
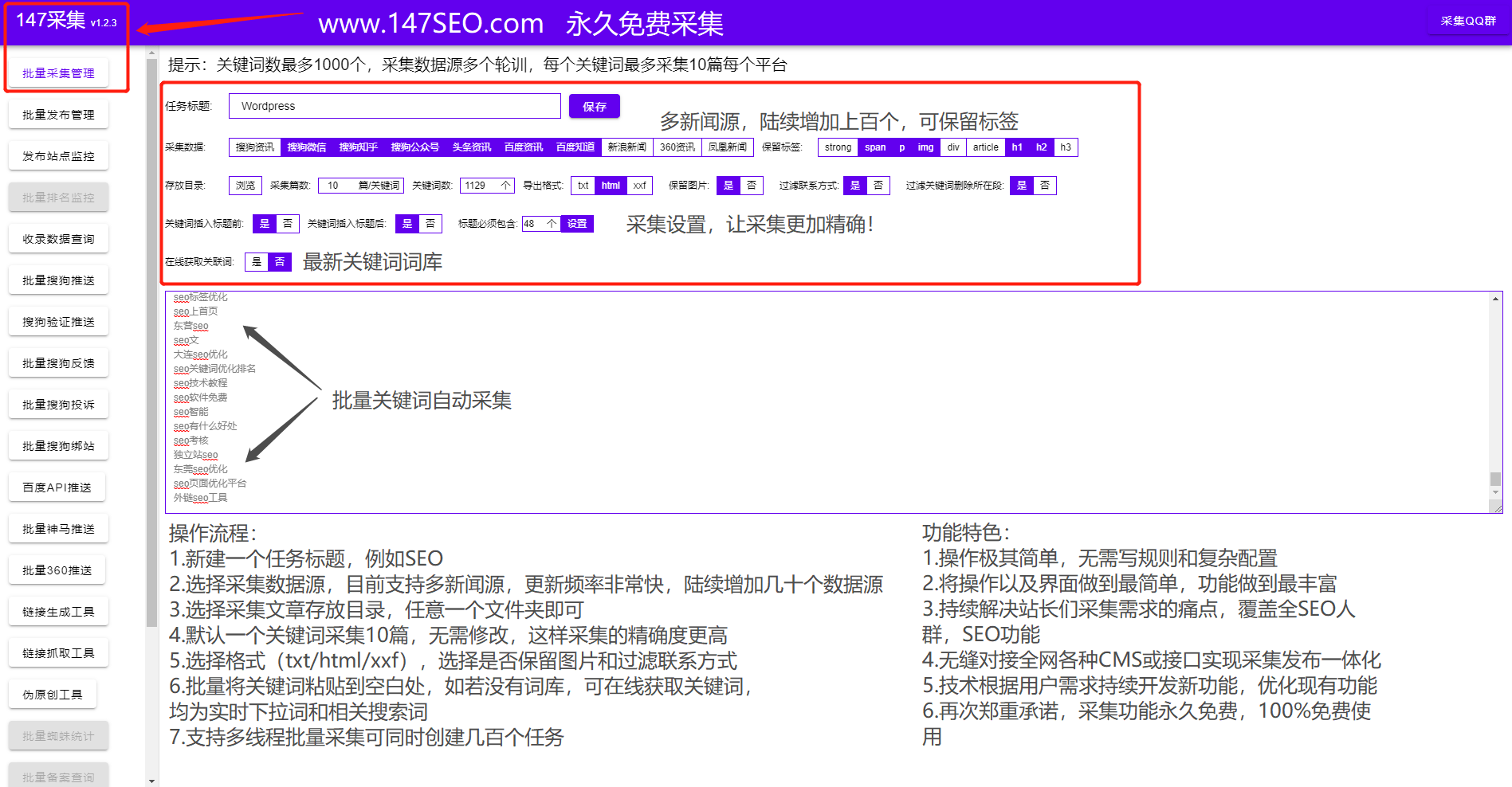
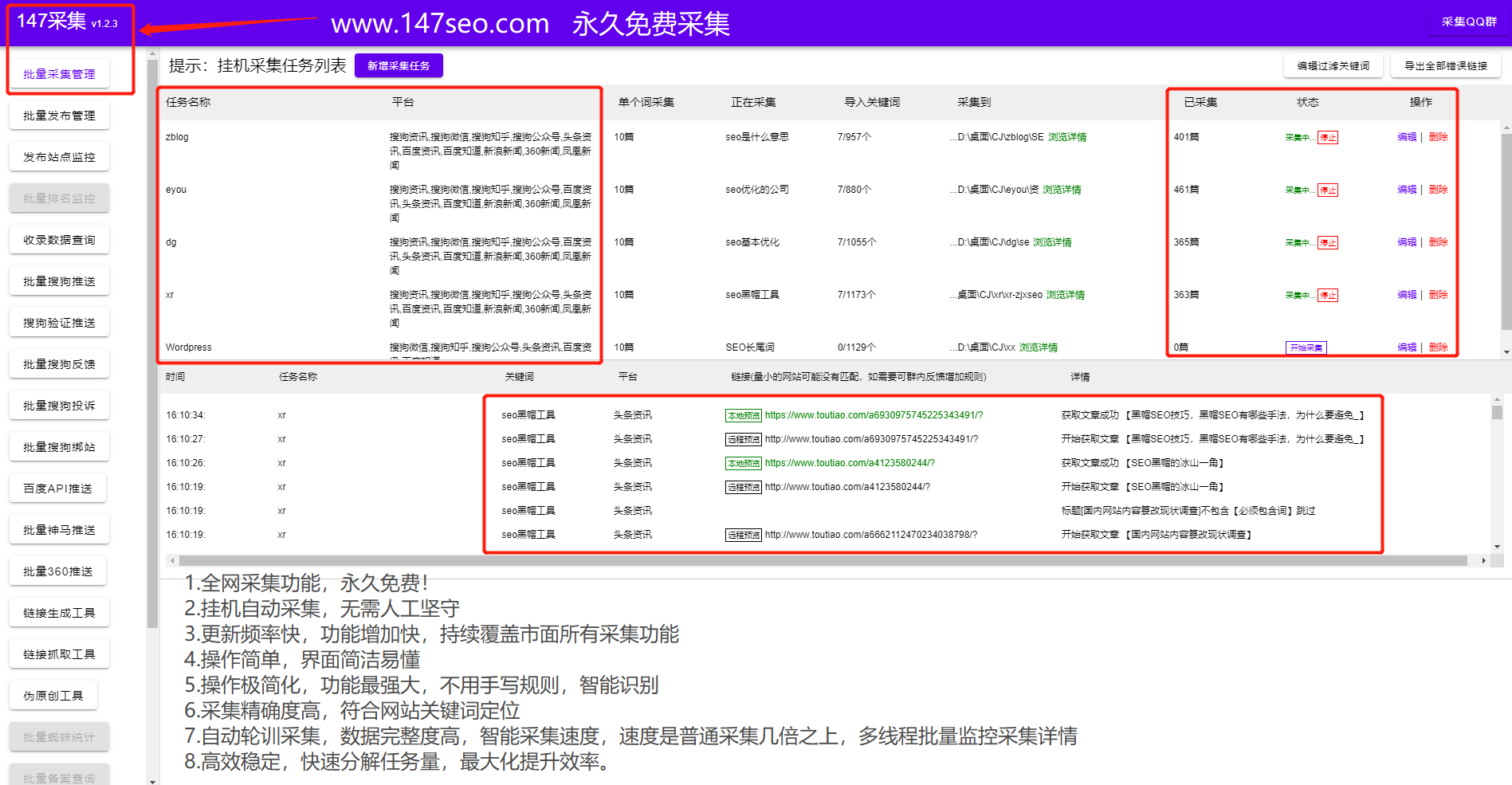
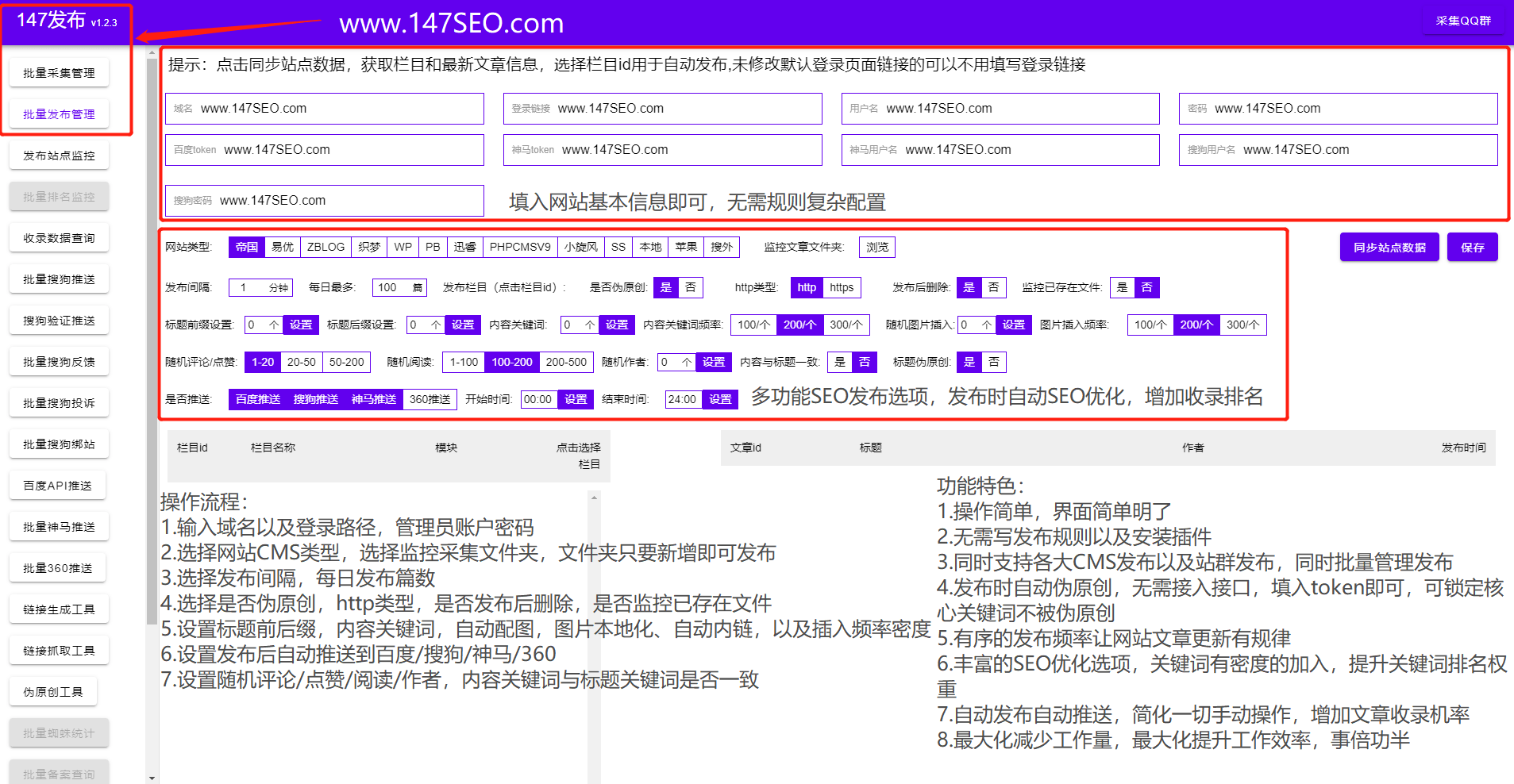
一键采集上传常见的细节问题
一键采集上传常见的细节问题(大数据架构和kappa架构的设计思路及难点)
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2022-03-27 01:08
近年来,随着IT技术、大数据、机器学习、算法的不断发展,越来越多的企业意识到数据的价值,将数据作为自己的宝贵资产进行管理,利用大数据和机器学习。挖掘、识别和利用数据资产的能力。如果缺乏有效的整体数据架构设计或缺乏某些能力,就会导致业务层难以直接使用大数据和大数据,造成大数据与业务之间的巨大差距。存在数据不可知论、需求实现难、数据共享难等一系列问题。本文介绍了一些数据平台设计思路,帮助企业减少数据开发的痛点和难点。
本文主要包括以下章节:
本文第一部分介绍了大数据的基本组成部分和相关知识。第二部分将介绍 lambda 架构和 kappa 架构。第三部分将介绍 lambda 和 kappa 架构模式下的通用大数据架构。第四部分将介绍暴露的数据架构体系下数据端到端的难点和痛点。第五部分介绍了优秀大数据架构的整体设计。从第五部分开始,介绍通过各种数据平台和组件将这些大数据组件组合起来,打造一套高效易用的数据平台,提高业务系统的效率。让业务开发不怕复杂的数据开发组件,并且不需要关注底层实现。只需要能够使用 SQL 完成一站式开发并完成数据返回,让大数据不再是数据工程师独有的技能。
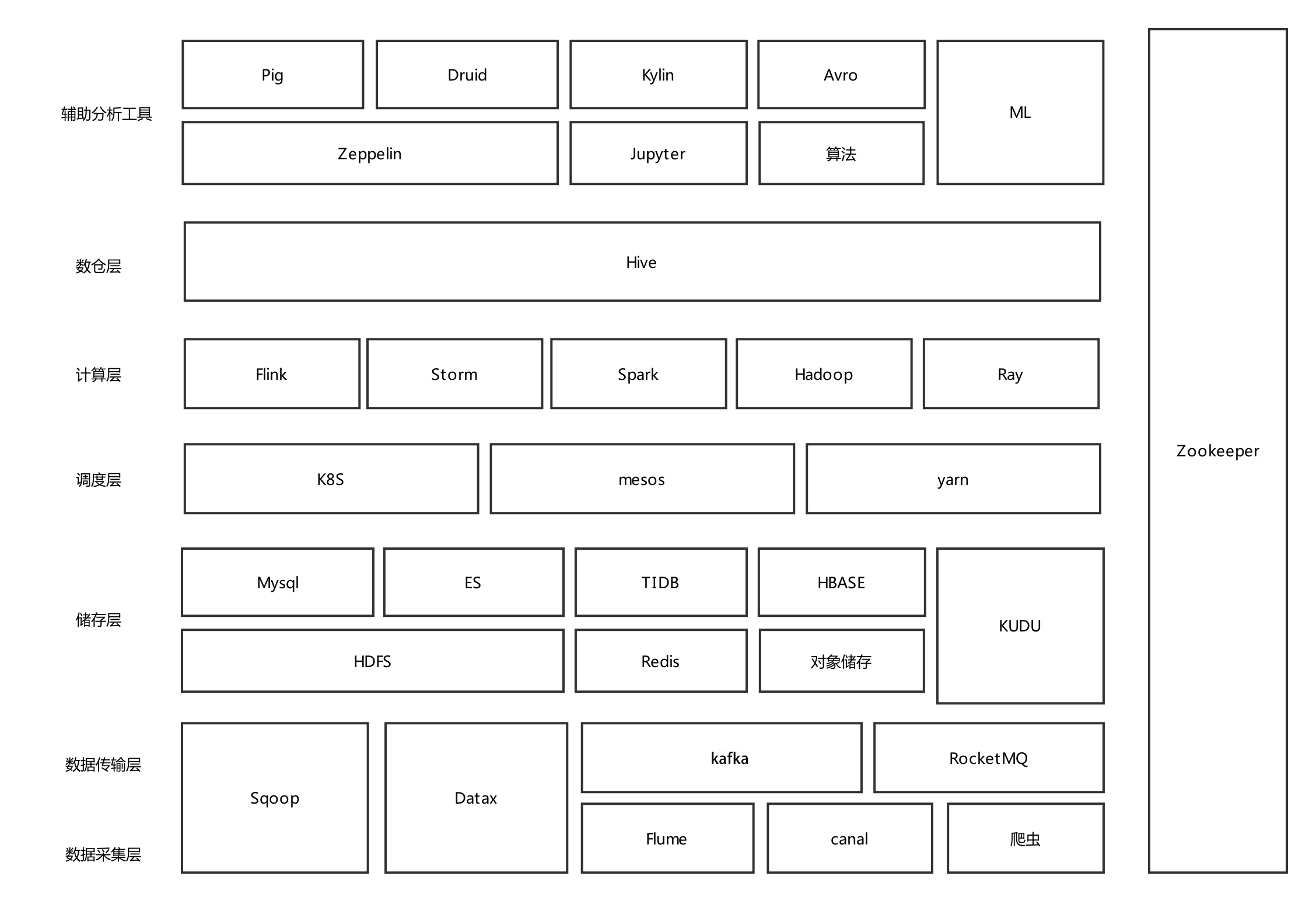
一、大数据技术栈
大数据的整个过程涉及到很多模块,每个模块都比较复杂。下图列出了这些模块和组件及其功能特性。将有专题详细介绍相关模块的领域知识,如数据采集、数据传输、实时计算、离线计算、大数据存储等相关模块。
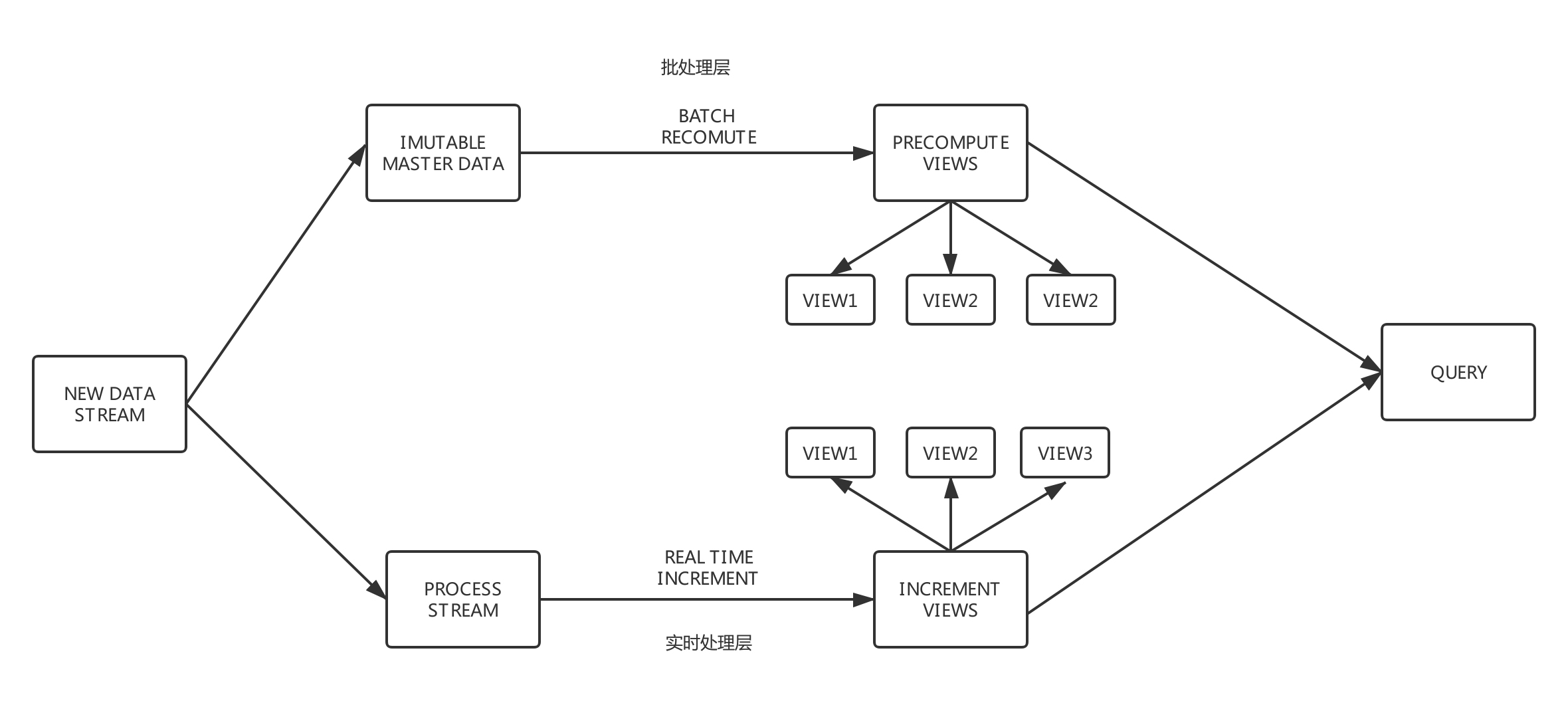
二、lambda 架构和 kappa 架构
目前,基本上所有的大数据架构都是基于lambda和kappa架构,不同的公司都基于这两种架构模式设计了符合公司数据架构的数据架构。lambda 架构使开发人员能够构建大规模的分布式数据处理系统。它具有良好的灵活性和可扩展性,对硬件故障和人为错误也具有良好的容错能力。您可以在 Internet 文章 上找到很多关于 lambda 架构的信息。kappa架构解决了lambda架构中存在的两组数据处理系统带来的各种成本问题。这也是当前流批集成的研究方向。许多公司已经开始使用这种更高级的架构。
Lambda 架构
卡帕建筑
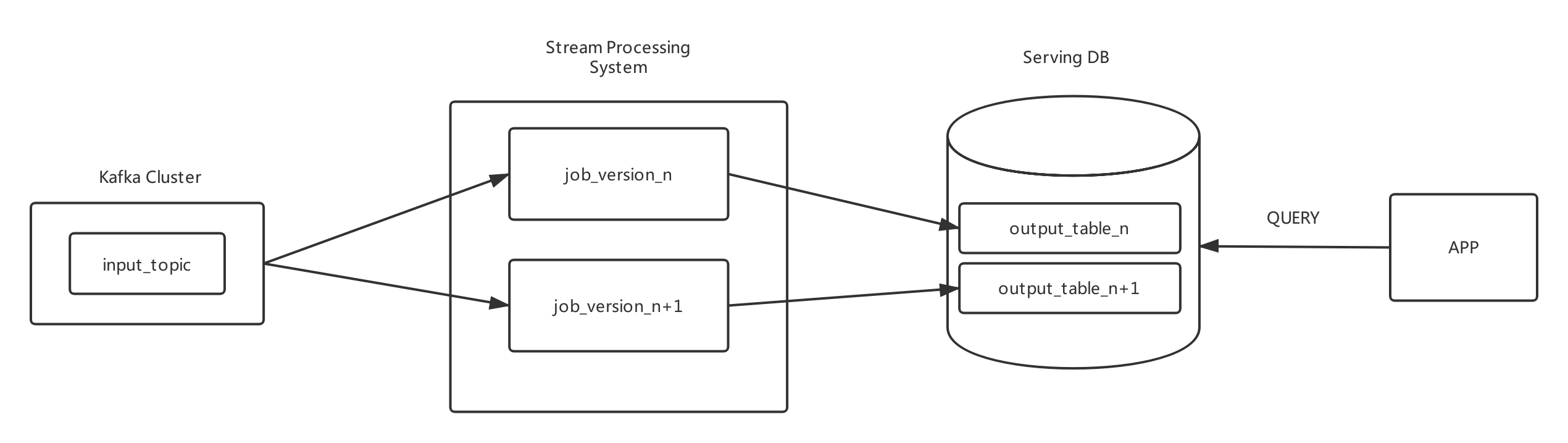
三、kappa架构和lambda架构下的大数据架构
目前各大公司基本都采用kappa架构或者lambda架构模式。这两种模式下的大数据整体架构在早期发展阶段可能如下:
四、数据端到端痛点
虽然上面的架构看似连接了各种大数据组件来实现集成化管理,但是接触过数据开发的人会强烈地感觉到,这样的裸架构业务数据开发需要注意很多基础工具的使用。在实际数据开发中存在很多痛点和难点,具体体现在以下几个方面。
没有一套数据开发IDE来管理整个数据开发流程,长期的流程是无法管理的。没有标准的数据建模体系,导致不同的数据工程师对指标的计算口径有不同的误解。大数据组件的开发要求很高,普通业务直接使用Hbase、ES等技术组件会导致各种问题。基本上每个公司的大数据团队都会很复杂,涉及的环节很多,遇到问题很难找到对应的负责人。数据孤岛难以打破,团队和部门之间难以共享数据,彼此之间也不清楚对方拥有哪些数据。两组计算模型,批计算和流计算,需要维护,很难开始开发。需要为流和批处理提供一套统一的SQL。缺乏公司级元数据系统规划,难以实时和离线复用同一条数据,每个开发任务都需要多方梳理。
基本上,大部分企业在数据平台的治理和开放能力的提供上都存在上述问题和痛点。在复杂的数据架构下,对于数据适用方来说,每个环节的不清晰或者功能的不友好,都会让复杂的环节变化更加复杂。要解决这些痛点,就需要精心打磨每一个环节,无缝对接以上技术组件,让业务端到端的数据使用就像写SQL查询数据库一样简单。
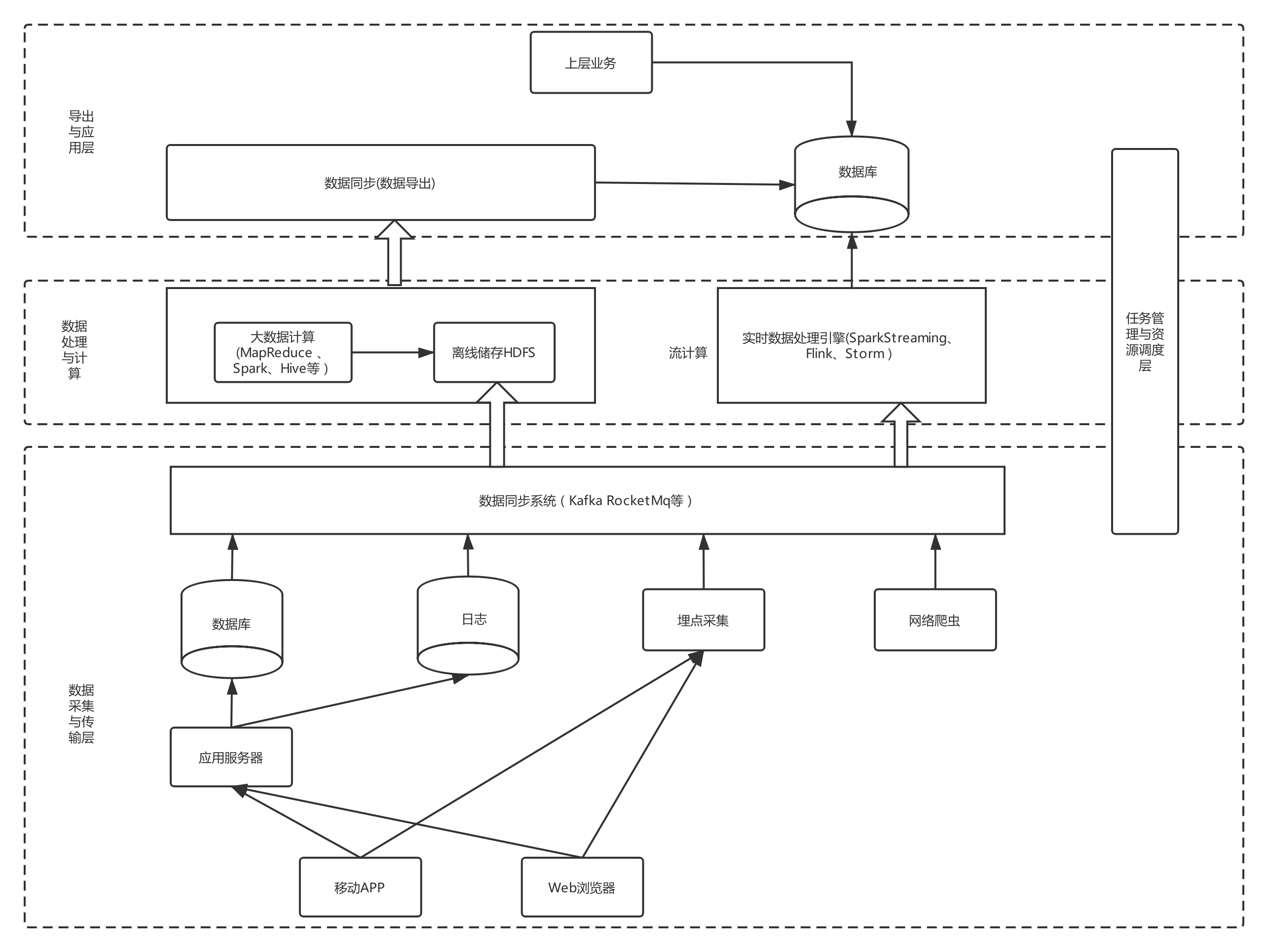
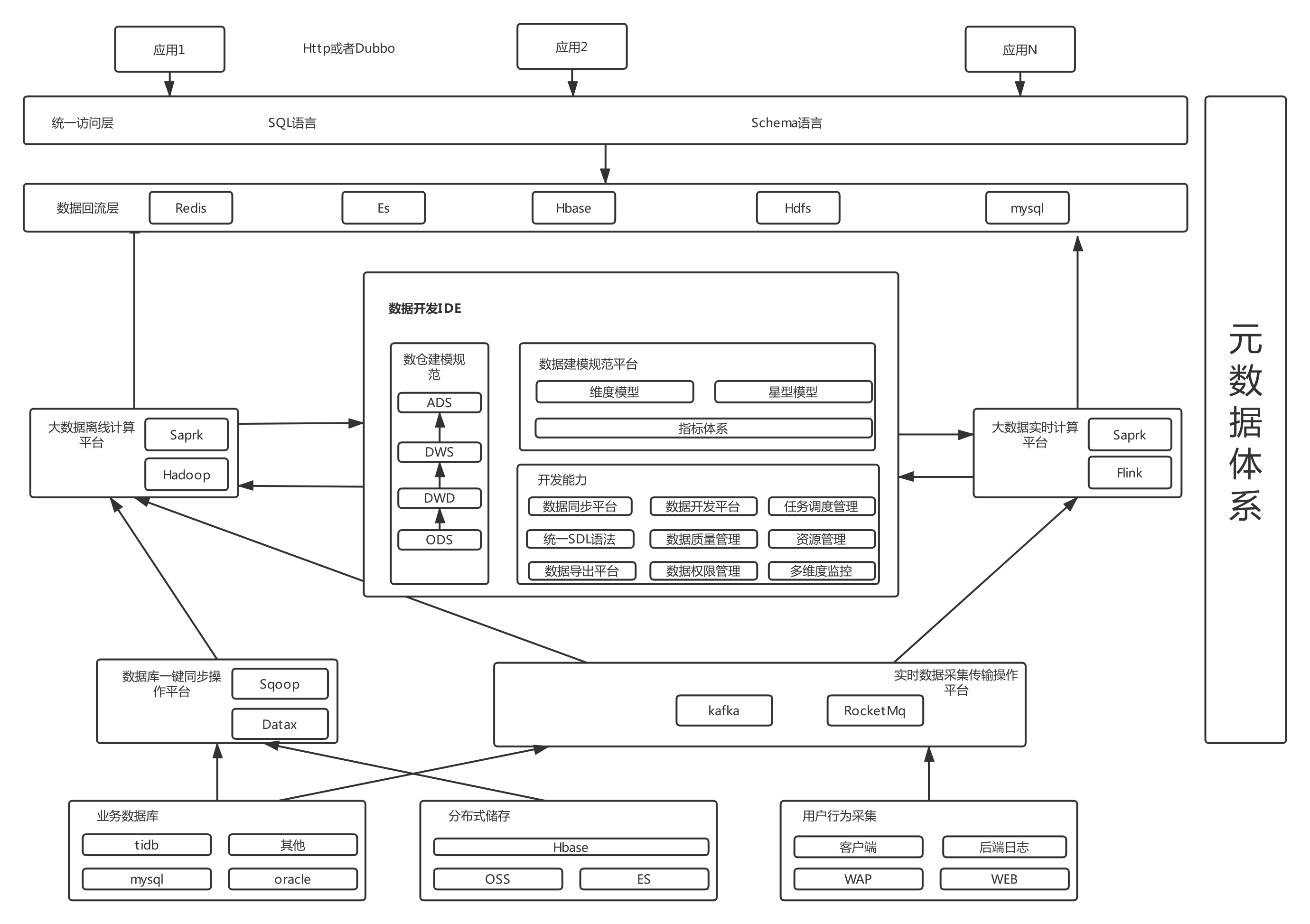
五、优秀的大数据整体架构设计
提供多种平台和工具助力数据平台:data采集多数据源平台、一键数据同步平台、数据质量与建模平台、元数据系统、数据统一接入平台、实时和离线计算平台、资源调度平台、一站式开发IDE。
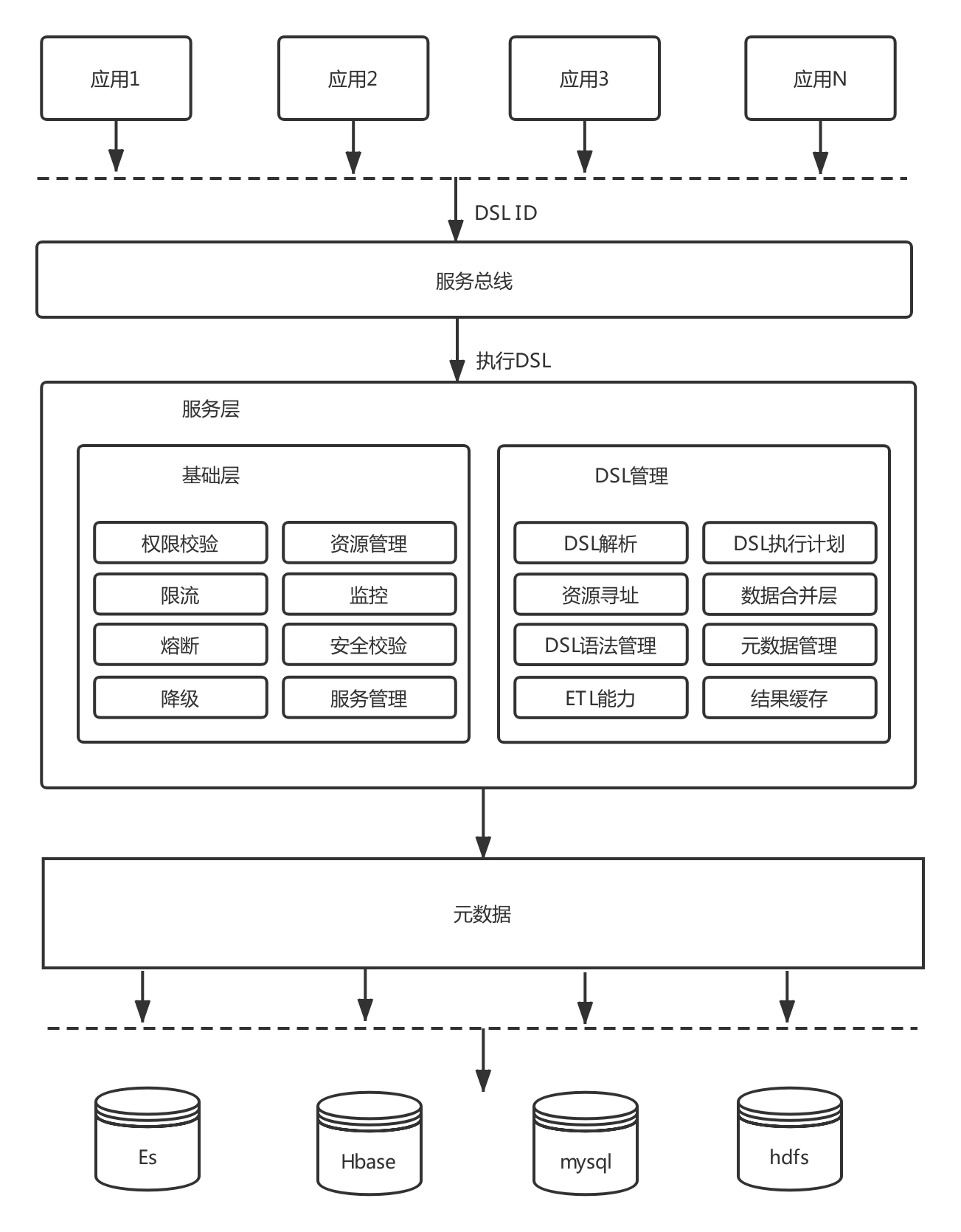
六、元数据——大数据系统的基石
元数据连接数据源、数据仓库和数据应用,记录数据生成到消费的完整环节。元数据收录静态表、列、分区信息(即 MetaStore)。动态任务与表依赖映射关系;数据仓库模型定义、数据生命周期;ETL任务调度信息、输入输出等元数据是数据管理、数据内容和数据应用的基础。例如,元数据可用于构建任务、表、列和用户之间的数据图;构建任务 DAG 依赖关系,并安排任务执行顺序;建立任务画像以管理任务质量;为个人或BUs概述等提供资产管理和计算资源消耗。
可以认为整个大数据数据流是由元数据管理的。如果没有一套完整的元数据设计,上述数据将难以追踪、权限难以控制、资源难以管理、数据难以共享。
很多公司都依赖hive来管理元数据,但是我个人认为,在发展到一定阶段,还是需要搭建一个元数据平台来匹配相关架构。
七、流批一体化计算
如果维护两套计算引擎,比如离线计算Spark和实时计算Flink,会给用户带来很大的麻烦,需要同时学习流计算知识和批计算领域知识。如果你离线使用 Flink 来实时使用 Spark 或 Hadoop,你可以开发自定义的 DSL 描述语言来匹配不同计算引擎的语法。上层用户无需关注底层的具体执行细节。他们只需要掌握一门 DSL 语言即可完成 Spark。接入Hadoop、Flink等计算引擎。
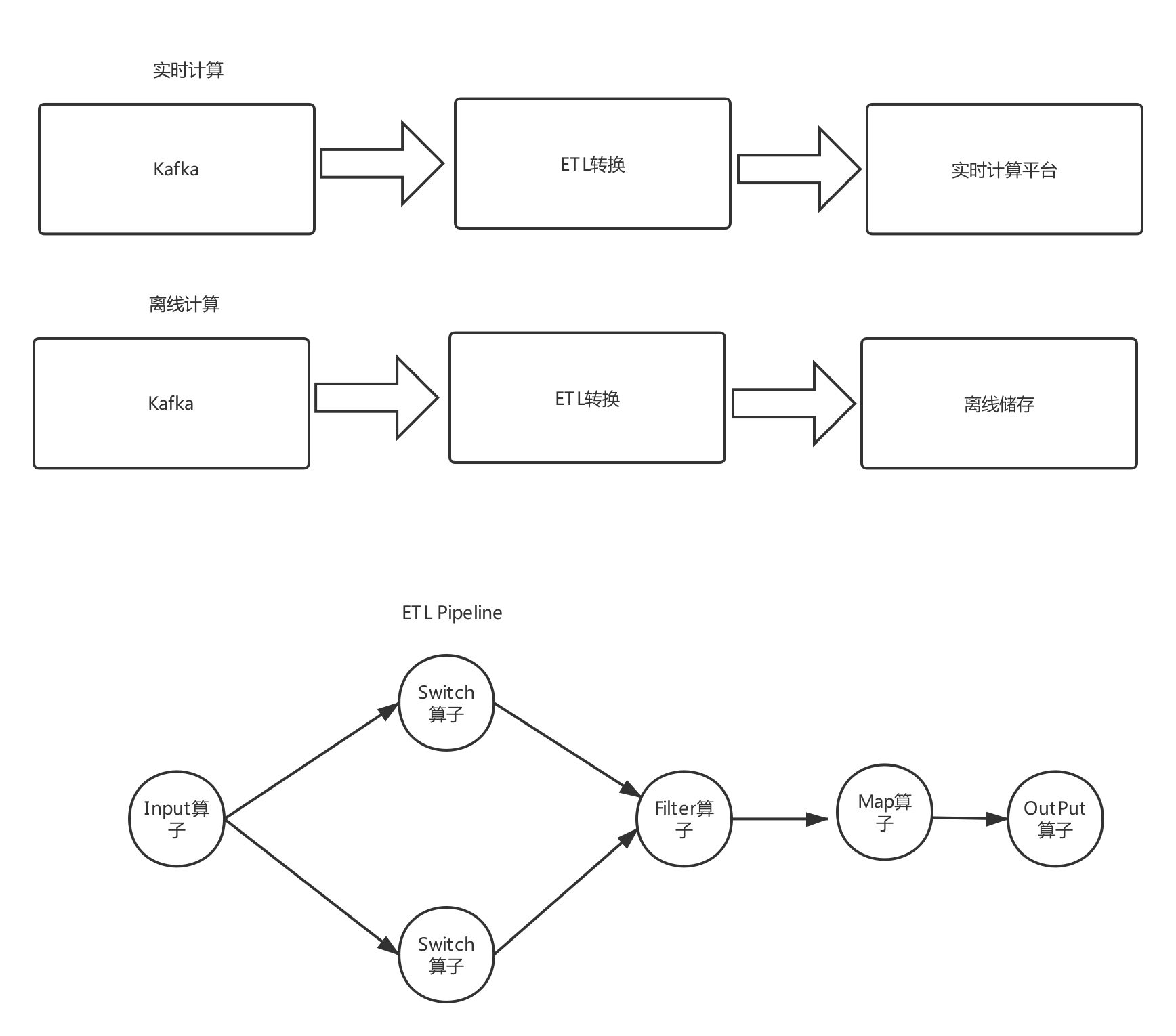
八、直播和离线ETL平台
ETL 代表 Extract-Transform-Load,用于描述从源到目的地提取、转换和加载数据的过程。ETL 一词在数据仓库中更常用,但它的对象并不限于数据仓库。一般来说,ETL平台在数据清洗、数据格式转换、数据补全、数据质量管理等方面发挥着重要作用。ETL作为重要的数据清洗中间层,一般来说至少要具备以下功能:
支持多种数据源,如消息系统、文件系统等 支持多种算子,过滤、拆分、变换、输出、查询数据源补全等算子能力 支持动态变化逻辑,如上述算子通过动态提交jar 可以做不停的发布变化
九、智能统一查询平台
大多数数据查询都是由需求驱动的。每个需求开发一个或多个接口,编写接口文档,开放给业务方调用。这种模型在大数据系统中存在很多问题:
这种架构简单,但是接口粒度很粗,灵活性不高,可扩展性差,复用率低。随着业务需求的增加,接口数量大幅增加,维护成本高。同时,开发效率不高,对于海量数据系统显然会造成大量重复开发,数据和逻辑难以复用,业务适用方的经验严重降低。如果没有统一的查询平台直接将Hbase等库暴露给业务,后续对数据权限的运维管理会更加困难。访问大数据组件对于业务适用方来说也是非常痛苦的,一不小心就会出现各种问题。.
通过一组智能查询解决上述大数据查询痛点
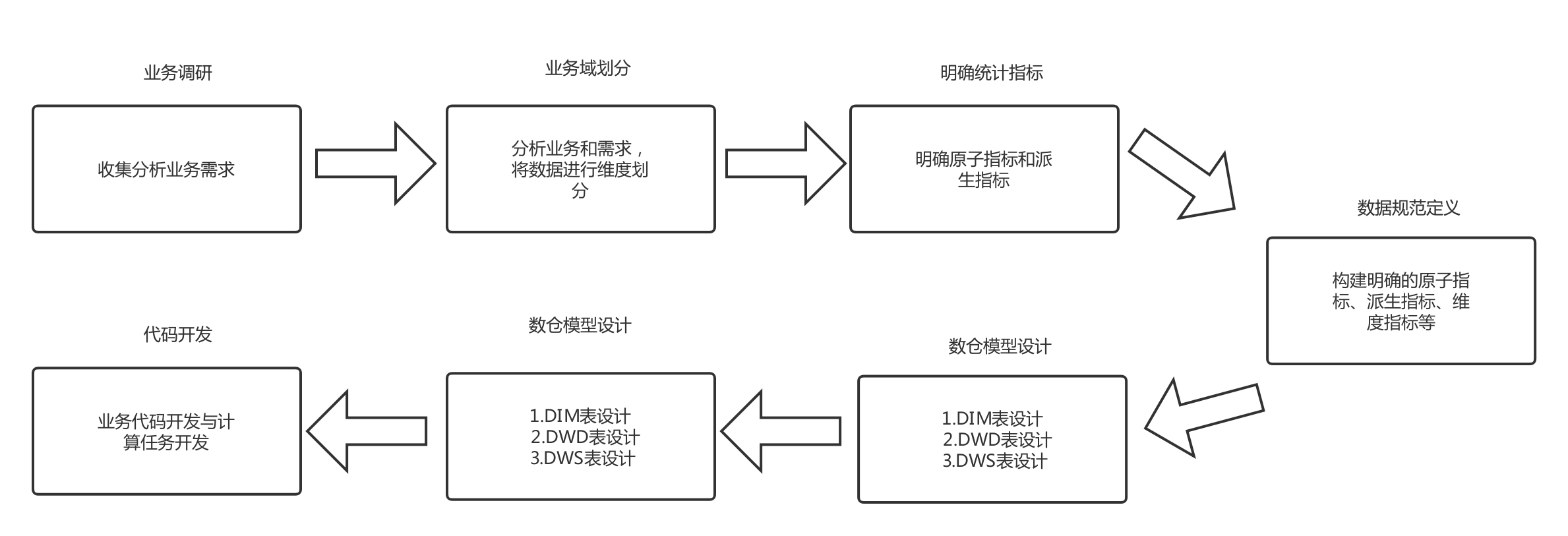
十、数据仓库建模规范体系
随着业务复杂度和数据规模的增加,数据调用和复制混乱,重复建设造成的资源浪费,数据指标定义不同造成的模糊,数据使用门槛越来越高。以笔者实际业务跟踪和数据仓库使用的见证为例,同产品名的表字段有的叫good_id,有的叫spu_id,还有很多其他的名字,会给想用的人带来很大的麻烦这些数据。因此,如果没有完整的大数据建模体系,会给数据治理带来很大的困难,表现在以下几个方面:
数据标准不一致,即使命名相同,但定义口径不一致。例如,仅 uv 之类的指标就有十几个定义。问题是:它们都是UV,我用哪一个?都是uv,为什么数据不一样?研发成本巨大,每个工程师都需要从头到尾了解研发过程的每一个细节,每个人都会再次踩到同一个“坑”,浪费了研发人员的时间和精力成本。这也是目标作者遇到的问题。实际开发和提取数据太难了。没有统一的标准管理,造成重复计算等资源浪费。数据表的层次和粒度不清晰,也使得重复存储很严重。
所以大数据开发和数仓表设计必须遵循设计原则,数据平台可以开发平台来约束不合理的设计,比如阿里巴巴的OneData body。一般来说,数据开发是根据以下准则进行的:
有兴趣的可以参考阿里巴巴的OneData设计系统。
十大一、一键集成平台
一键采集将各种数据传输到数据平台非常简单,通过数据传输平台将数据无缝连接到ETL平台。ETL与元数据平台对接,标准化Schema定义,然后将数据转换分发到实时和离线计算平台。后续对数据的任何离线实时处理,只需要申请元数据表的权限,即可完成开发任务并完成计算。data采集支持多种数据源,如binlog、log采集、前端埋点、kafka消息队列等。
十个二、数据开发IDE——高效的端到端工具
高效的数据开发一站式解决方案工具。实时计算和离线计算任务开发可以通过IDE完成,以上平台对接,提供一站式解决方案。数据开发IDE提供数据集成、数据开发、数据管理、数据质量和数据服务等全方位的产品服务,一站式开发管理界面。数据的传输、转换和集成都是通过数据IDE完成的。从不同的数据存储导入数据,转换开发,最终将处理后的数据同步到其他数据系统。通过一个高效的大数据开发IDE,大数据工程师可以基本屏蔽各种痛点,结合上述各种平台能力,
数据开发工具请参考阿里云DataWorks。
解决端到端的难题还需要其他几个能力的辅助,这里不再赘述。有兴趣的同学可以自学。
十个三、其他
一个完整的数据系统的开发还包括报警监控中心、资源调度中心、资源计算隔离、数据质量检测、一站式数据处理系统,这里不再赘述。
如果您认为 文章 写得好,编码并不容易:
请1.关注作者~你的关注是我写作的最大动力
2.私信我“大数据”
给大家分享一套最新的大数据学习资源和全套开发工具 查看全部
一键采集上传常见的细节问题(大数据架构和kappa架构的设计思路及难点)
近年来,随着IT技术、大数据、机器学习、算法的不断发展,越来越多的企业意识到数据的价值,将数据作为自己的宝贵资产进行管理,利用大数据和机器学习。挖掘、识别和利用数据资产的能力。如果缺乏有效的整体数据架构设计或缺乏某些能力,就会导致业务层难以直接使用大数据和大数据,造成大数据与业务之间的巨大差距。存在数据不可知论、需求实现难、数据共享难等一系列问题。本文介绍了一些数据平台设计思路,帮助企业减少数据开发的痛点和难点。
本文主要包括以下章节:
本文第一部分介绍了大数据的基本组成部分和相关知识。第二部分将介绍 lambda 架构和 kappa 架构。第三部分将介绍 lambda 和 kappa 架构模式下的通用大数据架构。第四部分将介绍暴露的数据架构体系下数据端到端的难点和痛点。第五部分介绍了优秀大数据架构的整体设计。从第五部分开始,介绍通过各种数据平台和组件将这些大数据组件组合起来,打造一套高效易用的数据平台,提高业务系统的效率。让业务开发不怕复杂的数据开发组件,并且不需要关注底层实现。只需要能够使用 SQL 完成一站式开发并完成数据返回,让大数据不再是数据工程师独有的技能。
一、大数据技术栈
大数据的整个过程涉及到很多模块,每个模块都比较复杂。下图列出了这些模块和组件及其功能特性。将有专题详细介绍相关模块的领域知识,如数据采集、数据传输、实时计算、离线计算、大数据存储等相关模块。

二、lambda 架构和 kappa 架构
目前,基本上所有的大数据架构都是基于lambda和kappa架构,不同的公司都基于这两种架构模式设计了符合公司数据架构的数据架构。lambda 架构使开发人员能够构建大规模的分布式数据处理系统。它具有良好的灵活性和可扩展性,对硬件故障和人为错误也具有良好的容错能力。您可以在 Internet 文章 上找到很多关于 lambda 架构的信息。kappa架构解决了lambda架构中存在的两组数据处理系统带来的各种成本问题。这也是当前流批集成的研究方向。许多公司已经开始使用这种更高级的架构。
Lambda 架构

卡帕建筑

三、kappa架构和lambda架构下的大数据架构
目前各大公司基本都采用kappa架构或者lambda架构模式。这两种模式下的大数据整体架构在早期发展阶段可能如下:

四、数据端到端痛点
虽然上面的架构看似连接了各种大数据组件来实现集成化管理,但是接触过数据开发的人会强烈地感觉到,这样的裸架构业务数据开发需要注意很多基础工具的使用。在实际数据开发中存在很多痛点和难点,具体体现在以下几个方面。
没有一套数据开发IDE来管理整个数据开发流程,长期的流程是无法管理的。没有标准的数据建模体系,导致不同的数据工程师对指标的计算口径有不同的误解。大数据组件的开发要求很高,普通业务直接使用Hbase、ES等技术组件会导致各种问题。基本上每个公司的大数据团队都会很复杂,涉及的环节很多,遇到问题很难找到对应的负责人。数据孤岛难以打破,团队和部门之间难以共享数据,彼此之间也不清楚对方拥有哪些数据。两组计算模型,批计算和流计算,需要维护,很难开始开发。需要为流和批处理提供一套统一的SQL。缺乏公司级元数据系统规划,难以实时和离线复用同一条数据,每个开发任务都需要多方梳理。
基本上,大部分企业在数据平台的治理和开放能力的提供上都存在上述问题和痛点。在复杂的数据架构下,对于数据适用方来说,每个环节的不清晰或者功能的不友好,都会让复杂的环节变化更加复杂。要解决这些痛点,就需要精心打磨每一个环节,无缝对接以上技术组件,让业务端到端的数据使用就像写SQL查询数据库一样简单。
五、优秀的大数据整体架构设计
提供多种平台和工具助力数据平台:data采集多数据源平台、一键数据同步平台、数据质量与建模平台、元数据系统、数据统一接入平台、实时和离线计算平台、资源调度平台、一站式开发IDE。

六、元数据——大数据系统的基石
元数据连接数据源、数据仓库和数据应用,记录数据生成到消费的完整环节。元数据收录静态表、列、分区信息(即 MetaStore)。动态任务与表依赖映射关系;数据仓库模型定义、数据生命周期;ETL任务调度信息、输入输出等元数据是数据管理、数据内容和数据应用的基础。例如,元数据可用于构建任务、表、列和用户之间的数据图;构建任务 DAG 依赖关系,并安排任务执行顺序;建立任务画像以管理任务质量;为个人或BUs概述等提供资产管理和计算资源消耗。
可以认为整个大数据数据流是由元数据管理的。如果没有一套完整的元数据设计,上述数据将难以追踪、权限难以控制、资源难以管理、数据难以共享。
很多公司都依赖hive来管理元数据,但是我个人认为,在发展到一定阶段,还是需要搭建一个元数据平台来匹配相关架构。
七、流批一体化计算
如果维护两套计算引擎,比如离线计算Spark和实时计算Flink,会给用户带来很大的麻烦,需要同时学习流计算知识和批计算领域知识。如果你离线使用 Flink 来实时使用 Spark 或 Hadoop,你可以开发自定义的 DSL 描述语言来匹配不同计算引擎的语法。上层用户无需关注底层的具体执行细节。他们只需要掌握一门 DSL 语言即可完成 Spark。接入Hadoop、Flink等计算引擎。
八、直播和离线ETL平台
ETL 代表 Extract-Transform-Load,用于描述从源到目的地提取、转换和加载数据的过程。ETL 一词在数据仓库中更常用,但它的对象并不限于数据仓库。一般来说,ETL平台在数据清洗、数据格式转换、数据补全、数据质量管理等方面发挥着重要作用。ETL作为重要的数据清洗中间层,一般来说至少要具备以下功能:
支持多种数据源,如消息系统、文件系统等 支持多种算子,过滤、拆分、变换、输出、查询数据源补全等算子能力 支持动态变化逻辑,如上述算子通过动态提交jar 可以做不停的发布变化

九、智能统一查询平台
大多数数据查询都是由需求驱动的。每个需求开发一个或多个接口,编写接口文档,开放给业务方调用。这种模型在大数据系统中存在很多问题:
这种架构简单,但是接口粒度很粗,灵活性不高,可扩展性差,复用率低。随着业务需求的增加,接口数量大幅增加,维护成本高。同时,开发效率不高,对于海量数据系统显然会造成大量重复开发,数据和逻辑难以复用,业务适用方的经验严重降低。如果没有统一的查询平台直接将Hbase等库暴露给业务,后续对数据权限的运维管理会更加困难。访问大数据组件对于业务适用方来说也是非常痛苦的,一不小心就会出现各种问题。.
通过一组智能查询解决上述大数据查询痛点

十、数据仓库建模规范体系
随着业务复杂度和数据规模的增加,数据调用和复制混乱,重复建设造成的资源浪费,数据指标定义不同造成的模糊,数据使用门槛越来越高。以笔者实际业务跟踪和数据仓库使用的见证为例,同产品名的表字段有的叫good_id,有的叫spu_id,还有很多其他的名字,会给想用的人带来很大的麻烦这些数据。因此,如果没有完整的大数据建模体系,会给数据治理带来很大的困难,表现在以下几个方面:
数据标准不一致,即使命名相同,但定义口径不一致。例如,仅 uv 之类的指标就有十几个定义。问题是:它们都是UV,我用哪一个?都是uv,为什么数据不一样?研发成本巨大,每个工程师都需要从头到尾了解研发过程的每一个细节,每个人都会再次踩到同一个“坑”,浪费了研发人员的时间和精力成本。这也是目标作者遇到的问题。实际开发和提取数据太难了。没有统一的标准管理,造成重复计算等资源浪费。数据表的层次和粒度不清晰,也使得重复存储很严重。
所以大数据开发和数仓表设计必须遵循设计原则,数据平台可以开发平台来约束不合理的设计,比如阿里巴巴的OneData body。一般来说,数据开发是根据以下准则进行的:

有兴趣的可以参考阿里巴巴的OneData设计系统。
十大一、一键集成平台
一键采集将各种数据传输到数据平台非常简单,通过数据传输平台将数据无缝连接到ETL平台。ETL与元数据平台对接,标准化Schema定义,然后将数据转换分发到实时和离线计算平台。后续对数据的任何离线实时处理,只需要申请元数据表的权限,即可完成开发任务并完成计算。data采集支持多种数据源,如binlog、log采集、前端埋点、kafka消息队列等。
十个二、数据开发IDE——高效的端到端工具
高效的数据开发一站式解决方案工具。实时计算和离线计算任务开发可以通过IDE完成,以上平台对接,提供一站式解决方案。数据开发IDE提供数据集成、数据开发、数据管理、数据质量和数据服务等全方位的产品服务,一站式开发管理界面。数据的传输、转换和集成都是通过数据IDE完成的。从不同的数据存储导入数据,转换开发,最终将处理后的数据同步到其他数据系统。通过一个高效的大数据开发IDE,大数据工程师可以基本屏蔽各种痛点,结合上述各种平台能力,
数据开发工具请参考阿里云DataWorks。
解决端到端的难题还需要其他几个能力的辅助,这里不再赘述。有兴趣的同学可以自学。
十个三、其他
一个完整的数据系统的开发还包括报警监控中心、资源调度中心、资源计算隔离、数据质量检测、一站式数据处理系统,这里不再赘述。
如果您认为 文章 写得好,编码并不容易:
请1.关注作者~你的关注是我写作的最大动力
2.私信我“大数据”
给大家分享一套最新的大数据学习资源和全套开发工具
一键采集上传常见的细节问题(大数据架构和kappa架构的设计思路及难点)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2022-03-27 01:02
近年来,随着IT技术、大数据、机器学习、算法的不断发展,越来越多的企业意识到数据的价值,将数据作为自己的宝贵资产进行管理,利用大数据和机器学习。挖掘、识别和利用数据资产的能力。如果缺乏有效的整体数据架构设计或缺乏某些能力,就会导致业务层难以直接使用大数据和大数据,造成大数据与业务之间的巨大差距。存在数据不可知论、需求实现难、数据共享难等一系列问题。本文介绍了一些数据平台设计思路,帮助企业减少数据开发的痛点和难点。
本文主要包括以下章节:
本文第一部分介绍了大数据的基本组成部分和相关知识。
第二部分将介绍 lambda 架构和 kappa 架构。
第三部分将介绍 lambda 和 kappa 架构模式下的通用大数据架构
第四部分介绍了裸露的数据架构体系下数据端到端的难点和痛点。
第五部分介绍优秀大数据架构的整体设计
从第五部分开始,介绍通过各种数据平台和组件将这些大数据组件组合起来,打造一套高效易用的数据平台,提高业务系统的效率,让业务发展无所畏惧复杂的数据开发组件,无需关注底层实现,只需要会使用SQL即可完成一站式开发,完成数据回流,让大数据不再是技能数据工程师。
一、大数据技术栈
大数据的整个过程涉及到很多模块,每个模块都比较复杂。下图列出了这些模块和组件及其功能特性。将有专题详细介绍相关模块的领域知识,如数据采集、数据传输、实时计算、离线计算、大数据存储等相关模块。
二、lambda 架构和 kappa 架构
目前,基本上所有的大数据架构都是基于lambda和kappa架构,不同的公司都基于这两种架构模式设计了符合公司数据架构的数据架构。lambda 架构使开发人员能够构建大规模的分布式数据处理系统。它具有良好的灵活性和可扩展性,对硬件故障和人为错误也具有良好的容错能力。您可以在 Internet 文章 上找到很多关于 lambda 架构的信息。kappa架构解决了lambda架构中存在的两组数据处理系统带来的各种成本问题。这也是当前流批集成的研究方向。许多公司已经开始使用这种更高级的架构。
Lambda 架构
卡帕建筑
三、kappa架构和lambda架构下的大数据架构
目前各大公司基本都采用kappa架构或者lambda架构模式。这两种模式下的大数据整体架构在早期发展阶段可能如下:
四、数据端到端痛点
虽然上面的架构看似连接了各种大数据组件来实现集成化管理,但是接触过数据开发的人会强烈地感觉到,这样的裸架构业务数据开发需要注意很多基础工具的使用。在实际数据开发中存在很多痛点和难点,具体体现在以下几个方面。如果你对大数据开发感兴趣,想系统地学习大数据,可以加入大数据技术学习交流。
没有一套数据开发IDE来管理整个数据开发流程,长期的流程是无法管理的。
没有标准的数据建模体系,导致不同的数据工程师对指标的计算口径有不同的误解。
大数据组件的开发要求很高,普通业务直接使用Hbase、ES等技术组件会导致各种问题。
基本上每个公司的大数据团队都会很复杂,涉及的环节很多,遇到问题很难找到对应的负责人。
数据孤岛难以打破,团队和部门之间难以共享数据,彼此之间也不清楚对方拥有哪些数据。
批计算和流计算两套计算模型需要维护,很难上手开发。需要为流和批处理提供一套统一的SQL。
缺乏公司级元数据系统规划,难以实时和离线复用同一条数据,每个开发任务都需要多方梳理。
基本上,大部分企业在数据平台的治理和开放能力的提供上都存在上述问题和痛点。在复杂的数据架构下,对于数据适用方来说,每个环节的不清晰或者功能的不友好,都会让复杂的环节变化更加复杂。要解决这些痛点,就需要精心打磨每一个环节,无缝对接以上技术组件,让业务端到端的数据使用就像写SQL查询数据库一样简单。
五、优秀的大数据整体架构设计
提供多种平台和工具助力数据平台:data采集多数据源平台、一键数据同步平台、数据质量与建模平台、元数据系统、数据统一接入平台、实时和离线计算平台、资源调度平台、一站式开发IDE。
六、元数据——大数据系统的基石
元数据连接数据源、数据仓库和数据应用,记录数据生成到消费的完整环节。元数据收录静态表、列、分区信息(即 MetaStore)。动态任务与表依赖映射关系;数据仓库模型定义、数据生命周期;ETL任务调度信息、输入输出等元数据是数据管理、数据内容和数据应用的基础。例如,元数据可用于构建任务、表、列和用户之间的数据图;构建任务 DAG 依赖关系,并安排任务执行顺序;建立任务画像以管理任务质量;为个人或BUs概述等提供资产管理和计算资源消耗。
可以认为整个大数据数据流是由元数据管理的。如果没有一套完整的元数据设计,上述数据将难以追踪、权限难以控制、资源难以管理、数据难以共享。
很多公司都依赖hive来管理元数据,但是我个人认为,在发展到一定阶段,还是需要搭建一个元数据平台来匹配相关架构。
七、流批一体化计算
如果维护两套计算引擎,比如离线计算Spark和实时计算Flink,会给用户带来很大的麻烦,需要同时学习流计算知识和批计算领域知识。如果你离线使用 Flink 来实时使用 Spark 或 Hadoop,你可以开发自定义的 DSL 描述语言来匹配不同计算引擎的语法。上层用户无需关注底层的具体执行细节。他们只需要掌握一门 DSL 语言即可完成 Spark。接入Hadoop、Flink等计算引擎。
八、直播和离线ETL平台
ETL 代表 Extract-Transform-Load,用于描述从源到目的地提取、转换和加载数据的过程。ETL 一词在数据仓库中更常用,但它的对象并不限于数据仓库。一般来说,ETL平台在数据清洗、数据格式转换、数据补全、数据质量管理等方面发挥着重要作用。ETL作为重要的数据清洗中间层,一般来说至少要具备以下功能:
支持多种数据源,如消息系统、文件系统等
支持多种算子,过滤、拆分、转换、输出、查询数据源补全等算子能力
支持动态变化逻辑。比如上面的算子可以通过动态jar提交,不停机释放变化。
九、智能统一查询平台
大多数数据查询都是由需求驱动的。每个需求开发一个或多个接口,编写接口文档,开放给业务方调用。这种模型在大数据系统中存在很多问题:
这种架构简单,但是接口粒度很粗,灵活性不高,可扩展性差,复用率低。随着业务需求的增加,接口数量大幅增加,维护成本高。
同时,开发效率不高,对于海量数据系统显然会造成大量重复开发,数据和逻辑难以复用,业务适用方的经验严重降低。
如果没有统一的查询平台直接将Hbase等库暴露给业务,后续对数据权限的运维管理会更加困难。访问大数据组件对于业务适用方来说也是非常痛苦的,一不小心就会出现各种问题。.
通过一组智能查询解决上述大数据查询痛点
十、数据仓库建模规范体系
随着业务复杂度和数据规模的增加,数据调用和复制混乱,重复建设造成的资源浪费,数据指标定义不同造成的模糊,数据使用门槛越来越高。以笔者实际业务跟踪和数据仓库使用的见证为例,同产品名的表字段有的叫good_id,有的叫spu_id,还有很多其他的名字,会给想用的人带来很大的麻烦这些数据。因此,如果没有完整的大数据建模体系,会给数据治理带来很大的困难,表现在以下几个方面:
数据标准不一致,即使命名相同,但定义口径不一致。例如,仅 uv 之类的指标就有十几个定义。问题是:它们都是UV,我用哪一个?都是uv,为什么数据不一样?
研发成本巨大,每个工程师都需要从头到尾了解研发过程的每一个细节,每个人都会再次踩到同一个“坑”,浪费了研发人员的时间和精力成本。这也是目标作者遇到的问题。实际开发和提取数据太难了。
没有统一的标准管理,造成重复计算等资源浪费。数据表的层次和粒度不明确,这也使得重复存储变得严格。
所以大数据开发和数仓表设计必须遵循设计原则,数据平台可以开发平台来约束不合理的设计,比如阿里巴巴的OneData body。一般来说,数据开发是根据以下准则进行的:
有兴趣的可以参考阿里巴巴的OneData设计系统。
十大一、一键集成平台
一键采集将各种数据传输到数据平台非常简单,通过数据传输平台将数据无缝连接到ETL平台。ETL与元数据平台对接,标准化Schema定义,然后将数据转换分发到实时和离线计算平台。后续对数据的任何离线实时处理,只需要申请元数据表的权限,即可完成开发任务并完成计算。data采集支持多种数据源,如binlog、log采集、前端埋点、kafka消息队列等。
十个二、数据开发IDE——高效的端到端工具
高效的数据开发一站式解决方案工具。实时计算和离线计算任务开发可以通过IDE完成,以上平台对接,提供一站式解决方案。数据开发IDE提供数据集成、数据开发、数据管理、数据质量和数据服务等全方位的产品服务,一站式开发管理界面。数据的传输、转换和集成都是通过数据IDE完成的。从不同的数据存储导入数据,转换开发,最终将处理后的数据同步到其他数据系统。通过一个高效的大数据开发IDE,大数据工程师可以基本屏蔽各种痛点,结合上述各种平台能力,
数据开发工具请参考阿里云DataWorks。
解决端到端的难题还需要其他几个能力的辅助,这里不再赘述。有兴趣的同学可以自学。
十个三、其他
一个完整的数据系统的开发还包括报警监控中心、资源调度中心、资源计算隔离、数据质量检测、一站式数据处理系统,这里不再赘述。 查看全部
一键采集上传常见的细节问题(大数据架构和kappa架构的设计思路及难点)
近年来,随着IT技术、大数据、机器学习、算法的不断发展,越来越多的企业意识到数据的价值,将数据作为自己的宝贵资产进行管理,利用大数据和机器学习。挖掘、识别和利用数据资产的能力。如果缺乏有效的整体数据架构设计或缺乏某些能力,就会导致业务层难以直接使用大数据和大数据,造成大数据与业务之间的巨大差距。存在数据不可知论、需求实现难、数据共享难等一系列问题。本文介绍了一些数据平台设计思路,帮助企业减少数据开发的痛点和难点。
本文主要包括以下章节:
本文第一部分介绍了大数据的基本组成部分和相关知识。
第二部分将介绍 lambda 架构和 kappa 架构。
第三部分将介绍 lambda 和 kappa 架构模式下的通用大数据架构
第四部分介绍了裸露的数据架构体系下数据端到端的难点和痛点。
第五部分介绍优秀大数据架构的整体设计
从第五部分开始,介绍通过各种数据平台和组件将这些大数据组件组合起来,打造一套高效易用的数据平台,提高业务系统的效率,让业务发展无所畏惧复杂的数据开发组件,无需关注底层实现,只需要会使用SQL即可完成一站式开发,完成数据回流,让大数据不再是技能数据工程师。
一、大数据技术栈
大数据的整个过程涉及到很多模块,每个模块都比较复杂。下图列出了这些模块和组件及其功能特性。将有专题详细介绍相关模块的领域知识,如数据采集、数据传输、实时计算、离线计算、大数据存储等相关模块。
二、lambda 架构和 kappa 架构
目前,基本上所有的大数据架构都是基于lambda和kappa架构,不同的公司都基于这两种架构模式设计了符合公司数据架构的数据架构。lambda 架构使开发人员能够构建大规模的分布式数据处理系统。它具有良好的灵活性和可扩展性,对硬件故障和人为错误也具有良好的容错能力。您可以在 Internet 文章 上找到很多关于 lambda 架构的信息。kappa架构解决了lambda架构中存在的两组数据处理系统带来的各种成本问题。这也是当前流批集成的研究方向。许多公司已经开始使用这种更高级的架构。
Lambda 架构
卡帕建筑
三、kappa架构和lambda架构下的大数据架构
目前各大公司基本都采用kappa架构或者lambda架构模式。这两种模式下的大数据整体架构在早期发展阶段可能如下:
四、数据端到端痛点
虽然上面的架构看似连接了各种大数据组件来实现集成化管理,但是接触过数据开发的人会强烈地感觉到,这样的裸架构业务数据开发需要注意很多基础工具的使用。在实际数据开发中存在很多痛点和难点,具体体现在以下几个方面。如果你对大数据开发感兴趣,想系统地学习大数据,可以加入大数据技术学习交流。
没有一套数据开发IDE来管理整个数据开发流程,长期的流程是无法管理的。
没有标准的数据建模体系,导致不同的数据工程师对指标的计算口径有不同的误解。
大数据组件的开发要求很高,普通业务直接使用Hbase、ES等技术组件会导致各种问题。
基本上每个公司的大数据团队都会很复杂,涉及的环节很多,遇到问题很难找到对应的负责人。
数据孤岛难以打破,团队和部门之间难以共享数据,彼此之间也不清楚对方拥有哪些数据。
批计算和流计算两套计算模型需要维护,很难上手开发。需要为流和批处理提供一套统一的SQL。
缺乏公司级元数据系统规划,难以实时和离线复用同一条数据,每个开发任务都需要多方梳理。
基本上,大部分企业在数据平台的治理和开放能力的提供上都存在上述问题和痛点。在复杂的数据架构下,对于数据适用方来说,每个环节的不清晰或者功能的不友好,都会让复杂的环节变化更加复杂。要解决这些痛点,就需要精心打磨每一个环节,无缝对接以上技术组件,让业务端到端的数据使用就像写SQL查询数据库一样简单。
五、优秀的大数据整体架构设计
提供多种平台和工具助力数据平台:data采集多数据源平台、一键数据同步平台、数据质量与建模平台、元数据系统、数据统一接入平台、实时和离线计算平台、资源调度平台、一站式开发IDE。
六、元数据——大数据系统的基石
元数据连接数据源、数据仓库和数据应用,记录数据生成到消费的完整环节。元数据收录静态表、列、分区信息(即 MetaStore)。动态任务与表依赖映射关系;数据仓库模型定义、数据生命周期;ETL任务调度信息、输入输出等元数据是数据管理、数据内容和数据应用的基础。例如,元数据可用于构建任务、表、列和用户之间的数据图;构建任务 DAG 依赖关系,并安排任务执行顺序;建立任务画像以管理任务质量;为个人或BUs概述等提供资产管理和计算资源消耗。
可以认为整个大数据数据流是由元数据管理的。如果没有一套完整的元数据设计,上述数据将难以追踪、权限难以控制、资源难以管理、数据难以共享。
很多公司都依赖hive来管理元数据,但是我个人认为,在发展到一定阶段,还是需要搭建一个元数据平台来匹配相关架构。
七、流批一体化计算
如果维护两套计算引擎,比如离线计算Spark和实时计算Flink,会给用户带来很大的麻烦,需要同时学习流计算知识和批计算领域知识。如果你离线使用 Flink 来实时使用 Spark 或 Hadoop,你可以开发自定义的 DSL 描述语言来匹配不同计算引擎的语法。上层用户无需关注底层的具体执行细节。他们只需要掌握一门 DSL 语言即可完成 Spark。接入Hadoop、Flink等计算引擎。
八、直播和离线ETL平台
ETL 代表 Extract-Transform-Load,用于描述从源到目的地提取、转换和加载数据的过程。ETL 一词在数据仓库中更常用,但它的对象并不限于数据仓库。一般来说,ETL平台在数据清洗、数据格式转换、数据补全、数据质量管理等方面发挥着重要作用。ETL作为重要的数据清洗中间层,一般来说至少要具备以下功能:
支持多种数据源,如消息系统、文件系统等
支持多种算子,过滤、拆分、转换、输出、查询数据源补全等算子能力
支持动态变化逻辑。比如上面的算子可以通过动态jar提交,不停机释放变化。
九、智能统一查询平台
大多数数据查询都是由需求驱动的。每个需求开发一个或多个接口,编写接口文档,开放给业务方调用。这种模型在大数据系统中存在很多问题:
这种架构简单,但是接口粒度很粗,灵活性不高,可扩展性差,复用率低。随着业务需求的增加,接口数量大幅增加,维护成本高。
同时,开发效率不高,对于海量数据系统显然会造成大量重复开发,数据和逻辑难以复用,业务适用方的经验严重降低。
如果没有统一的查询平台直接将Hbase等库暴露给业务,后续对数据权限的运维管理会更加困难。访问大数据组件对于业务适用方来说也是非常痛苦的,一不小心就会出现各种问题。.
通过一组智能查询解决上述大数据查询痛点
十、数据仓库建模规范体系
随着业务复杂度和数据规模的增加,数据调用和复制混乱,重复建设造成的资源浪费,数据指标定义不同造成的模糊,数据使用门槛越来越高。以笔者实际业务跟踪和数据仓库使用的见证为例,同产品名的表字段有的叫good_id,有的叫spu_id,还有很多其他的名字,会给想用的人带来很大的麻烦这些数据。因此,如果没有完整的大数据建模体系,会给数据治理带来很大的困难,表现在以下几个方面:
数据标准不一致,即使命名相同,但定义口径不一致。例如,仅 uv 之类的指标就有十几个定义。问题是:它们都是UV,我用哪一个?都是uv,为什么数据不一样?
研发成本巨大,每个工程师都需要从头到尾了解研发过程的每一个细节,每个人都会再次踩到同一个“坑”,浪费了研发人员的时间和精力成本。这也是目标作者遇到的问题。实际开发和提取数据太难了。
没有统一的标准管理,造成重复计算等资源浪费。数据表的层次和粒度不明确,这也使得重复存储变得严格。
所以大数据开发和数仓表设计必须遵循设计原则,数据平台可以开发平台来约束不合理的设计,比如阿里巴巴的OneData body。一般来说,数据开发是根据以下准则进行的:
有兴趣的可以参考阿里巴巴的OneData设计系统。
十大一、一键集成平台
一键采集将各种数据传输到数据平台非常简单,通过数据传输平台将数据无缝连接到ETL平台。ETL与元数据平台对接,标准化Schema定义,然后将数据转换分发到实时和离线计算平台。后续对数据的任何离线实时处理,只需要申请元数据表的权限,即可完成开发任务并完成计算。data采集支持多种数据源,如binlog、log采集、前端埋点、kafka消息队列等。
十个二、数据开发IDE——高效的端到端工具
高效的数据开发一站式解决方案工具。实时计算和离线计算任务开发可以通过IDE完成,以上平台对接,提供一站式解决方案。数据开发IDE提供数据集成、数据开发、数据管理、数据质量和数据服务等全方位的产品服务,一站式开发管理界面。数据的传输、转换和集成都是通过数据IDE完成的。从不同的数据存储导入数据,转换开发,最终将处理后的数据同步到其他数据系统。通过一个高效的大数据开发IDE,大数据工程师可以基本屏蔽各种痛点,结合上述各种平台能力,
数据开发工具请参考阿里云DataWorks。
解决端到端的难题还需要其他几个能力的辅助,这里不再赘述。有兴趣的同学可以自学。
十个三、其他
一个完整的数据系统的开发还包括报警监控中心、资源调度中心、资源计算隔离、数据质量检测、一站式数据处理系统,这里不再赘述。
一键采集上传常见的细节问题(大数据架构和kappa架构的设计思路及难点)
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2022-03-27 01:01
近年来,随着IT技术、大数据、机器学习、算法的不断发展,越来越多的企业意识到数据的价值,将数据作为自己的宝贵资产进行管理,利用大数据和机器学习。挖掘、识别和利用数据资产的能力。如果缺乏有效的整体数据架构设计或缺乏某些能力,就会导致业务层难以直接使用大数据和大数据,造成大数据与业务之间的巨大差距。存在数据不可知论、需求实现难、数据共享难等一系列问题。本文介绍了一些数据平台设计思路,帮助企业减少数据开发的痛点和难点。
本文主要包括以下章节:
本文第一部分介绍了大数据的基本组成部分和相关知识。
第二部分将介绍 lambda 架构和 kappa 架构。
第三部分将介绍 lambda 和 kappa 架构模式下的通用大数据架构
第四部分介绍了裸露的数据架构体系下数据端到端的难点和痛点。
第五部分介绍优秀大数据架构的整体设计
从第五部分开始,介绍通过各种数据平台和组件将这些大数据组件组合起来,打造一套高效易用的数据平台,提高业务系统的效率,让业务发展无所畏惧复杂的数据开发组件,无需关注底层实现,只需要会使用SQL即可完成一站式开发,完成数据回流,让大数据不再是技能数据工程师。
一、大数据技术栈
大数据的整个过程涉及到很多模块,每个模块都比较复杂。下图列出了这些模块和组件及其功能特性。将有专题详细介绍相关模块的领域知识,如数据采集、数据传输、实时计算、离线计算、大数据存储等相关模块。
二、lambda 架构和 kappa 架构
目前,基本上所有的大数据架构都是基于lambda和kappa架构,不同的公司都基于这两种架构模式设计了符合公司数据架构的数据架构。lambda 架构使开发人员能够构建大规模的分布式数据处理系统。它具有良好的灵活性和可扩展性,对硬件故障和人为错误也具有良好的容错能力。您可以在 Internet 文章 上找到很多关于 lambda 架构的信息。kappa架构解决了lambda架构中存在的两组数据处理系统带来的各种成本问题。这也是当前流批集成的研究方向。许多公司已经开始使用这种更高级的架构。
Lambda 架构
卡帕建筑
三、kappa架构和lambda架构下的大数据架构
目前各大公司基本都采用kappa架构或者lambda架构模式。这两种模式下的大数据整体架构在早期发展阶段可能如下:
四、数据端到端痛点
虽然上面的架构看似连接了各种大数据组件来实现集成化管理,但是接触过数据开发的人会强烈地感觉到,这样的裸架构业务数据开发需要注意很多基础工具的使用。在实际数据开发中存在很多痛点和难点,具体体现在以下几个方面。
没有一套数据开发IDE来管理整个数据开发流程,长期的流程是无法管理的。
没有标准的数据建模体系,导致不同的数据工程师对指标的计算口径有不同的误解。
大数据组件的开发要求很高,普通业务直接使用Hbase、ES等技术组件会导致各种问题。
基本上每个公司的大数据团队都会很复杂,涉及的环节很多,遇到问题很难找到对应的负责人。
数据孤岛难以打破,团队和部门之间难以共享数据,彼此之间也不清楚对方拥有哪些数据。
批计算和流计算两套计算模型需要维护,很难上手开发。需要为流和批处理提供一套统一的SQL。
缺乏公司级元数据系统规划,难以实时和离线复用同一条数据,每个开发任务都需要多方梳理。
基本上,大部分企业在数据平台的治理和开放能力的提供上都存在上述问题和痛点。在复杂的数据架构下,对于数据适用方来说,每个环节的不清晰或者功能的不友好,都会让复杂的环节变化更加复杂。要解决这些痛点,就需要精心打磨每一个环节,无缝对接以上技术组件,让业务端到端的数据使用就像写SQL查询数据库一样简单。
五、优秀的大数据整体架构设计
提供多种平台和工具助力数据平台:data采集多数据源平台、一键数据同步平台、数据质量与建模平台、元数据系统、数据统一接入平台、实时和离线计算平台、资源调度平台、一站式开发IDE。
六、元数据——大数据系统的基石
元数据连接数据源、数据仓库和数据应用,记录数据生成到消费的完整环节。元数据收录静态表、列、分区信息(即 MetaStore)。动态任务与表依赖映射关系;数据仓库模型定义、数据生命周期;ETL任务调度信息、输入输出等元数据是数据管理、数据内容和数据应用的基础。例如,元数据可用于构建任务、表、列和用户之间的数据图;构建任务 DAG 依赖关系,并安排任务执行顺序;建立任务画像以管理任务质量;为个人或BUs概述等提供资产管理和计算资源消耗。
可以认为整个大数据数据流是由元数据管理的。如果没有一套完整的元数据设计,上述数据将难以追踪、权限难以控制、资源难以管理、数据难以共享。
很多公司都依赖hive来管理元数据,但是我个人认为,在发展到一定阶段,还是需要搭建一个元数据平台来匹配相关架构。
元数据可以参考饿了么和一些实战:
七、流批一体化计算
如果维护两套计算引擎,比如离线计算Spark和实时计算Flink,会给用户带来很大的麻烦,需要同时学习流计算知识和批计算领域知识。如果你离线使用 Flink 来实时使用 Spark 或 Hadoop,你可以开发自定义的 DSL 描述语言来匹配不同计算引擎的语法。上层用户无需关注底层的具体执行细节。他们只需要掌握一门 DSL 语言即可完成 Spark。接入Hadoop、Flink等计算引擎。
八、直播和离线ETL平台
ETL 代表 Extract-Transform-Load,用于描述从源到目的地提取、转换和加载数据的过程。ETL 一词在数据仓库中更常用,但它的对象并不限于数据仓库。一般来说,ETL平台在数据清洗、数据格式转换、数据补全、数据质量管理等方面发挥着重要作用。ETL作为重要的数据清洗中间层,一般来说至少要具备以下功能:
支持多种数据源,如消息系统、文件系统等
支持多种算子,过滤、拆分、转换、输出、查询数据源补全等算子能力
支持动态变化逻辑。比如上面的算子可以通过动态jar提交,不停机释放变化。
九、智能统一查询平台
大多数数据查询都是由需求驱动的。每个需求开发一个或多个接口,编写接口文档,开放给业务方调用。这种模型在大数据系统中存在很多问题:
这种架构简单,但是接口粒度很粗,灵活性不高,可扩展性差,复用率低。随着业务需求的增加,接口数量大幅增加,维护成本高。
同时,开发效率不高,对于海量数据系统显然会造成大量重复开发,数据和逻辑难以复用,业务适用方的经验严重降低。
如果没有统一的查询平台直接将Hbase等库暴露给业务,后续对数据权限的运维管理会更加困难。访问大数据组件对于业务适用方来说也是非常痛苦的,一不小心就会出现各种问题。.
通过一组智能查询解决上述大数据查询痛点
十、数据仓库建模规范体系
随着业务复杂度和数据规模的增加,数据调用和复制混乱,重复建设造成的资源浪费,数据指标定义不同造成的模糊,数据使用门槛越来越高。以笔者实际业务跟踪和数据仓库使用的见证为例,同产品名的表字段有的叫good_id,有的叫spu_id,还有很多其他的名字,会给想用的人带来很大的麻烦这些数据。因此,如果没有完整的大数据建模体系,会给数据治理带来很大的困难,表现在以下几个方面:
数据标准不一致,即使命名相同,但定义口径不一致。例如,仅 uv 之类的指标就有十几个定义。问题是:它们都是UV,我用哪一个?都是uv,为什么数据不一样?
研发成本巨大,每个工程师都需要从头到尾了解研发过程的每一个细节,每个人都会再次踩到同一个“坑”,浪费了研发人员的时间和精力成本。这也是目标作者遇到的问题。实际开发和提取数据太难了。
没有统一的标准管理,造成重复计算等资源浪费。数据表的层次和粒度不清晰,也使得重复存储很严重。
所以大数据开发和数仓表设计必须遵循设计原则,数据平台可以开发平台来约束不合理的设计,比如阿里巴巴的OneData body。一般来说,数据开发是根据以下准则进行的:
有兴趣的可以参考阿里巴巴的OneData设计系统。
十大一、一键集成平台
一键采集将各种数据传输到数据平台非常简单,通过数据传输平台将数据无缝连接到ETL平台。ETL与元数据平台对接,标准化Schema定义,然后将数据转换分发到实时和离线计算平台。后续对数据的任何离线实时处理,只需要申请元数据表的权限,即可完成开发任务并完成计算。data采集支持多种数据源,如binlog、log采集、前端埋点、kafka消息队列等。
十个二、数据开发IDE——高效的端到端工具
高效的数据开发一站式解决方案工具。实时计算和离线计算任务开发可以通过IDE完成,以上平台对接,提供一站式解决方案。数据开发IDE提供数据集成、数据开发、数据管理、数据质量和数据服务等全方位的产品服务,一站式开发管理界面。数据的传输、转换和集成都是通过数据IDE完成的。从不同的数据存储导入数据,转换开发,最终将处理后的数据同步到其他数据系统。通过一个高效的大数据开发IDE,大数据工程师可以基本屏蔽各种痛点,结合上述各种平台能力,
数据开发工具请参考阿里云DataWorks。
解决端到端的难题还需要其他几个能力的辅助,这里不再赘述。有兴趣的同学可以自学。
十个三、其他
一个完整的数据系统的开发还包括报警监控中心、资源调度中心、资源计算隔离、数据质量检测、一站式数据处理系统,这里不再赘述。 查看全部
一键采集上传常见的细节问题(大数据架构和kappa架构的设计思路及难点)
近年来,随着IT技术、大数据、机器学习、算法的不断发展,越来越多的企业意识到数据的价值,将数据作为自己的宝贵资产进行管理,利用大数据和机器学习。挖掘、识别和利用数据资产的能力。如果缺乏有效的整体数据架构设计或缺乏某些能力,就会导致业务层难以直接使用大数据和大数据,造成大数据与业务之间的巨大差距。存在数据不可知论、需求实现难、数据共享难等一系列问题。本文介绍了一些数据平台设计思路,帮助企业减少数据开发的痛点和难点。
本文主要包括以下章节:
本文第一部分介绍了大数据的基本组成部分和相关知识。
第二部分将介绍 lambda 架构和 kappa 架构。
第三部分将介绍 lambda 和 kappa 架构模式下的通用大数据架构
第四部分介绍了裸露的数据架构体系下数据端到端的难点和痛点。
第五部分介绍优秀大数据架构的整体设计
从第五部分开始,介绍通过各种数据平台和组件将这些大数据组件组合起来,打造一套高效易用的数据平台,提高业务系统的效率,让业务发展无所畏惧复杂的数据开发组件,无需关注底层实现,只需要会使用SQL即可完成一站式开发,完成数据回流,让大数据不再是技能数据工程师。
一、大数据技术栈
大数据的整个过程涉及到很多模块,每个模块都比较复杂。下图列出了这些模块和组件及其功能特性。将有专题详细介绍相关模块的领域知识,如数据采集、数据传输、实时计算、离线计算、大数据存储等相关模块。
二、lambda 架构和 kappa 架构
目前,基本上所有的大数据架构都是基于lambda和kappa架构,不同的公司都基于这两种架构模式设计了符合公司数据架构的数据架构。lambda 架构使开发人员能够构建大规模的分布式数据处理系统。它具有良好的灵活性和可扩展性,对硬件故障和人为错误也具有良好的容错能力。您可以在 Internet 文章 上找到很多关于 lambda 架构的信息。kappa架构解决了lambda架构中存在的两组数据处理系统带来的各种成本问题。这也是当前流批集成的研究方向。许多公司已经开始使用这种更高级的架构。
Lambda 架构
卡帕建筑
三、kappa架构和lambda架构下的大数据架构
目前各大公司基本都采用kappa架构或者lambda架构模式。这两种模式下的大数据整体架构在早期发展阶段可能如下:
四、数据端到端痛点
虽然上面的架构看似连接了各种大数据组件来实现集成化管理,但是接触过数据开发的人会强烈地感觉到,这样的裸架构业务数据开发需要注意很多基础工具的使用。在实际数据开发中存在很多痛点和难点,具体体现在以下几个方面。
没有一套数据开发IDE来管理整个数据开发流程,长期的流程是无法管理的。
没有标准的数据建模体系,导致不同的数据工程师对指标的计算口径有不同的误解。
大数据组件的开发要求很高,普通业务直接使用Hbase、ES等技术组件会导致各种问题。
基本上每个公司的大数据团队都会很复杂,涉及的环节很多,遇到问题很难找到对应的负责人。
数据孤岛难以打破,团队和部门之间难以共享数据,彼此之间也不清楚对方拥有哪些数据。
批计算和流计算两套计算模型需要维护,很难上手开发。需要为流和批处理提供一套统一的SQL。
缺乏公司级元数据系统规划,难以实时和离线复用同一条数据,每个开发任务都需要多方梳理。
基本上,大部分企业在数据平台的治理和开放能力的提供上都存在上述问题和痛点。在复杂的数据架构下,对于数据适用方来说,每个环节的不清晰或者功能的不友好,都会让复杂的环节变化更加复杂。要解决这些痛点,就需要精心打磨每一个环节,无缝对接以上技术组件,让业务端到端的数据使用就像写SQL查询数据库一样简单。
五、优秀的大数据整体架构设计
提供多种平台和工具助力数据平台:data采集多数据源平台、一键数据同步平台、数据质量与建模平台、元数据系统、数据统一接入平台、实时和离线计算平台、资源调度平台、一站式开发IDE。
六、元数据——大数据系统的基石
元数据连接数据源、数据仓库和数据应用,记录数据生成到消费的完整环节。元数据收录静态表、列、分区信息(即 MetaStore)。动态任务与表依赖映射关系;数据仓库模型定义、数据生命周期;ETL任务调度信息、输入输出等元数据是数据管理、数据内容和数据应用的基础。例如,元数据可用于构建任务、表、列和用户之间的数据图;构建任务 DAG 依赖关系,并安排任务执行顺序;建立任务画像以管理任务质量;为个人或BUs概述等提供资产管理和计算资源消耗。
可以认为整个大数据数据流是由元数据管理的。如果没有一套完整的元数据设计,上述数据将难以追踪、权限难以控制、资源难以管理、数据难以共享。
很多公司都依赖hive来管理元数据,但是我个人认为,在发展到一定阶段,还是需要搭建一个元数据平台来匹配相关架构。
元数据可以参考饿了么和一些实战:
七、流批一体化计算
如果维护两套计算引擎,比如离线计算Spark和实时计算Flink,会给用户带来很大的麻烦,需要同时学习流计算知识和批计算领域知识。如果你离线使用 Flink 来实时使用 Spark 或 Hadoop,你可以开发自定义的 DSL 描述语言来匹配不同计算引擎的语法。上层用户无需关注底层的具体执行细节。他们只需要掌握一门 DSL 语言即可完成 Spark。接入Hadoop、Flink等计算引擎。
八、直播和离线ETL平台
ETL 代表 Extract-Transform-Load,用于描述从源到目的地提取、转换和加载数据的过程。ETL 一词在数据仓库中更常用,但它的对象并不限于数据仓库。一般来说,ETL平台在数据清洗、数据格式转换、数据补全、数据质量管理等方面发挥着重要作用。ETL作为重要的数据清洗中间层,一般来说至少要具备以下功能:
支持多种数据源,如消息系统、文件系统等
支持多种算子,过滤、拆分、转换、输出、查询数据源补全等算子能力
支持动态变化逻辑。比如上面的算子可以通过动态jar提交,不停机释放变化。
九、智能统一查询平台
大多数数据查询都是由需求驱动的。每个需求开发一个或多个接口,编写接口文档,开放给业务方调用。这种模型在大数据系统中存在很多问题:
这种架构简单,但是接口粒度很粗,灵活性不高,可扩展性差,复用率低。随着业务需求的增加,接口数量大幅增加,维护成本高。
同时,开发效率不高,对于海量数据系统显然会造成大量重复开发,数据和逻辑难以复用,业务适用方的经验严重降低。
如果没有统一的查询平台直接将Hbase等库暴露给业务,后续对数据权限的运维管理会更加困难。访问大数据组件对于业务适用方来说也是非常痛苦的,一不小心就会出现各种问题。.
通过一组智能查询解决上述大数据查询痛点
十、数据仓库建模规范体系
随着业务复杂度和数据规模的增加,数据调用和复制混乱,重复建设造成的资源浪费,数据指标定义不同造成的模糊,数据使用门槛越来越高。以笔者实际业务跟踪和数据仓库使用的见证为例,同产品名的表字段有的叫good_id,有的叫spu_id,还有很多其他的名字,会给想用的人带来很大的麻烦这些数据。因此,如果没有完整的大数据建模体系,会给数据治理带来很大的困难,表现在以下几个方面:
数据标准不一致,即使命名相同,但定义口径不一致。例如,仅 uv 之类的指标就有十几个定义。问题是:它们都是UV,我用哪一个?都是uv,为什么数据不一样?
研发成本巨大,每个工程师都需要从头到尾了解研发过程的每一个细节,每个人都会再次踩到同一个“坑”,浪费了研发人员的时间和精力成本。这也是目标作者遇到的问题。实际开发和提取数据太难了。
没有统一的标准管理,造成重复计算等资源浪费。数据表的层次和粒度不清晰,也使得重复存储很严重。
所以大数据开发和数仓表设计必须遵循设计原则,数据平台可以开发平台来约束不合理的设计,比如阿里巴巴的OneData body。一般来说,数据开发是根据以下准则进行的:
有兴趣的可以参考阿里巴巴的OneData设计系统。
十大一、一键集成平台
一键采集将各种数据传输到数据平台非常简单,通过数据传输平台将数据无缝连接到ETL平台。ETL与元数据平台对接,标准化Schema定义,然后将数据转换分发到实时和离线计算平台。后续对数据的任何离线实时处理,只需要申请元数据表的权限,即可完成开发任务并完成计算。data采集支持多种数据源,如binlog、log采集、前端埋点、kafka消息队列等。
十个二、数据开发IDE——高效的端到端工具
高效的数据开发一站式解决方案工具。实时计算和离线计算任务开发可以通过IDE完成,以上平台对接,提供一站式解决方案。数据开发IDE提供数据集成、数据开发、数据管理、数据质量和数据服务等全方位的产品服务,一站式开发管理界面。数据的传输、转换和集成都是通过数据IDE完成的。从不同的数据存储导入数据,转换开发,最终将处理后的数据同步到其他数据系统。通过一个高效的大数据开发IDE,大数据工程师可以基本屏蔽各种痛点,结合上述各种平台能力,
数据开发工具请参考阿里云DataWorks。
解决端到端的难题还需要其他几个能力的辅助,这里不再赘述。有兴趣的同学可以自学。
十个三、其他
一个完整的数据系统的开发还包括报警监控中心、资源调度中心、资源计算隔离、数据质量检测、一站式数据处理系统,这里不再赘述。
一键采集上传常见的细节问题(优采云数据采集器如何解决网站更新困难,网站内容充实等问题)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-03-21 11:28
优采云数据采集器,通过将关键词采集分配给全网数据源文章,网站可以有大量的文章生成与网站定位相关的@>,解决网站难以更新和网站内容丰富的问题。网站 的核心是内容。只有产生足够多的优质内容,才能吸引搜索引擎和用户的搜索需求。从长远来看,我们可以获得大量的流量,达到建立网站的根本目的。
优采云数据采集器通信是内容质量的核心部分。普通网页上的内容类型很多,如文章、视频,主要是内容,还有下载、查询工具等类型的操作,还有主页、个人主页、列表页、很快。不管是什么类型的页面,它都承担着传递信息的目的。在向用户传递信息时,能否满足用户的需求,解决用户访问的问题,对这些页面类型的指导意义在于互通。
优采云data采集器的内容要清晰明了,写得合乎逻辑,用词优美,读起来舒服。从内容的特点来看,可以增强用户吸收内容后的获得感。比如优采云data采集器内容发人深省、轻松愉快、文笔好、有说服力等。严谨优雅的文笔更能体现行业的专业性,比如使用专业术语、词汇和思维方法。能够深入挖掘原因和逻辑,从多角度、多方面综合分析和阐述观点。对于需要指导用户操作的内容,要求明确、实用。如果无法通过文字等清楚地表达,
优采云Data采集器 的文章 内容精心打造,以改善用户的视觉和浏览体验。这里我们考察最常见也最容易被忽略的内容元素,例如:字体、段落、布局、大小标题、匹配辅助图片和视频等。优采云数据采集器要求是丰富美观,层次分明,贴合主题,升华主题,帮助用户更好地理解内容,获得连贯舒适的阅读体验。两个相对相似的内容可能由于布局不同而具有不同的质量分数。
使用优采云Data采集器的体验是流畅的,和上面提到的精致制作不同。精美的制作考察的是内容主体部分的美化,而这里考察的是页面的整体布局和核心。交互性、功能体验和舒适度。优采云数据采集器在设计页面时,首先要考虑核心需求需要哪些辅助功能和信息,帮助用户更好地理解内容。搜索排名受多种因素影响,例如用户偏好、网站整体质量等。原创单靠一个维度无法衡量为什么内容不是收录。如果站长觉得他的内容质量很高,他应该得到更好的搜索表示。 查看全部
一键采集上传常见的细节问题(优采云数据采集器如何解决网站更新困难,网站内容充实等问题)
优采云数据采集器,通过将关键词采集分配给全网数据源文章,网站可以有大量的文章生成与网站定位相关的@>,解决网站难以更新和网站内容丰富的问题。网站 的核心是内容。只有产生足够多的优质内容,才能吸引搜索引擎和用户的搜索需求。从长远来看,我们可以获得大量的流量,达到建立网站的根本目的。
优采云数据采集器通信是内容质量的核心部分。普通网页上的内容类型很多,如文章、视频,主要是内容,还有下载、查询工具等类型的操作,还有主页、个人主页、列表页、很快。不管是什么类型的页面,它都承担着传递信息的目的。在向用户传递信息时,能否满足用户的需求,解决用户访问的问题,对这些页面类型的指导意义在于互通。
优采云data采集器的内容要清晰明了,写得合乎逻辑,用词优美,读起来舒服。从内容的特点来看,可以增强用户吸收内容后的获得感。比如优采云data采集器内容发人深省、轻松愉快、文笔好、有说服力等。严谨优雅的文笔更能体现行业的专业性,比如使用专业术语、词汇和思维方法。能够深入挖掘原因和逻辑,从多角度、多方面综合分析和阐述观点。对于需要指导用户操作的内容,要求明确、实用。如果无法通过文字等清楚地表达,
优采云Data采集器 的文章 内容精心打造,以改善用户的视觉和浏览体验。这里我们考察最常见也最容易被忽略的内容元素,例如:字体、段落、布局、大小标题、匹配辅助图片和视频等。优采云数据采集器要求是丰富美观,层次分明,贴合主题,升华主题,帮助用户更好地理解内容,获得连贯舒适的阅读体验。两个相对相似的内容可能由于布局不同而具有不同的质量分数。
使用优采云Data采集器的体验是流畅的,和上面提到的精致制作不同。精美的制作考察的是内容主体部分的美化,而这里考察的是页面的整体布局和核心。交互性、功能体验和舒适度。优采云数据采集器在设计页面时,首先要考虑核心需求需要哪些辅助功能和信息,帮助用户更好地理解内容。搜索排名受多种因素影响,例如用户偏好、网站整体质量等。原创单靠一个维度无法衡量为什么内容不是收录。如果站长觉得他的内容质量很高,他应该得到更好的搜索表示。
一键采集上传常见的细节问题(优采云数据采集器如何解决网站更新困难,网站内容充实等问题 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2022-03-21 04:13
)
优采云数据采集器,通过将关键词采集分配给全网数据源文章,网站可以有大量的文章生成与网站定位相关的@>,解决网站难以更新和网站内容丰富的问题。网站 的核心是内容。只有产生足够多的优质内容,才能吸引搜索引擎和用户的搜索需求。从长远来看,我们可以获得大量的流量,达到建立网站的根本目的。
优采云数据采集器通信是内容质量的核心部分。普通网页上的内容类型很多,如文章、视频,主要是内容,还有下载、查询工具等类型的操作,还有主页、个人主页、列表页、很快。不管是什么类型的页面,它都承担着传递信息的目的。在向用户传递信息时,能否满足用户的需求,解决用户访问的问题,对这些页面类型的指导意义在于互通。
优采云data采集器的内容要清晰明了,写得合乎逻辑,用词优美,读起来舒服。从内容的特点来看,可以增强用户吸收内容后的获得感。比如优采云data采集器内容发人深省、轻松愉快、文笔好、有说服力等。严谨优雅的文笔更能体现行业的专业性,比如使用专业术语、词汇和思维方法。能够深入挖掘原因和逻辑,从多角度、多方面综合分析和阐述观点。对于需要指导用户操作的内容,要求明确、实用。如果无法通过文字等清楚地表达,
优采云Data采集器 的文章 内容精心打造,以改善用户的视觉和浏览体验。这里我们考察最常见也最容易被忽略的内容元素,例如:字体、段落、布局、大小标题、匹配辅助图片和视频等。优采云数据采集器要求是丰富美观,层次分明,贴合主题,升华主题,帮助用户更好地理解内容,获得连贯舒适的阅读体验。两个相对相似的内容可能由于布局不同而具有不同的质量分数。
使用优采云Data采集器的体验是流畅的,和上面提到的精致制作不同。精美的制作考察的是内容主体部分的美化,而这里考察的是页面的整体布局和核心。交互性、功能体验和舒适度。优采云数据采集器在设计页面时,首先要考虑核心需求需要哪些辅助功能和信息,帮助用户更好地理解内容。搜索排名受多种因素影响,例如用户偏好、网站整体质量等。原创单靠一个维度无法衡量为什么内容不是收录。如果站长觉得他的内容质量很高,他应该得到更好的搜索表示。
查看全部
一键采集上传常见的细节问题(优采云数据采集器如何解决网站更新困难,网站内容充实等问题
)
优采云数据采集器,通过将关键词采集分配给全网数据源文章,网站可以有大量的文章生成与网站定位相关的@>,解决网站难以更新和网站内容丰富的问题。网站 的核心是内容。只有产生足够多的优质内容,才能吸引搜索引擎和用户的搜索需求。从长远来看,我们可以获得大量的流量,达到建立网站的根本目的。
优采云数据采集器通信是内容质量的核心部分。普通网页上的内容类型很多,如文章、视频,主要是内容,还有下载、查询工具等类型的操作,还有主页、个人主页、列表页、很快。不管是什么类型的页面,它都承担着传递信息的目的。在向用户传递信息时,能否满足用户的需求,解决用户访问的问题,对这些页面类型的指导意义在于互通。
优采云data采集器的内容要清晰明了,写得合乎逻辑,用词优美,读起来舒服。从内容的特点来看,可以增强用户吸收内容后的获得感。比如优采云data采集器内容发人深省、轻松愉快、文笔好、有说服力等。严谨优雅的文笔更能体现行业的专业性,比如使用专业术语、词汇和思维方法。能够深入挖掘原因和逻辑,从多角度、多方面综合分析和阐述观点。对于需要指导用户操作的内容,要求明确、实用。如果无法通过文字等清楚地表达,
优采云Data采集器 的文章 内容精心打造,以改善用户的视觉和浏览体验。这里我们考察最常见也最容易被忽略的内容元素,例如:字体、段落、布局、大小标题、匹配辅助图片和视频等。优采云数据采集器要求是丰富美观,层次分明,贴合主题,升华主题,帮助用户更好地理解内容,获得连贯舒适的阅读体验。两个相对相似的内容可能由于布局不同而具有不同的质量分数。

使用优采云Data采集器的体验是流畅的,和上面提到的精致制作不同。精美的制作考察的是内容主体部分的美化,而这里考察的是页面的整体布局和核心。交互性、功能体验和舒适度。优采云数据采集器在设计页面时,首先要考虑核心需求需要哪些辅助功能和信息,帮助用户更好地理解内容。搜索排名受多种因素影响,例如用户偏好、网站整体质量等。原创单靠一个维度无法衡量为什么内容不是收录。如果站长觉得他的内容质量很高,他应该得到更好的搜索表示。

一键采集上传常见的细节问题(优采云数据采集器如何解决网站更新困难,网站内容充实等问题 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2022-03-21 04:12
)
优采云数据采集器,通过将关键词采集分配给全网数据源文章,网站可以有大量的文章生成与网站定位相关的@>,解决网站难以更新和网站内容丰富的问题。网站 的核心是内容。只有产生足够多的优质内容,才能吸引搜索引擎和用户的搜索需求。从长远来看,我们可以获得大量的流量,达到建立网站的根本目的。
优采云数据采集器通信是内容质量的核心部分。普通网页上的内容类型很多,如文章、视频,主要是内容,还有下载、查询工具等类型的操作,还有主页、个人主页、列表页、很快。不管是什么类型的页面,它都承担着传递信息的目的。在向用户传递信息时,能否满足用户的需求,解决用户访问的问题,对这些页面类型的指导意义在于互通。
优采云data采集器的内容要清晰明了,写得合乎逻辑,用词优美,读起来舒服。从内容的特点来看,可以增强用户吸收内容后的获得感。比如优采云data采集器内容发人深省、轻松愉快、文笔好、有说服力等。严谨优雅的文笔更能体现行业的专业性,比如使用专业术语、词汇和思维方法。能够深入挖掘原因和逻辑,从多角度、多方面综合分析和阐述观点。对于需要指导用户操作的内容,要求明确、实用。如果无法通过文字等清楚地表达,
优采云Data采集器 的文章 内容精心打造,以改善用户的视觉和浏览体验。这里我们考察最常见也最容易被忽略的内容元素,例如:字体、段落、布局、大小标题、匹配辅助图片和视频等。优采云数据采集器要求是丰富美观,层次分明,贴合主题,升华主题,帮助用户更好地理解内容,获得连贯舒适的阅读体验。两个相对相似的内容可能由于布局不同而具有不同的质量分数。
使用优采云Data采集器的体验是流畅的,和上面提到的精致制作不同。精美的制作考察的是内容主体部分的美化,而这里考察的是页面的整体布局和核心。交互性、功能体验和舒适度。优采云数据采集器在设计页面时,首先要考虑核心需求需要哪些辅助功能和信息,帮助用户更好地理解内容。搜索排名受多种因素影响,例如用户偏好、网站整体质量等。原创单靠一个维度无法衡量为什么内容不是收录。如果站长觉得他的内容质量很高,他应该得到更好的搜索表示。
查看全部
一键采集上传常见的细节问题(优采云数据采集器如何解决网站更新困难,网站内容充实等问题
)
优采云数据采集器,通过将关键词采集分配给全网数据源文章,网站可以有大量的文章生成与网站定位相关的@>,解决网站难以更新和网站内容丰富的问题。网站 的核心是内容。只有产生足够多的优质内容,才能吸引搜索引擎和用户的搜索需求。从长远来看,我们可以获得大量的流量,达到建立网站的根本目的。
优采云数据采集器通信是内容质量的核心部分。普通网页上的内容类型很多,如文章、视频,主要是内容,还有下载、查询工具等类型的操作,还有主页、个人主页、列表页、很快。不管是什么类型的页面,它都承担着传递信息的目的。在向用户传递信息时,能否满足用户的需求,解决用户访问的问题,对这些页面类型的指导意义在于互通。
优采云data采集器的内容要清晰明了,写得合乎逻辑,用词优美,读起来舒服。从内容的特点来看,可以增强用户吸收内容后的获得感。比如优采云data采集器内容发人深省、轻松愉快、文笔好、有说服力等。严谨优雅的文笔更能体现行业的专业性,比如使用专业术语、词汇和思维方法。能够深入挖掘原因和逻辑,从多角度、多方面综合分析和阐述观点。对于需要指导用户操作的内容,要求明确、实用。如果无法通过文字等清楚地表达,
优采云Data采集器 的文章 内容精心打造,以改善用户的视觉和浏览体验。这里我们考察最常见也最容易被忽略的内容元素,例如:字体、段落、布局、大小标题、匹配辅助图片和视频等。优采云数据采集器要求是丰富美观,层次分明,贴合主题,升华主题,帮助用户更好地理解内容,获得连贯舒适的阅读体验。两个相对相似的内容可能由于布局不同而具有不同的质量分数。
使用优采云Data采集器的体验是流畅的,和上面提到的精致制作不同。精美的制作考察的是内容主体部分的美化,而这里考察的是页面的整体布局和核心。交互性、功能体验和舒适度。优采云数据采集器在设计页面时,首先要考虑核心需求需要哪些辅助功能和信息,帮助用户更好地理解内容。搜索排名受多种因素影响,例如用户偏好、网站整体质量等。原创单靠一个维度无法衡量为什么内容不是收录。如果站长觉得他的内容质量很高,他应该得到更好的搜索表示。
一键采集上传常见的细节问题(2个神仙功能,帮你快速收发文件并且做好归类)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-03-20 23:17
在日常工作中,我们经常需要采集各种信息,比如老师收作业、老板收工作报告等等。
但是,在使用常见的微信/QQ/邮箱/采集时,会出现以下问题:
1)采集100个文件,需要打开对话框100次,保存文件为100次
2)微信聊天中的文件经常面临3天过期、自动清理的风险
3)每个人提交的文件命名不能保证完全一致,后续分类管理不便
今天给大家带来2个神仙功能,帮你快速收发文件,分类好。一起来了解一下吧~
01WPS文件助手小程序帮你批量采集多个文件
最初采集文件时,必须手动将每个副本另存为,然后分类到文件夹中。
现在,使用“WPS文件助手”小程序,可以一键生成采集链接,提醒大家在线提交,轻松批量采集多个文件。
如何发起采集?
微信搜索“WPS文件助手”,打开下图小程序:
然后,只需 3 个步骤,就可以帮助教师、项目经理、管理员、组织者等小伙伴高效地采集和分类文件。
具体操作流程如下:
①选择文件采集类型,点击“发起采集” ②添加要采集的内容和信息,例如采集头脑风暴计划需要提交姓名;也可以设置提交截止时间③点击“邀请微信好友提交”,发到微信提醒大家填写提交
如果需要采集其他类型的文档,采集步骤同上~
如何让别人快速提交文件?
转发给微信好友后,对方只需点击小程序或链接即可进入提交界面:
具体操作流程如下:
①点击“选择文件提交”,可以选择云文件、微信聊天文件、微信图片、相册文件,根据自己的需要进行选择 ②比如点击“选择云文件”,选择文件后点击“选择文件上传” "
③填写采集器设置的信息,点击“确认提交”
如何查看采集结果
发起文档请求后,只有接收者可以查看文档采集结果。有3种查看方式:
①小程序:进入小程序首页,点击“查看采集记录”
② WPS手机版:点击底部“文档”,找到以提交内容命名的文件夹
③ WPS电脑版:点击我的电脑中的“WPS网盘”,找到以提交内容命名的文件夹
值得强调的是,采集结果实时更新,自动汇总到同一个文件夹中。
同时也为你省去重复下载的麻烦,打开文件就可以直接查看,甚至成为团队的知识库。
02使用“共享文件夹”告别重复通信,一次收发文件
在解决了多文档采集困难的问题后,人们经常会遇到文档需要重复发送,文档更新时需要重复通知的问题。
WPS“共享文件夹”功能让您可以一次将文件发送给多人,文件更新后无需重复通知。
例如,教师可以提前将课件、试卷、作业提交要求等文件放在一个文件夹中,然后将该文件夹设置为“共享文件夹”,邀请学生加入。
成功添加文件夹后,学生可以看到老师准备的学习资料,然后将作业直接上传到文件夹,形成班级作业库。
运营流程
① WPS手机版:
点击下方“文档”,选择已有文件夹或新建文件夹,将需要采集的文件内容和需求写入文档,然后通过微信、QQ等方式邀请会员。
② WPS电脑版:
点击首页左侧“文档-我的云文档”,新建文件夹或选择已有文件夹,选择“共享-立即共享”。
以上就是今天的介绍啦!希望这个“WPS文件助手”小程序和“共享文件夹”功能可以帮助你快速解决收发文件的问题~ 查看全部
一键采集上传常见的细节问题(2个神仙功能,帮你快速收发文件并且做好归类)
在日常工作中,我们经常需要采集各种信息,比如老师收作业、老板收工作报告等等。
但是,在使用常见的微信/QQ/邮箱/采集时,会出现以下问题:
1)采集100个文件,需要打开对话框100次,保存文件为100次
2)微信聊天中的文件经常面临3天过期、自动清理的风险
3)每个人提交的文件命名不能保证完全一致,后续分类管理不便
今天给大家带来2个神仙功能,帮你快速收发文件,分类好。一起来了解一下吧~
01WPS文件助手小程序帮你批量采集多个文件
最初采集文件时,必须手动将每个副本另存为,然后分类到文件夹中。
现在,使用“WPS文件助手”小程序,可以一键生成采集链接,提醒大家在线提交,轻松批量采集多个文件。
如何发起采集?
微信搜索“WPS文件助手”,打开下图小程序:

然后,只需 3 个步骤,就可以帮助教师、项目经理、管理员、组织者等小伙伴高效地采集和分类文件。
具体操作流程如下:
①选择文件采集类型,点击“发起采集” ②添加要采集的内容和信息,例如采集头脑风暴计划需要提交姓名;也可以设置提交截止时间③点击“邀请微信好友提交”,发到微信提醒大家填写提交

如果需要采集其他类型的文档,采集步骤同上~
如何让别人快速提交文件?
转发给微信好友后,对方只需点击小程序或链接即可进入提交界面:

具体操作流程如下:
①点击“选择文件提交”,可以选择云文件、微信聊天文件、微信图片、相册文件,根据自己的需要进行选择 ②比如点击“选择云文件”,选择文件后点击“选择文件上传” "
③填写采集器设置的信息,点击“确认提交”
如何查看采集结果
发起文档请求后,只有接收者可以查看文档采集结果。有3种查看方式:
①小程序:进入小程序首页,点击“查看采集记录”
② WPS手机版:点击底部“文档”,找到以提交内容命名的文件夹
③ WPS电脑版:点击我的电脑中的“WPS网盘”,找到以提交内容命名的文件夹
值得强调的是,采集结果实时更新,自动汇总到同一个文件夹中。
同时也为你省去重复下载的麻烦,打开文件就可以直接查看,甚至成为团队的知识库。
02使用“共享文件夹”告别重复通信,一次收发文件
在解决了多文档采集困难的问题后,人们经常会遇到文档需要重复发送,文档更新时需要重复通知的问题。
WPS“共享文件夹”功能让您可以一次将文件发送给多人,文件更新后无需重复通知。
例如,教师可以提前将课件、试卷、作业提交要求等文件放在一个文件夹中,然后将该文件夹设置为“共享文件夹”,邀请学生加入。
成功添加文件夹后,学生可以看到老师准备的学习资料,然后将作业直接上传到文件夹,形成班级作业库。
运营流程
① WPS手机版:
点击下方“文档”,选择已有文件夹或新建文件夹,将需要采集的文件内容和需求写入文档,然后通过微信、QQ等方式邀请会员。

② WPS电脑版:
点击首页左侧“文档-我的云文档”,新建文件夹或选择已有文件夹,选择“共享-立即共享”。
以上就是今天的介绍啦!希望这个“WPS文件助手”小程序和“共享文件夹”功能可以帮助你快速解决收发文件的问题~
一键采集上传常见的细节问题(10.未找到任何可发布的内容.答:程序会保存的选项 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2022-03-19 05:14
)
10.找不到可发布的内容。
答:这是程序在本地数据库中找不到未标记为未发出的记录。在这种情况下,您已经发布了所有数据,或者您没有选择任务栏中的内容。
11.测试或发布时,“只能一个账号同时在线,或者你的账号已经被禁用”
A:这是因为网站系统不允许一个账号同时在线,比如英制。在这种情况下,建议您使用 采集 发布的专用帐户。请勿使用它登录 网站。
12.有时候明明已经正确获取了web cookie,但是测试还是没有登录?
A:一个是cookie过期的问题,另一个可能是我们的程序没有正确获取到(抱歉,目前程序无法正确获取所有cookie)。在这种情况下,建议您使用专业的抓包软件,比如WSockExpert,来抓取cookies,然后将抓取到的cookies填入程序保存cookies的地方。
13.如何设置发布速度?
A:请在“编辑任务”的“文件保存和高级设置”中设置采集和发布速度,时间单位为毫秒。
14.采集地址重复。
A:程序会保存采集页面的地址,如果已经采集,默认不去采集。如果需要重新采集,可以删除所有原任务地址库和本地采集的数据。如果您要采集的网页内容不断变化,可以选择不检测重复选项
15.论坛怎么改用户发帖,一个用户太假了?
答:如果您使用网络上在线发布的方式,那么程序发布就相当于手动发布。您不能同时登录多个帐户,因此该程序不能。要实现多账号发帖,需要修改原有的论坛程序,让他可以使用多个用户名发帖。discuz的随机发布界面是一个修改后的程序,使用不同的用户发布到自己的论坛。
14.测试的URL采集是正常的,但是当真正的采集时却漏掉了很多。
A:程序默认会过滤掉重复的URL。如果一个 URL 已经在同一个站点下被获取,它不会转到 采集。
1 7.采集的数据入库后,显示很多问号?
答:这一般是入库时没有选对码造成的,请注意选码;
查看全部
一键采集上传常见的细节问题(10.未找到任何可发布的内容.答:程序会保存的选项
)
10.找不到可发布的内容。
答:这是程序在本地数据库中找不到未标记为未发出的记录。在这种情况下,您已经发布了所有数据,或者您没有选择任务栏中的内容。
11.测试或发布时,“只能一个账号同时在线,或者你的账号已经被禁用”
A:这是因为网站系统不允许一个账号同时在线,比如英制。在这种情况下,建议您使用 采集 发布的专用帐户。请勿使用它登录 网站。
12.有时候明明已经正确获取了web cookie,但是测试还是没有登录?
A:一个是cookie过期的问题,另一个可能是我们的程序没有正确获取到(抱歉,目前程序无法正确获取所有cookie)。在这种情况下,建议您使用专业的抓包软件,比如WSockExpert,来抓取cookies,然后将抓取到的cookies填入程序保存cookies的地方。
13.如何设置发布速度?
A:请在“编辑任务”的“文件保存和高级设置”中设置采集和发布速度,时间单位为毫秒。
14.采集地址重复。
A:程序会保存采集页面的地址,如果已经采集,默认不去采集。如果需要重新采集,可以删除所有原任务地址库和本地采集的数据。如果您要采集的网页内容不断变化,可以选择不检测重复选项

15.论坛怎么改用户发帖,一个用户太假了?
答:如果您使用网络上在线发布的方式,那么程序发布就相当于手动发布。您不能同时登录多个帐户,因此该程序不能。要实现多账号发帖,需要修改原有的论坛程序,让他可以使用多个用户名发帖。discuz的随机发布界面是一个修改后的程序,使用不同的用户发布到自己的论坛。
14.测试的URL采集是正常的,但是当真正的采集时却漏掉了很多。
A:程序默认会过滤掉重复的URL。如果一个 URL 已经在同一个站点下被获取,它不会转到 采集。
1 7.采集的数据入库后,显示很多问号?
答:这一般是入库时没有选对码造成的,请注意选码;

一键采集上传常见的细节问题(创壳网络科技-创想软件开发工作室开发和运营的外贸工具介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2022-03-17 16:04
创意亚马逊asin采集软件是创意软件开发工作室开发运营的外贸工具。是专为亚马逊开发的采集器,功能强大。
一、创意亚马逊asin采集软件主要功能如下:
·支持批量各种产品listing页面采集(店面前台、搜索结果、品类TOP100等);
·支持采集;
包括北美和欧洲在内的全球 12 个亚马逊网站
·支持采集子项(变体)信息;
·支持采集产品ASIN码、价格、评论数、跟进(offer)数、上架时间、Rank分类排名、主产品标题、短描述和长描述;
·支持采集高清图片、缩略图、产品细节图、变体高清缩略图、变体细节图;
·支持自定义正则配置,支持自定义字段设置,方便HTML文本提取,支持调试,支持多结果和自定义过滤,采集你需要的数据;
·支持过滤,可过滤指定价格、报价、过滤词、分类、排名、变体模型、强网页过滤等;
·支持批量修改价格;
·支持采集指定ASIN商品信息、所有买家评论、Q&A信息、所有合卖卖家信息、相关商品、最低报价等;
·支持条件删除器,自由选择不同的自定义过滤器配置,手动过滤删除导入或采集完成的数据,支持过滤器原因输出;
·支持自动删除非变体产品,删除主产品有变体,删除与主产品相同ASIN的变体,仅采集与主产品相同ASIN的变体;
·支持导出Excel/txt/WEB/XML;
二、创意亚马逊asin采集软件主要功能如下:
1、合卖产品:批量采集店铺资料分批合卖(一般为定制产品,货源充足),采集所有价格均为报价,支持出口以及后续购买模板,一键批量导出亚马逊专属联卖模板。它简单快捷。
2、竞品分析:采集竞品listing评论等数据,分析差评数量,词频统计分析评价词热度,分析其他产品综合数据(数量评论、评分、RANK 等)。
3、选品丰富:采集可对指定品类、TOP100产品页面、店铺、搜索结果等数据进行批量过滤整理,提取最佳产品,提高选品效率。
4、定点监控:支持定时或手动采集数据,支持比较器,分析产品时间区间内排名、评论、报价数量、价格等变化,自带脚本规划工具,可自动完成所需任务,自动保存指定项目不同时间段的数据快照。
5、数据分析:采集指定商品评论、QA问答、相关商品等,支持评论月度统计,按型号统计,统计图表,支持词频统计,支持快速过滤以查找差评数据。
6、数据搬家:采集将指定商品的数据和图片编辑成其他平台的上传模板,用于上传和分发商品。
7、图片采集:快速抓取产品和子产品的一个批次或一个ASIN的所有图片和详细图片,并支持自定义文件名。
8、提高办公效率:过滤产品,丰富采集辅助工具,采集各类页面数据,一键分析变异图片采集,数据统计、数据删除等功能定期更新,大大提高办公效率。 查看全部
一键采集上传常见的细节问题(创壳网络科技-创想软件开发工作室开发和运营的外贸工具介绍)
创意亚马逊asin采集软件是创意软件开发工作室开发运营的外贸工具。是专为亚马逊开发的采集器,功能强大。

一、创意亚马逊asin采集软件主要功能如下:
·支持批量各种产品listing页面采集(店面前台、搜索结果、品类TOP100等);
·支持采集;
包括北美和欧洲在内的全球 12 个亚马逊网站
·支持采集子项(变体)信息;
·支持采集产品ASIN码、价格、评论数、跟进(offer)数、上架时间、Rank分类排名、主产品标题、短描述和长描述;
·支持采集高清图片、缩略图、产品细节图、变体高清缩略图、变体细节图;
·支持自定义正则配置,支持自定义字段设置,方便HTML文本提取,支持调试,支持多结果和自定义过滤,采集你需要的数据;
·支持过滤,可过滤指定价格、报价、过滤词、分类、排名、变体模型、强网页过滤等;
·支持批量修改价格;
·支持采集指定ASIN商品信息、所有买家评论、Q&A信息、所有合卖卖家信息、相关商品、最低报价等;
·支持条件删除器,自由选择不同的自定义过滤器配置,手动过滤删除导入或采集完成的数据,支持过滤器原因输出;
·支持自动删除非变体产品,删除主产品有变体,删除与主产品相同ASIN的变体,仅采集与主产品相同ASIN的变体;
·支持导出Excel/txt/WEB/XML;
二、创意亚马逊asin采集软件主要功能如下:
1、合卖产品:批量采集店铺资料分批合卖(一般为定制产品,货源充足),采集所有价格均为报价,支持出口以及后续购买模板,一键批量导出亚马逊专属联卖模板。它简单快捷。
2、竞品分析:采集竞品listing评论等数据,分析差评数量,词频统计分析评价词热度,分析其他产品综合数据(数量评论、评分、RANK 等)。
3、选品丰富:采集可对指定品类、TOP100产品页面、店铺、搜索结果等数据进行批量过滤整理,提取最佳产品,提高选品效率。
4、定点监控:支持定时或手动采集数据,支持比较器,分析产品时间区间内排名、评论、报价数量、价格等变化,自带脚本规划工具,可自动完成所需任务,自动保存指定项目不同时间段的数据快照。
5、数据分析:采集指定商品评论、QA问答、相关商品等,支持评论月度统计,按型号统计,统计图表,支持词频统计,支持快速过滤以查找差评数据。
6、数据搬家:采集将指定商品的数据和图片编辑成其他平台的上传模板,用于上传和分发商品。
7、图片采集:快速抓取产品和子产品的一个批次或一个ASIN的所有图片和详细图片,并支持自定义文件名。
8、提高办公效率:过滤产品,丰富采集辅助工具,采集各类页面数据,一键分析变异图片采集,数据统计、数据删除等功能定期更新,大大提高办公效率。
一键采集上传常见的细节问题(一下需求收集平台-fileinput文件上传插件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2022-03-10 13:21
本项目前端形式采用bootstrap-fileinput的风格。bootstrap-fileinput 是一个非常强大的文件上传插件。请注意,它是文件上传,而不仅仅是图像上传。当您第一次接触它时,您只需将其调整为您想要的样式。也花了半天时间。下面简单介绍一下需求采集平台项目中用到的插件的一些细节。
对了,别忘了详细阅读官方文档:Bootstrap File Input - © Kartik,英文,如果你看的话,你必须阅读它。
1. 提交模式
首先文档简单对比一下两种上传方式,一种是表单提交,一种是Ajax提交。从下图可以看出,官方推荐大家通过Ajax上传。显然,通过 Ajax 上传更自由,可以获得更多的功能。
2. 导入文件
然后你需要导入必要的 CSS 和 JS 文件。必须导入以下内容。调试了半天,发现插件没有导入。
引导程序.css
引导程序.js
jQuery.js
引导文件输入/css/fileinput.css
引导文件输入/js/fileinput.js
bootstrap-fileinput/js/locales/zh.js(中文文件,是否导入)
自己check in,找到对应的文件。以上6个必须导入。bootstrap-fileinput/js/plugins/目录下也有一些插件,根据具体要导入的功能而定。
3. 基本用法
下一步是使用插件。起初,我只是想改进一下文件类型表单的样式。默认的文件上传风格实在是让人无法忍受。
当不引入bootstrap-fileinput插件相关文件时,html代码如下:
文件输入
显示效果如下:
引入bootstrap-fileinput插件后,同样的html代码,显示效果如下:
基本文件引入后,添加一行js代码 $('#myfile').fileinput(); 在页面底部,会出现不同的效果。完整的HTML代码如下:
fileinput-example
fileinput-example
文件输入
$('#myfile').fileinput();
接下来,上传一些文件来试用默认样式。
看起来不错,项目最终看起来像这样:
该功能有一些限制,比如允许上传多张照片,但只能上传3张照片,每张照片最多只能达到1MB。要实现一些控制,有必要了解以下一些参数。
4. 控制参数
官方文档中有介绍,但是很多时候虽然有说明,但不一定能看懂。这个插件的功能我不是很熟悉。我刚刚达到了我想要的效果,我很感兴趣。可以自学。
以下是项目中配置的一些参数:
$("#input-id").fileinput({
showUpload: false,
previewFileType: 'any',
language: 'zh',
browseLabel: '图片多选',
browseClass: 'btn btn-default',
allowedFileTypes: ['image'], // 限制文件类型为图片
allowedFileExtensions: ['jpg', 'png'], // 限制文件后缀名为jpg,png,gif
maxFileCount: 3, // 限制最多3张图片
maxFileSize: 1024, // 限制图片大小,最大1024KB
allowedPreviewTypes: ['image'], // 允许预览的文件类型
initialCaption: '可以选择最多3张图片,格式为png或者jpg,大小不超过1M', // 初始化说明框框,比如该项目上默认显示:可以选择最多3张图片,格式为png或者jpg,大小不超过1M
layoutTemplates: {
main1: '{preview}\n' +
'\n' +
' \n' +
' {browse}\n' +
' {remove}\n' +
' \n' +
' {caption}\n' +
'',
footer: '\n' +
' {caption}{size}\n' +
''
}
}); // 修改默认样式,比如按钮移到左侧,预览窗口中图片的脚标等等(这里只显示文件名,如下图)
这里只是简单介绍一下bootstrap-fileinput插件的简单功能。更多功能的学习还是要靠自己的研究,尤其是Ajax上传功能。作者的研究深度有限,暂时不做过多介绍。如果有机会,我会做深入研究和分享。 查看全部
一键采集上传常见的细节问题(一下需求收集平台-fileinput文件上传插件)
本项目前端形式采用bootstrap-fileinput的风格。bootstrap-fileinput 是一个非常强大的文件上传插件。请注意,它是文件上传,而不仅仅是图像上传。当您第一次接触它时,您只需将其调整为您想要的样式。也花了半天时间。下面简单介绍一下需求采集平台项目中用到的插件的一些细节。
对了,别忘了详细阅读官方文档:Bootstrap File Input - © Kartik,英文,如果你看的话,你必须阅读它。
1. 提交模式
首先文档简单对比一下两种上传方式,一种是表单提交,一种是Ajax提交。从下图可以看出,官方推荐大家通过Ajax上传。显然,通过 Ajax 上传更自由,可以获得更多的功能。

2. 导入文件
然后你需要导入必要的 CSS 和 JS 文件。必须导入以下内容。调试了半天,发现插件没有导入。
引导程序.css
引导程序.js
jQuery.js
引导文件输入/css/fileinput.css
引导文件输入/js/fileinput.js
bootstrap-fileinput/js/locales/zh.js(中文文件,是否导入)
自己check in,找到对应的文件。以上6个必须导入。bootstrap-fileinput/js/plugins/目录下也有一些插件,根据具体要导入的功能而定。
3. 基本用法
下一步是使用插件。起初,我只是想改进一下文件类型表单的样式。默认的文件上传风格实在是让人无法忍受。
当不引入bootstrap-fileinput插件相关文件时,html代码如下:
文件输入
显示效果如下:

引入bootstrap-fileinput插件后,同样的html代码,显示效果如下:

基本文件引入后,添加一行js代码 $('#myfile').fileinput(); 在页面底部,会出现不同的效果。完整的HTML代码如下:
fileinput-example
fileinput-example
文件输入
$('#myfile').fileinput();
接下来,上传一些文件来试用默认样式。
看起来不错,项目最终看起来像这样:

该功能有一些限制,比如允许上传多张照片,但只能上传3张照片,每张照片最多只能达到1MB。要实现一些控制,有必要了解以下一些参数。
4. 控制参数
官方文档中有介绍,但是很多时候虽然有说明,但不一定能看懂。这个插件的功能我不是很熟悉。我刚刚达到了我想要的效果,我很感兴趣。可以自学。
以下是项目中配置的一些参数:
$("#input-id").fileinput({
showUpload: false,
previewFileType: 'any',
language: 'zh',
browseLabel: '图片多选',
browseClass: 'btn btn-default',
allowedFileTypes: ['image'], // 限制文件类型为图片
allowedFileExtensions: ['jpg', 'png'], // 限制文件后缀名为jpg,png,gif
maxFileCount: 3, // 限制最多3张图片
maxFileSize: 1024, // 限制图片大小,最大1024KB
allowedPreviewTypes: ['image'], // 允许预览的文件类型
initialCaption: '可以选择最多3张图片,格式为png或者jpg,大小不超过1M', // 初始化说明框框,比如该项目上默认显示:可以选择最多3张图片,格式为png或者jpg,大小不超过1M
layoutTemplates: {
main1: '{preview}\n' +
'\n' +
' \n' +
' {browse}\n' +
' {remove}\n' +
' \n' +
' {caption}\n' +
'',
footer: '\n' +
' {caption}{size}\n' +
''
}
}); // 修改默认样式,比如按钮移到左侧,预览窗口中图片的脚标等等(这里只显示文件名,如下图)

这里只是简单介绍一下bootstrap-fileinput插件的简单功能。更多功能的学习还是要靠自己的研究,尤其是Ajax上传功能。作者的研究深度有限,暂时不做过多介绍。如果有机会,我会做深入研究和分享。
一键采集上传常见的细节问题(SEO商务营销王中英文网站全自动更新系统概述及原理介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-03-06 10:19
SEO商务营销王中英文网站自动更新系统有cms+SEO技术+中英文关键词分析+蜘蛛爬虫+网页智能信息抓取技术,目前支持织梦(DEDEcms), Empire(Empirecms), Wordpress, Z-blog, Dongyi, 5UCKS, discuz, phpwind等系统自动导入并自动生成静态页面,软件基于在预设信息上自动采集并发布,目标站每天可以自动维护和更新。是站长获取流量的绝佳工具。
软件功能概述及原理介绍
智能蜘蛛系统(采集)
只需设置采集目标站和采集规则,可以手动或自动采集目标站内容,同步目标站更新采集,使用蜘蛛内核模拟蜘蛛抓取网站内容不被拦截,强大的正则化轻松采集你想要的所有信息,包括邮箱、QQ和手机号等,不只做你想要的,还能过滤掉所有不需要的内容;
海拔伪原创系统
如果你觉得采集的文章不够原创,那么我们强大的伪原创系统可以解决这个问题,程序会按照你的要求执行,包括自动断头,文章前后自动添加原创文字,段落中随机插入短句或图片,替换约定词,完成文章拆分成多页合并同一主题的多个页面等。相似度降低文章,使搜索引擎判断为高权重原创文章;
多任务定时自动采集发布系统(无人值守)
您可以根据自己的需要自由设置采集的时间和发布文章的时间间隔,尽量科学、全自动地管理您的网站。您只需要定期检查发布的内容和软件输出。提示,根据搜索引擎的变化调整采集和发布的时间间隔;
强大的内部链接系统(SEO)
网站内部链接是SEO的重中之重。系统可以自由设置需要重点排名的关键词,并在发布时自动生成专门的页面,将出现在文章中的关键词放在... 查看全部
一键采集上传常见的细节问题(SEO商务营销王中英文网站全自动更新系统概述及原理介绍)
SEO商务营销王中英文网站自动更新系统有cms+SEO技术+中英文关键词分析+蜘蛛爬虫+网页智能信息抓取技术,目前支持织梦(DEDEcms), Empire(Empirecms), Wordpress, Z-blog, Dongyi, 5UCKS, discuz, phpwind等系统自动导入并自动生成静态页面,软件基于在预设信息上自动采集并发布,目标站每天可以自动维护和更新。是站长获取流量的绝佳工具。
软件功能概述及原理介绍
智能蜘蛛系统(采集)
只需设置采集目标站和采集规则,可以手动或自动采集目标站内容,同步目标站更新采集,使用蜘蛛内核模拟蜘蛛抓取网站内容不被拦截,强大的正则化轻松采集你想要的所有信息,包括邮箱、QQ和手机号等,不只做你想要的,还能过滤掉所有不需要的内容;
海拔伪原创系统
如果你觉得采集的文章不够原创,那么我们强大的伪原创系统可以解决这个问题,程序会按照你的要求执行,包括自动断头,文章前后自动添加原创文字,段落中随机插入短句或图片,替换约定词,完成文章拆分成多页合并同一主题的多个页面等。相似度降低文章,使搜索引擎判断为高权重原创文章;
多任务定时自动采集发布系统(无人值守)
您可以根据自己的需要自由设置采集的时间和发布文章的时间间隔,尽量科学、全自动地管理您的网站。您只需要定期检查发布的内容和软件输出。提示,根据搜索引擎的变化调整采集和发布的时间间隔;
强大的内部链接系统(SEO)
网站内部链接是SEO的重中之重。系统可以自由设置需要重点排名的关键词,并在发布时自动生成专门的页面,将出现在文章中的关键词放在...
一键采集上传常见的细节问题(更快发布到Emlog,怎样填写分类及设置分类??)
采集交流 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-03-06 01:19
为了更快上手入门资料采集并发布到Emlog网站网站,优采云采集特别总结了一些新手遇到的操作问题,为了让大家更熟练使用,列表如下:
1. 发帖到 Emlog,分类怎么填?
【分类】对应的值为Emlog的分类名称,在Emlog的后台--》分类;
2. 发帖到Emlog,发帖目标的对应字段如何填写?
'目标网站的字段名'是Emlog系统端对应的属性;
'value source 1'栏是选择采集字段和其他一些特殊参数;
'value source 2'栏一般都是用固定值填充的;
详细解释以下重要字段:
标题(必填):一般对应采集字段标题,可以从'source value 1'中选择;(可以多选组合字段);
内容(必填):为body部分,一般对应采集字段内容,可以从'Source Value 1'中选择;(可多选组合字段);
Category:发布数据的类别,值为Emlog的类别名称,不存在的类别会自动创建,不支持多类别发布,不填会发布到Uncategorized .
通常在‘源值2’中填写一个固定值,也可以选择‘值源1’中的采集字段(详见数据发布-设置分类(列)技巧);
Author:设置文章的发布者,该值可以是Emlog中已经存在的用户名或ID,不存在系统会自动创建;
一般在‘源值2’中填写一个固定值;(如果不选择不填,系统会自动映射Emlog管理员的名字)。
发布时间:设置文章的发布时间,默认发布时间(相当于实时,发布时显示什么时间)。 查看全部
一键采集上传常见的细节问题(更快发布到Emlog,怎样填写分类及设置分类??)
为了更快上手入门资料采集并发布到Emlog网站网站,优采云采集特别总结了一些新手遇到的操作问题,为了让大家更熟练使用,列表如下:
1. 发帖到 Emlog,分类怎么填?
【分类】对应的值为Emlog的分类名称,在Emlog的后台--》分类;

2. 发帖到Emlog,发帖目标的对应字段如何填写?
'目标网站的字段名'是Emlog系统端对应的属性;
'value source 1'栏是选择采集字段和其他一些特殊参数;
'value source 2'栏一般都是用固定值填充的;
详细解释以下重要字段:
标题(必填):一般对应采集字段标题,可以从'source value 1'中选择;(可以多选组合字段);
内容(必填):为body部分,一般对应采集字段内容,可以从'Source Value 1'中选择;(可多选组合字段);
Category:发布数据的类别,值为Emlog的类别名称,不存在的类别会自动创建,不支持多类别发布,不填会发布到Uncategorized .
通常在‘源值2’中填写一个固定值,也可以选择‘值源1’中的采集字段(详见数据发布-设置分类(列)技巧);
Author:设置文章的发布者,该值可以是Emlog中已经存在的用户名或ID,不存在系统会自动创建;
一般在‘源值2’中填写一个固定值;(如果不选择不填,系统会自动映射Emlog管理员的名字)。
发布时间:设置文章的发布时间,默认发布时间(相当于实时,发布时显示什么时间)。
一键采集上传常见的细节问题(数据采集软件更新网页内容,内容排版布局需要注意什么?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2022-03-02 00:22
数据采集软件,通过对全网数据进行采集,挖掘出文章对网站有帮助的内容数据,然后发布到网站经过二次处理@>. 数据采集软件拥有多种网页采集策略和配套资源,帮助整个采集流程实现数据的完整性和稳定性。站长无需了解爬虫编程技术,通过简单的操作即可轻松采集网页数据,然后一键导出多种格式,快速导入数据库。
数据采集软件优化网站内页和内容文章,主要是内容标题优化、图片优化、Alt标签优化、关键词布局优化,比如只有一个h1标签可以出现在一篇文章文章中,其他h标签不能大量使用。3 到 5 个 H 标签就足够了。alt标签的内容也要符合图片的内容,不能太多。堆叠产品 关键词 并自然地做。
数据采集软件seo注意事项,当一个新的网站运行了两个月甚至更长的时间,发现网站已经很久没有收录了。不要对网站进行大的改动,这对网站收录和排名非常不利,也会因为你的不合理改动而被搜索引擎降级。数据采集软件聚合文章,通俗的讲就是把重复的文章放在一起形成一个候选集,另外还有文章发布时间、评论、站点历史、转发轨迹等因素来识别和判断原创的内容。
其实大家都知道优质内容对于网站优化的重要性,但是坚持更新原创内容是一件费时费力的事情。为了解决这个问题,采集软件会将采集过来的数据文章简单的处理成一段伪原创内容,而文章可读性流畅,用户体验也能得到提升,对搜索引擎也会更加友好。
优化网站我们只需要记住一件事,那就是不断提升用户体验。这个话题永远不会过时。搜索引擎虽然有些方面并不完美,但一直在朝着好的方向努力。
数据 采集 软件更新网页内容。应特别注意内容的布局和布局。与文章主题无关的信息和不可用功能无法出现,可能会干扰用户阅读浏览,影响用户体验。网站内容来自全网,数据采集软件对网站自身内容生产力不足或内容生产力差的问题有很大帮助,整个网站很低。小编的建议:多制作对用户有价值的内容,让用户和搜索引擎对你更加友好。站点产生与 网站 域相关的内容,并通过域焦点获得搜索引擎的喜欢。不要采集 跨域内容以获取短期利益,这将导致 网站 域关注度下降。影响搜索引擎的评级。返回搜狐,查看更多 查看全部
一键采集上传常见的细节问题(数据采集软件更新网页内容,内容排版布局需要注意什么?)
数据采集软件,通过对全网数据进行采集,挖掘出文章对网站有帮助的内容数据,然后发布到网站经过二次处理@>. 数据采集软件拥有多种网页采集策略和配套资源,帮助整个采集流程实现数据的完整性和稳定性。站长无需了解爬虫编程技术,通过简单的操作即可轻松采集网页数据,然后一键导出多种格式,快速导入数据库。
数据采集软件优化网站内页和内容文章,主要是内容标题优化、图片优化、Alt标签优化、关键词布局优化,比如只有一个h1标签可以出现在一篇文章文章中,其他h标签不能大量使用。3 到 5 个 H 标签就足够了。alt标签的内容也要符合图片的内容,不能太多。堆叠产品 关键词 并自然地做。
数据采集软件seo注意事项,当一个新的网站运行了两个月甚至更长的时间,发现网站已经很久没有收录了。不要对网站进行大的改动,这对网站收录和排名非常不利,也会因为你的不合理改动而被搜索引擎降级。数据采集软件聚合文章,通俗的讲就是把重复的文章放在一起形成一个候选集,另外还有文章发布时间、评论、站点历史、转发轨迹等因素来识别和判断原创的内容。
其实大家都知道优质内容对于网站优化的重要性,但是坚持更新原创内容是一件费时费力的事情。为了解决这个问题,采集软件会将采集过来的数据文章简单的处理成一段伪原创内容,而文章可读性流畅,用户体验也能得到提升,对搜索引擎也会更加友好。

优化网站我们只需要记住一件事,那就是不断提升用户体验。这个话题永远不会过时。搜索引擎虽然有些方面并不完美,但一直在朝着好的方向努力。

数据 采集 软件更新网页内容。应特别注意内容的布局和布局。与文章主题无关的信息和不可用功能无法出现,可能会干扰用户阅读浏览,影响用户体验。网站内容来自全网,数据采集软件对网站自身内容生产力不足或内容生产力差的问题有很大帮助,整个网站很低。小编的建议:多制作对用户有价值的内容,让用户和搜索引擎对你更加友好。站点产生与 网站 域相关的内容,并通过域焦点获得搜索引擎的喜欢。不要采集 跨域内容以获取短期利益,这将导致 网站 域关注度下降。影响搜索引擎的评级。返回搜狐,查看更多
一键采集上传常见的细节问题(数据采集软件更新网页内容,内容排版布局需要注意什么?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 366 次浏览 • 2022-03-02 00:22
数据采集软件,通过对全网数据进行采集,挖掘出文章对网站有帮助的内容数据,然后发布到网站经过二次处理@>. 数据采集软件拥有多种网页采集策略和配套资源,帮助整个采集流程实现数据的完整性和稳定性。站长无需了解爬虫编程技术,通过简单的操作即可轻松采集网页数据,然后一键导出多种格式,快速导入数据库。
数据采集软件优化网站内页和内容文章,主要是内容标题优化、图片优化、Alt标签优化、关键词布局优化,比如只有一个h1标签可以出现在一篇文章文章中,其他h标签不能大量使用。3 到 5 个 H 标签就足够了。alt标签的内容也要符合图片的内容,不能太多。堆叠产品 关键词 并自然地做。
数据采集软件seo注意事项,当一个新的网站运行了两个月甚至更长的时间,发现网站已经很久没有收录了。不要对网站进行大的改动,这对网站收录和排名非常不利,也会因为你的不合理改动而被搜索引擎降级。数据采集软件聚合文章,通俗的讲就是把重复的文章放在一起形成一个候选集,另外还有文章发布时间、评论、站点历史、转发轨迹等因素来识别和判断原创的内容。
其实大家都知道优质内容对于网站优化的重要性,但是坚持更新原创内容是一件费时费力的事情。为了解决这个问题,采集软件会将采集过来的数据文章简单的处理成一段伪原创内容,而文章可读性流畅,用户体验也能得到提升,对搜索引擎也会更加友好。
优化网站我们只需要记住一件事,那就是不断提升用户体验。这个话题永远不会过时。搜索引擎虽然有些方面并不完美,但一直在朝着好的方向努力。
数据 采集 软件更新网页内容。应特别注意内容的布局和布局。与文章主题无关的信息和不可用功能无法出现,可能会干扰用户阅读浏览,影响用户体验。网站内容来自全网,数据采集软件对网站自身内容生产力不足或内容生产力差的问题有很大帮助,整个网站很低。小编的建议:多制作对用户有价值的内容,让用户和搜索引擎对你更加友好。站点产生与 网站 域相关的内容,并通过域焦点获得搜索引擎的喜欢。不要采集 跨域内容以获取短期利益,这将导致 网站 域关注度下降。影响搜索引擎的评级。返回搜狐,查看更多 查看全部
一键采集上传常见的细节问题(数据采集软件更新网页内容,内容排版布局需要注意什么?)
数据采集软件,通过对全网数据进行采集,挖掘出文章对网站有帮助的内容数据,然后发布到网站经过二次处理@>. 数据采集软件拥有多种网页采集策略和配套资源,帮助整个采集流程实现数据的完整性和稳定性。站长无需了解爬虫编程技术,通过简单的操作即可轻松采集网页数据,然后一键导出多种格式,快速导入数据库。
数据采集软件优化网站内页和内容文章,主要是内容标题优化、图片优化、Alt标签优化、关键词布局优化,比如只有一个h1标签可以出现在一篇文章文章中,其他h标签不能大量使用。3 到 5 个 H 标签就足够了。alt标签的内容也要符合图片的内容,不能太多。堆叠产品 关键词 并自然地做。
数据采集软件seo注意事项,当一个新的网站运行了两个月甚至更长的时间,发现网站已经很久没有收录了。不要对网站进行大的改动,这对网站收录和排名非常不利,也会因为你的不合理改动而被搜索引擎降级。数据采集软件聚合文章,通俗的讲就是把重复的文章放在一起形成一个候选集,另外还有文章发布时间、评论、站点历史、转发轨迹等因素来识别和判断原创的内容。
其实大家都知道优质内容对于网站优化的重要性,但是坚持更新原创内容是一件费时费力的事情。为了解决这个问题,采集软件会将采集过来的数据文章简单的处理成一段伪原创内容,而文章可读性流畅,用户体验也能得到提升,对搜索引擎也会更加友好。
优化网站我们只需要记住一件事,那就是不断提升用户体验。这个话题永远不会过时。搜索引擎虽然有些方面并不完美,但一直在朝着好的方向努力。
数据 采集 软件更新网页内容。应特别注意内容的布局和布局。与文章主题无关的信息和不可用功能无法出现,可能会干扰用户阅读浏览,影响用户体验。网站内容来自全网,数据采集软件对网站自身内容生产力不足或内容生产力差的问题有很大帮助,整个网站很低。小编的建议:多制作对用户有价值的内容,让用户和搜索引擎对你更加友好。站点产生与 网站 域相关的内容,并通过域焦点获得搜索引擎的喜欢。不要采集 跨域内容以获取短期利益,这将导致 网站 域关注度下降。影响搜索引擎的评级。返回搜狐,查看更多
一键采集上传常见的细节问题(()文件上传的内容上传内容及内容解析 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-02-28 14:25
)
一:文件上传:javascript
要求:
1:jsp的页面:
一:表格形式:
b:帖子提交:
c: form 指定一个属性:enctype="multipart/form-data"
d:文件组件:
2:小服务程序:
request.getParamter("name");//不生效:
ServletInputStream in = request.getInputStream();
把得到的数据封装进去,理论上可以解析数据。
3:请求在请求正文中:css
发布请求正文:
请求第一行:
请求头信息:html
请求正文:
------------------
普通组件:只有一个标头:Content-Dispositon:name="xxx"java
请求正文:mrzhang:填写内容。
------------------
文件上传字段:两个标题:
内容处置:表单数据;;文件名="C:\Users\Mrzhang\Desktop\copy2.txt"
内容类型:文本/纯 MIMEweb
文件上传内容:
xxxx阿帕奇
- - - - - - - 大批
二:解析请求中的请求体:
1:jar:Apache组织提供的公共组件:
公共文件上传
commons-io
文件上传相关的两个组件,这两个组件是强依赖的。
2:原理:
请求体中各个组件的内容被封装成一个对象:
FileItem 对象:使用对象的方法和属性来获取数据。
3:获取文件项:
a:获取工厂:
b:获取解析器:
c:使用解析器解析请求,获取fileItme对象:
对象代码:
// 获取工厂:
DiskFileItemFactory 工厂 = new DiskFileItemFactory();
// 获取解析器:
ServletFileUpload 上传 = 新的 ServletFileUpload(Factory);
// 解析请求并获取所有 FileItem 对象:
List list=upload.parseRequest(request); 浏览器
4:FileItem类详解:
isFormField() 判断组件是普通组件还是文件上传组件:true,普通组件:false:文件上传组件:
getFieldName() 返回普通字段属性的值。name= username 获取用户名的值:
获取字符串();获取普通字段的上传内容。
文件上传组件:
获取名称();获取文件名:
获取尺寸();将以字节为单位上传文件大小。长
获取输入流();获取文件上传对应的流:
写(文件文件);将文件内容写入指定位置:
雄猫
三:文件上传的具体代码;
(1)引入jar包:
(2)准备页面:
(3)准备 Servlet:
四:详情:
1:上传的普通字段内容:乱码:getString("utf-8");
2:上传的文件不能被外界直接访问,应隐藏:目的、安全;
应该是上传到web-inf,内容不能被外界直接访问。安全
获取 web-inf/files 的位置:tomcat 上的真实位置:
ServletContext.getRealPath("/WEB-INF/files");
3:文件的文件路径问题:
不同浏览器上传的路径不一致。一些浏览器上传相对路径,而另一些浏览器上传绝对路径。大多数浏览器上传的相对路径。
一个.txt
c:\user\mrzhang\files\a.txt
提取文件名:
字符串文件名 = f2.getName();
//截距:
int index = filename.lastIndexOf("\\");
如果(索引!=-1){
文件名 = 文件名.subString(index+1);
}
4:上传文件名乱码:
request.setCharacterEncoding("utf-8");
解析器提供了一个方法:
servletFileUpload.setHeaderEncoding("utf-8");// 提供的解析器。高优先级:request.setCharacterEncoding("utf-8")的封装;
5:文件名相同的问题:
解决方案1:uuid+“文件名”。后缀名;
解决方案2:new Date().getTime()+"filename";
6:上传的文件不能在同一个目录下: 上传的目录被打散了:
a:时间分手:获取当前时间,创建目录:
b: 文件名首字母分散:abc.txt : charAt("0")
c:散列分解:
实施步骤:
(1) 获取文件名:
(2)获取哈希值:hashCode(); int
(3)转换为十六进制: Integer.toHexString(); //String: 9A8B7C
(4) 获取字符串的前两位:第一个字母为一级目录,第二个字母为二级目录。16*16
package com.yidongxueyuan.web.servlet;
import java.io.File;
import java.io.IOException;
import java.util.List;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.apache.commons.fileupload.FileItem;
import org.apache.commons.fileupload.FileUploadException;
import org.apache.commons.fileupload.disk.DiskFileItemFactory;
import org.apache.commons.fileupload.servlet.ServletFileUpload;
/*
* 处理文件上传的servlet:
*
* 1:细节:
* 乱码解决了文件名称上传的乱码,
* 普通字段: getString("utf-8");
*
* 2:对相对路径进行了处理: subString();
*
* 3: 文件名称同名的问题,处理:
*
* 4: 哈希打散:
* filename.hashCode();
* filename.toHexString();
* filename.charAt(0);
*
* File dir= new File(root, charAt(0)+"\"+charAt(1));
*
* File destFile = new File(dir, savefilename);
*
* write();
*
*
*
*
*/
public class FileUploadServlet extends HttpServlet {
public void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
//解决上传文件名称的乱码问题:
request.setCharacterEncoding("utf-8");
response.setContentType("text/html;charset=utf-8");//告知客户端浏览器响应的内容: text/html charset=utf-8
/*
* 三步走:
* 1:得到工厂:
* 2: 得到解析器:
* 3:解析request:
*/
//得到得到解析器工厂;
DiskFileItemFactory factory = new DiskFileItemFactory(1024*20,new File("C:/Users/Mrzhang/javaEE/javaEE-07/temp"));
// DiskFileItemFactory factory = new DiskFileItemFactory();
//得到解析器:
ServletFileUpload upload = new ServletFileUpload(factory);
//解析以前设置上传单个文件的大小:
// upload.setFileSizeMax(1024*10);//这是最大是10K:
// upload.setSizeMax(1024*1024*10); //设置了整个request 的大小, 若是上传的request 大于设定的最大值, 也会触发异常
//解析request: 获List
try {
List fileItem = upload.parseRequest(request);
//解析fileItem当中的内容: web-inf下的: 目录安全: 不能被外界随机的访问:
FileItem f2 = fileItem.get(1);//文件上传的组件:
/*
* 得到文件的名称:
* f2.getName();
* f2.getInputStream(); 文件当中的内容:
* new FileOutputStream("path");
* 实现流对接:
*/
/*
* 得到要保存的路径:
* WEB-INF/files/
* 目的: 安全: 不能被外界直接经过浏览器访问:
* 得到ServletContext对象: 得到真实路径:
*/
String root = this.getServletContext().getRealPath("/WEB-INF/files/");
//得到上传文件的名称:
String filename = f2.getName();
/*
* 细节的处理:
* 1: 绝对路径的问题: 兼顾小部分浏览器:
*/
int index = filename.lastIndexOf("\\");
if(index != -1){//说明路径当中存在\\ :
filename = filename.substring(index+1);
}
/*
* 处理文件同名的问题: uuid
*/
String savename = CommonsUtils.uuid()+"_"+filename;
/*
* 哈希码 生产多个目录: 将上传的文件存放在多个目录当中:
*/
// 1:得到文件名称的哈希值:
int code = filename.hashCode();// int
// 2:得到code 的十六进制的值:
String hex = Integer.toHexString(code);// 9c0a1d
// 得到前两位: 充当第一层目录 和第二层目录:
char firstDir = hex.charAt(0);
char secDir = hex.charAt(1);
/*
* 得到保存的文件路径:
*/
File dirFile = new File(root, firstDir+"/"+secDir);//存放的目录:
//dirFile 若是不存在,建立:
if(!dirFile.exists()){//说明不存在
//建立“:
dirFile.mkdirs();//建立多层的目录:
}
//建立保存的文件:
File destFile = new File(dirFile, savename);
//保存:
try {
f2.write(destFile);
} catch (Exception e) {
e.printStackTrace();
}
} catch (FileUploadException e) {
// 触发异常: 说明文件过大:
request.setAttribute("msg", "您传的文件过大");
request.getRequestDispatcher("/index.jsp").forward(request, response);
e.printStackTrace();
}
}
}
文件下载
文件下载:
原来:服务器响应返回的数据:text/html 浏览器可以自动解析:
原理:现在要求服务端传递的数据是字节数组:服务端只需要响应一个字节流。
下载具有两个标头的流需要满足的条件:
Stream:服务器端响应返回的字节流。new FileOutputStream("字符串路径");
设置两个标题:
* Content-Type:这是文件类型的 MIME 类型:text/css text/javascript : tomcat : web.xml
* Content-Disposition : 默认值:inline 在浏览器中打开。
文件下载:附件;文件名=xxxx;
下载详情:
1:下载的文件名乱码:
一般解决方案:
新字符串(name.getBytes("gbk"),"iso-8859-1");
缺点:这种方法可以解决大部分浏览器,但是个别特殊字符无法解决:
不同的浏览器对文件名进行不同的编码:
修复狐:Base64:
其他浏览器:url
2:通用方式:提供一个工具类,稍后搜索:
文件下载servlet代码如下:
package com.yidongxueyuan.web.servlet;
import java.io.FileInputStream;
import java.io.IOException;
import java.net.URLEncoder;
import javax.servlet.ServletException;
import javax.servlet.ServletOutputStream;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.apache.commons.io.IOUtils;
import sun.misc.BASE64Encoder;
/*
* 负责下载的Servlet:
*/
public class DownLoadFileServlet extends HttpServlet {
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
/* request.setCharacterEncoding("utf-8");
response.setContentType("text/html;charset=utf-8");*/
/*
* 1: 文件的下载具有一个流: 两个头:
*/
String filename = "C:/Users/Mrzhang/Desktop/API/a练习图片/girl.jpg";
//头信息:
// Content-Type: MIME 文件的MIME类型:
String conentType= this.getServletContext().getMimeType(filename);//可以得到.jpg文件的MIME类型: image/jpeg
String name = "凤姐.jpg";
// String savename = new String(name.getBytes("gbk"),"iso-8859-1"); 解决 大部分状况:
String savename = FilenameEncodingUtils.filenameEncoding(name, request);
String contentDisposition = "attachment;filename="+savename;
//设置响应头信息:
response.setHeader("Content-Type",conentType );
response.setHeader("Content-Disposition", contentDisposition);
//准备的一个流:
//将图片读取到fis当中:
FileInputStream fis = new FileInputStream(filename);
//响应输出流:
ServletOutputStream out = response.getOutputStream();
//流对接: IOUtils
IOUtils.copy(fis, out);
fis.close();
out.close();
}
}
class FilenameEncodingUtils {
// 用来对下载的文件名称进行编码的!
public static String filenameEncoding(String filename, HttpServletRequest request) throws IOException {
String agent = request.getHeader("User-Agent"); //获取浏览器
if (agent.contains("Firefox")) {
BASE64Encoder base64Encoder = new BASE64Encoder();
filename = "=?utf-8?B?"
+ base64Encoder.encode(filename.getBytes("utf-8"))
+ "?=";
} else if(agent.contains("MSIE")) {
filename = URLEncoder.encode(filename, "utf-8");
} else {
filename = URLEncoder.encode(filename, "utf-8");
}
return filename;
}
} 查看全部
一键采集上传常见的细节问题(()文件上传的内容上传内容及内容解析
)
一:文件上传:javascript
要求:
1:jsp的页面:
一:表格形式:
b:帖子提交:
c: form 指定一个属性:enctype="multipart/form-data"
d:文件组件:
2:小服务程序:
request.getParamter("name");//不生效:
ServletInputStream in = request.getInputStream();
把得到的数据封装进去,理论上可以解析数据。
3:请求在请求正文中:css
发布请求正文:
请求第一行:
请求头信息:html
请求正文:
------------------
普通组件:只有一个标头:Content-Dispositon:name="xxx"java
请求正文:mrzhang:填写内容。
------------------
文件上传字段:两个标题:
内容处置:表单数据;;文件名="C:\Users\Mrzhang\Desktop\copy2.txt"
内容类型:文本/纯 MIMEweb
文件上传内容:
xxxx阿帕奇
- - - - - - - 大批
二:解析请求中的请求体:
1:jar:Apache组织提供的公共组件:
公共文件上传
commons-io
文件上传相关的两个组件,这两个组件是强依赖的。
2:原理:
请求体中各个组件的内容被封装成一个对象:
FileItem 对象:使用对象的方法和属性来获取数据。
3:获取文件项:
a:获取工厂:
b:获取解析器:
c:使用解析器解析请求,获取fileItme对象:
对象代码:
// 获取工厂:
DiskFileItemFactory 工厂 = new DiskFileItemFactory();
// 获取解析器:
ServletFileUpload 上传 = 新的 ServletFileUpload(Factory);
// 解析请求并获取所有 FileItem 对象:
List list=upload.parseRequest(request); 浏览器
4:FileItem类详解:
isFormField() 判断组件是普通组件还是文件上传组件:true,普通组件:false:文件上传组件:
getFieldName() 返回普通字段属性的值。name= username 获取用户名的值:
获取字符串();获取普通字段的上传内容。
文件上传组件:
获取名称();获取文件名:
获取尺寸();将以字节为单位上传文件大小。长
获取输入流();获取文件上传对应的流:
写(文件文件);将文件内容写入指定位置:
雄猫
三:文件上传的具体代码;
(1)引入jar包:
(2)准备页面:
(3)准备 Servlet:
四:详情:
1:上传的普通字段内容:乱码:getString("utf-8");
2:上传的文件不能被外界直接访问,应隐藏:目的、安全;
应该是上传到web-inf,内容不能被外界直接访问。安全
获取 web-inf/files 的位置:tomcat 上的真实位置:
ServletContext.getRealPath("/WEB-INF/files");
3:文件的文件路径问题:
不同浏览器上传的路径不一致。一些浏览器上传相对路径,而另一些浏览器上传绝对路径。大多数浏览器上传的相对路径。
一个.txt
c:\user\mrzhang\files\a.txt
提取文件名:
字符串文件名 = f2.getName();
//截距:
int index = filename.lastIndexOf("\\");
如果(索引!=-1){
文件名 = 文件名.subString(index+1);
}
4:上传文件名乱码:
request.setCharacterEncoding("utf-8");
解析器提供了一个方法:
servletFileUpload.setHeaderEncoding("utf-8");// 提供的解析器。高优先级:request.setCharacterEncoding("utf-8")的封装;
5:文件名相同的问题:
解决方案1:uuid+“文件名”。后缀名;
解决方案2:new Date().getTime()+"filename";
6:上传的文件不能在同一个目录下: 上传的目录被打散了:
a:时间分手:获取当前时间,创建目录:
b: 文件名首字母分散:abc.txt : charAt("0")
c:散列分解:
实施步骤:
(1) 获取文件名:
(2)获取哈希值:hashCode(); int
(3)转换为十六进制: Integer.toHexString(); //String: 9A8B7C
(4) 获取字符串的前两位:第一个字母为一级目录,第二个字母为二级目录。16*16
package com.yidongxueyuan.web.servlet;
import java.io.File;
import java.io.IOException;
import java.util.List;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.apache.commons.fileupload.FileItem;
import org.apache.commons.fileupload.FileUploadException;
import org.apache.commons.fileupload.disk.DiskFileItemFactory;
import org.apache.commons.fileupload.servlet.ServletFileUpload;
/*
* 处理文件上传的servlet:
*
* 1:细节:
* 乱码解决了文件名称上传的乱码,
* 普通字段: getString("utf-8");
*
* 2:对相对路径进行了处理: subString();
*
* 3: 文件名称同名的问题,处理:
*
* 4: 哈希打散:
* filename.hashCode();
* filename.toHexString();
* filename.charAt(0);
*
* File dir= new File(root, charAt(0)+"\"+charAt(1));
*
* File destFile = new File(dir, savefilename);
*
* write();
*
*
*
*
*/
public class FileUploadServlet extends HttpServlet {
public void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
//解决上传文件名称的乱码问题:
request.setCharacterEncoding("utf-8");
response.setContentType("text/html;charset=utf-8");//告知客户端浏览器响应的内容: text/html charset=utf-8
/*
* 三步走:
* 1:得到工厂:
* 2: 得到解析器:
* 3:解析request:
*/
//得到得到解析器工厂;
DiskFileItemFactory factory = new DiskFileItemFactory(1024*20,new File("C:/Users/Mrzhang/javaEE/javaEE-07/temp"));
// DiskFileItemFactory factory = new DiskFileItemFactory();
//得到解析器:
ServletFileUpload upload = new ServletFileUpload(factory);
//解析以前设置上传单个文件的大小:
// upload.setFileSizeMax(1024*10);//这是最大是10K:
// upload.setSizeMax(1024*1024*10); //设置了整个request 的大小, 若是上传的request 大于设定的最大值, 也会触发异常
//解析request: 获List
try {
List fileItem = upload.parseRequest(request);
//解析fileItem当中的内容: web-inf下的: 目录安全: 不能被外界随机的访问:
FileItem f2 = fileItem.get(1);//文件上传的组件:
/*
* 得到文件的名称:
* f2.getName();
* f2.getInputStream(); 文件当中的内容:
* new FileOutputStream("path");
* 实现流对接:
*/
/*
* 得到要保存的路径:
* WEB-INF/files/
* 目的: 安全: 不能被外界直接经过浏览器访问:
* 得到ServletContext对象: 得到真实路径:
*/
String root = this.getServletContext().getRealPath("/WEB-INF/files/");
//得到上传文件的名称:
String filename = f2.getName();
/*
* 细节的处理:
* 1: 绝对路径的问题: 兼顾小部分浏览器:
*/
int index = filename.lastIndexOf("\\");
if(index != -1){//说明路径当中存在\\ :
filename = filename.substring(index+1);
}
/*
* 处理文件同名的问题: uuid
*/
String savename = CommonsUtils.uuid()+"_"+filename;
/*
* 哈希码 生产多个目录: 将上传的文件存放在多个目录当中:
*/
// 1:得到文件名称的哈希值:
int code = filename.hashCode();// int
// 2:得到code 的十六进制的值:
String hex = Integer.toHexString(code);// 9c0a1d
// 得到前两位: 充当第一层目录 和第二层目录:
char firstDir = hex.charAt(0);
char secDir = hex.charAt(1);
/*
* 得到保存的文件路径:
*/
File dirFile = new File(root, firstDir+"/"+secDir);//存放的目录:
//dirFile 若是不存在,建立:
if(!dirFile.exists()){//说明不存在
//建立“:
dirFile.mkdirs();//建立多层的目录:
}
//建立保存的文件:
File destFile = new File(dirFile, savename);
//保存:
try {
f2.write(destFile);
} catch (Exception e) {
e.printStackTrace();
}
} catch (FileUploadException e) {
// 触发异常: 说明文件过大:
request.setAttribute("msg", "您传的文件过大");
request.getRequestDispatcher("/index.jsp").forward(request, response);
e.printStackTrace();
}
}
}
文件下载
文件下载:
原来:服务器响应返回的数据:text/html 浏览器可以自动解析:
原理:现在要求服务端传递的数据是字节数组:服务端只需要响应一个字节流。
下载具有两个标头的流需要满足的条件:
Stream:服务器端响应返回的字节流。new FileOutputStream("字符串路径");
设置两个标题:
* Content-Type:这是文件类型的 MIME 类型:text/css text/javascript : tomcat : web.xml
* Content-Disposition : 默认值:inline 在浏览器中打开。
文件下载:附件;文件名=xxxx;
下载详情:
1:下载的文件名乱码:
一般解决方案:
新字符串(name.getBytes("gbk"),"iso-8859-1");
缺点:这种方法可以解决大部分浏览器,但是个别特殊字符无法解决:
不同的浏览器对文件名进行不同的编码:
修复狐:Base64:
其他浏览器:url
2:通用方式:提供一个工具类,稍后搜索:
文件下载servlet代码如下:
package com.yidongxueyuan.web.servlet;
import java.io.FileInputStream;
import java.io.IOException;
import java.net.URLEncoder;
import javax.servlet.ServletException;
import javax.servlet.ServletOutputStream;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.apache.commons.io.IOUtils;
import sun.misc.BASE64Encoder;
/*
* 负责下载的Servlet:
*/
public class DownLoadFileServlet extends HttpServlet {
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
/* request.setCharacterEncoding("utf-8");
response.setContentType("text/html;charset=utf-8");*/
/*
* 1: 文件的下载具有一个流: 两个头:
*/
String filename = "C:/Users/Mrzhang/Desktop/API/a练习图片/girl.jpg";
//头信息:
// Content-Type: MIME 文件的MIME类型:
String conentType= this.getServletContext().getMimeType(filename);//可以得到.jpg文件的MIME类型: image/jpeg
String name = "凤姐.jpg";
// String savename = new String(name.getBytes("gbk"),"iso-8859-1"); 解决 大部分状况:
String savename = FilenameEncodingUtils.filenameEncoding(name, request);
String contentDisposition = "attachment;filename="+savename;
//设置响应头信息:
response.setHeader("Content-Type",conentType );
response.setHeader("Content-Disposition", contentDisposition);
//准备的一个流:
//将图片读取到fis当中:
FileInputStream fis = new FileInputStream(filename);
//响应输出流:
ServletOutputStream out = response.getOutputStream();
//流对接: IOUtils
IOUtils.copy(fis, out);
fis.close();
out.close();
}
}
class FilenameEncodingUtils {
// 用来对下载的文件名称进行编码的!
public static String filenameEncoding(String filename, HttpServletRequest request) throws IOException {
String agent = request.getHeader("User-Agent"); //获取浏览器
if (agent.contains("Firefox")) {
BASE64Encoder base64Encoder = new BASE64Encoder();
filename = "=?utf-8?B?"
+ base64Encoder.encode(filename.getBytes("utf-8"))
+ "?=";
} else if(agent.contains("MSIE")) {
filename = URLEncoder.encode(filename, "utf-8");
} else {
filename = URLEncoder.encode(filename, "utf-8");
}
return filename;
}
}
一键采集上传常见的细节问题(简单用css和js实现小图片细节的功能,实现原理)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-02-28 11:06
在很多电商商品展示页面中,都会出现放大商品详情的功能。这里根据主要原理,简单的使用css和js来实现这个效果:
实施原则:
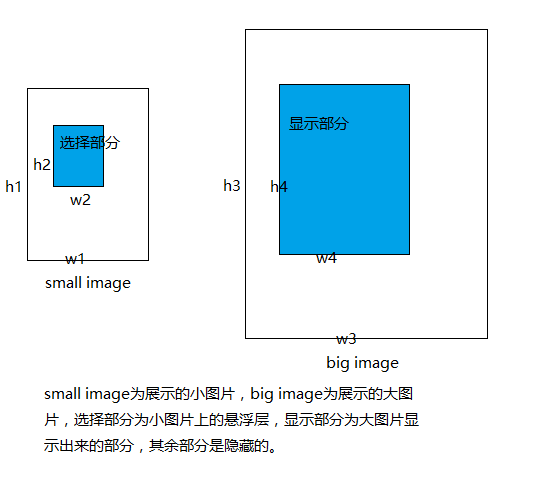
1、选择两张内容相同、大小不同的图片,一张是小图,有细节待选,一张是大图,展示细节。
2、要显示“小图的哪个细节”,就显示“大图的同一部分的细节”。这里涉及到比例的问题,也就是在小图中,
鼠标选择的细节大小和整个小图的纵横比要与大图和大图显示的区域的纵横比一致,这样效果才会真实。
如下所示:
根据等比例我们可以得到公式: h1/h2 = h3/h4 ; w1/w2 = w3/w4
由于在选择的时候图片的长宽已经固定了,所以需要改变的是根据比例改变小图片上浮动层的大小。
3、鼠标在小图上移动时,大图按比例在显示区域内移动,从而出现效果。
源代码展示:
<p> 1 doctype html>
2
3
4
5
6
7
8
9 自定义图片放大器
10
11
12 *{margin:0;padding:0;}
13
14 #show_bigger_pic{
15 position:absolute;
16 width:800px;
17 height:400px;
18 top:200px;
19 left:200px;
20 }
21 .small_pic_div{
22 width:273px;
23 height:177px;
24 border:1px solid;
25 float:left;
26 position:relative;/* cover:absolute定位使用*/
27 }
28 .big_pic_div{
29 width:273px;
30 height:177px;
31 border:1px solid;
32 float:left;
33 margin-left:10px;
34 display:none;
35 overflow:hidden;
36 }
37 .big_pic_div>img{
38 position:relative;
39 }
40 .cover{
41 width:273px;
42 height:177px;
43 position:absolute;
44 border:1px solid;
45 z-index:2;
46 left:0;
47 top:0;
48 }
49 .float_span{
50 width:80px;
51 height:80px;
52 position:absolute;
53 z-index:1;
54 background:#B2DFEE;
55 opacity:0.5;
56 display:none;
57 border:1px solid;
58 left:0;
59 top:0;
60 }
61
62
63
64
65 function gbc(tparent,tclass){//获取指定父元素的指定类的子元素的函数
66 var allclass=tparent.getElementsByTagName('*');
67 var result=[];
68 for (var i=0;i 查看全部
一键采集上传常见的细节问题(简单用css和js实现小图片细节的功能,实现原理)
在很多电商商品展示页面中,都会出现放大商品详情的功能。这里根据主要原理,简单的使用css和js来实现这个效果:
实施原则:
1、选择两张内容相同、大小不同的图片,一张是小图,有细节待选,一张是大图,展示细节。
2、要显示“小图的哪个细节”,就显示“大图的同一部分的细节”。这里涉及到比例的问题,也就是在小图中,
鼠标选择的细节大小和整个小图的纵横比要与大图和大图显示的区域的纵横比一致,这样效果才会真实。
如下所示:
根据等比例我们可以得到公式: h1/h2 = h3/h4 ; w1/w2 = w3/w4
由于在选择的时候图片的长宽已经固定了,所以需要改变的是根据比例改变小图片上浮动层的大小。
3、鼠标在小图上移动时,大图按比例在显示区域内移动,从而出现效果。
源代码展示:
<p> 1 doctype html>
2
3
4
5
6
7
8
9 自定义图片放大器
10
11
12 *{margin:0;padding:0;}
13
14 #show_bigger_pic{
15 position:absolute;
16 width:800px;
17 height:400px;
18 top:200px;
19 left:200px;
20 }
21 .small_pic_div{
22 width:273px;
23 height:177px;
24 border:1px solid;
25 float:left;
26 position:relative;/* cover:absolute定位使用*/
27 }
28 .big_pic_div{
29 width:273px;
30 height:177px;
31 border:1px solid;
32 float:left;
33 margin-left:10px;
34 display:none;
35 overflow:hidden;
36 }
37 .big_pic_div>img{
38 position:relative;
39 }
40 .cover{
41 width:273px;
42 height:177px;
43 position:absolute;
44 border:1px solid;
45 z-index:2;
46 left:0;
47 top:0;
48 }
49 .float_span{
50 width:80px;
51 height:80px;
52 position:absolute;
53 z-index:1;
54 background:#B2DFEE;
55 opacity:0.5;
56 display:none;
57 border:1px solid;
58 left:0;
59 top:0;
60 }
61
62
63
64
65 function gbc(tparent,tclass){//获取指定父元素的指定类的子元素的函数
66 var allclass=tparent.getElementsByTagName('*');
67 var result=[];
68 for (var i=0;i
一键采集上传常见的细节问题(优质内容的打造对于没时间来做网站优化的站长来说 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-02-26 06:26
)
罗马不是一天建成的,我们SEO的核心精神也是坚持。网站有自己的关键词,SEO也有自己的核心关键词,那就是坚持。我们不仅需要每天更新网站内容,关键词创建、分析网站数据,还需要关注站内外用户体验和优化。
创造高质量的内容
对于没有时间做网站优化的站长,我们也可以通过一些cms采集软件来实现一些SEO技巧,cms采集软件功能强大,只要输入采集规则完成采集任务,通过软件自动采集和释放文章,也可以设置自动下载图片和替换链接(图片本地化),图片存储方式支持:阿里云、七牛、腾讯云、游拍云等。同时还配备自动内链,前后插入一定内容内容或标题形成“伪原创”。
cms采集软件支持按规则自动插入本地图片文章,提高原创作者的创作效率。
cms采集软件还具有直接监控已发布、待发布、是否伪原创、发布状态、URL、程序、发布时间等功能。@收录、网站 权重!
在我们的实践过程中,我们需要灵活运用我们的SEO理论知识。cms采集软件和SEO知识是我们从容应对工作中复杂情况的基础。SEO主要侧重于实际操作,这要求我们灵活应用,而不是机械地应用。
考虑用户的搜索习惯和需求
在我们编辑网站的内容之前,不妨想想用户的搜索习惯和需求。一个醒目的标题,总能打动用户的心。为什么其他人可以创建大量内容?学位源于标题的吸引力。我们如何分析用户的搜索习惯和需求,一般通过下拉框、相关搜索、百度索引等工具。同时,内容需要高度相关,关键词的密度要合理,而不是仅仅依靠标题来留住用户。一定要对用户进行细分。
把握市场脉搏
我们需要掌握的是各种搜索引擎的算法及其发展趋势。请注意排名规则的更新,这方面通常有很多需要学习和研究的地方。因为互联网正在飞速发展,要想从竞争对手中脱颖而出,就需要比竞争对手付出更多的努力。我们必须紧跟市场脉搏,紧跟市场发展的潮流。
不断学习和提高
无论搜索引擎有多少排名算法,核心始终是尽快将最好的质量和最好的用户体验呈现给用户。围绕这个核心,我们不会偏离方向。在学习的过程中,总结很重要。不同的人有不同的理解,我们要在实践中不断总结和形成自己的想法。
查看全部
一键采集上传常见的细节问题(优质内容的打造对于没时间来做网站优化的站长来说
)
罗马不是一天建成的,我们SEO的核心精神也是坚持。网站有自己的关键词,SEO也有自己的核心关键词,那就是坚持。我们不仅需要每天更新网站内容,关键词创建、分析网站数据,还需要关注站内外用户体验和优化。

创造高质量的内容
对于没有时间做网站优化的站长,我们也可以通过一些cms采集软件来实现一些SEO技巧,cms采集软件功能强大,只要输入采集规则完成采集任务,通过软件自动采集和释放文章,也可以设置自动下载图片和替换链接(图片本地化),图片存储方式支持:阿里云、七牛、腾讯云、游拍云等。同时还配备自动内链,前后插入一定内容内容或标题形成“伪原创”。
cms采集软件支持按规则自动插入本地图片文章,提高原创作者的创作效率。
cms采集软件还具有直接监控已发布、待发布、是否伪原创、发布状态、URL、程序、发布时间等功能。@收录、网站 权重!
在我们的实践过程中,我们需要灵活运用我们的SEO理论知识。cms采集软件和SEO知识是我们从容应对工作中复杂情况的基础。SEO主要侧重于实际操作,这要求我们灵活应用,而不是机械地应用。
考虑用户的搜索习惯和需求
在我们编辑网站的内容之前,不妨想想用户的搜索习惯和需求。一个醒目的标题,总能打动用户的心。为什么其他人可以创建大量内容?学位源于标题的吸引力。我们如何分析用户的搜索习惯和需求,一般通过下拉框、相关搜索、百度索引等工具。同时,内容需要高度相关,关键词的密度要合理,而不是仅仅依靠标题来留住用户。一定要对用户进行细分。
把握市场脉搏
我们需要掌握的是各种搜索引擎的算法及其发展趋势。请注意排名规则的更新,这方面通常有很多需要学习和研究的地方。因为互联网正在飞速发展,要想从竞争对手中脱颖而出,就需要比竞争对手付出更多的努力。我们必须紧跟市场脉搏,紧跟市场发展的潮流。
不断学习和提高
无论搜索引擎有多少排名算法,核心始终是尽快将最好的质量和最好的用户体验呈现给用户。围绕这个核心,我们不会偏离方向。在学习的过程中,总结很重要。不同的人有不同的理解,我们要在实践中不断总结和形成自己的想法。

一键采集上传常见的细节问题(不上资源站API的几种原因及解决办法!(建议收藏))
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-02-23 12:16
在插件中选择资源站,点击进入,提示XML格式不正确,不支持采集,或者服务器网络不稳定或禁用采集怎么办@>?
如图,如果提示这个,说明资源站API无法链接,可能是以下原因造成的1、你的服务器连接对方资源站的延迟是比较高,数据返回慢,导致程序报出这个错误。2、资源站有问题,导致API失效,无法连接。比如关闭,不工作,停止更新,没有它怎么链接采集?3、自己服务器的网络问题,如果资源站没有出现故障并且还在运行,说明自己的服务器网络无法连接到对方的服务器,所以可以理解,有人想说,我怎么开资源站,有资料, 网络怎么会有问题?网络好坏,每个资源站都是不同人做的,不是我的插件。他们的服务器在不同的地区。您可以打开资源站并指明您的服务器可以访问的区域。未打开的资源站点指示您的服务器无法访问的区域。说了这么多,不知道怎么解释,还有人看不懂!首先你要清楚,插件中提供的多个资源站,并不是每个资源站,你的服务器都可以连接。你的服务器网络问题,或者对方资源站api的问题想采集,但是连接不上,怎么解决?第一种情况:进入程序后台的系统设置,切换到“
第二种情况:如果其他资源站宕机,无法连接,你着急也没用。就算掉线了怎么连接?建议更换其他资源站采集第三种情况:如果是因为你的服务器内部网络不稳定,除非你换服务器才能解决。看看哪个服务器的网络可以连接,就像你家的宽带网络一样,能保证在日本、韩国、美国、新加坡任何地区都能访问网站吗?不同的资源站使用不同的服务器。有些服务器可能在日本,有些可能在美国,有些可能在香港。建议换服务器!总结:插件只是一个类似于中介的角色,它只是提供了多个资源站供您选择。如果这个采集不行,你可以选择其他的采集,取其采集采集哪个,插件不直接解决你和你的连接问题对方的资源站! 查看全部
一键采集上传常见的细节问题(不上资源站API的几种原因及解决办法!(建议收藏))
在插件中选择资源站,点击进入,提示XML格式不正确,不支持采集,或者服务器网络不稳定或禁用采集怎么办@>?
 https://xiaoyichuanmeigzs.cn/w ... 4.jpg 300w, https://xiaoyichuanmeigzs.cn/w ... 4.jpg 768w" />
https://xiaoyichuanmeigzs.cn/w ... 4.jpg 300w, https://xiaoyichuanmeigzs.cn/w ... 4.jpg 768w" />如图,如果提示这个,说明资源站API无法链接,可能是以下原因造成的1、你的服务器连接对方资源站的延迟是比较高,数据返回慢,导致程序报出这个错误。2、资源站有问题,导致API失效,无法连接。比如关闭,不工作,停止更新,没有它怎么链接采集?3、自己服务器的网络问题,如果资源站没有出现故障并且还在运行,说明自己的服务器网络无法连接到对方的服务器,所以可以理解,有人想说,我怎么开资源站,有资料, 网络怎么会有问题?网络好坏,每个资源站都是不同人做的,不是我的插件。他们的服务器在不同的地区。您可以打开资源站并指明您的服务器可以访问的区域。未打开的资源站点指示您的服务器无法访问的区域。说了这么多,不知道怎么解释,还有人看不懂!首先你要清楚,插件中提供的多个资源站,并不是每个资源站,你的服务器都可以连接。你的服务器网络问题,或者对方资源站api的问题想采集,但是连接不上,怎么解决?第一种情况:进入程序后台的系统设置,切换到“
 https://xiaoyichuanmeigzs.cn/w ... 3.jpg 300w" />
https://xiaoyichuanmeigzs.cn/w ... 3.jpg 300w" />第二种情况:如果其他资源站宕机,无法连接,你着急也没用。就算掉线了怎么连接?建议更换其他资源站采集第三种情况:如果是因为你的服务器内部网络不稳定,除非你换服务器才能解决。看看哪个服务器的网络可以连接,就像你家的宽带网络一样,能保证在日本、韩国、美国、新加坡任何地区都能访问网站吗?不同的资源站使用不同的服务器。有些服务器可能在日本,有些可能在美国,有些可能在香港。建议换服务器!总结:插件只是一个类似于中介的角色,它只是提供了多个资源站供您选择。如果这个采集不行,你可以选择其他的采集,取其采集采集哪个,插件不直接解决你和你的连接问题对方的资源站!
一键采集上传常见的细节问题(直击痛点:产品原型支持无缝接入摹客的产品经理工作大有裨益)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-02-20 16:04
2019年6月6日,产品协同设计平台Mocket全新升级,支持Axure和Mockplus原型上传,为产品原型提供协同设计新途径。
产品原型设计是软件产品上市前不可或缺的环节。在一个产品原型交付之前,会面临无数次的沟通、讨论、修改、迭代……作为项目的核心负责人,产品经理会花费大量的时间和精力去沟通和沟通关于需求对接、产品文档、团队意见、项目进度等。
产品经理的处境有多糟糕?从下面UPA(国际用户体验专业协会)发布的完整产品用户体验设计流程图可以看出。
不难看出,设计开发过程曲折复杂,会极大地消耗产品经理的时间和精力,进而影响到整个产品团队。
如何减轻产品经理的负担,让产品团队受益?
自 Mockplus 创建以来,Mockplus 团队一直在为之努力。Mockplus的Mockplus快速原型设计深受产品经理的青睐。此外,Axure作为老牌原型制作工具,也是国内设计团队常用的工具。虽然这两个工具非常适合产品经理的工作,但它们也存在一些问题——
Axure 的原型设计不能在国内在线发布,也不能进行评论评分;
Axure 和 Mockplus 的原型无法同时查看所有页面的全貌;
Axure 和 Mockplus 的原型线框无法从视觉设计中查看;
Axure、Mockplus绘制的原型无法标注裁剪,轻量级项目无法直接交付开发;
...
针对以上痛点,Mocket 团队做了详细的检查,最终找到了问题的根源——产品原型无法连接到工作流。
现在,直击痛点!Axure和Mockplus的产品原型支持无缝接入Mockplus!
通过一键上传Axure和Mockplus的原型到Mockplus,将产品原型连接到Mockplus灵活的工作流程,为产品原型提供高效的协作方式,解决产品经理沟通难、协调难、效率低的问题,并进一步推动产品团队快速成长,最大化服务产品团队。
与工具相比,基于平台的协作具有更全面、更智能的优势。与传统方法相比,大大节省了人工操作带来的时间和成本。
几个核心功能点包括:原型即时发布、原型在线审核、产品文档管理、原型文档全局查看。
手动导出和发送原型是一种传统的方法,既繁琐又容易出错。Iggler 支持产品原型即时发布,一键分享,在线演示时完美呈现原生交互设计。现在,无需手动导出或上传,产品经理可以通过Mockplus插件一键将Axure和Mockplus的原型发布到Mockplus。
匹配需求、召开会议、交流讨论、总结修改意见……太多无用、低效的琐事占据了产品经理的日常生活。产品经理迫切需要一种更有效的方式来采集意见和跟踪反馈。
Mocket的在线评论可以满足这个需求。Mocket 支持多人协作处理一个文档,提供多种评论和注释工具,可以根据需要进行选择,更直观地表达意见。评论还支持@team 成员并标记评论以获取解决状态。. 并且基于灵活的工作流协作模式,在高效的同时又不失自由度和灵活性,可以完美满足不同规模团队的高效协作。
文档管理一直是一项繁琐的工作,新版本和旧版本,高保真和低保真,原型和设计图纸……无数产品经理淹没在浩瀚的文件中。Iggler实现了设计稿和原型图的一键切换,不仅让设计稿的对比更加直观,也便于管理。支持源文件自动备份,自动生成历史版本,简化文件管理。
在Axure和Mockplus中,只能逐页查看原型图,无法预览原型图全图,整个产品逻辑一目了然。针对这个问题,Mocket 实现了一个无限大的画板,将所有页面全视图展示,并用逻辑线制作了一个简单的流程图,为产品经理提供了上帝视角和原型的全貌。
Mock作为新一代产品协同设计平台,是产品经理、UI设计师、开发工程师高效协作的舞台。Mock拥有长达十年的产品团队和开发团队,为产品团队搭建了良好的支撑和架构,以Code是材料,浇筑了坚固的钢筋混凝土,帮助产品团队跳舞,绽放,散发出最耀眼的光芒产品光。 查看全部
一键采集上传常见的细节问题(直击痛点:产品原型支持无缝接入摹客的产品经理工作大有裨益)
2019年6月6日,产品协同设计平台Mocket全新升级,支持Axure和Mockplus原型上传,为产品原型提供协同设计新途径。
产品原型设计是软件产品上市前不可或缺的环节。在一个产品原型交付之前,会面临无数次的沟通、讨论、修改、迭代……作为项目的核心负责人,产品经理会花费大量的时间和精力去沟通和沟通关于需求对接、产品文档、团队意见、项目进度等。
产品经理的处境有多糟糕?从下面UPA(国际用户体验专业协会)发布的完整产品用户体验设计流程图可以看出。
不难看出,设计开发过程曲折复杂,会极大地消耗产品经理的时间和精力,进而影响到整个产品团队。
如何减轻产品经理的负担,让产品团队受益?
自 Mockplus 创建以来,Mockplus 团队一直在为之努力。Mockplus的Mockplus快速原型设计深受产品经理的青睐。此外,Axure作为老牌原型制作工具,也是国内设计团队常用的工具。虽然这两个工具非常适合产品经理的工作,但它们也存在一些问题——
Axure 的原型设计不能在国内在线发布,也不能进行评论评分;
Axure 和 Mockplus 的原型无法同时查看所有页面的全貌;
Axure 和 Mockplus 的原型线框无法从视觉设计中查看;
Axure、Mockplus绘制的原型无法标注裁剪,轻量级项目无法直接交付开发;
...
针对以上痛点,Mocket 团队做了详细的检查,最终找到了问题的根源——产品原型无法连接到工作流。
现在,直击痛点!Axure和Mockplus的产品原型支持无缝接入Mockplus!
通过一键上传Axure和Mockplus的原型到Mockplus,将产品原型连接到Mockplus灵活的工作流程,为产品原型提供高效的协作方式,解决产品经理沟通难、协调难、效率低的问题,并进一步推动产品团队快速成长,最大化服务产品团队。
与工具相比,基于平台的协作具有更全面、更智能的优势。与传统方法相比,大大节省了人工操作带来的时间和成本。

几个核心功能点包括:原型即时发布、原型在线审核、产品文档管理、原型文档全局查看。
手动导出和发送原型是一种传统的方法,既繁琐又容易出错。Iggler 支持产品原型即时发布,一键分享,在线演示时完美呈现原生交互设计。现在,无需手动导出或上传,产品经理可以通过Mockplus插件一键将Axure和Mockplus的原型发布到Mockplus。
匹配需求、召开会议、交流讨论、总结修改意见……太多无用、低效的琐事占据了产品经理的日常生活。产品经理迫切需要一种更有效的方式来采集意见和跟踪反馈。
Mocket的在线评论可以满足这个需求。Mocket 支持多人协作处理一个文档,提供多种评论和注释工具,可以根据需要进行选择,更直观地表达意见。评论还支持@team 成员并标记评论以获取解决状态。. 并且基于灵活的工作流协作模式,在高效的同时又不失自由度和灵活性,可以完美满足不同规模团队的高效协作。
文档管理一直是一项繁琐的工作,新版本和旧版本,高保真和低保真,原型和设计图纸……无数产品经理淹没在浩瀚的文件中。Iggler实现了设计稿和原型图的一键切换,不仅让设计稿的对比更加直观,也便于管理。支持源文件自动备份,自动生成历史版本,简化文件管理。
在Axure和Mockplus中,只能逐页查看原型图,无法预览原型图全图,整个产品逻辑一目了然。针对这个问题,Mocket 实现了一个无限大的画板,将所有页面全视图展示,并用逻辑线制作了一个简单的流程图,为产品经理提供了上帝视角和原型的全貌。

Mock作为新一代产品协同设计平台,是产品经理、UI设计师、开发工程师高效协作的舞台。Mock拥有长达十年的产品团队和开发团队,为产品团队搭建了良好的支撑和架构,以Code是材料,浇筑了坚固的钢筋混凝土,帮助产品团队跳舞,绽放,散发出最耀眼的光芒产品光。
一键采集上传常见的细节问题(优采云站群软件V18.01.02更新如下内容介绍及应用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2022-02-19 23:14
优采云站群管理系统是多任务系统,只需要输入关键词,即可采集到最新的相关内容,自动发布SEO到指定网站 站群管理系统,可24小时不间断维护数百个网站。优采云站群管理系统可以根据设置关键词自动爬取各大搜索引擎的相关搜索词和相关长尾词,然后根据设置爬取大量最新的衍生词数据,彻底摒弃普通采集软件所需的繁琐规则定制,实现一键式采集一键发布。优采云站群管理系统无需绑定电脑或IP,网站的数量没有限制,可以24小时挂机采集维护,让站长轻松管理上百个网站。软件独有的内容采集引擎,可以及时准确地采集互联网上的最新内容。内置文章伪原创功能,可以大大增加网站的收录,为站长带来更多流量!
优采云站群软件已经支持的核心功能:
无限添加域名,网站,中文站群采集,英文站群采集,指定网址采集,自定义发布界面,自定义生成原创文章,长尾关键词采集,相关图片采集,全球SEO链轮,文章自动加入内链,随机抽取内容为标题,交换不同内容段落,随机插入指定关键字,定时发布文章,自动内容伪原创,群参设置,群链接库互联,自动监听挂机采集发布,自动更新网站首页栏目内页为静态等。
优采云站群软件V18.01.02更新如下:
1、修复一些js报错bug
2、修复日志错误
3、修复挂机时异常过冲的bug
4、完善其他细节功能
5、完善群发外链工具
6、添加指定ie绑定子程序,发布指定采集效率更高
7、界面工具增加页面坐标定位等功能
8、新增每组可单独设置允许更新时间范围
9、新增至尊版用户,挂机时每个站文件夹自动导入txt
10、新增文章列库分库功能,实现单站理论上无限数据存储
11、为避免百度清风算法添加,详见分组参数中3.2.1.4中的参数
12、网站日志和seo查询作为子程序独立运行,避免与主程序抢资源
13、优化所有子程序,运行效率更高
14、新增启动程序,方便设置和发送桌面快捷方式。原来站群是主程序,不应该修改启动程序的名字,以免出现异常。
15、新增2个效率选项,在主程序左上角从系统中选择
优采云站群软件V17.06.16更新如下内容:
1、修复之前独立子程序积累的所有bug,完善更详细的功能
2、增加子组参数自动切换功能
3、新增至尊版自定义题库功能
4、群发外链工具V170321入门版也可以用
5、修复英文采集
6、修复视频采集
7、仅当新标题或内容收录指定的域名时才会添加到数据库中
8、添加内容编辑器2,修复之前无法编辑的文章用户使用
9、界面工具修复个别bug
10、改进其他细节
优采云站群软件V17.02.24更新如下内容:
1、增强关键词采集文章及指定域名采集文章的高质量自动识别
2、修复至尊版用户栏目调用段落库的bug
3、改善群发外链工具卡死的问题
4、关键词采集文章修复采集实图
5、搜狗推荐新闻bug
6、Content伪原创 中的时间参数
7、指定域名支持前端采集解决一些网页后端采集为空
8、添加文章 用于导出处理的个别详细功能
9、添加挂机是间隔分钟的设置
查看全部
一键采集上传常见的细节问题(优采云站群软件V18.01.02更新如下内容介绍及应用)
优采云站群管理系统是多任务系统,只需要输入关键词,即可采集到最新的相关内容,自动发布SEO到指定网站 站群管理系统,可24小时不间断维护数百个网站。优采云站群管理系统可以根据设置关键词自动爬取各大搜索引擎的相关搜索词和相关长尾词,然后根据设置爬取大量最新的衍生词数据,彻底摒弃普通采集软件所需的繁琐规则定制,实现一键式采集一键发布。优采云站群管理系统无需绑定电脑或IP,网站的数量没有限制,可以24小时挂机采集维护,让站长轻松管理上百个网站。软件独有的内容采集引擎,可以及时准确地采集互联网上的最新内容。内置文章伪原创功能,可以大大增加网站的收录,为站长带来更多流量!
优采云站群软件已经支持的核心功能:
无限添加域名,网站,中文站群采集,英文站群采集,指定网址采集,自定义发布界面,自定义生成原创文章,长尾关键词采集,相关图片采集,全球SEO链轮,文章自动加入内链,随机抽取内容为标题,交换不同内容段落,随机插入指定关键字,定时发布文章,自动内容伪原创,群参设置,群链接库互联,自动监听挂机采集发布,自动更新网站首页栏目内页为静态等。
优采云站群软件V18.01.02更新如下:
1、修复一些js报错bug
2、修复日志错误
3、修复挂机时异常过冲的bug
4、完善其他细节功能
5、完善群发外链工具
6、添加指定ie绑定子程序,发布指定采集效率更高
7、界面工具增加页面坐标定位等功能
8、新增每组可单独设置允许更新时间范围
9、新增至尊版用户,挂机时每个站文件夹自动导入txt
10、新增文章列库分库功能,实现单站理论上无限数据存储
11、为避免百度清风算法添加,详见分组参数中3.2.1.4中的参数
12、网站日志和seo查询作为子程序独立运行,避免与主程序抢资源
13、优化所有子程序,运行效率更高
14、新增启动程序,方便设置和发送桌面快捷方式。原来站群是主程序,不应该修改启动程序的名字,以免出现异常。
15、新增2个效率选项,在主程序左上角从系统中选择
优采云站群软件V17.06.16更新如下内容:
1、修复之前独立子程序积累的所有bug,完善更详细的功能
2、增加子组参数自动切换功能
3、新增至尊版自定义题库功能
4、群发外链工具V170321入门版也可以用
5、修复英文采集
6、修复视频采集
7、仅当新标题或内容收录指定的域名时才会添加到数据库中
8、添加内容编辑器2,修复之前无法编辑的文章用户使用
9、界面工具修复个别bug
10、改进其他细节
优采云站群软件V17.02.24更新如下内容:
1、增强关键词采集文章及指定域名采集文章的高质量自动识别
2、修复至尊版用户栏目调用段落库的bug
3、改善群发外链工具卡死的问题
4、关键词采集文章修复采集实图
5、搜狗推荐新闻bug
6、Content伪原创 中的时间参数
7、指定域名支持前端采集解决一些网页后端采集为空
8、添加文章 用于导出处理的个别详细功能
9、添加挂机是间隔分钟的设置
一键采集上传常见的细节问题(大数据架构和kappa架构的设计思路及难点)
采集交流 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2022-03-27 01:08
近年来,随着IT技术、大数据、机器学习、算法的不断发展,越来越多的企业意识到数据的价值,将数据作为自己的宝贵资产进行管理,利用大数据和机器学习。挖掘、识别和利用数据资产的能力。如果缺乏有效的整体数据架构设计或缺乏某些能力,就会导致业务层难以直接使用大数据和大数据,造成大数据与业务之间的巨大差距。存在数据不可知论、需求实现难、数据共享难等一系列问题。本文介绍了一些数据平台设计思路,帮助企业减少数据开发的痛点和难点。
本文主要包括以下章节:
本文第一部分介绍了大数据的基本组成部分和相关知识。第二部分将介绍 lambda 架构和 kappa 架构。第三部分将介绍 lambda 和 kappa 架构模式下的通用大数据架构。第四部分将介绍暴露的数据架构体系下数据端到端的难点和痛点。第五部分介绍了优秀大数据架构的整体设计。从第五部分开始,介绍通过各种数据平台和组件将这些大数据组件组合起来,打造一套高效易用的数据平台,提高业务系统的效率。让业务开发不怕复杂的数据开发组件,并且不需要关注底层实现。只需要能够使用 SQL 完成一站式开发并完成数据返回,让大数据不再是数据工程师独有的技能。
一、大数据技术栈
大数据的整个过程涉及到很多模块,每个模块都比较复杂。下图列出了这些模块和组件及其功能特性。将有专题详细介绍相关模块的领域知识,如数据采集、数据传输、实时计算、离线计算、大数据存储等相关模块。
二、lambda 架构和 kappa 架构
目前,基本上所有的大数据架构都是基于lambda和kappa架构,不同的公司都基于这两种架构模式设计了符合公司数据架构的数据架构。lambda 架构使开发人员能够构建大规模的分布式数据处理系统。它具有良好的灵活性和可扩展性,对硬件故障和人为错误也具有良好的容错能力。您可以在 Internet 文章 上找到很多关于 lambda 架构的信息。kappa架构解决了lambda架构中存在的两组数据处理系统带来的各种成本问题。这也是当前流批集成的研究方向。许多公司已经开始使用这种更高级的架构。
Lambda 架构
卡帕建筑
三、kappa架构和lambda架构下的大数据架构
目前各大公司基本都采用kappa架构或者lambda架构模式。这两种模式下的大数据整体架构在早期发展阶段可能如下:
四、数据端到端痛点
虽然上面的架构看似连接了各种大数据组件来实现集成化管理,但是接触过数据开发的人会强烈地感觉到,这样的裸架构业务数据开发需要注意很多基础工具的使用。在实际数据开发中存在很多痛点和难点,具体体现在以下几个方面。
没有一套数据开发IDE来管理整个数据开发流程,长期的流程是无法管理的。没有标准的数据建模体系,导致不同的数据工程师对指标的计算口径有不同的误解。大数据组件的开发要求很高,普通业务直接使用Hbase、ES等技术组件会导致各种问题。基本上每个公司的大数据团队都会很复杂,涉及的环节很多,遇到问题很难找到对应的负责人。数据孤岛难以打破,团队和部门之间难以共享数据,彼此之间也不清楚对方拥有哪些数据。两组计算模型,批计算和流计算,需要维护,很难开始开发。需要为流和批处理提供一套统一的SQL。缺乏公司级元数据系统规划,难以实时和离线复用同一条数据,每个开发任务都需要多方梳理。
基本上,大部分企业在数据平台的治理和开放能力的提供上都存在上述问题和痛点。在复杂的数据架构下,对于数据适用方来说,每个环节的不清晰或者功能的不友好,都会让复杂的环节变化更加复杂。要解决这些痛点,就需要精心打磨每一个环节,无缝对接以上技术组件,让业务端到端的数据使用就像写SQL查询数据库一样简单。
五、优秀的大数据整体架构设计
提供多种平台和工具助力数据平台:data采集多数据源平台、一键数据同步平台、数据质量与建模平台、元数据系统、数据统一接入平台、实时和离线计算平台、资源调度平台、一站式开发IDE。
六、元数据——大数据系统的基石
元数据连接数据源、数据仓库和数据应用,记录数据生成到消费的完整环节。元数据收录静态表、列、分区信息(即 MetaStore)。动态任务与表依赖映射关系;数据仓库模型定义、数据生命周期;ETL任务调度信息、输入输出等元数据是数据管理、数据内容和数据应用的基础。例如,元数据可用于构建任务、表、列和用户之间的数据图;构建任务 DAG 依赖关系,并安排任务执行顺序;建立任务画像以管理任务质量;为个人或BUs概述等提供资产管理和计算资源消耗。
可以认为整个大数据数据流是由元数据管理的。如果没有一套完整的元数据设计,上述数据将难以追踪、权限难以控制、资源难以管理、数据难以共享。
很多公司都依赖hive来管理元数据,但是我个人认为,在发展到一定阶段,还是需要搭建一个元数据平台来匹配相关架构。
七、流批一体化计算
如果维护两套计算引擎,比如离线计算Spark和实时计算Flink,会给用户带来很大的麻烦,需要同时学习流计算知识和批计算领域知识。如果你离线使用 Flink 来实时使用 Spark 或 Hadoop,你可以开发自定义的 DSL 描述语言来匹配不同计算引擎的语法。上层用户无需关注底层的具体执行细节。他们只需要掌握一门 DSL 语言即可完成 Spark。接入Hadoop、Flink等计算引擎。
八、直播和离线ETL平台
ETL 代表 Extract-Transform-Load,用于描述从源到目的地提取、转换和加载数据的过程。ETL 一词在数据仓库中更常用,但它的对象并不限于数据仓库。一般来说,ETL平台在数据清洗、数据格式转换、数据补全、数据质量管理等方面发挥着重要作用。ETL作为重要的数据清洗中间层,一般来说至少要具备以下功能:
支持多种数据源,如消息系统、文件系统等 支持多种算子,过滤、拆分、变换、输出、查询数据源补全等算子能力 支持动态变化逻辑,如上述算子通过动态提交jar 可以做不停的发布变化
九、智能统一查询平台
大多数数据查询都是由需求驱动的。每个需求开发一个或多个接口,编写接口文档,开放给业务方调用。这种模型在大数据系统中存在很多问题:
这种架构简单,但是接口粒度很粗,灵活性不高,可扩展性差,复用率低。随着业务需求的增加,接口数量大幅增加,维护成本高。同时,开发效率不高,对于海量数据系统显然会造成大量重复开发,数据和逻辑难以复用,业务适用方的经验严重降低。如果没有统一的查询平台直接将Hbase等库暴露给业务,后续对数据权限的运维管理会更加困难。访问大数据组件对于业务适用方来说也是非常痛苦的,一不小心就会出现各种问题。.
通过一组智能查询解决上述大数据查询痛点
十、数据仓库建模规范体系
随着业务复杂度和数据规模的增加,数据调用和复制混乱,重复建设造成的资源浪费,数据指标定义不同造成的模糊,数据使用门槛越来越高。以笔者实际业务跟踪和数据仓库使用的见证为例,同产品名的表字段有的叫good_id,有的叫spu_id,还有很多其他的名字,会给想用的人带来很大的麻烦这些数据。因此,如果没有完整的大数据建模体系,会给数据治理带来很大的困难,表现在以下几个方面:
数据标准不一致,即使命名相同,但定义口径不一致。例如,仅 uv 之类的指标就有十几个定义。问题是:它们都是UV,我用哪一个?都是uv,为什么数据不一样?研发成本巨大,每个工程师都需要从头到尾了解研发过程的每一个细节,每个人都会再次踩到同一个“坑”,浪费了研发人员的时间和精力成本。这也是目标作者遇到的问题。实际开发和提取数据太难了。没有统一的标准管理,造成重复计算等资源浪费。数据表的层次和粒度不清晰,也使得重复存储很严重。
所以大数据开发和数仓表设计必须遵循设计原则,数据平台可以开发平台来约束不合理的设计,比如阿里巴巴的OneData body。一般来说,数据开发是根据以下准则进行的:
有兴趣的可以参考阿里巴巴的OneData设计系统。
十大一、一键集成平台
一键采集将各种数据传输到数据平台非常简单,通过数据传输平台将数据无缝连接到ETL平台。ETL与元数据平台对接,标准化Schema定义,然后将数据转换分发到实时和离线计算平台。后续对数据的任何离线实时处理,只需要申请元数据表的权限,即可完成开发任务并完成计算。data采集支持多种数据源,如binlog、log采集、前端埋点、kafka消息队列等。
十个二、数据开发IDE——高效的端到端工具
高效的数据开发一站式解决方案工具。实时计算和离线计算任务开发可以通过IDE完成,以上平台对接,提供一站式解决方案。数据开发IDE提供数据集成、数据开发、数据管理、数据质量和数据服务等全方位的产品服务,一站式开发管理界面。数据的传输、转换和集成都是通过数据IDE完成的。从不同的数据存储导入数据,转换开发,最终将处理后的数据同步到其他数据系统。通过一个高效的大数据开发IDE,大数据工程师可以基本屏蔽各种痛点,结合上述各种平台能力,
数据开发工具请参考阿里云DataWorks。
解决端到端的难题还需要其他几个能力的辅助,这里不再赘述。有兴趣的同学可以自学。
十个三、其他
一个完整的数据系统的开发还包括报警监控中心、资源调度中心、资源计算隔离、数据质量检测、一站式数据处理系统,这里不再赘述。
如果您认为 文章 写得好,编码并不容易:
请1.关注作者~你的关注是我写作的最大动力
2.私信我“大数据”
给大家分享一套最新的大数据学习资源和全套开发工具 查看全部
一键采集上传常见的细节问题(大数据架构和kappa架构的设计思路及难点)
近年来,随着IT技术、大数据、机器学习、算法的不断发展,越来越多的企业意识到数据的价值,将数据作为自己的宝贵资产进行管理,利用大数据和机器学习。挖掘、识别和利用数据资产的能力。如果缺乏有效的整体数据架构设计或缺乏某些能力,就会导致业务层难以直接使用大数据和大数据,造成大数据与业务之间的巨大差距。存在数据不可知论、需求实现难、数据共享难等一系列问题。本文介绍了一些数据平台设计思路,帮助企业减少数据开发的痛点和难点。
本文主要包括以下章节:
本文第一部分介绍了大数据的基本组成部分和相关知识。第二部分将介绍 lambda 架构和 kappa 架构。第三部分将介绍 lambda 和 kappa 架构模式下的通用大数据架构。第四部分将介绍暴露的数据架构体系下数据端到端的难点和痛点。第五部分介绍了优秀大数据架构的整体设计。从第五部分开始,介绍通过各种数据平台和组件将这些大数据组件组合起来,打造一套高效易用的数据平台,提高业务系统的效率。让业务开发不怕复杂的数据开发组件,并且不需要关注底层实现。只需要能够使用 SQL 完成一站式开发并完成数据返回,让大数据不再是数据工程师独有的技能。
一、大数据技术栈
大数据的整个过程涉及到很多模块,每个模块都比较复杂。下图列出了这些模块和组件及其功能特性。将有专题详细介绍相关模块的领域知识,如数据采集、数据传输、实时计算、离线计算、大数据存储等相关模块。
二、lambda 架构和 kappa 架构
目前,基本上所有的大数据架构都是基于lambda和kappa架构,不同的公司都基于这两种架构模式设计了符合公司数据架构的数据架构。lambda 架构使开发人员能够构建大规模的分布式数据处理系统。它具有良好的灵活性和可扩展性,对硬件故障和人为错误也具有良好的容错能力。您可以在 Internet 文章 上找到很多关于 lambda 架构的信息。kappa架构解决了lambda架构中存在的两组数据处理系统带来的各种成本问题。这也是当前流批集成的研究方向。许多公司已经开始使用这种更高级的架构。
Lambda 架构
卡帕建筑
三、kappa架构和lambda架构下的大数据架构
目前各大公司基本都采用kappa架构或者lambda架构模式。这两种模式下的大数据整体架构在早期发展阶段可能如下:
四、数据端到端痛点
虽然上面的架构看似连接了各种大数据组件来实现集成化管理,但是接触过数据开发的人会强烈地感觉到,这样的裸架构业务数据开发需要注意很多基础工具的使用。在实际数据开发中存在很多痛点和难点,具体体现在以下几个方面。
没有一套数据开发IDE来管理整个数据开发流程,长期的流程是无法管理的。没有标准的数据建模体系,导致不同的数据工程师对指标的计算口径有不同的误解。大数据组件的开发要求很高,普通业务直接使用Hbase、ES等技术组件会导致各种问题。基本上每个公司的大数据团队都会很复杂,涉及的环节很多,遇到问题很难找到对应的负责人。数据孤岛难以打破,团队和部门之间难以共享数据,彼此之间也不清楚对方拥有哪些数据。两组计算模型,批计算和流计算,需要维护,很难开始开发。需要为流和批处理提供一套统一的SQL。缺乏公司级元数据系统规划,难以实时和离线复用同一条数据,每个开发任务都需要多方梳理。
基本上,大部分企业在数据平台的治理和开放能力的提供上都存在上述问题和痛点。在复杂的数据架构下,对于数据适用方来说,每个环节的不清晰或者功能的不友好,都会让复杂的环节变化更加复杂。要解决这些痛点,就需要精心打磨每一个环节,无缝对接以上技术组件,让业务端到端的数据使用就像写SQL查询数据库一样简单。
五、优秀的大数据整体架构设计
提供多种平台和工具助力数据平台:data采集多数据源平台、一键数据同步平台、数据质量与建模平台、元数据系统、数据统一接入平台、实时和离线计算平台、资源调度平台、一站式开发IDE。
六、元数据——大数据系统的基石
元数据连接数据源、数据仓库和数据应用,记录数据生成到消费的完整环节。元数据收录静态表、列、分区信息(即 MetaStore)。动态任务与表依赖映射关系;数据仓库模型定义、数据生命周期;ETL任务调度信息、输入输出等元数据是数据管理、数据内容和数据应用的基础。例如,元数据可用于构建任务、表、列和用户之间的数据图;构建任务 DAG 依赖关系,并安排任务执行顺序;建立任务画像以管理任务质量;为个人或BUs概述等提供资产管理和计算资源消耗。
可以认为整个大数据数据流是由元数据管理的。如果没有一套完整的元数据设计,上述数据将难以追踪、权限难以控制、资源难以管理、数据难以共享。
很多公司都依赖hive来管理元数据,但是我个人认为,在发展到一定阶段,还是需要搭建一个元数据平台来匹配相关架构。
七、流批一体化计算
如果维护两套计算引擎,比如离线计算Spark和实时计算Flink,会给用户带来很大的麻烦,需要同时学习流计算知识和批计算领域知识。如果你离线使用 Flink 来实时使用 Spark 或 Hadoop,你可以开发自定义的 DSL 描述语言来匹配不同计算引擎的语法。上层用户无需关注底层的具体执行细节。他们只需要掌握一门 DSL 语言即可完成 Spark。接入Hadoop、Flink等计算引擎。
八、直播和离线ETL平台
ETL 代表 Extract-Transform-Load,用于描述从源到目的地提取、转换和加载数据的过程。ETL 一词在数据仓库中更常用,但它的对象并不限于数据仓库。一般来说,ETL平台在数据清洗、数据格式转换、数据补全、数据质量管理等方面发挥着重要作用。ETL作为重要的数据清洗中间层,一般来说至少要具备以下功能:
支持多种数据源,如消息系统、文件系统等 支持多种算子,过滤、拆分、变换、输出、查询数据源补全等算子能力 支持动态变化逻辑,如上述算子通过动态提交jar 可以做不停的发布变化
九、智能统一查询平台
大多数数据查询都是由需求驱动的。每个需求开发一个或多个接口,编写接口文档,开放给业务方调用。这种模型在大数据系统中存在很多问题:
这种架构简单,但是接口粒度很粗,灵活性不高,可扩展性差,复用率低。随着业务需求的增加,接口数量大幅增加,维护成本高。同时,开发效率不高,对于海量数据系统显然会造成大量重复开发,数据和逻辑难以复用,业务适用方的经验严重降低。如果没有统一的查询平台直接将Hbase等库暴露给业务,后续对数据权限的运维管理会更加困难。访问大数据组件对于业务适用方来说也是非常痛苦的,一不小心就会出现各种问题。.
通过一组智能查询解决上述大数据查询痛点
十、数据仓库建模规范体系
随着业务复杂度和数据规模的增加,数据调用和复制混乱,重复建设造成的资源浪费,数据指标定义不同造成的模糊,数据使用门槛越来越高。以笔者实际业务跟踪和数据仓库使用的见证为例,同产品名的表字段有的叫good_id,有的叫spu_id,还有很多其他的名字,会给想用的人带来很大的麻烦这些数据。因此,如果没有完整的大数据建模体系,会给数据治理带来很大的困难,表现在以下几个方面:
数据标准不一致,即使命名相同,但定义口径不一致。例如,仅 uv 之类的指标就有十几个定义。问题是:它们都是UV,我用哪一个?都是uv,为什么数据不一样?研发成本巨大,每个工程师都需要从头到尾了解研发过程的每一个细节,每个人都会再次踩到同一个“坑”,浪费了研发人员的时间和精力成本。这也是目标作者遇到的问题。实际开发和提取数据太难了。没有统一的标准管理,造成重复计算等资源浪费。数据表的层次和粒度不清晰,也使得重复存储很严重。
所以大数据开发和数仓表设计必须遵循设计原则,数据平台可以开发平台来约束不合理的设计,比如阿里巴巴的OneData body。一般来说,数据开发是根据以下准则进行的:
有兴趣的可以参考阿里巴巴的OneData设计系统。
十大一、一键集成平台
一键采集将各种数据传输到数据平台非常简单,通过数据传输平台将数据无缝连接到ETL平台。ETL与元数据平台对接,标准化Schema定义,然后将数据转换分发到实时和离线计算平台。后续对数据的任何离线实时处理,只需要申请元数据表的权限,即可完成开发任务并完成计算。data采集支持多种数据源,如binlog、log采集、前端埋点、kafka消息队列等。
十个二、数据开发IDE——高效的端到端工具
高效的数据开发一站式解决方案工具。实时计算和离线计算任务开发可以通过IDE完成,以上平台对接,提供一站式解决方案。数据开发IDE提供数据集成、数据开发、数据管理、数据质量和数据服务等全方位的产品服务,一站式开发管理界面。数据的传输、转换和集成都是通过数据IDE完成的。从不同的数据存储导入数据,转换开发,最终将处理后的数据同步到其他数据系统。通过一个高效的大数据开发IDE,大数据工程师可以基本屏蔽各种痛点,结合上述各种平台能力,
数据开发工具请参考阿里云DataWorks。
解决端到端的难题还需要其他几个能力的辅助,这里不再赘述。有兴趣的同学可以自学。
十个三、其他
一个完整的数据系统的开发还包括报警监控中心、资源调度中心、资源计算隔离、数据质量检测、一站式数据处理系统,这里不再赘述。
如果您认为 文章 写得好,编码并不容易:
请1.关注作者~你的关注是我写作的最大动力
2.私信我“大数据”
给大家分享一套最新的大数据学习资源和全套开发工具
一键采集上传常见的细节问题(大数据架构和kappa架构的设计思路及难点)
采集交流 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2022-03-27 01:02
近年来,随着IT技术、大数据、机器学习、算法的不断发展,越来越多的企业意识到数据的价值,将数据作为自己的宝贵资产进行管理,利用大数据和机器学习。挖掘、识别和利用数据资产的能力。如果缺乏有效的整体数据架构设计或缺乏某些能力,就会导致业务层难以直接使用大数据和大数据,造成大数据与业务之间的巨大差距。存在数据不可知论、需求实现难、数据共享难等一系列问题。本文介绍了一些数据平台设计思路,帮助企业减少数据开发的痛点和难点。
本文主要包括以下章节:
本文第一部分介绍了大数据的基本组成部分和相关知识。
第二部分将介绍 lambda 架构和 kappa 架构。
第三部分将介绍 lambda 和 kappa 架构模式下的通用大数据架构
第四部分介绍了裸露的数据架构体系下数据端到端的难点和痛点。
第五部分介绍优秀大数据架构的整体设计
从第五部分开始,介绍通过各种数据平台和组件将这些大数据组件组合起来,打造一套高效易用的数据平台,提高业务系统的效率,让业务发展无所畏惧复杂的数据开发组件,无需关注底层实现,只需要会使用SQL即可完成一站式开发,完成数据回流,让大数据不再是技能数据工程师。
一、大数据技术栈
大数据的整个过程涉及到很多模块,每个模块都比较复杂。下图列出了这些模块和组件及其功能特性。将有专题详细介绍相关模块的领域知识,如数据采集、数据传输、实时计算、离线计算、大数据存储等相关模块。
二、lambda 架构和 kappa 架构
目前,基本上所有的大数据架构都是基于lambda和kappa架构,不同的公司都基于这两种架构模式设计了符合公司数据架构的数据架构。lambda 架构使开发人员能够构建大规模的分布式数据处理系统。它具有良好的灵活性和可扩展性,对硬件故障和人为错误也具有良好的容错能力。您可以在 Internet 文章 上找到很多关于 lambda 架构的信息。kappa架构解决了lambda架构中存在的两组数据处理系统带来的各种成本问题。这也是当前流批集成的研究方向。许多公司已经开始使用这种更高级的架构。
Lambda 架构
卡帕建筑
三、kappa架构和lambda架构下的大数据架构
目前各大公司基本都采用kappa架构或者lambda架构模式。这两种模式下的大数据整体架构在早期发展阶段可能如下:
四、数据端到端痛点
虽然上面的架构看似连接了各种大数据组件来实现集成化管理,但是接触过数据开发的人会强烈地感觉到,这样的裸架构业务数据开发需要注意很多基础工具的使用。在实际数据开发中存在很多痛点和难点,具体体现在以下几个方面。如果你对大数据开发感兴趣,想系统地学习大数据,可以加入大数据技术学习交流。
没有一套数据开发IDE来管理整个数据开发流程,长期的流程是无法管理的。
没有标准的数据建模体系,导致不同的数据工程师对指标的计算口径有不同的误解。
大数据组件的开发要求很高,普通业务直接使用Hbase、ES等技术组件会导致各种问题。
基本上每个公司的大数据团队都会很复杂,涉及的环节很多,遇到问题很难找到对应的负责人。
数据孤岛难以打破,团队和部门之间难以共享数据,彼此之间也不清楚对方拥有哪些数据。
批计算和流计算两套计算模型需要维护,很难上手开发。需要为流和批处理提供一套统一的SQL。
缺乏公司级元数据系统规划,难以实时和离线复用同一条数据,每个开发任务都需要多方梳理。
基本上,大部分企业在数据平台的治理和开放能力的提供上都存在上述问题和痛点。在复杂的数据架构下,对于数据适用方来说,每个环节的不清晰或者功能的不友好,都会让复杂的环节变化更加复杂。要解决这些痛点,就需要精心打磨每一个环节,无缝对接以上技术组件,让业务端到端的数据使用就像写SQL查询数据库一样简单。
五、优秀的大数据整体架构设计
提供多种平台和工具助力数据平台:data采集多数据源平台、一键数据同步平台、数据质量与建模平台、元数据系统、数据统一接入平台、实时和离线计算平台、资源调度平台、一站式开发IDE。
六、元数据——大数据系统的基石
元数据连接数据源、数据仓库和数据应用,记录数据生成到消费的完整环节。元数据收录静态表、列、分区信息(即 MetaStore)。动态任务与表依赖映射关系;数据仓库模型定义、数据生命周期;ETL任务调度信息、输入输出等元数据是数据管理、数据内容和数据应用的基础。例如,元数据可用于构建任务、表、列和用户之间的数据图;构建任务 DAG 依赖关系,并安排任务执行顺序;建立任务画像以管理任务质量;为个人或BUs概述等提供资产管理和计算资源消耗。
可以认为整个大数据数据流是由元数据管理的。如果没有一套完整的元数据设计,上述数据将难以追踪、权限难以控制、资源难以管理、数据难以共享。
很多公司都依赖hive来管理元数据,但是我个人认为,在发展到一定阶段,还是需要搭建一个元数据平台来匹配相关架构。
七、流批一体化计算
如果维护两套计算引擎,比如离线计算Spark和实时计算Flink,会给用户带来很大的麻烦,需要同时学习流计算知识和批计算领域知识。如果你离线使用 Flink 来实时使用 Spark 或 Hadoop,你可以开发自定义的 DSL 描述语言来匹配不同计算引擎的语法。上层用户无需关注底层的具体执行细节。他们只需要掌握一门 DSL 语言即可完成 Spark。接入Hadoop、Flink等计算引擎。
八、直播和离线ETL平台
ETL 代表 Extract-Transform-Load,用于描述从源到目的地提取、转换和加载数据的过程。ETL 一词在数据仓库中更常用,但它的对象并不限于数据仓库。一般来说,ETL平台在数据清洗、数据格式转换、数据补全、数据质量管理等方面发挥着重要作用。ETL作为重要的数据清洗中间层,一般来说至少要具备以下功能:
支持多种数据源,如消息系统、文件系统等
支持多种算子,过滤、拆分、转换、输出、查询数据源补全等算子能力
支持动态变化逻辑。比如上面的算子可以通过动态jar提交,不停机释放变化。
九、智能统一查询平台
大多数数据查询都是由需求驱动的。每个需求开发一个或多个接口,编写接口文档,开放给业务方调用。这种模型在大数据系统中存在很多问题:
这种架构简单,但是接口粒度很粗,灵活性不高,可扩展性差,复用率低。随着业务需求的增加,接口数量大幅增加,维护成本高。
同时,开发效率不高,对于海量数据系统显然会造成大量重复开发,数据和逻辑难以复用,业务适用方的经验严重降低。
如果没有统一的查询平台直接将Hbase等库暴露给业务,后续对数据权限的运维管理会更加困难。访问大数据组件对于业务适用方来说也是非常痛苦的,一不小心就会出现各种问题。.
通过一组智能查询解决上述大数据查询痛点
十、数据仓库建模规范体系
随着业务复杂度和数据规模的增加,数据调用和复制混乱,重复建设造成的资源浪费,数据指标定义不同造成的模糊,数据使用门槛越来越高。以笔者实际业务跟踪和数据仓库使用的见证为例,同产品名的表字段有的叫good_id,有的叫spu_id,还有很多其他的名字,会给想用的人带来很大的麻烦这些数据。因此,如果没有完整的大数据建模体系,会给数据治理带来很大的困难,表现在以下几个方面:
数据标准不一致,即使命名相同,但定义口径不一致。例如,仅 uv 之类的指标就有十几个定义。问题是:它们都是UV,我用哪一个?都是uv,为什么数据不一样?
研发成本巨大,每个工程师都需要从头到尾了解研发过程的每一个细节,每个人都会再次踩到同一个“坑”,浪费了研发人员的时间和精力成本。这也是目标作者遇到的问题。实际开发和提取数据太难了。
没有统一的标准管理,造成重复计算等资源浪费。数据表的层次和粒度不明确,这也使得重复存储变得严格。
所以大数据开发和数仓表设计必须遵循设计原则,数据平台可以开发平台来约束不合理的设计,比如阿里巴巴的OneData body。一般来说,数据开发是根据以下准则进行的:
有兴趣的可以参考阿里巴巴的OneData设计系统。
十大一、一键集成平台
一键采集将各种数据传输到数据平台非常简单,通过数据传输平台将数据无缝连接到ETL平台。ETL与元数据平台对接,标准化Schema定义,然后将数据转换分发到实时和离线计算平台。后续对数据的任何离线实时处理,只需要申请元数据表的权限,即可完成开发任务并完成计算。data采集支持多种数据源,如binlog、log采集、前端埋点、kafka消息队列等。
十个二、数据开发IDE——高效的端到端工具
高效的数据开发一站式解决方案工具。实时计算和离线计算任务开发可以通过IDE完成,以上平台对接,提供一站式解决方案。数据开发IDE提供数据集成、数据开发、数据管理、数据质量和数据服务等全方位的产品服务,一站式开发管理界面。数据的传输、转换和集成都是通过数据IDE完成的。从不同的数据存储导入数据,转换开发,最终将处理后的数据同步到其他数据系统。通过一个高效的大数据开发IDE,大数据工程师可以基本屏蔽各种痛点,结合上述各种平台能力,
数据开发工具请参考阿里云DataWorks。
解决端到端的难题还需要其他几个能力的辅助,这里不再赘述。有兴趣的同学可以自学。
十个三、其他
一个完整的数据系统的开发还包括报警监控中心、资源调度中心、资源计算隔离、数据质量检测、一站式数据处理系统,这里不再赘述。 查看全部
一键采集上传常见的细节问题(大数据架构和kappa架构的设计思路及难点)
近年来,随着IT技术、大数据、机器学习、算法的不断发展,越来越多的企业意识到数据的价值,将数据作为自己的宝贵资产进行管理,利用大数据和机器学习。挖掘、识别和利用数据资产的能力。如果缺乏有效的整体数据架构设计或缺乏某些能力,就会导致业务层难以直接使用大数据和大数据,造成大数据与业务之间的巨大差距。存在数据不可知论、需求实现难、数据共享难等一系列问题。本文介绍了一些数据平台设计思路,帮助企业减少数据开发的痛点和难点。
本文主要包括以下章节:
本文第一部分介绍了大数据的基本组成部分和相关知识。
第二部分将介绍 lambda 架构和 kappa 架构。
第三部分将介绍 lambda 和 kappa 架构模式下的通用大数据架构
第四部分介绍了裸露的数据架构体系下数据端到端的难点和痛点。
第五部分介绍优秀大数据架构的整体设计
从第五部分开始,介绍通过各种数据平台和组件将这些大数据组件组合起来,打造一套高效易用的数据平台,提高业务系统的效率,让业务发展无所畏惧复杂的数据开发组件,无需关注底层实现,只需要会使用SQL即可完成一站式开发,完成数据回流,让大数据不再是技能数据工程师。
一、大数据技术栈
大数据的整个过程涉及到很多模块,每个模块都比较复杂。下图列出了这些模块和组件及其功能特性。将有专题详细介绍相关模块的领域知识,如数据采集、数据传输、实时计算、离线计算、大数据存储等相关模块。
二、lambda 架构和 kappa 架构
目前,基本上所有的大数据架构都是基于lambda和kappa架构,不同的公司都基于这两种架构模式设计了符合公司数据架构的数据架构。lambda 架构使开发人员能够构建大规模的分布式数据处理系统。它具有良好的灵活性和可扩展性,对硬件故障和人为错误也具有良好的容错能力。您可以在 Internet 文章 上找到很多关于 lambda 架构的信息。kappa架构解决了lambda架构中存在的两组数据处理系统带来的各种成本问题。这也是当前流批集成的研究方向。许多公司已经开始使用这种更高级的架构。
Lambda 架构
卡帕建筑
三、kappa架构和lambda架构下的大数据架构
目前各大公司基本都采用kappa架构或者lambda架构模式。这两种模式下的大数据整体架构在早期发展阶段可能如下:
四、数据端到端痛点
虽然上面的架构看似连接了各种大数据组件来实现集成化管理,但是接触过数据开发的人会强烈地感觉到,这样的裸架构业务数据开发需要注意很多基础工具的使用。在实际数据开发中存在很多痛点和难点,具体体现在以下几个方面。如果你对大数据开发感兴趣,想系统地学习大数据,可以加入大数据技术学习交流。
没有一套数据开发IDE来管理整个数据开发流程,长期的流程是无法管理的。
没有标准的数据建模体系,导致不同的数据工程师对指标的计算口径有不同的误解。
大数据组件的开发要求很高,普通业务直接使用Hbase、ES等技术组件会导致各种问题。
基本上每个公司的大数据团队都会很复杂,涉及的环节很多,遇到问题很难找到对应的负责人。
数据孤岛难以打破,团队和部门之间难以共享数据,彼此之间也不清楚对方拥有哪些数据。
批计算和流计算两套计算模型需要维护,很难上手开发。需要为流和批处理提供一套统一的SQL。
缺乏公司级元数据系统规划,难以实时和离线复用同一条数据,每个开发任务都需要多方梳理。
基本上,大部分企业在数据平台的治理和开放能力的提供上都存在上述问题和痛点。在复杂的数据架构下,对于数据适用方来说,每个环节的不清晰或者功能的不友好,都会让复杂的环节变化更加复杂。要解决这些痛点,就需要精心打磨每一个环节,无缝对接以上技术组件,让业务端到端的数据使用就像写SQL查询数据库一样简单。
五、优秀的大数据整体架构设计
提供多种平台和工具助力数据平台:data采集多数据源平台、一键数据同步平台、数据质量与建模平台、元数据系统、数据统一接入平台、实时和离线计算平台、资源调度平台、一站式开发IDE。
六、元数据——大数据系统的基石
元数据连接数据源、数据仓库和数据应用,记录数据生成到消费的完整环节。元数据收录静态表、列、分区信息(即 MetaStore)。动态任务与表依赖映射关系;数据仓库模型定义、数据生命周期;ETL任务调度信息、输入输出等元数据是数据管理、数据内容和数据应用的基础。例如,元数据可用于构建任务、表、列和用户之间的数据图;构建任务 DAG 依赖关系,并安排任务执行顺序;建立任务画像以管理任务质量;为个人或BUs概述等提供资产管理和计算资源消耗。
可以认为整个大数据数据流是由元数据管理的。如果没有一套完整的元数据设计,上述数据将难以追踪、权限难以控制、资源难以管理、数据难以共享。
很多公司都依赖hive来管理元数据,但是我个人认为,在发展到一定阶段,还是需要搭建一个元数据平台来匹配相关架构。
七、流批一体化计算
如果维护两套计算引擎,比如离线计算Spark和实时计算Flink,会给用户带来很大的麻烦,需要同时学习流计算知识和批计算领域知识。如果你离线使用 Flink 来实时使用 Spark 或 Hadoop,你可以开发自定义的 DSL 描述语言来匹配不同计算引擎的语法。上层用户无需关注底层的具体执行细节。他们只需要掌握一门 DSL 语言即可完成 Spark。接入Hadoop、Flink等计算引擎。
八、直播和离线ETL平台
ETL 代表 Extract-Transform-Load,用于描述从源到目的地提取、转换和加载数据的过程。ETL 一词在数据仓库中更常用,但它的对象并不限于数据仓库。一般来说,ETL平台在数据清洗、数据格式转换、数据补全、数据质量管理等方面发挥着重要作用。ETL作为重要的数据清洗中间层,一般来说至少要具备以下功能:
支持多种数据源,如消息系统、文件系统等
支持多种算子,过滤、拆分、转换、输出、查询数据源补全等算子能力
支持动态变化逻辑。比如上面的算子可以通过动态jar提交,不停机释放变化。
九、智能统一查询平台
大多数数据查询都是由需求驱动的。每个需求开发一个或多个接口,编写接口文档,开放给业务方调用。这种模型在大数据系统中存在很多问题:
这种架构简单,但是接口粒度很粗,灵活性不高,可扩展性差,复用率低。随着业务需求的增加,接口数量大幅增加,维护成本高。
同时,开发效率不高,对于海量数据系统显然会造成大量重复开发,数据和逻辑难以复用,业务适用方的经验严重降低。
如果没有统一的查询平台直接将Hbase等库暴露给业务,后续对数据权限的运维管理会更加困难。访问大数据组件对于业务适用方来说也是非常痛苦的,一不小心就会出现各种问题。.
通过一组智能查询解决上述大数据查询痛点
十、数据仓库建模规范体系
随着业务复杂度和数据规模的增加,数据调用和复制混乱,重复建设造成的资源浪费,数据指标定义不同造成的模糊,数据使用门槛越来越高。以笔者实际业务跟踪和数据仓库使用的见证为例,同产品名的表字段有的叫good_id,有的叫spu_id,还有很多其他的名字,会给想用的人带来很大的麻烦这些数据。因此,如果没有完整的大数据建模体系,会给数据治理带来很大的困难,表现在以下几个方面:
数据标准不一致,即使命名相同,但定义口径不一致。例如,仅 uv 之类的指标就有十几个定义。问题是:它们都是UV,我用哪一个?都是uv,为什么数据不一样?
研发成本巨大,每个工程师都需要从头到尾了解研发过程的每一个细节,每个人都会再次踩到同一个“坑”,浪费了研发人员的时间和精力成本。这也是目标作者遇到的问题。实际开发和提取数据太难了。
没有统一的标准管理,造成重复计算等资源浪费。数据表的层次和粒度不明确,这也使得重复存储变得严格。
所以大数据开发和数仓表设计必须遵循设计原则,数据平台可以开发平台来约束不合理的设计,比如阿里巴巴的OneData body。一般来说,数据开发是根据以下准则进行的:
有兴趣的可以参考阿里巴巴的OneData设计系统。
十大一、一键集成平台
一键采集将各种数据传输到数据平台非常简单,通过数据传输平台将数据无缝连接到ETL平台。ETL与元数据平台对接,标准化Schema定义,然后将数据转换分发到实时和离线计算平台。后续对数据的任何离线实时处理,只需要申请元数据表的权限,即可完成开发任务并完成计算。data采集支持多种数据源,如binlog、log采集、前端埋点、kafka消息队列等。
十个二、数据开发IDE——高效的端到端工具
高效的数据开发一站式解决方案工具。实时计算和离线计算任务开发可以通过IDE完成,以上平台对接,提供一站式解决方案。数据开发IDE提供数据集成、数据开发、数据管理、数据质量和数据服务等全方位的产品服务,一站式开发管理界面。数据的传输、转换和集成都是通过数据IDE完成的。从不同的数据存储导入数据,转换开发,最终将处理后的数据同步到其他数据系统。通过一个高效的大数据开发IDE,大数据工程师可以基本屏蔽各种痛点,结合上述各种平台能力,
数据开发工具请参考阿里云DataWorks。
解决端到端的难题还需要其他几个能力的辅助,这里不再赘述。有兴趣的同学可以自学。
十个三、其他
一个完整的数据系统的开发还包括报警监控中心、资源调度中心、资源计算隔离、数据质量检测、一站式数据处理系统,这里不再赘述。
一键采集上传常见的细节问题(大数据架构和kappa架构的设计思路及难点)
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2022-03-27 01:01
近年来,随着IT技术、大数据、机器学习、算法的不断发展,越来越多的企业意识到数据的价值,将数据作为自己的宝贵资产进行管理,利用大数据和机器学习。挖掘、识别和利用数据资产的能力。如果缺乏有效的整体数据架构设计或缺乏某些能力,就会导致业务层难以直接使用大数据和大数据,造成大数据与业务之间的巨大差距。存在数据不可知论、需求实现难、数据共享难等一系列问题。本文介绍了一些数据平台设计思路,帮助企业减少数据开发的痛点和难点。
本文主要包括以下章节:
本文第一部分介绍了大数据的基本组成部分和相关知识。
第二部分将介绍 lambda 架构和 kappa 架构。
第三部分将介绍 lambda 和 kappa 架构模式下的通用大数据架构
第四部分介绍了裸露的数据架构体系下数据端到端的难点和痛点。
第五部分介绍优秀大数据架构的整体设计
从第五部分开始,介绍通过各种数据平台和组件将这些大数据组件组合起来,打造一套高效易用的数据平台,提高业务系统的效率,让业务发展无所畏惧复杂的数据开发组件,无需关注底层实现,只需要会使用SQL即可完成一站式开发,完成数据回流,让大数据不再是技能数据工程师。
一、大数据技术栈
大数据的整个过程涉及到很多模块,每个模块都比较复杂。下图列出了这些模块和组件及其功能特性。将有专题详细介绍相关模块的领域知识,如数据采集、数据传输、实时计算、离线计算、大数据存储等相关模块。
二、lambda 架构和 kappa 架构
目前,基本上所有的大数据架构都是基于lambda和kappa架构,不同的公司都基于这两种架构模式设计了符合公司数据架构的数据架构。lambda 架构使开发人员能够构建大规模的分布式数据处理系统。它具有良好的灵活性和可扩展性,对硬件故障和人为错误也具有良好的容错能力。您可以在 Internet 文章 上找到很多关于 lambda 架构的信息。kappa架构解决了lambda架构中存在的两组数据处理系统带来的各种成本问题。这也是当前流批集成的研究方向。许多公司已经开始使用这种更高级的架构。
Lambda 架构
卡帕建筑
三、kappa架构和lambda架构下的大数据架构
目前各大公司基本都采用kappa架构或者lambda架构模式。这两种模式下的大数据整体架构在早期发展阶段可能如下:
四、数据端到端痛点
虽然上面的架构看似连接了各种大数据组件来实现集成化管理,但是接触过数据开发的人会强烈地感觉到,这样的裸架构业务数据开发需要注意很多基础工具的使用。在实际数据开发中存在很多痛点和难点,具体体现在以下几个方面。
没有一套数据开发IDE来管理整个数据开发流程,长期的流程是无法管理的。
没有标准的数据建模体系,导致不同的数据工程师对指标的计算口径有不同的误解。
大数据组件的开发要求很高,普通业务直接使用Hbase、ES等技术组件会导致各种问题。
基本上每个公司的大数据团队都会很复杂,涉及的环节很多,遇到问题很难找到对应的负责人。
数据孤岛难以打破,团队和部门之间难以共享数据,彼此之间也不清楚对方拥有哪些数据。
批计算和流计算两套计算模型需要维护,很难上手开发。需要为流和批处理提供一套统一的SQL。
缺乏公司级元数据系统规划,难以实时和离线复用同一条数据,每个开发任务都需要多方梳理。
基本上,大部分企业在数据平台的治理和开放能力的提供上都存在上述问题和痛点。在复杂的数据架构下,对于数据适用方来说,每个环节的不清晰或者功能的不友好,都会让复杂的环节变化更加复杂。要解决这些痛点,就需要精心打磨每一个环节,无缝对接以上技术组件,让业务端到端的数据使用就像写SQL查询数据库一样简单。
五、优秀的大数据整体架构设计
提供多种平台和工具助力数据平台:data采集多数据源平台、一键数据同步平台、数据质量与建模平台、元数据系统、数据统一接入平台、实时和离线计算平台、资源调度平台、一站式开发IDE。
六、元数据——大数据系统的基石
元数据连接数据源、数据仓库和数据应用,记录数据生成到消费的完整环节。元数据收录静态表、列、分区信息(即 MetaStore)。动态任务与表依赖映射关系;数据仓库模型定义、数据生命周期;ETL任务调度信息、输入输出等元数据是数据管理、数据内容和数据应用的基础。例如,元数据可用于构建任务、表、列和用户之间的数据图;构建任务 DAG 依赖关系,并安排任务执行顺序;建立任务画像以管理任务质量;为个人或BUs概述等提供资产管理和计算资源消耗。
可以认为整个大数据数据流是由元数据管理的。如果没有一套完整的元数据设计,上述数据将难以追踪、权限难以控制、资源难以管理、数据难以共享。
很多公司都依赖hive来管理元数据,但是我个人认为,在发展到一定阶段,还是需要搭建一个元数据平台来匹配相关架构。
元数据可以参考饿了么和一些实战:
七、流批一体化计算
如果维护两套计算引擎,比如离线计算Spark和实时计算Flink,会给用户带来很大的麻烦,需要同时学习流计算知识和批计算领域知识。如果你离线使用 Flink 来实时使用 Spark 或 Hadoop,你可以开发自定义的 DSL 描述语言来匹配不同计算引擎的语法。上层用户无需关注底层的具体执行细节。他们只需要掌握一门 DSL 语言即可完成 Spark。接入Hadoop、Flink等计算引擎。
八、直播和离线ETL平台
ETL 代表 Extract-Transform-Load,用于描述从源到目的地提取、转换和加载数据的过程。ETL 一词在数据仓库中更常用,但它的对象并不限于数据仓库。一般来说,ETL平台在数据清洗、数据格式转换、数据补全、数据质量管理等方面发挥着重要作用。ETL作为重要的数据清洗中间层,一般来说至少要具备以下功能:
支持多种数据源,如消息系统、文件系统等
支持多种算子,过滤、拆分、转换、输出、查询数据源补全等算子能力
支持动态变化逻辑。比如上面的算子可以通过动态jar提交,不停机释放变化。
九、智能统一查询平台
大多数数据查询都是由需求驱动的。每个需求开发一个或多个接口,编写接口文档,开放给业务方调用。这种模型在大数据系统中存在很多问题:
这种架构简单,但是接口粒度很粗,灵活性不高,可扩展性差,复用率低。随着业务需求的增加,接口数量大幅增加,维护成本高。
同时,开发效率不高,对于海量数据系统显然会造成大量重复开发,数据和逻辑难以复用,业务适用方的经验严重降低。
如果没有统一的查询平台直接将Hbase等库暴露给业务,后续对数据权限的运维管理会更加困难。访问大数据组件对于业务适用方来说也是非常痛苦的,一不小心就会出现各种问题。.
通过一组智能查询解决上述大数据查询痛点
十、数据仓库建模规范体系
随着业务复杂度和数据规模的增加,数据调用和复制混乱,重复建设造成的资源浪费,数据指标定义不同造成的模糊,数据使用门槛越来越高。以笔者实际业务跟踪和数据仓库使用的见证为例,同产品名的表字段有的叫good_id,有的叫spu_id,还有很多其他的名字,会给想用的人带来很大的麻烦这些数据。因此,如果没有完整的大数据建模体系,会给数据治理带来很大的困难,表现在以下几个方面:
数据标准不一致,即使命名相同,但定义口径不一致。例如,仅 uv 之类的指标就有十几个定义。问题是:它们都是UV,我用哪一个?都是uv,为什么数据不一样?
研发成本巨大,每个工程师都需要从头到尾了解研发过程的每一个细节,每个人都会再次踩到同一个“坑”,浪费了研发人员的时间和精力成本。这也是目标作者遇到的问题。实际开发和提取数据太难了。
没有统一的标准管理,造成重复计算等资源浪费。数据表的层次和粒度不清晰,也使得重复存储很严重。
所以大数据开发和数仓表设计必须遵循设计原则,数据平台可以开发平台来约束不合理的设计,比如阿里巴巴的OneData body。一般来说,数据开发是根据以下准则进行的:
有兴趣的可以参考阿里巴巴的OneData设计系统。
十大一、一键集成平台
一键采集将各种数据传输到数据平台非常简单,通过数据传输平台将数据无缝连接到ETL平台。ETL与元数据平台对接,标准化Schema定义,然后将数据转换分发到实时和离线计算平台。后续对数据的任何离线实时处理,只需要申请元数据表的权限,即可完成开发任务并完成计算。data采集支持多种数据源,如binlog、log采集、前端埋点、kafka消息队列等。
十个二、数据开发IDE——高效的端到端工具
高效的数据开发一站式解决方案工具。实时计算和离线计算任务开发可以通过IDE完成,以上平台对接,提供一站式解决方案。数据开发IDE提供数据集成、数据开发、数据管理、数据质量和数据服务等全方位的产品服务,一站式开发管理界面。数据的传输、转换和集成都是通过数据IDE完成的。从不同的数据存储导入数据,转换开发,最终将处理后的数据同步到其他数据系统。通过一个高效的大数据开发IDE,大数据工程师可以基本屏蔽各种痛点,结合上述各种平台能力,
数据开发工具请参考阿里云DataWorks。
解决端到端的难题还需要其他几个能力的辅助,这里不再赘述。有兴趣的同学可以自学。
十个三、其他
一个完整的数据系统的开发还包括报警监控中心、资源调度中心、资源计算隔离、数据质量检测、一站式数据处理系统,这里不再赘述。 查看全部
一键采集上传常见的细节问题(大数据架构和kappa架构的设计思路及难点)
近年来,随着IT技术、大数据、机器学习、算法的不断发展,越来越多的企业意识到数据的价值,将数据作为自己的宝贵资产进行管理,利用大数据和机器学习。挖掘、识别和利用数据资产的能力。如果缺乏有效的整体数据架构设计或缺乏某些能力,就会导致业务层难以直接使用大数据和大数据,造成大数据与业务之间的巨大差距。存在数据不可知论、需求实现难、数据共享难等一系列问题。本文介绍了一些数据平台设计思路,帮助企业减少数据开发的痛点和难点。
本文主要包括以下章节:
本文第一部分介绍了大数据的基本组成部分和相关知识。
第二部分将介绍 lambda 架构和 kappa 架构。
第三部分将介绍 lambda 和 kappa 架构模式下的通用大数据架构
第四部分介绍了裸露的数据架构体系下数据端到端的难点和痛点。
第五部分介绍优秀大数据架构的整体设计
从第五部分开始,介绍通过各种数据平台和组件将这些大数据组件组合起来,打造一套高效易用的数据平台,提高业务系统的效率,让业务发展无所畏惧复杂的数据开发组件,无需关注底层实现,只需要会使用SQL即可完成一站式开发,完成数据回流,让大数据不再是技能数据工程师。
一、大数据技术栈
大数据的整个过程涉及到很多模块,每个模块都比较复杂。下图列出了这些模块和组件及其功能特性。将有专题详细介绍相关模块的领域知识,如数据采集、数据传输、实时计算、离线计算、大数据存储等相关模块。
二、lambda 架构和 kappa 架构
目前,基本上所有的大数据架构都是基于lambda和kappa架构,不同的公司都基于这两种架构模式设计了符合公司数据架构的数据架构。lambda 架构使开发人员能够构建大规模的分布式数据处理系统。它具有良好的灵活性和可扩展性,对硬件故障和人为错误也具有良好的容错能力。您可以在 Internet 文章 上找到很多关于 lambda 架构的信息。kappa架构解决了lambda架构中存在的两组数据处理系统带来的各种成本问题。这也是当前流批集成的研究方向。许多公司已经开始使用这种更高级的架构。
Lambda 架构
卡帕建筑
三、kappa架构和lambda架构下的大数据架构
目前各大公司基本都采用kappa架构或者lambda架构模式。这两种模式下的大数据整体架构在早期发展阶段可能如下:
四、数据端到端痛点
虽然上面的架构看似连接了各种大数据组件来实现集成化管理,但是接触过数据开发的人会强烈地感觉到,这样的裸架构业务数据开发需要注意很多基础工具的使用。在实际数据开发中存在很多痛点和难点,具体体现在以下几个方面。
没有一套数据开发IDE来管理整个数据开发流程,长期的流程是无法管理的。
没有标准的数据建模体系,导致不同的数据工程师对指标的计算口径有不同的误解。
大数据组件的开发要求很高,普通业务直接使用Hbase、ES等技术组件会导致各种问题。
基本上每个公司的大数据团队都会很复杂,涉及的环节很多,遇到问题很难找到对应的负责人。
数据孤岛难以打破,团队和部门之间难以共享数据,彼此之间也不清楚对方拥有哪些数据。
批计算和流计算两套计算模型需要维护,很难上手开发。需要为流和批处理提供一套统一的SQL。
缺乏公司级元数据系统规划,难以实时和离线复用同一条数据,每个开发任务都需要多方梳理。
基本上,大部分企业在数据平台的治理和开放能力的提供上都存在上述问题和痛点。在复杂的数据架构下,对于数据适用方来说,每个环节的不清晰或者功能的不友好,都会让复杂的环节变化更加复杂。要解决这些痛点,就需要精心打磨每一个环节,无缝对接以上技术组件,让业务端到端的数据使用就像写SQL查询数据库一样简单。
五、优秀的大数据整体架构设计
提供多种平台和工具助力数据平台:data采集多数据源平台、一键数据同步平台、数据质量与建模平台、元数据系统、数据统一接入平台、实时和离线计算平台、资源调度平台、一站式开发IDE。
六、元数据——大数据系统的基石
元数据连接数据源、数据仓库和数据应用,记录数据生成到消费的完整环节。元数据收录静态表、列、分区信息(即 MetaStore)。动态任务与表依赖映射关系;数据仓库模型定义、数据生命周期;ETL任务调度信息、输入输出等元数据是数据管理、数据内容和数据应用的基础。例如,元数据可用于构建任务、表、列和用户之间的数据图;构建任务 DAG 依赖关系,并安排任务执行顺序;建立任务画像以管理任务质量;为个人或BUs概述等提供资产管理和计算资源消耗。
可以认为整个大数据数据流是由元数据管理的。如果没有一套完整的元数据设计,上述数据将难以追踪、权限难以控制、资源难以管理、数据难以共享。
很多公司都依赖hive来管理元数据,但是我个人认为,在发展到一定阶段,还是需要搭建一个元数据平台来匹配相关架构。
元数据可以参考饿了么和一些实战:
七、流批一体化计算
如果维护两套计算引擎,比如离线计算Spark和实时计算Flink,会给用户带来很大的麻烦,需要同时学习流计算知识和批计算领域知识。如果你离线使用 Flink 来实时使用 Spark 或 Hadoop,你可以开发自定义的 DSL 描述语言来匹配不同计算引擎的语法。上层用户无需关注底层的具体执行细节。他们只需要掌握一门 DSL 语言即可完成 Spark。接入Hadoop、Flink等计算引擎。
八、直播和离线ETL平台
ETL 代表 Extract-Transform-Load,用于描述从源到目的地提取、转换和加载数据的过程。ETL 一词在数据仓库中更常用,但它的对象并不限于数据仓库。一般来说,ETL平台在数据清洗、数据格式转换、数据补全、数据质量管理等方面发挥着重要作用。ETL作为重要的数据清洗中间层,一般来说至少要具备以下功能:
支持多种数据源,如消息系统、文件系统等
支持多种算子,过滤、拆分、转换、输出、查询数据源补全等算子能力
支持动态变化逻辑。比如上面的算子可以通过动态jar提交,不停机释放变化。
九、智能统一查询平台
大多数数据查询都是由需求驱动的。每个需求开发一个或多个接口,编写接口文档,开放给业务方调用。这种模型在大数据系统中存在很多问题:
这种架构简单,但是接口粒度很粗,灵活性不高,可扩展性差,复用率低。随着业务需求的增加,接口数量大幅增加,维护成本高。
同时,开发效率不高,对于海量数据系统显然会造成大量重复开发,数据和逻辑难以复用,业务适用方的经验严重降低。
如果没有统一的查询平台直接将Hbase等库暴露给业务,后续对数据权限的运维管理会更加困难。访问大数据组件对于业务适用方来说也是非常痛苦的,一不小心就会出现各种问题。.
通过一组智能查询解决上述大数据查询痛点
十、数据仓库建模规范体系
随着业务复杂度和数据规模的增加,数据调用和复制混乱,重复建设造成的资源浪费,数据指标定义不同造成的模糊,数据使用门槛越来越高。以笔者实际业务跟踪和数据仓库使用的见证为例,同产品名的表字段有的叫good_id,有的叫spu_id,还有很多其他的名字,会给想用的人带来很大的麻烦这些数据。因此,如果没有完整的大数据建模体系,会给数据治理带来很大的困难,表现在以下几个方面:
数据标准不一致,即使命名相同,但定义口径不一致。例如,仅 uv 之类的指标就有十几个定义。问题是:它们都是UV,我用哪一个?都是uv,为什么数据不一样?
研发成本巨大,每个工程师都需要从头到尾了解研发过程的每一个细节,每个人都会再次踩到同一个“坑”,浪费了研发人员的时间和精力成本。这也是目标作者遇到的问题。实际开发和提取数据太难了。
没有统一的标准管理,造成重复计算等资源浪费。数据表的层次和粒度不清晰,也使得重复存储很严重。
所以大数据开发和数仓表设计必须遵循设计原则,数据平台可以开发平台来约束不合理的设计,比如阿里巴巴的OneData body。一般来说,数据开发是根据以下准则进行的:
有兴趣的可以参考阿里巴巴的OneData设计系统。
十大一、一键集成平台
一键采集将各种数据传输到数据平台非常简单,通过数据传输平台将数据无缝连接到ETL平台。ETL与元数据平台对接,标准化Schema定义,然后将数据转换分发到实时和离线计算平台。后续对数据的任何离线实时处理,只需要申请元数据表的权限,即可完成开发任务并完成计算。data采集支持多种数据源,如binlog、log采集、前端埋点、kafka消息队列等。
十个二、数据开发IDE——高效的端到端工具
高效的数据开发一站式解决方案工具。实时计算和离线计算任务开发可以通过IDE完成,以上平台对接,提供一站式解决方案。数据开发IDE提供数据集成、数据开发、数据管理、数据质量和数据服务等全方位的产品服务,一站式开发管理界面。数据的传输、转换和集成都是通过数据IDE完成的。从不同的数据存储导入数据,转换开发,最终将处理后的数据同步到其他数据系统。通过一个高效的大数据开发IDE,大数据工程师可以基本屏蔽各种痛点,结合上述各种平台能力,
数据开发工具请参考阿里云DataWorks。
解决端到端的难题还需要其他几个能力的辅助,这里不再赘述。有兴趣的同学可以自学。
十个三、其他
一个完整的数据系统的开发还包括报警监控中心、资源调度中心、资源计算隔离、数据质量检测、一站式数据处理系统,这里不再赘述。
一键采集上传常见的细节问题(优采云数据采集器如何解决网站更新困难,网站内容充实等问题)
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-03-21 11:28
优采云数据采集器,通过将关键词采集分配给全网数据源文章,网站可以有大量的文章生成与网站定位相关的@>,解决网站难以更新和网站内容丰富的问题。网站 的核心是内容。只有产生足够多的优质内容,才能吸引搜索引擎和用户的搜索需求。从长远来看,我们可以获得大量的流量,达到建立网站的根本目的。
优采云数据采集器通信是内容质量的核心部分。普通网页上的内容类型很多,如文章、视频,主要是内容,还有下载、查询工具等类型的操作,还有主页、个人主页、列表页、很快。不管是什么类型的页面,它都承担着传递信息的目的。在向用户传递信息时,能否满足用户的需求,解决用户访问的问题,对这些页面类型的指导意义在于互通。
优采云data采集器的内容要清晰明了,写得合乎逻辑,用词优美,读起来舒服。从内容的特点来看,可以增强用户吸收内容后的获得感。比如优采云data采集器内容发人深省、轻松愉快、文笔好、有说服力等。严谨优雅的文笔更能体现行业的专业性,比如使用专业术语、词汇和思维方法。能够深入挖掘原因和逻辑,从多角度、多方面综合分析和阐述观点。对于需要指导用户操作的内容,要求明确、实用。如果无法通过文字等清楚地表达,
优采云Data采集器 的文章 内容精心打造,以改善用户的视觉和浏览体验。这里我们考察最常见也最容易被忽略的内容元素,例如:字体、段落、布局、大小标题、匹配辅助图片和视频等。优采云数据采集器要求是丰富美观,层次分明,贴合主题,升华主题,帮助用户更好地理解内容,获得连贯舒适的阅读体验。两个相对相似的内容可能由于布局不同而具有不同的质量分数。
使用优采云Data采集器的体验是流畅的,和上面提到的精致制作不同。精美的制作考察的是内容主体部分的美化,而这里考察的是页面的整体布局和核心。交互性、功能体验和舒适度。优采云数据采集器在设计页面时,首先要考虑核心需求需要哪些辅助功能和信息,帮助用户更好地理解内容。搜索排名受多种因素影响,例如用户偏好、网站整体质量等。原创单靠一个维度无法衡量为什么内容不是收录。如果站长觉得他的内容质量很高,他应该得到更好的搜索表示。 查看全部
一键采集上传常见的细节问题(优采云数据采集器如何解决网站更新困难,网站内容充实等问题)
优采云数据采集器,通过将关键词采集分配给全网数据源文章,网站可以有大量的文章生成与网站定位相关的@>,解决网站难以更新和网站内容丰富的问题。网站 的核心是内容。只有产生足够多的优质内容,才能吸引搜索引擎和用户的搜索需求。从长远来看,我们可以获得大量的流量,达到建立网站的根本目的。
优采云数据采集器通信是内容质量的核心部分。普通网页上的内容类型很多,如文章、视频,主要是内容,还有下载、查询工具等类型的操作,还有主页、个人主页、列表页、很快。不管是什么类型的页面,它都承担着传递信息的目的。在向用户传递信息时,能否满足用户的需求,解决用户访问的问题,对这些页面类型的指导意义在于互通。
优采云data采集器的内容要清晰明了,写得合乎逻辑,用词优美,读起来舒服。从内容的特点来看,可以增强用户吸收内容后的获得感。比如优采云data采集器内容发人深省、轻松愉快、文笔好、有说服力等。严谨优雅的文笔更能体现行业的专业性,比如使用专业术语、词汇和思维方法。能够深入挖掘原因和逻辑,从多角度、多方面综合分析和阐述观点。对于需要指导用户操作的内容,要求明确、实用。如果无法通过文字等清楚地表达,
优采云Data采集器 的文章 内容精心打造,以改善用户的视觉和浏览体验。这里我们考察最常见也最容易被忽略的内容元素,例如:字体、段落、布局、大小标题、匹配辅助图片和视频等。优采云数据采集器要求是丰富美观,层次分明,贴合主题,升华主题,帮助用户更好地理解内容,获得连贯舒适的阅读体验。两个相对相似的内容可能由于布局不同而具有不同的质量分数。
使用优采云Data采集器的体验是流畅的,和上面提到的精致制作不同。精美的制作考察的是内容主体部分的美化,而这里考察的是页面的整体布局和核心。交互性、功能体验和舒适度。优采云数据采集器在设计页面时,首先要考虑核心需求需要哪些辅助功能和信息,帮助用户更好地理解内容。搜索排名受多种因素影响,例如用户偏好、网站整体质量等。原创单靠一个维度无法衡量为什么内容不是收录。如果站长觉得他的内容质量很高,他应该得到更好的搜索表示。
一键采集上传常见的细节问题(优采云数据采集器如何解决网站更新困难,网站内容充实等问题 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 156 次浏览 • 2022-03-21 04:13
)
优采云数据采集器,通过将关键词采集分配给全网数据源文章,网站可以有大量的文章生成与网站定位相关的@>,解决网站难以更新和网站内容丰富的问题。网站 的核心是内容。只有产生足够多的优质内容,才能吸引搜索引擎和用户的搜索需求。从长远来看,我们可以获得大量的流量,达到建立网站的根本目的。
优采云数据采集器通信是内容质量的核心部分。普通网页上的内容类型很多,如文章、视频,主要是内容,还有下载、查询工具等类型的操作,还有主页、个人主页、列表页、很快。不管是什么类型的页面,它都承担着传递信息的目的。在向用户传递信息时,能否满足用户的需求,解决用户访问的问题,对这些页面类型的指导意义在于互通。
优采云data采集器的内容要清晰明了,写得合乎逻辑,用词优美,读起来舒服。从内容的特点来看,可以增强用户吸收内容后的获得感。比如优采云data采集器内容发人深省、轻松愉快、文笔好、有说服力等。严谨优雅的文笔更能体现行业的专业性,比如使用专业术语、词汇和思维方法。能够深入挖掘原因和逻辑,从多角度、多方面综合分析和阐述观点。对于需要指导用户操作的内容,要求明确、实用。如果无法通过文字等清楚地表达,
优采云Data采集器 的文章 内容精心打造,以改善用户的视觉和浏览体验。这里我们考察最常见也最容易被忽略的内容元素,例如:字体、段落、布局、大小标题、匹配辅助图片和视频等。优采云数据采集器要求是丰富美观,层次分明,贴合主题,升华主题,帮助用户更好地理解内容,获得连贯舒适的阅读体验。两个相对相似的内容可能由于布局不同而具有不同的质量分数。
使用优采云Data采集器的体验是流畅的,和上面提到的精致制作不同。精美的制作考察的是内容主体部分的美化,而这里考察的是页面的整体布局和核心。交互性、功能体验和舒适度。优采云数据采集器在设计页面时,首先要考虑核心需求需要哪些辅助功能和信息,帮助用户更好地理解内容。搜索排名受多种因素影响,例如用户偏好、网站整体质量等。原创单靠一个维度无法衡量为什么内容不是收录。如果站长觉得他的内容质量很高,他应该得到更好的搜索表示。
查看全部
一键采集上传常见的细节问题(优采云数据采集器如何解决网站更新困难,网站内容充实等问题
)
优采云数据采集器,通过将关键词采集分配给全网数据源文章,网站可以有大量的文章生成与网站定位相关的@>,解决网站难以更新和网站内容丰富的问题。网站 的核心是内容。只有产生足够多的优质内容,才能吸引搜索引擎和用户的搜索需求。从长远来看,我们可以获得大量的流量,达到建立网站的根本目的。
优采云数据采集器通信是内容质量的核心部分。普通网页上的内容类型很多,如文章、视频,主要是内容,还有下载、查询工具等类型的操作,还有主页、个人主页、列表页、很快。不管是什么类型的页面,它都承担着传递信息的目的。在向用户传递信息时,能否满足用户的需求,解决用户访问的问题,对这些页面类型的指导意义在于互通。
优采云data采集器的内容要清晰明了,写得合乎逻辑,用词优美,读起来舒服。从内容的特点来看,可以增强用户吸收内容后的获得感。比如优采云data采集器内容发人深省、轻松愉快、文笔好、有说服力等。严谨优雅的文笔更能体现行业的专业性,比如使用专业术语、词汇和思维方法。能够深入挖掘原因和逻辑,从多角度、多方面综合分析和阐述观点。对于需要指导用户操作的内容,要求明确、实用。如果无法通过文字等清楚地表达,
优采云Data采集器 的文章 内容精心打造,以改善用户的视觉和浏览体验。这里我们考察最常见也最容易被忽略的内容元素,例如:字体、段落、布局、大小标题、匹配辅助图片和视频等。优采云数据采集器要求是丰富美观,层次分明,贴合主题,升华主题,帮助用户更好地理解内容,获得连贯舒适的阅读体验。两个相对相似的内容可能由于布局不同而具有不同的质量分数。
使用优采云Data采集器的体验是流畅的,和上面提到的精致制作不同。精美的制作考察的是内容主体部分的美化,而这里考察的是页面的整体布局和核心。交互性、功能体验和舒适度。优采云数据采集器在设计页面时,首先要考虑核心需求需要哪些辅助功能和信息,帮助用户更好地理解内容。搜索排名受多种因素影响,例如用户偏好、网站整体质量等。原创单靠一个维度无法衡量为什么内容不是收录。如果站长觉得他的内容质量很高,他应该得到更好的搜索表示。
一键采集上传常见的细节问题(优采云数据采集器如何解决网站更新困难,网站内容充实等问题 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 179 次浏览 • 2022-03-21 04:12
)
优采云数据采集器,通过将关键词采集分配给全网数据源文章,网站可以有大量的文章生成与网站定位相关的@>,解决网站难以更新和网站内容丰富的问题。网站 的核心是内容。只有产生足够多的优质内容,才能吸引搜索引擎和用户的搜索需求。从长远来看,我们可以获得大量的流量,达到建立网站的根本目的。
优采云数据采集器通信是内容质量的核心部分。普通网页上的内容类型很多,如文章、视频,主要是内容,还有下载、查询工具等类型的操作,还有主页、个人主页、列表页、很快。不管是什么类型的页面,它都承担着传递信息的目的。在向用户传递信息时,能否满足用户的需求,解决用户访问的问题,对这些页面类型的指导意义在于互通。
优采云data采集器的内容要清晰明了,写得合乎逻辑,用词优美,读起来舒服。从内容的特点来看,可以增强用户吸收内容后的获得感。比如优采云data采集器内容发人深省、轻松愉快、文笔好、有说服力等。严谨优雅的文笔更能体现行业的专业性,比如使用专业术语、词汇和思维方法。能够深入挖掘原因和逻辑,从多角度、多方面综合分析和阐述观点。对于需要指导用户操作的内容,要求明确、实用。如果无法通过文字等清楚地表达,
优采云Data采集器 的文章 内容精心打造,以改善用户的视觉和浏览体验。这里我们考察最常见也最容易被忽略的内容元素,例如:字体、段落、布局、大小标题、匹配辅助图片和视频等。优采云数据采集器要求是丰富美观,层次分明,贴合主题,升华主题,帮助用户更好地理解内容,获得连贯舒适的阅读体验。两个相对相似的内容可能由于布局不同而具有不同的质量分数。
使用优采云Data采集器的体验是流畅的,和上面提到的精致制作不同。精美的制作考察的是内容主体部分的美化,而这里考察的是页面的整体布局和核心。交互性、功能体验和舒适度。优采云数据采集器在设计页面时,首先要考虑核心需求需要哪些辅助功能和信息,帮助用户更好地理解内容。搜索排名受多种因素影响,例如用户偏好、网站整体质量等。原创单靠一个维度无法衡量为什么内容不是收录。如果站长觉得他的内容质量很高,他应该得到更好的搜索表示。
查看全部
一键采集上传常见的细节问题(优采云数据采集器如何解决网站更新困难,网站内容充实等问题
)
优采云数据采集器,通过将关键词采集分配给全网数据源文章,网站可以有大量的文章生成与网站定位相关的@>,解决网站难以更新和网站内容丰富的问题。网站 的核心是内容。只有产生足够多的优质内容,才能吸引搜索引擎和用户的搜索需求。从长远来看,我们可以获得大量的流量,达到建立网站的根本目的。
优采云数据采集器通信是内容质量的核心部分。普通网页上的内容类型很多,如文章、视频,主要是内容,还有下载、查询工具等类型的操作,还有主页、个人主页、列表页、很快。不管是什么类型的页面,它都承担着传递信息的目的。在向用户传递信息时,能否满足用户的需求,解决用户访问的问题,对这些页面类型的指导意义在于互通。
优采云data采集器的内容要清晰明了,写得合乎逻辑,用词优美,读起来舒服。从内容的特点来看,可以增强用户吸收内容后的获得感。比如优采云data采集器内容发人深省、轻松愉快、文笔好、有说服力等。严谨优雅的文笔更能体现行业的专业性,比如使用专业术语、词汇和思维方法。能够深入挖掘原因和逻辑,从多角度、多方面综合分析和阐述观点。对于需要指导用户操作的内容,要求明确、实用。如果无法通过文字等清楚地表达,
优采云Data采集器 的文章 内容精心打造,以改善用户的视觉和浏览体验。这里我们考察最常见也最容易被忽略的内容元素,例如:字体、段落、布局、大小标题、匹配辅助图片和视频等。优采云数据采集器要求是丰富美观,层次分明,贴合主题,升华主题,帮助用户更好地理解内容,获得连贯舒适的阅读体验。两个相对相似的内容可能由于布局不同而具有不同的质量分数。
使用优采云Data采集器的体验是流畅的,和上面提到的精致制作不同。精美的制作考察的是内容主体部分的美化,而这里考察的是页面的整体布局和核心。交互性、功能体验和舒适度。优采云数据采集器在设计页面时,首先要考虑核心需求需要哪些辅助功能和信息,帮助用户更好地理解内容。搜索排名受多种因素影响,例如用户偏好、网站整体质量等。原创单靠一个维度无法衡量为什么内容不是收录。如果站长觉得他的内容质量很高,他应该得到更好的搜索表示。
一键采集上传常见的细节问题(2个神仙功能,帮你快速收发文件并且做好归类)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-03-20 23:17
在日常工作中,我们经常需要采集各种信息,比如老师收作业、老板收工作报告等等。
但是,在使用常见的微信/QQ/邮箱/采集时,会出现以下问题:
1)采集100个文件,需要打开对话框100次,保存文件为100次
2)微信聊天中的文件经常面临3天过期、自动清理的风险
3)每个人提交的文件命名不能保证完全一致,后续分类管理不便
今天给大家带来2个神仙功能,帮你快速收发文件,分类好。一起来了解一下吧~
01WPS文件助手小程序帮你批量采集多个文件
最初采集文件时,必须手动将每个副本另存为,然后分类到文件夹中。
现在,使用“WPS文件助手”小程序,可以一键生成采集链接,提醒大家在线提交,轻松批量采集多个文件。
如何发起采集?
微信搜索“WPS文件助手”,打开下图小程序:
然后,只需 3 个步骤,就可以帮助教师、项目经理、管理员、组织者等小伙伴高效地采集和分类文件。
具体操作流程如下:
①选择文件采集类型,点击“发起采集” ②添加要采集的内容和信息,例如采集头脑风暴计划需要提交姓名;也可以设置提交截止时间③点击“邀请微信好友提交”,发到微信提醒大家填写提交
如果需要采集其他类型的文档,采集步骤同上~
如何让别人快速提交文件?
转发给微信好友后,对方只需点击小程序或链接即可进入提交界面:
具体操作流程如下:
①点击“选择文件提交”,可以选择云文件、微信聊天文件、微信图片、相册文件,根据自己的需要进行选择 ②比如点击“选择云文件”,选择文件后点击“选择文件上传” "
③填写采集器设置的信息,点击“确认提交”
如何查看采集结果
发起文档请求后,只有接收者可以查看文档采集结果。有3种查看方式:
①小程序:进入小程序首页,点击“查看采集记录”
② WPS手机版:点击底部“文档”,找到以提交内容命名的文件夹
③ WPS电脑版:点击我的电脑中的“WPS网盘”,找到以提交内容命名的文件夹
值得强调的是,采集结果实时更新,自动汇总到同一个文件夹中。
同时也为你省去重复下载的麻烦,打开文件就可以直接查看,甚至成为团队的知识库。
02使用“共享文件夹”告别重复通信,一次收发文件
在解决了多文档采集困难的问题后,人们经常会遇到文档需要重复发送,文档更新时需要重复通知的问题。
WPS“共享文件夹”功能让您可以一次将文件发送给多人,文件更新后无需重复通知。
例如,教师可以提前将课件、试卷、作业提交要求等文件放在一个文件夹中,然后将该文件夹设置为“共享文件夹”,邀请学生加入。
成功添加文件夹后,学生可以看到老师准备的学习资料,然后将作业直接上传到文件夹,形成班级作业库。
运营流程
① WPS手机版:
点击下方“文档”,选择已有文件夹或新建文件夹,将需要采集的文件内容和需求写入文档,然后通过微信、QQ等方式邀请会员。
② WPS电脑版:
点击首页左侧“文档-我的云文档”,新建文件夹或选择已有文件夹,选择“共享-立即共享”。
以上就是今天的介绍啦!希望这个“WPS文件助手”小程序和“共享文件夹”功能可以帮助你快速解决收发文件的问题~ 查看全部
一键采集上传常见的细节问题(2个神仙功能,帮你快速收发文件并且做好归类)
在日常工作中,我们经常需要采集各种信息,比如老师收作业、老板收工作报告等等。
但是,在使用常见的微信/QQ/邮箱/采集时,会出现以下问题:
1)采集100个文件,需要打开对话框100次,保存文件为100次
2)微信聊天中的文件经常面临3天过期、自动清理的风险
3)每个人提交的文件命名不能保证完全一致,后续分类管理不便
今天给大家带来2个神仙功能,帮你快速收发文件,分类好。一起来了解一下吧~
01WPS文件助手小程序帮你批量采集多个文件
最初采集文件时,必须手动将每个副本另存为,然后分类到文件夹中。
现在,使用“WPS文件助手”小程序,可以一键生成采集链接,提醒大家在线提交,轻松批量采集多个文件。
如何发起采集?
微信搜索“WPS文件助手”,打开下图小程序:
然后,只需 3 个步骤,就可以帮助教师、项目经理、管理员、组织者等小伙伴高效地采集和分类文件。
具体操作流程如下:
①选择文件采集类型,点击“发起采集” ②添加要采集的内容和信息,例如采集头脑风暴计划需要提交姓名;也可以设置提交截止时间③点击“邀请微信好友提交”,发到微信提醒大家填写提交
如果需要采集其他类型的文档,采集步骤同上~
如何让别人快速提交文件?
转发给微信好友后,对方只需点击小程序或链接即可进入提交界面:
具体操作流程如下:
①点击“选择文件提交”,可以选择云文件、微信聊天文件、微信图片、相册文件,根据自己的需要进行选择 ②比如点击“选择云文件”,选择文件后点击“选择文件上传” "
③填写采集器设置的信息,点击“确认提交”
如何查看采集结果
发起文档请求后,只有接收者可以查看文档采集结果。有3种查看方式:
①小程序:进入小程序首页,点击“查看采集记录”
② WPS手机版:点击底部“文档”,找到以提交内容命名的文件夹
③ WPS电脑版:点击我的电脑中的“WPS网盘”,找到以提交内容命名的文件夹
值得强调的是,采集结果实时更新,自动汇总到同一个文件夹中。
同时也为你省去重复下载的麻烦,打开文件就可以直接查看,甚至成为团队的知识库。
02使用“共享文件夹”告别重复通信,一次收发文件
在解决了多文档采集困难的问题后,人们经常会遇到文档需要重复发送,文档更新时需要重复通知的问题。
WPS“共享文件夹”功能让您可以一次将文件发送给多人,文件更新后无需重复通知。
例如,教师可以提前将课件、试卷、作业提交要求等文件放在一个文件夹中,然后将该文件夹设置为“共享文件夹”,邀请学生加入。
成功添加文件夹后,学生可以看到老师准备的学习资料,然后将作业直接上传到文件夹,形成班级作业库。
运营流程
① WPS手机版:
点击下方“文档”,选择已有文件夹或新建文件夹,将需要采集的文件内容和需求写入文档,然后通过微信、QQ等方式邀请会员。
② WPS电脑版:
点击首页左侧“文档-我的云文档”,新建文件夹或选择已有文件夹,选择“共享-立即共享”。
以上就是今天的介绍啦!希望这个“WPS文件助手”小程序和“共享文件夹”功能可以帮助你快速解决收发文件的问题~
一键采集上传常见的细节问题(10.未找到任何可发布的内容.答:程序会保存的选项 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 132 次浏览 • 2022-03-19 05:14
)
10.找不到可发布的内容。
答:这是程序在本地数据库中找不到未标记为未发出的记录。在这种情况下,您已经发布了所有数据,或者您没有选择任务栏中的内容。
11.测试或发布时,“只能一个账号同时在线,或者你的账号已经被禁用”
A:这是因为网站系统不允许一个账号同时在线,比如英制。在这种情况下,建议您使用 采集 发布的专用帐户。请勿使用它登录 网站。
12.有时候明明已经正确获取了web cookie,但是测试还是没有登录?
A:一个是cookie过期的问题,另一个可能是我们的程序没有正确获取到(抱歉,目前程序无法正确获取所有cookie)。在这种情况下,建议您使用专业的抓包软件,比如WSockExpert,来抓取cookies,然后将抓取到的cookies填入程序保存cookies的地方。
13.如何设置发布速度?
A:请在“编辑任务”的“文件保存和高级设置”中设置采集和发布速度,时间单位为毫秒。
14.采集地址重复。
A:程序会保存采集页面的地址,如果已经采集,默认不去采集。如果需要重新采集,可以删除所有原任务地址库和本地采集的数据。如果您要采集的网页内容不断变化,可以选择不检测重复选项
15.论坛怎么改用户发帖,一个用户太假了?
答:如果您使用网络上在线发布的方式,那么程序发布就相当于手动发布。您不能同时登录多个帐户,因此该程序不能。要实现多账号发帖,需要修改原有的论坛程序,让他可以使用多个用户名发帖。discuz的随机发布界面是一个修改后的程序,使用不同的用户发布到自己的论坛。
14.测试的URL采集是正常的,但是当真正的采集时却漏掉了很多。
A:程序默认会过滤掉重复的URL。如果一个 URL 已经在同一个站点下被获取,它不会转到 采集。
1 7.采集的数据入库后,显示很多问号?
答:这一般是入库时没有选对码造成的,请注意选码;
查看全部
一键采集上传常见的细节问题(10.未找到任何可发布的内容.答:程序会保存的选项
)
10.找不到可发布的内容。
答:这是程序在本地数据库中找不到未标记为未发出的记录。在这种情况下,您已经发布了所有数据,或者您没有选择任务栏中的内容。
11.测试或发布时,“只能一个账号同时在线,或者你的账号已经被禁用”
A:这是因为网站系统不允许一个账号同时在线,比如英制。在这种情况下,建议您使用 采集 发布的专用帐户。请勿使用它登录 网站。
12.有时候明明已经正确获取了web cookie,但是测试还是没有登录?
A:一个是cookie过期的问题,另一个可能是我们的程序没有正确获取到(抱歉,目前程序无法正确获取所有cookie)。在这种情况下,建议您使用专业的抓包软件,比如WSockExpert,来抓取cookies,然后将抓取到的cookies填入程序保存cookies的地方。
13.如何设置发布速度?
A:请在“编辑任务”的“文件保存和高级设置”中设置采集和发布速度,时间单位为毫秒。
14.采集地址重复。
A:程序会保存采集页面的地址,如果已经采集,默认不去采集。如果需要重新采集,可以删除所有原任务地址库和本地采集的数据。如果您要采集的网页内容不断变化,可以选择不检测重复选项
15.论坛怎么改用户发帖,一个用户太假了?
答:如果您使用网络上在线发布的方式,那么程序发布就相当于手动发布。您不能同时登录多个帐户,因此该程序不能。要实现多账号发帖,需要修改原有的论坛程序,让他可以使用多个用户名发帖。discuz的随机发布界面是一个修改后的程序,使用不同的用户发布到自己的论坛。
14.测试的URL采集是正常的,但是当真正的采集时却漏掉了很多。
A:程序默认会过滤掉重复的URL。如果一个 URL 已经在同一个站点下被获取,它不会转到 采集。
1 7.采集的数据入库后,显示很多问号?
答:这一般是入库时没有选对码造成的,请注意选码;
一键采集上传常见的细节问题(创壳网络科技-创想软件开发工作室开发和运营的外贸工具介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2022-03-17 16:04
创意亚马逊asin采集软件是创意软件开发工作室开发运营的外贸工具。是专为亚马逊开发的采集器,功能强大。
一、创意亚马逊asin采集软件主要功能如下:
·支持批量各种产品listing页面采集(店面前台、搜索结果、品类TOP100等);
·支持采集;
包括北美和欧洲在内的全球 12 个亚马逊网站
·支持采集子项(变体)信息;
·支持采集产品ASIN码、价格、评论数、跟进(offer)数、上架时间、Rank分类排名、主产品标题、短描述和长描述;
·支持采集高清图片、缩略图、产品细节图、变体高清缩略图、变体细节图;
·支持自定义正则配置,支持自定义字段设置,方便HTML文本提取,支持调试,支持多结果和自定义过滤,采集你需要的数据;
·支持过滤,可过滤指定价格、报价、过滤词、分类、排名、变体模型、强网页过滤等;
·支持批量修改价格;
·支持采集指定ASIN商品信息、所有买家评论、Q&A信息、所有合卖卖家信息、相关商品、最低报价等;
·支持条件删除器,自由选择不同的自定义过滤器配置,手动过滤删除导入或采集完成的数据,支持过滤器原因输出;
·支持自动删除非变体产品,删除主产品有变体,删除与主产品相同ASIN的变体,仅采集与主产品相同ASIN的变体;
·支持导出Excel/txt/WEB/XML;
二、创意亚马逊asin采集软件主要功能如下:
1、合卖产品:批量采集店铺资料分批合卖(一般为定制产品,货源充足),采集所有价格均为报价,支持出口以及后续购买模板,一键批量导出亚马逊专属联卖模板。它简单快捷。
2、竞品分析:采集竞品listing评论等数据,分析差评数量,词频统计分析评价词热度,分析其他产品综合数据(数量评论、评分、RANK 等)。
3、选品丰富:采集可对指定品类、TOP100产品页面、店铺、搜索结果等数据进行批量过滤整理,提取最佳产品,提高选品效率。
4、定点监控:支持定时或手动采集数据,支持比较器,分析产品时间区间内排名、评论、报价数量、价格等变化,自带脚本规划工具,可自动完成所需任务,自动保存指定项目不同时间段的数据快照。
5、数据分析:采集指定商品评论、QA问答、相关商品等,支持评论月度统计,按型号统计,统计图表,支持词频统计,支持快速过滤以查找差评数据。
6、数据搬家:采集将指定商品的数据和图片编辑成其他平台的上传模板,用于上传和分发商品。
7、图片采集:快速抓取产品和子产品的一个批次或一个ASIN的所有图片和详细图片,并支持自定义文件名。
8、提高办公效率:过滤产品,丰富采集辅助工具,采集各类页面数据,一键分析变异图片采集,数据统计、数据删除等功能定期更新,大大提高办公效率。 查看全部
一键采集上传常见的细节问题(创壳网络科技-创想软件开发工作室开发和运营的外贸工具介绍)
创意亚马逊asin采集软件是创意软件开发工作室开发运营的外贸工具。是专为亚马逊开发的采集器,功能强大。
一、创意亚马逊asin采集软件主要功能如下:
·支持批量各种产品listing页面采集(店面前台、搜索结果、品类TOP100等);
·支持采集;
包括北美和欧洲在内的全球 12 个亚马逊网站
·支持采集子项(变体)信息;
·支持采集产品ASIN码、价格、评论数、跟进(offer)数、上架时间、Rank分类排名、主产品标题、短描述和长描述;
·支持采集高清图片、缩略图、产品细节图、变体高清缩略图、变体细节图;
·支持自定义正则配置,支持自定义字段设置,方便HTML文本提取,支持调试,支持多结果和自定义过滤,采集你需要的数据;
·支持过滤,可过滤指定价格、报价、过滤词、分类、排名、变体模型、强网页过滤等;
·支持批量修改价格;
·支持采集指定ASIN商品信息、所有买家评论、Q&A信息、所有合卖卖家信息、相关商品、最低报价等;
·支持条件删除器,自由选择不同的自定义过滤器配置,手动过滤删除导入或采集完成的数据,支持过滤器原因输出;
·支持自动删除非变体产品,删除主产品有变体,删除与主产品相同ASIN的变体,仅采集与主产品相同ASIN的变体;
·支持导出Excel/txt/WEB/XML;
二、创意亚马逊asin采集软件主要功能如下:
1、合卖产品:批量采集店铺资料分批合卖(一般为定制产品,货源充足),采集所有价格均为报价,支持出口以及后续购买模板,一键批量导出亚马逊专属联卖模板。它简单快捷。
2、竞品分析:采集竞品listing评论等数据,分析差评数量,词频统计分析评价词热度,分析其他产品综合数据(数量评论、评分、RANK 等)。
3、选品丰富:采集可对指定品类、TOP100产品页面、店铺、搜索结果等数据进行批量过滤整理,提取最佳产品,提高选品效率。
4、定点监控:支持定时或手动采集数据,支持比较器,分析产品时间区间内排名、评论、报价数量、价格等变化,自带脚本规划工具,可自动完成所需任务,自动保存指定项目不同时间段的数据快照。
5、数据分析:采集指定商品评论、QA问答、相关商品等,支持评论月度统计,按型号统计,统计图表,支持词频统计,支持快速过滤以查找差评数据。
6、数据搬家:采集将指定商品的数据和图片编辑成其他平台的上传模板,用于上传和分发商品。
7、图片采集:快速抓取产品和子产品的一个批次或一个ASIN的所有图片和详细图片,并支持自定义文件名。
8、提高办公效率:过滤产品,丰富采集辅助工具,采集各类页面数据,一键分析变异图片采集,数据统计、数据删除等功能定期更新,大大提高办公效率。
一键采集上传常见的细节问题(一下需求收集平台-fileinput文件上传插件)
采集交流 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2022-03-10 13:21
本项目前端形式采用bootstrap-fileinput的风格。bootstrap-fileinput 是一个非常强大的文件上传插件。请注意,它是文件上传,而不仅仅是图像上传。当您第一次接触它时,您只需将其调整为您想要的样式。也花了半天时间。下面简单介绍一下需求采集平台项目中用到的插件的一些细节。
对了,别忘了详细阅读官方文档:Bootstrap File Input - © Kartik,英文,如果你看的话,你必须阅读它。
1. 提交模式
首先文档简单对比一下两种上传方式,一种是表单提交,一种是Ajax提交。从下图可以看出,官方推荐大家通过Ajax上传。显然,通过 Ajax 上传更自由,可以获得更多的功能。
2. 导入文件
然后你需要导入必要的 CSS 和 JS 文件。必须导入以下内容。调试了半天,发现插件没有导入。
引导程序.css
引导程序.js
jQuery.js
引导文件输入/css/fileinput.css
引导文件输入/js/fileinput.js
bootstrap-fileinput/js/locales/zh.js(中文文件,是否导入)
自己check in,找到对应的文件。以上6个必须导入。bootstrap-fileinput/js/plugins/目录下也有一些插件,根据具体要导入的功能而定。
3. 基本用法
下一步是使用插件。起初,我只是想改进一下文件类型表单的样式。默认的文件上传风格实在是让人无法忍受。
当不引入bootstrap-fileinput插件相关文件时,html代码如下:
文件输入
显示效果如下:
引入bootstrap-fileinput插件后,同样的html代码,显示效果如下:
基本文件引入后,添加一行js代码 $('#myfile').fileinput(); 在页面底部,会出现不同的效果。完整的HTML代码如下:
fileinput-example
fileinput-example
文件输入
$('#myfile').fileinput();
接下来,上传一些文件来试用默认样式。
看起来不错,项目最终看起来像这样:
该功能有一些限制,比如允许上传多张照片,但只能上传3张照片,每张照片最多只能达到1MB。要实现一些控制,有必要了解以下一些参数。
4. 控制参数
官方文档中有介绍,但是很多时候虽然有说明,但不一定能看懂。这个插件的功能我不是很熟悉。我刚刚达到了我想要的效果,我很感兴趣。可以自学。
以下是项目中配置的一些参数:
$("#input-id").fileinput({
showUpload: false,
previewFileType: 'any',
language: 'zh',
browseLabel: '图片多选',
browseClass: 'btn btn-default',
allowedFileTypes: ['image'], // 限制文件类型为图片
allowedFileExtensions: ['jpg', 'png'], // 限制文件后缀名为jpg,png,gif
maxFileCount: 3, // 限制最多3张图片
maxFileSize: 1024, // 限制图片大小,最大1024KB
allowedPreviewTypes: ['image'], // 允许预览的文件类型
initialCaption: '可以选择最多3张图片,格式为png或者jpg,大小不超过1M', // 初始化说明框框,比如该项目上默认显示:可以选择最多3张图片,格式为png或者jpg,大小不超过1M
layoutTemplates: {
main1: '{preview}\n' +
'\n' +
' \n' +
' {browse}\n' +
' {remove}\n' +
' \n' +
' {caption}\n' +
'',
footer: '\n' +
' {caption}{size}\n' +
''
}
}); // 修改默认样式,比如按钮移到左侧,预览窗口中图片的脚标等等(这里只显示文件名,如下图)
这里只是简单介绍一下bootstrap-fileinput插件的简单功能。更多功能的学习还是要靠自己的研究,尤其是Ajax上传功能。作者的研究深度有限,暂时不做过多介绍。如果有机会,我会做深入研究和分享。 查看全部
一键采集上传常见的细节问题(一下需求收集平台-fileinput文件上传插件)
本项目前端形式采用bootstrap-fileinput的风格。bootstrap-fileinput 是一个非常强大的文件上传插件。请注意,它是文件上传,而不仅仅是图像上传。当您第一次接触它时,您只需将其调整为您想要的样式。也花了半天时间。下面简单介绍一下需求采集平台项目中用到的插件的一些细节。
对了,别忘了详细阅读官方文档:Bootstrap File Input - © Kartik,英文,如果你看的话,你必须阅读它。
1. 提交模式
首先文档简单对比一下两种上传方式,一种是表单提交,一种是Ajax提交。从下图可以看出,官方推荐大家通过Ajax上传。显然,通过 Ajax 上传更自由,可以获得更多的功能。
2. 导入文件
然后你需要导入必要的 CSS 和 JS 文件。必须导入以下内容。调试了半天,发现插件没有导入。
引导程序.css
引导程序.js
jQuery.js
引导文件输入/css/fileinput.css
引导文件输入/js/fileinput.js
bootstrap-fileinput/js/locales/zh.js(中文文件,是否导入)
自己check in,找到对应的文件。以上6个必须导入。bootstrap-fileinput/js/plugins/目录下也有一些插件,根据具体要导入的功能而定。
3. 基本用法
下一步是使用插件。起初,我只是想改进一下文件类型表单的样式。默认的文件上传风格实在是让人无法忍受。
当不引入bootstrap-fileinput插件相关文件时,html代码如下:
文件输入
显示效果如下:
引入bootstrap-fileinput插件后,同样的html代码,显示效果如下:
基本文件引入后,添加一行js代码 $('#myfile').fileinput(); 在页面底部,会出现不同的效果。完整的HTML代码如下:
fileinput-example
fileinput-example
文件输入
$('#myfile').fileinput();
接下来,上传一些文件来试用默认样式。
看起来不错,项目最终看起来像这样:
该功能有一些限制,比如允许上传多张照片,但只能上传3张照片,每张照片最多只能达到1MB。要实现一些控制,有必要了解以下一些参数。
4. 控制参数
官方文档中有介绍,但是很多时候虽然有说明,但不一定能看懂。这个插件的功能我不是很熟悉。我刚刚达到了我想要的效果,我很感兴趣。可以自学。
以下是项目中配置的一些参数:
$("#input-id").fileinput({
showUpload: false,
previewFileType: 'any',
language: 'zh',
browseLabel: '图片多选',
browseClass: 'btn btn-default',
allowedFileTypes: ['image'], // 限制文件类型为图片
allowedFileExtensions: ['jpg', 'png'], // 限制文件后缀名为jpg,png,gif
maxFileCount: 3, // 限制最多3张图片
maxFileSize: 1024, // 限制图片大小,最大1024KB
allowedPreviewTypes: ['image'], // 允许预览的文件类型
initialCaption: '可以选择最多3张图片,格式为png或者jpg,大小不超过1M', // 初始化说明框框,比如该项目上默认显示:可以选择最多3张图片,格式为png或者jpg,大小不超过1M
layoutTemplates: {
main1: '{preview}\n' +
'\n' +
' \n' +
' {browse}\n' +
' {remove}\n' +
' \n' +
' {caption}\n' +
'',
footer: '\n' +
' {caption}{size}\n' +
''
}
}); // 修改默认样式,比如按钮移到左侧,预览窗口中图片的脚标等等(这里只显示文件名,如下图)
这里只是简单介绍一下bootstrap-fileinput插件的简单功能。更多功能的学习还是要靠自己的研究,尤其是Ajax上传功能。作者的研究深度有限,暂时不做过多介绍。如果有机会,我会做深入研究和分享。
一键采集上传常见的细节问题(SEO商务营销王中英文网站全自动更新系统概述及原理介绍)
采集交流 • 优采云 发表了文章 • 0 个评论 • 91 次浏览 • 2022-03-06 10:19
SEO商务营销王中英文网站自动更新系统有cms+SEO技术+中英文关键词分析+蜘蛛爬虫+网页智能信息抓取技术,目前支持织梦(DEDEcms), Empire(Empirecms), Wordpress, Z-blog, Dongyi, 5UCKS, discuz, phpwind等系统自动导入并自动生成静态页面,软件基于在预设信息上自动采集并发布,目标站每天可以自动维护和更新。是站长获取流量的绝佳工具。
软件功能概述及原理介绍
智能蜘蛛系统(采集)
只需设置采集目标站和采集规则,可以手动或自动采集目标站内容,同步目标站更新采集,使用蜘蛛内核模拟蜘蛛抓取网站内容不被拦截,强大的正则化轻松采集你想要的所有信息,包括邮箱、QQ和手机号等,不只做你想要的,还能过滤掉所有不需要的内容;
海拔伪原创系统
如果你觉得采集的文章不够原创,那么我们强大的伪原创系统可以解决这个问题,程序会按照你的要求执行,包括自动断头,文章前后自动添加原创文字,段落中随机插入短句或图片,替换约定词,完成文章拆分成多页合并同一主题的多个页面等。相似度降低文章,使搜索引擎判断为高权重原创文章;
多任务定时自动采集发布系统(无人值守)
您可以根据自己的需要自由设置采集的时间和发布文章的时间间隔,尽量科学、全自动地管理您的网站。您只需要定期检查发布的内容和软件输出。提示,根据搜索引擎的变化调整采集和发布的时间间隔;
强大的内部链接系统(SEO)
网站内部链接是SEO的重中之重。系统可以自由设置需要重点排名的关键词,并在发布时自动生成专门的页面,将出现在文章中的关键词放在... 查看全部
一键采集上传常见的细节问题(SEO商务营销王中英文网站全自动更新系统概述及原理介绍)
SEO商务营销王中英文网站自动更新系统有cms+SEO技术+中英文关键词分析+蜘蛛爬虫+网页智能信息抓取技术,目前支持织梦(DEDEcms), Empire(Empirecms), Wordpress, Z-blog, Dongyi, 5UCKS, discuz, phpwind等系统自动导入并自动生成静态页面,软件基于在预设信息上自动采集并发布,目标站每天可以自动维护和更新。是站长获取流量的绝佳工具。
软件功能概述及原理介绍
智能蜘蛛系统(采集)
只需设置采集目标站和采集规则,可以手动或自动采集目标站内容,同步目标站更新采集,使用蜘蛛内核模拟蜘蛛抓取网站内容不被拦截,强大的正则化轻松采集你想要的所有信息,包括邮箱、QQ和手机号等,不只做你想要的,还能过滤掉所有不需要的内容;
海拔伪原创系统
如果你觉得采集的文章不够原创,那么我们强大的伪原创系统可以解决这个问题,程序会按照你的要求执行,包括自动断头,文章前后自动添加原创文字,段落中随机插入短句或图片,替换约定词,完成文章拆分成多页合并同一主题的多个页面等。相似度降低文章,使搜索引擎判断为高权重原创文章;
多任务定时自动采集发布系统(无人值守)
您可以根据自己的需要自由设置采集的时间和发布文章的时间间隔,尽量科学、全自动地管理您的网站。您只需要定期检查发布的内容和软件输出。提示,根据搜索引擎的变化调整采集和发布的时间间隔;
强大的内部链接系统(SEO)
网站内部链接是SEO的重中之重。系统可以自由设置需要重点排名的关键词,并在发布时自动生成专门的页面,将出现在文章中的关键词放在...
一键采集上传常见的细节问题(更快发布到Emlog,怎样填写分类及设置分类??)
采集交流 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-03-06 01:19
为了更快上手入门资料采集并发布到Emlog网站网站,优采云采集特别总结了一些新手遇到的操作问题,为了让大家更熟练使用,列表如下:
1. 发帖到 Emlog,分类怎么填?
【分类】对应的值为Emlog的分类名称,在Emlog的后台--》分类;
2. 发帖到Emlog,发帖目标的对应字段如何填写?
'目标网站的字段名'是Emlog系统端对应的属性;
'value source 1'栏是选择采集字段和其他一些特殊参数;
'value source 2'栏一般都是用固定值填充的;
详细解释以下重要字段:
标题(必填):一般对应采集字段标题,可以从'source value 1'中选择;(可以多选组合字段);
内容(必填):为body部分,一般对应采集字段内容,可以从'Source Value 1'中选择;(可多选组合字段);
Category:发布数据的类别,值为Emlog的类别名称,不存在的类别会自动创建,不支持多类别发布,不填会发布到Uncategorized .
通常在‘源值2’中填写一个固定值,也可以选择‘值源1’中的采集字段(详见数据发布-设置分类(列)技巧);
Author:设置文章的发布者,该值可以是Emlog中已经存在的用户名或ID,不存在系统会自动创建;
一般在‘源值2’中填写一个固定值;(如果不选择不填,系统会自动映射Emlog管理员的名字)。
发布时间:设置文章的发布时间,默认发布时间(相当于实时,发布时显示什么时间)。 查看全部
一键采集上传常见的细节问题(更快发布到Emlog,怎样填写分类及设置分类??)
为了更快上手入门资料采集并发布到Emlog网站网站,优采云采集特别总结了一些新手遇到的操作问题,为了让大家更熟练使用,列表如下:
1. 发帖到 Emlog,分类怎么填?
【分类】对应的值为Emlog的分类名称,在Emlog的后台--》分类;
2. 发帖到Emlog,发帖目标的对应字段如何填写?
'目标网站的字段名'是Emlog系统端对应的属性;
'value source 1'栏是选择采集字段和其他一些特殊参数;
'value source 2'栏一般都是用固定值填充的;
详细解释以下重要字段:
标题(必填):一般对应采集字段标题,可以从'source value 1'中选择;(可以多选组合字段);
内容(必填):为body部分,一般对应采集字段内容,可以从'Source Value 1'中选择;(可多选组合字段);
Category:发布数据的类别,值为Emlog的类别名称,不存在的类别会自动创建,不支持多类别发布,不填会发布到Uncategorized .
通常在‘源值2’中填写一个固定值,也可以选择‘值源1’中的采集字段(详见数据发布-设置分类(列)技巧);
Author:设置文章的发布者,该值可以是Emlog中已经存在的用户名或ID,不存在系统会自动创建;
一般在‘源值2’中填写一个固定值;(如果不选择不填,系统会自动映射Emlog管理员的名字)。
发布时间:设置文章的发布时间,默认发布时间(相当于实时,发布时显示什么时间)。
一键采集上传常见的细节问题(数据采集软件更新网页内容,内容排版布局需要注意什么?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2022-03-02 00:22
数据采集软件,通过对全网数据进行采集,挖掘出文章对网站有帮助的内容数据,然后发布到网站经过二次处理@>. 数据采集软件拥有多种网页采集策略和配套资源,帮助整个采集流程实现数据的完整性和稳定性。站长无需了解爬虫编程技术,通过简单的操作即可轻松采集网页数据,然后一键导出多种格式,快速导入数据库。
数据采集软件优化网站内页和内容文章,主要是内容标题优化、图片优化、Alt标签优化、关键词布局优化,比如只有一个h1标签可以出现在一篇文章文章中,其他h标签不能大量使用。3 到 5 个 H 标签就足够了。alt标签的内容也要符合图片的内容,不能太多。堆叠产品 关键词 并自然地做。
数据采集软件seo注意事项,当一个新的网站运行了两个月甚至更长的时间,发现网站已经很久没有收录了。不要对网站进行大的改动,这对网站收录和排名非常不利,也会因为你的不合理改动而被搜索引擎降级。数据采集软件聚合文章,通俗的讲就是把重复的文章放在一起形成一个候选集,另外还有文章发布时间、评论、站点历史、转发轨迹等因素来识别和判断原创的内容。
其实大家都知道优质内容对于网站优化的重要性,但是坚持更新原创内容是一件费时费力的事情。为了解决这个问题,采集软件会将采集过来的数据文章简单的处理成一段伪原创内容,而文章可读性流畅,用户体验也能得到提升,对搜索引擎也会更加友好。
优化网站我们只需要记住一件事,那就是不断提升用户体验。这个话题永远不会过时。搜索引擎虽然有些方面并不完美,但一直在朝着好的方向努力。
数据 采集 软件更新网页内容。应特别注意内容的布局和布局。与文章主题无关的信息和不可用功能无法出现,可能会干扰用户阅读浏览,影响用户体验。网站内容来自全网,数据采集软件对网站自身内容生产力不足或内容生产力差的问题有很大帮助,整个网站很低。小编的建议:多制作对用户有价值的内容,让用户和搜索引擎对你更加友好。站点产生与 网站 域相关的内容,并通过域焦点获得搜索引擎的喜欢。不要采集 跨域内容以获取短期利益,这将导致 网站 域关注度下降。影响搜索引擎的评级。返回搜狐,查看更多 查看全部
一键采集上传常见的细节问题(数据采集软件更新网页内容,内容排版布局需要注意什么?)
数据采集软件,通过对全网数据进行采集,挖掘出文章对网站有帮助的内容数据,然后发布到网站经过二次处理@>. 数据采集软件拥有多种网页采集策略和配套资源,帮助整个采集流程实现数据的完整性和稳定性。站长无需了解爬虫编程技术,通过简单的操作即可轻松采集网页数据,然后一键导出多种格式,快速导入数据库。
数据采集软件优化网站内页和内容文章,主要是内容标题优化、图片优化、Alt标签优化、关键词布局优化,比如只有一个h1标签可以出现在一篇文章文章中,其他h标签不能大量使用。3 到 5 个 H 标签就足够了。alt标签的内容也要符合图片的内容,不能太多。堆叠产品 关键词 并自然地做。
数据采集软件seo注意事项,当一个新的网站运行了两个月甚至更长的时间,发现网站已经很久没有收录了。不要对网站进行大的改动,这对网站收录和排名非常不利,也会因为你的不合理改动而被搜索引擎降级。数据采集软件聚合文章,通俗的讲就是把重复的文章放在一起形成一个候选集,另外还有文章发布时间、评论、站点历史、转发轨迹等因素来识别和判断原创的内容。
其实大家都知道优质内容对于网站优化的重要性,但是坚持更新原创内容是一件费时费力的事情。为了解决这个问题,采集软件会将采集过来的数据文章简单的处理成一段伪原创内容,而文章可读性流畅,用户体验也能得到提升,对搜索引擎也会更加友好。
优化网站我们只需要记住一件事,那就是不断提升用户体验。这个话题永远不会过时。搜索引擎虽然有些方面并不完美,但一直在朝着好的方向努力。
数据 采集 软件更新网页内容。应特别注意内容的布局和布局。与文章主题无关的信息和不可用功能无法出现,可能会干扰用户阅读浏览,影响用户体验。网站内容来自全网,数据采集软件对网站自身内容生产力不足或内容生产力差的问题有很大帮助,整个网站很低。小编的建议:多制作对用户有价值的内容,让用户和搜索引擎对你更加友好。站点产生与 网站 域相关的内容,并通过域焦点获得搜索引擎的喜欢。不要采集 跨域内容以获取短期利益,这将导致 网站 域关注度下降。影响搜索引擎的评级。返回搜狐,查看更多
一键采集上传常见的细节问题(数据采集软件更新网页内容,内容排版布局需要注意什么?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 366 次浏览 • 2022-03-02 00:22
数据采集软件,通过对全网数据进行采集,挖掘出文章对网站有帮助的内容数据,然后发布到网站经过二次处理@>. 数据采集软件拥有多种网页采集策略和配套资源,帮助整个采集流程实现数据的完整性和稳定性。站长无需了解爬虫编程技术,通过简单的操作即可轻松采集网页数据,然后一键导出多种格式,快速导入数据库。
数据采集软件优化网站内页和内容文章,主要是内容标题优化、图片优化、Alt标签优化、关键词布局优化,比如只有一个h1标签可以出现在一篇文章文章中,其他h标签不能大量使用。3 到 5 个 H 标签就足够了。alt标签的内容也要符合图片的内容,不能太多。堆叠产品 关键词 并自然地做。
数据采集软件seo注意事项,当一个新的网站运行了两个月甚至更长的时间,发现网站已经很久没有收录了。不要对网站进行大的改动,这对网站收录和排名非常不利,也会因为你的不合理改动而被搜索引擎降级。数据采集软件聚合文章,通俗的讲就是把重复的文章放在一起形成一个候选集,另外还有文章发布时间、评论、站点历史、转发轨迹等因素来识别和判断原创的内容。
其实大家都知道优质内容对于网站优化的重要性,但是坚持更新原创内容是一件费时费力的事情。为了解决这个问题,采集软件会将采集过来的数据文章简单的处理成一段伪原创内容,而文章可读性流畅,用户体验也能得到提升,对搜索引擎也会更加友好。
优化网站我们只需要记住一件事,那就是不断提升用户体验。这个话题永远不会过时。搜索引擎虽然有些方面并不完美,但一直在朝着好的方向努力。
数据 采集 软件更新网页内容。应特别注意内容的布局和布局。与文章主题无关的信息和不可用功能无法出现,可能会干扰用户阅读浏览,影响用户体验。网站内容来自全网,数据采集软件对网站自身内容生产力不足或内容生产力差的问题有很大帮助,整个网站很低。小编的建议:多制作对用户有价值的内容,让用户和搜索引擎对你更加友好。站点产生与 网站 域相关的内容,并通过域焦点获得搜索引擎的喜欢。不要采集 跨域内容以获取短期利益,这将导致 网站 域关注度下降。影响搜索引擎的评级。返回搜狐,查看更多 查看全部
一键采集上传常见的细节问题(数据采集软件更新网页内容,内容排版布局需要注意什么?)
数据采集软件,通过对全网数据进行采集,挖掘出文章对网站有帮助的内容数据,然后发布到网站经过二次处理@>. 数据采集软件拥有多种网页采集策略和配套资源,帮助整个采集流程实现数据的完整性和稳定性。站长无需了解爬虫编程技术,通过简单的操作即可轻松采集网页数据,然后一键导出多种格式,快速导入数据库。
数据采集软件优化网站内页和内容文章,主要是内容标题优化、图片优化、Alt标签优化、关键词布局优化,比如只有一个h1标签可以出现在一篇文章文章中,其他h标签不能大量使用。3 到 5 个 H 标签就足够了。alt标签的内容也要符合图片的内容,不能太多。堆叠产品 关键词 并自然地做。
数据采集软件seo注意事项,当一个新的网站运行了两个月甚至更长的时间,发现网站已经很久没有收录了。不要对网站进行大的改动,这对网站收录和排名非常不利,也会因为你的不合理改动而被搜索引擎降级。数据采集软件聚合文章,通俗的讲就是把重复的文章放在一起形成一个候选集,另外还有文章发布时间、评论、站点历史、转发轨迹等因素来识别和判断原创的内容。
其实大家都知道优质内容对于网站优化的重要性,但是坚持更新原创内容是一件费时费力的事情。为了解决这个问题,采集软件会将采集过来的数据文章简单的处理成一段伪原创内容,而文章可读性流畅,用户体验也能得到提升,对搜索引擎也会更加友好。
优化网站我们只需要记住一件事,那就是不断提升用户体验。这个话题永远不会过时。搜索引擎虽然有些方面并不完美,但一直在朝着好的方向努力。
数据 采集 软件更新网页内容。应特别注意内容的布局和布局。与文章主题无关的信息和不可用功能无法出现,可能会干扰用户阅读浏览,影响用户体验。网站内容来自全网,数据采集软件对网站自身内容生产力不足或内容生产力差的问题有很大帮助,整个网站很低。小编的建议:多制作对用户有价值的内容,让用户和搜索引擎对你更加友好。站点产生与 网站 域相关的内容,并通过域焦点获得搜索引擎的喜欢。不要采集 跨域内容以获取短期利益,这将导致 网站 域关注度下降。影响搜索引擎的评级。返回搜狐,查看更多
一键采集上传常见的细节问题(()文件上传的内容上传内容及内容解析 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-02-28 14:25
)
一:文件上传:javascript
要求:
1:jsp的页面:
一:表格形式:
b:帖子提交:
c: form 指定一个属性:enctype="multipart/form-data"
d:文件组件:
2:小服务程序:
request.getParamter("name");//不生效:
ServletInputStream in = request.getInputStream();
把得到的数据封装进去,理论上可以解析数据。
3:请求在请求正文中:css
发布请求正文:
请求第一行:
请求头信息:html
请求正文:
------------------
普通组件:只有一个标头:Content-Dispositon:name="xxx"java
请求正文:mrzhang:填写内容。
------------------
文件上传字段:两个标题:
内容处置:表单数据;;文件名="C:\Users\Mrzhang\Desktop\copy2.txt"
内容类型:文本/纯 MIMEweb
文件上传内容:
xxxx阿帕奇
- - - - - - - 大批
二:解析请求中的请求体:
1:jar:Apache组织提供的公共组件:
公共文件上传
commons-io
文件上传相关的两个组件,这两个组件是强依赖的。
2:原理:
请求体中各个组件的内容被封装成一个对象:
FileItem 对象:使用对象的方法和属性来获取数据。
3:获取文件项:
a:获取工厂:
b:获取解析器:
c:使用解析器解析请求,获取fileItme对象:
对象代码:
// 获取工厂:
DiskFileItemFactory 工厂 = new DiskFileItemFactory();
// 获取解析器:
ServletFileUpload 上传 = 新的 ServletFileUpload(Factory);
// 解析请求并获取所有 FileItem 对象:
List list=upload.parseRequest(request); 浏览器
4:FileItem类详解:
isFormField() 判断组件是普通组件还是文件上传组件:true,普通组件:false:文件上传组件:
getFieldName() 返回普通字段属性的值。name= username 获取用户名的值:
获取字符串();获取普通字段的上传内容。
文件上传组件:
获取名称();获取文件名:
获取尺寸();将以字节为单位上传文件大小。长
获取输入流();获取文件上传对应的流:
写(文件文件);将文件内容写入指定位置:
雄猫
三:文件上传的具体代码;
(1)引入jar包:
(2)准备页面:
(3)准备 Servlet:
四:详情:
1:上传的普通字段内容:乱码:getString("utf-8");
2:上传的文件不能被外界直接访问,应隐藏:目的、安全;
应该是上传到web-inf,内容不能被外界直接访问。安全
获取 web-inf/files 的位置:tomcat 上的真实位置:
ServletContext.getRealPath("/WEB-INF/files");
3:文件的文件路径问题:
不同浏览器上传的路径不一致。一些浏览器上传相对路径,而另一些浏览器上传绝对路径。大多数浏览器上传的相对路径。
一个.txt
c:\user\mrzhang\files\a.txt
提取文件名:
字符串文件名 = f2.getName();
//截距:
int index = filename.lastIndexOf("\\");
如果(索引!=-1){
文件名 = 文件名.subString(index+1);
}
4:上传文件名乱码:
request.setCharacterEncoding("utf-8");
解析器提供了一个方法:
servletFileUpload.setHeaderEncoding("utf-8");// 提供的解析器。高优先级:request.setCharacterEncoding("utf-8")的封装;
5:文件名相同的问题:
解决方案1:uuid+“文件名”。后缀名;
解决方案2:new Date().getTime()+"filename";
6:上传的文件不能在同一个目录下: 上传的目录被打散了:
a:时间分手:获取当前时间,创建目录:
b: 文件名首字母分散:abc.txt : charAt("0")
c:散列分解:
实施步骤:
(1) 获取文件名:
(2)获取哈希值:hashCode(); int
(3)转换为十六进制: Integer.toHexString(); //String: 9A8B7C
(4) 获取字符串的前两位:第一个字母为一级目录,第二个字母为二级目录。16*16
package com.yidongxueyuan.web.servlet;
import java.io.File;
import java.io.IOException;
import java.util.List;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.apache.commons.fileupload.FileItem;
import org.apache.commons.fileupload.FileUploadException;
import org.apache.commons.fileupload.disk.DiskFileItemFactory;
import org.apache.commons.fileupload.servlet.ServletFileUpload;
/*
* 处理文件上传的servlet:
*
* 1:细节:
* 乱码解决了文件名称上传的乱码,
* 普通字段: getString("utf-8");
*
* 2:对相对路径进行了处理: subString();
*
* 3: 文件名称同名的问题,处理:
*
* 4: 哈希打散:
* filename.hashCode();
* filename.toHexString();
* filename.charAt(0);
*
* File dir= new File(root, charAt(0)+"\"+charAt(1));
*
* File destFile = new File(dir, savefilename);
*
* write();
*
*
*
*
*/
public class FileUploadServlet extends HttpServlet {
public void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
//解决上传文件名称的乱码问题:
request.setCharacterEncoding("utf-8");
response.setContentType("text/html;charset=utf-8");//告知客户端浏览器响应的内容: text/html charset=utf-8
/*
* 三步走:
* 1:得到工厂:
* 2: 得到解析器:
* 3:解析request:
*/
//得到得到解析器工厂;
DiskFileItemFactory factory = new DiskFileItemFactory(1024*20,new File("C:/Users/Mrzhang/javaEE/javaEE-07/temp"));
// DiskFileItemFactory factory = new DiskFileItemFactory();
//得到解析器:
ServletFileUpload upload = new ServletFileUpload(factory);
//解析以前设置上传单个文件的大小:
// upload.setFileSizeMax(1024*10);//这是最大是10K:
// upload.setSizeMax(1024*1024*10); //设置了整个request 的大小, 若是上传的request 大于设定的最大值, 也会触发异常
//解析request: 获List
try {
List fileItem = upload.parseRequest(request);
//解析fileItem当中的内容: web-inf下的: 目录安全: 不能被外界随机的访问:
FileItem f2 = fileItem.get(1);//文件上传的组件:
/*
* 得到文件的名称:
* f2.getName();
* f2.getInputStream(); 文件当中的内容:
* new FileOutputStream("path");
* 实现流对接:
*/
/*
* 得到要保存的路径:
* WEB-INF/files/
* 目的: 安全: 不能被外界直接经过浏览器访问:
* 得到ServletContext对象: 得到真实路径:
*/
String root = this.getServletContext().getRealPath("/WEB-INF/files/");
//得到上传文件的名称:
String filename = f2.getName();
/*
* 细节的处理:
* 1: 绝对路径的问题: 兼顾小部分浏览器:
*/
int index = filename.lastIndexOf("\\");
if(index != -1){//说明路径当中存在\\ :
filename = filename.substring(index+1);
}
/*
* 处理文件同名的问题: uuid
*/
String savename = CommonsUtils.uuid()+"_"+filename;
/*
* 哈希码 生产多个目录: 将上传的文件存放在多个目录当中:
*/
// 1:得到文件名称的哈希值:
int code = filename.hashCode();// int
// 2:得到code 的十六进制的值:
String hex = Integer.toHexString(code);// 9c0a1d
// 得到前两位: 充当第一层目录 和第二层目录:
char firstDir = hex.charAt(0);
char secDir = hex.charAt(1);
/*
* 得到保存的文件路径:
*/
File dirFile = new File(root, firstDir+"/"+secDir);//存放的目录:
//dirFile 若是不存在,建立:
if(!dirFile.exists()){//说明不存在
//建立“:
dirFile.mkdirs();//建立多层的目录:
}
//建立保存的文件:
File destFile = new File(dirFile, savename);
//保存:
try {
f2.write(destFile);
} catch (Exception e) {
e.printStackTrace();
}
} catch (FileUploadException e) {
// 触发异常: 说明文件过大:
request.setAttribute("msg", "您传的文件过大");
request.getRequestDispatcher("/index.jsp").forward(request, response);
e.printStackTrace();
}
}
}
文件下载
文件下载:
原来:服务器响应返回的数据:text/html 浏览器可以自动解析:
原理:现在要求服务端传递的数据是字节数组:服务端只需要响应一个字节流。
下载具有两个标头的流需要满足的条件:
Stream:服务器端响应返回的字节流。new FileOutputStream("字符串路径");
设置两个标题:
* Content-Type:这是文件类型的 MIME 类型:text/css text/javascript : tomcat : web.xml
* Content-Disposition : 默认值:inline 在浏览器中打开。
文件下载:附件;文件名=xxxx;
下载详情:
1:下载的文件名乱码:
一般解决方案:
新字符串(name.getBytes("gbk"),"iso-8859-1");
缺点:这种方法可以解决大部分浏览器,但是个别特殊字符无法解决:
不同的浏览器对文件名进行不同的编码:
修复狐:Base64:
其他浏览器:url
2:通用方式:提供一个工具类,稍后搜索:
文件下载servlet代码如下:
package com.yidongxueyuan.web.servlet;
import java.io.FileInputStream;
import java.io.IOException;
import java.net.URLEncoder;
import javax.servlet.ServletException;
import javax.servlet.ServletOutputStream;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.apache.commons.io.IOUtils;
import sun.misc.BASE64Encoder;
/*
* 负责下载的Servlet:
*/
public class DownLoadFileServlet extends HttpServlet {
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
/* request.setCharacterEncoding("utf-8");
response.setContentType("text/html;charset=utf-8");*/
/*
* 1: 文件的下载具有一个流: 两个头:
*/
String filename = "C:/Users/Mrzhang/Desktop/API/a练习图片/girl.jpg";
//头信息:
// Content-Type: MIME 文件的MIME类型:
String conentType= this.getServletContext().getMimeType(filename);//可以得到.jpg文件的MIME类型: image/jpeg
String name = "凤姐.jpg";
// String savename = new String(name.getBytes("gbk"),"iso-8859-1"); 解决 大部分状况:
String savename = FilenameEncodingUtils.filenameEncoding(name, request);
String contentDisposition = "attachment;filename="+savename;
//设置响应头信息:
response.setHeader("Content-Type",conentType );
response.setHeader("Content-Disposition", contentDisposition);
//准备的一个流:
//将图片读取到fis当中:
FileInputStream fis = new FileInputStream(filename);
//响应输出流:
ServletOutputStream out = response.getOutputStream();
//流对接: IOUtils
IOUtils.copy(fis, out);
fis.close();
out.close();
}
}
class FilenameEncodingUtils {
// 用来对下载的文件名称进行编码的!
public static String filenameEncoding(String filename, HttpServletRequest request) throws IOException {
String agent = request.getHeader("User-Agent"); //获取浏览器
if (agent.contains("Firefox")) {
BASE64Encoder base64Encoder = new BASE64Encoder();
filename = "=?utf-8?B?"
+ base64Encoder.encode(filename.getBytes("utf-8"))
+ "?=";
} else if(agent.contains("MSIE")) {
filename = URLEncoder.encode(filename, "utf-8");
} else {
filename = URLEncoder.encode(filename, "utf-8");
}
return filename;
}
} 查看全部
一键采集上传常见的细节问题(()文件上传的内容上传内容及内容解析
)
一:文件上传:javascript
要求:
1:jsp的页面:
一:表格形式:
b:帖子提交:
c: form 指定一个属性:enctype="multipart/form-data"
d:文件组件:
2:小服务程序:
request.getParamter("name");//不生效:
ServletInputStream in = request.getInputStream();
把得到的数据封装进去,理论上可以解析数据。
3:请求在请求正文中:css
发布请求正文:
请求第一行:
请求头信息:html
请求正文:
------------------
普通组件:只有一个标头:Content-Dispositon:name="xxx"java
请求正文:mrzhang:填写内容。
------------------
文件上传字段:两个标题:
内容处置:表单数据;;文件名="C:\Users\Mrzhang\Desktop\copy2.txt"
内容类型:文本/纯 MIMEweb
文件上传内容:
xxxx阿帕奇
- - - - - - - 大批
二:解析请求中的请求体:
1:jar:Apache组织提供的公共组件:
公共文件上传
commons-io
文件上传相关的两个组件,这两个组件是强依赖的。
2:原理:
请求体中各个组件的内容被封装成一个对象:
FileItem 对象:使用对象的方法和属性来获取数据。
3:获取文件项:
a:获取工厂:
b:获取解析器:
c:使用解析器解析请求,获取fileItme对象:
对象代码:
// 获取工厂:
DiskFileItemFactory 工厂 = new DiskFileItemFactory();
// 获取解析器:
ServletFileUpload 上传 = 新的 ServletFileUpload(Factory);
// 解析请求并获取所有 FileItem 对象:
List list=upload.parseRequest(request); 浏览器
4:FileItem类详解:
isFormField() 判断组件是普通组件还是文件上传组件:true,普通组件:false:文件上传组件:
getFieldName() 返回普通字段属性的值。name= username 获取用户名的值:
获取字符串();获取普通字段的上传内容。
文件上传组件:
获取名称();获取文件名:
获取尺寸();将以字节为单位上传文件大小。长
获取输入流();获取文件上传对应的流:
写(文件文件);将文件内容写入指定位置:
雄猫
三:文件上传的具体代码;
(1)引入jar包:
(2)准备页面:
(3)准备 Servlet:
四:详情:
1:上传的普通字段内容:乱码:getString("utf-8");
2:上传的文件不能被外界直接访问,应隐藏:目的、安全;
应该是上传到web-inf,内容不能被外界直接访问。安全
获取 web-inf/files 的位置:tomcat 上的真实位置:
ServletContext.getRealPath("/WEB-INF/files");
3:文件的文件路径问题:
不同浏览器上传的路径不一致。一些浏览器上传相对路径,而另一些浏览器上传绝对路径。大多数浏览器上传的相对路径。
一个.txt
c:\user\mrzhang\files\a.txt
提取文件名:
字符串文件名 = f2.getName();
//截距:
int index = filename.lastIndexOf("\\");
如果(索引!=-1){
文件名 = 文件名.subString(index+1);
}
4:上传文件名乱码:
request.setCharacterEncoding("utf-8");
解析器提供了一个方法:
servletFileUpload.setHeaderEncoding("utf-8");// 提供的解析器。高优先级:request.setCharacterEncoding("utf-8")的封装;
5:文件名相同的问题:
解决方案1:uuid+“文件名”。后缀名;
解决方案2:new Date().getTime()+"filename";
6:上传的文件不能在同一个目录下: 上传的目录被打散了:
a:时间分手:获取当前时间,创建目录:
b: 文件名首字母分散:abc.txt : charAt("0")
c:散列分解:
实施步骤:
(1) 获取文件名:
(2)获取哈希值:hashCode(); int
(3)转换为十六进制: Integer.toHexString(); //String: 9A8B7C
(4) 获取字符串的前两位:第一个字母为一级目录,第二个字母为二级目录。16*16
package com.yidongxueyuan.web.servlet;
import java.io.File;
import java.io.IOException;
import java.util.List;
import javax.servlet.ServletException;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.apache.commons.fileupload.FileItem;
import org.apache.commons.fileupload.FileUploadException;
import org.apache.commons.fileupload.disk.DiskFileItemFactory;
import org.apache.commons.fileupload.servlet.ServletFileUpload;
/*
* 处理文件上传的servlet:
*
* 1:细节:
* 乱码解决了文件名称上传的乱码,
* 普通字段: getString("utf-8");
*
* 2:对相对路径进行了处理: subString();
*
* 3: 文件名称同名的问题,处理:
*
* 4: 哈希打散:
* filename.hashCode();
* filename.toHexString();
* filename.charAt(0);
*
* File dir= new File(root, charAt(0)+"\"+charAt(1));
*
* File destFile = new File(dir, savefilename);
*
* write();
*
*
*
*
*/
public class FileUploadServlet extends HttpServlet {
public void doPost(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
//解决上传文件名称的乱码问题:
request.setCharacterEncoding("utf-8");
response.setContentType("text/html;charset=utf-8");//告知客户端浏览器响应的内容: text/html charset=utf-8
/*
* 三步走:
* 1:得到工厂:
* 2: 得到解析器:
* 3:解析request:
*/
//得到得到解析器工厂;
DiskFileItemFactory factory = new DiskFileItemFactory(1024*20,new File("C:/Users/Mrzhang/javaEE/javaEE-07/temp"));
// DiskFileItemFactory factory = new DiskFileItemFactory();
//得到解析器:
ServletFileUpload upload = new ServletFileUpload(factory);
//解析以前设置上传单个文件的大小:
// upload.setFileSizeMax(1024*10);//这是最大是10K:
// upload.setSizeMax(1024*1024*10); //设置了整个request 的大小, 若是上传的request 大于设定的最大值, 也会触发异常
//解析request: 获List
try {
List fileItem = upload.parseRequest(request);
//解析fileItem当中的内容: web-inf下的: 目录安全: 不能被外界随机的访问:
FileItem f2 = fileItem.get(1);//文件上传的组件:
/*
* 得到文件的名称:
* f2.getName();
* f2.getInputStream(); 文件当中的内容:
* new FileOutputStream("path");
* 实现流对接:
*/
/*
* 得到要保存的路径:
* WEB-INF/files/
* 目的: 安全: 不能被外界直接经过浏览器访问:
* 得到ServletContext对象: 得到真实路径:
*/
String root = this.getServletContext().getRealPath("/WEB-INF/files/");
//得到上传文件的名称:
String filename = f2.getName();
/*
* 细节的处理:
* 1: 绝对路径的问题: 兼顾小部分浏览器:
*/
int index = filename.lastIndexOf("\\");
if(index != -1){//说明路径当中存在\\ :
filename = filename.substring(index+1);
}
/*
* 处理文件同名的问题: uuid
*/
String savename = CommonsUtils.uuid()+"_"+filename;
/*
* 哈希码 生产多个目录: 将上传的文件存放在多个目录当中:
*/
// 1:得到文件名称的哈希值:
int code = filename.hashCode();// int
// 2:得到code 的十六进制的值:
String hex = Integer.toHexString(code);// 9c0a1d
// 得到前两位: 充当第一层目录 和第二层目录:
char firstDir = hex.charAt(0);
char secDir = hex.charAt(1);
/*
* 得到保存的文件路径:
*/
File dirFile = new File(root, firstDir+"/"+secDir);//存放的目录:
//dirFile 若是不存在,建立:
if(!dirFile.exists()){//说明不存在
//建立“:
dirFile.mkdirs();//建立多层的目录:
}
//建立保存的文件:
File destFile = new File(dirFile, savename);
//保存:
try {
f2.write(destFile);
} catch (Exception e) {
e.printStackTrace();
}
} catch (FileUploadException e) {
// 触发异常: 说明文件过大:
request.setAttribute("msg", "您传的文件过大");
request.getRequestDispatcher("/index.jsp").forward(request, response);
e.printStackTrace();
}
}
}
文件下载
文件下载:
原来:服务器响应返回的数据:text/html 浏览器可以自动解析:
原理:现在要求服务端传递的数据是字节数组:服务端只需要响应一个字节流。
下载具有两个标头的流需要满足的条件:
Stream:服务器端响应返回的字节流。new FileOutputStream("字符串路径");
设置两个标题:
* Content-Type:这是文件类型的 MIME 类型:text/css text/javascript : tomcat : web.xml
* Content-Disposition : 默认值:inline 在浏览器中打开。
文件下载:附件;文件名=xxxx;
下载详情:
1:下载的文件名乱码:
一般解决方案:
新字符串(name.getBytes("gbk"),"iso-8859-1");
缺点:这种方法可以解决大部分浏览器,但是个别特殊字符无法解决:
不同的浏览器对文件名进行不同的编码:
修复狐:Base64:
其他浏览器:url
2:通用方式:提供一个工具类,稍后搜索:
文件下载servlet代码如下:
package com.yidongxueyuan.web.servlet;
import java.io.FileInputStream;
import java.io.IOException;
import java.net.URLEncoder;
import javax.servlet.ServletException;
import javax.servlet.ServletOutputStream;
import javax.servlet.http.HttpServlet;
import javax.servlet.http.HttpServletRequest;
import javax.servlet.http.HttpServletResponse;
import org.apache.commons.io.IOUtils;
import sun.misc.BASE64Encoder;
/*
* 负责下载的Servlet:
*/
public class DownLoadFileServlet extends HttpServlet {
public void doGet(HttpServletRequest request, HttpServletResponse response)
throws ServletException, IOException {
/* request.setCharacterEncoding("utf-8");
response.setContentType("text/html;charset=utf-8");*/
/*
* 1: 文件的下载具有一个流: 两个头:
*/
String filename = "C:/Users/Mrzhang/Desktop/API/a练习图片/girl.jpg";
//头信息:
// Content-Type: MIME 文件的MIME类型:
String conentType= this.getServletContext().getMimeType(filename);//可以得到.jpg文件的MIME类型: image/jpeg
String name = "凤姐.jpg";
// String savename = new String(name.getBytes("gbk"),"iso-8859-1"); 解决 大部分状况:
String savename = FilenameEncodingUtils.filenameEncoding(name, request);
String contentDisposition = "attachment;filename="+savename;
//设置响应头信息:
response.setHeader("Content-Type",conentType );
response.setHeader("Content-Disposition", contentDisposition);
//准备的一个流:
//将图片读取到fis当中:
FileInputStream fis = new FileInputStream(filename);
//响应输出流:
ServletOutputStream out = response.getOutputStream();
//流对接: IOUtils
IOUtils.copy(fis, out);
fis.close();
out.close();
}
}
class FilenameEncodingUtils {
// 用来对下载的文件名称进行编码的!
public static String filenameEncoding(String filename, HttpServletRequest request) throws IOException {
String agent = request.getHeader("User-Agent"); //获取浏览器
if (agent.contains("Firefox")) {
BASE64Encoder base64Encoder = new BASE64Encoder();
filename = "=?utf-8?B?"
+ base64Encoder.encode(filename.getBytes("utf-8"))
+ "?=";
} else if(agent.contains("MSIE")) {
filename = URLEncoder.encode(filename, "utf-8");
} else {
filename = URLEncoder.encode(filename, "utf-8");
}
return filename;
}
}
一键采集上传常见的细节问题(简单用css和js实现小图片细节的功能,实现原理)
采集交流 • 优采云 发表了文章 • 0 个评论 • 127 次浏览 • 2022-02-28 11:06
在很多电商商品展示页面中,都会出现放大商品详情的功能。这里根据主要原理,简单的使用css和js来实现这个效果:
实施原则:
1、选择两张内容相同、大小不同的图片,一张是小图,有细节待选,一张是大图,展示细节。
2、要显示“小图的哪个细节”,就显示“大图的同一部分的细节”。这里涉及到比例的问题,也就是在小图中,
鼠标选择的细节大小和整个小图的纵横比要与大图和大图显示的区域的纵横比一致,这样效果才会真实。
如下所示:
根据等比例我们可以得到公式: h1/h2 = h3/h4 ; w1/w2 = w3/w4
由于在选择的时候图片的长宽已经固定了,所以需要改变的是根据比例改变小图片上浮动层的大小。
3、鼠标在小图上移动时,大图按比例在显示区域内移动,从而出现效果。
源代码展示:
<p> 1 doctype html>
2
3
4
5
6
7
8
9 自定义图片放大器
10
11
12 *{margin:0;padding:0;}
13
14 #show_bigger_pic{
15 position:absolute;
16 width:800px;
17 height:400px;
18 top:200px;
19 left:200px;
20 }
21 .small_pic_div{
22 width:273px;
23 height:177px;
24 border:1px solid;
25 float:left;
26 position:relative;/* cover:absolute定位使用*/
27 }
28 .big_pic_div{
29 width:273px;
30 height:177px;
31 border:1px solid;
32 float:left;
33 margin-left:10px;
34 display:none;
35 overflow:hidden;
36 }
37 .big_pic_div>img{
38 position:relative;
39 }
40 .cover{
41 width:273px;
42 height:177px;
43 position:absolute;
44 border:1px solid;
45 z-index:2;
46 left:0;
47 top:0;
48 }
49 .float_span{
50 width:80px;
51 height:80px;
52 position:absolute;
53 z-index:1;
54 background:#B2DFEE;
55 opacity:0.5;
56 display:none;
57 border:1px solid;
58 left:0;
59 top:0;
60 }
61
62
63
64
65 function gbc(tparent,tclass){//获取指定父元素的指定类的子元素的函数
66 var allclass=tparent.getElementsByTagName('*');
67 var result=[];
68 for (var i=0;i 查看全部
一键采集上传常见的细节问题(简单用css和js实现小图片细节的功能,实现原理)
在很多电商商品展示页面中,都会出现放大商品详情的功能。这里根据主要原理,简单的使用css和js来实现这个效果:
实施原则:
1、选择两张内容相同、大小不同的图片,一张是小图,有细节待选,一张是大图,展示细节。
2、要显示“小图的哪个细节”,就显示“大图的同一部分的细节”。这里涉及到比例的问题,也就是在小图中,
鼠标选择的细节大小和整个小图的纵横比要与大图和大图显示的区域的纵横比一致,这样效果才会真实。
如下所示:
根据等比例我们可以得到公式: h1/h2 = h3/h4 ; w1/w2 = w3/w4
由于在选择的时候图片的长宽已经固定了,所以需要改变的是根据比例改变小图片上浮动层的大小。
3、鼠标在小图上移动时,大图按比例在显示区域内移动,从而出现效果。
源代码展示:
<p> 1 doctype html>
2
3
4
5
6
7
8
9 自定义图片放大器
10
11
12 *{margin:0;padding:0;}
13
14 #show_bigger_pic{
15 position:absolute;
16 width:800px;
17 height:400px;
18 top:200px;
19 left:200px;
20 }
21 .small_pic_div{
22 width:273px;
23 height:177px;
24 border:1px solid;
25 float:left;
26 position:relative;/* cover:absolute定位使用*/
27 }
28 .big_pic_div{
29 width:273px;
30 height:177px;
31 border:1px solid;
32 float:left;
33 margin-left:10px;
34 display:none;
35 overflow:hidden;
36 }
37 .big_pic_div>img{
38 position:relative;
39 }
40 .cover{
41 width:273px;
42 height:177px;
43 position:absolute;
44 border:1px solid;
45 z-index:2;
46 left:0;
47 top:0;
48 }
49 .float_span{
50 width:80px;
51 height:80px;
52 position:absolute;
53 z-index:1;
54 background:#B2DFEE;
55 opacity:0.5;
56 display:none;
57 border:1px solid;
58 left:0;
59 top:0;
60 }
61
62
63
64
65 function gbc(tparent,tclass){//获取指定父元素的指定类的子元素的函数
66 var allclass=tparent.getElementsByTagName('*');
67 var result=[];
68 for (var i=0;i
一键采集上传常见的细节问题(优质内容的打造对于没时间来做网站优化的站长来说 )
采集交流 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-02-26 06:26
)
罗马不是一天建成的,我们SEO的核心精神也是坚持。网站有自己的关键词,SEO也有自己的核心关键词,那就是坚持。我们不仅需要每天更新网站内容,关键词创建、分析网站数据,还需要关注站内外用户体验和优化。
创造高质量的内容
对于没有时间做网站优化的站长,我们也可以通过一些cms采集软件来实现一些SEO技巧,cms采集软件功能强大,只要输入采集规则完成采集任务,通过软件自动采集和释放文章,也可以设置自动下载图片和替换链接(图片本地化),图片存储方式支持:阿里云、七牛、腾讯云、游拍云等。同时还配备自动内链,前后插入一定内容内容或标题形成“伪原创”。
cms采集软件支持按规则自动插入本地图片文章,提高原创作者的创作效率。
cms采集软件还具有直接监控已发布、待发布、是否伪原创、发布状态、URL、程序、发布时间等功能。@收录、网站 权重!
在我们的实践过程中,我们需要灵活运用我们的SEO理论知识。cms采集软件和SEO知识是我们从容应对工作中复杂情况的基础。SEO主要侧重于实际操作,这要求我们灵活应用,而不是机械地应用。
考虑用户的搜索习惯和需求
在我们编辑网站的内容之前,不妨想想用户的搜索习惯和需求。一个醒目的标题,总能打动用户的心。为什么其他人可以创建大量内容?学位源于标题的吸引力。我们如何分析用户的搜索习惯和需求,一般通过下拉框、相关搜索、百度索引等工具。同时,内容需要高度相关,关键词的密度要合理,而不是仅仅依靠标题来留住用户。一定要对用户进行细分。
把握市场脉搏
我们需要掌握的是各种搜索引擎的算法及其发展趋势。请注意排名规则的更新,这方面通常有很多需要学习和研究的地方。因为互联网正在飞速发展,要想从竞争对手中脱颖而出,就需要比竞争对手付出更多的努力。我们必须紧跟市场脉搏,紧跟市场发展的潮流。
不断学习和提高
无论搜索引擎有多少排名算法,核心始终是尽快将最好的质量和最好的用户体验呈现给用户。围绕这个核心,我们不会偏离方向。在学习的过程中,总结很重要。不同的人有不同的理解,我们要在实践中不断总结和形成自己的想法。
查看全部
一键采集上传常见的细节问题(优质内容的打造对于没时间来做网站优化的站长来说
)
罗马不是一天建成的,我们SEO的核心精神也是坚持。网站有自己的关键词,SEO也有自己的核心关键词,那就是坚持。我们不仅需要每天更新网站内容,关键词创建、分析网站数据,还需要关注站内外用户体验和优化。
创造高质量的内容
对于没有时间做网站优化的站长,我们也可以通过一些cms采集软件来实现一些SEO技巧,cms采集软件功能强大,只要输入采集规则完成采集任务,通过软件自动采集和释放文章,也可以设置自动下载图片和替换链接(图片本地化),图片存储方式支持:阿里云、七牛、腾讯云、游拍云等。同时还配备自动内链,前后插入一定内容内容或标题形成“伪原创”。
cms采集软件支持按规则自动插入本地图片文章,提高原创作者的创作效率。
cms采集软件还具有直接监控已发布、待发布、是否伪原创、发布状态、URL、程序、发布时间等功能。@收录、网站 权重!
在我们的实践过程中,我们需要灵活运用我们的SEO理论知识。cms采集软件和SEO知识是我们从容应对工作中复杂情况的基础。SEO主要侧重于实际操作,这要求我们灵活应用,而不是机械地应用。
考虑用户的搜索习惯和需求
在我们编辑网站的内容之前,不妨想想用户的搜索习惯和需求。一个醒目的标题,总能打动用户的心。为什么其他人可以创建大量内容?学位源于标题的吸引力。我们如何分析用户的搜索习惯和需求,一般通过下拉框、相关搜索、百度索引等工具。同时,内容需要高度相关,关键词的密度要合理,而不是仅仅依靠标题来留住用户。一定要对用户进行细分。
把握市场脉搏
我们需要掌握的是各种搜索引擎的算法及其发展趋势。请注意排名规则的更新,这方面通常有很多需要学习和研究的地方。因为互联网正在飞速发展,要想从竞争对手中脱颖而出,就需要比竞争对手付出更多的努力。我们必须紧跟市场脉搏,紧跟市场发展的潮流。
不断学习和提高
无论搜索引擎有多少排名算法,核心始终是尽快将最好的质量和最好的用户体验呈现给用户。围绕这个核心,我们不会偏离方向。在学习的过程中,总结很重要。不同的人有不同的理解,我们要在实践中不断总结和形成自己的想法。
一键采集上传常见的细节问题(不上资源站API的几种原因及解决办法!(建议收藏))
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-02-23 12:16
在插件中选择资源站,点击进入,提示XML格式不正确,不支持采集,或者服务器网络不稳定或禁用采集怎么办@>?
如图,如果提示这个,说明资源站API无法链接,可能是以下原因造成的1、你的服务器连接对方资源站的延迟是比较高,数据返回慢,导致程序报出这个错误。2、资源站有问题,导致API失效,无法连接。比如关闭,不工作,停止更新,没有它怎么链接采集?3、自己服务器的网络问题,如果资源站没有出现故障并且还在运行,说明自己的服务器网络无法连接到对方的服务器,所以可以理解,有人想说,我怎么开资源站,有资料, 网络怎么会有问题?网络好坏,每个资源站都是不同人做的,不是我的插件。他们的服务器在不同的地区。您可以打开资源站并指明您的服务器可以访问的区域。未打开的资源站点指示您的服务器无法访问的区域。说了这么多,不知道怎么解释,还有人看不懂!首先你要清楚,插件中提供的多个资源站,并不是每个资源站,你的服务器都可以连接。你的服务器网络问题,或者对方资源站api的问题想采集,但是连接不上,怎么解决?第一种情况:进入程序后台的系统设置,切换到“
第二种情况:如果其他资源站宕机,无法连接,你着急也没用。就算掉线了怎么连接?建议更换其他资源站采集第三种情况:如果是因为你的服务器内部网络不稳定,除非你换服务器才能解决。看看哪个服务器的网络可以连接,就像你家的宽带网络一样,能保证在日本、韩国、美国、新加坡任何地区都能访问网站吗?不同的资源站使用不同的服务器。有些服务器可能在日本,有些可能在美国,有些可能在香港。建议换服务器!总结:插件只是一个类似于中介的角色,它只是提供了多个资源站供您选择。如果这个采集不行,你可以选择其他的采集,取其采集采集哪个,插件不直接解决你和你的连接问题对方的资源站! 查看全部
一键采集上传常见的细节问题(不上资源站API的几种原因及解决办法!(建议收藏))
在插件中选择资源站,点击进入,提示XML格式不正确,不支持采集,或者服务器网络不稳定或禁用采集怎么办@>?
https://xiaoyichuanmeigzs.cn/w ... 4.jpg 300w, https://xiaoyichuanmeigzs.cn/w ... 4.jpg 768w" />如图,如果提示这个,说明资源站API无法链接,可能是以下原因造成的1、你的服务器连接对方资源站的延迟是比较高,数据返回慢,导致程序报出这个错误。2、资源站有问题,导致API失效,无法连接。比如关闭,不工作,停止更新,没有它怎么链接采集?3、自己服务器的网络问题,如果资源站没有出现故障并且还在运行,说明自己的服务器网络无法连接到对方的服务器,所以可以理解,有人想说,我怎么开资源站,有资料, 网络怎么会有问题?网络好坏,每个资源站都是不同人做的,不是我的插件。他们的服务器在不同的地区。您可以打开资源站并指明您的服务器可以访问的区域。未打开的资源站点指示您的服务器无法访问的区域。说了这么多,不知道怎么解释,还有人看不懂!首先你要清楚,插件中提供的多个资源站,并不是每个资源站,你的服务器都可以连接。你的服务器网络问题,或者对方资源站api的问题想采集,但是连接不上,怎么解决?第一种情况:进入程序后台的系统设置,切换到“
https://xiaoyichuanmeigzs.cn/w ... 3.jpg 300w" />第二种情况:如果其他资源站宕机,无法连接,你着急也没用。就算掉线了怎么连接?建议更换其他资源站采集第三种情况:如果是因为你的服务器内部网络不稳定,除非你换服务器才能解决。看看哪个服务器的网络可以连接,就像你家的宽带网络一样,能保证在日本、韩国、美国、新加坡任何地区都能访问网站吗?不同的资源站使用不同的服务器。有些服务器可能在日本,有些可能在美国,有些可能在香港。建议换服务器!总结:插件只是一个类似于中介的角色,它只是提供了多个资源站供您选择。如果这个采集不行,你可以选择其他的采集,取其采集采集哪个,插件不直接解决你和你的连接问题对方的资源站!
一键采集上传常见的细节问题(直击痛点:产品原型支持无缝接入摹客的产品经理工作大有裨益)
采集交流 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-02-20 16:04
2019年6月6日,产品协同设计平台Mocket全新升级,支持Axure和Mockplus原型上传,为产品原型提供协同设计新途径。
产品原型设计是软件产品上市前不可或缺的环节。在一个产品原型交付之前,会面临无数次的沟通、讨论、修改、迭代……作为项目的核心负责人,产品经理会花费大量的时间和精力去沟通和沟通关于需求对接、产品文档、团队意见、项目进度等。
产品经理的处境有多糟糕?从下面UPA(国际用户体验专业协会)发布的完整产品用户体验设计流程图可以看出。
不难看出,设计开发过程曲折复杂,会极大地消耗产品经理的时间和精力,进而影响到整个产品团队。
如何减轻产品经理的负担,让产品团队受益?
自 Mockplus 创建以来,Mockplus 团队一直在为之努力。Mockplus的Mockplus快速原型设计深受产品经理的青睐。此外,Axure作为老牌原型制作工具,也是国内设计团队常用的工具。虽然这两个工具非常适合产品经理的工作,但它们也存在一些问题——
Axure 的原型设计不能在国内在线发布,也不能进行评论评分;
Axure 和 Mockplus 的原型无法同时查看所有页面的全貌;
Axure 和 Mockplus 的原型线框无法从视觉设计中查看;
Axure、Mockplus绘制的原型无法标注裁剪,轻量级项目无法直接交付开发;
...
针对以上痛点,Mocket 团队做了详细的检查,最终找到了问题的根源——产品原型无法连接到工作流。
现在,直击痛点!Axure和Mockplus的产品原型支持无缝接入Mockplus!
通过一键上传Axure和Mockplus的原型到Mockplus,将产品原型连接到Mockplus灵活的工作流程,为产品原型提供高效的协作方式,解决产品经理沟通难、协调难、效率低的问题,并进一步推动产品团队快速成长,最大化服务产品团队。
与工具相比,基于平台的协作具有更全面、更智能的优势。与传统方法相比,大大节省了人工操作带来的时间和成本。
几个核心功能点包括:原型即时发布、原型在线审核、产品文档管理、原型文档全局查看。
手动导出和发送原型是一种传统的方法,既繁琐又容易出错。Iggler 支持产品原型即时发布,一键分享,在线演示时完美呈现原生交互设计。现在,无需手动导出或上传,产品经理可以通过Mockplus插件一键将Axure和Mockplus的原型发布到Mockplus。
匹配需求、召开会议、交流讨论、总结修改意见……太多无用、低效的琐事占据了产品经理的日常生活。产品经理迫切需要一种更有效的方式来采集意见和跟踪反馈。
Mocket的在线评论可以满足这个需求。Mocket 支持多人协作处理一个文档,提供多种评论和注释工具,可以根据需要进行选择,更直观地表达意见。评论还支持@team 成员并标记评论以获取解决状态。. 并且基于灵活的工作流协作模式,在高效的同时又不失自由度和灵活性,可以完美满足不同规模团队的高效协作。
文档管理一直是一项繁琐的工作,新版本和旧版本,高保真和低保真,原型和设计图纸……无数产品经理淹没在浩瀚的文件中。Iggler实现了设计稿和原型图的一键切换,不仅让设计稿的对比更加直观,也便于管理。支持源文件自动备份,自动生成历史版本,简化文件管理。
在Axure和Mockplus中,只能逐页查看原型图,无法预览原型图全图,整个产品逻辑一目了然。针对这个问题,Mocket 实现了一个无限大的画板,将所有页面全视图展示,并用逻辑线制作了一个简单的流程图,为产品经理提供了上帝视角和原型的全貌。
Mock作为新一代产品协同设计平台,是产品经理、UI设计师、开发工程师高效协作的舞台。Mock拥有长达十年的产品团队和开发团队,为产品团队搭建了良好的支撑和架构,以Code是材料,浇筑了坚固的钢筋混凝土,帮助产品团队跳舞,绽放,散发出最耀眼的光芒产品光。 查看全部
一键采集上传常见的细节问题(直击痛点:产品原型支持无缝接入摹客的产品经理工作大有裨益)
2019年6月6日,产品协同设计平台Mocket全新升级,支持Axure和Mockplus原型上传,为产品原型提供协同设计新途径。
产品原型设计是软件产品上市前不可或缺的环节。在一个产品原型交付之前,会面临无数次的沟通、讨论、修改、迭代……作为项目的核心负责人,产品经理会花费大量的时间和精力去沟通和沟通关于需求对接、产品文档、团队意见、项目进度等。
产品经理的处境有多糟糕?从下面UPA(国际用户体验专业协会)发布的完整产品用户体验设计流程图可以看出。
不难看出,设计开发过程曲折复杂,会极大地消耗产品经理的时间和精力,进而影响到整个产品团队。
如何减轻产品经理的负担,让产品团队受益?
自 Mockplus 创建以来,Mockplus 团队一直在为之努力。Mockplus的Mockplus快速原型设计深受产品经理的青睐。此外,Axure作为老牌原型制作工具,也是国内设计团队常用的工具。虽然这两个工具非常适合产品经理的工作,但它们也存在一些问题——
Axure 的原型设计不能在国内在线发布,也不能进行评论评分;
Axure 和 Mockplus 的原型无法同时查看所有页面的全貌;
Axure 和 Mockplus 的原型线框无法从视觉设计中查看;
Axure、Mockplus绘制的原型无法标注裁剪,轻量级项目无法直接交付开发;
...
针对以上痛点,Mocket 团队做了详细的检查,最终找到了问题的根源——产品原型无法连接到工作流。
现在,直击痛点!Axure和Mockplus的产品原型支持无缝接入Mockplus!
通过一键上传Axure和Mockplus的原型到Mockplus,将产品原型连接到Mockplus灵活的工作流程,为产品原型提供高效的协作方式,解决产品经理沟通难、协调难、效率低的问题,并进一步推动产品团队快速成长,最大化服务产品团队。
与工具相比,基于平台的协作具有更全面、更智能的优势。与传统方法相比,大大节省了人工操作带来的时间和成本。
几个核心功能点包括:原型即时发布、原型在线审核、产品文档管理、原型文档全局查看。
手动导出和发送原型是一种传统的方法,既繁琐又容易出错。Iggler 支持产品原型即时发布,一键分享,在线演示时完美呈现原生交互设计。现在,无需手动导出或上传,产品经理可以通过Mockplus插件一键将Axure和Mockplus的原型发布到Mockplus。
匹配需求、召开会议、交流讨论、总结修改意见……太多无用、低效的琐事占据了产品经理的日常生活。产品经理迫切需要一种更有效的方式来采集意见和跟踪反馈。
Mocket的在线评论可以满足这个需求。Mocket 支持多人协作处理一个文档,提供多种评论和注释工具,可以根据需要进行选择,更直观地表达意见。评论还支持@team 成员并标记评论以获取解决状态。. 并且基于灵活的工作流协作模式,在高效的同时又不失自由度和灵活性,可以完美满足不同规模团队的高效协作。
文档管理一直是一项繁琐的工作,新版本和旧版本,高保真和低保真,原型和设计图纸……无数产品经理淹没在浩瀚的文件中。Iggler实现了设计稿和原型图的一键切换,不仅让设计稿的对比更加直观,也便于管理。支持源文件自动备份,自动生成历史版本,简化文件管理。
在Axure和Mockplus中,只能逐页查看原型图,无法预览原型图全图,整个产品逻辑一目了然。针对这个问题,Mocket 实现了一个无限大的画板,将所有页面全视图展示,并用逻辑线制作了一个简单的流程图,为产品经理提供了上帝视角和原型的全貌。
Mock作为新一代产品协同设计平台,是产品经理、UI设计师、开发工程师高效协作的舞台。Mock拥有长达十年的产品团队和开发团队,为产品团队搭建了良好的支撑和架构,以Code是材料,浇筑了坚固的钢筋混凝土,帮助产品团队跳舞,绽放,散发出最耀眼的光芒产品光。
一键采集上传常见的细节问题(优采云站群软件V18.01.02更新如下内容介绍及应用)
采集交流 • 优采云 发表了文章 • 0 个评论 • 140 次浏览 • 2022-02-19 23:14
优采云站群管理系统是多任务系统,只需要输入关键词,即可采集到最新的相关内容,自动发布SEO到指定网站 站群管理系统,可24小时不间断维护数百个网站。优采云站群管理系统可以根据设置关键词自动爬取各大搜索引擎的相关搜索词和相关长尾词,然后根据设置爬取大量最新的衍生词数据,彻底摒弃普通采集软件所需的繁琐规则定制,实现一键式采集一键发布。优采云站群管理系统无需绑定电脑或IP,网站的数量没有限制,可以24小时挂机采集维护,让站长轻松管理上百个网站。软件独有的内容采集引擎,可以及时准确地采集互联网上的最新内容。内置文章伪原创功能,可以大大增加网站的收录,为站长带来更多流量!
优采云站群软件已经支持的核心功能:
无限添加域名,网站,中文站群采集,英文站群采集,指定网址采集,自定义发布界面,自定义生成原创文章,长尾关键词采集,相关图片采集,全球SEO链轮,文章自动加入内链,随机抽取内容为标题,交换不同内容段落,随机插入指定关键字,定时发布文章,自动内容伪原创,群参设置,群链接库互联,自动监听挂机采集发布,自动更新网站首页栏目内页为静态等。
优采云站群软件V18.01.02更新如下:
1、修复一些js报错bug
2、修复日志错误
3、修复挂机时异常过冲的bug
4、完善其他细节功能
5、完善群发外链工具
6、添加指定ie绑定子程序,发布指定采集效率更高
7、界面工具增加页面坐标定位等功能
8、新增每组可单独设置允许更新时间范围
9、新增至尊版用户,挂机时每个站文件夹自动导入txt
10、新增文章列库分库功能,实现单站理论上无限数据存储
11、为避免百度清风算法添加,详见分组参数中3.2.1.4中的参数
12、网站日志和seo查询作为子程序独立运行,避免与主程序抢资源
13、优化所有子程序,运行效率更高
14、新增启动程序,方便设置和发送桌面快捷方式。原来站群是主程序,不应该修改启动程序的名字,以免出现异常。
15、新增2个效率选项,在主程序左上角从系统中选择
优采云站群软件V17.06.16更新如下内容:
1、修复之前独立子程序积累的所有bug,完善更详细的功能
2、增加子组参数自动切换功能
3、新增至尊版自定义题库功能
4、群发外链工具V170321入门版也可以用
5、修复英文采集
6、修复视频采集
7、仅当新标题或内容收录指定的域名时才会添加到数据库中
8、添加内容编辑器2,修复之前无法编辑的文章用户使用
9、界面工具修复个别bug
10、改进其他细节
优采云站群软件V17.02.24更新如下内容:
1、增强关键词采集文章及指定域名采集文章的高质量自动识别
2、修复至尊版用户栏目调用段落库的bug
3、改善群发外链工具卡死的问题
4、关键词采集文章修复采集实图
5、搜狗推荐新闻bug
6、Content伪原创 中的时间参数
7、指定域名支持前端采集解决一些网页后端采集为空
8、添加文章 用于导出处理的个别详细功能
9、添加挂机是间隔分钟的设置
查看全部
一键采集上传常见的细节问题(优采云站群软件V18.01.02更新如下内容介绍及应用)
优采云站群管理系统是多任务系统,只需要输入关键词,即可采集到最新的相关内容,自动发布SEO到指定网站 站群管理系统,可24小时不间断维护数百个网站。优采云站群管理系统可以根据设置关键词自动爬取各大搜索引擎的相关搜索词和相关长尾词,然后根据设置爬取大量最新的衍生词数据,彻底摒弃普通采集软件所需的繁琐规则定制,实现一键式采集一键发布。优采云站群管理系统无需绑定电脑或IP,网站的数量没有限制,可以24小时挂机采集维护,让站长轻松管理上百个网站。软件独有的内容采集引擎,可以及时准确地采集互联网上的最新内容。内置文章伪原创功能,可以大大增加网站的收录,为站长带来更多流量!
优采云站群软件已经支持的核心功能:
无限添加域名,网站,中文站群采集,英文站群采集,指定网址采集,自定义发布界面,自定义生成原创文章,长尾关键词采集,相关图片采集,全球SEO链轮,文章自动加入内链,随机抽取内容为标题,交换不同内容段落,随机插入指定关键字,定时发布文章,自动内容伪原创,群参设置,群链接库互联,自动监听挂机采集发布,自动更新网站首页栏目内页为静态等。
优采云站群软件V18.01.02更新如下:
1、修复一些js报错bug
2、修复日志错误
3、修复挂机时异常过冲的bug
4、完善其他细节功能
5、完善群发外链工具
6、添加指定ie绑定子程序,发布指定采集效率更高
7、界面工具增加页面坐标定位等功能
8、新增每组可单独设置允许更新时间范围
9、新增至尊版用户,挂机时每个站文件夹自动导入txt
10、新增文章列库分库功能,实现单站理论上无限数据存储
11、为避免百度清风算法添加,详见分组参数中3.2.1.4中的参数
12、网站日志和seo查询作为子程序独立运行,避免与主程序抢资源
13、优化所有子程序,运行效率更高
14、新增启动程序,方便设置和发送桌面快捷方式。原来站群是主程序,不应该修改启动程序的名字,以免出现异常。
15、新增2个效率选项,在主程序左上角从系统中选择
优采云站群软件V17.06.16更新如下内容:
1、修复之前独立子程序积累的所有bug,完善更详细的功能
2、增加子组参数自动切换功能
3、新增至尊版自定义题库功能
4、群发外链工具V170321入门版也可以用
5、修复英文采集
6、修复视频采集
7、仅当新标题或内容收录指定的域名时才会添加到数据库中
8、添加内容编辑器2,修复之前无法编辑的文章用户使用
9、界面工具修复个别bug
10、改进其他细节
优采云站群软件V17.02.24更新如下内容:
1、增强关键词采集文章及指定域名采集文章的高质量自动识别
2、修复至尊版用户栏目调用段落库的bug
3、改善群发外链工具卡死的问题
4、关键词采集文章修复采集实图
5、搜狗推荐新闻bug
6、Content伪原创 中的时间参数
7、指定域名支持前端采集解决一些网页后端采集为空
8、添加文章 用于导出处理的个别详细功能
9、添加挂机是间隔分钟的设置

