
python网页数据抓取
python网页数据抓取(python抓取网页数据.txt51自信是永不枯竭的源泉,自信)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-02-22 09:14
Python爬取网页数据.txt51 自信是取之不尽的源泉,自信是无穷无尽的浪潮,自信是快速进步的通道,自信是真正成功之母。使用python抓取页面并处理 2009-02-19 15:09:50| 分类:Python 标签:无|字号订阅 主要用途:抓取网页的源代码,处理其中需要的数据,并存入数据库。已经实现了爬取页面和读取数据。Step 一、 爬取页面,这一步很简单,导入urllib,使用urlopen打开URL,使用read()方法读取数据。为了方便测试,使用本地文本文件代替爬取网页二、的步骤来处理数据。如果页面代码比较规范,可以使用HTMLParser进行简单的处理,但具体情况需要详细分析,我觉得还是用正则表达式比较好。顺便练习一下刚刚学过的正则表达式。其实正则也是一种比较简单的语言,符号很多,有点晦涩难懂。只能多练多练。三、这一步将处理后的数据保存到数据库中,可以用pymssql处理。在这里,它只是保存到一个文本文件中。通过扩展,该功能还可用于截取整个网站图片,自动认领sitemap文件等功能。下一个任务,研究python的socket函数importurllib import re #pager=urllib.urlopen() #data=pager.read() #pager.close() f=open(r"D:\2.txt" ) data =f。 查看全部
python网页数据抓取(python抓取网页数据.txt51自信是永不枯竭的源泉,自信)
Python爬取网页数据.txt51 自信是取之不尽的源泉,自信是无穷无尽的浪潮,自信是快速进步的通道,自信是真正成功之母。使用python抓取页面并处理 2009-02-19 15:09:50| 分类:Python 标签:无|字号订阅 主要用途:抓取网页的源代码,处理其中需要的数据,并存入数据库。已经实现了爬取页面和读取数据。Step 一、 爬取页面,这一步很简单,导入urllib,使用urlopen打开URL,使用read()方法读取数据。为了方便测试,使用本地文本文件代替爬取网页二、的步骤来处理数据。如果页面代码比较规范,可以使用HTMLParser进行简单的处理,但具体情况需要详细分析,我觉得还是用正则表达式比较好。顺便练习一下刚刚学过的正则表达式。其实正则也是一种比较简单的语言,符号很多,有点晦涩难懂。只能多练多练。三、这一步将处理后的数据保存到数据库中,可以用pymssql处理。在这里,它只是保存到一个文本文件中。通过扩展,该功能还可用于截取整个网站图片,自动认领sitemap文件等功能。下一个任务,研究python的socket函数importurllib import re #pager=urllib.urlopen() #data=pager.read() #pager.close() f=open(r"D:\2.txt" ) data =f。
python网页数据抓取( 2020年03月16日08:49:43作者:5sh)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-02-21 22:00
2020年03月16日08:49:43作者:5sh)
Django从html页面表单获取输入数据的例子
更新时间:2020-03-16 08:49:43 作者:5sh
这篇文章主要介绍了Django从html页面表单获取输入数据的例子,有很好的参考价值,希望对大家有所帮助。跟我来看看
本文主要讲解如何获取用户在html页面中输入的信息。
1.先写一个自定义的html页面
登录.html
test
form表单中的action{%url 'check'%}对应urls.py中的name值
2.配置urls.py文件
urlpatterns = [
path('reg/',views.reg,name='check'),
path('',views.login),
]
3.配置views.py文件
def login(request):
return render(request,'login.html')
def reg(request):
if request.method == 'POST':
name=request.POST.get('name')
pwd=request.POST.get('pwd')
print(name,pwd)
return render(request,'login.html')
4.打开服务,进入首页localhost:8000,输入用户名和密码,点击提交
这时候会报403错误
您需要在 login.html 文件中的表单表单中添加以下代码行
{%csrf_token%}
{% csrf_token %}
重启服务,再次输入用户名和密码
可以获取页面输入的信息
上面django从html页面表单获取的输入数据的例子就是编辑器共享的所有内容。希望能给大家一个参考,也希望大家多多支持脚本之家。 查看全部
python网页数据抓取(
2020年03月16日08:49:43作者:5sh)
Django从html页面表单获取输入数据的例子
更新时间:2020-03-16 08:49:43 作者:5sh
这篇文章主要介绍了Django从html页面表单获取输入数据的例子,有很好的参考价值,希望对大家有所帮助。跟我来看看
本文主要讲解如何获取用户在html页面中输入的信息。
1.先写一个自定义的html页面
登录.html
test
form表单中的action{%url 'check'%}对应urls.py中的name值

2.配置urls.py文件
urlpatterns = [
path('reg/',views.reg,name='check'),
path('',views.login),
]
3.配置views.py文件
def login(request):
return render(request,'login.html')
def reg(request):
if request.method == 'POST':
name=request.POST.get('name')
pwd=request.POST.get('pwd')
print(name,pwd)
return render(request,'login.html')
4.打开服务,进入首页localhost:8000,输入用户名和密码,点击提交
这时候会报403错误

您需要在 login.html 文件中的表单表单中添加以下代码行
{%csrf_token%}
{% csrf_token %}
重启服务,再次输入用户名和密码
可以获取页面输入的信息

上面django从html页面表单获取的输入数据的例子就是编辑器共享的所有内容。希望能给大家一个参考,也希望大家多多支持脚本之家。
python网页数据抓取(通过Python访问网站的HTML代码获取特定的img标签中的图片地址 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-02-21 21:28
)
================爬虫原理====================
通过Python访问网站,获取网站的HTML代码,通过正则表达式获取特定img标签中src的图片地址。
之后,访问图片地址,通过IO操作将图片保存到本地。
================脚本代码====================
import urllib.request # 网络访问模块
import random # 随机数生成模块
import re # 正则表达式模块
import os # 目录结构处理模块
# 初始化配置参数
number = 10 # 图片收集数量
path = 'img/' # 图片存放目录
# 文件操作
if not os.path.exists(path):
os.makedirs(path)
# 图片保存
def save_img(url, path):
message = None
try:
file = open(path + os.path.basename(url), 'wb')
request = urllib.request.urlopen(url)
file.write(request.read())
except Exception as e:
message = str(e)
else:
message = os.path.basename(url)
finally:
if not file.closed:
file.close()
return message
# 网络连接
http = 'http://zerospace.asika.tw/photo/' # 目标网址
position = 290 + int((1000 - number) * random.random())
ids = range(position, position + number)
for id in ids:
try:
url = "%s%d.html" % (http, id) # 后缀生成
request = urllib.request.urlopen(url)
except Exception as e:
print(e)
continue
else:
buffer = request.read()
buffer = buffer.decode('utf8')
pattern = 'class="content-img".+\s+.+src="(.+\.jpg)"'
imgurl = re.findall(pattern, buffer) # 过滤规则
if len(imgurl) != 0:
print(save_img(imgurl[0], path))
else:
continue
pass
================运行结果====================
查看全部
python网页数据抓取(通过Python访问网站的HTML代码获取特定的img标签中的图片地址
)
================爬虫原理====================
通过Python访问网站,获取网站的HTML代码,通过正则表达式获取特定img标签中src的图片地址。
之后,访问图片地址,通过IO操作将图片保存到本地。
================脚本代码====================
import urllib.request # 网络访问模块
import random # 随机数生成模块
import re # 正则表达式模块
import os # 目录结构处理模块
# 初始化配置参数
number = 10 # 图片收集数量
path = 'img/' # 图片存放目录
# 文件操作
if not os.path.exists(path):
os.makedirs(path)
# 图片保存
def save_img(url, path):
message = None
try:
file = open(path + os.path.basename(url), 'wb')
request = urllib.request.urlopen(url)
file.write(request.read())
except Exception as e:
message = str(e)
else:
message = os.path.basename(url)
finally:
if not file.closed:
file.close()
return message
# 网络连接
http = 'http://zerospace.asika.tw/photo/' # 目标网址
position = 290 + int((1000 - number) * random.random())
ids = range(position, position + number)
for id in ids:
try:
url = "%s%d.html" % (http, id) # 后缀生成
request = urllib.request.urlopen(url)
except Exception as e:
print(e)
continue
else:
buffer = request.read()
buffer = buffer.decode('utf8')
pattern = 'class="content-img".+\s+.+src="(.+\.jpg)"'
imgurl = re.findall(pattern, buffer) # 过滤规则
if len(imgurl) != 0:
print(save_img(imgurl[0], path))
else:
continue
pass
================运行结果====================


python网页数据抓取(python爬虫简单概括获取网页数据(图)代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-02-21 20:17
文章目录
前言:python爬虫的简单总结其实就是获取网页数据,然后按需提取!过程虽然简单,但需要结合多种技术,掌握爬虫库,编写高效的爬虫代码。
一、先了解用户如何获取网络数据
1、用户使用浏览器:浏览器提交请求—>下载网页代码—>解析成页面
2、代码自动获取:模拟浏览器发送请求(获取网页代码html、css、javascript)->提取有用数据->存入数据库或文件
python爬虫使用代码自动获取。具体流程为:
二、简单了解网页源代码的构成1、web的基本编程语言
简单了解可以上菜鸟教程
1)HTML、CSS、JavaScript是Web开发者必须学习的3种语言。他们相互合作,形成了各种丰富的网站
(1)HTML 定义了网页的内容
(2)CSS 描述了页面的布局
(3)JavaScript 控制页面的行为
2)html5 简单示例
3)html 中的 javaScript
4)HTML 中的 CSS
2、使用浏览器查看网页源代码
1)网页右键查看源码(也就是我们要得到的)
2)html代码,这里需要我们稍微了解一下它的组成,然后根据内容提取出来
三、爬虫概述1、了解爬虫
我们熟悉的一系列搜索引擎都是大型网络爬虫,比如百度、搜狗、360浏览器、谷歌搜索等等。每个搜索引擎都有自己的爬虫。比如360浏览器的爬虫叫360Spider,搜狗的爬虫叫Sogospider。
2、python 爬虫
百度搜索引擎,其实可以更形象的叫做百度蜘蛛(Baiduspider),它每天都会从海量互联网信息中抓取优质信息,并进行收录。当用户通过百度搜索关键词时,百度会先分析用户输入的关键词,然后从收录的网页中找出相关的网页,并根据网页排名排名规则。排序,最后将排序后的结果呈现给用户。在这个过程中,百度蜘蛛发挥了非常重要的作用。
百度工程师为“百度蜘蛛”编写了相应的爬虫算法。通过应用这些算法,“百度蜘蛛”可以实现相应的搜索策略,如过滤掉重复网页、过滤优质网页等。应用不同的算法,爬虫的效率和爬取结果会有所不同。
3、爬虫分类
爬虫可以分为三类:一般网络爬虫、聚焦网络爬虫和增量网络爬虫。
1)万能网络爬虫:是搜索引擎的重要组成部分,上面已经介绍过了,这里不再赘述。一般网络爬虫需要遵守robots协议,网站告诉搜索引擎哪些页面可以爬,哪些页面不可以爬。
机器人协议:是一种“常规”协议,没有法律效力。体现了互联网人的“契约精神”。行业从业者会自觉遵守协议,故又称“君子协议”。
2)专注网络爬虫:是针对特定需求的网络爬虫程序。它与一般爬虫的区别在于,聚焦爬虫在实现网页爬虫时会对网页内容进行过滤处理,并尽量保证只抓取与需求相关的网页信息。专注于网络爬虫,大大节省了硬件和网络资源。由于保存的页面少,所以更新速度很快,也满足了一些特定人群对特定领域信息的需求。
3)增量网络爬虫:指对下载的网页进行增量更新。它是一种只抓取新生成或更改的网页的爬虫程序,可以在一定程度上保证抓取到的网页。获取的页面是最新的页面。
4、爬虫应用
随着互联网的飞速发展,万维网已经成为海量信息的载体。如何有效地提取和利用这些信息已成为一个巨大的挑战。于是,爬虫应运而生。它不仅可以用于搜索引擎领域,还可以用于大数据分析,并在商业领域得到了大规模应用。
1) 数据分析
在数据分析领域,网络爬虫通常是采集海量数据的必备工具。对于数据分析师来说,要进行数据分析,首先要有数据源,通过学习爬虫,可以获得更多的数据源。在采集过程中,数据分析师可以根据自己的目的采集更多有价值的数据,并过滤掉那些无效数据。
2) 业务
对于企业来说,及时获取市场动态和产品信息非常重要。企业可以通过第三方平台购买数据,比如贵阳大数据交易所、数据堂等。当然,如果贵公司有爬虫工程师,也可以通过爬虫获取想要的信息。
5、爬行动物是一把双刃剑
爬虫是一把双刃剑,它给我们带来便利的同时,也给网络安全带来隐患。一些不法分子利用爬虫非法采集互联网上的网友信息,或者利用爬虫恶意攻击他人网站,造成网站瘫痪的严重后果。关于爬虫的合法使用,建议阅读《中华人民共和国网络安全法》。
6、python爬虫教程
为了限制爬虫带来的危险,大部分网站都有很好的反爬措施,所以在使用爬虫的时候一定要自觉遵守约定,不要非法获取他人信息,或者做对他人有害的事情。其他网站 的事情。
为什么使用 Python 作为爬虫
首先你要清楚,不仅Python可以做爬虫,PHP、Java、C/C++等都可以用来写爬虫程序,但是Python做爬虫是最简单的。以下是它们的优缺点的简要比较:
PHP:对多线程和异步的支持不是很好,并发处理能力较弱;Java也常用于编写爬虫程序,但Java语言本身非常繁琐,代码量大,对初学者入门门槛较高;尽管 C/C++ 运行效率很高,但学习和开发的成本很高。编写一个小型爬虫可能需要很长时间。
Python语言语法优美,代码简洁,开发效率高,支持多种爬虫模块,如urllib、requests、Bs4等。Python的request模块和解析模块丰富成熟,还提供了强大的Scrapy框架使编写爬虫程序更容易。因此,使用 Python 编写爬虫程序是一个非常不错的选择。
7、爬虫的编写过程
爬虫程序与其他程序不同,它的思维逻辑大体相似,所以我们不需要在逻辑上花很多时间。下面简单介绍一下用Python编写爬虫程序的过程:
首先通过urllib模块的request方法打开URL,获取网页的HTML对象。
使用浏览器打开网页源代码,分析网页结构和元素节点。
通过 Beautiful Soup 或正则表达式提取数据。
将数据存储到本地磁盘或数据库。
当然,不限于上述一种过程。编写爬虫程序,需要具备良好的Python编程能力,这样在编写过程中会得心应手。爬虫需要尽量伪装成人类访问网站,而不是机器访问,否则会被网站的反爬策略限制,甚至直接封IP。
四、python爬虫实践——获取博客浏览量
废话不多说,代码
<p>import re
import requests
from requests import RequestException
import urllib.request
url = "https://blog.csdn.net/STCNXPAR ... ot%3B
def get_page(url):
try:
#请求头部,如果不加头部,则会被反爬虫网站识别出是爬虫,会导致获取不到数据
headers = {
'Referer': 'https://blog.csdn.net', # 伪装成从CSDN博客搜索到的文章
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Safari/537.36' # 伪装成浏览器
}
#获取网页源代码数据
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
except RequestException:
print('请求出错')
return None
def parse_page(html):
try:
#使用正则匹配html代码中浏览量字段
read_num = int(re.compile(' 查看全部
python网页数据抓取(python爬虫简单概括获取网页数据(图)代码)
文章目录
前言:python爬虫的简单总结其实就是获取网页数据,然后按需提取!过程虽然简单,但需要结合多种技术,掌握爬虫库,编写高效的爬虫代码。
一、先了解用户如何获取网络数据
1、用户使用浏览器:浏览器提交请求—>下载网页代码—>解析成页面
2、代码自动获取:模拟浏览器发送请求(获取网页代码html、css、javascript)->提取有用数据->存入数据库或文件
python爬虫使用代码自动获取。具体流程为:

二、简单了解网页源代码的构成1、web的基本编程语言
简单了解可以上菜鸟教程
1)HTML、CSS、JavaScript是Web开发者必须学习的3种语言。他们相互合作,形成了各种丰富的网站
(1)HTML 定义了网页的内容
(2)CSS 描述了页面的布局
(3)JavaScript 控制页面的行为
2)html5 简单示例

3)html 中的 javaScript

4)HTML 中的 CSS

2、使用浏览器查看网页源代码
1)网页右键查看源码(也就是我们要得到的)

2)html代码,这里需要我们稍微了解一下它的组成,然后根据内容提取出来

三、爬虫概述1、了解爬虫
我们熟悉的一系列搜索引擎都是大型网络爬虫,比如百度、搜狗、360浏览器、谷歌搜索等等。每个搜索引擎都有自己的爬虫。比如360浏览器的爬虫叫360Spider,搜狗的爬虫叫Sogospider。
2、python 爬虫
百度搜索引擎,其实可以更形象的叫做百度蜘蛛(Baiduspider),它每天都会从海量互联网信息中抓取优质信息,并进行收录。当用户通过百度搜索关键词时,百度会先分析用户输入的关键词,然后从收录的网页中找出相关的网页,并根据网页排名排名规则。排序,最后将排序后的结果呈现给用户。在这个过程中,百度蜘蛛发挥了非常重要的作用。
百度工程师为“百度蜘蛛”编写了相应的爬虫算法。通过应用这些算法,“百度蜘蛛”可以实现相应的搜索策略,如过滤掉重复网页、过滤优质网页等。应用不同的算法,爬虫的效率和爬取结果会有所不同。
3、爬虫分类
爬虫可以分为三类:一般网络爬虫、聚焦网络爬虫和增量网络爬虫。
1)万能网络爬虫:是搜索引擎的重要组成部分,上面已经介绍过了,这里不再赘述。一般网络爬虫需要遵守robots协议,网站告诉搜索引擎哪些页面可以爬,哪些页面不可以爬。
机器人协议:是一种“常规”协议,没有法律效力。体现了互联网人的“契约精神”。行业从业者会自觉遵守协议,故又称“君子协议”。
2)专注网络爬虫:是针对特定需求的网络爬虫程序。它与一般爬虫的区别在于,聚焦爬虫在实现网页爬虫时会对网页内容进行过滤处理,并尽量保证只抓取与需求相关的网页信息。专注于网络爬虫,大大节省了硬件和网络资源。由于保存的页面少,所以更新速度很快,也满足了一些特定人群对特定领域信息的需求。
3)增量网络爬虫:指对下载的网页进行增量更新。它是一种只抓取新生成或更改的网页的爬虫程序,可以在一定程度上保证抓取到的网页。获取的页面是最新的页面。
4、爬虫应用
随着互联网的飞速发展,万维网已经成为海量信息的载体。如何有效地提取和利用这些信息已成为一个巨大的挑战。于是,爬虫应运而生。它不仅可以用于搜索引擎领域,还可以用于大数据分析,并在商业领域得到了大规模应用。
1) 数据分析
在数据分析领域,网络爬虫通常是采集海量数据的必备工具。对于数据分析师来说,要进行数据分析,首先要有数据源,通过学习爬虫,可以获得更多的数据源。在采集过程中,数据分析师可以根据自己的目的采集更多有价值的数据,并过滤掉那些无效数据。
2) 业务
对于企业来说,及时获取市场动态和产品信息非常重要。企业可以通过第三方平台购买数据,比如贵阳大数据交易所、数据堂等。当然,如果贵公司有爬虫工程师,也可以通过爬虫获取想要的信息。
5、爬行动物是一把双刃剑
爬虫是一把双刃剑,它给我们带来便利的同时,也给网络安全带来隐患。一些不法分子利用爬虫非法采集互联网上的网友信息,或者利用爬虫恶意攻击他人网站,造成网站瘫痪的严重后果。关于爬虫的合法使用,建议阅读《中华人民共和国网络安全法》。
6、python爬虫教程
为了限制爬虫带来的危险,大部分网站都有很好的反爬措施,所以在使用爬虫的时候一定要自觉遵守约定,不要非法获取他人信息,或者做对他人有害的事情。其他网站 的事情。
为什么使用 Python 作为爬虫
首先你要清楚,不仅Python可以做爬虫,PHP、Java、C/C++等都可以用来写爬虫程序,但是Python做爬虫是最简单的。以下是它们的优缺点的简要比较:
PHP:对多线程和异步的支持不是很好,并发处理能力较弱;Java也常用于编写爬虫程序,但Java语言本身非常繁琐,代码量大,对初学者入门门槛较高;尽管 C/C++ 运行效率很高,但学习和开发的成本很高。编写一个小型爬虫可能需要很长时间。
Python语言语法优美,代码简洁,开发效率高,支持多种爬虫模块,如urllib、requests、Bs4等。Python的request模块和解析模块丰富成熟,还提供了强大的Scrapy框架使编写爬虫程序更容易。因此,使用 Python 编写爬虫程序是一个非常不错的选择。
7、爬虫的编写过程
爬虫程序与其他程序不同,它的思维逻辑大体相似,所以我们不需要在逻辑上花很多时间。下面简单介绍一下用Python编写爬虫程序的过程:
首先通过urllib模块的request方法打开URL,获取网页的HTML对象。
使用浏览器打开网页源代码,分析网页结构和元素节点。
通过 Beautiful Soup 或正则表达式提取数据。
将数据存储到本地磁盘或数据库。
当然,不限于上述一种过程。编写爬虫程序,需要具备良好的Python编程能力,这样在编写过程中会得心应手。爬虫需要尽量伪装成人类访问网站,而不是机器访问,否则会被网站的反爬策略限制,甚至直接封IP。
四、python爬虫实践——获取博客浏览量
废话不多说,代码
<p>import re
import requests
from requests import RequestException
import urllib.request
url = "https://blog.csdn.net/STCNXPAR ... ot%3B
def get_page(url):
try:
#请求头部,如果不加头部,则会被反爬虫网站识别出是爬虫,会导致获取不到数据
headers = {
'Referer': 'https://blog.csdn.net', # 伪装成从CSDN博客搜索到的文章
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Safari/537.36' # 伪装成浏览器
}
#获取网页源代码数据
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
except RequestException:
print('请求出错')
return None
def parse_page(html):
try:
#使用正则匹配html代码中浏览量字段
read_num = int(re.compile('
python网页数据抓取(我已经看过这个问题,但那里没有提到python)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-02-21 08:02
我看过这个关于抓取 ajax 的问题,但那里没有提到 python。我考虑过使用scrapy,我相信他们有一些关于这个主题的文档,但正如你所看到的, 网站 已关闭。所以我不知道该怎么办。我想做以下事情:
我已经看过这个关于抓取 ajax 的问题,但那里没有提到 python。我考虑过使用scrapy,我相信他们有一些关于这个主题的文档,但是你可以看到网站已经关闭。所以我不知道该怎么办。我想做以下事情:
我只有一个url,你可以通过点击提交从一个页面跳转到另一个页面,url不会改变,因为他们使用ajax显示内容。我想抓取每个页面的内容,怎么做?
我只有一个 url,你通过点击提交从一个页面转到另一个页面,因为他们使用 ajax 来显示内容,所以 url 不会改变。我想抓取每个页面的内容,怎么做?
假设我只是想抓取数字,除了scrapy,我还能做些什么吗?如果没有,你能否给我一个关于如何做的片段,只是因为他们的 网站 已关闭,所以我无法访问文档。
假设我只想抓取数字,除了scrapy之外还有什么可以做到的吗?如果没有,你能给我一个关于如何做的片段吗,只是因为他们的网站已经关闭,所以我无法访问文档。 查看全部
python网页数据抓取(我已经看过这个问题,但那里没有提到python)
我看过这个关于抓取 ajax 的问题,但那里没有提到 python。我考虑过使用scrapy,我相信他们有一些关于这个主题的文档,但正如你所看到的, 网站 已关闭。所以我不知道该怎么办。我想做以下事情:
我已经看过这个关于抓取 ajax 的问题,但那里没有提到 python。我考虑过使用scrapy,我相信他们有一些关于这个主题的文档,但是你可以看到网站已经关闭。所以我不知道该怎么办。我想做以下事情:
我只有一个url,你可以通过点击提交从一个页面跳转到另一个页面,url不会改变,因为他们使用ajax显示内容。我想抓取每个页面的内容,怎么做?
我只有一个 url,你通过点击提交从一个页面转到另一个页面,因为他们使用 ajax 来显示内容,所以 url 不会改变。我想抓取每个页面的内容,怎么做?
假设我只是想抓取数字,除了scrapy,我还能做些什么吗?如果没有,你能否给我一个关于如何做的片段,只是因为他们的 网站 已关闭,所以我无法访问文档。
假设我只想抓取数字,除了scrapy之外还有什么可以做到的吗?如果没有,你能给我一个关于如何做的片段吗,只是因为他们的网站已经关闭,所以我无法访问文档。
python网页数据抓取(三种数据抓取的方法(库)(bs4))
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-02-19 15:20
本期文章将与大家分享如何在python中实现数据采集。小编觉得很实用,所以分享给大家作为参考,也跟着小编一起来看看吧。
三种数据采集方法
正则表达式(重新库)
BeautifulSoup (bs4)
lxml
*利用之前构建的下载网页函数获取目标网页的html,我们以获取html为例。
from get_html import download
url = 'https://guojiadiqu.bmcx.com/AF ... ntent = download(url)
*假设我们需要抓取这个网页中的国名和简介,我们会依次使用这三种数据抓取方式来实现数据抓取。
1.正则表达式
from get_html import downloadimport re
url = 'https://guojiadiqu.bmcx.com/AF ... ntent = download(url)country = re.findall('class="h3dabiaoti">(.*?)', page_content) #注意返回的是listsurvey_data = re.findall('(.*?)', page_content)survey_info_list = re.findall('<p> (.*?)', survey_data[0])survey_info = ''.join(survey_info_list)print(country[0],survey_info)</p>
2.美汤(bs4)
from get_html import downloadfrom bs4 import BeautifulSoup
url = 'https://guojiadiqu.bmcx.com/AF ... Bhtml = download(url)#创建 beautifulsoup 对象soup = BeautifulSoup(html,"html.parser")#搜索country = soup.find(attrs={'class':'h3dabiaoti'}).text
survey_info = soup.find(attrs={'id':'wzneirong'}).textprint(country,survey_info)
3.lxml
from get_html import downloadfrom lxml import etree #解析树url = 'https://guojiadiqu.bmcx.com/AF ... ntent = download(url)selector = etree.HTML(page_content)#可进行xpath解析country_select = selector.xpath('//*[@id="main_content"]/h3') #返回列表for country in country_select:
print(country.text)survey_select = selector.xpath('//*[@id="wzneirong"]/p')for survey_content in survey_select:
print(survey_content.text,end='')
运行结果:
最后参考《用Python编写网络爬虫》中三种方式的性能对比,如下图:
仅供参考。
谢谢阅读!《如何在python中实现数据捕获》的文章文章分享到这里。希望以上内容能够对大家有所帮助,让大家学习到更多的知识。如果你觉得文章是的,你可以分享出来让更多人看到! 查看全部
python网页数据抓取(三种数据抓取的方法(库)(bs4))
本期文章将与大家分享如何在python中实现数据采集。小编觉得很实用,所以分享给大家作为参考,也跟着小编一起来看看吧。
三种数据采集方法
正则表达式(重新库)
BeautifulSoup (bs4)
lxml
*利用之前构建的下载网页函数获取目标网页的html,我们以获取html为例。

from get_html import download
url = 'https://guojiadiqu.bmcx.com/AF ... ntent = download(url)
*假设我们需要抓取这个网页中的国名和简介,我们会依次使用这三种数据抓取方式来实现数据抓取。
1.正则表达式
from get_html import downloadimport re
url = 'https://guojiadiqu.bmcx.com/AF ... ntent = download(url)country = re.findall('class="h3dabiaoti">(.*?)', page_content) #注意返回的是listsurvey_data = re.findall('(.*?)', page_content)survey_info_list = re.findall('<p> (.*?)', survey_data[0])survey_info = ''.join(survey_info_list)print(country[0],survey_info)</p>
2.美汤(bs4)
from get_html import downloadfrom bs4 import BeautifulSoup
url = 'https://guojiadiqu.bmcx.com/AF ... Bhtml = download(url)#创建 beautifulsoup 对象soup = BeautifulSoup(html,"html.parser")#搜索country = soup.find(attrs={'class':'h3dabiaoti'}).text
survey_info = soup.find(attrs={'id':'wzneirong'}).textprint(country,survey_info)
3.lxml
from get_html import downloadfrom lxml import etree #解析树url = 'https://guojiadiqu.bmcx.com/AF ... ntent = download(url)selector = etree.HTML(page_content)#可进行xpath解析country_select = selector.xpath('//*[@id="main_content"]/h3') #返回列表for country in country_select:
print(country.text)survey_select = selector.xpath('//*[@id="wzneirong"]/p')for survey_content in survey_select:
print(survey_content.text,end='')
运行结果:

最后参考《用Python编写网络爬虫》中三种方式的性能对比,如下图:

仅供参考。
谢谢阅读!《如何在python中实现数据捕获》的文章文章分享到这里。希望以上内容能够对大家有所帮助,让大家学习到更多的知识。如果你觉得文章是的,你可以分享出来让更多人看到!
python网页数据抓取(Python用做数据处理还是相当不错的,如果你想要做爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2022-02-19 15:17
Python非常适合数据处理。如果你想做爬虫,Python是个不错的选择。它有很多已经编写好的类包,只要调用它就可以完成很多复杂的功能。
1 Pyhton获取网页内容(即源码)(推荐学习:Python视频教程)
page = urllib2.urlopen(url)
contents = page.read()
#获得了整个网页的内容也就是源代码
print(contents)
url代表网址,contents代表网址对应的源码,urllib2是需要使用的包。以上三行代码就可以得到网页的全部源代码
2 在网页中获取你想要的内容(先获取网页的源代码,然后分析网页的源代码,找到对应的标签,然后提取标签中的内容)
以豆瓣电影排名为例
现在我需要获取当前页面上所有电影的名称、评分、评论人数、链接
#coding:utf-8
'''''
@author: jsjxy
'''
import urllib2
import re
from bs4 import BeautifulSoup
from distutils.filelist import findall
page = urllib2.urlopen('http://movie.douban.com/top250?format=text')
contents = page.read()
#print(contents)
soup = BeautifulSoup(contents,"html.parser")
print("豆瓣电影TOP250" + "\n" +" 影片名 评分 评价人数 链接 ")
for tag in soup.find_all('div', class_='info'):
# print tag
m_name = tag.find('span', class_='title').get_text()
m_rating_score = float(tag.find('span',class_='rating_num').get_text())
m_people = tag.find('div',class_="star")
m_span = m_people.findAll('span')
m_peoplecount = m_span[3].contents[0]
m_url=tag.find('a').get('href')
print( m_name+" " + str(m_rating_score) + " " + m_peoplecount + " " + m_url )
控制台输出,也可以写入文件
更多Python相关技术文章,请访问Python教程专栏学习!
以上就是python如何获取网页内容的详细内容。更多详情请关注php中文网文章其他相关话题! 查看全部
python网页数据抓取(Python用做数据处理还是相当不错的,如果你想要做爬虫)
Python非常适合数据处理。如果你想做爬虫,Python是个不错的选择。它有很多已经编写好的类包,只要调用它就可以完成很多复杂的功能。

1 Pyhton获取网页内容(即源码)(推荐学习:Python视频教程)
page = urllib2.urlopen(url)
contents = page.read()
#获得了整个网页的内容也就是源代码
print(contents)
url代表网址,contents代表网址对应的源码,urllib2是需要使用的包。以上三行代码就可以得到网页的全部源代码
2 在网页中获取你想要的内容(先获取网页的源代码,然后分析网页的源代码,找到对应的标签,然后提取标签中的内容)
以豆瓣电影排名为例
现在我需要获取当前页面上所有电影的名称、评分、评论人数、链接
#coding:utf-8
'''''
@author: jsjxy
'''
import urllib2
import re
from bs4 import BeautifulSoup
from distutils.filelist import findall
page = urllib2.urlopen('http://movie.douban.com/top250?format=text')
contents = page.read()
#print(contents)
soup = BeautifulSoup(contents,"html.parser")
print("豆瓣电影TOP250" + "\n" +" 影片名 评分 评价人数 链接 ")
for tag in soup.find_all('div', class_='info'):
# print tag
m_name = tag.find('span', class_='title').get_text()
m_rating_score = float(tag.find('span',class_='rating_num').get_text())
m_people = tag.find('div',class_="star")
m_span = m_people.findAll('span')
m_peoplecount = m_span[3].contents[0]
m_url=tag.find('a').get('href')
print( m_name+" " + str(m_rating_score) + " " + m_peoplecount + " " + m_url )
控制台输出,也可以写入文件
更多Python相关技术文章,请访问Python教程专栏学习!
以上就是python如何获取网页内容的详细内容。更多详情请关注php中文网文章其他相关话题!
python网页数据抓取(一下爬虫爬虫项目的基本步骤和基本操作步骤(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2022-02-17 15:01
Python爬虫--scrapy爬虫框架介绍写在前面
在编写爬虫之前,我从未使用过爬虫框架。其实我之前写的就是一个爬虫写的小练习的demo。只能说是从网上抓取一点数据,直接用python脚本解决爬虫的所有功能。循环获取更多数据页。后来了解了代理池系统,稍微了解了一下,爬虫其实也算是一个项目。该项目分为模块。不同的模块负责不同的功能。有些模块负责封装http请求,有些模块负责处理请求。(数据采集),有些模块负责数据分析,有些模块负责数据存储。这样一个框架的原型已经出现,这可以帮助我们更加专注和高效地抓取数据。对于scrapy,一开始并不想过多解释scrapy框架各部分的组成和功能,而是直接在实际运行中感受一下框架是如何分工协作的,各个模块负责什么功能,最后关注一下这个框架。一些原则应该是学习scrapy框架的最好方法。
scrapy爬虫的基本步骤创建一个scrapy爬虫项目。创建一个 Spider 爬虫类来爬取网页内容并解析它。定义数据模型(Item)并将捕获的数据封装到Item中。使用Item Pipeline来存储和抓取Items,即数据实体对象。一、创建一个scrapy爬虫项目
安装scrapy后,运行命令scrapy startproject project name,创建scrapy爬虫项目。例如运行scrapy startproject test1会生成一个test1文件夹,目录结构如下:
二、创建一个Spider爬虫类来爬取网页内容并解析它。
爬虫的代码写在spider文件夹下,所以在spider目录下创建一个python文件,爬取方天下的数据,所以创建一个python文件,命名为ftx_spider.py。
接下来,开始在 ftx_spider.py 中编写爬虫代码:
import scrapy
class FtxSpider(scrapy.Spider):
"""
一、创建一个爬虫类,继承scrapy.Spider
二、通过name属性,给爬虫类定义一个名称
三、指定要抓取的网页链接urls,发送http请求
方式一:
1.继承scrapy.Spider的start_requests()方法。
2.指定要爬取的url,通过scrapy.Request(url=url, callback=self.parse)发送请求,callback指定解析函数。
方式二(简化):
1.直接通过start_urls常量指定要爬取的urls。
2.框架会自动发送http请求,这里框架默认html解析函数parse().
四、针对http请求的response结果,编写解析方法,parse()
"""
name = 'ftx'
# 方式一:通过scrapy.Request(url=url, callback=self.parse)发送请求,指定解析函数
# def start_requests(self):
# urls = ['http://wuhan.esf.fang.com/house-a013126/i3']
# for url in urls:
# yield scrapy.Request(url=url, callback=self.parse)
#
# def parse(self, response):
# # 这里对抓取到的html页面进行解析
# print(response.url)
# 方式二(简化版):通过start_urls,框架自动发送请求,默认解析函数为parse()
start_urls = ['http://wuhan.esf.fang.com/house-a013126/i3']
def parse(self, response):
print(response.url)
三、数据模型Item,定义爬取数据的数据结构
这个Item相当于java中的域实体,或者javabean。在 items.py 中定义了一个类,它继承了 scrapy.Item。这样我们就可以将我们抓取的数据封装到一个对象中。
import scrapy
class FtxSpiderItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field() # 标题
huxing = scrapy.Field() # 户型
size = scrapy.Field() # 面积
floor = scrapy.Field() # 楼层
fangxiang = scrapy.Field() # 方向
year = scrapy.Field() # 建房时间
shop_community = scrapy.Field() # 小区
address = scrapy.Field() # 地址
total_price = scrapy.Field() # 总价(万)
price = scrapy.Field() # 单价(万/m2)
四、使用Item Pipeline存储和抓取item并将数据存储在MongoDB中
项目管道是项目管道。当 Item 生成后,会自动发送到 Item Pipeline 进行处理。
首先在setting.py中添加MongoDB数据库连接信息
# MongoDB
HOST = 'localhost'
PORT = 27017
DB_NAME = 'ftx'
COLL_NAME = 'roomprice'
然后在pipelines.py中创建一个类,连接数据库,插入数据
import pymongo
from scrapy.conf import settings
class FtxSpiderPipeline(object):
def __init__(self):
# 连接MongoDB
self.client = pymongo.MongoClient(host=settings['HOST'], port=settings['PORT'])
# 获取数据库
self.db = self.client[settings['DB_NAME']]
# 获取集合
self.collection = self.db[settings['COLL_NAME']]
def process_item(self, item, spider):
self.collection.insert(dict(item))
最后在setting.py中指定Item Pipeline使用的类和优先级
ITEM_PIPELINES = {
'ftx_spider.pipelines.FtxSpiderPipeline': 300
}
运行命令行scrapy crawl 'crawler name name',可以发现数据已经成功存入数据库daacheng/PythonBasic 查看全部
python网页数据抓取(一下爬虫爬虫项目的基本步骤和基本操作步骤(一))
Python爬虫--scrapy爬虫框架介绍写在前面
在编写爬虫之前,我从未使用过爬虫框架。其实我之前写的就是一个爬虫写的小练习的demo。只能说是从网上抓取一点数据,直接用python脚本解决爬虫的所有功能。循环获取更多数据页。后来了解了代理池系统,稍微了解了一下,爬虫其实也算是一个项目。该项目分为模块。不同的模块负责不同的功能。有些模块负责封装http请求,有些模块负责处理请求。(数据采集),有些模块负责数据分析,有些模块负责数据存储。这样一个框架的原型已经出现,这可以帮助我们更加专注和高效地抓取数据。对于scrapy,一开始并不想过多解释scrapy框架各部分的组成和功能,而是直接在实际运行中感受一下框架是如何分工协作的,各个模块负责什么功能,最后关注一下这个框架。一些原则应该是学习scrapy框架的最好方法。
scrapy爬虫的基本步骤创建一个scrapy爬虫项目。创建一个 Spider 爬虫类来爬取网页内容并解析它。定义数据模型(Item)并将捕获的数据封装到Item中。使用Item Pipeline来存储和抓取Items,即数据实体对象。一、创建一个scrapy爬虫项目
安装scrapy后,运行命令scrapy startproject project name,创建scrapy爬虫项目。例如运行scrapy startproject test1会生成一个test1文件夹,目录结构如下:

二、创建一个Spider爬虫类来爬取网页内容并解析它。
爬虫的代码写在spider文件夹下,所以在spider目录下创建一个python文件,爬取方天下的数据,所以创建一个python文件,命名为ftx_spider.py。
接下来,开始在 ftx_spider.py 中编写爬虫代码:
import scrapy
class FtxSpider(scrapy.Spider):
"""
一、创建一个爬虫类,继承scrapy.Spider
二、通过name属性,给爬虫类定义一个名称
三、指定要抓取的网页链接urls,发送http请求
方式一:
1.继承scrapy.Spider的start_requests()方法。
2.指定要爬取的url,通过scrapy.Request(url=url, callback=self.parse)发送请求,callback指定解析函数。
方式二(简化):
1.直接通过start_urls常量指定要爬取的urls。
2.框架会自动发送http请求,这里框架默认html解析函数parse().
四、针对http请求的response结果,编写解析方法,parse()
"""
name = 'ftx'
# 方式一:通过scrapy.Request(url=url, callback=self.parse)发送请求,指定解析函数
# def start_requests(self):
# urls = ['http://wuhan.esf.fang.com/house-a013126/i3']
# for url in urls:
# yield scrapy.Request(url=url, callback=self.parse)
#
# def parse(self, response):
# # 这里对抓取到的html页面进行解析
# print(response.url)
# 方式二(简化版):通过start_urls,框架自动发送请求,默认解析函数为parse()
start_urls = ['http://wuhan.esf.fang.com/house-a013126/i3']
def parse(self, response):
print(response.url)
三、数据模型Item,定义爬取数据的数据结构
这个Item相当于java中的域实体,或者javabean。在 items.py 中定义了一个类,它继承了 scrapy.Item。这样我们就可以将我们抓取的数据封装到一个对象中。
import scrapy
class FtxSpiderItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field() # 标题
huxing = scrapy.Field() # 户型
size = scrapy.Field() # 面积
floor = scrapy.Field() # 楼层
fangxiang = scrapy.Field() # 方向
year = scrapy.Field() # 建房时间
shop_community = scrapy.Field() # 小区
address = scrapy.Field() # 地址
total_price = scrapy.Field() # 总价(万)
price = scrapy.Field() # 单价(万/m2)
四、使用Item Pipeline存储和抓取item并将数据存储在MongoDB中
项目管道是项目管道。当 Item 生成后,会自动发送到 Item Pipeline 进行处理。
首先在setting.py中添加MongoDB数据库连接信息
# MongoDB
HOST = 'localhost'
PORT = 27017
DB_NAME = 'ftx'
COLL_NAME = 'roomprice'
然后在pipelines.py中创建一个类,连接数据库,插入数据
import pymongo
from scrapy.conf import settings
class FtxSpiderPipeline(object):
def __init__(self):
# 连接MongoDB
self.client = pymongo.MongoClient(host=settings['HOST'], port=settings['PORT'])
# 获取数据库
self.db = self.client[settings['DB_NAME']]
# 获取集合
self.collection = self.db[settings['COLL_NAME']]
def process_item(self, item, spider):
self.collection.insert(dict(item))
最后在setting.py中指定Item Pipeline使用的类和优先级
ITEM_PIPELINES = {
'ftx_spider.pipelines.FtxSpiderPipeline': 300
}
运行命令行scrapy crawl 'crawler name name',可以发现数据已经成功存入数据库daacheng/PythonBasic
python网页数据抓取( Python网站信息的资料请关注编程宝库(图)!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-02-17 14:21
Python网站信息的资料请关注编程宝库(图)!)
Python爬虫实现爬取电影网站信息并入库
一.环境设置1.下载安装包
访问Python官网下载地址:
下载适合您系统的安装包:
我使用的是Windows环境,所以直接从exe包安装。
下载完成后,双击下载包进入Python安装向导。安装非常简单,只需要使用默认设置,点击“下一步”,直到安装完成。
2.修改环境变量
右键单击“计算机”,然后单击“属性”;
然后点击“高级系统设置”-“环境变量”;
选择“系统变量”窗口下的“路径”添加python安装路径;
设置成功后,在cmd命令行输入命令“python”。如果显示,则配置成功。
3.安装依赖模块
我们的爬虫需要安装的依赖模块包括requests、lxml、pymysql。步骤如下:
进入python安装目录下的Scripts目录,点击地址栏输入“cmd”打开命令行工具:
在这个路径下安装对应的requests、lxml、pymysql依赖:
输入命令:
// 安装requests依赖
pip install requests
// 安装lxml依赖
pip install lxml
// 安装pymysql依赖
pip install pymysql
二.代码开发
开发collectMovies.py
#!/user/bin env python
# 获取电影天堂详细信息
import requests
import time
from lxml import etree
import pymysql
requests.adapters.DEFAULT_RETRIES = 5
# 伪装浏览器
HEADERS ={
'User-Agent':'Mozilla/5.(Windows NT 10.0; WOW64) AppleWebKit/537.3(KHTML, like Gecko) Chrome/63.0.3239.13Safari/537.36',
'Host':'www.dy2018.com'
}
# 定义全局变量
BASE_DOMAIN = 'https://www.dy2018.com/'
# 获取首页网页信息并解析
def getUrlText(url,coding):
s = requests.session()
#print("获取首页网页信息并解析:", url)
respons = s.get(url,headers=HEADERS)
print("请求URL:", url)
if(coding=='c'):
urlText = respons.content.decode('gbk')
html = etree.HTML(urlText) # 使用lxml解析网页
else:
urlText = respons.text
html = etree.HTML(urlText) # 使用lxml解析网页
s.keep_alive = False
return html
# 获取电影详情页的href,text解析
def getHref(url):
html = getUrlText(url,'t')
aHref = html.xpath('//table[@class="tbspan"]//a/@href')
print("获取电影详情页的href,text解析```")
htmlAll = map(lambda url:BASE_DOMAIN+url,aHref) # 给每个href补充BASE_DOMAIN
return htmlAll
# 使用content解析电影详情页,并获取详细信息数据
def getPage(url):
html = getUrlText(url,'c')
moveInfo = {} # 定义电影信息
mName = html.xpath('//div[@class="title_all"]//h1/text()')[0]
moveInfo['movie_name'] = mName
mDiv = html.xpath('//div[@id="Zoom"]')[0]
mImgSrc = mDiv.xpath('.//img/@src')
moveInfo['image_path'] = mImgSrc[0] # 获取海报src地址
if len(mImgSrc) >= 2:
moveInfo['screenshot'] = mImgSrc[1] # 获取电影截图src地址
mContnent = mDiv.xpath('.//text()')
def pares_info(info,rule):
'''
:param info: 字符串
:param rule: 替换字串
:return: 指定字符串替换为空,并剔除左右空格
'''
return info.replace(rule,'').strip()
for index,t in enumerate(mContnent):
if t.startswith('◎译 名'):
name = pares_info(t,'◎译 名')
moveInfo['translation']=name
elif t.startswith('◎片 名'):
name = pares_info(t,'◎片 名')
moveInfo['movie_title']=name
elif t.startswith('◎年 代'):
name = pares_info(t,'◎年 代')
moveInfo['movie_age']=name
elif t.startswith('◎产 地'):
name = pares_info(t,'◎产 地')
moveInfo['movie_place']=name
elif t.startswith('◎类 别'):
name = pares_info(t,'◎类 别')
moveInfo['category']=name
elif t.startswith('◎语 言'):
name = pares_info(t,'◎语 言')
moveInfo['language']=name
elif t.startswith('◎字 幕'):
name = pares_info(t,'◎字 幕')
moveInfo['subtitle']=name
elif t.startswith('◎上映日期'):
name = pares_info(t,'◎上映日期')
moveInfo['release_date']=name
elif t.startswith('◎豆瓣评分'):
name = pares_info(t,'◎豆瓣评分')
moveInfo['douban_score']=name
elif t.startswith('◎片 长'):
name = pares_info(t,'◎片 长')
moveInfo['file_length']=name
elif t.startswith('◎导 演'):
name = pares_info(t,'◎导 演')
moveInfo['director']=name
elif t.startswith('◎编 剧'):
name = pares_info(t, '◎编 剧')
writers = [name]
for i in range(index + 1, len(mContnent)):
writer = mContnent[i].strip()
if writer.startswith('◎'):
break
writers.append(writer)
moveInfo['screenwriter'] = writers
elif t.startswith('◎主 演'):
name = pares_info(t, '◎主 演')
actors = [name]
for i in range(index+1,len(mContnent)):
actor = mContnent[i].strip()
if actor.startswith('◎'):
break
actors.append(actor)
moveInfo['stars'] = " ".join(actors)
elif t.startswith('◎标 签'):
name = pares_info(t,'◎标 签')
moveInfo['tags']=name
elif t.startswith('◎简 介'):
name = pares_info(t,'◎简 介')
profiles = []
for i in range(index + 1, len(mContnent)):
profile = mContnent[i].strip()
if profile.startswith('◎获奖情况') or '【下载地址】' in profile:
break
profiles.append(profile)
moveInfo['introduction']=" ".join(profiles)
elif t.startswith('◎获奖情况'):
name = pares_info(t,'◎获奖情况')
awards = []
for i in range(index + 1, len(mContnent)):
award = mContnent[i].strip()
if '【下载地址】' in award:
break
awards.append(award)
moveInfo['awards']=" ".join(awards)
moveInfo['movie_url'] = url
return moveInfo
# 获取前n页所有电影的详情页href
def spider():
#连接数据库
base_url = 'https://www.dy2018.com/html/gndy/dyzz/index_{}.html'
moves = []
m = int(input('请输入您要获取的开始页:'))
n = int(input('请输入您要获取的结束页:'))
print('即将写入第{}页到第{}页的电影信息,请稍后...'.format(m, n))
for i in range(m,n+1):
print('******* 第{}页电影 正在写入 ********'.format(i))
if i == 1:
url = "https://www.dy2018.com/html/gndy/dyzz/"
else:
url = base_url.format(i)
moveHref = getHref(url)
print("休息2s后再进行操作")
time.sleep(2)
for index,mhref in enumerate(moveHref):
print('---- 正在处理第{}部电影----'.format(index+1))
move = getPage(mhref)
moves.append(move)
# 将电影信息写入数据库
db = pymysql.connect(host='127.0.0.1',user='root', password='123456', port=3306, db='你的数据库名称')
table = 'movies'
i = 1
for data in moves:
keys = ', '.join(data.keys())
values = ', '.join(['%s'] * len(data))
sql = 'INSERT INTO {table}(id,{keys}) VALUES (null,{values})'.format(table=table, keys=keys, values=values)
try:
cursor = db.cursor()
cursor.execute(sql, tuple(data.values()))
print('本条数据成功执行!')
if i==0:
db.commit()
except Exception as e:
print('将电影信息写入数据库发生异常!',repr(e))
db.rollback()
cursor.close()
i = i + 1
db.commit()
db.close()
print('写入数据库完成!')
if __name__ == '__main__':
spider()
三.运行测试1.新建电影信息表
CREATE TABLE `movies` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`movie_name` varchar(255) DEFAULT NULL,
`image_path` varchar(255) DEFAULT NULL,
`screenshot` varchar(255) DEFAULT NULL,
`translation` varchar(255) DEFAULT NULL,
`movie_title` varchar(255) DEFAULT NULL,
`movie_age` varchar(50) DEFAULT NULL,
`movie_place` varchar(50) DEFAULT NULL,
`category` varchar(100) DEFAULT NULL,
`language` varchar(100) DEFAULT NULL,
`subtitle` varchar(100) DEFAULT NULL,
`release_date` varchar(50) DEFAULT NULL,
`douban_score` varchar(50) DEFAULT NULL,
`file_length` varchar(255) DEFAULT NULL,
`director` varchar(100) DEFAULT NULL,
`screenwriter` varchar(100) DEFAULT NULL,
`stars` mediumtext,
`tags` varchar(255) DEFAULT NULL,
`introduction` mediumtext,
`awards` text,
`movie_url` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
2.代码运行
打开collectMovies.py所在目录,输入命令运行:
python collectMovies.py
结果如下:
查看数据库表,数据已经插入成功:
四.故障排除和修复1.空白字符错误
我第一次使用 Python,对它的规则并不熟悉。混合空格和制表符会报如下错误:
unindent does not match any outer indentation level
解决方案
下载Notepad++,选择“编辑”-“空白字符操作”-“空格到制表符(行首)”。
2.请求错误
修改格式后,再次运行,反复报请求的错误。错误信息主要包括以下内容:
ssl.SSLEOFError: EOF occurred in violation of protocol
······
Max retries exceeded with url
解决方案
我认为这是请求设置的问题。各种百度和pip install incremental也装了,还是不行。
后来我把请求的URL改成,没有报错,所以可以定位是访问原来的URL有问题,把采集源路径替换了,问题就出来了解决了。
以上就是Python爬虫实现爬取电影网站信息并入库的详细内容。更多Python爬取网站信息,请关注其他相关编程宝库文章!
下一节:Python将py文件编译成exe文件 Python编程技术
使用PyCharm工具编写的Python程序脚本,如何将.py文件编译成可执行的.exe文件需要已经安装了Python环境。第一步:在 PyCharm 中下载并安装 pyinstalle 库或使用 CMD 安装 P... 查看全部
python网页数据抓取(
Python网站信息的资料请关注编程宝库(图)!)
Python爬虫实现爬取电影网站信息并入库
一.环境设置1.下载安装包
访问Python官网下载地址:
下载适合您系统的安装包:

我使用的是Windows环境,所以直接从exe包安装。
下载完成后,双击下载包进入Python安装向导。安装非常简单,只需要使用默认设置,点击“下一步”,直到安装完成。
2.修改环境变量

右键单击“计算机”,然后单击“属性”;
然后点击“高级系统设置”-“环境变量”;
选择“系统变量”窗口下的“路径”添加python安装路径;
设置成功后,在cmd命令行输入命令“python”。如果显示,则配置成功。
3.安装依赖模块
我们的爬虫需要安装的依赖模块包括requests、lxml、pymysql。步骤如下:
进入python安装目录下的Scripts目录,点击地址栏输入“cmd”打开命令行工具:

在这个路径下安装对应的requests、lxml、pymysql依赖:

输入命令:
// 安装requests依赖
pip install requests
// 安装lxml依赖
pip install lxml
// 安装pymysql依赖
pip install pymysql
二.代码开发
开发collectMovies.py
#!/user/bin env python
# 获取电影天堂详细信息
import requests
import time
from lxml import etree
import pymysql
requests.adapters.DEFAULT_RETRIES = 5
# 伪装浏览器
HEADERS ={
'User-Agent':'Mozilla/5.(Windows NT 10.0; WOW64) AppleWebKit/537.3(KHTML, like Gecko) Chrome/63.0.3239.13Safari/537.36',
'Host':'www.dy2018.com'
}
# 定义全局变量
BASE_DOMAIN = 'https://www.dy2018.com/'
# 获取首页网页信息并解析
def getUrlText(url,coding):
s = requests.session()
#print("获取首页网页信息并解析:", url)
respons = s.get(url,headers=HEADERS)
print("请求URL:", url)
if(coding=='c'):
urlText = respons.content.decode('gbk')
html = etree.HTML(urlText) # 使用lxml解析网页
else:
urlText = respons.text
html = etree.HTML(urlText) # 使用lxml解析网页
s.keep_alive = False
return html
# 获取电影详情页的href,text解析
def getHref(url):
html = getUrlText(url,'t')
aHref = html.xpath('//table[@class="tbspan"]//a/@href')
print("获取电影详情页的href,text解析```")
htmlAll = map(lambda url:BASE_DOMAIN+url,aHref) # 给每个href补充BASE_DOMAIN
return htmlAll
# 使用content解析电影详情页,并获取详细信息数据
def getPage(url):
html = getUrlText(url,'c')
moveInfo = {} # 定义电影信息
mName = html.xpath('//div[@class="title_all"]//h1/text()')[0]
moveInfo['movie_name'] = mName
mDiv = html.xpath('//div[@id="Zoom"]')[0]
mImgSrc = mDiv.xpath('.//img/@src')
moveInfo['image_path'] = mImgSrc[0] # 获取海报src地址
if len(mImgSrc) >= 2:
moveInfo['screenshot'] = mImgSrc[1] # 获取电影截图src地址
mContnent = mDiv.xpath('.//text()')
def pares_info(info,rule):
'''
:param info: 字符串
:param rule: 替换字串
:return: 指定字符串替换为空,并剔除左右空格
'''
return info.replace(rule,'').strip()
for index,t in enumerate(mContnent):
if t.startswith('◎译 名'):
name = pares_info(t,'◎译 名')
moveInfo['translation']=name
elif t.startswith('◎片 名'):
name = pares_info(t,'◎片 名')
moveInfo['movie_title']=name
elif t.startswith('◎年 代'):
name = pares_info(t,'◎年 代')
moveInfo['movie_age']=name
elif t.startswith('◎产 地'):
name = pares_info(t,'◎产 地')
moveInfo['movie_place']=name
elif t.startswith('◎类 别'):
name = pares_info(t,'◎类 别')
moveInfo['category']=name
elif t.startswith('◎语 言'):
name = pares_info(t,'◎语 言')
moveInfo['language']=name
elif t.startswith('◎字 幕'):
name = pares_info(t,'◎字 幕')
moveInfo['subtitle']=name
elif t.startswith('◎上映日期'):
name = pares_info(t,'◎上映日期')
moveInfo['release_date']=name
elif t.startswith('◎豆瓣评分'):
name = pares_info(t,'◎豆瓣评分')
moveInfo['douban_score']=name
elif t.startswith('◎片 长'):
name = pares_info(t,'◎片 长')
moveInfo['file_length']=name
elif t.startswith('◎导 演'):
name = pares_info(t,'◎导 演')
moveInfo['director']=name
elif t.startswith('◎编 剧'):
name = pares_info(t, '◎编 剧')
writers = [name]
for i in range(index + 1, len(mContnent)):
writer = mContnent[i].strip()
if writer.startswith('◎'):
break
writers.append(writer)
moveInfo['screenwriter'] = writers
elif t.startswith('◎主 演'):
name = pares_info(t, '◎主 演')
actors = [name]
for i in range(index+1,len(mContnent)):
actor = mContnent[i].strip()
if actor.startswith('◎'):
break
actors.append(actor)
moveInfo['stars'] = " ".join(actors)
elif t.startswith('◎标 签'):
name = pares_info(t,'◎标 签')
moveInfo['tags']=name
elif t.startswith('◎简 介'):
name = pares_info(t,'◎简 介')
profiles = []
for i in range(index + 1, len(mContnent)):
profile = mContnent[i].strip()
if profile.startswith('◎获奖情况') or '【下载地址】' in profile:
break
profiles.append(profile)
moveInfo['introduction']=" ".join(profiles)
elif t.startswith('◎获奖情况'):
name = pares_info(t,'◎获奖情况')
awards = []
for i in range(index + 1, len(mContnent)):
award = mContnent[i].strip()
if '【下载地址】' in award:
break
awards.append(award)
moveInfo['awards']=" ".join(awards)
moveInfo['movie_url'] = url
return moveInfo
# 获取前n页所有电影的详情页href
def spider():
#连接数据库
base_url = 'https://www.dy2018.com/html/gndy/dyzz/index_{}.html'
moves = []
m = int(input('请输入您要获取的开始页:'))
n = int(input('请输入您要获取的结束页:'))
print('即将写入第{}页到第{}页的电影信息,请稍后...'.format(m, n))
for i in range(m,n+1):
print('******* 第{}页电影 正在写入 ********'.format(i))
if i == 1:
url = "https://www.dy2018.com/html/gndy/dyzz/"
else:
url = base_url.format(i)
moveHref = getHref(url)
print("休息2s后再进行操作")
time.sleep(2)
for index,mhref in enumerate(moveHref):
print('---- 正在处理第{}部电影----'.format(index+1))
move = getPage(mhref)
moves.append(move)
# 将电影信息写入数据库
db = pymysql.connect(host='127.0.0.1',user='root', password='123456', port=3306, db='你的数据库名称')
table = 'movies'
i = 1
for data in moves:
keys = ', '.join(data.keys())
values = ', '.join(['%s'] * len(data))
sql = 'INSERT INTO {table}(id,{keys}) VALUES (null,{values})'.format(table=table, keys=keys, values=values)
try:
cursor = db.cursor()
cursor.execute(sql, tuple(data.values()))
print('本条数据成功执行!')
if i==0:
db.commit()
except Exception as e:
print('将电影信息写入数据库发生异常!',repr(e))
db.rollback()
cursor.close()
i = i + 1
db.commit()
db.close()
print('写入数据库完成!')
if __name__ == '__main__':
spider()
三.运行测试1.新建电影信息表
CREATE TABLE `movies` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`movie_name` varchar(255) DEFAULT NULL,
`image_path` varchar(255) DEFAULT NULL,
`screenshot` varchar(255) DEFAULT NULL,
`translation` varchar(255) DEFAULT NULL,
`movie_title` varchar(255) DEFAULT NULL,
`movie_age` varchar(50) DEFAULT NULL,
`movie_place` varchar(50) DEFAULT NULL,
`category` varchar(100) DEFAULT NULL,
`language` varchar(100) DEFAULT NULL,
`subtitle` varchar(100) DEFAULT NULL,
`release_date` varchar(50) DEFAULT NULL,
`douban_score` varchar(50) DEFAULT NULL,
`file_length` varchar(255) DEFAULT NULL,
`director` varchar(100) DEFAULT NULL,
`screenwriter` varchar(100) DEFAULT NULL,
`stars` mediumtext,
`tags` varchar(255) DEFAULT NULL,
`introduction` mediumtext,
`awards` text,
`movie_url` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
2.代码运行
打开collectMovies.py所在目录,输入命令运行:
python collectMovies.py
结果如下:


查看数据库表,数据已经插入成功:

四.故障排除和修复1.空白字符错误
我第一次使用 Python,对它的规则并不熟悉。混合空格和制表符会报如下错误:
unindent does not match any outer indentation level
解决方案
下载Notepad++,选择“编辑”-“空白字符操作”-“空格到制表符(行首)”。
2.请求错误
修改格式后,再次运行,反复报请求的错误。错误信息主要包括以下内容:
ssl.SSLEOFError: EOF occurred in violation of protocol
······
Max retries exceeded with url
解决方案
我认为这是请求设置的问题。各种百度和pip install incremental也装了,还是不行。
后来我把请求的URL改成,没有报错,所以可以定位是访问原来的URL有问题,把采集源路径替换了,问题就出来了解决了。
以上就是Python爬虫实现爬取电影网站信息并入库的详细内容。更多Python爬取网站信息,请关注其他相关编程宝库文章!
下一节:Python将py文件编译成exe文件 Python编程技术
使用PyCharm工具编写的Python程序脚本,如何将.py文件编译成可执行的.exe文件需要已经安装了Python环境。第一步:在 PyCharm 中下载并安装 pyinstalle 库或使用 CMD 安装 P...
python网页数据抓取( 2018年05月25日11:41:25一下)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2022-02-16 12:36
2018年05月25日11:41:25一下)
python2.7实现抓取网页数据
更新时间:2018年5月25日11:41:25 作者:aasdsjk
本文文章主要详细介绍python2.7实现爬虫网页数据,具有一定的参考价值。有兴趣的朋友可以参考一下
最近刚学Python,做了一个简单的爬虫。作为一个简单的demo,希望对像我这样的初学者有所帮助。
代码使用python制作的爬虫2.7在51job上抓取职位、公司名称、工资、发布时间等。
直接上代码,代码中的注释比较清楚,如果没有安装mysql需要屏蔽相关代码:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
from bs4 import BeautifulSoup
import urllib
import urllib2
import codecs
import re
import time
import logging
import MySQLdb
class Jobs(object):
# 初始化
"""docstring for Jobs"""
def __init__(self):
super(Jobs, self).__init__()
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s')
#数据库的操作,没有mysql可以做屏蔽
self.db = MySQLdb.connect('127.0.0.1','root','rootroot','MySQL_Test',charset='utf8')
self.cursor = self.db.cursor()
#log日志的显示
self.logger = logging.getLogger("sjk")
self.logger.setLevel(level=logging.DEBUG)
formatter = logging.Formatter(
'%(asctime)s - %(name)s - %(levelname)s - %(message)s')
handler = logging.FileHandler('log.txt')
handler.setFormatter(formatter)
handler.setLevel(logging.DEBUG)
self.logger.addHandler(handler)
self.logger.info('初始化完成')
# 模拟请求数据
def jobshtml(self, key, page='1'):
try:
self.logger.info('开始请求第' + page + '页')
#网页url
searchurl = "https://search.51job.com/list/040000,000000,0000,00,9,99,{key},2,{page}.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare="
user_agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.13; rv:59.0) Gecko/20100101 Firefox/59.0'
#设置请求头
header = {'User-Agent': user_agent, 'Host': 'search.51job.com',
'Referer': 'https://www.51job.com/'}
#拼接url
finalUrl = searchurl.format(key=key, page=page)
request = urllib2.Request(finalUrl, headers=header)
response = urllib2.urlopen(request)
#等待网页加载完成
time.sleep(3)
#gbk格式解码
info = response.read().decode('gbk')
self.logger.info('请求网页网页')
self.decodeHtml(info=info, key=key, page=page)
except urllib2.HTTPError as e:
print e.reason
# 解析网页数据
def decodeHtml(self, info, key, page):
self.logger.info('开始解析网页数据')
#BeautifulSoup 解析网页
soup = BeautifulSoup(info, 'html.parser')
#找到class = t1 t2 t3 t4 t5 的标签数据
ps = soup.find_all(attrs={"class": re.compile(r'^t[1-5].*')})
#打开txt文件 a+ 代表追加
f = codecs.open(key + '.txt', 'a+', 'UTF-8')
#清除之前的数据信息
f.truncate()
f.write('\n------------' + page + '--------------\n')
count = 1
arr = []
#做一些字符串的处理,形成数据格式 iOS开发工程师 有限公司 深圳-南山区 0.9-1.6万/月 05-16
for pi in ps:
spe = " "
finalstr = pi.getText().strip()
arr.append(finalstr)
if count % 5 == 0:
#每一条数据插入数据库,如果没有安装mysql 可以将当前行注释掉
self.connectMySQL(arr=arr)
arr = []
spe = "\n"
writestr = finalstr + spe
count += 1
f.write(writestr)
f.close()
self.logger.info('解析完成')
#数据库操作 没有安装mysql 可以屏蔽掉
def connectMySQL(self,arr):
work=arr[0]
company=arr[1]
place=arr[2]
salary=arr[3]
time=arr[4]
query = "select * from Jobs_tab where \
company_name='%s' and work_name='%s' and work_place='%s' \
and salary='%s' and time='%s'" %(company,work,place,salary,time)
self.cursor.execute(query)
queryresult = self.cursor.fetchall()
#数据库中不存在就插入数据 存在就可以更新数据 不过我这边没有写
if len(queryresult) > 0:
sql = "insert into Jobs_tab(work_name,company_name,work_place,salary\
,time) values('%s','%s','%s','%s','%s')" %(work,company,place,salary,time)
try:
self.cursor.execute(sql)
self.db.commit()
except Exception as e:
self.logger.info('写入数据库失败')
#模拟登陆
# def login(self):
# data = {'action':'save','isread':'on','loginname':'18086514327','password':'kui4131sjk'}
# 开始抓取 主函数
def run(self, key):
# 只要前5页的数据 key代表搜索工做类型 这边我是用的ios page是页数
for x in xrange(1, 6):
self.jobshtml(key=key, page=str(x))
self.logger.info('写入数据库完成')
self.db.close()
if __name__ == '__main__':
Jobs().run(key='iOS')
这种方式获取的数据格式如下:
以上就是本文的全部内容。希望对大家的学习有所帮助,也希望大家多多支持Script Home。 查看全部
python网页数据抓取(
2018年05月25日11:41:25一下)
python2.7实现抓取网页数据
更新时间:2018年5月25日11:41:25 作者:aasdsjk
本文文章主要详细介绍python2.7实现爬虫网页数据,具有一定的参考价值。有兴趣的朋友可以参考一下
最近刚学Python,做了一个简单的爬虫。作为一个简单的demo,希望对像我这样的初学者有所帮助。
代码使用python制作的爬虫2.7在51job上抓取职位、公司名称、工资、发布时间等。
直接上代码,代码中的注释比较清楚,如果没有安装mysql需要屏蔽相关代码:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
from bs4 import BeautifulSoup
import urllib
import urllib2
import codecs
import re
import time
import logging
import MySQLdb
class Jobs(object):
# 初始化
"""docstring for Jobs"""
def __init__(self):
super(Jobs, self).__init__()
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s')
#数据库的操作,没有mysql可以做屏蔽
self.db = MySQLdb.connect('127.0.0.1','root','rootroot','MySQL_Test',charset='utf8')
self.cursor = self.db.cursor()
#log日志的显示
self.logger = logging.getLogger("sjk")
self.logger.setLevel(level=logging.DEBUG)
formatter = logging.Formatter(
'%(asctime)s - %(name)s - %(levelname)s - %(message)s')
handler = logging.FileHandler('log.txt')
handler.setFormatter(formatter)
handler.setLevel(logging.DEBUG)
self.logger.addHandler(handler)
self.logger.info('初始化完成')
# 模拟请求数据
def jobshtml(self, key, page='1'):
try:
self.logger.info('开始请求第' + page + '页')
#网页url
searchurl = "https://search.51job.com/list/040000,000000,0000,00,9,99,{key},2,{page}.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare="
user_agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.13; rv:59.0) Gecko/20100101 Firefox/59.0'
#设置请求头
header = {'User-Agent': user_agent, 'Host': 'search.51job.com',
'Referer': 'https://www.51job.com/'}
#拼接url
finalUrl = searchurl.format(key=key, page=page)
request = urllib2.Request(finalUrl, headers=header)
response = urllib2.urlopen(request)
#等待网页加载完成
time.sleep(3)
#gbk格式解码
info = response.read().decode('gbk')
self.logger.info('请求网页网页')
self.decodeHtml(info=info, key=key, page=page)
except urllib2.HTTPError as e:
print e.reason
# 解析网页数据
def decodeHtml(self, info, key, page):
self.logger.info('开始解析网页数据')
#BeautifulSoup 解析网页
soup = BeautifulSoup(info, 'html.parser')
#找到class = t1 t2 t3 t4 t5 的标签数据
ps = soup.find_all(attrs={"class": re.compile(r'^t[1-5].*')})
#打开txt文件 a+ 代表追加
f = codecs.open(key + '.txt', 'a+', 'UTF-8')
#清除之前的数据信息
f.truncate()
f.write('\n------------' + page + '--------------\n')
count = 1
arr = []
#做一些字符串的处理,形成数据格式 iOS开发工程师 有限公司 深圳-南山区 0.9-1.6万/月 05-16
for pi in ps:
spe = " "
finalstr = pi.getText().strip()
arr.append(finalstr)
if count % 5 == 0:
#每一条数据插入数据库,如果没有安装mysql 可以将当前行注释掉
self.connectMySQL(arr=arr)
arr = []
spe = "\n"
writestr = finalstr + spe
count += 1
f.write(writestr)
f.close()
self.logger.info('解析完成')
#数据库操作 没有安装mysql 可以屏蔽掉
def connectMySQL(self,arr):
work=arr[0]
company=arr[1]
place=arr[2]
salary=arr[3]
time=arr[4]
query = "select * from Jobs_tab where \
company_name='%s' and work_name='%s' and work_place='%s' \
and salary='%s' and time='%s'" %(company,work,place,salary,time)
self.cursor.execute(query)
queryresult = self.cursor.fetchall()
#数据库中不存在就插入数据 存在就可以更新数据 不过我这边没有写
if len(queryresult) > 0:
sql = "insert into Jobs_tab(work_name,company_name,work_place,salary\
,time) values('%s','%s','%s','%s','%s')" %(work,company,place,salary,time)
try:
self.cursor.execute(sql)
self.db.commit()
except Exception as e:
self.logger.info('写入数据库失败')
#模拟登陆
# def login(self):
# data = {'action':'save','isread':'on','loginname':'18086514327','password':'kui4131sjk'}
# 开始抓取 主函数
def run(self, key):
# 只要前5页的数据 key代表搜索工做类型 这边我是用的ios page是页数
for x in xrange(1, 6):
self.jobshtml(key=key, page=str(x))
self.logger.info('写入数据库完成')
self.db.close()
if __name__ == '__main__':
Jobs().run(key='iOS')
这种方式获取的数据格式如下:

以上就是本文的全部内容。希望对大家的学习有所帮助,也希望大家多多支持Script Home。
python网页数据抓取( Python大神用正则表达式教你搞定京东商品信息的精准匹配~)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-02-16 05:25
Python大神用正则表达式教你搞定京东商品信息的精准匹配~)
之前的小编使用Python正则表达式和BeautifulSoup来爬取京东商品信息。今天小编就用Xpath来演示如何实现京东商品信息的精准匹配~~
HTML文件实际上是由一组由尖括号组成的标签组织起来的,每一对尖括号组成一个标签,标签之间存在自上而下的关系,形成标签树;XPath 使用路径表达式来选择 XML 文档中的节点。通过遵循路径或步骤来选择节点。
京东狗粮产品
首先进入京东,输入你要查询的产品,向服务器发送网页请求。在这里,小编还是用关键词“狗粮”作为搜索对象,然后得到如下URL:%E7%8B%97%E7%B2%AE&enc=utf-8,其中参数表示我们的输入关键字,本例中该参数代表“狗粮”。详情请参考Python大神使用正则表达式教你获取京东产品信息。因此,只要输入关键字参数并对其进行编码,就可以得到目标网址。然后请求网页,得到响应,然后使用bs4选择器进行下一条数据采集。
京东官网部分产品信息源代码如下图所示:
京东官网狗粮信息源代码
仔细看源码可以发现,我们需要的目标信息就在标签下面,那么我们就像剥洋葱一样,一层一层的得到我们想要的信息。
通常URL编码的方式是将需要编码的字符转换成%xx的形式。一般来说,URL的编码都是基于UTF-8的,当然也和浏览器平台有关。Python的urllib库中提供了quote方法,可以对URL的字符串进行编码,从而可以进入对应的网页。
在线复制 Xpath 表达式
很多朋友觉得Xpath表达式很难写,但是掌握基本用法并不难。在线复制Xpath表达式如上图所示,可以很方便的复制Xpath表达式。但是这种方法得到的Xpath表达式一般不能在程序中使用,长的也看不出来。因此,Xpath 表达式一般要自己使用。
直接进入代码,使用Xpath提取目标信息,如商品名称、链接、图片、价格等。具体代码如下图所示:
爬虫代码
在这里,编辑器告诉您一种 Xpath 表达式匹配技术。之前看过几篇文章的文章,大佬们都推荐对Xpath表达式使用嵌套匹配。在此示例中,项目首先定义如下:
items = selector.xpath('//li[@class="gl-item"]')
然后使用range函数将网页中的目标信息一一匹配,而不是直接一步复制Xpath表达式。希望以后朋友们能少进这个坑~~
最终效果图如下:
最终效果图
新鲜的狗粮又出来了~
朋友们,有没有发现使用Xpath获取目标信息比使用正则表达式更容易?
如果你想了解更多关于Python网络爬虫和数据挖掘的知识,可以去专业的网站: 查看全部
python网页数据抓取(
Python大神用正则表达式教你搞定京东商品信息的精准匹配~)
之前的小编使用Python正则表达式和BeautifulSoup来爬取京东商品信息。今天小编就用Xpath来演示如何实现京东商品信息的精准匹配~~
HTML文件实际上是由一组由尖括号组成的标签组织起来的,每一对尖括号组成一个标签,标签之间存在自上而下的关系,形成标签树;XPath 使用路径表达式来选择 XML 文档中的节点。通过遵循路径或步骤来选择节点。
京东狗粮产品
首先进入京东,输入你要查询的产品,向服务器发送网页请求。在这里,小编还是用关键词“狗粮”作为搜索对象,然后得到如下URL:%E7%8B%97%E7%B2%AE&enc=utf-8,其中参数表示我们的输入关键字,本例中该参数代表“狗粮”。详情请参考Python大神使用正则表达式教你获取京东产品信息。因此,只要输入关键字参数并对其进行编码,就可以得到目标网址。然后请求网页,得到响应,然后使用bs4选择器进行下一条数据采集。
京东官网部分产品信息源代码如下图所示:
京东官网狗粮信息源代码
仔细看源码可以发现,我们需要的目标信息就在标签下面,那么我们就像剥洋葱一样,一层一层的得到我们想要的信息。
通常URL编码的方式是将需要编码的字符转换成%xx的形式。一般来说,URL的编码都是基于UTF-8的,当然也和浏览器平台有关。Python的urllib库中提供了quote方法,可以对URL的字符串进行编码,从而可以进入对应的网页。
在线复制 Xpath 表达式
很多朋友觉得Xpath表达式很难写,但是掌握基本用法并不难。在线复制Xpath表达式如上图所示,可以很方便的复制Xpath表达式。但是这种方法得到的Xpath表达式一般不能在程序中使用,长的也看不出来。因此,Xpath 表达式一般要自己使用。
直接进入代码,使用Xpath提取目标信息,如商品名称、链接、图片、价格等。具体代码如下图所示:
爬虫代码
在这里,编辑器告诉您一种 Xpath 表达式匹配技术。之前看过几篇文章的文章,大佬们都推荐对Xpath表达式使用嵌套匹配。在此示例中,项目首先定义如下:
items = selector.xpath('//li[@class="gl-item"]')
然后使用range函数将网页中的目标信息一一匹配,而不是直接一步复制Xpath表达式。希望以后朋友们能少进这个坑~~
最终效果图如下:
最终效果图
新鲜的狗粮又出来了~
朋友们,有没有发现使用Xpath获取目标信息比使用正则表达式更容易?
如果你想了解更多关于Python网络爬虫和数据挖掘的知识,可以去专业的网站:
python网页数据抓取(:如何从网页中提取数据,以tags文件为例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-02-16 05:05
python网页数据抓取可以参考一下我的文章,由于是爬虫,所以用了vcredis,其实就是基于一个缓存过滤器和正则表达式对页面进行爬取。也可以爬取些文本数据。这篇博客是对整个数据抓取流程,服务器架构和抓取时间线的综述,相对全面。在学习过程中,是根据自己的理解和遇到的问题提出问题和探索解决,希望对自己和大家有所帮助。
不同抓取方法本文只总结流程和一部分代码实现,期望其他人有更好的解决方案可以参考一下。本文要解决的问题:如何从网页中提取数据,以tags文件为例,包括分页抓取、分页excel抓取以及文字图片等不同网页抓取方式的实现。
一、python网页数据抓取流程1.1提取标签、tags文件先通过正则文件提取出标签。
代码:#-*-coding:utf-8-*-importreimportrequestsurl=''requests。get(url)tags=requests。get(url)classpost(scrapy。http。urlopen):classresponse(scrapy。http。urlopen):method='post'headers={'user-agent':'mozilla/5。0(macintosh;intelmacosx10_12_。
6)applewebkit/537。36(khtml,likegecko)chrome/69。3770。132safari/537。36'}req=requests。get(url)content=req。json()params={'tag':tags}def__init__(self,request,headers,soup=none):self。
__title=request。titleself。tags=request。tagsself。headers={'user-agent':'mozilla/5。0(windowsnt10。0;win64;x6。
4)applewebkit/537。36(khtml,likegecko)chrome/69。3770。132safari/537。36'}self。request=requests。get(self。__title,headers=self。headers)self。response=requests。
get(self。__title,headers=self。headers)self。content=requests。get(self。tags,headers=self。headers)#创建request对象,第一次请求到的时候写入tagsself。__headers={'user-agent':'mozilla/5。0(windowsnt10。0;win64;x6。
4)applewebkit/537。36(khtml,likegecko)chrome/69。3770。132safari/537。36'}req=requests。get(req。text,headers=self。headers)#tokenonlytoken={'params':params}token_len={'token':token,'time':'get','email':'@example。 查看全部
python网页数据抓取(:如何从网页中提取数据,以tags文件为例)
python网页数据抓取可以参考一下我的文章,由于是爬虫,所以用了vcredis,其实就是基于一个缓存过滤器和正则表达式对页面进行爬取。也可以爬取些文本数据。这篇博客是对整个数据抓取流程,服务器架构和抓取时间线的综述,相对全面。在学习过程中,是根据自己的理解和遇到的问题提出问题和探索解决,希望对自己和大家有所帮助。
不同抓取方法本文只总结流程和一部分代码实现,期望其他人有更好的解决方案可以参考一下。本文要解决的问题:如何从网页中提取数据,以tags文件为例,包括分页抓取、分页excel抓取以及文字图片等不同网页抓取方式的实现。
一、python网页数据抓取流程1.1提取标签、tags文件先通过正则文件提取出标签。
代码:#-*-coding:utf-8-*-importreimportrequestsurl=''requests。get(url)tags=requests。get(url)classpost(scrapy。http。urlopen):classresponse(scrapy。http。urlopen):method='post'headers={'user-agent':'mozilla/5。0(macintosh;intelmacosx10_12_。
6)applewebkit/537。36(khtml,likegecko)chrome/69。3770。132safari/537。36'}req=requests。get(url)content=req。json()params={'tag':tags}def__init__(self,request,headers,soup=none):self。
__title=request。titleself。tags=request。tagsself。headers={'user-agent':'mozilla/5。0(windowsnt10。0;win64;x6。
4)applewebkit/537。36(khtml,likegecko)chrome/69。3770。132safari/537。36'}self。request=requests。get(self。__title,headers=self。headers)self。response=requests。
get(self。__title,headers=self。headers)self。content=requests。get(self。tags,headers=self。headers)#创建request对象,第一次请求到的时候写入tagsself。__headers={'user-agent':'mozilla/5。0(windowsnt10。0;win64;x6。
4)applewebkit/537。36(khtml,likegecko)chrome/69。3770。132safari/537。36'}req=requests。get(req。text,headers=self。headers)#tokenonlytoken={'params':params}token_len={'token':token,'time':'get','email':'@example。
python网页数据抓取(Python內建使用urllib.request获取网页urllib是什么意思?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2022-02-14 14:38
1. 使用 urllib.request 获取网页
urllib 是 Python 中的内置 HTTP 库。使用 urllib,您只需非常简单的步骤即可高效地采集数据;配合Beautiful等HTML解析库,可以为采集网络数据编写大规模爬虫;
注意:示例代码是用Python3编写的;urllib是Python2中的urllib和urllib2的组合,Python2中的urllib2对应Python3中的urllib.request
简单的例子:
2. 伪造请求头信息
有时爬虫发起的请求会被服务器拒绝。在这种情况下,需要将爬虫伪装成人类用户的浏览器,这通常是通过伪造请求头信息来实现的,例如:
3. 伪造请求体
爬取一些网站时,需要POST数据到服务器,然后需要伪造请求体;
为了实现有道词典的在线翻译脚本,在Chrome中打开开发工具,在Network下用POST方法找到请求,观察数据发现请求体中的‘i’是URL编码的内容那是需要翻译的,所以可以伪造Request body,比如:
您还可以使用 add_header() 方法来伪造请求标头,例如:
4. 使用代理 IP
为了避免爬虫过于频繁导致IP阻塞的问题采集,可以使用代理IP,如:
注意:使用爬虫过于频繁地访问目标站点会占用大量服务器资源。大规模分布式爬虫集中爬取网站,甚至相当于对网站发起DDOS攻击;因此,在使用爬虫爬取数据时,应合理安排爬取的频率和时间;如:服务器比较空闲时爬取(如:清晨),完成爬取任务后暂停一段时间等;
5. 检测网页的编码
虽然大部分网页都是用UTF-8编码的,但是有时候你会遇到使用其他编码方式的网页,所以你必须知道网页的编码方式才能正确解码爬取的页面;
chardet是python的第三方模块,使用chardet可以自动检测网页的编码方式;
安装 chardet:pip install charest
利用:
6. 获取跳转链接
有时网页的一个页面需要根据原创URL进行一次甚至多次跳转才能最终到达目的页面,所以需要正确处理跳转;
通过requests模块的head()函数获取跳转链接的URL,如 查看全部
python网页数据抓取(Python內建使用urllib.request获取网页urllib是什么意思?)
1. 使用 urllib.request 获取网页
urllib 是 Python 中的内置 HTTP 库。使用 urllib,您只需非常简单的步骤即可高效地采集数据;配合Beautiful等HTML解析库,可以为采集网络数据编写大规模爬虫;
注意:示例代码是用Python3编写的;urllib是Python2中的urllib和urllib2的组合,Python2中的urllib2对应Python3中的urllib.request
简单的例子:
2. 伪造请求头信息
有时爬虫发起的请求会被服务器拒绝。在这种情况下,需要将爬虫伪装成人类用户的浏览器,这通常是通过伪造请求头信息来实现的,例如:
3. 伪造请求体
爬取一些网站时,需要POST数据到服务器,然后需要伪造请求体;
为了实现有道词典的在线翻译脚本,在Chrome中打开开发工具,在Network下用POST方法找到请求,观察数据发现请求体中的‘i’是URL编码的内容那是需要翻译的,所以可以伪造Request body,比如:
您还可以使用 add_header() 方法来伪造请求标头,例如:
4. 使用代理 IP
为了避免爬虫过于频繁导致IP阻塞的问题采集,可以使用代理IP,如:
注意:使用爬虫过于频繁地访问目标站点会占用大量服务器资源。大规模分布式爬虫集中爬取网站,甚至相当于对网站发起DDOS攻击;因此,在使用爬虫爬取数据时,应合理安排爬取的频率和时间;如:服务器比较空闲时爬取(如:清晨),完成爬取任务后暂停一段时间等;
5. 检测网页的编码
虽然大部分网页都是用UTF-8编码的,但是有时候你会遇到使用其他编码方式的网页,所以你必须知道网页的编码方式才能正确解码爬取的页面;
chardet是python的第三方模块,使用chardet可以自动检测网页的编码方式;
安装 chardet:pip install charest
利用:
6. 获取跳转链接
有时网页的一个页面需要根据原创URL进行一次甚至多次跳转才能最终到达目的页面,所以需要正确处理跳转;
通过requests模块的head()函数获取跳转链接的URL,如
python网页数据抓取(python网络爬虫(上)概述预备知识、如何处理登录问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-02-14 11:10
石斛2020-11-24 305次浏览Python原版网络爬虫(上)
关键词:
登山在山里充满爱,在海里看海充满意义。本文章主要介绍Python网络爬虫相关知识(上),希望对大家有所帮助。
python网络爬虫概述(上)
初步知识
1、如何处理大量(JS)的页面以及如何处理登录问题
2、屏幕抓取、数据挖掘、网络收获、网络爬虫、网络爬虫、机器人
3、网络爬虫的优势:一、同时处理上千甚至上百万个网页;二、不同于传统搜索引擎,可以获得更准确的数据信息;三、 相比API取数据,网络爬虫更灵活
4、网络爬虫用于:市场预测、机器语言翻译、医学诊断、新闻网站、文章、健康论坛、宏观经济学、生物基因、国际关系、健康论坛、艺术领域以及数据采集和分析的其他方面(分类和汇总)
5、网络爬虫涉及:数据库、网络服务器、HTTP协议、html语言(HyperTextMarkupLanguage)、网络安全、图像处理、数据科学等负面知识
6、网页的组成:HTML文本格式层、CSS样式层(CascadingStyleSheets)、javaScript执行层、图像渲染层
7、JavaScript思路:(1)学习C语言的基本语法,(2)学习Java语言的数据类型和内存管理,(3)学习Scheme语言,改进功能到“头等舱”(first class)的状态,(4)借鉴自Self语言,使用基于原型的继承机制。JavaScript组成:(1)核心(ECMAScript) ),描述语言的语法和基本对象,(2)文档对象模型(DOM),描述处理网页内容的方法和接口,(3)浏览器对象模型(BOM),它描述了与浏览器的交互 .JavaScript 库的方法和接口:jQuery、Prototype、MooTools 等。
8、HTML文本结构:HTML的结构是树状结构,在内存中形成一棵树
9、HTML只负责文档的结构和内容,表达完全交给CSS。基本 CSS 语法:选择器 { 属性:值;属性:值;属性:值;} (tagAttributes)
10、浏览器加载的网页需要加载很多相关的资源文件,包括:图片文件、JavaScript文件、CSS文件、链接其他网页的URL地址信息等。
11、浏览器加载服务器资源,根据标签如
,它创建一个数据包,指示操作系统向服务器发送请求,然后将获取的数据解释为图像。浏览器就是代码,代码可以分解成许多基本组件,可以根据需要重写、重用和修改
12、.get_text():清除HTML文档中所有无用的信息,如tagName、超链接、段落等。通常在准备打印、存储、操作最终数据时,使用 .get_text()!
开发工具及原理分析1、urllib标准库,urllib.request导入urlopen
1.1、urllib标准库的功能:网页请求数据、处理cookies、更改请求头和用户代理元数据的功能
1.2、urlopen函数功能:打开和读取从网络上获取的远程对象,可以读取HTML文件、图片文件,以及任何其他文件流
2、BeautifulSoup 库
2.1、XML 是一种可扩展的标记语言,而 HTML 是一种超文本标记语言:XML 语法更严格,HTML 语法更宽松;XML主要用于数据格式化存储,HTML主要用于编辑网页;XML 语言是对超文本标记语言的补充;为不同的目的而设计,XML被设计用来传输和存储数据,它的重点是数据的内容,HTML被设计用来显示数据,它的重点是数据的外观
2.2、BeautifulSoup 库通过定位 HTML 标签来格式化和组织复杂的网页信息;通过易于使用的 python 对象显示 XML 结构信息
2.3、BeautifulSoup 库创建 BeautifulSoup 对象:bs=BeautifulSoup(html.read(), 'html.parser'), bs.HTML 标签 (html.title, html.body.h1、html.body.div)
第一个参数:BeautifulSoup 对象所基于的 HTML 文本
第二个参数:BeautifulSoup 对象创建对象的解释器,'html.parser', 'lxml', 'html5lib'
1、'lxml', 'html5lib' 优点:容错,如果HTML标签(tagName)异常:未闭合,嵌套错误,缺少head标签,缺少body标签,'lxml','html5lib'可以优化
2、'html.parser', 'lxml', 'html5lib' 三个解释器爬网速度不同,'lxml'>'html.parser'>'html5lib',但关键问题和瓶颈不是宽带速度爬行速度!
2.4、网络爬虫异常,因为网络数据格式异常,网络爬虫异常:一、urlopen()有问题;二、print(bs .h1)有问题
一、urlopen() 的问题:
1、服务器上不存在网页:HTTPError: '404 PageNot Found', '505 Internet Server Error'
2、服务器不存在:URLError
二、print(bs.h1)有问题:
1、BeautifulSoup 对象标签异常,不存在!无--->属性错误!由于 BeautifulSoup 对象在标签不存在时调用它,所以它会返回 None。如果调用None下面的子标签,就会出现AttributeError,所以需要避免这两种情况的异常!
异常处理思路:try...except...else...添加异常检查点。
from urllib.request import urlopen
from urllib.error import HTTPError
from bs4 import BeautifulSoup
def getTitle(url):
try:
html = urlopen(url)
except HTTPError as e:
return None
try:
bsObj = BeautifulSoup(html.read(), "lxml")
title = bsObj.body.h1
except AttributeError as e:
return None
return title
title = getTitle("http://www.pythonscraping.com/ ... 6quot;)
if title == None:
print("Title could not be found")
else:
print(title)
3、HTML解析:BeautifulSoup,正则表达式
3.1、网页爬虫代码增强灵活性和可读性的思路:
1、方向一、比较网页PC版和APP版,比较PC版的HTML风格和APP版的HTML风格。选择更适用的版本,修改请求头状态,获取对应版本的状态。
2、方向二、JavaScript文件,通过网页加载的JavaScript文件中收录的信息
3、方向三、URL链接收录网页的标题,直接从URL链接获取目标信息
4、方向四、目标信息的来源页面
3.2、BeautifulSoup 用途:属性值搜索标签、标签组、CSS 语法中的导航树(BeautifulSoup 标签树导航)
1、bs.tagName
2、bs.find_all(tagName, tagAttributes)
3、写一个网络爬虫:scrapy
4、存储目标信息:mysql
应用示例
至此,这篇关于Python网络爬虫(上)的文章就讲完了。如果您的问题无法解决,请参考以下文章:
相关文章
如何使用Python网络爬虫抓取微信朋友圈动态(上)
003 Python网络爬虫和信息提取网络爬虫的“海盗”
Python爬虫入门
Python爬虫难学吗?容易学吗?
Python爬虫编程思路:网络爬虫基本原理
Web Crawler 入门:您的第一个爬虫项目(请求库)
爬虫学习06.Python网络爬虫请求模块
Python网络爬虫:空姐网尴尬xxx结果图及源码 查看全部
python网页数据抓取(python网络爬虫(上)概述预备知识、如何处理登录问题)
石斛2020-11-24 305次浏览Python原版网络爬虫(上)
关键词:
登山在山里充满爱,在海里看海充满意义。本文章主要介绍Python网络爬虫相关知识(上),希望对大家有所帮助。
python网络爬虫概述(上)
初步知识
1、如何处理大量(JS)的页面以及如何处理登录问题
2、屏幕抓取、数据挖掘、网络收获、网络爬虫、网络爬虫、机器人
3、网络爬虫的优势:一、同时处理上千甚至上百万个网页;二、不同于传统搜索引擎,可以获得更准确的数据信息;三、 相比API取数据,网络爬虫更灵活
4、网络爬虫用于:市场预测、机器语言翻译、医学诊断、新闻网站、文章、健康论坛、宏观经济学、生物基因、国际关系、健康论坛、艺术领域以及数据采集和分析的其他方面(分类和汇总)
5、网络爬虫涉及:数据库、网络服务器、HTTP协议、html语言(HyperTextMarkupLanguage)、网络安全、图像处理、数据科学等负面知识
6、网页的组成:HTML文本格式层、CSS样式层(CascadingStyleSheets)、javaScript执行层、图像渲染层
7、JavaScript思路:(1)学习C语言的基本语法,(2)学习Java语言的数据类型和内存管理,(3)学习Scheme语言,改进功能到“头等舱”(first class)的状态,(4)借鉴自Self语言,使用基于原型的继承机制。JavaScript组成:(1)核心(ECMAScript) ),描述语言的语法和基本对象,(2)文档对象模型(DOM),描述处理网页内容的方法和接口,(3)浏览器对象模型(BOM),它描述了与浏览器的交互 .JavaScript 库的方法和接口:jQuery、Prototype、MooTools 等。
8、HTML文本结构:HTML的结构是树状结构,在内存中形成一棵树
9、HTML只负责文档的结构和内容,表达完全交给CSS。基本 CSS 语法:选择器 { 属性:值;属性:值;属性:值;} (tagAttributes)
10、浏览器加载的网页需要加载很多相关的资源文件,包括:图片文件、JavaScript文件、CSS文件、链接其他网页的URL地址信息等。
11、浏览器加载服务器资源,根据标签如

,它创建一个数据包,指示操作系统向服务器发送请求,然后将获取的数据解释为图像。浏览器就是代码,代码可以分解成许多基本组件,可以根据需要重写、重用和修改
12、.get_text():清除HTML文档中所有无用的信息,如tagName、超链接、段落等。通常在准备打印、存储、操作最终数据时,使用 .get_text()!
开发工具及原理分析1、urllib标准库,urllib.request导入urlopen
1.1、urllib标准库的功能:网页请求数据、处理cookies、更改请求头和用户代理元数据的功能
1.2、urlopen函数功能:打开和读取从网络上获取的远程对象,可以读取HTML文件、图片文件,以及任何其他文件流
2、BeautifulSoup 库
2.1、XML 是一种可扩展的标记语言,而 HTML 是一种超文本标记语言:XML 语法更严格,HTML 语法更宽松;XML主要用于数据格式化存储,HTML主要用于编辑网页;XML 语言是对超文本标记语言的补充;为不同的目的而设计,XML被设计用来传输和存储数据,它的重点是数据的内容,HTML被设计用来显示数据,它的重点是数据的外观
2.2、BeautifulSoup 库通过定位 HTML 标签来格式化和组织复杂的网页信息;通过易于使用的 python 对象显示 XML 结构信息
2.3、BeautifulSoup 库创建 BeautifulSoup 对象:bs=BeautifulSoup(html.read(), 'html.parser'), bs.HTML 标签 (html.title, html.body.h1、html.body.div)
第一个参数:BeautifulSoup 对象所基于的 HTML 文本
第二个参数:BeautifulSoup 对象创建对象的解释器,'html.parser', 'lxml', 'html5lib'
1、'lxml', 'html5lib' 优点:容错,如果HTML标签(tagName)异常:未闭合,嵌套错误,缺少head标签,缺少body标签,'lxml','html5lib'可以优化
2、'html.parser', 'lxml', 'html5lib' 三个解释器爬网速度不同,'lxml'>'html.parser'>'html5lib',但关键问题和瓶颈不是宽带速度爬行速度!
2.4、网络爬虫异常,因为网络数据格式异常,网络爬虫异常:一、urlopen()有问题;二、print(bs .h1)有问题
一、urlopen() 的问题:
1、服务器上不存在网页:HTTPError: '404 PageNot Found', '505 Internet Server Error'
2、服务器不存在:URLError
二、print(bs.h1)有问题:
1、BeautifulSoup 对象标签异常,不存在!无--->属性错误!由于 BeautifulSoup 对象在标签不存在时调用它,所以它会返回 None。如果调用None下面的子标签,就会出现AttributeError,所以需要避免这两种情况的异常!
异常处理思路:try...except...else...添加异常检查点。
from urllib.request import urlopen
from urllib.error import HTTPError
from bs4 import BeautifulSoup
def getTitle(url):
try:
html = urlopen(url)
except HTTPError as e:
return None
try:
bsObj = BeautifulSoup(html.read(), "lxml")
title = bsObj.body.h1
except AttributeError as e:
return None
return title
title = getTitle("http://www.pythonscraping.com/ ... 6quot;)
if title == None:
print("Title could not be found")
else:
print(title)
3、HTML解析:BeautifulSoup,正则表达式
3.1、网页爬虫代码增强灵活性和可读性的思路:
1、方向一、比较网页PC版和APP版,比较PC版的HTML风格和APP版的HTML风格。选择更适用的版本,修改请求头状态,获取对应版本的状态。
2、方向二、JavaScript文件,通过网页加载的JavaScript文件中收录的信息
3、方向三、URL链接收录网页的标题,直接从URL链接获取目标信息
4、方向四、目标信息的来源页面
3.2、BeautifulSoup 用途:属性值搜索标签、标签组、CSS 语法中的导航树(BeautifulSoup 标签树导航)
1、bs.tagName
2、bs.find_all(tagName, tagAttributes)
3、写一个网络爬虫:scrapy
4、存储目标信息:mysql
应用示例
至此,这篇关于Python网络爬虫(上)的文章就讲完了。如果您的问题无法解决,请参考以下文章:
相关文章
如何使用Python网络爬虫抓取微信朋友圈动态(上)
003 Python网络爬虫和信息提取网络爬虫的“海盗”
Python爬虫入门
Python爬虫难学吗?容易学吗?
Python爬虫编程思路:网络爬虫基本原理
Web Crawler 入门:您的第一个爬虫项目(请求库)
爬虫学习06.Python网络爬虫请求模块
Python网络爬虫:空姐网尴尬xxx结果图及源码
python网页数据抓取(想了解判断网页编码的方法python版的相关内容吗 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-02-14 11:05
)
想知道python版的网页编码判断方法吗?在本文中,mickelfeng将讲解python网页编码判断方法的相关知识和一些代码示例。欢迎阅读和指正。方法,网页编码判断python代码一起来学习。
在web开发中,我们经常会遇到可以完成这个功能的各种语言的web爬取和分析。我喜欢用python实现它,因为python提供了很多成熟的模块,可以轻松实现网页抓取。
但是在爬取过程中会出现编码问题。今天,我们来看看如何判断网页的编码:
网上很多网页的编码格式一般都是GBK、GB2312UTF-8等。
获取网页的数据后,首先要判断网页的编码,以便将抓取到的内容的编码统一转换为我们可以处理的编码,避免出现乱码问题。
以下是确定网页编码的两种方法:
总结:第二种方法很准确。使用python模块分析网页代码分析的内容是最准确的,而分析元头信息的方法不是很准确。
方法一:使用urllib模块的getparam方法
方法二:使用chardet模块
#如果你的python没有安装chardet模块你需要首先安装一下chardet判断编码的模块哦
#author:pythontab.com
import chardet
import urllib
#先获取网页内容
data1 = urllib.urlopen('http://www.baidu.com').read()
#用chardet进行内容分析
chardit1 = chardet.detect(data1)
print chardit1['encoding'] # baidu 查看全部
python网页数据抓取(想了解判断网页编码的方法python版的相关内容吗
)
想知道python版的网页编码判断方法吗?在本文中,mickelfeng将讲解python网页编码判断方法的相关知识和一些代码示例。欢迎阅读和指正。方法,网页编码判断python代码一起来学习。
在web开发中,我们经常会遇到可以完成这个功能的各种语言的web爬取和分析。我喜欢用python实现它,因为python提供了很多成熟的模块,可以轻松实现网页抓取。
但是在爬取过程中会出现编码问题。今天,我们来看看如何判断网页的编码:
网上很多网页的编码格式一般都是GBK、GB2312UTF-8等。
获取网页的数据后,首先要判断网页的编码,以便将抓取到的内容的编码统一转换为我们可以处理的编码,避免出现乱码问题。
以下是确定网页编码的两种方法:
总结:第二种方法很准确。使用python模块分析网页代码分析的内容是最准确的,而分析元头信息的方法不是很准确。
方法一:使用urllib模块的getparam方法
方法二:使用chardet模块
#如果你的python没有安装chardet模块你需要首先安装一下chardet判断编码的模块哦
#author:pythontab.com
import chardet
import urllib
#先获取网页内容
data1 = urllib.urlopen('http://www.baidu.com').read()
#用chardet进行内容分析
chardit1 = chardet.detect(data1)
print chardit1['encoding'] # baidu
python网页数据抓取(先上代码看了一下应该是Pyecharts中Map的data_pair )
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-02-14 08:05
)
2021/07/15 更新:
没有及时看到评论区的反馈。我真的很抱歉。我把代码拉下来看了看。应该是Pyecharts中Map的data_pair数据类型发生了变化。现在将 dic_items 转换为列表。
代码已整理完善,完整源码已上传至Gitee,地址:完整源码
所有生成的csv、疫情图、可视化图表都在项目根目录下。
总结:
受2019-nCoV影响,一场没有硝烟的防疫阻击战已经打响。在全国人民的共同努力下,疫情正在逐步稳定,但我们仍不能掉以轻心。
疫情开始前,我每天都在关注疫情,尤其是全国疫情地图。在那之后,我一直想自己拿数据做一个,但我没有坚持去做。前几天用Python爬取了结果查询网站,照着做,完成了这个需求。
话不多说,先上图吧:
中国疫情地图
各省详情
湖北省各城市疫情数据分布
目录
数据源分析:
数据来自丁香博士:
博士。丁香的数据如下图所示:
看到这里,你可能觉得应该直接把这个数据放到tr,td或者ul,li里面,直接发送请求,获取页面DOM中的文本就行了
一开始我也是这么想的,但是看了网页的源码后才发现不是-_-||
其实中国每个省份的数据都是存储在脚本标签中,id为getAreaStat,然后动态渲染到视图上。
所以我们要做的就是获取脚本标签中id为getAreaStat的文本
数据管理:
不难看出script标签中的数据是以json的形式存储的。我们验证和格式化 json 字符串并组织其中的数据。
左边的密集数据格式化后,很直观的看到json字符串的内部存储,大致如下:在整个json字符串中,每个province是一个dict,每个province里面的city省是一个子列表存储该省的城市数据。
代码部分代码中要使用的第三方库如下:一、抓取全国各省疫情信息,生成csv文件基本
1.代码分析:
2.源码:
import requests
from pyquery import PyQuery as pq
import json
import pandas as pd
import time
def get_data():
url = "https://ncov.dxy.cn/ncovh5/view/pneumonia"
response = requests.get(url)
if response.status_code == 200:
response.encoding = "utf-8"
dom = pq(response.content)
data = dom("script#getAreaStat").text().split(" = ")[1].split("}catch")[0]
jsonObj = json.loads(data) # json对象
print("数据抓取成功...")
province_data = []
for item in jsonObj:
dic = {"省全称": item["provinceName"], "省简称": item["provinceShortName"], "现存确诊人数": item["currentConfirmedCount"],
"累计确诊人数": item["confirmedCount"], "疑似人数": item["suspectedCount"], "治愈人数": item["curedCount"],
"死亡人数": item["deadCount"]}
province_data.append(dic)
if len(province_data) > 0:
print("写入数据...")
try:
df = pd.DataFrame(province_data)
time_format = time.strftime("%Y-%m-%d_%H_%M_%S", time.localtime())
df.to_csv(time_format + "全国各省疫情数据.csv", encoding="gbk", index=False)
print("写入成功...")
except Exception as e:
print(f"写入失败....{e}")
if __name__ == '__main__':
get_data()
3.运行效果:
二、用pyecharts绘制中国疫情地图,进阶
一说到画表,首先想到的就是Apache开源的echarts框架,有效又强大。因为不熟悉Matplotlib库,拿到数据后想用echarts框架的前端自己画一个,后来才知道有专门的pyecharts,很不错!
建议不了解echarts或pyecharts的同学先阅读官方API,了解基本图表类型和各种参数。 (⊙﹏⊙))哦!
1.代码分析:
2.源码:
"""
@File : data_chart.py
@Modify Time @Author @Version @Desciption
------------ ------- -------- -----------
2021/7/15 9:25 wrzcoder 1.0 None
"""
from pyecharts import options as opts
from pyecharts.charts import Map
import requests
from pyquery import PyQuery as pq
import json
import time
def map_visual_map() -> Map:
c = (
Map(init_opts=opts.InitOpts(page_title="中国疫情地图"))
.add("现存确诊人数", data_pair=list(current_data_dic.items()), maptype="china")
.set_global_opts(
title_opts=opts.TitleOpts(title="中国疫情地图", subtitle="数据更新于" + time_format),
visualmap_opts=opts.VisualMapOpts(pieces=[
{"value": 0, "label": "无", "color": "#9AFF9A"},
{"min": 1, "max": 9, "label": "1~9", "color": "#FFCCCC"},
{"min": 10, "max": 99, "label": "10~99", "color": "#DB5A6B"},
{"min": 100, "max": 499, "label": "100~499", "color": "#FF6666"},
{"min": 500, "max": 999, "label": "500~999", "color": "#CC2929"},
{"min": 1000, "max": 9999, "label": "1000~9999", "color": "#8C0D0D"},
{"min": 10000, "label": ">10000", "color": "#9d2933"}
], is_piecewise=True),
)
)
return c
if __name__ == '__main__':
try:
url = "https://ncov.dxy.cn/ncovh5/view/pneumonia"
response = requests.get(url)
if response.status_code == 200:
response.encoding = "utf-8"
dom = pq(response.content)
data = dom("script#getAreaStat").text().split(" = ")[1].split("}catch")[0]
jsonObj = json.loads(data) # json对象
print("数据抓取成功...")
current_data_dic = {}
time_format = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
for item in jsonObj:
current_data_dic[item["provinceShortName"]] = item["currentConfirmedCount"]
print(list(current_data_dic.items()))
map_visual_map().render("疫情地图.html")
print('疫情地图已生成在项目根目录...')
except Exception as e:
print(e)
3.运行效果:
三、采集全国各省市的疫情数据,进行数据可视化扩展
上面我们只用到了各个省的数据,而且在分析之初,各个省的dict中还收录了该省的市(区)的数据,我们不能浪费这些数据,我们可以抓取它。为了充分利用它们,我们对全国各省市的所有疫情数据进行了分类和可视化。
这里我想说的是:我们在可视化每个省(直辖市)以下市(区)的疫情数据时,也可以使用pyecharts中的Map,但是为了更加熟悉pyecharts,我们会改这里的表格类型饼图。
看起来很麻烦。求各省的数据,包括城市,最后画个图,太麻烦了。太麻烦了,不过不是(*^▽^*)就30行代码
1.代码分析
2.源码
"""
@File : province_data_chart.py
@Modify Time @Author @Version @Desciption
------------ ------- -------- -----------
2021/7/15 9:45 wrzcoder 1.0 None
"""
import requests
import json
from pyecharts.charts import Pie
import pyecharts.options as opts
import time
from pyquery import PyQuery as pq
import os
def create_Pie(provinceName, dic_citys) -> Pie:
c = (
Pie(init_opts=opts.InitOpts(width="100%", height="800px", page_title=provinceName + "各市(区)情况"))
.add("", data_pair=list(dic_citys.items()), center=["50%", "58%"], )
.set_global_opts(title_opts=opts.TitleOpts(title=provinceName + "各市(区)情况", subtitle="数据更新于:" + timeformat))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
if not os.path.exists('./中国各省情况'):
os.mkdir('./中国各省情况')
c.render("./中国各省情况/" + provinceName + "各市(区)情况.html")
if __name__ == '__main__':
try:
url = "https://ncov.dxy.cn/ncovh5/view/pneumonia"
timeformat = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
response = requests.get(url)
response.encoding = "utf-8"
if response.status_code == 200:
print("数据抓取成功!")
dom = pq(response.text)
jsonobj = json.loads(dom("script#getAreaStat").text().split(" = ")[1].split("}catch")[0])
for province in jsonobj:
dic_city = {}
for city in province["cities"]:
dic_city[city["cityName"]] = city["currentConfirmedCount"]
if dic_city.__len__() > 0:
create_Pie(province["provinceName"], dic_city)
print(province["provinceName"] + "各市数据汇总完毕!")
except Exception as e:
print(e)
3.运行效果:
短短1.1s,我们爬取了全国所有省市的疫情数据,整理生成数据图表
打开随机饼图查看效果:
四川省各城市疫情数据汇总
至此,我们完成了全国各省市疫情实时数据的采集和处理,还绘制了中国疫情地图。在此基础上,我们进一步扩展,对中国各省、自治区、直辖市的疫情数据进行了批量整理和可视化。期间复习了requests库、pandas、pyquery库等,同时也学习和学习了强大的图表绘制pyecharts库,可以说是收获颇丰!因此,在这里一起分享和学习!
最后,加油武汉,加油中国!疫情终将过去,春天终将到来!
图片来自网络
希望你下次运行这段代码时,看到的疫情图是这样的:
查看全部
python网页数据抓取(先上代码看了一下应该是Pyecharts中Map的data_pair
)
2021/07/15 更新:
没有及时看到评论区的反馈。我真的很抱歉。我把代码拉下来看了看。应该是Pyecharts中Map的data_pair数据类型发生了变化。现在将 dic_items 转换为列表。
代码已整理完善,完整源码已上传至Gitee,地址:完整源码
所有生成的csv、疫情图、可视化图表都在项目根目录下。
总结:
受2019-nCoV影响,一场没有硝烟的防疫阻击战已经打响。在全国人民的共同努力下,疫情正在逐步稳定,但我们仍不能掉以轻心。
疫情开始前,我每天都在关注疫情,尤其是全国疫情地图。在那之后,我一直想自己拿数据做一个,但我没有坚持去做。前几天用Python爬取了结果查询网站,照着做,完成了这个需求。
话不多说,先上图吧:
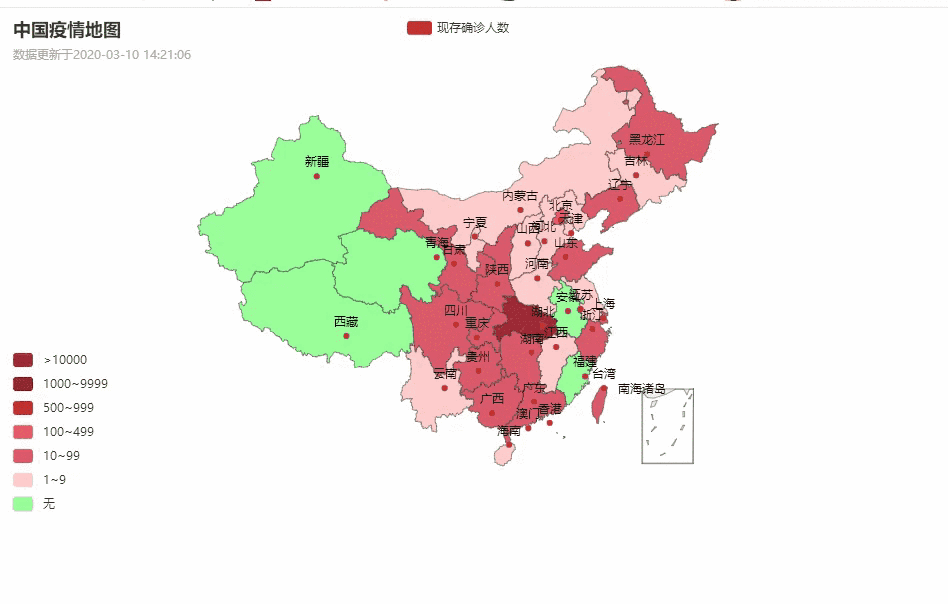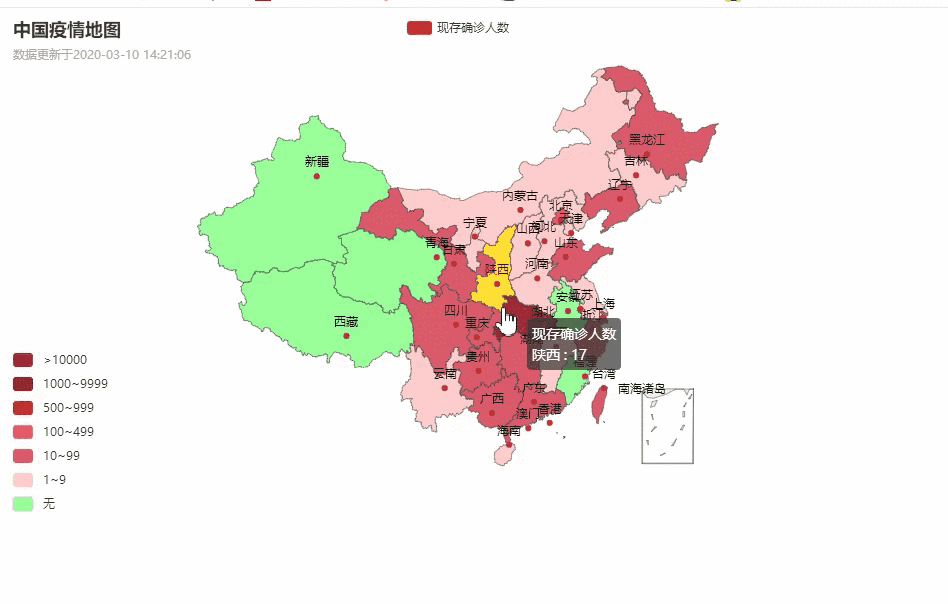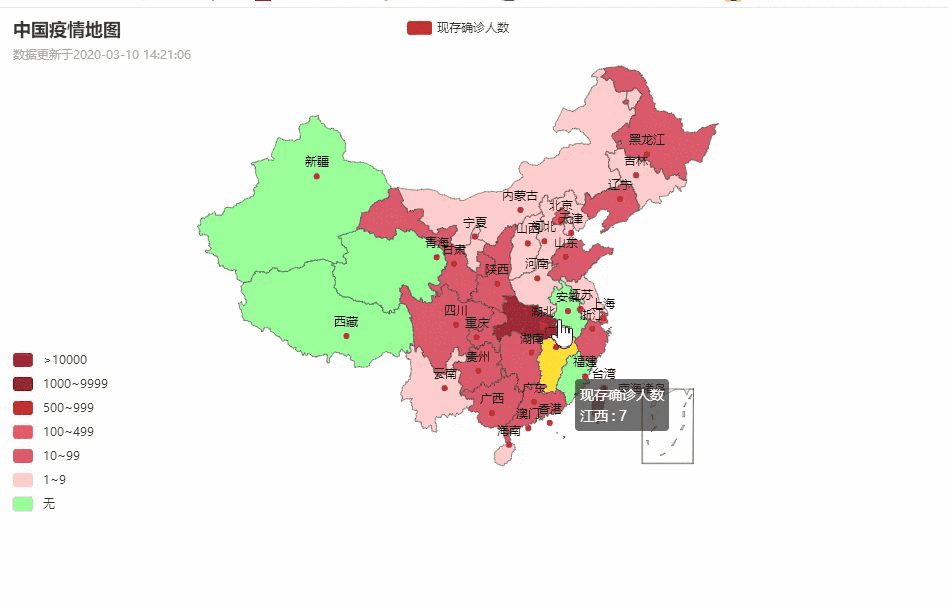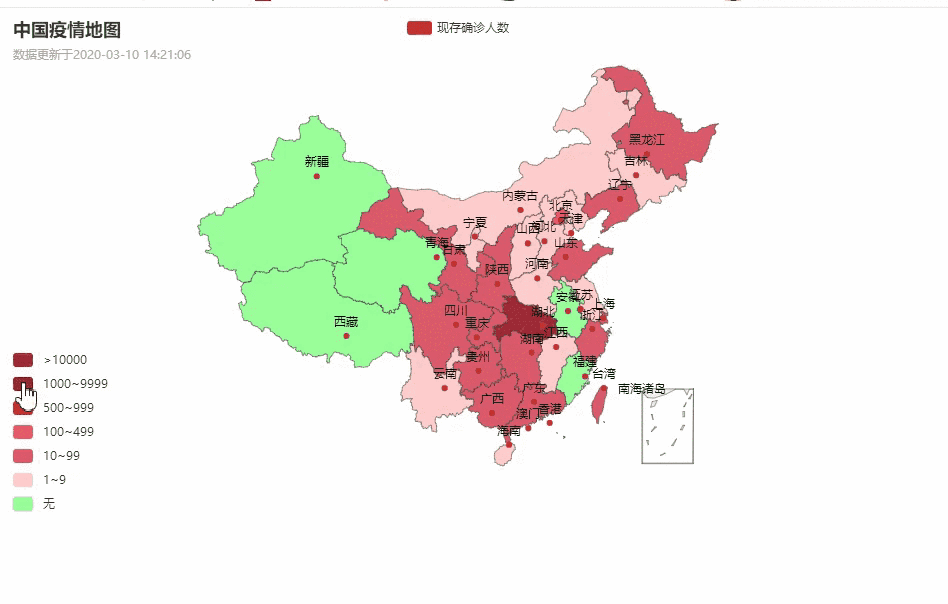
中国疫情地图
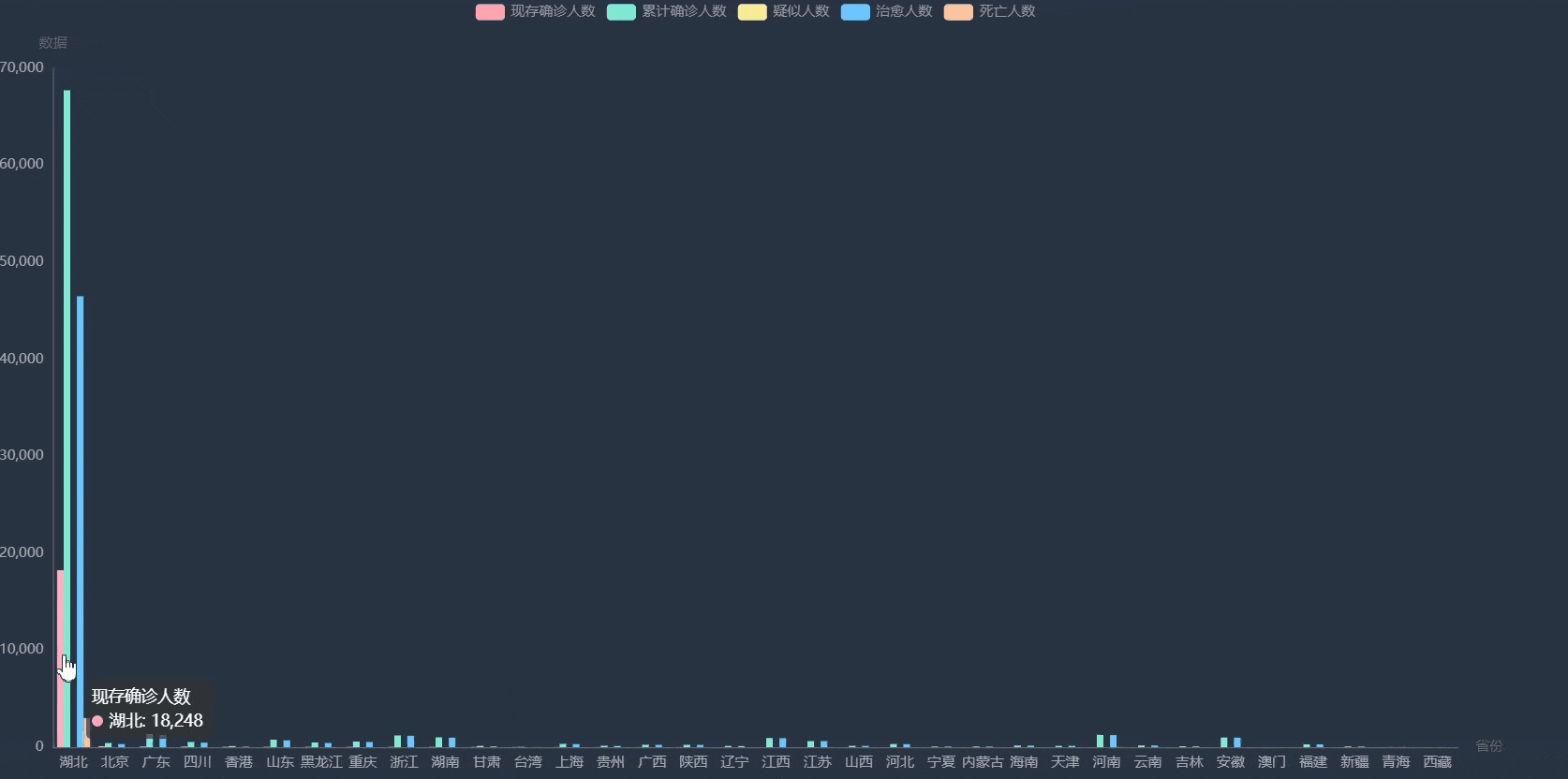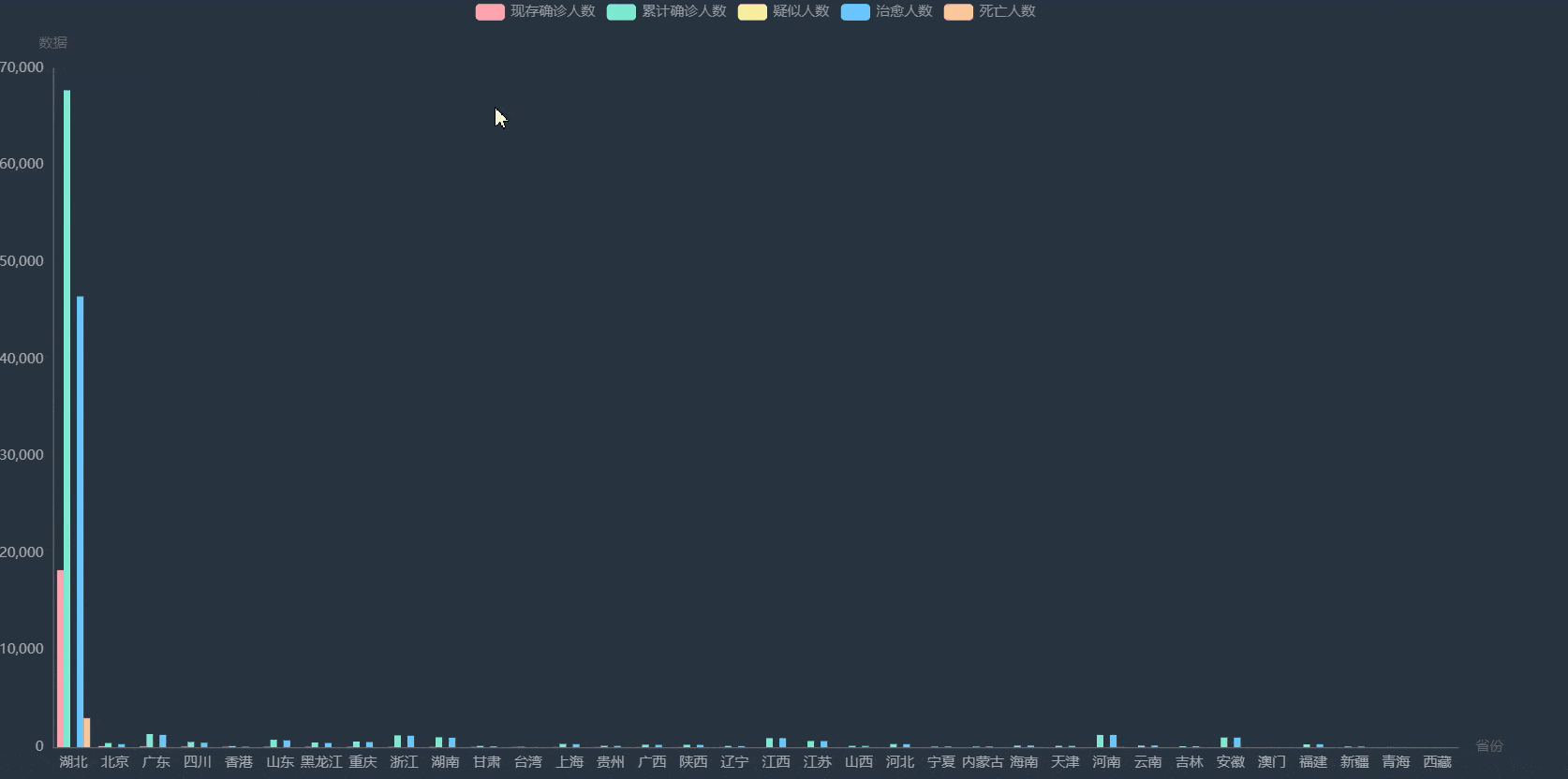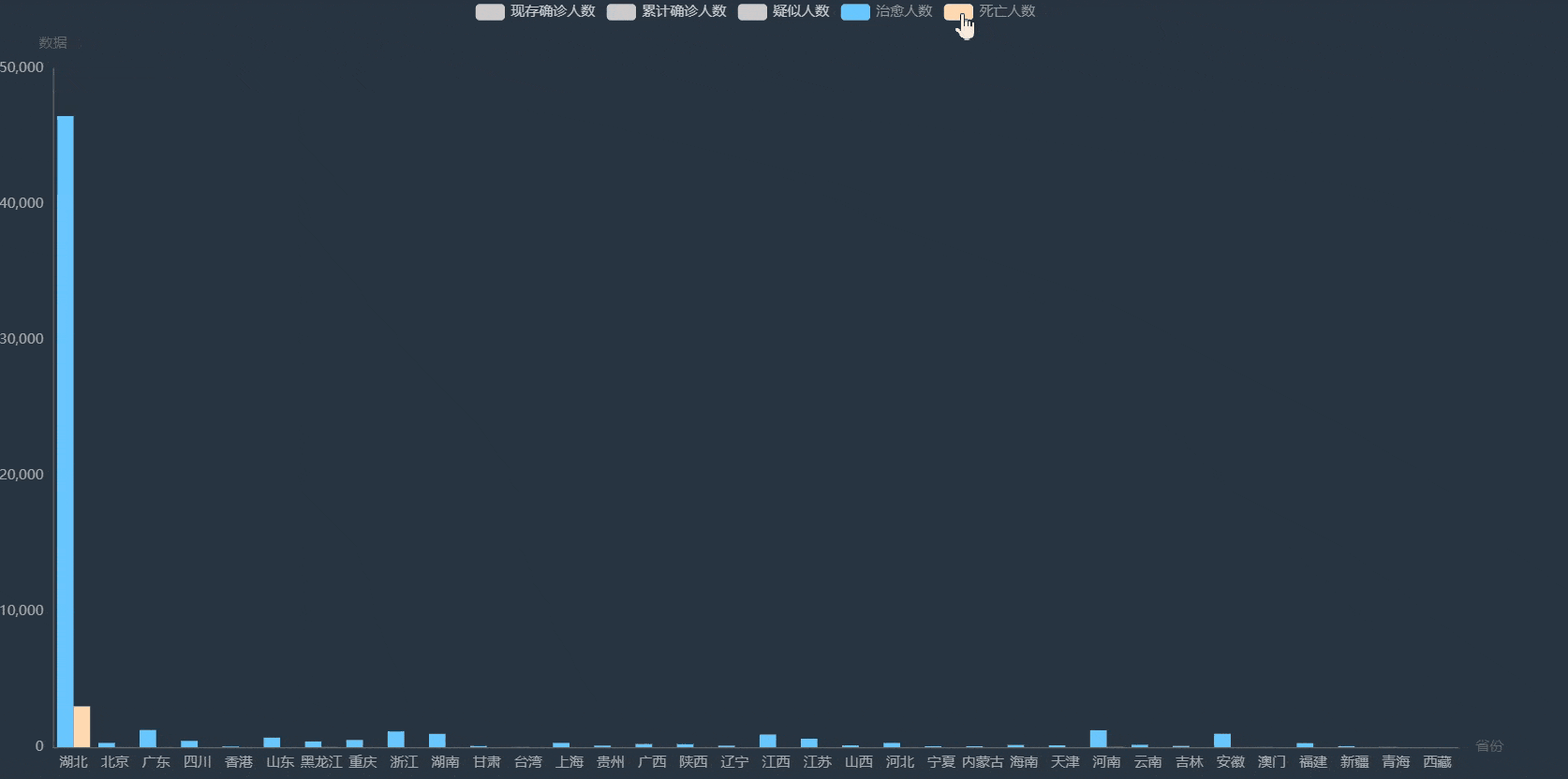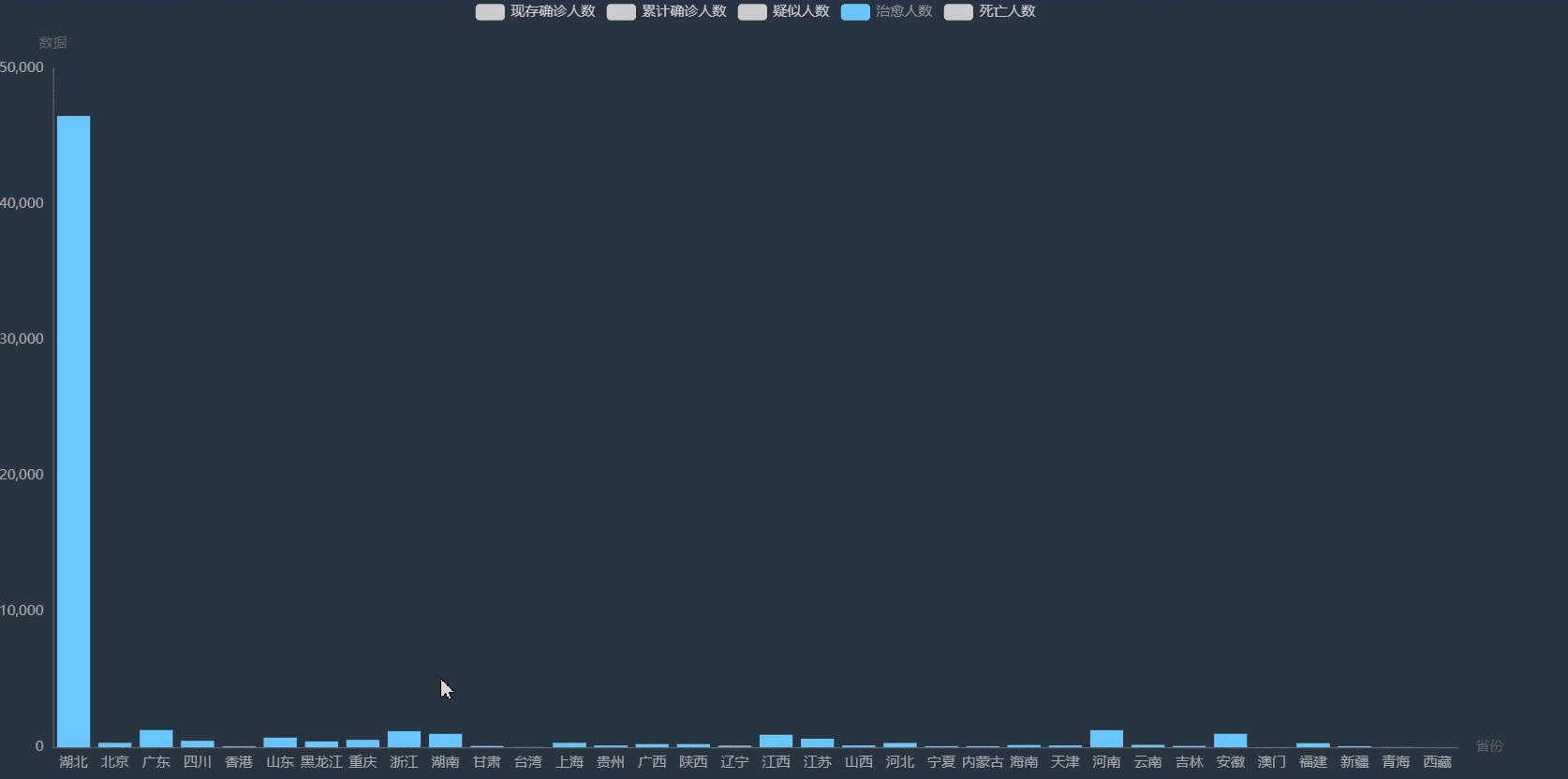
各省详情
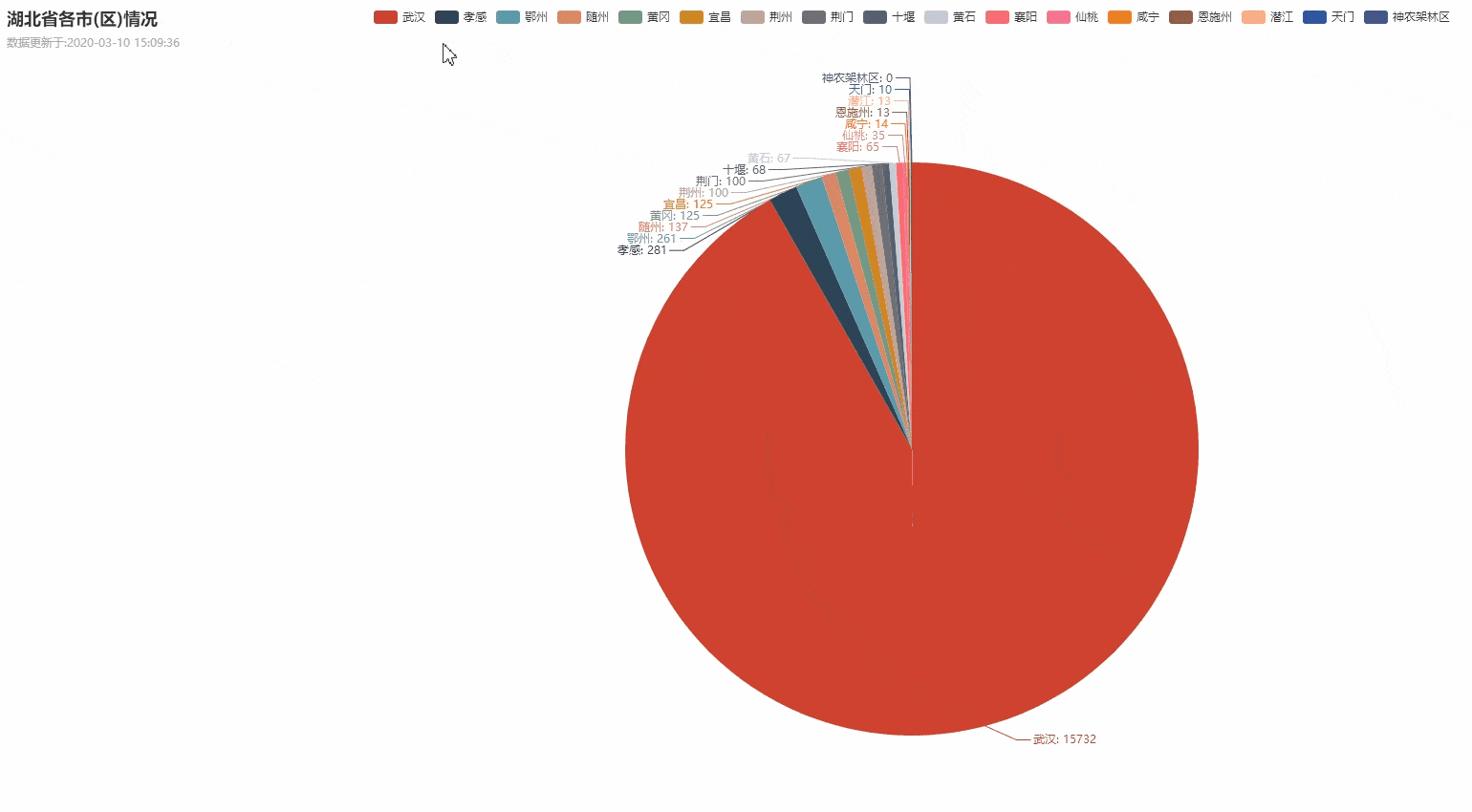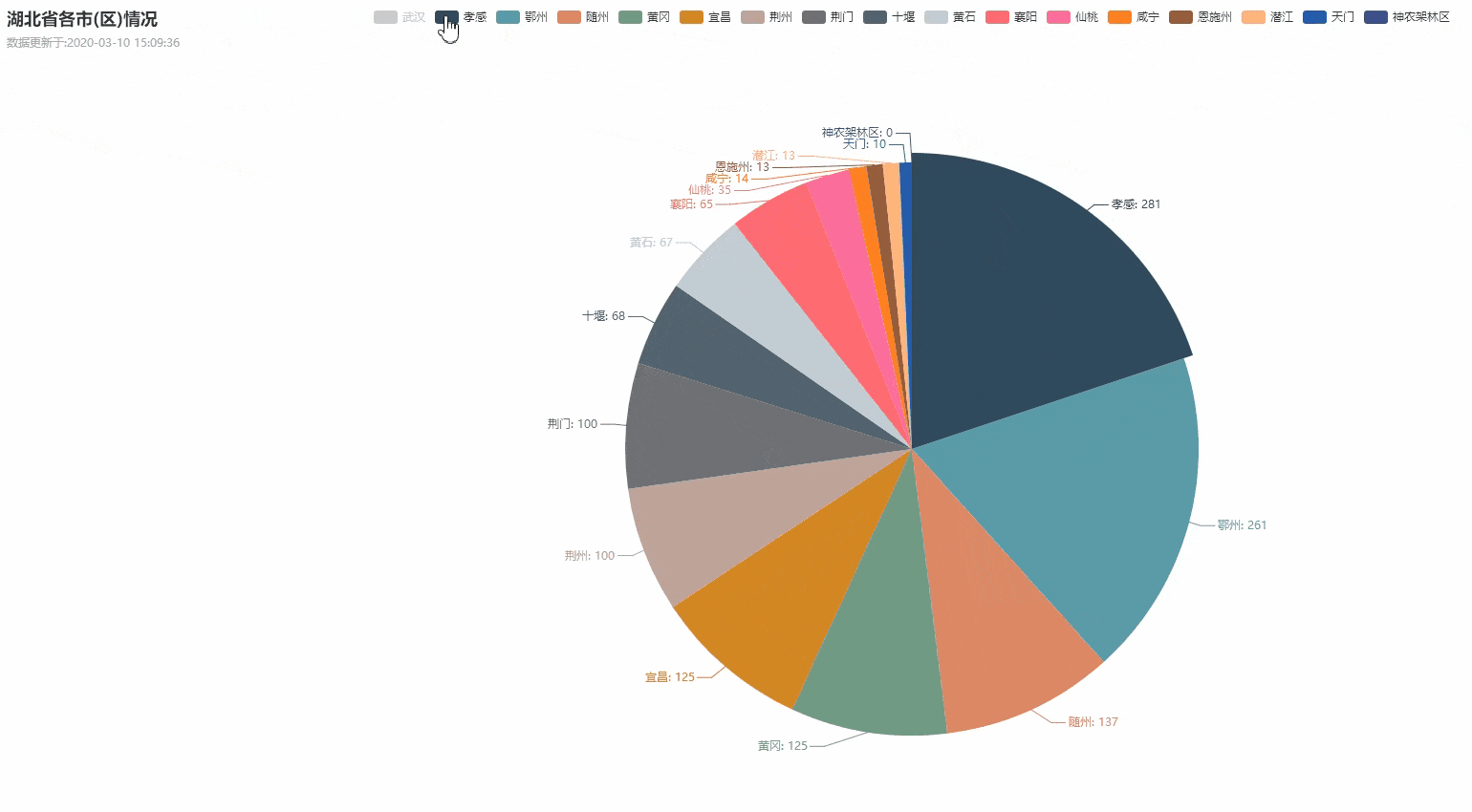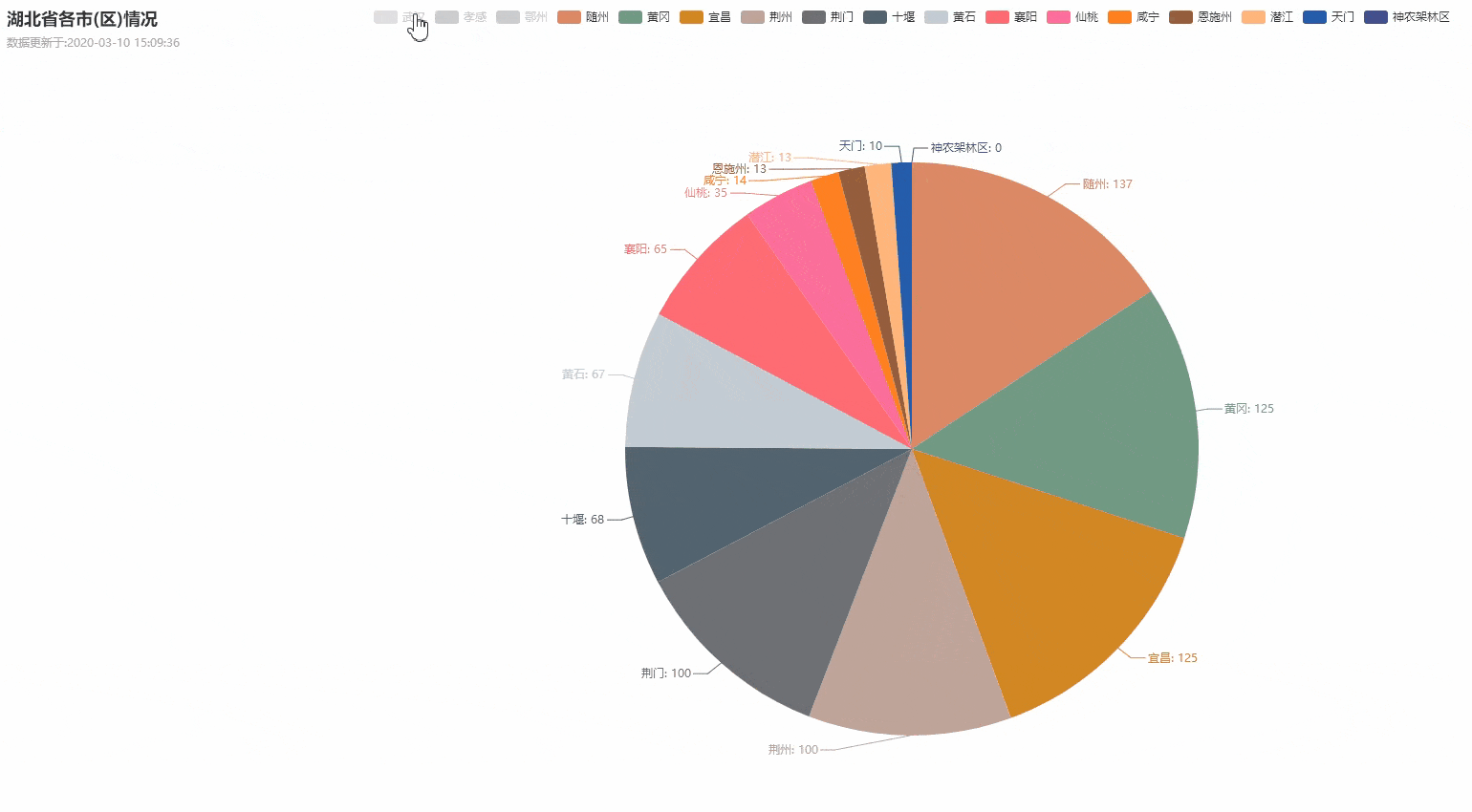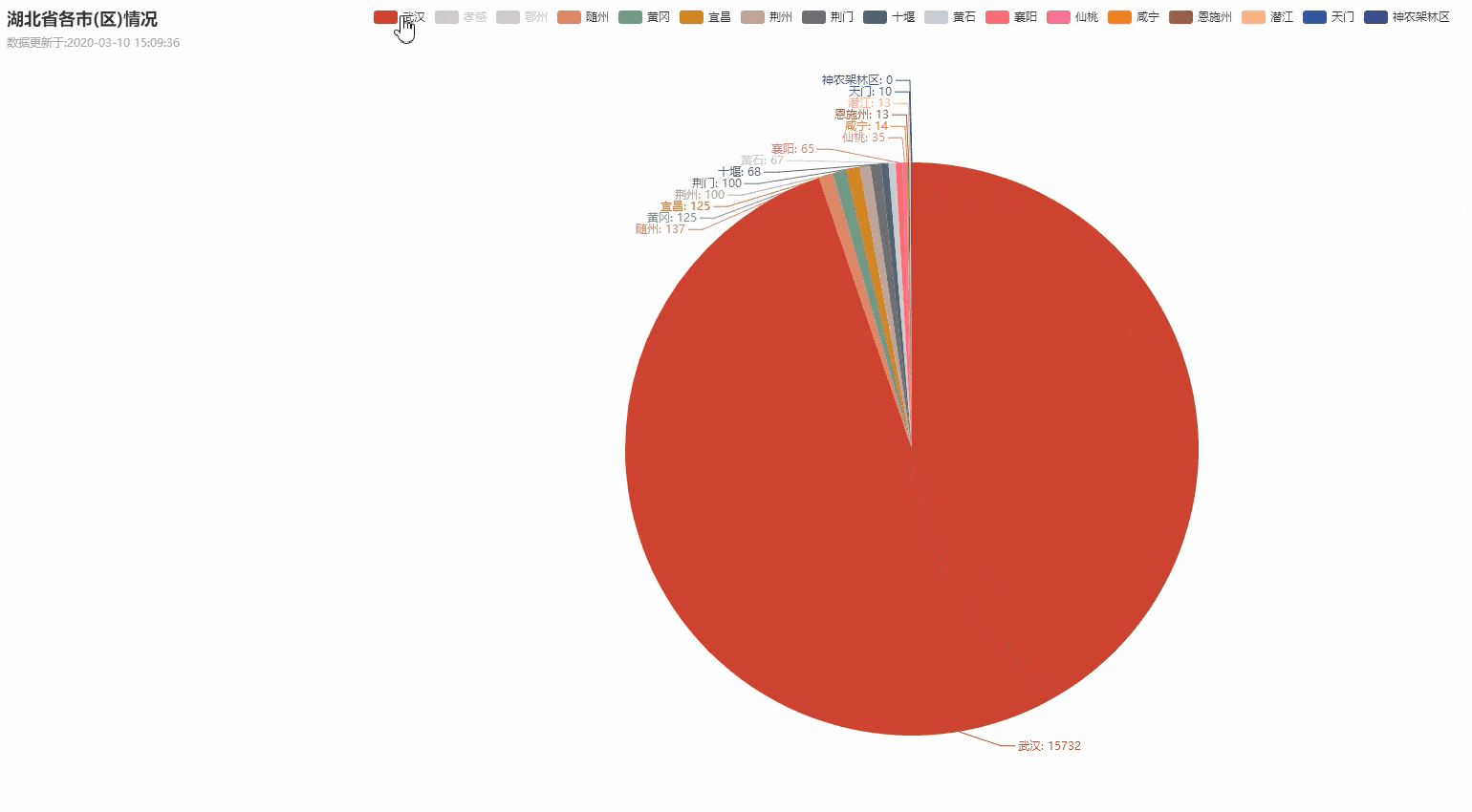
湖北省各城市疫情数据分布
目录
数据源分析:
数据来自丁香博士:
博士。丁香的数据如下图所示:


看到这里,你可能觉得应该直接把这个数据放到tr,td或者ul,li里面,直接发送请求,获取页面DOM中的文本就行了
一开始我也是这么想的,但是看了网页的源码后才发现不是-_-||


其实中国每个省份的数据都是存储在脚本标签中,id为getAreaStat,然后动态渲染到视图上。
所以我们要做的就是获取脚本标签中id为getAreaStat的文本
数据管理:
不难看出script标签中的数据是以json的形式存储的。我们验证和格式化 json 字符串并组织其中的数据。

左边的密集数据格式化后,很直观的看到json字符串的内部存储,大致如下:在整个json字符串中,每个province是一个dict,每个province里面的city省是一个子列表存储该省的城市数据。
代码部分代码中要使用的第三方库如下:一、抓取全国各省疫情信息,生成csv文件基本
1.代码分析:

2.源码:
import requests
from pyquery import PyQuery as pq
import json
import pandas as pd
import time
def get_data():
url = "https://ncov.dxy.cn/ncovh5/view/pneumonia"
response = requests.get(url)
if response.status_code == 200:
response.encoding = "utf-8"
dom = pq(response.content)
data = dom("script#getAreaStat").text().split(" = ")[1].split("}catch")[0]
jsonObj = json.loads(data) # json对象
print("数据抓取成功...")
province_data = []
for item in jsonObj:
dic = {"省全称": item["provinceName"], "省简称": item["provinceShortName"], "现存确诊人数": item["currentConfirmedCount"],
"累计确诊人数": item["confirmedCount"], "疑似人数": item["suspectedCount"], "治愈人数": item["curedCount"],
"死亡人数": item["deadCount"]}
province_data.append(dic)
if len(province_data) > 0:
print("写入数据...")
try:
df = pd.DataFrame(province_data)
time_format = time.strftime("%Y-%m-%d_%H_%M_%S", time.localtime())
df.to_csv(time_format + "全国各省疫情数据.csv", encoding="gbk", index=False)
print("写入成功...")
except Exception as e:
print(f"写入失败....{e}")
if __name__ == '__main__':
get_data()
3.运行效果:


二、用pyecharts绘制中国疫情地图,进阶
一说到画表,首先想到的就是Apache开源的echarts框架,有效又强大。因为不熟悉Matplotlib库,拿到数据后想用echarts框架的前端自己画一个,后来才知道有专门的pyecharts,很不错!
建议不了解echarts或pyecharts的同学先阅读官方API,了解基本图表类型和各种参数。 (⊙﹏⊙))哦!
1.代码分析:

2.源码:
"""
@File : data_chart.py
@Modify Time @Author @Version @Desciption
------------ ------- -------- -----------
2021/7/15 9:25 wrzcoder 1.0 None
"""
from pyecharts import options as opts
from pyecharts.charts import Map
import requests
from pyquery import PyQuery as pq
import json
import time
def map_visual_map() -> Map:
c = (
Map(init_opts=opts.InitOpts(page_title="中国疫情地图"))
.add("现存确诊人数", data_pair=list(current_data_dic.items()), maptype="china")
.set_global_opts(
title_opts=opts.TitleOpts(title="中国疫情地图", subtitle="数据更新于" + time_format),
visualmap_opts=opts.VisualMapOpts(pieces=[
{"value": 0, "label": "无", "color": "#9AFF9A"},
{"min": 1, "max": 9, "label": "1~9", "color": "#FFCCCC"},
{"min": 10, "max": 99, "label": "10~99", "color": "#DB5A6B"},
{"min": 100, "max": 499, "label": "100~499", "color": "#FF6666"},
{"min": 500, "max": 999, "label": "500~999", "color": "#CC2929"},
{"min": 1000, "max": 9999, "label": "1000~9999", "color": "#8C0D0D"},
{"min": 10000, "label": ">10000", "color": "#9d2933"}
], is_piecewise=True),
)
)
return c
if __name__ == '__main__':
try:
url = "https://ncov.dxy.cn/ncovh5/view/pneumonia"
response = requests.get(url)
if response.status_code == 200:
response.encoding = "utf-8"
dom = pq(response.content)
data = dom("script#getAreaStat").text().split(" = ")[1].split("}catch")[0]
jsonObj = json.loads(data) # json对象
print("数据抓取成功...")
current_data_dic = {}
time_format = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
for item in jsonObj:
current_data_dic[item["provinceShortName"]] = item["currentConfirmedCount"]
print(list(current_data_dic.items()))
map_visual_map().render("疫情地图.html")
print('疫情地图已生成在项目根目录...')
except Exception as e:
print(e)
3.运行效果:

三、采集全国各省市的疫情数据,进行数据可视化扩展
上面我们只用到了各个省的数据,而且在分析之初,各个省的dict中还收录了该省的市(区)的数据,我们不能浪费这些数据,我们可以抓取它。为了充分利用它们,我们对全国各省市的所有疫情数据进行了分类和可视化。
这里我想说的是:我们在可视化每个省(直辖市)以下市(区)的疫情数据时,也可以使用pyecharts中的Map,但是为了更加熟悉pyecharts,我们会改这里的表格类型饼图。
看起来很麻烦。求各省的数据,包括城市,最后画个图,太麻烦了。太麻烦了,不过不是(*^▽^*)就30行代码
1.代码分析

2.源码
"""
@File : province_data_chart.py
@Modify Time @Author @Version @Desciption
------------ ------- -------- -----------
2021/7/15 9:45 wrzcoder 1.0 None
"""
import requests
import json
from pyecharts.charts import Pie
import pyecharts.options as opts
import time
from pyquery import PyQuery as pq
import os
def create_Pie(provinceName, dic_citys) -> Pie:
c = (
Pie(init_opts=opts.InitOpts(width="100%", height="800px", page_title=provinceName + "各市(区)情况"))
.add("", data_pair=list(dic_citys.items()), center=["50%", "58%"], )
.set_global_opts(title_opts=opts.TitleOpts(title=provinceName + "各市(区)情况", subtitle="数据更新于:" + timeformat))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
if not os.path.exists('./中国各省情况'):
os.mkdir('./中国各省情况')
c.render("./中国各省情况/" + provinceName + "各市(区)情况.html")
if __name__ == '__main__':
try:
url = "https://ncov.dxy.cn/ncovh5/view/pneumonia"
timeformat = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
response = requests.get(url)
response.encoding = "utf-8"
if response.status_code == 200:
print("数据抓取成功!")
dom = pq(response.text)
jsonobj = json.loads(dom("script#getAreaStat").text().split(" = ")[1].split("}catch")[0])
for province in jsonobj:
dic_city = {}
for city in province["cities"]:
dic_city[city["cityName"]] = city["currentConfirmedCount"]
if dic_city.__len__() > 0:
create_Pie(province["provinceName"], dic_city)
print(province["provinceName"] + "各市数据汇总完毕!")
except Exception as e:
print(e)
3.运行效果:
短短1.1s,我们爬取了全国所有省市的疫情数据,整理生成数据图表


打开随机饼图查看效果:

四川省各城市疫情数据汇总
至此,我们完成了全国各省市疫情实时数据的采集和处理,还绘制了中国疫情地图。在此基础上,我们进一步扩展,对中国各省、自治区、直辖市的疫情数据进行了批量整理和可视化。期间复习了requests库、pandas、pyquery库等,同时也学习和学习了强大的图表绘制pyecharts库,可以说是收获颇丰!因此,在这里一起分享和学习!
最后,加油武汉,加油中国!疫情终将过去,春天终将到来!
图片来自网络
希望你下次运行这段代码时,看到的疫情图是这样的:

python网页数据抓取(Python1.方法简介及安装教程运行结果结果分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2022-02-13 17:12
1.方法介绍
在python3中从下载的网页中抓取数据主要有三种方式,分别是正则表达式、BeautifulSoup和Lxml。这三种方法各有特点。
正则表达式,也称为正则表达式。(英文:Regular Expression,在代码中常缩写为regex、regexp或RE),计算机科学中的一个概念。常规表通常用于检索和替换与特定模式(规则)匹配的文本。
BeautifulSoup 是一个用 Python 编写的 HTML/XML 解析器,可以很好地处理非标准标签并生成解析树。它提供了用于导航、搜索和修改解析树的简单而常用的操作。它可以大大节省您的编程时间。(安装教程传送门)
Lxml 是基于 XML 解析库 libxml2 的 Python 包装器。模块用C语言编写,解析速度比BeautifulSoup快,但安装过程也比较复杂。
2.性能对比代码
import time
import re
from bs4 import BeautifulSoup
import lxml.html
from urllib import request
def download(url, user_agent="wsap", num=2):
print("Downloading:"+url)
try:
req = request.Request(url)
req.add_header('user_agent', user_agent)
html = request.urlopen(req).read()
except Exception as e:
print('Download error:')
html = None
if num > 0:
if hasattr(e, "code") and 500 tr#places_{}__row > td.w2p_fw'.format(field))[0].text_content()
return results
NUM_LTERATION = 1000
html_copy = download('http://example.webscraping.com ... %2339;)
for name, scraper in [('Regular expressions', re_scraper),
('BeautifulSoup', beautiful_soup_scraper),
('Lxml', lxml_scraper)]:
start = time.time()
for i in range(NUM_LTERATION):
if scraper == re_scraper:
re.purge()
result = scraper(html_copy)
assert(result['area'] == '244,820 square kilometres')
end = time.time()
print('%s: %.2f seconds' % (name, end - start))
3.运行结果
4.结果分析
如果您的爬虫的瓶颈是下载页面,而不是提取数据,那么使用较慢的方法(如 BeautifulSoup)不是问题。如果你只需要抓取少量数据并想避免额外的依赖,那么正则表达式可能更合适。但是,lxml 通常是抓取数据的最佳选择,因为它快速且健壮,而正则表达式和 BeautifulSoup 仅在某些情况下有用。 查看全部
python网页数据抓取(Python1.方法简介及安装教程运行结果结果分析)
1.方法介绍
在python3中从下载的网页中抓取数据主要有三种方式,分别是正则表达式、BeautifulSoup和Lxml。这三种方法各有特点。
正则表达式,也称为正则表达式。(英文:Regular Expression,在代码中常缩写为regex、regexp或RE),计算机科学中的一个概念。常规表通常用于检索和替换与特定模式(规则)匹配的文本。
BeautifulSoup 是一个用 Python 编写的 HTML/XML 解析器,可以很好地处理非标准标签并生成解析树。它提供了用于导航、搜索和修改解析树的简单而常用的操作。它可以大大节省您的编程时间。(安装教程传送门)
Lxml 是基于 XML 解析库 libxml2 的 Python 包装器。模块用C语言编写,解析速度比BeautifulSoup快,但安装过程也比较复杂。
2.性能对比代码
import time
import re
from bs4 import BeautifulSoup
import lxml.html
from urllib import request
def download(url, user_agent="wsap", num=2):
print("Downloading:"+url)
try:
req = request.Request(url)
req.add_header('user_agent', user_agent)
html = request.urlopen(req).read()
except Exception as e:
print('Download error:')
html = None
if num > 0:
if hasattr(e, "code") and 500 tr#places_{}__row > td.w2p_fw'.format(field))[0].text_content()
return results
NUM_LTERATION = 1000
html_copy = download('http://example.webscraping.com ... %2339;)
for name, scraper in [('Regular expressions', re_scraper),
('BeautifulSoup', beautiful_soup_scraper),
('Lxml', lxml_scraper)]:
start = time.time()
for i in range(NUM_LTERATION):
if scraper == re_scraper:
re.purge()
result = scraper(html_copy)
assert(result['area'] == '244,820 square kilometres')
end = time.time()
print('%s: %.2f seconds' % (name, end - start))
3.运行结果

4.结果分析

如果您的爬虫的瓶颈是下载页面,而不是提取数据,那么使用较慢的方法(如 BeautifulSoup)不是问题。如果你只需要抓取少量数据并想避免额外的依赖,那么正则表达式可能更合适。但是,lxml 通常是抓取数据的最佳选择,因为它快速且健壮,而正则表达式和 BeautifulSoup 仅在某些情况下有用。
python网页数据抓取(网络爬虫提取出该网页中的新一轮URL的抓取环路)
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2022-02-13 11:15
一般我们要爬取一个网站的所有URL,先传递起始URL,然后通过网络爬虫提取网页中所有的URL链接,然后对每一个提取的URL进行爬取,提取新一轮的URL在每个网页中,依此类推。总体感觉是网页中的链接是从上到下爬的。理论上,整个站点的所有链接都可以被爬取。但是问题来了,一个指向 网站 中网页的链接是循环的。
比如在网站首页,我们可以看到首页链接,那么我们也可能在子页面中看到指向首页的链接,在子子页面。首页。按照我们之前的逻辑,爬取每个页面中的所有链接,然后继续爬取所有链接。以首页为例,我们首先抓取的就是它,然后子页面中有指向首页的链接,子子页面有指向首页的链接。如果进行这个爬取,会不会造成网页的重复爬取,而其他的网页根本没有机会爬取。我无法想象。解决这个问题并不难。这时候,我们就需要用到网络爬虫中的一个重要知识点,那就是网页去重。
首先介绍一个简单的思路,这也是一个经常使用的通用思路。我们将抓取的网页放入一个列表中。以首页为例。当主页被爬取时,我们将主页放在列表中。那么我们在爬取子页面的时候,如果再遇到首页,并且首页已经被爬取过了。这时候可以跳过首页,继续爬取其他页面,避免重复爬取首页的情况。这样,爬取整个站点的时候就不会出现循环。路。以此思路为出发点,将访问过的URL保存在数据库中,当获取到下一个URL时,在数据库中检查该URL是否被访问过。虽然数据库有缓存,但是当在数据库中查询每个URL时,效率会迅速下降,
第二种方法是将访问过的 URL 保存在集合中。这种方式获取url的速度非常快,基本不需要查询。然而,这种方法有一个缺点。将 URL 保存到集合实际上是将其保存到内存中。当 URL 数据量很大(比如 1 亿)时,内存压力会增加。对于小型爬虫来说,这种方法是非常可取的,但对于大型网络爬虫来说,这种方法很难实现。
第三种方式是对字符进行md5编码,可以将字符缩减到固定长度。一般来说,md5编码的长度在128bit左右,也就是16byte左右。在不缩减之前,假设一个URL占用的内存大小为50字节,1字节等于2字节,也就是100字节。可以看出,经过md5编码后,节省了大量的内存空间。通过md5方法,可以将任意长度的URL压缩成相同长度的md5字符串,不会出现重复,达到去重的效果。这样在很大程度上节省了内存。scrapy框架采用的方法有点类似于md5的方法。因此,正常情况下,即使 URL 数量达到数亿,scrapy占用的内存比set方法小。少得多。
第四种方法是使用位图方法进一步压缩字符。这种方法是指在计算机中申请8位,即8位,每个位用0或1表示,是计算机中的最小单位。8个比特组成1个字节,如果一个比特代表一个URL,为什么一个比特可以确定一个URL?因为我们可以对 URL 执行哈希函数,然后将其映射到位。例如,假设我们有8个URL,分别对应8个比特,然后通过比特上面的0和1的状态,我们可以指示URL是否存在,这个方法可以进一步压缩内存。
但是bitmap方式有一个非常大的缺点,就是它的冲突会非常高,因为使用了同一个hash函数,很有可能将两个不同的URL或者多个不同的URL映射到一个位置。其实这个hash方法也是set方法的一种实现原理。它对 URL 进行函数计算,然后将其映射到位位置,因此这种方法非常压缩内存。简单计算,还是用1亿个URL来计算,相当于1亿比特。通过计算,相当于12500000字节。除以 1024 后大约是 12207KB,也就是大约 12MB 的空间。在实际过程中,内存占用可能会大于12MB,但即便如此,与前面三种方式相比,这种方式还是大大减少了内存占用。但同时,与这种方法发生冲突的可能性非常高,所以这种方法不是很适合。那么有没有什么办法可以进一步优化bitmap这种重内存压缩的方法,减少冲突的可能性呢?答案是肯定的,这是第五种方式。
第五种方式是bloomfilter,通过多个hash函数减少冲突的可能性来改进位图。这样,一方面可以通过位图的方式达到减少内存的效果,另一方面也可以减少冲突。关于bloomfilter的原理和实现,后面我一定会介绍给大家。今天,让大家有个简单的认识。Bloomfilter适用于大型网络爬虫,尤其是数量级超大时,bloomfilter方法可以事半功倍,并且经常配合分布式爬虫达到爬取的目的。
网页爬取过程中的五种去重策略方法的介绍就先到这里了。如果你不明白,你应该明白。普及后,问题不大。希望对小伙伴的学习有所帮助。
有小伙伴提到,以上5种方法只适用于单进程条件。如果是多进程,则需要设置pipeline进行信息交换,也可以直接设置pipeline而不是set。感谢这位不愿露面的大佬~~ 查看全部
python网页数据抓取(网络爬虫提取出该网页中的新一轮URL的抓取环路)
一般我们要爬取一个网站的所有URL,先传递起始URL,然后通过网络爬虫提取网页中所有的URL链接,然后对每一个提取的URL进行爬取,提取新一轮的URL在每个网页中,依此类推。总体感觉是网页中的链接是从上到下爬的。理论上,整个站点的所有链接都可以被爬取。但是问题来了,一个指向 网站 中网页的链接是循环的。
比如在网站首页,我们可以看到首页链接,那么我们也可能在子页面中看到指向首页的链接,在子子页面。首页。按照我们之前的逻辑,爬取每个页面中的所有链接,然后继续爬取所有链接。以首页为例,我们首先抓取的就是它,然后子页面中有指向首页的链接,子子页面有指向首页的链接。如果进行这个爬取,会不会造成网页的重复爬取,而其他的网页根本没有机会爬取。我无法想象。解决这个问题并不难。这时候,我们就需要用到网络爬虫中的一个重要知识点,那就是网页去重。
首先介绍一个简单的思路,这也是一个经常使用的通用思路。我们将抓取的网页放入一个列表中。以首页为例。当主页被爬取时,我们将主页放在列表中。那么我们在爬取子页面的时候,如果再遇到首页,并且首页已经被爬取过了。这时候可以跳过首页,继续爬取其他页面,避免重复爬取首页的情况。这样,爬取整个站点的时候就不会出现循环。路。以此思路为出发点,将访问过的URL保存在数据库中,当获取到下一个URL时,在数据库中检查该URL是否被访问过。虽然数据库有缓存,但是当在数据库中查询每个URL时,效率会迅速下降,
第二种方法是将访问过的 URL 保存在集合中。这种方式获取url的速度非常快,基本不需要查询。然而,这种方法有一个缺点。将 URL 保存到集合实际上是将其保存到内存中。当 URL 数据量很大(比如 1 亿)时,内存压力会增加。对于小型爬虫来说,这种方法是非常可取的,但对于大型网络爬虫来说,这种方法很难实现。
第三种方式是对字符进行md5编码,可以将字符缩减到固定长度。一般来说,md5编码的长度在128bit左右,也就是16byte左右。在不缩减之前,假设一个URL占用的内存大小为50字节,1字节等于2字节,也就是100字节。可以看出,经过md5编码后,节省了大量的内存空间。通过md5方法,可以将任意长度的URL压缩成相同长度的md5字符串,不会出现重复,达到去重的效果。这样在很大程度上节省了内存。scrapy框架采用的方法有点类似于md5的方法。因此,正常情况下,即使 URL 数量达到数亿,scrapy占用的内存比set方法小。少得多。
第四种方法是使用位图方法进一步压缩字符。这种方法是指在计算机中申请8位,即8位,每个位用0或1表示,是计算机中的最小单位。8个比特组成1个字节,如果一个比特代表一个URL,为什么一个比特可以确定一个URL?因为我们可以对 URL 执行哈希函数,然后将其映射到位。例如,假设我们有8个URL,分别对应8个比特,然后通过比特上面的0和1的状态,我们可以指示URL是否存在,这个方法可以进一步压缩内存。
但是bitmap方式有一个非常大的缺点,就是它的冲突会非常高,因为使用了同一个hash函数,很有可能将两个不同的URL或者多个不同的URL映射到一个位置。其实这个hash方法也是set方法的一种实现原理。它对 URL 进行函数计算,然后将其映射到位位置,因此这种方法非常压缩内存。简单计算,还是用1亿个URL来计算,相当于1亿比特。通过计算,相当于12500000字节。除以 1024 后大约是 12207KB,也就是大约 12MB 的空间。在实际过程中,内存占用可能会大于12MB,但即便如此,与前面三种方式相比,这种方式还是大大减少了内存占用。但同时,与这种方法发生冲突的可能性非常高,所以这种方法不是很适合。那么有没有什么办法可以进一步优化bitmap这种重内存压缩的方法,减少冲突的可能性呢?答案是肯定的,这是第五种方式。
第五种方式是bloomfilter,通过多个hash函数减少冲突的可能性来改进位图。这样,一方面可以通过位图的方式达到减少内存的效果,另一方面也可以减少冲突。关于bloomfilter的原理和实现,后面我一定会介绍给大家。今天,让大家有个简单的认识。Bloomfilter适用于大型网络爬虫,尤其是数量级超大时,bloomfilter方法可以事半功倍,并且经常配合分布式爬虫达到爬取的目的。
网页爬取过程中的五种去重策略方法的介绍就先到这里了。如果你不明白,你应该明白。普及后,问题不大。希望对小伙伴的学习有所帮助。
有小伙伴提到,以上5种方法只适用于单进程条件。如果是多进程,则需要设置pipeline进行信息交换,也可以直接设置pipeline而不是set。感谢这位不愿露面的大佬~~
python网页数据抓取(如何用Python写爬虫网页数据机器学习(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2022-02-11 04:04
如何爬取网页数据,说到数据分析,可能需要使用爬虫爬取数据进行汇总分析,但是你知道爬虫很容易导致IP被封,同一个IP访问同一个< @网站 太多了,会被反爬虫限制。这时候就需要用到爬虫了: 几种提取网页数据的方法1、美汤2、Pyquery3、正则表达式4、scrapy自己的数据提取方法Selector(selector ) Selector 是基于 lxml 构建的,支持。
如何使用爬虫抓取数据的介绍工具/原材料 Python 3.0 requests library bs4 library 一般步骤1 比如我上手爬虫(五)获取整个HTML的功能网页在爬取网页数据之前已经实现,在获取HTML的基础上,增加了一些如:下载错误自动重试、用户代理、服务器代理、爬取深度、避免重爬、id遍历、链式。
<p>∪▽∪如何使用Python编写爬虫爬取网页数据机器学习面临的首要问题之一是准备数据。数据来源大概有几个:公司积累的数据、采购、交易所的数据,政府机构和企业披露的数据,以及通过爬虫从网上抓取的数据。在这篇文章中,对于爬虫,我们首先想到的是python,但是对于前端,我们通常使用node来编写爬虫,抓取 查看全部
python网页数据抓取(如何用Python写爬虫网页数据机器学习(组图))
如何爬取网页数据,说到数据分析,可能需要使用爬虫爬取数据进行汇总分析,但是你知道爬虫很容易导致IP被封,同一个IP访问同一个< @网站 太多了,会被反爬虫限制。这时候就需要用到爬虫了: 几种提取网页数据的方法1、美汤2、Pyquery3、正则表达式4、scrapy自己的数据提取方法Selector(selector ) Selector 是基于 lxml 构建的,支持。
如何使用爬虫抓取数据的介绍工具/原材料 Python 3.0 requests library bs4 library 一般步骤1 比如我上手爬虫(五)获取整个HTML的功能网页在爬取网页数据之前已经实现,在获取HTML的基础上,增加了一些如:下载错误自动重试、用户代理、服务器代理、爬取深度、避免重爬、id遍历、链式。
<p>∪▽∪如何使用Python编写爬虫爬取网页数据机器学习面临的首要问题之一是准备数据。数据来源大概有几个:公司积累的数据、采购、交易所的数据,政府机构和企业披露的数据,以及通过爬虫从网上抓取的数据。在这篇文章中,对于爬虫,我们首先想到的是python,但是对于前端,我们通常使用node来编写爬虫,抓取
python网页数据抓取(如何独立写出爬虫真不是件简单的事情?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-02-11 01:07
作为一个刚接触python的新手,独立写一个爬虫是不容易的。首先要学会各种包的管理,还要了解爬取网页数据最基本的技术。以下是我在学习时记录的一些内容。
一、了解与 网站 链接时要使用的包
与网站交互,熟悉python下与网页相关的urllib,或urllib2,或httplib包。这三个是python提供的与网页交互的基本模块,还有其他的,比如:mechanize
斗志昂扬。
二、解析网页
我在网上搜索了一些网页,知道了一些基本的方法。
(1)正则表达式。正则表达式很有用。熟悉它们可以节省很多时间。有时你不需要写脚本或查询数据库来清理数据。你可以直接在notepad++上使用正则表达式.
学习正则表达式链接:
(2) BeautifulSoup 模块。BeautifulSoup 是一个非常强大的模块,可以将 html 文件解析成一个对象,也就是一棵树。html 文件是树状的,比如 body -> table -> tbody -> tr,对于
节点 tbody 有许多 tr 的子节点。BeautifulSoup 可以很方便的获取特定节点,也可以针对单个节点获取其兄弟节点。
三、捕获数据
你可以把采集到的数据放到一个txt文件中,这是最基本的方法。当然,你也可以直接连接数据库而不是写入txt文件。python中的MySQLdb模块可以与MySQL数据库进行通信。
与 MySQL 数据库建立链接的逻辑与与 网站 服务器建立链接的逻辑类似。如果你之前学过数据库,那么学习使用 MySQLdb 模块与数据库交互是
这很简单;如果没有,则需要使用 coursera\stanford openEdX 平台上打开的 Introduction to Database 进行系统学习,w3school 作为参考或作为手册使用。
以上是我在学习的时候做的一些小笔记,也有一些借鉴别人的想法。具体代码还有待完善,会在下一篇学习笔记中更新。 查看全部
python网页数据抓取(如何独立写出爬虫真不是件简单的事情?-八维教育)
作为一个刚接触python的新手,独立写一个爬虫是不容易的。首先要学会各种包的管理,还要了解爬取网页数据最基本的技术。以下是我在学习时记录的一些内容。
一、了解与 网站 链接时要使用的包
与网站交互,熟悉python下与网页相关的urllib,或urllib2,或httplib包。这三个是python提供的与网页交互的基本模块,还有其他的,比如:mechanize
斗志昂扬。
二、解析网页
我在网上搜索了一些网页,知道了一些基本的方法。
(1)正则表达式。正则表达式很有用。熟悉它们可以节省很多时间。有时你不需要写脚本或查询数据库来清理数据。你可以直接在notepad++上使用正则表达式.
学习正则表达式链接:
(2) BeautifulSoup 模块。BeautifulSoup 是一个非常强大的模块,可以将 html 文件解析成一个对象,也就是一棵树。html 文件是树状的,比如 body -> table -> tbody -> tr,对于
节点 tbody 有许多 tr 的子节点。BeautifulSoup 可以很方便的获取特定节点,也可以针对单个节点获取其兄弟节点。
三、捕获数据
你可以把采集到的数据放到一个txt文件中,这是最基本的方法。当然,你也可以直接连接数据库而不是写入txt文件。python中的MySQLdb模块可以与MySQL数据库进行通信。
与 MySQL 数据库建立链接的逻辑与与 网站 服务器建立链接的逻辑类似。如果你之前学过数据库,那么学习使用 MySQLdb 模块与数据库交互是
这很简单;如果没有,则需要使用 coursera\stanford openEdX 平台上打开的 Introduction to Database 进行系统学习,w3school 作为参考或作为手册使用。
以上是我在学习的时候做的一些小笔记,也有一些借鉴别人的想法。具体代码还有待完善,会在下一篇学习笔记中更新。
python网页数据抓取(python抓取网页数据.txt51自信是永不枯竭的源泉,自信)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-02-22 09:14
Python爬取网页数据.txt51 自信是取之不尽的源泉,自信是无穷无尽的浪潮,自信是快速进步的通道,自信是真正成功之母。使用python抓取页面并处理 2009-02-19 15:09:50| 分类:Python 标签:无|字号订阅 主要用途:抓取网页的源代码,处理其中需要的数据,并存入数据库。已经实现了爬取页面和读取数据。Step 一、 爬取页面,这一步很简单,导入urllib,使用urlopen打开URL,使用read()方法读取数据。为了方便测试,使用本地文本文件代替爬取网页二、的步骤来处理数据。如果页面代码比较规范,可以使用HTMLParser进行简单的处理,但具体情况需要详细分析,我觉得还是用正则表达式比较好。顺便练习一下刚刚学过的正则表达式。其实正则也是一种比较简单的语言,符号很多,有点晦涩难懂。只能多练多练。三、这一步将处理后的数据保存到数据库中,可以用pymssql处理。在这里,它只是保存到一个文本文件中。通过扩展,该功能还可用于截取整个网站图片,自动认领sitemap文件等功能。下一个任务,研究python的socket函数importurllib import re #pager=urllib.urlopen() #data=pager.read() #pager.close() f=open(r"D:\2.txt" ) data =f。 查看全部
python网页数据抓取(python抓取网页数据.txt51自信是永不枯竭的源泉,自信)
Python爬取网页数据.txt51 自信是取之不尽的源泉,自信是无穷无尽的浪潮,自信是快速进步的通道,自信是真正成功之母。使用python抓取页面并处理 2009-02-19 15:09:50| 分类:Python 标签:无|字号订阅 主要用途:抓取网页的源代码,处理其中需要的数据,并存入数据库。已经实现了爬取页面和读取数据。Step 一、 爬取页面,这一步很简单,导入urllib,使用urlopen打开URL,使用read()方法读取数据。为了方便测试,使用本地文本文件代替爬取网页二、的步骤来处理数据。如果页面代码比较规范,可以使用HTMLParser进行简单的处理,但具体情况需要详细分析,我觉得还是用正则表达式比较好。顺便练习一下刚刚学过的正则表达式。其实正则也是一种比较简单的语言,符号很多,有点晦涩难懂。只能多练多练。三、这一步将处理后的数据保存到数据库中,可以用pymssql处理。在这里,它只是保存到一个文本文件中。通过扩展,该功能还可用于截取整个网站图片,自动认领sitemap文件等功能。下一个任务,研究python的socket函数importurllib import re #pager=urllib.urlopen() #data=pager.read() #pager.close() f=open(r"D:\2.txt" ) data =f。
python网页数据抓取( 2020年03月16日08:49:43作者:5sh)
网站优化 • 优采云 发表了文章 • 0 个评论 • 86 次浏览 • 2022-02-21 22:00
2020年03月16日08:49:43作者:5sh)
Django从html页面表单获取输入数据的例子
更新时间:2020-03-16 08:49:43 作者:5sh
这篇文章主要介绍了Django从html页面表单获取输入数据的例子,有很好的参考价值,希望对大家有所帮助。跟我来看看
本文主要讲解如何获取用户在html页面中输入的信息。
1.先写一个自定义的html页面
登录.html
test
form表单中的action{%url 'check'%}对应urls.py中的name值
2.配置urls.py文件
urlpatterns = [
path('reg/',views.reg,name='check'),
path('',views.login),
]
3.配置views.py文件
def login(request):
return render(request,'login.html')
def reg(request):
if request.method == 'POST':
name=request.POST.get('name')
pwd=request.POST.get('pwd')
print(name,pwd)
return render(request,'login.html')
4.打开服务,进入首页localhost:8000,输入用户名和密码,点击提交
这时候会报403错误
您需要在 login.html 文件中的表单表单中添加以下代码行
{%csrf_token%}
{% csrf_token %}
重启服务,再次输入用户名和密码
可以获取页面输入的信息
上面django从html页面表单获取的输入数据的例子就是编辑器共享的所有内容。希望能给大家一个参考,也希望大家多多支持脚本之家。 查看全部
python网页数据抓取(
2020年03月16日08:49:43作者:5sh)
Django从html页面表单获取输入数据的例子
更新时间:2020-03-16 08:49:43 作者:5sh
这篇文章主要介绍了Django从html页面表单获取输入数据的例子,有很好的参考价值,希望对大家有所帮助。跟我来看看
本文主要讲解如何获取用户在html页面中输入的信息。
1.先写一个自定义的html页面
登录.html
test
form表单中的action{%url 'check'%}对应urls.py中的name值
2.配置urls.py文件
urlpatterns = [
path('reg/',views.reg,name='check'),
path('',views.login),
]
3.配置views.py文件
def login(request):
return render(request,'login.html')
def reg(request):
if request.method == 'POST':
name=request.POST.get('name')
pwd=request.POST.get('pwd')
print(name,pwd)
return render(request,'login.html')
4.打开服务,进入首页localhost:8000,输入用户名和密码,点击提交
这时候会报403错误
您需要在 login.html 文件中的表单表单中添加以下代码行
{%csrf_token%}
{% csrf_token %}
重启服务,再次输入用户名和密码
可以获取页面输入的信息
上面django从html页面表单获取的输入数据的例子就是编辑器共享的所有内容。希望能给大家一个参考,也希望大家多多支持脚本之家。
python网页数据抓取(通过Python访问网站的HTML代码获取特定的img标签中的图片地址 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 129 次浏览 • 2022-02-21 21:28
)
================爬虫原理====================
通过Python访问网站,获取网站的HTML代码,通过正则表达式获取特定img标签中src的图片地址。
之后,访问图片地址,通过IO操作将图片保存到本地。
================脚本代码====================
import urllib.request # 网络访问模块
import random # 随机数生成模块
import re # 正则表达式模块
import os # 目录结构处理模块
# 初始化配置参数
number = 10 # 图片收集数量
path = 'img/' # 图片存放目录
# 文件操作
if not os.path.exists(path):
os.makedirs(path)
# 图片保存
def save_img(url, path):
message = None
try:
file = open(path + os.path.basename(url), 'wb')
request = urllib.request.urlopen(url)
file.write(request.read())
except Exception as e:
message = str(e)
else:
message = os.path.basename(url)
finally:
if not file.closed:
file.close()
return message
# 网络连接
http = 'http://zerospace.asika.tw/photo/' # 目标网址
position = 290 + int((1000 - number) * random.random())
ids = range(position, position + number)
for id in ids:
try:
url = "%s%d.html" % (http, id) # 后缀生成
request = urllib.request.urlopen(url)
except Exception as e:
print(e)
continue
else:
buffer = request.read()
buffer = buffer.decode('utf8')
pattern = 'class="content-img".+\s+.+src="(.+\.jpg)"'
imgurl = re.findall(pattern, buffer) # 过滤规则
if len(imgurl) != 0:
print(save_img(imgurl[0], path))
else:
continue
pass
================运行结果====================
查看全部
python网页数据抓取(通过Python访问网站的HTML代码获取特定的img标签中的图片地址
)
================爬虫原理====================
通过Python访问网站,获取网站的HTML代码,通过正则表达式获取特定img标签中src的图片地址。
之后,访问图片地址,通过IO操作将图片保存到本地。
================脚本代码====================
import urllib.request # 网络访问模块
import random # 随机数生成模块
import re # 正则表达式模块
import os # 目录结构处理模块
# 初始化配置参数
number = 10 # 图片收集数量
path = 'img/' # 图片存放目录
# 文件操作
if not os.path.exists(path):
os.makedirs(path)
# 图片保存
def save_img(url, path):
message = None
try:
file = open(path + os.path.basename(url), 'wb')
request = urllib.request.urlopen(url)
file.write(request.read())
except Exception as e:
message = str(e)
else:
message = os.path.basename(url)
finally:
if not file.closed:
file.close()
return message
# 网络连接
http = 'http://zerospace.asika.tw/photo/' # 目标网址
position = 290 + int((1000 - number) * random.random())
ids = range(position, position + number)
for id in ids:
try:
url = "%s%d.html" % (http, id) # 后缀生成
request = urllib.request.urlopen(url)
except Exception as e:
print(e)
continue
else:
buffer = request.read()
buffer = buffer.decode('utf8')
pattern = 'class="content-img".+\s+.+src="(.+\.jpg)"'
imgurl = re.findall(pattern, buffer) # 过滤规则
if len(imgurl) != 0:
print(save_img(imgurl[0], path))
else:
continue
pass
================运行结果====================
python网页数据抓取(python爬虫简单概括获取网页数据(图)代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-02-21 20:17
文章目录
前言:python爬虫的简单总结其实就是获取网页数据,然后按需提取!过程虽然简单,但需要结合多种技术,掌握爬虫库,编写高效的爬虫代码。
一、先了解用户如何获取网络数据
1、用户使用浏览器:浏览器提交请求—>下载网页代码—>解析成页面
2、代码自动获取:模拟浏览器发送请求(获取网页代码html、css、javascript)->提取有用数据->存入数据库或文件
python爬虫使用代码自动获取。具体流程为:
二、简单了解网页源代码的构成1、web的基本编程语言
简单了解可以上菜鸟教程
1)HTML、CSS、JavaScript是Web开发者必须学习的3种语言。他们相互合作,形成了各种丰富的网站
(1)HTML 定义了网页的内容
(2)CSS 描述了页面的布局
(3)JavaScript 控制页面的行为
2)html5 简单示例
3)html 中的 javaScript
4)HTML 中的 CSS
2、使用浏览器查看网页源代码
1)网页右键查看源码(也就是我们要得到的)
2)html代码,这里需要我们稍微了解一下它的组成,然后根据内容提取出来
三、爬虫概述1、了解爬虫
我们熟悉的一系列搜索引擎都是大型网络爬虫,比如百度、搜狗、360浏览器、谷歌搜索等等。每个搜索引擎都有自己的爬虫。比如360浏览器的爬虫叫360Spider,搜狗的爬虫叫Sogospider。
2、python 爬虫
百度搜索引擎,其实可以更形象的叫做百度蜘蛛(Baiduspider),它每天都会从海量互联网信息中抓取优质信息,并进行收录。当用户通过百度搜索关键词时,百度会先分析用户输入的关键词,然后从收录的网页中找出相关的网页,并根据网页排名排名规则。排序,最后将排序后的结果呈现给用户。在这个过程中,百度蜘蛛发挥了非常重要的作用。
百度工程师为“百度蜘蛛”编写了相应的爬虫算法。通过应用这些算法,“百度蜘蛛”可以实现相应的搜索策略,如过滤掉重复网页、过滤优质网页等。应用不同的算法,爬虫的效率和爬取结果会有所不同。
3、爬虫分类
爬虫可以分为三类:一般网络爬虫、聚焦网络爬虫和增量网络爬虫。
1)万能网络爬虫:是搜索引擎的重要组成部分,上面已经介绍过了,这里不再赘述。一般网络爬虫需要遵守robots协议,网站告诉搜索引擎哪些页面可以爬,哪些页面不可以爬。
机器人协议:是一种“常规”协议,没有法律效力。体现了互联网人的“契约精神”。行业从业者会自觉遵守协议,故又称“君子协议”。
2)专注网络爬虫:是针对特定需求的网络爬虫程序。它与一般爬虫的区别在于,聚焦爬虫在实现网页爬虫时会对网页内容进行过滤处理,并尽量保证只抓取与需求相关的网页信息。专注于网络爬虫,大大节省了硬件和网络资源。由于保存的页面少,所以更新速度很快,也满足了一些特定人群对特定领域信息的需求。
3)增量网络爬虫:指对下载的网页进行增量更新。它是一种只抓取新生成或更改的网页的爬虫程序,可以在一定程度上保证抓取到的网页。获取的页面是最新的页面。
4、爬虫应用
随着互联网的飞速发展,万维网已经成为海量信息的载体。如何有效地提取和利用这些信息已成为一个巨大的挑战。于是,爬虫应运而生。它不仅可以用于搜索引擎领域,还可以用于大数据分析,并在商业领域得到了大规模应用。
1) 数据分析
在数据分析领域,网络爬虫通常是采集海量数据的必备工具。对于数据分析师来说,要进行数据分析,首先要有数据源,通过学习爬虫,可以获得更多的数据源。在采集过程中,数据分析师可以根据自己的目的采集更多有价值的数据,并过滤掉那些无效数据。
2) 业务
对于企业来说,及时获取市场动态和产品信息非常重要。企业可以通过第三方平台购买数据,比如贵阳大数据交易所、数据堂等。当然,如果贵公司有爬虫工程师,也可以通过爬虫获取想要的信息。
5、爬行动物是一把双刃剑
爬虫是一把双刃剑,它给我们带来便利的同时,也给网络安全带来隐患。一些不法分子利用爬虫非法采集互联网上的网友信息,或者利用爬虫恶意攻击他人网站,造成网站瘫痪的严重后果。关于爬虫的合法使用,建议阅读《中华人民共和国网络安全法》。
6、python爬虫教程
为了限制爬虫带来的危险,大部分网站都有很好的反爬措施,所以在使用爬虫的时候一定要自觉遵守约定,不要非法获取他人信息,或者做对他人有害的事情。其他网站 的事情。
为什么使用 Python 作为爬虫
首先你要清楚,不仅Python可以做爬虫,PHP、Java、C/C++等都可以用来写爬虫程序,但是Python做爬虫是最简单的。以下是它们的优缺点的简要比较:
PHP:对多线程和异步的支持不是很好,并发处理能力较弱;Java也常用于编写爬虫程序,但Java语言本身非常繁琐,代码量大,对初学者入门门槛较高;尽管 C/C++ 运行效率很高,但学习和开发的成本很高。编写一个小型爬虫可能需要很长时间。
Python语言语法优美,代码简洁,开发效率高,支持多种爬虫模块,如urllib、requests、Bs4等。Python的request模块和解析模块丰富成熟,还提供了强大的Scrapy框架使编写爬虫程序更容易。因此,使用 Python 编写爬虫程序是一个非常不错的选择。
7、爬虫的编写过程
爬虫程序与其他程序不同,它的思维逻辑大体相似,所以我们不需要在逻辑上花很多时间。下面简单介绍一下用Python编写爬虫程序的过程:
首先通过urllib模块的request方法打开URL,获取网页的HTML对象。
使用浏览器打开网页源代码,分析网页结构和元素节点。
通过 Beautiful Soup 或正则表达式提取数据。
将数据存储到本地磁盘或数据库。
当然,不限于上述一种过程。编写爬虫程序,需要具备良好的Python编程能力,这样在编写过程中会得心应手。爬虫需要尽量伪装成人类访问网站,而不是机器访问,否则会被网站的反爬策略限制,甚至直接封IP。
四、python爬虫实践——获取博客浏览量
废话不多说,代码
<p>import re
import requests
from requests import RequestException
import urllib.request
url = "https://blog.csdn.net/STCNXPAR ... ot%3B
def get_page(url):
try:
#请求头部,如果不加头部,则会被反爬虫网站识别出是爬虫,会导致获取不到数据
headers = {
'Referer': 'https://blog.csdn.net', # 伪装成从CSDN博客搜索到的文章
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Safari/537.36' # 伪装成浏览器
}
#获取网页源代码数据
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
except RequestException:
print('请求出错')
return None
def parse_page(html):
try:
#使用正则匹配html代码中浏览量字段
read_num = int(re.compile(' 查看全部
python网页数据抓取(python爬虫简单概括获取网页数据(图)代码)
文章目录
前言:python爬虫的简单总结其实就是获取网页数据,然后按需提取!过程虽然简单,但需要结合多种技术,掌握爬虫库,编写高效的爬虫代码。
一、先了解用户如何获取网络数据
1、用户使用浏览器:浏览器提交请求—>下载网页代码—>解析成页面
2、代码自动获取:模拟浏览器发送请求(获取网页代码html、css、javascript)->提取有用数据->存入数据库或文件
python爬虫使用代码自动获取。具体流程为:
二、简单了解网页源代码的构成1、web的基本编程语言
简单了解可以上菜鸟教程
1)HTML、CSS、JavaScript是Web开发者必须学习的3种语言。他们相互合作,形成了各种丰富的网站
(1)HTML 定义了网页的内容
(2)CSS 描述了页面的布局
(3)JavaScript 控制页面的行为
2)html5 简单示例
3)html 中的 javaScript
4)HTML 中的 CSS
2、使用浏览器查看网页源代码
1)网页右键查看源码(也就是我们要得到的)
2)html代码,这里需要我们稍微了解一下它的组成,然后根据内容提取出来
三、爬虫概述1、了解爬虫
我们熟悉的一系列搜索引擎都是大型网络爬虫,比如百度、搜狗、360浏览器、谷歌搜索等等。每个搜索引擎都有自己的爬虫。比如360浏览器的爬虫叫360Spider,搜狗的爬虫叫Sogospider。
2、python 爬虫
百度搜索引擎,其实可以更形象的叫做百度蜘蛛(Baiduspider),它每天都会从海量互联网信息中抓取优质信息,并进行收录。当用户通过百度搜索关键词时,百度会先分析用户输入的关键词,然后从收录的网页中找出相关的网页,并根据网页排名排名规则。排序,最后将排序后的结果呈现给用户。在这个过程中,百度蜘蛛发挥了非常重要的作用。
百度工程师为“百度蜘蛛”编写了相应的爬虫算法。通过应用这些算法,“百度蜘蛛”可以实现相应的搜索策略,如过滤掉重复网页、过滤优质网页等。应用不同的算法,爬虫的效率和爬取结果会有所不同。
3、爬虫分类
爬虫可以分为三类:一般网络爬虫、聚焦网络爬虫和增量网络爬虫。
1)万能网络爬虫:是搜索引擎的重要组成部分,上面已经介绍过了,这里不再赘述。一般网络爬虫需要遵守robots协议,网站告诉搜索引擎哪些页面可以爬,哪些页面不可以爬。
机器人协议:是一种“常规”协议,没有法律效力。体现了互联网人的“契约精神”。行业从业者会自觉遵守协议,故又称“君子协议”。
2)专注网络爬虫:是针对特定需求的网络爬虫程序。它与一般爬虫的区别在于,聚焦爬虫在实现网页爬虫时会对网页内容进行过滤处理,并尽量保证只抓取与需求相关的网页信息。专注于网络爬虫,大大节省了硬件和网络资源。由于保存的页面少,所以更新速度很快,也满足了一些特定人群对特定领域信息的需求。
3)增量网络爬虫:指对下载的网页进行增量更新。它是一种只抓取新生成或更改的网页的爬虫程序,可以在一定程度上保证抓取到的网页。获取的页面是最新的页面。
4、爬虫应用
随着互联网的飞速发展,万维网已经成为海量信息的载体。如何有效地提取和利用这些信息已成为一个巨大的挑战。于是,爬虫应运而生。它不仅可以用于搜索引擎领域,还可以用于大数据分析,并在商业领域得到了大规模应用。
1) 数据分析
在数据分析领域,网络爬虫通常是采集海量数据的必备工具。对于数据分析师来说,要进行数据分析,首先要有数据源,通过学习爬虫,可以获得更多的数据源。在采集过程中,数据分析师可以根据自己的目的采集更多有价值的数据,并过滤掉那些无效数据。
2) 业务
对于企业来说,及时获取市场动态和产品信息非常重要。企业可以通过第三方平台购买数据,比如贵阳大数据交易所、数据堂等。当然,如果贵公司有爬虫工程师,也可以通过爬虫获取想要的信息。
5、爬行动物是一把双刃剑
爬虫是一把双刃剑,它给我们带来便利的同时,也给网络安全带来隐患。一些不法分子利用爬虫非法采集互联网上的网友信息,或者利用爬虫恶意攻击他人网站,造成网站瘫痪的严重后果。关于爬虫的合法使用,建议阅读《中华人民共和国网络安全法》。
6、python爬虫教程
为了限制爬虫带来的危险,大部分网站都有很好的反爬措施,所以在使用爬虫的时候一定要自觉遵守约定,不要非法获取他人信息,或者做对他人有害的事情。其他网站 的事情。
为什么使用 Python 作为爬虫
首先你要清楚,不仅Python可以做爬虫,PHP、Java、C/C++等都可以用来写爬虫程序,但是Python做爬虫是最简单的。以下是它们的优缺点的简要比较:
PHP:对多线程和异步的支持不是很好,并发处理能力较弱;Java也常用于编写爬虫程序,但Java语言本身非常繁琐,代码量大,对初学者入门门槛较高;尽管 C/C++ 运行效率很高,但学习和开发的成本很高。编写一个小型爬虫可能需要很长时间。
Python语言语法优美,代码简洁,开发效率高,支持多种爬虫模块,如urllib、requests、Bs4等。Python的request模块和解析模块丰富成熟,还提供了强大的Scrapy框架使编写爬虫程序更容易。因此,使用 Python 编写爬虫程序是一个非常不错的选择。
7、爬虫的编写过程
爬虫程序与其他程序不同,它的思维逻辑大体相似,所以我们不需要在逻辑上花很多时间。下面简单介绍一下用Python编写爬虫程序的过程:
首先通过urllib模块的request方法打开URL,获取网页的HTML对象。
使用浏览器打开网页源代码,分析网页结构和元素节点。
通过 Beautiful Soup 或正则表达式提取数据。
将数据存储到本地磁盘或数据库。
当然,不限于上述一种过程。编写爬虫程序,需要具备良好的Python编程能力,这样在编写过程中会得心应手。爬虫需要尽量伪装成人类访问网站,而不是机器访问,否则会被网站的反爬策略限制,甚至直接封IP。
四、python爬虫实践——获取博客浏览量
废话不多说,代码
<p>import re
import requests
from requests import RequestException
import urllib.request
url = "https://blog.csdn.net/STCNXPAR ... ot%3B
def get_page(url):
try:
#请求头部,如果不加头部,则会被反爬虫网站识别出是爬虫,会导致获取不到数据
headers = {
'Referer': 'https://blog.csdn.net', # 伪装成从CSDN博客搜索到的文章
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/68.0.3440.75 Safari/537.36' # 伪装成浏览器
}
#获取网页源代码数据
response = requests.get(url, headers=headers)
if response.status_code == 200:
return response.text
return None
except RequestException:
print('请求出错')
return None
def parse_page(html):
try:
#使用正则匹配html代码中浏览量字段
read_num = int(re.compile('
python网页数据抓取(我已经看过这个问题,但那里没有提到python)
网站优化 • 优采云 发表了文章 • 0 个评论 • 107 次浏览 • 2022-02-21 08:02
我看过这个关于抓取 ajax 的问题,但那里没有提到 python。我考虑过使用scrapy,我相信他们有一些关于这个主题的文档,但正如你所看到的, 网站 已关闭。所以我不知道该怎么办。我想做以下事情:
我已经看过这个关于抓取 ajax 的问题,但那里没有提到 python。我考虑过使用scrapy,我相信他们有一些关于这个主题的文档,但是你可以看到网站已经关闭。所以我不知道该怎么办。我想做以下事情:
我只有一个url,你可以通过点击提交从一个页面跳转到另一个页面,url不会改变,因为他们使用ajax显示内容。我想抓取每个页面的内容,怎么做?
我只有一个 url,你通过点击提交从一个页面转到另一个页面,因为他们使用 ajax 来显示内容,所以 url 不会改变。我想抓取每个页面的内容,怎么做?
假设我只是想抓取数字,除了scrapy,我还能做些什么吗?如果没有,你能否给我一个关于如何做的片段,只是因为他们的 网站 已关闭,所以我无法访问文档。
假设我只想抓取数字,除了scrapy之外还有什么可以做到的吗?如果没有,你能给我一个关于如何做的片段吗,只是因为他们的网站已经关闭,所以我无法访问文档。 查看全部
python网页数据抓取(我已经看过这个问题,但那里没有提到python)
我看过这个关于抓取 ajax 的问题,但那里没有提到 python。我考虑过使用scrapy,我相信他们有一些关于这个主题的文档,但正如你所看到的, 网站 已关闭。所以我不知道该怎么办。我想做以下事情:
我已经看过这个关于抓取 ajax 的问题,但那里没有提到 python。我考虑过使用scrapy,我相信他们有一些关于这个主题的文档,但是你可以看到网站已经关闭。所以我不知道该怎么办。我想做以下事情:
我只有一个url,你可以通过点击提交从一个页面跳转到另一个页面,url不会改变,因为他们使用ajax显示内容。我想抓取每个页面的内容,怎么做?
我只有一个 url,你通过点击提交从一个页面转到另一个页面,因为他们使用 ajax 来显示内容,所以 url 不会改变。我想抓取每个页面的内容,怎么做?
假设我只是想抓取数字,除了scrapy,我还能做些什么吗?如果没有,你能否给我一个关于如何做的片段,只是因为他们的 网站 已关闭,所以我无法访问文档。
假设我只想抓取数字,除了scrapy之外还有什么可以做到的吗?如果没有,你能给我一个关于如何做的片段吗,只是因为他们的网站已经关闭,所以我无法访问文档。
python网页数据抓取(三种数据抓取的方法(库)(bs4))
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2022-02-19 15:20
本期文章将与大家分享如何在python中实现数据采集。小编觉得很实用,所以分享给大家作为参考,也跟着小编一起来看看吧。
三种数据采集方法
正则表达式(重新库)
BeautifulSoup (bs4)
lxml
*利用之前构建的下载网页函数获取目标网页的html,我们以获取html为例。
from get_html import download
url = 'https://guojiadiqu.bmcx.com/AF ... ntent = download(url)
*假设我们需要抓取这个网页中的国名和简介,我们会依次使用这三种数据抓取方式来实现数据抓取。
1.正则表达式
from get_html import downloadimport re
url = 'https://guojiadiqu.bmcx.com/AF ... ntent = download(url)country = re.findall('class="h3dabiaoti">(.*?)', page_content) #注意返回的是listsurvey_data = re.findall('(.*?)', page_content)survey_info_list = re.findall('<p> (.*?)', survey_data[0])survey_info = ''.join(survey_info_list)print(country[0],survey_info)</p>
2.美汤(bs4)
from get_html import downloadfrom bs4 import BeautifulSoup
url = 'https://guojiadiqu.bmcx.com/AF ... Bhtml = download(url)#创建 beautifulsoup 对象soup = BeautifulSoup(html,"html.parser")#搜索country = soup.find(attrs={'class':'h3dabiaoti'}).text
survey_info = soup.find(attrs={'id':'wzneirong'}).textprint(country,survey_info)
3.lxml
from get_html import downloadfrom lxml import etree #解析树url = 'https://guojiadiqu.bmcx.com/AF ... ntent = download(url)selector = etree.HTML(page_content)#可进行xpath解析country_select = selector.xpath('//*[@id="main_content"]/h3') #返回列表for country in country_select:
print(country.text)survey_select = selector.xpath('//*[@id="wzneirong"]/p')for survey_content in survey_select:
print(survey_content.text,end='')
运行结果:
最后参考《用Python编写网络爬虫》中三种方式的性能对比,如下图:
仅供参考。
谢谢阅读!《如何在python中实现数据捕获》的文章文章分享到这里。希望以上内容能够对大家有所帮助,让大家学习到更多的知识。如果你觉得文章是的,你可以分享出来让更多人看到! 查看全部
python网页数据抓取(三种数据抓取的方法(库)(bs4))
本期文章将与大家分享如何在python中实现数据采集。小编觉得很实用,所以分享给大家作为参考,也跟着小编一起来看看吧。
三种数据采集方法
正则表达式(重新库)
BeautifulSoup (bs4)
lxml
*利用之前构建的下载网页函数获取目标网页的html,我们以获取html为例。
from get_html import download
url = 'https://guojiadiqu.bmcx.com/AF ... ntent = download(url)
*假设我们需要抓取这个网页中的国名和简介,我们会依次使用这三种数据抓取方式来实现数据抓取。
1.正则表达式
from get_html import downloadimport re
url = 'https://guojiadiqu.bmcx.com/AF ... ntent = download(url)country = re.findall('class="h3dabiaoti">(.*?)', page_content) #注意返回的是listsurvey_data = re.findall('(.*?)', page_content)survey_info_list = re.findall('<p> (.*?)', survey_data[0])survey_info = ''.join(survey_info_list)print(country[0],survey_info)</p>
2.美汤(bs4)
from get_html import downloadfrom bs4 import BeautifulSoup
url = 'https://guojiadiqu.bmcx.com/AF ... Bhtml = download(url)#创建 beautifulsoup 对象soup = BeautifulSoup(html,"html.parser")#搜索country = soup.find(attrs={'class':'h3dabiaoti'}).text
survey_info = soup.find(attrs={'id':'wzneirong'}).textprint(country,survey_info)
3.lxml
from get_html import downloadfrom lxml import etree #解析树url = 'https://guojiadiqu.bmcx.com/AF ... ntent = download(url)selector = etree.HTML(page_content)#可进行xpath解析country_select = selector.xpath('//*[@id="main_content"]/h3') #返回列表for country in country_select:
print(country.text)survey_select = selector.xpath('//*[@id="wzneirong"]/p')for survey_content in survey_select:
print(survey_content.text,end='')
运行结果:
最后参考《用Python编写网络爬虫》中三种方式的性能对比,如下图:
仅供参考。
谢谢阅读!《如何在python中实现数据捕获》的文章文章分享到这里。希望以上内容能够对大家有所帮助,让大家学习到更多的知识。如果你觉得文章是的,你可以分享出来让更多人看到!
python网页数据抓取(Python用做数据处理还是相当不错的,如果你想要做爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2022-02-19 15:17
Python非常适合数据处理。如果你想做爬虫,Python是个不错的选择。它有很多已经编写好的类包,只要调用它就可以完成很多复杂的功能。
1 Pyhton获取网页内容(即源码)(推荐学习:Python视频教程)
page = urllib2.urlopen(url)
contents = page.read()
#获得了整个网页的内容也就是源代码
print(contents)
url代表网址,contents代表网址对应的源码,urllib2是需要使用的包。以上三行代码就可以得到网页的全部源代码
2 在网页中获取你想要的内容(先获取网页的源代码,然后分析网页的源代码,找到对应的标签,然后提取标签中的内容)
以豆瓣电影排名为例
现在我需要获取当前页面上所有电影的名称、评分、评论人数、链接
#coding:utf-8
'''''
@author: jsjxy
'''
import urllib2
import re
from bs4 import BeautifulSoup
from distutils.filelist import findall
page = urllib2.urlopen('http://movie.douban.com/top250?format=text')
contents = page.read()
#print(contents)
soup = BeautifulSoup(contents,"html.parser")
print("豆瓣电影TOP250" + "\n" +" 影片名 评分 评价人数 链接 ")
for tag in soup.find_all('div', class_='info'):
# print tag
m_name = tag.find('span', class_='title').get_text()
m_rating_score = float(tag.find('span',class_='rating_num').get_text())
m_people = tag.find('div',class_="star")
m_span = m_people.findAll('span')
m_peoplecount = m_span[3].contents[0]
m_url=tag.find('a').get('href')
print( m_name+" " + str(m_rating_score) + " " + m_peoplecount + " " + m_url )
控制台输出,也可以写入文件
更多Python相关技术文章,请访问Python教程专栏学习!
以上就是python如何获取网页内容的详细内容。更多详情请关注php中文网文章其他相关话题! 查看全部
python网页数据抓取(Python用做数据处理还是相当不错的,如果你想要做爬虫)
Python非常适合数据处理。如果你想做爬虫,Python是个不错的选择。它有很多已经编写好的类包,只要调用它就可以完成很多复杂的功能。
1 Pyhton获取网页内容(即源码)(推荐学习:Python视频教程)
page = urllib2.urlopen(url)
contents = page.read()
#获得了整个网页的内容也就是源代码
print(contents)
url代表网址,contents代表网址对应的源码,urllib2是需要使用的包。以上三行代码就可以得到网页的全部源代码
2 在网页中获取你想要的内容(先获取网页的源代码,然后分析网页的源代码,找到对应的标签,然后提取标签中的内容)
以豆瓣电影排名为例
现在我需要获取当前页面上所有电影的名称、评分、评论人数、链接
#coding:utf-8
'''''
@author: jsjxy
'''
import urllib2
import re
from bs4 import BeautifulSoup
from distutils.filelist import findall
page = urllib2.urlopen('http://movie.douban.com/top250?format=text')
contents = page.read()
#print(contents)
soup = BeautifulSoup(contents,"html.parser")
print("豆瓣电影TOP250" + "\n" +" 影片名 评分 评价人数 链接 ")
for tag in soup.find_all('div', class_='info'):
# print tag
m_name = tag.find('span', class_='title').get_text()
m_rating_score = float(tag.find('span',class_='rating_num').get_text())
m_people = tag.find('div',class_="star")
m_span = m_people.findAll('span')
m_peoplecount = m_span[3].contents[0]
m_url=tag.find('a').get('href')
print( m_name+" " + str(m_rating_score) + " " + m_peoplecount + " " + m_url )
控制台输出,也可以写入文件
更多Python相关技术文章,请访问Python教程专栏学习!
以上就是python如何获取网页内容的详细内容。更多详情请关注php中文网文章其他相关话题!
python网页数据抓取(一下爬虫爬虫项目的基本步骤和基本操作步骤(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 100 次浏览 • 2022-02-17 15:01
Python爬虫--scrapy爬虫框架介绍写在前面
在编写爬虫之前,我从未使用过爬虫框架。其实我之前写的就是一个爬虫写的小练习的demo。只能说是从网上抓取一点数据,直接用python脚本解决爬虫的所有功能。循环获取更多数据页。后来了解了代理池系统,稍微了解了一下,爬虫其实也算是一个项目。该项目分为模块。不同的模块负责不同的功能。有些模块负责封装http请求,有些模块负责处理请求。(数据采集),有些模块负责数据分析,有些模块负责数据存储。这样一个框架的原型已经出现,这可以帮助我们更加专注和高效地抓取数据。对于scrapy,一开始并不想过多解释scrapy框架各部分的组成和功能,而是直接在实际运行中感受一下框架是如何分工协作的,各个模块负责什么功能,最后关注一下这个框架。一些原则应该是学习scrapy框架的最好方法。
scrapy爬虫的基本步骤创建一个scrapy爬虫项目。创建一个 Spider 爬虫类来爬取网页内容并解析它。定义数据模型(Item)并将捕获的数据封装到Item中。使用Item Pipeline来存储和抓取Items,即数据实体对象。一、创建一个scrapy爬虫项目
安装scrapy后,运行命令scrapy startproject project name,创建scrapy爬虫项目。例如运行scrapy startproject test1会生成一个test1文件夹,目录结构如下:
二、创建一个Spider爬虫类来爬取网页内容并解析它。
爬虫的代码写在spider文件夹下,所以在spider目录下创建一个python文件,爬取方天下的数据,所以创建一个python文件,命名为ftx_spider.py。
接下来,开始在 ftx_spider.py 中编写爬虫代码:
import scrapy
class FtxSpider(scrapy.Spider):
"""
一、创建一个爬虫类,继承scrapy.Spider
二、通过name属性,给爬虫类定义一个名称
三、指定要抓取的网页链接urls,发送http请求
方式一:
1.继承scrapy.Spider的start_requests()方法。
2.指定要爬取的url,通过scrapy.Request(url=url, callback=self.parse)发送请求,callback指定解析函数。
方式二(简化):
1.直接通过start_urls常量指定要爬取的urls。
2.框架会自动发送http请求,这里框架默认html解析函数parse().
四、针对http请求的response结果,编写解析方法,parse()
"""
name = 'ftx'
# 方式一:通过scrapy.Request(url=url, callback=self.parse)发送请求,指定解析函数
# def start_requests(self):
# urls = ['http://wuhan.esf.fang.com/house-a013126/i3']
# for url in urls:
# yield scrapy.Request(url=url, callback=self.parse)
#
# def parse(self, response):
# # 这里对抓取到的html页面进行解析
# print(response.url)
# 方式二(简化版):通过start_urls,框架自动发送请求,默认解析函数为parse()
start_urls = ['http://wuhan.esf.fang.com/house-a013126/i3']
def parse(self, response):
print(response.url)
三、数据模型Item,定义爬取数据的数据结构
这个Item相当于java中的域实体,或者javabean。在 items.py 中定义了一个类,它继承了 scrapy.Item。这样我们就可以将我们抓取的数据封装到一个对象中。
import scrapy
class FtxSpiderItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field() # 标题
huxing = scrapy.Field() # 户型
size = scrapy.Field() # 面积
floor = scrapy.Field() # 楼层
fangxiang = scrapy.Field() # 方向
year = scrapy.Field() # 建房时间
shop_community = scrapy.Field() # 小区
address = scrapy.Field() # 地址
total_price = scrapy.Field() # 总价(万)
price = scrapy.Field() # 单价(万/m2)
四、使用Item Pipeline存储和抓取item并将数据存储在MongoDB中
项目管道是项目管道。当 Item 生成后,会自动发送到 Item Pipeline 进行处理。
首先在setting.py中添加MongoDB数据库连接信息
# MongoDB
HOST = 'localhost'
PORT = 27017
DB_NAME = 'ftx'
COLL_NAME = 'roomprice'
然后在pipelines.py中创建一个类,连接数据库,插入数据
import pymongo
from scrapy.conf import settings
class FtxSpiderPipeline(object):
def __init__(self):
# 连接MongoDB
self.client = pymongo.MongoClient(host=settings['HOST'], port=settings['PORT'])
# 获取数据库
self.db = self.client[settings['DB_NAME']]
# 获取集合
self.collection = self.db[settings['COLL_NAME']]
def process_item(self, item, spider):
self.collection.insert(dict(item))
最后在setting.py中指定Item Pipeline使用的类和优先级
ITEM_PIPELINES = {
'ftx_spider.pipelines.FtxSpiderPipeline': 300
}
运行命令行scrapy crawl 'crawler name name',可以发现数据已经成功存入数据库daacheng/PythonBasic 查看全部
python网页数据抓取(一下爬虫爬虫项目的基本步骤和基本操作步骤(一))
Python爬虫--scrapy爬虫框架介绍写在前面
在编写爬虫之前,我从未使用过爬虫框架。其实我之前写的就是一个爬虫写的小练习的demo。只能说是从网上抓取一点数据,直接用python脚本解决爬虫的所有功能。循环获取更多数据页。后来了解了代理池系统,稍微了解了一下,爬虫其实也算是一个项目。该项目分为模块。不同的模块负责不同的功能。有些模块负责封装http请求,有些模块负责处理请求。(数据采集),有些模块负责数据分析,有些模块负责数据存储。这样一个框架的原型已经出现,这可以帮助我们更加专注和高效地抓取数据。对于scrapy,一开始并不想过多解释scrapy框架各部分的组成和功能,而是直接在实际运行中感受一下框架是如何分工协作的,各个模块负责什么功能,最后关注一下这个框架。一些原则应该是学习scrapy框架的最好方法。
scrapy爬虫的基本步骤创建一个scrapy爬虫项目。创建一个 Spider 爬虫类来爬取网页内容并解析它。定义数据模型(Item)并将捕获的数据封装到Item中。使用Item Pipeline来存储和抓取Items,即数据实体对象。一、创建一个scrapy爬虫项目
安装scrapy后,运行命令scrapy startproject project name,创建scrapy爬虫项目。例如运行scrapy startproject test1会生成一个test1文件夹,目录结构如下:
二、创建一个Spider爬虫类来爬取网页内容并解析它。
爬虫的代码写在spider文件夹下,所以在spider目录下创建一个python文件,爬取方天下的数据,所以创建一个python文件,命名为ftx_spider.py。
接下来,开始在 ftx_spider.py 中编写爬虫代码:
import scrapy
class FtxSpider(scrapy.Spider):
"""
一、创建一个爬虫类,继承scrapy.Spider
二、通过name属性,给爬虫类定义一个名称
三、指定要抓取的网页链接urls,发送http请求
方式一:
1.继承scrapy.Spider的start_requests()方法。
2.指定要爬取的url,通过scrapy.Request(url=url, callback=self.parse)发送请求,callback指定解析函数。
方式二(简化):
1.直接通过start_urls常量指定要爬取的urls。
2.框架会自动发送http请求,这里框架默认html解析函数parse().
四、针对http请求的response结果,编写解析方法,parse()
"""
name = 'ftx'
# 方式一:通过scrapy.Request(url=url, callback=self.parse)发送请求,指定解析函数
# def start_requests(self):
# urls = ['http://wuhan.esf.fang.com/house-a013126/i3']
# for url in urls:
# yield scrapy.Request(url=url, callback=self.parse)
#
# def parse(self, response):
# # 这里对抓取到的html页面进行解析
# print(response.url)
# 方式二(简化版):通过start_urls,框架自动发送请求,默认解析函数为parse()
start_urls = ['http://wuhan.esf.fang.com/house-a013126/i3']
def parse(self, response):
print(response.url)
三、数据模型Item,定义爬取数据的数据结构
这个Item相当于java中的域实体,或者javabean。在 items.py 中定义了一个类,它继承了 scrapy.Item。这样我们就可以将我们抓取的数据封装到一个对象中。
import scrapy
class FtxSpiderItem(scrapy.Item):
# define the fields for your item here like:
title = scrapy.Field() # 标题
huxing = scrapy.Field() # 户型
size = scrapy.Field() # 面积
floor = scrapy.Field() # 楼层
fangxiang = scrapy.Field() # 方向
year = scrapy.Field() # 建房时间
shop_community = scrapy.Field() # 小区
address = scrapy.Field() # 地址
total_price = scrapy.Field() # 总价(万)
price = scrapy.Field() # 单价(万/m2)
四、使用Item Pipeline存储和抓取item并将数据存储在MongoDB中
项目管道是项目管道。当 Item 生成后,会自动发送到 Item Pipeline 进行处理。
首先在setting.py中添加MongoDB数据库连接信息
# MongoDB
HOST = 'localhost'
PORT = 27017
DB_NAME = 'ftx'
COLL_NAME = 'roomprice'
然后在pipelines.py中创建一个类,连接数据库,插入数据
import pymongo
from scrapy.conf import settings
class FtxSpiderPipeline(object):
def __init__(self):
# 连接MongoDB
self.client = pymongo.MongoClient(host=settings['HOST'], port=settings['PORT'])
# 获取数据库
self.db = self.client[settings['DB_NAME']]
# 获取集合
self.collection = self.db[settings['COLL_NAME']]
def process_item(self, item, spider):
self.collection.insert(dict(item))
最后在setting.py中指定Item Pipeline使用的类和优先级
ITEM_PIPELINES = {
'ftx_spider.pipelines.FtxSpiderPipeline': 300
}
运行命令行scrapy crawl 'crawler name name',可以发现数据已经成功存入数据库daacheng/PythonBasic
python网页数据抓取( Python网站信息的资料请关注编程宝库(图)!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-02-17 14:21
Python网站信息的资料请关注编程宝库(图)!)
Python爬虫实现爬取电影网站信息并入库
一.环境设置1.下载安装包
访问Python官网下载地址:
下载适合您系统的安装包:
我使用的是Windows环境,所以直接从exe包安装。
下载完成后,双击下载包进入Python安装向导。安装非常简单,只需要使用默认设置,点击“下一步”,直到安装完成。
2.修改环境变量
右键单击“计算机”,然后单击“属性”;
然后点击“高级系统设置”-“环境变量”;
选择“系统变量”窗口下的“路径”添加python安装路径;
设置成功后,在cmd命令行输入命令“python”。如果显示,则配置成功。
3.安装依赖模块
我们的爬虫需要安装的依赖模块包括requests、lxml、pymysql。步骤如下:
进入python安装目录下的Scripts目录,点击地址栏输入“cmd”打开命令行工具:
在这个路径下安装对应的requests、lxml、pymysql依赖:
输入命令:
// 安装requests依赖
pip install requests
// 安装lxml依赖
pip install lxml
// 安装pymysql依赖
pip install pymysql
二.代码开发
开发collectMovies.py
#!/user/bin env python
# 获取电影天堂详细信息
import requests
import time
from lxml import etree
import pymysql
requests.adapters.DEFAULT_RETRIES = 5
# 伪装浏览器
HEADERS ={
'User-Agent':'Mozilla/5.(Windows NT 10.0; WOW64) AppleWebKit/537.3(KHTML, like Gecko) Chrome/63.0.3239.13Safari/537.36',
'Host':'www.dy2018.com'
}
# 定义全局变量
BASE_DOMAIN = 'https://www.dy2018.com/'
# 获取首页网页信息并解析
def getUrlText(url,coding):
s = requests.session()
#print("获取首页网页信息并解析:", url)
respons = s.get(url,headers=HEADERS)
print("请求URL:", url)
if(coding=='c'):
urlText = respons.content.decode('gbk')
html = etree.HTML(urlText) # 使用lxml解析网页
else:
urlText = respons.text
html = etree.HTML(urlText) # 使用lxml解析网页
s.keep_alive = False
return html
# 获取电影详情页的href,text解析
def getHref(url):
html = getUrlText(url,'t')
aHref = html.xpath('//table[@class="tbspan"]//a/@href')
print("获取电影详情页的href,text解析```")
htmlAll = map(lambda url:BASE_DOMAIN+url,aHref) # 给每个href补充BASE_DOMAIN
return htmlAll
# 使用content解析电影详情页,并获取详细信息数据
def getPage(url):
html = getUrlText(url,'c')
moveInfo = {} # 定义电影信息
mName = html.xpath('//div[@class="title_all"]//h1/text()')[0]
moveInfo['movie_name'] = mName
mDiv = html.xpath('//div[@id="Zoom"]')[0]
mImgSrc = mDiv.xpath('.//img/@src')
moveInfo['image_path'] = mImgSrc[0] # 获取海报src地址
if len(mImgSrc) >= 2:
moveInfo['screenshot'] = mImgSrc[1] # 获取电影截图src地址
mContnent = mDiv.xpath('.//text()')
def pares_info(info,rule):
'''
:param info: 字符串
:param rule: 替换字串
:return: 指定字符串替换为空,并剔除左右空格
'''
return info.replace(rule,'').strip()
for index,t in enumerate(mContnent):
if t.startswith('◎译 名'):
name = pares_info(t,'◎译 名')
moveInfo['translation']=name
elif t.startswith('◎片 名'):
name = pares_info(t,'◎片 名')
moveInfo['movie_title']=name
elif t.startswith('◎年 代'):
name = pares_info(t,'◎年 代')
moveInfo['movie_age']=name
elif t.startswith('◎产 地'):
name = pares_info(t,'◎产 地')
moveInfo['movie_place']=name
elif t.startswith('◎类 别'):
name = pares_info(t,'◎类 别')
moveInfo['category']=name
elif t.startswith('◎语 言'):
name = pares_info(t,'◎语 言')
moveInfo['language']=name
elif t.startswith('◎字 幕'):
name = pares_info(t,'◎字 幕')
moveInfo['subtitle']=name
elif t.startswith('◎上映日期'):
name = pares_info(t,'◎上映日期')
moveInfo['release_date']=name
elif t.startswith('◎豆瓣评分'):
name = pares_info(t,'◎豆瓣评分')
moveInfo['douban_score']=name
elif t.startswith('◎片 长'):
name = pares_info(t,'◎片 长')
moveInfo['file_length']=name
elif t.startswith('◎导 演'):
name = pares_info(t,'◎导 演')
moveInfo['director']=name
elif t.startswith('◎编 剧'):
name = pares_info(t, '◎编 剧')
writers = [name]
for i in range(index + 1, len(mContnent)):
writer = mContnent[i].strip()
if writer.startswith('◎'):
break
writers.append(writer)
moveInfo['screenwriter'] = writers
elif t.startswith('◎主 演'):
name = pares_info(t, '◎主 演')
actors = [name]
for i in range(index+1,len(mContnent)):
actor = mContnent[i].strip()
if actor.startswith('◎'):
break
actors.append(actor)
moveInfo['stars'] = " ".join(actors)
elif t.startswith('◎标 签'):
name = pares_info(t,'◎标 签')
moveInfo['tags']=name
elif t.startswith('◎简 介'):
name = pares_info(t,'◎简 介')
profiles = []
for i in range(index + 1, len(mContnent)):
profile = mContnent[i].strip()
if profile.startswith('◎获奖情况') or '【下载地址】' in profile:
break
profiles.append(profile)
moveInfo['introduction']=" ".join(profiles)
elif t.startswith('◎获奖情况'):
name = pares_info(t,'◎获奖情况')
awards = []
for i in range(index + 1, len(mContnent)):
award = mContnent[i].strip()
if '【下载地址】' in award:
break
awards.append(award)
moveInfo['awards']=" ".join(awards)
moveInfo['movie_url'] = url
return moveInfo
# 获取前n页所有电影的详情页href
def spider():
#连接数据库
base_url = 'https://www.dy2018.com/html/gndy/dyzz/index_{}.html'
moves = []
m = int(input('请输入您要获取的开始页:'))
n = int(input('请输入您要获取的结束页:'))
print('即将写入第{}页到第{}页的电影信息,请稍后...'.format(m, n))
for i in range(m,n+1):
print('******* 第{}页电影 正在写入 ********'.format(i))
if i == 1:
url = "https://www.dy2018.com/html/gndy/dyzz/"
else:
url = base_url.format(i)
moveHref = getHref(url)
print("休息2s后再进行操作")
time.sleep(2)
for index,mhref in enumerate(moveHref):
print('---- 正在处理第{}部电影----'.format(index+1))
move = getPage(mhref)
moves.append(move)
# 将电影信息写入数据库
db = pymysql.connect(host='127.0.0.1',user='root', password='123456', port=3306, db='你的数据库名称')
table = 'movies'
i = 1
for data in moves:
keys = ', '.join(data.keys())
values = ', '.join(['%s'] * len(data))
sql = 'INSERT INTO {table}(id,{keys}) VALUES (null,{values})'.format(table=table, keys=keys, values=values)
try:
cursor = db.cursor()
cursor.execute(sql, tuple(data.values()))
print('本条数据成功执行!')
if i==0:
db.commit()
except Exception as e:
print('将电影信息写入数据库发生异常!',repr(e))
db.rollback()
cursor.close()
i = i + 1
db.commit()
db.close()
print('写入数据库完成!')
if __name__ == '__main__':
spider()
三.运行测试1.新建电影信息表
CREATE TABLE `movies` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`movie_name` varchar(255) DEFAULT NULL,
`image_path` varchar(255) DEFAULT NULL,
`screenshot` varchar(255) DEFAULT NULL,
`translation` varchar(255) DEFAULT NULL,
`movie_title` varchar(255) DEFAULT NULL,
`movie_age` varchar(50) DEFAULT NULL,
`movie_place` varchar(50) DEFAULT NULL,
`category` varchar(100) DEFAULT NULL,
`language` varchar(100) DEFAULT NULL,
`subtitle` varchar(100) DEFAULT NULL,
`release_date` varchar(50) DEFAULT NULL,
`douban_score` varchar(50) DEFAULT NULL,
`file_length` varchar(255) DEFAULT NULL,
`director` varchar(100) DEFAULT NULL,
`screenwriter` varchar(100) DEFAULT NULL,
`stars` mediumtext,
`tags` varchar(255) DEFAULT NULL,
`introduction` mediumtext,
`awards` text,
`movie_url` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
2.代码运行
打开collectMovies.py所在目录,输入命令运行:
python collectMovies.py
结果如下:
查看数据库表,数据已经插入成功:
四.故障排除和修复1.空白字符错误
我第一次使用 Python,对它的规则并不熟悉。混合空格和制表符会报如下错误:
unindent does not match any outer indentation level
解决方案
下载Notepad++,选择“编辑”-“空白字符操作”-“空格到制表符(行首)”。
2.请求错误
修改格式后,再次运行,反复报请求的错误。错误信息主要包括以下内容:
ssl.SSLEOFError: EOF occurred in violation of protocol
······
Max retries exceeded with url
解决方案
我认为这是请求设置的问题。各种百度和pip install incremental也装了,还是不行。
后来我把请求的URL改成,没有报错,所以可以定位是访问原来的URL有问题,把采集源路径替换了,问题就出来了解决了。
以上就是Python爬虫实现爬取电影网站信息并入库的详细内容。更多Python爬取网站信息,请关注其他相关编程宝库文章!
下一节:Python将py文件编译成exe文件 Python编程技术
使用PyCharm工具编写的Python程序脚本,如何将.py文件编译成可执行的.exe文件需要已经安装了Python环境。第一步:在 PyCharm 中下载并安装 pyinstalle 库或使用 CMD 安装 P... 查看全部
python网页数据抓取(
Python网站信息的资料请关注编程宝库(图)!)
Python爬虫实现爬取电影网站信息并入库
一.环境设置1.下载安装包
访问Python官网下载地址:
下载适合您系统的安装包:
我使用的是Windows环境,所以直接从exe包安装。
下载完成后,双击下载包进入Python安装向导。安装非常简单,只需要使用默认设置,点击“下一步”,直到安装完成。
2.修改环境变量
右键单击“计算机”,然后单击“属性”;
然后点击“高级系统设置”-“环境变量”;
选择“系统变量”窗口下的“路径”添加python安装路径;
设置成功后,在cmd命令行输入命令“python”。如果显示,则配置成功。
3.安装依赖模块
我们的爬虫需要安装的依赖模块包括requests、lxml、pymysql。步骤如下:
进入python安装目录下的Scripts目录,点击地址栏输入“cmd”打开命令行工具:
在这个路径下安装对应的requests、lxml、pymysql依赖:
输入命令:
// 安装requests依赖
pip install requests
// 安装lxml依赖
pip install lxml
// 安装pymysql依赖
pip install pymysql
二.代码开发
开发collectMovies.py
#!/user/bin env python
# 获取电影天堂详细信息
import requests
import time
from lxml import etree
import pymysql
requests.adapters.DEFAULT_RETRIES = 5
# 伪装浏览器
HEADERS ={
'User-Agent':'Mozilla/5.(Windows NT 10.0; WOW64) AppleWebKit/537.3(KHTML, like Gecko) Chrome/63.0.3239.13Safari/537.36',
'Host':'www.dy2018.com'
}
# 定义全局变量
BASE_DOMAIN = 'https://www.dy2018.com/'
# 获取首页网页信息并解析
def getUrlText(url,coding):
s = requests.session()
#print("获取首页网页信息并解析:", url)
respons = s.get(url,headers=HEADERS)
print("请求URL:", url)
if(coding=='c'):
urlText = respons.content.decode('gbk')
html = etree.HTML(urlText) # 使用lxml解析网页
else:
urlText = respons.text
html = etree.HTML(urlText) # 使用lxml解析网页
s.keep_alive = False
return html
# 获取电影详情页的href,text解析
def getHref(url):
html = getUrlText(url,'t')
aHref = html.xpath('//table[@class="tbspan"]//a/@href')
print("获取电影详情页的href,text解析```")
htmlAll = map(lambda url:BASE_DOMAIN+url,aHref) # 给每个href补充BASE_DOMAIN
return htmlAll
# 使用content解析电影详情页,并获取详细信息数据
def getPage(url):
html = getUrlText(url,'c')
moveInfo = {} # 定义电影信息
mName = html.xpath('//div[@class="title_all"]//h1/text()')[0]
moveInfo['movie_name'] = mName
mDiv = html.xpath('//div[@id="Zoom"]')[0]
mImgSrc = mDiv.xpath('.//img/@src')
moveInfo['image_path'] = mImgSrc[0] # 获取海报src地址
if len(mImgSrc) >= 2:
moveInfo['screenshot'] = mImgSrc[1] # 获取电影截图src地址
mContnent = mDiv.xpath('.//text()')
def pares_info(info,rule):
'''
:param info: 字符串
:param rule: 替换字串
:return: 指定字符串替换为空,并剔除左右空格
'''
return info.replace(rule,'').strip()
for index,t in enumerate(mContnent):
if t.startswith('◎译 名'):
name = pares_info(t,'◎译 名')
moveInfo['translation']=name
elif t.startswith('◎片 名'):
name = pares_info(t,'◎片 名')
moveInfo['movie_title']=name
elif t.startswith('◎年 代'):
name = pares_info(t,'◎年 代')
moveInfo['movie_age']=name
elif t.startswith('◎产 地'):
name = pares_info(t,'◎产 地')
moveInfo['movie_place']=name
elif t.startswith('◎类 别'):
name = pares_info(t,'◎类 别')
moveInfo['category']=name
elif t.startswith('◎语 言'):
name = pares_info(t,'◎语 言')
moveInfo['language']=name
elif t.startswith('◎字 幕'):
name = pares_info(t,'◎字 幕')
moveInfo['subtitle']=name
elif t.startswith('◎上映日期'):
name = pares_info(t,'◎上映日期')
moveInfo['release_date']=name
elif t.startswith('◎豆瓣评分'):
name = pares_info(t,'◎豆瓣评分')
moveInfo['douban_score']=name
elif t.startswith('◎片 长'):
name = pares_info(t,'◎片 长')
moveInfo['file_length']=name
elif t.startswith('◎导 演'):
name = pares_info(t,'◎导 演')
moveInfo['director']=name
elif t.startswith('◎编 剧'):
name = pares_info(t, '◎编 剧')
writers = [name]
for i in range(index + 1, len(mContnent)):
writer = mContnent[i].strip()
if writer.startswith('◎'):
break
writers.append(writer)
moveInfo['screenwriter'] = writers
elif t.startswith('◎主 演'):
name = pares_info(t, '◎主 演')
actors = [name]
for i in range(index+1,len(mContnent)):
actor = mContnent[i].strip()
if actor.startswith('◎'):
break
actors.append(actor)
moveInfo['stars'] = " ".join(actors)
elif t.startswith('◎标 签'):
name = pares_info(t,'◎标 签')
moveInfo['tags']=name
elif t.startswith('◎简 介'):
name = pares_info(t,'◎简 介')
profiles = []
for i in range(index + 1, len(mContnent)):
profile = mContnent[i].strip()
if profile.startswith('◎获奖情况') or '【下载地址】' in profile:
break
profiles.append(profile)
moveInfo['introduction']=" ".join(profiles)
elif t.startswith('◎获奖情况'):
name = pares_info(t,'◎获奖情况')
awards = []
for i in range(index + 1, len(mContnent)):
award = mContnent[i].strip()
if '【下载地址】' in award:
break
awards.append(award)
moveInfo['awards']=" ".join(awards)
moveInfo['movie_url'] = url
return moveInfo
# 获取前n页所有电影的详情页href
def spider():
#连接数据库
base_url = 'https://www.dy2018.com/html/gndy/dyzz/index_{}.html'
moves = []
m = int(input('请输入您要获取的开始页:'))
n = int(input('请输入您要获取的结束页:'))
print('即将写入第{}页到第{}页的电影信息,请稍后...'.format(m, n))
for i in range(m,n+1):
print('******* 第{}页电影 正在写入 ********'.format(i))
if i == 1:
url = "https://www.dy2018.com/html/gndy/dyzz/"
else:
url = base_url.format(i)
moveHref = getHref(url)
print("休息2s后再进行操作")
time.sleep(2)
for index,mhref in enumerate(moveHref):
print('---- 正在处理第{}部电影----'.format(index+1))
move = getPage(mhref)
moves.append(move)
# 将电影信息写入数据库
db = pymysql.connect(host='127.0.0.1',user='root', password='123456', port=3306, db='你的数据库名称')
table = 'movies'
i = 1
for data in moves:
keys = ', '.join(data.keys())
values = ', '.join(['%s'] * len(data))
sql = 'INSERT INTO {table}(id,{keys}) VALUES (null,{values})'.format(table=table, keys=keys, values=values)
try:
cursor = db.cursor()
cursor.execute(sql, tuple(data.values()))
print('本条数据成功执行!')
if i==0:
db.commit()
except Exception as e:
print('将电影信息写入数据库发生异常!',repr(e))
db.rollback()
cursor.close()
i = i + 1
db.commit()
db.close()
print('写入数据库完成!')
if __name__ == '__main__':
spider()
三.运行测试1.新建电影信息表
CREATE TABLE `movies` (
`id` bigint(20) NOT NULL AUTO_INCREMENT,
`movie_name` varchar(255) DEFAULT NULL,
`image_path` varchar(255) DEFAULT NULL,
`screenshot` varchar(255) DEFAULT NULL,
`translation` varchar(255) DEFAULT NULL,
`movie_title` varchar(255) DEFAULT NULL,
`movie_age` varchar(50) DEFAULT NULL,
`movie_place` varchar(50) DEFAULT NULL,
`category` varchar(100) DEFAULT NULL,
`language` varchar(100) DEFAULT NULL,
`subtitle` varchar(100) DEFAULT NULL,
`release_date` varchar(50) DEFAULT NULL,
`douban_score` varchar(50) DEFAULT NULL,
`file_length` varchar(255) DEFAULT NULL,
`director` varchar(100) DEFAULT NULL,
`screenwriter` varchar(100) DEFAULT NULL,
`stars` mediumtext,
`tags` varchar(255) DEFAULT NULL,
`introduction` mediumtext,
`awards` text,
`movie_url` varchar(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=InnoDB AUTO_INCREMENT=1 DEFAULT CHARSET=utf8;
2.代码运行
打开collectMovies.py所在目录,输入命令运行:
python collectMovies.py
结果如下:
查看数据库表,数据已经插入成功:
四.故障排除和修复1.空白字符错误
我第一次使用 Python,对它的规则并不熟悉。混合空格和制表符会报如下错误:
unindent does not match any outer indentation level
解决方案
下载Notepad++,选择“编辑”-“空白字符操作”-“空格到制表符(行首)”。
2.请求错误
修改格式后,再次运行,反复报请求的错误。错误信息主要包括以下内容:
ssl.SSLEOFError: EOF occurred in violation of protocol
······
Max retries exceeded with url
解决方案
我认为这是请求设置的问题。各种百度和pip install incremental也装了,还是不行。
后来我把请求的URL改成,没有报错,所以可以定位是访问原来的URL有问题,把采集源路径替换了,问题就出来了解决了。
以上就是Python爬虫实现爬取电影网站信息并入库的详细内容。更多Python爬取网站信息,请关注其他相关编程宝库文章!
下一节:Python将py文件编译成exe文件 Python编程技术
使用PyCharm工具编写的Python程序脚本,如何将.py文件编译成可执行的.exe文件需要已经安装了Python环境。第一步:在 PyCharm 中下载并安装 pyinstalle 库或使用 CMD 安装 P...
python网页数据抓取( 2018年05月25日11:41:25一下)
网站优化 • 优采云 发表了文章 • 0 个评论 • 110 次浏览 • 2022-02-16 12:36
2018年05月25日11:41:25一下)
python2.7实现抓取网页数据
更新时间:2018年5月25日11:41:25 作者:aasdsjk
本文文章主要详细介绍python2.7实现爬虫网页数据,具有一定的参考价值。有兴趣的朋友可以参考一下
最近刚学Python,做了一个简单的爬虫。作为一个简单的demo,希望对像我这样的初学者有所帮助。
代码使用python制作的爬虫2.7在51job上抓取职位、公司名称、工资、发布时间等。
直接上代码,代码中的注释比较清楚,如果没有安装mysql需要屏蔽相关代码:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
from bs4 import BeautifulSoup
import urllib
import urllib2
import codecs
import re
import time
import logging
import MySQLdb
class Jobs(object):
# 初始化
"""docstring for Jobs"""
def __init__(self):
super(Jobs, self).__init__()
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s')
#数据库的操作,没有mysql可以做屏蔽
self.db = MySQLdb.connect('127.0.0.1','root','rootroot','MySQL_Test',charset='utf8')
self.cursor = self.db.cursor()
#log日志的显示
self.logger = logging.getLogger("sjk")
self.logger.setLevel(level=logging.DEBUG)
formatter = logging.Formatter(
'%(asctime)s - %(name)s - %(levelname)s - %(message)s')
handler = logging.FileHandler('log.txt')
handler.setFormatter(formatter)
handler.setLevel(logging.DEBUG)
self.logger.addHandler(handler)
self.logger.info('初始化完成')
# 模拟请求数据
def jobshtml(self, key, page='1'):
try:
self.logger.info('开始请求第' + page + '页')
#网页url
searchurl = "https://search.51job.com/list/040000,000000,0000,00,9,99,{key},2,{page}.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare="
user_agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.13; rv:59.0) Gecko/20100101 Firefox/59.0'
#设置请求头
header = {'User-Agent': user_agent, 'Host': 'search.51job.com',
'Referer': 'https://www.51job.com/'}
#拼接url
finalUrl = searchurl.format(key=key, page=page)
request = urllib2.Request(finalUrl, headers=header)
response = urllib2.urlopen(request)
#等待网页加载完成
time.sleep(3)
#gbk格式解码
info = response.read().decode('gbk')
self.logger.info('请求网页网页')
self.decodeHtml(info=info, key=key, page=page)
except urllib2.HTTPError as e:
print e.reason
# 解析网页数据
def decodeHtml(self, info, key, page):
self.logger.info('开始解析网页数据')
#BeautifulSoup 解析网页
soup = BeautifulSoup(info, 'html.parser')
#找到class = t1 t2 t3 t4 t5 的标签数据
ps = soup.find_all(attrs={"class": re.compile(r'^t[1-5].*')})
#打开txt文件 a+ 代表追加
f = codecs.open(key + '.txt', 'a+', 'UTF-8')
#清除之前的数据信息
f.truncate()
f.write('\n------------' + page + '--------------\n')
count = 1
arr = []
#做一些字符串的处理,形成数据格式 iOS开发工程师 有限公司 深圳-南山区 0.9-1.6万/月 05-16
for pi in ps:
spe = " "
finalstr = pi.getText().strip()
arr.append(finalstr)
if count % 5 == 0:
#每一条数据插入数据库,如果没有安装mysql 可以将当前行注释掉
self.connectMySQL(arr=arr)
arr = []
spe = "\n"
writestr = finalstr + spe
count += 1
f.write(writestr)
f.close()
self.logger.info('解析完成')
#数据库操作 没有安装mysql 可以屏蔽掉
def connectMySQL(self,arr):
work=arr[0]
company=arr[1]
place=arr[2]
salary=arr[3]
time=arr[4]
query = "select * from Jobs_tab where \
company_name='%s' and work_name='%s' and work_place='%s' \
and salary='%s' and time='%s'" %(company,work,place,salary,time)
self.cursor.execute(query)
queryresult = self.cursor.fetchall()
#数据库中不存在就插入数据 存在就可以更新数据 不过我这边没有写
if len(queryresult) > 0:
sql = "insert into Jobs_tab(work_name,company_name,work_place,salary\
,time) values('%s','%s','%s','%s','%s')" %(work,company,place,salary,time)
try:
self.cursor.execute(sql)
self.db.commit()
except Exception as e:
self.logger.info('写入数据库失败')
#模拟登陆
# def login(self):
# data = {'action':'save','isread':'on','loginname':'18086514327','password':'kui4131sjk'}
# 开始抓取 主函数
def run(self, key):
# 只要前5页的数据 key代表搜索工做类型 这边我是用的ios page是页数
for x in xrange(1, 6):
self.jobshtml(key=key, page=str(x))
self.logger.info('写入数据库完成')
self.db.close()
if __name__ == '__main__':
Jobs().run(key='iOS')
这种方式获取的数据格式如下:
以上就是本文的全部内容。希望对大家的学习有所帮助,也希望大家多多支持Script Home。 查看全部
python网页数据抓取(
2018年05月25日11:41:25一下)
python2.7实现抓取网页数据
更新时间:2018年5月25日11:41:25 作者:aasdsjk
本文文章主要详细介绍python2.7实现爬虫网页数据,具有一定的参考价值。有兴趣的朋友可以参考一下
最近刚学Python,做了一个简单的爬虫。作为一个简单的demo,希望对像我这样的初学者有所帮助。
代码使用python制作的爬虫2.7在51job上抓取职位、公司名称、工资、发布时间等。
直接上代码,代码中的注释比较清楚,如果没有安装mysql需要屏蔽相关代码:
#!/usr/bin/python
# -*- coding: UTF-8 -*-
from bs4 import BeautifulSoup
import urllib
import urllib2
import codecs
import re
import time
import logging
import MySQLdb
class Jobs(object):
# 初始化
"""docstring for Jobs"""
def __init__(self):
super(Jobs, self).__init__()
logging.basicConfig(level=logging.DEBUG,
format='%(asctime)s %(filename)s[line:%(lineno)d] %(levelname)s %(message)s')
#数据库的操作,没有mysql可以做屏蔽
self.db = MySQLdb.connect('127.0.0.1','root','rootroot','MySQL_Test',charset='utf8')
self.cursor = self.db.cursor()
#log日志的显示
self.logger = logging.getLogger("sjk")
self.logger.setLevel(level=logging.DEBUG)
formatter = logging.Formatter(
'%(asctime)s - %(name)s - %(levelname)s - %(message)s')
handler = logging.FileHandler('log.txt')
handler.setFormatter(formatter)
handler.setLevel(logging.DEBUG)
self.logger.addHandler(handler)
self.logger.info('初始化完成')
# 模拟请求数据
def jobshtml(self, key, page='1'):
try:
self.logger.info('开始请求第' + page + '页')
#网页url
searchurl = "https://search.51job.com/list/040000,000000,0000,00,9,99,{key},2,{page}.html?lang=c&stype=&postchannel=0000&workyear=99&cotype=99°reefrom=99&jobterm=99&companysize=99&providesalary=99&lonlat=0%2C0&radius=-1&ord_field=0&confirmdate=9&fromType=&dibiaoid=0&address=&line=&specialarea=00&from=&welfare="
user_agent = 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10.13; rv:59.0) Gecko/20100101 Firefox/59.0'
#设置请求头
header = {'User-Agent': user_agent, 'Host': 'search.51job.com',
'Referer': 'https://www.51job.com/'}
#拼接url
finalUrl = searchurl.format(key=key, page=page)
request = urllib2.Request(finalUrl, headers=header)
response = urllib2.urlopen(request)
#等待网页加载完成
time.sleep(3)
#gbk格式解码
info = response.read().decode('gbk')
self.logger.info('请求网页网页')
self.decodeHtml(info=info, key=key, page=page)
except urllib2.HTTPError as e:
print e.reason
# 解析网页数据
def decodeHtml(self, info, key, page):
self.logger.info('开始解析网页数据')
#BeautifulSoup 解析网页
soup = BeautifulSoup(info, 'html.parser')
#找到class = t1 t2 t3 t4 t5 的标签数据
ps = soup.find_all(attrs={"class": re.compile(r'^t[1-5].*')})
#打开txt文件 a+ 代表追加
f = codecs.open(key + '.txt', 'a+', 'UTF-8')
#清除之前的数据信息
f.truncate()
f.write('\n------------' + page + '--------------\n')
count = 1
arr = []
#做一些字符串的处理,形成数据格式 iOS开发工程师 有限公司 深圳-南山区 0.9-1.6万/月 05-16
for pi in ps:
spe = " "
finalstr = pi.getText().strip()
arr.append(finalstr)
if count % 5 == 0:
#每一条数据插入数据库,如果没有安装mysql 可以将当前行注释掉
self.connectMySQL(arr=arr)
arr = []
spe = "\n"
writestr = finalstr + spe
count += 1
f.write(writestr)
f.close()
self.logger.info('解析完成')
#数据库操作 没有安装mysql 可以屏蔽掉
def connectMySQL(self,arr):
work=arr[0]
company=arr[1]
place=arr[2]
salary=arr[3]
time=arr[4]
query = "select * from Jobs_tab where \
company_name='%s' and work_name='%s' and work_place='%s' \
and salary='%s' and time='%s'" %(company,work,place,salary,time)
self.cursor.execute(query)
queryresult = self.cursor.fetchall()
#数据库中不存在就插入数据 存在就可以更新数据 不过我这边没有写
if len(queryresult) > 0:
sql = "insert into Jobs_tab(work_name,company_name,work_place,salary\
,time) values('%s','%s','%s','%s','%s')" %(work,company,place,salary,time)
try:
self.cursor.execute(sql)
self.db.commit()
except Exception as e:
self.logger.info('写入数据库失败')
#模拟登陆
# def login(self):
# data = {'action':'save','isread':'on','loginname':'18086514327','password':'kui4131sjk'}
# 开始抓取 主函数
def run(self, key):
# 只要前5页的数据 key代表搜索工做类型 这边我是用的ios page是页数
for x in xrange(1, 6):
self.jobshtml(key=key, page=str(x))
self.logger.info('写入数据库完成')
self.db.close()
if __name__ == '__main__':
Jobs().run(key='iOS')
这种方式获取的数据格式如下:
以上就是本文的全部内容。希望对大家的学习有所帮助,也希望大家多多支持Script Home。
python网页数据抓取( Python大神用正则表达式教你搞定京东商品信息的精准匹配~)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2022-02-16 05:25
Python大神用正则表达式教你搞定京东商品信息的精准匹配~)
之前的小编使用Python正则表达式和BeautifulSoup来爬取京东商品信息。今天小编就用Xpath来演示如何实现京东商品信息的精准匹配~~
HTML文件实际上是由一组由尖括号组成的标签组织起来的,每一对尖括号组成一个标签,标签之间存在自上而下的关系,形成标签树;XPath 使用路径表达式来选择 XML 文档中的节点。通过遵循路径或步骤来选择节点。
京东狗粮产品
首先进入京东,输入你要查询的产品,向服务器发送网页请求。在这里,小编还是用关键词“狗粮”作为搜索对象,然后得到如下URL:%E7%8B%97%E7%B2%AE&enc=utf-8,其中参数表示我们的输入关键字,本例中该参数代表“狗粮”。详情请参考Python大神使用正则表达式教你获取京东产品信息。因此,只要输入关键字参数并对其进行编码,就可以得到目标网址。然后请求网页,得到响应,然后使用bs4选择器进行下一条数据采集。
京东官网部分产品信息源代码如下图所示:
京东官网狗粮信息源代码
仔细看源码可以发现,我们需要的目标信息就在标签下面,那么我们就像剥洋葱一样,一层一层的得到我们想要的信息。
通常URL编码的方式是将需要编码的字符转换成%xx的形式。一般来说,URL的编码都是基于UTF-8的,当然也和浏览器平台有关。Python的urllib库中提供了quote方法,可以对URL的字符串进行编码,从而可以进入对应的网页。
在线复制 Xpath 表达式
很多朋友觉得Xpath表达式很难写,但是掌握基本用法并不难。在线复制Xpath表达式如上图所示,可以很方便的复制Xpath表达式。但是这种方法得到的Xpath表达式一般不能在程序中使用,长的也看不出来。因此,Xpath 表达式一般要自己使用。
直接进入代码,使用Xpath提取目标信息,如商品名称、链接、图片、价格等。具体代码如下图所示:
爬虫代码
在这里,编辑器告诉您一种 Xpath 表达式匹配技术。之前看过几篇文章的文章,大佬们都推荐对Xpath表达式使用嵌套匹配。在此示例中,项目首先定义如下:
items = selector.xpath('//li[@class="gl-item"]')
然后使用range函数将网页中的目标信息一一匹配,而不是直接一步复制Xpath表达式。希望以后朋友们能少进这个坑~~
最终效果图如下:
最终效果图
新鲜的狗粮又出来了~
朋友们,有没有发现使用Xpath获取目标信息比使用正则表达式更容易?
如果你想了解更多关于Python网络爬虫和数据挖掘的知识,可以去专业的网站: 查看全部
python网页数据抓取(
Python大神用正则表达式教你搞定京东商品信息的精准匹配~)
之前的小编使用Python正则表达式和BeautifulSoup来爬取京东商品信息。今天小编就用Xpath来演示如何实现京东商品信息的精准匹配~~
HTML文件实际上是由一组由尖括号组成的标签组织起来的,每一对尖括号组成一个标签,标签之间存在自上而下的关系,形成标签树;XPath 使用路径表达式来选择 XML 文档中的节点。通过遵循路径或步骤来选择节点。
京东狗粮产品
首先进入京东,输入你要查询的产品,向服务器发送网页请求。在这里,小编还是用关键词“狗粮”作为搜索对象,然后得到如下URL:%E7%8B%97%E7%B2%AE&enc=utf-8,其中参数表示我们的输入关键字,本例中该参数代表“狗粮”。详情请参考Python大神使用正则表达式教你获取京东产品信息。因此,只要输入关键字参数并对其进行编码,就可以得到目标网址。然后请求网页,得到响应,然后使用bs4选择器进行下一条数据采集。
京东官网部分产品信息源代码如下图所示:
京东官网狗粮信息源代码
仔细看源码可以发现,我们需要的目标信息就在标签下面,那么我们就像剥洋葱一样,一层一层的得到我们想要的信息。
通常URL编码的方式是将需要编码的字符转换成%xx的形式。一般来说,URL的编码都是基于UTF-8的,当然也和浏览器平台有关。Python的urllib库中提供了quote方法,可以对URL的字符串进行编码,从而可以进入对应的网页。
在线复制 Xpath 表达式
很多朋友觉得Xpath表达式很难写,但是掌握基本用法并不难。在线复制Xpath表达式如上图所示,可以很方便的复制Xpath表达式。但是这种方法得到的Xpath表达式一般不能在程序中使用,长的也看不出来。因此,Xpath 表达式一般要自己使用。
直接进入代码,使用Xpath提取目标信息,如商品名称、链接、图片、价格等。具体代码如下图所示:
爬虫代码
在这里,编辑器告诉您一种 Xpath 表达式匹配技术。之前看过几篇文章的文章,大佬们都推荐对Xpath表达式使用嵌套匹配。在此示例中,项目首先定义如下:
items = selector.xpath('//li[@class="gl-item"]')
然后使用range函数将网页中的目标信息一一匹配,而不是直接一步复制Xpath表达式。希望以后朋友们能少进这个坑~~
最终效果图如下:
最终效果图
新鲜的狗粮又出来了~
朋友们,有没有发现使用Xpath获取目标信息比使用正则表达式更容易?
如果你想了解更多关于Python网络爬虫和数据挖掘的知识,可以去专业的网站:
python网页数据抓取(:如何从网页中提取数据,以tags文件为例)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2022-02-16 05:05
python网页数据抓取可以参考一下我的文章,由于是爬虫,所以用了vcredis,其实就是基于一个缓存过滤器和正则表达式对页面进行爬取。也可以爬取些文本数据。这篇博客是对整个数据抓取流程,服务器架构和抓取时间线的综述,相对全面。在学习过程中,是根据自己的理解和遇到的问题提出问题和探索解决,希望对自己和大家有所帮助。
不同抓取方法本文只总结流程和一部分代码实现,期望其他人有更好的解决方案可以参考一下。本文要解决的问题:如何从网页中提取数据,以tags文件为例,包括分页抓取、分页excel抓取以及文字图片等不同网页抓取方式的实现。
一、python网页数据抓取流程1.1提取标签、tags文件先通过正则文件提取出标签。
代码:#-*-coding:utf-8-*-importreimportrequestsurl=''requests。get(url)tags=requests。get(url)classpost(scrapy。http。urlopen):classresponse(scrapy。http。urlopen):method='post'headers={'user-agent':'mozilla/5。0(macintosh;intelmacosx10_12_。
6)applewebkit/537。36(khtml,likegecko)chrome/69。3770。132safari/537。36'}req=requests。get(url)content=req。json()params={'tag':tags}def__init__(self,request,headers,soup=none):self。
__title=request。titleself。tags=request。tagsself。headers={'user-agent':'mozilla/5。0(windowsnt10。0;win64;x6。
4)applewebkit/537。36(khtml,likegecko)chrome/69。3770。132safari/537。36'}self。request=requests。get(self。__title,headers=self。headers)self。response=requests。
get(self。__title,headers=self。headers)self。content=requests。get(self。tags,headers=self。headers)#创建request对象,第一次请求到的时候写入tagsself。__headers={'user-agent':'mozilla/5。0(windowsnt10。0;win64;x6。
4)applewebkit/537。36(khtml,likegecko)chrome/69。3770。132safari/537。36'}req=requests。get(req。text,headers=self。headers)#tokenonlytoken={'params':params}token_len={'token':token,'time':'get','email':'@example。 查看全部
python网页数据抓取(:如何从网页中提取数据,以tags文件为例)
python网页数据抓取可以参考一下我的文章,由于是爬虫,所以用了vcredis,其实就是基于一个缓存过滤器和正则表达式对页面进行爬取。也可以爬取些文本数据。这篇博客是对整个数据抓取流程,服务器架构和抓取时间线的综述,相对全面。在学习过程中,是根据自己的理解和遇到的问题提出问题和探索解决,希望对自己和大家有所帮助。
不同抓取方法本文只总结流程和一部分代码实现,期望其他人有更好的解决方案可以参考一下。本文要解决的问题:如何从网页中提取数据,以tags文件为例,包括分页抓取、分页excel抓取以及文字图片等不同网页抓取方式的实现。
一、python网页数据抓取流程1.1提取标签、tags文件先通过正则文件提取出标签。
代码:#-*-coding:utf-8-*-importreimportrequestsurl=''requests。get(url)tags=requests。get(url)classpost(scrapy。http。urlopen):classresponse(scrapy。http。urlopen):method='post'headers={'user-agent':'mozilla/5。0(macintosh;intelmacosx10_12_。
6)applewebkit/537。36(khtml,likegecko)chrome/69。3770。132safari/537。36'}req=requests。get(url)content=req。json()params={'tag':tags}def__init__(self,request,headers,soup=none):self。
__title=request。titleself。tags=request。tagsself。headers={'user-agent':'mozilla/5。0(windowsnt10。0;win64;x6。
4)applewebkit/537。36(khtml,likegecko)chrome/69。3770。132safari/537。36'}self。request=requests。get(self。__title,headers=self。headers)self。response=requests。
get(self。__title,headers=self。headers)self。content=requests。get(self。tags,headers=self。headers)#创建request对象,第一次请求到的时候写入tagsself。__headers={'user-agent':'mozilla/5。0(windowsnt10。0;win64;x6。
4)applewebkit/537。36(khtml,likegecko)chrome/69。3770。132safari/537。36'}req=requests。get(req。text,headers=self。headers)#tokenonlytoken={'params':params}token_len={'token':token,'time':'get','email':'@example。
python网页数据抓取(Python內建使用urllib.request获取网页urllib是什么意思?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2022-02-14 14:38
1. 使用 urllib.request 获取网页
urllib 是 Python 中的内置 HTTP 库。使用 urllib,您只需非常简单的步骤即可高效地采集数据;配合Beautiful等HTML解析库,可以为采集网络数据编写大规模爬虫;
注意:示例代码是用Python3编写的;urllib是Python2中的urllib和urllib2的组合,Python2中的urllib2对应Python3中的urllib.request
简单的例子:
2. 伪造请求头信息
有时爬虫发起的请求会被服务器拒绝。在这种情况下,需要将爬虫伪装成人类用户的浏览器,这通常是通过伪造请求头信息来实现的,例如:
3. 伪造请求体
爬取一些网站时,需要POST数据到服务器,然后需要伪造请求体;
为了实现有道词典的在线翻译脚本,在Chrome中打开开发工具,在Network下用POST方法找到请求,观察数据发现请求体中的‘i’是URL编码的内容那是需要翻译的,所以可以伪造Request body,比如:
您还可以使用 add_header() 方法来伪造请求标头,例如:
4. 使用代理 IP
为了避免爬虫过于频繁导致IP阻塞的问题采集,可以使用代理IP,如:
注意:使用爬虫过于频繁地访问目标站点会占用大量服务器资源。大规模分布式爬虫集中爬取网站,甚至相当于对网站发起DDOS攻击;因此,在使用爬虫爬取数据时,应合理安排爬取的频率和时间;如:服务器比较空闲时爬取(如:清晨),完成爬取任务后暂停一段时间等;
5. 检测网页的编码
虽然大部分网页都是用UTF-8编码的,但是有时候你会遇到使用其他编码方式的网页,所以你必须知道网页的编码方式才能正确解码爬取的页面;
chardet是python的第三方模块,使用chardet可以自动检测网页的编码方式;
安装 chardet:pip install charest
利用:
6. 获取跳转链接
有时网页的一个页面需要根据原创URL进行一次甚至多次跳转才能最终到达目的页面,所以需要正确处理跳转;
通过requests模块的head()函数获取跳转链接的URL,如 查看全部
python网页数据抓取(Python內建使用urllib.request获取网页urllib是什么意思?)
1. 使用 urllib.request 获取网页
urllib 是 Python 中的内置 HTTP 库。使用 urllib,您只需非常简单的步骤即可高效地采集数据;配合Beautiful等HTML解析库,可以为采集网络数据编写大规模爬虫;
注意:示例代码是用Python3编写的;urllib是Python2中的urllib和urllib2的组合,Python2中的urllib2对应Python3中的urllib.request
简单的例子:
2. 伪造请求头信息
有时爬虫发起的请求会被服务器拒绝。在这种情况下,需要将爬虫伪装成人类用户的浏览器,这通常是通过伪造请求头信息来实现的,例如:
3. 伪造请求体
爬取一些网站时,需要POST数据到服务器,然后需要伪造请求体;
为了实现有道词典的在线翻译脚本,在Chrome中打开开发工具,在Network下用POST方法找到请求,观察数据发现请求体中的‘i’是URL编码的内容那是需要翻译的,所以可以伪造Request body,比如:
您还可以使用 add_header() 方法来伪造请求标头,例如:
4. 使用代理 IP
为了避免爬虫过于频繁导致IP阻塞的问题采集,可以使用代理IP,如:
注意:使用爬虫过于频繁地访问目标站点会占用大量服务器资源。大规模分布式爬虫集中爬取网站,甚至相当于对网站发起DDOS攻击;因此,在使用爬虫爬取数据时,应合理安排爬取的频率和时间;如:服务器比较空闲时爬取(如:清晨),完成爬取任务后暂停一段时间等;
5. 检测网页的编码
虽然大部分网页都是用UTF-8编码的,但是有时候你会遇到使用其他编码方式的网页,所以你必须知道网页的编码方式才能正确解码爬取的页面;
chardet是python的第三方模块,使用chardet可以自动检测网页的编码方式;
安装 chardet:pip install charest
利用:
6. 获取跳转链接
有时网页的一个页面需要根据原创URL进行一次甚至多次跳转才能最终到达目的页面,所以需要正确处理跳转;
通过requests模块的head()函数获取跳转链接的URL,如
python网页数据抓取(python网络爬虫(上)概述预备知识、如何处理登录问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 141 次浏览 • 2022-02-14 11:10
石斛2020-11-24 305次浏览Python原版网络爬虫(上)
关键词:
登山在山里充满爱,在海里看海充满意义。本文章主要介绍Python网络爬虫相关知识(上),希望对大家有所帮助。
python网络爬虫概述(上)
初步知识
1、如何处理大量(JS)的页面以及如何处理登录问题
2、屏幕抓取、数据挖掘、网络收获、网络爬虫、网络爬虫、机器人
3、网络爬虫的优势:一、同时处理上千甚至上百万个网页;二、不同于传统搜索引擎,可以获得更准确的数据信息;三、 相比API取数据,网络爬虫更灵活
4、网络爬虫用于:市场预测、机器语言翻译、医学诊断、新闻网站、文章、健康论坛、宏观经济学、生物基因、国际关系、健康论坛、艺术领域以及数据采集和分析的其他方面(分类和汇总)
5、网络爬虫涉及:数据库、网络服务器、HTTP协议、html语言(HyperTextMarkupLanguage)、网络安全、图像处理、数据科学等负面知识
6、网页的组成:HTML文本格式层、CSS样式层(CascadingStyleSheets)、javaScript执行层、图像渲染层
7、JavaScript思路:(1)学习C语言的基本语法,(2)学习Java语言的数据类型和内存管理,(3)学习Scheme语言,改进功能到“头等舱”(first class)的状态,(4)借鉴自Self语言,使用基于原型的继承机制。JavaScript组成:(1)核心(ECMAScript) ),描述语言的语法和基本对象,(2)文档对象模型(DOM),描述处理网页内容的方法和接口,(3)浏览器对象模型(BOM),它描述了与浏览器的交互 .JavaScript 库的方法和接口:jQuery、Prototype、MooTools 等。
8、HTML文本结构:HTML的结构是树状结构,在内存中形成一棵树
9、HTML只负责文档的结构和内容,表达完全交给CSS。基本 CSS 语法:选择器 { 属性:值;属性:值;属性:值;} (tagAttributes)
10、浏览器加载的网页需要加载很多相关的资源文件,包括:图片文件、JavaScript文件、CSS文件、链接其他网页的URL地址信息等。
11、浏览器加载服务器资源,根据标签如
,它创建一个数据包,指示操作系统向服务器发送请求,然后将获取的数据解释为图像。浏览器就是代码,代码可以分解成许多基本组件,可以根据需要重写、重用和修改
12、.get_text():清除HTML文档中所有无用的信息,如tagName、超链接、段落等。通常在准备打印、存储、操作最终数据时,使用 .get_text()!
开发工具及原理分析1、urllib标准库,urllib.request导入urlopen
1.1、urllib标准库的功能:网页请求数据、处理cookies、更改请求头和用户代理元数据的功能
1.2、urlopen函数功能:打开和读取从网络上获取的远程对象,可以读取HTML文件、图片文件,以及任何其他文件流
2、BeautifulSoup 库
2.1、XML 是一种可扩展的标记语言,而 HTML 是一种超文本标记语言:XML 语法更严格,HTML 语法更宽松;XML主要用于数据格式化存储,HTML主要用于编辑网页;XML 语言是对超文本标记语言的补充;为不同的目的而设计,XML被设计用来传输和存储数据,它的重点是数据的内容,HTML被设计用来显示数据,它的重点是数据的外观
2.2、BeautifulSoup 库通过定位 HTML 标签来格式化和组织复杂的网页信息;通过易于使用的 python 对象显示 XML 结构信息
2.3、BeautifulSoup 库创建 BeautifulSoup 对象:bs=BeautifulSoup(html.read(), 'html.parser'), bs.HTML 标签 (html.title, html.body.h1、html.body.div)
第一个参数:BeautifulSoup 对象所基于的 HTML 文本
第二个参数:BeautifulSoup 对象创建对象的解释器,'html.parser', 'lxml', 'html5lib'
1、'lxml', 'html5lib' 优点:容错,如果HTML标签(tagName)异常:未闭合,嵌套错误,缺少head标签,缺少body标签,'lxml','html5lib'可以优化
2、'html.parser', 'lxml', 'html5lib' 三个解释器爬网速度不同,'lxml'>'html.parser'>'html5lib',但关键问题和瓶颈不是宽带速度爬行速度!
2.4、网络爬虫异常,因为网络数据格式异常,网络爬虫异常:一、urlopen()有问题;二、print(bs .h1)有问题
一、urlopen() 的问题:
1、服务器上不存在网页:HTTPError: '404 PageNot Found', '505 Internet Server Error'
2、服务器不存在:URLError
二、print(bs.h1)有问题:
1、BeautifulSoup 对象标签异常,不存在!无--->属性错误!由于 BeautifulSoup 对象在标签不存在时调用它,所以它会返回 None。如果调用None下面的子标签,就会出现AttributeError,所以需要避免这两种情况的异常!
异常处理思路:try...except...else...添加异常检查点。
from urllib.request import urlopen
from urllib.error import HTTPError
from bs4 import BeautifulSoup
def getTitle(url):
try:
html = urlopen(url)
except HTTPError as e:
return None
try:
bsObj = BeautifulSoup(html.read(), "lxml")
title = bsObj.body.h1
except AttributeError as e:
return None
return title
title = getTitle("http://www.pythonscraping.com/ ... 6quot;)
if title == None:
print("Title could not be found")
else:
print(title)
3、HTML解析:BeautifulSoup,正则表达式
3.1、网页爬虫代码增强灵活性和可读性的思路:
1、方向一、比较网页PC版和APP版,比较PC版的HTML风格和APP版的HTML风格。选择更适用的版本,修改请求头状态,获取对应版本的状态。
2、方向二、JavaScript文件,通过网页加载的JavaScript文件中收录的信息
3、方向三、URL链接收录网页的标题,直接从URL链接获取目标信息
4、方向四、目标信息的来源页面
3.2、BeautifulSoup 用途:属性值搜索标签、标签组、CSS 语法中的导航树(BeautifulSoup 标签树导航)
1、bs.tagName
2、bs.find_all(tagName, tagAttributes)
3、写一个网络爬虫:scrapy
4、存储目标信息:mysql
应用示例
至此,这篇关于Python网络爬虫(上)的文章就讲完了。如果您的问题无法解决,请参考以下文章:
相关文章
如何使用Python网络爬虫抓取微信朋友圈动态(上)
003 Python网络爬虫和信息提取网络爬虫的“海盗”
Python爬虫入门
Python爬虫难学吗?容易学吗?
Python爬虫编程思路:网络爬虫基本原理
Web Crawler 入门:您的第一个爬虫项目(请求库)
爬虫学习06.Python网络爬虫请求模块
Python网络爬虫:空姐网尴尬xxx结果图及源码 查看全部
python网页数据抓取(python网络爬虫(上)概述预备知识、如何处理登录问题)
石斛2020-11-24 305次浏览Python原版网络爬虫(上)
关键词:
登山在山里充满爱,在海里看海充满意义。本文章主要介绍Python网络爬虫相关知识(上),希望对大家有所帮助。
python网络爬虫概述(上)
初步知识
1、如何处理大量(JS)的页面以及如何处理登录问题
2、屏幕抓取、数据挖掘、网络收获、网络爬虫、网络爬虫、机器人
3、网络爬虫的优势:一、同时处理上千甚至上百万个网页;二、不同于传统搜索引擎,可以获得更准确的数据信息;三、 相比API取数据,网络爬虫更灵活
4、网络爬虫用于:市场预测、机器语言翻译、医学诊断、新闻网站、文章、健康论坛、宏观经济学、生物基因、国际关系、健康论坛、艺术领域以及数据采集和分析的其他方面(分类和汇总)
5、网络爬虫涉及:数据库、网络服务器、HTTP协议、html语言(HyperTextMarkupLanguage)、网络安全、图像处理、数据科学等负面知识
6、网页的组成:HTML文本格式层、CSS样式层(CascadingStyleSheets)、javaScript执行层、图像渲染层
7、JavaScript思路:(1)学习C语言的基本语法,(2)学习Java语言的数据类型和内存管理,(3)学习Scheme语言,改进功能到“头等舱”(first class)的状态,(4)借鉴自Self语言,使用基于原型的继承机制。JavaScript组成:(1)核心(ECMAScript) ),描述语言的语法和基本对象,(2)文档对象模型(DOM),描述处理网页内容的方法和接口,(3)浏览器对象模型(BOM),它描述了与浏览器的交互 .JavaScript 库的方法和接口:jQuery、Prototype、MooTools 等。
8、HTML文本结构:HTML的结构是树状结构,在内存中形成一棵树
9、HTML只负责文档的结构和内容,表达完全交给CSS。基本 CSS 语法:选择器 { 属性:值;属性:值;属性:值;} (tagAttributes)
10、浏览器加载的网页需要加载很多相关的资源文件,包括:图片文件、JavaScript文件、CSS文件、链接其他网页的URL地址信息等。
11、浏览器加载服务器资源,根据标签如
,它创建一个数据包,指示操作系统向服务器发送请求,然后将获取的数据解释为图像。浏览器就是代码,代码可以分解成许多基本组件,可以根据需要重写、重用和修改
12、.get_text():清除HTML文档中所有无用的信息,如tagName、超链接、段落等。通常在准备打印、存储、操作最终数据时,使用 .get_text()!
开发工具及原理分析1、urllib标准库,urllib.request导入urlopen
1.1、urllib标准库的功能:网页请求数据、处理cookies、更改请求头和用户代理元数据的功能
1.2、urlopen函数功能:打开和读取从网络上获取的远程对象,可以读取HTML文件、图片文件,以及任何其他文件流
2、BeautifulSoup 库
2.1、XML 是一种可扩展的标记语言,而 HTML 是一种超文本标记语言:XML 语法更严格,HTML 语法更宽松;XML主要用于数据格式化存储,HTML主要用于编辑网页;XML 语言是对超文本标记语言的补充;为不同的目的而设计,XML被设计用来传输和存储数据,它的重点是数据的内容,HTML被设计用来显示数据,它的重点是数据的外观
2.2、BeautifulSoup 库通过定位 HTML 标签来格式化和组织复杂的网页信息;通过易于使用的 python 对象显示 XML 结构信息
2.3、BeautifulSoup 库创建 BeautifulSoup 对象:bs=BeautifulSoup(html.read(), 'html.parser'), bs.HTML 标签 (html.title, html.body.h1、html.body.div)
第一个参数:BeautifulSoup 对象所基于的 HTML 文本
第二个参数:BeautifulSoup 对象创建对象的解释器,'html.parser', 'lxml', 'html5lib'
1、'lxml', 'html5lib' 优点:容错,如果HTML标签(tagName)异常:未闭合,嵌套错误,缺少head标签,缺少body标签,'lxml','html5lib'可以优化
2、'html.parser', 'lxml', 'html5lib' 三个解释器爬网速度不同,'lxml'>'html.parser'>'html5lib',但关键问题和瓶颈不是宽带速度爬行速度!
2.4、网络爬虫异常,因为网络数据格式异常,网络爬虫异常:一、urlopen()有问题;二、print(bs .h1)有问题
一、urlopen() 的问题:
1、服务器上不存在网页:HTTPError: '404 PageNot Found', '505 Internet Server Error'
2、服务器不存在:URLError
二、print(bs.h1)有问题:
1、BeautifulSoup 对象标签异常,不存在!无--->属性错误!由于 BeautifulSoup 对象在标签不存在时调用它,所以它会返回 None。如果调用None下面的子标签,就会出现AttributeError,所以需要避免这两种情况的异常!
异常处理思路:try...except...else...添加异常检查点。
from urllib.request import urlopen
from urllib.error import HTTPError
from bs4 import BeautifulSoup
def getTitle(url):
try:
html = urlopen(url)
except HTTPError as e:
return None
try:
bsObj = BeautifulSoup(html.read(), "lxml")
title = bsObj.body.h1
except AttributeError as e:
return None
return title
title = getTitle("http://www.pythonscraping.com/ ... 6quot;)
if title == None:
print("Title could not be found")
else:
print(title)
3、HTML解析:BeautifulSoup,正则表达式
3.1、网页爬虫代码增强灵活性和可读性的思路:
1、方向一、比较网页PC版和APP版,比较PC版的HTML风格和APP版的HTML风格。选择更适用的版本,修改请求头状态,获取对应版本的状态。
2、方向二、JavaScript文件,通过网页加载的JavaScript文件中收录的信息
3、方向三、URL链接收录网页的标题,直接从URL链接获取目标信息
4、方向四、目标信息的来源页面
3.2、BeautifulSoup 用途:属性值搜索标签、标签组、CSS 语法中的导航树(BeautifulSoup 标签树导航)
1、bs.tagName
2、bs.find_all(tagName, tagAttributes)
3、写一个网络爬虫:scrapy
4、存储目标信息:mysql
应用示例
至此,这篇关于Python网络爬虫(上)的文章就讲完了。如果您的问题无法解决,请参考以下文章:
相关文章
如何使用Python网络爬虫抓取微信朋友圈动态(上)
003 Python网络爬虫和信息提取网络爬虫的“海盗”
Python爬虫入门
Python爬虫难学吗?容易学吗?
Python爬虫编程思路:网络爬虫基本原理
Web Crawler 入门:您的第一个爬虫项目(请求库)
爬虫学习06.Python网络爬虫请求模块
Python网络爬虫:空姐网尴尬xxx结果图及源码
python网页数据抓取(想了解判断网页编码的方法python版的相关内容吗 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 122 次浏览 • 2022-02-14 11:05
)
想知道python版的网页编码判断方法吗?在本文中,mickelfeng将讲解python网页编码判断方法的相关知识和一些代码示例。欢迎阅读和指正。方法,网页编码判断python代码一起来学习。
在web开发中,我们经常会遇到可以完成这个功能的各种语言的web爬取和分析。我喜欢用python实现它,因为python提供了很多成熟的模块,可以轻松实现网页抓取。
但是在爬取过程中会出现编码问题。今天,我们来看看如何判断网页的编码:
网上很多网页的编码格式一般都是GBK、GB2312UTF-8等。
获取网页的数据后,首先要判断网页的编码,以便将抓取到的内容的编码统一转换为我们可以处理的编码,避免出现乱码问题。
以下是确定网页编码的两种方法:
总结:第二种方法很准确。使用python模块分析网页代码分析的内容是最准确的,而分析元头信息的方法不是很准确。
方法一:使用urllib模块的getparam方法
方法二:使用chardet模块
#如果你的python没有安装chardet模块你需要首先安装一下chardet判断编码的模块哦
#author:pythontab.com
import chardet
import urllib
#先获取网页内容
data1 = urllib.urlopen('http://www.baidu.com').read()
#用chardet进行内容分析
chardit1 = chardet.detect(data1)
print chardit1['encoding'] # baidu 查看全部
python网页数据抓取(想了解判断网页编码的方法python版的相关内容吗
)
想知道python版的网页编码判断方法吗?在本文中,mickelfeng将讲解python网页编码判断方法的相关知识和一些代码示例。欢迎阅读和指正。方法,网页编码判断python代码一起来学习。
在web开发中,我们经常会遇到可以完成这个功能的各种语言的web爬取和分析。我喜欢用python实现它,因为python提供了很多成熟的模块,可以轻松实现网页抓取。
但是在爬取过程中会出现编码问题。今天,我们来看看如何判断网页的编码:
网上很多网页的编码格式一般都是GBK、GB2312UTF-8等。
获取网页的数据后,首先要判断网页的编码,以便将抓取到的内容的编码统一转换为我们可以处理的编码,避免出现乱码问题。
以下是确定网页编码的两种方法:
总结:第二种方法很准确。使用python模块分析网页代码分析的内容是最准确的,而分析元头信息的方法不是很准确。
方法一:使用urllib模块的getparam方法
方法二:使用chardet模块
#如果你的python没有安装chardet模块你需要首先安装一下chardet判断编码的模块哦
#author:pythontab.com
import chardet
import urllib
#先获取网页内容
data1 = urllib.urlopen('http://www.baidu.com').read()
#用chardet进行内容分析
chardit1 = chardet.detect(data1)
print chardit1['encoding'] # baidu
python网页数据抓取(先上代码看了一下应该是Pyecharts中Map的data_pair )
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-02-14 08:05
)
2021/07/15 更新:
没有及时看到评论区的反馈。我真的很抱歉。我把代码拉下来看了看。应该是Pyecharts中Map的data_pair数据类型发生了变化。现在将 dic_items 转换为列表。
代码已整理完善,完整源码已上传至Gitee,地址:完整源码
所有生成的csv、疫情图、可视化图表都在项目根目录下。
总结:
受2019-nCoV影响,一场没有硝烟的防疫阻击战已经打响。在全国人民的共同努力下,疫情正在逐步稳定,但我们仍不能掉以轻心。
疫情开始前,我每天都在关注疫情,尤其是全国疫情地图。在那之后,我一直想自己拿数据做一个,但我没有坚持去做。前几天用Python爬取了结果查询网站,照着做,完成了这个需求。
话不多说,先上图吧:
中国疫情地图
各省详情
湖北省各城市疫情数据分布
目录
数据源分析:
数据来自丁香博士:
博士。丁香的数据如下图所示:
看到这里,你可能觉得应该直接把这个数据放到tr,td或者ul,li里面,直接发送请求,获取页面DOM中的文本就行了
一开始我也是这么想的,但是看了网页的源码后才发现不是-_-||
其实中国每个省份的数据都是存储在脚本标签中,id为getAreaStat,然后动态渲染到视图上。
所以我们要做的就是获取脚本标签中id为getAreaStat的文本
数据管理:
不难看出script标签中的数据是以json的形式存储的。我们验证和格式化 json 字符串并组织其中的数据。
左边的密集数据格式化后,很直观的看到json字符串的内部存储,大致如下:在整个json字符串中,每个province是一个dict,每个province里面的city省是一个子列表存储该省的城市数据。
代码部分代码中要使用的第三方库如下:一、抓取全国各省疫情信息,生成csv文件基本
1.代码分析:
2.源码:
import requests
from pyquery import PyQuery as pq
import json
import pandas as pd
import time
def get_data():
url = "https://ncov.dxy.cn/ncovh5/view/pneumonia"
response = requests.get(url)
if response.status_code == 200:
response.encoding = "utf-8"
dom = pq(response.content)
data = dom("script#getAreaStat").text().split(" = ")[1].split("}catch")[0]
jsonObj = json.loads(data) # json对象
print("数据抓取成功...")
province_data = []
for item in jsonObj:
dic = {"省全称": item["provinceName"], "省简称": item["provinceShortName"], "现存确诊人数": item["currentConfirmedCount"],
"累计确诊人数": item["confirmedCount"], "疑似人数": item["suspectedCount"], "治愈人数": item["curedCount"],
"死亡人数": item["deadCount"]}
province_data.append(dic)
if len(province_data) > 0:
print("写入数据...")
try:
df = pd.DataFrame(province_data)
time_format = time.strftime("%Y-%m-%d_%H_%M_%S", time.localtime())
df.to_csv(time_format + "全国各省疫情数据.csv", encoding="gbk", index=False)
print("写入成功...")
except Exception as e:
print(f"写入失败....{e}")
if __name__ == '__main__':
get_data()
3.运行效果:
二、用pyecharts绘制中国疫情地图,进阶
一说到画表,首先想到的就是Apache开源的echarts框架,有效又强大。因为不熟悉Matplotlib库,拿到数据后想用echarts框架的前端自己画一个,后来才知道有专门的pyecharts,很不错!
建议不了解echarts或pyecharts的同学先阅读官方API,了解基本图表类型和各种参数。 (⊙﹏⊙))哦!
1.代码分析:
2.源码:
"""
@File : data_chart.py
@Modify Time @Author @Version @Desciption
------------ ------- -------- -----------
2021/7/15 9:25 wrzcoder 1.0 None
"""
from pyecharts import options as opts
from pyecharts.charts import Map
import requests
from pyquery import PyQuery as pq
import json
import time
def map_visual_map() -> Map:
c = (
Map(init_opts=opts.InitOpts(page_title="中国疫情地图"))
.add("现存确诊人数", data_pair=list(current_data_dic.items()), maptype="china")
.set_global_opts(
title_opts=opts.TitleOpts(title="中国疫情地图", subtitle="数据更新于" + time_format),
visualmap_opts=opts.VisualMapOpts(pieces=[
{"value": 0, "label": "无", "color": "#9AFF9A"},
{"min": 1, "max": 9, "label": "1~9", "color": "#FFCCCC"},
{"min": 10, "max": 99, "label": "10~99", "color": "#DB5A6B"},
{"min": 100, "max": 499, "label": "100~499", "color": "#FF6666"},
{"min": 500, "max": 999, "label": "500~999", "color": "#CC2929"},
{"min": 1000, "max": 9999, "label": "1000~9999", "color": "#8C0D0D"},
{"min": 10000, "label": ">10000", "color": "#9d2933"}
], is_piecewise=True),
)
)
return c
if __name__ == '__main__':
try:
url = "https://ncov.dxy.cn/ncovh5/view/pneumonia"
response = requests.get(url)
if response.status_code == 200:
response.encoding = "utf-8"
dom = pq(response.content)
data = dom("script#getAreaStat").text().split(" = ")[1].split("}catch")[0]
jsonObj = json.loads(data) # json对象
print("数据抓取成功...")
current_data_dic = {}
time_format = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
for item in jsonObj:
current_data_dic[item["provinceShortName"]] = item["currentConfirmedCount"]
print(list(current_data_dic.items()))
map_visual_map().render("疫情地图.html")
print('疫情地图已生成在项目根目录...')
except Exception as e:
print(e)
3.运行效果:
三、采集全国各省市的疫情数据,进行数据可视化扩展
上面我们只用到了各个省的数据,而且在分析之初,各个省的dict中还收录了该省的市(区)的数据,我们不能浪费这些数据,我们可以抓取它。为了充分利用它们,我们对全国各省市的所有疫情数据进行了分类和可视化。
这里我想说的是:我们在可视化每个省(直辖市)以下市(区)的疫情数据时,也可以使用pyecharts中的Map,但是为了更加熟悉pyecharts,我们会改这里的表格类型饼图。
看起来很麻烦。求各省的数据,包括城市,最后画个图,太麻烦了。太麻烦了,不过不是(*^▽^*)就30行代码
1.代码分析
2.源码
"""
@File : province_data_chart.py
@Modify Time @Author @Version @Desciption
------------ ------- -------- -----------
2021/7/15 9:45 wrzcoder 1.0 None
"""
import requests
import json
from pyecharts.charts import Pie
import pyecharts.options as opts
import time
from pyquery import PyQuery as pq
import os
def create_Pie(provinceName, dic_citys) -> Pie:
c = (
Pie(init_opts=opts.InitOpts(width="100%", height="800px", page_title=provinceName + "各市(区)情况"))
.add("", data_pair=list(dic_citys.items()), center=["50%", "58%"], )
.set_global_opts(title_opts=opts.TitleOpts(title=provinceName + "各市(区)情况", subtitle="数据更新于:" + timeformat))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
if not os.path.exists('./中国各省情况'):
os.mkdir('./中国各省情况')
c.render("./中国各省情况/" + provinceName + "各市(区)情况.html")
if __name__ == '__main__':
try:
url = "https://ncov.dxy.cn/ncovh5/view/pneumonia"
timeformat = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
response = requests.get(url)
response.encoding = "utf-8"
if response.status_code == 200:
print("数据抓取成功!")
dom = pq(response.text)
jsonobj = json.loads(dom("script#getAreaStat").text().split(" = ")[1].split("}catch")[0])
for province in jsonobj:
dic_city = {}
for city in province["cities"]:
dic_city[city["cityName"]] = city["currentConfirmedCount"]
if dic_city.__len__() > 0:
create_Pie(province["provinceName"], dic_city)
print(province["provinceName"] + "各市数据汇总完毕!")
except Exception as e:
print(e)
3.运行效果:
短短1.1s,我们爬取了全国所有省市的疫情数据,整理生成数据图表
打开随机饼图查看效果:
四川省各城市疫情数据汇总
至此,我们完成了全国各省市疫情实时数据的采集和处理,还绘制了中国疫情地图。在此基础上,我们进一步扩展,对中国各省、自治区、直辖市的疫情数据进行了批量整理和可视化。期间复习了requests库、pandas、pyquery库等,同时也学习和学习了强大的图表绘制pyecharts库,可以说是收获颇丰!因此,在这里一起分享和学习!
最后,加油武汉,加油中国!疫情终将过去,春天终将到来!
图片来自网络
希望你下次运行这段代码时,看到的疫情图是这样的:
查看全部
python网页数据抓取(先上代码看了一下应该是Pyecharts中Map的data_pair
)
2021/07/15 更新:
没有及时看到评论区的反馈。我真的很抱歉。我把代码拉下来看了看。应该是Pyecharts中Map的data_pair数据类型发生了变化。现在将 dic_items 转换为列表。
代码已整理完善,完整源码已上传至Gitee,地址:完整源码
所有生成的csv、疫情图、可视化图表都在项目根目录下。
总结:
受2019-nCoV影响,一场没有硝烟的防疫阻击战已经打响。在全国人民的共同努力下,疫情正在逐步稳定,但我们仍不能掉以轻心。
疫情开始前,我每天都在关注疫情,尤其是全国疫情地图。在那之后,我一直想自己拿数据做一个,但我没有坚持去做。前几天用Python爬取了结果查询网站,照着做,完成了这个需求。
话不多说,先上图吧:
中国疫情地图
各省详情
湖北省各城市疫情数据分布
目录
数据源分析:
数据来自丁香博士:
博士。丁香的数据如下图所示:
看到这里,你可能觉得应该直接把这个数据放到tr,td或者ul,li里面,直接发送请求,获取页面DOM中的文本就行了
一开始我也是这么想的,但是看了网页的源码后才发现不是-_-||
其实中国每个省份的数据都是存储在脚本标签中,id为getAreaStat,然后动态渲染到视图上。
所以我们要做的就是获取脚本标签中id为getAreaStat的文本
数据管理:
不难看出script标签中的数据是以json的形式存储的。我们验证和格式化 json 字符串并组织其中的数据。
左边的密集数据格式化后,很直观的看到json字符串的内部存储,大致如下:在整个json字符串中,每个province是一个dict,每个province里面的city省是一个子列表存储该省的城市数据。
代码部分代码中要使用的第三方库如下:一、抓取全国各省疫情信息,生成csv文件基本
1.代码分析:
2.源码:
import requests
from pyquery import PyQuery as pq
import json
import pandas as pd
import time
def get_data():
url = "https://ncov.dxy.cn/ncovh5/view/pneumonia"
response = requests.get(url)
if response.status_code == 200:
response.encoding = "utf-8"
dom = pq(response.content)
data = dom("script#getAreaStat").text().split(" = ")[1].split("}catch")[0]
jsonObj = json.loads(data) # json对象
print("数据抓取成功...")
province_data = []
for item in jsonObj:
dic = {"省全称": item["provinceName"], "省简称": item["provinceShortName"], "现存确诊人数": item["currentConfirmedCount"],
"累计确诊人数": item["confirmedCount"], "疑似人数": item["suspectedCount"], "治愈人数": item["curedCount"],
"死亡人数": item["deadCount"]}
province_data.append(dic)
if len(province_data) > 0:
print("写入数据...")
try:
df = pd.DataFrame(province_data)
time_format = time.strftime("%Y-%m-%d_%H_%M_%S", time.localtime())
df.to_csv(time_format + "全国各省疫情数据.csv", encoding="gbk", index=False)
print("写入成功...")
except Exception as e:
print(f"写入失败....{e}")
if __name__ == '__main__':
get_data()
3.运行效果:
二、用pyecharts绘制中国疫情地图,进阶
一说到画表,首先想到的就是Apache开源的echarts框架,有效又强大。因为不熟悉Matplotlib库,拿到数据后想用echarts框架的前端自己画一个,后来才知道有专门的pyecharts,很不错!
建议不了解echarts或pyecharts的同学先阅读官方API,了解基本图表类型和各种参数。 (⊙﹏⊙))哦!
1.代码分析:
2.源码:
"""
@File : data_chart.py
@Modify Time @Author @Version @Desciption
------------ ------- -------- -----------
2021/7/15 9:25 wrzcoder 1.0 None
"""
from pyecharts import options as opts
from pyecharts.charts import Map
import requests
from pyquery import PyQuery as pq
import json
import time
def map_visual_map() -> Map:
c = (
Map(init_opts=opts.InitOpts(page_title="中国疫情地图"))
.add("现存确诊人数", data_pair=list(current_data_dic.items()), maptype="china")
.set_global_opts(
title_opts=opts.TitleOpts(title="中国疫情地图", subtitle="数据更新于" + time_format),
visualmap_opts=opts.VisualMapOpts(pieces=[
{"value": 0, "label": "无", "color": "#9AFF9A"},
{"min": 1, "max": 9, "label": "1~9", "color": "#FFCCCC"},
{"min": 10, "max": 99, "label": "10~99", "color": "#DB5A6B"},
{"min": 100, "max": 499, "label": "100~499", "color": "#FF6666"},
{"min": 500, "max": 999, "label": "500~999", "color": "#CC2929"},
{"min": 1000, "max": 9999, "label": "1000~9999", "color": "#8C0D0D"},
{"min": 10000, "label": ">10000", "color": "#9d2933"}
], is_piecewise=True),
)
)
return c
if __name__ == '__main__':
try:
url = "https://ncov.dxy.cn/ncovh5/view/pneumonia"
response = requests.get(url)
if response.status_code == 200:
response.encoding = "utf-8"
dom = pq(response.content)
data = dom("script#getAreaStat").text().split(" = ")[1].split("}catch")[0]
jsonObj = json.loads(data) # json对象
print("数据抓取成功...")
current_data_dic = {}
time_format = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
for item in jsonObj:
current_data_dic[item["provinceShortName"]] = item["currentConfirmedCount"]
print(list(current_data_dic.items()))
map_visual_map().render("疫情地图.html")
print('疫情地图已生成在项目根目录...')
except Exception as e:
print(e)
3.运行效果:
三、采集全国各省市的疫情数据,进行数据可视化扩展
上面我们只用到了各个省的数据,而且在分析之初,各个省的dict中还收录了该省的市(区)的数据,我们不能浪费这些数据,我们可以抓取它。为了充分利用它们,我们对全国各省市的所有疫情数据进行了分类和可视化。
这里我想说的是:我们在可视化每个省(直辖市)以下市(区)的疫情数据时,也可以使用pyecharts中的Map,但是为了更加熟悉pyecharts,我们会改这里的表格类型饼图。
看起来很麻烦。求各省的数据,包括城市,最后画个图,太麻烦了。太麻烦了,不过不是(*^▽^*)就30行代码
1.代码分析
2.源码
"""
@File : province_data_chart.py
@Modify Time @Author @Version @Desciption
------------ ------- -------- -----------
2021/7/15 9:45 wrzcoder 1.0 None
"""
import requests
import json
from pyecharts.charts import Pie
import pyecharts.options as opts
import time
from pyquery import PyQuery as pq
import os
def create_Pie(provinceName, dic_citys) -> Pie:
c = (
Pie(init_opts=opts.InitOpts(width="100%", height="800px", page_title=provinceName + "各市(区)情况"))
.add("", data_pair=list(dic_citys.items()), center=["50%", "58%"], )
.set_global_opts(title_opts=opts.TitleOpts(title=provinceName + "各市(区)情况", subtitle="数据更新于:" + timeformat))
.set_series_opts(label_opts=opts.LabelOpts(formatter="{b}: {c}"))
)
if not os.path.exists('./中国各省情况'):
os.mkdir('./中国各省情况')
c.render("./中国各省情况/" + provinceName + "各市(区)情况.html")
if __name__ == '__main__':
try:
url = "https://ncov.dxy.cn/ncovh5/view/pneumonia"
timeformat = time.strftime("%Y-%m-%d %H:%M:%S", time.localtime())
response = requests.get(url)
response.encoding = "utf-8"
if response.status_code == 200:
print("数据抓取成功!")
dom = pq(response.text)
jsonobj = json.loads(dom("script#getAreaStat").text().split(" = ")[1].split("}catch")[0])
for province in jsonobj:
dic_city = {}
for city in province["cities"]:
dic_city[city["cityName"]] = city["currentConfirmedCount"]
if dic_city.__len__() > 0:
create_Pie(province["provinceName"], dic_city)
print(province["provinceName"] + "各市数据汇总完毕!")
except Exception as e:
print(e)
3.运行效果:
短短1.1s,我们爬取了全国所有省市的疫情数据,整理生成数据图表
打开随机饼图查看效果:
四川省各城市疫情数据汇总
至此,我们完成了全国各省市疫情实时数据的采集和处理,还绘制了中国疫情地图。在此基础上,我们进一步扩展,对中国各省、自治区、直辖市的疫情数据进行了批量整理和可视化。期间复习了requests库、pandas、pyquery库等,同时也学习和学习了强大的图表绘制pyecharts库,可以说是收获颇丰!因此,在这里一起分享和学习!
最后,加油武汉,加油中国!疫情终将过去,春天终将到来!
图片来自网络
希望你下次运行这段代码时,看到的疫情图是这样的:
python网页数据抓取(Python1.方法简介及安装教程运行结果结果分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 174 次浏览 • 2022-02-13 17:12
1.方法介绍
在python3中从下载的网页中抓取数据主要有三种方式,分别是正则表达式、BeautifulSoup和Lxml。这三种方法各有特点。
正则表达式,也称为正则表达式。(英文:Regular Expression,在代码中常缩写为regex、regexp或RE),计算机科学中的一个概念。常规表通常用于检索和替换与特定模式(规则)匹配的文本。
BeautifulSoup 是一个用 Python 编写的 HTML/XML 解析器,可以很好地处理非标准标签并生成解析树。它提供了用于导航、搜索和修改解析树的简单而常用的操作。它可以大大节省您的编程时间。(安装教程传送门)
Lxml 是基于 XML 解析库 libxml2 的 Python 包装器。模块用C语言编写,解析速度比BeautifulSoup快,但安装过程也比较复杂。
2.性能对比代码
import time
import re
from bs4 import BeautifulSoup
import lxml.html
from urllib import request
def download(url, user_agent="wsap", num=2):
print("Downloading:"+url)
try:
req = request.Request(url)
req.add_header('user_agent', user_agent)
html = request.urlopen(req).read()
except Exception as e:
print('Download error:')
html = None
if num > 0:
if hasattr(e, "code") and 500 tr#places_{}__row > td.w2p_fw'.format(field))[0].text_content()
return results
NUM_LTERATION = 1000
html_copy = download('http://example.webscraping.com ... %2339;)
for name, scraper in [('Regular expressions', re_scraper),
('BeautifulSoup', beautiful_soup_scraper),
('Lxml', lxml_scraper)]:
start = time.time()
for i in range(NUM_LTERATION):
if scraper == re_scraper:
re.purge()
result = scraper(html_copy)
assert(result['area'] == '244,820 square kilometres')
end = time.time()
print('%s: %.2f seconds' % (name, end - start))
3.运行结果
4.结果分析
如果您的爬虫的瓶颈是下载页面,而不是提取数据,那么使用较慢的方法(如 BeautifulSoup)不是问题。如果你只需要抓取少量数据并想避免额外的依赖,那么正则表达式可能更合适。但是,lxml 通常是抓取数据的最佳选择,因为它快速且健壮,而正则表达式和 BeautifulSoup 仅在某些情况下有用。 查看全部
python网页数据抓取(Python1.方法简介及安装教程运行结果结果分析)
1.方法介绍
在python3中从下载的网页中抓取数据主要有三种方式,分别是正则表达式、BeautifulSoup和Lxml。这三种方法各有特点。
正则表达式,也称为正则表达式。(英文:Regular Expression,在代码中常缩写为regex、regexp或RE),计算机科学中的一个概念。常规表通常用于检索和替换与特定模式(规则)匹配的文本。
BeautifulSoup 是一个用 Python 编写的 HTML/XML 解析器,可以很好地处理非标准标签并生成解析树。它提供了用于导航、搜索和修改解析树的简单而常用的操作。它可以大大节省您的编程时间。(安装教程传送门)
Lxml 是基于 XML 解析库 libxml2 的 Python 包装器。模块用C语言编写,解析速度比BeautifulSoup快,但安装过程也比较复杂。
2.性能对比代码
import time
import re
from bs4 import BeautifulSoup
import lxml.html
from urllib import request
def download(url, user_agent="wsap", num=2):
print("Downloading:"+url)
try:
req = request.Request(url)
req.add_header('user_agent', user_agent)
html = request.urlopen(req).read()
except Exception as e:
print('Download error:')
html = None
if num > 0:
if hasattr(e, "code") and 500 tr#places_{}__row > td.w2p_fw'.format(field))[0].text_content()
return results
NUM_LTERATION = 1000
html_copy = download('http://example.webscraping.com ... %2339;)
for name, scraper in [('Regular expressions', re_scraper),
('BeautifulSoup', beautiful_soup_scraper),
('Lxml', lxml_scraper)]:
start = time.time()
for i in range(NUM_LTERATION):
if scraper == re_scraper:
re.purge()
result = scraper(html_copy)
assert(result['area'] == '244,820 square kilometres')
end = time.time()
print('%s: %.2f seconds' % (name, end - start))
3.运行结果
4.结果分析
如果您的爬虫的瓶颈是下载页面,而不是提取数据,那么使用较慢的方法(如 BeautifulSoup)不是问题。如果你只需要抓取少量数据并想避免额外的依赖,那么正则表达式可能更合适。但是,lxml 通常是抓取数据的最佳选择,因为它快速且健壮,而正则表达式和 BeautifulSoup 仅在某些情况下有用。
python网页数据抓取(网络爬虫提取出该网页中的新一轮URL的抓取环路)
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2022-02-13 11:15
一般我们要爬取一个网站的所有URL,先传递起始URL,然后通过网络爬虫提取网页中所有的URL链接,然后对每一个提取的URL进行爬取,提取新一轮的URL在每个网页中,依此类推。总体感觉是网页中的链接是从上到下爬的。理论上,整个站点的所有链接都可以被爬取。但是问题来了,一个指向 网站 中网页的链接是循环的。
比如在网站首页,我们可以看到首页链接,那么我们也可能在子页面中看到指向首页的链接,在子子页面。首页。按照我们之前的逻辑,爬取每个页面中的所有链接,然后继续爬取所有链接。以首页为例,我们首先抓取的就是它,然后子页面中有指向首页的链接,子子页面有指向首页的链接。如果进行这个爬取,会不会造成网页的重复爬取,而其他的网页根本没有机会爬取。我无法想象。解决这个问题并不难。这时候,我们就需要用到网络爬虫中的一个重要知识点,那就是网页去重。
首先介绍一个简单的思路,这也是一个经常使用的通用思路。我们将抓取的网页放入一个列表中。以首页为例。当主页被爬取时,我们将主页放在列表中。那么我们在爬取子页面的时候,如果再遇到首页,并且首页已经被爬取过了。这时候可以跳过首页,继续爬取其他页面,避免重复爬取首页的情况。这样,爬取整个站点的时候就不会出现循环。路。以此思路为出发点,将访问过的URL保存在数据库中,当获取到下一个URL时,在数据库中检查该URL是否被访问过。虽然数据库有缓存,但是当在数据库中查询每个URL时,效率会迅速下降,
第二种方法是将访问过的 URL 保存在集合中。这种方式获取url的速度非常快,基本不需要查询。然而,这种方法有一个缺点。将 URL 保存到集合实际上是将其保存到内存中。当 URL 数据量很大(比如 1 亿)时,内存压力会增加。对于小型爬虫来说,这种方法是非常可取的,但对于大型网络爬虫来说,这种方法很难实现。
第三种方式是对字符进行md5编码,可以将字符缩减到固定长度。一般来说,md5编码的长度在128bit左右,也就是16byte左右。在不缩减之前,假设一个URL占用的内存大小为50字节,1字节等于2字节,也就是100字节。可以看出,经过md5编码后,节省了大量的内存空间。通过md5方法,可以将任意长度的URL压缩成相同长度的md5字符串,不会出现重复,达到去重的效果。这样在很大程度上节省了内存。scrapy框架采用的方法有点类似于md5的方法。因此,正常情况下,即使 URL 数量达到数亿,scrapy占用的内存比set方法小。少得多。
第四种方法是使用位图方法进一步压缩字符。这种方法是指在计算机中申请8位,即8位,每个位用0或1表示,是计算机中的最小单位。8个比特组成1个字节,如果一个比特代表一个URL,为什么一个比特可以确定一个URL?因为我们可以对 URL 执行哈希函数,然后将其映射到位。例如,假设我们有8个URL,分别对应8个比特,然后通过比特上面的0和1的状态,我们可以指示URL是否存在,这个方法可以进一步压缩内存。
但是bitmap方式有一个非常大的缺点,就是它的冲突会非常高,因为使用了同一个hash函数,很有可能将两个不同的URL或者多个不同的URL映射到一个位置。其实这个hash方法也是set方法的一种实现原理。它对 URL 进行函数计算,然后将其映射到位位置,因此这种方法非常压缩内存。简单计算,还是用1亿个URL来计算,相当于1亿比特。通过计算,相当于12500000字节。除以 1024 后大约是 12207KB,也就是大约 12MB 的空间。在实际过程中,内存占用可能会大于12MB,但即便如此,与前面三种方式相比,这种方式还是大大减少了内存占用。但同时,与这种方法发生冲突的可能性非常高,所以这种方法不是很适合。那么有没有什么办法可以进一步优化bitmap这种重内存压缩的方法,减少冲突的可能性呢?答案是肯定的,这是第五种方式。
第五种方式是bloomfilter,通过多个hash函数减少冲突的可能性来改进位图。这样,一方面可以通过位图的方式达到减少内存的效果,另一方面也可以减少冲突。关于bloomfilter的原理和实现,后面我一定会介绍给大家。今天,让大家有个简单的认识。Bloomfilter适用于大型网络爬虫,尤其是数量级超大时,bloomfilter方法可以事半功倍,并且经常配合分布式爬虫达到爬取的目的。
网页爬取过程中的五种去重策略方法的介绍就先到这里了。如果你不明白,你应该明白。普及后,问题不大。希望对小伙伴的学习有所帮助。
有小伙伴提到,以上5种方法只适用于单进程条件。如果是多进程,则需要设置pipeline进行信息交换,也可以直接设置pipeline而不是set。感谢这位不愿露面的大佬~~ 查看全部
python网页数据抓取(网络爬虫提取出该网页中的新一轮URL的抓取环路)
一般我们要爬取一个网站的所有URL,先传递起始URL,然后通过网络爬虫提取网页中所有的URL链接,然后对每一个提取的URL进行爬取,提取新一轮的URL在每个网页中,依此类推。总体感觉是网页中的链接是从上到下爬的。理论上,整个站点的所有链接都可以被爬取。但是问题来了,一个指向 网站 中网页的链接是循环的。
比如在网站首页,我们可以看到首页链接,那么我们也可能在子页面中看到指向首页的链接,在子子页面。首页。按照我们之前的逻辑,爬取每个页面中的所有链接,然后继续爬取所有链接。以首页为例,我们首先抓取的就是它,然后子页面中有指向首页的链接,子子页面有指向首页的链接。如果进行这个爬取,会不会造成网页的重复爬取,而其他的网页根本没有机会爬取。我无法想象。解决这个问题并不难。这时候,我们就需要用到网络爬虫中的一个重要知识点,那就是网页去重。
首先介绍一个简单的思路,这也是一个经常使用的通用思路。我们将抓取的网页放入一个列表中。以首页为例。当主页被爬取时,我们将主页放在列表中。那么我们在爬取子页面的时候,如果再遇到首页,并且首页已经被爬取过了。这时候可以跳过首页,继续爬取其他页面,避免重复爬取首页的情况。这样,爬取整个站点的时候就不会出现循环。路。以此思路为出发点,将访问过的URL保存在数据库中,当获取到下一个URL时,在数据库中检查该URL是否被访问过。虽然数据库有缓存,但是当在数据库中查询每个URL时,效率会迅速下降,
第二种方法是将访问过的 URL 保存在集合中。这种方式获取url的速度非常快,基本不需要查询。然而,这种方法有一个缺点。将 URL 保存到集合实际上是将其保存到内存中。当 URL 数据量很大(比如 1 亿)时,内存压力会增加。对于小型爬虫来说,这种方法是非常可取的,但对于大型网络爬虫来说,这种方法很难实现。
第三种方式是对字符进行md5编码,可以将字符缩减到固定长度。一般来说,md5编码的长度在128bit左右,也就是16byte左右。在不缩减之前,假设一个URL占用的内存大小为50字节,1字节等于2字节,也就是100字节。可以看出,经过md5编码后,节省了大量的内存空间。通过md5方法,可以将任意长度的URL压缩成相同长度的md5字符串,不会出现重复,达到去重的效果。这样在很大程度上节省了内存。scrapy框架采用的方法有点类似于md5的方法。因此,正常情况下,即使 URL 数量达到数亿,scrapy占用的内存比set方法小。少得多。
第四种方法是使用位图方法进一步压缩字符。这种方法是指在计算机中申请8位,即8位,每个位用0或1表示,是计算机中的最小单位。8个比特组成1个字节,如果一个比特代表一个URL,为什么一个比特可以确定一个URL?因为我们可以对 URL 执行哈希函数,然后将其映射到位。例如,假设我们有8个URL,分别对应8个比特,然后通过比特上面的0和1的状态,我们可以指示URL是否存在,这个方法可以进一步压缩内存。
但是bitmap方式有一个非常大的缺点,就是它的冲突会非常高,因为使用了同一个hash函数,很有可能将两个不同的URL或者多个不同的URL映射到一个位置。其实这个hash方法也是set方法的一种实现原理。它对 URL 进行函数计算,然后将其映射到位位置,因此这种方法非常压缩内存。简单计算,还是用1亿个URL来计算,相当于1亿比特。通过计算,相当于12500000字节。除以 1024 后大约是 12207KB,也就是大约 12MB 的空间。在实际过程中,内存占用可能会大于12MB,但即便如此,与前面三种方式相比,这种方式还是大大减少了内存占用。但同时,与这种方法发生冲突的可能性非常高,所以这种方法不是很适合。那么有没有什么办法可以进一步优化bitmap这种重内存压缩的方法,减少冲突的可能性呢?答案是肯定的,这是第五种方式。
第五种方式是bloomfilter,通过多个hash函数减少冲突的可能性来改进位图。这样,一方面可以通过位图的方式达到减少内存的效果,另一方面也可以减少冲突。关于bloomfilter的原理和实现,后面我一定会介绍给大家。今天,让大家有个简单的认识。Bloomfilter适用于大型网络爬虫,尤其是数量级超大时,bloomfilter方法可以事半功倍,并且经常配合分布式爬虫达到爬取的目的。
网页爬取过程中的五种去重策略方法的介绍就先到这里了。如果你不明白,你应该明白。普及后,问题不大。希望对小伙伴的学习有所帮助。
有小伙伴提到,以上5种方法只适用于单进程条件。如果是多进程,则需要设置pipeline进行信息交换,也可以直接设置pipeline而不是set。感谢这位不愿露面的大佬~~
python网页数据抓取(如何用Python写爬虫网页数据机器学习(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 118 次浏览 • 2022-02-11 04:04
如何爬取网页数据,说到数据分析,可能需要使用爬虫爬取数据进行汇总分析,但是你知道爬虫很容易导致IP被封,同一个IP访问同一个< @网站 太多了,会被反爬虫限制。这时候就需要用到爬虫了: 几种提取网页数据的方法1、美汤2、Pyquery3、正则表达式4、scrapy自己的数据提取方法Selector(selector ) Selector 是基于 lxml 构建的,支持。
如何使用爬虫抓取数据的介绍工具/原材料 Python 3.0 requests library bs4 library 一般步骤1 比如我上手爬虫(五)获取整个HTML的功能网页在爬取网页数据之前已经实现,在获取HTML的基础上,增加了一些如:下载错误自动重试、用户代理、服务器代理、爬取深度、避免重爬、id遍历、链式。
<p>∪▽∪如何使用Python编写爬虫爬取网页数据机器学习面临的首要问题之一是准备数据。数据来源大概有几个:公司积累的数据、采购、交易所的数据,政府机构和企业披露的数据,以及通过爬虫从网上抓取的数据。在这篇文章中,对于爬虫,我们首先想到的是python,但是对于前端,我们通常使用node来编写爬虫,抓取 查看全部
python网页数据抓取(如何用Python写爬虫网页数据机器学习(组图))
如何爬取网页数据,说到数据分析,可能需要使用爬虫爬取数据进行汇总分析,但是你知道爬虫很容易导致IP被封,同一个IP访问同一个< @网站 太多了,会被反爬虫限制。这时候就需要用到爬虫了: 几种提取网页数据的方法1、美汤2、Pyquery3、正则表达式4、scrapy自己的数据提取方法Selector(selector ) Selector 是基于 lxml 构建的,支持。
如何使用爬虫抓取数据的介绍工具/原材料 Python 3.0 requests library bs4 library 一般步骤1 比如我上手爬虫(五)获取整个HTML的功能网页在爬取网页数据之前已经实现,在获取HTML的基础上,增加了一些如:下载错误自动重试、用户代理、服务器代理、爬取深度、避免重爬、id遍历、链式。
<p>∪▽∪如何使用Python编写爬虫爬取网页数据机器学习面临的首要问题之一是准备数据。数据来源大概有几个:公司积累的数据、采购、交易所的数据,政府机构和企业披露的数据,以及通过爬虫从网上抓取的数据。在这篇文章中,对于爬虫,我们首先想到的是python,但是对于前端,我们通常使用node来编写爬虫,抓取
python网页数据抓取(如何独立写出爬虫真不是件简单的事情?-八维教育)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-02-11 01:07
作为一个刚接触python的新手,独立写一个爬虫是不容易的。首先要学会各种包的管理,还要了解爬取网页数据最基本的技术。以下是我在学习时记录的一些内容。
一、了解与 网站 链接时要使用的包
与网站交互,熟悉python下与网页相关的urllib,或urllib2,或httplib包。这三个是python提供的与网页交互的基本模块,还有其他的,比如:mechanize
斗志昂扬。
二、解析网页
我在网上搜索了一些网页,知道了一些基本的方法。
(1)正则表达式。正则表达式很有用。熟悉它们可以节省很多时间。有时你不需要写脚本或查询数据库来清理数据。你可以直接在notepad++上使用正则表达式.
学习正则表达式链接:
(2) BeautifulSoup 模块。BeautifulSoup 是一个非常强大的模块,可以将 html 文件解析成一个对象,也就是一棵树。html 文件是树状的,比如 body -> table -> tbody -> tr,对于
节点 tbody 有许多 tr 的子节点。BeautifulSoup 可以很方便的获取特定节点,也可以针对单个节点获取其兄弟节点。
三、捕获数据
你可以把采集到的数据放到一个txt文件中,这是最基本的方法。当然,你也可以直接连接数据库而不是写入txt文件。python中的MySQLdb模块可以与MySQL数据库进行通信。
与 MySQL 数据库建立链接的逻辑与与 网站 服务器建立链接的逻辑类似。如果你之前学过数据库,那么学习使用 MySQLdb 模块与数据库交互是
这很简单;如果没有,则需要使用 coursera\stanford openEdX 平台上打开的 Introduction to Database 进行系统学习,w3school 作为参考或作为手册使用。
以上是我在学习的时候做的一些小笔记,也有一些借鉴别人的想法。具体代码还有待完善,会在下一篇学习笔记中更新。 查看全部
python网页数据抓取(如何独立写出爬虫真不是件简单的事情?-八维教育)
作为一个刚接触python的新手,独立写一个爬虫是不容易的。首先要学会各种包的管理,还要了解爬取网页数据最基本的技术。以下是我在学习时记录的一些内容。
一、了解与 网站 链接时要使用的包
与网站交互,熟悉python下与网页相关的urllib,或urllib2,或httplib包。这三个是python提供的与网页交互的基本模块,还有其他的,比如:mechanize
斗志昂扬。
二、解析网页
我在网上搜索了一些网页,知道了一些基本的方法。
(1)正则表达式。正则表达式很有用。熟悉它们可以节省很多时间。有时你不需要写脚本或查询数据库来清理数据。你可以直接在notepad++上使用正则表达式.
学习正则表达式链接:
(2) BeautifulSoup 模块。BeautifulSoup 是一个非常强大的模块,可以将 html 文件解析成一个对象,也就是一棵树。html 文件是树状的,比如 body -> table -> tbody -> tr,对于
节点 tbody 有许多 tr 的子节点。BeautifulSoup 可以很方便的获取特定节点,也可以针对单个节点获取其兄弟节点。
三、捕获数据
你可以把采集到的数据放到一个txt文件中,这是最基本的方法。当然,你也可以直接连接数据库而不是写入txt文件。python中的MySQLdb模块可以与MySQL数据库进行通信。
与 MySQL 数据库建立链接的逻辑与与 网站 服务器建立链接的逻辑类似。如果你之前学过数据库,那么学习使用 MySQLdb 模块与数据库交互是
这很简单;如果没有,则需要使用 coursera\stanford openEdX 平台上打开的 Introduction to Database 进行系统学习,w3school 作为参考或作为手册使用。
以上是我在学习的时候做的一些小笔记,也有一些借鉴别人的想法。具体代码还有待完善,会在下一篇学习笔记中更新。

