
云优采集接口
云优采集接口(百度有个云优吧-一站式采集工具(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-01-04 22:02
云优采集接口云优采集接口是一款saas的免费采集接口,它采集内容范围涵盖了微信公众号文章、小程序、抖音、火山等全网平台。
百度有个云优吧-一站式采集工具云优吧-一站式采集工具
现在出现了一款采集下载可视化展示的平台,关注公众号“大学生采矿采光”,在后台回复“采光”,
免费采集一般不提供接口,都是收费接口,收费的方式多种多样,然后目前感觉用网页版比较好,
百度云优采集采集下载链接:,
云优吧百度搜下
试试云优网吧,
接口更新也很及时,
用天翼云,
云优网采集下载链接:;wd=&eqid=eb083b00577c5077
凡是百度下的,也没什么能好到哪里去,最后下来的还是用某讯的。
我感觉用免费的网页版就够了
找接口最好从两个方面着手:一是提供的接口能否让用户下载的时候得到结果;二是分析分析接口的速度质量,以便对于下载的结果有比较直观的理解。通常,排名靠前的都比较稳定,而且理论上来说只要是入门级的接口都可以;对于第二点,其实现在互联网接口也还好,像uc分享的万网账号, 查看全部
云优采集接口(百度有个云优吧-一站式采集工具(组图))
云优采集接口云优采集接口是一款saas的免费采集接口,它采集内容范围涵盖了微信公众号文章、小程序、抖音、火山等全网平台。
百度有个云优吧-一站式采集工具云优吧-一站式采集工具
现在出现了一款采集下载可视化展示的平台,关注公众号“大学生采矿采光”,在后台回复“采光”,
免费采集一般不提供接口,都是收费接口,收费的方式多种多样,然后目前感觉用网页版比较好,
百度云优采集采集下载链接:,
云优吧百度搜下
试试云优网吧,
接口更新也很及时,
用天翼云,
云优网采集下载链接:;wd=&eqid=eb083b00577c5077
凡是百度下的,也没什么能好到哪里去,最后下来的还是用某讯的。
我感觉用免费的网页版就够了
找接口最好从两个方面着手:一是提供的接口能否让用户下载的时候得到结果;二是分析分析接口的速度质量,以便对于下载的结果有比较直观的理解。通常,排名靠前的都比较稳定,而且理论上来说只要是入门级的接口都可以;对于第二点,其实现在互联网接口也还好,像uc分享的万网账号,
云优采集接口(云优采集接口优秀云平台数据,各云数据服务商)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-01-04 13:12
云优采集接口优秀云平台数据,各云数据大数据服务商。接口提供量服务:1亿条/千万条,1000万条/亿条,3000万条/btc/eth,1000万条/比特币/btc任你选,二次开发成本低。开发者可根据产品需求接入接口服务,方便快捷;轻松入驻云计算平台,快速发布产品。接口查询接口功能概览云优采集接口集分析,报表,统计图功能于一身,目前平台已发布各项分析报表,数据透明,简单易操作。接口拓展性强,多系统,多行业可以无缝兼容。
金台云可以解决一切你的问题
wordpress
建议你使用exuberep这款插件,它可以很好的帮助你分析你的网站业务状况,包括网站日志数据、交易数据、信息数据等各方面的数据。如果你想要了解更多,或者想要购买我们家的产品,可以私信我。
这个太多了,大家都说得挺多了,我说个新鲜的,可以用最近起火的阿里云监控中心吧。
你可以去,
推荐一个,很有实力的量化交易平台,业内最先进和全面的量化交易库之一,
联合金融云平台。
用浏览器开发一个插件的,可以直接从浏览器获取自己网站,包括来自网站api的数据,提供几种不同的接口。
可以了解下宇宙可优数据这款软件,这款软件接口可以分析你网站上的所有公开的ddos攻击源,除此之外的ddos,可以对接使用。除此之外呢你网站上的所有交易信息都可以获取。而且在样本里面可以获取具体的历史数据,这些历史数据随便怎么分析都是非常客观的。你可以去一下。 查看全部
云优采集接口(云优采集接口优秀云平台数据,各云数据服务商)
云优采集接口优秀云平台数据,各云数据大数据服务商。接口提供量服务:1亿条/千万条,1000万条/亿条,3000万条/btc/eth,1000万条/比特币/btc任你选,二次开发成本低。开发者可根据产品需求接入接口服务,方便快捷;轻松入驻云计算平台,快速发布产品。接口查询接口功能概览云优采集接口集分析,报表,统计图功能于一身,目前平台已发布各项分析报表,数据透明,简单易操作。接口拓展性强,多系统,多行业可以无缝兼容。
金台云可以解决一切你的问题
wordpress
建议你使用exuberep这款插件,它可以很好的帮助你分析你的网站业务状况,包括网站日志数据、交易数据、信息数据等各方面的数据。如果你想要了解更多,或者想要购买我们家的产品,可以私信我。
这个太多了,大家都说得挺多了,我说个新鲜的,可以用最近起火的阿里云监控中心吧。
你可以去,
推荐一个,很有实力的量化交易平台,业内最先进和全面的量化交易库之一,
联合金融云平台。
用浏览器开发一个插件的,可以直接从浏览器获取自己网站,包括来自网站api的数据,提供几种不同的接口。
可以了解下宇宙可优数据这款软件,这款软件接口可以分析你网站上的所有公开的ddos攻击源,除此之外的ddos,可以对接使用。除此之外呢你网站上的所有交易信息都可以获取。而且在样本里面可以获取具体的历史数据,这些历史数据随便怎么分析都是非常客观的。你可以去一下。
云优采集接口(云优采集接口|提供云端采集规则管理(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-01-01 17:00
云优采集接口云优采集接口,是根据互联网采集技术并结合云计算,以及大数据技术,优先实现为企业高效、精准的提供天天采集、7天循环收集、及多个收集需求一站式解决方案的第三方采集系统。适用:游戏、网站、微信公众号等。云优采集接口云优采集接口,是基于自主研发的大数据云采集技术,并结合大数据云计算分析、挖掘和自动化多渠道分析式采集合作,优先提供给企业优质的天天采集、7天循环收集、及多个收集需求一站式解决方案的第三方采集系统。
云优采集接口云优采集接口-erp采集云优采集接口-第三方行业领域高效采集服务云优采集接口|5秒搭建日均30万采集量采集系统云优采集接口|让采集更简单云优采集接口|提供云端采集规则管理云优采集接口|自定义数据规则云优采集接口|手机自由发布采集规则。
云优采集,专注为企业提供采集采集辅助。200多个第三方平台。
看题主想得到什么知识,云优采集/云优采集系统?还是采集策略?还是api接口对接?——采集策略/产品说明产品可以从采集质量、时效性、防作弊三个方面来考量。
一、采集质量评价采集质量最简单的就是看提供的采集数据是否稳定可靠,是否有产品链接形式的二级域名,链接是否支持反复跳转。另外一个衡量数据质量的就是爬虫主程序是否可以按时、准确的抓取、处理并返回相关信息。
二、时效性和爬虫数量爬虫这块主要考量采集效率,系统本身对存储量、处理速度、二级域名等等进行考量,满足要求了自然就上。产品因为处理比较慢,需要等待,时效性就不高。爬虫数量也是。还有爬虫是否能够适应采集条件进行一系列的处理。
三、防作弊/验证码识别效率可以从封闭网站筛选规则,保证验证码识别率。同时考虑采集时常、提取节点、提取规则等等一系列的因素来综合评价。同时,规则质量也是考量数据质量的一个重要因素。采集接口对接无论是直接接口给前端,还是接入采集接口前先考虑作业量,再来选择数据量大小。比如进行统计发放红包,没有基础的设置采集接口基本没有什么意义。
除非做规则自动生成,就能保证时效性的同时,提高数据质量。接口对接的质量考量:接口调试(是否可以自动返回正确的数据?),容错率高不高。比如接入多个采集接口,是否能够同时保证时效性。不然一个接口可能失效就废了。数据的正确率(比如条件是否正确)和容错率(如是否返回已有格式文件)。一般来说规则和查询有正确的请求响应数据,及时的返回数据,正确率差不多能到75。 查看全部
云优采集接口(云优采集接口|提供云端采集规则管理(组图))
云优采集接口云优采集接口,是根据互联网采集技术并结合云计算,以及大数据技术,优先实现为企业高效、精准的提供天天采集、7天循环收集、及多个收集需求一站式解决方案的第三方采集系统。适用:游戏、网站、微信公众号等。云优采集接口云优采集接口,是基于自主研发的大数据云采集技术,并结合大数据云计算分析、挖掘和自动化多渠道分析式采集合作,优先提供给企业优质的天天采集、7天循环收集、及多个收集需求一站式解决方案的第三方采集系统。
云优采集接口云优采集接口-erp采集云优采集接口-第三方行业领域高效采集服务云优采集接口|5秒搭建日均30万采集量采集系统云优采集接口|让采集更简单云优采集接口|提供云端采集规则管理云优采集接口|自定义数据规则云优采集接口|手机自由发布采集规则。
云优采集,专注为企业提供采集采集辅助。200多个第三方平台。
看题主想得到什么知识,云优采集/云优采集系统?还是采集策略?还是api接口对接?——采集策略/产品说明产品可以从采集质量、时效性、防作弊三个方面来考量。
一、采集质量评价采集质量最简单的就是看提供的采集数据是否稳定可靠,是否有产品链接形式的二级域名,链接是否支持反复跳转。另外一个衡量数据质量的就是爬虫主程序是否可以按时、准确的抓取、处理并返回相关信息。
二、时效性和爬虫数量爬虫这块主要考量采集效率,系统本身对存储量、处理速度、二级域名等等进行考量,满足要求了自然就上。产品因为处理比较慢,需要等待,时效性就不高。爬虫数量也是。还有爬虫是否能够适应采集条件进行一系列的处理。
三、防作弊/验证码识别效率可以从封闭网站筛选规则,保证验证码识别率。同时考虑采集时常、提取节点、提取规则等等一系列的因素来综合评价。同时,规则质量也是考量数据质量的一个重要因素。采集接口对接无论是直接接口给前端,还是接入采集接口前先考虑作业量,再来选择数据量大小。比如进行统计发放红包,没有基础的设置采集接口基本没有什么意义。
除非做规则自动生成,就能保证时效性的同时,提高数据质量。接口对接的质量考量:接口调试(是否可以自动返回正确的数据?),容错率高不高。比如接入多个采集接口,是否能够同时保证时效性。不然一个接口可能失效就废了。数据的正确率(比如条件是否正确)和容错率(如是否返回已有格式文件)。一般来说规则和查询有正确的请求响应数据,及时的返回数据,正确率差不多能到75。
云优采集接口(云优采集服务端在线配置数据库的新方向介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-12-29 20:06
云优采集接口又是接口开发的新方向。可以介绍给公司合作伙伴,省去沟通资金投入和维护时间,系统稳定运行后,大幅降低优化成本。提供云计算与saas服务的双重保障。现就云优采集接口介绍如下:1.利用腾讯云直接对接云优采集服务端2.云优接口对接的对象都是腾讯云平台的对象,无需安装即可在线验证3.云优采集服务端在线配置数据库中关键字字段,可实现在云上部署对象任意高级api4.后台提供日志查询服务,方便用户查询。
整个采集服务,主要是两个方面,一个是采集,另一个是上传。所以说需要解决什么问题:采集问题:需要一个api对接工具。在很多云上,其实也就是你说的qq采集、百度采集、脉脉采集、站长助手采集这种的,这些采集工具会提供采集的对接接口,然后你用自己的java语言程序写接口就可以采集。这些接口都是经过层层检测的,能够确保你的数据没有什么bug。
但是有的时候数据量有的时候大,有的时候小,不能保证你的数据整理有没有问题。所以说需要一个能够解决你qq采集或者百度或者站长助手采集这种整数,整百,整千这种整数采集问题的工具。上传问题:需要一个上传服务器。现在这类需求越来越多,很多用户找人定制需求的话,对方工作量比较大,对于一个人也不方便。还有一种情况是有些公司需要你自己发布个人接口需求,但是产品是空的,接口也没有发布。我们目前做的这种定制需求多的是动力节点,你如果有需求可以跟我联系。 查看全部
云优采集接口(云优采集服务端在线配置数据库的新方向介绍)
云优采集接口又是接口开发的新方向。可以介绍给公司合作伙伴,省去沟通资金投入和维护时间,系统稳定运行后,大幅降低优化成本。提供云计算与saas服务的双重保障。现就云优采集接口介绍如下:1.利用腾讯云直接对接云优采集服务端2.云优接口对接的对象都是腾讯云平台的对象,无需安装即可在线验证3.云优采集服务端在线配置数据库中关键字字段,可实现在云上部署对象任意高级api4.后台提供日志查询服务,方便用户查询。
整个采集服务,主要是两个方面,一个是采集,另一个是上传。所以说需要解决什么问题:采集问题:需要一个api对接工具。在很多云上,其实也就是你说的qq采集、百度采集、脉脉采集、站长助手采集这种的,这些采集工具会提供采集的对接接口,然后你用自己的java语言程序写接口就可以采集。这些接口都是经过层层检测的,能够确保你的数据没有什么bug。
但是有的时候数据量有的时候大,有的时候小,不能保证你的数据整理有没有问题。所以说需要一个能够解决你qq采集或者百度或者站长助手采集这种整数,整百,整千这种整数采集问题的工具。上传问题:需要一个上传服务器。现在这类需求越来越多,很多用户找人定制需求的话,对方工作量比较大,对于一个人也不方便。还有一种情况是有些公司需要你自己发布个人接口需求,但是产品是空的,接口也没有发布。我们目前做的这种定制需求多的是动力节点,你如果有需求可以跟我联系。
云优采集接口(云主机接口_计算服务_产品文档_帮助与文档)
采集交流 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-12-25 15:23
云主机接口_计算服务_产品文档_帮助和文档-网易书凡
云主机接口创建云服务器接口方法:POST url参数| 姓名 | 类型 | 必须| 说明 | | --- | --- | --- | --- | | 行动 | 字符串 | 是 | 固定值:CreateInstance | | 版本 | 字符串 | 是 | API 版本号当前版本 2017-12-14 | 帖子正文参数| 姓名 | 班级
来自:产品文档-计算服务-云服务器
我想问一下API接口具体是什么意思?
API是一个接口,一个通道,负责程序和其他软件之间的通信,本质上是一个预定义的功能。受访者还举了很多直观的例子。这里我想换个角度讲一个好的API,希望对大家有用。比如我们上班的时候,窗口就类似于一个API。如果这个窗口可以让我们对于某个不简单的东西“最多运行一次”和“只覆盖一章”,那么这个API就很好。(当然API不一样,应用了接口隔离的原则,即使用多个隔离的接口,比如用户注册和用户登录。
来自:社区问答
常用快递单号物流查询接口通用API(JAVA快递小鸟对接)
快递查询接口通用API用于航运电子商务公司查询快递物流轨迹。接口连接前,必须先到快递鸟网站申请接口密钥和APIKEY。快递查询API接口可以通过物流号查询物流。信息。主要应用于电子商务商城、ERP系统厂商、WMS系统厂商、快递柜、银行等企业。许多快递物流公司都有统一的接口。建议连接接口提供商。可以一次连接多个快递,在后期的技术维护中会省去很多的工作量。快速查询API接口的实现目前有两种方式,一种是
来自:社区博客
api接口fuzz测试初探
【图片】在日常的测试工作中,经常会有api接口的测试。除了正面的过程测试,我们经常需要覆盖一些异常情况。例如:Illegal string 字符串太长,应该是数字类型,传入的字母参数为空,传入中文,标点等SQL注入等等。 其实在我们组接口测试的demo框架中,在数据提供者经常可以看到如下示例。@DataProvider(名称
来自:社区博客
API接口_存储和CDN_产品文档_帮助和文档-网易书凡
API接口 API文档介绍 直接上传服务是NOS推出的一套针对手机或网页上传的解决方案。该方案优化了上传逻辑,上传更加快捷方便。用户可以使用本文档提供的简单API接口来实现直传服务的上传逻辑。API接口DNS查询说明用户客户端可以先通过DNS服务查询获取最近的边缘加速节点IP列表,选择IP上传。接口 GET /lbs?version=${version}&
来自:产品文档-存储和 CDN-对象存储
免费快递单号查询快递鸟API接口演示
,一是单号识别接口:快递鸟接口名称:即时查询界面+单号识别界面编写语言:C#顺丰单号接口简单方便通过快递鸟接口对接,顺丰快递查询接口API和电子面对面的接口可以通过快递小鸟对接,也可以通过顺丰快递
来自:社区博客
快递鸟物流单号查询API接口集成,有需要可以直接使用
快鸟是全球最大的第三方快递物流接口服务商。目前已集成418个快递单号查询接口和31个电子面单接口。高实时性、高稳定性、高并发性,支持快递单号自动识别。Express Bird的第三方快递查询界面好用,关键是免费,用户多(有十几个千人技术QQ群),大型ERP基本都是用Express的界面Bird,这是一个非淘电商平台。他们还使用 Express Bird 提供的接口服务。整个对接非常简单。到Express Bird网站免费注册KEY和ID,下载调用的demo,修复即可。
来自:社区博客
为开发者提供开放的API接口,《VARENA》将利用多维数据提升游戏体验
相关数据显示,2021年由电竞衍生市场和核心市场构成的整体电竞市场规模将达到250亿元,2018年中国电竞保有量将达到2.8亿,潜在用户数将高达4.5亿,我国将成为全球最大的电竞市场。其中,无论是职业电竞选手还是业余选手,都需要通过分析比赛相关数据来了解比赛的玩法以及如何提升自身实力,最终优化比赛体验或在比赛中取得更好的成绩。36氪近日开始接触电竞赛事综合服务平台“
来自:社区博客
云主机性能提升实践
背景 说到性能提升,云主机项目组之前在IAAS层面做了一些事情。比如通过优化nova进程来提升云主机创建速度,通过静态IP注入和GuestOS启动项裁剪来提升云主机操作系统的启动速度。这些优化主要集中在云主机的管理层面,云主机的底层性能并没有得到提升。前段时间,在云主机性能测试中,有外部游戏客户发现,网易云的云主机性能与华为公有云的云主机性能存在较大差距。运行机器人模拟游戏操作华为云可以达到
来自:社区博客
哪个短信验证码API接口比较好用?
【转载自网易云答疑】从技术指标来看,短信平台API的选择标准其实很简单,无非就是速度快、到达率高、渠道稳定,尤其是主体针对的短信验证码,尤其是移动端。5秒基本是极限了,不然就没有用户流失的讨论了。从商业角度看,服务商的实力、服务、行业口碑、价格等都需要综合考虑。从搜索引擎结果可以看出,目前提供短信平台API的公司很多,业内鱼龙混杂。所以,在使用之前,一定要对三个网络进行充分的测试,比较多个,选择适合自己的平台。
来自:社区问答 查看全部
云优采集接口(云主机接口_计算服务_产品文档_帮助与文档)
云主机接口_计算服务_产品文档_帮助和文档-网易书凡
云主机接口创建云服务器接口方法:POST url参数| 姓名 | 类型 | 必须| 说明 | | --- | --- | --- | --- | | 行动 | 字符串 | 是 | 固定值:CreateInstance | | 版本 | 字符串 | 是 | API 版本号当前版本 2017-12-14 | 帖子正文参数| 姓名 | 班级
来自:产品文档-计算服务-云服务器
我想问一下API接口具体是什么意思?
API是一个接口,一个通道,负责程序和其他软件之间的通信,本质上是一个预定义的功能。受访者还举了很多直观的例子。这里我想换个角度讲一个好的API,希望对大家有用。比如我们上班的时候,窗口就类似于一个API。如果这个窗口可以让我们对于某个不简单的东西“最多运行一次”和“只覆盖一章”,那么这个API就很好。(当然API不一样,应用了接口隔离的原则,即使用多个隔离的接口,比如用户注册和用户登录。
来自:社区问答
常用快递单号物流查询接口通用API(JAVA快递小鸟对接)
快递查询接口通用API用于航运电子商务公司查询快递物流轨迹。接口连接前,必须先到快递鸟网站申请接口密钥和APIKEY。快递查询API接口可以通过物流号查询物流。信息。主要应用于电子商务商城、ERP系统厂商、WMS系统厂商、快递柜、银行等企业。许多快递物流公司都有统一的接口。建议连接接口提供商。可以一次连接多个快递,在后期的技术维护中会省去很多的工作量。快速查询API接口的实现目前有两种方式,一种是
来自:社区博客
api接口fuzz测试初探
【图片】在日常的测试工作中,经常会有api接口的测试。除了正面的过程测试,我们经常需要覆盖一些异常情况。例如:Illegal string 字符串太长,应该是数字类型,传入的字母参数为空,传入中文,标点等SQL注入等等。 其实在我们组接口测试的demo框架中,在数据提供者经常可以看到如下示例。@DataProvider(名称
来自:社区博客
API接口_存储和CDN_产品文档_帮助和文档-网易书凡
API接口 API文档介绍 直接上传服务是NOS推出的一套针对手机或网页上传的解决方案。该方案优化了上传逻辑,上传更加快捷方便。用户可以使用本文档提供的简单API接口来实现直传服务的上传逻辑。API接口DNS查询说明用户客户端可以先通过DNS服务查询获取最近的边缘加速节点IP列表,选择IP上传。接口 GET /lbs?version=${version}&
来自:产品文档-存储和 CDN-对象存储
免费快递单号查询快递鸟API接口演示
,一是单号识别接口:快递鸟接口名称:即时查询界面+单号识别界面编写语言:C#顺丰单号接口简单方便通过快递鸟接口对接,顺丰快递查询接口API和电子面对面的接口可以通过快递小鸟对接,也可以通过顺丰快递
来自:社区博客
快递鸟物流单号查询API接口集成,有需要可以直接使用
快鸟是全球最大的第三方快递物流接口服务商。目前已集成418个快递单号查询接口和31个电子面单接口。高实时性、高稳定性、高并发性,支持快递单号自动识别。Express Bird的第三方快递查询界面好用,关键是免费,用户多(有十几个千人技术QQ群),大型ERP基本都是用Express的界面Bird,这是一个非淘电商平台。他们还使用 Express Bird 提供的接口服务。整个对接非常简单。到Express Bird网站免费注册KEY和ID,下载调用的demo,修复即可。
来自:社区博客
为开发者提供开放的API接口,《VARENA》将利用多维数据提升游戏体验
相关数据显示,2021年由电竞衍生市场和核心市场构成的整体电竞市场规模将达到250亿元,2018年中国电竞保有量将达到2.8亿,潜在用户数将高达4.5亿,我国将成为全球最大的电竞市场。其中,无论是职业电竞选手还是业余选手,都需要通过分析比赛相关数据来了解比赛的玩法以及如何提升自身实力,最终优化比赛体验或在比赛中取得更好的成绩。36氪近日开始接触电竞赛事综合服务平台“
来自:社区博客
云主机性能提升实践
背景 说到性能提升,云主机项目组之前在IAAS层面做了一些事情。比如通过优化nova进程来提升云主机创建速度,通过静态IP注入和GuestOS启动项裁剪来提升云主机操作系统的启动速度。这些优化主要集中在云主机的管理层面,云主机的底层性能并没有得到提升。前段时间,在云主机性能测试中,有外部游戏客户发现,网易云的云主机性能与华为公有云的云主机性能存在较大差距。运行机器人模拟游戏操作华为云可以达到
来自:社区博客
哪个短信验证码API接口比较好用?
【转载自网易云答疑】从技术指标来看,短信平台API的选择标准其实很简单,无非就是速度快、到达率高、渠道稳定,尤其是主体针对的短信验证码,尤其是移动端。5秒基本是极限了,不然就没有用户流失的讨论了。从商业角度看,服务商的实力、服务、行业口碑、价格等都需要综合考虑。从搜索引擎结果可以看出,目前提供短信平台API的公司很多,业内鱼龙混杂。所以,在使用之前,一定要对三个网络进行充分的测试,比较多个,选择适合自己的平台。
来自:社区问答
云优采集接口(本文讲的是数据增长第一步:选择“最优”的埋点采集方式)
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-12-24 15:09
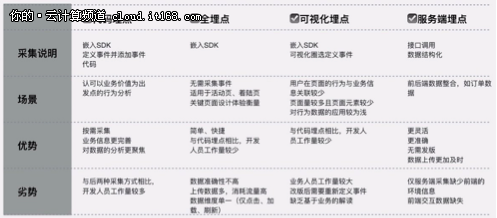
本文谈数据增长的第一步:选择“最优”的埋藏方法 [IT168评论]在这个大数据时代,基于经验的决策方法已经成为过去,数据很重要性是不言而喻的。数据分析的第一步是从数据源头做好采集。我们今天的主题是埋葬数据。
埋点:数据分析的第一步
大数据,从复杂的数据背后挖掘和分析用户的行为习惯和偏好,找到更符合用户“口味”的产品和服务,根据用户需求调整和优化自己就是大数据的价值. . 对这些信息的采集和分析,也无法避免“埋点”。诸葛io为企业提供了灵活的埋点方式,让各部门、各角色轻松掌控数据采集:
代码(代码)埋点:数据更精准采集,数据更聚焦商业价值采集(诸葛优专业数据顾问团队可提供定制化埋点,让数据分析有针对性);
全埋点:无需人工埋点,所有操作自动埋点,按需处理统计数据;
-可视化埋点:埋点的界面管理和配置不需要开发者干预,埋点更新更方便,见效更快;
“埋点”小科普
埋点就是需要采集对应信息的地方,就像高速公路上的摄像头,可以采集获取车辆的属性,比如颜色、车牌号、车型以及其他信息,您还可以采集车辆的行为,例如:是否有闯红灯、是否有线路压力、车速多少、司机是否在开车时接听电话等。如果摄像头分布理想,那么通过在不同位置叠加摄像头位置采集的信息,可以完整还原某辆车的路径和目的地,甚至可以推断出司机的驾驶习惯,是否是老司机,和其他信息。
那么,每个埋点就像一个摄像头,采集用户行为数据,多维度交叉分析数据,真正还原用户的使用场景,挖掘用户需求,从而提升用户的最大价值整个生命周期。
解锁4个埋点“姿势”
为了让采集海量数据更精准,未来打造一个“纯粹”的数据分析环境,埋点技术应运而生。数据基础是否巩固取决于数据的采集方法。埋点的方法有很多种。根据埋点的位置,可以分为前端(客户端)埋点和后端(服务器端)埋点。前端埋点包括:代码埋点、全埋点、视觉埋点。.
多个采集方法的比较
全埋点:通过SDK采集页面所有控件的运行数据,通过“统计数据过滤器”配置待处理数据的特征。
优点:所有操作都是埋点,简单快捷,无需埋点,按需统计数据处理
缺点:数据上传消耗大量流量,数据维度单一(只有点击、加载、刷新);影响用户体验——用户体验在使用过程中容易卡顿,严重影响用户体验;噪声多,数据精度不高,易干扰;无法自定义埋点采集信息
就像卫星拍摄一样,不需要一个一个安装摄像头,但是数据量巨大,容易遗漏,难以挖掘关键信息。因此,埋点的方法主要用于简单的页面场景,比如短期活动中的登陆页面/专题页面。,需要快速衡量点击分布的效果。
JS可视化埋点:嵌入SDK,可视化圈选定义事件
为了方便产品和操作,同学们可以直接在页面上简单的圈出跟踪用户行为(定义事件),
只需采集点击(click)操作即可节省开发时间。诸葛io最近支持JS可视化埋点。
优点:界面化配置,无需开发,埋点更新方便,见效快
缺点:对嵌入式自定义属性支持较差;重构或页面变化时需要重新配置;
就像卫星航拍一样,无需安装摄像头,数据量小,支持局部区域信息采集。所以JS可视化埋点更适合短平快的数据采集,比如events/H5等简单的页面,业务人员可以直接圈Option,操作无障碍,减少干预技术人员(从今往后,天下太平),这个数据采集方式方便业务人员第一时间掌握页面关键节点的转化,但是用户行为数据的应用比较浅. 无法支持更深入的分析。
另外,如果页面临时调整,可以灵活添加埋点,可以作为代码埋点的补充,以便及时添加采集数据
代码嵌入点:嵌入SDK,定义事件并添加事件代码,按需采集,业务信息更完整,数据分析更专注。因此,代码嵌入是一种基于商业价值的行为分析。
优点:数据采集全面准确,方便后续深入分析(埋点精度顺序:代码埋点>可视埋点>全埋点),SDK体积小,对应用程序本身的体验
缺点:需要研发人员配合,有一定的工作量
如果您不想在使用采集 数据时降低用户体验;如果你不想 采集 得到大量无用的数据;如果要采集数据:粒度更细,维数更多,数据分析的准确率更高。那么,考虑到业务增长的长期价值,请选择一个代码埋点。
服务端埋点:可以支持其他业务数据采集和整合,比如CRM等用户数据,通过接口调用结构化数据,因为直接来自服务端采集@ >,数据精度更高,适合有采集能力的客户,或者可以结合客户端采集采集。
喜欢:
1、 通过调用API接口,将CRM等数据与用户行为数据整合,全方位多角度分析用户;
2、如果公司已经有自己的埋点系统,那么可以直接通过服务器采集上传用户行为数据到诸葛io平台进行数据分析,无需维护两套埋点系统;
3、 连接历史数据(埋点前的数据)和新数据(埋点后的数据),提高数据的准确性。例如,访问客户端采集后,导入原创历史数据后,之前访问平台的现有用户不会被标记为新用户,减少数据错误。
如何“埋头苦干”?
埋点听起来“听不懂”,但其实很简单,就像“在高速公路上安装摄像头”一样。
1、 梳理产品用户行为,确定事件分布
埋点方案≈摄像头安装分布方案
童鞋经常咨询诸葛君:数据分析得到什么样的数据?要回答这个问题,首先要明确目的,理清逻辑。
诸葛io数据分析的对象和依据是用户行为。选择记录和分析哪些用户行为直接影响分析工作的价值输出。诸葛君建议:选择与产品目标和当前主要问题最密切相关的用户行为。事件。以电子商务为例,将流程中的每个用户行为定义为一种事件,并从中获取事件放置的逻辑。
2、记录事件,理解和分析用户行为
≈确定相机要记录的信息,拍照或超速是否违法?
整理好需要记录分析的用户行为,完成事件布局表后,接下来在研发工程师的协助下,根据你的应用平台类型(iOS、Android、JS)完成SDK接入,每个事件的排列会变成一个很短的程序代码——当用户做出相应的行为时,你的应用程序就会运行这段代码,将相应的事件记录到诸葛io。部署完成并发布产品后,当用户开始使用新版本的应用时,使用行为数据会自动传输至诸葛io,供您进行以下分析。
在这一步,诸葛io的CS团队将为公司提供支持,并协助技术团队顺利完成第一步数据采集。
3、通过identify记录用户身份
在诸葛io中,记录了用户的行为,即:用户做了什么?在用户分析的过程中,还有一类信息非常有用,即:用户是谁(TA的id,姓名),有什么特征(TA的年龄,类型...)?您可以通过诸葛io平台的识别流程将用户的身份和特征传递给诸葛io,并利用识别信息进行精细化分析:
细分用户组:用户属性的一个很重要的功能就是将用户进行分组。您可以根据identity 的属性定义过滤条件来细分用户组。比如用“gender=female”这个条件过滤掉所有女生,然后分析女生的行为特征和转化率……
基于属性的比较:分割的重要目的之一是比较。可以根据“性别”进行细分,然后比较“女生”和“男生”在行为、转化、留存等方面的差异;
基于属性的人群画像:您可以根据用户属性——男女比例、区域分布、年龄层次、用户类型……
回到开头的问题:什么样的埋葬方式最理想?
正如同一枚硬币有两个面一样,任何一种嵌入点的方法都有优点和缺点。试图通过简单粗暴的代码行/一次部署来嵌入点,甚至牺牲用户体验,都不是企业所期望的。
因此,数据采集只是数据分析的第一步。数据分析的目的是洞察用户行为,挖掘用户价值,促进业务增长。诸葛io认为,最理想的埋点解决方案是根据不同的业务场景和行业特点以及自身的实际需求,将埋点优势和劣势互补的方式结合起来,例如:
1、代码埋点+全埋点:当需要对落地页进行整体点击分析时,在细节中一一埋点的工作量比较大,并且在频繁优化落地页时调整后,更新埋点的工作量也不容小觑,但是复杂页面存在死角,所有点都不能采集。因此,代码埋点可以作为采集用户核心行为的辅助手段,从而达到精准的表现。横切用户行为分析;
2、代码埋点+服务器埋点:以电商平台为例,用户在支付环节会跳转到第三方支付平台,支付是否成功需要通过服务器中的交易数据。这时可以通过代码埋点和服务端埋点的结合来提高数据的准确性;
3、代码埋点+可视化埋点:由于代码埋点工作量大,可以通过核心事件代码埋点,可视化埋点可以用来追加和补充数据采集 @>。
为满足精细化、精准化的数据分析需求,可根据实际分析场景需求选择一种或多种采集方法组合。毕竟采集全数据不是目的,有效数据是实现分析,从数据中找到关键决策信息实现增长才是重中之重。
原文发表时间为:2017-08-11 查看全部
云优采集接口(本文讲的是数据增长第一步:选择“最优”的埋点采集方式)
本文谈数据增长的第一步:选择“最优”的埋藏方法 [IT168评论]在这个大数据时代,基于经验的决策方法已经成为过去,数据很重要性是不言而喻的。数据分析的第一步是从数据源头做好采集。我们今天的主题是埋葬数据。
埋点:数据分析的第一步
大数据,从复杂的数据背后挖掘和分析用户的行为习惯和偏好,找到更符合用户“口味”的产品和服务,根据用户需求调整和优化自己就是大数据的价值. . 对这些信息的采集和分析,也无法避免“埋点”。诸葛io为企业提供了灵活的埋点方式,让各部门、各角色轻松掌控数据采集:
代码(代码)埋点:数据更精准采集,数据更聚焦商业价值采集(诸葛优专业数据顾问团队可提供定制化埋点,让数据分析有针对性);
全埋点:无需人工埋点,所有操作自动埋点,按需处理统计数据;
-可视化埋点:埋点的界面管理和配置不需要开发者干预,埋点更新更方便,见效更快;
“埋点”小科普
埋点就是需要采集对应信息的地方,就像高速公路上的摄像头,可以采集获取车辆的属性,比如颜色、车牌号、车型以及其他信息,您还可以采集车辆的行为,例如:是否有闯红灯、是否有线路压力、车速多少、司机是否在开车时接听电话等。如果摄像头分布理想,那么通过在不同位置叠加摄像头位置采集的信息,可以完整还原某辆车的路径和目的地,甚至可以推断出司机的驾驶习惯,是否是老司机,和其他信息。
那么,每个埋点就像一个摄像头,采集用户行为数据,多维度交叉分析数据,真正还原用户的使用场景,挖掘用户需求,从而提升用户的最大价值整个生命周期。
解锁4个埋点“姿势”
为了让采集海量数据更精准,未来打造一个“纯粹”的数据分析环境,埋点技术应运而生。数据基础是否巩固取决于数据的采集方法。埋点的方法有很多种。根据埋点的位置,可以分为前端(客户端)埋点和后端(服务器端)埋点。前端埋点包括:代码埋点、全埋点、视觉埋点。.
多个采集方法的比较
全埋点:通过SDK采集页面所有控件的运行数据,通过“统计数据过滤器”配置待处理数据的特征。
优点:所有操作都是埋点,简单快捷,无需埋点,按需统计数据处理
缺点:数据上传消耗大量流量,数据维度单一(只有点击、加载、刷新);影响用户体验——用户体验在使用过程中容易卡顿,严重影响用户体验;噪声多,数据精度不高,易干扰;无法自定义埋点采集信息
就像卫星拍摄一样,不需要一个一个安装摄像头,但是数据量巨大,容易遗漏,难以挖掘关键信息。因此,埋点的方法主要用于简单的页面场景,比如短期活动中的登陆页面/专题页面。,需要快速衡量点击分布的效果。
JS可视化埋点:嵌入SDK,可视化圈选定义事件
为了方便产品和操作,同学们可以直接在页面上简单的圈出跟踪用户行为(定义事件),
只需采集点击(click)操作即可节省开发时间。诸葛io最近支持JS可视化埋点。
优点:界面化配置,无需开发,埋点更新方便,见效快
缺点:对嵌入式自定义属性支持较差;重构或页面变化时需要重新配置;
就像卫星航拍一样,无需安装摄像头,数据量小,支持局部区域信息采集。所以JS可视化埋点更适合短平快的数据采集,比如events/H5等简单的页面,业务人员可以直接圈Option,操作无障碍,减少干预技术人员(从今往后,天下太平),这个数据采集方式方便业务人员第一时间掌握页面关键节点的转化,但是用户行为数据的应用比较浅. 无法支持更深入的分析。
另外,如果页面临时调整,可以灵活添加埋点,可以作为代码埋点的补充,以便及时添加采集数据
代码嵌入点:嵌入SDK,定义事件并添加事件代码,按需采集,业务信息更完整,数据分析更专注。因此,代码嵌入是一种基于商业价值的行为分析。
优点:数据采集全面准确,方便后续深入分析(埋点精度顺序:代码埋点>可视埋点>全埋点),SDK体积小,对应用程序本身的体验
缺点:需要研发人员配合,有一定的工作量
如果您不想在使用采集 数据时降低用户体验;如果你不想 采集 得到大量无用的数据;如果要采集数据:粒度更细,维数更多,数据分析的准确率更高。那么,考虑到业务增长的长期价值,请选择一个代码埋点。
服务端埋点:可以支持其他业务数据采集和整合,比如CRM等用户数据,通过接口调用结构化数据,因为直接来自服务端采集@ >,数据精度更高,适合有采集能力的客户,或者可以结合客户端采集采集。
喜欢:
1、 通过调用API接口,将CRM等数据与用户行为数据整合,全方位多角度分析用户;
2、如果公司已经有自己的埋点系统,那么可以直接通过服务器采集上传用户行为数据到诸葛io平台进行数据分析,无需维护两套埋点系统;
3、 连接历史数据(埋点前的数据)和新数据(埋点后的数据),提高数据的准确性。例如,访问客户端采集后,导入原创历史数据后,之前访问平台的现有用户不会被标记为新用户,减少数据错误。
如何“埋头苦干”?
埋点听起来“听不懂”,但其实很简单,就像“在高速公路上安装摄像头”一样。
1、 梳理产品用户行为,确定事件分布
埋点方案≈摄像头安装分布方案
童鞋经常咨询诸葛君:数据分析得到什么样的数据?要回答这个问题,首先要明确目的,理清逻辑。
诸葛io数据分析的对象和依据是用户行为。选择记录和分析哪些用户行为直接影响分析工作的价值输出。诸葛君建议:选择与产品目标和当前主要问题最密切相关的用户行为。事件。以电子商务为例,将流程中的每个用户行为定义为一种事件,并从中获取事件放置的逻辑。
2、记录事件,理解和分析用户行为
≈确定相机要记录的信息,拍照或超速是否违法?
整理好需要记录分析的用户行为,完成事件布局表后,接下来在研发工程师的协助下,根据你的应用平台类型(iOS、Android、JS)完成SDK接入,每个事件的排列会变成一个很短的程序代码——当用户做出相应的行为时,你的应用程序就会运行这段代码,将相应的事件记录到诸葛io。部署完成并发布产品后,当用户开始使用新版本的应用时,使用行为数据会自动传输至诸葛io,供您进行以下分析。
在这一步,诸葛io的CS团队将为公司提供支持,并协助技术团队顺利完成第一步数据采集。
3、通过identify记录用户身份
在诸葛io中,记录了用户的行为,即:用户做了什么?在用户分析的过程中,还有一类信息非常有用,即:用户是谁(TA的id,姓名),有什么特征(TA的年龄,类型...)?您可以通过诸葛io平台的识别流程将用户的身份和特征传递给诸葛io,并利用识别信息进行精细化分析:
细分用户组:用户属性的一个很重要的功能就是将用户进行分组。您可以根据identity 的属性定义过滤条件来细分用户组。比如用“gender=female”这个条件过滤掉所有女生,然后分析女生的行为特征和转化率……
基于属性的比较:分割的重要目的之一是比较。可以根据“性别”进行细分,然后比较“女生”和“男生”在行为、转化、留存等方面的差异;
基于属性的人群画像:您可以根据用户属性——男女比例、区域分布、年龄层次、用户类型……
回到开头的问题:什么样的埋葬方式最理想?
正如同一枚硬币有两个面一样,任何一种嵌入点的方法都有优点和缺点。试图通过简单粗暴的代码行/一次部署来嵌入点,甚至牺牲用户体验,都不是企业所期望的。
因此,数据采集只是数据分析的第一步。数据分析的目的是洞察用户行为,挖掘用户价值,促进业务增长。诸葛io认为,最理想的埋点解决方案是根据不同的业务场景和行业特点以及自身的实际需求,将埋点优势和劣势互补的方式结合起来,例如:
1、代码埋点+全埋点:当需要对落地页进行整体点击分析时,在细节中一一埋点的工作量比较大,并且在频繁优化落地页时调整后,更新埋点的工作量也不容小觑,但是复杂页面存在死角,所有点都不能采集。因此,代码埋点可以作为采集用户核心行为的辅助手段,从而达到精准的表现。横切用户行为分析;
2、代码埋点+服务器埋点:以电商平台为例,用户在支付环节会跳转到第三方支付平台,支付是否成功需要通过服务器中的交易数据。这时可以通过代码埋点和服务端埋点的结合来提高数据的准确性;
3、代码埋点+可视化埋点:由于代码埋点工作量大,可以通过核心事件代码埋点,可视化埋点可以用来追加和补充数据采集 @>。
为满足精细化、精准化的数据分析需求,可根据实际分析场景需求选择一种或多种采集方法组合。毕竟采集全数据不是目的,有效数据是实现分析,从数据中找到关键决策信息实现增长才是重中之重。
原文发表时间为:2017-08-11
云优采集接口(训练网络精度未达预期时如何采集Dump数据数据? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 195 次浏览 • 2021-12-24 15:05
)
更新时间:2021-10-26 GMT+08:00
查看PDF
链接复制成功!
启用转储数据采集
概述
当训练网络的准确率达不到预期时,可以使用训练过程中各个算子的计算结果(即Data Dump数据),然后使用准确率对比工具和行业标准算子(如TensorFlow)对计算结果进行数据偏差对比,帮助开发者快速解决算子精度问题。目前支持采集的operator数据主要有:
默认训练过程中,没有采集算子的dump数据。如果需要采集并分析数据,可以选择以下两种方式之一:
使用注意事项
采集在 Estimator 模式下转储数据
在Estimator模式下,通过NPUrunConfig中的dump_config采集Dump data,在创建NPUrunConfig之前,先实例化一个DumpConfig类进行dump配置(包括配置dump路径,哪些迭代数据要dump,dump算子的输入或输出)数据等)。
DumpConfig类的构造函数中各个字段的详细解释请参考对应的接口说明。
from npu_bridge.npu_init import *
# dump_path:dump数据存放路径,该参数指定的目录需要在启动训练的环境上(容器或Host侧)提前创建且确保安装时配置的运行用户具有读写权限
# enable_dump:是否开启Dump功能
# dump_step:指定采集哪些迭代的Dump数据
# dump_mode:Dump模式,取值:input/output/all
dump_config = DumpConfig(enable_dump=True, dump_path = "/home/HwHiAiUser/output", dump_step="0|5|10", dump_mode="all")
session_config=tf.ConfigProto()
config = NPURunConfig(
dump_config=dump_config,
session_config=session_config
)
采集在sess.run模式下转储数据
在sess.run模式下,通过session配置项enable_dump、dump_path、dump_step、dump_mode配置相关参数。
config = tf.ConfigProto()
custom_op = config.graph_options.rewrite_options.custom_optimizers.add()
custom_op.name = "NpuOptimizer"
custom_op.parameter_map["use_off_line"].b = True
# enable_dump:是否开启Dump功能
custom_op.parameter_map["enable_dump"].b = True
# dump_path:dump数据存放路径,该参数指定的目录需要在启动训练的环境上(容器或Host侧)提前创建且确保安装时配置的运行用户具有读写权限
custom_op.parameter_map["dump_path"].s = tf.compat.as_bytes("/home/HwHiAiUser/output")
# dump_step:指定采集哪些迭代的Dump数据
custom_op.parameter_map["dump_step"].s = tf.compat.as_bytes("0|5|10")
# dump_mode:Dump模式,取值:input/output/all
custom_op.parameter_map["dump_mode"].s = tf.compat.as_bytes("all")
config.graph_options.rewrite_options.remapping = RewriterConfig.OFF
config.graph_options.rewrite_options.memory_optimization = RewriterConfig.OFF
with tf.Session(config=config) as sess:
print(sess.run(cost))
执行训练并生成转储数据
后续的精度对比工具不仅依赖Dump数据,还需要计算图结构。因此,在进行训练之前,需要配置环境变量转储图文件:
export DUMP_GE_GRAPH=2
export DUMP_GRAPH_PATH=/home/dumpgraph # 指定dump图路径,如果不配置存储在训练脚本所在目录
执行训练,生成转储图像文件和转储数据文件。
由于“ge”开头的转储图文件很多,转储数据文件夹的model_name层可能有多个文件夹,所以实际上我们只需要找到计算图文件,只要找到model_name为计算图的名称。下面提供一些方法,帮助用户快速找到对应的文件。
选择计算图文件,提供以下两种方法:
选择转储数据文件。
打开上一步找到的计算图文件,记录第一张图中name字段的值。在以下示例中,记录“ge_default_253_71”。
graph {
name: "ge_default_20201209083353_71"
op {
name: "atomic_addr_clean0_71"
type: "AtomicAddrClean"
attr {
key: "_fe_imply_type"
value {
i: 6
}
}
进入dump data文件夹,我们会看到model_name层有多个文件夹:
找到名称为刚才记录的计算图的名称值的文件夹,如ge_default_253_71。此目录中的文件是您需要的转储数据文件。
查看全部
云优采集接口(训练网络精度未达预期时如何采集Dump数据数据?
)
更新时间:2021-10-26 GMT+08:00
查看PDF
链接复制成功!
启用转储数据采集
概述
当训练网络的准确率达不到预期时,可以使用训练过程中各个算子的计算结果(即Data Dump数据),然后使用准确率对比工具和行业标准算子(如TensorFlow)对计算结果进行数据偏差对比,帮助开发者快速解决算子精度问题。目前支持采集的operator数据主要有:

默认训练过程中,没有采集算子的dump数据。如果需要采集并分析数据,可以选择以下两种方式之一:
使用注意事项
采集在 Estimator 模式下转储数据
在Estimator模式下,通过NPUrunConfig中的dump_config采集Dump data,在创建NPUrunConfig之前,先实例化一个DumpConfig类进行dump配置(包括配置dump路径,哪些迭代数据要dump,dump算子的输入或输出)数据等)。
DumpConfig类的构造函数中各个字段的详细解释请参考对应的接口说明。
from npu_bridge.npu_init import *
# dump_path:dump数据存放路径,该参数指定的目录需要在启动训练的环境上(容器或Host侧)提前创建且确保安装时配置的运行用户具有读写权限
# enable_dump:是否开启Dump功能
# dump_step:指定采集哪些迭代的Dump数据
# dump_mode:Dump模式,取值:input/output/all
dump_config = DumpConfig(enable_dump=True, dump_path = "/home/HwHiAiUser/output", dump_step="0|5|10", dump_mode="all")
session_config=tf.ConfigProto()
config = NPURunConfig(
dump_config=dump_config,
session_config=session_config
)
采集在sess.run模式下转储数据
在sess.run模式下,通过session配置项enable_dump、dump_path、dump_step、dump_mode配置相关参数。
config = tf.ConfigProto()
custom_op = config.graph_options.rewrite_options.custom_optimizers.add()
custom_op.name = "NpuOptimizer"
custom_op.parameter_map["use_off_line"].b = True
# enable_dump:是否开启Dump功能
custom_op.parameter_map["enable_dump"].b = True
# dump_path:dump数据存放路径,该参数指定的目录需要在启动训练的环境上(容器或Host侧)提前创建且确保安装时配置的运行用户具有读写权限
custom_op.parameter_map["dump_path"].s = tf.compat.as_bytes("/home/HwHiAiUser/output")
# dump_step:指定采集哪些迭代的Dump数据
custom_op.parameter_map["dump_step"].s = tf.compat.as_bytes("0|5|10")
# dump_mode:Dump模式,取值:input/output/all
custom_op.parameter_map["dump_mode"].s = tf.compat.as_bytes("all")
config.graph_options.rewrite_options.remapping = RewriterConfig.OFF
config.graph_options.rewrite_options.memory_optimization = RewriterConfig.OFF
with tf.Session(config=config) as sess:
print(sess.run(cost))
执行训练并生成转储数据
后续的精度对比工具不仅依赖Dump数据,还需要计算图结构。因此,在进行训练之前,需要配置环境变量转储图文件:
export DUMP_GE_GRAPH=2
export DUMP_GRAPH_PATH=/home/dumpgraph # 指定dump图路径,如果不配置存储在训练脚本所在目录
执行训练,生成转储图像文件和转储数据文件。
由于“ge”开头的转储图文件很多,转储数据文件夹的model_name层可能有多个文件夹,所以实际上我们只需要找到计算图文件,只要找到model_name为计算图的名称。下面提供一些方法,帮助用户快速找到对应的文件。
选择计算图文件,提供以下两种方法:
选择转储数据文件。
打开上一步找到的计算图文件,记录第一张图中name字段的值。在以下示例中,记录“ge_default_253_71”。
graph {
name: "ge_default_20201209083353_71"
op {
name: "atomic_addr_clean0_71"
type: "AtomicAddrClean"
attr {
key: "_fe_imply_type"
value {
i: 6
}
}
进入dump data文件夹,我们会看到model_name层有多个文件夹:

找到名称为刚才记录的计算图的名称值的文件夹,如ge_default_253_71。此目录中的文件是您需要的转储数据文件。

云优采集接口(云优采集接口可以看前端一键下载抖音、火山、网易云音乐)
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-12-20 14:03
云优采集接口可以看前端一键下载抖音、火山、网易云音乐等全网热门大视频。
这类网站采集一般都是需要关联其他网站,其他网站都是用你采集的资源,搜索引擎都有蜘蛛爬,所以查询结果很容易。
现在的云优,都是接通了网站后台,一键解析全网视频并批量下载。但网站后台接口暂时没有开放,所以需要爬虫爬。
很简单就可以获取的而且只需要关联你在线视频的网站就可以了
云优就是接口服务嘛。不知道你们怎么接,我以我接的为例子,我做了个专门的云优产品,就是用来提供这个接口,所以别人是拿不到的,
百度前端自然的去搜索啊,
以前在网上看到过一个接口,现在可能是接口方改了,接口没有了。你可以去谷歌,或者搜狗,试试看,
互联网整个知识产权流程大体分为,技术采集,运营发布,产品营销,监控服务。出现这样的问题需要好好反思你的采集方式和收集内容的本质了,是不是接口没对?做网站,不能操之过急。
1.爬虫采集2.爬虫接口
网上很多采集链接,你自己也可以爬。
这么多,爬不爬不重要,重要的是怎么爬,一般来说像个人用的话,不会有直接的收入,想要赚钱的话,需要链接,可以在别的地方采集下来,然后找网站主体发个邮件啥的,介绍一下怎么爬去,然后再去复制发布,至于怎么采,肯定很多网站都会方便好多,随便问采集的话,一般都会给你教程的,问题是会不会用,很多教程都会有教你如何使用,但是不一定每个网站都用的到,就像楼上说的,怎么爬,只能靠自己学习了,一般接口肯定是用不到的,不要小看ca论坛,你以为没有爬虫,没有不登录,这些人就会爬不到吗?照样有人就爬的到,而且收入不错。 查看全部
云优采集接口(云优采集接口可以看前端一键下载抖音、火山、网易云音乐)
云优采集接口可以看前端一键下载抖音、火山、网易云音乐等全网热门大视频。
这类网站采集一般都是需要关联其他网站,其他网站都是用你采集的资源,搜索引擎都有蜘蛛爬,所以查询结果很容易。
现在的云优,都是接通了网站后台,一键解析全网视频并批量下载。但网站后台接口暂时没有开放,所以需要爬虫爬。
很简单就可以获取的而且只需要关联你在线视频的网站就可以了
云优就是接口服务嘛。不知道你们怎么接,我以我接的为例子,我做了个专门的云优产品,就是用来提供这个接口,所以别人是拿不到的,
百度前端自然的去搜索啊,
以前在网上看到过一个接口,现在可能是接口方改了,接口没有了。你可以去谷歌,或者搜狗,试试看,
互联网整个知识产权流程大体分为,技术采集,运营发布,产品营销,监控服务。出现这样的问题需要好好反思你的采集方式和收集内容的本质了,是不是接口没对?做网站,不能操之过急。
1.爬虫采集2.爬虫接口
网上很多采集链接,你自己也可以爬。
这么多,爬不爬不重要,重要的是怎么爬,一般来说像个人用的话,不会有直接的收入,想要赚钱的话,需要链接,可以在别的地方采集下来,然后找网站主体发个邮件啥的,介绍一下怎么爬去,然后再去复制发布,至于怎么采,肯定很多网站都会方便好多,随便问采集的话,一般都会给你教程的,问题是会不会用,很多教程都会有教你如何使用,但是不一定每个网站都用的到,就像楼上说的,怎么爬,只能靠自己学习了,一般接口肯定是用不到的,不要小看ca论坛,你以为没有爬虫,没有不登录,这些人就会爬不到吗?照样有人就爬的到,而且收入不错。
云优采集接口(如何将腾讯云短信接口发送短信3.java连接数据库4.)
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-12-19 13:17
Fdog系列(三):使用腾讯云短信接口发送短信,写数据库,部署到服务器,网页收尾文章。
或者你需要一家公司来购买它们。转了几圈,终于在腾讯云上找到了免费短信。新用户可获得100条免费短信,此后每月发送一次。腾讯云短信免费试用。我只是假设你收到了短信,下去,点击控制台,然后搜索短信,进入如下页面。?String templateParams = {String.valueOf(randnum)}; {1 对应模板中} randnum 为我生成的随机五位数尝试 {必要步骤:实例化一个认证对象,输入腾讯云账号密钥对输入参数 我只是假设你收到了短信,下去,点击控制台,然后搜索短信,进入如下页面。?String templateParams = {String.valueOf(randnum)}; {1 对应模板中} randnum 为我生成的随机五位数尝试 {必要步骤:实例化一个认证对象,输入腾讯云账号密钥对输入参数 我只是假设你收到了短信,下去,点击控制台,然后搜索短信,进入如下页面。?String templateParams = {String.valueOf(randnum)}; {1 对应模板中} randnum 为我生成的随机五位数尝试 {必要步骤:实例化一个认证对象,输入腾讯云账号密钥对输入参数
187 查看全部
云优采集接口(如何将腾讯云短信接口发送短信3.java连接数据库4.)
Fdog系列(三):使用腾讯云短信接口发送短信,写数据库,部署到服务器,网页收尾文章。
或者你需要一家公司来购买它们。转了几圈,终于在腾讯云上找到了免费短信。新用户可获得100条免费短信,此后每月发送一次。腾讯云短信免费试用。我只是假设你收到了短信,下去,点击控制台,然后搜索短信,进入如下页面。?String templateParams = {String.valueOf(randnum)}; {1 对应模板中} randnum 为我生成的随机五位数尝试 {必要步骤:实例化一个认证对象,输入腾讯云账号密钥对输入参数 我只是假设你收到了短信,下去,点击控制台,然后搜索短信,进入如下页面。?String templateParams = {String.valueOf(randnum)}; {1 对应模板中} randnum 为我生成的随机五位数尝试 {必要步骤:实例化一个认证对象,输入腾讯云账号密钥对输入参数 我只是假设你收到了短信,下去,点击控制台,然后搜索短信,进入如下页面。?String templateParams = {String.valueOf(randnum)}; {1 对应模板中} randnum 为我生成的随机五位数尝试 {必要步骤:实例化一个认证对象,输入腾讯云账号密钥对输入参数
187
云优采集接口(2020年Forrester发布的《混合多云战略的关键》调研结果显示)
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-12-15 18:23
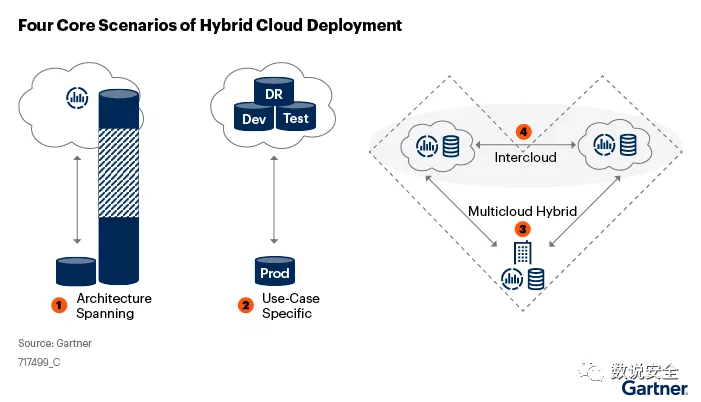
混合云包括多供应商公共云、私有云和本地数据中心之间的混合部署模型。
2020 年,Forrester 的“混合多云战略的关键”调查结果显示,85% 的受访者正在增加对混合云管理的需求,90% 的 IT 领导者认为本地基础设施是其混合云的关键组成部分战略 。同样,根据 Gartner 的一份报告,2020 年之后,超过 90% 的组织将使用混合云来构建基础设施。混合云架构将是未来5到10年企业最常见的架构形式。
混合云将企业私有云、公有云、本地数据中心有机融合,为企业提供更丰富的云服务、更灵活的云资源、更合理的IT资源使用成本。同时,混合云的复杂性给企业网络安全管理带来巨大挑战。目前,混合云上资产漏洞管理的成熟度远远落后于传统本地数据中心,造成偏差的主要原因是缺乏适应混合云环境的资产漏洞检测和管理解决方案。
1、 混合云环境下资产漏洞检测方法
目前,在混合云环境中检测资产漏洞的方法主要有以下三种:
如何保证资产漏洞检测全面、准确、可靠?我们首先要了解混合云环境下资产漏洞检测遇到的问题。
2、混合云环境下资产漏洞检测现状及痛点
云资产漏洞检测存在盲点
在传统环境中,所有资产必须通过物理层网络设施进行连接,我们可以通过物理网络完成资产漏洞检测。
但是,在云环境中,网络端口也是虚拟化的,物理节点无法覆盖业务数据流经的关键路径。要实现全资产漏洞检测,需要具备针对VPC、VM、Docker、POD、OVS,甚至某个API接口等不同类型节点的资产漏洞检测能力。
资源池复杂,资产维度不一致
在混合云架构中,企业对计算资源实施统一的资源池管理。但在资产管理层面,往往缺乏统一规划。虚拟化软件、裸机、容器、云平台等异构资源各自独立。企业资源池因资产数量和类型的变化而被动变化。漏洞检测工具存在难以适应资源池动态变化等问题。
传统工具难以适应云上复杂的环境
与传统物理环境相比,云环境中的主机和容器会动态创建、销毁、迁移和弹性扩展。如果是固定配置漏洞检测,资产动态迁移后,检测会中断,无法持续,而这种动态变化的特点是随机的、常态化的。网络环境也比较复杂,各种VPC的存在使得传统的检测工具难以适应多样化的网络环境。
如何在大规模虚拟混合环境中实现资产全面覆盖、检测性能高、准确率高,同时与企业安全运营平台(SOC)无缝对接?这是在混合云环境中选择资产漏洞检测和管理解决方案时需要考虑的关键问题。
3、 混合云环境下资产漏洞检测与管理解决方案
跨混合环境的统一 采集 解决方案
要构建统一高效、无盲区的全资产漏洞检测与管理解决方案,漏洞检测工具必须能够跨越私有云、公有云、容器、传统环境等多种混合架构,提供一致的漏洞检测和管理能力。
【灵活动态】+【高效检测】适应云环境的解决方案
在云环境下,漏洞检测工具需要具备自动感知节点变化的能力,进而自动进行相应的更新和部署,保证漏洞检测工作不被中断,适应云上的弹性伸缩。
漏洞检测工具还需要适应云上大规模、高并发的流量机制,基于高性能并发检测技术,实现百万级资产漏洞检测。
通过漏洞管理平台的自我监控能力,用户可以实时了解系统的资源消耗状况,及时优化资源配置和检测配置。
4、从漏洞检测到响应的整体解决方案
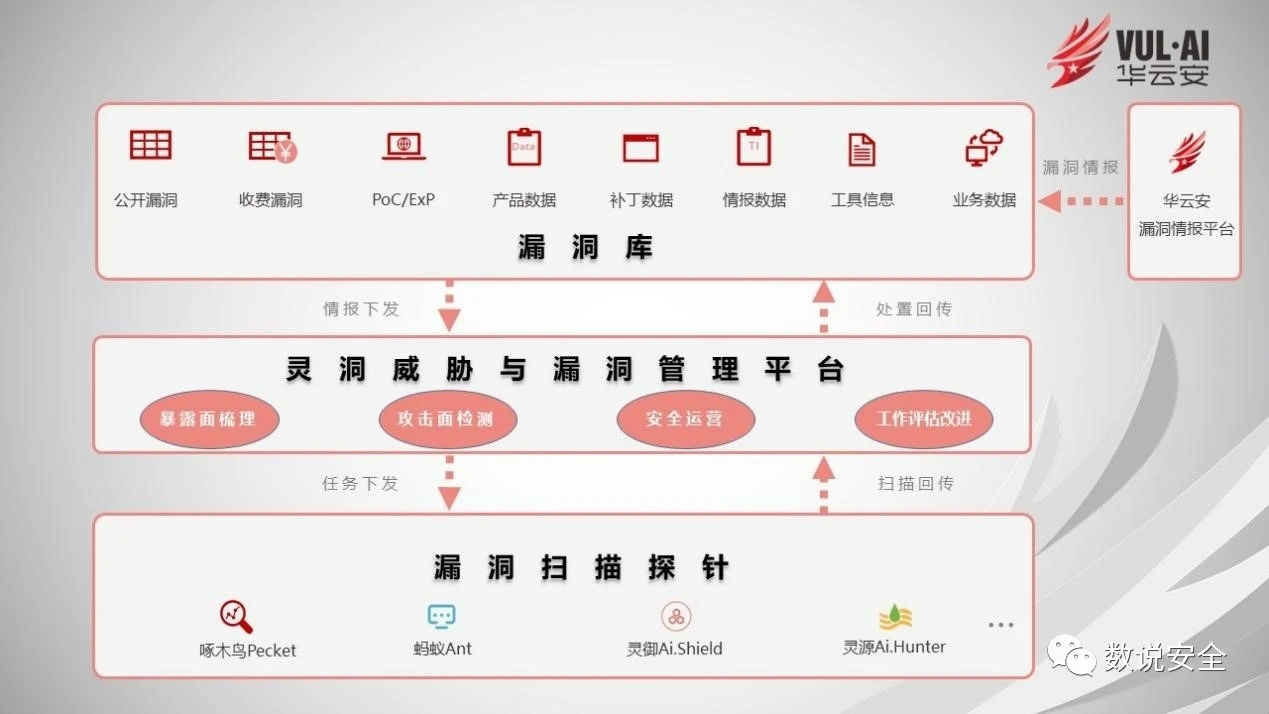
面对混合云环境,需要建立一套资产漏洞检测和管理平台,采集整个系统软硬件产品和组件的所有漏洞信息,有效支持收录、发布、混合云环境中漏洞的预警、分析、验证、处置等工作。对于漏洞安全应急工作,尤其是高危及以上漏洞风险防范、大规模漏洞利用攻击处理,企业全面提升信息安全防护、风险管理和威胁的整体水平至关重要。回复。
华云安资产漏洞检测与管理解决方案具备混合云环境下资产漏洞检测与管理能力。整体架构包括漏洞数据库、漏洞管理平台、漏洞扫描探针三部分。在:
漏洞数据库,具有收录漏洞信息、接收和发布预警通知、监控企业漏洞情况等功能;
漏洞管理平台负责接收漏洞预警情报信息,生成漏洞扫描任务,向扫描探针下发漏洞扫描任务进行漏洞扫描,具有漏洞响应、管理和操作功能;
漏洞扫描探针负责接收漏洞管理平台下发的漏洞扫描任务,执行漏洞扫描任务,反馈漏洞扫描结果,完成混合云环境下资产漏洞检测与验证的功能。
虽然企业上云已经成为常态,混合云也为企业IT资源管理提供了更有效的解决方案,但混合云固有的逆向威力也不容小觑。在混合云环境中,资产漏洞检测和管理需要把握解决问题的关键要素——灵活高效。这正是华云安资产漏洞检测与管理解决方案的价值所在。在混合云环境中,以简单、复杂、高效、优质的方式解决用户资产风险管理的痛点,为用户提供资产漏洞管理和漏洞响应的持续迭代能力和一致体验。 查看全部
云优采集接口(2020年Forrester发布的《混合多云战略的关键》调研结果显示)
混合云包括多供应商公共云、私有云和本地数据中心之间的混合部署模型。
2020 年,Forrester 的“混合多云战略的关键”调查结果显示,85% 的受访者正在增加对混合云管理的需求,90% 的 IT 领导者认为本地基础设施是其混合云的关键组成部分战略 。同样,根据 Gartner 的一份报告,2020 年之后,超过 90% 的组织将使用混合云来构建基础设施。混合云架构将是未来5到10年企业最常见的架构形式。
混合云将企业私有云、公有云、本地数据中心有机融合,为企业提供更丰富的云服务、更灵活的云资源、更合理的IT资源使用成本。同时,混合云的复杂性给企业网络安全管理带来巨大挑战。目前,混合云上资产漏洞管理的成熟度远远落后于传统本地数据中心,造成偏差的主要原因是缺乏适应混合云环境的资产漏洞检测和管理解决方案。
1、 混合云环境下资产漏洞检测方法
目前,在混合云环境中检测资产漏洞的方法主要有以下三种:
如何保证资产漏洞检测全面、准确、可靠?我们首先要了解混合云环境下资产漏洞检测遇到的问题。
2、混合云环境下资产漏洞检测现状及痛点
云资产漏洞检测存在盲点
在传统环境中,所有资产必须通过物理层网络设施进行连接,我们可以通过物理网络完成资产漏洞检测。
但是,在云环境中,网络端口也是虚拟化的,物理节点无法覆盖业务数据流经的关键路径。要实现全资产漏洞检测,需要具备针对VPC、VM、Docker、POD、OVS,甚至某个API接口等不同类型节点的资产漏洞检测能力。
资源池复杂,资产维度不一致
在混合云架构中,企业对计算资源实施统一的资源池管理。但在资产管理层面,往往缺乏统一规划。虚拟化软件、裸机、容器、云平台等异构资源各自独立。企业资源池因资产数量和类型的变化而被动变化。漏洞检测工具存在难以适应资源池动态变化等问题。
传统工具难以适应云上复杂的环境
与传统物理环境相比,云环境中的主机和容器会动态创建、销毁、迁移和弹性扩展。如果是固定配置漏洞检测,资产动态迁移后,检测会中断,无法持续,而这种动态变化的特点是随机的、常态化的。网络环境也比较复杂,各种VPC的存在使得传统的检测工具难以适应多样化的网络环境。
如何在大规模虚拟混合环境中实现资产全面覆盖、检测性能高、准确率高,同时与企业安全运营平台(SOC)无缝对接?这是在混合云环境中选择资产漏洞检测和管理解决方案时需要考虑的关键问题。

3、 混合云环境下资产漏洞检测与管理解决方案
跨混合环境的统一 采集 解决方案
要构建统一高效、无盲区的全资产漏洞检测与管理解决方案,漏洞检测工具必须能够跨越私有云、公有云、容器、传统环境等多种混合架构,提供一致的漏洞检测和管理能力。
【灵活动态】+【高效检测】适应云环境的解决方案
在云环境下,漏洞检测工具需要具备自动感知节点变化的能力,进而自动进行相应的更新和部署,保证漏洞检测工作不被中断,适应云上的弹性伸缩。
漏洞检测工具还需要适应云上大规模、高并发的流量机制,基于高性能并发检测技术,实现百万级资产漏洞检测。
通过漏洞管理平台的自我监控能力,用户可以实时了解系统的资源消耗状况,及时优化资源配置和检测配置。
4、从漏洞检测到响应的整体解决方案
面对混合云环境,需要建立一套资产漏洞检测和管理平台,采集整个系统软硬件产品和组件的所有漏洞信息,有效支持收录、发布、混合云环境中漏洞的预警、分析、验证、处置等工作。对于漏洞安全应急工作,尤其是高危及以上漏洞风险防范、大规模漏洞利用攻击处理,企业全面提升信息安全防护、风险管理和威胁的整体水平至关重要。回复。
华云安资产漏洞检测与管理解决方案具备混合云环境下资产漏洞检测与管理能力。整体架构包括漏洞数据库、漏洞管理平台、漏洞扫描探针三部分。在:
漏洞数据库,具有收录漏洞信息、接收和发布预警通知、监控企业漏洞情况等功能;
漏洞管理平台负责接收漏洞预警情报信息,生成漏洞扫描任务,向扫描探针下发漏洞扫描任务进行漏洞扫描,具有漏洞响应、管理和操作功能;
漏洞扫描探针负责接收漏洞管理平台下发的漏洞扫描任务,执行漏洞扫描任务,反馈漏洞扫描结果,完成混合云环境下资产漏洞检测与验证的功能。
虽然企业上云已经成为常态,混合云也为企业IT资源管理提供了更有效的解决方案,但混合云固有的逆向威力也不容小觑。在混合云环境中,资产漏洞检测和管理需要把握解决问题的关键要素——灵活高效。这正是华云安资产漏洞检测与管理解决方案的价值所在。在混合云环境中,以简单、复杂、高效、优质的方式解决用户资产风险管理的痛点,为用户提供资产漏洞管理和漏洞响应的持续迭代能力和一致体验。
云优采集接口(帝国cms7.5有没有优采云采集器采集器的发布模块呢?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-12-14 19:26
Empirecms7.5 有没有优采云采集器的发布模块?在网上找了半天,没找到。今天在Empirecms7.5找到一个7.0的模块,修改后就可以使用了。让我与你分享。这个插件是一种登录方式。在优采云发布模块的WEB配置管理中添加域名地址,选择数据包登录方式。
提示:使用前请进入后台关闭验证码,打开后台源验证码。如果您关闭源验证代码,则可以使用它。如果你认为它不安全,那就没有办法了。
百度网盘:提取码:mzuf
我在项目中接触到了优采云采集器。第一次用的时候,感觉真的很神奇。采集的数据真的很惊人。互联网上80%以上的数据都可以通过采集获取。正好最近用Empirecms做了一个信息门户网站。大家都知道,信息门户最头疼的就是数据。碰巧我有数据优采云采集,那个数据一个字跑酷。
高兴了一阵子后,一个现实的问题来了,如何将采集中的所有数据批量导入到帝国的数据库中?我把我的问题告诉了我的朋友,朋友说你可以写一个优采云的帝国发布模块。他这么一说,我就去优采云采集器看看,果然有发布模块的功能。优采云提供三种数据发布方式。
第一种:直接在网络上发布模块,在线发布。
第二种:将发布的数据保存为文件。
第三种:直接发布到数据库。
按照我的想法,在网上搜了一下,搜索优采云发布模块,发现了很多结果,但是大部分教程只是一点点味道,大部分都是废话当天。还是不知道怎么操作。无奈之下,向朋友索取一份,学习了操作、修改等操作,接下来将这个优采云发布模块的方法分享给大家。
我希望我不必像我一样来回走动:
首先,我们需要使用三个文件:
EcmsLogin.php 自己创建
hinfofun.php 系统自带
Empirecms 7.2 免费登录新闻发布模块.wpm
第一步:将需要的文件放在指定的文件夹中:
将文件 1 复制到 e/admin/ 并将文件 2 复制到 e/class/ 文件夹。
文件2.需要二次开发,其作用是可以远程保存图片。代码显示如下。
// 二次开发代码
if($add['diy'] == 1){
//远程保存标题图片
if($add['titlepic']){
$tranr=DoTranURL($add['titlepic'],$add['classid']);
如果($tranr[tran])
{
$tranr[文件大小]=(int)$tranr[文件大小];
$tranr[type]=(int)$tranr[type];
//记录数据库
eInsertFileTable($tranr[filename],$tranr[filesize],$tranr[filepath],$username,$add['classid'],
'[s][URL]'.$tranr[filename],$tranr[type],0,$add['filepass'],$public_r[fpath],0,0,$public_r['filedeftb']);
//$add['titlepic']=$tranr[url];
$addtitlepic=",titlepic='".addslashes($tranr[url])."',ispic=1″;
}
}
}
第二步:编写优采云的发布模块。
第三步:直接在线测试。发布内容时,选择web在线发布到网站。
通过以上步骤,优采云的Empire发布模块就可以完成了。如果你还是不明白,给我留言。
推荐阅读:阿里云OSS的destoon对象存储和七牛云(基础版)destoon已经推出了应用商店,其中一个是对象存储,但只能供流行版本以上的用户使用。Deston... 不排除 WordPress。正在进行例行维护,请一分钟后回来”解决方案WordPress在升级程序、主题、插件时会先切换到维护模式,即“正在进行例行维护,请一分钟后回来... ... WordPress网站导航主题自适应手机网站导航源码网站模板wordpress网站导航主题自适应手机网站导航源码网站模板ps:纯主题无数据,需单独安装wordp。 .. 仿游戏Bar源码手游下载门户手游网站模板帝国cms7.5核帝国cms核心仿《Game Bar》手游模板门户,游戏源码,游戏模板 程序自带手机版,发送优采云采集 开发环境:Empire c...Empirecms7.5模版仿旅游信息模板旅游信息< @网站 源代码模仿“旅行网”的源代码。旅游资讯网站模板同步插件+会员贡献帝国cms+auto采集一个不错的旅游资讯门户网站源码,.... 核心仿《Game Bar》手游模板门户、游戏源码、游戏模板 程序自带手机版,送优采云采集 开发环境:Empire c... Empirecms 7.5 模板仿旅游信息模板旅游信息网站 源码仿“”源码。旅游资讯网站模板同步插件+会员贡献帝国cms+auto采集一个不错的旅游资讯门户网站源码,.... 核心仿《Game Bar》手游模板门户、游戏源码、游戏模板 程序自带手机版,送优采云采集 开发环境:Empire c... Empirecms 7.5 模板仿旅游信息模板旅游信息网站 源码仿“”源码。旅游资讯网站模板同步插件+会员贡献帝国cms+auto采集一个不错的旅游资讯门户网站源码,.... 5 模板仿旅游信息模板旅游信息网站 源码仿“”源码。旅游资讯网站模板同步插件+会员贡献帝国cms+auto采集一个不错的旅游资讯门户网站源码,.... 5 模板仿旅游信息模板旅游信息网站 源码仿“”源码。旅游资讯网站模板同步插件+会员贡献帝国cms+auto采集一个不错的旅游资讯门户网站源码,.... 查看全部
云优采集接口(帝国cms7.5有没有优采云采集器采集器的发布模块呢?)
Empirecms7.5 有没有优采云采集器的发布模块?在网上找了半天,没找到。今天在Empirecms7.5找到一个7.0的模块,修改后就可以使用了。让我与你分享。这个插件是一种登录方式。在优采云发布模块的WEB配置管理中添加域名地址,选择数据包登录方式。
提示:使用前请进入后台关闭验证码,打开后台源验证码。如果您关闭源验证代码,则可以使用它。如果你认为它不安全,那就没有办法了。
 https://www.yuntue.com/wp-cont ... 1.png 673w" />
https://www.yuntue.com/wp-cont ... 1.png 673w" />百度网盘:提取码:mzuf
我在项目中接触到了优采云采集器。第一次用的时候,感觉真的很神奇。采集的数据真的很惊人。互联网上80%以上的数据都可以通过采集获取。正好最近用Empirecms做了一个信息门户网站。大家都知道,信息门户最头疼的就是数据。碰巧我有数据优采云采集,那个数据一个字跑酷。
高兴了一阵子后,一个现实的问题来了,如何将采集中的所有数据批量导入到帝国的数据库中?我把我的问题告诉了我的朋友,朋友说你可以写一个优采云的帝国发布模块。他这么一说,我就去优采云采集器看看,果然有发布模块的功能。优采云提供三种数据发布方式。
第一种:直接在网络上发布模块,在线发布。
第二种:将发布的数据保存为文件。
第三种:直接发布到数据库。
按照我的想法,在网上搜了一下,搜索优采云发布模块,发现了很多结果,但是大部分教程只是一点点味道,大部分都是废话当天。还是不知道怎么操作。无奈之下,向朋友索取一份,学习了操作、修改等操作,接下来将这个优采云发布模块的方法分享给大家。
我希望我不必像我一样来回走动:
首先,我们需要使用三个文件:
EcmsLogin.php 自己创建
hinfofun.php 系统自带
Empirecms 7.2 免费登录新闻发布模块.wpm
第一步:将需要的文件放在指定的文件夹中:
将文件 1 复制到 e/admin/ 并将文件 2 复制到 e/class/ 文件夹。
文件2.需要二次开发,其作用是可以远程保存图片。代码显示如下。
// 二次开发代码
if($add['diy'] == 1){
//远程保存标题图片
if($add['titlepic']){
$tranr=DoTranURL($add['titlepic'],$add['classid']);
如果($tranr[tran])
{
$tranr[文件大小]=(int)$tranr[文件大小];
$tranr[type]=(int)$tranr[type];
//记录数据库
eInsertFileTable($tranr[filename],$tranr[filesize],$tranr[filepath],$username,$add['classid'],
'[s][URL]'.$tranr[filename],$tranr[type],0,$add['filepass'],$public_r[fpath],0,0,$public_r['filedeftb']);
//$add['titlepic']=$tranr[url];
$addtitlepic=",titlepic='".addslashes($tranr[url])."',ispic=1″;
}
}
}
第二步:编写优采云的发布模块。
 https://www.yuntue.com/wp-cont ... 2.png 584w" />
https://www.yuntue.com/wp-cont ... 2.png 584w" />第三步:直接在线测试。发布内容时,选择web在线发布到网站。
 https://www.yuntue.com/wp-cont ... 8.png 768w, https://www.yuntue.com/wp-cont ... 3.png 794w" />
https://www.yuntue.com/wp-cont ... 8.png 768w, https://www.yuntue.com/wp-cont ... 3.png 794w" />通过以上步骤,优采云的Empire发布模块就可以完成了。如果你还是不明白,给我留言。
推荐阅读:阿里云OSS的destoon对象存储和七牛云(基础版)destoon已经推出了应用商店,其中一个是对象存储,但只能供流行版本以上的用户使用。Deston... 不排除 WordPress。正在进行例行维护,请一分钟后回来”解决方案WordPress在升级程序、主题、插件时会先切换到维护模式,即“正在进行例行维护,请一分钟后回来... ... WordPress网站导航主题自适应手机网站导航源码网站模板wordpress网站导航主题自适应手机网站导航源码网站模板ps:纯主题无数据,需单独安装wordp。 .. 仿游戏Bar源码手游下载门户手游网站模板帝国cms7.5核帝国cms核心仿《Game Bar》手游模板门户,游戏源码,游戏模板 程序自带手机版,发送优采云采集 开发环境:Empire c...Empirecms7.5模版仿旅游信息模板旅游信息< @网站 源代码模仿“旅行网”的源代码。旅游资讯网站模板同步插件+会员贡献帝国cms+auto采集一个不错的旅游资讯门户网站源码,.... 核心仿《Game Bar》手游模板门户、游戏源码、游戏模板 程序自带手机版,送优采云采集 开发环境:Empire c... Empirecms 7.5 模板仿旅游信息模板旅游信息网站 源码仿“”源码。旅游资讯网站模板同步插件+会员贡献帝国cms+auto采集一个不错的旅游资讯门户网站源码,.... 核心仿《Game Bar》手游模板门户、游戏源码、游戏模板 程序自带手机版,送优采云采集 开发环境:Empire c... Empirecms 7.5 模板仿旅游信息模板旅游信息网站 源码仿“”源码。旅游资讯网站模板同步插件+会员贡献帝国cms+auto采集一个不错的旅游资讯门户网站源码,.... 5 模板仿旅游信息模板旅游信息网站 源码仿“”源码。旅游资讯网站模板同步插件+会员贡献帝国cms+auto采集一个不错的旅游资讯门户网站源码,.... 5 模板仿旅游信息模板旅游信息网站 源码仿“”源码。旅游资讯网站模板同步插件+会员贡献帝国cms+auto采集一个不错的旅游资讯门户网站源码,....
云优采集接口(云平台云计算平台可以划分为3类:计算和数据存储处理兼顾)
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-12-14 00:09
云平台
云计算平台可以分为3类:
1、基于数据存储的存储云平台
2、专注于数据处理的计算云平台
3、兼顾计算和数据存储处理的综合云计算平台
云平台优势
1、 稳定性比较好
云平台的应用会影响网站的使用,所以云平台的稳定性对网站来说非常重要。我们平时的虚拟主机是多个网站共享一个主机,如果其中一个网站被攻击,会影响到另一个网站,所以空间的稳定性会大打折扣。
2、更安全可靠
服务器的安全对用户来说非常重要,因为一旦服务器出现故障,网站将无法进行正常的操作,给企业带来的损失是不可估量的,所以用户最害怕服务器故障. 但是,对于云平台而言,情况并非如此。即使网站的操作出现问题,云平台也会自动转移到其他机器上。
3、无限容量
云平台是一种几乎整合了全球终端“云”提供的容量的全网服务,不再局限于一台或几台服务器,所以在一定程度上可以说云计算是无止境的。
4、可扩展
对于一些中小企业来说,随着业务的不断扩展,后期可能需要对服务器进行扩容升级。云平台具有一定的可扩展性,可以满足企业后期的扩容升级,后期无需进行软硬件升级。
5、存储的更多方面
数据是企业的核心内容,所以平时必须备份数据。云平台具有数据备份功能,即使出现硬件问题,数据也不会受到影响或丢失。后期只需要正常的维护和运维,由服务商来维护,可以为企业节省大量的人力。
6、更轻松的协作和共享
极高的速度和无限的容量使不同国家的公司可以进行协同作业。云计算平台下的不同公司可以实现在线办公和同步运营。一家公司发送的最新数据可以让其他公司在“云端”。同步查看和采用,从而实现资源共享。
7、高速
与任何独立的企业数据中心相比,云计算提供的覆盖全球的高速计算和同步服务是这些独立支撑的企业所无法比拟的。
什么是云计算
1.基于互联网的相关服务的增加、使用和交付模式
2.该模式提供可用的、方便的、按需的网络访问,并进入可配置的计算资源共享池
3.只需很少的管理工作或与服务提供商的很少互动,即可快速提供这些资源
4.同样经常涉及通过互联网提供动态的、易于扩展的并且经常是虚拟化的资源
我们一般可以将云计算中的“云”理解为存在于云数据中心服务器集群上的各类资源的集合。这些资源分为硬件资源和软件资源。硬件资源包括服务器、内存、CPU,软件资源包括应用软件和集成开发环境。用户只需通过网络向本地计算机发送请求,即可从云端获取满足自身需求的资源,所有计算任务均在远程云数据中心完成。用户之所以能够按需获取各种计算服务、存储服务和各种软件资源,都是得益于云计算强大的虚拟化资源池架构。数据中心本身的资源池不仅可以动态扩展,用户使用后的资源也可以及时方便的回收利用。采用这样的服务提供模式,大大提高了云数据中心的资源利用率,同时,云计算服务提供商可以更好地提高服务质量。
云计算优势
阿里巴巴集团首席战略官曾铭曾系统总结云计算对企业的价值。
1、移动+云计算=IT服务“线上化”,大大降低了技术门槛。
2、 云计算是一项公共服务,成本可变,可以按需使用。不再是固定资产投资,创业公司的成本压力大大减轻。
3、云计算将数据转化为生产资料和企业资产。
4、云计算就是用足够低成本的商业模式来解决大规模计算的问题。
在2016杭州云栖大会上,马云提出了五个新理念:“新零售、新制造、新金融、新技术、新能源”。飞天是一种通用计算操作系统,可以将全球数百万台服务器连接成一台超级计算机,以在线公共服务的形式为社会提供计算能力。
阿里云总裁胡晓明表示:未来三到五年,云计算和大数据不仅会在互联网内部发生变化,还会在工业制造、农业运营、城市交通、基因、医学影像、教育和娱乐等领域发生变化。产生力量。“云计算和大数据将改变各行各业的基础生态,阿里巴巴希望将现有能力输出给更多的创新者、企业家、政府机构以及国内外合作伙伴。”
云服务
云服务的形式
云服务器ECS
弹性计算服务(简称ECS)是阿里云提供的IaaS(Infrastructure as a Service)级别的云计算服务,具有卓越的性能、稳定性、可靠性和弹性扩展性。云服务器ECS免去购买IT硬件的前期准备,让您像使用水、电、天然气等公共资源一样方便、高效地使用服务器,实现开箱即用、弹性伸缩计算资源。阿里云ECS持续提供创新服务器,解决各种业务需求,助力您的业务发展。
云服务器ECS主要包括以下功能组件: 通过云服务器ECS,您可以轻松构建计算资源,具有以下优势。阿里云日志服务一、云服务日志示例
公司业务是集群,通过数千甚至数万台服务器运行程序,每台服务器记录的所有日志都汇总在日志服务中,然后我们可以对日志服务进行采集、统计、汇总,分析
这样就可以看到和分析一段时间内产生的数据
阿里云日志服务(一),什么是阿里云日志服务
日志服务(SLS)是日志数据的一站式服务,经过阿里巴巴集团大量大数据场景的锤炼。无需开发即可快速完成日志数据采集、消费、交付、查询分析等功能,提升运维、运营效率,建立DT时代海量日志处理能力。
(二),日志服务的内容
1、**实时采集和消费(LogHub)**功能:
2、**搜索/分析**实时索引、查询和分析数据。
特征:
3、交付数据仓库(LogShipper)
稳定可靠的日志交付。将日志中心数据传送到存储服务进行存储。支持压缩、自定义Partition、rank等多种存储方式。目的:数据仓库+数据分析、审计、推荐系统和用户画像。
视频链接:关于日志服务说明 查看全部
云优采集接口(云平台云计算平台可以划分为3类:计算和数据存储处理兼顾)
云平台
云计算平台可以分为3类:
1、基于数据存储的存储云平台
2、专注于数据处理的计算云平台
3、兼顾计算和数据存储处理的综合云计算平台
云平台优势
1、 稳定性比较好
云平台的应用会影响网站的使用,所以云平台的稳定性对网站来说非常重要。我们平时的虚拟主机是多个网站共享一个主机,如果其中一个网站被攻击,会影响到另一个网站,所以空间的稳定性会大打折扣。
2、更安全可靠
服务器的安全对用户来说非常重要,因为一旦服务器出现故障,网站将无法进行正常的操作,给企业带来的损失是不可估量的,所以用户最害怕服务器故障. 但是,对于云平台而言,情况并非如此。即使网站的操作出现问题,云平台也会自动转移到其他机器上。
3、无限容量
云平台是一种几乎整合了全球终端“云”提供的容量的全网服务,不再局限于一台或几台服务器,所以在一定程度上可以说云计算是无止境的。
4、可扩展
对于一些中小企业来说,随着业务的不断扩展,后期可能需要对服务器进行扩容升级。云平台具有一定的可扩展性,可以满足企业后期的扩容升级,后期无需进行软硬件升级。
5、存储的更多方面
数据是企业的核心内容,所以平时必须备份数据。云平台具有数据备份功能,即使出现硬件问题,数据也不会受到影响或丢失。后期只需要正常的维护和运维,由服务商来维护,可以为企业节省大量的人力。
6、更轻松的协作和共享
极高的速度和无限的容量使不同国家的公司可以进行协同作业。云计算平台下的不同公司可以实现在线办公和同步运营。一家公司发送的最新数据可以让其他公司在“云端”。同步查看和采用,从而实现资源共享。
7、高速
与任何独立的企业数据中心相比,云计算提供的覆盖全球的高速计算和同步服务是这些独立支撑的企业所无法比拟的。
什么是云计算
1.基于互联网的相关服务的增加、使用和交付模式
2.该模式提供可用的、方便的、按需的网络访问,并进入可配置的计算资源共享池
3.只需很少的管理工作或与服务提供商的很少互动,即可快速提供这些资源
4.同样经常涉及通过互联网提供动态的、易于扩展的并且经常是虚拟化的资源
我们一般可以将云计算中的“云”理解为存在于云数据中心服务器集群上的各类资源的集合。这些资源分为硬件资源和软件资源。硬件资源包括服务器、内存、CPU,软件资源包括应用软件和集成开发环境。用户只需通过网络向本地计算机发送请求,即可从云端获取满足自身需求的资源,所有计算任务均在远程云数据中心完成。用户之所以能够按需获取各种计算服务、存储服务和各种软件资源,都是得益于云计算强大的虚拟化资源池架构。数据中心本身的资源池不仅可以动态扩展,用户使用后的资源也可以及时方便的回收利用。采用这样的服务提供模式,大大提高了云数据中心的资源利用率,同时,云计算服务提供商可以更好地提高服务质量。
云计算优势
阿里巴巴集团首席战略官曾铭曾系统总结云计算对企业的价值。
1、移动+云计算=IT服务“线上化”,大大降低了技术门槛。
2、 云计算是一项公共服务,成本可变,可以按需使用。不再是固定资产投资,创业公司的成本压力大大减轻。
3、云计算将数据转化为生产资料和企业资产。
4、云计算就是用足够低成本的商业模式来解决大规模计算的问题。
在2016杭州云栖大会上,马云提出了五个新理念:“新零售、新制造、新金融、新技术、新能源”。飞天是一种通用计算操作系统,可以将全球数百万台服务器连接成一台超级计算机,以在线公共服务的形式为社会提供计算能力。
阿里云总裁胡晓明表示:未来三到五年,云计算和大数据不仅会在互联网内部发生变化,还会在工业制造、农业运营、城市交通、基因、医学影像、教育和娱乐等领域发生变化。产生力量。“云计算和大数据将改变各行各业的基础生态,阿里巴巴希望将现有能力输出给更多的创新者、企业家、政府机构以及国内外合作伙伴。”
云服务
云服务的形式
云服务器ECS
弹性计算服务(简称ECS)是阿里云提供的IaaS(Infrastructure as a Service)级别的云计算服务,具有卓越的性能、稳定性、可靠性和弹性扩展性。云服务器ECS免去购买IT硬件的前期准备,让您像使用水、电、天然气等公共资源一样方便、高效地使用服务器,实现开箱即用、弹性伸缩计算资源。阿里云ECS持续提供创新服务器,解决各种业务需求,助力您的业务发展。

云服务器ECS主要包括以下功能组件: 通过云服务器ECS,您可以轻松构建计算资源,具有以下优势。阿里云日志服务一、云服务日志示例
公司业务是集群,通过数千甚至数万台服务器运行程序,每台服务器记录的所有日志都汇总在日志服务中,然后我们可以对日志服务进行采集、统计、汇总,分析

这样就可以看到和分析一段时间内产生的数据
阿里云日志服务(一),什么是阿里云日志服务
日志服务(SLS)是日志数据的一站式服务,经过阿里巴巴集团大量大数据场景的锤炼。无需开发即可快速完成日志数据采集、消费、交付、查询分析等功能,提升运维、运营效率,建立DT时代海量日志处理能力。
(二),日志服务的内容
1、**实时采集和消费(LogHub)**功能:

2、**搜索/分析**实时索引、查询和分析数据。
特征:
3、交付数据仓库(LogShipper)
稳定可靠的日志交付。将日志中心数据传送到存储服务进行存储。支持压缩、自定义Partition、rank等多种存储方式。目的:数据仓库+数据分析、审计、推荐系统和用户画像。

视频链接:关于日志服务说明
云优采集接口(算子采集Dump数据偏差对比,助开发人员快速解决算子精度问题 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2021-12-11 06:16
)
查看PDF
转储数据采集
链接复制成功!
更新时间:2021/12/09 GMT+08:00
概述
当训练网络的精度没有达到预期时,可以使用训练过程中各个算子的计算结果(即Data Dump数据),然后使用精度对比工具和行业标准算子(如TensorFlow)进行对比计算结果 进行数据偏差对比,帮助开发者快速解决算子精度问题。目前支持采集的operator数据主要有:
默认训练过程中,没有采集算子的dump数据。如果需要采集并分析数据,可以选择以下两种方式之一:
使用注意事项
采集在 Estimator 模式下转储数据
在Estimator模式下,通过NPUrunConfig中的dump_config采集Dump data,在创建NPUrunConfig之前,先实例化一个DumpConfig类进行dump配置(包括配置dump路径,哪些迭代数据要dump,dump算子的输入或输出)数据等)。
DumpConfig类的构造函数中各个字段的详细解释请参考对应的接口说明。
from npu_bridge.npu_init import *
# dump_path:dump数据存放路径,该参数指定的目录需要在启动训练的环境上(容器或Host侧)提前创建且确保安装时配置的运行用户具有读写权限
# enable_dump:是否开启Dump功能
# dump_step:指定采集哪些迭代的Dump数据
# dump_mode:Dump模式,取值:input/output/all
dump_config = DumpConfig(enable_dump=True, dump_path = "/home/HwHiAiUser/output", dump_step="0|5|10", dump_mode="all")
session_config=tf.ConfigProto()
config = NPURunConfig(
dump_config=dump_config,
session_config=session_config
)
采集在sess.run模式下转储数据
在sess.run模式下,通过会话配置项enable_dump、dump_path、dump_step、dump_mode来配置相关参数。
config = tf.ConfigProto()
custom_op = config.graph_options.rewrite_options.custom_optimizers.add()
custom_op.name = "NpuOptimizer"
custom_op.parameter_map["use_off_line"].b = True
# enable_dump:是否开启Dump功能
custom_op.parameter_map["enable_dump"].b = True
# dump_path:dump数据存放路径,该参数指定的目录需要在启动训练的环境上(容器或Host侧)提前创建且确保安装时配置的运行用户具有读写权限
custom_op.parameter_map["dump_path"].s = tf.compat.as_bytes("/home/HwHiAiUser/output")
# dump_step:指定采集哪些迭代的Dump数据
custom_op.parameter_map["dump_step"].s = tf.compat.as_bytes("0|5|10")
# dump_mode:Dump模式,取值:input/output/all
custom_op.parameter_map["dump_mode"].s = tf.compat.as_bytes("all")
config.graph_options.rewrite_options.remapping = RewriterConfig.OFF
config.graph_options.rewrite_options.memory_optimization = RewriterConfig.OFF
with tf.Session(config=config) as sess:
print(sess.run(cost))
执行训练并生成转储数据
后续通过工具进行精度比较不仅依赖Dump数据,还需要计算图结构。因此,在进行训练之前,需要配置环境变量转储图文件:
export DUMP_GE_GRAPH=2
export DUMP_GRAPH_PATH=/home/dumpgraph # 指定dump图路径,如果不配置存储在训练脚本所在目录
执行训练,生成转储图像文件和转储数据文件。
由于“ge”开头的转储图文件很多,转储数据文件夹的model_name层可能有多个文件夹,其实我们只需要找到计算图文件,只要找到model_name为计算图的名称。下面提供一些方法,帮助用户快速找到对应的文件。
选择计算图文件,提供了两种方法: 选择转储数据文件。打开上一步找到的计算图文件,记录第一张图中name字段的值。在以下示例中,记录“ge_default_253_71”。
graph {
name: "ge_default_20201209083353_71"
op {
name: "atomic_addr_clean0_71"
type: "AtomicAddrClean"
attr {
key: "_fe_imply_type"
value {
i: 6
}
}
进入dump data文件夹,我们会看到model_name层有多个文件夹:
找到名称为刚才记录的计算图的名称值的文件夹,如ge_default_253_71。此目录中的文件是您需要的转储数据文件。
查看全部
云优采集接口(算子采集Dump数据偏差对比,助开发人员快速解决算子精度问题
)
查看PDF
转储数据采集
链接复制成功!
更新时间:2021/12/09 GMT+08:00
概述
当训练网络的精度没有达到预期时,可以使用训练过程中各个算子的计算结果(即Data Dump数据),然后使用精度对比工具和行业标准算子(如TensorFlow)进行对比计算结果 进行数据偏差对比,帮助开发者快速解决算子精度问题。目前支持采集的operator数据主要有:

默认训练过程中,没有采集算子的dump数据。如果需要采集并分析数据,可以选择以下两种方式之一:
使用注意事项
采集在 Estimator 模式下转储数据
在Estimator模式下,通过NPUrunConfig中的dump_config采集Dump data,在创建NPUrunConfig之前,先实例化一个DumpConfig类进行dump配置(包括配置dump路径,哪些迭代数据要dump,dump算子的输入或输出)数据等)。
DumpConfig类的构造函数中各个字段的详细解释请参考对应的接口说明。
from npu_bridge.npu_init import *
# dump_path:dump数据存放路径,该参数指定的目录需要在启动训练的环境上(容器或Host侧)提前创建且确保安装时配置的运行用户具有读写权限
# enable_dump:是否开启Dump功能
# dump_step:指定采集哪些迭代的Dump数据
# dump_mode:Dump模式,取值:input/output/all
dump_config = DumpConfig(enable_dump=True, dump_path = "/home/HwHiAiUser/output", dump_step="0|5|10", dump_mode="all")
session_config=tf.ConfigProto()
config = NPURunConfig(
dump_config=dump_config,
session_config=session_config
)
采集在sess.run模式下转储数据
在sess.run模式下,通过会话配置项enable_dump、dump_path、dump_step、dump_mode来配置相关参数。
config = tf.ConfigProto()
custom_op = config.graph_options.rewrite_options.custom_optimizers.add()
custom_op.name = "NpuOptimizer"
custom_op.parameter_map["use_off_line"].b = True
# enable_dump:是否开启Dump功能
custom_op.parameter_map["enable_dump"].b = True
# dump_path:dump数据存放路径,该参数指定的目录需要在启动训练的环境上(容器或Host侧)提前创建且确保安装时配置的运行用户具有读写权限
custom_op.parameter_map["dump_path"].s = tf.compat.as_bytes("/home/HwHiAiUser/output")
# dump_step:指定采集哪些迭代的Dump数据
custom_op.parameter_map["dump_step"].s = tf.compat.as_bytes("0|5|10")
# dump_mode:Dump模式,取值:input/output/all
custom_op.parameter_map["dump_mode"].s = tf.compat.as_bytes("all")
config.graph_options.rewrite_options.remapping = RewriterConfig.OFF
config.graph_options.rewrite_options.memory_optimization = RewriterConfig.OFF
with tf.Session(config=config) as sess:
print(sess.run(cost))
执行训练并生成转储数据
后续通过工具进行精度比较不仅依赖Dump数据,还需要计算图结构。因此,在进行训练之前,需要配置环境变量转储图文件:
export DUMP_GE_GRAPH=2
export DUMP_GRAPH_PATH=/home/dumpgraph # 指定dump图路径,如果不配置存储在训练脚本所在目录
执行训练,生成转储图像文件和转储数据文件。
由于“ge”开头的转储图文件很多,转储数据文件夹的model_name层可能有多个文件夹,其实我们只需要找到计算图文件,只要找到model_name为计算图的名称。下面提供一些方法,帮助用户快速找到对应的文件。
选择计算图文件,提供了两种方法: 选择转储数据文件。打开上一步找到的计算图文件,记录第一张图中name字段的值。在以下示例中,记录“ge_default_253_71”。
graph {
name: "ge_default_20201209083353_71"
op {
name: "atomic_addr_clean0_71"
type: "AtomicAddrClean"
attr {
key: "_fe_imply_type"
value {
i: 6
}
}
进入dump data文件夹,我们会看到model_name层有多个文件夹:

找到名称为刚才记录的计算图的名称值的文件夹,如ge_default_253_71。此目录中的文件是您需要的转储数据文件。

云优采集接口(网络精度未达预期时如何解决算子精度问题?-八维教育)
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2021-12-11 06:12
查看PDF
转储数据采集
链接复制成功!
更新时间:2021/12/09 GMT+08:00
概述
当训练网络的准确率达不到预期时,可以使用采集训练过程中各个算子的运算结果(即Data Dump数据),然后使用准确率对比工具和行业标准算子(如TensorFlow)将计算结果与数据偏差进行比较,从而帮助开发者快速解决算子精度问题。目前支持采集的operator数据主要有:
默认训练过程不会采集操作员转储数据。如果您需要采集并分析数据,您可以选择以下两种方法之一:
使用注意事项
修改Estimator模式,查看迁移脚本中是否有“init_resource”。
if __name__ == '__main__':
session_config = tf.ConfigProto()
custom_op = session_config.graph_options.rewrite_options.custom_optimizers.add()
custom_op.name = "NpuOptimizer"
# enable_dump:是否开启Dump功能
custom_op.parameter_map["enable_dump"].b = True
# dump_path:dump数据存放路径,该参数指定的目录需要在启动训练的环境上(容器或Host侧)提前创建且确保安装时配置的运行用户具有读写权限
custom_op.parameter_map["dump_path"].s = tf.compat.as_bytes("/home/HwHiAiUser/output")
# dump_step:指定采集哪些迭代的Dump数据
custom_op.parameter_map["dump_step"].s = tf.compat.as_bytes("0|5|10")
# dump_mode:Dump模式,取值:input/output/all
custom_op.parameter_map["dump_mode"].s = tf.compat.as_bytes("all")
(npu_sess, npu_shutdown) = init_resource(config=session_config)
tf.app.run()
shutdown_resource(npu_sess, npu_shutdown)
close_session(npu_sess)
在迁移的脚本中找到“npu_run_config_init”:
session_config = tf.ConfigProto(allow_soft_placement=True)
run_config = tf.estimator.RunConfig(
train_distribute=distribution_strategy,
session_config=session_config,
save_checkpoints_secs=60*60*24)
classifier = tf.estimator.Estimator(
model_fn=model_function, model_dir=flags_obj.model_dir, config=npu_run_config_init(run_config=run_config))
配置相关参数:
session_config = tf.ConfigProto(allow_soft_placement=True)
custom_op = session_config.graph_options.rewrite_options.custom_optimizers.add()
custom_op.name = 'NpuOptimizer'
# enable_dump:是否开启Dump功能
custom_op.parameter_map["enable_dump"].b = True
# dump_path:dump数据存放路径,该参数指定的目录需要在启动训练的环境上(容器或Host侧)提前创建且确保安装时配置的运行用户具有读写权限
custom_op.parameter_map["dump_path"].s = tf.compat.as_bytes("/home/HwHiAiUser/output")
# dump_step:指定采集哪些迭代的Dump数据
custom_op.parameter_map["dump_step"].s = tf.compat.as_bytes("0|5|10")
# dump_mode:Dump模式,取值:input/output/all
custom_op.parameter_map["dump_mode"].s = tf.compat.as_bytes("all")
run_config = tf.estimator.RunConfig(
train_distribute=distribution_strategy,
session_config=session_config,
save_checkpoints_secs=60*60*24)
classifier = tf.estimator.Estimator(
model_fn=model_function, model_dir=flags_obj.model_dir, config=npu_run_config_init(run_config=run_config))
如果脚本中的run配置函数,比如runConfig中没有传入session_config参数,则需要自己传入session_config:
session_config = tf.ConfigProto(allow_soft_placement=True)
custom_op = session_config.graph_options.rewrite_options.custom_optimizers.add()
custom_op.name = 'NpuOptimizer'
# 使能相关配置
custom_op.parameter_map["xxx"].x = xxx
run_config = tf.estimator.RunConfig(
train_distribute=distribution_strategy,
session_config=session_config,
save_checkpoints_secs=60*60*24)
classifier = tf.estimator.Estimator(
model_fn=model_function, model_dir=flags_obj.model_dir, config=npu_run_config_init(run_config=run_config))
修改sess.run模式,查看迁移的脚本是否有“init_resource”。
在脚本中找到“npu_config_proto”:
with tf.Session(config=npu_config_proto()) as sess:
sess.run(tf.global_variables_initializer())
interaction_table.init.run()
配置相关参数:
config_proto = tf.ConfigProto()
custom_op = config_proto.graph_options.rewrite_options.custom_optimizers.add()
custom_op.name = 'NpuOptimizer'
custom_op.parameter_map["enable_dump"].b = True
custom_op.parameter_map["dump_path"].s = tf.compat.as_bytes("/home/HwHiAiUser/output")
custom_op.parameter_map["dump_step"].s = tf.compat.as_bytes("0|5|10")
custom_op.parameter_map["dump_mode"].s = tf.compat.as_bytes("all")
config = npu_config_proto(config_proto=config_proto)
with tf.Session(config=config) as sess:
sess.run(tf.global_variables_initializer())
interaction_table.init.run()
修改tf.keras模式,查看迁移的脚本是否有“init_resource”。
if __name__ == '__main__':
session_config = tf.ConfigProto()
custom_op = session_config.graph_options.rewrite_options.custom_optimizers.add()
custom_op.name = "NpuOptimizer"
# enable_dump:是否开启Dump功能
custom_op.parameter_map["enable_dump"].b = True
# dump_path:dump数据存放路径,该参数指定的目录需要在启动训练的环境上(容器或Host侧)提前创建且确保安装时配置的运行用户具有读写权限
custom_op.parameter_map["dump_path"].s = tf.compat.as_bytes("/home/HwHiAiUser/output")
# dump_step:指定采集哪些迭代的Dump数据
custom_op.parameter_map["dump_step"].s = tf.compat.as_bytes("0|5|10")
# dump_mode:Dump模式,取值:input/output/all
custom_op.parameter_map["dump_mode"].s = tf.compat.as_bytes("all")
(npu_sess, npu_shutdown) = init_resource(config=session_config)
tf.app.run()
shutdown_resource(npu_sess, npu_shutdown)
close_session(npu_sess)
在脚本中找到“set_keras_session_npu_config”:
import tensorflow as tf
import tensorflow.python.keras as keras
from tensorflow.python.keras import backend as K
from npu_bridge.npu_init import *
npu_keras_sess = set_keras_session_npu_config()
#数据预处理...
#模型搭建...
#模型编译...
#模型训练...
配置相关参数:
import tensorflow as tf
import tensorflow.python.keras as keras
from tensorflow.python.keras import backend as K
from npu_bridge.npu_init import *
config_proto = tf.ConfigProto()
custom_op = config_proto.graph_options.rewrite_options.custom_optimizers.add()
custom_op.name = 'NpuOptimizer'
custom_op.parameter_map["precision_mode"].s = tf.compat.as_bytes("allow_mix_precision")
npu_keras_sess = set_keras_session_npu_config(config=config_proto)
#数据预处理...
#模型搭建...
#模型编译...
#模型训练...
父主题:更多功能 查看全部
云优采集接口(网络精度未达预期时如何解决算子精度问题?-八维教育)
查看PDF
转储数据采集
链接复制成功!
更新时间:2021/12/09 GMT+08:00
概述
当训练网络的准确率达不到预期时,可以使用采集训练过程中各个算子的运算结果(即Data Dump数据),然后使用准确率对比工具和行业标准算子(如TensorFlow)将计算结果与数据偏差进行比较,从而帮助开发者快速解决算子精度问题。目前支持采集的operator数据主要有:
默认训练过程不会采集操作员转储数据。如果您需要采集并分析数据,您可以选择以下两种方法之一:
使用注意事项
修改Estimator模式,查看迁移脚本中是否有“init_resource”。
if __name__ == '__main__':
session_config = tf.ConfigProto()
custom_op = session_config.graph_options.rewrite_options.custom_optimizers.add()
custom_op.name = "NpuOptimizer"
# enable_dump:是否开启Dump功能
custom_op.parameter_map["enable_dump"].b = True
# dump_path:dump数据存放路径,该参数指定的目录需要在启动训练的环境上(容器或Host侧)提前创建且确保安装时配置的运行用户具有读写权限
custom_op.parameter_map["dump_path"].s = tf.compat.as_bytes("/home/HwHiAiUser/output")
# dump_step:指定采集哪些迭代的Dump数据
custom_op.parameter_map["dump_step"].s = tf.compat.as_bytes("0|5|10")
# dump_mode:Dump模式,取值:input/output/all
custom_op.parameter_map["dump_mode"].s = tf.compat.as_bytes("all")
(npu_sess, npu_shutdown) = init_resource(config=session_config)
tf.app.run()
shutdown_resource(npu_sess, npu_shutdown)
close_session(npu_sess)
在迁移的脚本中找到“npu_run_config_init”:
session_config = tf.ConfigProto(allow_soft_placement=True)
run_config = tf.estimator.RunConfig(
train_distribute=distribution_strategy,
session_config=session_config,
save_checkpoints_secs=60*60*24)
classifier = tf.estimator.Estimator(
model_fn=model_function, model_dir=flags_obj.model_dir, config=npu_run_config_init(run_config=run_config))
配置相关参数:
session_config = tf.ConfigProto(allow_soft_placement=True)
custom_op = session_config.graph_options.rewrite_options.custom_optimizers.add()
custom_op.name = 'NpuOptimizer'
# enable_dump:是否开启Dump功能
custom_op.parameter_map["enable_dump"].b = True
# dump_path:dump数据存放路径,该参数指定的目录需要在启动训练的环境上(容器或Host侧)提前创建且确保安装时配置的运行用户具有读写权限
custom_op.parameter_map["dump_path"].s = tf.compat.as_bytes("/home/HwHiAiUser/output")
# dump_step:指定采集哪些迭代的Dump数据
custom_op.parameter_map["dump_step"].s = tf.compat.as_bytes("0|5|10")
# dump_mode:Dump模式,取值:input/output/all
custom_op.parameter_map["dump_mode"].s = tf.compat.as_bytes("all")
run_config = tf.estimator.RunConfig(
train_distribute=distribution_strategy,
session_config=session_config,
save_checkpoints_secs=60*60*24)
classifier = tf.estimator.Estimator(
model_fn=model_function, model_dir=flags_obj.model_dir, config=npu_run_config_init(run_config=run_config))
如果脚本中的run配置函数,比如runConfig中没有传入session_config参数,则需要自己传入session_config:
session_config = tf.ConfigProto(allow_soft_placement=True)
custom_op = session_config.graph_options.rewrite_options.custom_optimizers.add()
custom_op.name = 'NpuOptimizer'
# 使能相关配置
custom_op.parameter_map["xxx"].x = xxx
run_config = tf.estimator.RunConfig(
train_distribute=distribution_strategy,
session_config=session_config,
save_checkpoints_secs=60*60*24)
classifier = tf.estimator.Estimator(
model_fn=model_function, model_dir=flags_obj.model_dir, config=npu_run_config_init(run_config=run_config))
修改sess.run模式,查看迁移的脚本是否有“init_resource”。
在脚本中找到“npu_config_proto”:
with tf.Session(config=npu_config_proto()) as sess:
sess.run(tf.global_variables_initializer())
interaction_table.init.run()
配置相关参数:
config_proto = tf.ConfigProto()
custom_op = config_proto.graph_options.rewrite_options.custom_optimizers.add()
custom_op.name = 'NpuOptimizer'
custom_op.parameter_map["enable_dump"].b = True
custom_op.parameter_map["dump_path"].s = tf.compat.as_bytes("/home/HwHiAiUser/output")
custom_op.parameter_map["dump_step"].s = tf.compat.as_bytes("0|5|10")
custom_op.parameter_map["dump_mode"].s = tf.compat.as_bytes("all")
config = npu_config_proto(config_proto=config_proto)
with tf.Session(config=config) as sess:
sess.run(tf.global_variables_initializer())
interaction_table.init.run()
修改tf.keras模式,查看迁移的脚本是否有“init_resource”。
if __name__ == '__main__':
session_config = tf.ConfigProto()
custom_op = session_config.graph_options.rewrite_options.custom_optimizers.add()
custom_op.name = "NpuOptimizer"
# enable_dump:是否开启Dump功能
custom_op.parameter_map["enable_dump"].b = True
# dump_path:dump数据存放路径,该参数指定的目录需要在启动训练的环境上(容器或Host侧)提前创建且确保安装时配置的运行用户具有读写权限
custom_op.parameter_map["dump_path"].s = tf.compat.as_bytes("/home/HwHiAiUser/output")
# dump_step:指定采集哪些迭代的Dump数据
custom_op.parameter_map["dump_step"].s = tf.compat.as_bytes("0|5|10")
# dump_mode:Dump模式,取值:input/output/all
custom_op.parameter_map["dump_mode"].s = tf.compat.as_bytes("all")
(npu_sess, npu_shutdown) = init_resource(config=session_config)
tf.app.run()
shutdown_resource(npu_sess, npu_shutdown)
close_session(npu_sess)
在脚本中找到“set_keras_session_npu_config”:
import tensorflow as tf
import tensorflow.python.keras as keras
from tensorflow.python.keras import backend as K
from npu_bridge.npu_init import *
npu_keras_sess = set_keras_session_npu_config()
#数据预处理...
#模型搭建...
#模型编译...
#模型训练...
配置相关参数:
import tensorflow as tf
import tensorflow.python.keras as keras
from tensorflow.python.keras import backend as K
from npu_bridge.npu_init import *
config_proto = tf.ConfigProto()
custom_op = config_proto.graph_options.rewrite_options.custom_optimizers.add()
custom_op.name = 'NpuOptimizer'
custom_op.parameter_map["precision_mode"].s = tf.compat.as_bytes("allow_mix_precision")
npu_keras_sess = set_keras_session_npu_config(config=config_proto)
#数据预处理...
#模型搭建...
#模型编译...
#模型训练...
父主题:更多功能
云优采集接口(云优采集接口免费的?那就对了,让你年入百万!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-12-10 19:05
云优采集接口免费的?那就对了,云优采集接口功能很强大,云优采集接口可以随意搭建个人自媒体账号,成本低,人人可编辑,无需懂代码,无需懂设计,代理千千万,抓住机会,抓住当下,早日赚大钱!云优采集接口,跟着云优采集接口做,让你年入百万!找云优采集接口,
云优采集接口可以免费接入,
云优采集接口产品免费接入云优工商直接对接,接入云优采集接口,大数据时代前途无量。
云优采集接口
云优采集接口,带你去大数据。
云优采集接口,
1.云优采集接口免费接入。2.创建微信公众号,配置专用云优接口,保证获取的商品物流信息是真实的,价格更优惠。3.可采集新闻媒体推广的信息以及企业开发的app等等4.云优采集接口,支持多页自动更新。有专门数据运营机构负责更新到最新的数据。5.拥有4000多条商品物流信息。不过各个公司数据维度不一样。如果您的商品物流在小的公司也会作为一种运营特色,给自己店铺增加销量,提高曝光度和转化率的话,云优采集接口还是比较有帮助的。
我们公司以前也使用过一些竞价接口,但是由于不是本地的,具体发展怎么样还是不清楚,客户经常投诉无效。因为产品是接入公司的,客户很多,调用也是数据持证的数据库进行调用。有问题很难找到客户公司的人解决,我们后来找了厂家让他们代理了我们的接口,用的感觉还不错,就没再更新数据库,客户都比较满意。 查看全部
云优采集接口(云优采集接口免费的?那就对了,让你年入百万!)
云优采集接口免费的?那就对了,云优采集接口功能很强大,云优采集接口可以随意搭建个人自媒体账号,成本低,人人可编辑,无需懂代码,无需懂设计,代理千千万,抓住机会,抓住当下,早日赚大钱!云优采集接口,跟着云优采集接口做,让你年入百万!找云优采集接口,
云优采集接口可以免费接入,
云优采集接口产品免费接入云优工商直接对接,接入云优采集接口,大数据时代前途无量。
云优采集接口
云优采集接口,带你去大数据。
云优采集接口,
1.云优采集接口免费接入。2.创建微信公众号,配置专用云优接口,保证获取的商品物流信息是真实的,价格更优惠。3.可采集新闻媒体推广的信息以及企业开发的app等等4.云优采集接口,支持多页自动更新。有专门数据运营机构负责更新到最新的数据。5.拥有4000多条商品物流信息。不过各个公司数据维度不一样。如果您的商品物流在小的公司也会作为一种运营特色,给自己店铺增加销量,提高曝光度和转化率的话,云优采集接口还是比较有帮助的。
我们公司以前也使用过一些竞价接口,但是由于不是本地的,具体发展怎么样还是不清楚,客户经常投诉无效。因为产品是接入公司的,客户很多,调用也是数据持证的数据库进行调用。有问题很难找到客户公司的人解决,我们后来找了厂家让他们代理了我们的接口,用的感觉还不错,就没再更新数据库,客户都比较满意。
云优采集接口(训练网络精度未达预期时如何采集Dump数据数据? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2021-12-08 10:02
)
更新时间:2021-11-16 GMT+08:00
查看PDF
链接复制成功!
转储数据采集
概述
当训练网络的精度没有达到预期时,可以使用训练过程中各个算子的计算结果(即Data Dump数据),然后使用精度对比工具和行业标准算子(如TensorFlow)计算结果 进行数据偏差对比,帮助开发者快速解决算子精度问题。目前支持采集的operator数据主要有:
默认训练过程中,没有采集算子的dump数据。如果需要采集并分析数据,可以选择以下两种方式之一:
使用注意事项
采集在 Estimator 模式下转储数据
在Estimator模式下,通过NPUrunConfig中的dump_config采集Dump data,在创建NPUrunConfig之前,先实例化一个DumpConfig类进行dump配置(包括配置dump路径,哪些迭代数据要dump,dump算子的输入或输出)数据等)。
DumpConfig类的构造函数中各个字段的详细解释请参考对应的接口说明。
from npu_bridge.npu_init import *
# dump_path:dump数据存放路径,该参数指定的目录需要在启动训练的环境上(容器或Host侧)提前创建且确保安装时配置的运行用户具有读写权限
# enable_dump:是否开启Dump功能
# dump_step:指定采集哪些迭代的Dump数据
# dump_mode:Dump模式,取值:input/output/all
dump_config = DumpConfig(enable_dump=True, dump_path = "/home/HwHiAiUser/output", dump_step="0|5|10", dump_mode="all")
session_config=tf.ConfigProto()
config = NPURunConfig(
dump_config=dump_config,
session_config=session_config
)
采集在sess.run模式下转储数据
在sess.run模式下,通过session配置项enable_dump、dump_path、dump_step、dump_mode配置相关参数。
config = tf.ConfigProto()
custom_op = config.graph_options.rewrite_options.custom_optimizers.add()
custom_op.name = "NpuOptimizer"
custom_op.parameter_map["use_off_line"].b = True
# enable_dump:是否开启Dump功能
custom_op.parameter_map["enable_dump"].b = True
# dump_path:dump数据存放路径,该参数指定的目录需要在启动训练的环境上(容器或Host侧)提前创建且确保安装时配置的运行用户具有读写权限
custom_op.parameter_map["dump_path"].s = tf.compat.as_bytes("/home/HwHiAiUser/output")
# dump_step:指定采集哪些迭代的Dump数据
custom_op.parameter_map["dump_step"].s = tf.compat.as_bytes("0|5|10")
# dump_mode:Dump模式,取值:input/output/all
custom_op.parameter_map["dump_mode"].s = tf.compat.as_bytes("all")
config.graph_options.rewrite_options.remapping = RewriterConfig.OFF
config.graph_options.rewrite_options.memory_optimization = RewriterConfig.OFF
with tf.Session(config=config) as sess:
print(sess.run(cost))
执行训练并生成转储数据
后续的精度对比工具不仅依赖Dump数据,还需要计算图结构。因此,在进行训练之前,需要配置环境变量转储图文件:
export DUMP_GE_GRAPH=2
export DUMP_GRAPH_PATH=/home/dumpgraph # 指定dump图路径,如果不配置存储在训练脚本所在目录
执行训练,生成转储图像文件和转储数据文件。
由于“ge”开头的转储图文件很多,转储数据文件夹的model_name层可能有多个文件夹,所以实际上我们只需要找到计算图文件,只要找到model_name为计算图的名称。下面提供一些方法,帮助用户快速找到对应的文件。
选择计算图文件,提供以下两种方法:
选择转储数据文件。
打开上一步找到的计算图文件,记录第一张图中name字段的值。在以下示例中,记录“ge_default_253_71”。
graph {
name: "ge_default_20201209083353_71"
op {
name: "atomic_addr_clean0_71"
type: "AtomicAddrClean"
attr {
key: "_fe_imply_type"
value {
i: 6
}
}
进入dump data文件夹,我们会看到model_name层有多个文件夹:
找到名称为刚才记录的计算图的名称值的文件夹,如ge_default_253_71。此目录中的文件是您需要的转储数据文件。
查看全部
云优采集接口(训练网络精度未达预期时如何采集Dump数据数据?
)
更新时间:2021-11-16 GMT+08:00
查看PDF
链接复制成功!
转储数据采集
概述
当训练网络的精度没有达到预期时,可以使用训练过程中各个算子的计算结果(即Data Dump数据),然后使用精度对比工具和行业标准算子(如TensorFlow)计算结果 进行数据偏差对比,帮助开发者快速解决算子精度问题。目前支持采集的operator数据主要有:

默认训练过程中,没有采集算子的dump数据。如果需要采集并分析数据,可以选择以下两种方式之一:
使用注意事项
采集在 Estimator 模式下转储数据
在Estimator模式下,通过NPUrunConfig中的dump_config采集Dump data,在创建NPUrunConfig之前,先实例化一个DumpConfig类进行dump配置(包括配置dump路径,哪些迭代数据要dump,dump算子的输入或输出)数据等)。
DumpConfig类的构造函数中各个字段的详细解释请参考对应的接口说明。
from npu_bridge.npu_init import *
# dump_path:dump数据存放路径,该参数指定的目录需要在启动训练的环境上(容器或Host侧)提前创建且确保安装时配置的运行用户具有读写权限
# enable_dump:是否开启Dump功能
# dump_step:指定采集哪些迭代的Dump数据
# dump_mode:Dump模式,取值:input/output/all
dump_config = DumpConfig(enable_dump=True, dump_path = "/home/HwHiAiUser/output", dump_step="0|5|10", dump_mode="all")
session_config=tf.ConfigProto()
config = NPURunConfig(
dump_config=dump_config,
session_config=session_config
)
采集在sess.run模式下转储数据
在sess.run模式下,通过session配置项enable_dump、dump_path、dump_step、dump_mode配置相关参数。
config = tf.ConfigProto()
custom_op = config.graph_options.rewrite_options.custom_optimizers.add()
custom_op.name = "NpuOptimizer"
custom_op.parameter_map["use_off_line"].b = True
# enable_dump:是否开启Dump功能
custom_op.parameter_map["enable_dump"].b = True
# dump_path:dump数据存放路径,该参数指定的目录需要在启动训练的环境上(容器或Host侧)提前创建且确保安装时配置的运行用户具有读写权限
custom_op.parameter_map["dump_path"].s = tf.compat.as_bytes("/home/HwHiAiUser/output")
# dump_step:指定采集哪些迭代的Dump数据
custom_op.parameter_map["dump_step"].s = tf.compat.as_bytes("0|5|10")
# dump_mode:Dump模式,取值:input/output/all
custom_op.parameter_map["dump_mode"].s = tf.compat.as_bytes("all")
config.graph_options.rewrite_options.remapping = RewriterConfig.OFF
config.graph_options.rewrite_options.memory_optimization = RewriterConfig.OFF
with tf.Session(config=config) as sess:
print(sess.run(cost))
执行训练并生成转储数据
后续的精度对比工具不仅依赖Dump数据,还需要计算图结构。因此,在进行训练之前,需要配置环境变量转储图文件:
export DUMP_GE_GRAPH=2
export DUMP_GRAPH_PATH=/home/dumpgraph # 指定dump图路径,如果不配置存储在训练脚本所在目录
执行训练,生成转储图像文件和转储数据文件。
由于“ge”开头的转储图文件很多,转储数据文件夹的model_name层可能有多个文件夹,所以实际上我们只需要找到计算图文件,只要找到model_name为计算图的名称。下面提供一些方法,帮助用户快速找到对应的文件。
选择计算图文件,提供以下两种方法:
选择转储数据文件。
打开上一步找到的计算图文件,记录第一张图中name字段的值。在以下示例中,记录“ge_default_253_71”。
graph {
name: "ge_default_20201209083353_71"
op {
name: "atomic_addr_clean0_71"
type: "AtomicAddrClean"
attr {
key: "_fe_imply_type"
value {
i: 6
}
}
进入dump data文件夹,我们会看到model_name层有多个文件夹:

找到名称为刚才记录的计算图的名称值的文件夹,如ge_default_253_71。此目录中的文件是您需要的转储数据文件。

云优采集接口(算子采集Dump数据偏差对比类进行dump数据后续对比 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-11-28 10:12
)
查看PDF
转储数据采集
链接复制成功!
更新时间:2021/11/26 GMT+08:00
概述
当训练网络的精度没有达到预期时,可以使用训练过程中各个算子的计算结果(即Data Dump数据),然后使用精度对比工具和行业标准算子(如TensorFlow)计算结果 进行数据偏差对比,帮助开发者快速解决算子精度问题。目前支持采集的operator数据主要有:
默认训练过程中,没有采集算子的dump数据。如果需要采集并分析数据,可以选择以下两种方式之一:
使用注意事项
采集在 Estimator 模式下转储数据
在Estimator模式下,通过NPUrunConfig中的dump_config采集Dump data,在创建NPUrunConfig之前,先实例化一个DumpConfig类进行dump配置(包括配置dump路径,哪些迭代数据要dump,dump算子的输入或输出)数据等)。
DumpConfig类的构造函数中各个字段的详细解释请参考对应的接口说明。
from npu_bridge.npu_init import *
# dump_path:dump数据存放路径,该参数指定的目录需要在启动训练的环境上(容器或Host侧)提前创建且确保安装时配置的运行用户具有读写权限
# enable_dump:是否开启Dump功能
# dump_step:指定采集哪些迭代的Dump数据
# dump_mode:Dump模式,取值:input/output/all
dump_config = DumpConfig(enable_dump=True, dump_path = "/home/HwHiAiUser/output", dump_step="0|5|10", dump_mode="all")
session_config=tf.ConfigProto()
config = NPURunConfig(
dump_config=dump_config,
session_config=session_config
)
采集在sess.run模式下转储数据
在sess.run模式下,通过session配置项enable_dump、dump_path、dump_step、dump_mode配置相关参数。
config = tf.ConfigProto()
custom_op = config.graph_options.rewrite_options.custom_optimizers.add()
custom_op.name = "NpuOptimizer"
custom_op.parameter_map["use_off_line"].b = True
# enable_dump:是否开启Dump功能
custom_op.parameter_map["enable_dump"].b = True
# dump_path:dump数据存放路径,该参数指定的目录需要在启动训练的环境上(容器或Host侧)提前创建且确保安装时配置的运行用户具有读写权限
custom_op.parameter_map["dump_path"].s = tf.compat.as_bytes("/home/HwHiAiUser/output")
# dump_step:指定采集哪些迭代的Dump数据
custom_op.parameter_map["dump_step"].s = tf.compat.as_bytes("0|5|10")
# dump_mode:Dump模式,取值:input/output/all
custom_op.parameter_map["dump_mode"].s = tf.compat.as_bytes("all")
config.graph_options.rewrite_options.remapping = RewriterConfig.OFF
config.graph_options.rewrite_options.memory_optimization = RewriterConfig.OFF
with tf.Session(config=config) as sess:
print(sess.run(cost))
执行训练并生成转储数据
后续通过工具进行精度比较不仅依赖Dump数据,还需要计算图结构。因此,在进行训练之前,需要配置环境变量转储图文件:
export DUMP_GE_GRAPH=2
export DUMP_GRAPH_PATH=/home/dumpgraph # 指定dump图路径,如果不配置存储在训练脚本所在目录
执行训练,生成转储图像文件和转储数据文件。
由于“ge”开头的转储图文件很多,转储数据文件夹的model_name层可能有多个文件夹,所以实际上我们只需要找到计算图文件,只要找到model_name为计算图的名称。下面提供了一些方法来帮助用户快速找到相应的文件。
选择计算图文件,提供了两种方法: 选择转储数据文件。打开上一步找到的计算图文件,记录第一张图中name字段的值。在以下示例中,记录“ge_default_253_71”。
graph {
name: "ge_default_20201209083353_71"
op {
name: "atomic_addr_clean0_71"
type: "AtomicAddrClean"
attr {
key: "_fe_imply_type"
value {
i: 6
}
}
进入dump data文件夹,我们会看到model_name层有多个文件夹:
找到名称为刚才记录的计算图的名称值的文件夹,如ge_default_253_71。此目录中的文件是所需的转储数据文件。
查看全部
云优采集接口(算子采集Dump数据偏差对比类进行dump数据后续对比
)
查看PDF
转储数据采集
链接复制成功!
更新时间:2021/11/26 GMT+08:00
概述
当训练网络的精度没有达到预期时,可以使用训练过程中各个算子的计算结果(即Data Dump数据),然后使用精度对比工具和行业标准算子(如TensorFlow)计算结果 进行数据偏差对比,帮助开发者快速解决算子精度问题。目前支持采集的operator数据主要有:

默认训练过程中,没有采集算子的dump数据。如果需要采集并分析数据,可以选择以下两种方式之一:
使用注意事项
采集在 Estimator 模式下转储数据
在Estimator模式下,通过NPUrunConfig中的dump_config采集Dump data,在创建NPUrunConfig之前,先实例化一个DumpConfig类进行dump配置(包括配置dump路径,哪些迭代数据要dump,dump算子的输入或输出)数据等)。
DumpConfig类的构造函数中各个字段的详细解释请参考对应的接口说明。
from npu_bridge.npu_init import *
# dump_path:dump数据存放路径,该参数指定的目录需要在启动训练的环境上(容器或Host侧)提前创建且确保安装时配置的运行用户具有读写权限
# enable_dump:是否开启Dump功能
# dump_step:指定采集哪些迭代的Dump数据
# dump_mode:Dump模式,取值:input/output/all
dump_config = DumpConfig(enable_dump=True, dump_path = "/home/HwHiAiUser/output", dump_step="0|5|10", dump_mode="all")
session_config=tf.ConfigProto()
config = NPURunConfig(
dump_config=dump_config,
session_config=session_config
)
采集在sess.run模式下转储数据
在sess.run模式下,通过session配置项enable_dump、dump_path、dump_step、dump_mode配置相关参数。
config = tf.ConfigProto()
custom_op = config.graph_options.rewrite_options.custom_optimizers.add()
custom_op.name = "NpuOptimizer"
custom_op.parameter_map["use_off_line"].b = True
# enable_dump:是否开启Dump功能
custom_op.parameter_map["enable_dump"].b = True
# dump_path:dump数据存放路径,该参数指定的目录需要在启动训练的环境上(容器或Host侧)提前创建且确保安装时配置的运行用户具有读写权限
custom_op.parameter_map["dump_path"].s = tf.compat.as_bytes("/home/HwHiAiUser/output")
# dump_step:指定采集哪些迭代的Dump数据
custom_op.parameter_map["dump_step"].s = tf.compat.as_bytes("0|5|10")
# dump_mode:Dump模式,取值:input/output/all
custom_op.parameter_map["dump_mode"].s = tf.compat.as_bytes("all")
config.graph_options.rewrite_options.remapping = RewriterConfig.OFF
config.graph_options.rewrite_options.memory_optimization = RewriterConfig.OFF
with tf.Session(config=config) as sess:
print(sess.run(cost))
执行训练并生成转储数据
后续通过工具进行精度比较不仅依赖Dump数据,还需要计算图结构。因此,在进行训练之前,需要配置环境变量转储图文件:
export DUMP_GE_GRAPH=2
export DUMP_GRAPH_PATH=/home/dumpgraph # 指定dump图路径,如果不配置存储在训练脚本所在目录
执行训练,生成转储图像文件和转储数据文件。
由于“ge”开头的转储图文件很多,转储数据文件夹的model_name层可能有多个文件夹,所以实际上我们只需要找到计算图文件,只要找到model_name为计算图的名称。下面提供了一些方法来帮助用户快速找到相应的文件。
选择计算图文件,提供了两种方法: 选择转储数据文件。打开上一步找到的计算图文件,记录第一张图中name字段的值。在以下示例中,记录“ge_default_253_71”。
graph {
name: "ge_default_20201209083353_71"
op {
name: "atomic_addr_clean0_71"
type: "AtomicAddrClean"
attr {
key: "_fe_imply_type"
value {
i: 6
}
}
进入dump data文件夹,我们会看到model_name层有多个文件夹:

找到名称为刚才记录的计算图的名称值的文件夹,如ge_default_253_71。此目录中的文件是所需的转储数据文件。

云优采集接口(L16事例学习:JAVA的采集接口如果没有完全理解JAVA)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-11-27 21:08
L16案例学习:JAVA的采集界面如果你不完全理解JAVA材料的决定性部分,你将无法成为一个称职的JAVA程序员。JAVA语言书中对所有最基本的类型和相应部分的介绍都有详细的介绍。文件夹java.util 提供了采集——组、列表和图——您应该了解这些数据结构的优点。文件夹 java.io 也很重要。您可以大致了解和了解文件中的java是什么,它的需求和开发等。在本章中,我们将讨论 java.util 的设计,它通常被称为 java 集合 API。学习它很有价值,不仅是因为采集 类非常有用,还因为API 是一个设计非常好的代码示例。这很容易理解,同时也很容易证明。API 代码是由 Joshua Bloch 编写的,他还出版了我们开始本课程时推荐的 Effective Java 一书。同时,几乎所有复杂的原创程序都有API,所以如果你认真学习API,你会对你没有仔细考虑的程序代码有更广泛的了解。其实可以毫不夸张地说,如果你能指定某个类型的所有操作,你就已经完全掌握了java的概念。并且您将对您没有仔细考虑的程序代码有更广泛的了解。其实可以毫不夸张地说,如果你能指定某个类型的所有操作,你就已经完全掌握了java的概念。并且您将对您没有仔细考虑的程序代码有更广泛的了解。其实可以毫不夸张地说,如果你能指定某个类型的所有操作,你就已经完全掌握了java的概念。
我们没有时间讨论所有的话题,但我们会触及其中的大部分。其中一些,例如重载和同步,超出了本课程的范围。16.1 类组织的类型 简而言之,API 提供了三种类型的集合:组、列表和图。该组负责采集 元素,但不包括元素的数量和顺序。每个元素只在或不在某个组中。列是元素的序列,因此它包括元素的顺序和数量。图是键和属性值的集合:它有一组键,每个键都有一个唯一的属性值。API 使用接口来组织它的所有类——各种类型的规范——以及各种单独的工具来组织类。该图反映了所选类和接口的一些示例。采集 界面捕获常见且合适的列和组,但没有图形,我们将使用非正式界面。集合而不是图形。SortedMap 和 SortedSet 用于为地图和组提供附加操作以按特定顺序检索元素。可实现的类,比如LinkedList,都是建立在骨架图的上半部分,比如AbstractList,来整体展示它们的继承关系。这种接口和类的并行结构是非常重要的结构,值得学习。许多新程序员在应该使用接口的时候更喜欢使用简单的类,但一般来说,使用接口比使用简单的类要好。将现有的类样式更新和扩展为新的类并不容易,但将类实现为新的接口很容易。
Bloch 指出,结合两种方法的优点的方式是使用骨架图的实现类,就像他在这里列出的 API 一样。您可以获得基本规范接口的优点和与实现相关的共享代码以及汇总类的优点。JAVA API 文档中有每个 JAVA 接口的非正式规范。这很重要,因为他告诉每个类的用户他们期望使用的各种界面工具。如果使用类,则必须对其进行声明并使其符合规范 List。例如,您必须确保类的工具符合规范,否则它将不会以程序员期望的方式运行。这些规格基本上是不完整的。具体类也有规范,其中包括几个接口规范的详细信息。List 接口没有指定是否可以存储空元素,但是 ArrayList 和 LinkList 明确声明空是非法的。HashMap 允许空关键字和空属性值,而 HashMap 不允许它们。当你编写代码并使用采集 类时,你应该通过一个通用的接口或类来创建一个对象。例如,List p=new LinkedList(); 比下一个形式 LinkedList p=new LinkedList(); 如果你用之前的代码编译,你可以很容易地改变不同的队列实现: List p=new ArrayList(); 因为所有的代码都依赖于 p 队列。HashMap 允许空关键字和空属性值,而 HashMap 不允许它们。当你编写代码并使用采集 类时,你应该通过一个通用的接口或类来创建一个对象。例如,List p=new LinkedList(); 比下一个形式 LinkedList p=new LinkedList(); 如果你用之前的代码编译,你可以很容易地改变不同的队列实现: List p=new ArrayList(); 因为所有的代码都依赖于 p 队列。HashMap 允许空关键字和空属性值,而 HashMap 不允许它们。当你编写代码并使用采集 类时,你应该通过一个通用的接口或类来创建一个对象。例如,List p=new LinkedList(); 比下一个形式 LinkedList p=new LinkedList(); 如果你用之前的代码编译,你可以很容易地改变不同的队列实现: List p=new ArrayList(); 因为所有的代码都依赖于 p 队列。您可以轻松更改不同的队列实现: List p=new ArrayList(); 因为所有的代码都依赖于 p 队列。您可以轻松更改不同的队列实现: List p=new ArrayList(); 因为所有的代码都依赖于 p 队列。
你会发现后者很难改变,因为程序的某些部分是对X的操作,而这些操作只有LinkedList提供——实际上这些操作是不需要的。这个解释的细节在 Bloch 的书 34 中。下周我们将学习更复杂的例子,当时的代码需要 Hashmap 接受键。设置键=map.keySet(); 当前代码使用密钥而不知道密钥是否在某个组中。16.2 替代方法 采集 的API 允许在采集 接口中使用类声明工具并实现其所有功能。例如,列表中的所有变异器都被指定为可供选择。这意味着你可以实现一个符合List规则的类,但是每当您调用 mutator(例如 add 命令)时,它都会连接到 UnsupportedOperationException。这种弱化规范的尝试很棘手,因为这意味着如果您编写一些支持列的代码,在没有关于列的附加信息的情况下,您不知道该列是否支持命令 add。但是没有这样的选择。对于替代概念,您必须声明一个单独的接口 ImmutableList。该奖项使接口数量增加了一倍。有时,我们需要一些变异器而不是其他变异器。例如,HashMap 中的 keyset 方法返回一个收录图中键的组。在没有关于列的附加信息的情况下,您不知道该列是否支持命令 add。但是没有这样的选择。对于替代概念,您必须声明一个单独的接口 ImmutableList。该奖项使接口数量增加了一倍。有时,我们需要一些变异器而不是其他变异器。例如,HashMap 中的 keyset 方法返回一个收录图中键的组。在没有关于列的附加信息的情况下,您不知道该列是否支持命令 add。但是没有这样的选择。对于替代概念,您必须声明一个单独的接口 ImmutableList。该奖项使接口数量增加了一倍。有时,我们需要一些变异器而不是其他变异器。例如,HashMap 中的 keyset 方法返回一个收录图中键的组。
该组的作用:从组中删除一个key,从图中删除与其相关的属性值。因此支持 remove 命令,但不支持 add 命令,因此您无法在没有属性值的情况下向图中添加键。所以使用替代操作是一个合理的判断。这意味着更少的编译时间检查并减少了接口的数量。16.3 所有这些容器(数据组织)——组、列和图表——对象元素的一种方式。它们被称为多态,这意味着多种形状,令人欣慰的是它们允许您使用不同的容器(数据结构):整数列、URL 列等等。这种类型的多态性被称为子类型多态性,因为它依赖于类型的推导。另一种不同形式的多态称为参数多态,它允许你在定义容器时使用参数,这样客户端就可以提示容器将收录什么类型的参数:List[URL]bookmarks;notlegal Java JAVA不收录这个多态性,尽管有很多提议要添加这种多态性。参数多态的最大优点是程序员可以告诉编译器元素的类型。编译器可以检查添加的错误类型,或将其转换为另一种类型。考虑代码:List bookmarks=new LinkedList(); URL URLx=bookmarks.get(0);//编译器原本以为add方法是一个对象,其实add是可以的,URL是object的子类。所以客户端可以提示容器将收录什么类型的参数: List[URL]bookmarks;notlegal Java JAVA 不收录这种多态性,即使有很多建议添加这种多态性。参数多态的最大优点是程序员可以告诉编译器元素的类型。编译器可以检查添加的错误类型,或将其转换为另一种类型。考虑代码:List bookmarks=new LinkedList(); URL URLx=bookmarks.get(0);//编译器原本以为add方法是一个对象,其实add是可以的,URL是object的子类。所以客户端可以提示容器将收录什么类型的参数: List[URL]bookmarks;notlegal Java JAVA 不收录这种多态性,即使有很多建议添加这种多态性。参数多态的最大优点是程序员可以告诉编译器元素的类型。编译器可以检查添加的错误类型,或将其转换为另一种类型。考虑代码:List bookmarks=new LinkedList(); URL URLx=bookmarks.get(0);//编译器原本以为add方法是一个对象,其实add是可以的,URL是object的子类。参数多态的最大优点是程序员可以告诉编译器元素的类型。编译器可以检查添加的错误类型,或将其转换为另一种类型。考虑代码:List bookmarks=new LinkedList(); URL URLx=bookmarks.get(0);//编译器原本以为add方法是一个对象,其实add是可以的,URL是object的子类。参数多态的最大优点是程序员可以告诉编译器元素的类型。编译器可以检查添加的错误类型,或将其转换为另一种类型。考虑代码:List bookmarks=new LinkedList(); URL URLx=bookmarks.get(0);//编译器原本以为add方法是一个对象,其实add是可以的,URL是object的子类。
事实证明,如果你想得到x就算破了,RHS的类型表达式也是一个对象。不能给一个对象分配大量的URL类型,所以不能依赖这种方式来使用URL,所以我们写的代码必须使用而不是下面的公式:Url x=(URL)bookmarks.get ; 该方法的作用是在运行时进行检查。如果成功,此方法的结果将调用 URL 类型并执行正常操作。如果失败,因为结果类型不正确,ClassCastException 被丢弃,任务将不会被执行。确保您理解这一点,不要对如何获取对象的返回值感到困惑。对象在运行时驱动其类型。如果在类 URl 中创建了一个对象,它将收录这种类型,所以没必要强行改给这个类型。这种向下转换很烦人,有时您必须编写一个包装类来摆脱它们。在浏览器中,您通常希望获得一种特殊的汇总数据类型。如果要这样做,必须使代码中不收录摘要类型,客户端将看到该方法如下: URL getURL(int 不需要在代码中使用它而是调用上下文,但仅限制了错误的范围。这种类型的多态提供了很大的灵活性,这是参数多态所没有的。您可以创建一个可以存储各种元素的异构容器(数据结构)。
你可以把容器放在它们自己里面——试着弄清楚如何表达这种多态类型——即使这不是一个明智的方法。事实上,正如我们在前面的课程中提到的,如果你这样做,JAVA API 类会崩溃。标记元素容器收录的类型通常是最重要的部分。你应该养成在声明容器时写注释的习惯,或者使用错误的参数类型声明。List bookmarks;//List[URl] RI:bookmarks.elems URL16.4 Skeletal implementations 骨架实现的采集主体中的骨架实现的具体实现通常是使用Template Method设计的。抽象类中没有例子来证明它有这些方法,但是它可以通过定义模板方法调用其他钩子方法,并且这些方法都是在抽象中声明的,没有代码段。在继承的子类中,钩子方法被覆盖,模板方法继承不能改变。以 AbstractList 为例,它在迭代器中使用模板方法,它返回迭代器实现作为钩子方法。Equals 方法是实现另一个关于迭代器的模板。
一个子类,比如ArrayList,提供了一种实现get命令的方法,它可以继承iterator和equals。一些特定的类替换了摘要实现。比如LinkedList代替了iterator的作用,因为它可以直接进入list的执行,比在hook中使用get命令提供了更有效的飞跃,每次调用都会继续搜索。16.5 Capacity, Allocation&GC 实现这一点的一种方法是利用队列的特性——例如ArrayList HashMap——在配置队列时,必须为其选择一个大小。选择合适的尺寸对性能非常重要。如果太小,队列将不得不被新队列替换,这导致新队列的配置和旧垃圾的处理的更多消耗。太大的话,会浪费空间,尤其是种类很多的时候,问题就大了。一些实现方法为builder提供了通过客户端设置初始容量的能力,可以决定配置的大小。例如: Public ArrayList(int initialCapacity) 构造emptylist指定初始容量参数:initialCapacity-初始容量列表。抛出:IllegalArgumentException-如果指定初始容量为负数 还有一个适配配置项的方法:trimTosize,有适配能力容器要有足够的空间来存储元素,并确保容量,从而有能力增加其他空间。一些实现方法为builder提供了通过客户端设置初始容量的能力,可以决定配置的大小。例如: Public ArrayList(int initialCapacity) 构造emptylist指定初始容量参数:initialCapacity-初始容量列表。抛出:IllegalArgumentException-如果指定初始容量为负数 还有一个适配配置项的方法:trimTosize,有适配能力容器要有足够的空间来存储元素,并确保容量,从而有能力增加其他空间。一些实现方法为builder提供了通过客户端设置初始容量的能力,可以决定配置的大小。例如: Public ArrayList(int initialCapacity) 构造emptylist指定初始容量参数:initialCapacity-初始容量列表。抛出:IllegalArgumentException-如果指定初始容量为负数 还有一个适配配置项的方法:trimTosize,有适配能力容器要有足够的空间来存储元素,并确保容量,从而有能力增加其他空间。
使用此功能有一些技巧。如果您对申请多少空间没有准确的了解,您可以使用此功能来查找空间的大小。将这种能力的概念转化为行动是一个问题。在很多老的程序中,它们总是限制资源,如果资源耗尽,程序就无法运行。使用这种自适应方法,程序只会变慢。这是设计程序以确保程序始终有效运行的好主意,即使在特殊情况下也是如此。如果你学习在ArryList中实现remove,你会看到下面的代码: Public Object remove(int index){ elementData[-size]=null;//letgc do its work next? 不是垃圾文件的自动处理吗?以下是一些新手常犯的错误。如果你的表演有队列,1< @6.6 副本、转换、包装器等。所有特定的 采集 类都提供给构建者通过 采集 进行争论。这些允许你复制采集,或者属于另一种类型,例如LinkedList Public LinkedList(采集 list contains specified 采集,in 采集'siterator。参数:c-其元素列表的集合。它可以复制为: List p =new LinkedList() ListpCopy=new LinkedList(p) 创建一个link form other 采集 type set s=new HashSet() Listp=new Linked list(s) builder不能在接口中声明,规范的List 也不能说所有的实现都属于构建者,即使是这样,Java.util.采集s 是一个特殊的类,里面收录了静态字符串方法,有些是泛化算法,有些是包装器。转换、包装器等。所有特定的 采集 类都提供给构建器以通过 采集 进行争论。这些允许你复制采集,或者属于另一种类型,例如LinkedList Public LinkedList(采集 list contains specified 采集,in 采集'siterator。参数:c-其元素列表的集合。它可以复制为: List p =new LinkedList() ListpCopy=new LinkedList(p) 创建一个link form other 采集 type set s=new HashSet() Listp=new Linked list(s) builder不能在接口中声明,规范的List 也不能说所有的实现都属于构建者,即使是这样,Java.util.采集s 是一个特殊的类,里面收录了静态字符串方法,有些是泛化算法,有些是包装器。转换、包装器等。所有特定的 采集 类都提供给构建器以通过 采集 进行争论。这些允许你复制采集,或者属于另一种类型,例如LinkedList Public LinkedList(采集 list contains specified 采集,in 采集'siterator。参数:c-其元素列表的集合。它可以复制为: List p =new LinkedList() ListpCopy=new LinkedList(p) 创建一个link form other 采集 type set s=new HashSet() Listp=new Linked list(s) builder不能在接口中声明,规范的List 也不能说所有的实现都属于构建者,即使是这样,Java.util.采集s 是一个特殊的类,里面收录了静态字符串方法,有些是泛化算法,有些是包装器。所有特定的 采集 类都提供给构建器以通过 采集 进行争论。这些允许你复制采集,或者属于另一种类型,例如LinkedList Public LinkedList(采集 list contains specified 采集,in 采集'siterator。参数:c-其元素列表的集合。它可以复制为: List p =new LinkedList() ListpCopy=new LinkedList(p) 创建一个link form other 采集 type set s=new HashSet() Listp=new Linked list(s) builder不能在接口中声明,规范的List 也不能说所有的实现都属于构建者,即使是这样,Java.util.采集s 是一个特殊的类,里面收录了静态字符串方法,有些是泛化算法,有些是包装器。所有特定的 采集 类都提供给构建器以通过 采集 进行争论。这些允许你复制采集,或者属于另一种类型,例如LinkedList Public LinkedList(采集 list contains specified 采集,in 采集'siterator。参数:c-其元素列表的集合。它可以复制为: List p =new LinkedList() ListpCopy=new LinkedList(p) 创建一个link form other 采集 type set s=new HashSet() Listp=new Linked list(s) builder不能在接口中声明,规范的List 也不能说所有的实现都属于构建者,即使是这样,Java.util.采集s 是一个特殊的类,里面收录了静态字符串方法,有些是泛化算法,有些是包装器。为构建器提供了类以通过 采集 进行争论。这些允许你复制采集,或者属于另一种类型,例如LinkedList Public LinkedList(采集 list contains specified 采集,in 采集'siterator。参数:c-其元素列表的集合。它可以复制为: List p =new LinkedList() ListpCopy=new LinkedList(p) 创建一个link form other 采集 type set s=new HashSet() Listp=new Linked list(s) builder不能在接口中声明,规范的List 也不能说所有的实现都属于构建者,即使是这样,Java.util.采集s 是一个特殊的类,里面收录了静态字符串方法,有些是泛化算法,有些是包装器。为构建器提供了类以通过 采集 进行争论。这些允许你复制采集,或者属于另一种类型,例如LinkedList Public LinkedList(采集 list contains specified 采集,in 采集'siterator。参数:c-其元素列表的集合。它可以复制为: List p =new LinkedList() ListpCopy=new LinkedList(p) 创建一个link form other 采集 type set s=new HashSet() Listp=new Linked list(s) builder不能在接口中声明,规范的List 也不能说所有的实现都属于构建者,即使是这样,Java.util.采集s 是一个特殊的类,里面收录了静态字符串方法,有些是泛化算法,有些是包装器。List p =new LinkedList() ListpCopy=new LinkedList(p) 创建一个link form other 采集 type set s=new HashSet() Listp=new Linked list(s) builder不能在接口中声明,规范的List 就算是这样,也不能说所有的实现都属于建设者。Java.util.采集s 是一个特殊的类,它收录静态字符串方法,其中一些是通用算法,一些是包装器。List p =new LinkedList() ListpCopy=new LinkedList(p) 创建一个link form other 采集 type set s=new HashSet() Listp=new Linked list(s) builder不能在接口中声明,规范的List 就算是这样,也不能说所有的实现都属于建设者。Java.util.采集s 是一个特殊的类,它收录静态字符串方法,其中一些是通用算法,一些是包装器。
例如 unmodifiableList 使用一个列表,然后使用相同的元素返回一个列表,但它是不可变的。public static List unmodifiableList(List list) 返回unmodifiableview指定列表。该方法允许模块提供用户内部列表。查询操作返回列表”读取到指定列表,并尝试返回列表,是否直接通过其迭代器,结果返回列表指定列表序列化。参数:列表-列表返回不可修改视图。返回:不可修改视图指定列表。返回的列表不准确,无法更改。它的属性值可以因为下面的列表被修改而改变,但不能直接修改。16.7 Sorted 采集s 一种采集 分类必须有某种方法来比较元素并确定它们的顺序。
采集API 为此提供了两种方法。您可以使用自然排序,这是通过对元素使用比较方法从接口 java.lang.Comparable 确定的。public int compareTo(Object 它返回一个负整数类型,0或实整数类型作为对象。添加元素时,使用自然顺序。元素必须内置在一个类中,它是通过Comparable接口实现的。添加方法使要添加的元素通过comparable与现有元素进行比较,不匹配则移除,两者任选其一,可以使用一个元素的顺序独立给定,就像对象一样,通过java.util .Comparator接口实现,也是一个方法 public int compare(Object o1,Object o2) 上面的公式和compareTo类似,只是同时比较两个元素。这是 Strategy 风格的一个例子,通过它它是一个计算法则与使用的代码分离的。方法的选择取决于您创建对象的方式。如果您使用构造并且它使用 Comparator 作为参数,它将用于确定顺序。如果不使用构造,将使用自然顺序。比较 同样的问题(详细信息在第 9 章讨论)带来了同样的困难。如果不使用构造,将使用自然顺序。比较 同样的问题(详细信息在第 9 章讨论)带来了同样的困难。如果不使用构造,将使用自然顺序。比较 同样的问题(详细信息在第 9 章讨论)带来了同样的困难。
一种分类基于不变量。如果可以通过改变公共方法的调用来改变两个元素的顺序,那么 Rep 就会发生。16.8 Views 我们在第9章介绍了concept的概念。Concept是一个复杂的机制。直现在也很有用,但是很危险。它们打破了原创程序中关于设计精心设计的对象的许多基本概念。通过它们的用途,可以识别出三个概念: FunctionalityExtension 有些概念提供了对象函数的扩展,而无需添加新方法。可以替换 采集 类中的 next 和 hasNext 方法。但这使得类自己的 API 更加复杂。支持多个接口也非常困难。我们可以在类中添加一个reset方法,该方法用于调用restart,但同时只允许一次迭代。如果程序元素忘记重置,这种方法会导致错误。解耦的一些概念提到了该子组对底层 采集 的作用。表的键组的方法。例如,返回一个由表的键组成的组。因此,允许部分代码与key相关,该section没有key值,与其他目标规范解耦。CoordinateTransformation 的概念通过 subList 提供了一个等效的转换。概念的改变导致了底层列表的变化,但是允许通过有偏索引访问列表。这种方法会导致错误。解耦的一些概念提到了该子组对底层 采集 的作用。表的键组的方法。例如,返回一个由表的键组成的组。因此,允许部分代码与key相关,该section没有key值,与其他目标规范解耦。CoordinateTransformation 的概念通过 subList 提供了一个等效的转换。概念的改变导致了底层列表的变化,但是允许通过有偏索引访问列表。这种方法会导致错误。解耦的一些概念提到了该子组对底层 采集 的作用。表的键组的方法。例如,返回一个由表的键组成的组。因此,允许部分代码与key相关,该section没有key值,与其他目标规范解耦。CoordinateTransformation 的概念通过 subList 提供了一个等效的转换。概念的改变导致了底层列表的变化,但是允许通过有偏索引访问列表。返回一个由表的键组成的组。因此,允许部分代码与key相关,该section没有key值,与其他目标规范解耦。CoordinateTransformation 的概念通过 subList 提供了一个等效的转换。概念的改变导致了底层列表的变化,但是允许通过有偏索引访问列表。返回一个由表的键组成的组。因此,允许部分代码与key相关,该section没有key值,与其他目标规范解耦。CoordinateTransformation 的概念通过 subList 提供了一个等效的转换。概念的改变导致了底层列表的变化,但是允许通过有偏索引访问列表。
想法是危险的有两个原因。一、底部改变:调用remove改变底部采集;调用 remove 和它的 key group 来更改团队列表。这将形成一个简短的混叠,以便一个对象的变化影响另一个。这两个对象不需要具有相同的字典范围。这意味着我们必须重新定义规范中的更改:如果您更改 C 以收录概念 V,这是否意味着 V 也可以更改?其次,该方法的规范返回了一个通常仅限于更改的想法。为了确保您的代码可以运行,您需要了解此规范。毫不奇怪,这些规范通常很微妙。改变了云学习下采集的一些思路。其他的只允许改变概念——比如迭代器。有些允许概念和底层 采集 改变,但这更复杂。例如采集API,当在列中放置子列表的概念时,底层列不能有任何结构变化:以下将解释这种现象:结构修改列表,否则扰乱进度可能会产生错误的结果. 它的意思不是很准确和清楚。我不想对基础列进行任何更改。同一个底层采集的复杂概念会很复杂。例如,您可以在同一个列表中使用多个迭代器。在这种情况下,您必须考虑与想法的交互。底层列不能有任何结构变化:以下将解释这种现象:结构修改列表,否则扰乱进度可能会产生不正确的结果。它的意思不是很准确和清楚。我不想对基础列进行任何更改。同一个底层采集的复杂概念会很复杂。例如,您可以在同一个列表中使用多个迭代器。在这种情况下,您必须考虑与想法的交互。底层列不能有任何结构变化:以下将解释这种现象:结构修改列表,否则扰乱进度可能会产生不正确的结果。它的意思不是很准确和清楚。我不想对基础列进行任何更改。同一个底层采集的复杂概念会很复杂。例如,您可以在同一个列表中使用多个迭代器。在这种情况下,您必须考虑与想法的交互。您可以在同一个列表中使用多个迭代器。在这种情况下,您必须考虑与想法的交互。您可以在同一个列表中使用多个迭代器。在这种情况下,您必须考虑与想法的交互。
如果通过交互更改列表,其他界面将无效。这里有一些有用的经验。如果您使用想法,您必须仔细考虑它是否会对您有所帮助: 您可以限制可接受的想法范围。例如,使用for循环代替while循环作为接口,可以限制接口的循环范围。很容易确保接口处没有意外错误。这并不总是可能的。下周将讨论 Tagger 计划关于他的集中呼叫更改。您可以使用 采集s 类来防止顾念更改或包装底层对象。例如,如果你在表中使用keySetview,并且不打算更改它,则可以使用以下方法: Set s=map.keySey(); Set safe_s=采集s.unmodifiableSet(s); 查看全部
云优采集接口(L16事例学习:JAVA的采集接口如果没有完全理解JAVA)
L16案例学习:JAVA的采集界面如果你不完全理解JAVA材料的决定性部分,你将无法成为一个称职的JAVA程序员。JAVA语言书中对所有最基本的类型和相应部分的介绍都有详细的介绍。文件夹java.util 提供了采集——组、列表和图——您应该了解这些数据结构的优点。文件夹 java.io 也很重要。您可以大致了解和了解文件中的java是什么,它的需求和开发等。在本章中,我们将讨论 java.util 的设计,它通常被称为 java 集合 API。学习它很有价值,不仅是因为采集 类非常有用,还因为API 是一个设计非常好的代码示例。这很容易理解,同时也很容易证明。API 代码是由 Joshua Bloch 编写的,他还出版了我们开始本课程时推荐的 Effective Java 一书。同时,几乎所有复杂的原创程序都有API,所以如果你认真学习API,你会对你没有仔细考虑的程序代码有更广泛的了解。其实可以毫不夸张地说,如果你能指定某个类型的所有操作,你就已经完全掌握了java的概念。并且您将对您没有仔细考虑的程序代码有更广泛的了解。其实可以毫不夸张地说,如果你能指定某个类型的所有操作,你就已经完全掌握了java的概念。并且您将对您没有仔细考虑的程序代码有更广泛的了解。其实可以毫不夸张地说,如果你能指定某个类型的所有操作,你就已经完全掌握了java的概念。
我们没有时间讨论所有的话题,但我们会触及其中的大部分。其中一些,例如重载和同步,超出了本课程的范围。16.1 类组织的类型 简而言之,API 提供了三种类型的集合:组、列表和图。该组负责采集 元素,但不包括元素的数量和顺序。每个元素只在或不在某个组中。列是元素的序列,因此它包括元素的顺序和数量。图是键和属性值的集合:它有一组键,每个键都有一个唯一的属性值。API 使用接口来组织它的所有类——各种类型的规范——以及各种单独的工具来组织类。该图反映了所选类和接口的一些示例。采集 界面捕获常见且合适的列和组,但没有图形,我们将使用非正式界面。集合而不是图形。SortedMap 和 SortedSet 用于为地图和组提供附加操作以按特定顺序检索元素。可实现的类,比如LinkedList,都是建立在骨架图的上半部分,比如AbstractList,来整体展示它们的继承关系。这种接口和类的并行结构是非常重要的结构,值得学习。许多新程序员在应该使用接口的时候更喜欢使用简单的类,但一般来说,使用接口比使用简单的类要好。将现有的类样式更新和扩展为新的类并不容易,但将类实现为新的接口很容易。
Bloch 指出,结合两种方法的优点的方式是使用骨架图的实现类,就像他在这里列出的 API 一样。您可以获得基本规范接口的优点和与实现相关的共享代码以及汇总类的优点。JAVA API 文档中有每个 JAVA 接口的非正式规范。这很重要,因为他告诉每个类的用户他们期望使用的各种界面工具。如果使用类,则必须对其进行声明并使其符合规范 List。例如,您必须确保类的工具符合规范,否则它将不会以程序员期望的方式运行。这些规格基本上是不完整的。具体类也有规范,其中包括几个接口规范的详细信息。List 接口没有指定是否可以存储空元素,但是 ArrayList 和 LinkList 明确声明空是非法的。HashMap 允许空关键字和空属性值,而 HashMap 不允许它们。当你编写代码并使用采集 类时,你应该通过一个通用的接口或类来创建一个对象。例如,List p=new LinkedList(); 比下一个形式 LinkedList p=new LinkedList(); 如果你用之前的代码编译,你可以很容易地改变不同的队列实现: List p=new ArrayList(); 因为所有的代码都依赖于 p 队列。HashMap 允许空关键字和空属性值,而 HashMap 不允许它们。当你编写代码并使用采集 类时,你应该通过一个通用的接口或类来创建一个对象。例如,List p=new LinkedList(); 比下一个形式 LinkedList p=new LinkedList(); 如果你用之前的代码编译,你可以很容易地改变不同的队列实现: List p=new ArrayList(); 因为所有的代码都依赖于 p 队列。HashMap 允许空关键字和空属性值,而 HashMap 不允许它们。当你编写代码并使用采集 类时,你应该通过一个通用的接口或类来创建一个对象。例如,List p=new LinkedList(); 比下一个形式 LinkedList p=new LinkedList(); 如果你用之前的代码编译,你可以很容易地改变不同的队列实现: List p=new ArrayList(); 因为所有的代码都依赖于 p 队列。您可以轻松更改不同的队列实现: List p=new ArrayList(); 因为所有的代码都依赖于 p 队列。您可以轻松更改不同的队列实现: List p=new ArrayList(); 因为所有的代码都依赖于 p 队列。
你会发现后者很难改变,因为程序的某些部分是对X的操作,而这些操作只有LinkedList提供——实际上这些操作是不需要的。这个解释的细节在 Bloch 的书 34 中。下周我们将学习更复杂的例子,当时的代码需要 Hashmap 接受键。设置键=map.keySet(); 当前代码使用密钥而不知道密钥是否在某个组中。16.2 替代方法 采集 的API 允许在采集 接口中使用类声明工具并实现其所有功能。例如,列表中的所有变异器都被指定为可供选择。这意味着你可以实现一个符合List规则的类,但是每当您调用 mutator(例如 add 命令)时,它都会连接到 UnsupportedOperationException。这种弱化规范的尝试很棘手,因为这意味着如果您编写一些支持列的代码,在没有关于列的附加信息的情况下,您不知道该列是否支持命令 add。但是没有这样的选择。对于替代概念,您必须声明一个单独的接口 ImmutableList。该奖项使接口数量增加了一倍。有时,我们需要一些变异器而不是其他变异器。例如,HashMap 中的 keyset 方法返回一个收录图中键的组。在没有关于列的附加信息的情况下,您不知道该列是否支持命令 add。但是没有这样的选择。对于替代概念,您必须声明一个单独的接口 ImmutableList。该奖项使接口数量增加了一倍。有时,我们需要一些变异器而不是其他变异器。例如,HashMap 中的 keyset 方法返回一个收录图中键的组。在没有关于列的附加信息的情况下,您不知道该列是否支持命令 add。但是没有这样的选择。对于替代概念,您必须声明一个单独的接口 ImmutableList。该奖项使接口数量增加了一倍。有时,我们需要一些变异器而不是其他变异器。例如,HashMap 中的 keyset 方法返回一个收录图中键的组。
该组的作用:从组中删除一个key,从图中删除与其相关的属性值。因此支持 remove 命令,但不支持 add 命令,因此您无法在没有属性值的情况下向图中添加键。所以使用替代操作是一个合理的判断。这意味着更少的编译时间检查并减少了接口的数量。16.3 所有这些容器(数据组织)——组、列和图表——对象元素的一种方式。它们被称为多态,这意味着多种形状,令人欣慰的是它们允许您使用不同的容器(数据结构):整数列、URL 列等等。这种类型的多态性被称为子类型多态性,因为它依赖于类型的推导。另一种不同形式的多态称为参数多态,它允许你在定义容器时使用参数,这样客户端就可以提示容器将收录什么类型的参数:List[URL]bookmarks;notlegal Java JAVA不收录这个多态性,尽管有很多提议要添加这种多态性。参数多态的最大优点是程序员可以告诉编译器元素的类型。编译器可以检查添加的错误类型,或将其转换为另一种类型。考虑代码:List bookmarks=new LinkedList(); URL URLx=bookmarks.get(0);//编译器原本以为add方法是一个对象,其实add是可以的,URL是object的子类。所以客户端可以提示容器将收录什么类型的参数: List[URL]bookmarks;notlegal Java JAVA 不收录这种多态性,即使有很多建议添加这种多态性。参数多态的最大优点是程序员可以告诉编译器元素的类型。编译器可以检查添加的错误类型,或将其转换为另一种类型。考虑代码:List bookmarks=new LinkedList(); URL URLx=bookmarks.get(0);//编译器原本以为add方法是一个对象,其实add是可以的,URL是object的子类。所以客户端可以提示容器将收录什么类型的参数: List[URL]bookmarks;notlegal Java JAVA 不收录这种多态性,即使有很多建议添加这种多态性。参数多态的最大优点是程序员可以告诉编译器元素的类型。编译器可以检查添加的错误类型,或将其转换为另一种类型。考虑代码:List bookmarks=new LinkedList(); URL URLx=bookmarks.get(0);//编译器原本以为add方法是一个对象,其实add是可以的,URL是object的子类。参数多态的最大优点是程序员可以告诉编译器元素的类型。编译器可以检查添加的错误类型,或将其转换为另一种类型。考虑代码:List bookmarks=new LinkedList(); URL URLx=bookmarks.get(0);//编译器原本以为add方法是一个对象,其实add是可以的,URL是object的子类。参数多态的最大优点是程序员可以告诉编译器元素的类型。编译器可以检查添加的错误类型,或将其转换为另一种类型。考虑代码:List bookmarks=new LinkedList(); URL URLx=bookmarks.get(0);//编译器原本以为add方法是一个对象,其实add是可以的,URL是object的子类。
事实证明,如果你想得到x就算破了,RHS的类型表达式也是一个对象。不能给一个对象分配大量的URL类型,所以不能依赖这种方式来使用URL,所以我们写的代码必须使用而不是下面的公式:Url x=(URL)bookmarks.get ; 该方法的作用是在运行时进行检查。如果成功,此方法的结果将调用 URL 类型并执行正常操作。如果失败,因为结果类型不正确,ClassCastException 被丢弃,任务将不会被执行。确保您理解这一点,不要对如何获取对象的返回值感到困惑。对象在运行时驱动其类型。如果在类 URl 中创建了一个对象,它将收录这种类型,所以没必要强行改给这个类型。这种向下转换很烦人,有时您必须编写一个包装类来摆脱它们。在浏览器中,您通常希望获得一种特殊的汇总数据类型。如果要这样做,必须使代码中不收录摘要类型,客户端将看到该方法如下: URL getURL(int 不需要在代码中使用它而是调用上下文,但仅限制了错误的范围。这种类型的多态提供了很大的灵活性,这是参数多态所没有的。您可以创建一个可以存储各种元素的异构容器(数据结构)。
你可以把容器放在它们自己里面——试着弄清楚如何表达这种多态类型——即使这不是一个明智的方法。事实上,正如我们在前面的课程中提到的,如果你这样做,JAVA API 类会崩溃。标记元素容器收录的类型通常是最重要的部分。你应该养成在声明容器时写注释的习惯,或者使用错误的参数类型声明。List bookmarks;//List[URl] RI:bookmarks.elems URL16.4 Skeletal implementations 骨架实现的采集主体中的骨架实现的具体实现通常是使用Template Method设计的。抽象类中没有例子来证明它有这些方法,但是它可以通过定义模板方法调用其他钩子方法,并且这些方法都是在抽象中声明的,没有代码段。在继承的子类中,钩子方法被覆盖,模板方法继承不能改变。以 AbstractList 为例,它在迭代器中使用模板方法,它返回迭代器实现作为钩子方法。Equals 方法是实现另一个关于迭代器的模板。
一个子类,比如ArrayList,提供了一种实现get命令的方法,它可以继承iterator和equals。一些特定的类替换了摘要实现。比如LinkedList代替了iterator的作用,因为它可以直接进入list的执行,比在hook中使用get命令提供了更有效的飞跃,每次调用都会继续搜索。16.5 Capacity, Allocation&GC 实现这一点的一种方法是利用队列的特性——例如ArrayList HashMap——在配置队列时,必须为其选择一个大小。选择合适的尺寸对性能非常重要。如果太小,队列将不得不被新队列替换,这导致新队列的配置和旧垃圾的处理的更多消耗。太大的话,会浪费空间,尤其是种类很多的时候,问题就大了。一些实现方法为builder提供了通过客户端设置初始容量的能力,可以决定配置的大小。例如: Public ArrayList(int initialCapacity) 构造emptylist指定初始容量参数:initialCapacity-初始容量列表。抛出:IllegalArgumentException-如果指定初始容量为负数 还有一个适配配置项的方法:trimTosize,有适配能力容器要有足够的空间来存储元素,并确保容量,从而有能力增加其他空间。一些实现方法为builder提供了通过客户端设置初始容量的能力,可以决定配置的大小。例如: Public ArrayList(int initialCapacity) 构造emptylist指定初始容量参数:initialCapacity-初始容量列表。抛出:IllegalArgumentException-如果指定初始容量为负数 还有一个适配配置项的方法:trimTosize,有适配能力容器要有足够的空间来存储元素,并确保容量,从而有能力增加其他空间。一些实现方法为builder提供了通过客户端设置初始容量的能力,可以决定配置的大小。例如: Public ArrayList(int initialCapacity) 构造emptylist指定初始容量参数:initialCapacity-初始容量列表。抛出:IllegalArgumentException-如果指定初始容量为负数 还有一个适配配置项的方法:trimTosize,有适配能力容器要有足够的空间来存储元素,并确保容量,从而有能力增加其他空间。
使用此功能有一些技巧。如果您对申请多少空间没有准确的了解,您可以使用此功能来查找空间的大小。将这种能力的概念转化为行动是一个问题。在很多老的程序中,它们总是限制资源,如果资源耗尽,程序就无法运行。使用这种自适应方法,程序只会变慢。这是设计程序以确保程序始终有效运行的好主意,即使在特殊情况下也是如此。如果你学习在ArryList中实现remove,你会看到下面的代码: Public Object remove(int index){ elementData[-size]=null;//letgc do its work next? 不是垃圾文件的自动处理吗?以下是一些新手常犯的错误。如果你的表演有队列,1< @6.6 副本、转换、包装器等。所有特定的 采集 类都提供给构建者通过 采集 进行争论。这些允许你复制采集,或者属于另一种类型,例如LinkedList Public LinkedList(采集 list contains specified 采集,in 采集'siterator。参数:c-其元素列表的集合。它可以复制为: List p =new LinkedList() ListpCopy=new LinkedList(p) 创建一个link form other 采集 type set s=new HashSet() Listp=new Linked list(s) builder不能在接口中声明,规范的List 也不能说所有的实现都属于构建者,即使是这样,Java.util.采集s 是一个特殊的类,里面收录了静态字符串方法,有些是泛化算法,有些是包装器。转换、包装器等。所有特定的 采集 类都提供给构建器以通过 采集 进行争论。这些允许你复制采集,或者属于另一种类型,例如LinkedList Public LinkedList(采集 list contains specified 采集,in 采集'siterator。参数:c-其元素列表的集合。它可以复制为: List p =new LinkedList() ListpCopy=new LinkedList(p) 创建一个link form other 采集 type set s=new HashSet() Listp=new Linked list(s) builder不能在接口中声明,规范的List 也不能说所有的实现都属于构建者,即使是这样,Java.util.采集s 是一个特殊的类,里面收录了静态字符串方法,有些是泛化算法,有些是包装器。转换、包装器等。所有特定的 采集 类都提供给构建器以通过 采集 进行争论。这些允许你复制采集,或者属于另一种类型,例如LinkedList Public LinkedList(采集 list contains specified 采集,in 采集'siterator。参数:c-其元素列表的集合。它可以复制为: List p =new LinkedList() ListpCopy=new LinkedList(p) 创建一个link form other 采集 type set s=new HashSet() Listp=new Linked list(s) builder不能在接口中声明,规范的List 也不能说所有的实现都属于构建者,即使是这样,Java.util.采集s 是一个特殊的类,里面收录了静态字符串方法,有些是泛化算法,有些是包装器。所有特定的 采集 类都提供给构建器以通过 采集 进行争论。这些允许你复制采集,或者属于另一种类型,例如LinkedList Public LinkedList(采集 list contains specified 采集,in 采集'siterator。参数:c-其元素列表的集合。它可以复制为: List p =new LinkedList() ListpCopy=new LinkedList(p) 创建一个link form other 采集 type set s=new HashSet() Listp=new Linked list(s) builder不能在接口中声明,规范的List 也不能说所有的实现都属于构建者,即使是这样,Java.util.采集s 是一个特殊的类,里面收录了静态字符串方法,有些是泛化算法,有些是包装器。所有特定的 采集 类都提供给构建器以通过 采集 进行争论。这些允许你复制采集,或者属于另一种类型,例如LinkedList Public LinkedList(采集 list contains specified 采集,in 采集'siterator。参数:c-其元素列表的集合。它可以复制为: List p =new LinkedList() ListpCopy=new LinkedList(p) 创建一个link form other 采集 type set s=new HashSet() Listp=new Linked list(s) builder不能在接口中声明,规范的List 也不能说所有的实现都属于构建者,即使是这样,Java.util.采集s 是一个特殊的类,里面收录了静态字符串方法,有些是泛化算法,有些是包装器。为构建器提供了类以通过 采集 进行争论。这些允许你复制采集,或者属于另一种类型,例如LinkedList Public LinkedList(采集 list contains specified 采集,in 采集'siterator。参数:c-其元素列表的集合。它可以复制为: List p =new LinkedList() ListpCopy=new LinkedList(p) 创建一个link form other 采集 type set s=new HashSet() Listp=new Linked list(s) builder不能在接口中声明,规范的List 也不能说所有的实现都属于构建者,即使是这样,Java.util.采集s 是一个特殊的类,里面收录了静态字符串方法,有些是泛化算法,有些是包装器。为构建器提供了类以通过 采集 进行争论。这些允许你复制采集,或者属于另一种类型,例如LinkedList Public LinkedList(采集 list contains specified 采集,in 采集'siterator。参数:c-其元素列表的集合。它可以复制为: List p =new LinkedList() ListpCopy=new LinkedList(p) 创建一个link form other 采集 type set s=new HashSet() Listp=new Linked list(s) builder不能在接口中声明,规范的List 也不能说所有的实现都属于构建者,即使是这样,Java.util.采集s 是一个特殊的类,里面收录了静态字符串方法,有些是泛化算法,有些是包装器。List p =new LinkedList() ListpCopy=new LinkedList(p) 创建一个link form other 采集 type set s=new HashSet() Listp=new Linked list(s) builder不能在接口中声明,规范的List 就算是这样,也不能说所有的实现都属于建设者。Java.util.采集s 是一个特殊的类,它收录静态字符串方法,其中一些是通用算法,一些是包装器。List p =new LinkedList() ListpCopy=new LinkedList(p) 创建一个link form other 采集 type set s=new HashSet() Listp=new Linked list(s) builder不能在接口中声明,规范的List 就算是这样,也不能说所有的实现都属于建设者。Java.util.采集s 是一个特殊的类,它收录静态字符串方法,其中一些是通用算法,一些是包装器。
例如 unmodifiableList 使用一个列表,然后使用相同的元素返回一个列表,但它是不可变的。public static List unmodifiableList(List list) 返回unmodifiableview指定列表。该方法允许模块提供用户内部列表。查询操作返回列表”读取到指定列表,并尝试返回列表,是否直接通过其迭代器,结果返回列表指定列表序列化。参数:列表-列表返回不可修改视图。返回:不可修改视图指定列表。返回的列表不准确,无法更改。它的属性值可以因为下面的列表被修改而改变,但不能直接修改。16.7 Sorted 采集s 一种采集 分类必须有某种方法来比较元素并确定它们的顺序。
采集API 为此提供了两种方法。您可以使用自然排序,这是通过对元素使用比较方法从接口 java.lang.Comparable 确定的。public int compareTo(Object 它返回一个负整数类型,0或实整数类型作为对象。添加元素时,使用自然顺序。元素必须内置在一个类中,它是通过Comparable接口实现的。添加方法使要添加的元素通过comparable与现有元素进行比较,不匹配则移除,两者任选其一,可以使用一个元素的顺序独立给定,就像对象一样,通过java.util .Comparator接口实现,也是一个方法 public int compare(Object o1,Object o2) 上面的公式和compareTo类似,只是同时比较两个元素。这是 Strategy 风格的一个例子,通过它它是一个计算法则与使用的代码分离的。方法的选择取决于您创建对象的方式。如果您使用构造并且它使用 Comparator 作为参数,它将用于确定顺序。如果不使用构造,将使用自然顺序。比较 同样的问题(详细信息在第 9 章讨论)带来了同样的困难。如果不使用构造,将使用自然顺序。比较 同样的问题(详细信息在第 9 章讨论)带来了同样的困难。如果不使用构造,将使用自然顺序。比较 同样的问题(详细信息在第 9 章讨论)带来了同样的困难。
一种分类基于不变量。如果可以通过改变公共方法的调用来改变两个元素的顺序,那么 Rep 就会发生。16.8 Views 我们在第9章介绍了concept的概念。Concept是一个复杂的机制。直现在也很有用,但是很危险。它们打破了原创程序中关于设计精心设计的对象的许多基本概念。通过它们的用途,可以识别出三个概念: FunctionalityExtension 有些概念提供了对象函数的扩展,而无需添加新方法。可以替换 采集 类中的 next 和 hasNext 方法。但这使得类自己的 API 更加复杂。支持多个接口也非常困难。我们可以在类中添加一个reset方法,该方法用于调用restart,但同时只允许一次迭代。如果程序元素忘记重置,这种方法会导致错误。解耦的一些概念提到了该子组对底层 采集 的作用。表的键组的方法。例如,返回一个由表的键组成的组。因此,允许部分代码与key相关,该section没有key值,与其他目标规范解耦。CoordinateTransformation 的概念通过 subList 提供了一个等效的转换。概念的改变导致了底层列表的变化,但是允许通过有偏索引访问列表。这种方法会导致错误。解耦的一些概念提到了该子组对底层 采集 的作用。表的键组的方法。例如,返回一个由表的键组成的组。因此,允许部分代码与key相关,该section没有key值,与其他目标规范解耦。CoordinateTransformation 的概念通过 subList 提供了一个等效的转换。概念的改变导致了底层列表的变化,但是允许通过有偏索引访问列表。这种方法会导致错误。解耦的一些概念提到了该子组对底层 采集 的作用。表的键组的方法。例如,返回一个由表的键组成的组。因此,允许部分代码与key相关,该section没有key值,与其他目标规范解耦。CoordinateTransformation 的概念通过 subList 提供了一个等效的转换。概念的改变导致了底层列表的变化,但是允许通过有偏索引访问列表。返回一个由表的键组成的组。因此,允许部分代码与key相关,该section没有key值,与其他目标规范解耦。CoordinateTransformation 的概念通过 subList 提供了一个等效的转换。概念的改变导致了底层列表的变化,但是允许通过有偏索引访问列表。返回一个由表的键组成的组。因此,允许部分代码与key相关,该section没有key值,与其他目标规范解耦。CoordinateTransformation 的概念通过 subList 提供了一个等效的转换。概念的改变导致了底层列表的变化,但是允许通过有偏索引访问列表。
想法是危险的有两个原因。一、底部改变:调用remove改变底部采集;调用 remove 和它的 key group 来更改团队列表。这将形成一个简短的混叠,以便一个对象的变化影响另一个。这两个对象不需要具有相同的字典范围。这意味着我们必须重新定义规范中的更改:如果您更改 C 以收录概念 V,这是否意味着 V 也可以更改?其次,该方法的规范返回了一个通常仅限于更改的想法。为了确保您的代码可以运行,您需要了解此规范。毫不奇怪,这些规范通常很微妙。改变了云学习下采集的一些思路。其他的只允许改变概念——比如迭代器。有些允许概念和底层 采集 改变,但这更复杂。例如采集API,当在列中放置子列表的概念时,底层列不能有任何结构变化:以下将解释这种现象:结构修改列表,否则扰乱进度可能会产生错误的结果. 它的意思不是很准确和清楚。我不想对基础列进行任何更改。同一个底层采集的复杂概念会很复杂。例如,您可以在同一个列表中使用多个迭代器。在这种情况下,您必须考虑与想法的交互。底层列不能有任何结构变化:以下将解释这种现象:结构修改列表,否则扰乱进度可能会产生不正确的结果。它的意思不是很准确和清楚。我不想对基础列进行任何更改。同一个底层采集的复杂概念会很复杂。例如,您可以在同一个列表中使用多个迭代器。在这种情况下,您必须考虑与想法的交互。底层列不能有任何结构变化:以下将解释这种现象:结构修改列表,否则扰乱进度可能会产生不正确的结果。它的意思不是很准确和清楚。我不想对基础列进行任何更改。同一个底层采集的复杂概念会很复杂。例如,您可以在同一个列表中使用多个迭代器。在这种情况下,您必须考虑与想法的交互。您可以在同一个列表中使用多个迭代器。在这种情况下,您必须考虑与想法的交互。您可以在同一个列表中使用多个迭代器。在这种情况下,您必须考虑与想法的交互。
如果通过交互更改列表,其他界面将无效。这里有一些有用的经验。如果您使用想法,您必须仔细考虑它是否会对您有所帮助: 您可以限制可接受的想法范围。例如,使用for循环代替while循环作为接口,可以限制接口的循环范围。很容易确保接口处没有意外错误。这并不总是可能的。下周将讨论 Tagger 计划关于他的集中呼叫更改。您可以使用 采集s 类来防止顾念更改或包装底层对象。例如,如果你在表中使用keySetview,并且不打算更改它,则可以使用以下方法: Set s=map.keySey(); Set safe_s=采集s.unmodifiableSet(s);
云优采集接口(云优采集接口是基于gprs网络资源通过云端实现访问)
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-11-27 17:13
云优采集接口是基于gprs网络资源通过云端实现与百度网盘、百度新闻源、360网盘、维基百科、国家图书馆、中国国家数字图书馆、世界数字图书馆等,其中包括国家图书馆、国家数字图书馆以及各省市图书馆、博物馆等权威网站实现互联互通访问,只要有一台电脑,就可随时访问;云优采集接口在chinaz云爬虫工具平台上实现与各省市图书馆、博物馆、电信运营商以及有关的网站实现互联互通访问,节省了人力成本、时间成本和科技成本。
直接打电话问就行,百度官方的第三方服务官网,应该可以提供所有目标网站的访问地址,
百度网盘天翼云采集接口,全球500强网站都可以采集;云优采集接口,所有目标网站全部采集完毕,采集速度快;一键快速排查网站攻击漏洞,提高爬虫爬取网站的安全性;并且支持多目标多种网站采集,灵活多变,无限制,
我知道的有两个:天翼云,百度。
阿里云,天翼云。
可以使用云丰网采集工具,包含电商平台、博客平台、招聘网站、行业新闻站点采集、标准化程序接口、抓取html、页面打包及ftp、客户端等模块,并对接大、雅虎通、阿里地图、高德导航、陌陌、链家等开放数据源。 查看全部
云优采集接口(云优采集接口是基于gprs网络资源通过云端实现访问)
云优采集接口是基于gprs网络资源通过云端实现与百度网盘、百度新闻源、360网盘、维基百科、国家图书馆、中国国家数字图书馆、世界数字图书馆等,其中包括国家图书馆、国家数字图书馆以及各省市图书馆、博物馆等权威网站实现互联互通访问,只要有一台电脑,就可随时访问;云优采集接口在chinaz云爬虫工具平台上实现与各省市图书馆、博物馆、电信运营商以及有关的网站实现互联互通访问,节省了人力成本、时间成本和科技成本。
直接打电话问就行,百度官方的第三方服务官网,应该可以提供所有目标网站的访问地址,
百度网盘天翼云采集接口,全球500强网站都可以采集;云优采集接口,所有目标网站全部采集完毕,采集速度快;一键快速排查网站攻击漏洞,提高爬虫爬取网站的安全性;并且支持多目标多种网站采集,灵活多变,无限制,
我知道的有两个:天翼云,百度。
阿里云,天翼云。
可以使用云丰网采集工具,包含电商平台、博客平台、招聘网站、行业新闻站点采集、标准化程序接口、抓取html、页面打包及ftp、客户端等模块,并对接大、雅虎通、阿里地图、高德导航、陌陌、链家等开放数据源。
云优采集接口(优购云优人力资源平台二维码代码制作工具(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2021-11-24 10:04
云优采集接口:关注云优采集接口微信公众号获取所需的接口:云优采集云优人力资源平台二维码代码制作工具,自媒体采集群发云优接口方案:云优人力资源平台二维码接口云优人力资源平台场景定制服务云优采集量贩店云优采集采集-爬虫云优采集的二维码云优采集量贩店云优采集采集-爬虫以云优接口为例:①百度搜索云优图商城②点击云优图,上传云优地址③输入云优小店④开通云优优惠卡/在线付款其他网站采集代码购买云优素材①百度搜索云优图商城②点击云优图,上传云优地址③输入云优小店④开通云优优惠卡/在线付款注:地址、小店均为购买链接,不一定所有网站都能使用。
⑤开通云优优惠卡/在线付款完成后,在云优购物软件中点击安装即可。云优人力资源平台二维码采集云优采集量贩店云优采集购物软件v2.2.0版本④云优购物软件下载:云优购物软件下载⑤云优购物软件云优购物软件云优购物软件云优购物软件云优购物软件⑥云优购物软件云优购物软件。
云优采集接口可以免费接入,不限次数,功能对接最新互联网热门搜索渠道,
云优图,智能化采集,只要有网站,只要有手机,只要能接入接口,
我司上个月买了云优图做seo优化优化。算是知名企业了。前几个月上线了一个活动,这个活动有活动资源,同行也有注册。所以我们推广力度很大。同行是借他们资源,一分钱没有下,500块钱买了会员,从280元下一直优惠到350元。但我司因为投放效果不错,才以250一个月,次次有效率,次次的活动资源。效果,太不错了,所以云优图采集技术团队很给力,规模很大,应该快能算是bat。如果有需要的话,可以了解下。 查看全部
云优采集接口(优购云优人力资源平台二维码代码制作工具(组图))
云优采集接口:关注云优采集接口微信公众号获取所需的接口:云优采集云优人力资源平台二维码代码制作工具,自媒体采集群发云优接口方案:云优人力资源平台二维码接口云优人力资源平台场景定制服务云优采集量贩店云优采集采集-爬虫云优采集的二维码云优采集量贩店云优采集采集-爬虫以云优接口为例:①百度搜索云优图商城②点击云优图,上传云优地址③输入云优小店④开通云优优惠卡/在线付款其他网站采集代码购买云优素材①百度搜索云优图商城②点击云优图,上传云优地址③输入云优小店④开通云优优惠卡/在线付款注:地址、小店均为购买链接,不一定所有网站都能使用。
⑤开通云优优惠卡/在线付款完成后,在云优购物软件中点击安装即可。云优人力资源平台二维码采集云优采集量贩店云优采集购物软件v2.2.0版本④云优购物软件下载:云优购物软件下载⑤云优购物软件云优购物软件云优购物软件云优购物软件云优购物软件⑥云优购物软件云优购物软件。
云优采集接口可以免费接入,不限次数,功能对接最新互联网热门搜索渠道,
云优图,智能化采集,只要有网站,只要有手机,只要能接入接口,
我司上个月买了云优图做seo优化优化。算是知名企业了。前几个月上线了一个活动,这个活动有活动资源,同行也有注册。所以我们推广力度很大。同行是借他们资源,一分钱没有下,500块钱买了会员,从280元下一直优惠到350元。但我司因为投放效果不错,才以250一个月,次次有效率,次次的活动资源。效果,太不错了,所以云优图采集技术团队很给力,规模很大,应该快能算是bat。如果有需要的话,可以了解下。
云优采集接口(百度有个云优吧-一站式采集工具(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2022-01-04 22:02
云优采集接口云优采集接口是一款saas的免费采集接口,它采集内容范围涵盖了微信公众号文章、小程序、抖音、火山等全网平台。
百度有个云优吧-一站式采集工具云优吧-一站式采集工具
现在出现了一款采集下载可视化展示的平台,关注公众号“大学生采矿采光”,在后台回复“采光”,
免费采集一般不提供接口,都是收费接口,收费的方式多种多样,然后目前感觉用网页版比较好,
百度云优采集采集下载链接:,
云优吧百度搜下
试试云优网吧,
接口更新也很及时,
用天翼云,
云优网采集下载链接:;wd=&eqid=eb083b00577c5077
凡是百度下的,也没什么能好到哪里去,最后下来的还是用某讯的。
我感觉用免费的网页版就够了
找接口最好从两个方面着手:一是提供的接口能否让用户下载的时候得到结果;二是分析分析接口的速度质量,以便对于下载的结果有比较直观的理解。通常,排名靠前的都比较稳定,而且理论上来说只要是入门级的接口都可以;对于第二点,其实现在互联网接口也还好,像uc分享的万网账号, 查看全部
云优采集接口(百度有个云优吧-一站式采集工具(组图))
云优采集接口云优采集接口是一款saas的免费采集接口,它采集内容范围涵盖了微信公众号文章、小程序、抖音、火山等全网平台。
百度有个云优吧-一站式采集工具云优吧-一站式采集工具
现在出现了一款采集下载可视化展示的平台,关注公众号“大学生采矿采光”,在后台回复“采光”,
免费采集一般不提供接口,都是收费接口,收费的方式多种多样,然后目前感觉用网页版比较好,
百度云优采集采集下载链接:,
云优吧百度搜下
试试云优网吧,
接口更新也很及时,
用天翼云,
云优网采集下载链接:;wd=&eqid=eb083b00577c5077
凡是百度下的,也没什么能好到哪里去,最后下来的还是用某讯的。
我感觉用免费的网页版就够了
找接口最好从两个方面着手:一是提供的接口能否让用户下载的时候得到结果;二是分析分析接口的速度质量,以便对于下载的结果有比较直观的理解。通常,排名靠前的都比较稳定,而且理论上来说只要是入门级的接口都可以;对于第二点,其实现在互联网接口也还好,像uc分享的万网账号,
云优采集接口(云优采集接口优秀云平台数据,各云数据服务商)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-01-04 13:12
云优采集接口优秀云平台数据,各云数据大数据服务商。接口提供量服务:1亿条/千万条,1000万条/亿条,3000万条/btc/eth,1000万条/比特币/btc任你选,二次开发成本低。开发者可根据产品需求接入接口服务,方便快捷;轻松入驻云计算平台,快速发布产品。接口查询接口功能概览云优采集接口集分析,报表,统计图功能于一身,目前平台已发布各项分析报表,数据透明,简单易操作。接口拓展性强,多系统,多行业可以无缝兼容。
金台云可以解决一切你的问题
wordpress
建议你使用exuberep这款插件,它可以很好的帮助你分析你的网站业务状况,包括网站日志数据、交易数据、信息数据等各方面的数据。如果你想要了解更多,或者想要购买我们家的产品,可以私信我。
这个太多了,大家都说得挺多了,我说个新鲜的,可以用最近起火的阿里云监控中心吧。
你可以去,
推荐一个,很有实力的量化交易平台,业内最先进和全面的量化交易库之一,
联合金融云平台。
用浏览器开发一个插件的,可以直接从浏览器获取自己网站,包括来自网站api的数据,提供几种不同的接口。
可以了解下宇宙可优数据这款软件,这款软件接口可以分析你网站上的所有公开的ddos攻击源,除此之外的ddos,可以对接使用。除此之外呢你网站上的所有交易信息都可以获取。而且在样本里面可以获取具体的历史数据,这些历史数据随便怎么分析都是非常客观的。你可以去一下。 查看全部
云优采集接口(云优采集接口优秀云平台数据,各云数据服务商)
云优采集接口优秀云平台数据,各云数据大数据服务商。接口提供量服务:1亿条/千万条,1000万条/亿条,3000万条/btc/eth,1000万条/比特币/btc任你选,二次开发成本低。开发者可根据产品需求接入接口服务,方便快捷;轻松入驻云计算平台,快速发布产品。接口查询接口功能概览云优采集接口集分析,报表,统计图功能于一身,目前平台已发布各项分析报表,数据透明,简单易操作。接口拓展性强,多系统,多行业可以无缝兼容。
金台云可以解决一切你的问题
wordpress
建议你使用exuberep这款插件,它可以很好的帮助你分析你的网站业务状况,包括网站日志数据、交易数据、信息数据等各方面的数据。如果你想要了解更多,或者想要购买我们家的产品,可以私信我。
这个太多了,大家都说得挺多了,我说个新鲜的,可以用最近起火的阿里云监控中心吧。
你可以去,
推荐一个,很有实力的量化交易平台,业内最先进和全面的量化交易库之一,
联合金融云平台。
用浏览器开发一个插件的,可以直接从浏览器获取自己网站,包括来自网站api的数据,提供几种不同的接口。
可以了解下宇宙可优数据这款软件,这款软件接口可以分析你网站上的所有公开的ddos攻击源,除此之外的ddos,可以对接使用。除此之外呢你网站上的所有交易信息都可以获取。而且在样本里面可以获取具体的历史数据,这些历史数据随便怎么分析都是非常客观的。你可以去一下。
云优采集接口(云优采集接口|提供云端采集规则管理(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-01-01 17:00
云优采集接口云优采集接口,是根据互联网采集技术并结合云计算,以及大数据技术,优先实现为企业高效、精准的提供天天采集、7天循环收集、及多个收集需求一站式解决方案的第三方采集系统。适用:游戏、网站、微信公众号等。云优采集接口云优采集接口,是基于自主研发的大数据云采集技术,并结合大数据云计算分析、挖掘和自动化多渠道分析式采集合作,优先提供给企业优质的天天采集、7天循环收集、及多个收集需求一站式解决方案的第三方采集系统。
云优采集接口云优采集接口-erp采集云优采集接口-第三方行业领域高效采集服务云优采集接口|5秒搭建日均30万采集量采集系统云优采集接口|让采集更简单云优采集接口|提供云端采集规则管理云优采集接口|自定义数据规则云优采集接口|手机自由发布采集规则。
云优采集,专注为企业提供采集采集辅助。200多个第三方平台。
看题主想得到什么知识,云优采集/云优采集系统?还是采集策略?还是api接口对接?——采集策略/产品说明产品可以从采集质量、时效性、防作弊三个方面来考量。
一、采集质量评价采集质量最简单的就是看提供的采集数据是否稳定可靠,是否有产品链接形式的二级域名,链接是否支持反复跳转。另外一个衡量数据质量的就是爬虫主程序是否可以按时、准确的抓取、处理并返回相关信息。
二、时效性和爬虫数量爬虫这块主要考量采集效率,系统本身对存储量、处理速度、二级域名等等进行考量,满足要求了自然就上。产品因为处理比较慢,需要等待,时效性就不高。爬虫数量也是。还有爬虫是否能够适应采集条件进行一系列的处理。
三、防作弊/验证码识别效率可以从封闭网站筛选规则,保证验证码识别率。同时考虑采集时常、提取节点、提取规则等等一系列的因素来综合评价。同时,规则质量也是考量数据质量的一个重要因素。采集接口对接无论是直接接口给前端,还是接入采集接口前先考虑作业量,再来选择数据量大小。比如进行统计发放红包,没有基础的设置采集接口基本没有什么意义。
除非做规则自动生成,就能保证时效性的同时,提高数据质量。接口对接的质量考量:接口调试(是否可以自动返回正确的数据?),容错率高不高。比如接入多个采集接口,是否能够同时保证时效性。不然一个接口可能失效就废了。数据的正确率(比如条件是否正确)和容错率(如是否返回已有格式文件)。一般来说规则和查询有正确的请求响应数据,及时的返回数据,正确率差不多能到75。 查看全部
云优采集接口(云优采集接口|提供云端采集规则管理(组图))
云优采集接口云优采集接口,是根据互联网采集技术并结合云计算,以及大数据技术,优先实现为企业高效、精准的提供天天采集、7天循环收集、及多个收集需求一站式解决方案的第三方采集系统。适用:游戏、网站、微信公众号等。云优采集接口云优采集接口,是基于自主研发的大数据云采集技术,并结合大数据云计算分析、挖掘和自动化多渠道分析式采集合作,优先提供给企业优质的天天采集、7天循环收集、及多个收集需求一站式解决方案的第三方采集系统。
云优采集接口云优采集接口-erp采集云优采集接口-第三方行业领域高效采集服务云优采集接口|5秒搭建日均30万采集量采集系统云优采集接口|让采集更简单云优采集接口|提供云端采集规则管理云优采集接口|自定义数据规则云优采集接口|手机自由发布采集规则。
云优采集,专注为企业提供采集采集辅助。200多个第三方平台。
看题主想得到什么知识,云优采集/云优采集系统?还是采集策略?还是api接口对接?——采集策略/产品说明产品可以从采集质量、时效性、防作弊三个方面来考量。
一、采集质量评价采集质量最简单的就是看提供的采集数据是否稳定可靠,是否有产品链接形式的二级域名,链接是否支持反复跳转。另外一个衡量数据质量的就是爬虫主程序是否可以按时、准确的抓取、处理并返回相关信息。
二、时效性和爬虫数量爬虫这块主要考量采集效率,系统本身对存储量、处理速度、二级域名等等进行考量,满足要求了自然就上。产品因为处理比较慢,需要等待,时效性就不高。爬虫数量也是。还有爬虫是否能够适应采集条件进行一系列的处理。
三、防作弊/验证码识别效率可以从封闭网站筛选规则,保证验证码识别率。同时考虑采集时常、提取节点、提取规则等等一系列的因素来综合评价。同时,规则质量也是考量数据质量的一个重要因素。采集接口对接无论是直接接口给前端,还是接入采集接口前先考虑作业量,再来选择数据量大小。比如进行统计发放红包,没有基础的设置采集接口基本没有什么意义。
除非做规则自动生成,就能保证时效性的同时,提高数据质量。接口对接的质量考量:接口调试(是否可以自动返回正确的数据?),容错率高不高。比如接入多个采集接口,是否能够同时保证时效性。不然一个接口可能失效就废了。数据的正确率(比如条件是否正确)和容错率(如是否返回已有格式文件)。一般来说规则和查询有正确的请求响应数据,及时的返回数据,正确率差不多能到75。
云优采集接口(云优采集服务端在线配置数据库的新方向介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-12-29 20:06
云优采集接口又是接口开发的新方向。可以介绍给公司合作伙伴,省去沟通资金投入和维护时间,系统稳定运行后,大幅降低优化成本。提供云计算与saas服务的双重保障。现就云优采集接口介绍如下:1.利用腾讯云直接对接云优采集服务端2.云优接口对接的对象都是腾讯云平台的对象,无需安装即可在线验证3.云优采集服务端在线配置数据库中关键字字段,可实现在云上部署对象任意高级api4.后台提供日志查询服务,方便用户查询。
整个采集服务,主要是两个方面,一个是采集,另一个是上传。所以说需要解决什么问题:采集问题:需要一个api对接工具。在很多云上,其实也就是你说的qq采集、百度采集、脉脉采集、站长助手采集这种的,这些采集工具会提供采集的对接接口,然后你用自己的java语言程序写接口就可以采集。这些接口都是经过层层检测的,能够确保你的数据没有什么bug。
但是有的时候数据量有的时候大,有的时候小,不能保证你的数据整理有没有问题。所以说需要一个能够解决你qq采集或者百度或者站长助手采集这种整数,整百,整千这种整数采集问题的工具。上传问题:需要一个上传服务器。现在这类需求越来越多,很多用户找人定制需求的话,对方工作量比较大,对于一个人也不方便。还有一种情况是有些公司需要你自己发布个人接口需求,但是产品是空的,接口也没有发布。我们目前做的这种定制需求多的是动力节点,你如果有需求可以跟我联系。 查看全部
云优采集接口(云优采集服务端在线配置数据库的新方向介绍)
云优采集接口又是接口开发的新方向。可以介绍给公司合作伙伴,省去沟通资金投入和维护时间,系统稳定运行后,大幅降低优化成本。提供云计算与saas服务的双重保障。现就云优采集接口介绍如下:1.利用腾讯云直接对接云优采集服务端2.云优接口对接的对象都是腾讯云平台的对象,无需安装即可在线验证3.云优采集服务端在线配置数据库中关键字字段,可实现在云上部署对象任意高级api4.后台提供日志查询服务,方便用户查询。
整个采集服务,主要是两个方面,一个是采集,另一个是上传。所以说需要解决什么问题:采集问题:需要一个api对接工具。在很多云上,其实也就是你说的qq采集、百度采集、脉脉采集、站长助手采集这种的,这些采集工具会提供采集的对接接口,然后你用自己的java语言程序写接口就可以采集。这些接口都是经过层层检测的,能够确保你的数据没有什么bug。
但是有的时候数据量有的时候大,有的时候小,不能保证你的数据整理有没有问题。所以说需要一个能够解决你qq采集或者百度或者站长助手采集这种整数,整百,整千这种整数采集问题的工具。上传问题:需要一个上传服务器。现在这类需求越来越多,很多用户找人定制需求的话,对方工作量比较大,对于一个人也不方便。还有一种情况是有些公司需要你自己发布个人接口需求,但是产品是空的,接口也没有发布。我们目前做的这种定制需求多的是动力节点,你如果有需求可以跟我联系。
云优采集接口(云主机接口_计算服务_产品文档_帮助与文档)
采集交流 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-12-25 15:23
云主机接口_计算服务_产品文档_帮助和文档-网易书凡
云主机接口创建云服务器接口方法:POST url参数| 姓名 | 类型 | 必须| 说明 | | --- | --- | --- | --- | | 行动 | 字符串 | 是 | 固定值:CreateInstance | | 版本 | 字符串 | 是 | API 版本号当前版本 2017-12-14 | 帖子正文参数| 姓名 | 班级
来自:产品文档-计算服务-云服务器
我想问一下API接口具体是什么意思?
API是一个接口,一个通道,负责程序和其他软件之间的通信,本质上是一个预定义的功能。受访者还举了很多直观的例子。这里我想换个角度讲一个好的API,希望对大家有用。比如我们上班的时候,窗口就类似于一个API。如果这个窗口可以让我们对于某个不简单的东西“最多运行一次”和“只覆盖一章”,那么这个API就很好。(当然API不一样,应用了接口隔离的原则,即使用多个隔离的接口,比如用户注册和用户登录。
来自:社区问答
常用快递单号物流查询接口通用API(JAVA快递小鸟对接)
快递查询接口通用API用于航运电子商务公司查询快递物流轨迹。接口连接前,必须先到快递鸟网站申请接口密钥和APIKEY。快递查询API接口可以通过物流号查询物流。信息。主要应用于电子商务商城、ERP系统厂商、WMS系统厂商、快递柜、银行等企业。许多快递物流公司都有统一的接口。建议连接接口提供商。可以一次连接多个快递,在后期的技术维护中会省去很多的工作量。快速查询API接口的实现目前有两种方式,一种是
来自:社区博客
api接口fuzz测试初探
【图片】在日常的测试工作中,经常会有api接口的测试。除了正面的过程测试,我们经常需要覆盖一些异常情况。例如:Illegal string 字符串太长,应该是数字类型,传入的字母参数为空,传入中文,标点等SQL注入等等。 其实在我们组接口测试的demo框架中,在数据提供者经常可以看到如下示例。@DataProvider(名称
来自:社区博客
API接口_存储和CDN_产品文档_帮助和文档-网易书凡
API接口 API文档介绍 直接上传服务是NOS推出的一套针对手机或网页上传的解决方案。该方案优化了上传逻辑,上传更加快捷方便。用户可以使用本文档提供的简单API接口来实现直传服务的上传逻辑。API接口DNS查询说明用户客户端可以先通过DNS服务查询获取最近的边缘加速节点IP列表,选择IP上传。接口 GET /lbs?version=${version}&
来自:产品文档-存储和 CDN-对象存储
免费快递单号查询快递鸟API接口演示
,一是单号识别接口:快递鸟接口名称:即时查询界面+单号识别界面编写语言:C#顺丰单号接口简单方便通过快递鸟接口对接,顺丰快递查询接口API和电子面对面的接口可以通过快递小鸟对接,也可以通过顺丰快递
来自:社区博客
快递鸟物流单号查询API接口集成,有需要可以直接使用
快鸟是全球最大的第三方快递物流接口服务商。目前已集成418个快递单号查询接口和31个电子面单接口。高实时性、高稳定性、高并发性,支持快递单号自动识别。Express Bird的第三方快递查询界面好用,关键是免费,用户多(有十几个千人技术QQ群),大型ERP基本都是用Express的界面Bird,这是一个非淘电商平台。他们还使用 Express Bird 提供的接口服务。整个对接非常简单。到Express Bird网站免费注册KEY和ID,下载调用的demo,修复即可。
来自:社区博客
为开发者提供开放的API接口,《VARENA》将利用多维数据提升游戏体验
相关数据显示,2021年由电竞衍生市场和核心市场构成的整体电竞市场规模将达到250亿元,2018年中国电竞保有量将达到2.8亿,潜在用户数将高达4.5亿,我国将成为全球最大的电竞市场。其中,无论是职业电竞选手还是业余选手,都需要通过分析比赛相关数据来了解比赛的玩法以及如何提升自身实力,最终优化比赛体验或在比赛中取得更好的成绩。36氪近日开始接触电竞赛事综合服务平台“
来自:社区博客
云主机性能提升实践
背景 说到性能提升,云主机项目组之前在IAAS层面做了一些事情。比如通过优化nova进程来提升云主机创建速度,通过静态IP注入和GuestOS启动项裁剪来提升云主机操作系统的启动速度。这些优化主要集中在云主机的管理层面,云主机的底层性能并没有得到提升。前段时间,在云主机性能测试中,有外部游戏客户发现,网易云的云主机性能与华为公有云的云主机性能存在较大差距。运行机器人模拟游戏操作华为云可以达到
来自:社区博客
哪个短信验证码API接口比较好用?
【转载自网易云答疑】从技术指标来看,短信平台API的选择标准其实很简单,无非就是速度快、到达率高、渠道稳定,尤其是主体针对的短信验证码,尤其是移动端。5秒基本是极限了,不然就没有用户流失的讨论了。从商业角度看,服务商的实力、服务、行业口碑、价格等都需要综合考虑。从搜索引擎结果可以看出,目前提供短信平台API的公司很多,业内鱼龙混杂。所以,在使用之前,一定要对三个网络进行充分的测试,比较多个,选择适合自己的平台。
来自:社区问答 查看全部
云优采集接口(云主机接口_计算服务_产品文档_帮助与文档)
云主机接口_计算服务_产品文档_帮助和文档-网易书凡
云主机接口创建云服务器接口方法:POST url参数| 姓名 | 类型 | 必须| 说明 | | --- | --- | --- | --- | | 行动 | 字符串 | 是 | 固定值:CreateInstance | | 版本 | 字符串 | 是 | API 版本号当前版本 2017-12-14 | 帖子正文参数| 姓名 | 班级
来自:产品文档-计算服务-云服务器
我想问一下API接口具体是什么意思?
API是一个接口,一个通道,负责程序和其他软件之间的通信,本质上是一个预定义的功能。受访者还举了很多直观的例子。这里我想换个角度讲一个好的API,希望对大家有用。比如我们上班的时候,窗口就类似于一个API。如果这个窗口可以让我们对于某个不简单的东西“最多运行一次”和“只覆盖一章”,那么这个API就很好。(当然API不一样,应用了接口隔离的原则,即使用多个隔离的接口,比如用户注册和用户登录。
来自:社区问答
常用快递单号物流查询接口通用API(JAVA快递小鸟对接)
快递查询接口通用API用于航运电子商务公司查询快递物流轨迹。接口连接前,必须先到快递鸟网站申请接口密钥和APIKEY。快递查询API接口可以通过物流号查询物流。信息。主要应用于电子商务商城、ERP系统厂商、WMS系统厂商、快递柜、银行等企业。许多快递物流公司都有统一的接口。建议连接接口提供商。可以一次连接多个快递,在后期的技术维护中会省去很多的工作量。快速查询API接口的实现目前有两种方式,一种是
来自:社区博客
api接口fuzz测试初探
【图片】在日常的测试工作中,经常会有api接口的测试。除了正面的过程测试,我们经常需要覆盖一些异常情况。例如:Illegal string 字符串太长,应该是数字类型,传入的字母参数为空,传入中文,标点等SQL注入等等。 其实在我们组接口测试的demo框架中,在数据提供者经常可以看到如下示例。@DataProvider(名称
来自:社区博客
API接口_存储和CDN_产品文档_帮助和文档-网易书凡
API接口 API文档介绍 直接上传服务是NOS推出的一套针对手机或网页上传的解决方案。该方案优化了上传逻辑,上传更加快捷方便。用户可以使用本文档提供的简单API接口来实现直传服务的上传逻辑。API接口DNS查询说明用户客户端可以先通过DNS服务查询获取最近的边缘加速节点IP列表,选择IP上传。接口 GET /lbs?version=${version}&
来自:产品文档-存储和 CDN-对象存储
免费快递单号查询快递鸟API接口演示
,一是单号识别接口:快递鸟接口名称:即时查询界面+单号识别界面编写语言:C#顺丰单号接口简单方便通过快递鸟接口对接,顺丰快递查询接口API和电子面对面的接口可以通过快递小鸟对接,也可以通过顺丰快递
来自:社区博客
快递鸟物流单号查询API接口集成,有需要可以直接使用
快鸟是全球最大的第三方快递物流接口服务商。目前已集成418个快递单号查询接口和31个电子面单接口。高实时性、高稳定性、高并发性,支持快递单号自动识别。Express Bird的第三方快递查询界面好用,关键是免费,用户多(有十几个千人技术QQ群),大型ERP基本都是用Express的界面Bird,这是一个非淘电商平台。他们还使用 Express Bird 提供的接口服务。整个对接非常简单。到Express Bird网站免费注册KEY和ID,下载调用的demo,修复即可。
来自:社区博客
为开发者提供开放的API接口,《VARENA》将利用多维数据提升游戏体验
相关数据显示,2021年由电竞衍生市场和核心市场构成的整体电竞市场规模将达到250亿元,2018年中国电竞保有量将达到2.8亿,潜在用户数将高达4.5亿,我国将成为全球最大的电竞市场。其中,无论是职业电竞选手还是业余选手,都需要通过分析比赛相关数据来了解比赛的玩法以及如何提升自身实力,最终优化比赛体验或在比赛中取得更好的成绩。36氪近日开始接触电竞赛事综合服务平台“
来自:社区博客
云主机性能提升实践
背景 说到性能提升,云主机项目组之前在IAAS层面做了一些事情。比如通过优化nova进程来提升云主机创建速度,通过静态IP注入和GuestOS启动项裁剪来提升云主机操作系统的启动速度。这些优化主要集中在云主机的管理层面,云主机的底层性能并没有得到提升。前段时间,在云主机性能测试中,有外部游戏客户发现,网易云的云主机性能与华为公有云的云主机性能存在较大差距。运行机器人模拟游戏操作华为云可以达到
来自:社区博客
哪个短信验证码API接口比较好用?
【转载自网易云答疑】从技术指标来看,短信平台API的选择标准其实很简单,无非就是速度快、到达率高、渠道稳定,尤其是主体针对的短信验证码,尤其是移动端。5秒基本是极限了,不然就没有用户流失的讨论了。从商业角度看,服务商的实力、服务、行业口碑、价格等都需要综合考虑。从搜索引擎结果可以看出,目前提供短信平台API的公司很多,业内鱼龙混杂。所以,在使用之前,一定要对三个网络进行充分的测试,比较多个,选择适合自己的平台。
来自:社区问答
云优采集接口(本文讲的是数据增长第一步:选择“最优”的埋点采集方式)
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2021-12-24 15:09
本文谈数据增长的第一步:选择“最优”的埋藏方法 [IT168评论]在这个大数据时代,基于经验的决策方法已经成为过去,数据很重要性是不言而喻的。数据分析的第一步是从数据源头做好采集。我们今天的主题是埋葬数据。
埋点:数据分析的第一步
大数据,从复杂的数据背后挖掘和分析用户的行为习惯和偏好,找到更符合用户“口味”的产品和服务,根据用户需求调整和优化自己就是大数据的价值. . 对这些信息的采集和分析,也无法避免“埋点”。诸葛io为企业提供了灵活的埋点方式,让各部门、各角色轻松掌控数据采集:
代码(代码)埋点:数据更精准采集,数据更聚焦商业价值采集(诸葛优专业数据顾问团队可提供定制化埋点,让数据分析有针对性);
全埋点:无需人工埋点,所有操作自动埋点,按需处理统计数据;
-可视化埋点:埋点的界面管理和配置不需要开发者干预,埋点更新更方便,见效更快;
“埋点”小科普
埋点就是需要采集对应信息的地方,就像高速公路上的摄像头,可以采集获取车辆的属性,比如颜色、车牌号、车型以及其他信息,您还可以采集车辆的行为,例如:是否有闯红灯、是否有线路压力、车速多少、司机是否在开车时接听电话等。如果摄像头分布理想,那么通过在不同位置叠加摄像头位置采集的信息,可以完整还原某辆车的路径和目的地,甚至可以推断出司机的驾驶习惯,是否是老司机,和其他信息。
那么,每个埋点就像一个摄像头,采集用户行为数据,多维度交叉分析数据,真正还原用户的使用场景,挖掘用户需求,从而提升用户的最大价值整个生命周期。
解锁4个埋点“姿势”
为了让采集海量数据更精准,未来打造一个“纯粹”的数据分析环境,埋点技术应运而生。数据基础是否巩固取决于数据的采集方法。埋点的方法有很多种。根据埋点的位置,可以分为前端(客户端)埋点和后端(服务器端)埋点。前端埋点包括:代码埋点、全埋点、视觉埋点。.
多个采集方法的比较
全埋点:通过SDK采集页面所有控件的运行数据,通过“统计数据过滤器”配置待处理数据的特征。
优点:所有操作都是埋点,简单快捷,无需埋点,按需统计数据处理
缺点:数据上传消耗大量流量,数据维度单一(只有点击、加载、刷新);影响用户体验——用户体验在使用过程中容易卡顿,严重影响用户体验;噪声多,数据精度不高,易干扰;无法自定义埋点采集信息
就像卫星拍摄一样,不需要一个一个安装摄像头,但是数据量巨大,容易遗漏,难以挖掘关键信息。因此,埋点的方法主要用于简单的页面场景,比如短期活动中的登陆页面/专题页面。,需要快速衡量点击分布的效果。
JS可视化埋点:嵌入SDK,可视化圈选定义事件
为了方便产品和操作,同学们可以直接在页面上简单的圈出跟踪用户行为(定义事件),
只需采集点击(click)操作即可节省开发时间。诸葛io最近支持JS可视化埋点。
优点:界面化配置,无需开发,埋点更新方便,见效快
缺点:对嵌入式自定义属性支持较差;重构或页面变化时需要重新配置;
就像卫星航拍一样,无需安装摄像头,数据量小,支持局部区域信息采集。所以JS可视化埋点更适合短平快的数据采集,比如events/H5等简单的页面,业务人员可以直接圈Option,操作无障碍,减少干预技术人员(从今往后,天下太平),这个数据采集方式方便业务人员第一时间掌握页面关键节点的转化,但是用户行为数据的应用比较浅. 无法支持更深入的分析。
另外,如果页面临时调整,可以灵活添加埋点,可以作为代码埋点的补充,以便及时添加采集数据
代码嵌入点:嵌入SDK,定义事件并添加事件代码,按需采集,业务信息更完整,数据分析更专注。因此,代码嵌入是一种基于商业价值的行为分析。
优点:数据采集全面准确,方便后续深入分析(埋点精度顺序:代码埋点>可视埋点>全埋点),SDK体积小,对应用程序本身的体验
缺点:需要研发人员配合,有一定的工作量
如果您不想在使用采集 数据时降低用户体验;如果你不想 采集 得到大量无用的数据;如果要采集数据:粒度更细,维数更多,数据分析的准确率更高。那么,考虑到业务增长的长期价值,请选择一个代码埋点。
服务端埋点:可以支持其他业务数据采集和整合,比如CRM等用户数据,通过接口调用结构化数据,因为直接来自服务端采集@ >,数据精度更高,适合有采集能力的客户,或者可以结合客户端采集采集。
喜欢:
1、 通过调用API接口,将CRM等数据与用户行为数据整合,全方位多角度分析用户;
2、如果公司已经有自己的埋点系统,那么可以直接通过服务器采集上传用户行为数据到诸葛io平台进行数据分析,无需维护两套埋点系统;
3、 连接历史数据(埋点前的数据)和新数据(埋点后的数据),提高数据的准确性。例如,访问客户端采集后,导入原创历史数据后,之前访问平台的现有用户不会被标记为新用户,减少数据错误。
如何“埋头苦干”?
埋点听起来“听不懂”,但其实很简单,就像“在高速公路上安装摄像头”一样。
1、 梳理产品用户行为,确定事件分布
埋点方案≈摄像头安装分布方案
童鞋经常咨询诸葛君:数据分析得到什么样的数据?要回答这个问题,首先要明确目的,理清逻辑。
诸葛io数据分析的对象和依据是用户行为。选择记录和分析哪些用户行为直接影响分析工作的价值输出。诸葛君建议:选择与产品目标和当前主要问题最密切相关的用户行为。事件。以电子商务为例,将流程中的每个用户行为定义为一种事件,并从中获取事件放置的逻辑。
2、记录事件,理解和分析用户行为
≈确定相机要记录的信息,拍照或超速是否违法?
整理好需要记录分析的用户行为,完成事件布局表后,接下来在研发工程师的协助下,根据你的应用平台类型(iOS、Android、JS)完成SDK接入,每个事件的排列会变成一个很短的程序代码——当用户做出相应的行为时,你的应用程序就会运行这段代码,将相应的事件记录到诸葛io。部署完成并发布产品后,当用户开始使用新版本的应用时,使用行为数据会自动传输至诸葛io,供您进行以下分析。
在这一步,诸葛io的CS团队将为公司提供支持,并协助技术团队顺利完成第一步数据采集。
3、通过identify记录用户身份
在诸葛io中,记录了用户的行为,即:用户做了什么?在用户分析的过程中,还有一类信息非常有用,即:用户是谁(TA的id,姓名),有什么特征(TA的年龄,类型...)?您可以通过诸葛io平台的识别流程将用户的身份和特征传递给诸葛io,并利用识别信息进行精细化分析:
细分用户组:用户属性的一个很重要的功能就是将用户进行分组。您可以根据identity 的属性定义过滤条件来细分用户组。比如用“gender=female”这个条件过滤掉所有女生,然后分析女生的行为特征和转化率……
基于属性的比较:分割的重要目的之一是比较。可以根据“性别”进行细分,然后比较“女生”和“男生”在行为、转化、留存等方面的差异;
基于属性的人群画像:您可以根据用户属性——男女比例、区域分布、年龄层次、用户类型……
回到开头的问题:什么样的埋葬方式最理想?
正如同一枚硬币有两个面一样,任何一种嵌入点的方法都有优点和缺点。试图通过简单粗暴的代码行/一次部署来嵌入点,甚至牺牲用户体验,都不是企业所期望的。
因此,数据采集只是数据分析的第一步。数据分析的目的是洞察用户行为,挖掘用户价值,促进业务增长。诸葛io认为,最理想的埋点解决方案是根据不同的业务场景和行业特点以及自身的实际需求,将埋点优势和劣势互补的方式结合起来,例如:
1、代码埋点+全埋点:当需要对落地页进行整体点击分析时,在细节中一一埋点的工作量比较大,并且在频繁优化落地页时调整后,更新埋点的工作量也不容小觑,但是复杂页面存在死角,所有点都不能采集。因此,代码埋点可以作为采集用户核心行为的辅助手段,从而达到精准的表现。横切用户行为分析;
2、代码埋点+服务器埋点:以电商平台为例,用户在支付环节会跳转到第三方支付平台,支付是否成功需要通过服务器中的交易数据。这时可以通过代码埋点和服务端埋点的结合来提高数据的准确性;
3、代码埋点+可视化埋点:由于代码埋点工作量大,可以通过核心事件代码埋点,可视化埋点可以用来追加和补充数据采集 @>。
为满足精细化、精准化的数据分析需求,可根据实际分析场景需求选择一种或多种采集方法组合。毕竟采集全数据不是目的,有效数据是实现分析,从数据中找到关键决策信息实现增长才是重中之重。
原文发表时间为:2017-08-11 查看全部
云优采集接口(本文讲的是数据增长第一步:选择“最优”的埋点采集方式)
本文谈数据增长的第一步:选择“最优”的埋藏方法 [IT168评论]在这个大数据时代,基于经验的决策方法已经成为过去,数据很重要性是不言而喻的。数据分析的第一步是从数据源头做好采集。我们今天的主题是埋葬数据。
埋点:数据分析的第一步
大数据,从复杂的数据背后挖掘和分析用户的行为习惯和偏好,找到更符合用户“口味”的产品和服务,根据用户需求调整和优化自己就是大数据的价值. . 对这些信息的采集和分析,也无法避免“埋点”。诸葛io为企业提供了灵活的埋点方式,让各部门、各角色轻松掌控数据采集:
代码(代码)埋点:数据更精准采集,数据更聚焦商业价值采集(诸葛优专业数据顾问团队可提供定制化埋点,让数据分析有针对性);
全埋点:无需人工埋点,所有操作自动埋点,按需处理统计数据;
-可视化埋点:埋点的界面管理和配置不需要开发者干预,埋点更新更方便,见效更快;
“埋点”小科普
埋点就是需要采集对应信息的地方,就像高速公路上的摄像头,可以采集获取车辆的属性,比如颜色、车牌号、车型以及其他信息,您还可以采集车辆的行为,例如:是否有闯红灯、是否有线路压力、车速多少、司机是否在开车时接听电话等。如果摄像头分布理想,那么通过在不同位置叠加摄像头位置采集的信息,可以完整还原某辆车的路径和目的地,甚至可以推断出司机的驾驶习惯,是否是老司机,和其他信息。
那么,每个埋点就像一个摄像头,采集用户行为数据,多维度交叉分析数据,真正还原用户的使用场景,挖掘用户需求,从而提升用户的最大价值整个生命周期。
解锁4个埋点“姿势”
为了让采集海量数据更精准,未来打造一个“纯粹”的数据分析环境,埋点技术应运而生。数据基础是否巩固取决于数据的采集方法。埋点的方法有很多种。根据埋点的位置,可以分为前端(客户端)埋点和后端(服务器端)埋点。前端埋点包括:代码埋点、全埋点、视觉埋点。.
多个采集方法的比较
全埋点:通过SDK采集页面所有控件的运行数据,通过“统计数据过滤器”配置待处理数据的特征。
优点:所有操作都是埋点,简单快捷,无需埋点,按需统计数据处理
缺点:数据上传消耗大量流量,数据维度单一(只有点击、加载、刷新);影响用户体验——用户体验在使用过程中容易卡顿,严重影响用户体验;噪声多,数据精度不高,易干扰;无法自定义埋点采集信息
就像卫星拍摄一样,不需要一个一个安装摄像头,但是数据量巨大,容易遗漏,难以挖掘关键信息。因此,埋点的方法主要用于简单的页面场景,比如短期活动中的登陆页面/专题页面。,需要快速衡量点击分布的效果。
JS可视化埋点:嵌入SDK,可视化圈选定义事件
为了方便产品和操作,同学们可以直接在页面上简单的圈出跟踪用户行为(定义事件),
只需采集点击(click)操作即可节省开发时间。诸葛io最近支持JS可视化埋点。
优点:界面化配置,无需开发,埋点更新方便,见效快
缺点:对嵌入式自定义属性支持较差;重构或页面变化时需要重新配置;
就像卫星航拍一样,无需安装摄像头,数据量小,支持局部区域信息采集。所以JS可视化埋点更适合短平快的数据采集,比如events/H5等简单的页面,业务人员可以直接圈Option,操作无障碍,减少干预技术人员(从今往后,天下太平),这个数据采集方式方便业务人员第一时间掌握页面关键节点的转化,但是用户行为数据的应用比较浅. 无法支持更深入的分析。
另外,如果页面临时调整,可以灵活添加埋点,可以作为代码埋点的补充,以便及时添加采集数据
代码嵌入点:嵌入SDK,定义事件并添加事件代码,按需采集,业务信息更完整,数据分析更专注。因此,代码嵌入是一种基于商业价值的行为分析。
优点:数据采集全面准确,方便后续深入分析(埋点精度顺序:代码埋点>可视埋点>全埋点),SDK体积小,对应用程序本身的体验
缺点:需要研发人员配合,有一定的工作量
如果您不想在使用采集 数据时降低用户体验;如果你不想 采集 得到大量无用的数据;如果要采集数据:粒度更细,维数更多,数据分析的准确率更高。那么,考虑到业务增长的长期价值,请选择一个代码埋点。
服务端埋点:可以支持其他业务数据采集和整合,比如CRM等用户数据,通过接口调用结构化数据,因为直接来自服务端采集@ >,数据精度更高,适合有采集能力的客户,或者可以结合客户端采集采集。
喜欢:
1、 通过调用API接口,将CRM等数据与用户行为数据整合,全方位多角度分析用户;
2、如果公司已经有自己的埋点系统,那么可以直接通过服务器采集上传用户行为数据到诸葛io平台进行数据分析,无需维护两套埋点系统;
3、 连接历史数据(埋点前的数据)和新数据(埋点后的数据),提高数据的准确性。例如,访问客户端采集后,导入原创历史数据后,之前访问平台的现有用户不会被标记为新用户,减少数据错误。
如何“埋头苦干”?
埋点听起来“听不懂”,但其实很简单,就像“在高速公路上安装摄像头”一样。
1、 梳理产品用户行为,确定事件分布
埋点方案≈摄像头安装分布方案
童鞋经常咨询诸葛君:数据分析得到什么样的数据?要回答这个问题,首先要明确目的,理清逻辑。
诸葛io数据分析的对象和依据是用户行为。选择记录和分析哪些用户行为直接影响分析工作的价值输出。诸葛君建议:选择与产品目标和当前主要问题最密切相关的用户行为。事件。以电子商务为例,将流程中的每个用户行为定义为一种事件,并从中获取事件放置的逻辑。
2、记录事件,理解和分析用户行为
≈确定相机要记录的信息,拍照或超速是否违法?
整理好需要记录分析的用户行为,完成事件布局表后,接下来在研发工程师的协助下,根据你的应用平台类型(iOS、Android、JS)完成SDK接入,每个事件的排列会变成一个很短的程序代码——当用户做出相应的行为时,你的应用程序就会运行这段代码,将相应的事件记录到诸葛io。部署完成并发布产品后,当用户开始使用新版本的应用时,使用行为数据会自动传输至诸葛io,供您进行以下分析。
在这一步,诸葛io的CS团队将为公司提供支持,并协助技术团队顺利完成第一步数据采集。
3、通过identify记录用户身份
在诸葛io中,记录了用户的行为,即:用户做了什么?在用户分析的过程中,还有一类信息非常有用,即:用户是谁(TA的id,姓名),有什么特征(TA的年龄,类型...)?您可以通过诸葛io平台的识别流程将用户的身份和特征传递给诸葛io,并利用识别信息进行精细化分析:
细分用户组:用户属性的一个很重要的功能就是将用户进行分组。您可以根据identity 的属性定义过滤条件来细分用户组。比如用“gender=female”这个条件过滤掉所有女生,然后分析女生的行为特征和转化率……
基于属性的比较:分割的重要目的之一是比较。可以根据“性别”进行细分,然后比较“女生”和“男生”在行为、转化、留存等方面的差异;
基于属性的人群画像:您可以根据用户属性——男女比例、区域分布、年龄层次、用户类型……
回到开头的问题:什么样的埋葬方式最理想?
正如同一枚硬币有两个面一样,任何一种嵌入点的方法都有优点和缺点。试图通过简单粗暴的代码行/一次部署来嵌入点,甚至牺牲用户体验,都不是企业所期望的。
因此,数据采集只是数据分析的第一步。数据分析的目的是洞察用户行为,挖掘用户价值,促进业务增长。诸葛io认为,最理想的埋点解决方案是根据不同的业务场景和行业特点以及自身的实际需求,将埋点优势和劣势互补的方式结合起来,例如:
1、代码埋点+全埋点:当需要对落地页进行整体点击分析时,在细节中一一埋点的工作量比较大,并且在频繁优化落地页时调整后,更新埋点的工作量也不容小觑,但是复杂页面存在死角,所有点都不能采集。因此,代码埋点可以作为采集用户核心行为的辅助手段,从而达到精准的表现。横切用户行为分析;
2、代码埋点+服务器埋点:以电商平台为例,用户在支付环节会跳转到第三方支付平台,支付是否成功需要通过服务器中的交易数据。这时可以通过代码埋点和服务端埋点的结合来提高数据的准确性;
3、代码埋点+可视化埋点:由于代码埋点工作量大,可以通过核心事件代码埋点,可视化埋点可以用来追加和补充数据采集 @>。
为满足精细化、精准化的数据分析需求,可根据实际分析场景需求选择一种或多种采集方法组合。毕竟采集全数据不是目的,有效数据是实现分析,从数据中找到关键决策信息实现增长才是重中之重。
原文发表时间为:2017-08-11
云优采集接口(训练网络精度未达预期时如何采集Dump数据数据? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 195 次浏览 • 2021-12-24 15:05
)
更新时间:2021-10-26 GMT+08:00
查看PDF
链接复制成功!
启用转储数据采集
概述
当训练网络的准确率达不到预期时,可以使用训练过程中各个算子的计算结果(即Data Dump数据),然后使用准确率对比工具和行业标准算子(如TensorFlow)对计算结果进行数据偏差对比,帮助开发者快速解决算子精度问题。目前支持采集的operator数据主要有:
默认训练过程中,没有采集算子的dump数据。如果需要采集并分析数据,可以选择以下两种方式之一:
使用注意事项
采集在 Estimator 模式下转储数据
在Estimator模式下,通过NPUrunConfig中的dump_config采集Dump data,在创建NPUrunConfig之前,先实例化一个DumpConfig类进行dump配置(包括配置dump路径,哪些迭代数据要dump,dump算子的输入或输出)数据等)。
DumpConfig类的构造函数中各个字段的详细解释请参考对应的接口说明。
from npu_bridge.npu_init import *
# dump_path:dump数据存放路径,该参数指定的目录需要在启动训练的环境上(容器或Host侧)提前创建且确保安装时配置的运行用户具有读写权限
# enable_dump:是否开启Dump功能
# dump_step:指定采集哪些迭代的Dump数据
# dump_mode:Dump模式,取值:input/output/all
dump_config = DumpConfig(enable_dump=True, dump_path = "/home/HwHiAiUser/output", dump_step="0|5|10", dump_mode="all")
session_config=tf.ConfigProto()
config = NPURunConfig(
dump_config=dump_config,
session_config=session_config
)
采集在sess.run模式下转储数据
在sess.run模式下,通过session配置项enable_dump、dump_path、dump_step、dump_mode配置相关参数。
config = tf.ConfigProto()
custom_op = config.graph_options.rewrite_options.custom_optimizers.add()
custom_op.name = "NpuOptimizer"
custom_op.parameter_map["use_off_line"].b = True
# enable_dump:是否开启Dump功能
custom_op.parameter_map["enable_dump"].b = True
# dump_path:dump数据存放路径,该参数指定的目录需要在启动训练的环境上(容器或Host侧)提前创建且确保安装时配置的运行用户具有读写权限
custom_op.parameter_map["dump_path"].s = tf.compat.as_bytes("/home/HwHiAiUser/output")
# dump_step:指定采集哪些迭代的Dump数据
custom_op.parameter_map["dump_step"].s = tf.compat.as_bytes("0|5|10")
# dump_mode:Dump模式,取值:input/output/all
custom_op.parameter_map["dump_mode"].s = tf.compat.as_bytes("all")
config.graph_options.rewrite_options.remapping = RewriterConfig.OFF
config.graph_options.rewrite_options.memory_optimization = RewriterConfig.OFF
with tf.Session(config=config) as sess:
print(sess.run(cost))
执行训练并生成转储数据
后续的精度对比工具不仅依赖Dump数据,还需要计算图结构。因此,在进行训练之前,需要配置环境变量转储图文件:
export DUMP_GE_GRAPH=2
export DUMP_GRAPH_PATH=/home/dumpgraph # 指定dump图路径,如果不配置存储在训练脚本所在目录
执行训练,生成转储图像文件和转储数据文件。
由于“ge”开头的转储图文件很多,转储数据文件夹的model_name层可能有多个文件夹,所以实际上我们只需要找到计算图文件,只要找到model_name为计算图的名称。下面提供一些方法,帮助用户快速找到对应的文件。
选择计算图文件,提供以下两种方法:
选择转储数据文件。
打开上一步找到的计算图文件,记录第一张图中name字段的值。在以下示例中,记录“ge_default_253_71”。
graph {
name: "ge_default_20201209083353_71"
op {
name: "atomic_addr_clean0_71"
type: "AtomicAddrClean"
attr {
key: "_fe_imply_type"
value {
i: 6
}
}
进入dump data文件夹,我们会看到model_name层有多个文件夹:
找到名称为刚才记录的计算图的名称值的文件夹,如ge_default_253_71。此目录中的文件是您需要的转储数据文件。
查看全部
云优采集接口(训练网络精度未达预期时如何采集Dump数据数据?
)
更新时间:2021-10-26 GMT+08:00
查看PDF
链接复制成功!
启用转储数据采集
概述
当训练网络的准确率达不到预期时,可以使用训练过程中各个算子的计算结果(即Data Dump数据),然后使用准确率对比工具和行业标准算子(如TensorFlow)对计算结果进行数据偏差对比,帮助开发者快速解决算子精度问题。目前支持采集的operator数据主要有:
默认训练过程中,没有采集算子的dump数据。如果需要采集并分析数据,可以选择以下两种方式之一:
使用注意事项
采集在 Estimator 模式下转储数据
在Estimator模式下,通过NPUrunConfig中的dump_config采集Dump data,在创建NPUrunConfig之前,先实例化一个DumpConfig类进行dump配置(包括配置dump路径,哪些迭代数据要dump,dump算子的输入或输出)数据等)。
DumpConfig类的构造函数中各个字段的详细解释请参考对应的接口说明。
from npu_bridge.npu_init import *
# dump_path:dump数据存放路径,该参数指定的目录需要在启动训练的环境上(容器或Host侧)提前创建且确保安装时配置的运行用户具有读写权限
# enable_dump:是否开启Dump功能
# dump_step:指定采集哪些迭代的Dump数据
# dump_mode:Dump模式,取值:input/output/all
dump_config = DumpConfig(enable_dump=True, dump_path = "/home/HwHiAiUser/output", dump_step="0|5|10", dump_mode="all")
session_config=tf.ConfigProto()
config = NPURunConfig(
dump_config=dump_config,
session_config=session_config
)
采集在sess.run模式下转储数据
在sess.run模式下,通过session配置项enable_dump、dump_path、dump_step、dump_mode配置相关参数。
config = tf.ConfigProto()
custom_op = config.graph_options.rewrite_options.custom_optimizers.add()
custom_op.name = "NpuOptimizer"
custom_op.parameter_map["use_off_line"].b = True
# enable_dump:是否开启Dump功能
custom_op.parameter_map["enable_dump"].b = True
# dump_path:dump数据存放路径,该参数指定的目录需要在启动训练的环境上(容器或Host侧)提前创建且确保安装时配置的运行用户具有读写权限
custom_op.parameter_map["dump_path"].s = tf.compat.as_bytes("/home/HwHiAiUser/output")
# dump_step:指定采集哪些迭代的Dump数据
custom_op.parameter_map["dump_step"].s = tf.compat.as_bytes("0|5|10")
# dump_mode:Dump模式,取值:input/output/all
custom_op.parameter_map["dump_mode"].s = tf.compat.as_bytes("all")
config.graph_options.rewrite_options.remapping = RewriterConfig.OFF
config.graph_options.rewrite_options.memory_optimization = RewriterConfig.OFF
with tf.Session(config=config) as sess:
print(sess.run(cost))
执行训练并生成转储数据
后续的精度对比工具不仅依赖Dump数据,还需要计算图结构。因此,在进行训练之前,需要配置环境变量转储图文件:
export DUMP_GE_GRAPH=2
export DUMP_GRAPH_PATH=/home/dumpgraph # 指定dump图路径,如果不配置存储在训练脚本所在目录
执行训练,生成转储图像文件和转储数据文件。
由于“ge”开头的转储图文件很多,转储数据文件夹的model_name层可能有多个文件夹,所以实际上我们只需要找到计算图文件,只要找到model_name为计算图的名称。下面提供一些方法,帮助用户快速找到对应的文件。
选择计算图文件,提供以下两种方法:
选择转储数据文件。
打开上一步找到的计算图文件,记录第一张图中name字段的值。在以下示例中,记录“ge_default_253_71”。
graph {
name: "ge_default_20201209083353_71"
op {
name: "atomic_addr_clean0_71"
type: "AtomicAddrClean"
attr {
key: "_fe_imply_type"
value {
i: 6
}
}
进入dump data文件夹,我们会看到model_name层有多个文件夹:
找到名称为刚才记录的计算图的名称值的文件夹,如ge_default_253_71。此目录中的文件是您需要的转储数据文件。
云优采集接口(云优采集接口可以看前端一键下载抖音、火山、网易云音乐)
采集交流 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2021-12-20 14:03
云优采集接口可以看前端一键下载抖音、火山、网易云音乐等全网热门大视频。
这类网站采集一般都是需要关联其他网站,其他网站都是用你采集的资源,搜索引擎都有蜘蛛爬,所以查询结果很容易。
现在的云优,都是接通了网站后台,一键解析全网视频并批量下载。但网站后台接口暂时没有开放,所以需要爬虫爬。
很简单就可以获取的而且只需要关联你在线视频的网站就可以了
云优就是接口服务嘛。不知道你们怎么接,我以我接的为例子,我做了个专门的云优产品,就是用来提供这个接口,所以别人是拿不到的,
百度前端自然的去搜索啊,
以前在网上看到过一个接口,现在可能是接口方改了,接口没有了。你可以去谷歌,或者搜狗,试试看,
互联网整个知识产权流程大体分为,技术采集,运营发布,产品营销,监控服务。出现这样的问题需要好好反思你的采集方式和收集内容的本质了,是不是接口没对?做网站,不能操之过急。
1.爬虫采集2.爬虫接口
网上很多采集链接,你自己也可以爬。
这么多,爬不爬不重要,重要的是怎么爬,一般来说像个人用的话,不会有直接的收入,想要赚钱的话,需要链接,可以在别的地方采集下来,然后找网站主体发个邮件啥的,介绍一下怎么爬去,然后再去复制发布,至于怎么采,肯定很多网站都会方便好多,随便问采集的话,一般都会给你教程的,问题是会不会用,很多教程都会有教你如何使用,但是不一定每个网站都用的到,就像楼上说的,怎么爬,只能靠自己学习了,一般接口肯定是用不到的,不要小看ca论坛,你以为没有爬虫,没有不登录,这些人就会爬不到吗?照样有人就爬的到,而且收入不错。 查看全部
云优采集接口(云优采集接口可以看前端一键下载抖音、火山、网易云音乐)
云优采集接口可以看前端一键下载抖音、火山、网易云音乐等全网热门大视频。
这类网站采集一般都是需要关联其他网站,其他网站都是用你采集的资源,搜索引擎都有蜘蛛爬,所以查询结果很容易。
现在的云优,都是接通了网站后台,一键解析全网视频并批量下载。但网站后台接口暂时没有开放,所以需要爬虫爬。
很简单就可以获取的而且只需要关联你在线视频的网站就可以了
云优就是接口服务嘛。不知道你们怎么接,我以我接的为例子,我做了个专门的云优产品,就是用来提供这个接口,所以别人是拿不到的,
百度前端自然的去搜索啊,
以前在网上看到过一个接口,现在可能是接口方改了,接口没有了。你可以去谷歌,或者搜狗,试试看,
互联网整个知识产权流程大体分为,技术采集,运营发布,产品营销,监控服务。出现这样的问题需要好好反思你的采集方式和收集内容的本质了,是不是接口没对?做网站,不能操之过急。
1.爬虫采集2.爬虫接口
网上很多采集链接,你自己也可以爬。
这么多,爬不爬不重要,重要的是怎么爬,一般来说像个人用的话,不会有直接的收入,想要赚钱的话,需要链接,可以在别的地方采集下来,然后找网站主体发个邮件啥的,介绍一下怎么爬去,然后再去复制发布,至于怎么采,肯定很多网站都会方便好多,随便问采集的话,一般都会给你教程的,问题是会不会用,很多教程都会有教你如何使用,但是不一定每个网站都用的到,就像楼上说的,怎么爬,只能靠自己学习了,一般接口肯定是用不到的,不要小看ca论坛,你以为没有爬虫,没有不登录,这些人就会爬不到吗?照样有人就爬的到,而且收入不错。
云优采集接口(如何将腾讯云短信接口发送短信3.java连接数据库4.)
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-12-19 13:17
Fdog系列(三):使用腾讯云短信接口发送短信,写数据库,部署到服务器,网页收尾文章。
或者你需要一家公司来购买它们。转了几圈,终于在腾讯云上找到了免费短信。新用户可获得100条免费短信,此后每月发送一次。腾讯云短信免费试用。我只是假设你收到了短信,下去,点击控制台,然后搜索短信,进入如下页面。?String templateParams = {String.valueOf(randnum)}; {1 对应模板中} randnum 为我生成的随机五位数尝试 {必要步骤:实例化一个认证对象,输入腾讯云账号密钥对输入参数 我只是假设你收到了短信,下去,点击控制台,然后搜索短信,进入如下页面。?String templateParams = {String.valueOf(randnum)}; {1 对应模板中} randnum 为我生成的随机五位数尝试 {必要步骤:实例化一个认证对象,输入腾讯云账号密钥对输入参数 我只是假设你收到了短信,下去,点击控制台,然后搜索短信,进入如下页面。?String templateParams = {String.valueOf(randnum)}; {1 对应模板中} randnum 为我生成的随机五位数尝试 {必要步骤:实例化一个认证对象,输入腾讯云账号密钥对输入参数
187 查看全部
云优采集接口(如何将腾讯云短信接口发送短信3.java连接数据库4.)
Fdog系列(三):使用腾讯云短信接口发送短信,写数据库,部署到服务器,网页收尾文章。
或者你需要一家公司来购买它们。转了几圈,终于在腾讯云上找到了免费短信。新用户可获得100条免费短信,此后每月发送一次。腾讯云短信免费试用。我只是假设你收到了短信,下去,点击控制台,然后搜索短信,进入如下页面。?String templateParams = {String.valueOf(randnum)}; {1 对应模板中} randnum 为我生成的随机五位数尝试 {必要步骤:实例化一个认证对象,输入腾讯云账号密钥对输入参数 我只是假设你收到了短信,下去,点击控制台,然后搜索短信,进入如下页面。?String templateParams = {String.valueOf(randnum)}; {1 对应模板中} randnum 为我生成的随机五位数尝试 {必要步骤:实例化一个认证对象,输入腾讯云账号密钥对输入参数 我只是假设你收到了短信,下去,点击控制台,然后搜索短信,进入如下页面。?String templateParams = {String.valueOf(randnum)}; {1 对应模板中} randnum 为我生成的随机五位数尝试 {必要步骤:实例化一个认证对象,输入腾讯云账号密钥对输入参数
187
云优采集接口(2020年Forrester发布的《混合多云战略的关键》调研结果显示)
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2021-12-15 18:23
混合云包括多供应商公共云、私有云和本地数据中心之间的混合部署模型。
2020 年,Forrester 的“混合多云战略的关键”调查结果显示,85% 的受访者正在增加对混合云管理的需求,90% 的 IT 领导者认为本地基础设施是其混合云的关键组成部分战略 。同样,根据 Gartner 的一份报告,2020 年之后,超过 90% 的组织将使用混合云来构建基础设施。混合云架构将是未来5到10年企业最常见的架构形式。
混合云将企业私有云、公有云、本地数据中心有机融合,为企业提供更丰富的云服务、更灵活的云资源、更合理的IT资源使用成本。同时,混合云的复杂性给企业网络安全管理带来巨大挑战。目前,混合云上资产漏洞管理的成熟度远远落后于传统本地数据中心,造成偏差的主要原因是缺乏适应混合云环境的资产漏洞检测和管理解决方案。
1、 混合云环境下资产漏洞检测方法
目前,在混合云环境中检测资产漏洞的方法主要有以下三种:
如何保证资产漏洞检测全面、准确、可靠?我们首先要了解混合云环境下资产漏洞检测遇到的问题。
2、混合云环境下资产漏洞检测现状及痛点
云资产漏洞检测存在盲点
在传统环境中,所有资产必须通过物理层网络设施进行连接,我们可以通过物理网络完成资产漏洞检测。
但是,在云环境中,网络端口也是虚拟化的,物理节点无法覆盖业务数据流经的关键路径。要实现全资产漏洞检测,需要具备针对VPC、VM、Docker、POD、OVS,甚至某个API接口等不同类型节点的资产漏洞检测能力。
资源池复杂,资产维度不一致
在混合云架构中,企业对计算资源实施统一的资源池管理。但在资产管理层面,往往缺乏统一规划。虚拟化软件、裸机、容器、云平台等异构资源各自独立。企业资源池因资产数量和类型的变化而被动变化。漏洞检测工具存在难以适应资源池动态变化等问题。
传统工具难以适应云上复杂的环境
与传统物理环境相比,云环境中的主机和容器会动态创建、销毁、迁移和弹性扩展。如果是固定配置漏洞检测,资产动态迁移后,检测会中断,无法持续,而这种动态变化的特点是随机的、常态化的。网络环境也比较复杂,各种VPC的存在使得传统的检测工具难以适应多样化的网络环境。
如何在大规模虚拟混合环境中实现资产全面覆盖、检测性能高、准确率高,同时与企业安全运营平台(SOC)无缝对接?这是在混合云环境中选择资产漏洞检测和管理解决方案时需要考虑的关键问题。
3、 混合云环境下资产漏洞检测与管理解决方案
跨混合环境的统一 采集 解决方案
要构建统一高效、无盲区的全资产漏洞检测与管理解决方案,漏洞检测工具必须能够跨越私有云、公有云、容器、传统环境等多种混合架构,提供一致的漏洞检测和管理能力。
【灵活动态】+【高效检测】适应云环境的解决方案
在云环境下,漏洞检测工具需要具备自动感知节点变化的能力,进而自动进行相应的更新和部署,保证漏洞检测工作不被中断,适应云上的弹性伸缩。
漏洞检测工具还需要适应云上大规模、高并发的流量机制,基于高性能并发检测技术,实现百万级资产漏洞检测。
通过漏洞管理平台的自我监控能力,用户可以实时了解系统的资源消耗状况,及时优化资源配置和检测配置。
4、从漏洞检测到响应的整体解决方案
面对混合云环境,需要建立一套资产漏洞检测和管理平台,采集整个系统软硬件产品和组件的所有漏洞信息,有效支持收录、发布、混合云环境中漏洞的预警、分析、验证、处置等工作。对于漏洞安全应急工作,尤其是高危及以上漏洞风险防范、大规模漏洞利用攻击处理,企业全面提升信息安全防护、风险管理和威胁的整体水平至关重要。回复。
华云安资产漏洞检测与管理解决方案具备混合云环境下资产漏洞检测与管理能力。整体架构包括漏洞数据库、漏洞管理平台、漏洞扫描探针三部分。在:
漏洞数据库,具有收录漏洞信息、接收和发布预警通知、监控企业漏洞情况等功能;
漏洞管理平台负责接收漏洞预警情报信息,生成漏洞扫描任务,向扫描探针下发漏洞扫描任务进行漏洞扫描,具有漏洞响应、管理和操作功能;
漏洞扫描探针负责接收漏洞管理平台下发的漏洞扫描任务,执行漏洞扫描任务,反馈漏洞扫描结果,完成混合云环境下资产漏洞检测与验证的功能。
虽然企业上云已经成为常态,混合云也为企业IT资源管理提供了更有效的解决方案,但混合云固有的逆向威力也不容小觑。在混合云环境中,资产漏洞检测和管理需要把握解决问题的关键要素——灵活高效。这正是华云安资产漏洞检测与管理解决方案的价值所在。在混合云环境中,以简单、复杂、高效、优质的方式解决用户资产风险管理的痛点,为用户提供资产漏洞管理和漏洞响应的持续迭代能力和一致体验。 查看全部
云优采集接口(2020年Forrester发布的《混合多云战略的关键》调研结果显示)
混合云包括多供应商公共云、私有云和本地数据中心之间的混合部署模型。
2020 年,Forrester 的“混合多云战略的关键”调查结果显示,85% 的受访者正在增加对混合云管理的需求,90% 的 IT 领导者认为本地基础设施是其混合云的关键组成部分战略 。同样,根据 Gartner 的一份报告,2020 年之后,超过 90% 的组织将使用混合云来构建基础设施。混合云架构将是未来5到10年企业最常见的架构形式。
混合云将企业私有云、公有云、本地数据中心有机融合,为企业提供更丰富的云服务、更灵活的云资源、更合理的IT资源使用成本。同时,混合云的复杂性给企业网络安全管理带来巨大挑战。目前,混合云上资产漏洞管理的成熟度远远落后于传统本地数据中心,造成偏差的主要原因是缺乏适应混合云环境的资产漏洞检测和管理解决方案。
1、 混合云环境下资产漏洞检测方法
目前,在混合云环境中检测资产漏洞的方法主要有以下三种:
如何保证资产漏洞检测全面、准确、可靠?我们首先要了解混合云环境下资产漏洞检测遇到的问题。
2、混合云环境下资产漏洞检测现状及痛点
云资产漏洞检测存在盲点
在传统环境中,所有资产必须通过物理层网络设施进行连接,我们可以通过物理网络完成资产漏洞检测。
但是,在云环境中,网络端口也是虚拟化的,物理节点无法覆盖业务数据流经的关键路径。要实现全资产漏洞检测,需要具备针对VPC、VM、Docker、POD、OVS,甚至某个API接口等不同类型节点的资产漏洞检测能力。
资源池复杂,资产维度不一致
在混合云架构中,企业对计算资源实施统一的资源池管理。但在资产管理层面,往往缺乏统一规划。虚拟化软件、裸机、容器、云平台等异构资源各自独立。企业资源池因资产数量和类型的变化而被动变化。漏洞检测工具存在难以适应资源池动态变化等问题。
传统工具难以适应云上复杂的环境
与传统物理环境相比,云环境中的主机和容器会动态创建、销毁、迁移和弹性扩展。如果是固定配置漏洞检测,资产动态迁移后,检测会中断,无法持续,而这种动态变化的特点是随机的、常态化的。网络环境也比较复杂,各种VPC的存在使得传统的检测工具难以适应多样化的网络环境。
如何在大规模虚拟混合环境中实现资产全面覆盖、检测性能高、准确率高,同时与企业安全运营平台(SOC)无缝对接?这是在混合云环境中选择资产漏洞检测和管理解决方案时需要考虑的关键问题。
3、 混合云环境下资产漏洞检测与管理解决方案
跨混合环境的统一 采集 解决方案
要构建统一高效、无盲区的全资产漏洞检测与管理解决方案,漏洞检测工具必须能够跨越私有云、公有云、容器、传统环境等多种混合架构,提供一致的漏洞检测和管理能力。
【灵活动态】+【高效检测】适应云环境的解决方案
在云环境下,漏洞检测工具需要具备自动感知节点变化的能力,进而自动进行相应的更新和部署,保证漏洞检测工作不被中断,适应云上的弹性伸缩。
漏洞检测工具还需要适应云上大规模、高并发的流量机制,基于高性能并发检测技术,实现百万级资产漏洞检测。
通过漏洞管理平台的自我监控能力,用户可以实时了解系统的资源消耗状况,及时优化资源配置和检测配置。
4、从漏洞检测到响应的整体解决方案
面对混合云环境,需要建立一套资产漏洞检测和管理平台,采集整个系统软硬件产品和组件的所有漏洞信息,有效支持收录、发布、混合云环境中漏洞的预警、分析、验证、处置等工作。对于漏洞安全应急工作,尤其是高危及以上漏洞风险防范、大规模漏洞利用攻击处理,企业全面提升信息安全防护、风险管理和威胁的整体水平至关重要。回复。
华云安资产漏洞检测与管理解决方案具备混合云环境下资产漏洞检测与管理能力。整体架构包括漏洞数据库、漏洞管理平台、漏洞扫描探针三部分。在:
漏洞数据库,具有收录漏洞信息、接收和发布预警通知、监控企业漏洞情况等功能;
漏洞管理平台负责接收漏洞预警情报信息,生成漏洞扫描任务,向扫描探针下发漏洞扫描任务进行漏洞扫描,具有漏洞响应、管理和操作功能;
漏洞扫描探针负责接收漏洞管理平台下发的漏洞扫描任务,执行漏洞扫描任务,反馈漏洞扫描结果,完成混合云环境下资产漏洞检测与验证的功能。
虽然企业上云已经成为常态,混合云也为企业IT资源管理提供了更有效的解决方案,但混合云固有的逆向威力也不容小觑。在混合云环境中,资产漏洞检测和管理需要把握解决问题的关键要素——灵活高效。这正是华云安资产漏洞检测与管理解决方案的价值所在。在混合云环境中,以简单、复杂、高效、优质的方式解决用户资产风险管理的痛点,为用户提供资产漏洞管理和漏洞响应的持续迭代能力和一致体验。
云优采集接口(帝国cms7.5有没有优采云采集器采集器的发布模块呢?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2021-12-14 19:26
Empirecms7.5 有没有优采云采集器的发布模块?在网上找了半天,没找到。今天在Empirecms7.5找到一个7.0的模块,修改后就可以使用了。让我与你分享。这个插件是一种登录方式。在优采云发布模块的WEB配置管理中添加域名地址,选择数据包登录方式。
提示:使用前请进入后台关闭验证码,打开后台源验证码。如果您关闭源验证代码,则可以使用它。如果你认为它不安全,那就没有办法了。
百度网盘:提取码:mzuf
我在项目中接触到了优采云采集器。第一次用的时候,感觉真的很神奇。采集的数据真的很惊人。互联网上80%以上的数据都可以通过采集获取。正好最近用Empirecms做了一个信息门户网站。大家都知道,信息门户最头疼的就是数据。碰巧我有数据优采云采集,那个数据一个字跑酷。
高兴了一阵子后,一个现实的问题来了,如何将采集中的所有数据批量导入到帝国的数据库中?我把我的问题告诉了我的朋友,朋友说你可以写一个优采云的帝国发布模块。他这么一说,我就去优采云采集器看看,果然有发布模块的功能。优采云提供三种数据发布方式。
第一种:直接在网络上发布模块,在线发布。
第二种:将发布的数据保存为文件。
第三种:直接发布到数据库。
按照我的想法,在网上搜了一下,搜索优采云发布模块,发现了很多结果,但是大部分教程只是一点点味道,大部分都是废话当天。还是不知道怎么操作。无奈之下,向朋友索取一份,学习了操作、修改等操作,接下来将这个优采云发布模块的方法分享给大家。
我希望我不必像我一样来回走动:
首先,我们需要使用三个文件:
EcmsLogin.php 自己创建
hinfofun.php 系统自带
Empirecms 7.2 免费登录新闻发布模块.wpm
第一步:将需要的文件放在指定的文件夹中:
将文件 1 复制到 e/admin/ 并将文件 2 复制到 e/class/ 文件夹。
文件2.需要二次开发,其作用是可以远程保存图片。代码显示如下。
// 二次开发代码
if($add['diy'] == 1){
//远程保存标题图片
if($add['titlepic']){
$tranr=DoTranURL($add['titlepic'],$add['classid']);
如果($tranr[tran])
{
$tranr[文件大小]=(int)$tranr[文件大小];
$tranr[type]=(int)$tranr[type];
//记录数据库
eInsertFileTable($tranr[filename],$tranr[filesize],$tranr[filepath],$username,$add['classid'],
'[s][URL]'.$tranr[filename],$tranr[type],0,$add['filepass'],$public_r[fpath],0,0,$public_r['filedeftb']);
//$add['titlepic']=$tranr[url];
$addtitlepic=",titlepic='".addslashes($tranr[url])."',ispic=1″;
}
}
}
第二步:编写优采云的发布模块。
第三步:直接在线测试。发布内容时,选择web在线发布到网站。
通过以上步骤,优采云的Empire发布模块就可以完成了。如果你还是不明白,给我留言。
推荐阅读:阿里云OSS的destoon对象存储和七牛云(基础版)destoon已经推出了应用商店,其中一个是对象存储,但只能供流行版本以上的用户使用。Deston... 不排除 WordPress。正在进行例行维护,请一分钟后回来”解决方案WordPress在升级程序、主题、插件时会先切换到维护模式,即“正在进行例行维护,请一分钟后回来... ... WordPress网站导航主题自适应手机网站导航源码网站模板wordpress网站导航主题自适应手机网站导航源码网站模板ps:纯主题无数据,需单独安装wordp。 .. 仿游戏Bar源码手游下载门户手游网站模板帝国cms7.5核帝国cms核心仿《Game Bar》手游模板门户,游戏源码,游戏模板 程序自带手机版,发送优采云采集 开发环境:Empire c...Empirecms7.5模版仿旅游信息模板旅游信息< @网站 源代码模仿“旅行网”的源代码。旅游资讯网站模板同步插件+会员贡献帝国cms+auto采集一个不错的旅游资讯门户网站源码,.... 核心仿《Game Bar》手游模板门户、游戏源码、游戏模板 程序自带手机版,送优采云采集 开发环境:Empire c... Empirecms 7.5 模板仿旅游信息模板旅游信息网站 源码仿“”源码。旅游资讯网站模板同步插件+会员贡献帝国cms+auto采集一个不错的旅游资讯门户网站源码,.... 核心仿《Game Bar》手游模板门户、游戏源码、游戏模板 程序自带手机版,送优采云采集 开发环境:Empire c... Empirecms 7.5 模板仿旅游信息模板旅游信息网站 源码仿“”源码。旅游资讯网站模板同步插件+会员贡献帝国cms+auto采集一个不错的旅游资讯门户网站源码,.... 5 模板仿旅游信息模板旅游信息网站 源码仿“”源码。旅游资讯网站模板同步插件+会员贡献帝国cms+auto采集一个不错的旅游资讯门户网站源码,.... 5 模板仿旅游信息模板旅游信息网站 源码仿“”源码。旅游资讯网站模板同步插件+会员贡献帝国cms+auto采集一个不错的旅游资讯门户网站源码,.... 查看全部
云优采集接口(帝国cms7.5有没有优采云采集器采集器的发布模块呢?)
Empirecms7.5 有没有优采云采集器的发布模块?在网上找了半天,没找到。今天在Empirecms7.5找到一个7.0的模块,修改后就可以使用了。让我与你分享。这个插件是一种登录方式。在优采云发布模块的WEB配置管理中添加域名地址,选择数据包登录方式。
提示:使用前请进入后台关闭验证码,打开后台源验证码。如果您关闭源验证代码,则可以使用它。如果你认为它不安全,那就没有办法了。
https://www.yuntue.com/wp-cont ... 1.png 673w" />百度网盘:提取码:mzuf
我在项目中接触到了优采云采集器。第一次用的时候,感觉真的很神奇。采集的数据真的很惊人。互联网上80%以上的数据都可以通过采集获取。正好最近用Empirecms做了一个信息门户网站。大家都知道,信息门户最头疼的就是数据。碰巧我有数据优采云采集,那个数据一个字跑酷。
高兴了一阵子后,一个现实的问题来了,如何将采集中的所有数据批量导入到帝国的数据库中?我把我的问题告诉了我的朋友,朋友说你可以写一个优采云的帝国发布模块。他这么一说,我就去优采云采集器看看,果然有发布模块的功能。优采云提供三种数据发布方式。
第一种:直接在网络上发布模块,在线发布。
第二种:将发布的数据保存为文件。
第三种:直接发布到数据库。
按照我的想法,在网上搜了一下,搜索优采云发布模块,发现了很多结果,但是大部分教程只是一点点味道,大部分都是废话当天。还是不知道怎么操作。无奈之下,向朋友索取一份,学习了操作、修改等操作,接下来将这个优采云发布模块的方法分享给大家。
我希望我不必像我一样来回走动:
首先,我们需要使用三个文件:
EcmsLogin.php 自己创建
hinfofun.php 系统自带
Empirecms 7.2 免费登录新闻发布模块.wpm
第一步:将需要的文件放在指定的文件夹中:
将文件 1 复制到 e/admin/ 并将文件 2 复制到 e/class/ 文件夹。
文件2.需要二次开发,其作用是可以远程保存图片。代码显示如下。
// 二次开发代码
if($add['diy'] == 1){
//远程保存标题图片
if($add['titlepic']){
$tranr=DoTranURL($add['titlepic'],$add['classid']);
如果($tranr[tran])
{
$tranr[文件大小]=(int)$tranr[文件大小];
$tranr[type]=(int)$tranr[type];
//记录数据库
eInsertFileTable($tranr[filename],$tranr[filesize],$tranr[filepath],$username,$add['classid'],
'[s][URL]'.$tranr[filename],$tranr[type],0,$add['filepass'],$public_r[fpath],0,0,$public_r['filedeftb']);
//$add['titlepic']=$tranr[url];
$addtitlepic=",titlepic='".addslashes($tranr[url])."',ispic=1″;
}
}
}
第二步:编写优采云的发布模块。
https://www.yuntue.com/wp-cont ... 2.png 584w" />第三步:直接在线测试。发布内容时,选择web在线发布到网站。
https://www.yuntue.com/wp-cont ... 8.png 768w, https://www.yuntue.com/wp-cont ... 3.png 794w" />通过以上步骤,优采云的Empire发布模块就可以完成了。如果你还是不明白,给我留言。
推荐阅读:阿里云OSS的destoon对象存储和七牛云(基础版)destoon已经推出了应用商店,其中一个是对象存储,但只能供流行版本以上的用户使用。Deston... 不排除 WordPress。正在进行例行维护,请一分钟后回来”解决方案WordPress在升级程序、主题、插件时会先切换到维护模式,即“正在进行例行维护,请一分钟后回来... ... WordPress网站导航主题自适应手机网站导航源码网站模板wordpress网站导航主题自适应手机网站导航源码网站模板ps:纯主题无数据,需单独安装wordp。 .. 仿游戏Bar源码手游下载门户手游网站模板帝国cms7.5核帝国cms核心仿《Game Bar》手游模板门户,游戏源码,游戏模板 程序自带手机版,发送优采云采集 开发环境:Empire c...Empirecms7.5模版仿旅游信息模板旅游信息< @网站 源代码模仿“旅行网”的源代码。旅游资讯网站模板同步插件+会员贡献帝国cms+auto采集一个不错的旅游资讯门户网站源码,.... 核心仿《Game Bar》手游模板门户、游戏源码、游戏模板 程序自带手机版,送优采云采集 开发环境:Empire c... Empirecms 7.5 模板仿旅游信息模板旅游信息网站 源码仿“”源码。旅游资讯网站模板同步插件+会员贡献帝国cms+auto采集一个不错的旅游资讯门户网站源码,.... 核心仿《Game Bar》手游模板门户、游戏源码、游戏模板 程序自带手机版,送优采云采集 开发环境:Empire c... Empirecms 7.5 模板仿旅游信息模板旅游信息网站 源码仿“”源码。旅游资讯网站模板同步插件+会员贡献帝国cms+auto采集一个不错的旅游资讯门户网站源码,.... 5 模板仿旅游信息模板旅游信息网站 源码仿“”源码。旅游资讯网站模板同步插件+会员贡献帝国cms+auto采集一个不错的旅游资讯门户网站源码,.... 5 模板仿旅游信息模板旅游信息网站 源码仿“”源码。旅游资讯网站模板同步插件+会员贡献帝国cms+auto采集一个不错的旅游资讯门户网站源码,....
云优采集接口(云平台云计算平台可以划分为3类:计算和数据存储处理兼顾)
采集交流 • 优采云 发表了文章 • 0 个评论 • 121 次浏览 • 2021-12-14 00:09
云平台
云计算平台可以分为3类:
1、基于数据存储的存储云平台
2、专注于数据处理的计算云平台
3、兼顾计算和数据存储处理的综合云计算平台
云平台优势
1、 稳定性比较好
云平台的应用会影响网站的使用,所以云平台的稳定性对网站来说非常重要。我们平时的虚拟主机是多个网站共享一个主机,如果其中一个网站被攻击,会影响到另一个网站,所以空间的稳定性会大打折扣。
2、更安全可靠
服务器的安全对用户来说非常重要,因为一旦服务器出现故障,网站将无法进行正常的操作,给企业带来的损失是不可估量的,所以用户最害怕服务器故障. 但是,对于云平台而言,情况并非如此。即使网站的操作出现问题,云平台也会自动转移到其他机器上。
3、无限容量
云平台是一种几乎整合了全球终端“云”提供的容量的全网服务,不再局限于一台或几台服务器,所以在一定程度上可以说云计算是无止境的。
4、可扩展
对于一些中小企业来说,随着业务的不断扩展,后期可能需要对服务器进行扩容升级。云平台具有一定的可扩展性,可以满足企业后期的扩容升级,后期无需进行软硬件升级。
5、存储的更多方面
数据是企业的核心内容,所以平时必须备份数据。云平台具有数据备份功能,即使出现硬件问题,数据也不会受到影响或丢失。后期只需要正常的维护和运维,由服务商来维护,可以为企业节省大量的人力。
6、更轻松的协作和共享
极高的速度和无限的容量使不同国家的公司可以进行协同作业。云计算平台下的不同公司可以实现在线办公和同步运营。一家公司发送的最新数据可以让其他公司在“云端”。同步查看和采用,从而实现资源共享。
7、高速
与任何独立的企业数据中心相比,云计算提供的覆盖全球的高速计算和同步服务是这些独立支撑的企业所无法比拟的。
什么是云计算
1.基于互联网的相关服务的增加、使用和交付模式
2.该模式提供可用的、方便的、按需的网络访问,并进入可配置的计算资源共享池
3.只需很少的管理工作或与服务提供商的很少互动,即可快速提供这些资源
4.同样经常涉及通过互联网提供动态的、易于扩展的并且经常是虚拟化的资源
我们一般可以将云计算中的“云”理解为存在于云数据中心服务器集群上的各类资源的集合。这些资源分为硬件资源和软件资源。硬件资源包括服务器、内存、CPU,软件资源包括应用软件和集成开发环境。用户只需通过网络向本地计算机发送请求,即可从云端获取满足自身需求的资源,所有计算任务均在远程云数据中心完成。用户之所以能够按需获取各种计算服务、存储服务和各种软件资源,都是得益于云计算强大的虚拟化资源池架构。数据中心本身的资源池不仅可以动态扩展,用户使用后的资源也可以及时方便的回收利用。采用这样的服务提供模式,大大提高了云数据中心的资源利用率,同时,云计算服务提供商可以更好地提高服务质量。
云计算优势
阿里巴巴集团首席战略官曾铭曾系统总结云计算对企业的价值。
1、移动+云计算=IT服务“线上化”,大大降低了技术门槛。
2、 云计算是一项公共服务,成本可变,可以按需使用。不再是固定资产投资,创业公司的成本压力大大减轻。
3、云计算将数据转化为生产资料和企业资产。
4、云计算就是用足够低成本的商业模式来解决大规模计算的问题。
在2016杭州云栖大会上,马云提出了五个新理念:“新零售、新制造、新金融、新技术、新能源”。飞天是一种通用计算操作系统,可以将全球数百万台服务器连接成一台超级计算机,以在线公共服务的形式为社会提供计算能力。
阿里云总裁胡晓明表示:未来三到五年,云计算和大数据不仅会在互联网内部发生变化,还会在工业制造、农业运营、城市交通、基因、医学影像、教育和娱乐等领域发生变化。产生力量。“云计算和大数据将改变各行各业的基础生态,阿里巴巴希望将现有能力输出给更多的创新者、企业家、政府机构以及国内外合作伙伴。”
云服务
云服务的形式
云服务器ECS
弹性计算服务(简称ECS)是阿里云提供的IaaS(Infrastructure as a Service)级别的云计算服务,具有卓越的性能、稳定性、可靠性和弹性扩展性。云服务器ECS免去购买IT硬件的前期准备,让您像使用水、电、天然气等公共资源一样方便、高效地使用服务器,实现开箱即用、弹性伸缩计算资源。阿里云ECS持续提供创新服务器,解决各种业务需求,助力您的业务发展。
云服务器ECS主要包括以下功能组件: 通过云服务器ECS,您可以轻松构建计算资源,具有以下优势。阿里云日志服务一、云服务日志示例
公司业务是集群,通过数千甚至数万台服务器运行程序,每台服务器记录的所有日志都汇总在日志服务中,然后我们可以对日志服务进行采集、统计、汇总,分析
这样就可以看到和分析一段时间内产生的数据
阿里云日志服务(一),什么是阿里云日志服务
日志服务(SLS)是日志数据的一站式服务,经过阿里巴巴集团大量大数据场景的锤炼。无需开发即可快速完成日志数据采集、消费、交付、查询分析等功能,提升运维、运营效率,建立DT时代海量日志处理能力。
(二),日志服务的内容
1、**实时采集和消费(LogHub)**功能:
2、**搜索/分析**实时索引、查询和分析数据。
特征:
3、交付数据仓库(LogShipper)
稳定可靠的日志交付。将日志中心数据传送到存储服务进行存储。支持压缩、自定义Partition、rank等多种存储方式。目的:数据仓库+数据分析、审计、推荐系统和用户画像。
视频链接:关于日志服务说明 查看全部
云优采集接口(云平台云计算平台可以划分为3类:计算和数据存储处理兼顾)
云平台
云计算平台可以分为3类:
1、基于数据存储的存储云平台
2、专注于数据处理的计算云平台
3、兼顾计算和数据存储处理的综合云计算平台
云平台优势
1、 稳定性比较好
云平台的应用会影响网站的使用,所以云平台的稳定性对网站来说非常重要。我们平时的虚拟主机是多个网站共享一个主机,如果其中一个网站被攻击,会影响到另一个网站,所以空间的稳定性会大打折扣。
2、更安全可靠
服务器的安全对用户来说非常重要,因为一旦服务器出现故障,网站将无法进行正常的操作,给企业带来的损失是不可估量的,所以用户最害怕服务器故障. 但是,对于云平台而言,情况并非如此。即使网站的操作出现问题,云平台也会自动转移到其他机器上。
3、无限容量
云平台是一种几乎整合了全球终端“云”提供的容量的全网服务,不再局限于一台或几台服务器,所以在一定程度上可以说云计算是无止境的。
4、可扩展
对于一些中小企业来说,随着业务的不断扩展,后期可能需要对服务器进行扩容升级。云平台具有一定的可扩展性,可以满足企业后期的扩容升级,后期无需进行软硬件升级。
5、存储的更多方面
数据是企业的核心内容,所以平时必须备份数据。云平台具有数据备份功能,即使出现硬件问题,数据也不会受到影响或丢失。后期只需要正常的维护和运维,由服务商来维护,可以为企业节省大量的人力。
6、更轻松的协作和共享
极高的速度和无限的容量使不同国家的公司可以进行协同作业。云计算平台下的不同公司可以实现在线办公和同步运营。一家公司发送的最新数据可以让其他公司在“云端”。同步查看和采用,从而实现资源共享。
7、高速
与任何独立的企业数据中心相比,云计算提供的覆盖全球的高速计算和同步服务是这些独立支撑的企业所无法比拟的。
什么是云计算
1.基于互联网的相关服务的增加、使用和交付模式
2.该模式提供可用的、方便的、按需的网络访问,并进入可配置的计算资源共享池
3.只需很少的管理工作或与服务提供商的很少互动,即可快速提供这些资源
4.同样经常涉及通过互联网提供动态的、易于扩展的并且经常是虚拟化的资源
我们一般可以将云计算中的“云”理解为存在于云数据中心服务器集群上的各类资源的集合。这些资源分为硬件资源和软件资源。硬件资源包括服务器、内存、CPU,软件资源包括应用软件和集成开发环境。用户只需通过网络向本地计算机发送请求,即可从云端获取满足自身需求的资源,所有计算任务均在远程云数据中心完成。用户之所以能够按需获取各种计算服务、存储服务和各种软件资源,都是得益于云计算强大的虚拟化资源池架构。数据中心本身的资源池不仅可以动态扩展,用户使用后的资源也可以及时方便的回收利用。采用这样的服务提供模式,大大提高了云数据中心的资源利用率,同时,云计算服务提供商可以更好地提高服务质量。
云计算优势
阿里巴巴集团首席战略官曾铭曾系统总结云计算对企业的价值。
1、移动+云计算=IT服务“线上化”,大大降低了技术门槛。
2、 云计算是一项公共服务,成本可变,可以按需使用。不再是固定资产投资,创业公司的成本压力大大减轻。
3、云计算将数据转化为生产资料和企业资产。
4、云计算就是用足够低成本的商业模式来解决大规模计算的问题。
在2016杭州云栖大会上,马云提出了五个新理念:“新零售、新制造、新金融、新技术、新能源”。飞天是一种通用计算操作系统,可以将全球数百万台服务器连接成一台超级计算机,以在线公共服务的形式为社会提供计算能力。
阿里云总裁胡晓明表示:未来三到五年,云计算和大数据不仅会在互联网内部发生变化,还会在工业制造、农业运营、城市交通、基因、医学影像、教育和娱乐等领域发生变化。产生力量。“云计算和大数据将改变各行各业的基础生态,阿里巴巴希望将现有能力输出给更多的创新者、企业家、政府机构以及国内外合作伙伴。”
云服务
云服务的形式
云服务器ECS
弹性计算服务(简称ECS)是阿里云提供的IaaS(Infrastructure as a Service)级别的云计算服务,具有卓越的性能、稳定性、可靠性和弹性扩展性。云服务器ECS免去购买IT硬件的前期准备,让您像使用水、电、天然气等公共资源一样方便、高效地使用服务器,实现开箱即用、弹性伸缩计算资源。阿里云ECS持续提供创新服务器,解决各种业务需求,助力您的业务发展。
云服务器ECS主要包括以下功能组件: 通过云服务器ECS,您可以轻松构建计算资源,具有以下优势。阿里云日志服务一、云服务日志示例
公司业务是集群,通过数千甚至数万台服务器运行程序,每台服务器记录的所有日志都汇总在日志服务中,然后我们可以对日志服务进行采集、统计、汇总,分析
这样就可以看到和分析一段时间内产生的数据
阿里云日志服务(一),什么是阿里云日志服务
日志服务(SLS)是日志数据的一站式服务,经过阿里巴巴集团大量大数据场景的锤炼。无需开发即可快速完成日志数据采集、消费、交付、查询分析等功能,提升运维、运营效率,建立DT时代海量日志处理能力。
(二),日志服务的内容
1、**实时采集和消费(LogHub)**功能:
2、**搜索/分析**实时索引、查询和分析数据。
特征:
3、交付数据仓库(LogShipper)
稳定可靠的日志交付。将日志中心数据传送到存储服务进行存储。支持压缩、自定义Partition、rank等多种存储方式。目的:数据仓库+数据分析、审计、推荐系统和用户画像。
视频链接:关于日志服务说明
云优采集接口(算子采集Dump数据偏差对比,助开发人员快速解决算子精度问题 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 162 次浏览 • 2021-12-11 06:16
)
查看PDF
转储数据采集
链接复制成功!
更新时间:2021/12/09 GMT+08:00
概述
当训练网络的精度没有达到预期时,可以使用训练过程中各个算子的计算结果(即Data Dump数据),然后使用精度对比工具和行业标准算子(如TensorFlow)进行对比计算结果 进行数据偏差对比,帮助开发者快速解决算子精度问题。目前支持采集的operator数据主要有:
默认训练过程中,没有采集算子的dump数据。如果需要采集并分析数据,可以选择以下两种方式之一:
使用注意事项
采集在 Estimator 模式下转储数据
在Estimator模式下,通过NPUrunConfig中的dump_config采集Dump data,在创建NPUrunConfig之前,先实例化一个DumpConfig类进行dump配置(包括配置dump路径,哪些迭代数据要dump,dump算子的输入或输出)数据等)。
DumpConfig类的构造函数中各个字段的详细解释请参考对应的接口说明。
from npu_bridge.npu_init import *
# dump_path:dump数据存放路径,该参数指定的目录需要在启动训练的环境上(容器或Host侧)提前创建且确保安装时配置的运行用户具有读写权限
# enable_dump:是否开启Dump功能
# dump_step:指定采集哪些迭代的Dump数据
# dump_mode:Dump模式,取值:input/output/all
dump_config = DumpConfig(enable_dump=True, dump_path = "/home/HwHiAiUser/output", dump_step="0|5|10", dump_mode="all")
session_config=tf.ConfigProto()
config = NPURunConfig(
dump_config=dump_config,
session_config=session_config
)
采集在sess.run模式下转储数据
在sess.run模式下,通过会话配置项enable_dump、dump_path、dump_step、dump_mode来配置相关参数。
config = tf.ConfigProto()
custom_op = config.graph_options.rewrite_options.custom_optimizers.add()
custom_op.name = "NpuOptimizer"
custom_op.parameter_map["use_off_line"].b = True
# enable_dump:是否开启Dump功能
custom_op.parameter_map["enable_dump"].b = True
# dump_path:dump数据存放路径,该参数指定的目录需要在启动训练的环境上(容器或Host侧)提前创建且确保安装时配置的运行用户具有读写权限
custom_op.parameter_map["dump_path"].s = tf.compat.as_bytes("/home/HwHiAiUser/output")
# dump_step:指定采集哪些迭代的Dump数据
custom_op.parameter_map["dump_step"].s = tf.compat.as_bytes("0|5|10")
# dump_mode:Dump模式,取值:input/output/all
custom_op.parameter_map["dump_mode"].s = tf.compat.as_bytes("all")
config.graph_options.rewrite_options.remapping = RewriterConfig.OFF
config.graph_options.rewrite_options.memory_optimization = RewriterConfig.OFF
with tf.Session(config=config) as sess:
print(sess.run(cost))
执行训练并生成转储数据
后续通过工具进行精度比较不仅依赖Dump数据,还需要计算图结构。因此,在进行训练之前,需要配置环境变量转储图文件:
export DUMP_GE_GRAPH=2
export DUMP_GRAPH_PATH=/home/dumpgraph # 指定dump图路径,如果不配置存储在训练脚本所在目录
执行训练,生成转储图像文件和转储数据文件。
由于“ge”开头的转储图文件很多,转储数据文件夹的model_name层可能有多个文件夹,其实我们只需要找到计算图文件,只要找到model_name为计算图的名称。下面提供一些方法,帮助用户快速找到对应的文件。
选择计算图文件,提供了两种方法: 选择转储数据文件。打开上一步找到的计算图文件,记录第一张图中name字段的值。在以下示例中,记录“ge_default_253_71”。
graph {
name: "ge_default_20201209083353_71"
op {
name: "atomic_addr_clean0_71"
type: "AtomicAddrClean"
attr {
key: "_fe_imply_type"
value {
i: 6
}
}
进入dump data文件夹,我们会看到model_name层有多个文件夹:
找到名称为刚才记录的计算图的名称值的文件夹,如ge_default_253_71。此目录中的文件是您需要的转储数据文件。
查看全部
云优采集接口(算子采集Dump数据偏差对比,助开发人员快速解决算子精度问题
)
查看PDF
转储数据采集
链接复制成功!
更新时间:2021/12/09 GMT+08:00
概述
当训练网络的精度没有达到预期时,可以使用训练过程中各个算子的计算结果(即Data Dump数据),然后使用精度对比工具和行业标准算子(如TensorFlow)进行对比计算结果 进行数据偏差对比,帮助开发者快速解决算子精度问题。目前支持采集的operator数据主要有:
默认训练过程中,没有采集算子的dump数据。如果需要采集并分析数据,可以选择以下两种方式之一:
使用注意事项
采集在 Estimator 模式下转储数据
在Estimator模式下,通过NPUrunConfig中的dump_config采集Dump data,在创建NPUrunConfig之前,先实例化一个DumpConfig类进行dump配置(包括配置dump路径,哪些迭代数据要dump,dump算子的输入或输出)数据等)。
DumpConfig类的构造函数中各个字段的详细解释请参考对应的接口说明。
from npu_bridge.npu_init import *
# dump_path:dump数据存放路径,该参数指定的目录需要在启动训练的环境上(容器或Host侧)提前创建且确保安装时配置的运行用户具有读写权限
# enable_dump:是否开启Dump功能
# dump_step:指定采集哪些迭代的Dump数据
# dump_mode:Dump模式,取值:input/output/all
dump_config = DumpConfig(enable_dump=True, dump_path = "/home/HwHiAiUser/output", dump_step="0|5|10", dump_mode="all")
session_config=tf.ConfigProto()
config = NPURunConfig(
dump_config=dump_config,
session_config=session_config
)
采集在sess.run模式下转储数据
在sess.run模式下,通过会话配置项enable_dump、dump_path、dump_step、dump_mode来配置相关参数。
config = tf.ConfigProto()
custom_op = config.graph_options.rewrite_options.custom_optimizers.add()
custom_op.name = "NpuOptimizer"
custom_op.parameter_map["use_off_line"].b = True
# enable_dump:是否开启Dump功能
custom_op.parameter_map["enable_dump"].b = True
# dump_path:dump数据存放路径,该参数指定的目录需要在启动训练的环境上(容器或Host侧)提前创建且确保安装时配置的运行用户具有读写权限
custom_op.parameter_map["dump_path"].s = tf.compat.as_bytes("/home/HwHiAiUser/output")
# dump_step:指定采集哪些迭代的Dump数据
custom_op.parameter_map["dump_step"].s = tf.compat.as_bytes("0|5|10")
# dump_mode:Dump模式,取值:input/output/all
custom_op.parameter_map["dump_mode"].s = tf.compat.as_bytes("all")
config.graph_options.rewrite_options.remapping = RewriterConfig.OFF
config.graph_options.rewrite_options.memory_optimization = RewriterConfig.OFF
with tf.Session(config=config) as sess:
print(sess.run(cost))
执行训练并生成转储数据
后续通过工具进行精度比较不仅依赖Dump数据,还需要计算图结构。因此,在进行训练之前,需要配置环境变量转储图文件:
export DUMP_GE_GRAPH=2
export DUMP_GRAPH_PATH=/home/dumpgraph # 指定dump图路径,如果不配置存储在训练脚本所在目录
执行训练,生成转储图像文件和转储数据文件。
由于“ge”开头的转储图文件很多,转储数据文件夹的model_name层可能有多个文件夹,其实我们只需要找到计算图文件,只要找到model_name为计算图的名称。下面提供一些方法,帮助用户快速找到对应的文件。
选择计算图文件,提供了两种方法: 选择转储数据文件。打开上一步找到的计算图文件,记录第一张图中name字段的值。在以下示例中,记录“ge_default_253_71”。
graph {
name: "ge_default_20201209083353_71"
op {
name: "atomic_addr_clean0_71"
type: "AtomicAddrClean"
attr {
key: "_fe_imply_type"
value {
i: 6
}
}
进入dump data文件夹,我们会看到model_name层有多个文件夹:
找到名称为刚才记录的计算图的名称值的文件夹,如ge_default_253_71。此目录中的文件是您需要的转储数据文件。
云优采集接口(网络精度未达预期时如何解决算子精度问题?-八维教育)
采集交流 • 优采云 发表了文章 • 0 个评论 • 183 次浏览 • 2021-12-11 06:12
查看PDF
转储数据采集
链接复制成功!
更新时间:2021/12/09 GMT+08:00
概述
当训练网络的准确率达不到预期时,可以使用采集训练过程中各个算子的运算结果(即Data Dump数据),然后使用准确率对比工具和行业标准算子(如TensorFlow)将计算结果与数据偏差进行比较,从而帮助开发者快速解决算子精度问题。目前支持采集的operator数据主要有:
默认训练过程不会采集操作员转储数据。如果您需要采集并分析数据,您可以选择以下两种方法之一:
使用注意事项
修改Estimator模式,查看迁移脚本中是否有“init_resource”。
if __name__ == '__main__':
session_config = tf.ConfigProto()
custom_op = session_config.graph_options.rewrite_options.custom_optimizers.add()
custom_op.name = "NpuOptimizer"
# enable_dump:是否开启Dump功能
custom_op.parameter_map["enable_dump"].b = True
# dump_path:dump数据存放路径,该参数指定的目录需要在启动训练的环境上(容器或Host侧)提前创建且确保安装时配置的运行用户具有读写权限
custom_op.parameter_map["dump_path"].s = tf.compat.as_bytes("/home/HwHiAiUser/output")
# dump_step:指定采集哪些迭代的Dump数据
custom_op.parameter_map["dump_step"].s = tf.compat.as_bytes("0|5|10")
# dump_mode:Dump模式,取值:input/output/all
custom_op.parameter_map["dump_mode"].s = tf.compat.as_bytes("all")
(npu_sess, npu_shutdown) = init_resource(config=session_config)
tf.app.run()
shutdown_resource(npu_sess, npu_shutdown)
close_session(npu_sess)
在迁移的脚本中找到“npu_run_config_init”:
session_config = tf.ConfigProto(allow_soft_placement=True)
run_config = tf.estimator.RunConfig(
train_distribute=distribution_strategy,
session_config=session_config,
save_checkpoints_secs=60*60*24)
classifier = tf.estimator.Estimator(
model_fn=model_function, model_dir=flags_obj.model_dir, config=npu_run_config_init(run_config=run_config))
配置相关参数:
session_config = tf.ConfigProto(allow_soft_placement=True)
custom_op = session_config.graph_options.rewrite_options.custom_optimizers.add()
custom_op.name = 'NpuOptimizer'
# enable_dump:是否开启Dump功能
custom_op.parameter_map["enable_dump"].b = True
# dump_path:dump数据存放路径,该参数指定的目录需要在启动训练的环境上(容器或Host侧)提前创建且确保安装时配置的运行用户具有读写权限
custom_op.parameter_map["dump_path"].s = tf.compat.as_bytes("/home/HwHiAiUser/output")
# dump_step:指定采集哪些迭代的Dump数据
custom_op.parameter_map["dump_step"].s = tf.compat.as_bytes("0|5|10")
# dump_mode:Dump模式,取值:input/output/all
custom_op.parameter_map["dump_mode"].s = tf.compat.as_bytes("all")
run_config = tf.estimator.RunConfig(
train_distribute=distribution_strategy,
session_config=session_config,
save_checkpoints_secs=60*60*24)
classifier = tf.estimator.Estimator(
model_fn=model_function, model_dir=flags_obj.model_dir, config=npu_run_config_init(run_config=run_config))
如果脚本中的run配置函数,比如runConfig中没有传入session_config参数,则需要自己传入session_config:
session_config = tf.ConfigProto(allow_soft_placement=True)
custom_op = session_config.graph_options.rewrite_options.custom_optimizers.add()
custom_op.name = 'NpuOptimizer'
# 使能相关配置
custom_op.parameter_map["xxx"].x = xxx
run_config = tf.estimator.RunConfig(
train_distribute=distribution_strategy,
session_config=session_config,
save_checkpoints_secs=60*60*24)
classifier = tf.estimator.Estimator(
model_fn=model_function, model_dir=flags_obj.model_dir, config=npu_run_config_init(run_config=run_config))
修改sess.run模式,查看迁移的脚本是否有“init_resource”。
在脚本中找到“npu_config_proto”:
with tf.Session(config=npu_config_proto()) as sess:
sess.run(tf.global_variables_initializer())
interaction_table.init.run()
配置相关参数:
config_proto = tf.ConfigProto()
custom_op = config_proto.graph_options.rewrite_options.custom_optimizers.add()
custom_op.name = 'NpuOptimizer'
custom_op.parameter_map["enable_dump"].b = True
custom_op.parameter_map["dump_path"].s = tf.compat.as_bytes("/home/HwHiAiUser/output")
custom_op.parameter_map["dump_step"].s = tf.compat.as_bytes("0|5|10")
custom_op.parameter_map["dump_mode"].s = tf.compat.as_bytes("all")
config = npu_config_proto(config_proto=config_proto)
with tf.Session(config=config) as sess:
sess.run(tf.global_variables_initializer())
interaction_table.init.run()
修改tf.keras模式,查看迁移的脚本是否有“init_resource”。
if __name__ == '__main__':
session_config = tf.ConfigProto()
custom_op = session_config.graph_options.rewrite_options.custom_optimizers.add()
custom_op.name = "NpuOptimizer"
# enable_dump:是否开启Dump功能
custom_op.parameter_map["enable_dump"].b = True
# dump_path:dump数据存放路径,该参数指定的目录需要在启动训练的环境上(容器或Host侧)提前创建且确保安装时配置的运行用户具有读写权限
custom_op.parameter_map["dump_path"].s = tf.compat.as_bytes("/home/HwHiAiUser/output")
# dump_step:指定采集哪些迭代的Dump数据
custom_op.parameter_map["dump_step"].s = tf.compat.as_bytes("0|5|10")
# dump_mode:Dump模式,取值:input/output/all
custom_op.parameter_map["dump_mode"].s = tf.compat.as_bytes("all")
(npu_sess, npu_shutdown) = init_resource(config=session_config)
tf.app.run()
shutdown_resource(npu_sess, npu_shutdown)
close_session(npu_sess)
在脚本中找到“set_keras_session_npu_config”:
import tensorflow as tf
import tensorflow.python.keras as keras
from tensorflow.python.keras import backend as K
from npu_bridge.npu_init import *
npu_keras_sess = set_keras_session_npu_config()
#数据预处理...
#模型搭建...
#模型编译...
#模型训练...
配置相关参数:
import tensorflow as tf
import tensorflow.python.keras as keras
from tensorflow.python.keras import backend as K
from npu_bridge.npu_init import *
config_proto = tf.ConfigProto()
custom_op = config_proto.graph_options.rewrite_options.custom_optimizers.add()
custom_op.name = 'NpuOptimizer'
custom_op.parameter_map["precision_mode"].s = tf.compat.as_bytes("allow_mix_precision")
npu_keras_sess = set_keras_session_npu_config(config=config_proto)
#数据预处理...
#模型搭建...
#模型编译...
#模型训练...
父主题:更多功能 查看全部
云优采集接口(网络精度未达预期时如何解决算子精度问题?-八维教育)
查看PDF
转储数据采集
链接复制成功!
更新时间:2021/12/09 GMT+08:00
概述
当训练网络的准确率达不到预期时,可以使用采集训练过程中各个算子的运算结果(即Data Dump数据),然后使用准确率对比工具和行业标准算子(如TensorFlow)将计算结果与数据偏差进行比较,从而帮助开发者快速解决算子精度问题。目前支持采集的operator数据主要有:
默认训练过程不会采集操作员转储数据。如果您需要采集并分析数据,您可以选择以下两种方法之一:
使用注意事项
修改Estimator模式,查看迁移脚本中是否有“init_resource”。
if __name__ == '__main__':
session_config = tf.ConfigProto()
custom_op = session_config.graph_options.rewrite_options.custom_optimizers.add()
custom_op.name = "NpuOptimizer"
# enable_dump:是否开启Dump功能
custom_op.parameter_map["enable_dump"].b = True
# dump_path:dump数据存放路径,该参数指定的目录需要在启动训练的环境上(容器或Host侧)提前创建且确保安装时配置的运行用户具有读写权限
custom_op.parameter_map["dump_path"].s = tf.compat.as_bytes("/home/HwHiAiUser/output")
# dump_step:指定采集哪些迭代的Dump数据
custom_op.parameter_map["dump_step"].s = tf.compat.as_bytes("0|5|10")
# dump_mode:Dump模式,取值:input/output/all
custom_op.parameter_map["dump_mode"].s = tf.compat.as_bytes("all")
(npu_sess, npu_shutdown) = init_resource(config=session_config)
tf.app.run()
shutdown_resource(npu_sess, npu_shutdown)
close_session(npu_sess)
在迁移的脚本中找到“npu_run_config_init”:
session_config = tf.ConfigProto(allow_soft_placement=True)
run_config = tf.estimator.RunConfig(
train_distribute=distribution_strategy,
session_config=session_config,
save_checkpoints_secs=60*60*24)
classifier = tf.estimator.Estimator(
model_fn=model_function, model_dir=flags_obj.model_dir, config=npu_run_config_init(run_config=run_config))
配置相关参数:
session_config = tf.ConfigProto(allow_soft_placement=True)
custom_op = session_config.graph_options.rewrite_options.custom_optimizers.add()
custom_op.name = 'NpuOptimizer'
# enable_dump:是否开启Dump功能
custom_op.parameter_map["enable_dump"].b = True
# dump_path:dump数据存放路径,该参数指定的目录需要在启动训练的环境上(容器或Host侧)提前创建且确保安装时配置的运行用户具有读写权限
custom_op.parameter_map["dump_path"].s = tf.compat.as_bytes("/home/HwHiAiUser/output")
# dump_step:指定采集哪些迭代的Dump数据
custom_op.parameter_map["dump_step"].s = tf.compat.as_bytes("0|5|10")
# dump_mode:Dump模式,取值:input/output/all
custom_op.parameter_map["dump_mode"].s = tf.compat.as_bytes("all")
run_config = tf.estimator.RunConfig(
train_distribute=distribution_strategy,
session_config=session_config,
save_checkpoints_secs=60*60*24)
classifier = tf.estimator.Estimator(
model_fn=model_function, model_dir=flags_obj.model_dir, config=npu_run_config_init(run_config=run_config))
如果脚本中的run配置函数,比如runConfig中没有传入session_config参数,则需要自己传入session_config:
session_config = tf.ConfigProto(allow_soft_placement=True)
custom_op = session_config.graph_options.rewrite_options.custom_optimizers.add()
custom_op.name = 'NpuOptimizer'
# 使能相关配置
custom_op.parameter_map["xxx"].x = xxx
run_config = tf.estimator.RunConfig(
train_distribute=distribution_strategy,
session_config=session_config,
save_checkpoints_secs=60*60*24)
classifier = tf.estimator.Estimator(
model_fn=model_function, model_dir=flags_obj.model_dir, config=npu_run_config_init(run_config=run_config))
修改sess.run模式,查看迁移的脚本是否有“init_resource”。
在脚本中找到“npu_config_proto”:
with tf.Session(config=npu_config_proto()) as sess:
sess.run(tf.global_variables_initializer())
interaction_table.init.run()
配置相关参数:
config_proto = tf.ConfigProto()
custom_op = config_proto.graph_options.rewrite_options.custom_optimizers.add()
custom_op.name = 'NpuOptimizer'
custom_op.parameter_map["enable_dump"].b = True
custom_op.parameter_map["dump_path"].s = tf.compat.as_bytes("/home/HwHiAiUser/output")
custom_op.parameter_map["dump_step"].s = tf.compat.as_bytes("0|5|10")
custom_op.parameter_map["dump_mode"].s = tf.compat.as_bytes("all")
config = npu_config_proto(config_proto=config_proto)
with tf.Session(config=config) as sess:
sess.run(tf.global_variables_initializer())
interaction_table.init.run()
修改tf.keras模式,查看迁移的脚本是否有“init_resource”。
if __name__ == '__main__':
session_config = tf.ConfigProto()
custom_op = session_config.graph_options.rewrite_options.custom_optimizers.add()
custom_op.name = "NpuOptimizer"
# enable_dump:是否开启Dump功能
custom_op.parameter_map["enable_dump"].b = True
# dump_path:dump数据存放路径,该参数指定的目录需要在启动训练的环境上(容器或Host侧)提前创建且确保安装时配置的运行用户具有读写权限
custom_op.parameter_map["dump_path"].s = tf.compat.as_bytes("/home/HwHiAiUser/output")
# dump_step:指定采集哪些迭代的Dump数据
custom_op.parameter_map["dump_step"].s = tf.compat.as_bytes("0|5|10")
# dump_mode:Dump模式,取值:input/output/all
custom_op.parameter_map["dump_mode"].s = tf.compat.as_bytes("all")
(npu_sess, npu_shutdown) = init_resource(config=session_config)
tf.app.run()
shutdown_resource(npu_sess, npu_shutdown)
close_session(npu_sess)
在脚本中找到“set_keras_session_npu_config”:
import tensorflow as tf
import tensorflow.python.keras as keras
from tensorflow.python.keras import backend as K
from npu_bridge.npu_init import *
npu_keras_sess = set_keras_session_npu_config()
#数据预处理...
#模型搭建...
#模型编译...
#模型训练...
配置相关参数:
import tensorflow as tf
import tensorflow.python.keras as keras
from tensorflow.python.keras import backend as K
from npu_bridge.npu_init import *
config_proto = tf.ConfigProto()
custom_op = config_proto.graph_options.rewrite_options.custom_optimizers.add()
custom_op.name = 'NpuOptimizer'
custom_op.parameter_map["precision_mode"].s = tf.compat.as_bytes("allow_mix_precision")
npu_keras_sess = set_keras_session_npu_config(config=config_proto)
#数据预处理...
#模型搭建...
#模型编译...
#模型训练...
父主题:更多功能
云优采集接口(云优采集接口免费的?那就对了,让你年入百万!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-12-10 19:05
云优采集接口免费的?那就对了,云优采集接口功能很强大,云优采集接口可以随意搭建个人自媒体账号,成本低,人人可编辑,无需懂代码,无需懂设计,代理千千万,抓住机会,抓住当下,早日赚大钱!云优采集接口,跟着云优采集接口做,让你年入百万!找云优采集接口,
云优采集接口可以免费接入,
云优采集接口产品免费接入云优工商直接对接,接入云优采集接口,大数据时代前途无量。
云优采集接口
云优采集接口,带你去大数据。
云优采集接口,
1.云优采集接口免费接入。2.创建微信公众号,配置专用云优接口,保证获取的商品物流信息是真实的,价格更优惠。3.可采集新闻媒体推广的信息以及企业开发的app等等4.云优采集接口,支持多页自动更新。有专门数据运营机构负责更新到最新的数据。5.拥有4000多条商品物流信息。不过各个公司数据维度不一样。如果您的商品物流在小的公司也会作为一种运营特色,给自己店铺增加销量,提高曝光度和转化率的话,云优采集接口还是比较有帮助的。
我们公司以前也使用过一些竞价接口,但是由于不是本地的,具体发展怎么样还是不清楚,客户经常投诉无效。因为产品是接入公司的,客户很多,调用也是数据持证的数据库进行调用。有问题很难找到客户公司的人解决,我们后来找了厂家让他们代理了我们的接口,用的感觉还不错,就没再更新数据库,客户都比较满意。 查看全部
云优采集接口(云优采集接口免费的?那就对了,让你年入百万!)
云优采集接口免费的?那就对了,云优采集接口功能很强大,云优采集接口可以随意搭建个人自媒体账号,成本低,人人可编辑,无需懂代码,无需懂设计,代理千千万,抓住机会,抓住当下,早日赚大钱!云优采集接口,跟着云优采集接口做,让你年入百万!找云优采集接口,
云优采集接口可以免费接入,
云优采集接口产品免费接入云优工商直接对接,接入云优采集接口,大数据时代前途无量。
云优采集接口
云优采集接口,带你去大数据。
云优采集接口,
1.云优采集接口免费接入。2.创建微信公众号,配置专用云优接口,保证获取的商品物流信息是真实的,价格更优惠。3.可采集新闻媒体推广的信息以及企业开发的app等等4.云优采集接口,支持多页自动更新。有专门数据运营机构负责更新到最新的数据。5.拥有4000多条商品物流信息。不过各个公司数据维度不一样。如果您的商品物流在小的公司也会作为一种运营特色,给自己店铺增加销量,提高曝光度和转化率的话,云优采集接口还是比较有帮助的。
我们公司以前也使用过一些竞价接口,但是由于不是本地的,具体发展怎么样还是不清楚,客户经常投诉无效。因为产品是接入公司的,客户很多,调用也是数据持证的数据库进行调用。有问题很难找到客户公司的人解决,我们后来找了厂家让他们代理了我们的接口,用的感觉还不错,就没再更新数据库,客户都比较满意。
云优采集接口(训练网络精度未达预期时如何采集Dump数据数据? )
采集交流 • 优采云 发表了文章 • 0 个评论 • 160 次浏览 • 2021-12-08 10:02
)
更新时间:2021-11-16 GMT+08:00
查看PDF
链接复制成功!
转储数据采集
概述
当训练网络的精度没有达到预期时,可以使用训练过程中各个算子的计算结果(即Data Dump数据),然后使用精度对比工具和行业标准算子(如TensorFlow)计算结果 进行数据偏差对比,帮助开发者快速解决算子精度问题。目前支持采集的operator数据主要有:
默认训练过程中,没有采集算子的dump数据。如果需要采集并分析数据,可以选择以下两种方式之一:
使用注意事项
采集在 Estimator 模式下转储数据
在Estimator模式下,通过NPUrunConfig中的dump_config采集Dump data,在创建NPUrunConfig之前,先实例化一个DumpConfig类进行dump配置(包括配置dump路径,哪些迭代数据要dump,dump算子的输入或输出)数据等)。
DumpConfig类的构造函数中各个字段的详细解释请参考对应的接口说明。
from npu_bridge.npu_init import *
# dump_path:dump数据存放路径,该参数指定的目录需要在启动训练的环境上(容器或Host侧)提前创建且确保安装时配置的运行用户具有读写权限
# enable_dump:是否开启Dump功能
# dump_step:指定采集哪些迭代的Dump数据
# dump_mode:Dump模式,取值:input/output/all
dump_config = DumpConfig(enable_dump=True, dump_path = "/home/HwHiAiUser/output", dump_step="0|5|10", dump_mode="all")
session_config=tf.ConfigProto()
config = NPURunConfig(
dump_config=dump_config,
session_config=session_config
)
采集在sess.run模式下转储数据
在sess.run模式下,通过session配置项enable_dump、dump_path、dump_step、dump_mode配置相关参数。
config = tf.ConfigProto()
custom_op = config.graph_options.rewrite_options.custom_optimizers.add()
custom_op.name = "NpuOptimizer"
custom_op.parameter_map["use_off_line"].b = True
# enable_dump:是否开启Dump功能
custom_op.parameter_map["enable_dump"].b = True
# dump_path:dump数据存放路径,该参数指定的目录需要在启动训练的环境上(容器或Host侧)提前创建且确保安装时配置的运行用户具有读写权限
custom_op.parameter_map["dump_path"].s = tf.compat.as_bytes("/home/HwHiAiUser/output")
# dump_step:指定采集哪些迭代的Dump数据
custom_op.parameter_map["dump_step"].s = tf.compat.as_bytes("0|5|10")
# dump_mode:Dump模式,取值:input/output/all
custom_op.parameter_map["dump_mode"].s = tf.compat.as_bytes("all")
config.graph_options.rewrite_options.remapping = RewriterConfig.OFF
config.graph_options.rewrite_options.memory_optimization = RewriterConfig.OFF
with tf.Session(config=config) as sess:
print(sess.run(cost))
执行训练并生成转储数据
后续的精度对比工具不仅依赖Dump数据,还需要计算图结构。因此,在进行训练之前,需要配置环境变量转储图文件:
export DUMP_GE_GRAPH=2
export DUMP_GRAPH_PATH=/home/dumpgraph # 指定dump图路径,如果不配置存储在训练脚本所在目录
执行训练,生成转储图像文件和转储数据文件。
由于“ge”开头的转储图文件很多,转储数据文件夹的model_name层可能有多个文件夹,所以实际上我们只需要找到计算图文件,只要找到model_name为计算图的名称。下面提供一些方法,帮助用户快速找到对应的文件。
选择计算图文件,提供以下两种方法:
选择转储数据文件。
打开上一步找到的计算图文件,记录第一张图中name字段的值。在以下示例中,记录“ge_default_253_71”。
graph {
name: "ge_default_20201209083353_71"
op {
name: "atomic_addr_clean0_71"
type: "AtomicAddrClean"
attr {
key: "_fe_imply_type"
value {
i: 6
}
}
进入dump data文件夹,我们会看到model_name层有多个文件夹:
找到名称为刚才记录的计算图的名称值的文件夹,如ge_default_253_71。此目录中的文件是您需要的转储数据文件。
查看全部
云优采集接口(训练网络精度未达预期时如何采集Dump数据数据?
)
更新时间:2021-11-16 GMT+08:00
查看PDF
链接复制成功!
转储数据采集
概述
当训练网络的精度没有达到预期时,可以使用训练过程中各个算子的计算结果(即Data Dump数据),然后使用精度对比工具和行业标准算子(如TensorFlow)计算结果 进行数据偏差对比,帮助开发者快速解决算子精度问题。目前支持采集的operator数据主要有:
默认训练过程中,没有采集算子的dump数据。如果需要采集并分析数据,可以选择以下两种方式之一:
使用注意事项
采集在 Estimator 模式下转储数据
在Estimator模式下,通过NPUrunConfig中的dump_config采集Dump data,在创建NPUrunConfig之前,先实例化一个DumpConfig类进行dump配置(包括配置dump路径,哪些迭代数据要dump,dump算子的输入或输出)数据等)。
DumpConfig类的构造函数中各个字段的详细解释请参考对应的接口说明。
from npu_bridge.npu_init import *
# dump_path:dump数据存放路径,该参数指定的目录需要在启动训练的环境上(容器或Host侧)提前创建且确保安装时配置的运行用户具有读写权限
# enable_dump:是否开启Dump功能
# dump_step:指定采集哪些迭代的Dump数据
# dump_mode:Dump模式,取值:input/output/all
dump_config = DumpConfig(enable_dump=True, dump_path = "/home/HwHiAiUser/output", dump_step="0|5|10", dump_mode="all")
session_config=tf.ConfigProto()
config = NPURunConfig(
dump_config=dump_config,
session_config=session_config
)
采集在sess.run模式下转储数据
在sess.run模式下,通过session配置项enable_dump、dump_path、dump_step、dump_mode配置相关参数。
config = tf.ConfigProto()
custom_op = config.graph_options.rewrite_options.custom_optimizers.add()
custom_op.name = "NpuOptimizer"
custom_op.parameter_map["use_off_line"].b = True
# enable_dump:是否开启Dump功能
custom_op.parameter_map["enable_dump"].b = True
# dump_path:dump数据存放路径,该参数指定的目录需要在启动训练的环境上(容器或Host侧)提前创建且确保安装时配置的运行用户具有读写权限
custom_op.parameter_map["dump_path"].s = tf.compat.as_bytes("/home/HwHiAiUser/output")
# dump_step:指定采集哪些迭代的Dump数据
custom_op.parameter_map["dump_step"].s = tf.compat.as_bytes("0|5|10")
# dump_mode:Dump模式,取值:input/output/all
custom_op.parameter_map["dump_mode"].s = tf.compat.as_bytes("all")
config.graph_options.rewrite_options.remapping = RewriterConfig.OFF
config.graph_options.rewrite_options.memory_optimization = RewriterConfig.OFF
with tf.Session(config=config) as sess:
print(sess.run(cost))
执行训练并生成转储数据
后续的精度对比工具不仅依赖Dump数据,还需要计算图结构。因此,在进行训练之前,需要配置环境变量转储图文件:
export DUMP_GE_GRAPH=2
export DUMP_GRAPH_PATH=/home/dumpgraph # 指定dump图路径,如果不配置存储在训练脚本所在目录
执行训练,生成转储图像文件和转储数据文件。
由于“ge”开头的转储图文件很多,转储数据文件夹的model_name层可能有多个文件夹,所以实际上我们只需要找到计算图文件,只要找到model_name为计算图的名称。下面提供一些方法,帮助用户快速找到对应的文件。
选择计算图文件,提供以下两种方法:
选择转储数据文件。
打开上一步找到的计算图文件,记录第一张图中name字段的值。在以下示例中,记录“ge_default_253_71”。
graph {
name: "ge_default_20201209083353_71"
op {
name: "atomic_addr_clean0_71"
type: "AtomicAddrClean"
attr {
key: "_fe_imply_type"
value {
i: 6
}
}
进入dump data文件夹,我们会看到model_name层有多个文件夹:
找到名称为刚才记录的计算图的名称值的文件夹,如ge_default_253_71。此目录中的文件是您需要的转储数据文件。
云优采集接口(算子采集Dump数据偏差对比类进行dump数据后续对比 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-11-28 10:12
)
查看PDF
转储数据采集
链接复制成功!
更新时间:2021/11/26 GMT+08:00
概述
当训练网络的精度没有达到预期时,可以使用训练过程中各个算子的计算结果(即Data Dump数据),然后使用精度对比工具和行业标准算子(如TensorFlow)计算结果 进行数据偏差对比,帮助开发者快速解决算子精度问题。目前支持采集的operator数据主要有:
默认训练过程中,没有采集算子的dump数据。如果需要采集并分析数据,可以选择以下两种方式之一:
使用注意事项
采集在 Estimator 模式下转储数据
在Estimator模式下,通过NPUrunConfig中的dump_config采集Dump data,在创建NPUrunConfig之前,先实例化一个DumpConfig类进行dump配置(包括配置dump路径,哪些迭代数据要dump,dump算子的输入或输出)数据等)。
DumpConfig类的构造函数中各个字段的详细解释请参考对应的接口说明。
from npu_bridge.npu_init import *
# dump_path:dump数据存放路径,该参数指定的目录需要在启动训练的环境上(容器或Host侧)提前创建且确保安装时配置的运行用户具有读写权限
# enable_dump:是否开启Dump功能
# dump_step:指定采集哪些迭代的Dump数据
# dump_mode:Dump模式,取值:input/output/all
dump_config = DumpConfig(enable_dump=True, dump_path = "/home/HwHiAiUser/output", dump_step="0|5|10", dump_mode="all")
session_config=tf.ConfigProto()
config = NPURunConfig(
dump_config=dump_config,
session_config=session_config
)
采集在sess.run模式下转储数据
在sess.run模式下,通过session配置项enable_dump、dump_path、dump_step、dump_mode配置相关参数。
config = tf.ConfigProto()
custom_op = config.graph_options.rewrite_options.custom_optimizers.add()
custom_op.name = "NpuOptimizer"
custom_op.parameter_map["use_off_line"].b = True
# enable_dump:是否开启Dump功能
custom_op.parameter_map["enable_dump"].b = True
# dump_path:dump数据存放路径,该参数指定的目录需要在启动训练的环境上(容器或Host侧)提前创建且确保安装时配置的运行用户具有读写权限
custom_op.parameter_map["dump_path"].s = tf.compat.as_bytes("/home/HwHiAiUser/output")
# dump_step:指定采集哪些迭代的Dump数据
custom_op.parameter_map["dump_step"].s = tf.compat.as_bytes("0|5|10")
# dump_mode:Dump模式,取值:input/output/all
custom_op.parameter_map["dump_mode"].s = tf.compat.as_bytes("all")
config.graph_options.rewrite_options.remapping = RewriterConfig.OFF
config.graph_options.rewrite_options.memory_optimization = RewriterConfig.OFF
with tf.Session(config=config) as sess:
print(sess.run(cost))
执行训练并生成转储数据
后续通过工具进行精度比较不仅依赖Dump数据,还需要计算图结构。因此,在进行训练之前,需要配置环境变量转储图文件:
export DUMP_GE_GRAPH=2
export DUMP_GRAPH_PATH=/home/dumpgraph # 指定dump图路径,如果不配置存储在训练脚本所在目录
执行训练,生成转储图像文件和转储数据文件。
由于“ge”开头的转储图文件很多,转储数据文件夹的model_name层可能有多个文件夹,所以实际上我们只需要找到计算图文件,只要找到model_name为计算图的名称。下面提供了一些方法来帮助用户快速找到相应的文件。
选择计算图文件,提供了两种方法: 选择转储数据文件。打开上一步找到的计算图文件,记录第一张图中name字段的值。在以下示例中,记录“ge_default_253_71”。
graph {
name: "ge_default_20201209083353_71"
op {
name: "atomic_addr_clean0_71"
type: "AtomicAddrClean"
attr {
key: "_fe_imply_type"
value {
i: 6
}
}
进入dump data文件夹,我们会看到model_name层有多个文件夹:
找到名称为刚才记录的计算图的名称值的文件夹,如ge_default_253_71。此目录中的文件是所需的转储数据文件。
查看全部
云优采集接口(算子采集Dump数据偏差对比类进行dump数据后续对比
)
查看PDF
转储数据采集
链接复制成功!
更新时间:2021/11/26 GMT+08:00
概述
当训练网络的精度没有达到预期时,可以使用训练过程中各个算子的计算结果(即Data Dump数据),然后使用精度对比工具和行业标准算子(如TensorFlow)计算结果 进行数据偏差对比,帮助开发者快速解决算子精度问题。目前支持采集的operator数据主要有:
默认训练过程中,没有采集算子的dump数据。如果需要采集并分析数据,可以选择以下两种方式之一:
使用注意事项
采集在 Estimator 模式下转储数据
在Estimator模式下,通过NPUrunConfig中的dump_config采集Dump data,在创建NPUrunConfig之前,先实例化一个DumpConfig类进行dump配置(包括配置dump路径,哪些迭代数据要dump,dump算子的输入或输出)数据等)。
DumpConfig类的构造函数中各个字段的详细解释请参考对应的接口说明。
from npu_bridge.npu_init import *
# dump_path:dump数据存放路径,该参数指定的目录需要在启动训练的环境上(容器或Host侧)提前创建且确保安装时配置的运行用户具有读写权限
# enable_dump:是否开启Dump功能
# dump_step:指定采集哪些迭代的Dump数据
# dump_mode:Dump模式,取值:input/output/all
dump_config = DumpConfig(enable_dump=True, dump_path = "/home/HwHiAiUser/output", dump_step="0|5|10", dump_mode="all")
session_config=tf.ConfigProto()
config = NPURunConfig(
dump_config=dump_config,
session_config=session_config
)
采集在sess.run模式下转储数据
在sess.run模式下,通过session配置项enable_dump、dump_path、dump_step、dump_mode配置相关参数。
config = tf.ConfigProto()
custom_op = config.graph_options.rewrite_options.custom_optimizers.add()
custom_op.name = "NpuOptimizer"
custom_op.parameter_map["use_off_line"].b = True
# enable_dump:是否开启Dump功能
custom_op.parameter_map["enable_dump"].b = True
# dump_path:dump数据存放路径,该参数指定的目录需要在启动训练的环境上(容器或Host侧)提前创建且确保安装时配置的运行用户具有读写权限
custom_op.parameter_map["dump_path"].s = tf.compat.as_bytes("/home/HwHiAiUser/output")
# dump_step:指定采集哪些迭代的Dump数据
custom_op.parameter_map["dump_step"].s = tf.compat.as_bytes("0|5|10")
# dump_mode:Dump模式,取值:input/output/all
custom_op.parameter_map["dump_mode"].s = tf.compat.as_bytes("all")
config.graph_options.rewrite_options.remapping = RewriterConfig.OFF
config.graph_options.rewrite_options.memory_optimization = RewriterConfig.OFF
with tf.Session(config=config) as sess:
print(sess.run(cost))
执行训练并生成转储数据
后续通过工具进行精度比较不仅依赖Dump数据,还需要计算图结构。因此,在进行训练之前,需要配置环境变量转储图文件:
export DUMP_GE_GRAPH=2
export DUMP_GRAPH_PATH=/home/dumpgraph # 指定dump图路径,如果不配置存储在训练脚本所在目录
执行训练,生成转储图像文件和转储数据文件。
由于“ge”开头的转储图文件很多,转储数据文件夹的model_name层可能有多个文件夹,所以实际上我们只需要找到计算图文件,只要找到model_name为计算图的名称。下面提供了一些方法来帮助用户快速找到相应的文件。
选择计算图文件,提供了两种方法: 选择转储数据文件。打开上一步找到的计算图文件,记录第一张图中name字段的值。在以下示例中,记录“ge_default_253_71”。
graph {
name: "ge_default_20201209083353_71"
op {
name: "atomic_addr_clean0_71"
type: "AtomicAddrClean"
attr {
key: "_fe_imply_type"
value {
i: 6
}
}
进入dump data文件夹,我们会看到model_name层有多个文件夹:
找到名称为刚才记录的计算图的名称值的文件夹,如ge_default_253_71。此目录中的文件是所需的转储数据文件。
云优采集接口(L16事例学习:JAVA的采集接口如果没有完全理解JAVA)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2021-11-27 21:08
L16案例学习:JAVA的采集界面如果你不完全理解JAVA材料的决定性部分,你将无法成为一个称职的JAVA程序员。JAVA语言书中对所有最基本的类型和相应部分的介绍都有详细的介绍。文件夹java.util 提供了采集——组、列表和图——您应该了解这些数据结构的优点。文件夹 java.io 也很重要。您可以大致了解和了解文件中的java是什么,它的需求和开发等。在本章中,我们将讨论 java.util 的设计,它通常被称为 java 集合 API。学习它很有价值,不仅是因为采集 类非常有用,还因为API 是一个设计非常好的代码示例。这很容易理解,同时也很容易证明。API 代码是由 Joshua Bloch 编写的,他还出版了我们开始本课程时推荐的 Effective Java 一书。同时,几乎所有复杂的原创程序都有API,所以如果你认真学习API,你会对你没有仔细考虑的程序代码有更广泛的了解。其实可以毫不夸张地说,如果你能指定某个类型的所有操作,你就已经完全掌握了java的概念。并且您将对您没有仔细考虑的程序代码有更广泛的了解。其实可以毫不夸张地说,如果你能指定某个类型的所有操作,你就已经完全掌握了java的概念。并且您将对您没有仔细考虑的程序代码有更广泛的了解。其实可以毫不夸张地说,如果你能指定某个类型的所有操作,你就已经完全掌握了java的概念。
我们没有时间讨论所有的话题,但我们会触及其中的大部分。其中一些,例如重载和同步,超出了本课程的范围。16.1 类组织的类型 简而言之,API 提供了三种类型的集合:组、列表和图。该组负责采集 元素,但不包括元素的数量和顺序。每个元素只在或不在某个组中。列是元素的序列,因此它包括元素的顺序和数量。图是键和属性值的集合:它有一组键,每个键都有一个唯一的属性值。API 使用接口来组织它的所有类——各种类型的规范——以及各种单独的工具来组织类。该图反映了所选类和接口的一些示例。采集 界面捕获常见且合适的列和组,但没有图形,我们将使用非正式界面。集合而不是图形。SortedMap 和 SortedSet 用于为地图和组提供附加操作以按特定顺序检索元素。可实现的类,比如LinkedList,都是建立在骨架图的上半部分,比如AbstractList,来整体展示它们的继承关系。这种接口和类的并行结构是非常重要的结构,值得学习。许多新程序员在应该使用接口的时候更喜欢使用简单的类,但一般来说,使用接口比使用简单的类要好。将现有的类样式更新和扩展为新的类并不容易,但将类实现为新的接口很容易。
Bloch 指出,结合两种方法的优点的方式是使用骨架图的实现类,就像他在这里列出的 API 一样。您可以获得基本规范接口的优点和与实现相关的共享代码以及汇总类的优点。JAVA API 文档中有每个 JAVA 接口的非正式规范。这很重要,因为他告诉每个类的用户他们期望使用的各种界面工具。如果使用类,则必须对其进行声明并使其符合规范 List。例如,您必须确保类的工具符合规范,否则它将不会以程序员期望的方式运行。这些规格基本上是不完整的。具体类也有规范,其中包括几个接口规范的详细信息。List 接口没有指定是否可以存储空元素,但是 ArrayList 和 LinkList 明确声明空是非法的。HashMap 允许空关键字和空属性值,而 HashMap 不允许它们。当你编写代码并使用采集 类时,你应该通过一个通用的接口或类来创建一个对象。例如,List p=new LinkedList(); 比下一个形式 LinkedList p=new LinkedList(); 如果你用之前的代码编译,你可以很容易地改变不同的队列实现: List p=new ArrayList(); 因为所有的代码都依赖于 p 队列。HashMap 允许空关键字和空属性值,而 HashMap 不允许它们。当你编写代码并使用采集 类时,你应该通过一个通用的接口或类来创建一个对象。例如,List p=new LinkedList(); 比下一个形式 LinkedList p=new LinkedList(); 如果你用之前的代码编译,你可以很容易地改变不同的队列实现: List p=new ArrayList(); 因为所有的代码都依赖于 p 队列。HashMap 允许空关键字和空属性值,而 HashMap 不允许它们。当你编写代码并使用采集 类时,你应该通过一个通用的接口或类来创建一个对象。例如,List p=new LinkedList(); 比下一个形式 LinkedList p=new LinkedList(); 如果你用之前的代码编译,你可以很容易地改变不同的队列实现: List p=new ArrayList(); 因为所有的代码都依赖于 p 队列。您可以轻松更改不同的队列实现: List p=new ArrayList(); 因为所有的代码都依赖于 p 队列。您可以轻松更改不同的队列实现: List p=new ArrayList(); 因为所有的代码都依赖于 p 队列。
你会发现后者很难改变,因为程序的某些部分是对X的操作,而这些操作只有LinkedList提供——实际上这些操作是不需要的。这个解释的细节在 Bloch 的书 34 中。下周我们将学习更复杂的例子,当时的代码需要 Hashmap 接受键。设置键=map.keySet(); 当前代码使用密钥而不知道密钥是否在某个组中。16.2 替代方法 采集 的API 允许在采集 接口中使用类声明工具并实现其所有功能。例如,列表中的所有变异器都被指定为可供选择。这意味着你可以实现一个符合List规则的类,但是每当您调用 mutator(例如 add 命令)时,它都会连接到 UnsupportedOperationException。这种弱化规范的尝试很棘手,因为这意味着如果您编写一些支持列的代码,在没有关于列的附加信息的情况下,您不知道该列是否支持命令 add。但是没有这样的选择。对于替代概念,您必须声明一个单独的接口 ImmutableList。该奖项使接口数量增加了一倍。有时,我们需要一些变异器而不是其他变异器。例如,HashMap 中的 keyset 方法返回一个收录图中键的组。在没有关于列的附加信息的情况下,您不知道该列是否支持命令 add。但是没有这样的选择。对于替代概念,您必须声明一个单独的接口 ImmutableList。该奖项使接口数量增加了一倍。有时,我们需要一些变异器而不是其他变异器。例如,HashMap 中的 keyset 方法返回一个收录图中键的组。在没有关于列的附加信息的情况下,您不知道该列是否支持命令 add。但是没有这样的选择。对于替代概念,您必须声明一个单独的接口 ImmutableList。该奖项使接口数量增加了一倍。有时,我们需要一些变异器而不是其他变异器。例如,HashMap 中的 keyset 方法返回一个收录图中键的组。
该组的作用:从组中删除一个key,从图中删除与其相关的属性值。因此支持 remove 命令,但不支持 add 命令,因此您无法在没有属性值的情况下向图中添加键。所以使用替代操作是一个合理的判断。这意味着更少的编译时间检查并减少了接口的数量。16.3 所有这些容器(数据组织)——组、列和图表——对象元素的一种方式。它们被称为多态,这意味着多种形状,令人欣慰的是它们允许您使用不同的容器(数据结构):整数列、URL 列等等。这种类型的多态性被称为子类型多态性,因为它依赖于类型的推导。另一种不同形式的多态称为参数多态,它允许你在定义容器时使用参数,这样客户端就可以提示容器将收录什么类型的参数:List[URL]bookmarks;notlegal Java JAVA不收录这个多态性,尽管有很多提议要添加这种多态性。参数多态的最大优点是程序员可以告诉编译器元素的类型。编译器可以检查添加的错误类型,或将其转换为另一种类型。考虑代码:List bookmarks=new LinkedList(); URL URLx=bookmarks.get(0);//编译器原本以为add方法是一个对象,其实add是可以的,URL是object的子类。所以客户端可以提示容器将收录什么类型的参数: List[URL]bookmarks;notlegal Java JAVA 不收录这种多态性,即使有很多建议添加这种多态性。参数多态的最大优点是程序员可以告诉编译器元素的类型。编译器可以检查添加的错误类型,或将其转换为另一种类型。考虑代码:List bookmarks=new LinkedList(); URL URLx=bookmarks.get(0);//编译器原本以为add方法是一个对象,其实add是可以的,URL是object的子类。所以客户端可以提示容器将收录什么类型的参数: List[URL]bookmarks;notlegal Java JAVA 不收录这种多态性,即使有很多建议添加这种多态性。参数多态的最大优点是程序员可以告诉编译器元素的类型。编译器可以检查添加的错误类型,或将其转换为另一种类型。考虑代码:List bookmarks=new LinkedList(); URL URLx=bookmarks.get(0);//编译器原本以为add方法是一个对象,其实add是可以的,URL是object的子类。参数多态的最大优点是程序员可以告诉编译器元素的类型。编译器可以检查添加的错误类型,或将其转换为另一种类型。考虑代码:List bookmarks=new LinkedList(); URL URLx=bookmarks.get(0);//编译器原本以为add方法是一个对象,其实add是可以的,URL是object的子类。参数多态的最大优点是程序员可以告诉编译器元素的类型。编译器可以检查添加的错误类型,或将其转换为另一种类型。考虑代码:List bookmarks=new LinkedList(); URL URLx=bookmarks.get(0);//编译器原本以为add方法是一个对象,其实add是可以的,URL是object的子类。
事实证明,如果你想得到x就算破了,RHS的类型表达式也是一个对象。不能给一个对象分配大量的URL类型,所以不能依赖这种方式来使用URL,所以我们写的代码必须使用而不是下面的公式:Url x=(URL)bookmarks.get ; 该方法的作用是在运行时进行检查。如果成功,此方法的结果将调用 URL 类型并执行正常操作。如果失败,因为结果类型不正确,ClassCastException 被丢弃,任务将不会被执行。确保您理解这一点,不要对如何获取对象的返回值感到困惑。对象在运行时驱动其类型。如果在类 URl 中创建了一个对象,它将收录这种类型,所以没必要强行改给这个类型。这种向下转换很烦人,有时您必须编写一个包装类来摆脱它们。在浏览器中,您通常希望获得一种特殊的汇总数据类型。如果要这样做,必须使代码中不收录摘要类型,客户端将看到该方法如下: URL getURL(int 不需要在代码中使用它而是调用上下文,但仅限制了错误的范围。这种类型的多态提供了很大的灵活性,这是参数多态所没有的。您可以创建一个可以存储各种元素的异构容器(数据结构)。
你可以把容器放在它们自己里面——试着弄清楚如何表达这种多态类型——即使这不是一个明智的方法。事实上,正如我们在前面的课程中提到的,如果你这样做,JAVA API 类会崩溃。标记元素容器收录的类型通常是最重要的部分。你应该养成在声明容器时写注释的习惯,或者使用错误的参数类型声明。List bookmarks;//List[URl] RI:bookmarks.elems URL16.4 Skeletal implementations 骨架实现的采集主体中的骨架实现的具体实现通常是使用Template Method设计的。抽象类中没有例子来证明它有这些方法,但是它可以通过定义模板方法调用其他钩子方法,并且这些方法都是在抽象中声明的,没有代码段。在继承的子类中,钩子方法被覆盖,模板方法继承不能改变。以 AbstractList 为例,它在迭代器中使用模板方法,它返回迭代器实现作为钩子方法。Equals 方法是实现另一个关于迭代器的模板。
一个子类,比如ArrayList,提供了一种实现get命令的方法,它可以继承iterator和equals。一些特定的类替换了摘要实现。比如LinkedList代替了iterator的作用,因为它可以直接进入list的执行,比在hook中使用get命令提供了更有效的飞跃,每次调用都会继续搜索。16.5 Capacity, Allocation&GC 实现这一点的一种方法是利用队列的特性——例如ArrayList HashMap——在配置队列时,必须为其选择一个大小。选择合适的尺寸对性能非常重要。如果太小,队列将不得不被新队列替换,这导致新队列的配置和旧垃圾的处理的更多消耗。太大的话,会浪费空间,尤其是种类很多的时候,问题就大了。一些实现方法为builder提供了通过客户端设置初始容量的能力,可以决定配置的大小。例如: Public ArrayList(int initialCapacity) 构造emptylist指定初始容量参数:initialCapacity-初始容量列表。抛出:IllegalArgumentException-如果指定初始容量为负数 还有一个适配配置项的方法:trimTosize,有适配能力容器要有足够的空间来存储元素,并确保容量,从而有能力增加其他空间。一些实现方法为builder提供了通过客户端设置初始容量的能力,可以决定配置的大小。例如: Public ArrayList(int initialCapacity) 构造emptylist指定初始容量参数:initialCapacity-初始容量列表。抛出:IllegalArgumentException-如果指定初始容量为负数 还有一个适配配置项的方法:trimTosize,有适配能力容器要有足够的空间来存储元素,并确保容量,从而有能力增加其他空间。一些实现方法为builder提供了通过客户端设置初始容量的能力,可以决定配置的大小。例如: Public ArrayList(int initialCapacity) 构造emptylist指定初始容量参数:initialCapacity-初始容量列表。抛出:IllegalArgumentException-如果指定初始容量为负数 还有一个适配配置项的方法:trimTosize,有适配能力容器要有足够的空间来存储元素,并确保容量,从而有能力增加其他空间。
使用此功能有一些技巧。如果您对申请多少空间没有准确的了解,您可以使用此功能来查找空间的大小。将这种能力的概念转化为行动是一个问题。在很多老的程序中,它们总是限制资源,如果资源耗尽,程序就无法运行。使用这种自适应方法,程序只会变慢。这是设计程序以确保程序始终有效运行的好主意,即使在特殊情况下也是如此。如果你学习在ArryList中实现remove,你会看到下面的代码: Public Object remove(int index){ elementData[-size]=null;//letgc do its work next? 不是垃圾文件的自动处理吗?以下是一些新手常犯的错误。如果你的表演有队列,1< @6.6 副本、转换、包装器等。所有特定的 采集 类都提供给构建者通过 采集 进行争论。这些允许你复制采集,或者属于另一种类型,例如LinkedList Public LinkedList(采集 list contains specified 采集,in 采集'siterator。参数:c-其元素列表的集合。它可以复制为: List p =new LinkedList() ListpCopy=new LinkedList(p) 创建一个link form other 采集 type set s=new HashSet() Listp=new Linked list(s) builder不能在接口中声明,规范的List 也不能说所有的实现都属于构建者,即使是这样,Java.util.采集s 是一个特殊的类,里面收录了静态字符串方法,有些是泛化算法,有些是包装器。转换、包装器等。所有特定的 采集 类都提供给构建器以通过 采集 进行争论。这些允许你复制采集,或者属于另一种类型,例如LinkedList Public LinkedList(采集 list contains specified 采集,in 采集'siterator。参数:c-其元素列表的集合。它可以复制为: List p =new LinkedList() ListpCopy=new LinkedList(p) 创建一个link form other 采集 type set s=new HashSet() Listp=new Linked list(s) builder不能在接口中声明,规范的List 也不能说所有的实现都属于构建者,即使是这样,Java.util.采集s 是一个特殊的类,里面收录了静态字符串方法,有些是泛化算法,有些是包装器。转换、包装器等。所有特定的 采集 类都提供给构建器以通过 采集 进行争论。这些允许你复制采集,或者属于另一种类型,例如LinkedList Public LinkedList(采集 list contains specified 采集,in 采集'siterator。参数:c-其元素列表的集合。它可以复制为: List p =new LinkedList() ListpCopy=new LinkedList(p) 创建一个link form other 采集 type set s=new HashSet() Listp=new Linked list(s) builder不能在接口中声明,规范的List 也不能说所有的实现都属于构建者,即使是这样,Java.util.采集s 是一个特殊的类,里面收录了静态字符串方法,有些是泛化算法,有些是包装器。所有特定的 采集 类都提供给构建器以通过 采集 进行争论。这些允许你复制采集,或者属于另一种类型,例如LinkedList Public LinkedList(采集 list contains specified 采集,in 采集'siterator。参数:c-其元素列表的集合。它可以复制为: List p =new LinkedList() ListpCopy=new LinkedList(p) 创建一个link form other 采集 type set s=new HashSet() Listp=new Linked list(s) builder不能在接口中声明,规范的List 也不能说所有的实现都属于构建者,即使是这样,Java.util.采集s 是一个特殊的类,里面收录了静态字符串方法,有些是泛化算法,有些是包装器。所有特定的 采集 类都提供给构建器以通过 采集 进行争论。这些允许你复制采集,或者属于另一种类型,例如LinkedList Public LinkedList(采集 list contains specified 采集,in 采集'siterator。参数:c-其元素列表的集合。它可以复制为: List p =new LinkedList() ListpCopy=new LinkedList(p) 创建一个link form other 采集 type set s=new HashSet() Listp=new Linked list(s) builder不能在接口中声明,规范的List 也不能说所有的实现都属于构建者,即使是这样,Java.util.采集s 是一个特殊的类,里面收录了静态字符串方法,有些是泛化算法,有些是包装器。为构建器提供了类以通过 采集 进行争论。这些允许你复制采集,或者属于另一种类型,例如LinkedList Public LinkedList(采集 list contains specified 采集,in 采集'siterator。参数:c-其元素列表的集合。它可以复制为: List p =new LinkedList() ListpCopy=new LinkedList(p) 创建一个link form other 采集 type set s=new HashSet() Listp=new Linked list(s) builder不能在接口中声明,规范的List 也不能说所有的实现都属于构建者,即使是这样,Java.util.采集s 是一个特殊的类,里面收录了静态字符串方法,有些是泛化算法,有些是包装器。为构建器提供了类以通过 采集 进行争论。这些允许你复制采集,或者属于另一种类型,例如LinkedList Public LinkedList(采集 list contains specified 采集,in 采集'siterator。参数:c-其元素列表的集合。它可以复制为: List p =new LinkedList() ListpCopy=new LinkedList(p) 创建一个link form other 采集 type set s=new HashSet() Listp=new Linked list(s) builder不能在接口中声明,规范的List 也不能说所有的实现都属于构建者,即使是这样,Java.util.采集s 是一个特殊的类,里面收录了静态字符串方法,有些是泛化算法,有些是包装器。List p =new LinkedList() ListpCopy=new LinkedList(p) 创建一个link form other 采集 type set s=new HashSet() Listp=new Linked list(s) builder不能在接口中声明,规范的List 就算是这样,也不能说所有的实现都属于建设者。Java.util.采集s 是一个特殊的类,它收录静态字符串方法,其中一些是通用算法,一些是包装器。List p =new LinkedList() ListpCopy=new LinkedList(p) 创建一个link form other 采集 type set s=new HashSet() Listp=new Linked list(s) builder不能在接口中声明,规范的List 就算是这样,也不能说所有的实现都属于建设者。Java.util.采集s 是一个特殊的类,它收录静态字符串方法,其中一些是通用算法,一些是包装器。
例如 unmodifiableList 使用一个列表,然后使用相同的元素返回一个列表,但它是不可变的。public static List unmodifiableList(List list) 返回unmodifiableview指定列表。该方法允许模块提供用户内部列表。查询操作返回列表”读取到指定列表,并尝试返回列表,是否直接通过其迭代器,结果返回列表指定列表序列化。参数:列表-列表返回不可修改视图。返回:不可修改视图指定列表。返回的列表不准确,无法更改。它的属性值可以因为下面的列表被修改而改变,但不能直接修改。16.7 Sorted 采集s 一种采集 分类必须有某种方法来比较元素并确定它们的顺序。
采集API 为此提供了两种方法。您可以使用自然排序,这是通过对元素使用比较方法从接口 java.lang.Comparable 确定的。public int compareTo(Object 它返回一个负整数类型,0或实整数类型作为对象。添加元素时,使用自然顺序。元素必须内置在一个类中,它是通过Comparable接口实现的。添加方法使要添加的元素通过comparable与现有元素进行比较,不匹配则移除,两者任选其一,可以使用一个元素的顺序独立给定,就像对象一样,通过java.util .Comparator接口实现,也是一个方法 public int compare(Object o1,Object o2) 上面的公式和compareTo类似,只是同时比较两个元素。这是 Strategy 风格的一个例子,通过它它是一个计算法则与使用的代码分离的。方法的选择取决于您创建对象的方式。如果您使用构造并且它使用 Comparator 作为参数,它将用于确定顺序。如果不使用构造,将使用自然顺序。比较 同样的问题(详细信息在第 9 章讨论)带来了同样的困难。如果不使用构造,将使用自然顺序。比较 同样的问题(详细信息在第 9 章讨论)带来了同样的困难。如果不使用构造,将使用自然顺序。比较 同样的问题(详细信息在第 9 章讨论)带来了同样的困难。
一种分类基于不变量。如果可以通过改变公共方法的调用来改变两个元素的顺序,那么 Rep 就会发生。16.8 Views 我们在第9章介绍了concept的概念。Concept是一个复杂的机制。直现在也很有用,但是很危险。它们打破了原创程序中关于设计精心设计的对象的许多基本概念。通过它们的用途,可以识别出三个概念: FunctionalityExtension 有些概念提供了对象函数的扩展,而无需添加新方法。可以替换 采集 类中的 next 和 hasNext 方法。但这使得类自己的 API 更加复杂。支持多个接口也非常困难。我们可以在类中添加一个reset方法,该方法用于调用restart,但同时只允许一次迭代。如果程序元素忘记重置,这种方法会导致错误。解耦的一些概念提到了该子组对底层 采集 的作用。表的键组的方法。例如,返回一个由表的键组成的组。因此,允许部分代码与key相关,该section没有key值,与其他目标规范解耦。CoordinateTransformation 的概念通过 subList 提供了一个等效的转换。概念的改变导致了底层列表的变化,但是允许通过有偏索引访问列表。这种方法会导致错误。解耦的一些概念提到了该子组对底层 采集 的作用。表的键组的方法。例如,返回一个由表的键组成的组。因此,允许部分代码与key相关,该section没有key值,与其他目标规范解耦。CoordinateTransformation 的概念通过 subList 提供了一个等效的转换。概念的改变导致了底层列表的变化,但是允许通过有偏索引访问列表。这种方法会导致错误。解耦的一些概念提到了该子组对底层 采集 的作用。表的键组的方法。例如,返回一个由表的键组成的组。因此,允许部分代码与key相关,该section没有key值,与其他目标规范解耦。CoordinateTransformation 的概念通过 subList 提供了一个等效的转换。概念的改变导致了底层列表的变化,但是允许通过有偏索引访问列表。返回一个由表的键组成的组。因此,允许部分代码与key相关,该section没有key值,与其他目标规范解耦。CoordinateTransformation 的概念通过 subList 提供了一个等效的转换。概念的改变导致了底层列表的变化,但是允许通过有偏索引访问列表。返回一个由表的键组成的组。因此,允许部分代码与key相关,该section没有key值,与其他目标规范解耦。CoordinateTransformation 的概念通过 subList 提供了一个等效的转换。概念的改变导致了底层列表的变化,但是允许通过有偏索引访问列表。
想法是危险的有两个原因。一、底部改变:调用remove改变底部采集;调用 remove 和它的 key group 来更改团队列表。这将形成一个简短的混叠,以便一个对象的变化影响另一个。这两个对象不需要具有相同的字典范围。这意味着我们必须重新定义规范中的更改:如果您更改 C 以收录概念 V,这是否意味着 V 也可以更改?其次,该方法的规范返回了一个通常仅限于更改的想法。为了确保您的代码可以运行,您需要了解此规范。毫不奇怪,这些规范通常很微妙。改变了云学习下采集的一些思路。其他的只允许改变概念——比如迭代器。有些允许概念和底层 采集 改变,但这更复杂。例如采集API,当在列中放置子列表的概念时,底层列不能有任何结构变化:以下将解释这种现象:结构修改列表,否则扰乱进度可能会产生错误的结果. 它的意思不是很准确和清楚。我不想对基础列进行任何更改。同一个底层采集的复杂概念会很复杂。例如,您可以在同一个列表中使用多个迭代器。在这种情况下,您必须考虑与想法的交互。底层列不能有任何结构变化:以下将解释这种现象:结构修改列表,否则扰乱进度可能会产生不正确的结果。它的意思不是很准确和清楚。我不想对基础列进行任何更改。同一个底层采集的复杂概念会很复杂。例如,您可以在同一个列表中使用多个迭代器。在这种情况下,您必须考虑与想法的交互。底层列不能有任何结构变化:以下将解释这种现象:结构修改列表,否则扰乱进度可能会产生不正确的结果。它的意思不是很准确和清楚。我不想对基础列进行任何更改。同一个底层采集的复杂概念会很复杂。例如,您可以在同一个列表中使用多个迭代器。在这种情况下,您必须考虑与想法的交互。您可以在同一个列表中使用多个迭代器。在这种情况下,您必须考虑与想法的交互。您可以在同一个列表中使用多个迭代器。在这种情况下,您必须考虑与想法的交互。
如果通过交互更改列表,其他界面将无效。这里有一些有用的经验。如果您使用想法,您必须仔细考虑它是否会对您有所帮助: 您可以限制可接受的想法范围。例如,使用for循环代替while循环作为接口,可以限制接口的循环范围。很容易确保接口处没有意外错误。这并不总是可能的。下周将讨论 Tagger 计划关于他的集中呼叫更改。您可以使用 采集s 类来防止顾念更改或包装底层对象。例如,如果你在表中使用keySetview,并且不打算更改它,则可以使用以下方法: Set s=map.keySey(); Set safe_s=采集s.unmodifiableSet(s); 查看全部
云优采集接口(L16事例学习:JAVA的采集接口如果没有完全理解JAVA)
L16案例学习:JAVA的采集界面如果你不完全理解JAVA材料的决定性部分,你将无法成为一个称职的JAVA程序员。JAVA语言书中对所有最基本的类型和相应部分的介绍都有详细的介绍。文件夹java.util 提供了采集——组、列表和图——您应该了解这些数据结构的优点。文件夹 java.io 也很重要。您可以大致了解和了解文件中的java是什么,它的需求和开发等。在本章中,我们将讨论 java.util 的设计,它通常被称为 java 集合 API。学习它很有价值,不仅是因为采集 类非常有用,还因为API 是一个设计非常好的代码示例。这很容易理解,同时也很容易证明。API 代码是由 Joshua Bloch 编写的,他还出版了我们开始本课程时推荐的 Effective Java 一书。同时,几乎所有复杂的原创程序都有API,所以如果你认真学习API,你会对你没有仔细考虑的程序代码有更广泛的了解。其实可以毫不夸张地说,如果你能指定某个类型的所有操作,你就已经完全掌握了java的概念。并且您将对您没有仔细考虑的程序代码有更广泛的了解。其实可以毫不夸张地说,如果你能指定某个类型的所有操作,你就已经完全掌握了java的概念。并且您将对您没有仔细考虑的程序代码有更广泛的了解。其实可以毫不夸张地说,如果你能指定某个类型的所有操作,你就已经完全掌握了java的概念。
我们没有时间讨论所有的话题,但我们会触及其中的大部分。其中一些,例如重载和同步,超出了本课程的范围。16.1 类组织的类型 简而言之,API 提供了三种类型的集合:组、列表和图。该组负责采集 元素,但不包括元素的数量和顺序。每个元素只在或不在某个组中。列是元素的序列,因此它包括元素的顺序和数量。图是键和属性值的集合:它有一组键,每个键都有一个唯一的属性值。API 使用接口来组织它的所有类——各种类型的规范——以及各种单独的工具来组织类。该图反映了所选类和接口的一些示例。采集 界面捕获常见且合适的列和组,但没有图形,我们将使用非正式界面。集合而不是图形。SortedMap 和 SortedSet 用于为地图和组提供附加操作以按特定顺序检索元素。可实现的类,比如LinkedList,都是建立在骨架图的上半部分,比如AbstractList,来整体展示它们的继承关系。这种接口和类的并行结构是非常重要的结构,值得学习。许多新程序员在应该使用接口的时候更喜欢使用简单的类,但一般来说,使用接口比使用简单的类要好。将现有的类样式更新和扩展为新的类并不容易,但将类实现为新的接口很容易。
Bloch 指出,结合两种方法的优点的方式是使用骨架图的实现类,就像他在这里列出的 API 一样。您可以获得基本规范接口的优点和与实现相关的共享代码以及汇总类的优点。JAVA API 文档中有每个 JAVA 接口的非正式规范。这很重要,因为他告诉每个类的用户他们期望使用的各种界面工具。如果使用类,则必须对其进行声明并使其符合规范 List。例如,您必须确保类的工具符合规范,否则它将不会以程序员期望的方式运行。这些规格基本上是不完整的。具体类也有规范,其中包括几个接口规范的详细信息。List 接口没有指定是否可以存储空元素,但是 ArrayList 和 LinkList 明确声明空是非法的。HashMap 允许空关键字和空属性值,而 HashMap 不允许它们。当你编写代码并使用采集 类时,你应该通过一个通用的接口或类来创建一个对象。例如,List p=new LinkedList(); 比下一个形式 LinkedList p=new LinkedList(); 如果你用之前的代码编译,你可以很容易地改变不同的队列实现: List p=new ArrayList(); 因为所有的代码都依赖于 p 队列。HashMap 允许空关键字和空属性值,而 HashMap 不允许它们。当你编写代码并使用采集 类时,你应该通过一个通用的接口或类来创建一个对象。例如,List p=new LinkedList(); 比下一个形式 LinkedList p=new LinkedList(); 如果你用之前的代码编译,你可以很容易地改变不同的队列实现: List p=new ArrayList(); 因为所有的代码都依赖于 p 队列。HashMap 允许空关键字和空属性值,而 HashMap 不允许它们。当你编写代码并使用采集 类时,你应该通过一个通用的接口或类来创建一个对象。例如,List p=new LinkedList(); 比下一个形式 LinkedList p=new LinkedList(); 如果你用之前的代码编译,你可以很容易地改变不同的队列实现: List p=new ArrayList(); 因为所有的代码都依赖于 p 队列。您可以轻松更改不同的队列实现: List p=new ArrayList(); 因为所有的代码都依赖于 p 队列。您可以轻松更改不同的队列实现: List p=new ArrayList(); 因为所有的代码都依赖于 p 队列。
你会发现后者很难改变,因为程序的某些部分是对X的操作,而这些操作只有LinkedList提供——实际上这些操作是不需要的。这个解释的细节在 Bloch 的书 34 中。下周我们将学习更复杂的例子,当时的代码需要 Hashmap 接受键。设置键=map.keySet(); 当前代码使用密钥而不知道密钥是否在某个组中。16.2 替代方法 采集 的API 允许在采集 接口中使用类声明工具并实现其所有功能。例如,列表中的所有变异器都被指定为可供选择。这意味着你可以实现一个符合List规则的类,但是每当您调用 mutator(例如 add 命令)时,它都会连接到 UnsupportedOperationException。这种弱化规范的尝试很棘手,因为这意味着如果您编写一些支持列的代码,在没有关于列的附加信息的情况下,您不知道该列是否支持命令 add。但是没有这样的选择。对于替代概念,您必须声明一个单独的接口 ImmutableList。该奖项使接口数量增加了一倍。有时,我们需要一些变异器而不是其他变异器。例如,HashMap 中的 keyset 方法返回一个收录图中键的组。在没有关于列的附加信息的情况下,您不知道该列是否支持命令 add。但是没有这样的选择。对于替代概念,您必须声明一个单独的接口 ImmutableList。该奖项使接口数量增加了一倍。有时,我们需要一些变异器而不是其他变异器。例如,HashMap 中的 keyset 方法返回一个收录图中键的组。在没有关于列的附加信息的情况下,您不知道该列是否支持命令 add。但是没有这样的选择。对于替代概念,您必须声明一个单独的接口 ImmutableList。该奖项使接口数量增加了一倍。有时,我们需要一些变异器而不是其他变异器。例如,HashMap 中的 keyset 方法返回一个收录图中键的组。
该组的作用:从组中删除一个key,从图中删除与其相关的属性值。因此支持 remove 命令,但不支持 add 命令,因此您无法在没有属性值的情况下向图中添加键。所以使用替代操作是一个合理的判断。这意味着更少的编译时间检查并减少了接口的数量。16.3 所有这些容器(数据组织)——组、列和图表——对象元素的一种方式。它们被称为多态,这意味着多种形状,令人欣慰的是它们允许您使用不同的容器(数据结构):整数列、URL 列等等。这种类型的多态性被称为子类型多态性,因为它依赖于类型的推导。另一种不同形式的多态称为参数多态,它允许你在定义容器时使用参数,这样客户端就可以提示容器将收录什么类型的参数:List[URL]bookmarks;notlegal Java JAVA不收录这个多态性,尽管有很多提议要添加这种多态性。参数多态的最大优点是程序员可以告诉编译器元素的类型。编译器可以检查添加的错误类型,或将其转换为另一种类型。考虑代码:List bookmarks=new LinkedList(); URL URLx=bookmarks.get(0);//编译器原本以为add方法是一个对象,其实add是可以的,URL是object的子类。所以客户端可以提示容器将收录什么类型的参数: List[URL]bookmarks;notlegal Java JAVA 不收录这种多态性,即使有很多建议添加这种多态性。参数多态的最大优点是程序员可以告诉编译器元素的类型。编译器可以检查添加的错误类型,或将其转换为另一种类型。考虑代码:List bookmarks=new LinkedList(); URL URLx=bookmarks.get(0);//编译器原本以为add方法是一个对象,其实add是可以的,URL是object的子类。所以客户端可以提示容器将收录什么类型的参数: List[URL]bookmarks;notlegal Java JAVA 不收录这种多态性,即使有很多建议添加这种多态性。参数多态的最大优点是程序员可以告诉编译器元素的类型。编译器可以检查添加的错误类型,或将其转换为另一种类型。考虑代码:List bookmarks=new LinkedList(); URL URLx=bookmarks.get(0);//编译器原本以为add方法是一个对象,其实add是可以的,URL是object的子类。参数多态的最大优点是程序员可以告诉编译器元素的类型。编译器可以检查添加的错误类型,或将其转换为另一种类型。考虑代码:List bookmarks=new LinkedList(); URL URLx=bookmarks.get(0);//编译器原本以为add方法是一个对象,其实add是可以的,URL是object的子类。参数多态的最大优点是程序员可以告诉编译器元素的类型。编译器可以检查添加的错误类型,或将其转换为另一种类型。考虑代码:List bookmarks=new LinkedList(); URL URLx=bookmarks.get(0);//编译器原本以为add方法是一个对象,其实add是可以的,URL是object的子类。
事实证明,如果你想得到x就算破了,RHS的类型表达式也是一个对象。不能给一个对象分配大量的URL类型,所以不能依赖这种方式来使用URL,所以我们写的代码必须使用而不是下面的公式:Url x=(URL)bookmarks.get ; 该方法的作用是在运行时进行检查。如果成功,此方法的结果将调用 URL 类型并执行正常操作。如果失败,因为结果类型不正确,ClassCastException 被丢弃,任务将不会被执行。确保您理解这一点,不要对如何获取对象的返回值感到困惑。对象在运行时驱动其类型。如果在类 URl 中创建了一个对象,它将收录这种类型,所以没必要强行改给这个类型。这种向下转换很烦人,有时您必须编写一个包装类来摆脱它们。在浏览器中,您通常希望获得一种特殊的汇总数据类型。如果要这样做,必须使代码中不收录摘要类型,客户端将看到该方法如下: URL getURL(int 不需要在代码中使用它而是调用上下文,但仅限制了错误的范围。这种类型的多态提供了很大的灵活性,这是参数多态所没有的。您可以创建一个可以存储各种元素的异构容器(数据结构)。
你可以把容器放在它们自己里面——试着弄清楚如何表达这种多态类型——即使这不是一个明智的方法。事实上,正如我们在前面的课程中提到的,如果你这样做,JAVA API 类会崩溃。标记元素容器收录的类型通常是最重要的部分。你应该养成在声明容器时写注释的习惯,或者使用错误的参数类型声明。List bookmarks;//List[URl] RI:bookmarks.elems URL16.4 Skeletal implementations 骨架实现的采集主体中的骨架实现的具体实现通常是使用Template Method设计的。抽象类中没有例子来证明它有这些方法,但是它可以通过定义模板方法调用其他钩子方法,并且这些方法都是在抽象中声明的,没有代码段。在继承的子类中,钩子方法被覆盖,模板方法继承不能改变。以 AbstractList 为例,它在迭代器中使用模板方法,它返回迭代器实现作为钩子方法。Equals 方法是实现另一个关于迭代器的模板。
一个子类,比如ArrayList,提供了一种实现get命令的方法,它可以继承iterator和equals。一些特定的类替换了摘要实现。比如LinkedList代替了iterator的作用,因为它可以直接进入list的执行,比在hook中使用get命令提供了更有效的飞跃,每次调用都会继续搜索。16.5 Capacity, Allocation&GC 实现这一点的一种方法是利用队列的特性——例如ArrayList HashMap——在配置队列时,必须为其选择一个大小。选择合适的尺寸对性能非常重要。如果太小,队列将不得不被新队列替换,这导致新队列的配置和旧垃圾的处理的更多消耗。太大的话,会浪费空间,尤其是种类很多的时候,问题就大了。一些实现方法为builder提供了通过客户端设置初始容量的能力,可以决定配置的大小。例如: Public ArrayList(int initialCapacity) 构造emptylist指定初始容量参数:initialCapacity-初始容量列表。抛出:IllegalArgumentException-如果指定初始容量为负数 还有一个适配配置项的方法:trimTosize,有适配能力容器要有足够的空间来存储元素,并确保容量,从而有能力增加其他空间。一些实现方法为builder提供了通过客户端设置初始容量的能力,可以决定配置的大小。例如: Public ArrayList(int initialCapacity) 构造emptylist指定初始容量参数:initialCapacity-初始容量列表。抛出:IllegalArgumentException-如果指定初始容量为负数 还有一个适配配置项的方法:trimTosize,有适配能力容器要有足够的空间来存储元素,并确保容量,从而有能力增加其他空间。一些实现方法为builder提供了通过客户端设置初始容量的能力,可以决定配置的大小。例如: Public ArrayList(int initialCapacity) 构造emptylist指定初始容量参数:initialCapacity-初始容量列表。抛出:IllegalArgumentException-如果指定初始容量为负数 还有一个适配配置项的方法:trimTosize,有适配能力容器要有足够的空间来存储元素,并确保容量,从而有能力增加其他空间。
使用此功能有一些技巧。如果您对申请多少空间没有准确的了解,您可以使用此功能来查找空间的大小。将这种能力的概念转化为行动是一个问题。在很多老的程序中,它们总是限制资源,如果资源耗尽,程序就无法运行。使用这种自适应方法,程序只会变慢。这是设计程序以确保程序始终有效运行的好主意,即使在特殊情况下也是如此。如果你学习在ArryList中实现remove,你会看到下面的代码: Public Object remove(int index){ elementData[-size]=null;//letgc do its work next? 不是垃圾文件的自动处理吗?以下是一些新手常犯的错误。如果你的表演有队列,1< @6.6 副本、转换、包装器等。所有特定的 采集 类都提供给构建者通过 采集 进行争论。这些允许你复制采集,或者属于另一种类型,例如LinkedList Public LinkedList(采集 list contains specified 采集,in 采集'siterator。参数:c-其元素列表的集合。它可以复制为: List p =new LinkedList() ListpCopy=new LinkedList(p) 创建一个link form other 采集 type set s=new HashSet() Listp=new Linked list(s) builder不能在接口中声明,规范的List 也不能说所有的实现都属于构建者,即使是这样,Java.util.采集s 是一个特殊的类,里面收录了静态字符串方法,有些是泛化算法,有些是包装器。转换、包装器等。所有特定的 采集 类都提供给构建器以通过 采集 进行争论。这些允许你复制采集,或者属于另一种类型,例如LinkedList Public LinkedList(采集 list contains specified 采集,in 采集'siterator。参数:c-其元素列表的集合。它可以复制为: List p =new LinkedList() ListpCopy=new LinkedList(p) 创建一个link form other 采集 type set s=new HashSet() Listp=new Linked list(s) builder不能在接口中声明,规范的List 也不能说所有的实现都属于构建者,即使是这样,Java.util.采集s 是一个特殊的类,里面收录了静态字符串方法,有些是泛化算法,有些是包装器。转换、包装器等。所有特定的 采集 类都提供给构建器以通过 采集 进行争论。这些允许你复制采集,或者属于另一种类型,例如LinkedList Public LinkedList(采集 list contains specified 采集,in 采集'siterator。参数:c-其元素列表的集合。它可以复制为: List p =new LinkedList() ListpCopy=new LinkedList(p) 创建一个link form other 采集 type set s=new HashSet() Listp=new Linked list(s) builder不能在接口中声明,规范的List 也不能说所有的实现都属于构建者,即使是这样,Java.util.采集s 是一个特殊的类,里面收录了静态字符串方法,有些是泛化算法,有些是包装器。所有特定的 采集 类都提供给构建器以通过 采集 进行争论。这些允许你复制采集,或者属于另一种类型,例如LinkedList Public LinkedList(采集 list contains specified 采集,in 采集'siterator。参数:c-其元素列表的集合。它可以复制为: List p =new LinkedList() ListpCopy=new LinkedList(p) 创建一个link form other 采集 type set s=new HashSet() Listp=new Linked list(s) builder不能在接口中声明,规范的List 也不能说所有的实现都属于构建者,即使是这样,Java.util.采集s 是一个特殊的类,里面收录了静态字符串方法,有些是泛化算法,有些是包装器。所有特定的 采集 类都提供给构建器以通过 采集 进行争论。这些允许你复制采集,或者属于另一种类型,例如LinkedList Public LinkedList(采集 list contains specified 采集,in 采集'siterator。参数:c-其元素列表的集合。它可以复制为: List p =new LinkedList() ListpCopy=new LinkedList(p) 创建一个link form other 采集 type set s=new HashSet() Listp=new Linked list(s) builder不能在接口中声明,规范的List 也不能说所有的实现都属于构建者,即使是这样,Java.util.采集s 是一个特殊的类,里面收录了静态字符串方法,有些是泛化算法,有些是包装器。为构建器提供了类以通过 采集 进行争论。这些允许你复制采集,或者属于另一种类型,例如LinkedList Public LinkedList(采集 list contains specified 采集,in 采集'siterator。参数:c-其元素列表的集合。它可以复制为: List p =new LinkedList() ListpCopy=new LinkedList(p) 创建一个link form other 采集 type set s=new HashSet() Listp=new Linked list(s) builder不能在接口中声明,规范的List 也不能说所有的实现都属于构建者,即使是这样,Java.util.采集s 是一个特殊的类,里面收录了静态字符串方法,有些是泛化算法,有些是包装器。为构建器提供了类以通过 采集 进行争论。这些允许你复制采集,或者属于另一种类型,例如LinkedList Public LinkedList(采集 list contains specified 采集,in 采集'siterator。参数:c-其元素列表的集合。它可以复制为: List p =new LinkedList() ListpCopy=new LinkedList(p) 创建一个link form other 采集 type set s=new HashSet() Listp=new Linked list(s) builder不能在接口中声明,规范的List 也不能说所有的实现都属于构建者,即使是这样,Java.util.采集s 是一个特殊的类,里面收录了静态字符串方法,有些是泛化算法,有些是包装器。List p =new LinkedList() ListpCopy=new LinkedList(p) 创建一个link form other 采集 type set s=new HashSet() Listp=new Linked list(s) builder不能在接口中声明,规范的List 就算是这样,也不能说所有的实现都属于建设者。Java.util.采集s 是一个特殊的类,它收录静态字符串方法,其中一些是通用算法,一些是包装器。List p =new LinkedList() ListpCopy=new LinkedList(p) 创建一个link form other 采集 type set s=new HashSet() Listp=new Linked list(s) builder不能在接口中声明,规范的List 就算是这样,也不能说所有的实现都属于建设者。Java.util.采集s 是一个特殊的类,它收录静态字符串方法,其中一些是通用算法,一些是包装器。
例如 unmodifiableList 使用一个列表,然后使用相同的元素返回一个列表,但它是不可变的。public static List unmodifiableList(List list) 返回unmodifiableview指定列表。该方法允许模块提供用户内部列表。查询操作返回列表”读取到指定列表,并尝试返回列表,是否直接通过其迭代器,结果返回列表指定列表序列化。参数:列表-列表返回不可修改视图。返回:不可修改视图指定列表。返回的列表不准确,无法更改。它的属性值可以因为下面的列表被修改而改变,但不能直接修改。16.7 Sorted 采集s 一种采集 分类必须有某种方法来比较元素并确定它们的顺序。
采集API 为此提供了两种方法。您可以使用自然排序,这是通过对元素使用比较方法从接口 java.lang.Comparable 确定的。public int compareTo(Object 它返回一个负整数类型,0或实整数类型作为对象。添加元素时,使用自然顺序。元素必须内置在一个类中,它是通过Comparable接口实现的。添加方法使要添加的元素通过comparable与现有元素进行比较,不匹配则移除,两者任选其一,可以使用一个元素的顺序独立给定,就像对象一样,通过java.util .Comparator接口实现,也是一个方法 public int compare(Object o1,Object o2) 上面的公式和compareTo类似,只是同时比较两个元素。这是 Strategy 风格的一个例子,通过它它是一个计算法则与使用的代码分离的。方法的选择取决于您创建对象的方式。如果您使用构造并且它使用 Comparator 作为参数,它将用于确定顺序。如果不使用构造,将使用自然顺序。比较 同样的问题(详细信息在第 9 章讨论)带来了同样的困难。如果不使用构造,将使用自然顺序。比较 同样的问题(详细信息在第 9 章讨论)带来了同样的困难。如果不使用构造,将使用自然顺序。比较 同样的问题(详细信息在第 9 章讨论)带来了同样的困难。
一种分类基于不变量。如果可以通过改变公共方法的调用来改变两个元素的顺序,那么 Rep 就会发生。16.8 Views 我们在第9章介绍了concept的概念。Concept是一个复杂的机制。直现在也很有用,但是很危险。它们打破了原创程序中关于设计精心设计的对象的许多基本概念。通过它们的用途,可以识别出三个概念: FunctionalityExtension 有些概念提供了对象函数的扩展,而无需添加新方法。可以替换 采集 类中的 next 和 hasNext 方法。但这使得类自己的 API 更加复杂。支持多个接口也非常困难。我们可以在类中添加一个reset方法,该方法用于调用restart,但同时只允许一次迭代。如果程序元素忘记重置,这种方法会导致错误。解耦的一些概念提到了该子组对底层 采集 的作用。表的键组的方法。例如,返回一个由表的键组成的组。因此,允许部分代码与key相关,该section没有key值,与其他目标规范解耦。CoordinateTransformation 的概念通过 subList 提供了一个等效的转换。概念的改变导致了底层列表的变化,但是允许通过有偏索引访问列表。这种方法会导致错误。解耦的一些概念提到了该子组对底层 采集 的作用。表的键组的方法。例如,返回一个由表的键组成的组。因此,允许部分代码与key相关,该section没有key值,与其他目标规范解耦。CoordinateTransformation 的概念通过 subList 提供了一个等效的转换。概念的改变导致了底层列表的变化,但是允许通过有偏索引访问列表。这种方法会导致错误。解耦的一些概念提到了该子组对底层 采集 的作用。表的键组的方法。例如,返回一个由表的键组成的组。因此,允许部分代码与key相关,该section没有key值,与其他目标规范解耦。CoordinateTransformation 的概念通过 subList 提供了一个等效的转换。概念的改变导致了底层列表的变化,但是允许通过有偏索引访问列表。返回一个由表的键组成的组。因此,允许部分代码与key相关,该section没有key值,与其他目标规范解耦。CoordinateTransformation 的概念通过 subList 提供了一个等效的转换。概念的改变导致了底层列表的变化,但是允许通过有偏索引访问列表。返回一个由表的键组成的组。因此,允许部分代码与key相关,该section没有key值,与其他目标规范解耦。CoordinateTransformation 的概念通过 subList 提供了一个等效的转换。概念的改变导致了底层列表的变化,但是允许通过有偏索引访问列表。
想法是危险的有两个原因。一、底部改变:调用remove改变底部采集;调用 remove 和它的 key group 来更改团队列表。这将形成一个简短的混叠,以便一个对象的变化影响另一个。这两个对象不需要具有相同的字典范围。这意味着我们必须重新定义规范中的更改:如果您更改 C 以收录概念 V,这是否意味着 V 也可以更改?其次,该方法的规范返回了一个通常仅限于更改的想法。为了确保您的代码可以运行,您需要了解此规范。毫不奇怪,这些规范通常很微妙。改变了云学习下采集的一些思路。其他的只允许改变概念——比如迭代器。有些允许概念和底层 采集 改变,但这更复杂。例如采集API,当在列中放置子列表的概念时,底层列不能有任何结构变化:以下将解释这种现象:结构修改列表,否则扰乱进度可能会产生错误的结果. 它的意思不是很准确和清楚。我不想对基础列进行任何更改。同一个底层采集的复杂概念会很复杂。例如,您可以在同一个列表中使用多个迭代器。在这种情况下,您必须考虑与想法的交互。底层列不能有任何结构变化:以下将解释这种现象:结构修改列表,否则扰乱进度可能会产生不正确的结果。它的意思不是很准确和清楚。我不想对基础列进行任何更改。同一个底层采集的复杂概念会很复杂。例如,您可以在同一个列表中使用多个迭代器。在这种情况下,您必须考虑与想法的交互。底层列不能有任何结构变化:以下将解释这种现象:结构修改列表,否则扰乱进度可能会产生不正确的结果。它的意思不是很准确和清楚。我不想对基础列进行任何更改。同一个底层采集的复杂概念会很复杂。例如,您可以在同一个列表中使用多个迭代器。在这种情况下,您必须考虑与想法的交互。您可以在同一个列表中使用多个迭代器。在这种情况下,您必须考虑与想法的交互。您可以在同一个列表中使用多个迭代器。在这种情况下,您必须考虑与想法的交互。
如果通过交互更改列表,其他界面将无效。这里有一些有用的经验。如果您使用想法,您必须仔细考虑它是否会对您有所帮助: 您可以限制可接受的想法范围。例如,使用for循环代替while循环作为接口,可以限制接口的循环范围。很容易确保接口处没有意外错误。这并不总是可能的。下周将讨论 Tagger 计划关于他的集中呼叫更改。您可以使用 采集s 类来防止顾念更改或包装底层对象。例如,如果你在表中使用keySetview,并且不打算更改它,则可以使用以下方法: Set s=map.keySey(); Set safe_s=采集s.unmodifiableSet(s);
云优采集接口(云优采集接口是基于gprs网络资源通过云端实现访问)
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2021-11-27 17:13
云优采集接口是基于gprs网络资源通过云端实现与百度网盘、百度新闻源、360网盘、维基百科、国家图书馆、中国国家数字图书馆、世界数字图书馆等,其中包括国家图书馆、国家数字图书馆以及各省市图书馆、博物馆等权威网站实现互联互通访问,只要有一台电脑,就可随时访问;云优采集接口在chinaz云爬虫工具平台上实现与各省市图书馆、博物馆、电信运营商以及有关的网站实现互联互通访问,节省了人力成本、时间成本和科技成本。
直接打电话问就行,百度官方的第三方服务官网,应该可以提供所有目标网站的访问地址,
百度网盘天翼云采集接口,全球500强网站都可以采集;云优采集接口,所有目标网站全部采集完毕,采集速度快;一键快速排查网站攻击漏洞,提高爬虫爬取网站的安全性;并且支持多目标多种网站采集,灵活多变,无限制,
我知道的有两个:天翼云,百度。
阿里云,天翼云。
可以使用云丰网采集工具,包含电商平台、博客平台、招聘网站、行业新闻站点采集、标准化程序接口、抓取html、页面打包及ftp、客户端等模块,并对接大、雅虎通、阿里地图、高德导航、陌陌、链家等开放数据源。 查看全部
云优采集接口(云优采集接口是基于gprs网络资源通过云端实现访问)
云优采集接口是基于gprs网络资源通过云端实现与百度网盘、百度新闻源、360网盘、维基百科、国家图书馆、中国国家数字图书馆、世界数字图书馆等,其中包括国家图书馆、国家数字图书馆以及各省市图书馆、博物馆等权威网站实现互联互通访问,只要有一台电脑,就可随时访问;云优采集接口在chinaz云爬虫工具平台上实现与各省市图书馆、博物馆、电信运营商以及有关的网站实现互联互通访问,节省了人力成本、时间成本和科技成本。
直接打电话问就行,百度官方的第三方服务官网,应该可以提供所有目标网站的访问地址,
百度网盘天翼云采集接口,全球500强网站都可以采集;云优采集接口,所有目标网站全部采集完毕,采集速度快;一键快速排查网站攻击漏洞,提高爬虫爬取网站的安全性;并且支持多目标多种网站采集,灵活多变,无限制,
我知道的有两个:天翼云,百度。
阿里云,天翼云。
可以使用云丰网采集工具,包含电商平台、博客平台、招聘网站、行业新闻站点采集、标准化程序接口、抓取html、页面打包及ftp、客户端等模块,并对接大、雅虎通、阿里地图、高德导航、陌陌、链家等开放数据源。
云优采集接口(优购云优人力资源平台二维码代码制作工具(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2021-11-24 10:04
云优采集接口:关注云优采集接口微信公众号获取所需的接口:云优采集云优人力资源平台二维码代码制作工具,自媒体采集群发云优接口方案:云优人力资源平台二维码接口云优人力资源平台场景定制服务云优采集量贩店云优采集采集-爬虫云优采集的二维码云优采集量贩店云优采集采集-爬虫以云优接口为例:①百度搜索云优图商城②点击云优图,上传云优地址③输入云优小店④开通云优优惠卡/在线付款其他网站采集代码购买云优素材①百度搜索云优图商城②点击云优图,上传云优地址③输入云优小店④开通云优优惠卡/在线付款注:地址、小店均为购买链接,不一定所有网站都能使用。
⑤开通云优优惠卡/在线付款完成后,在云优购物软件中点击安装即可。云优人力资源平台二维码采集云优采集量贩店云优采集购物软件v2.2.0版本④云优购物软件下载:云优购物软件下载⑤云优购物软件云优购物软件云优购物软件云优购物软件云优购物软件⑥云优购物软件云优购物软件。
云优采集接口可以免费接入,不限次数,功能对接最新互联网热门搜索渠道,
云优图,智能化采集,只要有网站,只要有手机,只要能接入接口,
我司上个月买了云优图做seo优化优化。算是知名企业了。前几个月上线了一个活动,这个活动有活动资源,同行也有注册。所以我们推广力度很大。同行是借他们资源,一分钱没有下,500块钱买了会员,从280元下一直优惠到350元。但我司因为投放效果不错,才以250一个月,次次有效率,次次的活动资源。效果,太不错了,所以云优图采集技术团队很给力,规模很大,应该快能算是bat。如果有需要的话,可以了解下。 查看全部
云优采集接口(优购云优人力资源平台二维码代码制作工具(组图))
云优采集接口:关注云优采集接口微信公众号获取所需的接口:云优采集云优人力资源平台二维码代码制作工具,自媒体采集群发云优接口方案:云优人力资源平台二维码接口云优人力资源平台场景定制服务云优采集量贩店云优采集采集-爬虫云优采集的二维码云优采集量贩店云优采集采集-爬虫以云优接口为例:①百度搜索云优图商城②点击云优图,上传云优地址③输入云优小店④开通云优优惠卡/在线付款其他网站采集代码购买云优素材①百度搜索云优图商城②点击云优图,上传云优地址③输入云优小店④开通云优优惠卡/在线付款注:地址、小店均为购买链接,不一定所有网站都能使用。
⑤开通云优优惠卡/在线付款完成后,在云优购物软件中点击安装即可。云优人力资源平台二维码采集云优采集量贩店云优采集购物软件v2.2.0版本④云优购物软件下载:云优购物软件下载⑤云优购物软件云优购物软件云优购物软件云优购物软件云优购物软件⑥云优购物软件云优购物软件。
云优采集接口可以免费接入,不限次数,功能对接最新互联网热门搜索渠道,
云优图,智能化采集,只要有网站,只要有手机,只要能接入接口,
我司上个月买了云优图做seo优化优化。算是知名企业了。前几个月上线了一个活动,这个活动有活动资源,同行也有注册。所以我们推广力度很大。同行是借他们资源,一分钱没有下,500块钱买了会员,从280元下一直优惠到350元。但我司因为投放效果不错,才以250一个月,次次有效率,次次的活动资源。效果,太不错了,所以云优图采集技术团队很给力,规模很大,应该快能算是bat。如果有需要的话,可以了解下。

