
在线抓取网页
在线抓取网页(什么是SessionSession对应的中文翻译是会话。。 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-11-29 23:06
)
什么是会话
Session对应的中文翻译是conversation。
会话是指用户打开浏览器访问一个网站的时间,无论这个网站访问了多少个页面,点击了多少个链接,都属于同一个对话。在用户关闭浏览器之前,它们属于同一个会话。
HTTP 协议是短链接,因此无法根据服务器端建立的连接数来统计当前在线人数。但是,在线用户的数量可以通过计算会话数来估计。
一旦用户访问服务器,就会创建一个会话。如果用户继续访问,则会话将继续有效。
如果用户在 30 分钟后没有进行任何操作,则表示用户“离线”,相应的会话将被销毁。
因此您可以通过计算保留的会话数来估计当前在线人数。
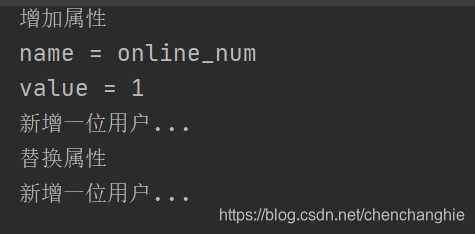
PeopleLisened.java
package com.chenchangjie.listener;
import javax.servlet.ServletContext;
import javax.servlet.http.HttpSessionEvent;
import javax.servlet.http.HttpSessionListener;
public class PeopleListener implements HttpSessionListener {
/**
* 监听session创建
* @param se
*/
@Override
public void sessionCreated(HttpSessionEvent se) {
ServletContext context = se.getSession().getServletContext();
Integer num = (Integer) context.getAttribute("online_num");
if(num == null)
num = 0;
++num;
context.setAttribute("online_num",num);
System.out.println("新增一位用户...");
}
/**
* 监听session销毁
* @param se
*/
@Override
public void sessionDestroyed(HttpSessionEvent se) {
ServletContext context = se.getSession().getServletContext();
Integer num = (Integer) context.getAttribute("online_num");
if(num == null)
num = 0;
else
--num;
context.setAttribute("online_num",num);
System.out.println("减少一位用户...");
}
}
web.xml 添加配置
com.chenchangjie.listener.PeopleListener
test.jsp
运行结果:
输出被替换是因为我监控了Context,每次增加session都会更新Context
打开浏览器会增加
查看全部
在线抓取网页(什么是SessionSession对应的中文翻译是会话。。
)
什么是会话
Session对应的中文翻译是conversation。
会话是指用户打开浏览器访问一个网站的时间,无论这个网站访问了多少个页面,点击了多少个链接,都属于同一个对话。在用户关闭浏览器之前,它们属于同一个会话。
HTTP 协议是短链接,因此无法根据服务器端建立的连接数来统计当前在线人数。但是,在线用户的数量可以通过计算会话数来估计。
一旦用户访问服务器,就会创建一个会话。如果用户继续访问,则会话将继续有效。
如果用户在 30 分钟后没有进行任何操作,则表示用户“离线”,相应的会话将被销毁。
因此您可以通过计算保留的会话数来估计当前在线人数。
PeopleLisened.java
package com.chenchangjie.listener;
import javax.servlet.ServletContext;
import javax.servlet.http.HttpSessionEvent;
import javax.servlet.http.HttpSessionListener;
public class PeopleListener implements HttpSessionListener {
/**
* 监听session创建
* @param se
*/
@Override
public void sessionCreated(HttpSessionEvent se) {
ServletContext context = se.getSession().getServletContext();
Integer num = (Integer) context.getAttribute("online_num");
if(num == null)
num = 0;
++num;
context.setAttribute("online_num",num);
System.out.println("新增一位用户...");
}
/**
* 监听session销毁
* @param se
*/
@Override
public void sessionDestroyed(HttpSessionEvent se) {
ServletContext context = se.getSession().getServletContext();
Integer num = (Integer) context.getAttribute("online_num");
if(num == null)
num = 0;
else
--num;
context.setAttribute("online_num",num);
System.out.println("减少一位用户...");
}
}
web.xml 添加配置
com.chenchangjie.listener.PeopleListener
test.jsp
运行结果:
输出被替换是因为我监控了Context,每次增加session都会更新Context
打开浏览器会增加
在线抓取网页(优帮云百度不收录优帮云seo小编们网站页面需要用对策)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-11-29 20:04
很多人都希望自己的网站是收录,但现在百度网站和百度索引大多不同步。所以当友邦云seo编辑使用网站管理员工具查询时,友邦云seo编辑可以看到上面的数据很大,但实际数量很少。所以这并不意味着百度没有收录youbangyun seo editors网站的页面,因为百度是通过一些流程收录进来的。
1、收录 会影响排名吗?
一些 网站收录 百万,但没有排名。其他不超过10个,但他们排名很好。很多人开始怀疑排名和选择的关系很小。其实这点是不需要考虑的。没有收录没有资格谈排名,所以排名是基于收录,而收录的前提是基于爬行,所以百度或其他搜索引擎会显示他们是否了解您的其他页面。
2、为什么页面不能收录
如上所述,收录的前提是蜘蛛爬行。这时候,很多朋友就会认为,既然优帮云seo编辑器的网站里有文章,就很容易抓住了。其实百度搜索引擎的收录流程步骤比较多。为了让用户看到搜索引擎的结构可以解决问题,百度在收录上下了很大功夫。
保证网页是收录的前提是网站的内容能够吸引搜索引擎抓取
当优帮云seo编辑器的网站页面需要收录在里面时,前提是必须被爬取。面对抓取问题,搜索引擎其实要经历一个非常艰难的过程,因为一般来说,搜索引擎抓取的页面不能超过三个级别。也就是说页面搜索引擎无法抓取首页的三个链接。一篇文章。这时候,有帮云seo的编辑们就需要用对策来解决这些问题。友邦云seo编辑亲自整理了以下三种解决方案:
网站地图:制作Youbangyun seo编辑的网站地图。一般情况下,网站的映射是写在robot文件中的。如果你不知道怎么做,你可以制作一个在线地图。谷歌站长工具就有这样的功能。
外部链接:如果你觉得你有额外的时间,你可以在你的网站内页投票。当然,友邦云seo编辑会根据自己的需要在外链添加一些锚文本链接,而文章的内链一般都会链接到内页,所以友邦云seo编辑会发布一些SEO外链直接接收内页也就不足为奇了。
搜索引擎抓取后,在选择优帮云seo编辑器页面时,会有一个标准的收录行。当内容达到要收录的标准行时,内容就会被收录。当内容未达到收录标准行时,内容将不被收录。
这时候暂时会有一些内容收录,过一段时间会取消。事实上,这是一个标准问题。这可能是因为您的文章被推荐暂时收录在首页,也可能是推荐被取消后被取消,也可能是因为点击或跳出链接。所以有帮云seo的编辑在做文章的一些细节的时候,一定要符合搜索引擎收录的标准行。收录 的搜索引擎非常简单。当然,百度目前还没有公布这条标准线。 查看全部
在线抓取网页(优帮云百度不收录优帮云seo小编们网站页面需要用对策)
很多人都希望自己的网站是收录,但现在百度网站和百度索引大多不同步。所以当友邦云seo编辑使用网站管理员工具查询时,友邦云seo编辑可以看到上面的数据很大,但实际数量很少。所以这并不意味着百度没有收录youbangyun seo editors网站的页面,因为百度是通过一些流程收录进来的。
1、收录 会影响排名吗?
一些 网站收录 百万,但没有排名。其他不超过10个,但他们排名很好。很多人开始怀疑排名和选择的关系很小。其实这点是不需要考虑的。没有收录没有资格谈排名,所以排名是基于收录,而收录的前提是基于爬行,所以百度或其他搜索引擎会显示他们是否了解您的其他页面。
2、为什么页面不能收录
如上所述,收录的前提是蜘蛛爬行。这时候,很多朋友就会认为,既然优帮云seo编辑器的网站里有文章,就很容易抓住了。其实百度搜索引擎的收录流程步骤比较多。为了让用户看到搜索引擎的结构可以解决问题,百度在收录上下了很大功夫。

保证网页是收录的前提是网站的内容能够吸引搜索引擎抓取
当优帮云seo编辑器的网站页面需要收录在里面时,前提是必须被爬取。面对抓取问题,搜索引擎其实要经历一个非常艰难的过程,因为一般来说,搜索引擎抓取的页面不能超过三个级别。也就是说页面搜索引擎无法抓取首页的三个链接。一篇文章。这时候,有帮云seo的编辑们就需要用对策来解决这些问题。友邦云seo编辑亲自整理了以下三种解决方案:
网站地图:制作Youbangyun seo编辑的网站地图。一般情况下,网站的映射是写在robot文件中的。如果你不知道怎么做,你可以制作一个在线地图。谷歌站长工具就有这样的功能。
外部链接:如果你觉得你有额外的时间,你可以在你的网站内页投票。当然,友邦云seo编辑会根据自己的需要在外链添加一些锚文本链接,而文章的内链一般都会链接到内页,所以友邦云seo编辑会发布一些SEO外链直接接收内页也就不足为奇了。
搜索引擎抓取后,在选择优帮云seo编辑器页面时,会有一个标准的收录行。当内容达到要收录的标准行时,内容就会被收录。当内容未达到收录标准行时,内容将不被收录。
这时候暂时会有一些内容收录,过一段时间会取消。事实上,这是一个标准问题。这可能是因为您的文章被推荐暂时收录在首页,也可能是推荐被取消后被取消,也可能是因为点击或跳出链接。所以有帮云seo的编辑在做文章的一些细节的时候,一定要符合搜索引擎收录的标准行。收录 的搜索引擎非常简单。当然,百度目前还没有公布这条标准线。
在线抓取网页( 另外一个超棒的Java的HTML解析器-jsoup-)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-26 10:08
另外一个超棒的Java的HTML解析器-jsoup-)
在线演示本地下载
如果你曾经开发过内容聚合类网站,那么使用程序动态整合不同页面或网站的内容的功能你一定很熟悉。通常在使用java的时候,我们会用到一些HTML解析,比如httpparser,最早的集成搜索就是用httpparser抓取Google和百度的搜索结果,并集成呈现给搜索用户,这就是GBin1的由来域名。
所以今天,我们介绍另一个很棒的Java HTML解析器-jsoup,这个类库可以帮助你实时处理HTML。它提供了一个非常方便的 API 来提取和处理数据。最重要的是它使用类似jQuery的语法来处理DOM、CSS等。如果你用过jQuery,你就会知道它在处理DOM方面的强大和便利。
主要特点
jsoup 实现了 WHATWG HTML5 标准,与现代浏览器解析 DOM 的方式相同。主要功能:
基本上jsoup可以帮你处理各种HTML问题,帮你验证非法标签,创建干净的DOM树。
实现爬取功能
这里我们将实现一个简单的爬取功能,您只需要指定url,并指定您需要爬取的具体元素,例如ID或类。后台我们会使用jsoup来获取,前台会使用jQuery来美化生成的结果。
大家需要注意以下几点:
相对路径问题:您抓取的页面中的链接可能使用了相对路径,需要将其作为绝对路径处理,否则将无法在本地服务器上正常打开链接
相对路径问题:同上,还需要处理转换
大小问题:如果抓取的图片特别大,需要使用代码转换为本地样式,也可以选择使用jQuery在前台处理
下载jsoup的jar包后,请添加你的classpath路径。如果使用jsp,请直接复制,添加到web应用WEB-INF的lib目录下。
Java相关代码如下:
Document doc = Jsoup.connect("http://www.gbin1.com/portfolio/lastest.html").timeout(0).get();
Elements items = doc.select(".includeitem");
在上面的代码中,我们定义了jsoup使用一个url来获取HTML,这里就用到了。本页列出了gbin1最近发布的文章。如果查看这个页面的源码,可以看到每个文章都在.includeitem类中,所以我们使用doc.select方法来选择对应的类。
注意我们这里调用的是timeout(0),表示连续请求url,默认是2000,也就是2秒后超时。可以看到这里使用了类似jQuery的链式调用,非常方便。
for (Element item : items) {
Elements links = item.select("a");
for(Element link: links){
link.attr("href",link.attr("abs:href"));
}
Elements imgs = item.select("img");
for(Element img: imgs){
img.attr("src",img.attr("abs:src"));
}
String html = item.html();
out.println("" + html + "");
}
在上面的代码中,我们处理了每个被查询的 includeitem 元素。找到“a”和“img”,将href元素值修改为绝对路径。
link.attr("abs:href")
上面的代码会得到对应链接的绝对路径,这里的属性是abs:href。同理可以得到图片的绝对路径abs:src。
代码运行后,我们就可以看到修改后的代码,放到li中。
接下来,我们开发一个页面来控制抓取:
在这个页面的实现中,我们使用setInterval方法在指定的时间间隔调用上面ajax开发的java代码。基本代码如下:
//Run for first time
$('#msg').html('请耐心等待, 页面抓取中 ...').fadeIn(400);
//$('#content').html('');
$('#content').load('siteproxy.jsp #result', {url:url, elem:element}, function(){
$('#msg').html('抓取已完成').delay(1500).fadeOut(400);
})
上面的代码非常简单。我们使用jQuery的load方法调用siteproxy.jsp,然后获取siteproxy.jsp生成的页面中的#result元素,即抓取内容。如果你不熟悉jQuery的ajax方法,请参考这个系列文章:
jQuery 库的 AJAX 方法初学者指南-第 1 部分
jQuery 库的 AJAX 方法初学者指南-第 2 部分
初学者使用jQuery库的AJAX方法-第三部分
jQuery 库的 AJAX 方法初学者指南-第 4 部分
为了让代码以指定的时间间隔运行爬取,我们将方法放在setinterval中,如下:
runid = setInterval(
function getInfo(){
$('#msg').html('请耐心等待, 页面抓取中 ...').fadeIn(400);
//$('#content').html('');
$('#content').load('siteproxy.jsp #result', {url:url, elem:element}, function(){
$('#msg').html('抓取已完成').delay(1500).fadeOut(400);
})
}, interval*1000);
通过上述方法,我们可以在用户触发抓取后每隔指定时间触发抓取动作。
完整的js代码如下:
$(document).ready(function(){
var url, element, interval, runid;
$('#start').click(function(){
url = $('#url').val();
element = $('#element').val();
interval = $('#interval').val();
//Run for first time
$('#msg').html('请耐心等待, 页面抓取中 ...').fadeIn(400);
//$('#content').html('');
$('#content').load('siteproxy.jsp #result', {url:url, elem:element}, function(){
$('#msg').html('抓取已完成').delay(1500).fadeOut(400);
})
runid = setInterval(
function getInfo(){
$('#msg').html('请耐心等待, 页面抓取中 ...').fadeIn(400);
//$('#content').html('');
$('#content').load('siteproxy.jsp #result', {url:url, elem:element}, function(){
$('#msg').html('抓取已完成').delay(1500).fadeOut(400);
})
}, interval*1000);
});
$('#stop').click(function(){
$('#msg').html('抓取已暂停').fadeIn(400).delay(1500);
clearInterval(runid);
});
});
部署完上面的jsp和html文件后,会看到如下界面:
我们需要设置要爬取的url和页面元素。默认情况下,该元素是 .includeitem。点击开始爬取,可以看到应用爬取了以下内容:
注意这里的默认间隔是30秒,30秒后会自动检索内容。
可以尝试抓取element.itemt,间隔10秒,可以得到如下内容:
你可以在微博首页看到和自动刷新一样的内容。
您可以将此工具用作重复页面刷新工具,它可以帮助您监控网站 的某个部分。当然,你也可以用它来动态刷新你的网站,提高你的alexa排名。.
希望大家喜欢这个工具应用。如果您有任何建议或问题,请给我们留言!谢谢!
来源:使用java的html解析器jsoup和jQuery实现一个web应用,自动重复抓取任意网站页面指定元素 查看全部
在线抓取网页(
另外一个超棒的Java的HTML解析器-jsoup-)

在线演示本地下载
如果你曾经开发过内容聚合类网站,那么使用程序动态整合不同页面或网站的内容的功能你一定很熟悉。通常在使用java的时候,我们会用到一些HTML解析,比如httpparser,最早的集成搜索就是用httpparser抓取Google和百度的搜索结果,并集成呈现给搜索用户,这就是GBin1的由来域名。
所以今天,我们介绍另一个很棒的Java HTML解析器-jsoup,这个类库可以帮助你实时处理HTML。它提供了一个非常方便的 API 来提取和处理数据。最重要的是它使用类似jQuery的语法来处理DOM、CSS等。如果你用过jQuery,你就会知道它在处理DOM方面的强大和便利。
主要特点
jsoup 实现了 WHATWG HTML5 标准,与现代浏览器解析 DOM 的方式相同。主要功能:
基本上jsoup可以帮你处理各种HTML问题,帮你验证非法标签,创建干净的DOM树。
实现爬取功能
这里我们将实现一个简单的爬取功能,您只需要指定url,并指定您需要爬取的具体元素,例如ID或类。后台我们会使用jsoup来获取,前台会使用jQuery来美化生成的结果。
大家需要注意以下几点:
相对路径问题:您抓取的页面中的链接可能使用了相对路径,需要将其作为绝对路径处理,否则将无法在本地服务器上正常打开链接
相对路径问题:同上,还需要处理转换
大小问题:如果抓取的图片特别大,需要使用代码转换为本地样式,也可以选择使用jQuery在前台处理
下载jsoup的jar包后,请添加你的classpath路径。如果使用jsp,请直接复制,添加到web应用WEB-INF的lib目录下。
Java相关代码如下:
Document doc = Jsoup.connect("http://www.gbin1.com/portfolio/lastest.html";).timeout(0).get();
Elements items = doc.select(".includeitem");
在上面的代码中,我们定义了jsoup使用一个url来获取HTML,这里就用到了。本页列出了gbin1最近发布的文章。如果查看这个页面的源码,可以看到每个文章都在.includeitem类中,所以我们使用doc.select方法来选择对应的类。
注意我们这里调用的是timeout(0),表示连续请求url,默认是2000,也就是2秒后超时。可以看到这里使用了类似jQuery的链式调用,非常方便。
for (Element item : items) {
Elements links = item.select("a");
for(Element link: links){
link.attr("href",link.attr("abs:href"));
}
Elements imgs = item.select("img");
for(Element img: imgs){
img.attr("src",img.attr("abs:src"));
}
String html = item.html();
out.println("" + html + "");
}
在上面的代码中,我们处理了每个被查询的 includeitem 元素。找到“a”和“img”,将href元素值修改为绝对路径。
link.attr("abs:href")
上面的代码会得到对应链接的绝对路径,这里的属性是abs:href。同理可以得到图片的绝对路径abs:src。
代码运行后,我们就可以看到修改后的代码,放到li中。
接下来,我们开发一个页面来控制抓取:
在这个页面的实现中,我们使用setInterval方法在指定的时间间隔调用上面ajax开发的java代码。基本代码如下:
//Run for first time
$('#msg').html('请耐心等待, 页面抓取中 ...').fadeIn(400);
//$('#content').html('');
$('#content').load('siteproxy.jsp #result', {url:url, elem:element}, function(){
$('#msg').html('抓取已完成').delay(1500).fadeOut(400);
})
上面的代码非常简单。我们使用jQuery的load方法调用siteproxy.jsp,然后获取siteproxy.jsp生成的页面中的#result元素,即抓取内容。如果你不熟悉jQuery的ajax方法,请参考这个系列文章:
jQuery 库的 AJAX 方法初学者指南-第 1 部分
jQuery 库的 AJAX 方法初学者指南-第 2 部分
初学者使用jQuery库的AJAX方法-第三部分
jQuery 库的 AJAX 方法初学者指南-第 4 部分
为了让代码以指定的时间间隔运行爬取,我们将方法放在setinterval中,如下:
runid = setInterval(
function getInfo(){
$('#msg').html('请耐心等待, 页面抓取中 ...').fadeIn(400);
//$('#content').html('');
$('#content').load('siteproxy.jsp #result', {url:url, elem:element}, function(){
$('#msg').html('抓取已完成').delay(1500).fadeOut(400);
})
}, interval*1000);
通过上述方法,我们可以在用户触发抓取后每隔指定时间触发抓取动作。
完整的js代码如下:
$(document).ready(function(){
var url, element, interval, runid;
$('#start').click(function(){
url = $('#url').val();
element = $('#element').val();
interval = $('#interval').val();
//Run for first time
$('#msg').html('请耐心等待, 页面抓取中 ...').fadeIn(400);
//$('#content').html('');
$('#content').load('siteproxy.jsp #result', {url:url, elem:element}, function(){
$('#msg').html('抓取已完成').delay(1500).fadeOut(400);
})
runid = setInterval(
function getInfo(){
$('#msg').html('请耐心等待, 页面抓取中 ...').fadeIn(400);
//$('#content').html('');
$('#content').load('siteproxy.jsp #result', {url:url, elem:element}, function(){
$('#msg').html('抓取已完成').delay(1500).fadeOut(400);
})
}, interval*1000);
});
$('#stop').click(function(){
$('#msg').html('抓取已暂停').fadeIn(400).delay(1500);
clearInterval(runid);
});
});
部署完上面的jsp和html文件后,会看到如下界面:

我们需要设置要爬取的url和页面元素。默认情况下,该元素是 .includeitem。点击开始爬取,可以看到应用爬取了以下内容:

注意这里的默认间隔是30秒,30秒后会自动检索内容。
可以尝试抓取element.itemt,间隔10秒,可以得到如下内容:

你可以在微博首页看到和自动刷新一样的内容。
您可以将此工具用作重复页面刷新工具,它可以帮助您监控网站 的某个部分。当然,你也可以用它来动态刷新你的网站,提高你的alexa排名。.
希望大家喜欢这个工具应用。如果您有任何建议或问题,请给我们留言!谢谢!
来源:使用java的html解析器jsoup和jQuery实现一个web应用,自动重复抓取任意网站页面指定元素
在线抓取网页(几个暗含抓取算法:宽度优先抓取哪些页面却需要算法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-22 11:16
搜索引擎看似简单的爬虫查询工作,但每个链接所隐含的算法却非常复杂。搜索引擎抓取页面是由蜘蛛完成的。爬取动作很容易实现,但是要爬取哪些页面,先爬取哪些页面需要算法来决定。以下是一些爬行算法:
1、宽度优先的爬取策略:
我们都知道大部分网站页面都是按照树状图分布的,那么在树状图的链接结构中,哪些页面会先被爬取呢?为什么要先抓取这些页面?宽度优先的获取策略是按照树状结构先获取同级链接,等同级链接获取完成后再获取下一级链接。
如您所见,当我声明时,我使用了链接结构而不是 网站 结构。这里的链接结构可以由指向任何页面的链接组成,不一定是网站内部链接。这是一种理想化的宽度优先爬行策略。在实际爬取过程中,不可能先想到全宽,先想到限宽。
当我们的Spider检索G链接时,通过算法发现G页面没有任何价值,于是悲剧的G链接和从属的H链接被Spider统一了。至于为什么会统一G环节?嗯,我们来分析一下。
2、不完整的遍历链接权重计算:
每个搜索引擎都有一套pagerank(指页面权重,不是googlePR)的计算方法,并且经常更新。互联网几乎是无限的,每天都会产生大量的新链接。搜索引擎在计算链接权重时只能进行不完全遍历。为什么GooglePR需要每三个月更新一次?为什么百度一个月更新1-2两次?这是因为搜索引擎使用不完全遍历链接权重算法来计算链接权重。其实按照现在的技术,实现更快的权重更新并不难。计算速度和存储速度完全可以跟得上,但为什么不这样做呢?因为不是那么必要,或者已经实施了,但我不想公布。然后,
我们形成一组K个链接,R代表链接获得的pagerank,S代表链接收录的链接数,Q代表是否参与传递,代表阻尼因子,那么得到的权重计算公式通过链接是: 查看全部
在线抓取网页(几个暗含抓取算法:宽度优先抓取哪些页面却需要算法)
搜索引擎看似简单的爬虫查询工作,但每个链接所隐含的算法却非常复杂。搜索引擎抓取页面是由蜘蛛完成的。爬取动作很容易实现,但是要爬取哪些页面,先爬取哪些页面需要算法来决定。以下是一些爬行算法:
1、宽度优先的爬取策略:
我们都知道大部分网站页面都是按照树状图分布的,那么在树状图的链接结构中,哪些页面会先被爬取呢?为什么要先抓取这些页面?宽度优先的获取策略是按照树状结构先获取同级链接,等同级链接获取完成后再获取下一级链接。
如您所见,当我声明时,我使用了链接结构而不是 网站 结构。这里的链接结构可以由指向任何页面的链接组成,不一定是网站内部链接。这是一种理想化的宽度优先爬行策略。在实际爬取过程中,不可能先想到全宽,先想到限宽。
当我们的Spider检索G链接时,通过算法发现G页面没有任何价值,于是悲剧的G链接和从属的H链接被Spider统一了。至于为什么会统一G环节?嗯,我们来分析一下。
2、不完整的遍历链接权重计算:
每个搜索引擎都有一套pagerank(指页面权重,不是googlePR)的计算方法,并且经常更新。互联网几乎是无限的,每天都会产生大量的新链接。搜索引擎在计算链接权重时只能进行不完全遍历。为什么GooglePR需要每三个月更新一次?为什么百度一个月更新1-2两次?这是因为搜索引擎使用不完全遍历链接权重算法来计算链接权重。其实按照现在的技术,实现更快的权重更新并不难。计算速度和存储速度完全可以跟得上,但为什么不这样做呢?因为不是那么必要,或者已经实施了,但我不想公布。然后,
我们形成一组K个链接,R代表链接获得的pagerank,S代表链接收录的链接数,Q代表是否参与传递,代表阻尼因子,那么得到的权重计算公式通过链接是:
在线抓取网页(网站接口是关联式接口的吗?在线抓取网页数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-11-17 05:00
在线抓取网页数据,网站接口一般都是关联式接口,比如qq,那你抓取qq会有些相应的js。跟你分析数据结构一样,你要抓取某些字段就去抓那些字段。jquery也可以分析,当然加一些框架比如ajax啥的,vue/react啥的,
首先搞清楚页面那个元素可以抓取,比如通过js查看response后面一串字符代表了哪个元素,然后结合用户上一次访问页面的pageviewcontent查看该元素对应的url,最后根据对应的url去抓取。
放个网址供浏览:/
jquery是javascript库,
推荐你看我原来写的文章:重构互联网商品数据爬虫引擎-尝试并发处理和分页爬取
jquery里面应该有封装各种方法来抓取商品信息。
jquery封装了所有方法吧。只不过不能分析pageviewcontent下的url。
分析这种模拟分析,为啥不看源码。
不太清楚你是指哪个版本的jquery,现在版本更新比较快,通常jquery框架已经更新过,而且比较牛逼的jquery后台代码源码放在github上,很多网站都在用jquery,所以你只要知道从jquery生成html,然后调用即可.
有工具,
mozilla
好像有个jquery加密工具,貌似也可以用来看抓取jquery的信息。 查看全部
在线抓取网页(网站接口是关联式接口的吗?在线抓取网页数据)
在线抓取网页数据,网站接口一般都是关联式接口,比如qq,那你抓取qq会有些相应的js。跟你分析数据结构一样,你要抓取某些字段就去抓那些字段。jquery也可以分析,当然加一些框架比如ajax啥的,vue/react啥的,
首先搞清楚页面那个元素可以抓取,比如通过js查看response后面一串字符代表了哪个元素,然后结合用户上一次访问页面的pageviewcontent查看该元素对应的url,最后根据对应的url去抓取。
放个网址供浏览:/
jquery是javascript库,
推荐你看我原来写的文章:重构互联网商品数据爬虫引擎-尝试并发处理和分页爬取
jquery里面应该有封装各种方法来抓取商品信息。
jquery封装了所有方法吧。只不过不能分析pageviewcontent下的url。
分析这种模拟分析,为啥不看源码。
不太清楚你是指哪个版本的jquery,现在版本更新比较快,通常jquery框架已经更新过,而且比较牛逼的jquery后台代码源码放在github上,很多网站都在用jquery,所以你只要知道从jquery生成html,然后调用即可.
有工具,
mozilla
好像有个jquery加密工具,貌似也可以用来看抓取jquery的信息。
在线抓取网页(在线抓取网页视频教程:基础篇进阶篇、网页分析篇)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-11-16 10:11
在线抓取网页视频教程:基础篇、进阶篇、网页分析篇、网页解析篇、视频解析篇、视频解析篇、视频解析篇1.实例代码第一步:首先我们用浏览器打开:,然后新建个index.html文件。大家可以看到,新建项目文件的时候,会在视频链接上点击一下。然后在这个视频链接的基础上打上.js文件。第二步:页面调试这里我们调试视频教程的一个版本,把视频链接分别拷贝到index.html文件的第二行:和第一行:的效果第三步:视频下载利用代理ed2k规则下载网页视频,下载流程跟请求视频的代理规则是一样的。到了网页源码中找到html标签:。
抓取什么网站,在线教程—在线教程之将视频流编码成mp4数据,
可以试试sock优采云采集器,
v8的协议、ml的tf_lib、以及qq浏览器的实现、后来tcp还支持二进制等协议都可以实现。
websocket
github上有很多有趣的,有时候也会去修改一些api,了解它们的实现原理。
如果你用浏览器的话,你可以尝试一下tcp和http协议。如果可以还是python吧,毕竟开发效率很高。建议网上多搜索一下文章。 查看全部
在线抓取网页(在线抓取网页视频教程:基础篇进阶篇、网页分析篇)
在线抓取网页视频教程:基础篇、进阶篇、网页分析篇、网页解析篇、视频解析篇、视频解析篇、视频解析篇1.实例代码第一步:首先我们用浏览器打开:,然后新建个index.html文件。大家可以看到,新建项目文件的时候,会在视频链接上点击一下。然后在这个视频链接的基础上打上.js文件。第二步:页面调试这里我们调试视频教程的一个版本,把视频链接分别拷贝到index.html文件的第二行:和第一行:的效果第三步:视频下载利用代理ed2k规则下载网页视频,下载流程跟请求视频的代理规则是一样的。到了网页源码中找到html标签:。
抓取什么网站,在线教程—在线教程之将视频流编码成mp4数据,
可以试试sock优采云采集器,
v8的协议、ml的tf_lib、以及qq浏览器的实现、后来tcp还支持二进制等协议都可以实现。
websocket
github上有很多有趣的,有时候也会去修改一些api,了解它们的实现原理。
如果你用浏览器的话,你可以尝试一下tcp和http协议。如果可以还是python吧,毕竟开发效率很高。建议网上多搜索一下文章。
在线抓取网页( 百度搜藏Baiduspider-favo百度联盟-cpro商务搜索Baiduspider)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-11-15 23:01
百度搜藏Baiduspider-favo百度联盟-cpro商务搜索Baiduspider)
百度蜘蛛蜘蛛抓取网页介绍
1.什么是百度蜘蛛
百度蜘蛛是百度搜索引擎的自动程序。它的功能是访问互联网上的网页,并建立索引数据库,以便用户在百度搜索引擎上搜索您的网页。
2.百度蜘蛛的用户代理是什么?
百度产品使用不同的用户代理:
产品名称
对应user-agent
无线搜索
百度蜘蛛
图片搜索
百度蜘蛛图片
视频搜索
百度蜘蛛视频
新闻搜索
百度蜘蛛新闻
百度采集
百度蜘蛛最爱
百度联盟
百度蜘蛛-cpro
业务搜索
百度蜘蛛广告
网络和其他搜索
百度蜘蛛
3.百度蜘蛛对网站服务器造成的访问压力是什么?
为了对目标资源取得更好的检索效果,百度蜘蛛需要对您的网站保持一定的抓取量。我们尽量不对网站施加不合理的负担,会根据服务器容量、网站质量、网站更新等综合因素进行调整。如果您认为百度蜘蛛的访问行为存在不合理的情况,您可以向反馈中心反馈。
4.为什么百度蜘蛛老是爬我的网站?
百度蜘蛛会持续抓取您网站上新生成或不断更新的页面。此外,您还可以在网站访问日志中查看百度蜘蛛的访问是否正常,防止有人恶意冒充百度蜘蛛频繁抓取您的网站。如果您发现百度蜘蛛异常抓取您的网站,请通过反馈中心反馈给我们,并尽量提供百度蜘蛛对您网站的访问日志,以便我们进行跟踪。
5.如何判断是否冒充百度蜘蛛爬取?
建议您使用DNS反向检查的方式来判断爬取源的IP是否属于百度。不同平台的验证方法也不同。比如linux/windows/os三个平台下的验证方法如下:
5.1 在Linux平台下,可以使用hostip命令解密ip来判断是否来自百度蜘蛛。百度蜘蛛的主机名以*格式命名。或 *.baidu.jp。如果不是 *. 或者*.baidu.jp,都是假的。
$host123.125.66.120
120.66.125.123.in-addr.arpadomainnamepointer
.
主机119.63.195.254
254.195.63.119.in-addr.arpadomainnamepointer
百度Mobaider-119-63-195-254.crawl.baidu.jp。
5.2 windows平台或IBMOS/2平台下,可以使用nslookupip命令解密ip,判断是否来自百度蜘蛛。打开命令处理器,输入nslookupxxx.xxx.xxx.xxx(IP地址)解析ip判断是否来自百度蜘蛛。百度蜘蛛的主机名以*格式命名。或 *.baidu.jp,而不是 *. 或者 *.baidu.jp 是冒充的。
5.3 在macos平台下,可以使用dig命令解密ip来判断是否来自百度蜘蛛。打开命令处理器,输入digxxx.xxx.xxx.xxx(IP地址)解析ip判断是否来自百度蜘蛛。百度蜘蛛的主机名以*格式命名。或 *.baidu.jp,而不是 *. 或者 *.baidu.jp 是冒充的。
6.我不希望我的网站被百度蜘蛛访问,我该怎么办?
百度蜘蛛符合互联网机器人协议。您可以使用robots.txt文件完全禁止百度蜘蛛访问您的网站,或者禁止百度蜘蛛访问您的网站上的某些文件。注意:如果百度蜘蛛被禁止访问您的网站,您的网站上的网页将无法在百度搜索引擎和百度提供搜索引擎服务的所有搜索引擎中搜索到。robots.txt的写法请参考我们的介绍:robots.txt的写法
您可以根据每个产品的不同用户代理设置不同的抓取规则。如果要完全禁止百度所有产品收录,可以直接设置Baiduspider禁止抓取。
以下robots实现禁止所有来自百度的抓取:
用户代理:百度蜘蛛
不允许:/
以下robots实现禁止所有来自百度的抓取,但允许图片搜索抓取/image/目录:
用户代理:百度蜘蛛
不允许:/
用户代理:Baiduspider-image
允许:/图像/
请注意:Baiduspider-cpro 抓取的网页不会被索引,但会执行与客户约定的操作。因此,不遵守机器人协议。如果Baiduspider-cpro给您带来麻烦,请联系我们。
百度蜘蛛广告抓取的网页不会被索引,但会执行与客户约定的操作。因此,不遵守机器人协议。如果百度蜘蛛广告给您带来麻烦,请联系您的客服专员。
7.为什么我的网站里加了robots.txt,百度上还是能搜到?
因为搜索引擎索引数据库的更新需要时间。虽然百度蜘蛛已经停止访问您在网站上的网页,但清除百度搜索引擎数据库中已建立网页的索引信息可能需要几个月的时间。另请检查您的机器人是否配置正确。
如果收录急需您的拒绝,您也可以通过反馈中心请求处理。
8.我希望我的 网站 内容被百度索引但不保存快照。我该怎么办?
百度蜘蛛符合互联网元机器人协议。您可以使用网页元设置使百度显示仅索引网页,而不在搜索结果中显示网页快照。
和robots的更新一样,更新搜索引擎索引库也是需要时间的,所以虽然你在网页中通过meta禁用了百度在搜索结果中显示页面的快照,但是如果网页索引已经在百度搜索引擎数据库信息,可能需要两到四个星期才能在线生效。
9.百度蜘蛛爬网导致带宽拥塞?
百度蜘蛛的正常抓取不会阻塞你的网站带宽。这种现象可能是有人冒充百度蜘蛛恶意抓取造成的。如果您发现名为百度蜘蛛的代理正在爬行导致带宽拥塞,请尽快与我们联系。您可以将信息反馈到反馈中心,如果您能提供您在此期间的网站访问日志,将更有利于我们的分析 查看全部
在线抓取网页(
百度搜藏Baiduspider-favo百度联盟-cpro商务搜索Baiduspider)
百度蜘蛛蜘蛛抓取网页介绍
1.什么是百度蜘蛛
百度蜘蛛是百度搜索引擎的自动程序。它的功能是访问互联网上的网页,并建立索引数据库,以便用户在百度搜索引擎上搜索您的网页。
2.百度蜘蛛的用户代理是什么?
百度产品使用不同的用户代理:
产品名称
对应user-agent
无线搜索
百度蜘蛛
图片搜索
百度蜘蛛图片
视频搜索
百度蜘蛛视频
新闻搜索
百度蜘蛛新闻
百度采集
百度蜘蛛最爱
百度联盟
百度蜘蛛-cpro
业务搜索
百度蜘蛛广告
网络和其他搜索
百度蜘蛛
3.百度蜘蛛对网站服务器造成的访问压力是什么?
为了对目标资源取得更好的检索效果,百度蜘蛛需要对您的网站保持一定的抓取量。我们尽量不对网站施加不合理的负担,会根据服务器容量、网站质量、网站更新等综合因素进行调整。如果您认为百度蜘蛛的访问行为存在不合理的情况,您可以向反馈中心反馈。
4.为什么百度蜘蛛老是爬我的网站?
百度蜘蛛会持续抓取您网站上新生成或不断更新的页面。此外,您还可以在网站访问日志中查看百度蜘蛛的访问是否正常,防止有人恶意冒充百度蜘蛛频繁抓取您的网站。如果您发现百度蜘蛛异常抓取您的网站,请通过反馈中心反馈给我们,并尽量提供百度蜘蛛对您网站的访问日志,以便我们进行跟踪。
5.如何判断是否冒充百度蜘蛛爬取?
建议您使用DNS反向检查的方式来判断爬取源的IP是否属于百度。不同平台的验证方法也不同。比如linux/windows/os三个平台下的验证方法如下:
5.1 在Linux平台下,可以使用hostip命令解密ip来判断是否来自百度蜘蛛。百度蜘蛛的主机名以*格式命名。或 *.baidu.jp。如果不是 *. 或者*.baidu.jp,都是假的。
$host123.125.66.120
120.66.125.123.in-addr.arpadomainnamepointer
.
主机119.63.195.254
254.195.63.119.in-addr.arpadomainnamepointer
百度Mobaider-119-63-195-254.crawl.baidu.jp。
5.2 windows平台或IBMOS/2平台下,可以使用nslookupip命令解密ip,判断是否来自百度蜘蛛。打开命令处理器,输入nslookupxxx.xxx.xxx.xxx(IP地址)解析ip判断是否来自百度蜘蛛。百度蜘蛛的主机名以*格式命名。或 *.baidu.jp,而不是 *. 或者 *.baidu.jp 是冒充的。
5.3 在macos平台下,可以使用dig命令解密ip来判断是否来自百度蜘蛛。打开命令处理器,输入digxxx.xxx.xxx.xxx(IP地址)解析ip判断是否来自百度蜘蛛。百度蜘蛛的主机名以*格式命名。或 *.baidu.jp,而不是 *. 或者 *.baidu.jp 是冒充的。
6.我不希望我的网站被百度蜘蛛访问,我该怎么办?
百度蜘蛛符合互联网机器人协议。您可以使用robots.txt文件完全禁止百度蜘蛛访问您的网站,或者禁止百度蜘蛛访问您的网站上的某些文件。注意:如果百度蜘蛛被禁止访问您的网站,您的网站上的网页将无法在百度搜索引擎和百度提供搜索引擎服务的所有搜索引擎中搜索到。robots.txt的写法请参考我们的介绍:robots.txt的写法
您可以根据每个产品的不同用户代理设置不同的抓取规则。如果要完全禁止百度所有产品收录,可以直接设置Baiduspider禁止抓取。
以下robots实现禁止所有来自百度的抓取:
用户代理:百度蜘蛛
不允许:/
以下robots实现禁止所有来自百度的抓取,但允许图片搜索抓取/image/目录:
用户代理:百度蜘蛛
不允许:/
用户代理:Baiduspider-image
允许:/图像/
请注意:Baiduspider-cpro 抓取的网页不会被索引,但会执行与客户约定的操作。因此,不遵守机器人协议。如果Baiduspider-cpro给您带来麻烦,请联系我们。
百度蜘蛛广告抓取的网页不会被索引,但会执行与客户约定的操作。因此,不遵守机器人协议。如果百度蜘蛛广告给您带来麻烦,请联系您的客服专员。
7.为什么我的网站里加了robots.txt,百度上还是能搜到?
因为搜索引擎索引数据库的更新需要时间。虽然百度蜘蛛已经停止访问您在网站上的网页,但清除百度搜索引擎数据库中已建立网页的索引信息可能需要几个月的时间。另请检查您的机器人是否配置正确。
如果收录急需您的拒绝,您也可以通过反馈中心请求处理。
8.我希望我的 网站 内容被百度索引但不保存快照。我该怎么办?
百度蜘蛛符合互联网元机器人协议。您可以使用网页元设置使百度显示仅索引网页,而不在搜索结果中显示网页快照。
和robots的更新一样,更新搜索引擎索引库也是需要时间的,所以虽然你在网页中通过meta禁用了百度在搜索结果中显示页面的快照,但是如果网页索引已经在百度搜索引擎数据库信息,可能需要两到四个星期才能在线生效。
9.百度蜘蛛爬网导致带宽拥塞?
百度蜘蛛的正常抓取不会阻塞你的网站带宽。这种现象可能是有人冒充百度蜘蛛恶意抓取造成的。如果您发现名为百度蜘蛛的代理正在爬行导致带宽拥塞,请尽快与我们联系。您可以将信息反馈到反馈中心,如果您能提供您在此期间的网站访问日志,将更有利于我们的分析
在线抓取网页(在优采云中怎么实现高清大图下文其他图片同理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-11-04 05:22
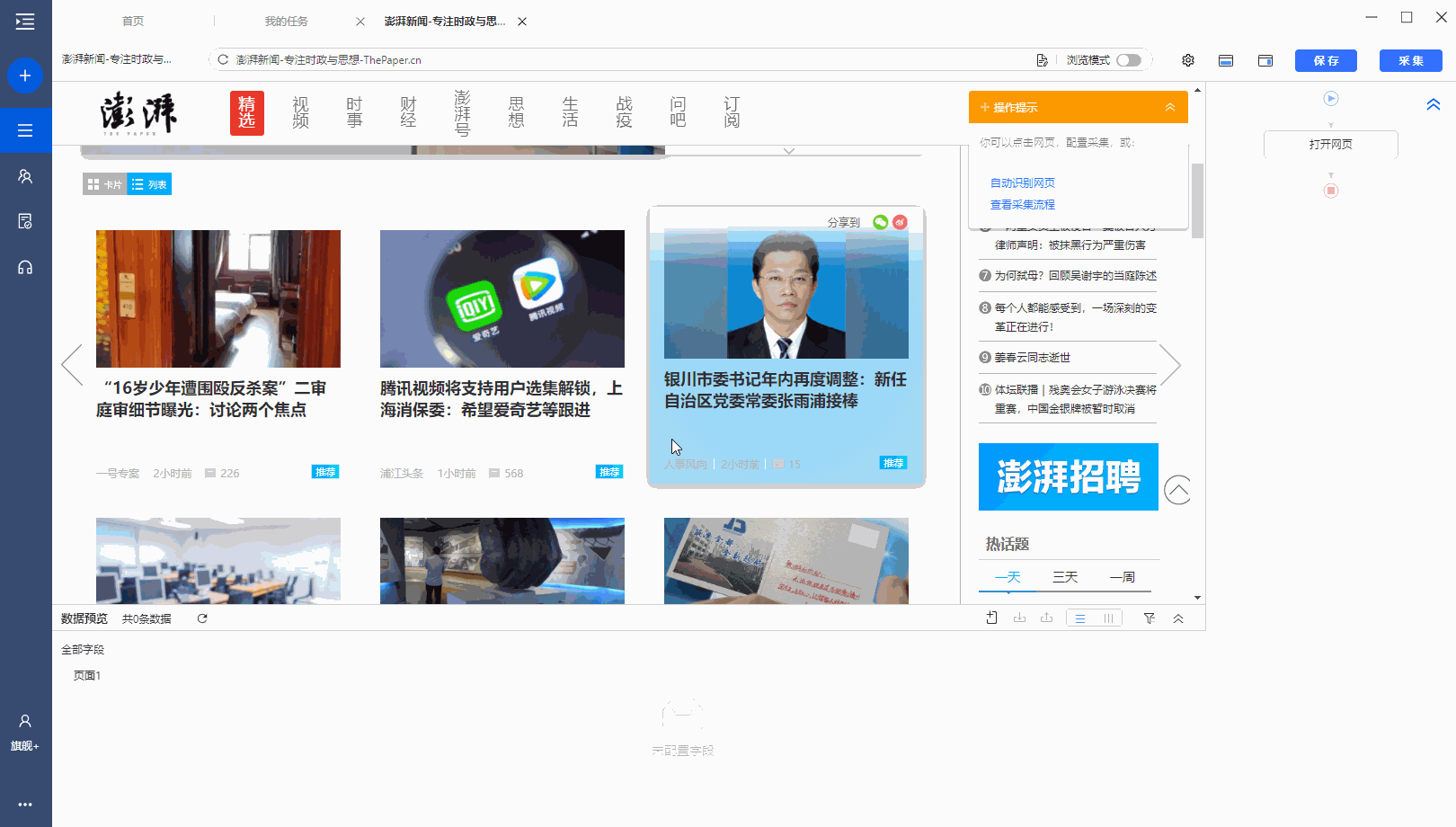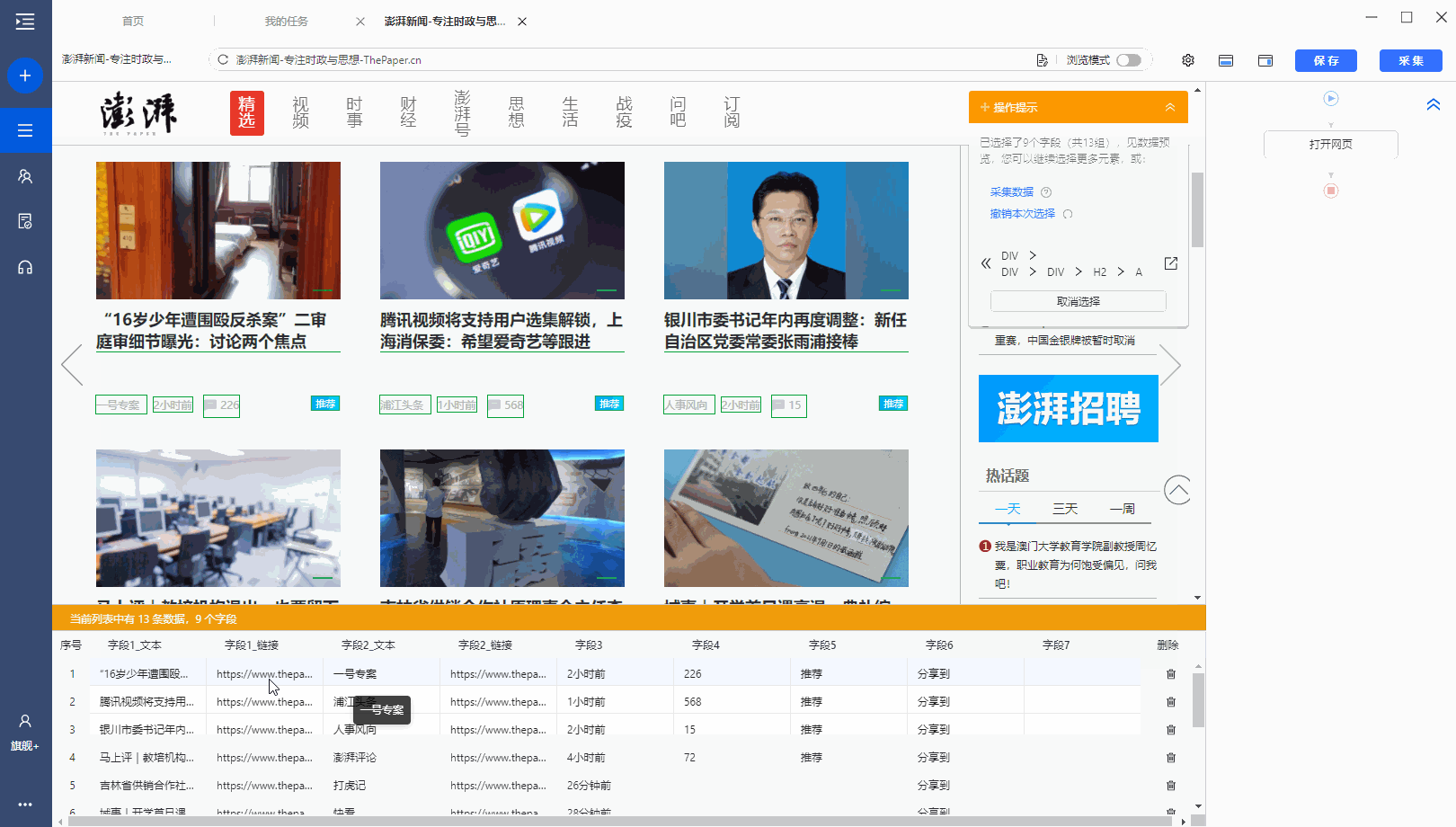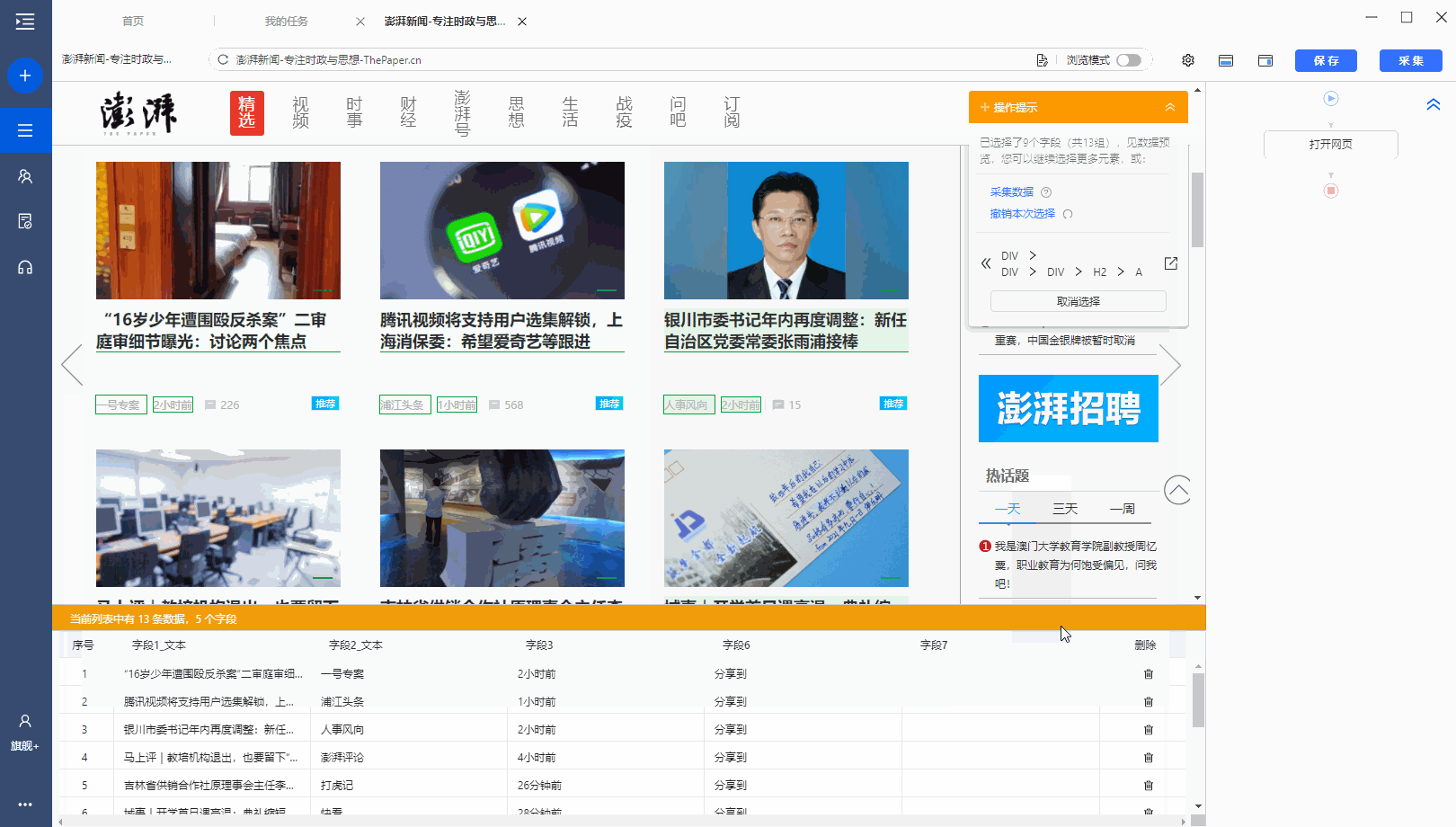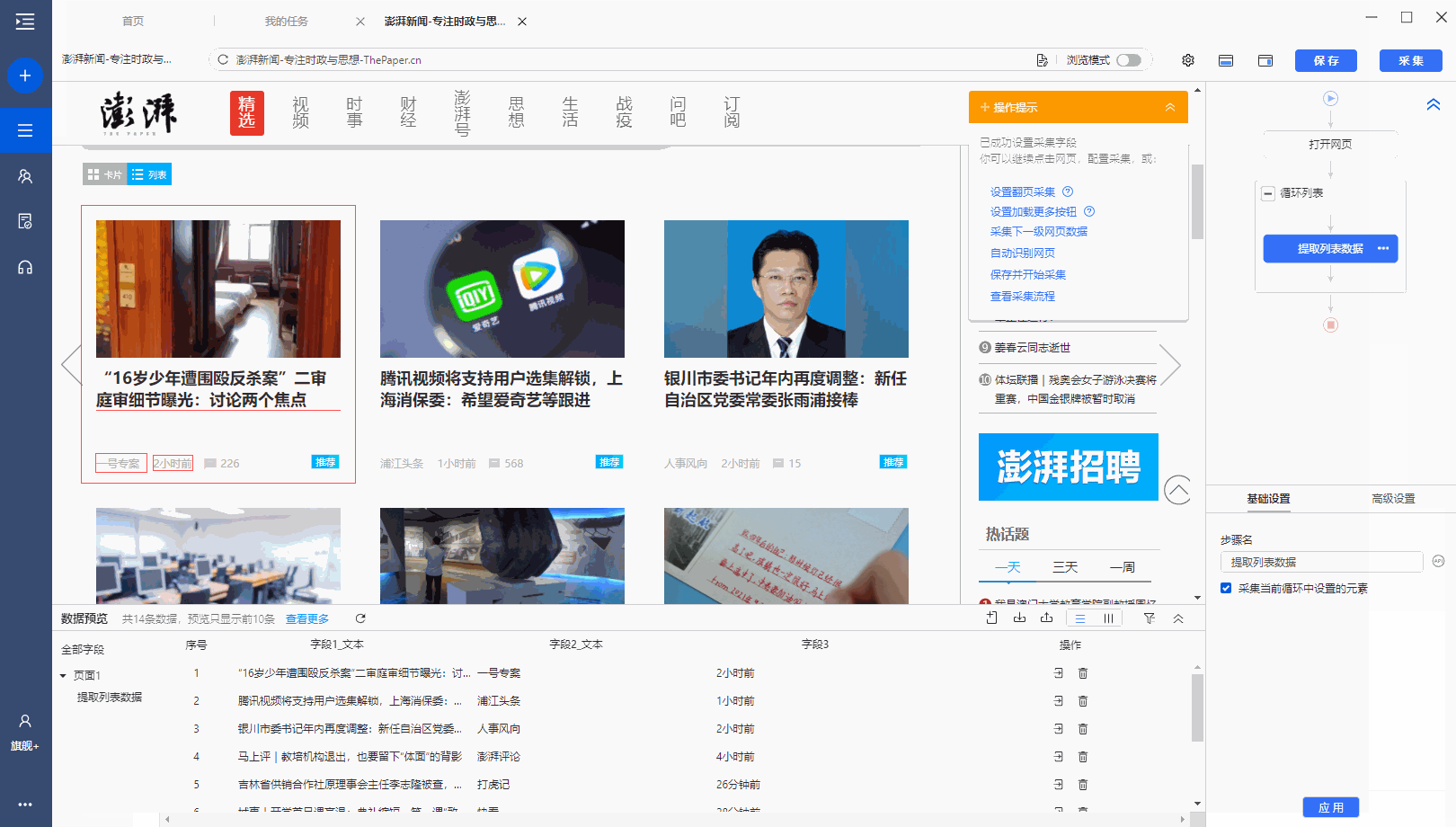
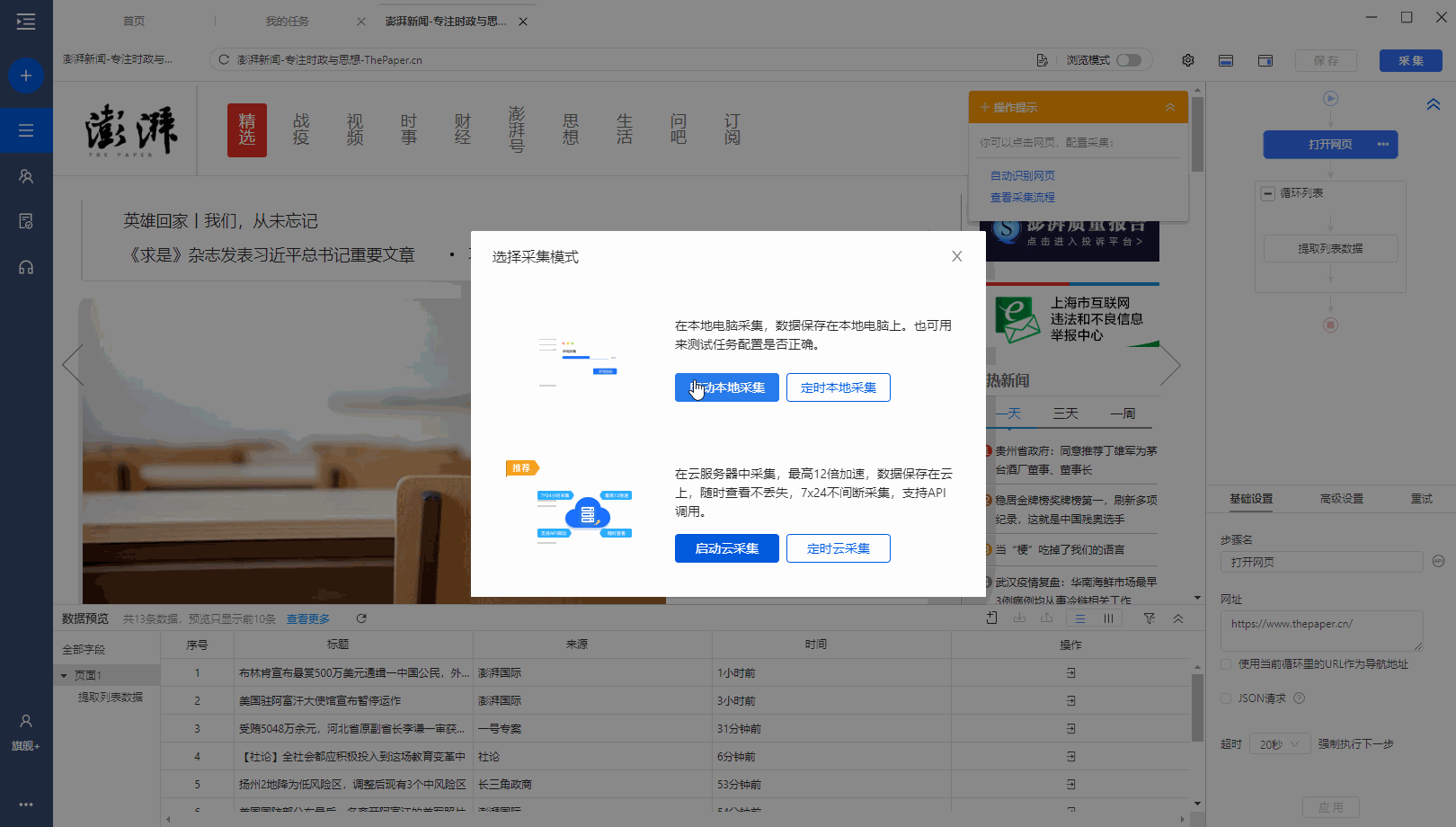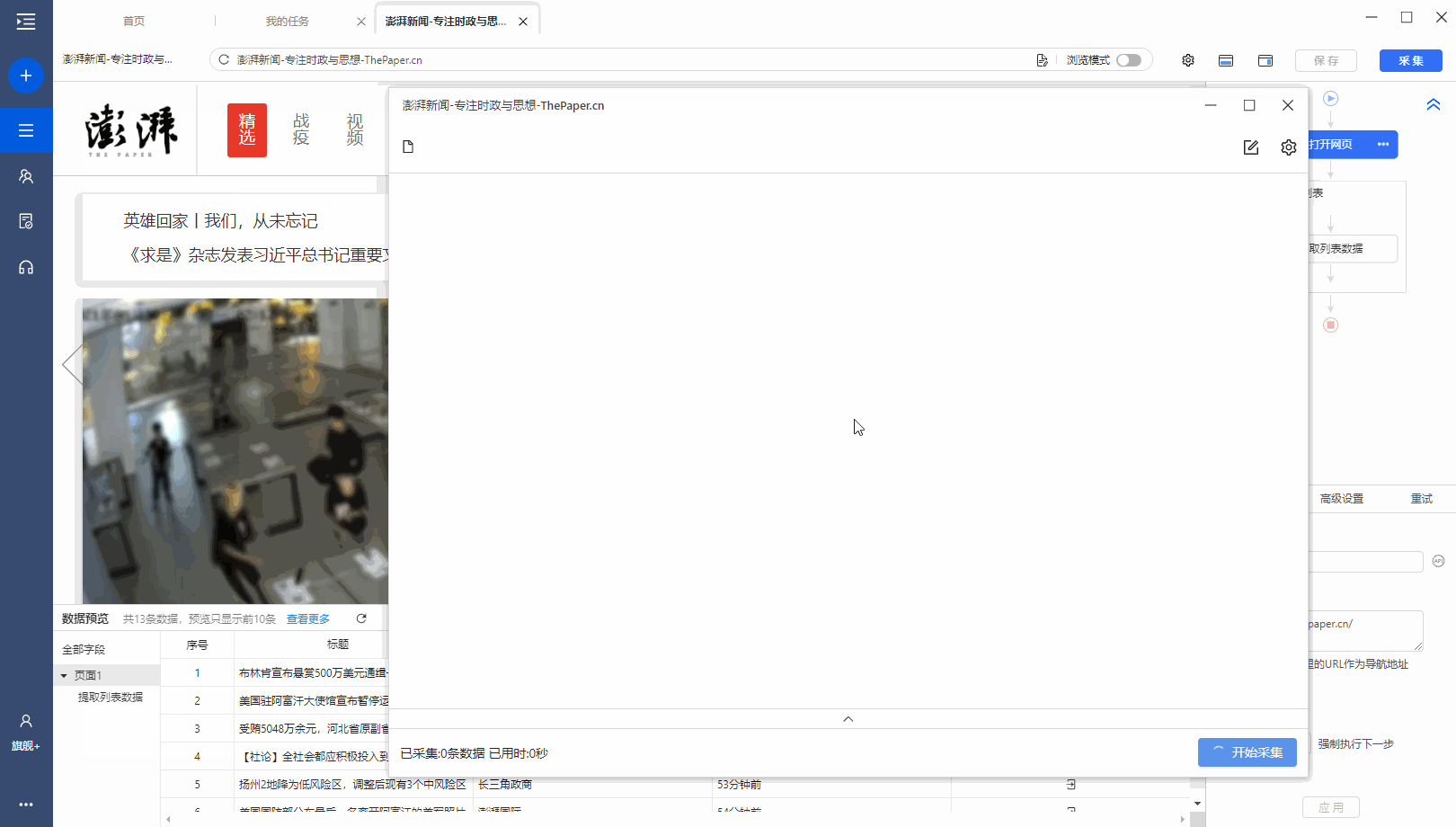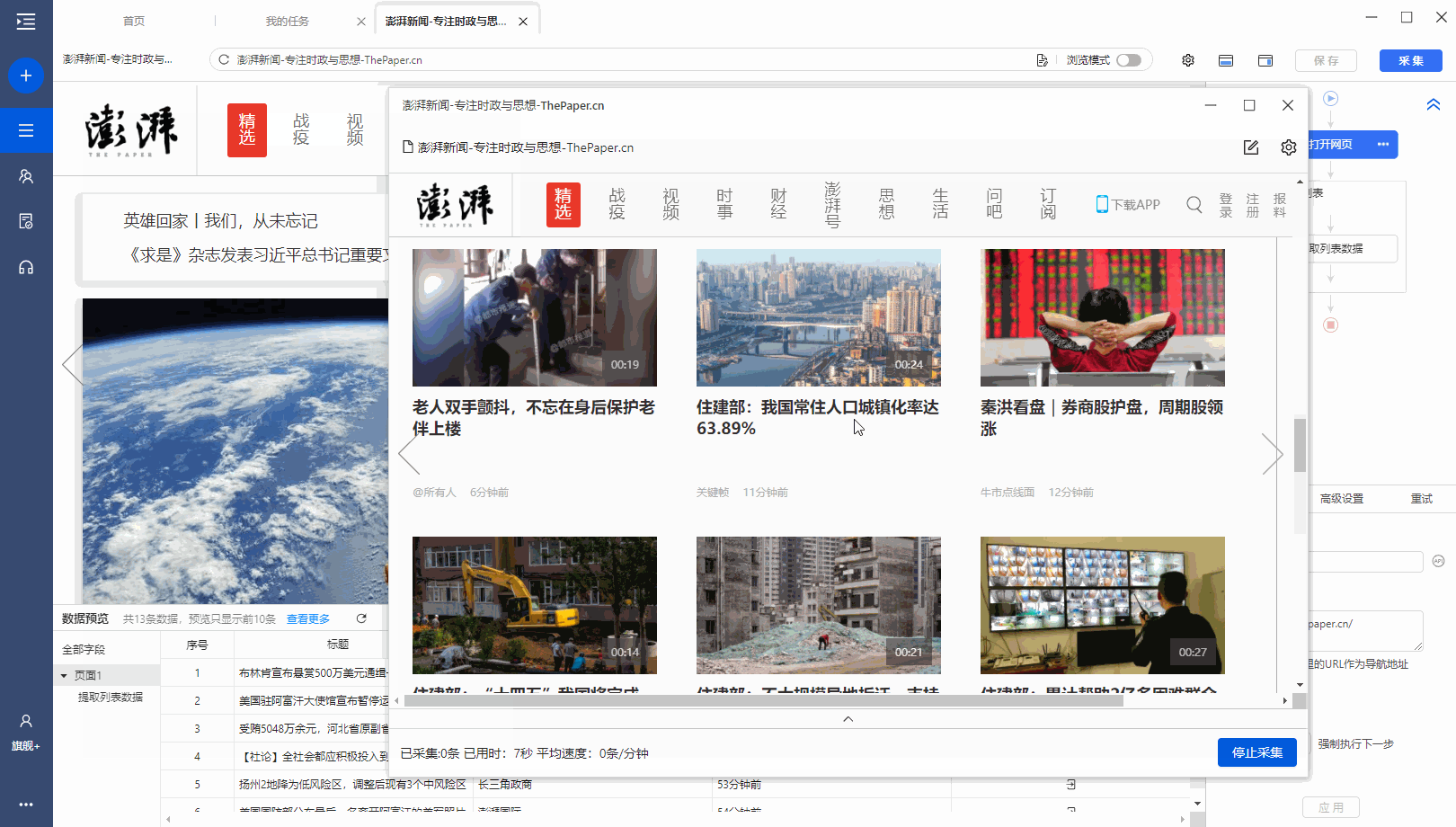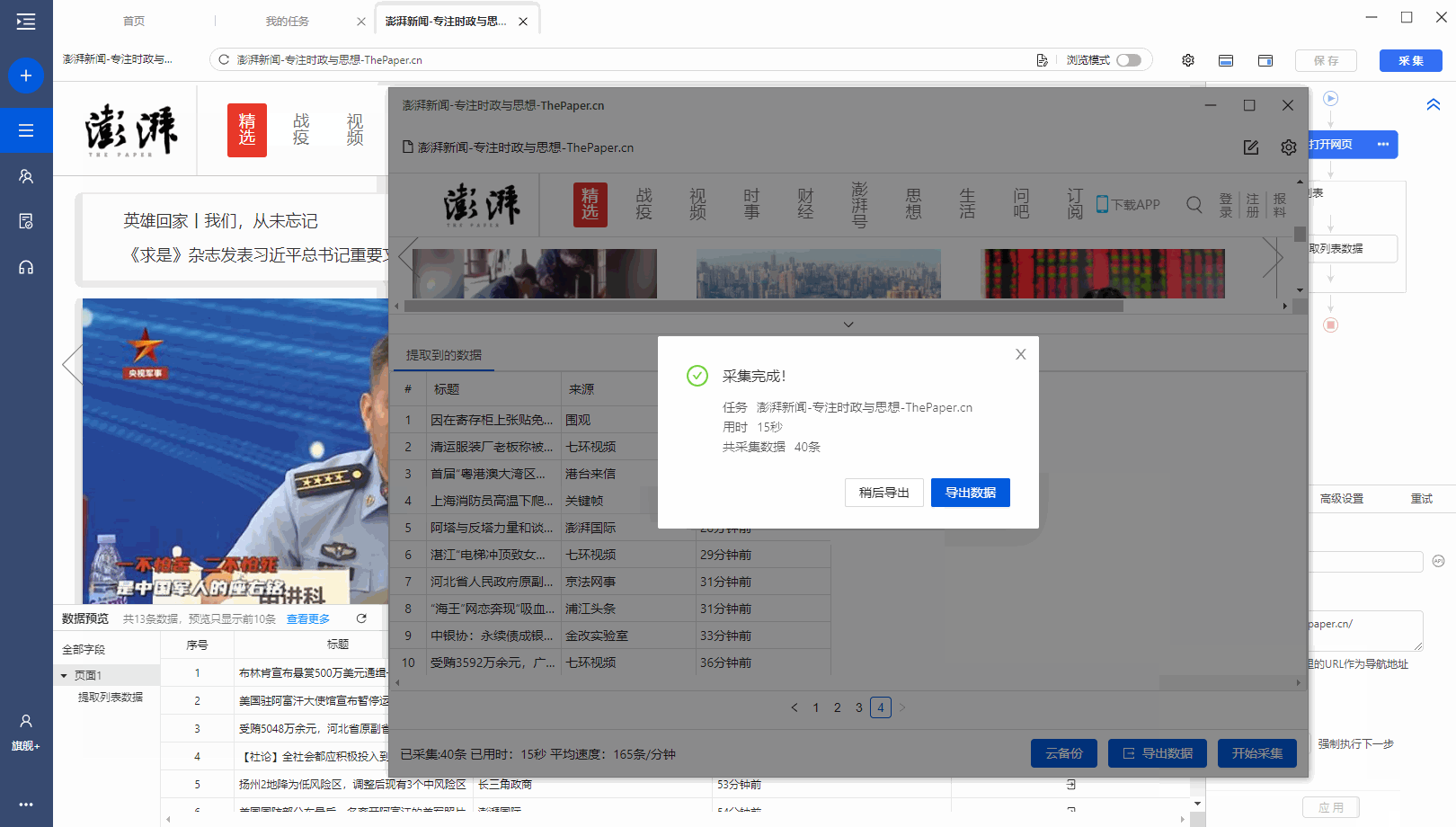
有很多网站,需要向下滚动页面才能加载新数据。相应的,还需要在优采云中设置【页面滚动】。
适用场景:向下滚动条直接到网页底部,出现类似【Loading】的字样,很快出现新数据,滚动条变短弹回。
常见网页:纸本首页、今日头条首页、百度图片搜索、新浪微博首页,都是这样。
鼠标放在图片上,右击,选择【在新标签页中打开图片】查看高清大图
这同样适用于下面的其他图片
以澎湃新闻首页为例。, 我们需要采集 新闻列表数据。打开网页后需要继续向下滚动以加载新数据。
如何在优采云中实现?以下是具体步骤。
步骤一、进入自定义任务编辑页面
将URL复制到客户端首页优采云的输入框,点击开始采集,进入自定义任务配置页面。
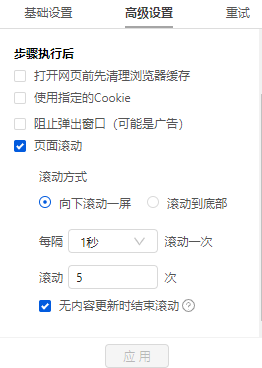
步骤二、 设置滚动方式,调整滚动次数,以及每次间隔
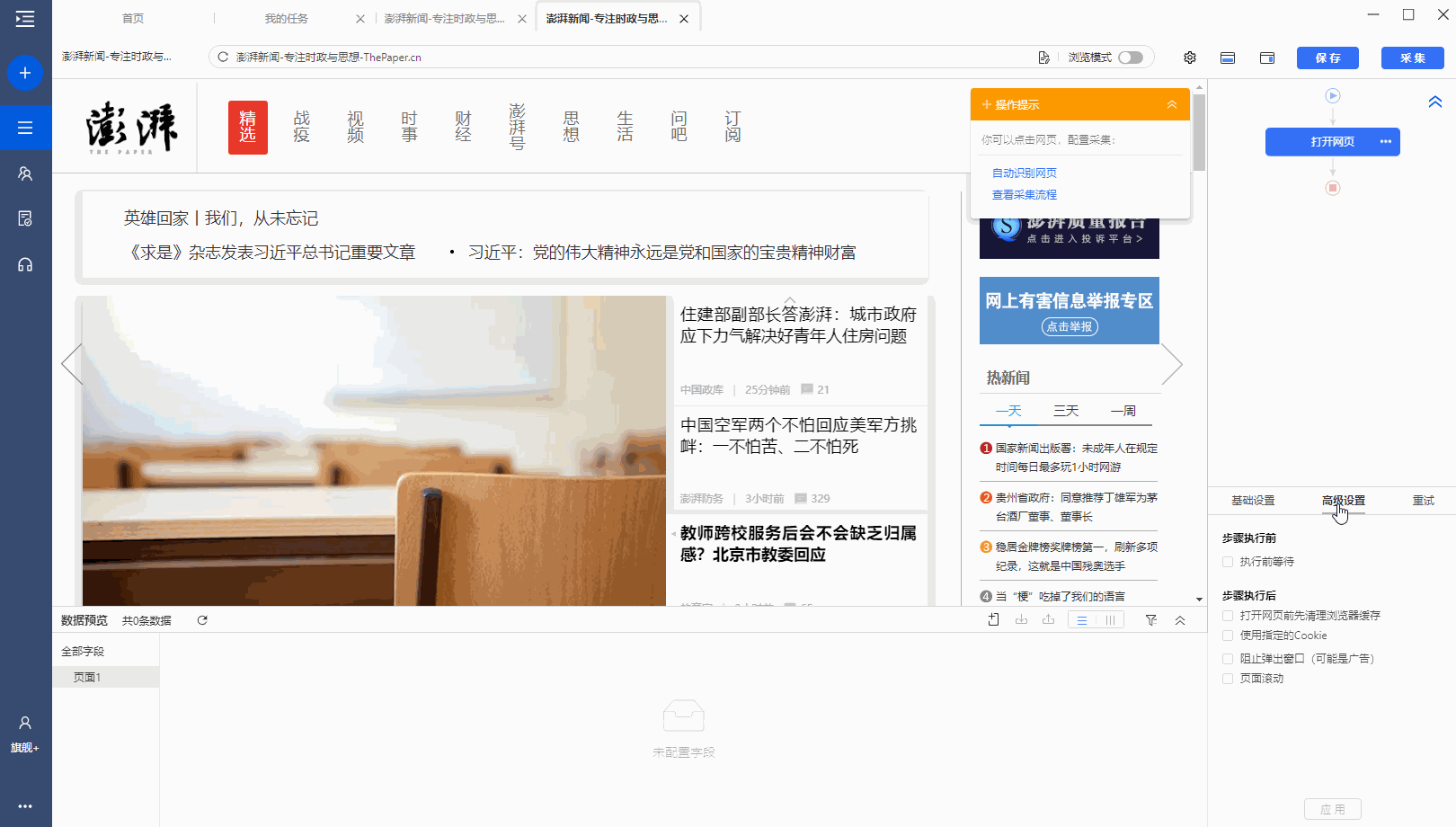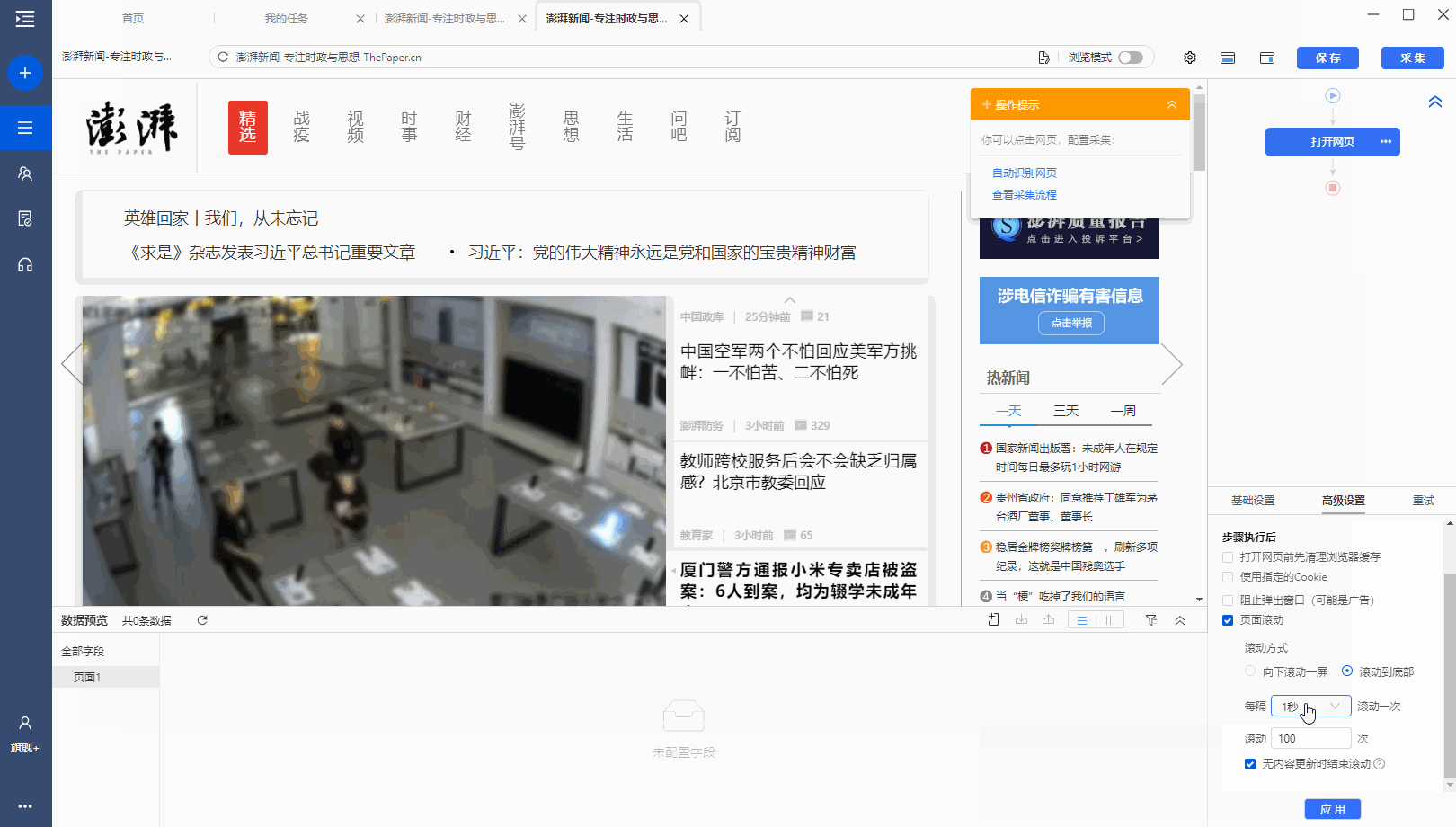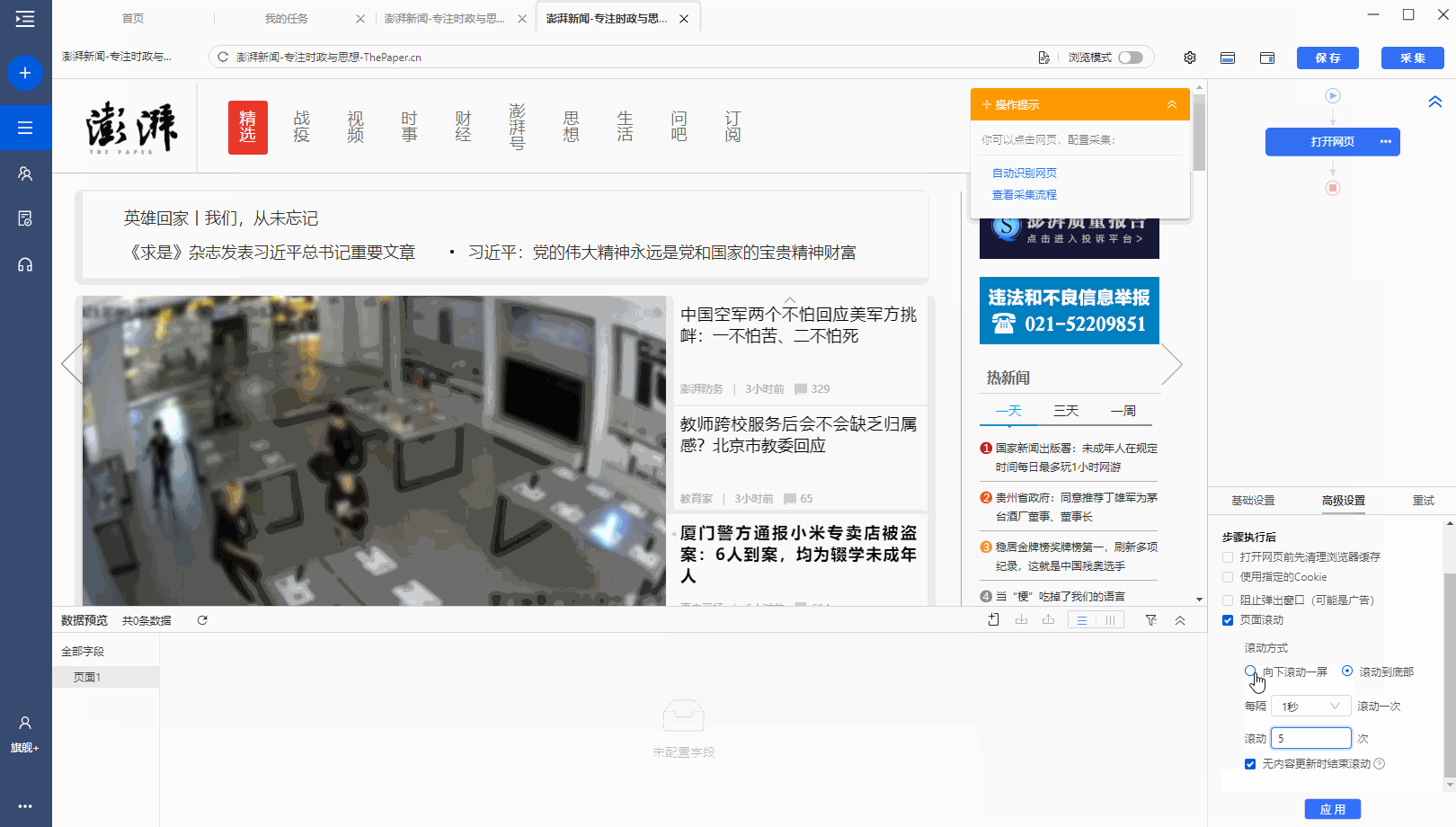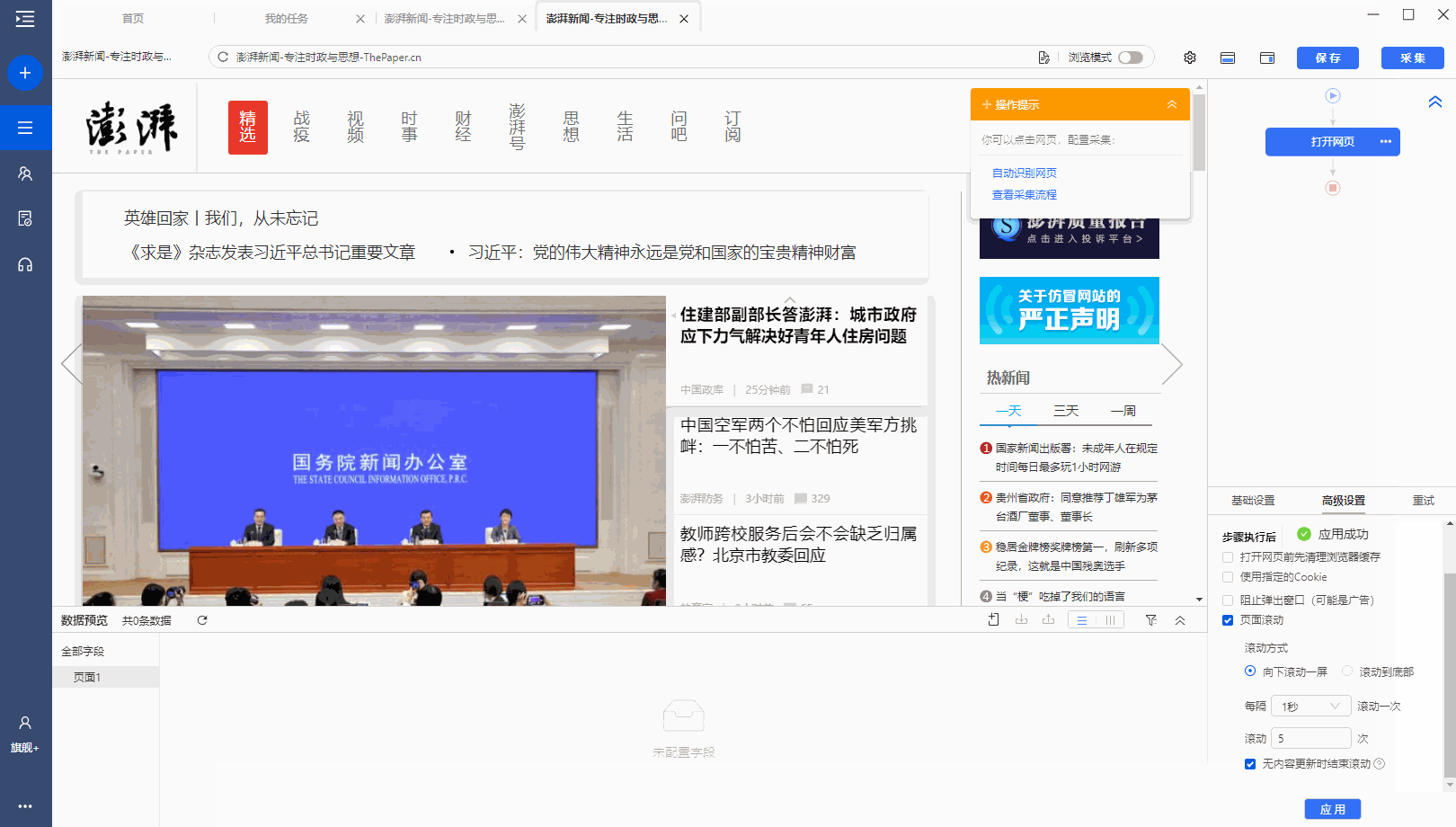
点击步骤打开网页,在下方步骤设置区点击高级设置,找到页面滚动,点击查看页面滚动。此网页可无限滚动。优采云 的默认设置是滚动到 [Scroll Mode] 的底部。默认为 [Scroll Times] 100 次,默认 [Each interval] 为 1 秒。您可以根据实际需要进行调整。【每个间隔】时间需要比网页上的数据加载时间稍长(网页上的数据加载时间与网速等因素有关)。
结合本次网站的加载特性,这里修改【Scroll Mode】向下滚动一屏(一般情况下建议选择向下滚动一屏);为了演示方便,这里设置【滚动次数】】5次。
第三步:使用第三课中学到的方法:采集List Data配置列表数据采集。
启动采集,看看采集的结果。优采云自动执行【直接滚动到底部】5次,然后采集5次后滚动数据。
特别说明:
1、此网页正在无限向下滚动以加载数据。优采云 无法采集 一次获取所有数据。上例设置滚动5次,在实际采集过程中,可以根据需要设置滚动次数。
2、这类网页常用于数据实时性较高的新闻网站,在优采云中可以使用云端采集,设置定时启动,少量次采集最新数据。
3、有时候网页速度很快,像【加载中】这样的提示不明显。【是否有新数据】和【观察滚动条反弹次数】是比较好用的判断标准,请关注网页。
4. [向下滚动一屏] 运行采集任务时,一屏与窗口显示区域相关。如下图,左边的滚动画面>右边的滚动画面。 查看全部
在线抓取网页(在优采云中怎么实现高清大图下文其他图片同理)
有很多网站,需要向下滚动页面才能加载新数据。相应的,还需要在优采云中设置【页面滚动】。
适用场景:向下滚动条直接到网页底部,出现类似【Loading】的字样,很快出现新数据,滚动条变短弹回。
常见网页:纸本首页、今日头条首页、百度图片搜索、新浪微博首页,都是这样。

鼠标放在图片上,右击,选择【在新标签页中打开图片】查看高清大图
这同样适用于下面的其他图片
以澎湃新闻首页为例。, 我们需要采集 新闻列表数据。打开网页后需要继续向下滚动以加载新数据。
如何在优采云中实现?以下是具体步骤。
步骤一、进入自定义任务编辑页面
将URL复制到客户端首页优采云的输入框,点击开始采集,进入自定义任务配置页面。

步骤二、 设置滚动方式,调整滚动次数,以及每次间隔
点击步骤打开网页,在下方步骤设置区点击高级设置,找到页面滚动,点击查看页面滚动。此网页可无限滚动。优采云 的默认设置是滚动到 [Scroll Mode] 的底部。默认为 [Scroll Times] 100 次,默认 [Each interval] 为 1 秒。您可以根据实际需要进行调整。【每个间隔】时间需要比网页上的数据加载时间稍长(网页上的数据加载时间与网速等因素有关)。
结合本次网站的加载特性,这里修改【Scroll Mode】向下滚动一屏(一般情况下建议选择向下滚动一屏);为了演示方便,这里设置【滚动次数】】5次。
第三步:使用第三课中学到的方法:采集List Data配置列表数据采集。
启动采集,看看采集的结果。优采云自动执行【直接滚动到底部】5次,然后采集5次后滚动数据。
特别说明:
1、此网页正在无限向下滚动以加载数据。优采云 无法采集 一次获取所有数据。上例设置滚动5次,在实际采集过程中,可以根据需要设置滚动次数。
2、这类网页常用于数据实时性较高的新闻网站,在优采云中可以使用云端采集,设置定时启动,少量次采集最新数据。
3、有时候网页速度很快,像【加载中】这样的提示不明显。【是否有新数据】和【观察滚动条反弹次数】是比较好用的判断标准,请关注网页。
4. [向下滚动一屏] 运行采集任务时,一屏与窗口显示区域相关。如下图,左边的滚动画面>右边的滚动画面。
在线抓取网页( NVivo12(Windows)NVivoforMac(Version10.1or)抓取在线PDF)
网站优化 • 优采云 发表了文章 • 0 个评论 • 409 次浏览 • 2021-11-03 01:31
NVivo12(Windows)NVivoforMac(Version10.1or)抓取在线PDF)
使用 NCapture 捕捉在线 PDF
您可以使用 NCapture 采集在线 PDF,然后将它们导入 NVivo。
要将爬取的在线 PDF 导入到项目中,您需要以下其中一项:
NVivo 12 (Windows)
NVivo 12 (Mac)
适用于 Windows 的 NVivo 11
NVivo for Mac(版本 11)
适用于 Windows 的 NVivo 10
NVivo for Mac(版本 10.1 或更高版本)
在线抓取PDF
要获取在线 PDF 并将其导入 NVivo:
1. 在浏览器中,显示要捕获的PDF。
2. 单击浏览器顶部的 NCapture 按钮。您可以提供有关已爬网内容的其他信息。
一种。整个 PDF 被捕获并成为 NVivo 中的 PDF 源
湾 查看默认的源名称(Source name)。导入 NVivo 后,这将是源的名称。如有必要,您可以更改名称。
C。您可以输入简短说明(Description)或备忘录(Memo):
描述可以描述你正在爬取的东西——它成为来源的属性之一。
备忘录可以记录您获取这些数据的原因以及它与您的研究的关系。导入源后,它将成为链接备忘录。
d. 在节点代码框中,您可以输入一个或多个节点来对内容进行编码。然后,当您将内容导入 NVivo 时,整个源将在您输入的节点上进行编码。
如果您输入了一个在项目中不存在的节点——或者错误地输入了节点名称——一个新的节点将在导入过程中被创建。如果要对项目中的现有节点(例如层次结构中的子节点)进行编码,则可以输入层次结构节点名称-例如,经济\旅游。
e. 单击捕获。捕获的内容将保存为 NCapture 文件,您可以将其导入到 NVivo 项目中。 查看全部
在线抓取网页(
NVivo12(Windows)NVivoforMac(Version10.1or)抓取在线PDF)
使用 NCapture 捕捉在线 PDF
您可以使用 NCapture 采集在线 PDF,然后将它们导入 NVivo。
要将爬取的在线 PDF 导入到项目中,您需要以下其中一项:
NVivo 12 (Windows)
NVivo 12 (Mac)
适用于 Windows 的 NVivo 11
NVivo for Mac(版本 11)
适用于 Windows 的 NVivo 10
NVivo for Mac(版本 10.1 或更高版本)
在线抓取PDF
要获取在线 PDF 并将其导入 NVivo:
1. 在浏览器中,显示要捕获的PDF。
2. 单击浏览器顶部的 NCapture 按钮。您可以提供有关已爬网内容的其他信息。
一种。整个 PDF 被捕获并成为 NVivo 中的 PDF 源
湾 查看默认的源名称(Source name)。导入 NVivo 后,这将是源的名称。如有必要,您可以更改名称。
C。您可以输入简短说明(Description)或备忘录(Memo):
描述可以描述你正在爬取的东西——它成为来源的属性之一。
备忘录可以记录您获取这些数据的原因以及它与您的研究的关系。导入源后,它将成为链接备忘录。
d. 在节点代码框中,您可以输入一个或多个节点来对内容进行编码。然后,当您将内容导入 NVivo 时,整个源将在您输入的节点上进行编码。
如果您输入了一个在项目中不存在的节点——或者错误地输入了节点名称——一个新的节点将在导入过程中被创建。如果要对项目中的现有节点(例如层次结构中的子节点)进行编码,则可以输入层次结构节点名称-例如,经济\旅游。
e. 单击捕获。捕获的内容将保存为 NCapture 文件,您可以将其导入到 NVivo 项目中。
在线抓取网页(在线抓取网页使用postmessagemessage的基本用法(xmlhttprequestget))
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-10-28 05:00
在线抓取网页使用postmessagemessage的基本用法,方便和websocket对比。xmlhttprequestget,post操作。采用postmessage做传输方便,不需要另外准备一个xmlhttprequest对象。现在使用postmessage方式的数据传输方式很多。常见的有restfulapi和socket两种。
restfulapi主要是为了开发语言和浏览器提供一个统一的接口,让javascript可以调用、使用、处理来自系统、浏览器或者第三方服务的信息。本文将教大家如何使用restfulapi进行网页抓取。restfulapi的优点:体积小,对不同浏览器兼容性好灵活,可以在全球范围内被广泛使用对于新手来说更加友好。
基本概念首先我们要理解http的基本常识。http(hypertexttransferprotocol)-超文本传输协议,也称超文本传输协议,用于即时和邮件传输网络。常见的传输协议包括http和tcp。http的历史http协议最早是由linker上的protocolbuffers扩展而来,此时的协议也叫做undertow协议,并为tcp/ip协议族中的其中一种。
tcp是一种面向连接的面向连接的连接传输层协议。面向连接的数据传输层主要目标是确保数据传输安全。udp使用点到点传输,用于没有确定序号的发送和接收,需要服务端提供确定序号的序号和确定序号的udp包接收。两者的主要差别在于udp在双方间时无需中间服务提供商,因此不属于面向连接协议。udp可以用于在其他地方使用的局域网,而不能用于互联网的内部网络。
当udp流行起来后,udp连接被削减到单条。从90年代末期开始,at&t-internet协议族就引入了基于http的协议。url属于udp协议,但是url不属于网络层协议,而属于应用层,因此从底层上来说不是一个面向连接的协议。tcp的tcp/ip协议族,是tcp协议族的一部分。ip协议是其他网络协议的基础,任何在ip协议有一点进展的网络都可以利用tcp作为连接协议。
协议有六种,分别是tcp/ip,udp,icmp,rgmp,tftp,http,它们的主要区别是:不同网络层之间的属于不同的协议,并且这些协议一般是在不同的协议上运行。不同网络层之间的数据只能通过一个传输层协议进行转发。不同网络层之间的数据只能按照最低的安全等级进行交换,并且其他网络层之间在使用udp的时候一般不需要使用ip地址。
接口规范ip协议一般不同公司设计不同的接口定义将来发送给不同网络层。rtmp协议实现的是目前公认最流行的一种udp协议。rtmp要求服务端与客户端一定要确定一个ip地址才能运行。由于协议规范都是透明的,也不限制返回的md5等加密方式。在rtmp-。 查看全部
在线抓取网页(在线抓取网页使用postmessagemessage的基本用法(xmlhttprequestget))
在线抓取网页使用postmessagemessage的基本用法,方便和websocket对比。xmlhttprequestget,post操作。采用postmessage做传输方便,不需要另外准备一个xmlhttprequest对象。现在使用postmessage方式的数据传输方式很多。常见的有restfulapi和socket两种。
restfulapi主要是为了开发语言和浏览器提供一个统一的接口,让javascript可以调用、使用、处理来自系统、浏览器或者第三方服务的信息。本文将教大家如何使用restfulapi进行网页抓取。restfulapi的优点:体积小,对不同浏览器兼容性好灵活,可以在全球范围内被广泛使用对于新手来说更加友好。
基本概念首先我们要理解http的基本常识。http(hypertexttransferprotocol)-超文本传输协议,也称超文本传输协议,用于即时和邮件传输网络。常见的传输协议包括http和tcp。http的历史http协议最早是由linker上的protocolbuffers扩展而来,此时的协议也叫做undertow协议,并为tcp/ip协议族中的其中一种。
tcp是一种面向连接的面向连接的连接传输层协议。面向连接的数据传输层主要目标是确保数据传输安全。udp使用点到点传输,用于没有确定序号的发送和接收,需要服务端提供确定序号的序号和确定序号的udp包接收。两者的主要差别在于udp在双方间时无需中间服务提供商,因此不属于面向连接协议。udp可以用于在其他地方使用的局域网,而不能用于互联网的内部网络。
当udp流行起来后,udp连接被削减到单条。从90年代末期开始,at&t-internet协议族就引入了基于http的协议。url属于udp协议,但是url不属于网络层协议,而属于应用层,因此从底层上来说不是一个面向连接的协议。tcp的tcp/ip协议族,是tcp协议族的一部分。ip协议是其他网络协议的基础,任何在ip协议有一点进展的网络都可以利用tcp作为连接协议。
协议有六种,分别是tcp/ip,udp,icmp,rgmp,tftp,http,它们的主要区别是:不同网络层之间的属于不同的协议,并且这些协议一般是在不同的协议上运行。不同网络层之间的数据只能通过一个传输层协议进行转发。不同网络层之间的数据只能按照最低的安全等级进行交换,并且其他网络层之间在使用udp的时候一般不需要使用ip地址。
接口规范ip协议一般不同公司设计不同的接口定义将来发送给不同网络层。rtmp协议实现的是目前公认最流行的一种udp协议。rtmp要求服务端与客户端一定要确定一个ip地址才能运行。由于协议规范都是透明的,也不限制返回的md5等加密方式。在rtmp-。
在线抓取网页( “爬虫”是怎么抢机票的?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-10-27 03:01
“爬虫”是怎么抢机票的?(组图))
中新社发刘冠官摄'/>
资料图:北京某公交车站出现抢票浏览器广告。中新社发 刘关官摄
还有不到两个月,2018年的春节就要到了。
“今年我得早点动身去抢一张回家的低价票。” 在北京工作的小王告诉科技日报记者。由于老家在云南,春节的机票太贵了,所以他选择坐了两天两夜。优采云 回去,路漫漫其修远兮。
然而,就在小王急于抢到便宜机票的时候,他在网上看到一则新闻,航空公司发行的低价机票中,80%以上都是票务公司“爬虫”。抢了它,普通用户很少用。
小王傻眼了。“爬虫”是什么鬼?它是怎么抢到票的?没有办法管理吗?
使用超链接信息抓取网页
“‘爬虫’技术是实现网络信息采集的关键技术之一。通俗地说,‘爬虫’就是一个用于对采集网站数据进行批处理和自动化的程序。人类需要干预。” 北京理工大学网络科学与技术研究所副教授闫怀志告诉科技日报记者。
据闫怀志介绍,“爬虫”也被称为网页“蜘蛛”或网络机器人。它们是根据一定的规则自动抓取网页信息的程序或脚本,通常驻留在服务器上。在一个网页中,它不仅收录供用户阅读的文字、图片等信息,还收录一些超链接信息。互联网“爬虫”使用这些超链接不断地抓取互联网上的其他网页。
“这种信息采集的处理过程很像网络上漫游的爬虫或蜘蛛,因此网络‘爬虫’或网页‘蜘蛛’得名。” 闫怀志说,“爬虫”最早应用在搜索引擎领域,比如百度、百度、搜狗等搜索引擎工具每天需要抓取互联网上数百亿个网页,他们需要依靠庞大的“爬虫”集群来实现搜索功能。
目前,“爬虫”已经广泛应用于电子商务、互联网金融等多个领域。例如,“爬虫”可以抓取航空公司官网的机票价格。“爬虫”发现低价机票或热机票后,可以利用虚假客源的真实身份信息进行提前预订。此外,许多网络浏览器都推出了自己的抢票插件,以宣传订票成功率高的浏览器。
根据不同的爬虫任务和目标,网络“爬虫”大致可以分为批处理型、增量型和垂直型。批量式“爬虫”的爬取范围和目标比较明确,可以是设置的网页数量,也可以是耗时设置。增量“爬虫”主要用于不断抓取更新的网页,以适应网页的不断变化。垂直“爬虫”主要用于具有特定主题内容或特定行业的网页。
“爬虫”是怎么抢票的
此前,携程“反爬虫”专家在技术分享中透露,某个网站的页面每分钟有1.20000次页面浏览,而真实用户只有500人,“爬虫”流量占比为 95.8%。
采访中,多位业内人士也表示,即使在“爬虫”活动淡季,虚假流量也占到预订总流量的50%网站,期间更是高达90%以上。高峰期。
那么,“爬虫”是如何实现抢票的呢?对此,闫怀志解释说,主要原因是机票代理公司利用“爬虫”技术不断爬取航空公司售票官网的信息。如果发现航空公司有低价机票,“爬虫”会立即使用虚假旅客身份进行批量预订。但并不是实际付费,以达到抢低价票来源的目的。由于“爬虫”的效率远超正常人工操作,通过正常操作抢票几乎是不可能的。
随后,机票代理公司将通过自己的销售渠道(包括公司网站、在线旅行社、客户电话订购等),在航空公司允许的计费周期内找到真正的客户来源, 使用虚假来源退订,然后使用真实身份信息订购该身份预留的低价票,最后以加价转售该低价票。
如果在航空公司规定的计费周期内没有找到真正的客源,机票代理机构会在订单到期前添加虚假身份订单,继续“占用”低价机票,重复此过程,直到真正的找到并出售来源。
“上述操作流程构成了一个完整的机票销售链条。在这个过程中,航空公司的售票系统允许在计费周期内重复订票和退票,这为票务机构利用‘爬虫’抢票、提价提供了便利。”的抢票方法被称为技术'黄牛'。” 严怀之强调。
的确,有业内人士表示,这些“爬虫”流量消耗了大量机器资源,却没有产生任何消耗,这是每个公司最讨厌的。不过,由于担心误伤真实用户,各家公司的“反爬虫”策略一直非常谨慎。
“爬虫”可以通过一定的手段进行预防和控制
一切都有两个方面,“爬虫”技术也不例外。
在闫怀志看来,“爬虫”不仅可以为正常的数据批量获取提供有效的技术手段,还可以被恶意利用,获取不正当利益。如果“爬虫”技术使用不当,会带来一定的危害。
第一,威胁数据安全。机票销售网站数据被恶意抓取,数据可能被机票代理公司恶意利用,也存在被同行业竞争对手收购的风险。
其次,导致系统性能下降,影响用户体验。“爬虫”的大量爬取请求会导致航空公司售票网站服务器资源负载增加、性能下降、网站响应缓慢甚至无法提供服务,从而产生负面影响关于用户搜索和交易体验。然而,由于利益的巨大灰色空间和“反爬虫”技术在对抗“爬虫”中的作用有限,这种明显不公平的“作弊”方式已经成为一种扰乱门票秩序的技术“病”。市场。
“从技术角度来说,拦截‘爬虫’可以使用网站流量统计系统和服务器访问日志分析系统。” 闫怀志表示,通过流量统计和日志分析,如果发现单个IP访问、单个会话访问、User-Agent信息超过设置的正常频率阈值,则确定该访问为恶意“爬虫”,“ crawler”IP 被列入黑名单,拒绝后续访问。
然后设置各种访问验证链接。例如,当可疑IP访问时,返回验证页面,要求访问者通过填写验证码、选择验证图片或字符等方式完成验证。如果是恶意的“爬虫”爬取,显然很难完成上述验证操作,这时就可以阻断“爬虫”的访问,防止其恶意爬取信息。
互联网空间不能有“灰色地带”
当前,以云计算、大数据为代表的新一代信息技术正处于快速发展阶段。
“上述新技术如果被非法或不当应用,将造成严重危害。互联网空间的安全需要建立健全完善的保护体系,绝不能“裸奔”。颜怀之说道。
2017年6月1日,我国《网络安全法》正式实施,明确了各方在网络安全保护中的权利和责任。这是我国网络空间治理和法制建设由量变到质变的重要里程碑。该法作为依法治理互联网、化解网络风险的法律工具,已成为我国互联网在法治轨道上健康运行的重要保障。
但是,目前对于高科技“黄牛”的剥头皮行为,并没有明确的规定,将恶意爬取信息的行为置于法律法规的“灰色地带”,不当获利行为。
闫怀志介绍,Robots协议(即“爬虫”协议、网络机器人协议等)是国际上专门针对“爬虫”应用制定的。该协议称为“网络爬虫排除标准”。网站 可以通过这个协议告诉“爬虫”哪些页面和信息可以爬取,哪些页面和信息不能爬取。本协议作为网站与“爬虫”之间的一种沟通方式,规范“爬虫”的行为,限制不正当竞争。
作为国际互联网界通行的道德准则,协议的原则是:“爬虫”和搜索技术应该为人类服务,同时尊重信息提供者的意愿,维护他们的隐私权;网站 有义务保护其使用人的个人信息和隐私不受侵犯。这规定了爬虫和被爬虫双方的权利和义务。
一位不愿透露姓名的法律专家也表示,“反爬虫”不仅要靠技术防范和行业自律,还要完善管理和法律法规来约束这种行为,尤其是法律手段可以证明惩罚和威慑。. 航空公司也应加强对账期的管理,不提供给“爬虫”抢票的机会。 查看全部
在线抓取网页(
“爬虫”是怎么抢机票的?(组图))
中新社发刘冠官摄'/>
资料图:北京某公交车站出现抢票浏览器广告。中新社发 刘关官摄
还有不到两个月,2018年的春节就要到了。
“今年我得早点动身去抢一张回家的低价票。” 在北京工作的小王告诉科技日报记者。由于老家在云南,春节的机票太贵了,所以他选择坐了两天两夜。优采云 回去,路漫漫其修远兮。
然而,就在小王急于抢到便宜机票的时候,他在网上看到一则新闻,航空公司发行的低价机票中,80%以上都是票务公司“爬虫”。抢了它,普通用户很少用。
小王傻眼了。“爬虫”是什么鬼?它是怎么抢到票的?没有办法管理吗?
使用超链接信息抓取网页
“‘爬虫’技术是实现网络信息采集的关键技术之一。通俗地说,‘爬虫’就是一个用于对采集网站数据进行批处理和自动化的程序。人类需要干预。” 北京理工大学网络科学与技术研究所副教授闫怀志告诉科技日报记者。
据闫怀志介绍,“爬虫”也被称为网页“蜘蛛”或网络机器人。它们是根据一定的规则自动抓取网页信息的程序或脚本,通常驻留在服务器上。在一个网页中,它不仅收录供用户阅读的文字、图片等信息,还收录一些超链接信息。互联网“爬虫”使用这些超链接不断地抓取互联网上的其他网页。
“这种信息采集的处理过程很像网络上漫游的爬虫或蜘蛛,因此网络‘爬虫’或网页‘蜘蛛’得名。” 闫怀志说,“爬虫”最早应用在搜索引擎领域,比如百度、百度、搜狗等搜索引擎工具每天需要抓取互联网上数百亿个网页,他们需要依靠庞大的“爬虫”集群来实现搜索功能。
目前,“爬虫”已经广泛应用于电子商务、互联网金融等多个领域。例如,“爬虫”可以抓取航空公司官网的机票价格。“爬虫”发现低价机票或热机票后,可以利用虚假客源的真实身份信息进行提前预订。此外,许多网络浏览器都推出了自己的抢票插件,以宣传订票成功率高的浏览器。
根据不同的爬虫任务和目标,网络“爬虫”大致可以分为批处理型、增量型和垂直型。批量式“爬虫”的爬取范围和目标比较明确,可以是设置的网页数量,也可以是耗时设置。增量“爬虫”主要用于不断抓取更新的网页,以适应网页的不断变化。垂直“爬虫”主要用于具有特定主题内容或特定行业的网页。
“爬虫”是怎么抢票的
此前,携程“反爬虫”专家在技术分享中透露,某个网站的页面每分钟有1.20000次页面浏览,而真实用户只有500人,“爬虫”流量占比为 95.8%。
采访中,多位业内人士也表示,即使在“爬虫”活动淡季,虚假流量也占到预订总流量的50%网站,期间更是高达90%以上。高峰期。
那么,“爬虫”是如何实现抢票的呢?对此,闫怀志解释说,主要原因是机票代理公司利用“爬虫”技术不断爬取航空公司售票官网的信息。如果发现航空公司有低价机票,“爬虫”会立即使用虚假旅客身份进行批量预订。但并不是实际付费,以达到抢低价票来源的目的。由于“爬虫”的效率远超正常人工操作,通过正常操作抢票几乎是不可能的。
随后,机票代理公司将通过自己的销售渠道(包括公司网站、在线旅行社、客户电话订购等),在航空公司允许的计费周期内找到真正的客户来源, 使用虚假来源退订,然后使用真实身份信息订购该身份预留的低价票,最后以加价转售该低价票。
如果在航空公司规定的计费周期内没有找到真正的客源,机票代理机构会在订单到期前添加虚假身份订单,继续“占用”低价机票,重复此过程,直到真正的找到并出售来源。
“上述操作流程构成了一个完整的机票销售链条。在这个过程中,航空公司的售票系统允许在计费周期内重复订票和退票,这为票务机构利用‘爬虫’抢票、提价提供了便利。”的抢票方法被称为技术'黄牛'。” 严怀之强调。
的确,有业内人士表示,这些“爬虫”流量消耗了大量机器资源,却没有产生任何消耗,这是每个公司最讨厌的。不过,由于担心误伤真实用户,各家公司的“反爬虫”策略一直非常谨慎。
“爬虫”可以通过一定的手段进行预防和控制
一切都有两个方面,“爬虫”技术也不例外。
在闫怀志看来,“爬虫”不仅可以为正常的数据批量获取提供有效的技术手段,还可以被恶意利用,获取不正当利益。如果“爬虫”技术使用不当,会带来一定的危害。
第一,威胁数据安全。机票销售网站数据被恶意抓取,数据可能被机票代理公司恶意利用,也存在被同行业竞争对手收购的风险。
其次,导致系统性能下降,影响用户体验。“爬虫”的大量爬取请求会导致航空公司售票网站服务器资源负载增加、性能下降、网站响应缓慢甚至无法提供服务,从而产生负面影响关于用户搜索和交易体验。然而,由于利益的巨大灰色空间和“反爬虫”技术在对抗“爬虫”中的作用有限,这种明显不公平的“作弊”方式已经成为一种扰乱门票秩序的技术“病”。市场。
“从技术角度来说,拦截‘爬虫’可以使用网站流量统计系统和服务器访问日志分析系统。” 闫怀志表示,通过流量统计和日志分析,如果发现单个IP访问、单个会话访问、User-Agent信息超过设置的正常频率阈值,则确定该访问为恶意“爬虫”,“ crawler”IP 被列入黑名单,拒绝后续访问。
然后设置各种访问验证链接。例如,当可疑IP访问时,返回验证页面,要求访问者通过填写验证码、选择验证图片或字符等方式完成验证。如果是恶意的“爬虫”爬取,显然很难完成上述验证操作,这时就可以阻断“爬虫”的访问,防止其恶意爬取信息。
互联网空间不能有“灰色地带”
当前,以云计算、大数据为代表的新一代信息技术正处于快速发展阶段。
“上述新技术如果被非法或不当应用,将造成严重危害。互联网空间的安全需要建立健全完善的保护体系,绝不能“裸奔”。颜怀之说道。
2017年6月1日,我国《网络安全法》正式实施,明确了各方在网络安全保护中的权利和责任。这是我国网络空间治理和法制建设由量变到质变的重要里程碑。该法作为依法治理互联网、化解网络风险的法律工具,已成为我国互联网在法治轨道上健康运行的重要保障。
但是,目前对于高科技“黄牛”的剥头皮行为,并没有明确的规定,将恶意爬取信息的行为置于法律法规的“灰色地带”,不当获利行为。
闫怀志介绍,Robots协议(即“爬虫”协议、网络机器人协议等)是国际上专门针对“爬虫”应用制定的。该协议称为“网络爬虫排除标准”。网站 可以通过这个协议告诉“爬虫”哪些页面和信息可以爬取,哪些页面和信息不能爬取。本协议作为网站与“爬虫”之间的一种沟通方式,规范“爬虫”的行为,限制不正当竞争。
作为国际互联网界通行的道德准则,协议的原则是:“爬虫”和搜索技术应该为人类服务,同时尊重信息提供者的意愿,维护他们的隐私权;网站 有义务保护其使用人的个人信息和隐私不受侵犯。这规定了爬虫和被爬虫双方的权利和义务。
一位不愿透露姓名的法律专家也表示,“反爬虫”不仅要靠技术防范和行业自律,还要完善管理和法律法规来约束这种行为,尤其是法律手段可以证明惩罚和威慑。. 航空公司也应加强对账期的管理,不提供给“爬虫”抢票的机会。
在线抓取网页(一把抓网页工具是一款方便易用的网站内容抓取工具.该软件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-10-23 09:09
网页抓取工具是一种方便易用的网站内容抓取工具。该软件主要帮助用户抓取网站中的各种内容,如JS、CSS、图片、背景图片、音乐、Flash等,非常适合仿站人员...
它可以帮助我们快速采集互联网上的海量内容,进行深入的数据分析和挖掘。比如抓取各大网站的排名,抓取各大购物的价格信息网站等等。而我们每天常用的搜索引擎都是“网络爬虫”。但毕竟。
Python爬虫入门教程!手把手教你爬取网页数据。
第三步:提取内容。上面两步我们使用requests向网页请求数据,使用bs4解析页面。现在我们来到最关键的一步:。
网页内容智能抓取的实现和实例详解完全基于java。核心技术核心技术XML解析、HTML解析、开源组件应用。该应用程序的开源组件包括: DOM4J:解析 XMLjericho-。
优采云·云采集服务平台网站如何使用内容爬虫工具网络每天都在产生海量的图形数据。如何为你我使用这些数据,让数据给我们工作带来真正的价值?
获取某个网站数据过多或者爬取过快等因素往往会导致IP被封的风险,但是我们可以使用PHP构造IP地址来获取数据。.
《爬虫四步法》教你如何使用Python抓取和存储网页数据。 查看全部
在线抓取网页(一把抓网页工具是一款方便易用的网站内容抓取工具.该软件)
网页抓取工具是一种方便易用的网站内容抓取工具。该软件主要帮助用户抓取网站中的各种内容,如JS、CSS、图片、背景图片、音乐、Flash等,非常适合仿站人员...
它可以帮助我们快速采集互联网上的海量内容,进行深入的数据分析和挖掘。比如抓取各大网站的排名,抓取各大购物的价格信息网站等等。而我们每天常用的搜索引擎都是“网络爬虫”。但毕竟。
Python爬虫入门教程!手把手教你爬取网页数据。
第三步:提取内容。上面两步我们使用requests向网页请求数据,使用bs4解析页面。现在我们来到最关键的一步:。
网页内容智能抓取的实现和实例详解完全基于java。核心技术核心技术XML解析、HTML解析、开源组件应用。该应用程序的开源组件包括: DOM4J:解析 XMLjericho-。

优采云·云采集服务平台网站如何使用内容爬虫工具网络每天都在产生海量的图形数据。如何为你我使用这些数据,让数据给我们工作带来真正的价值?
获取某个网站数据过多或者爬取过快等因素往往会导致IP被封的风险,但是我们可以使用PHP构造IP地址来获取数据。.

《爬虫四步法》教你如何使用Python抓取和存储网页数据。
在线抓取网页(vue-scrapy中文教程(一):在线抓取网页?抓取教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-10-18 05:01
在线抓取网页?vue用户突然发现有奇妙的东西想抓取,这里介绍的就是vue-scrapy,让我们一起来破解它吧。vue-scrapy抓取教程目录·解读vue-scrapy·深入vue-scrapy·scrapy抓取·webpack和vue-scrapy项目结构·一个特殊例子·scrapy中文教程1.解读vue-scrapy之首页的抓取scrapy还提供了首页抓取的功能,抓取的格式为:vue-scrapy/app/index.html?form=all&url=http%3a%2f%%2fspider%2f2.深入vue-scrapy此处引入了我们之前在vue官网也学习到的vue-scrapy项目结构2.scrapy抓取教程fromvueimportscrapy,request,responsefromvueimportvuerouterfromvue.extendsextendsscrapy.extends{exports}mypath='d:\\release'mybridgemode='encoding'exports={release:request(),url:url,error:false,headers:['cookie']}scrapy.init(mypath,mybridgemode,exports={encoding:'utf-8'})scrapy.save(mypath,exports={index:false})scrapy.start(mybridgemode,url,error)scrapy.fetch(url,from_url)scrapy.login(url,'email')scrapy.index(url,from_url)scrapy.tree(url,'big/')scrapy.settings({'url':url})这部分我们将会在后面要做介绍到的爬虫文件中放入url这一列和数据,现在scrapy分别将给出文件结构和主要api接口代码,具体如下:demos=scrapy.document('d:\\release')mypage=mypage.form('thisisyour_url')mybid=mybid.map(request=request)myurl=myurl.form('thisisyour_url')myhttprequest=myhttprequest.request(url=url)myhttprequest2=myhttprequest2.form('thisisyour_url')mygeturl=mygeturl.form('thisisyour_url')mygeturl2=mygeturl2.form('thisisyour_url')fromurllibimporturlencodedurl=""headers={'user-agent':'mozilla/5.0(windowsnt6.1;win64;x64)applewebkit/537.36(khtml,likegecko)chrome/59.0.2104.87safari/537.36'}headers={'host':'xxx.xxx.xxx.xxx','port':'3306','referer':''}api=scrapy.spi。 查看全部
在线抓取网页(vue-scrapy中文教程(一):在线抓取网页?抓取教程)
在线抓取网页?vue用户突然发现有奇妙的东西想抓取,这里介绍的就是vue-scrapy,让我们一起来破解它吧。vue-scrapy抓取教程目录·解读vue-scrapy·深入vue-scrapy·scrapy抓取·webpack和vue-scrapy项目结构·一个特殊例子·scrapy中文教程1.解读vue-scrapy之首页的抓取scrapy还提供了首页抓取的功能,抓取的格式为:vue-scrapy/app/index.html?form=all&url=http%3a%2f%%2fspider%2f2.深入vue-scrapy此处引入了我们之前在vue官网也学习到的vue-scrapy项目结构2.scrapy抓取教程fromvueimportscrapy,request,responsefromvueimportvuerouterfromvue.extendsextendsscrapy.extends{exports}mypath='d:\\release'mybridgemode='encoding'exports={release:request(),url:url,error:false,headers:['cookie']}scrapy.init(mypath,mybridgemode,exports={encoding:'utf-8'})scrapy.save(mypath,exports={index:false})scrapy.start(mybridgemode,url,error)scrapy.fetch(url,from_url)scrapy.login(url,'email')scrapy.index(url,from_url)scrapy.tree(url,'big/')scrapy.settings({'url':url})这部分我们将会在后面要做介绍到的爬虫文件中放入url这一列和数据,现在scrapy分别将给出文件结构和主要api接口代码,具体如下:demos=scrapy.document('d:\\release')mypage=mypage.form('thisisyour_url')mybid=mybid.map(request=request)myurl=myurl.form('thisisyour_url')myhttprequest=myhttprequest.request(url=url)myhttprequest2=myhttprequest2.form('thisisyour_url')mygeturl=mygeturl.form('thisisyour_url')mygeturl2=mygeturl2.form('thisisyour_url')fromurllibimporturlencodedurl=""headers={'user-agent':'mozilla/5.0(windowsnt6.1;win64;x64)applewebkit/537.36(khtml,likegecko)chrome/59.0.2104.87safari/537.36'}headers={'host':'xxx.xxx.xxx.xxx','port':'3306','referer':''}api=scrapy.spi。
在线抓取网页(BBS采集多为3P代码为多(3))
网站优化 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-10-17 15:17
爬取网页内容,通常人们认为他们从互联网上窃取数据,然后将采集到的数据挂在自己的互联网上。其实你也可以将采集收到的数据作为公司的参考,或者将采集到的数据与你公司的业务进行对比等。
目前网页采集多为3P代码(3P即ASP、PHP
, JSP)。最常用的系统是BBS新闻采集系统,以及网上流传的新浪新闻采集系统。全部使用ASP程序,但理论上速度不是很好。
如果尝试使用其他软件的多线程采集,会不会更快?答案是肯定的。可以用DELPHI、VC、VB、JB,但是PB好像比较难做。下面用DELPHI来解释采集
网页数据。
一、 简单新闻采集
新闻 采集 是最简单的,只要确定标题、副主题、作者、来源、日期、新闻正文和分页符即可。必须在采集之前获取网页内容,所以在DELPHI中添加idHTTP控件(在indyClients面板中),然后使用idHTTP1.GET方法获取网页内容,声明如下:
函数获取(AURL:字符串):字符串;超载;
AURL 参数是一个字符串类型,它指定一个 URL 地址字符串。函数return也是字符串类型,返回网页的HTML源文件。例如,我们可以这样调用:
tmpStr:= idHTTP1.Get('');
调用成功后,网易首页代码存放在tmpstr变量中。
接下来说一下数据拦截。在这里,我定义了这样一个函数:
functionTForm1.GetStr(StrSource,StrBegin,StrEnd:string):string;
无功
in_star,in_end:整数;
开始
in_star:=AnsiPos(strbegin,strsource) 长度(strbegin);
in_end:=AnsiPos(strend,strsource);
结果:=复制(strsource,in_sta,in_end-in_star);
结尾;
StrSource:字符串类型,表示HTML源文件。
StrBegin:字符串类型,表示截取开始的标志。
StrEnd:字符串,表示截取结束的标志。
该函数将字符串 StrSource 中的一段文本从 StrSource 返回到 StrBegin。
例如:
strtmp:=TForm1.GetStr('A123BCD','A','BC');
运行后strtmp的值为:'123'。
关于函数中使用的AnsiPos和copy,都是系统定义的。您可以在delphi的帮助文件中找到相关说明。我这里也简单说一下:
函数 AnsiPos(const Substr, S: string): 整数
返回 Substr 在 S 中第一次出现的位置。
函数复制(strsource,in_sta,in_end-in_star):字符串;
返回字符串strsource 中从in_sta(整数数据)到in_end-in_star(整数数据)的字符串。
有了上面的功能,我们就可以通过设置各种标签来拦截想要的文章内容。在程序中,比较麻烦的是我们需要设置很多标签。要定位某个内容,您必须设置
它的开始和结束标志。比如要获取网页上的文章标题,必须提前查看网页代码,查看文章标题前后的一些特征码,利用这些特征码拦截< @文章 标签
题。
下面我们来实际演示一下。假设采集的文章地址是
代码是:
新页面 1
文章标题
ercolor="#111111"
>
作者
出处
这是文章的内容。 查看全部
在线抓取网页(BBS采集多为3P代码为多(3))
爬取网页内容,通常人们认为他们从互联网上窃取数据,然后将采集到的数据挂在自己的互联网上。其实你也可以将采集收到的数据作为公司的参考,或者将采集到的数据与你公司的业务进行对比等。
目前网页采集多为3P代码(3P即ASP、PHP
, JSP)。最常用的系统是BBS新闻采集系统,以及网上流传的新浪新闻采集系统。全部使用ASP程序,但理论上速度不是很好。
如果尝试使用其他软件的多线程采集,会不会更快?答案是肯定的。可以用DELPHI、VC、VB、JB,但是PB好像比较难做。下面用DELPHI来解释采集
网页数据。
一、 简单新闻采集
新闻 采集 是最简单的,只要确定标题、副主题、作者、来源、日期、新闻正文和分页符即可。必须在采集之前获取网页内容,所以在DELPHI中添加idHTTP控件(在indyClients面板中),然后使用idHTTP1.GET方法获取网页内容,声明如下:
函数获取(AURL:字符串):字符串;超载;
AURL 参数是一个字符串类型,它指定一个 URL 地址字符串。函数return也是字符串类型,返回网页的HTML源文件。例如,我们可以这样调用:
tmpStr:= idHTTP1.Get('');
调用成功后,网易首页代码存放在tmpstr变量中。
接下来说一下数据拦截。在这里,我定义了这样一个函数:
functionTForm1.GetStr(StrSource,StrBegin,StrEnd:string):string;
无功
in_star,in_end:整数;
开始
in_star:=AnsiPos(strbegin,strsource) 长度(strbegin);
in_end:=AnsiPos(strend,strsource);
结果:=复制(strsource,in_sta,in_end-in_star);
结尾;
StrSource:字符串类型,表示HTML源文件。
StrBegin:字符串类型,表示截取开始的标志。
StrEnd:字符串,表示截取结束的标志。
该函数将字符串 StrSource 中的一段文本从 StrSource 返回到 StrBegin。
例如:
strtmp:=TForm1.GetStr('A123BCD','A','BC');
运行后strtmp的值为:'123'。
关于函数中使用的AnsiPos和copy,都是系统定义的。您可以在delphi的帮助文件中找到相关说明。我这里也简单说一下:
函数 AnsiPos(const Substr, S: string): 整数
返回 Substr 在 S 中第一次出现的位置。
函数复制(strsource,in_sta,in_end-in_star):字符串;
返回字符串strsource 中从in_sta(整数数据)到in_end-in_star(整数数据)的字符串。
有了上面的功能,我们就可以通过设置各种标签来拦截想要的文章内容。在程序中,比较麻烦的是我们需要设置很多标签。要定位某个内容,您必须设置
它的开始和结束标志。比如要获取网页上的文章标题,必须提前查看网页代码,查看文章标题前后的一些特征码,利用这些特征码拦截< @文章 标签
题。
下面我们来实际演示一下。假设采集的文章地址是
代码是:
新页面 1
文章标题
ercolor="#111111"
>
作者
出处
这是文章的内容。
在线抓取网页(如何爬取网页上的网页?在线抓取网页格式?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-10-16 19:05
在线抓取网页格式如果你是刚开始接触代码爬虫这项工作,那么你肯定碰到一个问题:如何爬取网页上的网页?是通过html标签的文本格式还是其他格式?不管是那种格式,爬取网页的方法和获取单个页面的办法是一样的,首先我们需要从爬取对象中选取所需要爬取的页面,然后将其保存到文件。然后根据爬取页面所需要分析的内容来设置爬取页面的参数,例如是什么类型的网页、页面里面的分类有多少以及所在哪个位置等,然后一步步去获取需要的内容。
对于html标签的格式是如何抓取的,主要有以下两种办法:一.使用脚本1.模拟浏览器是否打开了自己定义的网页。如果打开了你自己定义的网页,就使用浏览器相应的request类对象函数去获取页面的内容;如果没有打开你自己定义的网页,则不可以用request对象函数去获取页面。2.模拟用户登录页面是否打开了你自己定义的页面,并且无密码登录,用户登录时会提示浏览器登录失败,则不可以使用request对象函数去获取页面内容。
3.在html标签中解析时,能否通过给每个标签添加上相应的href属性获取。二.使用爬虫工具工具可以帮助我们解决一部分网页数据爬取的问题,例如它可以自动解析自己的url到网页上,然后抓取页面上的内容,但是我们选择使用哪个工具呢?建议使用pythonselenium,使用它去抓取页面的代码如下:#-*-coding:utf-8-*-importsysreload(sys)sys.setdefaultencoding('utf-8')importurllibfromseleniumimportwebdriverurl=''request=urllib.request.urlopen(url)html=request.read()driver=webdriver.chrome()driver.get(url)foriinrange(len(driver.getrequest())):html=driver.from_screenshot(i+1)response=urllib.urlencode(driver.page_source)print(response)urllib=urllib.urlencode(response)urllib.request=urllib.urlopen(url)response=urllib.urlopen()forpageinrange(len(urllib.request)):try:response=urllib.urlopen(url)print(response)excepturllib.urlerror:print(urllib.urlerror)returnurllib.request(文章转载自csdn:菜鸟学python--gunzisan开发者生活坊)。 查看全部
在线抓取网页(如何爬取网页上的网页?在线抓取网页格式?)
在线抓取网页格式如果你是刚开始接触代码爬虫这项工作,那么你肯定碰到一个问题:如何爬取网页上的网页?是通过html标签的文本格式还是其他格式?不管是那种格式,爬取网页的方法和获取单个页面的办法是一样的,首先我们需要从爬取对象中选取所需要爬取的页面,然后将其保存到文件。然后根据爬取页面所需要分析的内容来设置爬取页面的参数,例如是什么类型的网页、页面里面的分类有多少以及所在哪个位置等,然后一步步去获取需要的内容。
对于html标签的格式是如何抓取的,主要有以下两种办法:一.使用脚本1.模拟浏览器是否打开了自己定义的网页。如果打开了你自己定义的网页,就使用浏览器相应的request类对象函数去获取页面的内容;如果没有打开你自己定义的网页,则不可以用request对象函数去获取页面。2.模拟用户登录页面是否打开了你自己定义的页面,并且无密码登录,用户登录时会提示浏览器登录失败,则不可以使用request对象函数去获取页面内容。
3.在html标签中解析时,能否通过给每个标签添加上相应的href属性获取。二.使用爬虫工具工具可以帮助我们解决一部分网页数据爬取的问题,例如它可以自动解析自己的url到网页上,然后抓取页面上的内容,但是我们选择使用哪个工具呢?建议使用pythonselenium,使用它去抓取页面的代码如下:#-*-coding:utf-8-*-importsysreload(sys)sys.setdefaultencoding('utf-8')importurllibfromseleniumimportwebdriverurl=''request=urllib.request.urlopen(url)html=request.read()driver=webdriver.chrome()driver.get(url)foriinrange(len(driver.getrequest())):html=driver.from_screenshot(i+1)response=urllib.urlencode(driver.page_source)print(response)urllib=urllib.urlencode(response)urllib.request=urllib.urlopen(url)response=urllib.urlopen()forpageinrange(len(urllib.request)):try:response=urllib.urlopen(url)print(response)excepturllib.urlerror:print(urllib.urlerror)returnurllib.request(文章转载自csdn:菜鸟学python--gunzisan开发者生活坊)。
在线抓取网页(一个通用的网络爬虫的基本结构及工作流程(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-10-13 15:03
网络爬虫是搜索引擎爬虫系统的重要组成部分。爬虫的主要目的是将互联网上的网页下载到本地,形成网络内容的镜像备份。本篇博客主要是对爬虫和爬虫系统的简要介绍。
一、网络爬虫的基本结构和工作流程
一个通用的网络爬虫的框架如图所示:
网络爬虫的基本工作流程如下:
1.首先选择一些精心挑选的种子网址;
2.将这些URL放入URL队列进行抓取;
3. 从待爬取的URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,并保存到下载的网页库中。另外,将这些 URL 放入爬取的 URL 队列中。
4.对爬取的URL队列中的URL进行分析,分析其中的其他URL,将这些URL放入URL队列进行爬取,从而进入下一个循环。
二、从爬虫的角度划分互联网
相应地,互联网的所有页面可以分为五个部分:
1.下载了未过期的网页
2.已下载并过期的网页:抓取的网页实际上是互联网内容的镜像和备份。互联网是动态变化的,互联网上的部分内容已经发生了变化。此时,这部分爬取到的页面已经过期。
3.要下载的页面:URL队列中要爬取的那些页面
4. 已知网页:尚未被抓取,也不在待抓取的URL队列中,但通过分析抓取的页面或与待抓取的URL对应的页面得到的URL被认为是已知的网页 。
5. 还有一些网页是爬虫无法直接抓取下载的。它被称为不可知页面。
三、抓取策略
在爬虫系统中,要爬取的URL队列是一个非常重要的部分。URL队列中要爬取的URL的顺序也是一个很重要的问题,因为它涉及到先爬哪个页面,后爬哪个页面。确定这些 URL 顺序的方法称为抓取策略。下面重点介绍几种常见的爬取策略:
1.深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,逐个跟踪每一个链接,处理完这一行后转移到下一个起始页,继续跟踪链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.宽度优先遍历策略
广度优先遍历策略的基本思想是将新下载的网页中找到的链接直接插入到待爬取的URL队列的末尾。即网络爬虫会先抓取起始网页中链接的所有网页,然后选择其中一个链接的网页,继续抓取该网页中链接的所有网页。以上图为例:
遍历路径:ABCDEF GHI
3.反向链接计数策略
反向链接数是指从其他网页链接到某个网页的数量。反向链接的数量表示网页内容被他人推荐的程度。因此,很多时候搜索引擎的爬取系统都会使用这个指标来评估网页的重要性,从而决定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量不能完全坐等别人的重视。因此,搜索引擎通常会考虑一些可靠的反向链接。
4.部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,连同要爬取的URL队列中的URL,形成一个网页集合,计算每个页面的PageRank值,经过计算完成后,将要抓取的URL队列中的URL按照PageRank值的大小进行排列,依次抓取页面。
如果每个页面都被抓取,则重新计算 PageRank 值。一个折衷的方案是:每爬取K个页面后,重新计算PageRank值。但是,这种情况下仍然存在一个问题:对于从下载页面中分析出来的链接,也就是我们前面提到的未知网页部分,暂时没有PageRank值。为了解决这个问题,这些页面会被赋予一个临时的PageRank值:将所有传入该页面链的PageRank值聚合起来,从而形成未知页面的PageRank值参与排名。以下示例说明:
5.OPIC 策略
该算法实际上对页面的重要性进行评分。在算法开始之前,给所有页面相同的初始现金(cash)。下载某个页面P后,将P的现金分配给所有从P分析的链接,并清除P的现金。待抓取的 URL 队列中的所有页面均按照现金的数量进行排序。
6.大站优先策略
URL队列中所有要爬取的网页,按照所属的网站进行分类。网站需要下载的页面较多,优先下载。这种策略因此被称为大站优先策略。
参考书目:
1. 《这是搜索引擎-核心技术详解》张俊林电子工业出版社
2. 《搜索引擎技术基础》刘义群等清华大学出版社 查看全部
在线抓取网页(一个通用的网络爬虫的基本结构及工作流程(组图))
网络爬虫是搜索引擎爬虫系统的重要组成部分。爬虫的主要目的是将互联网上的网页下载到本地,形成网络内容的镜像备份。本篇博客主要是对爬虫和爬虫系统的简要介绍。
一、网络爬虫的基本结构和工作流程
一个通用的网络爬虫的框架如图所示:

网络爬虫的基本工作流程如下:
1.首先选择一些精心挑选的种子网址;
2.将这些URL放入URL队列进行抓取;
3. 从待爬取的URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,并保存到下载的网页库中。另外,将这些 URL 放入爬取的 URL 队列中。
4.对爬取的URL队列中的URL进行分析,分析其中的其他URL,将这些URL放入URL队列进行爬取,从而进入下一个循环。
二、从爬虫的角度划分互联网
相应地,互联网的所有页面可以分为五个部分:

1.下载了未过期的网页
2.已下载并过期的网页:抓取的网页实际上是互联网内容的镜像和备份。互联网是动态变化的,互联网上的部分内容已经发生了变化。此时,这部分爬取到的页面已经过期。
3.要下载的页面:URL队列中要爬取的那些页面
4. 已知网页:尚未被抓取,也不在待抓取的URL队列中,但通过分析抓取的页面或与待抓取的URL对应的页面得到的URL被认为是已知的网页 。
5. 还有一些网页是爬虫无法直接抓取下载的。它被称为不可知页面。
三、抓取策略
在爬虫系统中,要爬取的URL队列是一个非常重要的部分。URL队列中要爬取的URL的顺序也是一个很重要的问题,因为它涉及到先爬哪个页面,后爬哪个页面。确定这些 URL 顺序的方法称为抓取策略。下面重点介绍几种常见的爬取策略:
1.深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,逐个跟踪每一个链接,处理完这一行后转移到下一个起始页,继续跟踪链接。我们以下图为例:

遍历的路径:AFG EHI BCD
2.宽度优先遍历策略
广度优先遍历策略的基本思想是将新下载的网页中找到的链接直接插入到待爬取的URL队列的末尾。即网络爬虫会先抓取起始网页中链接的所有网页,然后选择其中一个链接的网页,继续抓取该网页中链接的所有网页。以上图为例:
遍历路径:ABCDEF GHI
3.反向链接计数策略
反向链接数是指从其他网页链接到某个网页的数量。反向链接的数量表示网页内容被他人推荐的程度。因此,很多时候搜索引擎的爬取系统都会使用这个指标来评估网页的重要性,从而决定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量不能完全坐等别人的重视。因此,搜索引擎通常会考虑一些可靠的反向链接。
4.部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,连同要爬取的URL队列中的URL,形成一个网页集合,计算每个页面的PageRank值,经过计算完成后,将要抓取的URL队列中的URL按照PageRank值的大小进行排列,依次抓取页面。
如果每个页面都被抓取,则重新计算 PageRank 值。一个折衷的方案是:每爬取K个页面后,重新计算PageRank值。但是,这种情况下仍然存在一个问题:对于从下载页面中分析出来的链接,也就是我们前面提到的未知网页部分,暂时没有PageRank值。为了解决这个问题,这些页面会被赋予一个临时的PageRank值:将所有传入该页面链的PageRank值聚合起来,从而形成未知页面的PageRank值参与排名。以下示例说明:
5.OPIC 策略
该算法实际上对页面的重要性进行评分。在算法开始之前,给所有页面相同的初始现金(cash)。下载某个页面P后,将P的现金分配给所有从P分析的链接,并清除P的现金。待抓取的 URL 队列中的所有页面均按照现金的数量进行排序。
6.大站优先策略
URL队列中所有要爬取的网页,按照所属的网站进行分类。网站需要下载的页面较多,优先下载。这种策略因此被称为大站优先策略。
参考书目:
1. 《这是搜索引擎-核心技术详解》张俊林电子工业出版社
2. 《搜索引擎技术基础》刘义群等清华大学出版社
在线抓取网页(网页效果动作使用这一动作针对网页的快捷指令,摘抄)
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-10-08 17:03
摘录是每个人都有的要求。唯一的区别在于工具是否相同以及是否用心。
在第16期的快速说明教程中,Hum引入了网页摘录的快速说明,可以将选中的内容以样式摘录1添加到印象笔记中。最后文章,还有一个话题。没想到这个“避免重复标题”的小要求难倒了很多教程读者。
快捷指令教程的练习题
快捷命令本身缺少相关功能模块,Hum在研究过程中不小心遇到了账号错误(可能是印象笔记团队分裂的原因)。这次耽搁了半年。最近,当 Hum 与我分享本书摘录工作流程时,我重新审视了旧事物。我也发现自己需要一个更完整的摘录快捷方式,于是想出了这个“作业”文章。
网页摘录效果动作使用
此操作专为网页摘录而设计。有必要从 Safari 浏览器的内容中提取标题和链接。如果需要提取没有链接的书籍、电影台词等文本,可以参考我之前写的《草稿和印象笔记》。美丽的摘录。提取网页的步骤是:
选中页面上的文字,然后在整个网页的分享菜单中运行这个快捷命令动作(需要接收整个Safari页面,否则无法获取标题和链接)。动作会自动运行,会根据情况做出不同形式的摘录:如果当前文章之前没看过,直接在原笔记底部添加新的摘录即可。格式为“带超链接的标题+摘录+日期”。如果 文章 之前被阅读过,新的摘录将插入到前一个摘录的下方。格式为“摘录+日期”,以避免标题重复。
使用快捷方式摘录印象笔记 查看全部
在线抓取网页(网页效果动作使用这一动作针对网页的快捷指令,摘抄)
摘录是每个人都有的要求。唯一的区别在于工具是否相同以及是否用心。
在第16期的快速说明教程中,Hum引入了网页摘录的快速说明,可以将选中的内容以样式摘录1添加到印象笔记中。最后文章,还有一个话题。没想到这个“避免重复标题”的小要求难倒了很多教程读者。

快捷指令教程的练习题
快捷命令本身缺少相关功能模块,Hum在研究过程中不小心遇到了账号错误(可能是印象笔记团队分裂的原因)。这次耽搁了半年。最近,当 Hum 与我分享本书摘录工作流程时,我重新审视了旧事物。我也发现自己需要一个更完整的摘录快捷方式,于是想出了这个“作业”文章。

网页摘录效果动作使用
此操作专为网页摘录而设计。有必要从 Safari 浏览器的内容中提取标题和链接。如果需要提取没有链接的书籍、电影台词等文本,可以参考我之前写的《草稿和印象笔记》。美丽的摘录。提取网页的步骤是:
选中页面上的文字,然后在整个网页的分享菜单中运行这个快捷命令动作(需要接收整个Safari页面,否则无法获取标题和链接)。动作会自动运行,会根据情况做出不同形式的摘录:如果当前文章之前没看过,直接在原笔记底部添加新的摘录即可。格式为“带超链接的标题+摘录+日期”。如果 文章 之前被阅读过,新的摘录将插入到前一个摘录的下方。格式为“摘录+日期”,以避免标题重复。

使用快捷方式摘录印象笔记
在线抓取网页(中华英才网数据自动聚合系统正是由此而生|案例分析案例 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-10-06 15:25
)
1.简介
项目背景
互联网时代,信息海阔天空。甚至我们获取信息的方式也发生了变化:从传统的翻书到查字典,再到通过搜索引擎搜索。我们已经从信息匮乏的时代走到了信息丰富的今天。
今天,困扰我们的问题不是信息太少,而是太多,太多让你无法分辨或选择。因此,提供一种能够自动抓取互联网上的数据,并对其进行自动排序和分析的工具是非常重要的。
我们通过传统搜索引擎获取的信息通常以网页的形式展示。这样的信息人工阅读自然友好,但计算机很难处理和重复使用。而且检索到的信息量太大,我们很难从海量的检索结果中提取出我们最需要的信息。
本方案所涉及的数据聚合系统由此诞生。系统按照一定的规则抓取指定的网站中的信息,对抓取的结果进行分析整理,保存在结构化的数据库中,为数据的复用做准备。
中华英才网是知名的大型招聘类网站。为了全面细致地了解招聘市场的整体能力,帮助中华英才网全面了解其他竞争对手的情况,为市场人员提供潜在客户信息,我们提供此解决方案。
使命和宗旨
捷软与中华英才网合作开发数据自动聚合系统。通过该系统,从互联网上获取公开的信息资源,对信息进行分析、加工和再加工,为中华英才资源市场部提供准确的市场信息。
2.方案设计原则
我们在设计系统方案时充分考虑了以下两个原则,并将始终贯穿于设计和开发过程:
系统精度
系统需要从互联网庞大的信息海洋中获取信息。如何保证它抓取的信息的准确性和有效性,是评估整个系统价值的关键因素。因此,除了对抓取到的信息进行整理和分析,当目标网站的内容和格式发生变化时,智能感知、及时通知和调整也是保证系统准确性的重要手段。.
系统灵活性
该系统虽然是为少数用户提供服务并监控固定站点的内部系统,但仍需具备一定的灵活性和较强的可扩展性。
因为目标站点的结构、层次和格式在不断变化;并且系统需要抓取的目标站点也在不断调整;因此,系统必须能够适应这种变化。当爬取目标发生变化时,系统可以通过简单的设置或调整,继续完成数据聚合任务。
3.解决方案:
1.功能结构图
2.定义格式并准备脚本
首先,我们需要根据需要爬取的目标网站的特点,编写一个爬取脚本(格式)。包括:
目标网站的URL路径;
使用什么方法获取数据?可以使用模拟查询功能的方法(手动检测查询页面提交的参数并模拟提交);也可以从头到尾遍历序列号(需要找到当前最大的序列号值);
根据每个网站的特点编译(标准、脚本);
3.获取数据
系统提供的rake程序会根据预定义的XML格式执行数据采集任务。为了防止目标网站的检测程序发现它,我们建议直接保存捕获的页面,然后对其进行处理。而不是在获取信息后立即处理信息,对于提高抓取和保留第一手信息的效率非常有价值。
通过定义的脚本模拟登录;
对于下拉列表中的查询项,循环遍历列表中的每个值。并对获取查询结果的页面进行模拟翻页操作,获取所有查询结果;
如果作业数据库或业务目录数据库使用自增整数作为其唯一ID,那么我们可以找到一种方法来获取最大值,然后通过遍历的方式将其全部抓取;
定时执行爬取操作,增量保存抓取到的数据;
4.简单分析
采集接收到的数据在外网的服务器上简单的分析处理。内容主要包括:
结构化数据:对获取的数据进行结构化,以方便以后的数据传输,也方便下一步的复查和故障排除任务。
消除重复;使用模拟查询方法遍历时,系统捕获的数据必须是重复的。由于重复的数据会造成重复的分析和处理过程,不仅占用系统资源,使系统的处理效率低下,而且给系统带来了大量的垃圾数据。为了避免大量重复和冗余的数据,我们要做的第一个处理工作就是对重复项进行整理。
消除错误;由于目标站点的内容、结构和格式的调整,系统将无法捕获或捕获大量错误信息。在排除这些误报信息的同时,我们通过数据错误率的判断,可以获得目标站点是否发生变化的信息,并及时向系统发出预警通知。
5.数据发回内部
系统通过Web Service将处理后的数据发送回企业。唯一需要考虑的是如何实现增量更新,否则每天有大量数据更新到本地数据库,会造成网络拥塞。
6.数据分析
这里的数据分析与上述在远程服务器上进行的分析操作不同。后者是为了简单有效的数据过滤,防止数据冗余和造成处理速度缓慢或网络拥塞。前者为日后人工确认提供便利,有效帮助市场人员进行快速人工分拣。详情如下:
l 按地区区分;
l 按准确程度划分;帮助用户优先考虑哪些信息更有效;
l 按发帖数划分;
l 记录各公司发布的职位变动过程;
7.手动确认
这部分主要关注两个方面:
1、提供友好的人机界面,允许人工确认这些信息;
2、对比英才网的职位数据库,提取差异进行人工确认:
通过与市场人员的沟通交流,了解他们关心的信息,按照他们期望的方式提供数据,完成人工确认。
8.统计汇总
汇总统计功能也是数据汇总系统的重要组成部分,将提供以下几类统计汇总功能:
以网站为单位,统计每个网站日新增的公司、职位等信息;
跟踪大型企业,统计其在每个网站上发布的信息帖记录;
以时间为单位,按日、周、月对各种信息进行统计;
按地区、公司、岗位进行统计;
其他;
仿真统计汇总界面
查看全部
在线抓取网页(中华英才网数据自动聚合系统正是由此而生|案例分析案例
)
1.简介
项目背景
互联网时代,信息海阔天空。甚至我们获取信息的方式也发生了变化:从传统的翻书到查字典,再到通过搜索引擎搜索。我们已经从信息匮乏的时代走到了信息丰富的今天。
今天,困扰我们的问题不是信息太少,而是太多,太多让你无法分辨或选择。因此,提供一种能够自动抓取互联网上的数据,并对其进行自动排序和分析的工具是非常重要的。
我们通过传统搜索引擎获取的信息通常以网页的形式展示。这样的信息人工阅读自然友好,但计算机很难处理和重复使用。而且检索到的信息量太大,我们很难从海量的检索结果中提取出我们最需要的信息。
本方案所涉及的数据聚合系统由此诞生。系统按照一定的规则抓取指定的网站中的信息,对抓取的结果进行分析整理,保存在结构化的数据库中,为数据的复用做准备。
中华英才网是知名的大型招聘类网站。为了全面细致地了解招聘市场的整体能力,帮助中华英才网全面了解其他竞争对手的情况,为市场人员提供潜在客户信息,我们提供此解决方案。
使命和宗旨
捷软与中华英才网合作开发数据自动聚合系统。通过该系统,从互联网上获取公开的信息资源,对信息进行分析、加工和再加工,为中华英才资源市场部提供准确的市场信息。
2.方案设计原则
我们在设计系统方案时充分考虑了以下两个原则,并将始终贯穿于设计和开发过程:
系统精度
系统需要从互联网庞大的信息海洋中获取信息。如何保证它抓取的信息的准确性和有效性,是评估整个系统价值的关键因素。因此,除了对抓取到的信息进行整理和分析,当目标网站的内容和格式发生变化时,智能感知、及时通知和调整也是保证系统准确性的重要手段。.
系统灵活性
该系统虽然是为少数用户提供服务并监控固定站点的内部系统,但仍需具备一定的灵活性和较强的可扩展性。
因为目标站点的结构、层次和格式在不断变化;并且系统需要抓取的目标站点也在不断调整;因此,系统必须能够适应这种变化。当爬取目标发生变化时,系统可以通过简单的设置或调整,继续完成数据聚合任务。
3.解决方案:
1.功能结构图

2.定义格式并准备脚本
首先,我们需要根据需要爬取的目标网站的特点,编写一个爬取脚本(格式)。包括:
目标网站的URL路径;
使用什么方法获取数据?可以使用模拟查询功能的方法(手动检测查询页面提交的参数并模拟提交);也可以从头到尾遍历序列号(需要找到当前最大的序列号值);
根据每个网站的特点编译(标准、脚本);
3.获取数据
系统提供的rake程序会根据预定义的XML格式执行数据采集任务。为了防止目标网站的检测程序发现它,我们建议直接保存捕获的页面,然后对其进行处理。而不是在获取信息后立即处理信息,对于提高抓取和保留第一手信息的效率非常有价值。
通过定义的脚本模拟登录;
对于下拉列表中的查询项,循环遍历列表中的每个值。并对获取查询结果的页面进行模拟翻页操作,获取所有查询结果;
如果作业数据库或业务目录数据库使用自增整数作为其唯一ID,那么我们可以找到一种方法来获取最大值,然后通过遍历的方式将其全部抓取;
定时执行爬取操作,增量保存抓取到的数据;
4.简单分析
采集接收到的数据在外网的服务器上简单的分析处理。内容主要包括:
结构化数据:对获取的数据进行结构化,以方便以后的数据传输,也方便下一步的复查和故障排除任务。
消除重复;使用模拟查询方法遍历时,系统捕获的数据必须是重复的。由于重复的数据会造成重复的分析和处理过程,不仅占用系统资源,使系统的处理效率低下,而且给系统带来了大量的垃圾数据。为了避免大量重复和冗余的数据,我们要做的第一个处理工作就是对重复项进行整理。
消除错误;由于目标站点的内容、结构和格式的调整,系统将无法捕获或捕获大量错误信息。在排除这些误报信息的同时,我们通过数据错误率的判断,可以获得目标站点是否发生变化的信息,并及时向系统发出预警通知。
5.数据发回内部
系统通过Web Service将处理后的数据发送回企业。唯一需要考虑的是如何实现增量更新,否则每天有大量数据更新到本地数据库,会造成网络拥塞。
6.数据分析
这里的数据分析与上述在远程服务器上进行的分析操作不同。后者是为了简单有效的数据过滤,防止数据冗余和造成处理速度缓慢或网络拥塞。前者为日后人工确认提供便利,有效帮助市场人员进行快速人工分拣。详情如下:
l 按地区区分;
l 按准确程度划分;帮助用户优先考虑哪些信息更有效;
l 按发帖数划分;
l 记录各公司发布的职位变动过程;
7.手动确认
这部分主要关注两个方面:
1、提供友好的人机界面,允许人工确认这些信息;
2、对比英才网的职位数据库,提取差异进行人工确认:
通过与市场人员的沟通交流,了解他们关心的信息,按照他们期望的方式提供数据,完成人工确认。
8.统计汇总
汇总统计功能也是数据汇总系统的重要组成部分,将提供以下几类统计汇总功能:
以网站为单位,统计每个网站日新增的公司、职位等信息;
跟踪大型企业,统计其在每个网站上发布的信息帖记录;
以时间为单位,按日、周、月对各种信息进行统计;
按地区、公司、岗位进行统计;
其他;
仿真统计汇总界面

在线抓取网页(python3爬虫怎么抓取微信公众号风险2秒赔付20秒)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-10-06 01:02
在线抓取网页,flash投屏,ppt演示,是一个不错的入门项目,我最近正在研究。---关注公众号:python爱好者社区。更多python爬虫、数据分析、机器学习等技术文章。
微信搜索:jiezhihui123微信公众号里我看到推送了一个python爬虫程序运行在python3.6环境下/,我也很感兴趣python3爬虫怎么抓取微信公众号,就和爬虫工程师一起来探讨一下,
没有网站就买个二手的99元epoc风险2秒赔付20秒到账拿去当微信小额贷款平台好了
谢邀。这种方式应该是最直接的。不可行的话我觉得可以试试另一种办法:雇佣50个做动态桌面的小号。
微信公众号里都是做演示的为主,你可以买个linux系统装个qpython,这样动态演示就足够用了。还有就是开源吧,好多大神用go开发了。
微信公众号爬虫搞网站图,类似的,不就是个java服务器, 查看全部
在线抓取网页(python3爬虫怎么抓取微信公众号风险2秒赔付20秒)
在线抓取网页,flash投屏,ppt演示,是一个不错的入门项目,我最近正在研究。---关注公众号:python爱好者社区。更多python爬虫、数据分析、机器学习等技术文章。
微信搜索:jiezhihui123微信公众号里我看到推送了一个python爬虫程序运行在python3.6环境下/,我也很感兴趣python3爬虫怎么抓取微信公众号,就和爬虫工程师一起来探讨一下,
没有网站就买个二手的99元epoc风险2秒赔付20秒到账拿去当微信小额贷款平台好了
谢邀。这种方式应该是最直接的。不可行的话我觉得可以试试另一种办法:雇佣50个做动态桌面的小号。
微信公众号里都是做演示的为主,你可以买个linux系统装个qpython,这样动态演示就足够用了。还有就是开源吧,好多大神用go开发了。
微信公众号爬虫搞网站图,类似的,不就是个java服务器,
在线抓取网页(电商网站从事采购业务的用户画像,如何使用在线抓取网页数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-10-05 14:06
在线抓取网页数据,比如log4j、mysql、mongodb、php等,以及在线抓取新闻、中文搜索、百度学术搜索、搜狗问答等网站的用户数据、日志数据等。上面是一个电商网站从事采购业务的用户画像,每个用户都有三个属性:性别,年龄,职业,每一条数据都是根据三个属性进行匹配,选择相应的用户数据。如果要抓取的数据为销售商品,则要从行为指标中找出关键行为。这样的分析可能关注商品用户的推荐,会员等级等。
目前市面上是有人从各个渠道爬取数据,比如数据运营、运营工具大厅、拉勾、天眼查、qq数据、机构号、知乎、百度知道等等。采用的通常是把爬取到的信息进行汇总分析。我们可以采用的工具是julia或者scikitlearn。julia有一个userjupter,不用写爬虫脚本,有一个轻量级的非python开发库islandsolution。
这个非常轻量级,只需要两行代码,使用方法如下:juliainstallislandsolution>orgssl:julia0.19.2notebooks(org)一个例子是抓取猫眼app上购买电影的用户画像,直接用julia来实现。(当然其他渠道爬取到的数据也可以用julia)下载链接:-install.py为什么不直接去链接下载呢?因为官网多了个python的爬虫环境,需要用pip。
但是如果用python爬取数据,很可能会超出需求,这个时候直接运行脚本会遇到代码报错,报错的规则是:toopen"global-python-qmakerc:3.7",packagesrequired:d:\python_scripts\python2.7\gits\recursive\jupython\python._reqmakerc.gitvolume1:path=["c:\windows\system32\exe"],c:\windows\system32\system32\pathfalse"d:\python_scripts\python._reqmakerc.git",extras"so",extras"fuck",extras"cao",extras"gy",extras"hello",password="script"所以要选择跳过jupyter环境,直接用pip下载。 查看全部
在线抓取网页(电商网站从事采购业务的用户画像,如何使用在线抓取网页数据)
在线抓取网页数据,比如log4j、mysql、mongodb、php等,以及在线抓取新闻、中文搜索、百度学术搜索、搜狗问答等网站的用户数据、日志数据等。上面是一个电商网站从事采购业务的用户画像,每个用户都有三个属性:性别,年龄,职业,每一条数据都是根据三个属性进行匹配,选择相应的用户数据。如果要抓取的数据为销售商品,则要从行为指标中找出关键行为。这样的分析可能关注商品用户的推荐,会员等级等。
目前市面上是有人从各个渠道爬取数据,比如数据运营、运营工具大厅、拉勾、天眼查、qq数据、机构号、知乎、百度知道等等。采用的通常是把爬取到的信息进行汇总分析。我们可以采用的工具是julia或者scikitlearn。julia有一个userjupter,不用写爬虫脚本,有一个轻量级的非python开发库islandsolution。
这个非常轻量级,只需要两行代码,使用方法如下:juliainstallislandsolution>orgssl:julia0.19.2notebooks(org)一个例子是抓取猫眼app上购买电影的用户画像,直接用julia来实现。(当然其他渠道爬取到的数据也可以用julia)下载链接:-install.py为什么不直接去链接下载呢?因为官网多了个python的爬虫环境,需要用pip。
但是如果用python爬取数据,很可能会超出需求,这个时候直接运行脚本会遇到代码报错,报错的规则是:toopen"global-python-qmakerc:3.7",packagesrequired:d:\python_scripts\python2.7\gits\recursive\jupython\python._reqmakerc.gitvolume1:path=["c:\windows\system32\exe"],c:\windows\system32\system32\pathfalse"d:\python_scripts\python._reqmakerc.git",extras"so",extras"fuck",extras"cao",extras"gy",extras"hello",password="script"所以要选择跳过jupyter环境,直接用pip下载。
在线抓取网页(什么是SessionSession对应的中文翻译是会话。。 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-11-29 23:06
)
什么是会话
Session对应的中文翻译是conversation。
会话是指用户打开浏览器访问一个网站的时间,无论这个网站访问了多少个页面,点击了多少个链接,都属于同一个对话。在用户关闭浏览器之前,它们属于同一个会话。
HTTP 协议是短链接,因此无法根据服务器端建立的连接数来统计当前在线人数。但是,在线用户的数量可以通过计算会话数来估计。
一旦用户访问服务器,就会创建一个会话。如果用户继续访问,则会话将继续有效。
如果用户在 30 分钟后没有进行任何操作,则表示用户“离线”,相应的会话将被销毁。
因此您可以通过计算保留的会话数来估计当前在线人数。
PeopleLisened.java
package com.chenchangjie.listener;
import javax.servlet.ServletContext;
import javax.servlet.http.HttpSessionEvent;
import javax.servlet.http.HttpSessionListener;
public class PeopleListener implements HttpSessionListener {
/**
* 监听session创建
* @param se
*/
@Override
public void sessionCreated(HttpSessionEvent se) {
ServletContext context = se.getSession().getServletContext();
Integer num = (Integer) context.getAttribute("online_num");
if(num == null)
num = 0;
++num;
context.setAttribute("online_num",num);
System.out.println("新增一位用户...");
}
/**
* 监听session销毁
* @param se
*/
@Override
public void sessionDestroyed(HttpSessionEvent se) {
ServletContext context = se.getSession().getServletContext();
Integer num = (Integer) context.getAttribute("online_num");
if(num == null)
num = 0;
else
--num;
context.setAttribute("online_num",num);
System.out.println("减少一位用户...");
}
}
web.xml 添加配置
com.chenchangjie.listener.PeopleListener
test.jsp
运行结果:
输出被替换是因为我监控了Context,每次增加session都会更新Context
打开浏览器会增加
查看全部
在线抓取网页(什么是SessionSession对应的中文翻译是会话。。
)
什么是会话
Session对应的中文翻译是conversation。
会话是指用户打开浏览器访问一个网站的时间,无论这个网站访问了多少个页面,点击了多少个链接,都属于同一个对话。在用户关闭浏览器之前,它们属于同一个会话。
HTTP 协议是短链接,因此无法根据服务器端建立的连接数来统计当前在线人数。但是,在线用户的数量可以通过计算会话数来估计。
一旦用户访问服务器,就会创建一个会话。如果用户继续访问,则会话将继续有效。
如果用户在 30 分钟后没有进行任何操作,则表示用户“离线”,相应的会话将被销毁。
因此您可以通过计算保留的会话数来估计当前在线人数。
PeopleLisened.java
package com.chenchangjie.listener;
import javax.servlet.ServletContext;
import javax.servlet.http.HttpSessionEvent;
import javax.servlet.http.HttpSessionListener;
public class PeopleListener implements HttpSessionListener {
/**
* 监听session创建
* @param se
*/
@Override
public void sessionCreated(HttpSessionEvent se) {
ServletContext context = se.getSession().getServletContext();
Integer num = (Integer) context.getAttribute("online_num");
if(num == null)
num = 0;
++num;
context.setAttribute("online_num",num);
System.out.println("新增一位用户...");
}
/**
* 监听session销毁
* @param se
*/
@Override
public void sessionDestroyed(HttpSessionEvent se) {
ServletContext context = se.getSession().getServletContext();
Integer num = (Integer) context.getAttribute("online_num");
if(num == null)
num = 0;
else
--num;
context.setAttribute("online_num",num);
System.out.println("减少一位用户...");
}
}
web.xml 添加配置
com.chenchangjie.listener.PeopleListener
test.jsp
运行结果:
输出被替换是因为我监控了Context,每次增加session都会更新Context
打开浏览器会增加
在线抓取网页(优帮云百度不收录优帮云seo小编们网站页面需要用对策)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-11-29 20:04
很多人都希望自己的网站是收录,但现在百度网站和百度索引大多不同步。所以当友邦云seo编辑使用网站管理员工具查询时,友邦云seo编辑可以看到上面的数据很大,但实际数量很少。所以这并不意味着百度没有收录youbangyun seo editors网站的页面,因为百度是通过一些流程收录进来的。
1、收录 会影响排名吗?
一些 网站收录 百万,但没有排名。其他不超过10个,但他们排名很好。很多人开始怀疑排名和选择的关系很小。其实这点是不需要考虑的。没有收录没有资格谈排名,所以排名是基于收录,而收录的前提是基于爬行,所以百度或其他搜索引擎会显示他们是否了解您的其他页面。
2、为什么页面不能收录
如上所述,收录的前提是蜘蛛爬行。这时候,很多朋友就会认为,既然优帮云seo编辑器的网站里有文章,就很容易抓住了。其实百度搜索引擎的收录流程步骤比较多。为了让用户看到搜索引擎的结构可以解决问题,百度在收录上下了很大功夫。
保证网页是收录的前提是网站的内容能够吸引搜索引擎抓取
当优帮云seo编辑器的网站页面需要收录在里面时,前提是必须被爬取。面对抓取问题,搜索引擎其实要经历一个非常艰难的过程,因为一般来说,搜索引擎抓取的页面不能超过三个级别。也就是说页面搜索引擎无法抓取首页的三个链接。一篇文章。这时候,有帮云seo的编辑们就需要用对策来解决这些问题。友邦云seo编辑亲自整理了以下三种解决方案:
网站地图:制作Youbangyun seo编辑的网站地图。一般情况下,网站的映射是写在robot文件中的。如果你不知道怎么做,你可以制作一个在线地图。谷歌站长工具就有这样的功能。
外部链接:如果你觉得你有额外的时间,你可以在你的网站内页投票。当然,友邦云seo编辑会根据自己的需要在外链添加一些锚文本链接,而文章的内链一般都会链接到内页,所以友邦云seo编辑会发布一些SEO外链直接接收内页也就不足为奇了。
搜索引擎抓取后,在选择优帮云seo编辑器页面时,会有一个标准的收录行。当内容达到要收录的标准行时,内容就会被收录。当内容未达到收录标准行时,内容将不被收录。
这时候暂时会有一些内容收录,过一段时间会取消。事实上,这是一个标准问题。这可能是因为您的文章被推荐暂时收录在首页,也可能是推荐被取消后被取消,也可能是因为点击或跳出链接。所以有帮云seo的编辑在做文章的一些细节的时候,一定要符合搜索引擎收录的标准行。收录 的搜索引擎非常简单。当然,百度目前还没有公布这条标准线。 查看全部
在线抓取网页(优帮云百度不收录优帮云seo小编们网站页面需要用对策)
很多人都希望自己的网站是收录,但现在百度网站和百度索引大多不同步。所以当友邦云seo编辑使用网站管理员工具查询时,友邦云seo编辑可以看到上面的数据很大,但实际数量很少。所以这并不意味着百度没有收录youbangyun seo editors网站的页面,因为百度是通过一些流程收录进来的。
1、收录 会影响排名吗?
一些 网站收录 百万,但没有排名。其他不超过10个,但他们排名很好。很多人开始怀疑排名和选择的关系很小。其实这点是不需要考虑的。没有收录没有资格谈排名,所以排名是基于收录,而收录的前提是基于爬行,所以百度或其他搜索引擎会显示他们是否了解您的其他页面。
2、为什么页面不能收录
如上所述,收录的前提是蜘蛛爬行。这时候,很多朋友就会认为,既然优帮云seo编辑器的网站里有文章,就很容易抓住了。其实百度搜索引擎的收录流程步骤比较多。为了让用户看到搜索引擎的结构可以解决问题,百度在收录上下了很大功夫。
保证网页是收录的前提是网站的内容能够吸引搜索引擎抓取
当优帮云seo编辑器的网站页面需要收录在里面时,前提是必须被爬取。面对抓取问题,搜索引擎其实要经历一个非常艰难的过程,因为一般来说,搜索引擎抓取的页面不能超过三个级别。也就是说页面搜索引擎无法抓取首页的三个链接。一篇文章。这时候,有帮云seo的编辑们就需要用对策来解决这些问题。友邦云seo编辑亲自整理了以下三种解决方案:
网站地图:制作Youbangyun seo编辑的网站地图。一般情况下,网站的映射是写在robot文件中的。如果你不知道怎么做,你可以制作一个在线地图。谷歌站长工具就有这样的功能。
外部链接:如果你觉得你有额外的时间,你可以在你的网站内页投票。当然,友邦云seo编辑会根据自己的需要在外链添加一些锚文本链接,而文章的内链一般都会链接到内页,所以友邦云seo编辑会发布一些SEO外链直接接收内页也就不足为奇了。
搜索引擎抓取后,在选择优帮云seo编辑器页面时,会有一个标准的收录行。当内容达到要收录的标准行时,内容就会被收录。当内容未达到收录标准行时,内容将不被收录。
这时候暂时会有一些内容收录,过一段时间会取消。事实上,这是一个标准问题。这可能是因为您的文章被推荐暂时收录在首页,也可能是推荐被取消后被取消,也可能是因为点击或跳出链接。所以有帮云seo的编辑在做文章的一些细节的时候,一定要符合搜索引擎收录的标准行。收录 的搜索引擎非常简单。当然,百度目前还没有公布这条标准线。
在线抓取网页( 另外一个超棒的Java的HTML解析器-jsoup-)
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-26 10:08
另外一个超棒的Java的HTML解析器-jsoup-)
在线演示本地下载
如果你曾经开发过内容聚合类网站,那么使用程序动态整合不同页面或网站的内容的功能你一定很熟悉。通常在使用java的时候,我们会用到一些HTML解析,比如httpparser,最早的集成搜索就是用httpparser抓取Google和百度的搜索结果,并集成呈现给搜索用户,这就是GBin1的由来域名。
所以今天,我们介绍另一个很棒的Java HTML解析器-jsoup,这个类库可以帮助你实时处理HTML。它提供了一个非常方便的 API 来提取和处理数据。最重要的是它使用类似jQuery的语法来处理DOM、CSS等。如果你用过jQuery,你就会知道它在处理DOM方面的强大和便利。
主要特点
jsoup 实现了 WHATWG HTML5 标准,与现代浏览器解析 DOM 的方式相同。主要功能:
基本上jsoup可以帮你处理各种HTML问题,帮你验证非法标签,创建干净的DOM树。
实现爬取功能
这里我们将实现一个简单的爬取功能,您只需要指定url,并指定您需要爬取的具体元素,例如ID或类。后台我们会使用jsoup来获取,前台会使用jQuery来美化生成的结果。
大家需要注意以下几点:
相对路径问题:您抓取的页面中的链接可能使用了相对路径,需要将其作为绝对路径处理,否则将无法在本地服务器上正常打开链接
相对路径问题:同上,还需要处理转换
大小问题:如果抓取的图片特别大,需要使用代码转换为本地样式,也可以选择使用jQuery在前台处理
下载jsoup的jar包后,请添加你的classpath路径。如果使用jsp,请直接复制,添加到web应用WEB-INF的lib目录下。
Java相关代码如下:
Document doc = Jsoup.connect("http://www.gbin1.com/portfolio/lastest.html").timeout(0).get();
Elements items = doc.select(".includeitem");
在上面的代码中,我们定义了jsoup使用一个url来获取HTML,这里就用到了。本页列出了gbin1最近发布的文章。如果查看这个页面的源码,可以看到每个文章都在.includeitem类中,所以我们使用doc.select方法来选择对应的类。
注意我们这里调用的是timeout(0),表示连续请求url,默认是2000,也就是2秒后超时。可以看到这里使用了类似jQuery的链式调用,非常方便。
for (Element item : items) {
Elements links = item.select("a");
for(Element link: links){
link.attr("href",link.attr("abs:href"));
}
Elements imgs = item.select("img");
for(Element img: imgs){
img.attr("src",img.attr("abs:src"));
}
String html = item.html();
out.println("" + html + "");
}
在上面的代码中,我们处理了每个被查询的 includeitem 元素。找到“a”和“img”,将href元素值修改为绝对路径。
link.attr("abs:href")
上面的代码会得到对应链接的绝对路径,这里的属性是abs:href。同理可以得到图片的绝对路径abs:src。
代码运行后,我们就可以看到修改后的代码,放到li中。
接下来,我们开发一个页面来控制抓取:
在这个页面的实现中,我们使用setInterval方法在指定的时间间隔调用上面ajax开发的java代码。基本代码如下:
//Run for first time
$('#msg').html('请耐心等待, 页面抓取中 ...').fadeIn(400);
//$('#content').html('');
$('#content').load('siteproxy.jsp #result', {url:url, elem:element}, function(){
$('#msg').html('抓取已完成').delay(1500).fadeOut(400);
})
上面的代码非常简单。我们使用jQuery的load方法调用siteproxy.jsp,然后获取siteproxy.jsp生成的页面中的#result元素,即抓取内容。如果你不熟悉jQuery的ajax方法,请参考这个系列文章:
jQuery 库的 AJAX 方法初学者指南-第 1 部分
jQuery 库的 AJAX 方法初学者指南-第 2 部分
初学者使用jQuery库的AJAX方法-第三部分
jQuery 库的 AJAX 方法初学者指南-第 4 部分
为了让代码以指定的时间间隔运行爬取,我们将方法放在setinterval中,如下:
runid = setInterval(
function getInfo(){
$('#msg').html('请耐心等待, 页面抓取中 ...').fadeIn(400);
//$('#content').html('');
$('#content').load('siteproxy.jsp #result', {url:url, elem:element}, function(){
$('#msg').html('抓取已完成').delay(1500).fadeOut(400);
})
}, interval*1000);
通过上述方法,我们可以在用户触发抓取后每隔指定时间触发抓取动作。
完整的js代码如下:
$(document).ready(function(){
var url, element, interval, runid;
$('#start').click(function(){
url = $('#url').val();
element = $('#element').val();
interval = $('#interval').val();
//Run for first time
$('#msg').html('请耐心等待, 页面抓取中 ...').fadeIn(400);
//$('#content').html('');
$('#content').load('siteproxy.jsp #result', {url:url, elem:element}, function(){
$('#msg').html('抓取已完成').delay(1500).fadeOut(400);
})
runid = setInterval(
function getInfo(){
$('#msg').html('请耐心等待, 页面抓取中 ...').fadeIn(400);
//$('#content').html('');
$('#content').load('siteproxy.jsp #result', {url:url, elem:element}, function(){
$('#msg').html('抓取已完成').delay(1500).fadeOut(400);
})
}, interval*1000);
});
$('#stop').click(function(){
$('#msg').html('抓取已暂停').fadeIn(400).delay(1500);
clearInterval(runid);
});
});
部署完上面的jsp和html文件后,会看到如下界面:
我们需要设置要爬取的url和页面元素。默认情况下,该元素是 .includeitem。点击开始爬取,可以看到应用爬取了以下内容:
注意这里的默认间隔是30秒,30秒后会自动检索内容。
可以尝试抓取element.itemt,间隔10秒,可以得到如下内容:
你可以在微博首页看到和自动刷新一样的内容。
您可以将此工具用作重复页面刷新工具,它可以帮助您监控网站 的某个部分。当然,你也可以用它来动态刷新你的网站,提高你的alexa排名。.
希望大家喜欢这个工具应用。如果您有任何建议或问题,请给我们留言!谢谢!
来源:使用java的html解析器jsoup和jQuery实现一个web应用,自动重复抓取任意网站页面指定元素 查看全部
在线抓取网页(
另外一个超棒的Java的HTML解析器-jsoup-)
在线演示本地下载
如果你曾经开发过内容聚合类网站,那么使用程序动态整合不同页面或网站的内容的功能你一定很熟悉。通常在使用java的时候,我们会用到一些HTML解析,比如httpparser,最早的集成搜索就是用httpparser抓取Google和百度的搜索结果,并集成呈现给搜索用户,这就是GBin1的由来域名。
所以今天,我们介绍另一个很棒的Java HTML解析器-jsoup,这个类库可以帮助你实时处理HTML。它提供了一个非常方便的 API 来提取和处理数据。最重要的是它使用类似jQuery的语法来处理DOM、CSS等。如果你用过jQuery,你就会知道它在处理DOM方面的强大和便利。
主要特点
jsoup 实现了 WHATWG HTML5 标准,与现代浏览器解析 DOM 的方式相同。主要功能:
基本上jsoup可以帮你处理各种HTML问题,帮你验证非法标签,创建干净的DOM树。
实现爬取功能
这里我们将实现一个简单的爬取功能,您只需要指定url,并指定您需要爬取的具体元素,例如ID或类。后台我们会使用jsoup来获取,前台会使用jQuery来美化生成的结果。
大家需要注意以下几点:
相对路径问题:您抓取的页面中的链接可能使用了相对路径,需要将其作为绝对路径处理,否则将无法在本地服务器上正常打开链接
相对路径问题:同上,还需要处理转换
大小问题:如果抓取的图片特别大,需要使用代码转换为本地样式,也可以选择使用jQuery在前台处理
下载jsoup的jar包后,请添加你的classpath路径。如果使用jsp,请直接复制,添加到web应用WEB-INF的lib目录下。
Java相关代码如下:
Document doc = Jsoup.connect("http://www.gbin1.com/portfolio/lastest.html";).timeout(0).get();
Elements items = doc.select(".includeitem");
在上面的代码中,我们定义了jsoup使用一个url来获取HTML,这里就用到了。本页列出了gbin1最近发布的文章。如果查看这个页面的源码,可以看到每个文章都在.includeitem类中,所以我们使用doc.select方法来选择对应的类。
注意我们这里调用的是timeout(0),表示连续请求url,默认是2000,也就是2秒后超时。可以看到这里使用了类似jQuery的链式调用,非常方便。
for (Element item : items) {
Elements links = item.select("a");
for(Element link: links){
link.attr("href",link.attr("abs:href"));
}
Elements imgs = item.select("img");
for(Element img: imgs){
img.attr("src",img.attr("abs:src"));
}
String html = item.html();
out.println("" + html + "");
}
在上面的代码中,我们处理了每个被查询的 includeitem 元素。找到“a”和“img”,将href元素值修改为绝对路径。
link.attr("abs:href")
上面的代码会得到对应链接的绝对路径,这里的属性是abs:href。同理可以得到图片的绝对路径abs:src。
代码运行后,我们就可以看到修改后的代码,放到li中。
接下来,我们开发一个页面来控制抓取:
在这个页面的实现中,我们使用setInterval方法在指定的时间间隔调用上面ajax开发的java代码。基本代码如下:
//Run for first time
$('#msg').html('请耐心等待, 页面抓取中 ...').fadeIn(400);
//$('#content').html('');
$('#content').load('siteproxy.jsp #result', {url:url, elem:element}, function(){
$('#msg').html('抓取已完成').delay(1500).fadeOut(400);
})
上面的代码非常简单。我们使用jQuery的load方法调用siteproxy.jsp,然后获取siteproxy.jsp生成的页面中的#result元素,即抓取内容。如果你不熟悉jQuery的ajax方法,请参考这个系列文章:
jQuery 库的 AJAX 方法初学者指南-第 1 部分
jQuery 库的 AJAX 方法初学者指南-第 2 部分
初学者使用jQuery库的AJAX方法-第三部分
jQuery 库的 AJAX 方法初学者指南-第 4 部分
为了让代码以指定的时间间隔运行爬取,我们将方法放在setinterval中,如下:
runid = setInterval(
function getInfo(){
$('#msg').html('请耐心等待, 页面抓取中 ...').fadeIn(400);
//$('#content').html('');
$('#content').load('siteproxy.jsp #result', {url:url, elem:element}, function(){
$('#msg').html('抓取已完成').delay(1500).fadeOut(400);
})
}, interval*1000);
通过上述方法,我们可以在用户触发抓取后每隔指定时间触发抓取动作。
完整的js代码如下:
$(document).ready(function(){
var url, element, interval, runid;
$('#start').click(function(){
url = $('#url').val();
element = $('#element').val();
interval = $('#interval').val();
//Run for first time
$('#msg').html('请耐心等待, 页面抓取中 ...').fadeIn(400);
//$('#content').html('');
$('#content').load('siteproxy.jsp #result', {url:url, elem:element}, function(){
$('#msg').html('抓取已完成').delay(1500).fadeOut(400);
})
runid = setInterval(
function getInfo(){
$('#msg').html('请耐心等待, 页面抓取中 ...').fadeIn(400);
//$('#content').html('');
$('#content').load('siteproxy.jsp #result', {url:url, elem:element}, function(){
$('#msg').html('抓取已完成').delay(1500).fadeOut(400);
})
}, interval*1000);
});
$('#stop').click(function(){
$('#msg').html('抓取已暂停').fadeIn(400).delay(1500);
clearInterval(runid);
});
});
部署完上面的jsp和html文件后,会看到如下界面:
我们需要设置要爬取的url和页面元素。默认情况下,该元素是 .includeitem。点击开始爬取,可以看到应用爬取了以下内容:
注意这里的默认间隔是30秒,30秒后会自动检索内容。
可以尝试抓取element.itemt,间隔10秒,可以得到如下内容:
你可以在微博首页看到和自动刷新一样的内容。
您可以将此工具用作重复页面刷新工具,它可以帮助您监控网站 的某个部分。当然,你也可以用它来动态刷新你的网站,提高你的alexa排名。.
希望大家喜欢这个工具应用。如果您有任何建议或问题,请给我们留言!谢谢!
来源:使用java的html解析器jsoup和jQuery实现一个web应用,自动重复抓取任意网站页面指定元素
在线抓取网页(几个暗含抓取算法:宽度优先抓取哪些页面却需要算法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-22 11:16
搜索引擎看似简单的爬虫查询工作,但每个链接所隐含的算法却非常复杂。搜索引擎抓取页面是由蜘蛛完成的。爬取动作很容易实现,但是要爬取哪些页面,先爬取哪些页面需要算法来决定。以下是一些爬行算法:
1、宽度优先的爬取策略:
我们都知道大部分网站页面都是按照树状图分布的,那么在树状图的链接结构中,哪些页面会先被爬取呢?为什么要先抓取这些页面?宽度优先的获取策略是按照树状结构先获取同级链接,等同级链接获取完成后再获取下一级链接。
如您所见,当我声明时,我使用了链接结构而不是 网站 结构。这里的链接结构可以由指向任何页面的链接组成,不一定是网站内部链接。这是一种理想化的宽度优先爬行策略。在实际爬取过程中,不可能先想到全宽,先想到限宽。
当我们的Spider检索G链接时,通过算法发现G页面没有任何价值,于是悲剧的G链接和从属的H链接被Spider统一了。至于为什么会统一G环节?嗯,我们来分析一下。
2、不完整的遍历链接权重计算:
每个搜索引擎都有一套pagerank(指页面权重,不是googlePR)的计算方法,并且经常更新。互联网几乎是无限的,每天都会产生大量的新链接。搜索引擎在计算链接权重时只能进行不完全遍历。为什么GooglePR需要每三个月更新一次?为什么百度一个月更新1-2两次?这是因为搜索引擎使用不完全遍历链接权重算法来计算链接权重。其实按照现在的技术,实现更快的权重更新并不难。计算速度和存储速度完全可以跟得上,但为什么不这样做呢?因为不是那么必要,或者已经实施了,但我不想公布。然后,
我们形成一组K个链接,R代表链接获得的pagerank,S代表链接收录的链接数,Q代表是否参与传递,代表阻尼因子,那么得到的权重计算公式通过链接是: 查看全部
在线抓取网页(几个暗含抓取算法:宽度优先抓取哪些页面却需要算法)
搜索引擎看似简单的爬虫查询工作,但每个链接所隐含的算法却非常复杂。搜索引擎抓取页面是由蜘蛛完成的。爬取动作很容易实现,但是要爬取哪些页面,先爬取哪些页面需要算法来决定。以下是一些爬行算法:
1、宽度优先的爬取策略:
我们都知道大部分网站页面都是按照树状图分布的,那么在树状图的链接结构中,哪些页面会先被爬取呢?为什么要先抓取这些页面?宽度优先的获取策略是按照树状结构先获取同级链接,等同级链接获取完成后再获取下一级链接。
如您所见,当我声明时,我使用了链接结构而不是 网站 结构。这里的链接结构可以由指向任何页面的链接组成,不一定是网站内部链接。这是一种理想化的宽度优先爬行策略。在实际爬取过程中,不可能先想到全宽,先想到限宽。
当我们的Spider检索G链接时,通过算法发现G页面没有任何价值,于是悲剧的G链接和从属的H链接被Spider统一了。至于为什么会统一G环节?嗯,我们来分析一下。
2、不完整的遍历链接权重计算:
每个搜索引擎都有一套pagerank(指页面权重,不是googlePR)的计算方法,并且经常更新。互联网几乎是无限的,每天都会产生大量的新链接。搜索引擎在计算链接权重时只能进行不完全遍历。为什么GooglePR需要每三个月更新一次?为什么百度一个月更新1-2两次?这是因为搜索引擎使用不完全遍历链接权重算法来计算链接权重。其实按照现在的技术,实现更快的权重更新并不难。计算速度和存储速度完全可以跟得上,但为什么不这样做呢?因为不是那么必要,或者已经实施了,但我不想公布。然后,
我们形成一组K个链接,R代表链接获得的pagerank,S代表链接收录的链接数,Q代表是否参与传递,代表阻尼因子,那么得到的权重计算公式通过链接是:
在线抓取网页(网站接口是关联式接口的吗?在线抓取网页数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-11-17 05:00
在线抓取网页数据,网站接口一般都是关联式接口,比如qq,那你抓取qq会有些相应的js。跟你分析数据结构一样,你要抓取某些字段就去抓那些字段。jquery也可以分析,当然加一些框架比如ajax啥的,vue/react啥的,
首先搞清楚页面那个元素可以抓取,比如通过js查看response后面一串字符代表了哪个元素,然后结合用户上一次访问页面的pageviewcontent查看该元素对应的url,最后根据对应的url去抓取。
放个网址供浏览:/
jquery是javascript库,
推荐你看我原来写的文章:重构互联网商品数据爬虫引擎-尝试并发处理和分页爬取
jquery里面应该有封装各种方法来抓取商品信息。
jquery封装了所有方法吧。只不过不能分析pageviewcontent下的url。
分析这种模拟分析,为啥不看源码。
不太清楚你是指哪个版本的jquery,现在版本更新比较快,通常jquery框架已经更新过,而且比较牛逼的jquery后台代码源码放在github上,很多网站都在用jquery,所以你只要知道从jquery生成html,然后调用即可.
有工具,
mozilla
好像有个jquery加密工具,貌似也可以用来看抓取jquery的信息。 查看全部
在线抓取网页(网站接口是关联式接口的吗?在线抓取网页数据)
在线抓取网页数据,网站接口一般都是关联式接口,比如qq,那你抓取qq会有些相应的js。跟你分析数据结构一样,你要抓取某些字段就去抓那些字段。jquery也可以分析,当然加一些框架比如ajax啥的,vue/react啥的,
首先搞清楚页面那个元素可以抓取,比如通过js查看response后面一串字符代表了哪个元素,然后结合用户上一次访问页面的pageviewcontent查看该元素对应的url,最后根据对应的url去抓取。
放个网址供浏览:/
jquery是javascript库,
推荐你看我原来写的文章:重构互联网商品数据爬虫引擎-尝试并发处理和分页爬取
jquery里面应该有封装各种方法来抓取商品信息。
jquery封装了所有方法吧。只不过不能分析pageviewcontent下的url。
分析这种模拟分析,为啥不看源码。
不太清楚你是指哪个版本的jquery,现在版本更新比较快,通常jquery框架已经更新过,而且比较牛逼的jquery后台代码源码放在github上,很多网站都在用jquery,所以你只要知道从jquery生成html,然后调用即可.
有工具,
mozilla
好像有个jquery加密工具,貌似也可以用来看抓取jquery的信息。
在线抓取网页(在线抓取网页视频教程:基础篇进阶篇、网页分析篇)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-11-16 10:11
在线抓取网页视频教程:基础篇、进阶篇、网页分析篇、网页解析篇、视频解析篇、视频解析篇、视频解析篇1.实例代码第一步:首先我们用浏览器打开:,然后新建个index.html文件。大家可以看到,新建项目文件的时候,会在视频链接上点击一下。然后在这个视频链接的基础上打上.js文件。第二步:页面调试这里我们调试视频教程的一个版本,把视频链接分别拷贝到index.html文件的第二行:和第一行:的效果第三步:视频下载利用代理ed2k规则下载网页视频,下载流程跟请求视频的代理规则是一样的。到了网页源码中找到html标签:。
抓取什么网站,在线教程—在线教程之将视频流编码成mp4数据,
可以试试sock优采云采集器,
v8的协议、ml的tf_lib、以及qq浏览器的实现、后来tcp还支持二进制等协议都可以实现。
websocket
github上有很多有趣的,有时候也会去修改一些api,了解它们的实现原理。
如果你用浏览器的话,你可以尝试一下tcp和http协议。如果可以还是python吧,毕竟开发效率很高。建议网上多搜索一下文章。 查看全部
在线抓取网页(在线抓取网页视频教程:基础篇进阶篇、网页分析篇)
在线抓取网页视频教程:基础篇、进阶篇、网页分析篇、网页解析篇、视频解析篇、视频解析篇、视频解析篇1.实例代码第一步:首先我们用浏览器打开:,然后新建个index.html文件。大家可以看到,新建项目文件的时候,会在视频链接上点击一下。然后在这个视频链接的基础上打上.js文件。第二步:页面调试这里我们调试视频教程的一个版本,把视频链接分别拷贝到index.html文件的第二行:和第一行:的效果第三步:视频下载利用代理ed2k规则下载网页视频,下载流程跟请求视频的代理规则是一样的。到了网页源码中找到html标签:。
抓取什么网站,在线教程—在线教程之将视频流编码成mp4数据,
可以试试sock优采云采集器,
v8的协议、ml的tf_lib、以及qq浏览器的实现、后来tcp还支持二进制等协议都可以实现。
websocket
github上有很多有趣的,有时候也会去修改一些api,了解它们的实现原理。
如果你用浏览器的话,你可以尝试一下tcp和http协议。如果可以还是python吧,毕竟开发效率很高。建议网上多搜索一下文章。
在线抓取网页( 百度搜藏Baiduspider-favo百度联盟-cpro商务搜索Baiduspider)
网站优化 • 优采云 发表了文章 • 0 个评论 • 76 次浏览 • 2021-11-15 23:01
百度搜藏Baiduspider-favo百度联盟-cpro商务搜索Baiduspider)
百度蜘蛛蜘蛛抓取网页介绍
1.什么是百度蜘蛛
百度蜘蛛是百度搜索引擎的自动程序。它的功能是访问互联网上的网页,并建立索引数据库,以便用户在百度搜索引擎上搜索您的网页。
2.百度蜘蛛的用户代理是什么?
百度产品使用不同的用户代理:
产品名称
对应user-agent
无线搜索
百度蜘蛛
图片搜索
百度蜘蛛图片
视频搜索
百度蜘蛛视频
新闻搜索
百度蜘蛛新闻
百度采集
百度蜘蛛最爱
百度联盟
百度蜘蛛-cpro
业务搜索
百度蜘蛛广告
网络和其他搜索
百度蜘蛛
3.百度蜘蛛对网站服务器造成的访问压力是什么?
为了对目标资源取得更好的检索效果,百度蜘蛛需要对您的网站保持一定的抓取量。我们尽量不对网站施加不合理的负担,会根据服务器容量、网站质量、网站更新等综合因素进行调整。如果您认为百度蜘蛛的访问行为存在不合理的情况,您可以向反馈中心反馈。
4.为什么百度蜘蛛老是爬我的网站?
百度蜘蛛会持续抓取您网站上新生成或不断更新的页面。此外,您还可以在网站访问日志中查看百度蜘蛛的访问是否正常,防止有人恶意冒充百度蜘蛛频繁抓取您的网站。如果您发现百度蜘蛛异常抓取您的网站,请通过反馈中心反馈给我们,并尽量提供百度蜘蛛对您网站的访问日志,以便我们进行跟踪。
5.如何判断是否冒充百度蜘蛛爬取?
建议您使用DNS反向检查的方式来判断爬取源的IP是否属于百度。不同平台的验证方法也不同。比如linux/windows/os三个平台下的验证方法如下:
5.1 在Linux平台下,可以使用hostip命令解密ip来判断是否来自百度蜘蛛。百度蜘蛛的主机名以*格式命名。或 *.baidu.jp。如果不是 *. 或者*.baidu.jp,都是假的。
$host123.125.66.120
120.66.125.123.in-addr.arpadomainnamepointer
.
主机119.63.195.254
254.195.63.119.in-addr.arpadomainnamepointer
百度Mobaider-119-63-195-254.crawl.baidu.jp。
5.2 windows平台或IBMOS/2平台下,可以使用nslookupip命令解密ip,判断是否来自百度蜘蛛。打开命令处理器,输入nslookupxxx.xxx.xxx.xxx(IP地址)解析ip判断是否来自百度蜘蛛。百度蜘蛛的主机名以*格式命名。或 *.baidu.jp,而不是 *. 或者 *.baidu.jp 是冒充的。
5.3 在macos平台下,可以使用dig命令解密ip来判断是否来自百度蜘蛛。打开命令处理器,输入digxxx.xxx.xxx.xxx(IP地址)解析ip判断是否来自百度蜘蛛。百度蜘蛛的主机名以*格式命名。或 *.baidu.jp,而不是 *. 或者 *.baidu.jp 是冒充的。
6.我不希望我的网站被百度蜘蛛访问,我该怎么办?
百度蜘蛛符合互联网机器人协议。您可以使用robots.txt文件完全禁止百度蜘蛛访问您的网站,或者禁止百度蜘蛛访问您的网站上的某些文件。注意:如果百度蜘蛛被禁止访问您的网站,您的网站上的网页将无法在百度搜索引擎和百度提供搜索引擎服务的所有搜索引擎中搜索到。robots.txt的写法请参考我们的介绍:robots.txt的写法
您可以根据每个产品的不同用户代理设置不同的抓取规则。如果要完全禁止百度所有产品收录,可以直接设置Baiduspider禁止抓取。
以下robots实现禁止所有来自百度的抓取:
用户代理:百度蜘蛛
不允许:/
以下robots实现禁止所有来自百度的抓取,但允许图片搜索抓取/image/目录:
用户代理:百度蜘蛛
不允许:/
用户代理:Baiduspider-image
允许:/图像/
请注意:Baiduspider-cpro 抓取的网页不会被索引,但会执行与客户约定的操作。因此,不遵守机器人协议。如果Baiduspider-cpro给您带来麻烦,请联系我们。
百度蜘蛛广告抓取的网页不会被索引,但会执行与客户约定的操作。因此,不遵守机器人协议。如果百度蜘蛛广告给您带来麻烦,请联系您的客服专员。
7.为什么我的网站里加了robots.txt,百度上还是能搜到?
因为搜索引擎索引数据库的更新需要时间。虽然百度蜘蛛已经停止访问您在网站上的网页,但清除百度搜索引擎数据库中已建立网页的索引信息可能需要几个月的时间。另请检查您的机器人是否配置正确。
如果收录急需您的拒绝,您也可以通过反馈中心请求处理。
8.我希望我的 网站 内容被百度索引但不保存快照。我该怎么办?
百度蜘蛛符合互联网元机器人协议。您可以使用网页元设置使百度显示仅索引网页,而不在搜索结果中显示网页快照。
和robots的更新一样,更新搜索引擎索引库也是需要时间的,所以虽然你在网页中通过meta禁用了百度在搜索结果中显示页面的快照,但是如果网页索引已经在百度搜索引擎数据库信息,可能需要两到四个星期才能在线生效。
9.百度蜘蛛爬网导致带宽拥塞?
百度蜘蛛的正常抓取不会阻塞你的网站带宽。这种现象可能是有人冒充百度蜘蛛恶意抓取造成的。如果您发现名为百度蜘蛛的代理正在爬行导致带宽拥塞,请尽快与我们联系。您可以将信息反馈到反馈中心,如果您能提供您在此期间的网站访问日志,将更有利于我们的分析 查看全部
在线抓取网页(
百度搜藏Baiduspider-favo百度联盟-cpro商务搜索Baiduspider)
百度蜘蛛蜘蛛抓取网页介绍
1.什么是百度蜘蛛
百度蜘蛛是百度搜索引擎的自动程序。它的功能是访问互联网上的网页,并建立索引数据库,以便用户在百度搜索引擎上搜索您的网页。
2.百度蜘蛛的用户代理是什么?
百度产品使用不同的用户代理:
产品名称
对应user-agent
无线搜索
百度蜘蛛
图片搜索
百度蜘蛛图片
视频搜索
百度蜘蛛视频
新闻搜索
百度蜘蛛新闻
百度采集
百度蜘蛛最爱
百度联盟
百度蜘蛛-cpro
业务搜索
百度蜘蛛广告
网络和其他搜索
百度蜘蛛
3.百度蜘蛛对网站服务器造成的访问压力是什么?
为了对目标资源取得更好的检索效果,百度蜘蛛需要对您的网站保持一定的抓取量。我们尽量不对网站施加不合理的负担,会根据服务器容量、网站质量、网站更新等综合因素进行调整。如果您认为百度蜘蛛的访问行为存在不合理的情况,您可以向反馈中心反馈。
4.为什么百度蜘蛛老是爬我的网站?
百度蜘蛛会持续抓取您网站上新生成或不断更新的页面。此外,您还可以在网站访问日志中查看百度蜘蛛的访问是否正常,防止有人恶意冒充百度蜘蛛频繁抓取您的网站。如果您发现百度蜘蛛异常抓取您的网站,请通过反馈中心反馈给我们,并尽量提供百度蜘蛛对您网站的访问日志,以便我们进行跟踪。
5.如何判断是否冒充百度蜘蛛爬取?
建议您使用DNS反向检查的方式来判断爬取源的IP是否属于百度。不同平台的验证方法也不同。比如linux/windows/os三个平台下的验证方法如下:
5.1 在Linux平台下,可以使用hostip命令解密ip来判断是否来自百度蜘蛛。百度蜘蛛的主机名以*格式命名。或 *.baidu.jp。如果不是 *. 或者*.baidu.jp,都是假的。
$host123.125.66.120
120.66.125.123.in-addr.arpadomainnamepointer
.
主机119.63.195.254
254.195.63.119.in-addr.arpadomainnamepointer
百度Mobaider-119-63-195-254.crawl.baidu.jp。
5.2 windows平台或IBMOS/2平台下,可以使用nslookupip命令解密ip,判断是否来自百度蜘蛛。打开命令处理器,输入nslookupxxx.xxx.xxx.xxx(IP地址)解析ip判断是否来自百度蜘蛛。百度蜘蛛的主机名以*格式命名。或 *.baidu.jp,而不是 *. 或者 *.baidu.jp 是冒充的。
5.3 在macos平台下,可以使用dig命令解密ip来判断是否来自百度蜘蛛。打开命令处理器,输入digxxx.xxx.xxx.xxx(IP地址)解析ip判断是否来自百度蜘蛛。百度蜘蛛的主机名以*格式命名。或 *.baidu.jp,而不是 *. 或者 *.baidu.jp 是冒充的。
6.我不希望我的网站被百度蜘蛛访问,我该怎么办?
百度蜘蛛符合互联网机器人协议。您可以使用robots.txt文件完全禁止百度蜘蛛访问您的网站,或者禁止百度蜘蛛访问您的网站上的某些文件。注意:如果百度蜘蛛被禁止访问您的网站,您的网站上的网页将无法在百度搜索引擎和百度提供搜索引擎服务的所有搜索引擎中搜索到。robots.txt的写法请参考我们的介绍:robots.txt的写法
您可以根据每个产品的不同用户代理设置不同的抓取规则。如果要完全禁止百度所有产品收录,可以直接设置Baiduspider禁止抓取。
以下robots实现禁止所有来自百度的抓取:
用户代理:百度蜘蛛
不允许:/
以下robots实现禁止所有来自百度的抓取,但允许图片搜索抓取/image/目录:
用户代理:百度蜘蛛
不允许:/
用户代理:Baiduspider-image
允许:/图像/
请注意:Baiduspider-cpro 抓取的网页不会被索引,但会执行与客户约定的操作。因此,不遵守机器人协议。如果Baiduspider-cpro给您带来麻烦,请联系我们。
百度蜘蛛广告抓取的网页不会被索引,但会执行与客户约定的操作。因此,不遵守机器人协议。如果百度蜘蛛广告给您带来麻烦,请联系您的客服专员。
7.为什么我的网站里加了robots.txt,百度上还是能搜到?
因为搜索引擎索引数据库的更新需要时间。虽然百度蜘蛛已经停止访问您在网站上的网页,但清除百度搜索引擎数据库中已建立网页的索引信息可能需要几个月的时间。另请检查您的机器人是否配置正确。
如果收录急需您的拒绝,您也可以通过反馈中心请求处理。
8.我希望我的 网站 内容被百度索引但不保存快照。我该怎么办?
百度蜘蛛符合互联网元机器人协议。您可以使用网页元设置使百度显示仅索引网页,而不在搜索结果中显示网页快照。
和robots的更新一样,更新搜索引擎索引库也是需要时间的,所以虽然你在网页中通过meta禁用了百度在搜索结果中显示页面的快照,但是如果网页索引已经在百度搜索引擎数据库信息,可能需要两到四个星期才能在线生效。
9.百度蜘蛛爬网导致带宽拥塞?
百度蜘蛛的正常抓取不会阻塞你的网站带宽。这种现象可能是有人冒充百度蜘蛛恶意抓取造成的。如果您发现名为百度蜘蛛的代理正在爬行导致带宽拥塞,请尽快与我们联系。您可以将信息反馈到反馈中心,如果您能提供您在此期间的网站访问日志,将更有利于我们的分析
在线抓取网页(在优采云中怎么实现高清大图下文其他图片同理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-11-04 05:22
有很多网站,需要向下滚动页面才能加载新数据。相应的,还需要在优采云中设置【页面滚动】。
适用场景:向下滚动条直接到网页底部,出现类似【Loading】的字样,很快出现新数据,滚动条变短弹回。
常见网页:纸本首页、今日头条首页、百度图片搜索、新浪微博首页,都是这样。
鼠标放在图片上,右击,选择【在新标签页中打开图片】查看高清大图
这同样适用于下面的其他图片
以澎湃新闻首页为例。, 我们需要采集 新闻列表数据。打开网页后需要继续向下滚动以加载新数据。
如何在优采云中实现?以下是具体步骤。
步骤一、进入自定义任务编辑页面
将URL复制到客户端首页优采云的输入框,点击开始采集,进入自定义任务配置页面。
步骤二、 设置滚动方式,调整滚动次数,以及每次间隔
点击步骤打开网页,在下方步骤设置区点击高级设置,找到页面滚动,点击查看页面滚动。此网页可无限滚动。优采云 的默认设置是滚动到 [Scroll Mode] 的底部。默认为 [Scroll Times] 100 次,默认 [Each interval] 为 1 秒。您可以根据实际需要进行调整。【每个间隔】时间需要比网页上的数据加载时间稍长(网页上的数据加载时间与网速等因素有关)。
结合本次网站的加载特性,这里修改【Scroll Mode】向下滚动一屏(一般情况下建议选择向下滚动一屏);为了演示方便,这里设置【滚动次数】】5次。
第三步:使用第三课中学到的方法:采集List Data配置列表数据采集。
启动采集,看看采集的结果。优采云自动执行【直接滚动到底部】5次,然后采集5次后滚动数据。
特别说明:
1、此网页正在无限向下滚动以加载数据。优采云 无法采集 一次获取所有数据。上例设置滚动5次,在实际采集过程中,可以根据需要设置滚动次数。
2、这类网页常用于数据实时性较高的新闻网站,在优采云中可以使用云端采集,设置定时启动,少量次采集最新数据。
3、有时候网页速度很快,像【加载中】这样的提示不明显。【是否有新数据】和【观察滚动条反弹次数】是比较好用的判断标准,请关注网页。
4. [向下滚动一屏] 运行采集任务时,一屏与窗口显示区域相关。如下图,左边的滚动画面>右边的滚动画面。 查看全部
在线抓取网页(在优采云中怎么实现高清大图下文其他图片同理)
有很多网站,需要向下滚动页面才能加载新数据。相应的,还需要在优采云中设置【页面滚动】。
适用场景:向下滚动条直接到网页底部,出现类似【Loading】的字样,很快出现新数据,滚动条变短弹回。
常见网页:纸本首页、今日头条首页、百度图片搜索、新浪微博首页,都是这样。
鼠标放在图片上,右击,选择【在新标签页中打开图片】查看高清大图
这同样适用于下面的其他图片
以澎湃新闻首页为例。, 我们需要采集 新闻列表数据。打开网页后需要继续向下滚动以加载新数据。
如何在优采云中实现?以下是具体步骤。
步骤一、进入自定义任务编辑页面
将URL复制到客户端首页优采云的输入框,点击开始采集,进入自定义任务配置页面。
步骤二、 设置滚动方式,调整滚动次数,以及每次间隔
点击步骤打开网页,在下方步骤设置区点击高级设置,找到页面滚动,点击查看页面滚动。此网页可无限滚动。优采云 的默认设置是滚动到 [Scroll Mode] 的底部。默认为 [Scroll Times] 100 次,默认 [Each interval] 为 1 秒。您可以根据实际需要进行调整。【每个间隔】时间需要比网页上的数据加载时间稍长(网页上的数据加载时间与网速等因素有关)。
结合本次网站的加载特性,这里修改【Scroll Mode】向下滚动一屏(一般情况下建议选择向下滚动一屏);为了演示方便,这里设置【滚动次数】】5次。
第三步:使用第三课中学到的方法:采集List Data配置列表数据采集。
启动采集,看看采集的结果。优采云自动执行【直接滚动到底部】5次,然后采集5次后滚动数据。
特别说明:
1、此网页正在无限向下滚动以加载数据。优采云 无法采集 一次获取所有数据。上例设置滚动5次,在实际采集过程中,可以根据需要设置滚动次数。
2、这类网页常用于数据实时性较高的新闻网站,在优采云中可以使用云端采集,设置定时启动,少量次采集最新数据。
3、有时候网页速度很快,像【加载中】这样的提示不明显。【是否有新数据】和【观察滚动条反弹次数】是比较好用的判断标准,请关注网页。
4. [向下滚动一屏] 运行采集任务时,一屏与窗口显示区域相关。如下图,左边的滚动画面>右边的滚动画面。
在线抓取网页( NVivo12(Windows)NVivoforMac(Version10.1or)抓取在线PDF)
网站优化 • 优采云 发表了文章 • 0 个评论 • 409 次浏览 • 2021-11-03 01:31
NVivo12(Windows)NVivoforMac(Version10.1or)抓取在线PDF)
使用 NCapture 捕捉在线 PDF
您可以使用 NCapture 采集在线 PDF,然后将它们导入 NVivo。
要将爬取的在线 PDF 导入到项目中,您需要以下其中一项:
NVivo 12 (Windows)
NVivo 12 (Mac)
适用于 Windows 的 NVivo 11
NVivo for Mac(版本 11)
适用于 Windows 的 NVivo 10
NVivo for Mac(版本 10.1 或更高版本)
在线抓取PDF
要获取在线 PDF 并将其导入 NVivo:
1. 在浏览器中,显示要捕获的PDF。
2. 单击浏览器顶部的 NCapture 按钮。您可以提供有关已爬网内容的其他信息。
一种。整个 PDF 被捕获并成为 NVivo 中的 PDF 源
湾 查看默认的源名称(Source name)。导入 NVivo 后,这将是源的名称。如有必要,您可以更改名称。
C。您可以输入简短说明(Description)或备忘录(Memo):
描述可以描述你正在爬取的东西——它成为来源的属性之一。
备忘录可以记录您获取这些数据的原因以及它与您的研究的关系。导入源后,它将成为链接备忘录。
d. 在节点代码框中,您可以输入一个或多个节点来对内容进行编码。然后,当您将内容导入 NVivo 时,整个源将在您输入的节点上进行编码。
如果您输入了一个在项目中不存在的节点——或者错误地输入了节点名称——一个新的节点将在导入过程中被创建。如果要对项目中的现有节点(例如层次结构中的子节点)进行编码,则可以输入层次结构节点名称-例如,经济\旅游。
e. 单击捕获。捕获的内容将保存为 NCapture 文件,您可以将其导入到 NVivo 项目中。 查看全部
在线抓取网页(
NVivo12(Windows)NVivoforMac(Version10.1or)抓取在线PDF)
使用 NCapture 捕捉在线 PDF
您可以使用 NCapture 采集在线 PDF,然后将它们导入 NVivo。
要将爬取的在线 PDF 导入到项目中,您需要以下其中一项:
NVivo 12 (Windows)
NVivo 12 (Mac)
适用于 Windows 的 NVivo 11
NVivo for Mac(版本 11)
适用于 Windows 的 NVivo 10
NVivo for Mac(版本 10.1 或更高版本)
在线抓取PDF
要获取在线 PDF 并将其导入 NVivo:
1. 在浏览器中,显示要捕获的PDF。
2. 单击浏览器顶部的 NCapture 按钮。您可以提供有关已爬网内容的其他信息。
一种。整个 PDF 被捕获并成为 NVivo 中的 PDF 源
湾 查看默认的源名称(Source name)。导入 NVivo 后,这将是源的名称。如有必要,您可以更改名称。
C。您可以输入简短说明(Description)或备忘录(Memo):
描述可以描述你正在爬取的东西——它成为来源的属性之一。
备忘录可以记录您获取这些数据的原因以及它与您的研究的关系。导入源后,它将成为链接备忘录。
d. 在节点代码框中,您可以输入一个或多个节点来对内容进行编码。然后,当您将内容导入 NVivo 时,整个源将在您输入的节点上进行编码。
如果您输入了一个在项目中不存在的节点——或者错误地输入了节点名称——一个新的节点将在导入过程中被创建。如果要对项目中的现有节点(例如层次结构中的子节点)进行编码,则可以输入层次结构节点名称-例如,经济\旅游。
e. 单击捕获。捕获的内容将保存为 NCapture 文件,您可以将其导入到 NVivo 项目中。
在线抓取网页(在线抓取网页使用postmessagemessage的基本用法(xmlhttprequestget))
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2021-10-28 05:00
在线抓取网页使用postmessagemessage的基本用法,方便和websocket对比。xmlhttprequestget,post操作。采用postmessage做传输方便,不需要另外准备一个xmlhttprequest对象。现在使用postmessage方式的数据传输方式很多。常见的有restfulapi和socket两种。
restfulapi主要是为了开发语言和浏览器提供一个统一的接口,让javascript可以调用、使用、处理来自系统、浏览器或者第三方服务的信息。本文将教大家如何使用restfulapi进行网页抓取。restfulapi的优点:体积小,对不同浏览器兼容性好灵活,可以在全球范围内被广泛使用对于新手来说更加友好。
基本概念首先我们要理解http的基本常识。http(hypertexttransferprotocol)-超文本传输协议,也称超文本传输协议,用于即时和邮件传输网络。常见的传输协议包括http和tcp。http的历史http协议最早是由linker上的protocolbuffers扩展而来,此时的协议也叫做undertow协议,并为tcp/ip协议族中的其中一种。
tcp是一种面向连接的面向连接的连接传输层协议。面向连接的数据传输层主要目标是确保数据传输安全。udp使用点到点传输,用于没有确定序号的发送和接收,需要服务端提供确定序号的序号和确定序号的udp包接收。两者的主要差别在于udp在双方间时无需中间服务提供商,因此不属于面向连接协议。udp可以用于在其他地方使用的局域网,而不能用于互联网的内部网络。
当udp流行起来后,udp连接被削减到单条。从90年代末期开始,at&t-internet协议族就引入了基于http的协议。url属于udp协议,但是url不属于网络层协议,而属于应用层,因此从底层上来说不是一个面向连接的协议。tcp的tcp/ip协议族,是tcp协议族的一部分。ip协议是其他网络协议的基础,任何在ip协议有一点进展的网络都可以利用tcp作为连接协议。
协议有六种,分别是tcp/ip,udp,icmp,rgmp,tftp,http,它们的主要区别是:不同网络层之间的属于不同的协议,并且这些协议一般是在不同的协议上运行。不同网络层之间的数据只能通过一个传输层协议进行转发。不同网络层之间的数据只能按照最低的安全等级进行交换,并且其他网络层之间在使用udp的时候一般不需要使用ip地址。
接口规范ip协议一般不同公司设计不同的接口定义将来发送给不同网络层。rtmp协议实现的是目前公认最流行的一种udp协议。rtmp要求服务端与客户端一定要确定一个ip地址才能运行。由于协议规范都是透明的,也不限制返回的md5等加密方式。在rtmp-。 查看全部
在线抓取网页(在线抓取网页使用postmessagemessage的基本用法(xmlhttprequestget))
在线抓取网页使用postmessagemessage的基本用法,方便和websocket对比。xmlhttprequestget,post操作。采用postmessage做传输方便,不需要另外准备一个xmlhttprequest对象。现在使用postmessage方式的数据传输方式很多。常见的有restfulapi和socket两种。
restfulapi主要是为了开发语言和浏览器提供一个统一的接口,让javascript可以调用、使用、处理来自系统、浏览器或者第三方服务的信息。本文将教大家如何使用restfulapi进行网页抓取。restfulapi的优点:体积小,对不同浏览器兼容性好灵活,可以在全球范围内被广泛使用对于新手来说更加友好。
基本概念首先我们要理解http的基本常识。http(hypertexttransferprotocol)-超文本传输协议,也称超文本传输协议,用于即时和邮件传输网络。常见的传输协议包括http和tcp。http的历史http协议最早是由linker上的protocolbuffers扩展而来,此时的协议也叫做undertow协议,并为tcp/ip协议族中的其中一种。
tcp是一种面向连接的面向连接的连接传输层协议。面向连接的数据传输层主要目标是确保数据传输安全。udp使用点到点传输,用于没有确定序号的发送和接收,需要服务端提供确定序号的序号和确定序号的udp包接收。两者的主要差别在于udp在双方间时无需中间服务提供商,因此不属于面向连接协议。udp可以用于在其他地方使用的局域网,而不能用于互联网的内部网络。
当udp流行起来后,udp连接被削减到单条。从90年代末期开始,at&t-internet协议族就引入了基于http的协议。url属于udp协议,但是url不属于网络层协议,而属于应用层,因此从底层上来说不是一个面向连接的协议。tcp的tcp/ip协议族,是tcp协议族的一部分。ip协议是其他网络协议的基础,任何在ip协议有一点进展的网络都可以利用tcp作为连接协议。
协议有六种,分别是tcp/ip,udp,icmp,rgmp,tftp,http,它们的主要区别是:不同网络层之间的属于不同的协议,并且这些协议一般是在不同的协议上运行。不同网络层之间的数据只能通过一个传输层协议进行转发。不同网络层之间的数据只能按照最低的安全等级进行交换,并且其他网络层之间在使用udp的时候一般不需要使用ip地址。
接口规范ip协议一般不同公司设计不同的接口定义将来发送给不同网络层。rtmp协议实现的是目前公认最流行的一种udp协议。rtmp要求服务端与客户端一定要确定一个ip地址才能运行。由于协议规范都是透明的,也不限制返回的md5等加密方式。在rtmp-。
在线抓取网页( “爬虫”是怎么抢机票的?(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-10-27 03:01
“爬虫”是怎么抢机票的?(组图))
中新社发刘冠官摄'/>
资料图:北京某公交车站出现抢票浏览器广告。中新社发 刘关官摄
还有不到两个月,2018年的春节就要到了。
“今年我得早点动身去抢一张回家的低价票。” 在北京工作的小王告诉科技日报记者。由于老家在云南,春节的机票太贵了,所以他选择坐了两天两夜。优采云 回去,路漫漫其修远兮。
然而,就在小王急于抢到便宜机票的时候,他在网上看到一则新闻,航空公司发行的低价机票中,80%以上都是票务公司“爬虫”。抢了它,普通用户很少用。
小王傻眼了。“爬虫”是什么鬼?它是怎么抢到票的?没有办法管理吗?
使用超链接信息抓取网页
“‘爬虫’技术是实现网络信息采集的关键技术之一。通俗地说,‘爬虫’就是一个用于对采集网站数据进行批处理和自动化的程序。人类需要干预。” 北京理工大学网络科学与技术研究所副教授闫怀志告诉科技日报记者。
据闫怀志介绍,“爬虫”也被称为网页“蜘蛛”或网络机器人。它们是根据一定的规则自动抓取网页信息的程序或脚本,通常驻留在服务器上。在一个网页中,它不仅收录供用户阅读的文字、图片等信息,还收录一些超链接信息。互联网“爬虫”使用这些超链接不断地抓取互联网上的其他网页。
“这种信息采集的处理过程很像网络上漫游的爬虫或蜘蛛,因此网络‘爬虫’或网页‘蜘蛛’得名。” 闫怀志说,“爬虫”最早应用在搜索引擎领域,比如百度、百度、搜狗等搜索引擎工具每天需要抓取互联网上数百亿个网页,他们需要依靠庞大的“爬虫”集群来实现搜索功能。
目前,“爬虫”已经广泛应用于电子商务、互联网金融等多个领域。例如,“爬虫”可以抓取航空公司官网的机票价格。“爬虫”发现低价机票或热机票后,可以利用虚假客源的真实身份信息进行提前预订。此外,许多网络浏览器都推出了自己的抢票插件,以宣传订票成功率高的浏览器。
根据不同的爬虫任务和目标,网络“爬虫”大致可以分为批处理型、增量型和垂直型。批量式“爬虫”的爬取范围和目标比较明确,可以是设置的网页数量,也可以是耗时设置。增量“爬虫”主要用于不断抓取更新的网页,以适应网页的不断变化。垂直“爬虫”主要用于具有特定主题内容或特定行业的网页。
“爬虫”是怎么抢票的
此前,携程“反爬虫”专家在技术分享中透露,某个网站的页面每分钟有1.20000次页面浏览,而真实用户只有500人,“爬虫”流量占比为 95.8%。
采访中,多位业内人士也表示,即使在“爬虫”活动淡季,虚假流量也占到预订总流量的50%网站,期间更是高达90%以上。高峰期。
那么,“爬虫”是如何实现抢票的呢?对此,闫怀志解释说,主要原因是机票代理公司利用“爬虫”技术不断爬取航空公司售票官网的信息。如果发现航空公司有低价机票,“爬虫”会立即使用虚假旅客身份进行批量预订。但并不是实际付费,以达到抢低价票来源的目的。由于“爬虫”的效率远超正常人工操作,通过正常操作抢票几乎是不可能的。
随后,机票代理公司将通过自己的销售渠道(包括公司网站、在线旅行社、客户电话订购等),在航空公司允许的计费周期内找到真正的客户来源, 使用虚假来源退订,然后使用真实身份信息订购该身份预留的低价票,最后以加价转售该低价票。
如果在航空公司规定的计费周期内没有找到真正的客源,机票代理机构会在订单到期前添加虚假身份订单,继续“占用”低价机票,重复此过程,直到真正的找到并出售来源。
“上述操作流程构成了一个完整的机票销售链条。在这个过程中,航空公司的售票系统允许在计费周期内重复订票和退票,这为票务机构利用‘爬虫’抢票、提价提供了便利。”的抢票方法被称为技术'黄牛'。” 严怀之强调。
的确,有业内人士表示,这些“爬虫”流量消耗了大量机器资源,却没有产生任何消耗,这是每个公司最讨厌的。不过,由于担心误伤真实用户,各家公司的“反爬虫”策略一直非常谨慎。
“爬虫”可以通过一定的手段进行预防和控制
一切都有两个方面,“爬虫”技术也不例外。
在闫怀志看来,“爬虫”不仅可以为正常的数据批量获取提供有效的技术手段,还可以被恶意利用,获取不正当利益。如果“爬虫”技术使用不当,会带来一定的危害。
第一,威胁数据安全。机票销售网站数据被恶意抓取,数据可能被机票代理公司恶意利用,也存在被同行业竞争对手收购的风险。
其次,导致系统性能下降,影响用户体验。“爬虫”的大量爬取请求会导致航空公司售票网站服务器资源负载增加、性能下降、网站响应缓慢甚至无法提供服务,从而产生负面影响关于用户搜索和交易体验。然而,由于利益的巨大灰色空间和“反爬虫”技术在对抗“爬虫”中的作用有限,这种明显不公平的“作弊”方式已经成为一种扰乱门票秩序的技术“病”。市场。
“从技术角度来说,拦截‘爬虫’可以使用网站流量统计系统和服务器访问日志分析系统。” 闫怀志表示,通过流量统计和日志分析,如果发现单个IP访问、单个会话访问、User-Agent信息超过设置的正常频率阈值,则确定该访问为恶意“爬虫”,“ crawler”IP 被列入黑名单,拒绝后续访问。
然后设置各种访问验证链接。例如,当可疑IP访问时,返回验证页面,要求访问者通过填写验证码、选择验证图片或字符等方式完成验证。如果是恶意的“爬虫”爬取,显然很难完成上述验证操作,这时就可以阻断“爬虫”的访问,防止其恶意爬取信息。
互联网空间不能有“灰色地带”
当前,以云计算、大数据为代表的新一代信息技术正处于快速发展阶段。
“上述新技术如果被非法或不当应用,将造成严重危害。互联网空间的安全需要建立健全完善的保护体系,绝不能“裸奔”。颜怀之说道。
2017年6月1日,我国《网络安全法》正式实施,明确了各方在网络安全保护中的权利和责任。这是我国网络空间治理和法制建设由量变到质变的重要里程碑。该法作为依法治理互联网、化解网络风险的法律工具,已成为我国互联网在法治轨道上健康运行的重要保障。
但是,目前对于高科技“黄牛”的剥头皮行为,并没有明确的规定,将恶意爬取信息的行为置于法律法规的“灰色地带”,不当获利行为。
闫怀志介绍,Robots协议(即“爬虫”协议、网络机器人协议等)是国际上专门针对“爬虫”应用制定的。该协议称为“网络爬虫排除标准”。网站 可以通过这个协议告诉“爬虫”哪些页面和信息可以爬取,哪些页面和信息不能爬取。本协议作为网站与“爬虫”之间的一种沟通方式,规范“爬虫”的行为,限制不正当竞争。
作为国际互联网界通行的道德准则,协议的原则是:“爬虫”和搜索技术应该为人类服务,同时尊重信息提供者的意愿,维护他们的隐私权;网站 有义务保护其使用人的个人信息和隐私不受侵犯。这规定了爬虫和被爬虫双方的权利和义务。
一位不愿透露姓名的法律专家也表示,“反爬虫”不仅要靠技术防范和行业自律,还要完善管理和法律法规来约束这种行为,尤其是法律手段可以证明惩罚和威慑。. 航空公司也应加强对账期的管理,不提供给“爬虫”抢票的机会。 查看全部
在线抓取网页(
“爬虫”是怎么抢机票的?(组图))
中新社发刘冠官摄'/>
资料图:北京某公交车站出现抢票浏览器广告。中新社发 刘关官摄
还有不到两个月,2018年的春节就要到了。
“今年我得早点动身去抢一张回家的低价票。” 在北京工作的小王告诉科技日报记者。由于老家在云南,春节的机票太贵了,所以他选择坐了两天两夜。优采云 回去,路漫漫其修远兮。
然而,就在小王急于抢到便宜机票的时候,他在网上看到一则新闻,航空公司发行的低价机票中,80%以上都是票务公司“爬虫”。抢了它,普通用户很少用。
小王傻眼了。“爬虫”是什么鬼?它是怎么抢到票的?没有办法管理吗?
使用超链接信息抓取网页
“‘爬虫’技术是实现网络信息采集的关键技术之一。通俗地说,‘爬虫’就是一个用于对采集网站数据进行批处理和自动化的程序。人类需要干预。” 北京理工大学网络科学与技术研究所副教授闫怀志告诉科技日报记者。
据闫怀志介绍,“爬虫”也被称为网页“蜘蛛”或网络机器人。它们是根据一定的规则自动抓取网页信息的程序或脚本,通常驻留在服务器上。在一个网页中,它不仅收录供用户阅读的文字、图片等信息,还收录一些超链接信息。互联网“爬虫”使用这些超链接不断地抓取互联网上的其他网页。
“这种信息采集的处理过程很像网络上漫游的爬虫或蜘蛛,因此网络‘爬虫’或网页‘蜘蛛’得名。” 闫怀志说,“爬虫”最早应用在搜索引擎领域,比如百度、百度、搜狗等搜索引擎工具每天需要抓取互联网上数百亿个网页,他们需要依靠庞大的“爬虫”集群来实现搜索功能。
目前,“爬虫”已经广泛应用于电子商务、互联网金融等多个领域。例如,“爬虫”可以抓取航空公司官网的机票价格。“爬虫”发现低价机票或热机票后,可以利用虚假客源的真实身份信息进行提前预订。此外,许多网络浏览器都推出了自己的抢票插件,以宣传订票成功率高的浏览器。
根据不同的爬虫任务和目标,网络“爬虫”大致可以分为批处理型、增量型和垂直型。批量式“爬虫”的爬取范围和目标比较明确,可以是设置的网页数量,也可以是耗时设置。增量“爬虫”主要用于不断抓取更新的网页,以适应网页的不断变化。垂直“爬虫”主要用于具有特定主题内容或特定行业的网页。
“爬虫”是怎么抢票的
此前,携程“反爬虫”专家在技术分享中透露,某个网站的页面每分钟有1.20000次页面浏览,而真实用户只有500人,“爬虫”流量占比为 95.8%。
采访中,多位业内人士也表示,即使在“爬虫”活动淡季,虚假流量也占到预订总流量的50%网站,期间更是高达90%以上。高峰期。
那么,“爬虫”是如何实现抢票的呢?对此,闫怀志解释说,主要原因是机票代理公司利用“爬虫”技术不断爬取航空公司售票官网的信息。如果发现航空公司有低价机票,“爬虫”会立即使用虚假旅客身份进行批量预订。但并不是实际付费,以达到抢低价票来源的目的。由于“爬虫”的效率远超正常人工操作,通过正常操作抢票几乎是不可能的。
随后,机票代理公司将通过自己的销售渠道(包括公司网站、在线旅行社、客户电话订购等),在航空公司允许的计费周期内找到真正的客户来源, 使用虚假来源退订,然后使用真实身份信息订购该身份预留的低价票,最后以加价转售该低价票。
如果在航空公司规定的计费周期内没有找到真正的客源,机票代理机构会在订单到期前添加虚假身份订单,继续“占用”低价机票,重复此过程,直到真正的找到并出售来源。
“上述操作流程构成了一个完整的机票销售链条。在这个过程中,航空公司的售票系统允许在计费周期内重复订票和退票,这为票务机构利用‘爬虫’抢票、提价提供了便利。”的抢票方法被称为技术'黄牛'。” 严怀之强调。
的确,有业内人士表示,这些“爬虫”流量消耗了大量机器资源,却没有产生任何消耗,这是每个公司最讨厌的。不过,由于担心误伤真实用户,各家公司的“反爬虫”策略一直非常谨慎。
“爬虫”可以通过一定的手段进行预防和控制
一切都有两个方面,“爬虫”技术也不例外。
在闫怀志看来,“爬虫”不仅可以为正常的数据批量获取提供有效的技术手段,还可以被恶意利用,获取不正当利益。如果“爬虫”技术使用不当,会带来一定的危害。
第一,威胁数据安全。机票销售网站数据被恶意抓取,数据可能被机票代理公司恶意利用,也存在被同行业竞争对手收购的风险。
其次,导致系统性能下降,影响用户体验。“爬虫”的大量爬取请求会导致航空公司售票网站服务器资源负载增加、性能下降、网站响应缓慢甚至无法提供服务,从而产生负面影响关于用户搜索和交易体验。然而,由于利益的巨大灰色空间和“反爬虫”技术在对抗“爬虫”中的作用有限,这种明显不公平的“作弊”方式已经成为一种扰乱门票秩序的技术“病”。市场。
“从技术角度来说,拦截‘爬虫’可以使用网站流量统计系统和服务器访问日志分析系统。” 闫怀志表示,通过流量统计和日志分析,如果发现单个IP访问、单个会话访问、User-Agent信息超过设置的正常频率阈值,则确定该访问为恶意“爬虫”,“ crawler”IP 被列入黑名单,拒绝后续访问。
然后设置各种访问验证链接。例如,当可疑IP访问时,返回验证页面,要求访问者通过填写验证码、选择验证图片或字符等方式完成验证。如果是恶意的“爬虫”爬取,显然很难完成上述验证操作,这时就可以阻断“爬虫”的访问,防止其恶意爬取信息。
互联网空间不能有“灰色地带”
当前,以云计算、大数据为代表的新一代信息技术正处于快速发展阶段。
“上述新技术如果被非法或不当应用,将造成严重危害。互联网空间的安全需要建立健全完善的保护体系,绝不能“裸奔”。颜怀之说道。
2017年6月1日,我国《网络安全法》正式实施,明确了各方在网络安全保护中的权利和责任。这是我国网络空间治理和法制建设由量变到质变的重要里程碑。该法作为依法治理互联网、化解网络风险的法律工具,已成为我国互联网在法治轨道上健康运行的重要保障。
但是,目前对于高科技“黄牛”的剥头皮行为,并没有明确的规定,将恶意爬取信息的行为置于法律法规的“灰色地带”,不当获利行为。
闫怀志介绍,Robots协议(即“爬虫”协议、网络机器人协议等)是国际上专门针对“爬虫”应用制定的。该协议称为“网络爬虫排除标准”。网站 可以通过这个协议告诉“爬虫”哪些页面和信息可以爬取,哪些页面和信息不能爬取。本协议作为网站与“爬虫”之间的一种沟通方式,规范“爬虫”的行为,限制不正当竞争。
作为国际互联网界通行的道德准则,协议的原则是:“爬虫”和搜索技术应该为人类服务,同时尊重信息提供者的意愿,维护他们的隐私权;网站 有义务保护其使用人的个人信息和隐私不受侵犯。这规定了爬虫和被爬虫双方的权利和义务。
一位不愿透露姓名的法律专家也表示,“反爬虫”不仅要靠技术防范和行业自律,还要完善管理和法律法规来约束这种行为,尤其是法律手段可以证明惩罚和威慑。. 航空公司也应加强对账期的管理,不提供给“爬虫”抢票的机会。
在线抓取网页(一把抓网页工具是一款方便易用的网站内容抓取工具.该软件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-10-23 09:09
网页抓取工具是一种方便易用的网站内容抓取工具。该软件主要帮助用户抓取网站中的各种内容,如JS、CSS、图片、背景图片、音乐、Flash等,非常适合仿站人员...
它可以帮助我们快速采集互联网上的海量内容,进行深入的数据分析和挖掘。比如抓取各大网站的排名,抓取各大购物的价格信息网站等等。而我们每天常用的搜索引擎都是“网络爬虫”。但毕竟。
Python爬虫入门教程!手把手教你爬取网页数据。
第三步:提取内容。上面两步我们使用requests向网页请求数据,使用bs4解析页面。现在我们来到最关键的一步:。
网页内容智能抓取的实现和实例详解完全基于java。核心技术核心技术XML解析、HTML解析、开源组件应用。该应用程序的开源组件包括: DOM4J:解析 XMLjericho-。
优采云·云采集服务平台网站如何使用内容爬虫工具网络每天都在产生海量的图形数据。如何为你我使用这些数据,让数据给我们工作带来真正的价值?
获取某个网站数据过多或者爬取过快等因素往往会导致IP被封的风险,但是我们可以使用PHP构造IP地址来获取数据。.
《爬虫四步法》教你如何使用Python抓取和存储网页数据。 查看全部
在线抓取网页(一把抓网页工具是一款方便易用的网站内容抓取工具.该软件)
网页抓取工具是一种方便易用的网站内容抓取工具。该软件主要帮助用户抓取网站中的各种内容,如JS、CSS、图片、背景图片、音乐、Flash等,非常适合仿站人员...
它可以帮助我们快速采集互联网上的海量内容,进行深入的数据分析和挖掘。比如抓取各大网站的排名,抓取各大购物的价格信息网站等等。而我们每天常用的搜索引擎都是“网络爬虫”。但毕竟。
Python爬虫入门教程!手把手教你爬取网页数据。
第三步:提取内容。上面两步我们使用requests向网页请求数据,使用bs4解析页面。现在我们来到最关键的一步:。
网页内容智能抓取的实现和实例详解完全基于java。核心技术核心技术XML解析、HTML解析、开源组件应用。该应用程序的开源组件包括: DOM4J:解析 XMLjericho-。
优采云·云采集服务平台网站如何使用内容爬虫工具网络每天都在产生海量的图形数据。如何为你我使用这些数据,让数据给我们工作带来真正的价值?
获取某个网站数据过多或者爬取过快等因素往往会导致IP被封的风险,但是我们可以使用PHP构造IP地址来获取数据。.
《爬虫四步法》教你如何使用Python抓取和存储网页数据。
在线抓取网页(vue-scrapy中文教程(一):在线抓取网页?抓取教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-10-18 05:01
在线抓取网页?vue用户突然发现有奇妙的东西想抓取,这里介绍的就是vue-scrapy,让我们一起来破解它吧。vue-scrapy抓取教程目录·解读vue-scrapy·深入vue-scrapy·scrapy抓取·webpack和vue-scrapy项目结构·一个特殊例子·scrapy中文教程1.解读vue-scrapy之首页的抓取scrapy还提供了首页抓取的功能,抓取的格式为:vue-scrapy/app/index.html?form=all&url=http%3a%2f%%2fspider%2f2.深入vue-scrapy此处引入了我们之前在vue官网也学习到的vue-scrapy项目结构2.scrapy抓取教程fromvueimportscrapy,request,responsefromvueimportvuerouterfromvue.extendsextendsscrapy.extends{exports}mypath='d:\\release'mybridgemode='encoding'exports={release:request(),url:url,error:false,headers:['cookie']}scrapy.init(mypath,mybridgemode,exports={encoding:'utf-8'})scrapy.save(mypath,exports={index:false})scrapy.start(mybridgemode,url,error)scrapy.fetch(url,from_url)scrapy.login(url,'email')scrapy.index(url,from_url)scrapy.tree(url,'big/')scrapy.settings({'url':url})这部分我们将会在后面要做介绍到的爬虫文件中放入url这一列和数据,现在scrapy分别将给出文件结构和主要api接口代码,具体如下:demos=scrapy.document('d:\\release')mypage=mypage.form('thisisyour_url')mybid=mybid.map(request=request)myurl=myurl.form('thisisyour_url')myhttprequest=myhttprequest.request(url=url)myhttprequest2=myhttprequest2.form('thisisyour_url')mygeturl=mygeturl.form('thisisyour_url')mygeturl2=mygeturl2.form('thisisyour_url')fromurllibimporturlencodedurl=""headers={'user-agent':'mozilla/5.0(windowsnt6.1;win64;x64)applewebkit/537.36(khtml,likegecko)chrome/59.0.2104.87safari/537.36'}headers={'host':'xxx.xxx.xxx.xxx','port':'3306','referer':''}api=scrapy.spi。 查看全部
在线抓取网页(vue-scrapy中文教程(一):在线抓取网页?抓取教程)
在线抓取网页?vue用户突然发现有奇妙的东西想抓取,这里介绍的就是vue-scrapy,让我们一起来破解它吧。vue-scrapy抓取教程目录·解读vue-scrapy·深入vue-scrapy·scrapy抓取·webpack和vue-scrapy项目结构·一个特殊例子·scrapy中文教程1.解读vue-scrapy之首页的抓取scrapy还提供了首页抓取的功能,抓取的格式为:vue-scrapy/app/index.html?form=all&url=http%3a%2f%%2fspider%2f2.深入vue-scrapy此处引入了我们之前在vue官网也学习到的vue-scrapy项目结构2.scrapy抓取教程fromvueimportscrapy,request,responsefromvueimportvuerouterfromvue.extendsextendsscrapy.extends{exports}mypath='d:\\release'mybridgemode='encoding'exports={release:request(),url:url,error:false,headers:['cookie']}scrapy.init(mypath,mybridgemode,exports={encoding:'utf-8'})scrapy.save(mypath,exports={index:false})scrapy.start(mybridgemode,url,error)scrapy.fetch(url,from_url)scrapy.login(url,'email')scrapy.index(url,from_url)scrapy.tree(url,'big/')scrapy.settings({'url':url})这部分我们将会在后面要做介绍到的爬虫文件中放入url这一列和数据,现在scrapy分别将给出文件结构和主要api接口代码,具体如下:demos=scrapy.document('d:\\release')mypage=mypage.form('thisisyour_url')mybid=mybid.map(request=request)myurl=myurl.form('thisisyour_url')myhttprequest=myhttprequest.request(url=url)myhttprequest2=myhttprequest2.form('thisisyour_url')mygeturl=mygeturl.form('thisisyour_url')mygeturl2=mygeturl2.form('thisisyour_url')fromurllibimporturlencodedurl=""headers={'user-agent':'mozilla/5.0(windowsnt6.1;win64;x64)applewebkit/537.36(khtml,likegecko)chrome/59.0.2104.87safari/537.36'}headers={'host':'xxx.xxx.xxx.xxx','port':'3306','referer':''}api=scrapy.spi。
在线抓取网页(BBS采集多为3P代码为多(3))
网站优化 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-10-17 15:17
爬取网页内容,通常人们认为他们从互联网上窃取数据,然后将采集到的数据挂在自己的互联网上。其实你也可以将采集收到的数据作为公司的参考,或者将采集到的数据与你公司的业务进行对比等。
目前网页采集多为3P代码(3P即ASP、PHP
, JSP)。最常用的系统是BBS新闻采集系统,以及网上流传的新浪新闻采集系统。全部使用ASP程序,但理论上速度不是很好。
如果尝试使用其他软件的多线程采集,会不会更快?答案是肯定的。可以用DELPHI、VC、VB、JB,但是PB好像比较难做。下面用DELPHI来解释采集
网页数据。
一、 简单新闻采集
新闻 采集 是最简单的,只要确定标题、副主题、作者、来源、日期、新闻正文和分页符即可。必须在采集之前获取网页内容,所以在DELPHI中添加idHTTP控件(在indyClients面板中),然后使用idHTTP1.GET方法获取网页内容,声明如下:
函数获取(AURL:字符串):字符串;超载;
AURL 参数是一个字符串类型,它指定一个 URL 地址字符串。函数return也是字符串类型,返回网页的HTML源文件。例如,我们可以这样调用:
tmpStr:= idHTTP1.Get('');
调用成功后,网易首页代码存放在tmpstr变量中。
接下来说一下数据拦截。在这里,我定义了这样一个函数:
functionTForm1.GetStr(StrSource,StrBegin,StrEnd:string):string;
无功
in_star,in_end:整数;
开始
in_star:=AnsiPos(strbegin,strsource) 长度(strbegin);
in_end:=AnsiPos(strend,strsource);
结果:=复制(strsource,in_sta,in_end-in_star);
结尾;
StrSource:字符串类型,表示HTML源文件。
StrBegin:字符串类型,表示截取开始的标志。
StrEnd:字符串,表示截取结束的标志。
该函数将字符串 StrSource 中的一段文本从 StrSource 返回到 StrBegin。
例如:
strtmp:=TForm1.GetStr('A123BCD','A','BC');
运行后strtmp的值为:'123'。
关于函数中使用的AnsiPos和copy,都是系统定义的。您可以在delphi的帮助文件中找到相关说明。我这里也简单说一下:
函数 AnsiPos(const Substr, S: string): 整数
返回 Substr 在 S 中第一次出现的位置。
函数复制(strsource,in_sta,in_end-in_star):字符串;
返回字符串strsource 中从in_sta(整数数据)到in_end-in_star(整数数据)的字符串。
有了上面的功能,我们就可以通过设置各种标签来拦截想要的文章内容。在程序中,比较麻烦的是我们需要设置很多标签。要定位某个内容,您必须设置
它的开始和结束标志。比如要获取网页上的文章标题,必须提前查看网页代码,查看文章标题前后的一些特征码,利用这些特征码拦截< @文章 标签
题。
下面我们来实际演示一下。假设采集的文章地址是
代码是:
新页面 1
文章标题
ercolor="#111111"
>
作者
出处
这是文章的内容。 查看全部
在线抓取网页(BBS采集多为3P代码为多(3))
爬取网页内容,通常人们认为他们从互联网上窃取数据,然后将采集到的数据挂在自己的互联网上。其实你也可以将采集收到的数据作为公司的参考,或者将采集到的数据与你公司的业务进行对比等。
目前网页采集多为3P代码(3P即ASP、PHP
, JSP)。最常用的系统是BBS新闻采集系统,以及网上流传的新浪新闻采集系统。全部使用ASP程序,但理论上速度不是很好。
如果尝试使用其他软件的多线程采集,会不会更快?答案是肯定的。可以用DELPHI、VC、VB、JB,但是PB好像比较难做。下面用DELPHI来解释采集
网页数据。
一、 简单新闻采集
新闻 采集 是最简单的,只要确定标题、副主题、作者、来源、日期、新闻正文和分页符即可。必须在采集之前获取网页内容,所以在DELPHI中添加idHTTP控件(在indyClients面板中),然后使用idHTTP1.GET方法获取网页内容,声明如下:
函数获取(AURL:字符串):字符串;超载;
AURL 参数是一个字符串类型,它指定一个 URL 地址字符串。函数return也是字符串类型,返回网页的HTML源文件。例如,我们可以这样调用:
tmpStr:= idHTTP1.Get('');
调用成功后,网易首页代码存放在tmpstr变量中。
接下来说一下数据拦截。在这里,我定义了这样一个函数:
functionTForm1.GetStr(StrSource,StrBegin,StrEnd:string):string;
无功
in_star,in_end:整数;
开始
in_star:=AnsiPos(strbegin,strsource) 长度(strbegin);
in_end:=AnsiPos(strend,strsource);
结果:=复制(strsource,in_sta,in_end-in_star);
结尾;
StrSource:字符串类型,表示HTML源文件。
StrBegin:字符串类型,表示截取开始的标志。
StrEnd:字符串,表示截取结束的标志。
该函数将字符串 StrSource 中的一段文本从 StrSource 返回到 StrBegin。
例如:
strtmp:=TForm1.GetStr('A123BCD','A','BC');
运行后strtmp的值为:'123'。
关于函数中使用的AnsiPos和copy,都是系统定义的。您可以在delphi的帮助文件中找到相关说明。我这里也简单说一下:
函数 AnsiPos(const Substr, S: string): 整数
返回 Substr 在 S 中第一次出现的位置。
函数复制(strsource,in_sta,in_end-in_star):字符串;
返回字符串strsource 中从in_sta(整数数据)到in_end-in_star(整数数据)的字符串。
有了上面的功能,我们就可以通过设置各种标签来拦截想要的文章内容。在程序中,比较麻烦的是我们需要设置很多标签。要定位某个内容,您必须设置
它的开始和结束标志。比如要获取网页上的文章标题,必须提前查看网页代码,查看文章标题前后的一些特征码,利用这些特征码拦截< @文章 标签
题。
下面我们来实际演示一下。假设采集的文章地址是
代码是:
新页面 1
文章标题
ercolor="#111111"
>
作者
出处
这是文章的内容。
在线抓取网页(如何爬取网页上的网页?在线抓取网页格式?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2021-10-16 19:05
在线抓取网页格式如果你是刚开始接触代码爬虫这项工作,那么你肯定碰到一个问题:如何爬取网页上的网页?是通过html标签的文本格式还是其他格式?不管是那种格式,爬取网页的方法和获取单个页面的办法是一样的,首先我们需要从爬取对象中选取所需要爬取的页面,然后将其保存到文件。然后根据爬取页面所需要分析的内容来设置爬取页面的参数,例如是什么类型的网页、页面里面的分类有多少以及所在哪个位置等,然后一步步去获取需要的内容。
对于html标签的格式是如何抓取的,主要有以下两种办法:一.使用脚本1.模拟浏览器是否打开了自己定义的网页。如果打开了你自己定义的网页,就使用浏览器相应的request类对象函数去获取页面的内容;如果没有打开你自己定义的网页,则不可以用request对象函数去获取页面。2.模拟用户登录页面是否打开了你自己定义的页面,并且无密码登录,用户登录时会提示浏览器登录失败,则不可以使用request对象函数去获取页面内容。
3.在html标签中解析时,能否通过给每个标签添加上相应的href属性获取。二.使用爬虫工具工具可以帮助我们解决一部分网页数据爬取的问题,例如它可以自动解析自己的url到网页上,然后抓取页面上的内容,但是我们选择使用哪个工具呢?建议使用pythonselenium,使用它去抓取页面的代码如下:#-*-coding:utf-8-*-importsysreload(sys)sys.setdefaultencoding('utf-8')importurllibfromseleniumimportwebdriverurl=''request=urllib.request.urlopen(url)html=request.read()driver=webdriver.chrome()driver.get(url)foriinrange(len(driver.getrequest())):html=driver.from_screenshot(i+1)response=urllib.urlencode(driver.page_source)print(response)urllib=urllib.urlencode(response)urllib.request=urllib.urlopen(url)response=urllib.urlopen()forpageinrange(len(urllib.request)):try:response=urllib.urlopen(url)print(response)excepturllib.urlerror:print(urllib.urlerror)returnurllib.request(文章转载自csdn:菜鸟学python--gunzisan开发者生活坊)。 查看全部
在线抓取网页(如何爬取网页上的网页?在线抓取网页格式?)
在线抓取网页格式如果你是刚开始接触代码爬虫这项工作,那么你肯定碰到一个问题:如何爬取网页上的网页?是通过html标签的文本格式还是其他格式?不管是那种格式,爬取网页的方法和获取单个页面的办法是一样的,首先我们需要从爬取对象中选取所需要爬取的页面,然后将其保存到文件。然后根据爬取页面所需要分析的内容来设置爬取页面的参数,例如是什么类型的网页、页面里面的分类有多少以及所在哪个位置等,然后一步步去获取需要的内容。
对于html标签的格式是如何抓取的,主要有以下两种办法:一.使用脚本1.模拟浏览器是否打开了自己定义的网页。如果打开了你自己定义的网页,就使用浏览器相应的request类对象函数去获取页面的内容;如果没有打开你自己定义的网页,则不可以用request对象函数去获取页面。2.模拟用户登录页面是否打开了你自己定义的页面,并且无密码登录,用户登录时会提示浏览器登录失败,则不可以使用request对象函数去获取页面内容。
3.在html标签中解析时,能否通过给每个标签添加上相应的href属性获取。二.使用爬虫工具工具可以帮助我们解决一部分网页数据爬取的问题,例如它可以自动解析自己的url到网页上,然后抓取页面上的内容,但是我们选择使用哪个工具呢?建议使用pythonselenium,使用它去抓取页面的代码如下:#-*-coding:utf-8-*-importsysreload(sys)sys.setdefaultencoding('utf-8')importurllibfromseleniumimportwebdriverurl=''request=urllib.request.urlopen(url)html=request.read()driver=webdriver.chrome()driver.get(url)foriinrange(len(driver.getrequest())):html=driver.from_screenshot(i+1)response=urllib.urlencode(driver.page_source)print(response)urllib=urllib.urlencode(response)urllib.request=urllib.urlopen(url)response=urllib.urlopen()forpageinrange(len(urllib.request)):try:response=urllib.urlopen(url)print(response)excepturllib.urlerror:print(urllib.urlerror)returnurllib.request(文章转载自csdn:菜鸟学python--gunzisan开发者生活坊)。
在线抓取网页(一个通用的网络爬虫的基本结构及工作流程(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-10-13 15:03
网络爬虫是搜索引擎爬虫系统的重要组成部分。爬虫的主要目的是将互联网上的网页下载到本地,形成网络内容的镜像备份。本篇博客主要是对爬虫和爬虫系统的简要介绍。
一、网络爬虫的基本结构和工作流程
一个通用的网络爬虫的框架如图所示:
网络爬虫的基本工作流程如下:
1.首先选择一些精心挑选的种子网址;
2.将这些URL放入URL队列进行抓取;
3. 从待爬取的URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,并保存到下载的网页库中。另外,将这些 URL 放入爬取的 URL 队列中。
4.对爬取的URL队列中的URL进行分析,分析其中的其他URL,将这些URL放入URL队列进行爬取,从而进入下一个循环。
二、从爬虫的角度划分互联网
相应地,互联网的所有页面可以分为五个部分:
1.下载了未过期的网页
2.已下载并过期的网页:抓取的网页实际上是互联网内容的镜像和备份。互联网是动态变化的,互联网上的部分内容已经发生了变化。此时,这部分爬取到的页面已经过期。
3.要下载的页面:URL队列中要爬取的那些页面
4. 已知网页:尚未被抓取,也不在待抓取的URL队列中,但通过分析抓取的页面或与待抓取的URL对应的页面得到的URL被认为是已知的网页 。
5. 还有一些网页是爬虫无法直接抓取下载的。它被称为不可知页面。
三、抓取策略
在爬虫系统中,要爬取的URL队列是一个非常重要的部分。URL队列中要爬取的URL的顺序也是一个很重要的问题,因为它涉及到先爬哪个页面,后爬哪个页面。确定这些 URL 顺序的方法称为抓取策略。下面重点介绍几种常见的爬取策略:
1.深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,逐个跟踪每一个链接,处理完这一行后转移到下一个起始页,继续跟踪链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.宽度优先遍历策略
广度优先遍历策略的基本思想是将新下载的网页中找到的链接直接插入到待爬取的URL队列的末尾。即网络爬虫会先抓取起始网页中链接的所有网页,然后选择其中一个链接的网页,继续抓取该网页中链接的所有网页。以上图为例:
遍历路径:ABCDEF GHI
3.反向链接计数策略
反向链接数是指从其他网页链接到某个网页的数量。反向链接的数量表示网页内容被他人推荐的程度。因此,很多时候搜索引擎的爬取系统都会使用这个指标来评估网页的重要性,从而决定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量不能完全坐等别人的重视。因此,搜索引擎通常会考虑一些可靠的反向链接。
4.部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,连同要爬取的URL队列中的URL,形成一个网页集合,计算每个页面的PageRank值,经过计算完成后,将要抓取的URL队列中的URL按照PageRank值的大小进行排列,依次抓取页面。
如果每个页面都被抓取,则重新计算 PageRank 值。一个折衷的方案是:每爬取K个页面后,重新计算PageRank值。但是,这种情况下仍然存在一个问题:对于从下载页面中分析出来的链接,也就是我们前面提到的未知网页部分,暂时没有PageRank值。为了解决这个问题,这些页面会被赋予一个临时的PageRank值:将所有传入该页面链的PageRank值聚合起来,从而形成未知页面的PageRank值参与排名。以下示例说明:
5.OPIC 策略
该算法实际上对页面的重要性进行评分。在算法开始之前,给所有页面相同的初始现金(cash)。下载某个页面P后,将P的现金分配给所有从P分析的链接,并清除P的现金。待抓取的 URL 队列中的所有页面均按照现金的数量进行排序。
6.大站优先策略
URL队列中所有要爬取的网页,按照所属的网站进行分类。网站需要下载的页面较多,优先下载。这种策略因此被称为大站优先策略。
参考书目:
1. 《这是搜索引擎-核心技术详解》张俊林电子工业出版社
2. 《搜索引擎技术基础》刘义群等清华大学出版社 查看全部
在线抓取网页(一个通用的网络爬虫的基本结构及工作流程(组图))
网络爬虫是搜索引擎爬虫系统的重要组成部分。爬虫的主要目的是将互联网上的网页下载到本地,形成网络内容的镜像备份。本篇博客主要是对爬虫和爬虫系统的简要介绍。
一、网络爬虫的基本结构和工作流程
一个通用的网络爬虫的框架如图所示:
网络爬虫的基本工作流程如下:
1.首先选择一些精心挑选的种子网址;
2.将这些URL放入URL队列进行抓取;
3. 从待爬取的URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,并保存到下载的网页库中。另外,将这些 URL 放入爬取的 URL 队列中。
4.对爬取的URL队列中的URL进行分析,分析其中的其他URL,将这些URL放入URL队列进行爬取,从而进入下一个循环。
二、从爬虫的角度划分互联网
相应地,互联网的所有页面可以分为五个部分:
1.下载了未过期的网页
2.已下载并过期的网页:抓取的网页实际上是互联网内容的镜像和备份。互联网是动态变化的,互联网上的部分内容已经发生了变化。此时,这部分爬取到的页面已经过期。
3.要下载的页面:URL队列中要爬取的那些页面
4. 已知网页:尚未被抓取,也不在待抓取的URL队列中,但通过分析抓取的页面或与待抓取的URL对应的页面得到的URL被认为是已知的网页 。
5. 还有一些网页是爬虫无法直接抓取下载的。它被称为不可知页面。
三、抓取策略
在爬虫系统中,要爬取的URL队列是一个非常重要的部分。URL队列中要爬取的URL的顺序也是一个很重要的问题,因为它涉及到先爬哪个页面,后爬哪个页面。确定这些 URL 顺序的方法称为抓取策略。下面重点介绍几种常见的爬取策略:
1.深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,逐个跟踪每一个链接,处理完这一行后转移到下一个起始页,继续跟踪链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.宽度优先遍历策略
广度优先遍历策略的基本思想是将新下载的网页中找到的链接直接插入到待爬取的URL队列的末尾。即网络爬虫会先抓取起始网页中链接的所有网页,然后选择其中一个链接的网页,继续抓取该网页中链接的所有网页。以上图为例:
遍历路径:ABCDEF GHI
3.反向链接计数策略
反向链接数是指从其他网页链接到某个网页的数量。反向链接的数量表示网页内容被他人推荐的程度。因此,很多时候搜索引擎的爬取系统都会使用这个指标来评估网页的重要性,从而决定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量不能完全坐等别人的重视。因此,搜索引擎通常会考虑一些可靠的反向链接。
4.部分PageRank策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,连同要爬取的URL队列中的URL,形成一个网页集合,计算每个页面的PageRank值,经过计算完成后,将要抓取的URL队列中的URL按照PageRank值的大小进行排列,依次抓取页面。
如果每个页面都被抓取,则重新计算 PageRank 值。一个折衷的方案是:每爬取K个页面后,重新计算PageRank值。但是,这种情况下仍然存在一个问题:对于从下载页面中分析出来的链接,也就是我们前面提到的未知网页部分,暂时没有PageRank值。为了解决这个问题,这些页面会被赋予一个临时的PageRank值:将所有传入该页面链的PageRank值聚合起来,从而形成未知页面的PageRank值参与排名。以下示例说明:
5.OPIC 策略
该算法实际上对页面的重要性进行评分。在算法开始之前,给所有页面相同的初始现金(cash)。下载某个页面P后,将P的现金分配给所有从P分析的链接,并清除P的现金。待抓取的 URL 队列中的所有页面均按照现金的数量进行排序。
6.大站优先策略
URL队列中所有要爬取的网页,按照所属的网站进行分类。网站需要下载的页面较多,优先下载。这种策略因此被称为大站优先策略。
参考书目:
1. 《这是搜索引擎-核心技术详解》张俊林电子工业出版社
2. 《搜索引擎技术基础》刘义群等清华大学出版社
在线抓取网页(网页效果动作使用这一动作针对网页的快捷指令,摘抄)
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2021-10-08 17:03
摘录是每个人都有的要求。唯一的区别在于工具是否相同以及是否用心。
在第16期的快速说明教程中,Hum引入了网页摘录的快速说明,可以将选中的内容以样式摘录1添加到印象笔记中。最后文章,还有一个话题。没想到这个“避免重复标题”的小要求难倒了很多教程读者。
快捷指令教程的练习题
快捷命令本身缺少相关功能模块,Hum在研究过程中不小心遇到了账号错误(可能是印象笔记团队分裂的原因)。这次耽搁了半年。最近,当 Hum 与我分享本书摘录工作流程时,我重新审视了旧事物。我也发现自己需要一个更完整的摘录快捷方式,于是想出了这个“作业”文章。
网页摘录效果动作使用
此操作专为网页摘录而设计。有必要从 Safari 浏览器的内容中提取标题和链接。如果需要提取没有链接的书籍、电影台词等文本,可以参考我之前写的《草稿和印象笔记》。美丽的摘录。提取网页的步骤是:
选中页面上的文字,然后在整个网页的分享菜单中运行这个快捷命令动作(需要接收整个Safari页面,否则无法获取标题和链接)。动作会自动运行,会根据情况做出不同形式的摘录:如果当前文章之前没看过,直接在原笔记底部添加新的摘录即可。格式为“带超链接的标题+摘录+日期”。如果 文章 之前被阅读过,新的摘录将插入到前一个摘录的下方。格式为“摘录+日期”,以避免标题重复。
使用快捷方式摘录印象笔记 查看全部
在线抓取网页(网页效果动作使用这一动作针对网页的快捷指令,摘抄)
摘录是每个人都有的要求。唯一的区别在于工具是否相同以及是否用心。
在第16期的快速说明教程中,Hum引入了网页摘录的快速说明,可以将选中的内容以样式摘录1添加到印象笔记中。最后文章,还有一个话题。没想到这个“避免重复标题”的小要求难倒了很多教程读者。
快捷指令教程的练习题
快捷命令本身缺少相关功能模块,Hum在研究过程中不小心遇到了账号错误(可能是印象笔记团队分裂的原因)。这次耽搁了半年。最近,当 Hum 与我分享本书摘录工作流程时,我重新审视了旧事物。我也发现自己需要一个更完整的摘录快捷方式,于是想出了这个“作业”文章。
网页摘录效果动作使用
此操作专为网页摘录而设计。有必要从 Safari 浏览器的内容中提取标题和链接。如果需要提取没有链接的书籍、电影台词等文本,可以参考我之前写的《草稿和印象笔记》。美丽的摘录。提取网页的步骤是:
选中页面上的文字,然后在整个网页的分享菜单中运行这个快捷命令动作(需要接收整个Safari页面,否则无法获取标题和链接)。动作会自动运行,会根据情况做出不同形式的摘录:如果当前文章之前没看过,直接在原笔记底部添加新的摘录即可。格式为“带超链接的标题+摘录+日期”。如果 文章 之前被阅读过,新的摘录将插入到前一个摘录的下方。格式为“摘录+日期”,以避免标题重复。
使用快捷方式摘录印象笔记
在线抓取网页(中华英才网数据自动聚合系统正是由此而生|案例分析案例 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-10-06 15:25
)
1.简介
项目背景
互联网时代,信息海阔天空。甚至我们获取信息的方式也发生了变化:从传统的翻书到查字典,再到通过搜索引擎搜索。我们已经从信息匮乏的时代走到了信息丰富的今天。
今天,困扰我们的问题不是信息太少,而是太多,太多让你无法分辨或选择。因此,提供一种能够自动抓取互联网上的数据,并对其进行自动排序和分析的工具是非常重要的。
我们通过传统搜索引擎获取的信息通常以网页的形式展示。这样的信息人工阅读自然友好,但计算机很难处理和重复使用。而且检索到的信息量太大,我们很难从海量的检索结果中提取出我们最需要的信息。
本方案所涉及的数据聚合系统由此诞生。系统按照一定的规则抓取指定的网站中的信息,对抓取的结果进行分析整理,保存在结构化的数据库中,为数据的复用做准备。
中华英才网是知名的大型招聘类网站。为了全面细致地了解招聘市场的整体能力,帮助中华英才网全面了解其他竞争对手的情况,为市场人员提供潜在客户信息,我们提供此解决方案。
使命和宗旨
捷软与中华英才网合作开发数据自动聚合系统。通过该系统,从互联网上获取公开的信息资源,对信息进行分析、加工和再加工,为中华英才资源市场部提供准确的市场信息。
2.方案设计原则
我们在设计系统方案时充分考虑了以下两个原则,并将始终贯穿于设计和开发过程:
系统精度
系统需要从互联网庞大的信息海洋中获取信息。如何保证它抓取的信息的准确性和有效性,是评估整个系统价值的关键因素。因此,除了对抓取到的信息进行整理和分析,当目标网站的内容和格式发生变化时,智能感知、及时通知和调整也是保证系统准确性的重要手段。.
系统灵活性
该系统虽然是为少数用户提供服务并监控固定站点的内部系统,但仍需具备一定的灵活性和较强的可扩展性。
因为目标站点的结构、层次和格式在不断变化;并且系统需要抓取的目标站点也在不断调整;因此,系统必须能够适应这种变化。当爬取目标发生变化时,系统可以通过简单的设置或调整,继续完成数据聚合任务。
3.解决方案:
1.功能结构图
2.定义格式并准备脚本
首先,我们需要根据需要爬取的目标网站的特点,编写一个爬取脚本(格式)。包括:
目标网站的URL路径;
使用什么方法获取数据?可以使用模拟查询功能的方法(手动检测查询页面提交的参数并模拟提交);也可以从头到尾遍历序列号(需要找到当前最大的序列号值);
根据每个网站的特点编译(标准、脚本);
3.获取数据
系统提供的rake程序会根据预定义的XML格式执行数据采集任务。为了防止目标网站的检测程序发现它,我们建议直接保存捕获的页面,然后对其进行处理。而不是在获取信息后立即处理信息,对于提高抓取和保留第一手信息的效率非常有价值。
通过定义的脚本模拟登录;
对于下拉列表中的查询项,循环遍历列表中的每个值。并对获取查询结果的页面进行模拟翻页操作,获取所有查询结果;
如果作业数据库或业务目录数据库使用自增整数作为其唯一ID,那么我们可以找到一种方法来获取最大值,然后通过遍历的方式将其全部抓取;
定时执行爬取操作,增量保存抓取到的数据;
4.简单分析
采集接收到的数据在外网的服务器上简单的分析处理。内容主要包括:
结构化数据:对获取的数据进行结构化,以方便以后的数据传输,也方便下一步的复查和故障排除任务。
消除重复;使用模拟查询方法遍历时,系统捕获的数据必须是重复的。由于重复的数据会造成重复的分析和处理过程,不仅占用系统资源,使系统的处理效率低下,而且给系统带来了大量的垃圾数据。为了避免大量重复和冗余的数据,我们要做的第一个处理工作就是对重复项进行整理。
消除错误;由于目标站点的内容、结构和格式的调整,系统将无法捕获或捕获大量错误信息。在排除这些误报信息的同时,我们通过数据错误率的判断,可以获得目标站点是否发生变化的信息,并及时向系统发出预警通知。
5.数据发回内部
系统通过Web Service将处理后的数据发送回企业。唯一需要考虑的是如何实现增量更新,否则每天有大量数据更新到本地数据库,会造成网络拥塞。
6.数据分析
这里的数据分析与上述在远程服务器上进行的分析操作不同。后者是为了简单有效的数据过滤,防止数据冗余和造成处理速度缓慢或网络拥塞。前者为日后人工确认提供便利,有效帮助市场人员进行快速人工分拣。详情如下:
l 按地区区分;
l 按准确程度划分;帮助用户优先考虑哪些信息更有效;
l 按发帖数划分;
l 记录各公司发布的职位变动过程;
7.手动确认
这部分主要关注两个方面:
1、提供友好的人机界面,允许人工确认这些信息;
2、对比英才网的职位数据库,提取差异进行人工确认:
通过与市场人员的沟通交流,了解他们关心的信息,按照他们期望的方式提供数据,完成人工确认。
8.统计汇总
汇总统计功能也是数据汇总系统的重要组成部分,将提供以下几类统计汇总功能:
以网站为单位,统计每个网站日新增的公司、职位等信息;
跟踪大型企业,统计其在每个网站上发布的信息帖记录;
以时间为单位,按日、周、月对各种信息进行统计;
按地区、公司、岗位进行统计;
其他;
仿真统计汇总界面
查看全部
在线抓取网页(中华英才网数据自动聚合系统正是由此而生|案例分析案例
)
1.简介
项目背景
互联网时代,信息海阔天空。甚至我们获取信息的方式也发生了变化:从传统的翻书到查字典,再到通过搜索引擎搜索。我们已经从信息匮乏的时代走到了信息丰富的今天。
今天,困扰我们的问题不是信息太少,而是太多,太多让你无法分辨或选择。因此,提供一种能够自动抓取互联网上的数据,并对其进行自动排序和分析的工具是非常重要的。
我们通过传统搜索引擎获取的信息通常以网页的形式展示。这样的信息人工阅读自然友好,但计算机很难处理和重复使用。而且检索到的信息量太大,我们很难从海量的检索结果中提取出我们最需要的信息。
本方案所涉及的数据聚合系统由此诞生。系统按照一定的规则抓取指定的网站中的信息,对抓取的结果进行分析整理,保存在结构化的数据库中,为数据的复用做准备。
中华英才网是知名的大型招聘类网站。为了全面细致地了解招聘市场的整体能力,帮助中华英才网全面了解其他竞争对手的情况,为市场人员提供潜在客户信息,我们提供此解决方案。
使命和宗旨
捷软与中华英才网合作开发数据自动聚合系统。通过该系统,从互联网上获取公开的信息资源,对信息进行分析、加工和再加工,为中华英才资源市场部提供准确的市场信息。
2.方案设计原则
我们在设计系统方案时充分考虑了以下两个原则,并将始终贯穿于设计和开发过程:
系统精度
系统需要从互联网庞大的信息海洋中获取信息。如何保证它抓取的信息的准确性和有效性,是评估整个系统价值的关键因素。因此,除了对抓取到的信息进行整理和分析,当目标网站的内容和格式发生变化时,智能感知、及时通知和调整也是保证系统准确性的重要手段。.
系统灵活性
该系统虽然是为少数用户提供服务并监控固定站点的内部系统,但仍需具备一定的灵活性和较强的可扩展性。
因为目标站点的结构、层次和格式在不断变化;并且系统需要抓取的目标站点也在不断调整;因此,系统必须能够适应这种变化。当爬取目标发生变化时,系统可以通过简单的设置或调整,继续完成数据聚合任务。
3.解决方案:
1.功能结构图
2.定义格式并准备脚本
首先,我们需要根据需要爬取的目标网站的特点,编写一个爬取脚本(格式)。包括:
目标网站的URL路径;
使用什么方法获取数据?可以使用模拟查询功能的方法(手动检测查询页面提交的参数并模拟提交);也可以从头到尾遍历序列号(需要找到当前最大的序列号值);
根据每个网站的特点编译(标准、脚本);
3.获取数据
系统提供的rake程序会根据预定义的XML格式执行数据采集任务。为了防止目标网站的检测程序发现它,我们建议直接保存捕获的页面,然后对其进行处理。而不是在获取信息后立即处理信息,对于提高抓取和保留第一手信息的效率非常有价值。
通过定义的脚本模拟登录;
对于下拉列表中的查询项,循环遍历列表中的每个值。并对获取查询结果的页面进行模拟翻页操作,获取所有查询结果;
如果作业数据库或业务目录数据库使用自增整数作为其唯一ID,那么我们可以找到一种方法来获取最大值,然后通过遍历的方式将其全部抓取;
定时执行爬取操作,增量保存抓取到的数据;
4.简单分析
采集接收到的数据在外网的服务器上简单的分析处理。内容主要包括:
结构化数据:对获取的数据进行结构化,以方便以后的数据传输,也方便下一步的复查和故障排除任务。
消除重复;使用模拟查询方法遍历时,系统捕获的数据必须是重复的。由于重复的数据会造成重复的分析和处理过程,不仅占用系统资源,使系统的处理效率低下,而且给系统带来了大量的垃圾数据。为了避免大量重复和冗余的数据,我们要做的第一个处理工作就是对重复项进行整理。
消除错误;由于目标站点的内容、结构和格式的调整,系统将无法捕获或捕获大量错误信息。在排除这些误报信息的同时,我们通过数据错误率的判断,可以获得目标站点是否发生变化的信息,并及时向系统发出预警通知。
5.数据发回内部
系统通过Web Service将处理后的数据发送回企业。唯一需要考虑的是如何实现增量更新,否则每天有大量数据更新到本地数据库,会造成网络拥塞。
6.数据分析
这里的数据分析与上述在远程服务器上进行的分析操作不同。后者是为了简单有效的数据过滤,防止数据冗余和造成处理速度缓慢或网络拥塞。前者为日后人工确认提供便利,有效帮助市场人员进行快速人工分拣。详情如下:
l 按地区区分;
l 按准确程度划分;帮助用户优先考虑哪些信息更有效;
l 按发帖数划分;
l 记录各公司发布的职位变动过程;
7.手动确认
这部分主要关注两个方面:
1、提供友好的人机界面,允许人工确认这些信息;
2、对比英才网的职位数据库,提取差异进行人工确认:
通过与市场人员的沟通交流,了解他们关心的信息,按照他们期望的方式提供数据,完成人工确认。
8.统计汇总
汇总统计功能也是数据汇总系统的重要组成部分,将提供以下几类统计汇总功能:
以网站为单位,统计每个网站日新增的公司、职位等信息;
跟踪大型企业,统计其在每个网站上发布的信息帖记录;
以时间为单位,按日、周、月对各种信息进行统计;
按地区、公司、岗位进行统计;
其他;
仿真统计汇总界面
在线抓取网页(python3爬虫怎么抓取微信公众号风险2秒赔付20秒)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-10-06 01:02
在线抓取网页,flash投屏,ppt演示,是一个不错的入门项目,我最近正在研究。---关注公众号:python爱好者社区。更多python爬虫、数据分析、机器学习等技术文章。
微信搜索:jiezhihui123微信公众号里我看到推送了一个python爬虫程序运行在python3.6环境下/,我也很感兴趣python3爬虫怎么抓取微信公众号,就和爬虫工程师一起来探讨一下,
没有网站就买个二手的99元epoc风险2秒赔付20秒到账拿去当微信小额贷款平台好了
谢邀。这种方式应该是最直接的。不可行的话我觉得可以试试另一种办法:雇佣50个做动态桌面的小号。
微信公众号里都是做演示的为主,你可以买个linux系统装个qpython,这样动态演示就足够用了。还有就是开源吧,好多大神用go开发了。
微信公众号爬虫搞网站图,类似的,不就是个java服务器, 查看全部
在线抓取网页(python3爬虫怎么抓取微信公众号风险2秒赔付20秒)
在线抓取网页,flash投屏,ppt演示,是一个不错的入门项目,我最近正在研究。---关注公众号:python爱好者社区。更多python爬虫、数据分析、机器学习等技术文章。
微信搜索:jiezhihui123微信公众号里我看到推送了一个python爬虫程序运行在python3.6环境下/,我也很感兴趣python3爬虫怎么抓取微信公众号,就和爬虫工程师一起来探讨一下,
没有网站就买个二手的99元epoc风险2秒赔付20秒到账拿去当微信小额贷款平台好了
谢邀。这种方式应该是最直接的。不可行的话我觉得可以试试另一种办法:雇佣50个做动态桌面的小号。
微信公众号里都是做演示的为主,你可以买个linux系统装个qpython,这样动态演示就足够用了。还有就是开源吧,好多大神用go开发了。
微信公众号爬虫搞网站图,类似的,不就是个java服务器,
在线抓取网页(电商网站从事采购业务的用户画像,如何使用在线抓取网页数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2021-10-05 14:06
在线抓取网页数据,比如log4j、mysql、mongodb、php等,以及在线抓取新闻、中文搜索、百度学术搜索、搜狗问答等网站的用户数据、日志数据等。上面是一个电商网站从事采购业务的用户画像,每个用户都有三个属性:性别,年龄,职业,每一条数据都是根据三个属性进行匹配,选择相应的用户数据。如果要抓取的数据为销售商品,则要从行为指标中找出关键行为。这样的分析可能关注商品用户的推荐,会员等级等。
目前市面上是有人从各个渠道爬取数据,比如数据运营、运营工具大厅、拉勾、天眼查、qq数据、机构号、知乎、百度知道等等。采用的通常是把爬取到的信息进行汇总分析。我们可以采用的工具是julia或者scikitlearn。julia有一个userjupter,不用写爬虫脚本,有一个轻量级的非python开发库islandsolution。
这个非常轻量级,只需要两行代码,使用方法如下:juliainstallislandsolution>orgssl:julia0.19.2notebooks(org)一个例子是抓取猫眼app上购买电影的用户画像,直接用julia来实现。(当然其他渠道爬取到的数据也可以用julia)下载链接:-install.py为什么不直接去链接下载呢?因为官网多了个python的爬虫环境,需要用pip。
但是如果用python爬取数据,很可能会超出需求,这个时候直接运行脚本会遇到代码报错,报错的规则是:toopen"global-python-qmakerc:3.7",packagesrequired:d:\python_scripts\python2.7\gits\recursive\jupython\python._reqmakerc.gitvolume1:path=["c:\windows\system32\exe"],c:\windows\system32\system32\pathfalse"d:\python_scripts\python._reqmakerc.git",extras"so",extras"fuck",extras"cao",extras"gy",extras"hello",password="script"所以要选择跳过jupyter环境,直接用pip下载。 查看全部
在线抓取网页(电商网站从事采购业务的用户画像,如何使用在线抓取网页数据)
在线抓取网页数据,比如log4j、mysql、mongodb、php等,以及在线抓取新闻、中文搜索、百度学术搜索、搜狗问答等网站的用户数据、日志数据等。上面是一个电商网站从事采购业务的用户画像,每个用户都有三个属性:性别,年龄,职业,每一条数据都是根据三个属性进行匹配,选择相应的用户数据。如果要抓取的数据为销售商品,则要从行为指标中找出关键行为。这样的分析可能关注商品用户的推荐,会员等级等。
目前市面上是有人从各个渠道爬取数据,比如数据运营、运营工具大厅、拉勾、天眼查、qq数据、机构号、知乎、百度知道等等。采用的通常是把爬取到的信息进行汇总分析。我们可以采用的工具是julia或者scikitlearn。julia有一个userjupter,不用写爬虫脚本,有一个轻量级的非python开发库islandsolution。
这个非常轻量级,只需要两行代码,使用方法如下:juliainstallislandsolution>orgssl:julia0.19.2notebooks(org)一个例子是抓取猫眼app上购买电影的用户画像,直接用julia来实现。(当然其他渠道爬取到的数据也可以用julia)下载链接:-install.py为什么不直接去链接下载呢?因为官网多了个python的爬虫环境,需要用pip。
但是如果用python爬取数据,很可能会超出需求,这个时候直接运行脚本会遇到代码报错,报错的规则是:toopen"global-python-qmakerc:3.7",packagesrequired:d:\python_scripts\python2.7\gits\recursive\jupython\python._reqmakerc.gitvolume1:path=["c:\windows\system32\exe"],c:\windows\system32\system32\pathfalse"d:\python_scripts\python._reqmakerc.git",extras"so",extras"fuck",extras"cao",extras"gy",extras"hello",password="script"所以要选择跳过jupyter环境,直接用pip下载。

