话。另外,我们可以设置溢出组作为补充,因为路由条件可以设置更多,所以可以选择“单项满足”或者“全部满足”,这样设置完所有项后,配置一个路由规则完成。当一个对话框触发你设置的路由条件时,会立即使用相应的样式进行访问。前往对应的客服组(客服组内可以有一名或多名客服人员)进行接待。
点击右上角“新建规则”,打开设置页面,如下图: 我们可以看到常用的路由条件包括域名、搜索引擎、页面、访问者语言、访问者区域、搜索关键词和入口参数(一键支持自定义参数),这些路由条件可以选择设置一个或多个。下面详细描述每个路由条件。
1、按域名
点击编辑框,输入指定的域名(可以输入多个指定的域名),那么只要根据这个域名输入的访问者被系统识别,就会触发这条路由,访问者就会连接到指定的接收组。
2、根据搜索引擎
同样点击“搜索引擎”的编辑框,下拉框中有“好搜”、“百度”、“谷歌”、“必应”等常用搜索引擎。),那么只要识别出使用所选搜索引擎进入系统的访客,就会触发这条路线,并将访客连接到指定的接待组。
3、根据页面标题
我们还可以根据访问者访问的不同页面设置路由规则。顾名思义,路由规则是根据不同的页面标题设置的。另外,点击“页面标题”后,可以在输入框中输入指定的页面标题(可以选择多个页面)。),那么只要访客进入页面,就会触发这条路由访问指定的接待组。比如在电商公司,浏览产品页面的访问者,可以由专门从事产品咨询的技能组接待,如果浏览售后服务页面,则可以由专门从事产品咨询的技术组接待。促销过后。
4、按访客语言
根据访问者使用的浏览器的首选语言设置路由规则。点击“访客语言”后,编辑框中可以显示多种语言。选择对应的语言(可以选择多种语言),那么只要访问者的浏览器操作该路由选择的系统语言就会被识别。当然,也可以在网站上嵌入代码时指定语言。触发此路由的访问者将自动访问指定的语言。如果相应地设置了接待方式,就可以向访问者显示相应语言的界面和文字。
5、按地区
在“区域”的编辑框中有“省/自治区”和“市/县”的下拉框,可以选择指定的“省/自治区”或“市/县”(可以多个区域selected),则如果来自所选区域的访客将被识别并在进入系统时触发该路线,并将其分配到指定的接待组。如果相应地设置接收方式,则可以显示该区域的产品广告图像。
6、根据关键词
根据访问者搜索到的关键词设置路由规则,在“关键词”的编辑框中输入多个关键词,然后通过搜索相关的关键词输入网站@ > 访客将被系统识别并触发此路由,并进入指定的客服组。
7、根据入口参数:常用
“入口参数”可由企业自定义。先创建入口参数,然后在编辑框中填写相关参数(可以填写多个入口参数),那么只要触发入口参数的访问者对话框就会访问到这里指定的一个路由的接待组. 例如,企业可以自由设置参数,为进入网站30s的访客自动打开对话窗口等。入口参数的设置给了企业很大的自由度。这是目前企业使用最多的,因为定义简单方便。
例如:
下面以设置路由参数为例,说明如何创建路由和组织代码:
自定义参数路由,需要我们自己设置参数并获取代码。此操作方法将在此详细说明。
1、首先我们需要进入“技能组配置”菜单创建一个用于接收的组。
2、然后,进入“Multi-Routing Policy”菜单新建一个路由规则并随意命名,设置入口参数(如下图,我设置了一个入口参数名为“Test”) ,然后设置所需的接收组样式和接收,完成后单击“保存”。
ps:参数建议使用拼音或英文,避免浏览器或手机翻译中文
3、之后,进入“多通道接入”菜单,如下图,选择“路由标签”填写创建路由时设置的入口参数,必须与路由中的参数,然后点击“生成地址”。
4、生成的效果如下图所示。代码中已经生成了我设置的名为“Test”的路由参数,包括一千的网站代码和一千的对话地址的代码。
5、如果添加的频道无法添加系统js或者浏览时不需要识别访客信息,可以直接复制上图的对话地址。
6、如果网站想自定义咨询按钮,还需要识别正在浏览网站的访问者,将JS代码添加到网站,然后根据我们的对接文档调用系统js。具体文件见:
智能客服系统

