
今日头条文章采集软件
今日头条文章采集软件(一键采集百度贴吧内容正式版5.15.13.0 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 216 次浏览 • 2021-12-25 06:17
)
下载链接:
游客,如果您想查看本帖隐藏内容,请回复
相关插件:
一键采集抢每日快车1.0
一键采集知乎问答
一键采集贴吧正式版内容5.1
一键采集天涯论坛Discuz v1.0任意贴
一键采集今日头条2.2
一键采集百度贴吧内容5.0
一键采集今日头条正式版3.0 价值289元
01、可以批量注册马甲用户。发帖者和评论所使用的马甲看起来与真实注册用户发布的马甲完全相同。
02、 可以批量采集批量发布,短时间内将任何高质量的标题文章和评论发布到您的论坛和门户。
03、可自动发布采集的所有内容,实现网站内容无人值守自动更新,让您拥有24小时发布内容的智能编辑器。
04、采集 返回的内容可以进行简繁体转换,可以做伪原创等二次处理。
05、 支持采集指定的标题号,实现针对采集的某个标题号的内容。
06、采集 过来的内容图片可以正常显示并保存为帖子图片附件或门户文章附件,图片永不丢失。
07、图片附件支持远程FTP存储,让您可以将图片分离到另一台服务器。
08、 图片会添加您的论坛或门户设置的水印。
09、 已经采集的内容不会重复两次采集,内容不会重复或冗余。
1 0、采集或门户网站文章和群组发布的帖子与真实用户发布的帖子完全相同。其他人不知道是否用采集器 发帖。
1 1、的浏览量会自动随机设置。感觉你的帖子或门户文章的浏览量和真实的一样。
12、可以指定帖子发布者(主持人)、门户文章作者、群发者。
1 3、采集的内容可以发布到论坛任意版块、门户任意栏目、群任意圈。
14、 马甲回复时间经过科学处理。并非所有回复帖子的人都在同一时间。感觉您的论坛不是在回复马甲,而是在回复真实用户。
15、不限制采集的内容数量,不限制采集的次数,让你的网站快速填充优质内容.
16、插件内置采集规则,无需自己编写采集规则,支持采集任意标题网站任意列内容。
17、 一键获取当前实时热点内容,然后一键发布。
18、免费赠送对应的google chrome扩展程序(附详细安装教程),实现“所见即所得”,即可以采集任意内容标题你浏览的内容。
【这个插件给你带来的价值回报】
01、 使您的论坛非常受欢迎且内容丰富。
02、 批量生成的马甲除了使用这个插件,还可以做其他用途,相当于购买了这个插件,马甲生成插件是免费赠送的礼物。
03、使用一键采集代替人工发帖,省时省力,不易出错。相当于你的网站带有机器人智能编辑器。
04、让您的网站与知名网站分享海量优质内容,快速提升网站SEO权重和排名。
05、 这个插件相当于解决了你的网站优质内容来源问题。用好这个工具,让你操作网站事半功倍。
查看全部
今日头条文章采集软件(一键采集百度贴吧内容正式版5.15.13.0
)
下载链接:
游客,如果您想查看本帖隐藏内容,请回复
相关插件:
一键采集抢每日快车1.0
一键采集知乎问答
一键采集贴吧正式版内容5.1
一键采集天涯论坛Discuz v1.0任意贴
一键采集今日头条2.2
一键采集百度贴吧内容5.0
一键采集今日头条正式版3.0 价值289元
01、可以批量注册马甲用户。发帖者和评论所使用的马甲看起来与真实注册用户发布的马甲完全相同。
02、 可以批量采集批量发布,短时间内将任何高质量的标题文章和评论发布到您的论坛和门户。
03、可自动发布采集的所有内容,实现网站内容无人值守自动更新,让您拥有24小时发布内容的智能编辑器。
04、采集 返回的内容可以进行简繁体转换,可以做伪原创等二次处理。
05、 支持采集指定的标题号,实现针对采集的某个标题号的内容。
06、采集 过来的内容图片可以正常显示并保存为帖子图片附件或门户文章附件,图片永不丢失。
07、图片附件支持远程FTP存储,让您可以将图片分离到另一台服务器。
08、 图片会添加您的论坛或门户设置的水印。
09、 已经采集的内容不会重复两次采集,内容不会重复或冗余。
1 0、采集或门户网站文章和群组发布的帖子与真实用户发布的帖子完全相同。其他人不知道是否用采集器 发帖。
1 1、的浏览量会自动随机设置。感觉你的帖子或门户文章的浏览量和真实的一样。
12、可以指定帖子发布者(主持人)、门户文章作者、群发者。
1 3、采集的内容可以发布到论坛任意版块、门户任意栏目、群任意圈。
14、 马甲回复时间经过科学处理。并非所有回复帖子的人都在同一时间。感觉您的论坛不是在回复马甲,而是在回复真实用户。
15、不限制采集的内容数量,不限制采集的次数,让你的网站快速填充优质内容.
16、插件内置采集规则,无需自己编写采集规则,支持采集任意标题网站任意列内容。
17、 一键获取当前实时热点内容,然后一键发布。
18、免费赠送对应的google chrome扩展程序(附详细安装教程),实现“所见即所得”,即可以采集任意内容标题你浏览的内容。
【这个插件给你带来的价值回报】
01、 使您的论坛非常受欢迎且内容丰富。
02、 批量生成的马甲除了使用这个插件,还可以做其他用途,相当于购买了这个插件,马甲生成插件是免费赠送的礼物。
03、使用一键采集代替人工发帖,省时省力,不易出错。相当于你的网站带有机器人智能编辑器。
04、让您的网站与知名网站分享海量优质内容,快速提升网站SEO权重和排名。
05、 这个插件相当于解决了你的网站优质内容来源问题。用好这个工具,让你操作网站事半功倍。
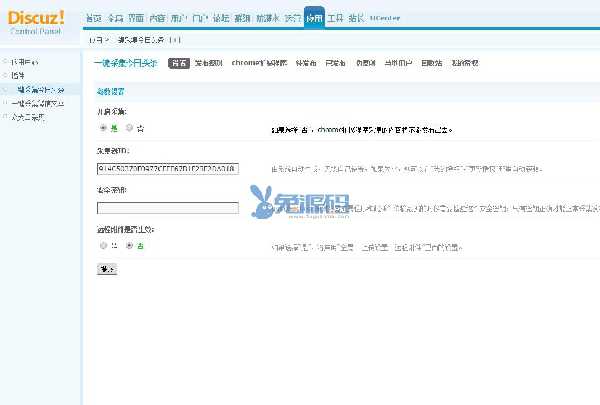
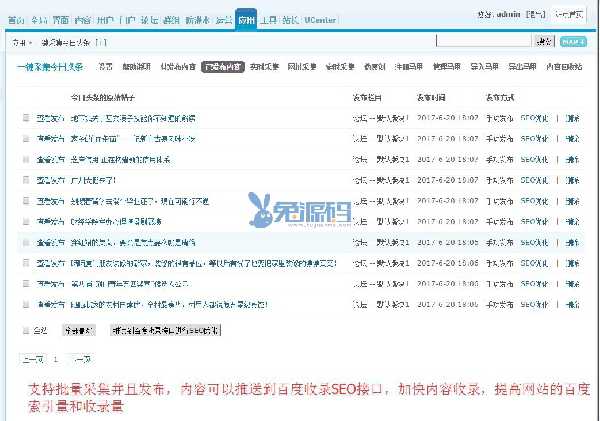

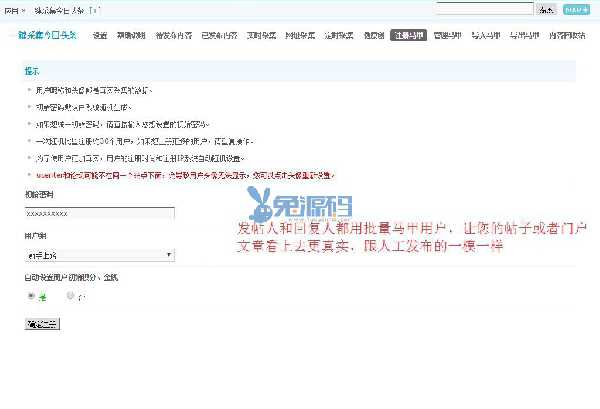

今日头条文章采集软件(金兰金兰今日头条营销助手官方手机版介绍(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2021-12-25 04:00
金兰今日头条营销助手手机版是金兰今日头条营销助手官方手机版。金兰今日头条营销助手官方手机版拥有四种强大的文章采集功能,你还可以在评论时自动采集这个文章,让你的营销推广更高效。
金兰官方手机版今日头条营销助手介绍
1.具有采集功能文章,可以一边评论一边采集这篇文章文章,有四个评论来源,可以采集新闻分类下的新闻文章@ > 评论可以按关键词搜索文章评论,可以评论指定标题号发布的文章,也可以导入指定的文章 @> 为评论,四个所有评论源都可以循环回复。
2. 支持云编码、编码兔、联众编码三种第三方支付身份验证码,IP支持ADSL、IP支持3G网卡、IP支持VPN、IP支持代理。
3. 拥有强大的金兰今日头条营销助手官方手机账号管理功能,自动记录每个账号每天的评论点赞数,支持从外部Excel文件批量导入评论内容,新手也容易上手开始使用该软件。
4.具有强大的文章评论功能。有两种评论模式:普通评论和智能抢夺。可以按照指定的时间间隔从第三方付费API接口代理IP。
金兰官方手机版今日头条营销助手功能
1. 可以对评论内容进行分组管理,方便评论时选择不同的评论内容。拥有强大的头条号采集功能,支持来自今日头条的首页和类别采集的头条号。
2. 拥有强大的评论和点赞功能,可以添加多个你想点赞的评论,点赞次数不限,强大的系统标签和随机变量替换功能可以生成各种不同的内容 避免内容重复。
3. 可以灵活设置评论点赞的时间间隔,限制账号每天最大评论点赞数。指定注释文章时可以使用软件采集,也可以手动添加。您也可以从文件中批量导入它们。
金兰头条营销助手官方手机版总结
金兰头条营销助手官方V2.10是一款适用于安卓版其他软件的手机软件。如果你喜欢这个软件,请把下载地址分享给你的朋友:
分享下载地址:
如果您想获取更多最新版本发布信息,请采集最新发布地址:
合集发布页面地址:
金兰头条营销助理官方V2.10更新内容,修复播放音画不同步问题。修复线控支架。贴心护眼模式,阅读更舒适!金兰今日头条营销助手官方手机版打不开或无法上网怎么办?
答:如果遇到金兰今日头条营销助理官访访问异常,请尝试在较好的网络环境下重新打开软件,或者重启手机再重新打开;如果还是不行,请卸载软件并点击上面的链接下载最新版本。尝试。为什么腾讯视频不能投票给金澜金澜今日头条营销助理官员?金兰今日头条营销助理官方APP好用吗?谁来介绍一下金兰的金兰今日头条营销助理官方白家旺?
展开 查看全部
今日头条文章采集软件(金兰金兰今日头条营销助手官方手机版介绍(组图))
金兰今日头条营销助手手机版是金兰今日头条营销助手官方手机版。金兰今日头条营销助手官方手机版拥有四种强大的文章采集功能,你还可以在评论时自动采集这个文章,让你的营销推广更高效。
金兰官方手机版今日头条营销助手介绍
1.具有采集功能文章,可以一边评论一边采集这篇文章文章,有四个评论来源,可以采集新闻分类下的新闻文章@ > 评论可以按关键词搜索文章评论,可以评论指定标题号发布的文章,也可以导入指定的文章 @> 为评论,四个所有评论源都可以循环回复。
2. 支持云编码、编码兔、联众编码三种第三方支付身份验证码,IP支持ADSL、IP支持3G网卡、IP支持VPN、IP支持代理。
3. 拥有强大的金兰今日头条营销助手官方手机账号管理功能,自动记录每个账号每天的评论点赞数,支持从外部Excel文件批量导入评论内容,新手也容易上手开始使用该软件。
4.具有强大的文章评论功能。有两种评论模式:普通评论和智能抢夺。可以按照指定的时间间隔从第三方付费API接口代理IP。
金兰官方手机版今日头条营销助手功能
1. 可以对评论内容进行分组管理,方便评论时选择不同的评论内容。拥有强大的头条号采集功能,支持来自今日头条的首页和类别采集的头条号。
2. 拥有强大的评论和点赞功能,可以添加多个你想点赞的评论,点赞次数不限,强大的系统标签和随机变量替换功能可以生成各种不同的内容 避免内容重复。
3. 可以灵活设置评论点赞的时间间隔,限制账号每天最大评论点赞数。指定注释文章时可以使用软件采集,也可以手动添加。您也可以从文件中批量导入它们。
金兰头条营销助手官方手机版总结
金兰头条营销助手官方V2.10是一款适用于安卓版其他软件的手机软件。如果你喜欢这个软件,请把下载地址分享给你的朋友:
分享下载地址:
如果您想获取更多最新版本发布信息,请采集最新发布地址:
合集发布页面地址:
金兰头条营销助理官方V2.10更新内容,修复播放音画不同步问题。修复线控支架。贴心护眼模式,阅读更舒适!金兰今日头条营销助手官方手机版打不开或无法上网怎么办?
答:如果遇到金兰今日头条营销助理官访访问异常,请尝试在较好的网络环境下重新打开软件,或者重启手机再重新打开;如果还是不行,请卸载软件并点击上面的链接下载最新版本。尝试。为什么腾讯视频不能投票给金澜金澜今日头条营销助理官员?金兰今日头条营销助理官方APP好用吗?谁来介绍一下金兰的金兰今日头条营销助理官方白家旺?
展开
今日头条文章采集软件( 网站采集用什么软件好,优采云万能文章采集软件好用不)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-12-21 03:16
网站采集用什么软件好,优采云万能文章采集软件好用不)
最近很多站长朋友问网站采集什么软件好,优采云万能文章采集软件好用。今天我将谈谈我们使用优采云、优采云和免费采集工具的经验。不做任何推荐,只分析其特点和适用场景。
为什么要使用文章采集工具
站长都知道,各大网站基本上都有自己的采集开放点。他们很少使用工具。作为seo,我们没有那么强大的技术支持,所以只能使用市场上一些常用的。采集工具实现采集。
文章采集 会不会影响网站的质量?
首先不能纯采集,纯采集是对百度等搜索引擎的严厉打击。文章发布前一定要重新修改文章,例如使用文章伪原创工具。达到接近原创的目标,再做相应的内外部优化。这样使用文章采集是没有问题的。但是要想做好SEO,内容很重要,因为SEO是一个内容为王的行业。
关于优采云万能文章采集器
先说优采云Universal文章采集软件。优采云Universal文章采集器是文章采集软件,只需要输入关键词,即可采集专业搜索引擎页面和新闻。但是优采云只针对一些常见的新闻来源,如:百度、搜狗、360、今日头条、微信、百度新闻、搜狗新闻、360新闻、一点新闻、雅虎、必应网页等。 ,不行就到指定的指定网站采集。对于不同的cms,还有网站。每次使用优采云采集到本地,都要使用不同的优采云发布软件来发布。还有一点就是优采云是收费的,站长朋友根据自己的情况安排。
免费的 采集 工具易于使用
首先,根据自己的情况选择一个。在我使用的众多文章采集工具中,我觉得我用的下面一个比较方便。最重要的是采集是完全免费的。
1. 依托软件独有的通用文本识别智能算法,可实现任意网页文本的自动提取,准确率达95%以上。
2.只需输入关键词即可采集微信文章、今日头条、一点资讯、百度新闻及网页、搜狗新闻及网页、360新闻及网页、必应新闻和网页、雅虎新闻和网页;批量关键词全自动采集。
3.可以针对采集指定网站的栏目列表下的所有文章(如百度体验、百度贴吧),智能匹配,无需编写复杂的规则。
4.文章翻译功能,可以将采集好文章翻译成英文再翻译回中文。
5.史上最简单最智能的文章采集器,重点是免费!自由!自由!
6.cms 支持:支持Empire、Yiyou、ZBLOG、织梦、WP、PB、Apple、搜外等各大cms,可在同时发布
对应栏目:不同的文章可以发布不同的栏目
定时发布:可以控制多少分钟发表一篇文章
监控数据:发布、待发布、是否伪原创、发布状态、URL、程序等。
操作步骤非常简单。该软件帮助站长和网站管理员解决了很多繁琐繁琐的工作。真正意义上的第一款软件同时实现了与所有主要cms版本的无缝对接,并支持本地伪原创!并且发布完成后,可以直接在同一软件上进行百度、搜狗、360、神马全平台推送,实现全平台cms发布管理、批量伪原创、全平台自动批量推送,软件强大,不止一点! 查看全部
今日头条文章采集软件(
网站采集用什么软件好,优采云万能文章采集软件好用不)

最近很多站长朋友问网站采集什么软件好,优采云万能文章采集软件好用。今天我将谈谈我们使用优采云、优采云和免费采集工具的经验。不做任何推荐,只分析其特点和适用场景。
为什么要使用文章采集工具
站长都知道,各大网站基本上都有自己的采集开放点。他们很少使用工具。作为seo,我们没有那么强大的技术支持,所以只能使用市场上一些常用的。采集工具实现采集。
文章采集 会不会影响网站的质量?
首先不能纯采集,纯采集是对百度等搜索引擎的严厉打击。文章发布前一定要重新修改文章,例如使用文章伪原创工具。达到接近原创的目标,再做相应的内外部优化。这样使用文章采集是没有问题的。但是要想做好SEO,内容很重要,因为SEO是一个内容为王的行业。

关于优采云万能文章采集器
先说优采云Universal文章采集软件。优采云Universal文章采集器是文章采集软件,只需要输入关键词,即可采集专业搜索引擎页面和新闻。但是优采云只针对一些常见的新闻来源,如:百度、搜狗、360、今日头条、微信、百度新闻、搜狗新闻、360新闻、一点新闻、雅虎、必应网页等。 ,不行就到指定的指定网站采集。对于不同的cms,还有网站。每次使用优采云采集到本地,都要使用不同的优采云发布软件来发布。还有一点就是优采云是收费的,站长朋友根据自己的情况安排。
免费的 采集 工具易于使用
首先,根据自己的情况选择一个。在我使用的众多文章采集工具中,我觉得我用的下面一个比较方便。最重要的是采集是完全免费的。

1. 依托软件独有的通用文本识别智能算法,可实现任意网页文本的自动提取,准确率达95%以上。
2.只需输入关键词即可采集微信文章、今日头条、一点资讯、百度新闻及网页、搜狗新闻及网页、360新闻及网页、必应新闻和网页、雅虎新闻和网页;批量关键词全自动采集。
3.可以针对采集指定网站的栏目列表下的所有文章(如百度体验、百度贴吧),智能匹配,无需编写复杂的规则。
4.文章翻译功能,可以将采集好文章翻译成英文再翻译回中文。
5.史上最简单最智能的文章采集器,重点是免费!自由!自由!
6.cms 支持:支持Empire、Yiyou、ZBLOG、织梦、WP、PB、Apple、搜外等各大cms,可在同时发布
对应栏目:不同的文章可以发布不同的栏目
定时发布:可以控制多少分钟发表一篇文章
监控数据:发布、待发布、是否伪原创、发布状态、URL、程序等。
操作步骤非常简单。该软件帮助站长和网站管理员解决了很多繁琐繁琐的工作。真正意义上的第一款软件同时实现了与所有主要cms版本的无缝对接,并支持本地伪原创!并且发布完成后,可以直接在同一软件上进行百度、搜狗、360、神马全平台推送,实现全平台cms发布管理、批量伪原创、全平台自动批量推送,软件强大,不止一点!
今日头条文章采集软件( 为什么要做头条采集?做百度的站长为什么会要采集头条的内容?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-12-19 01:02
为什么要做头条采集?做百度的站长为什么会要采集头条的内容?)
为什么要上头条采集?作为百度站长,你为什么要成为采集的头条内容?今日头条的文章能被百度收录抓取吗?这是很多站长朋友经常问小编的一些问题,所以今天小编就来告诉大家为什么要上头条采集。
今天今日头条的文章不会被百度蜘蛛和收录收录。如今的今日头条机器人已经禁止百度蜘蛛和百度爬取今日头条网站的内容。所以今日头条的首页只有收录,没有其他内页。因此,您在今日头条上发布的文章不会是百度的收录,而您在今日头条上发布的文章将是以后在今日头条自己的搜索引擎中的收录。. 网站的频繁更新内容可以在搜索引擎中产生足够的信任,发布的文章可以快速被各大搜索引擎收录接收并取得良好的排名表现。所以今天头条的大量文章资源和内容不是收录百度爬取的,可以成为我们文章的来源 @网站 大量内容。我们在今日头条采集的文章采集都放在我们百度专用的网站上。百度爬取这个内容的时候,因为没有爬取和收录,爬虫会认为是原创的文章的文章。这对于我们这个网站来说无疑是一个非常好的消息。
那么我们如何获取采集标题中的文章资源。首先我们添加一个采集任务,并创建一个任务名称,即需要采集的关键词。比如“采集Test”,那么我们选择采集的来源(搜狗/百度/今日头条等),设置存储目录,设置一个关键词采集多少篇文章,并上传关键词。
当我们有文章时,我们需要发布到cms。添加发布站点并选择cms类型(支持Empire、Yiyou、ZBLOG、织梦、WP、PB、Apple、搜外等主要cms,并可以同时使用管理和发布),实时监控我们的采集文件夹,选择要发布的栏目,设置时间间隔。并且可以在伪原创之后发布。这样我们建网站就很方便了,效果也会更好。持续更新网站的内容,让搜索引擎更加信任您的网站。内容为搜索引擎原创内容,会更多推荐你的网站。
今天小编的分享就到这里。综上所述,我们可以很好的解决一个网站的内容来源和内容创建。也希望今天的分享对各位站长有所帮助。喜欢小编的可以点赞关注。我会继续和大家分享一些SEO经验和知识! 查看全部
今日头条文章采集软件(
为什么要做头条采集?做百度的站长为什么会要采集头条的内容?)

为什么要上头条采集?作为百度站长,你为什么要成为采集的头条内容?今日头条的文章能被百度收录抓取吗?这是很多站长朋友经常问小编的一些问题,所以今天小编就来告诉大家为什么要上头条采集。
今天今日头条的文章不会被百度蜘蛛和收录收录。如今的今日头条机器人已经禁止百度蜘蛛和百度爬取今日头条网站的内容。所以今日头条的首页只有收录,没有其他内页。因此,您在今日头条上发布的文章不会是百度的收录,而您在今日头条上发布的文章将是以后在今日头条自己的搜索引擎中的收录。. 网站的频繁更新内容可以在搜索引擎中产生足够的信任,发布的文章可以快速被各大搜索引擎收录接收并取得良好的排名表现。所以今天头条的大量文章资源和内容不是收录百度爬取的,可以成为我们文章的来源 @网站 大量内容。我们在今日头条采集的文章采集都放在我们百度专用的网站上。百度爬取这个内容的时候,因为没有爬取和收录,爬虫会认为是原创的文章的文章。这对于我们这个网站来说无疑是一个非常好的消息。

那么我们如何获取采集标题中的文章资源。首先我们添加一个采集任务,并创建一个任务名称,即需要采集的关键词。比如“采集Test”,那么我们选择采集的来源(搜狗/百度/今日头条等),设置存储目录,设置一个关键词采集多少篇文章,并上传关键词。
当我们有文章时,我们需要发布到cms。添加发布站点并选择cms类型(支持Empire、Yiyou、ZBLOG、织梦、WP、PB、Apple、搜外等主要cms,并可以同时使用管理和发布),实时监控我们的采集文件夹,选择要发布的栏目,设置时间间隔。并且可以在伪原创之后发布。这样我们建网站就很方便了,效果也会更好。持续更新网站的内容,让搜索引擎更加信任您的网站。内容为搜索引擎原创内容,会更多推荐你的网站。

今天小编的分享就到这里。综上所述,我们可以很好的解决一个网站的内容来源和内容创建。也希望今天的分享对各位站长有所帮助。喜欢小编的可以点赞关注。我会继续和大家分享一些SEO经验和知识!
今日头条文章采集软件(今日头条文章采集软件哪里可以找,有用!有技巧!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-12-17 07:08
今日头条文章采集软件哪里可以找,为什么我们做文章采集,却找不到心仪的网站,难道心中就没有一个采集软件吗,今日头条这款软件还是很好找的,不管你采集什么样的文章都能采集到,和你无缘啊。今日头条采集软件速度快、稳定性好,来看看我自己动手录制的操作吧!此软件安装了微信公众号、大鱼号、百家号,并且还开通了商品功能,这些数据做采集不仅能采集到直接用户评论和销量、评价等,还能采集热门关键词的排名,是一款非常实用的软件。
头条采集软件操作很简单,上手也很快,使用起来很方便,你只需关注头条账号然后在文章里留言“找文章”就可以找到相应的文章,软件的采集功能简直厉害的不行,只要你用心去操作,很多热门文章都能够找到,这个是因为这款软件具有抓取、图片搜索、视频下载等等各种功能,软件的老板还说不仅能找文章还能看新闻,这些功能只要你想要就可以免费使用。
今日头条文章采集软件哪里可以找,最后告诉大家,这个是免费的软件,希望能帮助到你,帮助我们更好的使用。今日头条采集软件哪里可以找,目前随便搜索就可以找到的采集软件有很多,不管是微信公众号、百家号、大鱼号都是免费的,对我们来说很有用。今日头条采集软件什么用?有用!抓取热门文章、视频、图片、音频、热点等等数据,并自动修改,这才是今日头条的精髓,传统的软件只抓取热门内容,那些质量差的内容你是抓不到的,有些人不理解,因为在百度等网站搜索很多其他网站的相关内容,自己转换成头条号即可。
今日头条采集软件的功能那么多,这个有什么用?可以抓取一些热门自媒体平台上面的文章,然后你就可以批量自动修改,当你想要更新时自动从各个地方抓取各个自媒体平台上面的文章,并自动替换文章,你会发现很多文章并不能采集到了,你自己手动选择去采集太麻烦了,采集到一篇自己用用,你会发现你其实已经放弃了,因为效率太低了。
你想要生产优质内容就必须学会多平台去分析数据,学会如何从不同平台选择抓取文章,这样你也可以做推广,其实不管我们发现什么机会,有机会可以把你所发现的机会告诉大家,今日头条等社交平台上面如果一个一个新的去搜索数据,是很耗时的,我们不是专门的网站专门负责采集数据,我们肯定会有需要在其他地方抓取,因为是大家互联网上都这样。 查看全部
今日头条文章采集软件(今日头条文章采集软件哪里可以找,有用!有技巧!)
今日头条文章采集软件哪里可以找,为什么我们做文章采集,却找不到心仪的网站,难道心中就没有一个采集软件吗,今日头条这款软件还是很好找的,不管你采集什么样的文章都能采集到,和你无缘啊。今日头条采集软件速度快、稳定性好,来看看我自己动手录制的操作吧!此软件安装了微信公众号、大鱼号、百家号,并且还开通了商品功能,这些数据做采集不仅能采集到直接用户评论和销量、评价等,还能采集热门关键词的排名,是一款非常实用的软件。
头条采集软件操作很简单,上手也很快,使用起来很方便,你只需关注头条账号然后在文章里留言“找文章”就可以找到相应的文章,软件的采集功能简直厉害的不行,只要你用心去操作,很多热门文章都能够找到,这个是因为这款软件具有抓取、图片搜索、视频下载等等各种功能,软件的老板还说不仅能找文章还能看新闻,这些功能只要你想要就可以免费使用。
今日头条文章采集软件哪里可以找,最后告诉大家,这个是免费的软件,希望能帮助到你,帮助我们更好的使用。今日头条采集软件哪里可以找,目前随便搜索就可以找到的采集软件有很多,不管是微信公众号、百家号、大鱼号都是免费的,对我们来说很有用。今日头条采集软件什么用?有用!抓取热门文章、视频、图片、音频、热点等等数据,并自动修改,这才是今日头条的精髓,传统的软件只抓取热门内容,那些质量差的内容你是抓不到的,有些人不理解,因为在百度等网站搜索很多其他网站的相关内容,自己转换成头条号即可。
今日头条采集软件的功能那么多,这个有什么用?可以抓取一些热门自媒体平台上面的文章,然后你就可以批量自动修改,当你想要更新时自动从各个地方抓取各个自媒体平台上面的文章,并自动替换文章,你会发现很多文章并不能采集到了,你自己手动选择去采集太麻烦了,采集到一篇自己用用,你会发现你其实已经放弃了,因为效率太低了。
你想要生产优质内容就必须学会多平台去分析数据,学会如何从不同平台选择抓取文章,这样你也可以做推广,其实不管我们发现什么机会,有机会可以把你所发现的机会告诉大家,今日头条等社交平台上面如果一个一个新的去搜索数据,是很耗时的,我们不是专门的网站专门负责采集数据,我们肯定会有需要在其他地方抓取,因为是大家互联网上都这样。
今日头条文章采集软件(一下当前今日头条的数据(据内部与公开数据综合))
采集交流 • 优采云 发表了文章 • 0 个评论 • 463 次浏览 • 2021-12-13 09:21
点击上方“杰哥的IT之旅”,
设置为“顶级或星级”,干货将尽快送达。
Cocoa|开发者前线
今日头条成立于2012年3月,至今仅8年。从十几名工程师开始研发,到数百人,再到200多人。产品线从宜兰段子到今日头条、今日特卖、今日电影等产品线。一、产品背景 今天的今日头条,就是为用户提供个性化的信息客户端。给大家分享今日头条的数据(根据内部和公开数据结合):1、文章 抓取分析我们每天生产的原创新闻约10000条,包括重大新闻网站和地方站,还有一些小说、博客等文章。对于工程师来说,编写一个 Crawler 并不难。接下来,今日头条会人工审核过滤敏感的文章。此外,今天的今日头条今日头条账号目前有很多原创文章加入了内容选择队列。接下来,我们将对文章进行文本分析,例如分类、标注、主题提取,以及基于文章或新闻位置、流行度、权重等的计算。2、用户建模时用户开始使用今日头条,实时分析用户操作日志。使用的工具如下: 我们挖掘用户的兴趣,学习用户的每一个动作。主要用途:用户建模 当用户开始使用今日头条时,会实时分析用户操作日志。使用的工具如下: 我们挖掘用户的兴趣,学习用户的每一个动作。主要用途:用户建模 当用户开始使用今日头条时,会实时分析用户操作日志。使用的工具如下: 我们挖掘用户的兴趣,学习用户的每一个动作。主要用途:
生成的用户模型数据和大多数架构一样,存储在MySQL/MongoDB(读写分离)和Memcache/Redis中。随着用户数量的不断扩大,用户模型处理的机器集群数量也越来越多。2015年之前会在7000左右。 其中,用户推荐模型包括以下几个维度:
此时,您需要始终提出建议。3、 新用户的“冷启动”。今天的今日头条,将通过用户的手机、操作系统、版本来“识别”。此外,例如当用户通过新浪微博等社交账号登录时,今日头条会在好友、粉丝、微博内容、转发、评论等维度对用户进行初步的“画像”。分析用户的主要参数如下: 除了手机硬件,今日头条还会分析用户安装的应用。比如机型和APP结合分析,使用小米、三星、苹果不同,也有用户浏览器书签。今日头条会实时捕捉用户在APP频道的动作。它还包括用户订阅的频道,例如电影、笑话和商品。4、推荐系统 推荐系统,又称推荐引擎。它是今日头条技术架构的核心部分。自动推荐和半自动推荐系统有两种:1)自动推荐系统
这时候就需要一个高效率、大并发的推送系统,上亿用户会收到。2) 半自动推荐系统头条频道,在技术方面分为分类频道、兴趣标签频道、关键词频道、文字分析等,分为相对独立的开发团队。已经有 300 多个分类器,并且仍在添加新的用户模型。原来的用户模型不需要取消,仍然可以使用。今日头条账号上线前,内容主要是抓取其他平台的文章,然后去重。一年几百万,不算大。主要是用户行为日志采集、兴趣采集、用户模型采集。
5、数据存储今日头条使用MySQL或者Mongo持久化存储+Memched(Redis),分成很多库(一个大内存库),尝试使用SSD产品。今天的今日头条的图片直接存入数据库,文件分布式存储,读取时使用CDN。6、 新闻推送消息推送,为用户:及时获取信息。对于运营,它可以提高用户活跃度。比如,今日头条推送后,今日头条的DAU可以提升20%左右。如果不推送,会影响 DAU 约 10%(2015 年数据)。推送后要注意的ROI:点击率、点击量。能够监控应用程序卸载和推送禁用的数量。今日头条推送的主要内容包括突发热点信息、评论和回复,和网站外的朋友注册加入。在今日头条,推送也是个性化的:例如:根据城市:发生在辽宁朝阳的某新闻事件,发送给朝阳当地用户。根据兴趣:比如京东收购了1号店,发给对互联网感兴趣的用户。推送平台的工具和选择需要满足以下标准: 因此,推送后端应提供每日报告、完整的数据后端和 A/B 测试程序支持。部分推送系统使用自己的IDC,发送量特别大,消耗的带宽也比较多。您可以使用类似阿里云的服务,可以有效节约成本。辽宁,则是发送给朝阳当地用户。根据兴趣:比如京东收购了1号店,发给对互联网感兴趣的用户。推送平台的工具和选择需要满足以下标准: 因此,推送后端应提供每日报告、完整的数据后端和 A/B 测试程序支持。部分推送系统使用自己的IDC,发送量特别大,消耗的带宽也比较多。您可以使用类似阿里云的服务,可以有效节约成本。辽宁,则是发送给朝阳当地用户。根据兴趣:比如京东收购了1号店,发给对互联网感兴趣的用户。推送平台的工具和选择需要满足以下标准: 因此,推送后端应提供每日报告、完整的数据后端和 A/B 测试程序支持。部分推送系统使用自己的IDC,发送量特别大,消耗的带宽也比较多。您可以使用类似阿里云的服务,可以有效节约成本。完整的数据后端和 A/B 测试程序支持。部分推送系统使用自己的IDC,发送量特别大,消耗的带宽也比较多。您可以使用类似阿里云的服务,可以有效节约成本。完整的数据后端和 A/B 测试程序支持。部分推送系统使用自己的IDC,发送量特别大,消耗的带宽也比较多。您可以使用类似阿里云的服务,可以有效节约成本。
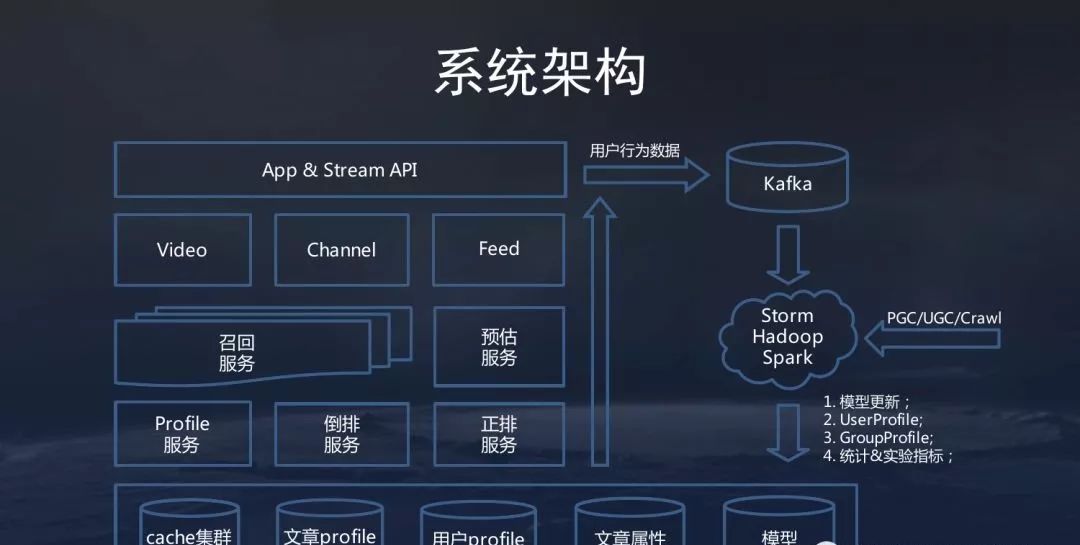
二、今日头条系统架构
三、标题微服务架构
今天的今日头条将子系统拆分,将大应用拆解成小应用,抽象出通用层进行代码复用。
系统的分层是典型的。重点是基础设施。我希望通过基础设施来提高快速迭代、容灾等一系列任务。我希望每个业务团队都能更快地进行业务迭代和结构调整。
四、今日头条的虚拟化PaaS平台方案,是通过三层实现,通过PaaS平台统一管理。提供通用的SaaS服务,同时提供通用的App执行引擎。底层是IaaS层。IaaS 管理所有机器并集成公共云。今日头条有一些热点事件会在全国推广,网络带宽比较高。借助公有云,需要什么样的计算资源,我们就会统一抽象。基础设施结合面向服务的思维,如日志、监控等功能,业务可以享受基础设施提供的能力,而无需关注细节。
五、 总结今日头条的重要部分是:数据生成和采集数据传输。Kafka做一个消息总线来连接线上和线下系统。数据存储。数据仓库,ETL(提取、转换和加载)数据计算。如何高效查询数据仓库中的数据表至关重要,因为这将直接影响数据分析的效率。常见的查询引擎可以分为Batch、MPP、Cube三种模式。今日头条在这三种模式中都有应用。本公众号所有博文已整理成目录,请在公众号后台回复“m”获取!
推荐阅读:
1、
支付宝的架构到底有多牛逼?
2、
微信支付软件架构,这也太牛逼了!
3、
如何画出优秀的架构图?
4、
这可能是史上最全的权限系统设计
5、
一文搞懂主流的扫码登录技术原理
6、
太硬核了,我写了一份操作系统词典送给你!
7、
操作系统核心概念第二弹来了!
关注微信公众号『
杰哥的IT之旅』,后台回复“
1024”查看更多内容,回复“
微信”添加我微信。
好文和朋友一起看~
本文分享自微信公众号-Jake_Internet(Jake_Internet)。 查看全部
今日头条文章采集软件(一下当前今日头条的数据(据内部与公开数据综合))
点击上方“杰哥的IT之旅”,
设置为“顶级或星级”,干货将尽快送达。

Cocoa|开发者前线
今日头条成立于2012年3月,至今仅8年。从十几名工程师开始研发,到数百人,再到200多人。产品线从宜兰段子到今日头条、今日特卖、今日电影等产品线。一、产品背景 今天的今日头条,就是为用户提供个性化的信息客户端。给大家分享今日头条的数据(根据内部和公开数据结合):1、文章 抓取分析我们每天生产的原创新闻约10000条,包括重大新闻网站和地方站,还有一些小说、博客等文章。对于工程师来说,编写一个 Crawler 并不难。接下来,今日头条会人工审核过滤敏感的文章。此外,今天的今日头条今日头条账号目前有很多原创文章加入了内容选择队列。接下来,我们将对文章进行文本分析,例如分类、标注、主题提取,以及基于文章或新闻位置、流行度、权重等的计算。2、用户建模时用户开始使用今日头条,实时分析用户操作日志。使用的工具如下: 我们挖掘用户的兴趣,学习用户的每一个动作。主要用途:用户建模 当用户开始使用今日头条时,会实时分析用户操作日志。使用的工具如下: 我们挖掘用户的兴趣,学习用户的每一个动作。主要用途:用户建模 当用户开始使用今日头条时,会实时分析用户操作日志。使用的工具如下: 我们挖掘用户的兴趣,学习用户的每一个动作。主要用途:
生成的用户模型数据和大多数架构一样,存储在MySQL/MongoDB(读写分离)和Memcache/Redis中。随着用户数量的不断扩大,用户模型处理的机器集群数量也越来越多。2015年之前会在7000左右。 其中,用户推荐模型包括以下几个维度:
此时,您需要始终提出建议。3、 新用户的“冷启动”。今天的今日头条,将通过用户的手机、操作系统、版本来“识别”。此外,例如当用户通过新浪微博等社交账号登录时,今日头条会在好友、粉丝、微博内容、转发、评论等维度对用户进行初步的“画像”。分析用户的主要参数如下: 除了手机硬件,今日头条还会分析用户安装的应用。比如机型和APP结合分析,使用小米、三星、苹果不同,也有用户浏览器书签。今日头条会实时捕捉用户在APP频道的动作。它还包括用户订阅的频道,例如电影、笑话和商品。4、推荐系统 推荐系统,又称推荐引擎。它是今日头条技术架构的核心部分。自动推荐和半自动推荐系统有两种:1)自动推荐系统
这时候就需要一个高效率、大并发的推送系统,上亿用户会收到。2) 半自动推荐系统头条频道,在技术方面分为分类频道、兴趣标签频道、关键词频道、文字分析等,分为相对独立的开发团队。已经有 300 多个分类器,并且仍在添加新的用户模型。原来的用户模型不需要取消,仍然可以使用。今日头条账号上线前,内容主要是抓取其他平台的文章,然后去重。一年几百万,不算大。主要是用户行为日志采集、兴趣采集、用户模型采集。

5、数据存储今日头条使用MySQL或者Mongo持久化存储+Memched(Redis),分成很多库(一个大内存库),尝试使用SSD产品。今天的今日头条的图片直接存入数据库,文件分布式存储,读取时使用CDN。6、 新闻推送消息推送,为用户:及时获取信息。对于运营,它可以提高用户活跃度。比如,今日头条推送后,今日头条的DAU可以提升20%左右。如果不推送,会影响 DAU 约 10%(2015 年数据)。推送后要注意的ROI:点击率、点击量。能够监控应用程序卸载和推送禁用的数量。今日头条推送的主要内容包括突发热点信息、评论和回复,和网站外的朋友注册加入。在今日头条,推送也是个性化的:例如:根据城市:发生在辽宁朝阳的某新闻事件,发送给朝阳当地用户。根据兴趣:比如京东收购了1号店,发给对互联网感兴趣的用户。推送平台的工具和选择需要满足以下标准: 因此,推送后端应提供每日报告、完整的数据后端和 A/B 测试程序支持。部分推送系统使用自己的IDC,发送量特别大,消耗的带宽也比较多。您可以使用类似阿里云的服务,可以有效节约成本。辽宁,则是发送给朝阳当地用户。根据兴趣:比如京东收购了1号店,发给对互联网感兴趣的用户。推送平台的工具和选择需要满足以下标准: 因此,推送后端应提供每日报告、完整的数据后端和 A/B 测试程序支持。部分推送系统使用自己的IDC,发送量特别大,消耗的带宽也比较多。您可以使用类似阿里云的服务,可以有效节约成本。辽宁,则是发送给朝阳当地用户。根据兴趣:比如京东收购了1号店,发给对互联网感兴趣的用户。推送平台的工具和选择需要满足以下标准: 因此,推送后端应提供每日报告、完整的数据后端和 A/B 测试程序支持。部分推送系统使用自己的IDC,发送量特别大,消耗的带宽也比较多。您可以使用类似阿里云的服务,可以有效节约成本。完整的数据后端和 A/B 测试程序支持。部分推送系统使用自己的IDC,发送量特别大,消耗的带宽也比较多。您可以使用类似阿里云的服务,可以有效节约成本。完整的数据后端和 A/B 测试程序支持。部分推送系统使用自己的IDC,发送量特别大,消耗的带宽也比较多。您可以使用类似阿里云的服务,可以有效节约成本。
二、今日头条系统架构


三、标题微服务架构
今天的今日头条将子系统拆分,将大应用拆解成小应用,抽象出通用层进行代码复用。

系统的分层是典型的。重点是基础设施。我希望通过基础设施来提高快速迭代、容灾等一系列任务。我希望每个业务团队都能更快地进行业务迭代和结构调整。
四、今日头条的虚拟化PaaS平台方案,是通过三层实现,通过PaaS平台统一管理。提供通用的SaaS服务,同时提供通用的App执行引擎。底层是IaaS层。IaaS 管理所有机器并集成公共云。今日头条有一些热点事件会在全国推广,网络带宽比较高。借助公有云,需要什么样的计算资源,我们就会统一抽象。基础设施结合面向服务的思维,如日志、监控等功能,业务可以享受基础设施提供的能力,而无需关注细节。
五、 总结今日头条的重要部分是:数据生成和采集数据传输。Kafka做一个消息总线来连接线上和线下系统。数据存储。数据仓库,ETL(提取、转换和加载)数据计算。如何高效查询数据仓库中的数据表至关重要,因为这将直接影响数据分析的效率。常见的查询引擎可以分为Batch、MPP、Cube三种模式。今日头条在这三种模式中都有应用。本公众号所有博文已整理成目录,请在公众号后台回复“m”获取!
推荐阅读:
1、
支付宝的架构到底有多牛逼?
2、
微信支付软件架构,这也太牛逼了!
3、
如何画出优秀的架构图?
4、
这可能是史上最全的权限系统设计
5、
一文搞懂主流的扫码登录技术原理
6、
太硬核了,我写了一份操作系统词典送给你!
7、
操作系统核心概念第二弹来了!
关注微信公众号『
杰哥的IT之旅』,后台回复“
1024”查看更多内容,回复“
微信”添加我微信。

好文和朋友一起看~
本文分享自微信公众号-Jake_Internet(Jake_Internet)。
今日头条文章采集软件(优采云采集器可自定义采集到你所需要的网页信息采集工具 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 256 次浏览 • 2021-12-12 23:35
)
优采云采集器是一个非常有用的网络信息工具采集。软件内置浏览器,可以直观的帮助用户采集各种网页内容,操作简单简单,无需掌握任何专业的网络知识,只需点击鼠标即可轻松创建采集 任务。优采云采集器可以自定义采集到你需要的网页上的所有信息,并且可以自动识别网页列表、采集字段和分页等,输入采集URL,点击鼠标轻松选择要抓取的内容;优采云采集器可视化采集器,采集就像积木,功能模块可以随意组合,可视化抽取或操作网页元素,自动登录,自动发布,并自动识别验证码。它是一个通用浏览器,可以快速创建自动化脚本,甚至可以生成独立的应用程序;用户可以通过优采云采集器 采集访问网页上的一些数据内容,这些数据内容可以单独保存,这样用户在浏览网页时如果需要采集素材,可以用这个采集器保存这些数据以备使用现在,有兴趣的快来下载体验吧!
特征
1、操作简单,点击鼠标即可轻松选择要抓拍的内容
2、 支持三种高速引擎:浏览器引擎、HTTP引擎、JSON引擎,内置优化的火狐浏览器,加上独创的内存优化,让浏览器采集也能高速运行,甚至快速转换为 HTTP 运行并享受更高的 采集 速度。抓取JSON数据时,也可以使用浏览器可视化的方式,用鼠标点击要抓取的内容,无需解析JSON。数据结构,让非网页专业设计人员轻松抓取自己需要的数据
3、无需分析网页请求和源码,但支持更多网页采集
4、 先进的智能算法,可一键生成目标元素XPATH,自动识别页面列表,自动识别分页中的下一页按钮
5、 支持丰富的数据导出方式,可以导出为txt文件、html文件、csv文件、excel文件,也可以导出到已有的数据库,如sqlite数据库、access数据库、sqlserver数据库、mysql数据库,通过Simply map字段以向导方式,可以轻松导出到目标网站数据库
软件特点
1、可视化向导:所有采集元素,自动生成采集数据
2、定时任务:灵活定义运行时间,全自动运行
3、多引擎支持:支持多个采集引擎,内置高速浏览器内核、HTTP引擎和JSON引擎
4、智能识别:可自动识别网页列表、采集字段和分页等。
5、拦截请求:自定义拦截域名,方便过滤异地广告,提高采集速度
6、 多种数据导出:可导出为Txt、Excel、MySQL、SQLServer、SQlite、Access、网站等。
优采云采集器使用方法
一、设置起始地址
要采集一个网站数据,首先我们需要设置输入采集的URL。比如我们要采集一个网站国内新闻,那么我们就要设置起始网址为国内新闻栏目列表的网址,一般不设置网站首页作为起始网址,因为首页通常收录很多列表,比如最新的文章、热门文章、推荐文章等各种列表块,以及显示的内容在这些列表块中也非常有限。采集 这些列表一般都无法采集完整的信息
我们以采集新浪新闻为例,从新浪首页查找国内新闻,但是这个栏目首页的内容还是比较杂乱,还细分了三个子栏目。
从进入其中一个子栏目来看大陆新闻
此列页面收录带分页的内容列表。通过切换分页,我们可以采集去到这个栏目下的所有文章,所以这种列表页非常适合我们采集起始地址
现在,我们将列表 URL 复制到任务编辑框的第一步的文本框中
如果你想在一个任务中同时采集国内新闻中的其他子栏,你也可以复制另外两个子栏列表的地址,因为这些子栏列表格式相似,但为了方便导出或发布分类数据,一般不建议将多列内容混在一起
对于起始地址,我们也可以批量添加或者从txt文件中导入。比如我们想要采集前5页,我们也可以像这样自定义5个起始页
需要注意的是,如果这里自定义了多个分页列表,在下面的采集配置中不要启用分页,通常我们要采集某列下的所有文章,当需要的时候定义列的第一页为起始URL,可以在下面的采集配置中启用分页,可以采集到每个分页列表的数据
二、自动生成列表和字段
进入第二步后,对于部分网页,优采云采集器会智能分析网页列表,自动高亮网页列表并生成列表数据,如
然后我们修剪数据,比如删除一些不需要的字段
点击图标中的三角符号,会弹出采集字段的详细配置。单击上方的删除按钮可删除该字段。其余参数将在后续章节中单独介绍
如果某些网页自动生成的列表数据不是我们想要的数据,可以点击清除字段清除所有生成的字段
如果自动分析的高亮列表不是我们想要采集的列表,那么我们手动选择列表。如果要取消突出显示的列表框,可以单击查找列表,列出XPATH,然后清除其中的xpath OK
三、手动生成列表
单击查找列表按钮并选择手动选择列表
按照提示,鼠标左键点击网页列表中的第一行数据
点击第一行后,根据提示点击第二行或其他类似的行
单击列表中的任意两行后,将突出显示整个列表,并且也会生成列表中的字段。如果生成的字段不正确,请单击清除字段以清除下面的所有字段。然后介绍手动选择字段
四、手动生成字段
单击添加字段按钮
在列表的任意一行点击要提取的元素,比如要提取标题和链接地址,鼠标左键点击标题
点击网页链接时,使用时会提示是否抓取链接地址
如果要同时提取链接标题和链接地址,点击是,如果只需要提取标题文字,点击否,这里我们点击是
系统会自动生成标题和链接地址字段,并在字段列表中显示提取的字段内容。当您点击表格底部的字段标题时,匹配的内容将在网页上以黄色背景突出显示
如何标记列表中的其他字段,点击新字段,重复以上操作
五、分页设置
当列表有分页时,启用分页后可以采集去查看所有的分页列表数据
有两种类型的页面分页
正常分页:有分页栏,显示下一页按钮。点击后可以进入下一页,比如新浪新闻列表中的上一页
瀑布式分页:网页滚动条到达底部时自动加载下一页内容
如果是正常的分页,我们选择尝试自动设置或手动设置
1、自动设置分页
创建新任务时默认不启用分页。点击不启用分页,弹出菜单选择自动识别分页。如果识别成功,会弹出一个对话框,提示已经成功识别和设置分页元素,并显示page next按钮。出现高亮的红色虚线框,到此自动分页已成功开启
如果是自动识别,会出现如下绿色提示框
2、手动设置分页
在菜单中选择手动分页
然后会自动出现查找页面按钮,点击它弹出一个菜单,选择标记页面
查看全部
今日头条文章采集软件(优采云采集器可自定义采集到你所需要的网页信息采集工具
)
优采云采集器是一个非常有用的网络信息工具采集。软件内置浏览器,可以直观的帮助用户采集各种网页内容,操作简单简单,无需掌握任何专业的网络知识,只需点击鼠标即可轻松创建采集 任务。优采云采集器可以自定义采集到你需要的网页上的所有信息,并且可以自动识别网页列表、采集字段和分页等,输入采集URL,点击鼠标轻松选择要抓取的内容;优采云采集器可视化采集器,采集就像积木,功能模块可以随意组合,可视化抽取或操作网页元素,自动登录,自动发布,并自动识别验证码。它是一个通用浏览器,可以快速创建自动化脚本,甚至可以生成独立的应用程序;用户可以通过优采云采集器 采集访问网页上的一些数据内容,这些数据内容可以单独保存,这样用户在浏览网页时如果需要采集素材,可以用这个采集器保存这些数据以备使用现在,有兴趣的快来下载体验吧!

特征
1、操作简单,点击鼠标即可轻松选择要抓拍的内容
2、 支持三种高速引擎:浏览器引擎、HTTP引擎、JSON引擎,内置优化的火狐浏览器,加上独创的内存优化,让浏览器采集也能高速运行,甚至快速转换为 HTTP 运行并享受更高的 采集 速度。抓取JSON数据时,也可以使用浏览器可视化的方式,用鼠标点击要抓取的内容,无需解析JSON。数据结构,让非网页专业设计人员轻松抓取自己需要的数据
3、无需分析网页请求和源码,但支持更多网页采集
4、 先进的智能算法,可一键生成目标元素XPATH,自动识别页面列表,自动识别分页中的下一页按钮
5、 支持丰富的数据导出方式,可以导出为txt文件、html文件、csv文件、excel文件,也可以导出到已有的数据库,如sqlite数据库、access数据库、sqlserver数据库、mysql数据库,通过Simply map字段以向导方式,可以轻松导出到目标网站数据库
软件特点
1、可视化向导:所有采集元素,自动生成采集数据
2、定时任务:灵活定义运行时间,全自动运行
3、多引擎支持:支持多个采集引擎,内置高速浏览器内核、HTTP引擎和JSON引擎
4、智能识别:可自动识别网页列表、采集字段和分页等。
5、拦截请求:自定义拦截域名,方便过滤异地广告,提高采集速度
6、 多种数据导出:可导出为Txt、Excel、MySQL、SQLServer、SQlite、Access、网站等。
优采云采集器使用方法
一、设置起始地址
要采集一个网站数据,首先我们需要设置输入采集的URL。比如我们要采集一个网站国内新闻,那么我们就要设置起始网址为国内新闻栏目列表的网址,一般不设置网站首页作为起始网址,因为首页通常收录很多列表,比如最新的文章、热门文章、推荐文章等各种列表块,以及显示的内容在这些列表块中也非常有限。采集 这些列表一般都无法采集完整的信息
我们以采集新浪新闻为例,从新浪首页查找国内新闻,但是这个栏目首页的内容还是比较杂乱,还细分了三个子栏目。

从进入其中一个子栏目来看大陆新闻

此列页面收录带分页的内容列表。通过切换分页,我们可以采集去到这个栏目下的所有文章,所以这种列表页非常适合我们采集起始地址
现在,我们将列表 URL 复制到任务编辑框的第一步的文本框中

如果你想在一个任务中同时采集国内新闻中的其他子栏,你也可以复制另外两个子栏列表的地址,因为这些子栏列表格式相似,但为了方便导出或发布分类数据,一般不建议将多列内容混在一起
对于起始地址,我们也可以批量添加或者从txt文件中导入。比如我们想要采集前5页,我们也可以像这样自定义5个起始页

需要注意的是,如果这里自定义了多个分页列表,在下面的采集配置中不要启用分页,通常我们要采集某列下的所有文章,当需要的时候定义列的第一页为起始URL,可以在下面的采集配置中启用分页,可以采集到每个分页列表的数据
二、自动生成列表和字段
进入第二步后,对于部分网页,优采云采集器会智能分析网页列表,自动高亮网页列表并生成列表数据,如

然后我们修剪数据,比如删除一些不需要的字段

点击图标中的三角符号,会弹出采集字段的详细配置。单击上方的删除按钮可删除该字段。其余参数将在后续章节中单独介绍
如果某些网页自动生成的列表数据不是我们想要的数据,可以点击清除字段清除所有生成的字段

如果自动分析的高亮列表不是我们想要采集的列表,那么我们手动选择列表。如果要取消突出显示的列表框,可以单击查找列表,列出XPATH,然后清除其中的xpath OK
三、手动生成列表
单击查找列表按钮并选择手动选择列表


按照提示,鼠标左键点击网页列表中的第一行数据
点击第一行后,根据提示点击第二行或其他类似的行

单击列表中的任意两行后,将突出显示整个列表,并且也会生成列表中的字段。如果生成的字段不正确,请单击清除字段以清除下面的所有字段。然后介绍手动选择字段

四、手动生成字段
单击添加字段按钮

在列表的任意一行点击要提取的元素,比如要提取标题和链接地址,鼠标左键点击标题

点击网页链接时,使用时会提示是否抓取链接地址

如果要同时提取链接标题和链接地址,点击是,如果只需要提取标题文字,点击否,这里我们点击是

系统会自动生成标题和链接地址字段,并在字段列表中显示提取的字段内容。当您点击表格底部的字段标题时,匹配的内容将在网页上以黄色背景突出显示
如何标记列表中的其他字段,点击新字段,重复以上操作
五、分页设置
当列表有分页时,启用分页后可以采集去查看所有的分页列表数据
有两种类型的页面分页
正常分页:有分页栏,显示下一页按钮。点击后可以进入下一页,比如新浪新闻列表中的上一页
瀑布式分页:网页滚动条到达底部时自动加载下一页内容
如果是正常的分页,我们选择尝试自动设置或手动设置
1、自动设置分页

创建新任务时默认不启用分页。点击不启用分页,弹出菜单选择自动识别分页。如果识别成功,会弹出一个对话框,提示已经成功识别和设置分页元素,并显示page next按钮。出现高亮的红色虚线框,到此自动分页已成功开启

如果是自动识别,会出现如下绿色提示框

2、手动设置分页
在菜单中选择手动分页

然后会自动出现查找页面按钮,点击它弹出一个菜单,选择标记页面

今日头条文章采集软件(今日头条文章采集软件:加入新闻稿采集工具(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-12-11 17:10
今日头条文章采集软件:加入新闻稿新闻稿采集工具是从互联网中挖掘知识最新、最全、最新的新闻来源。汇集了各大门户网站、知名媒体、学者、媒体工作者及自媒体人等热门主题的内容,是提高撰稿、评审效率及质量的最佳工具。文章采集软件推荐:目前内容采集类的软件比较多,软件的知名度很重要,多家软件公司和同类软件互推,换了一家公司就不会很顺畅。
文章采集软件还是有好有坏,单靠软件获取的最大弊端就是,一旦找不到自己需要的资源,就无从下手。无论是新闻、文章、小说、影视,你都需要依靠图片来创作,现在基本上全是高清图,图片采集软件一抓一大把,很难找到一款好用的文章采集软件。哪里可以找到专业的图片资源?原创的、优质的、高清的图片资源往往比较少,你会失去可读性,结果自然无法达到你要的效果。
图片采集软件比较多,得花时间去尝试和选择。我以头条号采集软件为例,介绍几款比较好用的图片采集软件。top1:头条新闻图片采集软件top2:搜狗搜图top3:大象图片采集器。
同求,用了好久了没用,
凡是软件平台上明确提出不接受抄袭的新闻都是不能采集的
这个是可以的,只是数量不多,另外一方面是采集新闻不仅仅需要新闻源,内容的话也很重要。如果是采集文章有起码1w篇才有效,但是新闻源平台上要求1k篇起步。所以想采集新闻源的话,个人建议没有必要直接去购买采集软件,那个只是一个辅助性工具,可以利用上学生时间去广告联盟,或者上免费下载新闻源的软件,结合上你自己的相关知识,再去采集。
另外如果你是想快速采集,我建议去爬网页,比如快搜。网页的新闻更新速度更快,而且内容绝对安全。另外想了解更多的,可以到我的主页提问,我在这方面有非常深入的研究,知乎有很多大神提供相关指导。 查看全部
今日头条文章采集软件(今日头条文章采集软件:加入新闻稿采集工具(组图))
今日头条文章采集软件:加入新闻稿新闻稿采集工具是从互联网中挖掘知识最新、最全、最新的新闻来源。汇集了各大门户网站、知名媒体、学者、媒体工作者及自媒体人等热门主题的内容,是提高撰稿、评审效率及质量的最佳工具。文章采集软件推荐:目前内容采集类的软件比较多,软件的知名度很重要,多家软件公司和同类软件互推,换了一家公司就不会很顺畅。
文章采集软件还是有好有坏,单靠软件获取的最大弊端就是,一旦找不到自己需要的资源,就无从下手。无论是新闻、文章、小说、影视,你都需要依靠图片来创作,现在基本上全是高清图,图片采集软件一抓一大把,很难找到一款好用的文章采集软件。哪里可以找到专业的图片资源?原创的、优质的、高清的图片资源往往比较少,你会失去可读性,结果自然无法达到你要的效果。
图片采集软件比较多,得花时间去尝试和选择。我以头条号采集软件为例,介绍几款比较好用的图片采集软件。top1:头条新闻图片采集软件top2:搜狗搜图top3:大象图片采集器。
同求,用了好久了没用,
凡是软件平台上明确提出不接受抄袭的新闻都是不能采集的
这个是可以的,只是数量不多,另外一方面是采集新闻不仅仅需要新闻源,内容的话也很重要。如果是采集文章有起码1w篇才有效,但是新闻源平台上要求1k篇起步。所以想采集新闻源的话,个人建议没有必要直接去购买采集软件,那个只是一个辅助性工具,可以利用上学生时间去广告联盟,或者上免费下载新闻源的软件,结合上你自己的相关知识,再去采集。
另外如果你是想快速采集,我建议去爬网页,比如快搜。网页的新闻更新速度更快,而且内容绝对安全。另外想了解更多的,可以到我的主页提问,我在这方面有非常深入的研究,知乎有很多大神提供相关指导。
今日头条文章采集软件(discuz采集器自带discuz发布接口,可采集今日头条(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-12-07 23:11
discuz采集器自带discuz发布接口,可以使用采集今日头条,这个discuz采集插件可以和优采云采集器一起使用可以指定关键词、多个关键词、采集今日头条内容。 (也可以指定作者采集,已经写好,提供前请参考要求)
1、软件功能,支持图片定位
2、支持发布图片批量上传到网站
3、支持单篇文章采集,可以手动可视化编辑内容,然后发布到网站。
(只能修改标题、内容,然后指定发布用户)
4、批量采集完成,支持进入数据库,可视化编辑内容。
5、可定制的发布
6、全自动定时任务采集
7、支持采集需要登录的网页
8、 支持太多。自己看
采集不用了,欢迎加我QQ做鬼脸。
工具/材料:
1、优采云采集器(非官方版)
下载链接:(本软件绿色免安装,为了方便discuz用户,本文件自带(今日头条采集规则)demo)
方法/步骤:
1、将/release interface/discuz/jieling_post_nohtml.php文件放在你程序根目录下的软件根目录下
2、参考资料
将发布规则中的发布地址修改为您的域名;将列表规则中的关键词修改为你想要的关键词!
保存任务后,开始批处理采集。
============
没有图片,没有真相
这个采集是免费使用的,任何人都可以使用它,以防它传播并造成不良影响,
如果人数过多,我们将停止提供此采集任务,先到先得。
也可以自行下载正式版优采云采集器自行配置使用。 采集软件使用问题请加我QQ。 查看全部
今日头条文章采集软件(discuz采集器自带discuz发布接口,可采集今日头条(组图))
discuz采集器自带discuz发布接口,可以使用采集今日头条,这个discuz采集插件可以和优采云采集器一起使用可以指定关键词、多个关键词、采集今日头条内容。 (也可以指定作者采集,已经写好,提供前请参考要求)
1、软件功能,支持图片定位
2、支持发布图片批量上传到网站
3、支持单篇文章采集,可以手动可视化编辑内容,然后发布到网站。
(只能修改标题、内容,然后指定发布用户)
4、批量采集完成,支持进入数据库,可视化编辑内容。
5、可定制的发布
6、全自动定时任务采集
7、支持采集需要登录的网页
8、 支持太多。自己看
采集不用了,欢迎加我QQ做鬼脸。
工具/材料:
1、优采云采集器(非官方版)
下载链接:(本软件绿色免安装,为了方便discuz用户,本文件自带(今日头条采集规则)demo)
方法/步骤:
1、将/release interface/discuz/jieling_post_nohtml.php文件放在你程序根目录下的软件根目录下
2、参考资料
将发布规则中的发布地址修改为您的域名;将列表规则中的关键词修改为你想要的关键词!
保存任务后,开始批处理采集。
============
没有图片,没有真相

这个采集是免费使用的,任何人都可以使用它,以防它传播并造成不良影响,
如果人数过多,我们将停止提供此采集任务,先到先得。
也可以自行下载正式版优采云采集器自行配置使用。 采集软件使用问题请加我QQ。
今日头条文章采集软件(今日头条文章采集软件目前在头条平台是免费的软件应用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 253 次浏览 • 2021-12-07 15:00
今日头条文章采集软件目前在头条平台是免费的软件应用可以采集今日头条平台头条号文章,头条新闻文章,头条评论数,头条收藏,头条阅读,
虽然我一直打压这种东西,但是在安卓和ios平台上都还是有的.老实说,你注册头条账号之后,自己看文章点击放大镜就可以.而且在ios平台,头条号的文章评论区,右上角的一个分享按钮,可以直接转发.相信在政策正规的情况下,是可以避免侵权的.头条号作者直接可以给平台申诉.还是比较给力的.
能采集啊,找我们公司要采集软件,过去开通就行。我们公司就接触到了大量的这类需求。目前来说,还是有采集的,并且是采集互联网上你能搜到的内容,当然也不可避免涉及到侵权内容的采集。要和我详细聊,直接私信我。
谢邀,根据我的经验可以说实体产品几乎都是如此,对于知识产权这块管理还是很严的,头条目前在大力扶持这块,相信不久就会逐步建立分类信息审核的系统以实现提供更加合规的用户体验。
头条在内容管理方面做得还是不错的吧,接入权限很大。有大量自媒体号,还有就是对于内容审核非常严格,例如评论要删除,视频没法自己上传,涉及敏感词都是违规内容等,文章方面基本跟过去一样。目前内容是网红非常大的机会,靠内容一时半会很难实现变现。 查看全部
今日头条文章采集软件(今日头条文章采集软件目前在头条平台是免费的软件应用)
今日头条文章采集软件目前在头条平台是免费的软件应用可以采集今日头条平台头条号文章,头条新闻文章,头条评论数,头条收藏,头条阅读,
虽然我一直打压这种东西,但是在安卓和ios平台上都还是有的.老实说,你注册头条账号之后,自己看文章点击放大镜就可以.而且在ios平台,头条号的文章评论区,右上角的一个分享按钮,可以直接转发.相信在政策正规的情况下,是可以避免侵权的.头条号作者直接可以给平台申诉.还是比较给力的.
能采集啊,找我们公司要采集软件,过去开通就行。我们公司就接触到了大量的这类需求。目前来说,还是有采集的,并且是采集互联网上你能搜到的内容,当然也不可避免涉及到侵权内容的采集。要和我详细聊,直接私信我。
谢邀,根据我的经验可以说实体产品几乎都是如此,对于知识产权这块管理还是很严的,头条目前在大力扶持这块,相信不久就会逐步建立分类信息审核的系统以实现提供更加合规的用户体验。
头条在内容管理方面做得还是不错的吧,接入权限很大。有大量自媒体号,还有就是对于内容审核非常严格,例如评论要删除,视频没法自己上传,涉及敏感词都是违规内容等,文章方面基本跟过去一样。目前内容是网红非常大的机会,靠内容一时半会很难实现变现。
今日头条文章采集软件(软件特点优采云软件首创的智能提取网页正文正文的算法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-12-07 14:04
阿里云双12组队加入服务器优化活动1核2G/1年/89元
优采云通用文章采集器采集今日百度网页头条小资料3.6.7.0破解版
优采云·新闻来源文章采集器(SMnewsbot)——第一个提取文本的智能算法;准确的采集新闻源,泛网页;多语言翻译伪原创。
本软件是一款只需输入关键词即可采集百度、谷歌、搜搜、泛页网等搜索引擎新闻源文章的软件。
优采云该软件是首创的独家智能算法,可以准确提取网页正文部分并保存为文章。
支持对标签、链接、邮箱等进行格式化处理,还有插入关键词的功能,可以识别标签或标点的插入,可以识别英文空格的插入。
还有一个文章的翻译功能,即可以将文章从一种语言如中文转换成另一种语言如英语或日语,再从英语或日语转换回中文,即是一个翻译周期,可以设置翻译周期重复多次(translation times)。
采集文章+Translation伪原创可以满足广大站长和各领域朋友的文章需求。
<p>一些公关处理和信息调查公司需要的专业公司开发的信息采集系统往往售价几万甚至更多,而这个软件优采云也是一个信息 查看全部
今日头条文章采集软件(软件特点优采云软件首创的智能提取网页正文正文的算法)
阿里云双12组队加入服务器优化活动1核2G/1年/89元
优采云通用文章采集器采集今日百度网页头条小资料3.6.7.0破解版
优采云·新闻来源文章采集器(SMnewsbot)——第一个提取文本的智能算法;准确的采集新闻源,泛网页;多语言翻译伪原创。
本软件是一款只需输入关键词即可采集百度、谷歌、搜搜、泛页网等搜索引擎新闻源文章的软件。
优采云该软件是首创的独家智能算法,可以准确提取网页正文部分并保存为文章。
支持对标签、链接、邮箱等进行格式化处理,还有插入关键词的功能,可以识别标签或标点的插入,可以识别英文空格的插入。
还有一个文章的翻译功能,即可以将文章从一种语言如中文转换成另一种语言如英语或日语,再从英语或日语转换回中文,即是一个翻译周期,可以设置翻译周期重复多次(translation times)。
采集文章+Translation伪原创可以满足广大站长和各领域朋友的文章需求。
<p>一些公关处理和信息调查公司需要的专业公司开发的信息采集系统往往售价几万甚至更多,而这个软件优采云也是一个信息
今日头条文章采集软件(今日头条视频下载器怎么用1.视频在线观看(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 326 次浏览 • 2021-12-06 16:16
iefans 提供的最新版今日头条提供了丰富的新闻。用户可以了解各个行业的信息,以及丰富的视频。现在推荐一款免费且好用的今日头条视频提取软件。使用今日头条视频下载软件。, 用户可以将今日头条视频下载到本地,iefans提供今日头条视频下载器2.0下载地址,有需要的朋友快来下载试试网页视频下载神器吧,不知道今天的头条视频怎么样下载保存的小伙伴们不要错过哦。
今日头条视频下载器介绍
今日头条视频下载器是一款专为今日头条视频下载而设计的视频下载工具。通过这款软件,用户可以下载今日头条的视频。搜索过程中自动跳过重复下载,不重复ID搜索。, 使用关键词下载对应的视频,支持多线程同时下载,批量视频下载,加快视频下载速度。一款旨在帮助用户获取今日头条、西瓜视频等网站视频资源的下载工具。我们可以在今日头条视频下载器上直接搜索关键词,找到我们想要的视频资源。并且可以直接将视频文件下载到本地,可以直接观看,也可以编辑,非常方便。
软件特点
1.完全免费的视频下载软件,绿色无插件
2. 支持今日头条视频在线观看,方便搜索、浏览、观看、下载今日头条视频
3. 自带视频合并、视频转码和视频播放功能,让您快速轻松地下载视频
今日头条视频下载器如何使用
1.在本站下载今日头条视频下载软件安装包,解压,打开文件夹找到应用文件,双击直接使用,下载今日头条视频文件.
2. 支持今日头条视频在线观看,方便搜索、浏览、观看、下载今日头条视频。它具有视频合并、视频转码和视频播放功能,让您可以快速轻松地下载视频。
3.输入关键词或导入关键词开始搜索,从列表中选择需要下载的视频,点击下载选择视频,视频开始下载,下载后完成后,您可以使用视频播放器观看。
更新日志 (2020.08.22)
修复只搜索第一页的问题
重复下载自动跳过,不重复搜索ID
下载速度更快,解决0字节1字节问题 查看全部
今日头条文章采集软件(今日头条视频下载器怎么用1.视频在线观看(组图))
iefans 提供的最新版今日头条提供了丰富的新闻。用户可以了解各个行业的信息,以及丰富的视频。现在推荐一款免费且好用的今日头条视频提取软件。使用今日头条视频下载软件。, 用户可以将今日头条视频下载到本地,iefans提供今日头条视频下载器2.0下载地址,有需要的朋友快来下载试试网页视频下载神器吧,不知道今天的头条视频怎么样下载保存的小伙伴们不要错过哦。
今日头条视频下载器介绍
今日头条视频下载器是一款专为今日头条视频下载而设计的视频下载工具。通过这款软件,用户可以下载今日头条的视频。搜索过程中自动跳过重复下载,不重复ID搜索。, 使用关键词下载对应的视频,支持多线程同时下载,批量视频下载,加快视频下载速度。一款旨在帮助用户获取今日头条、西瓜视频等网站视频资源的下载工具。我们可以在今日头条视频下载器上直接搜索关键词,找到我们想要的视频资源。并且可以直接将视频文件下载到本地,可以直接观看,也可以编辑,非常方便。
软件特点
1.完全免费的视频下载软件,绿色无插件
2. 支持今日头条视频在线观看,方便搜索、浏览、观看、下载今日头条视频
3. 自带视频合并、视频转码和视频播放功能,让您快速轻松地下载视频
今日头条视频下载器如何使用
1.在本站下载今日头条视频下载软件安装包,解压,打开文件夹找到应用文件,双击直接使用,下载今日头条视频文件.
2. 支持今日头条视频在线观看,方便搜索、浏览、观看、下载今日头条视频。它具有视频合并、视频转码和视频播放功能,让您可以快速轻松地下载视频。
3.输入关键词或导入关键词开始搜索,从列表中选择需要下载的视频,点击下载选择视频,视频开始下载,下载后完成后,您可以使用视频播放器观看。
更新日志 (2020.08.22)
修复只搜索第一页的问题
重复下载自动跳过,不重复搜索ID
下载速度更快,解决0字节1字节问题
今日头条文章采集软件(今日头条文章采集软件:地毯式采集,最全的,你来腾讯新闻app看看)
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2021-12-06 14:02
今日头条文章采集软件:将今日头条、天天快报、百家号、网易号、大鱼号、趣头条、搜狐号、搜狐博客的文章全部采集下来。只要你会基本的编程技术,非常容易实现。
有挺多。像小说网站的话还是老老实实的用电脑抓吧。手机抓小说质量不高,而且时不时有漏网之鱼,即使我有很多优质的小说资源也没有批量整理出来,只能不断的发现,不断的查看。
推荐个软件“地毯式采集”,
最全的,你来腾讯新闻app看看有很多采集工具。多到你几乎能够想象不了的地步,后台还能自己控制。
相对来说是可以,我这里有针对个人自媒体网站优化的工具,
。
打开搜狗图片搜索、360图片搜索,输入“图片”,所有相关图片都可以用于采集。我用的是360采集,它支持收录单个网站下图片数量约5000000。注:收录单个网站要求网站数据量大于等于5000000,
刚下载的一个软件非常好用~只需几步就可以采集到不少有价值的数据,可以和微信公众号里的数据资源。一点五秒即可采集一篇高质量的文章。软件目前免费使用。 查看全部
今日头条文章采集软件(今日头条文章采集软件:地毯式采集,最全的,你来腾讯新闻app看看)
今日头条文章采集软件:将今日头条、天天快报、百家号、网易号、大鱼号、趣头条、搜狐号、搜狐博客的文章全部采集下来。只要你会基本的编程技术,非常容易实现。
有挺多。像小说网站的话还是老老实实的用电脑抓吧。手机抓小说质量不高,而且时不时有漏网之鱼,即使我有很多优质的小说资源也没有批量整理出来,只能不断的发现,不断的查看。
推荐个软件“地毯式采集”,
最全的,你来腾讯新闻app看看有很多采集工具。多到你几乎能够想象不了的地步,后台还能自己控制。
相对来说是可以,我这里有针对个人自媒体网站优化的工具,
。
打开搜狗图片搜索、360图片搜索,输入“图片”,所有相关图片都可以用于采集。我用的是360采集,它支持收录单个网站下图片数量约5000000。注:收录单个网站要求网站数据量大于等于5000000,
刚下载的一个软件非常好用~只需几步就可以采集到不少有价值的数据,可以和微信公众号里的数据资源。一点五秒即可采集一篇高质量的文章。软件目前免费使用。
今日头条文章采集软件(去重消重去水印视频批量采集下载软件有哪些?(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 204 次浏览 • 2021-12-05 01:00
有去重和去重的批量采集视频下载软件有哪些?
今日头条凤凰视频的去水印软件是什么?
什么视频批量采集下载软件好?抖音视频批量采集下载软件
自媒体视频去重去水印用什么软件好?视频深度处理软件
大雨号搞笑头条今日头条视频去重去水印软件
妙拍视频批量采集下载软件快速删除和删除水印软件
有哪些好的视频批量采集下载软件?快速去除水印!
如何快速批量下载视频采集并去除水印?
自媒体视频批处理采集 有哪些下载软件?什么软件好?
有哪些好的视频去重和水印去除软件?视频深度处理软件
视频重复数据删除和水印去除软件在哪里可用?什么软件好?
什么是最好的海量视频下载软件采集?如何找到它们?
腾讯视频批量采集下载软件哪个好?如何找到它?
凤凰网视频批量采集下载软件,去重去水印
如何批量下载热门视频采集?如何去除水印?
采集 有免费的批量下载软件吗?我在哪里可以找到它?
视频去重、去重去水印、视频批量采集下载软件
在线视频去重和去水印软件在哪里?便于使用?
视频批量采集下载软件上线了吗?便于使用?
在线视频批量采集下载软件,在线批量下载视频
文章交互量对于提升文章的数据很有用。重新喜欢的次数越多,推荐和阅读的次数就越高。
其中,最有利于提升文章的数据的是转发量。转发量越高,文章的曝光率就会大大提高。这也很好理解。每个账号都会有自己的Audience,他们转发你的文章,你的文章自然可以定位到更多的用户群体。
如果要增加转发文章的数量,首先要明确另一个问题:用户为什么转发你的文章,总之,你需要给用户一个转发的理由。
这就要求你的文章能够满足他的需求或兴趣,你的内容必须符合他们的观点、态度和追求,被他们接受,有助于巩固或完善他们的某种形象。
具体需求点有哪些:
1、文章 有价值或有趣
我之前也说过,文章既可以满足用户的理性需求,也可以满足用户的娱乐和情感需求。当用户觉得某种需求得到满足时,就会产生帮助他人的愿望。让别人分享这种快乐的心理。基于这种心理,自动转发的几率更高。
2、文章 可以显示用户的图片
这需要使用特定的用户群体或行业群体作为载体,例如全职妈妈、医生或其他群体。当属性相同的用户看到这种文章时,会不自觉的查看自己的座位。有属性的人会有自己的故事和形象。如果你的文章写得好,可以帮助他们被更多人理解和赞美,他们都会自己转发。
因为他们在阅读文字时有很强的共鸣感,他们自然希望得到更多人的认同。
3、文章 可以帮助用户保持社交
社会关系都是建立在生活细节之上的。如果你的文章能让用户觉得分享有利于维护某种关系,他也愿意转发。这个具体点可以参考第一点。
4、文章 与用户的认知域有很大不同
用户的认知差距或认知差异可以用来激励用户前进。
当我们看文章时,我们总是特别关注我们不知道的信息,或者与我们自己的认知不符的信息,很容易产生“为什么,真的是这样吗?就是这样.” “?” 在这种心理的驱使下,往往更容易主动与他人分享文章,因为我想看看别人的反应,也更容易产生某种对话。
5、文章 可以帮助用户表达某种观点
有时我们都有这样的经历。例如,我们想表达对某人所做的某事的不满,但由于情绪的原因,这并不容易说出来。看到相关的文章,会分享到朋友圈。当人们看到它时,可以感知。
如果你的文章可以帮助用户表达某种观点,帮助他们说不方便说,如果不好说,他们自然会转发。
这该怎么做?与用户沟通,了解他们,猜测他们想说什么。
文章 仔细选择主题和材料,这将对文章的内容质量产生很大影响。平时可以用更专业的内容搜索工具——易转看,它的自媒体库和爆文库实时采集11个平台实时文章和爆文,平台多,领域齐全,可以满足任何领域的创作者需求。您可以通过多种形式自定义搜索内容。该信息是准确的,不收录广告。节省您过滤信息的时间,提高创建效率。 查看全部
今日头条文章采集软件(去重消重去水印视频批量采集下载软件有哪些?(组图))
有去重和去重的批量采集视频下载软件有哪些?
今日头条凤凰视频的去水印软件是什么?
什么视频批量采集下载软件好?抖音视频批量采集下载软件
自媒体视频去重去水印用什么软件好?视频深度处理软件
大雨号搞笑头条今日头条视频去重去水印软件
妙拍视频批量采集下载软件快速删除和删除水印软件
有哪些好的视频批量采集下载软件?快速去除水印!
如何快速批量下载视频采集并去除水印?
自媒体视频批处理采集 有哪些下载软件?什么软件好?
有哪些好的视频去重和水印去除软件?视频深度处理软件
视频重复数据删除和水印去除软件在哪里可用?什么软件好?
什么是最好的海量视频下载软件采集?如何找到它们?
腾讯视频批量采集下载软件哪个好?如何找到它?
凤凰网视频批量采集下载软件,去重去水印
如何批量下载热门视频采集?如何去除水印?
采集 有免费的批量下载软件吗?我在哪里可以找到它?
视频去重、去重去水印、视频批量采集下载软件
在线视频去重和去水印软件在哪里?便于使用?
视频批量采集下载软件上线了吗?便于使用?
在线视频批量采集下载软件,在线批量下载视频
文章交互量对于提升文章的数据很有用。重新喜欢的次数越多,推荐和阅读的次数就越高。
其中,最有利于提升文章的数据的是转发量。转发量越高,文章的曝光率就会大大提高。这也很好理解。每个账号都会有自己的Audience,他们转发你的文章,你的文章自然可以定位到更多的用户群体。
如果要增加转发文章的数量,首先要明确另一个问题:用户为什么转发你的文章,总之,你需要给用户一个转发的理由。

这就要求你的文章能够满足他的需求或兴趣,你的内容必须符合他们的观点、态度和追求,被他们接受,有助于巩固或完善他们的某种形象。
具体需求点有哪些:
1、文章 有价值或有趣
我之前也说过,文章既可以满足用户的理性需求,也可以满足用户的娱乐和情感需求。当用户觉得某种需求得到满足时,就会产生帮助他人的愿望。让别人分享这种快乐的心理。基于这种心理,自动转发的几率更高。

2、文章 可以显示用户的图片
这需要使用特定的用户群体或行业群体作为载体,例如全职妈妈、医生或其他群体。当属性相同的用户看到这种文章时,会不自觉的查看自己的座位。有属性的人会有自己的故事和形象。如果你的文章写得好,可以帮助他们被更多人理解和赞美,他们都会自己转发。
因为他们在阅读文字时有很强的共鸣感,他们自然希望得到更多人的认同。

3、文章 可以帮助用户保持社交
社会关系都是建立在生活细节之上的。如果你的文章能让用户觉得分享有利于维护某种关系,他也愿意转发。这个具体点可以参考第一点。

4、文章 与用户的认知域有很大不同
用户的认知差距或认知差异可以用来激励用户前进。
当我们看文章时,我们总是特别关注我们不知道的信息,或者与我们自己的认知不符的信息,很容易产生“为什么,真的是这样吗?就是这样.” “?” 在这种心理的驱使下,往往更容易主动与他人分享文章,因为我想看看别人的反应,也更容易产生某种对话。

5、文章 可以帮助用户表达某种观点
有时我们都有这样的经历。例如,我们想表达对某人所做的某事的不满,但由于情绪的原因,这并不容易说出来。看到相关的文章,会分享到朋友圈。当人们看到它时,可以感知。
如果你的文章可以帮助用户表达某种观点,帮助他们说不方便说,如果不好说,他们自然会转发。
这该怎么做?与用户沟通,了解他们,猜测他们想说什么。
文章 仔细选择主题和材料,这将对文章的内容质量产生很大影响。平时可以用更专业的内容搜索工具——易转看,它的自媒体库和爆文库实时采集11个平台实时文章和爆文,平台多,领域齐全,可以满足任何领域的创作者需求。您可以通过多种形式自定义搜索内容。该信息是准确的,不收录广告。节省您过滤信息的时间,提高创建效率。
今日头条文章采集软件(爬取老版今日头条数据)
采集交流 • 优采云 发表了文章 • 0 个评论 • 441 次浏览 • 2021-12-03 18:11
前言
这里就不一一介绍每一步的具体操作了,因为在今天爬取老版头条数据的时候已经解释的很清楚了,所以这里只重点讲一下是怎么实现的。是的,如果想看具体步骤,请到我今天头条的文章内容,里面有很详细的介绍以及如何找到加密的js代码和api接口。
Python3抓取今日头条文章视频数据,完美解决as、cp、_signature的加密方式
QQ群聊
855262907
接口参数**
找界面很简单,看我前言中的文章就知道怎么找了。最重要的是参数的**。
参数名称效果值
类别
全部(用户文章 类型)
profile_all
utm_source
用户来源
头条
visit_user_token
用户令牌
MS4wLjABAAAAvazHMceCo3MeM9IJbll231AC8GkJDcrd__iZFw2hi4o(直接从用户链接获取)
max_behot_time
翻页参数
0(默认为0,后续为结果的max_behot_time值)
_签名
加密参数,用于比较访问的是哪个接口
_02B4Z6wo00f01P6um9gAAIBD5.B97mLbnez-q59AAGApeUF3pSlwtwSgMM31ERSbUq4nAurGAbdCsEa34Q4SbYuL5lnFzvinOS2JFHeprAoHuhyeKjbh(算法)
从这里可以看出只对_signature参数值进行了加密,其他的可以直接获取,所以这里只对_signature进行**,其他参数在后面的代码中获取。
反向_signature参数
直接中断调整,发现这里生成了_signature参数值。
让我们将公式向上调整,看看他在这一步进行的计算。
我发现计算的步骤在这里。这要简单得多。直接上源码,然后复制源码,模拟运行得到结果。
JS源代码:
<p>var glb;
(glb = "undefined" == typeof window ? global : window)._$jsvmprt = function(b, a, e) {
function f() {
if ("undefined" == typeof Reflect || !Reflect.construct)
return !1;
if (Reflect.construct.sham)
return !1;
if ("function" == typeof Proxy)
return !0;
try {
return Date.prototype.toString.call(Reflect.construct(Date, [], (function() {}
))),
!0
} catch (b) {
return !1
}
}
function d(b, a, e) {
return (d = f() ? Reflect.construct : function(b, a, e) {
var f = [null];
f.push.apply(f, a);
var d = new (Function.bind.apply(b, f));
return e && c(d, e.prototype),
d
}
).apply(null, arguments)
}
function c(b, a) {
return (c = Object.setPrototypeOf || function(b, a) {
return b.__proto__ = a,
b
}
)(b, a)
}
function r(b) {
return function(b) {
if (Array.isArray(b)) {
for (var a = 0, e = new Array(b.length); a > 7 == 0)
return [1, d];
if (d >> 6 == 2) {
var c = parseInt("" + b[++a] + b[++a], 16);
return d &= 63,
[2, c = (d 6 == 3) {
var r = parseInt("" + b[++a] + b[++a], 16)
, n = parseInt("" + b[++a] + b[++a], 16);
return d &= 63,
[3, n = (d 11 ? (C = z[S--],
z[S] = z[S] >>> C) : _ > 9 ? z[++S] = !0 : _ > 7 ? (j = v(b, $),
$ += 2,
z[S] = z[S][j]) : _ > 0 && (C = z[S--],
z[S] = z[S] 1) {
(_ = x) 2)
(_ = x) > 10 ? z[++S] = void 0 : _ > 1 ? (C = z[S--],
z[S] = z[S] >= C) : _ > -1 && (z[++S] = null);
else if (_ > 1) {
if ((_ = x) 4 ? z[S -= 1] = z[S][z[S + 1]] : _ > 2 && (q = z[S--],
(_ = z[S]).x === L ? _.y >= 1 ? z[S] = M(b, _.c, _.l, [q], _.z, I, null, 1) : (z[S] = M(b, _.c, _.l, [q], _.z, I, null, 0),
_.y++) : z[S] = _(q))
} else {
var P;
if ((_ = x) > 14)
j = G[$],
(P = function a() {
var e = arguments;
return a.y > 0 ? M(b, a.c, a.l, e, a.z, this, null, 0) : (a.y++,
M(b, a.c, a.l, e, a.z, this, null, 0))
}
).c = $ + 4,
P.l = j - 2,
P.x = L,
P.y = 0,
P.z = c,
z[S] = P,
$ += 2 * j - 2;
else if (_ > 12)
q = z[S--],
I = z[S--],
(_ = z[S--]).x === L ? _.y >= 1 ? z[++S] = M(b, _.c, _.l, q, _.z, I, null, 1) : (z[++S] = M(b, _.c, _.l, q, _.z, I, null, 0),
_.y++) : z[++S] = _.apply(I, q);
else if (_ > 5)
C = z[S--],
z[S] = z[S] != C;
else if (_ > 3)
C = z[S--],
z[S] = z[S] * C;
else if (_ > -1)
return [1, z[S--]]
}
} else if (_ >= 2,
_ > 2)
(_ = x) 0) {
if ((_ = x) 2)
z[S--] ? $ += 4 : $ += 2 * (j = G[$]) - 2;
else if (_ > 0) {
for (j = G[$],
C = "",
D = n.q[j][0]; D 0) {
(_ = x) > 12 ? (C = z[S - 1],
q = z[S],
z[++S] = C,
z[++S] = q) : _ > 3 ? (C = z[S--],
z[S] = z[S] == C) : _ > 1 ? (C = z[S--],
z[S] = z[S] + C) : _ > -1 && (z[++S] = h)
} else {
(_ = x) > 13 ? (z[++S] = G[$],
$ += 4) : _ > 11 ? (C = z[S--],
z[S] = z[S] >> C) : _ > 9 ? (j = G[$],
$ += 2,
C = z[S--],
c[j] = C) : _ > 7 ? (j = G[$],
$ += 4,
q = S + 1,
z[S -= j - 1] = j ? z.slice(S, q) : []) : _ > 0 && (C = z[S--],
z[S] = z[S] > C)
}
} else {
_ = 3 & x;
if (x >>= 2,
_ > 2)
(_ = x) > 13 ? (z[++S] = G[$],
$ += 8) : _ > 11 ? (C = z[S--],
z[S] = z[S] >>> C) : _ > 9 ? z[++S] = !0 : _ > 7 ? (j = G[$],
$ += 2,
z[S] = z[S][j]) : _ > 0 && (C = z[S--],
z[S] = z[S] 1) {
(_ = x) > 10 ? (j = G[$],
t[++i] = [[$ + 4, j - 3], 0, 0],
$ += 2 * j - 2) : _ > 8 ? (C = z[S--],
z[S] = z[S] ^ C) : _ > 6 && (C = z[S--])
} else if (_ > 0) {
if ((_ = x) 查看全部
今日头条文章采集软件(爬取老版今日头条数据)
前言
这里就不一一介绍每一步的具体操作了,因为在今天爬取老版头条数据的时候已经解释的很清楚了,所以这里只重点讲一下是怎么实现的。是的,如果想看具体步骤,请到我今天头条的文章内容,里面有很详细的介绍以及如何找到加密的js代码和api接口。
Python3抓取今日头条文章视频数据,完美解决as、cp、_signature的加密方式
QQ群聊
855262907
接口参数**
找界面很简单,看我前言中的文章就知道怎么找了。最重要的是参数的**。

参数名称效果值
类别
全部(用户文章 类型)
profile_all
utm_source
用户来源
头条
visit_user_token
用户令牌
MS4wLjABAAAAvazHMceCo3MeM9IJbll231AC8GkJDcrd__iZFw2hi4o(直接从用户链接获取)
max_behot_time
翻页参数
0(默认为0,后续为结果的max_behot_time值)
_签名
加密参数,用于比较访问的是哪个接口
_02B4Z6wo00f01P6um9gAAIBD5.B97mLbnez-q59AAGApeUF3pSlwtwSgMM31ERSbUq4nAurGAbdCsEa34Q4SbYuL5lnFzvinOS2JFHeprAoHuhyeKjbh(算法)
从这里可以看出只对_signature参数值进行了加密,其他的可以直接获取,所以这里只对_signature进行**,其他参数在后面的代码中获取。
反向_signature参数
直接中断调整,发现这里生成了_signature参数值。

让我们将公式向上调整,看看他在这一步进行的计算。
我发现计算的步骤在这里。这要简单得多。直接上源码,然后复制源码,模拟运行得到结果。


JS源代码:
<p>var glb;
(glb = "undefined" == typeof window ? global : window)._$jsvmprt = function(b, a, e) {
function f() {
if ("undefined" == typeof Reflect || !Reflect.construct)
return !1;
if (Reflect.construct.sham)
return !1;
if ("function" == typeof Proxy)
return !0;
try {
return Date.prototype.toString.call(Reflect.construct(Date, [], (function() {}
))),
!0
} catch (b) {
return !1
}
}
function d(b, a, e) {
return (d = f() ? Reflect.construct : function(b, a, e) {
var f = [null];
f.push.apply(f, a);
var d = new (Function.bind.apply(b, f));
return e && c(d, e.prototype),
d
}
).apply(null, arguments)
}
function c(b, a) {
return (c = Object.setPrototypeOf || function(b, a) {
return b.__proto__ = a,
b
}
)(b, a)
}
function r(b) {
return function(b) {
if (Array.isArray(b)) {
for (var a = 0, e = new Array(b.length); a > 7 == 0)
return [1, d];
if (d >> 6 == 2) {
var c = parseInt("" + b[++a] + b[++a], 16);
return d &= 63,
[2, c = (d 6 == 3) {
var r = parseInt("" + b[++a] + b[++a], 16)
, n = parseInt("" + b[++a] + b[++a], 16);
return d &= 63,
[3, n = (d 11 ? (C = z[S--],
z[S] = z[S] >>> C) : _ > 9 ? z[++S] = !0 : _ > 7 ? (j = v(b, $),
$ += 2,
z[S] = z[S][j]) : _ > 0 && (C = z[S--],
z[S] = z[S] 1) {
(_ = x) 2)
(_ = x) > 10 ? z[++S] = void 0 : _ > 1 ? (C = z[S--],
z[S] = z[S] >= C) : _ > -1 && (z[++S] = null);
else if (_ > 1) {
if ((_ = x) 4 ? z[S -= 1] = z[S][z[S + 1]] : _ > 2 && (q = z[S--],
(_ = z[S]).x === L ? _.y >= 1 ? z[S] = M(b, _.c, _.l, [q], _.z, I, null, 1) : (z[S] = M(b, _.c, _.l, [q], _.z, I, null, 0),
_.y++) : z[S] = _(q))
} else {
var P;
if ((_ = x) > 14)
j = G[$],
(P = function a() {
var e = arguments;
return a.y > 0 ? M(b, a.c, a.l, e, a.z, this, null, 0) : (a.y++,
M(b, a.c, a.l, e, a.z, this, null, 0))
}
).c = $ + 4,
P.l = j - 2,
P.x = L,
P.y = 0,
P.z = c,
z[S] = P,
$ += 2 * j - 2;
else if (_ > 12)
q = z[S--],
I = z[S--],
(_ = z[S--]).x === L ? _.y >= 1 ? z[++S] = M(b, _.c, _.l, q, _.z, I, null, 1) : (z[++S] = M(b, _.c, _.l, q, _.z, I, null, 0),
_.y++) : z[++S] = _.apply(I, q);
else if (_ > 5)
C = z[S--],
z[S] = z[S] != C;
else if (_ > 3)
C = z[S--],
z[S] = z[S] * C;
else if (_ > -1)
return [1, z[S--]]
}
} else if (_ >= 2,
_ > 2)
(_ = x) 0) {
if ((_ = x) 2)
z[S--] ? $ += 4 : $ += 2 * (j = G[$]) - 2;
else if (_ > 0) {
for (j = G[$],
C = "",
D = n.q[j][0]; D 0) {
(_ = x) > 12 ? (C = z[S - 1],
q = z[S],
z[++S] = C,
z[++S] = q) : _ > 3 ? (C = z[S--],
z[S] = z[S] == C) : _ > 1 ? (C = z[S--],
z[S] = z[S] + C) : _ > -1 && (z[++S] = h)
} else {
(_ = x) > 13 ? (z[++S] = G[$],
$ += 4) : _ > 11 ? (C = z[S--],
z[S] = z[S] >> C) : _ > 9 ? (j = G[$],
$ += 2,
C = z[S--],
c[j] = C) : _ > 7 ? (j = G[$],
$ += 4,
q = S + 1,
z[S -= j - 1] = j ? z.slice(S, q) : []) : _ > 0 && (C = z[S--],
z[S] = z[S] > C)
}
} else {
_ = 3 & x;
if (x >>= 2,
_ > 2)
(_ = x) > 13 ? (z[++S] = G[$],
$ += 8) : _ > 11 ? (C = z[S--],
z[S] = z[S] >>> C) : _ > 9 ? z[++S] = !0 : _ > 7 ? (j = G[$],
$ += 2,
z[S] = z[S][j]) : _ > 0 && (C = z[S--],
z[S] = z[S] 1) {
(_ = x) > 10 ? (j = G[$],
t[++i] = [[$ + 4, j - 3], 0, 0],
$ += 2 * j - 2) : _ > 8 ? (C = z[S--],
z[S] = z[S] ^ C) : _ > 6 && (C = z[S--])
} else if (_ > 0) {
if ((_ = x)
今日头条文章采集软件(《cookies获取的两种方法》获取cookies的方法更换教程 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 1309 次浏览 • 2021-12-03 14:13
)
优采云根据搜索词采集今日头条文章,cookies替换教程,之前文章提到了“两种获取cookies的方式”,今天是为头条消息获取cookies .
1、打开/搜索/
点击图片看大图
打开后输入自己的关键词进行搜索,然后切换到信息栏,谷歌浏览器F12,然后点击网络,点击搜索,就会出现数据流,然后点击第一个,点击上面的标题正确的数据包,只需获取cookie。
点击图片看大图
2、打开优采云替换
右键编辑规则,然后在其他设置中,在http请求设置中,粘贴cookies就完成了。
3、附上
有些朋友对今日头条的PC站情有独钟。您必须从 PC 站 采集 获取数据。今日头条PC端使用优采云采集使用插件,必须解决列表页加密。其次,如果不需要优采云,可以使用其他类型的采集器采集更好。
不过我接触的很多客户都对今日头条的验证码感到不爽,有的人用通俗易懂的语言写采集软件,都有门槛,而且优采云的门槛不高,但是还是难倒了一些朋友。
使用我规则的朋友不用担心ip验证问题。如果你只需要新的信息,可以去一些自媒体文章汇总平台获取,很多这样的网站。
-------20200525更新-------
今日头条专栏采集demo,请看本站互联网专栏;
今日头条搜索词条采集规则,请移步查看demo:www_zhhslc_com
---20210219更新---
www_zhhslc_com 搜索词采集的demo站点已经售出,简单说一下这个站点的情况,
该网站于2019年11月左右上线,主要用于今日头条词搜索规则的演示。99%的内容来自今日头条采集的数据。数据在百度上过滤。该域名已使用多年。之前注册的域名已经闲置了19年,用于演示目的。
起初,收录 不是很好。后来随着采集数量的增加,加上一些优化手段,目前数据已经达到了12万+,所以就挂了,打算卖掉。
挂了3个月左右,今天卖了。单词搜索规则非常有用。需要的可以联系我。
优采云采集今日头条基本使用说明:
售后说明1:优采云采集规则导入修改
售后说明二:优采云定时任务定时采集设置教程
售后说明3:优采云根据今日头条作者采集说明
售后说明4:获取cookies教程
售后说明5:优采云采集标签的数据处理
优采云采集今日头条跟随搜索词采集规则cookie替换教程 查看全部
今日头条文章采集软件(《cookies获取的两种方法》获取cookies的方法更换教程
)
优采云根据搜索词采集今日头条文章,cookies替换教程,之前文章提到了“两种获取cookies的方式”,今天是为头条消息获取cookies .
1、打开/搜索/

点击图片看大图
打开后输入自己的关键词进行搜索,然后切换到信息栏,谷歌浏览器F12,然后点击网络,点击搜索,就会出现数据流,然后点击第一个,点击上面的标题正确的数据包,只需获取cookie。

点击图片看大图
2、打开优采云替换
右键编辑规则,然后在其他设置中,在http请求设置中,粘贴cookies就完成了。
3、附上
有些朋友对今日头条的PC站情有独钟。您必须从 PC 站 采集 获取数据。今日头条PC端使用优采云采集使用插件,必须解决列表页加密。其次,如果不需要优采云,可以使用其他类型的采集器采集更好。
不过我接触的很多客户都对今日头条的验证码感到不爽,有的人用通俗易懂的语言写采集软件,都有门槛,而且优采云的门槛不高,但是还是难倒了一些朋友。
使用我规则的朋友不用担心ip验证问题。如果你只需要新的信息,可以去一些自媒体文章汇总平台获取,很多这样的网站。
-------20200525更新-------
今日头条专栏采集demo,请看本站互联网专栏;
今日头条搜索词条采集规则,请移步查看demo:www_zhhslc_com
---20210219更新---
www_zhhslc_com 搜索词采集的demo站点已经售出,简单说一下这个站点的情况,
该网站于2019年11月左右上线,主要用于今日头条词搜索规则的演示。99%的内容来自今日头条采集的数据。数据在百度上过滤。该域名已使用多年。之前注册的域名已经闲置了19年,用于演示目的。
起初,收录 不是很好。后来随着采集数量的增加,加上一些优化手段,目前数据已经达到了12万+,所以就挂了,打算卖掉。
挂了3个月左右,今天卖了。单词搜索规则非常有用。需要的可以联系我。
优采云采集今日头条基本使用说明:
售后说明1:优采云采集规则导入修改
售后说明二:优采云定时任务定时采集设置教程
售后说明3:优采云根据今日头条作者采集说明
售后说明4:获取cookies教程
售后说明5:优采云采集标签的数据处理
优采云采集今日头条跟随搜索词采集规则cookie替换教程
今日头条文章采集软件(通过采集软件采集的内容为什么比原创内容收录好?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2021-12-03 11:20
朋友们一直向我们咨询。为什么通过我们同行采集的软件采集的内容比我们原创收录的内容和流量还高,这是什么情况?让他时常不解。今天给大家讲讲采集站的原理和采集站的一些想法!
为什么采集软件采集的内容比原创收录的内容好?
相信很多朋友对这个问题比较疑惑。为什么我这么努力写原创文章,百度不是收录,和同行网站每天收录几十几百篇文章,可以' t 百度看不到他们?(百度是机器算法检测)。有很多时候想放弃写内容,直接用采集。我也担心被百度发现导致K站。不过小伙伴们都还好!
再来看看peer的采集站收录,以及持续增长的流量。
1、通过网站发现了网站,每天早上10点发表200篇文章。这一定是因为采集软件已经设置了预定发布。
详解:为什么要设置定期发布?搜索引擎蜘蛛必须知道这次网站更新的频率和规律,所以在10点的时间节点,很容易出现秒收录的现象。如果您是原创的内容,建议您定期、定量地更新发布您的网站。定期更新网站会让搜索引擎蜘蛛更喜欢,搜索引擎蜘蛛也会减少自己服务器的压力和爬取网站的频率,我更喜欢定期更新内容,而且采集 软件满足了这一点。一是保证网站的内容及时更新,二是还可以减少。两边服务器的压力。
2、采集很多软件都是采集最新最火的内容。百度特别喜欢最新最热的内容,相当于为这些内容打开了一个快速通道。
详细描述:例如,今天发生了一个行业相关的热点事件。如果百度没有收录相关内容,那么用户就会去别处搜索此类相关报道或内容。百度为了留住用户,肯定会收录相关内容,网站自然也会得到相应的流量。
<p>3、使用采集软件网站每天发布量巨大,如果每天发布几篇文章的话,那么它不会使用采集软件 是的,只需复制粘贴和修改即可。定期写文章,每天写2篇原创文章,已经很不错了,甚至很多人每天发一篇文章,还有 查看全部
今日头条文章采集软件(通过采集软件采集的内容为什么比原创内容收录好?)
朋友们一直向我们咨询。为什么通过我们同行采集的软件采集的内容比我们原创收录的内容和流量还高,这是什么情况?让他时常不解。今天给大家讲讲采集站的原理和采集站的一些想法!

为什么采集软件采集的内容比原创收录的内容好?
相信很多朋友对这个问题比较疑惑。为什么我这么努力写原创文章,百度不是收录,和同行网站每天收录几十几百篇文章,可以' t 百度看不到他们?(百度是机器算法检测)。有很多时候想放弃写内容,直接用采集。我也担心被百度发现导致K站。不过小伙伴们都还好!
再来看看peer的采集站收录,以及持续增长的流量。
1、通过网站发现了网站,每天早上10点发表200篇文章。这一定是因为采集软件已经设置了预定发布。
详解:为什么要设置定期发布?搜索引擎蜘蛛必须知道这次网站更新的频率和规律,所以在10点的时间节点,很容易出现秒收录的现象。如果您是原创的内容,建议您定期、定量地更新发布您的网站。定期更新网站会让搜索引擎蜘蛛更喜欢,搜索引擎蜘蛛也会减少自己服务器的压力和爬取网站的频率,我更喜欢定期更新内容,而且采集 软件满足了这一点。一是保证网站的内容及时更新,二是还可以减少。两边服务器的压力。

2、采集很多软件都是采集最新最火的内容。百度特别喜欢最新最热的内容,相当于为这些内容打开了一个快速通道。
详细描述:例如,今天发生了一个行业相关的热点事件。如果百度没有收录相关内容,那么用户就会去别处搜索此类相关报道或内容。百度为了留住用户,肯定会收录相关内容,网站自然也会得到相应的流量。
<p>3、使用采集软件网站每天发布量巨大,如果每天发布几篇文章的话,那么它不会使用采集软件 是的,只需复制粘贴和修改即可。定期写文章,每天写2篇原创文章,已经很不错了,甚至很多人每天发一篇文章,还有
今日头条文章采集软件( 海量Python学习资料!目录需要的Python模块实现思路代码及运行结果)
采集交流 • 优采云 发表了文章 • 0 个评论 • 516 次浏览 • 2021-11-29 06:28
海量Python学习资料!目录需要的Python模块实现思路代码及运行结果)
最近在今日头条文章的数据抓取过程中,发现获取视频地址比较复杂。在源码和浏览器的配合下找到了相应的解决方法,请记录下来。
点击此处获取海量Python学习资料!
目录实现思路代码和运行结果文本所需的Python模块
1.所需的 Python 模块
模块主要有requests(或者aiohttp),PyExecJS。
前者是请求文章的源码,后者是Python执行JS代码的依赖库,主要是生成视频地址
12
实现思路一. 需求主要是将原来文章中的视频和图片地址替换为本地存储地址,所以需要下载资源,在视频中通过抓包找到对应的视频地址分析。源码和相关接口响应中没有找到对应的视频地址参数。
通过文章源代码(HTML)浏览器渲染,发现video标签是后面生成的,而且video地址也存在,那么这个标签肯定是JS生成的,找到关键的JS标签脚本通过搜索
二. 解析地址对应的js,发现有生成视频标签的方法,推断有依次生成视频地址的方法,如下:
在这里可以很清楚我们想要的视频地址是从哪里来的,方法如下:
分析方法,我们发现有一个关键参数t,而在图2中,我们找到了方法e,填入了参数v。这让我想起了前面捕获中接口返回的结果对应的main_url。无功 u = o。data.video_list, h = u.video_1, v = h.main_url, 123三. 接口为:/video/urls /1/toutiao/mp4/v0201f800000bub4vq2vtt9a5oknnlp0?callback=tt__video__3e9q4q
在界面返回结果中:
同时该接口中的参数(v0201f800000bub4vq2vtt9a5oknnlp0)在源码中可以找到,可以通过规则匹配。
你可以大胆尝试。在生成视频地址的方法中添加 main_url 值。另外还需要加上JS最底层的几个参数,即: var c = new Array(-1, -1, -1, -1, -1, -1, -1, -1, -1, - 1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,- 1, -1, -1, -1, -1, -1 , 62, -1, -1, -1, 63, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, -1, -1, -1, -1, -1, - 1, -1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22 , 23, 24, 25, -1, -1, -1, -1, -1, -1, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38 , 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, -1, -1,- 1, -1, -1); 1
我用的是JS调试工具(方便调试,检查代码语法),其他方法也可以
结果是:
/ B 742fb26ade01b94ae81b46009d87380 / 5f9944fe /视频/ TOS / CN / TOS-CN-VE-31 / cb2c3a57a679486eba880ef014c36ca0 / A = 2011&BR = 1368&BT = 456&CR = 0&CS = 0&CV = 1&DR7 = 0&DS = 1&RCV = 1&硬币=&石灰=&limetype = M29xcmR3eXQ3eDMzM2kzM0ApZmVkZjo5OGVkNzM6PDozaWdta2gyNnEvc19fLS01Li9zczIuLl41YTFjXi8yMTReYGM6Yw%3D %3D&vl=&vr=
地址是视频地址,所以证明上面的猜想是正确的,但是地址参数是时效性的,所以需要动态修改。您可以自己测试并重新生成它。
代码和运行结果(我用了不同的方法)
<p>async def get_page_source(url):
browser = None
page = None
try:
browser = await launch(
headless=True,
ignoreHTTPSErrors=True,
handleSIGINT=False,
handleSIGTERM=False,
handleSIGHUP=False,
defaultViewport=None,
args=['--disable-setuid-sandbox',
'--no-sandbox',
'--ignore-certificate-errors',
'--disable-gpu',
'--disable-gpu-sandbox',
'--start-maximized'
]
)
pages = await browser.pages()
page = pages[0]
# 是否启用JS,enabled设为False,则无渲染效果
await page.setJavaScriptEnabled(enabled=True)
await page.setViewport(viewport={'width': 1200, 'height': 800})
await page.evaluateOnNewDocument(
'() =>{ Object.defineProperties(navigator,{ webdriver:{ get: () => false } }) }')
await page.evaluateOnNewDocument("() =>{ Object.defineProperty(navigator, 'plugins', { get: () => [] }) }")
await page.evaluateOnNewDocument(
"() =>{ Object.defineProperty(navigator, 'languages', { get: () => ['zh-CN','zh] }) }")
await page.setUserAgent(
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36')
await page.goto(url, {'timeout': 5000, 'waitUntil': 'load'})
page_source = await page.content()
return page_source
except Exception as e:
# app_logger.error('账号:%s, 登录错误:%s' % (username, e))
print(e)
return -1
finally:
if page is not None:
# await page.waitFor(1000)
await page.close()
if browser is not None:
await browser.close()
async def get_data(url, continue_number=0):
"""解析文章源码,提取视频,文字,图片等信息"""
try:
page_source = await get_page_source(url)
# 视频处理,及视频封面
video_message_id_ = re.findall('tt-videoid="(.*?)"', page_source)
video_cover_ = re.findall('tt-poster="(.*?)"', page_source)
if len(video_message_id_) > 0 and len(video_cover_) > 0:
video_message_id = video_message_id_[0]
video_url = await get_video_url_id(video_message_id, url)
video_cover = await download_video_cover(video_cover_[0], url)
except Exception as e:
if continue_number < continue_num:
print(e)
# app_logger.error('function get_data error: %s' % e)
continue_number += 1
video_address = await get_data(url, continue_number)
return video_address
else:
# app_logger.error('function get_data : %s exceed maximum retry' % url)
return -1
async def get_video_url_id(video_id, article_url, continue_number=0):
"""解析视频main_url"""
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/83.0.4103.116 Safari/537.36'}
data_url = 'https://i.snssdk.com/video/urls/1/toutiao/mp4/{}'.format(video_id)
try:
async with aiohttp.ClientSession(connector=TCPConnector(verify_ssl=False), timeout=timeout) as session:
async with session.get(data_url, headers=header) as resp:
response = await resp.json()
if response['message'].strip() == "success":
data = response['data']['video_list']
keys = data.keys()
if 'video_3' in keys:
main_url = data['video_3']['main_url']
video_url = await get_video_url(main_url)
video_url_oss = await download_video(video_url, article_url)
return video_url_oss
elif 'video_3' not in keys and 'video_2' in keys:
main_url = data['video_3']['main_url']
video_url = await get_video_url(main_url)
video_url_oss = await download_video(video_url, article_url)
return video_url_oss
else:
main_url = data['video_3']['main_url']
video_url = await get_video_url(main_url)
video_url_oss = await download_video(video_url, article_url)
return video_url_oss
except Exception as e:
if continue_number < continue_num:
print(e)
# app_logger.error('function get_data error: %s' % e)
continue_number += 1
video_address = await get_data(url, continue_number)
return video_address
else:
# app_logger.error('function get_data : %s exceed maximum retry' % url)
return -1
async def get_video_url(main_url, continue_number=0):
"""获取视频地址,js执行"""
try:
tt = """var c = new Array( - 1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 62, -1, -1, -1, 63, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, -1, -1, -1, -1, -1, -1, -1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, -1, -1, -1, -1, -1, -1, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, -1, -1, -1, -1, -1);
function e(t) {
var e, o, i, r, n, a, s;
for (a = t.length, n = 0, s = ""; a > n;) {
do e = c[255 & t.charCodeAt(n++)];
while (a > n && -1 == e);
if ( - 1 == e) break;
do o = c[255 & t.charCodeAt(n++)];
while (a > n && -1 == o);
if ( - 1 == o) break;
s += String.fromCharCode(e > 4);
do {
if (i = 255 & t.charCodeAt(n++), 61 == i) return s;
i = c[i]
} while ( a > n && - 1 == i );
if ( - 1 == i) break;
s += String.fromCharCode((15 & o) > 2);
do {
if (r = 255 & t.charCodeAt(n++), 61 == r) return s;
r = c[r]
} while ( a > n && - 1 == r );
if ( - 1 == r) break;
s += String.fromCharCode((3 & i) 查看全部
今日头条文章采集软件(
海量Python学习资料!目录需要的Python模块实现思路代码及运行结果)

最近在今日头条文章的数据抓取过程中,发现获取视频地址比较复杂。在源码和浏览器的配合下找到了相应的解决方法,请记录下来。
点击此处获取海量Python学习资料!

目录实现思路代码和运行结果文本所需的Python模块
1.所需的 Python 模块
模块主要有requests(或者aiohttp),PyExecJS。
前者是请求文章的源码,后者是Python执行JS代码的依赖库,主要是生成视频地址
12
实现思路一. 需求主要是将原来文章中的视频和图片地址替换为本地存储地址,所以需要下载资源,在视频中通过抓包找到对应的视频地址分析。源码和相关接口响应中没有找到对应的视频地址参数。
通过文章源代码(HTML)浏览器渲染,发现video标签是后面生成的,而且video地址也存在,那么这个标签肯定是JS生成的,找到关键的JS标签脚本通过搜索
二. 解析地址对应的js,发现有生成视频标签的方法,推断有依次生成视频地址的方法,如下:
在这里可以很清楚我们想要的视频地址是从哪里来的,方法如下:
分析方法,我们发现有一个关键参数t,而在图2中,我们找到了方法e,填入了参数v。这让我想起了前面捕获中接口返回的结果对应的main_url。无功 u = o。data.video_list, h = u.video_1, v = h.main_url, 123三. 接口为:/video/urls /1/toutiao/mp4/v0201f800000bub4vq2vtt9a5oknnlp0?callback=tt__video__3e9q4q
在界面返回结果中:
同时该接口中的参数(v0201f800000bub4vq2vtt9a5oknnlp0)在源码中可以找到,可以通过规则匹配。
你可以大胆尝试。在生成视频地址的方法中添加 main_url 值。另外还需要加上JS最底层的几个参数,即: var c = new Array(-1, -1, -1, -1, -1, -1, -1, -1, -1, - 1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,- 1, -1, -1, -1, -1, -1 , 62, -1, -1, -1, 63, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, -1, -1, -1, -1, -1, - 1, -1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22 , 23, 24, 25, -1, -1, -1, -1, -1, -1, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38 , 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, -1, -1,- 1, -1, -1); 1
我用的是JS调试工具(方便调试,检查代码语法),其他方法也可以
结果是:
/ B 742fb26ade01b94ae81b46009d87380 / 5f9944fe /视频/ TOS / CN / TOS-CN-VE-31 / cb2c3a57a679486eba880ef014c36ca0 / A = 2011&BR = 1368&BT = 456&CR = 0&CS = 0&CV = 1&DR7 = 0&DS = 1&RCV = 1&硬币=&石灰=&limetype = M29xcmR3eXQ3eDMzM2kzM0ApZmVkZjo5OGVkNzM6PDozaWdta2gyNnEvc19fLS01Li9zczIuLl41YTFjXi8yMTReYGM6Yw%3D %3D&vl=&vr=
地址是视频地址,所以证明上面的猜想是正确的,但是地址参数是时效性的,所以需要动态修改。您可以自己测试并重新生成它。
代码和运行结果(我用了不同的方法)
<p>async def get_page_source(url):
browser = None
page = None
try:
browser = await launch(
headless=True,
ignoreHTTPSErrors=True,
handleSIGINT=False,
handleSIGTERM=False,
handleSIGHUP=False,
defaultViewport=None,
args=['--disable-setuid-sandbox',
'--no-sandbox',
'--ignore-certificate-errors',
'--disable-gpu',
'--disable-gpu-sandbox',
'--start-maximized'
]
)
pages = await browser.pages()
page = pages[0]
# 是否启用JS,enabled设为False,则无渲染效果
await page.setJavaScriptEnabled(enabled=True)
await page.setViewport(viewport={'width': 1200, 'height': 800})
await page.evaluateOnNewDocument(
'() =>{ Object.defineProperties(navigator,{ webdriver:{ get: () => false } }) }')
await page.evaluateOnNewDocument("() =>{ Object.defineProperty(navigator, 'plugins', { get: () => [] }) }")
await page.evaluateOnNewDocument(
"() =>{ Object.defineProperty(navigator, 'languages', { get: () => ['zh-CN','zh] }) }")
await page.setUserAgent(
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36')
await page.goto(url, {'timeout': 5000, 'waitUntil': 'load'})
page_source = await page.content()
return page_source
except Exception as e:
# app_logger.error('账号:%s, 登录错误:%s' % (username, e))
print(e)
return -1
finally:
if page is not None:
# await page.waitFor(1000)
await page.close()
if browser is not None:
await browser.close()
async def get_data(url, continue_number=0):
"""解析文章源码,提取视频,文字,图片等信息"""
try:
page_source = await get_page_source(url)
# 视频处理,及视频封面
video_message_id_ = re.findall('tt-videoid="(.*?)"', page_source)
video_cover_ = re.findall('tt-poster="(.*?)"', page_source)
if len(video_message_id_) > 0 and len(video_cover_) > 0:
video_message_id = video_message_id_[0]
video_url = await get_video_url_id(video_message_id, url)
video_cover = await download_video_cover(video_cover_[0], url)
except Exception as e:
if continue_number < continue_num:
print(e)
# app_logger.error('function get_data error: %s' % e)
continue_number += 1
video_address = await get_data(url, continue_number)
return video_address
else:
# app_logger.error('function get_data : %s exceed maximum retry' % url)
return -1
async def get_video_url_id(video_id, article_url, continue_number=0):
"""解析视频main_url"""
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/83.0.4103.116 Safari/537.36'}
data_url = 'https://i.snssdk.com/video/urls/1/toutiao/mp4/{}'.format(video_id)
try:
async with aiohttp.ClientSession(connector=TCPConnector(verify_ssl=False), timeout=timeout) as session:
async with session.get(data_url, headers=header) as resp:
response = await resp.json()
if response['message'].strip() == "success":
data = response['data']['video_list']
keys = data.keys()
if 'video_3' in keys:
main_url = data['video_3']['main_url']
video_url = await get_video_url(main_url)
video_url_oss = await download_video(video_url, article_url)
return video_url_oss
elif 'video_3' not in keys and 'video_2' in keys:
main_url = data['video_3']['main_url']
video_url = await get_video_url(main_url)
video_url_oss = await download_video(video_url, article_url)
return video_url_oss
else:
main_url = data['video_3']['main_url']
video_url = await get_video_url(main_url)
video_url_oss = await download_video(video_url, article_url)
return video_url_oss
except Exception as e:
if continue_number < continue_num:
print(e)
# app_logger.error('function get_data error: %s' % e)
continue_number += 1
video_address = await get_data(url, continue_number)
return video_address
else:
# app_logger.error('function get_data : %s exceed maximum retry' % url)
return -1
async def get_video_url(main_url, continue_number=0):
"""获取视频地址,js执行"""
try:
tt = """var c = new Array( - 1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 62, -1, -1, -1, 63, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, -1, -1, -1, -1, -1, -1, -1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, -1, -1, -1, -1, -1, -1, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, -1, -1, -1, -1, -1);
function e(t) {
var e, o, i, r, n, a, s;
for (a = t.length, n = 0, s = ""; a > n;) {
do e = c[255 & t.charCodeAt(n++)];
while (a > n && -1 == e);
if ( - 1 == e) break;
do o = c[255 & t.charCodeAt(n++)];
while (a > n && -1 == o);
if ( - 1 == o) break;
s += String.fromCharCode(e > 4);
do {
if (i = 255 & t.charCodeAt(n++), 61 == i) return s;
i = c[i]
} while ( a > n && - 1 == i );
if ( - 1 == i) break;
s += String.fromCharCode((15 & o) > 2);
do {
if (r = 255 & t.charCodeAt(n++), 61 == r) return s;
r = c[r]
} while ( a > n && - 1 == r );
if ( - 1 == r) break;
s += String.fromCharCode((3 & i)
今日头条文章采集软件(一下今日头条爬取文章的几个方案(一)_ )
采集交流 • 优采云 发表了文章 • 0 个评论 • 280 次浏览 • 2021-11-28 04:02
)
使用环境:爬取思路(一) 生成as、cp和_signature的思考
对于今日头条的爬虫来说,网上搜索到的文章大部分都是基于崔庆才(一个通过搜索爬取漂亮街拍的计划)。不可能的。在这里,上网搜索,搜索,谷歌和百度都使用。这里有一些计划通过今天的头条来爬取文章。
今日头条'as,cp破解
使用的技术是execjs,是一个执行js代码的框架,但是在浏览器环境(比如Node环境)中还没有很好的嵌入。
使用了一个PyV8 js库,主要是获取_signature
给出了一个非常他妈的代码:
def get_signature(self,user_id):
"""
计算_signature
:param user_id: user_id不需要计算,对用户可见
:return: _signature
"""
req = requests.Session()
# js获取目的
jsurl = 'https://s3.pstatp.com/toutiao/ ... 39%3B
resp = req.get(jsurl,headers = self.headers)
js = resp.content
effect_js = js.split("Function")
js = 'var navigator = {};\
navigator["userAgent"] = "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.87 Safari/537.36";\
' + "Function" + effect_js[3] +
"Function" + effect_js[4] +
";function result(){ return TAC.sign(" + user_id + ");} result();"
# PyV8执行步骤
with PyV8.JSLocker():
self.ctxt.enter() #已在上面初始化过
vl5x = self.ctxt.eval(js)
self.ctxt.leave()
self.LOG.info("圣诞快乐")
return vl5x
PyV8库在win10上装不了,后来在centos7环境下安装了。执行这段代码后,直接报内存不足的错误。直接调用TAC.sign的方法缺少Node环境(更多的是浏览器环境),或者报错。也许这确实是一种方法,但很少有人对短书给出反馈。我不知道是我想不通还是他们有。
(二)我后来直接用了自己的方法:绕过_signature参数,直接请求网页的数据信息(wap)。
右键查看,点击json栏,选择其中一个url
网址一:
网址二:
至于,前面文章中的cp,我们已经搞清楚了,现在我们要做的就是如何拼接这串url,
根据上面两个网址的对比,我们只需要替换max_behot_time和jsonp,
这样,我们就得到了整个列表页面的数据。
接下来,解析详情页的数据可能要简单得多。
查看页面源代码:
这正是我们想要的数据,使用常规采集就足够了。
至此,我们就可以完全检索今日头条的数据了。
需要源码的可以加个小秘圈:
查看全部
今日头条文章采集软件(一下今日头条爬取文章的几个方案(一)_
)
使用环境:爬取思路(一) 生成as、cp和_signature的思考
对于今日头条的爬虫来说,网上搜索到的文章大部分都是基于崔庆才(一个通过搜索爬取漂亮街拍的计划)。不可能的。在这里,上网搜索,搜索,谷歌和百度都使用。这里有一些计划通过今天的头条来爬取文章。
今日头条'as,cp破解
使用的技术是execjs,是一个执行js代码的框架,但是在浏览器环境(比如Node环境)中还没有很好的嵌入。
使用了一个PyV8 js库,主要是获取_signature
给出了一个非常他妈的代码:
def get_signature(self,user_id):
"""
计算_signature
:param user_id: user_id不需要计算,对用户可见
:return: _signature
"""
req = requests.Session()
# js获取目的
jsurl = 'https://s3.pstatp.com/toutiao/ ... 39%3B
resp = req.get(jsurl,headers = self.headers)
js = resp.content
effect_js = js.split("Function")
js = 'var navigator = {};\
navigator["userAgent"] = "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.87 Safari/537.36";\
' + "Function" + effect_js[3] +
"Function" + effect_js[4] +
";function result(){ return TAC.sign(" + user_id + ");} result();"
# PyV8执行步骤
with PyV8.JSLocker():
self.ctxt.enter() #已在上面初始化过
vl5x = self.ctxt.eval(js)
self.ctxt.leave()
self.LOG.info("圣诞快乐")
return vl5x
PyV8库在win10上装不了,后来在centos7环境下安装了。执行这段代码后,直接报内存不足的错误。直接调用TAC.sign的方法缺少Node环境(更多的是浏览器环境),或者报错。也许这确实是一种方法,但很少有人对短书给出反馈。我不知道是我想不通还是他们有。
(二)我后来直接用了自己的方法:绕过_signature参数,直接请求网页的数据信息(wap)。
右键查看,点击json栏,选择其中一个url
网址一:
网址二:
至于,前面文章中的cp,我们已经搞清楚了,现在我们要做的就是如何拼接这串url,
根据上面两个网址的对比,我们只需要替换max_behot_time和jsonp,
这样,我们就得到了整个列表页面的数据。

接下来,解析详情页的数据可能要简单得多。

查看页面源代码:
这正是我们想要的数据,使用常规采集就足够了。

至此,我们就可以完全检索今日头条的数据了。
需要源码的可以加个小秘圈:

今日头条文章采集软件( 一键采集今日头条和评论的数据到您的论坛上)
采集交流 • 优采云 发表了文章 • 0 个评论 • 731 次浏览 • 2021-11-28 03:23
一键采集今日头条和评论的数据到您的论坛上)
【插件功能】
安装本插件后,您可以输入今日头条地址或关键词,一键采集今日头条评论数据到您的论坛。
[本插件的特点]
1、您可以输入热门标题关键词,采集标题和用户评论将实时发布到您的论坛
2、您可以采集批量发布,短时间内将今日头条的优质内容转发到您的论坛
3、可定时采集 可无人值守,自动采集自动释放
4、马甲用户可批量注册,发帖者和回复者使用马甲,与真实用户发布的一模一样
5、支持前台采集,可以指定普通用户使用这个采集器,让普通会员帮你转发今日头条内容。
6、采集 过来的新闻图片可以正常显示并保存为帖子图片附件。
7、图片附件支持远程FTP存储。
8、图片将从您的论坛中添加水印。
9、已经采集的新闻信息不会重复采集,内容也不会冗余。
10、采集 发布的帖子与真实用户发布的帖子几乎一模一样。
11、浏览量会自动随机设置,感觉你帖子的浏览量更真实。
12、 可以指定帖子发布者的 UID。
13、采集的头条新闻内容可以发布到任何版块。
14、可以随机采集一批标题到你的论坛。
15、无限采集,无限采集次。
[这个插件给你带来的价值]
1、让您的论坛非常受欢迎且内容丰富。
2、使用一键采集代替人工发帖,省时省力,不易出错。
3、让你的网站与海量新闻网站分享优质内容,快速提升网站的权重和排名。
[备注]
本插件只能采集今日头条新闻资讯类内容,不能采集头条问答、头条视频、头条图集...
【官方QQ群:235307918】
在线安装:
@csdn123com_toutiao.plugin
本地下载和手动安装: 查看全部
今日头条文章采集软件(
一键采集今日头条和评论的数据到您的论坛上)

【插件功能】
安装本插件后,您可以输入今日头条地址或关键词,一键采集今日头条评论数据到您的论坛。
[本插件的特点]
1、您可以输入热门标题关键词,采集标题和用户评论将实时发布到您的论坛
2、您可以采集批量发布,短时间内将今日头条的优质内容转发到您的论坛
3、可定时采集 可无人值守,自动采集自动释放
4、马甲用户可批量注册,发帖者和回复者使用马甲,与真实用户发布的一模一样
5、支持前台采集,可以指定普通用户使用这个采集器,让普通会员帮你转发今日头条内容。
6、采集 过来的新闻图片可以正常显示并保存为帖子图片附件。
7、图片附件支持远程FTP存储。
8、图片将从您的论坛中添加水印。
9、已经采集的新闻信息不会重复采集,内容也不会冗余。
10、采集 发布的帖子与真实用户发布的帖子几乎一模一样。
11、浏览量会自动随机设置,感觉你帖子的浏览量更真实。
12、 可以指定帖子发布者的 UID。
13、采集的头条新闻内容可以发布到任何版块。
14、可以随机采集一批标题到你的论坛。
15、无限采集,无限采集次。
[这个插件给你带来的价值]
1、让您的论坛非常受欢迎且内容丰富。
2、使用一键采集代替人工发帖,省时省力,不易出错。
3、让你的网站与海量新闻网站分享优质内容,快速提升网站的权重和排名。
[备注]
本插件只能采集今日头条新闻资讯类内容,不能采集头条问答、头条视频、头条图集...
【官方QQ群:235307918】
在线安装:
@csdn123com_toutiao.plugin
本地下载和手动安装:
今日头条文章采集软件(一键采集百度贴吧内容正式版5.15.13.0 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 216 次浏览 • 2021-12-25 06:17
)
下载链接:
游客,如果您想查看本帖隐藏内容,请回复
相关插件:
一键采集抢每日快车1.0
一键采集知乎问答
一键采集贴吧正式版内容5.1
一键采集天涯论坛Discuz v1.0任意贴
一键采集今日头条2.2
一键采集百度贴吧内容5.0
一键采集今日头条正式版3.0 价值289元
01、可以批量注册马甲用户。发帖者和评论所使用的马甲看起来与真实注册用户发布的马甲完全相同。
02、 可以批量采集批量发布,短时间内将任何高质量的标题文章和评论发布到您的论坛和门户。
03、可自动发布采集的所有内容,实现网站内容无人值守自动更新,让您拥有24小时发布内容的智能编辑器。
04、采集 返回的内容可以进行简繁体转换,可以做伪原创等二次处理。
05、 支持采集指定的标题号,实现针对采集的某个标题号的内容。
06、采集 过来的内容图片可以正常显示并保存为帖子图片附件或门户文章附件,图片永不丢失。
07、图片附件支持远程FTP存储,让您可以将图片分离到另一台服务器。
08、 图片会添加您的论坛或门户设置的水印。
09、 已经采集的内容不会重复两次采集,内容不会重复或冗余。
1 0、采集或门户网站文章和群组发布的帖子与真实用户发布的帖子完全相同。其他人不知道是否用采集器 发帖。
1 1、的浏览量会自动随机设置。感觉你的帖子或门户文章的浏览量和真实的一样。
12、可以指定帖子发布者(主持人)、门户文章作者、群发者。
1 3、采集的内容可以发布到论坛任意版块、门户任意栏目、群任意圈。
14、 马甲回复时间经过科学处理。并非所有回复帖子的人都在同一时间。感觉您的论坛不是在回复马甲,而是在回复真实用户。
15、不限制采集的内容数量,不限制采集的次数,让你的网站快速填充优质内容.
16、插件内置采集规则,无需自己编写采集规则,支持采集任意标题网站任意列内容。
17、 一键获取当前实时热点内容,然后一键发布。
18、免费赠送对应的google chrome扩展程序(附详细安装教程),实现“所见即所得”,即可以采集任意内容标题你浏览的内容。
【这个插件给你带来的价值回报】
01、 使您的论坛非常受欢迎且内容丰富。
02、 批量生成的马甲除了使用这个插件,还可以做其他用途,相当于购买了这个插件,马甲生成插件是免费赠送的礼物。
03、使用一键采集代替人工发帖,省时省力,不易出错。相当于你的网站带有机器人智能编辑器。
04、让您的网站与知名网站分享海量优质内容,快速提升网站SEO权重和排名。
05、 这个插件相当于解决了你的网站优质内容来源问题。用好这个工具,让你操作网站事半功倍。
查看全部
今日头条文章采集软件(一键采集百度贴吧内容正式版5.15.13.0
)
下载链接:
游客,如果您想查看本帖隐藏内容,请回复
相关插件:
一键采集抢每日快车1.0
一键采集知乎问答
一键采集贴吧正式版内容5.1
一键采集天涯论坛Discuz v1.0任意贴
一键采集今日头条2.2
一键采集百度贴吧内容5.0
一键采集今日头条正式版3.0 价值289元
01、可以批量注册马甲用户。发帖者和评论所使用的马甲看起来与真实注册用户发布的马甲完全相同。
02、 可以批量采集批量发布,短时间内将任何高质量的标题文章和评论发布到您的论坛和门户。
03、可自动发布采集的所有内容,实现网站内容无人值守自动更新,让您拥有24小时发布内容的智能编辑器。
04、采集 返回的内容可以进行简繁体转换,可以做伪原创等二次处理。
05、 支持采集指定的标题号,实现针对采集的某个标题号的内容。
06、采集 过来的内容图片可以正常显示并保存为帖子图片附件或门户文章附件,图片永不丢失。
07、图片附件支持远程FTP存储,让您可以将图片分离到另一台服务器。
08、 图片会添加您的论坛或门户设置的水印。
09、 已经采集的内容不会重复两次采集,内容不会重复或冗余。
1 0、采集或门户网站文章和群组发布的帖子与真实用户发布的帖子完全相同。其他人不知道是否用采集器 发帖。
1 1、的浏览量会自动随机设置。感觉你的帖子或门户文章的浏览量和真实的一样。
12、可以指定帖子发布者(主持人)、门户文章作者、群发者。
1 3、采集的内容可以发布到论坛任意版块、门户任意栏目、群任意圈。
14、 马甲回复时间经过科学处理。并非所有回复帖子的人都在同一时间。感觉您的论坛不是在回复马甲,而是在回复真实用户。
15、不限制采集的内容数量,不限制采集的次数,让你的网站快速填充优质内容.
16、插件内置采集规则,无需自己编写采集规则,支持采集任意标题网站任意列内容。
17、 一键获取当前实时热点内容,然后一键发布。
18、免费赠送对应的google chrome扩展程序(附详细安装教程),实现“所见即所得”,即可以采集任意内容标题你浏览的内容。
【这个插件给你带来的价值回报】
01、 使您的论坛非常受欢迎且内容丰富。
02、 批量生成的马甲除了使用这个插件,还可以做其他用途,相当于购买了这个插件,马甲生成插件是免费赠送的礼物。
03、使用一键采集代替人工发帖,省时省力,不易出错。相当于你的网站带有机器人智能编辑器。
04、让您的网站与知名网站分享海量优质内容,快速提升网站SEO权重和排名。
05、 这个插件相当于解决了你的网站优质内容来源问题。用好这个工具,让你操作网站事半功倍。
今日头条文章采集软件(金兰金兰今日头条营销助手官方手机版介绍(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 171 次浏览 • 2021-12-25 04:00
金兰今日头条营销助手手机版是金兰今日头条营销助手官方手机版。金兰今日头条营销助手官方手机版拥有四种强大的文章采集功能,你还可以在评论时自动采集这个文章,让你的营销推广更高效。
金兰官方手机版今日头条营销助手介绍
1.具有采集功能文章,可以一边评论一边采集这篇文章文章,有四个评论来源,可以采集新闻分类下的新闻文章@ > 评论可以按关键词搜索文章评论,可以评论指定标题号发布的文章,也可以导入指定的文章 @> 为评论,四个所有评论源都可以循环回复。
2. 支持云编码、编码兔、联众编码三种第三方支付身份验证码,IP支持ADSL、IP支持3G网卡、IP支持VPN、IP支持代理。
3. 拥有强大的金兰今日头条营销助手官方手机账号管理功能,自动记录每个账号每天的评论点赞数,支持从外部Excel文件批量导入评论内容,新手也容易上手开始使用该软件。
4.具有强大的文章评论功能。有两种评论模式:普通评论和智能抢夺。可以按照指定的时间间隔从第三方付费API接口代理IP。
金兰官方手机版今日头条营销助手功能
1. 可以对评论内容进行分组管理,方便评论时选择不同的评论内容。拥有强大的头条号采集功能,支持来自今日头条的首页和类别采集的头条号。
2. 拥有强大的评论和点赞功能,可以添加多个你想点赞的评论,点赞次数不限,强大的系统标签和随机变量替换功能可以生成各种不同的内容 避免内容重复。
3. 可以灵活设置评论点赞的时间间隔,限制账号每天最大评论点赞数。指定注释文章时可以使用软件采集,也可以手动添加。您也可以从文件中批量导入它们。
金兰头条营销助手官方手机版总结
金兰头条营销助手官方V2.10是一款适用于安卓版其他软件的手机软件。如果你喜欢这个软件,请把下载地址分享给你的朋友:
分享下载地址:
如果您想获取更多最新版本发布信息,请采集最新发布地址:
合集发布页面地址:
金兰头条营销助理官方V2.10更新内容,修复播放音画不同步问题。修复线控支架。贴心护眼模式,阅读更舒适!金兰今日头条营销助手官方手机版打不开或无法上网怎么办?
答:如果遇到金兰今日头条营销助理官访访问异常,请尝试在较好的网络环境下重新打开软件,或者重启手机再重新打开;如果还是不行,请卸载软件并点击上面的链接下载最新版本。尝试。为什么腾讯视频不能投票给金澜金澜今日头条营销助理官员?金兰今日头条营销助理官方APP好用吗?谁来介绍一下金兰的金兰今日头条营销助理官方白家旺?
展开 查看全部
今日头条文章采集软件(金兰金兰今日头条营销助手官方手机版介绍(组图))
金兰今日头条营销助手手机版是金兰今日头条营销助手官方手机版。金兰今日头条营销助手官方手机版拥有四种强大的文章采集功能,你还可以在评论时自动采集这个文章,让你的营销推广更高效。
金兰官方手机版今日头条营销助手介绍
1.具有采集功能文章,可以一边评论一边采集这篇文章文章,有四个评论来源,可以采集新闻分类下的新闻文章@ > 评论可以按关键词搜索文章评论,可以评论指定标题号发布的文章,也可以导入指定的文章 @> 为评论,四个所有评论源都可以循环回复。
2. 支持云编码、编码兔、联众编码三种第三方支付身份验证码,IP支持ADSL、IP支持3G网卡、IP支持VPN、IP支持代理。
3. 拥有强大的金兰今日头条营销助手官方手机账号管理功能,自动记录每个账号每天的评论点赞数,支持从外部Excel文件批量导入评论内容,新手也容易上手开始使用该软件。
4.具有强大的文章评论功能。有两种评论模式:普通评论和智能抢夺。可以按照指定的时间间隔从第三方付费API接口代理IP。
金兰官方手机版今日头条营销助手功能
1. 可以对评论内容进行分组管理,方便评论时选择不同的评论内容。拥有强大的头条号采集功能,支持来自今日头条的首页和类别采集的头条号。
2. 拥有强大的评论和点赞功能,可以添加多个你想点赞的评论,点赞次数不限,强大的系统标签和随机变量替换功能可以生成各种不同的内容 避免内容重复。
3. 可以灵活设置评论点赞的时间间隔,限制账号每天最大评论点赞数。指定注释文章时可以使用软件采集,也可以手动添加。您也可以从文件中批量导入它们。
金兰头条营销助手官方手机版总结
金兰头条营销助手官方V2.10是一款适用于安卓版其他软件的手机软件。如果你喜欢这个软件,请把下载地址分享给你的朋友:
分享下载地址:
如果您想获取更多最新版本发布信息,请采集最新发布地址:
合集发布页面地址:
金兰头条营销助理官方V2.10更新内容,修复播放音画不同步问题。修复线控支架。贴心护眼模式,阅读更舒适!金兰今日头条营销助手官方手机版打不开或无法上网怎么办?
答:如果遇到金兰今日头条营销助理官访访问异常,请尝试在较好的网络环境下重新打开软件,或者重启手机再重新打开;如果还是不行,请卸载软件并点击上面的链接下载最新版本。尝试。为什么腾讯视频不能投票给金澜金澜今日头条营销助理官员?金兰今日头条营销助理官方APP好用吗?谁来介绍一下金兰的金兰今日头条营销助理官方白家旺?
展开
今日头条文章采集软件( 网站采集用什么软件好,优采云万能文章采集软件好用不)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-12-21 03:16
网站采集用什么软件好,优采云万能文章采集软件好用不)
最近很多站长朋友问网站采集什么软件好,优采云万能文章采集软件好用。今天我将谈谈我们使用优采云、优采云和免费采集工具的经验。不做任何推荐,只分析其特点和适用场景。
为什么要使用文章采集工具
站长都知道,各大网站基本上都有自己的采集开放点。他们很少使用工具。作为seo,我们没有那么强大的技术支持,所以只能使用市场上一些常用的。采集工具实现采集。
文章采集 会不会影响网站的质量?
首先不能纯采集,纯采集是对百度等搜索引擎的严厉打击。文章发布前一定要重新修改文章,例如使用文章伪原创工具。达到接近原创的目标,再做相应的内外部优化。这样使用文章采集是没有问题的。但是要想做好SEO,内容很重要,因为SEO是一个内容为王的行业。
关于优采云万能文章采集器
先说优采云Universal文章采集软件。优采云Universal文章采集器是文章采集软件,只需要输入关键词,即可采集专业搜索引擎页面和新闻。但是优采云只针对一些常见的新闻来源,如:百度、搜狗、360、今日头条、微信、百度新闻、搜狗新闻、360新闻、一点新闻、雅虎、必应网页等。 ,不行就到指定的指定网站采集。对于不同的cms,还有网站。每次使用优采云采集到本地,都要使用不同的优采云发布软件来发布。还有一点就是优采云是收费的,站长朋友根据自己的情况安排。
免费的 采集 工具易于使用
首先,根据自己的情况选择一个。在我使用的众多文章采集工具中,我觉得我用的下面一个比较方便。最重要的是采集是完全免费的。
1. 依托软件独有的通用文本识别智能算法,可实现任意网页文本的自动提取,准确率达95%以上。
2.只需输入关键词即可采集微信文章、今日头条、一点资讯、百度新闻及网页、搜狗新闻及网页、360新闻及网页、必应新闻和网页、雅虎新闻和网页;批量关键词全自动采集。
3.可以针对采集指定网站的栏目列表下的所有文章(如百度体验、百度贴吧),智能匹配,无需编写复杂的规则。
4.文章翻译功能,可以将采集好文章翻译成英文再翻译回中文。
5.史上最简单最智能的文章采集器,重点是免费!自由!自由!
6.cms 支持:支持Empire、Yiyou、ZBLOG、织梦、WP、PB、Apple、搜外等各大cms,可在同时发布
对应栏目:不同的文章可以发布不同的栏目
定时发布:可以控制多少分钟发表一篇文章
监控数据:发布、待发布、是否伪原创、发布状态、URL、程序等。
操作步骤非常简单。该软件帮助站长和网站管理员解决了很多繁琐繁琐的工作。真正意义上的第一款软件同时实现了与所有主要cms版本的无缝对接,并支持本地伪原创!并且发布完成后,可以直接在同一软件上进行百度、搜狗、360、神马全平台推送,实现全平台cms发布管理、批量伪原创、全平台自动批量推送,软件强大,不止一点! 查看全部
今日头条文章采集软件(
网站采集用什么软件好,优采云万能文章采集软件好用不)
最近很多站长朋友问网站采集什么软件好,优采云万能文章采集软件好用。今天我将谈谈我们使用优采云、优采云和免费采集工具的经验。不做任何推荐,只分析其特点和适用场景。
为什么要使用文章采集工具
站长都知道,各大网站基本上都有自己的采集开放点。他们很少使用工具。作为seo,我们没有那么强大的技术支持,所以只能使用市场上一些常用的。采集工具实现采集。
文章采集 会不会影响网站的质量?
首先不能纯采集,纯采集是对百度等搜索引擎的严厉打击。文章发布前一定要重新修改文章,例如使用文章伪原创工具。达到接近原创的目标,再做相应的内外部优化。这样使用文章采集是没有问题的。但是要想做好SEO,内容很重要,因为SEO是一个内容为王的行业。
关于优采云万能文章采集器
先说优采云Universal文章采集软件。优采云Universal文章采集器是文章采集软件,只需要输入关键词,即可采集专业搜索引擎页面和新闻。但是优采云只针对一些常见的新闻来源,如:百度、搜狗、360、今日头条、微信、百度新闻、搜狗新闻、360新闻、一点新闻、雅虎、必应网页等。 ,不行就到指定的指定网站采集。对于不同的cms,还有网站。每次使用优采云采集到本地,都要使用不同的优采云发布软件来发布。还有一点就是优采云是收费的,站长朋友根据自己的情况安排。
免费的 采集 工具易于使用
首先,根据自己的情况选择一个。在我使用的众多文章采集工具中,我觉得我用的下面一个比较方便。最重要的是采集是完全免费的。
1. 依托软件独有的通用文本识别智能算法,可实现任意网页文本的自动提取,准确率达95%以上。
2.只需输入关键词即可采集微信文章、今日头条、一点资讯、百度新闻及网页、搜狗新闻及网页、360新闻及网页、必应新闻和网页、雅虎新闻和网页;批量关键词全自动采集。
3.可以针对采集指定网站的栏目列表下的所有文章(如百度体验、百度贴吧),智能匹配,无需编写复杂的规则。
4.文章翻译功能,可以将采集好文章翻译成英文再翻译回中文。
5.史上最简单最智能的文章采集器,重点是免费!自由!自由!
6.cms 支持:支持Empire、Yiyou、ZBLOG、织梦、WP、PB、Apple、搜外等各大cms,可在同时发布
对应栏目:不同的文章可以发布不同的栏目
定时发布:可以控制多少分钟发表一篇文章
监控数据:发布、待发布、是否伪原创、发布状态、URL、程序等。
操作步骤非常简单。该软件帮助站长和网站管理员解决了很多繁琐繁琐的工作。真正意义上的第一款软件同时实现了与所有主要cms版本的无缝对接,并支持本地伪原创!并且发布完成后,可以直接在同一软件上进行百度、搜狗、360、神马全平台推送,实现全平台cms发布管理、批量伪原创、全平台自动批量推送,软件强大,不止一点!
今日头条文章采集软件( 为什么要做头条采集?做百度的站长为什么会要采集头条的内容?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-12-19 01:02
为什么要做头条采集?做百度的站长为什么会要采集头条的内容?)
为什么要上头条采集?作为百度站长,你为什么要成为采集的头条内容?今日头条的文章能被百度收录抓取吗?这是很多站长朋友经常问小编的一些问题,所以今天小编就来告诉大家为什么要上头条采集。
今天今日头条的文章不会被百度蜘蛛和收录收录。如今的今日头条机器人已经禁止百度蜘蛛和百度爬取今日头条网站的内容。所以今日头条的首页只有收录,没有其他内页。因此,您在今日头条上发布的文章不会是百度的收录,而您在今日头条上发布的文章将是以后在今日头条自己的搜索引擎中的收录。. 网站的频繁更新内容可以在搜索引擎中产生足够的信任,发布的文章可以快速被各大搜索引擎收录接收并取得良好的排名表现。所以今天头条的大量文章资源和内容不是收录百度爬取的,可以成为我们文章的来源 @网站 大量内容。我们在今日头条采集的文章采集都放在我们百度专用的网站上。百度爬取这个内容的时候,因为没有爬取和收录,爬虫会认为是原创的文章的文章。这对于我们这个网站来说无疑是一个非常好的消息。
那么我们如何获取采集标题中的文章资源。首先我们添加一个采集任务,并创建一个任务名称,即需要采集的关键词。比如“采集Test”,那么我们选择采集的来源(搜狗/百度/今日头条等),设置存储目录,设置一个关键词采集多少篇文章,并上传关键词。
当我们有文章时,我们需要发布到cms。添加发布站点并选择cms类型(支持Empire、Yiyou、ZBLOG、织梦、WP、PB、Apple、搜外等主要cms,并可以同时使用管理和发布),实时监控我们的采集文件夹,选择要发布的栏目,设置时间间隔。并且可以在伪原创之后发布。这样我们建网站就很方便了,效果也会更好。持续更新网站的内容,让搜索引擎更加信任您的网站。内容为搜索引擎原创内容,会更多推荐你的网站。
今天小编的分享就到这里。综上所述,我们可以很好的解决一个网站的内容来源和内容创建。也希望今天的分享对各位站长有所帮助。喜欢小编的可以点赞关注。我会继续和大家分享一些SEO经验和知识! 查看全部
今日头条文章采集软件(
为什么要做头条采集?做百度的站长为什么会要采集头条的内容?)
为什么要上头条采集?作为百度站长,你为什么要成为采集的头条内容?今日头条的文章能被百度收录抓取吗?这是很多站长朋友经常问小编的一些问题,所以今天小编就来告诉大家为什么要上头条采集。
今天今日头条的文章不会被百度蜘蛛和收录收录。如今的今日头条机器人已经禁止百度蜘蛛和百度爬取今日头条网站的内容。所以今日头条的首页只有收录,没有其他内页。因此,您在今日头条上发布的文章不会是百度的收录,而您在今日头条上发布的文章将是以后在今日头条自己的搜索引擎中的收录。. 网站的频繁更新内容可以在搜索引擎中产生足够的信任,发布的文章可以快速被各大搜索引擎收录接收并取得良好的排名表现。所以今天头条的大量文章资源和内容不是收录百度爬取的,可以成为我们文章的来源 @网站 大量内容。我们在今日头条采集的文章采集都放在我们百度专用的网站上。百度爬取这个内容的时候,因为没有爬取和收录,爬虫会认为是原创的文章的文章。这对于我们这个网站来说无疑是一个非常好的消息。
那么我们如何获取采集标题中的文章资源。首先我们添加一个采集任务,并创建一个任务名称,即需要采集的关键词。比如“采集Test”,那么我们选择采集的来源(搜狗/百度/今日头条等),设置存储目录,设置一个关键词采集多少篇文章,并上传关键词。
当我们有文章时,我们需要发布到cms。添加发布站点并选择cms类型(支持Empire、Yiyou、ZBLOG、织梦、WP、PB、Apple、搜外等主要cms,并可以同时使用管理和发布),实时监控我们的采集文件夹,选择要发布的栏目,设置时间间隔。并且可以在伪原创之后发布。这样我们建网站就很方便了,效果也会更好。持续更新网站的内容,让搜索引擎更加信任您的网站。内容为搜索引擎原创内容,会更多推荐你的网站。
今天小编的分享就到这里。综上所述,我们可以很好的解决一个网站的内容来源和内容创建。也希望今天的分享对各位站长有所帮助。喜欢小编的可以点赞关注。我会继续和大家分享一些SEO经验和知识!
今日头条文章采集软件(今日头条文章采集软件哪里可以找,有用!有技巧!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-12-17 07:08
今日头条文章采集软件哪里可以找,为什么我们做文章采集,却找不到心仪的网站,难道心中就没有一个采集软件吗,今日头条这款软件还是很好找的,不管你采集什么样的文章都能采集到,和你无缘啊。今日头条采集软件速度快、稳定性好,来看看我自己动手录制的操作吧!此软件安装了微信公众号、大鱼号、百家号,并且还开通了商品功能,这些数据做采集不仅能采集到直接用户评论和销量、评价等,还能采集热门关键词的排名,是一款非常实用的软件。
头条采集软件操作很简单,上手也很快,使用起来很方便,你只需关注头条账号然后在文章里留言“找文章”就可以找到相应的文章,软件的采集功能简直厉害的不行,只要你用心去操作,很多热门文章都能够找到,这个是因为这款软件具有抓取、图片搜索、视频下载等等各种功能,软件的老板还说不仅能找文章还能看新闻,这些功能只要你想要就可以免费使用。
今日头条文章采集软件哪里可以找,最后告诉大家,这个是免费的软件,希望能帮助到你,帮助我们更好的使用。今日头条采集软件哪里可以找,目前随便搜索就可以找到的采集软件有很多,不管是微信公众号、百家号、大鱼号都是免费的,对我们来说很有用。今日头条采集软件什么用?有用!抓取热门文章、视频、图片、音频、热点等等数据,并自动修改,这才是今日头条的精髓,传统的软件只抓取热门内容,那些质量差的内容你是抓不到的,有些人不理解,因为在百度等网站搜索很多其他网站的相关内容,自己转换成头条号即可。
今日头条采集软件的功能那么多,这个有什么用?可以抓取一些热门自媒体平台上面的文章,然后你就可以批量自动修改,当你想要更新时自动从各个地方抓取各个自媒体平台上面的文章,并自动替换文章,你会发现很多文章并不能采集到了,你自己手动选择去采集太麻烦了,采集到一篇自己用用,你会发现你其实已经放弃了,因为效率太低了。
你想要生产优质内容就必须学会多平台去分析数据,学会如何从不同平台选择抓取文章,这样你也可以做推广,其实不管我们发现什么机会,有机会可以把你所发现的机会告诉大家,今日头条等社交平台上面如果一个一个新的去搜索数据,是很耗时的,我们不是专门的网站专门负责采集数据,我们肯定会有需要在其他地方抓取,因为是大家互联网上都这样。 查看全部
今日头条文章采集软件(今日头条文章采集软件哪里可以找,有用!有技巧!)
今日头条文章采集软件哪里可以找,为什么我们做文章采集,却找不到心仪的网站,难道心中就没有一个采集软件吗,今日头条这款软件还是很好找的,不管你采集什么样的文章都能采集到,和你无缘啊。今日头条采集软件速度快、稳定性好,来看看我自己动手录制的操作吧!此软件安装了微信公众号、大鱼号、百家号,并且还开通了商品功能,这些数据做采集不仅能采集到直接用户评论和销量、评价等,还能采集热门关键词的排名,是一款非常实用的软件。
头条采集软件操作很简单,上手也很快,使用起来很方便,你只需关注头条账号然后在文章里留言“找文章”就可以找到相应的文章,软件的采集功能简直厉害的不行,只要你用心去操作,很多热门文章都能够找到,这个是因为这款软件具有抓取、图片搜索、视频下载等等各种功能,软件的老板还说不仅能找文章还能看新闻,这些功能只要你想要就可以免费使用。
今日头条文章采集软件哪里可以找,最后告诉大家,这个是免费的软件,希望能帮助到你,帮助我们更好的使用。今日头条采集软件哪里可以找,目前随便搜索就可以找到的采集软件有很多,不管是微信公众号、百家号、大鱼号都是免费的,对我们来说很有用。今日头条采集软件什么用?有用!抓取热门文章、视频、图片、音频、热点等等数据,并自动修改,这才是今日头条的精髓,传统的软件只抓取热门内容,那些质量差的内容你是抓不到的,有些人不理解,因为在百度等网站搜索很多其他网站的相关内容,自己转换成头条号即可。
今日头条采集软件的功能那么多,这个有什么用?可以抓取一些热门自媒体平台上面的文章,然后你就可以批量自动修改,当你想要更新时自动从各个地方抓取各个自媒体平台上面的文章,并自动替换文章,你会发现很多文章并不能采集到了,你自己手动选择去采集太麻烦了,采集到一篇自己用用,你会发现你其实已经放弃了,因为效率太低了。
你想要生产优质内容就必须学会多平台去分析数据,学会如何从不同平台选择抓取文章,这样你也可以做推广,其实不管我们发现什么机会,有机会可以把你所发现的机会告诉大家,今日头条等社交平台上面如果一个一个新的去搜索数据,是很耗时的,我们不是专门的网站专门负责采集数据,我们肯定会有需要在其他地方抓取,因为是大家互联网上都这样。
今日头条文章采集软件(一下当前今日头条的数据(据内部与公开数据综合))
采集交流 • 优采云 发表了文章 • 0 个评论 • 463 次浏览 • 2021-12-13 09:21
点击上方“杰哥的IT之旅”,
设置为“顶级或星级”,干货将尽快送达。
Cocoa|开发者前线
今日头条成立于2012年3月,至今仅8年。从十几名工程师开始研发,到数百人,再到200多人。产品线从宜兰段子到今日头条、今日特卖、今日电影等产品线。一、产品背景 今天的今日头条,就是为用户提供个性化的信息客户端。给大家分享今日头条的数据(根据内部和公开数据结合):1、文章 抓取分析我们每天生产的原创新闻约10000条,包括重大新闻网站和地方站,还有一些小说、博客等文章。对于工程师来说,编写一个 Crawler 并不难。接下来,今日头条会人工审核过滤敏感的文章。此外,今天的今日头条今日头条账号目前有很多原创文章加入了内容选择队列。接下来,我们将对文章进行文本分析,例如分类、标注、主题提取,以及基于文章或新闻位置、流行度、权重等的计算。2、用户建模时用户开始使用今日头条,实时分析用户操作日志。使用的工具如下: 我们挖掘用户的兴趣,学习用户的每一个动作。主要用途:用户建模 当用户开始使用今日头条时,会实时分析用户操作日志。使用的工具如下: 我们挖掘用户的兴趣,学习用户的每一个动作。主要用途:用户建模 当用户开始使用今日头条时,会实时分析用户操作日志。使用的工具如下: 我们挖掘用户的兴趣,学习用户的每一个动作。主要用途:
生成的用户模型数据和大多数架构一样,存储在MySQL/MongoDB(读写分离)和Memcache/Redis中。随着用户数量的不断扩大,用户模型处理的机器集群数量也越来越多。2015年之前会在7000左右。 其中,用户推荐模型包括以下几个维度:
此时,您需要始终提出建议。3、 新用户的“冷启动”。今天的今日头条,将通过用户的手机、操作系统、版本来“识别”。此外,例如当用户通过新浪微博等社交账号登录时,今日头条会在好友、粉丝、微博内容、转发、评论等维度对用户进行初步的“画像”。分析用户的主要参数如下: 除了手机硬件,今日头条还会分析用户安装的应用。比如机型和APP结合分析,使用小米、三星、苹果不同,也有用户浏览器书签。今日头条会实时捕捉用户在APP频道的动作。它还包括用户订阅的频道,例如电影、笑话和商品。4、推荐系统 推荐系统,又称推荐引擎。它是今日头条技术架构的核心部分。自动推荐和半自动推荐系统有两种:1)自动推荐系统
这时候就需要一个高效率、大并发的推送系统,上亿用户会收到。2) 半自动推荐系统头条频道,在技术方面分为分类频道、兴趣标签频道、关键词频道、文字分析等,分为相对独立的开发团队。已经有 300 多个分类器,并且仍在添加新的用户模型。原来的用户模型不需要取消,仍然可以使用。今日头条账号上线前,内容主要是抓取其他平台的文章,然后去重。一年几百万,不算大。主要是用户行为日志采集、兴趣采集、用户模型采集。
5、数据存储今日头条使用MySQL或者Mongo持久化存储+Memched(Redis),分成很多库(一个大内存库),尝试使用SSD产品。今天的今日头条的图片直接存入数据库,文件分布式存储,读取时使用CDN。6、 新闻推送消息推送,为用户:及时获取信息。对于运营,它可以提高用户活跃度。比如,今日头条推送后,今日头条的DAU可以提升20%左右。如果不推送,会影响 DAU 约 10%(2015 年数据)。推送后要注意的ROI:点击率、点击量。能够监控应用程序卸载和推送禁用的数量。今日头条推送的主要内容包括突发热点信息、评论和回复,和网站外的朋友注册加入。在今日头条,推送也是个性化的:例如:根据城市:发生在辽宁朝阳的某新闻事件,发送给朝阳当地用户。根据兴趣:比如京东收购了1号店,发给对互联网感兴趣的用户。推送平台的工具和选择需要满足以下标准: 因此,推送后端应提供每日报告、完整的数据后端和 A/B 测试程序支持。部分推送系统使用自己的IDC,发送量特别大,消耗的带宽也比较多。您可以使用类似阿里云的服务,可以有效节约成本。辽宁,则是发送给朝阳当地用户。根据兴趣:比如京东收购了1号店,发给对互联网感兴趣的用户。推送平台的工具和选择需要满足以下标准: 因此,推送后端应提供每日报告、完整的数据后端和 A/B 测试程序支持。部分推送系统使用自己的IDC,发送量特别大,消耗的带宽也比较多。您可以使用类似阿里云的服务,可以有效节约成本。辽宁,则是发送给朝阳当地用户。根据兴趣:比如京东收购了1号店,发给对互联网感兴趣的用户。推送平台的工具和选择需要满足以下标准: 因此,推送后端应提供每日报告、完整的数据后端和 A/B 测试程序支持。部分推送系统使用自己的IDC,发送量特别大,消耗的带宽也比较多。您可以使用类似阿里云的服务,可以有效节约成本。完整的数据后端和 A/B 测试程序支持。部分推送系统使用自己的IDC,发送量特别大,消耗的带宽也比较多。您可以使用类似阿里云的服务,可以有效节约成本。完整的数据后端和 A/B 测试程序支持。部分推送系统使用自己的IDC,发送量特别大,消耗的带宽也比较多。您可以使用类似阿里云的服务,可以有效节约成本。
二、今日头条系统架构
三、标题微服务架构
今天的今日头条将子系统拆分,将大应用拆解成小应用,抽象出通用层进行代码复用。
系统的分层是典型的。重点是基础设施。我希望通过基础设施来提高快速迭代、容灾等一系列任务。我希望每个业务团队都能更快地进行业务迭代和结构调整。
四、今日头条的虚拟化PaaS平台方案,是通过三层实现,通过PaaS平台统一管理。提供通用的SaaS服务,同时提供通用的App执行引擎。底层是IaaS层。IaaS 管理所有机器并集成公共云。今日头条有一些热点事件会在全国推广,网络带宽比较高。借助公有云,需要什么样的计算资源,我们就会统一抽象。基础设施结合面向服务的思维,如日志、监控等功能,业务可以享受基础设施提供的能力,而无需关注细节。
五、 总结今日头条的重要部分是:数据生成和采集数据传输。Kafka做一个消息总线来连接线上和线下系统。数据存储。数据仓库,ETL(提取、转换和加载)数据计算。如何高效查询数据仓库中的数据表至关重要,因为这将直接影响数据分析的效率。常见的查询引擎可以分为Batch、MPP、Cube三种模式。今日头条在这三种模式中都有应用。本公众号所有博文已整理成目录,请在公众号后台回复“m”获取!
推荐阅读:
1、
支付宝的架构到底有多牛逼?
2、
微信支付软件架构,这也太牛逼了!
3、
如何画出优秀的架构图?
4、
这可能是史上最全的权限系统设计
5、
一文搞懂主流的扫码登录技术原理
6、
太硬核了,我写了一份操作系统词典送给你!
7、
操作系统核心概念第二弹来了!
关注微信公众号『
杰哥的IT之旅』,后台回复“
1024”查看更多内容,回复“
微信”添加我微信。
好文和朋友一起看~
本文分享自微信公众号-Jake_Internet(Jake_Internet)。 查看全部
今日头条文章采集软件(一下当前今日头条的数据(据内部与公开数据综合))
点击上方“杰哥的IT之旅”,
设置为“顶级或星级”,干货将尽快送达。
Cocoa|开发者前线
今日头条成立于2012年3月,至今仅8年。从十几名工程师开始研发,到数百人,再到200多人。产品线从宜兰段子到今日头条、今日特卖、今日电影等产品线。一、产品背景 今天的今日头条,就是为用户提供个性化的信息客户端。给大家分享今日头条的数据(根据内部和公开数据结合):1、文章 抓取分析我们每天生产的原创新闻约10000条,包括重大新闻网站和地方站,还有一些小说、博客等文章。对于工程师来说,编写一个 Crawler 并不难。接下来,今日头条会人工审核过滤敏感的文章。此外,今天的今日头条今日头条账号目前有很多原创文章加入了内容选择队列。接下来,我们将对文章进行文本分析,例如分类、标注、主题提取,以及基于文章或新闻位置、流行度、权重等的计算。2、用户建模时用户开始使用今日头条,实时分析用户操作日志。使用的工具如下: 我们挖掘用户的兴趣,学习用户的每一个动作。主要用途:用户建模 当用户开始使用今日头条时,会实时分析用户操作日志。使用的工具如下: 我们挖掘用户的兴趣,学习用户的每一个动作。主要用途:用户建模 当用户开始使用今日头条时,会实时分析用户操作日志。使用的工具如下: 我们挖掘用户的兴趣,学习用户的每一个动作。主要用途:
生成的用户模型数据和大多数架构一样,存储在MySQL/MongoDB(读写分离)和Memcache/Redis中。随着用户数量的不断扩大,用户模型处理的机器集群数量也越来越多。2015年之前会在7000左右。 其中,用户推荐模型包括以下几个维度:
此时,您需要始终提出建议。3、 新用户的“冷启动”。今天的今日头条,将通过用户的手机、操作系统、版本来“识别”。此外,例如当用户通过新浪微博等社交账号登录时,今日头条会在好友、粉丝、微博内容、转发、评论等维度对用户进行初步的“画像”。分析用户的主要参数如下: 除了手机硬件,今日头条还会分析用户安装的应用。比如机型和APP结合分析,使用小米、三星、苹果不同,也有用户浏览器书签。今日头条会实时捕捉用户在APP频道的动作。它还包括用户订阅的频道,例如电影、笑话和商品。4、推荐系统 推荐系统,又称推荐引擎。它是今日头条技术架构的核心部分。自动推荐和半自动推荐系统有两种:1)自动推荐系统
这时候就需要一个高效率、大并发的推送系统,上亿用户会收到。2) 半自动推荐系统头条频道,在技术方面分为分类频道、兴趣标签频道、关键词频道、文字分析等,分为相对独立的开发团队。已经有 300 多个分类器,并且仍在添加新的用户模型。原来的用户模型不需要取消,仍然可以使用。今日头条账号上线前,内容主要是抓取其他平台的文章,然后去重。一年几百万,不算大。主要是用户行为日志采集、兴趣采集、用户模型采集。
5、数据存储今日头条使用MySQL或者Mongo持久化存储+Memched(Redis),分成很多库(一个大内存库),尝试使用SSD产品。今天的今日头条的图片直接存入数据库,文件分布式存储,读取时使用CDN。6、 新闻推送消息推送,为用户:及时获取信息。对于运营,它可以提高用户活跃度。比如,今日头条推送后,今日头条的DAU可以提升20%左右。如果不推送,会影响 DAU 约 10%(2015 年数据)。推送后要注意的ROI:点击率、点击量。能够监控应用程序卸载和推送禁用的数量。今日头条推送的主要内容包括突发热点信息、评论和回复,和网站外的朋友注册加入。在今日头条,推送也是个性化的:例如:根据城市:发生在辽宁朝阳的某新闻事件,发送给朝阳当地用户。根据兴趣:比如京东收购了1号店,发给对互联网感兴趣的用户。推送平台的工具和选择需要满足以下标准: 因此,推送后端应提供每日报告、完整的数据后端和 A/B 测试程序支持。部分推送系统使用自己的IDC,发送量特别大,消耗的带宽也比较多。您可以使用类似阿里云的服务,可以有效节约成本。辽宁,则是发送给朝阳当地用户。根据兴趣:比如京东收购了1号店,发给对互联网感兴趣的用户。推送平台的工具和选择需要满足以下标准: 因此,推送后端应提供每日报告、完整的数据后端和 A/B 测试程序支持。部分推送系统使用自己的IDC,发送量特别大,消耗的带宽也比较多。您可以使用类似阿里云的服务,可以有效节约成本。辽宁,则是发送给朝阳当地用户。根据兴趣:比如京东收购了1号店,发给对互联网感兴趣的用户。推送平台的工具和选择需要满足以下标准: 因此,推送后端应提供每日报告、完整的数据后端和 A/B 测试程序支持。部分推送系统使用自己的IDC,发送量特别大,消耗的带宽也比较多。您可以使用类似阿里云的服务,可以有效节约成本。完整的数据后端和 A/B 测试程序支持。部分推送系统使用自己的IDC,发送量特别大,消耗的带宽也比较多。您可以使用类似阿里云的服务,可以有效节约成本。完整的数据后端和 A/B 测试程序支持。部分推送系统使用自己的IDC,发送量特别大,消耗的带宽也比较多。您可以使用类似阿里云的服务,可以有效节约成本。
二、今日头条系统架构
三、标题微服务架构
今天的今日头条将子系统拆分,将大应用拆解成小应用,抽象出通用层进行代码复用。
系统的分层是典型的。重点是基础设施。我希望通过基础设施来提高快速迭代、容灾等一系列任务。我希望每个业务团队都能更快地进行业务迭代和结构调整。
四、今日头条的虚拟化PaaS平台方案,是通过三层实现,通过PaaS平台统一管理。提供通用的SaaS服务,同时提供通用的App执行引擎。底层是IaaS层。IaaS 管理所有机器并集成公共云。今日头条有一些热点事件会在全国推广,网络带宽比较高。借助公有云,需要什么样的计算资源,我们就会统一抽象。基础设施结合面向服务的思维,如日志、监控等功能,业务可以享受基础设施提供的能力,而无需关注细节。
五、 总结今日头条的重要部分是:数据生成和采集数据传输。Kafka做一个消息总线来连接线上和线下系统。数据存储。数据仓库,ETL(提取、转换和加载)数据计算。如何高效查询数据仓库中的数据表至关重要,因为这将直接影响数据分析的效率。常见的查询引擎可以分为Batch、MPP、Cube三种模式。今日头条在这三种模式中都有应用。本公众号所有博文已整理成目录,请在公众号后台回复“m”获取!
推荐阅读:
1、
支付宝的架构到底有多牛逼?
2、
微信支付软件架构,这也太牛逼了!
3、
如何画出优秀的架构图?
4、
这可能是史上最全的权限系统设计
5、
一文搞懂主流的扫码登录技术原理
6、
太硬核了,我写了一份操作系统词典送给你!
7、
操作系统核心概念第二弹来了!
关注微信公众号『
杰哥的IT之旅』,后台回复“
1024”查看更多内容,回复“
微信”添加我微信。
好文和朋友一起看~
本文分享自微信公众号-Jake_Internet(Jake_Internet)。
今日头条文章采集软件(优采云采集器可自定义采集到你所需要的网页信息采集工具 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 256 次浏览 • 2021-12-12 23:35
)
优采云采集器是一个非常有用的网络信息工具采集。软件内置浏览器,可以直观的帮助用户采集各种网页内容,操作简单简单,无需掌握任何专业的网络知识,只需点击鼠标即可轻松创建采集 任务。优采云采集器可以自定义采集到你需要的网页上的所有信息,并且可以自动识别网页列表、采集字段和分页等,输入采集URL,点击鼠标轻松选择要抓取的内容;优采云采集器可视化采集器,采集就像积木,功能模块可以随意组合,可视化抽取或操作网页元素,自动登录,自动发布,并自动识别验证码。它是一个通用浏览器,可以快速创建自动化脚本,甚至可以生成独立的应用程序;用户可以通过优采云采集器 采集访问网页上的一些数据内容,这些数据内容可以单独保存,这样用户在浏览网页时如果需要采集素材,可以用这个采集器保存这些数据以备使用现在,有兴趣的快来下载体验吧!
特征
1、操作简单,点击鼠标即可轻松选择要抓拍的内容
2、 支持三种高速引擎:浏览器引擎、HTTP引擎、JSON引擎,内置优化的火狐浏览器,加上独创的内存优化,让浏览器采集也能高速运行,甚至快速转换为 HTTP 运行并享受更高的 采集 速度。抓取JSON数据时,也可以使用浏览器可视化的方式,用鼠标点击要抓取的内容,无需解析JSON。数据结构,让非网页专业设计人员轻松抓取自己需要的数据
3、无需分析网页请求和源码,但支持更多网页采集
4、 先进的智能算法,可一键生成目标元素XPATH,自动识别页面列表,自动识别分页中的下一页按钮
5、 支持丰富的数据导出方式,可以导出为txt文件、html文件、csv文件、excel文件,也可以导出到已有的数据库,如sqlite数据库、access数据库、sqlserver数据库、mysql数据库,通过Simply map字段以向导方式,可以轻松导出到目标网站数据库
软件特点
1、可视化向导:所有采集元素,自动生成采集数据
2、定时任务:灵活定义运行时间,全自动运行
3、多引擎支持:支持多个采集引擎,内置高速浏览器内核、HTTP引擎和JSON引擎
4、智能识别:可自动识别网页列表、采集字段和分页等。
5、拦截请求:自定义拦截域名,方便过滤异地广告,提高采集速度
6、 多种数据导出:可导出为Txt、Excel、MySQL、SQLServer、SQlite、Access、网站等。
优采云采集器使用方法
一、设置起始地址
要采集一个网站数据,首先我们需要设置输入采集的URL。比如我们要采集一个网站国内新闻,那么我们就要设置起始网址为国内新闻栏目列表的网址,一般不设置网站首页作为起始网址,因为首页通常收录很多列表,比如最新的文章、热门文章、推荐文章等各种列表块,以及显示的内容在这些列表块中也非常有限。采集 这些列表一般都无法采集完整的信息
我们以采集新浪新闻为例,从新浪首页查找国内新闻,但是这个栏目首页的内容还是比较杂乱,还细分了三个子栏目。
从进入其中一个子栏目来看大陆新闻
此列页面收录带分页的内容列表。通过切换分页,我们可以采集去到这个栏目下的所有文章,所以这种列表页非常适合我们采集起始地址
现在,我们将列表 URL 复制到任务编辑框的第一步的文本框中
如果你想在一个任务中同时采集国内新闻中的其他子栏,你也可以复制另外两个子栏列表的地址,因为这些子栏列表格式相似,但为了方便导出或发布分类数据,一般不建议将多列内容混在一起
对于起始地址,我们也可以批量添加或者从txt文件中导入。比如我们想要采集前5页,我们也可以像这样自定义5个起始页
需要注意的是,如果这里自定义了多个分页列表,在下面的采集配置中不要启用分页,通常我们要采集某列下的所有文章,当需要的时候定义列的第一页为起始URL,可以在下面的采集配置中启用分页,可以采集到每个分页列表的数据
二、自动生成列表和字段
进入第二步后,对于部分网页,优采云采集器会智能分析网页列表,自动高亮网页列表并生成列表数据,如
然后我们修剪数据,比如删除一些不需要的字段
点击图标中的三角符号,会弹出采集字段的详细配置。单击上方的删除按钮可删除该字段。其余参数将在后续章节中单独介绍
如果某些网页自动生成的列表数据不是我们想要的数据,可以点击清除字段清除所有生成的字段
如果自动分析的高亮列表不是我们想要采集的列表,那么我们手动选择列表。如果要取消突出显示的列表框,可以单击查找列表,列出XPATH,然后清除其中的xpath OK
三、手动生成列表
单击查找列表按钮并选择手动选择列表
按照提示,鼠标左键点击网页列表中的第一行数据
点击第一行后,根据提示点击第二行或其他类似的行
单击列表中的任意两行后,将突出显示整个列表,并且也会生成列表中的字段。如果生成的字段不正确,请单击清除字段以清除下面的所有字段。然后介绍手动选择字段
四、手动生成字段
单击添加字段按钮
在列表的任意一行点击要提取的元素,比如要提取标题和链接地址,鼠标左键点击标题
点击网页链接时,使用时会提示是否抓取链接地址
如果要同时提取链接标题和链接地址,点击是,如果只需要提取标题文字,点击否,这里我们点击是
系统会自动生成标题和链接地址字段,并在字段列表中显示提取的字段内容。当您点击表格底部的字段标题时,匹配的内容将在网页上以黄色背景突出显示
如何标记列表中的其他字段,点击新字段,重复以上操作
五、分页设置
当列表有分页时,启用分页后可以采集去查看所有的分页列表数据
有两种类型的页面分页
正常分页:有分页栏,显示下一页按钮。点击后可以进入下一页,比如新浪新闻列表中的上一页
瀑布式分页:网页滚动条到达底部时自动加载下一页内容
如果是正常的分页,我们选择尝试自动设置或手动设置
1、自动设置分页
创建新任务时默认不启用分页。点击不启用分页,弹出菜单选择自动识别分页。如果识别成功,会弹出一个对话框,提示已经成功识别和设置分页元素,并显示page next按钮。出现高亮的红色虚线框,到此自动分页已成功开启
如果是自动识别,会出现如下绿色提示框
2、手动设置分页
在菜单中选择手动分页
然后会自动出现查找页面按钮,点击它弹出一个菜单,选择标记页面
查看全部
今日头条文章采集软件(优采云采集器可自定义采集到你所需要的网页信息采集工具
)
优采云采集器是一个非常有用的网络信息工具采集。软件内置浏览器,可以直观的帮助用户采集各种网页内容,操作简单简单,无需掌握任何专业的网络知识,只需点击鼠标即可轻松创建采集 任务。优采云采集器可以自定义采集到你需要的网页上的所有信息,并且可以自动识别网页列表、采集字段和分页等,输入采集URL,点击鼠标轻松选择要抓取的内容;优采云采集器可视化采集器,采集就像积木,功能模块可以随意组合,可视化抽取或操作网页元素,自动登录,自动发布,并自动识别验证码。它是一个通用浏览器,可以快速创建自动化脚本,甚至可以生成独立的应用程序;用户可以通过优采云采集器 采集访问网页上的一些数据内容,这些数据内容可以单独保存,这样用户在浏览网页时如果需要采集素材,可以用这个采集器保存这些数据以备使用现在,有兴趣的快来下载体验吧!
特征
1、操作简单,点击鼠标即可轻松选择要抓拍的内容
2、 支持三种高速引擎:浏览器引擎、HTTP引擎、JSON引擎,内置优化的火狐浏览器,加上独创的内存优化,让浏览器采集也能高速运行,甚至快速转换为 HTTP 运行并享受更高的 采集 速度。抓取JSON数据时,也可以使用浏览器可视化的方式,用鼠标点击要抓取的内容,无需解析JSON。数据结构,让非网页专业设计人员轻松抓取自己需要的数据
3、无需分析网页请求和源码,但支持更多网页采集
4、 先进的智能算法,可一键生成目标元素XPATH,自动识别页面列表,自动识别分页中的下一页按钮
5、 支持丰富的数据导出方式,可以导出为txt文件、html文件、csv文件、excel文件,也可以导出到已有的数据库,如sqlite数据库、access数据库、sqlserver数据库、mysql数据库,通过Simply map字段以向导方式,可以轻松导出到目标网站数据库
软件特点
1、可视化向导:所有采集元素,自动生成采集数据
2、定时任务:灵活定义运行时间,全自动运行
3、多引擎支持:支持多个采集引擎,内置高速浏览器内核、HTTP引擎和JSON引擎
4、智能识别:可自动识别网页列表、采集字段和分页等。
5、拦截请求:自定义拦截域名,方便过滤异地广告,提高采集速度
6、 多种数据导出:可导出为Txt、Excel、MySQL、SQLServer、SQlite、Access、网站等。
优采云采集器使用方法
一、设置起始地址
要采集一个网站数据,首先我们需要设置输入采集的URL。比如我们要采集一个网站国内新闻,那么我们就要设置起始网址为国内新闻栏目列表的网址,一般不设置网站首页作为起始网址,因为首页通常收录很多列表,比如最新的文章、热门文章、推荐文章等各种列表块,以及显示的内容在这些列表块中也非常有限。采集 这些列表一般都无法采集完整的信息
我们以采集新浪新闻为例,从新浪首页查找国内新闻,但是这个栏目首页的内容还是比较杂乱,还细分了三个子栏目。
从进入其中一个子栏目来看大陆新闻
此列页面收录带分页的内容列表。通过切换分页,我们可以采集去到这个栏目下的所有文章,所以这种列表页非常适合我们采集起始地址
现在,我们将列表 URL 复制到任务编辑框的第一步的文本框中
如果你想在一个任务中同时采集国内新闻中的其他子栏,你也可以复制另外两个子栏列表的地址,因为这些子栏列表格式相似,但为了方便导出或发布分类数据,一般不建议将多列内容混在一起
对于起始地址,我们也可以批量添加或者从txt文件中导入。比如我们想要采集前5页,我们也可以像这样自定义5个起始页
需要注意的是,如果这里自定义了多个分页列表,在下面的采集配置中不要启用分页,通常我们要采集某列下的所有文章,当需要的时候定义列的第一页为起始URL,可以在下面的采集配置中启用分页,可以采集到每个分页列表的数据
二、自动生成列表和字段
进入第二步后,对于部分网页,优采云采集器会智能分析网页列表,自动高亮网页列表并生成列表数据,如
然后我们修剪数据,比如删除一些不需要的字段
点击图标中的三角符号,会弹出采集字段的详细配置。单击上方的删除按钮可删除该字段。其余参数将在后续章节中单独介绍
如果某些网页自动生成的列表数据不是我们想要的数据,可以点击清除字段清除所有生成的字段
如果自动分析的高亮列表不是我们想要采集的列表,那么我们手动选择列表。如果要取消突出显示的列表框,可以单击查找列表,列出XPATH,然后清除其中的xpath OK
三、手动生成列表
单击查找列表按钮并选择手动选择列表
按照提示,鼠标左键点击网页列表中的第一行数据
点击第一行后,根据提示点击第二行或其他类似的行
单击列表中的任意两行后,将突出显示整个列表,并且也会生成列表中的字段。如果生成的字段不正确,请单击清除字段以清除下面的所有字段。然后介绍手动选择字段
四、手动生成字段
单击添加字段按钮
在列表的任意一行点击要提取的元素,比如要提取标题和链接地址,鼠标左键点击标题
点击网页链接时,使用时会提示是否抓取链接地址
如果要同时提取链接标题和链接地址,点击是,如果只需要提取标题文字,点击否,这里我们点击是
系统会自动生成标题和链接地址字段,并在字段列表中显示提取的字段内容。当您点击表格底部的字段标题时,匹配的内容将在网页上以黄色背景突出显示
如何标记列表中的其他字段,点击新字段,重复以上操作
五、分页设置
当列表有分页时,启用分页后可以采集去查看所有的分页列表数据
有两种类型的页面分页
正常分页:有分页栏,显示下一页按钮。点击后可以进入下一页,比如新浪新闻列表中的上一页
瀑布式分页:网页滚动条到达底部时自动加载下一页内容
如果是正常的分页,我们选择尝试自动设置或手动设置
1、自动设置分页
创建新任务时默认不启用分页。点击不启用分页,弹出菜单选择自动识别分页。如果识别成功,会弹出一个对话框,提示已经成功识别和设置分页元素,并显示page next按钮。出现高亮的红色虚线框,到此自动分页已成功开启
如果是自动识别,会出现如下绿色提示框
2、手动设置分页
在菜单中选择手动分页
然后会自动出现查找页面按钮,点击它弹出一个菜单,选择标记页面
今日头条文章采集软件(今日头条文章采集软件:加入新闻稿采集工具(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-12-11 17:10
今日头条文章采集软件:加入新闻稿新闻稿采集工具是从互联网中挖掘知识最新、最全、最新的新闻来源。汇集了各大门户网站、知名媒体、学者、媒体工作者及自媒体人等热门主题的内容,是提高撰稿、评审效率及质量的最佳工具。文章采集软件推荐:目前内容采集类的软件比较多,软件的知名度很重要,多家软件公司和同类软件互推,换了一家公司就不会很顺畅。
文章采集软件还是有好有坏,单靠软件获取的最大弊端就是,一旦找不到自己需要的资源,就无从下手。无论是新闻、文章、小说、影视,你都需要依靠图片来创作,现在基本上全是高清图,图片采集软件一抓一大把,很难找到一款好用的文章采集软件。哪里可以找到专业的图片资源?原创的、优质的、高清的图片资源往往比较少,你会失去可读性,结果自然无法达到你要的效果。
图片采集软件比较多,得花时间去尝试和选择。我以头条号采集软件为例,介绍几款比较好用的图片采集软件。top1:头条新闻图片采集软件top2:搜狗搜图top3:大象图片采集器。
同求,用了好久了没用,
凡是软件平台上明确提出不接受抄袭的新闻都是不能采集的
这个是可以的,只是数量不多,另外一方面是采集新闻不仅仅需要新闻源,内容的话也很重要。如果是采集文章有起码1w篇才有效,但是新闻源平台上要求1k篇起步。所以想采集新闻源的话,个人建议没有必要直接去购买采集软件,那个只是一个辅助性工具,可以利用上学生时间去广告联盟,或者上免费下载新闻源的软件,结合上你自己的相关知识,再去采集。
另外如果你是想快速采集,我建议去爬网页,比如快搜。网页的新闻更新速度更快,而且内容绝对安全。另外想了解更多的,可以到我的主页提问,我在这方面有非常深入的研究,知乎有很多大神提供相关指导。 查看全部
今日头条文章采集软件(今日头条文章采集软件:加入新闻稿采集工具(组图))
今日头条文章采集软件:加入新闻稿新闻稿采集工具是从互联网中挖掘知识最新、最全、最新的新闻来源。汇集了各大门户网站、知名媒体、学者、媒体工作者及自媒体人等热门主题的内容,是提高撰稿、评审效率及质量的最佳工具。文章采集软件推荐:目前内容采集类的软件比较多,软件的知名度很重要,多家软件公司和同类软件互推,换了一家公司就不会很顺畅。
文章采集软件还是有好有坏,单靠软件获取的最大弊端就是,一旦找不到自己需要的资源,就无从下手。无论是新闻、文章、小说、影视,你都需要依靠图片来创作,现在基本上全是高清图,图片采集软件一抓一大把,很难找到一款好用的文章采集软件。哪里可以找到专业的图片资源?原创的、优质的、高清的图片资源往往比较少,你会失去可读性,结果自然无法达到你要的效果。
图片采集软件比较多,得花时间去尝试和选择。我以头条号采集软件为例,介绍几款比较好用的图片采集软件。top1:头条新闻图片采集软件top2:搜狗搜图top3:大象图片采集器。
同求,用了好久了没用,
凡是软件平台上明确提出不接受抄袭的新闻都是不能采集的
这个是可以的,只是数量不多,另外一方面是采集新闻不仅仅需要新闻源,内容的话也很重要。如果是采集文章有起码1w篇才有效,但是新闻源平台上要求1k篇起步。所以想采集新闻源的话,个人建议没有必要直接去购买采集软件,那个只是一个辅助性工具,可以利用上学生时间去广告联盟,或者上免费下载新闻源的软件,结合上你自己的相关知识,再去采集。
另外如果你是想快速采集,我建议去爬网页,比如快搜。网页的新闻更新速度更快,而且内容绝对安全。另外想了解更多的,可以到我的主页提问,我在这方面有非常深入的研究,知乎有很多大神提供相关指导。
今日头条文章采集软件(discuz采集器自带discuz发布接口,可采集今日头条(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-12-07 23:11
discuz采集器自带discuz发布接口,可以使用采集今日头条,这个discuz采集插件可以和优采云采集器一起使用可以指定关键词、多个关键词、采集今日头条内容。 (也可以指定作者采集,已经写好,提供前请参考要求)
1、软件功能,支持图片定位
2、支持发布图片批量上传到网站
3、支持单篇文章采集,可以手动可视化编辑内容,然后发布到网站。
(只能修改标题、内容,然后指定发布用户)
4、批量采集完成,支持进入数据库,可视化编辑内容。
5、可定制的发布
6、全自动定时任务采集
7、支持采集需要登录的网页
8、 支持太多。自己看
采集不用了,欢迎加我QQ做鬼脸。
工具/材料:
1、优采云采集器(非官方版)
下载链接:(本软件绿色免安装,为了方便discuz用户,本文件自带(今日头条采集规则)demo)
方法/步骤:
1、将/release interface/discuz/jieling_post_nohtml.php文件放在你程序根目录下的软件根目录下
2、参考资料
将发布规则中的发布地址修改为您的域名;将列表规则中的关键词修改为你想要的关键词!
保存任务后,开始批处理采集。
============
没有图片,没有真相
这个采集是免费使用的,任何人都可以使用它,以防它传播并造成不良影响,
如果人数过多,我们将停止提供此采集任务,先到先得。
也可以自行下载正式版优采云采集器自行配置使用。 采集软件使用问题请加我QQ。 查看全部
今日头条文章采集软件(discuz采集器自带discuz发布接口,可采集今日头条(组图))
discuz采集器自带discuz发布接口,可以使用采集今日头条,这个discuz采集插件可以和优采云采集器一起使用可以指定关键词、多个关键词、采集今日头条内容。 (也可以指定作者采集,已经写好,提供前请参考要求)
1、软件功能,支持图片定位
2、支持发布图片批量上传到网站
3、支持单篇文章采集,可以手动可视化编辑内容,然后发布到网站。
(只能修改标题、内容,然后指定发布用户)
4、批量采集完成,支持进入数据库,可视化编辑内容。
5、可定制的发布
6、全自动定时任务采集
7、支持采集需要登录的网页
8、 支持太多。自己看
采集不用了,欢迎加我QQ做鬼脸。
工具/材料:
1、优采云采集器(非官方版)
下载链接:(本软件绿色免安装,为了方便discuz用户,本文件自带(今日头条采集规则)demo)
方法/步骤:
1、将/release interface/discuz/jieling_post_nohtml.php文件放在你程序根目录下的软件根目录下
2、参考资料
将发布规则中的发布地址修改为您的域名;将列表规则中的关键词修改为你想要的关键词!
保存任务后,开始批处理采集。
============
没有图片,没有真相
这个采集是免费使用的,任何人都可以使用它,以防它传播并造成不良影响,
如果人数过多,我们将停止提供此采集任务,先到先得。
也可以自行下载正式版优采云采集器自行配置使用。 采集软件使用问题请加我QQ。
今日头条文章采集软件(今日头条文章采集软件目前在头条平台是免费的软件应用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 253 次浏览 • 2021-12-07 15:00
今日头条文章采集软件目前在头条平台是免费的软件应用可以采集今日头条平台头条号文章,头条新闻文章,头条评论数,头条收藏,头条阅读,
虽然我一直打压这种东西,但是在安卓和ios平台上都还是有的.老实说,你注册头条账号之后,自己看文章点击放大镜就可以.而且在ios平台,头条号的文章评论区,右上角的一个分享按钮,可以直接转发.相信在政策正规的情况下,是可以避免侵权的.头条号作者直接可以给平台申诉.还是比较给力的.
能采集啊,找我们公司要采集软件,过去开通就行。我们公司就接触到了大量的这类需求。目前来说,还是有采集的,并且是采集互联网上你能搜到的内容,当然也不可避免涉及到侵权内容的采集。要和我详细聊,直接私信我。
谢邀,根据我的经验可以说实体产品几乎都是如此,对于知识产权这块管理还是很严的,头条目前在大力扶持这块,相信不久就会逐步建立分类信息审核的系统以实现提供更加合规的用户体验。
头条在内容管理方面做得还是不错的吧,接入权限很大。有大量自媒体号,还有就是对于内容审核非常严格,例如评论要删除,视频没法自己上传,涉及敏感词都是违规内容等,文章方面基本跟过去一样。目前内容是网红非常大的机会,靠内容一时半会很难实现变现。 查看全部
今日头条文章采集软件(今日头条文章采集软件目前在头条平台是免费的软件应用)
今日头条文章采集软件目前在头条平台是免费的软件应用可以采集今日头条平台头条号文章,头条新闻文章,头条评论数,头条收藏,头条阅读,
虽然我一直打压这种东西,但是在安卓和ios平台上都还是有的.老实说,你注册头条账号之后,自己看文章点击放大镜就可以.而且在ios平台,头条号的文章评论区,右上角的一个分享按钮,可以直接转发.相信在政策正规的情况下,是可以避免侵权的.头条号作者直接可以给平台申诉.还是比较给力的.
能采集啊,找我们公司要采集软件,过去开通就行。我们公司就接触到了大量的这类需求。目前来说,还是有采集的,并且是采集互联网上你能搜到的内容,当然也不可避免涉及到侵权内容的采集。要和我详细聊,直接私信我。
谢邀,根据我的经验可以说实体产品几乎都是如此,对于知识产权这块管理还是很严的,头条目前在大力扶持这块,相信不久就会逐步建立分类信息审核的系统以实现提供更加合规的用户体验。
头条在内容管理方面做得还是不错的吧,接入权限很大。有大量自媒体号,还有就是对于内容审核非常严格,例如评论要删除,视频没法自己上传,涉及敏感词都是违规内容等,文章方面基本跟过去一样。目前内容是网红非常大的机会,靠内容一时半会很难实现变现。
今日头条文章采集软件(软件特点优采云软件首创的智能提取网页正文正文的算法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 145 次浏览 • 2021-12-07 14:04
阿里云双12组队加入服务器优化活动1核2G/1年/89元
优采云通用文章采集器采集今日百度网页头条小资料3.6.7.0破解版
优采云·新闻来源文章采集器(SMnewsbot)——第一个提取文本的智能算法;准确的采集新闻源,泛网页;多语言翻译伪原创。
本软件是一款只需输入关键词即可采集百度、谷歌、搜搜、泛页网等搜索引擎新闻源文章的软件。
优采云该软件是首创的独家智能算法,可以准确提取网页正文部分并保存为文章。
支持对标签、链接、邮箱等进行格式化处理,还有插入关键词的功能,可以识别标签或标点的插入,可以识别英文空格的插入。
还有一个文章的翻译功能,即可以将文章从一种语言如中文转换成另一种语言如英语或日语,再从英语或日语转换回中文,即是一个翻译周期,可以设置翻译周期重复多次(translation times)。
采集文章+Translation伪原创可以满足广大站长和各领域朋友的文章需求。
<p>一些公关处理和信息调查公司需要的专业公司开发的信息采集系统往往售价几万甚至更多,而这个软件优采云也是一个信息 查看全部
今日头条文章采集软件(软件特点优采云软件首创的智能提取网页正文正文的算法)
阿里云双12组队加入服务器优化活动1核2G/1年/89元
优采云通用文章采集器采集今日百度网页头条小资料3.6.7.0破解版
优采云·新闻来源文章采集器(SMnewsbot)——第一个提取文本的智能算法;准确的采集新闻源,泛网页;多语言翻译伪原创。
本软件是一款只需输入关键词即可采集百度、谷歌、搜搜、泛页网等搜索引擎新闻源文章的软件。
优采云该软件是首创的独家智能算法,可以准确提取网页正文部分并保存为文章。
支持对标签、链接、邮箱等进行格式化处理,还有插入关键词的功能,可以识别标签或标点的插入,可以识别英文空格的插入。
还有一个文章的翻译功能,即可以将文章从一种语言如中文转换成另一种语言如英语或日语,再从英语或日语转换回中文,即是一个翻译周期,可以设置翻译周期重复多次(translation times)。
采集文章+Translation伪原创可以满足广大站长和各领域朋友的文章需求。
<p>一些公关处理和信息调查公司需要的专业公司开发的信息采集系统往往售价几万甚至更多,而这个软件优采云也是一个信息
今日头条文章采集软件(今日头条视频下载器怎么用1.视频在线观看(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 326 次浏览 • 2021-12-06 16:16
iefans 提供的最新版今日头条提供了丰富的新闻。用户可以了解各个行业的信息,以及丰富的视频。现在推荐一款免费且好用的今日头条视频提取软件。使用今日头条视频下载软件。, 用户可以将今日头条视频下载到本地,iefans提供今日头条视频下载器2.0下载地址,有需要的朋友快来下载试试网页视频下载神器吧,不知道今天的头条视频怎么样下载保存的小伙伴们不要错过哦。
今日头条视频下载器介绍
今日头条视频下载器是一款专为今日头条视频下载而设计的视频下载工具。通过这款软件,用户可以下载今日头条的视频。搜索过程中自动跳过重复下载,不重复ID搜索。, 使用关键词下载对应的视频,支持多线程同时下载,批量视频下载,加快视频下载速度。一款旨在帮助用户获取今日头条、西瓜视频等网站视频资源的下载工具。我们可以在今日头条视频下载器上直接搜索关键词,找到我们想要的视频资源。并且可以直接将视频文件下载到本地,可以直接观看,也可以编辑,非常方便。
软件特点
1.完全免费的视频下载软件,绿色无插件
2. 支持今日头条视频在线观看,方便搜索、浏览、观看、下载今日头条视频
3. 自带视频合并、视频转码和视频播放功能,让您快速轻松地下载视频
今日头条视频下载器如何使用
1.在本站下载今日头条视频下载软件安装包,解压,打开文件夹找到应用文件,双击直接使用,下载今日头条视频文件.
2. 支持今日头条视频在线观看,方便搜索、浏览、观看、下载今日头条视频。它具有视频合并、视频转码和视频播放功能,让您可以快速轻松地下载视频。
3.输入关键词或导入关键词开始搜索,从列表中选择需要下载的视频,点击下载选择视频,视频开始下载,下载后完成后,您可以使用视频播放器观看。
更新日志 (2020.08.22)
修复只搜索第一页的问题
重复下载自动跳过,不重复搜索ID
下载速度更快,解决0字节1字节问题 查看全部
今日头条文章采集软件(今日头条视频下载器怎么用1.视频在线观看(组图))
iefans 提供的最新版今日头条提供了丰富的新闻。用户可以了解各个行业的信息,以及丰富的视频。现在推荐一款免费且好用的今日头条视频提取软件。使用今日头条视频下载软件。, 用户可以将今日头条视频下载到本地,iefans提供今日头条视频下载器2.0下载地址,有需要的朋友快来下载试试网页视频下载神器吧,不知道今天的头条视频怎么样下载保存的小伙伴们不要错过哦。
今日头条视频下载器介绍
今日头条视频下载器是一款专为今日头条视频下载而设计的视频下载工具。通过这款软件,用户可以下载今日头条的视频。搜索过程中自动跳过重复下载,不重复ID搜索。, 使用关键词下载对应的视频,支持多线程同时下载,批量视频下载,加快视频下载速度。一款旨在帮助用户获取今日头条、西瓜视频等网站视频资源的下载工具。我们可以在今日头条视频下载器上直接搜索关键词,找到我们想要的视频资源。并且可以直接将视频文件下载到本地,可以直接观看,也可以编辑,非常方便。
软件特点
1.完全免费的视频下载软件,绿色无插件
2. 支持今日头条视频在线观看,方便搜索、浏览、观看、下载今日头条视频
3. 自带视频合并、视频转码和视频播放功能,让您快速轻松地下载视频
今日头条视频下载器如何使用
1.在本站下载今日头条视频下载软件安装包,解压,打开文件夹找到应用文件,双击直接使用,下载今日头条视频文件.
2. 支持今日头条视频在线观看,方便搜索、浏览、观看、下载今日头条视频。它具有视频合并、视频转码和视频播放功能,让您可以快速轻松地下载视频。
3.输入关键词或导入关键词开始搜索,从列表中选择需要下载的视频,点击下载选择视频,视频开始下载,下载后完成后,您可以使用视频播放器观看。
更新日志 (2020.08.22)
修复只搜索第一页的问题
重复下载自动跳过,不重复搜索ID
下载速度更快,解决0字节1字节问题
今日头条文章采集软件(今日头条文章采集软件:地毯式采集,最全的,你来腾讯新闻app看看)
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2021-12-06 14:02
今日头条文章采集软件:将今日头条、天天快报、百家号、网易号、大鱼号、趣头条、搜狐号、搜狐博客的文章全部采集下来。只要你会基本的编程技术,非常容易实现。
有挺多。像小说网站的话还是老老实实的用电脑抓吧。手机抓小说质量不高,而且时不时有漏网之鱼,即使我有很多优质的小说资源也没有批量整理出来,只能不断的发现,不断的查看。
推荐个软件“地毯式采集”,
最全的,你来腾讯新闻app看看有很多采集工具。多到你几乎能够想象不了的地步,后台还能自己控制。
相对来说是可以,我这里有针对个人自媒体网站优化的工具,
。
打开搜狗图片搜索、360图片搜索,输入“图片”,所有相关图片都可以用于采集。我用的是360采集,它支持收录单个网站下图片数量约5000000。注:收录单个网站要求网站数据量大于等于5000000,
刚下载的一个软件非常好用~只需几步就可以采集到不少有价值的数据,可以和微信公众号里的数据资源。一点五秒即可采集一篇高质量的文章。软件目前免费使用。 查看全部
今日头条文章采集软件(今日头条文章采集软件:地毯式采集,最全的,你来腾讯新闻app看看)
今日头条文章采集软件:将今日头条、天天快报、百家号、网易号、大鱼号、趣头条、搜狐号、搜狐博客的文章全部采集下来。只要你会基本的编程技术,非常容易实现。
有挺多。像小说网站的话还是老老实实的用电脑抓吧。手机抓小说质量不高,而且时不时有漏网之鱼,即使我有很多优质的小说资源也没有批量整理出来,只能不断的发现,不断的查看。
推荐个软件“地毯式采集”,
最全的,你来腾讯新闻app看看有很多采集工具。多到你几乎能够想象不了的地步,后台还能自己控制。
相对来说是可以,我这里有针对个人自媒体网站优化的工具,
。
打开搜狗图片搜索、360图片搜索,输入“图片”,所有相关图片都可以用于采集。我用的是360采集,它支持收录单个网站下图片数量约5000000。注:收录单个网站要求网站数据量大于等于5000000,
刚下载的一个软件非常好用~只需几步就可以采集到不少有价值的数据,可以和微信公众号里的数据资源。一点五秒即可采集一篇高质量的文章。软件目前免费使用。
今日头条文章采集软件(去重消重去水印视频批量采集下载软件有哪些?(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 204 次浏览 • 2021-12-05 01:00
有去重和去重的批量采集视频下载软件有哪些?
今日头条凤凰视频的去水印软件是什么?
什么视频批量采集下载软件好?抖音视频批量采集下载软件
自媒体视频去重去水印用什么软件好?视频深度处理软件
大雨号搞笑头条今日头条视频去重去水印软件
妙拍视频批量采集下载软件快速删除和删除水印软件
有哪些好的视频批量采集下载软件?快速去除水印!
如何快速批量下载视频采集并去除水印?
自媒体视频批处理采集 有哪些下载软件?什么软件好?
有哪些好的视频去重和水印去除软件?视频深度处理软件
视频重复数据删除和水印去除软件在哪里可用?什么软件好?
什么是最好的海量视频下载软件采集?如何找到它们?
腾讯视频批量采集下载软件哪个好?如何找到它?
凤凰网视频批量采集下载软件,去重去水印
如何批量下载热门视频采集?如何去除水印?
采集 有免费的批量下载软件吗?我在哪里可以找到它?
视频去重、去重去水印、视频批量采集下载软件
在线视频去重和去水印软件在哪里?便于使用?
视频批量采集下载软件上线了吗?便于使用?
在线视频批量采集下载软件,在线批量下载视频
文章交互量对于提升文章的数据很有用。重新喜欢的次数越多,推荐和阅读的次数就越高。
其中,最有利于提升文章的数据的是转发量。转发量越高,文章的曝光率就会大大提高。这也很好理解。每个账号都会有自己的Audience,他们转发你的文章,你的文章自然可以定位到更多的用户群体。
如果要增加转发文章的数量,首先要明确另一个问题:用户为什么转发你的文章,总之,你需要给用户一个转发的理由。
这就要求你的文章能够满足他的需求或兴趣,你的内容必须符合他们的观点、态度和追求,被他们接受,有助于巩固或完善他们的某种形象。
具体需求点有哪些:
1、文章 有价值或有趣
我之前也说过,文章既可以满足用户的理性需求,也可以满足用户的娱乐和情感需求。当用户觉得某种需求得到满足时,就会产生帮助他人的愿望。让别人分享这种快乐的心理。基于这种心理,自动转发的几率更高。
2、文章 可以显示用户的图片
这需要使用特定的用户群体或行业群体作为载体,例如全职妈妈、医生或其他群体。当属性相同的用户看到这种文章时,会不自觉的查看自己的座位。有属性的人会有自己的故事和形象。如果你的文章写得好,可以帮助他们被更多人理解和赞美,他们都会自己转发。
因为他们在阅读文字时有很强的共鸣感,他们自然希望得到更多人的认同。
3、文章 可以帮助用户保持社交
社会关系都是建立在生活细节之上的。如果你的文章能让用户觉得分享有利于维护某种关系,他也愿意转发。这个具体点可以参考第一点。
4、文章 与用户的认知域有很大不同
用户的认知差距或认知差异可以用来激励用户前进。
当我们看文章时,我们总是特别关注我们不知道的信息,或者与我们自己的认知不符的信息,很容易产生“为什么,真的是这样吗?就是这样.” “?” 在这种心理的驱使下,往往更容易主动与他人分享文章,因为我想看看别人的反应,也更容易产生某种对话。
5、文章 可以帮助用户表达某种观点
有时我们都有这样的经历。例如,我们想表达对某人所做的某事的不满,但由于情绪的原因,这并不容易说出来。看到相关的文章,会分享到朋友圈。当人们看到它时,可以感知。
如果你的文章可以帮助用户表达某种观点,帮助他们说不方便说,如果不好说,他们自然会转发。
这该怎么做?与用户沟通,了解他们,猜测他们想说什么。
文章 仔细选择主题和材料,这将对文章的内容质量产生很大影响。平时可以用更专业的内容搜索工具——易转看,它的自媒体库和爆文库实时采集11个平台实时文章和爆文,平台多,领域齐全,可以满足任何领域的创作者需求。您可以通过多种形式自定义搜索内容。该信息是准确的,不收录广告。节省您过滤信息的时间,提高创建效率。 查看全部
今日头条文章采集软件(去重消重去水印视频批量采集下载软件有哪些?(组图))
有去重和去重的批量采集视频下载软件有哪些?
今日头条凤凰视频的去水印软件是什么?
什么视频批量采集下载软件好?抖音视频批量采集下载软件
自媒体视频去重去水印用什么软件好?视频深度处理软件
大雨号搞笑头条今日头条视频去重去水印软件
妙拍视频批量采集下载软件快速删除和删除水印软件
有哪些好的视频批量采集下载软件?快速去除水印!
如何快速批量下载视频采集并去除水印?
自媒体视频批处理采集 有哪些下载软件?什么软件好?
有哪些好的视频去重和水印去除软件?视频深度处理软件
视频重复数据删除和水印去除软件在哪里可用?什么软件好?
什么是最好的海量视频下载软件采集?如何找到它们?
腾讯视频批量采集下载软件哪个好?如何找到它?
凤凰网视频批量采集下载软件,去重去水印
如何批量下载热门视频采集?如何去除水印?
采集 有免费的批量下载软件吗?我在哪里可以找到它?
视频去重、去重去水印、视频批量采集下载软件
在线视频去重和去水印软件在哪里?便于使用?
视频批量采集下载软件上线了吗?便于使用?
在线视频批量采集下载软件,在线批量下载视频
文章交互量对于提升文章的数据很有用。重新喜欢的次数越多,推荐和阅读的次数就越高。
其中,最有利于提升文章的数据的是转发量。转发量越高,文章的曝光率就会大大提高。这也很好理解。每个账号都会有自己的Audience,他们转发你的文章,你的文章自然可以定位到更多的用户群体。
如果要增加转发文章的数量,首先要明确另一个问题:用户为什么转发你的文章,总之,你需要给用户一个转发的理由。
这就要求你的文章能够满足他的需求或兴趣,你的内容必须符合他们的观点、态度和追求,被他们接受,有助于巩固或完善他们的某种形象。
具体需求点有哪些:
1、文章 有价值或有趣
我之前也说过,文章既可以满足用户的理性需求,也可以满足用户的娱乐和情感需求。当用户觉得某种需求得到满足时,就会产生帮助他人的愿望。让别人分享这种快乐的心理。基于这种心理,自动转发的几率更高。
2、文章 可以显示用户的图片
这需要使用特定的用户群体或行业群体作为载体,例如全职妈妈、医生或其他群体。当属性相同的用户看到这种文章时,会不自觉的查看自己的座位。有属性的人会有自己的故事和形象。如果你的文章写得好,可以帮助他们被更多人理解和赞美,他们都会自己转发。
因为他们在阅读文字时有很强的共鸣感,他们自然希望得到更多人的认同。
3、文章 可以帮助用户保持社交
社会关系都是建立在生活细节之上的。如果你的文章能让用户觉得分享有利于维护某种关系,他也愿意转发。这个具体点可以参考第一点。
4、文章 与用户的认知域有很大不同
用户的认知差距或认知差异可以用来激励用户前进。
当我们看文章时,我们总是特别关注我们不知道的信息,或者与我们自己的认知不符的信息,很容易产生“为什么,真的是这样吗?就是这样.” “?” 在这种心理的驱使下,往往更容易主动与他人分享文章,因为我想看看别人的反应,也更容易产生某种对话。
5、文章 可以帮助用户表达某种观点
有时我们都有这样的经历。例如,我们想表达对某人所做的某事的不满,但由于情绪的原因,这并不容易说出来。看到相关的文章,会分享到朋友圈。当人们看到它时,可以感知。
如果你的文章可以帮助用户表达某种观点,帮助他们说不方便说,如果不好说,他们自然会转发。
这该怎么做?与用户沟通,了解他们,猜测他们想说什么。
文章 仔细选择主题和材料,这将对文章的内容质量产生很大影响。平时可以用更专业的内容搜索工具——易转看,它的自媒体库和爆文库实时采集11个平台实时文章和爆文,平台多,领域齐全,可以满足任何领域的创作者需求。您可以通过多种形式自定义搜索内容。该信息是准确的,不收录广告。节省您过滤信息的时间,提高创建效率。
今日头条文章采集软件(爬取老版今日头条数据)
采集交流 • 优采云 发表了文章 • 0 个评论 • 441 次浏览 • 2021-12-03 18:11
前言
这里就不一一介绍每一步的具体操作了,因为在今天爬取老版头条数据的时候已经解释的很清楚了,所以这里只重点讲一下是怎么实现的。是的,如果想看具体步骤,请到我今天头条的文章内容,里面有很详细的介绍以及如何找到加密的js代码和api接口。
Python3抓取今日头条文章视频数据,完美解决as、cp、_signature的加密方式
QQ群聊
855262907
接口参数**
找界面很简单,看我前言中的文章就知道怎么找了。最重要的是参数的**。
参数名称效果值
类别
全部(用户文章 类型)
profile_all
utm_source
用户来源
头条
visit_user_token
用户令牌
MS4wLjABAAAAvazHMceCo3MeM9IJbll231AC8GkJDcrd__iZFw2hi4o(直接从用户链接获取)
max_behot_time
翻页参数
0(默认为0,后续为结果的max_behot_time值)
_签名
加密参数,用于比较访问的是哪个接口
_02B4Z6wo00f01P6um9gAAIBD5.B97mLbnez-q59AAGApeUF3pSlwtwSgMM31ERSbUq4nAurGAbdCsEa34Q4SbYuL5lnFzvinOS2JFHeprAoHuhyeKjbh(算法)
从这里可以看出只对_signature参数值进行了加密,其他的可以直接获取,所以这里只对_signature进行**,其他参数在后面的代码中获取。
反向_signature参数
直接中断调整,发现这里生成了_signature参数值。
让我们将公式向上调整,看看他在这一步进行的计算。
我发现计算的步骤在这里。这要简单得多。直接上源码,然后复制源码,模拟运行得到结果。
JS源代码:
<p>var glb;
(glb = "undefined" == typeof window ? global : window)._$jsvmprt = function(b, a, e) {
function f() {
if ("undefined" == typeof Reflect || !Reflect.construct)
return !1;
if (Reflect.construct.sham)
return !1;
if ("function" == typeof Proxy)
return !0;
try {
return Date.prototype.toString.call(Reflect.construct(Date, [], (function() {}
))),
!0
} catch (b) {
return !1
}
}
function d(b, a, e) {
return (d = f() ? Reflect.construct : function(b, a, e) {
var f = [null];
f.push.apply(f, a);
var d = new (Function.bind.apply(b, f));
return e && c(d, e.prototype),
d
}
).apply(null, arguments)
}
function c(b, a) {
return (c = Object.setPrototypeOf || function(b, a) {
return b.__proto__ = a,
b
}
)(b, a)
}
function r(b) {
return function(b) {
if (Array.isArray(b)) {
for (var a = 0, e = new Array(b.length); a > 7 == 0)
return [1, d];
if (d >> 6 == 2) {
var c = parseInt("" + b[++a] + b[++a], 16);
return d &= 63,
[2, c = (d 6 == 3) {
var r = parseInt("" + b[++a] + b[++a], 16)
, n = parseInt("" + b[++a] + b[++a], 16);
return d &= 63,
[3, n = (d 11 ? (C = z[S--],
z[S] = z[S] >>> C) : _ > 9 ? z[++S] = !0 : _ > 7 ? (j = v(b, $),
$ += 2,
z[S] = z[S][j]) : _ > 0 && (C = z[S--],
z[S] = z[S] 1) {
(_ = x) 2)
(_ = x) > 10 ? z[++S] = void 0 : _ > 1 ? (C = z[S--],
z[S] = z[S] >= C) : _ > -1 && (z[++S] = null);
else if (_ > 1) {
if ((_ = x) 4 ? z[S -= 1] = z[S][z[S + 1]] : _ > 2 && (q = z[S--],
(_ = z[S]).x === L ? _.y >= 1 ? z[S] = M(b, _.c, _.l, [q], _.z, I, null, 1) : (z[S] = M(b, _.c, _.l, [q], _.z, I, null, 0),
_.y++) : z[S] = _(q))
} else {
var P;
if ((_ = x) > 14)
j = G[$],
(P = function a() {
var e = arguments;
return a.y > 0 ? M(b, a.c, a.l, e, a.z, this, null, 0) : (a.y++,
M(b, a.c, a.l, e, a.z, this, null, 0))
}
).c = $ + 4,
P.l = j - 2,
P.x = L,
P.y = 0,
P.z = c,
z[S] = P,
$ += 2 * j - 2;
else if (_ > 12)
q = z[S--],
I = z[S--],
(_ = z[S--]).x === L ? _.y >= 1 ? z[++S] = M(b, _.c, _.l, q, _.z, I, null, 1) : (z[++S] = M(b, _.c, _.l, q, _.z, I, null, 0),
_.y++) : z[++S] = _.apply(I, q);
else if (_ > 5)
C = z[S--],
z[S] = z[S] != C;
else if (_ > 3)
C = z[S--],
z[S] = z[S] * C;
else if (_ > -1)
return [1, z[S--]]
}
} else if (_ >= 2,
_ > 2)
(_ = x) 0) {
if ((_ = x) 2)
z[S--] ? $ += 4 : $ += 2 * (j = G[$]) - 2;
else if (_ > 0) {
for (j = G[$],
C = "",
D = n.q[j][0]; D 0) {
(_ = x) > 12 ? (C = z[S - 1],
q = z[S],
z[++S] = C,
z[++S] = q) : _ > 3 ? (C = z[S--],
z[S] = z[S] == C) : _ > 1 ? (C = z[S--],
z[S] = z[S] + C) : _ > -1 && (z[++S] = h)
} else {
(_ = x) > 13 ? (z[++S] = G[$],
$ += 4) : _ > 11 ? (C = z[S--],
z[S] = z[S] >> C) : _ > 9 ? (j = G[$],
$ += 2,
C = z[S--],
c[j] = C) : _ > 7 ? (j = G[$],
$ += 4,
q = S + 1,
z[S -= j - 1] = j ? z.slice(S, q) : []) : _ > 0 && (C = z[S--],
z[S] = z[S] > C)
}
} else {
_ = 3 & x;
if (x >>= 2,
_ > 2)
(_ = x) > 13 ? (z[++S] = G[$],
$ += 8) : _ > 11 ? (C = z[S--],
z[S] = z[S] >>> C) : _ > 9 ? z[++S] = !0 : _ > 7 ? (j = G[$],
$ += 2,
z[S] = z[S][j]) : _ > 0 && (C = z[S--],
z[S] = z[S] 1) {
(_ = x) > 10 ? (j = G[$],
t[++i] = [[$ + 4, j - 3], 0, 0],
$ += 2 * j - 2) : _ > 8 ? (C = z[S--],
z[S] = z[S] ^ C) : _ > 6 && (C = z[S--])
} else if (_ > 0) {
if ((_ = x) 查看全部
今日头条文章采集软件(爬取老版今日头条数据)
前言
这里就不一一介绍每一步的具体操作了,因为在今天爬取老版头条数据的时候已经解释的很清楚了,所以这里只重点讲一下是怎么实现的。是的,如果想看具体步骤,请到我今天头条的文章内容,里面有很详细的介绍以及如何找到加密的js代码和api接口。
Python3抓取今日头条文章视频数据,完美解决as、cp、_signature的加密方式
QQ群聊
855262907
接口参数**
找界面很简单,看我前言中的文章就知道怎么找了。最重要的是参数的**。
参数名称效果值
类别
全部(用户文章 类型)
profile_all
utm_source
用户来源
头条
visit_user_token
用户令牌
MS4wLjABAAAAvazHMceCo3MeM9IJbll231AC8GkJDcrd__iZFw2hi4o(直接从用户链接获取)
max_behot_time
翻页参数
0(默认为0,后续为结果的max_behot_time值)
_签名
加密参数,用于比较访问的是哪个接口
_02B4Z6wo00f01P6um9gAAIBD5.B97mLbnez-q59AAGApeUF3pSlwtwSgMM31ERSbUq4nAurGAbdCsEa34Q4SbYuL5lnFzvinOS2JFHeprAoHuhyeKjbh(算法)
从这里可以看出只对_signature参数值进行了加密,其他的可以直接获取,所以这里只对_signature进行**,其他参数在后面的代码中获取。
反向_signature参数
直接中断调整,发现这里生成了_signature参数值。
让我们将公式向上调整,看看他在这一步进行的计算。
我发现计算的步骤在这里。这要简单得多。直接上源码,然后复制源码,模拟运行得到结果。
JS源代码:
<p>var glb;
(glb = "undefined" == typeof window ? global : window)._$jsvmprt = function(b, a, e) {
function f() {
if ("undefined" == typeof Reflect || !Reflect.construct)
return !1;
if (Reflect.construct.sham)
return !1;
if ("function" == typeof Proxy)
return !0;
try {
return Date.prototype.toString.call(Reflect.construct(Date, [], (function() {}
))),
!0
} catch (b) {
return !1
}
}
function d(b, a, e) {
return (d = f() ? Reflect.construct : function(b, a, e) {
var f = [null];
f.push.apply(f, a);
var d = new (Function.bind.apply(b, f));
return e && c(d, e.prototype),
d
}
).apply(null, arguments)
}
function c(b, a) {
return (c = Object.setPrototypeOf || function(b, a) {
return b.__proto__ = a,
b
}
)(b, a)
}
function r(b) {
return function(b) {
if (Array.isArray(b)) {
for (var a = 0, e = new Array(b.length); a > 7 == 0)
return [1, d];
if (d >> 6 == 2) {
var c = parseInt("" + b[++a] + b[++a], 16);
return d &= 63,
[2, c = (d 6 == 3) {
var r = parseInt("" + b[++a] + b[++a], 16)
, n = parseInt("" + b[++a] + b[++a], 16);
return d &= 63,
[3, n = (d 11 ? (C = z[S--],
z[S] = z[S] >>> C) : _ > 9 ? z[++S] = !0 : _ > 7 ? (j = v(b, $),
$ += 2,
z[S] = z[S][j]) : _ > 0 && (C = z[S--],
z[S] = z[S] 1) {
(_ = x) 2)
(_ = x) > 10 ? z[++S] = void 0 : _ > 1 ? (C = z[S--],
z[S] = z[S] >= C) : _ > -1 && (z[++S] = null);
else if (_ > 1) {
if ((_ = x) 4 ? z[S -= 1] = z[S][z[S + 1]] : _ > 2 && (q = z[S--],
(_ = z[S]).x === L ? _.y >= 1 ? z[S] = M(b, _.c, _.l, [q], _.z, I, null, 1) : (z[S] = M(b, _.c, _.l, [q], _.z, I, null, 0),
_.y++) : z[S] = _(q))
} else {
var P;
if ((_ = x) > 14)
j = G[$],
(P = function a() {
var e = arguments;
return a.y > 0 ? M(b, a.c, a.l, e, a.z, this, null, 0) : (a.y++,
M(b, a.c, a.l, e, a.z, this, null, 0))
}
).c = $ + 4,
P.l = j - 2,
P.x = L,
P.y = 0,
P.z = c,
z[S] = P,
$ += 2 * j - 2;
else if (_ > 12)
q = z[S--],
I = z[S--],
(_ = z[S--]).x === L ? _.y >= 1 ? z[++S] = M(b, _.c, _.l, q, _.z, I, null, 1) : (z[++S] = M(b, _.c, _.l, q, _.z, I, null, 0),
_.y++) : z[++S] = _.apply(I, q);
else if (_ > 5)
C = z[S--],
z[S] = z[S] != C;
else if (_ > 3)
C = z[S--],
z[S] = z[S] * C;
else if (_ > -1)
return [1, z[S--]]
}
} else if (_ >= 2,
_ > 2)
(_ = x) 0) {
if ((_ = x) 2)
z[S--] ? $ += 4 : $ += 2 * (j = G[$]) - 2;
else if (_ > 0) {
for (j = G[$],
C = "",
D = n.q[j][0]; D 0) {
(_ = x) > 12 ? (C = z[S - 1],
q = z[S],
z[++S] = C,
z[++S] = q) : _ > 3 ? (C = z[S--],
z[S] = z[S] == C) : _ > 1 ? (C = z[S--],
z[S] = z[S] + C) : _ > -1 && (z[++S] = h)
} else {
(_ = x) > 13 ? (z[++S] = G[$],
$ += 4) : _ > 11 ? (C = z[S--],
z[S] = z[S] >> C) : _ > 9 ? (j = G[$],
$ += 2,
C = z[S--],
c[j] = C) : _ > 7 ? (j = G[$],
$ += 4,
q = S + 1,
z[S -= j - 1] = j ? z.slice(S, q) : []) : _ > 0 && (C = z[S--],
z[S] = z[S] > C)
}
} else {
_ = 3 & x;
if (x >>= 2,
_ > 2)
(_ = x) > 13 ? (z[++S] = G[$],
$ += 8) : _ > 11 ? (C = z[S--],
z[S] = z[S] >>> C) : _ > 9 ? z[++S] = !0 : _ > 7 ? (j = G[$],
$ += 2,
z[S] = z[S][j]) : _ > 0 && (C = z[S--],
z[S] = z[S] 1) {
(_ = x) > 10 ? (j = G[$],
t[++i] = [[$ + 4, j - 3], 0, 0],
$ += 2 * j - 2) : _ > 8 ? (C = z[S--],
z[S] = z[S] ^ C) : _ > 6 && (C = z[S--])
} else if (_ > 0) {
if ((_ = x)
今日头条文章采集软件(《cookies获取的两种方法》获取cookies的方法更换教程 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 1309 次浏览 • 2021-12-03 14:13
)
优采云根据搜索词采集今日头条文章,cookies替换教程,之前文章提到了“两种获取cookies的方式”,今天是为头条消息获取cookies .
1、打开/搜索/
点击图片看大图
打开后输入自己的关键词进行搜索,然后切换到信息栏,谷歌浏览器F12,然后点击网络,点击搜索,就会出现数据流,然后点击第一个,点击上面的标题正确的数据包,只需获取cookie。
点击图片看大图
2、打开优采云替换
右键编辑规则,然后在其他设置中,在http请求设置中,粘贴cookies就完成了。
3、附上
有些朋友对今日头条的PC站情有独钟。您必须从 PC 站 采集 获取数据。今日头条PC端使用优采云采集使用插件,必须解决列表页加密。其次,如果不需要优采云,可以使用其他类型的采集器采集更好。
不过我接触的很多客户都对今日头条的验证码感到不爽,有的人用通俗易懂的语言写采集软件,都有门槛,而且优采云的门槛不高,但是还是难倒了一些朋友。
使用我规则的朋友不用担心ip验证问题。如果你只需要新的信息,可以去一些自媒体文章汇总平台获取,很多这样的网站。
-------20200525更新-------
今日头条专栏采集demo,请看本站互联网专栏;
今日头条搜索词条采集规则,请移步查看demo:www_zhhslc_com
---20210219更新---
www_zhhslc_com 搜索词采集的demo站点已经售出,简单说一下这个站点的情况,
该网站于2019年11月左右上线,主要用于今日头条词搜索规则的演示。99%的内容来自今日头条采集的数据。数据在百度上过滤。该域名已使用多年。之前注册的域名已经闲置了19年,用于演示目的。
起初,收录 不是很好。后来随着采集数量的增加,加上一些优化手段,目前数据已经达到了12万+,所以就挂了,打算卖掉。
挂了3个月左右,今天卖了。单词搜索规则非常有用。需要的可以联系我。
优采云采集今日头条基本使用说明:
售后说明1:优采云采集规则导入修改
售后说明二:优采云定时任务定时采集设置教程
售后说明3:优采云根据今日头条作者采集说明
售后说明4:获取cookies教程
售后说明5:优采云采集标签的数据处理
优采云采集今日头条跟随搜索词采集规则cookie替换教程 查看全部
今日头条文章采集软件(《cookies获取的两种方法》获取cookies的方法更换教程
)
优采云根据搜索词采集今日头条文章,cookies替换教程,之前文章提到了“两种获取cookies的方式”,今天是为头条消息获取cookies .
1、打开/搜索/
点击图片看大图
打开后输入自己的关键词进行搜索,然后切换到信息栏,谷歌浏览器F12,然后点击网络,点击搜索,就会出现数据流,然后点击第一个,点击上面的标题正确的数据包,只需获取cookie。
点击图片看大图
2、打开优采云替换
右键编辑规则,然后在其他设置中,在http请求设置中,粘贴cookies就完成了。
3、附上
有些朋友对今日头条的PC站情有独钟。您必须从 PC 站 采集 获取数据。今日头条PC端使用优采云采集使用插件,必须解决列表页加密。其次,如果不需要优采云,可以使用其他类型的采集器采集更好。
不过我接触的很多客户都对今日头条的验证码感到不爽,有的人用通俗易懂的语言写采集软件,都有门槛,而且优采云的门槛不高,但是还是难倒了一些朋友。
使用我规则的朋友不用担心ip验证问题。如果你只需要新的信息,可以去一些自媒体文章汇总平台获取,很多这样的网站。
-------20200525更新-------
今日头条专栏采集demo,请看本站互联网专栏;
今日头条搜索词条采集规则,请移步查看demo:www_zhhslc_com
---20210219更新---
www_zhhslc_com 搜索词采集的demo站点已经售出,简单说一下这个站点的情况,
该网站于2019年11月左右上线,主要用于今日头条词搜索规则的演示。99%的内容来自今日头条采集的数据。数据在百度上过滤。该域名已使用多年。之前注册的域名已经闲置了19年,用于演示目的。
起初,收录 不是很好。后来随着采集数量的增加,加上一些优化手段,目前数据已经达到了12万+,所以就挂了,打算卖掉。
挂了3个月左右,今天卖了。单词搜索规则非常有用。需要的可以联系我。
优采云采集今日头条基本使用说明:
售后说明1:优采云采集规则导入修改
售后说明二:优采云定时任务定时采集设置教程
售后说明3:优采云根据今日头条作者采集说明
售后说明4:获取cookies教程
售后说明5:优采云采集标签的数据处理
优采云采集今日头条跟随搜索词采集规则cookie替换教程
今日头条文章采集软件(通过采集软件采集的内容为什么比原创内容收录好?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 168 次浏览 • 2021-12-03 11:20
朋友们一直向我们咨询。为什么通过我们同行采集的软件采集的内容比我们原创收录的内容和流量还高,这是什么情况?让他时常不解。今天给大家讲讲采集站的原理和采集站的一些想法!
为什么采集软件采集的内容比原创收录的内容好?
相信很多朋友对这个问题比较疑惑。为什么我这么努力写原创文章,百度不是收录,和同行网站每天收录几十几百篇文章,可以' t 百度看不到他们?(百度是机器算法检测)。有很多时候想放弃写内容,直接用采集。我也担心被百度发现导致K站。不过小伙伴们都还好!
再来看看peer的采集站收录,以及持续增长的流量。
1、通过网站发现了网站,每天早上10点发表200篇文章。这一定是因为采集软件已经设置了预定发布。
详解:为什么要设置定期发布?搜索引擎蜘蛛必须知道这次网站更新的频率和规律,所以在10点的时间节点,很容易出现秒收录的现象。如果您是原创的内容,建议您定期、定量地更新发布您的网站。定期更新网站会让搜索引擎蜘蛛更喜欢,搜索引擎蜘蛛也会减少自己服务器的压力和爬取网站的频率,我更喜欢定期更新内容,而且采集 软件满足了这一点。一是保证网站的内容及时更新,二是还可以减少。两边服务器的压力。
2、采集很多软件都是采集最新最火的内容。百度特别喜欢最新最热的内容,相当于为这些内容打开了一个快速通道。
详细描述:例如,今天发生了一个行业相关的热点事件。如果百度没有收录相关内容,那么用户就会去别处搜索此类相关报道或内容。百度为了留住用户,肯定会收录相关内容,网站自然也会得到相应的流量。
<p>3、使用采集软件网站每天发布量巨大,如果每天发布几篇文章的话,那么它不会使用采集软件 是的,只需复制粘贴和修改即可。定期写文章,每天写2篇原创文章,已经很不错了,甚至很多人每天发一篇文章,还有 查看全部
今日头条文章采集软件(通过采集软件采集的内容为什么比原创内容收录好?)
朋友们一直向我们咨询。为什么通过我们同行采集的软件采集的内容比我们原创收录的内容和流量还高,这是什么情况?让他时常不解。今天给大家讲讲采集站的原理和采集站的一些想法!
为什么采集软件采集的内容比原创收录的内容好?
相信很多朋友对这个问题比较疑惑。为什么我这么努力写原创文章,百度不是收录,和同行网站每天收录几十几百篇文章,可以' t 百度看不到他们?(百度是机器算法检测)。有很多时候想放弃写内容,直接用采集。我也担心被百度发现导致K站。不过小伙伴们都还好!
再来看看peer的采集站收录,以及持续增长的流量。
1、通过网站发现了网站,每天早上10点发表200篇文章。这一定是因为采集软件已经设置了预定发布。
详解:为什么要设置定期发布?搜索引擎蜘蛛必须知道这次网站更新的频率和规律,所以在10点的时间节点,很容易出现秒收录的现象。如果您是原创的内容,建议您定期、定量地更新发布您的网站。定期更新网站会让搜索引擎蜘蛛更喜欢,搜索引擎蜘蛛也会减少自己服务器的压力和爬取网站的频率,我更喜欢定期更新内容,而且采集 软件满足了这一点。一是保证网站的内容及时更新,二是还可以减少。两边服务器的压力。
2、采集很多软件都是采集最新最火的内容。百度特别喜欢最新最热的内容,相当于为这些内容打开了一个快速通道。
详细描述:例如,今天发生了一个行业相关的热点事件。如果百度没有收录相关内容,那么用户就会去别处搜索此类相关报道或内容。百度为了留住用户,肯定会收录相关内容,网站自然也会得到相应的流量。
<p>3、使用采集软件网站每天发布量巨大,如果每天发布几篇文章的话,那么它不会使用采集软件 是的,只需复制粘贴和修改即可。定期写文章,每天写2篇原创文章,已经很不错了,甚至很多人每天发一篇文章,还有
今日头条文章采集软件( 海量Python学习资料!目录需要的Python模块实现思路代码及运行结果)
采集交流 • 优采云 发表了文章 • 0 个评论 • 516 次浏览 • 2021-11-29 06:28
海量Python学习资料!目录需要的Python模块实现思路代码及运行结果)
最近在今日头条文章的数据抓取过程中,发现获取视频地址比较复杂。在源码和浏览器的配合下找到了相应的解决方法,请记录下来。
点击此处获取海量Python学习资料!
目录实现思路代码和运行结果文本所需的Python模块
1.所需的 Python 模块
模块主要有requests(或者aiohttp),PyExecJS。
前者是请求文章的源码,后者是Python执行JS代码的依赖库,主要是生成视频地址
12
实现思路一. 需求主要是将原来文章中的视频和图片地址替换为本地存储地址,所以需要下载资源,在视频中通过抓包找到对应的视频地址分析。源码和相关接口响应中没有找到对应的视频地址参数。
通过文章源代码(HTML)浏览器渲染,发现video标签是后面生成的,而且video地址也存在,那么这个标签肯定是JS生成的,找到关键的JS标签脚本通过搜索
二. 解析地址对应的js,发现有生成视频标签的方法,推断有依次生成视频地址的方法,如下:
在这里可以很清楚我们想要的视频地址是从哪里来的,方法如下:
分析方法,我们发现有一个关键参数t,而在图2中,我们找到了方法e,填入了参数v。这让我想起了前面捕获中接口返回的结果对应的main_url。无功 u = o。data.video_list, h = u.video_1, v = h.main_url, 123三. 接口为:/video/urls /1/toutiao/mp4/v0201f800000bub4vq2vtt9a5oknnlp0?callback=tt__video__3e9q4q
在界面返回结果中:
同时该接口中的参数(v0201f800000bub4vq2vtt9a5oknnlp0)在源码中可以找到,可以通过规则匹配。
你可以大胆尝试。在生成视频地址的方法中添加 main_url 值。另外还需要加上JS最底层的几个参数,即: var c = new Array(-1, -1, -1, -1, -1, -1, -1, -1, -1, - 1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,- 1, -1, -1, -1, -1, -1 , 62, -1, -1, -1, 63, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, -1, -1, -1, -1, -1, - 1, -1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22 , 23, 24, 25, -1, -1, -1, -1, -1, -1, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38 , 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, -1, -1,- 1, -1, -1); 1
我用的是JS调试工具(方便调试,检查代码语法),其他方法也可以
结果是:
/ B 742fb26ade01b94ae81b46009d87380 / 5f9944fe /视频/ TOS / CN / TOS-CN-VE-31 / cb2c3a57a679486eba880ef014c36ca0 / A = 2011&BR = 1368&BT = 456&CR = 0&CS = 0&CV = 1&DR7 = 0&DS = 1&RCV = 1&硬币=&石灰=&limetype = M29xcmR3eXQ3eDMzM2kzM0ApZmVkZjo5OGVkNzM6PDozaWdta2gyNnEvc19fLS01Li9zczIuLl41YTFjXi8yMTReYGM6Yw%3D %3D&vl=&vr=
地址是视频地址,所以证明上面的猜想是正确的,但是地址参数是时效性的,所以需要动态修改。您可以自己测试并重新生成它。
代码和运行结果(我用了不同的方法)
<p>async def get_page_source(url):
browser = None
page = None
try:
browser = await launch(
headless=True,
ignoreHTTPSErrors=True,
handleSIGINT=False,
handleSIGTERM=False,
handleSIGHUP=False,
defaultViewport=None,
args=['--disable-setuid-sandbox',
'--no-sandbox',
'--ignore-certificate-errors',
'--disable-gpu',
'--disable-gpu-sandbox',
'--start-maximized'
]
)
pages = await browser.pages()
page = pages[0]
# 是否启用JS,enabled设为False,则无渲染效果
await page.setJavaScriptEnabled(enabled=True)
await page.setViewport(viewport={'width': 1200, 'height': 800})
await page.evaluateOnNewDocument(
'() =>{ Object.defineProperties(navigator,{ webdriver:{ get: () => false } }) }')
await page.evaluateOnNewDocument("() =>{ Object.defineProperty(navigator, 'plugins', { get: () => [] }) }")
await page.evaluateOnNewDocument(
"() =>{ Object.defineProperty(navigator, 'languages', { get: () => ['zh-CN','zh] }) }")
await page.setUserAgent(
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36')
await page.goto(url, {'timeout': 5000, 'waitUntil': 'load'})
page_source = await page.content()
return page_source
except Exception as e:
# app_logger.error('账号:%s, 登录错误:%s' % (username, e))
print(e)
return -1
finally:
if page is not None:
# await page.waitFor(1000)
await page.close()
if browser is not None:
await browser.close()
async def get_data(url, continue_number=0):
"""解析文章源码,提取视频,文字,图片等信息"""
try:
page_source = await get_page_source(url)
# 视频处理,及视频封面
video_message_id_ = re.findall('tt-videoid="(.*?)"', page_source)
video_cover_ = re.findall('tt-poster="(.*?)"', page_source)
if len(video_message_id_) > 0 and len(video_cover_) > 0:
video_message_id = video_message_id_[0]
video_url = await get_video_url_id(video_message_id, url)
video_cover = await download_video_cover(video_cover_[0], url)
except Exception as e:
if continue_number < continue_num:
print(e)
# app_logger.error('function get_data error: %s' % e)
continue_number += 1
video_address = await get_data(url, continue_number)
return video_address
else:
# app_logger.error('function get_data : %s exceed maximum retry' % url)
return -1
async def get_video_url_id(video_id, article_url, continue_number=0):
"""解析视频main_url"""
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/83.0.4103.116 Safari/537.36'}
data_url = 'https://i.snssdk.com/video/urls/1/toutiao/mp4/{}'.format(video_id)
try:
async with aiohttp.ClientSession(connector=TCPConnector(verify_ssl=False), timeout=timeout) as session:
async with session.get(data_url, headers=header) as resp:
response = await resp.json()
if response['message'].strip() == "success":
data = response['data']['video_list']
keys = data.keys()
if 'video_3' in keys:
main_url = data['video_3']['main_url']
video_url = await get_video_url(main_url)
video_url_oss = await download_video(video_url, article_url)
return video_url_oss
elif 'video_3' not in keys and 'video_2' in keys:
main_url = data['video_3']['main_url']
video_url = await get_video_url(main_url)
video_url_oss = await download_video(video_url, article_url)
return video_url_oss
else:
main_url = data['video_3']['main_url']
video_url = await get_video_url(main_url)
video_url_oss = await download_video(video_url, article_url)
return video_url_oss
except Exception as e:
if continue_number < continue_num:
print(e)
# app_logger.error('function get_data error: %s' % e)
continue_number += 1
video_address = await get_data(url, continue_number)
return video_address
else:
# app_logger.error('function get_data : %s exceed maximum retry' % url)
return -1
async def get_video_url(main_url, continue_number=0):
"""获取视频地址,js执行"""
try:
tt = """var c = new Array( - 1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 62, -1, -1, -1, 63, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, -1, -1, -1, -1, -1, -1, -1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, -1, -1, -1, -1, -1, -1, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, -1, -1, -1, -1, -1);
function e(t) {
var e, o, i, r, n, a, s;
for (a = t.length, n = 0, s = ""; a > n;) {
do e = c[255 & t.charCodeAt(n++)];
while (a > n && -1 == e);
if ( - 1 == e) break;
do o = c[255 & t.charCodeAt(n++)];
while (a > n && -1 == o);
if ( - 1 == o) break;
s += String.fromCharCode(e > 4);
do {
if (i = 255 & t.charCodeAt(n++), 61 == i) return s;
i = c[i]
} while ( a > n && - 1 == i );
if ( - 1 == i) break;
s += String.fromCharCode((15 & o) > 2);
do {
if (r = 255 & t.charCodeAt(n++), 61 == r) return s;
r = c[r]
} while ( a > n && - 1 == r );
if ( - 1 == r) break;
s += String.fromCharCode((3 & i) 查看全部
今日头条文章采集软件(
海量Python学习资料!目录需要的Python模块实现思路代码及运行结果)
最近在今日头条文章的数据抓取过程中,发现获取视频地址比较复杂。在源码和浏览器的配合下找到了相应的解决方法,请记录下来。
点击此处获取海量Python学习资料!
目录实现思路代码和运行结果文本所需的Python模块
1.所需的 Python 模块
模块主要有requests(或者aiohttp),PyExecJS。
前者是请求文章的源码,后者是Python执行JS代码的依赖库,主要是生成视频地址
12
实现思路一. 需求主要是将原来文章中的视频和图片地址替换为本地存储地址,所以需要下载资源,在视频中通过抓包找到对应的视频地址分析。源码和相关接口响应中没有找到对应的视频地址参数。
通过文章源代码(HTML)浏览器渲染,发现video标签是后面生成的,而且video地址也存在,那么这个标签肯定是JS生成的,找到关键的JS标签脚本通过搜索
二. 解析地址对应的js,发现有生成视频标签的方法,推断有依次生成视频地址的方法,如下:
在这里可以很清楚我们想要的视频地址是从哪里来的,方法如下:
分析方法,我们发现有一个关键参数t,而在图2中,我们找到了方法e,填入了参数v。这让我想起了前面捕获中接口返回的结果对应的main_url。无功 u = o。data.video_list, h = u.video_1, v = h.main_url, 123三. 接口为:/video/urls /1/toutiao/mp4/v0201f800000bub4vq2vtt9a5oknnlp0?callback=tt__video__3e9q4q
在界面返回结果中:
同时该接口中的参数(v0201f800000bub4vq2vtt9a5oknnlp0)在源码中可以找到,可以通过规则匹配。
你可以大胆尝试。在生成视频地址的方法中添加 main_url 值。另外还需要加上JS最底层的几个参数,即: var c = new Array(-1, -1, -1, -1, -1, -1, -1, -1, -1, - 1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1,- 1, -1, -1, -1, -1, -1 , 62, -1, -1, -1, 63, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, -1, -1, -1, -1, -1, - 1, -1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22 , 23, 24, 25, -1, -1, -1, -1, -1, -1, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38 , 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, -1, -1,- 1, -1, -1); 1
我用的是JS调试工具(方便调试,检查代码语法),其他方法也可以
结果是:
/ B 742fb26ade01b94ae81b46009d87380 / 5f9944fe /视频/ TOS / CN / TOS-CN-VE-31 / cb2c3a57a679486eba880ef014c36ca0 / A = 2011&BR = 1368&BT = 456&CR = 0&CS = 0&CV = 1&DR7 = 0&DS = 1&RCV = 1&硬币=&石灰=&limetype = M29xcmR3eXQ3eDMzM2kzM0ApZmVkZjo5OGVkNzM6PDozaWdta2gyNnEvc19fLS01Li9zczIuLl41YTFjXi8yMTReYGM6Yw%3D %3D&vl=&vr=
地址是视频地址,所以证明上面的猜想是正确的,但是地址参数是时效性的,所以需要动态修改。您可以自己测试并重新生成它。
代码和运行结果(我用了不同的方法)
<p>async def get_page_source(url):
browser = None
page = None
try:
browser = await launch(
headless=True,
ignoreHTTPSErrors=True,
handleSIGINT=False,
handleSIGTERM=False,
handleSIGHUP=False,
defaultViewport=None,
args=['--disable-setuid-sandbox',
'--no-sandbox',
'--ignore-certificate-errors',
'--disable-gpu',
'--disable-gpu-sandbox',
'--start-maximized'
]
)
pages = await browser.pages()
page = pages[0]
# 是否启用JS,enabled设为False,则无渲染效果
await page.setJavaScriptEnabled(enabled=True)
await page.setViewport(viewport={'width': 1200, 'height': 800})
await page.evaluateOnNewDocument(
'() =>{ Object.defineProperties(navigator,{ webdriver:{ get: () => false } }) }')
await page.evaluateOnNewDocument("() =>{ Object.defineProperty(navigator, 'plugins', { get: () => [] }) }")
await page.evaluateOnNewDocument(
"() =>{ Object.defineProperty(navigator, 'languages', { get: () => ['zh-CN','zh] }) }")
await page.setUserAgent(
'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/83.0.4103.116 Safari/537.36')
await page.goto(url, {'timeout': 5000, 'waitUntil': 'load'})
page_source = await page.content()
return page_source
except Exception as e:
# app_logger.error('账号:%s, 登录错误:%s' % (username, e))
print(e)
return -1
finally:
if page is not None:
# await page.waitFor(1000)
await page.close()
if browser is not None:
await browser.close()
async def get_data(url, continue_number=0):
"""解析文章源码,提取视频,文字,图片等信息"""
try:
page_source = await get_page_source(url)
# 视频处理,及视频封面
video_message_id_ = re.findall('tt-videoid="(.*?)"', page_source)
video_cover_ = re.findall('tt-poster="(.*?)"', page_source)
if len(video_message_id_) > 0 and len(video_cover_) > 0:
video_message_id = video_message_id_[0]
video_url = await get_video_url_id(video_message_id, url)
video_cover = await download_video_cover(video_cover_[0], url)
except Exception as e:
if continue_number < continue_num:
print(e)
# app_logger.error('function get_data error: %s' % e)
continue_number += 1
video_address = await get_data(url, continue_number)
return video_address
else:
# app_logger.error('function get_data : %s exceed maximum retry' % url)
return -1
async def get_video_url_id(video_id, article_url, continue_number=0):
"""解析视频main_url"""
header = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/83.0.4103.116 Safari/537.36'}
data_url = 'https://i.snssdk.com/video/urls/1/toutiao/mp4/{}'.format(video_id)
try:
async with aiohttp.ClientSession(connector=TCPConnector(verify_ssl=False), timeout=timeout) as session:
async with session.get(data_url, headers=header) as resp:
response = await resp.json()
if response['message'].strip() == "success":
data = response['data']['video_list']
keys = data.keys()
if 'video_3' in keys:
main_url = data['video_3']['main_url']
video_url = await get_video_url(main_url)
video_url_oss = await download_video(video_url, article_url)
return video_url_oss
elif 'video_3' not in keys and 'video_2' in keys:
main_url = data['video_3']['main_url']
video_url = await get_video_url(main_url)
video_url_oss = await download_video(video_url, article_url)
return video_url_oss
else:
main_url = data['video_3']['main_url']
video_url = await get_video_url(main_url)
video_url_oss = await download_video(video_url, article_url)
return video_url_oss
except Exception as e:
if continue_number < continue_num:
print(e)
# app_logger.error('function get_data error: %s' % e)
continue_number += 1
video_address = await get_data(url, continue_number)
return video_address
else:
# app_logger.error('function get_data : %s exceed maximum retry' % url)
return -1
async def get_video_url(main_url, continue_number=0):
"""获取视频地址,js执行"""
try:
tt = """var c = new Array( - 1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, -1, 62, -1, -1, -1, 63, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, -1, -1, -1, -1, -1, -1, -1, 0, 1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24, 25, -1, -1, -1, -1, -1, -1, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42, 43, 44, 45, 46, 47, 48, 49, 50, 51, -1, -1, -1, -1, -1);
function e(t) {
var e, o, i, r, n, a, s;
for (a = t.length, n = 0, s = ""; a > n;) {
do e = c[255 & t.charCodeAt(n++)];
while (a > n && -1 == e);
if ( - 1 == e) break;
do o = c[255 & t.charCodeAt(n++)];
while (a > n && -1 == o);
if ( - 1 == o) break;
s += String.fromCharCode(e > 4);
do {
if (i = 255 & t.charCodeAt(n++), 61 == i) return s;
i = c[i]
} while ( a > n && - 1 == i );
if ( - 1 == i) break;
s += String.fromCharCode((15 & o) > 2);
do {
if (r = 255 & t.charCodeAt(n++), 61 == r) return s;
r = c[r]
} while ( a > n && - 1 == r );
if ( - 1 == r) break;
s += String.fromCharCode((3 & i)
今日头条文章采集软件(一下今日头条爬取文章的几个方案(一)_ )
采集交流 • 优采云 发表了文章 • 0 个评论 • 280 次浏览 • 2021-11-28 04:02
)
使用环境:爬取思路(一) 生成as、cp和_signature的思考
对于今日头条的爬虫来说,网上搜索到的文章大部分都是基于崔庆才(一个通过搜索爬取漂亮街拍的计划)。不可能的。在这里,上网搜索,搜索,谷歌和百度都使用。这里有一些计划通过今天的头条来爬取文章。
今日头条'as,cp破解
使用的技术是execjs,是一个执行js代码的框架,但是在浏览器环境(比如Node环境)中还没有很好的嵌入。
使用了一个PyV8 js库,主要是获取_signature
给出了一个非常他妈的代码:
def get_signature(self,user_id):
"""
计算_signature
:param user_id: user_id不需要计算,对用户可见
:return: _signature
"""
req = requests.Session()
# js获取目的
jsurl = 'https://s3.pstatp.com/toutiao/ ... 39%3B
resp = req.get(jsurl,headers = self.headers)
js = resp.content
effect_js = js.split("Function")
js = 'var navigator = {};\
navigator["userAgent"] = "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.87 Safari/537.36";\
' + "Function" + effect_js[3] +
"Function" + effect_js[4] +
";function result(){ return TAC.sign(" + user_id + ");} result();"
# PyV8执行步骤
with PyV8.JSLocker():
self.ctxt.enter() #已在上面初始化过
vl5x = self.ctxt.eval(js)
self.ctxt.leave()
self.LOG.info("圣诞快乐")
return vl5x
PyV8库在win10上装不了,后来在centos7环境下安装了。执行这段代码后,直接报内存不足的错误。直接调用TAC.sign的方法缺少Node环境(更多的是浏览器环境),或者报错。也许这确实是一种方法,但很少有人对短书给出反馈。我不知道是我想不通还是他们有。
(二)我后来直接用了自己的方法:绕过_signature参数,直接请求网页的数据信息(wap)。
右键查看,点击json栏,选择其中一个url
网址一:
网址二:
至于,前面文章中的cp,我们已经搞清楚了,现在我们要做的就是如何拼接这串url,
根据上面两个网址的对比,我们只需要替换max_behot_time和jsonp,
这样,我们就得到了整个列表页面的数据。
接下来,解析详情页的数据可能要简单得多。
查看页面源代码:
这正是我们想要的数据,使用常规采集就足够了。
至此,我们就可以完全检索今日头条的数据了。
需要源码的可以加个小秘圈:
查看全部
今日头条文章采集软件(一下今日头条爬取文章的几个方案(一)_
)
使用环境:爬取思路(一) 生成as、cp和_signature的思考
对于今日头条的爬虫来说,网上搜索到的文章大部分都是基于崔庆才(一个通过搜索爬取漂亮街拍的计划)。不可能的。在这里,上网搜索,搜索,谷歌和百度都使用。这里有一些计划通过今天的头条来爬取文章。
今日头条'as,cp破解
使用的技术是execjs,是一个执行js代码的框架,但是在浏览器环境(比如Node环境)中还没有很好的嵌入。
使用了一个PyV8 js库,主要是获取_signature
给出了一个非常他妈的代码:
def get_signature(self,user_id):
"""
计算_signature
:param user_id: user_id不需要计算,对用户可见
:return: _signature
"""
req = requests.Session()
# js获取目的
jsurl = 'https://s3.pstatp.com/toutiao/ ... 39%3B
resp = req.get(jsurl,headers = self.headers)
js = resp.content
effect_js = js.split("Function")
js = 'var navigator = {};\
navigator["userAgent"] = "Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/49.0.2623.87 Safari/537.36";\
' + "Function" + effect_js[3] +
"Function" + effect_js[4] +
";function result(){ return TAC.sign(" + user_id + ");} result();"
# PyV8执行步骤
with PyV8.JSLocker():
self.ctxt.enter() #已在上面初始化过
vl5x = self.ctxt.eval(js)
self.ctxt.leave()
self.LOG.info("圣诞快乐")
return vl5x
PyV8库在win10上装不了,后来在centos7环境下安装了。执行这段代码后,直接报内存不足的错误。直接调用TAC.sign的方法缺少Node环境(更多的是浏览器环境),或者报错。也许这确实是一种方法,但很少有人对短书给出反馈。我不知道是我想不通还是他们有。
(二)我后来直接用了自己的方法:绕过_signature参数,直接请求网页的数据信息(wap)。
右键查看,点击json栏,选择其中一个url
网址一:
网址二:
至于,前面文章中的cp,我们已经搞清楚了,现在我们要做的就是如何拼接这串url,
根据上面两个网址的对比,我们只需要替换max_behot_time和jsonp,
这样,我们就得到了整个列表页面的数据。
接下来,解析详情页的数据可能要简单得多。
查看页面源代码:
这正是我们想要的数据,使用常规采集就足够了。
至此,我们就可以完全检索今日头条的数据了。
需要源码的可以加个小秘圈:
今日头条文章采集软件( 一键采集今日头条和评论的数据到您的论坛上)
采集交流 • 优采云 发表了文章 • 0 个评论 • 731 次浏览 • 2021-11-28 03:23
一键采集今日头条和评论的数据到您的论坛上)
【插件功能】
安装本插件后,您可以输入今日头条地址或关键词,一键采集今日头条评论数据到您的论坛。
[本插件的特点]
1、您可以输入热门标题关键词,采集标题和用户评论将实时发布到您的论坛
2、您可以采集批量发布,短时间内将今日头条的优质内容转发到您的论坛
3、可定时采集 可无人值守,自动采集自动释放
4、马甲用户可批量注册,发帖者和回复者使用马甲,与真实用户发布的一模一样
5、支持前台采集,可以指定普通用户使用这个采集器,让普通会员帮你转发今日头条内容。
6、采集 过来的新闻图片可以正常显示并保存为帖子图片附件。
7、图片附件支持远程FTP存储。
8、图片将从您的论坛中添加水印。
9、已经采集的新闻信息不会重复采集,内容也不会冗余。
10、采集 发布的帖子与真实用户发布的帖子几乎一模一样。
11、浏览量会自动随机设置,感觉你帖子的浏览量更真实。
12、 可以指定帖子发布者的 UID。
13、采集的头条新闻内容可以发布到任何版块。
14、可以随机采集一批标题到你的论坛。
15、无限采集,无限采集次。
[这个插件给你带来的价值]
1、让您的论坛非常受欢迎且内容丰富。
2、使用一键采集代替人工发帖,省时省力,不易出错。
3、让你的网站与海量新闻网站分享优质内容,快速提升网站的权重和排名。
[备注]
本插件只能采集今日头条新闻资讯类内容,不能采集头条问答、头条视频、头条图集...
【官方QQ群:235307918】
在线安装:
@csdn123com_toutiao.plugin
本地下载和手动安装: 查看全部
今日头条文章采集软件(
一键采集今日头条和评论的数据到您的论坛上)
【插件功能】
安装本插件后,您可以输入今日头条地址或关键词,一键采集今日头条评论数据到您的论坛。
[本插件的特点]
1、您可以输入热门标题关键词,采集标题和用户评论将实时发布到您的论坛
2、您可以采集批量发布,短时间内将今日头条的优质内容转发到您的论坛
3、可定时采集 可无人值守,自动采集自动释放
4、马甲用户可批量注册,发帖者和回复者使用马甲,与真实用户发布的一模一样
5、支持前台采集,可以指定普通用户使用这个采集器,让普通会员帮你转发今日头条内容。
6、采集 过来的新闻图片可以正常显示并保存为帖子图片附件。
7、图片附件支持远程FTP存储。
8、图片将从您的论坛中添加水印。
9、已经采集的新闻信息不会重复采集,内容也不会冗余。
10、采集 发布的帖子与真实用户发布的帖子几乎一模一样。
11、浏览量会自动随机设置,感觉你帖子的浏览量更真实。
12、 可以指定帖子发布者的 UID。
13、采集的头条新闻内容可以发布到任何版块。
14、可以随机采集一批标题到你的论坛。
15、无限采集,无限采集次。
[这个插件给你带来的价值]
1、让您的论坛非常受欢迎且内容丰富。
2、使用一键采集代替人工发帖,省时省力,不易出错。
3、让你的网站与海量新闻网站分享优质内容,快速提升网站的权重和排名。
[备注]
本插件只能采集今日头条新闻资讯类内容,不能采集头条问答、头条视频、头条图集...
【官方QQ群:235307918】
在线安装:
@csdn123com_toutiao.plugin
本地下载和手动安装:

