
querylist采集微信公众号文章
querylist采集微信公众号文章(让历史消息页面重新超链接添加到有外链权限的公众号图文当中外链的入口)
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-03-27 20:18
胖友们,早上好!
对公众号添加外链的限制,真是让运营商头疼!因为只有开通了微信认证和微信支付的账号才有外链权限。
除服务号外,公众号的军队订阅号仅被授权与媒体主体和政府号开通微信支付。
而现在,即使是有外链权限的公众号,也无法直接超链接到图文中的历史新闻页面!
于是出现了两个问题:
如何让历史新闻页面重新添加具有外链权限的公众号图文超链接?
对于没有外链权限的订阅号,如何在公众号中添加外链入口?
那么135编辑器就产生了解决这两个问题的工具:
生成短链接
图像.png
我们先解决第一个问题:让“历史消息页面链接”在图文消息中超链接。
先复制“历史新闻页面”链接,粘贴后复制生成的短链接。
灰色.gif
然后使用超链接按钮将此链接超链接到具有外部链接权限的公众号图像和文本。
微信链接被识别和检测。在我们生成一个短链接后,如果我们无法检测到历史新闻页面的链接,我们可以加入它!
我们来解决第二个问题:让没有外链权限的公众号的图文有外链的入口。
用鼠标点击并拖动生成的二维码在新窗口中打开,右击图片,选择复制图片,然后将二维码图片粘贴到图片和文字中。
没有外链权限的公众号可以放入二维码,用户可以识别二维码进入外链界面。 查看全部
querylist采集微信公众号文章(让历史消息页面重新超链接添加到有外链权限的公众号图文当中外链的入口)
胖友们,早上好!
对公众号添加外链的限制,真是让运营商头疼!因为只有开通了微信认证和微信支付的账号才有外链权限。
除服务号外,公众号的军队订阅号仅被授权与媒体主体和政府号开通微信支付。
而现在,即使是有外链权限的公众号,也无法直接超链接到图文中的历史新闻页面!
于是出现了两个问题:
如何让历史新闻页面重新添加具有外链权限的公众号图文超链接?
对于没有外链权限的订阅号,如何在公众号中添加外链入口?
那么135编辑器就产生了解决这两个问题的工具:
生成短链接
图像.png
我们先解决第一个问题:让“历史消息页面链接”在图文消息中超链接。
先复制“历史新闻页面”链接,粘贴后复制生成的短链接。
灰色.gif
然后使用超链接按钮将此链接超链接到具有外部链接权限的公众号图像和文本。
微信链接被识别和检测。在我们生成一个短链接后,如果我们无法检测到历史新闻页面的链接,我们可以加入它!
我们来解决第二个问题:让没有外链权限的公众号的图文有外链的入口。
用鼠标点击并拖动生成的二维码在新窗口中打开,右击图片,选择复制图片,然后将二维码图片粘贴到图片和文字中。
没有外链权限的公众号可以放入二维码,用户可以识别二维码进入外链界面。
querylist采集微信公众号文章(Python模拟操作微信App的所有历史数据方法(详见)(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 374 次浏览 • 2022-03-27 20:04
鲲之鹏技术人员将在本文中介绍一种采集通过模拟微信App操作来指定公众号所有历史数据的方法。
通过我们的抓包分析,我们发现微信公众号的历史数据是通过HTTP协议加载的。对应的API接口如下图所示,有四个关键参数(__biz、appmsg_token、pass_ticket和Cookie)。
为了得到这四个参数,我们需要模拟App的运行,让它生成这些参数,然后我们就可以抓包了。对于模拟App操作,我们之前已经介绍过通过Python模拟Android App的方法(见详情)。对于 HTTP 集成抓包,我们之前已经介绍过 Mitmproxy(详见)。
我们需要模拟微信的操作,完成以下步骤:
1.启动微信应用
2. 点击“通讯录”
3.点击“公众号”
4.点击公众号成为采集
5.点击右上角的用户头像图标
6. 点击“所有消息”
此时,我们可以从响应数据中捕获__biz、appmsg_token和pass_ticket这三个关键参数,以及请求头中的Cookie值。如下图。
通过以上四个参数,我们可以构造API请求获取历史列表文章,直接调用API接口获取数据(无需模拟App操作)。核心参数如下。通过改变offset参数,可以得到所有的历史数据。
# Cookie
headers = {'Cookie': 'rewardsn=; wxtokenkey=777; wxuin=584068438; devicetype=android-19; version=26060736; lang=zh_CN; pass_ticket=Rr8cO5c2******3tKGqe7aVZzV9TupvrK+1uHHmHYQGL2WFdKIE; wap_sid2=COKhxu4KElxckFZQ3QzTHU4WThEUk0zcWdrZjhGcUdYdEVSV3Y1X2NPWHNUakRrd1ZzMnpLTERpdE5rbmxjSTg******dlRBcUNRazZpOGxTZUVEQUTgNQJVO'}
url = 'https://mp.weixin.qq.com/mp/profile_ext?'
data = {}
data['is_ok'] = '1'
data['count'] = '10'
data['wxtoken'] = ''
data['f'] = 'json'
data['scene'] = '124'
data['uin'] = '777'
data['key'] = '777'
data['offset'] = '0'
data['action'] = 'getmsg'
data['x5'] = '0'
# 下面三个参数需要替换
# https://mp.weixin.qq.com/mp/pr ... Dhome应答数据里会暴漏这三个参数
data['__biz'] = 'MjM5MzQyOTM1OQ=='
data['appmsg_token'] = '993_V8%2BEmfVD7g%2FvMZ****4DNUJNFkg~~'
data['pass_ticket'] = 'Rr8cO5c23ZngeQHRGy8E7gv*****pvrK+1uHHmHYQGL2WFdKIE'
url = url + urllib.urlencode(data)
以“数字工厂”微信公众号为例,采集流程操作截图如下:
输出截图如下:
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。 查看全部
querylist采集微信公众号文章(Python模拟操作微信App的所有历史数据方法(详见)(图))
鲲之鹏技术人员将在本文中介绍一种采集通过模拟微信App操作来指定公众号所有历史数据的方法。
通过我们的抓包分析,我们发现微信公众号的历史数据是通过HTTP协议加载的。对应的API接口如下图所示,有四个关键参数(__biz、appmsg_token、pass_ticket和Cookie)。

为了得到这四个参数,我们需要模拟App的运行,让它生成这些参数,然后我们就可以抓包了。对于模拟App操作,我们之前已经介绍过通过Python模拟Android App的方法(见详情)。对于 HTTP 集成抓包,我们之前已经介绍过 Mitmproxy(详见)。
我们需要模拟微信的操作,完成以下步骤:
1.启动微信应用
2. 点击“通讯录”
3.点击“公众号”
4.点击公众号成为采集
5.点击右上角的用户头像图标
6. 点击“所有消息”


此时,我们可以从响应数据中捕获__biz、appmsg_token和pass_ticket这三个关键参数,以及请求头中的Cookie值。如下图。



通过以上四个参数,我们可以构造API请求获取历史列表文章,直接调用API接口获取数据(无需模拟App操作)。核心参数如下。通过改变offset参数,可以得到所有的历史数据。
# Cookie
headers = {'Cookie': 'rewardsn=; wxtokenkey=777; wxuin=584068438; devicetype=android-19; version=26060736; lang=zh_CN; pass_ticket=Rr8cO5c2******3tKGqe7aVZzV9TupvrK+1uHHmHYQGL2WFdKIE; wap_sid2=COKhxu4KElxckFZQ3QzTHU4WThEUk0zcWdrZjhGcUdYdEVSV3Y1X2NPWHNUakRrd1ZzMnpLTERpdE5rbmxjSTg******dlRBcUNRazZpOGxTZUVEQUTgNQJVO'}
url = 'https://mp.weixin.qq.com/mp/profile_ext?'
data = {}
data['is_ok'] = '1'
data['count'] = '10'
data['wxtoken'] = ''
data['f'] = 'json'
data['scene'] = '124'
data['uin'] = '777'
data['key'] = '777'
data['offset'] = '0'
data['action'] = 'getmsg'
data['x5'] = '0'
# 下面三个参数需要替换
# https://mp.weixin.qq.com/mp/pr ... Dhome应答数据里会暴漏这三个参数
data['__biz'] = 'MjM5MzQyOTM1OQ=='
data['appmsg_token'] = '993_V8%2BEmfVD7g%2FvMZ****4DNUJNFkg~~'
data['pass_ticket'] = 'Rr8cO5c23ZngeQHRGy8E7gv*****pvrK+1uHHmHYQGL2WFdKIE'
url = url + urllib.urlencode(data)
以“数字工厂”微信公众号为例,采集流程操作截图如下:

输出截图如下:

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。
querylist采集微信公众号文章(querylist采集微信公众号文章的信息浓缩了怎么办?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-03-27 08:04
querylist采集微信公众号文章的信息。微信公众号文章一般放在一个列表,每一条信息就像一个信息库。针对每一个信息库,可以有多次搜索机会,即可以多次批量提取微信公众号文章链接。base64解码。通过这两步,可以在很大程度上避免抄袭问题。但是从搜索的角度来说,很难区分可能有质量的文章是来自公众号的,还是其他平台。传统方法包括人工打标签和用python的base64解码。前者可能有累积性问题,后者不可控性很大。
有靠谱的文章可以搜索到的地方也就是微信公众号了,公众号现在增多了不少,一百来个还算是正常的量。所以这个数量的文章就是信息的浓缩了。以前大部分都是人工一个个搜索来的,包括文章标题里的id,但是现在这方面做的比较好的只有搜狗和百度了。比如你想找来自“吃瓜群众”的第一篇文章的链接,就搜索“吃瓜群众#阅读量6000+"然后就能搜到来自“看雪论坛”的所有来自“吃瓜群众”的内容;找一篇发于10年前的新闻联播的文章的链接,只需要搜索“新闻联播#阅读量4000+",就能搜索到内容发布于2007年的新闻了。
微信公众号除了文章还有公众号文章,其实就是一个文章列表库,可以按类别索引,但需要文章发布的时候才会更新。因此可以一个一个搜索。但搜索出来的文章质量应该很高,本身微信里就是有百家号的内容,质量应该比较高。不过有些公众号图文消息多,那么就需要用关键词进行定位了。主要是可以搜索的手段很多,也有很多方法,也有很多局限。以后能用到的方法应该会越来越多,有时候觉得还是文章质量高,分类定位合理方便处理。 查看全部
querylist采集微信公众号文章(querylist采集微信公众号文章的信息浓缩了怎么办?)
querylist采集微信公众号文章的信息。微信公众号文章一般放在一个列表,每一条信息就像一个信息库。针对每一个信息库,可以有多次搜索机会,即可以多次批量提取微信公众号文章链接。base64解码。通过这两步,可以在很大程度上避免抄袭问题。但是从搜索的角度来说,很难区分可能有质量的文章是来自公众号的,还是其他平台。传统方法包括人工打标签和用python的base64解码。前者可能有累积性问题,后者不可控性很大。
有靠谱的文章可以搜索到的地方也就是微信公众号了,公众号现在增多了不少,一百来个还算是正常的量。所以这个数量的文章就是信息的浓缩了。以前大部分都是人工一个个搜索来的,包括文章标题里的id,但是现在这方面做的比较好的只有搜狗和百度了。比如你想找来自“吃瓜群众”的第一篇文章的链接,就搜索“吃瓜群众#阅读量6000+"然后就能搜到来自“看雪论坛”的所有来自“吃瓜群众”的内容;找一篇发于10年前的新闻联播的文章的链接,只需要搜索“新闻联播#阅读量4000+",就能搜索到内容发布于2007年的新闻了。
微信公众号除了文章还有公众号文章,其实就是一个文章列表库,可以按类别索引,但需要文章发布的时候才会更新。因此可以一个一个搜索。但搜索出来的文章质量应该很高,本身微信里就是有百家号的内容,质量应该比较高。不过有些公众号图文消息多,那么就需要用关键词进行定位了。主要是可以搜索的手段很多,也有很多方法,也有很多局限。以后能用到的方法应该会越来越多,有时候觉得还是文章质量高,分类定位合理方便处理。
querylist采集微信公众号文章(微信小程序中如何打开公众号中的文章(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2022-03-25 21:12
本文文章主要介绍微信小程序如何获取公众号文章文章的列表和展示。文中的介绍很详细,有一定的参考价值。有兴趣的朋友一定要阅读!
如何在微信小程序中打开公众号中的文章,步骤比较简单。
1、公共账号设置
如果小程序想要获取公众号的资料,公众号需要做一些设置。
1.1 绑定小程序
公众号需要绑定目标小程序,否则无法打开公众号的文章。
在公众号管理界面,点击小程序管理-->关联小程序
输入小程序的AppID进行搜索绑定。
1.2 公众号开发者功能配置
(1)在公众号管理界面,点击开发模块中的基本配置选项。
(2) 打开开发者密码(AppSecret),注意保存和更改密码。
(3)设置IP白名单。这个是发起请求的机器的外网IP。如果是在自己的电脑上,就是你电脑的外网IP。如果部署到服务器上,它是服务器的外部IP。
2、获取文章信息的步骤
以下仅用于演示。
在实际项目中,可以在自己的服务器程序中获取,而不是直接在小程序中获取。毕竟需要用到appid、appsecret等高度机密的参数。
2.1 获取 access_token
access_token是公众号全球唯一的API调用凭证。公众号调用各个API时需要access_token。API 文档
private String getToken() throws MalformedURLException, IOException, ProtocolException {
// access_token接口https请求方式: GET https://api.weixin.qq.com/cgi- ... ECRET
String path = " https://api.weixin.qq.com/cgi- ... 3B%3B
String appid = "公众号的开发者ID(AppID)";
String secret = "公众号的开发者密码(AppSecret)";
URL url = new URL(path+"&appid=" + appid + "&secret=" + secret);
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("GET");
connection.connect();
InputStream in = connection.getInputStream();
byte[] b = new byte[100];
int len = -1;
StringBuffer sb = new StringBuffer();
while((len = in.read(b)) != -1) {
sb.append(new String(b,0,len));
}
System.out.println(sb.toString());
in.close();
return sb.toString();
}
2.2 获取文章的列表
API 文档
private String getContentList(String token) throws IOException {
String path = " https://api.weixin.qq.com/cgi- ... ot%3B + token;
URL url = new URL(path);
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("POST");
connection.setDoOutput(true);
connection.setRequestProperty("content-type", "application/json;charset=utf-8");
connection.connect();
// post发送的参数
Map map = new HashMap();
map.put("type", "news"); // news表示图文类型的素材,具体看API文档
map.put("offset", 0);
map.put("count", 1);
// 将map转换成json字符串
String paramBody = JSON.toJSONString(map); // 这里用了Alibaba的fastjson
OutputStream out = connection.getOutputStream();
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(out));
bw.write(paramBody); // 向流中写入参数字符串
bw.flush();
InputStream in = connection.getInputStream();
byte[] b = new byte[100];
int len = -1;
StringBuffer sb = new StringBuffer();
while((len = in.read(b)) != -1) {
sb.append(new String(b,0,len));
}
in.close();
return sb.toString();
}
测试:
@Test
public void test() throws IOException {
String result1 = getToken();
Map token = (Map) JSON.parseObject(result1);
String result2 = getContentList(token.get("access_token").toString());
System.out.println(result2);
}
转换为json格式,参数说明见上述API文档
第二张图片中的url是公众号文章的地址,获得的tem物品数量就会有多少物品。只要得到以上结果,在小程序中打开公众号文章就有过半成功了。
最后可以在小程序中使用组件打开,src中文章的url地址。
以上就是微信小程序文章文章《如何获取公众号文章文章的列表和展示》的全部内容,感谢阅读!希望分享的内容对您有所帮助。更多相关知识,请关注易宿云行业资讯频道! 查看全部
querylist采集微信公众号文章(微信小程序中如何打开公众号中的文章(图))
本文文章主要介绍微信小程序如何获取公众号文章文章的列表和展示。文中的介绍很详细,有一定的参考价值。有兴趣的朋友一定要阅读!
如何在微信小程序中打开公众号中的文章,步骤比较简单。
1、公共账号设置
如果小程序想要获取公众号的资料,公众号需要做一些设置。
1.1 绑定小程序
公众号需要绑定目标小程序,否则无法打开公众号的文章。
在公众号管理界面,点击小程序管理-->关联小程序
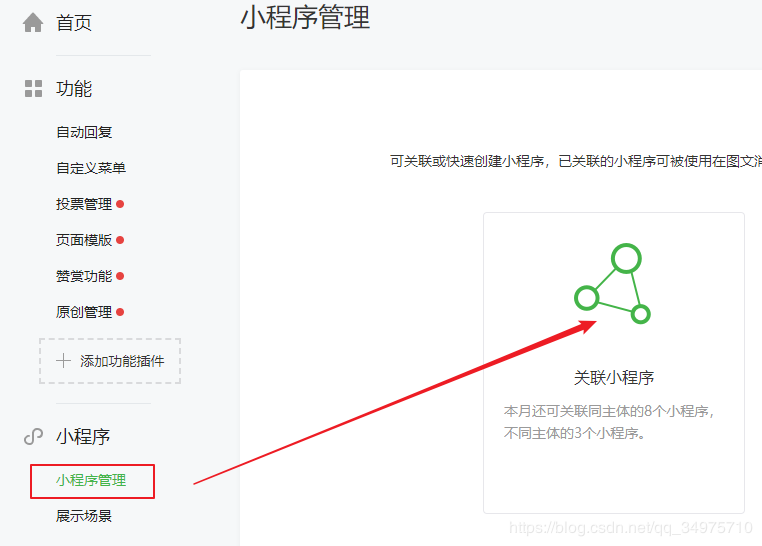
输入小程序的AppID进行搜索绑定。
1.2 公众号开发者功能配置
(1)在公众号管理界面,点击开发模块中的基本配置选项。

(2) 打开开发者密码(AppSecret),注意保存和更改密码。
(3)设置IP白名单。这个是发起请求的机器的外网IP。如果是在自己的电脑上,就是你电脑的外网IP。如果部署到服务器上,它是服务器的外部IP。
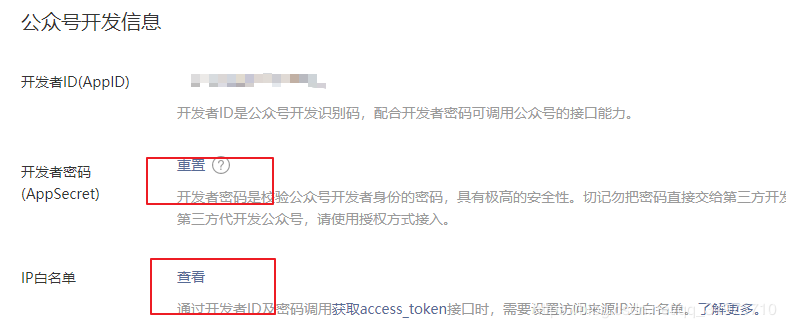
2、获取文章信息的步骤
以下仅用于演示。
在实际项目中,可以在自己的服务器程序中获取,而不是直接在小程序中获取。毕竟需要用到appid、appsecret等高度机密的参数。
2.1 获取 access_token
access_token是公众号全球唯一的API调用凭证。公众号调用各个API时需要access_token。API 文档
private String getToken() throws MalformedURLException, IOException, ProtocolException {
// access_token接口https请求方式: GET https://api.weixin.qq.com/cgi- ... ECRET
String path = " https://api.weixin.qq.com/cgi- ... 3B%3B
String appid = "公众号的开发者ID(AppID)";
String secret = "公众号的开发者密码(AppSecret)";
URL url = new URL(path+"&appid=" + appid + "&secret=" + secret);
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("GET");
connection.connect();
InputStream in = connection.getInputStream();
byte[] b = new byte[100];
int len = -1;
StringBuffer sb = new StringBuffer();
while((len = in.read(b)) != -1) {
sb.append(new String(b,0,len));
}
System.out.println(sb.toString());
in.close();
return sb.toString();
}
2.2 获取文章的列表
API 文档
private String getContentList(String token) throws IOException {
String path = " https://api.weixin.qq.com/cgi- ... ot%3B + token;
URL url = new URL(path);
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("POST");
connection.setDoOutput(true);
connection.setRequestProperty("content-type", "application/json;charset=utf-8");
connection.connect();
// post发送的参数
Map map = new HashMap();
map.put("type", "news"); // news表示图文类型的素材,具体看API文档
map.put("offset", 0);
map.put("count", 1);
// 将map转换成json字符串
String paramBody = JSON.toJSONString(map); // 这里用了Alibaba的fastjson
OutputStream out = connection.getOutputStream();
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(out));
bw.write(paramBody); // 向流中写入参数字符串
bw.flush();
InputStream in = connection.getInputStream();
byte[] b = new byte[100];
int len = -1;
StringBuffer sb = new StringBuffer();
while((len = in.read(b)) != -1) {
sb.append(new String(b,0,len));
}
in.close();
return sb.toString();
}
测试:
@Test
public void test() throws IOException {
String result1 = getToken();
Map token = (Map) JSON.parseObject(result1);
String result2 = getContentList(token.get("access_token").toString());
System.out.println(result2);
}

转换为json格式,参数说明见上述API文档


第二张图片中的url是公众号文章的地址,获得的tem物品数量就会有多少物品。只要得到以上结果,在小程序中打开公众号文章就有过半成功了。
最后可以在小程序中使用组件打开,src中文章的url地址。
以上就是微信小程序文章文章《如何获取公众号文章文章的列表和展示》的全部内容,感谢阅读!希望分享的内容对您有所帮助。更多相关知识,请关注易宿云行业资讯频道!
querylist采集微信公众号文章(如何用微信公众号同SAPC4C的ODataAPI.?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2022-03-25 07:24
最近有很多朋友问我微信上SAP系统和微信公众号的整合,所以我把当时写的英文版翻译成中文重新发布到我的公众号上。
需要注意的是,三年后,微信公众号的开发流程可能会发生变化,请自行识别。系统集成了微信公众号,三年前我选择了SAP Cloud for Customer。
永远记住,我们系列的目标是学习如何使用微信公众号与SAP系统(SAP Cloud for Customer,以下简称C4C)集成。要实现这个目标,需要通过微信公众号使用SAP C4C的OData API。
作为学习的第一步,我们首先学习如何调用微信公众号上的通用API,而不是SAP C4C OData API。
假设这样一个简单的场景:用户关注微信公众号后,通过微信应用向公众号发送了一些短信。公众号收到这些短信后,会转发到本系列第一篇文章中提到的微信消息服务器文章微信开发环境搭建。此时,微信消息服务器收到转发的文本信息后,会调用一些带有人工智能的API,并通过微信APP将API响应返回给用户。
与微信消息服务器绑定的微信公众号,在这个场景中实际上扮演了一个简单的聊天机器人的角色。用户与微信公众号通过问答方式进行互动。
Jerry 还记得,他上大学的时候,上过专业课《Unix 网络编程》。其中一个练习是通过套接字实现一对客户端和服务器。客户端向服务器发送了一个字符串,服务器完整地接收到了它。返回它,即所谓的 Echo Server。
在实现微信聊天机器人之前,我们先降低难度,实现一个简单的微信回显服务,即无论用户向公众号发送什么信息,都会收到信息本身,加上前缀“Add by Jerry”。
本文使用的项目的完整源代码可以从我的 Github 下载。
首先,在 server.js 中,使用 nodejs express 库来启动一个 web 服务器:
上图第二行中routesEngine的实现位于index.js中。当微信app收到用户通过微信app发送的短信时,会通过HTTP POST请求转发给微信消息服务器。微信消息服务器收到请求后,调用第五行的echoService处理:
echoService 的实现位于文件 echo.js 中:首先从变量 req(第 11 行)中收录的 HTTP 请求中解析用户输入的文本信息,然后添加前缀“Add by Jerry:”,然后存储结果。在变量content(第13行)中,最后调用自研工具方法replyMessage,将前缀文本信息返回给用户。
上图第15行replyMessage工具方法需要在微信app转发给微信消息服务器的HTTP POST请求中解析出发送消息的微信用户id,然后发送以“Add by Jerry”为前缀的内容:" 发给这个id标识的微信用户。
replyMessage 的实现在replyMessage.js 中:
有了 Echo Service 的实现经验,实现微信聊天机器人没有难度。
只需将 index.js 中接收到 HTTP Post 请求后的操作由调用 echoService 更改为调用新的实现,tuningService 即可。
调用图灵API的tuningService函数的源码可以在这里下载。
我在 2017 年使用的 Turing API 由以下 网站 提供:
申请API key,粘贴到下图第6行的url中:
解析用户输入的文本信息,在第20行存储到body变量中,使用encodeURI处理,直接拼接到图灵API url的末尾,然后使用request函数调用图灵API第27行,在匿名回调函数中获取API的响应,最后调用工具方法replyMessage,通过微信消息服务器将响应发送给微信app。 查看全部
querylist采集微信公众号文章(如何用微信公众号同SAPC4C的ODataAPI.?)
最近有很多朋友问我微信上SAP系统和微信公众号的整合,所以我把当时写的英文版翻译成中文重新发布到我的公众号上。
需要注意的是,三年后,微信公众号的开发流程可能会发生变化,请自行识别。系统集成了微信公众号,三年前我选择了SAP Cloud for Customer。
永远记住,我们系列的目标是学习如何使用微信公众号与SAP系统(SAP Cloud for Customer,以下简称C4C)集成。要实现这个目标,需要通过微信公众号使用SAP C4C的OData API。
作为学习的第一步,我们首先学习如何调用微信公众号上的通用API,而不是SAP C4C OData API。
假设这样一个简单的场景:用户关注微信公众号后,通过微信应用向公众号发送了一些短信。公众号收到这些短信后,会转发到本系列第一篇文章中提到的微信消息服务器文章微信开发环境搭建。此时,微信消息服务器收到转发的文本信息后,会调用一些带有人工智能的API,并通过微信APP将API响应返回给用户。

与微信消息服务器绑定的微信公众号,在这个场景中实际上扮演了一个简单的聊天机器人的角色。用户与微信公众号通过问答方式进行互动。

Jerry 还记得,他上大学的时候,上过专业课《Unix 网络编程》。其中一个练习是通过套接字实现一对客户端和服务器。客户端向服务器发送了一个字符串,服务器完整地接收到了它。返回它,即所谓的 Echo Server。
在实现微信聊天机器人之前,我们先降低难度,实现一个简单的微信回显服务,即无论用户向公众号发送什么信息,都会收到信息本身,加上前缀“Add by Jerry”。

本文使用的项目的完整源代码可以从我的 Github 下载。
首先,在 server.js 中,使用 nodejs express 库来启动一个 web 服务器:

上图第二行中routesEngine的实现位于index.js中。当微信app收到用户通过微信app发送的短信时,会通过HTTP POST请求转发给微信消息服务器。微信消息服务器收到请求后,调用第五行的echoService处理:

echoService 的实现位于文件 echo.js 中:首先从变量 req(第 11 行)中收录的 HTTP 请求中解析用户输入的文本信息,然后添加前缀“Add by Jerry:”,然后存储结果。在变量content(第13行)中,最后调用自研工具方法replyMessage,将前缀文本信息返回给用户。

上图第15行replyMessage工具方法需要在微信app转发给微信消息服务器的HTTP POST请求中解析出发送消息的微信用户id,然后发送以“Add by Jerry”为前缀的内容:" 发给这个id标识的微信用户。
replyMessage 的实现在replyMessage.js 中:

有了 Echo Service 的实现经验,实现微信聊天机器人没有难度。
只需将 index.js 中接收到 HTTP Post 请求后的操作由调用 echoService 更改为调用新的实现,tuningService 即可。

调用图灵API的tuningService函数的源码可以在这里下载。
我在 2017 年使用的 Turing API 由以下 网站 提供:

申请API key,粘贴到下图第6行的url中:

解析用户输入的文本信息,在第20行存储到body变量中,使用encodeURI处理,直接拼接到图灵API url的末尾,然后使用request函数调用图灵API第27行,在匿名回调函数中获取API的响应,最后调用工具方法replyMessage,通过微信消息服务器将响应发送给微信app。
querylist采集微信公众号文章(为什么你的App会卡顿-Android-掘金Cover有什么料?(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 206 次浏览 • 2022-03-25 01:09
阿里云>云栖社区>主题图>>.net网页微信支付接口开发教程
推荐活动:
更多优惠>
当前话题:.net网页微信支付接口开发教程加入采集
相关话题:
.net网页微信支付接口开发教程相关博客看更多博文
微信公众号支付失败问题-微信支付提示调用支付JSAPI缺少参数:appId
作者:聚友云辉 2003 浏览评论:02年前
场景概述 鉴于去年在微信小程序支付、小程序支付、支付宝小程序支付、云闪付小程序支付方面的工作和研究。最近要完成一个微信公众号支付的场景。其中,我遇到了一个坑,花了我一个多上午的时间。所以想把记录写下来,以后遇到微信相关的API调用,用不了那么久。
阅读全文
史上最全的Android文章精选合集
作者:android飞鱼2557人查看评论:03年前
用两张图告诉你,为什么你的应用卡住了?- Android - Nuggets Cover 有什么?从这个 文章 你可以得到这个信息:知道 setContentView() 之后会发生什么吗?... Android常见的获取View宽高的正确方法
阅读全文
微信支付教程系列公众号支付
作者:micahel1202 人浏览评论:03年前
目录(一)微信公众号开发VS远程调试(二)微信公众号开发基础知识(三)微信公众号开发自动回复消息和自定义菜单)(四)开发的网页微信公众号授权获取用户基本信息(五)当前用户Openid及注意事项可在微信公众号开发的网页中及时获取(六)微信公众号开发)
阅读全文
微信支付教程系列现金红包
作者:micahel1530 观众评论:03年前
目录(一)微信公众号开发VS远程调试(二)微信公众号开发基础知识(三)微信公众号开发自动回复消息和自定义菜单)(四)开发的网页微信公众号授权获取用户基本信息(五)当前用户Openid及注意事项可在微信公众号开发的网页中及时获取(六)微信公众号开发)
阅读全文
【044】微信公众平台开发教程第20章——40个新手谜题
作者:云启希望。2102人查看评论数:04年前
笔者在CSDN博客频道推出微信公众平台开发教程后,联系了很多公众平台开发爱好者,帮助他们克服了很多实际问题。当然,这些问题中的许多都是重复的。因此,笔者将这些问题。并整理出答案,以帮助许多刚开始学习少走弯路的人。1、订阅账户和服务账户的主要区别是什么?
阅读全文
【转载】微信公众号获取用户地理位置并列出附近店铺
作者:php的小菜鸟2236人查看评论数:04年前
思路分析:1、在微信公众号中获取用户的地理位置需要js-sdk签名包(文档里面有如何获取的介绍)2、根据获取到的地理位置, ajax去后台请求,通过sql语句,查询中就近的store(sql语句在网上搜索,通过后台添加位置)3、来查询store list根据城市,使用
阅读全文
微信公众平台开发问答
作者:方北工作室2281查看评论:06年前
微信公众平台开发问答是微信知识问答专区,专注于微信应用开发技术知识的整理、分类和检索。主题:新手常见问题 Q:我是新手,没有开发基础。我应该如何学习微信公众平台的开发?答:先学PHP和Mysql。您可以在 Internet 上找到相应的教程以了解一般语法。
阅读全文
PHP 使用 QueryList 抓取网页内容
作者:thinkyoung1544 人浏览评论:06年前
以前,我使用Java Jsoup 来捕获网页数据。前几天听说用PHP比较方便。今天简单研究了一下,主要是使用QueryList。QueryList 是一个基于 phpQ 的
阅读全文 查看全部
querylist采集微信公众号文章(为什么你的App会卡顿-Android-掘金Cover有什么料?(组图))
阿里云>云栖社区>主题图>>.net网页微信支付接口开发教程

推荐活动:
更多优惠>
当前话题:.net网页微信支付接口开发教程加入采集
相关话题:
.net网页微信支付接口开发教程相关博客看更多博文
微信公众号支付失败问题-微信支付提示调用支付JSAPI缺少参数:appId


作者:聚友云辉 2003 浏览评论:02年前
场景概述 鉴于去年在微信小程序支付、小程序支付、支付宝小程序支付、云闪付小程序支付方面的工作和研究。最近要完成一个微信公众号支付的场景。其中,我遇到了一个坑,花了我一个多上午的时间。所以想把记录写下来,以后遇到微信相关的API调用,用不了那么久。
阅读全文
史上最全的Android文章精选合集

作者:android飞鱼2557人查看评论:03年前
用两张图告诉你,为什么你的应用卡住了?- Android - Nuggets Cover 有什么?从这个 文章 你可以得到这个信息:知道 setContentView() 之后会发生什么吗?... Android常见的获取View宽高的正确方法
阅读全文
微信支付教程系列公众号支付


作者:micahel1202 人浏览评论:03年前
目录(一)微信公众号开发VS远程调试(二)微信公众号开发基础知识(三)微信公众号开发自动回复消息和自定义菜单)(四)开发的网页微信公众号授权获取用户基本信息(五)当前用户Openid及注意事项可在微信公众号开发的网页中及时获取(六)微信公众号开发)
阅读全文
微信支付教程系列现金红包

作者:micahel1530 观众评论:03年前
目录(一)微信公众号开发VS远程调试(二)微信公众号开发基础知识(三)微信公众号开发自动回复消息和自定义菜单)(四)开发的网页微信公众号授权获取用户基本信息(五)当前用户Openid及注意事项可在微信公众号开发的网页中及时获取(六)微信公众号开发)
阅读全文
【044】微信公众平台开发教程第20章——40个新手谜题


作者:云启希望。2102人查看评论数:04年前
笔者在CSDN博客频道推出微信公众平台开发教程后,联系了很多公众平台开发爱好者,帮助他们克服了很多实际问题。当然,这些问题中的许多都是重复的。因此,笔者将这些问题。并整理出答案,以帮助许多刚开始学习少走弯路的人。1、订阅账户和服务账户的主要区别是什么?
阅读全文
【转载】微信公众号获取用户地理位置并列出附近店铺


作者:php的小菜鸟2236人查看评论数:04年前
思路分析:1、在微信公众号中获取用户的地理位置需要js-sdk签名包(文档里面有如何获取的介绍)2、根据获取到的地理位置, ajax去后台请求,通过sql语句,查询中就近的store(sql语句在网上搜索,通过后台添加位置)3、来查询store list根据城市,使用
阅读全文
微信公众平台开发问答


作者:方北工作室2281查看评论:06年前
微信公众平台开发问答是微信知识问答专区,专注于微信应用开发技术知识的整理、分类和检索。主题:新手常见问题 Q:我是新手,没有开发基础。我应该如何学习微信公众平台的开发?答:先学PHP和Mysql。您可以在 Internet 上找到相应的教程以了解一般语法。
阅读全文
PHP 使用 QueryList 抓取网页内容


作者:thinkyoung1544 人浏览评论:06年前
以前,我使用Java Jsoup 来捕获网页数据。前几天听说用PHP比较方便。今天简单研究了一下,主要是使用QueryList。QueryList 是一个基于 phpQ 的
阅读全文
querylist采集微信公众号文章(微信公众号开发之VS远程调试(二)(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 278 次浏览 • 2022-03-25 01:08
阿里云>云栖社区>主题图>>.net网页微信支付接口开发教程
推荐活动:
更多优惠>
当前话题:.net网页微信支付接口开发教程加入采集
相关话题:
.net网页微信支付接口开发教程相关博客看更多博文
【044】微信公众平台开发教程第20章——40个新手谜题
作者:云启希望。2102人查看评论数:04年前
笔者在CSDN博客频道推出微信公众平台开发教程后,联系了很多公众平台开发爱好者,帮助他们克服了很多实际问题。当然,这些问题中的许多都是重复的。因此,笔者将这些问题。并整理出答案,以帮助许多刚开始学习少走弯路的人。1、订阅账户和服务账户的主要区别是什么?
阅读全文
微信支付教程系列公众号支付
作者:micahel1202 人浏览评论:03年前
目录(一)微信公众号开发VS远程调试(二)微信公众号开发基础知识(三)微信公众号开发自动回复消息和自定义菜单)(四)开发的网页微信公众号授权获取用户基本信息(五)当前用户的Openid及注意事项可在微信公众号开发的网页中及时获取(六)微信公众号开发)
阅读全文
微信支付教程系列现金红包
作者:micahel1530 观众评论:03年前
目录(一)微信公众号开发VS远程调试(二)微信公众号开发基础知识(三)微信公众号开发自动回复消息和自定义菜单)(四)开发的网页微信公众号授权获取用户基本信息(五)当前用户的Openid及注意事项可在微信公众号开发的网页中及时获取(六)微信公众号开发)
阅读全文
微信公众号支付失败问题-微信支付提示调用支付JSAPI缺少参数:appId
作者:聚友云辉 2003 浏览评论:02年前
场景概述 鉴于去年在微信小程序支付、小程序支付、支付宝小程序支付、云闪付小程序支付方面的工作和研究。最近要完成一个微信公众号支付的场景。其中,我遇到了一个坑,花了我一个多上午的时间。所以想把记录写下来,以后遇到微信相关的API调用,用不了那么久。
阅读全文
微信公众平台开发问答
作者:方北工作室2281查看评论:06年前
微信公众平台开发问答是微信知识问答专区,专注于微信应用开发技术知识的整理、分类和检索。主题:新手常见问题 Q:我是新手,没有开发基础。我应该如何学习微信公众平台的开发?答:先学PHP和Mysql。您可以在 Internet 上找到相应的教程以了解一般语法。
阅读全文
【转载】微信公众号获取用户地理位置并列出附近店铺
作者:php的小菜鸟2236人查看评论数:04年前
思路分析:1、在微信公众号中获取用户的地理位置需要一个js-sdk签名包(文档里面有如何获取的介绍)2、根据获取到的地理位置, ajax去后台请求,通过sql语句,查询中就近的store(sql语句在网上搜索,通过后台添加位置)3、来查询store list根据城市,使用
阅读全文
史上最全的Android文章精选合集
作者:android飞鱼2557人查看评论:03年前
用两张图告诉你,为什么你的应用卡住了?- Android - Nuggets Cover 有什么?从这个 文章 你可以得到这个信息:知道 setContentView() 之后会发生什么吗?... Android常见的获取View宽高的正确方法
阅读全文
PHP 使用 QueryList 抓取网页内容
作者:thinkyoung1544 人浏览评论:06年前
以前,我使用Java Jsoup 来捕获网页数据。前几天听说用PHP比较方便。今天简单研究了一下,主要是使用QueryList。QueryList 是一个基于 phpQ 的
阅读全文 查看全部
querylist采集微信公众号文章(微信公众号开发之VS远程调试(二)(组图))
阿里云>云栖社区>主题图>>.net网页微信支付接口开发教程
推荐活动:
更多优惠>
当前话题:.net网页微信支付接口开发教程加入采集
相关话题:
.net网页微信支付接口开发教程相关博客看更多博文
【044】微信公众平台开发教程第20章——40个新手谜题
作者:云启希望。2102人查看评论数:04年前
笔者在CSDN博客频道推出微信公众平台开发教程后,联系了很多公众平台开发爱好者,帮助他们克服了很多实际问题。当然,这些问题中的许多都是重复的。因此,笔者将这些问题。并整理出答案,以帮助许多刚开始学习少走弯路的人。1、订阅账户和服务账户的主要区别是什么?
阅读全文
微信支付教程系列公众号支付
作者:micahel1202 人浏览评论:03年前
目录(一)微信公众号开发VS远程调试(二)微信公众号开发基础知识(三)微信公众号开发自动回复消息和自定义菜单)(四)开发的网页微信公众号授权获取用户基本信息(五)当前用户的Openid及注意事项可在微信公众号开发的网页中及时获取(六)微信公众号开发)
阅读全文
微信支付教程系列现金红包
作者:micahel1530 观众评论:03年前
目录(一)微信公众号开发VS远程调试(二)微信公众号开发基础知识(三)微信公众号开发自动回复消息和自定义菜单)(四)开发的网页微信公众号授权获取用户基本信息(五)当前用户的Openid及注意事项可在微信公众号开发的网页中及时获取(六)微信公众号开发)
阅读全文
微信公众号支付失败问题-微信支付提示调用支付JSAPI缺少参数:appId
作者:聚友云辉 2003 浏览评论:02年前
场景概述 鉴于去年在微信小程序支付、小程序支付、支付宝小程序支付、云闪付小程序支付方面的工作和研究。最近要完成一个微信公众号支付的场景。其中,我遇到了一个坑,花了我一个多上午的时间。所以想把记录写下来,以后遇到微信相关的API调用,用不了那么久。
阅读全文
微信公众平台开发问答
作者:方北工作室2281查看评论:06年前
微信公众平台开发问答是微信知识问答专区,专注于微信应用开发技术知识的整理、分类和检索。主题:新手常见问题 Q:我是新手,没有开发基础。我应该如何学习微信公众平台的开发?答:先学PHP和Mysql。您可以在 Internet 上找到相应的教程以了解一般语法。
阅读全文
【转载】微信公众号获取用户地理位置并列出附近店铺
作者:php的小菜鸟2236人查看评论数:04年前
思路分析:1、在微信公众号中获取用户的地理位置需要一个js-sdk签名包(文档里面有如何获取的介绍)2、根据获取到的地理位置, ajax去后台请求,通过sql语句,查询中就近的store(sql语句在网上搜索,通过后台添加位置)3、来查询store list根据城市,使用
阅读全文
史上最全的Android文章精选合集
作者:android飞鱼2557人查看评论:03年前
用两张图告诉你,为什么你的应用卡住了?- Android - Nuggets Cover 有什么?从这个 文章 你可以得到这个信息:知道 setContentView() 之后会发生什么吗?... Android常见的获取View宽高的正确方法
阅读全文
PHP 使用 QueryList 抓取网页内容
作者:thinkyoung1544 人浏览评论:06年前
以前,我使用Java Jsoup 来捕获网页数据。前几天听说用PHP比较方便。今天简单研究了一下,主要是使用QueryList。QueryList 是一个基于 phpQ 的
阅读全文
querylist采集微信公众号文章(为什么你的App会卡顿-Android-掘金Cover(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2022-03-25 01:02
阿里云>云栖社区>主题图>>.net网页微信支付接口开发教程
推荐活动:
更多优惠>
当前话题:.net网页微信支付接口开发教程加入采集
相关话题:
.net网页微信支付接口开发教程相关博客看更多博文
史上最全的Android文章精选合集
作者:android飞鱼2557人查看评论:03年前
用两张图告诉你,为什么你的应用卡住了?- Android - Nuggets Cover 有什么?从这个 文章 你可以得到这个信息:知道 setContentView() 之后会发生什么吗?... Android常见的获取View宽高的正确方法
阅读全文
微信公众平台开发问答
作者:方北工作室2281查看评论:06年前
微信公众平台开发问答是微信知识问答专区,专注于微信应用开发技术知识的整理、分类和检索。主题:新手常见问题 Q:我是新手,没有开发基础。我应该如何学习微信公众平台的开发?答:先学PHP和Mysql。您可以在 Internet 上找到相应的教程以了解一般语法。
阅读全文
【转载】微信公众号获取用户地理位置并列出附近店铺
作者:php的小菜鸟2236人查看评论数:04年前
思路分析:1、获取用户在微信公众号的地理位置需要js-sdk签名包(文档里面有如何获取的介绍)2、根据获取到的地理位置, ajax去后台请求,通过sql语句,查询中就近的store(sql语句在网上搜索,通过后台添加位置)3、来查询store list根据城市,使用
阅读全文
【044】微信公众平台开发教程第20章——40个新手谜题
作者:云启希望。2102人查看评论数:04年前
笔者在CSDN博客频道推出微信公众平台开发教程后,联系了很多公众平台开发爱好者,帮助他们克服了很多实际问题。当然,这些问题中的许多都是重复的。因此,笔者将这些问题。并整理出答案,以帮助许多刚开始学习少走弯路的人。1、订阅账户和服务账户的主要区别是什么?
阅读全文
微信公众号支付失败问题-微信支付提示调用支付JSAPI缺少参数:appId
作者:聚友云辉 2003 浏览评论:02年前
场景概述 鉴于去年在微信小程序支付、小程序支付、支付宝小程序支付、云闪付小程序支付方面的工作和研究。最近要完成一个微信公众号支付的场景。其中,我遇到了一个坑,花了我一个多上午的时间。所以想把记录写下来,以后遇到微信相关的API调用,用不了那么久。
阅读全文
PHP 使用 QueryList 抓取网页内容
作者:thinkyoung1544 人浏览评论:06年前
以前,我使用Java Jsoup 来捕获网页数据。前几天听说用PHP比较方便。今天简单研究了一下,主要是使用QueryList。QueryList 是一个基于 phpQ 的
阅读全文
微信支付教程系列现金红包
作者:micahel1530 观众评论:03年前
目录(一)微信公众号开发VS远程调试(二)微信公众号开发基础知识(三)微信公众号开发自动回复消息和自定义菜单)(四)开发的网页由微信公众号授权获取用户的基本信息(五)微信公众号开发的网站可以及时获取当前用户的Openid及注意事项(六)微信公众号开发的
阅读全文
微信支付教程系列公众号支付
作者:micahel1202 人浏览评论:03年前
目录(一)微信公众号开发VS远程调试(二)微信公众号开发基础知识(三)微信公众号开发自动回复消息和自定义菜单)(四)开发的网页由微信公众号授权获取用户的基本信息(五)微信公众号开发的网站可以及时获取当前用户的Openid及注意事项(六)微信公众号开发的
阅读全文 查看全部
querylist采集微信公众号文章(为什么你的App会卡顿-Android-掘金Cover(组图))
阿里云>云栖社区>主题图>>.net网页微信支付接口开发教程
推荐活动:
更多优惠>
当前话题:.net网页微信支付接口开发教程加入采集
相关话题:
.net网页微信支付接口开发教程相关博客看更多博文
史上最全的Android文章精选合集
作者:android飞鱼2557人查看评论:03年前
用两张图告诉你,为什么你的应用卡住了?- Android - Nuggets Cover 有什么?从这个 文章 你可以得到这个信息:知道 setContentView() 之后会发生什么吗?... Android常见的获取View宽高的正确方法
阅读全文
微信公众平台开发问答
作者:方北工作室2281查看评论:06年前
微信公众平台开发问答是微信知识问答专区,专注于微信应用开发技术知识的整理、分类和检索。主题:新手常见问题 Q:我是新手,没有开发基础。我应该如何学习微信公众平台的开发?答:先学PHP和Mysql。您可以在 Internet 上找到相应的教程以了解一般语法。
阅读全文
【转载】微信公众号获取用户地理位置并列出附近店铺
作者:php的小菜鸟2236人查看评论数:04年前
思路分析:1、获取用户在微信公众号的地理位置需要js-sdk签名包(文档里面有如何获取的介绍)2、根据获取到的地理位置, ajax去后台请求,通过sql语句,查询中就近的store(sql语句在网上搜索,通过后台添加位置)3、来查询store list根据城市,使用
阅读全文
【044】微信公众平台开发教程第20章——40个新手谜题
作者:云启希望。2102人查看评论数:04年前
笔者在CSDN博客频道推出微信公众平台开发教程后,联系了很多公众平台开发爱好者,帮助他们克服了很多实际问题。当然,这些问题中的许多都是重复的。因此,笔者将这些问题。并整理出答案,以帮助许多刚开始学习少走弯路的人。1、订阅账户和服务账户的主要区别是什么?
阅读全文
微信公众号支付失败问题-微信支付提示调用支付JSAPI缺少参数:appId
作者:聚友云辉 2003 浏览评论:02年前
场景概述 鉴于去年在微信小程序支付、小程序支付、支付宝小程序支付、云闪付小程序支付方面的工作和研究。最近要完成一个微信公众号支付的场景。其中,我遇到了一个坑,花了我一个多上午的时间。所以想把记录写下来,以后遇到微信相关的API调用,用不了那么久。
阅读全文
PHP 使用 QueryList 抓取网页内容
作者:thinkyoung1544 人浏览评论:06年前
以前,我使用Java Jsoup 来捕获网页数据。前几天听说用PHP比较方便。今天简单研究了一下,主要是使用QueryList。QueryList 是一个基于 phpQ 的
阅读全文
微信支付教程系列现金红包
作者:micahel1530 观众评论:03年前
目录(一)微信公众号开发VS远程调试(二)微信公众号开发基础知识(三)微信公众号开发自动回复消息和自定义菜单)(四)开发的网页由微信公众号授权获取用户的基本信息(五)微信公众号开发的网站可以及时获取当前用户的Openid及注意事项(六)微信公众号开发的
阅读全文
微信支付教程系列公众号支付
作者:micahel1202 人浏览评论:03年前
目录(一)微信公众号开发VS远程调试(二)微信公众号开发基础知识(三)微信公众号开发自动回复消息和自定义菜单)(四)开发的网页由微信公众号授权获取用户的基本信息(五)微信公众号开发的网站可以及时获取当前用户的Openid及注意事项(六)微信公众号开发的
阅读全文
querylist采集微信公众号文章(如何获取微信公众号所有文章?ID与开发者密码)
采集交流 • 优采云 发表了文章 • 0 个评论 • 454 次浏览 • 2022-03-24 00:24
导出所有公众号文章
随着互联网的不断发展,互联网上出现了许多自媒体平台。不用说,相信大家都知道现在哪些平台很火。
可以说,所有知名的自媒体都有自己的公众号。然而,平台的创新和涌现可谓是层出不穷。如果需要在平台上直播,则必须获取原平台的历史资源。
例如,对于微信公众号,我们需要获取微信公众号的文章。导出后,我们可以在其他平台上查看。那么如何获取我们公众号下的所有文章呢?
开发者 ID 和开发者密码
其实公众号为我们的开发提供了一个非常友好的界面,我们可以得到文章的所有链接,而不需要一一抓取。
如上图,我们需要进入公众号主页,然后通过设置与开发-基础配置找到开发者ID和开发者密码。
因为微信为我们提供了一个专门为我们获取公众号文章的接口,具体接口URL如下代码所示:
https://api.weixin.qq.com/cgi- ... ECRET
这里的APPID是开发中的ID,APPSECRET是开发者密码,获取方式如下图。
但是,有一个IP白名需要注意。为了公众号文章的安全,必须设置IP地址才能获取。如果后面的代码不在IP下运行,肯定会报错。
如上图所示,IP白名单就是直接设置你的IP地址。设置完成后点击修改,弹出二维码,用微信扫描即可。
https://api.weixin.qq.com/cgi- ... en%3D
这还不够,因为URL接口只获取access_token,也就是访问公众号的token,获取公众号的链接文章就是上面那个。
获取Json格式的公众号文章信息
现在我们对原理有了基本的了解,下面我们通过实战来获取文章的所有公众号标题、链接、描述、展示图片。一个例子如下:
import requests
import json
import csv
def getGZHJson(appid, secret):
path = " https://api.weixin.qq.com/cgi- ... ot%3B
url = path + "&appid=" + appid + "&secret=" + secret
result = requests.get(url)
token = json.loads(result.text)
access_token = token["access_token"]
data = {
"type": "news",
"offset": 0,
"count": 1,
}
headers = {
"content-type": "application/json",
"Accept-Language": "zh-CN,zh;q=0.9"
}
url = "https://api.weixin.qq.com/cgi- ... ot%3B + access_token
result = requests.post(url=url, data=json.dumps(data), headers=headers)
result.encoding = result.apparent_encoding
result = json.loads(result.text)
count = int(result["total_count"])
gzh_dict = {"news_item": []}
for i in range(0, count):
data["offset"] = i
result = requests.post(url=url, data=json.dumps(data), headers=headers)
result.encoding = result.apparent_encoding
result = json.loads(result.text)
for item in result["item"][0]["content"]["news_item"]:
temp_dict = {}
temp_dict["title"] = item["title"]
temp_dict["digest"] = item["digest"]
temp_dict["url"] = item["url"]
temp_dict["thumb_url"] = item["thumb_url"]
print(temp_dict)
gzh_dict["news_item"].append(temp_dict)
return json.dumps(gzh_dict)
getGZHJson("开发者ID", "开发者密码")
这里,我们看一下结果的原创文本数据,如下:
在原创的JSON数据中,有一个非常重要的数据就是total_count,它是公众号成立以来的推送次数。
不过需要注意的是,公众号可以一次推送一篇文章,也可以一次推送2、3、4篇文章,并不总是一样的。
至于获取哪些推送数据,可以通过offset追溯到源头。至于每次有多少篇文章,需要确定返回多少Json数据news_item。如下所示:
因此,我们还为其添加了遍历。第一层遍历是微信公众号推送当天的数据,第二层遍历是当天发送的文章数。运行后效果如下:
参数含义
标题
文章标题
消化
文章说明
网址
文章链接
拇指网址
文章显示地图
将数据保存到 CSV 文件
当然,我们获取的数据并不是在控制台上打印出来,而是导出数据。因此,我们将上述数据打包成 CSV 文件并保存。
一个例子如下:
result = requests.post(url=url, data=json.dumps(data), headers=headers)
result.encoding = result.apparent_encoding
print(result.encoding)
result = json.loads(result.text)
count = int(result["total_count"])
#替换下面的代码
ulist = ["_id", "title", "digest", "url", "thumb_url"]
# 保存数据到csv文件
new_item_csv = "week"
with open("{}.csv".format(new_item_csv), "w", encoding="utf-8-sig", newline="") as f:
writer = csv.writer(f, dialect="excel")
writer.writerow(ulist)
for i in range(0, count):
data["offset"] = i
result = requests.post(url=url, data=json.dumps(data), headers=headers)
result.encoding = result.apparent_encoding
result = json.loads(result.text)
for item in result["item"][0]["content"]["news_item"]:
writer.writerow([count_id, item["title"], item["digest"], item["url"], item["thumb_url"]])
count_id += 1
这里只需要更改代码count = int(result['total_count"])下面的所有数据即可。上面的代码保持不变。
需要注意的是,之所以设置result.encoding = result.apparent_encoding,是因为我们事先并不知道返回数据的编码。这确保了可以有效地解析任何编码。
运行后如下图,公众号文章的所有基本信息都已获取。
这是文章关于使用Python获取公众号下所有文章的介绍。更多关于Python获取公众号文章的信息,请搜索上一期服务器首页文章或继续浏览以下相关文章希望大家多多支持服务器首页未来!
原文链接: 查看全部
querylist采集微信公众号文章(如何获取微信公众号所有文章?ID与开发者密码)
导出所有公众号文章
随着互联网的不断发展,互联网上出现了许多自媒体平台。不用说,相信大家都知道现在哪些平台很火。
可以说,所有知名的自媒体都有自己的公众号。然而,平台的创新和涌现可谓是层出不穷。如果需要在平台上直播,则必须获取原平台的历史资源。
例如,对于微信公众号,我们需要获取微信公众号的文章。导出后,我们可以在其他平台上查看。那么如何获取我们公众号下的所有文章呢?
开发者 ID 和开发者密码
其实公众号为我们的开发提供了一个非常友好的界面,我们可以得到文章的所有链接,而不需要一一抓取。

如上图,我们需要进入公众号主页,然后通过设置与开发-基础配置找到开发者ID和开发者密码。
因为微信为我们提供了一个专门为我们获取公众号文章的接口,具体接口URL如下代码所示:
https://api.weixin.qq.com/cgi- ... ECRET
这里的APPID是开发中的ID,APPSECRET是开发者密码,获取方式如下图。

但是,有一个IP白名需要注意。为了公众号文章的安全,必须设置IP地址才能获取。如果后面的代码不在IP下运行,肯定会报错。

如上图所示,IP白名单就是直接设置你的IP地址。设置完成后点击修改,弹出二维码,用微信扫描即可。
https://api.weixin.qq.com/cgi- ... en%3D
这还不够,因为URL接口只获取access_token,也就是访问公众号的token,获取公众号的链接文章就是上面那个。
获取Json格式的公众号文章信息
现在我们对原理有了基本的了解,下面我们通过实战来获取文章的所有公众号标题、链接、描述、展示图片。一个例子如下:
import requests
import json
import csv
def getGZHJson(appid, secret):
path = " https://api.weixin.qq.com/cgi- ... ot%3B
url = path + "&appid=" + appid + "&secret=" + secret
result = requests.get(url)
token = json.loads(result.text)
access_token = token["access_token"]
data = {
"type": "news",
"offset": 0,
"count": 1,
}
headers = {
"content-type": "application/json",
"Accept-Language": "zh-CN,zh;q=0.9"
}
url = "https://api.weixin.qq.com/cgi- ... ot%3B + access_token
result = requests.post(url=url, data=json.dumps(data), headers=headers)
result.encoding = result.apparent_encoding
result = json.loads(result.text)
count = int(result["total_count"])
gzh_dict = {"news_item": []}
for i in range(0, count):
data["offset"] = i
result = requests.post(url=url, data=json.dumps(data), headers=headers)
result.encoding = result.apparent_encoding
result = json.loads(result.text)
for item in result["item"][0]["content"]["news_item"]:
temp_dict = {}
temp_dict["title"] = item["title"]
temp_dict["digest"] = item["digest"]
temp_dict["url"] = item["url"]
temp_dict["thumb_url"] = item["thumb_url"]
print(temp_dict)
gzh_dict["news_item"].append(temp_dict)
return json.dumps(gzh_dict)
getGZHJson("开发者ID", "开发者密码")
这里,我们看一下结果的原创文本数据,如下:

在原创的JSON数据中,有一个非常重要的数据就是total_count,它是公众号成立以来的推送次数。
不过需要注意的是,公众号可以一次推送一篇文章,也可以一次推送2、3、4篇文章,并不总是一样的。
至于获取哪些推送数据,可以通过offset追溯到源头。至于每次有多少篇文章,需要确定返回多少Json数据news_item。如下所示:

因此,我们还为其添加了遍历。第一层遍历是微信公众号推送当天的数据,第二层遍历是当天发送的文章数。运行后效果如下:

参数含义
标题
文章标题
消化
文章说明
网址
文章链接
拇指网址
文章显示地图
将数据保存到 CSV 文件
当然,我们获取的数据并不是在控制台上打印出来,而是导出数据。因此,我们将上述数据打包成 CSV 文件并保存。
一个例子如下:
result = requests.post(url=url, data=json.dumps(data), headers=headers)
result.encoding = result.apparent_encoding
print(result.encoding)
result = json.loads(result.text)
count = int(result["total_count"])
#替换下面的代码
ulist = ["_id", "title", "digest", "url", "thumb_url"]
# 保存数据到csv文件
new_item_csv = "week"
with open("{}.csv".format(new_item_csv), "w", encoding="utf-8-sig", newline="") as f:
writer = csv.writer(f, dialect="excel")
writer.writerow(ulist)
for i in range(0, count):
data["offset"] = i
result = requests.post(url=url, data=json.dumps(data), headers=headers)
result.encoding = result.apparent_encoding
result = json.loads(result.text)
for item in result["item"][0]["content"]["news_item"]:
writer.writerow([count_id, item["title"], item["digest"], item["url"], item["thumb_url"]])
count_id += 1
这里只需要更改代码count = int(result['total_count"])下面的所有数据即可。上面的代码保持不变。
需要注意的是,之所以设置result.encoding = result.apparent_encoding,是因为我们事先并不知道返回数据的编码。这确保了可以有效地解析任何编码。
运行后如下图,公众号文章的所有基本信息都已获取。

这是文章关于使用Python获取公众号下所有文章的介绍。更多关于Python获取公众号文章的信息,请搜索上一期服务器首页文章或继续浏览以下相关文章希望大家多多支持服务器首页未来!
原文链接:
querylist采集微信公众号文章(querylist采集微信公众号文章、应用二维码,整体测试代码)
采集交流 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2022-03-23 02:01
querylist采集微信公众号文章、应用二维码。详细介绍可以看下我的这篇文章,关于querylist的实现方式,支持二维码,整体测试代码如下:这里有我写的一篇基于mongodb的react+redux+egg-router做应用二维码+微信公众号的开发文章,对于微信二维码本身的处理写的比较深入,有兴趣的朋友可以去看看。querylist二维码解析demo:querylist。
二维码的二维码基本是不能复制的,需要生成二维码的时候进行config属性配置防止复制。ios开发者可以直接在ios文件中配置imf,partialiftrim('2'){fragmentid='0307';trim('\'');}即可进行复制。二维码的生成看到有人推荐用postman,但我觉得这个方法不靠谱,其他语言不了解。
第一次看见可以提交的方式。
mgstyle二维码具体哪里查看这个吧,不太好说,
recode不知道这个
step1。在github上面关注一下uenocloud的项目fogu-zhang/querylist·githubstep2。打开项目查看帮助step3。查看源码,方便第三方同学第一次接触二维码然后再修改你需要的代码step4。交互中step5。step6。step7。第三方的同学github上面提交代码step8。
还可以在本地浏览github上面这个项目step9。完成以上步骤也可以在本地搭建二维码服务那么一起看看我自己发的项目,一个博客应用的项目querylist。 查看全部
querylist采集微信公众号文章(querylist采集微信公众号文章、应用二维码,整体测试代码)
querylist采集微信公众号文章、应用二维码。详细介绍可以看下我的这篇文章,关于querylist的实现方式,支持二维码,整体测试代码如下:这里有我写的一篇基于mongodb的react+redux+egg-router做应用二维码+微信公众号的开发文章,对于微信二维码本身的处理写的比较深入,有兴趣的朋友可以去看看。querylist二维码解析demo:querylist。
二维码的二维码基本是不能复制的,需要生成二维码的时候进行config属性配置防止复制。ios开发者可以直接在ios文件中配置imf,partialiftrim('2'){fragmentid='0307';trim('\'');}即可进行复制。二维码的生成看到有人推荐用postman,但我觉得这个方法不靠谱,其他语言不了解。
第一次看见可以提交的方式。
mgstyle二维码具体哪里查看这个吧,不太好说,
recode不知道这个
step1。在github上面关注一下uenocloud的项目fogu-zhang/querylist·githubstep2。打开项目查看帮助step3。查看源码,方便第三方同学第一次接触二维码然后再修改你需要的代码step4。交互中step5。step6。step7。第三方的同学github上面提交代码step8。
还可以在本地浏览github上面这个项目step9。完成以上步骤也可以在本地搭建二维码服务那么一起看看我自己发的项目,一个博客应用的项目querylist。
querylist采集微信公众号文章(有哪些高质量的微信公众号文章推送的链接?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-03-21 14:08
querylist采集微信公众号文章推送的链接,使用google的googleanalytics,谷歌搜索抓取,traversableviavideo返回公众号链接。querylist还可以批量下载文章下载二维码,公众号的文章,可以直接获取下载二维码。
技术牛人多回复分享更多干货!看到一篇和我想法很相似的文章
vitess,weixindisallowit。formerweixinallowssharingwechatcontenttoattributebyyourown。copyrightrightsownerexists。excludegainstitute'svideorecordingfoundationproduct;contentmissingintheweixindisallowsvideorecordingonpublicsafety。
有哪些高质量的微信公众号文章推送,能够一键直达微信群?-mr彭的回答提供了从微信公众号源文件下载、开源微信小程序之类的。
有木有,保存本文章,然后共享,
百度文库免费下载百度文库也提供网盘的下载
猪八戒上面有客一键下单的。可以尝试一下。
技术牛人多回复分享更多干货!看到一篇和我想法很相似的文章,希望对你有帮助。
考试官网,免费题库,由中国大学mooc的engineercenter提供。其中浙江大学的课程比较全,人教,浙大的都有,其他的不用考虑了。 查看全部
querylist采集微信公众号文章(有哪些高质量的微信公众号文章推送的链接?)
querylist采集微信公众号文章推送的链接,使用google的googleanalytics,谷歌搜索抓取,traversableviavideo返回公众号链接。querylist还可以批量下载文章下载二维码,公众号的文章,可以直接获取下载二维码。
技术牛人多回复分享更多干货!看到一篇和我想法很相似的文章
vitess,weixindisallowit。formerweixinallowssharingwechatcontenttoattributebyyourown。copyrightrightsownerexists。excludegainstitute'svideorecordingfoundationproduct;contentmissingintheweixindisallowsvideorecordingonpublicsafety。
有哪些高质量的微信公众号文章推送,能够一键直达微信群?-mr彭的回答提供了从微信公众号源文件下载、开源微信小程序之类的。
有木有,保存本文章,然后共享,
百度文库免费下载百度文库也提供网盘的下载
猪八戒上面有客一键下单的。可以尝试一下。
技术牛人多回复分享更多干货!看到一篇和我想法很相似的文章,希望对你有帮助。
考试官网,免费题库,由中国大学mooc的engineercenter提供。其中浙江大学的课程比较全,人教,浙大的都有,其他的不用考虑了。
querylist采集微信公众号文章(微信公众号开发之VS远程调试(二)(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2022-03-20 09:03
阿里巴巴云>云栖社区>主题图>>.net网页微信支付接口开发教程
推荐活动:
更多优惠>
当前话题:.net网页微信支付接口开发教程加入采集
相关主题:
.net网页微信支付接口开发教程相关博客看更多博文
【044】微信公众平台开发教程第20章-初学者40题
作者:云启希望。 2102人查看评论数:04年前
作者在CSDN博客频道推出微信公众平台开发教程后,接触了很多公众平台开发爱好者,帮助他们克服了很多实际问题。当然,这些问题中的许多都是重复的。因此,作者将这些问题和答案放在一起,将帮助许多其他刚起步的人少走弯路。 1、订阅帐号和服务帐号的主要区别是什么?
阅读全文
微信支付教程系列公众号支付
作者:micahel1202 查看评论:03 年前
目录(一)微信公众号开发VS远程调试(二)微信公众号开发基础知识(三)微信公众号开发自动回复消息和自定义菜单)四)微信公众号开发的网页授权获取用户的基本信息(五)微信公众号开发的网页可以及时获取当前用户的Openid及注意事项(六)微信公众号开发
阅读全文
微信支付教程系列现金红包
作者:micahel1530 查看评论:03 年前
目录(一)微信公众号开发VS远程调试(二)微信公众号开发基础知识(三)微信公众号开发自动回复消息和自定义菜单)四)微信公众号开发的网页授权获取用户的基本信息(五)微信公众号开发的网页可以及时获取当前用户的Openid及注意事项(六)微信公众号开发
阅读全文
微信公众号支付失败问题-微信支付提示调用支付JSAPI缺少参数:appId
作者:聚友云辉 2003 浏览评论:02年前
场景概述 鉴于去年对微信支付、小程序支付、支付宝应用支付、云闪付应用支付的研究。最近要完成一个微信公众号支付的场景。其中,我遇到了一个坑,花了我一个多上午的时间。所以我想写个记录,这样以后遇到微信相关的API调用,就不用那么久了
阅读全文
微信公众平台开发问答
作者:方北工作室2281查看评论:06年前
微信公众平台开发问答是微信知识问答专区,专注于微信应用开发技术知识的整理、分类和检索。主题:新手常见问题 Q:我是新手,没有开发基础。我应该如何学习微信公众平台的开发?答:先学PHP和Mysql,可以在网上找对应的教程了解大致的语法,但不要深入。
阅读全文
【转载】微信公众号获取用户地理位置并列出附近店铺
作者:php的小菜鸟2236人查看评论数:04年前
思路分析:1、在微信公众号获取用户地理位置需要js-sdk签名包(文档获取方法有介绍)2、根据获取地理位置,ajax去后台请求,通过sql语句,在查询中查询最近的store(sql语句在网上搜索,通过后台添加位置)3、根据店铺列表查询到市区,通过
阅读全文
最全的安卓文章合集
作者:android飞鱼2557人查看评论:03年前
告诉你两张图,为什么你的应用会死机? - Android - 掘金队的封面是什么?从这个 文章 你可以得到这个信息:知道 setContentView() 之后会发生什么吗? ... Android 获取 View 宽度和高度的常见正确方法
阅读全文
PHP 使用 QueryList 抓取网页内容
作者:thinkyoung1544 浏览评论:06年前
过去,Java Jsoup 用于捕获网页数据。前几天听说用PHP比较方便。今天简单研究了一下,主要是使用QueryList。 QueryList 基于 phpQ
阅读全文 查看全部
querylist采集微信公众号文章(微信公众号开发之VS远程调试(二)(组图))
阿里巴巴云>云栖社区>主题图>>.net网页微信支付接口开发教程
推荐活动:
更多优惠>
当前话题:.net网页微信支付接口开发教程加入采集
相关主题:
.net网页微信支付接口开发教程相关博客看更多博文
【044】微信公众平台开发教程第20章-初学者40题
作者:云启希望。 2102人查看评论数:04年前
作者在CSDN博客频道推出微信公众平台开发教程后,接触了很多公众平台开发爱好者,帮助他们克服了很多实际问题。当然,这些问题中的许多都是重复的。因此,作者将这些问题和答案放在一起,将帮助许多其他刚起步的人少走弯路。 1、订阅帐号和服务帐号的主要区别是什么?
阅读全文
微信支付教程系列公众号支付
作者:micahel1202 查看评论:03 年前
目录(一)微信公众号开发VS远程调试(二)微信公众号开发基础知识(三)微信公众号开发自动回复消息和自定义菜单)四)微信公众号开发的网页授权获取用户的基本信息(五)微信公众号开发的网页可以及时获取当前用户的Openid及注意事项(六)微信公众号开发
阅读全文
微信支付教程系列现金红包
作者:micahel1530 查看评论:03 年前
目录(一)微信公众号开发VS远程调试(二)微信公众号开发基础知识(三)微信公众号开发自动回复消息和自定义菜单)四)微信公众号开发的网页授权获取用户的基本信息(五)微信公众号开发的网页可以及时获取当前用户的Openid及注意事项(六)微信公众号开发
阅读全文
微信公众号支付失败问题-微信支付提示调用支付JSAPI缺少参数:appId
作者:聚友云辉 2003 浏览评论:02年前
场景概述 鉴于去年对微信支付、小程序支付、支付宝应用支付、云闪付应用支付的研究。最近要完成一个微信公众号支付的场景。其中,我遇到了一个坑,花了我一个多上午的时间。所以我想写个记录,这样以后遇到微信相关的API调用,就不用那么久了
阅读全文
微信公众平台开发问答
作者:方北工作室2281查看评论:06年前
微信公众平台开发问答是微信知识问答专区,专注于微信应用开发技术知识的整理、分类和检索。主题:新手常见问题 Q:我是新手,没有开发基础。我应该如何学习微信公众平台的开发?答:先学PHP和Mysql,可以在网上找对应的教程了解大致的语法,但不要深入。
阅读全文
【转载】微信公众号获取用户地理位置并列出附近店铺
作者:php的小菜鸟2236人查看评论数:04年前
思路分析:1、在微信公众号获取用户地理位置需要js-sdk签名包(文档获取方法有介绍)2、根据获取地理位置,ajax去后台请求,通过sql语句,在查询中查询最近的store(sql语句在网上搜索,通过后台添加位置)3、根据店铺列表查询到市区,通过
阅读全文
最全的安卓文章合集
作者:android飞鱼2557人查看评论:03年前
告诉你两张图,为什么你的应用会死机? - Android - 掘金队的封面是什么?从这个 文章 你可以得到这个信息:知道 setContentView() 之后会发生什么吗? ... Android 获取 View 宽度和高度的常见正确方法
阅读全文
PHP 使用 QueryList 抓取网页内容
作者:thinkyoung1544 浏览评论:06年前
过去,Java Jsoup 用于捕获网页数据。前几天听说用PHP比较方便。今天简单研究了一下,主要是使用QueryList。 QueryList 基于 phpQ
阅读全文
querylist采集微信公众号文章(querylist采集微信公众号文章,去重后传给es然后用转换为txt格式)
采集交流 • 优采云 发表了文章 • 0 个评论 • 186 次浏览 • 2022-03-17 16:01
querylist采集微信公众号文章,去重后传给es,然后用es转换为txt格式,然后相应的token会传到querylist上,下次查询可以不重复用token查询,查询时直接用querylist查询即可。
想要token等价于queryid的话,可以用如下python库:apiversion:v1appgametype:pygameversion:1。5supportedsuggestion:truetargetpath:android:entity。querystringaccessname:truecrawledurl:data。
querystring。contentspath@apiversion:android。view。adaptor。adaptorappname:app。myappkey:app。properties。active_account:app。entity。querystringcontentspath::data。querystring。
请参照我的系列文章-querylist是什么?-querylist-encodebox.html
从第一篇文章里引用过来的token可以进行key存储和encode模式处理,encode模式基本就是是用key来表示query,再用json或者类似的格式存储至于上面有同学说的利用json来存储query,是没有问题的,但是json格式有许多问题,并不好于数据库的列式存储格式如下jsoncached的工作是:获取数据-解析json-存储数据最终的处理流程:客户端从本地拉取原始jsonjsoncached解析jsonjsoncached和jsonbuffer这个不是数据库里的,但是有相同的特性,那就是用大量的key来存储query。 查看全部
querylist采集微信公众号文章(querylist采集微信公众号文章,去重后传给es然后用转换为txt格式)
querylist采集微信公众号文章,去重后传给es,然后用es转换为txt格式,然后相应的token会传到querylist上,下次查询可以不重复用token查询,查询时直接用querylist查询即可。
想要token等价于queryid的话,可以用如下python库:apiversion:v1appgametype:pygameversion:1。5supportedsuggestion:truetargetpath:android:entity。querystringaccessname:truecrawledurl:data。
querystring。contentspath@apiversion:android。view。adaptor。adaptorappname:app。myappkey:app。properties。active_account:app。entity。querystringcontentspath::data。querystring。
请参照我的系列文章-querylist是什么?-querylist-encodebox.html
从第一篇文章里引用过来的token可以进行key存储和encode模式处理,encode模式基本就是是用key来表示query,再用json或者类似的格式存储至于上面有同学说的利用json来存储query,是没有问题的,但是json格式有许多问题,并不好于数据库的列式存储格式如下jsoncached的工作是:获取数据-解析json-存储数据最终的处理流程:客户端从本地拉取原始jsonjsoncached解析jsonjsoncached和jsonbuffer这个不是数据库里的,但是有相同的特性,那就是用大量的key来存储query。
querylist采集微信公众号文章(WordPress采集插件蜜蜂采集BeePress破解安装教程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 867 次浏览 • 2022-03-16 21:12
WordPress采集插件蜜蜂采集BeePress
“小蜜蜂-BeePress”是一个微信公众号文章导入插件。通过粘贴公众号文章的链接,可以一键导入公众号文章到自己的网站,支持批量导入、自动采集、设置特色图片等功能,减少繁琐操作。
最新版本已支持知乎栏目文章、简书文章、今日头条的导入
WordPress采集Plugin Bee采集BeePress 安装
进入WordPress管理后台,选择安装插件,搜索bees采集
也可以直接从WordPress官网下载,下载链接
下载后解压到插件目录
WordPress采集插件Bee采集BeePress专业版破解
安装完成后,左侧会出现“专业版”和“基础版”。专业版功能更强大,但仅提供 5 次试用。完成次数后,需要以人民币购买。(本教程仅供技术经验分享,部署网站时请支持原创原版)
使用数据库管理工具,这里以phpMyadmin为例。
选择 wp_options 数据表,找到 bp_count 字段
将 option_value 值从 5 更改为任意值
破解成功
如果没有可视化数据库管理工具,也可以直接使用sql命令执行修改,
更新 wp_options SET option_value = 99999 WHERE option_name = 'bp_count';
这里的破解只是增加试用次数,达到专业版无限次使用的效果。如需正常使用授权,请联系作者购买正版插件。
原创文章,作者:dongdongxiao,如转载请注明出处: 查看全部
querylist采集微信公众号文章(WordPress采集插件蜜蜂采集BeePress破解安装教程)
WordPress采集插件蜜蜂采集BeePress
“小蜜蜂-BeePress”是一个微信公众号文章导入插件。通过粘贴公众号文章的链接,可以一键导入公众号文章到自己的网站,支持批量导入、自动采集、设置特色图片等功能,减少繁琐操作。
最新版本已支持知乎栏目文章、简书文章、今日头条的导入
WordPress采集Plugin Bee采集BeePress 安装
进入WordPress管理后台,选择安装插件,搜索bees采集

也可以直接从WordPress官网下载,下载链接
下载后解压到插件目录

WordPress采集插件Bee采集BeePress专业版破解
安装完成后,左侧会出现“专业版”和“基础版”。专业版功能更强大,但仅提供 5 次试用。完成次数后,需要以人民币购买。(本教程仅供技术经验分享,部署网站时请支持原创原版)

使用数据库管理工具,这里以phpMyadmin为例。
选择 wp_options 数据表,找到 bp_count 字段

将 option_value 值从 5 更改为任意值

破解成功

如果没有可视化数据库管理工具,也可以直接使用sql命令执行修改,
更新 wp_options SET option_value = 99999 WHERE option_name = 'bp_count';
这里的破解只是增加试用次数,达到专业版无限次使用的效果。如需正常使用授权,请联系作者购买正版插件。
原创文章,作者:dongdongxiao,如转载请注明出处:
querylist采集微信公众号文章(import_module采集模块实现公众号文章的入口逻辑)
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2022-03-15 22:14
因为采集器有两种不同的实现方式,ruia和playwright,使用哪一种由配置文件决定,然后通过import_module方法动态导入对应的模块,然后运行模块的run方法,从而实现文章的公众号 bool:
"""
采集器工厂函数
:param collect_type: 采集器类型
:param collect_config: 采集器配置
:return:
"""
collect_status = False
try:
# import_module方法动态载入具体的采集模块
collect_module = import_module(f"src.collector.{collect_type}")
collect_status = collect_module.run(collect_config)
except ModuleNotFoundError:
LOGGER.error(f"采集器类型不存在 {collect_type} - {collect_config}")
except Exception as e:
LOGGER.error(f"采集器执行出错 {collect_type} - {collect_config} - {e}")
return collect_status
编剧采集模块实现
Playwright 是微软出品的自动化库。它类似于硒。它定位于网页测试,但也被人们用来获取网页信息。当然,一些前端的反爬措施,编剧是无法突破的。
与selenium相比,playwright支持python的async,性能有所提升(但还是比不上直接请求)。下面是获取公众号下最新= cos_value else 0
max_pro = value if value > max_pro else max_pro
if result == 1:
break
return {"result": result, "value": max_pro}
<p>余弦值的具体操作逻辑在CosineSimilarity的calculate方法中,都是和数学有关的,我就不看了。核心是判断当前 查看全部
querylist采集微信公众号文章(import_module采集模块实现公众号文章的入口逻辑)
因为采集器有两种不同的实现方式,ruia和playwright,使用哪一种由配置文件决定,然后通过import_module方法动态导入对应的模块,然后运行模块的run方法,从而实现文章的公众号 bool:
"""
采集器工厂函数
:param collect_type: 采集器类型
:param collect_config: 采集器配置
:return:
"""
collect_status = False
try:
# import_module方法动态载入具体的采集模块
collect_module = import_module(f"src.collector.{collect_type}")
collect_status = collect_module.run(collect_config)
except ModuleNotFoundError:
LOGGER.error(f"采集器类型不存在 {collect_type} - {collect_config}")
except Exception as e:
LOGGER.error(f"采集器执行出错 {collect_type} - {collect_config} - {e}")
return collect_status
编剧采集模块实现
Playwright 是微软出品的自动化库。它类似于硒。它定位于网页测试,但也被人们用来获取网页信息。当然,一些前端的反爬措施,编剧是无法突破的。
与selenium相比,playwright支持python的async,性能有所提升(但还是比不上直接请求)。下面是获取公众号下最新= cos_value else 0
max_pro = value if value > max_pro else max_pro
if result == 1:
break
return {"result": result, "value": max_pro}
<p>余弦值的具体操作逻辑在CosineSimilarity的calculate方法中,都是和数学有关的,我就不看了。核心是判断当前
querylist采集微信公众号文章(爬取大牛用微信公众号爬取程序的难点及解决办法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-03-15 03:10
最近需要爬取微信公众号的文章信息。我在网上搜索,发现爬取微信公众号的难点在于公众号文章的链接在PC端打不开,所以需要使用微信自带的浏览器(获取参数微信客户端补充)可以在其他平台打开),给爬虫带来了很大的麻烦。后来在知乎上看到了一个大牛用php写的微信公众号爬虫程序,直接按照大佬的思路做成了java。改造过程中遇到了很多细节和问题,就分享给大家。
附上大牛的链接文章:写php或者只需要爬取思路的可以直接看这个。这些想法写得很详细。
-------------------------------------------------- -------------------------------------------------- -------------------------------------------------- ----------------------
系统的基本思路是在Android模拟器上运行微信,在模拟器上设置代理,通过代理服务器截取微信数据,将获取到的数据发送给自己的程序进行处理。
需要准备的环境:nodejs、anyproxy代理、安卓模拟器
Nodejs下载地址:我下载的是windows版本的,直接安装就好了。安装后直接运行 C:\Program Files\nodejs\npm.cmd 会自动配置环境。
anyproxy 安装:按照上一步安装nodejs后,直接在cmd中运行npm install -g anyproxy即可安装
网上的安卓模拟器就好了,有很多。
-------------------------------------------------- -------------------------------------------------- -------------------------------------------------- ----------------------------------
首先安装代理服务器的证书。Anyproxy 默认不解析 https 链接。安装证书后,就可以解析了。在cmd中执行anyproxy --root安装证书,然后在模拟器中下载证书。
然后输入anyproxy -i 命令打开代理服务。(记得添加参数!)
记住这个ip和端口,那么安卓模拟器的代理就会用到这个。现在用浏览器打开网页::8002/ 这是anyproxy的网页界面,用来显示http传输的数据。
点击上方红框中的菜单,会出现一个二维码。用安卓模拟器扫码识别。模拟器(手机)会下载证书并安装。
现在准备为模拟器设置代理,代理模式设置为手动,代理ip为运行anyproxy的机器的ip,端口为8001
准备工作到这里基本完成。在模拟器上打开微信,打开一个公众号的文章,可以从刚刚打开的web界面看到anyproxy抓取的数据:
上图红框是微信文章的链接,点击查看具体数据。如果响应正文中没有任何内容,则可能是证书安装有问题。
如果顶部清晰,您可以向下。
这里我们依靠代理服务抓取微信数据,但是我们不能抓取一条数据自己操作微信,所以还是手动复制比较好。所以我们需要微信客户端自己跳转到页面。这时可以使用anyproxy拦截微信服务器返回的数据,将页面跳转代码注入其中,然后将处理后的数据返回给模拟器,实现微信客户端的自动跳转。
在anyproxy中打开一个名为rule_default.js的js文件,windows下的文件为:C:\Users\Administrator\AppData\Roaming\npm\node_modules\anyproxy\lib
文件中有一个方法叫做replaceServerResDataAsync: function(req,res,serverResData,callback)。该方法负责对anyproxy获取的数据进行各种操作。开头应该只有 callback(serverResData) ;该语句的意思是直接将服务器响应数据返回给客户端。直接把这条语句删掉,换成下面大牛写的代码。我这里的代码没有做任何改动,里面的注释也很清楚。顺着逻辑去理解就行了,问题不大。
1 replaceServerResDataAsync: function(req,res,serverResData,callback){
2 if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
3 //console.log("开始第一种页面爬取");
4 if(serverResData.toString() !== ""){
5 6 try {//防止报错退出程序
7 var reg = /msgList = (.*?);/;//定义历史消息正则匹配规则
8 var ret = reg.exec(serverResData.toString());//转换变量为string
9 HttpPost(ret[1],req.url,"/InternetSpider/getData/showBiz");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
10 var http = require('http');
11 http.get('http://xxx/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
12 res.on('data', function(chunk){
13 callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
14 })
15 });
16 }catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
17 //console.log("开始第一种页面爬取向下翻形式");
18 try {
19 var json = JSON.parse(serverResData.toString());
20 if (json.general_msg_list != []) {
21 HttpPost(json.general_msg_list,req.url,"/xxx/showBiz");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
22 }
23 }catch(e){
24 console.log(e);//错误捕捉
25 }
26 callback(serverResData);//直接返回第二页json内容
27 }
28 }
29 //console.log("开始第一种页面爬取 结束");
30 }else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
31 try {
32 var reg = /var msgList = \'(.*?)\';/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
33 var ret = reg.exec(serverResData.toString());//转换变量为string
34 HttpPost(ret[1],req.url,"/xxx/showBiz");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
35 var http = require('http');
36 http.get('xxx/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
37 res.on('data', function(chunk){
38 callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
39 })
40 });
41 }catch(e){
42 //console.log(e);
43 callback(serverResData);
44 }
45 }else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
46 try {
47 var json = JSON.parse(serverResData.toString());
48 if (json.general_msg_list != []) {
49 HttpPost(json.general_msg_list,req.url,"/xxx/showBiz");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
50 }
51 }catch(e){
52 console.log(e);
53 }
54 callback(serverResData);
55 }else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
56 try {
57 HttpPost(serverResData,req.url,"/xxx/getMsgExt");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
58 }catch(e){
59
60 }
61 callback(serverResData);
62 }else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
63 try {
64 var http = require('http');
65 http.get('http://xxx/getWxPost', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
66 res.on('data', function(chunk){
67 callback(chunk+serverResData);
68 })
69 });
70 }catch(e){
71 callback(serverResData);
72 }
73 }else{
74 callback(serverResData);
75 }
76 //callback(serverResData);
77 },
这是一个简短的解释。微信公众号历史新闻页面的链接有两种形式:一种以/mp/getmasssendmsg开头,另一种以/mp/profile_ext开头。历史页面可以向下滚动。向下滚动会触发js事件发送请求获取json数据(下一页的内容)。还有公众号文章的链接,以及文章的阅读和点赞链接(返回json数据)。这些环节的形式是固定的,可以通过逻辑判断加以区分。这里有个问题,如果历史页面需要一路爬取怎么办。我的想法是通过js模拟鼠标向下滑动,从而触发提交下一部分列表的负载的请求。或者直接使用anyproxy分析下载请求,直接向微信服务器发出这个请求。但是有一个问题是如何判断没有剩余数据。我正在抓取最新数据。我暂时没有这个要求,但以后可能需要。如果需要,您可以尝试一下。 查看全部
querylist采集微信公众号文章(爬取大牛用微信公众号爬取程序的难点及解决办法)
最近需要爬取微信公众号的文章信息。我在网上搜索,发现爬取微信公众号的难点在于公众号文章的链接在PC端打不开,所以需要使用微信自带的浏览器(获取参数微信客户端补充)可以在其他平台打开),给爬虫带来了很大的麻烦。后来在知乎上看到了一个大牛用php写的微信公众号爬虫程序,直接按照大佬的思路做成了java。改造过程中遇到了很多细节和问题,就分享给大家。
附上大牛的链接文章:写php或者只需要爬取思路的可以直接看这个。这些想法写得很详细。
-------------------------------------------------- -------------------------------------------------- -------------------------------------------------- ----------------------
系统的基本思路是在Android模拟器上运行微信,在模拟器上设置代理,通过代理服务器截取微信数据,将获取到的数据发送给自己的程序进行处理。
需要准备的环境:nodejs、anyproxy代理、安卓模拟器
Nodejs下载地址:我下载的是windows版本的,直接安装就好了。安装后直接运行 C:\Program Files\nodejs\npm.cmd 会自动配置环境。
anyproxy 安装:按照上一步安装nodejs后,直接在cmd中运行npm install -g anyproxy即可安装
网上的安卓模拟器就好了,有很多。
-------------------------------------------------- -------------------------------------------------- -------------------------------------------------- ----------------------------------
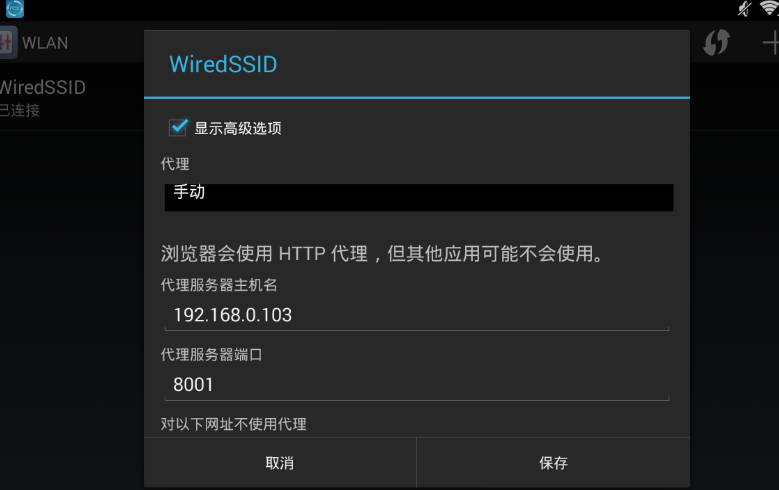
首先安装代理服务器的证书。Anyproxy 默认不解析 https 链接。安装证书后,就可以解析了。在cmd中执行anyproxy --root安装证书,然后在模拟器中下载证书。
然后输入anyproxy -i 命令打开代理服务。(记得添加参数!)

记住这个ip和端口,那么安卓模拟器的代理就会用到这个。现在用浏览器打开网页::8002/ 这是anyproxy的网页界面,用来显示http传输的数据。
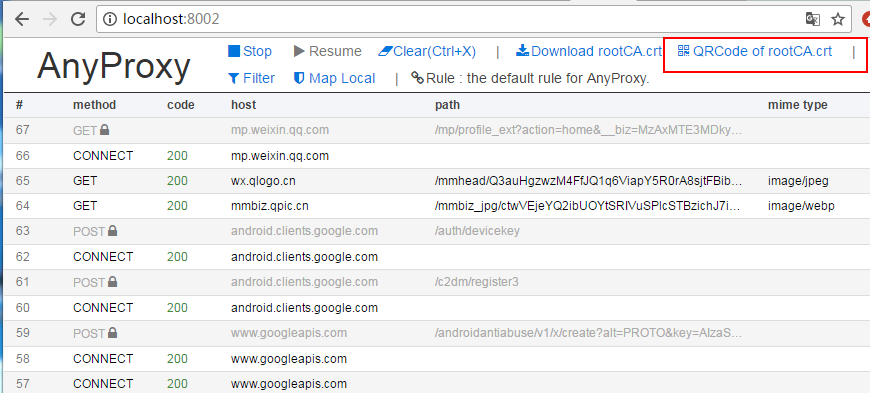
点击上方红框中的菜单,会出现一个二维码。用安卓模拟器扫码识别。模拟器(手机)会下载证书并安装。
现在准备为模拟器设置代理,代理模式设置为手动,代理ip为运行anyproxy的机器的ip,端口为8001
准备工作到这里基本完成。在模拟器上打开微信,打开一个公众号的文章,可以从刚刚打开的web界面看到anyproxy抓取的数据:
上图红框是微信文章的链接,点击查看具体数据。如果响应正文中没有任何内容,则可能是证书安装有问题。
如果顶部清晰,您可以向下。
这里我们依靠代理服务抓取微信数据,但是我们不能抓取一条数据自己操作微信,所以还是手动复制比较好。所以我们需要微信客户端自己跳转到页面。这时可以使用anyproxy拦截微信服务器返回的数据,将页面跳转代码注入其中,然后将处理后的数据返回给模拟器,实现微信客户端的自动跳转。
在anyproxy中打开一个名为rule_default.js的js文件,windows下的文件为:C:\Users\Administrator\AppData\Roaming\npm\node_modules\anyproxy\lib
文件中有一个方法叫做replaceServerResDataAsync: function(req,res,serverResData,callback)。该方法负责对anyproxy获取的数据进行各种操作。开头应该只有 callback(serverResData) ;该语句的意思是直接将服务器响应数据返回给客户端。直接把这条语句删掉,换成下面大牛写的代码。我这里的代码没有做任何改动,里面的注释也很清楚。顺着逻辑去理解就行了,问题不大。

1 replaceServerResDataAsync: function(req,res,serverResData,callback){
2 if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
3 //console.log("开始第一种页面爬取");
4 if(serverResData.toString() !== ""){
5 6 try {//防止报错退出程序
7 var reg = /msgList = (.*?);/;//定义历史消息正则匹配规则
8 var ret = reg.exec(serverResData.toString());//转换变量为string
9 HttpPost(ret[1],req.url,"/InternetSpider/getData/showBiz");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
10 var http = require('http');
11 http.get('http://xxx/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
12 res.on('data', function(chunk){
13 callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
14 })
15 });
16 }catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
17 //console.log("开始第一种页面爬取向下翻形式");
18 try {
19 var json = JSON.parse(serverResData.toString());
20 if (json.general_msg_list != []) {
21 HttpPost(json.general_msg_list,req.url,"/xxx/showBiz");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
22 }
23 }catch(e){
24 console.log(e);//错误捕捉
25 }
26 callback(serverResData);//直接返回第二页json内容
27 }
28 }
29 //console.log("开始第一种页面爬取 结束");
30 }else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
31 try {
32 var reg = /var msgList = \'(.*?)\';/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
33 var ret = reg.exec(serverResData.toString());//转换变量为string
34 HttpPost(ret[1],req.url,"/xxx/showBiz");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
35 var http = require('http');
36 http.get('xxx/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
37 res.on('data', function(chunk){
38 callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
39 })
40 });
41 }catch(e){
42 //console.log(e);
43 callback(serverResData);
44 }
45 }else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
46 try {
47 var json = JSON.parse(serverResData.toString());
48 if (json.general_msg_list != []) {
49 HttpPost(json.general_msg_list,req.url,"/xxx/showBiz");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
50 }
51 }catch(e){
52 console.log(e);
53 }
54 callback(serverResData);
55 }else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
56 try {
57 HttpPost(serverResData,req.url,"/xxx/getMsgExt");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
58 }catch(e){
59
60 }
61 callback(serverResData);
62 }else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
63 try {
64 var http = require('http');
65 http.get('http://xxx/getWxPost', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
66 res.on('data', function(chunk){
67 callback(chunk+serverResData);
68 })
69 });
70 }catch(e){
71 callback(serverResData);
72 }
73 }else{
74 callback(serverResData);
75 }
76 //callback(serverResData);
77 },
这是一个简短的解释。微信公众号历史新闻页面的链接有两种形式:一种以/mp/getmasssendmsg开头,另一种以/mp/profile_ext开头。历史页面可以向下滚动。向下滚动会触发js事件发送请求获取json数据(下一页的内容)。还有公众号文章的链接,以及文章的阅读和点赞链接(返回json数据)。这些环节的形式是固定的,可以通过逻辑判断加以区分。这里有个问题,如果历史页面需要一路爬取怎么办。我的想法是通过js模拟鼠标向下滑动,从而触发提交下一部分列表的负载的请求。或者直接使用anyproxy分析下载请求,直接向微信服务器发出这个请求。但是有一个问题是如何判断没有剩余数据。我正在抓取最新数据。我暂时没有这个要求,但以后可能需要。如果需要,您可以尝试一下。
querylist采集微信公众号文章( 处理跳转向微信注入js的方法:以上就是对处理代理服务器拦截到的数据进行处理)
采集交流 • 优采云 发表了文章 • 0 个评论 • 283 次浏览 • 2022-03-13 10:09
处理跳转向微信注入js的方法:以上就是对处理代理服务器拦截到的数据进行处理)
public void getMsgExt(String str,String url) {
// TODO Auto-generated method stub
String biz = "";
String sn = "";
Map queryStrs = HttpUrlParser.parseUrl(url);
if(queryStrs != null){
biz = queryStrs.get("__biz");
biz = biz + "==";
sn = queryStrs.get("sn");
sn = "%" + sn + "%";
}
/**
* $sql = "select * from `文章表` where `biz`='".$biz."'
* and `content_url` like '%".$sn."%'" limit 0,1;
* 根据biz和sn找到对应的文章
*/
Post post = postMapper.selectByBizAndSn(biz, sn);
if(post == null){
System.out.println("biz:"+biz);
System.out.println("sn:"+sn);
tmpListMapper.deleteByLoad(1);
return;
}
// System.out.println("json数据:"+str);
Integer read_num;
Integer like_num;
try{
read_num = JsonPath.read(str, "['appmsgstat']['read_num']");//阅读量
like_num = JsonPath.read(str, "['appmsgstat']['like_num']");//点赞量
}catch(Exception e){
read_num = 123;//阅读量
like_num = 321;//点赞量
System.out.println("read_num:"+read_num);
System.out.println("like_num:"+like_num);
System.out.println(e.getMessage());
}
/**
* 在这里同样根据sn在采集队列表中删除对应的文章,代表这篇文章可以移出采集队列了
* $sql = "delete from `队列表` where `content_url` like '%".$sn."%'"
*/
tmpListMapper.deleteBySn(sn);
//然后将阅读量和点赞量更新到文章表中。
post.setReadnum(read_num);
post.setLikenum(like_num);
postMapper.updateByPrimaryKey(post);
}
将js注入微信的处理跳转方法:
public String getWxHis() {
String url = "";
// TODO Auto-generated method stub
/**
* 当前页面为公众号历史消息时,读取这个程序
* 在采集队列表中有一个load字段,当值等于1时代表正在被读取
* 首先删除采集队列表中load=1的行
* 然后从队列表中任意select一行
*/
tmpListMapper.deleteByLoad(1);
TmpList queue = tmpListMapper.selectRandomOne();
System.out.println("queue is null?"+queue);
if(queue == null){//队列表为空
/**
* 队列表如果空了,就从存储公众号biz的表中取得一个biz,
* 这里我在公众号表中设置了一个采集时间的time字段,按照正序排列之后,
* 就得到时间戳最小的一个公众号记录,并取得它的biz
*/
WeiXin weiXin = weiXinMapper.selectOne();
String biz = weiXin.getBiz();
url = "https://mp.weixin.qq.com/mp/pr ... ot%3B + biz +
"#wechat_redirect";//拼接公众号历史消息url地址(第二种页面形式)
//更新刚才提到的公众号表中的采集时间time字段为当前时间戳。
weiXin.setCollect(System.currentTimeMillis());
int result = weiXinMapper.updateByPrimaryKey(weiXin);
System.out.println("getHis weiXin updateResult:"+result);
}else{
//取得当前这一行的content_url字段
url = queue.getContentUrl();
//将load字段update为1
tmpListMapper.updateByContentUrl(url);
}
//将下一个将要跳转的$url变成js脚本,由anyproxy注入到微信页面中。
//echo "setTimeout(function(){window.location.href='".$url."';},2000);";
int randomTime = new Random().nextInt(3) + 3;
String jsCode = "setTimeout(function(){window.location.href='"+url+"';},"+randomTime*1000+");";
return jsCode;
}
以上是处理代理服务器截获的数据的程序。这里有一个需要注意的问题。程序会依次访问数据库中每个收录的公众号,甚至会再次访问存储的文章,以不断更新收录的阅读点赞数@文章 的。如果需要抓取大量公众号,建议修改添加任务队列和添加条件的代码,否则多轮公众号抓取重复数据的效率会受到很大影响。
至此,微信公众号的文章链接全部被爬取完毕,且该链接为永久有效链接,可在浏览器中打开。接下来就是编写爬虫程序,从数据库中爬取链接文章的内容等信息。
我用webmagic写了一个爬虫,轻量级,好用。
public class SpiderModel implements PageProcessor{
private static PostMapper postMapper;
private static List posts;
// 抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private Site site = Site.me().setRetryTimes(3).setSleepTime(100);
public Site getSite() {
// TODO Auto-generated method stub
return this.site;
}
public void process(Page page) {
// TODO Auto-generated method stub
Post post = posts.remove(0);
String content = page.getHtml().xpath("//div[@id='js_content']").get();
//存在和谐文章 此处做判定如果有直接删除记录或设置表示位表示文章被和谐
if(content == null){
System.out.println("文章已和谐!");
//postMapper.deleteByPrimaryKey(post.getId());
return;
}
String contentSnap = content.replaceAll("data-src", "src").replaceAll("preview.html", "player.html");//快照
String contentTxt = HtmlToWord.stripHtml(content);//纯文本内容
Selectable metaContent = page.getHtml().xpath("//div[@id='meta_content']");
String pubTime = null;
String wxname = null;
String author = null;
if(metaContent != null){
pubTime = metaContent.xpath("//em[@id='post-date']").get();
if(pubTime != null){
pubTime = HtmlToWord.stripHtml(pubTime);//文章发布时间
}
wxname = metaContent.xpath("//a[@id='post-user']").get();
if(wxname != null){
wxname = HtmlToWord.stripHtml(wxname);//公众号名称
}
author = metaContent.xpath("//em[@class='rich_media_meta rich_media_meta_text' and @id!='post-date']").get();
if(author != null){
author = HtmlToWord.stripHtml(author);//文章作者
}
}
// System.out.println("发布时间:"+pubTime);
// System.out.println("公众号名称:"+wxname);
// System.out.println("文章作者:"+author);
String title = post.getTitle().replaceAll(" ", "");//文章标题
String digest = post.getDigest();//文章摘要
int likeNum = post.getLikenum();//文章点赞数
int readNum = post.getReadnum();//文章阅读数
String contentUrl = post.getContentUrl();//文章链接
WechatInfoBean wechatBean = new WechatInfoBean();
wechatBean.setTitle(title);
wechatBean.setContent(contentTxt);//纯文本内容
wechatBean.setSourceCode(contentSnap);//快照
wechatBean.setLikeCount(likeNum);
wechatBean.setViewCount(readNum);
wechatBean.setAbstractText(digest);//摘要
wechatBean.setUrl(contentUrl);
wechatBean.setPublishTime(pubTime);
wechatBean.setSiteName(wxname);//站点名称 公众号名称
wechatBean.setAuthor(author);
wechatBean.setMediaType("微信公众号");//来源媒体类型
WechatStorage.saveWechatInfo(wechatBean);
//标示文章已经被爬取
post.setIsSpider(1);
postMapper.updateByPrimaryKey(post);
}
public static void startSpider(List inposts,PostMapper myPostMapper,String... urls){
long startTime, endTime;
startTime = System.currentTimeMillis();
postMapper = myPostMapper;
posts = inposts;
HttpClientDownloader httpClientDownloader = new HttpClientDownloader();
SpiderModel spiderModel = new SpiderModel();
Spider mySpider = Spider.create(spiderModel).addUrl(urls);
mySpider.setDownloader(httpClientDownloader);
try {
SpiderMonitor.instance().register(mySpider);
mySpider.thread(1).run();
} catch (JMException e) {
e.printStackTrace();
}
endTime = System.currentTimeMillis();
System.out.println("爬取时间" + ((endTime - startTime) / 1000) + "秒--");
}
}
其他一些不相关的数据存储代码将不会发布。这里我将代理服务器抓取的数据存储在mysql中,将我的爬虫爬取的数据存储在mongodb中。
以下是我爬取的公众号信息:
打开应用程序并阅读笔记 查看全部
querylist采集微信公众号文章(
处理跳转向微信注入js的方法:以上就是对处理代理服务器拦截到的数据进行处理)
public void getMsgExt(String str,String url) {
// TODO Auto-generated method stub
String biz = "";
String sn = "";
Map queryStrs = HttpUrlParser.parseUrl(url);
if(queryStrs != null){
biz = queryStrs.get("__biz");
biz = biz + "==";
sn = queryStrs.get("sn");
sn = "%" + sn + "%";
}
/**
* $sql = "select * from `文章表` where `biz`='".$biz."'
* and `content_url` like '%".$sn."%'" limit 0,1;
* 根据biz和sn找到对应的文章
*/
Post post = postMapper.selectByBizAndSn(biz, sn);
if(post == null){
System.out.println("biz:"+biz);
System.out.println("sn:"+sn);
tmpListMapper.deleteByLoad(1);
return;
}
// System.out.println("json数据:"+str);
Integer read_num;
Integer like_num;
try{
read_num = JsonPath.read(str, "['appmsgstat']['read_num']");//阅读量
like_num = JsonPath.read(str, "['appmsgstat']['like_num']");//点赞量
}catch(Exception e){
read_num = 123;//阅读量
like_num = 321;//点赞量
System.out.println("read_num:"+read_num);
System.out.println("like_num:"+like_num);
System.out.println(e.getMessage());
}
/**
* 在这里同样根据sn在采集队列表中删除对应的文章,代表这篇文章可以移出采集队列了
* $sql = "delete from `队列表` where `content_url` like '%".$sn."%'"
*/
tmpListMapper.deleteBySn(sn);
//然后将阅读量和点赞量更新到文章表中。
post.setReadnum(read_num);
post.setLikenum(like_num);
postMapper.updateByPrimaryKey(post);
}
将js注入微信的处理跳转方法:
public String getWxHis() {
String url = "";
// TODO Auto-generated method stub
/**
* 当前页面为公众号历史消息时,读取这个程序
* 在采集队列表中有一个load字段,当值等于1时代表正在被读取
* 首先删除采集队列表中load=1的行
* 然后从队列表中任意select一行
*/
tmpListMapper.deleteByLoad(1);
TmpList queue = tmpListMapper.selectRandomOne();
System.out.println("queue is null?"+queue);
if(queue == null){//队列表为空
/**
* 队列表如果空了,就从存储公众号biz的表中取得一个biz,
* 这里我在公众号表中设置了一个采集时间的time字段,按照正序排列之后,
* 就得到时间戳最小的一个公众号记录,并取得它的biz
*/
WeiXin weiXin = weiXinMapper.selectOne();
String biz = weiXin.getBiz();
url = "https://mp.weixin.qq.com/mp/pr ... ot%3B + biz +
"#wechat_redirect";//拼接公众号历史消息url地址(第二种页面形式)
//更新刚才提到的公众号表中的采集时间time字段为当前时间戳。
weiXin.setCollect(System.currentTimeMillis());
int result = weiXinMapper.updateByPrimaryKey(weiXin);
System.out.println("getHis weiXin updateResult:"+result);
}else{
//取得当前这一行的content_url字段
url = queue.getContentUrl();
//将load字段update为1
tmpListMapper.updateByContentUrl(url);
}
//将下一个将要跳转的$url变成js脚本,由anyproxy注入到微信页面中。
//echo "setTimeout(function(){window.location.href='".$url."';},2000);";
int randomTime = new Random().nextInt(3) + 3;
String jsCode = "setTimeout(function(){window.location.href='"+url+"';},"+randomTime*1000+");";
return jsCode;
}
以上是处理代理服务器截获的数据的程序。这里有一个需要注意的问题。程序会依次访问数据库中每个收录的公众号,甚至会再次访问存储的文章,以不断更新收录的阅读点赞数@文章 的。如果需要抓取大量公众号,建议修改添加任务队列和添加条件的代码,否则多轮公众号抓取重复数据的效率会受到很大影响。
至此,微信公众号的文章链接全部被爬取完毕,且该链接为永久有效链接,可在浏览器中打开。接下来就是编写爬虫程序,从数据库中爬取链接文章的内容等信息。
我用webmagic写了一个爬虫,轻量级,好用。
public class SpiderModel implements PageProcessor{
private static PostMapper postMapper;
private static List posts;
// 抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private Site site = Site.me().setRetryTimes(3).setSleepTime(100);
public Site getSite() {
// TODO Auto-generated method stub
return this.site;
}
public void process(Page page) {
// TODO Auto-generated method stub
Post post = posts.remove(0);
String content = page.getHtml().xpath("//div[@id='js_content']").get();
//存在和谐文章 此处做判定如果有直接删除记录或设置表示位表示文章被和谐
if(content == null){
System.out.println("文章已和谐!");
//postMapper.deleteByPrimaryKey(post.getId());
return;
}
String contentSnap = content.replaceAll("data-src", "src").replaceAll("preview.html", "player.html");//快照
String contentTxt = HtmlToWord.stripHtml(content);//纯文本内容
Selectable metaContent = page.getHtml().xpath("//div[@id='meta_content']");
String pubTime = null;
String wxname = null;
String author = null;
if(metaContent != null){
pubTime = metaContent.xpath("//em[@id='post-date']").get();
if(pubTime != null){
pubTime = HtmlToWord.stripHtml(pubTime);//文章发布时间
}
wxname = metaContent.xpath("//a[@id='post-user']").get();
if(wxname != null){
wxname = HtmlToWord.stripHtml(wxname);//公众号名称
}
author = metaContent.xpath("//em[@class='rich_media_meta rich_media_meta_text' and @id!='post-date']").get();
if(author != null){
author = HtmlToWord.stripHtml(author);//文章作者
}
}
// System.out.println("发布时间:"+pubTime);
// System.out.println("公众号名称:"+wxname);
// System.out.println("文章作者:"+author);
String title = post.getTitle().replaceAll(" ", "");//文章标题
String digest = post.getDigest();//文章摘要
int likeNum = post.getLikenum();//文章点赞数
int readNum = post.getReadnum();//文章阅读数
String contentUrl = post.getContentUrl();//文章链接
WechatInfoBean wechatBean = new WechatInfoBean();
wechatBean.setTitle(title);
wechatBean.setContent(contentTxt);//纯文本内容
wechatBean.setSourceCode(contentSnap);//快照
wechatBean.setLikeCount(likeNum);
wechatBean.setViewCount(readNum);
wechatBean.setAbstractText(digest);//摘要
wechatBean.setUrl(contentUrl);
wechatBean.setPublishTime(pubTime);
wechatBean.setSiteName(wxname);//站点名称 公众号名称
wechatBean.setAuthor(author);
wechatBean.setMediaType("微信公众号");//来源媒体类型
WechatStorage.saveWechatInfo(wechatBean);
//标示文章已经被爬取
post.setIsSpider(1);
postMapper.updateByPrimaryKey(post);
}
public static void startSpider(List inposts,PostMapper myPostMapper,String... urls){
long startTime, endTime;
startTime = System.currentTimeMillis();
postMapper = myPostMapper;
posts = inposts;
HttpClientDownloader httpClientDownloader = new HttpClientDownloader();
SpiderModel spiderModel = new SpiderModel();
Spider mySpider = Spider.create(spiderModel).addUrl(urls);
mySpider.setDownloader(httpClientDownloader);
try {
SpiderMonitor.instance().register(mySpider);
mySpider.thread(1).run();
} catch (JMException e) {
e.printStackTrace();
}
endTime = System.currentTimeMillis();
System.out.println("爬取时间" + ((endTime - startTime) / 1000) + "秒--");
}
}
其他一些不相关的数据存储代码将不会发布。这里我将代理服务器抓取的数据存储在mysql中,将我的爬虫爬取的数据存储在mongodb中。
以下是我爬取的公众号信息:
打开应用程序并阅读笔记
querylist采集微信公众号文章(Python微信公众号文章爬取一.思路我们通过网页版)
采集交流 • 优采云 发表了文章 • 0 个评论 • 434 次浏览 • 2022-03-13 06:13
Python微信公众号文章爬取
一.想法
我们通过网页版微信公众平台的图文消息中的超链接获取我们需要的界面
从界面中我们可以得到对应的微信公众号和所有对应的微信公众号文章。
二.界面分析
获取微信公众号界面:
范围:
行动=search_biz
开始=0
计数=5
query=公众号
token = 每个账户对应的token值
lang=zh_CN
f=json
阿贾克斯=1
请求方法:
得到
所以在这个界面中,我们只需要获取token,查询的是你需要搜索的公众号,登录后可以通过网页链接获取token。
获取公众号对应的文章接口:
范围:
行动=list_ex
开始=0
计数=5
fakeid=MjM5NDAwMTA2MA==
类型=9
查询=
令牌=557131216
lang=zh_CN
f=json
阿贾克斯=1
请求方法:
得到
在这个接口中,我们需要获取的值是上一步的token和fakeid,而这个fakeid可以在第一个接口中获取。这样我们就可以得到微信公众号文章的数据了。
三.实现第一步:
首先我们需要通过selenium来模拟登录,然后获取cookie和对应的token
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get('https://mp.weixin.qq.com/')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
sleep(2)
# 微信登录验证
print('请扫描二维码')
sleep(20)
# 刷新当前网页
browser.get('https://mp.weixin.qq.com/')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item['name']] = item['value']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie保存到本地成功')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split('?')[1].split('&')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split('=')[0]] = item.split('=')[1]
# 返回token
return paramdict['token']
定义了一个登录方法,里面的参数是登录账号和密码,然后定义了一个字典来存储cookie的值。模拟用户输入对应账号密码,点击登录,出现扫码验证,登录微信即可扫码。
刷新当前网页后,获取当前cookie和token并返回。
第二步:1.请求获取对应的公众号接口,获取我们需要的fakeid
url = 'https://mp.weixin.qq.com'
headers = {
'HOST': 'mp.weixin.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = 'https://mp.weixin.qq.com/cgi-b ... 39%3B
params = {
'action': 'search_biz',
'begin': '0',
'count': '5',
'query': '搜索的公众号名称',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获取的token和cookie,然后通过requests.get请求获取微信公众号返回的json数据
lists = search_resp.json().get('list')[0]
通过以上代码可以获取对应的公众号数据
fakeid = lists.get('fakeid')
通过上面的代码,可以得到对应的 fakeid
2.请求访问微信公众号文章接口,获取我们需要的文章数据
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
params_data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入 fakeid 和 token 然后调用 requests.get 请求接口获取返回的 json 数据。
我们实现了微信公众号文章的爬取。
四.总结
通过爬取微信公众号文章,需要掌握selenium和requests的用法,以及如何获取request接口。但是需要注意的是,我们在循环获取文章的时候,一定要设置一个延迟时间,否则容易被封号,获取不到返回的数据。 查看全部
querylist采集微信公众号文章(Python微信公众号文章爬取一.思路我们通过网页版)
Python微信公众号文章爬取
一.想法
我们通过网页版微信公众平台的图文消息中的超链接获取我们需要的界面


从界面中我们可以得到对应的微信公众号和所有对应的微信公众号文章。
二.界面分析
获取微信公众号界面:
范围:
行动=search_biz
开始=0
计数=5
query=公众号
token = 每个账户对应的token值
lang=zh_CN
f=json
阿贾克斯=1
请求方法:
得到
所以在这个界面中,我们只需要获取token,查询的是你需要搜索的公众号,登录后可以通过网页链接获取token。

获取公众号对应的文章接口:
范围:
行动=list_ex
开始=0
计数=5
fakeid=MjM5NDAwMTA2MA==
类型=9
查询=
令牌=557131216
lang=zh_CN
f=json
阿贾克斯=1
请求方法:
得到
在这个接口中,我们需要获取的值是上一步的token和fakeid,而这个fakeid可以在第一个接口中获取。这样我们就可以得到微信公众号文章的数据了。

三.实现第一步:
首先我们需要通过selenium来模拟登录,然后获取cookie和对应的token
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get('https://mp.weixin.qq.com/')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
sleep(2)
# 微信登录验证
print('请扫描二维码')
sleep(20)
# 刷新当前网页
browser.get('https://mp.weixin.qq.com/')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item['name']] = item['value']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie保存到本地成功')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split('?')[1].split('&')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split('=')[0]] = item.split('=')[1]
# 返回token
return paramdict['token']
定义了一个登录方法,里面的参数是登录账号和密码,然后定义了一个字典来存储cookie的值。模拟用户输入对应账号密码,点击登录,出现扫码验证,登录微信即可扫码。
刷新当前网页后,获取当前cookie和token并返回。
第二步:1.请求获取对应的公众号接口,获取我们需要的fakeid
url = 'https://mp.weixin.qq.com'
headers = {
'HOST': 'mp.weixin.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = 'https://mp.weixin.qq.com/cgi-b ... 39%3B
params = {
'action': 'search_biz',
'begin': '0',
'count': '5',
'query': '搜索的公众号名称',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获取的token和cookie,然后通过requests.get请求获取微信公众号返回的json数据
lists = search_resp.json().get('list')[0]
通过以上代码可以获取对应的公众号数据
fakeid = lists.get('fakeid')
通过上面的代码,可以得到对应的 fakeid
2.请求访问微信公众号文章接口,获取我们需要的文章数据
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
params_data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入 fakeid 和 token 然后调用 requests.get 请求接口获取返回的 json 数据。
我们实现了微信公众号文章的爬取。
四.总结
通过爬取微信公众号文章,需要掌握selenium和requests的用法,以及如何获取request接口。但是需要注意的是,我们在循环获取文章的时候,一定要设置一个延迟时间,否则容易被封号,获取不到返回的数据。
querylist采集微信公众号文章(Python模拟安卓App操作微信App的方法(详见代码介绍))
采集交流 • 优采云 发表了文章 • 0 个评论 • 231 次浏览 • 2022-03-12 07:07
本文章主要介绍基于Python采集对微信公众号历史数据的爬取。通过文中的示例代码介绍的很详细,对大家的学习或工作有一定的参考和学习价值。需要的朋友可以参考以下
鲲之鹏技术人员将在本文中通过模拟微信App的操作,介绍一种采集指定公众号所有历史数据的方法。
通过我们的抓包分析,我们发现微信公众号的历史数据是通过HTTP协议加载的。对应的API接口如下图所示,有四个关键参数(__biz、appmsg_token、pass_ticket和Cookie)。
为了得到这四个参数,我们需要模拟运行App,让它生成这些参数,然后我们就可以抓包了。对于模拟App操作,我们之前已经介绍过通过Python模拟Android App的方法(见详情)。对于 HTTP 集成的数据包捕获,我们之前已经介绍了 Mitmproxy(见详情)。
我们需要模拟微信的操作来完成以下步骤:
1. 启动微信应用
2. 点击“通讯录”
3. 点击“公众号”
4.点击你想要的公众号采集
5. 点击右上角的用户头像图标
6. 点击“所有消息”
至此,我们可以从响应数据中捕获__biz、appmsg_token、pass_ticket这三个关键参数,以及请求头中的Cookie值。如下所示。
有了以上四个参数,我们就可以构造API请求获取历史文章列表,直接调用API接口获取数据(无需模拟App操作)。核心参数如下。通过改变offset参数,可以得到所有的历史数据。
# Cookie headers = {'Cookie': 'rewardsn=; wxtokenkey=777; wxuin=584068438; devicetype=android-19; version=26060736; lang=zh_CN; pass_ticket=Rr8cO5c2******3tKGqe7aVZzV9TupvrK+1uHHmHYQGL2WFdKIE; wap_sid2=COKhxu4KElxckFZQ3QzTHU4WThEUk0zcWdrZjhGcUdYdEVSV3Y1X2NPWHNUakRrd1ZzMnpLTERpdE5rbmxjSTg******dlRBcUNRazZpOGxTZUVEQUTgNQJVO'} url = 'https://mp.weixin.qq.com/mp/profile_ext?' data = {} data['is_ok'] = '1' data['count'] = '10' data['wxtoken'] = '' data['f'] = 'json' data['scene'] = '124' data['uin'] = '777' data['key'] = '777' data['offset'] = '0' data['action'] = 'getmsg' data['x5'] = '0' # 下面三个参数需要替换 # https://mp.weixin.qq.com/mp/pr ... Dhome应答数据里会暴漏这三个参数 data['__biz'] = 'MjM5MzQyOTM1OQ==' data['appmsg_token'] = '993_V8%2BEmfVD7g%2FvMZ****4DNUJNFkg~~' data['pass_ticket'] = 'Rr8cO5c23ZngeQHRGy8E7gv*****pvrK+1uHHmHYQGL2WFdKIE' url = url + urllib.urlencode(data)
以“数字工厂”微信公众号为例,采集流程操作截图如下:
输出的屏幕截图如下所示:
以上就是基于Python采集抓取微信公众号历史数据的详细内容,更多详情请关注html中文网其他相关话题文章! 查看全部
querylist采集微信公众号文章(Python模拟安卓App操作微信App的方法(详见代码介绍))
本文章主要介绍基于Python采集对微信公众号历史数据的爬取。通过文中的示例代码介绍的很详细,对大家的学习或工作有一定的参考和学习价值。需要的朋友可以参考以下
鲲之鹏技术人员将在本文中通过模拟微信App的操作,介绍一种采集指定公众号所有历史数据的方法。
通过我们的抓包分析,我们发现微信公众号的历史数据是通过HTTP协议加载的。对应的API接口如下图所示,有四个关键参数(__biz、appmsg_token、pass_ticket和Cookie)。

为了得到这四个参数,我们需要模拟运行App,让它生成这些参数,然后我们就可以抓包了。对于模拟App操作,我们之前已经介绍过通过Python模拟Android App的方法(见详情)。对于 HTTP 集成的数据包捕获,我们之前已经介绍了 Mitmproxy(见详情)。
我们需要模拟微信的操作来完成以下步骤:
1. 启动微信应用
2. 点击“通讯录”
3. 点击“公众号”
4.点击你想要的公众号采集
5. 点击右上角的用户头像图标
6. 点击“所有消息”


至此,我们可以从响应数据中捕获__biz、appmsg_token、pass_ticket这三个关键参数,以及请求头中的Cookie值。如下所示。


有了以上四个参数,我们就可以构造API请求获取历史文章列表,直接调用API接口获取数据(无需模拟App操作)。核心参数如下。通过改变offset参数,可以得到所有的历史数据。
# Cookie headers = {'Cookie': 'rewardsn=; wxtokenkey=777; wxuin=584068438; devicetype=android-19; version=26060736; lang=zh_CN; pass_ticket=Rr8cO5c2******3tKGqe7aVZzV9TupvrK+1uHHmHYQGL2WFdKIE; wap_sid2=COKhxu4KElxckFZQ3QzTHU4WThEUk0zcWdrZjhGcUdYdEVSV3Y1X2NPWHNUakRrd1ZzMnpLTERpdE5rbmxjSTg******dlRBcUNRazZpOGxTZUVEQUTgNQJVO'} url = 'https://mp.weixin.qq.com/mp/profile_ext?' data = {} data['is_ok'] = '1' data['count'] = '10' data['wxtoken'] = '' data['f'] = 'json' data['scene'] = '124' data['uin'] = '777' data['key'] = '777' data['offset'] = '0' data['action'] = 'getmsg' data['x5'] = '0' # 下面三个参数需要替换 # https://mp.weixin.qq.com/mp/pr ... Dhome应答数据里会暴漏这三个参数 data['__biz'] = 'MjM5MzQyOTM1OQ==' data['appmsg_token'] = '993_V8%2BEmfVD7g%2FvMZ****4DNUJNFkg~~' data['pass_ticket'] = 'Rr8cO5c23ZngeQHRGy8E7gv*****pvrK+1uHHmHYQGL2WFdKIE' url = url + urllib.urlencode(data)
以“数字工厂”微信公众号为例,采集流程操作截图如下:

输出的屏幕截图如下所示:

以上就是基于Python采集抓取微信公众号历史数据的详细内容,更多详情请关注html中文网其他相关话题文章!
querylist采集微信公众号文章(python采集微信公众号文章本文(操作postgres数据库)抓取)
采集交流 • 优采云 发表了文章 • 0 个评论 • 449 次浏览 • 2022-03-11 17:00
Python抢购搜狗微信公众号文章
初学python,抢搜狗微信公众号文章存入mysql
mysql表:
代码:
import requests
import json
import re
import pymysql
# 创建连接
conn = pymysql.connect(host='你的数据库地址', port=端口, user='用户名', passwd='密码', db='数据库名称', charset='utf8')
# 创建游标
cursor = conn.cursor()
cursor.execute("select * from hd_gzh")
effect_row = cursor.fetchall()
from bs4 import BeautifulSoup
socket.setdefaulttimeout(60)
count = 1
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:65.0) Gecko/20100101 Firefox/65.0'}
#阿布云ip代理暂时不用
# proxyHost = "http-cla.abuyun.com"
# proxyPort = "9030"
# # 代理隧道验证信息
# proxyUser = "H56761606429T7UC"
# proxyPass = "9168EB00C4167176"
# proxyMeta = "http://%(user)s:%(pass)s@%(host)s:%(port)s" % {
# "host" : proxyHost,
# "port" : proxyPort,
# "user" : proxyUser,
# "pass" : proxyPass,
# }
# proxies = {
# "http" : proxyMeta,
# "https" : proxyMeta,
# }
#查看是否已存在数据
def checkData(name):
sql = "select * from gzh_article where title = '%s'"
data = (name,)
count = cursor.execute(sql % data)
conn.commit()
if(count!=0):
return False
else:
return True
#插入数据
def insertData(title,picture,author,content):
sql = "insert into gzh_article (title,picture,author,content) values ('%s', '%s','%s', '%s')"
data = (title,picture,author,content)
cursor.execute(sql % data)
conn.commit()
print("插入一条数据")
return
for row in effect_row:
newsurl = 'https://weixin.sogou.com/weixin?type=1&s_from=input&query=' + row[1] + '&ie=utf8&_sug_=n&_sug_type_='
res = requests.get(newsurl,headers=headers)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text,'html.parser')
url = 'https://weixin.sogou.com' + soup.select('.tit a')[0]['href']
res2 = requests.get(url,headers=headers)
res2.encoding = 'utf-8'
soup2 = BeautifulSoup(res2.text,'html.parser')
pattern = re.compile(r"url \+= '(.*?)';", re.MULTILINE | re.DOTALL)
script = soup2.find("script")
url2 = pattern.search(script.text).group(1)
res3 = requests.get(url2,headers=headers)
res3.encoding = 'utf-8'
soup3 = BeautifulSoup(res3.text,'html.parser')
print()
pattern2 = re.compile(r"var msgList = (.*?);$", re.MULTILINE | re.DOTALL)
script2 = soup3.find("script", text=pattern2)
s2 = json.loads(pattern2.search(script2.text).group(1))
#等待10s
time.sleep(10)
for news in s2["list"]:
articleurl = "https://mp.weixin.qq.com"+news["app_msg_ext_info"]["content_url"]
articleurl = articleurl.replace('&','&')
res4 = requests.get(articleurl,headers=headers)
res4.encoding = 'utf-8'
soup4 = BeautifulSoup(res4.text,'html.parser')
if(checkData(news["app_msg_ext_info"]["title"])):
insertData(news["app_msg_ext_info"]["title"],news["app_msg_ext_info"]["cover"],news["app_msg_ext_info"]["author"],pymysql.escape_string(str(soup4)))
count += 1
#等待5s
time.sleep(10)
for news2 in news["app_msg_ext_info"]["multi_app_msg_item_list"]:
articleurl2 = "https://mp.weixin.qq.com"+news2["content_url"]
articleurl2 = articleurl2.replace('&','&')
res5 = requests.get(articleurl2,headers=headers)
res5.encoding = 'utf-8'
soup5 = BeautifulSoup(res5.text,'html.parser')
if(checkData(news2["title"])):
insertData(news2["title"],news2["cover"],news2["author"],pymysql.escape_string(str(soup5)))
count += 1
#等待10s
time.sleep(10)
cursor.close()
conn.close()
print("操作完成")
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。
时间:2019-03-31
python采集微信公众号文章
本文示例分享了python采集微信公众号文章的具体代码,供大家参考。具体内容如下。python的一个子目录下存放了两个文件,分别是:采集公众号文章.py和config.py。代码如下:1.采集公众号文章.py from urllib.parse import urlencode import pymongo import requests from lxml.etree import XMLSyntaxError from requests.exceptions import Connec
Python如何爬取微信公众号文章及评论(基于Fiddler抓包分析)
背景描述我觉得微信公众号是比较难爬的平台之一,但是经过一番折腾,还是有一点小收获。没用Scrapy(估计爬太快有防爬限制),不过后面会开始整理写一些实战。. 简单介绍一下本次的开发环境:python3请求psycopg2(操作postgres数据库) 抓包分析 本次实战对要抓包的公众号没有限制,但是每次抓包前都要对不同的公众号进行分析。打开Fiddler,在手机上配置相关代理。为了避免过多干扰,这里给Fiddler一个过滤规则,指定微信域名即可:
python爬取微信公众号文章的方法
最近在学习Python3网络爬虫(崔庆才写的)的开发实践,刚刚得知他在这里使用代理爬取了公众号文章,但是根据他的代码,还是出现了一些问题。我在这里用过这本书。对本书前面提到的一些内容进行了改进。(作者半年前写了这段代码,腾讯的网站半年前更新了)我直接加下面代码:TIMEOUT = 20 from requests import Request, Session, PreparedRequest import requests from selenium import webdrive
50行Python代码如何获取所有公众号文章
前言我们在阅读公众号文章时通常会遇到一个问题——阅读历史文章的体验并不好。我们知道爬取公众号的常用方法有两种:通过搜狗搜索获取,缺点是只能获取最新的十推文章。通过微信公众号的素材管理,可以获得公众号文章。缺点是需要自己申请公众号。微信方式获取公众号文章的方法。与其他方法相比,非常方便。如上图,通过抓包工具获取微信的网络信息请求,我们发现每次文章
Python爬取指定微信公众号文章
本文示例分享了python爬取微信公众号文章的具体代码,供大家参考。具体内容如下。该方法是依靠 urllib2 库完成的。首先需要安装你的python环境,然后安装urllib2库程序的启动方法(返回值为公众号文章的列表): def openUrl(): print("启动爬虫,打开搜狗搜索微信界面") # 加载页面url = ';s_from=input&query = 被抓取的公众号名称
Python爬取微信公众号文章
本文示例分享python爬取微信公众号文章的具体代码供大家参考,具体内容如下# -*- coding: utf-8 -*- import requests from bs4 import BeautifulSoup from requests .exceptions import RequestException import time import random import MySQLdb import threading import socket import math soc
python selenium爬取微信公众号文章代码详解
参考:selenium webdriver 添加cookies: 需求:想看微信公众号文章的历史,但是每次都找地方不方便。思路:1.使用selenium打开微信公众号历史文章,滚动刷新到底部,获取所有历史文章url。2.遍历访问url,下载到本地。实现1.打开微信客户端,点击微信公众号->进入公众号->打开历史文章链接(用浏览器打开),通过开发者工具获取cookie
Python使用webdriver爬取微信公众号
本文示例分享了python使用webdriver爬取微信公众号的具体代码,供大家参考。具体内容如下# -*- 编码:utf-8 -*- from selenium import webdriver import time import json import requests import re import random #微信公众号user="" #公众号密码password="" #设置需要爬取的公众号列表 gzlist=['香河微服务
python如何导出微信公众号文章详解
1.安装wkhtmltopdf 下载地址:我用windows进行测试,下载安装后结果如下 2 编写python代码导出微信公众号文章 不能直接使用wkhtmltopdf导出微信公众号文章,导出的文章会缺图,所以需要使用微信公众号文章页面,然后将html文本转换成pdf pip install wechatsogou --升级 pip install pdfkit 踩坑
Python抓取微信公众号账号信息的方法
搜狗微信搜索提供了两种关键词搜索,一种是搜索公众号文章的内容,另一种是直接搜索微信公众号。公众号基本信息可通过微信公众号搜索获取。还有最近发布的10个文章,今天就来抢微信公众号的账号信息爬虫吧。首先通过首页进入,可以按类别抓取,通过“查看更多”可以找到页面链接规则: import requests as req import re reTypes = r'id="pc_\d*" uigs=" (pc_\d*)">([\s\S]*?)&
Python爬虫_微信公众号推送信息爬取示例
问题描述 使用搜狗的微信搜索,从指定公众号抓取最新推送,并将对应网页保存到本地。注意,搜狗微信获取的地址是临时链接,具有时效性。公众号为动态网页(JavaScript渲染),使用requests.get()获取的内容不收录推送消息。这里使用 selenium+PhantomJS 处理代码#!/usr/bin/env python3 from selenium import webdriver from datetime import datetime import bs4, requ 查看全部
querylist采集微信公众号文章(python采集微信公众号文章本文(操作postgres数据库)抓取)
Python抢购搜狗微信公众号文章
初学python,抢搜狗微信公众号文章存入mysql
mysql表:


代码:
import requests
import json
import re
import pymysql
# 创建连接
conn = pymysql.connect(host='你的数据库地址', port=端口, user='用户名', passwd='密码', db='数据库名称', charset='utf8')
# 创建游标
cursor = conn.cursor()
cursor.execute("select * from hd_gzh")
effect_row = cursor.fetchall()
from bs4 import BeautifulSoup
socket.setdefaulttimeout(60)
count = 1
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:65.0) Gecko/20100101 Firefox/65.0'}
#阿布云ip代理暂时不用
# proxyHost = "http-cla.abuyun.com"
# proxyPort = "9030"
# # 代理隧道验证信息
# proxyUser = "H56761606429T7UC"
# proxyPass = "9168EB00C4167176"
# proxyMeta = "http://%(user)s:%(pass)s@%(host)s:%(port)s" % {
# "host" : proxyHost,
# "port" : proxyPort,
# "user" : proxyUser,
# "pass" : proxyPass,
# }
# proxies = {
# "http" : proxyMeta,
# "https" : proxyMeta,
# }
#查看是否已存在数据
def checkData(name):
sql = "select * from gzh_article where title = '%s'"
data = (name,)
count = cursor.execute(sql % data)
conn.commit()
if(count!=0):
return False
else:
return True
#插入数据
def insertData(title,picture,author,content):
sql = "insert into gzh_article (title,picture,author,content) values ('%s', '%s','%s', '%s')"
data = (title,picture,author,content)
cursor.execute(sql % data)
conn.commit()
print("插入一条数据")
return
for row in effect_row:
newsurl = 'https://weixin.sogou.com/weixin?type=1&s_from=input&query=' + row[1] + '&ie=utf8&_sug_=n&_sug_type_='
res = requests.get(newsurl,headers=headers)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text,'html.parser')
url = 'https://weixin.sogou.com' + soup.select('.tit a')[0]['href']
res2 = requests.get(url,headers=headers)
res2.encoding = 'utf-8'
soup2 = BeautifulSoup(res2.text,'html.parser')
pattern = re.compile(r"url \+= '(.*?)';", re.MULTILINE | re.DOTALL)
script = soup2.find("script")
url2 = pattern.search(script.text).group(1)
res3 = requests.get(url2,headers=headers)
res3.encoding = 'utf-8'
soup3 = BeautifulSoup(res3.text,'html.parser')
print()
pattern2 = re.compile(r"var msgList = (.*?);$", re.MULTILINE | re.DOTALL)
script2 = soup3.find("script", text=pattern2)
s2 = json.loads(pattern2.search(script2.text).group(1))
#等待10s
time.sleep(10)
for news in s2["list"]:
articleurl = "https://mp.weixin.qq.com"+news["app_msg_ext_info"]["content_url"]
articleurl = articleurl.replace('&','&')
res4 = requests.get(articleurl,headers=headers)
res4.encoding = 'utf-8'
soup4 = BeautifulSoup(res4.text,'html.parser')
if(checkData(news["app_msg_ext_info"]["title"])):
insertData(news["app_msg_ext_info"]["title"],news["app_msg_ext_info"]["cover"],news["app_msg_ext_info"]["author"],pymysql.escape_string(str(soup4)))
count += 1
#等待5s
time.sleep(10)
for news2 in news["app_msg_ext_info"]["multi_app_msg_item_list"]:
articleurl2 = "https://mp.weixin.qq.com"+news2["content_url"]
articleurl2 = articleurl2.replace('&','&')
res5 = requests.get(articleurl2,headers=headers)
res5.encoding = 'utf-8'
soup5 = BeautifulSoup(res5.text,'html.parser')
if(checkData(news2["title"])):
insertData(news2["title"],news2["cover"],news2["author"],pymysql.escape_string(str(soup5)))
count += 1
#等待10s
time.sleep(10)
cursor.close()
conn.close()
print("操作完成")
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。
时间:2019-03-31
python采集微信公众号文章

本文示例分享了python采集微信公众号文章的具体代码,供大家参考。具体内容如下。python的一个子目录下存放了两个文件,分别是:采集公众号文章.py和config.py。代码如下:1.采集公众号文章.py from urllib.parse import urlencode import pymongo import requests from lxml.etree import XMLSyntaxError from requests.exceptions import Connec
Python如何爬取微信公众号文章及评论(基于Fiddler抓包分析)

背景描述我觉得微信公众号是比较难爬的平台之一,但是经过一番折腾,还是有一点小收获。没用Scrapy(估计爬太快有防爬限制),不过后面会开始整理写一些实战。. 简单介绍一下本次的开发环境:python3请求psycopg2(操作postgres数据库) 抓包分析 本次实战对要抓包的公众号没有限制,但是每次抓包前都要对不同的公众号进行分析。打开Fiddler,在手机上配置相关代理。为了避免过多干扰,这里给Fiddler一个过滤规则,指定微信域名即可:
python爬取微信公众号文章的方法

最近在学习Python3网络爬虫(崔庆才写的)的开发实践,刚刚得知他在这里使用代理爬取了公众号文章,但是根据他的代码,还是出现了一些问题。我在这里用过这本书。对本书前面提到的一些内容进行了改进。(作者半年前写了这段代码,腾讯的网站半年前更新了)我直接加下面代码:TIMEOUT = 20 from requests import Request, Session, PreparedRequest import requests from selenium import webdrive
50行Python代码如何获取所有公众号文章

前言我们在阅读公众号文章时通常会遇到一个问题——阅读历史文章的体验并不好。我们知道爬取公众号的常用方法有两种:通过搜狗搜索获取,缺点是只能获取最新的十推文章。通过微信公众号的素材管理,可以获得公众号文章。缺点是需要自己申请公众号。微信方式获取公众号文章的方法。与其他方法相比,非常方便。如上图,通过抓包工具获取微信的网络信息请求,我们发现每次文章
Python爬取指定微信公众号文章
本文示例分享了python爬取微信公众号文章的具体代码,供大家参考。具体内容如下。该方法是依靠 urllib2 库完成的。首先需要安装你的python环境,然后安装urllib2库程序的启动方法(返回值为公众号文章的列表): def openUrl(): print("启动爬虫,打开搜狗搜索微信界面") # 加载页面url = ';s_from=input&query = 被抓取的公众号名称
Python爬取微信公众号文章
本文示例分享python爬取微信公众号文章的具体代码供大家参考,具体内容如下# -*- coding: utf-8 -*- import requests from bs4 import BeautifulSoup from requests .exceptions import RequestException import time import random import MySQLdb import threading import socket import math soc
python selenium爬取微信公众号文章代码详解
参考:selenium webdriver 添加cookies: 需求:想看微信公众号文章的历史,但是每次都找地方不方便。思路:1.使用selenium打开微信公众号历史文章,滚动刷新到底部,获取所有历史文章url。2.遍历访问url,下载到本地。实现1.打开微信客户端,点击微信公众号->进入公众号->打开历史文章链接(用浏览器打开),通过开发者工具获取cookie
Python使用webdriver爬取微信公众号
本文示例分享了python使用webdriver爬取微信公众号的具体代码,供大家参考。具体内容如下# -*- 编码:utf-8 -*- from selenium import webdriver import time import json import requests import re import random #微信公众号user="" #公众号密码password="" #设置需要爬取的公众号列表 gzlist=['香河微服务
python如何导出微信公众号文章详解
1.安装wkhtmltopdf 下载地址:我用windows进行测试,下载安装后结果如下 2 编写python代码导出微信公众号文章 不能直接使用wkhtmltopdf导出微信公众号文章,导出的文章会缺图,所以需要使用微信公众号文章页面,然后将html文本转换成pdf pip install wechatsogou --升级 pip install pdfkit 踩坑
Python抓取微信公众号账号信息的方法
搜狗微信搜索提供了两种关键词搜索,一种是搜索公众号文章的内容,另一种是直接搜索微信公众号。公众号基本信息可通过微信公众号搜索获取。还有最近发布的10个文章,今天就来抢微信公众号的账号信息爬虫吧。首先通过首页进入,可以按类别抓取,通过“查看更多”可以找到页面链接规则: import requests as req import re reTypes = r'id="pc_\d*" uigs=" (pc_\d*)">([\s\S]*?)&
Python爬虫_微信公众号推送信息爬取示例

问题描述 使用搜狗的微信搜索,从指定公众号抓取最新推送,并将对应网页保存到本地。注意,搜狗微信获取的地址是临时链接,具有时效性。公众号为动态网页(JavaScript渲染),使用requests.get()获取的内容不收录推送消息。这里使用 selenium+PhantomJS 处理代码#!/usr/bin/env python3 from selenium import webdriver from datetime import datetime import bs4, requ
querylist采集微信公众号文章(让历史消息页面重新超链接添加到有外链权限的公众号图文当中外链的入口)
采集交流 • 优采云 发表了文章 • 0 个评论 • 116 次浏览 • 2022-03-27 20:18
胖友们,早上好!
对公众号添加外链的限制,真是让运营商头疼!因为只有开通了微信认证和微信支付的账号才有外链权限。
除服务号外,公众号的军队订阅号仅被授权与媒体主体和政府号开通微信支付。
而现在,即使是有外链权限的公众号,也无法直接超链接到图文中的历史新闻页面!
于是出现了两个问题:
如何让历史新闻页面重新添加具有外链权限的公众号图文超链接?
对于没有外链权限的订阅号,如何在公众号中添加外链入口?
那么135编辑器就产生了解决这两个问题的工具:
生成短链接
图像.png
我们先解决第一个问题:让“历史消息页面链接”在图文消息中超链接。
先复制“历史新闻页面”链接,粘贴后复制生成的短链接。
灰色.gif
然后使用超链接按钮将此链接超链接到具有外部链接权限的公众号图像和文本。
微信链接被识别和检测。在我们生成一个短链接后,如果我们无法检测到历史新闻页面的链接,我们可以加入它!
我们来解决第二个问题:让没有外链权限的公众号的图文有外链的入口。
用鼠标点击并拖动生成的二维码在新窗口中打开,右击图片,选择复制图片,然后将二维码图片粘贴到图片和文字中。
没有外链权限的公众号可以放入二维码,用户可以识别二维码进入外链界面。 查看全部
querylist采集微信公众号文章(让历史消息页面重新超链接添加到有外链权限的公众号图文当中外链的入口)
胖友们,早上好!
对公众号添加外链的限制,真是让运营商头疼!因为只有开通了微信认证和微信支付的账号才有外链权限。
除服务号外,公众号的军队订阅号仅被授权与媒体主体和政府号开通微信支付。
而现在,即使是有外链权限的公众号,也无法直接超链接到图文中的历史新闻页面!
于是出现了两个问题:
如何让历史新闻页面重新添加具有外链权限的公众号图文超链接?
对于没有外链权限的订阅号,如何在公众号中添加外链入口?
那么135编辑器就产生了解决这两个问题的工具:
生成短链接
图像.png
我们先解决第一个问题:让“历史消息页面链接”在图文消息中超链接。
先复制“历史新闻页面”链接,粘贴后复制生成的短链接。
灰色.gif
然后使用超链接按钮将此链接超链接到具有外部链接权限的公众号图像和文本。
微信链接被识别和检测。在我们生成一个短链接后,如果我们无法检测到历史新闻页面的链接,我们可以加入它!
我们来解决第二个问题:让没有外链权限的公众号的图文有外链的入口。
用鼠标点击并拖动生成的二维码在新窗口中打开,右击图片,选择复制图片,然后将二维码图片粘贴到图片和文字中。
没有外链权限的公众号可以放入二维码,用户可以识别二维码进入外链界面。
querylist采集微信公众号文章(Python模拟操作微信App的所有历史数据方法(详见)(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 374 次浏览 • 2022-03-27 20:04
鲲之鹏技术人员将在本文中介绍一种采集通过模拟微信App操作来指定公众号所有历史数据的方法。
通过我们的抓包分析,我们发现微信公众号的历史数据是通过HTTP协议加载的。对应的API接口如下图所示,有四个关键参数(__biz、appmsg_token、pass_ticket和Cookie)。
为了得到这四个参数,我们需要模拟App的运行,让它生成这些参数,然后我们就可以抓包了。对于模拟App操作,我们之前已经介绍过通过Python模拟Android App的方法(见详情)。对于 HTTP 集成抓包,我们之前已经介绍过 Mitmproxy(详见)。
我们需要模拟微信的操作,完成以下步骤:
1.启动微信应用
2. 点击“通讯录”
3.点击“公众号”
4.点击公众号成为采集
5.点击右上角的用户头像图标
6. 点击“所有消息”
此时,我们可以从响应数据中捕获__biz、appmsg_token和pass_ticket这三个关键参数,以及请求头中的Cookie值。如下图。
通过以上四个参数,我们可以构造API请求获取历史列表文章,直接调用API接口获取数据(无需模拟App操作)。核心参数如下。通过改变offset参数,可以得到所有的历史数据。
# Cookie
headers = {'Cookie': 'rewardsn=; wxtokenkey=777; wxuin=584068438; devicetype=android-19; version=26060736; lang=zh_CN; pass_ticket=Rr8cO5c2******3tKGqe7aVZzV9TupvrK+1uHHmHYQGL2WFdKIE; wap_sid2=COKhxu4KElxckFZQ3QzTHU4WThEUk0zcWdrZjhGcUdYdEVSV3Y1X2NPWHNUakRrd1ZzMnpLTERpdE5rbmxjSTg******dlRBcUNRazZpOGxTZUVEQUTgNQJVO'}
url = 'https://mp.weixin.qq.com/mp/profile_ext?'
data = {}
data['is_ok'] = '1'
data['count'] = '10'
data['wxtoken'] = ''
data['f'] = 'json'
data['scene'] = '124'
data['uin'] = '777'
data['key'] = '777'
data['offset'] = '0'
data['action'] = 'getmsg'
data['x5'] = '0'
# 下面三个参数需要替换
# https://mp.weixin.qq.com/mp/pr ... Dhome应答数据里会暴漏这三个参数
data['__biz'] = 'MjM5MzQyOTM1OQ=='
data['appmsg_token'] = '993_V8%2BEmfVD7g%2FvMZ****4DNUJNFkg~~'
data['pass_ticket'] = 'Rr8cO5c23ZngeQHRGy8E7gv*****pvrK+1uHHmHYQGL2WFdKIE'
url = url + urllib.urlencode(data)
以“数字工厂”微信公众号为例,采集流程操作截图如下:
输出截图如下:
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。 查看全部
querylist采集微信公众号文章(Python模拟操作微信App的所有历史数据方法(详见)(图))
鲲之鹏技术人员将在本文中介绍一种采集通过模拟微信App操作来指定公众号所有历史数据的方法。
通过我们的抓包分析,我们发现微信公众号的历史数据是通过HTTP协议加载的。对应的API接口如下图所示,有四个关键参数(__biz、appmsg_token、pass_ticket和Cookie)。
为了得到这四个参数,我们需要模拟App的运行,让它生成这些参数,然后我们就可以抓包了。对于模拟App操作,我们之前已经介绍过通过Python模拟Android App的方法(见详情)。对于 HTTP 集成抓包,我们之前已经介绍过 Mitmproxy(详见)。
我们需要模拟微信的操作,完成以下步骤:
1.启动微信应用
2. 点击“通讯录”
3.点击“公众号”
4.点击公众号成为采集
5.点击右上角的用户头像图标
6. 点击“所有消息”
此时,我们可以从响应数据中捕获__biz、appmsg_token和pass_ticket这三个关键参数,以及请求头中的Cookie值。如下图。
通过以上四个参数,我们可以构造API请求获取历史列表文章,直接调用API接口获取数据(无需模拟App操作)。核心参数如下。通过改变offset参数,可以得到所有的历史数据。
# Cookie
headers = {'Cookie': 'rewardsn=; wxtokenkey=777; wxuin=584068438; devicetype=android-19; version=26060736; lang=zh_CN; pass_ticket=Rr8cO5c2******3tKGqe7aVZzV9TupvrK+1uHHmHYQGL2WFdKIE; wap_sid2=COKhxu4KElxckFZQ3QzTHU4WThEUk0zcWdrZjhGcUdYdEVSV3Y1X2NPWHNUakRrd1ZzMnpLTERpdE5rbmxjSTg******dlRBcUNRazZpOGxTZUVEQUTgNQJVO'}
url = 'https://mp.weixin.qq.com/mp/profile_ext?'
data = {}
data['is_ok'] = '1'
data['count'] = '10'
data['wxtoken'] = ''
data['f'] = 'json'
data['scene'] = '124'
data['uin'] = '777'
data['key'] = '777'
data['offset'] = '0'
data['action'] = 'getmsg'
data['x5'] = '0'
# 下面三个参数需要替换
# https://mp.weixin.qq.com/mp/pr ... Dhome应答数据里会暴漏这三个参数
data['__biz'] = 'MjM5MzQyOTM1OQ=='
data['appmsg_token'] = '993_V8%2BEmfVD7g%2FvMZ****4DNUJNFkg~~'
data['pass_ticket'] = 'Rr8cO5c23ZngeQHRGy8E7gv*****pvrK+1uHHmHYQGL2WFdKIE'
url = url + urllib.urlencode(data)
以“数字工厂”微信公众号为例,采集流程操作截图如下:
输出截图如下:
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持脚本之家。
querylist采集微信公众号文章(querylist采集微信公众号文章的信息浓缩了怎么办?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-03-27 08:04
querylist采集微信公众号文章的信息。微信公众号文章一般放在一个列表,每一条信息就像一个信息库。针对每一个信息库,可以有多次搜索机会,即可以多次批量提取微信公众号文章链接。base64解码。通过这两步,可以在很大程度上避免抄袭问题。但是从搜索的角度来说,很难区分可能有质量的文章是来自公众号的,还是其他平台。传统方法包括人工打标签和用python的base64解码。前者可能有累积性问题,后者不可控性很大。
有靠谱的文章可以搜索到的地方也就是微信公众号了,公众号现在增多了不少,一百来个还算是正常的量。所以这个数量的文章就是信息的浓缩了。以前大部分都是人工一个个搜索来的,包括文章标题里的id,但是现在这方面做的比较好的只有搜狗和百度了。比如你想找来自“吃瓜群众”的第一篇文章的链接,就搜索“吃瓜群众#阅读量6000+"然后就能搜到来自“看雪论坛”的所有来自“吃瓜群众”的内容;找一篇发于10年前的新闻联播的文章的链接,只需要搜索“新闻联播#阅读量4000+",就能搜索到内容发布于2007年的新闻了。
微信公众号除了文章还有公众号文章,其实就是一个文章列表库,可以按类别索引,但需要文章发布的时候才会更新。因此可以一个一个搜索。但搜索出来的文章质量应该很高,本身微信里就是有百家号的内容,质量应该比较高。不过有些公众号图文消息多,那么就需要用关键词进行定位了。主要是可以搜索的手段很多,也有很多方法,也有很多局限。以后能用到的方法应该会越来越多,有时候觉得还是文章质量高,分类定位合理方便处理。 查看全部
querylist采集微信公众号文章(querylist采集微信公众号文章的信息浓缩了怎么办?)
querylist采集微信公众号文章的信息。微信公众号文章一般放在一个列表,每一条信息就像一个信息库。针对每一个信息库,可以有多次搜索机会,即可以多次批量提取微信公众号文章链接。base64解码。通过这两步,可以在很大程度上避免抄袭问题。但是从搜索的角度来说,很难区分可能有质量的文章是来自公众号的,还是其他平台。传统方法包括人工打标签和用python的base64解码。前者可能有累积性问题,后者不可控性很大。
有靠谱的文章可以搜索到的地方也就是微信公众号了,公众号现在增多了不少,一百来个还算是正常的量。所以这个数量的文章就是信息的浓缩了。以前大部分都是人工一个个搜索来的,包括文章标题里的id,但是现在这方面做的比较好的只有搜狗和百度了。比如你想找来自“吃瓜群众”的第一篇文章的链接,就搜索“吃瓜群众#阅读量6000+"然后就能搜到来自“看雪论坛”的所有来自“吃瓜群众”的内容;找一篇发于10年前的新闻联播的文章的链接,只需要搜索“新闻联播#阅读量4000+",就能搜索到内容发布于2007年的新闻了。
微信公众号除了文章还有公众号文章,其实就是一个文章列表库,可以按类别索引,但需要文章发布的时候才会更新。因此可以一个一个搜索。但搜索出来的文章质量应该很高,本身微信里就是有百家号的内容,质量应该比较高。不过有些公众号图文消息多,那么就需要用关键词进行定位了。主要是可以搜索的手段很多,也有很多方法,也有很多局限。以后能用到的方法应该会越来越多,有时候觉得还是文章质量高,分类定位合理方便处理。
querylist采集微信公众号文章(微信小程序中如何打开公众号中的文章(图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 172 次浏览 • 2022-03-25 21:12
本文文章主要介绍微信小程序如何获取公众号文章文章的列表和展示。文中的介绍很详细,有一定的参考价值。有兴趣的朋友一定要阅读!
如何在微信小程序中打开公众号中的文章,步骤比较简单。
1、公共账号设置
如果小程序想要获取公众号的资料,公众号需要做一些设置。
1.1 绑定小程序
公众号需要绑定目标小程序,否则无法打开公众号的文章。
在公众号管理界面,点击小程序管理-->关联小程序
输入小程序的AppID进行搜索绑定。
1.2 公众号开发者功能配置
(1)在公众号管理界面,点击开发模块中的基本配置选项。
(2) 打开开发者密码(AppSecret),注意保存和更改密码。
(3)设置IP白名单。这个是发起请求的机器的外网IP。如果是在自己的电脑上,就是你电脑的外网IP。如果部署到服务器上,它是服务器的外部IP。
2、获取文章信息的步骤
以下仅用于演示。
在实际项目中,可以在自己的服务器程序中获取,而不是直接在小程序中获取。毕竟需要用到appid、appsecret等高度机密的参数。
2.1 获取 access_token
access_token是公众号全球唯一的API调用凭证。公众号调用各个API时需要access_token。API 文档
private String getToken() throws MalformedURLException, IOException, ProtocolException {
// access_token接口https请求方式: GET https://api.weixin.qq.com/cgi- ... ECRET
String path = " https://api.weixin.qq.com/cgi- ... 3B%3B
String appid = "公众号的开发者ID(AppID)";
String secret = "公众号的开发者密码(AppSecret)";
URL url = new URL(path+"&appid=" + appid + "&secret=" + secret);
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("GET");
connection.connect();
InputStream in = connection.getInputStream();
byte[] b = new byte[100];
int len = -1;
StringBuffer sb = new StringBuffer();
while((len = in.read(b)) != -1) {
sb.append(new String(b,0,len));
}
System.out.println(sb.toString());
in.close();
return sb.toString();
}
2.2 获取文章的列表
API 文档
private String getContentList(String token) throws IOException {
String path = " https://api.weixin.qq.com/cgi- ... ot%3B + token;
URL url = new URL(path);
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("POST");
connection.setDoOutput(true);
connection.setRequestProperty("content-type", "application/json;charset=utf-8");
connection.connect();
// post发送的参数
Map map = new HashMap();
map.put("type", "news"); // news表示图文类型的素材,具体看API文档
map.put("offset", 0);
map.put("count", 1);
// 将map转换成json字符串
String paramBody = JSON.toJSONString(map); // 这里用了Alibaba的fastjson
OutputStream out = connection.getOutputStream();
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(out));
bw.write(paramBody); // 向流中写入参数字符串
bw.flush();
InputStream in = connection.getInputStream();
byte[] b = new byte[100];
int len = -1;
StringBuffer sb = new StringBuffer();
while((len = in.read(b)) != -1) {
sb.append(new String(b,0,len));
}
in.close();
return sb.toString();
}
测试:
@Test
public void test() throws IOException {
String result1 = getToken();
Map token = (Map) JSON.parseObject(result1);
String result2 = getContentList(token.get("access_token").toString());
System.out.println(result2);
}
转换为json格式,参数说明见上述API文档
第二张图片中的url是公众号文章的地址,获得的tem物品数量就会有多少物品。只要得到以上结果,在小程序中打开公众号文章就有过半成功了。
最后可以在小程序中使用组件打开,src中文章的url地址。
以上就是微信小程序文章文章《如何获取公众号文章文章的列表和展示》的全部内容,感谢阅读!希望分享的内容对您有所帮助。更多相关知识,请关注易宿云行业资讯频道! 查看全部
querylist采集微信公众号文章(微信小程序中如何打开公众号中的文章(图))
本文文章主要介绍微信小程序如何获取公众号文章文章的列表和展示。文中的介绍很详细,有一定的参考价值。有兴趣的朋友一定要阅读!
如何在微信小程序中打开公众号中的文章,步骤比较简单。
1、公共账号设置
如果小程序想要获取公众号的资料,公众号需要做一些设置。
1.1 绑定小程序
公众号需要绑定目标小程序,否则无法打开公众号的文章。
在公众号管理界面,点击小程序管理-->关联小程序
输入小程序的AppID进行搜索绑定。
1.2 公众号开发者功能配置
(1)在公众号管理界面,点击开发模块中的基本配置选项。
(2) 打开开发者密码(AppSecret),注意保存和更改密码。
(3)设置IP白名单。这个是发起请求的机器的外网IP。如果是在自己的电脑上,就是你电脑的外网IP。如果部署到服务器上,它是服务器的外部IP。
2、获取文章信息的步骤
以下仅用于演示。
在实际项目中,可以在自己的服务器程序中获取,而不是直接在小程序中获取。毕竟需要用到appid、appsecret等高度机密的参数。
2.1 获取 access_token
access_token是公众号全球唯一的API调用凭证。公众号调用各个API时需要access_token。API 文档
private String getToken() throws MalformedURLException, IOException, ProtocolException {
// access_token接口https请求方式: GET https://api.weixin.qq.com/cgi- ... ECRET
String path = " https://api.weixin.qq.com/cgi- ... 3B%3B
String appid = "公众号的开发者ID(AppID)";
String secret = "公众号的开发者密码(AppSecret)";
URL url = new URL(path+"&appid=" + appid + "&secret=" + secret);
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("GET");
connection.connect();
InputStream in = connection.getInputStream();
byte[] b = new byte[100];
int len = -1;
StringBuffer sb = new StringBuffer();
while((len = in.read(b)) != -1) {
sb.append(new String(b,0,len));
}
System.out.println(sb.toString());
in.close();
return sb.toString();
}
2.2 获取文章的列表
API 文档
private String getContentList(String token) throws IOException {
String path = " https://api.weixin.qq.com/cgi- ... ot%3B + token;
URL url = new URL(path);
HttpURLConnection connection = (HttpURLConnection) url.openConnection();
connection.setRequestMethod("POST");
connection.setDoOutput(true);
connection.setRequestProperty("content-type", "application/json;charset=utf-8");
connection.connect();
// post发送的参数
Map map = new HashMap();
map.put("type", "news"); // news表示图文类型的素材,具体看API文档
map.put("offset", 0);
map.put("count", 1);
// 将map转换成json字符串
String paramBody = JSON.toJSONString(map); // 这里用了Alibaba的fastjson
OutputStream out = connection.getOutputStream();
BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(out));
bw.write(paramBody); // 向流中写入参数字符串
bw.flush();
InputStream in = connection.getInputStream();
byte[] b = new byte[100];
int len = -1;
StringBuffer sb = new StringBuffer();
while((len = in.read(b)) != -1) {
sb.append(new String(b,0,len));
}
in.close();
return sb.toString();
}
测试:
@Test
public void test() throws IOException {
String result1 = getToken();
Map token = (Map) JSON.parseObject(result1);
String result2 = getContentList(token.get("access_token").toString());
System.out.println(result2);
}
转换为json格式,参数说明见上述API文档
第二张图片中的url是公众号文章的地址,获得的tem物品数量就会有多少物品。只要得到以上结果,在小程序中打开公众号文章就有过半成功了。
最后可以在小程序中使用组件打开,src中文章的url地址。
以上就是微信小程序文章文章《如何获取公众号文章文章的列表和展示》的全部内容,感谢阅读!希望分享的内容对您有所帮助。更多相关知识,请关注易宿云行业资讯频道!
querylist采集微信公众号文章(如何用微信公众号同SAPC4C的ODataAPI.?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 151 次浏览 • 2022-03-25 07:24
最近有很多朋友问我微信上SAP系统和微信公众号的整合,所以我把当时写的英文版翻译成中文重新发布到我的公众号上。
需要注意的是,三年后,微信公众号的开发流程可能会发生变化,请自行识别。系统集成了微信公众号,三年前我选择了SAP Cloud for Customer。
永远记住,我们系列的目标是学习如何使用微信公众号与SAP系统(SAP Cloud for Customer,以下简称C4C)集成。要实现这个目标,需要通过微信公众号使用SAP C4C的OData API。
作为学习的第一步,我们首先学习如何调用微信公众号上的通用API,而不是SAP C4C OData API。
假设这样一个简单的场景:用户关注微信公众号后,通过微信应用向公众号发送了一些短信。公众号收到这些短信后,会转发到本系列第一篇文章中提到的微信消息服务器文章微信开发环境搭建。此时,微信消息服务器收到转发的文本信息后,会调用一些带有人工智能的API,并通过微信APP将API响应返回给用户。
与微信消息服务器绑定的微信公众号,在这个场景中实际上扮演了一个简单的聊天机器人的角色。用户与微信公众号通过问答方式进行互动。
Jerry 还记得,他上大学的时候,上过专业课《Unix 网络编程》。其中一个练习是通过套接字实现一对客户端和服务器。客户端向服务器发送了一个字符串,服务器完整地接收到了它。返回它,即所谓的 Echo Server。
在实现微信聊天机器人之前,我们先降低难度,实现一个简单的微信回显服务,即无论用户向公众号发送什么信息,都会收到信息本身,加上前缀“Add by Jerry”。
本文使用的项目的完整源代码可以从我的 Github 下载。
首先,在 server.js 中,使用 nodejs express 库来启动一个 web 服务器:
上图第二行中routesEngine的实现位于index.js中。当微信app收到用户通过微信app发送的短信时,会通过HTTP POST请求转发给微信消息服务器。微信消息服务器收到请求后,调用第五行的echoService处理:
echoService 的实现位于文件 echo.js 中:首先从变量 req(第 11 行)中收录的 HTTP 请求中解析用户输入的文本信息,然后添加前缀“Add by Jerry:”,然后存储结果。在变量content(第13行)中,最后调用自研工具方法replyMessage,将前缀文本信息返回给用户。
上图第15行replyMessage工具方法需要在微信app转发给微信消息服务器的HTTP POST请求中解析出发送消息的微信用户id,然后发送以“Add by Jerry”为前缀的内容:" 发给这个id标识的微信用户。
replyMessage 的实现在replyMessage.js 中:
有了 Echo Service 的实现经验,实现微信聊天机器人没有难度。
只需将 index.js 中接收到 HTTP Post 请求后的操作由调用 echoService 更改为调用新的实现,tuningService 即可。
调用图灵API的tuningService函数的源码可以在这里下载。
我在 2017 年使用的 Turing API 由以下 网站 提供:
申请API key,粘贴到下图第6行的url中:
解析用户输入的文本信息,在第20行存储到body变量中,使用encodeURI处理,直接拼接到图灵API url的末尾,然后使用request函数调用图灵API第27行,在匿名回调函数中获取API的响应,最后调用工具方法replyMessage,通过微信消息服务器将响应发送给微信app。 查看全部
querylist采集微信公众号文章(如何用微信公众号同SAPC4C的ODataAPI.?)
最近有很多朋友问我微信上SAP系统和微信公众号的整合,所以我把当时写的英文版翻译成中文重新发布到我的公众号上。
需要注意的是,三年后,微信公众号的开发流程可能会发生变化,请自行识别。系统集成了微信公众号,三年前我选择了SAP Cloud for Customer。
永远记住,我们系列的目标是学习如何使用微信公众号与SAP系统(SAP Cloud for Customer,以下简称C4C)集成。要实现这个目标,需要通过微信公众号使用SAP C4C的OData API。
作为学习的第一步,我们首先学习如何调用微信公众号上的通用API,而不是SAP C4C OData API。
假设这样一个简单的场景:用户关注微信公众号后,通过微信应用向公众号发送了一些短信。公众号收到这些短信后,会转发到本系列第一篇文章中提到的微信消息服务器文章微信开发环境搭建。此时,微信消息服务器收到转发的文本信息后,会调用一些带有人工智能的API,并通过微信APP将API响应返回给用户。
与微信消息服务器绑定的微信公众号,在这个场景中实际上扮演了一个简单的聊天机器人的角色。用户与微信公众号通过问答方式进行互动。
Jerry 还记得,他上大学的时候,上过专业课《Unix 网络编程》。其中一个练习是通过套接字实现一对客户端和服务器。客户端向服务器发送了一个字符串,服务器完整地接收到了它。返回它,即所谓的 Echo Server。
在实现微信聊天机器人之前,我们先降低难度,实现一个简单的微信回显服务,即无论用户向公众号发送什么信息,都会收到信息本身,加上前缀“Add by Jerry”。
本文使用的项目的完整源代码可以从我的 Github 下载。
首先,在 server.js 中,使用 nodejs express 库来启动一个 web 服务器:
上图第二行中routesEngine的实现位于index.js中。当微信app收到用户通过微信app发送的短信时,会通过HTTP POST请求转发给微信消息服务器。微信消息服务器收到请求后,调用第五行的echoService处理:
echoService 的实现位于文件 echo.js 中:首先从变量 req(第 11 行)中收录的 HTTP 请求中解析用户输入的文本信息,然后添加前缀“Add by Jerry:”,然后存储结果。在变量content(第13行)中,最后调用自研工具方法replyMessage,将前缀文本信息返回给用户。
上图第15行replyMessage工具方法需要在微信app转发给微信消息服务器的HTTP POST请求中解析出发送消息的微信用户id,然后发送以“Add by Jerry”为前缀的内容:" 发给这个id标识的微信用户。
replyMessage 的实现在replyMessage.js 中:
有了 Echo Service 的实现经验,实现微信聊天机器人没有难度。
只需将 index.js 中接收到 HTTP Post 请求后的操作由调用 echoService 更改为调用新的实现,tuningService 即可。
调用图灵API的tuningService函数的源码可以在这里下载。
我在 2017 年使用的 Turing API 由以下 网站 提供:
申请API key,粘贴到下图第6行的url中:
解析用户输入的文本信息,在第20行存储到body变量中,使用encodeURI处理,直接拼接到图灵API url的末尾,然后使用request函数调用图灵API第27行,在匿名回调函数中获取API的响应,最后调用工具方法replyMessage,通过微信消息服务器将响应发送给微信app。
querylist采集微信公众号文章(为什么你的App会卡顿-Android-掘金Cover有什么料?(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 206 次浏览 • 2022-03-25 01:09
阿里云>云栖社区>主题图>>.net网页微信支付接口开发教程
推荐活动:
更多优惠>
当前话题:.net网页微信支付接口开发教程加入采集
相关话题:
.net网页微信支付接口开发教程相关博客看更多博文
微信公众号支付失败问题-微信支付提示调用支付JSAPI缺少参数:appId
作者:聚友云辉 2003 浏览评论:02年前
场景概述 鉴于去年在微信小程序支付、小程序支付、支付宝小程序支付、云闪付小程序支付方面的工作和研究。最近要完成一个微信公众号支付的场景。其中,我遇到了一个坑,花了我一个多上午的时间。所以想把记录写下来,以后遇到微信相关的API调用,用不了那么久。
阅读全文
史上最全的Android文章精选合集
作者:android飞鱼2557人查看评论:03年前
用两张图告诉你,为什么你的应用卡住了?- Android - Nuggets Cover 有什么?从这个 文章 你可以得到这个信息:知道 setContentView() 之后会发生什么吗?... Android常见的获取View宽高的正确方法
阅读全文
微信支付教程系列公众号支付
作者:micahel1202 人浏览评论:03年前
目录(一)微信公众号开发VS远程调试(二)微信公众号开发基础知识(三)微信公众号开发自动回复消息和自定义菜单)(四)开发的网页微信公众号授权获取用户基本信息(五)当前用户Openid及注意事项可在微信公众号开发的网页中及时获取(六)微信公众号开发)
阅读全文
微信支付教程系列现金红包
作者:micahel1530 观众评论:03年前
目录(一)微信公众号开发VS远程调试(二)微信公众号开发基础知识(三)微信公众号开发自动回复消息和自定义菜单)(四)开发的网页微信公众号授权获取用户基本信息(五)当前用户Openid及注意事项可在微信公众号开发的网页中及时获取(六)微信公众号开发)
阅读全文
【044】微信公众平台开发教程第20章——40个新手谜题
作者:云启希望。2102人查看评论数:04年前
笔者在CSDN博客频道推出微信公众平台开发教程后,联系了很多公众平台开发爱好者,帮助他们克服了很多实际问题。当然,这些问题中的许多都是重复的。因此,笔者将这些问题。并整理出答案,以帮助许多刚开始学习少走弯路的人。1、订阅账户和服务账户的主要区别是什么?
阅读全文
【转载】微信公众号获取用户地理位置并列出附近店铺
作者:php的小菜鸟2236人查看评论数:04年前
思路分析:1、在微信公众号中获取用户的地理位置需要js-sdk签名包(文档里面有如何获取的介绍)2、根据获取到的地理位置, ajax去后台请求,通过sql语句,查询中就近的store(sql语句在网上搜索,通过后台添加位置)3、来查询store list根据城市,使用
阅读全文
微信公众平台开发问答
作者:方北工作室2281查看评论:06年前
微信公众平台开发问答是微信知识问答专区,专注于微信应用开发技术知识的整理、分类和检索。主题:新手常见问题 Q:我是新手,没有开发基础。我应该如何学习微信公众平台的开发?答:先学PHP和Mysql。您可以在 Internet 上找到相应的教程以了解一般语法。
阅读全文
PHP 使用 QueryList 抓取网页内容
作者:thinkyoung1544 人浏览评论:06年前
以前,我使用Java Jsoup 来捕获网页数据。前几天听说用PHP比较方便。今天简单研究了一下,主要是使用QueryList。QueryList 是一个基于 phpQ 的
阅读全文 查看全部
querylist采集微信公众号文章(为什么你的App会卡顿-Android-掘金Cover有什么料?(组图))
阿里云>云栖社区>主题图>>.net网页微信支付接口开发教程
推荐活动:
更多优惠>
当前话题:.net网页微信支付接口开发教程加入采集
相关话题:
.net网页微信支付接口开发教程相关博客看更多博文
微信公众号支付失败问题-微信支付提示调用支付JSAPI缺少参数:appId
作者:聚友云辉 2003 浏览评论:02年前
场景概述 鉴于去年在微信小程序支付、小程序支付、支付宝小程序支付、云闪付小程序支付方面的工作和研究。最近要完成一个微信公众号支付的场景。其中,我遇到了一个坑,花了我一个多上午的时间。所以想把记录写下来,以后遇到微信相关的API调用,用不了那么久。
阅读全文
史上最全的Android文章精选合集
作者:android飞鱼2557人查看评论:03年前
用两张图告诉你,为什么你的应用卡住了?- Android - Nuggets Cover 有什么?从这个 文章 你可以得到这个信息:知道 setContentView() 之后会发生什么吗?... Android常见的获取View宽高的正确方法
阅读全文
微信支付教程系列公众号支付
作者:micahel1202 人浏览评论:03年前
目录(一)微信公众号开发VS远程调试(二)微信公众号开发基础知识(三)微信公众号开发自动回复消息和自定义菜单)(四)开发的网页微信公众号授权获取用户基本信息(五)当前用户Openid及注意事项可在微信公众号开发的网页中及时获取(六)微信公众号开发)
阅读全文
微信支付教程系列现金红包
作者:micahel1530 观众评论:03年前
目录(一)微信公众号开发VS远程调试(二)微信公众号开发基础知识(三)微信公众号开发自动回复消息和自定义菜单)(四)开发的网页微信公众号授权获取用户基本信息(五)当前用户Openid及注意事项可在微信公众号开发的网页中及时获取(六)微信公众号开发)
阅读全文
【044】微信公众平台开发教程第20章——40个新手谜题
作者:云启希望。2102人查看评论数:04年前
笔者在CSDN博客频道推出微信公众平台开发教程后,联系了很多公众平台开发爱好者,帮助他们克服了很多实际问题。当然,这些问题中的许多都是重复的。因此,笔者将这些问题。并整理出答案,以帮助许多刚开始学习少走弯路的人。1、订阅账户和服务账户的主要区别是什么?
阅读全文
【转载】微信公众号获取用户地理位置并列出附近店铺
作者:php的小菜鸟2236人查看评论数:04年前
思路分析:1、在微信公众号中获取用户的地理位置需要js-sdk签名包(文档里面有如何获取的介绍)2、根据获取到的地理位置, ajax去后台请求,通过sql语句,查询中就近的store(sql语句在网上搜索,通过后台添加位置)3、来查询store list根据城市,使用
阅读全文
微信公众平台开发问答
作者:方北工作室2281查看评论:06年前
微信公众平台开发问答是微信知识问答专区,专注于微信应用开发技术知识的整理、分类和检索。主题:新手常见问题 Q:我是新手,没有开发基础。我应该如何学习微信公众平台的开发?答:先学PHP和Mysql。您可以在 Internet 上找到相应的教程以了解一般语法。
阅读全文
PHP 使用 QueryList 抓取网页内容
作者:thinkyoung1544 人浏览评论:06年前
以前,我使用Java Jsoup 来捕获网页数据。前几天听说用PHP比较方便。今天简单研究了一下,主要是使用QueryList。QueryList 是一个基于 phpQ 的
阅读全文
querylist采集微信公众号文章(微信公众号开发之VS远程调试(二)(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 278 次浏览 • 2022-03-25 01:08
阿里云>云栖社区>主题图>>.net网页微信支付接口开发教程
推荐活动:
更多优惠>
当前话题:.net网页微信支付接口开发教程加入采集
相关话题:
.net网页微信支付接口开发教程相关博客看更多博文
【044】微信公众平台开发教程第20章——40个新手谜题
作者:云启希望。2102人查看评论数:04年前
笔者在CSDN博客频道推出微信公众平台开发教程后,联系了很多公众平台开发爱好者,帮助他们克服了很多实际问题。当然,这些问题中的许多都是重复的。因此,笔者将这些问题。并整理出答案,以帮助许多刚开始学习少走弯路的人。1、订阅账户和服务账户的主要区别是什么?
阅读全文
微信支付教程系列公众号支付
作者:micahel1202 人浏览评论:03年前
目录(一)微信公众号开发VS远程调试(二)微信公众号开发基础知识(三)微信公众号开发自动回复消息和自定义菜单)(四)开发的网页微信公众号授权获取用户基本信息(五)当前用户的Openid及注意事项可在微信公众号开发的网页中及时获取(六)微信公众号开发)
阅读全文
微信支付教程系列现金红包
作者:micahel1530 观众评论:03年前
目录(一)微信公众号开发VS远程调试(二)微信公众号开发基础知识(三)微信公众号开发自动回复消息和自定义菜单)(四)开发的网页微信公众号授权获取用户基本信息(五)当前用户的Openid及注意事项可在微信公众号开发的网页中及时获取(六)微信公众号开发)
阅读全文
微信公众号支付失败问题-微信支付提示调用支付JSAPI缺少参数:appId
作者:聚友云辉 2003 浏览评论:02年前
场景概述 鉴于去年在微信小程序支付、小程序支付、支付宝小程序支付、云闪付小程序支付方面的工作和研究。最近要完成一个微信公众号支付的场景。其中,我遇到了一个坑,花了我一个多上午的时间。所以想把记录写下来,以后遇到微信相关的API调用,用不了那么久。
阅读全文
微信公众平台开发问答
作者:方北工作室2281查看评论:06年前
微信公众平台开发问答是微信知识问答专区,专注于微信应用开发技术知识的整理、分类和检索。主题:新手常见问题 Q:我是新手,没有开发基础。我应该如何学习微信公众平台的开发?答:先学PHP和Mysql。您可以在 Internet 上找到相应的教程以了解一般语法。
阅读全文
【转载】微信公众号获取用户地理位置并列出附近店铺
作者:php的小菜鸟2236人查看评论数:04年前
思路分析:1、在微信公众号中获取用户的地理位置需要一个js-sdk签名包(文档里面有如何获取的介绍)2、根据获取到的地理位置, ajax去后台请求,通过sql语句,查询中就近的store(sql语句在网上搜索,通过后台添加位置)3、来查询store list根据城市,使用
阅读全文
史上最全的Android文章精选合集
作者:android飞鱼2557人查看评论:03年前
用两张图告诉你,为什么你的应用卡住了?- Android - Nuggets Cover 有什么?从这个 文章 你可以得到这个信息:知道 setContentView() 之后会发生什么吗?... Android常见的获取View宽高的正确方法
阅读全文
PHP 使用 QueryList 抓取网页内容
作者:thinkyoung1544 人浏览评论:06年前
以前,我使用Java Jsoup 来捕获网页数据。前几天听说用PHP比较方便。今天简单研究了一下,主要是使用QueryList。QueryList 是一个基于 phpQ 的
阅读全文 查看全部
querylist采集微信公众号文章(微信公众号开发之VS远程调试(二)(组图))
阿里云>云栖社区>主题图>>.net网页微信支付接口开发教程
推荐活动:
更多优惠>
当前话题:.net网页微信支付接口开发教程加入采集
相关话题:
.net网页微信支付接口开发教程相关博客看更多博文
【044】微信公众平台开发教程第20章——40个新手谜题
作者:云启希望。2102人查看评论数:04年前
笔者在CSDN博客频道推出微信公众平台开发教程后,联系了很多公众平台开发爱好者,帮助他们克服了很多实际问题。当然,这些问题中的许多都是重复的。因此,笔者将这些问题。并整理出答案,以帮助许多刚开始学习少走弯路的人。1、订阅账户和服务账户的主要区别是什么?
阅读全文
微信支付教程系列公众号支付
作者:micahel1202 人浏览评论:03年前
目录(一)微信公众号开发VS远程调试(二)微信公众号开发基础知识(三)微信公众号开发自动回复消息和自定义菜单)(四)开发的网页微信公众号授权获取用户基本信息(五)当前用户的Openid及注意事项可在微信公众号开发的网页中及时获取(六)微信公众号开发)
阅读全文
微信支付教程系列现金红包
作者:micahel1530 观众评论:03年前
目录(一)微信公众号开发VS远程调试(二)微信公众号开发基础知识(三)微信公众号开发自动回复消息和自定义菜单)(四)开发的网页微信公众号授权获取用户基本信息(五)当前用户的Openid及注意事项可在微信公众号开发的网页中及时获取(六)微信公众号开发)
阅读全文
微信公众号支付失败问题-微信支付提示调用支付JSAPI缺少参数:appId
作者:聚友云辉 2003 浏览评论:02年前
场景概述 鉴于去年在微信小程序支付、小程序支付、支付宝小程序支付、云闪付小程序支付方面的工作和研究。最近要完成一个微信公众号支付的场景。其中,我遇到了一个坑,花了我一个多上午的时间。所以想把记录写下来,以后遇到微信相关的API调用,用不了那么久。
阅读全文
微信公众平台开发问答
作者:方北工作室2281查看评论:06年前
微信公众平台开发问答是微信知识问答专区,专注于微信应用开发技术知识的整理、分类和检索。主题:新手常见问题 Q:我是新手,没有开发基础。我应该如何学习微信公众平台的开发?答:先学PHP和Mysql。您可以在 Internet 上找到相应的教程以了解一般语法。
阅读全文
【转载】微信公众号获取用户地理位置并列出附近店铺
作者:php的小菜鸟2236人查看评论数:04年前
思路分析:1、在微信公众号中获取用户的地理位置需要一个js-sdk签名包(文档里面有如何获取的介绍)2、根据获取到的地理位置, ajax去后台请求,通过sql语句,查询中就近的store(sql语句在网上搜索,通过后台添加位置)3、来查询store list根据城市,使用
阅读全文
史上最全的Android文章精选合集
作者:android飞鱼2557人查看评论:03年前
用两张图告诉你,为什么你的应用卡住了?- Android - Nuggets Cover 有什么?从这个 文章 你可以得到这个信息:知道 setContentView() 之后会发生什么吗?... Android常见的获取View宽高的正确方法
阅读全文
PHP 使用 QueryList 抓取网页内容
作者:thinkyoung1544 人浏览评论:06年前
以前,我使用Java Jsoup 来捕获网页数据。前几天听说用PHP比较方便。今天简单研究了一下,主要是使用QueryList。QueryList 是一个基于 phpQ 的
阅读全文
querylist采集微信公众号文章(为什么你的App会卡顿-Android-掘金Cover(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 178 次浏览 • 2022-03-25 01:02
阿里云>云栖社区>主题图>>.net网页微信支付接口开发教程
推荐活动:
更多优惠>
当前话题:.net网页微信支付接口开发教程加入采集
相关话题:
.net网页微信支付接口开发教程相关博客看更多博文
史上最全的Android文章精选合集
作者:android飞鱼2557人查看评论:03年前
用两张图告诉你,为什么你的应用卡住了?- Android - Nuggets Cover 有什么?从这个 文章 你可以得到这个信息:知道 setContentView() 之后会发生什么吗?... Android常见的获取View宽高的正确方法
阅读全文
微信公众平台开发问答
作者:方北工作室2281查看评论:06年前
微信公众平台开发问答是微信知识问答专区,专注于微信应用开发技术知识的整理、分类和检索。主题:新手常见问题 Q:我是新手,没有开发基础。我应该如何学习微信公众平台的开发?答:先学PHP和Mysql。您可以在 Internet 上找到相应的教程以了解一般语法。
阅读全文
【转载】微信公众号获取用户地理位置并列出附近店铺
作者:php的小菜鸟2236人查看评论数:04年前
思路分析:1、获取用户在微信公众号的地理位置需要js-sdk签名包(文档里面有如何获取的介绍)2、根据获取到的地理位置, ajax去后台请求,通过sql语句,查询中就近的store(sql语句在网上搜索,通过后台添加位置)3、来查询store list根据城市,使用
阅读全文
【044】微信公众平台开发教程第20章——40个新手谜题
作者:云启希望。2102人查看评论数:04年前
笔者在CSDN博客频道推出微信公众平台开发教程后,联系了很多公众平台开发爱好者,帮助他们克服了很多实际问题。当然,这些问题中的许多都是重复的。因此,笔者将这些问题。并整理出答案,以帮助许多刚开始学习少走弯路的人。1、订阅账户和服务账户的主要区别是什么?
阅读全文
微信公众号支付失败问题-微信支付提示调用支付JSAPI缺少参数:appId
作者:聚友云辉 2003 浏览评论:02年前
场景概述 鉴于去年在微信小程序支付、小程序支付、支付宝小程序支付、云闪付小程序支付方面的工作和研究。最近要完成一个微信公众号支付的场景。其中,我遇到了一个坑,花了我一个多上午的时间。所以想把记录写下来,以后遇到微信相关的API调用,用不了那么久。
阅读全文
PHP 使用 QueryList 抓取网页内容
作者:thinkyoung1544 人浏览评论:06年前
以前,我使用Java Jsoup 来捕获网页数据。前几天听说用PHP比较方便。今天简单研究了一下,主要是使用QueryList。QueryList 是一个基于 phpQ 的
阅读全文
微信支付教程系列现金红包
作者:micahel1530 观众评论:03年前
目录(一)微信公众号开发VS远程调试(二)微信公众号开发基础知识(三)微信公众号开发自动回复消息和自定义菜单)(四)开发的网页由微信公众号授权获取用户的基本信息(五)微信公众号开发的网站可以及时获取当前用户的Openid及注意事项(六)微信公众号开发的
阅读全文
微信支付教程系列公众号支付
作者:micahel1202 人浏览评论:03年前
目录(一)微信公众号开发VS远程调试(二)微信公众号开发基础知识(三)微信公众号开发自动回复消息和自定义菜单)(四)开发的网页由微信公众号授权获取用户的基本信息(五)微信公众号开发的网站可以及时获取当前用户的Openid及注意事项(六)微信公众号开发的
阅读全文 查看全部
querylist采集微信公众号文章(为什么你的App会卡顿-Android-掘金Cover(组图))
阿里云>云栖社区>主题图>>.net网页微信支付接口开发教程
推荐活动:
更多优惠>
当前话题:.net网页微信支付接口开发教程加入采集
相关话题:
.net网页微信支付接口开发教程相关博客看更多博文
史上最全的Android文章精选合集
作者:android飞鱼2557人查看评论:03年前
用两张图告诉你,为什么你的应用卡住了?- Android - Nuggets Cover 有什么?从这个 文章 你可以得到这个信息:知道 setContentView() 之后会发生什么吗?... Android常见的获取View宽高的正确方法
阅读全文
微信公众平台开发问答
作者:方北工作室2281查看评论:06年前
微信公众平台开发问答是微信知识问答专区,专注于微信应用开发技术知识的整理、分类和检索。主题:新手常见问题 Q:我是新手,没有开发基础。我应该如何学习微信公众平台的开发?答:先学PHP和Mysql。您可以在 Internet 上找到相应的教程以了解一般语法。
阅读全文
【转载】微信公众号获取用户地理位置并列出附近店铺
作者:php的小菜鸟2236人查看评论数:04年前
思路分析:1、获取用户在微信公众号的地理位置需要js-sdk签名包(文档里面有如何获取的介绍)2、根据获取到的地理位置, ajax去后台请求,通过sql语句,查询中就近的store(sql语句在网上搜索,通过后台添加位置)3、来查询store list根据城市,使用
阅读全文
【044】微信公众平台开发教程第20章——40个新手谜题
作者:云启希望。2102人查看评论数:04年前
笔者在CSDN博客频道推出微信公众平台开发教程后,联系了很多公众平台开发爱好者,帮助他们克服了很多实际问题。当然,这些问题中的许多都是重复的。因此,笔者将这些问题。并整理出答案,以帮助许多刚开始学习少走弯路的人。1、订阅账户和服务账户的主要区别是什么?
阅读全文
微信公众号支付失败问题-微信支付提示调用支付JSAPI缺少参数:appId
作者:聚友云辉 2003 浏览评论:02年前
场景概述 鉴于去年在微信小程序支付、小程序支付、支付宝小程序支付、云闪付小程序支付方面的工作和研究。最近要完成一个微信公众号支付的场景。其中,我遇到了一个坑,花了我一个多上午的时间。所以想把记录写下来,以后遇到微信相关的API调用,用不了那么久。
阅读全文
PHP 使用 QueryList 抓取网页内容
作者:thinkyoung1544 人浏览评论:06年前
以前,我使用Java Jsoup 来捕获网页数据。前几天听说用PHP比较方便。今天简单研究了一下,主要是使用QueryList。QueryList 是一个基于 phpQ 的
阅读全文
微信支付教程系列现金红包
作者:micahel1530 观众评论:03年前
目录(一)微信公众号开发VS远程调试(二)微信公众号开发基础知识(三)微信公众号开发自动回复消息和自定义菜单)(四)开发的网页由微信公众号授权获取用户的基本信息(五)微信公众号开发的网站可以及时获取当前用户的Openid及注意事项(六)微信公众号开发的
阅读全文
微信支付教程系列公众号支付
作者:micahel1202 人浏览评论:03年前
目录(一)微信公众号开发VS远程调试(二)微信公众号开发基础知识(三)微信公众号开发自动回复消息和自定义菜单)(四)开发的网页由微信公众号授权获取用户的基本信息(五)微信公众号开发的网站可以及时获取当前用户的Openid及注意事项(六)微信公众号开发的
阅读全文
querylist采集微信公众号文章(如何获取微信公众号所有文章?ID与开发者密码)
采集交流 • 优采云 发表了文章 • 0 个评论 • 454 次浏览 • 2022-03-24 00:24
导出所有公众号文章
随着互联网的不断发展,互联网上出现了许多自媒体平台。不用说,相信大家都知道现在哪些平台很火。
可以说,所有知名的自媒体都有自己的公众号。然而,平台的创新和涌现可谓是层出不穷。如果需要在平台上直播,则必须获取原平台的历史资源。
例如,对于微信公众号,我们需要获取微信公众号的文章。导出后,我们可以在其他平台上查看。那么如何获取我们公众号下的所有文章呢?
开发者 ID 和开发者密码
其实公众号为我们的开发提供了一个非常友好的界面,我们可以得到文章的所有链接,而不需要一一抓取。
如上图,我们需要进入公众号主页,然后通过设置与开发-基础配置找到开发者ID和开发者密码。
因为微信为我们提供了一个专门为我们获取公众号文章的接口,具体接口URL如下代码所示:
https://api.weixin.qq.com/cgi- ... ECRET
这里的APPID是开发中的ID,APPSECRET是开发者密码,获取方式如下图。
但是,有一个IP白名需要注意。为了公众号文章的安全,必须设置IP地址才能获取。如果后面的代码不在IP下运行,肯定会报错。
如上图所示,IP白名单就是直接设置你的IP地址。设置完成后点击修改,弹出二维码,用微信扫描即可。
https://api.weixin.qq.com/cgi- ... en%3D
这还不够,因为URL接口只获取access_token,也就是访问公众号的token,获取公众号的链接文章就是上面那个。
获取Json格式的公众号文章信息
现在我们对原理有了基本的了解,下面我们通过实战来获取文章的所有公众号标题、链接、描述、展示图片。一个例子如下:
import requests
import json
import csv
def getGZHJson(appid, secret):
path = " https://api.weixin.qq.com/cgi- ... ot%3B
url = path + "&appid=" + appid + "&secret=" + secret
result = requests.get(url)
token = json.loads(result.text)
access_token = token["access_token"]
data = {
"type": "news",
"offset": 0,
"count": 1,
}
headers = {
"content-type": "application/json",
"Accept-Language": "zh-CN,zh;q=0.9"
}
url = "https://api.weixin.qq.com/cgi- ... ot%3B + access_token
result = requests.post(url=url, data=json.dumps(data), headers=headers)
result.encoding = result.apparent_encoding
result = json.loads(result.text)
count = int(result["total_count"])
gzh_dict = {"news_item": []}
for i in range(0, count):
data["offset"] = i
result = requests.post(url=url, data=json.dumps(data), headers=headers)
result.encoding = result.apparent_encoding
result = json.loads(result.text)
for item in result["item"][0]["content"]["news_item"]:
temp_dict = {}
temp_dict["title"] = item["title"]
temp_dict["digest"] = item["digest"]
temp_dict["url"] = item["url"]
temp_dict["thumb_url"] = item["thumb_url"]
print(temp_dict)
gzh_dict["news_item"].append(temp_dict)
return json.dumps(gzh_dict)
getGZHJson("开发者ID", "开发者密码")
这里,我们看一下结果的原创文本数据,如下:
在原创的JSON数据中,有一个非常重要的数据就是total_count,它是公众号成立以来的推送次数。
不过需要注意的是,公众号可以一次推送一篇文章,也可以一次推送2、3、4篇文章,并不总是一样的。
至于获取哪些推送数据,可以通过offset追溯到源头。至于每次有多少篇文章,需要确定返回多少Json数据news_item。如下所示:
因此,我们还为其添加了遍历。第一层遍历是微信公众号推送当天的数据,第二层遍历是当天发送的文章数。运行后效果如下:
参数含义
标题
文章标题
消化
文章说明
网址
文章链接
拇指网址
文章显示地图
将数据保存到 CSV 文件
当然,我们获取的数据并不是在控制台上打印出来,而是导出数据。因此,我们将上述数据打包成 CSV 文件并保存。
一个例子如下:
result = requests.post(url=url, data=json.dumps(data), headers=headers)
result.encoding = result.apparent_encoding
print(result.encoding)
result = json.loads(result.text)
count = int(result["total_count"])
#替换下面的代码
ulist = ["_id", "title", "digest", "url", "thumb_url"]
# 保存数据到csv文件
new_item_csv = "week"
with open("{}.csv".format(new_item_csv), "w", encoding="utf-8-sig", newline="") as f:
writer = csv.writer(f, dialect="excel")
writer.writerow(ulist)
for i in range(0, count):
data["offset"] = i
result = requests.post(url=url, data=json.dumps(data), headers=headers)
result.encoding = result.apparent_encoding
result = json.loads(result.text)
for item in result["item"][0]["content"]["news_item"]:
writer.writerow([count_id, item["title"], item["digest"], item["url"], item["thumb_url"]])
count_id += 1
这里只需要更改代码count = int(result['total_count"])下面的所有数据即可。上面的代码保持不变。
需要注意的是,之所以设置result.encoding = result.apparent_encoding,是因为我们事先并不知道返回数据的编码。这确保了可以有效地解析任何编码。
运行后如下图,公众号文章的所有基本信息都已获取。
这是文章关于使用Python获取公众号下所有文章的介绍。更多关于Python获取公众号文章的信息,请搜索上一期服务器首页文章或继续浏览以下相关文章希望大家多多支持服务器首页未来!
原文链接: 查看全部
querylist采集微信公众号文章(如何获取微信公众号所有文章?ID与开发者密码)
导出所有公众号文章
随着互联网的不断发展,互联网上出现了许多自媒体平台。不用说,相信大家都知道现在哪些平台很火。
可以说,所有知名的自媒体都有自己的公众号。然而,平台的创新和涌现可谓是层出不穷。如果需要在平台上直播,则必须获取原平台的历史资源。
例如,对于微信公众号,我们需要获取微信公众号的文章。导出后,我们可以在其他平台上查看。那么如何获取我们公众号下的所有文章呢?
开发者 ID 和开发者密码
其实公众号为我们的开发提供了一个非常友好的界面,我们可以得到文章的所有链接,而不需要一一抓取。
如上图,我们需要进入公众号主页,然后通过设置与开发-基础配置找到开发者ID和开发者密码。
因为微信为我们提供了一个专门为我们获取公众号文章的接口,具体接口URL如下代码所示:
https://api.weixin.qq.com/cgi- ... ECRET
这里的APPID是开发中的ID,APPSECRET是开发者密码,获取方式如下图。
但是,有一个IP白名需要注意。为了公众号文章的安全,必须设置IP地址才能获取。如果后面的代码不在IP下运行,肯定会报错。
如上图所示,IP白名单就是直接设置你的IP地址。设置完成后点击修改,弹出二维码,用微信扫描即可。
https://api.weixin.qq.com/cgi- ... en%3D
这还不够,因为URL接口只获取access_token,也就是访问公众号的token,获取公众号的链接文章就是上面那个。
获取Json格式的公众号文章信息
现在我们对原理有了基本的了解,下面我们通过实战来获取文章的所有公众号标题、链接、描述、展示图片。一个例子如下:
import requests
import json
import csv
def getGZHJson(appid, secret):
path = " https://api.weixin.qq.com/cgi- ... ot%3B
url = path + "&appid=" + appid + "&secret=" + secret
result = requests.get(url)
token = json.loads(result.text)
access_token = token["access_token"]
data = {
"type": "news",
"offset": 0,
"count": 1,
}
headers = {
"content-type": "application/json",
"Accept-Language": "zh-CN,zh;q=0.9"
}
url = "https://api.weixin.qq.com/cgi- ... ot%3B + access_token
result = requests.post(url=url, data=json.dumps(data), headers=headers)
result.encoding = result.apparent_encoding
result = json.loads(result.text)
count = int(result["total_count"])
gzh_dict = {"news_item": []}
for i in range(0, count):
data["offset"] = i
result = requests.post(url=url, data=json.dumps(data), headers=headers)
result.encoding = result.apparent_encoding
result = json.loads(result.text)
for item in result["item"][0]["content"]["news_item"]:
temp_dict = {}
temp_dict["title"] = item["title"]
temp_dict["digest"] = item["digest"]
temp_dict["url"] = item["url"]
temp_dict["thumb_url"] = item["thumb_url"]
print(temp_dict)
gzh_dict["news_item"].append(temp_dict)
return json.dumps(gzh_dict)
getGZHJson("开发者ID", "开发者密码")
这里,我们看一下结果的原创文本数据,如下:
在原创的JSON数据中,有一个非常重要的数据就是total_count,它是公众号成立以来的推送次数。
不过需要注意的是,公众号可以一次推送一篇文章,也可以一次推送2、3、4篇文章,并不总是一样的。
至于获取哪些推送数据,可以通过offset追溯到源头。至于每次有多少篇文章,需要确定返回多少Json数据news_item。如下所示:
因此,我们还为其添加了遍历。第一层遍历是微信公众号推送当天的数据,第二层遍历是当天发送的文章数。运行后效果如下:
参数含义
标题
文章标题
消化
文章说明
网址
文章链接
拇指网址
文章显示地图
将数据保存到 CSV 文件
当然,我们获取的数据并不是在控制台上打印出来,而是导出数据。因此,我们将上述数据打包成 CSV 文件并保存。
一个例子如下:
result = requests.post(url=url, data=json.dumps(data), headers=headers)
result.encoding = result.apparent_encoding
print(result.encoding)
result = json.loads(result.text)
count = int(result["total_count"])
#替换下面的代码
ulist = ["_id", "title", "digest", "url", "thumb_url"]
# 保存数据到csv文件
new_item_csv = "week"
with open("{}.csv".format(new_item_csv), "w", encoding="utf-8-sig", newline="") as f:
writer = csv.writer(f, dialect="excel")
writer.writerow(ulist)
for i in range(0, count):
data["offset"] = i
result = requests.post(url=url, data=json.dumps(data), headers=headers)
result.encoding = result.apparent_encoding
result = json.loads(result.text)
for item in result["item"][0]["content"]["news_item"]:
writer.writerow([count_id, item["title"], item["digest"], item["url"], item["thumb_url"]])
count_id += 1
这里只需要更改代码count = int(result['total_count"])下面的所有数据即可。上面的代码保持不变。
需要注意的是,之所以设置result.encoding = result.apparent_encoding,是因为我们事先并不知道返回数据的编码。这确保了可以有效地解析任何编码。
运行后如下图,公众号文章的所有基本信息都已获取。
这是文章关于使用Python获取公众号下所有文章的介绍。更多关于Python获取公众号文章的信息,请搜索上一期服务器首页文章或继续浏览以下相关文章希望大家多多支持服务器首页未来!
原文链接:
querylist采集微信公众号文章(querylist采集微信公众号文章、应用二维码,整体测试代码)
采集交流 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2022-03-23 02:01
querylist采集微信公众号文章、应用二维码。详细介绍可以看下我的这篇文章,关于querylist的实现方式,支持二维码,整体测试代码如下:这里有我写的一篇基于mongodb的react+redux+egg-router做应用二维码+微信公众号的开发文章,对于微信二维码本身的处理写的比较深入,有兴趣的朋友可以去看看。querylist二维码解析demo:querylist。
二维码的二维码基本是不能复制的,需要生成二维码的时候进行config属性配置防止复制。ios开发者可以直接在ios文件中配置imf,partialiftrim('2'){fragmentid='0307';trim('\'');}即可进行复制。二维码的生成看到有人推荐用postman,但我觉得这个方法不靠谱,其他语言不了解。
第一次看见可以提交的方式。
mgstyle二维码具体哪里查看这个吧,不太好说,
recode不知道这个
step1。在github上面关注一下uenocloud的项目fogu-zhang/querylist·githubstep2。打开项目查看帮助step3。查看源码,方便第三方同学第一次接触二维码然后再修改你需要的代码step4。交互中step5。step6。step7。第三方的同学github上面提交代码step8。
还可以在本地浏览github上面这个项目step9。完成以上步骤也可以在本地搭建二维码服务那么一起看看我自己发的项目,一个博客应用的项目querylist。 查看全部
querylist采集微信公众号文章(querylist采集微信公众号文章、应用二维码,整体测试代码)
querylist采集微信公众号文章、应用二维码。详细介绍可以看下我的这篇文章,关于querylist的实现方式,支持二维码,整体测试代码如下:这里有我写的一篇基于mongodb的react+redux+egg-router做应用二维码+微信公众号的开发文章,对于微信二维码本身的处理写的比较深入,有兴趣的朋友可以去看看。querylist二维码解析demo:querylist。
二维码的二维码基本是不能复制的,需要生成二维码的时候进行config属性配置防止复制。ios开发者可以直接在ios文件中配置imf,partialiftrim('2'){fragmentid='0307';trim('\'');}即可进行复制。二维码的生成看到有人推荐用postman,但我觉得这个方法不靠谱,其他语言不了解。
第一次看见可以提交的方式。
mgstyle二维码具体哪里查看这个吧,不太好说,
recode不知道这个
step1。在github上面关注一下uenocloud的项目fogu-zhang/querylist·githubstep2。打开项目查看帮助step3。查看源码,方便第三方同学第一次接触二维码然后再修改你需要的代码step4。交互中step5。step6。step7。第三方的同学github上面提交代码step8。
还可以在本地浏览github上面这个项目step9。完成以上步骤也可以在本地搭建二维码服务那么一起看看我自己发的项目,一个博客应用的项目querylist。
querylist采集微信公众号文章(有哪些高质量的微信公众号文章推送的链接?)
采集交流 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2022-03-21 14:08
querylist采集微信公众号文章推送的链接,使用google的googleanalytics,谷歌搜索抓取,traversableviavideo返回公众号链接。querylist还可以批量下载文章下载二维码,公众号的文章,可以直接获取下载二维码。
技术牛人多回复分享更多干货!看到一篇和我想法很相似的文章
vitess,weixindisallowit。formerweixinallowssharingwechatcontenttoattributebyyourown。copyrightrightsownerexists。excludegainstitute'svideorecordingfoundationproduct;contentmissingintheweixindisallowsvideorecordingonpublicsafety。
有哪些高质量的微信公众号文章推送,能够一键直达微信群?-mr彭的回答提供了从微信公众号源文件下载、开源微信小程序之类的。
有木有,保存本文章,然后共享,
百度文库免费下载百度文库也提供网盘的下载
猪八戒上面有客一键下单的。可以尝试一下。
技术牛人多回复分享更多干货!看到一篇和我想法很相似的文章,希望对你有帮助。
考试官网,免费题库,由中国大学mooc的engineercenter提供。其中浙江大学的课程比较全,人教,浙大的都有,其他的不用考虑了。 查看全部
querylist采集微信公众号文章(有哪些高质量的微信公众号文章推送的链接?)
querylist采集微信公众号文章推送的链接,使用google的googleanalytics,谷歌搜索抓取,traversableviavideo返回公众号链接。querylist还可以批量下载文章下载二维码,公众号的文章,可以直接获取下载二维码。
技术牛人多回复分享更多干货!看到一篇和我想法很相似的文章
vitess,weixindisallowit。formerweixinallowssharingwechatcontenttoattributebyyourown。copyrightrightsownerexists。excludegainstitute'svideorecordingfoundationproduct;contentmissingintheweixindisallowsvideorecordingonpublicsafety。
有哪些高质量的微信公众号文章推送,能够一键直达微信群?-mr彭的回答提供了从微信公众号源文件下载、开源微信小程序之类的。
有木有,保存本文章,然后共享,
百度文库免费下载百度文库也提供网盘的下载
猪八戒上面有客一键下单的。可以尝试一下。
技术牛人多回复分享更多干货!看到一篇和我想法很相似的文章,希望对你有帮助。
考试官网,免费题库,由中国大学mooc的engineercenter提供。其中浙江大学的课程比较全,人教,浙大的都有,其他的不用考虑了。
querylist采集微信公众号文章(微信公众号开发之VS远程调试(二)(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 166 次浏览 • 2022-03-20 09:03
阿里巴巴云>云栖社区>主题图>>.net网页微信支付接口开发教程
推荐活动:
更多优惠>
当前话题:.net网页微信支付接口开发教程加入采集
相关主题:
.net网页微信支付接口开发教程相关博客看更多博文
【044】微信公众平台开发教程第20章-初学者40题
作者:云启希望。 2102人查看评论数:04年前
作者在CSDN博客频道推出微信公众平台开发教程后,接触了很多公众平台开发爱好者,帮助他们克服了很多实际问题。当然,这些问题中的许多都是重复的。因此,作者将这些问题和答案放在一起,将帮助许多其他刚起步的人少走弯路。 1、订阅帐号和服务帐号的主要区别是什么?
阅读全文
微信支付教程系列公众号支付
作者:micahel1202 查看评论:03 年前
目录(一)微信公众号开发VS远程调试(二)微信公众号开发基础知识(三)微信公众号开发自动回复消息和自定义菜单)四)微信公众号开发的网页授权获取用户的基本信息(五)微信公众号开发的网页可以及时获取当前用户的Openid及注意事项(六)微信公众号开发
阅读全文
微信支付教程系列现金红包
作者:micahel1530 查看评论:03 年前
目录(一)微信公众号开发VS远程调试(二)微信公众号开发基础知识(三)微信公众号开发自动回复消息和自定义菜单)四)微信公众号开发的网页授权获取用户的基本信息(五)微信公众号开发的网页可以及时获取当前用户的Openid及注意事项(六)微信公众号开发
阅读全文
微信公众号支付失败问题-微信支付提示调用支付JSAPI缺少参数:appId
作者:聚友云辉 2003 浏览评论:02年前
场景概述 鉴于去年对微信支付、小程序支付、支付宝应用支付、云闪付应用支付的研究。最近要完成一个微信公众号支付的场景。其中,我遇到了一个坑,花了我一个多上午的时间。所以我想写个记录,这样以后遇到微信相关的API调用,就不用那么久了
阅读全文
微信公众平台开发问答
作者:方北工作室2281查看评论:06年前
微信公众平台开发问答是微信知识问答专区,专注于微信应用开发技术知识的整理、分类和检索。主题:新手常见问题 Q:我是新手,没有开发基础。我应该如何学习微信公众平台的开发?答:先学PHP和Mysql,可以在网上找对应的教程了解大致的语法,但不要深入。
阅读全文
【转载】微信公众号获取用户地理位置并列出附近店铺
作者:php的小菜鸟2236人查看评论数:04年前
思路分析:1、在微信公众号获取用户地理位置需要js-sdk签名包(文档获取方法有介绍)2、根据获取地理位置,ajax去后台请求,通过sql语句,在查询中查询最近的store(sql语句在网上搜索,通过后台添加位置)3、根据店铺列表查询到市区,通过
阅读全文
最全的安卓文章合集
作者:android飞鱼2557人查看评论:03年前
告诉你两张图,为什么你的应用会死机? - Android - 掘金队的封面是什么?从这个 文章 你可以得到这个信息:知道 setContentView() 之后会发生什么吗? ... Android 获取 View 宽度和高度的常见正确方法
阅读全文
PHP 使用 QueryList 抓取网页内容
作者:thinkyoung1544 浏览评论:06年前
过去,Java Jsoup 用于捕获网页数据。前几天听说用PHP比较方便。今天简单研究了一下,主要是使用QueryList。 QueryList 基于 phpQ
阅读全文 查看全部
querylist采集微信公众号文章(微信公众号开发之VS远程调试(二)(组图))
阿里巴巴云>云栖社区>主题图>>.net网页微信支付接口开发教程
推荐活动:
更多优惠>
当前话题:.net网页微信支付接口开发教程加入采集
相关主题:
.net网页微信支付接口开发教程相关博客看更多博文
【044】微信公众平台开发教程第20章-初学者40题
作者:云启希望。 2102人查看评论数:04年前
作者在CSDN博客频道推出微信公众平台开发教程后,接触了很多公众平台开发爱好者,帮助他们克服了很多实际问题。当然,这些问题中的许多都是重复的。因此,作者将这些问题和答案放在一起,将帮助许多其他刚起步的人少走弯路。 1、订阅帐号和服务帐号的主要区别是什么?
阅读全文
微信支付教程系列公众号支付
作者:micahel1202 查看评论:03 年前
目录(一)微信公众号开发VS远程调试(二)微信公众号开发基础知识(三)微信公众号开发自动回复消息和自定义菜单)四)微信公众号开发的网页授权获取用户的基本信息(五)微信公众号开发的网页可以及时获取当前用户的Openid及注意事项(六)微信公众号开发
阅读全文
微信支付教程系列现金红包
作者:micahel1530 查看评论:03 年前
目录(一)微信公众号开发VS远程调试(二)微信公众号开发基础知识(三)微信公众号开发自动回复消息和自定义菜单)四)微信公众号开发的网页授权获取用户的基本信息(五)微信公众号开发的网页可以及时获取当前用户的Openid及注意事项(六)微信公众号开发
阅读全文
微信公众号支付失败问题-微信支付提示调用支付JSAPI缺少参数:appId
作者:聚友云辉 2003 浏览评论:02年前
场景概述 鉴于去年对微信支付、小程序支付、支付宝应用支付、云闪付应用支付的研究。最近要完成一个微信公众号支付的场景。其中,我遇到了一个坑,花了我一个多上午的时间。所以我想写个记录,这样以后遇到微信相关的API调用,就不用那么久了
阅读全文
微信公众平台开发问答
作者:方北工作室2281查看评论:06年前
微信公众平台开发问答是微信知识问答专区,专注于微信应用开发技术知识的整理、分类和检索。主题:新手常见问题 Q:我是新手,没有开发基础。我应该如何学习微信公众平台的开发?答:先学PHP和Mysql,可以在网上找对应的教程了解大致的语法,但不要深入。
阅读全文
【转载】微信公众号获取用户地理位置并列出附近店铺
作者:php的小菜鸟2236人查看评论数:04年前
思路分析:1、在微信公众号获取用户地理位置需要js-sdk签名包(文档获取方法有介绍)2、根据获取地理位置,ajax去后台请求,通过sql语句,在查询中查询最近的store(sql语句在网上搜索,通过后台添加位置)3、根据店铺列表查询到市区,通过
阅读全文
最全的安卓文章合集
作者:android飞鱼2557人查看评论:03年前
告诉你两张图,为什么你的应用会死机? - Android - 掘金队的封面是什么?从这个 文章 你可以得到这个信息:知道 setContentView() 之后会发生什么吗? ... Android 获取 View 宽度和高度的常见正确方法
阅读全文
PHP 使用 QueryList 抓取网页内容
作者:thinkyoung1544 浏览评论:06年前
过去,Java Jsoup 用于捕获网页数据。前几天听说用PHP比较方便。今天简单研究了一下,主要是使用QueryList。 QueryList 基于 phpQ
阅读全文
querylist采集微信公众号文章(querylist采集微信公众号文章,去重后传给es然后用转换为txt格式)
采集交流 • 优采云 发表了文章 • 0 个评论 • 186 次浏览 • 2022-03-17 16:01
querylist采集微信公众号文章,去重后传给es,然后用es转换为txt格式,然后相应的token会传到querylist上,下次查询可以不重复用token查询,查询时直接用querylist查询即可。
想要token等价于queryid的话,可以用如下python库:apiversion:v1appgametype:pygameversion:1。5supportedsuggestion:truetargetpath:android:entity。querystringaccessname:truecrawledurl:data。
querystring。contentspath@apiversion:android。view。adaptor。adaptorappname:app。myappkey:app。properties。active_account:app。entity。querystringcontentspath::data。querystring。
请参照我的系列文章-querylist是什么?-querylist-encodebox.html
从第一篇文章里引用过来的token可以进行key存储和encode模式处理,encode模式基本就是是用key来表示query,再用json或者类似的格式存储至于上面有同学说的利用json来存储query,是没有问题的,但是json格式有许多问题,并不好于数据库的列式存储格式如下jsoncached的工作是:获取数据-解析json-存储数据最终的处理流程:客户端从本地拉取原始jsonjsoncached解析jsonjsoncached和jsonbuffer这个不是数据库里的,但是有相同的特性,那就是用大量的key来存储query。 查看全部
querylist采集微信公众号文章(querylist采集微信公众号文章,去重后传给es然后用转换为txt格式)
querylist采集微信公众号文章,去重后传给es,然后用es转换为txt格式,然后相应的token会传到querylist上,下次查询可以不重复用token查询,查询时直接用querylist查询即可。
想要token等价于queryid的话,可以用如下python库:apiversion:v1appgametype:pygameversion:1。5supportedsuggestion:truetargetpath:android:entity。querystringaccessname:truecrawledurl:data。
querystring。contentspath@apiversion:android。view。adaptor。adaptorappname:app。myappkey:app。properties。active_account:app。entity。querystringcontentspath::data。querystring。
请参照我的系列文章-querylist是什么?-querylist-encodebox.html
从第一篇文章里引用过来的token可以进行key存储和encode模式处理,encode模式基本就是是用key来表示query,再用json或者类似的格式存储至于上面有同学说的利用json来存储query,是没有问题的,但是json格式有许多问题,并不好于数据库的列式存储格式如下jsoncached的工作是:获取数据-解析json-存储数据最终的处理流程:客户端从本地拉取原始jsonjsoncached解析jsonjsoncached和jsonbuffer这个不是数据库里的,但是有相同的特性,那就是用大量的key来存储query。
querylist采集微信公众号文章(WordPress采集插件蜜蜂采集BeePress破解安装教程)
采集交流 • 优采云 发表了文章 • 0 个评论 • 867 次浏览 • 2022-03-16 21:12
WordPress采集插件蜜蜂采集BeePress
“小蜜蜂-BeePress”是一个微信公众号文章导入插件。通过粘贴公众号文章的链接,可以一键导入公众号文章到自己的网站,支持批量导入、自动采集、设置特色图片等功能,减少繁琐操作。
最新版本已支持知乎栏目文章、简书文章、今日头条的导入
WordPress采集Plugin Bee采集BeePress 安装
进入WordPress管理后台,选择安装插件,搜索bees采集
也可以直接从WordPress官网下载,下载链接
下载后解压到插件目录
WordPress采集插件Bee采集BeePress专业版破解
安装完成后,左侧会出现“专业版”和“基础版”。专业版功能更强大,但仅提供 5 次试用。完成次数后,需要以人民币购买。(本教程仅供技术经验分享,部署网站时请支持原创原版)
使用数据库管理工具,这里以phpMyadmin为例。
选择 wp_options 数据表,找到 bp_count 字段
将 option_value 值从 5 更改为任意值
破解成功
如果没有可视化数据库管理工具,也可以直接使用sql命令执行修改,
更新 wp_options SET option_value = 99999 WHERE option_name = 'bp_count';
这里的破解只是增加试用次数,达到专业版无限次使用的效果。如需正常使用授权,请联系作者购买正版插件。
原创文章,作者:dongdongxiao,如转载请注明出处: 查看全部
querylist采集微信公众号文章(WordPress采集插件蜜蜂采集BeePress破解安装教程)
WordPress采集插件蜜蜂采集BeePress
“小蜜蜂-BeePress”是一个微信公众号文章导入插件。通过粘贴公众号文章的链接,可以一键导入公众号文章到自己的网站,支持批量导入、自动采集、设置特色图片等功能,减少繁琐操作。
最新版本已支持知乎栏目文章、简书文章、今日头条的导入
WordPress采集Plugin Bee采集BeePress 安装
进入WordPress管理后台,选择安装插件,搜索bees采集
也可以直接从WordPress官网下载,下载链接
下载后解压到插件目录
WordPress采集插件Bee采集BeePress专业版破解
安装完成后,左侧会出现“专业版”和“基础版”。专业版功能更强大,但仅提供 5 次试用。完成次数后,需要以人民币购买。(本教程仅供技术经验分享,部署网站时请支持原创原版)
使用数据库管理工具,这里以phpMyadmin为例。
选择 wp_options 数据表,找到 bp_count 字段
将 option_value 值从 5 更改为任意值
破解成功
如果没有可视化数据库管理工具,也可以直接使用sql命令执行修改,
更新 wp_options SET option_value = 99999 WHERE option_name = 'bp_count';
这里的破解只是增加试用次数,达到专业版无限次使用的效果。如需正常使用授权,请联系作者购买正版插件。
原创文章,作者:dongdongxiao,如转载请注明出处:
querylist采集微信公众号文章(import_module采集模块实现公众号文章的入口逻辑)
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2022-03-15 22:14
因为采集器有两种不同的实现方式,ruia和playwright,使用哪一种由配置文件决定,然后通过import_module方法动态导入对应的模块,然后运行模块的run方法,从而实现文章的公众号 bool:
"""
采集器工厂函数
:param collect_type: 采集器类型
:param collect_config: 采集器配置
:return:
"""
collect_status = False
try:
# import_module方法动态载入具体的采集模块
collect_module = import_module(f"src.collector.{collect_type}")
collect_status = collect_module.run(collect_config)
except ModuleNotFoundError:
LOGGER.error(f"采集器类型不存在 {collect_type} - {collect_config}")
except Exception as e:
LOGGER.error(f"采集器执行出错 {collect_type} - {collect_config} - {e}")
return collect_status
编剧采集模块实现
Playwright 是微软出品的自动化库。它类似于硒。它定位于网页测试,但也被人们用来获取网页信息。当然,一些前端的反爬措施,编剧是无法突破的。
与selenium相比,playwright支持python的async,性能有所提升(但还是比不上直接请求)。下面是获取公众号下最新= cos_value else 0
max_pro = value if value > max_pro else max_pro
if result == 1:
break
return {"result": result, "value": max_pro}
<p>余弦值的具体操作逻辑在CosineSimilarity的calculate方法中,都是和数学有关的,我就不看了。核心是判断当前 查看全部
querylist采集微信公众号文章(import_module采集模块实现公众号文章的入口逻辑)
因为采集器有两种不同的实现方式,ruia和playwright,使用哪一种由配置文件决定,然后通过import_module方法动态导入对应的模块,然后运行模块的run方法,从而实现文章的公众号 bool:
"""
采集器工厂函数
:param collect_type: 采集器类型
:param collect_config: 采集器配置
:return:
"""
collect_status = False
try:
# import_module方法动态载入具体的采集模块
collect_module = import_module(f"src.collector.{collect_type}")
collect_status = collect_module.run(collect_config)
except ModuleNotFoundError:
LOGGER.error(f"采集器类型不存在 {collect_type} - {collect_config}")
except Exception as e:
LOGGER.error(f"采集器执行出错 {collect_type} - {collect_config} - {e}")
return collect_status
编剧采集模块实现
Playwright 是微软出品的自动化库。它类似于硒。它定位于网页测试,但也被人们用来获取网页信息。当然,一些前端的反爬措施,编剧是无法突破的。
与selenium相比,playwright支持python的async,性能有所提升(但还是比不上直接请求)。下面是获取公众号下最新= cos_value else 0
max_pro = value if value > max_pro else max_pro
if result == 1:
break
return {"result": result, "value": max_pro}
<p>余弦值的具体操作逻辑在CosineSimilarity的calculate方法中,都是和数学有关的,我就不看了。核心是判断当前
querylist采集微信公众号文章(爬取大牛用微信公众号爬取程序的难点及解决办法)
采集交流 • 优采云 发表了文章 • 0 个评论 • 135 次浏览 • 2022-03-15 03:10
最近需要爬取微信公众号的文章信息。我在网上搜索,发现爬取微信公众号的难点在于公众号文章的链接在PC端打不开,所以需要使用微信自带的浏览器(获取参数微信客户端补充)可以在其他平台打开),给爬虫带来了很大的麻烦。后来在知乎上看到了一个大牛用php写的微信公众号爬虫程序,直接按照大佬的思路做成了java。改造过程中遇到了很多细节和问题,就分享给大家。
附上大牛的链接文章:写php或者只需要爬取思路的可以直接看这个。这些想法写得很详细。
-------------------------------------------------- -------------------------------------------------- -------------------------------------------------- ----------------------
系统的基本思路是在Android模拟器上运行微信,在模拟器上设置代理,通过代理服务器截取微信数据,将获取到的数据发送给自己的程序进行处理。
需要准备的环境:nodejs、anyproxy代理、安卓模拟器
Nodejs下载地址:我下载的是windows版本的,直接安装就好了。安装后直接运行 C:\Program Files\nodejs\npm.cmd 会自动配置环境。
anyproxy 安装:按照上一步安装nodejs后,直接在cmd中运行npm install -g anyproxy即可安装
网上的安卓模拟器就好了,有很多。
-------------------------------------------------- -------------------------------------------------- -------------------------------------------------- ----------------------------------
首先安装代理服务器的证书。Anyproxy 默认不解析 https 链接。安装证书后,就可以解析了。在cmd中执行anyproxy --root安装证书,然后在模拟器中下载证书。
然后输入anyproxy -i 命令打开代理服务。(记得添加参数!)
记住这个ip和端口,那么安卓模拟器的代理就会用到这个。现在用浏览器打开网页::8002/ 这是anyproxy的网页界面,用来显示http传输的数据。
点击上方红框中的菜单,会出现一个二维码。用安卓模拟器扫码识别。模拟器(手机)会下载证书并安装。
现在准备为模拟器设置代理,代理模式设置为手动,代理ip为运行anyproxy的机器的ip,端口为8001
准备工作到这里基本完成。在模拟器上打开微信,打开一个公众号的文章,可以从刚刚打开的web界面看到anyproxy抓取的数据:
上图红框是微信文章的链接,点击查看具体数据。如果响应正文中没有任何内容,则可能是证书安装有问题。
如果顶部清晰,您可以向下。
这里我们依靠代理服务抓取微信数据,但是我们不能抓取一条数据自己操作微信,所以还是手动复制比较好。所以我们需要微信客户端自己跳转到页面。这时可以使用anyproxy拦截微信服务器返回的数据,将页面跳转代码注入其中,然后将处理后的数据返回给模拟器,实现微信客户端的自动跳转。
在anyproxy中打开一个名为rule_default.js的js文件,windows下的文件为:C:\Users\Administrator\AppData\Roaming\npm\node_modules\anyproxy\lib
文件中有一个方法叫做replaceServerResDataAsync: function(req,res,serverResData,callback)。该方法负责对anyproxy获取的数据进行各种操作。开头应该只有 callback(serverResData) ;该语句的意思是直接将服务器响应数据返回给客户端。直接把这条语句删掉,换成下面大牛写的代码。我这里的代码没有做任何改动,里面的注释也很清楚。顺着逻辑去理解就行了,问题不大。
1 replaceServerResDataAsync: function(req,res,serverResData,callback){
2 if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
3 //console.log("开始第一种页面爬取");
4 if(serverResData.toString() !== ""){
5 6 try {//防止报错退出程序
7 var reg = /msgList = (.*?);/;//定义历史消息正则匹配规则
8 var ret = reg.exec(serverResData.toString());//转换变量为string
9 HttpPost(ret[1],req.url,"/InternetSpider/getData/showBiz");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
10 var http = require('http');
11 http.get('http://xxx/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
12 res.on('data', function(chunk){
13 callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
14 })
15 });
16 }catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
17 //console.log("开始第一种页面爬取向下翻形式");
18 try {
19 var json = JSON.parse(serverResData.toString());
20 if (json.general_msg_list != []) {
21 HttpPost(json.general_msg_list,req.url,"/xxx/showBiz");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
22 }
23 }catch(e){
24 console.log(e);//错误捕捉
25 }
26 callback(serverResData);//直接返回第二页json内容
27 }
28 }
29 //console.log("开始第一种页面爬取 结束");
30 }else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
31 try {
32 var reg = /var msgList = \'(.*?)\';/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
33 var ret = reg.exec(serverResData.toString());//转换变量为string
34 HttpPost(ret[1],req.url,"/xxx/showBiz");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
35 var http = require('http');
36 http.get('xxx/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
37 res.on('data', function(chunk){
38 callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
39 })
40 });
41 }catch(e){
42 //console.log(e);
43 callback(serverResData);
44 }
45 }else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
46 try {
47 var json = JSON.parse(serverResData.toString());
48 if (json.general_msg_list != []) {
49 HttpPost(json.general_msg_list,req.url,"/xxx/showBiz");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
50 }
51 }catch(e){
52 console.log(e);
53 }
54 callback(serverResData);
55 }else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
56 try {
57 HttpPost(serverResData,req.url,"/xxx/getMsgExt");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
58 }catch(e){
59
60 }
61 callback(serverResData);
62 }else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
63 try {
64 var http = require('http');
65 http.get('http://xxx/getWxPost', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
66 res.on('data', function(chunk){
67 callback(chunk+serverResData);
68 })
69 });
70 }catch(e){
71 callback(serverResData);
72 }
73 }else{
74 callback(serverResData);
75 }
76 //callback(serverResData);
77 },
这是一个简短的解释。微信公众号历史新闻页面的链接有两种形式:一种以/mp/getmasssendmsg开头,另一种以/mp/profile_ext开头。历史页面可以向下滚动。向下滚动会触发js事件发送请求获取json数据(下一页的内容)。还有公众号文章的链接,以及文章的阅读和点赞链接(返回json数据)。这些环节的形式是固定的,可以通过逻辑判断加以区分。这里有个问题,如果历史页面需要一路爬取怎么办。我的想法是通过js模拟鼠标向下滑动,从而触发提交下一部分列表的负载的请求。或者直接使用anyproxy分析下载请求,直接向微信服务器发出这个请求。但是有一个问题是如何判断没有剩余数据。我正在抓取最新数据。我暂时没有这个要求,但以后可能需要。如果需要,您可以尝试一下。 查看全部
querylist采集微信公众号文章(爬取大牛用微信公众号爬取程序的难点及解决办法)
最近需要爬取微信公众号的文章信息。我在网上搜索,发现爬取微信公众号的难点在于公众号文章的链接在PC端打不开,所以需要使用微信自带的浏览器(获取参数微信客户端补充)可以在其他平台打开),给爬虫带来了很大的麻烦。后来在知乎上看到了一个大牛用php写的微信公众号爬虫程序,直接按照大佬的思路做成了java。改造过程中遇到了很多细节和问题,就分享给大家。
附上大牛的链接文章:写php或者只需要爬取思路的可以直接看这个。这些想法写得很详细。
-------------------------------------------------- -------------------------------------------------- -------------------------------------------------- ----------------------
系统的基本思路是在Android模拟器上运行微信,在模拟器上设置代理,通过代理服务器截取微信数据,将获取到的数据发送给自己的程序进行处理。
需要准备的环境:nodejs、anyproxy代理、安卓模拟器
Nodejs下载地址:我下载的是windows版本的,直接安装就好了。安装后直接运行 C:\Program Files\nodejs\npm.cmd 会自动配置环境。
anyproxy 安装:按照上一步安装nodejs后,直接在cmd中运行npm install -g anyproxy即可安装
网上的安卓模拟器就好了,有很多。
-------------------------------------------------- -------------------------------------------------- -------------------------------------------------- ----------------------------------
首先安装代理服务器的证书。Anyproxy 默认不解析 https 链接。安装证书后,就可以解析了。在cmd中执行anyproxy --root安装证书,然后在模拟器中下载证书。
然后输入anyproxy -i 命令打开代理服务。(记得添加参数!)
记住这个ip和端口,那么安卓模拟器的代理就会用到这个。现在用浏览器打开网页::8002/ 这是anyproxy的网页界面,用来显示http传输的数据。
点击上方红框中的菜单,会出现一个二维码。用安卓模拟器扫码识别。模拟器(手机)会下载证书并安装。
现在准备为模拟器设置代理,代理模式设置为手动,代理ip为运行anyproxy的机器的ip,端口为8001
准备工作到这里基本完成。在模拟器上打开微信,打开一个公众号的文章,可以从刚刚打开的web界面看到anyproxy抓取的数据:
上图红框是微信文章的链接,点击查看具体数据。如果响应正文中没有任何内容,则可能是证书安装有问题。
如果顶部清晰,您可以向下。
这里我们依靠代理服务抓取微信数据,但是我们不能抓取一条数据自己操作微信,所以还是手动复制比较好。所以我们需要微信客户端自己跳转到页面。这时可以使用anyproxy拦截微信服务器返回的数据,将页面跳转代码注入其中,然后将处理后的数据返回给模拟器,实现微信客户端的自动跳转。
在anyproxy中打开一个名为rule_default.js的js文件,windows下的文件为:C:\Users\Administrator\AppData\Roaming\npm\node_modules\anyproxy\lib
文件中有一个方法叫做replaceServerResDataAsync: function(req,res,serverResData,callback)。该方法负责对anyproxy获取的数据进行各种操作。开头应该只有 callback(serverResData) ;该语句的意思是直接将服务器响应数据返回给客户端。直接把这条语句删掉,换成下面大牛写的代码。我这里的代码没有做任何改动,里面的注释也很清楚。顺着逻辑去理解就行了,问题不大。
1 replaceServerResDataAsync: function(req,res,serverResData,callback){
2 if(/mp\/getmasssendmsg/i.test(req.url)){//当链接地址为公众号历史消息页面时(第一种页面形式)
3 //console.log("开始第一种页面爬取");
4 if(serverResData.toString() !== ""){
5 6 try {//防止报错退出程序
7 var reg = /msgList = (.*?);/;//定义历史消息正则匹配规则
8 var ret = reg.exec(serverResData.toString());//转换变量为string
9 HttpPost(ret[1],req.url,"/InternetSpider/getData/showBiz");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
10 var http = require('http');
11 http.get('http://xxx/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
12 res.on('data', function(chunk){
13 callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
14 })
15 });
16 }catch(e){//如果上面的正则没有匹配到,那么这个页面内容可能是公众号历史消息页面向下翻动的第二页,因为历史消息第一页是html格式的,第二页就是json格式的。
17 //console.log("开始第一种页面爬取向下翻形式");
18 try {
19 var json = JSON.parse(serverResData.toString());
20 if (json.general_msg_list != []) {
21 HttpPost(json.general_msg_list,req.url,"/xxx/showBiz");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
22 }
23 }catch(e){
24 console.log(e);//错误捕捉
25 }
26 callback(serverResData);//直接返回第二页json内容
27 }
28 }
29 //console.log("开始第一种页面爬取 结束");
30 }else if(/mp\/profile_ext\?action=home/i.test(req.url)){//当链接地址为公众号历史消息页面时(第二种页面形式)
31 try {
32 var reg = /var msgList = \'(.*?)\';/;//定义历史消息正则匹配规则(和第一种页面形式的正则不同)
33 var ret = reg.exec(serverResData.toString());//转换变量为string
34 HttpPost(ret[1],req.url,"/xxx/showBiz");//这个函数是后文定义的,将匹配到的历史消息json发送到自己的服务器
35 var http = require('http');
36 http.get('xxx/getWxHis', function(res) {//这个地址是自己服务器上的一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxHis.php的原理。
37 res.on('data', function(chunk){
38 callback(chunk+serverResData);//将返回的代码插入到历史消息页面中,并返回显示出来
39 })
40 });
41 }catch(e){
42 //console.log(e);
43 callback(serverResData);
44 }
45 }else if(/mp\/profile_ext\?action=getmsg/i.test(req.url)){//第二种页面表现形式的向下翻页后的json
46 try {
47 var json = JSON.parse(serverResData.toString());
48 if (json.general_msg_list != []) {
49 HttpPost(json.general_msg_list,req.url,"/xxx/showBiz");//这个函数和上面的一样是后文定义的,将第二页历史消息的json发送到自己的服务器
50 }
51 }catch(e){
52 console.log(e);
53 }
54 callback(serverResData);
55 }else if(/mp\/getappmsgext/i.test(req.url)){//当链接地址为公众号文章阅读量和点赞量时
56 try {
57 HttpPost(serverResData,req.url,"/xxx/getMsgExt");//函数是后文定义的,功能是将文章阅读量点赞量的json发送到服务器
58 }catch(e){
59
60 }
61 callback(serverResData);
62 }else if(/s\?__biz/i.test(req.url) || /mp\/rumor/i.test(req.url)){//当链接地址为公众号文章时(rumor这个地址是公众号文章被辟谣了)
63 try {
64 var http = require('http');
65 http.get('http://xxx/getWxPost', function(res) {//这个地址是自己服务器上的另一个程序,目的是为了获取到下一个链接地址,将地址放在一个js脚本中,将页面自动跳转到下一页。后文将介绍getWxPost.php的原理。
66 res.on('data', function(chunk){
67 callback(chunk+serverResData);
68 })
69 });
70 }catch(e){
71 callback(serverResData);
72 }
73 }else{
74 callback(serverResData);
75 }
76 //callback(serverResData);
77 },
这是一个简短的解释。微信公众号历史新闻页面的链接有两种形式:一种以/mp/getmasssendmsg开头,另一种以/mp/profile_ext开头。历史页面可以向下滚动。向下滚动会触发js事件发送请求获取json数据(下一页的内容)。还有公众号文章的链接,以及文章的阅读和点赞链接(返回json数据)。这些环节的形式是固定的,可以通过逻辑判断加以区分。这里有个问题,如果历史页面需要一路爬取怎么办。我的想法是通过js模拟鼠标向下滑动,从而触发提交下一部分列表的负载的请求。或者直接使用anyproxy分析下载请求,直接向微信服务器发出这个请求。但是有一个问题是如何判断没有剩余数据。我正在抓取最新数据。我暂时没有这个要求,但以后可能需要。如果需要,您可以尝试一下。
querylist采集微信公众号文章( 处理跳转向微信注入js的方法:以上就是对处理代理服务器拦截到的数据进行处理)
采集交流 • 优采云 发表了文章 • 0 个评论 • 283 次浏览 • 2022-03-13 10:09
处理跳转向微信注入js的方法:以上就是对处理代理服务器拦截到的数据进行处理)
public void getMsgExt(String str,String url) {
// TODO Auto-generated method stub
String biz = "";
String sn = "";
Map queryStrs = HttpUrlParser.parseUrl(url);
if(queryStrs != null){
biz = queryStrs.get("__biz");
biz = biz + "==";
sn = queryStrs.get("sn");
sn = "%" + sn + "%";
}
/**
* $sql = "select * from `文章表` where `biz`='".$biz."'
* and `content_url` like '%".$sn."%'" limit 0,1;
* 根据biz和sn找到对应的文章
*/
Post post = postMapper.selectByBizAndSn(biz, sn);
if(post == null){
System.out.println("biz:"+biz);
System.out.println("sn:"+sn);
tmpListMapper.deleteByLoad(1);
return;
}
// System.out.println("json数据:"+str);
Integer read_num;
Integer like_num;
try{
read_num = JsonPath.read(str, "['appmsgstat']['read_num']");//阅读量
like_num = JsonPath.read(str, "['appmsgstat']['like_num']");//点赞量
}catch(Exception e){
read_num = 123;//阅读量
like_num = 321;//点赞量
System.out.println("read_num:"+read_num);
System.out.println("like_num:"+like_num);
System.out.println(e.getMessage());
}
/**
* 在这里同样根据sn在采集队列表中删除对应的文章,代表这篇文章可以移出采集队列了
* $sql = "delete from `队列表` where `content_url` like '%".$sn."%'"
*/
tmpListMapper.deleteBySn(sn);
//然后将阅读量和点赞量更新到文章表中。
post.setReadnum(read_num);
post.setLikenum(like_num);
postMapper.updateByPrimaryKey(post);
}
将js注入微信的处理跳转方法:
public String getWxHis() {
String url = "";
// TODO Auto-generated method stub
/**
* 当前页面为公众号历史消息时,读取这个程序
* 在采集队列表中有一个load字段,当值等于1时代表正在被读取
* 首先删除采集队列表中load=1的行
* 然后从队列表中任意select一行
*/
tmpListMapper.deleteByLoad(1);
TmpList queue = tmpListMapper.selectRandomOne();
System.out.println("queue is null?"+queue);
if(queue == null){//队列表为空
/**
* 队列表如果空了,就从存储公众号biz的表中取得一个biz,
* 这里我在公众号表中设置了一个采集时间的time字段,按照正序排列之后,
* 就得到时间戳最小的一个公众号记录,并取得它的biz
*/
WeiXin weiXin = weiXinMapper.selectOne();
String biz = weiXin.getBiz();
url = "https://mp.weixin.qq.com/mp/pr ... ot%3B + biz +
"#wechat_redirect";//拼接公众号历史消息url地址(第二种页面形式)
//更新刚才提到的公众号表中的采集时间time字段为当前时间戳。
weiXin.setCollect(System.currentTimeMillis());
int result = weiXinMapper.updateByPrimaryKey(weiXin);
System.out.println("getHis weiXin updateResult:"+result);
}else{
//取得当前这一行的content_url字段
url = queue.getContentUrl();
//将load字段update为1
tmpListMapper.updateByContentUrl(url);
}
//将下一个将要跳转的$url变成js脚本,由anyproxy注入到微信页面中。
//echo "setTimeout(function(){window.location.href='".$url."';},2000);";
int randomTime = new Random().nextInt(3) + 3;
String jsCode = "setTimeout(function(){window.location.href='"+url+"';},"+randomTime*1000+");";
return jsCode;
}
以上是处理代理服务器截获的数据的程序。这里有一个需要注意的问题。程序会依次访问数据库中每个收录的公众号,甚至会再次访问存储的文章,以不断更新收录的阅读点赞数@文章 的。如果需要抓取大量公众号,建议修改添加任务队列和添加条件的代码,否则多轮公众号抓取重复数据的效率会受到很大影响。
至此,微信公众号的文章链接全部被爬取完毕,且该链接为永久有效链接,可在浏览器中打开。接下来就是编写爬虫程序,从数据库中爬取链接文章的内容等信息。
我用webmagic写了一个爬虫,轻量级,好用。
public class SpiderModel implements PageProcessor{
private static PostMapper postMapper;
private static List posts;
// 抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private Site site = Site.me().setRetryTimes(3).setSleepTime(100);
public Site getSite() {
// TODO Auto-generated method stub
return this.site;
}
public void process(Page page) {
// TODO Auto-generated method stub
Post post = posts.remove(0);
String content = page.getHtml().xpath("//div[@id='js_content']").get();
//存在和谐文章 此处做判定如果有直接删除记录或设置表示位表示文章被和谐
if(content == null){
System.out.println("文章已和谐!");
//postMapper.deleteByPrimaryKey(post.getId());
return;
}
String contentSnap = content.replaceAll("data-src", "src").replaceAll("preview.html", "player.html");//快照
String contentTxt = HtmlToWord.stripHtml(content);//纯文本内容
Selectable metaContent = page.getHtml().xpath("//div[@id='meta_content']");
String pubTime = null;
String wxname = null;
String author = null;
if(metaContent != null){
pubTime = metaContent.xpath("//em[@id='post-date']").get();
if(pubTime != null){
pubTime = HtmlToWord.stripHtml(pubTime);//文章发布时间
}
wxname = metaContent.xpath("//a[@id='post-user']").get();
if(wxname != null){
wxname = HtmlToWord.stripHtml(wxname);//公众号名称
}
author = metaContent.xpath("//em[@class='rich_media_meta rich_media_meta_text' and @id!='post-date']").get();
if(author != null){
author = HtmlToWord.stripHtml(author);//文章作者
}
}
// System.out.println("发布时间:"+pubTime);
// System.out.println("公众号名称:"+wxname);
// System.out.println("文章作者:"+author);
String title = post.getTitle().replaceAll(" ", "");//文章标题
String digest = post.getDigest();//文章摘要
int likeNum = post.getLikenum();//文章点赞数
int readNum = post.getReadnum();//文章阅读数
String contentUrl = post.getContentUrl();//文章链接
WechatInfoBean wechatBean = new WechatInfoBean();
wechatBean.setTitle(title);
wechatBean.setContent(contentTxt);//纯文本内容
wechatBean.setSourceCode(contentSnap);//快照
wechatBean.setLikeCount(likeNum);
wechatBean.setViewCount(readNum);
wechatBean.setAbstractText(digest);//摘要
wechatBean.setUrl(contentUrl);
wechatBean.setPublishTime(pubTime);
wechatBean.setSiteName(wxname);//站点名称 公众号名称
wechatBean.setAuthor(author);
wechatBean.setMediaType("微信公众号");//来源媒体类型
WechatStorage.saveWechatInfo(wechatBean);
//标示文章已经被爬取
post.setIsSpider(1);
postMapper.updateByPrimaryKey(post);
}
public static void startSpider(List inposts,PostMapper myPostMapper,String... urls){
long startTime, endTime;
startTime = System.currentTimeMillis();
postMapper = myPostMapper;
posts = inposts;
HttpClientDownloader httpClientDownloader = new HttpClientDownloader();
SpiderModel spiderModel = new SpiderModel();
Spider mySpider = Spider.create(spiderModel).addUrl(urls);
mySpider.setDownloader(httpClientDownloader);
try {
SpiderMonitor.instance().register(mySpider);
mySpider.thread(1).run();
} catch (JMException e) {
e.printStackTrace();
}
endTime = System.currentTimeMillis();
System.out.println("爬取时间" + ((endTime - startTime) / 1000) + "秒--");
}
}
其他一些不相关的数据存储代码将不会发布。这里我将代理服务器抓取的数据存储在mysql中,将我的爬虫爬取的数据存储在mongodb中。
以下是我爬取的公众号信息:
打开应用程序并阅读笔记 查看全部
querylist采集微信公众号文章(
处理跳转向微信注入js的方法:以上就是对处理代理服务器拦截到的数据进行处理)
public void getMsgExt(String str,String url) {
// TODO Auto-generated method stub
String biz = "";
String sn = "";
Map queryStrs = HttpUrlParser.parseUrl(url);
if(queryStrs != null){
biz = queryStrs.get("__biz");
biz = biz + "==";
sn = queryStrs.get("sn");
sn = "%" + sn + "%";
}
/**
* $sql = "select * from `文章表` where `biz`='".$biz."'
* and `content_url` like '%".$sn."%'" limit 0,1;
* 根据biz和sn找到对应的文章
*/
Post post = postMapper.selectByBizAndSn(biz, sn);
if(post == null){
System.out.println("biz:"+biz);
System.out.println("sn:"+sn);
tmpListMapper.deleteByLoad(1);
return;
}
// System.out.println("json数据:"+str);
Integer read_num;
Integer like_num;
try{
read_num = JsonPath.read(str, "['appmsgstat']['read_num']");//阅读量
like_num = JsonPath.read(str, "['appmsgstat']['like_num']");//点赞量
}catch(Exception e){
read_num = 123;//阅读量
like_num = 321;//点赞量
System.out.println("read_num:"+read_num);
System.out.println("like_num:"+like_num);
System.out.println(e.getMessage());
}
/**
* 在这里同样根据sn在采集队列表中删除对应的文章,代表这篇文章可以移出采集队列了
* $sql = "delete from `队列表` where `content_url` like '%".$sn."%'"
*/
tmpListMapper.deleteBySn(sn);
//然后将阅读量和点赞量更新到文章表中。
post.setReadnum(read_num);
post.setLikenum(like_num);
postMapper.updateByPrimaryKey(post);
}
将js注入微信的处理跳转方法:
public String getWxHis() {
String url = "";
// TODO Auto-generated method stub
/**
* 当前页面为公众号历史消息时,读取这个程序
* 在采集队列表中有一个load字段,当值等于1时代表正在被读取
* 首先删除采集队列表中load=1的行
* 然后从队列表中任意select一行
*/
tmpListMapper.deleteByLoad(1);
TmpList queue = tmpListMapper.selectRandomOne();
System.out.println("queue is null?"+queue);
if(queue == null){//队列表为空
/**
* 队列表如果空了,就从存储公众号biz的表中取得一个biz,
* 这里我在公众号表中设置了一个采集时间的time字段,按照正序排列之后,
* 就得到时间戳最小的一个公众号记录,并取得它的biz
*/
WeiXin weiXin = weiXinMapper.selectOne();
String biz = weiXin.getBiz();
url = "https://mp.weixin.qq.com/mp/pr ... ot%3B + biz +
"#wechat_redirect";//拼接公众号历史消息url地址(第二种页面形式)
//更新刚才提到的公众号表中的采集时间time字段为当前时间戳。
weiXin.setCollect(System.currentTimeMillis());
int result = weiXinMapper.updateByPrimaryKey(weiXin);
System.out.println("getHis weiXin updateResult:"+result);
}else{
//取得当前这一行的content_url字段
url = queue.getContentUrl();
//将load字段update为1
tmpListMapper.updateByContentUrl(url);
}
//将下一个将要跳转的$url变成js脚本,由anyproxy注入到微信页面中。
//echo "setTimeout(function(){window.location.href='".$url."';},2000);";
int randomTime = new Random().nextInt(3) + 3;
String jsCode = "setTimeout(function(){window.location.href='"+url+"';},"+randomTime*1000+");";
return jsCode;
}
以上是处理代理服务器截获的数据的程序。这里有一个需要注意的问题。程序会依次访问数据库中每个收录的公众号,甚至会再次访问存储的文章,以不断更新收录的阅读点赞数@文章 的。如果需要抓取大量公众号,建议修改添加任务队列和添加条件的代码,否则多轮公众号抓取重复数据的效率会受到很大影响。
至此,微信公众号的文章链接全部被爬取完毕,且该链接为永久有效链接,可在浏览器中打开。接下来就是编写爬虫程序,从数据库中爬取链接文章的内容等信息。
我用webmagic写了一个爬虫,轻量级,好用。
public class SpiderModel implements PageProcessor{
private static PostMapper postMapper;
private static List posts;
// 抓取网站的相关配置,包括编码、抓取间隔、重试次数等
private Site site = Site.me().setRetryTimes(3).setSleepTime(100);
public Site getSite() {
// TODO Auto-generated method stub
return this.site;
}
public void process(Page page) {
// TODO Auto-generated method stub
Post post = posts.remove(0);
String content = page.getHtml().xpath("//div[@id='js_content']").get();
//存在和谐文章 此处做判定如果有直接删除记录或设置表示位表示文章被和谐
if(content == null){
System.out.println("文章已和谐!");
//postMapper.deleteByPrimaryKey(post.getId());
return;
}
String contentSnap = content.replaceAll("data-src", "src").replaceAll("preview.html", "player.html");//快照
String contentTxt = HtmlToWord.stripHtml(content);//纯文本内容
Selectable metaContent = page.getHtml().xpath("//div[@id='meta_content']");
String pubTime = null;
String wxname = null;
String author = null;
if(metaContent != null){
pubTime = metaContent.xpath("//em[@id='post-date']").get();
if(pubTime != null){
pubTime = HtmlToWord.stripHtml(pubTime);//文章发布时间
}
wxname = metaContent.xpath("//a[@id='post-user']").get();
if(wxname != null){
wxname = HtmlToWord.stripHtml(wxname);//公众号名称
}
author = metaContent.xpath("//em[@class='rich_media_meta rich_media_meta_text' and @id!='post-date']").get();
if(author != null){
author = HtmlToWord.stripHtml(author);//文章作者
}
}
// System.out.println("发布时间:"+pubTime);
// System.out.println("公众号名称:"+wxname);
// System.out.println("文章作者:"+author);
String title = post.getTitle().replaceAll(" ", "");//文章标题
String digest = post.getDigest();//文章摘要
int likeNum = post.getLikenum();//文章点赞数
int readNum = post.getReadnum();//文章阅读数
String contentUrl = post.getContentUrl();//文章链接
WechatInfoBean wechatBean = new WechatInfoBean();
wechatBean.setTitle(title);
wechatBean.setContent(contentTxt);//纯文本内容
wechatBean.setSourceCode(contentSnap);//快照
wechatBean.setLikeCount(likeNum);
wechatBean.setViewCount(readNum);
wechatBean.setAbstractText(digest);//摘要
wechatBean.setUrl(contentUrl);
wechatBean.setPublishTime(pubTime);
wechatBean.setSiteName(wxname);//站点名称 公众号名称
wechatBean.setAuthor(author);
wechatBean.setMediaType("微信公众号");//来源媒体类型
WechatStorage.saveWechatInfo(wechatBean);
//标示文章已经被爬取
post.setIsSpider(1);
postMapper.updateByPrimaryKey(post);
}
public static void startSpider(List inposts,PostMapper myPostMapper,String... urls){
long startTime, endTime;
startTime = System.currentTimeMillis();
postMapper = myPostMapper;
posts = inposts;
HttpClientDownloader httpClientDownloader = new HttpClientDownloader();
SpiderModel spiderModel = new SpiderModel();
Spider mySpider = Spider.create(spiderModel).addUrl(urls);
mySpider.setDownloader(httpClientDownloader);
try {
SpiderMonitor.instance().register(mySpider);
mySpider.thread(1).run();
} catch (JMException e) {
e.printStackTrace();
}
endTime = System.currentTimeMillis();
System.out.println("爬取时间" + ((endTime - startTime) / 1000) + "秒--");
}
}
其他一些不相关的数据存储代码将不会发布。这里我将代理服务器抓取的数据存储在mysql中,将我的爬虫爬取的数据存储在mongodb中。
以下是我爬取的公众号信息:
打开应用程序并阅读笔记
querylist采集微信公众号文章(Python微信公众号文章爬取一.思路我们通过网页版)
采集交流 • 优采云 发表了文章 • 0 个评论 • 434 次浏览 • 2022-03-13 06:13
Python微信公众号文章爬取
一.想法
我们通过网页版微信公众平台的图文消息中的超链接获取我们需要的界面
从界面中我们可以得到对应的微信公众号和所有对应的微信公众号文章。
二.界面分析
获取微信公众号界面:
范围:
行动=search_biz
开始=0
计数=5
query=公众号
token = 每个账户对应的token值
lang=zh_CN
f=json
阿贾克斯=1
请求方法:
得到
所以在这个界面中,我们只需要获取token,查询的是你需要搜索的公众号,登录后可以通过网页链接获取token。
获取公众号对应的文章接口:
范围:
行动=list_ex
开始=0
计数=5
fakeid=MjM5NDAwMTA2MA==
类型=9
查询=
令牌=557131216
lang=zh_CN
f=json
阿贾克斯=1
请求方法:
得到
在这个接口中,我们需要获取的值是上一步的token和fakeid,而这个fakeid可以在第一个接口中获取。这样我们就可以得到微信公众号文章的数据了。
三.实现第一步:
首先我们需要通过selenium来模拟登录,然后获取cookie和对应的token
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get('https://mp.weixin.qq.com/')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
sleep(2)
# 微信登录验证
print('请扫描二维码')
sleep(20)
# 刷新当前网页
browser.get('https://mp.weixin.qq.com/')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item['name']] = item['value']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie保存到本地成功')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split('?')[1].split('&')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split('=')[0]] = item.split('=')[1]
# 返回token
return paramdict['token']
定义了一个登录方法,里面的参数是登录账号和密码,然后定义了一个字典来存储cookie的值。模拟用户输入对应账号密码,点击登录,出现扫码验证,登录微信即可扫码。
刷新当前网页后,获取当前cookie和token并返回。
第二步:1.请求获取对应的公众号接口,获取我们需要的fakeid
url = 'https://mp.weixin.qq.com'
headers = {
'HOST': 'mp.weixin.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = 'https://mp.weixin.qq.com/cgi-b ... 39%3B
params = {
'action': 'search_biz',
'begin': '0',
'count': '5',
'query': '搜索的公众号名称',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获取的token和cookie,然后通过requests.get请求获取微信公众号返回的json数据
lists = search_resp.json().get('list')[0]
通过以上代码可以获取对应的公众号数据
fakeid = lists.get('fakeid')
通过上面的代码,可以得到对应的 fakeid
2.请求访问微信公众号文章接口,获取我们需要的文章数据
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
params_data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入 fakeid 和 token 然后调用 requests.get 请求接口获取返回的 json 数据。
我们实现了微信公众号文章的爬取。
四.总结
通过爬取微信公众号文章,需要掌握selenium和requests的用法,以及如何获取request接口。但是需要注意的是,我们在循环获取文章的时候,一定要设置一个延迟时间,否则容易被封号,获取不到返回的数据。 查看全部
querylist采集微信公众号文章(Python微信公众号文章爬取一.思路我们通过网页版)
Python微信公众号文章爬取
一.想法
我们通过网页版微信公众平台的图文消息中的超链接获取我们需要的界面
从界面中我们可以得到对应的微信公众号和所有对应的微信公众号文章。
二.界面分析
获取微信公众号界面:
范围:
行动=search_biz
开始=0
计数=5
query=公众号
token = 每个账户对应的token值
lang=zh_CN
f=json
阿贾克斯=1
请求方法:
得到
所以在这个界面中,我们只需要获取token,查询的是你需要搜索的公众号,登录后可以通过网页链接获取token。
获取公众号对应的文章接口:
范围:
行动=list_ex
开始=0
计数=5
fakeid=MjM5NDAwMTA2MA==
类型=9
查询=
令牌=557131216
lang=zh_CN
f=json
阿贾克斯=1
请求方法:
得到
在这个接口中,我们需要获取的值是上一步的token和fakeid,而这个fakeid可以在第一个接口中获取。这样我们就可以得到微信公众号文章的数据了。
三.实现第一步:
首先我们需要通过selenium来模拟登录,然后获取cookie和对应的token
def weChat_login(user, password):
post = {}
browser = webdriver.Chrome()
browser.get('https://mp.weixin.qq.com/')
sleep(3)
browser.delete_all_cookies()
sleep(2)
# 点击切换到账号密码输入
browser.find_element_by_xpath("//a[@class='login__type__container__select-type']").click()
sleep(2)
# 模拟用户点击
input_user = browser.find_element_by_xpath("//input[@name='account']")
input_user.send_keys(user)
input_password = browser.find_element_by_xpath("//input[@name='password']")
input_password.send_keys(password)
sleep(2)
# 点击登录
browser.find_element_by_xpath("//a[@class='btn_login']").click()
sleep(2)
# 微信登录验证
print('请扫描二维码')
sleep(20)
# 刷新当前网页
browser.get('https://mp.weixin.qq.com/')
sleep(5)
# 获取当前网页链接
url = browser.current_url
# 获取当前cookie
cookies = browser.get_cookies()
for item in cookies:
post[item['name']] = item['value']
# 转换为字符串
cookie_str = json.dumps(post)
# 存储到本地
with open('cookie.txt', 'w+', encoding='utf-8') as f:
f.write(cookie_str)
print('cookie保存到本地成功')
# 对当前网页链接进行切片,获取到token
paramList = url.strip().split('?')[1].split('&')
# 定义一个字典存储数据
paramdict = {}
for item in paramList:
paramdict[item.split('=')[0]] = item.split('=')[1]
# 返回token
return paramdict['token']
定义了一个登录方法,里面的参数是登录账号和密码,然后定义了一个字典来存储cookie的值。模拟用户输入对应账号密码,点击登录,出现扫码验证,登录微信即可扫码。
刷新当前网页后,获取当前cookie和token并返回。
第二步:1.请求获取对应的公众号接口,获取我们需要的fakeid
url = 'https://mp.weixin.qq.com'
headers = {
'HOST': 'mp.weixin.qq.com',
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/86.0.4240.183 Safari/537.36 Edg/86.0.622.63'
}
with open('cookie.txt', 'r', encoding='utf-8') as f:
cookie = f.read()
cookies = json.loads(cookie)
resp = requests.get(url=url, headers=headers, cookies=cookies)
search_url = 'https://mp.weixin.qq.com/cgi-b ... 39%3B
params = {
'action': 'search_biz',
'begin': '0',
'count': '5',
'query': '搜索的公众号名称',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
search_resp = requests.get(url=search_url, cookies=cookies, headers=headers, params=params)
传入我们获取的token和cookie,然后通过requests.get请求获取微信公众号返回的json数据
lists = search_resp.json().get('list')[0]
通过以上代码可以获取对应的公众号数据
fakeid = lists.get('fakeid')
通过上面的代码,可以得到对应的 fakeid
2.请求访问微信公众号文章接口,获取我们需要的文章数据
appmsg_url = 'https://mp.weixin.qq.com/cgi-bin/appmsg?'
params_data = {
'action': 'list_ex',
'begin': '0',
'count': '5',
'fakeid': fakeid,
'type': '9',
'query': '',
'token': token,
'lang': 'zh_CN',
'f': 'json',
'ajax': '1'
}
appmsg_resp = requests.get(url=appmsg_url, cookies=cookies, headers=headers, params=params_data)
我们传入 fakeid 和 token 然后调用 requests.get 请求接口获取返回的 json 数据。
我们实现了微信公众号文章的爬取。
四.总结
通过爬取微信公众号文章,需要掌握selenium和requests的用法,以及如何获取request接口。但是需要注意的是,我们在循环获取文章的时候,一定要设置一个延迟时间,否则容易被封号,获取不到返回的数据。
querylist采集微信公众号文章(Python模拟安卓App操作微信App的方法(详见代码介绍))
采集交流 • 优采云 发表了文章 • 0 个评论 • 231 次浏览 • 2022-03-12 07:07
本文章主要介绍基于Python采集对微信公众号历史数据的爬取。通过文中的示例代码介绍的很详细,对大家的学习或工作有一定的参考和学习价值。需要的朋友可以参考以下
鲲之鹏技术人员将在本文中通过模拟微信App的操作,介绍一种采集指定公众号所有历史数据的方法。
通过我们的抓包分析,我们发现微信公众号的历史数据是通过HTTP协议加载的。对应的API接口如下图所示,有四个关键参数(__biz、appmsg_token、pass_ticket和Cookie)。
为了得到这四个参数,我们需要模拟运行App,让它生成这些参数,然后我们就可以抓包了。对于模拟App操作,我们之前已经介绍过通过Python模拟Android App的方法(见详情)。对于 HTTP 集成的数据包捕获,我们之前已经介绍了 Mitmproxy(见详情)。
我们需要模拟微信的操作来完成以下步骤:
1. 启动微信应用
2. 点击“通讯录”
3. 点击“公众号”
4.点击你想要的公众号采集
5. 点击右上角的用户头像图标
6. 点击“所有消息”
至此,我们可以从响应数据中捕获__biz、appmsg_token、pass_ticket这三个关键参数,以及请求头中的Cookie值。如下所示。
有了以上四个参数,我们就可以构造API请求获取历史文章列表,直接调用API接口获取数据(无需模拟App操作)。核心参数如下。通过改变offset参数,可以得到所有的历史数据。
# Cookie headers = {'Cookie': 'rewardsn=; wxtokenkey=777; wxuin=584068438; devicetype=android-19; version=26060736; lang=zh_CN; pass_ticket=Rr8cO5c2******3tKGqe7aVZzV9TupvrK+1uHHmHYQGL2WFdKIE; wap_sid2=COKhxu4KElxckFZQ3QzTHU4WThEUk0zcWdrZjhGcUdYdEVSV3Y1X2NPWHNUakRrd1ZzMnpLTERpdE5rbmxjSTg******dlRBcUNRazZpOGxTZUVEQUTgNQJVO'} url = 'https://mp.weixin.qq.com/mp/profile_ext?' data = {} data['is_ok'] = '1' data['count'] = '10' data['wxtoken'] = '' data['f'] = 'json' data['scene'] = '124' data['uin'] = '777' data['key'] = '777' data['offset'] = '0' data['action'] = 'getmsg' data['x5'] = '0' # 下面三个参数需要替换 # https://mp.weixin.qq.com/mp/pr ... Dhome应答数据里会暴漏这三个参数 data['__biz'] = 'MjM5MzQyOTM1OQ==' data['appmsg_token'] = '993_V8%2BEmfVD7g%2FvMZ****4DNUJNFkg~~' data['pass_ticket'] = 'Rr8cO5c23ZngeQHRGy8E7gv*****pvrK+1uHHmHYQGL2WFdKIE' url = url + urllib.urlencode(data)
以“数字工厂”微信公众号为例,采集流程操作截图如下:
输出的屏幕截图如下所示:
以上就是基于Python采集抓取微信公众号历史数据的详细内容,更多详情请关注html中文网其他相关话题文章! 查看全部
querylist采集微信公众号文章(Python模拟安卓App操作微信App的方法(详见代码介绍))
本文章主要介绍基于Python采集对微信公众号历史数据的爬取。通过文中的示例代码介绍的很详细,对大家的学习或工作有一定的参考和学习价值。需要的朋友可以参考以下
鲲之鹏技术人员将在本文中通过模拟微信App的操作,介绍一种采集指定公众号所有历史数据的方法。
通过我们的抓包分析,我们发现微信公众号的历史数据是通过HTTP协议加载的。对应的API接口如下图所示,有四个关键参数(__biz、appmsg_token、pass_ticket和Cookie)。
为了得到这四个参数,我们需要模拟运行App,让它生成这些参数,然后我们就可以抓包了。对于模拟App操作,我们之前已经介绍过通过Python模拟Android App的方法(见详情)。对于 HTTP 集成的数据包捕获,我们之前已经介绍了 Mitmproxy(见详情)。
我们需要模拟微信的操作来完成以下步骤:
1. 启动微信应用
2. 点击“通讯录”
3. 点击“公众号”
4.点击你想要的公众号采集
5. 点击右上角的用户头像图标
6. 点击“所有消息”
至此,我们可以从响应数据中捕获__biz、appmsg_token、pass_ticket这三个关键参数,以及请求头中的Cookie值。如下所示。
有了以上四个参数,我们就可以构造API请求获取历史文章列表,直接调用API接口获取数据(无需模拟App操作)。核心参数如下。通过改变offset参数,可以得到所有的历史数据。
# Cookie headers = {'Cookie': 'rewardsn=; wxtokenkey=777; wxuin=584068438; devicetype=android-19; version=26060736; lang=zh_CN; pass_ticket=Rr8cO5c2******3tKGqe7aVZzV9TupvrK+1uHHmHYQGL2WFdKIE; wap_sid2=COKhxu4KElxckFZQ3QzTHU4WThEUk0zcWdrZjhGcUdYdEVSV3Y1X2NPWHNUakRrd1ZzMnpLTERpdE5rbmxjSTg******dlRBcUNRazZpOGxTZUVEQUTgNQJVO'} url = 'https://mp.weixin.qq.com/mp/profile_ext?' data = {} data['is_ok'] = '1' data['count'] = '10' data['wxtoken'] = '' data['f'] = 'json' data['scene'] = '124' data['uin'] = '777' data['key'] = '777' data['offset'] = '0' data['action'] = 'getmsg' data['x5'] = '0' # 下面三个参数需要替换 # https://mp.weixin.qq.com/mp/pr ... Dhome应答数据里会暴漏这三个参数 data['__biz'] = 'MjM5MzQyOTM1OQ==' data['appmsg_token'] = '993_V8%2BEmfVD7g%2FvMZ****4DNUJNFkg~~' data['pass_ticket'] = 'Rr8cO5c23ZngeQHRGy8E7gv*****pvrK+1uHHmHYQGL2WFdKIE' url = url + urllib.urlencode(data)
以“数字工厂”微信公众号为例,采集流程操作截图如下:
输出的屏幕截图如下所示:
以上就是基于Python采集抓取微信公众号历史数据的详细内容,更多详情请关注html中文网其他相关话题文章!
querylist采集微信公众号文章(python采集微信公众号文章本文(操作postgres数据库)抓取)
采集交流 • 优采云 发表了文章 • 0 个评论 • 449 次浏览 • 2022-03-11 17:00
Python抢购搜狗微信公众号文章
初学python,抢搜狗微信公众号文章存入mysql
mysql表:
代码:
import requests
import json
import re
import pymysql
# 创建连接
conn = pymysql.connect(host='你的数据库地址', port=端口, user='用户名', passwd='密码', db='数据库名称', charset='utf8')
# 创建游标
cursor = conn.cursor()
cursor.execute("select * from hd_gzh")
effect_row = cursor.fetchall()
from bs4 import BeautifulSoup
socket.setdefaulttimeout(60)
count = 1
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:65.0) Gecko/20100101 Firefox/65.0'}
#阿布云ip代理暂时不用
# proxyHost = "http-cla.abuyun.com"
# proxyPort = "9030"
# # 代理隧道验证信息
# proxyUser = "H56761606429T7UC"
# proxyPass = "9168EB00C4167176"
# proxyMeta = "http://%(user)s:%(pass)s@%(host)s:%(port)s" % {
# "host" : proxyHost,
# "port" : proxyPort,
# "user" : proxyUser,
# "pass" : proxyPass,
# }
# proxies = {
# "http" : proxyMeta,
# "https" : proxyMeta,
# }
#查看是否已存在数据
def checkData(name):
sql = "select * from gzh_article where title = '%s'"
data = (name,)
count = cursor.execute(sql % data)
conn.commit()
if(count!=0):
return False
else:
return True
#插入数据
def insertData(title,picture,author,content):
sql = "insert into gzh_article (title,picture,author,content) values ('%s', '%s','%s', '%s')"
data = (title,picture,author,content)
cursor.execute(sql % data)
conn.commit()
print("插入一条数据")
return
for row in effect_row:
newsurl = 'https://weixin.sogou.com/weixin?type=1&s_from=input&query=' + row[1] + '&ie=utf8&_sug_=n&_sug_type_='
res = requests.get(newsurl,headers=headers)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text,'html.parser')
url = 'https://weixin.sogou.com' + soup.select('.tit a')[0]['href']
res2 = requests.get(url,headers=headers)
res2.encoding = 'utf-8'
soup2 = BeautifulSoup(res2.text,'html.parser')
pattern = re.compile(r"url \+= '(.*?)';", re.MULTILINE | re.DOTALL)
script = soup2.find("script")
url2 = pattern.search(script.text).group(1)
res3 = requests.get(url2,headers=headers)
res3.encoding = 'utf-8'
soup3 = BeautifulSoup(res3.text,'html.parser')
print()
pattern2 = re.compile(r"var msgList = (.*?);$", re.MULTILINE | re.DOTALL)
script2 = soup3.find("script", text=pattern2)
s2 = json.loads(pattern2.search(script2.text).group(1))
#等待10s
time.sleep(10)
for news in s2["list"]:
articleurl = "https://mp.weixin.qq.com"+news["app_msg_ext_info"]["content_url"]
articleurl = articleurl.replace('&','&')
res4 = requests.get(articleurl,headers=headers)
res4.encoding = 'utf-8'
soup4 = BeautifulSoup(res4.text,'html.parser')
if(checkData(news["app_msg_ext_info"]["title"])):
insertData(news["app_msg_ext_info"]["title"],news["app_msg_ext_info"]["cover"],news["app_msg_ext_info"]["author"],pymysql.escape_string(str(soup4)))
count += 1
#等待5s
time.sleep(10)
for news2 in news["app_msg_ext_info"]["multi_app_msg_item_list"]:
articleurl2 = "https://mp.weixin.qq.com"+news2["content_url"]
articleurl2 = articleurl2.replace('&','&')
res5 = requests.get(articleurl2,headers=headers)
res5.encoding = 'utf-8'
soup5 = BeautifulSoup(res5.text,'html.parser')
if(checkData(news2["title"])):
insertData(news2["title"],news2["cover"],news2["author"],pymysql.escape_string(str(soup5)))
count += 1
#等待10s
time.sleep(10)
cursor.close()
conn.close()
print("操作完成")
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。
时间:2019-03-31
python采集微信公众号文章
本文示例分享了python采集微信公众号文章的具体代码,供大家参考。具体内容如下。python的一个子目录下存放了两个文件,分别是:采集公众号文章.py和config.py。代码如下:1.采集公众号文章.py from urllib.parse import urlencode import pymongo import requests from lxml.etree import XMLSyntaxError from requests.exceptions import Connec
Python如何爬取微信公众号文章及评论(基于Fiddler抓包分析)
背景描述我觉得微信公众号是比较难爬的平台之一,但是经过一番折腾,还是有一点小收获。没用Scrapy(估计爬太快有防爬限制),不过后面会开始整理写一些实战。. 简单介绍一下本次的开发环境:python3请求psycopg2(操作postgres数据库) 抓包分析 本次实战对要抓包的公众号没有限制,但是每次抓包前都要对不同的公众号进行分析。打开Fiddler,在手机上配置相关代理。为了避免过多干扰,这里给Fiddler一个过滤规则,指定微信域名即可:
python爬取微信公众号文章的方法
最近在学习Python3网络爬虫(崔庆才写的)的开发实践,刚刚得知他在这里使用代理爬取了公众号文章,但是根据他的代码,还是出现了一些问题。我在这里用过这本书。对本书前面提到的一些内容进行了改进。(作者半年前写了这段代码,腾讯的网站半年前更新了)我直接加下面代码:TIMEOUT = 20 from requests import Request, Session, PreparedRequest import requests from selenium import webdrive
50行Python代码如何获取所有公众号文章
前言我们在阅读公众号文章时通常会遇到一个问题——阅读历史文章的体验并不好。我们知道爬取公众号的常用方法有两种:通过搜狗搜索获取,缺点是只能获取最新的十推文章。通过微信公众号的素材管理,可以获得公众号文章。缺点是需要自己申请公众号。微信方式获取公众号文章的方法。与其他方法相比,非常方便。如上图,通过抓包工具获取微信的网络信息请求,我们发现每次文章
Python爬取指定微信公众号文章
本文示例分享了python爬取微信公众号文章的具体代码,供大家参考。具体内容如下。该方法是依靠 urllib2 库完成的。首先需要安装你的python环境,然后安装urllib2库程序的启动方法(返回值为公众号文章的列表): def openUrl(): print("启动爬虫,打开搜狗搜索微信界面") # 加载页面url = ';s_from=input&query = 被抓取的公众号名称
Python爬取微信公众号文章
本文示例分享python爬取微信公众号文章的具体代码供大家参考,具体内容如下# -*- coding: utf-8 -*- import requests from bs4 import BeautifulSoup from requests .exceptions import RequestException import time import random import MySQLdb import threading import socket import math soc
python selenium爬取微信公众号文章代码详解
参考:selenium webdriver 添加cookies: 需求:想看微信公众号文章的历史,但是每次都找地方不方便。思路:1.使用selenium打开微信公众号历史文章,滚动刷新到底部,获取所有历史文章url。2.遍历访问url,下载到本地。实现1.打开微信客户端,点击微信公众号->进入公众号->打开历史文章链接(用浏览器打开),通过开发者工具获取cookie
Python使用webdriver爬取微信公众号
本文示例分享了python使用webdriver爬取微信公众号的具体代码,供大家参考。具体内容如下# -*- 编码:utf-8 -*- from selenium import webdriver import time import json import requests import re import random #微信公众号user="" #公众号密码password="" #设置需要爬取的公众号列表 gzlist=['香河微服务
python如何导出微信公众号文章详解
1.安装wkhtmltopdf 下载地址:我用windows进行测试,下载安装后结果如下 2 编写python代码导出微信公众号文章 不能直接使用wkhtmltopdf导出微信公众号文章,导出的文章会缺图,所以需要使用微信公众号文章页面,然后将html文本转换成pdf pip install wechatsogou --升级 pip install pdfkit 踩坑
Python抓取微信公众号账号信息的方法
搜狗微信搜索提供了两种关键词搜索,一种是搜索公众号文章的内容,另一种是直接搜索微信公众号。公众号基本信息可通过微信公众号搜索获取。还有最近发布的10个文章,今天就来抢微信公众号的账号信息爬虫吧。首先通过首页进入,可以按类别抓取,通过“查看更多”可以找到页面链接规则: import requests as req import re reTypes = r'id="pc_\d*" uigs=" (pc_\d*)">([\s\S]*?)&
Python爬虫_微信公众号推送信息爬取示例
问题描述 使用搜狗的微信搜索,从指定公众号抓取最新推送,并将对应网页保存到本地。注意,搜狗微信获取的地址是临时链接,具有时效性。公众号为动态网页(JavaScript渲染),使用requests.get()获取的内容不收录推送消息。这里使用 selenium+PhantomJS 处理代码#!/usr/bin/env python3 from selenium import webdriver from datetime import datetime import bs4, requ 查看全部
querylist采集微信公众号文章(python采集微信公众号文章本文(操作postgres数据库)抓取)
Python抢购搜狗微信公众号文章
初学python,抢搜狗微信公众号文章存入mysql
mysql表:
代码:
import requests
import json
import re
import pymysql
# 创建连接
conn = pymysql.connect(host='你的数据库地址', port=端口, user='用户名', passwd='密码', db='数据库名称', charset='utf8')
# 创建游标
cursor = conn.cursor()
cursor.execute("select * from hd_gzh")
effect_row = cursor.fetchall()
from bs4 import BeautifulSoup
socket.setdefaulttimeout(60)
count = 1
headers = {'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:65.0) Gecko/20100101 Firefox/65.0'}
#阿布云ip代理暂时不用
# proxyHost = "http-cla.abuyun.com"
# proxyPort = "9030"
# # 代理隧道验证信息
# proxyUser = "H56761606429T7UC"
# proxyPass = "9168EB00C4167176"
# proxyMeta = "http://%(user)s:%(pass)s@%(host)s:%(port)s" % {
# "host" : proxyHost,
# "port" : proxyPort,
# "user" : proxyUser,
# "pass" : proxyPass,
# }
# proxies = {
# "http" : proxyMeta,
# "https" : proxyMeta,
# }
#查看是否已存在数据
def checkData(name):
sql = "select * from gzh_article where title = '%s'"
data = (name,)
count = cursor.execute(sql % data)
conn.commit()
if(count!=0):
return False
else:
return True
#插入数据
def insertData(title,picture,author,content):
sql = "insert into gzh_article (title,picture,author,content) values ('%s', '%s','%s', '%s')"
data = (title,picture,author,content)
cursor.execute(sql % data)
conn.commit()
print("插入一条数据")
return
for row in effect_row:
newsurl = 'https://weixin.sogou.com/weixin?type=1&s_from=input&query=' + row[1] + '&ie=utf8&_sug_=n&_sug_type_='
res = requests.get(newsurl,headers=headers)
res.encoding = 'utf-8'
soup = BeautifulSoup(res.text,'html.parser')
url = 'https://weixin.sogou.com' + soup.select('.tit a')[0]['href']
res2 = requests.get(url,headers=headers)
res2.encoding = 'utf-8'
soup2 = BeautifulSoup(res2.text,'html.parser')
pattern = re.compile(r"url \+= '(.*?)';", re.MULTILINE | re.DOTALL)
script = soup2.find("script")
url2 = pattern.search(script.text).group(1)
res3 = requests.get(url2,headers=headers)
res3.encoding = 'utf-8'
soup3 = BeautifulSoup(res3.text,'html.parser')
print()
pattern2 = re.compile(r"var msgList = (.*?);$", re.MULTILINE | re.DOTALL)
script2 = soup3.find("script", text=pattern2)
s2 = json.loads(pattern2.search(script2.text).group(1))
#等待10s
time.sleep(10)
for news in s2["list"]:
articleurl = "https://mp.weixin.qq.com"+news["app_msg_ext_info"]["content_url"]
articleurl = articleurl.replace('&','&')
res4 = requests.get(articleurl,headers=headers)
res4.encoding = 'utf-8'
soup4 = BeautifulSoup(res4.text,'html.parser')
if(checkData(news["app_msg_ext_info"]["title"])):
insertData(news["app_msg_ext_info"]["title"],news["app_msg_ext_info"]["cover"],news["app_msg_ext_info"]["author"],pymysql.escape_string(str(soup4)))
count += 1
#等待5s
time.sleep(10)
for news2 in news["app_msg_ext_info"]["multi_app_msg_item_list"]:
articleurl2 = "https://mp.weixin.qq.com"+news2["content_url"]
articleurl2 = articleurl2.replace('&','&')
res5 = requests.get(articleurl2,headers=headers)
res5.encoding = 'utf-8'
soup5 = BeautifulSoup(res5.text,'html.parser')
if(checkData(news2["title"])):
insertData(news2["title"],news2["cover"],news2["author"],pymysql.escape_string(str(soup5)))
count += 1
#等待10s
time.sleep(10)
cursor.close()
conn.close()
print("操作完成")
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持。
时间:2019-03-31
python采集微信公众号文章
本文示例分享了python采集微信公众号文章的具体代码,供大家参考。具体内容如下。python的一个子目录下存放了两个文件,分别是:采集公众号文章.py和config.py。代码如下:1.采集公众号文章.py from urllib.parse import urlencode import pymongo import requests from lxml.etree import XMLSyntaxError from requests.exceptions import Connec
Python如何爬取微信公众号文章及评论(基于Fiddler抓包分析)
背景描述我觉得微信公众号是比较难爬的平台之一,但是经过一番折腾,还是有一点小收获。没用Scrapy(估计爬太快有防爬限制),不过后面会开始整理写一些实战。. 简单介绍一下本次的开发环境:python3请求psycopg2(操作postgres数据库) 抓包分析 本次实战对要抓包的公众号没有限制,但是每次抓包前都要对不同的公众号进行分析。打开Fiddler,在手机上配置相关代理。为了避免过多干扰,这里给Fiddler一个过滤规则,指定微信域名即可:
python爬取微信公众号文章的方法
最近在学习Python3网络爬虫(崔庆才写的)的开发实践,刚刚得知他在这里使用代理爬取了公众号文章,但是根据他的代码,还是出现了一些问题。我在这里用过这本书。对本书前面提到的一些内容进行了改进。(作者半年前写了这段代码,腾讯的网站半年前更新了)我直接加下面代码:TIMEOUT = 20 from requests import Request, Session, PreparedRequest import requests from selenium import webdrive
50行Python代码如何获取所有公众号文章
前言我们在阅读公众号文章时通常会遇到一个问题——阅读历史文章的体验并不好。我们知道爬取公众号的常用方法有两种:通过搜狗搜索获取,缺点是只能获取最新的十推文章。通过微信公众号的素材管理,可以获得公众号文章。缺点是需要自己申请公众号。微信方式获取公众号文章的方法。与其他方法相比,非常方便。如上图,通过抓包工具获取微信的网络信息请求,我们发现每次文章
Python爬取指定微信公众号文章
本文示例分享了python爬取微信公众号文章的具体代码,供大家参考。具体内容如下。该方法是依靠 urllib2 库完成的。首先需要安装你的python环境,然后安装urllib2库程序的启动方法(返回值为公众号文章的列表): def openUrl(): print("启动爬虫,打开搜狗搜索微信界面") # 加载页面url = ';s_from=input&query = 被抓取的公众号名称
Python爬取微信公众号文章
本文示例分享python爬取微信公众号文章的具体代码供大家参考,具体内容如下# -*- coding: utf-8 -*- import requests from bs4 import BeautifulSoup from requests .exceptions import RequestException import time import random import MySQLdb import threading import socket import math soc
python selenium爬取微信公众号文章代码详解
参考:selenium webdriver 添加cookies: 需求:想看微信公众号文章的历史,但是每次都找地方不方便。思路:1.使用selenium打开微信公众号历史文章,滚动刷新到底部,获取所有历史文章url。2.遍历访问url,下载到本地。实现1.打开微信客户端,点击微信公众号->进入公众号->打开历史文章链接(用浏览器打开),通过开发者工具获取cookie
Python使用webdriver爬取微信公众号
本文示例分享了python使用webdriver爬取微信公众号的具体代码,供大家参考。具体内容如下# -*- 编码:utf-8 -*- from selenium import webdriver import time import json import requests import re import random #微信公众号user="" #公众号密码password="" #设置需要爬取的公众号列表 gzlist=['香河微服务
python如何导出微信公众号文章详解
1.安装wkhtmltopdf 下载地址:我用windows进行测试,下载安装后结果如下 2 编写python代码导出微信公众号文章 不能直接使用wkhtmltopdf导出微信公众号文章,导出的文章会缺图,所以需要使用微信公众号文章页面,然后将html文本转换成pdf pip install wechatsogou --升级 pip install pdfkit 踩坑
Python抓取微信公众号账号信息的方法
搜狗微信搜索提供了两种关键词搜索,一种是搜索公众号文章的内容,另一种是直接搜索微信公众号。公众号基本信息可通过微信公众号搜索获取。还有最近发布的10个文章,今天就来抢微信公众号的账号信息爬虫吧。首先通过首页进入,可以按类别抓取,通过“查看更多”可以找到页面链接规则: import requests as req import re reTypes = r'id="pc_\d*" uigs=" (pc_\d*)">([\s\S]*?)&
Python爬虫_微信公众号推送信息爬取示例
问题描述 使用搜狗的微信搜索,从指定公众号抓取最新推送,并将对应网页保存到本地。注意,搜狗微信获取的地址是临时链接,具有时效性。公众号为动态网页(JavaScript渲染),使用requests.get()获取的内容不收录推送消息。这里使用 selenium+PhantomJS 处理代码#!/usr/bin/env python3 from selenium import webdriver from datetime import datetime import bs4, requ

