
在线抓取网页
在线抓取网页(免费网页在线客服系统代码应该如何快速获取呢?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-10-03 08:01
大多数网站在建站初期都需要一个基于网络的在线客服系统,最直接的方式就是从网上获取一个免费的客服系统代码。很多人搜遍了,很难找到直接贴出来的代码。那么这个免费的网页在线客服系统代码应该如何快速获取呢?
免费网页在线客服系统代码获取方法
一、在线客服系统客户端下载
任何网页在线客服系统要获取页面代码,必须先下载客服软件客户端。注册账号并登录后,客户端会用你登录的账号生成对应的客服系统代码放入网站才可以实现,这里我们以快商通为例。
免费注册,快速获取客服系统代码
二、生成客服系统代码
找到设置中心-生成码,进入后马上就可以得到我们想要的网页在线客服系统码。因为快商通可以永久免费供用户使用,据说用这串代码生成网页的在线客服系统可以正常使用,无需支付任何费用。
把这行代码复制到你要生成的web客服系统的页面代码中即可。如果要在整个站点上生成它,请将其复制到页脚文件中。一般来说,公司希望不同的站点使用不同的在线客服系统代码,只要他们创建一个新站点然后生成JS代码即可。
免费在线客服系统稳定吗?
网页在线客服系统的稳定性取决于服务商为客服系统使用的服务器的质量以及客服系统本身代码水平的完善程度。
市场上的免费网络在线客服系统大多使用与其付费版本相同的一套软件代码,但限制了功能的使用,而不是两个不同版本的软件。换句话说,如果付费版的客服系统足够稳定,那么免费版也是稳定的,只是功能上的区别。
总结:
无论是免费的网页在线客服系统代码还是收费的,都需要先下载客服系统客户端,然后通过客户端生成代码并复制到网页中才能生效。并且每个code在参数里都有对应的site绑定,也就是说,拿一串免费的网页在线客服系统code是不通用的。 查看全部
在线抓取网页(免费网页在线客服系统代码应该如何快速获取呢?(图))
大多数网站在建站初期都需要一个基于网络的在线客服系统,最直接的方式就是从网上获取一个免费的客服系统代码。很多人搜遍了,很难找到直接贴出来的代码。那么这个免费的网页在线客服系统代码应该如何快速获取呢?
免费网页在线客服系统代码获取方法
一、在线客服系统客户端下载
任何网页在线客服系统要获取页面代码,必须先下载客服软件客户端。注册账号并登录后,客户端会用你登录的账号生成对应的客服系统代码放入网站才可以实现,这里我们以快商通为例。
免费注册,快速获取客服系统代码
二、生成客服系统代码
找到设置中心-生成码,进入后马上就可以得到我们想要的网页在线客服系统码。因为快商通可以永久免费供用户使用,据说用这串代码生成网页的在线客服系统可以正常使用,无需支付任何费用。
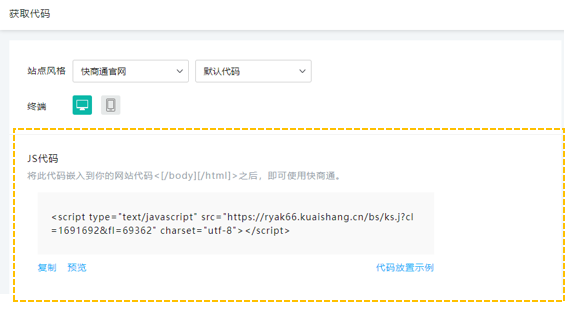
把这行代码复制到你要生成的web客服系统的页面代码中即可。如果要在整个站点上生成它,请将其复制到页脚文件中。一般来说,公司希望不同的站点使用不同的在线客服系统代码,只要他们创建一个新站点然后生成JS代码即可。
免费在线客服系统稳定吗?
网页在线客服系统的稳定性取决于服务商为客服系统使用的服务器的质量以及客服系统本身代码水平的完善程度。
市场上的免费网络在线客服系统大多使用与其付费版本相同的一套软件代码,但限制了功能的使用,而不是两个不同版本的软件。换句话说,如果付费版的客服系统足够稳定,那么免费版也是稳定的,只是功能上的区别。
总结:
无论是免费的网页在线客服系统代码还是收费的,都需要先下载客服系统客户端,然后通过客户端生成代码并复制到网页中才能生效。并且每个code在参数里都有对应的site绑定,也就是说,拿一串免费的网页在线客服系统code是不通用的。
在线抓取网页(几近一个的抓取与收录、收录的演讲内容以及要点概括)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-10-02 04:13
许多关于网站的结构、爬取和收录,甚至排名的问题都可以归结为一个核心问题,那就是:搜索引擎爬取你的网站有多容易?我们在最近的几个事件中讨论了这个话题。下面你将看到我们关于这个问题的演讲内容和主要观点的总结。
网络世界是巨大的;每时每刻都在产生新的内容。谷歌自己的资源是有限的。当面对几乎无穷无尽的网络内容时,Googlebot 只能查找和抓取一定比例的内容。然后,我们只能索引我们抓取的部分内容。
URL就像网站和搜索引擎爬虫之间的桥梁:为了能够抓取你的内容网站,爬虫需要能够找到并跨越这些桥梁(即找到并抓取你的URLs )。如果你的 URL 很复杂或者很长,爬虫就不得不花时间反复跟踪这些 URL;如果你的 URL 是常规的并且直接指向你的独特内容,那么爬虫可以专注于理解你的内容,而不是仅仅抓取空网页或被不同的 URL 引导,最终抓取的是相同的重复内容。
在上面的幻灯片中,您可以看到一些我们应该避免的反例——这些都是现实中存在的 URL 的示例(尽管出于隐私原因,它们的名称已被替换),这些示例包括被黑的 URL 和编码、伪装成一部分的冗余参数URL 路径、无限爬取空间等,您还可以找到一些建议,帮助您理顺这些 URL 迷宫,帮助爬虫更快更好地找到您的内容,包括:
1)去除URL中的用户相关参数
URL 中不影响网页内容的参数——例如会话 ID 或排序参数——可以从 URL 中删除并由 cookie 记录。通过将此信息添加到 cookie,然后 301 重定向到“干净”的 URL,您可以保留原创内容并减少指向相同内容的 URL 数量。
控制无限空间
你的网站上有日历吗,上面的链接指向无数过去和未来的日期(每个链接地址都是唯一的二)?你的网页地址是不是加了一个&page = 3563参数后,还可以返回200个代码,即使根本没有那么多页面?如果这样的话,你的网站上就会出现所谓的“无限空间”。这种情况会浪费爬虫机器人和你的带宽网站.如何控制“无限空间”,请参考这里的一些技巧。
2)防止 Google 抓取工具抓取它们无法处理的页面
通过使用您的 robots.txt 文件,您可以防止您的登录页面、联系信息、购物车和其他爬虫无法处理的页面被抓取。(爬行动物以吝啬和害羞着称,所以一般不会“添加商品到购物车”或“联系我们”)。这样,你可以让爬虫花更多的时间在你的网站上爬取他们能处理的东西。
一人一票。一个网址,一段内容
在理想的世界中,URL 和内容是一一对应的:每个 URL 对应一个唯一的内容,每个内容只能通过唯一的 URL 访问。越接近这种理想情况,您的 网站 就越容易被捕获和 收录。如果您的内容管理系统或当前的网站 建立难以实施,您可以尝试使用 rel=canonical 元素来设置您要用于指示特定内容的 URL。 查看全部
在线抓取网页(几近一个的抓取与收录、收录的演讲内容以及要点概括)
许多关于网站的结构、爬取和收录,甚至排名的问题都可以归结为一个核心问题,那就是:搜索引擎爬取你的网站有多容易?我们在最近的几个事件中讨论了这个话题。下面你将看到我们关于这个问题的演讲内容和主要观点的总结。
网络世界是巨大的;每时每刻都在产生新的内容。谷歌自己的资源是有限的。当面对几乎无穷无尽的网络内容时,Googlebot 只能查找和抓取一定比例的内容。然后,我们只能索引我们抓取的部分内容。
URL就像网站和搜索引擎爬虫之间的桥梁:为了能够抓取你的内容网站,爬虫需要能够找到并跨越这些桥梁(即找到并抓取你的URLs )。如果你的 URL 很复杂或者很长,爬虫就不得不花时间反复跟踪这些 URL;如果你的 URL 是常规的并且直接指向你的独特内容,那么爬虫可以专注于理解你的内容,而不是仅仅抓取空网页或被不同的 URL 引导,最终抓取的是相同的重复内容。
在上面的幻灯片中,您可以看到一些我们应该避免的反例——这些都是现实中存在的 URL 的示例(尽管出于隐私原因,它们的名称已被替换),这些示例包括被黑的 URL 和编码、伪装成一部分的冗余参数URL 路径、无限爬取空间等,您还可以找到一些建议,帮助您理顺这些 URL 迷宫,帮助爬虫更快更好地找到您的内容,包括:
1)去除URL中的用户相关参数
URL 中不影响网页内容的参数——例如会话 ID 或排序参数——可以从 URL 中删除并由 cookie 记录。通过将此信息添加到 cookie,然后 301 重定向到“干净”的 URL,您可以保留原创内容并减少指向相同内容的 URL 数量。
控制无限空间
你的网站上有日历吗,上面的链接指向无数过去和未来的日期(每个链接地址都是唯一的二)?你的网页地址是不是加了一个&page = 3563参数后,还可以返回200个代码,即使根本没有那么多页面?如果这样的话,你的网站上就会出现所谓的“无限空间”。这种情况会浪费爬虫机器人和你的带宽网站.如何控制“无限空间”,请参考这里的一些技巧。
2)防止 Google 抓取工具抓取它们无法处理的页面
通过使用您的 robots.txt 文件,您可以防止您的登录页面、联系信息、购物车和其他爬虫无法处理的页面被抓取。(爬行动物以吝啬和害羞着称,所以一般不会“添加商品到购物车”或“联系我们”)。这样,你可以让爬虫花更多的时间在你的网站上爬取他们能处理的东西。
一人一票。一个网址,一段内容
在理想的世界中,URL 和内容是一一对应的:每个 URL 对应一个唯一的内容,每个内容只能通过唯一的 URL 访问。越接近这种理想情况,您的 网站 就越容易被捕获和 收录。如果您的内容管理系统或当前的网站 建立难以实施,您可以尝试使用 rel=canonical 元素来设置您要用于指示特定内容的 URL。
在线抓取网页(网络监听有如下几种方法:在线抓取网页地址的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-10-01 17:02
在线抓取网页地址的方法有好几种,普通的http协议的抓取有很多抓包软件,也有现成的.net抓包工具,eclipse也可以抓包,https的抓包可以从终端命令行得到地址信息,登录浏览器网址输入,然后输入抓包工具里的getencode、getencoding、getencolor即可获取请求地址的值。网络监听有如下几种方法:。
一、用windows自带的网络监听;
二、抓包三段式,首先抓取动态网页地址,
三、不同的网络上通过代理服务器抓取https地址;
四、二进制文件处理,用python读取然后转为png或者jpg(虽然这些方法都是很不安全的,但是很多时候做个跳板是很好用的)。
百度提供的抓包工具比起http的那些抓包工具,简直是小巫见大巫啊。你在百度上搜“抓包”,第一个搜索结果就是抓包工具,分分钟秒杀!一个比一个强大,满满的都是干货啊!比如,有自动抓包的工具等,绝对无法媲美的抓包!!!我是彭老师,
天天抓包,就用drupal/fastcomet方便实用。
推荐你用开源的httpscheme或者xmlhttprequest
ultraiso可以抓
用chrome浏览器搜索,
其实直接windowscmd界面上copy地址进去也可以. 查看全部
在线抓取网页(网络监听有如下几种方法:在线抓取网页地址的方法)
在线抓取网页地址的方法有好几种,普通的http协议的抓取有很多抓包软件,也有现成的.net抓包工具,eclipse也可以抓包,https的抓包可以从终端命令行得到地址信息,登录浏览器网址输入,然后输入抓包工具里的getencode、getencoding、getencolor即可获取请求地址的值。网络监听有如下几种方法:。
一、用windows自带的网络监听;
二、抓包三段式,首先抓取动态网页地址,
三、不同的网络上通过代理服务器抓取https地址;
四、二进制文件处理,用python读取然后转为png或者jpg(虽然这些方法都是很不安全的,但是很多时候做个跳板是很好用的)。
百度提供的抓包工具比起http的那些抓包工具,简直是小巫见大巫啊。你在百度上搜“抓包”,第一个搜索结果就是抓包工具,分分钟秒杀!一个比一个强大,满满的都是干货啊!比如,有自动抓包的工具等,绝对无法媲美的抓包!!!我是彭老师,
天天抓包,就用drupal/fastcomet方便实用。
推荐你用开源的httpscheme或者xmlhttprequest
ultraiso可以抓
用chrome浏览器搜索,
其实直接windowscmd界面上copy地址进去也可以.
在线抓取网页( Python实现抓取网页并且解析的功能实例,(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-09-28 15:27
Python实现抓取网页并且解析的功能实例,(图))
爬取网页和解析示例的Python实现
更新时间:2014-09-20 17:39:07 投稿:shichen2014
本文文章主要介绍Python对网页抓取和解析功能实例的实现。主要以百度问答的分析为例,说明其原理和方法。有需要的朋友可以参考以下
本文以示例的形式介绍了Python中网页的爬取和解析功能。主要分析问答和百度首页。分享给大家,供大家参考。
主要功能代码如下:
#!/usr/bin/python
#coding=utf-8
import sys
import re
import urllib2
from urllib import urlencode
from urllib import quote
import time
maxline = 2000
wenda = re.compile("href=\"http://wenda.so.com/q/.+\?src=(.+?)\"")
baidu = re.compile("<a href=\"http://www.baidu.com/link\?url=.+\".*?>更多知道相关问题.*?</a>")
f1 = open("baidupage.txt","w")
f2 = open("wendapage.txt","w")
for line in sys.stdin:
if maxline == 0:
break
query = line.strip();
time.sleep(1);
recall_url = "http://www.so.com/s?&q=" + query;
response = urllib2.urlopen(recall_url);
html = response.read();
f1.write(html)
m = wenda.search(html);
if m:
if m.group(1) == "110":
print query + "\twenda\t0";
else:
print query + "\twenda\t1";
else:
print query + "\twenda\t0";
recall_url = "http://www.baidu.com/s?wd=" + query +"&ie=utf-8";
response = urllib2.urlopen(recall_url);
html = response.read();
f2.write(html)
m = baidu.search(html);
if m:
print query + "\tbaidu\t1";
else:
print query + "\tbaidu\t0";
maxline = maxline - 1;
f1.close()
f2.close()
我希望这篇文章能帮助你学习 Python 编程。 查看全部
在线抓取网页(
Python实现抓取网页并且解析的功能实例,(图))
爬取网页和解析示例的Python实现
更新时间:2014-09-20 17:39:07 投稿:shichen2014
本文文章主要介绍Python对网页抓取和解析功能实例的实现。主要以百度问答的分析为例,说明其原理和方法。有需要的朋友可以参考以下
本文以示例的形式介绍了Python中网页的爬取和解析功能。主要分析问答和百度首页。分享给大家,供大家参考。
主要功能代码如下:
#!/usr/bin/python
#coding=utf-8
import sys
import re
import urllib2
from urllib import urlencode
from urllib import quote
import time
maxline = 2000
wenda = re.compile("href=\"http://wenda.so.com/q/.+\?src=(.+?)\"")
baidu = re.compile("<a href=\"http://www.baidu.com/link\?url=.+\".*?>更多知道相关问题.*?</a>")
f1 = open("baidupage.txt","w")
f2 = open("wendapage.txt","w")
for line in sys.stdin:
if maxline == 0:
break
query = line.strip();
time.sleep(1);
recall_url = "http://www.so.com/s?&q=" + query;
response = urllib2.urlopen(recall_url);
html = response.read();
f1.write(html)
m = wenda.search(html);
if m:
if m.group(1) == "110":
print query + "\twenda\t0";
else:
print query + "\twenda\t1";
else:
print query + "\twenda\t0";
recall_url = "http://www.baidu.com/s?wd=" + query +"&ie=utf-8";
response = urllib2.urlopen(recall_url);
html = response.read();
f2.write(html)
m = baidu.search(html);
if m:
print query + "\tbaidu\t1";
else:
print query + "\tbaidu\t0";
maxline = maxline - 1;
f1.close()
f2.close()
我希望这篇文章能帮助你学习 Python 编程。
在线抓取网页(如何使用这个类来抓取网页中需要的信息?运行结果)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-09-23 20:27
云翔在线聊天室提供在线聊天室,WEBIM,网络磁盘和其他服务,WEBIM可以免费建立一个组(无限数),聊天日志在线存储。
当您之前做聊天室时,由于聊天室中的新闻读取的功能,您从网页中写了一类(例如最新的标题新闻,新闻来源,标题,内容等。),本文如何使用此类来捕获网页中所需的信息。本文将拍摄博客标题和Blogguan主页的链接作为示例:
图片显示博客花园主页的DOM树。很明显,只有班级是post_item的div,然后从TileLnk的一旗中提取类。此类功能可以通过以下功能实现:
///
/// 在文本html的文本查找标志名为tagName,并且属性attrName的值为attrValue的所有标志
/// 例如:FindTagByAttr(html, "div", "class", "demo")
/// 返回所有class为demo的div标志
///
public static List FindTagByAttr(String html, String tagName, String attrName, String attrValue)
{
String format = String.Format(@"", tagName, attrName, attrValue);
return FindTag(html, tagName, format);
}
public static List FindTag(String html, String name, String format)
{
Regex reg = new Regex(format, RegexOptions.IgnoreCase);
Regex tagReg = new Regex(String.Format(@"", name), RegexOptions.IgnoreCase);
List tags = new List();
int start = 0;
while (true)
{
Match match = reg.Match(html, start);
if (match.Success)
{
start = match.Index + match.Length;
Match tagMatch = null;
int beginTagCount = 1;
while (true)
{
tagMatch = tagReg.Match(html, start);
if (!tagMatch.Success)
{
tagMatch = null;
break;
}
start = tagMatch.Index + tagMatch.Length;
if (tagMatch.Groups[1].Value == "/") beginTagCount--;
else beginTagCount++;
if (beginTagCount == 0) break;
}
if (tagMatch != null)
{
HtmlTag tag = new HtmlTag(name, match.Value, html.Substring(match.Index + match.Length, tagMatch.Index - match.Index - match.Length));
tags.Add(tag);
}
else
{
break;
}
}
else
{
break;
}
}
return tags;
}
使用上述功能,您可以提取所需的HTML标志。为实现,您需要下载下载Web的功能:
public static String GetHtml(string url)
{
try
{
HttpWebRequest req = HttpWebRequest.Create(url) as HttpWebRequest;
req.Timeout = 30 * 1000;
HttpWebResponse response = req.GetResponse() as HttpWebResponse;
Stream stream = response.GetResponseStream();
MemoryStream buffer = new MemoryStream();
Byte[] temp = new Byte[4096];
int count = 0;
while ((count = stream.Read(temp, 0, 4096)) > 0)
{
buffer.Write(temp, 0, count);
}
return Encoding.GetEncoding(response.CharacterSet).GetString(buffer.GetBuffer());
}
catch
{
return String.Empty;
}
}
以下要获取文章标题和博客主页的链接作为一个例子,介绍如何使用htmltag类来捕获Web信息:
class Program
{
static void Main(string[] args)
{
String html = HtmlTag.GetHtml("http://www.cnblogs.com");
List tags = HtmlTag.FindTagByAttr(html, "div", "id", "post_list");
if (tags.Count > 0)
{
List item_tags = tags[0].FindTagByAttr("div", "class", "post_item");
foreach (HtmlTag item_tag in item_tags)
{
List a_tags = item_tag.FindTagByAttr("a", "class", "titlelnk");
if (a_tags.Count > 0)
{
Console.WriteLine("标题:{0}", a_tags[0].InnerHTML);
Console.WriteLine("链接:{0}", a_tags[0].GetAttribute("href"));
Console.WriteLine("");
}
}
}
}
}
结果如下:
源代码下载 查看全部
在线抓取网页(如何使用这个类来抓取网页中需要的信息?运行结果)
云翔在线聊天室提供在线聊天室,WEBIM,网络磁盘和其他服务,WEBIM可以免费建立一个组(无限数),聊天日志在线存储。
当您之前做聊天室时,由于聊天室中的新闻读取的功能,您从网页中写了一类(例如最新的标题新闻,新闻来源,标题,内容等。),本文如何使用此类来捕获网页中所需的信息。本文将拍摄博客标题和Blogguan主页的链接作为示例:

图片显示博客花园主页的DOM树。很明显,只有班级是post_item的div,然后从TileLnk的一旗中提取类。此类功能可以通过以下功能实现:
///
/// 在文本html的文本查找标志名为tagName,并且属性attrName的值为attrValue的所有标志
/// 例如:FindTagByAttr(html, "div", "class", "demo")
/// 返回所有class为demo的div标志
///
public static List FindTagByAttr(String html, String tagName, String attrName, String attrValue)
{
String format = String.Format(@"", tagName, attrName, attrValue);
return FindTag(html, tagName, format);
}
public static List FindTag(String html, String name, String format)
{
Regex reg = new Regex(format, RegexOptions.IgnoreCase);
Regex tagReg = new Regex(String.Format(@"", name), RegexOptions.IgnoreCase);
List tags = new List();
int start = 0;
while (true)
{
Match match = reg.Match(html, start);
if (match.Success)
{
start = match.Index + match.Length;
Match tagMatch = null;
int beginTagCount = 1;
while (true)
{
tagMatch = tagReg.Match(html, start);
if (!tagMatch.Success)
{
tagMatch = null;
break;
}
start = tagMatch.Index + tagMatch.Length;
if (tagMatch.Groups[1].Value == "/") beginTagCount--;
else beginTagCount++;
if (beginTagCount == 0) break;
}
if (tagMatch != null)
{
HtmlTag tag = new HtmlTag(name, match.Value, html.Substring(match.Index + match.Length, tagMatch.Index - match.Index - match.Length));
tags.Add(tag);
}
else
{
break;
}
}
else
{
break;
}
}
return tags;
}
使用上述功能,您可以提取所需的HTML标志。为实现,您需要下载下载Web的功能:
public static String GetHtml(string url)
{
try
{
HttpWebRequest req = HttpWebRequest.Create(url) as HttpWebRequest;
req.Timeout = 30 * 1000;
HttpWebResponse response = req.GetResponse() as HttpWebResponse;
Stream stream = response.GetResponseStream();
MemoryStream buffer = new MemoryStream();
Byte[] temp = new Byte[4096];
int count = 0;
while ((count = stream.Read(temp, 0, 4096)) > 0)
{
buffer.Write(temp, 0, count);
}
return Encoding.GetEncoding(response.CharacterSet).GetString(buffer.GetBuffer());
}
catch
{
return String.Empty;
}
}
以下要获取文章标题和博客主页的链接作为一个例子,介绍如何使用htmltag类来捕获Web信息:
class Program
{
static void Main(string[] args)
{
String html = HtmlTag.GetHtml("http://www.cnblogs.com";);
List tags = HtmlTag.FindTagByAttr(html, "div", "id", "post_list");
if (tags.Count > 0)
{
List item_tags = tags[0].FindTagByAttr("div", "class", "post_item");
foreach (HtmlTag item_tag in item_tags)
{
List a_tags = item_tag.FindTagByAttr("a", "class", "titlelnk");
if (a_tags.Count > 0)
{
Console.WriteLine("标题:{0}", a_tags[0].InnerHTML);
Console.WriteLine("链接:{0}", a_tags[0].GetAttribute("href"));
Console.WriteLine("");
}
}
}
}
}
结果如下:

源代码下载
在线抓取网页(抓取网站,模拟登陆,抓取动态网页的原理和实现)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-09-23 20:25
网站的详细解释,模拟的原理和实现的动态网页(Python和C#等)版本:V□的1. 1 crifan里摘要本文主要介绍了抓网站,模拟登录,履带逻辑,原理以及如何实现相关的动态网页。主要包括:如何使用相应的网络分析工具,如相应的网页分析工具,如F12,铬按Ctrl + Shift + J,Firefox的萤火虫,如IE9,火狐的萤火来分析相应的逻辑网站,模拟登录,抢动态网页,都给出一个完整可用的,多语言的示例代码:Python和C#,Java的,围棋等,提供多种格式:在线阅读HTML下载(7ZIP压缩包)HTML PDF10 CHM 11 TXT 12 RTF在线地址的13 WebHelp的14 HTML的版本是:scrape_emulate_login.html有任何意见,建议,提交bug等.Webhelp.7z修订历史修订@ 1. 1 2013年9月22日CRL添加新的岗位链接:模拟登录百度的Java版本,围棋语言版本的详细抢网站,模拟登录,抢动态网页和执行(Python和C#Crifanli版本的原则:v□的1. 1日发布2013-09- 22版权所有2013crifan,这个文章遵:署名 - 非商业性我们Einstein @ Home2. 5中国大陆(CC BY-NC 2.5)@ 15 @ 15 #cc_by_nc IV目录前言3.1.@ @(多语言实现)模拟登录百度@ K272.@ @(多语言实现)模拟登陆GOGOLE 4.1.@ @抢动态网页例如:网易163博客心情美文FeelingCard本文本文,如何让逻辑和具体实现从无到有的动态网页,了解登录,并抓住逻辑和具体实施动态网页。
网站爬网,模拟登录,爬行动态网页的旧文章如何使用Python,C#等语言来实现静态网页+捕捉动态网页+模拟登录网站 [相关的通用逻辑整理]每个开发人员在浏览器DeveloperTools:IE9 F12,铬按Ctrl + Shift + J,火狐萤火虫[解决]字符集格式(GB2312,GBK,UTF-8,ISO8859- 1等)的说明[订购]幅抓斗,模拟登录,抢动态Web内容等,头部的信息,cookie信息,数据后处理逻辑相关的老帖[教程]抓住网络并提取网页如何模拟信息登录到登录网站需要,给予更多的例子:3.1.@ @(多语言实现)模拟登录百度第一次使用工具分析逻辑:[教程]教你如何使用它的工具(IE9 F1 2)去分析模模模过程过程过程版版版版版版版版版模】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】实现登录百度模拟@ K272.@ @(MUL tiple语言实现)模拟登陆gogole,也拿到了,模拟登陆谷歌:[记录]模拟登录谷歌去看看:[教程]如何捕捉如何捕捉采取动态网页内容了解,抓取动态网页的逻辑。转到下面的例子:4.1.@ @捕捉动态网页例如:网易163博客心随FeelingCard [记录]添加支持blogstowordpress网易心情随笔导出到捕捉静态或动态网页和模拟登录,并总结相关的旧帖子[概要]静态web抓斗,动态网页,模拟登录的预防措施和经验 查看全部
在线抓取网页(抓取网站,模拟登陆,抓取动态网页的原理和实现)
网站的详细解释,模拟的原理和实现的动态网页(Python和C#等)版本:V□的1. 1 crifan里摘要本文主要介绍了抓网站,模拟登录,履带逻辑,原理以及如何实现相关的动态网页。主要包括:如何使用相应的网络分析工具,如相应的网页分析工具,如F12,铬按Ctrl + Shift + J,Firefox的萤火虫,如IE9,火狐的萤火来分析相应的逻辑网站,模拟登录,抢动态网页,都给出一个完整可用的,多语言的示例代码:Python和C#,Java的,围棋等,提供多种格式:在线阅读HTML下载(7ZIP压缩包)HTML PDF10 CHM 11 TXT 12 RTF在线地址的13 WebHelp的14 HTML的版本是:scrape_emulate_login.html有任何意见,建议,提交bug等.Webhelp.7z修订历史修订@ 1. 1 2013年9月22日CRL添加新的岗位链接:模拟登录百度的Java版本,围棋语言版本的详细抢网站,模拟登录,抢动态网页和执行(Python和C#Crifanli版本的原则:v□的1. 1日发布2013-09- 22版权所有2013crifan,这个文章遵:署名 - 非商业性我们Einstein @ Home2. 5中国大陆(CC BY-NC 2.5)@ 15 @ 15 #cc_by_nc IV目录前言3.1.@ @(多语言实现)模拟登录百度@ K272.@ @(多语言实现)模拟登陆GOGOLE 4.1.@ @抢动态网页例如:网易163博客心情美文FeelingCard本文本文,如何让逻辑和具体实现从无到有的动态网页,了解登录,并抓住逻辑和具体实施动态网页。
网站爬网,模拟登录,爬行动态网页的旧文章如何使用Python,C#等语言来实现静态网页+捕捉动态网页+模拟登录网站 [相关的通用逻辑整理]每个开发人员在浏览器DeveloperTools:IE9 F12,铬按Ctrl + Shift + J,火狐萤火虫[解决]字符集格式(GB2312,GBK,UTF-8,ISO8859- 1等)的说明[订购]幅抓斗,模拟登录,抢动态Web内容等,头部的信息,cookie信息,数据后处理逻辑相关的老帖[教程]抓住网络并提取网页如何模拟信息登录到登录网站需要,给予更多的例子:3.1.@ @(多语言实现)模拟登录百度第一次使用工具分析逻辑:[教程]教你如何使用它的工具(IE9 F1 2)去分析模模模过程过程过程版版版版版版版版版模】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】实现登录百度模拟@ K272.@ @(MUL tiple语言实现)模拟登陆gogole,也拿到了,模拟登陆谷歌:[记录]模拟登录谷歌去看看:[教程]如何捕捉如何捕捉采取动态网页内容了解,抓取动态网页的逻辑。转到下面的例子:4.1.@ @捕捉动态网页例如:网易163博客心随FeelingCard [记录]添加支持blogstowordpress网易心情随笔导出到捕捉静态或动态网页和模拟登录,并总结相关的旧帖子[概要]静态web抓斗,动态网页,模拟登录的预防措施和经验
在线抓取网页(说到“网站地图”生成软件生成工具,一个本地)
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-09-20 08:11
前言:
说到“网站map”,我相信很多SEOER或网站管理员不会感到奇怪,网站map对于搜索引擎和用户来说非常重要
网站map只是一个收录几乎所有网站链接的页面。它为搜索引擎和用户提供了清晰的网站体系结构和内容,并改进了网站高质量内容页面的捕获和收录
然而,许多在线工具已经试用过了。有的广告数量众多,有的不够专业,有的功能有限,比如只抓拍不到200个网站。这里推荐两种不同的方法网站sitemap生成工具,一个用于本地,一个用于在线网站use
1、网站地图在线生成工具
单击以输入XML-sitemaps网站
① 点击以上按钮进入网站地图在线生成页面,填写网站,点击“开始”进行扫描
② 此在线站点可以捕获网站的所有连接,适用于HTTPS协议网站。以下是一个测试屏幕截图,在阅读进度条后完成
注:国外is网站站太低。如果太滞后,你可以在中国尝试同样类型的网站map站点地图:点击网站. p>
2、tiger站点地图生成器
这是一个绿色和简单的网站地图生成软件。操作简单易懂。主要原因是没有像其他软件一样的限制,没有对URL数量的限制,也没有广告。唯一的缺点是该软件无法捕获HTTPS协议网站,HTTPS网站如果您需要生成站点地图,建议使用上面的在线生成方法
① 建立项目并进行相关设置。设置非常简单。你一眼就能看到它们。如果你不明白,试着自己找出答案
② 设置完成后,点击“开始”,可以看到整个捕获过程。完成后,将自动保存在set目录文件夹中
Tiger站点地图生成器软件下载:
下载地址 查看全部
在线抓取网页(说到“网站地图”生成软件生成工具,一个本地)
前言:
说到“网站map”,我相信很多SEOER或网站管理员不会感到奇怪,网站map对于搜索引擎和用户来说非常重要
网站map只是一个收录几乎所有网站链接的页面。它为搜索引擎和用户提供了清晰的网站体系结构和内容,并改进了网站高质量内容页面的捕获和收录
然而,许多在线工具已经试用过了。有的广告数量众多,有的不够专业,有的功能有限,比如只抓拍不到200个网站。这里推荐两种不同的方法网站sitemap生成工具,一个用于本地,一个用于在线网站use
1、网站地图在线生成工具
单击以输入XML-sitemaps网站
① 点击以上按钮进入网站地图在线生成页面,填写网站,点击“开始”进行扫描

② 此在线站点可以捕获网站的所有连接,适用于HTTPS协议网站。以下是一个测试屏幕截图,在阅读进度条后完成

注:国外is网站站太低。如果太滞后,你可以在中国尝试同样类型的网站map站点地图:点击网站. p>
2、tiger站点地图生成器
这是一个绿色和简单的网站地图生成软件。操作简单易懂。主要原因是没有像其他软件一样的限制,没有对URL数量的限制,也没有广告。唯一的缺点是该软件无法捕获HTTPS协议网站,HTTPS网站如果您需要生成站点地图,建议使用上面的在线生成方法
① 建立项目并进行相关设置。设置非常简单。你一眼就能看到它们。如果你不明白,试着自己找出答案

② 设置完成后,点击“开始”,可以看到整个捕获过程。完成后,将自动保存在set目录文件夹中

Tiger站点地图生成器软件下载:
下载地址
在线抓取网页(初识webscraper开发人员安装方式(图):请输入图片描述本地)
网站优化 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-09-20 08:05
Web scraper是一个免费的爬虫工具,面向普通用户(不需要专业IT技术)。它可以通过鼠标和简单的配置轻松获得您想要的数据。例如知乎答案列表、热门微博、微博评论、电商网站产品信息、博客文章列表等
安装过程
在线安装模式
在线安装需要FQ网络和访问chrome应用商店
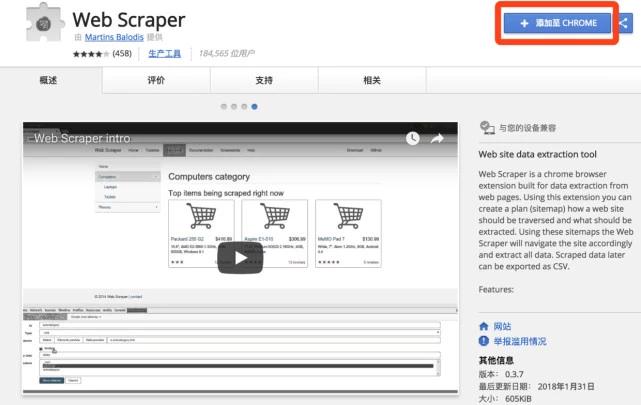
1、在线访问web scraper插件并单击“添加到chrome”
请输入图片描述
2、然后在弹出框中单击“添加扩展”
请输入图片描述
3、安装完成后,顶部工具栏中会显示刮网器图标
请输入图片描述
本地安装模式
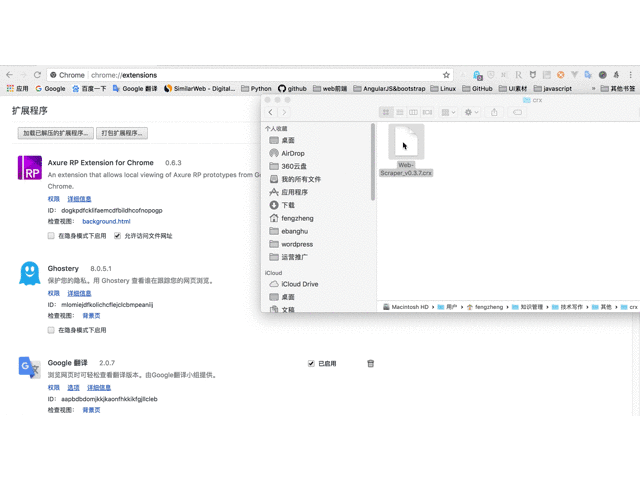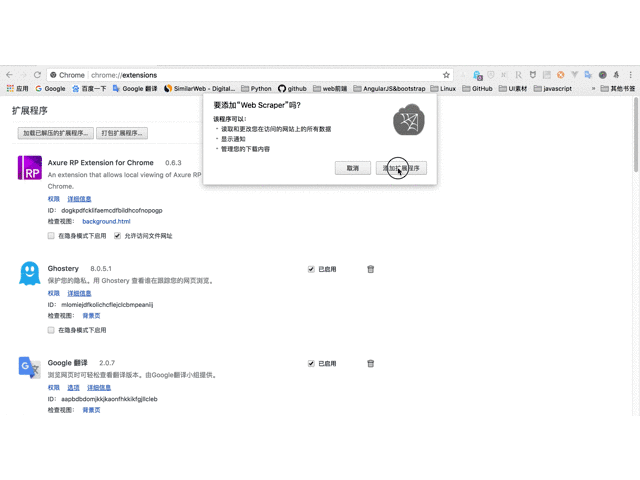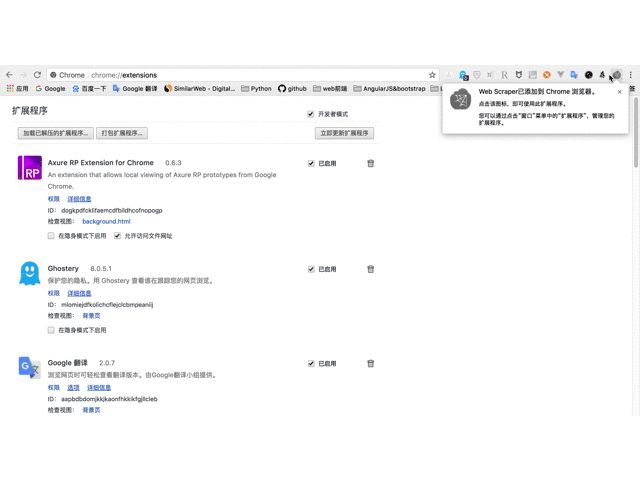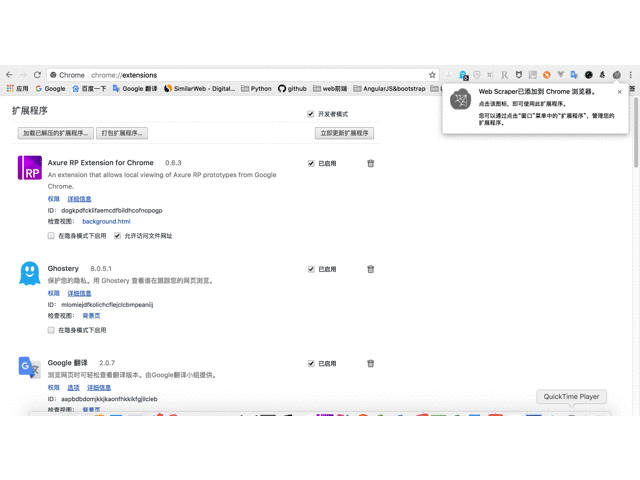
1、打开chrome并在地址栏中输入chrome://extensions/ ,进入扩展管理界面,然后下载扩展webv0.3.@7.crx拖到此页并单击“添加到扩展”以完成安装。如图所示:
请输入图片描述
2、安装完成后,顶部工具栏中会显示刮网器图标
${{2}$
请输入图片描述
了解网络刮刀
开式刮板机
开发人员可以路过并回头看
快捷键F12可在Windows系统下使用。某些型号的笔记本电脑需要按FN+F12
在MAC系统下,您可以使用快捷键command+option+I
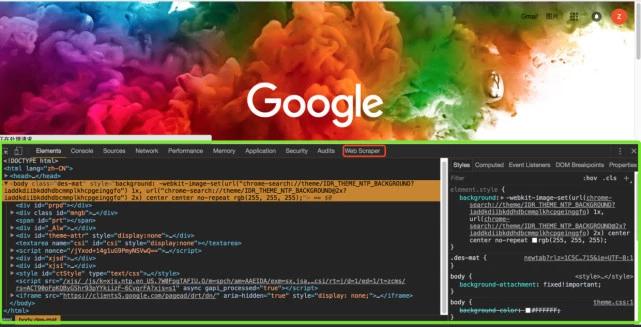
您也可以直接在chrome界面上操作,然后单击设置->;更多工具->;开发工具
请输入图片描述
打开后的效果如下。绿框部分是开发工具的完整界面,红框部分是web刮板区域,也就是我们以后要操作的部分
请输入图片描述
注意:如果在浏览器的右侧区域打开“开发人员”工具,则需要将“开发人员”工具的位置调整到浏览器的底部
请输入图片描述
原理与功能描述
数据爬网的思想可以概括如下:
1、通过一个或多个入口地址获取初始数据。例如,文章list页面,或具有特定规则的页面,例如具有分页的列表页面
2、根据进入页面的一些信息,如链接指向,进入下一级页面以获取必要的信息
3、根据上一级的链接,继续下一级以获取必要的信息(此步骤可以无限循环)
原理大致相同。接下来,让我们正式了解web scraper工具。打开developer工具,单击Web scraper的选项卡栏,可以看到它分为三个部分:
请输入图片描述
创建新的站点地图:首先理解站点地图,字面上是网站map,它可以理解为一个入口地址,对应于网站和一个需求。如果您想获得关于知乎的问题的答案,请创建一个站点地图,将问题的地址设置为站点地图的起始URL,然后单击“创建站点地图”,您可以创建一个站点地图
请输入图片描述
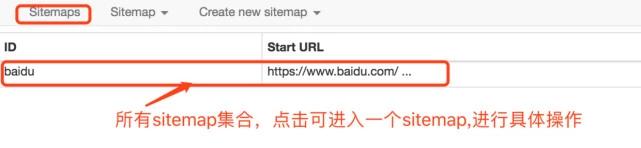
站点地图:站点地图的集合。所有创建的站点地图都将显示在此处,您可以在此处输入站点地图以进行修改、数据捕获和其他操作
请输入图片描述
站点地图:进入站点地图后,可以执行一系列操作,如下图所示:
请输入图片描述
在红色框中添加新选择器是必不可少的步骤。什么是选择器?字面意思:选择器对应于网页的一部分,即收录我们想要采集的数据的部分
应该解释的是,一个站点地图下可以有多个选择器。每个选择器都可以收录子选择器。选择器只能对应一个标题或整个区域。此区域可能收录标题、副标题、作者信息、内容等
选择器:查看所有选择器
选择器图:查看当前站点地图的拓扑,根节点是什么,包括选择器下的几个选择器和子选择器
编辑元数据:您可以修改站点地图信息、标题和起始地址
Scratch:开始数据捕获
以CSV格式导出数据:以CSV格式导出捕获的数据
在这里,简单的理解就足够了。真正的知识来自实践,具体的操作案例具有说服力。这里有几个例子来解释具体用法
案例实践
简易水压试验hao123
从简单到深入,首先以最简单的示例作为入口,这只是进一步了解web服务的一种方式
需求背景:请参见下面hao123页面中的红色框。我们的要求是统计该区域中所有网站名称和链接地址,并最终将它们生成excel。因为这部分内容足够简单,当然,实际需要可能比这更复杂,而且手动统计这些数据的时间也非常快
请输入图片描述
启动操作
1、假设我们打开了hao123页面,打开了页面底部的开发者工具,并找到了web scraper选项卡
2、单击“创建站点地图”
请输入图片描述
3、然后输入站点地图名称和开始URL。这个名字只是为了我们的方便。它名为hao123(注意不支持中文)。起始URL是hao123的网址,然后单击“创建站点地图”
请输入图片描述
4、然后web刮板将自动定位站点地图。接下来,我们将添加一个选择器并单击“添加新选择器”
请输入图片描述
5、first为选择器分配一个ID,这只是一个易于识别的名称。我觉得这里很热。由于要获取名称和链接,请将类型设置为link。此类型是专门为网页链接准备的。选择链接类型后,将自动提取名称和链接这两个属性
请输入图片描述
6、然后单击选择,然后我们在网页上移动光标。我们将发现光标的颜色将变为绿色,表示它是当前选定的区域。我们将光标定位在需求中提到的列中的链接上,例如第一条标题新闻,然后单击此处。此零件将变为红色,表示它已被选中。我们的目的是选择多个,所以在选择这个之后,继续选择第二个,我们会发现这一行中的链接变成红色。没错,这就是我们想要的效果。然后单击“执行选择!”(数据预览是所选元素的标识符,可以手动修改。按类和元素名称确定元素,如div.p_name a)。最后,不要忘记检查multiple,这意味着您需要采集多个数据段
请输入图片描述
7、finally save,save selector。单击“图元预览”预览选定区域,然后单击“数据预览”在浏览器中预览捕获的数据。对于理解技术的学生来说,后面文本框中的内容非常清楚。这是XPath。我们可以直接编写XPath而无需鼠标操作
完整的操作流程如下:
请输入图片描述
8、在上一步之后,您可以实际导出。别担心。看看其他的操作。您可以在sitemap hao123下的选择器图中看到拓扑图。根是根选择器。当你创建一个站点地图时,会有一个自动的根节点,你可以看到它的子选择器,这是我们创建的热选择器
请输入图片描述
9、Scrape,开始提取数据
10、hao123站点地图下的@Browse可以通过浏览器直接查看最终捕获的结果,需要更新
请输入图片描述
11、最后,使用导出数据作为CSV以CSV格式导出,其中热列是标题,热href列是链接
请输入图片描述
试试怎么样
软件定制|网站construction |获取更多干货 查看全部
在线抓取网页(初识webscraper开发人员安装方式(图):请输入图片描述本地)
Web scraper是一个免费的爬虫工具,面向普通用户(不需要专业IT技术)。它可以通过鼠标和简单的配置轻松获得您想要的数据。例如知乎答案列表、热门微博、微博评论、电商网站产品信息、博客文章列表等
安装过程
在线安装模式
在线安装需要FQ网络和访问chrome应用商店
1、在线访问web scraper插件并单击“添加到chrome”
请输入图片描述
2、然后在弹出框中单击“添加扩展”

请输入图片描述
3、安装完成后,顶部工具栏中会显示刮网器图标

请输入图片描述
本地安装模式
1、打开chrome并在地址栏中输入chrome://extensions/ ,进入扩展管理界面,然后下载扩展webv0.3.@7.crx拖到此页并单击“添加到扩展”以完成安装。如图所示:
请输入图片描述
2、安装完成后,顶部工具栏中会显示刮网器图标
${{2}$
请输入图片描述
了解网络刮刀
开式刮板机
开发人员可以路过并回头看
快捷键F12可在Windows系统下使用。某些型号的笔记本电脑需要按FN+F12
在MAC系统下,您可以使用快捷键command+option+I
您也可以直接在chrome界面上操作,然后单击设置->;更多工具->;开发工具

请输入图片描述
打开后的效果如下。绿框部分是开发工具的完整界面,红框部分是web刮板区域,也就是我们以后要操作的部分
请输入图片描述
注意:如果在浏览器的右侧区域打开“开发人员”工具,则需要将“开发人员”工具的位置调整到浏览器的底部

请输入图片描述
原理与功能描述
数据爬网的思想可以概括如下:
1、通过一个或多个入口地址获取初始数据。例如,文章list页面,或具有特定规则的页面,例如具有分页的列表页面
2、根据进入页面的一些信息,如链接指向,进入下一级页面以获取必要的信息
3、根据上一级的链接,继续下一级以获取必要的信息(此步骤可以无限循环)
原理大致相同。接下来,让我们正式了解web scraper工具。打开developer工具,单击Web scraper的选项卡栏,可以看到它分为三个部分:

请输入图片描述
创建新的站点地图:首先理解站点地图,字面上是网站map,它可以理解为一个入口地址,对应于网站和一个需求。如果您想获得关于知乎的问题的答案,请创建一个站点地图,将问题的地址设置为站点地图的起始URL,然后单击“创建站点地图”,您可以创建一个站点地图
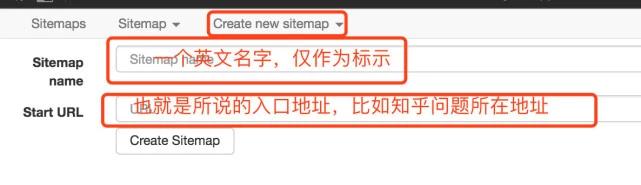
请输入图片描述
站点地图:站点地图的集合。所有创建的站点地图都将显示在此处,您可以在此处输入站点地图以进行修改、数据捕获和其他操作
请输入图片描述
站点地图:进入站点地图后,可以执行一系列操作,如下图所示:

请输入图片描述
在红色框中添加新选择器是必不可少的步骤。什么是选择器?字面意思:选择器对应于网页的一部分,即收录我们想要采集的数据的部分
应该解释的是,一个站点地图下可以有多个选择器。每个选择器都可以收录子选择器。选择器只能对应一个标题或整个区域。此区域可能收录标题、副标题、作者信息、内容等
选择器:查看所有选择器
选择器图:查看当前站点地图的拓扑,根节点是什么,包括选择器下的几个选择器和子选择器
编辑元数据:您可以修改站点地图信息、标题和起始地址
Scratch:开始数据捕获
以CSV格式导出数据:以CSV格式导出捕获的数据
在这里,简单的理解就足够了。真正的知识来自实践,具体的操作案例具有说服力。这里有几个例子来解释具体用法
案例实践
简易水压试验hao123
从简单到深入,首先以最简单的示例作为入口,这只是进一步了解web服务的一种方式
需求背景:请参见下面hao123页面中的红色框。我们的要求是统计该区域中所有网站名称和链接地址,并最终将它们生成excel。因为这部分内容足够简单,当然,实际需要可能比这更复杂,而且手动统计这些数据的时间也非常快
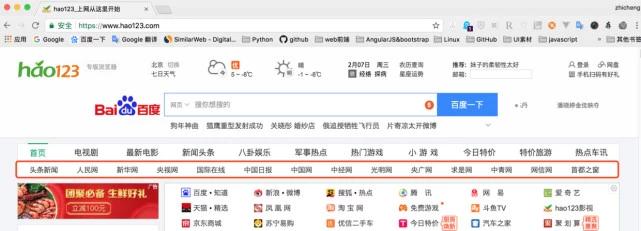
请输入图片描述
启动操作
1、假设我们打开了hao123页面,打开了页面底部的开发者工具,并找到了web scraper选项卡
2、单击“创建站点地图”

请输入图片描述
3、然后输入站点地图名称和开始URL。这个名字只是为了我们的方便。它名为hao123(注意不支持中文)。起始URL是hao123的网址,然后单击“创建站点地图”
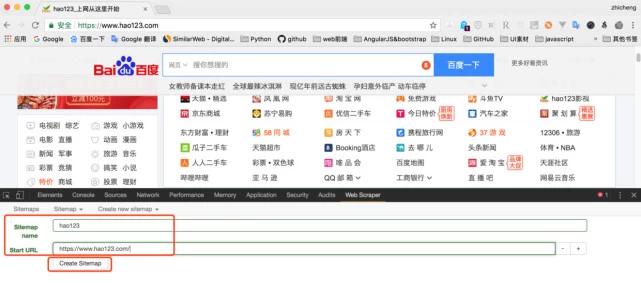
请输入图片描述
4、然后web刮板将自动定位站点地图。接下来,我们将添加一个选择器并单击“添加新选择器”
请输入图片描述
5、first为选择器分配一个ID,这只是一个易于识别的名称。我觉得这里很热。由于要获取名称和链接,请将类型设置为link。此类型是专门为网页链接准备的。选择链接类型后,将自动提取名称和链接这两个属性

请输入图片描述
6、然后单击选择,然后我们在网页上移动光标。我们将发现光标的颜色将变为绿色,表示它是当前选定的区域。我们将光标定位在需求中提到的列中的链接上,例如第一条标题新闻,然后单击此处。此零件将变为红色,表示它已被选中。我们的目的是选择多个,所以在选择这个之后,继续选择第二个,我们会发现这一行中的链接变成红色。没错,这就是我们想要的效果。然后单击“执行选择!”(数据预览是所选元素的标识符,可以手动修改。按类和元素名称确定元素,如div.p_name a)。最后,不要忘记检查multiple,这意味着您需要采集多个数据段
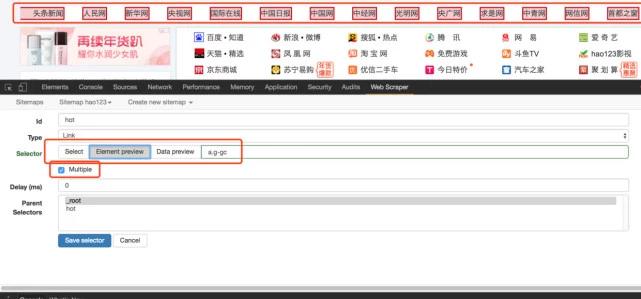
请输入图片描述
7、finally save,save selector。单击“图元预览”预览选定区域,然后单击“数据预览”在浏览器中预览捕获的数据。对于理解技术的学生来说,后面文本框中的内容非常清楚。这是XPath。我们可以直接编写XPath而无需鼠标操作
完整的操作流程如下:

请输入图片描述
8、在上一步之后,您可以实际导出。别担心。看看其他的操作。您可以在sitemap hao123下的选择器图中看到拓扑图。根是根选择器。当你创建一个站点地图时,会有一个自动的根节点,你可以看到它的子选择器,这是我们创建的热选择器

请输入图片描述
9、Scrape,开始提取数据
10、hao123站点地图下的@Browse可以通过浏览器直接查看最终捕获的结果,需要更新

请输入图片描述
11、最后,使用导出数据作为CSV以CSV格式导出,其中热列是标题,热href列是链接
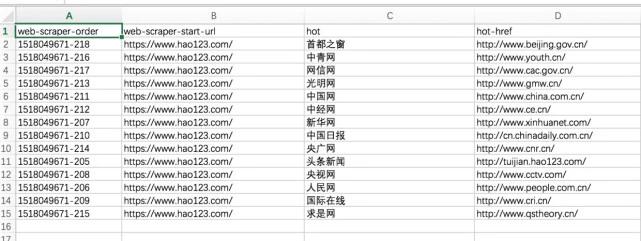
请输入图片描述
试试怎么样
软件定制|网站construction |获取更多干货
在线抓取网页(集搜客GooSeeker网页抓取软件与在线打码平台对接需要配置 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-09-18 15:09
)
jisoke Gooseek的网页捕获软件可以连接在线编码平台。如果捕获的网站需要输入验证码,验证码将转发到在线编码平台,Gooseek将自动将编码平台返回的结果输入网页,完成编码过程。吉索克探索者V5.1.0此版本支持以下功能
注意:crontab.xml文件是DS打印机用于自动和定期安排多个爬虫程序窗口的指令文件。有关详细信息,请参阅谷歌搜索者对此文件的解释。下面将详细说明为编码平台的自动登录和对接配置的参数
目录
一,。自动登录和自动编码所需的参数
请注意:此版本的Gooseek无法自动识别登录过程是否需要编码。如果使用以下配置参数,则必须对登录过程进行编码。如果您只需要自动登录,请使用专用的登录crontab命令
下面是crontab.xml文件中相关说明的示例。Zip(单击下载示例):
二,。参数描述
其他通用参数请参考如何通过crontab程序实现周期性增量采集数据。下面主要解释几个特殊参数
例如,在where to log in页面上,您可以看到上面的界面。此参数是URL%3A%2F%2F%2F
这是您需要在上图中输入的帐户名
这是您需要在上图中输入的密码
这是一个标准的XPath。您可以使用MS服务器打开内容定位功能。单击浏览器中的帐户输入框,在“网页结构”窗口中找到此输入框。单击“ShowXPath”按钮查看用于定位此输入框的XPath表达式,如下所示
/html/body/div[position()=2]/div[position()=3]/div[position()=2]/div[position()=1]/form/div[position()=2]/div[position()=1]/input
为了准确定位,您可以使用定位标志,即网页中的@class和@ID。对于网站,使用定位标志后的XPath将是:
//div[@class='field-login']/div[contains(@class, 'username-field')]/input
可以看出,它缩短了很多,适应性也得到了很大的提高
类似于在帐户输入框中查找XPath
使用类似的方法,可以获得XPath表达式://div[@id='captcha']//p/img[@id='vcodeimg']
如果手动输入验证码,请在此输入框中输入字母数字。此参数也是一个XPath
登录页面通常会显示一个引人注目的“登录”按钮,该按钮位于XPath。在网页中,它不一定是按钮,也可能是div,只要它用于单击
通常,如果登录成功,将显示一个网页,上面会显示“欢迎XXX”,这可以作为成功登录的标志
请自行开户并充值,并在这两个参数中配置账号和密码
三,。完全爬虫调度
上面的crontab.xml只有一个登录步骤。通常,在网站登录后,只要不关闭浏览器并打开其他网页,就不需要登录。因此,当使用自动登录时,有两个选项
如果您已经登录,DS将根据loginmark标志直接跳过登录过程
四,。处理记录和虚假电话上诉
查找捕获结果文件夹,该文件夹通常位于datasnaperworks目录下。此目录的父目录可以是“文件”->;在DS打印机的菜单上;根据“存储路径”,取数结果按主题名称存储,上面示例的主题名称为testcase_uuAutoLogin_uu步骤,您可以找到此文件夹。打开后,您可以看到一个子目录captcha。完整的目录结构如下图所示
1660287210文件夹是特定时间编码的停靠记录。进入此文件夹可查看原创验证代码图和编码平台返回的结果。如果编码平台的错误率非常高,您可以使用此记录信息联系编码平台,并要求对方提高服务质量
五,。确保信息安全
如上所述,此配置文件存储在用户的本地计算机上,而不是Gooseek ECs上,因此不会透露上述帐户和密码
如有疑问,或
查看全部
在线抓取网页(集搜客GooSeeker网页抓取软件与在线打码平台对接需要配置
)
jisoke Gooseek的网页捕获软件可以连接在线编码平台。如果捕获的网站需要输入验证码,验证码将转发到在线编码平台,Gooseek将自动将编码平台返回的结果输入网页,完成编码过程。吉索克探索者V5.1.0此版本支持以下功能
注意:crontab.xml文件是DS打印机用于自动和定期安排多个爬虫程序窗口的指令文件。有关详细信息,请参阅谷歌搜索者对此文件的解释。下面将详细说明为编码平台的自动登录和对接配置的参数
目录
一,。自动登录和自动编码所需的参数
请注意:此版本的Gooseek无法自动识别登录过程是否需要编码。如果使用以下配置参数,则必须对登录过程进行编码。如果您只需要自动登录,请使用专用的登录crontab命令
下面是crontab.xml文件中相关说明的示例。Zip(单击下载示例):

二,。参数描述
其他通用参数请参考如何通过crontab程序实现周期性增量采集数据。下面主要解释几个特殊参数

例如,在where to log in页面上,您可以看到上面的界面。此参数是URL%3A%2F%2F%2F
这是您需要在上图中输入的帐户名
这是您需要在上图中输入的密码
这是一个标准的XPath。您可以使用MS服务器打开内容定位功能。单击浏览器中的帐户输入框,在“网页结构”窗口中找到此输入框。单击“ShowXPath”按钮查看用于定位此输入框的XPath表达式,如下所示
/html/body/div[position()=2]/div[position()=3]/div[position()=2]/div[position()=1]/form/div[position()=2]/div[position()=1]/input
为了准确定位,您可以使用定位标志,即网页中的@class和@ID。对于网站,使用定位标志后的XPath将是:
//div[@class='field-login']/div[contains(@class, 'username-field')]/input
可以看出,它缩短了很多,适应性也得到了很大的提高
类似于在帐户输入框中查找XPath
使用类似的方法,可以获得XPath表达式://div[@id='captcha']//p/img[@id='vcodeimg']
如果手动输入验证码,请在此输入框中输入字母数字。此参数也是一个XPath
登录页面通常会显示一个引人注目的“登录”按钮,该按钮位于XPath。在网页中,它不一定是按钮,也可能是div,只要它用于单击
通常,如果登录成功,将显示一个网页,上面会显示“欢迎XXX”,这可以作为成功登录的标志
请自行开户并充值,并在这两个参数中配置账号和密码
三,。完全爬虫调度
上面的crontab.xml只有一个登录步骤。通常,在网站登录后,只要不关闭浏览器并打开其他网页,就不需要登录。因此,当使用自动登录时,有两个选项
如果您已经登录,DS将根据loginmark标志直接跳过登录过程
四,。处理记录和虚假电话上诉
查找捕获结果文件夹,该文件夹通常位于datasnaperworks目录下。此目录的父目录可以是“文件”->;在DS打印机的菜单上;根据“存储路径”,取数结果按主题名称存储,上面示例的主题名称为testcase_uuAutoLogin_uu步骤,您可以找到此文件夹。打开后,您可以看到一个子目录captcha。完整的目录结构如下图所示

1660287210文件夹是特定时间编码的停靠记录。进入此文件夹可查看原创验证代码图和编码平台返回的结果。如果编码平台的错误率非常高,您可以使用此记录信息联系编码平台,并要求对方提高服务质量
五,。确保信息安全
如上所述,此配置文件存储在用户的本地计算机上,而不是Gooseek ECs上,因此不会透露上述帐户和密码
如有疑问,或

在线抓取网页(百度音乐在线试听-下载音乐-网易云音乐歌词翻译)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-09-11 22:02
在线抓取网页以及音频或视频还有各种非本地访问的小工具。
一)、网页抓取与下载
1、爱采集本地css效果:不需要科学上网,即可高速下载所有css,无论多少。性能:因为采用webpack+fiddler代理协议,确保了下载速度。
2、asyncio
(异步编程与分布式开发)接口响应迅速,好处:编译效率、分布式开发等。
二)、在线音频/视频下载
一、推荐用讯飞输入法支持的免费在线音频分享。
1、万格乐师:免费使用音频,但要下载个人版。收费版是要花45元才能下载。推荐图片中的「万格乐师」作为手机版。
2、曹冲称象:接口只支持免费的1分钟音频,收费每年2840元,目前依然是不好下,可以通过其他免费接口获取到,也可以在线下载到。
3、天天在线:接口只支持10分钟音频,收费48元每年,目前还没有好用的用户下载。推荐1v1天天在线:天天在线同样支持10分钟音频下载。
注:数据在数据库,
二、推荐
1、waveflash:在线音频格式转换;支持转换vox、bandizip、百度文件等mp
3、flac等多种音频格式,支持下载和复制。
推荐
2、:万格乐师、上传无损音乐;功能支持不限速网速下载,支持格式还能在线转换、每小时重复下载等。目前还没发现有好用的接口。
三、音乐的,转换成mp3格式。
1)数据在图片中
2)转换成mp3格式
3)转换成wav格式
4)mp3转wav、jpg转wav、swf、wav转mp
3、mp3音频转mp3格式转换器/下载器/工具百度音乐在线试听-下载音乐-网易云音乐歌词页音乐试听百度音乐歌词翻译百度音乐歌词翻译在线音乐歌词转换-txt歌词转换 查看全部
在线抓取网页(百度音乐在线试听-下载音乐-网易云音乐歌词翻译)
在线抓取网页以及音频或视频还有各种非本地访问的小工具。
一)、网页抓取与下载
1、爱采集本地css效果:不需要科学上网,即可高速下载所有css,无论多少。性能:因为采用webpack+fiddler代理协议,确保了下载速度。
2、asyncio
(异步编程与分布式开发)接口响应迅速,好处:编译效率、分布式开发等。
二)、在线音频/视频下载
一、推荐用讯飞输入法支持的免费在线音频分享。
1、万格乐师:免费使用音频,但要下载个人版。收费版是要花45元才能下载。推荐图片中的「万格乐师」作为手机版。
2、曹冲称象:接口只支持免费的1分钟音频,收费每年2840元,目前依然是不好下,可以通过其他免费接口获取到,也可以在线下载到。
3、天天在线:接口只支持10分钟音频,收费48元每年,目前还没有好用的用户下载。推荐1v1天天在线:天天在线同样支持10分钟音频下载。
注:数据在数据库,
二、推荐
1、waveflash:在线音频格式转换;支持转换vox、bandizip、百度文件等mp
3、flac等多种音频格式,支持下载和复制。
推荐
2、:万格乐师、上传无损音乐;功能支持不限速网速下载,支持格式还能在线转换、每小时重复下载等。目前还没发现有好用的接口。
三、音乐的,转换成mp3格式。
1)数据在图片中
2)转换成mp3格式
3)转换成wav格式
4)mp3转wav、jpg转wav、swf、wav转mp
3、mp3音频转mp3格式转换器/下载器/工具百度音乐在线试听-下载音乐-网易云音乐歌词页音乐试听百度音乐歌词翻译百度音乐歌词翻译在线音乐歌词转换-txt歌词转换
在线抓取网页(免费网页在线客服系统代码应该如何快速获取呢?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2021-10-03 08:01
大多数网站在建站初期都需要一个基于网络的在线客服系统,最直接的方式就是从网上获取一个免费的客服系统代码。很多人搜遍了,很难找到直接贴出来的代码。那么这个免费的网页在线客服系统代码应该如何快速获取呢?
免费网页在线客服系统代码获取方法
一、在线客服系统客户端下载
任何网页在线客服系统要获取页面代码,必须先下载客服软件客户端。注册账号并登录后,客户端会用你登录的账号生成对应的客服系统代码放入网站才可以实现,这里我们以快商通为例。
免费注册,快速获取客服系统代码
二、生成客服系统代码
找到设置中心-生成码,进入后马上就可以得到我们想要的网页在线客服系统码。因为快商通可以永久免费供用户使用,据说用这串代码生成网页的在线客服系统可以正常使用,无需支付任何费用。
把这行代码复制到你要生成的web客服系统的页面代码中即可。如果要在整个站点上生成它,请将其复制到页脚文件中。一般来说,公司希望不同的站点使用不同的在线客服系统代码,只要他们创建一个新站点然后生成JS代码即可。
免费在线客服系统稳定吗?
网页在线客服系统的稳定性取决于服务商为客服系统使用的服务器的质量以及客服系统本身代码水平的完善程度。
市场上的免费网络在线客服系统大多使用与其付费版本相同的一套软件代码,但限制了功能的使用,而不是两个不同版本的软件。换句话说,如果付费版的客服系统足够稳定,那么免费版也是稳定的,只是功能上的区别。
总结:
无论是免费的网页在线客服系统代码还是收费的,都需要先下载客服系统客户端,然后通过客户端生成代码并复制到网页中才能生效。并且每个code在参数里都有对应的site绑定,也就是说,拿一串免费的网页在线客服系统code是不通用的。 查看全部
在线抓取网页(免费网页在线客服系统代码应该如何快速获取呢?(图))
大多数网站在建站初期都需要一个基于网络的在线客服系统,最直接的方式就是从网上获取一个免费的客服系统代码。很多人搜遍了,很难找到直接贴出来的代码。那么这个免费的网页在线客服系统代码应该如何快速获取呢?
免费网页在线客服系统代码获取方法
一、在线客服系统客户端下载
任何网页在线客服系统要获取页面代码,必须先下载客服软件客户端。注册账号并登录后,客户端会用你登录的账号生成对应的客服系统代码放入网站才可以实现,这里我们以快商通为例。
免费注册,快速获取客服系统代码
二、生成客服系统代码
找到设置中心-生成码,进入后马上就可以得到我们想要的网页在线客服系统码。因为快商通可以永久免费供用户使用,据说用这串代码生成网页的在线客服系统可以正常使用,无需支付任何费用。
把这行代码复制到你要生成的web客服系统的页面代码中即可。如果要在整个站点上生成它,请将其复制到页脚文件中。一般来说,公司希望不同的站点使用不同的在线客服系统代码,只要他们创建一个新站点然后生成JS代码即可。
免费在线客服系统稳定吗?
网页在线客服系统的稳定性取决于服务商为客服系统使用的服务器的质量以及客服系统本身代码水平的完善程度。
市场上的免费网络在线客服系统大多使用与其付费版本相同的一套软件代码,但限制了功能的使用,而不是两个不同版本的软件。换句话说,如果付费版的客服系统足够稳定,那么免费版也是稳定的,只是功能上的区别。
总结:
无论是免费的网页在线客服系统代码还是收费的,都需要先下载客服系统客户端,然后通过客户端生成代码并复制到网页中才能生效。并且每个code在参数里都有对应的site绑定,也就是说,拿一串免费的网页在线客服系统code是不通用的。
在线抓取网页(几近一个的抓取与收录、收录的演讲内容以及要点概括)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-10-02 04:13
许多关于网站的结构、爬取和收录,甚至排名的问题都可以归结为一个核心问题,那就是:搜索引擎爬取你的网站有多容易?我们在最近的几个事件中讨论了这个话题。下面你将看到我们关于这个问题的演讲内容和主要观点的总结。
网络世界是巨大的;每时每刻都在产生新的内容。谷歌自己的资源是有限的。当面对几乎无穷无尽的网络内容时,Googlebot 只能查找和抓取一定比例的内容。然后,我们只能索引我们抓取的部分内容。
URL就像网站和搜索引擎爬虫之间的桥梁:为了能够抓取你的内容网站,爬虫需要能够找到并跨越这些桥梁(即找到并抓取你的URLs )。如果你的 URL 很复杂或者很长,爬虫就不得不花时间反复跟踪这些 URL;如果你的 URL 是常规的并且直接指向你的独特内容,那么爬虫可以专注于理解你的内容,而不是仅仅抓取空网页或被不同的 URL 引导,最终抓取的是相同的重复内容。
在上面的幻灯片中,您可以看到一些我们应该避免的反例——这些都是现实中存在的 URL 的示例(尽管出于隐私原因,它们的名称已被替换),这些示例包括被黑的 URL 和编码、伪装成一部分的冗余参数URL 路径、无限爬取空间等,您还可以找到一些建议,帮助您理顺这些 URL 迷宫,帮助爬虫更快更好地找到您的内容,包括:
1)去除URL中的用户相关参数
URL 中不影响网页内容的参数——例如会话 ID 或排序参数——可以从 URL 中删除并由 cookie 记录。通过将此信息添加到 cookie,然后 301 重定向到“干净”的 URL,您可以保留原创内容并减少指向相同内容的 URL 数量。
控制无限空间
你的网站上有日历吗,上面的链接指向无数过去和未来的日期(每个链接地址都是唯一的二)?你的网页地址是不是加了一个&page = 3563参数后,还可以返回200个代码,即使根本没有那么多页面?如果这样的话,你的网站上就会出现所谓的“无限空间”。这种情况会浪费爬虫机器人和你的带宽网站.如何控制“无限空间”,请参考这里的一些技巧。
2)防止 Google 抓取工具抓取它们无法处理的页面
通过使用您的 robots.txt 文件,您可以防止您的登录页面、联系信息、购物车和其他爬虫无法处理的页面被抓取。(爬行动物以吝啬和害羞着称,所以一般不会“添加商品到购物车”或“联系我们”)。这样,你可以让爬虫花更多的时间在你的网站上爬取他们能处理的东西。
一人一票。一个网址,一段内容
在理想的世界中,URL 和内容是一一对应的:每个 URL 对应一个唯一的内容,每个内容只能通过唯一的 URL 访问。越接近这种理想情况,您的 网站 就越容易被捕获和 收录。如果您的内容管理系统或当前的网站 建立难以实施,您可以尝试使用 rel=canonical 元素来设置您要用于指示特定内容的 URL。 查看全部
在线抓取网页(几近一个的抓取与收录、收录的演讲内容以及要点概括)
许多关于网站的结构、爬取和收录,甚至排名的问题都可以归结为一个核心问题,那就是:搜索引擎爬取你的网站有多容易?我们在最近的几个事件中讨论了这个话题。下面你将看到我们关于这个问题的演讲内容和主要观点的总结。
网络世界是巨大的;每时每刻都在产生新的内容。谷歌自己的资源是有限的。当面对几乎无穷无尽的网络内容时,Googlebot 只能查找和抓取一定比例的内容。然后,我们只能索引我们抓取的部分内容。
URL就像网站和搜索引擎爬虫之间的桥梁:为了能够抓取你的内容网站,爬虫需要能够找到并跨越这些桥梁(即找到并抓取你的URLs )。如果你的 URL 很复杂或者很长,爬虫就不得不花时间反复跟踪这些 URL;如果你的 URL 是常规的并且直接指向你的独特内容,那么爬虫可以专注于理解你的内容,而不是仅仅抓取空网页或被不同的 URL 引导,最终抓取的是相同的重复内容。
在上面的幻灯片中,您可以看到一些我们应该避免的反例——这些都是现实中存在的 URL 的示例(尽管出于隐私原因,它们的名称已被替换),这些示例包括被黑的 URL 和编码、伪装成一部分的冗余参数URL 路径、无限爬取空间等,您还可以找到一些建议,帮助您理顺这些 URL 迷宫,帮助爬虫更快更好地找到您的内容,包括:
1)去除URL中的用户相关参数
URL 中不影响网页内容的参数——例如会话 ID 或排序参数——可以从 URL 中删除并由 cookie 记录。通过将此信息添加到 cookie,然后 301 重定向到“干净”的 URL,您可以保留原创内容并减少指向相同内容的 URL 数量。
控制无限空间
你的网站上有日历吗,上面的链接指向无数过去和未来的日期(每个链接地址都是唯一的二)?你的网页地址是不是加了一个&page = 3563参数后,还可以返回200个代码,即使根本没有那么多页面?如果这样的话,你的网站上就会出现所谓的“无限空间”。这种情况会浪费爬虫机器人和你的带宽网站.如何控制“无限空间”,请参考这里的一些技巧。
2)防止 Google 抓取工具抓取它们无法处理的页面
通过使用您的 robots.txt 文件,您可以防止您的登录页面、联系信息、购物车和其他爬虫无法处理的页面被抓取。(爬行动物以吝啬和害羞着称,所以一般不会“添加商品到购物车”或“联系我们”)。这样,你可以让爬虫花更多的时间在你的网站上爬取他们能处理的东西。
一人一票。一个网址,一段内容
在理想的世界中,URL 和内容是一一对应的:每个 URL 对应一个唯一的内容,每个内容只能通过唯一的 URL 访问。越接近这种理想情况,您的 网站 就越容易被捕获和 收录。如果您的内容管理系统或当前的网站 建立难以实施,您可以尝试使用 rel=canonical 元素来设置您要用于指示特定内容的 URL。
在线抓取网页(网络监听有如下几种方法:在线抓取网页地址的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-10-01 17:02
在线抓取网页地址的方法有好几种,普通的http协议的抓取有很多抓包软件,也有现成的.net抓包工具,eclipse也可以抓包,https的抓包可以从终端命令行得到地址信息,登录浏览器网址输入,然后输入抓包工具里的getencode、getencoding、getencolor即可获取请求地址的值。网络监听有如下几种方法:。
一、用windows自带的网络监听;
二、抓包三段式,首先抓取动态网页地址,
三、不同的网络上通过代理服务器抓取https地址;
四、二进制文件处理,用python读取然后转为png或者jpg(虽然这些方法都是很不安全的,但是很多时候做个跳板是很好用的)。
百度提供的抓包工具比起http的那些抓包工具,简直是小巫见大巫啊。你在百度上搜“抓包”,第一个搜索结果就是抓包工具,分分钟秒杀!一个比一个强大,满满的都是干货啊!比如,有自动抓包的工具等,绝对无法媲美的抓包!!!我是彭老师,
天天抓包,就用drupal/fastcomet方便实用。
推荐你用开源的httpscheme或者xmlhttprequest
ultraiso可以抓
用chrome浏览器搜索,
其实直接windowscmd界面上copy地址进去也可以. 查看全部
在线抓取网页(网络监听有如下几种方法:在线抓取网页地址的方法)
在线抓取网页地址的方法有好几种,普通的http协议的抓取有很多抓包软件,也有现成的.net抓包工具,eclipse也可以抓包,https的抓包可以从终端命令行得到地址信息,登录浏览器网址输入,然后输入抓包工具里的getencode、getencoding、getencolor即可获取请求地址的值。网络监听有如下几种方法:。
一、用windows自带的网络监听;
二、抓包三段式,首先抓取动态网页地址,
三、不同的网络上通过代理服务器抓取https地址;
四、二进制文件处理,用python读取然后转为png或者jpg(虽然这些方法都是很不安全的,但是很多时候做个跳板是很好用的)。
百度提供的抓包工具比起http的那些抓包工具,简直是小巫见大巫啊。你在百度上搜“抓包”,第一个搜索结果就是抓包工具,分分钟秒杀!一个比一个强大,满满的都是干货啊!比如,有自动抓包的工具等,绝对无法媲美的抓包!!!我是彭老师,
天天抓包,就用drupal/fastcomet方便实用。
推荐你用开源的httpscheme或者xmlhttprequest
ultraiso可以抓
用chrome浏览器搜索,
其实直接windowscmd界面上copy地址进去也可以.
在线抓取网页( Python实现抓取网页并且解析的功能实例,(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 142 次浏览 • 2021-09-28 15:27
Python实现抓取网页并且解析的功能实例,(图))
爬取网页和解析示例的Python实现
更新时间:2014-09-20 17:39:07 投稿:shichen2014
本文文章主要介绍Python对网页抓取和解析功能实例的实现。主要以百度问答的分析为例,说明其原理和方法。有需要的朋友可以参考以下
本文以示例的形式介绍了Python中网页的爬取和解析功能。主要分析问答和百度首页。分享给大家,供大家参考。
主要功能代码如下:
#!/usr/bin/python
#coding=utf-8
import sys
import re
import urllib2
from urllib import urlencode
from urllib import quote
import time
maxline = 2000
wenda = re.compile("href=\"http://wenda.so.com/q/.+\?src=(.+?)\"")
baidu = re.compile("<a href=\"http://www.baidu.com/link\?url=.+\".*?>更多知道相关问题.*?</a>")
f1 = open("baidupage.txt","w")
f2 = open("wendapage.txt","w")
for line in sys.stdin:
if maxline == 0:
break
query = line.strip();
time.sleep(1);
recall_url = "http://www.so.com/s?&q=" + query;
response = urllib2.urlopen(recall_url);
html = response.read();
f1.write(html)
m = wenda.search(html);
if m:
if m.group(1) == "110":
print query + "\twenda\t0";
else:
print query + "\twenda\t1";
else:
print query + "\twenda\t0";
recall_url = "http://www.baidu.com/s?wd=" + query +"&ie=utf-8";
response = urllib2.urlopen(recall_url);
html = response.read();
f2.write(html)
m = baidu.search(html);
if m:
print query + "\tbaidu\t1";
else:
print query + "\tbaidu\t0";
maxline = maxline - 1;
f1.close()
f2.close()
我希望这篇文章能帮助你学习 Python 编程。 查看全部
在线抓取网页(
Python实现抓取网页并且解析的功能实例,(图))
爬取网页和解析示例的Python实现
更新时间:2014-09-20 17:39:07 投稿:shichen2014
本文文章主要介绍Python对网页抓取和解析功能实例的实现。主要以百度问答的分析为例,说明其原理和方法。有需要的朋友可以参考以下
本文以示例的形式介绍了Python中网页的爬取和解析功能。主要分析问答和百度首页。分享给大家,供大家参考。
主要功能代码如下:
#!/usr/bin/python
#coding=utf-8
import sys
import re
import urllib2
from urllib import urlencode
from urllib import quote
import time
maxline = 2000
wenda = re.compile("href=\"http://wenda.so.com/q/.+\?src=(.+?)\"")
baidu = re.compile("<a href=\"http://www.baidu.com/link\?url=.+\".*?>更多知道相关问题.*?</a>")
f1 = open("baidupage.txt","w")
f2 = open("wendapage.txt","w")
for line in sys.stdin:
if maxline == 0:
break
query = line.strip();
time.sleep(1);
recall_url = "http://www.so.com/s?&q=" + query;
response = urllib2.urlopen(recall_url);
html = response.read();
f1.write(html)
m = wenda.search(html);
if m:
if m.group(1) == "110":
print query + "\twenda\t0";
else:
print query + "\twenda\t1";
else:
print query + "\twenda\t0";
recall_url = "http://www.baidu.com/s?wd=" + query +"&ie=utf-8";
response = urllib2.urlopen(recall_url);
html = response.read();
f2.write(html)
m = baidu.search(html);
if m:
print query + "\tbaidu\t1";
else:
print query + "\tbaidu\t0";
maxline = maxline - 1;
f1.close()
f2.close()
我希望这篇文章能帮助你学习 Python 编程。
在线抓取网页(如何使用这个类来抓取网页中需要的信息?运行结果)
网站优化 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-09-23 20:27
云翔在线聊天室提供在线聊天室,WEBIM,网络磁盘和其他服务,WEBIM可以免费建立一个组(无限数),聊天日志在线存储。
当您之前做聊天室时,由于聊天室中的新闻读取的功能,您从网页中写了一类(例如最新的标题新闻,新闻来源,标题,内容等。),本文如何使用此类来捕获网页中所需的信息。本文将拍摄博客标题和Blogguan主页的链接作为示例:
图片显示博客花园主页的DOM树。很明显,只有班级是post_item的div,然后从TileLnk的一旗中提取类。此类功能可以通过以下功能实现:
///
/// 在文本html的文本查找标志名为tagName,并且属性attrName的值为attrValue的所有标志
/// 例如:FindTagByAttr(html, "div", "class", "demo")
/// 返回所有class为demo的div标志
///
public static List FindTagByAttr(String html, String tagName, String attrName, String attrValue)
{
String format = String.Format(@"", tagName, attrName, attrValue);
return FindTag(html, tagName, format);
}
public static List FindTag(String html, String name, String format)
{
Regex reg = new Regex(format, RegexOptions.IgnoreCase);
Regex tagReg = new Regex(String.Format(@"", name), RegexOptions.IgnoreCase);
List tags = new List();
int start = 0;
while (true)
{
Match match = reg.Match(html, start);
if (match.Success)
{
start = match.Index + match.Length;
Match tagMatch = null;
int beginTagCount = 1;
while (true)
{
tagMatch = tagReg.Match(html, start);
if (!tagMatch.Success)
{
tagMatch = null;
break;
}
start = tagMatch.Index + tagMatch.Length;
if (tagMatch.Groups[1].Value == "/") beginTagCount--;
else beginTagCount++;
if (beginTagCount == 0) break;
}
if (tagMatch != null)
{
HtmlTag tag = new HtmlTag(name, match.Value, html.Substring(match.Index + match.Length, tagMatch.Index - match.Index - match.Length));
tags.Add(tag);
}
else
{
break;
}
}
else
{
break;
}
}
return tags;
}
使用上述功能,您可以提取所需的HTML标志。为实现,您需要下载下载Web的功能:
public static String GetHtml(string url)
{
try
{
HttpWebRequest req = HttpWebRequest.Create(url) as HttpWebRequest;
req.Timeout = 30 * 1000;
HttpWebResponse response = req.GetResponse() as HttpWebResponse;
Stream stream = response.GetResponseStream();
MemoryStream buffer = new MemoryStream();
Byte[] temp = new Byte[4096];
int count = 0;
while ((count = stream.Read(temp, 0, 4096)) > 0)
{
buffer.Write(temp, 0, count);
}
return Encoding.GetEncoding(response.CharacterSet).GetString(buffer.GetBuffer());
}
catch
{
return String.Empty;
}
}
以下要获取文章标题和博客主页的链接作为一个例子,介绍如何使用htmltag类来捕获Web信息:
class Program
{
static void Main(string[] args)
{
String html = HtmlTag.GetHtml("http://www.cnblogs.com");
List tags = HtmlTag.FindTagByAttr(html, "div", "id", "post_list");
if (tags.Count > 0)
{
List item_tags = tags[0].FindTagByAttr("div", "class", "post_item");
foreach (HtmlTag item_tag in item_tags)
{
List a_tags = item_tag.FindTagByAttr("a", "class", "titlelnk");
if (a_tags.Count > 0)
{
Console.WriteLine("标题:{0}", a_tags[0].InnerHTML);
Console.WriteLine("链接:{0}", a_tags[0].GetAttribute("href"));
Console.WriteLine("");
}
}
}
}
}
结果如下:
源代码下载 查看全部
在线抓取网页(如何使用这个类来抓取网页中需要的信息?运行结果)
云翔在线聊天室提供在线聊天室,WEBIM,网络磁盘和其他服务,WEBIM可以免费建立一个组(无限数),聊天日志在线存储。
当您之前做聊天室时,由于聊天室中的新闻读取的功能,您从网页中写了一类(例如最新的标题新闻,新闻来源,标题,内容等。),本文如何使用此类来捕获网页中所需的信息。本文将拍摄博客标题和Blogguan主页的链接作为示例:
图片显示博客花园主页的DOM树。很明显,只有班级是post_item的div,然后从TileLnk的一旗中提取类。此类功能可以通过以下功能实现:
///
/// 在文本html的文本查找标志名为tagName,并且属性attrName的值为attrValue的所有标志
/// 例如:FindTagByAttr(html, "div", "class", "demo")
/// 返回所有class为demo的div标志
///
public static List FindTagByAttr(String html, String tagName, String attrName, String attrValue)
{
String format = String.Format(@"", tagName, attrName, attrValue);
return FindTag(html, tagName, format);
}
public static List FindTag(String html, String name, String format)
{
Regex reg = new Regex(format, RegexOptions.IgnoreCase);
Regex tagReg = new Regex(String.Format(@"", name), RegexOptions.IgnoreCase);
List tags = new List();
int start = 0;
while (true)
{
Match match = reg.Match(html, start);
if (match.Success)
{
start = match.Index + match.Length;
Match tagMatch = null;
int beginTagCount = 1;
while (true)
{
tagMatch = tagReg.Match(html, start);
if (!tagMatch.Success)
{
tagMatch = null;
break;
}
start = tagMatch.Index + tagMatch.Length;
if (tagMatch.Groups[1].Value == "/") beginTagCount--;
else beginTagCount++;
if (beginTagCount == 0) break;
}
if (tagMatch != null)
{
HtmlTag tag = new HtmlTag(name, match.Value, html.Substring(match.Index + match.Length, tagMatch.Index - match.Index - match.Length));
tags.Add(tag);
}
else
{
break;
}
}
else
{
break;
}
}
return tags;
}
使用上述功能,您可以提取所需的HTML标志。为实现,您需要下载下载Web的功能:
public static String GetHtml(string url)
{
try
{
HttpWebRequest req = HttpWebRequest.Create(url) as HttpWebRequest;
req.Timeout = 30 * 1000;
HttpWebResponse response = req.GetResponse() as HttpWebResponse;
Stream stream = response.GetResponseStream();
MemoryStream buffer = new MemoryStream();
Byte[] temp = new Byte[4096];
int count = 0;
while ((count = stream.Read(temp, 0, 4096)) > 0)
{
buffer.Write(temp, 0, count);
}
return Encoding.GetEncoding(response.CharacterSet).GetString(buffer.GetBuffer());
}
catch
{
return String.Empty;
}
}
以下要获取文章标题和博客主页的链接作为一个例子,介绍如何使用htmltag类来捕获Web信息:
class Program
{
static void Main(string[] args)
{
String html = HtmlTag.GetHtml("http://www.cnblogs.com";);
List tags = HtmlTag.FindTagByAttr(html, "div", "id", "post_list");
if (tags.Count > 0)
{
List item_tags = tags[0].FindTagByAttr("div", "class", "post_item");
foreach (HtmlTag item_tag in item_tags)
{
List a_tags = item_tag.FindTagByAttr("a", "class", "titlelnk");
if (a_tags.Count > 0)
{
Console.WriteLine("标题:{0}", a_tags[0].InnerHTML);
Console.WriteLine("链接:{0}", a_tags[0].GetAttribute("href"));
Console.WriteLine("");
}
}
}
}
}
结果如下:
源代码下载
在线抓取网页(抓取网站,模拟登陆,抓取动态网页的原理和实现)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-09-23 20:25
网站的详细解释,模拟的原理和实现的动态网页(Python和C#等)版本:V□的1. 1 crifan里摘要本文主要介绍了抓网站,模拟登录,履带逻辑,原理以及如何实现相关的动态网页。主要包括:如何使用相应的网络分析工具,如相应的网页分析工具,如F12,铬按Ctrl + Shift + J,Firefox的萤火虫,如IE9,火狐的萤火来分析相应的逻辑网站,模拟登录,抢动态网页,都给出一个完整可用的,多语言的示例代码:Python和C#,Java的,围棋等,提供多种格式:在线阅读HTML下载(7ZIP压缩包)HTML PDF10 CHM 11 TXT 12 RTF在线地址的13 WebHelp的14 HTML的版本是:scrape_emulate_login.html有任何意见,建议,提交bug等.Webhelp.7z修订历史修订@ 1. 1 2013年9月22日CRL添加新的岗位链接:模拟登录百度的Java版本,围棋语言版本的详细抢网站,模拟登录,抢动态网页和执行(Python和C#Crifanli版本的原则:v□的1. 1日发布2013-09- 22版权所有2013crifan,这个文章遵:署名 - 非商业性我们Einstein @ Home2. 5中国大陆(CC BY-NC 2.5)@ 15 @ 15 #cc_by_nc IV目录前言3.1.@ @(多语言实现)模拟登录百度@ K272.@ @(多语言实现)模拟登陆GOGOLE 4.1.@ @抢动态网页例如:网易163博客心情美文FeelingCard本文本文,如何让逻辑和具体实现从无到有的动态网页,了解登录,并抓住逻辑和具体实施动态网页。
网站爬网,模拟登录,爬行动态网页的旧文章如何使用Python,C#等语言来实现静态网页+捕捉动态网页+模拟登录网站 [相关的通用逻辑整理]每个开发人员在浏览器DeveloperTools:IE9 F12,铬按Ctrl + Shift + J,火狐萤火虫[解决]字符集格式(GB2312,GBK,UTF-8,ISO8859- 1等)的说明[订购]幅抓斗,模拟登录,抢动态Web内容等,头部的信息,cookie信息,数据后处理逻辑相关的老帖[教程]抓住网络并提取网页如何模拟信息登录到登录网站需要,给予更多的例子:3.1.@ @(多语言实现)模拟登录百度第一次使用工具分析逻辑:[教程]教你如何使用它的工具(IE9 F1 2)去分析模模模过程过程过程版版版版版版版版版模】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】实现登录百度模拟@ K272.@ @(MUL tiple语言实现)模拟登陆gogole,也拿到了,模拟登陆谷歌:[记录]模拟登录谷歌去看看:[教程]如何捕捉如何捕捉采取动态网页内容了解,抓取动态网页的逻辑。转到下面的例子:4.1.@ @捕捉动态网页例如:网易163博客心随FeelingCard [记录]添加支持blogstowordpress网易心情随笔导出到捕捉静态或动态网页和模拟登录,并总结相关的旧帖子[概要]静态web抓斗,动态网页,模拟登录的预防措施和经验 查看全部
在线抓取网页(抓取网站,模拟登陆,抓取动态网页的原理和实现)
网站的详细解释,模拟的原理和实现的动态网页(Python和C#等)版本:V□的1. 1 crifan里摘要本文主要介绍了抓网站,模拟登录,履带逻辑,原理以及如何实现相关的动态网页。主要包括:如何使用相应的网络分析工具,如相应的网页分析工具,如F12,铬按Ctrl + Shift + J,Firefox的萤火虫,如IE9,火狐的萤火来分析相应的逻辑网站,模拟登录,抢动态网页,都给出一个完整可用的,多语言的示例代码:Python和C#,Java的,围棋等,提供多种格式:在线阅读HTML下载(7ZIP压缩包)HTML PDF10 CHM 11 TXT 12 RTF在线地址的13 WebHelp的14 HTML的版本是:scrape_emulate_login.html有任何意见,建议,提交bug等.Webhelp.7z修订历史修订@ 1. 1 2013年9月22日CRL添加新的岗位链接:模拟登录百度的Java版本,围棋语言版本的详细抢网站,模拟登录,抢动态网页和执行(Python和C#Crifanli版本的原则:v□的1. 1日发布2013-09- 22版权所有2013crifan,这个文章遵:署名 - 非商业性我们Einstein @ Home2. 5中国大陆(CC BY-NC 2.5)@ 15 @ 15 #cc_by_nc IV目录前言3.1.@ @(多语言实现)模拟登录百度@ K272.@ @(多语言实现)模拟登陆GOGOLE 4.1.@ @抢动态网页例如:网易163博客心情美文FeelingCard本文本文,如何让逻辑和具体实现从无到有的动态网页,了解登录,并抓住逻辑和具体实施动态网页。
网站爬网,模拟登录,爬行动态网页的旧文章如何使用Python,C#等语言来实现静态网页+捕捉动态网页+模拟登录网站 [相关的通用逻辑整理]每个开发人员在浏览器DeveloperTools:IE9 F12,铬按Ctrl + Shift + J,火狐萤火虫[解决]字符集格式(GB2312,GBK,UTF-8,ISO8859- 1等)的说明[订购]幅抓斗,模拟登录,抢动态Web内容等,头部的信息,cookie信息,数据后处理逻辑相关的老帖[教程]抓住网络并提取网页如何模拟信息登录到登录网站需要,给予更多的例子:3.1.@ @(多语言实现)模拟登录百度第一次使用工具分析逻辑:[教程]教你如何使用它的工具(IE9 F1 2)去分析模模模过程过程过程版版版版版版版版版模】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】】实现登录百度模拟@ K272.@ @(MUL tiple语言实现)模拟登陆gogole,也拿到了,模拟登陆谷歌:[记录]模拟登录谷歌去看看:[教程]如何捕捉如何捕捉采取动态网页内容了解,抓取动态网页的逻辑。转到下面的例子:4.1.@ @捕捉动态网页例如:网易163博客心随FeelingCard [记录]添加支持blogstowordpress网易心情随笔导出到捕捉静态或动态网页和模拟登录,并总结相关的旧帖子[概要]静态web抓斗,动态网页,模拟登录的预防措施和经验
在线抓取网页(说到“网站地图”生成软件生成工具,一个本地)
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-09-20 08:11
前言:
说到“网站map”,我相信很多SEOER或网站管理员不会感到奇怪,网站map对于搜索引擎和用户来说非常重要
网站map只是一个收录几乎所有网站链接的页面。它为搜索引擎和用户提供了清晰的网站体系结构和内容,并改进了网站高质量内容页面的捕获和收录
然而,许多在线工具已经试用过了。有的广告数量众多,有的不够专业,有的功能有限,比如只抓拍不到200个网站。这里推荐两种不同的方法网站sitemap生成工具,一个用于本地,一个用于在线网站use
1、网站地图在线生成工具
单击以输入XML-sitemaps网站
① 点击以上按钮进入网站地图在线生成页面,填写网站,点击“开始”进行扫描
② 此在线站点可以捕获网站的所有连接,适用于HTTPS协议网站。以下是一个测试屏幕截图,在阅读进度条后完成
注:国外is网站站太低。如果太滞后,你可以在中国尝试同样类型的网站map站点地图:点击网站. p>
2、tiger站点地图生成器
这是一个绿色和简单的网站地图生成软件。操作简单易懂。主要原因是没有像其他软件一样的限制,没有对URL数量的限制,也没有广告。唯一的缺点是该软件无法捕获HTTPS协议网站,HTTPS网站如果您需要生成站点地图,建议使用上面的在线生成方法
① 建立项目并进行相关设置。设置非常简单。你一眼就能看到它们。如果你不明白,试着自己找出答案
② 设置完成后,点击“开始”,可以看到整个捕获过程。完成后,将自动保存在set目录文件夹中
Tiger站点地图生成器软件下载:
下载地址 查看全部
在线抓取网页(说到“网站地图”生成软件生成工具,一个本地)
前言:
说到“网站map”,我相信很多SEOER或网站管理员不会感到奇怪,网站map对于搜索引擎和用户来说非常重要
网站map只是一个收录几乎所有网站链接的页面。它为搜索引擎和用户提供了清晰的网站体系结构和内容,并改进了网站高质量内容页面的捕获和收录
然而,许多在线工具已经试用过了。有的广告数量众多,有的不够专业,有的功能有限,比如只抓拍不到200个网站。这里推荐两种不同的方法网站sitemap生成工具,一个用于本地,一个用于在线网站use
1、网站地图在线生成工具
单击以输入XML-sitemaps网站
① 点击以上按钮进入网站地图在线生成页面,填写网站,点击“开始”进行扫描
② 此在线站点可以捕获网站的所有连接,适用于HTTPS协议网站。以下是一个测试屏幕截图,在阅读进度条后完成
注:国外is网站站太低。如果太滞后,你可以在中国尝试同样类型的网站map站点地图:点击网站. p>
2、tiger站点地图生成器
这是一个绿色和简单的网站地图生成软件。操作简单易懂。主要原因是没有像其他软件一样的限制,没有对URL数量的限制,也没有广告。唯一的缺点是该软件无法捕获HTTPS协议网站,HTTPS网站如果您需要生成站点地图,建议使用上面的在线生成方法
① 建立项目并进行相关设置。设置非常简单。你一眼就能看到它们。如果你不明白,试着自己找出答案
② 设置完成后,点击“开始”,可以看到整个捕获过程。完成后,将自动保存在set目录文件夹中
Tiger站点地图生成器软件下载:
下载地址
在线抓取网页(初识webscraper开发人员安装方式(图):请输入图片描述本地)
网站优化 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-09-20 08:05
Web scraper是一个免费的爬虫工具,面向普通用户(不需要专业IT技术)。它可以通过鼠标和简单的配置轻松获得您想要的数据。例如知乎答案列表、热门微博、微博评论、电商网站产品信息、博客文章列表等
安装过程
在线安装模式
在线安装需要FQ网络和访问chrome应用商店
1、在线访问web scraper插件并单击“添加到chrome”
请输入图片描述
2、然后在弹出框中单击“添加扩展”
请输入图片描述
3、安装完成后,顶部工具栏中会显示刮网器图标
请输入图片描述
本地安装模式
1、打开chrome并在地址栏中输入chrome://extensions/ ,进入扩展管理界面,然后下载扩展webv0.3.@7.crx拖到此页并单击“添加到扩展”以完成安装。如图所示:
请输入图片描述
2、安装完成后,顶部工具栏中会显示刮网器图标
${{2}$
请输入图片描述
了解网络刮刀
开式刮板机
开发人员可以路过并回头看
快捷键F12可在Windows系统下使用。某些型号的笔记本电脑需要按FN+F12
在MAC系统下,您可以使用快捷键command+option+I
您也可以直接在chrome界面上操作,然后单击设置->;更多工具->;开发工具
请输入图片描述
打开后的效果如下。绿框部分是开发工具的完整界面,红框部分是web刮板区域,也就是我们以后要操作的部分
请输入图片描述
注意:如果在浏览器的右侧区域打开“开发人员”工具,则需要将“开发人员”工具的位置调整到浏览器的底部
请输入图片描述
原理与功能描述
数据爬网的思想可以概括如下:
1、通过一个或多个入口地址获取初始数据。例如,文章list页面,或具有特定规则的页面,例如具有分页的列表页面
2、根据进入页面的一些信息,如链接指向,进入下一级页面以获取必要的信息
3、根据上一级的链接,继续下一级以获取必要的信息(此步骤可以无限循环)
原理大致相同。接下来,让我们正式了解web scraper工具。打开developer工具,单击Web scraper的选项卡栏,可以看到它分为三个部分:
请输入图片描述
创建新的站点地图:首先理解站点地图,字面上是网站map,它可以理解为一个入口地址,对应于网站和一个需求。如果您想获得关于知乎的问题的答案,请创建一个站点地图,将问题的地址设置为站点地图的起始URL,然后单击“创建站点地图”,您可以创建一个站点地图
请输入图片描述
站点地图:站点地图的集合。所有创建的站点地图都将显示在此处,您可以在此处输入站点地图以进行修改、数据捕获和其他操作
请输入图片描述
站点地图:进入站点地图后,可以执行一系列操作,如下图所示:
请输入图片描述
在红色框中添加新选择器是必不可少的步骤。什么是选择器?字面意思:选择器对应于网页的一部分,即收录我们想要采集的数据的部分
应该解释的是,一个站点地图下可以有多个选择器。每个选择器都可以收录子选择器。选择器只能对应一个标题或整个区域。此区域可能收录标题、副标题、作者信息、内容等
选择器:查看所有选择器
选择器图:查看当前站点地图的拓扑,根节点是什么,包括选择器下的几个选择器和子选择器
编辑元数据:您可以修改站点地图信息、标题和起始地址
Scratch:开始数据捕获
以CSV格式导出数据:以CSV格式导出捕获的数据
在这里,简单的理解就足够了。真正的知识来自实践,具体的操作案例具有说服力。这里有几个例子来解释具体用法
案例实践
简易水压试验hao123
从简单到深入,首先以最简单的示例作为入口,这只是进一步了解web服务的一种方式
需求背景:请参见下面hao123页面中的红色框。我们的要求是统计该区域中所有网站名称和链接地址,并最终将它们生成excel。因为这部分内容足够简单,当然,实际需要可能比这更复杂,而且手动统计这些数据的时间也非常快
请输入图片描述
启动操作
1、假设我们打开了hao123页面,打开了页面底部的开发者工具,并找到了web scraper选项卡
2、单击“创建站点地图”
请输入图片描述
3、然后输入站点地图名称和开始URL。这个名字只是为了我们的方便。它名为hao123(注意不支持中文)。起始URL是hao123的网址,然后单击“创建站点地图”
请输入图片描述
4、然后web刮板将自动定位站点地图。接下来,我们将添加一个选择器并单击“添加新选择器”
请输入图片描述
5、first为选择器分配一个ID,这只是一个易于识别的名称。我觉得这里很热。由于要获取名称和链接,请将类型设置为link。此类型是专门为网页链接准备的。选择链接类型后,将自动提取名称和链接这两个属性
请输入图片描述
6、然后单击选择,然后我们在网页上移动光标。我们将发现光标的颜色将变为绿色,表示它是当前选定的区域。我们将光标定位在需求中提到的列中的链接上,例如第一条标题新闻,然后单击此处。此零件将变为红色,表示它已被选中。我们的目的是选择多个,所以在选择这个之后,继续选择第二个,我们会发现这一行中的链接变成红色。没错,这就是我们想要的效果。然后单击“执行选择!”(数据预览是所选元素的标识符,可以手动修改。按类和元素名称确定元素,如div.p_name a)。最后,不要忘记检查multiple,这意味着您需要采集多个数据段
请输入图片描述
7、finally save,save selector。单击“图元预览”预览选定区域,然后单击“数据预览”在浏览器中预览捕获的数据。对于理解技术的学生来说,后面文本框中的内容非常清楚。这是XPath。我们可以直接编写XPath而无需鼠标操作
完整的操作流程如下:
请输入图片描述
8、在上一步之后,您可以实际导出。别担心。看看其他的操作。您可以在sitemap hao123下的选择器图中看到拓扑图。根是根选择器。当你创建一个站点地图时,会有一个自动的根节点,你可以看到它的子选择器,这是我们创建的热选择器
请输入图片描述
9、Scrape,开始提取数据
10、hao123站点地图下的@Browse可以通过浏览器直接查看最终捕获的结果,需要更新
请输入图片描述
11、最后,使用导出数据作为CSV以CSV格式导出,其中热列是标题,热href列是链接
请输入图片描述
试试怎么样
软件定制|网站construction |获取更多干货 查看全部
在线抓取网页(初识webscraper开发人员安装方式(图):请输入图片描述本地)
Web scraper是一个免费的爬虫工具,面向普通用户(不需要专业IT技术)。它可以通过鼠标和简单的配置轻松获得您想要的数据。例如知乎答案列表、热门微博、微博评论、电商网站产品信息、博客文章列表等
安装过程
在线安装模式
在线安装需要FQ网络和访问chrome应用商店
1、在线访问web scraper插件并单击“添加到chrome”
请输入图片描述
2、然后在弹出框中单击“添加扩展”
请输入图片描述
3、安装完成后,顶部工具栏中会显示刮网器图标
请输入图片描述
本地安装模式
1、打开chrome并在地址栏中输入chrome://extensions/ ,进入扩展管理界面,然后下载扩展webv0.3.@7.crx拖到此页并单击“添加到扩展”以完成安装。如图所示:
请输入图片描述
2、安装完成后,顶部工具栏中会显示刮网器图标
${{2}$
请输入图片描述
了解网络刮刀
开式刮板机
开发人员可以路过并回头看
快捷键F12可在Windows系统下使用。某些型号的笔记本电脑需要按FN+F12
在MAC系统下,您可以使用快捷键command+option+I
您也可以直接在chrome界面上操作,然后单击设置->;更多工具->;开发工具
请输入图片描述
打开后的效果如下。绿框部分是开发工具的完整界面,红框部分是web刮板区域,也就是我们以后要操作的部分
请输入图片描述
注意:如果在浏览器的右侧区域打开“开发人员”工具,则需要将“开发人员”工具的位置调整到浏览器的底部
请输入图片描述
原理与功能描述
数据爬网的思想可以概括如下:
1、通过一个或多个入口地址获取初始数据。例如,文章list页面,或具有特定规则的页面,例如具有分页的列表页面
2、根据进入页面的一些信息,如链接指向,进入下一级页面以获取必要的信息
3、根据上一级的链接,继续下一级以获取必要的信息(此步骤可以无限循环)
原理大致相同。接下来,让我们正式了解web scraper工具。打开developer工具,单击Web scraper的选项卡栏,可以看到它分为三个部分:
请输入图片描述
创建新的站点地图:首先理解站点地图,字面上是网站map,它可以理解为一个入口地址,对应于网站和一个需求。如果您想获得关于知乎的问题的答案,请创建一个站点地图,将问题的地址设置为站点地图的起始URL,然后单击“创建站点地图”,您可以创建一个站点地图
请输入图片描述
站点地图:站点地图的集合。所有创建的站点地图都将显示在此处,您可以在此处输入站点地图以进行修改、数据捕获和其他操作
请输入图片描述
站点地图:进入站点地图后,可以执行一系列操作,如下图所示:
请输入图片描述
在红色框中添加新选择器是必不可少的步骤。什么是选择器?字面意思:选择器对应于网页的一部分,即收录我们想要采集的数据的部分
应该解释的是,一个站点地图下可以有多个选择器。每个选择器都可以收录子选择器。选择器只能对应一个标题或整个区域。此区域可能收录标题、副标题、作者信息、内容等
选择器:查看所有选择器
选择器图:查看当前站点地图的拓扑,根节点是什么,包括选择器下的几个选择器和子选择器
编辑元数据:您可以修改站点地图信息、标题和起始地址
Scratch:开始数据捕获
以CSV格式导出数据:以CSV格式导出捕获的数据
在这里,简单的理解就足够了。真正的知识来自实践,具体的操作案例具有说服力。这里有几个例子来解释具体用法
案例实践
简易水压试验hao123
从简单到深入,首先以最简单的示例作为入口,这只是进一步了解web服务的一种方式
需求背景:请参见下面hao123页面中的红色框。我们的要求是统计该区域中所有网站名称和链接地址,并最终将它们生成excel。因为这部分内容足够简单,当然,实际需要可能比这更复杂,而且手动统计这些数据的时间也非常快
请输入图片描述
启动操作
1、假设我们打开了hao123页面,打开了页面底部的开发者工具,并找到了web scraper选项卡
2、单击“创建站点地图”
请输入图片描述
3、然后输入站点地图名称和开始URL。这个名字只是为了我们的方便。它名为hao123(注意不支持中文)。起始URL是hao123的网址,然后单击“创建站点地图”
请输入图片描述
4、然后web刮板将自动定位站点地图。接下来,我们将添加一个选择器并单击“添加新选择器”
请输入图片描述
5、first为选择器分配一个ID,这只是一个易于识别的名称。我觉得这里很热。由于要获取名称和链接,请将类型设置为link。此类型是专门为网页链接准备的。选择链接类型后,将自动提取名称和链接这两个属性
请输入图片描述
6、然后单击选择,然后我们在网页上移动光标。我们将发现光标的颜色将变为绿色,表示它是当前选定的区域。我们将光标定位在需求中提到的列中的链接上,例如第一条标题新闻,然后单击此处。此零件将变为红色,表示它已被选中。我们的目的是选择多个,所以在选择这个之后,继续选择第二个,我们会发现这一行中的链接变成红色。没错,这就是我们想要的效果。然后单击“执行选择!”(数据预览是所选元素的标识符,可以手动修改。按类和元素名称确定元素,如div.p_name a)。最后,不要忘记检查multiple,这意味着您需要采集多个数据段
请输入图片描述
7、finally save,save selector。单击“图元预览”预览选定区域,然后单击“数据预览”在浏览器中预览捕获的数据。对于理解技术的学生来说,后面文本框中的内容非常清楚。这是XPath。我们可以直接编写XPath而无需鼠标操作
完整的操作流程如下:
请输入图片描述
8、在上一步之后,您可以实际导出。别担心。看看其他的操作。您可以在sitemap hao123下的选择器图中看到拓扑图。根是根选择器。当你创建一个站点地图时,会有一个自动的根节点,你可以看到它的子选择器,这是我们创建的热选择器
请输入图片描述
9、Scrape,开始提取数据
10、hao123站点地图下的@Browse可以通过浏览器直接查看最终捕获的结果,需要更新
请输入图片描述
11、最后,使用导出数据作为CSV以CSV格式导出,其中热列是标题,热href列是链接
请输入图片描述
试试怎么样
软件定制|网站construction |获取更多干货
在线抓取网页(集搜客GooSeeker网页抓取软件与在线打码平台对接需要配置 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-09-18 15:09
)
jisoke Gooseek的网页捕获软件可以连接在线编码平台。如果捕获的网站需要输入验证码,验证码将转发到在线编码平台,Gooseek将自动将编码平台返回的结果输入网页,完成编码过程。吉索克探索者V5.1.0此版本支持以下功能
注意:crontab.xml文件是DS打印机用于自动和定期安排多个爬虫程序窗口的指令文件。有关详细信息,请参阅谷歌搜索者对此文件的解释。下面将详细说明为编码平台的自动登录和对接配置的参数
目录
一,。自动登录和自动编码所需的参数
请注意:此版本的Gooseek无法自动识别登录过程是否需要编码。如果使用以下配置参数,则必须对登录过程进行编码。如果您只需要自动登录,请使用专用的登录crontab命令
下面是crontab.xml文件中相关说明的示例。Zip(单击下载示例):
二,。参数描述
其他通用参数请参考如何通过crontab程序实现周期性增量采集数据。下面主要解释几个特殊参数
例如,在where to log in页面上,您可以看到上面的界面。此参数是URL%3A%2F%2F%2F
这是您需要在上图中输入的帐户名
这是您需要在上图中输入的密码
这是一个标准的XPath。您可以使用MS服务器打开内容定位功能。单击浏览器中的帐户输入框,在“网页结构”窗口中找到此输入框。单击“ShowXPath”按钮查看用于定位此输入框的XPath表达式,如下所示
/html/body/div[position()=2]/div[position()=3]/div[position()=2]/div[position()=1]/form/div[position()=2]/div[position()=1]/input
为了准确定位,您可以使用定位标志,即网页中的@class和@ID。对于网站,使用定位标志后的XPath将是:
//div[@class='field-login']/div[contains(@class, 'username-field')]/input
可以看出,它缩短了很多,适应性也得到了很大的提高
类似于在帐户输入框中查找XPath
使用类似的方法,可以获得XPath表达式://div[@id='captcha']//p/img[@id='vcodeimg']
如果手动输入验证码,请在此输入框中输入字母数字。此参数也是一个XPath
登录页面通常会显示一个引人注目的“登录”按钮,该按钮位于XPath。在网页中,它不一定是按钮,也可能是div,只要它用于单击
通常,如果登录成功,将显示一个网页,上面会显示“欢迎XXX”,这可以作为成功登录的标志
请自行开户并充值,并在这两个参数中配置账号和密码
三,。完全爬虫调度
上面的crontab.xml只有一个登录步骤。通常,在网站登录后,只要不关闭浏览器并打开其他网页,就不需要登录。因此,当使用自动登录时,有两个选项
如果您已经登录,DS将根据loginmark标志直接跳过登录过程
四,。处理记录和虚假电话上诉
查找捕获结果文件夹,该文件夹通常位于datasnaperworks目录下。此目录的父目录可以是“文件”->;在DS打印机的菜单上;根据“存储路径”,取数结果按主题名称存储,上面示例的主题名称为testcase_uuAutoLogin_uu步骤,您可以找到此文件夹。打开后,您可以看到一个子目录captcha。完整的目录结构如下图所示
1660287210文件夹是特定时间编码的停靠记录。进入此文件夹可查看原创验证代码图和编码平台返回的结果。如果编码平台的错误率非常高,您可以使用此记录信息联系编码平台,并要求对方提高服务质量
五,。确保信息安全
如上所述,此配置文件存储在用户的本地计算机上,而不是Gooseek ECs上,因此不会透露上述帐户和密码
如有疑问,或
查看全部
在线抓取网页(集搜客GooSeeker网页抓取软件与在线打码平台对接需要配置
)
jisoke Gooseek的网页捕获软件可以连接在线编码平台。如果捕获的网站需要输入验证码,验证码将转发到在线编码平台,Gooseek将自动将编码平台返回的结果输入网页,完成编码过程。吉索克探索者V5.1.0此版本支持以下功能
注意:crontab.xml文件是DS打印机用于自动和定期安排多个爬虫程序窗口的指令文件。有关详细信息,请参阅谷歌搜索者对此文件的解释。下面将详细说明为编码平台的自动登录和对接配置的参数
目录
一,。自动登录和自动编码所需的参数
请注意:此版本的Gooseek无法自动识别登录过程是否需要编码。如果使用以下配置参数,则必须对登录过程进行编码。如果您只需要自动登录,请使用专用的登录crontab命令
下面是crontab.xml文件中相关说明的示例。Zip(单击下载示例):
二,。参数描述
其他通用参数请参考如何通过crontab程序实现周期性增量采集数据。下面主要解释几个特殊参数
例如,在where to log in页面上,您可以看到上面的界面。此参数是URL%3A%2F%2F%2F
这是您需要在上图中输入的帐户名
这是您需要在上图中输入的密码
这是一个标准的XPath。您可以使用MS服务器打开内容定位功能。单击浏览器中的帐户输入框,在“网页结构”窗口中找到此输入框。单击“ShowXPath”按钮查看用于定位此输入框的XPath表达式,如下所示
/html/body/div[position()=2]/div[position()=3]/div[position()=2]/div[position()=1]/form/div[position()=2]/div[position()=1]/input
为了准确定位,您可以使用定位标志,即网页中的@class和@ID。对于网站,使用定位标志后的XPath将是:
//div[@class='field-login']/div[contains(@class, 'username-field')]/input
可以看出,它缩短了很多,适应性也得到了很大的提高
类似于在帐户输入框中查找XPath
使用类似的方法,可以获得XPath表达式://div[@id='captcha']//p/img[@id='vcodeimg']
如果手动输入验证码,请在此输入框中输入字母数字。此参数也是一个XPath
登录页面通常会显示一个引人注目的“登录”按钮,该按钮位于XPath。在网页中,它不一定是按钮,也可能是div,只要它用于单击
通常,如果登录成功,将显示一个网页,上面会显示“欢迎XXX”,这可以作为成功登录的标志
请自行开户并充值,并在这两个参数中配置账号和密码
三,。完全爬虫调度
上面的crontab.xml只有一个登录步骤。通常,在网站登录后,只要不关闭浏览器并打开其他网页,就不需要登录。因此,当使用自动登录时,有两个选项
如果您已经登录,DS将根据loginmark标志直接跳过登录过程
四,。处理记录和虚假电话上诉
查找捕获结果文件夹,该文件夹通常位于datasnaperworks目录下。此目录的父目录可以是“文件”->;在DS打印机的菜单上;根据“存储路径”,取数结果按主题名称存储,上面示例的主题名称为testcase_uuAutoLogin_uu步骤,您可以找到此文件夹。打开后,您可以看到一个子目录captcha。完整的目录结构如下图所示
1660287210文件夹是特定时间编码的停靠记录。进入此文件夹可查看原创验证代码图和编码平台返回的结果。如果编码平台的错误率非常高,您可以使用此记录信息联系编码平台,并要求对方提高服务质量
五,。确保信息安全
如上所述,此配置文件存储在用户的本地计算机上,而不是Gooseek ECs上,因此不会透露上述帐户和密码
如有疑问,或
在线抓取网页(百度音乐在线试听-下载音乐-网易云音乐歌词翻译)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-09-11 22:02
在线抓取网页以及音频或视频还有各种非本地访问的小工具。
一)、网页抓取与下载
1、爱采集本地css效果:不需要科学上网,即可高速下载所有css,无论多少。性能:因为采用webpack+fiddler代理协议,确保了下载速度。
2、asyncio
(异步编程与分布式开发)接口响应迅速,好处:编译效率、分布式开发等。
二)、在线音频/视频下载
一、推荐用讯飞输入法支持的免费在线音频分享。
1、万格乐师:免费使用音频,但要下载个人版。收费版是要花45元才能下载。推荐图片中的「万格乐师」作为手机版。
2、曹冲称象:接口只支持免费的1分钟音频,收费每年2840元,目前依然是不好下,可以通过其他免费接口获取到,也可以在线下载到。
3、天天在线:接口只支持10分钟音频,收费48元每年,目前还没有好用的用户下载。推荐1v1天天在线:天天在线同样支持10分钟音频下载。
注:数据在数据库,
二、推荐
1、waveflash:在线音频格式转换;支持转换vox、bandizip、百度文件等mp
3、flac等多种音频格式,支持下载和复制。
推荐
2、:万格乐师、上传无损音乐;功能支持不限速网速下载,支持格式还能在线转换、每小时重复下载等。目前还没发现有好用的接口。
三、音乐的,转换成mp3格式。
1)数据在图片中
2)转换成mp3格式
3)转换成wav格式
4)mp3转wav、jpg转wav、swf、wav转mp
3、mp3音频转mp3格式转换器/下载器/工具百度音乐在线试听-下载音乐-网易云音乐歌词页音乐试听百度音乐歌词翻译百度音乐歌词翻译在线音乐歌词转换-txt歌词转换 查看全部
在线抓取网页(百度音乐在线试听-下载音乐-网易云音乐歌词翻译)
在线抓取网页以及音频或视频还有各种非本地访问的小工具。
一)、网页抓取与下载
1、爱采集本地css效果:不需要科学上网,即可高速下载所有css,无论多少。性能:因为采用webpack+fiddler代理协议,确保了下载速度。
2、asyncio
(异步编程与分布式开发)接口响应迅速,好处:编译效率、分布式开发等。
二)、在线音频/视频下载
一、推荐用讯飞输入法支持的免费在线音频分享。
1、万格乐师:免费使用音频,但要下载个人版。收费版是要花45元才能下载。推荐图片中的「万格乐师」作为手机版。
2、曹冲称象:接口只支持免费的1分钟音频,收费每年2840元,目前依然是不好下,可以通过其他免费接口获取到,也可以在线下载到。
3、天天在线:接口只支持10分钟音频,收费48元每年,目前还没有好用的用户下载。推荐1v1天天在线:天天在线同样支持10分钟音频下载。
注:数据在数据库,
二、推荐
1、waveflash:在线音频格式转换;支持转换vox、bandizip、百度文件等mp
3、flac等多种音频格式,支持下载和复制。
推荐
2、:万格乐师、上传无损音乐;功能支持不限速网速下载,支持格式还能在线转换、每小时重复下载等。目前还没发现有好用的接口。
三、音乐的,转换成mp3格式。
1)数据在图片中
2)转换成mp3格式
3)转换成wav格式
4)mp3转wav、jpg转wav、swf、wav转mp
3、mp3音频转mp3格式转换器/下载器/工具百度音乐在线试听-下载音乐-网易云音乐歌词页音乐试听百度音乐歌词翻译百度音乐歌词翻译在线音乐歌词转换-txt歌词转换

