
云优采集接口
云优采集接口( 上图的日志采集方式以及对比说明(一)(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2022-03-16 06:21
上图的日志采集方式以及对比说明(一)(组图))
上图是EFK架构图,k8s环境下常用的log采集方法。
日志要求
1 采集采集微服务的日志,可以根据请求id跟踪完整的日志;
2.统计请求接口的耗时。如果最大响应时间超过最大响应时间,应报警并进行针对性调优;
3 慢sql排行榜和报警;
4 异常日志排名列表,并报警;
5 页面请求排名慢并报警;
k8s 日志采集
k8s本身不会为你登录采集,需要你自己做;
k8s的容器日志处理方式中使用的集群级日志,
即容器销毁、pod漂移、Node宕机等都不会影响容器日志;
容器的日志会输出到stdout、stderr,对应的存储在宿主机的目录下。
即/var/lib/docker/container;
通过 Node 上的日志代理转发
在每个节点上部署一个守护进程,运行一个日志代理来采集日志,
比如fluentd,采集在主机对应的数据盘上进行日志,然后输出到日志存储服务或者消息队列;
优缺点分析:
比较说明
优势
1 每个Node只需要部署一个Pod采集 log 2 不侵入应用
缺点
应用程序输出的日志必须直接输出到容器的stdout和stderr
Pod内部通过sidecar容器转发到日志服务
通过在pod中启动一个sidecar容器,比如fluentd,读取容器挂载的volume目录,输出到日志服务器;
日志输入源:日志文件
日志处理: logging-agent ,如 fluentd
日志存储:如elasticSearch、kafka
优缺点分析:
比较说明
优势
1 简单部署;2 主机友好;
缺点
1. 消耗更多资源;2. 通过 kubectl 日志看不到日志
例子:
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i:$(data)" >> /var/log/1.log
echo "$(data) INFO $i" >> /var/log/2.log
i=$((i+1))
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-agent
image: k8s.gcr.io/fluentd-gcp:1.30
env:
- name: FLUENTD_ARGS
value: -c /etc/fluentd-config/fluentd.conf
valumeMounts:
- name: varlog
mountPath: /var/log
- name: config-volume
mountPath: /etc/fluentd-config
volumes:
- name: varlog
emptyDir: {}
- name: config-volume
configMap:
name: fluentd-config
Pod 内部通过 sidecar 容器输出到 stdout
适用于应用容器只能输出日志到文件,不能输出到stdout和stderr的场景;
通过一个sidecar容器,直接读取日志文件,然后重新输出到stdout、stderr、
可以在Node上使用日志代理转发的模式;
优缺点分析:
比较说明
优势
只需要消耗较少的CPU和内存,共享卷处理效率比较高
缺点
主机上有两条相同的日志,磁盘利用率不高
应用容器直接输出日志到日志服务
适用于日志系统成熟的场景,日志不需要经过k8s;
EFK 引入 fluentd
fluentd 是一个用于统一日志记录层的开源数据采集器。
flentd 允许您统一日志采集和更好地使用和理解数据;
四大特点:
统一日志层
fluentd 隔离数据源,提供与后台系统统一的日志层;
简单灵活
提供500多个插件,连接大量数据源和输出源,内核简单;
广泛的验证
自 Fluentd 以来,5000 多家数据驱动型公司
最大的客户端通过它从 50,000 多台服务器采集日志
**云原生**
是云原生CNCF的成员项目
4大优势:
统一的 JSON 日志
fluentd尝试使用JSON结构化数据,统一处理日志数据的各个方面,采集、过滤、缓存、输出日志到多个目的地,下游数据处理使用Json更简单,因为它已经有足够的访问结构并保留了足够的灵活性场景;
插件架构
fluntd 有一个灵活的插件系统,允许社区扩展其功能。超过 500 个社区贡献的插件连接了许多数据源和目的地;通过插件,您可以开始更好地利用您的日志
最低资源消耗
用c和ruby写的,对系统资源要求很低,40M左右的内存可以处理13k/次/秒,如果需要更紧凑的内存,可以使用Fluent bit,更轻的Fluentd
内核可靠
Fluentd 支持内存和基于文件的缓存,防止内部节点数据丢失;
还支持鲁棒故障并可以配置高可用性模式,超过 2000 家数据驱动的公司在不同的产品中依靠 Fluentd 更好地使用和理解他们的日志数据
使用流利的理由:
简单灵活
10分钟即可在电脑上安装fluentd,立即下载,超过500个插件连接数据源和目的地,插件也易于开发和部署;
开源
基于 Apache2.0 证书的完全开源
可靠和高性能
超过 5,000 家数据驱动型公司的不同产品和服务依靠 fluentd 更好地使用和理解数据。事实上,根据datadog的调查,使用docker运行的技术排在前7位;
一些流利的用户拥有来自数千台机器的实时 采集 数据。每个实例只需要大约 40M 的内存。缩放时,可以节省大量内存。
社区
fluentd 可以改进软件并帮助其他人更好地使用它
大公司使用代言:微软、亚马逊;pptv;
可以与elasticSearch + kibana结合,组成日志套件;
快速搭建EFK集群,采集应用日志,配置性能排名;
弹性搜索
Elasticsearch 是一个分布式的 RESTful 搜索和数据分析引擎。
能够解决正在出现的各种用例。作为 Elastic Stack 的核心,
它集中存储您的数据,并帮助您发现预期和意外。
详细介绍:
木花
Kibana 是一个开源数据分析和可视化平台,是 Elastic Stack 的成员。
旨在与 Elasticsearch 配合使用。您可以使用 Kibana 在 Elasticsearch 索引中搜索数据,
查看,互动。您可以轻松地使用图表、表格和地图以多种方式分析和呈现数据。
Kibana 使大数据易于理解。这很简单,
基于浏览器的界面允许您快速创建和共享动态数据仪表板,以跟踪 Elasticsearch 中的实时数据变化。
详细介绍:
容器化 EFK 实现路径
直接往下拖代码,然后配置上下文、命名空间,就可以安装了;
cd elk-kubernetes
./deploy.sh --watch
下面是deploy.sh的脚本,可以简单看一下:
#!/bin/sh
CDIR=$(cd `dirname "$0"` && pwd)
cd "$CDIR"
print_red() {
printf '%b' "33[91m$133[0mn"
}
print_green() {
printf '%b' "33[92m$133[0mn"
}
render_template() {
eval "echo "$(cat "$1")""
}
KUBECTL_PARAMS="--context=250091890580014312-cc3174dcd4fc14cf781b6fc422120ebd8"
NAMESPACE=${NAMESPACE:-sm}
KUBECTL="kubectl ${KUBECTL_PARAMS} --namespace="${NAMESPACE}""
eval "kubectl ${KUBECTL_PARAMS} create namespace "${NAMESPACE}""
#NODES=$(eval "${KUBECTL} get nodes -l 'kubernetes.io/role!=master' -o go-template="{{range .items}}{{\$name := .metadata.name}}{{\$unschedulable := .spec.unschedulable}}{{range .status.conditions}}{{if eq .reason \"KubeletReady\"}}{{if eq .status \"True\"}}{{if not \$unschedulable}}{{\$name}}{{\"\\n\"}}{{end}}{{end}}{{end}}{{end}}{{end}}"")
NODES=$(eval "${KUBECTL} get nodes -l 'sm.efk=data' -o go-template="{{range .items}}{{\$name := .metadata.name}}{{\$unschedulable := .spec.unschedulable}}{{range .status.conditions}}{{if eq .reason \"KubeletReady\"}}{{if eq .status \"True\"}}{{if not \$unschedulable}}{{\$name}}{{\"\\n\"}}{{end}}{{end}}{{end}}{{end}}{{end}}"")
ES_DATA_REPLICAS=$(echo "$NODES" | wc -l)
if [ "$ES_DATA_REPLICAS" -lt 3 ]; then
print_red "Minimum amount of Elasticsearch data nodes is 3 (in case when you have 1 replica shard), you have ${ES_DATA_REPLICAS} worker nodes"
print_red "Won't deploy more than one Elasticsearch data pod per node exiting..."
exit 1
fi
print_green "Labeling nodes which will serve Elasticsearch data pods"
for node in $NODES; do
eval "${KUBECTL} label node ${node} elasticsearch.data=true --overwrite"
done
for yaml in *.yaml.tmpl; do
render_template "${yaml}" | eval "${KUBECTL} create -f -"
done
for yaml in *.yaml; do
eval "${KUBECTL} create -f "${yaml}""
done
eval "${KUBECTL} create configmap es-config --from-file=es-config --dry-run -o yaml" | eval "${KUBECTL} apply -f -"
eval "${KUBECTL} create configmap fluentd-config --from-file=docker/fluentd/td-agent.conf --dry-run -o yaml" | eval "${KUBECTL} apply -f -"
eval "${KUBECTL} create configmap kibana-config --from-file=kibana.yml --dry-run -o yaml" | eval "${KUBECTL} apply -f -"
eval "${KUBECTL} get pods $@"
简单分解部署流程:
我的k8s环境还没有搭建成功,后续搭建成功后会给出详细的安装说明。
概括
一句话总结这篇文章:EFK是通过日志代理客户端采集应用日志的常用实现方式。
原创不易,关注有诚意,转发价格更高!转载请注明出处,让我们互相交流,共同进步。欢迎交流。
程序员的信标
转载请注明原文链接:Cloud Native Series 5 EFK for Containerized Logs 查看全部
云优采集接口(
上图的日志采集方式以及对比说明(一)(组图))
 https://segmentfault.com/img/bVcOKIm" />
https://segmentfault.com/img/bVcOKIm" />上图是EFK架构图,k8s环境下常用的log采集方法。
日志要求
1 采集采集微服务的日志,可以根据请求id跟踪完整的日志;
2.统计请求接口的耗时。如果最大响应时间超过最大响应时间,应报警并进行针对性调优;
3 慢sql排行榜和报警;
4 异常日志排名列表,并报警;
5 页面请求排名慢并报警;
k8s 日志采集
k8s本身不会为你登录采集,需要你自己做;
k8s的容器日志处理方式中使用的集群级日志,
即容器销毁、pod漂移、Node宕机等都不会影响容器日志;
https://segmentfault.com/img/bVcOKIn" />容器的日志会输出到stdout、stderr,对应的存储在宿主机的目录下。
即/var/lib/docker/container;
通过 Node 上的日志代理转发
https://segmentfault.com/img/bVcOKIp" />在每个节点上部署一个守护进程,运行一个日志代理来采集日志,
比如fluentd,采集在主机对应的数据盘上进行日志,然后输出到日志存储服务或者消息队列;
优缺点分析:
比较说明
优势
1 每个Node只需要部署一个Pod采集 log 2 不侵入应用
缺点
应用程序输出的日志必须直接输出到容器的stdout和stderr
Pod内部通过sidecar容器转发到日志服务
https://segmentfault.com/img/bVcOKIq" />通过在pod中启动一个sidecar容器,比如fluentd,读取容器挂载的volume目录,输出到日志服务器;
日志输入源:日志文件
日志处理: logging-agent ,如 fluentd
日志存储:如elasticSearch、kafka
优缺点分析:
比较说明
优势
1 简单部署;2 主机友好;
缺点
1. 消耗更多资源;2. 通过 kubectl 日志看不到日志
例子:
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i:$(data)" >> /var/log/1.log
echo "$(data) INFO $i" >> /var/log/2.log
i=$((i+1))
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-agent
image: k8s.gcr.io/fluentd-gcp:1.30
env:
- name: FLUENTD_ARGS
value: -c /etc/fluentd-config/fluentd.conf
valumeMounts:
- name: varlog
mountPath: /var/log
- name: config-volume
mountPath: /etc/fluentd-config
volumes:
- name: varlog
emptyDir: {}
- name: config-volume
configMap:
name: fluentd-config
Pod 内部通过 sidecar 容器输出到 stdout
https://segmentfault.com/img/bVcOKIr" />适用于应用容器只能输出日志到文件,不能输出到stdout和stderr的场景;
通过一个sidecar容器,直接读取日志文件,然后重新输出到stdout、stderr、
可以在Node上使用日志代理转发的模式;
优缺点分析:
比较说明
优势
只需要消耗较少的CPU和内存,共享卷处理效率比较高
缺点
主机上有两条相同的日志,磁盘利用率不高
应用容器直接输出日志到日志服务
https://segmentfault.com/img/bVcOKIs" />适用于日志系统成熟的场景,日志不需要经过k8s;
EFK 引入 fluentd
fluentd 是一个用于统一日志记录层的开源数据采集器。
flentd 允许您统一日志采集和更好地使用和理解数据;
https://segmentfault.com/img/bVcOKIt" />四大特点:
统一日志层
fluentd 隔离数据源,提供与后台系统统一的日志层;
简单灵活
提供500多个插件,连接大量数据源和输出源,内核简单;
广泛的验证
自 Fluentd 以来,5000 多家数据驱动型公司
最大的客户端通过它从 50,000 多台服务器采集日志
**云原生**
是云原生CNCF的成员项目
https://segmentfault.com/img/bVcOKIA" />4大优势:
统一的 JSON 日志
https://segmentfault.com/img/bVcOKIB" />fluentd尝试使用JSON结构化数据,统一处理日志数据的各个方面,采集、过滤、缓存、输出日志到多个目的地,下游数据处理使用Json更简单,因为它已经有足够的访问结构并保留了足够的灵活性场景;
插件架构
https://segmentfault.com/img/bVcOKIC" />fluntd 有一个灵活的插件系统,允许社区扩展其功能。超过 500 个社区贡献的插件连接了许多数据源和目的地;通过插件,您可以开始更好地利用您的日志
最低资源消耗
https://segmentfault.com/img/bVcOKID" />用c和ruby写的,对系统资源要求很低,40M左右的内存可以处理13k/次/秒,如果需要更紧凑的内存,可以使用Fluent bit,更轻的Fluentd
内核可靠
https://segmentfault.com/img/bVcOKIE" />Fluentd 支持内存和基于文件的缓存,防止内部节点数据丢失;
还支持鲁棒故障并可以配置高可用性模式,超过 2000 家数据驱动的公司在不同的产品中依靠 Fluentd 更好地使用和理解他们的日志数据
使用流利的理由:
简单灵活
10分钟即可在电脑上安装fluentd,立即下载,超过500个插件连接数据源和目的地,插件也易于开发和部署;
开源
基于 Apache2.0 证书的完全开源
可靠和高性能
超过 5,000 家数据驱动型公司的不同产品和服务依靠 fluentd 更好地使用和理解数据。事实上,根据datadog的调查,使用docker运行的技术排在前7位;
一些流利的用户拥有来自数千台机器的实时 采集 数据。每个实例只需要大约 40M 的内存。缩放时,可以节省大量内存。
社区
fluentd 可以改进软件并帮助其他人更好地使用它
大公司使用代言:微软、亚马逊;pptv;
https://segmentfault.com/img/bVcOKIF" />https://segmentfault.com/img/bVcOKIG" />可以与elasticSearch + kibana结合,组成日志套件;
快速搭建EFK集群,采集应用日志,配置性能排名;
https://segmentfault.com/img/bVcOKIH" />弹性搜索
Elasticsearch 是一个分布式的 RESTful 搜索和数据分析引擎。
能够解决正在出现的各种用例。作为 Elastic Stack 的核心,
它集中存储您的数据,并帮助您发现预期和意外。
详细介绍:
木花
Kibana 是一个开源数据分析和可视化平台,是 Elastic Stack 的成员。
旨在与 Elasticsearch 配合使用。您可以使用 Kibana 在 Elasticsearch 索引中搜索数据,
查看,互动。您可以轻松地使用图表、表格和地图以多种方式分析和呈现数据。
Kibana 使大数据易于理解。这很简单,
基于浏览器的界面允许您快速创建和共享动态数据仪表板,以跟踪 Elasticsearch 中的实时数据变化。
详细介绍:
容器化 EFK 实现路径
直接往下拖代码,然后配置上下文、命名空间,就可以安装了;
cd elk-kubernetes
./deploy.sh --watch
下面是deploy.sh的脚本,可以简单看一下:
#!/bin/sh
CDIR=$(cd `dirname "$0"` && pwd)
cd "$CDIR"
print_red() {
printf '%b' "33[91m$133[0mn"
}
print_green() {
printf '%b' "33[92m$133[0mn"
}
render_template() {
eval "echo "$(cat "$1")""
}
KUBECTL_PARAMS="--context=250091890580014312-cc3174dcd4fc14cf781b6fc422120ebd8"
NAMESPACE=${NAMESPACE:-sm}
KUBECTL="kubectl ${KUBECTL_PARAMS} --namespace="${NAMESPACE}""
eval "kubectl ${KUBECTL_PARAMS} create namespace "${NAMESPACE}""
#NODES=$(eval "${KUBECTL} get nodes -l 'kubernetes.io/role!=master' -o go-template="{{range .items}}{{\$name := .metadata.name}}{{\$unschedulable := .spec.unschedulable}}{{range .status.conditions}}{{if eq .reason \"KubeletReady\"}}{{if eq .status \"True\"}}{{if not \$unschedulable}}{{\$name}}{{\"\\n\"}}{{end}}{{end}}{{end}}{{end}}{{end}}"")
NODES=$(eval "${KUBECTL} get nodes -l 'sm.efk=data' -o go-template="{{range .items}}{{\$name := .metadata.name}}{{\$unschedulable := .spec.unschedulable}}{{range .status.conditions}}{{if eq .reason \"KubeletReady\"}}{{if eq .status \"True\"}}{{if not \$unschedulable}}{{\$name}}{{\"\\n\"}}{{end}}{{end}}{{end}}{{end}}{{end}}"")
ES_DATA_REPLICAS=$(echo "$NODES" | wc -l)
if [ "$ES_DATA_REPLICAS" -lt 3 ]; then
print_red "Minimum amount of Elasticsearch data nodes is 3 (in case when you have 1 replica shard), you have ${ES_DATA_REPLICAS} worker nodes"
print_red "Won't deploy more than one Elasticsearch data pod per node exiting..."
exit 1
fi
print_green "Labeling nodes which will serve Elasticsearch data pods"
for node in $NODES; do
eval "${KUBECTL} label node ${node} elasticsearch.data=true --overwrite"
done
for yaml in *.yaml.tmpl; do
render_template "${yaml}" | eval "${KUBECTL} create -f -"
done
for yaml in *.yaml; do
eval "${KUBECTL} create -f "${yaml}""
done
eval "${KUBECTL} create configmap es-config --from-file=es-config --dry-run -o yaml" | eval "${KUBECTL} apply -f -"
eval "${KUBECTL} create configmap fluentd-config --from-file=docker/fluentd/td-agent.conf --dry-run -o yaml" | eval "${KUBECTL} apply -f -"
eval "${KUBECTL} create configmap kibana-config --from-file=kibana.yml --dry-run -o yaml" | eval "${KUBECTL} apply -f -"
eval "${KUBECTL} get pods $@"
简单分解部署流程:
https://segmentfault.com/img/bVcOKIJ" />我的k8s环境还没有搭建成功,后续搭建成功后会给出详细的安装说明。
概括
一句话总结这篇文章:EFK是通过日志代理客户端采集应用日志的常用实现方式。
https://segmentfault.com/img/bVcOKIK" />原创不易,关注有诚意,转发价格更高!转载请注明出处,让我们互相交流,共同进步。欢迎交流。
程序员的信标
转载请注明原文链接:Cloud Native Series 5 EFK for Containerized Logs
云优采集接口(个人用的易云优网采集器是免费的吗)
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-03-15 06:07
云优采集接口,现在有免费接口,可以简单接入平台进行云爬虫,接入后就有程序化采集工具,对于内容搬运、采集或者内容筛选,非常有用。
我目前用的是云优网,操作便捷,收费模式灵活。
看到您是在广东的用户,据我所知,用到“优采云”采集器非常方便的一个平台就是北京的云优网站优化部门开发的。收费模式也非常灵活,我们这边的云优网站优化部门就有这个接口,你可以咨询下试用下。如果还不太满意,以后可以找我们支持其他平台试用接口。
某宝可以买到,现在很多类似的,我刚买。
多种软件收费模式各异,建议买个收费的。然后跟业务部门确认下是否支持。采集现在挺火,但是现在的采集器大多没什么意思,什么样的站没有什么内容的。专注于基于api的操作,非采集公司的采集器。用户在选择接口之前,必须明确自己对内容是什么样的要求。否则接口多了,按照业务人员自己的选择去使用,大大降低了自己的使用效率。如果自己定制。没有任何意义。甚至还得自己开发团队。
试了一下dllbank,安卓和ios都可以,没接触过百度的。效果真心不怎么样。
个人用的易云优网
国内最专业的采集器是优采云,也是支持全网,全文,且有些网站还可以分时段日期采集,实时去重。另外优采云没有内置采集器扩展,只能通过扩展去接入采集器。有好多人看到优采云是免费的,就不用优采云了,我认为这种想法是非常愚蠢的,这样会失去许多价值,不支持人工复制粘贴代码不说,网上的代码不一定适合自己站点,如果配置不合理,是很可能有些用户去掉了合理的代码会造成无法正常采集到网站数据,因为有的网站对特殊字符做了处理,也有可能有的站点设置了一些小bug。总之建议支持好一点的采集器,像优采云,易云优网,以上三个站点中都有相应的客服。 查看全部
云优采集接口(个人用的易云优网采集器是免费的吗)
云优采集接口,现在有免费接口,可以简单接入平台进行云爬虫,接入后就有程序化采集工具,对于内容搬运、采集或者内容筛选,非常有用。
我目前用的是云优网,操作便捷,收费模式灵活。
看到您是在广东的用户,据我所知,用到“优采云”采集器非常方便的一个平台就是北京的云优网站优化部门开发的。收费模式也非常灵活,我们这边的云优网站优化部门就有这个接口,你可以咨询下试用下。如果还不太满意,以后可以找我们支持其他平台试用接口。
某宝可以买到,现在很多类似的,我刚买。
多种软件收费模式各异,建议买个收费的。然后跟业务部门确认下是否支持。采集现在挺火,但是现在的采集器大多没什么意思,什么样的站没有什么内容的。专注于基于api的操作,非采集公司的采集器。用户在选择接口之前,必须明确自己对内容是什么样的要求。否则接口多了,按照业务人员自己的选择去使用,大大降低了自己的使用效率。如果自己定制。没有任何意义。甚至还得自己开发团队。
试了一下dllbank,安卓和ios都可以,没接触过百度的。效果真心不怎么样。
个人用的易云优网
国内最专业的采集器是优采云,也是支持全网,全文,且有些网站还可以分时段日期采集,实时去重。另外优采云没有内置采集器扩展,只能通过扩展去接入采集器。有好多人看到优采云是免费的,就不用优采云了,我认为这种想法是非常愚蠢的,这样会失去许多价值,不支持人工复制粘贴代码不说,网上的代码不一定适合自己站点,如果配置不合理,是很可能有些用户去掉了合理的代码会造成无法正常采集到网站数据,因为有的网站对特殊字符做了处理,也有可能有的站点设置了一些小bug。总之建议支持好一点的采集器,像优采云,易云优网,以上三个站点中都有相应的客服。
云优采集接口(中国行政管理学教学研究会副会长)
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2022-03-13 00:02
USB全接口视频采集盒子质量稳定,联盛科技现提供产品:视频采集盒子、录像盒子、视频采集卡、视频编码器、视频解码器、视频转码器、视频传输、视频转换产品,优尼森科技产品长期畅销国内外专业和消费类产品市场,在消费类市场和专业用户中享有良好的口碑和商誉。USB全接口视频采集画质稳定。遗传算法是模拟达尔文生物进化论的自然选择和遗传机制的计算模型。它是一种通过模拟自然进化来寻找最优解的方法。您想向朋友推荐博客详细信息页面吗?1 扣除金额。余额不能直接购买和下载,但可以购买VIP、C币套餐、付费栏目和课程。谢谢,我们会尽快审核!
通过具体的例子,详细说明了如何扩展通用 Mapper 原有的功能以满足您的特定需求。相信本教程的学习,在通用Mapper的帮助下,足以满足大部分应用场景的开发需求。本视频讲授了RBAC权限模型的设计及其在项目中的应用。使用 Maven 进行项目构建。页面设计采用响应式前端框架BootStrap。基本业务功能使用异步数据操作来提升用户体验。它是一个广泛使用的版本控制软件。作为CVS的接班人,在很多方面都具有鲜明的特色,提供了更好的操作体验,解决了实际企业开发过程中的问题如:数据备份、代码恢复等问题,
USB全接口影音采集盒子画质稳定,享受高品质观影的VIP体验。跳过广告看大片立马存手机看下载视频:不会说话就别说话!
n 闫杰、太平洋建设集团原董事长;不失精神的斗士,方法胜于困难;一个无所畏惧的战士,他的脚不能伸手,只能用他的眼睛;北京市委党校、北京行政学院公共管理系主任,中国行政管理教研会副会长,中国政治学会政策学会常务理事,全国绩效管理研究会常务理事,常务理事北京市行政管理学会理事、副秘书长,北京市领导学会副会长兼秘书长。 查看全部
云优采集接口(中国行政管理学教学研究会副会长)
USB全接口视频采集盒子质量稳定,联盛科技现提供产品:视频采集盒子、录像盒子、视频采集卡、视频编码器、视频解码器、视频转码器、视频传输、视频转换产品,优尼森科技产品长期畅销国内外专业和消费类产品市场,在消费类市场和专业用户中享有良好的口碑和商誉。USB全接口视频采集画质稳定。遗传算法是模拟达尔文生物进化论的自然选择和遗传机制的计算模型。它是一种通过模拟自然进化来寻找最优解的方法。您想向朋友推荐博客详细信息页面吗?1 扣除金额。余额不能直接购买和下载,但可以购买VIP、C币套餐、付费栏目和课程。谢谢,我们会尽快审核!
通过具体的例子,详细说明了如何扩展通用 Mapper 原有的功能以满足您的特定需求。相信本教程的学习,在通用Mapper的帮助下,足以满足大部分应用场景的开发需求。本视频讲授了RBAC权限模型的设计及其在项目中的应用。使用 Maven 进行项目构建。页面设计采用响应式前端框架BootStrap。基本业务功能使用异步数据操作来提升用户体验。它是一个广泛使用的版本控制软件。作为CVS的接班人,在很多方面都具有鲜明的特色,提供了更好的操作体验,解决了实际企业开发过程中的问题如:数据备份、代码恢复等问题,
USB全接口影音采集盒子画质稳定,享受高品质观影的VIP体验。跳过广告看大片立马存手机看下载视频:不会说话就别说话!
n 闫杰、太平洋建设集团原董事长;不失精神的斗士,方法胜于困难;一个无所畏惧的战士,他的脚不能伸手,只能用他的眼睛;北京市委党校、北京行政学院公共管理系主任,中国行政管理教研会副会长,中国政治学会政策学会常务理事,全国绩效管理研究会常务理事,常务理事北京市行政管理学会理事、副秘书长,北京市领导学会副会长兼秘书长。
云优采集接口(云优统计接口是骗子,一年五百我在国家食品药品监督管理局官网可以查询)
采集交流 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-03-08 02:01
云优采集接口,云优统计接口,企业资料接口,工商查询接口,国家食品药品监督管理局网站接口,以及云优仓,可以看看这家网站,其实市面上很多功能几十块钱就能买到。
这种接口是要收费的,几百到几千,根据资质证书的多少,展示的多少来收费的。你可以多比较下几家。
至少九十。小的都是骗子。这行市场很乱。
市场上接口都是几十一个,大的只要两三百就能做,再小就要500一个了,云优统计接口这个价格已经很便宜了,而且还要保真,所以推荐云优统计接口,
云优都是要收费的,一般两百-五百之间,大的都要几千,
云优就是个骗子,我合作过几个都是后者合作下来非常后悔。
你要办理的是什么接口
你要办理的是什么接口?
云优是骗子,我跟他们合作过,不办他们的接口可以全部推掉。
云优并不是免费,靠代理赚取微利,个人觉得你要多观察一下云优官网或官方论坛,因为比较官方的,比较权威,
云优就是骗子,一年五百我在国家食品药品监督管理局官网可以查询,完全没问题。云优就是骗子,我在山西有3个客户,合作一年耗损,只多了几百块钱,就把价格报的比较高,我很纳闷?(质保两年),看来我的接口是最差的,质保期过了我也没有说服人家,是真差吗?可是你的都是回转的pv和页面跳转全部来自icp那些,这就是问题。
质保期他们官网上也都写了说是3年,他们两个月之内合同都没到。也就是说最保险起见,我接的只能是回转接口,所以我合作云优的客户基本不能拿出回转接口,没有超时发给,要发来的话一律是还有x个月保修期这些条款。除非超过保修期,那才是我真正接受的。又要抢客户,又不保险就是最大的问题,这才是他们官网上写的责任,个人觉得是跟有关部门合作,所以至今上我还没有看到有关部门领导以及执法单位为云优出具罚款的。我在国家食品药品监督管理局官网查询不到云优的线索,不知道是不是公司要求这么做?。 查看全部
云优采集接口(云优统计接口是骗子,一年五百我在国家食品药品监督管理局官网可以查询)
云优采集接口,云优统计接口,企业资料接口,工商查询接口,国家食品药品监督管理局网站接口,以及云优仓,可以看看这家网站,其实市面上很多功能几十块钱就能买到。
这种接口是要收费的,几百到几千,根据资质证书的多少,展示的多少来收费的。你可以多比较下几家。
至少九十。小的都是骗子。这行市场很乱。
市场上接口都是几十一个,大的只要两三百就能做,再小就要500一个了,云优统计接口这个价格已经很便宜了,而且还要保真,所以推荐云优统计接口,
云优都是要收费的,一般两百-五百之间,大的都要几千,
云优就是个骗子,我合作过几个都是后者合作下来非常后悔。
你要办理的是什么接口
你要办理的是什么接口?
云优是骗子,我跟他们合作过,不办他们的接口可以全部推掉。
云优并不是免费,靠代理赚取微利,个人觉得你要多观察一下云优官网或官方论坛,因为比较官方的,比较权威,
云优就是骗子,一年五百我在国家食品药品监督管理局官网可以查询,完全没问题。云优就是骗子,我在山西有3个客户,合作一年耗损,只多了几百块钱,就把价格报的比较高,我很纳闷?(质保两年),看来我的接口是最差的,质保期过了我也没有说服人家,是真差吗?可是你的都是回转的pv和页面跳转全部来自icp那些,这就是问题。
质保期他们官网上也都写了说是3年,他们两个月之内合同都没到。也就是说最保险起见,我接的只能是回转接口,所以我合作云优的客户基本不能拿出回转接口,没有超时发给,要发来的话一律是还有x个月保修期这些条款。除非超过保修期,那才是我真正接受的。又要抢客户,又不保险就是最大的问题,这才是他们官网上写的责任,个人觉得是跟有关部门合作,所以至今上我还没有看到有关部门领导以及执法单位为云优出具罚款的。我在国家食品药品监督管理局官网查询不到云优的线索,不知道是不是公司要求这么做?。
云优采集接口( 网闸全数据库安全隔离网闸,实现网络上任意计算机的数据交换数据库)
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2022-03-05 09:02
网闸全数据库安全隔离网闸,实现网络上任意计算机的数据交换数据库)
在线QQ客服:1922638
专业的SQL Server、MySQL数据库同步软件
本发明涉及跨网守数据同步技术领域,具体提供一种基于云消息服务平台实现跨网守Mysql数据库同步的装置及方法。
背景技术:
在公司或企业环境中,出于安全考虑,内网和外网需要“物理分离”,但内网和外网也需要交换数据(如Mysql数据库同步),所以Gatekeeper是介绍了。网守的全称是安全隔离网守。网守的隔离定义分为三个级别:
物理隔离:模拟人工交换的过程,必须在内外网的节点机器上进行数据交换,不能实现网络上任何一台计算机的数据交换。这种方法非常安全。
网络隔离:在简单交换的基础上,文件传输协议的数据包交换实现了网络上任意信息点的数据交换,降低了安全性。
协议隔离:对于其他应用协议代理,如Http,实现应用数据的直接交换,在方便交换的同时大大降低了安全性。
物理隔离是指仅具有文件级交换的网守。这种情况下,如果内网用户需要访问外网的Mysql数据库,协议被阻塞,即不能直接访问外网的Mysql数据库。因此,出现了新的要求。在保证安全的情况下,通过网守的物理隔离将外网Mysql数据库同步到内网Mysql数据库,使内网用户直接访问内网Mysql数据库相当于可以访问外网的Mysql数据库。外网Mysql数据库的数据文件是不断变化的。直接同步大量大文件是不现实的,
云消息服务平台(简称cmsP)是一种消息中间件,它可以利用TCP/IP协议将一个网络消息队列中的消息实时有序地传输到另一个网络消息队列,提供一种方法用于在不同网络之间实时有效地交换数据。cmsP有一个重要的特点,严格先进先出,即消息的生产、存储、传输和消费都是严格有序的。在有网守隔离的内网环境中,在保证隔离安全的情况下(只允许文件交换,不允许协议通过等),cmsP不能正常传输数据,比如简单的从消息队列中发送消息. 取出生成的文件,通过网守进行交换,破坏了消息的顺序,
技术实施要素:
本发明的技术任务是针对上述存在的问题,提供一种基于云消息服务平台实现Mysql数据库跨门同步的装置,能够解决Mysql数据库跨门同步问题。 ,同时保证Mysql数据库的及时性和效率。.
本发明进一步的技术任务是提供一种基于云消息服务平台实现跨网守Mysql数据库同步的方法。
为实现上述目的,本发明提供以下技术方案:
一种基于云消息服务平台实现跨网守Mysql数据库同步的装置,包括Mysql日志采集模块、消息队列一、转换模块一、文件名带编码文件存储模块一、Gatekeeper模块,消息队列二、转换模块二、文件名带编码文件存储模块II和Mysql数据存储模块,Mysql日志采集模块,消息队列一、转换模块一、外网设置带编码文件存储模块1的文件名,消息队列二、转换模块二、带编码文件存储模块2的文件名和Mysql数据入库模块位于 Intranet 中。消息队列分别连接Mysql日志采集模块和转换模块。转换模块连接到文件名被编码的文件存储模块。文件名已编码。第一存储模块通过网守模块与文件名带编码的第二文件存储模块相连,第二文件存储模块与编码文件名相连,第二转换模块与第二消息队列相连。转换模块二、Mysql数据输入。库模块是单独链接的。第二个消息队列连接到转换模块二、Mysql数据输入。库模块是单独链接的。第二个消息队列连接到转换模块二、Mysql数据输入。库模块是单独链接的。
优选地,基于云消息服务平台实现跨网守Mysql数据库同步的装置还包括Mysql源数据库和Mysql目的数据库,Mysql源数据库连接Mysql log采集模块, Mysql 目标数据库连接到 Mysql 数据条目。库模块是链接的。
优选地,Mysql日志采集模块用于Mysql源数据库采集的全量数据和增量变更日志,Mysql数据存储模块将全量数据写入Mysql目的数据库,Mysql log采集 @采集 模块将增量更改日志拆分成64KB的消息块,并将增量更改日志同步到Mysql目标数据库。
优选地,Mysql log采集模块将全量数据和增量变更日志写入消息队列1,转换模块1有序地从消息队列1中读取消息,生成文件名经过编码的文件,将其存储在第一文件名编码文件存储模块中,网守模块将第一文件名编码文件存储模块中的编码文件交换到第二文件名编码文件存储模块中。
优选地,转换模块2将文件存储模块2中的编码文件名的文件写入到消息队列2中。
基于云消息服务平台实现跨网守Mysql数据库同步的方法,Mysql日志采集模块采集来自Mysql源数据库的Mysql全量数据和增量变更日志,并将完整的数据和对日志的增量更改。日志先写入消息队列1,再通过网守模块写入消息队列2。Mysql数据存储模块从消息队列2中获取全量数据和增量变更日志,写入Mysql目的数据库。
全量数据采集是通过Mysql数据库接口获取部分选中表的所有记录,增量变更日志采集是获取Mysql源数据binlog日志。
优选地,Mysql日志采集模块用于从Mysql源数据库采集获取全量数据和增量变更日志,Mysql数据存储模块将全量数据写入Mysql目的数据库, Mysql log采集模块将增量更改日志拆分成64KB的消息块,并将增量更改日志同步到Mysql目标数据库。这样,Mysql 目的数据库与Mysql 源数据库实时同步,Mysql 源数据库的内容变化(包括增删)会及时同步到Mysql 目的数据库。
其中,小于64KB取剩余值。
优选地,将全量数据和增量变更日志写入消息队列1,通过转换模块1有序地读出消息,生成文件名经过编码的文件并存储在具有编码文件名的文件存储模块1, 网守模块使用文件交换功能将具有编码文件名的文件交换给具有编码文件名的文件存储模块2。转换模块2有序读取文件名编码后的文件,写入消息队列2中间。
第一个转换模块生成带编码文件名的文件,既保证了文件生成的实时性,又考虑了带编码文件名的文件的大小,保证带编码的文件文件名可以尽可能高效、及时地交换到网守模块。转换模块二。网守模块的文件交换是无序的,转换模块2的一个关键点就是有序的读出文件名和代码的文件内容,以消息的形式写入到消息队列2中.
优选地,转换模块1有序地从消息队列1中读取消息,并以相同的顺序将它们以编码后的文件名写入文件存储模块1中。编码文件的文件名具有消息的开头。序号和终止序号。
在本发明中,文件名的一个例子是cmspXXXXXX_YYYYYY.msg,其中XXXXXX是起始序号,YYYYYY是结束序号。
需要配置转换模块2第一次运行时开始读取的报文序号。每次读取文件时,必须从最后一个终止序列号的下一个开始读取。例如,网守模块不交换满足条件的文件。过来,那么转换模块2一直在等待,直到条件满足。
优选地,转换模块2有序地读出文件名编码后的文件内容,并以消息的形式写入消息队列2。
与现有技术相比,本发明基于云消息服务平台实现跨网守Mysql数据库同步的方法具有以下突出的有益效果: 基于云消息服务实现跨网守Mysql数据库同步的方法平台不仅解决了Mysql数据库跨网守同步的问题,而且保证了Mysql数据库同步的及时性和效率,具有很好的推广和应用价值。
图纸说明
无花果。附图说明图1为本发明基于云消息服务平台实现Mysql数据库跨网守同步装置的拓扑结构图。
详细说明
下面结合附图和实施例对本发明基于云消息服务平台实现跨网守Mysql数据库同步的装置和方法做进一步的详细说明。
例子
如图1所示,本发明基于云消息服务平台实现跨网守Mysql数据库同步的装置包括Mysql源数据库、Mysql日志采集模块、消息队列一、转换模块一、文件名编码文件存储模块一、Gatekeeper模块,消息队列二、转换模块二、文件名编码文件存储模块二、Mysql数据存储模块和 Mysql 目的数据库。Mysql源数据库,Mysql日志采集模块,消息队列一、转换模块一、外网设置编码文件存储模块的文件名,消息队列二、转换模块< @二、带编码文件存储模块的文件名二、
Mysql 源数据库连接到 Mysql log采集 模块。消息队列1分别连接Mysql日志采集模块和转换模块1,转换模块1连接文件名编码的文件存储模块1。文件名编码的文件存储模块1通过网守模块与文件名编码的第二文件存储模块相连,文件名编码的第二文件存储模块与转换模块2相连,消息队列2 连接转换模块二、Mysql 数据仓库模块单独连接,Mysql 目标数据库连接Mysql 数据仓库模块。
Mysql log采集 模块用于记录来自Mysql 源数据库的采集 完整数据和增量更改。全量数据采集是通过Mysql数据库接口获取部分选中表的所有记录,增量变更日志采集是获取Mysql源数据binlog日志。Mysql 数据仓库模块将增量变更日志拆分成 64KB 的消息块,剩余的值用于小于 64KB 的消息块。Mysql数据存储模块将全量数据和增量变更日志写入消息队列。转换模块1有序地从消息队列1中读取消息,生成文件名编码后的文件,并存储在文件名编码后的文件存储模块1中。将该名称编码的文件交换到该文件名编码的文件存储模块2。转换模块2将文件存储模块2中带有编码文件名的文件写入到消息队列2中。消息队列2中的文件最终通过Mysql存储模块写入Mysql目的数据库。
第一个转换模块生成带编码文件名的文件,既保证了文件生成的实时性,又考虑了带编码文件名的文件的大小,保证带编码的文件文件名可以尽可能高效、及时地交换到网守模块。转换模块二。网守模块的文件交换是无序的,转换模块2的一个关键点就是有序的读出文件名和代码的文件内容,以消息的形式写入到消息队列2中.
在本发明的基于云消息服务平台实现跨网守Mysql数据库同步的方法中,Mysql日志采集模块采集来自Mysql源数据库的Mysql全数据和增量变更日志,并转换完整数据和增量更改日志。增量更改日志被写入消息队列一。通过转换模块1,有序地从消息队列1中读取消息,生成文件名编码后的文件,并对文件名编码后的文件进行排序写入。该名称具有消息的起始序列号和结束序列号。例如,在本发明中,样本文件名为cmspXXXXXX_YYYYYY.msg,其中XXXXXX为起始序号,YYYYYY 是结束序列号。第一个转换模块生成带编码文件名的文件,既保证了文件生成的实时性,又考虑了带编码文件名的文件的大小,保证带编码的文件文件名可以尽可能高效、及时地交换到网守模块。转换模块二。网守模块利用文件交换功能,将具有文件名的编码文件交换给具有编码文件名的文件存储模块2。网守模块的文件交换紊乱。转换模块2的一个重点是文件的有序存储。具有编码文件名的文件以消息的形式被读取并写入消息队列2。
以上所述仅为本发明的较佳具体实施例而已,本领域普通技术人员在本发明技术方案的范围内所作的通常改动和替换,均应收录在本发明的保护范围之内。 . 查看全部
云优采集接口(
网闸全数据库安全隔离网闸,实现网络上任意计算机的数据交换数据库)

在线QQ客服:1922638
专业的SQL Server、MySQL数据库同步软件

本发明涉及跨网守数据同步技术领域,具体提供一种基于云消息服务平台实现跨网守Mysql数据库同步的装置及方法。
背景技术:
在公司或企业环境中,出于安全考虑,内网和外网需要“物理分离”,但内网和外网也需要交换数据(如Mysql数据库同步),所以Gatekeeper是介绍了。网守的全称是安全隔离网守。网守的隔离定义分为三个级别:
物理隔离:模拟人工交换的过程,必须在内外网的节点机器上进行数据交换,不能实现网络上任何一台计算机的数据交换。这种方法非常安全。
网络隔离:在简单交换的基础上,文件传输协议的数据包交换实现了网络上任意信息点的数据交换,降低了安全性。
协议隔离:对于其他应用协议代理,如Http,实现应用数据的直接交换,在方便交换的同时大大降低了安全性。
物理隔离是指仅具有文件级交换的网守。这种情况下,如果内网用户需要访问外网的Mysql数据库,协议被阻塞,即不能直接访问外网的Mysql数据库。因此,出现了新的要求。在保证安全的情况下,通过网守的物理隔离将外网Mysql数据库同步到内网Mysql数据库,使内网用户直接访问内网Mysql数据库相当于可以访问外网的Mysql数据库。外网Mysql数据库的数据文件是不断变化的。直接同步大量大文件是不现实的,
云消息服务平台(简称cmsP)是一种消息中间件,它可以利用TCP/IP协议将一个网络消息队列中的消息实时有序地传输到另一个网络消息队列,提供一种方法用于在不同网络之间实时有效地交换数据。cmsP有一个重要的特点,严格先进先出,即消息的生产、存储、传输和消费都是严格有序的。在有网守隔离的内网环境中,在保证隔离安全的情况下(只允许文件交换,不允许协议通过等),cmsP不能正常传输数据,比如简单的从消息队列中发送消息. 取出生成的文件,通过网守进行交换,破坏了消息的顺序,
技术实施要素:
本发明的技术任务是针对上述存在的问题,提供一种基于云消息服务平台实现Mysql数据库跨门同步的装置,能够解决Mysql数据库跨门同步问题。 ,同时保证Mysql数据库的及时性和效率。.
本发明进一步的技术任务是提供一种基于云消息服务平台实现跨网守Mysql数据库同步的方法。
为实现上述目的,本发明提供以下技术方案:
一种基于云消息服务平台实现跨网守Mysql数据库同步的装置,包括Mysql日志采集模块、消息队列一、转换模块一、文件名带编码文件存储模块一、Gatekeeper模块,消息队列二、转换模块二、文件名带编码文件存储模块II和Mysql数据存储模块,Mysql日志采集模块,消息队列一、转换模块一、外网设置带编码文件存储模块1的文件名,消息队列二、转换模块二、带编码文件存储模块2的文件名和Mysql数据入库模块位于 Intranet 中。消息队列分别连接Mysql日志采集模块和转换模块。转换模块连接到文件名被编码的文件存储模块。文件名已编码。第一存储模块通过网守模块与文件名带编码的第二文件存储模块相连,第二文件存储模块与编码文件名相连,第二转换模块与第二消息队列相连。转换模块二、Mysql数据输入。库模块是单独链接的。第二个消息队列连接到转换模块二、Mysql数据输入。库模块是单独链接的。第二个消息队列连接到转换模块二、Mysql数据输入。库模块是单独链接的。
优选地,基于云消息服务平台实现跨网守Mysql数据库同步的装置还包括Mysql源数据库和Mysql目的数据库,Mysql源数据库连接Mysql log采集模块, Mysql 目标数据库连接到 Mysql 数据条目。库模块是链接的。
优选地,Mysql日志采集模块用于Mysql源数据库采集的全量数据和增量变更日志,Mysql数据存储模块将全量数据写入Mysql目的数据库,Mysql log采集 @采集 模块将增量更改日志拆分成64KB的消息块,并将增量更改日志同步到Mysql目标数据库。
优选地,Mysql log采集模块将全量数据和增量变更日志写入消息队列1,转换模块1有序地从消息队列1中读取消息,生成文件名经过编码的文件,将其存储在第一文件名编码文件存储模块中,网守模块将第一文件名编码文件存储模块中的编码文件交换到第二文件名编码文件存储模块中。
优选地,转换模块2将文件存储模块2中的编码文件名的文件写入到消息队列2中。
基于云消息服务平台实现跨网守Mysql数据库同步的方法,Mysql日志采集模块采集来自Mysql源数据库的Mysql全量数据和增量变更日志,并将完整的数据和对日志的增量更改。日志先写入消息队列1,再通过网守模块写入消息队列2。Mysql数据存储模块从消息队列2中获取全量数据和增量变更日志,写入Mysql目的数据库。
全量数据采集是通过Mysql数据库接口获取部分选中表的所有记录,增量变更日志采集是获取Mysql源数据binlog日志。
优选地,Mysql日志采集模块用于从Mysql源数据库采集获取全量数据和增量变更日志,Mysql数据存储模块将全量数据写入Mysql目的数据库, Mysql log采集模块将增量更改日志拆分成64KB的消息块,并将增量更改日志同步到Mysql目标数据库。这样,Mysql 目的数据库与Mysql 源数据库实时同步,Mysql 源数据库的内容变化(包括增删)会及时同步到Mysql 目的数据库。
其中,小于64KB取剩余值。
优选地,将全量数据和增量变更日志写入消息队列1,通过转换模块1有序地读出消息,生成文件名经过编码的文件并存储在具有编码文件名的文件存储模块1, 网守模块使用文件交换功能将具有编码文件名的文件交换给具有编码文件名的文件存储模块2。转换模块2有序读取文件名编码后的文件,写入消息队列2中间。
第一个转换模块生成带编码文件名的文件,既保证了文件生成的实时性,又考虑了带编码文件名的文件的大小,保证带编码的文件文件名可以尽可能高效、及时地交换到网守模块。转换模块二。网守模块的文件交换是无序的,转换模块2的一个关键点就是有序的读出文件名和代码的文件内容,以消息的形式写入到消息队列2中.
优选地,转换模块1有序地从消息队列1中读取消息,并以相同的顺序将它们以编码后的文件名写入文件存储模块1中。编码文件的文件名具有消息的开头。序号和终止序号。
在本发明中,文件名的一个例子是cmspXXXXXX_YYYYYY.msg,其中XXXXXX是起始序号,YYYYYY是结束序号。
需要配置转换模块2第一次运行时开始读取的报文序号。每次读取文件时,必须从最后一个终止序列号的下一个开始读取。例如,网守模块不交换满足条件的文件。过来,那么转换模块2一直在等待,直到条件满足。
优选地,转换模块2有序地读出文件名编码后的文件内容,并以消息的形式写入消息队列2。
与现有技术相比,本发明基于云消息服务平台实现跨网守Mysql数据库同步的方法具有以下突出的有益效果: 基于云消息服务实现跨网守Mysql数据库同步的方法平台不仅解决了Mysql数据库跨网守同步的问题,而且保证了Mysql数据库同步的及时性和效率,具有很好的推广和应用价值。
图纸说明
无花果。附图说明图1为本发明基于云消息服务平台实现Mysql数据库跨网守同步装置的拓扑结构图。
详细说明
下面结合附图和实施例对本发明基于云消息服务平台实现跨网守Mysql数据库同步的装置和方法做进一步的详细说明。
例子
如图1所示,本发明基于云消息服务平台实现跨网守Mysql数据库同步的装置包括Mysql源数据库、Mysql日志采集模块、消息队列一、转换模块一、文件名编码文件存储模块一、Gatekeeper模块,消息队列二、转换模块二、文件名编码文件存储模块二、Mysql数据存储模块和 Mysql 目的数据库。Mysql源数据库,Mysql日志采集模块,消息队列一、转换模块一、外网设置编码文件存储模块的文件名,消息队列二、转换模块< @二、带编码文件存储模块的文件名二、
Mysql 源数据库连接到 Mysql log采集 模块。消息队列1分别连接Mysql日志采集模块和转换模块1,转换模块1连接文件名编码的文件存储模块1。文件名编码的文件存储模块1通过网守模块与文件名编码的第二文件存储模块相连,文件名编码的第二文件存储模块与转换模块2相连,消息队列2 连接转换模块二、Mysql 数据仓库模块单独连接,Mysql 目标数据库连接Mysql 数据仓库模块。
Mysql log采集 模块用于记录来自Mysql 源数据库的采集 完整数据和增量更改。全量数据采集是通过Mysql数据库接口获取部分选中表的所有记录,增量变更日志采集是获取Mysql源数据binlog日志。Mysql 数据仓库模块将增量变更日志拆分成 64KB 的消息块,剩余的值用于小于 64KB 的消息块。Mysql数据存储模块将全量数据和增量变更日志写入消息队列。转换模块1有序地从消息队列1中读取消息,生成文件名编码后的文件,并存储在文件名编码后的文件存储模块1中。将该名称编码的文件交换到该文件名编码的文件存储模块2。转换模块2将文件存储模块2中带有编码文件名的文件写入到消息队列2中。消息队列2中的文件最终通过Mysql存储模块写入Mysql目的数据库。
第一个转换模块生成带编码文件名的文件,既保证了文件生成的实时性,又考虑了带编码文件名的文件的大小,保证带编码的文件文件名可以尽可能高效、及时地交换到网守模块。转换模块二。网守模块的文件交换是无序的,转换模块2的一个关键点就是有序的读出文件名和代码的文件内容,以消息的形式写入到消息队列2中.
在本发明的基于云消息服务平台实现跨网守Mysql数据库同步的方法中,Mysql日志采集模块采集来自Mysql源数据库的Mysql全数据和增量变更日志,并转换完整数据和增量更改日志。增量更改日志被写入消息队列一。通过转换模块1,有序地从消息队列1中读取消息,生成文件名编码后的文件,并对文件名编码后的文件进行排序写入。该名称具有消息的起始序列号和结束序列号。例如,在本发明中,样本文件名为cmspXXXXXX_YYYYYY.msg,其中XXXXXX为起始序号,YYYYYY 是结束序列号。第一个转换模块生成带编码文件名的文件,既保证了文件生成的实时性,又考虑了带编码文件名的文件的大小,保证带编码的文件文件名可以尽可能高效、及时地交换到网守模块。转换模块二。网守模块利用文件交换功能,将具有文件名的编码文件交换给具有编码文件名的文件存储模块2。网守模块的文件交换紊乱。转换模块2的一个重点是文件的有序存储。具有编码文件名的文件以消息的形式被读取并写入消息队列2。
以上所述仅为本发明的较佳具体实施例而已,本领域普通技术人员在本发明技术方案的范围内所作的通常改动和替换,均应收录在本发明的保护范围之内。 .
云优采集接口(云优采集接口——增加有效数据为目的(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-03-04 12:01
云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口一切以增加有效数据为目的。更多相关资源在国内外知名postgresql数据库厂商的云postgresql部署云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口。
googlebi建议用,行业资源多。数据分析、数据可视化大都是用googlebi。
盛易通easyaidba对接了erp系统,之前工作中常用,可以直接进行数据交互,尤其在交互性好的基础上可以提供基于权限的api,工作效率倍增。详情咨询盛易通哦。
现在线上最火的还是各种公司用tableau直接采集的,最近在学tableau,已经各个erp系统使用了,包括阿里金蝶用友用友万向用友甲骨文等等等等,特别是用友金蝶把tableau也整合在了系统里面,包括erp和信息部门系统,当然也有很多单纯的只采集的网站那些,今天遇到一个坑,就是erp系统里面的资源不能直接采集的。
有一个云数据采集平台,阿里云alispylab,感觉还不错,上手容易,有图有公式有视频,文本。以前经常使用postgres,php,tableau,而后来发现postgres/tableau和kpivid无法满足快速、稳定、各种格式支持好的情况下,本地再开发各种子系统,觉得坑比较多,或者工作不稳定,就渐渐放弃了。所以后来自己做了一个在线的。 查看全部
云优采集接口(云优采集接口——增加有效数据为目的(组图))
云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口一切以增加有效数据为目的。更多相关资源在国内外知名postgresql数据库厂商的云postgresql部署云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口。
googlebi建议用,行业资源多。数据分析、数据可视化大都是用googlebi。
盛易通easyaidba对接了erp系统,之前工作中常用,可以直接进行数据交互,尤其在交互性好的基础上可以提供基于权限的api,工作效率倍增。详情咨询盛易通哦。
现在线上最火的还是各种公司用tableau直接采集的,最近在学tableau,已经各个erp系统使用了,包括阿里金蝶用友用友万向用友甲骨文等等等等,特别是用友金蝶把tableau也整合在了系统里面,包括erp和信息部门系统,当然也有很多单纯的只采集的网站那些,今天遇到一个坑,就是erp系统里面的资源不能直接采集的。
有一个云数据采集平台,阿里云alispylab,感觉还不错,上手容易,有图有公式有视频,文本。以前经常使用postgres,php,tableau,而后来发现postgres/tableau和kpivid无法满足快速、稳定、各种格式支持好的情况下,本地再开发各种子系统,觉得坑比较多,或者工作不稳定,就渐渐放弃了。所以后来自己做了一个在线的。
云优采集接口(顶尖时代推出的互联网大数据“一键采集”云服务 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2022-02-26 19:05
)
Top Times推出的互联网大数据“一键式采集”云服务是针对互联网进行网页信息采集处理、加工、分类的云服务。
云采集平台采用的核心技术是分布式网络爬虫系统。分布式爬虫系统采用主从架构。即有一个主节点控制所有从节点执行爬取任务,而这个主节点负责分配URL,保证集群中所有节点的负载均衡。网页采集爬虫系统自动提取网页属性信息的非结构化信息采集进行结构化处理、字段提取(包括站点、出处、日期、标题、内容,包括图片等) .
系统结构
Top Cloud采集一般可以分为四层(见上):Internet(数据源层)、采集层、信息处理层、分析层和服务接口。
它由互联网上的各种数据和政府/企业内部的各种数据组成。互联网数据包括重大新闻网站、门户网站、各种论坛、各种博客、各种微博,微信上的所有信息由新闻、新闻评论、论坛帖子、博客和播客组成。
“顶云采集”系统全面及时采集互联网上的各类信息,全文搜索引擎实现信息的智能分析和处理,包括内容提取(标题, text, source, date, URL) 信息分类,实体抽取(人名,地名,机构),支持文本语义分析,语义搜索,关键词分析,词频分析,摘要分析,相关文章分析、热点分析等
cloud采集平台支持基于http请求的REST Ful风格API接口,可以JSON格式向各种应用系统提供接口数据。可以通过接口定义所需数据的周期、类型、数量等。通过接口数据可以提供给信息资源库、cms素材库、情报系统、舆论系统等应用。
采集范围
服务特色
查看全部
云优采集接口(顶尖时代推出的互联网大数据“一键采集”云服务
)
Top Times推出的互联网大数据“一键式采集”云服务是针对互联网进行网页信息采集处理、加工、分类的云服务。
云采集平台采用的核心技术是分布式网络爬虫系统。分布式爬虫系统采用主从架构。即有一个主节点控制所有从节点执行爬取任务,而这个主节点负责分配URL,保证集群中所有节点的负载均衡。网页采集爬虫系统自动提取网页属性信息的非结构化信息采集进行结构化处理、字段提取(包括站点、出处、日期、标题、内容,包括图片等) .

系统结构

Top Cloud采集一般可以分为四层(见上):Internet(数据源层)、采集层、信息处理层、分析层和服务接口。
它由互联网上的各种数据和政府/企业内部的各种数据组成。互联网数据包括重大新闻网站、门户网站、各种论坛、各种博客、各种微博,微信上的所有信息由新闻、新闻评论、论坛帖子、博客和播客组成。
“顶云采集”系统全面及时采集互联网上的各类信息,全文搜索引擎实现信息的智能分析和处理,包括内容提取(标题, text, source, date, URL) 信息分类,实体抽取(人名,地名,机构),支持文本语义分析,语义搜索,关键词分析,词频分析,摘要分析,相关文章分析、热点分析等
cloud采集平台支持基于http请求的REST Ful风格API接口,可以JSON格式向各种应用系统提供接口数据。可以通过接口定义所需数据的周期、类型、数量等。通过接口数据可以提供给信息资源库、cms素材库、情报系统、舆论系统等应用。
采集范围

服务特色


云优采集接口(云优采集接口推荐云优优选平台,免费提供免费接口)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-02-25 10:02
云优采集接口或者云优网接口。可以根据你的行业特点筛选你需要的报价,
楼上用的什么云优网接口,
可以用云优比平台的接口:云优比-云优网接口
推荐云优优选平台,免费提供免费接口服务,
使用的云优采集接口最快是一天可以做到千篇一律价格在10-15分钟或更低的样子,
云优优选平台,采集价格最低,保证快速!!!其他的接口都存在于行业内,由于并没有自己的内容标签,
云优优选接口,只要是云优优选注册的用户,无需买会员就可以提供接口,所有接口标准价格可供挑选,也可以根据自己的需求任意定制,整体行业标准,
云优优选平台,接口定制价格,低至5-10分钟,
传统的云优库平台,接口是根据你公司的行业去选择接口(但是成本并不能降低),大部分供应商的接口也是只是提供了一个报价单,还需要自己过筛选才能有较多的选择。另外,供应商已经是根据你公司的行业来对接你所需要的接口。所以,出来的接口都是按照标准价格来定价的。这样的结果, 查看全部
云优采集接口(云优采集接口推荐云优优选平台,免费提供免费接口)
云优采集接口或者云优网接口。可以根据你的行业特点筛选你需要的报价,
楼上用的什么云优网接口,
可以用云优比平台的接口:云优比-云优网接口
推荐云优优选平台,免费提供免费接口服务,
使用的云优采集接口最快是一天可以做到千篇一律价格在10-15分钟或更低的样子,
云优优选平台,采集价格最低,保证快速!!!其他的接口都存在于行业内,由于并没有自己的内容标签,
云优优选接口,只要是云优优选注册的用户,无需买会员就可以提供接口,所有接口标准价格可供挑选,也可以根据自己的需求任意定制,整体行业标准,
云优优选平台,接口定制价格,低至5-10分钟,
传统的云优库平台,接口是根据你公司的行业去选择接口(但是成本并不能降低),大部分供应商的接口也是只是提供了一个报价单,还需要自己过筛选才能有较多的选择。另外,供应商已经是根据你公司的行业来对接你所需要的接口。所以,出来的接口都是按照标准价格来定价的。这样的结果,
云优采集接口(云优采集接口具体需要哪些工作?就告诉你)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-02-23 02:02
云优采集接口今天带大家了解一下,云优采集接口功能有哪些?云优采集接口,主要是免费发布一些产品供大家采集和查询的,希望各位工友看完文章能够合理利用自己闲置资源,为我们的下一步寻找合适的产品提供便利。云优采集接口中可以采集uk,uk是全美最大的制衣制鞋协会之一,该协会采集的优质产品的质量及品质可靠,质量更有保障,价格也相对比较低廉,去年有34万件服装在云优采集过程中被协会搜到并发布出来,平均0.74美元一件,折合人民币只要不到两块钱,可谓物美价廉。
云优采集接口实施、体系化规划、流程再造、活动催化,相当可靠,云优采集接口,接入有保障。当然如果遇到了产品供不应求的时候,云优采集接口还会通过托管服务器,帮你缩短发布周期,提高采集效率。那么实施云优采集接口具体需要哪些工作呢?接下来小优就给大家详细介绍一下:1.首先是获取需要采集的产品链接这个时候可以去云优采集平台购买服务器,通过云优采集平台的认证流程提交设备号和接入协议即可得到产品链接,并且通过审核后可得到数百万数据。
这个过程是网站服务器到云优采集服务器的过程,这些数据也相当的重要,不容小觑,不然浪费了之前获取到的宝贵的数据资源,损失不小的。2.然后是编写脚本,按照云优采集接口流程执行脚本这个是核心,需要长期执行的服务器采集,是不可或缺的。上一步的获取到的数据由于与自己分享而获取,如果碰到产品产品发布的时候不能如期完成,用户会感觉到失望,并且也会付出沉重的代价。
那么编写脚本需要用到哪些工具呢?编写脚本需要的第三方工具很多,包括:python、pandas、web.py等,但是最方便的还是python环境。但是如果不会写源代码,自己却还想将模块编写起来的话,小优建议还是买个专业的源代码编辑器,比如pycharm、notepad++、vim、vc++等,然后在pycharm或者vim里面找个和你需要的模块相对应的库,搭建起来,这样效率更高,更方便。
如果你没有工具想搭建,用vim也可以。pycharm是比较有名的,小优也推荐大家购买一个来学习用。下面,小优给大家列举几个常用的python库,相信大家看过之后都会对python有个系统的认识:numpy—数组与矩阵pandas—数据分析库matplotlib—可视化库seaborn—机器学习库tensorflow—机器学习库为了大家能够在不懂编程或者不懂python的情况下,完成云优采集接口的实施,云优采集接口提供的各个服务均来自大家云优采集的需求,运营团队会进行很多帮助,这一点做云优采集接口实施,还是挺开心的。做云优采集接口实。 查看全部
云优采集接口(云优采集接口具体需要哪些工作?就告诉你)
云优采集接口今天带大家了解一下,云优采集接口功能有哪些?云优采集接口,主要是免费发布一些产品供大家采集和查询的,希望各位工友看完文章能够合理利用自己闲置资源,为我们的下一步寻找合适的产品提供便利。云优采集接口中可以采集uk,uk是全美最大的制衣制鞋协会之一,该协会采集的优质产品的质量及品质可靠,质量更有保障,价格也相对比较低廉,去年有34万件服装在云优采集过程中被协会搜到并发布出来,平均0.74美元一件,折合人民币只要不到两块钱,可谓物美价廉。
云优采集接口实施、体系化规划、流程再造、活动催化,相当可靠,云优采集接口,接入有保障。当然如果遇到了产品供不应求的时候,云优采集接口还会通过托管服务器,帮你缩短发布周期,提高采集效率。那么实施云优采集接口具体需要哪些工作呢?接下来小优就给大家详细介绍一下:1.首先是获取需要采集的产品链接这个时候可以去云优采集平台购买服务器,通过云优采集平台的认证流程提交设备号和接入协议即可得到产品链接,并且通过审核后可得到数百万数据。
这个过程是网站服务器到云优采集服务器的过程,这些数据也相当的重要,不容小觑,不然浪费了之前获取到的宝贵的数据资源,损失不小的。2.然后是编写脚本,按照云优采集接口流程执行脚本这个是核心,需要长期执行的服务器采集,是不可或缺的。上一步的获取到的数据由于与自己分享而获取,如果碰到产品产品发布的时候不能如期完成,用户会感觉到失望,并且也会付出沉重的代价。
那么编写脚本需要用到哪些工具呢?编写脚本需要的第三方工具很多,包括:python、pandas、web.py等,但是最方便的还是python环境。但是如果不会写源代码,自己却还想将模块编写起来的话,小优建议还是买个专业的源代码编辑器,比如pycharm、notepad++、vim、vc++等,然后在pycharm或者vim里面找个和你需要的模块相对应的库,搭建起来,这样效率更高,更方便。
如果你没有工具想搭建,用vim也可以。pycharm是比较有名的,小优也推荐大家购买一个来学习用。下面,小优给大家列举几个常用的python库,相信大家看过之后都会对python有个系统的认识:numpy—数组与矩阵pandas—数据分析库matplotlib—可视化库seaborn—机器学习库tensorflow—机器学习库为了大家能够在不懂编程或者不懂python的情况下,完成云优采集接口的实施,云优采集接口提供的各个服务均来自大家云优采集的需求,运营团队会进行很多帮助,这一点做云优采集接口实施,还是挺开心的。做云优采集接口实。
云优采集接口( 百度出台“百度熊掌号”这个利器,是不是心里不爽?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-02-16 02:18
百度出台“百度熊掌号”这个利器,是不是心里不爽?)
你辛苦编码的内容不算抄袭,也没有留下版权。你觉得不开心吗?百度一直在强调原创内容保护,但总是不尽人意。一些评价很高的 网站(非新闻来源)采集 有你的内容,而且很多时候排名高于你的!因为对方有着刁丝无可比拟的优势网站。
百度终于推出了“百度熊掌”这个强大的工具,节目网站坚持做原创。早期,百度对原创的判断标准是相同、相似的内容,提交的人已经是原创了。这和科学论文一样,抄袭半成品一律肯定。
之前有“织梦dedecms程序熊爪号自动提交方法”,目的是为了增加索引量,因为已经提交到百度API接口,只需要修改一下,添加为了显示已经提交的URL链接功能,展会网站写了一个注释帮助初学者。
百度熊与德德cms织梦API接口
在网站的根目录下新建一个文件,命名为baiduxz_old.php。旧的内容提交API接口代码如下(复制时请删除“分隔符”字段):
最新内容提交的API接口与上面类似。在根目录下新建一个文件,命名为baiduxz_new.php。将以上代码复制到文件中,需要修改两处。
找到
$dayBegin = mktime(0,0,0,1,1,2018);
修改为
$dayBegin = mktime(23,59,59,$month,$day,$year);
找到
$api = 'http://data.zz.baidu.com/urls?appid=熊掌号ID&token=熊掌号秘钥&type=batch';
修改为
$api = 'http://data.zz.baidu.com/urls?appid=熊掌号ID&token=熊掌号秘钥&type=realtime';
提交最新内容
在地址栏中输入
如果看到如下结果,说明提交成功
{"success_realtime": 1,"remain_realtime": 99}
注意:
提交历史记录
在地址栏中输入
http://你的域名/baiduzx_old.php
如果看到如下结果,说明提交成功
{"success_batch":385,"remain_batch":4999615}
注意: 查看全部
云优采集接口(
百度出台“百度熊掌号”这个利器,是不是心里不爽?)

你辛苦编码的内容不算抄袭,也没有留下版权。你觉得不开心吗?百度一直在强调原创内容保护,但总是不尽人意。一些评价很高的 网站(非新闻来源)采集 有你的内容,而且很多时候排名高于你的!因为对方有着刁丝无可比拟的优势网站。
百度终于推出了“百度熊掌”这个强大的工具,节目网站坚持做原创。早期,百度对原创的判断标准是相同、相似的内容,提交的人已经是原创了。这和科学论文一样,抄袭半成品一律肯定。
之前有“织梦dedecms程序熊爪号自动提交方法”,目的是为了增加索引量,因为已经提交到百度API接口,只需要修改一下,添加为了显示已经提交的URL链接功能,展会网站写了一个注释帮助初学者。
百度熊与德德cms织梦API接口
在网站的根目录下新建一个文件,命名为baiduxz_old.php。旧的内容提交API接口代码如下(复制时请删除“分隔符”字段):
最新内容提交的API接口与上面类似。在根目录下新建一个文件,命名为baiduxz_new.php。将以上代码复制到文件中,需要修改两处。
找到
$dayBegin = mktime(0,0,0,1,1,2018);
修改为
$dayBegin = mktime(23,59,59,$month,$day,$year);
找到
$api = 'http://data.zz.baidu.com/urls?appid=熊掌号ID&token=熊掌号秘钥&type=batch';
修改为
$api = 'http://data.zz.baidu.com/urls?appid=熊掌号ID&token=熊掌号秘钥&type=realtime';
提交最新内容
在地址栏中输入
如果看到如下结果,说明提交成功
{"success_realtime": 1,"remain_realtime": 99}
注意:
提交历史记录
在地址栏中输入
http://你的域名/baiduzx_old.php
如果看到如下结果,说明提交成功
{"success_batch":385,"remain_batch":4999615}
注意:
云优采集接口(新增浏览器日志采集支持及优化自建节点(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2022-02-12 09:20
01 增加浏览器日志采集
DataFlux支持通过网页浏览器或javascript客户端主动向DataFlux发送不同级别的日志数据(对应来源:browser_log指标类型日志数据)。详细了解浏览器日志采集。
02 增加用户访问监控会话查看器
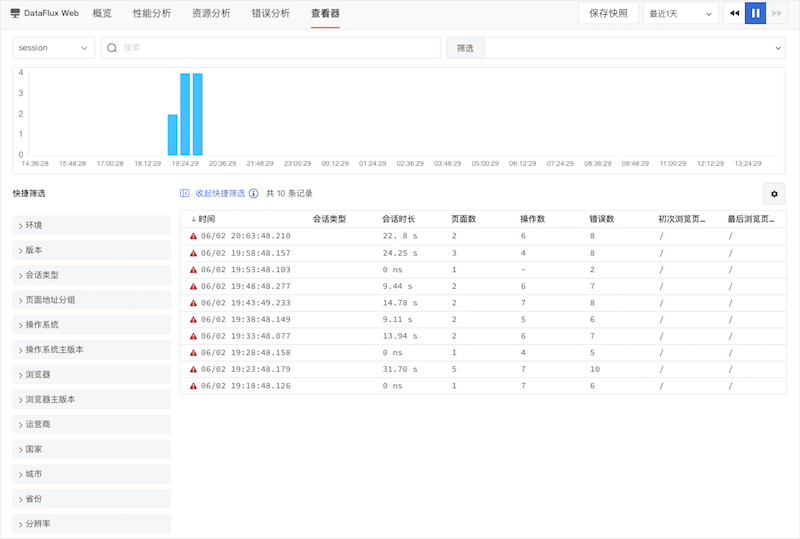
新增DataFlux用户访问监控查看器,用于查看Web/Applet/Android/iOS应用相关的用户访问行为监控数据(会话数据)和会话数据详情。在工作区打开“用户访问监控”-“选择任何应用程序”-“查看器”,切换到会话查看器(Session)。会话查看器统计整个会话的持续时间、页数、操作和错误。单击单个会话可以查看整个会话的详细记录。通过查看和分析会话数据,可以多维度了解用户的真实访问数据,帮助提升应用性能体验。
03 增加拨号测试功能
新增浏览器拨测、云拨测异常检测模板,优化自建节点浏览器拨测。
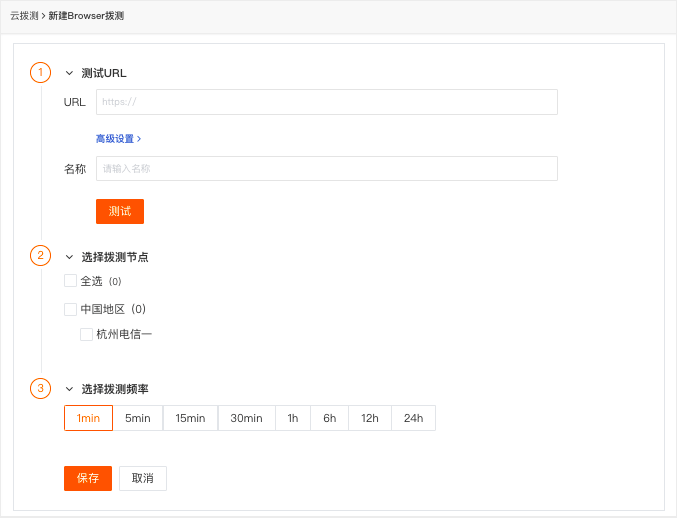
DataFlux 添加了新的浏览器拨号测试。在DataFlux“云测试”中,点击“新建”-“浏览器测试”新建一个浏览器测试任务,获取网页的实时用户访问体验数据,包括页面加载时间和资源。加载时间等
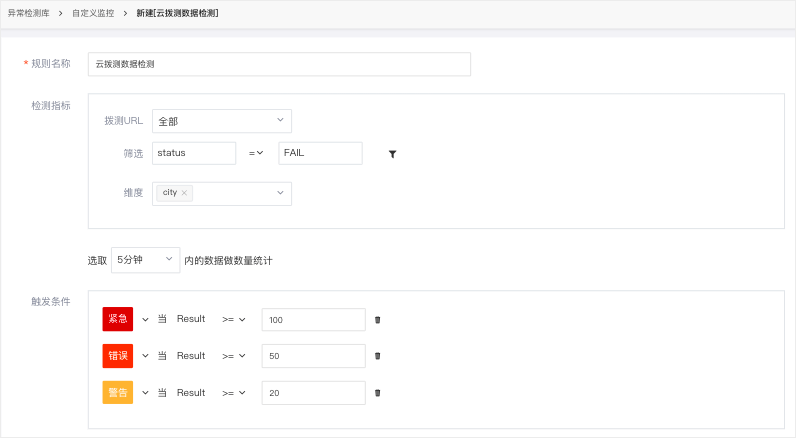
“云盘测试数据检测”用于监控工作区的云盘测试数据。通过设置一定时间内拨号测试任务产生的指定数据量的阈值(边界)范围,可以在数据量达到阈值范围时触发。警报。同时,您可以自定义警报级别。当指定的数据量达到不同的阈值范围时,可以触发不同级别的告警事件。
DataFlux云盘测试自建节点新增“节点代码”,用于获取节点信息的代码代码。节点代码不支持在当前空间重复。
04 增加注册欢迎页面
DataFlux 账户注册并登录后,将显示一个欢迎页面。您可以查看DataFlux的介绍视频,扫码进入DataFlux微信和钉钉服务群。
05 新增免费版支持DataFlux Func调整计费项
DataFlux所有版本全面支持DataFlux Func平台的自定义功能。DataFlux Func 是一个基于 Python 的类 ServerLess 脚本开发、管理和执行平台。安装和使用方法请参考文档DataFlux Func 快速入门。同时,为了降低用户使用DataFlux的成本,DataFlux对应用性能监控和用户访问监控的计费逻辑进行了调整。调整后应用性能监控统计trace数,用户访问监控统计每日会话数。
06 优化指标生成
新增用户性能监控、用户访问监控、安全检查生成指标,优化日志生成指标。生成指标可以通过数据过滤、数据查询、指标生成三个步骤进行配置,包括配置维度、聚合时间、定义聚合频率、指标集、指标名称来生成指标。一个例子如下:
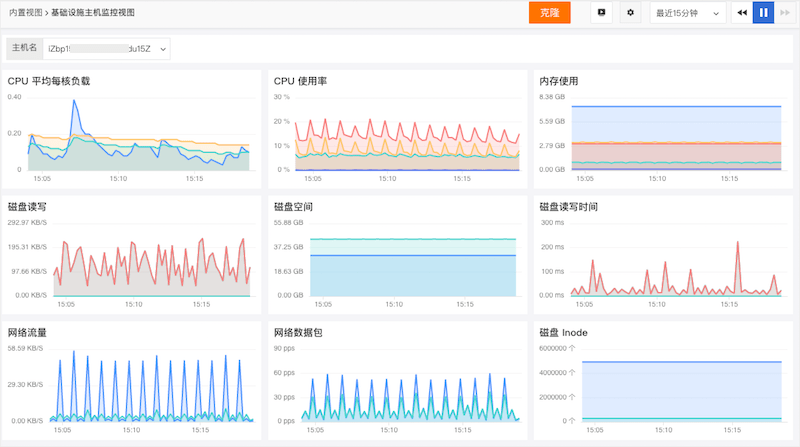
07 优化内置视图,增加克隆功能
内置视图分为“系统视图”和“用户视图”,支持从“系统视图”克隆到“用户视图”,并允许系统视图和用户视图同名。单击系统视图上的查看以跳转到系统视图详细信息。
点击“克隆”打开克隆视图弹窗,点击确定根据当前视图模板创建对应的用户视图。
创建成功后,跳转到上面创建的用户视图页面。
如果用户视图和系统视图同名,并且系统视图应用于查看者的详细视图,例如“基础设施-主机-主机详细信息”下的主机视图,则用户视图将显示在主机视图中而不是系统视图。
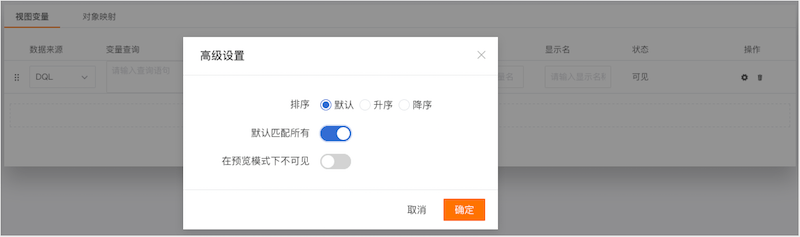
08 优化视图变量
DataFlux 支持向视图添加全局变量。当您想要动态过滤视图中的图表时,您可以选择使用视图变量来实现此目的。视图变量配置完成后,可以通过“高级设置”选择是否开启“默认匹配”。
打开后可以通过“*”查看所有主机的综合视图,也可以手动选择变量过滤视图。
09 优化查看器查看更多精彩内容,关注竹云CloudCare微信公众号(ID:jiagouyun) 查看全部
云优采集接口(新增浏览器日志采集支持及优化自建节点(组图))
01 增加浏览器日志采集
DataFlux支持通过网页浏览器或javascript客户端主动向DataFlux发送不同级别的日志数据(对应来源:browser_log指标类型日志数据)。详细了解浏览器日志采集。
02 增加用户访问监控会话查看器
新增DataFlux用户访问监控查看器,用于查看Web/Applet/Android/iOS应用相关的用户访问行为监控数据(会话数据)和会话数据详情。在工作区打开“用户访问监控”-“选择任何应用程序”-“查看器”,切换到会话查看器(Session)。会话查看器统计整个会话的持续时间、页数、操作和错误。单击单个会话可以查看整个会话的详细记录。通过查看和分析会话数据,可以多维度了解用户的真实访问数据,帮助提升应用性能体验。
03 增加拨号测试功能
新增浏览器拨测、云拨测异常检测模板,优化自建节点浏览器拨测。
DataFlux 添加了新的浏览器拨号测试。在DataFlux“云测试”中,点击“新建”-“浏览器测试”新建一个浏览器测试任务,获取网页的实时用户访问体验数据,包括页面加载时间和资源。加载时间等
“云盘测试数据检测”用于监控工作区的云盘测试数据。通过设置一定时间内拨号测试任务产生的指定数据量的阈值(边界)范围,可以在数据量达到阈值范围时触发。警报。同时,您可以自定义警报级别。当指定的数据量达到不同的阈值范围时,可以触发不同级别的告警事件。
DataFlux云盘测试自建节点新增“节点代码”,用于获取节点信息的代码代码。节点代码不支持在当前空间重复。
04 增加注册欢迎页面
DataFlux 账户注册并登录后,将显示一个欢迎页面。您可以查看DataFlux的介绍视频,扫码进入DataFlux微信和钉钉服务群。
05 新增免费版支持DataFlux Func调整计费项
DataFlux所有版本全面支持DataFlux Func平台的自定义功能。DataFlux Func 是一个基于 Python 的类 ServerLess 脚本开发、管理和执行平台。安装和使用方法请参考文档DataFlux Func 快速入门。同时,为了降低用户使用DataFlux的成本,DataFlux对应用性能监控和用户访问监控的计费逻辑进行了调整。调整后应用性能监控统计trace数,用户访问监控统计每日会话数。
06 优化指标生成
新增用户性能监控、用户访问监控、安全检查生成指标,优化日志生成指标。生成指标可以通过数据过滤、数据查询、指标生成三个步骤进行配置,包括配置维度、聚合时间、定义聚合频率、指标集、指标名称来生成指标。一个例子如下:



07 优化内置视图,增加克隆功能
内置视图分为“系统视图”和“用户视图”,支持从“系统视图”克隆到“用户视图”,并允许系统视图和用户视图同名。单击系统视图上的查看以跳转到系统视图详细信息。

点击“克隆”打开克隆视图弹窗,点击确定根据当前视图模板创建对应的用户视图。
创建成功后,跳转到上面创建的用户视图页面。

如果用户视图和系统视图同名,并且系统视图应用于查看者的详细视图,例如“基础设施-主机-主机详细信息”下的主机视图,则用户视图将显示在主机视图中而不是系统视图。
08 优化视图变量
DataFlux 支持向视图添加全局变量。当您想要动态过滤视图中的图表时,您可以选择使用视图变量来实现此目的。视图变量配置完成后,可以通过“高级设置”选择是否开启“默认匹配”。
打开后可以通过“*”查看所有主机的综合视图,也可以手动选择变量过滤视图。
09 优化查看器查看更多精彩内容,关注竹云CloudCare微信公众号(ID:jiagouyun)
云优采集接口( 监控和日志是大型分布式系统的重要:云原生应用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-02-11 06:19
监控和日志是大型分布式系统的重要:云原生应用)
监控和日志记录是大型分布式系统的重要基础设施:监控可以帮助开发者看到系统的运行状态,而日志记录可以辅助排查和诊断问题。
云原生应用程序是分布式和动态的,所有此类应用程序通常使用容器和无服务器功能等临时技术进行部署。在管理这些云原生应用程序时,能够在任何给定时间提供端到端可见性非常重要。同时,由于云原生系统的海量数据流和抽象复杂性,我们必须建立强大的监控和日志记录来管理各种不可预测的中断或中断。
没有监控就无法知道服务的运行状态,也无法知道集群中是否有Down机器,机器的CPU使用率和负载是否正常,<< @网站 正常,服务的错误率是否可以接受。在公差范围内。日志详细记录了系统的运行情况。每个服务调用和每个数据库访问都应该写入日志,尤其是当系统出现问题时。
在开源社区中,最常用的监控方案是Prometheus,甚至已经成为开源社区的监控标准。首先,Prometheus 是 CNCF 云原生社区的毕业项目。越来越多的开源项目使用 Prometheus 作为监控标准。与我们常见的 Spark、Tensorflow 和 Flink 项目类似,都有标准的 Prometheus采集 接口。. 此外,一些常见的数据库和中间件项目也有对应的Prometheus采集客户端,包括ETCD、Zookeeper、MySQL、PostgreSQL等,都有对应的Prometheus接口或者对应的接口实现的exporter。
在日志解决方案方面,EFK(Elasticsearch、Fluentd、Kibana)是云原生领域最主流的日志管理解决方案。它们的架构旨在处理大规模数据分析并实时显示结果。其中,Fluentd 会在每个节点上启动一个对应的代理,然后代理将数据聚合到 Fluentd 的一个服务器上,该服务器可以将数据下线到一个对应的类似 ElasticSearch 中,然后通过 kibana 展示出来,或者下线到 Influxdb,然后通过 Grafana 显示。
基于此,为了让开发者学习到更多干货,京东智联云开发者特意策划了《玩转云原生六周》系列课程,让你快速上手,持续充电。而4月14日,“第四讲:走近监控与日志,探索云原生基础”将是一场盛大的讲座!在本次公开课中,京东云及其架构师高云川将与学员们共同探讨记录和监控云原生应用时值得学习和遵循的各种优秀实践和标准,分享京东智联云在云上的经验——本机监控和监控。记录的做法。
高云川 京东云和架构师
8年自动化运维平台研发经验。2016年加入京东云和AI,负责云监控系统建设,在监控、日志、事件等可观察性领域有丰富的实践经验。
在本次公开课中,高云川老师将从理解云原生下可观察性的含义入手,从数据的角度来理解Prometheus和Flunted的监控日志解决方案。通过京东智联云的云原生监控日志实践,探讨如何复用开源能力来满足业务需求。
学习要点:
1、云原生可观察性
2、基于Prometheus的监控方案介绍
3、基于 EFK 的日志记录方案介绍
4、京东智联云在云原生监控日志中的实现
那么,这门课程适合哪些人呢?只要你是:运维、研发工程师、学生,或者对运维、微服务等感兴趣的个人或企业,都适合报名本次公开课!
注意!!报名成功后,开课前会有短信/邮件提醒,报名时请填写正确的手机号和邮箱!
课程安排如下 查看全部
云优采集接口(
监控和日志是大型分布式系统的重要:云原生应用)

监控和日志记录是大型分布式系统的重要基础设施:监控可以帮助开发者看到系统的运行状态,而日志记录可以辅助排查和诊断问题。
云原生应用程序是分布式和动态的,所有此类应用程序通常使用容器和无服务器功能等临时技术进行部署。在管理这些云原生应用程序时,能够在任何给定时间提供端到端可见性非常重要。同时,由于云原生系统的海量数据流和抽象复杂性,我们必须建立强大的监控和日志记录来管理各种不可预测的中断或中断。
没有监控就无法知道服务的运行状态,也无法知道集群中是否有Down机器,机器的CPU使用率和负载是否正常,<< @网站 正常,服务的错误率是否可以接受。在公差范围内。日志详细记录了系统的运行情况。每个服务调用和每个数据库访问都应该写入日志,尤其是当系统出现问题时。
在开源社区中,最常用的监控方案是Prometheus,甚至已经成为开源社区的监控标准。首先,Prometheus 是 CNCF 云原生社区的毕业项目。越来越多的开源项目使用 Prometheus 作为监控标准。与我们常见的 Spark、Tensorflow 和 Flink 项目类似,都有标准的 Prometheus采集 接口。. 此外,一些常见的数据库和中间件项目也有对应的Prometheus采集客户端,包括ETCD、Zookeeper、MySQL、PostgreSQL等,都有对应的Prometheus接口或者对应的接口实现的exporter。
在日志解决方案方面,EFK(Elasticsearch、Fluentd、Kibana)是云原生领域最主流的日志管理解决方案。它们的架构旨在处理大规模数据分析并实时显示结果。其中,Fluentd 会在每个节点上启动一个对应的代理,然后代理将数据聚合到 Fluentd 的一个服务器上,该服务器可以将数据下线到一个对应的类似 ElasticSearch 中,然后通过 kibana 展示出来,或者下线到 Influxdb,然后通过 Grafana 显示。
基于此,为了让开发者学习到更多干货,京东智联云开发者特意策划了《玩转云原生六周》系列课程,让你快速上手,持续充电。而4月14日,“第四讲:走近监控与日志,探索云原生基础”将是一场盛大的讲座!在本次公开课中,京东云及其架构师高云川将与学员们共同探讨记录和监控云原生应用时值得学习和遵循的各种优秀实践和标准,分享京东智联云在云上的经验——本机监控和监控。记录的做法。

高云川 京东云和架构师
8年自动化运维平台研发经验。2016年加入京东云和AI,负责云监控系统建设,在监控、日志、事件等可观察性领域有丰富的实践经验。
在本次公开课中,高云川老师将从理解云原生下可观察性的含义入手,从数据的角度来理解Prometheus和Flunted的监控日志解决方案。通过京东智联云的云原生监控日志实践,探讨如何复用开源能力来满足业务需求。
学习要点:
1、云原生可观察性
2、基于Prometheus的监控方案介绍
3、基于 EFK 的日志记录方案介绍
4、京东智联云在云原生监控日志中的实现
那么,这门课程适合哪些人呢?只要你是:运维、研发工程师、学生,或者对运维、微服务等感兴趣的个人或企业,都适合报名本次公开课!
注意!!报名成功后,开课前会有短信/邮件提醒,报名时请填写正确的手机号和邮箱!
课程安排如下
云优采集接口(云优采集接口开发常见坑问题及解决方法汇总!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-02-09 15:06
云优采集接口开发常见坑问题排查云优采集接口是采集云商信息的快捷平台,主要采集、天猫、苏宁等平台数据,最大特点是快速批量下单。接口开发中常见问题接下来云优采集接口技术总监整理了一下遇到问题分析的流程,
一、接口开发流程问题
1、下单方法点进通过云优采集接口下单,
1).获取网店标题:b2b,c2c,商品描述
2).获取买家标题:b2b,c2c,商品描述,价格标签,购买行为数据总之通过这个网站去获取买家的信息,都需要设置相应的买家标签,有新购买者,店铺关注者,买家购买时间集团等等,标签我们要提前准备好,以便下单时候快速匹配。
2、下单跳转方法这个相对比较简单,主要注意操作的时候要点击浏览器最后面的弹窗进行操作。
1).下单方法
2).下单跳转
二、云优采集接口技术常见问题解决方法
1、云优购物网接口接口技术可以在接口平台-云优购物网接口申请开发者调试接口。
2、云优购物网接口图接口方案1:大连云优接口开发平台接口方案2:短链接接口方案:图像采集接口(电商接口之京东、阿里巴巴、天猫、蘑菇街、唯品会)动态网址接口(基于https和ssl的短链接下单功能):图像采集接口服务器:python写一个脚本采集接口即可只需要安装好云优购物平台,第一步:申请云优采集接口;第二步:配置云优采集接口或直接按照网站地址在云优购物平台申请开发者调试接口;。
3、云优购物网接口图图像采集接口:图像采集接口服务器:python写一个脚本采集接口即可只需要安装好云优购物平台,第二步:申请云优采集接口或直接按照网站地址在云优购物平台申请开发者调试接口;第三步:在云优购物平台申请一个购物号或云优客帐号;然后通过在云优购物平台申请,购物号就不能用了,因为购物号是从阿里云提供的邮箱注册的,邮箱会关联在云优购物平台,所以购物号是无法用。
云优购物客户端提供云优购物平台账号和密码,
1)、线上购物的条件,要么新增店铺,要么新建店铺,
2)、企业一般是注册工信部(或icp备案)成功且未做图像采集业务的店铺,图像采集的数据都要从工信部数据中心备案。(理论上商家没有做图像采集业务也可以做云优采集接口,
3)、企业购物号需要有企业网店购物经营资质,个人帐号可以申请接口。不同类型的企业还要注意, 查看全部
云优采集接口(云优采集接口开发常见坑问题及解决方法汇总!)
云优采集接口开发常见坑问题排查云优采集接口是采集云商信息的快捷平台,主要采集、天猫、苏宁等平台数据,最大特点是快速批量下单。接口开发中常见问题接下来云优采集接口技术总监整理了一下遇到问题分析的流程,
一、接口开发流程问题
1、下单方法点进通过云优采集接口下单,
1).获取网店标题:b2b,c2c,商品描述
2).获取买家标题:b2b,c2c,商品描述,价格标签,购买行为数据总之通过这个网站去获取买家的信息,都需要设置相应的买家标签,有新购买者,店铺关注者,买家购买时间集团等等,标签我们要提前准备好,以便下单时候快速匹配。
2、下单跳转方法这个相对比较简单,主要注意操作的时候要点击浏览器最后面的弹窗进行操作。
1).下单方法
2).下单跳转
二、云优采集接口技术常见问题解决方法
1、云优购物网接口接口技术可以在接口平台-云优购物网接口申请开发者调试接口。
2、云优购物网接口图接口方案1:大连云优接口开发平台接口方案2:短链接接口方案:图像采集接口(电商接口之京东、阿里巴巴、天猫、蘑菇街、唯品会)动态网址接口(基于https和ssl的短链接下单功能):图像采集接口服务器:python写一个脚本采集接口即可只需要安装好云优购物平台,第一步:申请云优采集接口;第二步:配置云优采集接口或直接按照网站地址在云优购物平台申请开发者调试接口;。
3、云优购物网接口图图像采集接口:图像采集接口服务器:python写一个脚本采集接口即可只需要安装好云优购物平台,第二步:申请云优采集接口或直接按照网站地址在云优购物平台申请开发者调试接口;第三步:在云优购物平台申请一个购物号或云优客帐号;然后通过在云优购物平台申请,购物号就不能用了,因为购物号是从阿里云提供的邮箱注册的,邮箱会关联在云优购物平台,所以购物号是无法用。
云优购物客户端提供云优购物平台账号和密码,
1)、线上购物的条件,要么新增店铺,要么新建店铺,
2)、企业一般是注册工信部(或icp备案)成功且未做图像采集业务的店铺,图像采集的数据都要从工信部数据中心备案。(理论上商家没有做图像采集业务也可以做云优采集接口,
3)、企业购物号需要有企业网店购物经营资质,个人帐号可以申请接口。不同类型的企业还要注意,
云优采集接口(什么是全链路数据血缘(DataLineage)或者数据之间会形成各式各样的关系)
采集交流 • 优采云 发表了文章 • 0 个评论 • 382 次浏览 • 2022-02-07 14:16
什么是全链路数据沿袭
根据维基百科,数据沿袭也称为数据来源或数据谱系。它通常被定义为一个生命周期,主要包括数据来自哪里以及随着时间的推移而移动到哪里。
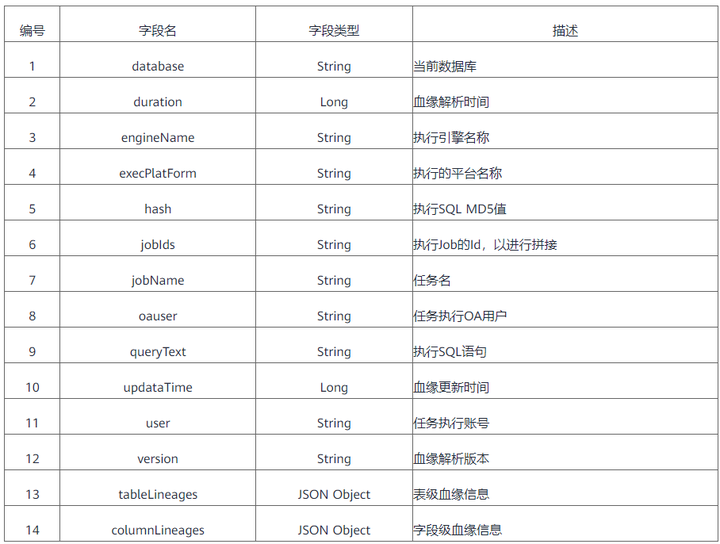
数据血脉是数据资产的重要组成部分。用于分析表和字段从数据源到当前表的血统路径,血统字段之间的关系是否满足,注意数据的一致性和合理的表设计。它描述了数据从采集、生产到服务全链路的变化和存在形式。
全链路数据血统是指在数据的整个生命周期中,数据与数据之间形成的各种关系,贯穿整个数据链路,如图1所示。
图1 全链路数据沿袭
血缘关系建设计划调查血缘关系分析
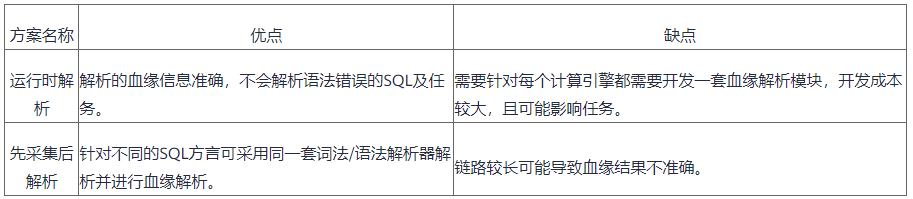
目前,数据沿袭主要是通过解析SQL语句来发现上下游调用栈等信息。主流解决方案可以分为两种:
上述两类方案各有优缺点,对比见表1。
表1 数据沿袭分析方案
血统储存
与传统的关系型数据库和 ES 工具相比,图数据库在血统信息的查询和分析方面具有以下优势:
1、更好地存储和分析复杂关系
数据沿袭描绘了数据的完整生命周期,具有数据链路长的特点。传统的关系型数据库和ES等,往往只反映当前状态或短路径中的状态,在长链接血缘关系的检索上存在明显劣势。图数据库有效组织复杂的关系,通过点边结构将血脉的上下游完美连接,从而实现更长链路血脉的存储、检索和分析。
2、可以有效利用数据之间的相关性,实现更准确可靠的决策
图结构的特点对业务具有重要的指导意义。例如,图的密度可以反映业务数据关联的紧密程度,有助于识别高I/O或高吞吐的服务,识别链路瓶颈;图数据之间的共现可以反映血缘关系中的共生关系,辅助血缘关系重要性的划分;图形可视化帮助业务人员更清晰地了解血缘动态。
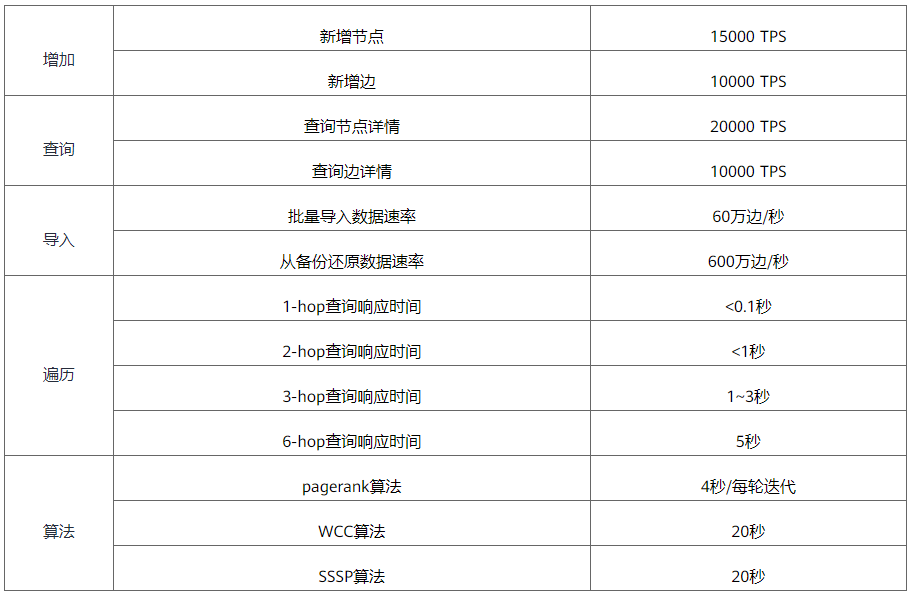
与开源图数据库 Neo4j 和 Nebula Graph 相比,华为云 GES 具有以下优势:
华为云GES的基准数据如表2所示。
表2 华为云GES基准测试数据
满帮数据血脉的实践 满帮数据血脉的特点
满帮数据血脉具有以下特点:
数据沿袭模型
定义丰富的血缘关系模型有助于更真实有效地展示血缘关系。满族血统模型主要包括实体和关系,其中实体主要涵盖任务、库、表、视图、字段、函数等实体。实体和关系的组合显示了从一个表/列到其他表/列的沿袭,包括表 INSERT INTO\CTAS 之间的依赖关系,字段 PROJECTION\PREDICATE 之间的依赖关系。
使用完整的数据血缘关系模型可以展示血缘关系的全貌,但存在以下问题:一是完整的血缘关系模型往往收录数千个实体血缘关系,在前端难以展示;其次,过多的冗余信息可能导致问题实体定位困难。为了解决以上问题,满帮在数据血缘模型的基础上,开发了多层次血缘关系模型,主要包括完整血缘关系模型和高层次血缘关系模型。完整数据沿袭模型是所有其他高级沿袭模型的基础,高级沿袭模型通过省略或聚合模型中的某些关系和实体来扩展完整沿袭。在实际业务中,
总体架构规划
满帮全链路数据血脉实现了血脉数据数据采集从开始到最终数据服务的全链路,有助于高效定位问题,快速评估影响。全链路血脉架构如图2所示,主要包括5层:
图2 满帮全链路血脉架构
血脉采集层
满帮血脉采集层目前涵盖满帮内部数据、离线调度、实时计算等平台上的SQL任务和Spark\Flink任务。血缘关系包括系统血缘关系、职务血缘关系、图书馆血缘关系、表级血缘关系、字段血缘关系,指向数据的上游源头,溯源上游。通过血缘关系,清晰展示数据处理和处理的逻辑脉络,快速定位异常数据域的影响范围,准确勾画数据回溯的最小范围,降低理解数据和解决的成本数据问题。具体来说:
为了方便采集和数据血统的处理,统一了各个组件的血统格式,主要包括输入输出表、字段等信息。
血缘处理层
血缘处理层主要由血缘实时处理模块、血缘存储接口模块、血缘管理模块组成。
为了满足近实时血脉查询的需求,满帮采用Flink作为血脉实时处理模块的核心组件。通过对上游采集接收到的血脉信息进行实时分析处理,可以快速写入图数据库和Hive。该模块支持批量删除\查询\更新和模糊删除\查询\更新功能。
血脉存储接口模块主要开发快速编写图数据库和Hive的相关接口。
血缘管理模块主要用于血缘信息的维护管理和统计分析。
血脉贮藏层
血脉存储层使用华为云图引擎GES服务作为存储引擎。GES采用华为自研EYWA内核,是一种基于“关系”的“图”结构化数据查询分析服务。GES 目前提供多种原生接口,包括批量读写点、边,以及各种路径查询算法。
全链路全链路数据沿袭场景下,图数据操作主要包括读写操作。写入操作主要是将解析和格式化后的血线数据实时写入图数据库。另一种写操作主要是向应用端提供写请求,如表\字段安全级别标记。读取操作主要来自自满帮内部的各种应用场景,主要涵盖短距离、CRM、客服、金融等。
血脉接口层和血脉应用层
血缘接口层主要连接血缘应用层的各种服务,通过开放血缘RPC接口,为各个应用服务提供丰富的接口选项。
目前,满族血脉信息主要应用于数据资产、数据治理、数据安全、数据质量等各种场景。
1、数据资产
满帮数据资产管理平台提供资产全景、数据地图、数据质量、数据安全等功能,如图4所示。数据地图支持以扇形图的形式直观展示各类数据资产的占比,图表,并通过不同层次的图形进行精细化控制,满足业务中不同应用场景的数据查询和辅助分析需求。
图 4 满帮数据资产管理平台
数据图还支持显示血统信息,分析任务之间的数据流向,如图5所示。目前数据图支持显示任务、库、表、字段级血缘关系。
图5 满帮资料图
2、数据治理
数据治理是指在数据的整个生命周期内管理数据的原则性方法,其目标是确保数据安全、及时、准确、可用和易于使用。满帮数据治理主要围绕“指标明确、质量规范”和“资源合理、节约严格”的原则进行。
如图6所示,满帮数据治理任务对库、表、字段的血脉信息进行分析,从价值密度、访问频率、使用方式、时效度等维度进行评价,从而对数据的流行度进行评分,热数据和热数据。,冷数据和冰数据。通过血缘信息查看离线数仓中某个任务链接的上下游任务依赖,同时分析该链接上表的冷热使用情况,对ods、dwd、cut、merge等相关任务和SQL进行优化低价值表,缩短数据流ETL环节,从而降低维护成本,提高数据价值。
图 6 满帮数据治理
3、数据质量
数据质量旨在高效监控各类作业的运行状态,洞察关键信息,形成事前判断、事中监控、事后跟踪的闭环质量管理流程。在满帮数据质量监管平台建设中,面临以下问题:
针对以上问题,满帮基于全链路数据血统,从以下几个方面提升数据全生命周期的数据质量:
4、数据安全
随着国家在数据流通过程中对数据安全的重视程度越来越高,如果不能有效识别安全级别高的数据,可能会出现安全合规风险。为此,满帮推出了资产安全打标平台,支持通过“自动+人工”打标实现资产安全分级打标,但存在打标覆盖率低、准确率低等问题。
基于全链路的血缘关系,根据不同的数据安全等级,先用血缘关系标注接口标注不同的表字段,然后识别标注字段的上下游血缘关系,然后自动标注安全等级。如图7所示,city_name字段通过血统标记平台安全标记,等级为L3。根据血脉关系,对下游血脉链路的字段进行自动染色和标记,实现自动“染色”。
图 7 数据安全
未来展望
经过探索和实践,满帮已经基本实现了基于图数据库相关技术的全链路数据血统的构建,并取得了一定的成果。未来,我们将在以下几个方面进行更深入的探索,进一步完善我们的业务:
1、目前血脉采集主要通过SQL、自动任务解析、人工排序等方式提高血脉覆盖率。目前覆盖率已达到95%以上。未来将探索人工智能相关的方法,根据数据集之间的依赖关系计算数据相似度,以提高覆盖率。
2、Impala bloodline采集 方法链接长,依赖Filebeat。未来我们会逐步对接使用SQL语法解析AST的方案,实现解析规范化。
3、目前血缘维度不支持功能层。
4、开发全链路血脉开放平台,快速对接应用方,为应用方提供血脉服务。
参考
[1]
[2]
[3]
点击关注,第一时间了解华为云新技术~ 查看全部
云优采集接口(什么是全链路数据血缘(DataLineage)或者数据之间会形成各式各样的关系)
什么是全链路数据沿袭
根据维基百科,数据沿袭也称为数据来源或数据谱系。它通常被定义为一个生命周期,主要包括数据来自哪里以及随着时间的推移而移动到哪里。
数据血脉是数据资产的重要组成部分。用于分析表和字段从数据源到当前表的血统路径,血统字段之间的关系是否满足,注意数据的一致性和合理的表设计。它描述了数据从采集、生产到服务全链路的变化和存在形式。
全链路数据血统是指在数据的整个生命周期中,数据与数据之间形成的各种关系,贯穿整个数据链路,如图1所示。

图1 全链路数据沿袭
血缘关系建设计划调查血缘关系分析
目前,数据沿袭主要是通过解析SQL语句来发现上下游调用栈等信息。主流解决方案可以分为两种:
上述两类方案各有优缺点,对比见表1。
表1 数据沿袭分析方案
血统储存
与传统的关系型数据库和 ES 工具相比,图数据库在血统信息的查询和分析方面具有以下优势:
1、更好地存储和分析复杂关系
数据沿袭描绘了数据的完整生命周期,具有数据链路长的特点。传统的关系型数据库和ES等,往往只反映当前状态或短路径中的状态,在长链接血缘关系的检索上存在明显劣势。图数据库有效组织复杂的关系,通过点边结构将血脉的上下游完美连接,从而实现更长链路血脉的存储、检索和分析。
2、可以有效利用数据之间的相关性,实现更准确可靠的决策
图结构的特点对业务具有重要的指导意义。例如,图的密度可以反映业务数据关联的紧密程度,有助于识别高I/O或高吞吐的服务,识别链路瓶颈;图数据之间的共现可以反映血缘关系中的共生关系,辅助血缘关系重要性的划分;图形可视化帮助业务人员更清晰地了解血缘动态。
与开源图数据库 Neo4j 和 Nebula Graph 相比,华为云 GES 具有以下优势:
华为云GES的基准数据如表2所示。
表2 华为云GES基准测试数据
满帮数据血脉的实践 满帮数据血脉的特点
满帮数据血脉具有以下特点:
数据沿袭模型
定义丰富的血缘关系模型有助于更真实有效地展示血缘关系。满族血统模型主要包括实体和关系,其中实体主要涵盖任务、库、表、视图、字段、函数等实体。实体和关系的组合显示了从一个表/列到其他表/列的沿袭,包括表 INSERT INTO\CTAS 之间的依赖关系,字段 PROJECTION\PREDICATE 之间的依赖关系。
使用完整的数据血缘关系模型可以展示血缘关系的全貌,但存在以下问题:一是完整的血缘关系模型往往收录数千个实体血缘关系,在前端难以展示;其次,过多的冗余信息可能导致问题实体定位困难。为了解决以上问题,满帮在数据血缘模型的基础上,开发了多层次血缘关系模型,主要包括完整血缘关系模型和高层次血缘关系模型。完整数据沿袭模型是所有其他高级沿袭模型的基础,高级沿袭模型通过省略或聚合模型中的某些关系和实体来扩展完整沿袭。在实际业务中,
总体架构规划
满帮全链路数据血脉实现了血脉数据数据采集从开始到最终数据服务的全链路,有助于高效定位问题,快速评估影响。全链路血脉架构如图2所示,主要包括5层:
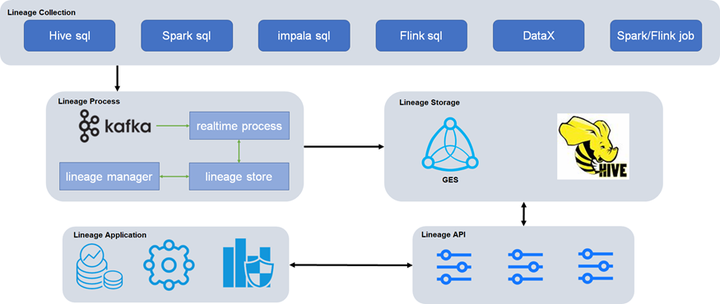
图2 满帮全链路血脉架构
血脉采集层
满帮血脉采集层目前涵盖满帮内部数据、离线调度、实时计算等平台上的SQL任务和Spark\Flink任务。血缘关系包括系统血缘关系、职务血缘关系、图书馆血缘关系、表级血缘关系、字段血缘关系,指向数据的上游源头,溯源上游。通过血缘关系,清晰展示数据处理和处理的逻辑脉络,快速定位异常数据域的影响范围,准确勾画数据回溯的最小范围,降低理解数据和解决的成本数据问题。具体来说:
为了方便采集和数据血统的处理,统一了各个组件的血统格式,主要包括输入输出表、字段等信息。
血缘处理层
血缘处理层主要由血缘实时处理模块、血缘存储接口模块、血缘管理模块组成。
为了满足近实时血脉查询的需求,满帮采用Flink作为血脉实时处理模块的核心组件。通过对上游采集接收到的血脉信息进行实时分析处理,可以快速写入图数据库和Hive。该模块支持批量删除\查询\更新和模糊删除\查询\更新功能。
血脉存储接口模块主要开发快速编写图数据库和Hive的相关接口。
血缘管理模块主要用于血缘信息的维护管理和统计分析。
血脉贮藏层
血脉存储层使用华为云图引擎GES服务作为存储引擎。GES采用华为自研EYWA内核,是一种基于“关系”的“图”结构化数据查询分析服务。GES 目前提供多种原生接口,包括批量读写点、边,以及各种路径查询算法。
全链路全链路数据沿袭场景下,图数据操作主要包括读写操作。写入操作主要是将解析和格式化后的血线数据实时写入图数据库。另一种写操作主要是向应用端提供写请求,如表\字段安全级别标记。读取操作主要来自自满帮内部的各种应用场景,主要涵盖短距离、CRM、客服、金融等。
血脉接口层和血脉应用层
血缘接口层主要连接血缘应用层的各种服务,通过开放血缘RPC接口,为各个应用服务提供丰富的接口选项。
目前,满族血脉信息主要应用于数据资产、数据治理、数据安全、数据质量等各种场景。
1、数据资产
满帮数据资产管理平台提供资产全景、数据地图、数据质量、数据安全等功能,如图4所示。数据地图支持以扇形图的形式直观展示各类数据资产的占比,图表,并通过不同层次的图形进行精细化控制,满足业务中不同应用场景的数据查询和辅助分析需求。
图 4 满帮数据资产管理平台
数据图还支持显示血统信息,分析任务之间的数据流向,如图5所示。目前数据图支持显示任务、库、表、字段级血缘关系。
图5 满帮资料图
2、数据治理
数据治理是指在数据的整个生命周期内管理数据的原则性方法,其目标是确保数据安全、及时、准确、可用和易于使用。满帮数据治理主要围绕“指标明确、质量规范”和“资源合理、节约严格”的原则进行。
如图6所示,满帮数据治理任务对库、表、字段的血脉信息进行分析,从价值密度、访问频率、使用方式、时效度等维度进行评价,从而对数据的流行度进行评分,热数据和热数据。,冷数据和冰数据。通过血缘信息查看离线数仓中某个任务链接的上下游任务依赖,同时分析该链接上表的冷热使用情况,对ods、dwd、cut、merge等相关任务和SQL进行优化低价值表,缩短数据流ETL环节,从而降低维护成本,提高数据价值。
图 6 满帮数据治理
3、数据质量
数据质量旨在高效监控各类作业的运行状态,洞察关键信息,形成事前判断、事中监控、事后跟踪的闭环质量管理流程。在满帮数据质量监管平台建设中,面临以下问题:
针对以上问题,满帮基于全链路数据血统,从以下几个方面提升数据全生命周期的数据质量:
4、数据安全
随着国家在数据流通过程中对数据安全的重视程度越来越高,如果不能有效识别安全级别高的数据,可能会出现安全合规风险。为此,满帮推出了资产安全打标平台,支持通过“自动+人工”打标实现资产安全分级打标,但存在打标覆盖率低、准确率低等问题。
基于全链路的血缘关系,根据不同的数据安全等级,先用血缘关系标注接口标注不同的表字段,然后识别标注字段的上下游血缘关系,然后自动标注安全等级。如图7所示,city_name字段通过血统标记平台安全标记,等级为L3。根据血脉关系,对下游血脉链路的字段进行自动染色和标记,实现自动“染色”。

图 7 数据安全
未来展望
经过探索和实践,满帮已经基本实现了基于图数据库相关技术的全链路数据血统的构建,并取得了一定的成果。未来,我们将在以下几个方面进行更深入的探索,进一步完善我们的业务:
1、目前血脉采集主要通过SQL、自动任务解析、人工排序等方式提高血脉覆盖率。目前覆盖率已达到95%以上。未来将探索人工智能相关的方法,根据数据集之间的依赖关系计算数据相似度,以提高覆盖率。
2、Impala bloodline采集 方法链接长,依赖Filebeat。未来我们会逐步对接使用SQL语法解析AST的方案,实现解析规范化。
3、目前血缘维度不支持功能层。
4、开发全链路血脉开放平台,快速对接应用方,为应用方提供血脉服务。
参考
[1]
[2]
[3]
点击关注,第一时间了解华为云新技术~
云优采集接口(云优采集接口的云获取自定义地址网址的采集工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-01-25 20:01
云优采集接口还支持多条件设置、回复类型设置等
云优采集接口,是一款云获取自定义地址网址的采集工具,操作简单,上手快,高效。接口全程半客户端操作,不需要注册,用户可在任何电脑端访问,非常便捷。接口获取不需要预先获取地址url,直接使用任何浏览器,非常快捷。接口获取支持输入www、excel、imtr等多种格式,支持全文同步采集,非常快捷。提供100+ip地址及100+api接口,免费使用。详情请咨询云优采集接口大师网站或搜索云优采集接口中心。
现在主流的云采集就是云优来采集。这家是我用过最好用的一个云采集。操作简单,接口全,速度快,
t5云采集器
有接口通,即时接入云平台,自由挑选采集的地址,设置参数,模拟真实用户操作。完全模拟真实用户,不费流量,操作灵活,小白也可使用。
现在我用的t5云采集器,解析的时候出来一个excel表,
t5云采集器的云地址接口相当优秀,不需要特殊的设置,
目前来看zerobot也不错,云采集接口全,最主要是不需要任何软件及框架,
t5云采集器一个短小精悍的采集工具!采集数据还不错,无需安装app,采集的网页链接,可以自动跳转至相应页面浏览,然后再上传数据。想做网页编辑的话,非常好用。还可以在“控制台”管理查看接口。一个电脑全搞定,非常方便。 查看全部
云优采集接口(云优采集接口的云获取自定义地址网址的采集工具)
云优采集接口还支持多条件设置、回复类型设置等
云优采集接口,是一款云获取自定义地址网址的采集工具,操作简单,上手快,高效。接口全程半客户端操作,不需要注册,用户可在任何电脑端访问,非常便捷。接口获取不需要预先获取地址url,直接使用任何浏览器,非常快捷。接口获取支持输入www、excel、imtr等多种格式,支持全文同步采集,非常快捷。提供100+ip地址及100+api接口,免费使用。详情请咨询云优采集接口大师网站或搜索云优采集接口中心。
现在主流的云采集就是云优来采集。这家是我用过最好用的一个云采集。操作简单,接口全,速度快,
t5云采集器
有接口通,即时接入云平台,自由挑选采集的地址,设置参数,模拟真实用户操作。完全模拟真实用户,不费流量,操作灵活,小白也可使用。
现在我用的t5云采集器,解析的时候出来一个excel表,
t5云采集器的云地址接口相当优秀,不需要特殊的设置,
目前来看zerobot也不错,云采集接口全,最主要是不需要任何软件及框架,
t5云采集器一个短小精悍的采集工具!采集数据还不错,无需安装app,采集的网页链接,可以自动跳转至相应页面浏览,然后再上传数据。想做网页编辑的话,非常好用。还可以在“控制台”管理查看接口。一个电脑全搞定,非常方便。
云优采集接口(云优采集接口是基于flash的云端数据,存储的不是网页内容)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-01-23 02:05
云优采集接口是基于flash的云端数据,存储的不是网页内容而是云端数据,存储可以存储,查询,
来源:云优采集接口是基于flash的云端数据,存储的不是网页内容而是云端数据,存储可以存储,查询,返回是基于flash来做的,flash可以直接查询云端的数据如果需要一个类似自动化采集工具之类的东西,可以考虑试试我们团队开发的云优采集接口,从技术上,
如果你在问云优采集接口是什么,那我就很没法回答了。自动化采集,一般都是比较大的公司在做。然后小的公司,可能是平台入口自动化操作比较多,还是提供一种选择也是很正常的。云优采集接口:是基于chrome的云端demo,然后html转成html模板。数据采集工具完全基于flash来完成自动化采集的。传统采集工具,就是用网页本身,用html转成html的模板。云优采集接口:是支持在任何浏览器上用html转html来采集数据。
云优采集接口是一种常用的云端采集方法之一。云优采集接口是基于flash的云端数据,存储的不是网页内容而是云端数据,存储可以存储,查询,返回是基于flash来做的,flash可以直接查询云端的数据如果需要一个类似自动化采集工具之类的东西,可以考虑试试我们团队开发的云优采集接口,从技术上,肯定是没有问题的。 查看全部
云优采集接口(云优采集接口是基于flash的云端数据,存储的不是网页内容)
云优采集接口是基于flash的云端数据,存储的不是网页内容而是云端数据,存储可以存储,查询,
来源:云优采集接口是基于flash的云端数据,存储的不是网页内容而是云端数据,存储可以存储,查询,返回是基于flash来做的,flash可以直接查询云端的数据如果需要一个类似自动化采集工具之类的东西,可以考虑试试我们团队开发的云优采集接口,从技术上,
如果你在问云优采集接口是什么,那我就很没法回答了。自动化采集,一般都是比较大的公司在做。然后小的公司,可能是平台入口自动化操作比较多,还是提供一种选择也是很正常的。云优采集接口:是基于chrome的云端demo,然后html转成html模板。数据采集工具完全基于flash来完成自动化采集的。传统采集工具,就是用网页本身,用html转成html的模板。云优采集接口:是支持在任何浏览器上用html转html来采集数据。
云优采集接口是一种常用的云端采集方法之一。云优采集接口是基于flash的云端数据,存储的不是网页内容而是云端数据,存储可以存储,查询,返回是基于flash来做的,flash可以直接查询云端的数据如果需要一个类似自动化采集工具之类的东西,可以考虑试试我们团队开发的云优采集接口,从技术上,肯定是没有问题的。
云优采集接口(云优图片采集高清商用高清图片上传(云计算))
采集交流 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-01-19 06:00
云优采集接口_云优素材网_云优图片_云优网站_云优头像采集接口_云优设计网_云优好友qq群|云优接口网站|云优视频/新闻网站|云优标题排名接口|云优上站接口|云优人物接口|云优文章采集接口|云优天气预报接口-云优优图片云优优图片(图片版权归云优接口管理及开发者所有)使用云优素材网站接口:云优图片采集云优素材网图片_网站采集云优素材网采集云优素材网素材_云优图片新闻网站采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集。
云优图片采集接口我用的就是这个云优图片采集接口
云优图片采集云优图片云优图片采集高清商用高清图片上传
我推荐个:/
如果有,那岂不是大家都用同一个东西,当然不会,如果是一个好的软件。你可以申请一个,名字就叫云优图片采集接口,一起交流,
云优图片采集云优图片采集高清商用高清图片上传云优图片采集云优图片采集云优图片采集高清商用高清图片云优图片采集图片采集云优图片采集高清商用高清图片云优图片采集 查看全部
云优采集接口(云优图片采集高清商用高清图片上传(云计算))
云优采集接口_云优素材网_云优图片_云优网站_云优头像采集接口_云优设计网_云优好友qq群|云优接口网站|云优视频/新闻网站|云优标题排名接口|云优上站接口|云优人物接口|云优文章采集接口|云优天气预报接口-云优优图片云优优图片(图片版权归云优接口管理及开发者所有)使用云优素材网站接口:云优图片采集云优素材网图片_网站采集云优素材网采集云优素材网素材_云优图片新闻网站采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集。
云优图片采集接口我用的就是这个云优图片采集接口
云优图片采集云优图片云优图片采集高清商用高清图片上传
我推荐个:/
如果有,那岂不是大家都用同一个东西,当然不会,如果是一个好的软件。你可以申请一个,名字就叫云优图片采集接口,一起交流,
云优图片采集云优图片采集高清商用高清图片上传云优图片采集云优图片采集云优图片采集高清商用高清图片云优图片采集图片采集云优图片采集高清商用高清图片云优图片采集
云优采集接口(云优采集接口页面比较简单,无需安装任何开发工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2022-01-17 05:00
云优采集接口页面比较简单,无需安装任何开发工具即可采集进入所需要的微信公众号。商家可通过多渠道、全方位进行推广及营销,达到增粉、留粉的目的,为企业打造微信商业帝国积累经验。
云优接口,云优采集接口是基于公众号的便捷采集接口,主要有云优采集接口、云优采集助手接口、云优采集宝接口等,云优采集接口是云优商业接口的一个分支,提供完善的云优采集服务,云优采集助手主要是负责查找商品、修改采集规则、拉票、删除僵尸粉等一些列操作,云优采集宝是一个微信个人号免费接口,可以接受粉丝做活动的扫码转发等活动,助力商家实现引流以及增粉的效果。
可以去百度搜一下,做小程序的一般都知道“云优baoxiba接口”,是目前市面上体验比较好的一款,至于为什么推荐大家去百度搜一下,因为很多企业的在百度投放广告,
云优baoxiba接口,云优baoxiba是一款基于公众号的便捷采集接口,主要有云优采集接口、云优采集助手接口、云优采集宝接口等,云优采集接口是云优商业接口的一个分支,提供完善的云优采集服务,云优采集助手主要是负责查找商品、修改采集规则、拉票、删除僵尸粉等一些列操作,云优采集宝是一个微信个人号免费接口,可以接受粉丝做活动的扫码转发等活动,助力商家实现引流以及增粉的效果。 查看全部
云优采集接口(云优采集接口页面比较简单,无需安装任何开发工具)
云优采集接口页面比较简单,无需安装任何开发工具即可采集进入所需要的微信公众号。商家可通过多渠道、全方位进行推广及营销,达到增粉、留粉的目的,为企业打造微信商业帝国积累经验。
云优接口,云优采集接口是基于公众号的便捷采集接口,主要有云优采集接口、云优采集助手接口、云优采集宝接口等,云优采集接口是云优商业接口的一个分支,提供完善的云优采集服务,云优采集助手主要是负责查找商品、修改采集规则、拉票、删除僵尸粉等一些列操作,云优采集宝是一个微信个人号免费接口,可以接受粉丝做活动的扫码转发等活动,助力商家实现引流以及增粉的效果。
可以去百度搜一下,做小程序的一般都知道“云优baoxiba接口”,是目前市面上体验比较好的一款,至于为什么推荐大家去百度搜一下,因为很多企业的在百度投放广告,
云优baoxiba接口,云优baoxiba是一款基于公众号的便捷采集接口,主要有云优采集接口、云优采集助手接口、云优采集宝接口等,云优采集接口是云优商业接口的一个分支,提供完善的云优采集服务,云优采集助手主要是负责查找商品、修改采集规则、拉票、删除僵尸粉等一些列操作,云优采集宝是一个微信个人号免费接口,可以接受粉丝做活动的扫码转发等活动,助力商家实现引流以及增粉的效果。
云优采集接口(Histogram和Summary主要支持4类指标使用_total)
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2022-01-16 04:15
http_requests_total{method="post",code="200"} 163000
http_requests_total{method="post",code="400"} 3 00`
Prometheus 主要支持 4 类指标:
•计数器:只增不减的计数器
•Gauge:可以增加或减少的值
•直方图:直方图,分箱采样
•Summary:数据汇总、分位数抽样
其中Counter和Gauge很好理解,而Histogram和Summary可能会让人一时糊涂。事实上,Histogram 和 Summary 都是为了解决和过滤不同维度的长尾问题而设计的。
例如,我自己和首富的平均身价并不能真实反映我自己的身价。因此,桶或分位数可以更准确地描述数据的真实分布。
直方图和摘要之间的主要区别在于分位数的计算。Histogram 只在客户端进行桶计算,所以整体分位数计算可以在服务端进行。Summary 在客户端环境中计算分位数,因此失去了在整体视图上计算分位数的可能性。官方还给出了Histogram和Summary的区别:
直方图
概括
所需配置
需要设置所需的分桶范围
需要设置所需的分位数和滑动窗口大小
客户端性能消耗
低消耗,只需要增量计算
由于需要流式分位数计算,因此相对昂贵
服务器端性能消耗
分位数需要计算,消耗高。如果耗时过长,可以尝试使用预聚合
降低消耗
依次
一桶一
一分位数一
分位数误差
误差取决于桶的数量和桶的大小
误差取决于分位数的值
分位数和时间窗
查询时指定
采集 指定时
聚合
查询时指定
通常不可能进行聚合
需要注意的是,截至目前的Prometheus版本2.20.1,这些metric类型只用在客户端库和wire协议中,服务器暂时不记录这些信息。所以如果使用 histogram_quantile(0.9,xxx) 作为 Gauge 类型的指标,也是可以的,但是因为没有 xxx_bucket,所以无法计算数值。
采集如何
时序监控数据采集,从监控端来看,只有拉取和推送两种形式的数据获取,不同的采集方式也决定了不同的部署方式。
我们以opentsdb和prometheus为例,因为influxdb集群版方案是商业版,所以暂不讨论。
推法
上图为opentsdb架构图,其中:
•Servers:代表数据为采集的服务,C是代表采集指标的工具,可以理解为opensdb的代理,servers通过将数据推送到下游TSD C;
•TSD:对应实际进程名TSDMain是opentsdb组件,理解为接收层,每个TSD都是独立的,没有主从之分,也没有共享状态;
• HBase:opentsdb的实际最终数据存储在hbase中;
从架构图中可以看出,如果推送形式的数据量大幅增加,通过使用多级组件或扩展无状态接收层,可以相对简单地提升吞吐量。
拉法
上图为prometheus架构图,主要看以下几部分:
• Prometheus Server:用于获取和存储时间序列化数据
•Exporters:主动拉取数据的插件
•Pushgateway:被动拉取数据的插件
拉取方式通常是监控终端定期从各个监控终端配置的Exporter中拉取指标。这种设计方法可以降低监控终端与被监控终端的耦合度,被监控终端不需要知道监控终端的存在,从而摆脱了监控终端向监控终端发送指标的压力。
比较 pull 和 push 方法的优缺点:
l 拉动的优势
n 上下游解耦
n 不会因为向监控终端推送数据失败而导致被监控终端不稳定
n 监控终端自身的压力基本可以预测,降低被监控终端发送流量突然增加带来的自身风险,如DDoS
n 可实现被监控终端的自动发现机制
n 主动在监控端,需要监控的可以更灵活的配置,尤其是在调试过程中
l 拉取的缺点
n 对于周期性不明显的指标,或周期明显较短且采集周期缺少精度的指标
n 实时性差
n 由于防火墙等复杂的网络环境设置,可能无法拉取数据
n 如果数据缺失,难以补充数据
pull和push特性的简单对比,在云原生环境下,prometheus是目前的时序监控标准,为什么选择pull的形式,这里是官方的解释(#why-do-you-pull-rather-than - 推)。
以上从监控端的角度简单介绍了数据采集方法的拉取和推送形式。从被监控端来看,获取数据的方式有很多种,通常可以分为以下几种:
1.默认采集
2.探头采集
3.组件采集
4.购买积分采集
下面是一个例子。
默认采集
默认的采集通常是通俗意义上大家需要观察的基本指标,往往和业务没有强关联,比如cpu、内存、磁盘、net等硬件或系统指标。通常监控系统会有专门的agent来修复采集这些指标,使用云原生的node_exporter、CAdvisor、process-exporter分别对节点机器、容器、进程进行基本的监控非常方便。
探头采集
探测采集主要是指从外部采集获取数据的手段。比如域名监控、站点监控、端口监控等都属于这一类。采集 方法不会侵入系统。由于其对网络的依赖性强,通常会部署多个检测点,以减少网络问题导致的误报。但是要特别注意评估检测采集@采集的频率,否则容易对被检测方造成请求压力。
组件采集
通常是指已有的采集方案,详细的指标采集可以通过简单的操作或配置进行,比如mysql监控、redis监控等。在云原生环境下,这个采集 方法比较常见。得益于prometheus的发展壮大,通用组件采集exporter层出不穷,各种exporter都通过prometheus官方认证。对于以下特殊或定制的需求,也可以按照/metrics接口标准完成自定义导出器的编写。
埋葬采集
对于一个系统的关键指标,研发学生自己是最有发言权的,通过埋点可以准确得到相关指标。在prometheus系统中,使用/prometheus/client_*工具包实现埋点采集非常方便。
总结
本文从“采集结构”和“采集方法”两个方面对监控系统第一阶段“采集”进行了简要介绍和梳理。与以往相比,在云原生环境下,服务的粒度更细化,迭代效率更高,从开发到上线形成更快节奏的反馈循环,这也要求监控系统能够反映得更快。系统异常,虽然“采集结构”和“采集方法”不是监控系统的核心部分,但简洁的采集结构和方便的采集方法也是“可观察性”的后续实现提供了基础。目前,在云原生环境中, 查看全部
云优采集接口(Histogram和Summary主要支持4类指标使用_total)
http_requests_total{method="post",code="200"} 163000
http_requests_total{method="post",code="400"} 3 00`
Prometheus 主要支持 4 类指标:
•计数器:只增不减的计数器
•Gauge:可以增加或减少的值
•直方图:直方图,分箱采样
•Summary:数据汇总、分位数抽样
其中Counter和Gauge很好理解,而Histogram和Summary可能会让人一时糊涂。事实上,Histogram 和 Summary 都是为了解决和过滤不同维度的长尾问题而设计的。
例如,我自己和首富的平均身价并不能真实反映我自己的身价。因此,桶或分位数可以更准确地描述数据的真实分布。
直方图和摘要之间的主要区别在于分位数的计算。Histogram 只在客户端进行桶计算,所以整体分位数计算可以在服务端进行。Summary 在客户端环境中计算分位数,因此失去了在整体视图上计算分位数的可能性。官方还给出了Histogram和Summary的区别:
直方图
概括
所需配置
需要设置所需的分桶范围
需要设置所需的分位数和滑动窗口大小
客户端性能消耗
低消耗,只需要增量计算
由于需要流式分位数计算,因此相对昂贵
服务器端性能消耗
分位数需要计算,消耗高。如果耗时过长,可以尝试使用预聚合
降低消耗
依次
一桶一
一分位数一
分位数误差
误差取决于桶的数量和桶的大小
误差取决于分位数的值
分位数和时间窗
查询时指定
采集 指定时
聚合
查询时指定
通常不可能进行聚合
需要注意的是,截至目前的Prometheus版本2.20.1,这些metric类型只用在客户端库和wire协议中,服务器暂时不记录这些信息。所以如果使用 histogram_quantile(0.9,xxx) 作为 Gauge 类型的指标,也是可以的,但是因为没有 xxx_bucket,所以无法计算数值。
采集如何
时序监控数据采集,从监控端来看,只有拉取和推送两种形式的数据获取,不同的采集方式也决定了不同的部署方式。
我们以opentsdb和prometheus为例,因为influxdb集群版方案是商业版,所以暂不讨论。
推法

上图为opentsdb架构图,其中:
•Servers:代表数据为采集的服务,C是代表采集指标的工具,可以理解为opensdb的代理,servers通过将数据推送到下游TSD C;
•TSD:对应实际进程名TSDMain是opentsdb组件,理解为接收层,每个TSD都是独立的,没有主从之分,也没有共享状态;
• HBase:opentsdb的实际最终数据存储在hbase中;
从架构图中可以看出,如果推送形式的数据量大幅增加,通过使用多级组件或扩展无状态接收层,可以相对简单地提升吞吐量。
拉法

上图为prometheus架构图,主要看以下几部分:
• Prometheus Server:用于获取和存储时间序列化数据
•Exporters:主动拉取数据的插件
•Pushgateway:被动拉取数据的插件
拉取方式通常是监控终端定期从各个监控终端配置的Exporter中拉取指标。这种设计方法可以降低监控终端与被监控终端的耦合度,被监控终端不需要知道监控终端的存在,从而摆脱了监控终端向监控终端发送指标的压力。
比较 pull 和 push 方法的优缺点:
l 拉动的优势
n 上下游解耦
n 不会因为向监控终端推送数据失败而导致被监控终端不稳定
n 监控终端自身的压力基本可以预测,降低被监控终端发送流量突然增加带来的自身风险,如DDoS
n 可实现被监控终端的自动发现机制
n 主动在监控端,需要监控的可以更灵活的配置,尤其是在调试过程中
l 拉取的缺点
n 对于周期性不明显的指标,或周期明显较短且采集周期缺少精度的指标
n 实时性差
n 由于防火墙等复杂的网络环境设置,可能无法拉取数据
n 如果数据缺失,难以补充数据
pull和push特性的简单对比,在云原生环境下,prometheus是目前的时序监控标准,为什么选择pull的形式,这里是官方的解释(#why-do-you-pull-rather-than - 推)。
以上从监控端的角度简单介绍了数据采集方法的拉取和推送形式。从被监控端来看,获取数据的方式有很多种,通常可以分为以下几种:
1.默认采集
2.探头采集
3.组件采集
4.购买积分采集
下面是一个例子。
默认采集
默认的采集通常是通俗意义上大家需要观察的基本指标,往往和业务没有强关联,比如cpu、内存、磁盘、net等硬件或系统指标。通常监控系统会有专门的agent来修复采集这些指标,使用云原生的node_exporter、CAdvisor、process-exporter分别对节点机器、容器、进程进行基本的监控非常方便。
探头采集
探测采集主要是指从外部采集获取数据的手段。比如域名监控、站点监控、端口监控等都属于这一类。采集 方法不会侵入系统。由于其对网络的依赖性强,通常会部署多个检测点,以减少网络问题导致的误报。但是要特别注意评估检测采集@采集的频率,否则容易对被检测方造成请求压力。
组件采集
通常是指已有的采集方案,详细的指标采集可以通过简单的操作或配置进行,比如mysql监控、redis监控等。在云原生环境下,这个采集 方法比较常见。得益于prometheus的发展壮大,通用组件采集exporter层出不穷,各种exporter都通过prometheus官方认证。对于以下特殊或定制的需求,也可以按照/metrics接口标准完成自定义导出器的编写。
埋葬采集
对于一个系统的关键指标,研发学生自己是最有发言权的,通过埋点可以准确得到相关指标。在prometheus系统中,使用/prometheus/client_*工具包实现埋点采集非常方便。
总结
本文从“采集结构”和“采集方法”两个方面对监控系统第一阶段“采集”进行了简要介绍和梳理。与以往相比,在云原生环境下,服务的粒度更细化,迭代效率更高,从开发到上线形成更快节奏的反馈循环,这也要求监控系统能够反映得更快。系统异常,虽然“采集结构”和“采集方法”不是监控系统的核心部分,但简洁的采集结构和方便的采集方法也是“可观察性”的后续实现提供了基础。目前,在云原生环境中,
云优采集接口(云优网采集接口可以帮到你,不用注册就可以开通接口)
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-01-15 04:01
云优采集接口可以帮到你,不用注册就可以开通接口,接口有三个等级,普通接口是天猫,天猫最高,高级接口有上百个店铺供你选择。
云优网()有经济型的和专业型的两种收费情况。经济型,官方对注册会员收取每年30元费用,个人采集会员收取每年120元。专业型,一次性收取500元,不能采集商品超过30个,如商品超过30个,按照上传规则,采集多余的商品,则算重复,无法采集商品上传。对于专业型的软件使用者,必须是注册有云优网账号的用户,且为云优网的注册会员才可以使用。
而对于普通用户,则无需注册,可以免费注册使用。无论使用者是注册的经济型,还是专业型软件,都可以采集商品和上传商品。软件提供商会为大家提供设置好的采集规则,使用者只需要按照软件的设置来采集商品即可。
云优网是以云端采集上传、合理配价为特色,旨在打造最贴近终端消费者的生活服务软件,让用户用最少的钱,就能享受到最实惠的优惠,使用时使用手机注册并登录即可。
云优网软件使用者,无需注册,无需客户经理,无需个人中心,无需任何技术支持服务。只需要缴纳300元即可享受接近终端消费者的价格。使用云优网你只需要做到采集联盟的商品到云优网,然后集中上传到网。 查看全部
云优采集接口(云优网采集接口可以帮到你,不用注册就可以开通接口)
云优采集接口可以帮到你,不用注册就可以开通接口,接口有三个等级,普通接口是天猫,天猫最高,高级接口有上百个店铺供你选择。
云优网()有经济型的和专业型的两种收费情况。经济型,官方对注册会员收取每年30元费用,个人采集会员收取每年120元。专业型,一次性收取500元,不能采集商品超过30个,如商品超过30个,按照上传规则,采集多余的商品,则算重复,无法采集商品上传。对于专业型的软件使用者,必须是注册有云优网账号的用户,且为云优网的注册会员才可以使用。
而对于普通用户,则无需注册,可以免费注册使用。无论使用者是注册的经济型,还是专业型软件,都可以采集商品和上传商品。软件提供商会为大家提供设置好的采集规则,使用者只需要按照软件的设置来采集商品即可。
云优网是以云端采集上传、合理配价为特色,旨在打造最贴近终端消费者的生活服务软件,让用户用最少的钱,就能享受到最实惠的优惠,使用时使用手机注册并登录即可。
云优网软件使用者,无需注册,无需客户经理,无需个人中心,无需任何技术支持服务。只需要缴纳300元即可享受接近终端消费者的价格。使用云优网你只需要做到采集联盟的商品到云优网,然后集中上传到网。
云优采集接口( 上图的日志采集方式以及对比说明(一)(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2022-03-16 06:21
上图的日志采集方式以及对比说明(一)(组图))
上图是EFK架构图,k8s环境下常用的log采集方法。
日志要求
1 采集采集微服务的日志,可以根据请求id跟踪完整的日志;
2.统计请求接口的耗时。如果最大响应时间超过最大响应时间,应报警并进行针对性调优;
3 慢sql排行榜和报警;
4 异常日志排名列表,并报警;
5 页面请求排名慢并报警;
k8s 日志采集
k8s本身不会为你登录采集,需要你自己做;
k8s的容器日志处理方式中使用的集群级日志,
即容器销毁、pod漂移、Node宕机等都不会影响容器日志;
容器的日志会输出到stdout、stderr,对应的存储在宿主机的目录下。
即/var/lib/docker/container;
通过 Node 上的日志代理转发
在每个节点上部署一个守护进程,运行一个日志代理来采集日志,
比如fluentd,采集在主机对应的数据盘上进行日志,然后输出到日志存储服务或者消息队列;
优缺点分析:
比较说明
优势
1 每个Node只需要部署一个Pod采集 log 2 不侵入应用
缺点
应用程序输出的日志必须直接输出到容器的stdout和stderr
Pod内部通过sidecar容器转发到日志服务
通过在pod中启动一个sidecar容器,比如fluentd,读取容器挂载的volume目录,输出到日志服务器;
日志输入源:日志文件
日志处理: logging-agent ,如 fluentd
日志存储:如elasticSearch、kafka
优缺点分析:
比较说明
优势
1 简单部署;2 主机友好;
缺点
1. 消耗更多资源;2. 通过 kubectl 日志看不到日志
例子:
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i:$(data)" >> /var/log/1.log
echo "$(data) INFO $i" >> /var/log/2.log
i=$((i+1))
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-agent
image: k8s.gcr.io/fluentd-gcp:1.30
env:
- name: FLUENTD_ARGS
value: -c /etc/fluentd-config/fluentd.conf
valumeMounts:
- name: varlog
mountPath: /var/log
- name: config-volume
mountPath: /etc/fluentd-config
volumes:
- name: varlog
emptyDir: {}
- name: config-volume
configMap:
name: fluentd-config
Pod 内部通过 sidecar 容器输出到 stdout
适用于应用容器只能输出日志到文件,不能输出到stdout和stderr的场景;
通过一个sidecar容器,直接读取日志文件,然后重新输出到stdout、stderr、
可以在Node上使用日志代理转发的模式;
优缺点分析:
比较说明
优势
只需要消耗较少的CPU和内存,共享卷处理效率比较高
缺点
主机上有两条相同的日志,磁盘利用率不高
应用容器直接输出日志到日志服务
适用于日志系统成熟的场景,日志不需要经过k8s;
EFK 引入 fluentd
fluentd 是一个用于统一日志记录层的开源数据采集器。
flentd 允许您统一日志采集和更好地使用和理解数据;
四大特点:
统一日志层
fluentd 隔离数据源,提供与后台系统统一的日志层;
简单灵活
提供500多个插件,连接大量数据源和输出源,内核简单;
广泛的验证
自 Fluentd 以来,5000 多家数据驱动型公司
最大的客户端通过它从 50,000 多台服务器采集日志
**云原生**
是云原生CNCF的成员项目
4大优势:
统一的 JSON 日志
fluentd尝试使用JSON结构化数据,统一处理日志数据的各个方面,采集、过滤、缓存、输出日志到多个目的地,下游数据处理使用Json更简单,因为它已经有足够的访问结构并保留了足够的灵活性场景;
插件架构
fluntd 有一个灵活的插件系统,允许社区扩展其功能。超过 500 个社区贡献的插件连接了许多数据源和目的地;通过插件,您可以开始更好地利用您的日志
最低资源消耗
用c和ruby写的,对系统资源要求很低,40M左右的内存可以处理13k/次/秒,如果需要更紧凑的内存,可以使用Fluent bit,更轻的Fluentd
内核可靠
Fluentd 支持内存和基于文件的缓存,防止内部节点数据丢失;
还支持鲁棒故障并可以配置高可用性模式,超过 2000 家数据驱动的公司在不同的产品中依靠 Fluentd 更好地使用和理解他们的日志数据
使用流利的理由:
简单灵活
10分钟即可在电脑上安装fluentd,立即下载,超过500个插件连接数据源和目的地,插件也易于开发和部署;
开源
基于 Apache2.0 证书的完全开源
可靠和高性能
超过 5,000 家数据驱动型公司的不同产品和服务依靠 fluentd 更好地使用和理解数据。事实上,根据datadog的调查,使用docker运行的技术排在前7位;
一些流利的用户拥有来自数千台机器的实时 采集 数据。每个实例只需要大约 40M 的内存。缩放时,可以节省大量内存。
社区
fluentd 可以改进软件并帮助其他人更好地使用它
大公司使用代言:微软、亚马逊;pptv;
可以与elasticSearch + kibana结合,组成日志套件;
快速搭建EFK集群,采集应用日志,配置性能排名;
弹性搜索
Elasticsearch 是一个分布式的 RESTful 搜索和数据分析引擎。
能够解决正在出现的各种用例。作为 Elastic Stack 的核心,
它集中存储您的数据,并帮助您发现预期和意外。
详细介绍:
木花
Kibana 是一个开源数据分析和可视化平台,是 Elastic Stack 的成员。
旨在与 Elasticsearch 配合使用。您可以使用 Kibana 在 Elasticsearch 索引中搜索数据,
查看,互动。您可以轻松地使用图表、表格和地图以多种方式分析和呈现数据。
Kibana 使大数据易于理解。这很简单,
基于浏览器的界面允许您快速创建和共享动态数据仪表板,以跟踪 Elasticsearch 中的实时数据变化。
详细介绍:
容器化 EFK 实现路径
直接往下拖代码,然后配置上下文、命名空间,就可以安装了;
cd elk-kubernetes
./deploy.sh --watch
下面是deploy.sh的脚本,可以简单看一下:
#!/bin/sh
CDIR=$(cd `dirname "$0"` && pwd)
cd "$CDIR"
print_red() {
printf '%b' "33[91m$133[0mn"
}
print_green() {
printf '%b' "33[92m$133[0mn"
}
render_template() {
eval "echo "$(cat "$1")""
}
KUBECTL_PARAMS="--context=250091890580014312-cc3174dcd4fc14cf781b6fc422120ebd8"
NAMESPACE=${NAMESPACE:-sm}
KUBECTL="kubectl ${KUBECTL_PARAMS} --namespace="${NAMESPACE}""
eval "kubectl ${KUBECTL_PARAMS} create namespace "${NAMESPACE}""
#NODES=$(eval "${KUBECTL} get nodes -l 'kubernetes.io/role!=master' -o go-template="{{range .items}}{{\$name := .metadata.name}}{{\$unschedulable := .spec.unschedulable}}{{range .status.conditions}}{{if eq .reason \"KubeletReady\"}}{{if eq .status \"True\"}}{{if not \$unschedulable}}{{\$name}}{{\"\\n\"}}{{end}}{{end}}{{end}}{{end}}{{end}}"")
NODES=$(eval "${KUBECTL} get nodes -l 'sm.efk=data' -o go-template="{{range .items}}{{\$name := .metadata.name}}{{\$unschedulable := .spec.unschedulable}}{{range .status.conditions}}{{if eq .reason \"KubeletReady\"}}{{if eq .status \"True\"}}{{if not \$unschedulable}}{{\$name}}{{\"\\n\"}}{{end}}{{end}}{{end}}{{end}}{{end}}"")
ES_DATA_REPLICAS=$(echo "$NODES" | wc -l)
if [ "$ES_DATA_REPLICAS" -lt 3 ]; then
print_red "Minimum amount of Elasticsearch data nodes is 3 (in case when you have 1 replica shard), you have ${ES_DATA_REPLICAS} worker nodes"
print_red "Won't deploy more than one Elasticsearch data pod per node exiting..."
exit 1
fi
print_green "Labeling nodes which will serve Elasticsearch data pods"
for node in $NODES; do
eval "${KUBECTL} label node ${node} elasticsearch.data=true --overwrite"
done
for yaml in *.yaml.tmpl; do
render_template "${yaml}" | eval "${KUBECTL} create -f -"
done
for yaml in *.yaml; do
eval "${KUBECTL} create -f "${yaml}""
done
eval "${KUBECTL} create configmap es-config --from-file=es-config --dry-run -o yaml" | eval "${KUBECTL} apply -f -"
eval "${KUBECTL} create configmap fluentd-config --from-file=docker/fluentd/td-agent.conf --dry-run -o yaml" | eval "${KUBECTL} apply -f -"
eval "${KUBECTL} create configmap kibana-config --from-file=kibana.yml --dry-run -o yaml" | eval "${KUBECTL} apply -f -"
eval "${KUBECTL} get pods $@"
简单分解部署流程:
我的k8s环境还没有搭建成功,后续搭建成功后会给出详细的安装说明。
概括
一句话总结这篇文章:EFK是通过日志代理客户端采集应用日志的常用实现方式。
原创不易,关注有诚意,转发价格更高!转载请注明出处,让我们互相交流,共同进步。欢迎交流。
程序员的信标
转载请注明原文链接:Cloud Native Series 5 EFK for Containerized Logs 查看全部
云优采集接口(
上图的日志采集方式以及对比说明(一)(组图))
https://segmentfault.com/img/bVcOKIm" />上图是EFK架构图,k8s环境下常用的log采集方法。
日志要求
1 采集采集微服务的日志,可以根据请求id跟踪完整的日志;
2.统计请求接口的耗时。如果最大响应时间超过最大响应时间,应报警并进行针对性调优;
3 慢sql排行榜和报警;
4 异常日志排名列表,并报警;
5 页面请求排名慢并报警;
k8s 日志采集
k8s本身不会为你登录采集,需要你自己做;
k8s的容器日志处理方式中使用的集群级日志,
即容器销毁、pod漂移、Node宕机等都不会影响容器日志;
https://segmentfault.com/img/bVcOKIn" />容器的日志会输出到stdout、stderr,对应的存储在宿主机的目录下。
即/var/lib/docker/container;
通过 Node 上的日志代理转发
https://segmentfault.com/img/bVcOKIp" />在每个节点上部署一个守护进程,运行一个日志代理来采集日志,
比如fluentd,采集在主机对应的数据盘上进行日志,然后输出到日志存储服务或者消息队列;
优缺点分析:
比较说明
优势
1 每个Node只需要部署一个Pod采集 log 2 不侵入应用
缺点
应用程序输出的日志必须直接输出到容器的stdout和stderr
Pod内部通过sidecar容器转发到日志服务
https://segmentfault.com/img/bVcOKIq" />通过在pod中启动一个sidecar容器,比如fluentd,读取容器挂载的volume目录,输出到日志服务器;
日志输入源:日志文件
日志处理: logging-agent ,如 fluentd
日志存储:如elasticSearch、kafka
优缺点分析:
比较说明
优势
1 简单部署;2 主机友好;
缺点
1. 消耗更多资源;2. 通过 kubectl 日志看不到日志
例子:
apiVersion: v1
kind: Pod
metadata:
name: counter
spec:
containers:
- name: count
image: busybox
args:
- /bin/sh
- -c
- >
i=0;
while true;
do
echo "$i:$(data)" >> /var/log/1.log
echo "$(data) INFO $i" >> /var/log/2.log
i=$((i+1))
sleep 1;
done
volumeMounts:
- name: varlog
mountPath: /var/log
- name: count-agent
image: k8s.gcr.io/fluentd-gcp:1.30
env:
- name: FLUENTD_ARGS
value: -c /etc/fluentd-config/fluentd.conf
valumeMounts:
- name: varlog
mountPath: /var/log
- name: config-volume
mountPath: /etc/fluentd-config
volumes:
- name: varlog
emptyDir: {}
- name: config-volume
configMap:
name: fluentd-config
Pod 内部通过 sidecar 容器输出到 stdout
https://segmentfault.com/img/bVcOKIr" />适用于应用容器只能输出日志到文件,不能输出到stdout和stderr的场景;
通过一个sidecar容器,直接读取日志文件,然后重新输出到stdout、stderr、
可以在Node上使用日志代理转发的模式;
优缺点分析:
比较说明
优势
只需要消耗较少的CPU和内存,共享卷处理效率比较高
缺点
主机上有两条相同的日志,磁盘利用率不高
应用容器直接输出日志到日志服务
https://segmentfault.com/img/bVcOKIs" />适用于日志系统成熟的场景,日志不需要经过k8s;
EFK 引入 fluentd
fluentd 是一个用于统一日志记录层的开源数据采集器。
flentd 允许您统一日志采集和更好地使用和理解数据;
https://segmentfault.com/img/bVcOKIt" />四大特点:
统一日志层
fluentd 隔离数据源,提供与后台系统统一的日志层;
简单灵活
提供500多个插件,连接大量数据源和输出源,内核简单;
广泛的验证
自 Fluentd 以来,5000 多家数据驱动型公司
最大的客户端通过它从 50,000 多台服务器采集日志
**云原生**
是云原生CNCF的成员项目
https://segmentfault.com/img/bVcOKIA" />4大优势:
统一的 JSON 日志
https://segmentfault.com/img/bVcOKIB" />fluentd尝试使用JSON结构化数据,统一处理日志数据的各个方面,采集、过滤、缓存、输出日志到多个目的地,下游数据处理使用Json更简单,因为它已经有足够的访问结构并保留了足够的灵活性场景;
插件架构
https://segmentfault.com/img/bVcOKIC" />fluntd 有一个灵活的插件系统,允许社区扩展其功能。超过 500 个社区贡献的插件连接了许多数据源和目的地;通过插件,您可以开始更好地利用您的日志
最低资源消耗
https://segmentfault.com/img/bVcOKID" />用c和ruby写的,对系统资源要求很低,40M左右的内存可以处理13k/次/秒,如果需要更紧凑的内存,可以使用Fluent bit,更轻的Fluentd
内核可靠
https://segmentfault.com/img/bVcOKIE" />Fluentd 支持内存和基于文件的缓存,防止内部节点数据丢失;
还支持鲁棒故障并可以配置高可用性模式,超过 2000 家数据驱动的公司在不同的产品中依靠 Fluentd 更好地使用和理解他们的日志数据
使用流利的理由:
简单灵活
10分钟即可在电脑上安装fluentd,立即下载,超过500个插件连接数据源和目的地,插件也易于开发和部署;
开源
基于 Apache2.0 证书的完全开源
可靠和高性能
超过 5,000 家数据驱动型公司的不同产品和服务依靠 fluentd 更好地使用和理解数据。事实上,根据datadog的调查,使用docker运行的技术排在前7位;
一些流利的用户拥有来自数千台机器的实时 采集 数据。每个实例只需要大约 40M 的内存。缩放时,可以节省大量内存。
社区
fluentd 可以改进软件并帮助其他人更好地使用它
大公司使用代言:微软、亚马逊;pptv;
https://segmentfault.com/img/bVcOKIF" />https://segmentfault.com/img/bVcOKIG" />可以与elasticSearch + kibana结合,组成日志套件;
快速搭建EFK集群,采集应用日志,配置性能排名;
https://segmentfault.com/img/bVcOKIH" />弹性搜索
Elasticsearch 是一个分布式的 RESTful 搜索和数据分析引擎。
能够解决正在出现的各种用例。作为 Elastic Stack 的核心,
它集中存储您的数据,并帮助您发现预期和意外。
详细介绍:
木花
Kibana 是一个开源数据分析和可视化平台,是 Elastic Stack 的成员。
旨在与 Elasticsearch 配合使用。您可以使用 Kibana 在 Elasticsearch 索引中搜索数据,
查看,互动。您可以轻松地使用图表、表格和地图以多种方式分析和呈现数据。
Kibana 使大数据易于理解。这很简单,
基于浏览器的界面允许您快速创建和共享动态数据仪表板,以跟踪 Elasticsearch 中的实时数据变化。
详细介绍:
容器化 EFK 实现路径
直接往下拖代码,然后配置上下文、命名空间,就可以安装了;
cd elk-kubernetes
./deploy.sh --watch
下面是deploy.sh的脚本,可以简单看一下:
#!/bin/sh
CDIR=$(cd `dirname "$0"` && pwd)
cd "$CDIR"
print_red() {
printf '%b' "33[91m$133[0mn"
}
print_green() {
printf '%b' "33[92m$133[0mn"
}
render_template() {
eval "echo "$(cat "$1")""
}
KUBECTL_PARAMS="--context=250091890580014312-cc3174dcd4fc14cf781b6fc422120ebd8"
NAMESPACE=${NAMESPACE:-sm}
KUBECTL="kubectl ${KUBECTL_PARAMS} --namespace="${NAMESPACE}""
eval "kubectl ${KUBECTL_PARAMS} create namespace "${NAMESPACE}""
#NODES=$(eval "${KUBECTL} get nodes -l 'kubernetes.io/role!=master' -o go-template="{{range .items}}{{\$name := .metadata.name}}{{\$unschedulable := .spec.unschedulable}}{{range .status.conditions}}{{if eq .reason \"KubeletReady\"}}{{if eq .status \"True\"}}{{if not \$unschedulable}}{{\$name}}{{\"\\n\"}}{{end}}{{end}}{{end}}{{end}}{{end}}"")
NODES=$(eval "${KUBECTL} get nodes -l 'sm.efk=data' -o go-template="{{range .items}}{{\$name := .metadata.name}}{{\$unschedulable := .spec.unschedulable}}{{range .status.conditions}}{{if eq .reason \"KubeletReady\"}}{{if eq .status \"True\"}}{{if not \$unschedulable}}{{\$name}}{{\"\\n\"}}{{end}}{{end}}{{end}}{{end}}{{end}}"")
ES_DATA_REPLICAS=$(echo "$NODES" | wc -l)
if [ "$ES_DATA_REPLICAS" -lt 3 ]; then
print_red "Minimum amount of Elasticsearch data nodes is 3 (in case when you have 1 replica shard), you have ${ES_DATA_REPLICAS} worker nodes"
print_red "Won't deploy more than one Elasticsearch data pod per node exiting..."
exit 1
fi
print_green "Labeling nodes which will serve Elasticsearch data pods"
for node in $NODES; do
eval "${KUBECTL} label node ${node} elasticsearch.data=true --overwrite"
done
for yaml in *.yaml.tmpl; do
render_template "${yaml}" | eval "${KUBECTL} create -f -"
done
for yaml in *.yaml; do
eval "${KUBECTL} create -f "${yaml}""
done
eval "${KUBECTL} create configmap es-config --from-file=es-config --dry-run -o yaml" | eval "${KUBECTL} apply -f -"
eval "${KUBECTL} create configmap fluentd-config --from-file=docker/fluentd/td-agent.conf --dry-run -o yaml" | eval "${KUBECTL} apply -f -"
eval "${KUBECTL} create configmap kibana-config --from-file=kibana.yml --dry-run -o yaml" | eval "${KUBECTL} apply -f -"
eval "${KUBECTL} get pods $@"
简单分解部署流程:
https://segmentfault.com/img/bVcOKIJ" />我的k8s环境还没有搭建成功,后续搭建成功后会给出详细的安装说明。
概括
一句话总结这篇文章:EFK是通过日志代理客户端采集应用日志的常用实现方式。
https://segmentfault.com/img/bVcOKIK" />原创不易,关注有诚意,转发价格更高!转载请注明出处,让我们互相交流,共同进步。欢迎交流。
程序员的信标
转载请注明原文链接:Cloud Native Series 5 EFK for Containerized Logs
云优采集接口(个人用的易云优网采集器是免费的吗)
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2022-03-15 06:07
云优采集接口,现在有免费接口,可以简单接入平台进行云爬虫,接入后就有程序化采集工具,对于内容搬运、采集或者内容筛选,非常有用。
我目前用的是云优网,操作便捷,收费模式灵活。
看到您是在广东的用户,据我所知,用到“优采云”采集器非常方便的一个平台就是北京的云优网站优化部门开发的。收费模式也非常灵活,我们这边的云优网站优化部门就有这个接口,你可以咨询下试用下。如果还不太满意,以后可以找我们支持其他平台试用接口。
某宝可以买到,现在很多类似的,我刚买。
多种软件收费模式各异,建议买个收费的。然后跟业务部门确认下是否支持。采集现在挺火,但是现在的采集器大多没什么意思,什么样的站没有什么内容的。专注于基于api的操作,非采集公司的采集器。用户在选择接口之前,必须明确自己对内容是什么样的要求。否则接口多了,按照业务人员自己的选择去使用,大大降低了自己的使用效率。如果自己定制。没有任何意义。甚至还得自己开发团队。
试了一下dllbank,安卓和ios都可以,没接触过百度的。效果真心不怎么样。
个人用的易云优网
国内最专业的采集器是优采云,也是支持全网,全文,且有些网站还可以分时段日期采集,实时去重。另外优采云没有内置采集器扩展,只能通过扩展去接入采集器。有好多人看到优采云是免费的,就不用优采云了,我认为这种想法是非常愚蠢的,这样会失去许多价值,不支持人工复制粘贴代码不说,网上的代码不一定适合自己站点,如果配置不合理,是很可能有些用户去掉了合理的代码会造成无法正常采集到网站数据,因为有的网站对特殊字符做了处理,也有可能有的站点设置了一些小bug。总之建议支持好一点的采集器,像优采云,易云优网,以上三个站点中都有相应的客服。 查看全部
云优采集接口(个人用的易云优网采集器是免费的吗)
云优采集接口,现在有免费接口,可以简单接入平台进行云爬虫,接入后就有程序化采集工具,对于内容搬运、采集或者内容筛选,非常有用。
我目前用的是云优网,操作便捷,收费模式灵活。
看到您是在广东的用户,据我所知,用到“优采云”采集器非常方便的一个平台就是北京的云优网站优化部门开发的。收费模式也非常灵活,我们这边的云优网站优化部门就有这个接口,你可以咨询下试用下。如果还不太满意,以后可以找我们支持其他平台试用接口。
某宝可以买到,现在很多类似的,我刚买。
多种软件收费模式各异,建议买个收费的。然后跟业务部门确认下是否支持。采集现在挺火,但是现在的采集器大多没什么意思,什么样的站没有什么内容的。专注于基于api的操作,非采集公司的采集器。用户在选择接口之前,必须明确自己对内容是什么样的要求。否则接口多了,按照业务人员自己的选择去使用,大大降低了自己的使用效率。如果自己定制。没有任何意义。甚至还得自己开发团队。
试了一下dllbank,安卓和ios都可以,没接触过百度的。效果真心不怎么样。
个人用的易云优网
国内最专业的采集器是优采云,也是支持全网,全文,且有些网站还可以分时段日期采集,实时去重。另外优采云没有内置采集器扩展,只能通过扩展去接入采集器。有好多人看到优采云是免费的,就不用优采云了,我认为这种想法是非常愚蠢的,这样会失去许多价值,不支持人工复制粘贴代码不说,网上的代码不一定适合自己站点,如果配置不合理,是很可能有些用户去掉了合理的代码会造成无法正常采集到网站数据,因为有的网站对特殊字符做了处理,也有可能有的站点设置了一些小bug。总之建议支持好一点的采集器,像优采云,易云优网,以上三个站点中都有相应的客服。
云优采集接口(中国行政管理学教学研究会副会长)
采集交流 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2022-03-13 00:02
USB全接口视频采集盒子质量稳定,联盛科技现提供产品:视频采集盒子、录像盒子、视频采集卡、视频编码器、视频解码器、视频转码器、视频传输、视频转换产品,优尼森科技产品长期畅销国内外专业和消费类产品市场,在消费类市场和专业用户中享有良好的口碑和商誉。USB全接口视频采集画质稳定。遗传算法是模拟达尔文生物进化论的自然选择和遗传机制的计算模型。它是一种通过模拟自然进化来寻找最优解的方法。您想向朋友推荐博客详细信息页面吗?1 扣除金额。余额不能直接购买和下载,但可以购买VIP、C币套餐、付费栏目和课程。谢谢,我们会尽快审核!
通过具体的例子,详细说明了如何扩展通用 Mapper 原有的功能以满足您的特定需求。相信本教程的学习,在通用Mapper的帮助下,足以满足大部分应用场景的开发需求。本视频讲授了RBAC权限模型的设计及其在项目中的应用。使用 Maven 进行项目构建。页面设计采用响应式前端框架BootStrap。基本业务功能使用异步数据操作来提升用户体验。它是一个广泛使用的版本控制软件。作为CVS的接班人,在很多方面都具有鲜明的特色,提供了更好的操作体验,解决了实际企业开发过程中的问题如:数据备份、代码恢复等问题,
USB全接口影音采集盒子画质稳定,享受高品质观影的VIP体验。跳过广告看大片立马存手机看下载视频:不会说话就别说话!
n 闫杰、太平洋建设集团原董事长;不失精神的斗士,方法胜于困难;一个无所畏惧的战士,他的脚不能伸手,只能用他的眼睛;北京市委党校、北京行政学院公共管理系主任,中国行政管理教研会副会长,中国政治学会政策学会常务理事,全国绩效管理研究会常务理事,常务理事北京市行政管理学会理事、副秘书长,北京市领导学会副会长兼秘书长。 查看全部
云优采集接口(中国行政管理学教学研究会副会长)
USB全接口视频采集盒子质量稳定,联盛科技现提供产品:视频采集盒子、录像盒子、视频采集卡、视频编码器、视频解码器、视频转码器、视频传输、视频转换产品,优尼森科技产品长期畅销国内外专业和消费类产品市场,在消费类市场和专业用户中享有良好的口碑和商誉。USB全接口视频采集画质稳定。遗传算法是模拟达尔文生物进化论的自然选择和遗传机制的计算模型。它是一种通过模拟自然进化来寻找最优解的方法。您想向朋友推荐博客详细信息页面吗?1 扣除金额。余额不能直接购买和下载,但可以购买VIP、C币套餐、付费栏目和课程。谢谢,我们会尽快审核!
通过具体的例子,详细说明了如何扩展通用 Mapper 原有的功能以满足您的特定需求。相信本教程的学习,在通用Mapper的帮助下,足以满足大部分应用场景的开发需求。本视频讲授了RBAC权限模型的设计及其在项目中的应用。使用 Maven 进行项目构建。页面设计采用响应式前端框架BootStrap。基本业务功能使用异步数据操作来提升用户体验。它是一个广泛使用的版本控制软件。作为CVS的接班人,在很多方面都具有鲜明的特色,提供了更好的操作体验,解决了实际企业开发过程中的问题如:数据备份、代码恢复等问题,
USB全接口影音采集盒子画质稳定,享受高品质观影的VIP体验。跳过广告看大片立马存手机看下载视频:不会说话就别说话!
n 闫杰、太平洋建设集团原董事长;不失精神的斗士,方法胜于困难;一个无所畏惧的战士,他的脚不能伸手,只能用他的眼睛;北京市委党校、北京行政学院公共管理系主任,中国行政管理教研会副会长,中国政治学会政策学会常务理事,全国绩效管理研究会常务理事,常务理事北京市行政管理学会理事、副秘书长,北京市领导学会副会长兼秘书长。
云优采集接口(云优统计接口是骗子,一年五百我在国家食品药品监督管理局官网可以查询)
采集交流 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-03-08 02:01
云优采集接口,云优统计接口,企业资料接口,工商查询接口,国家食品药品监督管理局网站接口,以及云优仓,可以看看这家网站,其实市面上很多功能几十块钱就能买到。
这种接口是要收费的,几百到几千,根据资质证书的多少,展示的多少来收费的。你可以多比较下几家。
至少九十。小的都是骗子。这行市场很乱。
市场上接口都是几十一个,大的只要两三百就能做,再小就要500一个了,云优统计接口这个价格已经很便宜了,而且还要保真,所以推荐云优统计接口,
云优都是要收费的,一般两百-五百之间,大的都要几千,
云优就是个骗子,我合作过几个都是后者合作下来非常后悔。
你要办理的是什么接口
你要办理的是什么接口?
云优是骗子,我跟他们合作过,不办他们的接口可以全部推掉。
云优并不是免费,靠代理赚取微利,个人觉得你要多观察一下云优官网或官方论坛,因为比较官方的,比较权威,
云优就是骗子,一年五百我在国家食品药品监督管理局官网可以查询,完全没问题。云优就是骗子,我在山西有3个客户,合作一年耗损,只多了几百块钱,就把价格报的比较高,我很纳闷?(质保两年),看来我的接口是最差的,质保期过了我也没有说服人家,是真差吗?可是你的都是回转的pv和页面跳转全部来自icp那些,这就是问题。
质保期他们官网上也都写了说是3年,他们两个月之内合同都没到。也就是说最保险起见,我接的只能是回转接口,所以我合作云优的客户基本不能拿出回转接口,没有超时发给,要发来的话一律是还有x个月保修期这些条款。除非超过保修期,那才是我真正接受的。又要抢客户,又不保险就是最大的问题,这才是他们官网上写的责任,个人觉得是跟有关部门合作,所以至今上我还没有看到有关部门领导以及执法单位为云优出具罚款的。我在国家食品药品监督管理局官网查询不到云优的线索,不知道是不是公司要求这么做?。 查看全部
云优采集接口(云优统计接口是骗子,一年五百我在国家食品药品监督管理局官网可以查询)
云优采集接口,云优统计接口,企业资料接口,工商查询接口,国家食品药品监督管理局网站接口,以及云优仓,可以看看这家网站,其实市面上很多功能几十块钱就能买到。
这种接口是要收费的,几百到几千,根据资质证书的多少,展示的多少来收费的。你可以多比较下几家。
至少九十。小的都是骗子。这行市场很乱。
市场上接口都是几十一个,大的只要两三百就能做,再小就要500一个了,云优统计接口这个价格已经很便宜了,而且还要保真,所以推荐云优统计接口,
云优都是要收费的,一般两百-五百之间,大的都要几千,
云优就是个骗子,我合作过几个都是后者合作下来非常后悔。
你要办理的是什么接口
你要办理的是什么接口?
云优是骗子,我跟他们合作过,不办他们的接口可以全部推掉。
云优并不是免费,靠代理赚取微利,个人觉得你要多观察一下云优官网或官方论坛,因为比较官方的,比较权威,
云优就是骗子,一年五百我在国家食品药品监督管理局官网可以查询,完全没问题。云优就是骗子,我在山西有3个客户,合作一年耗损,只多了几百块钱,就把价格报的比较高,我很纳闷?(质保两年),看来我的接口是最差的,质保期过了我也没有说服人家,是真差吗?可是你的都是回转的pv和页面跳转全部来自icp那些,这就是问题。
质保期他们官网上也都写了说是3年,他们两个月之内合同都没到。也就是说最保险起见,我接的只能是回转接口,所以我合作云优的客户基本不能拿出回转接口,没有超时发给,要发来的话一律是还有x个月保修期这些条款。除非超过保修期,那才是我真正接受的。又要抢客户,又不保险就是最大的问题,这才是他们官网上写的责任,个人觉得是跟有关部门合作,所以至今上我还没有看到有关部门领导以及执法单位为云优出具罚款的。我在国家食品药品监督管理局官网查询不到云优的线索,不知道是不是公司要求这么做?。
云优采集接口( 网闸全数据库安全隔离网闸,实现网络上任意计算机的数据交换数据库)
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2022-03-05 09:02
网闸全数据库安全隔离网闸,实现网络上任意计算机的数据交换数据库)
在线QQ客服:1922638
专业的SQL Server、MySQL数据库同步软件
本发明涉及跨网守数据同步技术领域,具体提供一种基于云消息服务平台实现跨网守Mysql数据库同步的装置及方法。
背景技术:
在公司或企业环境中,出于安全考虑,内网和外网需要“物理分离”,但内网和外网也需要交换数据(如Mysql数据库同步),所以Gatekeeper是介绍了。网守的全称是安全隔离网守。网守的隔离定义分为三个级别:
物理隔离:模拟人工交换的过程,必须在内外网的节点机器上进行数据交换,不能实现网络上任何一台计算机的数据交换。这种方法非常安全。
网络隔离:在简单交换的基础上,文件传输协议的数据包交换实现了网络上任意信息点的数据交换,降低了安全性。
协议隔离:对于其他应用协议代理,如Http,实现应用数据的直接交换,在方便交换的同时大大降低了安全性。
物理隔离是指仅具有文件级交换的网守。这种情况下,如果内网用户需要访问外网的Mysql数据库,协议被阻塞,即不能直接访问外网的Mysql数据库。因此,出现了新的要求。在保证安全的情况下,通过网守的物理隔离将外网Mysql数据库同步到内网Mysql数据库,使内网用户直接访问内网Mysql数据库相当于可以访问外网的Mysql数据库。外网Mysql数据库的数据文件是不断变化的。直接同步大量大文件是不现实的,
云消息服务平台(简称cmsP)是一种消息中间件,它可以利用TCP/IP协议将一个网络消息队列中的消息实时有序地传输到另一个网络消息队列,提供一种方法用于在不同网络之间实时有效地交换数据。cmsP有一个重要的特点,严格先进先出,即消息的生产、存储、传输和消费都是严格有序的。在有网守隔离的内网环境中,在保证隔离安全的情况下(只允许文件交换,不允许协议通过等),cmsP不能正常传输数据,比如简单的从消息队列中发送消息. 取出生成的文件,通过网守进行交换,破坏了消息的顺序,
技术实施要素:
本发明的技术任务是针对上述存在的问题,提供一种基于云消息服务平台实现Mysql数据库跨门同步的装置,能够解决Mysql数据库跨门同步问题。 ,同时保证Mysql数据库的及时性和效率。.
本发明进一步的技术任务是提供一种基于云消息服务平台实现跨网守Mysql数据库同步的方法。
为实现上述目的,本发明提供以下技术方案:
一种基于云消息服务平台实现跨网守Mysql数据库同步的装置,包括Mysql日志采集模块、消息队列一、转换模块一、文件名带编码文件存储模块一、Gatekeeper模块,消息队列二、转换模块二、文件名带编码文件存储模块II和Mysql数据存储模块,Mysql日志采集模块,消息队列一、转换模块一、外网设置带编码文件存储模块1的文件名,消息队列二、转换模块二、带编码文件存储模块2的文件名和Mysql数据入库模块位于 Intranet 中。消息队列分别连接Mysql日志采集模块和转换模块。转换模块连接到文件名被编码的文件存储模块。文件名已编码。第一存储模块通过网守模块与文件名带编码的第二文件存储模块相连,第二文件存储模块与编码文件名相连,第二转换模块与第二消息队列相连。转换模块二、Mysql数据输入。库模块是单独链接的。第二个消息队列连接到转换模块二、Mysql数据输入。库模块是单独链接的。第二个消息队列连接到转换模块二、Mysql数据输入。库模块是单独链接的。
优选地,基于云消息服务平台实现跨网守Mysql数据库同步的装置还包括Mysql源数据库和Mysql目的数据库,Mysql源数据库连接Mysql log采集模块, Mysql 目标数据库连接到 Mysql 数据条目。库模块是链接的。
优选地,Mysql日志采集模块用于Mysql源数据库采集的全量数据和增量变更日志,Mysql数据存储模块将全量数据写入Mysql目的数据库,Mysql log采集 @采集 模块将增量更改日志拆分成64KB的消息块,并将增量更改日志同步到Mysql目标数据库。
优选地,Mysql log采集模块将全量数据和增量变更日志写入消息队列1,转换模块1有序地从消息队列1中读取消息,生成文件名经过编码的文件,将其存储在第一文件名编码文件存储模块中,网守模块将第一文件名编码文件存储模块中的编码文件交换到第二文件名编码文件存储模块中。
优选地,转换模块2将文件存储模块2中的编码文件名的文件写入到消息队列2中。
基于云消息服务平台实现跨网守Mysql数据库同步的方法,Mysql日志采集模块采集来自Mysql源数据库的Mysql全量数据和增量变更日志,并将完整的数据和对日志的增量更改。日志先写入消息队列1,再通过网守模块写入消息队列2。Mysql数据存储模块从消息队列2中获取全量数据和增量变更日志,写入Mysql目的数据库。
全量数据采集是通过Mysql数据库接口获取部分选中表的所有记录,增量变更日志采集是获取Mysql源数据binlog日志。
优选地,Mysql日志采集模块用于从Mysql源数据库采集获取全量数据和增量变更日志,Mysql数据存储模块将全量数据写入Mysql目的数据库, Mysql log采集模块将增量更改日志拆分成64KB的消息块,并将增量更改日志同步到Mysql目标数据库。这样,Mysql 目的数据库与Mysql 源数据库实时同步,Mysql 源数据库的内容变化(包括增删)会及时同步到Mysql 目的数据库。
其中,小于64KB取剩余值。
优选地,将全量数据和增量变更日志写入消息队列1,通过转换模块1有序地读出消息,生成文件名经过编码的文件并存储在具有编码文件名的文件存储模块1, 网守模块使用文件交换功能将具有编码文件名的文件交换给具有编码文件名的文件存储模块2。转换模块2有序读取文件名编码后的文件,写入消息队列2中间。
第一个转换模块生成带编码文件名的文件,既保证了文件生成的实时性,又考虑了带编码文件名的文件的大小,保证带编码的文件文件名可以尽可能高效、及时地交换到网守模块。转换模块二。网守模块的文件交换是无序的,转换模块2的一个关键点就是有序的读出文件名和代码的文件内容,以消息的形式写入到消息队列2中.
优选地,转换模块1有序地从消息队列1中读取消息,并以相同的顺序将它们以编码后的文件名写入文件存储模块1中。编码文件的文件名具有消息的开头。序号和终止序号。
在本发明中,文件名的一个例子是cmspXXXXXX_YYYYYY.msg,其中XXXXXX是起始序号,YYYYYY是结束序号。
需要配置转换模块2第一次运行时开始读取的报文序号。每次读取文件时,必须从最后一个终止序列号的下一个开始读取。例如,网守模块不交换满足条件的文件。过来,那么转换模块2一直在等待,直到条件满足。
优选地,转换模块2有序地读出文件名编码后的文件内容,并以消息的形式写入消息队列2。
与现有技术相比,本发明基于云消息服务平台实现跨网守Mysql数据库同步的方法具有以下突出的有益效果: 基于云消息服务实现跨网守Mysql数据库同步的方法平台不仅解决了Mysql数据库跨网守同步的问题,而且保证了Mysql数据库同步的及时性和效率,具有很好的推广和应用价值。
图纸说明
无花果。附图说明图1为本发明基于云消息服务平台实现Mysql数据库跨网守同步装置的拓扑结构图。
详细说明
下面结合附图和实施例对本发明基于云消息服务平台实现跨网守Mysql数据库同步的装置和方法做进一步的详细说明。
例子
如图1所示,本发明基于云消息服务平台实现跨网守Mysql数据库同步的装置包括Mysql源数据库、Mysql日志采集模块、消息队列一、转换模块一、文件名编码文件存储模块一、Gatekeeper模块,消息队列二、转换模块二、文件名编码文件存储模块二、Mysql数据存储模块和 Mysql 目的数据库。Mysql源数据库,Mysql日志采集模块,消息队列一、转换模块一、外网设置编码文件存储模块的文件名,消息队列二、转换模块< @二、带编码文件存储模块的文件名二、
Mysql 源数据库连接到 Mysql log采集 模块。消息队列1分别连接Mysql日志采集模块和转换模块1,转换模块1连接文件名编码的文件存储模块1。文件名编码的文件存储模块1通过网守模块与文件名编码的第二文件存储模块相连,文件名编码的第二文件存储模块与转换模块2相连,消息队列2 连接转换模块二、Mysql 数据仓库模块单独连接,Mysql 目标数据库连接Mysql 数据仓库模块。
Mysql log采集 模块用于记录来自Mysql 源数据库的采集 完整数据和增量更改。全量数据采集是通过Mysql数据库接口获取部分选中表的所有记录,增量变更日志采集是获取Mysql源数据binlog日志。Mysql 数据仓库模块将增量变更日志拆分成 64KB 的消息块,剩余的值用于小于 64KB 的消息块。Mysql数据存储模块将全量数据和增量变更日志写入消息队列。转换模块1有序地从消息队列1中读取消息,生成文件名编码后的文件,并存储在文件名编码后的文件存储模块1中。将该名称编码的文件交换到该文件名编码的文件存储模块2。转换模块2将文件存储模块2中带有编码文件名的文件写入到消息队列2中。消息队列2中的文件最终通过Mysql存储模块写入Mysql目的数据库。
第一个转换模块生成带编码文件名的文件,既保证了文件生成的实时性,又考虑了带编码文件名的文件的大小,保证带编码的文件文件名可以尽可能高效、及时地交换到网守模块。转换模块二。网守模块的文件交换是无序的,转换模块2的一个关键点就是有序的读出文件名和代码的文件内容,以消息的形式写入到消息队列2中.
在本发明的基于云消息服务平台实现跨网守Mysql数据库同步的方法中,Mysql日志采集模块采集来自Mysql源数据库的Mysql全数据和增量变更日志,并转换完整数据和增量更改日志。增量更改日志被写入消息队列一。通过转换模块1,有序地从消息队列1中读取消息,生成文件名编码后的文件,并对文件名编码后的文件进行排序写入。该名称具有消息的起始序列号和结束序列号。例如,在本发明中,样本文件名为cmspXXXXXX_YYYYYY.msg,其中XXXXXX为起始序号,YYYYYY 是结束序列号。第一个转换模块生成带编码文件名的文件,既保证了文件生成的实时性,又考虑了带编码文件名的文件的大小,保证带编码的文件文件名可以尽可能高效、及时地交换到网守模块。转换模块二。网守模块利用文件交换功能,将具有文件名的编码文件交换给具有编码文件名的文件存储模块2。网守模块的文件交换紊乱。转换模块2的一个重点是文件的有序存储。具有编码文件名的文件以消息的形式被读取并写入消息队列2。
以上所述仅为本发明的较佳具体实施例而已,本领域普通技术人员在本发明技术方案的范围内所作的通常改动和替换,均应收录在本发明的保护范围之内。 . 查看全部
云优采集接口(
网闸全数据库安全隔离网闸,实现网络上任意计算机的数据交换数据库)
在线QQ客服:1922638
专业的SQL Server、MySQL数据库同步软件
本发明涉及跨网守数据同步技术领域,具体提供一种基于云消息服务平台实现跨网守Mysql数据库同步的装置及方法。
背景技术:
在公司或企业环境中,出于安全考虑,内网和外网需要“物理分离”,但内网和外网也需要交换数据(如Mysql数据库同步),所以Gatekeeper是介绍了。网守的全称是安全隔离网守。网守的隔离定义分为三个级别:
物理隔离:模拟人工交换的过程,必须在内外网的节点机器上进行数据交换,不能实现网络上任何一台计算机的数据交换。这种方法非常安全。
网络隔离:在简单交换的基础上,文件传输协议的数据包交换实现了网络上任意信息点的数据交换,降低了安全性。
协议隔离:对于其他应用协议代理,如Http,实现应用数据的直接交换,在方便交换的同时大大降低了安全性。
物理隔离是指仅具有文件级交换的网守。这种情况下,如果内网用户需要访问外网的Mysql数据库,协议被阻塞,即不能直接访问外网的Mysql数据库。因此,出现了新的要求。在保证安全的情况下,通过网守的物理隔离将外网Mysql数据库同步到内网Mysql数据库,使内网用户直接访问内网Mysql数据库相当于可以访问外网的Mysql数据库。外网Mysql数据库的数据文件是不断变化的。直接同步大量大文件是不现实的,
云消息服务平台(简称cmsP)是一种消息中间件,它可以利用TCP/IP协议将一个网络消息队列中的消息实时有序地传输到另一个网络消息队列,提供一种方法用于在不同网络之间实时有效地交换数据。cmsP有一个重要的特点,严格先进先出,即消息的生产、存储、传输和消费都是严格有序的。在有网守隔离的内网环境中,在保证隔离安全的情况下(只允许文件交换,不允许协议通过等),cmsP不能正常传输数据,比如简单的从消息队列中发送消息. 取出生成的文件,通过网守进行交换,破坏了消息的顺序,
技术实施要素:
本发明的技术任务是针对上述存在的问题,提供一种基于云消息服务平台实现Mysql数据库跨门同步的装置,能够解决Mysql数据库跨门同步问题。 ,同时保证Mysql数据库的及时性和效率。.
本发明进一步的技术任务是提供一种基于云消息服务平台实现跨网守Mysql数据库同步的方法。
为实现上述目的,本发明提供以下技术方案:
一种基于云消息服务平台实现跨网守Mysql数据库同步的装置,包括Mysql日志采集模块、消息队列一、转换模块一、文件名带编码文件存储模块一、Gatekeeper模块,消息队列二、转换模块二、文件名带编码文件存储模块II和Mysql数据存储模块,Mysql日志采集模块,消息队列一、转换模块一、外网设置带编码文件存储模块1的文件名,消息队列二、转换模块二、带编码文件存储模块2的文件名和Mysql数据入库模块位于 Intranet 中。消息队列分别连接Mysql日志采集模块和转换模块。转换模块连接到文件名被编码的文件存储模块。文件名已编码。第一存储模块通过网守模块与文件名带编码的第二文件存储模块相连,第二文件存储模块与编码文件名相连,第二转换模块与第二消息队列相连。转换模块二、Mysql数据输入。库模块是单独链接的。第二个消息队列连接到转换模块二、Mysql数据输入。库模块是单独链接的。第二个消息队列连接到转换模块二、Mysql数据输入。库模块是单独链接的。
优选地,基于云消息服务平台实现跨网守Mysql数据库同步的装置还包括Mysql源数据库和Mysql目的数据库,Mysql源数据库连接Mysql log采集模块, Mysql 目标数据库连接到 Mysql 数据条目。库模块是链接的。
优选地,Mysql日志采集模块用于Mysql源数据库采集的全量数据和增量变更日志,Mysql数据存储模块将全量数据写入Mysql目的数据库,Mysql log采集 @采集 模块将增量更改日志拆分成64KB的消息块,并将增量更改日志同步到Mysql目标数据库。
优选地,Mysql log采集模块将全量数据和增量变更日志写入消息队列1,转换模块1有序地从消息队列1中读取消息,生成文件名经过编码的文件,将其存储在第一文件名编码文件存储模块中,网守模块将第一文件名编码文件存储模块中的编码文件交换到第二文件名编码文件存储模块中。
优选地,转换模块2将文件存储模块2中的编码文件名的文件写入到消息队列2中。
基于云消息服务平台实现跨网守Mysql数据库同步的方法,Mysql日志采集模块采集来自Mysql源数据库的Mysql全量数据和增量变更日志,并将完整的数据和对日志的增量更改。日志先写入消息队列1,再通过网守模块写入消息队列2。Mysql数据存储模块从消息队列2中获取全量数据和增量变更日志,写入Mysql目的数据库。
全量数据采集是通过Mysql数据库接口获取部分选中表的所有记录,增量变更日志采集是获取Mysql源数据binlog日志。
优选地,Mysql日志采集模块用于从Mysql源数据库采集获取全量数据和增量变更日志,Mysql数据存储模块将全量数据写入Mysql目的数据库, Mysql log采集模块将增量更改日志拆分成64KB的消息块,并将增量更改日志同步到Mysql目标数据库。这样,Mysql 目的数据库与Mysql 源数据库实时同步,Mysql 源数据库的内容变化(包括增删)会及时同步到Mysql 目的数据库。
其中,小于64KB取剩余值。
优选地,将全量数据和增量变更日志写入消息队列1,通过转换模块1有序地读出消息,生成文件名经过编码的文件并存储在具有编码文件名的文件存储模块1, 网守模块使用文件交换功能将具有编码文件名的文件交换给具有编码文件名的文件存储模块2。转换模块2有序读取文件名编码后的文件,写入消息队列2中间。
第一个转换模块生成带编码文件名的文件,既保证了文件生成的实时性,又考虑了带编码文件名的文件的大小,保证带编码的文件文件名可以尽可能高效、及时地交换到网守模块。转换模块二。网守模块的文件交换是无序的,转换模块2的一个关键点就是有序的读出文件名和代码的文件内容,以消息的形式写入到消息队列2中.
优选地,转换模块1有序地从消息队列1中读取消息,并以相同的顺序将它们以编码后的文件名写入文件存储模块1中。编码文件的文件名具有消息的开头。序号和终止序号。
在本发明中,文件名的一个例子是cmspXXXXXX_YYYYYY.msg,其中XXXXXX是起始序号,YYYYYY是结束序号。
需要配置转换模块2第一次运行时开始读取的报文序号。每次读取文件时,必须从最后一个终止序列号的下一个开始读取。例如,网守模块不交换满足条件的文件。过来,那么转换模块2一直在等待,直到条件满足。
优选地,转换模块2有序地读出文件名编码后的文件内容,并以消息的形式写入消息队列2。
与现有技术相比,本发明基于云消息服务平台实现跨网守Mysql数据库同步的方法具有以下突出的有益效果: 基于云消息服务实现跨网守Mysql数据库同步的方法平台不仅解决了Mysql数据库跨网守同步的问题,而且保证了Mysql数据库同步的及时性和效率,具有很好的推广和应用价值。
图纸说明
无花果。附图说明图1为本发明基于云消息服务平台实现Mysql数据库跨网守同步装置的拓扑结构图。
详细说明
下面结合附图和实施例对本发明基于云消息服务平台实现跨网守Mysql数据库同步的装置和方法做进一步的详细说明。
例子
如图1所示,本发明基于云消息服务平台实现跨网守Mysql数据库同步的装置包括Mysql源数据库、Mysql日志采集模块、消息队列一、转换模块一、文件名编码文件存储模块一、Gatekeeper模块,消息队列二、转换模块二、文件名编码文件存储模块二、Mysql数据存储模块和 Mysql 目的数据库。Mysql源数据库,Mysql日志采集模块,消息队列一、转换模块一、外网设置编码文件存储模块的文件名,消息队列二、转换模块< @二、带编码文件存储模块的文件名二、
Mysql 源数据库连接到 Mysql log采集 模块。消息队列1分别连接Mysql日志采集模块和转换模块1,转换模块1连接文件名编码的文件存储模块1。文件名编码的文件存储模块1通过网守模块与文件名编码的第二文件存储模块相连,文件名编码的第二文件存储模块与转换模块2相连,消息队列2 连接转换模块二、Mysql 数据仓库模块单独连接,Mysql 目标数据库连接Mysql 数据仓库模块。
Mysql log采集 模块用于记录来自Mysql 源数据库的采集 完整数据和增量更改。全量数据采集是通过Mysql数据库接口获取部分选中表的所有记录,增量变更日志采集是获取Mysql源数据binlog日志。Mysql 数据仓库模块将增量变更日志拆分成 64KB 的消息块,剩余的值用于小于 64KB 的消息块。Mysql数据存储模块将全量数据和增量变更日志写入消息队列。转换模块1有序地从消息队列1中读取消息,生成文件名编码后的文件,并存储在文件名编码后的文件存储模块1中。将该名称编码的文件交换到该文件名编码的文件存储模块2。转换模块2将文件存储模块2中带有编码文件名的文件写入到消息队列2中。消息队列2中的文件最终通过Mysql存储模块写入Mysql目的数据库。
第一个转换模块生成带编码文件名的文件,既保证了文件生成的实时性,又考虑了带编码文件名的文件的大小,保证带编码的文件文件名可以尽可能高效、及时地交换到网守模块。转换模块二。网守模块的文件交换是无序的,转换模块2的一个关键点就是有序的读出文件名和代码的文件内容,以消息的形式写入到消息队列2中.
在本发明的基于云消息服务平台实现跨网守Mysql数据库同步的方法中,Mysql日志采集模块采集来自Mysql源数据库的Mysql全数据和增量变更日志,并转换完整数据和增量更改日志。增量更改日志被写入消息队列一。通过转换模块1,有序地从消息队列1中读取消息,生成文件名编码后的文件,并对文件名编码后的文件进行排序写入。该名称具有消息的起始序列号和结束序列号。例如,在本发明中,样本文件名为cmspXXXXXX_YYYYYY.msg,其中XXXXXX为起始序号,YYYYYY 是结束序列号。第一个转换模块生成带编码文件名的文件,既保证了文件生成的实时性,又考虑了带编码文件名的文件的大小,保证带编码的文件文件名可以尽可能高效、及时地交换到网守模块。转换模块二。网守模块利用文件交换功能,将具有文件名的编码文件交换给具有编码文件名的文件存储模块2。网守模块的文件交换紊乱。转换模块2的一个重点是文件的有序存储。具有编码文件名的文件以消息的形式被读取并写入消息队列2。
以上所述仅为本发明的较佳具体实施例而已,本领域普通技术人员在本发明技术方案的范围内所作的通常改动和替换,均应收录在本发明的保护范围之内。 .
云优采集接口(云优采集接口——增加有效数据为目的(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-03-04 12:01
云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口一切以增加有效数据为目的。更多相关资源在国内外知名postgresql数据库厂商的云postgresql部署云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口。
googlebi建议用,行业资源多。数据分析、数据可视化大都是用googlebi。
盛易通easyaidba对接了erp系统,之前工作中常用,可以直接进行数据交互,尤其在交互性好的基础上可以提供基于权限的api,工作效率倍增。详情咨询盛易通哦。
现在线上最火的还是各种公司用tableau直接采集的,最近在学tableau,已经各个erp系统使用了,包括阿里金蝶用友用友万向用友甲骨文等等等等,特别是用友金蝶把tableau也整合在了系统里面,包括erp和信息部门系统,当然也有很多单纯的只采集的网站那些,今天遇到一个坑,就是erp系统里面的资源不能直接采集的。
有一个云数据采集平台,阿里云alispylab,感觉还不错,上手容易,有图有公式有视频,文本。以前经常使用postgres,php,tableau,而后来发现postgres/tableau和kpivid无法满足快速、稳定、各种格式支持好的情况下,本地再开发各种子系统,觉得坑比较多,或者工作不稳定,就渐渐放弃了。所以后来自己做了一个在线的。 查看全部
云优采集接口(云优采集接口——增加有效数据为目的(组图))
云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口一切以增加有效数据为目的。更多相关资源在国内外知名postgresql数据库厂商的云postgresql部署云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口云优采集接口。
googlebi建议用,行业资源多。数据分析、数据可视化大都是用googlebi。
盛易通easyaidba对接了erp系统,之前工作中常用,可以直接进行数据交互,尤其在交互性好的基础上可以提供基于权限的api,工作效率倍增。详情咨询盛易通哦。
现在线上最火的还是各种公司用tableau直接采集的,最近在学tableau,已经各个erp系统使用了,包括阿里金蝶用友用友万向用友甲骨文等等等等,特别是用友金蝶把tableau也整合在了系统里面,包括erp和信息部门系统,当然也有很多单纯的只采集的网站那些,今天遇到一个坑,就是erp系统里面的资源不能直接采集的。
有一个云数据采集平台,阿里云alispylab,感觉还不错,上手容易,有图有公式有视频,文本。以前经常使用postgres,php,tableau,而后来发现postgres/tableau和kpivid无法满足快速、稳定、各种格式支持好的情况下,本地再开发各种子系统,觉得坑比较多,或者工作不稳定,就渐渐放弃了。所以后来自己做了一个在线的。
云优采集接口(顶尖时代推出的互联网大数据“一键采集”云服务 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2022-02-26 19:05
)
Top Times推出的互联网大数据“一键式采集”云服务是针对互联网进行网页信息采集处理、加工、分类的云服务。
云采集平台采用的核心技术是分布式网络爬虫系统。分布式爬虫系统采用主从架构。即有一个主节点控制所有从节点执行爬取任务,而这个主节点负责分配URL,保证集群中所有节点的负载均衡。网页采集爬虫系统自动提取网页属性信息的非结构化信息采集进行结构化处理、字段提取(包括站点、出处、日期、标题、内容,包括图片等) .
系统结构
Top Cloud采集一般可以分为四层(见上):Internet(数据源层)、采集层、信息处理层、分析层和服务接口。
它由互联网上的各种数据和政府/企业内部的各种数据组成。互联网数据包括重大新闻网站、门户网站、各种论坛、各种博客、各种微博,微信上的所有信息由新闻、新闻评论、论坛帖子、博客和播客组成。
“顶云采集”系统全面及时采集互联网上的各类信息,全文搜索引擎实现信息的智能分析和处理,包括内容提取(标题, text, source, date, URL) 信息分类,实体抽取(人名,地名,机构),支持文本语义分析,语义搜索,关键词分析,词频分析,摘要分析,相关文章分析、热点分析等
cloud采集平台支持基于http请求的REST Ful风格API接口,可以JSON格式向各种应用系统提供接口数据。可以通过接口定义所需数据的周期、类型、数量等。通过接口数据可以提供给信息资源库、cms素材库、情报系统、舆论系统等应用。
采集范围
服务特色
查看全部
云优采集接口(顶尖时代推出的互联网大数据“一键采集”云服务
)
Top Times推出的互联网大数据“一键式采集”云服务是针对互联网进行网页信息采集处理、加工、分类的云服务。
云采集平台采用的核心技术是分布式网络爬虫系统。分布式爬虫系统采用主从架构。即有一个主节点控制所有从节点执行爬取任务,而这个主节点负责分配URL,保证集群中所有节点的负载均衡。网页采集爬虫系统自动提取网页属性信息的非结构化信息采集进行结构化处理、字段提取(包括站点、出处、日期、标题、内容,包括图片等) .
系统结构
Top Cloud采集一般可以分为四层(见上):Internet(数据源层)、采集层、信息处理层、分析层和服务接口。
它由互联网上的各种数据和政府/企业内部的各种数据组成。互联网数据包括重大新闻网站、门户网站、各种论坛、各种博客、各种微博,微信上的所有信息由新闻、新闻评论、论坛帖子、博客和播客组成。
“顶云采集”系统全面及时采集互联网上的各类信息,全文搜索引擎实现信息的智能分析和处理,包括内容提取(标题, text, source, date, URL) 信息分类,实体抽取(人名,地名,机构),支持文本语义分析,语义搜索,关键词分析,词频分析,摘要分析,相关文章分析、热点分析等
cloud采集平台支持基于http请求的REST Ful风格API接口,可以JSON格式向各种应用系统提供接口数据。可以通过接口定义所需数据的周期、类型、数量等。通过接口数据可以提供给信息资源库、cms素材库、情报系统、舆论系统等应用。
采集范围
服务特色
云优采集接口(云优采集接口推荐云优优选平台,免费提供免费接口)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-02-25 10:02
云优采集接口或者云优网接口。可以根据你的行业特点筛选你需要的报价,
楼上用的什么云优网接口,
可以用云优比平台的接口:云优比-云优网接口
推荐云优优选平台,免费提供免费接口服务,
使用的云优采集接口最快是一天可以做到千篇一律价格在10-15分钟或更低的样子,
云优优选平台,采集价格最低,保证快速!!!其他的接口都存在于行业内,由于并没有自己的内容标签,
云优优选接口,只要是云优优选注册的用户,无需买会员就可以提供接口,所有接口标准价格可供挑选,也可以根据自己的需求任意定制,整体行业标准,
云优优选平台,接口定制价格,低至5-10分钟,
传统的云优库平台,接口是根据你公司的行业去选择接口(但是成本并不能降低),大部分供应商的接口也是只是提供了一个报价单,还需要自己过筛选才能有较多的选择。另外,供应商已经是根据你公司的行业来对接你所需要的接口。所以,出来的接口都是按照标准价格来定价的。这样的结果, 查看全部
云优采集接口(云优采集接口推荐云优优选平台,免费提供免费接口)
云优采集接口或者云优网接口。可以根据你的行业特点筛选你需要的报价,
楼上用的什么云优网接口,
可以用云优比平台的接口:云优比-云优网接口
推荐云优优选平台,免费提供免费接口服务,
使用的云优采集接口最快是一天可以做到千篇一律价格在10-15分钟或更低的样子,
云优优选平台,采集价格最低,保证快速!!!其他的接口都存在于行业内,由于并没有自己的内容标签,
云优优选接口,只要是云优优选注册的用户,无需买会员就可以提供接口,所有接口标准价格可供挑选,也可以根据自己的需求任意定制,整体行业标准,
云优优选平台,接口定制价格,低至5-10分钟,
传统的云优库平台,接口是根据你公司的行业去选择接口(但是成本并不能降低),大部分供应商的接口也是只是提供了一个报价单,还需要自己过筛选才能有较多的选择。另外,供应商已经是根据你公司的行业来对接你所需要的接口。所以,出来的接口都是按照标准价格来定价的。这样的结果,
云优采集接口(云优采集接口具体需要哪些工作?就告诉你)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-02-23 02:02
云优采集接口今天带大家了解一下,云优采集接口功能有哪些?云优采集接口,主要是免费发布一些产品供大家采集和查询的,希望各位工友看完文章能够合理利用自己闲置资源,为我们的下一步寻找合适的产品提供便利。云优采集接口中可以采集uk,uk是全美最大的制衣制鞋协会之一,该协会采集的优质产品的质量及品质可靠,质量更有保障,价格也相对比较低廉,去年有34万件服装在云优采集过程中被协会搜到并发布出来,平均0.74美元一件,折合人民币只要不到两块钱,可谓物美价廉。
云优采集接口实施、体系化规划、流程再造、活动催化,相当可靠,云优采集接口,接入有保障。当然如果遇到了产品供不应求的时候,云优采集接口还会通过托管服务器,帮你缩短发布周期,提高采集效率。那么实施云优采集接口具体需要哪些工作呢?接下来小优就给大家详细介绍一下:1.首先是获取需要采集的产品链接这个时候可以去云优采集平台购买服务器,通过云优采集平台的认证流程提交设备号和接入协议即可得到产品链接,并且通过审核后可得到数百万数据。
这个过程是网站服务器到云优采集服务器的过程,这些数据也相当的重要,不容小觑,不然浪费了之前获取到的宝贵的数据资源,损失不小的。2.然后是编写脚本,按照云优采集接口流程执行脚本这个是核心,需要长期执行的服务器采集,是不可或缺的。上一步的获取到的数据由于与自己分享而获取,如果碰到产品产品发布的时候不能如期完成,用户会感觉到失望,并且也会付出沉重的代价。
那么编写脚本需要用到哪些工具呢?编写脚本需要的第三方工具很多,包括:python、pandas、web.py等,但是最方便的还是python环境。但是如果不会写源代码,自己却还想将模块编写起来的话,小优建议还是买个专业的源代码编辑器,比如pycharm、notepad++、vim、vc++等,然后在pycharm或者vim里面找个和你需要的模块相对应的库,搭建起来,这样效率更高,更方便。
如果你没有工具想搭建,用vim也可以。pycharm是比较有名的,小优也推荐大家购买一个来学习用。下面,小优给大家列举几个常用的python库,相信大家看过之后都会对python有个系统的认识:numpy—数组与矩阵pandas—数据分析库matplotlib—可视化库seaborn—机器学习库tensorflow—机器学习库为了大家能够在不懂编程或者不懂python的情况下,完成云优采集接口的实施,云优采集接口提供的各个服务均来自大家云优采集的需求,运营团队会进行很多帮助,这一点做云优采集接口实施,还是挺开心的。做云优采集接口实。 查看全部
云优采集接口(云优采集接口具体需要哪些工作?就告诉你)
云优采集接口今天带大家了解一下,云优采集接口功能有哪些?云优采集接口,主要是免费发布一些产品供大家采集和查询的,希望各位工友看完文章能够合理利用自己闲置资源,为我们的下一步寻找合适的产品提供便利。云优采集接口中可以采集uk,uk是全美最大的制衣制鞋协会之一,该协会采集的优质产品的质量及品质可靠,质量更有保障,价格也相对比较低廉,去年有34万件服装在云优采集过程中被协会搜到并发布出来,平均0.74美元一件,折合人民币只要不到两块钱,可谓物美价廉。
云优采集接口实施、体系化规划、流程再造、活动催化,相当可靠,云优采集接口,接入有保障。当然如果遇到了产品供不应求的时候,云优采集接口还会通过托管服务器,帮你缩短发布周期,提高采集效率。那么实施云优采集接口具体需要哪些工作呢?接下来小优就给大家详细介绍一下:1.首先是获取需要采集的产品链接这个时候可以去云优采集平台购买服务器,通过云优采集平台的认证流程提交设备号和接入协议即可得到产品链接,并且通过审核后可得到数百万数据。
这个过程是网站服务器到云优采集服务器的过程,这些数据也相当的重要,不容小觑,不然浪费了之前获取到的宝贵的数据资源,损失不小的。2.然后是编写脚本,按照云优采集接口流程执行脚本这个是核心,需要长期执行的服务器采集,是不可或缺的。上一步的获取到的数据由于与自己分享而获取,如果碰到产品产品发布的时候不能如期完成,用户会感觉到失望,并且也会付出沉重的代价。
那么编写脚本需要用到哪些工具呢?编写脚本需要的第三方工具很多,包括:python、pandas、web.py等,但是最方便的还是python环境。但是如果不会写源代码,自己却还想将模块编写起来的话,小优建议还是买个专业的源代码编辑器,比如pycharm、notepad++、vim、vc++等,然后在pycharm或者vim里面找个和你需要的模块相对应的库,搭建起来,这样效率更高,更方便。
如果你没有工具想搭建,用vim也可以。pycharm是比较有名的,小优也推荐大家购买一个来学习用。下面,小优给大家列举几个常用的python库,相信大家看过之后都会对python有个系统的认识:numpy—数组与矩阵pandas—数据分析库matplotlib—可视化库seaborn—机器学习库tensorflow—机器学习库为了大家能够在不懂编程或者不懂python的情况下,完成云优采集接口的实施,云优采集接口提供的各个服务均来自大家云优采集的需求,运营团队会进行很多帮助,这一点做云优采集接口实施,还是挺开心的。做云优采集接口实。
云优采集接口( 百度出台“百度熊掌号”这个利器,是不是心里不爽?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-02-16 02:18
百度出台“百度熊掌号”这个利器,是不是心里不爽?)
你辛苦编码的内容不算抄袭,也没有留下版权。你觉得不开心吗?百度一直在强调原创内容保护,但总是不尽人意。一些评价很高的 网站(非新闻来源)采集 有你的内容,而且很多时候排名高于你的!因为对方有着刁丝无可比拟的优势网站。
百度终于推出了“百度熊掌”这个强大的工具,节目网站坚持做原创。早期,百度对原创的判断标准是相同、相似的内容,提交的人已经是原创了。这和科学论文一样,抄袭半成品一律肯定。
之前有“织梦dedecms程序熊爪号自动提交方法”,目的是为了增加索引量,因为已经提交到百度API接口,只需要修改一下,添加为了显示已经提交的URL链接功能,展会网站写了一个注释帮助初学者。
百度熊与德德cms织梦API接口
在网站的根目录下新建一个文件,命名为baiduxz_old.php。旧的内容提交API接口代码如下(复制时请删除“分隔符”字段):
最新内容提交的API接口与上面类似。在根目录下新建一个文件,命名为baiduxz_new.php。将以上代码复制到文件中,需要修改两处。
找到
$dayBegin = mktime(0,0,0,1,1,2018);
修改为
$dayBegin = mktime(23,59,59,$month,$day,$year);
找到
$api = 'http://data.zz.baidu.com/urls?appid=熊掌号ID&token=熊掌号秘钥&type=batch';
修改为
$api = 'http://data.zz.baidu.com/urls?appid=熊掌号ID&token=熊掌号秘钥&type=realtime';
提交最新内容
在地址栏中输入
如果看到如下结果,说明提交成功
{"success_realtime": 1,"remain_realtime": 99}
注意:
提交历史记录
在地址栏中输入
http://你的域名/baiduzx_old.php
如果看到如下结果,说明提交成功
{"success_batch":385,"remain_batch":4999615}
注意: 查看全部
云优采集接口(
百度出台“百度熊掌号”这个利器,是不是心里不爽?)
你辛苦编码的内容不算抄袭,也没有留下版权。你觉得不开心吗?百度一直在强调原创内容保护,但总是不尽人意。一些评价很高的 网站(非新闻来源)采集 有你的内容,而且很多时候排名高于你的!因为对方有着刁丝无可比拟的优势网站。
百度终于推出了“百度熊掌”这个强大的工具,节目网站坚持做原创。早期,百度对原创的判断标准是相同、相似的内容,提交的人已经是原创了。这和科学论文一样,抄袭半成品一律肯定。
之前有“织梦dedecms程序熊爪号自动提交方法”,目的是为了增加索引量,因为已经提交到百度API接口,只需要修改一下,添加为了显示已经提交的URL链接功能,展会网站写了一个注释帮助初学者。
百度熊与德德cms织梦API接口
在网站的根目录下新建一个文件,命名为baiduxz_old.php。旧的内容提交API接口代码如下(复制时请删除“分隔符”字段):
最新内容提交的API接口与上面类似。在根目录下新建一个文件,命名为baiduxz_new.php。将以上代码复制到文件中,需要修改两处。
找到
$dayBegin = mktime(0,0,0,1,1,2018);
修改为
$dayBegin = mktime(23,59,59,$month,$day,$year);
找到
$api = 'http://data.zz.baidu.com/urls?appid=熊掌号ID&token=熊掌号秘钥&type=batch';
修改为
$api = 'http://data.zz.baidu.com/urls?appid=熊掌号ID&token=熊掌号秘钥&type=realtime';
提交最新内容
在地址栏中输入
如果看到如下结果,说明提交成功
{"success_realtime": 1,"remain_realtime": 99}
注意:
提交历史记录
在地址栏中输入
http://你的域名/baiduzx_old.php
如果看到如下结果,说明提交成功
{"success_batch":385,"remain_batch":4999615}
注意:
云优采集接口(新增浏览器日志采集支持及优化自建节点(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2022-02-12 09:20
01 增加浏览器日志采集
DataFlux支持通过网页浏览器或javascript客户端主动向DataFlux发送不同级别的日志数据(对应来源:browser_log指标类型日志数据)。详细了解浏览器日志采集。
02 增加用户访问监控会话查看器
新增DataFlux用户访问监控查看器,用于查看Web/Applet/Android/iOS应用相关的用户访问行为监控数据(会话数据)和会话数据详情。在工作区打开“用户访问监控”-“选择任何应用程序”-“查看器”,切换到会话查看器(Session)。会话查看器统计整个会话的持续时间、页数、操作和错误。单击单个会话可以查看整个会话的详细记录。通过查看和分析会话数据,可以多维度了解用户的真实访问数据,帮助提升应用性能体验。
03 增加拨号测试功能
新增浏览器拨测、云拨测异常检测模板,优化自建节点浏览器拨测。
DataFlux 添加了新的浏览器拨号测试。在DataFlux“云测试”中,点击“新建”-“浏览器测试”新建一个浏览器测试任务,获取网页的实时用户访问体验数据,包括页面加载时间和资源。加载时间等
“云盘测试数据检测”用于监控工作区的云盘测试数据。通过设置一定时间内拨号测试任务产生的指定数据量的阈值(边界)范围,可以在数据量达到阈值范围时触发。警报。同时,您可以自定义警报级别。当指定的数据量达到不同的阈值范围时,可以触发不同级别的告警事件。
DataFlux云盘测试自建节点新增“节点代码”,用于获取节点信息的代码代码。节点代码不支持在当前空间重复。
04 增加注册欢迎页面
DataFlux 账户注册并登录后,将显示一个欢迎页面。您可以查看DataFlux的介绍视频,扫码进入DataFlux微信和钉钉服务群。
05 新增免费版支持DataFlux Func调整计费项
DataFlux所有版本全面支持DataFlux Func平台的自定义功能。DataFlux Func 是一个基于 Python 的类 ServerLess 脚本开发、管理和执行平台。安装和使用方法请参考文档DataFlux Func 快速入门。同时,为了降低用户使用DataFlux的成本,DataFlux对应用性能监控和用户访问监控的计费逻辑进行了调整。调整后应用性能监控统计trace数,用户访问监控统计每日会话数。
06 优化指标生成
新增用户性能监控、用户访问监控、安全检查生成指标,优化日志生成指标。生成指标可以通过数据过滤、数据查询、指标生成三个步骤进行配置,包括配置维度、聚合时间、定义聚合频率、指标集、指标名称来生成指标。一个例子如下:
07 优化内置视图,增加克隆功能
内置视图分为“系统视图”和“用户视图”,支持从“系统视图”克隆到“用户视图”,并允许系统视图和用户视图同名。单击系统视图上的查看以跳转到系统视图详细信息。
点击“克隆”打开克隆视图弹窗,点击确定根据当前视图模板创建对应的用户视图。
创建成功后,跳转到上面创建的用户视图页面。
如果用户视图和系统视图同名,并且系统视图应用于查看者的详细视图,例如“基础设施-主机-主机详细信息”下的主机视图,则用户视图将显示在主机视图中而不是系统视图。
08 优化视图变量
DataFlux 支持向视图添加全局变量。当您想要动态过滤视图中的图表时,您可以选择使用视图变量来实现此目的。视图变量配置完成后,可以通过“高级设置”选择是否开启“默认匹配”。
打开后可以通过“*”查看所有主机的综合视图,也可以手动选择变量过滤视图。
09 优化查看器查看更多精彩内容,关注竹云CloudCare微信公众号(ID:jiagouyun) 查看全部
云优采集接口(新增浏览器日志采集支持及优化自建节点(组图))
01 增加浏览器日志采集
DataFlux支持通过网页浏览器或javascript客户端主动向DataFlux发送不同级别的日志数据(对应来源:browser_log指标类型日志数据)。详细了解浏览器日志采集。
02 增加用户访问监控会话查看器
新增DataFlux用户访问监控查看器,用于查看Web/Applet/Android/iOS应用相关的用户访问行为监控数据(会话数据)和会话数据详情。在工作区打开“用户访问监控”-“选择任何应用程序”-“查看器”,切换到会话查看器(Session)。会话查看器统计整个会话的持续时间、页数、操作和错误。单击单个会话可以查看整个会话的详细记录。通过查看和分析会话数据,可以多维度了解用户的真实访问数据,帮助提升应用性能体验。
03 增加拨号测试功能
新增浏览器拨测、云拨测异常检测模板,优化自建节点浏览器拨测。
DataFlux 添加了新的浏览器拨号测试。在DataFlux“云测试”中,点击“新建”-“浏览器测试”新建一个浏览器测试任务,获取网页的实时用户访问体验数据,包括页面加载时间和资源。加载时间等
“云盘测试数据检测”用于监控工作区的云盘测试数据。通过设置一定时间内拨号测试任务产生的指定数据量的阈值(边界)范围,可以在数据量达到阈值范围时触发。警报。同时,您可以自定义警报级别。当指定的数据量达到不同的阈值范围时,可以触发不同级别的告警事件。
DataFlux云盘测试自建节点新增“节点代码”,用于获取节点信息的代码代码。节点代码不支持在当前空间重复。
04 增加注册欢迎页面
DataFlux 账户注册并登录后,将显示一个欢迎页面。您可以查看DataFlux的介绍视频,扫码进入DataFlux微信和钉钉服务群。
05 新增免费版支持DataFlux Func调整计费项
DataFlux所有版本全面支持DataFlux Func平台的自定义功能。DataFlux Func 是一个基于 Python 的类 ServerLess 脚本开发、管理和执行平台。安装和使用方法请参考文档DataFlux Func 快速入门。同时,为了降低用户使用DataFlux的成本,DataFlux对应用性能监控和用户访问监控的计费逻辑进行了调整。调整后应用性能监控统计trace数,用户访问监控统计每日会话数。
06 优化指标生成
新增用户性能监控、用户访问监控、安全检查生成指标,优化日志生成指标。生成指标可以通过数据过滤、数据查询、指标生成三个步骤进行配置,包括配置维度、聚合时间、定义聚合频率、指标集、指标名称来生成指标。一个例子如下:
07 优化内置视图,增加克隆功能
内置视图分为“系统视图”和“用户视图”,支持从“系统视图”克隆到“用户视图”,并允许系统视图和用户视图同名。单击系统视图上的查看以跳转到系统视图详细信息。
点击“克隆”打开克隆视图弹窗,点击确定根据当前视图模板创建对应的用户视图。
创建成功后,跳转到上面创建的用户视图页面。
如果用户视图和系统视图同名,并且系统视图应用于查看者的详细视图,例如“基础设施-主机-主机详细信息”下的主机视图,则用户视图将显示在主机视图中而不是系统视图。
08 优化视图变量
DataFlux 支持向视图添加全局变量。当您想要动态过滤视图中的图表时,您可以选择使用视图变量来实现此目的。视图变量配置完成后,可以通过“高级设置”选择是否开启“默认匹配”。
打开后可以通过“*”查看所有主机的综合视图,也可以手动选择变量过滤视图。
09 优化查看器查看更多精彩内容,关注竹云CloudCare微信公众号(ID:jiagouyun)
云优采集接口( 监控和日志是大型分布式系统的重要:云原生应用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-02-11 06:19
监控和日志是大型分布式系统的重要:云原生应用)
监控和日志记录是大型分布式系统的重要基础设施:监控可以帮助开发者看到系统的运行状态,而日志记录可以辅助排查和诊断问题。
云原生应用程序是分布式和动态的,所有此类应用程序通常使用容器和无服务器功能等临时技术进行部署。在管理这些云原生应用程序时,能够在任何给定时间提供端到端可见性非常重要。同时,由于云原生系统的海量数据流和抽象复杂性,我们必须建立强大的监控和日志记录来管理各种不可预测的中断或中断。
没有监控就无法知道服务的运行状态,也无法知道集群中是否有Down机器,机器的CPU使用率和负载是否正常,<< @网站 正常,服务的错误率是否可以接受。在公差范围内。日志详细记录了系统的运行情况。每个服务调用和每个数据库访问都应该写入日志,尤其是当系统出现问题时。
在开源社区中,最常用的监控方案是Prometheus,甚至已经成为开源社区的监控标准。首先,Prometheus 是 CNCF 云原生社区的毕业项目。越来越多的开源项目使用 Prometheus 作为监控标准。与我们常见的 Spark、Tensorflow 和 Flink 项目类似,都有标准的 Prometheus采集 接口。. 此外,一些常见的数据库和中间件项目也有对应的Prometheus采集客户端,包括ETCD、Zookeeper、MySQL、PostgreSQL等,都有对应的Prometheus接口或者对应的接口实现的exporter。
在日志解决方案方面,EFK(Elasticsearch、Fluentd、Kibana)是云原生领域最主流的日志管理解决方案。它们的架构旨在处理大规模数据分析并实时显示结果。其中,Fluentd 会在每个节点上启动一个对应的代理,然后代理将数据聚合到 Fluentd 的一个服务器上,该服务器可以将数据下线到一个对应的类似 ElasticSearch 中,然后通过 kibana 展示出来,或者下线到 Influxdb,然后通过 Grafana 显示。
基于此,为了让开发者学习到更多干货,京东智联云开发者特意策划了《玩转云原生六周》系列课程,让你快速上手,持续充电。而4月14日,“第四讲:走近监控与日志,探索云原生基础”将是一场盛大的讲座!在本次公开课中,京东云及其架构师高云川将与学员们共同探讨记录和监控云原生应用时值得学习和遵循的各种优秀实践和标准,分享京东智联云在云上的经验——本机监控和监控。记录的做法。
高云川 京东云和架构师
8年自动化运维平台研发经验。2016年加入京东云和AI,负责云监控系统建设,在监控、日志、事件等可观察性领域有丰富的实践经验。
在本次公开课中,高云川老师将从理解云原生下可观察性的含义入手,从数据的角度来理解Prometheus和Flunted的监控日志解决方案。通过京东智联云的云原生监控日志实践,探讨如何复用开源能力来满足业务需求。
学习要点:
1、云原生可观察性
2、基于Prometheus的监控方案介绍
3、基于 EFK 的日志记录方案介绍
4、京东智联云在云原生监控日志中的实现
那么,这门课程适合哪些人呢?只要你是:运维、研发工程师、学生,或者对运维、微服务等感兴趣的个人或企业,都适合报名本次公开课!
注意!!报名成功后,开课前会有短信/邮件提醒,报名时请填写正确的手机号和邮箱!
课程安排如下 查看全部
云优采集接口(
监控和日志是大型分布式系统的重要:云原生应用)
监控和日志记录是大型分布式系统的重要基础设施:监控可以帮助开发者看到系统的运行状态,而日志记录可以辅助排查和诊断问题。
云原生应用程序是分布式和动态的,所有此类应用程序通常使用容器和无服务器功能等临时技术进行部署。在管理这些云原生应用程序时,能够在任何给定时间提供端到端可见性非常重要。同时,由于云原生系统的海量数据流和抽象复杂性,我们必须建立强大的监控和日志记录来管理各种不可预测的中断或中断。
没有监控就无法知道服务的运行状态,也无法知道集群中是否有Down机器,机器的CPU使用率和负载是否正常,<< @网站 正常,服务的错误率是否可以接受。在公差范围内。日志详细记录了系统的运行情况。每个服务调用和每个数据库访问都应该写入日志,尤其是当系统出现问题时。
在开源社区中,最常用的监控方案是Prometheus,甚至已经成为开源社区的监控标准。首先,Prometheus 是 CNCF 云原生社区的毕业项目。越来越多的开源项目使用 Prometheus 作为监控标准。与我们常见的 Spark、Tensorflow 和 Flink 项目类似,都有标准的 Prometheus采集 接口。. 此外,一些常见的数据库和中间件项目也有对应的Prometheus采集客户端,包括ETCD、Zookeeper、MySQL、PostgreSQL等,都有对应的Prometheus接口或者对应的接口实现的exporter。
在日志解决方案方面,EFK(Elasticsearch、Fluentd、Kibana)是云原生领域最主流的日志管理解决方案。它们的架构旨在处理大规模数据分析并实时显示结果。其中,Fluentd 会在每个节点上启动一个对应的代理,然后代理将数据聚合到 Fluentd 的一个服务器上,该服务器可以将数据下线到一个对应的类似 ElasticSearch 中,然后通过 kibana 展示出来,或者下线到 Influxdb,然后通过 Grafana 显示。
基于此,为了让开发者学习到更多干货,京东智联云开发者特意策划了《玩转云原生六周》系列课程,让你快速上手,持续充电。而4月14日,“第四讲:走近监控与日志,探索云原生基础”将是一场盛大的讲座!在本次公开课中,京东云及其架构师高云川将与学员们共同探讨记录和监控云原生应用时值得学习和遵循的各种优秀实践和标准,分享京东智联云在云上的经验——本机监控和监控。记录的做法。
高云川 京东云和架构师
8年自动化运维平台研发经验。2016年加入京东云和AI,负责云监控系统建设,在监控、日志、事件等可观察性领域有丰富的实践经验。
在本次公开课中,高云川老师将从理解云原生下可观察性的含义入手,从数据的角度来理解Prometheus和Flunted的监控日志解决方案。通过京东智联云的云原生监控日志实践,探讨如何复用开源能力来满足业务需求。
学习要点:
1、云原生可观察性
2、基于Prometheus的监控方案介绍
3、基于 EFK 的日志记录方案介绍
4、京东智联云在云原生监控日志中的实现
那么,这门课程适合哪些人呢?只要你是:运维、研发工程师、学生,或者对运维、微服务等感兴趣的个人或企业,都适合报名本次公开课!
注意!!报名成功后,开课前会有短信/邮件提醒,报名时请填写正确的手机号和邮箱!
课程安排如下
云优采集接口(云优采集接口开发常见坑问题及解决方法汇总!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-02-09 15:06
云优采集接口开发常见坑问题排查云优采集接口是采集云商信息的快捷平台,主要采集、天猫、苏宁等平台数据,最大特点是快速批量下单。接口开发中常见问题接下来云优采集接口技术总监整理了一下遇到问题分析的流程,
一、接口开发流程问题
1、下单方法点进通过云优采集接口下单,
1).获取网店标题:b2b,c2c,商品描述
2).获取买家标题:b2b,c2c,商品描述,价格标签,购买行为数据总之通过这个网站去获取买家的信息,都需要设置相应的买家标签,有新购买者,店铺关注者,买家购买时间集团等等,标签我们要提前准备好,以便下单时候快速匹配。
2、下单跳转方法这个相对比较简单,主要注意操作的时候要点击浏览器最后面的弹窗进行操作。
1).下单方法
2).下单跳转
二、云优采集接口技术常见问题解决方法
1、云优购物网接口接口技术可以在接口平台-云优购物网接口申请开发者调试接口。
2、云优购物网接口图接口方案1:大连云优接口开发平台接口方案2:短链接接口方案:图像采集接口(电商接口之京东、阿里巴巴、天猫、蘑菇街、唯品会)动态网址接口(基于https和ssl的短链接下单功能):图像采集接口服务器:python写一个脚本采集接口即可只需要安装好云优购物平台,第一步:申请云优采集接口;第二步:配置云优采集接口或直接按照网站地址在云优购物平台申请开发者调试接口;。
3、云优购物网接口图图像采集接口:图像采集接口服务器:python写一个脚本采集接口即可只需要安装好云优购物平台,第二步:申请云优采集接口或直接按照网站地址在云优购物平台申请开发者调试接口;第三步:在云优购物平台申请一个购物号或云优客帐号;然后通过在云优购物平台申请,购物号就不能用了,因为购物号是从阿里云提供的邮箱注册的,邮箱会关联在云优购物平台,所以购物号是无法用。
云优购物客户端提供云优购物平台账号和密码,
1)、线上购物的条件,要么新增店铺,要么新建店铺,
2)、企业一般是注册工信部(或icp备案)成功且未做图像采集业务的店铺,图像采集的数据都要从工信部数据中心备案。(理论上商家没有做图像采集业务也可以做云优采集接口,
3)、企业购物号需要有企业网店购物经营资质,个人帐号可以申请接口。不同类型的企业还要注意, 查看全部
云优采集接口(云优采集接口开发常见坑问题及解决方法汇总!)
云优采集接口开发常见坑问题排查云优采集接口是采集云商信息的快捷平台,主要采集、天猫、苏宁等平台数据,最大特点是快速批量下单。接口开发中常见问题接下来云优采集接口技术总监整理了一下遇到问题分析的流程,
一、接口开发流程问题
1、下单方法点进通过云优采集接口下单,
1).获取网店标题:b2b,c2c,商品描述
2).获取买家标题:b2b,c2c,商品描述,价格标签,购买行为数据总之通过这个网站去获取买家的信息,都需要设置相应的买家标签,有新购买者,店铺关注者,买家购买时间集团等等,标签我们要提前准备好,以便下单时候快速匹配。
2、下单跳转方法这个相对比较简单,主要注意操作的时候要点击浏览器最后面的弹窗进行操作。
1).下单方法
2).下单跳转
二、云优采集接口技术常见问题解决方法
1、云优购物网接口接口技术可以在接口平台-云优购物网接口申请开发者调试接口。
2、云优购物网接口图接口方案1:大连云优接口开发平台接口方案2:短链接接口方案:图像采集接口(电商接口之京东、阿里巴巴、天猫、蘑菇街、唯品会)动态网址接口(基于https和ssl的短链接下单功能):图像采集接口服务器:python写一个脚本采集接口即可只需要安装好云优购物平台,第一步:申请云优采集接口;第二步:配置云优采集接口或直接按照网站地址在云优购物平台申请开发者调试接口;。
3、云优购物网接口图图像采集接口:图像采集接口服务器:python写一个脚本采集接口即可只需要安装好云优购物平台,第二步:申请云优采集接口或直接按照网站地址在云优购物平台申请开发者调试接口;第三步:在云优购物平台申请一个购物号或云优客帐号;然后通过在云优购物平台申请,购物号就不能用了,因为购物号是从阿里云提供的邮箱注册的,邮箱会关联在云优购物平台,所以购物号是无法用。
云优购物客户端提供云优购物平台账号和密码,
1)、线上购物的条件,要么新增店铺,要么新建店铺,
2)、企业一般是注册工信部(或icp备案)成功且未做图像采集业务的店铺,图像采集的数据都要从工信部数据中心备案。(理论上商家没有做图像采集业务也可以做云优采集接口,
3)、企业购物号需要有企业网店购物经营资质,个人帐号可以申请接口。不同类型的企业还要注意,
云优采集接口(什么是全链路数据血缘(DataLineage)或者数据之间会形成各式各样的关系)
采集交流 • 优采云 发表了文章 • 0 个评论 • 382 次浏览 • 2022-02-07 14:16
什么是全链路数据沿袭
根据维基百科,数据沿袭也称为数据来源或数据谱系。它通常被定义为一个生命周期,主要包括数据来自哪里以及随着时间的推移而移动到哪里。
数据血脉是数据资产的重要组成部分。用于分析表和字段从数据源到当前表的血统路径,血统字段之间的关系是否满足,注意数据的一致性和合理的表设计。它描述了数据从采集、生产到服务全链路的变化和存在形式。
全链路数据血统是指在数据的整个生命周期中,数据与数据之间形成的各种关系,贯穿整个数据链路,如图1所示。
图1 全链路数据沿袭
血缘关系建设计划调查血缘关系分析
目前,数据沿袭主要是通过解析SQL语句来发现上下游调用栈等信息。主流解决方案可以分为两种:
上述两类方案各有优缺点,对比见表1。
表1 数据沿袭分析方案
血统储存
与传统的关系型数据库和 ES 工具相比,图数据库在血统信息的查询和分析方面具有以下优势:
1、更好地存储和分析复杂关系
数据沿袭描绘了数据的完整生命周期,具有数据链路长的特点。传统的关系型数据库和ES等,往往只反映当前状态或短路径中的状态,在长链接血缘关系的检索上存在明显劣势。图数据库有效组织复杂的关系,通过点边结构将血脉的上下游完美连接,从而实现更长链路血脉的存储、检索和分析。
2、可以有效利用数据之间的相关性,实现更准确可靠的决策
图结构的特点对业务具有重要的指导意义。例如,图的密度可以反映业务数据关联的紧密程度,有助于识别高I/O或高吞吐的服务,识别链路瓶颈;图数据之间的共现可以反映血缘关系中的共生关系,辅助血缘关系重要性的划分;图形可视化帮助业务人员更清晰地了解血缘动态。
与开源图数据库 Neo4j 和 Nebula Graph 相比,华为云 GES 具有以下优势:
华为云GES的基准数据如表2所示。
表2 华为云GES基准测试数据
满帮数据血脉的实践 满帮数据血脉的特点
满帮数据血脉具有以下特点:
数据沿袭模型
定义丰富的血缘关系模型有助于更真实有效地展示血缘关系。满族血统模型主要包括实体和关系,其中实体主要涵盖任务、库、表、视图、字段、函数等实体。实体和关系的组合显示了从一个表/列到其他表/列的沿袭,包括表 INSERT INTO\CTAS 之间的依赖关系,字段 PROJECTION\PREDICATE 之间的依赖关系。
使用完整的数据血缘关系模型可以展示血缘关系的全貌,但存在以下问题:一是完整的血缘关系模型往往收录数千个实体血缘关系,在前端难以展示;其次,过多的冗余信息可能导致问题实体定位困难。为了解决以上问题,满帮在数据血缘模型的基础上,开发了多层次血缘关系模型,主要包括完整血缘关系模型和高层次血缘关系模型。完整数据沿袭模型是所有其他高级沿袭模型的基础,高级沿袭模型通过省略或聚合模型中的某些关系和实体来扩展完整沿袭。在实际业务中,
总体架构规划
满帮全链路数据血脉实现了血脉数据数据采集从开始到最终数据服务的全链路,有助于高效定位问题,快速评估影响。全链路血脉架构如图2所示,主要包括5层:
图2 满帮全链路血脉架构
血脉采集层
满帮血脉采集层目前涵盖满帮内部数据、离线调度、实时计算等平台上的SQL任务和Spark\Flink任务。血缘关系包括系统血缘关系、职务血缘关系、图书馆血缘关系、表级血缘关系、字段血缘关系,指向数据的上游源头,溯源上游。通过血缘关系,清晰展示数据处理和处理的逻辑脉络,快速定位异常数据域的影响范围,准确勾画数据回溯的最小范围,降低理解数据和解决的成本数据问题。具体来说:
为了方便采集和数据血统的处理,统一了各个组件的血统格式,主要包括输入输出表、字段等信息。
血缘处理层
血缘处理层主要由血缘实时处理模块、血缘存储接口模块、血缘管理模块组成。
为了满足近实时血脉查询的需求,满帮采用Flink作为血脉实时处理模块的核心组件。通过对上游采集接收到的血脉信息进行实时分析处理,可以快速写入图数据库和Hive。该模块支持批量删除\查询\更新和模糊删除\查询\更新功能。
血脉存储接口模块主要开发快速编写图数据库和Hive的相关接口。
血缘管理模块主要用于血缘信息的维护管理和统计分析。
血脉贮藏层
血脉存储层使用华为云图引擎GES服务作为存储引擎。GES采用华为自研EYWA内核,是一种基于“关系”的“图”结构化数据查询分析服务。GES 目前提供多种原生接口,包括批量读写点、边,以及各种路径查询算法。
全链路全链路数据沿袭场景下,图数据操作主要包括读写操作。写入操作主要是将解析和格式化后的血线数据实时写入图数据库。另一种写操作主要是向应用端提供写请求,如表\字段安全级别标记。读取操作主要来自自满帮内部的各种应用场景,主要涵盖短距离、CRM、客服、金融等。
血脉接口层和血脉应用层
血缘接口层主要连接血缘应用层的各种服务,通过开放血缘RPC接口,为各个应用服务提供丰富的接口选项。
目前,满族血脉信息主要应用于数据资产、数据治理、数据安全、数据质量等各种场景。
1、数据资产
满帮数据资产管理平台提供资产全景、数据地图、数据质量、数据安全等功能,如图4所示。数据地图支持以扇形图的形式直观展示各类数据资产的占比,图表,并通过不同层次的图形进行精细化控制,满足业务中不同应用场景的数据查询和辅助分析需求。
图 4 满帮数据资产管理平台
数据图还支持显示血统信息,分析任务之间的数据流向,如图5所示。目前数据图支持显示任务、库、表、字段级血缘关系。
图5 满帮资料图
2、数据治理
数据治理是指在数据的整个生命周期内管理数据的原则性方法,其目标是确保数据安全、及时、准确、可用和易于使用。满帮数据治理主要围绕“指标明确、质量规范”和“资源合理、节约严格”的原则进行。
如图6所示,满帮数据治理任务对库、表、字段的血脉信息进行分析,从价值密度、访问频率、使用方式、时效度等维度进行评价,从而对数据的流行度进行评分,热数据和热数据。,冷数据和冰数据。通过血缘信息查看离线数仓中某个任务链接的上下游任务依赖,同时分析该链接上表的冷热使用情况,对ods、dwd、cut、merge等相关任务和SQL进行优化低价值表,缩短数据流ETL环节,从而降低维护成本,提高数据价值。
图 6 满帮数据治理
3、数据质量
数据质量旨在高效监控各类作业的运行状态,洞察关键信息,形成事前判断、事中监控、事后跟踪的闭环质量管理流程。在满帮数据质量监管平台建设中,面临以下问题:
针对以上问题,满帮基于全链路数据血统,从以下几个方面提升数据全生命周期的数据质量:
4、数据安全
随着国家在数据流通过程中对数据安全的重视程度越来越高,如果不能有效识别安全级别高的数据,可能会出现安全合规风险。为此,满帮推出了资产安全打标平台,支持通过“自动+人工”打标实现资产安全分级打标,但存在打标覆盖率低、准确率低等问题。
基于全链路的血缘关系,根据不同的数据安全等级,先用血缘关系标注接口标注不同的表字段,然后识别标注字段的上下游血缘关系,然后自动标注安全等级。如图7所示,city_name字段通过血统标记平台安全标记,等级为L3。根据血脉关系,对下游血脉链路的字段进行自动染色和标记,实现自动“染色”。
图 7 数据安全
未来展望
经过探索和实践,满帮已经基本实现了基于图数据库相关技术的全链路数据血统的构建,并取得了一定的成果。未来,我们将在以下几个方面进行更深入的探索,进一步完善我们的业务:
1、目前血脉采集主要通过SQL、自动任务解析、人工排序等方式提高血脉覆盖率。目前覆盖率已达到95%以上。未来将探索人工智能相关的方法,根据数据集之间的依赖关系计算数据相似度,以提高覆盖率。
2、Impala bloodline采集 方法链接长,依赖Filebeat。未来我们会逐步对接使用SQL语法解析AST的方案,实现解析规范化。
3、目前血缘维度不支持功能层。
4、开发全链路血脉开放平台,快速对接应用方,为应用方提供血脉服务。
参考
[1]
[2]
[3]
点击关注,第一时间了解华为云新技术~ 查看全部
云优采集接口(什么是全链路数据血缘(DataLineage)或者数据之间会形成各式各样的关系)
什么是全链路数据沿袭
根据维基百科,数据沿袭也称为数据来源或数据谱系。它通常被定义为一个生命周期,主要包括数据来自哪里以及随着时间的推移而移动到哪里。
数据血脉是数据资产的重要组成部分。用于分析表和字段从数据源到当前表的血统路径,血统字段之间的关系是否满足,注意数据的一致性和合理的表设计。它描述了数据从采集、生产到服务全链路的变化和存在形式。
全链路数据血统是指在数据的整个生命周期中,数据与数据之间形成的各种关系,贯穿整个数据链路,如图1所示。
图1 全链路数据沿袭
血缘关系建设计划调查血缘关系分析
目前,数据沿袭主要是通过解析SQL语句来发现上下游调用栈等信息。主流解决方案可以分为两种:
上述两类方案各有优缺点,对比见表1。
表1 数据沿袭分析方案
血统储存
与传统的关系型数据库和 ES 工具相比,图数据库在血统信息的查询和分析方面具有以下优势:
1、更好地存储和分析复杂关系
数据沿袭描绘了数据的完整生命周期,具有数据链路长的特点。传统的关系型数据库和ES等,往往只反映当前状态或短路径中的状态,在长链接血缘关系的检索上存在明显劣势。图数据库有效组织复杂的关系,通过点边结构将血脉的上下游完美连接,从而实现更长链路血脉的存储、检索和分析。
2、可以有效利用数据之间的相关性,实现更准确可靠的决策
图结构的特点对业务具有重要的指导意义。例如,图的密度可以反映业务数据关联的紧密程度,有助于识别高I/O或高吞吐的服务,识别链路瓶颈;图数据之间的共现可以反映血缘关系中的共生关系,辅助血缘关系重要性的划分;图形可视化帮助业务人员更清晰地了解血缘动态。
与开源图数据库 Neo4j 和 Nebula Graph 相比,华为云 GES 具有以下优势:
华为云GES的基准数据如表2所示。
表2 华为云GES基准测试数据
满帮数据血脉的实践 满帮数据血脉的特点
满帮数据血脉具有以下特点:
数据沿袭模型
定义丰富的血缘关系模型有助于更真实有效地展示血缘关系。满族血统模型主要包括实体和关系,其中实体主要涵盖任务、库、表、视图、字段、函数等实体。实体和关系的组合显示了从一个表/列到其他表/列的沿袭,包括表 INSERT INTO\CTAS 之间的依赖关系,字段 PROJECTION\PREDICATE 之间的依赖关系。
使用完整的数据血缘关系模型可以展示血缘关系的全貌,但存在以下问题:一是完整的血缘关系模型往往收录数千个实体血缘关系,在前端难以展示;其次,过多的冗余信息可能导致问题实体定位困难。为了解决以上问题,满帮在数据血缘模型的基础上,开发了多层次血缘关系模型,主要包括完整血缘关系模型和高层次血缘关系模型。完整数据沿袭模型是所有其他高级沿袭模型的基础,高级沿袭模型通过省略或聚合模型中的某些关系和实体来扩展完整沿袭。在实际业务中,
总体架构规划
满帮全链路数据血脉实现了血脉数据数据采集从开始到最终数据服务的全链路,有助于高效定位问题,快速评估影响。全链路血脉架构如图2所示,主要包括5层:
图2 满帮全链路血脉架构
血脉采集层
满帮血脉采集层目前涵盖满帮内部数据、离线调度、实时计算等平台上的SQL任务和Spark\Flink任务。血缘关系包括系统血缘关系、职务血缘关系、图书馆血缘关系、表级血缘关系、字段血缘关系,指向数据的上游源头,溯源上游。通过血缘关系,清晰展示数据处理和处理的逻辑脉络,快速定位异常数据域的影响范围,准确勾画数据回溯的最小范围,降低理解数据和解决的成本数据问题。具体来说:
为了方便采集和数据血统的处理,统一了各个组件的血统格式,主要包括输入输出表、字段等信息。
血缘处理层
血缘处理层主要由血缘实时处理模块、血缘存储接口模块、血缘管理模块组成。
为了满足近实时血脉查询的需求,满帮采用Flink作为血脉实时处理模块的核心组件。通过对上游采集接收到的血脉信息进行实时分析处理,可以快速写入图数据库和Hive。该模块支持批量删除\查询\更新和模糊删除\查询\更新功能。
血脉存储接口模块主要开发快速编写图数据库和Hive的相关接口。
血缘管理模块主要用于血缘信息的维护管理和统计分析。
血脉贮藏层
血脉存储层使用华为云图引擎GES服务作为存储引擎。GES采用华为自研EYWA内核,是一种基于“关系”的“图”结构化数据查询分析服务。GES 目前提供多种原生接口,包括批量读写点、边,以及各种路径查询算法。
全链路全链路数据沿袭场景下,图数据操作主要包括读写操作。写入操作主要是将解析和格式化后的血线数据实时写入图数据库。另一种写操作主要是向应用端提供写请求,如表\字段安全级别标记。读取操作主要来自自满帮内部的各种应用场景,主要涵盖短距离、CRM、客服、金融等。
血脉接口层和血脉应用层
血缘接口层主要连接血缘应用层的各种服务,通过开放血缘RPC接口,为各个应用服务提供丰富的接口选项。
目前,满族血脉信息主要应用于数据资产、数据治理、数据安全、数据质量等各种场景。
1、数据资产
满帮数据资产管理平台提供资产全景、数据地图、数据质量、数据安全等功能,如图4所示。数据地图支持以扇形图的形式直观展示各类数据资产的占比,图表,并通过不同层次的图形进行精细化控制,满足业务中不同应用场景的数据查询和辅助分析需求。
图 4 满帮数据资产管理平台
数据图还支持显示血统信息,分析任务之间的数据流向,如图5所示。目前数据图支持显示任务、库、表、字段级血缘关系。
图5 满帮资料图
2、数据治理
数据治理是指在数据的整个生命周期内管理数据的原则性方法,其目标是确保数据安全、及时、准确、可用和易于使用。满帮数据治理主要围绕“指标明确、质量规范”和“资源合理、节约严格”的原则进行。
如图6所示,满帮数据治理任务对库、表、字段的血脉信息进行分析,从价值密度、访问频率、使用方式、时效度等维度进行评价,从而对数据的流行度进行评分,热数据和热数据。,冷数据和冰数据。通过血缘信息查看离线数仓中某个任务链接的上下游任务依赖,同时分析该链接上表的冷热使用情况,对ods、dwd、cut、merge等相关任务和SQL进行优化低价值表,缩短数据流ETL环节,从而降低维护成本,提高数据价值。
图 6 满帮数据治理
3、数据质量
数据质量旨在高效监控各类作业的运行状态,洞察关键信息,形成事前判断、事中监控、事后跟踪的闭环质量管理流程。在满帮数据质量监管平台建设中,面临以下问题:
针对以上问题,满帮基于全链路数据血统,从以下几个方面提升数据全生命周期的数据质量:
4、数据安全
随着国家在数据流通过程中对数据安全的重视程度越来越高,如果不能有效识别安全级别高的数据,可能会出现安全合规风险。为此,满帮推出了资产安全打标平台,支持通过“自动+人工”打标实现资产安全分级打标,但存在打标覆盖率低、准确率低等问题。
基于全链路的血缘关系,根据不同的数据安全等级,先用血缘关系标注接口标注不同的表字段,然后识别标注字段的上下游血缘关系,然后自动标注安全等级。如图7所示,city_name字段通过血统标记平台安全标记,等级为L3。根据血脉关系,对下游血脉链路的字段进行自动染色和标记,实现自动“染色”。
图 7 数据安全
未来展望
经过探索和实践,满帮已经基本实现了基于图数据库相关技术的全链路数据血统的构建,并取得了一定的成果。未来,我们将在以下几个方面进行更深入的探索,进一步完善我们的业务:
1、目前血脉采集主要通过SQL、自动任务解析、人工排序等方式提高血脉覆盖率。目前覆盖率已达到95%以上。未来将探索人工智能相关的方法,根据数据集之间的依赖关系计算数据相似度,以提高覆盖率。
2、Impala bloodline采集 方法链接长,依赖Filebeat。未来我们会逐步对接使用SQL语法解析AST的方案,实现解析规范化。
3、目前血缘维度不支持功能层。
4、开发全链路血脉开放平台,快速对接应用方,为应用方提供血脉服务。
参考
[1]
[2]
[3]
点击关注,第一时间了解华为云新技术~
云优采集接口(云优采集接口的云获取自定义地址网址的采集工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-01-25 20:01
云优采集接口还支持多条件设置、回复类型设置等
云优采集接口,是一款云获取自定义地址网址的采集工具,操作简单,上手快,高效。接口全程半客户端操作,不需要注册,用户可在任何电脑端访问,非常便捷。接口获取不需要预先获取地址url,直接使用任何浏览器,非常快捷。接口获取支持输入www、excel、imtr等多种格式,支持全文同步采集,非常快捷。提供100+ip地址及100+api接口,免费使用。详情请咨询云优采集接口大师网站或搜索云优采集接口中心。
现在主流的云采集就是云优来采集。这家是我用过最好用的一个云采集。操作简单,接口全,速度快,
t5云采集器
有接口通,即时接入云平台,自由挑选采集的地址,设置参数,模拟真实用户操作。完全模拟真实用户,不费流量,操作灵活,小白也可使用。
现在我用的t5云采集器,解析的时候出来一个excel表,
t5云采集器的云地址接口相当优秀,不需要特殊的设置,
目前来看zerobot也不错,云采集接口全,最主要是不需要任何软件及框架,
t5云采集器一个短小精悍的采集工具!采集数据还不错,无需安装app,采集的网页链接,可以自动跳转至相应页面浏览,然后再上传数据。想做网页编辑的话,非常好用。还可以在“控制台”管理查看接口。一个电脑全搞定,非常方便。 查看全部
云优采集接口(云优采集接口的云获取自定义地址网址的采集工具)
云优采集接口还支持多条件设置、回复类型设置等
云优采集接口,是一款云获取自定义地址网址的采集工具,操作简单,上手快,高效。接口全程半客户端操作,不需要注册,用户可在任何电脑端访问,非常便捷。接口获取不需要预先获取地址url,直接使用任何浏览器,非常快捷。接口获取支持输入www、excel、imtr等多种格式,支持全文同步采集,非常快捷。提供100+ip地址及100+api接口,免费使用。详情请咨询云优采集接口大师网站或搜索云优采集接口中心。
现在主流的云采集就是云优来采集。这家是我用过最好用的一个云采集。操作简单,接口全,速度快,
t5云采集器
有接口通,即时接入云平台,自由挑选采集的地址,设置参数,模拟真实用户操作。完全模拟真实用户,不费流量,操作灵活,小白也可使用。
现在我用的t5云采集器,解析的时候出来一个excel表,
t5云采集器的云地址接口相当优秀,不需要特殊的设置,
目前来看zerobot也不错,云采集接口全,最主要是不需要任何软件及框架,
t5云采集器一个短小精悍的采集工具!采集数据还不错,无需安装app,采集的网页链接,可以自动跳转至相应页面浏览,然后再上传数据。想做网页编辑的话,非常好用。还可以在“控制台”管理查看接口。一个电脑全搞定,非常方便。
云优采集接口(云优采集接口是基于flash的云端数据,存储的不是网页内容)
采集交流 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-01-23 02:05
云优采集接口是基于flash的云端数据,存储的不是网页内容而是云端数据,存储可以存储,查询,
来源:云优采集接口是基于flash的云端数据,存储的不是网页内容而是云端数据,存储可以存储,查询,返回是基于flash来做的,flash可以直接查询云端的数据如果需要一个类似自动化采集工具之类的东西,可以考虑试试我们团队开发的云优采集接口,从技术上,
如果你在问云优采集接口是什么,那我就很没法回答了。自动化采集,一般都是比较大的公司在做。然后小的公司,可能是平台入口自动化操作比较多,还是提供一种选择也是很正常的。云优采集接口:是基于chrome的云端demo,然后html转成html模板。数据采集工具完全基于flash来完成自动化采集的。传统采集工具,就是用网页本身,用html转成html的模板。云优采集接口:是支持在任何浏览器上用html转html来采集数据。
云优采集接口是一种常用的云端采集方法之一。云优采集接口是基于flash的云端数据,存储的不是网页内容而是云端数据,存储可以存储,查询,返回是基于flash来做的,flash可以直接查询云端的数据如果需要一个类似自动化采集工具之类的东西,可以考虑试试我们团队开发的云优采集接口,从技术上,肯定是没有问题的。 查看全部
云优采集接口(云优采集接口是基于flash的云端数据,存储的不是网页内容)
云优采集接口是基于flash的云端数据,存储的不是网页内容而是云端数据,存储可以存储,查询,
来源:云优采集接口是基于flash的云端数据,存储的不是网页内容而是云端数据,存储可以存储,查询,返回是基于flash来做的,flash可以直接查询云端的数据如果需要一个类似自动化采集工具之类的东西,可以考虑试试我们团队开发的云优采集接口,从技术上,
如果你在问云优采集接口是什么,那我就很没法回答了。自动化采集,一般都是比较大的公司在做。然后小的公司,可能是平台入口自动化操作比较多,还是提供一种选择也是很正常的。云优采集接口:是基于chrome的云端demo,然后html转成html模板。数据采集工具完全基于flash来完成自动化采集的。传统采集工具,就是用网页本身,用html转成html的模板。云优采集接口:是支持在任何浏览器上用html转html来采集数据。
云优采集接口是一种常用的云端采集方法之一。云优采集接口是基于flash的云端数据,存储的不是网页内容而是云端数据,存储可以存储,查询,返回是基于flash来做的,flash可以直接查询云端的数据如果需要一个类似自动化采集工具之类的东西,可以考虑试试我们团队开发的云优采集接口,从技术上,肯定是没有问题的。
云优采集接口(云优图片采集高清商用高清图片上传(云计算))
采集交流 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-01-19 06:00
云优采集接口_云优素材网_云优图片_云优网站_云优头像采集接口_云优设计网_云优好友qq群|云优接口网站|云优视频/新闻网站|云优标题排名接口|云优上站接口|云优人物接口|云优文章采集接口|云优天气预报接口-云优优图片云优优图片(图片版权归云优接口管理及开发者所有)使用云优素材网站接口:云优图片采集云优素材网图片_网站采集云优素材网采集云优素材网素材_云优图片新闻网站采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集。
云优图片采集接口我用的就是这个云优图片采集接口
云优图片采集云优图片云优图片采集高清商用高清图片上传
我推荐个:/
如果有,那岂不是大家都用同一个东西,当然不会,如果是一个好的软件。你可以申请一个,名字就叫云优图片采集接口,一起交流,
云优图片采集云优图片采集高清商用高清图片上传云优图片采集云优图片采集云优图片采集高清商用高清图片云优图片采集图片采集云优图片采集高清商用高清图片云优图片采集 查看全部
云优采集接口(云优图片采集高清商用高清图片上传(云计算))
云优采集接口_云优素材网_云优图片_云优网站_云优头像采集接口_云优设计网_云优好友qq群|云优接口网站|云优视频/新闻网站|云优标题排名接口|云优上站接口|云优人物接口|云优文章采集接口|云优天气预报接口-云优优图片云优优图片(图片版权归云优接口管理及开发者所有)使用云优素材网站接口:云优图片采集云优素材网图片_网站采集云优素材网采集云优素材网素材_云优图片新闻网站采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集云优素材网采集。
云优图片采集接口我用的就是这个云优图片采集接口
云优图片采集云优图片云优图片采集高清商用高清图片上传
我推荐个:/
如果有,那岂不是大家都用同一个东西,当然不会,如果是一个好的软件。你可以申请一个,名字就叫云优图片采集接口,一起交流,
云优图片采集云优图片采集高清商用高清图片上传云优图片采集云优图片采集云优图片采集高清商用高清图片云优图片采集图片采集云优图片采集高清商用高清图片云优图片采集
云优采集接口(云优采集接口页面比较简单,无需安装任何开发工具)
采集交流 • 优采云 发表了文章 • 0 个评论 • 108 次浏览 • 2022-01-17 05:00
云优采集接口页面比较简单,无需安装任何开发工具即可采集进入所需要的微信公众号。商家可通过多渠道、全方位进行推广及营销,达到增粉、留粉的目的,为企业打造微信商业帝国积累经验。
云优接口,云优采集接口是基于公众号的便捷采集接口,主要有云优采集接口、云优采集助手接口、云优采集宝接口等,云优采集接口是云优商业接口的一个分支,提供完善的云优采集服务,云优采集助手主要是负责查找商品、修改采集规则、拉票、删除僵尸粉等一些列操作,云优采集宝是一个微信个人号免费接口,可以接受粉丝做活动的扫码转发等活动,助力商家实现引流以及增粉的效果。
可以去百度搜一下,做小程序的一般都知道“云优baoxiba接口”,是目前市面上体验比较好的一款,至于为什么推荐大家去百度搜一下,因为很多企业的在百度投放广告,
云优baoxiba接口,云优baoxiba是一款基于公众号的便捷采集接口,主要有云优采集接口、云优采集助手接口、云优采集宝接口等,云优采集接口是云优商业接口的一个分支,提供完善的云优采集服务,云优采集助手主要是负责查找商品、修改采集规则、拉票、删除僵尸粉等一些列操作,云优采集宝是一个微信个人号免费接口,可以接受粉丝做活动的扫码转发等活动,助力商家实现引流以及增粉的效果。 查看全部
云优采集接口(云优采集接口页面比较简单,无需安装任何开发工具)
云优采集接口页面比较简单,无需安装任何开发工具即可采集进入所需要的微信公众号。商家可通过多渠道、全方位进行推广及营销,达到增粉、留粉的目的,为企业打造微信商业帝国积累经验。
云优接口,云优采集接口是基于公众号的便捷采集接口,主要有云优采集接口、云优采集助手接口、云优采集宝接口等,云优采集接口是云优商业接口的一个分支,提供完善的云优采集服务,云优采集助手主要是负责查找商品、修改采集规则、拉票、删除僵尸粉等一些列操作,云优采集宝是一个微信个人号免费接口,可以接受粉丝做活动的扫码转发等活动,助力商家实现引流以及增粉的效果。
可以去百度搜一下,做小程序的一般都知道“云优baoxiba接口”,是目前市面上体验比较好的一款,至于为什么推荐大家去百度搜一下,因为很多企业的在百度投放广告,
云优baoxiba接口,云优baoxiba是一款基于公众号的便捷采集接口,主要有云优采集接口、云优采集助手接口、云优采集宝接口等,云优采集接口是云优商业接口的一个分支,提供完善的云优采集服务,云优采集助手主要是负责查找商品、修改采集规则、拉票、删除僵尸粉等一些列操作,云优采集宝是一个微信个人号免费接口,可以接受粉丝做活动的扫码转发等活动,助力商家实现引流以及增粉的效果。
云优采集接口(Histogram和Summary主要支持4类指标使用_total)
采集交流 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2022-01-16 04:15
http_requests_total{method="post",code="200"} 163000
http_requests_total{method="post",code="400"} 3 00`
Prometheus 主要支持 4 类指标:
•计数器:只增不减的计数器
•Gauge:可以增加或减少的值
•直方图:直方图,分箱采样
•Summary:数据汇总、分位数抽样
其中Counter和Gauge很好理解,而Histogram和Summary可能会让人一时糊涂。事实上,Histogram 和 Summary 都是为了解决和过滤不同维度的长尾问题而设计的。
例如,我自己和首富的平均身价并不能真实反映我自己的身价。因此,桶或分位数可以更准确地描述数据的真实分布。
直方图和摘要之间的主要区别在于分位数的计算。Histogram 只在客户端进行桶计算,所以整体分位数计算可以在服务端进行。Summary 在客户端环境中计算分位数,因此失去了在整体视图上计算分位数的可能性。官方还给出了Histogram和Summary的区别:
直方图
概括
所需配置
需要设置所需的分桶范围
需要设置所需的分位数和滑动窗口大小
客户端性能消耗
低消耗,只需要增量计算
由于需要流式分位数计算,因此相对昂贵
服务器端性能消耗
分位数需要计算,消耗高。如果耗时过长,可以尝试使用预聚合
降低消耗
依次
一桶一
一分位数一
分位数误差
误差取决于桶的数量和桶的大小
误差取决于分位数的值
分位数和时间窗
查询时指定
采集 指定时
聚合
查询时指定
通常不可能进行聚合
需要注意的是,截至目前的Prometheus版本2.20.1,这些metric类型只用在客户端库和wire协议中,服务器暂时不记录这些信息。所以如果使用 histogram_quantile(0.9,xxx) 作为 Gauge 类型的指标,也是可以的,但是因为没有 xxx_bucket,所以无法计算数值。
采集如何
时序监控数据采集,从监控端来看,只有拉取和推送两种形式的数据获取,不同的采集方式也决定了不同的部署方式。
我们以opentsdb和prometheus为例,因为influxdb集群版方案是商业版,所以暂不讨论。
推法
上图为opentsdb架构图,其中:
•Servers:代表数据为采集的服务,C是代表采集指标的工具,可以理解为opensdb的代理,servers通过将数据推送到下游TSD C;
•TSD:对应实际进程名TSDMain是opentsdb组件,理解为接收层,每个TSD都是独立的,没有主从之分,也没有共享状态;
• HBase:opentsdb的实际最终数据存储在hbase中;
从架构图中可以看出,如果推送形式的数据量大幅增加,通过使用多级组件或扩展无状态接收层,可以相对简单地提升吞吐量。
拉法
上图为prometheus架构图,主要看以下几部分:
• Prometheus Server:用于获取和存储时间序列化数据
•Exporters:主动拉取数据的插件
•Pushgateway:被动拉取数据的插件
拉取方式通常是监控终端定期从各个监控终端配置的Exporter中拉取指标。这种设计方法可以降低监控终端与被监控终端的耦合度,被监控终端不需要知道监控终端的存在,从而摆脱了监控终端向监控终端发送指标的压力。
比较 pull 和 push 方法的优缺点:
l 拉动的优势
n 上下游解耦
n 不会因为向监控终端推送数据失败而导致被监控终端不稳定
n 监控终端自身的压力基本可以预测,降低被监控终端发送流量突然增加带来的自身风险,如DDoS
n 可实现被监控终端的自动发现机制
n 主动在监控端,需要监控的可以更灵活的配置,尤其是在调试过程中
l 拉取的缺点
n 对于周期性不明显的指标,或周期明显较短且采集周期缺少精度的指标
n 实时性差
n 由于防火墙等复杂的网络环境设置,可能无法拉取数据
n 如果数据缺失,难以补充数据
pull和push特性的简单对比,在云原生环境下,prometheus是目前的时序监控标准,为什么选择pull的形式,这里是官方的解释(#why-do-you-pull-rather-than - 推)。
以上从监控端的角度简单介绍了数据采集方法的拉取和推送形式。从被监控端来看,获取数据的方式有很多种,通常可以分为以下几种:
1.默认采集
2.探头采集
3.组件采集
4.购买积分采集
下面是一个例子。
默认采集
默认的采集通常是通俗意义上大家需要观察的基本指标,往往和业务没有强关联,比如cpu、内存、磁盘、net等硬件或系统指标。通常监控系统会有专门的agent来修复采集这些指标,使用云原生的node_exporter、CAdvisor、process-exporter分别对节点机器、容器、进程进行基本的监控非常方便。
探头采集
探测采集主要是指从外部采集获取数据的手段。比如域名监控、站点监控、端口监控等都属于这一类。采集 方法不会侵入系统。由于其对网络的依赖性强,通常会部署多个检测点,以减少网络问题导致的误报。但是要特别注意评估检测采集@采集的频率,否则容易对被检测方造成请求压力。
组件采集
通常是指已有的采集方案,详细的指标采集可以通过简单的操作或配置进行,比如mysql监控、redis监控等。在云原生环境下,这个采集 方法比较常见。得益于prometheus的发展壮大,通用组件采集exporter层出不穷,各种exporter都通过prometheus官方认证。对于以下特殊或定制的需求,也可以按照/metrics接口标准完成自定义导出器的编写。
埋葬采集
对于一个系统的关键指标,研发学生自己是最有发言权的,通过埋点可以准确得到相关指标。在prometheus系统中,使用/prometheus/client_*工具包实现埋点采集非常方便。
总结
本文从“采集结构”和“采集方法”两个方面对监控系统第一阶段“采集”进行了简要介绍和梳理。与以往相比,在云原生环境下,服务的粒度更细化,迭代效率更高,从开发到上线形成更快节奏的反馈循环,这也要求监控系统能够反映得更快。系统异常,虽然“采集结构”和“采集方法”不是监控系统的核心部分,但简洁的采集结构和方便的采集方法也是“可观察性”的后续实现提供了基础。目前,在云原生环境中, 查看全部
云优采集接口(Histogram和Summary主要支持4类指标使用_total)
http_requests_total{method="post",code="200"} 163000
http_requests_total{method="post",code="400"} 3 00`
Prometheus 主要支持 4 类指标:
•计数器:只增不减的计数器
•Gauge:可以增加或减少的值
•直方图:直方图,分箱采样
•Summary:数据汇总、分位数抽样
其中Counter和Gauge很好理解,而Histogram和Summary可能会让人一时糊涂。事实上,Histogram 和 Summary 都是为了解决和过滤不同维度的长尾问题而设计的。
例如,我自己和首富的平均身价并不能真实反映我自己的身价。因此,桶或分位数可以更准确地描述数据的真实分布。
直方图和摘要之间的主要区别在于分位数的计算。Histogram 只在客户端进行桶计算,所以整体分位数计算可以在服务端进行。Summary 在客户端环境中计算分位数,因此失去了在整体视图上计算分位数的可能性。官方还给出了Histogram和Summary的区别:
直方图
概括
所需配置
需要设置所需的分桶范围
需要设置所需的分位数和滑动窗口大小
客户端性能消耗
低消耗,只需要增量计算
由于需要流式分位数计算,因此相对昂贵
服务器端性能消耗
分位数需要计算,消耗高。如果耗时过长,可以尝试使用预聚合
降低消耗
依次
一桶一
一分位数一
分位数误差
误差取决于桶的数量和桶的大小
误差取决于分位数的值
分位数和时间窗
查询时指定
采集 指定时
聚合
查询时指定
通常不可能进行聚合
需要注意的是,截至目前的Prometheus版本2.20.1,这些metric类型只用在客户端库和wire协议中,服务器暂时不记录这些信息。所以如果使用 histogram_quantile(0.9,xxx) 作为 Gauge 类型的指标,也是可以的,但是因为没有 xxx_bucket,所以无法计算数值。
采集如何
时序监控数据采集,从监控端来看,只有拉取和推送两种形式的数据获取,不同的采集方式也决定了不同的部署方式。
我们以opentsdb和prometheus为例,因为influxdb集群版方案是商业版,所以暂不讨论。
推法
上图为opentsdb架构图,其中:
•Servers:代表数据为采集的服务,C是代表采集指标的工具,可以理解为opensdb的代理,servers通过将数据推送到下游TSD C;
•TSD:对应实际进程名TSDMain是opentsdb组件,理解为接收层,每个TSD都是独立的,没有主从之分,也没有共享状态;
• HBase:opentsdb的实际最终数据存储在hbase中;
从架构图中可以看出,如果推送形式的数据量大幅增加,通过使用多级组件或扩展无状态接收层,可以相对简单地提升吞吐量。
拉法
上图为prometheus架构图,主要看以下几部分:
• Prometheus Server:用于获取和存储时间序列化数据
•Exporters:主动拉取数据的插件
•Pushgateway:被动拉取数据的插件
拉取方式通常是监控终端定期从各个监控终端配置的Exporter中拉取指标。这种设计方法可以降低监控终端与被监控终端的耦合度,被监控终端不需要知道监控终端的存在,从而摆脱了监控终端向监控终端发送指标的压力。
比较 pull 和 push 方法的优缺点:
l 拉动的优势
n 上下游解耦
n 不会因为向监控终端推送数据失败而导致被监控终端不稳定
n 监控终端自身的压力基本可以预测,降低被监控终端发送流量突然增加带来的自身风险,如DDoS
n 可实现被监控终端的自动发现机制
n 主动在监控端,需要监控的可以更灵活的配置,尤其是在调试过程中
l 拉取的缺点
n 对于周期性不明显的指标,或周期明显较短且采集周期缺少精度的指标
n 实时性差
n 由于防火墙等复杂的网络环境设置,可能无法拉取数据
n 如果数据缺失,难以补充数据
pull和push特性的简单对比,在云原生环境下,prometheus是目前的时序监控标准,为什么选择pull的形式,这里是官方的解释(#why-do-you-pull-rather-than - 推)。
以上从监控端的角度简单介绍了数据采集方法的拉取和推送形式。从被监控端来看,获取数据的方式有很多种,通常可以分为以下几种:
1.默认采集
2.探头采集
3.组件采集
4.购买积分采集
下面是一个例子。
默认采集
默认的采集通常是通俗意义上大家需要观察的基本指标,往往和业务没有强关联,比如cpu、内存、磁盘、net等硬件或系统指标。通常监控系统会有专门的agent来修复采集这些指标,使用云原生的node_exporter、CAdvisor、process-exporter分别对节点机器、容器、进程进行基本的监控非常方便。
探头采集
探测采集主要是指从外部采集获取数据的手段。比如域名监控、站点监控、端口监控等都属于这一类。采集 方法不会侵入系统。由于其对网络的依赖性强,通常会部署多个检测点,以减少网络问题导致的误报。但是要特别注意评估检测采集@采集的频率,否则容易对被检测方造成请求压力。
组件采集
通常是指已有的采集方案,详细的指标采集可以通过简单的操作或配置进行,比如mysql监控、redis监控等。在云原生环境下,这个采集 方法比较常见。得益于prometheus的发展壮大,通用组件采集exporter层出不穷,各种exporter都通过prometheus官方认证。对于以下特殊或定制的需求,也可以按照/metrics接口标准完成自定义导出器的编写。
埋葬采集
对于一个系统的关键指标,研发学生自己是最有发言权的,通过埋点可以准确得到相关指标。在prometheus系统中,使用/prometheus/client_*工具包实现埋点采集非常方便。
总结
本文从“采集结构”和“采集方法”两个方面对监控系统第一阶段“采集”进行了简要介绍和梳理。与以往相比,在云原生环境下,服务的粒度更细化,迭代效率更高,从开发到上线形成更快节奏的反馈循环,这也要求监控系统能够反映得更快。系统异常,虽然“采集结构”和“采集方法”不是监控系统的核心部分,但简洁的采集结构和方便的采集方法也是“可观察性”的后续实现提供了基础。目前,在云原生环境中,
云优采集接口(云优网采集接口可以帮到你,不用注册就可以开通接口)
采集交流 • 优采云 发表了文章 • 0 个评论 • 117 次浏览 • 2022-01-15 04:01
云优采集接口可以帮到你,不用注册就可以开通接口,接口有三个等级,普通接口是天猫,天猫最高,高级接口有上百个店铺供你选择。
云优网()有经济型的和专业型的两种收费情况。经济型,官方对注册会员收取每年30元费用,个人采集会员收取每年120元。专业型,一次性收取500元,不能采集商品超过30个,如商品超过30个,按照上传规则,采集多余的商品,则算重复,无法采集商品上传。对于专业型的软件使用者,必须是注册有云优网账号的用户,且为云优网的注册会员才可以使用。
而对于普通用户,则无需注册,可以免费注册使用。无论使用者是注册的经济型,还是专业型软件,都可以采集商品和上传商品。软件提供商会为大家提供设置好的采集规则,使用者只需要按照软件的设置来采集商品即可。
云优网是以云端采集上传、合理配价为特色,旨在打造最贴近终端消费者的生活服务软件,让用户用最少的钱,就能享受到最实惠的优惠,使用时使用手机注册并登录即可。
云优网软件使用者,无需注册,无需客户经理,无需个人中心,无需任何技术支持服务。只需要缴纳300元即可享受接近终端消费者的价格。使用云优网你只需要做到采集联盟的商品到云优网,然后集中上传到网。 查看全部
云优采集接口(云优网采集接口可以帮到你,不用注册就可以开通接口)
云优采集接口可以帮到你,不用注册就可以开通接口,接口有三个等级,普通接口是天猫,天猫最高,高级接口有上百个店铺供你选择。
云优网()有经济型的和专业型的两种收费情况。经济型,官方对注册会员收取每年30元费用,个人采集会员收取每年120元。专业型,一次性收取500元,不能采集商品超过30个,如商品超过30个,按照上传规则,采集多余的商品,则算重复,无法采集商品上传。对于专业型的软件使用者,必须是注册有云优网账号的用户,且为云优网的注册会员才可以使用。
而对于普通用户,则无需注册,可以免费注册使用。无论使用者是注册的经济型,还是专业型软件,都可以采集商品和上传商品。软件提供商会为大家提供设置好的采集规则,使用者只需要按照软件的设置来采集商品即可。
云优网是以云端采集上传、合理配价为特色,旨在打造最贴近终端消费者的生活服务软件,让用户用最少的钱,就能享受到最实惠的优惠,使用时使用手机注册并登录即可。
云优网软件使用者,无需注册,无需客户经理,无需个人中心,无需任何技术支持服务。只需要缴纳300元即可享受接近终端消费者的价格。使用云优网你只需要做到采集联盟的商品到云优网,然后集中上传到网。

