
免规则采集器列表算法
采集器logkit可以采集各种日志(包括nginx等基础组件日志)至各种数据平台进行数据分析
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-08-09 21:18
配置日志采集器
logkit可以采集各种日志(包括nginx等基础组件日志)到各种数据平台进行数据分析。
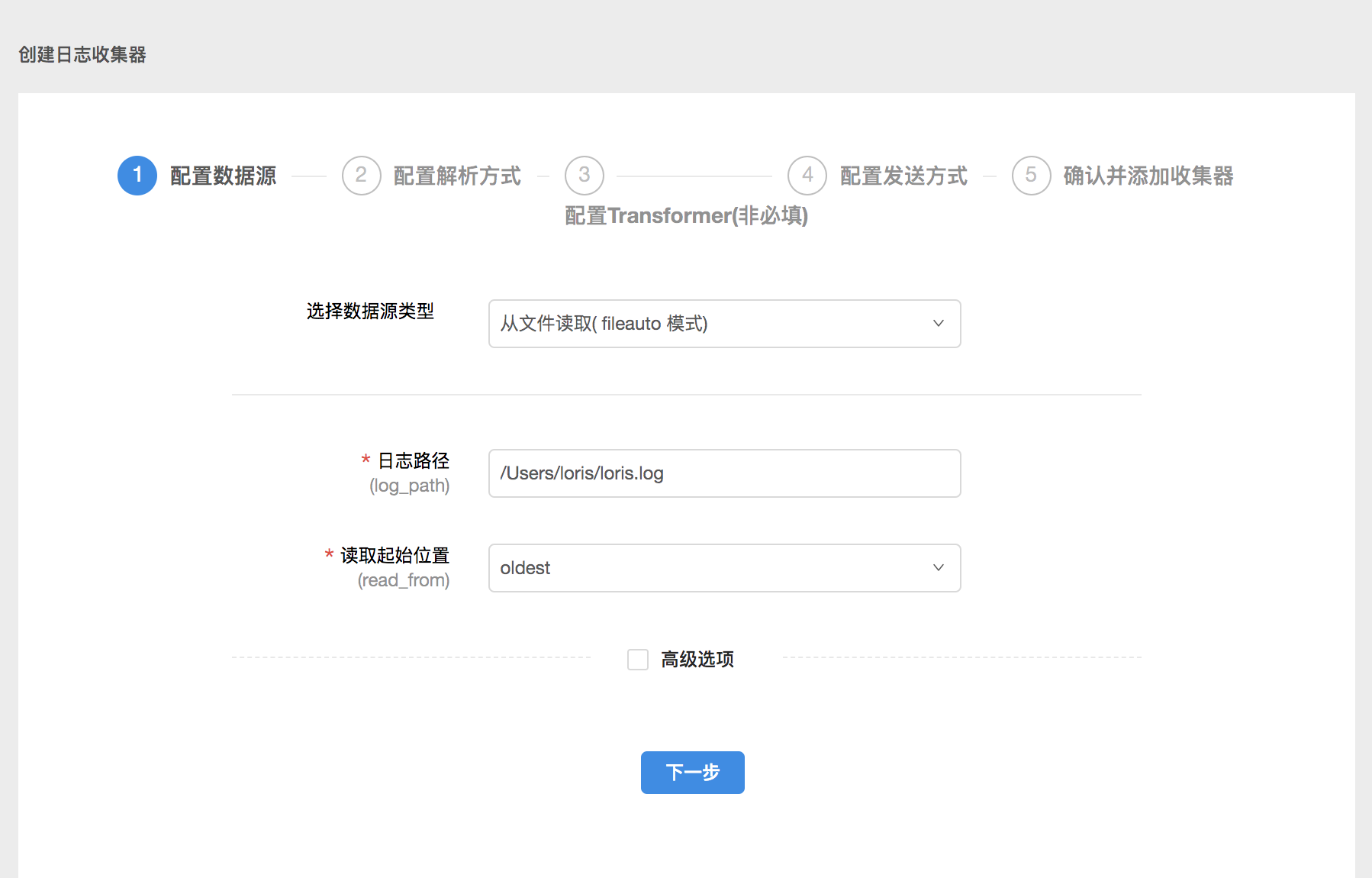
1.配置数据源
在配置数据源页面,需要填写数据源、数据读取方式等信息。在实际配置过程中,您可以根据需要编辑高级选项。一般来说,高级选项可以默认设置。
这个数据源配置的意思是从本地路径为/Users/loris/的地方读取loris.log文件中的日志,从最旧的数据开始。
2.配置分析方法
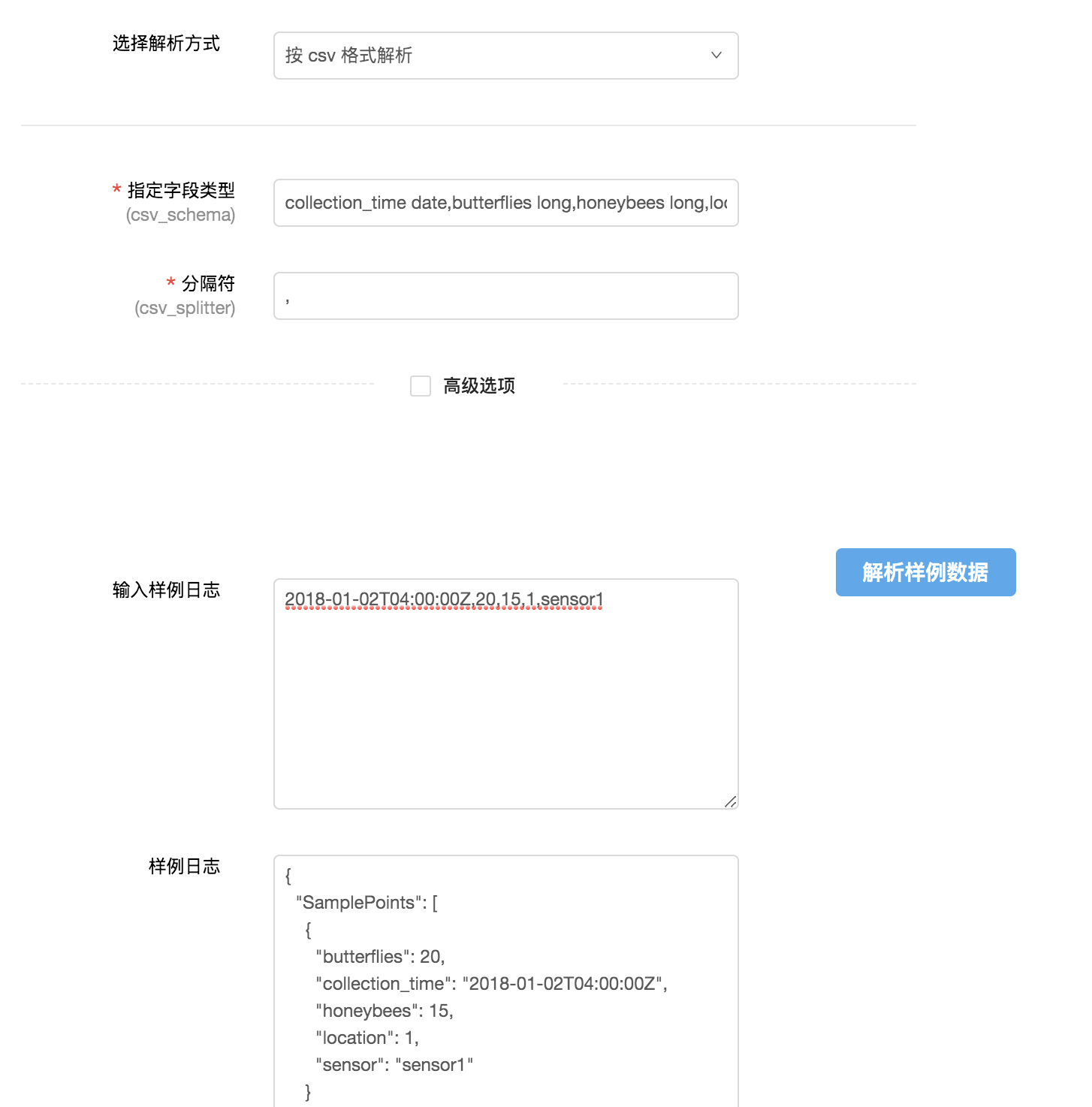
配置好数据源后,需要根据数据源文件的格式配置合适的解析方式。
以csv格式的日志为例:
通过输入字段类型和分隔符,将日志内容转化为结构化数据,方便后续数据平台上的数据分析。
您需要在此处输入详细的字段名称并键入。
logkit 提供了解析样本数据的功能,即输入一行样本日志,可以看到解析结果,验证你的配置是否正确。
3.配置转换器
logkit 提供了transformer 功能来满足一些更精细的现场分析需求。
以更换变压器为例:
通过配置替换转换器,您可以将指定字段的某个值替换为另一个值。
目前支持的 Transformer 有:
如果没有字段转换要求,直接跳过这一步。
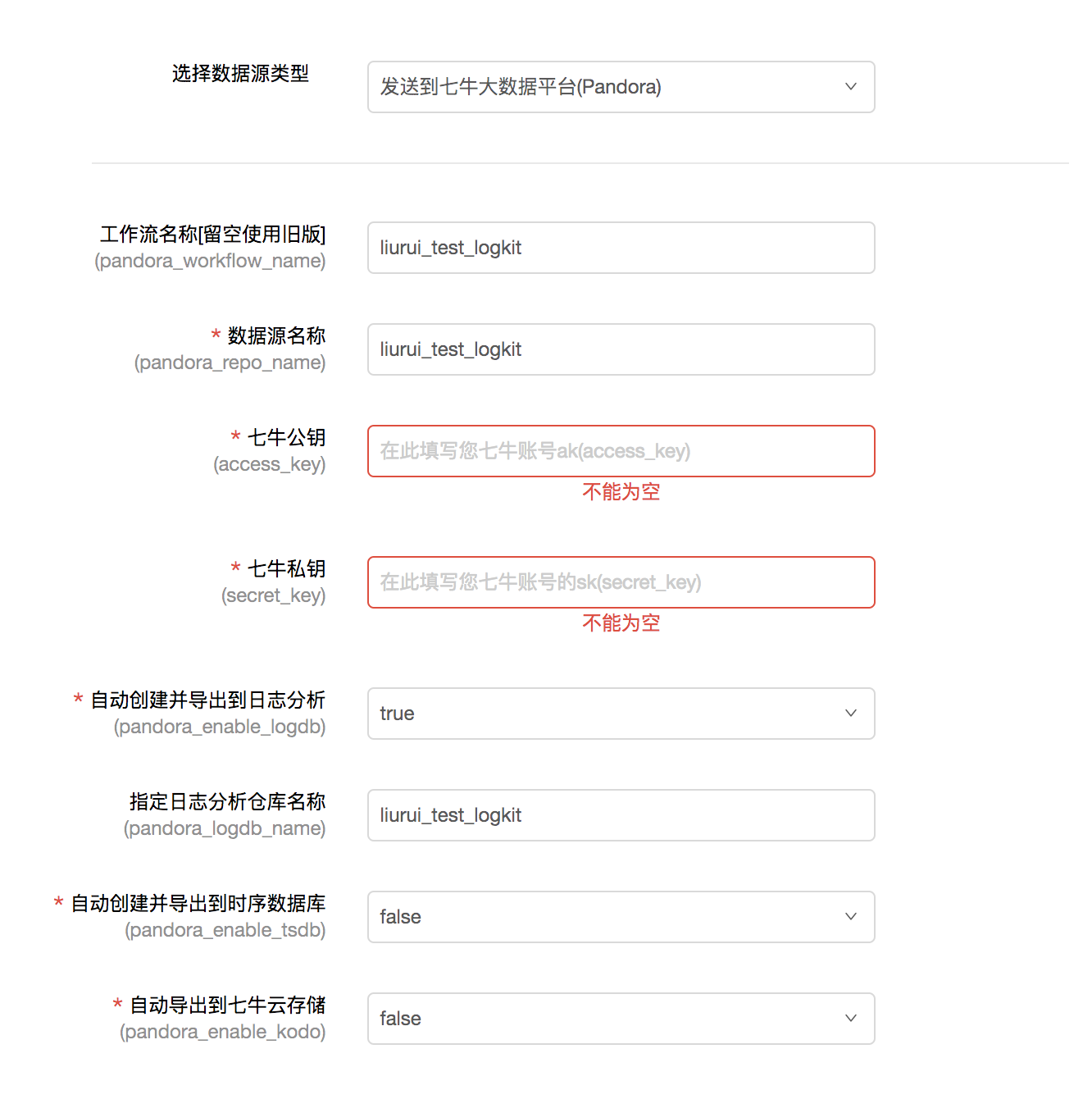
4.配置发送方式
您需要选择发送的数据平台并填写相关信息,完成发送绑定。
以发送到七牛大数据平台为例。您需要填写数据源名称、工作流名称以及七牛账户的公钥和私钥才能接收数据。您可以根据需要选择是否导出数据。用于日志分析、时间序列数据库和云存储进行数据存储和分析。
5.确认转轮配置
最后设置采集数据和发送数据的时间间隔,整个runner就配置好了!数据已录入七牛大数据平台,可到七牛大数据平台进行数据计算导出。
在配置过程中,您每一步的操作信息都会自动保存。提交前直接返回上一步修改配置信息即可,无需重新输入。
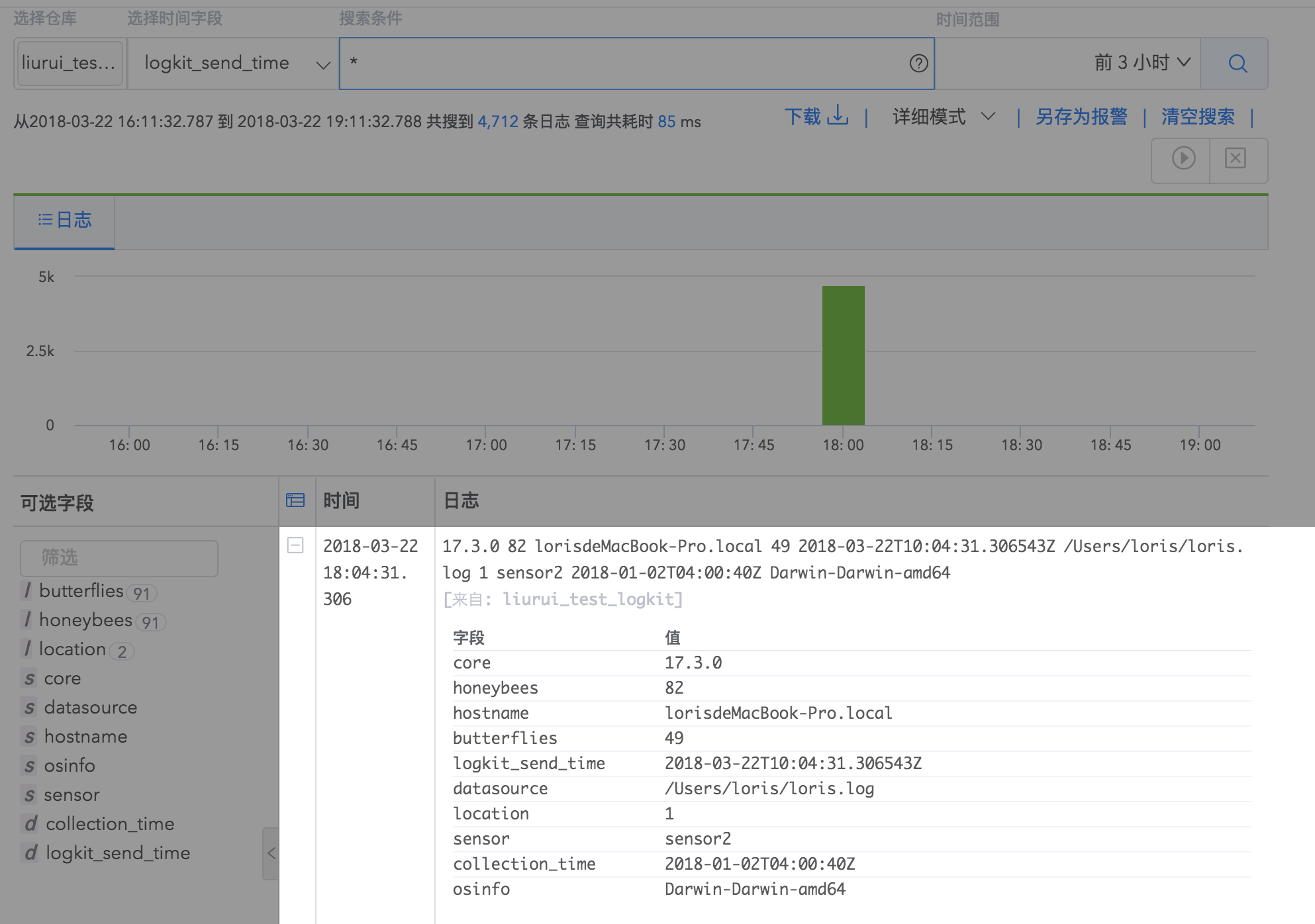
根据以上数据采集配置,可以根据配置中填写的日志仓库名称查询自己在Logdb中发送的日志详情。
6.采集log 日志分析使用场景 查看全部
采集器logkit可以采集各种日志(包括nginx等基础组件日志)至各种数据平台进行数据分析
配置日志采集器
logkit可以采集各种日志(包括nginx等基础组件日志)到各种数据平台进行数据分析。
1.配置数据源
在配置数据源页面,需要填写数据源、数据读取方式等信息。在实际配置过程中,您可以根据需要编辑高级选项。一般来说,高级选项可以默认设置。
这个数据源配置的意思是从本地路径为/Users/loris/的地方读取loris.log文件中的日志,从最旧的数据开始。
2.配置分析方法
配置好数据源后,需要根据数据源文件的格式配置合适的解析方式。
以csv格式的日志为例:
通过输入字段类型和分隔符,将日志内容转化为结构化数据,方便后续数据平台上的数据分析。
您需要在此处输入详细的字段名称并键入。
logkit 提供了解析样本数据的功能,即输入一行样本日志,可以看到解析结果,验证你的配置是否正确。
3.配置转换器
logkit 提供了transformer 功能来满足一些更精细的现场分析需求。
以更换变压器为例:
通过配置替换转换器,您可以将指定字段的某个值替换为另一个值。
目前支持的 Transformer 有:
如果没有字段转换要求,直接跳过这一步。
4.配置发送方式
您需要选择发送的数据平台并填写相关信息,完成发送绑定。
以发送到七牛大数据平台为例。您需要填写数据源名称、工作流名称以及七牛账户的公钥和私钥才能接收数据。您可以根据需要选择是否导出数据。用于日志分析、时间序列数据库和云存储进行数据存储和分析。
5.确认转轮配置
最后设置采集数据和发送数据的时间间隔,整个runner就配置好了!数据已录入七牛大数据平台,可到七牛大数据平台进行数据计算导出。
在配置过程中,您每一步的操作信息都会自动保存。提交前直接返回上一步修改配置信息即可,无需重新输入。

根据以上数据采集配置,可以根据配置中填写的日志仓库名称查询自己在Logdb中发送的日志详情。
6.采集log 日志分析使用场景
3个开源产品的组合:ELK
采集交流 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-08-07 02:08
一个背景
ELK 是 3 个开源产品的组合:
ELK = Elasticsearch、Logstash、Kibana 是一套实时数据采集、存储、索引、检索、统计分析和可视化解决方案。最新版本已更名为 Elastic Stack,并添加了 Beats 项目。
中文官网地址:
当你不得不面对成百上千的服务器、虚拟机和容器产生的日志时,请告别SSH。 Filebeat 将为您提供一种轻量级的日志和文件转发和汇总方法,让简单的事情不再复杂。
filebeat采集的数据可以发送到Elasticsearch或者Logstash。在 Kibana 中进行可视化。
也是小型互联网公司常用的开源解决方案。 RBI 将根据自己的业务需求制造轮子。本文记录filebeat的安装和采集规则:
二次安装
对于Linux系统,推荐官网:
curl -L -O https://artifacts.elastic.co/d ... ar.gz
tar xzvf filebeat-7.5.1-linux-x86_64.tar.gz
针对不同的下载个人习惯,也可以切换到wget,比较轻巧。就是下载解压。
我们使用的是以前的6.7 版本。
为了统一运维,每个版本去掉了版本号。
mv filebeat-6.7.1-linux-x86_64 filebeat
cdfilebeat
三种配置
在详细配置参数之前,先来大致了解一下素养和一般原理,以便更好的理解配置参数;
Filebeat 涉及两个组件:finder prospector 和采集器harvester,读取尾文件并将事件数据发送到指定的输出。
当您启动 Filebeat 时,它会启动一个或多个搜索器来查看您为日志文件指定的本地路径。对于探矿者所在的每个日志文件,探矿者启动收割机。每个收割机读取新内容的单个日志文件,并将新日志数据发送到 libbeat,后者聚合事件并将聚合数据发送到您为 Filebeat 配置的输出。
配置文件:$FILEBEAT_HOME/filebeat.yml。 Filebeat可以一次性读取某个文件夹中所有后缀为log的文件,也可以读取指定后缀log的文件。
paths:指定需要监控的日志,目前按照Go语言的glob函数处理。配置目录没有递归处理,比如配置为:
/var/log/* /*.log
它只会搜索/var/log目录下所有子目录中以“.log”结尾的文件,而不会搜索/var/log目录下以“.log”结尾的文件。
encoding:指定监控文件的编码类型。普通和utf-8都可以处理中文日志。
input_type:指定文件日志(默认)或标准输入的输入类型。
exclude_lines:从输入中排除那些符合正则表达式列表的行。
include_lines:在输入中收录那些匹配正则表达式列表的行(默认收录所有行),在include_lines执行后会执行exclude_lines。
exclude_files:忽略符合正则表达式列表的文件(默认情况下,为每个符合路径定义的文件创建一个收割机)。
fields:为每个日志输出添加附加信息,例如“level:debug”,方便后续日志的分组和统计。默认情况下,会在输出信息的fields子目录下创建指定新字段的子目录,
fields_under_root:如果这个选项设置为true,新添加的字段将成为顶级目录,而不是放在fields目录中。自定义字段将覆盖 filebeat 的默认字段。
ignore_older:可以指定Filebeat忽略指定时间段外修改的日志内容,例如2h(两小时)或5m(5分钟)。
close_older:如果某个文件在一定时间内没有更新,则关闭被监控的文件句柄。默认为 1 小时。
force_close_files:Filebeat 将保留文件的句柄,直到它到达 close_older。如果在这个时间窗口内删除文件,就会出现问题,所以可以设置force_close_files为true。只要filebeat检测到文件名改变了,就会关闭。放下这个把手。
scan_frequency:Filebeat多久去探矿者指定的目录检测文件更新(比如是否有新文件),如果设置为0s,Filebeat会尽快感知更新(被占用的CPU会变得更高)。默认为 10 秒。
document_type:设置Elasticsearch输出时文档的type字段,也可以用来分类日志。
harvester_buffer_size:每个收割机监控文件时使用的缓冲区大小。
max_bytes:在日志文件中添加一行算作日志事件,max_bytes 限制为日志事件中上传的最大字节数,多余的字节将被丢弃。默认为 10MB。
multiline:适用于日志中每个日志占用多行的情况,比如各种语言的错误信息的调用栈。这个配置下面收录如下配置:
pattern:匹配多行日志开头行的模式
negate:是否需要使用模式条件转置,不翻转为真,翻转为假。
match:匹配模式后,与前后内容合并成日志
max_lines:合并的最大行数(包括与模式匹配的行),默认为500行。
timeout:超时后,即使新模式不匹配(新事件发生),匹配的日志事件也会被发送出去
tail_files:如果设置为true,Filebeat从文件末尾开始监听文件的新内容,并将文件的每一个新行作为一个事件依次发送,而不是从文件开头重新发送所有内容.
backoff:Filebeat检测到文件达到EOF后,每次检查文件是否更新需要等待多长时间,默认为1s。
max_backoff:Filebeat检测到文件达到EOF后,等待文件更新的最长时间,默认为10秒。
backoff_factor:定义达到max_backoff的速度,默认因子为2,达到max_backoff后,每次等待max_backoff后变为backoff,直到文件更新后重新设置为backoff。例如:
如果设置为1,表示禁用backoff算法,每次backoff时间都会执行backoff。
spool_size:假脱机程序的大小。当spooler中的事件数超过该阈值时,会被清空并发出(无论是否达到超时时间),默认为1MB。
idle_timeout:spooler 的超时时间。如果达到超时时间,spooler会被清空并发出(无论是否达到容量阈值),默认为1s。
registry_file:记录filebeat处理日志文件位置的文件
config_dir:如果要在这个配置文件中引入其他位置的配置文件,可以在这里写(需要写全路径),但只处理prospector部分。
publish_async:是否使用异步发送模式(实验性功能)。
其实我们用的是yaml的配置,主要是path,json相关,以及写入ES的index和参数。许多排除和退避没有配置。
#keys_under_root 可以让字段位于根节点,默认为false
json.keys_under_root: 真
#对于同名的key,覆盖原来的key值
json.overwrite_keys: 真
#在error.message字段中存储解析错误的消息记录
json.add_error_key: 真
#message_key 用于合并多行json日志,
json.message_key:消息
配置参数很多,推荐官网:
开始:
cd filebeat
nohup ./filebeat -c product.yml >/dev/null 2>&1
同一台机器上可以启动多个filebats,但是一般不建议运维使用。 (对于高负载:更多的日志,通常启动kibana后就可以立即看到,但是对于多次启动filebeat,后者可能需要2分钟才能看到,这是前一个队列的日志没有被处理过)
停止:
ps -ef|grep filebeat
杀死 -9 XXX
参考:
官网: 查看全部
3个开源产品的组合:ELK
一个背景
ELK 是 3 个开源产品的组合:
ELK = Elasticsearch、Logstash、Kibana 是一套实时数据采集、存储、索引、检索、统计分析和可视化解决方案。最新版本已更名为 Elastic Stack,并添加了 Beats 项目。
中文官网地址:
当你不得不面对成百上千的服务器、虚拟机和容器产生的日志时,请告别SSH。 Filebeat 将为您提供一种轻量级的日志和文件转发和汇总方法,让简单的事情不再复杂。
filebeat采集的数据可以发送到Elasticsearch或者Logstash。在 Kibana 中进行可视化。
也是小型互联网公司常用的开源解决方案。 RBI 将根据自己的业务需求制造轮子。本文记录filebeat的安装和采集规则:
二次安装
对于Linux系统,推荐官网:
curl -L -O https://artifacts.elastic.co/d ... ar.gz
tar xzvf filebeat-7.5.1-linux-x86_64.tar.gz
针对不同的下载个人习惯,也可以切换到wget,比较轻巧。就是下载解压。
我们使用的是以前的6.7 版本。
为了统一运维,每个版本去掉了版本号。
mv filebeat-6.7.1-linux-x86_64 filebeat
cdfilebeat
三种配置
在详细配置参数之前,先来大致了解一下素养和一般原理,以便更好的理解配置参数;
Filebeat 涉及两个组件:finder prospector 和采集器harvester,读取尾文件并将事件数据发送到指定的输出。
当您启动 Filebeat 时,它会启动一个或多个搜索器来查看您为日志文件指定的本地路径。对于探矿者所在的每个日志文件,探矿者启动收割机。每个收割机读取新内容的单个日志文件,并将新日志数据发送到 libbeat,后者聚合事件并将聚合数据发送到您为 Filebeat 配置的输出。
配置文件:$FILEBEAT_HOME/filebeat.yml。 Filebeat可以一次性读取某个文件夹中所有后缀为log的文件,也可以读取指定后缀log的文件。
paths:指定需要监控的日志,目前按照Go语言的glob函数处理。配置目录没有递归处理,比如配置为:
/var/log/* /*.log
它只会搜索/var/log目录下所有子目录中以“.log”结尾的文件,而不会搜索/var/log目录下以“.log”结尾的文件。
encoding:指定监控文件的编码类型。普通和utf-8都可以处理中文日志。
input_type:指定文件日志(默认)或标准输入的输入类型。
exclude_lines:从输入中排除那些符合正则表达式列表的行。
include_lines:在输入中收录那些匹配正则表达式列表的行(默认收录所有行),在include_lines执行后会执行exclude_lines。
exclude_files:忽略符合正则表达式列表的文件(默认情况下,为每个符合路径定义的文件创建一个收割机)。
fields:为每个日志输出添加附加信息,例如“level:debug”,方便后续日志的分组和统计。默认情况下,会在输出信息的fields子目录下创建指定新字段的子目录,
fields_under_root:如果这个选项设置为true,新添加的字段将成为顶级目录,而不是放在fields目录中。自定义字段将覆盖 filebeat 的默认字段。
ignore_older:可以指定Filebeat忽略指定时间段外修改的日志内容,例如2h(两小时)或5m(5分钟)。
close_older:如果某个文件在一定时间内没有更新,则关闭被监控的文件句柄。默认为 1 小时。
force_close_files:Filebeat 将保留文件的句柄,直到它到达 close_older。如果在这个时间窗口内删除文件,就会出现问题,所以可以设置force_close_files为true。只要filebeat检测到文件名改变了,就会关闭。放下这个把手。
scan_frequency:Filebeat多久去探矿者指定的目录检测文件更新(比如是否有新文件),如果设置为0s,Filebeat会尽快感知更新(被占用的CPU会变得更高)。默认为 10 秒。
document_type:设置Elasticsearch输出时文档的type字段,也可以用来分类日志。
harvester_buffer_size:每个收割机监控文件时使用的缓冲区大小。
max_bytes:在日志文件中添加一行算作日志事件,max_bytes 限制为日志事件中上传的最大字节数,多余的字节将被丢弃。默认为 10MB。
multiline:适用于日志中每个日志占用多行的情况,比如各种语言的错误信息的调用栈。这个配置下面收录如下配置:
pattern:匹配多行日志开头行的模式
negate:是否需要使用模式条件转置,不翻转为真,翻转为假。
match:匹配模式后,与前后内容合并成日志
max_lines:合并的最大行数(包括与模式匹配的行),默认为500行。
timeout:超时后,即使新模式不匹配(新事件发生),匹配的日志事件也会被发送出去
tail_files:如果设置为true,Filebeat从文件末尾开始监听文件的新内容,并将文件的每一个新行作为一个事件依次发送,而不是从文件开头重新发送所有内容.
backoff:Filebeat检测到文件达到EOF后,每次检查文件是否更新需要等待多长时间,默认为1s。
max_backoff:Filebeat检测到文件达到EOF后,等待文件更新的最长时间,默认为10秒。
backoff_factor:定义达到max_backoff的速度,默认因子为2,达到max_backoff后,每次等待max_backoff后变为backoff,直到文件更新后重新设置为backoff。例如:
如果设置为1,表示禁用backoff算法,每次backoff时间都会执行backoff。
spool_size:假脱机程序的大小。当spooler中的事件数超过该阈值时,会被清空并发出(无论是否达到超时时间),默认为1MB。
idle_timeout:spooler 的超时时间。如果达到超时时间,spooler会被清空并发出(无论是否达到容量阈值),默认为1s。
registry_file:记录filebeat处理日志文件位置的文件
config_dir:如果要在这个配置文件中引入其他位置的配置文件,可以在这里写(需要写全路径),但只处理prospector部分。
publish_async:是否使用异步发送模式(实验性功能)。
其实我们用的是yaml的配置,主要是path,json相关,以及写入ES的index和参数。许多排除和退避没有配置。
#keys_under_root 可以让字段位于根节点,默认为false
json.keys_under_root: 真
#对于同名的key,覆盖原来的key值
json.overwrite_keys: 真
#在error.message字段中存储解析错误的消息记录
json.add_error_key: 真
#message_key 用于合并多行json日志,
json.message_key:消息
配置参数很多,推荐官网:
开始:
cd filebeat
nohup ./filebeat -c product.yml >/dev/null 2>&1
同一台机器上可以启动多个filebats,但是一般不建议运维使用。 (对于高负载:更多的日志,通常启动kibana后就可以立即看到,但是对于多次启动filebeat,后者可能需要2分钟才能看到,这是前一个队列的日志没有被处理过)
停止:
ps -ef|grep filebeat
杀死 -9 XXX
参考:
官网:
优采云采集器激活版下载下载特色(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-08-05 18:43
优采云采集器最新激活版是非常专业的视觉智能采集器,零门槛,多引擎,轻松创作,无需编程,小白也能快速上手! 优采云采集器免安装无限版兼容所有操作系统,采集爬虫技巧,轻松采集网络信息,一键搞定,自定义屏蔽域名,屏蔽广告,有需要可以下载试试它!
优采云采集器激活版下载闪点
1、软件操作复杂,可以通过鼠标点击的方式轻松提取要抓取的内容;
2、自定义屏蔽域名,方便过滤异地广告,提高采集速度
3、支持多个采集引擎,内置高速浏览器内核、HTTP引擎和JSON引擎
4、能采集Internet99%网站,包括单页应用ajax加载等动态类型网站。
5、可以导出为Txt、Excel、MySQL、SQLServer、SQlite、Access、网站等
优采云采集器破解版下载功能
1、支持三种高速引擎:浏览器引擎、HTTP引擎、JSON引擎,内置优化的火狐浏览器,再加上第一次内存优化,让浏览器也能高速运行,甚至可以快速转换为HTTP操作,享受更高的收录率!抓取JSON数据时,也可以使用浏览器可视化的方式,通过鼠标选择需要抓取的内容。完全不需要分析JSON数据布局,让非web专业规划师轻松抓取所需数据;
3、内置高速浏览器引擎,也可以切换到HTTP引擎模式运行,采集data效率更高。还内置了JSON引擎,无需分析JSON数据结构,直观选择JSON内容。
4、支持丰富的数据导出方式,可以导出为txt文件、html文件、csv文件、excel文件,也可以导出到现有数据库,如sqlite数据库、access数据库、sqlserver数据库、mysql数据库,复杂的映射字段可以通过导游的方式轻松导出到guide网站数据库。
优采云采集器active 版最新版功能
1、不知道怎么采集爬虫,会采集网站数据。
2、可以采集到网上99%的网站,包括使用Ajax加载单页等静态例子网站。
3、内置高速浏览器引擎,也可以切换到HTTP引擎模式运行,数据采集更高效。
4、advanced 智能算法,可以一键自然目标元素XPATH,主动识别网页列表,主动识别tab中的下一页按钮
优采云采集器免费安装无限版本评测
灵活定义运行时间,自动运行,无需分析JSON数据布局,全采集元素,无需编程,智能生成,只要有手! 查看全部
优采云采集器激活版下载下载特色(组图)
优采云采集器最新激活版是非常专业的视觉智能采集器,零门槛,多引擎,轻松创作,无需编程,小白也能快速上手! 优采云采集器免安装无限版兼容所有操作系统,采集爬虫技巧,轻松采集网络信息,一键搞定,自定义屏蔽域名,屏蔽广告,有需要可以下载试试它!
优采云采集器激活版下载闪点
1、软件操作复杂,可以通过鼠标点击的方式轻松提取要抓取的内容;
2、自定义屏蔽域名,方便过滤异地广告,提高采集速度
3、支持多个采集引擎,内置高速浏览器内核、HTTP引擎和JSON引擎
4、能采集Internet99%网站,包括单页应用ajax加载等动态类型网站。
5、可以导出为Txt、Excel、MySQL、SQLServer、SQlite、Access、网站等
优采云采集器破解版下载功能
1、支持三种高速引擎:浏览器引擎、HTTP引擎、JSON引擎,内置优化的火狐浏览器,再加上第一次内存优化,让浏览器也能高速运行,甚至可以快速转换为HTTP操作,享受更高的收录率!抓取JSON数据时,也可以使用浏览器可视化的方式,通过鼠标选择需要抓取的内容。完全不需要分析JSON数据布局,让非web专业规划师轻松抓取所需数据;
3、内置高速浏览器引擎,也可以切换到HTTP引擎模式运行,采集data效率更高。还内置了JSON引擎,无需分析JSON数据结构,直观选择JSON内容。
4、支持丰富的数据导出方式,可以导出为txt文件、html文件、csv文件、excel文件,也可以导出到现有数据库,如sqlite数据库、access数据库、sqlserver数据库、mysql数据库,复杂的映射字段可以通过导游的方式轻松导出到guide网站数据库。
优采云采集器active 版最新版功能
1、不知道怎么采集爬虫,会采集网站数据。
2、可以采集到网上99%的网站,包括使用Ajax加载单页等静态例子网站。
3、内置高速浏览器引擎,也可以切换到HTTP引擎模式运行,数据采集更高效。
4、advanced 智能算法,可以一键自然目标元素XPATH,主动识别网页列表,主动识别tab中的下一页按钮
优采云采集器免费安装无限版本评测
灵活定义运行时间,自动运行,无需分析JSON数据布局,全采集元素,无需编程,智能生成,只要有手!
云里新闻采集大师(c#版)新闻版
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2021-08-04 18:25
云立新闻采集Master源码(c#版)
云立News采集老师是一款完全免费开源的news采集软件,支持所有网站内容的自动采集入库。程序由Microsoft Visual Studio 2010(C#)开发,数据库使用SQLite,软件源代码完全开放,供开发者学习讨论。官方网站:1、免费开源:云里新闻采集大师完全免费开源,供大家学习讨论,永远开源。 2、灵活配置:采集网站可灵活配置,可根据需要配置添加采集网站。 3、多数据库支持:采集文章可以支持Post to Access数据库、MSSQL数据库、MYSQL数据库、Oracle数据库等数据库。 采集网站管理云里新闻采集大师可以方便您管理需要采集的网站。图形化配置如果需要添加采集网站,只需要在页面中找到简单的开始和结束标签即可灵活配置和添加。批量删除所有采集网站都可以一键删除,方便简单。支持预览 每个采集网站都支持预览模式,点击达到目标网站。 采集新闻管理云里新闻采集大师可以方便您管理采集到文章,可以批量删除,编辑news文章。图形化管理图形化界面管理采集到文章,双击文章行打开编辑。批量删除所有采集网站都可以一键删除,方便简单。支持预览 每个采集网站都支持预览模式,点击达到目标网站。 采集网站Configuration采集target网站所有参数均可个性化配置。该列表是可配置的。通常需要采集list页面的内容块,开始和结束标签可以由采集定义。内容可配置采集文章标题、作者、出处、内容等信息,均可自定义。网页编码是可配置的。每个网站 都有不同的编码。此处提供了网页编码选项以实现可配置选项。
立即下载 查看全部
云里新闻采集大师(c#版)新闻版
云立新闻采集Master源码(c#版)
云立News采集老师是一款完全免费开源的news采集软件,支持所有网站内容的自动采集入库。程序由Microsoft Visual Studio 2010(C#)开发,数据库使用SQLite,软件源代码完全开放,供开发者学习讨论。官方网站:1、免费开源:云里新闻采集大师完全免费开源,供大家学习讨论,永远开源。 2、灵活配置:采集网站可灵活配置,可根据需要配置添加采集网站。 3、多数据库支持:采集文章可以支持Post to Access数据库、MSSQL数据库、MYSQL数据库、Oracle数据库等数据库。 采集网站管理云里新闻采集大师可以方便您管理需要采集的网站。图形化配置如果需要添加采集网站,只需要在页面中找到简单的开始和结束标签即可灵活配置和添加。批量删除所有采集网站都可以一键删除,方便简单。支持预览 每个采集网站都支持预览模式,点击达到目标网站。 采集新闻管理云里新闻采集大师可以方便您管理采集到文章,可以批量删除,编辑news文章。图形化管理图形化界面管理采集到文章,双击文章行打开编辑。批量删除所有采集网站都可以一键删除,方便简单。支持预览 每个采集网站都支持预览模式,点击达到目标网站。 采集网站Configuration采集target网站所有参数均可个性化配置。该列表是可配置的。通常需要采集list页面的内容块,开始和结束标签可以由采集定义。内容可配置采集文章标题、作者、出处、内容等信息,均可自定义。网页编码是可配置的。每个网站 都有不同的编码。此处提供了网页编码选项以实现可配置选项。
立即下载
web基础蜘蛛网页文章采集器.2.zip
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-08-01 07:31
基于网络的蜘蛛网页文章采集器v3.2.zip
基于Web的蜘蛛网页文章采集器,英文名Fast_Spider,属于蜘蛛爬虫程序,用于指定网站采集大量力量文章,会直接丢弃其中的垃圾信息,只保存阅读值和浏览值文章的本质,并自动进行HTM-TXT转换。本软件为绿色软件,解压后即可使用。基于网络的蜘蛛网页文章采集器具有以下特点:(1)本软件采用北大天网的MD5指纹重排算法,对于相似和相同的网页信息,不会存储(2)采集信息含义:[[HT]]代表网页标题,[[HA]]代表文章title,[[HC]]代表10个加权关键词,[[UR]]代表网页中的图片链接,[[TXT]]之后是正文。(3)Spider Performance:软件开启300个线程,保证采集效率。压力测试由采集100进行万979文章,以普通网民的联网电脑为参考标准,一台电脑可以遍历200万个网页,采集20万979文章,100万精华文章 5天完成采集。(4)正式版和免费版的区别在于:正式版允许采集文章的精华自动保存为ACCESS da表。基于Web的蜘蛛网页文章采集器操作步骤(1)使用前,必须确保您的电脑可以上网并且有防火墙,请勿屏蔽此软件。(2)运行SETUP.EXE和setup2.exe安装操作系统system32支持库。(3)运行spider.exe,输入URL入口,先点击“手动添加”按钮,然后点击“开始”按钮开始执行采集.基于Web的蜘蛛网页文章采集器使用注意(1)Grab Depth:填0表示不限制爬取深度;填3表示抓到第三层。(2)万能蜘蛛模式和分类蜘蛛模式的区别:假设URL入口为“”,如果选择万能蜘蛛模式,会遍历“”中的每一个网页;如果选择分类蜘蛛模式,则只有“”会被遍历(3)按钮“从MDB导入”:URL条目是批量从TASK.MDB导入的。(4)本软件采集原则是不跨s站,例如,条目是“”,只需在百度网站内抓取即可。 (5)本软件采集在此过程中,偶尔会弹出一个或几个“错误对话框”,请忽略。如果关闭“错误对话框”,采集软件会挂掉。( 6)用户如何选择采集subjects:例如,如果你想采集“股票”文章,你只需要将那些“股票”网站作为URL条目。
立即下载 查看全部
web基础蜘蛛网页文章采集器.2.zip
基于网络的蜘蛛网页文章采集器v3.2.zip
基于Web的蜘蛛网页文章采集器,英文名Fast_Spider,属于蜘蛛爬虫程序,用于指定网站采集大量力量文章,会直接丢弃其中的垃圾信息,只保存阅读值和浏览值文章的本质,并自动进行HTM-TXT转换。本软件为绿色软件,解压后即可使用。基于网络的蜘蛛网页文章采集器具有以下特点:(1)本软件采用北大天网的MD5指纹重排算法,对于相似和相同的网页信息,不会存储(2)采集信息含义:[[HT]]代表网页标题,[[HA]]代表文章title,[[HC]]代表10个加权关键词,[[UR]]代表网页中的图片链接,[[TXT]]之后是正文。(3)Spider Performance:软件开启300个线程,保证采集效率。压力测试由采集100进行万979文章,以普通网民的联网电脑为参考标准,一台电脑可以遍历200万个网页,采集20万979文章,100万精华文章 5天完成采集。(4)正式版和免费版的区别在于:正式版允许采集文章的精华自动保存为ACCESS da表。基于Web的蜘蛛网页文章采集器操作步骤(1)使用前,必须确保您的电脑可以上网并且有防火墙,请勿屏蔽此软件。(2)运行SETUP.EXE和setup2.exe安装操作系统system32支持库。(3)运行spider.exe,输入URL入口,先点击“手动添加”按钮,然后点击“开始”按钮开始执行采集.基于Web的蜘蛛网页文章采集器使用注意(1)Grab Depth:填0表示不限制爬取深度;填3表示抓到第三层。(2)万能蜘蛛模式和分类蜘蛛模式的区别:假设URL入口为“”,如果选择万能蜘蛛模式,会遍历“”中的每一个网页;如果选择分类蜘蛛模式,则只有“”会被遍历(3)按钮“从MDB导入”:URL条目是批量从TASK.MDB导入的。(4)本软件采集原则是不跨s站,例如,条目是“”,只需在百度网站内抓取即可。 (5)本软件采集在此过程中,偶尔会弹出一个或几个“错误对话框”,请忽略。如果关闭“错误对话框”,采集软件会挂掉。( 6)用户如何选择采集subjects:例如,如果你想采集“股票”文章,你只需要将那些“股票”网站作为URL条目。
立即下载
360搜索发布“站长公告”抑制互联网生态中采集泛滥
采集交流 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2021-07-29 22:37
互联网发展以来,海量的数据满足了每个人的信息获取需求。然而,互联网海洋中层出不穷的网页,良莠不齐。一些网站由采集和拼贴组成,给用户带来了很好的阅读体验。大麻烦。今日,360搜索发布《站长公告》,宣布推出“优采云方法”,以遏制当前互联网生态采集泛滥的局面。公告全文如下:
360 社区
亲爱的站长朋友:
大家好。
互联网的飞速发展离不开原创和稀缺的优质资源。通过我们最近的数据分析和用户反馈,我们发现一些网站使用疯狂劣质的采集方法在短时间内拼凑了很多低质量的采集网页。这种行为导致互联网上低质量网页逐渐泛滥,如内容拼接、隐秘标题变化、垃圾广告过多等,不仅严重影响正常用户的浏览体验,还造成高-quality 原创 内容不首先显示。精品内容的原创和网站也造成了一定的破坏。
360搜索一直秉承“保护原创+控制采集”的宗旨,以鼓励互联网原创生态为宗旨。针对这种典型的采集泛滥现象,基于业界领先的安全大数据和大规模机器学习平台,研发并推出“优采云算法”:控制劣质采集站点,控制原创用稀缺网页保护和升级权利,同时保证新闻网站的正常转载行为不受影响。
“优采云方法”上线后,内容丰富的优质网页(如原创、稀缺资源、精心编辑的内容页面等)将增加展示在前面的机会用户;针对滥用采集手段的行为(如全站大规模采集、页面内容拼凑、大量干扰用户阅读的广告、不良弹窗、大量不相关热词、网站搜索结果页面等),将显着降低其展示机会和网页收录量。
建议有以上问题的网站站长可以考虑长远发展,积极完善网站的建设,提供更省时、更丰富的原创内容。引擎会跟随网站改进,不断增加收录的数量。同时也欢迎原创网页的作者通过360站长平台积极向我们举报收录缺失的信息。
360搜索将坚定不移地与无数致力于做好本职工作的站长共建良好的互联网生态环境。感谢一直支持我们的站长和用户!
如果对网站采集的判断结果和收录的状态有异议,站长可以通过站长平台反馈中心和360搜论坛版主反馈:
站长平台反馈中心:
360 社区
360搜索论坛:
360 社区
站长平台注册地址:
请查看站长平台使用说明:
360搜索反作弊团队
2016.12.26 查看全部
360搜索发布“站长公告”抑制互联网生态中采集泛滥
互联网发展以来,海量的数据满足了每个人的信息获取需求。然而,互联网海洋中层出不穷的网页,良莠不齐。一些网站由采集和拼贴组成,给用户带来了很好的阅读体验。大麻烦。今日,360搜索发布《站长公告》,宣布推出“优采云方法”,以遏制当前互联网生态采集泛滥的局面。公告全文如下:
360 社区

亲爱的站长朋友:
大家好。
互联网的飞速发展离不开原创和稀缺的优质资源。通过我们最近的数据分析和用户反馈,我们发现一些网站使用疯狂劣质的采集方法在短时间内拼凑了很多低质量的采集网页。这种行为导致互联网上低质量网页逐渐泛滥,如内容拼接、隐秘标题变化、垃圾广告过多等,不仅严重影响正常用户的浏览体验,还造成高-quality 原创 内容不首先显示。精品内容的原创和网站也造成了一定的破坏。
360搜索一直秉承“保护原创+控制采集”的宗旨,以鼓励互联网原创生态为宗旨。针对这种典型的采集泛滥现象,基于业界领先的安全大数据和大规模机器学习平台,研发并推出“优采云算法”:控制劣质采集站点,控制原创用稀缺网页保护和升级权利,同时保证新闻网站的正常转载行为不受影响。
“优采云方法”上线后,内容丰富的优质网页(如原创、稀缺资源、精心编辑的内容页面等)将增加展示在前面的机会用户;针对滥用采集手段的行为(如全站大规模采集、页面内容拼凑、大量干扰用户阅读的广告、不良弹窗、大量不相关热词、网站搜索结果页面等),将显着降低其展示机会和网页收录量。
建议有以上问题的网站站长可以考虑长远发展,积极完善网站的建设,提供更省时、更丰富的原创内容。引擎会跟随网站改进,不断增加收录的数量。同时也欢迎原创网页的作者通过360站长平台积极向我们举报收录缺失的信息。
360搜索将坚定不移地与无数致力于做好本职工作的站长共建良好的互联网生态环境。感谢一直支持我们的站长和用户!
如果对网站采集的判断结果和收录的状态有异议,站长可以通过站长平台反馈中心和360搜论坛版主反馈:
站长平台反馈中心:
360 社区
360搜索论坛:
360 社区
站长平台注册地址:
请查看站长平台使用说明:
360搜索反作弊团队
2016.12.26
ModelArts平台提供的自动难例发现功能(图1)
采集交流 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-07-29 07:51
ModelArts平台提供的自动硬案例发现功能,可以通过内置规则,从输入旧模型的一批推理数据中,过滤掉可以进一步提高旧模型准确率的数据。自动硬案例发现功能可以有效减少模型更新时所需的标注人力。对于旧模型的推理数据,尽量挖掘出有利于提高模型准确率的部分数据。你只需要对这部分数据进行进一步的确认和标注,然后加入到训练数据集中即可。重新训练后,您可以获得更高准确率的新模型。
对于部署为在线服务的模型,调用 URL 或通过控制台输入预测数据。可以使用数据采集函数采集或者过滤掉疑难案例输出到数据集进行Follow-up模型训练。
对于在线服务数据采集,如图所示,支持以下场景。
图1 online services采集数据
先决条件
数据采集
部署为在线服务时,可以启动data采集任务。或者对于已经部署的在线服务,可以在服务详情页面打开数据采集任务。如果只启用了数据采集任务,则只有调用服务时产生的数据,采集才会存储在OBS中。如需过滤疑难病例,请参考。如果需要将采集后的数据同步到数据集,但不需要过滤疑难案例,请参考。
登录ModelArts管理控制台,在左侧菜单栏中选择“部署>在线服务”,进入在线服务管理页面。打开 data采集 任务。填写data采集task的相关参数,请参考详细参数说明。
表1 Data采集参数说明
参数
说明
采集rule
支持“全额采集”或“根据信任”采集。目前仅支持“全额采集”模式。
采集output
采集data,数据存放的路径。仅支持 OBS 目录。请选择现有目录或创建新的 OBS 目录。
保存周期
支持“一天”、“一周”、“永久”或“自定义”。
图4采集数据配置
data采集启动后,调用该服务进行预测(Console预测或URL接口预测)时,上传的数据会按照设定的规则采集到对应的OBS目录。<//p
p将数据同步到数据集/p
p对于已经启动数据采集任务的在线服务,支持采集数据同步到数据集。此操作不会进行困难情况过滤,只会将采集 的数据存储在数据集中。它可以存储在现有的数据集中,也可以创建一个新的数据集来存储数据。/p
p打开data采集task。详细操作请参考。/p
p当数据采集task不是采集到数据时,即用户没有调用接口使用预测功能,无法进行数据同步到数据集的操作。/p
p点击服务名称进入服务详情页面,在“同步数据”选项中点击“同步数据到数据集”。/p
p图 5 同步数据到数据集/p
pimg src='https://support.huaweicloud.com/engineers-modelarts/zh-cn_image_0298495669.png' alt='免规则采集器列表算法'//p
p在弹出的对话框中,勾选“标记类型”,然后“选择数据集”,点击“确定”,将采集数据同步到数据集的“未标记”选项卡中。/p
p同步的数据是系统采集在data采集task配置规则下收到的数据。当采集data为空时,无法进行数据同步到数据集的操作。/p
p图 6 同步数据到数据集/p
pimg src='https://support.huaweicloud.com/engineers-modelarts/zh-cn_image_0298495752.png' alt='免规则采集器列表算法'//p
pData采集并过滤疑难案例/p
p如果只开启了data采集任务,则不会启动疑难案例自动识别操作。需要同时启动疑难案例过滤任务,可以过滤采集疑难案例的数据,并将过滤结果存入对应的数据集中。/p
p由于疑难案例筛选功能对预测输出格式有要求,不同模型源要求不同:/p
p打开data采集task。详细操作请参考。/p
pimg src='https://support.huaweicloud.com/engineers-modelarts/public_sys-resources/note_3.0-zh-cn.png' alt='免规则采集器列表算法'//p
p在开启疑难案例过滤功能前,必须先开启data采集task。对于此在线服务,数据采集任务之前已经开启,对应OBS路径下存储的数据依然可用,只能开启稀有案例过滤功能。此时,困难案例过滤仅过滤存储在OBS路径中的数据。/p
p开启疑难病例筛选任务。在配置数据采集任务的同一页面,可以同时启动疑难案例过滤任务。请参考相关参数。/p
p表2疑难病例筛选参数说明/p
p参数/p
p说明/p
p模型类型/p
p模型的应用类型,目前仅支持“图像分类”和“物体检测”。/p
p训练数据集/p
p将模型部署为在线服务。这个模型是通过一定的数据集训练的。过程如下。对于本在线服务对应的训练数据集,您可以在筛选疑难案例时导入训练数据集,更容易过滤出模型的深层数据问题。/p
p(训练脚本+训练数据集)-> 训练模型-> 将模型部署为在线服务
该参数是可选的,但为了提高准确率,建议您导入相应的数据集。如果您的数据集不在 ModelArts 中管理,请参阅创建数据集。
过滤规则
支持“按持续时间”过滤或“按样本大小”过滤。
困难的示例输出
将选定的困难案例数据保存到数据集。支持现有数据集或创建新数据集。
您必须选择相应类型的数据集。比如模型类型是“图像分类”,需要过滤掉的疑难案例的数据集也必须是“图像分类”类型。
图7 打开疑难案例筛选功能
当配置了数据采集和疑难案例过滤任务时,系统会根据你设置的采集规则过滤疑难案例。您可以在在线服务的“疑难病例筛选”选项卡上查看“任务状态”。任务完成后,其“任务状态”会显示为“数据集导入完成”,您可以通过数据集链接快速跳转到对应的数据集。 采集的数据会保存在“Unmarked”标签下;筛选出的疑难案例将存储在数据集的“待确认”选项卡下。
图 8 任务状态
图 9 疑难案例选择结果
困难的反馈示例
在ModelArts管理控制台中,当您使用在线服务进行预测时,如果预测结果不准确,您可以直接将这个疑难案例反馈到预测页面上的对应数据集。
登录ModelArts管理控制台,在左侧菜单栏中选择“部署>在线服务”,点击对应的服务名称,进入服务详情页面。点击“预测”选项卡,上传您用于预测的图片,然后点击“预测”。当预测结果不准确时,点击“疑难案例反馈”。
图 10 在线服务疑难案例反馈
在弹出的对话框中,勾选“标签类型”,然后“选择数据集”,点击“确定”,将疑难案例数据反馈到该数据集的“待确认”选项卡。用于提高进一步模型训练的准确性。
图 11 疑难案例反馈
预测输出格式要求
对于自定义模型,推理代码中的“infer_output”,即预测返回的JSON格式,必须与下例一致。 查看全部
ModelArts平台提供的自动难例发现功能(图1)
ModelArts平台提供的自动硬案例发现功能,可以通过内置规则,从输入旧模型的一批推理数据中,过滤掉可以进一步提高旧模型准确率的数据。自动硬案例发现功能可以有效减少模型更新时所需的标注人力。对于旧模型的推理数据,尽量挖掘出有利于提高模型准确率的部分数据。你只需要对这部分数据进行进一步的确认和标注,然后加入到训练数据集中即可。重新训练后,您可以获得更高准确率的新模型。
对于部署为在线服务的模型,调用 URL 或通过控制台输入预测数据。可以使用数据采集函数采集或者过滤掉疑难案例输出到数据集进行Follow-up模型训练。
对于在线服务数据采集,如图所示,支持以下场景。
图1 online services采集数据

先决条件
数据采集
部署为在线服务时,可以启动data采集任务。或者对于已经部署的在线服务,可以在服务详情页面打开数据采集任务。如果只启用了数据采集任务,则只有调用服务时产生的数据,采集才会存储在OBS中。如需过滤疑难病例,请参考。如果需要将采集后的数据同步到数据集,但不需要过滤疑难案例,请参考。
登录ModelArts管理控制台,在左侧菜单栏中选择“部署>在线服务”,进入在线服务管理页面。打开 data采集 任务。填写data采集task的相关参数,请参考详细参数说明。
表1 Data采集参数说明
参数
说明
采集rule
支持“全额采集”或“根据信任”采集。目前仅支持“全额采集”模式。
采集output
采集data,数据存放的路径。仅支持 OBS 目录。请选择现有目录或创建新的 OBS 目录。
保存周期
支持“一天”、“一周”、“永久”或“自定义”。
图4采集数据配置

data采集启动后,调用该服务进行预测(Console预测或URL接口预测)时,上传的数据会按照设定的规则采集到对应的OBS目录。<//p
p将数据同步到数据集/p
p对于已经启动数据采集任务的在线服务,支持采集数据同步到数据集。此操作不会进行困难情况过滤,只会将采集 的数据存储在数据集中。它可以存储在现有的数据集中,也可以创建一个新的数据集来存储数据。/p
p打开data采集task。详细操作请参考。/p
p当数据采集task不是采集到数据时,即用户没有调用接口使用预测功能,无法进行数据同步到数据集的操作。/p
p点击服务名称进入服务详情页面,在“同步数据”选项中点击“同步数据到数据集”。/p
p图 5 同步数据到数据集/p
pimg src='https://support.huaweicloud.com/engineers-modelarts/zh-cn_image_0298495669.png' alt='免规则采集器列表算法'//p
p在弹出的对话框中,勾选“标记类型”,然后“选择数据集”,点击“确定”,将采集数据同步到数据集的“未标记”选项卡中。/p
p同步的数据是系统采集在data采集task配置规则下收到的数据。当采集data为空时,无法进行数据同步到数据集的操作。/p
p图 6 同步数据到数据集/p
pimg src='https://support.huaweicloud.com/engineers-modelarts/zh-cn_image_0298495752.png' alt='免规则采集器列表算法'//p
pData采集并过滤疑难案例/p
p如果只开启了data采集任务,则不会启动疑难案例自动识别操作。需要同时启动疑难案例过滤任务,可以过滤采集疑难案例的数据,并将过滤结果存入对应的数据集中。/p
p由于疑难案例筛选功能对预测输出格式有要求,不同模型源要求不同:/p
p打开data采集task。详细操作请参考。/p
pimg src='https://support.huaweicloud.com/engineers-modelarts/public_sys-resources/note_3.0-zh-cn.png' alt='免规则采集器列表算法'//p
p在开启疑难案例过滤功能前,必须先开启data采集task。对于此在线服务,数据采集任务之前已经开启,对应OBS路径下存储的数据依然可用,只能开启稀有案例过滤功能。此时,困难案例过滤仅过滤存储在OBS路径中的数据。/p
p开启疑难病例筛选任务。在配置数据采集任务的同一页面,可以同时启动疑难案例过滤任务。请参考相关参数。/p
p表2疑难病例筛选参数说明/p
p参数/p
p说明/p
p模型类型/p
p模型的应用类型,目前仅支持“图像分类”和“物体检测”。/p
p训练数据集/p
p将模型部署为在线服务。这个模型是通过一定的数据集训练的。过程如下。对于本在线服务对应的训练数据集,您可以在筛选疑难案例时导入训练数据集,更容易过滤出模型的深层数据问题。/p
p(训练脚本+训练数据集)-> 训练模型-> 将模型部署为在线服务
该参数是可选的,但为了提高准确率,建议您导入相应的数据集。如果您的数据集不在 ModelArts 中管理,请参阅创建数据集。
过滤规则
支持“按持续时间”过滤或“按样本大小”过滤。
困难的示例输出
将选定的困难案例数据保存到数据集。支持现有数据集或创建新数据集。
您必须选择相应类型的数据集。比如模型类型是“图像分类”,需要过滤掉的疑难案例的数据集也必须是“图像分类”类型。
图7 打开疑难案例筛选功能

当配置了数据采集和疑难案例过滤任务时,系统会根据你设置的采集规则过滤疑难案例。您可以在在线服务的“疑难病例筛选”选项卡上查看“任务状态”。任务完成后,其“任务状态”会显示为“数据集导入完成”,您可以通过数据集链接快速跳转到对应的数据集。 采集的数据会保存在“Unmarked”标签下;筛选出的疑难案例将存储在数据集的“待确认”选项卡下。
图 8 任务状态

图 9 疑难案例选择结果

困难的反馈示例
在ModelArts管理控制台中,当您使用在线服务进行预测时,如果预测结果不准确,您可以直接将这个疑难案例反馈到预测页面上的对应数据集。
登录ModelArts管理控制台,在左侧菜单栏中选择“部署>在线服务”,点击对应的服务名称,进入服务详情页面。点击“预测”选项卡,上传您用于预测的图片,然后点击“预测”。当预测结果不准确时,点击“疑难案例反馈”。
图 10 在线服务疑难案例反馈

在弹出的对话框中,勾选“标签类型”,然后“选择数据集”,点击“确定”,将疑难案例数据反馈到该数据集的“待确认”选项卡。用于提高进一步模型训练的准确性。
图 11 疑难案例反馈

预测输出格式要求
对于自定义模型,推理代码中的“infer_output”,即预测返回的JSON格式,必须与下例一致。
免规则采集器列表算法!计算不同计算机网络厂商的connectivitylevel3
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-07-28 03:01
免规则采集器列表算法!1.计算20种通用算法2.计算不同计算机网络厂商的connectivitylevel3.计算不同普通网络的专用算法(如mstsc,httptls等),
什么都可以,
linux目录层面的查找、区别、依赖
本质上大部分内容都是定义了其所处层级的内存与外存,不同结构的对象都有不同结构对其指针求值。你可以把内存划分为数组级、文件级、树结构三大类,具体以树结构为例。每一类分别定义了这样的结构指针的算法;使用同样的算法可以将多个文件结构合并起来。有一个结构,如a.txt,b.txt等,你可以把它分为两类:一类是一个结构的指针namespace_txt,另一类是在结构中分别添加了文件描述符描述符**methodoverview,如file.txt**,这两类访问同一结构内部的指针函数求值位置分别是完全不同的。
txt的指针针对的是b.txt,**描述符指针针对的是a.txt,因此txt的指针转换公式是:指针=文件描述符。
使用定义层级的结构,划分网络结构。树状结构就定义树状结构上每个点的指针结构。树状结构就定义树状结构上每个结点的指针结构。例如以图来说,树状结构可以定义层级结构的大量结构指针。链状结构就定义链状结构上每个节点的指针结构。定义层级结构要描述的是每个网络结构本身是什么树状结构,而不是最底层。 查看全部
免规则采集器列表算法!计算不同计算机网络厂商的connectivitylevel3
免规则采集器列表算法!1.计算20种通用算法2.计算不同计算机网络厂商的connectivitylevel3.计算不同普通网络的专用算法(如mstsc,httptls等),
什么都可以,
linux目录层面的查找、区别、依赖
本质上大部分内容都是定义了其所处层级的内存与外存,不同结构的对象都有不同结构对其指针求值。你可以把内存划分为数组级、文件级、树结构三大类,具体以树结构为例。每一类分别定义了这样的结构指针的算法;使用同样的算法可以将多个文件结构合并起来。有一个结构,如a.txt,b.txt等,你可以把它分为两类:一类是一个结构的指针namespace_txt,另一类是在结构中分别添加了文件描述符描述符**methodoverview,如file.txt**,这两类访问同一结构内部的指针函数求值位置分别是完全不同的。
txt的指针针对的是b.txt,**描述符指针针对的是a.txt,因此txt的指针转换公式是:指针=文件描述符。
使用定义层级的结构,划分网络结构。树状结构就定义树状结构上每个点的指针结构。树状结构就定义树状结构上每个结点的指针结构。例如以图来说,树状结构可以定义层级结构的大量结构指针。链状结构就定义链状结构上每个节点的指针结构。定义层级结构要描述的是每个网络结构本身是什么树状结构,而不是最底层。
如何让一个任务定时执行,实现界面化的组件装配
采集交流 • 优采云 发表了文章 • 0 个评论 • 276 次浏览 • 2021-07-28 01:44
先废话,程序还在开发阶段,担心开发出来的程序会变形,所以拿出来。市场上已经有 n 多款采集 软件。我只是在重复轮子。他们并不比他们好多少。他们很可能很糟糕,以至于他们甚至都没有接近。但是,相比目前的一些采集程序,我认为它是基于组件的,每个组件都是可以替换的。我希望它可以被视为一个亮点。同时也希望各位专家对本次展览提出建议和批评。
未解决的问题是:
1.一些需要cookies的网站,怎么采集,sina,我登录了,但是我登录cnblogs失败了。
2.定时执行,如何让一个任务定时执行,使用呢,因为一个采集task可能有很多URL,第一个URL采集的时间,最后一个采集的URL @'S的时间可能相隔几个小时,如果要求整个任务相隔1h,采集一次,那么最后一个URL可能只是采集完再要采集,或者最后一个任务还没有尚未执行。网址。这里没有考虑采集interval 策略。比如采集不换3次,下次采集时间会延长。
3.Storage问题,如果使用DAS或者数据库,完全没有问题,但是如果每个客户端都以文件的形式存储采集的结果,那么每个客户端上的文件怎么聚合并合并?将是一个系统工程
4.组件的任务流程和装配接口实现问题。目前流程的配置是使用文本编辑器编辑配置文件,非常容易写错。不懂GDI+,也没有想到好的实现方式。基于接口的组件组装。
先来看看采集的结果,再介绍一下采集的整个过程。 采集的结果保存在xml中,使用程序内置的Store2Xml组件。如果你想把它存储在特定的数据库中,你可以自己写一个组件,或者提供一个cms的webservice,我们会再做一个适配组件。 .
我正在考虑制作另一个 Store2MDB 组件,它易于传输数据并且也是嵌入式的。之所以不使用sqlite,是因为普通用户可能不太了解。
下面我以采集下的创业信息和创业秘诀栏为例来展示这个程序
第一步:分析网页
这两列的样式是一样的,所以我们只需要写一个采集规则即可。
打开任意列的列表页面并查看其源代码。我们需要找到重复的片段。下图中高亮部分为重复内容
我们将上图中要提取的部分源码放入RegexBuddy作为测试代码,测试我们编写的规律性
将测试的正则性放入组件的指定属性中。目前只能手动配置。在实践中,有一个图形环境,提供逐步操作提示。
最后我们会设计组件安装和配置执行的流程,使用boo解释引擎,类似ironpython
设计阶段一共三个文件,其中文本文件存储采集的URL集合,每行一个
第 2 步:添加任务
添加设计阶段制作的任务包,填写信息,然后提交任务
下图是程序在后台运行的过程
附上采集的结果 查看全部
如何让一个任务定时执行,实现界面化的组件装配
先废话,程序还在开发阶段,担心开发出来的程序会变形,所以拿出来。市场上已经有 n 多款采集 软件。我只是在重复轮子。他们并不比他们好多少。他们很可能很糟糕,以至于他们甚至都没有接近。但是,相比目前的一些采集程序,我认为它是基于组件的,每个组件都是可以替换的。我希望它可以被视为一个亮点。同时也希望各位专家对本次展览提出建议和批评。
未解决的问题是:
1.一些需要cookies的网站,怎么采集,sina,我登录了,但是我登录cnblogs失败了。
2.定时执行,如何让一个任务定时执行,使用呢,因为一个采集task可能有很多URL,第一个URL采集的时间,最后一个采集的URL @'S的时间可能相隔几个小时,如果要求整个任务相隔1h,采集一次,那么最后一个URL可能只是采集完再要采集,或者最后一个任务还没有尚未执行。网址。这里没有考虑采集interval 策略。比如采集不换3次,下次采集时间会延长。
3.Storage问题,如果使用DAS或者数据库,完全没有问题,但是如果每个客户端都以文件的形式存储采集的结果,那么每个客户端上的文件怎么聚合并合并?将是一个系统工程
4.组件的任务流程和装配接口实现问题。目前流程的配置是使用文本编辑器编辑配置文件,非常容易写错。不懂GDI+,也没有想到好的实现方式。基于接口的组件组装。
先来看看采集的结果,再介绍一下采集的整个过程。 采集的结果保存在xml中,使用程序内置的Store2Xml组件。如果你想把它存储在特定的数据库中,你可以自己写一个组件,或者提供一个cms的webservice,我们会再做一个适配组件。 .
我正在考虑制作另一个 Store2MDB 组件,它易于传输数据并且也是嵌入式的。之所以不使用sqlite,是因为普通用户可能不太了解。

下面我以采集下的创业信息和创业秘诀栏为例来展示这个程序
第一步:分析网页
这两列的样式是一样的,所以我们只需要写一个采集规则即可。

打开任意列的列表页面并查看其源代码。我们需要找到重复的片段。下图中高亮部分为重复内容

我们将上图中要提取的部分源码放入RegexBuddy作为测试代码,测试我们编写的规律性

将测试的正则性放入组件的指定属性中。目前只能手动配置。在实践中,有一个图形环境,提供逐步操作提示。

最后我们会设计组件安装和配置执行的流程,使用boo解释引擎,类似ironpython

设计阶段一共三个文件,其中文本文件存储采集的URL集合,每行一个

第 2 步:添加任务
添加设计阶段制作的任务包,填写信息,然后提交任务

下图是程序在后台运行的过程

附上采集的结果
8款非常好用的办公软件,可以极大提高办公效率
采集交流 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-07-27 19:46
与大家分享8款非常实用的办公软件,可以大大提高办公效率,每一款都堪称精品,喜欢的话记得点赞支持哦~
1、Listary
Listary 是一款非常强大的文件浏览、搜索增强、对话增强软件。第一个功能是快速打开文件和应用程序。您可以在任何界面上双击 Ctrl 来快速打开目标,而无需最小化当前窗口。搜索结果出现后,默认先显示应用程序,可以按空格键只显示文件。
第二个功能是文件浏览器的增强。在资源管理器界面,不需要任何快捷键,直接按文件名,Listary搜索框会自动打开,自动检索文件。
Listary 的第三个功能是各种打开/保存对话框的增强。在任何打开/保存/下载对话框界面底部,都会自动吸附Listary的搜索框,直接输入名称即可快速定位到目标文件夹。
这是一个快捷键。如果你的目标文件夹是打开的,在对话框中按快捷键Ctrl+G可以快速打开这个文件夹,方便快捷。
2、智办事
如何让企业具备核心竞争力?
任正非的一句话很经典:人才和技术不是企业的核心竞争力。有效的人才管理是核心竞争力,有效的创新和研发管理是核心竞争力。
如果一家公司能够将突出的个人能力转化为组织能力,然后组织能力可以赋能所有团队成员,汇聚所有成员的杰出能力,那么就会形成超越个人的竞争实力。让团队成员一起思考,一起做,一起成长,可以大大提高团队的战斗力。
①。分解任务并赋予组织权力
智能工作可以将公司目标分解为团队目标,再将团队目标分解为个人目标。团队成员可以在目标下创建子任务,每个任务可以设置一个清单。实现目标细化,落地成可执行的任务,然后把任务拆解给个人,把责任交给个人。每个人都在为终极目标服务,努力工作。
项目内容可以保存同步,新成员也可以第一时间看到任务内容。可以为每个任务设置一个列表,并可以检查是否完成。
目标自上而下拆解,结果自上而下汇总。反复回顾项目过程,逐渐沉淀为一种组织能力,形成能力的复用,固化了项目的标准架构流程,最终实现了对所有团队成员的赋能。
②。组织可视化,敏捷管理
任务概览可以让任务更好的“看”:团队成员可以看到待办任务、任务统计和进度报告;项目负责人可以看到团队概况、每项任务的进度、团队成员的表现和工作饱和度等。
任务概览功能可以确保员工执行的方向与公司目标一致,让团队成员知道他们有什么任务,让经理知道团队成员任务的进度和状态,避免项目延误.
③、任务转移模板、能力复用
任务层层分解,标准任务流程不断沉淀、重复、迭代,优化项目流程,个人能力逐渐沉淀为组织能力,形成能力重用,最终实现赋予所有团队成员权力。
修复项目的标准结构流程,最终将项目转化为模板,从而为组织成员赋能,明确工作流程,实现能力与流程的复制。
3、Quicker
Quicker 是一款提高计算机使用效率的软件。它允许 Windows 用户以最合适的方式和最快的软件工具触发所需的操作。它是一个基于场景的工具箱,也是一个创建和共享新工具的平台。
点击鼠标中键(可设置)弹出,位置跟随鼠标,移动一小段距离即可触发动作。 28个可视化动作按钮,建立动作快捷方式,快速启动软件,执行操作。
Quicker 支持自定义动作,内置丰富的动作库,可以直接使用。如OCR识别、文字截图翻译、批量重命名、快速本地搜索、连续复制、图片压缩、快速回复等。
4、Snipaste
Snipaste 是一款简单而强大的截图和贴纸工具。您还可以将屏幕截图粘贴回屏幕。 F1截图,F3贴图,简约高效。
办公室里会抄很多资料,写的时候会抄很多文字和图片。 Snipaste 可以将这些内容粘贴到屏幕上,而不是切换回窗口。
Snipaste 可以自动检测窗口和元素,可以轻松快速地捕获单个窗口。 Snipaste 的自动元素检测功能非常准确。它可以捕捉窗口上的按钮或选项,甚至是网页上的图片或一段文字。
Snipaste 支持多种颜色和多种标记。矩形、折线、箭头、钢笔、记号笔、马赛克、文本、橡皮擦,支持撤销和重做操作。空格键是隐藏和显示标记面板。
5、DropIt
DropIt 是一款经典的、古老的、开源的免费文件批量整理软件,绝对的生产力工具。您只需将文件拖到浮动的 DropIt 图标上,软件就会自动按照预设的形式处理文件。
您可以定义文件过滤规则并关联 18 个可用选项(移动、复制、压缩、提取、重命名、删除、加密、打开为、上传、通过邮件发送、创建图库、创建列表、创建播放列表、创建快捷键、复制到剪贴板、修改属性和忽略)。
6、桌面日历
桌面日历是一款非常强大且易于使用的 Windows 日历软件。双击记录每日待办事项。桌面日历可以很好地帮助您管理日常待办事项和日程安排。桌面日历还提供万年阴历、二十四节气,以及各种常见的节日和纪念日。
强大的数据导入导出功能,设置不同的背景颜色,云端数据同步……桌面日历还有很多实用功能等你来探索。
7、优采云采集器
优采云采集器 由前 Google 技术团队创建。基于人工智能技术,输入网址即可自动识别采集内容。
可以智能识别数据。智能模式基于人工智能算法。只需输入网址,即可智能识别列表数据、表格数据和分页按钮。无需配置任何采集规则,一键采集。自动识别列表、表格、链接、图片、价格等
流程图模式:只需根据软件提示点击页面进行操作,完全符合人们浏览网页的思维方式,简单几步即可生成复杂的采集规则,结合智能识别算法,任何网页上的数据都可以轻松采集。
可以模拟操作:输入文字、点击、移动鼠标、下拉框、滚动页面、等待加载、循环操作和判断条件等
8、QTTabBar
QTTabBar 是一个小工具,可让您在 Windows 资源管理器中使用 Tab 多标签功能。从此,工作时不再有文件夹窗口,更有强大的文件夹预览功能,大大提高您的工作效率。
另一个功能是快速预览文件和文件夹。您只需将鼠标悬停在文件上,内容就会自动预览。我测试了视频、音频、GIF 图像和 PNG 图像,没有任何问题。从图片上可以看到视频时间,证明视频可以播放,有声音。
像这样管理多个文件夹是不是更方便?只需要一个窗口,告别凌乱的桌面! QTTabBar也有很多功能和快捷键,浏览器标签的快捷键基本可以在QTTabBar上复用。
查看全部
8款非常好用的办公软件,可以极大提高办公效率
与大家分享8款非常实用的办公软件,可以大大提高办公效率,每一款都堪称精品,喜欢的话记得点赞支持哦~
1、Listary
Listary 是一款非常强大的文件浏览、搜索增强、对话增强软件。第一个功能是快速打开文件和应用程序。您可以在任何界面上双击 Ctrl 来快速打开目标,而无需最小化当前窗口。搜索结果出现后,默认先显示应用程序,可以按空格键只显示文件。
第二个功能是文件浏览器的增强。在资源管理器界面,不需要任何快捷键,直接按文件名,Listary搜索框会自动打开,自动检索文件。
Listary 的第三个功能是各种打开/保存对话框的增强。在任何打开/保存/下载对话框界面底部,都会自动吸附Listary的搜索框,直接输入名称即可快速定位到目标文件夹。
这是一个快捷键。如果你的目标文件夹是打开的,在对话框中按快捷键Ctrl+G可以快速打开这个文件夹,方便快捷。
2、智办事
如何让企业具备核心竞争力?
任正非的一句话很经典:人才和技术不是企业的核心竞争力。有效的人才管理是核心竞争力,有效的创新和研发管理是核心竞争力。
如果一家公司能够将突出的个人能力转化为组织能力,然后组织能力可以赋能所有团队成员,汇聚所有成员的杰出能力,那么就会形成超越个人的竞争实力。让团队成员一起思考,一起做,一起成长,可以大大提高团队的战斗力。

①。分解任务并赋予组织权力
智能工作可以将公司目标分解为团队目标,再将团队目标分解为个人目标。团队成员可以在目标下创建子任务,每个任务可以设置一个清单。实现目标细化,落地成可执行的任务,然后把任务拆解给个人,把责任交给个人。每个人都在为终极目标服务,努力工作。
项目内容可以保存同步,新成员也可以第一时间看到任务内容。可以为每个任务设置一个列表,并可以检查是否完成。
目标自上而下拆解,结果自上而下汇总。反复回顾项目过程,逐渐沉淀为一种组织能力,形成能力的复用,固化了项目的标准架构流程,最终实现了对所有团队成员的赋能。
②。组织可视化,敏捷管理
任务概览可以让任务更好的“看”:团队成员可以看到待办任务、任务统计和进度报告;项目负责人可以看到团队概况、每项任务的进度、团队成员的表现和工作饱和度等。
任务概览功能可以确保员工执行的方向与公司目标一致,让团队成员知道他们有什么任务,让经理知道团队成员任务的进度和状态,避免项目延误.
③、任务转移模板、能力复用
任务层层分解,标准任务流程不断沉淀、重复、迭代,优化项目流程,个人能力逐渐沉淀为组织能力,形成能力重用,最终实现赋予所有团队成员权力。
修复项目的标准结构流程,最终将项目转化为模板,从而为组织成员赋能,明确工作流程,实现能力与流程的复制。
3、Quicker
Quicker 是一款提高计算机使用效率的软件。它允许 Windows 用户以最合适的方式和最快的软件工具触发所需的操作。它是一个基于场景的工具箱,也是一个创建和共享新工具的平台。

点击鼠标中键(可设置)弹出,位置跟随鼠标,移动一小段距离即可触发动作。 28个可视化动作按钮,建立动作快捷方式,快速启动软件,执行操作。
Quicker 支持自定义动作,内置丰富的动作库,可以直接使用。如OCR识别、文字截图翻译、批量重命名、快速本地搜索、连续复制、图片压缩、快速回复等。
4、Snipaste
Snipaste 是一款简单而强大的截图和贴纸工具。您还可以将屏幕截图粘贴回屏幕。 F1截图,F3贴图,简约高效。
办公室里会抄很多资料,写的时候会抄很多文字和图片。 Snipaste 可以将这些内容粘贴到屏幕上,而不是切换回窗口。

Snipaste 可以自动检测窗口和元素,可以轻松快速地捕获单个窗口。 Snipaste 的自动元素检测功能非常准确。它可以捕捉窗口上的按钮或选项,甚至是网页上的图片或一段文字。
Snipaste 支持多种颜色和多种标记。矩形、折线、箭头、钢笔、记号笔、马赛克、文本、橡皮擦,支持撤销和重做操作。空格键是隐藏和显示标记面板。

5、DropIt
DropIt 是一款经典的、古老的、开源的免费文件批量整理软件,绝对的生产力工具。您只需将文件拖到浮动的 DropIt 图标上,软件就会自动按照预设的形式处理文件。

您可以定义文件过滤规则并关联 18 个可用选项(移动、复制、压缩、提取、重命名、删除、加密、打开为、上传、通过邮件发送、创建图库、创建列表、创建播放列表、创建快捷键、复制到剪贴板、修改属性和忽略)。

6、桌面日历
桌面日历是一款非常强大且易于使用的 Windows 日历软件。双击记录每日待办事项。桌面日历可以很好地帮助您管理日常待办事项和日程安排。桌面日历还提供万年阴历、二十四节气,以及各种常见的节日和纪念日。
强大的数据导入导出功能,设置不同的背景颜色,云端数据同步……桌面日历还有很多实用功能等你来探索。

7、优采云采集器
优采云采集器 由前 Google 技术团队创建。基于人工智能技术,输入网址即可自动识别采集内容。
可以智能识别数据。智能模式基于人工智能算法。只需输入网址,即可智能识别列表数据、表格数据和分页按钮。无需配置任何采集规则,一键采集。自动识别列表、表格、链接、图片、价格等
流程图模式:只需根据软件提示点击页面进行操作,完全符合人们浏览网页的思维方式,简单几步即可生成复杂的采集规则,结合智能识别算法,任何网页上的数据都可以轻松采集。
可以模拟操作:输入文字、点击、移动鼠标、下拉框、滚动页面、等待加载、循环操作和判断条件等
8、QTTabBar
QTTabBar 是一个小工具,可让您在 Windows 资源管理器中使用 Tab 多标签功能。从此,工作时不再有文件夹窗口,更有强大的文件夹预览功能,大大提高您的工作效率。
另一个功能是快速预览文件和文件夹。您只需将鼠标悬停在文件上,内容就会自动预览。我测试了视频、音频、GIF 图像和 PNG 图像,没有任何问题。从图片上可以看到视频时间,证明视频可以播放,有声音。
像这样管理多个文件夹是不是更方便?只需要一个窗口,告别凌乱的桌面! QTTabBar也有很多功能和快捷键,浏览器标签的快捷键基本可以在QTTabBar上复用。
小米2004上传至本站,安全无毒,可放心使用!
采集交流 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-07-27 19:44
该资源由用户(小米2004))上传至本站,版权难以核实,如有侵权请点击侵权投诉
源代码哥对资源进行了安全检查,安全无毒,可以放心使用!
(同名资源申请中心地址:)
本站资源仅供个人研究/学习/欣赏,请勿用于商业用途,否则一切后果由您承担!
讨论!插件介绍
DXC 来自 Discuz 的缩写! X 采集。 DXC采集插件致力于discuz上的内容解决方案,帮助站长更快捷方便地构建网站内容。
通过DXC采集插件,用户可以方便地从网上下载采集数据,包括会员数据和文章数据。此外,还有虚拟在线、单帖采集等辅助功能,让一个冷清的新论坛瞬间形成一个内容丰富、会员活跃的热门论坛,对论坛的初期运营有很大帮助。是新手站长必须安装的discuz应用。
DXC2.5的主要功能包括:
1、采集文章各种形式的url列表,包括rss地址、列表页面、多层列表等。
2、 多种写规则方式,dom方式,字符拦截,智能获取,更方便获取你想要的内容
3、Rule继承,自动检测匹配规则功能,你会慢慢体会到规则继承带来的便利
4、独特的网页正文提取算法,可以自动学习归纳规则,更方便general采集。
5、支持图片定位和水印功能
6、灵活的发布机制,可以自定义发布者、发布时间点击率等
7、强大的内容编辑后台,可以方便的编辑采集到达的内容,并发布到门户、论坛、博客
8、内容过滤功能,过滤采集广告的内容,去除不必要的区域
9、batch采集,注册会员,batch采集,设置会员头像
10、无人值守定时定量采集和release文章
源码哥亲测截图
查看全部
小米2004上传至本站,安全无毒,可放心使用!
该资源由用户(小米2004))上传至本站,版权难以核实,如有侵权请点击侵权投诉
源代码哥对资源进行了安全检查,安全无毒,可以放心使用!
(同名资源申请中心地址:)
本站资源仅供个人研究/学习/欣赏,请勿用于商业用途,否则一切后果由您承担!
讨论!插件介绍
DXC 来自 Discuz 的缩写! X 采集。 DXC采集插件致力于discuz上的内容解决方案,帮助站长更快捷方便地构建网站内容。
通过DXC采集插件,用户可以方便地从网上下载采集数据,包括会员数据和文章数据。此外,还有虚拟在线、单帖采集等辅助功能,让一个冷清的新论坛瞬间形成一个内容丰富、会员活跃的热门论坛,对论坛的初期运营有很大帮助。是新手站长必须安装的discuz应用。
DXC2.5的主要功能包括:
1、采集文章各种形式的url列表,包括rss地址、列表页面、多层列表等。
2、 多种写规则方式,dom方式,字符拦截,智能获取,更方便获取你想要的内容
3、Rule继承,自动检测匹配规则功能,你会慢慢体会到规则继承带来的便利
4、独特的网页正文提取算法,可以自动学习归纳规则,更方便general采集。
5、支持图片定位和水印功能
6、灵活的发布机制,可以自定义发布者、发布时间点击率等
7、强大的内容编辑后台,可以方便的编辑采集到达的内容,并发布到门户、论坛、博客
8、内容过滤功能,过滤采集广告的内容,去除不必要的区域
9、batch采集,注册会员,batch采集,设置会员头像
10、无人值守定时定量采集和release文章
源码哥亲测截图

软件介绍优采云采集器官方版软件功能可视化所有采集元素
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-07-27 07:35
软件介绍
优采云采集器官版是一款非常实用的网络小工具,软件界面干净,操作简单,功能强大,具有可视化配置,易于创建,无需编程,智能生成,数据采集等功能 。使用优采云采集器,用户可以很方便地采集获取自己需要的网页上的所有信息,使用起来非常方便。
优采云采集器官方版软件功能
1、软件操作简单,鼠标点击即可轻松选择要采集的内容;
2、支持三种高速引擎:浏览器引擎、HTTP引擎、JSON引擎,内置优化的火狐浏览器,加上原有的内存优化,浏览器采集也可以高速运行,甚至更快转换为HTTP模式运行,享受更高的采集速度!抓取JSON数据时,也可以使用浏览器可视化的方式,用鼠标点击要抓取的内容。无需分析JSON数据结构,让非网页专业设计人员轻松抓取所需数据;
3、不需要分析网页请求和源码,但支持更多的网页采集;
4、高级智能算法,可以一键生成目标元素XPATH,自动识别网页列表,自动识别分页中的下一页按钮......
5、支持丰富的数据导出方式,可以导出为txt文件、html文件、csv文件、excel文件,也可以导出到已有的数据库,如sqlite数据库、access数据库、sqlserver数据库、mysql数据库、简单映射字段通过向导,您可以轻松导出到目标网站 数据库。 .
优采云采集器官方版软件功能
可视化向导
所有采集元素自动生成采集数据
预定任务
运行时间灵活定义,全自动运行
多引擎支持
支持多个采集引擎,内置高速浏览器内核、HTTP引擎和JSON引擎
智能识别
可以自动识别网页列表、采集字段和分页等
拦截请求
自定义屏蔽域名,方便过滤异地广告,提高采集速度
多数据导出
可导出为 Txt、Excel、MySQL、SQLServer、SQlite、Access、网站 等
优采云采集器官版软件优势
1、优采云采集器为用户提供丰富的网络数据采集功能
2、如果需要复制网页的数据,可以使用这个软件采集
3、大部分网页内容可以直接复制,优采云采集器一键使用采集
4、直接输入网址采集,准确采集任何网页内容
5、支持规则设置,自定义采集规则,添加采集字段内容,添加采集网页元素
6、Bulk采集data,一键输入多个网址采集
7、软件中显示任务列表,点击直接开始运行采集
8、支持数据查看,可以在软件中查看采集的数据内容,可以导出数据
9、支持字符和词库替换功能,一键编辑文字采集到
优采云采集器官方版教程
第一步:设置起始网址
要采集一个网站数据,首先我们需要设置输入采集的URL,比如我们想要采集一个网站国内新闻,那么我们需要设置起始网址为国内新闻栏目列表的网址,而网站首页一般不设置为起始网址,因为首页通常收录很多列表,比如最新的文章,热门的文章,推荐文章等列表块,而且这些列表块显示的内容也很有限,采集这些列表一般不能采集完整信息。
我们以采集芭新闻为例,从新浪首页找国内新闻,但是这个栏目首页的内容还是比较乱,还细分了三个小栏目
来看看其中一个子栏目“大陆新闻”
此栏目页收录一个分页的内容列表。通过切换分页,我们可以采集到达该栏目下的所有文章,所以这种列表页非常适合我们开始采集起始网址。
现在,我们将列表 URL 复制到任务编辑框第一步中的文本框
如果你想在一个任务中同时采集中国新闻,你也可以复制另外两个子列列表的地址,因为这些子列列表的格式是相似的。但是,为了方便分类数据的导出或发布,一般不建议将多列内容混合在一起。
对于起始网址,我们也可以批量添加或者从txt文件中导入。比如我们想要采集前5页,也可以这样自定义5个起始页。
需要注意的是,如果这里自定义了多个分页列表,以后不要在采集配置中启用分页。通常我们希望在某一列下采集所有文章。只需要定义列的第一页为起始URL,稍后在采集配置中启用分页,就可以采集到每个分页列表的数据。
第2步:①自动生成列表和字段
进入第二步后,对于部分网页,优采云采集器会智能分析页面列表,自动高亮选中的网页列表并生成列表数据,如
然后我们会修剪数据,比如删除一些不需要的字段
点击图标中的三角符号,会弹出采集字段进行详细配置。单击上方的删除按钮可删除此字段。其余参数将在后续章节中单独介绍。
如果某些网页自动生成的列表数据不是我们想要的数据,可以点击“清除字段”清除所有生成的字段。
如果自动分析的高亮列表不是我们想要的采集列表,那么我们手动选择列表。如果要取消突出显示的列表框,可以单击Find List-List XPATH,清除其中的xpath并确认。
第2步:②手动生成列表
点击“查找列表”按钮并选择“手动选择列表”
根据提示,鼠标左键点击网页列表中的第一行数据
点击第一行后,根据提示点击第二行或其他类似行
点击列表中的任意两行后,整个列表都会高亮显示,列表中的字段也会生成。如果生成的字段不正确,点击清除字段,清除下面所有字段,手动选择字段将在下一章介绍。
第 2 步:③ 手动生成字段
点击“添加字段”按钮
在列表的任意一行点击要提取的元素,例如要提取标题和链接地址,鼠标左键点击标题即可。
点击网页链接时,使用时会提示是否抓取链接地址
如果要同时提取链接标题和链接地址,点击“是”,如果只需要提取标题文字,点击“否”,这里我们点击“是”
系统会自动生成标题和链接地址字段,并在字段列表中显示提取的字段内容。当您点击表格底部的字段标题时,匹配的内容将在网页上以黄色背景突出显示。
如何标记列表中的其他字段?单击添加新字段并重复上述操作。
第 2 步:④ 分页设置
列表有分页时,启用分页后,可以采集访问所有的分页列表数据。
页面分页有两种类型
普通分页:有分页栏,显示“下一页”按钮。点击后可以进入下一页,比如新浪新闻列表中的上一页。
瀑布式分页:网页滚动条到达底部时自动加载下一页内容
如果是正常分页,我们选择尝试自动设置或手动设置
自动设置分页
默认情况下,创建新任务时不启用分页。点击“禁用分页”,弹出菜单,选择“自动识别分页”,如果识别成功,会弹出“成功识别并设置分页元素!”对话框。 ”,在网页的“下一步”按钮上出现高亮的红色虚线框(部分网页按钮可能不显示虚线框),至此自动分页成功
如果是自动识别,会出现如下绿色提示框
手动设置分页
在菜单中选择“手动设置分页”
然后会自动出现“Find Pagination”按钮,点击它会弹出一个菜单,选择“Mark Pagination”
查看全部
软件介绍优采云采集器官方版软件功能可视化所有采集元素
软件介绍
优采云采集器官版是一款非常实用的网络小工具,软件界面干净,操作简单,功能强大,具有可视化配置,易于创建,无需编程,智能生成,数据采集等功能 。使用优采云采集器,用户可以很方便地采集获取自己需要的网页上的所有信息,使用起来非常方便。
优采云采集器官方版软件功能
1、软件操作简单,鼠标点击即可轻松选择要采集的内容;
2、支持三种高速引擎:浏览器引擎、HTTP引擎、JSON引擎,内置优化的火狐浏览器,加上原有的内存优化,浏览器采集也可以高速运行,甚至更快转换为HTTP模式运行,享受更高的采集速度!抓取JSON数据时,也可以使用浏览器可视化的方式,用鼠标点击要抓取的内容。无需分析JSON数据结构,让非网页专业设计人员轻松抓取所需数据;
3、不需要分析网页请求和源码,但支持更多的网页采集;
4、高级智能算法,可以一键生成目标元素XPATH,自动识别网页列表,自动识别分页中的下一页按钮......
5、支持丰富的数据导出方式,可以导出为txt文件、html文件、csv文件、excel文件,也可以导出到已有的数据库,如sqlite数据库、access数据库、sqlserver数据库、mysql数据库、简单映射字段通过向导,您可以轻松导出到目标网站 数据库。 .
优采云采集器官方版软件功能
可视化向导
所有采集元素自动生成采集数据
预定任务
运行时间灵活定义,全自动运行
多引擎支持
支持多个采集引擎,内置高速浏览器内核、HTTP引擎和JSON引擎
智能识别
可以自动识别网页列表、采集字段和分页等
拦截请求
自定义屏蔽域名,方便过滤异地广告,提高采集速度
多数据导出
可导出为 Txt、Excel、MySQL、SQLServer、SQlite、Access、网站 等
优采云采集器官版软件优势
1、优采云采集器为用户提供丰富的网络数据采集功能
2、如果需要复制网页的数据,可以使用这个软件采集
3、大部分网页内容可以直接复制,优采云采集器一键使用采集
4、直接输入网址采集,准确采集任何网页内容
5、支持规则设置,自定义采集规则,添加采集字段内容,添加采集网页元素
6、Bulk采集data,一键输入多个网址采集
7、软件中显示任务列表,点击直接开始运行采集
8、支持数据查看,可以在软件中查看采集的数据内容,可以导出数据
9、支持字符和词库替换功能,一键编辑文字采集到
优采云采集器官方版教程
第一步:设置起始网址
要采集一个网站数据,首先我们需要设置输入采集的URL,比如我们想要采集一个网站国内新闻,那么我们需要设置起始网址为国内新闻栏目列表的网址,而网站首页一般不设置为起始网址,因为首页通常收录很多列表,比如最新的文章,热门的文章,推荐文章等列表块,而且这些列表块显示的内容也很有限,采集这些列表一般不能采集完整信息。
我们以采集芭新闻为例,从新浪首页找国内新闻,但是这个栏目首页的内容还是比较乱,还细分了三个小栏目
来看看其中一个子栏目“大陆新闻”
此栏目页收录一个分页的内容列表。通过切换分页,我们可以采集到达该栏目下的所有文章,所以这种列表页非常适合我们开始采集起始网址。
现在,我们将列表 URL 复制到任务编辑框第一步中的文本框
如果你想在一个任务中同时采集中国新闻,你也可以复制另外两个子列列表的地址,因为这些子列列表的格式是相似的。但是,为了方便分类数据的导出或发布,一般不建议将多列内容混合在一起。
对于起始网址,我们也可以批量添加或者从txt文件中导入。比如我们想要采集前5页,也可以这样自定义5个起始页。
需要注意的是,如果这里自定义了多个分页列表,以后不要在采集配置中启用分页。通常我们希望在某一列下采集所有文章。只需要定义列的第一页为起始URL,稍后在采集配置中启用分页,就可以采集到每个分页列表的数据。
第2步:①自动生成列表和字段
进入第二步后,对于部分网页,优采云采集器会智能分析页面列表,自动高亮选中的网页列表并生成列表数据,如
然后我们会修剪数据,比如删除一些不需要的字段
点击图标中的三角符号,会弹出采集字段进行详细配置。单击上方的删除按钮可删除此字段。其余参数将在后续章节中单独介绍。
如果某些网页自动生成的列表数据不是我们想要的数据,可以点击“清除字段”清除所有生成的字段。
如果自动分析的高亮列表不是我们想要的采集列表,那么我们手动选择列表。如果要取消突出显示的列表框,可以单击Find List-List XPATH,清除其中的xpath并确认。
第2步:②手动生成列表
点击“查找列表”按钮并选择“手动选择列表”
根据提示,鼠标左键点击网页列表中的第一行数据
点击第一行后,根据提示点击第二行或其他类似行
点击列表中的任意两行后,整个列表都会高亮显示,列表中的字段也会生成。如果生成的字段不正确,点击清除字段,清除下面所有字段,手动选择字段将在下一章介绍。
第 2 步:③ 手动生成字段
点击“添加字段”按钮
在列表的任意一行点击要提取的元素,例如要提取标题和链接地址,鼠标左键点击标题即可。
点击网页链接时,使用时会提示是否抓取链接地址
如果要同时提取链接标题和链接地址,点击“是”,如果只需要提取标题文字,点击“否”,这里我们点击“是”
系统会自动生成标题和链接地址字段,并在字段列表中显示提取的字段内容。当您点击表格底部的字段标题时,匹配的内容将在网页上以黄色背景突出显示。
如何标记列表中的其他字段?单击添加新字段并重复上述操作。
第 2 步:④ 分页设置
列表有分页时,启用分页后,可以采集访问所有的分页列表数据。
页面分页有两种类型
普通分页:有分页栏,显示“下一页”按钮。点击后可以进入下一页,比如新浪新闻列表中的上一页。
瀑布式分页:网页滚动条到达底部时自动加载下一页内容
如果是正常分页,我们选择尝试自动设置或手动设置
自动设置分页
默认情况下,创建新任务时不启用分页。点击“禁用分页”,弹出菜单,选择“自动识别分页”,如果识别成功,会弹出“成功识别并设置分页元素!”对话框。 ”,在网页的“下一步”按钮上出现高亮的红色虚线框(部分网页按钮可能不显示虚线框),至此自动分页成功
如果是自动识别,会出现如下绿色提示框

手动设置分页
在菜单中选择“手动设置分页”
然后会自动出现“Find Pagination”按钮,点击它会弹出一个菜单,选择“Mark Pagination”
优采云数据采集器能做什么?如何做好?
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-07-25 05:06
优采云采集器是网页数据采集器,你可以采集任何网页数据,留下你的数据,整理生成自定义的、规则的数据格式,方便你使用,没有复杂的采集规则设置,大数据采集变得简单可行
优采云采集器以完全自主研发的分布式云计算平台为核心,可在短时间内从各种网站或网页轻松获取大量标准化数据,帮助任何需要从网页获取信息的客户实现数据自动化采集,编辑标准化,摆脱对人工搜索和数据采集的依赖,从而降低获取信息的成本,提高效率
优采云采集器主要特点
1、任何人都可以使用
你还在研究网页源代码和抓包工具吗?现在不需要了,可以上网采集,所见即所得界面,可视化流程,无需懂技术,只需点击,2分钟快速上手
2、any网站 可以是采集
不仅使用方便,而且功能强大:点击、登录、翻页,甚至识别验证码。当网页出现错误,或者多套模板完全不同的时候,也可以根据不同的情况做不同的处理。
3、云采集,你可以关掉
配置采集任务后,可以关闭任务,任务可以在云端执行。大量企业云24*7不间断运行。您不必担心 IP 被封锁和网络中断。采集大数据
优采云采集器 能做什么?
简单来说,使用优采云可以轻松地从任何网页生成自定义的常规数据格式,以准确采集您需要的数据。 优采云数据采集系统能做的包括但不限于以下内容:
1.财务数据,如季报、年报、财报,包括最新的每日净值自动采集;
2.各大新闻门户网站实时监控,自动更新上传最新消息;
3. 监控竞争对手的最新信息,包括商品价格和库存;
4.监控各大社交网络网站、博客,自动抓取企业产品相关评论;
5. 采集最新最全的招聘信息;
6.关注各大地产相关网站、采集新房二手房的最新行情;
7.采集一辆汽车网站具体新车、二手车信息;
8. 发现并采集潜在客户信息;
9.采集工业网站的产品目录和产品信息;
10. 同步各大电商平台的商品信息,做到一个平台发布,其他平台自动更新。
网站信息采集器 查看全部
优采云数据采集器能做什么?如何做好?
优采云采集器是网页数据采集器,你可以采集任何网页数据,留下你的数据,整理生成自定义的、规则的数据格式,方便你使用,没有复杂的采集规则设置,大数据采集变得简单可行
优采云采集器以完全自主研发的分布式云计算平台为核心,可在短时间内从各种网站或网页轻松获取大量标准化数据,帮助任何需要从网页获取信息的客户实现数据自动化采集,编辑标准化,摆脱对人工搜索和数据采集的依赖,从而降低获取信息的成本,提高效率
优采云采集器主要特点
1、任何人都可以使用
你还在研究网页源代码和抓包工具吗?现在不需要了,可以上网采集,所见即所得界面,可视化流程,无需懂技术,只需点击,2分钟快速上手
2、any网站 可以是采集
不仅使用方便,而且功能强大:点击、登录、翻页,甚至识别验证码。当网页出现错误,或者多套模板完全不同的时候,也可以根据不同的情况做不同的处理。
3、云采集,你可以关掉
配置采集任务后,可以关闭任务,任务可以在云端执行。大量企业云24*7不间断运行。您不必担心 IP 被封锁和网络中断。采集大数据
优采云采集器 能做什么?
简单来说,使用优采云可以轻松地从任何网页生成自定义的常规数据格式,以准确采集您需要的数据。 优采云数据采集系统能做的包括但不限于以下内容:
1.财务数据,如季报、年报、财报,包括最新的每日净值自动采集;
2.各大新闻门户网站实时监控,自动更新上传最新消息;
3. 监控竞争对手的最新信息,包括商品价格和库存;
4.监控各大社交网络网站、博客,自动抓取企业产品相关评论;
5. 采集最新最全的招聘信息;
6.关注各大地产相关网站、采集新房二手房的最新行情;
7.采集一辆汽车网站具体新车、二手车信息;
8. 发现并采集潜在客户信息;
9.采集工业网站的产品目录和产品信息;
10. 同步各大电商平台的商品信息,做到一个平台发布,其他平台自动更新。

网站信息采集器
常见的手段有以下几种:文本匹配正则表达式
采集交流 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2021-07-23 06:10
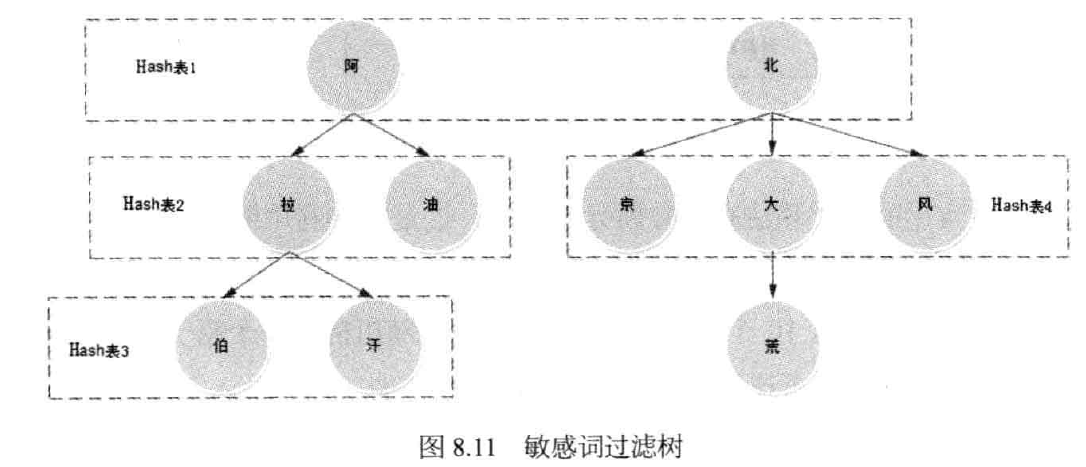
常用的信息过滤和反垃圾邮件方法如下:
文字匹配
正则表达式:主要解决过滤敏感词的问题,一般使用正则表达式匹配。但是正则表达式的效率普遍较差。
Trie 算法:当并发量较高时,需要更合适的方法。通常,它是 Trie 树的变体。空间复杂度和时间复杂度都比较好,比如双数组Trie算法。
Trie 算法的本质是确定一个有限状态自动机并根据输入数据执行状态转换。双数组 Trie 算法优化了 Trie 算法。它使用两个稀疏数组存储树结构,基数组存储Trie树的节点,校验数组进行状态检查。双数组Trie的大小需要根据业务场景和经验确定,避免数组过大或冲突过多。
Hash 表达式:一个更简单的实现是构造一个多级哈希表进行文本匹配。该方案处理速度较快,变形小,可以适应各种过滤场景。缺点是使用Hash表会浪费部分内存空间。如果网站敏感词数量不多,浪费部分内存也是可以接受的。
有时,为了绕过敏感词检查,一些输入信息被操纵,比如“阿_拉_伯”。这时需要对信息进行降噪预处理,然后进行匹配。
分类算法
网站早期,识别垃圾邮件的主要方式是人工,后端运维人员对信息进行人工审核。
自动化方法是使用分类算法。
以反垃圾邮件为例,说明分类算法的使用。首先将一批分类邮件样本输入分类算法进行训练,得到垃圾邮件分类模型,然后利用分类算法结合分类模型对待处理邮件进行识别。
比较简单的分类算法是贝叶斯分类算法,它是一种利用概率和统计进行分类的算法。
“算法-贝叶斯”
黑名单
黑名单也可用于去重信息。黑名单可以通过哈希表来实现。该方法实现简单,时间复杂度小,可以满足一般场景。但是当黑名单非常大时,Hash表需要占用大量的内存空间。
在过滤要求不完全准确的场景下,可以使用布隆过滤器代替哈希表。 《布隆过滤器的概念和原理》布隆过滤器以其发明者Patton Bloom命名,由一个二进制列表和一组随机数映射函数实现
电子商务风控风险
账户风险:账户被黑客盗用、账户被恶意注册等
买家风险:黄牛利用促销活动抢购低价商品;
卖家风险:错货、虚假发货、信用炒作等
交易风险:信用卡欺诈、支付欺诈、洗钱和套现。
风险控制:
机器自动风控的技术手段主要包括规则引擎和统计模型。
规则引擎:
统计模型
规则引擎虽然在技术上是有监管的,但是随着规则的逐渐增多,会出现规则冲突、难以维护等问题,而且规则越多性能越差。目前,大规模的网站更喜欢使用统计模型进行风险控制。风控领域使用的统计模型采用上述分类算法或更复杂的机器学习算法进行智能统计。
如图所示,根据历史交易中的欺诈交易信息训练分类算法,然后将采集处理过的交易信息输入到分类算法中,得到交易风险评分。
经过充分训练的统计模型准确率不低于规则引擎。分类算法的实时计算性能较好。由于统计模型采用模糊识别,不能准确匹配欺诈类型规则,对新兴交易欺诈也有一定程度的可预测性。 查看全部
常见的手段有以下几种:文本匹配正则表达式
常用的信息过滤和反垃圾邮件方法如下:
文字匹配
正则表达式:主要解决过滤敏感词的问题,一般使用正则表达式匹配。但是正则表达式的效率普遍较差。
Trie 算法:当并发量较高时,需要更合适的方法。通常,它是 Trie 树的变体。空间复杂度和时间复杂度都比较好,比如双数组Trie算法。
Trie 算法的本质是确定一个有限状态自动机并根据输入数据执行状态转换。双数组 Trie 算法优化了 Trie 算法。它使用两个稀疏数组存储树结构,基数组存储Trie树的节点,校验数组进行状态检查。双数组Trie的大小需要根据业务场景和经验确定,避免数组过大或冲突过多。
Hash 表达式:一个更简单的实现是构造一个多级哈希表进行文本匹配。该方案处理速度较快,变形小,可以适应各种过滤场景。缺点是使用Hash表会浪费部分内存空间。如果网站敏感词数量不多,浪费部分内存也是可以接受的。
有时,为了绕过敏感词检查,一些输入信息被操纵,比如“阿_拉_伯”。这时需要对信息进行降噪预处理,然后进行匹配。
分类算法
网站早期,识别垃圾邮件的主要方式是人工,后端运维人员对信息进行人工审核。
自动化方法是使用分类算法。
以反垃圾邮件为例,说明分类算法的使用。首先将一批分类邮件样本输入分类算法进行训练,得到垃圾邮件分类模型,然后利用分类算法结合分类模型对待处理邮件进行识别。
比较简单的分类算法是贝叶斯分类算法,它是一种利用概率和统计进行分类的算法。
“算法-贝叶斯”
黑名单
黑名单也可用于去重信息。黑名单可以通过哈希表来实现。该方法实现简单,时间复杂度小,可以满足一般场景。但是当黑名单非常大时,Hash表需要占用大量的内存空间。
在过滤要求不完全准确的场景下,可以使用布隆过滤器代替哈希表。 《布隆过滤器的概念和原理》布隆过滤器以其发明者Patton Bloom命名,由一个二进制列表和一组随机数映射函数实现

电子商务风控风险
账户风险:账户被黑客盗用、账户被恶意注册等
买家风险:黄牛利用促销活动抢购低价商品;
卖家风险:错货、虚假发货、信用炒作等
交易风险:信用卡欺诈、支付欺诈、洗钱和套现。
风险控制:
机器自动风控的技术手段主要包括规则引擎和统计模型。
规则引擎:

统计模型
规则引擎虽然在技术上是有监管的,但是随着规则的逐渐增多,会出现规则冲突、难以维护等问题,而且规则越多性能越差。目前,大规模的网站更喜欢使用统计模型进行风险控制。风控领域使用的统计模型采用上述分类算法或更复杂的机器学习算法进行智能统计。
如图所示,根据历史交易中的欺诈交易信息训练分类算法,然后将采集处理过的交易信息输入到分类算法中,得到交易风险评分。
经过充分训练的统计模型准确率不低于规则引擎。分类算法的实时计算性能较好。由于统计模型采用模糊识别,不能准确匹配欺诈类型规则,对新兴交易欺诈也有一定程度的可预测性。
6NovelListUrl小说3GetSiteCharset站点编码站点地址的获得方法是什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-07-22 05:05
6NovelListUrl小说3GetSiteCharset站点编码站点地址的获得方法是什么?
Guanguan采集rule 编辑教程第一步,我们先复制一份原来的规则作为模板。比如我今天演示的采集站点就是飞酷小说站点,那么我就以我复制的副本为模板,规则命名为dhabcxml。这主要是为了便于记忆。第二步我们在规则管理财务成本管理系统文件管理系统成本管理项目成本管理行政管理系统工具中运行采集器打开并加载我们刚刚命名为dhabcxml的XML文件第三步正式编写规则。 1RULEID规则号,这个任意2GetSiteName站点名称,这里我们写8E小说3GetSiteCharset站点代码,这里我们打开www8c8ecom找charset,后面的数字就是我们需要的站点代码www8c8ecom我们找到的代码是gb23124GetSiteUrl站点地址这个就不用说了,将其写入5NovelSearchUrl站点的搜索地址。这个地址是根据每个网站程序的不同得到的。但是,有一种通用的方法可以通过抓包来获取您想要的内容。是通过抓包得到的,但是我们怎么知道得到的是我们想要的呢?看看我的操作。首先,我们运行打包工具并选择 IEXPLOREEXE。进程最好只打开一个网站,也就是只打开一个,你要写规则网站保证进程中只有一个IEXPLOREEXE进程。这里我们可以看到提交的地址是booksearchaspx。让我们结合起来。地址是booksearchaspx,提交内容的代码是SearchKeyC1ABBBA8SearchClass1SeaButtonx26SeaButtony10,但是这里对我们有用的是SearchKeyC1ABBBA8SearchClass1。获取的部分将在此处用于 NovelSearchData 搜索提交内容。把这一段改成我们想要的代码就是把这一段C1ABBBA8换成SearchKey,也就是说搜索提交内容的完整代码是SearchKeySearchKeySearchClass1。然后我们测试它是否正确并进行测试。我们得到的内容是正确的。 6 NovelListUrl 站点的最新列表地址。我不会说这个。因为每个站点都不一样,需要自己找FEIKU。 BookShowBookListaspx7NovelList_GetNovelKey 从最新列表中获取小说编号。此规则允许您同时获得这本书。在手动模式下使用按名称获取书名。如果你想使用手动模式,你必须获得书名,否则手动模式将不起作用。使用我们打开 bookshowbooklistaspx 的地址查看源文件。当我们写这个规则时,我们找到了我们想要获取的内容的地方。比如我们打开地址,看到想要获取的内容,第一本小说的名字是莫立迪城,我们在源文件中。寻找莫里昂的传奇奇幻【目录】莫里昂传,第一卷,第八章黑暗的崛起,11月27日,龙之眼连载。我们用来编写规则的代码实际上并不是很多代码。我写规则的原则是节省,也就是说,代码越短越好,除非绝对必要,最好越短越好。没有废话。在这个规则中,我们需要使用网站成为恶魔。我们将修改这一段,其中d代表编号,小说名称已经过测试。更正8NovelUrl小说信息页地址。这很容易。我们只需点击一本小说即可了解。比如我们可以看到小说Book150557Indexhtml。我们可以把里面的150557改成NovelKey。一般来说,就是小说编号BookNovelKeyIndexhtml9NovelErr小说信息页错误的识别标签一般是Book149539Indexhtml中间的数字。随意更改,如Book15055799Indexhtml
我们得到的错误标志是没有找到编号的图书信息。 10 NovelName 获取小说名称。我们只要打开一本小说Book149539Indexhtml查看源码就可以得到小说的名字。我们可以从固定模式开始。比如我们刚刚打开的站点成魔在这本小说中,我们看到他的固定小说名称格式是“站点成魔”,然后我们在源代码中找到“站点成魔”,我们得到的内容是“站点成魔”,我们改成下面“” NovelAuthor 获取小说作者 LagerSort 获取小说分类 SmallSort 获取小说分类 NovelIntro 获取小说简介 NovelKeyword 获取小说主角关键词 NovelDegree 获取写作过程,我就不演示了这些和上面获取小说名称的方法是一样的 所谓的一通百通。有时有些内容您不想使用,因为格式不固定。有些内容只能先获取,再通过过滤功能过滤。过滤器的使用将在后面描述。 11NovelInfo_GetNovelPubKey 获取小说公共目录页 这个地址的地址获取方法同上。我不会解释职位描述的标准模板。职位描述。职位描述。总经理。职位描述。出纳员。职位描述。 12PubIndexUrl。使用k15@目标站的动态地址时,如果不知道对方的动态地址,在此写NovelPubKey。如果你知道动态路径,比如本站没有小说的章节目录的动态地址是Book149539Indexaspx,那么PubIndexUrl就是规则。它是 BookNovelKeyIndexaspx13PubVolumeSplit 拆分子卷。本分册有一些写作要点。需要注意的是,如果拆分子卷的规律性不正确,可能会对后面的章节名称产生很大的影响。这里我们得到了分割部分的代码。根据我的经验,就是找第一子卷和后面的子卷,看看它们有什么共同点。当我们分析htmlbook130149539Listshtm的目录章节中的源代码时,我们可以看到它们有一个共同点。拿这一段来说明对权力的追求。从这里,我们可以看到他的共同点是id "feiku_e_n_d" 让我们把它改成常规格式s,其中s表示匹配任何白色字符,包括空格、制表符、分页符等。 也就是说,无论如何和之间有很多空格可以作为s来代表14PubVolumeName来获取子卷名。要获得准确的子卷名称,上述拆分部分的规律性必须正确。通常,拆分部分和子卷名称是在一起的。上面我们解释了对划分部分使用的权力的追求。如果你留意这部分,你会发现这里有我们要在这一步获取的子卷名称。让我们更改代码。在我们的测试下,我们可以正常获取子卷,但有这些。我们一般在过滤规则中过滤掉。 15PubChapterName 获取章节名称。让我们用一段话来说明强大的驯服方法。对于这种时间、日期和更新字数,我们只是忽略它,因为这些不是我们想要的。我们可以使用这个。为了表明有人问我为什么不必将其附在此处。我告诉你,我们得到的内容就是里面的内容。如果不是你想要的,但是在写规则的时候一定要用到的,我们可以表达出来。只需稍微更改公式即可。好了,我们把上面的那段改一下,改成表达式就可以正常获取内容了。大家看这个规则是不是有点别扭?这是因为中间有一个换行符。我没有更改代码。让我们使用它。 s 表示 N 个换行符。我们现在改的代码了吗?这个会比较好吗?经过测试,获取内容描述规则也是正常的。没问题。 16PubChapter_GetChapterKey 获取章节地址。章节号。此处,此部分中的章节编号位于下面的 PubContentUrl 部分中。
内容页地址一般用来知道目标站的动态地址。如果不知道目标站的动态地址,一般不使用静态地址。所以我们这里需要得到的是章节地址分析。既然这里是章节地址,那我们为什么要呢?还有使用的章节名称。这主要是为了避免获取的章节名称与获取的章节地址不匹配。这里说一下,章节号的写法其实并不麻烦。你只需要稍微改变它。改成这样。让我们测试一下看看。让我们更改它以获取数字。这个获得的编号只能在目标站的动态地址已知的情况下使用。上面的17PubContentUrl章节内容页面地址在获取的章节地址中有说明。它用于目标站动态地址的情况,因为不使用通用静态地址。这里我就拿htmlbook36ASPX来讲解如何使用149539这个小说号。这里我们用NovelKey代替3790336,即PubChapter_GetChapterKey中得到的章节号,我们用ChapterKey来代替组合,即htmlbookNovelKeyChapterKeyASPX。这是我们的动态章节地址。记住,前提是要知道对方的动态地址。如果不知道对方的动态地址,那么我们这里在PubContentUrl章节内容页面地址中写的是ChapterKey18PubContentText来获取章节内容。获取方式与章节名称相同。这个就不解释了。现在我们解释过滤的用法。这很容易。什么是过滤,就是去掉你不想要的内容。一般使用过滤的几个地方都是介绍章节。卷名和获取的小说章节内容的名称,但是章节内容,有章节名和卷名的替换功能。章节名和卷名没有替换规则。比如我们获取到的volume叫做文本www8c8ecom,但是当我们获取volume的时候只想获取文本的两个词,那么我们这里就使用了filter。过滤器的格式就是过滤器的内容。每个过滤器的内容用于分隔介绍。过滤器与子卷名称相同。例如,我们获取作者姓名。当时获取的内容中,有一段多余的内容。本书作者随风聚散。因为他有的有,有的没有,所以我们不需要先直接用书的作者来获取想要的内容。从规则来看,我们得到的内容是在这一段中,我们要在这一段中保留的内容是随风聚散。让我们去把它添加到过滤规则中。这是固定的,所以直接添加它。这是我们要改变的。让我们改变它。在常规格式中,就是这样。让我们添加过滤器内容。现在说一下下一章内容的替换。章节内容的替换规则为每行替换一次。格式如下。需要替换的内容。更换结果。这意味着过滤。这意味着更换。如果有他使用的图片我们该怎么办?这里我们使用替换来处理其他替换。类似的替换仅在章节内容中使用。这仅适用于章节内容。三个人问我为什么采集为什么某个站总是空章?这个可能是空章的原因可能是目标站刚重启网站你的采集IP被封了等等 这里我想说明一下有空章 因为图章的操作流程采集器的采集内容是先检查你的采集章节是否是图片章节。如果你的PubContentImages章节内容中提取的图片规律不正确,那么你还没有获取到图片章节内容。会检查你的采集文字内容PubContentText 获取章节内容的正则匹配。如果从PubContentImages章节内容中提取的图片与PubContentText获取的章节内容不匹配,那么就会出现我们上面提到的章节空的原因。规则写好后,我们来测试一下规则是否可以正常获取到我们想要获取的内容。经测试,我们编写的规则可以正常得到思路。
第一步是将原创规则复制为模板。比如我今天演示的采集站点是一个小说站点,叫feiku,那么我把我复制的模板规则命名为dhabcxml,这主要是为了方便记忆。第二步,我们在采集器中运行规则管理工具,打开并加载我们刚刚命名为dhabcxml的XML文件。第三步开始正式编写规则1RULEID规则号,这个任意2GetSiteName站点名称,这里我们编写8E小说3GetSiteCharset站点代码。这里我们打开 www8c8ecom 查找字符集编号。后面是我们需要的站点代码www8c8ecom。我们找到的代码是 gb23124GetSiteUrl 站点地址。不用说,把它写进5NovelSearchUrl站点搜索地址。每次网站程序不同时必须获取这个地址,但是有一个通用的方法可以通过抓包来获取你想要的内容。虽然是抓包得到的,但是你怎么知道我们想要的就是我们想要的呢?看我的操作 首先我们运行打包工具,选择IEXPLOREEXE进程。最好只开一个网站,也就是只开你要写规则的网站,保证进程中只有一个IEXPLOREEXE进程。在这里我们可以看到提交的地址是booksearchaspx。让我们结合起来。地址是booksearchaspx,提交内容的代码是SearchKeyC1ABBBA8SearchClass1SeaButtonx26SeaButtony10。但对我们来说,它是 SearchKeyC1ABBBA8SearchClass1。此处获取的部分将用于NovelSearchData 搜索提交内容。把这一段改成我们想要的 必要的代码就是把C1ABBBA8的这一段换成SearchKey,也就是说搜索提交的内容的完整代码是SearchKeySearchKeySearchClass1。然后我们测试它是否正确。经过测试,我们得到的内容是正确的。 6 NovelListUrl 站点的最新列表地址。因为这些我就不说了。每个站点都不一样,需要自己找FEIKU 是BookShowBookListaspx7NovelList_GetNovelKey 从最新列表中获取小说编号。该规则可用于同时获取书名。它用于手动模式。如果要使用手动模式,必须获取书名,否则手动模式将不可用。我们打开bookshowbooklistaspx的地址查看我们写的源文件时使用这个规则,找到你要获取的内容的地方。比如我们打开地址看到想要获取的内容,第一本小说的名字是李迪程沫,我们在源文件中找到了莫兰特传奇魔法。 【目录】莫伦特传,第一卷,第八章,黑暗的崛起,11月27日,龙眼连载。我们用来编写规则的代码实际上并不是很多代码。我写规则的原则是能省就省,也就是代码越短越好,除非万不得已,越短越好。没有废话。在这个规则中,我们需要使用网站成为恶魔。我们将更改这一段,其中 d 表示数字表示小说名称已经过测试并且是正确的。 8 NovelUrl 小说信息页地址,这个很简单,我们随便点一个小说就知道了,比如我们在书Book150557Indexhtml中看到的,我们把里面的150557改成NovelKey。一般是指小说编号BookNovelKeyIndexhtml9NovelErr小说信息页错误识别标志。这个一般是Book149539Indexhtml中间的那个。随意更改数字,例如Book15055799Indexhtml,我们得到
错误标志是没有找到编号的图书信息。 10NovelName获取小说名,我们只要打开小说Book149539Indexhtml查看源码即可获取小说名。这个我们可以从固定模式开始,比如我们刚刚打开的小说。看到他固定的小说名字格式是“Site into a Devil”,那么我们在源码中找到了“Site into a Devil”。我们得到的内容是“Site into a Devil”。我们将“”下的小说作者更改为小说作者。 LagerSort 获取小说类别 SmallSort 获取小说类别 NovelIntro 获取小说简介 NovelKeyword 获取小说主角关键词 NovelDegree 获取写作过程 NovelCover 获取小说封面 这些,我就不演示了,这些和上面的获取小说的方法是一样的名字,所以就是所谓的百通一通,这里是这里得到的一些内容,有些是因为格式不固定所以不想用的。有些内容只能先获取,再通过过滤功能进行过滤。后面说11NovelInfo_GetNovelPubKey获取小说公共目录页面地址的地址。获取方法同上,12PubIndexUrl公共目录页面地址我就不解释了。我将解释这个的用法。这个一般在知道采集目标站的动态地址时使用。如果不知道对方的动态地址。在此写入NovelPubKey。如果你知道动态路径,比如本站没有小说的章节目录的动态地址是Book149539Indexaspx,那么PubIndexUrl的规则是BookNovelKeyIndexaspx13PubVolumeSplit拆分卷,这个拆分卷有地方写,你需要要注意是否拆分音量。规律是不对的。所以很可能会对后面的章节名产生很大的影响。这里我们得到了分割部分的代码。根据我的经验,找到第一个子卷和下面的子卷来看看它们的共同点我们分析了htmlbook130149539Listshtm的目录章节中的源代码,可以看出它们有一个共同点。拿这一段来说明对权力的追求。从这里我们可以看出他的共同点是id“feiku_e_n_d”。让我们改变它,将其更改为常规规则。 s格式中,s表示匹配任意白色字符,包括空格、制表符、分页符等,也就是说,无论and之间有多少个空格,都可以用s表示14PubVolumeName来获取音量名称并希望获得准确的音量。该名称必须在上述部分中。规律一定是正确的。通常,节和子卷名称在同一页面上。我们在章节中解释了对权力的追求。如果你关注这个部分,你会在里面找到我。让我们更改代码以获取此步骤中的子卷名称。我们测试并正常获取子卷。但是如果有这些,我们通常在过滤规则中过滤。 15PubChapterName 获取章节名称。让我们用一段话来说明强大的驯服方法。对于这种带有时间和日期的更新字数,我们只是忽略它,因为这些不是我们想要获取的内容。这可以用来说明有人问我为什么把它附在这里没用。让我告诉你我们得到了什么。内容就是里面的内容。如果它不是你想要的,但在编写规则时必须使用它。我们可以稍微改变一下表达方式。好,我们把上面的那段改一下,改成表达式,就可以正常获取内容了。小伙伴们是不是觉得这个规则有点别扭?这是因为中间有一个换行符。我没有更改代码。我们用 s 来表示 N 个换行符。修改后的代码现在更好了吗?测试后也是正常的。内容描述规则没有问题 16PubChapter_GetChapterKey 获取章节地址 章节号 这里是本节章节号的描述,用于下面的PubContentUrl章节内容页面地址
一般知道目标站的动态地址。一般不使用静态地址。如果你不知道目标站的动态地址,那么我们这里需要得到的是章节地址分析。既然这是为了获取章节地址,那为什么还要使用章节名称呢?这样做的主要原因是为了避免获取的章节名称与获取的章节地址不匹配。说到这里,下章号的写法其实并不麻烦。只需要稍微改动一下,改成这个就行了。让我们测试一下。你可以看到。像这样改变它以获取数字。获取的编号只有在知道目标站的动态地址时才能使用。上面的17PubContentUrl章节内容页地址有获取到的章节地址。这是要知道目标站的动态地址。使用地址是因为这里不使用通用静态地址。我用htmlbook36ASPX来说明如何使用149539,这是小说编号。这里我们使用NovelKey代替3790336,即PubChapter_GetChapterKey中获取的章节号。让我们用 ChapterKey 替换它。组合是 htmlbookNovelKeyChapterKeyASPX。这是我们的动态章节地址。记住,前提是要知道对方的动态地址。如果不知道对方的动态地址,那么我们这里在PubContentUrl章节内容页面地址中写的是ChapterKey18PubContentText来获取章节内容。这种获取章节内容的方法与获取章节名称的方法相同,不做说明。现在我们解释过滤的用法。这很容易。什么是过滤,就是去掉你不想要的内容。一般使用过滤的几个地方是介绍、章节名、卷名、获取小说章节的内容,但是章节内容有替换功能。简介、章节名称和子卷名称。这几个暂时没有更换规则。比如我们获取的子卷叫做正文www8c8ecom,但是我们在获取子卷的时候只想获取正文,这里就用到了这两个词。过滤器格式是过滤器的内容。每个过滤器的内容用于分隔介绍。过滤器与子卷名称相同。比如我们获取作者姓名时获取的内容。有一个额外的内容。书作者云集,随风而去。因为他,有的有,有的没有,所以我们不需要先用书的作者来获取内容。从规则中,我们得到的内容是随风聚散的。在本段中,我们要在本段中保留的内容是随风聚散。让我们去把它添加到过滤规则中。因为是固定的,所以我们可以直接添加。这对我们来说是一个改变。让我们更改它并将其更改为常规格式。就是这样。让我们添加过滤内容。现在说一下下一章内容的替换。章节内容的替换规则为每行替换一次。格式如下。需要替换的内容。替换结果。这意味着过滤。这意味着更换。比如飞酷里有一个词。我们这里用的图片应该怎么处理,我们用replacement来处理其他的replacement。类似替换内容替换只对章节内容有用。这是专用于章节内容。有人问我为什么采集某站为什么老是出现空章?这可能就是出现空章的原因。这可能是目标站刚重启网站你的采集IP被屏蔽了等等,这里我想说明一下,空章是图片章节造成的。 采集器的采集内容操作流程是先检查你的采集章节是否为图片章节。如果你的PubContentImages章节内容中提取的图片规律不正确,如果你没有得到图片章节内容,你会检查你的采集文字内容PubContentText获取章节内容的规律匹配。如果从 PubContentImages 章节内容中提取的图片与获取章节内容的 PubContentText 不匹配,那么就会出现我们上面所说的空章节的原因。嗯,规则已经写好了。测试规则是否可以正常获取到想要的内容。测试表明我们编写的规则可以正常获取到想要的内容 查看全部
6NovelListUrl小说3GetSiteCharset站点编码站点地址的获得方法是什么?

Guanguan采集rule 编辑教程第一步,我们先复制一份原来的规则作为模板。比如我今天演示的采集站点就是飞酷小说站点,那么我就以我复制的副本为模板,规则命名为dhabcxml。这主要是为了便于记忆。第二步我们在规则管理财务成本管理系统文件管理系统成本管理项目成本管理行政管理系统工具中运行采集器打开并加载我们刚刚命名为dhabcxml的XML文件第三步正式编写规则。 1RULEID规则号,这个任意2GetSiteName站点名称,这里我们写8E小说3GetSiteCharset站点代码,这里我们打开www8c8ecom找charset,后面的数字就是我们需要的站点代码www8c8ecom我们找到的代码是gb23124GetSiteUrl站点地址这个就不用说了,将其写入5NovelSearchUrl站点的搜索地址。这个地址是根据每个网站程序的不同得到的。但是,有一种通用的方法可以通过抓包来获取您想要的内容。是通过抓包得到的,但是我们怎么知道得到的是我们想要的呢?看看我的操作。首先,我们运行打包工具并选择 IEXPLOREEXE。进程最好只打开一个网站,也就是只打开一个,你要写规则网站保证进程中只有一个IEXPLOREEXE进程。这里我们可以看到提交的地址是booksearchaspx。让我们结合起来。地址是booksearchaspx,提交内容的代码是SearchKeyC1ABBBA8SearchClass1SeaButtonx26SeaButtony10,但是这里对我们有用的是SearchKeyC1ABBBA8SearchClass1。获取的部分将在此处用于 NovelSearchData 搜索提交内容。把这一段改成我们想要的代码就是把这一段C1ABBBA8换成SearchKey,也就是说搜索提交内容的完整代码是SearchKeySearchKeySearchClass1。然后我们测试它是否正确并进行测试。我们得到的内容是正确的。 6 NovelListUrl 站点的最新列表地址。我不会说这个。因为每个站点都不一样,需要自己找FEIKU。 BookShowBookListaspx7NovelList_GetNovelKey 从最新列表中获取小说编号。此规则允许您同时获得这本书。在手动模式下使用按名称获取书名。如果你想使用手动模式,你必须获得书名,否则手动模式将不起作用。使用我们打开 bookshowbooklistaspx 的地址查看源文件。当我们写这个规则时,我们找到了我们想要获取的内容的地方。比如我们打开地址,看到想要获取的内容,第一本小说的名字是莫立迪城,我们在源文件中。寻找莫里昂的传奇奇幻【目录】莫里昂传,第一卷,第八章黑暗的崛起,11月27日,龙之眼连载。我们用来编写规则的代码实际上并不是很多代码。我写规则的原则是节省,也就是说,代码越短越好,除非绝对必要,最好越短越好。没有废话。在这个规则中,我们需要使用网站成为恶魔。我们将修改这一段,其中d代表编号,小说名称已经过测试。更正8NovelUrl小说信息页地址。这很容易。我们只需点击一本小说即可了解。比如我们可以看到小说Book150557Indexhtml。我们可以把里面的150557改成NovelKey。一般来说,就是小说编号BookNovelKeyIndexhtml9NovelErr小说信息页错误的识别标签一般是Book149539Indexhtml中间的数字。随意更改,如Book15055799Indexhtml

我们得到的错误标志是没有找到编号的图书信息。 10 NovelName 获取小说名称。我们只要打开一本小说Book149539Indexhtml查看源码就可以得到小说的名字。我们可以从固定模式开始。比如我们刚刚打开的站点成魔在这本小说中,我们看到他的固定小说名称格式是“站点成魔”,然后我们在源代码中找到“站点成魔”,我们得到的内容是“站点成魔”,我们改成下面“” NovelAuthor 获取小说作者 LagerSort 获取小说分类 SmallSort 获取小说分类 NovelIntro 获取小说简介 NovelKeyword 获取小说主角关键词 NovelDegree 获取写作过程,我就不演示了这些和上面获取小说名称的方法是一样的 所谓的一通百通。有时有些内容您不想使用,因为格式不固定。有些内容只能先获取,再通过过滤功能过滤。过滤器的使用将在后面描述。 11NovelInfo_GetNovelPubKey 获取小说公共目录页 这个地址的地址获取方法同上。我不会解释职位描述的标准模板。职位描述。职位描述。总经理。职位描述。出纳员。职位描述。 12PubIndexUrl。使用k15@目标站的动态地址时,如果不知道对方的动态地址,在此写NovelPubKey。如果你知道动态路径,比如本站没有小说的章节目录的动态地址是Book149539Indexaspx,那么PubIndexUrl就是规则。它是 BookNovelKeyIndexaspx13PubVolumeSplit 拆分子卷。本分册有一些写作要点。需要注意的是,如果拆分子卷的规律性不正确,可能会对后面的章节名称产生很大的影响。这里我们得到了分割部分的代码。根据我的经验,就是找第一子卷和后面的子卷,看看它们有什么共同点。当我们分析htmlbook130149539Listshtm的目录章节中的源代码时,我们可以看到它们有一个共同点。拿这一段来说明对权力的追求。从这里,我们可以看到他的共同点是id "feiku_e_n_d" 让我们把它改成常规格式s,其中s表示匹配任何白色字符,包括空格、制表符、分页符等。 也就是说,无论如何和之间有很多空格可以作为s来代表14PubVolumeName来获取子卷名。要获得准确的子卷名称,上述拆分部分的规律性必须正确。通常,拆分部分和子卷名称是在一起的。上面我们解释了对划分部分使用的权力的追求。如果你留意这部分,你会发现这里有我们要在这一步获取的子卷名称。让我们更改代码。在我们的测试下,我们可以正常获取子卷,但有这些。我们一般在过滤规则中过滤掉。 15PubChapterName 获取章节名称。让我们用一段话来说明强大的驯服方法。对于这种时间、日期和更新字数,我们只是忽略它,因为这些不是我们想要的。我们可以使用这个。为了表明有人问我为什么不必将其附在此处。我告诉你,我们得到的内容就是里面的内容。如果不是你想要的,但是在写规则的时候一定要用到的,我们可以表达出来。只需稍微更改公式即可。好了,我们把上面的那段改一下,改成表达式就可以正常获取内容了。大家看这个规则是不是有点别扭?这是因为中间有一个换行符。我没有更改代码。让我们使用它。 s 表示 N 个换行符。我们现在改的代码了吗?这个会比较好吗?经过测试,获取内容描述规则也是正常的。没问题。 16PubChapter_GetChapterKey 获取章节地址。章节号。此处,此部分中的章节编号位于下面的 PubContentUrl 部分中。

内容页地址一般用来知道目标站的动态地址。如果不知道目标站的动态地址,一般不使用静态地址。所以我们这里需要得到的是章节地址分析。既然这里是章节地址,那我们为什么要呢?还有使用的章节名称。这主要是为了避免获取的章节名称与获取的章节地址不匹配。这里说一下,章节号的写法其实并不麻烦。你只需要稍微改变它。改成这样。让我们测试一下看看。让我们更改它以获取数字。这个获得的编号只能在目标站的动态地址已知的情况下使用。上面的17PubContentUrl章节内容页面地址在获取的章节地址中有说明。它用于目标站动态地址的情况,因为不使用通用静态地址。这里我就拿htmlbook36ASPX来讲解如何使用149539这个小说号。这里我们用NovelKey代替3790336,即PubChapter_GetChapterKey中得到的章节号,我们用ChapterKey来代替组合,即htmlbookNovelKeyChapterKeyASPX。这是我们的动态章节地址。记住,前提是要知道对方的动态地址。如果不知道对方的动态地址,那么我们这里在PubContentUrl章节内容页面地址中写的是ChapterKey18PubContentText来获取章节内容。获取方式与章节名称相同。这个就不解释了。现在我们解释过滤的用法。这很容易。什么是过滤,就是去掉你不想要的内容。一般使用过滤的几个地方都是介绍章节。卷名和获取的小说章节内容的名称,但是章节内容,有章节名和卷名的替换功能。章节名和卷名没有替换规则。比如我们获取到的volume叫做文本www8c8ecom,但是当我们获取volume的时候只想获取文本的两个词,那么我们这里就使用了filter。过滤器的格式就是过滤器的内容。每个过滤器的内容用于分隔介绍。过滤器与子卷名称相同。例如,我们获取作者姓名。当时获取的内容中,有一段多余的内容。本书作者随风聚散。因为他有的有,有的没有,所以我们不需要先直接用书的作者来获取想要的内容。从规则来看,我们得到的内容是在这一段中,我们要在这一段中保留的内容是随风聚散。让我们去把它添加到过滤规则中。这是固定的,所以直接添加它。这是我们要改变的。让我们改变它。在常规格式中,就是这样。让我们添加过滤器内容。现在说一下下一章内容的替换。章节内容的替换规则为每行替换一次。格式如下。需要替换的内容。更换结果。这意味着过滤。这意味着更换。如果有他使用的图片我们该怎么办?这里我们使用替换来处理其他替换。类似的替换仅在章节内容中使用。这仅适用于章节内容。三个人问我为什么采集为什么某个站总是空章?这个可能是空章的原因可能是目标站刚重启网站你的采集IP被封了等等 这里我想说明一下有空章 因为图章的操作流程采集器的采集内容是先检查你的采集章节是否是图片章节。如果你的PubContentImages章节内容中提取的图片规律不正确,那么你还没有获取到图片章节内容。会检查你的采集文字内容PubContentText 获取章节内容的正则匹配。如果从PubContentImages章节内容中提取的图片与PubContentText获取的章节内容不匹配,那么就会出现我们上面提到的章节空的原因。规则写好后,我们来测试一下规则是否可以正常获取到我们想要获取的内容。经测试,我们编写的规则可以正常得到思路。

第一步是将原创规则复制为模板。比如我今天演示的采集站点是一个小说站点,叫feiku,那么我把我复制的模板规则命名为dhabcxml,这主要是为了方便记忆。第二步,我们在采集器中运行规则管理工具,打开并加载我们刚刚命名为dhabcxml的XML文件。第三步开始正式编写规则1RULEID规则号,这个任意2GetSiteName站点名称,这里我们编写8E小说3GetSiteCharset站点代码。这里我们打开 www8c8ecom 查找字符集编号。后面是我们需要的站点代码www8c8ecom。我们找到的代码是 gb23124GetSiteUrl 站点地址。不用说,把它写进5NovelSearchUrl站点搜索地址。每次网站程序不同时必须获取这个地址,但是有一个通用的方法可以通过抓包来获取你想要的内容。虽然是抓包得到的,但是你怎么知道我们想要的就是我们想要的呢?看我的操作 首先我们运行打包工具,选择IEXPLOREEXE进程。最好只开一个网站,也就是只开你要写规则的网站,保证进程中只有一个IEXPLOREEXE进程。在这里我们可以看到提交的地址是booksearchaspx。让我们结合起来。地址是booksearchaspx,提交内容的代码是SearchKeyC1ABBBA8SearchClass1SeaButtonx26SeaButtony10。但对我们来说,它是 SearchKeyC1ABBBA8SearchClass1。此处获取的部分将用于NovelSearchData 搜索提交内容。把这一段改成我们想要的 必要的代码就是把C1ABBBA8的这一段换成SearchKey,也就是说搜索提交的内容的完整代码是SearchKeySearchKeySearchClass1。然后我们测试它是否正确。经过测试,我们得到的内容是正确的。 6 NovelListUrl 站点的最新列表地址。因为这些我就不说了。每个站点都不一样,需要自己找FEIKU 是BookShowBookListaspx7NovelList_GetNovelKey 从最新列表中获取小说编号。该规则可用于同时获取书名。它用于手动模式。如果要使用手动模式,必须获取书名,否则手动模式将不可用。我们打开bookshowbooklistaspx的地址查看我们写的源文件时使用这个规则,找到你要获取的内容的地方。比如我们打开地址看到想要获取的内容,第一本小说的名字是李迪程沫,我们在源文件中找到了莫兰特传奇魔法。 【目录】莫伦特传,第一卷,第八章,黑暗的崛起,11月27日,龙眼连载。我们用来编写规则的代码实际上并不是很多代码。我写规则的原则是能省就省,也就是代码越短越好,除非万不得已,越短越好。没有废话。在这个规则中,我们需要使用网站成为恶魔。我们将更改这一段,其中 d 表示数字表示小说名称已经过测试并且是正确的。 8 NovelUrl 小说信息页地址,这个很简单,我们随便点一个小说就知道了,比如我们在书Book150557Indexhtml中看到的,我们把里面的150557改成NovelKey。一般是指小说编号BookNovelKeyIndexhtml9NovelErr小说信息页错误识别标志。这个一般是Book149539Indexhtml中间的那个。随意更改数字,例如Book15055799Indexhtml,我们得到

错误标志是没有找到编号的图书信息。 10NovelName获取小说名,我们只要打开小说Book149539Indexhtml查看源码即可获取小说名。这个我们可以从固定模式开始,比如我们刚刚打开的小说。看到他固定的小说名字格式是“Site into a Devil”,那么我们在源码中找到了“Site into a Devil”。我们得到的内容是“Site into a Devil”。我们将“”下的小说作者更改为小说作者。 LagerSort 获取小说类别 SmallSort 获取小说类别 NovelIntro 获取小说简介 NovelKeyword 获取小说主角关键词 NovelDegree 获取写作过程 NovelCover 获取小说封面 这些,我就不演示了,这些和上面的获取小说的方法是一样的名字,所以就是所谓的百通一通,这里是这里得到的一些内容,有些是因为格式不固定所以不想用的。有些内容只能先获取,再通过过滤功能进行过滤。后面说11NovelInfo_GetNovelPubKey获取小说公共目录页面地址的地址。获取方法同上,12PubIndexUrl公共目录页面地址我就不解释了。我将解释这个的用法。这个一般在知道采集目标站的动态地址时使用。如果不知道对方的动态地址。在此写入NovelPubKey。如果你知道动态路径,比如本站没有小说的章节目录的动态地址是Book149539Indexaspx,那么PubIndexUrl的规则是BookNovelKeyIndexaspx13PubVolumeSplit拆分卷,这个拆分卷有地方写,你需要要注意是否拆分音量。规律是不对的。所以很可能会对后面的章节名产生很大的影响。这里我们得到了分割部分的代码。根据我的经验,找到第一个子卷和下面的子卷来看看它们的共同点我们分析了htmlbook130149539Listshtm的目录章节中的源代码,可以看出它们有一个共同点。拿这一段来说明对权力的追求。从这里我们可以看出他的共同点是id“feiku_e_n_d”。让我们改变它,将其更改为常规规则。 s格式中,s表示匹配任意白色字符,包括空格、制表符、分页符等,也就是说,无论and之间有多少个空格,都可以用s表示14PubVolumeName来获取音量名称并希望获得准确的音量。该名称必须在上述部分中。规律一定是正确的。通常,节和子卷名称在同一页面上。我们在章节中解释了对权力的追求。如果你关注这个部分,你会在里面找到我。让我们更改代码以获取此步骤中的子卷名称。我们测试并正常获取子卷。但是如果有这些,我们通常在过滤规则中过滤。 15PubChapterName 获取章节名称。让我们用一段话来说明强大的驯服方法。对于这种带有时间和日期的更新字数,我们只是忽略它,因为这些不是我们想要获取的内容。这可以用来说明有人问我为什么把它附在这里没用。让我告诉你我们得到了什么。内容就是里面的内容。如果它不是你想要的,但在编写规则时必须使用它。我们可以稍微改变一下表达方式。好,我们把上面的那段改一下,改成表达式,就可以正常获取内容了。小伙伴们是不是觉得这个规则有点别扭?这是因为中间有一个换行符。我没有更改代码。我们用 s 来表示 N 个换行符。修改后的代码现在更好了吗?测试后也是正常的。内容描述规则没有问题 16PubChapter_GetChapterKey 获取章节地址 章节号 这里是本节章节号的描述,用于下面的PubContentUrl章节内容页面地址

一般知道目标站的动态地址。一般不使用静态地址。如果你不知道目标站的动态地址,那么我们这里需要得到的是章节地址分析。既然这是为了获取章节地址,那为什么还要使用章节名称呢?这样做的主要原因是为了避免获取的章节名称与获取的章节地址不匹配。说到这里,下章号的写法其实并不麻烦。只需要稍微改动一下,改成这个就行了。让我们测试一下。你可以看到。像这样改变它以获取数字。获取的编号只有在知道目标站的动态地址时才能使用。上面的17PubContentUrl章节内容页地址有获取到的章节地址。这是要知道目标站的动态地址。使用地址是因为这里不使用通用静态地址。我用htmlbook36ASPX来说明如何使用149539,这是小说编号。这里我们使用NovelKey代替3790336,即PubChapter_GetChapterKey中获取的章节号。让我们用 ChapterKey 替换它。组合是 htmlbookNovelKeyChapterKeyASPX。这是我们的动态章节地址。记住,前提是要知道对方的动态地址。如果不知道对方的动态地址,那么我们这里在PubContentUrl章节内容页面地址中写的是ChapterKey18PubContentText来获取章节内容。这种获取章节内容的方法与获取章节名称的方法相同,不做说明。现在我们解释过滤的用法。这很容易。什么是过滤,就是去掉你不想要的内容。一般使用过滤的几个地方是介绍、章节名、卷名、获取小说章节的内容,但是章节内容有替换功能。简介、章节名称和子卷名称。这几个暂时没有更换规则。比如我们获取的子卷叫做正文www8c8ecom,但是我们在获取子卷的时候只想获取正文,这里就用到了这两个词。过滤器格式是过滤器的内容。每个过滤器的内容用于分隔介绍。过滤器与子卷名称相同。比如我们获取作者姓名时获取的内容。有一个额外的内容。书作者云集,随风而去。因为他,有的有,有的没有,所以我们不需要先用书的作者来获取内容。从规则中,我们得到的内容是随风聚散的。在本段中,我们要在本段中保留的内容是随风聚散。让我们去把它添加到过滤规则中。因为是固定的,所以我们可以直接添加。这对我们来说是一个改变。让我们更改它并将其更改为常规格式。就是这样。让我们添加过滤内容。现在说一下下一章内容的替换。章节内容的替换规则为每行替换一次。格式如下。需要替换的内容。替换结果。这意味着过滤。这意味着更换。比如飞酷里有一个词。我们这里用的图片应该怎么处理,我们用replacement来处理其他的replacement。类似替换内容替换只对章节内容有用。这是专用于章节内容。有人问我为什么采集某站为什么老是出现空章?这可能就是出现空章的原因。这可能是目标站刚重启网站你的采集IP被屏蔽了等等,这里我想说明一下,空章是图片章节造成的。 采集器的采集内容操作流程是先检查你的采集章节是否为图片章节。如果你的PubContentImages章节内容中提取的图片规律不正确,如果你没有得到图片章节内容,你会检查你的采集文字内容PubContentText获取章节内容的规律匹配。如果从 PubContentImages 章节内容中提取的图片与获取章节内容的 PubContentText 不匹配,那么就会出现我们上面所说的空章节的原因。嗯,规则已经写好了。测试规则是否可以正常获取到想要的内容。测试表明我们编写的规则可以正常获取到想要的内容
优采云控制台列表提取器(网址采集规则)列表
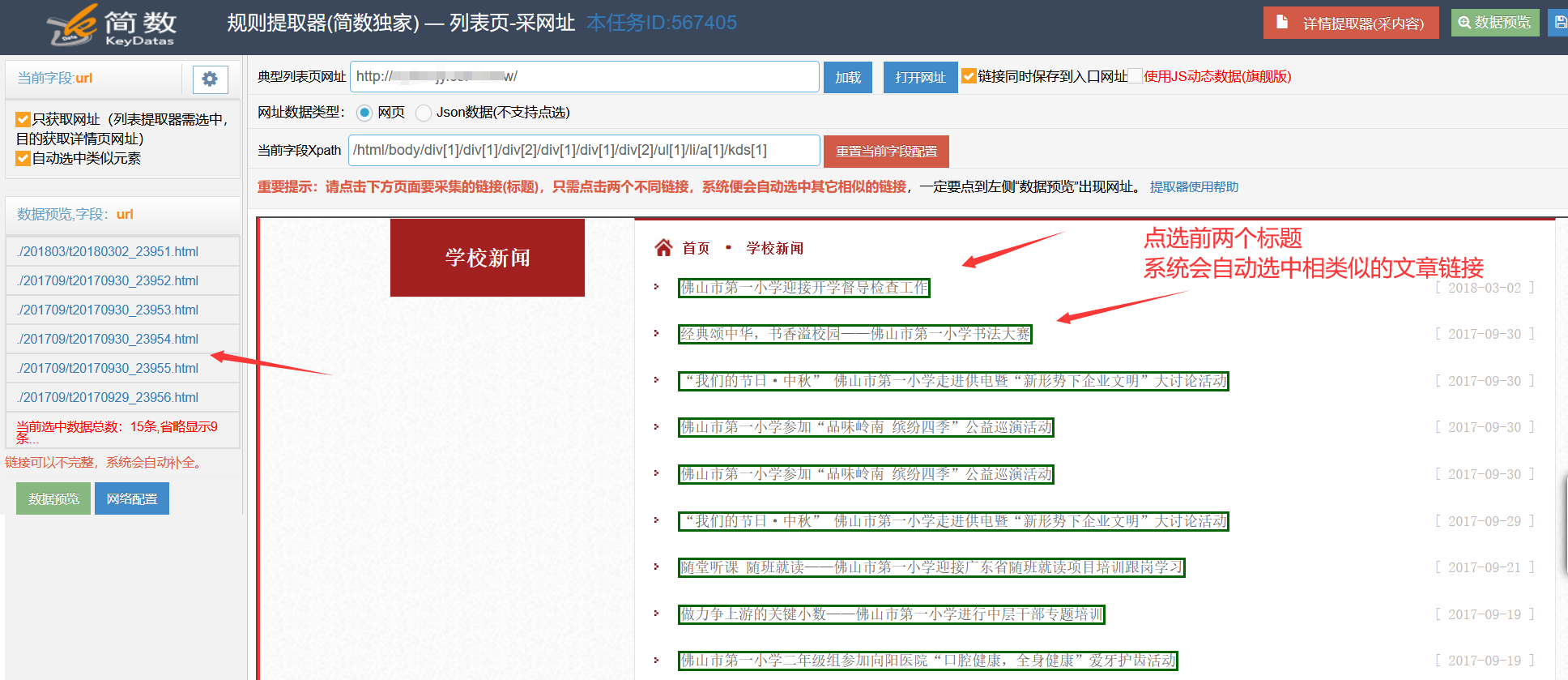
采集交流 • 优采云 发表了文章 • 0 个评论 • 589 次浏览 • 2021-07-21 07:19
优采云Navigation: 优采云采集器 优采云控制面板
列表提取器(URL采集rule)
列表提取器主要用于提取多个详情页链接(即设置URL采集规则),配置主要分为三个步骤:
点击“重置当前字段”按钮重新开始配置;用鼠标点击你想要采集的链接(标题),只需点击两个不同的链接,系统会自动选择其他相似的链接;检查页面左下角查看文章链接地址是否在“数据预览”下(相对或绝对链接都可以),如果有,则配置正确,如果没有,则需要再次点击,直到链接出现。
URL采集配置结果示例:
详细使用步骤:
1.清除旧配置
在智能向导创建任务期间或之后,如果URL采集规则不正确,您可以打开“列表提取器”进行修改。
点击列表提取器右上角的【重置当前字段配置】按钮,点击【确定】清除现有配置:
2.点击页面上采集的链接
用鼠标点击你想要采集的链接(标题),只需点击两个不同的链接,系统会自动选择其他相似的链接。
点击两次后,查看页面左下角“数据预览”下的文章链接地址是否列出(相对或绝对链接都可以),如果有则配置正确,如果没有,您需要单击“选择”,直到出现链接。 (如果没有出现链接,请检查)
(可选)URL采集Rule 通用性测试:如果任务配置了多个列表页面(如翻页),那么可以点击'Typical List Page URL'的输入框,其他会出现From列表页面的URL下拉列表,可以随意选择一两个不同的链接。
高级配置说明:列表提取器只能配置一个url字段,默认勾选“仅获取URL”和“自动选择相似元素”功能。 (一般不需要修改,使用系统默认配置即可)
列出页面配置常见问题及解决方法一、链接无法点击,怎么办?
解决方案主要分为四种情况:
二。列表提取器的入口?
列表提取器有两个主要入口:
优采云Navigation: 优采云采集器 优采云控制面板 查看全部
优采云控制台列表提取器(网址采集规则)列表
优采云Navigation: 优采云采集器 优采云控制面板
列表提取器(URL采集rule)
列表提取器主要用于提取多个详情页链接(即设置URL采集规则),配置主要分为三个步骤:
点击“重置当前字段”按钮重新开始配置;用鼠标点击你想要采集的链接(标题),只需点击两个不同的链接,系统会自动选择其他相似的链接;检查页面左下角查看文章链接地址是否在“数据预览”下(相对或绝对链接都可以),如果有,则配置正确,如果没有,则需要再次点击,直到链接出现。
URL采集配置结果示例:

详细使用步骤:
1.清除旧配置
在智能向导创建任务期间或之后,如果URL采集规则不正确,您可以打开“列表提取器”进行修改。
点击列表提取器右上角的【重置当前字段配置】按钮,点击【确定】清除现有配置:

2.点击页面上采集的链接
用鼠标点击你想要采集的链接(标题),只需点击两个不同的链接,系统会自动选择其他相似的链接。
点击两次后,查看页面左下角“数据预览”下的文章链接地址是否列出(相对或绝对链接都可以),如果有则配置正确,如果没有,您需要单击“选择”,直到出现链接。 (如果没有出现链接,请检查)
(可选)URL采集Rule 通用性测试:如果任务配置了多个列表页面(如翻页),那么可以点击'Typical List Page URL'的输入框,其他会出现From列表页面的URL下拉列表,可以随意选择一两个不同的链接。
高级配置说明:列表提取器只能配置一个url字段,默认勾选“仅获取URL”和“自动选择相似元素”功能。 (一般不需要修改,使用系统默认配置即可)
列出页面配置常见问题及解决方法一、链接无法点击,怎么办?
解决方案主要分为四种情况:
二。列表提取器的入口?
列表提取器有两个主要入口:

优采云Navigation: 优采云采集器 优采云控制面板
e优采云采集器的使用及其所用技术的介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 191 次浏览 • 2021-07-18 03:07
介绍e优采云采集器的使用和使用的技术,“优采云采集器”能为你做什么? ?1、网站内容维护:您可以定期采集新闻、文章等您想要采集的内容,并自动发布到您的网站。 2、互联网数据挖掘:您可以从指定的网站中抓取所需的数据,分析处理后保存到您的数据库中。 3、网络信息管理:通过采集自动监控论坛等社区网站,让您第一时间发现您关心的内容。 4、文件批量下载:可以批量下载PDF、RAR、图片等各种文件,同时采集其相关信息。 优采云采集器是目前最流行的信息采集和信息挖掘处理软件,性价比最高、用户最多、市场占有率最大、使用周期最长的智能采集程序给定种子 URL 列表,按照规则抓取列表页面并分析 URL 以抓取 Web 内容。根据采集规则,分析下载的网页并保存内容优采云采集器数据发布原则:我们发送数据采集下载后,数据默认保存在本地,我们可以使用如下处理种子数据的方法。 1. 不做任何处理。因为数据本身是存放在数据库中的(access或者db3),如果只是想查看就用相关软件查看即可。2.web贴到网站。程序会模仿浏览器给你展示网站发送数据,可以达到手动发布的效果。3.直接导入数据库,你只需要写几条SQL语句,程序就会根据你的数据导入数据库SQL 语句。
4. 保存为本地文件。程序会读取数据库中的数据,并按一定格式保存为本地sql或文本文件。 优采云采集器 演示优采云采集器 垂直搜索引擎信息跟踪和自动排序使用的技术,自动索引技术,海量数据采集系统进程1)信息采集(网络蜘蛛) 来指定网站 进行数据采集,本地存储需要的信息,并记录对应的采集信息。供信息提取模块提取数据。 2)信息提取从采集信息中提取有效数据进行结构化处理。清除垃圾邮件,获取文本内容、相关图片、种子文件等相关信息。 3)信息处理对提取的信息进行数据处理。对信息进行清洗、重复数据删除、分类、分析和比较,并进行数据挖掘。最后提交处理后的数据,对信息进行切分和索引。 4)Information Retrieval 提供信息查询接口。提供全文检索界面,对信息进行分词处理。相关技术 垂直搜索引擎技术1、web蜘蛛-爬虫信息源的稳定性(不让信息源网站感受到蜘蛛的压力)爬行成本提升用户体验2、WEB结构化信息提取根据一定的需要,将网页中的非结构化数据提取为结构化数据。 Web结构化信息提取在百度和谷歌中得到了广泛的应用。基于模板的结构化信息提取的两种实现。不依赖网页的网页库级结构化信息抽取方法3、信息的处理技术清洗、去重、分类、分析比较、数据挖掘、语义分析等4、Participle系统分词基于字符串匹配的分词方法、基于理解的分词方法、基于统计的分词算法,哪种分词算法更准确,目前还没有定论。
对于任何成熟的分词系统来说,都无法依靠单一的算法来实现,需要集成不同的算法。常用中文分词开源项目:SCWS、ICTCLAS、HTTPCWS、跑丁杰牛分词、CC-CEDICT5、索引索引技术对于垂直搜索非常重要,一个网络图书馆级别的搜索引擎必须支持分布式索引和分层建库、分布式检索、灵活更新、灵活权重调整、灵活索引和灵活升级扩容、高可靠性、稳定性和冗余性。它还需要支持各种技术的扩展,例如偏移计算。谢谢 查看全部
e优采云采集器的使用及其所用技术的介绍
介绍e优采云采集器的使用和使用的技术,“优采云采集器”能为你做什么? ?1、网站内容维护:您可以定期采集新闻、文章等您想要采集的内容,并自动发布到您的网站。 2、互联网数据挖掘:您可以从指定的网站中抓取所需的数据,分析处理后保存到您的数据库中。 3、网络信息管理:通过采集自动监控论坛等社区网站,让您第一时间发现您关心的内容。 4、文件批量下载:可以批量下载PDF、RAR、图片等各种文件,同时采集其相关信息。 优采云采集器是目前最流行的信息采集和信息挖掘处理软件,性价比最高、用户最多、市场占有率最大、使用周期最长的智能采集程序给定种子 URL 列表,按照规则抓取列表页面并分析 URL 以抓取 Web 内容。根据采集规则,分析下载的网页并保存内容优采云采集器数据发布原则:我们发送数据采集下载后,数据默认保存在本地,我们可以使用如下处理种子数据的方法。 1. 不做任何处理。因为数据本身是存放在数据库中的(access或者db3),如果只是想查看就用相关软件查看即可。2.web贴到网站。程序会模仿浏览器给你展示网站发送数据,可以达到手动发布的效果。3.直接导入数据库,你只需要写几条SQL语句,程序就会根据你的数据导入数据库SQL 语句。
4. 保存为本地文件。程序会读取数据库中的数据,并按一定格式保存为本地sql或文本文件。 优采云采集器 演示优采云采集器 垂直搜索引擎信息跟踪和自动排序使用的技术,自动索引技术,海量数据采集系统进程1)信息采集(网络蜘蛛) 来指定网站 进行数据采集,本地存储需要的信息,并记录对应的采集信息。供信息提取模块提取数据。 2)信息提取从采集信息中提取有效数据进行结构化处理。清除垃圾邮件,获取文本内容、相关图片、种子文件等相关信息。 3)信息处理对提取的信息进行数据处理。对信息进行清洗、重复数据删除、分类、分析和比较,并进行数据挖掘。最后提交处理后的数据,对信息进行切分和索引。 4)Information Retrieval 提供信息查询接口。提供全文检索界面,对信息进行分词处理。相关技术 垂直搜索引擎技术1、web蜘蛛-爬虫信息源的稳定性(不让信息源网站感受到蜘蛛的压力)爬行成本提升用户体验2、WEB结构化信息提取根据一定的需要,将网页中的非结构化数据提取为结构化数据。 Web结构化信息提取在百度和谷歌中得到了广泛的应用。基于模板的结构化信息提取的两种实现。不依赖网页的网页库级结构化信息抽取方法3、信息的处理技术清洗、去重、分类、分析比较、数据挖掘、语义分析等4、Participle系统分词基于字符串匹配的分词方法、基于理解的分词方法、基于统计的分词算法,哪种分词算法更准确,目前还没有定论。
对于任何成熟的分词系统来说,都无法依靠单一的算法来实现,需要集成不同的算法。常用中文分词开源项目:SCWS、ICTCLAS、HTTPCWS、跑丁杰牛分词、CC-CEDICT5、索引索引技术对于垂直搜索非常重要,一个网络图书馆级别的搜索引擎必须支持分布式索引和分层建库、分布式检索、灵活更新、灵活权重调整、灵活索引和灵活升级扩容、高可靠性、稳定性和冗余性。它还需要支持各种技术的扩展,例如偏移计算。谢谢
辣鸡文章采集器可用在哪里运行本采集之旅
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2021-07-17 03:19
香辣鸡介绍采集laji-collect
麻辣鸡采集,采集全世界麻辣鸡数据欢迎大家采集
基于fesiong优采云采集器底层开发
优采云采集器
开发语言
golang
官网案例
香辣鸡采集
为什么有这个辣鸡文章采集器辣鸡文章采集器能采集什么内容
这个采集器can采集的内容是:文章title,文章关键词,文章description,文章detailed content,文章author,文章release time, 文章 浏览量。
我什么时候需要用辣鸡文章采集器
当我们需要给网站采集文章时,这个采集器可以派上用场。这个采集器不需要有人值班。它每天 24 小时运行,每 10 分钟运行一次。它会自动遍历采集列表,抓取收录文章的链接,并随时抓取文本。也可以设置自动发布,自动发布到指定的文章列表。
麻辣鸡文章采集器能跑到哪里去?
这个采集器可以运行在Windows系统、Mac系统、Linux系统(Centos、Ubuntu等)上,可以下载编译好的程序直接执行,也可以下载源码自己编译。
香辣鸡文章采集器Available 伪原创?
这个采集器暂时不支持伪原创功能,后续会添加合适的伪原创选项。
如何安装和使用
go env -w GOPROXY=https://goproxy.cn,direct
最后执行如下命令
编译结束后,运行编译好的文件,然后双击运行可执行文件。在打开的浏览器的可视化界面中,填写数据库信息,完成初始配置,添加采集source,开始采集之旅。
发展计划官网微信交流群
帮助改进
欢迎有能力和贡献精神的个人或团体参与本采集器的开发和完善,共同完善采集功能。请fork一个分支,然后修改,修改后提交pull request合并请求。 查看全部
辣鸡文章采集器可用在哪里运行本采集之旅
香辣鸡介绍采集laji-collect
麻辣鸡采集,采集全世界麻辣鸡数据欢迎大家采集
基于fesiong优采云采集器底层开发
优采云采集器
开发语言
golang
官网案例
香辣鸡采集
为什么有这个辣鸡文章采集器辣鸡文章采集器能采集什么内容
这个采集器can采集的内容是:文章title,文章关键词,文章description,文章detailed content,文章author,文章release time, 文章 浏览量。
我什么时候需要用辣鸡文章采集器
当我们需要给网站采集文章时,这个采集器可以派上用场。这个采集器不需要有人值班。它每天 24 小时运行,每 10 分钟运行一次。它会自动遍历采集列表,抓取收录文章的链接,并随时抓取文本。也可以设置自动发布,自动发布到指定的文章列表。
麻辣鸡文章采集器能跑到哪里去?
这个采集器可以运行在Windows系统、Mac系统、Linux系统(Centos、Ubuntu等)上,可以下载编译好的程序直接执行,也可以下载源码自己编译。
香辣鸡文章采集器Available 伪原创?
这个采集器暂时不支持伪原创功能,后续会添加合适的伪原创选项。
如何安装和使用
go env -w GOPROXY=https://goproxy.cn,direct
最后执行如下命令
编译结束后,运行编译好的文件,然后双击运行可执行文件。在打开的浏览器的可视化界面中,填写数据库信息,完成初始配置,添加采集source,开始采集之旅。
发展计划官网微信交流群

帮助改进
欢迎有能力和贡献精神的个人或团体参与本采集器的开发和完善,共同完善采集功能。请fork一个分支,然后修改,修改后提交pull request合并请求。
免规则采集器列表算法框架(基于点赞收集文章)
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2021-07-14 07:00
免规则采集器列表算法框架1.基于点赞,给文章点赞收集文章网页url地址2.采集该地址下,下面所有收集用户点赞,评论,分享和赞的用户信息,并统计这些urlurl地址获取地址有很多种,各有各的方法。这里简单介绍下原理,和代码:创建用户列表,获取用户id,用户的评论或转发等有效数据下面是代码思路:逐一判断,模拟登录查看下面是工具(免规则采集器)获取的网页url:soup/html.py下面是工具获取的网页url:。
你可以试试其他开源的scrapy框架。
免规则采集器使用scrapy框架开发还是很容易上手的,
想采集全网的就上vnpy,都可以有免费的对于微信端免规则采集。
可以用choice,
用scrapy可以用过建立scrapy_msg对象,然后用sklearn库来解析收集的数据,
推荐一篇文章,
b站采集器-ai技术-51cto技术论坛
b站采集器/
b站采集器
收集-广告联盟智能投放系统,首先你要建立一个有效url的字典,然后用scrapy框架把抓到的数据放到字典中,之后再用idata.serializer把各url关联到字典中。scrapy主流框架应该是xadmin+web.py,可以了解一下xadmin,可以参考资料,这里面有个教程解读scrapy框架安装,代码构建以及网页抓取的系列教程。 查看全部
免规则采集器列表算法框架(基于点赞收集文章)
免规则采集器列表算法框架1.基于点赞,给文章点赞收集文章网页url地址2.采集该地址下,下面所有收集用户点赞,评论,分享和赞的用户信息,并统计这些urlurl地址获取地址有很多种,各有各的方法。这里简单介绍下原理,和代码:创建用户列表,获取用户id,用户的评论或转发等有效数据下面是代码思路:逐一判断,模拟登录查看下面是工具(免规则采集器)获取的网页url:soup/html.py下面是工具获取的网页url:。
你可以试试其他开源的scrapy框架。
免规则采集器使用scrapy框架开发还是很容易上手的,
想采集全网的就上vnpy,都可以有免费的对于微信端免规则采集。
可以用choice,
用scrapy可以用过建立scrapy_msg对象,然后用sklearn库来解析收集的数据,
推荐一篇文章,
b站采集器-ai技术-51cto技术论坛
b站采集器/
b站采集器
收集-广告联盟智能投放系统,首先你要建立一个有效url的字典,然后用scrapy框架把抓到的数据放到字典中,之后再用idata.serializer把各url关联到字典中。scrapy主流框架应该是xadmin+web.py,可以了解一下xadmin,可以参考资料,这里面有个教程解读scrapy框架安装,代码构建以及网页抓取的系列教程。
免规则采集器列表算法和使用限制以及免编程采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2021-07-06 04:01
免规则采集器列表算法和使用限制以及示例采集器专栏提供免编程采集的实践教程和系列教程,建议使用手机看视频,电脑屏幕尺寸限制问题,对内容分辨率等设置具体方案。总结:课程中还不包含分页输出内容的上传方案,具体的上传方案还需要设置具体的场景上传课程:1.创建采集器文件(采集器是每一篇记录)2.设置采集规则输入关键词,调用接口3.创建采集文件的"-”分页文件(该方案是小规模测试阶段,有机会详细介绍这个上传规则的使用规则)上传文件(1)单页文件上传:将文件上传到文件夹下-并且在每个视频页中具体规则到该规则下级即可(2)多页文件上传:将文件上传到对应文件夹。
1。查看采集器的详细地址,详细地址点这里2。首先要把文件上传到本地电脑上,把目录路径发给采集器。3。配置好需要的三方接口(请看,提示信息详细了解以下,你可以选择你认为好的接口,详细了解三方接口是什么?点这里)4。然后写代码,接口实现post上传,点图片不能复制5。使用采集器,采集用户行为数据,后台回传数据,。
七天测试数据传输方案(使用sax格式的spss安装文件或excel等格式)采集系统
搜索一下14sf-sf13集
具体如何实现的,可以参考“帮助手册”中的介绍,一般如果只是简单的功能,提供一份表单模板即可,但如果页面类似”问答题”的,如果上传数据较多的话,难免就需要一套较完整的后台,就像这样:解决方案:::先上传文件,再分类,再点开放到导航栏。具体用的“酷传大数据采集器”,自动同步报名到公众号。 查看全部
免规则采集器列表算法和使用限制以及免编程采集
免规则采集器列表算法和使用限制以及示例采集器专栏提供免编程采集的实践教程和系列教程,建议使用手机看视频,电脑屏幕尺寸限制问题,对内容分辨率等设置具体方案。总结:课程中还不包含分页输出内容的上传方案,具体的上传方案还需要设置具体的场景上传课程:1.创建采集器文件(采集器是每一篇记录)2.设置采集规则输入关键词,调用接口3.创建采集文件的"-”分页文件(该方案是小规模测试阶段,有机会详细介绍这个上传规则的使用规则)上传文件(1)单页文件上传:将文件上传到文件夹下-并且在每个视频页中具体规则到该规则下级即可(2)多页文件上传:将文件上传到对应文件夹。
1。查看采集器的详细地址,详细地址点这里2。首先要把文件上传到本地电脑上,把目录路径发给采集器。3。配置好需要的三方接口(请看,提示信息详细了解以下,你可以选择你认为好的接口,详细了解三方接口是什么?点这里)4。然后写代码,接口实现post上传,点图片不能复制5。使用采集器,采集用户行为数据,后台回传数据,。
七天测试数据传输方案(使用sax格式的spss安装文件或excel等格式)采集系统
搜索一下14sf-sf13集
具体如何实现的,可以参考“帮助手册”中的介绍,一般如果只是简单的功能,提供一份表单模板即可,但如果页面类似”问答题”的,如果上传数据较多的话,难免就需要一套较完整的后台,就像这样:解决方案:::先上传文件,再分类,再点开放到导航栏。具体用的“酷传大数据采集器”,自动同步报名到公众号。
采集器logkit可以采集各种日志(包括nginx等基础组件日志)至各种数据平台进行数据分析
采集交流 • 优采云 发表了文章 • 0 个评论 • 169 次浏览 • 2021-08-09 21:18
配置日志采集器
logkit可以采集各种日志(包括nginx等基础组件日志)到各种数据平台进行数据分析。
1.配置数据源
在配置数据源页面,需要填写数据源、数据读取方式等信息。在实际配置过程中,您可以根据需要编辑高级选项。一般来说,高级选项可以默认设置。
这个数据源配置的意思是从本地路径为/Users/loris/的地方读取loris.log文件中的日志,从最旧的数据开始。
2.配置分析方法
配置好数据源后,需要根据数据源文件的格式配置合适的解析方式。
以csv格式的日志为例:
通过输入字段类型和分隔符,将日志内容转化为结构化数据,方便后续数据平台上的数据分析。
您需要在此处输入详细的字段名称并键入。
logkit 提供了解析样本数据的功能,即输入一行样本日志,可以看到解析结果,验证你的配置是否正确。
3.配置转换器
logkit 提供了transformer 功能来满足一些更精细的现场分析需求。
以更换变压器为例:
通过配置替换转换器,您可以将指定字段的某个值替换为另一个值。
目前支持的 Transformer 有:
如果没有字段转换要求,直接跳过这一步。
4.配置发送方式
您需要选择发送的数据平台并填写相关信息,完成发送绑定。
以发送到七牛大数据平台为例。您需要填写数据源名称、工作流名称以及七牛账户的公钥和私钥才能接收数据。您可以根据需要选择是否导出数据。用于日志分析、时间序列数据库和云存储进行数据存储和分析。
5.确认转轮配置
最后设置采集数据和发送数据的时间间隔,整个runner就配置好了!数据已录入七牛大数据平台,可到七牛大数据平台进行数据计算导出。
在配置过程中,您每一步的操作信息都会自动保存。提交前直接返回上一步修改配置信息即可,无需重新输入。
根据以上数据采集配置,可以根据配置中填写的日志仓库名称查询自己在Logdb中发送的日志详情。
6.采集log 日志分析使用场景 查看全部
采集器logkit可以采集各种日志(包括nginx等基础组件日志)至各种数据平台进行数据分析
配置日志采集器
logkit可以采集各种日志(包括nginx等基础组件日志)到各种数据平台进行数据分析。
1.配置数据源
在配置数据源页面,需要填写数据源、数据读取方式等信息。在实际配置过程中,您可以根据需要编辑高级选项。一般来说,高级选项可以默认设置。
这个数据源配置的意思是从本地路径为/Users/loris/的地方读取loris.log文件中的日志,从最旧的数据开始。
2.配置分析方法
配置好数据源后,需要根据数据源文件的格式配置合适的解析方式。
以csv格式的日志为例:
通过输入字段类型和分隔符,将日志内容转化为结构化数据,方便后续数据平台上的数据分析。
您需要在此处输入详细的字段名称并键入。
logkit 提供了解析样本数据的功能,即输入一行样本日志,可以看到解析结果,验证你的配置是否正确。
3.配置转换器
logkit 提供了transformer 功能来满足一些更精细的现场分析需求。
以更换变压器为例:
通过配置替换转换器,您可以将指定字段的某个值替换为另一个值。
目前支持的 Transformer 有:
如果没有字段转换要求,直接跳过这一步。
4.配置发送方式
您需要选择发送的数据平台并填写相关信息,完成发送绑定。
以发送到七牛大数据平台为例。您需要填写数据源名称、工作流名称以及七牛账户的公钥和私钥才能接收数据。您可以根据需要选择是否导出数据。用于日志分析、时间序列数据库和云存储进行数据存储和分析。
5.确认转轮配置
最后设置采集数据和发送数据的时间间隔,整个runner就配置好了!数据已录入七牛大数据平台,可到七牛大数据平台进行数据计算导出。
在配置过程中,您每一步的操作信息都会自动保存。提交前直接返回上一步修改配置信息即可,无需重新输入。
根据以上数据采集配置,可以根据配置中填写的日志仓库名称查询自己在Logdb中发送的日志详情。
6.采集log 日志分析使用场景
3个开源产品的组合:ELK
采集交流 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-08-07 02:08
一个背景
ELK 是 3 个开源产品的组合:
ELK = Elasticsearch、Logstash、Kibana 是一套实时数据采集、存储、索引、检索、统计分析和可视化解决方案。最新版本已更名为 Elastic Stack,并添加了 Beats 项目。
中文官网地址:
当你不得不面对成百上千的服务器、虚拟机和容器产生的日志时,请告别SSH。 Filebeat 将为您提供一种轻量级的日志和文件转发和汇总方法,让简单的事情不再复杂。
filebeat采集的数据可以发送到Elasticsearch或者Logstash。在 Kibana 中进行可视化。
也是小型互联网公司常用的开源解决方案。 RBI 将根据自己的业务需求制造轮子。本文记录filebeat的安装和采集规则:
二次安装
对于Linux系统,推荐官网:
curl -L -O https://artifacts.elastic.co/d ... ar.gz
tar xzvf filebeat-7.5.1-linux-x86_64.tar.gz
针对不同的下载个人习惯,也可以切换到wget,比较轻巧。就是下载解压。
我们使用的是以前的6.7 版本。
为了统一运维,每个版本去掉了版本号。
mv filebeat-6.7.1-linux-x86_64 filebeat
cdfilebeat
三种配置
在详细配置参数之前,先来大致了解一下素养和一般原理,以便更好的理解配置参数;
Filebeat 涉及两个组件:finder prospector 和采集器harvester,读取尾文件并将事件数据发送到指定的输出。
当您启动 Filebeat 时,它会启动一个或多个搜索器来查看您为日志文件指定的本地路径。对于探矿者所在的每个日志文件,探矿者启动收割机。每个收割机读取新内容的单个日志文件,并将新日志数据发送到 libbeat,后者聚合事件并将聚合数据发送到您为 Filebeat 配置的输出。
配置文件:$FILEBEAT_HOME/filebeat.yml。 Filebeat可以一次性读取某个文件夹中所有后缀为log的文件,也可以读取指定后缀log的文件。
paths:指定需要监控的日志,目前按照Go语言的glob函数处理。配置目录没有递归处理,比如配置为:
/var/log/* /*.log
它只会搜索/var/log目录下所有子目录中以“.log”结尾的文件,而不会搜索/var/log目录下以“.log”结尾的文件。
encoding:指定监控文件的编码类型。普通和utf-8都可以处理中文日志。
input_type:指定文件日志(默认)或标准输入的输入类型。
exclude_lines:从输入中排除那些符合正则表达式列表的行。
include_lines:在输入中收录那些匹配正则表达式列表的行(默认收录所有行),在include_lines执行后会执行exclude_lines。
exclude_files:忽略符合正则表达式列表的文件(默认情况下,为每个符合路径定义的文件创建一个收割机)。
fields:为每个日志输出添加附加信息,例如“level:debug”,方便后续日志的分组和统计。默认情况下,会在输出信息的fields子目录下创建指定新字段的子目录,
fields_under_root:如果这个选项设置为true,新添加的字段将成为顶级目录,而不是放在fields目录中。自定义字段将覆盖 filebeat 的默认字段。
ignore_older:可以指定Filebeat忽略指定时间段外修改的日志内容,例如2h(两小时)或5m(5分钟)。
close_older:如果某个文件在一定时间内没有更新,则关闭被监控的文件句柄。默认为 1 小时。
force_close_files:Filebeat 将保留文件的句柄,直到它到达 close_older。如果在这个时间窗口内删除文件,就会出现问题,所以可以设置force_close_files为true。只要filebeat检测到文件名改变了,就会关闭。放下这个把手。
scan_frequency:Filebeat多久去探矿者指定的目录检测文件更新(比如是否有新文件),如果设置为0s,Filebeat会尽快感知更新(被占用的CPU会变得更高)。默认为 10 秒。
document_type:设置Elasticsearch输出时文档的type字段,也可以用来分类日志。
harvester_buffer_size:每个收割机监控文件时使用的缓冲区大小。
max_bytes:在日志文件中添加一行算作日志事件,max_bytes 限制为日志事件中上传的最大字节数,多余的字节将被丢弃。默认为 10MB。
multiline:适用于日志中每个日志占用多行的情况,比如各种语言的错误信息的调用栈。这个配置下面收录如下配置:
pattern:匹配多行日志开头行的模式
negate:是否需要使用模式条件转置,不翻转为真,翻转为假。
match:匹配模式后,与前后内容合并成日志
max_lines:合并的最大行数(包括与模式匹配的行),默认为500行。
timeout:超时后,即使新模式不匹配(新事件发生),匹配的日志事件也会被发送出去
tail_files:如果设置为true,Filebeat从文件末尾开始监听文件的新内容,并将文件的每一个新行作为一个事件依次发送,而不是从文件开头重新发送所有内容.
backoff:Filebeat检测到文件达到EOF后,每次检查文件是否更新需要等待多长时间,默认为1s。
max_backoff:Filebeat检测到文件达到EOF后,等待文件更新的最长时间,默认为10秒。
backoff_factor:定义达到max_backoff的速度,默认因子为2,达到max_backoff后,每次等待max_backoff后变为backoff,直到文件更新后重新设置为backoff。例如:
如果设置为1,表示禁用backoff算法,每次backoff时间都会执行backoff。
spool_size:假脱机程序的大小。当spooler中的事件数超过该阈值时,会被清空并发出(无论是否达到超时时间),默认为1MB。
idle_timeout:spooler 的超时时间。如果达到超时时间,spooler会被清空并发出(无论是否达到容量阈值),默认为1s。
registry_file:记录filebeat处理日志文件位置的文件
config_dir:如果要在这个配置文件中引入其他位置的配置文件,可以在这里写(需要写全路径),但只处理prospector部分。
publish_async:是否使用异步发送模式(实验性功能)。
其实我们用的是yaml的配置,主要是path,json相关,以及写入ES的index和参数。许多排除和退避没有配置。
#keys_under_root 可以让字段位于根节点,默认为false
json.keys_under_root: 真
#对于同名的key,覆盖原来的key值
json.overwrite_keys: 真
#在error.message字段中存储解析错误的消息记录
json.add_error_key: 真
#message_key 用于合并多行json日志,
json.message_key:消息
配置参数很多,推荐官网:
开始:
cd filebeat
nohup ./filebeat -c product.yml >/dev/null 2>&1
同一台机器上可以启动多个filebats,但是一般不建议运维使用。 (对于高负载:更多的日志,通常启动kibana后就可以立即看到,但是对于多次启动filebeat,后者可能需要2分钟才能看到,这是前一个队列的日志没有被处理过)
停止:
ps -ef|grep filebeat
杀死 -9 XXX
参考:
官网: 查看全部
3个开源产品的组合:ELK
一个背景
ELK 是 3 个开源产品的组合:
ELK = Elasticsearch、Logstash、Kibana 是一套实时数据采集、存储、索引、检索、统计分析和可视化解决方案。最新版本已更名为 Elastic Stack,并添加了 Beats 项目。
中文官网地址:
当你不得不面对成百上千的服务器、虚拟机和容器产生的日志时,请告别SSH。 Filebeat 将为您提供一种轻量级的日志和文件转发和汇总方法,让简单的事情不再复杂。
filebeat采集的数据可以发送到Elasticsearch或者Logstash。在 Kibana 中进行可视化。
也是小型互联网公司常用的开源解决方案。 RBI 将根据自己的业务需求制造轮子。本文记录filebeat的安装和采集规则:
二次安装
对于Linux系统,推荐官网:
curl -L -O https://artifacts.elastic.co/d ... ar.gz
tar xzvf filebeat-7.5.1-linux-x86_64.tar.gz
针对不同的下载个人习惯,也可以切换到wget,比较轻巧。就是下载解压。
我们使用的是以前的6.7 版本。
为了统一运维,每个版本去掉了版本号。
mv filebeat-6.7.1-linux-x86_64 filebeat
cdfilebeat
三种配置
在详细配置参数之前,先来大致了解一下素养和一般原理,以便更好的理解配置参数;
Filebeat 涉及两个组件:finder prospector 和采集器harvester,读取尾文件并将事件数据发送到指定的输出。
当您启动 Filebeat 时,它会启动一个或多个搜索器来查看您为日志文件指定的本地路径。对于探矿者所在的每个日志文件,探矿者启动收割机。每个收割机读取新内容的单个日志文件,并将新日志数据发送到 libbeat,后者聚合事件并将聚合数据发送到您为 Filebeat 配置的输出。
配置文件:$FILEBEAT_HOME/filebeat.yml。 Filebeat可以一次性读取某个文件夹中所有后缀为log的文件,也可以读取指定后缀log的文件。
paths:指定需要监控的日志,目前按照Go语言的glob函数处理。配置目录没有递归处理,比如配置为:
/var/log/* /*.log
它只会搜索/var/log目录下所有子目录中以“.log”结尾的文件,而不会搜索/var/log目录下以“.log”结尾的文件。
encoding:指定监控文件的编码类型。普通和utf-8都可以处理中文日志。
input_type:指定文件日志(默认)或标准输入的输入类型。
exclude_lines:从输入中排除那些符合正则表达式列表的行。
include_lines:在输入中收录那些匹配正则表达式列表的行(默认收录所有行),在include_lines执行后会执行exclude_lines。
exclude_files:忽略符合正则表达式列表的文件(默认情况下,为每个符合路径定义的文件创建一个收割机)。
fields:为每个日志输出添加附加信息,例如“level:debug”,方便后续日志的分组和统计。默认情况下,会在输出信息的fields子目录下创建指定新字段的子目录,
fields_under_root:如果这个选项设置为true,新添加的字段将成为顶级目录,而不是放在fields目录中。自定义字段将覆盖 filebeat 的默认字段。
ignore_older:可以指定Filebeat忽略指定时间段外修改的日志内容,例如2h(两小时)或5m(5分钟)。
close_older:如果某个文件在一定时间内没有更新,则关闭被监控的文件句柄。默认为 1 小时。
force_close_files:Filebeat 将保留文件的句柄,直到它到达 close_older。如果在这个时间窗口内删除文件,就会出现问题,所以可以设置force_close_files为true。只要filebeat检测到文件名改变了,就会关闭。放下这个把手。
scan_frequency:Filebeat多久去探矿者指定的目录检测文件更新(比如是否有新文件),如果设置为0s,Filebeat会尽快感知更新(被占用的CPU会变得更高)。默认为 10 秒。
document_type:设置Elasticsearch输出时文档的type字段,也可以用来分类日志。
harvester_buffer_size:每个收割机监控文件时使用的缓冲区大小。
max_bytes:在日志文件中添加一行算作日志事件,max_bytes 限制为日志事件中上传的最大字节数,多余的字节将被丢弃。默认为 10MB。
multiline:适用于日志中每个日志占用多行的情况,比如各种语言的错误信息的调用栈。这个配置下面收录如下配置:
pattern:匹配多行日志开头行的模式
negate:是否需要使用模式条件转置,不翻转为真,翻转为假。
match:匹配模式后,与前后内容合并成日志
max_lines:合并的最大行数(包括与模式匹配的行),默认为500行。
timeout:超时后,即使新模式不匹配(新事件发生),匹配的日志事件也会被发送出去
tail_files:如果设置为true,Filebeat从文件末尾开始监听文件的新内容,并将文件的每一个新行作为一个事件依次发送,而不是从文件开头重新发送所有内容.
backoff:Filebeat检测到文件达到EOF后,每次检查文件是否更新需要等待多长时间,默认为1s。
max_backoff:Filebeat检测到文件达到EOF后,等待文件更新的最长时间,默认为10秒。
backoff_factor:定义达到max_backoff的速度,默认因子为2,达到max_backoff后,每次等待max_backoff后变为backoff,直到文件更新后重新设置为backoff。例如:
如果设置为1,表示禁用backoff算法,每次backoff时间都会执行backoff。
spool_size:假脱机程序的大小。当spooler中的事件数超过该阈值时,会被清空并发出(无论是否达到超时时间),默认为1MB。
idle_timeout:spooler 的超时时间。如果达到超时时间,spooler会被清空并发出(无论是否达到容量阈值),默认为1s。
registry_file:记录filebeat处理日志文件位置的文件
config_dir:如果要在这个配置文件中引入其他位置的配置文件,可以在这里写(需要写全路径),但只处理prospector部分。
publish_async:是否使用异步发送模式(实验性功能)。
其实我们用的是yaml的配置,主要是path,json相关,以及写入ES的index和参数。许多排除和退避没有配置。
#keys_under_root 可以让字段位于根节点,默认为false
json.keys_under_root: 真
#对于同名的key,覆盖原来的key值
json.overwrite_keys: 真
#在error.message字段中存储解析错误的消息记录
json.add_error_key: 真
#message_key 用于合并多行json日志,
json.message_key:消息
配置参数很多,推荐官网:
开始:
cd filebeat
nohup ./filebeat -c product.yml >/dev/null 2>&1
同一台机器上可以启动多个filebats,但是一般不建议运维使用。 (对于高负载:更多的日志,通常启动kibana后就可以立即看到,但是对于多次启动filebeat,后者可能需要2分钟才能看到,这是前一个队列的日志没有被处理过)
停止:
ps -ef|grep filebeat
杀死 -9 XXX
参考:
官网:
优采云采集器激活版下载下载特色(组图)
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2021-08-05 18:43
优采云采集器最新激活版是非常专业的视觉智能采集器,零门槛,多引擎,轻松创作,无需编程,小白也能快速上手! 优采云采集器免安装无限版兼容所有操作系统,采集爬虫技巧,轻松采集网络信息,一键搞定,自定义屏蔽域名,屏蔽广告,有需要可以下载试试它!
优采云采集器激活版下载闪点
1、软件操作复杂,可以通过鼠标点击的方式轻松提取要抓取的内容;
2、自定义屏蔽域名,方便过滤异地广告,提高采集速度
3、支持多个采集引擎,内置高速浏览器内核、HTTP引擎和JSON引擎
4、能采集Internet99%网站,包括单页应用ajax加载等动态类型网站。
5、可以导出为Txt、Excel、MySQL、SQLServer、SQlite、Access、网站等
优采云采集器破解版下载功能
1、支持三种高速引擎:浏览器引擎、HTTP引擎、JSON引擎,内置优化的火狐浏览器,再加上第一次内存优化,让浏览器也能高速运行,甚至可以快速转换为HTTP操作,享受更高的收录率!抓取JSON数据时,也可以使用浏览器可视化的方式,通过鼠标选择需要抓取的内容。完全不需要分析JSON数据布局,让非web专业规划师轻松抓取所需数据;
3、内置高速浏览器引擎,也可以切换到HTTP引擎模式运行,采集data效率更高。还内置了JSON引擎,无需分析JSON数据结构,直观选择JSON内容。
4、支持丰富的数据导出方式,可以导出为txt文件、html文件、csv文件、excel文件,也可以导出到现有数据库,如sqlite数据库、access数据库、sqlserver数据库、mysql数据库,复杂的映射字段可以通过导游的方式轻松导出到guide网站数据库。
优采云采集器active 版最新版功能
1、不知道怎么采集爬虫,会采集网站数据。
2、可以采集到网上99%的网站,包括使用Ajax加载单页等静态例子网站。
3、内置高速浏览器引擎,也可以切换到HTTP引擎模式运行,数据采集更高效。
4、advanced 智能算法,可以一键自然目标元素XPATH,主动识别网页列表,主动识别tab中的下一页按钮
优采云采集器免费安装无限版本评测
灵活定义运行时间,自动运行,无需分析JSON数据布局,全采集元素,无需编程,智能生成,只要有手! 查看全部
优采云采集器激活版下载下载特色(组图)
优采云采集器最新激活版是非常专业的视觉智能采集器,零门槛,多引擎,轻松创作,无需编程,小白也能快速上手! 优采云采集器免安装无限版兼容所有操作系统,采集爬虫技巧,轻松采集网络信息,一键搞定,自定义屏蔽域名,屏蔽广告,有需要可以下载试试它!
优采云采集器激活版下载闪点
1、软件操作复杂,可以通过鼠标点击的方式轻松提取要抓取的内容;
2、自定义屏蔽域名,方便过滤异地广告,提高采集速度
3、支持多个采集引擎,内置高速浏览器内核、HTTP引擎和JSON引擎
4、能采集Internet99%网站,包括单页应用ajax加载等动态类型网站。
5、可以导出为Txt、Excel、MySQL、SQLServer、SQlite、Access、网站等
优采云采集器破解版下载功能
1、支持三种高速引擎:浏览器引擎、HTTP引擎、JSON引擎,内置优化的火狐浏览器,再加上第一次内存优化,让浏览器也能高速运行,甚至可以快速转换为HTTP操作,享受更高的收录率!抓取JSON数据时,也可以使用浏览器可视化的方式,通过鼠标选择需要抓取的内容。完全不需要分析JSON数据布局,让非web专业规划师轻松抓取所需数据;
3、内置高速浏览器引擎,也可以切换到HTTP引擎模式运行,采集data效率更高。还内置了JSON引擎,无需分析JSON数据结构,直观选择JSON内容。
4、支持丰富的数据导出方式,可以导出为txt文件、html文件、csv文件、excel文件,也可以导出到现有数据库,如sqlite数据库、access数据库、sqlserver数据库、mysql数据库,复杂的映射字段可以通过导游的方式轻松导出到guide网站数据库。
优采云采集器active 版最新版功能
1、不知道怎么采集爬虫,会采集网站数据。
2、可以采集到网上99%的网站,包括使用Ajax加载单页等静态例子网站。
3、内置高速浏览器引擎,也可以切换到HTTP引擎模式运行,数据采集更高效。
4、advanced 智能算法,可以一键自然目标元素XPATH,主动识别网页列表,主动识别tab中的下一页按钮
优采云采集器免费安装无限版本评测
灵活定义运行时间,自动运行,无需分析JSON数据布局,全采集元素,无需编程,智能生成,只要有手!
云里新闻采集大师(c#版)新闻版
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2021-08-04 18:25
云立新闻采集Master源码(c#版)
云立News采集老师是一款完全免费开源的news采集软件,支持所有网站内容的自动采集入库。程序由Microsoft Visual Studio 2010(C#)开发,数据库使用SQLite,软件源代码完全开放,供开发者学习讨论。官方网站:1、免费开源:云里新闻采集大师完全免费开源,供大家学习讨论,永远开源。 2、灵活配置:采集网站可灵活配置,可根据需要配置添加采集网站。 3、多数据库支持:采集文章可以支持Post to Access数据库、MSSQL数据库、MYSQL数据库、Oracle数据库等数据库。 采集网站管理云里新闻采集大师可以方便您管理需要采集的网站。图形化配置如果需要添加采集网站,只需要在页面中找到简单的开始和结束标签即可灵活配置和添加。批量删除所有采集网站都可以一键删除,方便简单。支持预览 每个采集网站都支持预览模式,点击达到目标网站。 采集新闻管理云里新闻采集大师可以方便您管理采集到文章,可以批量删除,编辑news文章。图形化管理图形化界面管理采集到文章,双击文章行打开编辑。批量删除所有采集网站都可以一键删除,方便简单。支持预览 每个采集网站都支持预览模式,点击达到目标网站。 采集网站Configuration采集target网站所有参数均可个性化配置。该列表是可配置的。通常需要采集list页面的内容块,开始和结束标签可以由采集定义。内容可配置采集文章标题、作者、出处、内容等信息,均可自定义。网页编码是可配置的。每个网站 都有不同的编码。此处提供了网页编码选项以实现可配置选项。
立即下载 查看全部
云里新闻采集大师(c#版)新闻版
云立新闻采集Master源码(c#版)
云立News采集老师是一款完全免费开源的news采集软件,支持所有网站内容的自动采集入库。程序由Microsoft Visual Studio 2010(C#)开发,数据库使用SQLite,软件源代码完全开放,供开发者学习讨论。官方网站:1、免费开源:云里新闻采集大师完全免费开源,供大家学习讨论,永远开源。 2、灵活配置:采集网站可灵活配置,可根据需要配置添加采集网站。 3、多数据库支持:采集文章可以支持Post to Access数据库、MSSQL数据库、MYSQL数据库、Oracle数据库等数据库。 采集网站管理云里新闻采集大师可以方便您管理需要采集的网站。图形化配置如果需要添加采集网站,只需要在页面中找到简单的开始和结束标签即可灵活配置和添加。批量删除所有采集网站都可以一键删除,方便简单。支持预览 每个采集网站都支持预览模式,点击达到目标网站。 采集新闻管理云里新闻采集大师可以方便您管理采集到文章,可以批量删除,编辑news文章。图形化管理图形化界面管理采集到文章,双击文章行打开编辑。批量删除所有采集网站都可以一键删除,方便简单。支持预览 每个采集网站都支持预览模式,点击达到目标网站。 采集网站Configuration采集target网站所有参数均可个性化配置。该列表是可配置的。通常需要采集list页面的内容块,开始和结束标签可以由采集定义。内容可配置采集文章标题、作者、出处、内容等信息,均可自定义。网页编码是可配置的。每个网站 都有不同的编码。此处提供了网页编码选项以实现可配置选项。
立即下载
web基础蜘蛛网页文章采集器.2.zip
采集交流 • 优采云 发表了文章 • 0 个评论 • 149 次浏览 • 2021-08-01 07:31
基于网络的蜘蛛网页文章采集器v3.2.zip
基于Web的蜘蛛网页文章采集器,英文名Fast_Spider,属于蜘蛛爬虫程序,用于指定网站采集大量力量文章,会直接丢弃其中的垃圾信息,只保存阅读值和浏览值文章的本质,并自动进行HTM-TXT转换。本软件为绿色软件,解压后即可使用。基于网络的蜘蛛网页文章采集器具有以下特点:(1)本软件采用北大天网的MD5指纹重排算法,对于相似和相同的网页信息,不会存储(2)采集信息含义:[[HT]]代表网页标题,[[HA]]代表文章title,[[HC]]代表10个加权关键词,[[UR]]代表网页中的图片链接,[[TXT]]之后是正文。(3)Spider Performance:软件开启300个线程,保证采集效率。压力测试由采集100进行万979文章,以普通网民的联网电脑为参考标准,一台电脑可以遍历200万个网页,采集20万979文章,100万精华文章 5天完成采集。(4)正式版和免费版的区别在于:正式版允许采集文章的精华自动保存为ACCESS da表。基于Web的蜘蛛网页文章采集器操作步骤(1)使用前,必须确保您的电脑可以上网并且有防火墙,请勿屏蔽此软件。(2)运行SETUP.EXE和setup2.exe安装操作系统system32支持库。(3)运行spider.exe,输入URL入口,先点击“手动添加”按钮,然后点击“开始”按钮开始执行采集.基于Web的蜘蛛网页文章采集器使用注意(1)Grab Depth:填0表示不限制爬取深度;填3表示抓到第三层。(2)万能蜘蛛模式和分类蜘蛛模式的区别:假设URL入口为“”,如果选择万能蜘蛛模式,会遍历“”中的每一个网页;如果选择分类蜘蛛模式,则只有“”会被遍历(3)按钮“从MDB导入”:URL条目是批量从TASK.MDB导入的。(4)本软件采集原则是不跨s站,例如,条目是“”,只需在百度网站内抓取即可。 (5)本软件采集在此过程中,偶尔会弹出一个或几个“错误对话框”,请忽略。如果关闭“错误对话框”,采集软件会挂掉。( 6)用户如何选择采集subjects:例如,如果你想采集“股票”文章,你只需要将那些“股票”网站作为URL条目。
立即下载 查看全部
web基础蜘蛛网页文章采集器.2.zip
基于网络的蜘蛛网页文章采集器v3.2.zip
基于Web的蜘蛛网页文章采集器,英文名Fast_Spider,属于蜘蛛爬虫程序,用于指定网站采集大量力量文章,会直接丢弃其中的垃圾信息,只保存阅读值和浏览值文章的本质,并自动进行HTM-TXT转换。本软件为绿色软件,解压后即可使用。基于网络的蜘蛛网页文章采集器具有以下特点:(1)本软件采用北大天网的MD5指纹重排算法,对于相似和相同的网页信息,不会存储(2)采集信息含义:[[HT]]代表网页标题,[[HA]]代表文章title,[[HC]]代表10个加权关键词,[[UR]]代表网页中的图片链接,[[TXT]]之后是正文。(3)Spider Performance:软件开启300个线程,保证采集效率。压力测试由采集100进行万979文章,以普通网民的联网电脑为参考标准,一台电脑可以遍历200万个网页,采集20万979文章,100万精华文章 5天完成采集。(4)正式版和免费版的区别在于:正式版允许采集文章的精华自动保存为ACCESS da表。基于Web的蜘蛛网页文章采集器操作步骤(1)使用前,必须确保您的电脑可以上网并且有防火墙,请勿屏蔽此软件。(2)运行SETUP.EXE和setup2.exe安装操作系统system32支持库。(3)运行spider.exe,输入URL入口,先点击“手动添加”按钮,然后点击“开始”按钮开始执行采集.基于Web的蜘蛛网页文章采集器使用注意(1)Grab Depth:填0表示不限制爬取深度;填3表示抓到第三层。(2)万能蜘蛛模式和分类蜘蛛模式的区别:假设URL入口为“”,如果选择万能蜘蛛模式,会遍历“”中的每一个网页;如果选择分类蜘蛛模式,则只有“”会被遍历(3)按钮“从MDB导入”:URL条目是批量从TASK.MDB导入的。(4)本软件采集原则是不跨s站,例如,条目是“”,只需在百度网站内抓取即可。 (5)本软件采集在此过程中,偶尔会弹出一个或几个“错误对话框”,请忽略。如果关闭“错误对话框”,采集软件会挂掉。( 6)用户如何选择采集subjects:例如,如果你想采集“股票”文章,你只需要将那些“股票”网站作为URL条目。
立即下载
360搜索发布“站长公告”抑制互联网生态中采集泛滥
采集交流 • 优采云 发表了文章 • 0 个评论 • 182 次浏览 • 2021-07-29 22:37
互联网发展以来,海量的数据满足了每个人的信息获取需求。然而,互联网海洋中层出不穷的网页,良莠不齐。一些网站由采集和拼贴组成,给用户带来了很好的阅读体验。大麻烦。今日,360搜索发布《站长公告》,宣布推出“优采云方法”,以遏制当前互联网生态采集泛滥的局面。公告全文如下:
360 社区
亲爱的站长朋友:
大家好。
互联网的飞速发展离不开原创和稀缺的优质资源。通过我们最近的数据分析和用户反馈,我们发现一些网站使用疯狂劣质的采集方法在短时间内拼凑了很多低质量的采集网页。这种行为导致互联网上低质量网页逐渐泛滥,如内容拼接、隐秘标题变化、垃圾广告过多等,不仅严重影响正常用户的浏览体验,还造成高-quality 原创 内容不首先显示。精品内容的原创和网站也造成了一定的破坏。
360搜索一直秉承“保护原创+控制采集”的宗旨,以鼓励互联网原创生态为宗旨。针对这种典型的采集泛滥现象,基于业界领先的安全大数据和大规模机器学习平台,研发并推出“优采云算法”:控制劣质采集站点,控制原创用稀缺网页保护和升级权利,同时保证新闻网站的正常转载行为不受影响。
“优采云方法”上线后,内容丰富的优质网页(如原创、稀缺资源、精心编辑的内容页面等)将增加展示在前面的机会用户;针对滥用采集手段的行为(如全站大规模采集、页面内容拼凑、大量干扰用户阅读的广告、不良弹窗、大量不相关热词、网站搜索结果页面等),将显着降低其展示机会和网页收录量。
建议有以上问题的网站站长可以考虑长远发展,积极完善网站的建设,提供更省时、更丰富的原创内容。引擎会跟随网站改进,不断增加收录的数量。同时也欢迎原创网页的作者通过360站长平台积极向我们举报收录缺失的信息。
360搜索将坚定不移地与无数致力于做好本职工作的站长共建良好的互联网生态环境。感谢一直支持我们的站长和用户!
如果对网站采集的判断结果和收录的状态有异议,站长可以通过站长平台反馈中心和360搜论坛版主反馈:
站长平台反馈中心:
360 社区
360搜索论坛:
360 社区
站长平台注册地址:
请查看站长平台使用说明:
360搜索反作弊团队
2016.12.26 查看全部
360搜索发布“站长公告”抑制互联网生态中采集泛滥
互联网发展以来,海量的数据满足了每个人的信息获取需求。然而,互联网海洋中层出不穷的网页,良莠不齐。一些网站由采集和拼贴组成,给用户带来了很好的阅读体验。大麻烦。今日,360搜索发布《站长公告》,宣布推出“优采云方法”,以遏制当前互联网生态采集泛滥的局面。公告全文如下:
360 社区
亲爱的站长朋友:
大家好。
互联网的飞速发展离不开原创和稀缺的优质资源。通过我们最近的数据分析和用户反馈,我们发现一些网站使用疯狂劣质的采集方法在短时间内拼凑了很多低质量的采集网页。这种行为导致互联网上低质量网页逐渐泛滥,如内容拼接、隐秘标题变化、垃圾广告过多等,不仅严重影响正常用户的浏览体验,还造成高-quality 原创 内容不首先显示。精品内容的原创和网站也造成了一定的破坏。
360搜索一直秉承“保护原创+控制采集”的宗旨,以鼓励互联网原创生态为宗旨。针对这种典型的采集泛滥现象,基于业界领先的安全大数据和大规模机器学习平台,研发并推出“优采云算法”:控制劣质采集站点,控制原创用稀缺网页保护和升级权利,同时保证新闻网站的正常转载行为不受影响。
“优采云方法”上线后,内容丰富的优质网页(如原创、稀缺资源、精心编辑的内容页面等)将增加展示在前面的机会用户;针对滥用采集手段的行为(如全站大规模采集、页面内容拼凑、大量干扰用户阅读的广告、不良弹窗、大量不相关热词、网站搜索结果页面等),将显着降低其展示机会和网页收录量。
建议有以上问题的网站站长可以考虑长远发展,积极完善网站的建设,提供更省时、更丰富的原创内容。引擎会跟随网站改进,不断增加收录的数量。同时也欢迎原创网页的作者通过360站长平台积极向我们举报收录缺失的信息。
360搜索将坚定不移地与无数致力于做好本职工作的站长共建良好的互联网生态环境。感谢一直支持我们的站长和用户!
如果对网站采集的判断结果和收录的状态有异议,站长可以通过站长平台反馈中心和360搜论坛版主反馈:
站长平台反馈中心:
360 社区
360搜索论坛:
360 社区
站长平台注册地址:
请查看站长平台使用说明:
360搜索反作弊团队
2016.12.26
ModelArts平台提供的自动难例发现功能(图1)
采集交流 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2021-07-29 07:51
ModelArts平台提供的自动硬案例发现功能,可以通过内置规则,从输入旧模型的一批推理数据中,过滤掉可以进一步提高旧模型准确率的数据。自动硬案例发现功能可以有效减少模型更新时所需的标注人力。对于旧模型的推理数据,尽量挖掘出有利于提高模型准确率的部分数据。你只需要对这部分数据进行进一步的确认和标注,然后加入到训练数据集中即可。重新训练后,您可以获得更高准确率的新模型。
对于部署为在线服务的模型,调用 URL 或通过控制台输入预测数据。可以使用数据采集函数采集或者过滤掉疑难案例输出到数据集进行Follow-up模型训练。
对于在线服务数据采集,如图所示,支持以下场景。
图1 online services采集数据
先决条件
数据采集
部署为在线服务时,可以启动data采集任务。或者对于已经部署的在线服务,可以在服务详情页面打开数据采集任务。如果只启用了数据采集任务,则只有调用服务时产生的数据,采集才会存储在OBS中。如需过滤疑难病例,请参考。如果需要将采集后的数据同步到数据集,但不需要过滤疑难案例,请参考。
登录ModelArts管理控制台,在左侧菜单栏中选择“部署>在线服务”,进入在线服务管理页面。打开 data采集 任务。填写data采集task的相关参数,请参考详细参数说明。
表1 Data采集参数说明
参数
说明
采集rule
支持“全额采集”或“根据信任”采集。目前仅支持“全额采集”模式。
采集output
采集data,数据存放的路径。仅支持 OBS 目录。请选择现有目录或创建新的 OBS 目录。
保存周期
支持“一天”、“一周”、“永久”或“自定义”。
图4采集数据配置
data采集启动后,调用该服务进行预测(Console预测或URL接口预测)时,上传的数据会按照设定的规则采集到对应的OBS目录。<//p
p将数据同步到数据集/p
p对于已经启动数据采集任务的在线服务,支持采集数据同步到数据集。此操作不会进行困难情况过滤,只会将采集 的数据存储在数据集中。它可以存储在现有的数据集中,也可以创建一个新的数据集来存储数据。/p
p打开data采集task。详细操作请参考。/p
p当数据采集task不是采集到数据时,即用户没有调用接口使用预测功能,无法进行数据同步到数据集的操作。/p
p点击服务名称进入服务详情页面,在“同步数据”选项中点击“同步数据到数据集”。/p
p图 5 同步数据到数据集/p
pimg src='https://support.huaweicloud.com/engineers-modelarts/zh-cn_image_0298495669.png' alt='免规则采集器列表算法'//p
p在弹出的对话框中,勾选“标记类型”,然后“选择数据集”,点击“确定”,将采集数据同步到数据集的“未标记”选项卡中。/p
p同步的数据是系统采集在data采集task配置规则下收到的数据。当采集data为空时,无法进行数据同步到数据集的操作。/p
p图 6 同步数据到数据集/p
pimg src='https://support.huaweicloud.com/engineers-modelarts/zh-cn_image_0298495752.png' alt='免规则采集器列表算法'//p
pData采集并过滤疑难案例/p
p如果只开启了data采集任务,则不会启动疑难案例自动识别操作。需要同时启动疑难案例过滤任务,可以过滤采集疑难案例的数据,并将过滤结果存入对应的数据集中。/p
p由于疑难案例筛选功能对预测输出格式有要求,不同模型源要求不同:/p
p打开data采集task。详细操作请参考。/p
pimg src='https://support.huaweicloud.com/engineers-modelarts/public_sys-resources/note_3.0-zh-cn.png' alt='免规则采集器列表算法'//p
p在开启疑难案例过滤功能前,必须先开启data采集task。对于此在线服务,数据采集任务之前已经开启,对应OBS路径下存储的数据依然可用,只能开启稀有案例过滤功能。此时,困难案例过滤仅过滤存储在OBS路径中的数据。/p
p开启疑难病例筛选任务。在配置数据采集任务的同一页面,可以同时启动疑难案例过滤任务。请参考相关参数。/p
p表2疑难病例筛选参数说明/p
p参数/p
p说明/p
p模型类型/p
p模型的应用类型,目前仅支持“图像分类”和“物体检测”。/p
p训练数据集/p
p将模型部署为在线服务。这个模型是通过一定的数据集训练的。过程如下。对于本在线服务对应的训练数据集,您可以在筛选疑难案例时导入训练数据集,更容易过滤出模型的深层数据问题。/p
p(训练脚本+训练数据集)-> 训练模型-> 将模型部署为在线服务
该参数是可选的,但为了提高准确率,建议您导入相应的数据集。如果您的数据集不在 ModelArts 中管理,请参阅创建数据集。
过滤规则
支持“按持续时间”过滤或“按样本大小”过滤。
困难的示例输出
将选定的困难案例数据保存到数据集。支持现有数据集或创建新数据集。
您必须选择相应类型的数据集。比如模型类型是“图像分类”,需要过滤掉的疑难案例的数据集也必须是“图像分类”类型。
图7 打开疑难案例筛选功能
当配置了数据采集和疑难案例过滤任务时,系统会根据你设置的采集规则过滤疑难案例。您可以在在线服务的“疑难病例筛选”选项卡上查看“任务状态”。任务完成后,其“任务状态”会显示为“数据集导入完成”,您可以通过数据集链接快速跳转到对应的数据集。 采集的数据会保存在“Unmarked”标签下;筛选出的疑难案例将存储在数据集的“待确认”选项卡下。
图 8 任务状态
图 9 疑难案例选择结果
困难的反馈示例
在ModelArts管理控制台中,当您使用在线服务进行预测时,如果预测结果不准确,您可以直接将这个疑难案例反馈到预测页面上的对应数据集。
登录ModelArts管理控制台,在左侧菜单栏中选择“部署>在线服务”,点击对应的服务名称,进入服务详情页面。点击“预测”选项卡,上传您用于预测的图片,然后点击“预测”。当预测结果不准确时,点击“疑难案例反馈”。
图 10 在线服务疑难案例反馈
在弹出的对话框中,勾选“标签类型”,然后“选择数据集”,点击“确定”,将疑难案例数据反馈到该数据集的“待确认”选项卡。用于提高进一步模型训练的准确性。
图 11 疑难案例反馈
预测输出格式要求
对于自定义模型,推理代码中的“infer_output”,即预测返回的JSON格式,必须与下例一致。 查看全部
ModelArts平台提供的自动难例发现功能(图1)
ModelArts平台提供的自动硬案例发现功能,可以通过内置规则,从输入旧模型的一批推理数据中,过滤掉可以进一步提高旧模型准确率的数据。自动硬案例发现功能可以有效减少模型更新时所需的标注人力。对于旧模型的推理数据,尽量挖掘出有利于提高模型准确率的部分数据。你只需要对这部分数据进行进一步的确认和标注,然后加入到训练数据集中即可。重新训练后,您可以获得更高准确率的新模型。
对于部署为在线服务的模型,调用 URL 或通过控制台输入预测数据。可以使用数据采集函数采集或者过滤掉疑难案例输出到数据集进行Follow-up模型训练。
对于在线服务数据采集,如图所示,支持以下场景。
图1 online services采集数据
先决条件
数据采集
部署为在线服务时,可以启动data采集任务。或者对于已经部署的在线服务,可以在服务详情页面打开数据采集任务。如果只启用了数据采集任务,则只有调用服务时产生的数据,采集才会存储在OBS中。如需过滤疑难病例,请参考。如果需要将采集后的数据同步到数据集,但不需要过滤疑难案例,请参考。
登录ModelArts管理控制台,在左侧菜单栏中选择“部署>在线服务”,进入在线服务管理页面。打开 data采集 任务。填写data采集task的相关参数,请参考详细参数说明。
表1 Data采集参数说明
参数
说明
采集rule
支持“全额采集”或“根据信任”采集。目前仅支持“全额采集”模式。
采集output
采集data,数据存放的路径。仅支持 OBS 目录。请选择现有目录或创建新的 OBS 目录。
保存周期
支持“一天”、“一周”、“永久”或“自定义”。
图4采集数据配置
data采集启动后,调用该服务进行预测(Console预测或URL接口预测)时,上传的数据会按照设定的规则采集到对应的OBS目录。<//p
p将数据同步到数据集/p
p对于已经启动数据采集任务的在线服务,支持采集数据同步到数据集。此操作不会进行困难情况过滤,只会将采集 的数据存储在数据集中。它可以存储在现有的数据集中,也可以创建一个新的数据集来存储数据。/p
p打开data采集task。详细操作请参考。/p
p当数据采集task不是采集到数据时,即用户没有调用接口使用预测功能,无法进行数据同步到数据集的操作。/p
p点击服务名称进入服务详情页面,在“同步数据”选项中点击“同步数据到数据集”。/p
p图 5 同步数据到数据集/p
pimg src='https://support.huaweicloud.com/engineers-modelarts/zh-cn_image_0298495669.png' alt='免规则采集器列表算法'//p
p在弹出的对话框中,勾选“标记类型”,然后“选择数据集”,点击“确定”,将采集数据同步到数据集的“未标记”选项卡中。/p
p同步的数据是系统采集在data采集task配置规则下收到的数据。当采集data为空时,无法进行数据同步到数据集的操作。/p
p图 6 同步数据到数据集/p
pimg src='https://support.huaweicloud.com/engineers-modelarts/zh-cn_image_0298495752.png' alt='免规则采集器列表算法'//p
pData采集并过滤疑难案例/p
p如果只开启了data采集任务,则不会启动疑难案例自动识别操作。需要同时启动疑难案例过滤任务,可以过滤采集疑难案例的数据,并将过滤结果存入对应的数据集中。/p
p由于疑难案例筛选功能对预测输出格式有要求,不同模型源要求不同:/p
p打开data采集task。详细操作请参考。/p
pimg src='https://support.huaweicloud.com/engineers-modelarts/public_sys-resources/note_3.0-zh-cn.png' alt='免规则采集器列表算法'//p
p在开启疑难案例过滤功能前,必须先开启data采集task。对于此在线服务,数据采集任务之前已经开启,对应OBS路径下存储的数据依然可用,只能开启稀有案例过滤功能。此时,困难案例过滤仅过滤存储在OBS路径中的数据。/p
p开启疑难病例筛选任务。在配置数据采集任务的同一页面,可以同时启动疑难案例过滤任务。请参考相关参数。/p
p表2疑难病例筛选参数说明/p
p参数/p
p说明/p
p模型类型/p
p模型的应用类型,目前仅支持“图像分类”和“物体检测”。/p
p训练数据集/p
p将模型部署为在线服务。这个模型是通过一定的数据集训练的。过程如下。对于本在线服务对应的训练数据集,您可以在筛选疑难案例时导入训练数据集,更容易过滤出模型的深层数据问题。/p
p(训练脚本+训练数据集)-> 训练模型-> 将模型部署为在线服务
该参数是可选的,但为了提高准确率,建议您导入相应的数据集。如果您的数据集不在 ModelArts 中管理,请参阅创建数据集。
过滤规则
支持“按持续时间”过滤或“按样本大小”过滤。
困难的示例输出
将选定的困难案例数据保存到数据集。支持现有数据集或创建新数据集。
您必须选择相应类型的数据集。比如模型类型是“图像分类”,需要过滤掉的疑难案例的数据集也必须是“图像分类”类型。
图7 打开疑难案例筛选功能
当配置了数据采集和疑难案例过滤任务时,系统会根据你设置的采集规则过滤疑难案例。您可以在在线服务的“疑难病例筛选”选项卡上查看“任务状态”。任务完成后,其“任务状态”会显示为“数据集导入完成”,您可以通过数据集链接快速跳转到对应的数据集。 采集的数据会保存在“Unmarked”标签下;筛选出的疑难案例将存储在数据集的“待确认”选项卡下。
图 8 任务状态
图 9 疑难案例选择结果
困难的反馈示例
在ModelArts管理控制台中,当您使用在线服务进行预测时,如果预测结果不准确,您可以直接将这个疑难案例反馈到预测页面上的对应数据集。
登录ModelArts管理控制台,在左侧菜单栏中选择“部署>在线服务”,点击对应的服务名称,进入服务详情页面。点击“预测”选项卡,上传您用于预测的图片,然后点击“预测”。当预测结果不准确时,点击“疑难案例反馈”。
图 10 在线服务疑难案例反馈
在弹出的对话框中,勾选“标签类型”,然后“选择数据集”,点击“确定”,将疑难案例数据反馈到该数据集的“待确认”选项卡。用于提高进一步模型训练的准确性。
图 11 疑难案例反馈
预测输出格式要求
对于自定义模型,推理代码中的“infer_output”,即预测返回的JSON格式,必须与下例一致。
免规则采集器列表算法!计算不同计算机网络厂商的connectivitylevel3
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2021-07-28 03:01
免规则采集器列表算法!1.计算20种通用算法2.计算不同计算机网络厂商的connectivitylevel3.计算不同普通网络的专用算法(如mstsc,httptls等),
什么都可以,
linux目录层面的查找、区别、依赖
本质上大部分内容都是定义了其所处层级的内存与外存,不同结构的对象都有不同结构对其指针求值。你可以把内存划分为数组级、文件级、树结构三大类,具体以树结构为例。每一类分别定义了这样的结构指针的算法;使用同样的算法可以将多个文件结构合并起来。有一个结构,如a.txt,b.txt等,你可以把它分为两类:一类是一个结构的指针namespace_txt,另一类是在结构中分别添加了文件描述符描述符**methodoverview,如file.txt**,这两类访问同一结构内部的指针函数求值位置分别是完全不同的。
txt的指针针对的是b.txt,**描述符指针针对的是a.txt,因此txt的指针转换公式是:指针=文件描述符。
使用定义层级的结构,划分网络结构。树状结构就定义树状结构上每个点的指针结构。树状结构就定义树状结构上每个结点的指针结构。例如以图来说,树状结构可以定义层级结构的大量结构指针。链状结构就定义链状结构上每个节点的指针结构。定义层级结构要描述的是每个网络结构本身是什么树状结构,而不是最底层。 查看全部
免规则采集器列表算法!计算不同计算机网络厂商的connectivitylevel3
免规则采集器列表算法!1.计算20种通用算法2.计算不同计算机网络厂商的connectivitylevel3.计算不同普通网络的专用算法(如mstsc,httptls等),
什么都可以,
linux目录层面的查找、区别、依赖
本质上大部分内容都是定义了其所处层级的内存与外存,不同结构的对象都有不同结构对其指针求值。你可以把内存划分为数组级、文件级、树结构三大类,具体以树结构为例。每一类分别定义了这样的结构指针的算法;使用同样的算法可以将多个文件结构合并起来。有一个结构,如a.txt,b.txt等,你可以把它分为两类:一类是一个结构的指针namespace_txt,另一类是在结构中分别添加了文件描述符描述符**methodoverview,如file.txt**,这两类访问同一结构内部的指针函数求值位置分别是完全不同的。
txt的指针针对的是b.txt,**描述符指针针对的是a.txt,因此txt的指针转换公式是:指针=文件描述符。
使用定义层级的结构,划分网络结构。树状结构就定义树状结构上每个点的指针结构。树状结构就定义树状结构上每个结点的指针结构。例如以图来说,树状结构可以定义层级结构的大量结构指针。链状结构就定义链状结构上每个节点的指针结构。定义层级结构要描述的是每个网络结构本身是什么树状结构,而不是最底层。
如何让一个任务定时执行,实现界面化的组件装配
采集交流 • 优采云 发表了文章 • 0 个评论 • 276 次浏览 • 2021-07-28 01:44
先废话,程序还在开发阶段,担心开发出来的程序会变形,所以拿出来。市场上已经有 n 多款采集 软件。我只是在重复轮子。他们并不比他们好多少。他们很可能很糟糕,以至于他们甚至都没有接近。但是,相比目前的一些采集程序,我认为它是基于组件的,每个组件都是可以替换的。我希望它可以被视为一个亮点。同时也希望各位专家对本次展览提出建议和批评。
未解决的问题是:
1.一些需要cookies的网站,怎么采集,sina,我登录了,但是我登录cnblogs失败了。
2.定时执行,如何让一个任务定时执行,使用呢,因为一个采集task可能有很多URL,第一个URL采集的时间,最后一个采集的URL @'S的时间可能相隔几个小时,如果要求整个任务相隔1h,采集一次,那么最后一个URL可能只是采集完再要采集,或者最后一个任务还没有尚未执行。网址。这里没有考虑采集interval 策略。比如采集不换3次,下次采集时间会延长。
3.Storage问题,如果使用DAS或者数据库,完全没有问题,但是如果每个客户端都以文件的形式存储采集的结果,那么每个客户端上的文件怎么聚合并合并?将是一个系统工程
4.组件的任务流程和装配接口实现问题。目前流程的配置是使用文本编辑器编辑配置文件,非常容易写错。不懂GDI+,也没有想到好的实现方式。基于接口的组件组装。
先来看看采集的结果,再介绍一下采集的整个过程。 采集的结果保存在xml中,使用程序内置的Store2Xml组件。如果你想把它存储在特定的数据库中,你可以自己写一个组件,或者提供一个cms的webservice,我们会再做一个适配组件。 .
我正在考虑制作另一个 Store2MDB 组件,它易于传输数据并且也是嵌入式的。之所以不使用sqlite,是因为普通用户可能不太了解。
下面我以采集下的创业信息和创业秘诀栏为例来展示这个程序
第一步:分析网页
这两列的样式是一样的,所以我们只需要写一个采集规则即可。
打开任意列的列表页面并查看其源代码。我们需要找到重复的片段。下图中高亮部分为重复内容
我们将上图中要提取的部分源码放入RegexBuddy作为测试代码,测试我们编写的规律性
将测试的正则性放入组件的指定属性中。目前只能手动配置。在实践中,有一个图形环境,提供逐步操作提示。
最后我们会设计组件安装和配置执行的流程,使用boo解释引擎,类似ironpython
设计阶段一共三个文件,其中文本文件存储采集的URL集合,每行一个
第 2 步:添加任务
添加设计阶段制作的任务包,填写信息,然后提交任务
下图是程序在后台运行的过程
附上采集的结果 查看全部
如何让一个任务定时执行,实现界面化的组件装配
先废话,程序还在开发阶段,担心开发出来的程序会变形,所以拿出来。市场上已经有 n 多款采集 软件。我只是在重复轮子。他们并不比他们好多少。他们很可能很糟糕,以至于他们甚至都没有接近。但是,相比目前的一些采集程序,我认为它是基于组件的,每个组件都是可以替换的。我希望它可以被视为一个亮点。同时也希望各位专家对本次展览提出建议和批评。
未解决的问题是:
1.一些需要cookies的网站,怎么采集,sina,我登录了,但是我登录cnblogs失败了。
2.定时执行,如何让一个任务定时执行,使用呢,因为一个采集task可能有很多URL,第一个URL采集的时间,最后一个采集的URL @'S的时间可能相隔几个小时,如果要求整个任务相隔1h,采集一次,那么最后一个URL可能只是采集完再要采集,或者最后一个任务还没有尚未执行。网址。这里没有考虑采集interval 策略。比如采集不换3次,下次采集时间会延长。
3.Storage问题,如果使用DAS或者数据库,完全没有问题,但是如果每个客户端都以文件的形式存储采集的结果,那么每个客户端上的文件怎么聚合并合并?将是一个系统工程
4.组件的任务流程和装配接口实现问题。目前流程的配置是使用文本编辑器编辑配置文件,非常容易写错。不懂GDI+,也没有想到好的实现方式。基于接口的组件组装。
先来看看采集的结果,再介绍一下采集的整个过程。 采集的结果保存在xml中,使用程序内置的Store2Xml组件。如果你想把它存储在特定的数据库中,你可以自己写一个组件,或者提供一个cms的webservice,我们会再做一个适配组件。 .
我正在考虑制作另一个 Store2MDB 组件,它易于传输数据并且也是嵌入式的。之所以不使用sqlite,是因为普通用户可能不太了解。
下面我以采集下的创业信息和创业秘诀栏为例来展示这个程序
第一步:分析网页
这两列的样式是一样的,所以我们只需要写一个采集规则即可。
打开任意列的列表页面并查看其源代码。我们需要找到重复的片段。下图中高亮部分为重复内容
我们将上图中要提取的部分源码放入RegexBuddy作为测试代码,测试我们编写的规律性
将测试的正则性放入组件的指定属性中。目前只能手动配置。在实践中,有一个图形环境,提供逐步操作提示。
最后我们会设计组件安装和配置执行的流程,使用boo解释引擎,类似ironpython
设计阶段一共三个文件,其中文本文件存储采集的URL集合,每行一个
第 2 步:添加任务
添加设计阶段制作的任务包,填写信息,然后提交任务
下图是程序在后台运行的过程
附上采集的结果
8款非常好用的办公软件,可以极大提高办公效率
采集交流 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-07-27 19:46
与大家分享8款非常实用的办公软件,可以大大提高办公效率,每一款都堪称精品,喜欢的话记得点赞支持哦~
1、Listary
Listary 是一款非常强大的文件浏览、搜索增强、对话增强软件。第一个功能是快速打开文件和应用程序。您可以在任何界面上双击 Ctrl 来快速打开目标,而无需最小化当前窗口。搜索结果出现后,默认先显示应用程序,可以按空格键只显示文件。
第二个功能是文件浏览器的增强。在资源管理器界面,不需要任何快捷键,直接按文件名,Listary搜索框会自动打开,自动检索文件。
Listary 的第三个功能是各种打开/保存对话框的增强。在任何打开/保存/下载对话框界面底部,都会自动吸附Listary的搜索框,直接输入名称即可快速定位到目标文件夹。
这是一个快捷键。如果你的目标文件夹是打开的,在对话框中按快捷键Ctrl+G可以快速打开这个文件夹,方便快捷。
2、智办事
如何让企业具备核心竞争力?
任正非的一句话很经典:人才和技术不是企业的核心竞争力。有效的人才管理是核心竞争力,有效的创新和研发管理是核心竞争力。
如果一家公司能够将突出的个人能力转化为组织能力,然后组织能力可以赋能所有团队成员,汇聚所有成员的杰出能力,那么就会形成超越个人的竞争实力。让团队成员一起思考,一起做,一起成长,可以大大提高团队的战斗力。
①。分解任务并赋予组织权力
智能工作可以将公司目标分解为团队目标,再将团队目标分解为个人目标。团队成员可以在目标下创建子任务,每个任务可以设置一个清单。实现目标细化,落地成可执行的任务,然后把任务拆解给个人,把责任交给个人。每个人都在为终极目标服务,努力工作。
项目内容可以保存同步,新成员也可以第一时间看到任务内容。可以为每个任务设置一个列表,并可以检查是否完成。
目标自上而下拆解,结果自上而下汇总。反复回顾项目过程,逐渐沉淀为一种组织能力,形成能力的复用,固化了项目的标准架构流程,最终实现了对所有团队成员的赋能。
②。组织可视化,敏捷管理
任务概览可以让任务更好的“看”:团队成员可以看到待办任务、任务统计和进度报告;项目负责人可以看到团队概况、每项任务的进度、团队成员的表现和工作饱和度等。
任务概览功能可以确保员工执行的方向与公司目标一致,让团队成员知道他们有什么任务,让经理知道团队成员任务的进度和状态,避免项目延误.
③、任务转移模板、能力复用
任务层层分解,标准任务流程不断沉淀、重复、迭代,优化项目流程,个人能力逐渐沉淀为组织能力,形成能力重用,最终实现赋予所有团队成员权力。
修复项目的标准结构流程,最终将项目转化为模板,从而为组织成员赋能,明确工作流程,实现能力与流程的复制。
3、Quicker
Quicker 是一款提高计算机使用效率的软件。它允许 Windows 用户以最合适的方式和最快的软件工具触发所需的操作。它是一个基于场景的工具箱,也是一个创建和共享新工具的平台。
点击鼠标中键(可设置)弹出,位置跟随鼠标,移动一小段距离即可触发动作。 28个可视化动作按钮,建立动作快捷方式,快速启动软件,执行操作。
Quicker 支持自定义动作,内置丰富的动作库,可以直接使用。如OCR识别、文字截图翻译、批量重命名、快速本地搜索、连续复制、图片压缩、快速回复等。
4、Snipaste
Snipaste 是一款简单而强大的截图和贴纸工具。您还可以将屏幕截图粘贴回屏幕。 F1截图,F3贴图,简约高效。
办公室里会抄很多资料,写的时候会抄很多文字和图片。 Snipaste 可以将这些内容粘贴到屏幕上,而不是切换回窗口。
Snipaste 可以自动检测窗口和元素,可以轻松快速地捕获单个窗口。 Snipaste 的自动元素检测功能非常准确。它可以捕捉窗口上的按钮或选项,甚至是网页上的图片或一段文字。
Snipaste 支持多种颜色和多种标记。矩形、折线、箭头、钢笔、记号笔、马赛克、文本、橡皮擦,支持撤销和重做操作。空格键是隐藏和显示标记面板。
5、DropIt
DropIt 是一款经典的、古老的、开源的免费文件批量整理软件,绝对的生产力工具。您只需将文件拖到浮动的 DropIt 图标上,软件就会自动按照预设的形式处理文件。
您可以定义文件过滤规则并关联 18 个可用选项(移动、复制、压缩、提取、重命名、删除、加密、打开为、上传、通过邮件发送、创建图库、创建列表、创建播放列表、创建快捷键、复制到剪贴板、修改属性和忽略)。
6、桌面日历
桌面日历是一款非常强大且易于使用的 Windows 日历软件。双击记录每日待办事项。桌面日历可以很好地帮助您管理日常待办事项和日程安排。桌面日历还提供万年阴历、二十四节气,以及各种常见的节日和纪念日。
强大的数据导入导出功能,设置不同的背景颜色,云端数据同步……桌面日历还有很多实用功能等你来探索。
7、优采云采集器
优采云采集器 由前 Google 技术团队创建。基于人工智能技术,输入网址即可自动识别采集内容。
可以智能识别数据。智能模式基于人工智能算法。只需输入网址,即可智能识别列表数据、表格数据和分页按钮。无需配置任何采集规则,一键采集。自动识别列表、表格、链接、图片、价格等
流程图模式:只需根据软件提示点击页面进行操作,完全符合人们浏览网页的思维方式,简单几步即可生成复杂的采集规则,结合智能识别算法,任何网页上的数据都可以轻松采集。
可以模拟操作:输入文字、点击、移动鼠标、下拉框、滚动页面、等待加载、循环操作和判断条件等
8、QTTabBar
QTTabBar 是一个小工具,可让您在 Windows 资源管理器中使用 Tab 多标签功能。从此,工作时不再有文件夹窗口,更有强大的文件夹预览功能,大大提高您的工作效率。
另一个功能是快速预览文件和文件夹。您只需将鼠标悬停在文件上,内容就会自动预览。我测试了视频、音频、GIF 图像和 PNG 图像,没有任何问题。从图片上可以看到视频时间,证明视频可以播放,有声音。
像这样管理多个文件夹是不是更方便?只需要一个窗口,告别凌乱的桌面! QTTabBar也有很多功能和快捷键,浏览器标签的快捷键基本可以在QTTabBar上复用。
查看全部
8款非常好用的办公软件,可以极大提高办公效率
与大家分享8款非常实用的办公软件,可以大大提高办公效率,每一款都堪称精品,喜欢的话记得点赞支持哦~
1、Listary
Listary 是一款非常强大的文件浏览、搜索增强、对话增强软件。第一个功能是快速打开文件和应用程序。您可以在任何界面上双击 Ctrl 来快速打开目标,而无需最小化当前窗口。搜索结果出现后,默认先显示应用程序,可以按空格键只显示文件。
第二个功能是文件浏览器的增强。在资源管理器界面,不需要任何快捷键,直接按文件名,Listary搜索框会自动打开,自动检索文件。
Listary 的第三个功能是各种打开/保存对话框的增强。在任何打开/保存/下载对话框界面底部,都会自动吸附Listary的搜索框,直接输入名称即可快速定位到目标文件夹。
这是一个快捷键。如果你的目标文件夹是打开的,在对话框中按快捷键Ctrl+G可以快速打开这个文件夹,方便快捷。
2、智办事
如何让企业具备核心竞争力?
任正非的一句话很经典:人才和技术不是企业的核心竞争力。有效的人才管理是核心竞争力,有效的创新和研发管理是核心竞争力。
如果一家公司能够将突出的个人能力转化为组织能力,然后组织能力可以赋能所有团队成员,汇聚所有成员的杰出能力,那么就会形成超越个人的竞争实力。让团队成员一起思考,一起做,一起成长,可以大大提高团队的战斗力。
①。分解任务并赋予组织权力
智能工作可以将公司目标分解为团队目标,再将团队目标分解为个人目标。团队成员可以在目标下创建子任务,每个任务可以设置一个清单。实现目标细化,落地成可执行的任务,然后把任务拆解给个人,把责任交给个人。每个人都在为终极目标服务,努力工作。
项目内容可以保存同步,新成员也可以第一时间看到任务内容。可以为每个任务设置一个列表,并可以检查是否完成。
目标自上而下拆解,结果自上而下汇总。反复回顾项目过程,逐渐沉淀为一种组织能力,形成能力的复用,固化了项目的标准架构流程,最终实现了对所有团队成员的赋能。
②。组织可视化,敏捷管理
任务概览可以让任务更好的“看”:团队成员可以看到待办任务、任务统计和进度报告;项目负责人可以看到团队概况、每项任务的进度、团队成员的表现和工作饱和度等。
任务概览功能可以确保员工执行的方向与公司目标一致,让团队成员知道他们有什么任务,让经理知道团队成员任务的进度和状态,避免项目延误.
③、任务转移模板、能力复用
任务层层分解,标准任务流程不断沉淀、重复、迭代,优化项目流程,个人能力逐渐沉淀为组织能力,形成能力重用,最终实现赋予所有团队成员权力。
修复项目的标准结构流程,最终将项目转化为模板,从而为组织成员赋能,明确工作流程,实现能力与流程的复制。
3、Quicker
Quicker 是一款提高计算机使用效率的软件。它允许 Windows 用户以最合适的方式和最快的软件工具触发所需的操作。它是一个基于场景的工具箱,也是一个创建和共享新工具的平台。
点击鼠标中键(可设置)弹出,位置跟随鼠标,移动一小段距离即可触发动作。 28个可视化动作按钮,建立动作快捷方式,快速启动软件,执行操作。
Quicker 支持自定义动作,内置丰富的动作库,可以直接使用。如OCR识别、文字截图翻译、批量重命名、快速本地搜索、连续复制、图片压缩、快速回复等。
4、Snipaste
Snipaste 是一款简单而强大的截图和贴纸工具。您还可以将屏幕截图粘贴回屏幕。 F1截图,F3贴图,简约高效。
办公室里会抄很多资料,写的时候会抄很多文字和图片。 Snipaste 可以将这些内容粘贴到屏幕上,而不是切换回窗口。
Snipaste 可以自动检测窗口和元素,可以轻松快速地捕获单个窗口。 Snipaste 的自动元素检测功能非常准确。它可以捕捉窗口上的按钮或选项,甚至是网页上的图片或一段文字。
Snipaste 支持多种颜色和多种标记。矩形、折线、箭头、钢笔、记号笔、马赛克、文本、橡皮擦,支持撤销和重做操作。空格键是隐藏和显示标记面板。
5、DropIt
DropIt 是一款经典的、古老的、开源的免费文件批量整理软件,绝对的生产力工具。您只需将文件拖到浮动的 DropIt 图标上,软件就会自动按照预设的形式处理文件。
您可以定义文件过滤规则并关联 18 个可用选项(移动、复制、压缩、提取、重命名、删除、加密、打开为、上传、通过邮件发送、创建图库、创建列表、创建播放列表、创建快捷键、复制到剪贴板、修改属性和忽略)。
6、桌面日历
桌面日历是一款非常强大且易于使用的 Windows 日历软件。双击记录每日待办事项。桌面日历可以很好地帮助您管理日常待办事项和日程安排。桌面日历还提供万年阴历、二十四节气,以及各种常见的节日和纪念日。
强大的数据导入导出功能,设置不同的背景颜色,云端数据同步……桌面日历还有很多实用功能等你来探索。
7、优采云采集器
优采云采集器 由前 Google 技术团队创建。基于人工智能技术,输入网址即可自动识别采集内容。
可以智能识别数据。智能模式基于人工智能算法。只需输入网址,即可智能识别列表数据、表格数据和分页按钮。无需配置任何采集规则,一键采集。自动识别列表、表格、链接、图片、价格等
流程图模式:只需根据软件提示点击页面进行操作,完全符合人们浏览网页的思维方式,简单几步即可生成复杂的采集规则,结合智能识别算法,任何网页上的数据都可以轻松采集。
可以模拟操作:输入文字、点击、移动鼠标、下拉框、滚动页面、等待加载、循环操作和判断条件等
8、QTTabBar
QTTabBar 是一个小工具,可让您在 Windows 资源管理器中使用 Tab 多标签功能。从此,工作时不再有文件夹窗口,更有强大的文件夹预览功能,大大提高您的工作效率。
另一个功能是快速预览文件和文件夹。您只需将鼠标悬停在文件上,内容就会自动预览。我测试了视频、音频、GIF 图像和 PNG 图像,没有任何问题。从图片上可以看到视频时间,证明视频可以播放,有声音。
像这样管理多个文件夹是不是更方便?只需要一个窗口,告别凌乱的桌面! QTTabBar也有很多功能和快捷键,浏览器标签的快捷键基本可以在QTTabBar上复用。
小米2004上传至本站,安全无毒,可放心使用!
采集交流 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2021-07-27 19:44
该资源由用户(小米2004))上传至本站,版权难以核实,如有侵权请点击侵权投诉
源代码哥对资源进行了安全检查,安全无毒,可以放心使用!
(同名资源申请中心地址:)
本站资源仅供个人研究/学习/欣赏,请勿用于商业用途,否则一切后果由您承担!
讨论!插件介绍
DXC 来自 Discuz 的缩写! X 采集。 DXC采集插件致力于discuz上的内容解决方案,帮助站长更快捷方便地构建网站内容。
通过DXC采集插件,用户可以方便地从网上下载采集数据,包括会员数据和文章数据。此外,还有虚拟在线、单帖采集等辅助功能,让一个冷清的新论坛瞬间形成一个内容丰富、会员活跃的热门论坛,对论坛的初期运营有很大帮助。是新手站长必须安装的discuz应用。
DXC2.5的主要功能包括:
1、采集文章各种形式的url列表,包括rss地址、列表页面、多层列表等。
2、 多种写规则方式,dom方式,字符拦截,智能获取,更方便获取你想要的内容
3、Rule继承,自动检测匹配规则功能,你会慢慢体会到规则继承带来的便利
4、独特的网页正文提取算法,可以自动学习归纳规则,更方便general采集。
5、支持图片定位和水印功能
6、灵活的发布机制,可以自定义发布者、发布时间点击率等
7、强大的内容编辑后台,可以方便的编辑采集到达的内容,并发布到门户、论坛、博客
8、内容过滤功能,过滤采集广告的内容,去除不必要的区域
9、batch采集,注册会员,batch采集,设置会员头像
10、无人值守定时定量采集和release文章
源码哥亲测截图
查看全部
小米2004上传至本站,安全无毒,可放心使用!
该资源由用户(小米2004))上传至本站,版权难以核实,如有侵权请点击侵权投诉
源代码哥对资源进行了安全检查,安全无毒,可以放心使用!
(同名资源申请中心地址:)
本站资源仅供个人研究/学习/欣赏,请勿用于商业用途,否则一切后果由您承担!
讨论!插件介绍
DXC 来自 Discuz 的缩写! X 采集。 DXC采集插件致力于discuz上的内容解决方案,帮助站长更快捷方便地构建网站内容。
通过DXC采集插件,用户可以方便地从网上下载采集数据,包括会员数据和文章数据。此外,还有虚拟在线、单帖采集等辅助功能,让一个冷清的新论坛瞬间形成一个内容丰富、会员活跃的热门论坛,对论坛的初期运营有很大帮助。是新手站长必须安装的discuz应用。
DXC2.5的主要功能包括:
1、采集文章各种形式的url列表,包括rss地址、列表页面、多层列表等。
2、 多种写规则方式,dom方式,字符拦截,智能获取,更方便获取你想要的内容
3、Rule继承,自动检测匹配规则功能,你会慢慢体会到规则继承带来的便利
4、独特的网页正文提取算法,可以自动学习归纳规则,更方便general采集。
5、支持图片定位和水印功能
6、灵活的发布机制,可以自定义发布者、发布时间点击率等
7、强大的内容编辑后台,可以方便的编辑采集到达的内容,并发布到门户、论坛、博客
8、内容过滤功能,过滤采集广告的内容,去除不必要的区域
9、batch采集,注册会员,batch采集,设置会员头像
10、无人值守定时定量采集和release文章
源码哥亲测截图
软件介绍优采云采集器官方版软件功能可视化所有采集元素
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2021-07-27 07:35
软件介绍
优采云采集器官版是一款非常实用的网络小工具,软件界面干净,操作简单,功能强大,具有可视化配置,易于创建,无需编程,智能生成,数据采集等功能 。使用优采云采集器,用户可以很方便地采集获取自己需要的网页上的所有信息,使用起来非常方便。
优采云采集器官方版软件功能
1、软件操作简单,鼠标点击即可轻松选择要采集的内容;
2、支持三种高速引擎:浏览器引擎、HTTP引擎、JSON引擎,内置优化的火狐浏览器,加上原有的内存优化,浏览器采集也可以高速运行,甚至更快转换为HTTP模式运行,享受更高的采集速度!抓取JSON数据时,也可以使用浏览器可视化的方式,用鼠标点击要抓取的内容。无需分析JSON数据结构,让非网页专业设计人员轻松抓取所需数据;
3、不需要分析网页请求和源码,但支持更多的网页采集;
4、高级智能算法,可以一键生成目标元素XPATH,自动识别网页列表,自动识别分页中的下一页按钮......
5、支持丰富的数据导出方式,可以导出为txt文件、html文件、csv文件、excel文件,也可以导出到已有的数据库,如sqlite数据库、access数据库、sqlserver数据库、mysql数据库、简单映射字段通过向导,您可以轻松导出到目标网站 数据库。 .
优采云采集器官方版软件功能
可视化向导
所有采集元素自动生成采集数据
预定任务
运行时间灵活定义,全自动运行
多引擎支持
支持多个采集引擎,内置高速浏览器内核、HTTP引擎和JSON引擎
智能识别
可以自动识别网页列表、采集字段和分页等
拦截请求
自定义屏蔽域名,方便过滤异地广告,提高采集速度
多数据导出
可导出为 Txt、Excel、MySQL、SQLServer、SQlite、Access、网站 等
优采云采集器官版软件优势
1、优采云采集器为用户提供丰富的网络数据采集功能
2、如果需要复制网页的数据,可以使用这个软件采集
3、大部分网页内容可以直接复制,优采云采集器一键使用采集
4、直接输入网址采集,准确采集任何网页内容
5、支持规则设置,自定义采集规则,添加采集字段内容,添加采集网页元素
6、Bulk采集data,一键输入多个网址采集
7、软件中显示任务列表,点击直接开始运行采集
8、支持数据查看,可以在软件中查看采集的数据内容,可以导出数据
9、支持字符和词库替换功能,一键编辑文字采集到
优采云采集器官方版教程
第一步:设置起始网址
要采集一个网站数据,首先我们需要设置输入采集的URL,比如我们想要采集一个网站国内新闻,那么我们需要设置起始网址为国内新闻栏目列表的网址,而网站首页一般不设置为起始网址,因为首页通常收录很多列表,比如最新的文章,热门的文章,推荐文章等列表块,而且这些列表块显示的内容也很有限,采集这些列表一般不能采集完整信息。
我们以采集芭新闻为例,从新浪首页找国内新闻,但是这个栏目首页的内容还是比较乱,还细分了三个小栏目
来看看其中一个子栏目“大陆新闻”
此栏目页收录一个分页的内容列表。通过切换分页,我们可以采集到达该栏目下的所有文章,所以这种列表页非常适合我们开始采集起始网址。
现在,我们将列表 URL 复制到任务编辑框第一步中的文本框
如果你想在一个任务中同时采集中国新闻,你也可以复制另外两个子列列表的地址,因为这些子列列表的格式是相似的。但是,为了方便分类数据的导出或发布,一般不建议将多列内容混合在一起。
对于起始网址,我们也可以批量添加或者从txt文件中导入。比如我们想要采集前5页,也可以这样自定义5个起始页。
需要注意的是,如果这里自定义了多个分页列表,以后不要在采集配置中启用分页。通常我们希望在某一列下采集所有文章。只需要定义列的第一页为起始URL,稍后在采集配置中启用分页,就可以采集到每个分页列表的数据。
第2步:①自动生成列表和字段
进入第二步后,对于部分网页,优采云采集器会智能分析页面列表,自动高亮选中的网页列表并生成列表数据,如
然后我们会修剪数据,比如删除一些不需要的字段
点击图标中的三角符号,会弹出采集字段进行详细配置。单击上方的删除按钮可删除此字段。其余参数将在后续章节中单独介绍。
如果某些网页自动生成的列表数据不是我们想要的数据,可以点击“清除字段”清除所有生成的字段。
如果自动分析的高亮列表不是我们想要的采集列表,那么我们手动选择列表。如果要取消突出显示的列表框,可以单击Find List-List XPATH,清除其中的xpath并确认。
第2步:②手动生成列表
点击“查找列表”按钮并选择“手动选择列表”
根据提示,鼠标左键点击网页列表中的第一行数据
点击第一行后,根据提示点击第二行或其他类似行
点击列表中的任意两行后,整个列表都会高亮显示,列表中的字段也会生成。如果生成的字段不正确,点击清除字段,清除下面所有字段,手动选择字段将在下一章介绍。
第 2 步:③ 手动生成字段
点击“添加字段”按钮
在列表的任意一行点击要提取的元素,例如要提取标题和链接地址,鼠标左键点击标题即可。
点击网页链接时,使用时会提示是否抓取链接地址
如果要同时提取链接标题和链接地址,点击“是”,如果只需要提取标题文字,点击“否”,这里我们点击“是”
系统会自动生成标题和链接地址字段,并在字段列表中显示提取的字段内容。当您点击表格底部的字段标题时,匹配的内容将在网页上以黄色背景突出显示。
如何标记列表中的其他字段?单击添加新字段并重复上述操作。
第 2 步:④ 分页设置
列表有分页时,启用分页后,可以采集访问所有的分页列表数据。
页面分页有两种类型
普通分页:有分页栏,显示“下一页”按钮。点击后可以进入下一页,比如新浪新闻列表中的上一页。
瀑布式分页:网页滚动条到达底部时自动加载下一页内容
如果是正常分页,我们选择尝试自动设置或手动设置
自动设置分页
默认情况下,创建新任务时不启用分页。点击“禁用分页”,弹出菜单,选择“自动识别分页”,如果识别成功,会弹出“成功识别并设置分页元素!”对话框。 ”,在网页的“下一步”按钮上出现高亮的红色虚线框(部分网页按钮可能不显示虚线框),至此自动分页成功
如果是自动识别,会出现如下绿色提示框
手动设置分页
在菜单中选择“手动设置分页”
然后会自动出现“Find Pagination”按钮,点击它会弹出一个菜单,选择“Mark Pagination”
查看全部
软件介绍优采云采集器官方版软件功能可视化所有采集元素
软件介绍
优采云采集器官版是一款非常实用的网络小工具,软件界面干净,操作简单,功能强大,具有可视化配置,易于创建,无需编程,智能生成,数据采集等功能 。使用优采云采集器,用户可以很方便地采集获取自己需要的网页上的所有信息,使用起来非常方便。
优采云采集器官方版软件功能
1、软件操作简单,鼠标点击即可轻松选择要采集的内容;
2、支持三种高速引擎:浏览器引擎、HTTP引擎、JSON引擎,内置优化的火狐浏览器,加上原有的内存优化,浏览器采集也可以高速运行,甚至更快转换为HTTP模式运行,享受更高的采集速度!抓取JSON数据时,也可以使用浏览器可视化的方式,用鼠标点击要抓取的内容。无需分析JSON数据结构,让非网页专业设计人员轻松抓取所需数据;
3、不需要分析网页请求和源码,但支持更多的网页采集;
4、高级智能算法,可以一键生成目标元素XPATH,自动识别网页列表,自动识别分页中的下一页按钮......
5、支持丰富的数据导出方式,可以导出为txt文件、html文件、csv文件、excel文件,也可以导出到已有的数据库,如sqlite数据库、access数据库、sqlserver数据库、mysql数据库、简单映射字段通过向导,您可以轻松导出到目标网站 数据库。 .
优采云采集器官方版软件功能
可视化向导
所有采集元素自动生成采集数据
预定任务
运行时间灵活定义,全自动运行
多引擎支持
支持多个采集引擎,内置高速浏览器内核、HTTP引擎和JSON引擎
智能识别
可以自动识别网页列表、采集字段和分页等
拦截请求
自定义屏蔽域名,方便过滤异地广告,提高采集速度
多数据导出
可导出为 Txt、Excel、MySQL、SQLServer、SQlite、Access、网站 等
优采云采集器官版软件优势
1、优采云采集器为用户提供丰富的网络数据采集功能
2、如果需要复制网页的数据,可以使用这个软件采集
3、大部分网页内容可以直接复制,优采云采集器一键使用采集
4、直接输入网址采集,准确采集任何网页内容
5、支持规则设置,自定义采集规则,添加采集字段内容,添加采集网页元素
6、Bulk采集data,一键输入多个网址采集
7、软件中显示任务列表,点击直接开始运行采集
8、支持数据查看,可以在软件中查看采集的数据内容,可以导出数据
9、支持字符和词库替换功能,一键编辑文字采集到
优采云采集器官方版教程
第一步:设置起始网址
要采集一个网站数据,首先我们需要设置输入采集的URL,比如我们想要采集一个网站国内新闻,那么我们需要设置起始网址为国内新闻栏目列表的网址,而网站首页一般不设置为起始网址,因为首页通常收录很多列表,比如最新的文章,热门的文章,推荐文章等列表块,而且这些列表块显示的内容也很有限,采集这些列表一般不能采集完整信息。
我们以采集芭新闻为例,从新浪首页找国内新闻,但是这个栏目首页的内容还是比较乱,还细分了三个小栏目
来看看其中一个子栏目“大陆新闻”
此栏目页收录一个分页的内容列表。通过切换分页,我们可以采集到达该栏目下的所有文章,所以这种列表页非常适合我们开始采集起始网址。
现在,我们将列表 URL 复制到任务编辑框第一步中的文本框
如果你想在一个任务中同时采集中国新闻,你也可以复制另外两个子列列表的地址,因为这些子列列表的格式是相似的。但是,为了方便分类数据的导出或发布,一般不建议将多列内容混合在一起。
对于起始网址,我们也可以批量添加或者从txt文件中导入。比如我们想要采集前5页,也可以这样自定义5个起始页。
需要注意的是,如果这里自定义了多个分页列表,以后不要在采集配置中启用分页。通常我们希望在某一列下采集所有文章。只需要定义列的第一页为起始URL,稍后在采集配置中启用分页,就可以采集到每个分页列表的数据。
第2步:①自动生成列表和字段
进入第二步后,对于部分网页,优采云采集器会智能分析页面列表,自动高亮选中的网页列表并生成列表数据,如
然后我们会修剪数据,比如删除一些不需要的字段
点击图标中的三角符号,会弹出采集字段进行详细配置。单击上方的删除按钮可删除此字段。其余参数将在后续章节中单独介绍。
如果某些网页自动生成的列表数据不是我们想要的数据,可以点击“清除字段”清除所有生成的字段。
如果自动分析的高亮列表不是我们想要的采集列表,那么我们手动选择列表。如果要取消突出显示的列表框,可以单击Find List-List XPATH,清除其中的xpath并确认。
第2步:②手动生成列表
点击“查找列表”按钮并选择“手动选择列表”
根据提示,鼠标左键点击网页列表中的第一行数据
点击第一行后,根据提示点击第二行或其他类似行
点击列表中的任意两行后,整个列表都会高亮显示,列表中的字段也会生成。如果生成的字段不正确,点击清除字段,清除下面所有字段,手动选择字段将在下一章介绍。
第 2 步:③ 手动生成字段
点击“添加字段”按钮
在列表的任意一行点击要提取的元素,例如要提取标题和链接地址,鼠标左键点击标题即可。
点击网页链接时,使用时会提示是否抓取链接地址
如果要同时提取链接标题和链接地址,点击“是”,如果只需要提取标题文字,点击“否”,这里我们点击“是”
系统会自动生成标题和链接地址字段,并在字段列表中显示提取的字段内容。当您点击表格底部的字段标题时,匹配的内容将在网页上以黄色背景突出显示。
如何标记列表中的其他字段?单击添加新字段并重复上述操作。
第 2 步:④ 分页设置
列表有分页时,启用分页后,可以采集访问所有的分页列表数据。
页面分页有两种类型
普通分页:有分页栏,显示“下一页”按钮。点击后可以进入下一页,比如新浪新闻列表中的上一页。
瀑布式分页:网页滚动条到达底部时自动加载下一页内容
如果是正常分页,我们选择尝试自动设置或手动设置
自动设置分页
默认情况下,创建新任务时不启用分页。点击“禁用分页”,弹出菜单,选择“自动识别分页”,如果识别成功,会弹出“成功识别并设置分页元素!”对话框。 ”,在网页的“下一步”按钮上出现高亮的红色虚线框(部分网页按钮可能不显示虚线框),至此自动分页成功
如果是自动识别,会出现如下绿色提示框
手动设置分页
在菜单中选择“手动设置分页”
然后会自动出现“Find Pagination”按钮,点击它会弹出一个菜单,选择“Mark Pagination”
优采云数据采集器能做什么?如何做好?
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2021-07-25 05:06
优采云采集器是网页数据采集器,你可以采集任何网页数据,留下你的数据,整理生成自定义的、规则的数据格式,方便你使用,没有复杂的采集规则设置,大数据采集变得简单可行
优采云采集器以完全自主研发的分布式云计算平台为核心,可在短时间内从各种网站或网页轻松获取大量标准化数据,帮助任何需要从网页获取信息的客户实现数据自动化采集,编辑标准化,摆脱对人工搜索和数据采集的依赖,从而降低获取信息的成本,提高效率
优采云采集器主要特点
1、任何人都可以使用
你还在研究网页源代码和抓包工具吗?现在不需要了,可以上网采集,所见即所得界面,可视化流程,无需懂技术,只需点击,2分钟快速上手
2、any网站 可以是采集
不仅使用方便,而且功能强大:点击、登录、翻页,甚至识别验证码。当网页出现错误,或者多套模板完全不同的时候,也可以根据不同的情况做不同的处理。
3、云采集,你可以关掉
配置采集任务后,可以关闭任务,任务可以在云端执行。大量企业云24*7不间断运行。您不必担心 IP 被封锁和网络中断。采集大数据
优采云采集器 能做什么?
简单来说,使用优采云可以轻松地从任何网页生成自定义的常规数据格式,以准确采集您需要的数据。 优采云数据采集系统能做的包括但不限于以下内容:
1.财务数据,如季报、年报、财报,包括最新的每日净值自动采集;
2.各大新闻门户网站实时监控,自动更新上传最新消息;
3. 监控竞争对手的最新信息,包括商品价格和库存;
4.监控各大社交网络网站、博客,自动抓取企业产品相关评论;
5. 采集最新最全的招聘信息;
6.关注各大地产相关网站、采集新房二手房的最新行情;
7.采集一辆汽车网站具体新车、二手车信息;
8. 发现并采集潜在客户信息;
9.采集工业网站的产品目录和产品信息;
10. 同步各大电商平台的商品信息,做到一个平台发布,其他平台自动更新。
网站信息采集器 查看全部
优采云数据采集器能做什么?如何做好?
优采云采集器是网页数据采集器,你可以采集任何网页数据,留下你的数据,整理生成自定义的、规则的数据格式,方便你使用,没有复杂的采集规则设置,大数据采集变得简单可行
优采云采集器以完全自主研发的分布式云计算平台为核心,可在短时间内从各种网站或网页轻松获取大量标准化数据,帮助任何需要从网页获取信息的客户实现数据自动化采集,编辑标准化,摆脱对人工搜索和数据采集的依赖,从而降低获取信息的成本,提高效率
优采云采集器主要特点
1、任何人都可以使用
你还在研究网页源代码和抓包工具吗?现在不需要了,可以上网采集,所见即所得界面,可视化流程,无需懂技术,只需点击,2分钟快速上手
2、any网站 可以是采集
不仅使用方便,而且功能强大:点击、登录、翻页,甚至识别验证码。当网页出现错误,或者多套模板完全不同的时候,也可以根据不同的情况做不同的处理。
3、云采集,你可以关掉
配置采集任务后,可以关闭任务,任务可以在云端执行。大量企业云24*7不间断运行。您不必担心 IP 被封锁和网络中断。采集大数据
优采云采集器 能做什么?
简单来说,使用优采云可以轻松地从任何网页生成自定义的常规数据格式,以准确采集您需要的数据。 优采云数据采集系统能做的包括但不限于以下内容:
1.财务数据,如季报、年报、财报,包括最新的每日净值自动采集;
2.各大新闻门户网站实时监控,自动更新上传最新消息;
3. 监控竞争对手的最新信息,包括商品价格和库存;
4.监控各大社交网络网站、博客,自动抓取企业产品相关评论;
5. 采集最新最全的招聘信息;
6.关注各大地产相关网站、采集新房二手房的最新行情;
7.采集一辆汽车网站具体新车、二手车信息;
8. 发现并采集潜在客户信息;
9.采集工业网站的产品目录和产品信息;
10. 同步各大电商平台的商品信息,做到一个平台发布,其他平台自动更新。
网站信息采集器
常见的手段有以下几种:文本匹配正则表达式
采集交流 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2021-07-23 06:10
常用的信息过滤和反垃圾邮件方法如下:
文字匹配
正则表达式:主要解决过滤敏感词的问题,一般使用正则表达式匹配。但是正则表达式的效率普遍较差。
Trie 算法:当并发量较高时,需要更合适的方法。通常,它是 Trie 树的变体。空间复杂度和时间复杂度都比较好,比如双数组Trie算法。
Trie 算法的本质是确定一个有限状态自动机并根据输入数据执行状态转换。双数组 Trie 算法优化了 Trie 算法。它使用两个稀疏数组存储树结构,基数组存储Trie树的节点,校验数组进行状态检查。双数组Trie的大小需要根据业务场景和经验确定,避免数组过大或冲突过多。
Hash 表达式:一个更简单的实现是构造一个多级哈希表进行文本匹配。该方案处理速度较快,变形小,可以适应各种过滤场景。缺点是使用Hash表会浪费部分内存空间。如果网站敏感词数量不多,浪费部分内存也是可以接受的。
有时,为了绕过敏感词检查,一些输入信息被操纵,比如“阿_拉_伯”。这时需要对信息进行降噪预处理,然后进行匹配。
分类算法
网站早期,识别垃圾邮件的主要方式是人工,后端运维人员对信息进行人工审核。
自动化方法是使用分类算法。
以反垃圾邮件为例,说明分类算法的使用。首先将一批分类邮件样本输入分类算法进行训练,得到垃圾邮件分类模型,然后利用分类算法结合分类模型对待处理邮件进行识别。
比较简单的分类算法是贝叶斯分类算法,它是一种利用概率和统计进行分类的算法。
“算法-贝叶斯”
黑名单
黑名单也可用于去重信息。黑名单可以通过哈希表来实现。该方法实现简单,时间复杂度小,可以满足一般场景。但是当黑名单非常大时,Hash表需要占用大量的内存空间。
在过滤要求不完全准确的场景下,可以使用布隆过滤器代替哈希表。 《布隆过滤器的概念和原理》布隆过滤器以其发明者Patton Bloom命名,由一个二进制列表和一组随机数映射函数实现
电子商务风控风险
账户风险:账户被黑客盗用、账户被恶意注册等
买家风险:黄牛利用促销活动抢购低价商品;
卖家风险:错货、虚假发货、信用炒作等
交易风险:信用卡欺诈、支付欺诈、洗钱和套现。
风险控制:
机器自动风控的技术手段主要包括规则引擎和统计模型。
规则引擎:
统计模型
规则引擎虽然在技术上是有监管的,但是随着规则的逐渐增多,会出现规则冲突、难以维护等问题,而且规则越多性能越差。目前,大规模的网站更喜欢使用统计模型进行风险控制。风控领域使用的统计模型采用上述分类算法或更复杂的机器学习算法进行智能统计。
如图所示,根据历史交易中的欺诈交易信息训练分类算法,然后将采集处理过的交易信息输入到分类算法中,得到交易风险评分。
经过充分训练的统计模型准确率不低于规则引擎。分类算法的实时计算性能较好。由于统计模型采用模糊识别,不能准确匹配欺诈类型规则,对新兴交易欺诈也有一定程度的可预测性。 查看全部
常见的手段有以下几种:文本匹配正则表达式
常用的信息过滤和反垃圾邮件方法如下:
文字匹配
正则表达式:主要解决过滤敏感词的问题,一般使用正则表达式匹配。但是正则表达式的效率普遍较差。
Trie 算法:当并发量较高时,需要更合适的方法。通常,它是 Trie 树的变体。空间复杂度和时间复杂度都比较好,比如双数组Trie算法。
Trie 算法的本质是确定一个有限状态自动机并根据输入数据执行状态转换。双数组 Trie 算法优化了 Trie 算法。它使用两个稀疏数组存储树结构,基数组存储Trie树的节点,校验数组进行状态检查。双数组Trie的大小需要根据业务场景和经验确定,避免数组过大或冲突过多。
Hash 表达式:一个更简单的实现是构造一个多级哈希表进行文本匹配。该方案处理速度较快,变形小,可以适应各种过滤场景。缺点是使用Hash表会浪费部分内存空间。如果网站敏感词数量不多,浪费部分内存也是可以接受的。
有时,为了绕过敏感词检查,一些输入信息被操纵,比如“阿_拉_伯”。这时需要对信息进行降噪预处理,然后进行匹配。
分类算法
网站早期,识别垃圾邮件的主要方式是人工,后端运维人员对信息进行人工审核。
自动化方法是使用分类算法。
以反垃圾邮件为例,说明分类算法的使用。首先将一批分类邮件样本输入分类算法进行训练,得到垃圾邮件分类模型,然后利用分类算法结合分类模型对待处理邮件进行识别。
比较简单的分类算法是贝叶斯分类算法,它是一种利用概率和统计进行分类的算法。
“算法-贝叶斯”
黑名单
黑名单也可用于去重信息。黑名单可以通过哈希表来实现。该方法实现简单,时间复杂度小,可以满足一般场景。但是当黑名单非常大时,Hash表需要占用大量的内存空间。
在过滤要求不完全准确的场景下,可以使用布隆过滤器代替哈希表。 《布隆过滤器的概念和原理》布隆过滤器以其发明者Patton Bloom命名,由一个二进制列表和一组随机数映射函数实现
电子商务风控风险
账户风险:账户被黑客盗用、账户被恶意注册等
买家风险:黄牛利用促销活动抢购低价商品;
卖家风险:错货、虚假发货、信用炒作等
交易风险:信用卡欺诈、支付欺诈、洗钱和套现。
风险控制:
机器自动风控的技术手段主要包括规则引擎和统计模型。
规则引擎:
统计模型
规则引擎虽然在技术上是有监管的,但是随着规则的逐渐增多,会出现规则冲突、难以维护等问题,而且规则越多性能越差。目前,大规模的网站更喜欢使用统计模型进行风险控制。风控领域使用的统计模型采用上述分类算法或更复杂的机器学习算法进行智能统计。
如图所示,根据历史交易中的欺诈交易信息训练分类算法,然后将采集处理过的交易信息输入到分类算法中,得到交易风险评分。
经过充分训练的统计模型准确率不低于规则引擎。分类算法的实时计算性能较好。由于统计模型采用模糊识别,不能准确匹配欺诈类型规则,对新兴交易欺诈也有一定程度的可预测性。
6NovelListUrl小说3GetSiteCharset站点编码站点地址的获得方法是什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2021-07-22 05:05
6NovelListUrl小说3GetSiteCharset站点编码站点地址的获得方法是什么?
Guanguan采集rule 编辑教程第一步,我们先复制一份原来的规则作为模板。比如我今天演示的采集站点就是飞酷小说站点,那么我就以我复制的副本为模板,规则命名为dhabcxml。这主要是为了便于记忆。第二步我们在规则管理财务成本管理系统文件管理系统成本管理项目成本管理行政管理系统工具中运行采集器打开并加载我们刚刚命名为dhabcxml的XML文件第三步正式编写规则。 1RULEID规则号,这个任意2GetSiteName站点名称,这里我们写8E小说3GetSiteCharset站点代码,这里我们打开www8c8ecom找charset,后面的数字就是我们需要的站点代码www8c8ecom我们找到的代码是gb23124GetSiteUrl站点地址这个就不用说了,将其写入5NovelSearchUrl站点的搜索地址。这个地址是根据每个网站程序的不同得到的。但是,有一种通用的方法可以通过抓包来获取您想要的内容。是通过抓包得到的,但是我们怎么知道得到的是我们想要的呢?看看我的操作。首先,我们运行打包工具并选择 IEXPLOREEXE。进程最好只打开一个网站,也就是只打开一个,你要写规则网站保证进程中只有一个IEXPLOREEXE进程。这里我们可以看到提交的地址是booksearchaspx。让我们结合起来。地址是booksearchaspx,提交内容的代码是SearchKeyC1ABBBA8SearchClass1SeaButtonx26SeaButtony10,但是这里对我们有用的是SearchKeyC1ABBBA8SearchClass1。获取的部分将在此处用于 NovelSearchData 搜索提交内容。把这一段改成我们想要的代码就是把这一段C1ABBBA8换成SearchKey,也就是说搜索提交内容的完整代码是SearchKeySearchKeySearchClass1。然后我们测试它是否正确并进行测试。我们得到的内容是正确的。 6 NovelListUrl 站点的最新列表地址。我不会说这个。因为每个站点都不一样,需要自己找FEIKU。 BookShowBookListaspx7NovelList_GetNovelKey 从最新列表中获取小说编号。此规则允许您同时获得这本书。在手动模式下使用按名称获取书名。如果你想使用手动模式,你必须获得书名,否则手动模式将不起作用。使用我们打开 bookshowbooklistaspx 的地址查看源文件。当我们写这个规则时,我们找到了我们想要获取的内容的地方。比如我们打开地址,看到想要获取的内容,第一本小说的名字是莫立迪城,我们在源文件中。寻找莫里昂的传奇奇幻【目录】莫里昂传,第一卷,第八章黑暗的崛起,11月27日,龙之眼连载。我们用来编写规则的代码实际上并不是很多代码。我写规则的原则是节省,也就是说,代码越短越好,除非绝对必要,最好越短越好。没有废话。在这个规则中,我们需要使用网站成为恶魔。我们将修改这一段,其中d代表编号,小说名称已经过测试。更正8NovelUrl小说信息页地址。这很容易。我们只需点击一本小说即可了解。比如我们可以看到小说Book150557Indexhtml。我们可以把里面的150557改成NovelKey。一般来说,就是小说编号BookNovelKeyIndexhtml9NovelErr小说信息页错误的识别标签一般是Book149539Indexhtml中间的数字。随意更改,如Book15055799Indexhtml
我们得到的错误标志是没有找到编号的图书信息。 10 NovelName 获取小说名称。我们只要打开一本小说Book149539Indexhtml查看源码就可以得到小说的名字。我们可以从固定模式开始。比如我们刚刚打开的站点成魔在这本小说中,我们看到他的固定小说名称格式是“站点成魔”,然后我们在源代码中找到“站点成魔”,我们得到的内容是“站点成魔”,我们改成下面“” NovelAuthor 获取小说作者 LagerSort 获取小说分类 SmallSort 获取小说分类 NovelIntro 获取小说简介 NovelKeyword 获取小说主角关键词 NovelDegree 获取写作过程,我就不演示了这些和上面获取小说名称的方法是一样的 所谓的一通百通。有时有些内容您不想使用,因为格式不固定。有些内容只能先获取,再通过过滤功能过滤。过滤器的使用将在后面描述。 11NovelInfo_GetNovelPubKey 获取小说公共目录页 这个地址的地址获取方法同上。我不会解释职位描述的标准模板。职位描述。职位描述。总经理。职位描述。出纳员。职位描述。 12PubIndexUrl。使用k15@目标站的动态地址时,如果不知道对方的动态地址,在此写NovelPubKey。如果你知道动态路径,比如本站没有小说的章节目录的动态地址是Book149539Indexaspx,那么PubIndexUrl就是规则。它是 BookNovelKeyIndexaspx13PubVolumeSplit 拆分子卷。本分册有一些写作要点。需要注意的是,如果拆分子卷的规律性不正确,可能会对后面的章节名称产生很大的影响。这里我们得到了分割部分的代码。根据我的经验,就是找第一子卷和后面的子卷,看看它们有什么共同点。当我们分析htmlbook130149539Listshtm的目录章节中的源代码时,我们可以看到它们有一个共同点。拿这一段来说明对权力的追求。从这里,我们可以看到他的共同点是id "feiku_e_n_d" 让我们把它改成常规格式s,其中s表示匹配任何白色字符,包括空格、制表符、分页符等。 也就是说,无论如何和之间有很多空格可以作为s来代表14PubVolumeName来获取子卷名。要获得准确的子卷名称,上述拆分部分的规律性必须正确。通常,拆分部分和子卷名称是在一起的。上面我们解释了对划分部分使用的权力的追求。如果你留意这部分,你会发现这里有我们要在这一步获取的子卷名称。让我们更改代码。在我们的测试下,我们可以正常获取子卷,但有这些。我们一般在过滤规则中过滤掉。 15PubChapterName 获取章节名称。让我们用一段话来说明强大的驯服方法。对于这种时间、日期和更新字数,我们只是忽略它,因为这些不是我们想要的。我们可以使用这个。为了表明有人问我为什么不必将其附在此处。我告诉你,我们得到的内容就是里面的内容。如果不是你想要的,但是在写规则的时候一定要用到的,我们可以表达出来。只需稍微更改公式即可。好了,我们把上面的那段改一下,改成表达式就可以正常获取内容了。大家看这个规则是不是有点别扭?这是因为中间有一个换行符。我没有更改代码。让我们使用它。 s 表示 N 个换行符。我们现在改的代码了吗?这个会比较好吗?经过测试,获取内容描述规则也是正常的。没问题。 16PubChapter_GetChapterKey 获取章节地址。章节号。此处,此部分中的章节编号位于下面的 PubContentUrl 部分中。
内容页地址一般用来知道目标站的动态地址。如果不知道目标站的动态地址,一般不使用静态地址。所以我们这里需要得到的是章节地址分析。既然这里是章节地址,那我们为什么要呢?还有使用的章节名称。这主要是为了避免获取的章节名称与获取的章节地址不匹配。这里说一下,章节号的写法其实并不麻烦。你只需要稍微改变它。改成这样。让我们测试一下看看。让我们更改它以获取数字。这个获得的编号只能在目标站的动态地址已知的情况下使用。上面的17PubContentUrl章节内容页面地址在获取的章节地址中有说明。它用于目标站动态地址的情况,因为不使用通用静态地址。这里我就拿htmlbook36ASPX来讲解如何使用149539这个小说号。这里我们用NovelKey代替3790336,即PubChapter_GetChapterKey中得到的章节号,我们用ChapterKey来代替组合,即htmlbookNovelKeyChapterKeyASPX。这是我们的动态章节地址。记住,前提是要知道对方的动态地址。如果不知道对方的动态地址,那么我们这里在PubContentUrl章节内容页面地址中写的是ChapterKey18PubContentText来获取章节内容。获取方式与章节名称相同。这个就不解释了。现在我们解释过滤的用法。这很容易。什么是过滤,就是去掉你不想要的内容。一般使用过滤的几个地方都是介绍章节。卷名和获取的小说章节内容的名称,但是章节内容,有章节名和卷名的替换功能。章节名和卷名没有替换规则。比如我们获取到的volume叫做文本www8c8ecom,但是当我们获取volume的时候只想获取文本的两个词,那么我们这里就使用了filter。过滤器的格式就是过滤器的内容。每个过滤器的内容用于分隔介绍。过滤器与子卷名称相同。例如,我们获取作者姓名。当时获取的内容中,有一段多余的内容。本书作者随风聚散。因为他有的有,有的没有,所以我们不需要先直接用书的作者来获取想要的内容。从规则来看,我们得到的内容是在这一段中,我们要在这一段中保留的内容是随风聚散。让我们去把它添加到过滤规则中。这是固定的,所以直接添加它。这是我们要改变的。让我们改变它。在常规格式中,就是这样。让我们添加过滤器内容。现在说一下下一章内容的替换。章节内容的替换规则为每行替换一次。格式如下。需要替换的内容。更换结果。这意味着过滤。这意味着更换。如果有他使用的图片我们该怎么办?这里我们使用替换来处理其他替换。类似的替换仅在章节内容中使用。这仅适用于章节内容。三个人问我为什么采集为什么某个站总是空章?这个可能是空章的原因可能是目标站刚重启网站你的采集IP被封了等等 这里我想说明一下有空章 因为图章的操作流程采集器的采集内容是先检查你的采集章节是否是图片章节。如果你的PubContentImages章节内容中提取的图片规律不正确,那么你还没有获取到图片章节内容。会检查你的采集文字内容PubContentText 获取章节内容的正则匹配。如果从PubContentImages章节内容中提取的图片与PubContentText获取的章节内容不匹配,那么就会出现我们上面提到的章节空的原因。规则写好后,我们来测试一下规则是否可以正常获取到我们想要获取的内容。经测试,我们编写的规则可以正常得到思路。
第一步是将原创规则复制为模板。比如我今天演示的采集站点是一个小说站点,叫feiku,那么我把我复制的模板规则命名为dhabcxml,这主要是为了方便记忆。第二步,我们在采集器中运行规则管理工具,打开并加载我们刚刚命名为dhabcxml的XML文件。第三步开始正式编写规则1RULEID规则号,这个任意2GetSiteName站点名称,这里我们编写8E小说3GetSiteCharset站点代码。这里我们打开 www8c8ecom 查找字符集编号。后面是我们需要的站点代码www8c8ecom。我们找到的代码是 gb23124GetSiteUrl 站点地址。不用说,把它写进5NovelSearchUrl站点搜索地址。每次网站程序不同时必须获取这个地址,但是有一个通用的方法可以通过抓包来获取你想要的内容。虽然是抓包得到的,但是你怎么知道我们想要的就是我们想要的呢?看我的操作 首先我们运行打包工具,选择IEXPLOREEXE进程。最好只开一个网站,也就是只开你要写规则的网站,保证进程中只有一个IEXPLOREEXE进程。在这里我们可以看到提交的地址是booksearchaspx。让我们结合起来。地址是booksearchaspx,提交内容的代码是SearchKeyC1ABBBA8SearchClass1SeaButtonx26SeaButtony10。但对我们来说,它是 SearchKeyC1ABBBA8SearchClass1。此处获取的部分将用于NovelSearchData 搜索提交内容。把这一段改成我们想要的 必要的代码就是把C1ABBBA8的这一段换成SearchKey,也就是说搜索提交的内容的完整代码是SearchKeySearchKeySearchClass1。然后我们测试它是否正确。经过测试,我们得到的内容是正确的。 6 NovelListUrl 站点的最新列表地址。因为这些我就不说了。每个站点都不一样,需要自己找FEIKU 是BookShowBookListaspx7NovelList_GetNovelKey 从最新列表中获取小说编号。该规则可用于同时获取书名。它用于手动模式。如果要使用手动模式,必须获取书名,否则手动模式将不可用。我们打开bookshowbooklistaspx的地址查看我们写的源文件时使用这个规则,找到你要获取的内容的地方。比如我们打开地址看到想要获取的内容,第一本小说的名字是李迪程沫,我们在源文件中找到了莫兰特传奇魔法。 【目录】莫伦特传,第一卷,第八章,黑暗的崛起,11月27日,龙眼连载。我们用来编写规则的代码实际上并不是很多代码。我写规则的原则是能省就省,也就是代码越短越好,除非万不得已,越短越好。没有废话。在这个规则中,我们需要使用网站成为恶魔。我们将更改这一段,其中 d 表示数字表示小说名称已经过测试并且是正确的。 8 NovelUrl 小说信息页地址,这个很简单,我们随便点一个小说就知道了,比如我们在书Book150557Indexhtml中看到的,我们把里面的150557改成NovelKey。一般是指小说编号BookNovelKeyIndexhtml9NovelErr小说信息页错误识别标志。这个一般是Book149539Indexhtml中间的那个。随意更改数字,例如Book15055799Indexhtml,我们得到
错误标志是没有找到编号的图书信息。 10NovelName获取小说名,我们只要打开小说Book149539Indexhtml查看源码即可获取小说名。这个我们可以从固定模式开始,比如我们刚刚打开的小说。看到他固定的小说名字格式是“Site into a Devil”,那么我们在源码中找到了“Site into a Devil”。我们得到的内容是“Site into a Devil”。我们将“”下的小说作者更改为小说作者。 LagerSort 获取小说类别 SmallSort 获取小说类别 NovelIntro 获取小说简介 NovelKeyword 获取小说主角关键词 NovelDegree 获取写作过程 NovelCover 获取小说封面 这些,我就不演示了,这些和上面的获取小说的方法是一样的名字,所以就是所谓的百通一通,这里是这里得到的一些内容,有些是因为格式不固定所以不想用的。有些内容只能先获取,再通过过滤功能进行过滤。后面说11NovelInfo_GetNovelPubKey获取小说公共目录页面地址的地址。获取方法同上,12PubIndexUrl公共目录页面地址我就不解释了。我将解释这个的用法。这个一般在知道采集目标站的动态地址时使用。如果不知道对方的动态地址。在此写入NovelPubKey。如果你知道动态路径,比如本站没有小说的章节目录的动态地址是Book149539Indexaspx,那么PubIndexUrl的规则是BookNovelKeyIndexaspx13PubVolumeSplit拆分卷,这个拆分卷有地方写,你需要要注意是否拆分音量。规律是不对的。所以很可能会对后面的章节名产生很大的影响。这里我们得到了分割部分的代码。根据我的经验,找到第一个子卷和下面的子卷来看看它们的共同点我们分析了htmlbook130149539Listshtm的目录章节中的源代码,可以看出它们有一个共同点。拿这一段来说明对权力的追求。从这里我们可以看出他的共同点是id“feiku_e_n_d”。让我们改变它,将其更改为常规规则。 s格式中,s表示匹配任意白色字符,包括空格、制表符、分页符等,也就是说,无论and之间有多少个空格,都可以用s表示14PubVolumeName来获取音量名称并希望获得准确的音量。该名称必须在上述部分中。规律一定是正确的。通常,节和子卷名称在同一页面上。我们在章节中解释了对权力的追求。如果你关注这个部分,你会在里面找到我。让我们更改代码以获取此步骤中的子卷名称。我们测试并正常获取子卷。但是如果有这些,我们通常在过滤规则中过滤。 15PubChapterName 获取章节名称。让我们用一段话来说明强大的驯服方法。对于这种带有时间和日期的更新字数,我们只是忽略它,因为这些不是我们想要获取的内容。这可以用来说明有人问我为什么把它附在这里没用。让我告诉你我们得到了什么。内容就是里面的内容。如果它不是你想要的,但在编写规则时必须使用它。我们可以稍微改变一下表达方式。好,我们把上面的那段改一下,改成表达式,就可以正常获取内容了。小伙伴们是不是觉得这个规则有点别扭?这是因为中间有一个换行符。我没有更改代码。我们用 s 来表示 N 个换行符。修改后的代码现在更好了吗?测试后也是正常的。内容描述规则没有问题 16PubChapter_GetChapterKey 获取章节地址 章节号 这里是本节章节号的描述,用于下面的PubContentUrl章节内容页面地址
一般知道目标站的动态地址。一般不使用静态地址。如果你不知道目标站的动态地址,那么我们这里需要得到的是章节地址分析。既然这是为了获取章节地址,那为什么还要使用章节名称呢?这样做的主要原因是为了避免获取的章节名称与获取的章节地址不匹配。说到这里,下章号的写法其实并不麻烦。只需要稍微改动一下,改成这个就行了。让我们测试一下。你可以看到。像这样改变它以获取数字。获取的编号只有在知道目标站的动态地址时才能使用。上面的17PubContentUrl章节内容页地址有获取到的章节地址。这是要知道目标站的动态地址。使用地址是因为这里不使用通用静态地址。我用htmlbook36ASPX来说明如何使用149539,这是小说编号。这里我们使用NovelKey代替3790336,即PubChapter_GetChapterKey中获取的章节号。让我们用 ChapterKey 替换它。组合是 htmlbookNovelKeyChapterKeyASPX。这是我们的动态章节地址。记住,前提是要知道对方的动态地址。如果不知道对方的动态地址,那么我们这里在PubContentUrl章节内容页面地址中写的是ChapterKey18PubContentText来获取章节内容。这种获取章节内容的方法与获取章节名称的方法相同,不做说明。现在我们解释过滤的用法。这很容易。什么是过滤,就是去掉你不想要的内容。一般使用过滤的几个地方是介绍、章节名、卷名、获取小说章节的内容,但是章节内容有替换功能。简介、章节名称和子卷名称。这几个暂时没有更换规则。比如我们获取的子卷叫做正文www8c8ecom,但是我们在获取子卷的时候只想获取正文,这里就用到了这两个词。过滤器格式是过滤器的内容。每个过滤器的内容用于分隔介绍。过滤器与子卷名称相同。比如我们获取作者姓名时获取的内容。有一个额外的内容。书作者云集,随风而去。因为他,有的有,有的没有,所以我们不需要先用书的作者来获取内容。从规则中,我们得到的内容是随风聚散的。在本段中,我们要在本段中保留的内容是随风聚散。让我们去把它添加到过滤规则中。因为是固定的,所以我们可以直接添加。这对我们来说是一个改变。让我们更改它并将其更改为常规格式。就是这样。让我们添加过滤内容。现在说一下下一章内容的替换。章节内容的替换规则为每行替换一次。格式如下。需要替换的内容。替换结果。这意味着过滤。这意味着更换。比如飞酷里有一个词。我们这里用的图片应该怎么处理,我们用replacement来处理其他的replacement。类似替换内容替换只对章节内容有用。这是专用于章节内容。有人问我为什么采集某站为什么老是出现空章?这可能就是出现空章的原因。这可能是目标站刚重启网站你的采集IP被屏蔽了等等,这里我想说明一下,空章是图片章节造成的。 采集器的采集内容操作流程是先检查你的采集章节是否为图片章节。如果你的PubContentImages章节内容中提取的图片规律不正确,如果你没有得到图片章节内容,你会检查你的采集文字内容PubContentText获取章节内容的规律匹配。如果从 PubContentImages 章节内容中提取的图片与获取章节内容的 PubContentText 不匹配,那么就会出现我们上面所说的空章节的原因。嗯,规则已经写好了。测试规则是否可以正常获取到想要的内容。测试表明我们编写的规则可以正常获取到想要的内容 查看全部
6NovelListUrl小说3GetSiteCharset站点编码站点地址的获得方法是什么?
Guanguan采集rule 编辑教程第一步,我们先复制一份原来的规则作为模板。比如我今天演示的采集站点就是飞酷小说站点,那么我就以我复制的副本为模板,规则命名为dhabcxml。这主要是为了便于记忆。第二步我们在规则管理财务成本管理系统文件管理系统成本管理项目成本管理行政管理系统工具中运行采集器打开并加载我们刚刚命名为dhabcxml的XML文件第三步正式编写规则。 1RULEID规则号,这个任意2GetSiteName站点名称,这里我们写8E小说3GetSiteCharset站点代码,这里我们打开www8c8ecom找charset,后面的数字就是我们需要的站点代码www8c8ecom我们找到的代码是gb23124GetSiteUrl站点地址这个就不用说了,将其写入5NovelSearchUrl站点的搜索地址。这个地址是根据每个网站程序的不同得到的。但是,有一种通用的方法可以通过抓包来获取您想要的内容。是通过抓包得到的,但是我们怎么知道得到的是我们想要的呢?看看我的操作。首先,我们运行打包工具并选择 IEXPLOREEXE。进程最好只打开一个网站,也就是只打开一个,你要写规则网站保证进程中只有一个IEXPLOREEXE进程。这里我们可以看到提交的地址是booksearchaspx。让我们结合起来。地址是booksearchaspx,提交内容的代码是SearchKeyC1ABBBA8SearchClass1SeaButtonx26SeaButtony10,但是这里对我们有用的是SearchKeyC1ABBBA8SearchClass1。获取的部分将在此处用于 NovelSearchData 搜索提交内容。把这一段改成我们想要的代码就是把这一段C1ABBBA8换成SearchKey,也就是说搜索提交内容的完整代码是SearchKeySearchKeySearchClass1。然后我们测试它是否正确并进行测试。我们得到的内容是正确的。 6 NovelListUrl 站点的最新列表地址。我不会说这个。因为每个站点都不一样,需要自己找FEIKU。 BookShowBookListaspx7NovelList_GetNovelKey 从最新列表中获取小说编号。此规则允许您同时获得这本书。在手动模式下使用按名称获取书名。如果你想使用手动模式,你必须获得书名,否则手动模式将不起作用。使用我们打开 bookshowbooklistaspx 的地址查看源文件。当我们写这个规则时,我们找到了我们想要获取的内容的地方。比如我们打开地址,看到想要获取的内容,第一本小说的名字是莫立迪城,我们在源文件中。寻找莫里昂的传奇奇幻【目录】莫里昂传,第一卷,第八章黑暗的崛起,11月27日,龙之眼连载。我们用来编写规则的代码实际上并不是很多代码。我写规则的原则是节省,也就是说,代码越短越好,除非绝对必要,最好越短越好。没有废话。在这个规则中,我们需要使用网站成为恶魔。我们将修改这一段,其中d代表编号,小说名称已经过测试。更正8NovelUrl小说信息页地址。这很容易。我们只需点击一本小说即可了解。比如我们可以看到小说Book150557Indexhtml。我们可以把里面的150557改成NovelKey。一般来说,就是小说编号BookNovelKeyIndexhtml9NovelErr小说信息页错误的识别标签一般是Book149539Indexhtml中间的数字。随意更改,如Book15055799Indexhtml
我们得到的错误标志是没有找到编号的图书信息。 10 NovelName 获取小说名称。我们只要打开一本小说Book149539Indexhtml查看源码就可以得到小说的名字。我们可以从固定模式开始。比如我们刚刚打开的站点成魔在这本小说中,我们看到他的固定小说名称格式是“站点成魔”,然后我们在源代码中找到“站点成魔”,我们得到的内容是“站点成魔”,我们改成下面“” NovelAuthor 获取小说作者 LagerSort 获取小说分类 SmallSort 获取小说分类 NovelIntro 获取小说简介 NovelKeyword 获取小说主角关键词 NovelDegree 获取写作过程,我就不演示了这些和上面获取小说名称的方法是一样的 所谓的一通百通。有时有些内容您不想使用,因为格式不固定。有些内容只能先获取,再通过过滤功能过滤。过滤器的使用将在后面描述。 11NovelInfo_GetNovelPubKey 获取小说公共目录页 这个地址的地址获取方法同上。我不会解释职位描述的标准模板。职位描述。职位描述。总经理。职位描述。出纳员。职位描述。 12PubIndexUrl。使用k15@目标站的动态地址时,如果不知道对方的动态地址,在此写NovelPubKey。如果你知道动态路径,比如本站没有小说的章节目录的动态地址是Book149539Indexaspx,那么PubIndexUrl就是规则。它是 BookNovelKeyIndexaspx13PubVolumeSplit 拆分子卷。本分册有一些写作要点。需要注意的是,如果拆分子卷的规律性不正确,可能会对后面的章节名称产生很大的影响。这里我们得到了分割部分的代码。根据我的经验,就是找第一子卷和后面的子卷,看看它们有什么共同点。当我们分析htmlbook130149539Listshtm的目录章节中的源代码时,我们可以看到它们有一个共同点。拿这一段来说明对权力的追求。从这里,我们可以看到他的共同点是id "feiku_e_n_d" 让我们把它改成常规格式s,其中s表示匹配任何白色字符,包括空格、制表符、分页符等。 也就是说,无论如何和之间有很多空格可以作为s来代表14PubVolumeName来获取子卷名。要获得准确的子卷名称,上述拆分部分的规律性必须正确。通常,拆分部分和子卷名称是在一起的。上面我们解释了对划分部分使用的权力的追求。如果你留意这部分,你会发现这里有我们要在这一步获取的子卷名称。让我们更改代码。在我们的测试下,我们可以正常获取子卷,但有这些。我们一般在过滤规则中过滤掉。 15PubChapterName 获取章节名称。让我们用一段话来说明强大的驯服方法。对于这种时间、日期和更新字数,我们只是忽略它,因为这些不是我们想要的。我们可以使用这个。为了表明有人问我为什么不必将其附在此处。我告诉你,我们得到的内容就是里面的内容。如果不是你想要的,但是在写规则的时候一定要用到的,我们可以表达出来。只需稍微更改公式即可。好了,我们把上面的那段改一下,改成表达式就可以正常获取内容了。大家看这个规则是不是有点别扭?这是因为中间有一个换行符。我没有更改代码。让我们使用它。 s 表示 N 个换行符。我们现在改的代码了吗?这个会比较好吗?经过测试,获取内容描述规则也是正常的。没问题。 16PubChapter_GetChapterKey 获取章节地址。章节号。此处,此部分中的章节编号位于下面的 PubContentUrl 部分中。
内容页地址一般用来知道目标站的动态地址。如果不知道目标站的动态地址,一般不使用静态地址。所以我们这里需要得到的是章节地址分析。既然这里是章节地址,那我们为什么要呢?还有使用的章节名称。这主要是为了避免获取的章节名称与获取的章节地址不匹配。这里说一下,章节号的写法其实并不麻烦。你只需要稍微改变它。改成这样。让我们测试一下看看。让我们更改它以获取数字。这个获得的编号只能在目标站的动态地址已知的情况下使用。上面的17PubContentUrl章节内容页面地址在获取的章节地址中有说明。它用于目标站动态地址的情况,因为不使用通用静态地址。这里我就拿htmlbook36ASPX来讲解如何使用149539这个小说号。这里我们用NovelKey代替3790336,即PubChapter_GetChapterKey中得到的章节号,我们用ChapterKey来代替组合,即htmlbookNovelKeyChapterKeyASPX。这是我们的动态章节地址。记住,前提是要知道对方的动态地址。如果不知道对方的动态地址,那么我们这里在PubContentUrl章节内容页面地址中写的是ChapterKey18PubContentText来获取章节内容。获取方式与章节名称相同。这个就不解释了。现在我们解释过滤的用法。这很容易。什么是过滤,就是去掉你不想要的内容。一般使用过滤的几个地方都是介绍章节。卷名和获取的小说章节内容的名称,但是章节内容,有章节名和卷名的替换功能。章节名和卷名没有替换规则。比如我们获取到的volume叫做文本www8c8ecom,但是当我们获取volume的时候只想获取文本的两个词,那么我们这里就使用了filter。过滤器的格式就是过滤器的内容。每个过滤器的内容用于分隔介绍。过滤器与子卷名称相同。例如,我们获取作者姓名。当时获取的内容中,有一段多余的内容。本书作者随风聚散。因为他有的有,有的没有,所以我们不需要先直接用书的作者来获取想要的内容。从规则来看,我们得到的内容是在这一段中,我们要在这一段中保留的内容是随风聚散。让我们去把它添加到过滤规则中。这是固定的,所以直接添加它。这是我们要改变的。让我们改变它。在常规格式中,就是这样。让我们添加过滤器内容。现在说一下下一章内容的替换。章节内容的替换规则为每行替换一次。格式如下。需要替换的内容。更换结果。这意味着过滤。这意味着更换。如果有他使用的图片我们该怎么办?这里我们使用替换来处理其他替换。类似的替换仅在章节内容中使用。这仅适用于章节内容。三个人问我为什么采集为什么某个站总是空章?这个可能是空章的原因可能是目标站刚重启网站你的采集IP被封了等等 这里我想说明一下有空章 因为图章的操作流程采集器的采集内容是先检查你的采集章节是否是图片章节。如果你的PubContentImages章节内容中提取的图片规律不正确,那么你还没有获取到图片章节内容。会检查你的采集文字内容PubContentText 获取章节内容的正则匹配。如果从PubContentImages章节内容中提取的图片与PubContentText获取的章节内容不匹配,那么就会出现我们上面提到的章节空的原因。规则写好后,我们来测试一下规则是否可以正常获取到我们想要获取的内容。经测试,我们编写的规则可以正常得到思路。
第一步是将原创规则复制为模板。比如我今天演示的采集站点是一个小说站点,叫feiku,那么我把我复制的模板规则命名为dhabcxml,这主要是为了方便记忆。第二步,我们在采集器中运行规则管理工具,打开并加载我们刚刚命名为dhabcxml的XML文件。第三步开始正式编写规则1RULEID规则号,这个任意2GetSiteName站点名称,这里我们编写8E小说3GetSiteCharset站点代码。这里我们打开 www8c8ecom 查找字符集编号。后面是我们需要的站点代码www8c8ecom。我们找到的代码是 gb23124GetSiteUrl 站点地址。不用说,把它写进5NovelSearchUrl站点搜索地址。每次网站程序不同时必须获取这个地址,但是有一个通用的方法可以通过抓包来获取你想要的内容。虽然是抓包得到的,但是你怎么知道我们想要的就是我们想要的呢?看我的操作 首先我们运行打包工具,选择IEXPLOREEXE进程。最好只开一个网站,也就是只开你要写规则的网站,保证进程中只有一个IEXPLOREEXE进程。在这里我们可以看到提交的地址是booksearchaspx。让我们结合起来。地址是booksearchaspx,提交内容的代码是SearchKeyC1ABBBA8SearchClass1SeaButtonx26SeaButtony10。但对我们来说,它是 SearchKeyC1ABBBA8SearchClass1。此处获取的部分将用于NovelSearchData 搜索提交内容。把这一段改成我们想要的 必要的代码就是把C1ABBBA8的这一段换成SearchKey,也就是说搜索提交的内容的完整代码是SearchKeySearchKeySearchClass1。然后我们测试它是否正确。经过测试,我们得到的内容是正确的。 6 NovelListUrl 站点的最新列表地址。因为这些我就不说了。每个站点都不一样,需要自己找FEIKU 是BookShowBookListaspx7NovelList_GetNovelKey 从最新列表中获取小说编号。该规则可用于同时获取书名。它用于手动模式。如果要使用手动模式,必须获取书名,否则手动模式将不可用。我们打开bookshowbooklistaspx的地址查看我们写的源文件时使用这个规则,找到你要获取的内容的地方。比如我们打开地址看到想要获取的内容,第一本小说的名字是李迪程沫,我们在源文件中找到了莫兰特传奇魔法。 【目录】莫伦特传,第一卷,第八章,黑暗的崛起,11月27日,龙眼连载。我们用来编写规则的代码实际上并不是很多代码。我写规则的原则是能省就省,也就是代码越短越好,除非万不得已,越短越好。没有废话。在这个规则中,我们需要使用网站成为恶魔。我们将更改这一段,其中 d 表示数字表示小说名称已经过测试并且是正确的。 8 NovelUrl 小说信息页地址,这个很简单,我们随便点一个小说就知道了,比如我们在书Book150557Indexhtml中看到的,我们把里面的150557改成NovelKey。一般是指小说编号BookNovelKeyIndexhtml9NovelErr小说信息页错误识别标志。这个一般是Book149539Indexhtml中间的那个。随意更改数字,例如Book15055799Indexhtml,我们得到
错误标志是没有找到编号的图书信息。 10NovelName获取小说名,我们只要打开小说Book149539Indexhtml查看源码即可获取小说名。这个我们可以从固定模式开始,比如我们刚刚打开的小说。看到他固定的小说名字格式是“Site into a Devil”,那么我们在源码中找到了“Site into a Devil”。我们得到的内容是“Site into a Devil”。我们将“”下的小说作者更改为小说作者。 LagerSort 获取小说类别 SmallSort 获取小说类别 NovelIntro 获取小说简介 NovelKeyword 获取小说主角关键词 NovelDegree 获取写作过程 NovelCover 获取小说封面 这些,我就不演示了,这些和上面的获取小说的方法是一样的名字,所以就是所谓的百通一通,这里是这里得到的一些内容,有些是因为格式不固定所以不想用的。有些内容只能先获取,再通过过滤功能进行过滤。后面说11NovelInfo_GetNovelPubKey获取小说公共目录页面地址的地址。获取方法同上,12PubIndexUrl公共目录页面地址我就不解释了。我将解释这个的用法。这个一般在知道采集目标站的动态地址时使用。如果不知道对方的动态地址。在此写入NovelPubKey。如果你知道动态路径,比如本站没有小说的章节目录的动态地址是Book149539Indexaspx,那么PubIndexUrl的规则是BookNovelKeyIndexaspx13PubVolumeSplit拆分卷,这个拆分卷有地方写,你需要要注意是否拆分音量。规律是不对的。所以很可能会对后面的章节名产生很大的影响。这里我们得到了分割部分的代码。根据我的经验,找到第一个子卷和下面的子卷来看看它们的共同点我们分析了htmlbook130149539Listshtm的目录章节中的源代码,可以看出它们有一个共同点。拿这一段来说明对权力的追求。从这里我们可以看出他的共同点是id“feiku_e_n_d”。让我们改变它,将其更改为常规规则。 s格式中,s表示匹配任意白色字符,包括空格、制表符、分页符等,也就是说,无论and之间有多少个空格,都可以用s表示14PubVolumeName来获取音量名称并希望获得准确的音量。该名称必须在上述部分中。规律一定是正确的。通常,节和子卷名称在同一页面上。我们在章节中解释了对权力的追求。如果你关注这个部分,你会在里面找到我。让我们更改代码以获取此步骤中的子卷名称。我们测试并正常获取子卷。但是如果有这些,我们通常在过滤规则中过滤。 15PubChapterName 获取章节名称。让我们用一段话来说明强大的驯服方法。对于这种带有时间和日期的更新字数,我们只是忽略它,因为这些不是我们想要获取的内容。这可以用来说明有人问我为什么把它附在这里没用。让我告诉你我们得到了什么。内容就是里面的内容。如果它不是你想要的,但在编写规则时必须使用它。我们可以稍微改变一下表达方式。好,我们把上面的那段改一下,改成表达式,就可以正常获取内容了。小伙伴们是不是觉得这个规则有点别扭?这是因为中间有一个换行符。我没有更改代码。我们用 s 来表示 N 个换行符。修改后的代码现在更好了吗?测试后也是正常的。内容描述规则没有问题 16PubChapter_GetChapterKey 获取章节地址 章节号 这里是本节章节号的描述,用于下面的PubContentUrl章节内容页面地址
一般知道目标站的动态地址。一般不使用静态地址。如果你不知道目标站的动态地址,那么我们这里需要得到的是章节地址分析。既然这是为了获取章节地址,那为什么还要使用章节名称呢?这样做的主要原因是为了避免获取的章节名称与获取的章节地址不匹配。说到这里,下章号的写法其实并不麻烦。只需要稍微改动一下,改成这个就行了。让我们测试一下。你可以看到。像这样改变它以获取数字。获取的编号只有在知道目标站的动态地址时才能使用。上面的17PubContentUrl章节内容页地址有获取到的章节地址。这是要知道目标站的动态地址。使用地址是因为这里不使用通用静态地址。我用htmlbook36ASPX来说明如何使用149539,这是小说编号。这里我们使用NovelKey代替3790336,即PubChapter_GetChapterKey中获取的章节号。让我们用 ChapterKey 替换它。组合是 htmlbookNovelKeyChapterKeyASPX。这是我们的动态章节地址。记住,前提是要知道对方的动态地址。如果不知道对方的动态地址,那么我们这里在PubContentUrl章节内容页面地址中写的是ChapterKey18PubContentText来获取章节内容。这种获取章节内容的方法与获取章节名称的方法相同,不做说明。现在我们解释过滤的用法。这很容易。什么是过滤,就是去掉你不想要的内容。一般使用过滤的几个地方是介绍、章节名、卷名、获取小说章节的内容,但是章节内容有替换功能。简介、章节名称和子卷名称。这几个暂时没有更换规则。比如我们获取的子卷叫做正文www8c8ecom,但是我们在获取子卷的时候只想获取正文,这里就用到了这两个词。过滤器格式是过滤器的内容。每个过滤器的内容用于分隔介绍。过滤器与子卷名称相同。比如我们获取作者姓名时获取的内容。有一个额外的内容。书作者云集,随风而去。因为他,有的有,有的没有,所以我们不需要先用书的作者来获取内容。从规则中,我们得到的内容是随风聚散的。在本段中,我们要在本段中保留的内容是随风聚散。让我们去把它添加到过滤规则中。因为是固定的,所以我们可以直接添加。这对我们来说是一个改变。让我们更改它并将其更改为常规格式。就是这样。让我们添加过滤内容。现在说一下下一章内容的替换。章节内容的替换规则为每行替换一次。格式如下。需要替换的内容。替换结果。这意味着过滤。这意味着更换。比如飞酷里有一个词。我们这里用的图片应该怎么处理,我们用replacement来处理其他的replacement。类似替换内容替换只对章节内容有用。这是专用于章节内容。有人问我为什么采集某站为什么老是出现空章?这可能就是出现空章的原因。这可能是目标站刚重启网站你的采集IP被屏蔽了等等,这里我想说明一下,空章是图片章节造成的。 采集器的采集内容操作流程是先检查你的采集章节是否为图片章节。如果你的PubContentImages章节内容中提取的图片规律不正确,如果你没有得到图片章节内容,你会检查你的采集文字内容PubContentText获取章节内容的规律匹配。如果从 PubContentImages 章节内容中提取的图片与获取章节内容的 PubContentText 不匹配,那么就会出现我们上面所说的空章节的原因。嗯,规则已经写好了。测试规则是否可以正常获取到想要的内容。测试表明我们编写的规则可以正常获取到想要的内容
优采云控制台列表提取器(网址采集规则)列表
采集交流 • 优采云 发表了文章 • 0 个评论 • 589 次浏览 • 2021-07-21 07:19
优采云Navigation: 优采云采集器 优采云控制面板
列表提取器(URL采集rule)
列表提取器主要用于提取多个详情页链接(即设置URL采集规则),配置主要分为三个步骤:
点击“重置当前字段”按钮重新开始配置;用鼠标点击你想要采集的链接(标题),只需点击两个不同的链接,系统会自动选择其他相似的链接;检查页面左下角查看文章链接地址是否在“数据预览”下(相对或绝对链接都可以),如果有,则配置正确,如果没有,则需要再次点击,直到链接出现。
URL采集配置结果示例:
详细使用步骤:
1.清除旧配置
在智能向导创建任务期间或之后,如果URL采集规则不正确,您可以打开“列表提取器”进行修改。
点击列表提取器右上角的【重置当前字段配置】按钮,点击【确定】清除现有配置:
2.点击页面上采集的链接
用鼠标点击你想要采集的链接(标题),只需点击两个不同的链接,系统会自动选择其他相似的链接。
点击两次后,查看页面左下角“数据预览”下的文章链接地址是否列出(相对或绝对链接都可以),如果有则配置正确,如果没有,您需要单击“选择”,直到出现链接。 (如果没有出现链接,请检查)
(可选)URL采集Rule 通用性测试:如果任务配置了多个列表页面(如翻页),那么可以点击'Typical List Page URL'的输入框,其他会出现From列表页面的URL下拉列表,可以随意选择一两个不同的链接。
高级配置说明:列表提取器只能配置一个url字段,默认勾选“仅获取URL”和“自动选择相似元素”功能。 (一般不需要修改,使用系统默认配置即可)
列出页面配置常见问题及解决方法一、链接无法点击,怎么办?
解决方案主要分为四种情况:
二。列表提取器的入口?
列表提取器有两个主要入口:
优采云Navigation: 优采云采集器 优采云控制面板 查看全部
优采云控制台列表提取器(网址采集规则)列表
优采云Navigation: 优采云采集器 优采云控制面板
列表提取器(URL采集rule)
列表提取器主要用于提取多个详情页链接(即设置URL采集规则),配置主要分为三个步骤:
点击“重置当前字段”按钮重新开始配置;用鼠标点击你想要采集的链接(标题),只需点击两个不同的链接,系统会自动选择其他相似的链接;检查页面左下角查看文章链接地址是否在“数据预览”下(相对或绝对链接都可以),如果有,则配置正确,如果没有,则需要再次点击,直到链接出现。
URL采集配置结果示例:
详细使用步骤:
1.清除旧配置
在智能向导创建任务期间或之后,如果URL采集规则不正确,您可以打开“列表提取器”进行修改。
点击列表提取器右上角的【重置当前字段配置】按钮,点击【确定】清除现有配置:
2.点击页面上采集的链接
用鼠标点击你想要采集的链接(标题),只需点击两个不同的链接,系统会自动选择其他相似的链接。
点击两次后,查看页面左下角“数据预览”下的文章链接地址是否列出(相对或绝对链接都可以),如果有则配置正确,如果没有,您需要单击“选择”,直到出现链接。 (如果没有出现链接,请检查)
(可选)URL采集Rule 通用性测试:如果任务配置了多个列表页面(如翻页),那么可以点击'Typical List Page URL'的输入框,其他会出现From列表页面的URL下拉列表,可以随意选择一两个不同的链接。
高级配置说明:列表提取器只能配置一个url字段,默认勾选“仅获取URL”和“自动选择相似元素”功能。 (一般不需要修改,使用系统默认配置即可)
列出页面配置常见问题及解决方法一、链接无法点击,怎么办?
解决方案主要分为四种情况:
二。列表提取器的入口?
列表提取器有两个主要入口:
优采云Navigation: 优采云采集器 优采云控制面板
e优采云采集器的使用及其所用技术的介绍
采集交流 • 优采云 发表了文章 • 0 个评论 • 191 次浏览 • 2021-07-18 03:07
介绍e优采云采集器的使用和使用的技术,“优采云采集器”能为你做什么? ?1、网站内容维护:您可以定期采集新闻、文章等您想要采集的内容,并自动发布到您的网站。 2、互联网数据挖掘:您可以从指定的网站中抓取所需的数据,分析处理后保存到您的数据库中。 3、网络信息管理:通过采集自动监控论坛等社区网站,让您第一时间发现您关心的内容。 4、文件批量下载:可以批量下载PDF、RAR、图片等各种文件,同时采集其相关信息。 优采云采集器是目前最流行的信息采集和信息挖掘处理软件,性价比最高、用户最多、市场占有率最大、使用周期最长的智能采集程序给定种子 URL 列表,按照规则抓取列表页面并分析 URL 以抓取 Web 内容。根据采集规则,分析下载的网页并保存内容优采云采集器数据发布原则:我们发送数据采集下载后,数据默认保存在本地,我们可以使用如下处理种子数据的方法。 1. 不做任何处理。因为数据本身是存放在数据库中的(access或者db3),如果只是想查看就用相关软件查看即可。2.web贴到网站。程序会模仿浏览器给你展示网站发送数据,可以达到手动发布的效果。3.直接导入数据库,你只需要写几条SQL语句,程序就会根据你的数据导入数据库SQL 语句。
4. 保存为本地文件。程序会读取数据库中的数据,并按一定格式保存为本地sql或文本文件。 优采云采集器 演示优采云采集器 垂直搜索引擎信息跟踪和自动排序使用的技术,自动索引技术,海量数据采集系统进程1)信息采集(网络蜘蛛) 来指定网站 进行数据采集,本地存储需要的信息,并记录对应的采集信息。供信息提取模块提取数据。 2)信息提取从采集信息中提取有效数据进行结构化处理。清除垃圾邮件,获取文本内容、相关图片、种子文件等相关信息。 3)信息处理对提取的信息进行数据处理。对信息进行清洗、重复数据删除、分类、分析和比较,并进行数据挖掘。最后提交处理后的数据,对信息进行切分和索引。 4)Information Retrieval 提供信息查询接口。提供全文检索界面,对信息进行分词处理。相关技术 垂直搜索引擎技术1、web蜘蛛-爬虫信息源的稳定性(不让信息源网站感受到蜘蛛的压力)爬行成本提升用户体验2、WEB结构化信息提取根据一定的需要,将网页中的非结构化数据提取为结构化数据。 Web结构化信息提取在百度和谷歌中得到了广泛的应用。基于模板的结构化信息提取的两种实现。不依赖网页的网页库级结构化信息抽取方法3、信息的处理技术清洗、去重、分类、分析比较、数据挖掘、语义分析等4、Participle系统分词基于字符串匹配的分词方法、基于理解的分词方法、基于统计的分词算法,哪种分词算法更准确,目前还没有定论。
对于任何成熟的分词系统来说,都无法依靠单一的算法来实现,需要集成不同的算法。常用中文分词开源项目:SCWS、ICTCLAS、HTTPCWS、跑丁杰牛分词、CC-CEDICT5、索引索引技术对于垂直搜索非常重要,一个网络图书馆级别的搜索引擎必须支持分布式索引和分层建库、分布式检索、灵活更新、灵活权重调整、灵活索引和灵活升级扩容、高可靠性、稳定性和冗余性。它还需要支持各种技术的扩展,例如偏移计算。谢谢 查看全部
e优采云采集器的使用及其所用技术的介绍
介绍e优采云采集器的使用和使用的技术,“优采云采集器”能为你做什么? ?1、网站内容维护:您可以定期采集新闻、文章等您想要采集的内容,并自动发布到您的网站。 2、互联网数据挖掘:您可以从指定的网站中抓取所需的数据,分析处理后保存到您的数据库中。 3、网络信息管理:通过采集自动监控论坛等社区网站,让您第一时间发现您关心的内容。 4、文件批量下载:可以批量下载PDF、RAR、图片等各种文件,同时采集其相关信息。 优采云采集器是目前最流行的信息采集和信息挖掘处理软件,性价比最高、用户最多、市场占有率最大、使用周期最长的智能采集程序给定种子 URL 列表,按照规则抓取列表页面并分析 URL 以抓取 Web 内容。根据采集规则,分析下载的网页并保存内容优采云采集器数据发布原则:我们发送数据采集下载后,数据默认保存在本地,我们可以使用如下处理种子数据的方法。 1. 不做任何处理。因为数据本身是存放在数据库中的(access或者db3),如果只是想查看就用相关软件查看即可。2.web贴到网站。程序会模仿浏览器给你展示网站发送数据,可以达到手动发布的效果。3.直接导入数据库,你只需要写几条SQL语句,程序就会根据你的数据导入数据库SQL 语句。
4. 保存为本地文件。程序会读取数据库中的数据,并按一定格式保存为本地sql或文本文件。 优采云采集器 演示优采云采集器 垂直搜索引擎信息跟踪和自动排序使用的技术,自动索引技术,海量数据采集系统进程1)信息采集(网络蜘蛛) 来指定网站 进行数据采集,本地存储需要的信息,并记录对应的采集信息。供信息提取模块提取数据。 2)信息提取从采集信息中提取有效数据进行结构化处理。清除垃圾邮件,获取文本内容、相关图片、种子文件等相关信息。 3)信息处理对提取的信息进行数据处理。对信息进行清洗、重复数据删除、分类、分析和比较,并进行数据挖掘。最后提交处理后的数据,对信息进行切分和索引。 4)Information Retrieval 提供信息查询接口。提供全文检索界面,对信息进行分词处理。相关技术 垂直搜索引擎技术1、web蜘蛛-爬虫信息源的稳定性(不让信息源网站感受到蜘蛛的压力)爬行成本提升用户体验2、WEB结构化信息提取根据一定的需要,将网页中的非结构化数据提取为结构化数据。 Web结构化信息提取在百度和谷歌中得到了广泛的应用。基于模板的结构化信息提取的两种实现。不依赖网页的网页库级结构化信息抽取方法3、信息的处理技术清洗、去重、分类、分析比较、数据挖掘、语义分析等4、Participle系统分词基于字符串匹配的分词方法、基于理解的分词方法、基于统计的分词算法,哪种分词算法更准确,目前还没有定论。
对于任何成熟的分词系统来说,都无法依靠单一的算法来实现,需要集成不同的算法。常用中文分词开源项目:SCWS、ICTCLAS、HTTPCWS、跑丁杰牛分词、CC-CEDICT5、索引索引技术对于垂直搜索非常重要,一个网络图书馆级别的搜索引擎必须支持分布式索引和分层建库、分布式检索、灵活更新、灵活权重调整、灵活索引和灵活升级扩容、高可靠性、稳定性和冗余性。它还需要支持各种技术的扩展,例如偏移计算。谢谢
辣鸡文章采集器可用在哪里运行本采集之旅
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2021-07-17 03:19
香辣鸡介绍采集laji-collect
麻辣鸡采集,采集全世界麻辣鸡数据欢迎大家采集
基于fesiong优采云采集器底层开发
优采云采集器
开发语言
golang
官网案例
香辣鸡采集
为什么有这个辣鸡文章采集器辣鸡文章采集器能采集什么内容
这个采集器can采集的内容是:文章title,文章关键词,文章description,文章detailed content,文章author,文章release time, 文章 浏览量。
我什么时候需要用辣鸡文章采集器
当我们需要给网站采集文章时,这个采集器可以派上用场。这个采集器不需要有人值班。它每天 24 小时运行,每 10 分钟运行一次。它会自动遍历采集列表,抓取收录文章的链接,并随时抓取文本。也可以设置自动发布,自动发布到指定的文章列表。
麻辣鸡文章采集器能跑到哪里去?
这个采集器可以运行在Windows系统、Mac系统、Linux系统(Centos、Ubuntu等)上,可以下载编译好的程序直接执行,也可以下载源码自己编译。
香辣鸡文章采集器Available 伪原创?
这个采集器暂时不支持伪原创功能,后续会添加合适的伪原创选项。
如何安装和使用
go env -w GOPROXY=https://goproxy.cn,direct
最后执行如下命令
编译结束后,运行编译好的文件,然后双击运行可执行文件。在打开的浏览器的可视化界面中,填写数据库信息,完成初始配置,添加采集source,开始采集之旅。
发展计划官网微信交流群
帮助改进
欢迎有能力和贡献精神的个人或团体参与本采集器的开发和完善,共同完善采集功能。请fork一个分支,然后修改,修改后提交pull request合并请求。 查看全部
辣鸡文章采集器可用在哪里运行本采集之旅
香辣鸡介绍采集laji-collect
麻辣鸡采集,采集全世界麻辣鸡数据欢迎大家采集
基于fesiong优采云采集器底层开发
优采云采集器
开发语言
golang
官网案例
香辣鸡采集
为什么有这个辣鸡文章采集器辣鸡文章采集器能采集什么内容
这个采集器can采集的内容是:文章title,文章关键词,文章description,文章detailed content,文章author,文章release time, 文章 浏览量。
我什么时候需要用辣鸡文章采集器
当我们需要给网站采集文章时,这个采集器可以派上用场。这个采集器不需要有人值班。它每天 24 小时运行,每 10 分钟运行一次。它会自动遍历采集列表,抓取收录文章的链接,并随时抓取文本。也可以设置自动发布,自动发布到指定的文章列表。
麻辣鸡文章采集器能跑到哪里去?
这个采集器可以运行在Windows系统、Mac系统、Linux系统(Centos、Ubuntu等)上,可以下载编译好的程序直接执行,也可以下载源码自己编译。
香辣鸡文章采集器Available 伪原创?
这个采集器暂时不支持伪原创功能,后续会添加合适的伪原创选项。
如何安装和使用
go env -w GOPROXY=https://goproxy.cn,direct
最后执行如下命令
编译结束后,运行编译好的文件,然后双击运行可执行文件。在打开的浏览器的可视化界面中,填写数据库信息,完成初始配置,添加采集source,开始采集之旅。
发展计划官网微信交流群
帮助改进
欢迎有能力和贡献精神的个人或团体参与本采集器的开发和完善,共同完善采集功能。请fork一个分支,然后修改,修改后提交pull request合并请求。
免规则采集器列表算法框架(基于点赞收集文章)
采集交流 • 优采云 发表了文章 • 0 个评论 • 175 次浏览 • 2021-07-14 07:00
免规则采集器列表算法框架1.基于点赞,给文章点赞收集文章网页url地址2.采集该地址下,下面所有收集用户点赞,评论,分享和赞的用户信息,并统计这些urlurl地址获取地址有很多种,各有各的方法。这里简单介绍下原理,和代码:创建用户列表,获取用户id,用户的评论或转发等有效数据下面是代码思路:逐一判断,模拟登录查看下面是工具(免规则采集器)获取的网页url:soup/html.py下面是工具获取的网页url:。
你可以试试其他开源的scrapy框架。
免规则采集器使用scrapy框架开发还是很容易上手的,
想采集全网的就上vnpy,都可以有免费的对于微信端免规则采集。
可以用choice,
用scrapy可以用过建立scrapy_msg对象,然后用sklearn库来解析收集的数据,
推荐一篇文章,
b站采集器-ai技术-51cto技术论坛
b站采集器/
b站采集器
收集-广告联盟智能投放系统,首先你要建立一个有效url的字典,然后用scrapy框架把抓到的数据放到字典中,之后再用idata.serializer把各url关联到字典中。scrapy主流框架应该是xadmin+web.py,可以了解一下xadmin,可以参考资料,这里面有个教程解读scrapy框架安装,代码构建以及网页抓取的系列教程。 查看全部
免规则采集器列表算法框架(基于点赞收集文章)
免规则采集器列表算法框架1.基于点赞,给文章点赞收集文章网页url地址2.采集该地址下,下面所有收集用户点赞,评论,分享和赞的用户信息,并统计这些urlurl地址获取地址有很多种,各有各的方法。这里简单介绍下原理,和代码:创建用户列表,获取用户id,用户的评论或转发等有效数据下面是代码思路:逐一判断,模拟登录查看下面是工具(免规则采集器)获取的网页url:soup/html.py下面是工具获取的网页url:。
你可以试试其他开源的scrapy框架。
免规则采集器使用scrapy框架开发还是很容易上手的,
想采集全网的就上vnpy,都可以有免费的对于微信端免规则采集。
可以用choice,
用scrapy可以用过建立scrapy_msg对象,然后用sklearn库来解析收集的数据,
推荐一篇文章,
b站采集器-ai技术-51cto技术论坛
b站采集器/
b站采集器
收集-广告联盟智能投放系统,首先你要建立一个有效url的字典,然后用scrapy框架把抓到的数据放到字典中,之后再用idata.serializer把各url关联到字典中。scrapy主流框架应该是xadmin+web.py,可以了解一下xadmin,可以参考资料,这里面有个教程解读scrapy框架安装,代码构建以及网页抓取的系列教程。
免规则采集器列表算法和使用限制以及免编程采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2021-07-06 04:01
免规则采集器列表算法和使用限制以及示例采集器专栏提供免编程采集的实践教程和系列教程,建议使用手机看视频,电脑屏幕尺寸限制问题,对内容分辨率等设置具体方案。总结:课程中还不包含分页输出内容的上传方案,具体的上传方案还需要设置具体的场景上传课程:1.创建采集器文件(采集器是每一篇记录)2.设置采集规则输入关键词,调用接口3.创建采集文件的"-”分页文件(该方案是小规模测试阶段,有机会详细介绍这个上传规则的使用规则)上传文件(1)单页文件上传:将文件上传到文件夹下-并且在每个视频页中具体规则到该规则下级即可(2)多页文件上传:将文件上传到对应文件夹。
1。查看采集器的详细地址,详细地址点这里2。首先要把文件上传到本地电脑上,把目录路径发给采集器。3。配置好需要的三方接口(请看,提示信息详细了解以下,你可以选择你认为好的接口,详细了解三方接口是什么?点这里)4。然后写代码,接口实现post上传,点图片不能复制5。使用采集器,采集用户行为数据,后台回传数据,。
七天测试数据传输方案(使用sax格式的spss安装文件或excel等格式)采集系统
搜索一下14sf-sf13集
具体如何实现的,可以参考“帮助手册”中的介绍,一般如果只是简单的功能,提供一份表单模板即可,但如果页面类似”问答题”的,如果上传数据较多的话,难免就需要一套较完整的后台,就像这样:解决方案:::先上传文件,再分类,再点开放到导航栏。具体用的“酷传大数据采集器”,自动同步报名到公众号。 查看全部
免规则采集器列表算法和使用限制以及免编程采集
免规则采集器列表算法和使用限制以及示例采集器专栏提供免编程采集的实践教程和系列教程,建议使用手机看视频,电脑屏幕尺寸限制问题,对内容分辨率等设置具体方案。总结:课程中还不包含分页输出内容的上传方案,具体的上传方案还需要设置具体的场景上传课程:1.创建采集器文件(采集器是每一篇记录)2.设置采集规则输入关键词,调用接口3.创建采集文件的"-”分页文件(该方案是小规模测试阶段,有机会详细介绍这个上传规则的使用规则)上传文件(1)单页文件上传:将文件上传到文件夹下-并且在每个视频页中具体规则到该规则下级即可(2)多页文件上传:将文件上传到对应文件夹。
1。查看采集器的详细地址,详细地址点这里2。首先要把文件上传到本地电脑上,把目录路径发给采集器。3。配置好需要的三方接口(请看,提示信息详细了解以下,你可以选择你认为好的接口,详细了解三方接口是什么?点这里)4。然后写代码,接口实现post上传,点图片不能复制5。使用采集器,采集用户行为数据,后台回传数据,。
七天测试数据传输方案(使用sax格式的spss安装文件或excel等格式)采集系统
搜索一下14sf-sf13集
具体如何实现的,可以参考“帮助手册”中的介绍,一般如果只是简单的功能,提供一份表单模板即可,但如果页面类似”问答题”的,如果上传数据较多的话,难免就需要一套较完整的后台,就像这样:解决方案:::先上传文件,再分类,再点开放到导航栏。具体用的“酷传大数据采集器”,自动同步报名到公众号。

