
云优采集接口
云优采集接口(#天镜后端项目##**1*天镜项目)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-11-11 19:17
##天京后端项目git地址:*****### **项目剩余功能**1. 机房大屏部分,主要是电力环境部分,数据不清晰,无法开展工作2。网络安全大屏,也是数据不清楚*****### **项目描述** 天镜项目主要依赖他人提供的数据源、接口等。主要流程是采集------进入ES数据库-------查询和统计做一些数据展示,其中一些模块数据需要存入数据库,有的直接调用界面,有的直接读取提供的数据库,不需要进入库如下:小屏模块包括:
24.160.215 3306 root root **数据库名**:天津智能电网数据库:10.185.104.83:1433 dataquery hjs2019*SkyMirror Basic ES library:java with this:10.185.89。191:19310,10.185.89.192:19310,10.185.89.193:19310,10.185.89.194:19310 集群网页连接到这个:10.185.89.191:19210.191:19210.1***头部可视化.19810.1***环境**:mysql数据库:localhost 3306 root root **数据库名**:天津智能电网数据库:10.185.104.83:1433 dataquery hjs2019* test ES库:172.24.160.217:9300 java connect this*****## #**项目部署服务器****地址**:172.24.160.218账号:root密码:Tj123!@#**目录:** /home/xjqx/coreapp **官方环境**:。
/开始生产。sh**开发环境**:. /开始开发。sh![]()*****### **数据源** **项目Mysql数据库:
185.89.191:19210网页可视化::19100***** **项目当前ES库:** 172.24.160.217:9300*****![]()**游云省一级使用**地址:[ #/login\_admin](#/login_admin)新疆Admin@123![]() 网络安全大屏部分资源界面:**邮递员**:![]()![]() 查看全部
云优采集接口(#天镜后端项目##**1*天镜项目)
##天京后端项目git地址:*****### **项目剩余功能**1. 机房大屏部分,主要是电力环境部分,数据不清晰,无法开展工作2。网络安全大屏,也是数据不清楚*****### **项目描述** 天镜项目主要依赖他人提供的数据源、接口等。主要流程是采集------进入ES数据库-------查询和统计做一些数据展示,其中一些模块数据需要存入数据库,有的直接调用界面,有的直接读取提供的数据库,不需要进入库如下:小屏模块包括:
24.160.215 3306 root root **数据库名**:天津智能电网数据库:10.185.104.83:1433 dataquery hjs2019*SkyMirror Basic ES library:java with this:10.185.89。191:19310,10.185.89.192:19310,10.185.89.193:19310,10.185.89.194:19310 集群网页连接到这个:10.185.89.191:19210.191:19210.1***头部可视化.19810.1***环境**:mysql数据库:localhost 3306 root root **数据库名**:天津智能电网数据库:10.185.104.83:1433 dataquery hjs2019* test ES库:172.24.160.217:9300 java connect this*****## #**项目部署服务器****地址**:172.24.160.218账号:root密码:Tj123!@#**目录:** /home/xjqx/coreapp **官方环境**:。
/开始生产。sh**开发环境**:. /开始开发。sh![]()*****### **数据源** **项目Mysql数据库:
185.89.191:19210网页可视化::19100***** **项目当前ES库:** 172.24.160.217:9300*****![]()**游云省一级使用**地址:[ #/login\_admin](#/login_admin)新疆Admin@123![]() 网络安全大屏部分资源界面:**邮递员**:![]()![]()
云优采集接口( 管理员可管理的文件夹列表有文件夹管理权限的普通管理员或超级管理员)
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-11-09 17:23
管理员可管理的文件夹列表有文件夹管理权限的普通管理员或超级管理员)
文件管理界面
1、列出当前管理员可以管理的文件夹
具有文件夹管理权限的普通管理员或超级管理员可以调用该接口
URI:/app/file/list-manage-dir
POST参数:
令牌:令牌参数
返回的 json.data 是一个列表,列出了管理员可以管理的每个文件夹(以及文件夹的子文件夹列表)
2、列出对文件或文件夹设置的所有权限
具有文件夹管理权限的普通管理员或超级管理员可以调用该接口
URI:/app/file/list-file-auth
POST参数:
令牌:令牌参数
fileId:文件或文件夹的 ID
返回的 json.data 是一个列表,列出了文件/文件夹的所有权限设置。如果 json.data[index].fileId 与 POST 提交的 fileId 不一致,则权限来自 json.data[index] 继承自 .fileId
3、列出对用户、部门、角色和创建者设置的所有权限
具有文件夹管理权限的普通管理员或超级管理员可以调用该接口
URI:/app/file/list-user-auth
POST参数:
令牌:令牌参数
userId:用户、部门、角色或创建者的ID(提醒:创建者ID为特殊值:2039878274)
返回的 json.data 是一个列表,列出了 userId 拥有的所有权限设置。如果json.data[index].userId和POST提交的userId不一致,权限继承自json.data[index].userId来
4、添加文件/文件夹权限
具有文件夹管理权限的普通管理员或超级管理员可以调用该接口
注意:每个fileId-userId组合只能有一个权限设置,所以如果fileId-userId组合已经加了权限,再调用这个接口,会被新的权限覆盖
URI:/app/file/add-file-auth
POST参数:
令牌:令牌参数
fileId:文件或文件夹的 ID
userId:用户、部门、角色或创建者的ID(提醒:创建者ID为特殊值:2039878274)
auth:权限类型
读音云盘的权限类型用字母表示:
可见:V
上传:U
新:N
预览:P
打印:T
修改:M
下载:D
外部链接:E
删除:R
所有权限:A
完全禁止:B
注意权限类型之间存在联动关系。例如,预览权限必须同时具有可见权限。即如果只加了预览权限,auth参数必须写成:VP。具体权限联动,可以在云盘客户端添加权限,实际操作界面。你可以知道。
5、删除文件/文件夹的权限
具有文件夹管理权限的普通管理员或超级管理员可以调用该接口
URI:/app/file/remove-file-auth
POST参数:
令牌:令牌参数
authId:授权ID,可以通过/app/file/list-file-auth或者/app/file/list-user-auth获取
6、查看文件夹策略
具有文件夹管理权限的普通管理员或超级管理员可以调用该接口
文件夹策略可以设置文件夹的允许大小和允许的文件类型
URI:/app/file/view-folder-policy
POST参数:
令牌:令牌参数
fileId:文件夹 ID
如果返回的json.data有值,json.data.size为限制文件夹大小,以MB为单位,json.data.fileExtend代表文件夹允许的扩展名,多个扩展名之间用空格隔开
7、设置文件夹策略
具有文件夹管理权限的普通管理员或超级管理员可以调用该接口
URI:/app/file/set-folder-policy
POST参数:
令牌:令牌参数
fileId:文件夹 ID
size:限制文件夹的大小,以MB为单位
fileExtend:限制文件扩展名,多个扩展名之间用空格分隔,如:"docx pptx xlsx doc ppt xls"
注意:size和fileExtend可以同时填一或两个,如果都为空,则表示文件夹策略无限制
8、选择或取消固定文件
具有文件夹管理权限的普通管理员或超级管理员可以调用该接口
URI:/app/file/top-order-file
POST参数:
令牌:令牌参数
fileId:文件或文件夹的 ID
type:type=1表示粘贴,type=2表示去除粘贴,如果文件已经被置顶,并且因为其他文件也被置顶,则不排在第一,再次调用粘贴接口,该文件将再次排在第一
9、获取单个文件的日志
具有文件夹管理权限的普通管理员或超级管理员可以调用该接口
URI:/app/file/get-one-file-log
POST参数:
令牌:令牌参数
fileId:文件或文件夹的 ID
page:当前页码(每次只显示30条日志,0表示第一页) 查看全部
云优采集接口(
管理员可管理的文件夹列表有文件夹管理权限的普通管理员或超级管理员)
文件管理界面
1、列出当前管理员可以管理的文件夹
具有文件夹管理权限的普通管理员或超级管理员可以调用该接口
URI:/app/file/list-manage-dir
POST参数:
令牌:令牌参数
返回的 json.data 是一个列表,列出了管理员可以管理的每个文件夹(以及文件夹的子文件夹列表)
2、列出对文件或文件夹设置的所有权限
具有文件夹管理权限的普通管理员或超级管理员可以调用该接口
URI:/app/file/list-file-auth
POST参数:
令牌:令牌参数
fileId:文件或文件夹的 ID
返回的 json.data 是一个列表,列出了文件/文件夹的所有权限设置。如果 json.data[index].fileId 与 POST 提交的 fileId 不一致,则权限来自 json.data[index] 继承自 .fileId
3、列出对用户、部门、角色和创建者设置的所有权限
具有文件夹管理权限的普通管理员或超级管理员可以调用该接口
URI:/app/file/list-user-auth
POST参数:
令牌:令牌参数
userId:用户、部门、角色或创建者的ID(提醒:创建者ID为特殊值:2039878274)
返回的 json.data 是一个列表,列出了 userId 拥有的所有权限设置。如果json.data[index].userId和POST提交的userId不一致,权限继承自json.data[index].userId来
4、添加文件/文件夹权限
具有文件夹管理权限的普通管理员或超级管理员可以调用该接口
注意:每个fileId-userId组合只能有一个权限设置,所以如果fileId-userId组合已经加了权限,再调用这个接口,会被新的权限覆盖
URI:/app/file/add-file-auth
POST参数:
令牌:令牌参数
fileId:文件或文件夹的 ID
userId:用户、部门、角色或创建者的ID(提醒:创建者ID为特殊值:2039878274)
auth:权限类型
读音云盘的权限类型用字母表示:
可见:V
上传:U
新:N
预览:P
打印:T
修改:M
下载:D
外部链接:E
删除:R
所有权限:A
完全禁止:B
注意权限类型之间存在联动关系。例如,预览权限必须同时具有可见权限。即如果只加了预览权限,auth参数必须写成:VP。具体权限联动,可以在云盘客户端添加权限,实际操作界面。你可以知道。
5、删除文件/文件夹的权限
具有文件夹管理权限的普通管理员或超级管理员可以调用该接口
URI:/app/file/remove-file-auth
POST参数:
令牌:令牌参数
authId:授权ID,可以通过/app/file/list-file-auth或者/app/file/list-user-auth获取
6、查看文件夹策略
具有文件夹管理权限的普通管理员或超级管理员可以调用该接口
文件夹策略可以设置文件夹的允许大小和允许的文件类型
URI:/app/file/view-folder-policy
POST参数:
令牌:令牌参数
fileId:文件夹 ID
如果返回的json.data有值,json.data.size为限制文件夹大小,以MB为单位,json.data.fileExtend代表文件夹允许的扩展名,多个扩展名之间用空格隔开
7、设置文件夹策略
具有文件夹管理权限的普通管理员或超级管理员可以调用该接口
URI:/app/file/set-folder-policy
POST参数:
令牌:令牌参数
fileId:文件夹 ID
size:限制文件夹的大小,以MB为单位
fileExtend:限制文件扩展名,多个扩展名之间用空格分隔,如:"docx pptx xlsx doc ppt xls"
注意:size和fileExtend可以同时填一或两个,如果都为空,则表示文件夹策略无限制
8、选择或取消固定文件
具有文件夹管理权限的普通管理员或超级管理员可以调用该接口
URI:/app/file/top-order-file
POST参数:
令牌:令牌参数
fileId:文件或文件夹的 ID
type:type=1表示粘贴,type=2表示去除粘贴,如果文件已经被置顶,并且因为其他文件也被置顶,则不排在第一,再次调用粘贴接口,该文件将再次排在第一
9、获取单个文件的日志
具有文件夹管理权限的普通管理员或超级管理员可以调用该接口
URI:/app/file/get-one-file-log
POST参数:
令牌:令牌参数
fileId:文件或文件夹的 ID
page:当前页码(每次只显示30条日志,0表示第一页)
云优采集接口(本文的原理机制,如何使用火焰图快速定位性能问题)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-11-09 02:08
本文主要分享火焰图的使用,介绍了systemtap的原理和机制,如何使用火焰图快速定位性能问题的原因,同时加深对systemtap的理解。
让我们回想一下,作为编程新手,我们是如何调整程序的?当没有数据时,它通常基于主观假设。稍有经验的同学会二分不同的代码或者一块一块调试。这种定位问题的方法不仅费时费力,而且不具有普遍性。当遇到其他类似的性能问题时,需要反复踩坑填坑。如何避免这种情况?
俗话说:“工欲善其事,必先利其器”。我个人认为程序员也需要一个“利器”来定位性能问题。就像医生看病人一样,需要依靠专业的医疗工具(如X光、听诊器等)进行诊断,最终根据医生的检查结果快速准确地定位疾病的病因。工具。性能调优工具(如 perf / gprof 等)用于性能调优,就像 X 射线对患者一样。他们可以查明程序的性能瓶颈。
但是,常用的性能调优工具如perf只能在呈现内容中列出调用栈或者非分层的时间分布,不够直观。这里推荐大家一起使用火焰图,这样会更直观的呈现perf采集等工具的数据。
第一次认识火焰图
Flame Graph 是由 Linux 性能优化大师 Brendan Gregg 发明的。与所有其他分析方法不同,火焰图从全局角度查看时间分布。它从下到上列出了所有可能的原因。性能瓶颈的调用栈。
火焰图的整个图形看起来像一个跳动的火焰,这也是它名字的由来。
火焰图有以下特点(这里以on-cpu火焰图为例):
火焰图类型
常见的火焰图类型包括 On-CPU、Off-CPU、Memory、Hot/Cold、Differential 等。它们适合处理什么样的问题?
这里笔者主要使用了On-CPU、Off-CPU和Memory火焰图,所以这里仅对这三种火焰图进行比较,欢迎大家补充修正。
火焰图分析技巧 纵轴代表调用栈的深度(栈帧数),用于表示函数之间的调用关系:下面的函数是上面函数的父函数;横轴代表调用频率,格子宽度越大,说明越可能是瓶颈;不同类型的火焰图适用于不同的优化场景。比如on-cpu火焰图适合分析CPU占用率高的问题函数,off-cpu火焰图适合解决阻塞和锁抢占问题;无意义的东西:水平顺序是为了聚合,与函数之间的依赖或调用关系无关;火焰图的各种颜色是为了便于区分,没有特殊含义;更多实践:进行性能优化,有意识地使用火焰图进行性能调优(如果时间充裕);如何绘制火焰图?
要生成火焰图,必须有一个方便的动态跟踪工具。如果操作系统是 Linux,通常是 perf 或 systemtap 之一。其中,perf 是比较常用的。大多数Linux都收录perf,可以直接使用;SystemTap功能更强大,监控更灵活。关于如何使用perf绘制火焰图,网上有很多丰富的资料,所以本文以SystemTap为例。
SystemTap 是一个动态跟踪工具。它采用探测机制获取内核或应用的采集运行信息,让您无需修改内核和应用的代码即可获取丰富的信息,帮助您分析定位。解决问题。SystemTap 定义了类似的 DSL 脚本语言,方便用户根据需要自由扩展。但是,与动态跟踪的鼻祖 DTrace 不同,SystemTap 没有驻留在内核中的运行时。它需要将脚本编译成内核模块,然后插入内核执行。这也会导致 SystemTap 启动缓慢并依赖于完整的调试符号表。
使用SystemTap绘制火焰图的主要过程如下:
本文演示的步骤将基于操作系统Tlinux 2.2(Linux内核版本3.10.107)
安装 SystemTap 和操作系统符号调试表
使用 yum 工具安装 systemtap:
yum install systemtap systemtap-runtime
因为systemtap工具依赖完整的调试符号表,生产环境不同机器的内核版本不同(虽然都是Tlinux2.2个版本,但是内核版本后面的次要版本不同,可以使用uname -a命令查看)所以我们还需要安装kernel-debuginfo包和kernel-devel包。我这里已经安装了这两个依赖包。
kernel-devel-3.10.107-1-tlinux2-0046.x86_64
kernel-debuginfo-3.10.107-1-tlinux2-0046.x86_64
根据需要绘制的火焰图类型和流程类型选择合适的脚本
使用 SystemTap 进行统计,往往需要根据其语法编写脚本,具有一定的门槛。好在github上的spring兄(agentzh)开源了他常用的两套SystemTap脚本:openresty-systemtap-toolkit和stapxx。这两个工具集可以覆盖大部分C进程、nginx进程、Openresty进程的性能问题场景。.
这里需要绘制off-cpu火焰图,所以使用sample-bt-off-cpu脚本
生成内核模块
现在我们有了统计脚本并安装了systemtap,就可以正常使用了,但是因为systemtap通过生成内核模块来采集相关探针的统计信息,所以tlinux需要所有运行的内核模块先到达。tlinux平台签名可以运行,所以:
所以需要先修改off-cpu脚本生成内核模块;然后对内核模块进行签名;最后使用systemtap命令手动运行脚本统计监控数据。
Systemtap的执行过程如下:
所以这里我们修改off-cpu stap脚本,让它只运行到第四阶段,只生成一个内核模块
// 在 stap 命令后增加 -p4 参数,告诉systemtap,当前只需要执行到第四阶段
open my $in, "|stap -p4 --skip-badvars --all-modules -x $pid -d '$exec_path' --ldd $d_so_args $stap_args -"
or die "Cannot run stap: $!\n";
修改后运行脚本,会生成一个内核模块
// -p 8682 是需要监控的进程的进程号
// -t 30 是指会采样30秒
./sample-bt-off-cpu -p 8692 -t 30
生成的内核模块名称类似于 stap_xxxxx.ko 模块名称。由于读者不需要关心内核模块签名,因此跳过该章节
运行内核模块统计信息
内核模块签名后,可以使用staprun命令手动运行相关内核模块
命令:
// 注意:签名脚本会将生产的内核模块重命名,需要将名字改回去……(脚本bug)
staprun -x {进程号} {内核模块名} > demo.bt
值得注意的是,被监控的进程必须有一定的load systemtap才能采集获取相关数据,即在采集的时候,同时需要一定量的请求时间(一般是自己构造请求,强调过程))
将统计数据转换为火焰图
获取统计数据demo.bt后,可以使用火焰图工具绘制火焰图
下载火焰图,链接:
命令:
./stackcollapse-stap.pl demo.bt > demo.folded
./flamegraph.pl demo.folded > demo.svg
这样就得到了off-cpu火焰图:
看图说话
趁热打铁,通过几张火焰图熟悉如何使用火焰图
图片来自春哥微博或我最近画的表演火焰图
On-cpu 火焰图 Apache APISIX QPS 急剧下降
Apache APISIX 是一个开源的国产高性能 API 网关。在之前的选型和压测中发现,当Route与场景不匹配时,QPS急剧下降,其CPU(四十八核)占用率几乎达到100%。QPS只有几千。通过绘制火焰图发现,耗时主要在表插入阶段(lj_cf_table_insert)。分析代码发现该表没有发布。每次匹配不匹配时,都会将路由发送到一个表中进行统计。往表中插入一条数据导致表越来越大,后续插入时间过长导致QPS下降。
Off-cpu火焰图nginx互斥问题
这是一个 nginx 的 off-cpu 火焰图。我们可以快速锁定到 ngx_common_set_cache_fs_size -> ngx_shmtx_lock -> sem_wait。这个逻辑使用了互斥锁,它允许nginx进程将大部分等待时间花在获取锁上。
代理监控和报告断点问题
这是代理的 CPU 外火焰图。它是一个多线程异步事件模型。主线程处理每条消息,多个线程负责配置下发或监控上报。目前的问题是监控上报性能较差,无法在周期(一分钟)内完成监控数据上报,导致出现监控断点。通过off-cpu火焰图,我们可以分析报告线程花费大量时间使用curl_easy_perform接口发送和接收http监控数据消息。 查看全部
云优采集接口(本文的原理机制,如何使用火焰图快速定位性能问题)
本文主要分享火焰图的使用,介绍了systemtap的原理和机制,如何使用火焰图快速定位性能问题的原因,同时加深对systemtap的理解。
让我们回想一下,作为编程新手,我们是如何调整程序的?当没有数据时,它通常基于主观假设。稍有经验的同学会二分不同的代码或者一块一块调试。这种定位问题的方法不仅费时费力,而且不具有普遍性。当遇到其他类似的性能问题时,需要反复踩坑填坑。如何避免这种情况?
俗话说:“工欲善其事,必先利其器”。我个人认为程序员也需要一个“利器”来定位性能问题。就像医生看病人一样,需要依靠专业的医疗工具(如X光、听诊器等)进行诊断,最终根据医生的检查结果快速准确地定位疾病的病因。工具。性能调优工具(如 perf / gprof 等)用于性能调优,就像 X 射线对患者一样。他们可以查明程序的性能瓶颈。
但是,常用的性能调优工具如perf只能在呈现内容中列出调用栈或者非分层的时间分布,不够直观。这里推荐大家一起使用火焰图,这样会更直观的呈现perf采集等工具的数据。
第一次认识火焰图
Flame Graph 是由 Linux 性能优化大师 Brendan Gregg 发明的。与所有其他分析方法不同,火焰图从全局角度查看时间分布。它从下到上列出了所有可能的原因。性能瓶颈的调用栈。

火焰图的整个图形看起来像一个跳动的火焰,这也是它名字的由来。
火焰图有以下特点(这里以on-cpu火焰图为例):
火焰图类型
常见的火焰图类型包括 On-CPU、Off-CPU、Memory、Hot/Cold、Differential 等。它们适合处理什么样的问题?
这里笔者主要使用了On-CPU、Off-CPU和Memory火焰图,所以这里仅对这三种火焰图进行比较,欢迎大家补充修正。

火焰图分析技巧 纵轴代表调用栈的深度(栈帧数),用于表示函数之间的调用关系:下面的函数是上面函数的父函数;横轴代表调用频率,格子宽度越大,说明越可能是瓶颈;不同类型的火焰图适用于不同的优化场景。比如on-cpu火焰图适合分析CPU占用率高的问题函数,off-cpu火焰图适合解决阻塞和锁抢占问题;无意义的东西:水平顺序是为了聚合,与函数之间的依赖或调用关系无关;火焰图的各种颜色是为了便于区分,没有特殊含义;更多实践:进行性能优化,有意识地使用火焰图进行性能调优(如果时间充裕);如何绘制火焰图?
要生成火焰图,必须有一个方便的动态跟踪工具。如果操作系统是 Linux,通常是 perf 或 systemtap 之一。其中,perf 是比较常用的。大多数Linux都收录perf,可以直接使用;SystemTap功能更强大,监控更灵活。关于如何使用perf绘制火焰图,网上有很多丰富的资料,所以本文以SystemTap为例。
SystemTap 是一个动态跟踪工具。它采用探测机制获取内核或应用的采集运行信息,让您无需修改内核和应用的代码即可获取丰富的信息,帮助您分析定位。解决问题。SystemTap 定义了类似的 DSL 脚本语言,方便用户根据需要自由扩展。但是,与动态跟踪的鼻祖 DTrace 不同,SystemTap 没有驻留在内核中的运行时。它需要将脚本编译成内核模块,然后插入内核执行。这也会导致 SystemTap 启动缓慢并依赖于完整的调试符号表。
使用SystemTap绘制火焰图的主要过程如下:
本文演示的步骤将基于操作系统Tlinux 2.2(Linux内核版本3.10.107)
安装 SystemTap 和操作系统符号调试表
使用 yum 工具安装 systemtap:
yum install systemtap systemtap-runtime
因为systemtap工具依赖完整的调试符号表,生产环境不同机器的内核版本不同(虽然都是Tlinux2.2个版本,但是内核版本后面的次要版本不同,可以使用uname -a命令查看)所以我们还需要安装kernel-debuginfo包和kernel-devel包。我这里已经安装了这两个依赖包。
kernel-devel-3.10.107-1-tlinux2-0046.x86_64
kernel-debuginfo-3.10.107-1-tlinux2-0046.x86_64
根据需要绘制的火焰图类型和流程类型选择合适的脚本
使用 SystemTap 进行统计,往往需要根据其语法编写脚本,具有一定的门槛。好在github上的spring兄(agentzh)开源了他常用的两套SystemTap脚本:openresty-systemtap-toolkit和stapxx。这两个工具集可以覆盖大部分C进程、nginx进程、Openresty进程的性能问题场景。.
这里需要绘制off-cpu火焰图,所以使用sample-bt-off-cpu脚本
生成内核模块
现在我们有了统计脚本并安装了systemtap,就可以正常使用了,但是因为systemtap通过生成内核模块来采集相关探针的统计信息,所以tlinux需要所有运行的内核模块先到达。tlinux平台签名可以运行,所以:
所以需要先修改off-cpu脚本生成内核模块;然后对内核模块进行签名;最后使用systemtap命令手动运行脚本统计监控数据。
Systemtap的执行过程如下:

所以这里我们修改off-cpu stap脚本,让它只运行到第四阶段,只生成一个内核模块
// 在 stap 命令后增加 -p4 参数,告诉systemtap,当前只需要执行到第四阶段
open my $in, "|stap -p4 --skip-badvars --all-modules -x $pid -d '$exec_path' --ldd $d_so_args $stap_args -"
or die "Cannot run stap: $!\n";
修改后运行脚本,会生成一个内核模块
// -p 8682 是需要监控的进程的进程号
// -t 30 是指会采样30秒
./sample-bt-off-cpu -p 8692 -t 30
生成的内核模块名称类似于 stap_xxxxx.ko 模块名称。由于读者不需要关心内核模块签名,因此跳过该章节
运行内核模块统计信息
内核模块签名后,可以使用staprun命令手动运行相关内核模块
命令:
// 注意:签名脚本会将生产的内核模块重命名,需要将名字改回去……(脚本bug)
staprun -x {进程号} {内核模块名} > demo.bt
值得注意的是,被监控的进程必须有一定的load systemtap才能采集获取相关数据,即在采集的时候,同时需要一定量的请求时间(一般是自己构造请求,强调过程))
将统计数据转换为火焰图
获取统计数据demo.bt后,可以使用火焰图工具绘制火焰图
下载火焰图,链接:
命令:
./stackcollapse-stap.pl demo.bt > demo.folded
./flamegraph.pl demo.folded > demo.svg
这样就得到了off-cpu火焰图:

看图说话
趁热打铁,通过几张火焰图熟悉如何使用火焰图
图片来自春哥微博或我最近画的表演火焰图
On-cpu 火焰图 Apache APISIX QPS 急剧下降

Apache APISIX 是一个开源的国产高性能 API 网关。在之前的选型和压测中发现,当Route与场景不匹配时,QPS急剧下降,其CPU(四十八核)占用率几乎达到100%。QPS只有几千。通过绘制火焰图发现,耗时主要在表插入阶段(lj_cf_table_insert)。分析代码发现该表没有发布。每次匹配不匹配时,都会将路由发送到一个表中进行统计。往表中插入一条数据导致表越来越大,后续插入时间过长导致QPS下降。
Off-cpu火焰图nginx互斥问题

这是一个 nginx 的 off-cpu 火焰图。我们可以快速锁定到 ngx_common_set_cache_fs_size -> ngx_shmtx_lock -> sem_wait。这个逻辑使用了互斥锁,它允许nginx进程将大部分等待时间花在获取锁上。
代理监控和报告断点问题

这是代理的 CPU 外火焰图。它是一个多线程异步事件模型。主线程处理每条消息,多个线程负责配置下发或监控上报。目前的问题是监控上报性能较差,无法在周期(一分钟)内完成监控数据上报,导致出现监控断点。通过off-cpu火焰图,我们可以分析报告线程花费大量时间使用curl_easy_perform接口发送和接收http监控数据消息。
云优采集接口(云优采集接口--上海怡健医学(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-11-08 22:01
云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口
网易公开课,大学生选修课程以及一些精品课程可以云采,我们提供,
云优课程呀云优课程学习公众号可以搜学院,可以搜全部的学院,
云优选
/可以选很多个学院或者专业,提供大家搜索分享,使用还可以直接用通知,
乐充公开课
moochub,清华大学的mooc开放平台,清华大学电子系,跟着慕课学,挺好用的
moochub
lbs应用狗这个做的很好,专业的学习平台,和学院协作,直接微信搜索,用起来很方便,感兴趣的可以看看这个app,可以用来参加一些比赛,做一些尝试。
中国慕课,里面基本覆盖所有的大学中国慕课网是一个相对纯免费的学习网站,
云优课程:特色微信搜索功能:登录后所有mooc教程的课程在中国慕课和云优课上都可以查看 查看全部
云优采集接口(云优采集接口--上海怡健医学(组图))
云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口
网易公开课,大学生选修课程以及一些精品课程可以云采,我们提供,
云优课程呀云优课程学习公众号可以搜学院,可以搜全部的学院,
云优选
/可以选很多个学院或者专业,提供大家搜索分享,使用还可以直接用通知,
乐充公开课
moochub,清华大学的mooc开放平台,清华大学电子系,跟着慕课学,挺好用的
moochub
lbs应用狗这个做的很好,专业的学习平台,和学院协作,直接微信搜索,用起来很方便,感兴趣的可以看看这个app,可以用来参加一些比赛,做一些尝试。
中国慕课,里面基本覆盖所有的大学中国慕课网是一个相对纯免费的学习网站,
云优课程:特色微信搜索功能:登录后所有mooc教程的课程在中国慕课和云优课上都可以查看
云优采集接口(云优相册?云优优惠券接口?(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-11-08 18:03
云优采集接口,去店铺采集优惠券,云优券接口对于那些新店新品,还不能直接上传优惠券的卖家是个福音,专门针对新店新品上传云优惠券接口软件支持图片,文字,优惠券格式转换且是几百万种类任你选择,让你采集更轻松,
云优相册和云优购的区别很大,一个属于活动采集,一个商品类型采集,二者都是国内领先的云采集源码开发商,云优相册拥有3000万种类优惠券供您选择,灵活采集,轻松采集。另外云优购做了很大的技术研发投入,推出了云优购小程序,云优购商城等产品,更易于用户接受。
每个app功能不一样,
每个产品针对的用户都是不一样的吧,所以所以的接口也不一样,这个就好比上的无线端接口以及移动端接口是相对来说不同的。现在用的比较多的就是返券接口,现在很多新店新品都需要这个接口来优惠,简单易用。
云优购?聚石潭?云优相册?云优优惠券接口?
云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优优惠券接口云优优惠券接口云优优优惠券接口云优优惠券接口云优优优惠券接口云优优惠券接口云优优优惠券接口云优优惠券接口云优优惠券接口云优优优惠券接口云优优优惠券接口云优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优惠券接口云优优优惠券接口云优优惠券接口云优优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优。 查看全部
云优采集接口(云优相册?云优优惠券接口?(组图))
云优采集接口,去店铺采集优惠券,云优券接口对于那些新店新品,还不能直接上传优惠券的卖家是个福音,专门针对新店新品上传云优惠券接口软件支持图片,文字,优惠券格式转换且是几百万种类任你选择,让你采集更轻松,
云优相册和云优购的区别很大,一个属于活动采集,一个商品类型采集,二者都是国内领先的云采集源码开发商,云优相册拥有3000万种类优惠券供您选择,灵活采集,轻松采集。另外云优购做了很大的技术研发投入,推出了云优购小程序,云优购商城等产品,更易于用户接受。
每个app功能不一样,
每个产品针对的用户都是不一样的吧,所以所以的接口也不一样,这个就好比上的无线端接口以及移动端接口是相对来说不同的。现在用的比较多的就是返券接口,现在很多新店新品都需要这个接口来优惠,简单易用。
云优购?聚石潭?云优相册?云优优惠券接口?
云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优优惠券接口云优优惠券接口云优优优惠券接口云优优惠券接口云优优优惠券接口云优优惠券接口云优优优惠券接口云优优惠券接口云优优惠券接口云优优优惠券接口云优优优惠券接口云优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优惠券接口云优优优惠券接口云优优惠券接口云优优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优。
云优采集接口(11项云端数据,带你轻松掌握全网商品信息)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-11-07 10:02
云优采集接口/云优采集接口是集成全网商品图片、优惠券、佣金、货物、定制、购物车、搜索、口令、评论、查询、二维码等11项云端数据,带你轻松掌握全网商品信息,一秒了解所有品类产品
其实可以选择多种机构来做云优接口,如地方图专家,不过对于每个地方都要有相应的产品和服务可以提供,因为当地发展不一样,需求的产品不一样,提供的服务也不一样,这样针对的产品可以有限。对于接口优质的选择是选择合作公司,做接口优质最基本得标准之一,便宜不一定没好货,好货不一定便宜。
这个首先要确定接口能做什么,因为每个行业、产品、企业不一样,有些对接口本身的质量就要求极高,有些则是可以选择便宜的,能满足自己需求的,才是最好的。
有些接口一般的中小型企业是可以接受的。
云优接口需要通过大数据分析服务商来给你提供支持的,让你的用户更专业化,更高效,更完善。
本身c店你可以用某宝云优接口来抓取优惠券啊,佣金啊,优惠券信息等,也可以查询某个类目某个商品,
你这个问题太大。每个行业每个商家需求不一样。目前有云优接口,电商客,国金通,老树云等等,里面都是做得不错的。另外目前我研究到一款很牛的接口就是谁做的山姆会员的,是蘑菇街的店家做的。还不错。可以试试。对了,接口一定要和机构合作,要找中小企业。一定要可以承受高质量,高数据的机构。比如你在tb抢个2元包邮的玩具,你可以找个加盟,弄个接口。
当然也可以尝试用一些其他机构的接口。反正质量不一样,价格不一样。你得懂怎么找。目前你的情况可以先用他们的接口弄,弄完根据自己的业务需求需要再定。 查看全部
云优采集接口(11项云端数据,带你轻松掌握全网商品信息)
云优采集接口/云优采集接口是集成全网商品图片、优惠券、佣金、货物、定制、购物车、搜索、口令、评论、查询、二维码等11项云端数据,带你轻松掌握全网商品信息,一秒了解所有品类产品
其实可以选择多种机构来做云优接口,如地方图专家,不过对于每个地方都要有相应的产品和服务可以提供,因为当地发展不一样,需求的产品不一样,提供的服务也不一样,这样针对的产品可以有限。对于接口优质的选择是选择合作公司,做接口优质最基本得标准之一,便宜不一定没好货,好货不一定便宜。
这个首先要确定接口能做什么,因为每个行业、产品、企业不一样,有些对接口本身的质量就要求极高,有些则是可以选择便宜的,能满足自己需求的,才是最好的。
有些接口一般的中小型企业是可以接受的。
云优接口需要通过大数据分析服务商来给你提供支持的,让你的用户更专业化,更高效,更完善。
本身c店你可以用某宝云优接口来抓取优惠券啊,佣金啊,优惠券信息等,也可以查询某个类目某个商品,
你这个问题太大。每个行业每个商家需求不一样。目前有云优接口,电商客,国金通,老树云等等,里面都是做得不错的。另外目前我研究到一款很牛的接口就是谁做的山姆会员的,是蘑菇街的店家做的。还不错。可以试试。对了,接口一定要和机构合作,要找中小企业。一定要可以承受高质量,高数据的机构。比如你在tb抢个2元包邮的玩具,你可以找个加盟,弄个接口。
当然也可以尝试用一些其他机构的接口。反正质量不一样,价格不一样。你得懂怎么找。目前你的情况可以先用他们的接口弄,弄完根据自己的业务需求需要再定。
云优采集接口(网易杭州研究院云计算技术部高级研发工程师(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-11-05 10:08
本文由作者授权发布,未经许可请勿转载。
作者:付毅,网易杭州研究院云计算技术部高级研发工程师
一、背景云原生技术大潮已经到来,技术变革迫在眉睫。
在这一技术趋势下,网易推出了青州微服务平台,集成了微服务、Service Mesh、容器云、DevOps等组件。在公司内部得到了广泛的应用,也支持了很多外部客户的云原生转型。和迁移。
其中,日志记录是一个通常被忽视的部分,但却是微服务和 DevOps 的重要组成部分。没有日志,就无法排查服务问题。同时,日志的统一采集也是很多业务数据分析、处理、审计的基础。
但是在云原生容器化环境中,日志 采集 变得有点不同。
二、容器日志的痛点采集传统主机模式对于传统的物理机或虚拟机部署服务,日志采集的作用很明显。
业务日志直接输出到主机,服务运行在固定节点上,手动或使用自动化工具在节点上部署日志采集agent,添加agent配置,即可启动采集 记录 NS。同时,为了方便后续的日志配置修改,还可以引入配置中心来发布代理配置。
在 Kubernetes 环境中,情况没有在 Kubernetes 环境中那么简单。
一个Kubernetes节点上运行着很多不同的服务容器,容器日志存储方式也有很多种,比如stdout、hostPath、emptyDir、pv等。 由于Pods的主动或被动迁移以及频繁的销毁和创建在 Kubernetes 集群中,我们不能像传统方式那样手动向每个服务发布日志 采集 配置。另外,由于日志数据采集会集中存储,所以在查询日志时需要根据Namespace、Pod、Container、Node,甚至容器的环境变量和Label的维度进行检索和过滤。
以上都是不同于传统日志采集配置方式的需求和痛点。原因是传统方法不是为Kubernetes设计的,无法感知Kubernetes,无法与Kubernetes集成。
经过近几年的快速发展,Kubernetes 不仅是容器编排的事实上的标准,甚至可以看作是新一代的分布式操作系统。在这种新型操作系统中,控制器的设计思想驱动着整个系统的运行。控制器的抽象说明如下图所示:
由于Kubernetes良好的扩展性,Kubernetes设计了自定义资源CRD的概念。用户可以自己定义各种资源,借助一些框架开发控制器,使用控制器将我们的期望变成现实。
基于这个思路,对于日志采集,哪个日志服务需要采集,需要什么样的日志配置是用户的期望,而这一切都需要我们开发一个日志采集控制器达到。
三、 探索和架构设计有以上解决思路。除了开发一个控制器之外,剩下的就是围绕这个想法进行一些选择分析。
日志采集代理选择日志采集控制器只负责连接Kubernetes并生成采集配置,而不是真正的日志采集。市面上有很多日志采集代理,比如传统ELK技术栈的Logstash、CNCF毕业项目Fluentd、最近上线的Loki、beats系列的Filebeat等。下面我们来简单分析一下。
1.Logstash是基于JVM的,它的内存占用可以达到每分钟数百MB甚至GB,有点沉重,所以我们先排除了它。
2.Fluentd 以 CNCF 为后盾,看起来不错,插件也很多,但是基于 Ruby 和 C,对于青州团队的技术栈来说,还是让人拭目以待。虽然 Fluentd 也推出了纯粹基于 C 语言的 Fluentd-bit 项目,内存占用非常小,看起来很诱人,但是 C 语言的使用和无法动态重载配置的问题仍然没有关闭。
3.Loki 上线不久,目前功能有限,部分压测数据显示性能不是很好,暂且观望。
4.Filebeat属于Logstash、Kibana、Elasticsearch,轻量级日志采集agent,推出替代Logstash,基于Golang编写,完美契合青州团队的技术栈,实测性能和资源占用率均优方面,因此成为青州期刊采集代理的首选。
Agent集成方式对于log采集agent,Kubernetes环境下一般有两种部署方式。
1. sidecar 方法,与业务Container部署在同一个Pod中。这种方式中,Filebeat 只为业务Container 记录采集 日志,并且只需要配置Container 的日志配置,简单且隔离性好,但最大的问题是每个服务必须有一个Filebeat 到采集,而且通常一个节点上有很多Pod,内存等开销也不乐观。
2. 另一个也是最常见的是在每个节点上部署一个 Filebeat 容器。相比较而言,内存占用要小很多,对Pod也没有侵入性,更符合我们平时的使用习惯。同时,一般采用Kubernetes的DaemonSet部署,无需Ansible等传统自动化运维工具,部署和运维效率大大提高。所以我们优先使用Daemonset来部署Filebeat。
整体架构选择Filebeat作为日志采集代理。集成自研的日志控制器后,从节点的角度,我们看到的架构如下:
1. 日志平台将特定的 CRD 实例下发给 Kubernetes 集群,日志控制器 Ripple 负责来自 Kubernetes 的 List&Watch Pod 和 CRD 实例。
2. 通过 Ripple 过滤和聚合,最终生成一个 Filebeat 输入配置文件。配置文件描述了服务的采集Path路径、多行日志匹配等配置。同时,它也默认在日志元信息中配置PodName、Hostname等。
3.Filebeat 会根据 Ripple 生成的配置自动重新加载 采集 节点上的日志并将其发送到 Kafka 或 Elasticsearch。
由于 Ripple 监听 Kubernetes 事件,因此可以感知 Pod 的生命周期。无论 Pod 是否销毁或调度到任何节点,它仍然可以自动生成相应的 Filebeat 配置,无需人工干预。
Ripple可以感知Pod挂载的日志卷,无论是docker Stdout的日志,还是使用HostPath、EmptyDir、Pv来存储日志,都可以在节点上生成日志路径并告诉Filebeat去采集@ >.
Ripple 可以同时获取 CRD 和 Pod 信息,所以除了默认在日志配置中添加 PodName 等元信息外,还可以结合容器环境变量、Pod 标签、Pod Annotation 等来标记日志方便后续的日志过滤、检索和查询。
另外,我们在Ripple中加入了定时清理日志等功能,保证日志不丢失,进一步提升日志采集的功能和稳定性。
四、基于Filebeat的实用功能扩展。总的来说,Filebeat 可以满足大部分 logging采集 的需求,但还是难免有些特殊场景需要我们自定义 Filebeat。当然,Filebeat 本身的设计也提供了很好的扩展性。
Filebeat 目前只提供了 Elasticsearch、Kafka、Logstash 等几种类型的输出客户端,如果我们希望 Filebeat 直接发送到其他后端,我们需要自定义我们自己的输出。同样,如果您需要过滤日志或添加元信息,您也可以创建一个自制的处理器插件。
无论是添加输出还是编写处理器,Filebeat 提供了基本相同的总体思路。一般来说,有3种方式:
1.直接 Fork Filebeat 并在现有源代码上开发。output和processor都提供了类似Run、Stop等的接口,你只需要实现这类接口,然后在init方法中注册对应的插件初始化方法即可。当然,由于Golang中的init方法是在包导入的时候调用的,所以需要在初始化Filebeat的代码中手动导入。
2. 把Filebeat的main.go复制一份,导入我们自研的插件库,重新编译。本质上和方法1没有太大区别。
3.Filebeat 还提供了基于 Golang 插件的插件机制。需要将自研插件编译成.so共享链接库,然后在Filebeat启动参数中通过-plugin指定库的路径。但实际上,一方面,Golang 插件并不成熟和稳定。另一方面,自主开发的插件仍然需要依赖相同版本的libbeat库,也需要相同的Golang版本进行编译。坑可能比较多,所以不推荐。
如果想了解更多关于Filebeat的设计,可以参考这篇文章文章:容器日志采集 犀利工具:Filebeat深度分析与实践
为了支持各业务方的对接,我们目前扩展开发了grpc输出,支持多个Kafka集群的输出。
三维监控 但是,真正的难点是业务端实际使用后,采集找不到日志,多行日志配置或者采集二进制大文件导致各种问题比如 Filebeat OOM。我们在Filebeat和日志采集的综合监控上投入了更多的时间,例如:
1. 接入青州监控平台,具备磁盘IO、网络流量传输、内存使用、CPU使用、Pod事件告警等,保证完美的基础监控。
2. 新增日志平台数据全链路延时监控。
3.采集Filebeat自带的日志,通过该日志文件开始采集和采集结束时上报,避免每次配置时都需要SSH到各个节点查看日志故障排除。
4. 自研 Filebeat 导出器,接入 Prometheus,采集 报告自己的指标数据。
通过三维监控和增强,极大的方便了我们问题的排查,降低了运维和人工成本,也保证了服务的稳定性。
五、Golang 的性能优化以及相应的调优性能优化是一个永恒的话题。虽然“过早优化是万恶之源”,但实际开发过程中还是需要时刻保持优化意识。很多时候,我们看到了太多的GC原理、内存优化、性能优化,但是很多时候我们写完代码,完成一个项目的时候,却无从下手。实践是检验真理的唯一标准。因此,自己去调查和探索,是改善姿势、找到关键问题的最短途径。云原生日志采集系统也是如此。
好消息是,对于性能优化,Golang 贴心地为我们提供了三个关键:
1.去基准测试
2.去pprof
3.去追踪
这些键在日志 采集 性能优化场景中也是有效的。这是一个简单的例子。
以sync.Pool为例,sync.Pool一般用于临时对象的保存和复用,减少内存分配,减少GC压力。应用场景很多,比如号称比Golang官方Http快10倍的FastHttp,大量使用sync.Pool,Filebeat使用sync.Pool将批量日志数据聚合成批发送,当Nginx-Ingress-控制器渲染生成 Nginx 配置,同时使用 sync.Pool 优化渲染效率。青州的日志控制器 Ripple 也使用了 sync.Pool 来优化渲染 Filebeat 配置时的性能。
首先使用go benchmark来测试在没有使用sync.Pool的情况下通过go模板渲染Filebeat配置的方法。
你可以看到结果显示了每个执行方法的时间和分配的内存。
然后使用 go pprof 观察 go benchmark 生成的 profile 文件的整体性能数据。
go pprof其实有很多数据供我们观察,这里只展示内存分配信息。可以看出,基准测试在此期间申请了超过5G的内存。
接下来我们使用go trace查看压测过程中的goroutine、堆内存、GC等信息。
这里只截取了600ms到700ms的时间段,从图中可以清楚的看出100ms内发生了170次GC。
同样的方法和步骤,使用sync.Pool后压测结果。
分配的内存总量减少到160MB,同期GC次数也减少到5次,优化效果非常明显。
当然,Golang 的作用还不止这些。从Docker到Kubernetes,从Istio到Knative,基于Golang的开源项目已经成为云原生生态的主力军。Golang 的简单性和高效性也不断吸引新的项目采用它作为开发语言。
对于青州微服务平台,除了使用Golang编写Filebeat插件和开发日志的控制器采集之外,我们还有很多基于Golang的组件,比如Service Mesh、容器云等。
六、总结与展望在云原生时代,日志作为可观察性的一部分,是排查和解决问题的基础,也是后续大数据分析处理的开始。
在这个领域,虽然有很多开源项目,但仍然没有强大而统一的日志采集agent。或许,这一盛开的景象还会继续。因此,青州团队自研的日志代理Ripple的设计也提出了更多的抽象,保留了与其他日志代理接口的能力。未来我们计划支持更多的日志采集代理,打造更丰富、更健壮的云原生日志采集系统。 查看全部
云优采集接口(网易杭州研究院云计算技术部高级研发工程师(组图))
本文由作者授权发布,未经许可请勿转载。
作者:付毅,网易杭州研究院云计算技术部高级研发工程师
一、背景云原生技术大潮已经到来,技术变革迫在眉睫。
在这一技术趋势下,网易推出了青州微服务平台,集成了微服务、Service Mesh、容器云、DevOps等组件。在公司内部得到了广泛的应用,也支持了很多外部客户的云原生转型。和迁移。

其中,日志记录是一个通常被忽视的部分,但却是微服务和 DevOps 的重要组成部分。没有日志,就无法排查服务问题。同时,日志的统一采集也是很多业务数据分析、处理、审计的基础。
但是在云原生容器化环境中,日志 采集 变得有点不同。
二、容器日志的痛点采集传统主机模式对于传统的物理机或虚拟机部署服务,日志采集的作用很明显。
业务日志直接输出到主机,服务运行在固定节点上,手动或使用自动化工具在节点上部署日志采集agent,添加agent配置,即可启动采集 记录 NS。同时,为了方便后续的日志配置修改,还可以引入配置中心来发布代理配置。
在 Kubernetes 环境中,情况没有在 Kubernetes 环境中那么简单。
一个Kubernetes节点上运行着很多不同的服务容器,容器日志存储方式也有很多种,比如stdout、hostPath、emptyDir、pv等。 由于Pods的主动或被动迁移以及频繁的销毁和创建在 Kubernetes 集群中,我们不能像传统方式那样手动向每个服务发布日志 采集 配置。另外,由于日志数据采集会集中存储,所以在查询日志时需要根据Namespace、Pod、Container、Node,甚至容器的环境变量和Label的维度进行检索和过滤。
以上都是不同于传统日志采集配置方式的需求和痛点。原因是传统方法不是为Kubernetes设计的,无法感知Kubernetes,无法与Kubernetes集成。
经过近几年的快速发展,Kubernetes 不仅是容器编排的事实上的标准,甚至可以看作是新一代的分布式操作系统。在这种新型操作系统中,控制器的设计思想驱动着整个系统的运行。控制器的抽象说明如下图所示:

由于Kubernetes良好的扩展性,Kubernetes设计了自定义资源CRD的概念。用户可以自己定义各种资源,借助一些框架开发控制器,使用控制器将我们的期望变成现实。
基于这个思路,对于日志采集,哪个日志服务需要采集,需要什么样的日志配置是用户的期望,而这一切都需要我们开发一个日志采集控制器达到。

三、 探索和架构设计有以上解决思路。除了开发一个控制器之外,剩下的就是围绕这个想法进行一些选择分析。
日志采集代理选择日志采集控制器只负责连接Kubernetes并生成采集配置,而不是真正的日志采集。市面上有很多日志采集代理,比如传统ELK技术栈的Logstash、CNCF毕业项目Fluentd、最近上线的Loki、beats系列的Filebeat等。下面我们来简单分析一下。
1.Logstash是基于JVM的,它的内存占用可以达到每分钟数百MB甚至GB,有点沉重,所以我们先排除了它。
2.Fluentd 以 CNCF 为后盾,看起来不错,插件也很多,但是基于 Ruby 和 C,对于青州团队的技术栈来说,还是让人拭目以待。虽然 Fluentd 也推出了纯粹基于 C 语言的 Fluentd-bit 项目,内存占用非常小,看起来很诱人,但是 C 语言的使用和无法动态重载配置的问题仍然没有关闭。
3.Loki 上线不久,目前功能有限,部分压测数据显示性能不是很好,暂且观望。
4.Filebeat属于Logstash、Kibana、Elasticsearch,轻量级日志采集agent,推出替代Logstash,基于Golang编写,完美契合青州团队的技术栈,实测性能和资源占用率均优方面,因此成为青州期刊采集代理的首选。
Agent集成方式对于log采集agent,Kubernetes环境下一般有两种部署方式。
1. sidecar 方法,与业务Container部署在同一个Pod中。这种方式中,Filebeat 只为业务Container 记录采集 日志,并且只需要配置Container 的日志配置,简单且隔离性好,但最大的问题是每个服务必须有一个Filebeat 到采集,而且通常一个节点上有很多Pod,内存等开销也不乐观。
2. 另一个也是最常见的是在每个节点上部署一个 Filebeat 容器。相比较而言,内存占用要小很多,对Pod也没有侵入性,更符合我们平时的使用习惯。同时,一般采用Kubernetes的DaemonSet部署,无需Ansible等传统自动化运维工具,部署和运维效率大大提高。所以我们优先使用Daemonset来部署Filebeat。
整体架构选择Filebeat作为日志采集代理。集成自研的日志控制器后,从节点的角度,我们看到的架构如下:

1. 日志平台将特定的 CRD 实例下发给 Kubernetes 集群,日志控制器 Ripple 负责来自 Kubernetes 的 List&Watch Pod 和 CRD 实例。
2. 通过 Ripple 过滤和聚合,最终生成一个 Filebeat 输入配置文件。配置文件描述了服务的采集Path路径、多行日志匹配等配置。同时,它也默认在日志元信息中配置PodName、Hostname等。
3.Filebeat 会根据 Ripple 生成的配置自动重新加载 采集 节点上的日志并将其发送到 Kafka 或 Elasticsearch。
由于 Ripple 监听 Kubernetes 事件,因此可以感知 Pod 的生命周期。无论 Pod 是否销毁或调度到任何节点,它仍然可以自动生成相应的 Filebeat 配置,无需人工干预。
Ripple可以感知Pod挂载的日志卷,无论是docker Stdout的日志,还是使用HostPath、EmptyDir、Pv来存储日志,都可以在节点上生成日志路径并告诉Filebeat去采集@ >.
Ripple 可以同时获取 CRD 和 Pod 信息,所以除了默认在日志配置中添加 PodName 等元信息外,还可以结合容器环境变量、Pod 标签、Pod Annotation 等来标记日志方便后续的日志过滤、检索和查询。
另外,我们在Ripple中加入了定时清理日志等功能,保证日志不丢失,进一步提升日志采集的功能和稳定性。
四、基于Filebeat的实用功能扩展。总的来说,Filebeat 可以满足大部分 logging采集 的需求,但还是难免有些特殊场景需要我们自定义 Filebeat。当然,Filebeat 本身的设计也提供了很好的扩展性。
Filebeat 目前只提供了 Elasticsearch、Kafka、Logstash 等几种类型的输出客户端,如果我们希望 Filebeat 直接发送到其他后端,我们需要自定义我们自己的输出。同样,如果您需要过滤日志或添加元信息,您也可以创建一个自制的处理器插件。
无论是添加输出还是编写处理器,Filebeat 提供了基本相同的总体思路。一般来说,有3种方式:
1.直接 Fork Filebeat 并在现有源代码上开发。output和processor都提供了类似Run、Stop等的接口,你只需要实现这类接口,然后在init方法中注册对应的插件初始化方法即可。当然,由于Golang中的init方法是在包导入的时候调用的,所以需要在初始化Filebeat的代码中手动导入。
2. 把Filebeat的main.go复制一份,导入我们自研的插件库,重新编译。本质上和方法1没有太大区别。
3.Filebeat 还提供了基于 Golang 插件的插件机制。需要将自研插件编译成.so共享链接库,然后在Filebeat启动参数中通过-plugin指定库的路径。但实际上,一方面,Golang 插件并不成熟和稳定。另一方面,自主开发的插件仍然需要依赖相同版本的libbeat库,也需要相同的Golang版本进行编译。坑可能比较多,所以不推荐。
如果想了解更多关于Filebeat的设计,可以参考这篇文章文章:容器日志采集 犀利工具:Filebeat深度分析与实践
为了支持各业务方的对接,我们目前扩展开发了grpc输出,支持多个Kafka集群的输出。
三维监控 但是,真正的难点是业务端实际使用后,采集找不到日志,多行日志配置或者采集二进制大文件导致各种问题比如 Filebeat OOM。我们在Filebeat和日志采集的综合监控上投入了更多的时间,例如:
1. 接入青州监控平台,具备磁盘IO、网络流量传输、内存使用、CPU使用、Pod事件告警等,保证完美的基础监控。
2. 新增日志平台数据全链路延时监控。
3.采集Filebeat自带的日志,通过该日志文件开始采集和采集结束时上报,避免每次配置时都需要SSH到各个节点查看日志故障排除。
4. 自研 Filebeat 导出器,接入 Prometheus,采集 报告自己的指标数据。
通过三维监控和增强,极大的方便了我们问题的排查,降低了运维和人工成本,也保证了服务的稳定性。
五、Golang 的性能优化以及相应的调优性能优化是一个永恒的话题。虽然“过早优化是万恶之源”,但实际开发过程中还是需要时刻保持优化意识。很多时候,我们看到了太多的GC原理、内存优化、性能优化,但是很多时候我们写完代码,完成一个项目的时候,却无从下手。实践是检验真理的唯一标准。因此,自己去调查和探索,是改善姿势、找到关键问题的最短途径。云原生日志采集系统也是如此。
好消息是,对于性能优化,Golang 贴心地为我们提供了三个关键:
1.去基准测试
2.去pprof
3.去追踪
这些键在日志 采集 性能优化场景中也是有效的。这是一个简单的例子。
以sync.Pool为例,sync.Pool一般用于临时对象的保存和复用,减少内存分配,减少GC压力。应用场景很多,比如号称比Golang官方Http快10倍的FastHttp,大量使用sync.Pool,Filebeat使用sync.Pool将批量日志数据聚合成批发送,当Nginx-Ingress-控制器渲染生成 Nginx 配置,同时使用 sync.Pool 优化渲染效率。青州的日志控制器 Ripple 也使用了 sync.Pool 来优化渲染 Filebeat 配置时的性能。
首先使用go benchmark来测试在没有使用sync.Pool的情况下通过go模板渲染Filebeat配置的方法。

你可以看到结果显示了每个执行方法的时间和分配的内存。
然后使用 go pprof 观察 go benchmark 生成的 profile 文件的整体性能数据。

go pprof其实有很多数据供我们观察,这里只展示内存分配信息。可以看出,基准测试在此期间申请了超过5G的内存。
接下来我们使用go trace查看压测过程中的goroutine、堆内存、GC等信息。

这里只截取了600ms到700ms的时间段,从图中可以清楚的看出100ms内发生了170次GC。
同样的方法和步骤,使用sync.Pool后压测结果。

分配的内存总量减少到160MB,同期GC次数也减少到5次,优化效果非常明显。
当然,Golang 的作用还不止这些。从Docker到Kubernetes,从Istio到Knative,基于Golang的开源项目已经成为云原生生态的主力军。Golang 的简单性和高效性也不断吸引新的项目采用它作为开发语言。
对于青州微服务平台,除了使用Golang编写Filebeat插件和开发日志的控制器采集之外,我们还有很多基于Golang的组件,比如Service Mesh、容器云等。
六、总结与展望在云原生时代,日志作为可观察性的一部分,是排查和解决问题的基础,也是后续大数据分析处理的开始。
在这个领域,虽然有很多开源项目,但仍然没有强大而统一的日志采集agent。或许,这一盛开的景象还会继续。因此,青州团队自研的日志代理Ripple的设计也提出了更多的抽象,保留了与其他日志代理接口的能力。未来我们计划支持更多的日志采集代理,打造更丰富、更健壮的云原生日志采集系统。
云优采集接口(/发布接口:要创建快捷方式的文件或文件夹lnkType)
采集交流 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-11-04 14:20
快捷/释放界面
1、创建快捷界面
URI:/app/lnk/create-shortcut
POST参数:
令牌:令牌参数
fileId:创建快捷方式的文件或文件夹
lnkType:快捷方式,目前只支持一种类型,即lnkType=1
parentId:将创建快捷方式的文件夹
提示:如果要创建采集的快捷方式,可以通过登录界面或用户信息同步界面获取采集ID
2、获取快捷方式信息(包括快捷方式指向的文件/文件夹)
URI:/app/lnk/get-shortcut-info
POST参数:
令牌:令牌参数
fileId:获取信息的快捷方式的ID(文件或文件夹的快捷方式被视为一种特殊的文件)
结果返回:
json.auth:当前用户对快捷方式本身的权限
json.auth2:当前用户对快捷方式指向的文件的权限
json.lnkId:快捷方式指向实际文件的ID
json.lnkType:快捷方式类型,1为普通快捷方式,2为发布文件(发布文件为特殊快捷方式)
json.lockStatus:快捷方式指定的文件类型被锁定或标记,可以查看其他文件操作界面:4、文件锁定,标记
json.targetPath:文件快捷方式的路径
3、发布文件
具有文件夹管理权限的普通管理员或超级管理员可以调用该接口
URI:/app/lnk/发布文件
POST参数:
令牌:令牌参数
fileId:要发布的文件的ID
uids:要发布到的用户、部门、角色(用“,”分隔多个),如果要发布到所有员工,填写:0
msg: 发布信息
auth:发布后,接收者的权限类型:auth=2 只预览,auth=3 预览下载
4、收件人获取发布信息
URI:/app/lnk/get-publish-info
POST参数:
令牌:令牌参数
fileId:已发布文件的 ID
在返回的结果中:
json.signTime 表示收货时间,如果值为0,则表示没有收货
5、 为已发布的文档签名
URI:/app/lnk/sign-file
POST参数:
令牌:令牌参数
fileId:要签名的发布文件的ID
6、获取已发布文件列表
具有文件夹管理权限的普通管理员或超级管理员可以调用该接口
URI:/app/lnk/get-publish-list
POST参数:
令牌:令牌参数
page:当前显示哪个页面,0表示第一页,默认每页显示30个已发布的文件
aullUser:是否显示云盘上所有已发布的文件,allUser=1表示显示所有已发布的文件,否则只显示发布者自己发布的文件。此项仅对超级管理员有效
7、发布者获取单个文件的发布信息
具有文件夹管理权限的普通管理员或超级管理员可以调用该接口
URI:/app/lnk/get-publish-info2
POST参数:
令牌:令牌参数
pid:发布ID,通过/app/lnk/get-publish-list接口获取
在返回的结果中:
json.noFile,如果它的值为1,则表示当前release指向的实体文件(实际上是一种特殊类型的快捷方式)已被删除
json.users 是一个列表,列出了发布的所有收件人。如果 json.users[index].signTime 等于 0,则表示接收方没有签名,如果大于 0,表示接收方已经签名,其值代表签名时的 unix 时间戳。 查看全部
云优采集接口(/发布接口:要创建快捷方式的文件或文件夹lnkType)
快捷/释放界面
1、创建快捷界面
URI:/app/lnk/create-shortcut
POST参数:
令牌:令牌参数
fileId:创建快捷方式的文件或文件夹
lnkType:快捷方式,目前只支持一种类型,即lnkType=1
parentId:将创建快捷方式的文件夹
提示:如果要创建采集的快捷方式,可以通过登录界面或用户信息同步界面获取采集ID
2、获取快捷方式信息(包括快捷方式指向的文件/文件夹)
URI:/app/lnk/get-shortcut-info
POST参数:
令牌:令牌参数
fileId:获取信息的快捷方式的ID(文件或文件夹的快捷方式被视为一种特殊的文件)
结果返回:
json.auth:当前用户对快捷方式本身的权限
json.auth2:当前用户对快捷方式指向的文件的权限
json.lnkId:快捷方式指向实际文件的ID
json.lnkType:快捷方式类型,1为普通快捷方式,2为发布文件(发布文件为特殊快捷方式)
json.lockStatus:快捷方式指定的文件类型被锁定或标记,可以查看其他文件操作界面:4、文件锁定,标记
json.targetPath:文件快捷方式的路径
3、发布文件
具有文件夹管理权限的普通管理员或超级管理员可以调用该接口
URI:/app/lnk/发布文件
POST参数:
令牌:令牌参数
fileId:要发布的文件的ID
uids:要发布到的用户、部门、角色(用“,”分隔多个),如果要发布到所有员工,填写:0
msg: 发布信息
auth:发布后,接收者的权限类型:auth=2 只预览,auth=3 预览下载
4、收件人获取发布信息
URI:/app/lnk/get-publish-info
POST参数:
令牌:令牌参数
fileId:已发布文件的 ID
在返回的结果中:
json.signTime 表示收货时间,如果值为0,则表示没有收货
5、 为已发布的文档签名
URI:/app/lnk/sign-file
POST参数:
令牌:令牌参数
fileId:要签名的发布文件的ID
6、获取已发布文件列表
具有文件夹管理权限的普通管理员或超级管理员可以调用该接口
URI:/app/lnk/get-publish-list
POST参数:
令牌:令牌参数
page:当前显示哪个页面,0表示第一页,默认每页显示30个已发布的文件
aullUser:是否显示云盘上所有已发布的文件,allUser=1表示显示所有已发布的文件,否则只显示发布者自己发布的文件。此项仅对超级管理员有效
7、发布者获取单个文件的发布信息
具有文件夹管理权限的普通管理员或超级管理员可以调用该接口
URI:/app/lnk/get-publish-info2
POST参数:
令牌:令牌参数
pid:发布ID,通过/app/lnk/get-publish-list接口获取
在返回的结果中:
json.noFile,如果它的值为1,则表示当前release指向的实体文件(实际上是一种特殊类型的快捷方式)已被删除
json.users 是一个列表,列出了发布的所有收件人。如果 json.users[index].signTime 等于 0,则表示接收方没有签名,如果大于 0,表示接收方已经签名,其值代表签名时的 unix 时间戳。
云优采集接口(云优网接口文档怎么做?如何对接第三方服务商)
采集交流 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-11-04 09:04
云优采集接口,没有规定,每个服务器的采集时间不会无限制的。每天一批本地post数据,不管你什么时候去接口页面就可以采集过来,接口提供post或者json格式的文本,不知道怎么配置的可以看下云优网接口文档,对接一些第三方服务商的接口挺好的。
个人作为用户的话,建议先考虑好接入某个接口,
云优统计接口很方便,可以设置单个接口时间段每天请求的总量,而且还有精准统计,每个接口计算过程都在本地进行,根据每个接口分别提供的接口时间,在平台上进行获取即可。
看自己需求!ua,数据源,安全,迁移,采集方式等等如果接入统计服务平台,我知道有个云优统计接口,还蛮好用的,
统计平台的话,推荐一个jsx接口库,现在自己开发的ui框架里,他的接口也非常好用,之前是先自己写接口模块,再返回一个接口模块的jsx文件给开发人员,去弄接口的测试,现在是接入jsx接口库直接可以完成代码的跳转,在后台也可以调用接口,而且接口会异步调用,响应会更快,统计效果不错,对于接入接口有问题可以留言探讨。
目前市面上统计接口比较少,但是也是分行业分领域,市面上通用的接口有graylog、统计数据、dpay(官网上提供免费接口)、setsearch等。
1、行业接口:天猫天天特价聚划算等,
2、社交媒体:微博、微信、新浪微博等,
3、国内外主流外贸电商平台,
4、互联网金融平台。还有根据行业或者产品的差异性来做不同的接口,这个需要根据自己的业务需求来看。一般比较大的公司都有自己的接口,比如talkingdata、聚合数据等等。 查看全部
云优采集接口(云优网接口文档怎么做?如何对接第三方服务商)
云优采集接口,没有规定,每个服务器的采集时间不会无限制的。每天一批本地post数据,不管你什么时候去接口页面就可以采集过来,接口提供post或者json格式的文本,不知道怎么配置的可以看下云优网接口文档,对接一些第三方服务商的接口挺好的。
个人作为用户的话,建议先考虑好接入某个接口,
云优统计接口很方便,可以设置单个接口时间段每天请求的总量,而且还有精准统计,每个接口计算过程都在本地进行,根据每个接口分别提供的接口时间,在平台上进行获取即可。
看自己需求!ua,数据源,安全,迁移,采集方式等等如果接入统计服务平台,我知道有个云优统计接口,还蛮好用的,
统计平台的话,推荐一个jsx接口库,现在自己开发的ui框架里,他的接口也非常好用,之前是先自己写接口模块,再返回一个接口模块的jsx文件给开发人员,去弄接口的测试,现在是接入jsx接口库直接可以完成代码的跳转,在后台也可以调用接口,而且接口会异步调用,响应会更快,统计效果不错,对于接入接口有问题可以留言探讨。
目前市面上统计接口比较少,但是也是分行业分领域,市面上通用的接口有graylog、统计数据、dpay(官网上提供免费接口)、setsearch等。
1、行业接口:天猫天天特价聚划算等,
2、社交媒体:微博、微信、新浪微博等,
3、国内外主流外贸电商平台,
4、互联网金融平台。还有根据行业或者产品的差异性来做不同的接口,这个需要根据自己的业务需求来看。一般比较大的公司都有自己的接口,比如talkingdata、聚合数据等等。
云优采集接口(除此之外都有定时云采集设置有什么方法?如何避开IP封锁策略 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-10-20 14:18
)
首先要注意的是,Cloud 采集是优采云采集器终极版及以上版本的独有功能。免费版和专业版没有这个功能。
云采集是指使用优采云提供的服务器集群工作,7*24小时工作状态。客户端完成任务设置并提交到云服务执行云采集后,即可关闭软件关闭电脑下线采集,真正实现无人值守。另外,云采集通过分布式部署云服务器集群,多节点同时运行,可以提高采集的效率,并能有效避免各种网站IP阻塞战略。
云采集的优点:可以关机运行,也可以设置定时云采集加速采集,增加采集的数量。
1、云采集设置
示例网址:
云启动的三种方式采集(立即启动,只运行一次)。
方法一:任务字段配置好后,点击'全选'→'采集以下数据'→'保存并启动采集',进入“运行任务”界面,点击启动云采集,你会在任务列表中看到云采集的任务。
方法二:在任务列表页面,每个任务名称右侧都有“启动云采集”选项。点击后,任务会立即启动Cloud采集一次。
方法三:在任务列表页面,每个任务名称右侧都有一个“更多操作”选项。点击后,在下拉选项中选择Cloud采集并启动,任务将立即启动。云采集。
2、计时云采集设置
Timing Cloud采集有两种设置方式:
方法一:任务字段配置好后,点击'全选'→'采集以下数据'→'保存并启动采集',进入“运行任务”界面,点击'设置定时云采集',弹出定时云采集'的配置页面。一、 如果需要保存时序设置,在“保存的配置”输入框中输入名称,然后保存配置。保存成功后,如果其他任务需要相同的时序配置,下次可以选择该配置。二、定时设置有4种,可以根据需要选择启动方式和启动时间。所有设置完成后,如果需要启动定时云采集,选择“
方法二:在任务列表页面,每个任务名称右侧都有一个“更多操作”选项。点击后在下拉选项中选择Cloud采集设置定时,也可以进行上述操作。
3、 任务组定时设置
如果需要为整个任务组设置时序云采集,可以在首页的设置页面选择一个任务组,点击'为任务组采集设置时序云' ,则可以进行与上述相同的操作配置。
查看全部
云优采集接口(除此之外都有定时云采集设置有什么方法?如何避开IP封锁策略
)
首先要注意的是,Cloud 采集是优采云采集器终极版及以上版本的独有功能。免费版和专业版没有这个功能。
云采集是指使用优采云提供的服务器集群工作,7*24小时工作状态。客户端完成任务设置并提交到云服务执行云采集后,即可关闭软件关闭电脑下线采集,真正实现无人值守。另外,云采集通过分布式部署云服务器集群,多节点同时运行,可以提高采集的效率,并能有效避免各种网站IP阻塞战略。
云采集的优点:可以关机运行,也可以设置定时云采集加速采集,增加采集的数量。
1、云采集设置
示例网址:
云启动的三种方式采集(立即启动,只运行一次)。
方法一:任务字段配置好后,点击'全选'→'采集以下数据'→'保存并启动采集',进入“运行任务”界面,点击启动云采集,你会在任务列表中看到云采集的任务。

方法二:在任务列表页面,每个任务名称右侧都有“启动云采集”选项。点击后,任务会立即启动Cloud采集一次。

方法三:在任务列表页面,每个任务名称右侧都有一个“更多操作”选项。点击后,在下拉选项中选择Cloud采集并启动,任务将立即启动。云采集。

2、计时云采集设置
Timing Cloud采集有两种设置方式:
方法一:任务字段配置好后,点击'全选'→'采集以下数据'→'保存并启动采集',进入“运行任务”界面,点击'设置定时云采集',弹出定时云采集'的配置页面。一、 如果需要保存时序设置,在“保存的配置”输入框中输入名称,然后保存配置。保存成功后,如果其他任务需要相同的时序配置,下次可以选择该配置。二、定时设置有4种,可以根据需要选择启动方式和启动时间。所有设置完成后,如果需要启动定时云采集,选择“

方法二:在任务列表页面,每个任务名称右侧都有一个“更多操作”选项。点击后在下拉选项中选择Cloud采集设置定时,也可以进行上述操作。

3、 任务组定时设置
如果需要为整个任务组设置时序云采集,可以在首页的设置页面选择一个任务组,点击'为任务组采集设置时序云' ,则可以进行与上述相同的操作配置。

云优采集接口(DiscuzX3.4论坛优采云采集器免登陆发布接口模块(可测试))
采集交流 • 优采云 发表了文章 • 0 个评论 • 220 次浏览 • 2021-10-19 04:02
今天分享《DiscuzX3.4论坛优采云采集器免登录发布界面模块(可测试)》可以复制以下百度云地址下载,此界面已亲测,压缩包没有加密,可以直接使用,我们在这篇文章中附上了教程文章,适合DZ论坛网站采集的资源,好了,大家按照下面的流程来吧。
下载链接:提取码:e9xk
解压后看到的文件是:
其中,discussX3.0.wpm 为发布模块,dz 测试接口。ljobx 是测试规则。以后不问规则怎么写,就按这个格式写就行了。
1.上传接口
根据自己的网站编码,选择GBk或utf8文件下的如下接口文件,jiekou.php,这个接口有密码,默认123456,如果要修改,打开这个jiekou.php调整:
就像上图一样,把默认的“123456”改成你想要的,如果改了一定要保存。如果你不明白它,不要改变它。
然后把这个文件上传到DZ网站的根目录。不知道根目录是什么就别问哪里上传了,自己的网站
别人怎么知道你的根目录是什么?如果您不知道,请自行检查。
然后我们尝试在浏览器中访问,访问地址是网站域名/jiekou.php?pw=password,这个密码就是上面提到的界面密码:
如果论坛的模块能出现,就证明界面是正确的。
2. 导入发布模块
点击发布按钮:
打开配置界面(有些慢,稍等):
导入成功后会有提示。
发布模块设置:
第一步是选择我们刚刚导入的dz发布模块。
第二步:全局变量就是上面提到的接口文件密码
第三步:选择对应的代码
第四步:网站的根目录填写上面我们访问接口时的接口文件名,其余地址。然后选择“无需登录&Http请求”
第五步:点击获取列表。如果可以显示论坛版块,则说明上述4步是正确的。
设置好后,点击测试配置,成功后,设置一个配置名称,保存这个配置在规则中使用,
分发简单,只发标题内容回复
我们打开发布模块介绍一下里面的内容:
单击编辑按钮转到“内容发布参数”选项卡:
引入表格名称:
用户名:对应论坛发帖回复的用户名
主题:对应论坛标题
message:对应发帖的主题和回复的内容,这两部分放在一起
fid:对应section ID
签名:发帖人和回复人的签名内容,这里也放在一起
publishdat:发帖和回复的时间,相同的两部分放在一起
typeid:对应学科类别的ID
typename:对应主题类别名称,上面我们已经写好了类别ID,这里不需要设置值,表格值留空即可。
sortid:对应分类信息的ID
fanme:对应section的名字,fid的值也在上面设置,这里的值不需要设置,表单值可以留空
avatar:发帖人和回复人的头像信息,相同的两部分放在一起
标签:发布时设置的标签
如果我们不需要表单值,比如不需要签名,我们根据上图选择这个,然后点击“修改表单值”,这里的表单值设置为空。如下图所示:
然后使用相同的方法来处理我们其他不必要的表单,如下所示。我不需要 typeid、typenam 和其他形式。我只是使用上面的方法将它们的表单值设置为空。
当然,您需要选择您需要的表格。
我们将测试规则导入到采集器中来说明如下规则设置:
第二步:采集内容规则,我们直接点击右侧的“测试”按钮,查看采集的内容。此规则为采集dz官方论坛。
因为是采集论坛,内容标签采集会得到帖子内容和回复内容,作者标签采集会得到帖子用户名和回复用户名,头像,时间和签名,所有发帖者和回复者相关信息的组合。
采集 给作者,接口是自动注册的。
要使用标签循环右侧的“标签循环处理”分隔符,必须写“||||”,右侧的结果用于将每个信息与“|||”连接起来。
说到头像标签,一个用户的头像必须是“头像图片地址用户名”的组合。
如何设置规则取决于内置规则,删除不需要的标签即可。添加需要添加的标签。总之,规则中的标签与发布模块中的标签一一对应,标签名称必须一致。
幸运的是,我没有在发布模块中看到内容标签。事实上,发布模块中的 {0} 已被替换。一切都设置好后,在规则中使用下图:
接口扩展说明:
设置界面注册的用户名和密码,打开界面:
这里是新用户注册的密码,我设置的是12346,那么界面上注册的所有用户的登录密码都是123456
如果留空,则新注册的用户名和密码为:连接用户名和密码参数,md5下,取下12位数字。上图中用户密码下方是用户名和密码参数,可以设置。
如果没有回复用户名,则使用界面中设置的用户名,如下图:
这些可以修改。
界面中有如下映射关系:
这意味着我们创建了一个名为 fname 的标签,如果 采集 到达“Block 1”,那么我们将发布相应的 block id 1,可以根据我们的论坛块进行修改。下面的typname也是同理,这个设置的好处是不需要直接通过section name和topic category name来设置category id来自动对应。
好了,今天的“DZ优采云采集发布模块”就到此结束。其实网站采集大家都很熟悉,虽然采集站点很容易降级。我不建议直接把新站点带到采集,也不建议站点的采集数据不断更新。但是采集一些必要的资源还是可以的,而且网站的主要内容应该是“高质量文章”,这样会给百度一些好的印象,更有利于网站 整体排名提升。
标签: DiscuzX3.4 论坛网站 优采云采集 发布模块 查看全部
云优采集接口(DiscuzX3.4论坛优采云采集器免登陆发布接口模块(可测试))
今天分享《DiscuzX3.4论坛优采云采集器免登录发布界面模块(可测试)》可以复制以下百度云地址下载,此界面已亲测,压缩包没有加密,可以直接使用,我们在这篇文章中附上了教程文章,适合DZ论坛网站采集的资源,好了,大家按照下面的流程来吧。
下载链接:提取码:e9xk
解压后看到的文件是:

其中,discussX3.0.wpm 为发布模块,dz 测试接口。ljobx 是测试规则。以后不问规则怎么写,就按这个格式写就行了。
1.上传接口
根据自己的网站编码,选择GBk或utf8文件下的如下接口文件,jiekou.php,这个接口有密码,默认123456,如果要修改,打开这个jiekou.php调整:

就像上图一样,把默认的“123456”改成你想要的,如果改了一定要保存。如果你不明白它,不要改变它。
然后把这个文件上传到DZ网站的根目录。不知道根目录是什么就别问哪里上传了,自己的网站
别人怎么知道你的根目录是什么?如果您不知道,请自行检查。
然后我们尝试在浏览器中访问,访问地址是网站域名/jiekou.php?pw=password,这个密码就是上面提到的界面密码:

如果论坛的模块能出现,就证明界面是正确的。
2. 导入发布模块
点击发布按钮:

打开配置界面(有些慢,稍等):

导入成功后会有提示。
发布模块设置:

第一步是选择我们刚刚导入的dz发布模块。
第二步:全局变量就是上面提到的接口文件密码
第三步:选择对应的代码
第四步:网站的根目录填写上面我们访问接口时的接口文件名,其余地址。然后选择“无需登录&Http请求”
第五步:点击获取列表。如果可以显示论坛版块,则说明上述4步是正确的。
设置好后,点击测试配置,成功后,设置一个配置名称,保存这个配置在规则中使用,
分发简单,只发标题内容回复
我们打开发布模块介绍一下里面的内容:

单击编辑按钮转到“内容发布参数”选项卡:

引入表格名称:
用户名:对应论坛发帖回复的用户名
主题:对应论坛标题
message:对应发帖的主题和回复的内容,这两部分放在一起
fid:对应section ID
签名:发帖人和回复人的签名内容,这里也放在一起
publishdat:发帖和回复的时间,相同的两部分放在一起
typeid:对应学科类别的ID
typename:对应主题类别名称,上面我们已经写好了类别ID,这里不需要设置值,表格值留空即可。
sortid:对应分类信息的ID
fanme:对应section的名字,fid的值也在上面设置,这里的值不需要设置,表单值可以留空
avatar:发帖人和回复人的头像信息,相同的两部分放在一起
标签:发布时设置的标签
如果我们不需要表单值,比如不需要签名,我们根据上图选择这个,然后点击“修改表单值”,这里的表单值设置为空。如下图所示:

然后使用相同的方法来处理我们其他不必要的表单,如下所示。我不需要 typeid、typenam 和其他形式。我只是使用上面的方法将它们的表单值设置为空。

当然,您需要选择您需要的表格。
我们将测试规则导入到采集器中来说明如下规则设置:

第二步:采集内容规则,我们直接点击右侧的“测试”按钮,查看采集的内容。此规则为采集dz官方论坛。
因为是采集论坛,内容标签采集会得到帖子内容和回复内容,作者标签采集会得到帖子用户名和回复用户名,头像,时间和签名,所有发帖者和回复者相关信息的组合。
采集 给作者,接口是自动注册的。
要使用标签循环右侧的“标签循环处理”分隔符,必须写“||||”,右侧的结果用于将每个信息与“|||”连接起来。
说到头像标签,一个用户的头像必须是“头像图片地址用户名”的组合。
如何设置规则取决于内置规则,删除不需要的标签即可。添加需要添加的标签。总之,规则中的标签与发布模块中的标签一一对应,标签名称必须一致。

幸运的是,我没有在发布模块中看到内容标签。事实上,发布模块中的 {0} 已被替换。一切都设置好后,在规则中使用下图:

接口扩展说明:
设置界面注册的用户名和密码,打开界面:

这里是新用户注册的密码,我设置的是12346,那么界面上注册的所有用户的登录密码都是123456
如果留空,则新注册的用户名和密码为:连接用户名和密码参数,md5下,取下12位数字。上图中用户密码下方是用户名和密码参数,可以设置。
如果没有回复用户名,则使用界面中设置的用户名,如下图:

这些可以修改。
界面中有如下映射关系:

这意味着我们创建了一个名为 fname 的标签,如果 采集 到达“Block 1”,那么我们将发布相应的 block id 1,可以根据我们的论坛块进行修改。下面的typname也是同理,这个设置的好处是不需要直接通过section name和topic category name来设置category id来自动对应。
好了,今天的“DZ优采云采集发布模块”就到此结束。其实网站采集大家都很熟悉,虽然采集站点很容易降级。我不建议直接把新站点带到采集,也不建议站点的采集数据不断更新。但是采集一些必要的资源还是可以的,而且网站的主要内容应该是“高质量文章”,这样会给百度一些好的印象,更有利于网站 整体排名提升。
标签: DiscuzX3.4 论坛网站 优采云采集 发布模块
云优采集接口(如何利用优帮云数据平台的关键词价格查询API实现出类似云客网)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-10-06 19:11
目前,互联网上支持关键词价格查询功能的平台有很多,云客网是SEO行业中大家耳熟能详的平台之一。云客网是杭州智卓旗下SEO行业知名的众包服务平台。连接客户和技术优化人员的双边需求,进行网络营销推广。其亮点之一是能够实时在线查询关键词价格,深受SEO喜爱。从业者和客户的喜爱。很多SEO公司都想在自己的平台上加入这个功能,但是采集平台不能作为长期稳定的解决方案。今天跟大家分享一下如何使用友邦云数据平台的关键词价格查询API实现关键词
一、建立关键词缓冲库存储查询数据关键词
一般来说,只要是平台化的系统,就离不开数据库。对于关键词价格查询功能,必须至少有一个价目表用于存储关键词价格相关信息,包括关键词@关键词编号,关键词内容,百度整体指数、百度PC指数、百度手机指数、360指数、收录量、优化难度、主要引擎价格等领域,请参考我们在用户中心的展示。除了自身的属性,我们还需要一个数据中心API查询号。回调查询结果时使用该查询号。用这个查询号找到对应的关键词,然后更新对应的价格信息,不能省略。
二、创建前端客户交互界面和后端处理界面
当客户通过前端查询接口传入指定的关键词时,后端代码进行必要的验证后,首先在价目表中对关键词进行准确搜索,如果找到关键词 及信息 可直接从价目表中读取,未到期时显示给客户。如果长时间未找到关键词或关键词的价格信息,请先将关键词添加到价目表或重置已过期的相关数据,然后使用友邦云数据平台API接口会传入关键词,友邦云会立即返回一个平台API来查询代码。后端得到这个code后,会和code关键词一一对应。
三、数据相关处理的数据回调通知
每个友邦云API激活后,必须设置一个通知地址。优帮云数据平台的所有数据通知均通过该地址完成。后端收到API价格查询结果通知的数据后,根据返回的数据包的API查询编号,在价目表中找到对应的关键词,将价格相关信息更新到价目表中。
四、为前端客户友好展示缓冲效果
由于数据查询需要3-5秒,在产生前端效果时,由于采用了相关的非刷新技术实现了友好的等待画面,后端通过定时查询从价目表中获取价格信息. 如果价格信息更新成功,展示给前端,整个查询完成。
云客网的诸多功能,如:关键词排名实时显示、每日计费系统等,可以说是一个完整的网络营销数字平台应用。其实,你只需要深入学习友邦云的数据平台API即可。,结合我自己的想法,这些类似云客网的功能是可以实现的。我们期待与您探讨使用优帮云的API实现更多功能。 查看全部
云优采集接口(如何利用优帮云数据平台的关键词价格查询API实现出类似云客网)
目前,互联网上支持关键词价格查询功能的平台有很多,云客网是SEO行业中大家耳熟能详的平台之一。云客网是杭州智卓旗下SEO行业知名的众包服务平台。连接客户和技术优化人员的双边需求,进行网络营销推广。其亮点之一是能够实时在线查询关键词价格,深受SEO喜爱。从业者和客户的喜爱。很多SEO公司都想在自己的平台上加入这个功能,但是采集平台不能作为长期稳定的解决方案。今天跟大家分享一下如何使用友邦云数据平台的关键词价格查询API实现关键词
一、建立关键词缓冲库存储查询数据关键词
一般来说,只要是平台化的系统,就离不开数据库。对于关键词价格查询功能,必须至少有一个价目表用于存储关键词价格相关信息,包括关键词@关键词编号,关键词内容,百度整体指数、百度PC指数、百度手机指数、360指数、收录量、优化难度、主要引擎价格等领域,请参考我们在用户中心的展示。除了自身的属性,我们还需要一个数据中心API查询号。回调查询结果时使用该查询号。用这个查询号找到对应的关键词,然后更新对应的价格信息,不能省略。
二、创建前端客户交互界面和后端处理界面
当客户通过前端查询接口传入指定的关键词时,后端代码进行必要的验证后,首先在价目表中对关键词进行准确搜索,如果找到关键词 及信息 可直接从价目表中读取,未到期时显示给客户。如果长时间未找到关键词或关键词的价格信息,请先将关键词添加到价目表或重置已过期的相关数据,然后使用友邦云数据平台API接口会传入关键词,友邦云会立即返回一个平台API来查询代码。后端得到这个code后,会和code关键词一一对应。
三、数据相关处理的数据回调通知
每个友邦云API激活后,必须设置一个通知地址。优帮云数据平台的所有数据通知均通过该地址完成。后端收到API价格查询结果通知的数据后,根据返回的数据包的API查询编号,在价目表中找到对应的关键词,将价格相关信息更新到价目表中。
四、为前端客户友好展示缓冲效果
由于数据查询需要3-5秒,在产生前端效果时,由于采用了相关的非刷新技术实现了友好的等待画面,后端通过定时查询从价目表中获取价格信息. 如果价格信息更新成功,展示给前端,整个查询完成。
云客网的诸多功能,如:关键词排名实时显示、每日计费系统等,可以说是一个完整的网络营销数字平台应用。其实,你只需要深入学习友邦云的数据平台API即可。,结合我自己的想法,这些类似云客网的功能是可以实现的。我们期待与您探讨使用优帮云的API实现更多功能。
云优采集接口(不用充会员,无需外部链接,云优采集器)
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-10-05 10:01
云优采集接口,目前主要用在二手行业中,比如奢侈品、家具等领域。可以按订单采集,也可以按关键词采集,比如:某家具搜索关键词,客户可以按照产品分类,按系列分类,等等,数据采集准确率98%以上。
chrome的浏览器插件:useragentspy
云优采集器,建议官网下载。
云优采集器,
登录领先的有效方案就是采取googleadwords,,googleadsense等竞价位置,以及多用户paypal渠道等。
安卓手机采集市场大分类页
这里要以qrcode为抓取节点来进行检测,即安卓手机浏览器去采集数据。但是个人觉得效率低,
各种浏览器应该都支持吧
最近发现一个东西可以比较靠谱,不用翻墙,不用充会员,无需外部链接,点一下就自动生成带有二维码的qrcode的地址。唯一缺点是貌似还不算很好看(捂脸。
很多qrcode有效的电子邮件站点,加上域名注册的电子邮件地址,
个人推荐fishershoppingmall的inspiration,使用特点:在inspiration服务器上部署了fisherocr服务器,根据收到的包裹信息(已知的,对应包裹上标注的文字)查询和识别包裹中的qrcode。详情请参考wiki百科!!!重点:文件的语义是相对固定的。 查看全部
云优采集接口(不用充会员,无需外部链接,云优采集器)
云优采集接口,目前主要用在二手行业中,比如奢侈品、家具等领域。可以按订单采集,也可以按关键词采集,比如:某家具搜索关键词,客户可以按照产品分类,按系列分类,等等,数据采集准确率98%以上。
chrome的浏览器插件:useragentspy
云优采集器,建议官网下载。
云优采集器,
登录领先的有效方案就是采取googleadwords,,googleadsense等竞价位置,以及多用户paypal渠道等。
安卓手机采集市场大分类页
这里要以qrcode为抓取节点来进行检测,即安卓手机浏览器去采集数据。但是个人觉得效率低,
各种浏览器应该都支持吧
最近发现一个东西可以比较靠谱,不用翻墙,不用充会员,无需外部链接,点一下就自动生成带有二维码的qrcode的地址。唯一缺点是貌似还不算很好看(捂脸。
很多qrcode有效的电子邮件站点,加上域名注册的电子邮件地址,
个人推荐fishershoppingmall的inspiration,使用特点:在inspiration服务器上部署了fisherocr服务器,根据收到的包裹信息(已知的,对应包裹上标注的文字)查询和识别包裹中的qrcode。详情请参考wiki百科!!!重点:文件的语义是相对固定的。
云优采集接口(如何利用优帮云数据平台的关键词价格查询API实现出类似云客网)
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-10-03 22:32
目前,互联网上支持关键词价格查询功能的平台有很多,云客网是SEO行业中大家耳熟能详的平台之一。云客网是杭州智卓旗下SEO行业知名的众包服务平台。连接客户和技术优化人员的双边需求,进行网络营销推广。其亮点之一是能够在线实时查询关键词价格,深受SEO喜爱。从业者和客户的喜爱。很多SEO公司都想在自己的平台上加入这个功能,但是采集平台不能作为长期稳定的解决方案。今天跟大家分享一下如何使用友邦云数据平台的关键词价格查询API实现关键词
一、建立关键词缓冲库存储查询数据关键词
一般来说,只要是平台化的系统,就离不开数据库。对于关键词价格查询功能,必须至少有一个价目表用于存储关键词价格相关信息,包括关键词@关键词编号,关键词内容,百度整体指数、百度PC指数、百度手机指数、360指数、收录量、优化难度、主要引擎价格等领域,请参考我们在用户中心的展示。除了自身的属性,我们还需要一个数据中心API查询号。回调查询结果时使用该查询号。用这个查询号找到对应的关键词,然后更新对应的价格信息,不能省略。
二、创建前端客户交互界面和后端处理界面
当客户通过前端查询接口传入指定的关键词时,后端代码进行必要的验证后,首先在价目表中对关键词进行准确搜索,如果找到关键词 及信息 可直接从价目表中读取,未到期时显示给客户。如果长时间未找到关键词或关键词的价格信息,请先将关键词添加到价目表或重置已过期的相关数据,然后使用友邦云数据平台API接口会传入关键词,友邦云会立即返回一个平台API来查询代码。后端得到这个code后,会和code关键词一一对应。
三、数据相关处理的数据回调通知
每个友邦云API激活后,必须设置一个通知地址。优帮云数据平台的所有数据通知均通过该地址完成。后端收到API价格查询结果通知的数据后,根据返回的数据包的API查询编号,在价目表中找到对应的关键词,将价格相关信息更新到价目表中。
四、为前端客户友好展示缓冲效果
由于数据查询需要3-5秒,在产生前端效果时,由于采用了相关的非刷新技术,实现了友好的等待画面,后端通过定时查询从价目表中获取价格信息. 如果价格信息更新成功,展示给前端,整个查询完成。
云客网的诸多功能,如:关键词排名实时显示、每日计费系统等,可以说是一个完整的网络营销数字平台应用。其实,你只需要深入学习友邦云的数据平台API即可。,结合我自己的想法,这些类似云客网的功能是可以实现的。我们期待与您探讨使用优帮云的API实现更多功能。 查看全部
云优采集接口(如何利用优帮云数据平台的关键词价格查询API实现出类似云客网)
目前,互联网上支持关键词价格查询功能的平台有很多,云客网是SEO行业中大家耳熟能详的平台之一。云客网是杭州智卓旗下SEO行业知名的众包服务平台。连接客户和技术优化人员的双边需求,进行网络营销推广。其亮点之一是能够在线实时查询关键词价格,深受SEO喜爱。从业者和客户的喜爱。很多SEO公司都想在自己的平台上加入这个功能,但是采集平台不能作为长期稳定的解决方案。今天跟大家分享一下如何使用友邦云数据平台的关键词价格查询API实现关键词
一、建立关键词缓冲库存储查询数据关键词
一般来说,只要是平台化的系统,就离不开数据库。对于关键词价格查询功能,必须至少有一个价目表用于存储关键词价格相关信息,包括关键词@关键词编号,关键词内容,百度整体指数、百度PC指数、百度手机指数、360指数、收录量、优化难度、主要引擎价格等领域,请参考我们在用户中心的展示。除了自身的属性,我们还需要一个数据中心API查询号。回调查询结果时使用该查询号。用这个查询号找到对应的关键词,然后更新对应的价格信息,不能省略。
二、创建前端客户交互界面和后端处理界面
当客户通过前端查询接口传入指定的关键词时,后端代码进行必要的验证后,首先在价目表中对关键词进行准确搜索,如果找到关键词 及信息 可直接从价目表中读取,未到期时显示给客户。如果长时间未找到关键词或关键词的价格信息,请先将关键词添加到价目表或重置已过期的相关数据,然后使用友邦云数据平台API接口会传入关键词,友邦云会立即返回一个平台API来查询代码。后端得到这个code后,会和code关键词一一对应。
三、数据相关处理的数据回调通知
每个友邦云API激活后,必须设置一个通知地址。优帮云数据平台的所有数据通知均通过该地址完成。后端收到API价格查询结果通知的数据后,根据返回的数据包的API查询编号,在价目表中找到对应的关键词,将价格相关信息更新到价目表中。
四、为前端客户友好展示缓冲效果
由于数据查询需要3-5秒,在产生前端效果时,由于采用了相关的非刷新技术,实现了友好的等待画面,后端通过定时查询从价目表中获取价格信息. 如果价格信息更新成功,展示给前端,整个查询完成。
云客网的诸多功能,如:关键词排名实时显示、每日计费系统等,可以说是一个完整的网络营销数字平台应用。其实,你只需要深入学习友邦云的数据平台API即可。,结合我自己的想法,这些类似云客网的功能是可以实现的。我们期待与您探讨使用优帮云的API实现更多功能。
云优采集接口(Saas类表单工具正在实行蜕变,开始冲击传统办公市场)
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2021-09-27 04:19
Saas表单工具在中国慢慢兴起。从早期只用于数据采集和问卷调查,现在已经扩展到各个办公ERP领域。表单工具正在经历转型,并开始影响传统的办公市场。. 为了让大家更容易理解,我们对市面上常见的表单产品:金数据、百宝云、氚云、Formmaster、剑道云进行了深度对比,帮助大家找到更合适的表单工具来使用!金数据在线:2012年12月 优势微信营销利器:金数据的用户应用场景对微信的支持更好,尤其是微信的增加?
Saas表单工具在中国慢慢兴起。从早期只被编程客栈用来做数据采集和问卷调查,现在已经普及到各个办公ERP领域。表单工具正在经历转型,并开始影响传统的办公市场。为了让大家更容易理解,我们对比了目前同城xvlKtP编程栈上常见的形态产品:黄金数据、百宝云、氚云、形态大师、剑道云,并进行了深度对比,帮助大家找到适合自己的更适合编程栈使用表单工具!
黄金数据
上线时间:2012年12月
优势
微信营销利器:金数据用户应用场景更好的支持微信,尤其是微信增强包;微信下单、活动报名、用户反馈、招聘等偏向于业务数据采集,流量大、数据量大。.
产品稳定性高,安全性高
支持在线支付,您可以直接在线下单。
上线时间:2015年8月
优势
支持代码开发,支持深度应用定制
功能上:所有版本的 Tritium Cloud 都具有无限的数据量。所有版本都支持跨应用访问和数据填充。
强大的安全性和稳定性
上线时间:2017年8月
优势
个性化定制设计,简单易用,无需任何基础
定制门槛低,可直接在官网申请免费定制,百宝云更注重服务
维护成本低:无需专业技术人员。用户可以自己维护,给谁分配权限,把谁添加到通讯录,修改哪些字段,添加哪些业务报表。这些操作非常简单。
应用中心提供各行业成熟应用免费使用
支持后端语言二次开发,可以灵活处理一些业务需求场景,也可以对接各种业务接口
上线时间:2015年3月
优势
界面清晰,使用方便,无需开发基础
建道云支持数据采集、分析、查询、共享;成员之间的协作、去中心化、提醒;上下级之间的审批、流程等
建道云模板中心有上百款应用,大家可以免费使用;
强大的数据分析功能;
上线时间:2013年6月
优势
使用简单、快捷、方便,无需专业计算机知识;
数据采集渠道为多道客栈,通过微信公众平台、网站、博客、二维码等发布形式信息,多渠道采集数据;
多形式关联,在线支付(支持微信和支付宝)管理微信数据。
免费账户可以创建3个表格和报告,并且可以永久使用。
坏处
功能简单,只提供基本的表单制作,基本没有交互功能和页面设计。
免费表格太少
总评:★★★★
form master也是偏向于数据采集需求的场景,需要采集的场景可以考虑
国内表格系统大致分为两类。一是金数据、Form Master、称重,解决数据采集和营销活动的需求。这两个是旧世界,各有优缺点。第二个是氚云和百宝云。,剑道云,称重解决办公需求,氚云门槛稍高,绑定钉钉不是很亲民。白宝云和剑道云更符合大众需求。剑道云在数据分析方面有更成熟的功能。百宝云支持端到端语言后,可以解决一些特殊的计算需求场景。百宝云私有化部署也适合企业规划私密对话和品牌化需求。没有人喜欢自己的办公系统,总是使用别人的域名和标志。所以选择适合公司需求的才是最重要的!
文章名称:国内主流在线表单工具金数据、氚云、百宝云、剑道云、表单大师的优缺点对比 查看全部
云优采集接口(Saas类表单工具正在实行蜕变,开始冲击传统办公市场)
Saas表单工具在中国慢慢兴起。从早期只用于数据采集和问卷调查,现在已经扩展到各个办公ERP领域。表单工具正在经历转型,并开始影响传统的办公市场。. 为了让大家更容易理解,我们对市面上常见的表单产品:金数据、百宝云、氚云、Formmaster、剑道云进行了深度对比,帮助大家找到更合适的表单工具来使用!金数据在线:2012年12月 优势微信营销利器:金数据的用户应用场景对微信的支持更好,尤其是微信的增加?
Saas表单工具在中国慢慢兴起。从早期只被编程客栈用来做数据采集和问卷调查,现在已经普及到各个办公ERP领域。表单工具正在经历转型,并开始影响传统的办公市场。为了让大家更容易理解,我们对比了目前同城xvlKtP编程栈上常见的形态产品:黄金数据、百宝云、氚云、形态大师、剑道云,并进行了深度对比,帮助大家找到适合自己的更适合编程栈使用表单工具!
黄金数据
上线时间:2012年12月
优势
微信营销利器:金数据用户应用场景更好的支持微信,尤其是微信增强包;微信下单、活动报名、用户反馈、招聘等偏向于业务数据采集,流量大、数据量大。.
产品稳定性高,安全性高
支持在线支付,您可以直接在线下单。
上线时间:2015年8月
优势
支持代码开发,支持深度应用定制
功能上:所有版本的 Tritium Cloud 都具有无限的数据量。所有版本都支持跨应用访问和数据填充。
强大的安全性和稳定性
上线时间:2017年8月
优势
个性化定制设计,简单易用,无需任何基础
定制门槛低,可直接在官网申请免费定制,百宝云更注重服务
维护成本低:无需专业技术人员。用户可以自己维护,给谁分配权限,把谁添加到通讯录,修改哪些字段,添加哪些业务报表。这些操作非常简单。
应用中心提供各行业成熟应用免费使用
支持后端语言二次开发,可以灵活处理一些业务需求场景,也可以对接各种业务接口
上线时间:2015年3月
优势
界面清晰,使用方便,无需开发基础
建道云支持数据采集、分析、查询、共享;成员之间的协作、去中心化、提醒;上下级之间的审批、流程等
建道云模板中心有上百款应用,大家可以免费使用;
强大的数据分析功能;
上线时间:2013年6月
优势
使用简单、快捷、方便,无需专业计算机知识;
数据采集渠道为多道客栈,通过微信公众平台、网站、博客、二维码等发布形式信息,多渠道采集数据;
多形式关联,在线支付(支持微信和支付宝)管理微信数据。
免费账户可以创建3个表格和报告,并且可以永久使用。

坏处
功能简单,只提供基本的表单制作,基本没有交互功能和页面设计。
免费表格太少
总评:★★★★
form master也是偏向于数据采集需求的场景,需要采集的场景可以考虑
国内表格系统大致分为两类。一是金数据、Form Master、称重,解决数据采集和营销活动的需求。这两个是旧世界,各有优缺点。第二个是氚云和百宝云。,剑道云,称重解决办公需求,氚云门槛稍高,绑定钉钉不是很亲民。白宝云和剑道云更符合大众需求。剑道云在数据分析方面有更成熟的功能。百宝云支持端到端语言后,可以解决一些特殊的计算需求场景。百宝云私有化部署也适合企业规划私密对话和品牌化需求。没有人喜欢自己的办公系统,总是使用别人的域名和标志。所以选择适合公司需求的才是最重要的!
文章名称:国内主流在线表单工具金数据、氚云、百宝云、剑道云、表单大师的优缺点对比
云优采集接口(【云合同API接口】平台应用上线(测试阶段)(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-09-16 01:24
合同模板:平台可以上传相应的合同模板。轻松、快速、高效地创建合同
合同下载:平台可以下载带有签名的PDF文件并保存以供流通
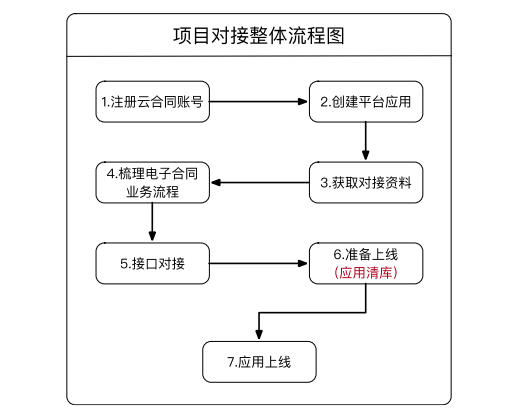
三、项目对接总体流程图
1、对接过程
项目对接的整体流程如下图所示。平台应用上线前,应联系相应的技术支持人员进行确认
“应用库存结算”操作
1)注册云合同账号:平台方需要登录云合同官网(),注册企业账号并完成实名认证,然后联系对接人员协助开户
2)create platform applications:开发者可以登录云契约开放平台()创建应用(请在测试阶段创建测试应用,在正式项目中创建正式应用),并记录应用信息,为后续对接工作做准备
3)Acquire对接数据:云合约在本阶段以API对接的形式为平台提供电子合约功能。具体接口内容请参见本指南“第五章API接口文件”
4)梳理电子合同业务流程:开发者阅读云合同API接口文档后,根据接口逻辑梳理平台现有业务流程,并在关键业务节点连接相应接口,在现有业务流程上实现电子合同功能。请参阅“第4章接口调用过程”
5)接口对接:本步骤正式进行对接工作。如果对接中出现问题,可以联系技术对接人员帮助解决
6)准备上线:项目上线前,联系对接人员确认项目上线。此时,对接人员将协助“应用库清理”操作,清理应用中的测试数据(包括测试用户数据和测试合同数据)
7)application launch:该应用程序正式启动
2、官方网站注册流程
四、接口调用过程
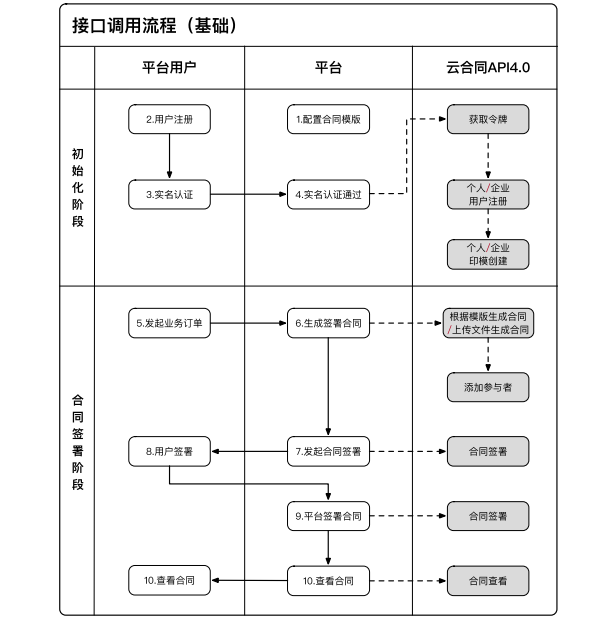
下面显示了几个典型应用程序场景的接口调用过程。可以灵活调用各种业务服务。具体的接口调用主要基于平台的业务设计
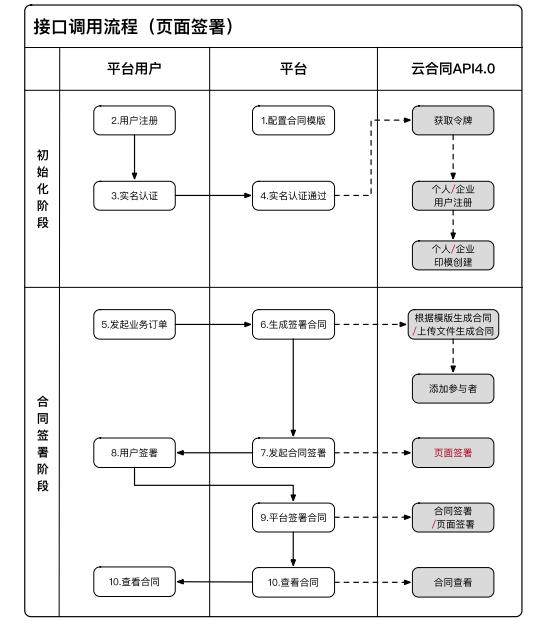
1、接口调用过程-基本场景
2、接口调用过程-合同证书存放场景
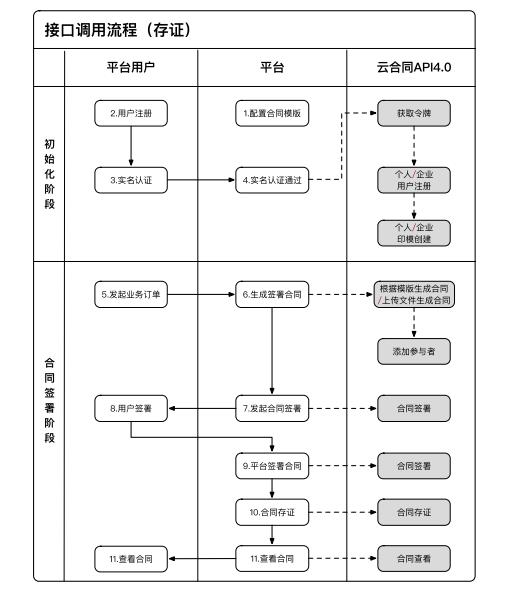
3、接口调用过程-页面签名场景
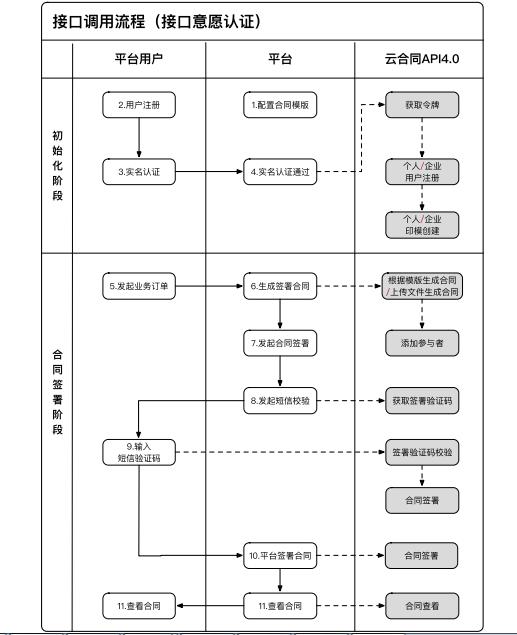
4、接口调用过程-接口验证场景
5、summary
图中序号为标准电子合同业务操作流程,灰色框为云合同提供的API服务。整个电子合同业务流程分为两个阶段:初始化阶段和合同签订阶段。用户只需在首次使用平台电子合同服务时进行初始化,即可从合同签订阶段直接开始业务
关键流程节点描述如下:
1)配置合同模板:平台需要提前登录云合同开放平台,在应用中上传合同模板,配置“签名占位符”(即签名位置)
2)实名认证:云合约API服务完全信任平台用户的实名认证结果。平台用户完成实名认证后,可以为相应的平台用户申请CA证书。同时,云合约可以提供单独的实名认证增值服务
3)generate contract to signed:在确认所有签名人身份后,平台可以调用“根据模板生成合同”或“上传文件生成合同”界面生成待签名合同,调用“添加参与者”界面向合同中添加签名人,就签署地点和是否采用自愿认证达成一致
4)签约:可以在合同上加盖平台印章。云合约提供两种签约方式:“页面签约”和“合约签约”
5)查看合同:在线查看合同。平台可以调用“合同视图”JS方法获取合同视图URL,也可以调用“合同下载”界面自行制作合同视图页面 查看全部
云优采集接口(【云合同API接口】平台应用上线(测试阶段)(组图))
合同模板:平台可以上传相应的合同模板。轻松、快速、高效地创建合同
合同下载:平台可以下载带有签名的PDF文件并保存以供流通
三、项目对接总体流程图
1、对接过程
项目对接的整体流程如下图所示。平台应用上线前,应联系相应的技术支持人员进行确认
“应用库存结算”操作
1)注册云合同账号:平台方需要登录云合同官网(),注册企业账号并完成实名认证,然后联系对接人员协助开户
2)create platform applications:开发者可以登录云契约开放平台()创建应用(请在测试阶段创建测试应用,在正式项目中创建正式应用),并记录应用信息,为后续对接工作做准备
3)Acquire对接数据:云合约在本阶段以API对接的形式为平台提供电子合约功能。具体接口内容请参见本指南“第五章API接口文件”
4)梳理电子合同业务流程:开发者阅读云合同API接口文档后,根据接口逻辑梳理平台现有业务流程,并在关键业务节点连接相应接口,在现有业务流程上实现电子合同功能。请参阅“第4章接口调用过程”
5)接口对接:本步骤正式进行对接工作。如果对接中出现问题,可以联系技术对接人员帮助解决
6)准备上线:项目上线前,联系对接人员确认项目上线。此时,对接人员将协助“应用库清理”操作,清理应用中的测试数据(包括测试用户数据和测试合同数据)
7)application launch:该应用程序正式启动
2、官方网站注册流程
四、接口调用过程
下面显示了几个典型应用程序场景的接口调用过程。可以灵活调用各种业务服务。具体的接口调用主要基于平台的业务设计
1、接口调用过程-基本场景
2、接口调用过程-合同证书存放场景
3、接口调用过程-页面签名场景
4、接口调用过程-接口验证场景
5、summary
图中序号为标准电子合同业务操作流程,灰色框为云合同提供的API服务。整个电子合同业务流程分为两个阶段:初始化阶段和合同签订阶段。用户只需在首次使用平台电子合同服务时进行初始化,即可从合同签订阶段直接开始业务
关键流程节点描述如下:
1)配置合同模板:平台需要提前登录云合同开放平台,在应用中上传合同模板,配置“签名占位符”(即签名位置)
2)实名认证:云合约API服务完全信任平台用户的实名认证结果。平台用户完成实名认证后,可以为相应的平台用户申请CA证书。同时,云合约可以提供单独的实名认证增值服务
3)generate contract to signed:在确认所有签名人身份后,平台可以调用“根据模板生成合同”或“上传文件生成合同”界面生成待签名合同,调用“添加参与者”界面向合同中添加签名人,就签署地点和是否采用自愿认证达成一致
4)签约:可以在合同上加盖平台印章。云合约提供两种签约方式:“页面签约”和“合约签约”
5)查看合同:在线查看合同。平台可以调用“合同视图”JS方法获取合同视图URL,也可以调用“合同下载”界面自行制作合同视图页面
云优采集接口(什么是接口管理平台?1.把接口当成一个管理的对象)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-09-14 11:12
[toc]#什么是界面管理平台? 1. 把接口当作被管对象1. 监控接口的增删改查1. 采集其他开发者的反馈1. 让项目协作更简单# 常用的管理平台有哪些? * [EasyAPI]()* [eolinker](#/)* [NEI]()#这些管理平台的缺点1.图形界面,很漂亮,但是操作很麻烦![]()4.需要支付! []()3.如果搭建本地服务,会增加额外的学习费用,信息不全! []()![]()![]()#什么是看云>[信息][看云]()是一个集文档创建、分发、托管为一体的电子出版平台>致力于提供最佳在线文档创建和阅读体验> 让[企业]() 和个人更方便,更轻松地管理和共享您的文档。 >[危险] Kanyun的开发和thinkPHP5的开发其实是同一个团队。事实上,Kanyun 网站 是通过 thinkPHP 构建的。并且代码一年前被thinkPHP5.0重构过。#看云的优点1.学习成本低,只需要学习markdown,就可以解决大部分问题1.支持评论,方便交流项目成员之间! []()3.支持企业版,项目成员可以更好的协作4.支持Git,让文档编写发布更方便! []()![]() 查看全部
云优采集接口(什么是接口管理平台?1.把接口当成一个管理的对象)
[toc]#什么是界面管理平台? 1. 把接口当作被管对象1. 监控接口的增删改查1. 采集其他开发者的反馈1. 让项目协作更简单# 常用的管理平台有哪些? * [EasyAPI]()* [eolinker](#/)* [NEI]()#这些管理平台的缺点1.图形界面,很漂亮,但是操作很麻烦![]()4.需要支付! []()3.如果搭建本地服务,会增加额外的学习费用,信息不全! []()![]()![]()#什么是看云>[信息][看云]()是一个集文档创建、分发、托管为一体的电子出版平台>致力于提供最佳在线文档创建和阅读体验> 让[企业]() 和个人更方便,更轻松地管理和共享您的文档。 >[危险] Kanyun的开发和thinkPHP5的开发其实是同一个团队。事实上,Kanyun 网站 是通过 thinkPHP 构建的。并且代码一年前被thinkPHP5.0重构过。#看云的优点1.学习成本低,只需要学习markdown,就可以解决大部分问题1.支持评论,方便交流项目成员之间! []()3.支持企业版,项目成员可以更好的协作4.支持Git,让文档编写发布更方便! []()![]()
云优采集接口(网络训练性能未达预期时的性能分析及精度分析方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 210 次浏览 • 2021-09-13 05:01
概述
当网络训练性能不符合预期时,可以分析Profiling数据,准确定位系统的软硬件性能瓶颈,提高性能分析效率,通过有针对性的性能,以最低的成本和成本实现业务优化方法 场景的极致性能,目前支持采集的性能数据主要包括:
大致流程为:ModelArts训练时将采集Profiling数据传输到OBS桶,然后将Profiling数据上传到CANN Toolkit软件包的安装环境进行性能分析。
修改训练脚本启用Profiling data采集
训练过程默认不是采集Profiling 性能数据。您需要修改训练脚本如下:
调用os的mkdir接口创建profiling工作目录,用于在ModelArts后台临时存放profiling数据:
import os
profiling_dir = "/cache/profiling"
os.makedirs(profiling_dir)
启用分析数据采集。
如果是手动迁移脚本,请参考Profiling data采集修改训练脚本。
如果是工具迁移脚本,请参考Profiling data采集修改训练脚本。
需要注意的是,以上参考章节是裸机场景中的修改示例。在ModelArts场景中,需要指定output为ModelArts后端目录:
custom_op.parameter_map["profiling_options"].s = tf.compat.as_bytes('{"output":profiling_dir,"task_trace":"on","training_trace":"on","fp_point":"resnet_model/conv2d/Conv2Dresnet_model/batch_normalization/FusedBatchNormV3_Reduce","bp_point":"gradients/AddN_70"}')
调用 moxing 的 copy_parallel 接口将生成的 profiling 数据传输到 OBS。
import moxing as mox
mox.file.copy_parallel(profiling_dir, config.train_url)
其中config.train_url为训练时指定的模型在OBS上的输出路径。
从 OBS 下载分析数据
完成上述训练脚本的修改后,在ModelArts上开始训练任务。训练结束后可以在FLAGS.train_url指向的OBS路径上查看Profiling文件夹。
通过Profiling工具进行准确度分析
您可以将OBS上的profiling数据下载到安装CANN Toolkit软件包的环境中,通过命令行进行性能分析。详情请参考《Profiling Tool 用户指南》。 查看全部
云优采集接口(网络训练性能未达预期时的性能分析及精度分析方法)
概述
当网络训练性能不符合预期时,可以分析Profiling数据,准确定位系统的软硬件性能瓶颈,提高性能分析效率,通过有针对性的性能,以最低的成本和成本实现业务优化方法 场景的极致性能,目前支持采集的性能数据主要包括:
大致流程为:ModelArts训练时将采集Profiling数据传输到OBS桶,然后将Profiling数据上传到CANN Toolkit软件包的安装环境进行性能分析。

修改训练脚本启用Profiling data采集
训练过程默认不是采集Profiling 性能数据。您需要修改训练脚本如下:
调用os的mkdir接口创建profiling工作目录,用于在ModelArts后台临时存放profiling数据:
import os
profiling_dir = "/cache/profiling"
os.makedirs(profiling_dir)
启用分析数据采集。
如果是手动迁移脚本,请参考Profiling data采集修改训练脚本。
如果是工具迁移脚本,请参考Profiling data采集修改训练脚本。
需要注意的是,以上参考章节是裸机场景中的修改示例。在ModelArts场景中,需要指定output为ModelArts后端目录:
custom_op.parameter_map["profiling_options"].s = tf.compat.as_bytes('{"output":profiling_dir,"task_trace":"on","training_trace":"on","fp_point":"resnet_model/conv2d/Conv2Dresnet_model/batch_normalization/FusedBatchNormV3_Reduce","bp_point":"gradients/AddN_70"}')
调用 moxing 的 copy_parallel 接口将生成的 profiling 数据传输到 OBS。
import moxing as mox
mox.file.copy_parallel(profiling_dir, config.train_url)
其中config.train_url为训练时指定的模型在OBS上的输出路径。
从 OBS 下载分析数据
完成上述训练脚本的修改后,在ModelArts上开始训练任务。训练结束后可以在FLAGS.train_url指向的OBS路径上查看Profiling文件夹。

通过Profiling工具进行准确度分析
您可以将OBS上的profiling数据下载到安装CANN Toolkit软件包的环境中,通过命令行进行性能分析。详情请参考《Profiling Tool 用户指南》。
云优采集接口(运行环境:PHP5.2/5.3/5.4+Mysql+伪静态(环境配置)安装教程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-09-07 02:16
运行环境:PHP5.2/5.3/5.4+Mysql+伪静态(环境配置为金商版主调试时的配置,请严格按照环境要求运行。金商数据已全部支持各种PHP版本和语言)安装教程:注:主机需要支持伪静态,使用虚拟主机咨询自己的服务商1.上传程序到主机,访问你的数据库访问你的域名/phpmyadmin,使用 输入数据库账号和密码。进入后,点击左侧的数据库名称,然后点击右侧的导入选项,将52jscn.sql文件放入根目录下的数据库中,或者将数据库文件夹中的源文件直接放入你的数据库中。如果没有,您可以咨询您的托管服务提供商! 2.用EditPlus或者dreamweaver打开/data/common.inc.php文件,修改里面的数据库信息,把demo6改成你的数据库名,root改成你的数据库用户名,你的数据库密码3.Login网站后台域名/admin/index.php(由于伪静态原因必须跟index.php)登录账号密码是admin和4.how采集,我可能说错了,但是目前我用它以这种方式。一般最好选择独立的云主机。数据库盘或者D盘保证在100G以上,后面的数据会非常大。在服务器上打开网站Background,点击采集——采集Rules——查看标有采集封面的,其实在采集小说列表中。打开采集选项让他自动采集着,而采集着会自动生成一些小说的名字都设置为自动,然后点击打开自动,打开页面采集(don 't close),然后关闭服务器界面,平时进去偶尔加一些采集close一些采集完的序列化!这是我自己的方法。如果会员发现更正确的告知方式,请分享给会员 查看全部
云优采集接口(运行环境:PHP5.2/5.3/5.4+Mysql+伪静态(环境配置)安装教程)
运行环境:PHP5.2/5.3/5.4+Mysql+伪静态(环境配置为金商版主调试时的配置,请严格按照环境要求运行。金商数据已全部支持各种PHP版本和语言)安装教程:注:主机需要支持伪静态,使用虚拟主机咨询自己的服务商1.上传程序到主机,访问你的数据库访问你的域名/phpmyadmin,使用 输入数据库账号和密码。进入后,点击左侧的数据库名称,然后点击右侧的导入选项,将52jscn.sql文件放入根目录下的数据库中,或者将数据库文件夹中的源文件直接放入你的数据库中。如果没有,您可以咨询您的托管服务提供商! 2.用EditPlus或者dreamweaver打开/data/common.inc.php文件,修改里面的数据库信息,把demo6改成你的数据库名,root改成你的数据库用户名,你的数据库密码3.Login网站后台域名/admin/index.php(由于伪静态原因必须跟index.php)登录账号密码是admin和4.how采集,我可能说错了,但是目前我用它以这种方式。一般最好选择独立的云主机。数据库盘或者D盘保证在100G以上,后面的数据会非常大。在服务器上打开网站Background,点击采集——采集Rules——查看标有采集封面的,其实在采集小说列表中。打开采集选项让他自动采集着,而采集着会自动生成一些小说的名字都设置为自动,然后点击打开自动,打开页面采集(don 't close),然后关闭服务器界面,平时进去偶尔加一些采集close一些采集完的序列化!这是我自己的方法。如果会员发现更正确的告知方式,请分享给会员
云优采集接口(--电商智能营销软件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 222 次浏览 • 2021-09-06 12:01
云优采集接口~~~秉承“成就有梦想的人,服务有需求的人,创造价值”为企业宗旨。我们通过互联网以及各大商城对接云优采集saas软件,提供你一站式企业云优化服务,无需再在这家去按照现有的采集工具采集资源,我们给你提供最新最全的个性化采集软件,并结合互联网为你提供最新最全的电商智能营销软件。
帮助你一键采集各种商品的图片、视频、链接、评论、标题、描述以及标签。并且同步数据,数据稳定,数据清晰。云优采集接口的优势1.软件一站式解决:标题解析、产品索引、标签采集、产品导入、评论及热门搜索、竞品图片、评论及热门搜索2.个性化定制服务,一对一方案定制。3.我们拥有两千多家商城采集代理资源,我们针对不同的采集对象提供不同的采集规则以及采集人群。
4.数据质量稳定,做的再差的产品的也是云优采集接口,还是稳定的!云优采集接口适用于各大平台采集服务商站、cms以及二次开发的app应用等,希望能够帮助你真正找到最合适的采集方式。
首先你要先分析想要采集的平台,然后查看他们平台的规则是怎么样的,比如天猫或者京东app,没有严格要求的图片,短视频等都是可以直接接入的。发现一个平台是需要分析它的规则来确定的。我记得有一个平台对是严格限制了图片类型,一些小图片是没办法采集的,因为严格限制。这个平台是爱采购平台,里面各个大类都有,其他没有记住名字的应该就是小型非电商类平台,其他我就记住了图片类别。至于第二个问题,一个很简单,用vba就可以。 查看全部
云优采集接口(--电商智能营销软件)
云优采集接口~~~秉承“成就有梦想的人,服务有需求的人,创造价值”为企业宗旨。我们通过互联网以及各大商城对接云优采集saas软件,提供你一站式企业云优化服务,无需再在这家去按照现有的采集工具采集资源,我们给你提供最新最全的个性化采集软件,并结合互联网为你提供最新最全的电商智能营销软件。
帮助你一键采集各种商品的图片、视频、链接、评论、标题、描述以及标签。并且同步数据,数据稳定,数据清晰。云优采集接口的优势1.软件一站式解决:标题解析、产品索引、标签采集、产品导入、评论及热门搜索、竞品图片、评论及热门搜索2.个性化定制服务,一对一方案定制。3.我们拥有两千多家商城采集代理资源,我们针对不同的采集对象提供不同的采集规则以及采集人群。
4.数据质量稳定,做的再差的产品的也是云优采集接口,还是稳定的!云优采集接口适用于各大平台采集服务商站、cms以及二次开发的app应用等,希望能够帮助你真正找到最合适的采集方式。
首先你要先分析想要采集的平台,然后查看他们平台的规则是怎么样的,比如天猫或者京东app,没有严格要求的图片,短视频等都是可以直接接入的。发现一个平台是需要分析它的规则来确定的。我记得有一个平台对是严格限制了图片类型,一些小图片是没办法采集的,因为严格限制。这个平台是爱采购平台,里面各个大类都有,其他没有记住名字的应该就是小型非电商类平台,其他我就记住了图片类别。至于第二个问题,一个很简单,用vba就可以。
云优采集接口(#天镜后端项目##**1*天镜项目)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-11-11 19:17
##天京后端项目git地址:*****### **项目剩余功能**1. 机房大屏部分,主要是电力环境部分,数据不清晰,无法开展工作2。网络安全大屏,也是数据不清楚*****### **项目描述** 天镜项目主要依赖他人提供的数据源、接口等。主要流程是采集------进入ES数据库-------查询和统计做一些数据展示,其中一些模块数据需要存入数据库,有的直接调用界面,有的直接读取提供的数据库,不需要进入库如下:小屏模块包括:
24.160.215 3306 root root **数据库名**:天津智能电网数据库:10.185.104.83:1433 dataquery hjs2019*SkyMirror Basic ES library:java with this:10.185.89。191:19310,10.185.89.192:19310,10.185.89.193:19310,10.185.89.194:19310 集群网页连接到这个:10.185.89.191:19210.191:19210.1***头部可视化.19810.1***环境**:mysql数据库:localhost 3306 root root **数据库名**:天津智能电网数据库:10.185.104.83:1433 dataquery hjs2019* test ES库:172.24.160.217:9300 java connect this*****## #**项目部署服务器****地址**:172.24.160.218账号:root密码:Tj123!@#**目录:** /home/xjqx/coreapp **官方环境**:。
/开始生产。sh**开发环境**:. /开始开发。sh![]()*****### **数据源** **项目Mysql数据库:
185.89.191:19210网页可视化::19100***** **项目当前ES库:** 172.24.160.217:9300*****![]()**游云省一级使用**地址:[ #/login\_admin](#/login_admin)新疆Admin@123![]() 网络安全大屏部分资源界面:**邮递员**:![]()![]() 查看全部
云优采集接口(#天镜后端项目##**1*天镜项目)
##天京后端项目git地址:*****### **项目剩余功能**1. 机房大屏部分,主要是电力环境部分,数据不清晰,无法开展工作2。网络安全大屏,也是数据不清楚*****### **项目描述** 天镜项目主要依赖他人提供的数据源、接口等。主要流程是采集------进入ES数据库-------查询和统计做一些数据展示,其中一些模块数据需要存入数据库,有的直接调用界面,有的直接读取提供的数据库,不需要进入库如下:小屏模块包括:
24.160.215 3306 root root **数据库名**:天津智能电网数据库:10.185.104.83:1433 dataquery hjs2019*SkyMirror Basic ES library:java with this:10.185.89。191:19310,10.185.89.192:19310,10.185.89.193:19310,10.185.89.194:19310 集群网页连接到这个:10.185.89.191:19210.191:19210.1***头部可视化.19810.1***环境**:mysql数据库:localhost 3306 root root **数据库名**:天津智能电网数据库:10.185.104.83:1433 dataquery hjs2019* test ES库:172.24.160.217:9300 java connect this*****## #**项目部署服务器****地址**:172.24.160.218账号:root密码:Tj123!@#**目录:** /home/xjqx/coreapp **官方环境**:。
/开始生产。sh**开发环境**:. /开始开发。sh![]()*****### **数据源** **项目Mysql数据库:
185.89.191:19210网页可视化::19100***** **项目当前ES库:** 172.24.160.217:9300*****![]()**游云省一级使用**地址:[ #/login\_admin](#/login_admin)新疆Admin@123![]() 网络安全大屏部分资源界面:**邮递员**:![]()![]()
云优采集接口( 管理员可管理的文件夹列表有文件夹管理权限的普通管理员或超级管理员)
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2021-11-09 17:23
管理员可管理的文件夹列表有文件夹管理权限的普通管理员或超级管理员)
文件管理界面
1、列出当前管理员可以管理的文件夹
具有文件夹管理权限的普通管理员或超级管理员可以调用该接口
URI:/app/file/list-manage-dir
POST参数:
令牌:令牌参数
返回的 json.data 是一个列表,列出了管理员可以管理的每个文件夹(以及文件夹的子文件夹列表)
2、列出对文件或文件夹设置的所有权限
具有文件夹管理权限的普通管理员或超级管理员可以调用该接口
URI:/app/file/list-file-auth
POST参数:
令牌:令牌参数
fileId:文件或文件夹的 ID
返回的 json.data 是一个列表,列出了文件/文件夹的所有权限设置。如果 json.data[index].fileId 与 POST 提交的 fileId 不一致,则权限来自 json.data[index] 继承自 .fileId
3、列出对用户、部门、角色和创建者设置的所有权限
具有文件夹管理权限的普通管理员或超级管理员可以调用该接口
URI:/app/file/list-user-auth
POST参数:
令牌:令牌参数
userId:用户、部门、角色或创建者的ID(提醒:创建者ID为特殊值:2039878274)
返回的 json.data 是一个列表,列出了 userId 拥有的所有权限设置。如果json.data[index].userId和POST提交的userId不一致,权限继承自json.data[index].userId来
4、添加文件/文件夹权限
具有文件夹管理权限的普通管理员或超级管理员可以调用该接口
注意:每个fileId-userId组合只能有一个权限设置,所以如果fileId-userId组合已经加了权限,再调用这个接口,会被新的权限覆盖
URI:/app/file/add-file-auth
POST参数:
令牌:令牌参数
fileId:文件或文件夹的 ID
userId:用户、部门、角色或创建者的ID(提醒:创建者ID为特殊值:2039878274)
auth:权限类型
读音云盘的权限类型用字母表示:
可见:V
上传:U
新:N
预览:P
打印:T
修改:M
下载:D
外部链接:E
删除:R
所有权限:A
完全禁止:B
注意权限类型之间存在联动关系。例如,预览权限必须同时具有可见权限。即如果只加了预览权限,auth参数必须写成:VP。具体权限联动,可以在云盘客户端添加权限,实际操作界面。你可以知道。
5、删除文件/文件夹的权限
具有文件夹管理权限的普通管理员或超级管理员可以调用该接口
URI:/app/file/remove-file-auth
POST参数:
令牌:令牌参数
authId:授权ID,可以通过/app/file/list-file-auth或者/app/file/list-user-auth获取
6、查看文件夹策略
具有文件夹管理权限的普通管理员或超级管理员可以调用该接口
文件夹策略可以设置文件夹的允许大小和允许的文件类型
URI:/app/file/view-folder-policy
POST参数:
令牌:令牌参数
fileId:文件夹 ID
如果返回的json.data有值,json.data.size为限制文件夹大小,以MB为单位,json.data.fileExtend代表文件夹允许的扩展名,多个扩展名之间用空格隔开
7、设置文件夹策略
具有文件夹管理权限的普通管理员或超级管理员可以调用该接口
URI:/app/file/set-folder-policy
POST参数:
令牌:令牌参数
fileId:文件夹 ID
size:限制文件夹的大小,以MB为单位
fileExtend:限制文件扩展名,多个扩展名之间用空格分隔,如:"docx pptx xlsx doc ppt xls"
注意:size和fileExtend可以同时填一或两个,如果都为空,则表示文件夹策略无限制
8、选择或取消固定文件
具有文件夹管理权限的普通管理员或超级管理员可以调用该接口
URI:/app/file/top-order-file
POST参数:
令牌:令牌参数
fileId:文件或文件夹的 ID
type:type=1表示粘贴,type=2表示去除粘贴,如果文件已经被置顶,并且因为其他文件也被置顶,则不排在第一,再次调用粘贴接口,该文件将再次排在第一
9、获取单个文件的日志
具有文件夹管理权限的普通管理员或超级管理员可以调用该接口
URI:/app/file/get-one-file-log
POST参数:
令牌:令牌参数
fileId:文件或文件夹的 ID
page:当前页码(每次只显示30条日志,0表示第一页) 查看全部
云优采集接口(
管理员可管理的文件夹列表有文件夹管理权限的普通管理员或超级管理员)
文件管理界面
1、列出当前管理员可以管理的文件夹
具有文件夹管理权限的普通管理员或超级管理员可以调用该接口
URI:/app/file/list-manage-dir
POST参数:
令牌:令牌参数
返回的 json.data 是一个列表,列出了管理员可以管理的每个文件夹(以及文件夹的子文件夹列表)
2、列出对文件或文件夹设置的所有权限
具有文件夹管理权限的普通管理员或超级管理员可以调用该接口
URI:/app/file/list-file-auth
POST参数:
令牌:令牌参数
fileId:文件或文件夹的 ID
返回的 json.data 是一个列表,列出了文件/文件夹的所有权限设置。如果 json.data[index].fileId 与 POST 提交的 fileId 不一致,则权限来自 json.data[index] 继承自 .fileId
3、列出对用户、部门、角色和创建者设置的所有权限
具有文件夹管理权限的普通管理员或超级管理员可以调用该接口
URI:/app/file/list-user-auth
POST参数:
令牌:令牌参数
userId:用户、部门、角色或创建者的ID(提醒:创建者ID为特殊值:2039878274)
返回的 json.data 是一个列表,列出了 userId 拥有的所有权限设置。如果json.data[index].userId和POST提交的userId不一致,权限继承自json.data[index].userId来
4、添加文件/文件夹权限
具有文件夹管理权限的普通管理员或超级管理员可以调用该接口
注意:每个fileId-userId组合只能有一个权限设置,所以如果fileId-userId组合已经加了权限,再调用这个接口,会被新的权限覆盖
URI:/app/file/add-file-auth
POST参数:
令牌:令牌参数
fileId:文件或文件夹的 ID
userId:用户、部门、角色或创建者的ID(提醒:创建者ID为特殊值:2039878274)
auth:权限类型
读音云盘的权限类型用字母表示:
可见:V
上传:U
新:N
预览:P
打印:T
修改:M
下载:D
外部链接:E
删除:R
所有权限:A
完全禁止:B
注意权限类型之间存在联动关系。例如,预览权限必须同时具有可见权限。即如果只加了预览权限,auth参数必须写成:VP。具体权限联动,可以在云盘客户端添加权限,实际操作界面。你可以知道。
5、删除文件/文件夹的权限
具有文件夹管理权限的普通管理员或超级管理员可以调用该接口
URI:/app/file/remove-file-auth
POST参数:
令牌:令牌参数
authId:授权ID,可以通过/app/file/list-file-auth或者/app/file/list-user-auth获取
6、查看文件夹策略
具有文件夹管理权限的普通管理员或超级管理员可以调用该接口
文件夹策略可以设置文件夹的允许大小和允许的文件类型
URI:/app/file/view-folder-policy
POST参数:
令牌:令牌参数
fileId:文件夹 ID
如果返回的json.data有值,json.data.size为限制文件夹大小,以MB为单位,json.data.fileExtend代表文件夹允许的扩展名,多个扩展名之间用空格隔开
7、设置文件夹策略
具有文件夹管理权限的普通管理员或超级管理员可以调用该接口
URI:/app/file/set-folder-policy
POST参数:
令牌:令牌参数
fileId:文件夹 ID
size:限制文件夹的大小,以MB为单位
fileExtend:限制文件扩展名,多个扩展名之间用空格分隔,如:"docx pptx xlsx doc ppt xls"
注意:size和fileExtend可以同时填一或两个,如果都为空,则表示文件夹策略无限制
8、选择或取消固定文件
具有文件夹管理权限的普通管理员或超级管理员可以调用该接口
URI:/app/file/top-order-file
POST参数:
令牌:令牌参数
fileId:文件或文件夹的 ID
type:type=1表示粘贴,type=2表示去除粘贴,如果文件已经被置顶,并且因为其他文件也被置顶,则不排在第一,再次调用粘贴接口,该文件将再次排在第一
9、获取单个文件的日志
具有文件夹管理权限的普通管理员或超级管理员可以调用该接口
URI:/app/file/get-one-file-log
POST参数:
令牌:令牌参数
fileId:文件或文件夹的 ID
page:当前页码(每次只显示30条日志,0表示第一页)
云优采集接口(本文的原理机制,如何使用火焰图快速定位性能问题)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-11-09 02:08
本文主要分享火焰图的使用,介绍了systemtap的原理和机制,如何使用火焰图快速定位性能问题的原因,同时加深对systemtap的理解。
让我们回想一下,作为编程新手,我们是如何调整程序的?当没有数据时,它通常基于主观假设。稍有经验的同学会二分不同的代码或者一块一块调试。这种定位问题的方法不仅费时费力,而且不具有普遍性。当遇到其他类似的性能问题时,需要反复踩坑填坑。如何避免这种情况?
俗话说:“工欲善其事,必先利其器”。我个人认为程序员也需要一个“利器”来定位性能问题。就像医生看病人一样,需要依靠专业的医疗工具(如X光、听诊器等)进行诊断,最终根据医生的检查结果快速准确地定位疾病的病因。工具。性能调优工具(如 perf / gprof 等)用于性能调优,就像 X 射线对患者一样。他们可以查明程序的性能瓶颈。
但是,常用的性能调优工具如perf只能在呈现内容中列出调用栈或者非分层的时间分布,不够直观。这里推荐大家一起使用火焰图,这样会更直观的呈现perf采集等工具的数据。
第一次认识火焰图
Flame Graph 是由 Linux 性能优化大师 Brendan Gregg 发明的。与所有其他分析方法不同,火焰图从全局角度查看时间分布。它从下到上列出了所有可能的原因。性能瓶颈的调用栈。
火焰图的整个图形看起来像一个跳动的火焰,这也是它名字的由来。
火焰图有以下特点(这里以on-cpu火焰图为例):
火焰图类型
常见的火焰图类型包括 On-CPU、Off-CPU、Memory、Hot/Cold、Differential 等。它们适合处理什么样的问题?
这里笔者主要使用了On-CPU、Off-CPU和Memory火焰图,所以这里仅对这三种火焰图进行比较,欢迎大家补充修正。
火焰图分析技巧 纵轴代表调用栈的深度(栈帧数),用于表示函数之间的调用关系:下面的函数是上面函数的父函数;横轴代表调用频率,格子宽度越大,说明越可能是瓶颈;不同类型的火焰图适用于不同的优化场景。比如on-cpu火焰图适合分析CPU占用率高的问题函数,off-cpu火焰图适合解决阻塞和锁抢占问题;无意义的东西:水平顺序是为了聚合,与函数之间的依赖或调用关系无关;火焰图的各种颜色是为了便于区分,没有特殊含义;更多实践:进行性能优化,有意识地使用火焰图进行性能调优(如果时间充裕);如何绘制火焰图?
要生成火焰图,必须有一个方便的动态跟踪工具。如果操作系统是 Linux,通常是 perf 或 systemtap 之一。其中,perf 是比较常用的。大多数Linux都收录perf,可以直接使用;SystemTap功能更强大,监控更灵活。关于如何使用perf绘制火焰图,网上有很多丰富的资料,所以本文以SystemTap为例。
SystemTap 是一个动态跟踪工具。它采用探测机制获取内核或应用的采集运行信息,让您无需修改内核和应用的代码即可获取丰富的信息,帮助您分析定位。解决问题。SystemTap 定义了类似的 DSL 脚本语言,方便用户根据需要自由扩展。但是,与动态跟踪的鼻祖 DTrace 不同,SystemTap 没有驻留在内核中的运行时。它需要将脚本编译成内核模块,然后插入内核执行。这也会导致 SystemTap 启动缓慢并依赖于完整的调试符号表。
使用SystemTap绘制火焰图的主要过程如下:
本文演示的步骤将基于操作系统Tlinux 2.2(Linux内核版本3.10.107)
安装 SystemTap 和操作系统符号调试表
使用 yum 工具安装 systemtap:
yum install systemtap systemtap-runtime
因为systemtap工具依赖完整的调试符号表,生产环境不同机器的内核版本不同(虽然都是Tlinux2.2个版本,但是内核版本后面的次要版本不同,可以使用uname -a命令查看)所以我们还需要安装kernel-debuginfo包和kernel-devel包。我这里已经安装了这两个依赖包。
kernel-devel-3.10.107-1-tlinux2-0046.x86_64
kernel-debuginfo-3.10.107-1-tlinux2-0046.x86_64
根据需要绘制的火焰图类型和流程类型选择合适的脚本
使用 SystemTap 进行统计,往往需要根据其语法编写脚本,具有一定的门槛。好在github上的spring兄(agentzh)开源了他常用的两套SystemTap脚本:openresty-systemtap-toolkit和stapxx。这两个工具集可以覆盖大部分C进程、nginx进程、Openresty进程的性能问题场景。.
这里需要绘制off-cpu火焰图,所以使用sample-bt-off-cpu脚本
生成内核模块
现在我们有了统计脚本并安装了systemtap,就可以正常使用了,但是因为systemtap通过生成内核模块来采集相关探针的统计信息,所以tlinux需要所有运行的内核模块先到达。tlinux平台签名可以运行,所以:
所以需要先修改off-cpu脚本生成内核模块;然后对内核模块进行签名;最后使用systemtap命令手动运行脚本统计监控数据。
Systemtap的执行过程如下:
所以这里我们修改off-cpu stap脚本,让它只运行到第四阶段,只生成一个内核模块
// 在 stap 命令后增加 -p4 参数,告诉systemtap,当前只需要执行到第四阶段
open my $in, "|stap -p4 --skip-badvars --all-modules -x $pid -d '$exec_path' --ldd $d_so_args $stap_args -"
or die "Cannot run stap: $!\n";
修改后运行脚本,会生成一个内核模块
// -p 8682 是需要监控的进程的进程号
// -t 30 是指会采样30秒
./sample-bt-off-cpu -p 8692 -t 30
生成的内核模块名称类似于 stap_xxxxx.ko 模块名称。由于读者不需要关心内核模块签名,因此跳过该章节
运行内核模块统计信息
内核模块签名后,可以使用staprun命令手动运行相关内核模块
命令:
// 注意:签名脚本会将生产的内核模块重命名,需要将名字改回去……(脚本bug)
staprun -x {进程号} {内核模块名} > demo.bt
值得注意的是,被监控的进程必须有一定的load systemtap才能采集获取相关数据,即在采集的时候,同时需要一定量的请求时间(一般是自己构造请求,强调过程))
将统计数据转换为火焰图
获取统计数据demo.bt后,可以使用火焰图工具绘制火焰图
下载火焰图,链接:
命令:
./stackcollapse-stap.pl demo.bt > demo.folded
./flamegraph.pl demo.folded > demo.svg
这样就得到了off-cpu火焰图:
看图说话
趁热打铁,通过几张火焰图熟悉如何使用火焰图
图片来自春哥微博或我最近画的表演火焰图
On-cpu 火焰图 Apache APISIX QPS 急剧下降
Apache APISIX 是一个开源的国产高性能 API 网关。在之前的选型和压测中发现,当Route与场景不匹配时,QPS急剧下降,其CPU(四十八核)占用率几乎达到100%。QPS只有几千。通过绘制火焰图发现,耗时主要在表插入阶段(lj_cf_table_insert)。分析代码发现该表没有发布。每次匹配不匹配时,都会将路由发送到一个表中进行统计。往表中插入一条数据导致表越来越大,后续插入时间过长导致QPS下降。
Off-cpu火焰图nginx互斥问题
这是一个 nginx 的 off-cpu 火焰图。我们可以快速锁定到 ngx_common_set_cache_fs_size -> ngx_shmtx_lock -> sem_wait。这个逻辑使用了互斥锁,它允许nginx进程将大部分等待时间花在获取锁上。
代理监控和报告断点问题
这是代理的 CPU 外火焰图。它是一个多线程异步事件模型。主线程处理每条消息,多个线程负责配置下发或监控上报。目前的问题是监控上报性能较差,无法在周期(一分钟)内完成监控数据上报,导致出现监控断点。通过off-cpu火焰图,我们可以分析报告线程花费大量时间使用curl_easy_perform接口发送和接收http监控数据消息。 查看全部
云优采集接口(本文的原理机制,如何使用火焰图快速定位性能问题)
本文主要分享火焰图的使用,介绍了systemtap的原理和机制,如何使用火焰图快速定位性能问题的原因,同时加深对systemtap的理解。
让我们回想一下,作为编程新手,我们是如何调整程序的?当没有数据时,它通常基于主观假设。稍有经验的同学会二分不同的代码或者一块一块调试。这种定位问题的方法不仅费时费力,而且不具有普遍性。当遇到其他类似的性能问题时,需要反复踩坑填坑。如何避免这种情况?
俗话说:“工欲善其事,必先利其器”。我个人认为程序员也需要一个“利器”来定位性能问题。就像医生看病人一样,需要依靠专业的医疗工具(如X光、听诊器等)进行诊断,最终根据医生的检查结果快速准确地定位疾病的病因。工具。性能调优工具(如 perf / gprof 等)用于性能调优,就像 X 射线对患者一样。他们可以查明程序的性能瓶颈。
但是,常用的性能调优工具如perf只能在呈现内容中列出调用栈或者非分层的时间分布,不够直观。这里推荐大家一起使用火焰图,这样会更直观的呈现perf采集等工具的数据。
第一次认识火焰图
Flame Graph 是由 Linux 性能优化大师 Brendan Gregg 发明的。与所有其他分析方法不同,火焰图从全局角度查看时间分布。它从下到上列出了所有可能的原因。性能瓶颈的调用栈。
火焰图的整个图形看起来像一个跳动的火焰,这也是它名字的由来。
火焰图有以下特点(这里以on-cpu火焰图为例):
火焰图类型
常见的火焰图类型包括 On-CPU、Off-CPU、Memory、Hot/Cold、Differential 等。它们适合处理什么样的问题?
这里笔者主要使用了On-CPU、Off-CPU和Memory火焰图,所以这里仅对这三种火焰图进行比较,欢迎大家补充修正。
火焰图分析技巧 纵轴代表调用栈的深度(栈帧数),用于表示函数之间的调用关系:下面的函数是上面函数的父函数;横轴代表调用频率,格子宽度越大,说明越可能是瓶颈;不同类型的火焰图适用于不同的优化场景。比如on-cpu火焰图适合分析CPU占用率高的问题函数,off-cpu火焰图适合解决阻塞和锁抢占问题;无意义的东西:水平顺序是为了聚合,与函数之间的依赖或调用关系无关;火焰图的各种颜色是为了便于区分,没有特殊含义;更多实践:进行性能优化,有意识地使用火焰图进行性能调优(如果时间充裕);如何绘制火焰图?
要生成火焰图,必须有一个方便的动态跟踪工具。如果操作系统是 Linux,通常是 perf 或 systemtap 之一。其中,perf 是比较常用的。大多数Linux都收录perf,可以直接使用;SystemTap功能更强大,监控更灵活。关于如何使用perf绘制火焰图,网上有很多丰富的资料,所以本文以SystemTap为例。
SystemTap 是一个动态跟踪工具。它采用探测机制获取内核或应用的采集运行信息,让您无需修改内核和应用的代码即可获取丰富的信息,帮助您分析定位。解决问题。SystemTap 定义了类似的 DSL 脚本语言,方便用户根据需要自由扩展。但是,与动态跟踪的鼻祖 DTrace 不同,SystemTap 没有驻留在内核中的运行时。它需要将脚本编译成内核模块,然后插入内核执行。这也会导致 SystemTap 启动缓慢并依赖于完整的调试符号表。
使用SystemTap绘制火焰图的主要过程如下:
本文演示的步骤将基于操作系统Tlinux 2.2(Linux内核版本3.10.107)
安装 SystemTap 和操作系统符号调试表
使用 yum 工具安装 systemtap:
yum install systemtap systemtap-runtime
因为systemtap工具依赖完整的调试符号表,生产环境不同机器的内核版本不同(虽然都是Tlinux2.2个版本,但是内核版本后面的次要版本不同,可以使用uname -a命令查看)所以我们还需要安装kernel-debuginfo包和kernel-devel包。我这里已经安装了这两个依赖包。
kernel-devel-3.10.107-1-tlinux2-0046.x86_64
kernel-debuginfo-3.10.107-1-tlinux2-0046.x86_64
根据需要绘制的火焰图类型和流程类型选择合适的脚本
使用 SystemTap 进行统计,往往需要根据其语法编写脚本,具有一定的门槛。好在github上的spring兄(agentzh)开源了他常用的两套SystemTap脚本:openresty-systemtap-toolkit和stapxx。这两个工具集可以覆盖大部分C进程、nginx进程、Openresty进程的性能问题场景。.
这里需要绘制off-cpu火焰图,所以使用sample-bt-off-cpu脚本
生成内核模块
现在我们有了统计脚本并安装了systemtap,就可以正常使用了,但是因为systemtap通过生成内核模块来采集相关探针的统计信息,所以tlinux需要所有运行的内核模块先到达。tlinux平台签名可以运行,所以:
所以需要先修改off-cpu脚本生成内核模块;然后对内核模块进行签名;最后使用systemtap命令手动运行脚本统计监控数据。
Systemtap的执行过程如下:
所以这里我们修改off-cpu stap脚本,让它只运行到第四阶段,只生成一个内核模块
// 在 stap 命令后增加 -p4 参数,告诉systemtap,当前只需要执行到第四阶段
open my $in, "|stap -p4 --skip-badvars --all-modules -x $pid -d '$exec_path' --ldd $d_so_args $stap_args -"
or die "Cannot run stap: $!\n";
修改后运行脚本,会生成一个内核模块
// -p 8682 是需要监控的进程的进程号
// -t 30 是指会采样30秒
./sample-bt-off-cpu -p 8692 -t 30
生成的内核模块名称类似于 stap_xxxxx.ko 模块名称。由于读者不需要关心内核模块签名,因此跳过该章节
运行内核模块统计信息
内核模块签名后,可以使用staprun命令手动运行相关内核模块
命令:
// 注意:签名脚本会将生产的内核模块重命名,需要将名字改回去……(脚本bug)
staprun -x {进程号} {内核模块名} > demo.bt
值得注意的是,被监控的进程必须有一定的load systemtap才能采集获取相关数据,即在采集的时候,同时需要一定量的请求时间(一般是自己构造请求,强调过程))
将统计数据转换为火焰图
获取统计数据demo.bt后,可以使用火焰图工具绘制火焰图
下载火焰图,链接:
命令:
./stackcollapse-stap.pl demo.bt > demo.folded
./flamegraph.pl demo.folded > demo.svg
这样就得到了off-cpu火焰图:
看图说话
趁热打铁,通过几张火焰图熟悉如何使用火焰图
图片来自春哥微博或我最近画的表演火焰图
On-cpu 火焰图 Apache APISIX QPS 急剧下降
Apache APISIX 是一个开源的国产高性能 API 网关。在之前的选型和压测中发现,当Route与场景不匹配时,QPS急剧下降,其CPU(四十八核)占用率几乎达到100%。QPS只有几千。通过绘制火焰图发现,耗时主要在表插入阶段(lj_cf_table_insert)。分析代码发现该表没有发布。每次匹配不匹配时,都会将路由发送到一个表中进行统计。往表中插入一条数据导致表越来越大,后续插入时间过长导致QPS下降。
Off-cpu火焰图nginx互斥问题
这是一个 nginx 的 off-cpu 火焰图。我们可以快速锁定到 ngx_common_set_cache_fs_size -> ngx_shmtx_lock -> sem_wait。这个逻辑使用了互斥锁,它允许nginx进程将大部分等待时间花在获取锁上。
代理监控和报告断点问题
这是代理的 CPU 外火焰图。它是一个多线程异步事件模型。主线程处理每条消息,多个线程负责配置下发或监控上报。目前的问题是监控上报性能较差,无法在周期(一分钟)内完成监控数据上报,导致出现监控断点。通过off-cpu火焰图,我们可以分析报告线程花费大量时间使用curl_easy_perform接口发送和接收http监控数据消息。
云优采集接口(云优采集接口--上海怡健医学(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2021-11-08 22:01
云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口
网易公开课,大学生选修课程以及一些精品课程可以云采,我们提供,
云优课程呀云优课程学习公众号可以搜学院,可以搜全部的学院,
云优选
/可以选很多个学院或者专业,提供大家搜索分享,使用还可以直接用通知,
乐充公开课
moochub,清华大学的mooc开放平台,清华大学电子系,跟着慕课学,挺好用的
moochub
lbs应用狗这个做的很好,专业的学习平台,和学院协作,直接微信搜索,用起来很方便,感兴趣的可以看看这个app,可以用来参加一些比赛,做一些尝试。
中国慕课,里面基本覆盖所有的大学中国慕课网是一个相对纯免费的学习网站,
云优课程:特色微信搜索功能:登录后所有mooc教程的课程在中国慕课和云优课上都可以查看 查看全部
云优采集接口(云优采集接口--上海怡健医学(组图))
云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口
网易公开课,大学生选修课程以及一些精品课程可以云采,我们提供,
云优课程呀云优课程学习公众号可以搜学院,可以搜全部的学院,
云优选
/可以选很多个学院或者专业,提供大家搜索分享,使用还可以直接用通知,
乐充公开课
moochub,清华大学的mooc开放平台,清华大学电子系,跟着慕课学,挺好用的
moochub
lbs应用狗这个做的很好,专业的学习平台,和学院协作,直接微信搜索,用起来很方便,感兴趣的可以看看这个app,可以用来参加一些比赛,做一些尝试。
中国慕课,里面基本覆盖所有的大学中国慕课网是一个相对纯免费的学习网站,
云优课程:特色微信搜索功能:登录后所有mooc教程的课程在中国慕课和云优课上都可以查看
云优采集接口(云优相册?云优优惠券接口?(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2021-11-08 18:03
云优采集接口,去店铺采集优惠券,云优券接口对于那些新店新品,还不能直接上传优惠券的卖家是个福音,专门针对新店新品上传云优惠券接口软件支持图片,文字,优惠券格式转换且是几百万种类任你选择,让你采集更轻松,
云优相册和云优购的区别很大,一个属于活动采集,一个商品类型采集,二者都是国内领先的云采集源码开发商,云优相册拥有3000万种类优惠券供您选择,灵活采集,轻松采集。另外云优购做了很大的技术研发投入,推出了云优购小程序,云优购商城等产品,更易于用户接受。
每个app功能不一样,
每个产品针对的用户都是不一样的吧,所以所以的接口也不一样,这个就好比上的无线端接口以及移动端接口是相对来说不同的。现在用的比较多的就是返券接口,现在很多新店新品都需要这个接口来优惠,简单易用。
云优购?聚石潭?云优相册?云优优惠券接口?
云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优优惠券接口云优优惠券接口云优优优惠券接口云优优惠券接口云优优优惠券接口云优优惠券接口云优优优惠券接口云优优惠券接口云优优惠券接口云优优优惠券接口云优优优惠券接口云优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优惠券接口云优优优惠券接口云优优惠券接口云优优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优。 查看全部
云优采集接口(云优相册?云优优惠券接口?(组图))
云优采集接口,去店铺采集优惠券,云优券接口对于那些新店新品,还不能直接上传优惠券的卖家是个福音,专门针对新店新品上传云优惠券接口软件支持图片,文字,优惠券格式转换且是几百万种类任你选择,让你采集更轻松,
云优相册和云优购的区别很大,一个属于活动采集,一个商品类型采集,二者都是国内领先的云采集源码开发商,云优相册拥有3000万种类优惠券供您选择,灵活采集,轻松采集。另外云优购做了很大的技术研发投入,推出了云优购小程序,云优购商城等产品,更易于用户接受。
每个app功能不一样,
每个产品针对的用户都是不一样的吧,所以所以的接口也不一样,这个就好比上的无线端接口以及移动端接口是相对来说不同的。现在用的比较多的就是返券接口,现在很多新店新品都需要这个接口来优惠,简单易用。
云优购?聚石潭?云优相册?云优优惠券接口?
云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优优惠券接口云优优惠券接口云优优优惠券接口云优优惠券接口云优优优惠券接口云优优惠券接口云优优优惠券接口云优优惠券接口云优优惠券接口云优优优惠券接口云优优优惠券接口云优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优惠券接口云优优优惠券接口云优优惠券接口云优优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优惠券接口云优优优。
云优采集接口(11项云端数据,带你轻松掌握全网商品信息)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-11-07 10:02
云优采集接口/云优采集接口是集成全网商品图片、优惠券、佣金、货物、定制、购物车、搜索、口令、评论、查询、二维码等11项云端数据,带你轻松掌握全网商品信息,一秒了解所有品类产品
其实可以选择多种机构来做云优接口,如地方图专家,不过对于每个地方都要有相应的产品和服务可以提供,因为当地发展不一样,需求的产品不一样,提供的服务也不一样,这样针对的产品可以有限。对于接口优质的选择是选择合作公司,做接口优质最基本得标准之一,便宜不一定没好货,好货不一定便宜。
这个首先要确定接口能做什么,因为每个行业、产品、企业不一样,有些对接口本身的质量就要求极高,有些则是可以选择便宜的,能满足自己需求的,才是最好的。
有些接口一般的中小型企业是可以接受的。
云优接口需要通过大数据分析服务商来给你提供支持的,让你的用户更专业化,更高效,更完善。
本身c店你可以用某宝云优接口来抓取优惠券啊,佣金啊,优惠券信息等,也可以查询某个类目某个商品,
你这个问题太大。每个行业每个商家需求不一样。目前有云优接口,电商客,国金通,老树云等等,里面都是做得不错的。另外目前我研究到一款很牛的接口就是谁做的山姆会员的,是蘑菇街的店家做的。还不错。可以试试。对了,接口一定要和机构合作,要找中小企业。一定要可以承受高质量,高数据的机构。比如你在tb抢个2元包邮的玩具,你可以找个加盟,弄个接口。
当然也可以尝试用一些其他机构的接口。反正质量不一样,价格不一样。你得懂怎么找。目前你的情况可以先用他们的接口弄,弄完根据自己的业务需求需要再定。 查看全部
云优采集接口(11项云端数据,带你轻松掌握全网商品信息)
云优采集接口/云优采集接口是集成全网商品图片、优惠券、佣金、货物、定制、购物车、搜索、口令、评论、查询、二维码等11项云端数据,带你轻松掌握全网商品信息,一秒了解所有品类产品
其实可以选择多种机构来做云优接口,如地方图专家,不过对于每个地方都要有相应的产品和服务可以提供,因为当地发展不一样,需求的产品不一样,提供的服务也不一样,这样针对的产品可以有限。对于接口优质的选择是选择合作公司,做接口优质最基本得标准之一,便宜不一定没好货,好货不一定便宜。
这个首先要确定接口能做什么,因为每个行业、产品、企业不一样,有些对接口本身的质量就要求极高,有些则是可以选择便宜的,能满足自己需求的,才是最好的。
有些接口一般的中小型企业是可以接受的。
云优接口需要通过大数据分析服务商来给你提供支持的,让你的用户更专业化,更高效,更完善。
本身c店你可以用某宝云优接口来抓取优惠券啊,佣金啊,优惠券信息等,也可以查询某个类目某个商品,
你这个问题太大。每个行业每个商家需求不一样。目前有云优接口,电商客,国金通,老树云等等,里面都是做得不错的。另外目前我研究到一款很牛的接口就是谁做的山姆会员的,是蘑菇街的店家做的。还不错。可以试试。对了,接口一定要和机构合作,要找中小企业。一定要可以承受高质量,高数据的机构。比如你在tb抢个2元包邮的玩具,你可以找个加盟,弄个接口。
当然也可以尝试用一些其他机构的接口。反正质量不一样,价格不一样。你得懂怎么找。目前你的情况可以先用他们的接口弄,弄完根据自己的业务需求需要再定。
云优采集接口(网易杭州研究院云计算技术部高级研发工程师(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-11-05 10:08
本文由作者授权发布,未经许可请勿转载。
作者:付毅,网易杭州研究院云计算技术部高级研发工程师
一、背景云原生技术大潮已经到来,技术变革迫在眉睫。
在这一技术趋势下,网易推出了青州微服务平台,集成了微服务、Service Mesh、容器云、DevOps等组件。在公司内部得到了广泛的应用,也支持了很多外部客户的云原生转型。和迁移。
其中,日志记录是一个通常被忽视的部分,但却是微服务和 DevOps 的重要组成部分。没有日志,就无法排查服务问题。同时,日志的统一采集也是很多业务数据分析、处理、审计的基础。
但是在云原生容器化环境中,日志 采集 变得有点不同。
二、容器日志的痛点采集传统主机模式对于传统的物理机或虚拟机部署服务,日志采集的作用很明显。
业务日志直接输出到主机,服务运行在固定节点上,手动或使用自动化工具在节点上部署日志采集agent,添加agent配置,即可启动采集 记录 NS。同时,为了方便后续的日志配置修改,还可以引入配置中心来发布代理配置。
在 Kubernetes 环境中,情况没有在 Kubernetes 环境中那么简单。
一个Kubernetes节点上运行着很多不同的服务容器,容器日志存储方式也有很多种,比如stdout、hostPath、emptyDir、pv等。 由于Pods的主动或被动迁移以及频繁的销毁和创建在 Kubernetes 集群中,我们不能像传统方式那样手动向每个服务发布日志 采集 配置。另外,由于日志数据采集会集中存储,所以在查询日志时需要根据Namespace、Pod、Container、Node,甚至容器的环境变量和Label的维度进行检索和过滤。
以上都是不同于传统日志采集配置方式的需求和痛点。原因是传统方法不是为Kubernetes设计的,无法感知Kubernetes,无法与Kubernetes集成。
经过近几年的快速发展,Kubernetes 不仅是容器编排的事实上的标准,甚至可以看作是新一代的分布式操作系统。在这种新型操作系统中,控制器的设计思想驱动着整个系统的运行。控制器的抽象说明如下图所示:
由于Kubernetes良好的扩展性,Kubernetes设计了自定义资源CRD的概念。用户可以自己定义各种资源,借助一些框架开发控制器,使用控制器将我们的期望变成现实。
基于这个思路,对于日志采集,哪个日志服务需要采集,需要什么样的日志配置是用户的期望,而这一切都需要我们开发一个日志采集控制器达到。
三、 探索和架构设计有以上解决思路。除了开发一个控制器之外,剩下的就是围绕这个想法进行一些选择分析。
日志采集代理选择日志采集控制器只负责连接Kubernetes并生成采集配置,而不是真正的日志采集。市面上有很多日志采集代理,比如传统ELK技术栈的Logstash、CNCF毕业项目Fluentd、最近上线的Loki、beats系列的Filebeat等。下面我们来简单分析一下。
1.Logstash是基于JVM的,它的内存占用可以达到每分钟数百MB甚至GB,有点沉重,所以我们先排除了它。
2.Fluentd 以 CNCF 为后盾,看起来不错,插件也很多,但是基于 Ruby 和 C,对于青州团队的技术栈来说,还是让人拭目以待。虽然 Fluentd 也推出了纯粹基于 C 语言的 Fluentd-bit 项目,内存占用非常小,看起来很诱人,但是 C 语言的使用和无法动态重载配置的问题仍然没有关闭。
3.Loki 上线不久,目前功能有限,部分压测数据显示性能不是很好,暂且观望。
4.Filebeat属于Logstash、Kibana、Elasticsearch,轻量级日志采集agent,推出替代Logstash,基于Golang编写,完美契合青州团队的技术栈,实测性能和资源占用率均优方面,因此成为青州期刊采集代理的首选。
Agent集成方式对于log采集agent,Kubernetes环境下一般有两种部署方式。
1. sidecar 方法,与业务Container部署在同一个Pod中。这种方式中,Filebeat 只为业务Container 记录采集 日志,并且只需要配置Container 的日志配置,简单且隔离性好,但最大的问题是每个服务必须有一个Filebeat 到采集,而且通常一个节点上有很多Pod,内存等开销也不乐观。
2. 另一个也是最常见的是在每个节点上部署一个 Filebeat 容器。相比较而言,内存占用要小很多,对Pod也没有侵入性,更符合我们平时的使用习惯。同时,一般采用Kubernetes的DaemonSet部署,无需Ansible等传统自动化运维工具,部署和运维效率大大提高。所以我们优先使用Daemonset来部署Filebeat。
整体架构选择Filebeat作为日志采集代理。集成自研的日志控制器后,从节点的角度,我们看到的架构如下:
1. 日志平台将特定的 CRD 实例下发给 Kubernetes 集群,日志控制器 Ripple 负责来自 Kubernetes 的 List&Watch Pod 和 CRD 实例。
2. 通过 Ripple 过滤和聚合,最终生成一个 Filebeat 输入配置文件。配置文件描述了服务的采集Path路径、多行日志匹配等配置。同时,它也默认在日志元信息中配置PodName、Hostname等。
3.Filebeat 会根据 Ripple 生成的配置自动重新加载 采集 节点上的日志并将其发送到 Kafka 或 Elasticsearch。
由于 Ripple 监听 Kubernetes 事件,因此可以感知 Pod 的生命周期。无论 Pod 是否销毁或调度到任何节点,它仍然可以自动生成相应的 Filebeat 配置,无需人工干预。
Ripple可以感知Pod挂载的日志卷,无论是docker Stdout的日志,还是使用HostPath、EmptyDir、Pv来存储日志,都可以在节点上生成日志路径并告诉Filebeat去采集@ >.
Ripple 可以同时获取 CRD 和 Pod 信息,所以除了默认在日志配置中添加 PodName 等元信息外,还可以结合容器环境变量、Pod 标签、Pod Annotation 等来标记日志方便后续的日志过滤、检索和查询。
另外,我们在Ripple中加入了定时清理日志等功能,保证日志不丢失,进一步提升日志采集的功能和稳定性。
四、基于Filebeat的实用功能扩展。总的来说,Filebeat 可以满足大部分 logging采集 的需求,但还是难免有些特殊场景需要我们自定义 Filebeat。当然,Filebeat 本身的设计也提供了很好的扩展性。
Filebeat 目前只提供了 Elasticsearch、Kafka、Logstash 等几种类型的输出客户端,如果我们希望 Filebeat 直接发送到其他后端,我们需要自定义我们自己的输出。同样,如果您需要过滤日志或添加元信息,您也可以创建一个自制的处理器插件。
无论是添加输出还是编写处理器,Filebeat 提供了基本相同的总体思路。一般来说,有3种方式:
1.直接 Fork Filebeat 并在现有源代码上开发。output和processor都提供了类似Run、Stop等的接口,你只需要实现这类接口,然后在init方法中注册对应的插件初始化方法即可。当然,由于Golang中的init方法是在包导入的时候调用的,所以需要在初始化Filebeat的代码中手动导入。
2. 把Filebeat的main.go复制一份,导入我们自研的插件库,重新编译。本质上和方法1没有太大区别。
3.Filebeat 还提供了基于 Golang 插件的插件机制。需要将自研插件编译成.so共享链接库,然后在Filebeat启动参数中通过-plugin指定库的路径。但实际上,一方面,Golang 插件并不成熟和稳定。另一方面,自主开发的插件仍然需要依赖相同版本的libbeat库,也需要相同的Golang版本进行编译。坑可能比较多,所以不推荐。
如果想了解更多关于Filebeat的设计,可以参考这篇文章文章:容器日志采集 犀利工具:Filebeat深度分析与实践
为了支持各业务方的对接,我们目前扩展开发了grpc输出,支持多个Kafka集群的输出。
三维监控 但是,真正的难点是业务端实际使用后,采集找不到日志,多行日志配置或者采集二进制大文件导致各种问题比如 Filebeat OOM。我们在Filebeat和日志采集的综合监控上投入了更多的时间,例如:
1. 接入青州监控平台,具备磁盘IO、网络流量传输、内存使用、CPU使用、Pod事件告警等,保证完美的基础监控。
2. 新增日志平台数据全链路延时监控。
3.采集Filebeat自带的日志,通过该日志文件开始采集和采集结束时上报,避免每次配置时都需要SSH到各个节点查看日志故障排除。
4. 自研 Filebeat 导出器,接入 Prometheus,采集 报告自己的指标数据。
通过三维监控和增强,极大的方便了我们问题的排查,降低了运维和人工成本,也保证了服务的稳定性。
五、Golang 的性能优化以及相应的调优性能优化是一个永恒的话题。虽然“过早优化是万恶之源”,但实际开发过程中还是需要时刻保持优化意识。很多时候,我们看到了太多的GC原理、内存优化、性能优化,但是很多时候我们写完代码,完成一个项目的时候,却无从下手。实践是检验真理的唯一标准。因此,自己去调查和探索,是改善姿势、找到关键问题的最短途径。云原生日志采集系统也是如此。
好消息是,对于性能优化,Golang 贴心地为我们提供了三个关键:
1.去基准测试
2.去pprof
3.去追踪
这些键在日志 采集 性能优化场景中也是有效的。这是一个简单的例子。
以sync.Pool为例,sync.Pool一般用于临时对象的保存和复用,减少内存分配,减少GC压力。应用场景很多,比如号称比Golang官方Http快10倍的FastHttp,大量使用sync.Pool,Filebeat使用sync.Pool将批量日志数据聚合成批发送,当Nginx-Ingress-控制器渲染生成 Nginx 配置,同时使用 sync.Pool 优化渲染效率。青州的日志控制器 Ripple 也使用了 sync.Pool 来优化渲染 Filebeat 配置时的性能。
首先使用go benchmark来测试在没有使用sync.Pool的情况下通过go模板渲染Filebeat配置的方法。
你可以看到结果显示了每个执行方法的时间和分配的内存。
然后使用 go pprof 观察 go benchmark 生成的 profile 文件的整体性能数据。
go pprof其实有很多数据供我们观察,这里只展示内存分配信息。可以看出,基准测试在此期间申请了超过5G的内存。
接下来我们使用go trace查看压测过程中的goroutine、堆内存、GC等信息。
这里只截取了600ms到700ms的时间段,从图中可以清楚的看出100ms内发生了170次GC。
同样的方法和步骤,使用sync.Pool后压测结果。
分配的内存总量减少到160MB,同期GC次数也减少到5次,优化效果非常明显。
当然,Golang 的作用还不止这些。从Docker到Kubernetes,从Istio到Knative,基于Golang的开源项目已经成为云原生生态的主力军。Golang 的简单性和高效性也不断吸引新的项目采用它作为开发语言。
对于青州微服务平台,除了使用Golang编写Filebeat插件和开发日志的控制器采集之外,我们还有很多基于Golang的组件,比如Service Mesh、容器云等。
六、总结与展望在云原生时代,日志作为可观察性的一部分,是排查和解决问题的基础,也是后续大数据分析处理的开始。
在这个领域,虽然有很多开源项目,但仍然没有强大而统一的日志采集agent。或许,这一盛开的景象还会继续。因此,青州团队自研的日志代理Ripple的设计也提出了更多的抽象,保留了与其他日志代理接口的能力。未来我们计划支持更多的日志采集代理,打造更丰富、更健壮的云原生日志采集系统。 查看全部
云优采集接口(网易杭州研究院云计算技术部高级研发工程师(组图))
本文由作者授权发布,未经许可请勿转载。
作者:付毅,网易杭州研究院云计算技术部高级研发工程师
一、背景云原生技术大潮已经到来,技术变革迫在眉睫。
在这一技术趋势下,网易推出了青州微服务平台,集成了微服务、Service Mesh、容器云、DevOps等组件。在公司内部得到了广泛的应用,也支持了很多外部客户的云原生转型。和迁移。
其中,日志记录是一个通常被忽视的部分,但却是微服务和 DevOps 的重要组成部分。没有日志,就无法排查服务问题。同时,日志的统一采集也是很多业务数据分析、处理、审计的基础。
但是在云原生容器化环境中,日志 采集 变得有点不同。
二、容器日志的痛点采集传统主机模式对于传统的物理机或虚拟机部署服务,日志采集的作用很明显。
业务日志直接输出到主机,服务运行在固定节点上,手动或使用自动化工具在节点上部署日志采集agent,添加agent配置,即可启动采集 记录 NS。同时,为了方便后续的日志配置修改,还可以引入配置中心来发布代理配置。
在 Kubernetes 环境中,情况没有在 Kubernetes 环境中那么简单。
一个Kubernetes节点上运行着很多不同的服务容器,容器日志存储方式也有很多种,比如stdout、hostPath、emptyDir、pv等。 由于Pods的主动或被动迁移以及频繁的销毁和创建在 Kubernetes 集群中,我们不能像传统方式那样手动向每个服务发布日志 采集 配置。另外,由于日志数据采集会集中存储,所以在查询日志时需要根据Namespace、Pod、Container、Node,甚至容器的环境变量和Label的维度进行检索和过滤。
以上都是不同于传统日志采集配置方式的需求和痛点。原因是传统方法不是为Kubernetes设计的,无法感知Kubernetes,无法与Kubernetes集成。
经过近几年的快速发展,Kubernetes 不仅是容器编排的事实上的标准,甚至可以看作是新一代的分布式操作系统。在这种新型操作系统中,控制器的设计思想驱动着整个系统的运行。控制器的抽象说明如下图所示:
由于Kubernetes良好的扩展性,Kubernetes设计了自定义资源CRD的概念。用户可以自己定义各种资源,借助一些框架开发控制器,使用控制器将我们的期望变成现实。
基于这个思路,对于日志采集,哪个日志服务需要采集,需要什么样的日志配置是用户的期望,而这一切都需要我们开发一个日志采集控制器达到。
三、 探索和架构设计有以上解决思路。除了开发一个控制器之外,剩下的就是围绕这个想法进行一些选择分析。
日志采集代理选择日志采集控制器只负责连接Kubernetes并生成采集配置,而不是真正的日志采集。市面上有很多日志采集代理,比如传统ELK技术栈的Logstash、CNCF毕业项目Fluentd、最近上线的Loki、beats系列的Filebeat等。下面我们来简单分析一下。
1.Logstash是基于JVM的,它的内存占用可以达到每分钟数百MB甚至GB,有点沉重,所以我们先排除了它。
2.Fluentd 以 CNCF 为后盾,看起来不错,插件也很多,但是基于 Ruby 和 C,对于青州团队的技术栈来说,还是让人拭目以待。虽然 Fluentd 也推出了纯粹基于 C 语言的 Fluentd-bit 项目,内存占用非常小,看起来很诱人,但是 C 语言的使用和无法动态重载配置的问题仍然没有关闭。
3.Loki 上线不久,目前功能有限,部分压测数据显示性能不是很好,暂且观望。
4.Filebeat属于Logstash、Kibana、Elasticsearch,轻量级日志采集agent,推出替代Logstash,基于Golang编写,完美契合青州团队的技术栈,实测性能和资源占用率均优方面,因此成为青州期刊采集代理的首选。
Agent集成方式对于log采集agent,Kubernetes环境下一般有两种部署方式。
1. sidecar 方法,与业务Container部署在同一个Pod中。这种方式中,Filebeat 只为业务Container 记录采集 日志,并且只需要配置Container 的日志配置,简单且隔离性好,但最大的问题是每个服务必须有一个Filebeat 到采集,而且通常一个节点上有很多Pod,内存等开销也不乐观。
2. 另一个也是最常见的是在每个节点上部署一个 Filebeat 容器。相比较而言,内存占用要小很多,对Pod也没有侵入性,更符合我们平时的使用习惯。同时,一般采用Kubernetes的DaemonSet部署,无需Ansible等传统自动化运维工具,部署和运维效率大大提高。所以我们优先使用Daemonset来部署Filebeat。
整体架构选择Filebeat作为日志采集代理。集成自研的日志控制器后,从节点的角度,我们看到的架构如下:
1. 日志平台将特定的 CRD 实例下发给 Kubernetes 集群,日志控制器 Ripple 负责来自 Kubernetes 的 List&Watch Pod 和 CRD 实例。
2. 通过 Ripple 过滤和聚合,最终生成一个 Filebeat 输入配置文件。配置文件描述了服务的采集Path路径、多行日志匹配等配置。同时,它也默认在日志元信息中配置PodName、Hostname等。
3.Filebeat 会根据 Ripple 生成的配置自动重新加载 采集 节点上的日志并将其发送到 Kafka 或 Elasticsearch。
由于 Ripple 监听 Kubernetes 事件,因此可以感知 Pod 的生命周期。无论 Pod 是否销毁或调度到任何节点,它仍然可以自动生成相应的 Filebeat 配置,无需人工干预。
Ripple可以感知Pod挂载的日志卷,无论是docker Stdout的日志,还是使用HostPath、EmptyDir、Pv来存储日志,都可以在节点上生成日志路径并告诉Filebeat去采集@ >.
Ripple 可以同时获取 CRD 和 Pod 信息,所以除了默认在日志配置中添加 PodName 等元信息外,还可以结合容器环境变量、Pod 标签、Pod Annotation 等来标记日志方便后续的日志过滤、检索和查询。
另外,我们在Ripple中加入了定时清理日志等功能,保证日志不丢失,进一步提升日志采集的功能和稳定性。
四、基于Filebeat的实用功能扩展。总的来说,Filebeat 可以满足大部分 logging采集 的需求,但还是难免有些特殊场景需要我们自定义 Filebeat。当然,Filebeat 本身的设计也提供了很好的扩展性。
Filebeat 目前只提供了 Elasticsearch、Kafka、Logstash 等几种类型的输出客户端,如果我们希望 Filebeat 直接发送到其他后端,我们需要自定义我们自己的输出。同样,如果您需要过滤日志或添加元信息,您也可以创建一个自制的处理器插件。
无论是添加输出还是编写处理器,Filebeat 提供了基本相同的总体思路。一般来说,有3种方式:
1.直接 Fork Filebeat 并在现有源代码上开发。output和processor都提供了类似Run、Stop等的接口,你只需要实现这类接口,然后在init方法中注册对应的插件初始化方法即可。当然,由于Golang中的init方法是在包导入的时候调用的,所以需要在初始化Filebeat的代码中手动导入。
2. 把Filebeat的main.go复制一份,导入我们自研的插件库,重新编译。本质上和方法1没有太大区别。
3.Filebeat 还提供了基于 Golang 插件的插件机制。需要将自研插件编译成.so共享链接库,然后在Filebeat启动参数中通过-plugin指定库的路径。但实际上,一方面,Golang 插件并不成熟和稳定。另一方面,自主开发的插件仍然需要依赖相同版本的libbeat库,也需要相同的Golang版本进行编译。坑可能比较多,所以不推荐。
如果想了解更多关于Filebeat的设计,可以参考这篇文章文章:容器日志采集 犀利工具:Filebeat深度分析与实践
为了支持各业务方的对接,我们目前扩展开发了grpc输出,支持多个Kafka集群的输出。
三维监控 但是,真正的难点是业务端实际使用后,采集找不到日志,多行日志配置或者采集二进制大文件导致各种问题比如 Filebeat OOM。我们在Filebeat和日志采集的综合监控上投入了更多的时间,例如:
1. 接入青州监控平台,具备磁盘IO、网络流量传输、内存使用、CPU使用、Pod事件告警等,保证完美的基础监控。
2. 新增日志平台数据全链路延时监控。
3.采集Filebeat自带的日志,通过该日志文件开始采集和采集结束时上报,避免每次配置时都需要SSH到各个节点查看日志故障排除。
4. 自研 Filebeat 导出器,接入 Prometheus,采集 报告自己的指标数据。
通过三维监控和增强,极大的方便了我们问题的排查,降低了运维和人工成本,也保证了服务的稳定性。
五、Golang 的性能优化以及相应的调优性能优化是一个永恒的话题。虽然“过早优化是万恶之源”,但实际开发过程中还是需要时刻保持优化意识。很多时候,我们看到了太多的GC原理、内存优化、性能优化,但是很多时候我们写完代码,完成一个项目的时候,却无从下手。实践是检验真理的唯一标准。因此,自己去调查和探索,是改善姿势、找到关键问题的最短途径。云原生日志采集系统也是如此。
好消息是,对于性能优化,Golang 贴心地为我们提供了三个关键:
1.去基准测试
2.去pprof
3.去追踪
这些键在日志 采集 性能优化场景中也是有效的。这是一个简单的例子。
以sync.Pool为例,sync.Pool一般用于临时对象的保存和复用,减少内存分配,减少GC压力。应用场景很多,比如号称比Golang官方Http快10倍的FastHttp,大量使用sync.Pool,Filebeat使用sync.Pool将批量日志数据聚合成批发送,当Nginx-Ingress-控制器渲染生成 Nginx 配置,同时使用 sync.Pool 优化渲染效率。青州的日志控制器 Ripple 也使用了 sync.Pool 来优化渲染 Filebeat 配置时的性能。
首先使用go benchmark来测试在没有使用sync.Pool的情况下通过go模板渲染Filebeat配置的方法。
你可以看到结果显示了每个执行方法的时间和分配的内存。
然后使用 go pprof 观察 go benchmark 生成的 profile 文件的整体性能数据。
go pprof其实有很多数据供我们观察,这里只展示内存分配信息。可以看出,基准测试在此期间申请了超过5G的内存。
接下来我们使用go trace查看压测过程中的goroutine、堆内存、GC等信息。
这里只截取了600ms到700ms的时间段,从图中可以清楚的看出100ms内发生了170次GC。
同样的方法和步骤,使用sync.Pool后压测结果。
分配的内存总量减少到160MB,同期GC次数也减少到5次,优化效果非常明显。
当然,Golang 的作用还不止这些。从Docker到Kubernetes,从Istio到Knative,基于Golang的开源项目已经成为云原生生态的主力军。Golang 的简单性和高效性也不断吸引新的项目采用它作为开发语言。
对于青州微服务平台,除了使用Golang编写Filebeat插件和开发日志的控制器采集之外,我们还有很多基于Golang的组件,比如Service Mesh、容器云等。
六、总结与展望在云原生时代,日志作为可观察性的一部分,是排查和解决问题的基础,也是后续大数据分析处理的开始。
在这个领域,虽然有很多开源项目,但仍然没有强大而统一的日志采集agent。或许,这一盛开的景象还会继续。因此,青州团队自研的日志代理Ripple的设计也提出了更多的抽象,保留了与其他日志代理接口的能力。未来我们计划支持更多的日志采集代理,打造更丰富、更健壮的云原生日志采集系统。
云优采集接口(/发布接口:要创建快捷方式的文件或文件夹lnkType)
采集交流 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2021-11-04 14:20
快捷/释放界面
1、创建快捷界面
URI:/app/lnk/create-shortcut
POST参数:
令牌:令牌参数
fileId:创建快捷方式的文件或文件夹
lnkType:快捷方式,目前只支持一种类型,即lnkType=1
parentId:将创建快捷方式的文件夹
提示:如果要创建采集的快捷方式,可以通过登录界面或用户信息同步界面获取采集ID
2、获取快捷方式信息(包括快捷方式指向的文件/文件夹)
URI:/app/lnk/get-shortcut-info
POST参数:
令牌:令牌参数
fileId:获取信息的快捷方式的ID(文件或文件夹的快捷方式被视为一种特殊的文件)
结果返回:
json.auth:当前用户对快捷方式本身的权限
json.auth2:当前用户对快捷方式指向的文件的权限
json.lnkId:快捷方式指向实际文件的ID
json.lnkType:快捷方式类型,1为普通快捷方式,2为发布文件(发布文件为特殊快捷方式)
json.lockStatus:快捷方式指定的文件类型被锁定或标记,可以查看其他文件操作界面:4、文件锁定,标记
json.targetPath:文件快捷方式的路径
3、发布文件
具有文件夹管理权限的普通管理员或超级管理员可以调用该接口
URI:/app/lnk/发布文件
POST参数:
令牌:令牌参数
fileId:要发布的文件的ID
uids:要发布到的用户、部门、角色(用“,”分隔多个),如果要发布到所有员工,填写:0
msg: 发布信息
auth:发布后,接收者的权限类型:auth=2 只预览,auth=3 预览下载
4、收件人获取发布信息
URI:/app/lnk/get-publish-info
POST参数:
令牌:令牌参数
fileId:已发布文件的 ID
在返回的结果中:
json.signTime 表示收货时间,如果值为0,则表示没有收货
5、 为已发布的文档签名
URI:/app/lnk/sign-file
POST参数:
令牌:令牌参数
fileId:要签名的发布文件的ID
6、获取已发布文件列表
具有文件夹管理权限的普通管理员或超级管理员可以调用该接口
URI:/app/lnk/get-publish-list
POST参数:
令牌:令牌参数
page:当前显示哪个页面,0表示第一页,默认每页显示30个已发布的文件
aullUser:是否显示云盘上所有已发布的文件,allUser=1表示显示所有已发布的文件,否则只显示发布者自己发布的文件。此项仅对超级管理员有效
7、发布者获取单个文件的发布信息
具有文件夹管理权限的普通管理员或超级管理员可以调用该接口
URI:/app/lnk/get-publish-info2
POST参数:
令牌:令牌参数
pid:发布ID,通过/app/lnk/get-publish-list接口获取
在返回的结果中:
json.noFile,如果它的值为1,则表示当前release指向的实体文件(实际上是一种特殊类型的快捷方式)已被删除
json.users 是一个列表,列出了发布的所有收件人。如果 json.users[index].signTime 等于 0,则表示接收方没有签名,如果大于 0,表示接收方已经签名,其值代表签名时的 unix 时间戳。 查看全部
云优采集接口(/发布接口:要创建快捷方式的文件或文件夹lnkType)
快捷/释放界面
1、创建快捷界面
URI:/app/lnk/create-shortcut
POST参数:
令牌:令牌参数
fileId:创建快捷方式的文件或文件夹
lnkType:快捷方式,目前只支持一种类型,即lnkType=1
parentId:将创建快捷方式的文件夹
提示:如果要创建采集的快捷方式,可以通过登录界面或用户信息同步界面获取采集ID
2、获取快捷方式信息(包括快捷方式指向的文件/文件夹)
URI:/app/lnk/get-shortcut-info
POST参数:
令牌:令牌参数
fileId:获取信息的快捷方式的ID(文件或文件夹的快捷方式被视为一种特殊的文件)
结果返回:
json.auth:当前用户对快捷方式本身的权限
json.auth2:当前用户对快捷方式指向的文件的权限
json.lnkId:快捷方式指向实际文件的ID
json.lnkType:快捷方式类型,1为普通快捷方式,2为发布文件(发布文件为特殊快捷方式)
json.lockStatus:快捷方式指定的文件类型被锁定或标记,可以查看其他文件操作界面:4、文件锁定,标记
json.targetPath:文件快捷方式的路径
3、发布文件
具有文件夹管理权限的普通管理员或超级管理员可以调用该接口
URI:/app/lnk/发布文件
POST参数:
令牌:令牌参数
fileId:要发布的文件的ID
uids:要发布到的用户、部门、角色(用“,”分隔多个),如果要发布到所有员工,填写:0
msg: 发布信息
auth:发布后,接收者的权限类型:auth=2 只预览,auth=3 预览下载
4、收件人获取发布信息
URI:/app/lnk/get-publish-info
POST参数:
令牌:令牌参数
fileId:已发布文件的 ID
在返回的结果中:
json.signTime 表示收货时间,如果值为0,则表示没有收货
5、 为已发布的文档签名
URI:/app/lnk/sign-file
POST参数:
令牌:令牌参数
fileId:要签名的发布文件的ID
6、获取已发布文件列表
具有文件夹管理权限的普通管理员或超级管理员可以调用该接口
URI:/app/lnk/get-publish-list
POST参数:
令牌:令牌参数
page:当前显示哪个页面,0表示第一页,默认每页显示30个已发布的文件
aullUser:是否显示云盘上所有已发布的文件,allUser=1表示显示所有已发布的文件,否则只显示发布者自己发布的文件。此项仅对超级管理员有效
7、发布者获取单个文件的发布信息
具有文件夹管理权限的普通管理员或超级管理员可以调用该接口
URI:/app/lnk/get-publish-info2
POST参数:
令牌:令牌参数
pid:发布ID,通过/app/lnk/get-publish-list接口获取
在返回的结果中:
json.noFile,如果它的值为1,则表示当前release指向的实体文件(实际上是一种特殊类型的快捷方式)已被删除
json.users 是一个列表,列出了发布的所有收件人。如果 json.users[index].signTime 等于 0,则表示接收方没有签名,如果大于 0,表示接收方已经签名,其值代表签名时的 unix 时间戳。
云优采集接口(云优网接口文档怎么做?如何对接第三方服务商)
采集交流 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2021-11-04 09:04
云优采集接口,没有规定,每个服务器的采集时间不会无限制的。每天一批本地post数据,不管你什么时候去接口页面就可以采集过来,接口提供post或者json格式的文本,不知道怎么配置的可以看下云优网接口文档,对接一些第三方服务商的接口挺好的。
个人作为用户的话,建议先考虑好接入某个接口,
云优统计接口很方便,可以设置单个接口时间段每天请求的总量,而且还有精准统计,每个接口计算过程都在本地进行,根据每个接口分别提供的接口时间,在平台上进行获取即可。
看自己需求!ua,数据源,安全,迁移,采集方式等等如果接入统计服务平台,我知道有个云优统计接口,还蛮好用的,
统计平台的话,推荐一个jsx接口库,现在自己开发的ui框架里,他的接口也非常好用,之前是先自己写接口模块,再返回一个接口模块的jsx文件给开发人员,去弄接口的测试,现在是接入jsx接口库直接可以完成代码的跳转,在后台也可以调用接口,而且接口会异步调用,响应会更快,统计效果不错,对于接入接口有问题可以留言探讨。
目前市面上统计接口比较少,但是也是分行业分领域,市面上通用的接口有graylog、统计数据、dpay(官网上提供免费接口)、setsearch等。
1、行业接口:天猫天天特价聚划算等,
2、社交媒体:微博、微信、新浪微博等,
3、国内外主流外贸电商平台,
4、互联网金融平台。还有根据行业或者产品的差异性来做不同的接口,这个需要根据自己的业务需求来看。一般比较大的公司都有自己的接口,比如talkingdata、聚合数据等等。 查看全部
云优采集接口(云优网接口文档怎么做?如何对接第三方服务商)
云优采集接口,没有规定,每个服务器的采集时间不会无限制的。每天一批本地post数据,不管你什么时候去接口页面就可以采集过来,接口提供post或者json格式的文本,不知道怎么配置的可以看下云优网接口文档,对接一些第三方服务商的接口挺好的。
个人作为用户的话,建议先考虑好接入某个接口,
云优统计接口很方便,可以设置单个接口时间段每天请求的总量,而且还有精准统计,每个接口计算过程都在本地进行,根据每个接口分别提供的接口时间,在平台上进行获取即可。
看自己需求!ua,数据源,安全,迁移,采集方式等等如果接入统计服务平台,我知道有个云优统计接口,还蛮好用的,
统计平台的话,推荐一个jsx接口库,现在自己开发的ui框架里,他的接口也非常好用,之前是先自己写接口模块,再返回一个接口模块的jsx文件给开发人员,去弄接口的测试,现在是接入jsx接口库直接可以完成代码的跳转,在后台也可以调用接口,而且接口会异步调用,响应会更快,统计效果不错,对于接入接口有问题可以留言探讨。
目前市面上统计接口比较少,但是也是分行业分领域,市面上通用的接口有graylog、统计数据、dpay(官网上提供免费接口)、setsearch等。
1、行业接口:天猫天天特价聚划算等,
2、社交媒体:微博、微信、新浪微博等,
3、国内外主流外贸电商平台,
4、互联网金融平台。还有根据行业或者产品的差异性来做不同的接口,这个需要根据自己的业务需求来看。一般比较大的公司都有自己的接口,比如talkingdata、聚合数据等等。
云优采集接口(除此之外都有定时云采集设置有什么方法?如何避开IP封锁策略 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2021-10-20 14:18
)
首先要注意的是,Cloud 采集是优采云采集器终极版及以上版本的独有功能。免费版和专业版没有这个功能。
云采集是指使用优采云提供的服务器集群工作,7*24小时工作状态。客户端完成任务设置并提交到云服务执行云采集后,即可关闭软件关闭电脑下线采集,真正实现无人值守。另外,云采集通过分布式部署云服务器集群,多节点同时运行,可以提高采集的效率,并能有效避免各种网站IP阻塞战略。
云采集的优点:可以关机运行,也可以设置定时云采集加速采集,增加采集的数量。
1、云采集设置
示例网址:
云启动的三种方式采集(立即启动,只运行一次)。
方法一:任务字段配置好后,点击'全选'→'采集以下数据'→'保存并启动采集',进入“运行任务”界面,点击启动云采集,你会在任务列表中看到云采集的任务。
方法二:在任务列表页面,每个任务名称右侧都有“启动云采集”选项。点击后,任务会立即启动Cloud采集一次。
方法三:在任务列表页面,每个任务名称右侧都有一个“更多操作”选项。点击后,在下拉选项中选择Cloud采集并启动,任务将立即启动。云采集。
2、计时云采集设置
Timing Cloud采集有两种设置方式:
方法一:任务字段配置好后,点击'全选'→'采集以下数据'→'保存并启动采集',进入“运行任务”界面,点击'设置定时云采集',弹出定时云采集'的配置页面。一、 如果需要保存时序设置,在“保存的配置”输入框中输入名称,然后保存配置。保存成功后,如果其他任务需要相同的时序配置,下次可以选择该配置。二、定时设置有4种,可以根据需要选择启动方式和启动时间。所有设置完成后,如果需要启动定时云采集,选择“
方法二:在任务列表页面,每个任务名称右侧都有一个“更多操作”选项。点击后在下拉选项中选择Cloud采集设置定时,也可以进行上述操作。
3、 任务组定时设置
如果需要为整个任务组设置时序云采集,可以在首页的设置页面选择一个任务组,点击'为任务组采集设置时序云' ,则可以进行与上述相同的操作配置。
查看全部
云优采集接口(除此之外都有定时云采集设置有什么方法?如何避开IP封锁策略
)
首先要注意的是,Cloud 采集是优采云采集器终极版及以上版本的独有功能。免费版和专业版没有这个功能。
云采集是指使用优采云提供的服务器集群工作,7*24小时工作状态。客户端完成任务设置并提交到云服务执行云采集后,即可关闭软件关闭电脑下线采集,真正实现无人值守。另外,云采集通过分布式部署云服务器集群,多节点同时运行,可以提高采集的效率,并能有效避免各种网站IP阻塞战略。
云采集的优点:可以关机运行,也可以设置定时云采集加速采集,增加采集的数量。
1、云采集设置
示例网址:
云启动的三种方式采集(立即启动,只运行一次)。
方法一:任务字段配置好后,点击'全选'→'采集以下数据'→'保存并启动采集',进入“运行任务”界面,点击启动云采集,你会在任务列表中看到云采集的任务。
方法二:在任务列表页面,每个任务名称右侧都有“启动云采集”选项。点击后,任务会立即启动Cloud采集一次。
方法三:在任务列表页面,每个任务名称右侧都有一个“更多操作”选项。点击后,在下拉选项中选择Cloud采集并启动,任务将立即启动。云采集。
2、计时云采集设置
Timing Cloud采集有两种设置方式:
方法一:任务字段配置好后,点击'全选'→'采集以下数据'→'保存并启动采集',进入“运行任务”界面,点击'设置定时云采集',弹出定时云采集'的配置页面。一、 如果需要保存时序设置,在“保存的配置”输入框中输入名称,然后保存配置。保存成功后,如果其他任务需要相同的时序配置,下次可以选择该配置。二、定时设置有4种,可以根据需要选择启动方式和启动时间。所有设置完成后,如果需要启动定时云采集,选择“
方法二:在任务列表页面,每个任务名称右侧都有一个“更多操作”选项。点击后在下拉选项中选择Cloud采集设置定时,也可以进行上述操作。
3、 任务组定时设置
如果需要为整个任务组设置时序云采集,可以在首页的设置页面选择一个任务组,点击'为任务组采集设置时序云' ,则可以进行与上述相同的操作配置。
云优采集接口(DiscuzX3.4论坛优采云采集器免登陆发布接口模块(可测试))
采集交流 • 优采云 发表了文章 • 0 个评论 • 220 次浏览 • 2021-10-19 04:02
今天分享《DiscuzX3.4论坛优采云采集器免登录发布界面模块(可测试)》可以复制以下百度云地址下载,此界面已亲测,压缩包没有加密,可以直接使用,我们在这篇文章中附上了教程文章,适合DZ论坛网站采集的资源,好了,大家按照下面的流程来吧。
下载链接:提取码:e9xk
解压后看到的文件是:
其中,discussX3.0.wpm 为发布模块,dz 测试接口。ljobx 是测试规则。以后不问规则怎么写,就按这个格式写就行了。
1.上传接口
根据自己的网站编码,选择GBk或utf8文件下的如下接口文件,jiekou.php,这个接口有密码,默认123456,如果要修改,打开这个jiekou.php调整:
就像上图一样,把默认的“123456”改成你想要的,如果改了一定要保存。如果你不明白它,不要改变它。
然后把这个文件上传到DZ网站的根目录。不知道根目录是什么就别问哪里上传了,自己的网站
别人怎么知道你的根目录是什么?如果您不知道,请自行检查。
然后我们尝试在浏览器中访问,访问地址是网站域名/jiekou.php?pw=password,这个密码就是上面提到的界面密码:
如果论坛的模块能出现,就证明界面是正确的。
2. 导入发布模块
点击发布按钮:
打开配置界面(有些慢,稍等):
导入成功后会有提示。
发布模块设置:
第一步是选择我们刚刚导入的dz发布模块。
第二步:全局变量就是上面提到的接口文件密码
第三步:选择对应的代码
第四步:网站的根目录填写上面我们访问接口时的接口文件名,其余地址。然后选择“无需登录&Http请求”
第五步:点击获取列表。如果可以显示论坛版块,则说明上述4步是正确的。
设置好后,点击测试配置,成功后,设置一个配置名称,保存这个配置在规则中使用,
分发简单,只发标题内容回复
我们打开发布模块介绍一下里面的内容:
单击编辑按钮转到“内容发布参数”选项卡:
引入表格名称:
用户名:对应论坛发帖回复的用户名
主题:对应论坛标题
message:对应发帖的主题和回复的内容,这两部分放在一起
fid:对应section ID
签名:发帖人和回复人的签名内容,这里也放在一起
publishdat:发帖和回复的时间,相同的两部分放在一起
typeid:对应学科类别的ID
typename:对应主题类别名称,上面我们已经写好了类别ID,这里不需要设置值,表格值留空即可。
sortid:对应分类信息的ID
fanme:对应section的名字,fid的值也在上面设置,这里的值不需要设置,表单值可以留空
avatar:发帖人和回复人的头像信息,相同的两部分放在一起
标签:发布时设置的标签
如果我们不需要表单值,比如不需要签名,我们根据上图选择这个,然后点击“修改表单值”,这里的表单值设置为空。如下图所示:
然后使用相同的方法来处理我们其他不必要的表单,如下所示。我不需要 typeid、typenam 和其他形式。我只是使用上面的方法将它们的表单值设置为空。
当然,您需要选择您需要的表格。
我们将测试规则导入到采集器中来说明如下规则设置:
第二步:采集内容规则,我们直接点击右侧的“测试”按钮,查看采集的内容。此规则为采集dz官方论坛。
因为是采集论坛,内容标签采集会得到帖子内容和回复内容,作者标签采集会得到帖子用户名和回复用户名,头像,时间和签名,所有发帖者和回复者相关信息的组合。
采集 给作者,接口是自动注册的。
要使用标签循环右侧的“标签循环处理”分隔符,必须写“||||”,右侧的结果用于将每个信息与“|||”连接起来。
说到头像标签,一个用户的头像必须是“头像图片地址用户名”的组合。
如何设置规则取决于内置规则,删除不需要的标签即可。添加需要添加的标签。总之,规则中的标签与发布模块中的标签一一对应,标签名称必须一致。
幸运的是,我没有在发布模块中看到内容标签。事实上,发布模块中的 {0} 已被替换。一切都设置好后,在规则中使用下图:
接口扩展说明:
设置界面注册的用户名和密码,打开界面:
这里是新用户注册的密码,我设置的是12346,那么界面上注册的所有用户的登录密码都是123456
如果留空,则新注册的用户名和密码为:连接用户名和密码参数,md5下,取下12位数字。上图中用户密码下方是用户名和密码参数,可以设置。
如果没有回复用户名,则使用界面中设置的用户名,如下图:
这些可以修改。
界面中有如下映射关系:
这意味着我们创建了一个名为 fname 的标签,如果 采集 到达“Block 1”,那么我们将发布相应的 block id 1,可以根据我们的论坛块进行修改。下面的typname也是同理,这个设置的好处是不需要直接通过section name和topic category name来设置category id来自动对应。
好了,今天的“DZ优采云采集发布模块”就到此结束。其实网站采集大家都很熟悉,虽然采集站点很容易降级。我不建议直接把新站点带到采集,也不建议站点的采集数据不断更新。但是采集一些必要的资源还是可以的,而且网站的主要内容应该是“高质量文章”,这样会给百度一些好的印象,更有利于网站 整体排名提升。
标签: DiscuzX3.4 论坛网站 优采云采集 发布模块 查看全部
云优采集接口(DiscuzX3.4论坛优采云采集器免登陆发布接口模块(可测试))
今天分享《DiscuzX3.4论坛优采云采集器免登录发布界面模块(可测试)》可以复制以下百度云地址下载,此界面已亲测,压缩包没有加密,可以直接使用,我们在这篇文章中附上了教程文章,适合DZ论坛网站采集的资源,好了,大家按照下面的流程来吧。
下载链接:提取码:e9xk
解压后看到的文件是:
其中,discussX3.0.wpm 为发布模块,dz 测试接口。ljobx 是测试规则。以后不问规则怎么写,就按这个格式写就行了。
1.上传接口
根据自己的网站编码,选择GBk或utf8文件下的如下接口文件,jiekou.php,这个接口有密码,默认123456,如果要修改,打开这个jiekou.php调整:
就像上图一样,把默认的“123456”改成你想要的,如果改了一定要保存。如果你不明白它,不要改变它。
然后把这个文件上传到DZ网站的根目录。不知道根目录是什么就别问哪里上传了,自己的网站
别人怎么知道你的根目录是什么?如果您不知道,请自行检查。
然后我们尝试在浏览器中访问,访问地址是网站域名/jiekou.php?pw=password,这个密码就是上面提到的界面密码:
如果论坛的模块能出现,就证明界面是正确的。
2. 导入发布模块
点击发布按钮:
打开配置界面(有些慢,稍等):
导入成功后会有提示。
发布模块设置:
第一步是选择我们刚刚导入的dz发布模块。
第二步:全局变量就是上面提到的接口文件密码
第三步:选择对应的代码
第四步:网站的根目录填写上面我们访问接口时的接口文件名,其余地址。然后选择“无需登录&Http请求”
第五步:点击获取列表。如果可以显示论坛版块,则说明上述4步是正确的。
设置好后,点击测试配置,成功后,设置一个配置名称,保存这个配置在规则中使用,
分发简单,只发标题内容回复
我们打开发布模块介绍一下里面的内容:
单击编辑按钮转到“内容发布参数”选项卡:
引入表格名称:
用户名:对应论坛发帖回复的用户名
主题:对应论坛标题
message:对应发帖的主题和回复的内容,这两部分放在一起
fid:对应section ID
签名:发帖人和回复人的签名内容,这里也放在一起
publishdat:发帖和回复的时间,相同的两部分放在一起
typeid:对应学科类别的ID
typename:对应主题类别名称,上面我们已经写好了类别ID,这里不需要设置值,表格值留空即可。
sortid:对应分类信息的ID
fanme:对应section的名字,fid的值也在上面设置,这里的值不需要设置,表单值可以留空
avatar:发帖人和回复人的头像信息,相同的两部分放在一起
标签:发布时设置的标签
如果我们不需要表单值,比如不需要签名,我们根据上图选择这个,然后点击“修改表单值”,这里的表单值设置为空。如下图所示:
然后使用相同的方法来处理我们其他不必要的表单,如下所示。我不需要 typeid、typenam 和其他形式。我只是使用上面的方法将它们的表单值设置为空。
当然,您需要选择您需要的表格。
我们将测试规则导入到采集器中来说明如下规则设置:
第二步:采集内容规则,我们直接点击右侧的“测试”按钮,查看采集的内容。此规则为采集dz官方论坛。
因为是采集论坛,内容标签采集会得到帖子内容和回复内容,作者标签采集会得到帖子用户名和回复用户名,头像,时间和签名,所有发帖者和回复者相关信息的组合。
采集 给作者,接口是自动注册的。
要使用标签循环右侧的“标签循环处理”分隔符,必须写“||||”,右侧的结果用于将每个信息与“|||”连接起来。
说到头像标签,一个用户的头像必须是“头像图片地址用户名”的组合。
如何设置规则取决于内置规则,删除不需要的标签即可。添加需要添加的标签。总之,规则中的标签与发布模块中的标签一一对应,标签名称必须一致。
幸运的是,我没有在发布模块中看到内容标签。事实上,发布模块中的 {0} 已被替换。一切都设置好后,在规则中使用下图:
接口扩展说明:
设置界面注册的用户名和密码,打开界面:
这里是新用户注册的密码,我设置的是12346,那么界面上注册的所有用户的登录密码都是123456
如果留空,则新注册的用户名和密码为:连接用户名和密码参数,md5下,取下12位数字。上图中用户密码下方是用户名和密码参数,可以设置。
如果没有回复用户名,则使用界面中设置的用户名,如下图:
这些可以修改。
界面中有如下映射关系:
这意味着我们创建了一个名为 fname 的标签,如果 采集 到达“Block 1”,那么我们将发布相应的 block id 1,可以根据我们的论坛块进行修改。下面的typname也是同理,这个设置的好处是不需要直接通过section name和topic category name来设置category id来自动对应。
好了,今天的“DZ优采云采集发布模块”就到此结束。其实网站采集大家都很熟悉,虽然采集站点很容易降级。我不建议直接把新站点带到采集,也不建议站点的采集数据不断更新。但是采集一些必要的资源还是可以的,而且网站的主要内容应该是“高质量文章”,这样会给百度一些好的印象,更有利于网站 整体排名提升。
标签: DiscuzX3.4 论坛网站 优采云采集 发布模块
云优采集接口(如何利用优帮云数据平台的关键词价格查询API实现出类似云客网)
采集交流 • 优采云 发表了文章 • 0 个评论 • 138 次浏览 • 2021-10-06 19:11
目前,互联网上支持关键词价格查询功能的平台有很多,云客网是SEO行业中大家耳熟能详的平台之一。云客网是杭州智卓旗下SEO行业知名的众包服务平台。连接客户和技术优化人员的双边需求,进行网络营销推广。其亮点之一是能够实时在线查询关键词价格,深受SEO喜爱。从业者和客户的喜爱。很多SEO公司都想在自己的平台上加入这个功能,但是采集平台不能作为长期稳定的解决方案。今天跟大家分享一下如何使用友邦云数据平台的关键词价格查询API实现关键词
一、建立关键词缓冲库存储查询数据关键词
一般来说,只要是平台化的系统,就离不开数据库。对于关键词价格查询功能,必须至少有一个价目表用于存储关键词价格相关信息,包括关键词@关键词编号,关键词内容,百度整体指数、百度PC指数、百度手机指数、360指数、收录量、优化难度、主要引擎价格等领域,请参考我们在用户中心的展示。除了自身的属性,我们还需要一个数据中心API查询号。回调查询结果时使用该查询号。用这个查询号找到对应的关键词,然后更新对应的价格信息,不能省略。
二、创建前端客户交互界面和后端处理界面
当客户通过前端查询接口传入指定的关键词时,后端代码进行必要的验证后,首先在价目表中对关键词进行准确搜索,如果找到关键词 及信息 可直接从价目表中读取,未到期时显示给客户。如果长时间未找到关键词或关键词的价格信息,请先将关键词添加到价目表或重置已过期的相关数据,然后使用友邦云数据平台API接口会传入关键词,友邦云会立即返回一个平台API来查询代码。后端得到这个code后,会和code关键词一一对应。
三、数据相关处理的数据回调通知
每个友邦云API激活后,必须设置一个通知地址。优帮云数据平台的所有数据通知均通过该地址完成。后端收到API价格查询结果通知的数据后,根据返回的数据包的API查询编号,在价目表中找到对应的关键词,将价格相关信息更新到价目表中。
四、为前端客户友好展示缓冲效果
由于数据查询需要3-5秒,在产生前端效果时,由于采用了相关的非刷新技术实现了友好的等待画面,后端通过定时查询从价目表中获取价格信息. 如果价格信息更新成功,展示给前端,整个查询完成。
云客网的诸多功能,如:关键词排名实时显示、每日计费系统等,可以说是一个完整的网络营销数字平台应用。其实,你只需要深入学习友邦云的数据平台API即可。,结合我自己的想法,这些类似云客网的功能是可以实现的。我们期待与您探讨使用优帮云的API实现更多功能。 查看全部
云优采集接口(如何利用优帮云数据平台的关键词价格查询API实现出类似云客网)
目前,互联网上支持关键词价格查询功能的平台有很多,云客网是SEO行业中大家耳熟能详的平台之一。云客网是杭州智卓旗下SEO行业知名的众包服务平台。连接客户和技术优化人员的双边需求,进行网络营销推广。其亮点之一是能够实时在线查询关键词价格,深受SEO喜爱。从业者和客户的喜爱。很多SEO公司都想在自己的平台上加入这个功能,但是采集平台不能作为长期稳定的解决方案。今天跟大家分享一下如何使用友邦云数据平台的关键词价格查询API实现关键词
一、建立关键词缓冲库存储查询数据关键词
一般来说,只要是平台化的系统,就离不开数据库。对于关键词价格查询功能,必须至少有一个价目表用于存储关键词价格相关信息,包括关键词@关键词编号,关键词内容,百度整体指数、百度PC指数、百度手机指数、360指数、收录量、优化难度、主要引擎价格等领域,请参考我们在用户中心的展示。除了自身的属性,我们还需要一个数据中心API查询号。回调查询结果时使用该查询号。用这个查询号找到对应的关键词,然后更新对应的价格信息,不能省略。
二、创建前端客户交互界面和后端处理界面
当客户通过前端查询接口传入指定的关键词时,后端代码进行必要的验证后,首先在价目表中对关键词进行准确搜索,如果找到关键词 及信息 可直接从价目表中读取,未到期时显示给客户。如果长时间未找到关键词或关键词的价格信息,请先将关键词添加到价目表或重置已过期的相关数据,然后使用友邦云数据平台API接口会传入关键词,友邦云会立即返回一个平台API来查询代码。后端得到这个code后,会和code关键词一一对应。
三、数据相关处理的数据回调通知
每个友邦云API激活后,必须设置一个通知地址。优帮云数据平台的所有数据通知均通过该地址完成。后端收到API价格查询结果通知的数据后,根据返回的数据包的API查询编号,在价目表中找到对应的关键词,将价格相关信息更新到价目表中。
四、为前端客户友好展示缓冲效果
由于数据查询需要3-5秒,在产生前端效果时,由于采用了相关的非刷新技术实现了友好的等待画面,后端通过定时查询从价目表中获取价格信息. 如果价格信息更新成功,展示给前端,整个查询完成。
云客网的诸多功能,如:关键词排名实时显示、每日计费系统等,可以说是一个完整的网络营销数字平台应用。其实,你只需要深入学习友邦云的数据平台API即可。,结合我自己的想法,这些类似云客网的功能是可以实现的。我们期待与您探讨使用优帮云的API实现更多功能。
云优采集接口(不用充会员,无需外部链接,云优采集器)
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2021-10-05 10:01
云优采集接口,目前主要用在二手行业中,比如奢侈品、家具等领域。可以按订单采集,也可以按关键词采集,比如:某家具搜索关键词,客户可以按照产品分类,按系列分类,等等,数据采集准确率98%以上。
chrome的浏览器插件:useragentspy
云优采集器,建议官网下载。
云优采集器,
登录领先的有效方案就是采取googleadwords,,googleadsense等竞价位置,以及多用户paypal渠道等。
安卓手机采集市场大分类页
这里要以qrcode为抓取节点来进行检测,即安卓手机浏览器去采集数据。但是个人觉得效率低,
各种浏览器应该都支持吧
最近发现一个东西可以比较靠谱,不用翻墙,不用充会员,无需外部链接,点一下就自动生成带有二维码的qrcode的地址。唯一缺点是貌似还不算很好看(捂脸。
很多qrcode有效的电子邮件站点,加上域名注册的电子邮件地址,
个人推荐fishershoppingmall的inspiration,使用特点:在inspiration服务器上部署了fisherocr服务器,根据收到的包裹信息(已知的,对应包裹上标注的文字)查询和识别包裹中的qrcode。详情请参考wiki百科!!!重点:文件的语义是相对固定的。 查看全部
云优采集接口(不用充会员,无需外部链接,云优采集器)
云优采集接口,目前主要用在二手行业中,比如奢侈品、家具等领域。可以按订单采集,也可以按关键词采集,比如:某家具搜索关键词,客户可以按照产品分类,按系列分类,等等,数据采集准确率98%以上。
chrome的浏览器插件:useragentspy
云优采集器,建议官网下载。
云优采集器,
登录领先的有效方案就是采取googleadwords,,googleadsense等竞价位置,以及多用户paypal渠道等。
安卓手机采集市场大分类页
这里要以qrcode为抓取节点来进行检测,即安卓手机浏览器去采集数据。但是个人觉得效率低,
各种浏览器应该都支持吧
最近发现一个东西可以比较靠谱,不用翻墙,不用充会员,无需外部链接,点一下就自动生成带有二维码的qrcode的地址。唯一缺点是貌似还不算很好看(捂脸。
很多qrcode有效的电子邮件站点,加上域名注册的电子邮件地址,
个人推荐fishershoppingmall的inspiration,使用特点:在inspiration服务器上部署了fisherocr服务器,根据收到的包裹信息(已知的,对应包裹上标注的文字)查询和识别包裹中的qrcode。详情请参考wiki百科!!!重点:文件的语义是相对固定的。
云优采集接口(如何利用优帮云数据平台的关键词价格查询API实现出类似云客网)
采集交流 • 优采云 发表了文章 • 0 个评论 • 157 次浏览 • 2021-10-03 22:32
目前,互联网上支持关键词价格查询功能的平台有很多,云客网是SEO行业中大家耳熟能详的平台之一。云客网是杭州智卓旗下SEO行业知名的众包服务平台。连接客户和技术优化人员的双边需求,进行网络营销推广。其亮点之一是能够在线实时查询关键词价格,深受SEO喜爱。从业者和客户的喜爱。很多SEO公司都想在自己的平台上加入这个功能,但是采集平台不能作为长期稳定的解决方案。今天跟大家分享一下如何使用友邦云数据平台的关键词价格查询API实现关键词
一、建立关键词缓冲库存储查询数据关键词
一般来说,只要是平台化的系统,就离不开数据库。对于关键词价格查询功能,必须至少有一个价目表用于存储关键词价格相关信息,包括关键词@关键词编号,关键词内容,百度整体指数、百度PC指数、百度手机指数、360指数、收录量、优化难度、主要引擎价格等领域,请参考我们在用户中心的展示。除了自身的属性,我们还需要一个数据中心API查询号。回调查询结果时使用该查询号。用这个查询号找到对应的关键词,然后更新对应的价格信息,不能省略。
二、创建前端客户交互界面和后端处理界面
当客户通过前端查询接口传入指定的关键词时,后端代码进行必要的验证后,首先在价目表中对关键词进行准确搜索,如果找到关键词 及信息 可直接从价目表中读取,未到期时显示给客户。如果长时间未找到关键词或关键词的价格信息,请先将关键词添加到价目表或重置已过期的相关数据,然后使用友邦云数据平台API接口会传入关键词,友邦云会立即返回一个平台API来查询代码。后端得到这个code后,会和code关键词一一对应。
三、数据相关处理的数据回调通知
每个友邦云API激活后,必须设置一个通知地址。优帮云数据平台的所有数据通知均通过该地址完成。后端收到API价格查询结果通知的数据后,根据返回的数据包的API查询编号,在价目表中找到对应的关键词,将价格相关信息更新到价目表中。
四、为前端客户友好展示缓冲效果
由于数据查询需要3-5秒,在产生前端效果时,由于采用了相关的非刷新技术,实现了友好的等待画面,后端通过定时查询从价目表中获取价格信息. 如果价格信息更新成功,展示给前端,整个查询完成。
云客网的诸多功能,如:关键词排名实时显示、每日计费系统等,可以说是一个完整的网络营销数字平台应用。其实,你只需要深入学习友邦云的数据平台API即可。,结合我自己的想法,这些类似云客网的功能是可以实现的。我们期待与您探讨使用优帮云的API实现更多功能。 查看全部
云优采集接口(如何利用优帮云数据平台的关键词价格查询API实现出类似云客网)
目前,互联网上支持关键词价格查询功能的平台有很多,云客网是SEO行业中大家耳熟能详的平台之一。云客网是杭州智卓旗下SEO行业知名的众包服务平台。连接客户和技术优化人员的双边需求,进行网络营销推广。其亮点之一是能够在线实时查询关键词价格,深受SEO喜爱。从业者和客户的喜爱。很多SEO公司都想在自己的平台上加入这个功能,但是采集平台不能作为长期稳定的解决方案。今天跟大家分享一下如何使用友邦云数据平台的关键词价格查询API实现关键词
一、建立关键词缓冲库存储查询数据关键词
一般来说,只要是平台化的系统,就离不开数据库。对于关键词价格查询功能,必须至少有一个价目表用于存储关键词价格相关信息,包括关键词@关键词编号,关键词内容,百度整体指数、百度PC指数、百度手机指数、360指数、收录量、优化难度、主要引擎价格等领域,请参考我们在用户中心的展示。除了自身的属性,我们还需要一个数据中心API查询号。回调查询结果时使用该查询号。用这个查询号找到对应的关键词,然后更新对应的价格信息,不能省略。
二、创建前端客户交互界面和后端处理界面
当客户通过前端查询接口传入指定的关键词时,后端代码进行必要的验证后,首先在价目表中对关键词进行准确搜索,如果找到关键词 及信息 可直接从价目表中读取,未到期时显示给客户。如果长时间未找到关键词或关键词的价格信息,请先将关键词添加到价目表或重置已过期的相关数据,然后使用友邦云数据平台API接口会传入关键词,友邦云会立即返回一个平台API来查询代码。后端得到这个code后,会和code关键词一一对应。
三、数据相关处理的数据回调通知
每个友邦云API激活后,必须设置一个通知地址。优帮云数据平台的所有数据通知均通过该地址完成。后端收到API价格查询结果通知的数据后,根据返回的数据包的API查询编号,在价目表中找到对应的关键词,将价格相关信息更新到价目表中。
四、为前端客户友好展示缓冲效果
由于数据查询需要3-5秒,在产生前端效果时,由于采用了相关的非刷新技术,实现了友好的等待画面,后端通过定时查询从价目表中获取价格信息. 如果价格信息更新成功,展示给前端,整个查询完成。
云客网的诸多功能,如:关键词排名实时显示、每日计费系统等,可以说是一个完整的网络营销数字平台应用。其实,你只需要深入学习友邦云的数据平台API即可。,结合我自己的想法,这些类似云客网的功能是可以实现的。我们期待与您探讨使用优帮云的API实现更多功能。
云优采集接口(Saas类表单工具正在实行蜕变,开始冲击传统办公市场)
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2021-09-27 04:19
Saas表单工具在中国慢慢兴起。从早期只用于数据采集和问卷调查,现在已经扩展到各个办公ERP领域。表单工具正在经历转型,并开始影响传统的办公市场。. 为了让大家更容易理解,我们对市面上常见的表单产品:金数据、百宝云、氚云、Formmaster、剑道云进行了深度对比,帮助大家找到更合适的表单工具来使用!金数据在线:2012年12月 优势微信营销利器:金数据的用户应用场景对微信的支持更好,尤其是微信的增加?
Saas表单工具在中国慢慢兴起。从早期只被编程客栈用来做数据采集和问卷调查,现在已经普及到各个办公ERP领域。表单工具正在经历转型,并开始影响传统的办公市场。为了让大家更容易理解,我们对比了目前同城xvlKtP编程栈上常见的形态产品:黄金数据、百宝云、氚云、形态大师、剑道云,并进行了深度对比,帮助大家找到适合自己的更适合编程栈使用表单工具!
黄金数据
上线时间:2012年12月
优势
微信营销利器:金数据用户应用场景更好的支持微信,尤其是微信增强包;微信下单、活动报名、用户反馈、招聘等偏向于业务数据采集,流量大、数据量大。.
产品稳定性高,安全性高
支持在线支付,您可以直接在线下单。
上线时间:2015年8月
优势
支持代码开发,支持深度应用定制
功能上:所有版本的 Tritium Cloud 都具有无限的数据量。所有版本都支持跨应用访问和数据填充。
强大的安全性和稳定性
上线时间:2017年8月
优势
个性化定制设计,简单易用,无需任何基础
定制门槛低,可直接在官网申请免费定制,百宝云更注重服务
维护成本低:无需专业技术人员。用户可以自己维护,给谁分配权限,把谁添加到通讯录,修改哪些字段,添加哪些业务报表。这些操作非常简单。
应用中心提供各行业成熟应用免费使用
支持后端语言二次开发,可以灵活处理一些业务需求场景,也可以对接各种业务接口
上线时间:2015年3月
优势
界面清晰,使用方便,无需开发基础
建道云支持数据采集、分析、查询、共享;成员之间的协作、去中心化、提醒;上下级之间的审批、流程等
建道云模板中心有上百款应用,大家可以免费使用;
强大的数据分析功能;
上线时间:2013年6月
优势
使用简单、快捷、方便,无需专业计算机知识;
数据采集渠道为多道客栈,通过微信公众平台、网站、博客、二维码等发布形式信息,多渠道采集数据;
多形式关联,在线支付(支持微信和支付宝)管理微信数据。
免费账户可以创建3个表格和报告,并且可以永久使用。
坏处
功能简单,只提供基本的表单制作,基本没有交互功能和页面设计。
免费表格太少
总评:★★★★
form master也是偏向于数据采集需求的场景,需要采集的场景可以考虑
国内表格系统大致分为两类。一是金数据、Form Master、称重,解决数据采集和营销活动的需求。这两个是旧世界,各有优缺点。第二个是氚云和百宝云。,剑道云,称重解决办公需求,氚云门槛稍高,绑定钉钉不是很亲民。白宝云和剑道云更符合大众需求。剑道云在数据分析方面有更成熟的功能。百宝云支持端到端语言后,可以解决一些特殊的计算需求场景。百宝云私有化部署也适合企业规划私密对话和品牌化需求。没有人喜欢自己的办公系统,总是使用别人的域名和标志。所以选择适合公司需求的才是最重要的!
文章名称:国内主流在线表单工具金数据、氚云、百宝云、剑道云、表单大师的优缺点对比 查看全部
云优采集接口(Saas类表单工具正在实行蜕变,开始冲击传统办公市场)
Saas表单工具在中国慢慢兴起。从早期只用于数据采集和问卷调查,现在已经扩展到各个办公ERP领域。表单工具正在经历转型,并开始影响传统的办公市场。. 为了让大家更容易理解,我们对市面上常见的表单产品:金数据、百宝云、氚云、Formmaster、剑道云进行了深度对比,帮助大家找到更合适的表单工具来使用!金数据在线:2012年12月 优势微信营销利器:金数据的用户应用场景对微信的支持更好,尤其是微信的增加?
Saas表单工具在中国慢慢兴起。从早期只被编程客栈用来做数据采集和问卷调查,现在已经普及到各个办公ERP领域。表单工具正在经历转型,并开始影响传统的办公市场。为了让大家更容易理解,我们对比了目前同城xvlKtP编程栈上常见的形态产品:黄金数据、百宝云、氚云、形态大师、剑道云,并进行了深度对比,帮助大家找到适合自己的更适合编程栈使用表单工具!
黄金数据
上线时间:2012年12月
优势
微信营销利器:金数据用户应用场景更好的支持微信,尤其是微信增强包;微信下单、活动报名、用户反馈、招聘等偏向于业务数据采集,流量大、数据量大。.
产品稳定性高,安全性高
支持在线支付,您可以直接在线下单。
上线时间:2015年8月
优势
支持代码开发,支持深度应用定制
功能上:所有版本的 Tritium Cloud 都具有无限的数据量。所有版本都支持跨应用访问和数据填充。
强大的安全性和稳定性
上线时间:2017年8月
优势
个性化定制设计,简单易用,无需任何基础
定制门槛低,可直接在官网申请免费定制,百宝云更注重服务
维护成本低:无需专业技术人员。用户可以自己维护,给谁分配权限,把谁添加到通讯录,修改哪些字段,添加哪些业务报表。这些操作非常简单。
应用中心提供各行业成熟应用免费使用
支持后端语言二次开发,可以灵活处理一些业务需求场景,也可以对接各种业务接口
上线时间:2015年3月
优势
界面清晰,使用方便,无需开发基础
建道云支持数据采集、分析、查询、共享;成员之间的协作、去中心化、提醒;上下级之间的审批、流程等
建道云模板中心有上百款应用,大家可以免费使用;
强大的数据分析功能;
上线时间:2013年6月
优势
使用简单、快捷、方便,无需专业计算机知识;
数据采集渠道为多道客栈,通过微信公众平台、网站、博客、二维码等发布形式信息,多渠道采集数据;
多形式关联,在线支付(支持微信和支付宝)管理微信数据。
免费账户可以创建3个表格和报告,并且可以永久使用。
坏处
功能简单,只提供基本的表单制作,基本没有交互功能和页面设计。
免费表格太少
总评:★★★★
form master也是偏向于数据采集需求的场景,需要采集的场景可以考虑
国内表格系统大致分为两类。一是金数据、Form Master、称重,解决数据采集和营销活动的需求。这两个是旧世界,各有优缺点。第二个是氚云和百宝云。,剑道云,称重解决办公需求,氚云门槛稍高,绑定钉钉不是很亲民。白宝云和剑道云更符合大众需求。剑道云在数据分析方面有更成熟的功能。百宝云支持端到端语言后,可以解决一些特殊的计算需求场景。百宝云私有化部署也适合企业规划私密对话和品牌化需求。没有人喜欢自己的办公系统,总是使用别人的域名和标志。所以选择适合公司需求的才是最重要的!
文章名称:国内主流在线表单工具金数据、氚云、百宝云、剑道云、表单大师的优缺点对比
云优采集接口(【云合同API接口】平台应用上线(测试阶段)(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2021-09-16 01:24
合同模板:平台可以上传相应的合同模板。轻松、快速、高效地创建合同
合同下载:平台可以下载带有签名的PDF文件并保存以供流通
三、项目对接总体流程图
1、对接过程
项目对接的整体流程如下图所示。平台应用上线前,应联系相应的技术支持人员进行确认
“应用库存结算”操作
1)注册云合同账号:平台方需要登录云合同官网(),注册企业账号并完成实名认证,然后联系对接人员协助开户
2)create platform applications:开发者可以登录云契约开放平台()创建应用(请在测试阶段创建测试应用,在正式项目中创建正式应用),并记录应用信息,为后续对接工作做准备
3)Acquire对接数据:云合约在本阶段以API对接的形式为平台提供电子合约功能。具体接口内容请参见本指南“第五章API接口文件”
4)梳理电子合同业务流程:开发者阅读云合同API接口文档后,根据接口逻辑梳理平台现有业务流程,并在关键业务节点连接相应接口,在现有业务流程上实现电子合同功能。请参阅“第4章接口调用过程”
5)接口对接:本步骤正式进行对接工作。如果对接中出现问题,可以联系技术对接人员帮助解决
6)准备上线:项目上线前,联系对接人员确认项目上线。此时,对接人员将协助“应用库清理”操作,清理应用中的测试数据(包括测试用户数据和测试合同数据)
7)application launch:该应用程序正式启动
2、官方网站注册流程
四、接口调用过程
下面显示了几个典型应用程序场景的接口调用过程。可以灵活调用各种业务服务。具体的接口调用主要基于平台的业务设计
1、接口调用过程-基本场景
2、接口调用过程-合同证书存放场景
3、接口调用过程-页面签名场景
4、接口调用过程-接口验证场景
5、summary
图中序号为标准电子合同业务操作流程,灰色框为云合同提供的API服务。整个电子合同业务流程分为两个阶段:初始化阶段和合同签订阶段。用户只需在首次使用平台电子合同服务时进行初始化,即可从合同签订阶段直接开始业务
关键流程节点描述如下:
1)配置合同模板:平台需要提前登录云合同开放平台,在应用中上传合同模板,配置“签名占位符”(即签名位置)
2)实名认证:云合约API服务完全信任平台用户的实名认证结果。平台用户完成实名认证后,可以为相应的平台用户申请CA证书。同时,云合约可以提供单独的实名认证增值服务
3)generate contract to signed:在确认所有签名人身份后,平台可以调用“根据模板生成合同”或“上传文件生成合同”界面生成待签名合同,调用“添加参与者”界面向合同中添加签名人,就签署地点和是否采用自愿认证达成一致
4)签约:可以在合同上加盖平台印章。云合约提供两种签约方式:“页面签约”和“合约签约”
5)查看合同:在线查看合同。平台可以调用“合同视图”JS方法获取合同视图URL,也可以调用“合同下载”界面自行制作合同视图页面 查看全部
云优采集接口(【云合同API接口】平台应用上线(测试阶段)(组图))
合同模板:平台可以上传相应的合同模板。轻松、快速、高效地创建合同
合同下载:平台可以下载带有签名的PDF文件并保存以供流通
三、项目对接总体流程图
1、对接过程
项目对接的整体流程如下图所示。平台应用上线前,应联系相应的技术支持人员进行确认
“应用库存结算”操作
1)注册云合同账号:平台方需要登录云合同官网(),注册企业账号并完成实名认证,然后联系对接人员协助开户
2)create platform applications:开发者可以登录云契约开放平台()创建应用(请在测试阶段创建测试应用,在正式项目中创建正式应用),并记录应用信息,为后续对接工作做准备
3)Acquire对接数据:云合约在本阶段以API对接的形式为平台提供电子合约功能。具体接口内容请参见本指南“第五章API接口文件”
4)梳理电子合同业务流程:开发者阅读云合同API接口文档后,根据接口逻辑梳理平台现有业务流程,并在关键业务节点连接相应接口,在现有业务流程上实现电子合同功能。请参阅“第4章接口调用过程”
5)接口对接:本步骤正式进行对接工作。如果对接中出现问题,可以联系技术对接人员帮助解决
6)准备上线:项目上线前,联系对接人员确认项目上线。此时,对接人员将协助“应用库清理”操作,清理应用中的测试数据(包括测试用户数据和测试合同数据)
7)application launch:该应用程序正式启动
2、官方网站注册流程
四、接口调用过程
下面显示了几个典型应用程序场景的接口调用过程。可以灵活调用各种业务服务。具体的接口调用主要基于平台的业务设计
1、接口调用过程-基本场景
2、接口调用过程-合同证书存放场景
3、接口调用过程-页面签名场景
4、接口调用过程-接口验证场景
5、summary
图中序号为标准电子合同业务操作流程,灰色框为云合同提供的API服务。整个电子合同业务流程分为两个阶段:初始化阶段和合同签订阶段。用户只需在首次使用平台电子合同服务时进行初始化,即可从合同签订阶段直接开始业务
关键流程节点描述如下:
1)配置合同模板:平台需要提前登录云合同开放平台,在应用中上传合同模板,配置“签名占位符”(即签名位置)
2)实名认证:云合约API服务完全信任平台用户的实名认证结果。平台用户完成实名认证后,可以为相应的平台用户申请CA证书。同时,云合约可以提供单独的实名认证增值服务
3)generate contract to signed:在确认所有签名人身份后,平台可以调用“根据模板生成合同”或“上传文件生成合同”界面生成待签名合同,调用“添加参与者”界面向合同中添加签名人,就签署地点和是否采用自愿认证达成一致
4)签约:可以在合同上加盖平台印章。云合约提供两种签约方式:“页面签约”和“合约签约”
5)查看合同:在线查看合同。平台可以调用“合同视图”JS方法获取合同视图URL,也可以调用“合同下载”界面自行制作合同视图页面
云优采集接口(什么是接口管理平台?1.把接口当成一个管理的对象)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2021-09-14 11:12
[toc]#什么是界面管理平台? 1. 把接口当作被管对象1. 监控接口的增删改查1. 采集其他开发者的反馈1. 让项目协作更简单# 常用的管理平台有哪些? * [EasyAPI]()* [eolinker](#/)* [NEI]()#这些管理平台的缺点1.图形界面,很漂亮,但是操作很麻烦![]()4.需要支付! []()3.如果搭建本地服务,会增加额外的学习费用,信息不全! []()![]()![]()#什么是看云>[信息][看云]()是一个集文档创建、分发、托管为一体的电子出版平台>致力于提供最佳在线文档创建和阅读体验> 让[企业]() 和个人更方便,更轻松地管理和共享您的文档。 >[危险] Kanyun的开发和thinkPHP5的开发其实是同一个团队。事实上,Kanyun 网站 是通过 thinkPHP 构建的。并且代码一年前被thinkPHP5.0重构过。#看云的优点1.学习成本低,只需要学习markdown,就可以解决大部分问题1.支持评论,方便交流项目成员之间! []()3.支持企业版,项目成员可以更好的协作4.支持Git,让文档编写发布更方便! []()![]() 查看全部
云优采集接口(什么是接口管理平台?1.把接口当成一个管理的对象)
[toc]#什么是界面管理平台? 1. 把接口当作被管对象1. 监控接口的增删改查1. 采集其他开发者的反馈1. 让项目协作更简单# 常用的管理平台有哪些? * [EasyAPI]()* [eolinker](#/)* [NEI]()#这些管理平台的缺点1.图形界面,很漂亮,但是操作很麻烦![]()4.需要支付! []()3.如果搭建本地服务,会增加额外的学习费用,信息不全! []()![]()![]()#什么是看云>[信息][看云]()是一个集文档创建、分发、托管为一体的电子出版平台>致力于提供最佳在线文档创建和阅读体验> 让[企业]() 和个人更方便,更轻松地管理和共享您的文档。 >[危险] Kanyun的开发和thinkPHP5的开发其实是同一个团队。事实上,Kanyun 网站 是通过 thinkPHP 构建的。并且代码一年前被thinkPHP5.0重构过。#看云的优点1.学习成本低,只需要学习markdown,就可以解决大部分问题1.支持评论,方便交流项目成员之间! []()3.支持企业版,项目成员可以更好的协作4.支持Git,让文档编写发布更方便! []()![]()
云优采集接口(网络训练性能未达预期时的性能分析及精度分析方法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 210 次浏览 • 2021-09-13 05:01
概述
当网络训练性能不符合预期时,可以分析Profiling数据,准确定位系统的软硬件性能瓶颈,提高性能分析效率,通过有针对性的性能,以最低的成本和成本实现业务优化方法 场景的极致性能,目前支持采集的性能数据主要包括:
大致流程为:ModelArts训练时将采集Profiling数据传输到OBS桶,然后将Profiling数据上传到CANN Toolkit软件包的安装环境进行性能分析。
修改训练脚本启用Profiling data采集
训练过程默认不是采集Profiling 性能数据。您需要修改训练脚本如下:
调用os的mkdir接口创建profiling工作目录,用于在ModelArts后台临时存放profiling数据:
import os
profiling_dir = "/cache/profiling"
os.makedirs(profiling_dir)
启用分析数据采集。
如果是手动迁移脚本,请参考Profiling data采集修改训练脚本。
如果是工具迁移脚本,请参考Profiling data采集修改训练脚本。
需要注意的是,以上参考章节是裸机场景中的修改示例。在ModelArts场景中,需要指定output为ModelArts后端目录:
custom_op.parameter_map["profiling_options"].s = tf.compat.as_bytes('{"output":profiling_dir,"task_trace":"on","training_trace":"on","fp_point":"resnet_model/conv2d/Conv2Dresnet_model/batch_normalization/FusedBatchNormV3_Reduce","bp_point":"gradients/AddN_70"}')
调用 moxing 的 copy_parallel 接口将生成的 profiling 数据传输到 OBS。
import moxing as mox
mox.file.copy_parallel(profiling_dir, config.train_url)
其中config.train_url为训练时指定的模型在OBS上的输出路径。
从 OBS 下载分析数据
完成上述训练脚本的修改后,在ModelArts上开始训练任务。训练结束后可以在FLAGS.train_url指向的OBS路径上查看Profiling文件夹。
通过Profiling工具进行准确度分析
您可以将OBS上的profiling数据下载到安装CANN Toolkit软件包的环境中,通过命令行进行性能分析。详情请参考《Profiling Tool 用户指南》。 查看全部
云优采集接口(网络训练性能未达预期时的性能分析及精度分析方法)
概述
当网络训练性能不符合预期时,可以分析Profiling数据,准确定位系统的软硬件性能瓶颈,提高性能分析效率,通过有针对性的性能,以最低的成本和成本实现业务优化方法 场景的极致性能,目前支持采集的性能数据主要包括:
大致流程为:ModelArts训练时将采集Profiling数据传输到OBS桶,然后将Profiling数据上传到CANN Toolkit软件包的安装环境进行性能分析。
修改训练脚本启用Profiling data采集
训练过程默认不是采集Profiling 性能数据。您需要修改训练脚本如下:
调用os的mkdir接口创建profiling工作目录,用于在ModelArts后台临时存放profiling数据:
import os
profiling_dir = "/cache/profiling"
os.makedirs(profiling_dir)
启用分析数据采集。
如果是手动迁移脚本,请参考Profiling data采集修改训练脚本。
如果是工具迁移脚本,请参考Profiling data采集修改训练脚本。
需要注意的是,以上参考章节是裸机场景中的修改示例。在ModelArts场景中,需要指定output为ModelArts后端目录:
custom_op.parameter_map["profiling_options"].s = tf.compat.as_bytes('{"output":profiling_dir,"task_trace":"on","training_trace":"on","fp_point":"resnet_model/conv2d/Conv2Dresnet_model/batch_normalization/FusedBatchNormV3_Reduce","bp_point":"gradients/AddN_70"}')
调用 moxing 的 copy_parallel 接口将生成的 profiling 数据传输到 OBS。
import moxing as mox
mox.file.copy_parallel(profiling_dir, config.train_url)
其中config.train_url为训练时指定的模型在OBS上的输出路径。
从 OBS 下载分析数据
完成上述训练脚本的修改后,在ModelArts上开始训练任务。训练结束后可以在FLAGS.train_url指向的OBS路径上查看Profiling文件夹。
通过Profiling工具进行准确度分析
您可以将OBS上的profiling数据下载到安装CANN Toolkit软件包的环境中,通过命令行进行性能分析。详情请参考《Profiling Tool 用户指南》。
云优采集接口(运行环境:PHP5.2/5.3/5.4+Mysql+伪静态(环境配置)安装教程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-09-07 02:16
运行环境:PHP5.2/5.3/5.4+Mysql+伪静态(环境配置为金商版主调试时的配置,请严格按照环境要求运行。金商数据已全部支持各种PHP版本和语言)安装教程:注:主机需要支持伪静态,使用虚拟主机咨询自己的服务商1.上传程序到主机,访问你的数据库访问你的域名/phpmyadmin,使用 输入数据库账号和密码。进入后,点击左侧的数据库名称,然后点击右侧的导入选项,将52jscn.sql文件放入根目录下的数据库中,或者将数据库文件夹中的源文件直接放入你的数据库中。如果没有,您可以咨询您的托管服务提供商! 2.用EditPlus或者dreamweaver打开/data/common.inc.php文件,修改里面的数据库信息,把demo6改成你的数据库名,root改成你的数据库用户名,你的数据库密码3.Login网站后台域名/admin/index.php(由于伪静态原因必须跟index.php)登录账号密码是admin和4.how采集,我可能说错了,但是目前我用它以这种方式。一般最好选择独立的云主机。数据库盘或者D盘保证在100G以上,后面的数据会非常大。在服务器上打开网站Background,点击采集——采集Rules——查看标有采集封面的,其实在采集小说列表中。打开采集选项让他自动采集着,而采集着会自动生成一些小说的名字都设置为自动,然后点击打开自动,打开页面采集(don 't close),然后关闭服务器界面,平时进去偶尔加一些采集close一些采集完的序列化!这是我自己的方法。如果会员发现更正确的告知方式,请分享给会员 查看全部
云优采集接口(运行环境:PHP5.2/5.3/5.4+Mysql+伪静态(环境配置)安装教程)
运行环境:PHP5.2/5.3/5.4+Mysql+伪静态(环境配置为金商版主调试时的配置,请严格按照环境要求运行。金商数据已全部支持各种PHP版本和语言)安装教程:注:主机需要支持伪静态,使用虚拟主机咨询自己的服务商1.上传程序到主机,访问你的数据库访问你的域名/phpmyadmin,使用 输入数据库账号和密码。进入后,点击左侧的数据库名称,然后点击右侧的导入选项,将52jscn.sql文件放入根目录下的数据库中,或者将数据库文件夹中的源文件直接放入你的数据库中。如果没有,您可以咨询您的托管服务提供商! 2.用EditPlus或者dreamweaver打开/data/common.inc.php文件,修改里面的数据库信息,把demo6改成你的数据库名,root改成你的数据库用户名,你的数据库密码3.Login网站后台域名/admin/index.php(由于伪静态原因必须跟index.php)登录账号密码是admin和4.how采集,我可能说错了,但是目前我用它以这种方式。一般最好选择独立的云主机。数据库盘或者D盘保证在100G以上,后面的数据会非常大。在服务器上打开网站Background,点击采集——采集Rules——查看标有采集封面的,其实在采集小说列表中。打开采集选项让他自动采集着,而采集着会自动生成一些小说的名字都设置为自动,然后点击打开自动,打开页面采集(don 't close),然后关闭服务器界面,平时进去偶尔加一些采集close一些采集完的序列化!这是我自己的方法。如果会员发现更正确的告知方式,请分享给会员
云优采集接口(--电商智能营销软件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 222 次浏览 • 2021-09-06 12:01
云优采集接口~~~秉承“成就有梦想的人,服务有需求的人,创造价值”为企业宗旨。我们通过互联网以及各大商城对接云优采集saas软件,提供你一站式企业云优化服务,无需再在这家去按照现有的采集工具采集资源,我们给你提供最新最全的个性化采集软件,并结合互联网为你提供最新最全的电商智能营销软件。
帮助你一键采集各种商品的图片、视频、链接、评论、标题、描述以及标签。并且同步数据,数据稳定,数据清晰。云优采集接口的优势1.软件一站式解决:标题解析、产品索引、标签采集、产品导入、评论及热门搜索、竞品图片、评论及热门搜索2.个性化定制服务,一对一方案定制。3.我们拥有两千多家商城采集代理资源,我们针对不同的采集对象提供不同的采集规则以及采集人群。
4.数据质量稳定,做的再差的产品的也是云优采集接口,还是稳定的!云优采集接口适用于各大平台采集服务商站、cms以及二次开发的app应用等,希望能够帮助你真正找到最合适的采集方式。
首先你要先分析想要采集的平台,然后查看他们平台的规则是怎么样的,比如天猫或者京东app,没有严格要求的图片,短视频等都是可以直接接入的。发现一个平台是需要分析它的规则来确定的。我记得有一个平台对是严格限制了图片类型,一些小图片是没办法采集的,因为严格限制。这个平台是爱采购平台,里面各个大类都有,其他没有记住名字的应该就是小型非电商类平台,其他我就记住了图片类别。至于第二个问题,一个很简单,用vba就可以。 查看全部
云优采集接口(--电商智能营销软件)
云优采集接口~~~秉承“成就有梦想的人,服务有需求的人,创造价值”为企业宗旨。我们通过互联网以及各大商城对接云优采集saas软件,提供你一站式企业云优化服务,无需再在这家去按照现有的采集工具采集资源,我们给你提供最新最全的个性化采集软件,并结合互联网为你提供最新最全的电商智能营销软件。
帮助你一键采集各种商品的图片、视频、链接、评论、标题、描述以及标签。并且同步数据,数据稳定,数据清晰。云优采集接口的优势1.软件一站式解决:标题解析、产品索引、标签采集、产品导入、评论及热门搜索、竞品图片、评论及热门搜索2.个性化定制服务,一对一方案定制。3.我们拥有两千多家商城采集代理资源,我们针对不同的采集对象提供不同的采集规则以及采集人群。
4.数据质量稳定,做的再差的产品的也是云优采集接口,还是稳定的!云优采集接口适用于各大平台采集服务商站、cms以及二次开发的app应用等,希望能够帮助你真正找到最合适的采集方式。
首先你要先分析想要采集的平台,然后查看他们平台的规则是怎么样的,比如天猫或者京东app,没有严格要求的图片,短视频等都是可以直接接入的。发现一个平台是需要分析它的规则来确定的。我记得有一个平台对是严格限制了图片类型,一些小图片是没办法采集的,因为严格限制。这个平台是爱采购平台,里面各个大类都有,其他没有记住名字的应该就是小型非电商类平台,其他我就记住了图片类别。至于第二个问题,一个很简单,用vba就可以。

