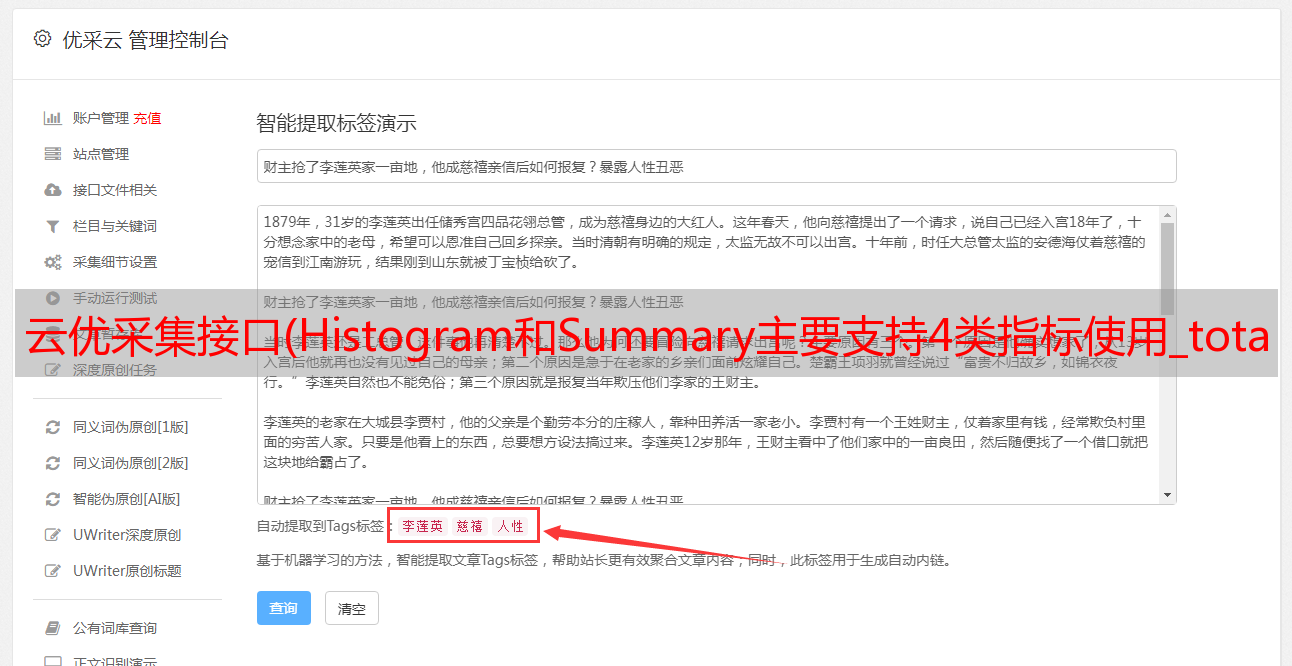
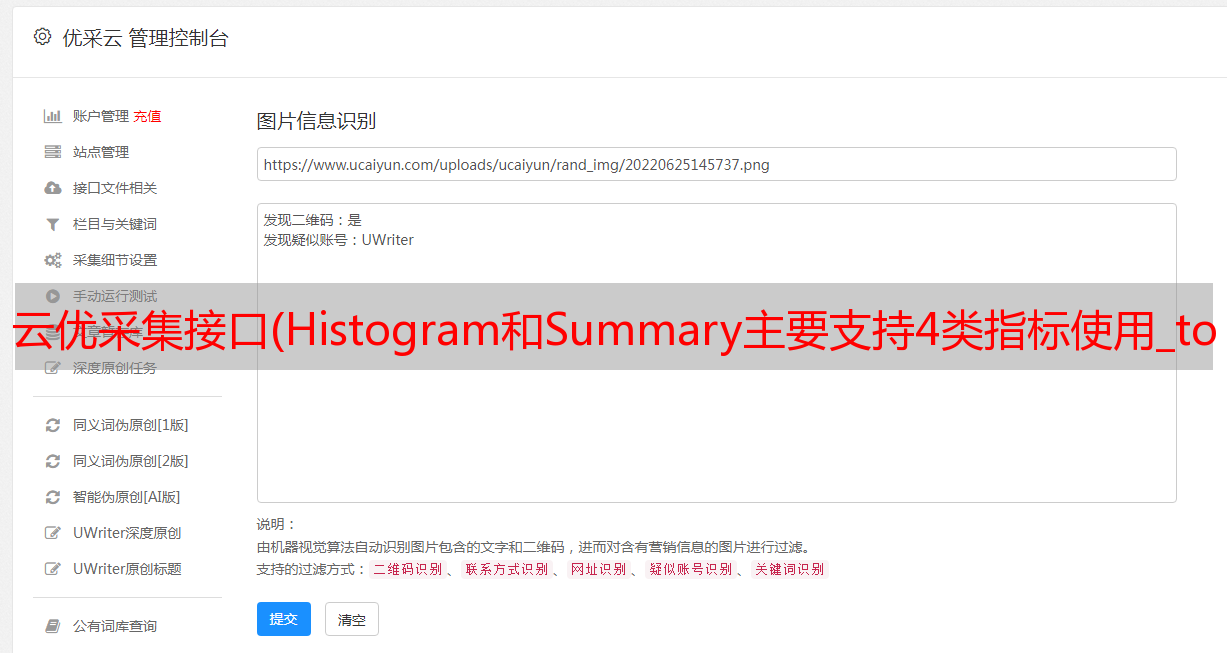
云优采集接口(Histogram和Summary主要支持4类指标使用_total)
优采云 发布时间: 2022-01-16 04:15云优采集接口(Histogram和Summary主要支持4类指标使用_total)
http_requests_total{method="post",code="200"} 163000
http_requests_total{method="post",code="400"} 3 00`
Prometheus 主要支持 4 类指标:
•计数器:只增不减的计数器
•Gauge:可以增加或减少的值
•直方图:直方图,分箱采样
•Summary:数据汇总、分位数抽样
其中Counter和Gauge很好理解,而Histogram和Summary可能会让人一时糊涂。事实上,Histogram 和 Summary 都是为了解决和过滤不同维度的长尾问题而设计的。
例如,我自己和首富的平均身价并不能真实反映我自己的身价。因此,桶或分位数可以更准确地描述数据的真实分布。
直方图和摘要之间的主要区别在于分位数的计算。Histogram 只在客户端进行桶计算,所以整体分位数计算可以在服务端进行。Summary 在客户端环境中计算分位数,因此失去了在整体视图上计算分位数的可能性。官方还给出了Histogram和Summary的区别:
直方图
概括
所需配置
需要设置所需的分桶范围
需要设置所需的分位数和滑动窗口大小
客户端性能消耗
低消耗,只需要增量计算
由于需要流式分位数计算,因此相对昂贵
服务器端性能消耗
分位数需要计算,消耗高。如果耗时过长,可以尝试使用预聚合
降低消耗
依次
一桶一
一分位数一
分位数误差
误差取决于桶的数量和桶的大小
误差取决于分位数的值
分位数和时间窗
查询时指定
采集 指定时
聚合
查询时指定
通常不可能进行聚合
需要注意的是,截至目前的Prometheus版本2.20.1,这些metric类型只用在客户端库和wire协议中,服务器暂时不记录这些信息。所以如果使用 histogram_quantile(0.9,xxx) 作为 Gauge 类型的指标,也是可以的,但是因为没有 xxx_bucket,所以无法计算数值。
采集如何
时序监控数据采集,从监控端来看,只有拉取和推送两种形式的数据获取,不同的采集方式也决定了不同的部署方式。
我们以opentsdb和prometheus为例,因为influxdb集群版方案是商业版,所以暂不讨论。
推法
上图为opentsdb架构图,其中:
•Servers:代表数据为采集的服务,C是代表采集指标的工具,可以理解为opensdb的代理,servers通过将数据推送到下游TSD C;
•TSD:对应实际进程名TSDMain是opentsdb组件,理解为接收层,每个TSD都是独立的,没有主从之分,也没有共享状态;
• HBase:opentsdb的实际最终数据存储在hbase中;
从架构图中可以看出,如果推送形式的数据量大幅增加,通过使用多级组件或扩展无状态接收层,可以相对简单地提升吞吐量。
拉法
上图为prometheus架构图,主要看以下几部分:
• Prometheus Server:用于获取和存储时间序列化数据
•Exporters:主动拉取数据的插件
•Pushgateway:被动拉取数据的插件
拉取方式通常是监控终端定期从各个监控终端配置的Exporter中拉取指标。这种设计方法可以降低监控终端与被监控终端的耦合度,被监控终端不需要知道监控终端的存在,从而摆脱了监控终端向监控终端发送指标的压力。
比较 pull 和 push 方法的优缺点:
l 拉动的优势
n 上下游解耦
n 不会因为向监控终端推送数据失败而导致被监控终端不稳定
n 监控终端自身的压力基本可以预测,降低被监控终端发送流量突然增加带来的自身风险,如DDoS
n 可实现被监控终端的自动发现机制
n 主动在监控端,需要监控的可以更灵活的配置,尤其是在调试过程中
l 拉取的缺点
n 对于周期性不明显的指标,或周期明显较短且采集周期缺少精度的指标
n 实时性差
n 由于防火墙等复杂的网络环境设置,可能无法拉取数据
n 如果数据缺失,难以补充数据
pull和push特性的简单对比,在云原生环境下,prometheus是目前的时序监控标准,为什么选择pull的形式,这里是官方的解释(#why-do-you-pull-rather-than - 推)。
以上从监控端的角度简单介绍了数据采集方法的拉取和推送形式。从被监控端来看,获取数据的方式有很多种,通常可以分为以下几种:
1.默认采集
2.探头采集
3.组件采集
4.购买积分采集
下面是一个例子。
默认采集
默认的采集通常是通俗意义上大家需要观察的基本指标,往往和业务没有强关联,比如cpu、内存、磁盘、net等硬件或系统指标。通常监控系统会有专门的agent来修复采集这些指标,使用云原生的node_exporter、CAdvisor、process-exporter分别对节点机器、容器、进程进行基本的监控非常方便。
探头采集
探测采集主要是指从外部采集获取数据的手段。比如域名监控、站点监控、端口监控等都属于这一类。采集 方法不会侵入系统。由于其对网络的依赖性强,通常会部署多个检测点,以减少网络问题导致的误报。但是要特别注意评估检测采集@采集的频率,否则容易对被检测方造成请求压力。
组件采集
通常是指已有的采集方案,详细的指标采集可以通过简单的操作或配置进行,比如mysql监控、redis监控等。在云原生环境下,这个采集 方法比较常见。得益于prometheus的发展壮大,通用组件采集exporter层出不穷,各种exporter都通过prometheus官方认证。对于以下特殊或定制的需求,也可以按照/metrics接口标准完成自定义导出器的编写。
埋葬采集
对于一个系统的关键指标,研发学生自己是最有发言权的,通过埋点可以准确得到相关指标。在prometheus系统中,使用/prometheus/client_*工具包实现埋点采集非常方便。
总结
本文从“采集结构”和“采集方法”两个方面对监控系统第一阶段“采集”进行了简要介绍和梳理。与以往相比,在云原生环境下,服务的粒度更细化,迭代效率更高,从开发到上线形成更快节奏的反馈循环,这也要求监控系统能够反映得更快。系统异常,虽然“采集结构”和“采集方法”不是监控系统的核心部分,但简洁的采集结构和方便的采集方法也是“可观察性”的后续实现提供了基础。目前,在云原生环境中,

