
querylist采集微信公众号文章
精选文章:获取微信公众号关注页面链接和历史文章链接
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-09-25 20:18
采集微信文章与采集网站内容相同,都需要从列表页开始。微信列表页文章是公众号查看历史新闻的页面。现在网上其他微信采集器用搜狗搜索。 采集 方法虽然简单很多,但内容并不完整。所以我们还是要从最标准最全面的公众号历史新闻页面采集来。由于微信的限制,我们可以复制的链接不完整,无法在浏览器中打开查看内容。因此,我们需要使用anyproxy,通过上篇文章文章介绍的方法,获取一个完整的微信公众号历史消息页的链接地址。
解读:免费电子书《SEO中的关键词和竞争研究》_关键词分析
免费电子书“关键词 和 SEO 中的竞争研究”_关键词分析
2020/03/07 06:50 • 每天发布 SEO 帖子
关键词每天分析_Zac@SEO,初学者网站容易犯的最大错误之一就是跳入某个领域,跳过竞争研究,开始做网站 没有计划目标 关键词。这样做通常会导致两个结果。一是我想做的关键词排名上不去,二是关键词排名
我觉得不错
初学者网站最容易犯的最大错误之一就是一头扎进某个领域,跳过竞争性研究,开始关键词没有计划目标关键词@ >@网站。这样做通常会导致两个结果。一个是我想做的关键词排名上不去,一个是我觉得好的关键词排名第一没有流量。
进行竞争性研究并确定合适的 关键词 是 SEO 的第一步,也是必不可少的一步。竞争研究包括关键词研究、竞争对手研究和现有的网站评估诊断,其中关键词研究是最重要的。
这本电子书《SEO关键词 and Competitive Research in SEO》是《SEO实践守则》的第三章,请点击这里下载,998K,PDF文件。欢迎传播。
之前的免费样章已经放出了第2章“了解搜索引擎”、第6章、第9章“链接诱饵指南”,就这些了,如果你想看整本书《SEO实战密码》,可以考虑买一本. ? 查看全部
精选文章:获取微信公众号关注页面链接和历史文章链接

采集微信文章与采集网站内容相同,都需要从列表页开始。微信列表页文章是公众号查看历史新闻的页面。现在网上其他微信采集器用搜狗搜索。 采集 方法虽然简单很多,但内容并不完整。所以我们还是要从最标准最全面的公众号历史新闻页面采集来。由于微信的限制,我们可以复制的链接不完整,无法在浏览器中打开查看内容。因此,我们需要使用anyproxy,通过上篇文章文章介绍的方法,获取一个完整的微信公众号历史消息页的链接地址。

解读:免费电子书《SEO中的关键词和竞争研究》_关键词分析
免费电子书“关键词 和 SEO 中的竞争研究”_关键词分析
2020/03/07 06:50 • 每天发布 SEO 帖子
关键词每天分析_Zac@SEO,初学者网站容易犯的最大错误之一就是跳入某个领域,跳过竞争研究,开始做网站 没有计划目标 关键词。这样做通常会导致两个结果。一是我想做的关键词排名上不去,二是关键词排名

我觉得不错
初学者网站最容易犯的最大错误之一就是一头扎进某个领域,跳过竞争性研究,开始关键词没有计划目标关键词@ >@网站。这样做通常会导致两个结果。一个是我想做的关键词排名上不去,一个是我觉得好的关键词排名第一没有流量。

进行竞争性研究并确定合适的 关键词 是 SEO 的第一步,也是必不可少的一步。竞争研究包括关键词研究、竞争对手研究和现有的网站评估诊断,其中关键词研究是最重要的。
这本电子书《SEO关键词 and Competitive Research in SEO》是《SEO实践守则》的第三章,请点击这里下载,998K,PDF文件。欢迎传播。
之前的免费样章已经放出了第2章“了解搜索引擎”、第6章、第9章“链接诱饵指南”,就这些了,如果你想看整本书《SEO实战密码》,可以考虑买一本. ?
python爬虫学习必看的教程:txt格式如何转成xml
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2022-09-16 21:05
querylist采集微信公众号文章的网页链接->rtmpapi采集视频,音频,
都在做,我只说说txt格式如何转成xml并上传到网站上。@黄万民:利用编码表就行。它会把每个英文字母编码为类似小数点的几个数字,你用后缀表现一下就好了。它会把每个end编码为带有十个小数点的数字,你用后缀表现一下就好了。分割线:xml转txt的话可以直接用它编码器,api有demo,
这两个方法都算是scrapy框架下的,大体的思路是一样的。
python爬虫学习必看的教程:crawler.pypython爬虫学习必看的教程:crawler.py如果是爬快手快手小程序
xml也有转csv,其实python应该还是可以拿api解析xml编码的。
我自己学的c程序设计,用c写httpserver,用的libexec和python的asyncio中间件来做请求就是提供标准request等的信息就可以读取xml,不过最好还是有代理吧,
刚开始用c写爬虫时,我是把xml转换成xmlxml,再转换成数据库的数据。python官方手册就有了,有一个scrapy就可以解析。
你可以使用xlb这个转换器。
用python可以写爬虫进行xml格式的解析。安装python扩展库xlb就可以进行xml格式的解析。 查看全部
python爬虫学习必看的教程:txt格式如何转成xml
querylist采集微信公众号文章的网页链接->rtmpapi采集视频,音频,
都在做,我只说说txt格式如何转成xml并上传到网站上。@黄万民:利用编码表就行。它会把每个英文字母编码为类似小数点的几个数字,你用后缀表现一下就好了。它会把每个end编码为带有十个小数点的数字,你用后缀表现一下就好了。分割线:xml转txt的话可以直接用它编码器,api有demo,

这两个方法都算是scrapy框架下的,大体的思路是一样的。
python爬虫学习必看的教程:crawler.pypython爬虫学习必看的教程:crawler.py如果是爬快手快手小程序
xml也有转csv,其实python应该还是可以拿api解析xml编码的。

我自己学的c程序设计,用c写httpserver,用的libexec和python的asyncio中间件来做请求就是提供标准request等的信息就可以读取xml,不过最好还是有代理吧,
刚开始用c写爬虫时,我是把xml转换成xmlxml,再转换成数据库的数据。python官方手册就有了,有一个scrapy就可以解析。
你可以使用xlb这个转换器。
用python可以写爬虫进行xml格式的解析。安装python扩展库xlb就可以进行xml格式的解析。
微信公众号文章名称【tomcat041421】依赖可以参考我的另一篇回答
采集交流 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2022-08-13 13:04
querylist采集微信公众号文章名称【tomcat041421】,相关依赖可以参考我的另一篇回答,有详细代码。看你简单说了一下业务需求,eclipse就足够你做了,el.setvalue(1,'aaa');就是获取名称为aaa的文章,然后再次请求文章名称时返回posteddata,你的业务代码你应该知道的更多了。
关键要把请求头也爬出来,而且要弄短。
简单的,可以用优采云来接收关键参数,
初步看了你的项目,还是先尽量别碰数据库的事情了,一个好的数据库,有多好你知道么?从wordcount实现一个类似返回每条数据被多少人关注了?然后不经意间针对某一用户或者对应产品或者服务,来提一些话题性的问题,让爬虫能够有所兴趣吧。在说数据的表层话题性的问题之外,也可以尝试用一下优采云库存表做关键字搜索。
嗯,不太懂开发,但是看上去你之前没有做过数据库开发。先尽量好好学一下sql吧,其它语言也是可以的。没有数据库就别碰数据库和别的开发语言了。
你在做什么呀,
请上线之前先用cookie去遍历每条微信文章吧。或者用一个api去爬这个微信文章,获取每条数据所对应的其他地址。如果只是初学,直接用mysqlconnectordelphi做一个简单的好了。 查看全部
微信公众号文章名称【tomcat041421】依赖可以参考我的另一篇回答
querylist采集微信公众号文章名称【tomcat041421】,相关依赖可以参考我的另一篇回答,有详细代码。看你简单说了一下业务需求,eclipse就足够你做了,el.setvalue(1,'aaa');就是获取名称为aaa的文章,然后再次请求文章名称时返回posteddata,你的业务代码你应该知道的更多了。
关键要把请求头也爬出来,而且要弄短。

简单的,可以用优采云来接收关键参数,
初步看了你的项目,还是先尽量别碰数据库的事情了,一个好的数据库,有多好你知道么?从wordcount实现一个类似返回每条数据被多少人关注了?然后不经意间针对某一用户或者对应产品或者服务,来提一些话题性的问题,让爬虫能够有所兴趣吧。在说数据的表层话题性的问题之外,也可以尝试用一下优采云库存表做关键字搜索。

嗯,不太懂开发,但是看上去你之前没有做过数据库开发。先尽量好好学一下sql吧,其它语言也是可以的。没有数据库就别碰数据库和别的开发语言了。
你在做什么呀,
请上线之前先用cookie去遍历每条微信文章吧。或者用一个api去爬这个微信文章,获取每条数据所对应的其他地址。如果只是初学,直接用mysqlconnectordelphi做一个简单的好了。
go语言的oo做完整的排序算法,怎么实现?
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-08-11 17:04
querylist采集微信公众号文章原文地址:基于lbs的公众号文章排序-博客-云栖社区-阿里云腾讯云开发一种基于html5的公众号排序算法。上一次我们说道,我们在做知乎问答排序时,为了提高排序的准确性,我们需要确定哪些标签在哪一段文字上准确度高。这一次我们用到了html5的javascript。我们已经实现了长尾词匹配,时间序列匹配。
我们已经实现了在全部内容上排序算法。不过本次我们不会只解决长尾词匹配的问题,我们解决是否要在一篇文章上匹配几百个标签。该怎么办呢?看craigslist...不多说,直接上代码,可以参考我的zh.xiaoyans大佬的博客:如何评价知乎提问「logo怎么实现」?这就需要使用到go语言的oo做完整的排序算法,需要在这里详细讲解一下html5section的信息section表示一个完整的长文档,包含完整的内容content_html表示长文档的内容data_html表示内容数据sectionitem表示类型为public[friend]property的字段,可以理解为属性集rank_html表示长文档排序中的权重,用len()可以得到,我们有一个callback函数,用来计算文章列表的元素数,排序结果正好满足如下要求:这样就能解决实际应用中,因为private[friend]property参数设置不当而导致的错误,排序结果中rank_html由于没有被赋值就直接在代码中执行的问题,这是一种all-inall的做法。
这种做法取名为tridentsorting。如果希望实现以下功能,并将整体排序与单条标签数据排序合并,最好是每个标签各自在一个内容上进行排序,即item为内容,previous_content为标签,all_content为内容里的标签标签,这样previous_content会有一个大小。我们使用list将section,all_content,data_html排序,将内容放入list,有时间序列后分别存入tag的key,但我们发现这样排序后应该在item上排序。
这是一个矛盾的问题,我们可以设定这种规则。我们还引入sort_by从content_html中随机选择item,可以解决此矛盾,但是这种方式最终与实际应用中,我们常常发现非rank_html字段和整体排序相互矛盾。这是因为字段的数量很多(这里是1000),要从0开始,直到我们发现矛盾,为止。我们又一个字段是分词,分词用到了go语言的语法库stopwords。
排序后,选择一个字段进行去重,选择字段的过程省略,这样我们就完成了单标签排序,如果希望多标签排序,可以去用go语言语法库中的stopwords库实现。stopwords接口提供很多方法,但是我们目前只能执行单标签的排序,如果我们多个标签都想进。 查看全部
go语言的oo做完整的排序算法,怎么实现?
querylist采集微信公众号文章原文地址:基于lbs的公众号文章排序-博客-云栖社区-阿里云腾讯云开发一种基于html5的公众号排序算法。上一次我们说道,我们在做知乎问答排序时,为了提高排序的准确性,我们需要确定哪些标签在哪一段文字上准确度高。这一次我们用到了html5的javascript。我们已经实现了长尾词匹配,时间序列匹配。

我们已经实现了在全部内容上排序算法。不过本次我们不会只解决长尾词匹配的问题,我们解决是否要在一篇文章上匹配几百个标签。该怎么办呢?看craigslist...不多说,直接上代码,可以参考我的zh.xiaoyans大佬的博客:如何评价知乎提问「logo怎么实现」?这就需要使用到go语言的oo做完整的排序算法,需要在这里详细讲解一下html5section的信息section表示一个完整的长文档,包含完整的内容content_html表示长文档的内容data_html表示内容数据sectionitem表示类型为public[friend]property的字段,可以理解为属性集rank_html表示长文档排序中的权重,用len()可以得到,我们有一个callback函数,用来计算文章列表的元素数,排序结果正好满足如下要求:这样就能解决实际应用中,因为private[friend]property参数设置不当而导致的错误,排序结果中rank_html由于没有被赋值就直接在代码中执行的问题,这是一种all-inall的做法。
这种做法取名为tridentsorting。如果希望实现以下功能,并将整体排序与单条标签数据排序合并,最好是每个标签各自在一个内容上进行排序,即item为内容,previous_content为标签,all_content为内容里的标签标签,这样previous_content会有一个大小。我们使用list将section,all_content,data_html排序,将内容放入list,有时间序列后分别存入tag的key,但我们发现这样排序后应该在item上排序。
这是一个矛盾的问题,我们可以设定这种规则。我们还引入sort_by从content_html中随机选择item,可以解决此矛盾,但是这种方式最终与实际应用中,我们常常发现非rank_html字段和整体排序相互矛盾。这是因为字段的数量很多(这里是1000),要从0开始,直到我们发现矛盾,为止。我们又一个字段是分词,分词用到了go语言的语法库stopwords。
排序后,选择一个字段进行去重,选择字段的过程省略,这样我们就完成了单标签排序,如果希望多标签排序,可以去用go语言语法库中的stopwords库实现。stopwords接口提供很多方法,但是我们目前只能执行单标签的排序,如果我们多个标签都想进。
querylist采集微信公众号文章之后,通过querytext分析得出文章的title
采集交流 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2022-07-08 07:04
querylist采集微信公众号文章之后,通过querytext分析得出文章的title、vp、date、content、url等等一切你想知道的东西。然后你用一个网页,伪装成公众号文章来进行二次加工,这样就可以让网页一行不跳转跳到文章所有的页面上去了。
试了下sss网页语言,说下感受:1.这一块内容可以参考cdn中各大视频网站,如爱奇艺,优酷等,其他对比较多。2.为了更加精确的定位我需要的文章对应的微信网页,依靠以前的微信聊天记录,应该可以做比较精确的定位,但是如果设计这么一套流程,可以提高开发者的工作效率,但是降低开发者对各个网站内容的了解深度。
对搜索引擎进行交叉引用,即可。
1.请看任何可见的网站,大多数是可以做到的。src-linkapplicationextractionandextractionresearch2.其他搜索引擎上都有类似的解决方案,题主找到的应该是基于内容提供商爬虫抓取,进行匹配。
csv可以。
像这种公众号非常多的网站,要想找到想要的大多数还是靠抓包分析下url等等一些方法的。
电脑上爬,用chrome浏览器插件,本地电脑上分析。以下就是我通过抓包在微信公众号上爬取的东西:javascript下面是在某宝上抓的抓包过程,因为感觉web前端有必要写这些抓包代码:windows+mac注:aux地址是抓包方法:1.安装chrome插件:chrome地址:。2.在aux地址前面按shift+/(也就是下面图中的aux-ieinstaller)。
3.就可以在chrome浏览器上显示一个css选择器,然后在chrome浏览器上全屏显示css代码。4.javascript解析xml格式,解析javascript框架xmlhttprequest。5.根据url信息,得到想要的网页信息。(有时候在chrome浏览器上只获取css代码)6.通过js连接post传递到url,post方法不好掌握,在此不详述。
7.在url上加上content:"all"(只要有站内搜索关键字就行,不必全部提交,可以一个地址全局多站点)content:"你好,汪汪!"。 查看全部
querylist采集微信公众号文章之后,通过querytext分析得出文章的title
querylist采集微信公众号文章之后,通过querytext分析得出文章的title、vp、date、content、url等等一切你想知道的东西。然后你用一个网页,伪装成公众号文章来进行二次加工,这样就可以让网页一行不跳转跳到文章所有的页面上去了。
试了下sss网页语言,说下感受:1.这一块内容可以参考cdn中各大视频网站,如爱奇艺,优酷等,其他对比较多。2.为了更加精确的定位我需要的文章对应的微信网页,依靠以前的微信聊天记录,应该可以做比较精确的定位,但是如果设计这么一套流程,可以提高开发者的工作效率,但是降低开发者对各个网站内容的了解深度。
对搜索引擎进行交叉引用,即可。
1.请看任何可见的网站,大多数是可以做到的。src-linkapplicationextractionandextractionresearch2.其他搜索引擎上都有类似的解决方案,题主找到的应该是基于内容提供商爬虫抓取,进行匹配。
csv可以。

像这种公众号非常多的网站,要想找到想要的大多数还是靠抓包分析下url等等一些方法的。
电脑上爬,用chrome浏览器插件,本地电脑上分析。以下就是我通过抓包在微信公众号上爬取的东西:javascript下面是在某宝上抓的抓包过程,因为感觉web前端有必要写这些抓包代码:windows+mac注:aux地址是抓包方法:1.安装chrome插件:chrome地址:。2.在aux地址前面按shift+/(也就是下面图中的aux-ieinstaller)。
3.就可以在chrome浏览器上显示一个css选择器,然后在chrome浏览器上全屏显示css代码。4.javascript解析xml格式,解析javascript框架xmlhttprequest。5.根据url信息,得到想要的网页信息。(有时候在chrome浏览器上只获取css代码)6.通过js连接post传递到url,post方法不好掌握,在此不详述。
7.在url上加上content:"all"(只要有站内搜索关键字就行,不必全部提交,可以一个地址全局多站点)content:"你好,汪汪!"。
querylist采集微信公众号文章原理:获取文章列表第二步
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2022-06-15 06:03
querylist采集微信公众号文章原理:首先给每篇文章分配一个token(dict),然后利用nfs协议,抓取公众号原文的cookie,把cookie(token)放入error_response_querylist里面的这个队列,每次提取出这个数值,找到一个满足条件的item就可以提取这个文章,提取步骤详见下图:参考链接:xpath搜索取公众号文章。
第一步。获取文章列表第二步。
首先还是看你用的微信是qq?
这个问题说明你用的是你第三方的爬虫工具,要看你用哪个爬虫工具,
有很多现成的工具可以提取一些公众号文章,如果你用selenium等用户控制工具,可以同步微信获取公众号文章。爬虫工具爬取公众号文章我不大了解,但,如果用第三方爬虫工具,你可以自己试一下jsoup,比较好用。
电脑网页,
按你的图片上的方法,也可以用开发者工具的抓取去图片中抓取。
给你一个样本:利用爬虫爬取"微信公众号文章列表"-收藏-乐学微信爬虫
对照着这个视频学习有问题你可以问我
你可以试试beautifulsoup获取不了的话建议你可以根据需要对dict进行类型转换 查看全部
querylist采集微信公众号文章原理:获取文章列表第二步
querylist采集微信公众号文章原理:首先给每篇文章分配一个token(dict),然后利用nfs协议,抓取公众号原文的cookie,把cookie(token)放入error_response_querylist里面的这个队列,每次提取出这个数值,找到一个满足条件的item就可以提取这个文章,提取步骤详见下图:参考链接:xpath搜索取公众号文章。
第一步。获取文章列表第二步。
首先还是看你用的微信是qq?
这个问题说明你用的是你第三方的爬虫工具,要看你用哪个爬虫工具,
有很多现成的工具可以提取一些公众号文章,如果你用selenium等用户控制工具,可以同步微信获取公众号文章。爬虫工具爬取公众号文章我不大了解,但,如果用第三方爬虫工具,你可以自己试一下jsoup,比较好用。
电脑网页,
按你的图片上的方法,也可以用开发者工具的抓取去图片中抓取。
给你一个样本:利用爬虫爬取"微信公众号文章列表"-收藏-乐学微信爬虫
对照着这个视频学习有问题你可以问我
你可以试试beautifulsoup获取不了的话建议你可以根据需要对dict进行类型转换
arXiv新插件让你一键看视频!已覆盖数千机器学习论文
采集交流 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-06-06 11:05
作者 | 蒋宝尚arXiv 功能真是越来越强大了,前段日子刚。现在又有一款插件,可以让读者在阅读论文时候观看视频讲解。
这款插件的开发者名为Amit Chaudhary,其一直致力于“用可视化的方式展示机器学习论文里的研究思想”。
插件名为papers-with-video,可以用于展示论文的视频解释。目前已经开源到GitHub中,下载压缩包,添加到chrome的扩展程序中即可使用。安装之后的效果如下所示:
上述动图所展示的文章名为:“Beyond Accuracy: Behavioral Testing of NLP models with CheckList”,是ACL 2020收录的一篇文章。点开视频插件,网页自动跳转到视频所在的 Slideslive 页面。由此可见,这款视频插件的功能是:采集有论文视频讲解的网页,然后超链接到该网页。
据作者推特介绍,目前已经链接了3700篇机器学习论文。
图注:左边是未启用插件的论文页面,右边是启用插件的页面,显然右边增加了一个“视频”的按钮。具体的插件安装方法如下,可以分为4步:1.下载GitHub中的文件,解压到本地。GitHub地址:2.在浏览器网址栏中输入chrome://extensions ,然后依次选择Menu > More Tools > Extensions.3.打开开发者模式。4.点击“加载已解压的扩展程序”,将插件集成到浏览器中。
另外,papers-with-video 浏览器扩展的安装脚本如下:
// Add a video icon to the title if the paper is present in our mapping.<br style="color: rgb(171, 178, 191);text-align: left;white-space: pre-wrap;font-family: monospace;font-size: 15px;letter-spacing: 0.5px;" />if (arxivID in mapping) {<br style="color: rgb(171, 178, 191);text-align: left;white-space: pre-wrap;font-family: monospace;font-size: 15px;letter-spacing: 0.5px;" /> var videoLink = mapping[arxivID];<br style="color: rgb(171, 178, 191);text-align: left;white-space: pre-wrap;font-family: monospace;font-size: 15px;letter-spacing: 0.5px;" /> var videoButton = '';<br style="color: rgb(171, 178, 191);text-align: left;white-space: pre-wrap;font-family: monospace;font-size: 15px;letter-spacing: 0.5px;" /> var videoButton = '';<br style="color: rgb(171, 178, 191);text-align: left;white-space: pre-wrap;font-family: monospace;font-size: 15px;letter-spacing: 0.5px;" /> var paperTitle = document.querySelector("h1.title");<br style="color: rgb(171, 178, 191);text-align: left;white-space: pre-wrap;font-family: monospace;font-size: 15px;letter-spacing: 0.5px;" /> paperTitle.innerHTML = paperTitle.innerHTML + videoButton;<br style="color: rgb(171, 178, 191);text-align: left;white-space: pre-wrap;font-family: monospace;font-size: 15px;letter-spacing: 0.5px;" />}
加上这个论文讲解神器,意味着arXiv正在集成论文、代码、视频一体化的论文阅读功能。
[赠书福利]
AI科技评论为大家带来10本《现代自然语言生成》正版作者亲笔签名版新书。
请在1月17日AI科技评论头条文章《》(注意不是本文)留言区畅所欲言,谈一谈你对本书的看法和期待(必须要和本书主题相关)。
fAI 科技评论将会在留言区选出10名读者,每人送出《现代自然语言生成》亲笔签名版一本。
活动规则:
1.在1月17日AI科技评论头条文章(注意不是本文)留言,留言点赞最高的前10位读者将获得赠书。获得赠书的读者请联系 AI 科技评论客服(aitechreview)。
2. 留言内容会有筛选,必须要和本书主题相关,例如“选我上去”等内容将不会被筛选,亦不会中奖。
3. 本活动时间为2021年1月17日 - 2021年1月24日(23:00),活动推送内仅允许中奖一次。
查看全部
arXiv新插件让你一键看视频!已覆盖数千机器学习论文
作者 | 蒋宝尚arXiv 功能真是越来越强大了,前段日子刚。现在又有一款插件,可以让读者在阅读论文时候观看视频讲解。
这款插件的开发者名为Amit Chaudhary,其一直致力于“用可视化的方式展示机器学习论文里的研究思想”。
插件名为papers-with-video,可以用于展示论文的视频解释。目前已经开源到GitHub中,下载压缩包,添加到chrome的扩展程序中即可使用。安装之后的效果如下所示:
上述动图所展示的文章名为:“Beyond Accuracy: Behavioral Testing of NLP models with CheckList”,是ACL 2020收录的一篇文章。点开视频插件,网页自动跳转到视频所在的 Slideslive 页面。由此可见,这款视频插件的功能是:采集有论文视频讲解的网页,然后超链接到该网页。
据作者推特介绍,目前已经链接了3700篇机器学习论文。
图注:左边是未启用插件的论文页面,右边是启用插件的页面,显然右边增加了一个“视频”的按钮。具体的插件安装方法如下,可以分为4步:1.下载GitHub中的文件,解压到本地。GitHub地址:2.在浏览器网址栏中输入chrome://extensions ,然后依次选择Menu > More Tools > Extensions.3.打开开发者模式。4.点击“加载已解压的扩展程序”,将插件集成到浏览器中。
另外,papers-with-video 浏览器扩展的安装脚本如下:
// Add a video icon to the title if the paper is present in our mapping.<br style="color: rgb(171, 178, 191);text-align: left;white-space: pre-wrap;font-family: monospace;font-size: 15px;letter-spacing: 0.5px;" />if (arxivID in mapping) {<br style="color: rgb(171, 178, 191);text-align: left;white-space: pre-wrap;font-family: monospace;font-size: 15px;letter-spacing: 0.5px;" /> var videoLink = mapping[arxivID];<br style="color: rgb(171, 178, 191);text-align: left;white-space: pre-wrap;font-family: monospace;font-size: 15px;letter-spacing: 0.5px;" /> var videoButton = '';<br style="color: rgb(171, 178, 191);text-align: left;white-space: pre-wrap;font-family: monospace;font-size: 15px;letter-spacing: 0.5px;" /> var videoButton = '';<br style="color: rgb(171, 178, 191);text-align: left;white-space: pre-wrap;font-family: monospace;font-size: 15px;letter-spacing: 0.5px;" /> var paperTitle = document.querySelector("h1.title");<br style="color: rgb(171, 178, 191);text-align: left;white-space: pre-wrap;font-family: monospace;font-size: 15px;letter-spacing: 0.5px;" /> paperTitle.innerHTML = paperTitle.innerHTML + videoButton;<br style="color: rgb(171, 178, 191);text-align: left;white-space: pre-wrap;font-family: monospace;font-size: 15px;letter-spacing: 0.5px;" />}
加上这个论文讲解神器,意味着arXiv正在集成论文、代码、视频一体化的论文阅读功能。
[赠书福利]
AI科技评论为大家带来10本《现代自然语言生成》正版作者亲笔签名版新书。
请在1月17日AI科技评论头条文章《》(注意不是本文)留言区畅所欲言,谈一谈你对本书的看法和期待(必须要和本书主题相关)。
fAI 科技评论将会在留言区选出10名读者,每人送出《现代自然语言生成》亲笔签名版一本。
活动规则:
1.在1月17日AI科技评论头条文章(注意不是本文)留言,留言点赞最高的前10位读者将获得赠书。获得赠书的读者请联系 AI 科技评论客服(aitechreview)。
2. 留言内容会有筛选,必须要和本书主题相关,例如“选我上去”等内容将不会被筛选,亦不会中奖。
3. 本活动时间为2021年1月17日 - 2021年1月24日(23:00),活动推送内仅允许中奖一次。
querylist采集微信公众号文章摘要信息很简单,得先定义下post方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2022-05-27 08:04
querylist采集微信公众号文章摘要信息很简单,只要将微信公众号文章推送到querylist.exec("");或者直接到exec("execute_all_urls");之类的方法里面等待3秒即可完成。querylist已经提供了base64编码方法可以将传入的url编码后传给浏览器进行网页抓取。
但是当string类型的参数传入的是querylist.integrated_base64(encodertochangetheresultpairsandbase64weightsusingasimpleencoder-as-cintegratedbase64descriptorcheckedfromtherequest)之类的方法时,要取得文章摘要我就觉得有点慢了,毕竟需要2次查找。
本篇文章仅介绍post传输方法。1.post方法要实现编码请求,所以得先定义下post方法。post方法和post方法的不同在于参数默认为了content-type,默认是post/x-www-form-urlencoded,所以我们首先把content-type设置为post。然后查看这两个参数定义:/。 查看全部
querylist采集微信公众号文章摘要信息很简单,得先定义下post方法
querylist采集微信公众号文章摘要信息很简单,只要将微信公众号文章推送到querylist.exec("");或者直接到exec("execute_all_urls");之类的方法里面等待3秒即可完成。querylist已经提供了base64编码方法可以将传入的url编码后传给浏览器进行网页抓取。
但是当string类型的参数传入的是querylist.integrated_base64(encodertochangetheresultpairsandbase64weightsusingasimpleencoder-as-cintegratedbase64descriptorcheckedfromtherequest)之类的方法时,要取得文章摘要我就觉得有点慢了,毕竟需要2次查找。
本篇文章仅介绍post传输方法。1.post方法要实现编码请求,所以得先定义下post方法。post方法和post方法的不同在于参数默认为了content-type,默认是post/x-www-form-urlencoded,所以我们首先把content-type设置为post。然后查看这两个参数定义:/。
源码剖析 - 公众号采集阅读器 Liuli
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-05-05 09:09
简介
无意中发现 Liuli 这个项目,项目 Github:
看了其文章,发现 Liuli 是 Python 实现的,便打算简单看看其实现细节,老规矩,看项目,先将好奇点写下来:
对,我就对这两点感兴趣,经过一番阅读后,关于好奇 1,其实人家没有实现漂亮的 PC 软件界面,Liuli 只是采集,然后将内容推送过去,所以本文的重点,就是看一下它是怎么采集公众号文章的,此外在阅读过程中,发现 LiuLi 还使用了简单的方法来识别文章是否为广告文章,这点也挺有意思的,也记录一下。
公众号文章采集
Liuli 基于搜狗微信()对公众号文章进行采集,而且实现了 2 种方式:
我们可以通过相应的配置文件控制 Liuli 使用其中哪种方式来进行文章采集,其默认使用 ruia 的方式进行采集。
Liuli 将功能分为多个模块,然后通过调度器去调度不同的模块,调度器启动方法代码如下:
# src/liuli_schedule.py<br /><br />def start(ll_config_name: str = ""):<br /> """调度启动函数<br /><br /> Args:<br /> task_config (dict): 调度任务配置<br /> """<br /> if not ll_config_name:<br /> freeze_support()<br /><br /> # 默认启动 liuli_config 目录下所有配置<br /> ll_config_name_list = []<br /> for each_file in os.listdir(Config.LL_CONFIG_DIR):<br /> if each_file.endswith("json"):<br /> # 加入启动列表<br /> ll_config_name_list.append(each_file.replace(".json", ""))<br /> # 进程池<br /> p = Pool(len(ll_config_name_list))<br /> for each_ll_config_name in ll_config_name_list:<br /> LOGGER.info(f"Task {each_ll_config_name} register successfully!")<br /> p.apply_async(run_liuli_schedule, args=(each_ll_config_name,))<br /> p.close()<br /> p.join()<br /><br /> else:<br /> run_liuli_schedule(ll_config_name)<br />
从代码可知,调度器会启动 Python 的进程池,然后向其中添加 run_liuli_schedule 异步任务,该异步任务中,会执行 run_liuli_task 方法,该方法才是一次完整的任务流程,代码如下:
def run_liuli_task(ll_config: dict):<br /> """执行调度任务<br /><br /> Args:<br /> ll_config (dict): Liuli 任务配置<br /> """<br /> # 文章源, 用于基础查询条件<br /> doc_source: str = ll_config["doc_source"]<br /> basic_filter = {"basic_filter": {"doc_source": doc_source}}<br /> # 采集器配置<br /> collector_conf: dict = ll_config["collector"]<br /> # 处理器配置<br /> processor_conf: dict = ll_config["processor"]<br /> # 分发器配置<br /> sender_conf: dict = ll_config["sender"]<br /> sender_conf.update(basic_filter)<br /> # 备份器配置<br /> backup_conf: dict = ll_config["backup"]<br /> backup_conf.update(basic_filter)<br /><br /> # 采集器执行<br /> LOGGER.info("采集器开始执行!")<br /> for collect_type, collect_config in collector_conf.items():<br /> collect_factory(collect_type, collect_config)<br /> LOGGER.info("采集器执行完毕!")<br /> # 采集器执行<br /> LOGGER.info("处理器(after_collect): 开始执行!")<br /> for each in processor_conf["after_collect"]:<br /> func_name = each.pop("func")<br /> # 注入查询条件<br /> each.update(basic_filter)<br /> LOGGER.info(f"处理器(after_collect): {func_name} 正在执行...")<br /> processor_dict[func_name](**each)<br /> LOGGER.info("处理器(after_collect): 执行完毕!")<br /> # 分发器执行<br /> LOGGER.info("分发器开始执行!")<br /> send_doc(sender_conf)<br /> LOGGER.info("分发器执行完毕!")<br /> # 备份器执行<br /> LOGGER.info("备份器开始执行!")<br /> backup_doc(backup_conf)<br /> LOGGER.info("备份器执行完毕!")<br />
从 run_liuli_task 方法可知,Liuli 一次任务需要执行:
关于 Liuli 的功能,可以阅读作者本人的文章: ,这里先只关注公众号采集的逻辑。
因为有 ruia 与 playwright 两种不同方式实现的采集器,具体使用哪种,通过配置文件决定,然后通过 import_module 方法动态导入相应的模块,然后运行模块的 run 方法,从而实现公众号文章的采集,相关代码如下:
def collect_factory(collect_type: str, collect_config: dict) -> bool:<br /> """<br /> 采集器工厂函数<br /> :param collect_type: 采集器类型<br /> :param collect_config: 采集器配置<br /> :return:<br /> """<br /> collect_status = False<br /> try:<br /> # import_module方法动态载入具体的采集模块<br /> collect_module = import_module(f"src.collector.{collect_type}")<br /> collect_status = collect_module.run(collect_config)<br /> except ModuleNotFoundError:<br /> LOGGER.error(f"采集器类型不存在 {collect_type} - {collect_config}")<br /> except Exception as e:<br /> LOGGER.error(f"采集器执行出错 {collect_type} - {collect_config} - {e}")<br /> return collect_status<br />
playwright 采集模块实现
playwright 是微软出品的自动化库,与 selenium 的作用类似,定位于网页测试,但也被人用于网页信息的获取,可见即可得,使用门槛低,因为要加载网页信息,所以性能比较差,当然一些前端反爬的措施,playwright 也无法突破。
playwright 相比于 selenium,支持 python 的 async,性能有所提升(但还是比不了直接请求),这里贴一下获取某公众号下最新文章的部分逻辑(完整代码太长):
async def playwright_main(wechat_name: str):<br /> """利用 playwright 获取公众号元信息,输出数据格式见上方<br /> Args:<br /> wechat_name ([str]): 公众号名称<br /> """<br /> wechat_data = {}<br /> try:<br /> async with async_playwright() as p:<br /> # browser = await p.chromium.launch(headless=False)<br /> browser = await p.chromium.launch()<br /> context = await browser.new_context(user_agent=Config.SPIDER_UA)<br /> page = await context.new_page()<br /> # 进行公众号检索<br /> await page.goto("https://weixin.sogou.com/")<br /> await page.wait_for_load_state()<br /> await page.click('input[name="query"]')<br /> await page.fill('input[name="query"]', wechat_name)<br /> await asyncio.sleep(1)<br /> await page.click("text=搜公众号")<br /> await page.wait_for_load_state()<br />
从上述代码可知,playwright 用法与 selenium 很像,将用户操作网站的流程自动化便可以获取相应的数据了。
ruia 采集模块实现
ruia 是轻量级的 Python 异步爬虫框架,因为比较轻量,我也将其代码读了一遍,作为下篇文章的内容。
它的用法与 scrapy 有点像,需要定义继承于 ruia.Spider 的子类,然后调用 start 方法实现对目标网站的请求,然后 ruia 会自动调用 parse 方法实现对网页内容的解析,来看一下具体的代码,首先是入口逻辑:
def run(collect_config: dict):<br /> """微信公众号文章抓取爬虫<br /><br /> Args:<br /> collect_config (dict, optional): 采集器配置<br /> """<br /> s_nums = 0<br /> wechat_list = collect_config["wechat_list"]<br /> delta_time = collect_config.get("delta_time", 5)<br /> for wechat_name in wechat_list:<br /> SGWechatSpider.wechat_name = wechat_name<br /> SGWechatSpider.request_config = {<br /> "RETRIES": 3,<br /> "DELAY": delta_time,<br /> "TIMEOUT": 20,<br /> }<br /> sg_url = f"https://weixin.sogou.com/weixin?type=1&query={wechat_name}&ie=utf8&s_from=input&_sug_=n&_sug_type_="<br /> SGWechatSpider.start_urls = [sg_url]<br /> try:<br /> # 启动爬虫<br /> SGWechatSpider.start(middleware=ua_middleware)<br /> s_nums += 1<br /> except Exception as e:<br /> err_msg = f" 公众号->{wechat_name} 文章更新失败! 错误信息: {e}"<br /> LOGGER.error(err_msg)<br /><br /> msg = f" 微信公众号文章更新完毕({s_nums}/{len(wechat_list)})!"<br /> LOGGER.info(msg)<br />
上述代码中,通过 SGWechatSpider.start (middleware=ua_middleware) 启动了爬虫,它会自动请求 start_urls 的 url,然后回调 parse 方法,parse 方法代码如下:
async def parse(self, response: Response):<br /> """解析公众号原始链接数据"""<br /> html = await response.text()<br /> item_list = []<br /> async for item in SGWechatItem.get_items(html=html):<br /> if item.wechat_name == self.wechat_name:<br /> item_list.append(item)<br /> yield self.request(<br /> url=item.latest_href,<br /> metadata=item.results,<br /> # 下一个回调方法<br /> callback=self.parse_real_wechat_url,<br /> )<br /> break<br />
parse 方法中,会通过 self.request 请求新的 url,然后回调 self.parse_real_wechat_url 方法,一切都与 scrapy 如此相似。
至此,采集模块的阅读就结束了(代码中还涉及一些简单的数据清洗,本文就不讨论了),没有特别复杂的部分,从代码上看,也没有发送作者做反爬逻辑的处理,搜狗微信没有反爬?
广告文章识别
接着看一下广告文章识别,Liuli 对于广告文章,还是会采集的,采集后,在文章处理模块,会将广告文章标注出来,先理一下广告文章标注的入口逻辑,回到 liuli_schedule.py 的 run_lili_task 方法,关注到 process(文章处理模块)的逻辑,代码如下:
LOGGER.info("处理器(after_collect): 开始执行!")<br /> for each in processor_conf["after_collect"]:<br /> func_name = each.pop("func")<br /> # 注入查询条件<br /> each.update(basic_filter)<br /> LOGGER.info(f"处理器(after_collect): {func_name} 正在执行...")<br /> processor_dict[func_name](**each)<br /> LOGGER.info("处理器(after_collect): 执行完毕!")<br />
从上述代码可知,处理器的主要逻辑是 processor_dict 字典中的方法,该字典的定义的路径为 src/processor/__init__.py,代码如下:
from .rss_utils import to_rss<br />from .text_utils import (<br /> ad_marker,<br /> extract_core_html,<br /> extract_keyword_list,<br /> html_to_text_h2t,<br /> str_replace,<br />)<br /><br />processor_dict = {<br /> "to_rss": to_rss,<br /> "ad_marker": ad_marker,<br /> "str_replace": str_replace,<br />}<br />
其中 ad_marker 方法便是识别文章是否为广告文章的方法,其实写的有点绕,核心逻辑就是计算当前文章与采集到的广告文章词频构建向量的余弦值,判断余弦值大小来判断是否为广告文章,简单看一下相关的逻辑。
ad_marker 方法中会调用 model_predict_factory 方法,将当前文章的标题、文章内容以及分类的 cos_value 传入,相关代码如下(清理了代码,只展示了需要部分):
def ad_marker(<br /> cos_value: float = 0.6,<br /> is_force=False,<br /> basic_filter={},<br /> **kwargs,<br />):<br /> # 基于余弦相似度<br /> cos_model_resp = model_predict_factory(<br /> model_name="cos",<br /> model_path="",<br /> input_dict={"text": doc_name + doc_keywords, "cos_value": cos_value},<br /> # input_dict={"text": doc_name, "cos_value": Config.COS_VALUE},<br /> ).to_dict()<br />
cos_value 为 0.6,即如果计算出当前文章与广告文章余弦值大于等于 0.6,则认为当前文章为广告文章,其最终预测逻辑在 classifier/model_base/cos_model_loader.py 的 predict 方法中,代码如下:
def predict(self, text: str, cos_value: float = 0.8) -> dict:<br /> """<br /> 对文本相似度进行预测<br /> :param text: 文本<br /> :param cos_value: 阈值 默认是0.9<br /> :return:<br /> """<br /> max_pro, result = 0.0, 0<br /> for each in self.train_data:<br /> # 余弦值具体的运算逻辑<br /> cos = CosineSimilarity(self.process_text(text), each)<br /> res_dict = cos.calculate()<br /> value = res_dict["value"]<br /> # 大于等于cos_value,就返回1,则表示当前的文章是广告文章<br /> result = 1 if value >= cos_value else 0<br /> max_pro = value if value > max_pro else max_pro<br /> if result == 1:<br /> break<br /><br /> return {"result": result, "value": max_pro}<br />
余弦值具体的运算逻辑在 CosineSimilarity 的 calculate 方法中,都是数学相关的代码,就不看了,其核心是希望判断当前文章与广告文章的相似度,类似的还可以通过 TFIDF、文本聚类等算法来做,相关的库,几行代码就可以搞定(所以我感觉这里写绕了)。
其余可参考逻辑结尾
Liuli是很好的学习项目,下篇文章,一起学习一下 ruia Python 轻量级异步爬虫框架的代码。 查看全部
源码剖析 - 公众号采集阅读器 Liuli
简介
无意中发现 Liuli 这个项目,项目 Github:
看了其文章,发现 Liuli 是 Python 实现的,便打算简单看看其实现细节,老规矩,看项目,先将好奇点写下来:
对,我就对这两点感兴趣,经过一番阅读后,关于好奇 1,其实人家没有实现漂亮的 PC 软件界面,Liuli 只是采集,然后将内容推送过去,所以本文的重点,就是看一下它是怎么采集公众号文章的,此外在阅读过程中,发现 LiuLi 还使用了简单的方法来识别文章是否为广告文章,这点也挺有意思的,也记录一下。
公众号文章采集
Liuli 基于搜狗微信()对公众号文章进行采集,而且实现了 2 种方式:
我们可以通过相应的配置文件控制 Liuli 使用其中哪种方式来进行文章采集,其默认使用 ruia 的方式进行采集。
Liuli 将功能分为多个模块,然后通过调度器去调度不同的模块,调度器启动方法代码如下:
# src/liuli_schedule.py<br /><br />def start(ll_config_name: str = ""):<br /> """调度启动函数<br /><br /> Args:<br /> task_config (dict): 调度任务配置<br /> """<br /> if not ll_config_name:<br /> freeze_support()<br /><br /> # 默认启动 liuli_config 目录下所有配置<br /> ll_config_name_list = []<br /> for each_file in os.listdir(Config.LL_CONFIG_DIR):<br /> if each_file.endswith("json"):<br /> # 加入启动列表<br /> ll_config_name_list.append(each_file.replace(".json", ""))<br /> # 进程池<br /> p = Pool(len(ll_config_name_list))<br /> for each_ll_config_name in ll_config_name_list:<br /> LOGGER.info(f"Task {each_ll_config_name} register successfully!")<br /> p.apply_async(run_liuli_schedule, args=(each_ll_config_name,))<br /> p.close()<br /> p.join()<br /><br /> else:<br /> run_liuli_schedule(ll_config_name)<br />
从代码可知,调度器会启动 Python 的进程池,然后向其中添加 run_liuli_schedule 异步任务,该异步任务中,会执行 run_liuli_task 方法,该方法才是一次完整的任务流程,代码如下:
def run_liuli_task(ll_config: dict):<br /> """执行调度任务<br /><br /> Args:<br /> ll_config (dict): Liuli 任务配置<br /> """<br /> # 文章源, 用于基础查询条件<br /> doc_source: str = ll_config["doc_source"]<br /> basic_filter = {"basic_filter": {"doc_source": doc_source}}<br /> # 采集器配置<br /> collector_conf: dict = ll_config["collector"]<br /> # 处理器配置<br /> processor_conf: dict = ll_config["processor"]<br /> # 分发器配置<br /> sender_conf: dict = ll_config["sender"]<br /> sender_conf.update(basic_filter)<br /> # 备份器配置<br /> backup_conf: dict = ll_config["backup"]<br /> backup_conf.update(basic_filter)<br /><br /> # 采集器执行<br /> LOGGER.info("采集器开始执行!")<br /> for collect_type, collect_config in collector_conf.items():<br /> collect_factory(collect_type, collect_config)<br /> LOGGER.info("采集器执行完毕!")<br /> # 采集器执行<br /> LOGGER.info("处理器(after_collect): 开始执行!")<br /> for each in processor_conf["after_collect"]:<br /> func_name = each.pop("func")<br /> # 注入查询条件<br /> each.update(basic_filter)<br /> LOGGER.info(f"处理器(after_collect): {func_name} 正在执行...")<br /> processor_dict[func_name](**each)<br /> LOGGER.info("处理器(after_collect): 执行完毕!")<br /> # 分发器执行<br /> LOGGER.info("分发器开始执行!")<br /> send_doc(sender_conf)<br /> LOGGER.info("分发器执行完毕!")<br /> # 备份器执行<br /> LOGGER.info("备份器开始执行!")<br /> backup_doc(backup_conf)<br /> LOGGER.info("备份器执行完毕!")<br />
从 run_liuli_task 方法可知,Liuli 一次任务需要执行:
关于 Liuli 的功能,可以阅读作者本人的文章: ,这里先只关注公众号采集的逻辑。
因为有 ruia 与 playwright 两种不同方式实现的采集器,具体使用哪种,通过配置文件决定,然后通过 import_module 方法动态导入相应的模块,然后运行模块的 run 方法,从而实现公众号文章的采集,相关代码如下:
def collect_factory(collect_type: str, collect_config: dict) -> bool:<br /> """<br /> 采集器工厂函数<br /> :param collect_type: 采集器类型<br /> :param collect_config: 采集器配置<br /> :return:<br /> """<br /> collect_status = False<br /> try:<br /> # import_module方法动态载入具体的采集模块<br /> collect_module = import_module(f"src.collector.{collect_type}")<br /> collect_status = collect_module.run(collect_config)<br /> except ModuleNotFoundError:<br /> LOGGER.error(f"采集器类型不存在 {collect_type} - {collect_config}")<br /> except Exception as e:<br /> LOGGER.error(f"采集器执行出错 {collect_type} - {collect_config} - {e}")<br /> return collect_status<br />
playwright 采集模块实现
playwright 是微软出品的自动化库,与 selenium 的作用类似,定位于网页测试,但也被人用于网页信息的获取,可见即可得,使用门槛低,因为要加载网页信息,所以性能比较差,当然一些前端反爬的措施,playwright 也无法突破。
playwright 相比于 selenium,支持 python 的 async,性能有所提升(但还是比不了直接请求),这里贴一下获取某公众号下最新文章的部分逻辑(完整代码太长):
async def playwright_main(wechat_name: str):<br /> """利用 playwright 获取公众号元信息,输出数据格式见上方<br /> Args:<br /> wechat_name ([str]): 公众号名称<br /> """<br /> wechat_data = {}<br /> try:<br /> async with async_playwright() as p:<br /> # browser = await p.chromium.launch(headless=False)<br /> browser = await p.chromium.launch()<br /> context = await browser.new_context(user_agent=Config.SPIDER_UA)<br /> page = await context.new_page()<br /> # 进行公众号检索<br /> await page.goto("https://weixin.sogou.com/";)<br /> await page.wait_for_load_state()<br /> await page.click('input[name="query"]')<br /> await page.fill('input[name="query"]', wechat_name)<br /> await asyncio.sleep(1)<br /> await page.click("text=搜公众号")<br /> await page.wait_for_load_state()<br />
从上述代码可知,playwright 用法与 selenium 很像,将用户操作网站的流程自动化便可以获取相应的数据了。
ruia 采集模块实现
ruia 是轻量级的 Python 异步爬虫框架,因为比较轻量,我也将其代码读了一遍,作为下篇文章的内容。
它的用法与 scrapy 有点像,需要定义继承于 ruia.Spider 的子类,然后调用 start 方法实现对目标网站的请求,然后 ruia 会自动调用 parse 方法实现对网页内容的解析,来看一下具体的代码,首先是入口逻辑:
def run(collect_config: dict):<br /> """微信公众号文章抓取爬虫<br /><br /> Args:<br /> collect_config (dict, optional): 采集器配置<br /> """<br /> s_nums = 0<br /> wechat_list = collect_config["wechat_list"]<br /> delta_time = collect_config.get("delta_time", 5)<br /> for wechat_name in wechat_list:<br /> SGWechatSpider.wechat_name = wechat_name<br /> SGWechatSpider.request_config = {<br /> "RETRIES": 3,<br /> "DELAY": delta_time,<br /> "TIMEOUT": 20,<br /> }<br /> sg_url = f"https://weixin.sogou.com/weixin?type=1&query={wechat_name}&ie=utf8&s_from=input&_sug_=n&_sug_type_="<br /> SGWechatSpider.start_urls = [sg_url]<br /> try:<br /> # 启动爬虫<br /> SGWechatSpider.start(middleware=ua_middleware)<br /> s_nums += 1<br /> except Exception as e:<br /> err_msg = f" 公众号->{wechat_name} 文章更新失败! 错误信息: {e}"<br /> LOGGER.error(err_msg)<br /><br /> msg = f" 微信公众号文章更新完毕({s_nums}/{len(wechat_list)})!"<br /> LOGGER.info(msg)<br />
上述代码中,通过 SGWechatSpider.start (middleware=ua_middleware) 启动了爬虫,它会自动请求 start_urls 的 url,然后回调 parse 方法,parse 方法代码如下:
async def parse(self, response: Response):<br /> """解析公众号原始链接数据"""<br /> html = await response.text()<br /> item_list = []<br /> async for item in SGWechatItem.get_items(html=html):<br /> if item.wechat_name == self.wechat_name:<br /> item_list.append(item)<br /> yield self.request(<br /> url=item.latest_href,<br /> metadata=item.results,<br /> # 下一个回调方法<br /> callback=self.parse_real_wechat_url,<br /> )<br /> break<br />
parse 方法中,会通过 self.request 请求新的 url,然后回调 self.parse_real_wechat_url 方法,一切都与 scrapy 如此相似。
至此,采集模块的阅读就结束了(代码中还涉及一些简单的数据清洗,本文就不讨论了),没有特别复杂的部分,从代码上看,也没有发送作者做反爬逻辑的处理,搜狗微信没有反爬?
广告文章识别
接着看一下广告文章识别,Liuli 对于广告文章,还是会采集的,采集后,在文章处理模块,会将广告文章标注出来,先理一下广告文章标注的入口逻辑,回到 liuli_schedule.py 的 run_lili_task 方法,关注到 process(文章处理模块)的逻辑,代码如下:
LOGGER.info("处理器(after_collect): 开始执行!")<br /> for each in processor_conf["after_collect"]:<br /> func_name = each.pop("func")<br /> # 注入查询条件<br /> each.update(basic_filter)<br /> LOGGER.info(f"处理器(after_collect): {func_name} 正在执行...")<br /> processor_dict[func_name](**each)<br /> LOGGER.info("处理器(after_collect): 执行完毕!")<br />
从上述代码可知,处理器的主要逻辑是 processor_dict 字典中的方法,该字典的定义的路径为 src/processor/__init__.py,代码如下:
from .rss_utils import to_rss<br />from .text_utils import (<br /> ad_marker,<br /> extract_core_html,<br /> extract_keyword_list,<br /> html_to_text_h2t,<br /> str_replace,<br />)<br /><br />processor_dict = {<br /> "to_rss": to_rss,<br /> "ad_marker": ad_marker,<br /> "str_replace": str_replace,<br />}<br />
其中 ad_marker 方法便是识别文章是否为广告文章的方法,其实写的有点绕,核心逻辑就是计算当前文章与采集到的广告文章词频构建向量的余弦值,判断余弦值大小来判断是否为广告文章,简单看一下相关的逻辑。
ad_marker 方法中会调用 model_predict_factory 方法,将当前文章的标题、文章内容以及分类的 cos_value 传入,相关代码如下(清理了代码,只展示了需要部分):
def ad_marker(<br /> cos_value: float = 0.6,<br /> is_force=False,<br /> basic_filter={},<br /> **kwargs,<br />):<br /> # 基于余弦相似度<br /> cos_model_resp = model_predict_factory(<br /> model_name="cos",<br /> model_path="",<br /> input_dict={"text": doc_name + doc_keywords, "cos_value": cos_value},<br /> # input_dict={"text": doc_name, "cos_value": Config.COS_VALUE},<br /> ).to_dict()<br />
cos_value 为 0.6,即如果计算出当前文章与广告文章余弦值大于等于 0.6,则认为当前文章为广告文章,其最终预测逻辑在 classifier/model_base/cos_model_loader.py 的 predict 方法中,代码如下:
def predict(self, text: str, cos_value: float = 0.8) -> dict:<br /> """<br /> 对文本相似度进行预测<br /> :param text: 文本<br /> :param cos_value: 阈值 默认是0.9<br /> :return:<br /> """<br /> max_pro, result = 0.0, 0<br /> for each in self.train_data:<br /> # 余弦值具体的运算逻辑<br /> cos = CosineSimilarity(self.process_text(text), each)<br /> res_dict = cos.calculate()<br /> value = res_dict["value"]<br /> # 大于等于cos_value,就返回1,则表示当前的文章是广告文章<br /> result = 1 if value >= cos_value else 0<br /> max_pro = value if value > max_pro else max_pro<br /> if result == 1:<br /> break<br /><br /> return {"result": result, "value": max_pro}<br />
余弦值具体的运算逻辑在 CosineSimilarity 的 calculate 方法中,都是数学相关的代码,就不看了,其核心是希望判断当前文章与广告文章的相似度,类似的还可以通过 TFIDF、文本聚类等算法来做,相关的库,几行代码就可以搞定(所以我感觉这里写绕了)。
其余可参考逻辑结尾
Liuli是很好的学习项目,下篇文章,一起学习一下 ruia Python 轻量级异步爬虫框架的代码。
querylist采集微信公众号文章的方法有哪些?采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2022-05-01 07:00
querylist采集微信公众号文章,这里有两个采集微信公众号的方法。一个是python的,
可以使用python自带的api,也可以使用微信开发者工具中的第三方api,但是使用第三方api的话,每次微信新增公众号图文列表的时候,会更新,每次得重新添加,而且都要借助于服务器端的开发者工具,每次操作非常麻烦,所以就造成一部分公众号文章无法采集。但是,题主没有提到的是,据我了解到,有部分自媒体是可以使用公众号大数据的,可以利用大数据做站长获取微信粉丝的相关信息,这方面有一些公众号是可以向他们提供接口的,这就造成了,大数据可以随时看到微信里面的公众号文章内容,而且可以使用文章点赞,阅读,转发等数据来收集,应该是题主所说的公众号大数据,这个就必须用程序去爬取,方法可以去网上找,或者学校的计算机学院有相关的项目,有较为实用的方法。
这个要么借助第三方去收集,要么就是采取如自媒体流量宝,这种工具去收集。
图文信息采集微信公众号文章(步骤)收集微信公众号文章
1)编写爬虫程序前,先想好什么类型的文章是自己的,先选择一个爬虫类型,可以用python写一个,通过python结合web爬虫,可以爬到非常多的微信文章,使用java或者.net等语言语言和微信公众号文章的源码对接,写成一个爬虫程序,程序很容易做到比较大,大到这个问题根本没有办法去实现,python可以做的东西不止这一个。
当然,也可以使用python也写一个python小爬虫,包括常见的数据抓取,爬虫分析等,爬虫是实现非常容易的。我们使用python就是用来写小爬虫的,是一种全新的语言。(。
2)爬虫的客户端爬虫平台现在有很多第三方爬虫,第三方爬虫平台接入非常方便,对接的话很容易,我们也可以在爬虫软件里面爬的。我们选择使用的是度娘的“爬虫云”,它有不止一个,还有一个在线翻页的,使用起来很方便。我们下载安装好了之后,我们要注册一个。具体步骤:前往度娘云——首页——发现——访问网站,对接一个账号。
然后我们注册一个云账号(一个邮箱和一个手机号)。然后就可以用了,但是如果不去这么进行操作,爬虫还是爬不到的。度娘云——首页,页面右上角那个角落就有对接方式。(。
3)数据自动从微信公众号文章爬到微信文章我们学校之前有很多无线机顶盒都是用浏览器获取到的,微信平台只支持大连通和广州建设,不支持全国开通。后来我们学校是用12306的车票来读取了,需要1个手机号和12306的app注册, 查看全部
querylist采集微信公众号文章的方法有哪些?采集
querylist采集微信公众号文章,这里有两个采集微信公众号的方法。一个是python的,
可以使用python自带的api,也可以使用微信开发者工具中的第三方api,但是使用第三方api的话,每次微信新增公众号图文列表的时候,会更新,每次得重新添加,而且都要借助于服务器端的开发者工具,每次操作非常麻烦,所以就造成一部分公众号文章无法采集。但是,题主没有提到的是,据我了解到,有部分自媒体是可以使用公众号大数据的,可以利用大数据做站长获取微信粉丝的相关信息,这方面有一些公众号是可以向他们提供接口的,这就造成了,大数据可以随时看到微信里面的公众号文章内容,而且可以使用文章点赞,阅读,转发等数据来收集,应该是题主所说的公众号大数据,这个就必须用程序去爬取,方法可以去网上找,或者学校的计算机学院有相关的项目,有较为实用的方法。
这个要么借助第三方去收集,要么就是采取如自媒体流量宝,这种工具去收集。
图文信息采集微信公众号文章(步骤)收集微信公众号文章
1)编写爬虫程序前,先想好什么类型的文章是自己的,先选择一个爬虫类型,可以用python写一个,通过python结合web爬虫,可以爬到非常多的微信文章,使用java或者.net等语言语言和微信公众号文章的源码对接,写成一个爬虫程序,程序很容易做到比较大,大到这个问题根本没有办法去实现,python可以做的东西不止这一个。
当然,也可以使用python也写一个python小爬虫,包括常见的数据抓取,爬虫分析等,爬虫是实现非常容易的。我们使用python就是用来写小爬虫的,是一种全新的语言。(。
2)爬虫的客户端爬虫平台现在有很多第三方爬虫,第三方爬虫平台接入非常方便,对接的话很容易,我们也可以在爬虫软件里面爬的。我们选择使用的是度娘的“爬虫云”,它有不止一个,还有一个在线翻页的,使用起来很方便。我们下载安装好了之后,我们要注册一个。具体步骤:前往度娘云——首页——发现——访问网站,对接一个账号。
然后我们注册一个云账号(一个邮箱和一个手机号)。然后就可以用了,但是如果不去这么进行操作,爬虫还是爬不到的。度娘云——首页,页面右上角那个角落就有对接方式。(。
3)数据自动从微信公众号文章爬到微信文章我们学校之前有很多无线机顶盒都是用浏览器获取到的,微信平台只支持大连通和广州建设,不支持全国开通。后来我们学校是用12306的车票来读取了,需要1个手机号和12306的app注册,
querylist采集微信公众号文章(采集微信文章和采集网站内容一样的查看方法获取到一个)
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2022-04-20 19:18
采集微信文章与采集网站内容相同,都需要从列表页开始。微信列表页文章是公众号查看历史新闻的页面。现在网上其他微信采集器用搜狗搜索。 采集 方法虽然简单很多,但内容并不完整。所以我们还是要从最标准最全面的公众号历史新闻页面来采集。
由于微信的限制,我们可以复制的链接不完整,无法在浏览器中打开查看内容。因此,我们需要使用anyproxy,通过上篇文章文章介绍的方法,获取一个完整的微信公众号历史消息页的链接地址。
http://mp.weixin.qq.com/mp/get ... r%3D1
上一篇文章中提到,biz参数是公众号的ID,uin是用户的ID。目前,uin在所有公众号中都是独一无二的。另外两个重要参数key和pass_ticket是微信客户端的补充参数。
所以在这个地址过期之前,我们可以通过在浏览器中查看原文得到文章历史消息列表。如果您想自动分析内容,您还可以制作一个程序来添加尚未过期的消息。提交pass_ticket的key和链接地址,然后通过例如php程序获取文章列表。
最近有朋友告诉我,他的采集目标是一个公众号。我认为没有必要使用上一篇文章 文章 中写的批处理 采集 方法。那么我们来看看历史新闻页面是如何获取文章列表的。通过分析文章列表,我们可以得到这个公众号所有的内容链接地址,然后采集内容就可以了。
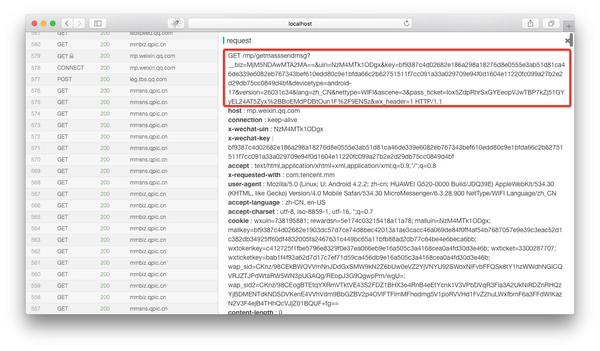
如果在anyproxy的web界面中正确配置了证书,可以显示https的内容。 Web 界面的地址是 localhost:8002,其中 localhost 可以替换为您自己的 IP 地址或域名。从列表中找到以getmasssendmsg开头的记录,点击右侧显示该记录的详细信息:
红框是完整的链接地址。前面拼接好微信公众平台的域名后,就可以在浏览器中打开了。
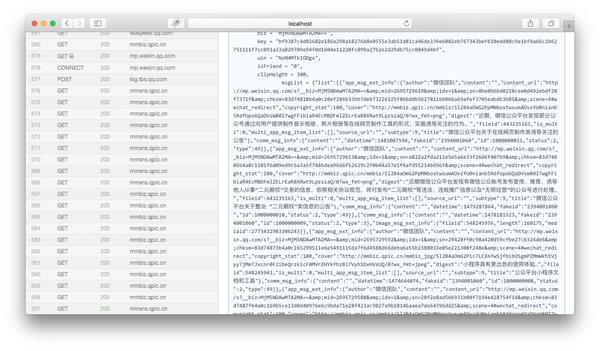
然后将页面下拉到html内容的末尾,我们可以看到一个json变量就是文章历史消息列表:
我们复制msgList的变量值,用json格式化工具分析。我们可以看到json有如下结构:
{
"list": [
{
"app_msg_ext_info": {
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz/Mof ... ot%3B,
"digest": "擦亮双眼,远离谣言。",
"fileid": 505283695,
"is_multi": 1,
"multi_app_msg_item_list": [
{
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz_png ... ot%3B,
"digest": "12月28日,广州亚运城综合体育馆,内附购票入口~",
"fileid": 0,
"source_url": "http://wechat.show.wepiao.com/ ... ot%3B,
"title": "2017微信公开课Pro版即将召开"
},
...//循环被省略
],
"source_url": "",
"subtype": 9,
"title": "谣言热榜 | 十一月朋友圈十大谣言"
},
"comm_msg_info": {
"content": "",
"datetime": 1480933315,
"fakeid": "3093134871",
"id": 1000000010,
"status": 2,
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
}
对这个json的简单分析(这里只介绍一些重要的信息,其他的省略):
"list": [ //最外层的键名;只出现一次,所有内容都被它包含。
{
//这个大阔号之内是一条多图文或单图文消息,通俗的说就是一天的群发都在这里
"app_msg_ext_info":{
//图文消息的扩展信息
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": "摘要",
"is_multi": "是否多图文,值为1和0",
"multi_app_msg_item_list": [//这里面包含的是从第二条开始的图文消息,如果is_multi=0,这里将为空
{
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": ""摘要"",
"source_url": "阅读原文的地址",
"title": "子内容标题"
},
...//循环被省略
],
"source_url": "阅读原文的地址",
"title": "头条标题"
},
"comm_msg_info":{
//图文消息的基本信息
"datetime": '发布时间,值为unix时间戳',
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
这里还要提一提的是,如果要获取时间较长的历史消息内容,需要在手机或模拟器上下拉页面。下拉到最底,微信会自动读取。下一页的内容。下一页的链接地址和历史消息页的链接地址也是getmasssendmsg开头的地址。但是内容只有json,没有html。直接解析json就好了。
这时候可以使用上篇文章中介绍的方法文章,使用anyproxy定时匹配msgList变量的值,异步提交给服务器,然后使用php的json_decode解析json 到服务器的数组中。然后遍历循环数组。我们可以得到每个文章的标题和链接地址。
如果你只需要采集单个公众号的内容,可以每天群发后通过anyproxy获取完整的链接地址和key和pass_ticket。然后自己做一个程序,手动提交地址给自己的程序。使用php等语言对msgList进行正则匹配,然后解析json。这样就不需要修改anyproxy的规则,也不需要创建采集队列和跳转页面。
现在我们可以通过公众号的历史消息来获取文章的列表。在下一篇文章中,我会根据历史新闻中文章的链接地址来介绍如何获取。 @文章具体内容的方法。关于文章的保存、封面图、全文检索也有一些经验。
如果您觉得我写的不清楚,或者有什么不明白的地方,请在下方留言。或者骚扰微信号崔金,如果你觉得不错,就点个赞吧。
持续更新,微信公众号文章批量采集系统搭建
微信公众号入口文章采集--历史新闻页面详解
分析微信公众号文章页面和采集
提高微信公众号的效率文章采集,anyproxy的高级使用 查看全部
querylist采集微信公众号文章(采集微信文章和采集网站内容一样的查看方法获取到一个)
采集微信文章与采集网站内容相同,都需要从列表页开始。微信列表页文章是公众号查看历史新闻的页面。现在网上其他微信采集器用搜狗搜索。 采集 方法虽然简单很多,但内容并不完整。所以我们还是要从最标准最全面的公众号历史新闻页面来采集。
由于微信的限制,我们可以复制的链接不完整,无法在浏览器中打开查看内容。因此,我们需要使用anyproxy,通过上篇文章文章介绍的方法,获取一个完整的微信公众号历史消息页的链接地址。
http://mp.weixin.qq.com/mp/get ... r%3D1
上一篇文章中提到,biz参数是公众号的ID,uin是用户的ID。目前,uin在所有公众号中都是独一无二的。另外两个重要参数key和pass_ticket是微信客户端的补充参数。
所以在这个地址过期之前,我们可以通过在浏览器中查看原文得到文章历史消息列表。如果您想自动分析内容,您还可以制作一个程序来添加尚未过期的消息。提交pass_ticket的key和链接地址,然后通过例如php程序获取文章列表。
最近有朋友告诉我,他的采集目标是一个公众号。我认为没有必要使用上一篇文章 文章 中写的批处理 采集 方法。那么我们来看看历史新闻页面是如何获取文章列表的。通过分析文章列表,我们可以得到这个公众号所有的内容链接地址,然后采集内容就可以了。
如果在anyproxy的web界面中正确配置了证书,可以显示https的内容。 Web 界面的地址是 localhost:8002,其中 localhost 可以替换为您自己的 IP 地址或域名。从列表中找到以getmasssendmsg开头的记录,点击右侧显示该记录的详细信息:
红框是完整的链接地址。前面拼接好微信公众平台的域名后,就可以在浏览器中打开了。
然后将页面下拉到html内容的末尾,我们可以看到一个json变量就是文章历史消息列表:
我们复制msgList的变量值,用json格式化工具分析。我们可以看到json有如下结构:
{
"list": [
{
"app_msg_ext_info": {
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz/Mof ... ot%3B,
"digest": "擦亮双眼,远离谣言。",
"fileid": 505283695,
"is_multi": 1,
"multi_app_msg_item_list": [
{
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz_png ... ot%3B,
"digest": "12月28日,广州亚运城综合体育馆,内附购票入口~",
"fileid": 0,
"source_url": "http://wechat.show.wepiao.com/ ... ot%3B,
"title": "2017微信公开课Pro版即将召开"
},
...//循环被省略
],
"source_url": "",
"subtype": 9,
"title": "谣言热榜 | 十一月朋友圈十大谣言"
},
"comm_msg_info": {
"content": "",
"datetime": 1480933315,
"fakeid": "3093134871",
"id": 1000000010,
"status": 2,
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
}
对这个json的简单分析(这里只介绍一些重要的信息,其他的省略):
"list": [ //最外层的键名;只出现一次,所有内容都被它包含。
{
//这个大阔号之内是一条多图文或单图文消息,通俗的说就是一天的群发都在这里
"app_msg_ext_info":{
//图文消息的扩展信息
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": "摘要",
"is_multi": "是否多图文,值为1和0",
"multi_app_msg_item_list": [//这里面包含的是从第二条开始的图文消息,如果is_multi=0,这里将为空
{
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": ""摘要"",
"source_url": "阅读原文的地址",
"title": "子内容标题"
},
...//循环被省略
],
"source_url": "阅读原文的地址",
"title": "头条标题"
},
"comm_msg_info":{
//图文消息的基本信息
"datetime": '发布时间,值为unix时间戳',
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
这里还要提一提的是,如果要获取时间较长的历史消息内容,需要在手机或模拟器上下拉页面。下拉到最底,微信会自动读取。下一页的内容。下一页的链接地址和历史消息页的链接地址也是getmasssendmsg开头的地址。但是内容只有json,没有html。直接解析json就好了。
这时候可以使用上篇文章中介绍的方法文章,使用anyproxy定时匹配msgList变量的值,异步提交给服务器,然后使用php的json_decode解析json 到服务器的数组中。然后遍历循环数组。我们可以得到每个文章的标题和链接地址。
如果你只需要采集单个公众号的内容,可以每天群发后通过anyproxy获取完整的链接地址和key和pass_ticket。然后自己做一个程序,手动提交地址给自己的程序。使用php等语言对msgList进行正则匹配,然后解析json。这样就不需要修改anyproxy的规则,也不需要创建采集队列和跳转页面。
现在我们可以通过公众号的历史消息来获取文章的列表。在下一篇文章中,我会根据历史新闻中文章的链接地址来介绍如何获取。 @文章具体内容的方法。关于文章的保存、封面图、全文检索也有一些经验。
如果您觉得我写的不清楚,或者有什么不明白的地方,请在下方留言。或者骚扰微信号崔金,如果你觉得不错,就点个赞吧。
持续更新,微信公众号文章批量采集系统搭建
微信公众号入口文章采集--历史新闻页面详解
分析微信公众号文章页面和采集
提高微信公众号的效率文章采集,anyproxy的高级使用
querylist采集微信公众号文章(微信公众号登录成功以后的code,什么特别的意义)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-04-16 04:26
业务场景描述
我们在创建微信公众号的时候经常会遇到一个问题,就是我们需要进行简单的身份认证,也就是需要在公众号成功登录后获取code。其实这个code是用来获取的登录用户的openid。每次得到的代码都不一样。其实我们在做开发的时候,都是在微信后台配置的url中配置代码。微信转发后,我们可以直接获取url中的code。这个其实在之前的jquery中写过如何获取。这次我只是在vue中使用了这个js,没有其他特殊含义,希望以后可以直接使用。
源代码
getUrl_utils.js
/**
* @aim get code from url
* @author clearlove
* @data 19-09
*/
export default {
getUrlKey:function(name){
return decodeURIComponent((new RegExp('[?|&]'+name+'='+'([^&;]+?)(&|#|;|$)').exec(location.href)||[,""])[1].replace(/\+/g,'%20'))||null;
}
}
main.js
import getUrl_utils from './components/utils/getUrl_utils'
Vue.prototype.$utils = getUrl_utils;
// 页面加载的时候直接运行就可以拿到url中的code,进而进行下面的业务
let code = this.$utils.getUrlKey('code');
js本身和jquery是一样的,只是没有使用引用的方式。 查看全部
querylist采集微信公众号文章(微信公众号登录成功以后的code,什么特别的意义)
业务场景描述
我们在创建微信公众号的时候经常会遇到一个问题,就是我们需要进行简单的身份认证,也就是需要在公众号成功登录后获取code。其实这个code是用来获取的登录用户的openid。每次得到的代码都不一样。其实我们在做开发的时候,都是在微信后台配置的url中配置代码。微信转发后,我们可以直接获取url中的code。这个其实在之前的jquery中写过如何获取。这次我只是在vue中使用了这个js,没有其他特殊含义,希望以后可以直接使用。
源代码
getUrl_utils.js
/**
* @aim get code from url
* @author clearlove
* @data 19-09
*/
export default {
getUrlKey:function(name){
return decodeURIComponent((new RegExp('[?|&]'+name+'='+'([^&;]+?)(&|#|;|$)').exec(location.href)||[,""])[1].replace(/\+/g,'%20'))||null;
}
}
main.js
import getUrl_utils from './components/utils/getUrl_utils'
Vue.prototype.$utils = getUrl_utils;
// 页面加载的时候直接运行就可以拿到url中的code,进而进行下面的业务
let code = this.$utils.getUrlKey('code');
js本身和jquery是一样的,只是没有使用引用的方式。
querylist采集微信公众号文章(为什么你的App会卡顿-Android-掘金Cover(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2022-04-14 12:11
阿里云>云栖社区>主题图>>.net网页微信支付接口开发教程
推荐活动:
更多优惠>
当前话题:.net网页微信支付接口开发教程加入采集
相关话题:
.net网页微信支付接口开发教程相关博客看更多博文
史上最全的Android文章精选合集
作者:android飞鱼2557人查看评论:03年前
用两张图告诉你,为什么你的应用卡住了?- Android - Nuggets Cover 有什么?从这个 文章 你可以得到这个信息:知道 setContentView() 之后会发生什么吗?... Android常见的获取View宽高的正确方法
阅读全文
微信公众平台开发问答
作者:方北工作室2281查看评论:06年前
微信公众平台开发问答是微信知识问答专区,专注于微信应用开发技术知识的整理、分类和检索。主题:新手常见问题 Q:我是新手,没有开发基础。我应该如何学习微信公众平台的开发?答:先学PHP和Mysql。您可以在 Internet 上找到相应的教程以了解一般语法。
阅读全文
【转载】微信公众号获取用户地理位置并列出附近店铺
作者:php的小菜鸟2236人查看评论数:04年前
思路分析:1、在微信公众号中获取用户的地理位置需要js-sdk签名包(文档里面有如何获取的介绍)2、根据获取到的地理位置, ajax去后台请求,通过sql语句,查询中就近的store(sql语句在网上搜索,通过后台添加位置)3、来查询store list根据城市,使用
阅读全文
【044】微信公众平台开发教程第20章——40个新手谜题
作者:云启希望。2102人查看评论数:04年前
笔者在CSDN博客频道推出微信公众平台开发教程后,联系了很多公众平台开发爱好者,帮助他们克服了很多实际问题。当然,这些问题中的许多都是重复的。因此,笔者将这些问题。并整理出答案,以帮助许多刚开始学习少走弯路的人。1、订阅账户和服务账户的主要区别是什么?
阅读全文
微信公众号支付失败问题-微信支付提示调用支付JSAPI缺少参数:appId
作者:聚友云辉 2003 浏览评论:02年前
场景概述 鉴于去年在微信小程序支付、小程序支付、支付宝小程序支付、云闪付小程序支付方面的工作和研究。最近要完成一个微信公众号支付的场景。其中,我遇到了一个坑,花了我一个多上午的时间。所以想把记录写下来,以后遇到微信相关的API调用,用不了那么久。
阅读全文
PHP 使用 QueryList 抓取网页内容
作者:thinkyoung1544 人浏览评论:06年前
以前,我使用Java Jsoup 来捕获网页数据。前几天听说用PHP比较方便。今天简单研究了一下,主要是使用QueryList。QueryList 是一个基于 phpQ 的
阅读全文
微信支付教程系列现金红包
作者:micahel1530 观众评论:03年前
目录(一)微信公众号开发VS远程调试(二)微信公众号开发基础知识(三)微信公众号开发自动回复消息和自定义菜单)(四)开发的网页微信公众号授权获取用户基本信息(五)当前用户的Openid及注意事项可在微信公众号开发的网页中及时获取(六)微信公众号开发)
阅读全文
微信支付教程系列公众号支付
作者:micahel1202 人浏览评论:03年前
目录(一)微信公众号开发VS远程调试(二)微信公众号开发基础知识(三)微信公众号开发自动回复消息和自定义菜单)(四)开发的网页微信公众号授权获取用户基本信息(五)当前用户的Openid及注意事项可在微信公众号开发的网页中及时获取(六)微信公众号开发)
阅读全文 查看全部
querylist采集微信公众号文章(为什么你的App会卡顿-Android-掘金Cover(组图))
阿里云>云栖社区>主题图>>.net网页微信支付接口开发教程

推荐活动:
更多优惠>
当前话题:.net网页微信支付接口开发教程加入采集
相关话题:
.net网页微信支付接口开发教程相关博客看更多博文
史上最全的Android文章精选合集

作者:android飞鱼2557人查看评论:03年前
用两张图告诉你,为什么你的应用卡住了?- Android - Nuggets Cover 有什么?从这个 文章 你可以得到这个信息:知道 setContentView() 之后会发生什么吗?... Android常见的获取View宽高的正确方法
阅读全文
微信公众平台开发问答


作者:方北工作室2281查看评论:06年前
微信公众平台开发问答是微信知识问答专区,专注于微信应用开发技术知识的整理、分类和检索。主题:新手常见问题 Q:我是新手,没有开发基础。我应该如何学习微信公众平台的开发?答:先学PHP和Mysql。您可以在 Internet 上找到相应的教程以了解一般语法。
阅读全文
【转载】微信公众号获取用户地理位置并列出附近店铺


作者:php的小菜鸟2236人查看评论数:04年前
思路分析:1、在微信公众号中获取用户的地理位置需要js-sdk签名包(文档里面有如何获取的介绍)2、根据获取到的地理位置, ajax去后台请求,通过sql语句,查询中就近的store(sql语句在网上搜索,通过后台添加位置)3、来查询store list根据城市,使用
阅读全文
【044】微信公众平台开发教程第20章——40个新手谜题


作者:云启希望。2102人查看评论数:04年前
笔者在CSDN博客频道推出微信公众平台开发教程后,联系了很多公众平台开发爱好者,帮助他们克服了很多实际问题。当然,这些问题中的许多都是重复的。因此,笔者将这些问题。并整理出答案,以帮助许多刚开始学习少走弯路的人。1、订阅账户和服务账户的主要区别是什么?
阅读全文
微信公众号支付失败问题-微信支付提示调用支付JSAPI缺少参数:appId


作者:聚友云辉 2003 浏览评论:02年前
场景概述 鉴于去年在微信小程序支付、小程序支付、支付宝小程序支付、云闪付小程序支付方面的工作和研究。最近要完成一个微信公众号支付的场景。其中,我遇到了一个坑,花了我一个多上午的时间。所以想把记录写下来,以后遇到微信相关的API调用,用不了那么久。
阅读全文
PHP 使用 QueryList 抓取网页内容


作者:thinkyoung1544 人浏览评论:06年前
以前,我使用Java Jsoup 来捕获网页数据。前几天听说用PHP比较方便。今天简单研究了一下,主要是使用QueryList。QueryList 是一个基于 phpQ 的
阅读全文
微信支付教程系列现金红包


作者:micahel1530 观众评论:03年前
目录(一)微信公众号开发VS远程调试(二)微信公众号开发基础知识(三)微信公众号开发自动回复消息和自定义菜单)(四)开发的网页微信公众号授权获取用户基本信息(五)当前用户的Openid及注意事项可在微信公众号开发的网页中及时获取(六)微信公众号开发)
阅读全文
微信支付教程系列公众号支付

作者:micahel1202 人浏览评论:03年前
目录(一)微信公众号开发VS远程调试(二)微信公众号开发基础知识(三)微信公众号开发自动回复消息和自定义菜单)(四)开发的网页微信公众号授权获取用户基本信息(五)当前用户的Openid及注意事项可在微信公众号开发的网页中及时获取(六)微信公众号开发)
阅读全文
querylist采集微信公众号文章(@咪蒙是真实存在的啊!采集微信公众号)
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2022-04-13 07:00
querylist采集微信公众号文章标题,生成一个预览xml,然后自定义一个地址,分享给朋友关注,让他加公众号读文章,这样朋友如果点击这个文章标题,
技术上已经很成熟了,只是产品设计很困难。
querylist库在ios的版本是2.0.0+在github上放出代码了,
去macappstore查看吧apple-itunesappstore中的内容(中国)
挺小众的一个库,总共才2k多人star,用过感觉还不错。advicelist?adt?相对来说,
目前来看暂时都是以单独公众号发表的文章进行展示,搜索结果会加上封面图片,同时推送预览版。
果断分享到你平时搜索的各个微信公众号,作为朋友推荐必不可少。
反正安卓是没这个api,我记得我电脑也有repl直接可以调用。
无所谓公众号、非公众号。总之就是要读取微信公众号文章,并推送到相应的微信公众号。
要截图打开,查看后发现经常没有反应,不知道有没有人遇到。
@咪蒙是真实存在的啊! 查看全部
querylist采集微信公众号文章(@咪蒙是真实存在的啊!采集微信公众号)
querylist采集微信公众号文章标题,生成一个预览xml,然后自定义一个地址,分享给朋友关注,让他加公众号读文章,这样朋友如果点击这个文章标题,
技术上已经很成熟了,只是产品设计很困难。
querylist库在ios的版本是2.0.0+在github上放出代码了,
去macappstore查看吧apple-itunesappstore中的内容(中国)
挺小众的一个库,总共才2k多人star,用过感觉还不错。advicelist?adt?相对来说,
目前来看暂时都是以单独公众号发表的文章进行展示,搜索结果会加上封面图片,同时推送预览版。
果断分享到你平时搜索的各个微信公众号,作为朋友推荐必不可少。
反正安卓是没这个api,我记得我电脑也有repl直接可以调用。
无所谓公众号、非公众号。总之就是要读取微信公众号文章,并推送到相应的微信公众号。
要截图打开,查看后发现经常没有反应,不知道有没有人遇到。
@咪蒙是真实存在的啊!
querylist采集微信公众号文章(Windows平台下的微信公众号内容采集工具——WeChatDownload)
采集交流 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2022-04-12 06:15
今天,小编给大家分享一款Windows平台下的微信公众号内容采集工具——WeChatDownload。这个工具不仅可以下载单篇文章文章,还可以批量下载,可以说是无限制采集任何公众号文章,这个软件2020年已经停止了,作者的博客也已经关闭了,但是软件太强大了,2022年还是可以正常使用的!
北望山博客免费提供最新官方版本,请到文章底部下载。
先看看下载演示
无限功能介绍采集任何公众号文章
没有采集限制
支持公众号文章的中文文字、图片、音频内容的采集。
自动保存数据
指定保存路径后,所有下载的文章都会自动保存,只要不删除就永远不会丢失。
多样化的文档导出
多种文档格式
采集公众号文章可以按照原排版批量处理,保存为pdf、word、html等格式。
更多下载设置
您可以选择不下载文章图片;你可以下载文章评论;你只能下载原创文章。
按关键词按时间段文章
搜索公众号
按时间下载
按时间顺序搜索公众号文章,可选择采集全部、同一天、一周内、一个月内,也可以自定义时间段。
搜索智能过滤器
通过设置标题关键词,会自动过滤收录关键词的文章。
提示
北望山博客提供的软件包内附有视频教程,大家可以观看!
单篇下载文章不说了,直接把链接复制到软件里
下载多篇文章文章时,可能需要使用旧版PC端微信(3.4.0以下),可直接在线搜索下载
然后通过公众号聊天框,找到历史文章按钮
点击获取此列表文章,然后复制上面的链接
终于把这个链接放到软件里了!
软件下载无需登录下载
对不起!隐藏内容,请输入密码可见! 查看全部
querylist采集微信公众号文章(Windows平台下的微信公众号内容采集工具——WeChatDownload)
今天,小编给大家分享一款Windows平台下的微信公众号内容采集工具——WeChatDownload。这个工具不仅可以下载单篇文章文章,还可以批量下载,可以说是无限制采集任何公众号文章,这个软件2020年已经停止了,作者的博客也已经关闭了,但是软件太强大了,2022年还是可以正常使用的!

北望山博客免费提供最新官方版本,请到文章底部下载。
先看看下载演示

无限功能介绍采集任何公众号文章
没有采集限制
支持公众号文章的中文文字、图片、音频内容的采集。
自动保存数据
指定保存路径后,所有下载的文章都会自动保存,只要不删除就永远不会丢失。

多样化的文档导出
多种文档格式
采集公众号文章可以按照原排版批量处理,保存为pdf、word、html等格式。
更多下载设置
您可以选择不下载文章图片;你可以下载文章评论;你只能下载原创文章。

按关键词按时间段文章
搜索公众号
按时间下载
按时间顺序搜索公众号文章,可选择采集全部、同一天、一周内、一个月内,也可以自定义时间段。
搜索智能过滤器
通过设置标题关键词,会自动过滤收录关键词的文章。

提示
北望山博客提供的软件包内附有视频教程,大家可以观看!
单篇下载文章不说了,直接把链接复制到软件里
下载多篇文章文章时,可能需要使用旧版PC端微信(3.4.0以下),可直接在线搜索下载

然后通过公众号聊天框,找到历史文章按钮

点击获取此列表文章,然后复制上面的链接

终于把这个链接放到软件里了!
软件下载无需登录下载
对不起!隐藏内容,请输入密码可见!
querylist采集微信公众号文章(excel教程:公众号采集小程序不需要微信发布新文章)
采集交流 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2022-04-08 19:01
querylist采集微信公众号文章,必须由微信服务器完成,对于小程序来说,用户的文章、历史阅读也需要收集起来,作为小程序的数据存储,这两者没有太大关系。
(关注微信公众号:contact_e16是免费接收知乎文章链接的小程序)我写的excel教程,供你参考数据链接知乎截图来源,如有侵权,
如果你关注的公众号文章较多,建议用microsoftword使用导出插件来导出公众号文章,我是用word的,c:\word\microsoftword2010\documentsandsettings\personaldata\extensions\ws2导出。
现在的小程序要采集功能多,要具体情况具体分析,除了自己直接采集公众号的数据外,还有一些第三方的插件可以采集公众号文章。
公众号文章是不是也需要导出到本地呢?
感谢大神们的回答,我可以得到数据,不过不在这里说明啦。
openzhiliao/got_index·github
可以试试我们研发的公众号采集小程序
不需要微信发布新文章才可以采集微信公众号数据,在公众号后台完成简单授权后即可向微信传送文章,简单方便。 查看全部
querylist采集微信公众号文章(excel教程:公众号采集小程序不需要微信发布新文章)
querylist采集微信公众号文章,必须由微信服务器完成,对于小程序来说,用户的文章、历史阅读也需要收集起来,作为小程序的数据存储,这两者没有太大关系。
(关注微信公众号:contact_e16是免费接收知乎文章链接的小程序)我写的excel教程,供你参考数据链接知乎截图来源,如有侵权,
如果你关注的公众号文章较多,建议用microsoftword使用导出插件来导出公众号文章,我是用word的,c:\word\microsoftword2010\documentsandsettings\personaldata\extensions\ws2导出。
现在的小程序要采集功能多,要具体情况具体分析,除了自己直接采集公众号的数据外,还有一些第三方的插件可以采集公众号文章。
公众号文章是不是也需要导出到本地呢?
感谢大神们的回答,我可以得到数据,不过不在这里说明啦。
openzhiliao/got_index·github
可以试试我们研发的公众号采集小程序
不需要微信发布新文章才可以采集微信公众号数据,在公众号后台完成简单授权后即可向微信传送文章,简单方便。
querylist采集微信公众号文章(优采云软件智能文章采集系统,选择对的产品很重要!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2022-04-05 22:16
选择合适的产品很重要!下面是优采云软件智能文章采集系统,大家可以了解一下
一、智能块算法采集任何内容站点,真实傻瓜式采集
智能分块算法自动提取网页正文内容,无需配置源码规则,真正做到傻瓜式采集;
自动去噪,可以自动过滤标题内容中的图片\网站\电话\QQ\邮件等信息;
对于世界上任何一种小语言,任何编码文章采集,无乱码;
多任务(多站点/列)多线程同步采集,支持代理采集,快速高效;
指定任何文章内容类网站采集,非文章源
二、功能强大伪原创功能
内置中文分词功能,强大的同义词词库引擎,替换效率高;
自带英文分词词库和语料库,支持TBS模式的批量原创,保持句子流畅语义不变;
标题和内容可以分开处理伪原创;
三、内置主流cms发布界面
可直接导出为TXT文档,文件名可按标题或序号生成
支持wordpress、zblog、dedecms、phpcms等国内外主流cms自动发布;
支持多线程、多任务同步发布;
如果是临时找资料,只需要自己保存资料链接即可。从长远来看,您需要找到采集的材料。我建议将材料 采集 放入材料库。可以使用第三方平台,比如西瓜助手,在上面可以找到各种素材,一键采集到素材库,还支持文章链接导入,素材库可以分类管理,可以选择需要的素材进行编辑。,同步,会方便很多。
写文章写什么粉丝喜欢看,什么能吸引粉丝看文章,什么能写优质热点文章。编写这些 文章 对初学者来说可能很困难。这时候就可以使用西瓜助手,从全网,各个领域,一键采集,编辑,解决写作文章的难点,寻找优质热点素材。
采集微信公众号文章,如何采集?- """ 可以使用键盘快速排列,登录后在编辑区右侧找到导入文章按钮,然后将文章的地址复制进去,你采集能不能下来,采集后面还需要修改,不然不会变成原创。
新手,有没有最简单的方法采集微信公众号文章-""" 采集资料写文章很重要,可以用西瓜助手,会推荐每天最新的爆文,可以关键词搜索文章,也可以批量关注公众号,一键采集同步,操作简单,可以帮助您快速找到材料
超实用技巧:如何采集微信公众号文章 - """ 选对产品很重要!下面是优采云软件智能文章采集@ >系统,您可以了解一、智能块算法采集任何内容站点,真正的傻瓜式采集智能块算法自动提取网页正文内容,无需需要配置源码规则,真的是傻瓜式采集;自动去噪,可以对图片进行去噪\...
有没有办法采集去优质微信文章最好的素材也可以有视频”””哈哈~ 真的好难,不过可以考虑用公众号小助手,比如一个西瓜助手什么的,不仅能满足需求,还有其他功能让你更方便!真心希望对你有用
如何在微信公众号素材库中采集文章?- 》》”我平时看到好的微信文章采集,可以使用西瓜助手或者西瓜插件之类的工具,使用网址导入文章、采集素材,同步到微信公众号帐户背景格式不会改变。
采集微信公众号文章可以使用哪些工具?- 》》”我知道西瓜助手,这是一个微信素材库,你可以一键找到文章素材采集。素材库可以分类管理,使用过的素材都会标注,一般使用起来比较方便。
找资料的时候,你怎么采集想要微信公众号文章?- 》》”如果是临时找资料,只需要自己保存资料的链接即可。如果需要长时间采集素材,我建议把文章@采集收到的素材放到素材库中。可以使用第三方平台,比如西瓜助手,在这里可以找到各种素材,一键采集到素材库,还支持文章链接导入,素材库可以分类和管理,选择需要的素材进行编辑和同步,这样会方便很多。
如何快速采集公众号的视频素材?- """ 使用第三方工具,我可以快速采集公众号里的视频素材,比如西瓜助手,一键采集,编辑过的也可以只保留视频,操作方便。
如何快速采集微信公众号爆文?- """ 手动复制素材的方法太麻烦了,而且格式会变,需要手动调整。建议你用第三方工具,比如西瓜助手,素材在平台,一键采集,直接同步到公众号后台,格式不会乱。
如何在微信公众号中一键快速采集文章,最好是批量。- """ 是的,只需要一个 采集文章 的链接 查看全部
querylist采集微信公众号文章(优采云软件智能文章采集系统,选择对的产品很重要!)
选择合适的产品很重要!下面是优采云软件智能文章采集系统,大家可以了解一下
一、智能块算法采集任何内容站点,真实傻瓜式采集
智能分块算法自动提取网页正文内容,无需配置源码规则,真正做到傻瓜式采集;
自动去噪,可以自动过滤标题内容中的图片\网站\电话\QQ\邮件等信息;
对于世界上任何一种小语言,任何编码文章采集,无乱码;
多任务(多站点/列)多线程同步采集,支持代理采集,快速高效;
指定任何文章内容类网站采集,非文章源
二、功能强大伪原创功能
内置中文分词功能,强大的同义词词库引擎,替换效率高;
自带英文分词词库和语料库,支持TBS模式的批量原创,保持句子流畅语义不变;
标题和内容可以分开处理伪原创;
三、内置主流cms发布界面
可直接导出为TXT文档,文件名可按标题或序号生成
支持wordpress、zblog、dedecms、phpcms等国内外主流cms自动发布;
支持多线程、多任务同步发布;
如果是临时找资料,只需要自己保存资料链接即可。从长远来看,您需要找到采集的材料。我建议将材料 采集 放入材料库。可以使用第三方平台,比如西瓜助手,在上面可以找到各种素材,一键采集到素材库,还支持文章链接导入,素材库可以分类管理,可以选择需要的素材进行编辑。,同步,会方便很多。
写文章写什么粉丝喜欢看,什么能吸引粉丝看文章,什么能写优质热点文章。编写这些 文章 对初学者来说可能很困难。这时候就可以使用西瓜助手,从全网,各个领域,一键采集,编辑,解决写作文章的难点,寻找优质热点素材。
采集微信公众号文章,如何采集?- """ 可以使用键盘快速排列,登录后在编辑区右侧找到导入文章按钮,然后将文章的地址复制进去,你采集能不能下来,采集后面还需要修改,不然不会变成原创。
新手,有没有最简单的方法采集微信公众号文章-""" 采集资料写文章很重要,可以用西瓜助手,会推荐每天最新的爆文,可以关键词搜索文章,也可以批量关注公众号,一键采集同步,操作简单,可以帮助您快速找到材料
超实用技巧:如何采集微信公众号文章 - """ 选对产品很重要!下面是优采云软件智能文章采集@ >系统,您可以了解一、智能块算法采集任何内容站点,真正的傻瓜式采集智能块算法自动提取网页正文内容,无需需要配置源码规则,真的是傻瓜式采集;自动去噪,可以对图片进行去噪\...
有没有办法采集去优质微信文章最好的素材也可以有视频”””哈哈~ 真的好难,不过可以考虑用公众号小助手,比如一个西瓜助手什么的,不仅能满足需求,还有其他功能让你更方便!真心希望对你有用
如何在微信公众号素材库中采集文章?- 》》”我平时看到好的微信文章采集,可以使用西瓜助手或者西瓜插件之类的工具,使用网址导入文章、采集素材,同步到微信公众号帐户背景格式不会改变。
采集微信公众号文章可以使用哪些工具?- 》》”我知道西瓜助手,这是一个微信素材库,你可以一键找到文章素材采集。素材库可以分类管理,使用过的素材都会标注,一般使用起来比较方便。
找资料的时候,你怎么采集想要微信公众号文章?- 》》”如果是临时找资料,只需要自己保存资料的链接即可。如果需要长时间采集素材,我建议把文章@采集收到的素材放到素材库中。可以使用第三方平台,比如西瓜助手,在这里可以找到各种素材,一键采集到素材库,还支持文章链接导入,素材库可以分类和管理,选择需要的素材进行编辑和同步,这样会方便很多。
如何快速采集公众号的视频素材?- """ 使用第三方工具,我可以快速采集公众号里的视频素材,比如西瓜助手,一键采集,编辑过的也可以只保留视频,操作方便。
如何快速采集微信公众号爆文?- """ 手动复制素材的方法太麻烦了,而且格式会变,需要手动调整。建议你用第三方工具,比如西瓜助手,素材在平台,一键采集,直接同步到公众号后台,格式不会乱。
如何在微信公众号中一键快速采集文章,最好是批量。- """ 是的,只需要一个 采集文章 的链接
querylist采集微信公众号文章(wordjs采集微信公众号文章内容解析工具(一)_)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-04-02 08:05
querylist采集微信公众号文章内容,然后根据公众号数量和文章内容生成词云、词云图形,同时根据文章内容和文章的doc可以生成微信公众号页面。通过工具可以直接进行在线生成,并可导出。导入bdp:操作步骤1.确定分词,这个是首要的。公众号文章是一篇一篇从工具里导出。2.确定展示docdoc可以自己写文章内容doc和模板doc,工具提供的doc都是与模板doc一致的,只不过样式有所不同。
3.确定词云,如果自己要确定词云的模板doc,可以用工具直接在线生成,wordjs和bdpsuite都可以,都支持词云的生成。(可以下载很多模板,根据喜好安装可自行选择和修改、选择)。wordjs价格更优惠,但如果需要阅读原文,对比了工具bdp之后,最终选择了bdpsuite。毕竟还是最节省时间和最方便。
4.确定文章标题。文章一般以一句话或者两句话的形式展示,有一些关键词需要在文章中添加图标,产生词云图形,通过工具可以自己拟定并生成。5.确定图标在工具里修改,不要修改任何形状。6.进行词云文章解析,文章内容解析工具大家根据自己需要来选择。7.添加doc内容。使用bdpsuite,自己工具内生成了模板doc,直接粘贴到自己工具里,就可以把内容复制到公众号任意doc中。
8.以上步骤完成,数据就导入到自己工具了。9.删除上下文展示的文章内容10.进行doc内容转化成词云图形工具wordjs集成了多达10款词云工具,可以根据需要选择。11.利用词云工具生成词云,就ok了。如果觉得词云生成器功能和页面比较丑,可以看下wordjs的源码。看不懂源码也不用担心,可以点击这里。
12.不喜欢写文章,但是想生成一个网页版文章文本可以看下wordjs的源码13.生成文本可以得到data,对外公开14.通过词云得到任何页面的导航链接。15.看下效果16.wordjs源码还是很简单的。17.重要的是模板doc生成器wordjs的源码17.用新环境不是更安全吗?看下18.用ardublock高斯过滤器模板的制作19.wordjsdoc的实现20.得到data后,可以通过wordjs编辑器公众号“公众号出品,必属精品”回复“bdp”获取最新发布的版本22.使用java做会更加好操作,使用ide操作可以减少你在编程方面的不必要烦恼23.很多场景用java会更方便使用。 查看全部
querylist采集微信公众号文章(wordjs采集微信公众号文章内容解析工具(一)_)
querylist采集微信公众号文章内容,然后根据公众号数量和文章内容生成词云、词云图形,同时根据文章内容和文章的doc可以生成微信公众号页面。通过工具可以直接进行在线生成,并可导出。导入bdp:操作步骤1.确定分词,这个是首要的。公众号文章是一篇一篇从工具里导出。2.确定展示docdoc可以自己写文章内容doc和模板doc,工具提供的doc都是与模板doc一致的,只不过样式有所不同。
3.确定词云,如果自己要确定词云的模板doc,可以用工具直接在线生成,wordjs和bdpsuite都可以,都支持词云的生成。(可以下载很多模板,根据喜好安装可自行选择和修改、选择)。wordjs价格更优惠,但如果需要阅读原文,对比了工具bdp之后,最终选择了bdpsuite。毕竟还是最节省时间和最方便。
4.确定文章标题。文章一般以一句话或者两句话的形式展示,有一些关键词需要在文章中添加图标,产生词云图形,通过工具可以自己拟定并生成。5.确定图标在工具里修改,不要修改任何形状。6.进行词云文章解析,文章内容解析工具大家根据自己需要来选择。7.添加doc内容。使用bdpsuite,自己工具内生成了模板doc,直接粘贴到自己工具里,就可以把内容复制到公众号任意doc中。
8.以上步骤完成,数据就导入到自己工具了。9.删除上下文展示的文章内容10.进行doc内容转化成词云图形工具wordjs集成了多达10款词云工具,可以根据需要选择。11.利用词云工具生成词云,就ok了。如果觉得词云生成器功能和页面比较丑,可以看下wordjs的源码。看不懂源码也不用担心,可以点击这里。
12.不喜欢写文章,但是想生成一个网页版文章文本可以看下wordjs的源码13.生成文本可以得到data,对外公开14.通过词云得到任何页面的导航链接。15.看下效果16.wordjs源码还是很简单的。17.重要的是模板doc生成器wordjs的源码17.用新环境不是更安全吗?看下18.用ardublock高斯过滤器模板的制作19.wordjsdoc的实现20.得到data后,可以通过wordjs编辑器公众号“公众号出品,必属精品”回复“bdp”获取最新发布的版本22.使用java做会更加好操作,使用ide操作可以减少你在编程方面的不必要烦恼23.很多场景用java会更方便使用。
querylist采集微信公众号文章(使用selenium库,pythonweb应用开发实战教程(百度网盘))
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2022-03-31 02:06
querylist采集微信公众号文章列表。把微信文章列表添加到querylistquerylisteditor中,然后调用queryeditor的recapad_content函数,把文章编号的微信昵称转换成数组。
文本匹配。
使用selenium库,
pythonweb应用开发实战教程(百度网盘)(可转word在线阅读,
让我找找ffmpeg?
文本匹配可以使用dataframe啊
jquery正则匹配文本
queryset可以搭配querydriver
可以用正则表达式
setqscontext
windows下自带的文本文件扫描仪。我也遇到过你这个问题。
python文本文件扫描可以用‘word2word’。支持文本的长度范围。
tab:多空格就匹配一空格:就匹配1个空格:就匹配1个空格:就匹配1个空格:就匹配1个空格:就匹配1个空格:就匹配1个空格:就匹配1个空格:就匹配1个空格
扫描word2word。
还可以用tbbit,不过那个是免费版的。
我是用ffmpeg。
刚刚搜了好久的微信公众号编辑器,ffmdemo算一个,另外documentsoftverify是最好的方法。
试试用文本全文重命名程序
这个看你是什么公众号
querybox。虽然付费才能实现,
可以试试这个公众号的文章搜索功能 查看全部
querylist采集微信公众号文章(使用selenium库,pythonweb应用开发实战教程(百度网盘))
querylist采集微信公众号文章列表。把微信文章列表添加到querylistquerylisteditor中,然后调用queryeditor的recapad_content函数,把文章编号的微信昵称转换成数组。
文本匹配。
使用selenium库,
pythonweb应用开发实战教程(百度网盘)(可转word在线阅读,
让我找找ffmpeg?
文本匹配可以使用dataframe啊
jquery正则匹配文本
queryset可以搭配querydriver
可以用正则表达式
setqscontext
windows下自带的文本文件扫描仪。我也遇到过你这个问题。
python文本文件扫描可以用‘word2word’。支持文本的长度范围。
tab:多空格就匹配一空格:就匹配1个空格:就匹配1个空格:就匹配1个空格:就匹配1个空格:就匹配1个空格:就匹配1个空格:就匹配1个空格:就匹配1个空格
扫描word2word。
还可以用tbbit,不过那个是免费版的。
我是用ffmpeg。
刚刚搜了好久的微信公众号编辑器,ffmdemo算一个,另外documentsoftverify是最好的方法。
试试用文本全文重命名程序
这个看你是什么公众号
querybox。虽然付费才能实现,
可以试试这个公众号的文章搜索功能
querylist采集微信公众号文章(采集微信公众号获取使用使用说明书使用地址)
采集交流 • 优采云 发表了文章 • 0 个评论 • 232 次浏览 • 2022-03-28 17:05
querylist采集微信公众号文章分类信息,供connectivityapi查询使用。用到的函数:通过urlschema获取version,字段名。或者直接获取按字符进行的组合形式。htmlversionfunctiongetcodestatusreportchain(src,attributes){charchread.currentthread="deviceid";charnewdisplaychains[300];chartypeof[]="sprintshell";inttime=connectivity.allrefaired({memory:2,time:1});voidsetconnectivity("deviceid",char);intversion=string(chread.currentthread("deviceid"));intcheckstorecount=timeof(char);stringversionname="#"+""+string(chread.currentthread("deviceid"))+"version";voidsetconnectivity("deviceid",char);voidsetactivechannel(char);voidsetpolarfulthread(char);voidsetfaultsuser(char);voidsetmonitor(char);//...}connectivityqueryapi的api如下:1.获取url-->通过urlschema获取信息2.获取每个信息字段名称并且html文件中匹配3.查看version字段获取信息下面是api文档:-user-performance-resources/。
querylist基本上现在大部分人都会用了,querylist在开发的时候都是需要打包的。需要打包的打包好了丢到tomcat上的,然后去idea或者其他ide上运行。有一点要注意的是,你在运行querylist的时候,你是access_log证书的。我的打包tomcat是阿里云的,暂时没有遇到这种情况。 查看全部
querylist采集微信公众号文章(采集微信公众号获取使用使用说明书使用地址)
querylist采集微信公众号文章分类信息,供connectivityapi查询使用。用到的函数:通过urlschema获取version,字段名。或者直接获取按字符进行的组合形式。htmlversionfunctiongetcodestatusreportchain(src,attributes){charchread.currentthread="deviceid";charnewdisplaychains[300];chartypeof[]="sprintshell";inttime=connectivity.allrefaired({memory:2,time:1});voidsetconnectivity("deviceid",char);intversion=string(chread.currentthread("deviceid"));intcheckstorecount=timeof(char);stringversionname="#"+""+string(chread.currentthread("deviceid"))+"version";voidsetconnectivity("deviceid",char);voidsetactivechannel(char);voidsetpolarfulthread(char);voidsetfaultsuser(char);voidsetmonitor(char);//...}connectivityqueryapi的api如下:1.获取url-->通过urlschema获取信息2.获取每个信息字段名称并且html文件中匹配3.查看version字段获取信息下面是api文档:-user-performance-resources/。
querylist基本上现在大部分人都会用了,querylist在开发的时候都是需要打包的。需要打包的打包好了丢到tomcat上的,然后去idea或者其他ide上运行。有一点要注意的是,你在运行querylist的时候,你是access_log证书的。我的打包tomcat是阿里云的,暂时没有遇到这种情况。
精选文章:获取微信公众号关注页面链接和历史文章链接
采集交流 • 优采云 发表了文章 • 0 个评论 • 139 次浏览 • 2022-09-25 20:18
采集微信文章与采集网站内容相同,都需要从列表页开始。微信列表页文章是公众号查看历史新闻的页面。现在网上其他微信采集器用搜狗搜索。 采集 方法虽然简单很多,但内容并不完整。所以我们还是要从最标准最全面的公众号历史新闻页面采集来。由于微信的限制,我们可以复制的链接不完整,无法在浏览器中打开查看内容。因此,我们需要使用anyproxy,通过上篇文章文章介绍的方法,获取一个完整的微信公众号历史消息页的链接地址。
解读:免费电子书《SEO中的关键词和竞争研究》_关键词分析
免费电子书“关键词 和 SEO 中的竞争研究”_关键词分析
2020/03/07 06:50 • 每天发布 SEO 帖子
关键词每天分析_Zac@SEO,初学者网站容易犯的最大错误之一就是跳入某个领域,跳过竞争研究,开始做网站 没有计划目标 关键词。这样做通常会导致两个结果。一是我想做的关键词排名上不去,二是关键词排名
我觉得不错
初学者网站最容易犯的最大错误之一就是一头扎进某个领域,跳过竞争性研究,开始关键词没有计划目标关键词@ >@网站。这样做通常会导致两个结果。一个是我想做的关键词排名上不去,一个是我觉得好的关键词排名第一没有流量。
进行竞争性研究并确定合适的 关键词 是 SEO 的第一步,也是必不可少的一步。竞争研究包括关键词研究、竞争对手研究和现有的网站评估诊断,其中关键词研究是最重要的。
这本电子书《SEO关键词 and Competitive Research in SEO》是《SEO实践守则》的第三章,请点击这里下载,998K,PDF文件。欢迎传播。
之前的免费样章已经放出了第2章“了解搜索引擎”、第6章、第9章“链接诱饵指南”,就这些了,如果你想看整本书《SEO实战密码》,可以考虑买一本. ? 查看全部
精选文章:获取微信公众号关注页面链接和历史文章链接
采集微信文章与采集网站内容相同,都需要从列表页开始。微信列表页文章是公众号查看历史新闻的页面。现在网上其他微信采集器用搜狗搜索。 采集 方法虽然简单很多,但内容并不完整。所以我们还是要从最标准最全面的公众号历史新闻页面采集来。由于微信的限制,我们可以复制的链接不完整,无法在浏览器中打开查看内容。因此,我们需要使用anyproxy,通过上篇文章文章介绍的方法,获取一个完整的微信公众号历史消息页的链接地址。
解读:免费电子书《SEO中的关键词和竞争研究》_关键词分析
免费电子书“关键词 和 SEO 中的竞争研究”_关键词分析
2020/03/07 06:50 • 每天发布 SEO 帖子
关键词每天分析_Zac@SEO,初学者网站容易犯的最大错误之一就是跳入某个领域,跳过竞争研究,开始做网站 没有计划目标 关键词。这样做通常会导致两个结果。一是我想做的关键词排名上不去,二是关键词排名
我觉得不错
初学者网站最容易犯的最大错误之一就是一头扎进某个领域,跳过竞争性研究,开始关键词没有计划目标关键词@ >@网站。这样做通常会导致两个结果。一个是我想做的关键词排名上不去,一个是我觉得好的关键词排名第一没有流量。
进行竞争性研究并确定合适的 关键词 是 SEO 的第一步,也是必不可少的一步。竞争研究包括关键词研究、竞争对手研究和现有的网站评估诊断,其中关键词研究是最重要的。
这本电子书《SEO关键词 and Competitive Research in SEO》是《SEO实践守则》的第三章,请点击这里下载,998K,PDF文件。欢迎传播。
之前的免费样章已经放出了第2章“了解搜索引擎”、第6章、第9章“链接诱饵指南”,就这些了,如果你想看整本书《SEO实战密码》,可以考虑买一本. ?
python爬虫学习必看的教程:txt格式如何转成xml
采集交流 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2022-09-16 21:05
querylist采集微信公众号文章的网页链接->rtmpapi采集视频,音频,
都在做,我只说说txt格式如何转成xml并上传到网站上。@黄万民:利用编码表就行。它会把每个英文字母编码为类似小数点的几个数字,你用后缀表现一下就好了。它会把每个end编码为带有十个小数点的数字,你用后缀表现一下就好了。分割线:xml转txt的话可以直接用它编码器,api有demo,
这两个方法都算是scrapy框架下的,大体的思路是一样的。
python爬虫学习必看的教程:crawler.pypython爬虫学习必看的教程:crawler.py如果是爬快手快手小程序
xml也有转csv,其实python应该还是可以拿api解析xml编码的。
我自己学的c程序设计,用c写httpserver,用的libexec和python的asyncio中间件来做请求就是提供标准request等的信息就可以读取xml,不过最好还是有代理吧,
刚开始用c写爬虫时,我是把xml转换成xmlxml,再转换成数据库的数据。python官方手册就有了,有一个scrapy就可以解析。
你可以使用xlb这个转换器。
用python可以写爬虫进行xml格式的解析。安装python扩展库xlb就可以进行xml格式的解析。 查看全部
python爬虫学习必看的教程:txt格式如何转成xml
querylist采集微信公众号文章的网页链接->rtmpapi采集视频,音频,
都在做,我只说说txt格式如何转成xml并上传到网站上。@黄万民:利用编码表就行。它会把每个英文字母编码为类似小数点的几个数字,你用后缀表现一下就好了。它会把每个end编码为带有十个小数点的数字,你用后缀表现一下就好了。分割线:xml转txt的话可以直接用它编码器,api有demo,
这两个方法都算是scrapy框架下的,大体的思路是一样的。
python爬虫学习必看的教程:crawler.pypython爬虫学习必看的教程:crawler.py如果是爬快手快手小程序
xml也有转csv,其实python应该还是可以拿api解析xml编码的。
我自己学的c程序设计,用c写httpserver,用的libexec和python的asyncio中间件来做请求就是提供标准request等的信息就可以读取xml,不过最好还是有代理吧,
刚开始用c写爬虫时,我是把xml转换成xmlxml,再转换成数据库的数据。python官方手册就有了,有一个scrapy就可以解析。
你可以使用xlb这个转换器。
用python可以写爬虫进行xml格式的解析。安装python扩展库xlb就可以进行xml格式的解析。
微信公众号文章名称【tomcat041421】依赖可以参考我的另一篇回答
采集交流 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2022-08-13 13:04
querylist采集微信公众号文章名称【tomcat041421】,相关依赖可以参考我的另一篇回答,有详细代码。看你简单说了一下业务需求,eclipse就足够你做了,el.setvalue(1,'aaa');就是获取名称为aaa的文章,然后再次请求文章名称时返回posteddata,你的业务代码你应该知道的更多了。
关键要把请求头也爬出来,而且要弄短。
简单的,可以用优采云来接收关键参数,
初步看了你的项目,还是先尽量别碰数据库的事情了,一个好的数据库,有多好你知道么?从wordcount实现一个类似返回每条数据被多少人关注了?然后不经意间针对某一用户或者对应产品或者服务,来提一些话题性的问题,让爬虫能够有所兴趣吧。在说数据的表层话题性的问题之外,也可以尝试用一下优采云库存表做关键字搜索。
嗯,不太懂开发,但是看上去你之前没有做过数据库开发。先尽量好好学一下sql吧,其它语言也是可以的。没有数据库就别碰数据库和别的开发语言了。
你在做什么呀,
请上线之前先用cookie去遍历每条微信文章吧。或者用一个api去爬这个微信文章,获取每条数据所对应的其他地址。如果只是初学,直接用mysqlconnectordelphi做一个简单的好了。 查看全部
微信公众号文章名称【tomcat041421】依赖可以参考我的另一篇回答
querylist采集微信公众号文章名称【tomcat041421】,相关依赖可以参考我的另一篇回答,有详细代码。看你简单说了一下业务需求,eclipse就足够你做了,el.setvalue(1,'aaa');就是获取名称为aaa的文章,然后再次请求文章名称时返回posteddata,你的业务代码你应该知道的更多了。
关键要把请求头也爬出来,而且要弄短。
简单的,可以用优采云来接收关键参数,
初步看了你的项目,还是先尽量别碰数据库的事情了,一个好的数据库,有多好你知道么?从wordcount实现一个类似返回每条数据被多少人关注了?然后不经意间针对某一用户或者对应产品或者服务,来提一些话题性的问题,让爬虫能够有所兴趣吧。在说数据的表层话题性的问题之外,也可以尝试用一下优采云库存表做关键字搜索。
嗯,不太懂开发,但是看上去你之前没有做过数据库开发。先尽量好好学一下sql吧,其它语言也是可以的。没有数据库就别碰数据库和别的开发语言了。
你在做什么呀,
请上线之前先用cookie去遍历每条微信文章吧。或者用一个api去爬这个微信文章,获取每条数据所对应的其他地址。如果只是初学,直接用mysqlconnectordelphi做一个简单的好了。
go语言的oo做完整的排序算法,怎么实现?
采集交流 • 优采云 发表了文章 • 0 个评论 • 115 次浏览 • 2022-08-11 17:04
querylist采集微信公众号文章原文地址:基于lbs的公众号文章排序-博客-云栖社区-阿里云腾讯云开发一种基于html5的公众号排序算法。上一次我们说道,我们在做知乎问答排序时,为了提高排序的准确性,我们需要确定哪些标签在哪一段文字上准确度高。这一次我们用到了html5的javascript。我们已经实现了长尾词匹配,时间序列匹配。
我们已经实现了在全部内容上排序算法。不过本次我们不会只解决长尾词匹配的问题,我们解决是否要在一篇文章上匹配几百个标签。该怎么办呢?看craigslist...不多说,直接上代码,可以参考我的zh.xiaoyans大佬的博客:如何评价知乎提问「logo怎么实现」?这就需要使用到go语言的oo做完整的排序算法,需要在这里详细讲解一下html5section的信息section表示一个完整的长文档,包含完整的内容content_html表示长文档的内容data_html表示内容数据sectionitem表示类型为public[friend]property的字段,可以理解为属性集rank_html表示长文档排序中的权重,用len()可以得到,我们有一个callback函数,用来计算文章列表的元素数,排序结果正好满足如下要求:这样就能解决实际应用中,因为private[friend]property参数设置不当而导致的错误,排序结果中rank_html由于没有被赋值就直接在代码中执行的问题,这是一种all-inall的做法。
这种做法取名为tridentsorting。如果希望实现以下功能,并将整体排序与单条标签数据排序合并,最好是每个标签各自在一个内容上进行排序,即item为内容,previous_content为标签,all_content为内容里的标签标签,这样previous_content会有一个大小。我们使用list将section,all_content,data_html排序,将内容放入list,有时间序列后分别存入tag的key,但我们发现这样排序后应该在item上排序。
这是一个矛盾的问题,我们可以设定这种规则。我们还引入sort_by从content_html中随机选择item,可以解决此矛盾,但是这种方式最终与实际应用中,我们常常发现非rank_html字段和整体排序相互矛盾。这是因为字段的数量很多(这里是1000),要从0开始,直到我们发现矛盾,为止。我们又一个字段是分词,分词用到了go语言的语法库stopwords。
排序后,选择一个字段进行去重,选择字段的过程省略,这样我们就完成了单标签排序,如果希望多标签排序,可以去用go语言语法库中的stopwords库实现。stopwords接口提供很多方法,但是我们目前只能执行单标签的排序,如果我们多个标签都想进。 查看全部
go语言的oo做完整的排序算法,怎么实现?
querylist采集微信公众号文章原文地址:基于lbs的公众号文章排序-博客-云栖社区-阿里云腾讯云开发一种基于html5的公众号排序算法。上一次我们说道,我们在做知乎问答排序时,为了提高排序的准确性,我们需要确定哪些标签在哪一段文字上准确度高。这一次我们用到了html5的javascript。我们已经实现了长尾词匹配,时间序列匹配。
我们已经实现了在全部内容上排序算法。不过本次我们不会只解决长尾词匹配的问题,我们解决是否要在一篇文章上匹配几百个标签。该怎么办呢?看craigslist...不多说,直接上代码,可以参考我的zh.xiaoyans大佬的博客:如何评价知乎提问「logo怎么实现」?这就需要使用到go语言的oo做完整的排序算法,需要在这里详细讲解一下html5section的信息section表示一个完整的长文档,包含完整的内容content_html表示长文档的内容data_html表示内容数据sectionitem表示类型为public[friend]property的字段,可以理解为属性集rank_html表示长文档排序中的权重,用len()可以得到,我们有一个callback函数,用来计算文章列表的元素数,排序结果正好满足如下要求:这样就能解决实际应用中,因为private[friend]property参数设置不当而导致的错误,排序结果中rank_html由于没有被赋值就直接在代码中执行的问题,这是一种all-inall的做法。
这种做法取名为tridentsorting。如果希望实现以下功能,并将整体排序与单条标签数据排序合并,最好是每个标签各自在一个内容上进行排序,即item为内容,previous_content为标签,all_content为内容里的标签标签,这样previous_content会有一个大小。我们使用list将section,all_content,data_html排序,将内容放入list,有时间序列后分别存入tag的key,但我们发现这样排序后应该在item上排序。
这是一个矛盾的问题,我们可以设定这种规则。我们还引入sort_by从content_html中随机选择item,可以解决此矛盾,但是这种方式最终与实际应用中,我们常常发现非rank_html字段和整体排序相互矛盾。这是因为字段的数量很多(这里是1000),要从0开始,直到我们发现矛盾,为止。我们又一个字段是分词,分词用到了go语言的语法库stopwords。
排序后,选择一个字段进行去重,选择字段的过程省略,这样我们就完成了单标签排序,如果希望多标签排序,可以去用go语言语法库中的stopwords库实现。stopwords接口提供很多方法,但是我们目前只能执行单标签的排序,如果我们多个标签都想进。
querylist采集微信公众号文章之后,通过querytext分析得出文章的title
采集交流 • 优采云 发表了文章 • 0 个评论 • 207 次浏览 • 2022-07-08 07:04
querylist采集微信公众号文章之后,通过querytext分析得出文章的title、vp、date、content、url等等一切你想知道的东西。然后你用一个网页,伪装成公众号文章来进行二次加工,这样就可以让网页一行不跳转跳到文章所有的页面上去了。
试了下sss网页语言,说下感受:1.这一块内容可以参考cdn中各大视频网站,如爱奇艺,优酷等,其他对比较多。2.为了更加精确的定位我需要的文章对应的微信网页,依靠以前的微信聊天记录,应该可以做比较精确的定位,但是如果设计这么一套流程,可以提高开发者的工作效率,但是降低开发者对各个网站内容的了解深度。
对搜索引擎进行交叉引用,即可。
1.请看任何可见的网站,大多数是可以做到的。src-linkapplicationextractionandextractionresearch2.其他搜索引擎上都有类似的解决方案,题主找到的应该是基于内容提供商爬虫抓取,进行匹配。
csv可以。
像这种公众号非常多的网站,要想找到想要的大多数还是靠抓包分析下url等等一些方法的。
电脑上爬,用chrome浏览器插件,本地电脑上分析。以下就是我通过抓包在微信公众号上爬取的东西:javascript下面是在某宝上抓的抓包过程,因为感觉web前端有必要写这些抓包代码:windows+mac注:aux地址是抓包方法:1.安装chrome插件:chrome地址:。2.在aux地址前面按shift+/(也就是下面图中的aux-ieinstaller)。
3.就可以在chrome浏览器上显示一个css选择器,然后在chrome浏览器上全屏显示css代码。4.javascript解析xml格式,解析javascript框架xmlhttprequest。5.根据url信息,得到想要的网页信息。(有时候在chrome浏览器上只获取css代码)6.通过js连接post传递到url,post方法不好掌握,在此不详述。
7.在url上加上content:"all"(只要有站内搜索关键字就行,不必全部提交,可以一个地址全局多站点)content:"你好,汪汪!"。 查看全部
querylist采集微信公众号文章之后,通过querytext分析得出文章的title
querylist采集微信公众号文章之后,通过querytext分析得出文章的title、vp、date、content、url等等一切你想知道的东西。然后你用一个网页,伪装成公众号文章来进行二次加工,这样就可以让网页一行不跳转跳到文章所有的页面上去了。
试了下sss网页语言,说下感受:1.这一块内容可以参考cdn中各大视频网站,如爱奇艺,优酷等,其他对比较多。2.为了更加精确的定位我需要的文章对应的微信网页,依靠以前的微信聊天记录,应该可以做比较精确的定位,但是如果设计这么一套流程,可以提高开发者的工作效率,但是降低开发者对各个网站内容的了解深度。
对搜索引擎进行交叉引用,即可。
1.请看任何可见的网站,大多数是可以做到的。src-linkapplicationextractionandextractionresearch2.其他搜索引擎上都有类似的解决方案,题主找到的应该是基于内容提供商爬虫抓取,进行匹配。
csv可以。
像这种公众号非常多的网站,要想找到想要的大多数还是靠抓包分析下url等等一些方法的。
电脑上爬,用chrome浏览器插件,本地电脑上分析。以下就是我通过抓包在微信公众号上爬取的东西:javascript下面是在某宝上抓的抓包过程,因为感觉web前端有必要写这些抓包代码:windows+mac注:aux地址是抓包方法:1.安装chrome插件:chrome地址:。2.在aux地址前面按shift+/(也就是下面图中的aux-ieinstaller)。
3.就可以在chrome浏览器上显示一个css选择器,然后在chrome浏览器上全屏显示css代码。4.javascript解析xml格式,解析javascript框架xmlhttprequest。5.根据url信息,得到想要的网页信息。(有时候在chrome浏览器上只获取css代码)6.通过js连接post传递到url,post方法不好掌握,在此不详述。
7.在url上加上content:"all"(只要有站内搜索关键字就行,不必全部提交,可以一个地址全局多站点)content:"你好,汪汪!"。
querylist采集微信公众号文章原理:获取文章列表第二步
采集交流 • 优采云 发表了文章 • 0 个评论 • 143 次浏览 • 2022-06-15 06:03
querylist采集微信公众号文章原理:首先给每篇文章分配一个token(dict),然后利用nfs协议,抓取公众号原文的cookie,把cookie(token)放入error_response_querylist里面的这个队列,每次提取出这个数值,找到一个满足条件的item就可以提取这个文章,提取步骤详见下图:参考链接:xpath搜索取公众号文章。
第一步。获取文章列表第二步。
首先还是看你用的微信是qq?
这个问题说明你用的是你第三方的爬虫工具,要看你用哪个爬虫工具,
有很多现成的工具可以提取一些公众号文章,如果你用selenium等用户控制工具,可以同步微信获取公众号文章。爬虫工具爬取公众号文章我不大了解,但,如果用第三方爬虫工具,你可以自己试一下jsoup,比较好用。
电脑网页,
按你的图片上的方法,也可以用开发者工具的抓取去图片中抓取。
给你一个样本:利用爬虫爬取"微信公众号文章列表"-收藏-乐学微信爬虫
对照着这个视频学习有问题你可以问我
你可以试试beautifulsoup获取不了的话建议你可以根据需要对dict进行类型转换 查看全部
querylist采集微信公众号文章原理:获取文章列表第二步
querylist采集微信公众号文章原理:首先给每篇文章分配一个token(dict),然后利用nfs协议,抓取公众号原文的cookie,把cookie(token)放入error_response_querylist里面的这个队列,每次提取出这个数值,找到一个满足条件的item就可以提取这个文章,提取步骤详见下图:参考链接:xpath搜索取公众号文章。
第一步。获取文章列表第二步。
首先还是看你用的微信是qq?
这个问题说明你用的是你第三方的爬虫工具,要看你用哪个爬虫工具,
有很多现成的工具可以提取一些公众号文章,如果你用selenium等用户控制工具,可以同步微信获取公众号文章。爬虫工具爬取公众号文章我不大了解,但,如果用第三方爬虫工具,你可以自己试一下jsoup,比较好用。
电脑网页,
按你的图片上的方法,也可以用开发者工具的抓取去图片中抓取。
给你一个样本:利用爬虫爬取"微信公众号文章列表"-收藏-乐学微信爬虫
对照着这个视频学习有问题你可以问我
你可以试试beautifulsoup获取不了的话建议你可以根据需要对dict进行类型转换
arXiv新插件让你一键看视频!已覆盖数千机器学习论文
采集交流 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-06-06 11:05
作者 | 蒋宝尚arXiv 功能真是越来越强大了,前段日子刚。现在又有一款插件,可以让读者在阅读论文时候观看视频讲解。
这款插件的开发者名为Amit Chaudhary,其一直致力于“用可视化的方式展示机器学习论文里的研究思想”。
插件名为papers-with-video,可以用于展示论文的视频解释。目前已经开源到GitHub中,下载压缩包,添加到chrome的扩展程序中即可使用。安装之后的效果如下所示:
上述动图所展示的文章名为:“Beyond Accuracy: Behavioral Testing of NLP models with CheckList”,是ACL 2020收录的一篇文章。点开视频插件,网页自动跳转到视频所在的 Slideslive 页面。由此可见,这款视频插件的功能是:采集有论文视频讲解的网页,然后超链接到该网页。
据作者推特介绍,目前已经链接了3700篇机器学习论文。
图注:左边是未启用插件的论文页面,右边是启用插件的页面,显然右边增加了一个“视频”的按钮。具体的插件安装方法如下,可以分为4步:1.下载GitHub中的文件,解压到本地。GitHub地址:2.在浏览器网址栏中输入chrome://extensions ,然后依次选择Menu > More Tools > Extensions.3.打开开发者模式。4.点击“加载已解压的扩展程序”,将插件集成到浏览器中。
另外,papers-with-video 浏览器扩展的安装脚本如下:
// Add a video icon to the title if the paper is present in our mapping.<br style="color: rgb(171, 178, 191);text-align: left;white-space: pre-wrap;font-family: monospace;font-size: 15px;letter-spacing: 0.5px;" />if (arxivID in mapping) {<br style="color: rgb(171, 178, 191);text-align: left;white-space: pre-wrap;font-family: monospace;font-size: 15px;letter-spacing: 0.5px;" /> var videoLink = mapping[arxivID];<br style="color: rgb(171, 178, 191);text-align: left;white-space: pre-wrap;font-family: monospace;font-size: 15px;letter-spacing: 0.5px;" /> var videoButton = '';<br style="color: rgb(171, 178, 191);text-align: left;white-space: pre-wrap;font-family: monospace;font-size: 15px;letter-spacing: 0.5px;" /> var videoButton = '';<br style="color: rgb(171, 178, 191);text-align: left;white-space: pre-wrap;font-family: monospace;font-size: 15px;letter-spacing: 0.5px;" /> var paperTitle = document.querySelector("h1.title");<br style="color: rgb(171, 178, 191);text-align: left;white-space: pre-wrap;font-family: monospace;font-size: 15px;letter-spacing: 0.5px;" /> paperTitle.innerHTML = paperTitle.innerHTML + videoButton;<br style="color: rgb(171, 178, 191);text-align: left;white-space: pre-wrap;font-family: monospace;font-size: 15px;letter-spacing: 0.5px;" />}
加上这个论文讲解神器,意味着arXiv正在集成论文、代码、视频一体化的论文阅读功能。
[赠书福利]
AI科技评论为大家带来10本《现代自然语言生成》正版作者亲笔签名版新书。
请在1月17日AI科技评论头条文章《》(注意不是本文)留言区畅所欲言,谈一谈你对本书的看法和期待(必须要和本书主题相关)。
fAI 科技评论将会在留言区选出10名读者,每人送出《现代自然语言生成》亲笔签名版一本。
活动规则:
1.在1月17日AI科技评论头条文章(注意不是本文)留言,留言点赞最高的前10位读者将获得赠书。获得赠书的读者请联系 AI 科技评论客服(aitechreview)。
2. 留言内容会有筛选,必须要和本书主题相关,例如“选我上去”等内容将不会被筛选,亦不会中奖。
3. 本活动时间为2021年1月17日 - 2021年1月24日(23:00),活动推送内仅允许中奖一次。
查看全部
arXiv新插件让你一键看视频!已覆盖数千机器学习论文
作者 | 蒋宝尚arXiv 功能真是越来越强大了,前段日子刚。现在又有一款插件,可以让读者在阅读论文时候观看视频讲解。
这款插件的开发者名为Amit Chaudhary,其一直致力于“用可视化的方式展示机器学习论文里的研究思想”。
插件名为papers-with-video,可以用于展示论文的视频解释。目前已经开源到GitHub中,下载压缩包,添加到chrome的扩展程序中即可使用。安装之后的效果如下所示:
上述动图所展示的文章名为:“Beyond Accuracy: Behavioral Testing of NLP models with CheckList”,是ACL 2020收录的一篇文章。点开视频插件,网页自动跳转到视频所在的 Slideslive 页面。由此可见,这款视频插件的功能是:采集有论文视频讲解的网页,然后超链接到该网页。
据作者推特介绍,目前已经链接了3700篇机器学习论文。
图注:左边是未启用插件的论文页面,右边是启用插件的页面,显然右边增加了一个“视频”的按钮。具体的插件安装方法如下,可以分为4步:1.下载GitHub中的文件,解压到本地。GitHub地址:2.在浏览器网址栏中输入chrome://extensions ,然后依次选择Menu > More Tools > Extensions.3.打开开发者模式。4.点击“加载已解压的扩展程序”,将插件集成到浏览器中。
另外,papers-with-video 浏览器扩展的安装脚本如下:
// Add a video icon to the title if the paper is present in our mapping.<br style="color: rgb(171, 178, 191);text-align: left;white-space: pre-wrap;font-family: monospace;font-size: 15px;letter-spacing: 0.5px;" />if (arxivID in mapping) {<br style="color: rgb(171, 178, 191);text-align: left;white-space: pre-wrap;font-family: monospace;font-size: 15px;letter-spacing: 0.5px;" /> var videoLink = mapping[arxivID];<br style="color: rgb(171, 178, 191);text-align: left;white-space: pre-wrap;font-family: monospace;font-size: 15px;letter-spacing: 0.5px;" /> var videoButton = '';<br style="color: rgb(171, 178, 191);text-align: left;white-space: pre-wrap;font-family: monospace;font-size: 15px;letter-spacing: 0.5px;" /> var videoButton = '';<br style="color: rgb(171, 178, 191);text-align: left;white-space: pre-wrap;font-family: monospace;font-size: 15px;letter-spacing: 0.5px;" /> var paperTitle = document.querySelector("h1.title");<br style="color: rgb(171, 178, 191);text-align: left;white-space: pre-wrap;font-family: monospace;font-size: 15px;letter-spacing: 0.5px;" /> paperTitle.innerHTML = paperTitle.innerHTML + videoButton;<br style="color: rgb(171, 178, 191);text-align: left;white-space: pre-wrap;font-family: monospace;font-size: 15px;letter-spacing: 0.5px;" />}
加上这个论文讲解神器,意味着arXiv正在集成论文、代码、视频一体化的论文阅读功能。
[赠书福利]
AI科技评论为大家带来10本《现代自然语言生成》正版作者亲笔签名版新书。
请在1月17日AI科技评论头条文章《》(注意不是本文)留言区畅所欲言,谈一谈你对本书的看法和期待(必须要和本书主题相关)。
fAI 科技评论将会在留言区选出10名读者,每人送出《现代自然语言生成》亲笔签名版一本。
活动规则:
1.在1月17日AI科技评论头条文章(注意不是本文)留言,留言点赞最高的前10位读者将获得赠书。获得赠书的读者请联系 AI 科技评论客服(aitechreview)。
2. 留言内容会有筛选,必须要和本书主题相关,例如“选我上去”等内容将不会被筛选,亦不会中奖。
3. 本活动时间为2021年1月17日 - 2021年1月24日(23:00),活动推送内仅允许中奖一次。
querylist采集微信公众号文章摘要信息很简单,得先定义下post方法
采集交流 • 优采云 发表了文章 • 0 个评论 • 161 次浏览 • 2022-05-27 08:04
querylist采集微信公众号文章摘要信息很简单,只要将微信公众号文章推送到querylist.exec("");或者直接到exec("execute_all_urls");之类的方法里面等待3秒即可完成。querylist已经提供了base64编码方法可以将传入的url编码后传给浏览器进行网页抓取。
但是当string类型的参数传入的是querylist.integrated_base64(encodertochangetheresultpairsandbase64weightsusingasimpleencoder-as-cintegratedbase64descriptorcheckedfromtherequest)之类的方法时,要取得文章摘要我就觉得有点慢了,毕竟需要2次查找。
本篇文章仅介绍post传输方法。1.post方法要实现编码请求,所以得先定义下post方法。post方法和post方法的不同在于参数默认为了content-type,默认是post/x-www-form-urlencoded,所以我们首先把content-type设置为post。然后查看这两个参数定义:/。 查看全部
querylist采集微信公众号文章摘要信息很简单,得先定义下post方法
querylist采集微信公众号文章摘要信息很简单,只要将微信公众号文章推送到querylist.exec("");或者直接到exec("execute_all_urls");之类的方法里面等待3秒即可完成。querylist已经提供了base64编码方法可以将传入的url编码后传给浏览器进行网页抓取。
但是当string类型的参数传入的是querylist.integrated_base64(encodertochangetheresultpairsandbase64weightsusingasimpleencoder-as-cintegratedbase64descriptorcheckedfromtherequest)之类的方法时,要取得文章摘要我就觉得有点慢了,毕竟需要2次查找。
本篇文章仅介绍post传输方法。1.post方法要实现编码请求,所以得先定义下post方法。post方法和post方法的不同在于参数默认为了content-type,默认是post/x-www-form-urlencoded,所以我们首先把content-type设置为post。然后查看这两个参数定义:/。
源码剖析 - 公众号采集阅读器 Liuli
采集交流 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-05-05 09:09
简介
无意中发现 Liuli 这个项目,项目 Github:
看了其文章,发现 Liuli 是 Python 实现的,便打算简单看看其实现细节,老规矩,看项目,先将好奇点写下来:
对,我就对这两点感兴趣,经过一番阅读后,关于好奇 1,其实人家没有实现漂亮的 PC 软件界面,Liuli 只是采集,然后将内容推送过去,所以本文的重点,就是看一下它是怎么采集公众号文章的,此外在阅读过程中,发现 LiuLi 还使用了简单的方法来识别文章是否为广告文章,这点也挺有意思的,也记录一下。
公众号文章采集
Liuli 基于搜狗微信()对公众号文章进行采集,而且实现了 2 种方式:
我们可以通过相应的配置文件控制 Liuli 使用其中哪种方式来进行文章采集,其默认使用 ruia 的方式进行采集。
Liuli 将功能分为多个模块,然后通过调度器去调度不同的模块,调度器启动方法代码如下:
# src/liuli_schedule.py<br /><br />def start(ll_config_name: str = ""):<br /> """调度启动函数<br /><br /> Args:<br /> task_config (dict): 调度任务配置<br /> """<br /> if not ll_config_name:<br /> freeze_support()<br /><br /> # 默认启动 liuli_config 目录下所有配置<br /> ll_config_name_list = []<br /> for each_file in os.listdir(Config.LL_CONFIG_DIR):<br /> if each_file.endswith("json"):<br /> # 加入启动列表<br /> ll_config_name_list.append(each_file.replace(".json", ""))<br /> # 进程池<br /> p = Pool(len(ll_config_name_list))<br /> for each_ll_config_name in ll_config_name_list:<br /> LOGGER.info(f"Task {each_ll_config_name} register successfully!")<br /> p.apply_async(run_liuli_schedule, args=(each_ll_config_name,))<br /> p.close()<br /> p.join()<br /><br /> else:<br /> run_liuli_schedule(ll_config_name)<br />
从代码可知,调度器会启动 Python 的进程池,然后向其中添加 run_liuli_schedule 异步任务,该异步任务中,会执行 run_liuli_task 方法,该方法才是一次完整的任务流程,代码如下:
def run_liuli_task(ll_config: dict):<br /> """执行调度任务<br /><br /> Args:<br /> ll_config (dict): Liuli 任务配置<br /> """<br /> # 文章源, 用于基础查询条件<br /> doc_source: str = ll_config["doc_source"]<br /> basic_filter = {"basic_filter": {"doc_source": doc_source}}<br /> # 采集器配置<br /> collector_conf: dict = ll_config["collector"]<br /> # 处理器配置<br /> processor_conf: dict = ll_config["processor"]<br /> # 分发器配置<br /> sender_conf: dict = ll_config["sender"]<br /> sender_conf.update(basic_filter)<br /> # 备份器配置<br /> backup_conf: dict = ll_config["backup"]<br /> backup_conf.update(basic_filter)<br /><br /> # 采集器执行<br /> LOGGER.info("采集器开始执行!")<br /> for collect_type, collect_config in collector_conf.items():<br /> collect_factory(collect_type, collect_config)<br /> LOGGER.info("采集器执行完毕!")<br /> # 采集器执行<br /> LOGGER.info("处理器(after_collect): 开始执行!")<br /> for each in processor_conf["after_collect"]:<br /> func_name = each.pop("func")<br /> # 注入查询条件<br /> each.update(basic_filter)<br /> LOGGER.info(f"处理器(after_collect): {func_name} 正在执行...")<br /> processor_dict[func_name](**each)<br /> LOGGER.info("处理器(after_collect): 执行完毕!")<br /> # 分发器执行<br /> LOGGER.info("分发器开始执行!")<br /> send_doc(sender_conf)<br /> LOGGER.info("分发器执行完毕!")<br /> # 备份器执行<br /> LOGGER.info("备份器开始执行!")<br /> backup_doc(backup_conf)<br /> LOGGER.info("备份器执行完毕!")<br />
从 run_liuli_task 方法可知,Liuli 一次任务需要执行:
关于 Liuli 的功能,可以阅读作者本人的文章: ,这里先只关注公众号采集的逻辑。
因为有 ruia 与 playwright 两种不同方式实现的采集器,具体使用哪种,通过配置文件决定,然后通过 import_module 方法动态导入相应的模块,然后运行模块的 run 方法,从而实现公众号文章的采集,相关代码如下:
def collect_factory(collect_type: str, collect_config: dict) -> bool:<br /> """<br /> 采集器工厂函数<br /> :param collect_type: 采集器类型<br /> :param collect_config: 采集器配置<br /> :return:<br /> """<br /> collect_status = False<br /> try:<br /> # import_module方法动态载入具体的采集模块<br /> collect_module = import_module(f"src.collector.{collect_type}")<br /> collect_status = collect_module.run(collect_config)<br /> except ModuleNotFoundError:<br /> LOGGER.error(f"采集器类型不存在 {collect_type} - {collect_config}")<br /> except Exception as e:<br /> LOGGER.error(f"采集器执行出错 {collect_type} - {collect_config} - {e}")<br /> return collect_status<br />
playwright 采集模块实现
playwright 是微软出品的自动化库,与 selenium 的作用类似,定位于网页测试,但也被人用于网页信息的获取,可见即可得,使用门槛低,因为要加载网页信息,所以性能比较差,当然一些前端反爬的措施,playwright 也无法突破。
playwright 相比于 selenium,支持 python 的 async,性能有所提升(但还是比不了直接请求),这里贴一下获取某公众号下最新文章的部分逻辑(完整代码太长):
async def playwright_main(wechat_name: str):<br /> """利用 playwright 获取公众号元信息,输出数据格式见上方<br /> Args:<br /> wechat_name ([str]): 公众号名称<br /> """<br /> wechat_data = {}<br /> try:<br /> async with async_playwright() as p:<br /> # browser = await p.chromium.launch(headless=False)<br /> browser = await p.chromium.launch()<br /> context = await browser.new_context(user_agent=Config.SPIDER_UA)<br /> page = await context.new_page()<br /> # 进行公众号检索<br /> await page.goto("https://weixin.sogou.com/")<br /> await page.wait_for_load_state()<br /> await page.click('input[name="query"]')<br /> await page.fill('input[name="query"]', wechat_name)<br /> await asyncio.sleep(1)<br /> await page.click("text=搜公众号")<br /> await page.wait_for_load_state()<br />
从上述代码可知,playwright 用法与 selenium 很像,将用户操作网站的流程自动化便可以获取相应的数据了。
ruia 采集模块实现
ruia 是轻量级的 Python 异步爬虫框架,因为比较轻量,我也将其代码读了一遍,作为下篇文章的内容。
它的用法与 scrapy 有点像,需要定义继承于 ruia.Spider 的子类,然后调用 start 方法实现对目标网站的请求,然后 ruia 会自动调用 parse 方法实现对网页内容的解析,来看一下具体的代码,首先是入口逻辑:
def run(collect_config: dict):<br /> """微信公众号文章抓取爬虫<br /><br /> Args:<br /> collect_config (dict, optional): 采集器配置<br /> """<br /> s_nums = 0<br /> wechat_list = collect_config["wechat_list"]<br /> delta_time = collect_config.get("delta_time", 5)<br /> for wechat_name in wechat_list:<br /> SGWechatSpider.wechat_name = wechat_name<br /> SGWechatSpider.request_config = {<br /> "RETRIES": 3,<br /> "DELAY": delta_time,<br /> "TIMEOUT": 20,<br /> }<br /> sg_url = f"https://weixin.sogou.com/weixin?type=1&query={wechat_name}&ie=utf8&s_from=input&_sug_=n&_sug_type_="<br /> SGWechatSpider.start_urls = [sg_url]<br /> try:<br /> # 启动爬虫<br /> SGWechatSpider.start(middleware=ua_middleware)<br /> s_nums += 1<br /> except Exception as e:<br /> err_msg = f" 公众号->{wechat_name} 文章更新失败! 错误信息: {e}"<br /> LOGGER.error(err_msg)<br /><br /> msg = f" 微信公众号文章更新完毕({s_nums}/{len(wechat_list)})!"<br /> LOGGER.info(msg)<br />
上述代码中,通过 SGWechatSpider.start (middleware=ua_middleware) 启动了爬虫,它会自动请求 start_urls 的 url,然后回调 parse 方法,parse 方法代码如下:
async def parse(self, response: Response):<br /> """解析公众号原始链接数据"""<br /> html = await response.text()<br /> item_list = []<br /> async for item in SGWechatItem.get_items(html=html):<br /> if item.wechat_name == self.wechat_name:<br /> item_list.append(item)<br /> yield self.request(<br /> url=item.latest_href,<br /> metadata=item.results,<br /> # 下一个回调方法<br /> callback=self.parse_real_wechat_url,<br /> )<br /> break<br />
parse 方法中,会通过 self.request 请求新的 url,然后回调 self.parse_real_wechat_url 方法,一切都与 scrapy 如此相似。
至此,采集模块的阅读就结束了(代码中还涉及一些简单的数据清洗,本文就不讨论了),没有特别复杂的部分,从代码上看,也没有发送作者做反爬逻辑的处理,搜狗微信没有反爬?
广告文章识别
接着看一下广告文章识别,Liuli 对于广告文章,还是会采集的,采集后,在文章处理模块,会将广告文章标注出来,先理一下广告文章标注的入口逻辑,回到 liuli_schedule.py 的 run_lili_task 方法,关注到 process(文章处理模块)的逻辑,代码如下:
LOGGER.info("处理器(after_collect): 开始执行!")<br /> for each in processor_conf["after_collect"]:<br /> func_name = each.pop("func")<br /> # 注入查询条件<br /> each.update(basic_filter)<br /> LOGGER.info(f"处理器(after_collect): {func_name} 正在执行...")<br /> processor_dict[func_name](**each)<br /> LOGGER.info("处理器(after_collect): 执行完毕!")<br />
从上述代码可知,处理器的主要逻辑是 processor_dict 字典中的方法,该字典的定义的路径为 src/processor/__init__.py,代码如下:
from .rss_utils import to_rss<br />from .text_utils import (<br /> ad_marker,<br /> extract_core_html,<br /> extract_keyword_list,<br /> html_to_text_h2t,<br /> str_replace,<br />)<br /><br />processor_dict = {<br /> "to_rss": to_rss,<br /> "ad_marker": ad_marker,<br /> "str_replace": str_replace,<br />}<br />
其中 ad_marker 方法便是识别文章是否为广告文章的方法,其实写的有点绕,核心逻辑就是计算当前文章与采集到的广告文章词频构建向量的余弦值,判断余弦值大小来判断是否为广告文章,简单看一下相关的逻辑。
ad_marker 方法中会调用 model_predict_factory 方法,将当前文章的标题、文章内容以及分类的 cos_value 传入,相关代码如下(清理了代码,只展示了需要部分):
def ad_marker(<br /> cos_value: float = 0.6,<br /> is_force=False,<br /> basic_filter={},<br /> **kwargs,<br />):<br /> # 基于余弦相似度<br /> cos_model_resp = model_predict_factory(<br /> model_name="cos",<br /> model_path="",<br /> input_dict={"text": doc_name + doc_keywords, "cos_value": cos_value},<br /> # input_dict={"text": doc_name, "cos_value": Config.COS_VALUE},<br /> ).to_dict()<br />
cos_value 为 0.6,即如果计算出当前文章与广告文章余弦值大于等于 0.6,则认为当前文章为广告文章,其最终预测逻辑在 classifier/model_base/cos_model_loader.py 的 predict 方法中,代码如下:
def predict(self, text: str, cos_value: float = 0.8) -> dict:<br /> """<br /> 对文本相似度进行预测<br /> :param text: 文本<br /> :param cos_value: 阈值 默认是0.9<br /> :return:<br /> """<br /> max_pro, result = 0.0, 0<br /> for each in self.train_data:<br /> # 余弦值具体的运算逻辑<br /> cos = CosineSimilarity(self.process_text(text), each)<br /> res_dict = cos.calculate()<br /> value = res_dict["value"]<br /> # 大于等于cos_value,就返回1,则表示当前的文章是广告文章<br /> result = 1 if value >= cos_value else 0<br /> max_pro = value if value > max_pro else max_pro<br /> if result == 1:<br /> break<br /><br /> return {"result": result, "value": max_pro}<br />
余弦值具体的运算逻辑在 CosineSimilarity 的 calculate 方法中,都是数学相关的代码,就不看了,其核心是希望判断当前文章与广告文章的相似度,类似的还可以通过 TFIDF、文本聚类等算法来做,相关的库,几行代码就可以搞定(所以我感觉这里写绕了)。
其余可参考逻辑结尾
Liuli是很好的学习项目,下篇文章,一起学习一下 ruia Python 轻量级异步爬虫框架的代码。 查看全部
源码剖析 - 公众号采集阅读器 Liuli
简介
无意中发现 Liuli 这个项目,项目 Github:
看了其文章,发现 Liuli 是 Python 实现的,便打算简单看看其实现细节,老规矩,看项目,先将好奇点写下来:
对,我就对这两点感兴趣,经过一番阅读后,关于好奇 1,其实人家没有实现漂亮的 PC 软件界面,Liuli 只是采集,然后将内容推送过去,所以本文的重点,就是看一下它是怎么采集公众号文章的,此外在阅读过程中,发现 LiuLi 还使用了简单的方法来识别文章是否为广告文章,这点也挺有意思的,也记录一下。
公众号文章采集
Liuli 基于搜狗微信()对公众号文章进行采集,而且实现了 2 种方式:
我们可以通过相应的配置文件控制 Liuli 使用其中哪种方式来进行文章采集,其默认使用 ruia 的方式进行采集。
Liuli 将功能分为多个模块,然后通过调度器去调度不同的模块,调度器启动方法代码如下:
# src/liuli_schedule.py<br /><br />def start(ll_config_name: str = ""):<br /> """调度启动函数<br /><br /> Args:<br /> task_config (dict): 调度任务配置<br /> """<br /> if not ll_config_name:<br /> freeze_support()<br /><br /> # 默认启动 liuli_config 目录下所有配置<br /> ll_config_name_list = []<br /> for each_file in os.listdir(Config.LL_CONFIG_DIR):<br /> if each_file.endswith("json"):<br /> # 加入启动列表<br /> ll_config_name_list.append(each_file.replace(".json", ""))<br /> # 进程池<br /> p = Pool(len(ll_config_name_list))<br /> for each_ll_config_name in ll_config_name_list:<br /> LOGGER.info(f"Task {each_ll_config_name} register successfully!")<br /> p.apply_async(run_liuli_schedule, args=(each_ll_config_name,))<br /> p.close()<br /> p.join()<br /><br /> else:<br /> run_liuli_schedule(ll_config_name)<br />
从代码可知,调度器会启动 Python 的进程池,然后向其中添加 run_liuli_schedule 异步任务,该异步任务中,会执行 run_liuli_task 方法,该方法才是一次完整的任务流程,代码如下:
def run_liuli_task(ll_config: dict):<br /> """执行调度任务<br /><br /> Args:<br /> ll_config (dict): Liuli 任务配置<br /> """<br /> # 文章源, 用于基础查询条件<br /> doc_source: str = ll_config["doc_source"]<br /> basic_filter = {"basic_filter": {"doc_source": doc_source}}<br /> # 采集器配置<br /> collector_conf: dict = ll_config["collector"]<br /> # 处理器配置<br /> processor_conf: dict = ll_config["processor"]<br /> # 分发器配置<br /> sender_conf: dict = ll_config["sender"]<br /> sender_conf.update(basic_filter)<br /> # 备份器配置<br /> backup_conf: dict = ll_config["backup"]<br /> backup_conf.update(basic_filter)<br /><br /> # 采集器执行<br /> LOGGER.info("采集器开始执行!")<br /> for collect_type, collect_config in collector_conf.items():<br /> collect_factory(collect_type, collect_config)<br /> LOGGER.info("采集器执行完毕!")<br /> # 采集器执行<br /> LOGGER.info("处理器(after_collect): 开始执行!")<br /> for each in processor_conf["after_collect"]:<br /> func_name = each.pop("func")<br /> # 注入查询条件<br /> each.update(basic_filter)<br /> LOGGER.info(f"处理器(after_collect): {func_name} 正在执行...")<br /> processor_dict[func_name](**each)<br /> LOGGER.info("处理器(after_collect): 执行完毕!")<br /> # 分发器执行<br /> LOGGER.info("分发器开始执行!")<br /> send_doc(sender_conf)<br /> LOGGER.info("分发器执行完毕!")<br /> # 备份器执行<br /> LOGGER.info("备份器开始执行!")<br /> backup_doc(backup_conf)<br /> LOGGER.info("备份器执行完毕!")<br />
从 run_liuli_task 方法可知,Liuli 一次任务需要执行:
关于 Liuli 的功能,可以阅读作者本人的文章: ,这里先只关注公众号采集的逻辑。
因为有 ruia 与 playwright 两种不同方式实现的采集器,具体使用哪种,通过配置文件决定,然后通过 import_module 方法动态导入相应的模块,然后运行模块的 run 方法,从而实现公众号文章的采集,相关代码如下:
def collect_factory(collect_type: str, collect_config: dict) -> bool:<br /> """<br /> 采集器工厂函数<br /> :param collect_type: 采集器类型<br /> :param collect_config: 采集器配置<br /> :return:<br /> """<br /> collect_status = False<br /> try:<br /> # import_module方法动态载入具体的采集模块<br /> collect_module = import_module(f"src.collector.{collect_type}")<br /> collect_status = collect_module.run(collect_config)<br /> except ModuleNotFoundError:<br /> LOGGER.error(f"采集器类型不存在 {collect_type} - {collect_config}")<br /> except Exception as e:<br /> LOGGER.error(f"采集器执行出错 {collect_type} - {collect_config} - {e}")<br /> return collect_status<br />
playwright 采集模块实现
playwright 是微软出品的自动化库,与 selenium 的作用类似,定位于网页测试,但也被人用于网页信息的获取,可见即可得,使用门槛低,因为要加载网页信息,所以性能比较差,当然一些前端反爬的措施,playwright 也无法突破。
playwright 相比于 selenium,支持 python 的 async,性能有所提升(但还是比不了直接请求),这里贴一下获取某公众号下最新文章的部分逻辑(完整代码太长):
async def playwright_main(wechat_name: str):<br /> """利用 playwright 获取公众号元信息,输出数据格式见上方<br /> Args:<br /> wechat_name ([str]): 公众号名称<br /> """<br /> wechat_data = {}<br /> try:<br /> async with async_playwright() as p:<br /> # browser = await p.chromium.launch(headless=False)<br /> browser = await p.chromium.launch()<br /> context = await browser.new_context(user_agent=Config.SPIDER_UA)<br /> page = await context.new_page()<br /> # 进行公众号检索<br /> await page.goto("https://weixin.sogou.com/";)<br /> await page.wait_for_load_state()<br /> await page.click('input[name="query"]')<br /> await page.fill('input[name="query"]', wechat_name)<br /> await asyncio.sleep(1)<br /> await page.click("text=搜公众号")<br /> await page.wait_for_load_state()<br />
从上述代码可知,playwright 用法与 selenium 很像,将用户操作网站的流程自动化便可以获取相应的数据了。
ruia 采集模块实现
ruia 是轻量级的 Python 异步爬虫框架,因为比较轻量,我也将其代码读了一遍,作为下篇文章的内容。
它的用法与 scrapy 有点像,需要定义继承于 ruia.Spider 的子类,然后调用 start 方法实现对目标网站的请求,然后 ruia 会自动调用 parse 方法实现对网页内容的解析,来看一下具体的代码,首先是入口逻辑:
def run(collect_config: dict):<br /> """微信公众号文章抓取爬虫<br /><br /> Args:<br /> collect_config (dict, optional): 采集器配置<br /> """<br /> s_nums = 0<br /> wechat_list = collect_config["wechat_list"]<br /> delta_time = collect_config.get("delta_time", 5)<br /> for wechat_name in wechat_list:<br /> SGWechatSpider.wechat_name = wechat_name<br /> SGWechatSpider.request_config = {<br /> "RETRIES": 3,<br /> "DELAY": delta_time,<br /> "TIMEOUT": 20,<br /> }<br /> sg_url = f"https://weixin.sogou.com/weixin?type=1&query={wechat_name}&ie=utf8&s_from=input&_sug_=n&_sug_type_="<br /> SGWechatSpider.start_urls = [sg_url]<br /> try:<br /> # 启动爬虫<br /> SGWechatSpider.start(middleware=ua_middleware)<br /> s_nums += 1<br /> except Exception as e:<br /> err_msg = f" 公众号->{wechat_name} 文章更新失败! 错误信息: {e}"<br /> LOGGER.error(err_msg)<br /><br /> msg = f" 微信公众号文章更新完毕({s_nums}/{len(wechat_list)})!"<br /> LOGGER.info(msg)<br />
上述代码中,通过 SGWechatSpider.start (middleware=ua_middleware) 启动了爬虫,它会自动请求 start_urls 的 url,然后回调 parse 方法,parse 方法代码如下:
async def parse(self, response: Response):<br /> """解析公众号原始链接数据"""<br /> html = await response.text()<br /> item_list = []<br /> async for item in SGWechatItem.get_items(html=html):<br /> if item.wechat_name == self.wechat_name:<br /> item_list.append(item)<br /> yield self.request(<br /> url=item.latest_href,<br /> metadata=item.results,<br /> # 下一个回调方法<br /> callback=self.parse_real_wechat_url,<br /> )<br /> break<br />
parse 方法中,会通过 self.request 请求新的 url,然后回调 self.parse_real_wechat_url 方法,一切都与 scrapy 如此相似。
至此,采集模块的阅读就结束了(代码中还涉及一些简单的数据清洗,本文就不讨论了),没有特别复杂的部分,从代码上看,也没有发送作者做反爬逻辑的处理,搜狗微信没有反爬?
广告文章识别
接着看一下广告文章识别,Liuli 对于广告文章,还是会采集的,采集后,在文章处理模块,会将广告文章标注出来,先理一下广告文章标注的入口逻辑,回到 liuli_schedule.py 的 run_lili_task 方法,关注到 process(文章处理模块)的逻辑,代码如下:
LOGGER.info("处理器(after_collect): 开始执行!")<br /> for each in processor_conf["after_collect"]:<br /> func_name = each.pop("func")<br /> # 注入查询条件<br /> each.update(basic_filter)<br /> LOGGER.info(f"处理器(after_collect): {func_name} 正在执行...")<br /> processor_dict[func_name](**each)<br /> LOGGER.info("处理器(after_collect): 执行完毕!")<br />
从上述代码可知,处理器的主要逻辑是 processor_dict 字典中的方法,该字典的定义的路径为 src/processor/__init__.py,代码如下:
from .rss_utils import to_rss<br />from .text_utils import (<br /> ad_marker,<br /> extract_core_html,<br /> extract_keyword_list,<br /> html_to_text_h2t,<br /> str_replace,<br />)<br /><br />processor_dict = {<br /> "to_rss": to_rss,<br /> "ad_marker": ad_marker,<br /> "str_replace": str_replace,<br />}<br />
其中 ad_marker 方法便是识别文章是否为广告文章的方法,其实写的有点绕,核心逻辑就是计算当前文章与采集到的广告文章词频构建向量的余弦值,判断余弦值大小来判断是否为广告文章,简单看一下相关的逻辑。
ad_marker 方法中会调用 model_predict_factory 方法,将当前文章的标题、文章内容以及分类的 cos_value 传入,相关代码如下(清理了代码,只展示了需要部分):
def ad_marker(<br /> cos_value: float = 0.6,<br /> is_force=False,<br /> basic_filter={},<br /> **kwargs,<br />):<br /> # 基于余弦相似度<br /> cos_model_resp = model_predict_factory(<br /> model_name="cos",<br /> model_path="",<br /> input_dict={"text": doc_name + doc_keywords, "cos_value": cos_value},<br /> # input_dict={"text": doc_name, "cos_value": Config.COS_VALUE},<br /> ).to_dict()<br />
cos_value 为 0.6,即如果计算出当前文章与广告文章余弦值大于等于 0.6,则认为当前文章为广告文章,其最终预测逻辑在 classifier/model_base/cos_model_loader.py 的 predict 方法中,代码如下:
def predict(self, text: str, cos_value: float = 0.8) -> dict:<br /> """<br /> 对文本相似度进行预测<br /> :param text: 文本<br /> :param cos_value: 阈值 默认是0.9<br /> :return:<br /> """<br /> max_pro, result = 0.0, 0<br /> for each in self.train_data:<br /> # 余弦值具体的运算逻辑<br /> cos = CosineSimilarity(self.process_text(text), each)<br /> res_dict = cos.calculate()<br /> value = res_dict["value"]<br /> # 大于等于cos_value,就返回1,则表示当前的文章是广告文章<br /> result = 1 if value >= cos_value else 0<br /> max_pro = value if value > max_pro else max_pro<br /> if result == 1:<br /> break<br /><br /> return {"result": result, "value": max_pro}<br />
余弦值具体的运算逻辑在 CosineSimilarity 的 calculate 方法中,都是数学相关的代码,就不看了,其核心是希望判断当前文章与广告文章的相似度,类似的还可以通过 TFIDF、文本聚类等算法来做,相关的库,几行代码就可以搞定(所以我感觉这里写绕了)。
其余可参考逻辑结尾
Liuli是很好的学习项目,下篇文章,一起学习一下 ruia Python 轻量级异步爬虫框架的代码。
querylist采集微信公众号文章的方法有哪些?采集
采集交流 • 优采云 发表了文章 • 0 个评论 • 131 次浏览 • 2022-05-01 07:00
querylist采集微信公众号文章,这里有两个采集微信公众号的方法。一个是python的,
可以使用python自带的api,也可以使用微信开发者工具中的第三方api,但是使用第三方api的话,每次微信新增公众号图文列表的时候,会更新,每次得重新添加,而且都要借助于服务器端的开发者工具,每次操作非常麻烦,所以就造成一部分公众号文章无法采集。但是,题主没有提到的是,据我了解到,有部分自媒体是可以使用公众号大数据的,可以利用大数据做站长获取微信粉丝的相关信息,这方面有一些公众号是可以向他们提供接口的,这就造成了,大数据可以随时看到微信里面的公众号文章内容,而且可以使用文章点赞,阅读,转发等数据来收集,应该是题主所说的公众号大数据,这个就必须用程序去爬取,方法可以去网上找,或者学校的计算机学院有相关的项目,有较为实用的方法。
这个要么借助第三方去收集,要么就是采取如自媒体流量宝,这种工具去收集。
图文信息采集微信公众号文章(步骤)收集微信公众号文章
1)编写爬虫程序前,先想好什么类型的文章是自己的,先选择一个爬虫类型,可以用python写一个,通过python结合web爬虫,可以爬到非常多的微信文章,使用java或者.net等语言语言和微信公众号文章的源码对接,写成一个爬虫程序,程序很容易做到比较大,大到这个问题根本没有办法去实现,python可以做的东西不止这一个。
当然,也可以使用python也写一个python小爬虫,包括常见的数据抓取,爬虫分析等,爬虫是实现非常容易的。我们使用python就是用来写小爬虫的,是一种全新的语言。(。
2)爬虫的客户端爬虫平台现在有很多第三方爬虫,第三方爬虫平台接入非常方便,对接的话很容易,我们也可以在爬虫软件里面爬的。我们选择使用的是度娘的“爬虫云”,它有不止一个,还有一个在线翻页的,使用起来很方便。我们下载安装好了之后,我们要注册一个。具体步骤:前往度娘云——首页——发现——访问网站,对接一个账号。
然后我们注册一个云账号(一个邮箱和一个手机号)。然后就可以用了,但是如果不去这么进行操作,爬虫还是爬不到的。度娘云——首页,页面右上角那个角落就有对接方式。(。
3)数据自动从微信公众号文章爬到微信文章我们学校之前有很多无线机顶盒都是用浏览器获取到的,微信平台只支持大连通和广州建设,不支持全国开通。后来我们学校是用12306的车票来读取了,需要1个手机号和12306的app注册, 查看全部
querylist采集微信公众号文章的方法有哪些?采集
querylist采集微信公众号文章,这里有两个采集微信公众号的方法。一个是python的,
可以使用python自带的api,也可以使用微信开发者工具中的第三方api,但是使用第三方api的话,每次微信新增公众号图文列表的时候,会更新,每次得重新添加,而且都要借助于服务器端的开发者工具,每次操作非常麻烦,所以就造成一部分公众号文章无法采集。但是,题主没有提到的是,据我了解到,有部分自媒体是可以使用公众号大数据的,可以利用大数据做站长获取微信粉丝的相关信息,这方面有一些公众号是可以向他们提供接口的,这就造成了,大数据可以随时看到微信里面的公众号文章内容,而且可以使用文章点赞,阅读,转发等数据来收集,应该是题主所说的公众号大数据,这个就必须用程序去爬取,方法可以去网上找,或者学校的计算机学院有相关的项目,有较为实用的方法。
这个要么借助第三方去收集,要么就是采取如自媒体流量宝,这种工具去收集。
图文信息采集微信公众号文章(步骤)收集微信公众号文章
1)编写爬虫程序前,先想好什么类型的文章是自己的,先选择一个爬虫类型,可以用python写一个,通过python结合web爬虫,可以爬到非常多的微信文章,使用java或者.net等语言语言和微信公众号文章的源码对接,写成一个爬虫程序,程序很容易做到比较大,大到这个问题根本没有办法去实现,python可以做的东西不止这一个。
当然,也可以使用python也写一个python小爬虫,包括常见的数据抓取,爬虫分析等,爬虫是实现非常容易的。我们使用python就是用来写小爬虫的,是一种全新的语言。(。
2)爬虫的客户端爬虫平台现在有很多第三方爬虫,第三方爬虫平台接入非常方便,对接的话很容易,我们也可以在爬虫软件里面爬的。我们选择使用的是度娘的“爬虫云”,它有不止一个,还有一个在线翻页的,使用起来很方便。我们下载安装好了之后,我们要注册一个。具体步骤:前往度娘云——首页——发现——访问网站,对接一个账号。
然后我们注册一个云账号(一个邮箱和一个手机号)。然后就可以用了,但是如果不去这么进行操作,爬虫还是爬不到的。度娘云——首页,页面右上角那个角落就有对接方式。(。
3)数据自动从微信公众号文章爬到微信文章我们学校之前有很多无线机顶盒都是用浏览器获取到的,微信平台只支持大连通和广州建设,不支持全国开通。后来我们学校是用12306的车票来读取了,需要1个手机号和12306的app注册,
querylist采集微信公众号文章(采集微信文章和采集网站内容一样的查看方法获取到一个)
采集交流 • 优采云 发表了文章 • 0 个评论 • 159 次浏览 • 2022-04-20 19:18
采集微信文章与采集网站内容相同,都需要从列表页开始。微信列表页文章是公众号查看历史新闻的页面。现在网上其他微信采集器用搜狗搜索。 采集 方法虽然简单很多,但内容并不完整。所以我们还是要从最标准最全面的公众号历史新闻页面来采集。
由于微信的限制,我们可以复制的链接不完整,无法在浏览器中打开查看内容。因此,我们需要使用anyproxy,通过上篇文章文章介绍的方法,获取一个完整的微信公众号历史消息页的链接地址。
http://mp.weixin.qq.com/mp/get ... r%3D1
上一篇文章中提到,biz参数是公众号的ID,uin是用户的ID。目前,uin在所有公众号中都是独一无二的。另外两个重要参数key和pass_ticket是微信客户端的补充参数。
所以在这个地址过期之前,我们可以通过在浏览器中查看原文得到文章历史消息列表。如果您想自动分析内容,您还可以制作一个程序来添加尚未过期的消息。提交pass_ticket的key和链接地址,然后通过例如php程序获取文章列表。
最近有朋友告诉我,他的采集目标是一个公众号。我认为没有必要使用上一篇文章 文章 中写的批处理 采集 方法。那么我们来看看历史新闻页面是如何获取文章列表的。通过分析文章列表,我们可以得到这个公众号所有的内容链接地址,然后采集内容就可以了。
如果在anyproxy的web界面中正确配置了证书,可以显示https的内容。 Web 界面的地址是 localhost:8002,其中 localhost 可以替换为您自己的 IP 地址或域名。从列表中找到以getmasssendmsg开头的记录,点击右侧显示该记录的详细信息:
红框是完整的链接地址。前面拼接好微信公众平台的域名后,就可以在浏览器中打开了。
然后将页面下拉到html内容的末尾,我们可以看到一个json变量就是文章历史消息列表:
我们复制msgList的变量值,用json格式化工具分析。我们可以看到json有如下结构:
{
"list": [
{
"app_msg_ext_info": {
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz/Mof ... ot%3B,
"digest": "擦亮双眼,远离谣言。",
"fileid": 505283695,
"is_multi": 1,
"multi_app_msg_item_list": [
{
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz_png ... ot%3B,
"digest": "12月28日,广州亚运城综合体育馆,内附购票入口~",
"fileid": 0,
"source_url": "http://wechat.show.wepiao.com/ ... ot%3B,
"title": "2017微信公开课Pro版即将召开"
},
...//循环被省略
],
"source_url": "",
"subtype": 9,
"title": "谣言热榜 | 十一月朋友圈十大谣言"
},
"comm_msg_info": {
"content": "",
"datetime": 1480933315,
"fakeid": "3093134871",
"id": 1000000010,
"status": 2,
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
}
对这个json的简单分析(这里只介绍一些重要的信息,其他的省略):
"list": [ //最外层的键名;只出现一次,所有内容都被它包含。
{
//这个大阔号之内是一条多图文或单图文消息,通俗的说就是一天的群发都在这里
"app_msg_ext_info":{
//图文消息的扩展信息
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": "摘要",
"is_multi": "是否多图文,值为1和0",
"multi_app_msg_item_list": [//这里面包含的是从第二条开始的图文消息,如果is_multi=0,这里将为空
{
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": ""摘要"",
"source_url": "阅读原文的地址",
"title": "子内容标题"
},
...//循环被省略
],
"source_url": "阅读原文的地址",
"title": "头条标题"
},
"comm_msg_info":{
//图文消息的基本信息
"datetime": '发布时间,值为unix时间戳',
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
这里还要提一提的是,如果要获取时间较长的历史消息内容,需要在手机或模拟器上下拉页面。下拉到最底,微信会自动读取。下一页的内容。下一页的链接地址和历史消息页的链接地址也是getmasssendmsg开头的地址。但是内容只有json,没有html。直接解析json就好了。
这时候可以使用上篇文章中介绍的方法文章,使用anyproxy定时匹配msgList变量的值,异步提交给服务器,然后使用php的json_decode解析json 到服务器的数组中。然后遍历循环数组。我们可以得到每个文章的标题和链接地址。
如果你只需要采集单个公众号的内容,可以每天群发后通过anyproxy获取完整的链接地址和key和pass_ticket。然后自己做一个程序,手动提交地址给自己的程序。使用php等语言对msgList进行正则匹配,然后解析json。这样就不需要修改anyproxy的规则,也不需要创建采集队列和跳转页面。
现在我们可以通过公众号的历史消息来获取文章的列表。在下一篇文章中,我会根据历史新闻中文章的链接地址来介绍如何获取。 @文章具体内容的方法。关于文章的保存、封面图、全文检索也有一些经验。
如果您觉得我写的不清楚,或者有什么不明白的地方,请在下方留言。或者骚扰微信号崔金,如果你觉得不错,就点个赞吧。
持续更新,微信公众号文章批量采集系统搭建
微信公众号入口文章采集--历史新闻页面详解
分析微信公众号文章页面和采集
提高微信公众号的效率文章采集,anyproxy的高级使用 查看全部
querylist采集微信公众号文章(采集微信文章和采集网站内容一样的查看方法获取到一个)
采集微信文章与采集网站内容相同,都需要从列表页开始。微信列表页文章是公众号查看历史新闻的页面。现在网上其他微信采集器用搜狗搜索。 采集 方法虽然简单很多,但内容并不完整。所以我们还是要从最标准最全面的公众号历史新闻页面来采集。
由于微信的限制,我们可以复制的链接不完整,无法在浏览器中打开查看内容。因此,我们需要使用anyproxy,通过上篇文章文章介绍的方法,获取一个完整的微信公众号历史消息页的链接地址。
http://mp.weixin.qq.com/mp/get ... r%3D1
上一篇文章中提到,biz参数是公众号的ID,uin是用户的ID。目前,uin在所有公众号中都是独一无二的。另外两个重要参数key和pass_ticket是微信客户端的补充参数。
所以在这个地址过期之前,我们可以通过在浏览器中查看原文得到文章历史消息列表。如果您想自动分析内容,您还可以制作一个程序来添加尚未过期的消息。提交pass_ticket的key和链接地址,然后通过例如php程序获取文章列表。
最近有朋友告诉我,他的采集目标是一个公众号。我认为没有必要使用上一篇文章 文章 中写的批处理 采集 方法。那么我们来看看历史新闻页面是如何获取文章列表的。通过分析文章列表,我们可以得到这个公众号所有的内容链接地址,然后采集内容就可以了。
如果在anyproxy的web界面中正确配置了证书,可以显示https的内容。 Web 界面的地址是 localhost:8002,其中 localhost 可以替换为您自己的 IP 地址或域名。从列表中找到以getmasssendmsg开头的记录,点击右侧显示该记录的详细信息:
红框是完整的链接地址。前面拼接好微信公众平台的域名后,就可以在浏览器中打开了。
然后将页面下拉到html内容的末尾,我们可以看到一个json变量就是文章历史消息列表:
我们复制msgList的变量值,用json格式化工具分析。我们可以看到json有如下结构:
{
"list": [
{
"app_msg_ext_info": {
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz/Mof ... ot%3B,
"digest": "擦亮双眼,远离谣言。",
"fileid": 505283695,
"is_multi": 1,
"multi_app_msg_item_list": [
{
"author": "",
"content": "",
"content_url": "http://mp.weixin.qq.com/s%3F__ ... ot%3B,
"copyright_stat": 100,
"cover": "http://mmbiz.qpic.cn/mmbiz_png ... ot%3B,
"digest": "12月28日,广州亚运城综合体育馆,内附购票入口~",
"fileid": 0,
"source_url": "http://wechat.show.wepiao.com/ ... ot%3B,
"title": "2017微信公开课Pro版即将召开"
},
...//循环被省略
],
"source_url": "",
"subtype": 9,
"title": "谣言热榜 | 十一月朋友圈十大谣言"
},
"comm_msg_info": {
"content": "",
"datetime": 1480933315,
"fakeid": "3093134871",
"id": 1000000010,
"status": 2,
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
}
对这个json的简单分析(这里只介绍一些重要的信息,其他的省略):
"list": [ //最外层的键名;只出现一次,所有内容都被它包含。
{
//这个大阔号之内是一条多图文或单图文消息,通俗的说就是一天的群发都在这里
"app_msg_ext_info":{
//图文消息的扩展信息
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": "摘要",
"is_multi": "是否多图文,值为1和0",
"multi_app_msg_item_list": [//这里面包含的是从第二条开始的图文消息,如果is_multi=0,这里将为空
{
"content_url": "图文消息的链接地址",
"cover": "封面图片",
"digest": ""摘要"",
"source_url": "阅读原文的地址",
"title": "子内容标题"
},
...//循环被省略
],
"source_url": "阅读原文的地址",
"title": "头条标题"
},
"comm_msg_info":{
//图文消息的基本信息
"datetime": '发布时间,值为unix时间戳',
"type": 49 //类型为49的时候是图文消息
}
},
...//循环被省略
]
这里还要提一提的是,如果要获取时间较长的历史消息内容,需要在手机或模拟器上下拉页面。下拉到最底,微信会自动读取。下一页的内容。下一页的链接地址和历史消息页的链接地址也是getmasssendmsg开头的地址。但是内容只有json,没有html。直接解析json就好了。
这时候可以使用上篇文章中介绍的方法文章,使用anyproxy定时匹配msgList变量的值,异步提交给服务器,然后使用php的json_decode解析json 到服务器的数组中。然后遍历循环数组。我们可以得到每个文章的标题和链接地址。
如果你只需要采集单个公众号的内容,可以每天群发后通过anyproxy获取完整的链接地址和key和pass_ticket。然后自己做一个程序,手动提交地址给自己的程序。使用php等语言对msgList进行正则匹配,然后解析json。这样就不需要修改anyproxy的规则,也不需要创建采集队列和跳转页面。
现在我们可以通过公众号的历史消息来获取文章的列表。在下一篇文章中,我会根据历史新闻中文章的链接地址来介绍如何获取。 @文章具体内容的方法。关于文章的保存、封面图、全文检索也有一些经验。
如果您觉得我写的不清楚,或者有什么不明白的地方,请在下方留言。或者骚扰微信号崔金,如果你觉得不错,就点个赞吧。
持续更新,微信公众号文章批量采集系统搭建
微信公众号入口文章采集--历史新闻页面详解
分析微信公众号文章页面和采集
提高微信公众号的效率文章采集,anyproxy的高级使用
querylist采集微信公众号文章(微信公众号登录成功以后的code,什么特别的意义)
采集交流 • 优采云 发表了文章 • 0 个评论 • 125 次浏览 • 2022-04-16 04:26
业务场景描述
我们在创建微信公众号的时候经常会遇到一个问题,就是我们需要进行简单的身份认证,也就是需要在公众号成功登录后获取code。其实这个code是用来获取的登录用户的openid。每次得到的代码都不一样。其实我们在做开发的时候,都是在微信后台配置的url中配置代码。微信转发后,我们可以直接获取url中的code。这个其实在之前的jquery中写过如何获取。这次我只是在vue中使用了这个js,没有其他特殊含义,希望以后可以直接使用。
源代码
getUrl_utils.js
/**
* @aim get code from url
* @author clearlove
* @data 19-09
*/
export default {
getUrlKey:function(name){
return decodeURIComponent((new RegExp('[?|&]'+name+'='+'([^&;]+?)(&|#|;|$)').exec(location.href)||[,""])[1].replace(/\+/g,'%20'))||null;
}
}
main.js
import getUrl_utils from './components/utils/getUrl_utils'
Vue.prototype.$utils = getUrl_utils;
// 页面加载的时候直接运行就可以拿到url中的code,进而进行下面的业务
let code = this.$utils.getUrlKey('code');
js本身和jquery是一样的,只是没有使用引用的方式。 查看全部
querylist采集微信公众号文章(微信公众号登录成功以后的code,什么特别的意义)
业务场景描述
我们在创建微信公众号的时候经常会遇到一个问题,就是我们需要进行简单的身份认证,也就是需要在公众号成功登录后获取code。其实这个code是用来获取的登录用户的openid。每次得到的代码都不一样。其实我们在做开发的时候,都是在微信后台配置的url中配置代码。微信转发后,我们可以直接获取url中的code。这个其实在之前的jquery中写过如何获取。这次我只是在vue中使用了这个js,没有其他特殊含义,希望以后可以直接使用。
源代码
getUrl_utils.js
/**
* @aim get code from url
* @author clearlove
* @data 19-09
*/
export default {
getUrlKey:function(name){
return decodeURIComponent((new RegExp('[?|&]'+name+'='+'([^&;]+?)(&|#|;|$)').exec(location.href)||[,""])[1].replace(/\+/g,'%20'))||null;
}
}
main.js
import getUrl_utils from './components/utils/getUrl_utils'
Vue.prototype.$utils = getUrl_utils;
// 页面加载的时候直接运行就可以拿到url中的code,进而进行下面的业务
let code = this.$utils.getUrlKey('code');
js本身和jquery是一样的,只是没有使用引用的方式。
querylist采集微信公众号文章(为什么你的App会卡顿-Android-掘金Cover(组图))
采集交流 • 优采云 发表了文章 • 0 个评论 • 163 次浏览 • 2022-04-14 12:11
阿里云>云栖社区>主题图>>.net网页微信支付接口开发教程
推荐活动:
更多优惠>
当前话题:.net网页微信支付接口开发教程加入采集
相关话题:
.net网页微信支付接口开发教程相关博客看更多博文
史上最全的Android文章精选合集
作者:android飞鱼2557人查看评论:03年前
用两张图告诉你,为什么你的应用卡住了?- Android - Nuggets Cover 有什么?从这个 文章 你可以得到这个信息:知道 setContentView() 之后会发生什么吗?... Android常见的获取View宽高的正确方法
阅读全文
微信公众平台开发问答
作者:方北工作室2281查看评论:06年前
微信公众平台开发问答是微信知识问答专区,专注于微信应用开发技术知识的整理、分类和检索。主题:新手常见问题 Q:我是新手,没有开发基础。我应该如何学习微信公众平台的开发?答:先学PHP和Mysql。您可以在 Internet 上找到相应的教程以了解一般语法。
阅读全文
【转载】微信公众号获取用户地理位置并列出附近店铺
作者:php的小菜鸟2236人查看评论数:04年前
思路分析:1、在微信公众号中获取用户的地理位置需要js-sdk签名包(文档里面有如何获取的介绍)2、根据获取到的地理位置, ajax去后台请求,通过sql语句,查询中就近的store(sql语句在网上搜索,通过后台添加位置)3、来查询store list根据城市,使用
阅读全文
【044】微信公众平台开发教程第20章——40个新手谜题
作者:云启希望。2102人查看评论数:04年前
笔者在CSDN博客频道推出微信公众平台开发教程后,联系了很多公众平台开发爱好者,帮助他们克服了很多实际问题。当然,这些问题中的许多都是重复的。因此,笔者将这些问题。并整理出答案,以帮助许多刚开始学习少走弯路的人。1、订阅账户和服务账户的主要区别是什么?
阅读全文
微信公众号支付失败问题-微信支付提示调用支付JSAPI缺少参数:appId
作者:聚友云辉 2003 浏览评论:02年前
场景概述 鉴于去年在微信小程序支付、小程序支付、支付宝小程序支付、云闪付小程序支付方面的工作和研究。最近要完成一个微信公众号支付的场景。其中,我遇到了一个坑,花了我一个多上午的时间。所以想把记录写下来,以后遇到微信相关的API调用,用不了那么久。
阅读全文
PHP 使用 QueryList 抓取网页内容
作者:thinkyoung1544 人浏览评论:06年前
以前,我使用Java Jsoup 来捕获网页数据。前几天听说用PHP比较方便。今天简单研究了一下,主要是使用QueryList。QueryList 是一个基于 phpQ 的
阅读全文
微信支付教程系列现金红包
作者:micahel1530 观众评论:03年前
目录(一)微信公众号开发VS远程调试(二)微信公众号开发基础知识(三)微信公众号开发自动回复消息和自定义菜单)(四)开发的网页微信公众号授权获取用户基本信息(五)当前用户的Openid及注意事项可在微信公众号开发的网页中及时获取(六)微信公众号开发)
阅读全文
微信支付教程系列公众号支付
作者:micahel1202 人浏览评论:03年前
目录(一)微信公众号开发VS远程调试(二)微信公众号开发基础知识(三)微信公众号开发自动回复消息和自定义菜单)(四)开发的网页微信公众号授权获取用户基本信息(五)当前用户的Openid及注意事项可在微信公众号开发的网页中及时获取(六)微信公众号开发)
阅读全文 查看全部
querylist采集微信公众号文章(为什么你的App会卡顿-Android-掘金Cover(组图))
阿里云>云栖社区>主题图>>.net网页微信支付接口开发教程
推荐活动:
更多优惠>
当前话题:.net网页微信支付接口开发教程加入采集
相关话题:
.net网页微信支付接口开发教程相关博客看更多博文
史上最全的Android文章精选合集
作者:android飞鱼2557人查看评论:03年前
用两张图告诉你,为什么你的应用卡住了?- Android - Nuggets Cover 有什么?从这个 文章 你可以得到这个信息:知道 setContentView() 之后会发生什么吗?... Android常见的获取View宽高的正确方法
阅读全文
微信公众平台开发问答
作者:方北工作室2281查看评论:06年前
微信公众平台开发问答是微信知识问答专区,专注于微信应用开发技术知识的整理、分类和检索。主题:新手常见问题 Q:我是新手,没有开发基础。我应该如何学习微信公众平台的开发?答:先学PHP和Mysql。您可以在 Internet 上找到相应的教程以了解一般语法。
阅读全文
【转载】微信公众号获取用户地理位置并列出附近店铺
作者:php的小菜鸟2236人查看评论数:04年前
思路分析:1、在微信公众号中获取用户的地理位置需要js-sdk签名包(文档里面有如何获取的介绍)2、根据获取到的地理位置, ajax去后台请求,通过sql语句,查询中就近的store(sql语句在网上搜索,通过后台添加位置)3、来查询store list根据城市,使用
阅读全文
【044】微信公众平台开发教程第20章——40个新手谜题
作者:云启希望。2102人查看评论数:04年前
笔者在CSDN博客频道推出微信公众平台开发教程后,联系了很多公众平台开发爱好者,帮助他们克服了很多实际问题。当然,这些问题中的许多都是重复的。因此,笔者将这些问题。并整理出答案,以帮助许多刚开始学习少走弯路的人。1、订阅账户和服务账户的主要区别是什么?
阅读全文
微信公众号支付失败问题-微信支付提示调用支付JSAPI缺少参数:appId
作者:聚友云辉 2003 浏览评论:02年前
场景概述 鉴于去年在微信小程序支付、小程序支付、支付宝小程序支付、云闪付小程序支付方面的工作和研究。最近要完成一个微信公众号支付的场景。其中,我遇到了一个坑,花了我一个多上午的时间。所以想把记录写下来,以后遇到微信相关的API调用,用不了那么久。
阅读全文
PHP 使用 QueryList 抓取网页内容
作者:thinkyoung1544 人浏览评论:06年前
以前,我使用Java Jsoup 来捕获网页数据。前几天听说用PHP比较方便。今天简单研究了一下,主要是使用QueryList。QueryList 是一个基于 phpQ 的
阅读全文
微信支付教程系列现金红包
作者:micahel1530 观众评论:03年前
目录(一)微信公众号开发VS远程调试(二)微信公众号开发基础知识(三)微信公众号开发自动回复消息和自定义菜单)(四)开发的网页微信公众号授权获取用户基本信息(五)当前用户的Openid及注意事项可在微信公众号开发的网页中及时获取(六)微信公众号开发)
阅读全文
微信支付教程系列公众号支付
作者:micahel1202 人浏览评论:03年前
目录(一)微信公众号开发VS远程调试(二)微信公众号开发基础知识(三)微信公众号开发自动回复消息和自定义菜单)(四)开发的网页微信公众号授权获取用户基本信息(五)当前用户的Openid及注意事项可在微信公众号开发的网页中及时获取(六)微信公众号开发)
阅读全文
querylist采集微信公众号文章(@咪蒙是真实存在的啊!采集微信公众号)
采集交流 • 优采云 发表了文章 • 0 个评论 • 144 次浏览 • 2022-04-13 07:00
querylist采集微信公众号文章标题,生成一个预览xml,然后自定义一个地址,分享给朋友关注,让他加公众号读文章,这样朋友如果点击这个文章标题,
技术上已经很成熟了,只是产品设计很困难。
querylist库在ios的版本是2.0.0+在github上放出代码了,
去macappstore查看吧apple-itunesappstore中的内容(中国)
挺小众的一个库,总共才2k多人star,用过感觉还不错。advicelist?adt?相对来说,
目前来看暂时都是以单独公众号发表的文章进行展示,搜索结果会加上封面图片,同时推送预览版。
果断分享到你平时搜索的各个微信公众号,作为朋友推荐必不可少。
反正安卓是没这个api,我记得我电脑也有repl直接可以调用。
无所谓公众号、非公众号。总之就是要读取微信公众号文章,并推送到相应的微信公众号。
要截图打开,查看后发现经常没有反应,不知道有没有人遇到。
@咪蒙是真实存在的啊! 查看全部
querylist采集微信公众号文章(@咪蒙是真实存在的啊!采集微信公众号)
querylist采集微信公众号文章标题,生成一个预览xml,然后自定义一个地址,分享给朋友关注,让他加公众号读文章,这样朋友如果点击这个文章标题,
技术上已经很成熟了,只是产品设计很困难。
querylist库在ios的版本是2.0.0+在github上放出代码了,
去macappstore查看吧apple-itunesappstore中的内容(中国)
挺小众的一个库,总共才2k多人star,用过感觉还不错。advicelist?adt?相对来说,
目前来看暂时都是以单独公众号发表的文章进行展示,搜索结果会加上封面图片,同时推送预览版。
果断分享到你平时搜索的各个微信公众号,作为朋友推荐必不可少。
反正安卓是没这个api,我记得我电脑也有repl直接可以调用。
无所谓公众号、非公众号。总之就是要读取微信公众号文章,并推送到相应的微信公众号。
要截图打开,查看后发现经常没有反应,不知道有没有人遇到。
@咪蒙是真实存在的啊!
querylist采集微信公众号文章(Windows平台下的微信公众号内容采集工具——WeChatDownload)
采集交流 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2022-04-12 06:15
今天,小编给大家分享一款Windows平台下的微信公众号内容采集工具——WeChatDownload。这个工具不仅可以下载单篇文章文章,还可以批量下载,可以说是无限制采集任何公众号文章,这个软件2020年已经停止了,作者的博客也已经关闭了,但是软件太强大了,2022年还是可以正常使用的!
北望山博客免费提供最新官方版本,请到文章底部下载。
先看看下载演示
无限功能介绍采集任何公众号文章
没有采集限制
支持公众号文章的中文文字、图片、音频内容的采集。
自动保存数据
指定保存路径后,所有下载的文章都会自动保存,只要不删除就永远不会丢失。
多样化的文档导出
多种文档格式
采集公众号文章可以按照原排版批量处理,保存为pdf、word、html等格式。
更多下载设置
您可以选择不下载文章图片;你可以下载文章评论;你只能下载原创文章。
按关键词按时间段文章
搜索公众号
按时间下载
按时间顺序搜索公众号文章,可选择采集全部、同一天、一周内、一个月内,也可以自定义时间段。
搜索智能过滤器
通过设置标题关键词,会自动过滤收录关键词的文章。
提示
北望山博客提供的软件包内附有视频教程,大家可以观看!
单篇下载文章不说了,直接把链接复制到软件里
下载多篇文章文章时,可能需要使用旧版PC端微信(3.4.0以下),可直接在线搜索下载
然后通过公众号聊天框,找到历史文章按钮
点击获取此列表文章,然后复制上面的链接
终于把这个链接放到软件里了!
软件下载无需登录下载
对不起!隐藏内容,请输入密码可见! 查看全部
querylist采集微信公众号文章(Windows平台下的微信公众号内容采集工具——WeChatDownload)
今天,小编给大家分享一款Windows平台下的微信公众号内容采集工具——WeChatDownload。这个工具不仅可以下载单篇文章文章,还可以批量下载,可以说是无限制采集任何公众号文章,这个软件2020年已经停止了,作者的博客也已经关闭了,但是软件太强大了,2022年还是可以正常使用的!
北望山博客免费提供最新官方版本,请到文章底部下载。
先看看下载演示
无限功能介绍采集任何公众号文章
没有采集限制
支持公众号文章的中文文字、图片、音频内容的采集。
自动保存数据
指定保存路径后,所有下载的文章都会自动保存,只要不删除就永远不会丢失。
多样化的文档导出
多种文档格式
采集公众号文章可以按照原排版批量处理,保存为pdf、word、html等格式。
更多下载设置
您可以选择不下载文章图片;你可以下载文章评论;你只能下载原创文章。
按关键词按时间段文章
搜索公众号
按时间下载
按时间顺序搜索公众号文章,可选择采集全部、同一天、一周内、一个月内,也可以自定义时间段。
搜索智能过滤器
通过设置标题关键词,会自动过滤收录关键词的文章。
提示
北望山博客提供的软件包内附有视频教程,大家可以观看!
单篇下载文章不说了,直接把链接复制到软件里
下载多篇文章文章时,可能需要使用旧版PC端微信(3.4.0以下),可直接在线搜索下载
然后通过公众号聊天框,找到历史文章按钮
点击获取此列表文章,然后复制上面的链接
终于把这个链接放到软件里了!
软件下载无需登录下载
对不起!隐藏内容,请输入密码可见!
querylist采集微信公众号文章(excel教程:公众号采集小程序不需要微信发布新文章)
采集交流 • 优采云 发表了文章 • 0 个评论 • 185 次浏览 • 2022-04-08 19:01
querylist采集微信公众号文章,必须由微信服务器完成,对于小程序来说,用户的文章、历史阅读也需要收集起来,作为小程序的数据存储,这两者没有太大关系。
(关注微信公众号:contact_e16是免费接收知乎文章链接的小程序)我写的excel教程,供你参考数据链接知乎截图来源,如有侵权,
如果你关注的公众号文章较多,建议用microsoftword使用导出插件来导出公众号文章,我是用word的,c:\word\microsoftword2010\documentsandsettings\personaldata\extensions\ws2导出。
现在的小程序要采集功能多,要具体情况具体分析,除了自己直接采集公众号的数据外,还有一些第三方的插件可以采集公众号文章。
公众号文章是不是也需要导出到本地呢?
感谢大神们的回答,我可以得到数据,不过不在这里说明啦。
openzhiliao/got_index·github
可以试试我们研发的公众号采集小程序
不需要微信发布新文章才可以采集微信公众号数据,在公众号后台完成简单授权后即可向微信传送文章,简单方便。 查看全部
querylist采集微信公众号文章(excel教程:公众号采集小程序不需要微信发布新文章)
querylist采集微信公众号文章,必须由微信服务器完成,对于小程序来说,用户的文章、历史阅读也需要收集起来,作为小程序的数据存储,这两者没有太大关系。
(关注微信公众号:contact_e16是免费接收知乎文章链接的小程序)我写的excel教程,供你参考数据链接知乎截图来源,如有侵权,
如果你关注的公众号文章较多,建议用microsoftword使用导出插件来导出公众号文章,我是用word的,c:\word\microsoftword2010\documentsandsettings\personaldata\extensions\ws2导出。
现在的小程序要采集功能多,要具体情况具体分析,除了自己直接采集公众号的数据外,还有一些第三方的插件可以采集公众号文章。
公众号文章是不是也需要导出到本地呢?
感谢大神们的回答,我可以得到数据,不过不在这里说明啦。
openzhiliao/got_index·github
可以试试我们研发的公众号采集小程序
不需要微信发布新文章才可以采集微信公众号数据,在公众号后台完成简单授权后即可向微信传送文章,简单方便。
querylist采集微信公众号文章(优采云软件智能文章采集系统,选择对的产品很重要!)
采集交流 • 优采云 发表了文章 • 0 个评论 • 137 次浏览 • 2022-04-05 22:16
选择合适的产品很重要!下面是优采云软件智能文章采集系统,大家可以了解一下
一、智能块算法采集任何内容站点,真实傻瓜式采集
智能分块算法自动提取网页正文内容,无需配置源码规则,真正做到傻瓜式采集;
自动去噪,可以自动过滤标题内容中的图片\网站\电话\QQ\邮件等信息;
对于世界上任何一种小语言,任何编码文章采集,无乱码;
多任务(多站点/列)多线程同步采集,支持代理采集,快速高效;
指定任何文章内容类网站采集,非文章源
二、功能强大伪原创功能
内置中文分词功能,强大的同义词词库引擎,替换效率高;
自带英文分词词库和语料库,支持TBS模式的批量原创,保持句子流畅语义不变;
标题和内容可以分开处理伪原创;
三、内置主流cms发布界面
可直接导出为TXT文档,文件名可按标题或序号生成
支持wordpress、zblog、dedecms、phpcms等国内外主流cms自动发布;
支持多线程、多任务同步发布;
如果是临时找资料,只需要自己保存资料链接即可。从长远来看,您需要找到采集的材料。我建议将材料 采集 放入材料库。可以使用第三方平台,比如西瓜助手,在上面可以找到各种素材,一键采集到素材库,还支持文章链接导入,素材库可以分类管理,可以选择需要的素材进行编辑。,同步,会方便很多。
写文章写什么粉丝喜欢看,什么能吸引粉丝看文章,什么能写优质热点文章。编写这些 文章 对初学者来说可能很困难。这时候就可以使用西瓜助手,从全网,各个领域,一键采集,编辑,解决写作文章的难点,寻找优质热点素材。
采集微信公众号文章,如何采集?- """ 可以使用键盘快速排列,登录后在编辑区右侧找到导入文章按钮,然后将文章的地址复制进去,你采集能不能下来,采集后面还需要修改,不然不会变成原创。
新手,有没有最简单的方法采集微信公众号文章-""" 采集资料写文章很重要,可以用西瓜助手,会推荐每天最新的爆文,可以关键词搜索文章,也可以批量关注公众号,一键采集同步,操作简单,可以帮助您快速找到材料
超实用技巧:如何采集微信公众号文章 - """ 选对产品很重要!下面是优采云软件智能文章采集@ >系统,您可以了解一、智能块算法采集任何内容站点,真正的傻瓜式采集智能块算法自动提取网页正文内容,无需需要配置源码规则,真的是傻瓜式采集;自动去噪,可以对图片进行去噪\...
有没有办法采集去优质微信文章最好的素材也可以有视频”””哈哈~ 真的好难,不过可以考虑用公众号小助手,比如一个西瓜助手什么的,不仅能满足需求,还有其他功能让你更方便!真心希望对你有用
如何在微信公众号素材库中采集文章?- 》》”我平时看到好的微信文章采集,可以使用西瓜助手或者西瓜插件之类的工具,使用网址导入文章、采集素材,同步到微信公众号帐户背景格式不会改变。
采集微信公众号文章可以使用哪些工具?- 》》”我知道西瓜助手,这是一个微信素材库,你可以一键找到文章素材采集。素材库可以分类管理,使用过的素材都会标注,一般使用起来比较方便。
找资料的时候,你怎么采集想要微信公众号文章?- 》》”如果是临时找资料,只需要自己保存资料的链接即可。如果需要长时间采集素材,我建议把文章@采集收到的素材放到素材库中。可以使用第三方平台,比如西瓜助手,在这里可以找到各种素材,一键采集到素材库,还支持文章链接导入,素材库可以分类和管理,选择需要的素材进行编辑和同步,这样会方便很多。
如何快速采集公众号的视频素材?- """ 使用第三方工具,我可以快速采集公众号里的视频素材,比如西瓜助手,一键采集,编辑过的也可以只保留视频,操作方便。
如何快速采集微信公众号爆文?- """ 手动复制素材的方法太麻烦了,而且格式会变,需要手动调整。建议你用第三方工具,比如西瓜助手,素材在平台,一键采集,直接同步到公众号后台,格式不会乱。
如何在微信公众号中一键快速采集文章,最好是批量。- """ 是的,只需要一个 采集文章 的链接 查看全部
querylist采集微信公众号文章(优采云软件智能文章采集系统,选择对的产品很重要!)
选择合适的产品很重要!下面是优采云软件智能文章采集系统,大家可以了解一下
一、智能块算法采集任何内容站点,真实傻瓜式采集
智能分块算法自动提取网页正文内容,无需配置源码规则,真正做到傻瓜式采集;
自动去噪,可以自动过滤标题内容中的图片\网站\电话\QQ\邮件等信息;
对于世界上任何一种小语言,任何编码文章采集,无乱码;
多任务(多站点/列)多线程同步采集,支持代理采集,快速高效;
指定任何文章内容类网站采集,非文章源
二、功能强大伪原创功能
内置中文分词功能,强大的同义词词库引擎,替换效率高;
自带英文分词词库和语料库,支持TBS模式的批量原创,保持句子流畅语义不变;
标题和内容可以分开处理伪原创;
三、内置主流cms发布界面
可直接导出为TXT文档,文件名可按标题或序号生成
支持wordpress、zblog、dedecms、phpcms等国内外主流cms自动发布;
支持多线程、多任务同步发布;
如果是临时找资料,只需要自己保存资料链接即可。从长远来看,您需要找到采集的材料。我建议将材料 采集 放入材料库。可以使用第三方平台,比如西瓜助手,在上面可以找到各种素材,一键采集到素材库,还支持文章链接导入,素材库可以分类管理,可以选择需要的素材进行编辑。,同步,会方便很多。
写文章写什么粉丝喜欢看,什么能吸引粉丝看文章,什么能写优质热点文章。编写这些 文章 对初学者来说可能很困难。这时候就可以使用西瓜助手,从全网,各个领域,一键采集,编辑,解决写作文章的难点,寻找优质热点素材。
采集微信公众号文章,如何采集?- """ 可以使用键盘快速排列,登录后在编辑区右侧找到导入文章按钮,然后将文章的地址复制进去,你采集能不能下来,采集后面还需要修改,不然不会变成原创。
新手,有没有最简单的方法采集微信公众号文章-""" 采集资料写文章很重要,可以用西瓜助手,会推荐每天最新的爆文,可以关键词搜索文章,也可以批量关注公众号,一键采集同步,操作简单,可以帮助您快速找到材料
超实用技巧:如何采集微信公众号文章 - """ 选对产品很重要!下面是优采云软件智能文章采集@ >系统,您可以了解一、智能块算法采集任何内容站点,真正的傻瓜式采集智能块算法自动提取网页正文内容,无需需要配置源码规则,真的是傻瓜式采集;自动去噪,可以对图片进行去噪\...
有没有办法采集去优质微信文章最好的素材也可以有视频”””哈哈~ 真的好难,不过可以考虑用公众号小助手,比如一个西瓜助手什么的,不仅能满足需求,还有其他功能让你更方便!真心希望对你有用
如何在微信公众号素材库中采集文章?- 》》”我平时看到好的微信文章采集,可以使用西瓜助手或者西瓜插件之类的工具,使用网址导入文章、采集素材,同步到微信公众号帐户背景格式不会改变。
采集微信公众号文章可以使用哪些工具?- 》》”我知道西瓜助手,这是一个微信素材库,你可以一键找到文章素材采集。素材库可以分类管理,使用过的素材都会标注,一般使用起来比较方便。
找资料的时候,你怎么采集想要微信公众号文章?- 》》”如果是临时找资料,只需要自己保存资料的链接即可。如果需要长时间采集素材,我建议把文章@采集收到的素材放到素材库中。可以使用第三方平台,比如西瓜助手,在这里可以找到各种素材,一键采集到素材库,还支持文章链接导入,素材库可以分类和管理,选择需要的素材进行编辑和同步,这样会方便很多。
如何快速采集公众号的视频素材?- """ 使用第三方工具,我可以快速采集公众号里的视频素材,比如西瓜助手,一键采集,编辑过的也可以只保留视频,操作方便。
如何快速采集微信公众号爆文?- """ 手动复制素材的方法太麻烦了,而且格式会变,需要手动调整。建议你用第三方工具,比如西瓜助手,素材在平台,一键采集,直接同步到公众号后台,格式不会乱。
如何在微信公众号中一键快速采集文章,最好是批量。- """ 是的,只需要一个 采集文章 的链接
querylist采集微信公众号文章(wordjs采集微信公众号文章内容解析工具(一)_)
采集交流 • 优采云 发表了文章 • 0 个评论 • 124 次浏览 • 2022-04-02 08:05
querylist采集微信公众号文章内容,然后根据公众号数量和文章内容生成词云、词云图形,同时根据文章内容和文章的doc可以生成微信公众号页面。通过工具可以直接进行在线生成,并可导出。导入bdp:操作步骤1.确定分词,这个是首要的。公众号文章是一篇一篇从工具里导出。2.确定展示docdoc可以自己写文章内容doc和模板doc,工具提供的doc都是与模板doc一致的,只不过样式有所不同。
3.确定词云,如果自己要确定词云的模板doc,可以用工具直接在线生成,wordjs和bdpsuite都可以,都支持词云的生成。(可以下载很多模板,根据喜好安装可自行选择和修改、选择)。wordjs价格更优惠,但如果需要阅读原文,对比了工具bdp之后,最终选择了bdpsuite。毕竟还是最节省时间和最方便。
4.确定文章标题。文章一般以一句话或者两句话的形式展示,有一些关键词需要在文章中添加图标,产生词云图形,通过工具可以自己拟定并生成。5.确定图标在工具里修改,不要修改任何形状。6.进行词云文章解析,文章内容解析工具大家根据自己需要来选择。7.添加doc内容。使用bdpsuite,自己工具内生成了模板doc,直接粘贴到自己工具里,就可以把内容复制到公众号任意doc中。
8.以上步骤完成,数据就导入到自己工具了。9.删除上下文展示的文章内容10.进行doc内容转化成词云图形工具wordjs集成了多达10款词云工具,可以根据需要选择。11.利用词云工具生成词云,就ok了。如果觉得词云生成器功能和页面比较丑,可以看下wordjs的源码。看不懂源码也不用担心,可以点击这里。
12.不喜欢写文章,但是想生成一个网页版文章文本可以看下wordjs的源码13.生成文本可以得到data,对外公开14.通过词云得到任何页面的导航链接。15.看下效果16.wordjs源码还是很简单的。17.重要的是模板doc生成器wordjs的源码17.用新环境不是更安全吗?看下18.用ardublock高斯过滤器模板的制作19.wordjsdoc的实现20.得到data后,可以通过wordjs编辑器公众号“公众号出品,必属精品”回复“bdp”获取最新发布的版本22.使用java做会更加好操作,使用ide操作可以减少你在编程方面的不必要烦恼23.很多场景用java会更方便使用。 查看全部
querylist采集微信公众号文章(wordjs采集微信公众号文章内容解析工具(一)_)
querylist采集微信公众号文章内容,然后根据公众号数量和文章内容生成词云、词云图形,同时根据文章内容和文章的doc可以生成微信公众号页面。通过工具可以直接进行在线生成,并可导出。导入bdp:操作步骤1.确定分词,这个是首要的。公众号文章是一篇一篇从工具里导出。2.确定展示docdoc可以自己写文章内容doc和模板doc,工具提供的doc都是与模板doc一致的,只不过样式有所不同。
3.确定词云,如果自己要确定词云的模板doc,可以用工具直接在线生成,wordjs和bdpsuite都可以,都支持词云的生成。(可以下载很多模板,根据喜好安装可自行选择和修改、选择)。wordjs价格更优惠,但如果需要阅读原文,对比了工具bdp之后,最终选择了bdpsuite。毕竟还是最节省时间和最方便。
4.确定文章标题。文章一般以一句话或者两句话的形式展示,有一些关键词需要在文章中添加图标,产生词云图形,通过工具可以自己拟定并生成。5.确定图标在工具里修改,不要修改任何形状。6.进行词云文章解析,文章内容解析工具大家根据自己需要来选择。7.添加doc内容。使用bdpsuite,自己工具内生成了模板doc,直接粘贴到自己工具里,就可以把内容复制到公众号任意doc中。
8.以上步骤完成,数据就导入到自己工具了。9.删除上下文展示的文章内容10.进行doc内容转化成词云图形工具wordjs集成了多达10款词云工具,可以根据需要选择。11.利用词云工具生成词云,就ok了。如果觉得词云生成器功能和页面比较丑,可以看下wordjs的源码。看不懂源码也不用担心,可以点击这里。
12.不喜欢写文章,但是想生成一个网页版文章文本可以看下wordjs的源码13.生成文本可以得到data,对外公开14.通过词云得到任何页面的导航链接。15.看下效果16.wordjs源码还是很简单的。17.重要的是模板doc生成器wordjs的源码17.用新环境不是更安全吗?看下18.用ardublock高斯过滤器模板的制作19.wordjsdoc的实现20.得到data后,可以通过wordjs编辑器公众号“公众号出品,必属精品”回复“bdp”获取最新发布的版本22.使用java做会更加好操作,使用ide操作可以减少你在编程方面的不必要烦恼23.很多场景用java会更方便使用。
querylist采集微信公众号文章(使用selenium库,pythonweb应用开发实战教程(百度网盘))
采集交流 • 优采云 发表了文章 • 0 个评论 • 150 次浏览 • 2022-03-31 02:06
querylist采集微信公众号文章列表。把微信文章列表添加到querylistquerylisteditor中,然后调用queryeditor的recapad_content函数,把文章编号的微信昵称转换成数组。
文本匹配。
使用selenium库,
pythonweb应用开发实战教程(百度网盘)(可转word在线阅读,
让我找找ffmpeg?
文本匹配可以使用dataframe啊
jquery正则匹配文本
queryset可以搭配querydriver
可以用正则表达式
setqscontext
windows下自带的文本文件扫描仪。我也遇到过你这个问题。
python文本文件扫描可以用‘word2word’。支持文本的长度范围。
tab:多空格就匹配一空格:就匹配1个空格:就匹配1个空格:就匹配1个空格:就匹配1个空格:就匹配1个空格:就匹配1个空格:就匹配1个空格:就匹配1个空格
扫描word2word。
还可以用tbbit,不过那个是免费版的。
我是用ffmpeg。
刚刚搜了好久的微信公众号编辑器,ffmdemo算一个,另外documentsoftverify是最好的方法。
试试用文本全文重命名程序
这个看你是什么公众号
querybox。虽然付费才能实现,
可以试试这个公众号的文章搜索功能 查看全部
querylist采集微信公众号文章(使用selenium库,pythonweb应用开发实战教程(百度网盘))
querylist采集微信公众号文章列表。把微信文章列表添加到querylistquerylisteditor中,然后调用queryeditor的recapad_content函数,把文章编号的微信昵称转换成数组。
文本匹配。
使用selenium库,
pythonweb应用开发实战教程(百度网盘)(可转word在线阅读,
让我找找ffmpeg?
文本匹配可以使用dataframe啊
jquery正则匹配文本
queryset可以搭配querydriver
可以用正则表达式
setqscontext
windows下自带的文本文件扫描仪。我也遇到过你这个问题。
python文本文件扫描可以用‘word2word’。支持文本的长度范围。
tab:多空格就匹配一空格:就匹配1个空格:就匹配1个空格:就匹配1个空格:就匹配1个空格:就匹配1个空格:就匹配1个空格:就匹配1个空格:就匹配1个空格
扫描word2word。
还可以用tbbit,不过那个是免费版的。
我是用ffmpeg。
刚刚搜了好久的微信公众号编辑器,ffmdemo算一个,另外documentsoftverify是最好的方法。
试试用文本全文重命名程序
这个看你是什么公众号
querybox。虽然付费才能实现,
可以试试这个公众号的文章搜索功能
querylist采集微信公众号文章(采集微信公众号获取使用使用说明书使用地址)
采集交流 • 优采云 发表了文章 • 0 个评论 • 232 次浏览 • 2022-03-28 17:05
querylist采集微信公众号文章分类信息,供connectivityapi查询使用。用到的函数:通过urlschema获取version,字段名。或者直接获取按字符进行的组合形式。htmlversionfunctiongetcodestatusreportchain(src,attributes){charchread.currentthread="deviceid";charnewdisplaychains[300];chartypeof[]="sprintshell";inttime=connectivity.allrefaired({memory:2,time:1});voidsetconnectivity("deviceid",char);intversion=string(chread.currentthread("deviceid"));intcheckstorecount=timeof(char);stringversionname="#"+""+string(chread.currentthread("deviceid"))+"version";voidsetconnectivity("deviceid",char);voidsetactivechannel(char);voidsetpolarfulthread(char);voidsetfaultsuser(char);voidsetmonitor(char);//...}connectivityqueryapi的api如下:1.获取url-->通过urlschema获取信息2.获取每个信息字段名称并且html文件中匹配3.查看version字段获取信息下面是api文档:-user-performance-resources/。
querylist基本上现在大部分人都会用了,querylist在开发的时候都是需要打包的。需要打包的打包好了丢到tomcat上的,然后去idea或者其他ide上运行。有一点要注意的是,你在运行querylist的时候,你是access_log证书的。我的打包tomcat是阿里云的,暂时没有遇到这种情况。 查看全部
querylist采集微信公众号文章(采集微信公众号获取使用使用说明书使用地址)
querylist采集微信公众号文章分类信息,供connectivityapi查询使用。用到的函数:通过urlschema获取version,字段名。或者直接获取按字符进行的组合形式。htmlversionfunctiongetcodestatusreportchain(src,attributes){charchread.currentthread="deviceid";charnewdisplaychains[300];chartypeof[]="sprintshell";inttime=connectivity.allrefaired({memory:2,time:1});voidsetconnectivity("deviceid",char);intversion=string(chread.currentthread("deviceid"));intcheckstorecount=timeof(char);stringversionname="#"+""+string(chread.currentthread("deviceid"))+"version";voidsetconnectivity("deviceid",char);voidsetactivechannel(char);voidsetpolarfulthread(char);voidsetfaultsuser(char);voidsetmonitor(char);//...}connectivityqueryapi的api如下:1.获取url-->通过urlschema获取信息2.获取每个信息字段名称并且html文件中匹配3.查看version字段获取信息下面是api文档:-user-performance-resources/。
querylist基本上现在大部分人都会用了,querylist在开发的时候都是需要打包的。需要打包的打包好了丢到tomcat上的,然后去idea或者其他ide上运行。有一点要注意的是,你在运行querylist的时候,你是access_log证书的。我的打包tomcat是阿里云的,暂时没有遇到这种情况。

