
云优采集接口
解决方法:微信小程序云开发教程-后端接口分析和接口返回值的格式定义 ... ...
采集交流 • 优采云 发表了文章 • 0 个评论 • 189 次浏览 • 2020-09-16 08:06
在最后一部分中,我们将学习如何定义后端接口。
在开发之前,我们必须分析后端必须提供哪些接口。
我们可以根据需求文档进行分析。
第一个功能是用户主动登录,因此我们的后端必须提供一个接口来实现用户西安人事考试网站的静默注册,什么是静默注册?我们将在后面的章节中详细解释。
第二个功能是显示搜索热词,因此我们的后端必须提供一个接口来获取系统中的所有热词。
第三个功能是搜索单词的同义词,因此我们的后端必须提供一个接口以返回单词的所有同义词。
第四个功能是赞美搜索效果,因此我们的后端必须提供一个接口来增加一对同义词的相干强度。
第五项功能是联系和反馈,因此我们的后端必须提供一个界面来接收和保存用户反馈。
第六个功能是向用户发送微信关注,因此我们的后端必须为前端提供一个接口,以获取订阅新闻模板的ID。
第七个功能是管理员可以查看所有反馈,因此我们的后端必须提供一个界面来显示用户提交的所有反馈。
第八项功能是管理员可以删除反馈,因此我们的后端必须提供删除特定反馈的界面。
在这一点上,我们已经阐明了后端必须提供哪些接口,但是该接口的详细定义将在以下章节中详细说明。
为了方便百度搜索引擎优化的前端调用和接口管理,必须预先定义所有接口的返回值格式。不管接口处理的效果如何,返回前端的接口必须相同。
我们规定接口的返回效果格式如下,返回的是一个具有三个字段的json对象:
第一个字段是errCode,它表示错误代码,0表示调用成功,其他数字表示失败。每个数字是什么意思?学生可以根据自己的情况定义它。
第二个字段是errMsg,它代表错误消息,用于解释错误代码。如果前端开发人员仅看到错误代码,他们将非常困惑。
第三个字段是数据,我们将所有其他数据放入其中。 查看全部
微信小程序云开发教程-后端接口分析和接口返回值格式定义...
在最后一部分中,我们将学习如何定义后端接口。

在开发之前,我们必须分析后端必须提供哪些接口。
我们可以根据需求文档进行分析。
第一个功能是用户主动登录,因此我们的后端必须提供一个接口来实现用户西安人事考试网站的静默注册,什么是静默注册?我们将在后面的章节中详细解释。
第二个功能是显示搜索热词,因此我们的后端必须提供一个接口来获取系统中的所有热词。
第三个功能是搜索单词的同义词,因此我们的后端必须提供一个接口以返回单词的所有同义词。
第四个功能是赞美搜索效果,因此我们的后端必须提供一个接口来增加一对同义词的相干强度。
第五项功能是联系和反馈,因此我们的后端必须提供一个界面来接收和保存用户反馈。
第六个功能是向用户发送微信关注,因此我们的后端必须为前端提供一个接口,以获取订阅新闻模板的ID。
第七个功能是管理员可以查看所有反馈,因此我们的后端必须提供一个界面来显示用户提交的所有反馈。
第八项功能是管理员可以删除反馈,因此我们的后端必须提供删除特定反馈的界面。
在这一点上,我们已经阐明了后端必须提供哪些接口,但是该接口的详细定义将在以下章节中详细说明。

为了方便百度搜索引擎优化的前端调用和接口管理,必须预先定义所有接口的返回值格式。不管接口处理的效果如何,返回前端的接口必须相同。
我们规定接口的返回效果格式如下,返回的是一个具有三个字段的json对象:
第一个字段是errCode,它表示错误代码,0表示调用成功,其他数字表示失败。每个数字是什么意思?学生可以根据自己的情况定义它。
第二个字段是errMsg,它代表错误消息,用于解释错误代码。如果前端开发人员仅看到错误代码,他们将非常困惑。
第三个字段是数据,我们将所有其他数据放入其中。
解决方案:优化|优采云采集器远程管理=私有云?
采集交流 • 优采云 发表了文章 • 0 个评论 • 393 次浏览 • 2020-09-03 08:25
您可能已经听说过公共云的概念. 公共云通常是指由第三方提供商提供的供用户使用的云. 公共云通常可以通过Internet获得,并且可以是免费的或低成本的. 公共云核心属性是共享资源服务. 这种云的实例很多,如今可以在整个开放的公共网络中提供服务.
由于存在公共云,因此自然会有私有云. 公共云的核心概念是共享资源服务,那么私有云的核心意义是什么?
一位著名的技术专家曾说过这样一句话: “每个人都有自己对云计算的定义. ”但是每个人都对云计算的许多方面达成了一定共识,例如三层架构. 除了三层架构,每个人都认为云可以分为三种类型: 公共云,私有云和混合云.
这实际上说明了私有云的重要性. 私有云(Private Clouds)是供单个客户使用而构建的,因此可以对数据,安全性和服务质量提供最有效的控制. 该公司拥有基础架构,并且可以控制如何在此基础架构上部署应用程序. 私有云可以部署在企业数据中心的防火墙中,也可以部署在安全的托管位置. 私有云的核心属性是专有资源. 话虽如此,您一定很好奇,为什么小蔡会谈论私有云的概念?
当然是有原因的. 请允许小才郑重介绍优采云 采集器的远程管理模块(类似于私有云概念的重要功能优化).
优采云 采集器企业版软件是专门为多人协作提供的版本,因此它具有易于管理的多种功能,而远程管理功能是其中的重要功能之一.
远程管理功能易于使用,但是开始时的接口界面相对简单. 因此,此V9版本已进行了重大修订. 界面,性能和功能已经过优化和更改. 下面详细介绍功能介绍和使用方法.
一个. 功能介绍
远程管理功能允许用户在本地启动服务界面,从而可以实现优采云 采集器软件的远程管理,例如创建,修改,运行和停止任务. 用户可以为其他人创建不同的帐户权限,以供其他人访问或控制.
两个. 用法介绍
1. 启动服务器管理
2. 开始任务后
(1)可以建立用户,用户可以授权两种类型: 管理员和只读用户. 管理员,用户选择哪些任务具有管理功能,包括新建,删除,修改,查看任务状态,查看任务数据等. 只读用户只能查看任务状态和采集的数据内容.
(2)您也可以选择右侧的“匿名访问”选项. 我们选择“ False”,这意味着不允许使用没有用户名和密码的访问. 您可以将此选项设置为“ True”,而无需通过用户. 一旦访问了名称和密码,就可以随意访问该界面.
3. 访问界面
接下来,您可以使用相应的用户名和密码访问内置界面,界面如下:
4. 手动刷新
我们可以在浏览器中修改任务,查看任务采集数据,运行和设置计划任务,但是请注意,页面数据不会自动刷新. 我们必须单击左上角的刷新按钮才能进行操作. 查看全部
优化| 优采云 采集器远程管理=私有云?
您可能已经听说过公共云的概念. 公共云通常是指由第三方提供商提供的供用户使用的云. 公共云通常可以通过Internet获得,并且可以是免费的或低成本的. 公共云核心属性是共享资源服务. 这种云的实例很多,如今可以在整个开放的公共网络中提供服务.
由于存在公共云,因此自然会有私有云. 公共云的核心概念是共享资源服务,那么私有云的核心意义是什么?
一位著名的技术专家曾说过这样一句话: “每个人都有自己对云计算的定义. ”但是每个人都对云计算的许多方面达成了一定共识,例如三层架构. 除了三层架构,每个人都认为云可以分为三种类型: 公共云,私有云和混合云.
这实际上说明了私有云的重要性. 私有云(Private Clouds)是供单个客户使用而构建的,因此可以对数据,安全性和服务质量提供最有效的控制. 该公司拥有基础架构,并且可以控制如何在此基础架构上部署应用程序. 私有云可以部署在企业数据中心的防火墙中,也可以部署在安全的托管位置. 私有云的核心属性是专有资源. 话虽如此,您一定很好奇,为什么小蔡会谈论私有云的概念?
当然是有原因的. 请允许小才郑重介绍优采云 采集器的远程管理模块(类似于私有云概念的重要功能优化).
优采云 采集器企业版软件是专门为多人协作提供的版本,因此它具有易于管理的多种功能,而远程管理功能是其中的重要功能之一.
远程管理功能易于使用,但是开始时的接口界面相对简单. 因此,此V9版本已进行了重大修订. 界面,性能和功能已经过优化和更改. 下面详细介绍功能介绍和使用方法.
一个. 功能介绍
远程管理功能允许用户在本地启动服务界面,从而可以实现优采云 采集器软件的远程管理,例如创建,修改,运行和停止任务. 用户可以为其他人创建不同的帐户权限,以供其他人访问或控制.
两个. 用法介绍
1. 启动服务器管理
2. 开始任务后
(1)可以建立用户,用户可以授权两种类型: 管理员和只读用户. 管理员,用户选择哪些任务具有管理功能,包括新建,删除,修改,查看任务状态,查看任务数据等. 只读用户只能查看任务状态和采集的数据内容.
(2)您也可以选择右侧的“匿名访问”选项. 我们选择“ False”,这意味着不允许使用没有用户名和密码的访问. 您可以将此选项设置为“ True”,而无需通过用户. 一旦访问了名称和密码,就可以随意访问该界面.
3. 访问界面
接下来,您可以使用相应的用户名和密码访问内置界面,界面如下:
4. 手动刷新
我们可以在浏览器中修改任务,查看任务采集数据,运行和设置计划任务,但是请注意,页面数据不会自动刷新. 我们必须单击左上角的刷新按钮才能进行操作.
完整的解决方案:使用SpreadJS开发在线问卷系统,构筑CCP(云数据采集)平台
采集交流 • 优采云 发表了文章 • 0 个评论 • 369 次浏览 • 2020-08-31 06:00
什么是CCP(云数据采集)平台?
图片来自互联网
CCP(云数据采集)平台诞生于大数据时代的背景下. 通过实时数据挖掘,发现了隐藏在海量云数据中的价值.
在线问卷系统作为CCP(云数据采集)平台的信息采集界面,可以帮助问卷设计者和数据分析人员通过采集网络信息来分析消费者在线的行为特征和态度. 准确地提取目标网页中的任何数据和信息,并快速实现实时信息获取.
是否可以更简洁,方便,准确地执行CCP(云数据采集)平台的数据采集取决于在线问卷系统的基本功能和体系结构.
因此,在线问卷系统通常需要包括以下四个功能模块: 在线问卷设计,数据采集,数据分析和导出.
在线问卷系统的基本功能模块
在线问卷设计要求:
问卷设计方法简便易行. 您可以自由修改调查表的外观,还可以创建带有公司徽标的调查表模板. 项目类型丰富,具有内置的多项选择题,填空题,评分,排序,个人信息采集和其他应用场景. 问卷,民意测验,满意度,表格,评估等的设计模板.
数据采集要求:
独特的自定义数据采集通道支持在手机上填写,可以无缝嵌入网站,APP和小程序中,可以通过第三方社交平台填写
需要数据分析:
调查数据可以实时查看. 支持多种数据显示,例如表格和图表. 提供数据过滤,交叉分析和原创数据下载,以提高数据源的可追溯性,趋势一目了然
需要导出:
支持导出为xlsx,CSV和其他格式,提供更安全的数据存储,出版物数量不受限制,并支持实现多个并发在线问卷系统
由于必须分析采集到的问卷数据并导出分析结果,因此系统需要支持图表,计算公式以及在线导入和导出功能.
经过全面评估,发现使用SpreadJS控件可以满足上述要求,原因如下:
可以生成交叉图: SpreadJS提供了双向数据绑定功能,可以将采集的数据绑定到表上,从而方便数据分析和显示.
图1生成交叉图分析页面
Excel文件的在线导入和导出: SpreadJS不需要任何后端代码和第三方组件,并且可以直接在浏览器中导入和导出Excel文件,PDF导出,打印和预览操作,并解决问题在前端导出Excel和CSV文件的过程. 用户可以方便地将问卷的统计分析结果导出到本地. 导出文件的比较效果如下图所示:
图2导出的Excel文件的比较
数据可视化: SpreadJS在Excel中支持450个公式和32个图表,可以帮助用户更全面地分析采集到的数据.
图3 SpreadJS内置的多个图表
数据过滤: 通过SpreadJS在后台显示从后台返回的数据,并提供数据过滤,排序,分组,注释和切片器等操作,以方便用户进一步分析统计结果.
图4数据过滤
通过将SpreadJS组件功能嵌入在线调查表系统中,我们可以专注于业务逻辑,而不是专注于如何实现基本功能模块. 在SpreadJS的帮助下,对问卷系统进行了组件化的重构,不仅降低了以后的测试成本,大大缩短了项目交付周期,而且为项目的第二阶段奠定了良好的基础.
如果您还需要进行此类系统开发,请访问SpreadJS产品的官方网站,以查看应用场景和各种技术资源,这些信息可以帮助您进行系统构建. 查看全部
使用SpreadJS开发在线问卷系统并建立CCP(云数据采集)平台
什么是CCP(云数据采集)平台?
图片来自互联网
CCP(云数据采集)平台诞生于大数据时代的背景下. 通过实时数据挖掘,发现了隐藏在海量云数据中的价值.
在线问卷系统作为CCP(云数据采集)平台的信息采集界面,可以帮助问卷设计者和数据分析人员通过采集网络信息来分析消费者在线的行为特征和态度. 准确地提取目标网页中的任何数据和信息,并快速实现实时信息获取.
是否可以更简洁,方便,准确地执行CCP(云数据采集)平台的数据采集取决于在线问卷系统的基本功能和体系结构.
因此,在线问卷系统通常需要包括以下四个功能模块: 在线问卷设计,数据采集,数据分析和导出.
在线问卷系统的基本功能模块
在线问卷设计要求:
问卷设计方法简便易行. 您可以自由修改调查表的外观,还可以创建带有公司徽标的调查表模板. 项目类型丰富,具有内置的多项选择题,填空题,评分,排序,个人信息采集和其他应用场景. 问卷,民意测验,满意度,表格,评估等的设计模板.
数据采集要求:
独特的自定义数据采集通道支持在手机上填写,可以无缝嵌入网站,APP和小程序中,可以通过第三方社交平台填写
需要数据分析:
调查数据可以实时查看. 支持多种数据显示,例如表格和图表. 提供数据过滤,交叉分析和原创数据下载,以提高数据源的可追溯性,趋势一目了然
需要导出:
支持导出为xlsx,CSV和其他格式,提供更安全的数据存储,出版物数量不受限制,并支持实现多个并发在线问卷系统
由于必须分析采集到的问卷数据并导出分析结果,因此系统需要支持图表,计算公式以及在线导入和导出功能.
经过全面评估,发现使用SpreadJS控件可以满足上述要求,原因如下:
可以生成交叉图: SpreadJS提供了双向数据绑定功能,可以将采集的数据绑定到表上,从而方便数据分析和显示.
图1生成交叉图分析页面
Excel文件的在线导入和导出: SpreadJS不需要任何后端代码和第三方组件,并且可以直接在浏览器中导入和导出Excel文件,PDF导出,打印和预览操作,并解决问题在前端导出Excel和CSV文件的过程. 用户可以方便地将问卷的统计分析结果导出到本地. 导出文件的比较效果如下图所示:
图2导出的Excel文件的比较
数据可视化: SpreadJS在Excel中支持450个公式和32个图表,可以帮助用户更全面地分析采集到的数据.
图3 SpreadJS内置的多个图表
数据过滤: 通过SpreadJS在后台显示从后台返回的数据,并提供数据过滤,排序,分组,注释和切片器等操作,以方便用户进一步分析统计结果.
图4数据过滤
通过将SpreadJS组件功能嵌入在线调查表系统中,我们可以专注于业务逻辑,而不是专注于如何实现基本功能模块. 在SpreadJS的帮助下,对问卷系统进行了组件化的重构,不仅降低了以后的测试成本,大大缩短了项目交付周期,而且为项目的第二阶段奠定了良好的基础.
如果您还需要进行此类系统开发,请访问SpreadJS产品的官方网站,以查看应用场景和各种技术资源,这些信息可以帮助您进行系统构建.
最佳实践:【解构云原生】基于Filebeat的日志采集服务设计与实践
采集交流 • 优采云 发表了文章 • 0 个评论 • 943 次浏览 • 2020-08-30 15:44
本文由作者授权发布,未经许可,请勿转载。
作者:傅轶,网易杭州研究院云计算技术部中级研制工程师
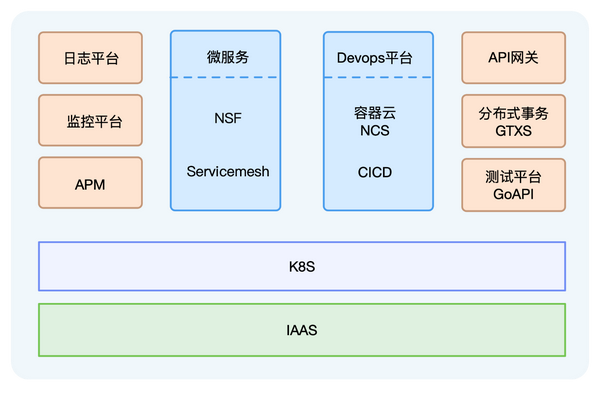
一、背景云原生技术大潮早已将至,技术变迁迫在眉睫。
在这股技术时尚之中,网易推出了轻舟微服务平台,集成了微服务、Service Mesh、容器云、DevOps等组件,已经广泛应用于公司内部,同时也支撑了好多外部顾客的云原生化整修和迁移。
在这其中,日志是平常很容易被人忽略的一部分,却是微服务、DevOps的重要一环。没有日志,服务问题排查无从谈起,同时日志的统一采集也是好多业务数据剖析、处理、审计的基础。
但是在云原生容器化环境下,日志的采集又显得有点不同。
二、容器日志采集的疼点传统主机模式对于传统的物理机或则虚拟机布署的服务,日志采集工作清晰明了。
业务日志直接输出到宿主机上,服务运行在固定的节点上,手动或则拿自动化工具把日志采集agent布署在节点上,加一下agent的配置,就可以开始采集日志了。同时为了便捷后续的日志配置更改,还可以引入一个配置中心,用来下发agent配置。
Kubernetes环境而在Kubernetes环境中,情况就没那么简单了。
一个Kubernetes node节点上有好多不同服务的容器在运行,容器的日志储存方法有好多不同的类型,例如stdout、hostPath、emptyDir、pv等。由于在Kubernetes集群中常常存在Pod主动或则被动的迁移,频繁的销毁、创建,我们没法象传统的方法一样人为给每位服务下发日志采集配置。另外,由于日志数据采集后会被集中储存,所以查询日志时,可以按照Namespace、Pod、Container、Node,甚至包括容器的环境变量、Label等维度来检索、过滤很重要。
以上都是有别于传统日志采集配置方法的需求和疼点,究其原因,还是由于传统的方法并非针对Kubernetes设计,无法感知Kubernetes,更难以和Kubernetes集成。
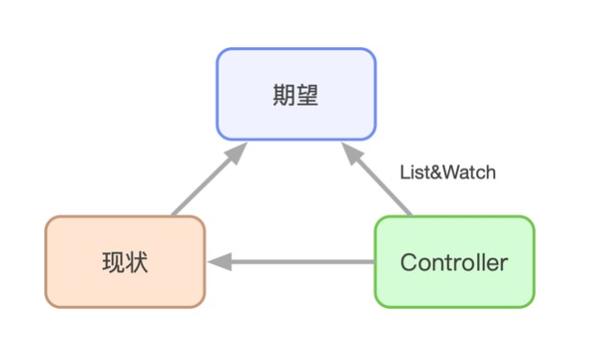
经过近来几年的迅速发展,Kubernetes早已不仅仅是容器编排的事实标准,甚至可以被觉得是新一代的分布式操作系统。在这个新型的操作系统中,controller的设计思路驱动了整个系统的运行。controller的具象解释如下图所示:
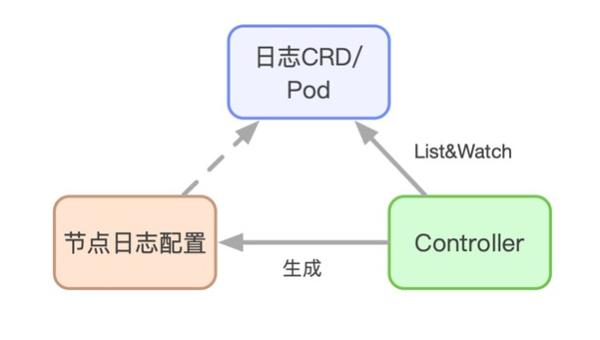
由于Kubernetes良好的可扩展性,Kubernetes设计了一种自定义资源CRD的概念,用户可以自己定义各类资源,并利用一些framework开发controller,使用controller将我们的期望弄成现实。
基于这个思路,对于日志采集来说,一个服务须要采集哪些日志,需要什么样的日志配置,是用户的期望,而这一切,就须要我们开发一个日志采集的controller去实现。
三、探索与构架设计有了前面的解决思路,除了开发一个controller,剩下的就是围绕着这个思路的一些选型剖析。
日志采集agent选型日志采集controller只负责对接Kubernetes,生成采集配置,并不负责真正的日志采集。目前市面上的日志采集agent有很多,例如传统ELK技术栈的Logstash,CNCF已结业项目Fluentd,最近推出不久的Loki,还有beats系列的Filebeat。 下面简单剖析一下。
1.Logstash基于JVM,分分钟显存占用达到几百MB甚至上GB,有点重,首先被我们排除。
2.Fluentd背靠CNCF看着不错,各种插件也多,不过基于Ruby和C编撰,对于轻舟团队的技术栈来说,还是使人止于观望。虽然Fluentd还推出了纯粹基于C语言的Fluentd-bit项目,内存占用太小,看着非常诱惑,但是使用C语言和不能动态reload配置,还是难以令人亲近。
3.Loki推出的时间不久,目前功能有限,而且一些压测数据表明性能不太好,暂时观望。
4.Filebeat和Logstash、Kibana、Elasticsearch同属Elastic公司,轻量级日志采集agent,推出就是为了替换Logstash,基于Golang编撰,和轻舟团队技术栈完美契合,实测出来性能、资源占用率各方面都比较优秀,于是成为了轻舟日志采集agent第一选择。
agent集成方法对于日志采集agent,在Kubernetes环境下通常有两种布署形式。
1.一种为sidecar的形式,即和业务Container布署在同一个Pod里,这种方法下,Filebeat只采集该业务Container的日志,也只需配置该Container的日志配置,简单、隔离性好,但最大的问题是, 每个服务都要有一个Filebeat去采集,而一个节点上一般有很多的Pod,内存等开支加上去不容豁达。
2.另外一种也是最常见的每位Node上布署一个Filebeat容器,相比而言,内存占用要小好多,而且对Pod无侵入性,比较符合我们的常规使用方法。同时通常使用Kubernetes的DaemonSet布署,无需传统的类似Ansible等自动化运维工具,部署运维效率大大提高。所以我们优先使用Daemonset布署Filebeat的形式。
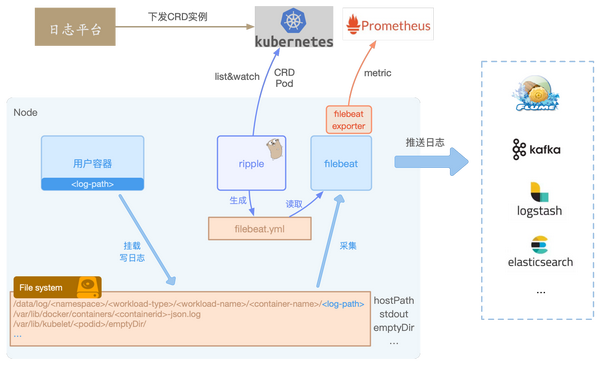
整体构架选择Filebeat作为日志采集agent,集成了自研的日志controller后,从节点的视角,我们看见的构架如下所示:
1.日志平台下发具体的CRD实例到Kubernetes集群中,日志controller Ripple则负责从Kubernetes中List&Watch Pod和CRD实例。
2.通过Ripple的过滤、聚合最终生成一个Filebeat的input配置文件,配置文件里描述了服务的采集Path路径、多行日志匹配等配置,同时就会默认把诸如PodName、Hostname等配置到日志元信息中。
3.Filebeat则按照Ripple生成的配置,自动reload并采集节点上的日志,发送至Kafka或则Elasticsearch等。
由于Ripple窃听了Kubernetes风波,可以感知到Pod的生命周期,不管Pod销毁还是调度到任意的节点,依然才能手动生成相应的Filebeat配置,无需人工干预。
Ripple能感知到Pod挂载的日志Volume,不管是docker Stdout的日志,还是使用HostPath、EmptyDir、Pv储存日志,均可以生成节点上的日志路径,告知Filebeat去采集。
Ripple可以同时获取CRD和Pod的信息,所以不仅默认给日志配置加上PodName等元信息外,还可以结合容器环境变量、Pod label、Pod Annotation等给日志打标,方便后续日志的过滤、检索查询。
除此之外,我们还给Ripple加入了日志定时清除,确保日志不遗失等功能,进一步提高了日志采集的功能和稳定性。
四、基于Filebeat的实践功能扩充通常情况下Filebeat可满足大部分的日志采集需求,但是依然防止不了一些特殊的场景须要我们对Filebeat进行多样化开发,当然Filebeat本身的设计也提供了良好的扩展性。
Filebeat目前只提供了象Elasticsearch、Kafka、Logstash等几类output客户端,如果我们想要Filebeat直接发送至其他前端,需要多样化开发自己的output。同样,如果须要对日志做过滤处理或则降低元信息,也可以自制processor插件。
无论是降低output还是写processor,Filebeat提供的大体思路基本相同。一般来讲有3种形式:
1.直接fork Filebeat,在现有的源码上开发。output或则processor都提供了类似Run、Stop等的插口,只须要实现该类插口,然后在init方式中注册相应的插件初始化方式即可。当然,由于Golang中init方式是在import包时才被调用,所以须要在初始化Filebeat的代码中自动import。
2.复制一份Filebeat的main.go,import我们自研的插件库,然后重新编译。本质上和形式1区别不大。
3.Filebeat还提供了基于Golang plugin的插件机制,需要把自研的插件编译成.so共享链接库,然后在Filebeat启动参数中通过-plugin指定库所在路径。不过实际上一方面Golang plugin还不够成熟稳定,另一方面自研的插件仍然须要依赖相同版本的libbeat库,而且还须要相同的Golang版本编译,坑可能更多,不太推荐。 查看全部
【解构云原生】基于Filebeat的日志采集服务设计与实践
本文由作者授权发布,未经许可,请勿转载。
作者:傅轶,网易杭州研究院云计算技术部中级研制工程师
一、背景云原生技术大潮早已将至,技术变迁迫在眉睫。
在这股技术时尚之中,网易推出了轻舟微服务平台,集成了微服务、Service Mesh、容器云、DevOps等组件,已经广泛应用于公司内部,同时也支撑了好多外部顾客的云原生化整修和迁移。

在这其中,日志是平常很容易被人忽略的一部分,却是微服务、DevOps的重要一环。没有日志,服务问题排查无从谈起,同时日志的统一采集也是好多业务数据剖析、处理、审计的基础。
但是在云原生容器化环境下,日志的采集又显得有点不同。
二、容器日志采集的疼点传统主机模式对于传统的物理机或则虚拟机布署的服务,日志采集工作清晰明了。
业务日志直接输出到宿主机上,服务运行在固定的节点上,手动或则拿自动化工具把日志采集agent布署在节点上,加一下agent的配置,就可以开始采集日志了。同时为了便捷后续的日志配置更改,还可以引入一个配置中心,用来下发agent配置。
Kubernetes环境而在Kubernetes环境中,情况就没那么简单了。
一个Kubernetes node节点上有好多不同服务的容器在运行,容器的日志储存方法有好多不同的类型,例如stdout、hostPath、emptyDir、pv等。由于在Kubernetes集群中常常存在Pod主动或则被动的迁移,频繁的销毁、创建,我们没法象传统的方法一样人为给每位服务下发日志采集配置。另外,由于日志数据采集后会被集中储存,所以查询日志时,可以按照Namespace、Pod、Container、Node,甚至包括容器的环境变量、Label等维度来检索、过滤很重要。
以上都是有别于传统日志采集配置方法的需求和疼点,究其原因,还是由于传统的方法并非针对Kubernetes设计,无法感知Kubernetes,更难以和Kubernetes集成。
经过近来几年的迅速发展,Kubernetes早已不仅仅是容器编排的事实标准,甚至可以被觉得是新一代的分布式操作系统。在这个新型的操作系统中,controller的设计思路驱动了整个系统的运行。controller的具象解释如下图所示:

由于Kubernetes良好的可扩展性,Kubernetes设计了一种自定义资源CRD的概念,用户可以自己定义各类资源,并利用一些framework开发controller,使用controller将我们的期望弄成现实。
基于这个思路,对于日志采集来说,一个服务须要采集哪些日志,需要什么样的日志配置,是用户的期望,而这一切,就须要我们开发一个日志采集的controller去实现。

三、探索与构架设计有了前面的解决思路,除了开发一个controller,剩下的就是围绕着这个思路的一些选型剖析。
日志采集agent选型日志采集controller只负责对接Kubernetes,生成采集配置,并不负责真正的日志采集。目前市面上的日志采集agent有很多,例如传统ELK技术栈的Logstash,CNCF已结业项目Fluentd,最近推出不久的Loki,还有beats系列的Filebeat。 下面简单剖析一下。
1.Logstash基于JVM,分分钟显存占用达到几百MB甚至上GB,有点重,首先被我们排除。
2.Fluentd背靠CNCF看着不错,各种插件也多,不过基于Ruby和C编撰,对于轻舟团队的技术栈来说,还是使人止于观望。虽然Fluentd还推出了纯粹基于C语言的Fluentd-bit项目,内存占用太小,看着非常诱惑,但是使用C语言和不能动态reload配置,还是难以令人亲近。
3.Loki推出的时间不久,目前功能有限,而且一些压测数据表明性能不太好,暂时观望。
4.Filebeat和Logstash、Kibana、Elasticsearch同属Elastic公司,轻量级日志采集agent,推出就是为了替换Logstash,基于Golang编撰,和轻舟团队技术栈完美契合,实测出来性能、资源占用率各方面都比较优秀,于是成为了轻舟日志采集agent第一选择。
agent集成方法对于日志采集agent,在Kubernetes环境下通常有两种布署形式。
1.一种为sidecar的形式,即和业务Container布署在同一个Pod里,这种方法下,Filebeat只采集该业务Container的日志,也只需配置该Container的日志配置,简单、隔离性好,但最大的问题是, 每个服务都要有一个Filebeat去采集,而一个节点上一般有很多的Pod,内存等开支加上去不容豁达。
2.另外一种也是最常见的每位Node上布署一个Filebeat容器,相比而言,内存占用要小好多,而且对Pod无侵入性,比较符合我们的常规使用方法。同时通常使用Kubernetes的DaemonSet布署,无需传统的类似Ansible等自动化运维工具,部署运维效率大大提高。所以我们优先使用Daemonset布署Filebeat的形式。
整体构架选择Filebeat作为日志采集agent,集成了自研的日志controller后,从节点的视角,我们看见的构架如下所示:

1.日志平台下发具体的CRD实例到Kubernetes集群中,日志controller Ripple则负责从Kubernetes中List&Watch Pod和CRD实例。
2.通过Ripple的过滤、聚合最终生成一个Filebeat的input配置文件,配置文件里描述了服务的采集Path路径、多行日志匹配等配置,同时就会默认把诸如PodName、Hostname等配置到日志元信息中。
3.Filebeat则按照Ripple生成的配置,自动reload并采集节点上的日志,发送至Kafka或则Elasticsearch等。
由于Ripple窃听了Kubernetes风波,可以感知到Pod的生命周期,不管Pod销毁还是调度到任意的节点,依然才能手动生成相应的Filebeat配置,无需人工干预。
Ripple能感知到Pod挂载的日志Volume,不管是docker Stdout的日志,还是使用HostPath、EmptyDir、Pv储存日志,均可以生成节点上的日志路径,告知Filebeat去采集。
Ripple可以同时获取CRD和Pod的信息,所以不仅默认给日志配置加上PodName等元信息外,还可以结合容器环境变量、Pod label、Pod Annotation等给日志打标,方便后续日志的过滤、检索查询。
除此之外,我们还给Ripple加入了日志定时清除,确保日志不遗失等功能,进一步提高了日志采集的功能和稳定性。
四、基于Filebeat的实践功能扩充通常情况下Filebeat可满足大部分的日志采集需求,但是依然防止不了一些特殊的场景须要我们对Filebeat进行多样化开发,当然Filebeat本身的设计也提供了良好的扩展性。
Filebeat目前只提供了象Elasticsearch、Kafka、Logstash等几类output客户端,如果我们想要Filebeat直接发送至其他前端,需要多样化开发自己的output。同样,如果须要对日志做过滤处理或则降低元信息,也可以自制processor插件。
无论是降低output还是写processor,Filebeat提供的大体思路基本相同。一般来讲有3种形式:
1.直接fork Filebeat,在现有的源码上开发。output或则processor都提供了类似Run、Stop等的插口,只须要实现该类插口,然后在init方式中注册相应的插件初始化方式即可。当然,由于Golang中init方式是在import包时才被调用,所以须要在初始化Filebeat的代码中自动import。
2.复制一份Filebeat的main.go,import我们自研的插件库,然后重新编译。本质上和形式1区别不大。
3.Filebeat还提供了基于Golang plugin的插件机制,需要把自研的插件编译成.so共享链接库,然后在Filebeat启动参数中通过-plugin指定库所在路径。不过实际上一方面Golang plugin还不够成熟稳定,另一方面自研的插件仍然须要依赖相同版本的libbeat库,而且还须要相同的Golang版本编译,坑可能更多,不太推荐。
解读:【解构云原生】基于Filebeat的日志采集服务设计与实践
采集交流 • 优采云 发表了文章 • 0 个评论 • 362 次浏览 • 2020-08-30 01:03
本文由作者授权发布,未经许可,请勿转载。
作者:傅轶,网易杭州研究院云计算技术部中级研制工程师
一、背景
云原生技术大潮早已将至,技术变迁迫在眉睫。
在这股技术时尚之中,网易推出了轻舟微服务平台,集成了微服务、Service Mesh、容器云、DevOps等组件,已经广泛应用于公司内部,同时也支撑了好多外部顾客的云原生化整修和迁移。
在这其中,日志是平常很容易被人忽略的一部分,却是微服务、DevOps的重要一环。没有日志,服务问题排查无从谈起,同时日志的统一采集也是好多业务数据剖析、处理、审计的基础。
但是在云原生容器化环境下,日志的采集又显得有点不同。
二、容器日志采集的疼点传统主机模式
对于传统的物理机或则虚拟机布署的服务,日志采集工作清晰明了。
业务日志直接输出到宿主机上,服务运行在固定的节点上,手动或则拿自动化工具把日志采集agent布署在节点上,加一下agent的配置,就可以开始采集日志了。同时为了便捷后续的日志配置更改,还可以引入一个配置中心,用来下发agent配置。
Kubernetes环境
而在Kubernetes环境中,情况就没那么简单了。
一个Kubernetes node节点上有好多不同服务的容器在运行,容器的日志储存方法有好多不同的类型,例如stdout、hostPath、emptyDir、pv等。由于在Kubernetes集群中常常存在Pod主动或则被动的迁移,频繁的销毁、创建,我们没法象传统的方法一样人为给每位服务下发日志采集配置。另外,由于日志数据采集后会被集中储存,所以查询日志时,可以按照Namespace、Pod、Container、Node,甚至包括容器的环境变量、Label等维度来检索、过滤很重要。
以上都是有别于传统日志采集配置方法的需求和疼点,究其原因,还是由于传统的方法并非针对Kubernetes设计,无法感知Kubernetes,更难以和Kubernetes集成。
经过近来几年的迅速发展,Kubernetes早已不仅仅是容器编排的事实标准,甚至可以被觉得是新一代的分布式操作系统。在这个新型的操作系统中,controller的设计思路驱动了整个系统的运行。controller的具象解释如下图所示:
由于Kubernetes良好的可扩展性,Kubernetes设计了一种自定义资源CRD的概念,用户可以自己定义各类资源,并利用一些framework开发controller,使用controller将我们的期望弄成现实。
基于这个思路,对于日志采集来说,一个服务须要采集哪些日志,需要什么样的日志配置,是用户的期望,而这一切,就须要我们开发一个日志采集的controller去实现。
三、探索与构架设计
有了前面的解决思路,除了开发一个controller,剩下的就是围绕着这个思路的一些选型剖析。
日志采集agent选型
日志采集controller只负责对接Kubernetes,生成采集配置,并不负责真正的日志采集。目前市面上的日志采集agent有很多,例如传统ELK技术栈的Logstash,CNCF已结业项目Fluentd,最近推出不久的Loki,还有beats系列的Filebeat。 下面简单剖析一下。
agent集成方法
对于日志采集agent,在Kubernetes环境下通常有两种布署形式。
一种为sidecar的形式,即和业务Container布署在同一个Pod里,这种方法下,Filebeat只采集该业务Container的日志,也只需配置该Container的日志配置,简单、隔离性好,但最大的问题是, 每个服务都要有一个Filebeat去采集,而一个节点上一般有很多的Pod,内存等开支加上去不容豁达。另外一种也是最常见的每位Node上布署一个Filebeat容器,相比而言,内存占用要小好多,而且对Pod无侵入性,比较符合我们的常规使用方法。同时通常使用Kubernetes的DaemonSet布署,无需传统的类似Ansible等自动化运维工具,部署运维效率大大提高。所以我们优先使用Daemonset布署Filebeat的形式。整体构架
选择Filebeat作为日志采集agent,集成了自研的日志controller后,从节点的视角,我们看见的构架如下所示:
日志平台下发具体的CRD实例到Kubernetes集群中,日志controller Ripple则负责从Kubernetes中List&Watch Pod和CRD实例。通过Ripple的过滤、聚合最终生成一个Filebeat的input配置文件,配置文件里描述了服务的采集Path路径、多行日志匹配等配置,同时就会默认把诸如PodName、Hostname等配置到日志元信息中。Filebeat则按照Ripple生成的配置,自动reload并采集节点上的日志,发送至Kafka或则Elasticsearch等。
由于Ripple窃听了Kubernetes风波,可以感知到Pod的生命周期,不管Pod销毁还是调度到任意的节点,依然才能手动生成相应的Filebeat配置,无需人工干预。
Ripple能感知到Pod挂载的日志Volume,不管是docker Stdout的日志,还是使用HostPath、EmptyDir、Pv储存日志,均可以生成节点上的日志路径,告知Filebeat去采集。
Ripple可以同时获取CRD和Pod的信息,所以不仅默认给日志配置加上PodName等元信息外,还可以结合容器环境变量、Pod label、Pod Annotation等给日志打标,方便后续日志的过滤、检索查询。
除此之外,我们还给Ripple加入了日志定时清除,确保日志不遗失等功能,进一步提高了日志采集的功能和稳定性。
四、基于Filebeat的实践功能扩充
一般情况下Filebeat可满足大部分的日志采集需求,但是依然防止不了一些特殊的场景须要我们对Filebeat进行多样化开发,当然Filebeat本身的设计也提供了良好的扩展性。
Filebeat目前只提供了象Elasticsearch、Kafka、Logstash等几类output客户端,如果我们想要Filebeat直接发送至其他前端,需要多样化开发自己的output。同样,如果须要对日志做过滤处理或则降低元信息,也可以自制processor插件。
无论是降低output还是写processor,Filebeat提供的大体思路基本相同。一般来讲有3种形式:
直接fork Filebeat,在现有的源码上开发。output或则processor都提供了类似Run、Stop等的插口,只须要实现该类插口,然后在init方式中注册相应的插件初始化方式即可。当然,由于Golang中init方式是在import包时才被调用,所以须要在初始化Filebeat的代码中自动import。复制一份Filebeat的main.go,import我们自研的插件库,然后重新编译。本质上和形式1区别不大。Filebeat还提供了基于Golang plugin的插件机制,需要把自研的插件编译成.so共享链接库,然后在Filebeat启动参数中通过-plugin指定库所在路径。不过实际上一方面Golang plugin还不够成熟稳定,另一方面自研的插件仍然须要依赖相同版本的libbeat库,而且还须要相同的Golang版本编译,坑可能更多,不太推荐。 查看全部
【解构云原生】基于Filebeat的日志采集服务设计与实践
本文由作者授权发布,未经许可,请勿转载。
作者:傅轶,网易杭州研究院云计算技术部中级研制工程师
一、背景
云原生技术大潮早已将至,技术变迁迫在眉睫。
在这股技术时尚之中,网易推出了轻舟微服务平台,集成了微服务、Service Mesh、容器云、DevOps等组件,已经广泛应用于公司内部,同时也支撑了好多外部顾客的云原生化整修和迁移。
在这其中,日志是平常很容易被人忽略的一部分,却是微服务、DevOps的重要一环。没有日志,服务问题排查无从谈起,同时日志的统一采集也是好多业务数据剖析、处理、审计的基础。
但是在云原生容器化环境下,日志的采集又显得有点不同。
二、容器日志采集的疼点传统主机模式
对于传统的物理机或则虚拟机布署的服务,日志采集工作清晰明了。
业务日志直接输出到宿主机上,服务运行在固定的节点上,手动或则拿自动化工具把日志采集agent布署在节点上,加一下agent的配置,就可以开始采集日志了。同时为了便捷后续的日志配置更改,还可以引入一个配置中心,用来下发agent配置。
Kubernetes环境
而在Kubernetes环境中,情况就没那么简单了。
一个Kubernetes node节点上有好多不同服务的容器在运行,容器的日志储存方法有好多不同的类型,例如stdout、hostPath、emptyDir、pv等。由于在Kubernetes集群中常常存在Pod主动或则被动的迁移,频繁的销毁、创建,我们没法象传统的方法一样人为给每位服务下发日志采集配置。另外,由于日志数据采集后会被集中储存,所以查询日志时,可以按照Namespace、Pod、Container、Node,甚至包括容器的环境变量、Label等维度来检索、过滤很重要。
以上都是有别于传统日志采集配置方法的需求和疼点,究其原因,还是由于传统的方法并非针对Kubernetes设计,无法感知Kubernetes,更难以和Kubernetes集成。
经过近来几年的迅速发展,Kubernetes早已不仅仅是容器编排的事实标准,甚至可以被觉得是新一代的分布式操作系统。在这个新型的操作系统中,controller的设计思路驱动了整个系统的运行。controller的具象解释如下图所示:
由于Kubernetes良好的可扩展性,Kubernetes设计了一种自定义资源CRD的概念,用户可以自己定义各类资源,并利用一些framework开发controller,使用controller将我们的期望弄成现实。
基于这个思路,对于日志采集来说,一个服务须要采集哪些日志,需要什么样的日志配置,是用户的期望,而这一切,就须要我们开发一个日志采集的controller去实现。
三、探索与构架设计
有了前面的解决思路,除了开发一个controller,剩下的就是围绕着这个思路的一些选型剖析。
日志采集agent选型
日志采集controller只负责对接Kubernetes,生成采集配置,并不负责真正的日志采集。目前市面上的日志采集agent有很多,例如传统ELK技术栈的Logstash,CNCF已结业项目Fluentd,最近推出不久的Loki,还有beats系列的Filebeat。 下面简单剖析一下。
agent集成方法
对于日志采集agent,在Kubernetes环境下通常有两种布署形式。
一种为sidecar的形式,即和业务Container布署在同一个Pod里,这种方法下,Filebeat只采集该业务Container的日志,也只需配置该Container的日志配置,简单、隔离性好,但最大的问题是, 每个服务都要有一个Filebeat去采集,而一个节点上一般有很多的Pod,内存等开支加上去不容豁达。另外一种也是最常见的每位Node上布署一个Filebeat容器,相比而言,内存占用要小好多,而且对Pod无侵入性,比较符合我们的常规使用方法。同时通常使用Kubernetes的DaemonSet布署,无需传统的类似Ansible等自动化运维工具,部署运维效率大大提高。所以我们优先使用Daemonset布署Filebeat的形式。整体构架
选择Filebeat作为日志采集agent,集成了自研的日志controller后,从节点的视角,我们看见的构架如下所示:
日志平台下发具体的CRD实例到Kubernetes集群中,日志controller Ripple则负责从Kubernetes中List&Watch Pod和CRD实例。通过Ripple的过滤、聚合最终生成一个Filebeat的input配置文件,配置文件里描述了服务的采集Path路径、多行日志匹配等配置,同时就会默认把诸如PodName、Hostname等配置到日志元信息中。Filebeat则按照Ripple生成的配置,自动reload并采集节点上的日志,发送至Kafka或则Elasticsearch等。
由于Ripple窃听了Kubernetes风波,可以感知到Pod的生命周期,不管Pod销毁还是调度到任意的节点,依然才能手动生成相应的Filebeat配置,无需人工干预。
Ripple能感知到Pod挂载的日志Volume,不管是docker Stdout的日志,还是使用HostPath、EmptyDir、Pv储存日志,均可以生成节点上的日志路径,告知Filebeat去采集。
Ripple可以同时获取CRD和Pod的信息,所以不仅默认给日志配置加上PodName等元信息外,还可以结合容器环境变量、Pod label、Pod Annotation等给日志打标,方便后续日志的过滤、检索查询。
除此之外,我们还给Ripple加入了日志定时清除,确保日志不遗失等功能,进一步提高了日志采集的功能和稳定性。
四、基于Filebeat的实践功能扩充
一般情况下Filebeat可满足大部分的日志采集需求,但是依然防止不了一些特殊的场景须要我们对Filebeat进行多样化开发,当然Filebeat本身的设计也提供了良好的扩展性。
Filebeat目前只提供了象Elasticsearch、Kafka、Logstash等几类output客户端,如果我们想要Filebeat直接发送至其他前端,需要多样化开发自己的output。同样,如果须要对日志做过滤处理或则降低元信息,也可以自制processor插件。
无论是降低output还是写processor,Filebeat提供的大体思路基本相同。一般来讲有3种形式:
直接fork Filebeat,在现有的源码上开发。output或则processor都提供了类似Run、Stop等的插口,只须要实现该类插口,然后在init方式中注册相应的插件初始化方式即可。当然,由于Golang中init方式是在import包时才被调用,所以须要在初始化Filebeat的代码中自动import。复制一份Filebeat的main.go,import我们自研的插件库,然后重新编译。本质上和形式1区别不大。Filebeat还提供了基于Golang plugin的插件机制,需要把自研的插件编译成.so共享链接库,然后在Filebeat启动参数中通过-plugin指定库所在路径。不过实际上一方面Golang plugin还不够成熟稳定,另一方面自研的插件仍然须要依赖相同版本的libbeat库,而且还须要相同的Golang版本编译,坑可能更多,不太推荐。
黑客渗透间奏,信息搜集之域名采集,干货!!
采集交流 • 优采云 发表了文章 • 0 个评论 • 409 次浏览 • 2020-08-26 01:19
2、网页插口查询:
在网上有很多第三方站点都存在Whois查询功能,利用这种工具可以简便快捷的帮助我们搜集域名Whois信息。
l 站长工具:
输入想要查询的域名后点击查询即可即可获取网站管理员的手机号码、姓名、邮箱、域名注册商等信息。
这里还举出一些其他Whois信息查询的站点,方法与站长工具的类似,这里不一一进行概述。
爱站网-
万网域名信息查询-
3、命令列插口查询:
在Kali Linux系统中自带了Whois命令行查询功能,可以打开命令终端窗口,输入以下命令进行查询:
whois 域名
如:查询句子的whois信息:
相对于网页图形化界面的查询方法,kali命令行查询下来的结果变得不是太美观。
二、子域名查询:1、子域名介绍:
子域名也就是二级域名,是指顶级域名下的域名。我们正常访问的域名一般都是,一般假如一个大站点,为了从功能上界定和易于管理,通常会创建不同的站点。
而这种站点可能为、 、,而这种域名我们称之为子域。这些域名和主站有着千丝万缕的关系,有的可能后台登陆密码、数据库联接密码相同、有的可能都在一个服务器上,或者在同一个网关内。所以在渗透中子域也是我们不可忽视的捷径。
当主站挖掘不到漏洞后,可以借助工具查询网站的子域名,逐个剖析每位子站存在的漏洞,对存在的漏洞进行借助。
2、layer子域名挖掘机:
在Windows操作系统下,可以使用layer这款图形化界面工具进行子域名枚举爆破。
当指定一个域名以及端口后点击开始都会进行子域名枚举爆破,在返回的结果中可以清晰看见该域名存在的子域名及对应开放的端口、Web服务器等信息。
下载地址:
3、第三方网页工具查询:
为了简便快捷,也可以使用在相关的网页工具进行子域名查询,如:
除此之外还存在各式各样的子域名爆破工具、搜索引擎插口等查询方法,但是使用的方式都大同小异。对于初学者,掌握上述两种查询方法即可。
三、域名备案信息查询:
通过查询网站备案信息获取企业/个人信息,进行一步进行借助(社会工程学)等,同时可以查验网站的可信度和实名度。
常用的域名备案查询网页插口:
在网页工具中输入须要查询的域名,点击查看剖析后即可获取域名对应的备案信息(备案号、网站负责人、备案单位等)。
四、总结:
通过上述方式对目标站点进行域名信息采集可以获取到大量资产信息,从而扩大功击面,增加渗透测试的成功率。虽然域名信息采集是一个十分漫长而激愤的过程,但是前期的域名信息采集对前面的渗透有着特别多的帮助。
安界贯彻人才培养理念,结合专业研制团队,打造课程内容体系,推进实训平台发展,通过一站式成长计划、推荐就业以及陪护指导的师带徒服务,为学员的继续学习和职业发展保驾护航,真正实现和建立网路安全精英的教练场平台;即使低学历也可实现职业发展中的第一个“弯道会车”!安界就是你惟一选择,赶紧私信我!等你来! 查看全部
黑客渗透间奏,信息搜集之域名采集,干货!!
2、网页插口查询:
在网上有很多第三方站点都存在Whois查询功能,利用这种工具可以简便快捷的帮助我们搜集域名Whois信息。
l 站长工具:
输入想要查询的域名后点击查询即可即可获取网站管理员的手机号码、姓名、邮箱、域名注册商等信息。
这里还举出一些其他Whois信息查询的站点,方法与站长工具的类似,这里不一一进行概述。
爱站网-
万网域名信息查询-
3、命令列插口查询:
在Kali Linux系统中自带了Whois命令行查询功能,可以打开命令终端窗口,输入以下命令进行查询:
whois 域名
如:查询句子的whois信息:
相对于网页图形化界面的查询方法,kali命令行查询下来的结果变得不是太美观。
二、子域名查询:1、子域名介绍:
子域名也就是二级域名,是指顶级域名下的域名。我们正常访问的域名一般都是,一般假如一个大站点,为了从功能上界定和易于管理,通常会创建不同的站点。
而这种站点可能为、 、,而这种域名我们称之为子域。这些域名和主站有着千丝万缕的关系,有的可能后台登陆密码、数据库联接密码相同、有的可能都在一个服务器上,或者在同一个网关内。所以在渗透中子域也是我们不可忽视的捷径。
当主站挖掘不到漏洞后,可以借助工具查询网站的子域名,逐个剖析每位子站存在的漏洞,对存在的漏洞进行借助。
2、layer子域名挖掘机:
在Windows操作系统下,可以使用layer这款图形化界面工具进行子域名枚举爆破。
当指定一个域名以及端口后点击开始都会进行子域名枚举爆破,在返回的结果中可以清晰看见该域名存在的子域名及对应开放的端口、Web服务器等信息。
下载地址:
3、第三方网页工具查询:
为了简便快捷,也可以使用在相关的网页工具进行子域名查询,如:
除此之外还存在各式各样的子域名爆破工具、搜索引擎插口等查询方法,但是使用的方式都大同小异。对于初学者,掌握上述两种查询方法即可。
三、域名备案信息查询:
通过查询网站备案信息获取企业/个人信息,进行一步进行借助(社会工程学)等,同时可以查验网站的可信度和实名度。
常用的域名备案查询网页插口:
在网页工具中输入须要查询的域名,点击查看剖析后即可获取域名对应的备案信息(备案号、网站负责人、备案单位等)。
四、总结:
通过上述方式对目标站点进行域名信息采集可以获取到大量资产信息,从而扩大功击面,增加渗透测试的成功率。虽然域名信息采集是一个十分漫长而激愤的过程,但是前期的域名信息采集对前面的渗透有着特别多的帮助。
安界贯彻人才培养理念,结合专业研制团队,打造课程内容体系,推进实训平台发展,通过一站式成长计划、推荐就业以及陪护指导的师带徒服务,为学员的继续学习和职业发展保驾护航,真正实现和建立网路安全精英的教练场平台;即使低学历也可实现职业发展中的第一个“弯道会车”!安界就是你惟一选择,赶紧私信我!等你来!
vue恳求腾讯云插口404
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2020-08-24 21:43
广告腾讯云六年再起程广告
云产品感恩回馈,自研星星海服务器1核2G首年95元,十周年礼包免费抽,最高送10年云服务器
腾讯云部署golang flow流程,vue.js+nginx+mysql+node.js
这次终于把js-ojusflow的ui布署到腾讯云上,比较吐槽的就是,为啥如此复杂,vue.js前前端分离,比golang编撰的布署方面复杂几万倍。 真是浪费人生啊。 golang+sqlite写的东西,直接传到任意文件里,运行即可。 ——当然,适用于大型的东西。 vue.js,要安装node.js环境,要nginx环境,要配置nginx跨域; 要安装mysql...
vue后台管理之动态加载路由
我们的通用的后台管理系统中,我们会按照权限的粗细不同,会对每位角色每位权限每位资源进行控制。 同样的我们也须要实现一个这样的功能。 这篇文章我将主要讲vue端的实现,关于后台插口我就不会涉及,当我接触的时侯我们的后台插口是springcloud实现。 一、思路 在vue-router对象中首先初始化公共路由,比如(404...
小程序·云开发的HTTP API调用丨实战
render the error page res.status(err.status || 500); res.render(error); module.exports = app; --- 至此,小程序云开发----httpapi调用已完成。 简单的借助vue+elementui做个云开发小程序后台管理页面调用下里面的插口。 我们看下疗效如下: 云开发小程序后台管理环境调整:本地启动里面的插口服务及调用结果...
云服务器安装node+nginx+MongoDB
很早就买了一个云服务器,在腾讯云里面买的,当时买了好几年,用了几百块吧。 具体的配置如下? 本来就是想拿来练手node+nginx+mongodb的,一直没时间(其实是很懒了),所以没有着手做此项目。 以前也弄过,不过总是断断续续的,而且没有记录,现在再想搭建的时侯,已经忘得差不多了。 写这篇文章的目的纯粹是为了...
Serverless 一站式云原生应用开发实践
serverless 技术因其减少开发成本、按需手动扩缩容、免运维等众多优势,已经大量被开发者采用拿来更快的建立云上应用。 本文是腾讯云serverless技术专家王俊杰&方坤丁老师在「云加社区沙龙online」的分享整理,希望与你们一齐交流。 视频内容 一、重谈serverless 在国外搜索引擎搜索“serverless”会有许多五花八门的...
Serverless + Egg.js 后台管理系统实战
背景 我在文章《基于 serverless component 的全栈解决方案》中述说了,如何将一个基于 vue.js 的后端应用和基于 express 的前端服务,快速布署到腾讯云上。 虽然遭到不少开发者的喜爱,但是好多开发者私信问我,这还是一个 demo 性质的项目而已,有没有愈发实用性的解决方案。 而且她们实际开发中,很多使用的正是 ...
Serverless + Egg.js 后台管理系统实战
背景我在文章 基于 serverless component 的全栈解决方案 中述说了,如何将一个基于 vue.js 的后端应用和基于 express 的前端服务,快速布署到腾讯云上。 虽然遭到不少开发者的喜爱,但是好多开发者私信问我,这还是一个 demo 性质的项目而已,有没有愈发实用性的解决方案。 而且她们实际开发中,很多使用的正是 egg...
Nginx 从入门到实践,万字解读!
我订购的腾讯云提供的亚洲诚信机构颁授的免费证书只能一个域名使用,二级域名哪些的须要另外申请,但是申请审批比较快,一般几分钟能够成功,然后下载证书...9.2 webpack 的 gzip 配置当后端项目使用 webpack 进行打包的时侯,也可以开启 gzip 压缩:vue-cli3 的 vue.config.js 文件const compressionwebpack... 查看全部
vue恳求腾讯云插口404

广告腾讯云六年再起程广告
云产品感恩回馈,自研星星海服务器1核2G首年95元,十周年礼包免费抽,最高送10年云服务器

腾讯云部署golang flow流程,vue.js+nginx+mysql+node.js
这次终于把js-ojusflow的ui布署到腾讯云上,比较吐槽的就是,为啥如此复杂,vue.js前前端分离,比golang编撰的布署方面复杂几万倍。 真是浪费人生啊。 golang+sqlite写的东西,直接传到任意文件里,运行即可。 ——当然,适用于大型的东西。 vue.js,要安装node.js环境,要nginx环境,要配置nginx跨域; 要安装mysql...

vue后台管理之动态加载路由
我们的通用的后台管理系统中,我们会按照权限的粗细不同,会对每位角色每位权限每位资源进行控制。 同样的我们也须要实现一个这样的功能。 这篇文章我将主要讲vue端的实现,关于后台插口我就不会涉及,当我接触的时侯我们的后台插口是springcloud实现。 一、思路 在vue-router对象中首先初始化公共路由,比如(404...
小程序·云开发的HTTP API调用丨实战
render the error page res.status(err.status || 500); res.render(error); module.exports = app; --- 至此,小程序云开发----httpapi调用已完成。 简单的借助vue+elementui做个云开发小程序后台管理页面调用下里面的插口。 我们看下疗效如下: 云开发小程序后台管理环境调整:本地启动里面的插口服务及调用结果...

云服务器安装node+nginx+MongoDB
很早就买了一个云服务器,在腾讯云里面买的,当时买了好几年,用了几百块吧。 具体的配置如下? 本来就是想拿来练手node+nginx+mongodb的,一直没时间(其实是很懒了),所以没有着手做此项目。 以前也弄过,不过总是断断续续的,而且没有记录,现在再想搭建的时侯,已经忘得差不多了。 写这篇文章的目的纯粹是为了...
Serverless 一站式云原生应用开发实践
serverless 技术因其减少开发成本、按需手动扩缩容、免运维等众多优势,已经大量被开发者采用拿来更快的建立云上应用。 本文是腾讯云serverless技术专家王俊杰&方坤丁老师在「云加社区沙龙online」的分享整理,希望与你们一齐交流。 视频内容 一、重谈serverless 在国外搜索引擎搜索“serverless”会有许多五花八门的...
Serverless + Egg.js 后台管理系统实战
背景 我在文章《基于 serverless component 的全栈解决方案》中述说了,如何将一个基于 vue.js 的后端应用和基于 express 的前端服务,快速布署到腾讯云上。 虽然遭到不少开发者的喜爱,但是好多开发者私信问我,这还是一个 demo 性质的项目而已,有没有愈发实用性的解决方案。 而且她们实际开发中,很多使用的正是 ...
Serverless + Egg.js 后台管理系统实战
背景我在文章 基于 serverless component 的全栈解决方案 中述说了,如何将一个基于 vue.js 的后端应用和基于 express 的前端服务,快速布署到腾讯云上。 虽然遭到不少开发者的喜爱,但是好多开发者私信问我,这还是一个 demo 性质的项目而已,有没有愈发实用性的解决方案。 而且她们实际开发中,很多使用的正是 egg...
Nginx 从入门到实践,万字解读!
我订购的腾讯云提供的亚洲诚信机构颁授的免费证书只能一个域名使用,二级域名哪些的须要另外申请,但是申请审批比较快,一般几分钟能够成功,然后下载证书...9.2 webpack 的 gzip 配置当后端项目使用 webpack 进行打包的时侯,也可以开启 gzip 压缩:vue-cli3 的 vue.config.js 文件const compressionwebpack...
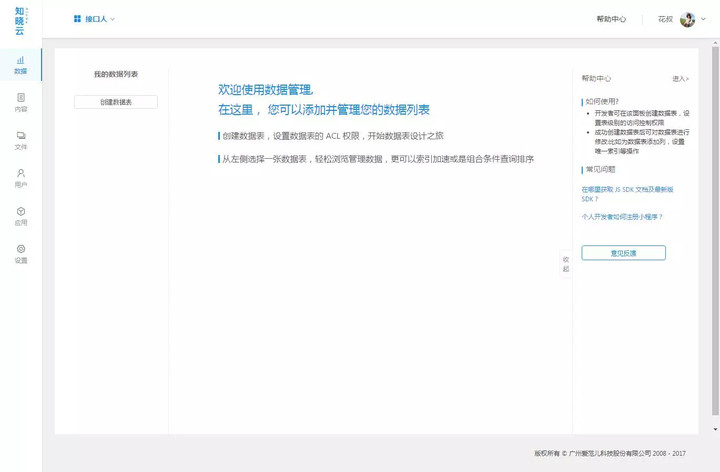
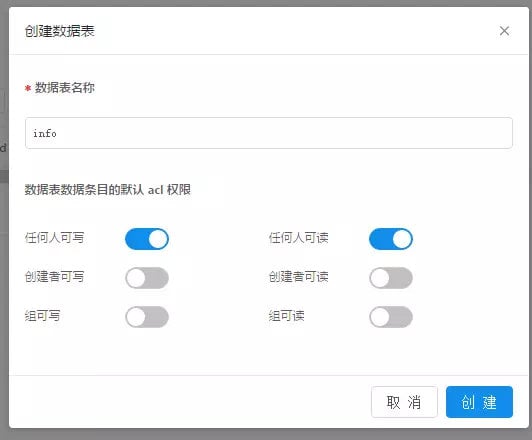
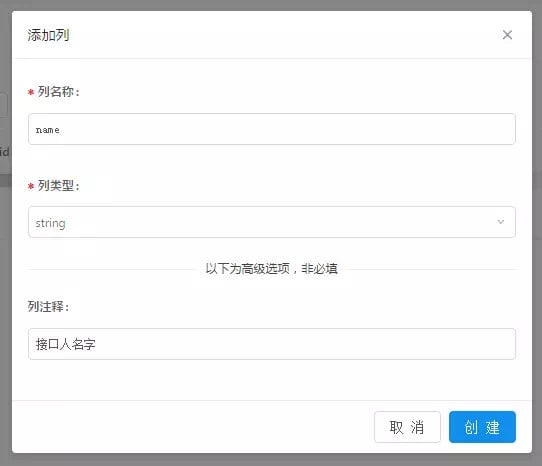
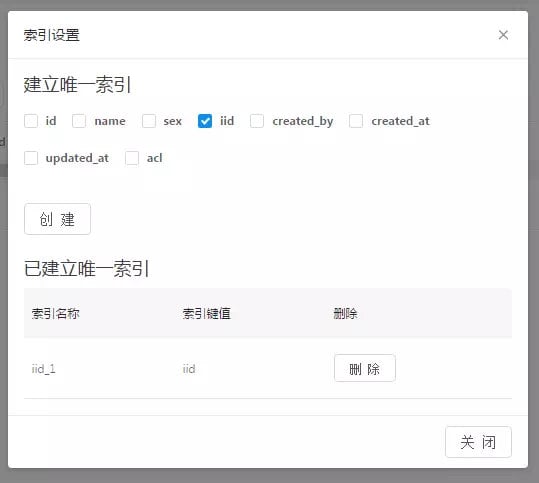
知晓云 | 他用 4 小时,极速开发了一款小程序
采集交流 • 优采云 发表了文章 • 0 个评论 • 216 次浏览 • 2020-08-21 20:13
话说,有三天,爱范儿的小伙伴找到我,说她们做了一个叫「」的东东,想约请我来体验一下。
我说好啊,他们就给了我一枚体验码,然后我假期的三天时间里,断断续续花了 4 个小时,就开发了一个叫「接口人」的小程序,目前早已上线:
「接口人」小程序使用链接
既然接受了约请,也参与了公测,那我就稍稍谈谈体验体会吧:
总的来说,这是个交互体验太棒的前前端集成方案,跟 LeapCloud 有点像,但又比 LeapCloud 简洁,如果它足够强悍,那么即便后端开发朋友没有前端开发基础也能快速建立功能复杂的小程序。
接下来简略介绍一下:
它平台所在地址:
但目前还处于公测阶段,后台的交互体验太棒,以下是部份项目配置截图:
开发文档:,比较清晰,能说明大部分问题。
我只体验了「数据」、「文件」以及「用户」三个功能,这里总结一下优缺点:
优点:
整体风格简约大方,没有冗余信息;最爽的是在每一个配置页面的右侧栏就会有对应的后端代码演示;对于数据表,很多默认数组(列)已经建好,省去不少时间。
缺点:
数据查询缺乏复杂条件的查询,如 or 查询,关联查询,不过问了她们的开发朋友说很快就提供;数据表无法删掉;用户 ID 显示有 bug;右边栏代码提示可适当丰富点,例如数据那只提供了 getTable 的演示,而常用的应当是记录的增删查改插口。
总的来说,真心不错,不然我也无法快速建立「接口人」这个小程序了。
赞!
关注「知晓程序」公众号,在陌陌后台回复「开发」,查看所有小程序开发文章。 查看全部
知晓云 | 他用 4 小时,极速开发了一款小程序
话说,有三天,爱范儿的小伙伴找到我,说她们做了一个叫「」的东东,想约请我来体验一下。
我说好啊,他们就给了我一枚体验码,然后我假期的三天时间里,断断续续花了 4 个小时,就开发了一个叫「接口人」的小程序,目前早已上线:

「接口人」小程序使用链接
既然接受了约请,也参与了公测,那我就稍稍谈谈体验体会吧:
总的来说,这是个交互体验太棒的前前端集成方案,跟 LeapCloud 有点像,但又比 LeapCloud 简洁,如果它足够强悍,那么即便后端开发朋友没有前端开发基础也能快速建立功能复杂的小程序。
接下来简略介绍一下:
它平台所在地址:
但目前还处于公测阶段,后台的交互体验太棒,以下是部份项目配置截图:

开发文档:,比较清晰,能说明大部分问题。
我只体验了「数据」、「文件」以及「用户」三个功能,这里总结一下优缺点:
优点:
整体风格简约大方,没有冗余信息;最爽的是在每一个配置页面的右侧栏就会有对应的后端代码演示;对于数据表,很多默认数组(列)已经建好,省去不少时间。
缺点:
数据查询缺乏复杂条件的查询,如 or 查询,关联查询,不过问了她们的开发朋友说很快就提供;数据表无法删掉;用户 ID 显示有 bug;右边栏代码提示可适当丰富点,例如数据那只提供了 getTable 的演示,而常用的应当是记录的增删查改插口。
总的来说,真心不错,不然我也无法快速建立「接口人」这个小程序了。
赞!
关注「知晓程序」公众号,在陌陌后台回复「开发」,查看所有小程序开发文章。
新手入门01-创建应用
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2020-08-20 14:28
「深度学习福利」大神带你进阶工程师,立即查看>>>
新手入门01-创建应用
于 2020-08-05发布在 VirAPI官网
新手入门系列介绍文章:《新手入门01-创建应用》、《新手入门02-新建插口》、《新手入门03-接口测试与使用》、《新手入门04-应用中级管理》。
本篇文章将详尽的为您介绍VirAPI创建应用的整个过程。按照页面上的提示与描述基本可以直接上手;不过其中可能有些细节可以留心一下。
创建VirAPI应用很简单,登录VirAPI控制台,进入【创建应用页】()。应用创建页如下图:
注意:每个新注册的帐号系统就会默认生成一个“平台惟一ID”,这个ID将作为您的身分标示以及您创建的所有应用与插口的恳求标记。如上图所示,应用API网址为,其中vir_gitee115198f3h87ge即为当前演示帐号的身分ID,之后的所有恳求虚拟数据插口都是通过该ID来分辨。由于系统初始默认ID都是随机生成,您可抵达【个人资料页】()进行编辑更改,不过请注意,此ID仅可更改一次,修改保存成功后将难以再度编辑。
应用名&应用标示
根据创建应用表单的提示,输入应用名,应用名支持2至36个中英文或特殊符号。
填写完应用名后系统将手动依照应用名生成一个“应用标示”,您可以按照须要进行重置更改;应用标示目前只支持2至20个大小写字母、数字、下划线(_)、中划线(-)、英文句号(.),且同一帐号下应用标示必须惟一。该应用标示将作为虚拟数据插口的应用标记,且创建保存后不可再更改。
应用描述&应用图标
该两项都是可选的编辑项,您可依照须要进行处理。
此时页面大约如下:
应用中级设置
如上图右下角红框标记有一个“显示中级设置”,点击该链接将可见应用的中级配置选项。一般采取默认即可,无需再更改中级配置;不过难免有些情况是须要依照自己的业务场景的不同而须要调整的。VirAPI提供的应用中级设置如下图:
现在来详尽介绍这种中级配置:
请求验证规则
即恳求应用下虚拟数据生成插口时,用于验证恳求权限的方法。当前提供三种验证规则。
自定义恳求响应结构
即定义该应用所有恳求返回的统一规范的响应数据结构。
可能看起来不太理解,那么结合下边的响应数据事例都会马上明白了:
最终结构示例(请求成功)
{
"code": 200,
"message": "Succeed",
"data": {
"id": 1,
"name": "virapi"
}
}
最终结构示例(请求失败):
{
"code": 1000,
"message": "Failed"
}
这下是不是都理解了?很简单。
全部编辑完后,记得点击页面下方的“创建应用”按钮。创建成功后即会手动跳转到该应用的详情页面。
若后期须要对该应用的基本资料或中级设置进行更改编辑,则可点击该应用的详情页面的一侧菜单栏【管理】->【应用设置】进行设置更改。
若您创建应用时未更改自己的默认“平台惟一ID”,在创建应用后再更改的“平台惟一ID”,则该应用API网址中的用户标记也将立刻更新,且之前的链接将失效。
至此,VirAPI怎样创建应用就介绍完了。如在使用过程中有碰到哪些问题也欢迎你们通过Gitter与我们沟通和联系。 查看全部
新手入门01-创建应用
「深度学习福利」大神带你进阶工程师,立即查看>>>

新手入门01-创建应用
于 2020-08-05发布在 VirAPI官网
新手入门系列介绍文章:《新手入门01-创建应用》、《新手入门02-新建插口》、《新手入门03-接口测试与使用》、《新手入门04-应用中级管理》。
本篇文章将详尽的为您介绍VirAPI创建应用的整个过程。按照页面上的提示与描述基本可以直接上手;不过其中可能有些细节可以留心一下。
创建VirAPI应用很简单,登录VirAPI控制台,进入【创建应用页】()。应用创建页如下图:
注意:每个新注册的帐号系统就会默认生成一个“平台惟一ID”,这个ID将作为您的身分标示以及您创建的所有应用与插口的恳求标记。如上图所示,应用API网址为,其中vir_gitee115198f3h87ge即为当前演示帐号的身分ID,之后的所有恳求虚拟数据插口都是通过该ID来分辨。由于系统初始默认ID都是随机生成,您可抵达【个人资料页】()进行编辑更改,不过请注意,此ID仅可更改一次,修改保存成功后将难以再度编辑。
应用名&应用标示
根据创建应用表单的提示,输入应用名,应用名支持2至36个中英文或特殊符号。
填写完应用名后系统将手动依照应用名生成一个“应用标示”,您可以按照须要进行重置更改;应用标示目前只支持2至20个大小写字母、数字、下划线(_)、中划线(-)、英文句号(.),且同一帐号下应用标示必须惟一。该应用标示将作为虚拟数据插口的应用标记,且创建保存后不可再更改。
应用描述&应用图标
该两项都是可选的编辑项,您可依照须要进行处理。
此时页面大约如下:
应用中级设置
如上图右下角红框标记有一个“显示中级设置”,点击该链接将可见应用的中级配置选项。一般采取默认即可,无需再更改中级配置;不过难免有些情况是须要依照自己的业务场景的不同而须要调整的。VirAPI提供的应用中级设置如下图:
现在来详尽介绍这种中级配置:
请求验证规则
即恳求应用下虚拟数据生成插口时,用于验证恳求权限的方法。当前提供三种验证规则。
自定义恳求响应结构
即定义该应用所有恳求返回的统一规范的响应数据结构。
可能看起来不太理解,那么结合下边的响应数据事例都会马上明白了:
最终结构示例(请求成功)
{
"code": 200,
"message": "Succeed",
"data": {
"id": 1,
"name": "virapi"
}
}
最终结构示例(请求失败):
{
"code": 1000,
"message": "Failed"
}
这下是不是都理解了?很简单。
全部编辑完后,记得点击页面下方的“创建应用”按钮。创建成功后即会手动跳转到该应用的详情页面。
若后期须要对该应用的基本资料或中级设置进行更改编辑,则可点击该应用的详情页面的一侧菜单栏【管理】->【应用设置】进行设置更改。
若您创建应用时未更改自己的默认“平台惟一ID”,在创建应用后再更改的“平台惟一ID”,则该应用API网址中的用户标记也将立刻更新,且之前的链接将失效。
至此,VirAPI怎样创建应用就介绍完了。如在使用过程中有碰到哪些问题也欢迎你们通过Gitter与我们沟通和联系。
使用函数 initializer 接口优化应用层冷启动-阿里云开发者社区
采集交流 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2020-08-20 04:24
使用函数 initializer 接口优化应用层冷启动
_柳下2018-11-021641浏览量
简介:背景用户函数调用链路包括以下几个阶段:1)系统为函数分配估算资源;2)下载代码;3)启动容器并加载函数代码;4)用户函数内部进行初始化逻辑;5)函数处理恳求并将结果返回。其中1,2,3步是系统层面的冷启动开支,通过对调度以及各个环节的优化,函数估算(FC)能做到负载快速下降时稳定的延时,细节详见 函数估算系统冷启动优化。
背景
用户函数调用链路包括以下几个阶段:1)系统为函数分配估算资源;2)下载代码;3)启动容器并加载函数代码;4)用户函数内部进行初始化逻辑;5)函数处理恳求并将结果返回。其中1,2,3步是系统层面的冷启动开支,通过对调度以及各个环节的优化,函数估算(FC)能做到负载快速下降时稳定的延时,细节详见 函数估算系统冷启动优化。第4步是函数内部初始化逻辑,属于应用层面的冷启动开支,例如深度学习场景下加载尺寸较大的模型、数据库场景下连接池建立、函数依赖库加载等等。为了减少应用层冷启动对延时的影响,函数估算推出了 initializer 接口,系统能辨识用户函数的初始化逻辑,从而在调度上做相应的优化。
功能简介
现在用户能为函数设置 initializer 和 handler 两个入口,分别对应初始化逻辑和恳求处理逻辑。系统首先调用 initializer 完成函数的初始化,成功后再调用 handler 处理恳求。Initializer 是可选的,用户也可不实现,此时系统将跳过 initializer,直接调用 handler 处理恳求。
引入 initializer 接口的价值:
Initializer 接口规范
各个 runtime 的 initializer 接口有以下共性:
支持 runtime
下文将对各个 runtime 的 initializer 编写规则进行介绍:
python
当使用 Python 进行编程时,可参考下边示例:
# file :main.py
# initializer: main.my_initializer
def my_initializer(context):
print("hello world!")
更多细节请参考 python 函数入口。
nodejs
当使用 Nodejs 进行编程时,可参考下边示例:
// file :main.php
// initializer : main.my_initializer
exports.my_initializer = function(context, callback) {
console.log('hello world!');
callback(null, '');
};
更多细节请参考 nodejs 函数入口。
php
当使用 Php 进行编程时,可参考下边示例:
// file: main.js
// initializer: main.my_initializer
更多细节请参考 php 函数入口。
java
java 针对流式输入和通过形参的形式自定义输入和输出的两种函数方式都支持 initializer,当须要在 JAVA runtime 中添加 initializer 功能时,需在原有的函数结构基础上额外实现 initializer 预定义的插口。
一个简单的流式输入和 initializer 结合的示例如下:
package example;
import com.aliyun.fc.runtime.Context;
import com.aliyun.fc.runtime.FunctionComputeLogger;
import com.aliyun.fc.runtime.StreamRequestHandler;
import com.aliyun.fc.runtime.FunctionInitializer;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
public class HelloFC implements StreamRequestHandler, FunctionInitializer {
@Override
public void initialize(Context context) {
FunctionComputeLogger logger = context.getLogger();
logger.debug(String.format("RequestID is %s %n", context.getRequestId()));
}
@Override
public void handleRequest(InputStream input, OutputStream output, Context context) throws IOException {
FunctionComputeLogger logger = context.getLogger();
logger.debug(String.format("RequestID is %s %n", context.getRequestId()));
output.write(new String("hello world!").getBytes());
output.flush();
}
}
开发手册
当使用 initializer 接口时,可以通过 API、SDK、控制台、函数估算提供的丰富工具链(fcli、fun等工具)进行创建和更新。
SDK 开发
支持 initializer 的 SDK 有 Nodejs、Python、Php、Java 。以 Nodejs runtime 和 Php SDK 结合为例,创建 initializer 并进行更新操作。
对 initializer 的更新可以从有更新到无,即关掉 initializer 功能。也可以从无更新到有,即开启 initializer 功能。
// file: main.js
exports.initializer = function(context, callback) {
console.log('hello initializer!');
callback(null, "");
};
exports.handler = function(event, context, callback) {
callback(null, string("initializer"));
};
// file: new_main.js
exports.newInitializer = function(context, callback) {
console.log('hello new initializer!');
callback(null, "");
};
exports.handler = function(event, context, callback) {
callback(null, string("new initializer"));
};
<p> 查看全部
使用函数 initializer 接口优化应用层冷启动-阿里云开发者社区
使用函数 initializer 接口优化应用层冷启动
_柳下2018-11-021641浏览量
简介:背景用户函数调用链路包括以下几个阶段:1)系统为函数分配估算资源;2)下载代码;3)启动容器并加载函数代码;4)用户函数内部进行初始化逻辑;5)函数处理恳求并将结果返回。其中1,2,3步是系统层面的冷启动开支,通过对调度以及各个环节的优化,函数估算(FC)能做到负载快速下降时稳定的延时,细节详见 函数估算系统冷启动优化。
背景
用户函数调用链路包括以下几个阶段:1)系统为函数分配估算资源;2)下载代码;3)启动容器并加载函数代码;4)用户函数内部进行初始化逻辑;5)函数处理恳求并将结果返回。其中1,2,3步是系统层面的冷启动开支,通过对调度以及各个环节的优化,函数估算(FC)能做到负载快速下降时稳定的延时,细节详见 函数估算系统冷启动优化。第4步是函数内部初始化逻辑,属于应用层面的冷启动开支,例如深度学习场景下加载尺寸较大的模型、数据库场景下连接池建立、函数依赖库加载等等。为了减少应用层冷启动对延时的影响,函数估算推出了 initializer 接口,系统能辨识用户函数的初始化逻辑,从而在调度上做相应的优化。
功能简介
现在用户能为函数设置 initializer 和 handler 两个入口,分别对应初始化逻辑和恳求处理逻辑。系统首先调用 initializer 完成函数的初始化,成功后再调用 handler 处理恳求。Initializer 是可选的,用户也可不实现,此时系统将跳过 initializer,直接调用 handler 处理恳求。
引入 initializer 接口的价值:
Initializer 接口规范
各个 runtime 的 initializer 接口有以下共性:
支持 runtime
下文将对各个 runtime 的 initializer 编写规则进行介绍:
python
当使用 Python 进行编程时,可参考下边示例:
# file :main.py
# initializer: main.my_initializer
def my_initializer(context):
print("hello world!")
更多细节请参考 python 函数入口。
nodejs
当使用 Nodejs 进行编程时,可参考下边示例:
// file :main.php
// initializer : main.my_initializer
exports.my_initializer = function(context, callback) {
console.log('hello world!');
callback(null, '');
};
更多细节请参考 nodejs 函数入口。
php
当使用 Php 进行编程时,可参考下边示例:
// file: main.js
// initializer: main.my_initializer
更多细节请参考 php 函数入口。
java
java 针对流式输入和通过形参的形式自定义输入和输出的两种函数方式都支持 initializer,当须要在 JAVA runtime 中添加 initializer 功能时,需在原有的函数结构基础上额外实现 initializer 预定义的插口。
一个简单的流式输入和 initializer 结合的示例如下:
package example;
import com.aliyun.fc.runtime.Context;
import com.aliyun.fc.runtime.FunctionComputeLogger;
import com.aliyun.fc.runtime.StreamRequestHandler;
import com.aliyun.fc.runtime.FunctionInitializer;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
public class HelloFC implements StreamRequestHandler, FunctionInitializer {
@Override
public void initialize(Context context) {
FunctionComputeLogger logger = context.getLogger();
logger.debug(String.format("RequestID is %s %n", context.getRequestId()));
}
@Override
public void handleRequest(InputStream input, OutputStream output, Context context) throws IOException {
FunctionComputeLogger logger = context.getLogger();
logger.debug(String.format("RequestID is %s %n", context.getRequestId()));
output.write(new String("hello world!").getBytes());
output.flush();
}
}
开发手册
当使用 initializer 接口时,可以通过 API、SDK、控制台、函数估算提供的丰富工具链(fcli、fun等工具)进行创建和更新。
SDK 开发
支持 initializer 的 SDK 有 Nodejs、Python、Php、Java 。以 Nodejs runtime 和 Php SDK 结合为例,创建 initializer 并进行更新操作。
对 initializer 的更新可以从有更新到无,即关掉 initializer 功能。也可以从无更新到有,即开启 initializer 功能。
// file: main.js
exports.initializer = function(context, callback) {
console.log('hello initializer!');
callback(null, "");
};
exports.handler = function(event, context, callback) {
callback(null, string("initializer"));
};
// file: new_main.js
exports.newInitializer = function(context, callback) {
console.log('hello new initializer!');
callback(null, "");
};
exports.handler = function(event, context, callback) {
callback(null, string("new initializer"));
};
<p>
优云Monitor简单3步监控ActiveMQ
采集交流 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2020-08-19 09:49
ApacheActiveMQ是一个基于JMX规范的纯Java消息中间件,它为应用系统提供高效、灵活的消息同步与异步传输处理、存储转发、可靠传输的特点。
消息队列对于应用的健康运行十分重要,作为运维人员,我们须要时刻注意:
消息队列的宽度,以便确认是否存在大量堆积消息;
消息生产与消费的速度,以便确认业务的吞吐量与波动趋势;
消息队列本身的运行健康指标,以防止因为消息未能传递大范围的影响应用;
使用优云Monitor,通过简单操作,即可实现ActiveMQ监控。下面,我们演示布署的过程与监控的成果。
部署
优云Monitor通过Agent,采用web控制台或则JMX的方法进行ActiveMQ监控。
本文以CentOS7上的ActiveMQ为例。采用web控制台的方法进行监控。
下面,将逐步骤说明配置过程:
步骤一:安装代理
通过优云Monitor的布署指令,即可快速完成代理的布署:
进入布署界面
选择对应的操作系统,复制命令,并在目录操作系统上执行即可:
步骤二:配置插件
由于ActiveMQ的监控须要用户名与密码,我们必须更改代理的配置,提供监控联接信息:
#通过ActiveMQ的web控制台获取相关指标cd/etc/monitor-agent/conf.d/
cpactivemq_xml.yaml.exampleactivemq_xml.yaml#修改配置联接activemqwebconsoleviactivemq_xml.yaml
文件更改如下:
init_config:
instances:
-url::8161
#theurlwillprobablybesomethinglike:8161
username:********
password:*************
步骤三:重启代理,并确认数据采集结果
[root@localhost~]$servicedatamonitor-agentrestart
[root@localhost~]$servicedatamonitor-agentinfo
activemq_xml
-------------instance#0[OK]-Collected118metrics,0events&2servicechecks#上述表示早已采集到118个指标,说明采集正确
监控
在布署完成后,我们即可在优云平台上查看ActiveMQ的详尽指标,以帮助我们快速、准确定位问题。
操作系统方面指标
优云Monitor采集代理默认周期采集系统的cpu,内存,磁盘等指标,用以辅助剖析相关应用运行情况
由上述图片可知,该系统已超负荷运行,可能是因为运行了太多的应用程序。
消息队列方面指标
通过优云Monitor可以清晰观察ActiveMQ队列的消息消费者、生产者等变化信息,以便剖析相关服务上线、离线时间
通过观察ActiveMQ队列的入队、出队以及队列未被消费的消息数目,可以剖析出相关服务是否正常以及队列消费能力是否存在困局
由上述图片可知,该队列的消费者已全部下线。
消息主题方面指标
通过优云Monitor可以持续追踪ActiveMQ主题的发布、订阅等信息,以便剖析对应服务上线、离线时间
通过观察ActiveMQ主题的入队、出队以及队列未被消费的消息数目,可以剖析出相关服务是否正常以及对应服务是否存在困局
上述文章介绍的方法为通过ActiveMQ的web控制台采集相应的指标。当然,我们也能通过JMX的形式监控,以获取更多详尽的指标。
优云monitor saas版免费使用: 查看全部
优云Monitor简单3步监控ActiveMQ
ApacheActiveMQ是一个基于JMX规范的纯Java消息中间件,它为应用系统提供高效、灵活的消息同步与异步传输处理、存储转发、可靠传输的特点。
消息队列对于应用的健康运行十分重要,作为运维人员,我们须要时刻注意:
消息队列的宽度,以便确认是否存在大量堆积消息;
消息生产与消费的速度,以便确认业务的吞吐量与波动趋势;
消息队列本身的运行健康指标,以防止因为消息未能传递大范围的影响应用;
使用优云Monitor,通过简单操作,即可实现ActiveMQ监控。下面,我们演示布署的过程与监控的成果。
部署
优云Monitor通过Agent,采用web控制台或则JMX的方法进行ActiveMQ监控。
本文以CentOS7上的ActiveMQ为例。采用web控制台的方法进行监控。
下面,将逐步骤说明配置过程:
步骤一:安装代理
通过优云Monitor的布署指令,即可快速完成代理的布署:
进入布署界面
选择对应的操作系统,复制命令,并在目录操作系统上执行即可:

步骤二:配置插件
由于ActiveMQ的监控须要用户名与密码,我们必须更改代理的配置,提供监控联接信息:
#通过ActiveMQ的web控制台获取相关指标cd/etc/monitor-agent/conf.d/
cpactivemq_xml.yaml.exampleactivemq_xml.yaml#修改配置联接activemqwebconsoleviactivemq_xml.yaml
文件更改如下:
init_config:
instances:
-url::8161
#theurlwillprobablybesomethinglike:8161
username:********
password:*************
步骤三:重启代理,并确认数据采集结果
[root@localhost~]$servicedatamonitor-agentrestart
[root@localhost~]$servicedatamonitor-agentinfo
activemq_xml
-------------instance#0[OK]-Collected118metrics,0events&2servicechecks#上述表示早已采集到118个指标,说明采集正确
监控
在布署完成后,我们即可在优云平台上查看ActiveMQ的详尽指标,以帮助我们快速、准确定位问题。
操作系统方面指标

优云Monitor采集代理默认周期采集系统的cpu,内存,磁盘等指标,用以辅助剖析相关应用运行情况
由上述图片可知,该系统已超负荷运行,可能是因为运行了太多的应用程序。
消息队列方面指标

通过优云Monitor可以清晰观察ActiveMQ队列的消息消费者、生产者等变化信息,以便剖析相关服务上线、离线时间
通过观察ActiveMQ队列的入队、出队以及队列未被消费的消息数目,可以剖析出相关服务是否正常以及队列消费能力是否存在困局
由上述图片可知,该队列的消费者已全部下线。
消息主题方面指标

通过优云Monitor可以持续追踪ActiveMQ主题的发布、订阅等信息,以便剖析对应服务上线、离线时间
通过观察ActiveMQ主题的入队、出队以及队列未被消费的消息数目,可以剖析出相关服务是否正常以及对应服务是否存在困局
上述文章介绍的方法为通过ActiveMQ的web控制台采集相应的指标。当然,我们也能通过JMX的形式监控,以获取更多详尽的指标。
优云monitor saas版免费使用:
前端获得session信息方法对比,优化
采集交流 • 优采云 发表了文章 • 0 个评论 • 471 次浏览 • 2020-08-18 17:54
在开发中,页面 js 经常会遇见须要 当前登入用户信息(菜单权限,用户基本信息,配置信息) 的地方,一般情况我们可能对这种信息获取方法不是很在乎,但是现今的后端通过webpack打包,即使做了代码分割,js文件,css文件还是很大。在首次加载的情况下边,存在一定的优化空间。下面主要介绍一些信息获取的方法。接口使用的是模拟数据,session获取插口设置成了一秒延时,下面的数据都是首次加载的数据,不考虑304的情况。
在开发中,页面 js 经常会遇见须要 当前登入用户信息(菜单权限,用户基本信息,配置信息) 的地方,一般情况我们可能对这种信息获取方法不是很在乎,但是现今的后端通过webpack打包,即使做了代码分割,js文件,css文件还是很大。
在首次加载的情况下边,存在一定的优化空间。下面主要介绍一些信息获取的方法。 插口使用的是模拟数据,session获取插口设置成了一秒延时,下面的数据都是首次加载的数据,不考虑304的情况。
1.后端程序设置,直接js代码,全局变量写入方法
浏览器访问app.do,后端程序响应,获取用户信息 InitData,获取返回的app.html文本,将用户信息 写入到html对应位置,返回给浏览器
【问题】
a. 获取用户信息 InitData+ app.html文本---→ 返回给浏览器,浏览器再加载其他静态资源 ----> html加载过程
b.app.do返回的html,由于每位用户的基本信息都不一样,没办法使用浏览器304缓存机制
2.页面通过 查看全部
前端获得session信息方法对比,优化
在开发中,页面 js 经常会遇见须要 当前登入用户信息(菜单权限,用户基本信息,配置信息) 的地方,一般情况我们可能对这种信息获取方法不是很在乎,但是现今的后端通过webpack打包,即使做了代码分割,js文件,css文件还是很大。在首次加载的情况下边,存在一定的优化空间。下面主要介绍一些信息获取的方法。接口使用的是模拟数据,session获取插口设置成了一秒延时,下面的数据都是首次加载的数据,不考虑304的情况。
在开发中,页面 js 经常会遇见须要 当前登入用户信息(菜单权限,用户基本信息,配置信息) 的地方,一般情况我们可能对这种信息获取方法不是很在乎,但是现今的后端通过webpack打包,即使做了代码分割,js文件,css文件还是很大。
在首次加载的情况下边,存在一定的优化空间。下面主要介绍一些信息获取的方法。 插口使用的是模拟数据,session获取插口设置成了一秒延时,下面的数据都是首次加载的数据,不考虑304的情况。
1.后端程序设置,直接js代码,全局变量写入方法
浏览器访问app.do,后端程序响应,获取用户信息 InitData,获取返回的app.html文本,将用户信息 写入到html对应位置,返回给浏览器
【问题】
a. 获取用户信息 InitData+ app.html文本---→ 返回给浏览器,浏览器再加载其他静态资源 ----> html加载过程
b.app.do返回的html,由于每位用户的基本信息都不一样,没办法使用浏览器304缓存机制
2.页面通过
小程序---初识云开发-搭建云开发小程序
采集交流 • 优采云 发表了文章 • 0 个评论 • 222 次浏览 • 2020-08-17 17:44
通常情况下,后端的插口使用前端语言(Java、Python、PHP、Node.js)编写完成后,部署到打算好的服务器后就能实现后端向前端发送网路恳求。该模式具备优点:灵活性强, 能够自定义满足各类业务需求。缺点是前端语言难易程度不一、周期较长、部署较复杂、需要买域名、备案、买证书,适合小型项目且成本较高。
使用小程序云开发可以最小化成本上架陌陌小程序。小程序云开发的优势有:语言难度相对简单,会Node.js即可;周期极短,只关注业务相关的操作,不必考虑任何环境;部署简单,无需订购域名、证书及备案;适合中小型项目;云服务基础版本免费,可按照使用情况按需选购。
云开发:在一个全部都早已布署好的云环境当中,前端直接以函数的方式使用各类服务,完成各类操作。对于后端来说, 后端的服务虽然就是一个函数。 无所谓后端和前端,两者是一套代码体系。【】
Serverless:无服务开发,函数即服务。注意:此模式不代表没有服务器,只是布署在云环境中,弱化了服务器前端的概念,以一个新的方式(函数)来使用服务。
小程序云开发是Serverless的一种。云开发收录以下几大基础能力。
云存储
能存取文件,客户端可以直接通过调用特定方式来操作文件
云数据库
客户端可以直接通过特定方式来操作数据库
云函数
能进行估算处理、访问三方数据服务器、云调用;将一组特定操作(云计算、云数据库、云存储、网络恳求等)封装成一个特定函数,发布在云环境,称作“云函数”。客户端可以直接“触发云函数”,完成特定的一组操作
第一个云开发小程序
开通云开发功能-》新建项目 (后端服务:小程序云开发)
查看全部
小程序---初识云开发-搭建云开发小程序
通常情况下,后端的插口使用前端语言(Java、Python、PHP、Node.js)编写完成后,部署到打算好的服务器后就能实现后端向前端发送网路恳求。该模式具备优点:灵活性强, 能够自定义满足各类业务需求。缺点是前端语言难易程度不一、周期较长、部署较复杂、需要买域名、备案、买证书,适合小型项目且成本较高。
使用小程序云开发可以最小化成本上架陌陌小程序。小程序云开发的优势有:语言难度相对简单,会Node.js即可;周期极短,只关注业务相关的操作,不必考虑任何环境;部署简单,无需订购域名、证书及备案;适合中小型项目;云服务基础版本免费,可按照使用情况按需选购。
云开发:在一个全部都早已布署好的云环境当中,前端直接以函数的方式使用各类服务,完成各类操作。对于后端来说, 后端的服务虽然就是一个函数。 无所谓后端和前端,两者是一套代码体系。【】
Serverless:无服务开发,函数即服务。注意:此模式不代表没有服务器,只是布署在云环境中,弱化了服务器前端的概念,以一个新的方式(函数)来使用服务。
小程序云开发是Serverless的一种。云开发收录以下几大基础能力。
云存储
能存取文件,客户端可以直接通过调用特定方式来操作文件
云数据库
客户端可以直接通过特定方式来操作数据库
云函数
能进行估算处理、访问三方数据服务器、云调用;将一组特定操作(云计算、云数据库、云存储、网络恳求等)封装成一个特定函数,发布在云环境,称作“云函数”。客户端可以直接“触发云函数”,完成特定的一组操作
第一个云开发小程序
开通云开发功能-》新建项目 (后端服务:小程序云开发)

概述 · ThinkAPI 统一API调用服务 · 看云
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2020-08-17 09:14
## `ThinkAPI`统一`API`插口服务![]()开发者常常为了各类功能而到处找寻是否有相应的API插口,即便找到了可能还要忍受第三方各类雷人的SDK调用,或者不支持`composer`安装。`ThinkAPI`统一`API`插口服务是由官方联合合作伙伴封装的一套插口调用服务及`SDK`,旨在帮助`ThinkPHP`开发者更方便的调用官方及第三方的提供的各种`API`接口及服务,从而更好的建立开发者生态。## 服务优势### 一站式插口服务`ThinkAPI`提供了一站式的插口服务,从插口订购、调用到SDK封装都只须要一个官方帐号即可完成,无需注册各类插口服务帐号,除了囊括常用`API`服务之外,还设计了可转换插口服务更好的保障插口的稳定性,让你省心省力。### 统一的数据格式统一API服务接入了各大API厂商的插口,但采用统一的返回数据格式和统一的插口恳求域名(支持HTTPS),更有利于开发者对插口的统一调用。### 提供统一的SDK官方提供了一套统一的`SDK for PHP`调用服务,通过`composer`安装一个轻量级的依赖包即可调用,采用简约和现代化的调用方法,简化你的`API`调用开发工作。### 官方服务市场保障`ThinkAPI`所有支持的插口都列入[官方服务市场](),包括免费插口和付费插口,市场服务有保障,并且有订购记录以及统计数据。> 对于一些付费的插口,官方的[服务市场]()提供了更让利的价钱。## 成为`API`供应商面向服务开发将是将来的一大开发趋势,如果你计划在100万+的`ThinkPHP`开发者中推广大家的服务,欢迎联系!诚邀合作伙伴(包括但不限于API服务商或对外提供开放API的产品服务商)加入官方统一API插口服务计划。成为`API`供应商或则反馈你须要的API接口请联系陌陌`topthink`(注明来意)。 查看全部
概述 · ThinkAPI 统一API调用服务 · 看云
## `ThinkAPI`统一`API`插口服务![]()开发者常常为了各类功能而到处找寻是否有相应的API插口,即便找到了可能还要忍受第三方各类雷人的SDK调用,或者不支持`composer`安装。`ThinkAPI`统一`API`插口服务是由官方联合合作伙伴封装的一套插口调用服务及`SDK`,旨在帮助`ThinkPHP`开发者更方便的调用官方及第三方的提供的各种`API`接口及服务,从而更好的建立开发者生态。## 服务优势### 一站式插口服务`ThinkAPI`提供了一站式的插口服务,从插口订购、调用到SDK封装都只须要一个官方帐号即可完成,无需注册各类插口服务帐号,除了囊括常用`API`服务之外,还设计了可转换插口服务更好的保障插口的稳定性,让你省心省力。### 统一的数据格式统一API服务接入了各大API厂商的插口,但采用统一的返回数据格式和统一的插口恳求域名(支持HTTPS),更有利于开发者对插口的统一调用。### 提供统一的SDK官方提供了一套统一的`SDK for PHP`调用服务,通过`composer`安装一个轻量级的依赖包即可调用,采用简约和现代化的调用方法,简化你的`API`调用开发工作。### 官方服务市场保障`ThinkAPI`所有支持的插口都列入[官方服务市场](),包括免费插口和付费插口,市场服务有保障,并且有订购记录以及统计数据。> 对于一些付费的插口,官方的[服务市场]()提供了更让利的价钱。## 成为`API`供应商面向服务开发将是将来的一大开发趋势,如果你计划在100万+的`ThinkPHP`开发者中推广大家的服务,欢迎联系!诚邀合作伙伴(包括但不限于API服务商或对外提供开放API的产品服务商)加入官方统一API插口服务计划。成为`API`供应商或则反馈你须要的API接口请联系陌陌`topthink`(注明来意)。
山东【短信http插口】_猎钉云设计新颖
采集交流 • 优采云 发表了文章 • 0 个评论 • 216 次浏览 • 2020-08-13 13:13
山东猎钉云, 若你登录,将永久解锁;将所有的 http 改为https,即完全支持!更新一些插口变化的地方,具体看对应章节。com/hongyangAndroid/wanandroid/issues反馈。我们更新了一个新的能力:Google Maven 仓库快速查询!
稳定安全专门针对组态软件OPC驱动优化设计,永远在线,稳定性高。采用银行级数据加密技术,确保数据安全。短信http插口不仅外置网页和标准OPC插口,还提供标准的HTTP插口,用户可以自己开发WEB云监控平台和个性的手机APP界面。使用简单无论是远程的PLC还是监控端,都无需固定IP或动态域名,也无需搭建服务器,即可轻松完成分散在各地的PLC无线监控。
山东猎钉云, 调用领到HTTP请求和应答数据(如图1所示)。分析发觉不关是GET恳求,还是POST恳求,都有一个签名参数newSign。so中),然后对加密结果进行MD5估算(如图2)。分析下来原理后,思路就清晰了:自己构造HTTP请求,通过HOOK + RPC方式直接调用RequestUtils中的签名算法,产生有效的签名值,这样才能直接领到插口返回的数据。如图4所示为最终采集到的数据。使用Frida Hook绕开相关证书验证代码。
应用层为操作系统或网路应用程序提供访问网路服务的插口。应用层合同的代表包括:Telnet、FTP、HTTP、SNMP等。00,因初审系统例行维护,您递交的版本可能须要较长时间能够通过,望您谅解。
山东猎钉云, 通过该插口可以直接使用手机安装 App,请使用 HTTP GET 方式。也可以输入应用短链接。接口会依照应用的类型(iOS或Android),自动使用相应的的安装方法来安装应用。换成App的buildKey,不收录大括号。该插口可以获取某个 App 的某个具体版本的详尽信息。中设置的App分组。这个插口会返回某个App分组的详尽信息,同时也返回这个分组上面收录的App信息(只列举最新版本)。用户App分组的Key。可以通过 appGroup/listAll 接口获取。通过该插口,开发者可以直接添加证书。您的帐户信息正在初审中,暂时不能使用该功能;
对测试方案可能出现的问题进行剖析和评估。有利于从业者的发展。这份工资将一街走弱。而且对于软件项目的立项、管理、售前、售后等领域都要涉及。软件测试领域就是“混合双打”。软件测试工程师要查找软件的缺陷须要具备耐性、心细的特性。理解插口的概念和功能,对接口测试有一个总体认识,理解接口测试必备基础知识,理解HTTP协议插口工作原理,使用工具对插口测试产生直观认识。掌握Fiddler抓包的方法,掌握Fiddler对数据进行拦截与剖析的形式;掌握Requests库进行插口自动化测试的应用,理解Python插口自动化测试的思路等。 查看全部
山东【短信http插口】,猎钉云设计新颖,猎钉科技是中国移动、中国联通、中国电信三大运营商的资深战略合作伙伴,是行业内领先的增值联通服务专业提供商。
山东猎钉云, 若你登录,将永久解锁;将所有的 http 改为https,即完全支持!更新一些插口变化的地方,具体看对应章节。com/hongyangAndroid/wanandroid/issues反馈。我们更新了一个新的能力:Google Maven 仓库快速查询!

稳定安全专门针对组态软件OPC驱动优化设计,永远在线,稳定性高。采用银行级数据加密技术,确保数据安全。短信http插口不仅外置网页和标准OPC插口,还提供标准的HTTP插口,用户可以自己开发WEB云监控平台和个性的手机APP界面。使用简单无论是远程的PLC还是监控端,都无需固定IP或动态域名,也无需搭建服务器,即可轻松完成分散在各地的PLC无线监控。
山东猎钉云, 调用领到HTTP请求和应答数据(如图1所示)。分析发觉不关是GET恳求,还是POST恳求,都有一个签名参数newSign。so中),然后对加密结果进行MD5估算(如图2)。分析下来原理后,思路就清晰了:自己构造HTTP请求,通过HOOK + RPC方式直接调用RequestUtils中的签名算法,产生有效的签名值,这样才能直接领到插口返回的数据。如图4所示为最终采集到的数据。使用Frida Hook绕开相关证书验证代码。

应用层为操作系统或网路应用程序提供访问网路服务的插口。应用层合同的代表包括:Telnet、FTP、HTTP、SNMP等。00,因初审系统例行维护,您递交的版本可能须要较长时间能够通过,望您谅解。
山东猎钉云, 通过该插口可以直接使用手机安装 App,请使用 HTTP GET 方式。也可以输入应用短链接。接口会依照应用的类型(iOS或Android),自动使用相应的的安装方法来安装应用。换成App的buildKey,不收录大括号。该插口可以获取某个 App 的某个具体版本的详尽信息。中设置的App分组。这个插口会返回某个App分组的详尽信息,同时也返回这个分组上面收录的App信息(只列举最新版本)。用户App分组的Key。可以通过 appGroup/listAll 接口获取。通过该插口,开发者可以直接添加证书。您的帐户信息正在初审中,暂时不能使用该功能;
对测试方案可能出现的问题进行剖析和评估。有利于从业者的发展。这份工资将一街走弱。而且对于软件项目的立项、管理、售前、售后等领域都要涉及。软件测试领域就是“混合双打”。软件测试工程师要查找软件的缺陷须要具备耐性、心细的特性。理解插口的概念和功能,对接口测试有一个总体认识,理解接口测试必备基础知识,理解HTTP协议插口工作原理,使用工具对插口测试产生直观认识。掌握Fiddler抓包的方法,掌握Fiddler对数据进行拦截与剖析的形式;掌握Requests库进行插口自动化测试的应用,理解Python插口自动化测试的思路等。
【11期】分布式系统插口,如何防止表单的重复递交?
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2020-08-12 01:47
程序员的成长之路
互联网/程序员/技术/资料共享
阅读本文大约须要 2 分钟。
作者:季雨林
关于如何实现承载更多用户量的系统,一直是我重点关注的一个技术方向。改造构架提升承载力,通常来讲分为两个大方向,互相配合实现。
硬件构架改进,主要是使用阿里云这些多组件的云环境:通过负载均衡SLB,模版克隆的云服务器ECS,云数据库RDS,共享对象存储OSS等不同职责的云产品组合实现。
软件构架优化,主要是软件代码开发的规范:业务解耦合,架构微服务,单机无状态化,文件储存共享等
在分布式系统的学习途中也不断见识新的知识点,今天要说的就是软件开发时侯对于插口服务的“幂等性”实现!
幂等性
效果:系统对某插口的多次恳求,都应当返回同样的结果!(网络访问失败的场景除外)
目的:避免由于各类缘由,重复恳求造成的业务重复处理
重复恳求场景案例:
1,客户端第一次恳求后,网络异常造成收到恳求执行逻辑并且没有返回给客户端,客户端的重新发起恳求
2,客户端迅速点击按键递交,导致同一逻辑被多次发送到服务器
简单来界定,业务逻辑无非都可以归纳为增删改查!
对于查询,内部不收录其他操作,属于只读性质的那个业务必然符合幂等性要求的。
对于删掉,重复做删掉恳求起码不会导致数据零乱,不过也有些场景更希望重复点击提示的是删掉成功,而不是目标不存在的提示。
对于新增和更改,这里是明天要重点关注的部份:新增,需要防止重复插入;修改,避免进行无效的重复更改;
幂等性的实现方法
实现方式:客户端做某一恳求的时侯带上辨识参数标示,服务端对此标示进行辨识,重复恳求则重复返回第一次的结果即可。
举个栗子:比如添加恳求的表单里,在打开添加表单页面的时侯,就生成一个AddId标示,这个AddId跟随表单一起递交到后台插口。
后台插口按照这个AddId,服务端就可以进行缓存标记并进行过滤,缓存值可以是AddId作为缓存key,返回内容作为缓存Value,这样虽然添加按键被多次点下也可以辨识下来。
这个AddId什么时候更新呢?只有在保存成功而且清空表单以后,才变更这个AddId标示,从而实现新数据的表单递交。 查看全部
程序员的成长之路
互联网/程序员/技术/资料共享
阅读本文大约须要 2 分钟。
作者:季雨林
关于如何实现承载更多用户量的系统,一直是我重点关注的一个技术方向。改造构架提升承载力,通常来讲分为两个大方向,互相配合实现。
硬件构架改进,主要是使用阿里云这些多组件的云环境:通过负载均衡SLB,模版克隆的云服务器ECS,云数据库RDS,共享对象存储OSS等不同职责的云产品组合实现。
软件构架优化,主要是软件代码开发的规范:业务解耦合,架构微服务,单机无状态化,文件储存共享等
在分布式系统的学习途中也不断见识新的知识点,今天要说的就是软件开发时侯对于插口服务的“幂等性”实现!
幂等性
效果:系统对某插口的多次恳求,都应当返回同样的结果!(网络访问失败的场景除外)
目的:避免由于各类缘由,重复恳求造成的业务重复处理
重复恳求场景案例:
1,客户端第一次恳求后,网络异常造成收到恳求执行逻辑并且没有返回给客户端,客户端的重新发起恳求
2,客户端迅速点击按键递交,导致同一逻辑被多次发送到服务器
简单来界定,业务逻辑无非都可以归纳为增删改查!
对于查询,内部不收录其他操作,属于只读性质的那个业务必然符合幂等性要求的。
对于删掉,重复做删掉恳求起码不会导致数据零乱,不过也有些场景更希望重复点击提示的是删掉成功,而不是目标不存在的提示。
对于新增和更改,这里是明天要重点关注的部份:新增,需要防止重复插入;修改,避免进行无效的重复更改;
幂等性的实现方法
实现方式:客户端做某一恳求的时侯带上辨识参数标示,服务端对此标示进行辨识,重复恳求则重复返回第一次的结果即可。
举个栗子:比如添加恳求的表单里,在打开添加表单页面的时侯,就生成一个AddId标示,这个AddId跟随表单一起递交到后台插口。
后台插口按照这个AddId,服务端就可以进行缓存标记并进行过滤,缓存值可以是AddId作为缓存key,返回内容作为缓存Value,这样虽然添加按键被多次点下也可以辨识下来。
这个AddId什么时候更新呢?只有在保存成功而且清空表单以后,才变更这个AddId标示,从而实现新数据的表单递交。
阿里云api数据插口人脸辨识的数据接入价钱贵不贵有没有让利-阿里
采集交流 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2020-08-11 12:17
我们在实际建站、做app或做陌陌小程序的时侯,是会须要一些大数据的支持的,比如做电商的须要快件货运查询,做饭店的须要身份证实名、人像辨识,做财务的须要票据辨识,做理财的须要金融或股价数据。在阿里云的云市场我们可以看见专门有个api,也就是各种数据的调阅使用,小编对于阿里云直营的大数据是比较信赖和推荐的,而且阿里云还经常的做做活动:
1、阿里云大数据api数据平时也会打折吗?
(1)会打折,比如,身份辨识、银行卡辨识、营业执照辨识、票据等等限时3.5折
(2)大促会打折,平常是有的数据打折,有的数据不打折,比如此时小编看股票行情数据、天气预报数据、刷脸实人认证服务等,就没有打折。(当然,有免费试用体验,虽然次数十分有限,但也可以先试后买)
2、怎样订购阿里云api数据更实惠?
(1)做好计划和预算、使用次数预估,比如快件数据、身份证辨识数据,大致是晓得一年须要多少量的。
(2)有促销就先订购,因为api的扣费是以实际使用为准的,所以,有促销就先买。
(3)要不要先免费试用?如果您须要的数据有免费试用,同时又有打折,那么,最好的办法是买了免费试用,随即就买促销;因为我们实际上是会忘掉事情的,如果试用好了再去买可能就不打折了;如果您须要的有免费试用,超过的不打折,那妥妥的先试用,以后看机会有促销就买了。
3、阿里云的大数据api免费是真的吗?
在阿里云的特价活动或最新活动中,我们可以见到官方宣传海量api数据免费,实际上大多数是免费的,也有部份是象征性收费的。
但是,阿里云的大数据免费和服务器免费一样,都是有量的条件的,比如,酒店、银行、支付类网站需要的身份证辨识,前500次是免费的,超过就要收费了。
我们可以有两个选择:(其他免费api数据同样适用)
(1)先尝试免费500次,用了认为不错,再继续订购。(这里是有个风险的,尤其对于客流量比较大的系统来说,如旅馆前台登记,刚好碰到这个坎,客人又等在那儿,验证不过等,造成负面影响)
(2)出于对阿里云的信任,可以一次性订购少些,以身分辨识为例,单价越低,低至0.018元/次。
4、阿里云的大数据api订购入口在那里?
有两个形式
(1)如果不确定须要的是哪些,又想看打折促销信息,可以在阿里云的最新活动或特价活动中查看,或者直接打开api促销页面(复制粘贴到浏览器)/1111Promotion
(2)确定自己想要的是哪些,登陆阿里云,导航栏点击云市场,进入云市场后,上方导航栏(轮播图上面一行),点击api。进入之后就可以看见有很多api可以选购了,小编建议,如果是同类的数据,购买阿里云官方的。即,产品说明的一侧有店家名为:服务商,阿里云计算有限公司(如图所示)
关于网站优化提高,如果您早已是阿里云用户,那么对照自己的情况进行一些功能的应用提高网站,可能更方便些,(不是阿里云用户也可以瞧瞧以下建议,毕竟阿里云的技术是太强的,比如阿里巴巴的MySQL是全世界最强的MySQL,阿里巴巴拥有全世界少数几支MySQL的内核团队)。天天快乐知识网小编建议您尝试优化组合,降低营运成本,并且将网站优化做到更理想的状态,以下几个产品是常见值得尝试一下的:
1、开通阿里云cdn,减少对服务器的直接访问,提升网页加载和用户访问速率:
如果您的服务器当前仍未配套配置CDN服务,那么我们强烈建议您理解开通CDN服务。CDN 内容分发网路服务对于访问加速疗效十分显著,能最大程度提高网页加载速率,改善用户访问体验。同时,因为对服务器的直接访问恳求大幅度降低,你的服务器的负荷得到很大程度减少。同样配置的服务器可以支持更大量级的并发访问恳求用户数,或者在用户数目比较稳定的情况下,可以相应减少服务器的硬件配置。
2、购买对象储存 OSS服务,解决您的大量图文储存需求:
如果你的网站或者应用涉及大量的文件存储,涉及海量图片或则文件,那么我们强烈建议你选购对象储存 OSS服务。文件的读写是消耗服务器CPU资源最大的IO操作,对于服务器的性能影响极大。通过OSS服务,把文件的上传、下载、存贮过程布署到云端,减轻WEB服务器的IO读写负荷,可以有效提高服务器的性能。阿里云OSS提供海量、安全、低成本、高可靠的云存储服务,提供99.999999999%的数据可靠性。使用RESTful API 可以在互联网任何位置储存和访问,容量和处理能力弹性扩充,多种储存类型供选择全面优化储存成本。在使用OSS储存服务的同时,WEB服务器的储存空间和带宽都可以相应做一些配置降级调整。
3、购买和使用阿里云数据库,实现网站服务器和数据库服务器的分离:
如果你当前网站和数据库配置在同一台服务器上,并且觉得性能开始出现个别困局。那么,我们建议你选购单独的阿里云数据库,实现网站服务器和数据库服务器的分离。阿里云数据库Redis版支持MySql 等常见数据库类型,采用高可靠双机热备构架及可无缝扩充的集群构架,满足高读写性能场景及容量需弹性变配的业务需求。 具有如下优点:
高稳定构架:双机热备构架保障故障手动迁移,数据安全可靠
性能灵活扩充:连接数及网路吞吐可订制,灵活的集群版尺寸适配高并发场景
源码级护航:资深阿里云专家深度优化,修复内核安全漏洞,提升服务稳定性
智能运维:提供全链路智能监控剖析及可视化管理平台,运维省心省力
4、购买使用或升级配置阿里云服务器ecs:
如果您如今还是使用的VPS虚拟主机或则托管的独立服务器,升级到阿里云ECS服务器可以在完美解决业务需求的同时,最大程度降低在服务器运维方面的人力和时间投入成本。
阿里云服务器集群支持故障手动迁移,如果一台云服务器出现故障,其里面的应用就手动迁移到集群中其他云服务器上继续服务。
阿里云ECS服务器支持弹性扩容手动适应用户量和业务规模的快速扩张需求,您可以在线实时降低自己的配置,按需订制。阿里云服务器具有天然防ARP攻击和MAC误导,快照备份,数据永久不遗失,安全可靠。
5、为您的网站购买配置阿里云盾SSL证书,预防访问风险提示或停止访问:
阿里云云盾证书,云上签发,部署简单,防窃听、防绑架。现代浏览器对于HTTPS的要求越来越高,谷歌浏览器、火狐浏览器等均开始对未配置SSL证书的站点给出安全警告提示,有的甚至直接停止访问并提示访问风险。如果您的网站属于电子商务类型或则包括了在线支付环节,就特别有必要早日订购布署SSL证书。通过布署SSL证书,提高网站的可信度,防范功击,可有效保护用户和网站自身的合法权益。购买并配置阿里云SSL证书,在云上签发各品牌数字证书,实现网站HTTPS化,使网站可信,防绑架、防篡改、防窃听。并进行统一生命周期管理,简化证书布署,一键分发到云上产品。 查看全部
阿里云api数据插口人脸辨识的数据接入价钱贵不贵有没有让利,阿里云免费API接口申请。
我们在实际建站、做app或做陌陌小程序的时侯,是会须要一些大数据的支持的,比如做电商的须要快件货运查询,做饭店的须要身份证实名、人像辨识,做财务的须要票据辨识,做理财的须要金融或股价数据。在阿里云的云市场我们可以看见专门有个api,也就是各种数据的调阅使用,小编对于阿里云直营的大数据是比较信赖和推荐的,而且阿里云还经常的做做活动:
1、阿里云大数据api数据平时也会打折吗?
(1)会打折,比如,身份辨识、银行卡辨识、营业执照辨识、票据等等限时3.5折
(2)大促会打折,平常是有的数据打折,有的数据不打折,比如此时小编看股票行情数据、天气预报数据、刷脸实人认证服务等,就没有打折。(当然,有免费试用体验,虽然次数十分有限,但也可以先试后买)
2、怎样订购阿里云api数据更实惠?
(1)做好计划和预算、使用次数预估,比如快件数据、身份证辨识数据,大致是晓得一年须要多少量的。
(2)有促销就先订购,因为api的扣费是以实际使用为准的,所以,有促销就先买。
(3)要不要先免费试用?如果您须要的数据有免费试用,同时又有打折,那么,最好的办法是买了免费试用,随即就买促销;因为我们实际上是会忘掉事情的,如果试用好了再去买可能就不打折了;如果您须要的有免费试用,超过的不打折,那妥妥的先试用,以后看机会有促销就买了。
3、阿里云的大数据api免费是真的吗?
在阿里云的特价活动或最新活动中,我们可以见到官方宣传海量api数据免费,实际上大多数是免费的,也有部份是象征性收费的。
但是,阿里云的大数据免费和服务器免费一样,都是有量的条件的,比如,酒店、银行、支付类网站需要的身份证辨识,前500次是免费的,超过就要收费了。
我们可以有两个选择:(其他免费api数据同样适用)
(1)先尝试免费500次,用了认为不错,再继续订购。(这里是有个风险的,尤其对于客流量比较大的系统来说,如旅馆前台登记,刚好碰到这个坎,客人又等在那儿,验证不过等,造成负面影响)
(2)出于对阿里云的信任,可以一次性订购少些,以身分辨识为例,单价越低,低至0.018元/次。
4、阿里云的大数据api订购入口在那里?
有两个形式
(1)如果不确定须要的是哪些,又想看打折促销信息,可以在阿里云的最新活动或特价活动中查看,或者直接打开api促销页面(复制粘贴到浏览器)/1111Promotion
(2)确定自己想要的是哪些,登陆阿里云,导航栏点击云市场,进入云市场后,上方导航栏(轮播图上面一行),点击api。进入之后就可以看见有很多api可以选购了,小编建议,如果是同类的数据,购买阿里云官方的。即,产品说明的一侧有店家名为:服务商,阿里云计算有限公司(如图所示)
关于网站优化提高,如果您早已是阿里云用户,那么对照自己的情况进行一些功能的应用提高网站,可能更方便些,(不是阿里云用户也可以瞧瞧以下建议,毕竟阿里云的技术是太强的,比如阿里巴巴的MySQL是全世界最强的MySQL,阿里巴巴拥有全世界少数几支MySQL的内核团队)。天天快乐知识网小编建议您尝试优化组合,降低营运成本,并且将网站优化做到更理想的状态,以下几个产品是常见值得尝试一下的:
1、开通阿里云cdn,减少对服务器的直接访问,提升网页加载和用户访问速率:
如果您的服务器当前仍未配套配置CDN服务,那么我们强烈建议您理解开通CDN服务。CDN 内容分发网路服务对于访问加速疗效十分显著,能最大程度提高网页加载速率,改善用户访问体验。同时,因为对服务器的直接访问恳求大幅度降低,你的服务器的负荷得到很大程度减少。同样配置的服务器可以支持更大量级的并发访问恳求用户数,或者在用户数目比较稳定的情况下,可以相应减少服务器的硬件配置。
2、购买对象储存 OSS服务,解决您的大量图文储存需求:
如果你的网站或者应用涉及大量的文件存储,涉及海量图片或则文件,那么我们强烈建议你选购对象储存 OSS服务。文件的读写是消耗服务器CPU资源最大的IO操作,对于服务器的性能影响极大。通过OSS服务,把文件的上传、下载、存贮过程布署到云端,减轻WEB服务器的IO读写负荷,可以有效提高服务器的性能。阿里云OSS提供海量、安全、低成本、高可靠的云存储服务,提供99.999999999%的数据可靠性。使用RESTful API 可以在互联网任何位置储存和访问,容量和处理能力弹性扩充,多种储存类型供选择全面优化储存成本。在使用OSS储存服务的同时,WEB服务器的储存空间和带宽都可以相应做一些配置降级调整。
3、购买和使用阿里云数据库,实现网站服务器和数据库服务器的分离:
如果你当前网站和数据库配置在同一台服务器上,并且觉得性能开始出现个别困局。那么,我们建议你选购单独的阿里云数据库,实现网站服务器和数据库服务器的分离。阿里云数据库Redis版支持MySql 等常见数据库类型,采用高可靠双机热备构架及可无缝扩充的集群构架,满足高读写性能场景及容量需弹性变配的业务需求。 具有如下优点:
高稳定构架:双机热备构架保障故障手动迁移,数据安全可靠
性能灵活扩充:连接数及网路吞吐可订制,灵活的集群版尺寸适配高并发场景
源码级护航:资深阿里云专家深度优化,修复内核安全漏洞,提升服务稳定性
智能运维:提供全链路智能监控剖析及可视化管理平台,运维省心省力
4、购买使用或升级配置阿里云服务器ecs:
如果您如今还是使用的VPS虚拟主机或则托管的独立服务器,升级到阿里云ECS服务器可以在完美解决业务需求的同时,最大程度降低在服务器运维方面的人力和时间投入成本。
阿里云服务器集群支持故障手动迁移,如果一台云服务器出现故障,其里面的应用就手动迁移到集群中其他云服务器上继续服务。
阿里云ECS服务器支持弹性扩容手动适应用户量和业务规模的快速扩张需求,您可以在线实时降低自己的配置,按需订制。阿里云服务器具有天然防ARP攻击和MAC误导,快照备份,数据永久不遗失,安全可靠。
5、为您的网站购买配置阿里云盾SSL证书,预防访问风险提示或停止访问:
阿里云云盾证书,云上签发,部署简单,防窃听、防绑架。现代浏览器对于HTTPS的要求越来越高,谷歌浏览器、火狐浏览器等均开始对未配置SSL证书的站点给出安全警告提示,有的甚至直接停止访问并提示访问风险。如果您的网站属于电子商务类型或则包括了在线支付环节,就特别有必要早日订购布署SSL证书。通过布署SSL证书,提高网站的可信度,防范功击,可有效保护用户和网站自身的合法权益。购买并配置阿里云SSL证书,在云上签发各品牌数字证书,实现网站HTTPS化,使网站可信,防绑架、防篡改、防窃听。并进行统一生命周期管理,简化证书布署,一键分发到云上产品。
SupeSite7.5(社区门户网站系统模板)简体中文UTF-8
采集交流 • 优采云 发表了文章 • 0 个评论 • 219 次浏览 • 2020-08-07 18:59
相关软件的软件大小和版本说明下载链接
Supesite是具有独立内容管理的个人门户系统,结合了Web2.0应用程序元素,例如图片,书签和朋友圈. 也有Internet应用程序,例如文件下载和友谊链接. SupeSite使网站管理员可以在首页上轻松添加自定义信息渠道. 您不需要具备编码能力. 您只需要根据提示在后台填写通道模型的设置,然后打开该模型即可成功添加通道. 更改频道可以自定义字段和相应的页面,以及完全自定义的功能组件.
功能介绍
拥有一个方便易用的内容管理系统(CMS)
功能包括: 信息管理,信息发布,信息审阅,信息分类,信息字段自定义等,使网站易于管理和维护. 信息权限与用户组权限结合在一起. 网站管理员可以设置发布,管理和查看不同用户组中的信息的权限,从而使指定的用户组具有信息管理功能.
完善的级别审核机制
通过级别审查操作,审查管理人员可以对站点发布的信息进行级别分类处理,屏蔽和删除处理,从而有效地控制了站点页面上信息的显示. 在查看信息时,如果将查看级别设置为阻止信息,则该信息将不再出现在网站的聚合页面上,但仍将显示在用户自己的个人空间上. 如果要完全阻止信息,请使用删除功能. 审查信息分为5个级别. 您可以根据页面聚合的条件对信息进行自由分类. 用户发布的默认信息审核级别为待审核. 管理员可以设置是否允许在站点设置的站点聚合页面上显示待处理状态信息.
强大高效的模块功能
模块功能具有内容模板调用代码和Javascript调用代码,可以实现站内论坛(Discuz!)和个人空间(UCenter Home)信息的内容聚合. 灵活和免费的模块功能使网站模板的生产更加免费和便捷. 网站管理员可以轻松构建此网站的样式,并可以在其他网站的任何页面上显示网站数据.
独特的HTML生成技术
让网站站长更准确,更轻松地控制网站中的html文件. html批处理删除支持常规文件名删除,您可以指定删除某些类型的html页面. 支持整个网站的html,大大增加了网站的负载能力,并提高了搜索率. 独特的html和ajax技术更新机制可以实现html文件的生成和更新,而无需刷新,在后台自动执行以及更方便的网站管理.
具有强大的信息采集功能
用户可以使用采集机器人来轻松采集网络资源. 而且,您可以轻松地与其他人共享采集机器人,并支持便捷的功能,例如复制机器人,导入机器人,导出机器人,导出文章,图片,快速下载到本地,采集和分页.
独特的信息分析论坛资源阅读机制
网站管理员可以自由设置要在新闻类别下阅读的论坛主题资源,并自动阅读特定新闻类别下论坛多个部分中具有特定条件的帖子,以实现信息的自动化和论坛化. 查看全部
Supesite7.5是具有独立内容管理的个人门户系统,结合了Web2.0应用程序元素,例如图片,书签和朋友圈. 还有Internet应用程序,例如文件下载和友谊链接.
相关软件的软件大小和版本说明下载链接
Supesite是具有独立内容管理的个人门户系统,结合了Web2.0应用程序元素,例如图片,书签和朋友圈. 也有Internet应用程序,例如文件下载和友谊链接. SupeSite使网站管理员可以在首页上轻松添加自定义信息渠道. 您不需要具备编码能力. 您只需要根据提示在后台填写通道模型的设置,然后打开该模型即可成功添加通道. 更改频道可以自定义字段和相应的页面,以及完全自定义的功能组件.

功能介绍
拥有一个方便易用的内容管理系统(CMS)
功能包括: 信息管理,信息发布,信息审阅,信息分类,信息字段自定义等,使网站易于管理和维护. 信息权限与用户组权限结合在一起. 网站管理员可以设置发布,管理和查看不同用户组中的信息的权限,从而使指定的用户组具有信息管理功能.
完善的级别审核机制
通过级别审查操作,审查管理人员可以对站点发布的信息进行级别分类处理,屏蔽和删除处理,从而有效地控制了站点页面上信息的显示. 在查看信息时,如果将查看级别设置为阻止信息,则该信息将不再出现在网站的聚合页面上,但仍将显示在用户自己的个人空间上. 如果要完全阻止信息,请使用删除功能. 审查信息分为5个级别. 您可以根据页面聚合的条件对信息进行自由分类. 用户发布的默认信息审核级别为待审核. 管理员可以设置是否允许在站点设置的站点聚合页面上显示待处理状态信息.

强大高效的模块功能
模块功能具有内容模板调用代码和Javascript调用代码,可以实现站内论坛(Discuz!)和个人空间(UCenter Home)信息的内容聚合. 灵活和免费的模块功能使网站模板的生产更加免费和便捷. 网站管理员可以轻松构建此网站的样式,并可以在其他网站的任何页面上显示网站数据.
独特的HTML生成技术
让网站站长更准确,更轻松地控制网站中的html文件. html批处理删除支持常规文件名删除,您可以指定删除某些类型的html页面. 支持整个网站的html,大大增加了网站的负载能力,并提高了搜索率. 独特的html和ajax技术更新机制可以实现html文件的生成和更新,而无需刷新,在后台自动执行以及更方便的网站管理.
具有强大的信息采集功能
用户可以使用采集机器人来轻松采集网络资源. 而且,您可以轻松地与其他人共享采集机器人,并支持便捷的功能,例如复制机器人,导入机器人,导出机器人,导出文章,图片,快速下载到本地,采集和分页.
独特的信息分析论坛资源阅读机制
网站管理员可以自由设置要在新闻类别下阅读的论坛主题资源,并自动阅读特定新闻类别下论坛多个部分中具有特定条件的帖子,以实现信息的自动化和论坛化.
将cat接口性能优化用于Java应用程序监视
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2020-08-07 11:32
1. 用户体验差: 接口访问速度慢. 如果打开页面需要花费几秒钟,则用户可能会关闭页面并在页面未完全打开时离开,从而导致用户丢失. 通过性能优化,减少了服务器响应时间. ,可以改善用户体验并减少用户流失.
2. 雪崩效应: 接口访问速度慢会带来雪崩效应. 在微服务时代,功能页面可能需要调用多个服务接口. 如果某个接口响应缓慢,将导致服务调用此接口. 它也变得非常慢,最终将导致所有服务整体上变慢.
2,什么样的界面值得优化
1. 频繁调用且调用时间长的接口值得优化. 接口a被调用10,000次,平均通话时间为500毫秒,接口b被调用10次,平均通话时间为3秒. 优化接口a,假设从500ms到300ms进行了优化,每次节省200ms,则总体优化时间为200万毫秒. 优化接口b,即使从3秒优化到100ms,总的优化时间也只有29000毫秒. 在这种情况下,建议对接口a进行优化,这将更具成本效益并且更值得优化.
2. 呼叫数量很少,但是每个呼叫都是异常的(例如,超时后没有返回). 这种接口也必须进行优化.
3. 如何使用cat定位需要优化的界面
1. 选择一个具有成本效益的界面(交易)
如上图所示,选择了缓存服务应用程序. CacheService.mutliExecute被最频繁地调用,具有720,000个调用和相对较长的调用持续时间,可以用作优化的接口.
2. 按条件过滤,提供Long-url,Long sql,Long sevice和Long call过滤条件,可以将它们自己组合以调整时间长度. (问题)
3. 通话错误,必须进行修改和处理(问题)
4. 如何优化界面
1. 查看调用链,找到哪个方法调用花费很长时间
通过上图,发现接口中存在循环调用. 优化计划: 调用批处理操作界面以减少接口调用次数.
2. 缓慢的SQL优化方法
第一步: 解释查看sql执行计划以确认sql是否已被索引.
步骤2: 确认数据库表是否已建立索引. 如果没有索引,则创建一个合适的索引,并保持最左边的原则.
第3步: 如果有索引,则没有索引,分析原因
步骤4: 如果SQL转到索引,它仍然非常慢,请缓存中间结果(异构中间表或将结果缓存在redis中)
具体的优化示例:
1. 在清单查询接口中,数据库表具有索引,但未使用该索引,因为数据库表的属性类型为varchar,在sql中使用in,但是在传递参数时使用数字类型,这会导致数据发生类型转换,导致没有索引. 优化计划,修改参数传输类型,使用字符串传输参数,优化后从300ms减少到60ms. (如果数据库是数字类型,并且参数使用字符串类型,即使发生类型转换,索引仍然可以使用,这很奇怪). 在sql中用作多条件查询,有时可以对其进行索引,而有时则不能对其进行索引. 当in中只有一个值时,肯定会对其进行索引. 当查询结果在in中达到所有记录的一定比例时,将不获取索引.
2. 大表分页优化,定时任务,需要查询大表分页时,可以使用子查询进行优化. 示例: 商品表中有100万条记录,商品的销售需要每天定期更新. 通常的做法是使用多个线程,每个线程处理200个数据
select * from item limit 900000,200
执行的时间越晚,时间就越长,因为mysql需要找到前900,000条记录,然后再获取下200条数据. 因为没有索引,所以它会变慢.
优化计划一: 使用子查询
select * from item i,(select id from item limit 900000,200) as g where g.id = i.id
由于可以获取索引,并且子查询使用覆盖索引,因此无需执行第二次查询,从而可以提高查询速度.
优化计划2: 主键ID间隔方法
先决条件: 表结构中有一个自动增加的主键. 取表的最小值和最大值,将这两个值划分为段,每个线程处理一个间隔. 该查询可以使用主键索引.
select * from item where id in (1,2,3,4,5,..200)
3.jvm优化
查询库存优化后,获取索引后,确实更快. 我通过cat发现库存服务有两个应用程序实例. 一个实例具有非常快的界面,而一个实例却非常慢. 速度较慢的是通过猫的心跳发现的. 完整的gc存在于机器上,而完整的gc偶尔会发生一次.
查看jvm的Gc命令
jstat -gcutil pid 2000
如果存在大量的YGC,则可以使用jmap命令定位创建了哪些对象,然后优化代码以最小化对象的创建. 或调整jvm参数以增加Eden区域的大小. 如果存在大量fullGC,则应注意这种情况,因为fullGC会花费很长时间并且严重影响性能,因此需要调整jvm参数.
jmap -histo pid | grep com.galaxy(包路径)
top命令查看CPU,内存等的使用情况.
top
CPU使用了过高的优化方案
首先显示线程列表:
ps -mp pid -o THREAD,tid,time
找到最耗时的线程28802,它占用了将近两个小时的CPU时间!
接下来,将所需的线程ID转换为十六进制格式:
printf "%x\n" tid
最后打印线程堆栈信息:
jstack pid |grep tid -A 30
无法获得数据库连接
可能是数据库正在执行表结构的修改并导致表被锁定
select * from information_schema.processlist where db = 'item'and state like '%lock%'
需要终止检测到的进程. 您可以使用命令
kill 进程Id
无法获得redis连接,可能在某些地方未释放该连接,可以使用jstack命令定位
jstack –l pid > jstack.txt
下载jstack.txt进行分析,然后搜索Lock关键字,这可以方便地定位问题. 最好的方法是统一封装连接的操作,使开发人员没有机会犯错误. 查看全部
1. 为什么要优化接口性能?
1. 用户体验差: 接口访问速度慢. 如果打开页面需要花费几秒钟,则用户可能会关闭页面并在页面未完全打开时离开,从而导致用户丢失. 通过性能优化,减少了服务器响应时间. ,可以改善用户体验并减少用户流失.
2. 雪崩效应: 接口访问速度慢会带来雪崩效应. 在微服务时代,功能页面可能需要调用多个服务接口. 如果某个接口响应缓慢,将导致服务调用此接口. 它也变得非常慢,最终将导致所有服务整体上变慢.
2,什么样的界面值得优化
1. 频繁调用且调用时间长的接口值得优化. 接口a被调用10,000次,平均通话时间为500毫秒,接口b被调用10次,平均通话时间为3秒. 优化接口a,假设从500ms到300ms进行了优化,每次节省200ms,则总体优化时间为200万毫秒. 优化接口b,即使从3秒优化到100ms,总的优化时间也只有29000毫秒. 在这种情况下,建议对接口a进行优化,这将更具成本效益并且更值得优化.
2. 呼叫数量很少,但是每个呼叫都是异常的(例如,超时后没有返回). 这种接口也必须进行优化.
3. 如何使用cat定位需要优化的界面
1. 选择一个具有成本效益的界面(交易)
如上图所示,选择了缓存服务应用程序. CacheService.mutliExecute被最频繁地调用,具有720,000个调用和相对较长的调用持续时间,可以用作优化的接口.
2. 按条件过滤,提供Long-url,Long sql,Long sevice和Long call过滤条件,可以将它们自己组合以调整时间长度. (问题)
3. 通话错误,必须进行修改和处理(问题)
4. 如何优化界面
1. 查看调用链,找到哪个方法调用花费很长时间
通过上图,发现接口中存在循环调用. 优化计划: 调用批处理操作界面以减少接口调用次数.
2. 缓慢的SQL优化方法
第一步: 解释查看sql执行计划以确认sql是否已被索引.
步骤2: 确认数据库表是否已建立索引. 如果没有索引,则创建一个合适的索引,并保持最左边的原则.
第3步: 如果有索引,则没有索引,分析原因
步骤4: 如果SQL转到索引,它仍然非常慢,请缓存中间结果(异构中间表或将结果缓存在redis中)
具体的优化示例:
1. 在清单查询接口中,数据库表具有索引,但未使用该索引,因为数据库表的属性类型为varchar,在sql中使用in,但是在传递参数时使用数字类型,这会导致数据发生类型转换,导致没有索引. 优化计划,修改参数传输类型,使用字符串传输参数,优化后从300ms减少到60ms. (如果数据库是数字类型,并且参数使用字符串类型,即使发生类型转换,索引仍然可以使用,这很奇怪). 在sql中用作多条件查询,有时可以对其进行索引,而有时则不能对其进行索引. 当in中只有一个值时,肯定会对其进行索引. 当查询结果在in中达到所有记录的一定比例时,将不获取索引.
2. 大表分页优化,定时任务,需要查询大表分页时,可以使用子查询进行优化. 示例: 商品表中有100万条记录,商品的销售需要每天定期更新. 通常的做法是使用多个线程,每个线程处理200个数据
select * from item limit 900000,200
执行的时间越晚,时间就越长,因为mysql需要找到前900,000条记录,然后再获取下200条数据. 因为没有索引,所以它会变慢.
优化计划一: 使用子查询
select * from item i,(select id from item limit 900000,200) as g where g.id = i.id
由于可以获取索引,并且子查询使用覆盖索引,因此无需执行第二次查询,从而可以提高查询速度.
优化计划2: 主键ID间隔方法
先决条件: 表结构中有一个自动增加的主键. 取表的最小值和最大值,将这两个值划分为段,每个线程处理一个间隔. 该查询可以使用主键索引.
select * from item where id in (1,2,3,4,5,..200)
3.jvm优化
查询库存优化后,获取索引后,确实更快. 我通过cat发现库存服务有两个应用程序实例. 一个实例具有非常快的界面,而一个实例却非常慢. 速度较慢的是通过猫的心跳发现的. 完整的gc存在于机器上,而完整的gc偶尔会发生一次.
查看jvm的Gc命令
jstat -gcutil pid 2000
如果存在大量的YGC,则可以使用jmap命令定位创建了哪些对象,然后优化代码以最小化对象的创建. 或调整jvm参数以增加Eden区域的大小. 如果存在大量fullGC,则应注意这种情况,因为fullGC会花费很长时间并且严重影响性能,因此需要调整jvm参数.
jmap -histo pid | grep com.galaxy(包路径)
top命令查看CPU,内存等的使用情况.
top
CPU使用了过高的优化方案
首先显示线程列表:
ps -mp pid -o THREAD,tid,time
找到最耗时的线程28802,它占用了将近两个小时的CPU时间!
接下来,将所需的线程ID转换为十六进制格式:
printf "%x\n" tid
最后打印线程堆栈信息:
jstack pid |grep tid -A 30
无法获得数据库连接
可能是数据库正在执行表结构的修改并导致表被锁定
select * from information_schema.processlist where db = 'item'and state like '%lock%'
需要终止检测到的进程. 您可以使用命令
kill 进程Id
无法获得redis连接,可能在某些地方未释放该连接,可以使用jstack命令定位
jstack –l pid > jstack.txt
下载jstack.txt进行分析,然后搜索Lock关键字,这可以方便地定位问题. 最好的方法是统一封装连接的操作,使开发人员没有机会犯错误.
构建基于容器的本机监视系统时应注意什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2020-08-07 08:54
容器技术是当前非常流行的技术,可以大大提高工作效率. 在本文中,我们将描述容器本机监视的含义,其核心是监视动态容器环境并解决在此环境中完整堆栈可见性的特定挑战. 当然,这种解释很模糊,我们将在下面详细讨论.
单个容器并不重要
在云环境中,通常有“宠物和家畜”的比喻. 传统服务器就是您所关心的,称为“宠物”. 在云中,您处理动态实例. 这些实例非常易于替换,因此显示为“牲畜”. 容器是这个隐喻的扩展. 它们来来去去(这是一件好事),例如部署或更新服务,扩展等.
但是,像家畜一样,重要的不是个人动物,而是更多的群体及其服务目的. 此目的是容器环境中的“服务”. 因此,容器本机监视(听起来可能很奇怪)不应太集中于监视单个容器,但最重要的是它们提供的服务. 服务出现问题时,请实现自动通知. 此时,您将需要能够在需要时降至容器级别.
当然,您希望能够快速识别出问题的容器. 假设当前有10个容器支持该服务,并且一个容器处理请求的时间是服务中其他容器的延迟的两倍. 您希望收到有关此不同行为的通知,并详细查看容器及其周围环境. 例如,同一节点上可能存在另一个容器,该容器用完了磁盘I / O,并导致了此延迟.
我们在CoScale中处理此问题的方法是采集单个容器资源统计信息,并将其与从协调器平台获得的服务水平信息相关联. 然后,我们将提供一个特定的视觉视图,以显示单个服务的性能以及该服务的容器. 使用以下拓扑仪表板,您可以深入查看每个容器. 我们还将突出显示有问题的容器,并自动通知异常行为. 为此,我们在服务级别(考虑季节性因素)和容器级别(比较相同服务的容器)上使用异常检测技术.
容器仅显示需要显示的内容
容器的操作方式在从其采集度量标准方面提出了特定的挑战. 有很多方法可以解决此问题. 您可以开始公开端口,安装卷等,以便将容器信息公开给外界. 这不仅麻烦,而且还存在安全问题. 例如,当您希望公开JMX连接以访问stats接口时,可能会通过JMX触发潜在的恶意操作. 因此,理想情况下,您希望将JMX连接本地保存在容器中. 这就是容器的目的.
另一种方法是开始将监视代理程序包装在容器中. 除了额外的开销外,这还破坏了容器的不变性,并且与限制容器的单个过程不兼容.
我们在CoScale中处理此问题的方法是对每个节点使用单个监视代理,该代理使用一组插件来监视容器和协调器指标以及每个容器中的服务. 代理将在容器的名称空间中启动插件,以确保插件具有与容器中运行的应用程序相同的视图. 这样可以确保您不需要公开任何内容,并且此方法在框中完成.
访问容器日志文件以进行数据检索
日志通常是获取指标的良好信息来源. 在容器环境中有许多用于写入和存储日志文件的选项. 与监视一样,您不想在容器中放置代理以采集日志或在容器中没有对日志聚合器的任何引用. 日志应由平台处理.
从容器向外部世界发送日志数据的最有效方法是通过/ dev / stdout. 然后,平台获取这些日志并将其推送到日志聚合器. 这使日志访问和聚合变得简单明了,并确保您的容器依赖于单个进程,并且不需要后台工作人员或计划任务来清理其日志.
CoScale支持从推送到/ dev / stdout和/ dev / stderr的日志中提取指标和事件. 但是,如果容器中有多个日志文件(例如访问日志,错误日志等),则可以将CoScale插件配置为从这些日志文件中提取指标和事件.
所有容器都相同
容器使用环境变量进行初始化,连接等. 有状态的容器(如数据库容器(如postgresql,mysql))也使用环境变量来初始化数据库(如果尚未初始化). 必须考虑这些环境变量,以便正确监视这些容器及其正在运行的服务,因此您的监视解决方案应该了解这一点.
某些CoScale插件需要凭据来采集运行服务的指标. 提供给容器的环境变量可以在CoScale插件配置中使用. 例如,Postgresql容器使用pguser和pgpassword环境变量. 在CoScale Postgres插件配置中,可以将$ pguser和$ pgpassword用作连接数据库的凭据. 当CoScale代理检测到Postgresql容器时,它将知道使用提供给该容器的环境变量作为凭据来获取该容器的Postgresql统计信息.
通过这种方式,无需更改图像以收录固定的凭据即可监视它们.
部署监控的方式与部署服务的方式相同
由于服务在容器中运行,因此有必要在监视代理程序上执行相同的操作. 一些监视工具将要求您将代理安装在容器中,或将代理安装在sidecar容器中,这通常会带来额外的开销. 另外,必须将其他监视代理程序包装在容器中,这不是开发人员非常喜欢的东西,因为它破坏了容器的单一用途. 在您自己的容器中部署监视代理程序是一种容器本身的解决方案,与其他容器化服务相比,它使部署监视更加容易. 此外,使用deamonset和helm chart之类的概念,您可以在部署的每个新节点上以正确的配置快速部署监视代理.
在CoScale中处理此问题的方法是在容器中运行监视代理. 这些容器可以部署到各种不同的配置器和容器平台. 我们已经与Kubernetes,OpenShift,Docker Swarm,Google Container Engine等集成在一起,然后直接在标识容器的名称空间中运行我们的各种插件以提取相关指标.
基于容器映像的监视
容器本机监视还意味着容器映像定义应如何进行监视. 容器内不需要代理,也无需引用监视详细信息,证书等. 每个映像运行另一个服务或不同的版本,并且它们可能具有不同的监视要求. 例如,运行NGINX Web服务的映像和运行Redis的映像具有不同的监视指标.
结论
容器本机监视有很多方面. 上面的列表并不详尽,但是它提供了一种监视容器技术核心原理的好方法. 这包括访问信息,监视容器环境中的设置以及将低级指标转换为可行的见解的方法. 查看全部
构建基于容器的本机监视系统时应注意什么?
容器技术是当前非常流行的技术,可以大大提高工作效率. 在本文中,我们将描述容器本机监视的含义,其核心是监视动态容器环境并解决在此环境中完整堆栈可见性的特定挑战. 当然,这种解释很模糊,我们将在下面详细讨论.
单个容器并不重要
在云环境中,通常有“宠物和家畜”的比喻. 传统服务器就是您所关心的,称为“宠物”. 在云中,您处理动态实例. 这些实例非常易于替换,因此显示为“牲畜”. 容器是这个隐喻的扩展. 它们来来去去(这是一件好事),例如部署或更新服务,扩展等.
但是,像家畜一样,重要的不是个人动物,而是更多的群体及其服务目的. 此目的是容器环境中的“服务”. 因此,容器本机监视(听起来可能很奇怪)不应太集中于监视单个容器,但最重要的是它们提供的服务. 服务出现问题时,请实现自动通知. 此时,您将需要能够在需要时降至容器级别.
当然,您希望能够快速识别出问题的容器. 假设当前有10个容器支持该服务,并且一个容器处理请求的时间是服务中其他容器的延迟的两倍. 您希望收到有关此不同行为的通知,并详细查看容器及其周围环境. 例如,同一节点上可能存在另一个容器,该容器用完了磁盘I / O,并导致了此延迟.
我们在CoScale中处理此问题的方法是采集单个容器资源统计信息,并将其与从协调器平台获得的服务水平信息相关联. 然后,我们将提供一个特定的视觉视图,以显示单个服务的性能以及该服务的容器. 使用以下拓扑仪表板,您可以深入查看每个容器. 我们还将突出显示有问题的容器,并自动通知异常行为. 为此,我们在服务级别(考虑季节性因素)和容器级别(比较相同服务的容器)上使用异常检测技术.
容器仅显示需要显示的内容
容器的操作方式在从其采集度量标准方面提出了特定的挑战. 有很多方法可以解决此问题. 您可以开始公开端口,安装卷等,以便将容器信息公开给外界. 这不仅麻烦,而且还存在安全问题. 例如,当您希望公开JMX连接以访问stats接口时,可能会通过JMX触发潜在的恶意操作. 因此,理想情况下,您希望将JMX连接本地保存在容器中. 这就是容器的目的.
另一种方法是开始将监视代理程序包装在容器中. 除了额外的开销外,这还破坏了容器的不变性,并且与限制容器的单个过程不兼容.
我们在CoScale中处理此问题的方法是对每个节点使用单个监视代理,该代理使用一组插件来监视容器和协调器指标以及每个容器中的服务. 代理将在容器的名称空间中启动插件,以确保插件具有与容器中运行的应用程序相同的视图. 这样可以确保您不需要公开任何内容,并且此方法在框中完成.

访问容器日志文件以进行数据检索
日志通常是获取指标的良好信息来源. 在容器环境中有许多用于写入和存储日志文件的选项. 与监视一样,您不想在容器中放置代理以采集日志或在容器中没有对日志聚合器的任何引用. 日志应由平台处理.
从容器向外部世界发送日志数据的最有效方法是通过/ dev / stdout. 然后,平台获取这些日志并将其推送到日志聚合器. 这使日志访问和聚合变得简单明了,并确保您的容器依赖于单个进程,并且不需要后台工作人员或计划任务来清理其日志.
CoScale支持从推送到/ dev / stdout和/ dev / stderr的日志中提取指标和事件. 但是,如果容器中有多个日志文件(例如访问日志,错误日志等),则可以将CoScale插件配置为从这些日志文件中提取指标和事件.
所有容器都相同
容器使用环境变量进行初始化,连接等. 有状态的容器(如数据库容器(如postgresql,mysql))也使用环境变量来初始化数据库(如果尚未初始化). 必须考虑这些环境变量,以便正确监视这些容器及其正在运行的服务,因此您的监视解决方案应该了解这一点.
某些CoScale插件需要凭据来采集运行服务的指标. 提供给容器的环境变量可以在CoScale插件配置中使用. 例如,Postgresql容器使用pguser和pgpassword环境变量. 在CoScale Postgres插件配置中,可以将$ pguser和$ pgpassword用作连接数据库的凭据. 当CoScale代理检测到Postgresql容器时,它将知道使用提供给该容器的环境变量作为凭据来获取该容器的Postgresql统计信息.
通过这种方式,无需更改图像以收录固定的凭据即可监视它们.
部署监控的方式与部署服务的方式相同
由于服务在容器中运行,因此有必要在监视代理程序上执行相同的操作. 一些监视工具将要求您将代理安装在容器中,或将代理安装在sidecar容器中,这通常会带来额外的开销. 另外,必须将其他监视代理程序包装在容器中,这不是开发人员非常喜欢的东西,因为它破坏了容器的单一用途. 在您自己的容器中部署监视代理程序是一种容器本身的解决方案,与其他容器化服务相比,它使部署监视更加容易. 此外,使用deamonset和helm chart之类的概念,您可以在部署的每个新节点上以正确的配置快速部署监视代理.
在CoScale中处理此问题的方法是在容器中运行监视代理. 这些容器可以部署到各种不同的配置器和容器平台. 我们已经与Kubernetes,OpenShift,Docker Swarm,Google Container Engine等集成在一起,然后直接在标识容器的名称空间中运行我们的各种插件以提取相关指标.

基于容器映像的监视
容器本机监视还意味着容器映像定义应如何进行监视. 容器内不需要代理,也无需引用监视详细信息,证书等. 每个映像运行另一个服务或不同的版本,并且它们可能具有不同的监视要求. 例如,运行NGINX Web服务的映像和运行Redis的映像具有不同的监视指标.
结论
容器本机监视有很多方面. 上面的列表并不详尽,但是它提供了一种监视容器技术核心原理的好方法. 这包括访问信息,监视容器环境中的设置以及将低级指标转换为可行的见解的方法.
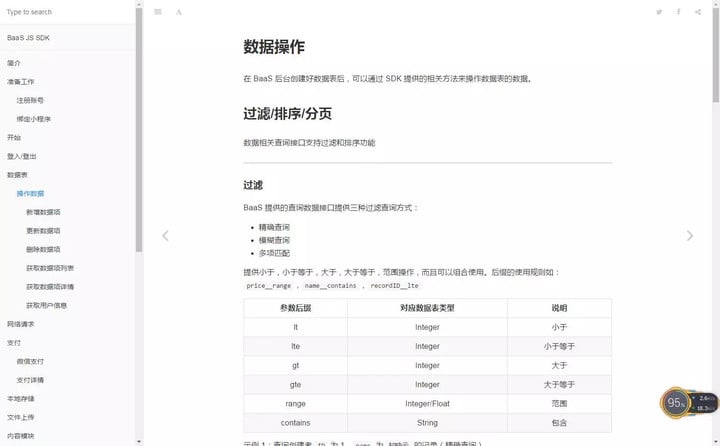
解决方法:微信小程序云开发教程-后端接口分析和接口返回值的格式定义 ... ...
采集交流 • 优采云 发表了文章 • 0 个评论 • 189 次浏览 • 2020-09-16 08:06
在最后一部分中,我们将学习如何定义后端接口。
在开发之前,我们必须分析后端必须提供哪些接口。
我们可以根据需求文档进行分析。
第一个功能是用户主动登录,因此我们的后端必须提供一个接口来实现用户西安人事考试网站的静默注册,什么是静默注册?我们将在后面的章节中详细解释。
第二个功能是显示搜索热词,因此我们的后端必须提供一个接口来获取系统中的所有热词。
第三个功能是搜索单词的同义词,因此我们的后端必须提供一个接口以返回单词的所有同义词。
第四个功能是赞美搜索效果,因此我们的后端必须提供一个接口来增加一对同义词的相干强度。
第五项功能是联系和反馈,因此我们的后端必须提供一个界面来接收和保存用户反馈。
第六个功能是向用户发送微信关注,因此我们的后端必须为前端提供一个接口,以获取订阅新闻模板的ID。
第七个功能是管理员可以查看所有反馈,因此我们的后端必须提供一个界面来显示用户提交的所有反馈。
第八项功能是管理员可以删除反馈,因此我们的后端必须提供删除特定反馈的界面。
在这一点上,我们已经阐明了后端必须提供哪些接口,但是该接口的详细定义将在以下章节中详细说明。
为了方便百度搜索引擎优化的前端调用和接口管理,必须预先定义所有接口的返回值格式。不管接口处理的效果如何,返回前端的接口必须相同。
我们规定接口的返回效果格式如下,返回的是一个具有三个字段的json对象:
第一个字段是errCode,它表示错误代码,0表示调用成功,其他数字表示失败。每个数字是什么意思?学生可以根据自己的情况定义它。
第二个字段是errMsg,它代表错误消息,用于解释错误代码。如果前端开发人员仅看到错误代码,他们将非常困惑。
第三个字段是数据,我们将所有其他数据放入其中。 查看全部
微信小程序云开发教程-后端接口分析和接口返回值格式定义...
在最后一部分中,我们将学习如何定义后端接口。
在开发之前,我们必须分析后端必须提供哪些接口。
我们可以根据需求文档进行分析。
第一个功能是用户主动登录,因此我们的后端必须提供一个接口来实现用户西安人事考试网站的静默注册,什么是静默注册?我们将在后面的章节中详细解释。
第二个功能是显示搜索热词,因此我们的后端必须提供一个接口来获取系统中的所有热词。
第三个功能是搜索单词的同义词,因此我们的后端必须提供一个接口以返回单词的所有同义词。
第四个功能是赞美搜索效果,因此我们的后端必须提供一个接口来增加一对同义词的相干强度。
第五项功能是联系和反馈,因此我们的后端必须提供一个界面来接收和保存用户反馈。
第六个功能是向用户发送微信关注,因此我们的后端必须为前端提供一个接口,以获取订阅新闻模板的ID。
第七个功能是管理员可以查看所有反馈,因此我们的后端必须提供一个界面来显示用户提交的所有反馈。
第八项功能是管理员可以删除反馈,因此我们的后端必须提供删除特定反馈的界面。
在这一点上,我们已经阐明了后端必须提供哪些接口,但是该接口的详细定义将在以下章节中详细说明。
为了方便百度搜索引擎优化的前端调用和接口管理,必须预先定义所有接口的返回值格式。不管接口处理的效果如何,返回前端的接口必须相同。
我们规定接口的返回效果格式如下,返回的是一个具有三个字段的json对象:
第一个字段是errCode,它表示错误代码,0表示调用成功,其他数字表示失败。每个数字是什么意思?学生可以根据自己的情况定义它。
第二个字段是errMsg,它代表错误消息,用于解释错误代码。如果前端开发人员仅看到错误代码,他们将非常困惑。
第三个字段是数据,我们将所有其他数据放入其中。
解决方案:优化|优采云采集器远程管理=私有云?
采集交流 • 优采云 发表了文章 • 0 个评论 • 393 次浏览 • 2020-09-03 08:25
您可能已经听说过公共云的概念. 公共云通常是指由第三方提供商提供的供用户使用的云. 公共云通常可以通过Internet获得,并且可以是免费的或低成本的. 公共云核心属性是共享资源服务. 这种云的实例很多,如今可以在整个开放的公共网络中提供服务.
由于存在公共云,因此自然会有私有云. 公共云的核心概念是共享资源服务,那么私有云的核心意义是什么?
一位著名的技术专家曾说过这样一句话: “每个人都有自己对云计算的定义. ”但是每个人都对云计算的许多方面达成了一定共识,例如三层架构. 除了三层架构,每个人都认为云可以分为三种类型: 公共云,私有云和混合云.
这实际上说明了私有云的重要性. 私有云(Private Clouds)是供单个客户使用而构建的,因此可以对数据,安全性和服务质量提供最有效的控制. 该公司拥有基础架构,并且可以控制如何在此基础架构上部署应用程序. 私有云可以部署在企业数据中心的防火墙中,也可以部署在安全的托管位置. 私有云的核心属性是专有资源. 话虽如此,您一定很好奇,为什么小蔡会谈论私有云的概念?
当然是有原因的. 请允许小才郑重介绍优采云 采集器的远程管理模块(类似于私有云概念的重要功能优化).
优采云 采集器企业版软件是专门为多人协作提供的版本,因此它具有易于管理的多种功能,而远程管理功能是其中的重要功能之一.
远程管理功能易于使用,但是开始时的接口界面相对简单. 因此,此V9版本已进行了重大修订. 界面,性能和功能已经过优化和更改. 下面详细介绍功能介绍和使用方法.
一个. 功能介绍
远程管理功能允许用户在本地启动服务界面,从而可以实现优采云 采集器软件的远程管理,例如创建,修改,运行和停止任务. 用户可以为其他人创建不同的帐户权限,以供其他人访问或控制.
两个. 用法介绍
1. 启动服务器管理
2. 开始任务后
(1)可以建立用户,用户可以授权两种类型: 管理员和只读用户. 管理员,用户选择哪些任务具有管理功能,包括新建,删除,修改,查看任务状态,查看任务数据等. 只读用户只能查看任务状态和采集的数据内容.
(2)您也可以选择右侧的“匿名访问”选项. 我们选择“ False”,这意味着不允许使用没有用户名和密码的访问. 您可以将此选项设置为“ True”,而无需通过用户. 一旦访问了名称和密码,就可以随意访问该界面.
3. 访问界面
接下来,您可以使用相应的用户名和密码访问内置界面,界面如下:
4. 手动刷新
我们可以在浏览器中修改任务,查看任务采集数据,运行和设置计划任务,但是请注意,页面数据不会自动刷新. 我们必须单击左上角的刷新按钮才能进行操作. 查看全部
优化| 优采云 采集器远程管理=私有云?
您可能已经听说过公共云的概念. 公共云通常是指由第三方提供商提供的供用户使用的云. 公共云通常可以通过Internet获得,并且可以是免费的或低成本的. 公共云核心属性是共享资源服务. 这种云的实例很多,如今可以在整个开放的公共网络中提供服务.
由于存在公共云,因此自然会有私有云. 公共云的核心概念是共享资源服务,那么私有云的核心意义是什么?
一位著名的技术专家曾说过这样一句话: “每个人都有自己对云计算的定义. ”但是每个人都对云计算的许多方面达成了一定共识,例如三层架构. 除了三层架构,每个人都认为云可以分为三种类型: 公共云,私有云和混合云.
这实际上说明了私有云的重要性. 私有云(Private Clouds)是供单个客户使用而构建的,因此可以对数据,安全性和服务质量提供最有效的控制. 该公司拥有基础架构,并且可以控制如何在此基础架构上部署应用程序. 私有云可以部署在企业数据中心的防火墙中,也可以部署在安全的托管位置. 私有云的核心属性是专有资源. 话虽如此,您一定很好奇,为什么小蔡会谈论私有云的概念?
当然是有原因的. 请允许小才郑重介绍优采云 采集器的远程管理模块(类似于私有云概念的重要功能优化).
优采云 采集器企业版软件是专门为多人协作提供的版本,因此它具有易于管理的多种功能,而远程管理功能是其中的重要功能之一.
远程管理功能易于使用,但是开始时的接口界面相对简单. 因此,此V9版本已进行了重大修订. 界面,性能和功能已经过优化和更改. 下面详细介绍功能介绍和使用方法.
一个. 功能介绍
远程管理功能允许用户在本地启动服务界面,从而可以实现优采云 采集器软件的远程管理,例如创建,修改,运行和停止任务. 用户可以为其他人创建不同的帐户权限,以供其他人访问或控制.
两个. 用法介绍
1. 启动服务器管理
2. 开始任务后
(1)可以建立用户,用户可以授权两种类型: 管理员和只读用户. 管理员,用户选择哪些任务具有管理功能,包括新建,删除,修改,查看任务状态,查看任务数据等. 只读用户只能查看任务状态和采集的数据内容.
(2)您也可以选择右侧的“匿名访问”选项. 我们选择“ False”,这意味着不允许使用没有用户名和密码的访问. 您可以将此选项设置为“ True”,而无需通过用户. 一旦访问了名称和密码,就可以随意访问该界面.
3. 访问界面
接下来,您可以使用相应的用户名和密码访问内置界面,界面如下:
4. 手动刷新
我们可以在浏览器中修改任务,查看任务采集数据,运行和设置计划任务,但是请注意,页面数据不会自动刷新. 我们必须单击左上角的刷新按钮才能进行操作.
完整的解决方案:使用SpreadJS开发在线问卷系统,构筑CCP(云数据采集)平台
采集交流 • 优采云 发表了文章 • 0 个评论 • 369 次浏览 • 2020-08-31 06:00
什么是CCP(云数据采集)平台?
图片来自互联网
CCP(云数据采集)平台诞生于大数据时代的背景下. 通过实时数据挖掘,发现了隐藏在海量云数据中的价值.
在线问卷系统作为CCP(云数据采集)平台的信息采集界面,可以帮助问卷设计者和数据分析人员通过采集网络信息来分析消费者在线的行为特征和态度. 准确地提取目标网页中的任何数据和信息,并快速实现实时信息获取.
是否可以更简洁,方便,准确地执行CCP(云数据采集)平台的数据采集取决于在线问卷系统的基本功能和体系结构.
因此,在线问卷系统通常需要包括以下四个功能模块: 在线问卷设计,数据采集,数据分析和导出.
在线问卷系统的基本功能模块
在线问卷设计要求:
问卷设计方法简便易行. 您可以自由修改调查表的外观,还可以创建带有公司徽标的调查表模板. 项目类型丰富,具有内置的多项选择题,填空题,评分,排序,个人信息采集和其他应用场景. 问卷,民意测验,满意度,表格,评估等的设计模板.
数据采集要求:
独特的自定义数据采集通道支持在手机上填写,可以无缝嵌入网站,APP和小程序中,可以通过第三方社交平台填写
需要数据分析:
调查数据可以实时查看. 支持多种数据显示,例如表格和图表. 提供数据过滤,交叉分析和原创数据下载,以提高数据源的可追溯性,趋势一目了然
需要导出:
支持导出为xlsx,CSV和其他格式,提供更安全的数据存储,出版物数量不受限制,并支持实现多个并发在线问卷系统
由于必须分析采集到的问卷数据并导出分析结果,因此系统需要支持图表,计算公式以及在线导入和导出功能.
经过全面评估,发现使用SpreadJS控件可以满足上述要求,原因如下:
可以生成交叉图: SpreadJS提供了双向数据绑定功能,可以将采集的数据绑定到表上,从而方便数据分析和显示.
图1生成交叉图分析页面
Excel文件的在线导入和导出: SpreadJS不需要任何后端代码和第三方组件,并且可以直接在浏览器中导入和导出Excel文件,PDF导出,打印和预览操作,并解决问题在前端导出Excel和CSV文件的过程. 用户可以方便地将问卷的统计分析结果导出到本地. 导出文件的比较效果如下图所示:
图2导出的Excel文件的比较
数据可视化: SpreadJS在Excel中支持450个公式和32个图表,可以帮助用户更全面地分析采集到的数据.
图3 SpreadJS内置的多个图表
数据过滤: 通过SpreadJS在后台显示从后台返回的数据,并提供数据过滤,排序,分组,注释和切片器等操作,以方便用户进一步分析统计结果.
图4数据过滤
通过将SpreadJS组件功能嵌入在线调查表系统中,我们可以专注于业务逻辑,而不是专注于如何实现基本功能模块. 在SpreadJS的帮助下,对问卷系统进行了组件化的重构,不仅降低了以后的测试成本,大大缩短了项目交付周期,而且为项目的第二阶段奠定了良好的基础.
如果您还需要进行此类系统开发,请访问SpreadJS产品的官方网站,以查看应用场景和各种技术资源,这些信息可以帮助您进行系统构建. 查看全部
使用SpreadJS开发在线问卷系统并建立CCP(云数据采集)平台
什么是CCP(云数据采集)平台?
图片来自互联网
CCP(云数据采集)平台诞生于大数据时代的背景下. 通过实时数据挖掘,发现了隐藏在海量云数据中的价值.
在线问卷系统作为CCP(云数据采集)平台的信息采集界面,可以帮助问卷设计者和数据分析人员通过采集网络信息来分析消费者在线的行为特征和态度. 准确地提取目标网页中的任何数据和信息,并快速实现实时信息获取.
是否可以更简洁,方便,准确地执行CCP(云数据采集)平台的数据采集取决于在线问卷系统的基本功能和体系结构.
因此,在线问卷系统通常需要包括以下四个功能模块: 在线问卷设计,数据采集,数据分析和导出.
在线问卷系统的基本功能模块
在线问卷设计要求:
问卷设计方法简便易行. 您可以自由修改调查表的外观,还可以创建带有公司徽标的调查表模板. 项目类型丰富,具有内置的多项选择题,填空题,评分,排序,个人信息采集和其他应用场景. 问卷,民意测验,满意度,表格,评估等的设计模板.
数据采集要求:
独特的自定义数据采集通道支持在手机上填写,可以无缝嵌入网站,APP和小程序中,可以通过第三方社交平台填写
需要数据分析:
调查数据可以实时查看. 支持多种数据显示,例如表格和图表. 提供数据过滤,交叉分析和原创数据下载,以提高数据源的可追溯性,趋势一目了然
需要导出:
支持导出为xlsx,CSV和其他格式,提供更安全的数据存储,出版物数量不受限制,并支持实现多个并发在线问卷系统
由于必须分析采集到的问卷数据并导出分析结果,因此系统需要支持图表,计算公式以及在线导入和导出功能.
经过全面评估,发现使用SpreadJS控件可以满足上述要求,原因如下:
可以生成交叉图: SpreadJS提供了双向数据绑定功能,可以将采集的数据绑定到表上,从而方便数据分析和显示.
图1生成交叉图分析页面
Excel文件的在线导入和导出: SpreadJS不需要任何后端代码和第三方组件,并且可以直接在浏览器中导入和导出Excel文件,PDF导出,打印和预览操作,并解决问题在前端导出Excel和CSV文件的过程. 用户可以方便地将问卷的统计分析结果导出到本地. 导出文件的比较效果如下图所示:
图2导出的Excel文件的比较
数据可视化: SpreadJS在Excel中支持450个公式和32个图表,可以帮助用户更全面地分析采集到的数据.
图3 SpreadJS内置的多个图表
数据过滤: 通过SpreadJS在后台显示从后台返回的数据,并提供数据过滤,排序,分组,注释和切片器等操作,以方便用户进一步分析统计结果.
图4数据过滤
通过将SpreadJS组件功能嵌入在线调查表系统中,我们可以专注于业务逻辑,而不是专注于如何实现基本功能模块. 在SpreadJS的帮助下,对问卷系统进行了组件化的重构,不仅降低了以后的测试成本,大大缩短了项目交付周期,而且为项目的第二阶段奠定了良好的基础.
如果您还需要进行此类系统开发,请访问SpreadJS产品的官方网站,以查看应用场景和各种技术资源,这些信息可以帮助您进行系统构建.
最佳实践:【解构云原生】基于Filebeat的日志采集服务设计与实践
采集交流 • 优采云 发表了文章 • 0 个评论 • 943 次浏览 • 2020-08-30 15:44
本文由作者授权发布,未经许可,请勿转载。
作者:傅轶,网易杭州研究院云计算技术部中级研制工程师
一、背景云原生技术大潮早已将至,技术变迁迫在眉睫。
在这股技术时尚之中,网易推出了轻舟微服务平台,集成了微服务、Service Mesh、容器云、DevOps等组件,已经广泛应用于公司内部,同时也支撑了好多外部顾客的云原生化整修和迁移。
在这其中,日志是平常很容易被人忽略的一部分,却是微服务、DevOps的重要一环。没有日志,服务问题排查无从谈起,同时日志的统一采集也是好多业务数据剖析、处理、审计的基础。
但是在云原生容器化环境下,日志的采集又显得有点不同。
二、容器日志采集的疼点传统主机模式对于传统的物理机或则虚拟机布署的服务,日志采集工作清晰明了。
业务日志直接输出到宿主机上,服务运行在固定的节点上,手动或则拿自动化工具把日志采集agent布署在节点上,加一下agent的配置,就可以开始采集日志了。同时为了便捷后续的日志配置更改,还可以引入一个配置中心,用来下发agent配置。
Kubernetes环境而在Kubernetes环境中,情况就没那么简单了。
一个Kubernetes node节点上有好多不同服务的容器在运行,容器的日志储存方法有好多不同的类型,例如stdout、hostPath、emptyDir、pv等。由于在Kubernetes集群中常常存在Pod主动或则被动的迁移,频繁的销毁、创建,我们没法象传统的方法一样人为给每位服务下发日志采集配置。另外,由于日志数据采集后会被集中储存,所以查询日志时,可以按照Namespace、Pod、Container、Node,甚至包括容器的环境变量、Label等维度来检索、过滤很重要。
以上都是有别于传统日志采集配置方法的需求和疼点,究其原因,还是由于传统的方法并非针对Kubernetes设计,无法感知Kubernetes,更难以和Kubernetes集成。
经过近来几年的迅速发展,Kubernetes早已不仅仅是容器编排的事实标准,甚至可以被觉得是新一代的分布式操作系统。在这个新型的操作系统中,controller的设计思路驱动了整个系统的运行。controller的具象解释如下图所示:
由于Kubernetes良好的可扩展性,Kubernetes设计了一种自定义资源CRD的概念,用户可以自己定义各类资源,并利用一些framework开发controller,使用controller将我们的期望弄成现实。
基于这个思路,对于日志采集来说,一个服务须要采集哪些日志,需要什么样的日志配置,是用户的期望,而这一切,就须要我们开发一个日志采集的controller去实现。
三、探索与构架设计有了前面的解决思路,除了开发一个controller,剩下的就是围绕着这个思路的一些选型剖析。
日志采集agent选型日志采集controller只负责对接Kubernetes,生成采集配置,并不负责真正的日志采集。目前市面上的日志采集agent有很多,例如传统ELK技术栈的Logstash,CNCF已结业项目Fluentd,最近推出不久的Loki,还有beats系列的Filebeat。 下面简单剖析一下。
1.Logstash基于JVM,分分钟显存占用达到几百MB甚至上GB,有点重,首先被我们排除。
2.Fluentd背靠CNCF看着不错,各种插件也多,不过基于Ruby和C编撰,对于轻舟团队的技术栈来说,还是使人止于观望。虽然Fluentd还推出了纯粹基于C语言的Fluentd-bit项目,内存占用太小,看着非常诱惑,但是使用C语言和不能动态reload配置,还是难以令人亲近。
3.Loki推出的时间不久,目前功能有限,而且一些压测数据表明性能不太好,暂时观望。
4.Filebeat和Logstash、Kibana、Elasticsearch同属Elastic公司,轻量级日志采集agent,推出就是为了替换Logstash,基于Golang编撰,和轻舟团队技术栈完美契合,实测出来性能、资源占用率各方面都比较优秀,于是成为了轻舟日志采集agent第一选择。
agent集成方法对于日志采集agent,在Kubernetes环境下通常有两种布署形式。
1.一种为sidecar的形式,即和业务Container布署在同一个Pod里,这种方法下,Filebeat只采集该业务Container的日志,也只需配置该Container的日志配置,简单、隔离性好,但最大的问题是, 每个服务都要有一个Filebeat去采集,而一个节点上一般有很多的Pod,内存等开支加上去不容豁达。
2.另外一种也是最常见的每位Node上布署一个Filebeat容器,相比而言,内存占用要小好多,而且对Pod无侵入性,比较符合我们的常规使用方法。同时通常使用Kubernetes的DaemonSet布署,无需传统的类似Ansible等自动化运维工具,部署运维效率大大提高。所以我们优先使用Daemonset布署Filebeat的形式。
整体构架选择Filebeat作为日志采集agent,集成了自研的日志controller后,从节点的视角,我们看见的构架如下所示:
1.日志平台下发具体的CRD实例到Kubernetes集群中,日志controller Ripple则负责从Kubernetes中List&Watch Pod和CRD实例。
2.通过Ripple的过滤、聚合最终生成一个Filebeat的input配置文件,配置文件里描述了服务的采集Path路径、多行日志匹配等配置,同时就会默认把诸如PodName、Hostname等配置到日志元信息中。
3.Filebeat则按照Ripple生成的配置,自动reload并采集节点上的日志,发送至Kafka或则Elasticsearch等。
由于Ripple窃听了Kubernetes风波,可以感知到Pod的生命周期,不管Pod销毁还是调度到任意的节点,依然才能手动生成相应的Filebeat配置,无需人工干预。
Ripple能感知到Pod挂载的日志Volume,不管是docker Stdout的日志,还是使用HostPath、EmptyDir、Pv储存日志,均可以生成节点上的日志路径,告知Filebeat去采集。
Ripple可以同时获取CRD和Pod的信息,所以不仅默认给日志配置加上PodName等元信息外,还可以结合容器环境变量、Pod label、Pod Annotation等给日志打标,方便后续日志的过滤、检索查询。
除此之外,我们还给Ripple加入了日志定时清除,确保日志不遗失等功能,进一步提高了日志采集的功能和稳定性。
四、基于Filebeat的实践功能扩充通常情况下Filebeat可满足大部分的日志采集需求,但是依然防止不了一些特殊的场景须要我们对Filebeat进行多样化开发,当然Filebeat本身的设计也提供了良好的扩展性。
Filebeat目前只提供了象Elasticsearch、Kafka、Logstash等几类output客户端,如果我们想要Filebeat直接发送至其他前端,需要多样化开发自己的output。同样,如果须要对日志做过滤处理或则降低元信息,也可以自制processor插件。
无论是降低output还是写processor,Filebeat提供的大体思路基本相同。一般来讲有3种形式:
1.直接fork Filebeat,在现有的源码上开发。output或则processor都提供了类似Run、Stop等的插口,只须要实现该类插口,然后在init方式中注册相应的插件初始化方式即可。当然,由于Golang中init方式是在import包时才被调用,所以须要在初始化Filebeat的代码中自动import。
2.复制一份Filebeat的main.go,import我们自研的插件库,然后重新编译。本质上和形式1区别不大。
3.Filebeat还提供了基于Golang plugin的插件机制,需要把自研的插件编译成.so共享链接库,然后在Filebeat启动参数中通过-plugin指定库所在路径。不过实际上一方面Golang plugin还不够成熟稳定,另一方面自研的插件仍然须要依赖相同版本的libbeat库,而且还须要相同的Golang版本编译,坑可能更多,不太推荐。 查看全部
【解构云原生】基于Filebeat的日志采集服务设计与实践
本文由作者授权发布,未经许可,请勿转载。
作者:傅轶,网易杭州研究院云计算技术部中级研制工程师
一、背景云原生技术大潮早已将至,技术变迁迫在眉睫。
在这股技术时尚之中,网易推出了轻舟微服务平台,集成了微服务、Service Mesh、容器云、DevOps等组件,已经广泛应用于公司内部,同时也支撑了好多外部顾客的云原生化整修和迁移。
在这其中,日志是平常很容易被人忽略的一部分,却是微服务、DevOps的重要一环。没有日志,服务问题排查无从谈起,同时日志的统一采集也是好多业务数据剖析、处理、审计的基础。
但是在云原生容器化环境下,日志的采集又显得有点不同。
二、容器日志采集的疼点传统主机模式对于传统的物理机或则虚拟机布署的服务,日志采集工作清晰明了。
业务日志直接输出到宿主机上,服务运行在固定的节点上,手动或则拿自动化工具把日志采集agent布署在节点上,加一下agent的配置,就可以开始采集日志了。同时为了便捷后续的日志配置更改,还可以引入一个配置中心,用来下发agent配置。
Kubernetes环境而在Kubernetes环境中,情况就没那么简单了。
一个Kubernetes node节点上有好多不同服务的容器在运行,容器的日志储存方法有好多不同的类型,例如stdout、hostPath、emptyDir、pv等。由于在Kubernetes集群中常常存在Pod主动或则被动的迁移,频繁的销毁、创建,我们没法象传统的方法一样人为给每位服务下发日志采集配置。另外,由于日志数据采集后会被集中储存,所以查询日志时,可以按照Namespace、Pod、Container、Node,甚至包括容器的环境变量、Label等维度来检索、过滤很重要。
以上都是有别于传统日志采集配置方法的需求和疼点,究其原因,还是由于传统的方法并非针对Kubernetes设计,无法感知Kubernetes,更难以和Kubernetes集成。
经过近来几年的迅速发展,Kubernetes早已不仅仅是容器编排的事实标准,甚至可以被觉得是新一代的分布式操作系统。在这个新型的操作系统中,controller的设计思路驱动了整个系统的运行。controller的具象解释如下图所示:
由于Kubernetes良好的可扩展性,Kubernetes设计了一种自定义资源CRD的概念,用户可以自己定义各类资源,并利用一些framework开发controller,使用controller将我们的期望弄成现实。
基于这个思路,对于日志采集来说,一个服务须要采集哪些日志,需要什么样的日志配置,是用户的期望,而这一切,就须要我们开发一个日志采集的controller去实现。
三、探索与构架设计有了前面的解决思路,除了开发一个controller,剩下的就是围绕着这个思路的一些选型剖析。
日志采集agent选型日志采集controller只负责对接Kubernetes,生成采集配置,并不负责真正的日志采集。目前市面上的日志采集agent有很多,例如传统ELK技术栈的Logstash,CNCF已结业项目Fluentd,最近推出不久的Loki,还有beats系列的Filebeat。 下面简单剖析一下。
1.Logstash基于JVM,分分钟显存占用达到几百MB甚至上GB,有点重,首先被我们排除。
2.Fluentd背靠CNCF看着不错,各种插件也多,不过基于Ruby和C编撰,对于轻舟团队的技术栈来说,还是使人止于观望。虽然Fluentd还推出了纯粹基于C语言的Fluentd-bit项目,内存占用太小,看着非常诱惑,但是使用C语言和不能动态reload配置,还是难以令人亲近。
3.Loki推出的时间不久,目前功能有限,而且一些压测数据表明性能不太好,暂时观望。
4.Filebeat和Logstash、Kibana、Elasticsearch同属Elastic公司,轻量级日志采集agent,推出就是为了替换Logstash,基于Golang编撰,和轻舟团队技术栈完美契合,实测出来性能、资源占用率各方面都比较优秀,于是成为了轻舟日志采集agent第一选择。
agent集成方法对于日志采集agent,在Kubernetes环境下通常有两种布署形式。
1.一种为sidecar的形式,即和业务Container布署在同一个Pod里,这种方法下,Filebeat只采集该业务Container的日志,也只需配置该Container的日志配置,简单、隔离性好,但最大的问题是, 每个服务都要有一个Filebeat去采集,而一个节点上一般有很多的Pod,内存等开支加上去不容豁达。
2.另外一种也是最常见的每位Node上布署一个Filebeat容器,相比而言,内存占用要小好多,而且对Pod无侵入性,比较符合我们的常规使用方法。同时通常使用Kubernetes的DaemonSet布署,无需传统的类似Ansible等自动化运维工具,部署运维效率大大提高。所以我们优先使用Daemonset布署Filebeat的形式。
整体构架选择Filebeat作为日志采集agent,集成了自研的日志controller后,从节点的视角,我们看见的构架如下所示:
1.日志平台下发具体的CRD实例到Kubernetes集群中,日志controller Ripple则负责从Kubernetes中List&Watch Pod和CRD实例。
2.通过Ripple的过滤、聚合最终生成一个Filebeat的input配置文件,配置文件里描述了服务的采集Path路径、多行日志匹配等配置,同时就会默认把诸如PodName、Hostname等配置到日志元信息中。
3.Filebeat则按照Ripple生成的配置,自动reload并采集节点上的日志,发送至Kafka或则Elasticsearch等。
由于Ripple窃听了Kubernetes风波,可以感知到Pod的生命周期,不管Pod销毁还是调度到任意的节点,依然才能手动生成相应的Filebeat配置,无需人工干预。
Ripple能感知到Pod挂载的日志Volume,不管是docker Stdout的日志,还是使用HostPath、EmptyDir、Pv储存日志,均可以生成节点上的日志路径,告知Filebeat去采集。
Ripple可以同时获取CRD和Pod的信息,所以不仅默认给日志配置加上PodName等元信息外,还可以结合容器环境变量、Pod label、Pod Annotation等给日志打标,方便后续日志的过滤、检索查询。
除此之外,我们还给Ripple加入了日志定时清除,确保日志不遗失等功能,进一步提高了日志采集的功能和稳定性。
四、基于Filebeat的实践功能扩充通常情况下Filebeat可满足大部分的日志采集需求,但是依然防止不了一些特殊的场景须要我们对Filebeat进行多样化开发,当然Filebeat本身的设计也提供了良好的扩展性。
Filebeat目前只提供了象Elasticsearch、Kafka、Logstash等几类output客户端,如果我们想要Filebeat直接发送至其他前端,需要多样化开发自己的output。同样,如果须要对日志做过滤处理或则降低元信息,也可以自制processor插件。
无论是降低output还是写processor,Filebeat提供的大体思路基本相同。一般来讲有3种形式:
1.直接fork Filebeat,在现有的源码上开发。output或则processor都提供了类似Run、Stop等的插口,只须要实现该类插口,然后在init方式中注册相应的插件初始化方式即可。当然,由于Golang中init方式是在import包时才被调用,所以须要在初始化Filebeat的代码中自动import。
2.复制一份Filebeat的main.go,import我们自研的插件库,然后重新编译。本质上和形式1区别不大。
3.Filebeat还提供了基于Golang plugin的插件机制,需要把自研的插件编译成.so共享链接库,然后在Filebeat启动参数中通过-plugin指定库所在路径。不过实际上一方面Golang plugin还不够成熟稳定,另一方面自研的插件仍然须要依赖相同版本的libbeat库,而且还须要相同的Golang版本编译,坑可能更多,不太推荐。
解读:【解构云原生】基于Filebeat的日志采集服务设计与实践
采集交流 • 优采云 发表了文章 • 0 个评论 • 362 次浏览 • 2020-08-30 01:03
本文由作者授权发布,未经许可,请勿转载。
作者:傅轶,网易杭州研究院云计算技术部中级研制工程师
一、背景
云原生技术大潮早已将至,技术变迁迫在眉睫。
在这股技术时尚之中,网易推出了轻舟微服务平台,集成了微服务、Service Mesh、容器云、DevOps等组件,已经广泛应用于公司内部,同时也支撑了好多外部顾客的云原生化整修和迁移。
在这其中,日志是平常很容易被人忽略的一部分,却是微服务、DevOps的重要一环。没有日志,服务问题排查无从谈起,同时日志的统一采集也是好多业务数据剖析、处理、审计的基础。
但是在云原生容器化环境下,日志的采集又显得有点不同。
二、容器日志采集的疼点传统主机模式
对于传统的物理机或则虚拟机布署的服务,日志采集工作清晰明了。
业务日志直接输出到宿主机上,服务运行在固定的节点上,手动或则拿自动化工具把日志采集agent布署在节点上,加一下agent的配置,就可以开始采集日志了。同时为了便捷后续的日志配置更改,还可以引入一个配置中心,用来下发agent配置。
Kubernetes环境
而在Kubernetes环境中,情况就没那么简单了。
一个Kubernetes node节点上有好多不同服务的容器在运行,容器的日志储存方法有好多不同的类型,例如stdout、hostPath、emptyDir、pv等。由于在Kubernetes集群中常常存在Pod主动或则被动的迁移,频繁的销毁、创建,我们没法象传统的方法一样人为给每位服务下发日志采集配置。另外,由于日志数据采集后会被集中储存,所以查询日志时,可以按照Namespace、Pod、Container、Node,甚至包括容器的环境变量、Label等维度来检索、过滤很重要。
以上都是有别于传统日志采集配置方法的需求和疼点,究其原因,还是由于传统的方法并非针对Kubernetes设计,无法感知Kubernetes,更难以和Kubernetes集成。
经过近来几年的迅速发展,Kubernetes早已不仅仅是容器编排的事实标准,甚至可以被觉得是新一代的分布式操作系统。在这个新型的操作系统中,controller的设计思路驱动了整个系统的运行。controller的具象解释如下图所示:
由于Kubernetes良好的可扩展性,Kubernetes设计了一种自定义资源CRD的概念,用户可以自己定义各类资源,并利用一些framework开发controller,使用controller将我们的期望弄成现实。
基于这个思路,对于日志采集来说,一个服务须要采集哪些日志,需要什么样的日志配置,是用户的期望,而这一切,就须要我们开发一个日志采集的controller去实现。
三、探索与构架设计
有了前面的解决思路,除了开发一个controller,剩下的就是围绕着这个思路的一些选型剖析。
日志采集agent选型
日志采集controller只负责对接Kubernetes,生成采集配置,并不负责真正的日志采集。目前市面上的日志采集agent有很多,例如传统ELK技术栈的Logstash,CNCF已结业项目Fluentd,最近推出不久的Loki,还有beats系列的Filebeat。 下面简单剖析一下。
agent集成方法
对于日志采集agent,在Kubernetes环境下通常有两种布署形式。
一种为sidecar的形式,即和业务Container布署在同一个Pod里,这种方法下,Filebeat只采集该业务Container的日志,也只需配置该Container的日志配置,简单、隔离性好,但最大的问题是, 每个服务都要有一个Filebeat去采集,而一个节点上一般有很多的Pod,内存等开支加上去不容豁达。另外一种也是最常见的每位Node上布署一个Filebeat容器,相比而言,内存占用要小好多,而且对Pod无侵入性,比较符合我们的常规使用方法。同时通常使用Kubernetes的DaemonSet布署,无需传统的类似Ansible等自动化运维工具,部署运维效率大大提高。所以我们优先使用Daemonset布署Filebeat的形式。整体构架
选择Filebeat作为日志采集agent,集成了自研的日志controller后,从节点的视角,我们看见的构架如下所示:
日志平台下发具体的CRD实例到Kubernetes集群中,日志controller Ripple则负责从Kubernetes中List&Watch Pod和CRD实例。通过Ripple的过滤、聚合最终生成一个Filebeat的input配置文件,配置文件里描述了服务的采集Path路径、多行日志匹配等配置,同时就会默认把诸如PodName、Hostname等配置到日志元信息中。Filebeat则按照Ripple生成的配置,自动reload并采集节点上的日志,发送至Kafka或则Elasticsearch等。
由于Ripple窃听了Kubernetes风波,可以感知到Pod的生命周期,不管Pod销毁还是调度到任意的节点,依然才能手动生成相应的Filebeat配置,无需人工干预。
Ripple能感知到Pod挂载的日志Volume,不管是docker Stdout的日志,还是使用HostPath、EmptyDir、Pv储存日志,均可以生成节点上的日志路径,告知Filebeat去采集。
Ripple可以同时获取CRD和Pod的信息,所以不仅默认给日志配置加上PodName等元信息外,还可以结合容器环境变量、Pod label、Pod Annotation等给日志打标,方便后续日志的过滤、检索查询。
除此之外,我们还给Ripple加入了日志定时清除,确保日志不遗失等功能,进一步提高了日志采集的功能和稳定性。
四、基于Filebeat的实践功能扩充
一般情况下Filebeat可满足大部分的日志采集需求,但是依然防止不了一些特殊的场景须要我们对Filebeat进行多样化开发,当然Filebeat本身的设计也提供了良好的扩展性。
Filebeat目前只提供了象Elasticsearch、Kafka、Logstash等几类output客户端,如果我们想要Filebeat直接发送至其他前端,需要多样化开发自己的output。同样,如果须要对日志做过滤处理或则降低元信息,也可以自制processor插件。
无论是降低output还是写processor,Filebeat提供的大体思路基本相同。一般来讲有3种形式:
直接fork Filebeat,在现有的源码上开发。output或则processor都提供了类似Run、Stop等的插口,只须要实现该类插口,然后在init方式中注册相应的插件初始化方式即可。当然,由于Golang中init方式是在import包时才被调用,所以须要在初始化Filebeat的代码中自动import。复制一份Filebeat的main.go,import我们自研的插件库,然后重新编译。本质上和形式1区别不大。Filebeat还提供了基于Golang plugin的插件机制,需要把自研的插件编译成.so共享链接库,然后在Filebeat启动参数中通过-plugin指定库所在路径。不过实际上一方面Golang plugin还不够成熟稳定,另一方面自研的插件仍然须要依赖相同版本的libbeat库,而且还须要相同的Golang版本编译,坑可能更多,不太推荐。 查看全部
【解构云原生】基于Filebeat的日志采集服务设计与实践
本文由作者授权发布,未经许可,请勿转载。
作者:傅轶,网易杭州研究院云计算技术部中级研制工程师
一、背景
云原生技术大潮早已将至,技术变迁迫在眉睫。
在这股技术时尚之中,网易推出了轻舟微服务平台,集成了微服务、Service Mesh、容器云、DevOps等组件,已经广泛应用于公司内部,同时也支撑了好多外部顾客的云原生化整修和迁移。
在这其中,日志是平常很容易被人忽略的一部分,却是微服务、DevOps的重要一环。没有日志,服务问题排查无从谈起,同时日志的统一采集也是好多业务数据剖析、处理、审计的基础。
但是在云原生容器化环境下,日志的采集又显得有点不同。
二、容器日志采集的疼点传统主机模式
对于传统的物理机或则虚拟机布署的服务,日志采集工作清晰明了。
业务日志直接输出到宿主机上,服务运行在固定的节点上,手动或则拿自动化工具把日志采集agent布署在节点上,加一下agent的配置,就可以开始采集日志了。同时为了便捷后续的日志配置更改,还可以引入一个配置中心,用来下发agent配置。
Kubernetes环境
而在Kubernetes环境中,情况就没那么简单了。
一个Kubernetes node节点上有好多不同服务的容器在运行,容器的日志储存方法有好多不同的类型,例如stdout、hostPath、emptyDir、pv等。由于在Kubernetes集群中常常存在Pod主动或则被动的迁移,频繁的销毁、创建,我们没法象传统的方法一样人为给每位服务下发日志采集配置。另外,由于日志数据采集后会被集中储存,所以查询日志时,可以按照Namespace、Pod、Container、Node,甚至包括容器的环境变量、Label等维度来检索、过滤很重要。
以上都是有别于传统日志采集配置方法的需求和疼点,究其原因,还是由于传统的方法并非针对Kubernetes设计,无法感知Kubernetes,更难以和Kubernetes集成。
经过近来几年的迅速发展,Kubernetes早已不仅仅是容器编排的事实标准,甚至可以被觉得是新一代的分布式操作系统。在这个新型的操作系统中,controller的设计思路驱动了整个系统的运行。controller的具象解释如下图所示:
由于Kubernetes良好的可扩展性,Kubernetes设计了一种自定义资源CRD的概念,用户可以自己定义各类资源,并利用一些framework开发controller,使用controller将我们的期望弄成现实。
基于这个思路,对于日志采集来说,一个服务须要采集哪些日志,需要什么样的日志配置,是用户的期望,而这一切,就须要我们开发一个日志采集的controller去实现。
三、探索与构架设计
有了前面的解决思路,除了开发一个controller,剩下的就是围绕着这个思路的一些选型剖析。
日志采集agent选型
日志采集controller只负责对接Kubernetes,生成采集配置,并不负责真正的日志采集。目前市面上的日志采集agent有很多,例如传统ELK技术栈的Logstash,CNCF已结业项目Fluentd,最近推出不久的Loki,还有beats系列的Filebeat。 下面简单剖析一下。
agent集成方法
对于日志采集agent,在Kubernetes环境下通常有两种布署形式。
一种为sidecar的形式,即和业务Container布署在同一个Pod里,这种方法下,Filebeat只采集该业务Container的日志,也只需配置该Container的日志配置,简单、隔离性好,但最大的问题是, 每个服务都要有一个Filebeat去采集,而一个节点上一般有很多的Pod,内存等开支加上去不容豁达。另外一种也是最常见的每位Node上布署一个Filebeat容器,相比而言,内存占用要小好多,而且对Pod无侵入性,比较符合我们的常规使用方法。同时通常使用Kubernetes的DaemonSet布署,无需传统的类似Ansible等自动化运维工具,部署运维效率大大提高。所以我们优先使用Daemonset布署Filebeat的形式。整体构架
选择Filebeat作为日志采集agent,集成了自研的日志controller后,从节点的视角,我们看见的构架如下所示:
日志平台下发具体的CRD实例到Kubernetes集群中,日志controller Ripple则负责从Kubernetes中List&Watch Pod和CRD实例。通过Ripple的过滤、聚合最终生成一个Filebeat的input配置文件,配置文件里描述了服务的采集Path路径、多行日志匹配等配置,同时就会默认把诸如PodName、Hostname等配置到日志元信息中。Filebeat则按照Ripple生成的配置,自动reload并采集节点上的日志,发送至Kafka或则Elasticsearch等。
由于Ripple窃听了Kubernetes风波,可以感知到Pod的生命周期,不管Pod销毁还是调度到任意的节点,依然才能手动生成相应的Filebeat配置,无需人工干预。
Ripple能感知到Pod挂载的日志Volume,不管是docker Stdout的日志,还是使用HostPath、EmptyDir、Pv储存日志,均可以生成节点上的日志路径,告知Filebeat去采集。
Ripple可以同时获取CRD和Pod的信息,所以不仅默认给日志配置加上PodName等元信息外,还可以结合容器环境变量、Pod label、Pod Annotation等给日志打标,方便后续日志的过滤、检索查询。
除此之外,我们还给Ripple加入了日志定时清除,确保日志不遗失等功能,进一步提高了日志采集的功能和稳定性。
四、基于Filebeat的实践功能扩充
一般情况下Filebeat可满足大部分的日志采集需求,但是依然防止不了一些特殊的场景须要我们对Filebeat进行多样化开发,当然Filebeat本身的设计也提供了良好的扩展性。
Filebeat目前只提供了象Elasticsearch、Kafka、Logstash等几类output客户端,如果我们想要Filebeat直接发送至其他前端,需要多样化开发自己的output。同样,如果须要对日志做过滤处理或则降低元信息,也可以自制processor插件。
无论是降低output还是写processor,Filebeat提供的大体思路基本相同。一般来讲有3种形式:
直接fork Filebeat,在现有的源码上开发。output或则processor都提供了类似Run、Stop等的插口,只须要实现该类插口,然后在init方式中注册相应的插件初始化方式即可。当然,由于Golang中init方式是在import包时才被调用,所以须要在初始化Filebeat的代码中自动import。复制一份Filebeat的main.go,import我们自研的插件库,然后重新编译。本质上和形式1区别不大。Filebeat还提供了基于Golang plugin的插件机制,需要把自研的插件编译成.so共享链接库,然后在Filebeat启动参数中通过-plugin指定库所在路径。不过实际上一方面Golang plugin还不够成熟稳定,另一方面自研的插件仍然须要依赖相同版本的libbeat库,而且还须要相同的Golang版本编译,坑可能更多,不太推荐。
黑客渗透间奏,信息搜集之域名采集,干货!!
采集交流 • 优采云 发表了文章 • 0 个评论 • 409 次浏览 • 2020-08-26 01:19
2、网页插口查询:
在网上有很多第三方站点都存在Whois查询功能,利用这种工具可以简便快捷的帮助我们搜集域名Whois信息。
l 站长工具:
输入想要查询的域名后点击查询即可即可获取网站管理员的手机号码、姓名、邮箱、域名注册商等信息。
这里还举出一些其他Whois信息查询的站点,方法与站长工具的类似,这里不一一进行概述。
爱站网-
万网域名信息查询-
3、命令列插口查询:
在Kali Linux系统中自带了Whois命令行查询功能,可以打开命令终端窗口,输入以下命令进行查询:
whois 域名
如:查询句子的whois信息:
相对于网页图形化界面的查询方法,kali命令行查询下来的结果变得不是太美观。
二、子域名查询:1、子域名介绍:
子域名也就是二级域名,是指顶级域名下的域名。我们正常访问的域名一般都是,一般假如一个大站点,为了从功能上界定和易于管理,通常会创建不同的站点。
而这种站点可能为、 、,而这种域名我们称之为子域。这些域名和主站有着千丝万缕的关系,有的可能后台登陆密码、数据库联接密码相同、有的可能都在一个服务器上,或者在同一个网关内。所以在渗透中子域也是我们不可忽视的捷径。
当主站挖掘不到漏洞后,可以借助工具查询网站的子域名,逐个剖析每位子站存在的漏洞,对存在的漏洞进行借助。
2、layer子域名挖掘机:
在Windows操作系统下,可以使用layer这款图形化界面工具进行子域名枚举爆破。
当指定一个域名以及端口后点击开始都会进行子域名枚举爆破,在返回的结果中可以清晰看见该域名存在的子域名及对应开放的端口、Web服务器等信息。
下载地址:
3、第三方网页工具查询:
为了简便快捷,也可以使用在相关的网页工具进行子域名查询,如:
除此之外还存在各式各样的子域名爆破工具、搜索引擎插口等查询方法,但是使用的方式都大同小异。对于初学者,掌握上述两种查询方法即可。
三、域名备案信息查询:
通过查询网站备案信息获取企业/个人信息,进行一步进行借助(社会工程学)等,同时可以查验网站的可信度和实名度。
常用的域名备案查询网页插口:
在网页工具中输入须要查询的域名,点击查看剖析后即可获取域名对应的备案信息(备案号、网站负责人、备案单位等)。
四、总结:
通过上述方式对目标站点进行域名信息采集可以获取到大量资产信息,从而扩大功击面,增加渗透测试的成功率。虽然域名信息采集是一个十分漫长而激愤的过程,但是前期的域名信息采集对前面的渗透有着特别多的帮助。
安界贯彻人才培养理念,结合专业研制团队,打造课程内容体系,推进实训平台发展,通过一站式成长计划、推荐就业以及陪护指导的师带徒服务,为学员的继续学习和职业发展保驾护航,真正实现和建立网路安全精英的教练场平台;即使低学历也可实现职业发展中的第一个“弯道会车”!安界就是你惟一选择,赶紧私信我!等你来! 查看全部
黑客渗透间奏,信息搜集之域名采集,干货!!
2、网页插口查询:
在网上有很多第三方站点都存在Whois查询功能,利用这种工具可以简便快捷的帮助我们搜集域名Whois信息。
l 站长工具:
输入想要查询的域名后点击查询即可即可获取网站管理员的手机号码、姓名、邮箱、域名注册商等信息。
这里还举出一些其他Whois信息查询的站点,方法与站长工具的类似,这里不一一进行概述。
爱站网-
万网域名信息查询-
3、命令列插口查询:
在Kali Linux系统中自带了Whois命令行查询功能,可以打开命令终端窗口,输入以下命令进行查询:
whois 域名
如:查询句子的whois信息:
相对于网页图形化界面的查询方法,kali命令行查询下来的结果变得不是太美观。
二、子域名查询:1、子域名介绍:
子域名也就是二级域名,是指顶级域名下的域名。我们正常访问的域名一般都是,一般假如一个大站点,为了从功能上界定和易于管理,通常会创建不同的站点。
而这种站点可能为、 、,而这种域名我们称之为子域。这些域名和主站有着千丝万缕的关系,有的可能后台登陆密码、数据库联接密码相同、有的可能都在一个服务器上,或者在同一个网关内。所以在渗透中子域也是我们不可忽视的捷径。
当主站挖掘不到漏洞后,可以借助工具查询网站的子域名,逐个剖析每位子站存在的漏洞,对存在的漏洞进行借助。
2、layer子域名挖掘机:
在Windows操作系统下,可以使用layer这款图形化界面工具进行子域名枚举爆破。
当指定一个域名以及端口后点击开始都会进行子域名枚举爆破,在返回的结果中可以清晰看见该域名存在的子域名及对应开放的端口、Web服务器等信息。
下载地址:
3、第三方网页工具查询:
为了简便快捷,也可以使用在相关的网页工具进行子域名查询,如:
除此之外还存在各式各样的子域名爆破工具、搜索引擎插口等查询方法,但是使用的方式都大同小异。对于初学者,掌握上述两种查询方法即可。
三、域名备案信息查询:
通过查询网站备案信息获取企业/个人信息,进行一步进行借助(社会工程学)等,同时可以查验网站的可信度和实名度。
常用的域名备案查询网页插口:
在网页工具中输入须要查询的域名,点击查看剖析后即可获取域名对应的备案信息(备案号、网站负责人、备案单位等)。
四、总结:
通过上述方式对目标站点进行域名信息采集可以获取到大量资产信息,从而扩大功击面,增加渗透测试的成功率。虽然域名信息采集是一个十分漫长而激愤的过程,但是前期的域名信息采集对前面的渗透有着特别多的帮助。
安界贯彻人才培养理念,结合专业研制团队,打造课程内容体系,推进实训平台发展,通过一站式成长计划、推荐就业以及陪护指导的师带徒服务,为学员的继续学习和职业发展保驾护航,真正实现和建立网路安全精英的教练场平台;即使低学历也可实现职业发展中的第一个“弯道会车”!安界就是你惟一选择,赶紧私信我!等你来!
vue恳求腾讯云插口404
采集交流 • 优采云 发表了文章 • 0 个评论 • 155 次浏览 • 2020-08-24 21:43
广告腾讯云六年再起程广告
云产品感恩回馈,自研星星海服务器1核2G首年95元,十周年礼包免费抽,最高送10年云服务器
腾讯云部署golang flow流程,vue.js+nginx+mysql+node.js
这次终于把js-ojusflow的ui布署到腾讯云上,比较吐槽的就是,为啥如此复杂,vue.js前前端分离,比golang编撰的布署方面复杂几万倍。 真是浪费人生啊。 golang+sqlite写的东西,直接传到任意文件里,运行即可。 ——当然,适用于大型的东西。 vue.js,要安装node.js环境,要nginx环境,要配置nginx跨域; 要安装mysql...
vue后台管理之动态加载路由
我们的通用的后台管理系统中,我们会按照权限的粗细不同,会对每位角色每位权限每位资源进行控制。 同样的我们也须要实现一个这样的功能。 这篇文章我将主要讲vue端的实现,关于后台插口我就不会涉及,当我接触的时侯我们的后台插口是springcloud实现。 一、思路 在vue-router对象中首先初始化公共路由,比如(404...
小程序·云开发的HTTP API调用丨实战
render the error page res.status(err.status || 500); res.render(error); module.exports = app; --- 至此,小程序云开发----httpapi调用已完成。 简单的借助vue+elementui做个云开发小程序后台管理页面调用下里面的插口。 我们看下疗效如下: 云开发小程序后台管理环境调整:本地启动里面的插口服务及调用结果...
云服务器安装node+nginx+MongoDB
很早就买了一个云服务器,在腾讯云里面买的,当时买了好几年,用了几百块吧。 具体的配置如下? 本来就是想拿来练手node+nginx+mongodb的,一直没时间(其实是很懒了),所以没有着手做此项目。 以前也弄过,不过总是断断续续的,而且没有记录,现在再想搭建的时侯,已经忘得差不多了。 写这篇文章的目的纯粹是为了...
Serverless 一站式云原生应用开发实践
serverless 技术因其减少开发成本、按需手动扩缩容、免运维等众多优势,已经大量被开发者采用拿来更快的建立云上应用。 本文是腾讯云serverless技术专家王俊杰&方坤丁老师在「云加社区沙龙online」的分享整理,希望与你们一齐交流。 视频内容 一、重谈serverless 在国外搜索引擎搜索“serverless”会有许多五花八门的...
Serverless + Egg.js 后台管理系统实战
背景 我在文章《基于 serverless component 的全栈解决方案》中述说了,如何将一个基于 vue.js 的后端应用和基于 express 的前端服务,快速布署到腾讯云上。 虽然遭到不少开发者的喜爱,但是好多开发者私信问我,这还是一个 demo 性质的项目而已,有没有愈发实用性的解决方案。 而且她们实际开发中,很多使用的正是 ...
Serverless + Egg.js 后台管理系统实战
背景我在文章 基于 serverless component 的全栈解决方案 中述说了,如何将一个基于 vue.js 的后端应用和基于 express 的前端服务,快速布署到腾讯云上。 虽然遭到不少开发者的喜爱,但是好多开发者私信问我,这还是一个 demo 性质的项目而已,有没有愈发实用性的解决方案。 而且她们实际开发中,很多使用的正是 egg...
Nginx 从入门到实践,万字解读!
我订购的腾讯云提供的亚洲诚信机构颁授的免费证书只能一个域名使用,二级域名哪些的须要另外申请,但是申请审批比较快,一般几分钟能够成功,然后下载证书...9.2 webpack 的 gzip 配置当后端项目使用 webpack 进行打包的时侯,也可以开启 gzip 压缩:vue-cli3 的 vue.config.js 文件const compressionwebpack... 查看全部
vue恳求腾讯云插口404
广告腾讯云六年再起程广告
云产品感恩回馈,自研星星海服务器1核2G首年95元,十周年礼包免费抽,最高送10年云服务器
腾讯云部署golang flow流程,vue.js+nginx+mysql+node.js
这次终于把js-ojusflow的ui布署到腾讯云上,比较吐槽的就是,为啥如此复杂,vue.js前前端分离,比golang编撰的布署方面复杂几万倍。 真是浪费人生啊。 golang+sqlite写的东西,直接传到任意文件里,运行即可。 ——当然,适用于大型的东西。 vue.js,要安装node.js环境,要nginx环境,要配置nginx跨域; 要安装mysql...
vue后台管理之动态加载路由
我们的通用的后台管理系统中,我们会按照权限的粗细不同,会对每位角色每位权限每位资源进行控制。 同样的我们也须要实现一个这样的功能。 这篇文章我将主要讲vue端的实现,关于后台插口我就不会涉及,当我接触的时侯我们的后台插口是springcloud实现。 一、思路 在vue-router对象中首先初始化公共路由,比如(404...
小程序·云开发的HTTP API调用丨实战
render the error page res.status(err.status || 500); res.render(error); module.exports = app; --- 至此,小程序云开发----httpapi调用已完成。 简单的借助vue+elementui做个云开发小程序后台管理页面调用下里面的插口。 我们看下疗效如下: 云开发小程序后台管理环境调整:本地启动里面的插口服务及调用结果...
云服务器安装node+nginx+MongoDB
很早就买了一个云服务器,在腾讯云里面买的,当时买了好几年,用了几百块吧。 具体的配置如下? 本来就是想拿来练手node+nginx+mongodb的,一直没时间(其实是很懒了),所以没有着手做此项目。 以前也弄过,不过总是断断续续的,而且没有记录,现在再想搭建的时侯,已经忘得差不多了。 写这篇文章的目的纯粹是为了...
Serverless 一站式云原生应用开发实践
serverless 技术因其减少开发成本、按需手动扩缩容、免运维等众多优势,已经大量被开发者采用拿来更快的建立云上应用。 本文是腾讯云serverless技术专家王俊杰&方坤丁老师在「云加社区沙龙online」的分享整理,希望与你们一齐交流。 视频内容 一、重谈serverless 在国外搜索引擎搜索“serverless”会有许多五花八门的...
Serverless + Egg.js 后台管理系统实战
背景 我在文章《基于 serverless component 的全栈解决方案》中述说了,如何将一个基于 vue.js 的后端应用和基于 express 的前端服务,快速布署到腾讯云上。 虽然遭到不少开发者的喜爱,但是好多开发者私信问我,这还是一个 demo 性质的项目而已,有没有愈发实用性的解决方案。 而且她们实际开发中,很多使用的正是 ...
Serverless + Egg.js 后台管理系统实战
背景我在文章 基于 serverless component 的全栈解决方案 中述说了,如何将一个基于 vue.js 的后端应用和基于 express 的前端服务,快速布署到腾讯云上。 虽然遭到不少开发者的喜爱,但是好多开发者私信问我,这还是一个 demo 性质的项目而已,有没有愈发实用性的解决方案。 而且她们实际开发中,很多使用的正是 egg...
Nginx 从入门到实践,万字解读!
我订购的腾讯云提供的亚洲诚信机构颁授的免费证书只能一个域名使用,二级域名哪些的须要另外申请,但是申请审批比较快,一般几分钟能够成功,然后下载证书...9.2 webpack 的 gzip 配置当后端项目使用 webpack 进行打包的时侯,也可以开启 gzip 压缩:vue-cli3 的 vue.config.js 文件const compressionwebpack...
知晓云 | 他用 4 小时,极速开发了一款小程序
采集交流 • 优采云 发表了文章 • 0 个评论 • 216 次浏览 • 2020-08-21 20:13
话说,有三天,爱范儿的小伙伴找到我,说她们做了一个叫「」的东东,想约请我来体验一下。
我说好啊,他们就给了我一枚体验码,然后我假期的三天时间里,断断续续花了 4 个小时,就开发了一个叫「接口人」的小程序,目前早已上线:
「接口人」小程序使用链接
既然接受了约请,也参与了公测,那我就稍稍谈谈体验体会吧:
总的来说,这是个交互体验太棒的前前端集成方案,跟 LeapCloud 有点像,但又比 LeapCloud 简洁,如果它足够强悍,那么即便后端开发朋友没有前端开发基础也能快速建立功能复杂的小程序。
接下来简略介绍一下:
它平台所在地址:
但目前还处于公测阶段,后台的交互体验太棒,以下是部份项目配置截图:
开发文档:,比较清晰,能说明大部分问题。
我只体验了「数据」、「文件」以及「用户」三个功能,这里总结一下优缺点:
优点:
整体风格简约大方,没有冗余信息;最爽的是在每一个配置页面的右侧栏就会有对应的后端代码演示;对于数据表,很多默认数组(列)已经建好,省去不少时间。
缺点:
数据查询缺乏复杂条件的查询,如 or 查询,关联查询,不过问了她们的开发朋友说很快就提供;数据表无法删掉;用户 ID 显示有 bug;右边栏代码提示可适当丰富点,例如数据那只提供了 getTable 的演示,而常用的应当是记录的增删查改插口。
总的来说,真心不错,不然我也无法快速建立「接口人」这个小程序了。
赞!
关注「知晓程序」公众号,在陌陌后台回复「开发」,查看所有小程序开发文章。 查看全部
知晓云 | 他用 4 小时,极速开发了一款小程序
话说,有三天,爱范儿的小伙伴找到我,说她们做了一个叫「」的东东,想约请我来体验一下。
我说好啊,他们就给了我一枚体验码,然后我假期的三天时间里,断断续续花了 4 个小时,就开发了一个叫「接口人」的小程序,目前早已上线:
「接口人」小程序使用链接
既然接受了约请,也参与了公测,那我就稍稍谈谈体验体会吧:
总的来说,这是个交互体验太棒的前前端集成方案,跟 LeapCloud 有点像,但又比 LeapCloud 简洁,如果它足够强悍,那么即便后端开发朋友没有前端开发基础也能快速建立功能复杂的小程序。
接下来简略介绍一下:
它平台所在地址:
但目前还处于公测阶段,后台的交互体验太棒,以下是部份项目配置截图:
开发文档:,比较清晰,能说明大部分问题。
我只体验了「数据」、「文件」以及「用户」三个功能,这里总结一下优缺点:
优点:
整体风格简约大方,没有冗余信息;最爽的是在每一个配置页面的右侧栏就会有对应的后端代码演示;对于数据表,很多默认数组(列)已经建好,省去不少时间。
缺点:
数据查询缺乏复杂条件的查询,如 or 查询,关联查询,不过问了她们的开发朋友说很快就提供;数据表无法删掉;用户 ID 显示有 bug;右边栏代码提示可适当丰富点,例如数据那只提供了 getTable 的演示,而常用的应当是记录的增删查改插口。
总的来说,真心不错,不然我也无法快速建立「接口人」这个小程序了。
赞!
关注「知晓程序」公众号,在陌陌后台回复「开发」,查看所有小程序开发文章。
新手入门01-创建应用
采集交流 • 优采云 发表了文章 • 0 个评论 • 165 次浏览 • 2020-08-20 14:28
「深度学习福利」大神带你进阶工程师,立即查看>>>
新手入门01-创建应用
于 2020-08-05发布在 VirAPI官网
新手入门系列介绍文章:《新手入门01-创建应用》、《新手入门02-新建插口》、《新手入门03-接口测试与使用》、《新手入门04-应用中级管理》。
本篇文章将详尽的为您介绍VirAPI创建应用的整个过程。按照页面上的提示与描述基本可以直接上手;不过其中可能有些细节可以留心一下。
创建VirAPI应用很简单,登录VirAPI控制台,进入【创建应用页】()。应用创建页如下图:
注意:每个新注册的帐号系统就会默认生成一个“平台惟一ID”,这个ID将作为您的身分标示以及您创建的所有应用与插口的恳求标记。如上图所示,应用API网址为,其中vir_gitee115198f3h87ge即为当前演示帐号的身分ID,之后的所有恳求虚拟数据插口都是通过该ID来分辨。由于系统初始默认ID都是随机生成,您可抵达【个人资料页】()进行编辑更改,不过请注意,此ID仅可更改一次,修改保存成功后将难以再度编辑。
应用名&应用标示
根据创建应用表单的提示,输入应用名,应用名支持2至36个中英文或特殊符号。
填写完应用名后系统将手动依照应用名生成一个“应用标示”,您可以按照须要进行重置更改;应用标示目前只支持2至20个大小写字母、数字、下划线(_)、中划线(-)、英文句号(.),且同一帐号下应用标示必须惟一。该应用标示将作为虚拟数据插口的应用标记,且创建保存后不可再更改。
应用描述&应用图标
该两项都是可选的编辑项,您可依照须要进行处理。
此时页面大约如下:
应用中级设置
如上图右下角红框标记有一个“显示中级设置”,点击该链接将可见应用的中级配置选项。一般采取默认即可,无需再更改中级配置;不过难免有些情况是须要依照自己的业务场景的不同而须要调整的。VirAPI提供的应用中级设置如下图:
现在来详尽介绍这种中级配置:
请求验证规则
即恳求应用下虚拟数据生成插口时,用于验证恳求权限的方法。当前提供三种验证规则。
自定义恳求响应结构
即定义该应用所有恳求返回的统一规范的响应数据结构。
可能看起来不太理解,那么结合下边的响应数据事例都会马上明白了:
最终结构示例(请求成功)
{
"code": 200,
"message": "Succeed",
"data": {
"id": 1,
"name": "virapi"
}
}
最终结构示例(请求失败):
{
"code": 1000,
"message": "Failed"
}
这下是不是都理解了?很简单。
全部编辑完后,记得点击页面下方的“创建应用”按钮。创建成功后即会手动跳转到该应用的详情页面。
若后期须要对该应用的基本资料或中级设置进行更改编辑,则可点击该应用的详情页面的一侧菜单栏【管理】->【应用设置】进行设置更改。
若您创建应用时未更改自己的默认“平台惟一ID”,在创建应用后再更改的“平台惟一ID”,则该应用API网址中的用户标记也将立刻更新,且之前的链接将失效。
至此,VirAPI怎样创建应用就介绍完了。如在使用过程中有碰到哪些问题也欢迎你们通过Gitter与我们沟通和联系。 查看全部
新手入门01-创建应用
「深度学习福利」大神带你进阶工程师,立即查看>>>
新手入门01-创建应用
于 2020-08-05发布在 VirAPI官网
新手入门系列介绍文章:《新手入门01-创建应用》、《新手入门02-新建插口》、《新手入门03-接口测试与使用》、《新手入门04-应用中级管理》。
本篇文章将详尽的为您介绍VirAPI创建应用的整个过程。按照页面上的提示与描述基本可以直接上手;不过其中可能有些细节可以留心一下。
创建VirAPI应用很简单,登录VirAPI控制台,进入【创建应用页】()。应用创建页如下图:
注意:每个新注册的帐号系统就会默认生成一个“平台惟一ID”,这个ID将作为您的身分标示以及您创建的所有应用与插口的恳求标记。如上图所示,应用API网址为,其中vir_gitee115198f3h87ge即为当前演示帐号的身分ID,之后的所有恳求虚拟数据插口都是通过该ID来分辨。由于系统初始默认ID都是随机生成,您可抵达【个人资料页】()进行编辑更改,不过请注意,此ID仅可更改一次,修改保存成功后将难以再度编辑。
应用名&应用标示
根据创建应用表单的提示,输入应用名,应用名支持2至36个中英文或特殊符号。
填写完应用名后系统将手动依照应用名生成一个“应用标示”,您可以按照须要进行重置更改;应用标示目前只支持2至20个大小写字母、数字、下划线(_)、中划线(-)、英文句号(.),且同一帐号下应用标示必须惟一。该应用标示将作为虚拟数据插口的应用标记,且创建保存后不可再更改。
应用描述&应用图标
该两项都是可选的编辑项,您可依照须要进行处理。
此时页面大约如下:
应用中级设置
如上图右下角红框标记有一个“显示中级设置”,点击该链接将可见应用的中级配置选项。一般采取默认即可,无需再更改中级配置;不过难免有些情况是须要依照自己的业务场景的不同而须要调整的。VirAPI提供的应用中级设置如下图:
现在来详尽介绍这种中级配置:
请求验证规则
即恳求应用下虚拟数据生成插口时,用于验证恳求权限的方法。当前提供三种验证规则。
自定义恳求响应结构
即定义该应用所有恳求返回的统一规范的响应数据结构。
可能看起来不太理解,那么结合下边的响应数据事例都会马上明白了:
最终结构示例(请求成功)
{
"code": 200,
"message": "Succeed",
"data": {
"id": 1,
"name": "virapi"
}
}
最终结构示例(请求失败):
{
"code": 1000,
"message": "Failed"
}
这下是不是都理解了?很简单。
全部编辑完后,记得点击页面下方的“创建应用”按钮。创建成功后即会手动跳转到该应用的详情页面。
若后期须要对该应用的基本资料或中级设置进行更改编辑,则可点击该应用的详情页面的一侧菜单栏【管理】->【应用设置】进行设置更改。
若您创建应用时未更改自己的默认“平台惟一ID”,在创建应用后再更改的“平台惟一ID”,则该应用API网址中的用户标记也将立刻更新,且之前的链接将失效。
至此,VirAPI怎样创建应用就介绍完了。如在使用过程中有碰到哪些问题也欢迎你们通过Gitter与我们沟通和联系。
使用函数 initializer 接口优化应用层冷启动-阿里云开发者社区
采集交流 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2020-08-20 04:24
使用函数 initializer 接口优化应用层冷启动
_柳下2018-11-021641浏览量
简介:背景用户函数调用链路包括以下几个阶段:1)系统为函数分配估算资源;2)下载代码;3)启动容器并加载函数代码;4)用户函数内部进行初始化逻辑;5)函数处理恳求并将结果返回。其中1,2,3步是系统层面的冷启动开支,通过对调度以及各个环节的优化,函数估算(FC)能做到负载快速下降时稳定的延时,细节详见 函数估算系统冷启动优化。
背景
用户函数调用链路包括以下几个阶段:1)系统为函数分配估算资源;2)下载代码;3)启动容器并加载函数代码;4)用户函数内部进行初始化逻辑;5)函数处理恳求并将结果返回。其中1,2,3步是系统层面的冷启动开支,通过对调度以及各个环节的优化,函数估算(FC)能做到负载快速下降时稳定的延时,细节详见 函数估算系统冷启动优化。第4步是函数内部初始化逻辑,属于应用层面的冷启动开支,例如深度学习场景下加载尺寸较大的模型、数据库场景下连接池建立、函数依赖库加载等等。为了减少应用层冷启动对延时的影响,函数估算推出了 initializer 接口,系统能辨识用户函数的初始化逻辑,从而在调度上做相应的优化。
功能简介
现在用户能为函数设置 initializer 和 handler 两个入口,分别对应初始化逻辑和恳求处理逻辑。系统首先调用 initializer 完成函数的初始化,成功后再调用 handler 处理恳求。Initializer 是可选的,用户也可不实现,此时系统将跳过 initializer,直接调用 handler 处理恳求。
引入 initializer 接口的价值:
Initializer 接口规范
各个 runtime 的 initializer 接口有以下共性:
支持 runtime
下文将对各个 runtime 的 initializer 编写规则进行介绍:
python
当使用 Python 进行编程时,可参考下边示例:
# file :main.py
# initializer: main.my_initializer
def my_initializer(context):
print("hello world!")
更多细节请参考 python 函数入口。
nodejs
当使用 Nodejs 进行编程时,可参考下边示例:
// file :main.php
// initializer : main.my_initializer
exports.my_initializer = function(context, callback) {
console.log('hello world!');
callback(null, '');
};
更多细节请参考 nodejs 函数入口。
php
当使用 Php 进行编程时,可参考下边示例:
// file: main.js
// initializer: main.my_initializer
更多细节请参考 php 函数入口。
java
java 针对流式输入和通过形参的形式自定义输入和输出的两种函数方式都支持 initializer,当须要在 JAVA runtime 中添加 initializer 功能时,需在原有的函数结构基础上额外实现 initializer 预定义的插口。
一个简单的流式输入和 initializer 结合的示例如下:
package example;
import com.aliyun.fc.runtime.Context;
import com.aliyun.fc.runtime.FunctionComputeLogger;
import com.aliyun.fc.runtime.StreamRequestHandler;
import com.aliyun.fc.runtime.FunctionInitializer;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
public class HelloFC implements StreamRequestHandler, FunctionInitializer {
@Override
public void initialize(Context context) {
FunctionComputeLogger logger = context.getLogger();
logger.debug(String.format("RequestID is %s %n", context.getRequestId()));
}
@Override
public void handleRequest(InputStream input, OutputStream output, Context context) throws IOException {
FunctionComputeLogger logger = context.getLogger();
logger.debug(String.format("RequestID is %s %n", context.getRequestId()));
output.write(new String("hello world!").getBytes());
output.flush();
}
}
开发手册
当使用 initializer 接口时,可以通过 API、SDK、控制台、函数估算提供的丰富工具链(fcli、fun等工具)进行创建和更新。
SDK 开发
支持 initializer 的 SDK 有 Nodejs、Python、Php、Java 。以 Nodejs runtime 和 Php SDK 结合为例,创建 initializer 并进行更新操作。
对 initializer 的更新可以从有更新到无,即关掉 initializer 功能。也可以从无更新到有,即开启 initializer 功能。
// file: main.js
exports.initializer = function(context, callback) {
console.log('hello initializer!');
callback(null, "");
};
exports.handler = function(event, context, callback) {
callback(null, string("initializer"));
};
// file: new_main.js
exports.newInitializer = function(context, callback) {
console.log('hello new initializer!');
callback(null, "");
};
exports.handler = function(event, context, callback) {
callback(null, string("new initializer"));
};
<p> 查看全部
使用函数 initializer 接口优化应用层冷启动-阿里云开发者社区
使用函数 initializer 接口优化应用层冷启动
_柳下2018-11-021641浏览量
简介:背景用户函数调用链路包括以下几个阶段:1)系统为函数分配估算资源;2)下载代码;3)启动容器并加载函数代码;4)用户函数内部进行初始化逻辑;5)函数处理恳求并将结果返回。其中1,2,3步是系统层面的冷启动开支,通过对调度以及各个环节的优化,函数估算(FC)能做到负载快速下降时稳定的延时,细节详见 函数估算系统冷启动优化。
背景
用户函数调用链路包括以下几个阶段:1)系统为函数分配估算资源;2)下载代码;3)启动容器并加载函数代码;4)用户函数内部进行初始化逻辑;5)函数处理恳求并将结果返回。其中1,2,3步是系统层面的冷启动开支,通过对调度以及各个环节的优化,函数估算(FC)能做到负载快速下降时稳定的延时,细节详见 函数估算系统冷启动优化。第4步是函数内部初始化逻辑,属于应用层面的冷启动开支,例如深度学习场景下加载尺寸较大的模型、数据库场景下连接池建立、函数依赖库加载等等。为了减少应用层冷启动对延时的影响,函数估算推出了 initializer 接口,系统能辨识用户函数的初始化逻辑,从而在调度上做相应的优化。
功能简介
现在用户能为函数设置 initializer 和 handler 两个入口,分别对应初始化逻辑和恳求处理逻辑。系统首先调用 initializer 完成函数的初始化,成功后再调用 handler 处理恳求。Initializer 是可选的,用户也可不实现,此时系统将跳过 initializer,直接调用 handler 处理恳求。
引入 initializer 接口的价值:
Initializer 接口规范
各个 runtime 的 initializer 接口有以下共性:
支持 runtime
下文将对各个 runtime 的 initializer 编写规则进行介绍:
python
当使用 Python 进行编程时,可参考下边示例:
# file :main.py
# initializer: main.my_initializer
def my_initializer(context):
print("hello world!")
更多细节请参考 python 函数入口。
nodejs
当使用 Nodejs 进行编程时,可参考下边示例:
// file :main.php
// initializer : main.my_initializer
exports.my_initializer = function(context, callback) {
console.log('hello world!');
callback(null, '');
};
更多细节请参考 nodejs 函数入口。
php
当使用 Php 进行编程时,可参考下边示例:
// file: main.js
// initializer: main.my_initializer
更多细节请参考 php 函数入口。
java
java 针对流式输入和通过形参的形式自定义输入和输出的两种函数方式都支持 initializer,当须要在 JAVA runtime 中添加 initializer 功能时,需在原有的函数结构基础上额外实现 initializer 预定义的插口。
一个简单的流式输入和 initializer 结合的示例如下:
package example;
import com.aliyun.fc.runtime.Context;
import com.aliyun.fc.runtime.FunctionComputeLogger;
import com.aliyun.fc.runtime.StreamRequestHandler;
import com.aliyun.fc.runtime.FunctionInitializer;
import java.io.IOException;
import java.io.InputStream;
import java.io.OutputStream;
public class HelloFC implements StreamRequestHandler, FunctionInitializer {
@Override
public void initialize(Context context) {
FunctionComputeLogger logger = context.getLogger();
logger.debug(String.format("RequestID is %s %n", context.getRequestId()));
}
@Override
public void handleRequest(InputStream input, OutputStream output, Context context) throws IOException {
FunctionComputeLogger logger = context.getLogger();
logger.debug(String.format("RequestID is %s %n", context.getRequestId()));
output.write(new String("hello world!").getBytes());
output.flush();
}
}
开发手册
当使用 initializer 接口时,可以通过 API、SDK、控制台、函数估算提供的丰富工具链(fcli、fun等工具)进行创建和更新。
SDK 开发
支持 initializer 的 SDK 有 Nodejs、Python、Php、Java 。以 Nodejs runtime 和 Php SDK 结合为例,创建 initializer 并进行更新操作。
对 initializer 的更新可以从有更新到无,即关掉 initializer 功能。也可以从无更新到有,即开启 initializer 功能。
// file: main.js
exports.initializer = function(context, callback) {
console.log('hello initializer!');
callback(null, "");
};
exports.handler = function(event, context, callback) {
callback(null, string("initializer"));
};
// file: new_main.js
exports.newInitializer = function(context, callback) {
console.log('hello new initializer!');
callback(null, "");
};
exports.handler = function(event, context, callback) {
callback(null, string("new initializer"));
};
<p>
优云Monitor简单3步监控ActiveMQ
采集交流 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2020-08-19 09:49
ApacheActiveMQ是一个基于JMX规范的纯Java消息中间件,它为应用系统提供高效、灵活的消息同步与异步传输处理、存储转发、可靠传输的特点。
消息队列对于应用的健康运行十分重要,作为运维人员,我们须要时刻注意:
消息队列的宽度,以便确认是否存在大量堆积消息;
消息生产与消费的速度,以便确认业务的吞吐量与波动趋势;
消息队列本身的运行健康指标,以防止因为消息未能传递大范围的影响应用;
使用优云Monitor,通过简单操作,即可实现ActiveMQ监控。下面,我们演示布署的过程与监控的成果。
部署
优云Monitor通过Agent,采用web控制台或则JMX的方法进行ActiveMQ监控。
本文以CentOS7上的ActiveMQ为例。采用web控制台的方法进行监控。
下面,将逐步骤说明配置过程:
步骤一:安装代理
通过优云Monitor的布署指令,即可快速完成代理的布署:
进入布署界面
选择对应的操作系统,复制命令,并在目录操作系统上执行即可:
步骤二:配置插件
由于ActiveMQ的监控须要用户名与密码,我们必须更改代理的配置,提供监控联接信息:
#通过ActiveMQ的web控制台获取相关指标cd/etc/monitor-agent/conf.d/
cpactivemq_xml.yaml.exampleactivemq_xml.yaml#修改配置联接activemqwebconsoleviactivemq_xml.yaml
文件更改如下:
init_config:
instances:
-url::8161
#theurlwillprobablybesomethinglike:8161
username:********
password:*************
步骤三:重启代理,并确认数据采集结果
[root@localhost~]$servicedatamonitor-agentrestart
[root@localhost~]$servicedatamonitor-agentinfo
activemq_xml
-------------instance#0[OK]-Collected118metrics,0events&2servicechecks#上述表示早已采集到118个指标,说明采集正确
监控
在布署完成后,我们即可在优云平台上查看ActiveMQ的详尽指标,以帮助我们快速、准确定位问题。
操作系统方面指标
优云Monitor采集代理默认周期采集系统的cpu,内存,磁盘等指标,用以辅助剖析相关应用运行情况
由上述图片可知,该系统已超负荷运行,可能是因为运行了太多的应用程序。
消息队列方面指标
通过优云Monitor可以清晰观察ActiveMQ队列的消息消费者、生产者等变化信息,以便剖析相关服务上线、离线时间
通过观察ActiveMQ队列的入队、出队以及队列未被消费的消息数目,可以剖析出相关服务是否正常以及队列消费能力是否存在困局
由上述图片可知,该队列的消费者已全部下线。
消息主题方面指标
通过优云Monitor可以持续追踪ActiveMQ主题的发布、订阅等信息,以便剖析对应服务上线、离线时间
通过观察ActiveMQ主题的入队、出队以及队列未被消费的消息数目,可以剖析出相关服务是否正常以及对应服务是否存在困局
上述文章介绍的方法为通过ActiveMQ的web控制台采集相应的指标。当然,我们也能通过JMX的形式监控,以获取更多详尽的指标。
优云monitor saas版免费使用: 查看全部
优云Monitor简单3步监控ActiveMQ
ApacheActiveMQ是一个基于JMX规范的纯Java消息中间件,它为应用系统提供高效、灵活的消息同步与异步传输处理、存储转发、可靠传输的特点。
消息队列对于应用的健康运行十分重要,作为运维人员,我们须要时刻注意:
消息队列的宽度,以便确认是否存在大量堆积消息;
消息生产与消费的速度,以便确认业务的吞吐量与波动趋势;
消息队列本身的运行健康指标,以防止因为消息未能传递大范围的影响应用;
使用优云Monitor,通过简单操作,即可实现ActiveMQ监控。下面,我们演示布署的过程与监控的成果。
部署
优云Monitor通过Agent,采用web控制台或则JMX的方法进行ActiveMQ监控。
本文以CentOS7上的ActiveMQ为例。采用web控制台的方法进行监控。
下面,将逐步骤说明配置过程:
步骤一:安装代理
通过优云Monitor的布署指令,即可快速完成代理的布署:
进入布署界面
选择对应的操作系统,复制命令,并在目录操作系统上执行即可:
步骤二:配置插件
由于ActiveMQ的监控须要用户名与密码,我们必须更改代理的配置,提供监控联接信息:
#通过ActiveMQ的web控制台获取相关指标cd/etc/monitor-agent/conf.d/
cpactivemq_xml.yaml.exampleactivemq_xml.yaml#修改配置联接activemqwebconsoleviactivemq_xml.yaml
文件更改如下:
init_config:
instances:
-url::8161
#theurlwillprobablybesomethinglike:8161
username:********
password:*************
步骤三:重启代理,并确认数据采集结果
[root@localhost~]$servicedatamonitor-agentrestart
[root@localhost~]$servicedatamonitor-agentinfo
activemq_xml
-------------instance#0[OK]-Collected118metrics,0events&2servicechecks#上述表示早已采集到118个指标,说明采集正确
监控
在布署完成后,我们即可在优云平台上查看ActiveMQ的详尽指标,以帮助我们快速、准确定位问题。
操作系统方面指标
优云Monitor采集代理默认周期采集系统的cpu,内存,磁盘等指标,用以辅助剖析相关应用运行情况
由上述图片可知,该系统已超负荷运行,可能是因为运行了太多的应用程序。
消息队列方面指标
通过优云Monitor可以清晰观察ActiveMQ队列的消息消费者、生产者等变化信息,以便剖析相关服务上线、离线时间
通过观察ActiveMQ队列的入队、出队以及队列未被消费的消息数目,可以剖析出相关服务是否正常以及队列消费能力是否存在困局
由上述图片可知,该队列的消费者已全部下线。
消息主题方面指标
通过优云Monitor可以持续追踪ActiveMQ主题的发布、订阅等信息,以便剖析对应服务上线、离线时间
通过观察ActiveMQ主题的入队、出队以及队列未被消费的消息数目,可以剖析出相关服务是否正常以及对应服务是否存在困局
上述文章介绍的方法为通过ActiveMQ的web控制台采集相应的指标。当然,我们也能通过JMX的形式监控,以获取更多详尽的指标。
优云monitor saas版免费使用:
前端获得session信息方法对比,优化
采集交流 • 优采云 发表了文章 • 0 个评论 • 471 次浏览 • 2020-08-18 17:54
在开发中,页面 js 经常会遇见须要 当前登入用户信息(菜单权限,用户基本信息,配置信息) 的地方,一般情况我们可能对这种信息获取方法不是很在乎,但是现今的后端通过webpack打包,即使做了代码分割,js文件,css文件还是很大。在首次加载的情况下边,存在一定的优化空间。下面主要介绍一些信息获取的方法。接口使用的是模拟数据,session获取插口设置成了一秒延时,下面的数据都是首次加载的数据,不考虑304的情况。
在开发中,页面 js 经常会遇见须要 当前登入用户信息(菜单权限,用户基本信息,配置信息) 的地方,一般情况我们可能对这种信息获取方法不是很在乎,但是现今的后端通过webpack打包,即使做了代码分割,js文件,css文件还是很大。
在首次加载的情况下边,存在一定的优化空间。下面主要介绍一些信息获取的方法。 插口使用的是模拟数据,session获取插口设置成了一秒延时,下面的数据都是首次加载的数据,不考虑304的情况。
1.后端程序设置,直接js代码,全局变量写入方法
浏览器访问app.do,后端程序响应,获取用户信息 InitData,获取返回的app.html文本,将用户信息 写入到html对应位置,返回给浏览器
【问题】
a. 获取用户信息 InitData+ app.html文本---→ 返回给浏览器,浏览器再加载其他静态资源 ----> html加载过程
b.app.do返回的html,由于每位用户的基本信息都不一样,没办法使用浏览器304缓存机制
2.页面通过 查看全部
前端获得session信息方法对比,优化
在开发中,页面 js 经常会遇见须要 当前登入用户信息(菜单权限,用户基本信息,配置信息) 的地方,一般情况我们可能对这种信息获取方法不是很在乎,但是现今的后端通过webpack打包,即使做了代码分割,js文件,css文件还是很大。在首次加载的情况下边,存在一定的优化空间。下面主要介绍一些信息获取的方法。接口使用的是模拟数据,session获取插口设置成了一秒延时,下面的数据都是首次加载的数据,不考虑304的情况。
在开发中,页面 js 经常会遇见须要 当前登入用户信息(菜单权限,用户基本信息,配置信息) 的地方,一般情况我们可能对这种信息获取方法不是很在乎,但是现今的后端通过webpack打包,即使做了代码分割,js文件,css文件还是很大。
在首次加载的情况下边,存在一定的优化空间。下面主要介绍一些信息获取的方法。 插口使用的是模拟数据,session获取插口设置成了一秒延时,下面的数据都是首次加载的数据,不考虑304的情况。
1.后端程序设置,直接js代码,全局变量写入方法
浏览器访问app.do,后端程序响应,获取用户信息 InitData,获取返回的app.html文本,将用户信息 写入到html对应位置,返回给浏览器
【问题】
a. 获取用户信息 InitData+ app.html文本---→ 返回给浏览器,浏览器再加载其他静态资源 ----> html加载过程
b.app.do返回的html,由于每位用户的基本信息都不一样,没办法使用浏览器304缓存机制
2.页面通过
小程序---初识云开发-搭建云开发小程序
采集交流 • 优采云 发表了文章 • 0 个评论 • 222 次浏览 • 2020-08-17 17:44
通常情况下,后端的插口使用前端语言(Java、Python、PHP、Node.js)编写完成后,部署到打算好的服务器后就能实现后端向前端发送网路恳求。该模式具备优点:灵活性强, 能够自定义满足各类业务需求。缺点是前端语言难易程度不一、周期较长、部署较复杂、需要买域名、备案、买证书,适合小型项目且成本较高。
使用小程序云开发可以最小化成本上架陌陌小程序。小程序云开发的优势有:语言难度相对简单,会Node.js即可;周期极短,只关注业务相关的操作,不必考虑任何环境;部署简单,无需订购域名、证书及备案;适合中小型项目;云服务基础版本免费,可按照使用情况按需选购。
云开发:在一个全部都早已布署好的云环境当中,前端直接以函数的方式使用各类服务,完成各类操作。对于后端来说, 后端的服务虽然就是一个函数。 无所谓后端和前端,两者是一套代码体系。【】
Serverless:无服务开发,函数即服务。注意:此模式不代表没有服务器,只是布署在云环境中,弱化了服务器前端的概念,以一个新的方式(函数)来使用服务。
小程序云开发是Serverless的一种。云开发收录以下几大基础能力。
云存储
能存取文件,客户端可以直接通过调用特定方式来操作文件
云数据库
客户端可以直接通过特定方式来操作数据库
云函数
能进行估算处理、访问三方数据服务器、云调用;将一组特定操作(云计算、云数据库、云存储、网络恳求等)封装成一个特定函数,发布在云环境,称作“云函数”。客户端可以直接“触发云函数”,完成特定的一组操作
第一个云开发小程序
开通云开发功能-》新建项目 (后端服务:小程序云开发)
查看全部
小程序---初识云开发-搭建云开发小程序
通常情况下,后端的插口使用前端语言(Java、Python、PHP、Node.js)编写完成后,部署到打算好的服务器后就能实现后端向前端发送网路恳求。该模式具备优点:灵活性强, 能够自定义满足各类业务需求。缺点是前端语言难易程度不一、周期较长、部署较复杂、需要买域名、备案、买证书,适合小型项目且成本较高。
使用小程序云开发可以最小化成本上架陌陌小程序。小程序云开发的优势有:语言难度相对简单,会Node.js即可;周期极短,只关注业务相关的操作,不必考虑任何环境;部署简单,无需订购域名、证书及备案;适合中小型项目;云服务基础版本免费,可按照使用情况按需选购。
云开发:在一个全部都早已布署好的云环境当中,前端直接以函数的方式使用各类服务,完成各类操作。对于后端来说, 后端的服务虽然就是一个函数。 无所谓后端和前端,两者是一套代码体系。【】
Serverless:无服务开发,函数即服务。注意:此模式不代表没有服务器,只是布署在云环境中,弱化了服务器前端的概念,以一个新的方式(函数)来使用服务。
小程序云开发是Serverless的一种。云开发收录以下几大基础能力。
云存储
能存取文件,客户端可以直接通过调用特定方式来操作文件
云数据库
客户端可以直接通过特定方式来操作数据库
云函数
能进行估算处理、访问三方数据服务器、云调用;将一组特定操作(云计算、云数据库、云存储、网络恳求等)封装成一个特定函数,发布在云环境,称作“云函数”。客户端可以直接“触发云函数”,完成特定的一组操作
第一个云开发小程序
开通云开发功能-》新建项目 (后端服务:小程序云开发)
概述 · ThinkAPI 统一API调用服务 · 看云
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2020-08-17 09:14
## `ThinkAPI`统一`API`插口服务![]()开发者常常为了各类功能而到处找寻是否有相应的API插口,即便找到了可能还要忍受第三方各类雷人的SDK调用,或者不支持`composer`安装。`ThinkAPI`统一`API`插口服务是由官方联合合作伙伴封装的一套插口调用服务及`SDK`,旨在帮助`ThinkPHP`开发者更方便的调用官方及第三方的提供的各种`API`接口及服务,从而更好的建立开发者生态。## 服务优势### 一站式插口服务`ThinkAPI`提供了一站式的插口服务,从插口订购、调用到SDK封装都只须要一个官方帐号即可完成,无需注册各类插口服务帐号,除了囊括常用`API`服务之外,还设计了可转换插口服务更好的保障插口的稳定性,让你省心省力。### 统一的数据格式统一API服务接入了各大API厂商的插口,但采用统一的返回数据格式和统一的插口恳求域名(支持HTTPS),更有利于开发者对插口的统一调用。### 提供统一的SDK官方提供了一套统一的`SDK for PHP`调用服务,通过`composer`安装一个轻量级的依赖包即可调用,采用简约和现代化的调用方法,简化你的`API`调用开发工作。### 官方服务市场保障`ThinkAPI`所有支持的插口都列入[官方服务市场](),包括免费插口和付费插口,市场服务有保障,并且有订购记录以及统计数据。> 对于一些付费的插口,官方的[服务市场]()提供了更让利的价钱。## 成为`API`供应商面向服务开发将是将来的一大开发趋势,如果你计划在100万+的`ThinkPHP`开发者中推广大家的服务,欢迎联系!诚邀合作伙伴(包括但不限于API服务商或对外提供开放API的产品服务商)加入官方统一API插口服务计划。成为`API`供应商或则反馈你须要的API接口请联系陌陌`topthink`(注明来意)。 查看全部
概述 · ThinkAPI 统一API调用服务 · 看云
## `ThinkAPI`统一`API`插口服务![]()开发者常常为了各类功能而到处找寻是否有相应的API插口,即便找到了可能还要忍受第三方各类雷人的SDK调用,或者不支持`composer`安装。`ThinkAPI`统一`API`插口服务是由官方联合合作伙伴封装的一套插口调用服务及`SDK`,旨在帮助`ThinkPHP`开发者更方便的调用官方及第三方的提供的各种`API`接口及服务,从而更好的建立开发者生态。## 服务优势### 一站式插口服务`ThinkAPI`提供了一站式的插口服务,从插口订购、调用到SDK封装都只须要一个官方帐号即可完成,无需注册各类插口服务帐号,除了囊括常用`API`服务之外,还设计了可转换插口服务更好的保障插口的稳定性,让你省心省力。### 统一的数据格式统一API服务接入了各大API厂商的插口,但采用统一的返回数据格式和统一的插口恳求域名(支持HTTPS),更有利于开发者对插口的统一调用。### 提供统一的SDK官方提供了一套统一的`SDK for PHP`调用服务,通过`composer`安装一个轻量级的依赖包即可调用,采用简约和现代化的调用方法,简化你的`API`调用开发工作。### 官方服务市场保障`ThinkAPI`所有支持的插口都列入[官方服务市场](),包括免费插口和付费插口,市场服务有保障,并且有订购记录以及统计数据。> 对于一些付费的插口,官方的[服务市场]()提供了更让利的价钱。## 成为`API`供应商面向服务开发将是将来的一大开发趋势,如果你计划在100万+的`ThinkPHP`开发者中推广大家的服务,欢迎联系!诚邀合作伙伴(包括但不限于API服务商或对外提供开放API的产品服务商)加入官方统一API插口服务计划。成为`API`供应商或则反馈你须要的API接口请联系陌陌`topthink`(注明来意)。
山东【短信http插口】_猎钉云设计新颖
采集交流 • 优采云 发表了文章 • 0 个评论 • 216 次浏览 • 2020-08-13 13:13
山东猎钉云, 若你登录,将永久解锁;将所有的 http 改为https,即完全支持!更新一些插口变化的地方,具体看对应章节。com/hongyangAndroid/wanandroid/issues反馈。我们更新了一个新的能力:Google Maven 仓库快速查询!
稳定安全专门针对组态软件OPC驱动优化设计,永远在线,稳定性高。采用银行级数据加密技术,确保数据安全。短信http插口不仅外置网页和标准OPC插口,还提供标准的HTTP插口,用户可以自己开发WEB云监控平台和个性的手机APP界面。使用简单无论是远程的PLC还是监控端,都无需固定IP或动态域名,也无需搭建服务器,即可轻松完成分散在各地的PLC无线监控。
山东猎钉云, 调用领到HTTP请求和应答数据(如图1所示)。分析发觉不关是GET恳求,还是POST恳求,都有一个签名参数newSign。so中),然后对加密结果进行MD5估算(如图2)。分析下来原理后,思路就清晰了:自己构造HTTP请求,通过HOOK + RPC方式直接调用RequestUtils中的签名算法,产生有效的签名值,这样才能直接领到插口返回的数据。如图4所示为最终采集到的数据。使用Frida Hook绕开相关证书验证代码。
应用层为操作系统或网路应用程序提供访问网路服务的插口。应用层合同的代表包括:Telnet、FTP、HTTP、SNMP等。00,因初审系统例行维护,您递交的版本可能须要较长时间能够通过,望您谅解。
山东猎钉云, 通过该插口可以直接使用手机安装 App,请使用 HTTP GET 方式。也可以输入应用短链接。接口会依照应用的类型(iOS或Android),自动使用相应的的安装方法来安装应用。换成App的buildKey,不收录大括号。该插口可以获取某个 App 的某个具体版本的详尽信息。中设置的App分组。这个插口会返回某个App分组的详尽信息,同时也返回这个分组上面收录的App信息(只列举最新版本)。用户App分组的Key。可以通过 appGroup/listAll 接口获取。通过该插口,开发者可以直接添加证书。您的帐户信息正在初审中,暂时不能使用该功能;
对测试方案可能出现的问题进行剖析和评估。有利于从业者的发展。这份工资将一街走弱。而且对于软件项目的立项、管理、售前、售后等领域都要涉及。软件测试领域就是“混合双打”。软件测试工程师要查找软件的缺陷须要具备耐性、心细的特性。理解插口的概念和功能,对接口测试有一个总体认识,理解接口测试必备基础知识,理解HTTP协议插口工作原理,使用工具对插口测试产生直观认识。掌握Fiddler抓包的方法,掌握Fiddler对数据进行拦截与剖析的形式;掌握Requests库进行插口自动化测试的应用,理解Python插口自动化测试的思路等。 查看全部
山东【短信http插口】,猎钉云设计新颖,猎钉科技是中国移动、中国联通、中国电信三大运营商的资深战略合作伙伴,是行业内领先的增值联通服务专业提供商。
山东猎钉云, 若你登录,将永久解锁;将所有的 http 改为https,即完全支持!更新一些插口变化的地方,具体看对应章节。com/hongyangAndroid/wanandroid/issues反馈。我们更新了一个新的能力:Google Maven 仓库快速查询!
稳定安全专门针对组态软件OPC驱动优化设计,永远在线,稳定性高。采用银行级数据加密技术,确保数据安全。短信http插口不仅外置网页和标准OPC插口,还提供标准的HTTP插口,用户可以自己开发WEB云监控平台和个性的手机APP界面。使用简单无论是远程的PLC还是监控端,都无需固定IP或动态域名,也无需搭建服务器,即可轻松完成分散在各地的PLC无线监控。
山东猎钉云, 调用领到HTTP请求和应答数据(如图1所示)。分析发觉不关是GET恳求,还是POST恳求,都有一个签名参数newSign。so中),然后对加密结果进行MD5估算(如图2)。分析下来原理后,思路就清晰了:自己构造HTTP请求,通过HOOK + RPC方式直接调用RequestUtils中的签名算法,产生有效的签名值,这样才能直接领到插口返回的数据。如图4所示为最终采集到的数据。使用Frida Hook绕开相关证书验证代码。
应用层为操作系统或网路应用程序提供访问网路服务的插口。应用层合同的代表包括:Telnet、FTP、HTTP、SNMP等。00,因初审系统例行维护,您递交的版本可能须要较长时间能够通过,望您谅解。
山东猎钉云, 通过该插口可以直接使用手机安装 App,请使用 HTTP GET 方式。也可以输入应用短链接。接口会依照应用的类型(iOS或Android),自动使用相应的的安装方法来安装应用。换成App的buildKey,不收录大括号。该插口可以获取某个 App 的某个具体版本的详尽信息。中设置的App分组。这个插口会返回某个App分组的详尽信息,同时也返回这个分组上面收录的App信息(只列举最新版本)。用户App分组的Key。可以通过 appGroup/listAll 接口获取。通过该插口,开发者可以直接添加证书。您的帐户信息正在初审中,暂时不能使用该功能;
对测试方案可能出现的问题进行剖析和评估。有利于从业者的发展。这份工资将一街走弱。而且对于软件项目的立项、管理、售前、售后等领域都要涉及。软件测试领域就是“混合双打”。软件测试工程师要查找软件的缺陷须要具备耐性、心细的特性。理解插口的概念和功能,对接口测试有一个总体认识,理解接口测试必备基础知识,理解HTTP协议插口工作原理,使用工具对插口测试产生直观认识。掌握Fiddler抓包的方法,掌握Fiddler对数据进行拦截与剖析的形式;掌握Requests库进行插口自动化测试的应用,理解Python插口自动化测试的思路等。
【11期】分布式系统插口,如何防止表单的重复递交?
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2020-08-12 01:47
程序员的成长之路
互联网/程序员/技术/资料共享
阅读本文大约须要 2 分钟。
作者:季雨林
关于如何实现承载更多用户量的系统,一直是我重点关注的一个技术方向。改造构架提升承载力,通常来讲分为两个大方向,互相配合实现。
硬件构架改进,主要是使用阿里云这些多组件的云环境:通过负载均衡SLB,模版克隆的云服务器ECS,云数据库RDS,共享对象存储OSS等不同职责的云产品组合实现。
软件构架优化,主要是软件代码开发的规范:业务解耦合,架构微服务,单机无状态化,文件储存共享等
在分布式系统的学习途中也不断见识新的知识点,今天要说的就是软件开发时侯对于插口服务的“幂等性”实现!
幂等性
效果:系统对某插口的多次恳求,都应当返回同样的结果!(网络访问失败的场景除外)
目的:避免由于各类缘由,重复恳求造成的业务重复处理
重复恳求场景案例:
1,客户端第一次恳求后,网络异常造成收到恳求执行逻辑并且没有返回给客户端,客户端的重新发起恳求
2,客户端迅速点击按键递交,导致同一逻辑被多次发送到服务器
简单来界定,业务逻辑无非都可以归纳为增删改查!
对于查询,内部不收录其他操作,属于只读性质的那个业务必然符合幂等性要求的。
对于删掉,重复做删掉恳求起码不会导致数据零乱,不过也有些场景更希望重复点击提示的是删掉成功,而不是目标不存在的提示。
对于新增和更改,这里是明天要重点关注的部份:新增,需要防止重复插入;修改,避免进行无效的重复更改;
幂等性的实现方法
实现方式:客户端做某一恳求的时侯带上辨识参数标示,服务端对此标示进行辨识,重复恳求则重复返回第一次的结果即可。
举个栗子:比如添加恳求的表单里,在打开添加表单页面的时侯,就生成一个AddId标示,这个AddId跟随表单一起递交到后台插口。
后台插口按照这个AddId,服务端就可以进行缓存标记并进行过滤,缓存值可以是AddId作为缓存key,返回内容作为缓存Value,这样虽然添加按键被多次点下也可以辨识下来。
这个AddId什么时候更新呢?只有在保存成功而且清空表单以后,才变更这个AddId标示,从而实现新数据的表单递交。 查看全部
程序员的成长之路
互联网/程序员/技术/资料共享
阅读本文大约须要 2 分钟。
作者:季雨林
关于如何实现承载更多用户量的系统,一直是我重点关注的一个技术方向。改造构架提升承载力,通常来讲分为两个大方向,互相配合实现。
硬件构架改进,主要是使用阿里云这些多组件的云环境:通过负载均衡SLB,模版克隆的云服务器ECS,云数据库RDS,共享对象存储OSS等不同职责的云产品组合实现。
软件构架优化,主要是软件代码开发的规范:业务解耦合,架构微服务,单机无状态化,文件储存共享等
在分布式系统的学习途中也不断见识新的知识点,今天要说的就是软件开发时侯对于插口服务的“幂等性”实现!
幂等性
效果:系统对某插口的多次恳求,都应当返回同样的结果!(网络访问失败的场景除外)
目的:避免由于各类缘由,重复恳求造成的业务重复处理
重复恳求场景案例:
1,客户端第一次恳求后,网络异常造成收到恳求执行逻辑并且没有返回给客户端,客户端的重新发起恳求
2,客户端迅速点击按键递交,导致同一逻辑被多次发送到服务器
简单来界定,业务逻辑无非都可以归纳为增删改查!
对于查询,内部不收录其他操作,属于只读性质的那个业务必然符合幂等性要求的。
对于删掉,重复做删掉恳求起码不会导致数据零乱,不过也有些场景更希望重复点击提示的是删掉成功,而不是目标不存在的提示。
对于新增和更改,这里是明天要重点关注的部份:新增,需要防止重复插入;修改,避免进行无效的重复更改;
幂等性的实现方法
实现方式:客户端做某一恳求的时侯带上辨识参数标示,服务端对此标示进行辨识,重复恳求则重复返回第一次的结果即可。
举个栗子:比如添加恳求的表单里,在打开添加表单页面的时侯,就生成一个AddId标示,这个AddId跟随表单一起递交到后台插口。
后台插口按照这个AddId,服务端就可以进行缓存标记并进行过滤,缓存值可以是AddId作为缓存key,返回内容作为缓存Value,这样虽然添加按键被多次点下也可以辨识下来。
这个AddId什么时候更新呢?只有在保存成功而且清空表单以后,才变更这个AddId标示,从而实现新数据的表单递交。
阿里云api数据插口人脸辨识的数据接入价钱贵不贵有没有让利-阿里
采集交流 • 优采云 发表了文章 • 0 个评论 • 176 次浏览 • 2020-08-11 12:17
我们在实际建站、做app或做陌陌小程序的时侯,是会须要一些大数据的支持的,比如做电商的须要快件货运查询,做饭店的须要身份证实名、人像辨识,做财务的须要票据辨识,做理财的须要金融或股价数据。在阿里云的云市场我们可以看见专门有个api,也就是各种数据的调阅使用,小编对于阿里云直营的大数据是比较信赖和推荐的,而且阿里云还经常的做做活动:
1、阿里云大数据api数据平时也会打折吗?
(1)会打折,比如,身份辨识、银行卡辨识、营业执照辨识、票据等等限时3.5折
(2)大促会打折,平常是有的数据打折,有的数据不打折,比如此时小编看股票行情数据、天气预报数据、刷脸实人认证服务等,就没有打折。(当然,有免费试用体验,虽然次数十分有限,但也可以先试后买)
2、怎样订购阿里云api数据更实惠?
(1)做好计划和预算、使用次数预估,比如快件数据、身份证辨识数据,大致是晓得一年须要多少量的。
(2)有促销就先订购,因为api的扣费是以实际使用为准的,所以,有促销就先买。
(3)要不要先免费试用?如果您须要的数据有免费试用,同时又有打折,那么,最好的办法是买了免费试用,随即就买促销;因为我们实际上是会忘掉事情的,如果试用好了再去买可能就不打折了;如果您须要的有免费试用,超过的不打折,那妥妥的先试用,以后看机会有促销就买了。
3、阿里云的大数据api免费是真的吗?
在阿里云的特价活动或最新活动中,我们可以见到官方宣传海量api数据免费,实际上大多数是免费的,也有部份是象征性收费的。
但是,阿里云的大数据免费和服务器免费一样,都是有量的条件的,比如,酒店、银行、支付类网站需要的身份证辨识,前500次是免费的,超过就要收费了。
我们可以有两个选择:(其他免费api数据同样适用)
(1)先尝试免费500次,用了认为不错,再继续订购。(这里是有个风险的,尤其对于客流量比较大的系统来说,如旅馆前台登记,刚好碰到这个坎,客人又等在那儿,验证不过等,造成负面影响)
(2)出于对阿里云的信任,可以一次性订购少些,以身分辨识为例,单价越低,低至0.018元/次。
4、阿里云的大数据api订购入口在那里?
有两个形式
(1)如果不确定须要的是哪些,又想看打折促销信息,可以在阿里云的最新活动或特价活动中查看,或者直接打开api促销页面(复制粘贴到浏览器)/1111Promotion
(2)确定自己想要的是哪些,登陆阿里云,导航栏点击云市场,进入云市场后,上方导航栏(轮播图上面一行),点击api。进入之后就可以看见有很多api可以选购了,小编建议,如果是同类的数据,购买阿里云官方的。即,产品说明的一侧有店家名为:服务商,阿里云计算有限公司(如图所示)
关于网站优化提高,如果您早已是阿里云用户,那么对照自己的情况进行一些功能的应用提高网站,可能更方便些,(不是阿里云用户也可以瞧瞧以下建议,毕竟阿里云的技术是太强的,比如阿里巴巴的MySQL是全世界最强的MySQL,阿里巴巴拥有全世界少数几支MySQL的内核团队)。天天快乐知识网小编建议您尝试优化组合,降低营运成本,并且将网站优化做到更理想的状态,以下几个产品是常见值得尝试一下的:
1、开通阿里云cdn,减少对服务器的直接访问,提升网页加载和用户访问速率:
如果您的服务器当前仍未配套配置CDN服务,那么我们强烈建议您理解开通CDN服务。CDN 内容分发网路服务对于访问加速疗效十分显著,能最大程度提高网页加载速率,改善用户访问体验。同时,因为对服务器的直接访问恳求大幅度降低,你的服务器的负荷得到很大程度减少。同样配置的服务器可以支持更大量级的并发访问恳求用户数,或者在用户数目比较稳定的情况下,可以相应减少服务器的硬件配置。
2、购买对象储存 OSS服务,解决您的大量图文储存需求:
如果你的网站或者应用涉及大量的文件存储,涉及海量图片或则文件,那么我们强烈建议你选购对象储存 OSS服务。文件的读写是消耗服务器CPU资源最大的IO操作,对于服务器的性能影响极大。通过OSS服务,把文件的上传、下载、存贮过程布署到云端,减轻WEB服务器的IO读写负荷,可以有效提高服务器的性能。阿里云OSS提供海量、安全、低成本、高可靠的云存储服务,提供99.999999999%的数据可靠性。使用RESTful API 可以在互联网任何位置储存和访问,容量和处理能力弹性扩充,多种储存类型供选择全面优化储存成本。在使用OSS储存服务的同时,WEB服务器的储存空间和带宽都可以相应做一些配置降级调整。
3、购买和使用阿里云数据库,实现网站服务器和数据库服务器的分离:
如果你当前网站和数据库配置在同一台服务器上,并且觉得性能开始出现个别困局。那么,我们建议你选购单独的阿里云数据库,实现网站服务器和数据库服务器的分离。阿里云数据库Redis版支持MySql 等常见数据库类型,采用高可靠双机热备构架及可无缝扩充的集群构架,满足高读写性能场景及容量需弹性变配的业务需求。 具有如下优点:
高稳定构架:双机热备构架保障故障手动迁移,数据安全可靠
性能灵活扩充:连接数及网路吞吐可订制,灵活的集群版尺寸适配高并发场景
源码级护航:资深阿里云专家深度优化,修复内核安全漏洞,提升服务稳定性
智能运维:提供全链路智能监控剖析及可视化管理平台,运维省心省力
4、购买使用或升级配置阿里云服务器ecs:
如果您如今还是使用的VPS虚拟主机或则托管的独立服务器,升级到阿里云ECS服务器可以在完美解决业务需求的同时,最大程度降低在服务器运维方面的人力和时间投入成本。
阿里云服务器集群支持故障手动迁移,如果一台云服务器出现故障,其里面的应用就手动迁移到集群中其他云服务器上继续服务。
阿里云ECS服务器支持弹性扩容手动适应用户量和业务规模的快速扩张需求,您可以在线实时降低自己的配置,按需订制。阿里云服务器具有天然防ARP攻击和MAC误导,快照备份,数据永久不遗失,安全可靠。
5、为您的网站购买配置阿里云盾SSL证书,预防访问风险提示或停止访问:
阿里云云盾证书,云上签发,部署简单,防窃听、防绑架。现代浏览器对于HTTPS的要求越来越高,谷歌浏览器、火狐浏览器等均开始对未配置SSL证书的站点给出安全警告提示,有的甚至直接停止访问并提示访问风险。如果您的网站属于电子商务类型或则包括了在线支付环节,就特别有必要早日订购布署SSL证书。通过布署SSL证书,提高网站的可信度,防范功击,可有效保护用户和网站自身的合法权益。购买并配置阿里云SSL证书,在云上签发各品牌数字证书,实现网站HTTPS化,使网站可信,防绑架、防篡改、防窃听。并进行统一生命周期管理,简化证书布署,一键分发到云上产品。 查看全部
阿里云api数据插口人脸辨识的数据接入价钱贵不贵有没有让利,阿里云免费API接口申请。
我们在实际建站、做app或做陌陌小程序的时侯,是会须要一些大数据的支持的,比如做电商的须要快件货运查询,做饭店的须要身份证实名、人像辨识,做财务的须要票据辨识,做理财的须要金融或股价数据。在阿里云的云市场我们可以看见专门有个api,也就是各种数据的调阅使用,小编对于阿里云直营的大数据是比较信赖和推荐的,而且阿里云还经常的做做活动:
1、阿里云大数据api数据平时也会打折吗?
(1)会打折,比如,身份辨识、银行卡辨识、营业执照辨识、票据等等限时3.5折
(2)大促会打折,平常是有的数据打折,有的数据不打折,比如此时小编看股票行情数据、天气预报数据、刷脸实人认证服务等,就没有打折。(当然,有免费试用体验,虽然次数十分有限,但也可以先试后买)
2、怎样订购阿里云api数据更实惠?
(1)做好计划和预算、使用次数预估,比如快件数据、身份证辨识数据,大致是晓得一年须要多少量的。
(2)有促销就先订购,因为api的扣费是以实际使用为准的,所以,有促销就先买。
(3)要不要先免费试用?如果您须要的数据有免费试用,同时又有打折,那么,最好的办法是买了免费试用,随即就买促销;因为我们实际上是会忘掉事情的,如果试用好了再去买可能就不打折了;如果您须要的有免费试用,超过的不打折,那妥妥的先试用,以后看机会有促销就买了。
3、阿里云的大数据api免费是真的吗?
在阿里云的特价活动或最新活动中,我们可以见到官方宣传海量api数据免费,实际上大多数是免费的,也有部份是象征性收费的。
但是,阿里云的大数据免费和服务器免费一样,都是有量的条件的,比如,酒店、银行、支付类网站需要的身份证辨识,前500次是免费的,超过就要收费了。
我们可以有两个选择:(其他免费api数据同样适用)
(1)先尝试免费500次,用了认为不错,再继续订购。(这里是有个风险的,尤其对于客流量比较大的系统来说,如旅馆前台登记,刚好碰到这个坎,客人又等在那儿,验证不过等,造成负面影响)
(2)出于对阿里云的信任,可以一次性订购少些,以身分辨识为例,单价越低,低至0.018元/次。
4、阿里云的大数据api订购入口在那里?
有两个形式
(1)如果不确定须要的是哪些,又想看打折促销信息,可以在阿里云的最新活动或特价活动中查看,或者直接打开api促销页面(复制粘贴到浏览器)/1111Promotion
(2)确定自己想要的是哪些,登陆阿里云,导航栏点击云市场,进入云市场后,上方导航栏(轮播图上面一行),点击api。进入之后就可以看见有很多api可以选购了,小编建议,如果是同类的数据,购买阿里云官方的。即,产品说明的一侧有店家名为:服务商,阿里云计算有限公司(如图所示)
关于网站优化提高,如果您早已是阿里云用户,那么对照自己的情况进行一些功能的应用提高网站,可能更方便些,(不是阿里云用户也可以瞧瞧以下建议,毕竟阿里云的技术是太强的,比如阿里巴巴的MySQL是全世界最强的MySQL,阿里巴巴拥有全世界少数几支MySQL的内核团队)。天天快乐知识网小编建议您尝试优化组合,降低营运成本,并且将网站优化做到更理想的状态,以下几个产品是常见值得尝试一下的:
1、开通阿里云cdn,减少对服务器的直接访问,提升网页加载和用户访问速率:
如果您的服务器当前仍未配套配置CDN服务,那么我们强烈建议您理解开通CDN服务。CDN 内容分发网路服务对于访问加速疗效十分显著,能最大程度提高网页加载速率,改善用户访问体验。同时,因为对服务器的直接访问恳求大幅度降低,你的服务器的负荷得到很大程度减少。同样配置的服务器可以支持更大量级的并发访问恳求用户数,或者在用户数目比较稳定的情况下,可以相应减少服务器的硬件配置。
2、购买对象储存 OSS服务,解决您的大量图文储存需求:
如果你的网站或者应用涉及大量的文件存储,涉及海量图片或则文件,那么我们强烈建议你选购对象储存 OSS服务。文件的读写是消耗服务器CPU资源最大的IO操作,对于服务器的性能影响极大。通过OSS服务,把文件的上传、下载、存贮过程布署到云端,减轻WEB服务器的IO读写负荷,可以有效提高服务器的性能。阿里云OSS提供海量、安全、低成本、高可靠的云存储服务,提供99.999999999%的数据可靠性。使用RESTful API 可以在互联网任何位置储存和访问,容量和处理能力弹性扩充,多种储存类型供选择全面优化储存成本。在使用OSS储存服务的同时,WEB服务器的储存空间和带宽都可以相应做一些配置降级调整。
3、购买和使用阿里云数据库,实现网站服务器和数据库服务器的分离:
如果你当前网站和数据库配置在同一台服务器上,并且觉得性能开始出现个别困局。那么,我们建议你选购单独的阿里云数据库,实现网站服务器和数据库服务器的分离。阿里云数据库Redis版支持MySql 等常见数据库类型,采用高可靠双机热备构架及可无缝扩充的集群构架,满足高读写性能场景及容量需弹性变配的业务需求。 具有如下优点:
高稳定构架:双机热备构架保障故障手动迁移,数据安全可靠
性能灵活扩充:连接数及网路吞吐可订制,灵活的集群版尺寸适配高并发场景
源码级护航:资深阿里云专家深度优化,修复内核安全漏洞,提升服务稳定性
智能运维:提供全链路智能监控剖析及可视化管理平台,运维省心省力
4、购买使用或升级配置阿里云服务器ecs:
如果您如今还是使用的VPS虚拟主机或则托管的独立服务器,升级到阿里云ECS服务器可以在完美解决业务需求的同时,最大程度降低在服务器运维方面的人力和时间投入成本。
阿里云服务器集群支持故障手动迁移,如果一台云服务器出现故障,其里面的应用就手动迁移到集群中其他云服务器上继续服务。
阿里云ECS服务器支持弹性扩容手动适应用户量和业务规模的快速扩张需求,您可以在线实时降低自己的配置,按需订制。阿里云服务器具有天然防ARP攻击和MAC误导,快照备份,数据永久不遗失,安全可靠。
5、为您的网站购买配置阿里云盾SSL证书,预防访问风险提示或停止访问:
阿里云云盾证书,云上签发,部署简单,防窃听、防绑架。现代浏览器对于HTTPS的要求越来越高,谷歌浏览器、火狐浏览器等均开始对未配置SSL证书的站点给出安全警告提示,有的甚至直接停止访问并提示访问风险。如果您的网站属于电子商务类型或则包括了在线支付环节,就特别有必要早日订购布署SSL证书。通过布署SSL证书,提高网站的可信度,防范功击,可有效保护用户和网站自身的合法权益。购买并配置阿里云SSL证书,在云上签发各品牌数字证书,实现网站HTTPS化,使网站可信,防绑架、防篡改、防窃听。并进行统一生命周期管理,简化证书布署,一键分发到云上产品。
SupeSite7.5(社区门户网站系统模板)简体中文UTF-8
采集交流 • 优采云 发表了文章 • 0 个评论 • 219 次浏览 • 2020-08-07 18:59
相关软件的软件大小和版本说明下载链接
Supesite是具有独立内容管理的个人门户系统,结合了Web2.0应用程序元素,例如图片,书签和朋友圈. 也有Internet应用程序,例如文件下载和友谊链接. SupeSite使网站管理员可以在首页上轻松添加自定义信息渠道. 您不需要具备编码能力. 您只需要根据提示在后台填写通道模型的设置,然后打开该模型即可成功添加通道. 更改频道可以自定义字段和相应的页面,以及完全自定义的功能组件.
功能介绍
拥有一个方便易用的内容管理系统(CMS)
功能包括: 信息管理,信息发布,信息审阅,信息分类,信息字段自定义等,使网站易于管理和维护. 信息权限与用户组权限结合在一起. 网站管理员可以设置发布,管理和查看不同用户组中的信息的权限,从而使指定的用户组具有信息管理功能.
完善的级别审核机制
通过级别审查操作,审查管理人员可以对站点发布的信息进行级别分类处理,屏蔽和删除处理,从而有效地控制了站点页面上信息的显示. 在查看信息时,如果将查看级别设置为阻止信息,则该信息将不再出现在网站的聚合页面上,但仍将显示在用户自己的个人空间上. 如果要完全阻止信息,请使用删除功能. 审查信息分为5个级别. 您可以根据页面聚合的条件对信息进行自由分类. 用户发布的默认信息审核级别为待审核. 管理员可以设置是否允许在站点设置的站点聚合页面上显示待处理状态信息.
强大高效的模块功能
模块功能具有内容模板调用代码和Javascript调用代码,可以实现站内论坛(Discuz!)和个人空间(UCenter Home)信息的内容聚合. 灵活和免费的模块功能使网站模板的生产更加免费和便捷. 网站管理员可以轻松构建此网站的样式,并可以在其他网站的任何页面上显示网站数据.
独特的HTML生成技术
让网站站长更准确,更轻松地控制网站中的html文件. html批处理删除支持常规文件名删除,您可以指定删除某些类型的html页面. 支持整个网站的html,大大增加了网站的负载能力,并提高了搜索率. 独特的html和ajax技术更新机制可以实现html文件的生成和更新,而无需刷新,在后台自动执行以及更方便的网站管理.
具有强大的信息采集功能
用户可以使用采集机器人来轻松采集网络资源. 而且,您可以轻松地与其他人共享采集机器人,并支持便捷的功能,例如复制机器人,导入机器人,导出机器人,导出文章,图片,快速下载到本地,采集和分页.
独特的信息分析论坛资源阅读机制
网站管理员可以自由设置要在新闻类别下阅读的论坛主题资源,并自动阅读特定新闻类别下论坛多个部分中具有特定条件的帖子,以实现信息的自动化和论坛化. 查看全部
Supesite7.5是具有独立内容管理的个人门户系统,结合了Web2.0应用程序元素,例如图片,书签和朋友圈. 还有Internet应用程序,例如文件下载和友谊链接.
相关软件的软件大小和版本说明下载链接
Supesite是具有独立内容管理的个人门户系统,结合了Web2.0应用程序元素,例如图片,书签和朋友圈. 也有Internet应用程序,例如文件下载和友谊链接. SupeSite使网站管理员可以在首页上轻松添加自定义信息渠道. 您不需要具备编码能力. 您只需要根据提示在后台填写通道模型的设置,然后打开该模型即可成功添加通道. 更改频道可以自定义字段和相应的页面,以及完全自定义的功能组件.
功能介绍
拥有一个方便易用的内容管理系统(CMS)
功能包括: 信息管理,信息发布,信息审阅,信息分类,信息字段自定义等,使网站易于管理和维护. 信息权限与用户组权限结合在一起. 网站管理员可以设置发布,管理和查看不同用户组中的信息的权限,从而使指定的用户组具有信息管理功能.
完善的级别审核机制
通过级别审查操作,审查管理人员可以对站点发布的信息进行级别分类处理,屏蔽和删除处理,从而有效地控制了站点页面上信息的显示. 在查看信息时,如果将查看级别设置为阻止信息,则该信息将不再出现在网站的聚合页面上,但仍将显示在用户自己的个人空间上. 如果要完全阻止信息,请使用删除功能. 审查信息分为5个级别. 您可以根据页面聚合的条件对信息进行自由分类. 用户发布的默认信息审核级别为待审核. 管理员可以设置是否允许在站点设置的站点聚合页面上显示待处理状态信息.
强大高效的模块功能
模块功能具有内容模板调用代码和Javascript调用代码,可以实现站内论坛(Discuz!)和个人空间(UCenter Home)信息的内容聚合. 灵活和免费的模块功能使网站模板的生产更加免费和便捷. 网站管理员可以轻松构建此网站的样式,并可以在其他网站的任何页面上显示网站数据.
独特的HTML生成技术
让网站站长更准确,更轻松地控制网站中的html文件. html批处理删除支持常规文件名删除,您可以指定删除某些类型的html页面. 支持整个网站的html,大大增加了网站的负载能力,并提高了搜索率. 独特的html和ajax技术更新机制可以实现html文件的生成和更新,而无需刷新,在后台自动执行以及更方便的网站管理.
具有强大的信息采集功能
用户可以使用采集机器人来轻松采集网络资源. 而且,您可以轻松地与其他人共享采集机器人,并支持便捷的功能,例如复制机器人,导入机器人,导出机器人,导出文章,图片,快速下载到本地,采集和分页.
独特的信息分析论坛资源阅读机制
网站管理员可以自由设置要在新闻类别下阅读的论坛主题资源,并自动阅读特定新闻类别下论坛多个部分中具有特定条件的帖子,以实现信息的自动化和论坛化.
将cat接口性能优化用于Java应用程序监视
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2020-08-07 11:32
1. 用户体验差: 接口访问速度慢. 如果打开页面需要花费几秒钟,则用户可能会关闭页面并在页面未完全打开时离开,从而导致用户丢失. 通过性能优化,减少了服务器响应时间. ,可以改善用户体验并减少用户流失.
2. 雪崩效应: 接口访问速度慢会带来雪崩效应. 在微服务时代,功能页面可能需要调用多个服务接口. 如果某个接口响应缓慢,将导致服务调用此接口. 它也变得非常慢,最终将导致所有服务整体上变慢.
2,什么样的界面值得优化
1. 频繁调用且调用时间长的接口值得优化. 接口a被调用10,000次,平均通话时间为500毫秒,接口b被调用10次,平均通话时间为3秒. 优化接口a,假设从500ms到300ms进行了优化,每次节省200ms,则总体优化时间为200万毫秒. 优化接口b,即使从3秒优化到100ms,总的优化时间也只有29000毫秒. 在这种情况下,建议对接口a进行优化,这将更具成本效益并且更值得优化.
2. 呼叫数量很少,但是每个呼叫都是异常的(例如,超时后没有返回). 这种接口也必须进行优化.
3. 如何使用cat定位需要优化的界面
1. 选择一个具有成本效益的界面(交易)
如上图所示,选择了缓存服务应用程序. CacheService.mutliExecute被最频繁地调用,具有720,000个调用和相对较长的调用持续时间,可以用作优化的接口.
2. 按条件过滤,提供Long-url,Long sql,Long sevice和Long call过滤条件,可以将它们自己组合以调整时间长度. (问题)
3. 通话错误,必须进行修改和处理(问题)
4. 如何优化界面
1. 查看调用链,找到哪个方法调用花费很长时间
通过上图,发现接口中存在循环调用. 优化计划: 调用批处理操作界面以减少接口调用次数.
2. 缓慢的SQL优化方法
第一步: 解释查看sql执行计划以确认sql是否已被索引.
步骤2: 确认数据库表是否已建立索引. 如果没有索引,则创建一个合适的索引,并保持最左边的原则.
第3步: 如果有索引,则没有索引,分析原因
步骤4: 如果SQL转到索引,它仍然非常慢,请缓存中间结果(异构中间表或将结果缓存在redis中)
具体的优化示例:
1. 在清单查询接口中,数据库表具有索引,但未使用该索引,因为数据库表的属性类型为varchar,在sql中使用in,但是在传递参数时使用数字类型,这会导致数据发生类型转换,导致没有索引. 优化计划,修改参数传输类型,使用字符串传输参数,优化后从300ms减少到60ms. (如果数据库是数字类型,并且参数使用字符串类型,即使发生类型转换,索引仍然可以使用,这很奇怪). 在sql中用作多条件查询,有时可以对其进行索引,而有时则不能对其进行索引. 当in中只有一个值时,肯定会对其进行索引. 当查询结果在in中达到所有记录的一定比例时,将不获取索引.
2. 大表分页优化,定时任务,需要查询大表分页时,可以使用子查询进行优化. 示例: 商品表中有100万条记录,商品的销售需要每天定期更新. 通常的做法是使用多个线程,每个线程处理200个数据
select * from item limit 900000,200
执行的时间越晚,时间就越长,因为mysql需要找到前900,000条记录,然后再获取下200条数据. 因为没有索引,所以它会变慢.
优化计划一: 使用子查询
select * from item i,(select id from item limit 900000,200) as g where g.id = i.id
由于可以获取索引,并且子查询使用覆盖索引,因此无需执行第二次查询,从而可以提高查询速度.
优化计划2: 主键ID间隔方法
先决条件: 表结构中有一个自动增加的主键. 取表的最小值和最大值,将这两个值划分为段,每个线程处理一个间隔. 该查询可以使用主键索引.
select * from item where id in (1,2,3,4,5,..200)
3.jvm优化
查询库存优化后,获取索引后,确实更快. 我通过cat发现库存服务有两个应用程序实例. 一个实例具有非常快的界面,而一个实例却非常慢. 速度较慢的是通过猫的心跳发现的. 完整的gc存在于机器上,而完整的gc偶尔会发生一次.
查看jvm的Gc命令
jstat -gcutil pid 2000
如果存在大量的YGC,则可以使用jmap命令定位创建了哪些对象,然后优化代码以最小化对象的创建. 或调整jvm参数以增加Eden区域的大小. 如果存在大量fullGC,则应注意这种情况,因为fullGC会花费很长时间并且严重影响性能,因此需要调整jvm参数.
jmap -histo pid | grep com.galaxy(包路径)
top命令查看CPU,内存等的使用情况.
top
CPU使用了过高的优化方案
首先显示线程列表:
ps -mp pid -o THREAD,tid,time
找到最耗时的线程28802,它占用了将近两个小时的CPU时间!
接下来,将所需的线程ID转换为十六进制格式:
printf "%x\n" tid
最后打印线程堆栈信息:
jstack pid |grep tid -A 30
无法获得数据库连接
可能是数据库正在执行表结构的修改并导致表被锁定
select * from information_schema.processlist where db = 'item'and state like '%lock%'
需要终止检测到的进程. 您可以使用命令
kill 进程Id
无法获得redis连接,可能在某些地方未释放该连接,可以使用jstack命令定位
jstack –l pid > jstack.txt
下载jstack.txt进行分析,然后搜索Lock关键字,这可以方便地定位问题. 最好的方法是统一封装连接的操作,使开发人员没有机会犯错误. 查看全部
1. 为什么要优化接口性能?
1. 用户体验差: 接口访问速度慢. 如果打开页面需要花费几秒钟,则用户可能会关闭页面并在页面未完全打开时离开,从而导致用户丢失. 通过性能优化,减少了服务器响应时间. ,可以改善用户体验并减少用户流失.
2. 雪崩效应: 接口访问速度慢会带来雪崩效应. 在微服务时代,功能页面可能需要调用多个服务接口. 如果某个接口响应缓慢,将导致服务调用此接口. 它也变得非常慢,最终将导致所有服务整体上变慢.
2,什么样的界面值得优化
1. 频繁调用且调用时间长的接口值得优化. 接口a被调用10,000次,平均通话时间为500毫秒,接口b被调用10次,平均通话时间为3秒. 优化接口a,假设从500ms到300ms进行了优化,每次节省200ms,则总体优化时间为200万毫秒. 优化接口b,即使从3秒优化到100ms,总的优化时间也只有29000毫秒. 在这种情况下,建议对接口a进行优化,这将更具成本效益并且更值得优化.
2. 呼叫数量很少,但是每个呼叫都是异常的(例如,超时后没有返回). 这种接口也必须进行优化.
3. 如何使用cat定位需要优化的界面
1. 选择一个具有成本效益的界面(交易)
如上图所示,选择了缓存服务应用程序. CacheService.mutliExecute被最频繁地调用,具有720,000个调用和相对较长的调用持续时间,可以用作优化的接口.
2. 按条件过滤,提供Long-url,Long sql,Long sevice和Long call过滤条件,可以将它们自己组合以调整时间长度. (问题)
3. 通话错误,必须进行修改和处理(问题)
4. 如何优化界面
1. 查看调用链,找到哪个方法调用花费很长时间
通过上图,发现接口中存在循环调用. 优化计划: 调用批处理操作界面以减少接口调用次数.
2. 缓慢的SQL优化方法
第一步: 解释查看sql执行计划以确认sql是否已被索引.
步骤2: 确认数据库表是否已建立索引. 如果没有索引,则创建一个合适的索引,并保持最左边的原则.
第3步: 如果有索引,则没有索引,分析原因
步骤4: 如果SQL转到索引,它仍然非常慢,请缓存中间结果(异构中间表或将结果缓存在redis中)
具体的优化示例:
1. 在清单查询接口中,数据库表具有索引,但未使用该索引,因为数据库表的属性类型为varchar,在sql中使用in,但是在传递参数时使用数字类型,这会导致数据发生类型转换,导致没有索引. 优化计划,修改参数传输类型,使用字符串传输参数,优化后从300ms减少到60ms. (如果数据库是数字类型,并且参数使用字符串类型,即使发生类型转换,索引仍然可以使用,这很奇怪). 在sql中用作多条件查询,有时可以对其进行索引,而有时则不能对其进行索引. 当in中只有一个值时,肯定会对其进行索引. 当查询结果在in中达到所有记录的一定比例时,将不获取索引.
2. 大表分页优化,定时任务,需要查询大表分页时,可以使用子查询进行优化. 示例: 商品表中有100万条记录,商品的销售需要每天定期更新. 通常的做法是使用多个线程,每个线程处理200个数据
select * from item limit 900000,200
执行的时间越晚,时间就越长,因为mysql需要找到前900,000条记录,然后再获取下200条数据. 因为没有索引,所以它会变慢.
优化计划一: 使用子查询
select * from item i,(select id from item limit 900000,200) as g where g.id = i.id
由于可以获取索引,并且子查询使用覆盖索引,因此无需执行第二次查询,从而可以提高查询速度.
优化计划2: 主键ID间隔方法
先决条件: 表结构中有一个自动增加的主键. 取表的最小值和最大值,将这两个值划分为段,每个线程处理一个间隔. 该查询可以使用主键索引.
select * from item where id in (1,2,3,4,5,..200)
3.jvm优化
查询库存优化后,获取索引后,确实更快. 我通过cat发现库存服务有两个应用程序实例. 一个实例具有非常快的界面,而一个实例却非常慢. 速度较慢的是通过猫的心跳发现的. 完整的gc存在于机器上,而完整的gc偶尔会发生一次.
查看jvm的Gc命令
jstat -gcutil pid 2000
如果存在大量的YGC,则可以使用jmap命令定位创建了哪些对象,然后优化代码以最小化对象的创建. 或调整jvm参数以增加Eden区域的大小. 如果存在大量fullGC,则应注意这种情况,因为fullGC会花费很长时间并且严重影响性能,因此需要调整jvm参数.
jmap -histo pid | grep com.galaxy(包路径)
top命令查看CPU,内存等的使用情况.
top
CPU使用了过高的优化方案
首先显示线程列表:
ps -mp pid -o THREAD,tid,time
找到最耗时的线程28802,它占用了将近两个小时的CPU时间!
接下来,将所需的线程ID转换为十六进制格式:
printf "%x\n" tid
最后打印线程堆栈信息:
jstack pid |grep tid -A 30
无法获得数据库连接
可能是数据库正在执行表结构的修改并导致表被锁定
select * from information_schema.processlist where db = 'item'and state like '%lock%'
需要终止检测到的进程. 您可以使用命令
kill 进程Id
无法获得redis连接,可能在某些地方未释放该连接,可以使用jstack命令定位
jstack –l pid > jstack.txt
下载jstack.txt进行分析,然后搜索Lock关键字,这可以方便地定位问题. 最好的方法是统一封装连接的操作,使开发人员没有机会犯错误.
构建基于容器的本机监视系统时应注意什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 146 次浏览 • 2020-08-07 08:54
容器技术是当前非常流行的技术,可以大大提高工作效率. 在本文中,我们将描述容器本机监视的含义,其核心是监视动态容器环境并解决在此环境中完整堆栈可见性的特定挑战. 当然,这种解释很模糊,我们将在下面详细讨论.
单个容器并不重要
在云环境中,通常有“宠物和家畜”的比喻. 传统服务器就是您所关心的,称为“宠物”. 在云中,您处理动态实例. 这些实例非常易于替换,因此显示为“牲畜”. 容器是这个隐喻的扩展. 它们来来去去(这是一件好事),例如部署或更新服务,扩展等.
但是,像家畜一样,重要的不是个人动物,而是更多的群体及其服务目的. 此目的是容器环境中的“服务”. 因此,容器本机监视(听起来可能很奇怪)不应太集中于监视单个容器,但最重要的是它们提供的服务. 服务出现问题时,请实现自动通知. 此时,您将需要能够在需要时降至容器级别.
当然,您希望能够快速识别出问题的容器. 假设当前有10个容器支持该服务,并且一个容器处理请求的时间是服务中其他容器的延迟的两倍. 您希望收到有关此不同行为的通知,并详细查看容器及其周围环境. 例如,同一节点上可能存在另一个容器,该容器用完了磁盘I / O,并导致了此延迟.
我们在CoScale中处理此问题的方法是采集单个容器资源统计信息,并将其与从协调器平台获得的服务水平信息相关联. 然后,我们将提供一个特定的视觉视图,以显示单个服务的性能以及该服务的容器. 使用以下拓扑仪表板,您可以深入查看每个容器. 我们还将突出显示有问题的容器,并自动通知异常行为. 为此,我们在服务级别(考虑季节性因素)和容器级别(比较相同服务的容器)上使用异常检测技术.
容器仅显示需要显示的内容
容器的操作方式在从其采集度量标准方面提出了特定的挑战. 有很多方法可以解决此问题. 您可以开始公开端口,安装卷等,以便将容器信息公开给外界. 这不仅麻烦,而且还存在安全问题. 例如,当您希望公开JMX连接以访问stats接口时,可能会通过JMX触发潜在的恶意操作. 因此,理想情况下,您希望将JMX连接本地保存在容器中. 这就是容器的目的.
另一种方法是开始将监视代理程序包装在容器中. 除了额外的开销外,这还破坏了容器的不变性,并且与限制容器的单个过程不兼容.
我们在CoScale中处理此问题的方法是对每个节点使用单个监视代理,该代理使用一组插件来监视容器和协调器指标以及每个容器中的服务. 代理将在容器的名称空间中启动插件,以确保插件具有与容器中运行的应用程序相同的视图. 这样可以确保您不需要公开任何内容,并且此方法在框中完成.
访问容器日志文件以进行数据检索
日志通常是获取指标的良好信息来源. 在容器环境中有许多用于写入和存储日志文件的选项. 与监视一样,您不想在容器中放置代理以采集日志或在容器中没有对日志聚合器的任何引用. 日志应由平台处理.
从容器向外部世界发送日志数据的最有效方法是通过/ dev / stdout. 然后,平台获取这些日志并将其推送到日志聚合器. 这使日志访问和聚合变得简单明了,并确保您的容器依赖于单个进程,并且不需要后台工作人员或计划任务来清理其日志.
CoScale支持从推送到/ dev / stdout和/ dev / stderr的日志中提取指标和事件. 但是,如果容器中有多个日志文件(例如访问日志,错误日志等),则可以将CoScale插件配置为从这些日志文件中提取指标和事件.
所有容器都相同
容器使用环境变量进行初始化,连接等. 有状态的容器(如数据库容器(如postgresql,mysql))也使用环境变量来初始化数据库(如果尚未初始化). 必须考虑这些环境变量,以便正确监视这些容器及其正在运行的服务,因此您的监视解决方案应该了解这一点.
某些CoScale插件需要凭据来采集运行服务的指标. 提供给容器的环境变量可以在CoScale插件配置中使用. 例如,Postgresql容器使用pguser和pgpassword环境变量. 在CoScale Postgres插件配置中,可以将$ pguser和$ pgpassword用作连接数据库的凭据. 当CoScale代理检测到Postgresql容器时,它将知道使用提供给该容器的环境变量作为凭据来获取该容器的Postgresql统计信息.
通过这种方式,无需更改图像以收录固定的凭据即可监视它们.
部署监控的方式与部署服务的方式相同
由于服务在容器中运行,因此有必要在监视代理程序上执行相同的操作. 一些监视工具将要求您将代理安装在容器中,或将代理安装在sidecar容器中,这通常会带来额外的开销. 另外,必须将其他监视代理程序包装在容器中,这不是开发人员非常喜欢的东西,因为它破坏了容器的单一用途. 在您自己的容器中部署监视代理程序是一种容器本身的解决方案,与其他容器化服务相比,它使部署监视更加容易. 此外,使用deamonset和helm chart之类的概念,您可以在部署的每个新节点上以正确的配置快速部署监视代理.
在CoScale中处理此问题的方法是在容器中运行监视代理. 这些容器可以部署到各种不同的配置器和容器平台. 我们已经与Kubernetes,OpenShift,Docker Swarm,Google Container Engine等集成在一起,然后直接在标识容器的名称空间中运行我们的各种插件以提取相关指标.
基于容器映像的监视
容器本机监视还意味着容器映像定义应如何进行监视. 容器内不需要代理,也无需引用监视详细信息,证书等. 每个映像运行另一个服务或不同的版本,并且它们可能具有不同的监视要求. 例如,运行NGINX Web服务的映像和运行Redis的映像具有不同的监视指标.
结论
容器本机监视有很多方面. 上面的列表并不详尽,但是它提供了一种监视容器技术核心原理的好方法. 这包括访问信息,监视容器环境中的设置以及将低级指标转换为可行的见解的方法. 查看全部
构建基于容器的本机监视系统时应注意什么?
容器技术是当前非常流行的技术,可以大大提高工作效率. 在本文中,我们将描述容器本机监视的含义,其核心是监视动态容器环境并解决在此环境中完整堆栈可见性的特定挑战. 当然,这种解释很模糊,我们将在下面详细讨论.
单个容器并不重要
在云环境中,通常有“宠物和家畜”的比喻. 传统服务器就是您所关心的,称为“宠物”. 在云中,您处理动态实例. 这些实例非常易于替换,因此显示为“牲畜”. 容器是这个隐喻的扩展. 它们来来去去(这是一件好事),例如部署或更新服务,扩展等.
但是,像家畜一样,重要的不是个人动物,而是更多的群体及其服务目的. 此目的是容器环境中的“服务”. 因此,容器本机监视(听起来可能很奇怪)不应太集中于监视单个容器,但最重要的是它们提供的服务. 服务出现问题时,请实现自动通知. 此时,您将需要能够在需要时降至容器级别.
当然,您希望能够快速识别出问题的容器. 假设当前有10个容器支持该服务,并且一个容器处理请求的时间是服务中其他容器的延迟的两倍. 您希望收到有关此不同行为的通知,并详细查看容器及其周围环境. 例如,同一节点上可能存在另一个容器,该容器用完了磁盘I / O,并导致了此延迟.
我们在CoScale中处理此问题的方法是采集单个容器资源统计信息,并将其与从协调器平台获得的服务水平信息相关联. 然后,我们将提供一个特定的视觉视图,以显示单个服务的性能以及该服务的容器. 使用以下拓扑仪表板,您可以深入查看每个容器. 我们还将突出显示有问题的容器,并自动通知异常行为. 为此,我们在服务级别(考虑季节性因素)和容器级别(比较相同服务的容器)上使用异常检测技术.
容器仅显示需要显示的内容
容器的操作方式在从其采集度量标准方面提出了特定的挑战. 有很多方法可以解决此问题. 您可以开始公开端口,安装卷等,以便将容器信息公开给外界. 这不仅麻烦,而且还存在安全问题. 例如,当您希望公开JMX连接以访问stats接口时,可能会通过JMX触发潜在的恶意操作. 因此,理想情况下,您希望将JMX连接本地保存在容器中. 这就是容器的目的.
另一种方法是开始将监视代理程序包装在容器中. 除了额外的开销外,这还破坏了容器的不变性,并且与限制容器的单个过程不兼容.
我们在CoScale中处理此问题的方法是对每个节点使用单个监视代理,该代理使用一组插件来监视容器和协调器指标以及每个容器中的服务. 代理将在容器的名称空间中启动插件,以确保插件具有与容器中运行的应用程序相同的视图. 这样可以确保您不需要公开任何内容,并且此方法在框中完成.
访问容器日志文件以进行数据检索
日志通常是获取指标的良好信息来源. 在容器环境中有许多用于写入和存储日志文件的选项. 与监视一样,您不想在容器中放置代理以采集日志或在容器中没有对日志聚合器的任何引用. 日志应由平台处理.
从容器向外部世界发送日志数据的最有效方法是通过/ dev / stdout. 然后,平台获取这些日志并将其推送到日志聚合器. 这使日志访问和聚合变得简单明了,并确保您的容器依赖于单个进程,并且不需要后台工作人员或计划任务来清理其日志.
CoScale支持从推送到/ dev / stdout和/ dev / stderr的日志中提取指标和事件. 但是,如果容器中有多个日志文件(例如访问日志,错误日志等),则可以将CoScale插件配置为从这些日志文件中提取指标和事件.
所有容器都相同
容器使用环境变量进行初始化,连接等. 有状态的容器(如数据库容器(如postgresql,mysql))也使用环境变量来初始化数据库(如果尚未初始化). 必须考虑这些环境变量,以便正确监视这些容器及其正在运行的服务,因此您的监视解决方案应该了解这一点.
某些CoScale插件需要凭据来采集运行服务的指标. 提供给容器的环境变量可以在CoScale插件配置中使用. 例如,Postgresql容器使用pguser和pgpassword环境变量. 在CoScale Postgres插件配置中,可以将$ pguser和$ pgpassword用作连接数据库的凭据. 当CoScale代理检测到Postgresql容器时,它将知道使用提供给该容器的环境变量作为凭据来获取该容器的Postgresql统计信息.
通过这种方式,无需更改图像以收录固定的凭据即可监视它们.
部署监控的方式与部署服务的方式相同
由于服务在容器中运行,因此有必要在监视代理程序上执行相同的操作. 一些监视工具将要求您将代理安装在容器中,或将代理安装在sidecar容器中,这通常会带来额外的开销. 另外,必须将其他监视代理程序包装在容器中,这不是开发人员非常喜欢的东西,因为它破坏了容器的单一用途. 在您自己的容器中部署监视代理程序是一种容器本身的解决方案,与其他容器化服务相比,它使部署监视更加容易. 此外,使用deamonset和helm chart之类的概念,您可以在部署的每个新节点上以正确的配置快速部署监视代理.
在CoScale中处理此问题的方法是在容器中运行监视代理. 这些容器可以部署到各种不同的配置器和容器平台. 我们已经与Kubernetes,OpenShift,Docker Swarm,Google Container Engine等集成在一起,然后直接在标识容器的名称空间中运行我们的各种插件以提取相关指标.
基于容器映像的监视
容器本机监视还意味着容器映像定义应如何进行监视. 容器内不需要代理,也无需引用监视详细信息,证书等. 每个映像运行另一个服务或不同的版本,并且它们可能具有不同的监视要求. 例如,运行NGINX Web服务的映像和运行Redis的映像具有不同的监视指标.
结论
容器本机监视有很多方面. 上面的列表并不详尽,但是它提供了一种监视容器技术核心原理的好方法. 这包括访问信息,监视容器环境中的设置以及将低级指标转换为可行的见解的方法.

