
python网页数据抓取
python网页数据抓取(利用Python网络爬虫抓取微信朋友圈动态——附代码(下))
网站优化 • 优采云 发表了文章 • 0 个评论 • 469 次浏览 • 2022-03-24 13:02
前几天给大家分享了使用Python网络爬虫爬取朋友圈的动态(上)和使用Python网络爬虫爬取朋友圈的动态——附代码(下),并对抓取到的数据进行Python处理。词云和艺术字可视化,有兴趣的小伙伴可以戳这个文章:使用Python词云和艺术字可视化工具,对朋友圈数据进行可视化。
今天我们继续关注微信,不过这次给大家带来的是使用Python网络爬虫抓取微信好友总数和微信好友性别分布。代码实现相当简单,具体教程如下。
相信大家都知道直接通过网页抓取微信数据是不可行的,但是强大的Python提供了一个itchat库,搭建了链接微信好友信息的友好桥梁,直接上传代码,如下图.
对代码的关键部分进行了注释,方便大家理解。程序运行时,会弹出一个微信二维码。这时候需要用手机扫码授权登录。如果你当时登录的是微信PC版,微信会强制你注销再授权。授权成功后程序会继续执行,过一会会返回给你微信好友数。
这里以小编的微信好友为例,程序运行后,获取到的信息如下图所示:
可以看到,小编一共有1637个微信好友。相信很多朋友已经知道,在手机微信页面的第二个标签“通讯录”下,将好友列表拉到最后,就可以看到自己的微信好友数量了。你可以试试看。Python程序捕获的数字是否一致。
接下来小编就继续带大家继续发掘微信好友中的男女比例。其实很简单,代码实现也很容易。这里有两种方式,如下图所示。(注:代码按照上一个程序继续写)
可以自定义一个函数来获取性别信息,也可以直接调用value_counts()方法,这样更方便统计每一项出现的次数。小编的男女微信好友数量如下图所示。这里,1代表男性,2代表女性,0代表未知性别(因为有些朋友没有设置性别)。
可以看到,小编有884个男性朋友,655个女性朋友,还有近100个性别不明的朋友。
至此,使用Python网络爬虫抓取微信好友数量和微信好友男女比例已经完成。小伙伴们可以打开电脑快速尝试一下。几行代码带你玩转微信好友~~~
这个文章的主要参考链接在这里:,感谢大佬提供的思路和方法。
下一篇文章,小编会继续和大家分享微信好友的那些事儿,并带大家使用Python爬虫抓取微信好友的省市分布,并进行可视化,敬请期待~~
本文由 dcpeng 创建,采用知识共享署名-相同方式共享3.0 中国大陆许可协议进行许可。
转载或引用前需联系作者,署名并注明文章出处。 查看全部
python网页数据抓取(利用Python网络爬虫抓取微信朋友圈动态——附代码(下))
前几天给大家分享了使用Python网络爬虫爬取朋友圈的动态(上)和使用Python网络爬虫爬取朋友圈的动态——附代码(下),并对抓取到的数据进行Python处理。词云和艺术字可视化,有兴趣的小伙伴可以戳这个文章:使用Python词云和艺术字可视化工具,对朋友圈数据进行可视化。
今天我们继续关注微信,不过这次给大家带来的是使用Python网络爬虫抓取微信好友总数和微信好友性别分布。代码实现相当简单,具体教程如下。
相信大家都知道直接通过网页抓取微信数据是不可行的,但是强大的Python提供了一个itchat库,搭建了链接微信好友信息的友好桥梁,直接上传代码,如下图.

对代码的关键部分进行了注释,方便大家理解。程序运行时,会弹出一个微信二维码。这时候需要用手机扫码授权登录。如果你当时登录的是微信PC版,微信会强制你注销再授权。授权成功后程序会继续执行,过一会会返回给你微信好友数。
这里以小编的微信好友为例,程序运行后,获取到的信息如下图所示:

可以看到,小编一共有1637个微信好友。相信很多朋友已经知道,在手机微信页面的第二个标签“通讯录”下,将好友列表拉到最后,就可以看到自己的微信好友数量了。你可以试试看。Python程序捕获的数字是否一致。
接下来小编就继续带大家继续发掘微信好友中的男女比例。其实很简单,代码实现也很容易。这里有两种方式,如下图所示。(注:代码按照上一个程序继续写)

可以自定义一个函数来获取性别信息,也可以直接调用value_counts()方法,这样更方便统计每一项出现的次数。小编的男女微信好友数量如下图所示。这里,1代表男性,2代表女性,0代表未知性别(因为有些朋友没有设置性别)。

可以看到,小编有884个男性朋友,655个女性朋友,还有近100个性别不明的朋友。
至此,使用Python网络爬虫抓取微信好友数量和微信好友男女比例已经完成。小伙伴们可以打开电脑快速尝试一下。几行代码带你玩转微信好友~~~
这个文章的主要参考链接在这里:,感谢大佬提供的思路和方法。
下一篇文章,小编会继续和大家分享微信好友的那些事儿,并带大家使用Python爬虫抓取微信好友的省市分布,并进行可视化,敬请期待~~
本文由 dcpeng 创建,采用知识共享署名-相同方式共享3.0 中国大陆许可协议进行许可。
转载或引用前需联系作者,署名并注明文章出处。
python网页数据抓取(HTML源码中的内容由前端的动态生成,我们应该如何对网页进行模拟访问 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-03-24 13:01
)
我们之前抓取的网页大多是从 HTML 静态生成的内容,而我们可以直接从 HTML 源代码中找到的数据和内容。但是,并不是所有的网页都是这样的。
部分网站内容是由前端JS动态生成的。由于网页显示的内容是JS生成的,所以我们在浏览器上可以看到,但是在HTML源代码中找不到。比如今日头条:
浏览器渲染的网页是这样的:
查看源码,其实是这样的:
网页的新闻在HTML源代码中找不到,都是由JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页呢?有两种方式:
1、从网页响应中找到JS脚本返回的JSON数据;2、使用Selenium模拟对网页的访问
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,然后根据接口返回的JSON数据进行加载和渲染。
这样我们就可以找到JS调用的数据接口,从数据接口中找到网页中最后渲染的数据。
以今日头条为例进行演示:
1、找到JS请求的数据接口
F12打开网页调试工具
选择“Network”选项卡后,我发现有很多响应,所以让我们过滤并仅查看 XHR 响应。
(XHR是Ajax中的一个概念,意思是XMLHTTPrequest)
然后我们发现了很多缺失的链接,随便点一个看:
我们选择城市,预览中有一串json数据:
让我们再次点击查看:
原来都是城市列表,应该是用来加载地区新闻的。
现在你大概明白如何找到JS请求的接口了吧?但是刚才没有找到我们想要的消息,我们再找找吧:
有一个焦点,我们点击查看:
首页图片新闻呈现的数据是一样的,所以应该有数据。
查看其他链接:
这应该是热搜关键词
这是图片新闻下的新闻。
我们打开一个界面链接看看:
返回一串乱码,但从响应中查看正常编码数据:
有了对应的数据接口,我们就可以按照前面的方法去请求并得到数据接口的响应了
2、请求和解析数据接口数据
先完整代码:
# coding:utf-8
import requests
import json
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
for n in news:
title = n['title']
img_url = n['image_url']
url = n['media_url']
print(url,title,img_url)
返回结果如下:
代码分为四部分
第 1 部分:导入相关库
# coding:utf-8
import requests
import json
第二部分:对数据接口的http请求
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text 查看全部
python网页数据抓取(HTML源码中的内容由前端的动态生成,我们应该如何对网页进行模拟访问
)
我们之前抓取的网页大多是从 HTML 静态生成的内容,而我们可以直接从 HTML 源代码中找到的数据和内容。但是,并不是所有的网页都是这样的。

部分网站内容是由前端JS动态生成的。由于网页显示的内容是JS生成的,所以我们在浏览器上可以看到,但是在HTML源代码中找不到。比如今日头条:
浏览器渲染的网页是这样的:

查看源码,其实是这样的:

网页的新闻在HTML源代码中找不到,都是由JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页呢?有两种方式:
1、从网页响应中找到JS脚本返回的JSON数据;2、使用Selenium模拟对网页的访问
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,然后根据接口返回的JSON数据进行加载和渲染。
这样我们就可以找到JS调用的数据接口,从数据接口中找到网页中最后渲染的数据。
以今日头条为例进行演示:
1、找到JS请求的数据接口
F12打开网页调试工具

选择“Network”选项卡后,我发现有很多响应,所以让我们过滤并仅查看 XHR 响应。
(XHR是Ajax中的一个概念,意思是XMLHTTPrequest)
然后我们发现了很多缺失的链接,随便点一个看:
我们选择城市,预览中有一串json数据:

让我们再次点击查看:

原来都是城市列表,应该是用来加载地区新闻的。
现在你大概明白如何找到JS请求的接口了吧?但是刚才没有找到我们想要的消息,我们再找找吧:
有一个焦点,我们点击查看:

首页图片新闻呈现的数据是一样的,所以应该有数据。
查看其他链接:
这应该是热搜关键词

这是图片新闻下的新闻。
我们打开一个界面链接看看:

返回一串乱码,但从响应中查看正常编码数据:

有了对应的数据接口,我们就可以按照前面的方法去请求并得到数据接口的响应了
2、请求和解析数据接口数据
先完整代码:
# coding:utf-8
import requests
import json
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
for n in news:
title = n['title']
img_url = n['image_url']
url = n['media_url']
print(url,title,img_url)
返回结果如下:

代码分为四部分
第 1 部分:导入相关库
# coding:utf-8
import requests
import json
第二部分:对数据接口的http请求
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
python网页数据抓取(抓取一下网易云课堂课程数据--提取post关键字 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2022-03-24 12:17
)
写在前面
今天,我们来抓取网易云课堂的课程数据。这个网站中的数据量并不是很大。我们只需要使用请求来快速抓取这部分数据。
你需要做的第一件事是打开所有课程的地址并找出爬虫规则。
地址如下:
简单看了一下,页面数据是基于
这个地址是异步加载的。您需要开发人员工具自己尝试
多次尝试后,以该地址获取的数据为准。
还有一点需要注意,这次是post提交方式,提交的数据是payload类型的。这个原因导致我们的代码与之前的代码略有不同。
提取post关键字,查看每个参数的含义。如果你爬够了网站,训练出来的灵敏度可以快速分析这些参数
{"pageindex":55, # 页码
"pagesize":50, # 每页数据大小
"relativeoffset":2700,
"frontcategoryid":-1,
"searchtimetype":-1,
"ordertype":50,
"pricetype":-1,
"activityid":0,
"keyword":"" # 搜索相关
}
好了,可以开始写代码了,核心代码是通过requests模块发送post请求
def get_json(index):
print(f"正在抓取{index}页数据")
payload = {"pageindex":index,
"pagesize":50,
"relativeoffset":50,
"frontcategoryid":-1,
"searchtimetype":-1,
"ordertype":50,
"pricetype":-1,
"activityid":0,
"keyword":""
}
headers = {"accept":"application/json",
"host":"study.163.com",
"origin":"https://study.163.com",
"content-type":"application/json",
"referer":"https://study.163.com/courses",
"user-agent":"自己去找个浏览器ua"
}
try:
# 请注意这个地方发送的是post请求
# csdn 博客 梦想橡皮擦
res = requests.post("https://study.163.com/p/search ... ot%3B,json=payload,headers=headers)
content_json = res.json()
if content_json and content_json["code"] == 0:
data = get_content(content_json) # 获取正确的数据
############################################
if len(data) > 0:
save_mongo(data) # 保存数据
############################################
except exception as e:
print("出现bug了")
print(e)
finally:
time.sleep(1)
index+=1
get_json(index)
def get_content(content_json):
if "result" in content_json:
return content_json["result"]["list"]
因为获取到的数据是json类型的,所以可以快速的将数据保存到mongodb中。保存数据的代码我还是留空,希望大家自己改进。
在很短的时间内,我们捕获了 3000 门课程
好吧,您需要代码和数据,请发表评论并留下我与您联系的方式。
查看全部
python网页数据抓取(抓取一下网易云课堂课程数据--提取post关键字
)
写在前面
今天,我们来抓取网易云课堂的课程数据。这个网站中的数据量并不是很大。我们只需要使用请求来快速抓取这部分数据。
你需要做的第一件事是打开所有课程的地址并找出爬虫规则。
地址如下:

简单看了一下,页面数据是基于
这个地址是异步加载的。您需要开发人员工具自己尝试
多次尝试后,以该地址获取的数据为准。
还有一点需要注意,这次是post提交方式,提交的数据是payload类型的。这个原因导致我们的代码与之前的代码略有不同。

提取post关键字,查看每个参数的含义。如果你爬够了网站,训练出来的灵敏度可以快速分析这些参数
{"pageindex":55, # 页码
"pagesize":50, # 每页数据大小
"relativeoffset":2700,
"frontcategoryid":-1,
"searchtimetype":-1,
"ordertype":50,
"pricetype":-1,
"activityid":0,
"keyword":"" # 搜索相关
}
好了,可以开始写代码了,核心代码是通过requests模块发送post请求
def get_json(index):
print(f"正在抓取{index}页数据")
payload = {"pageindex":index,
"pagesize":50,
"relativeoffset":50,
"frontcategoryid":-1,
"searchtimetype":-1,
"ordertype":50,
"pricetype":-1,
"activityid":0,
"keyword":""
}
headers = {"accept":"application/json",
"host":"study.163.com",
"origin":"https://study.163.com",
"content-type":"application/json",
"referer":"https://study.163.com/courses",
"user-agent":"自己去找个浏览器ua"
}
try:
# 请注意这个地方发送的是post请求
# csdn 博客 梦想橡皮擦
res = requests.post("https://study.163.com/p/search ... ot%3B,json=payload,headers=headers)
content_json = res.json()
if content_json and content_json["code"] == 0:
data = get_content(content_json) # 获取正确的数据
############################################
if len(data) > 0:
save_mongo(data) # 保存数据
############################################
except exception as e:
print("出现bug了")
print(e)
finally:
time.sleep(1)
index+=1
get_json(index)
def get_content(content_json):
if "result" in content_json:
return content_json["result"]["list"]
因为获取到的数据是json类型的,所以可以快速的将数据保存到mongodb中。保存数据的代码我还是留空,希望大家自己改进。
在很短的时间内,我们捕获了 3000 门课程

好吧,您需要代码和数据,请发表评论并留下我与您联系的方式。

python网页数据抓取(python框架,使用python进行网页数据,google网页爬虫及源码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-03-18 18:04
python网页数据抓取leap.find()爬取网页数据,google公开的源码pyspider框架,使用python进行网页数据抓取python爬虫python网页爬虫及源码
不了解,crawler功能应该可以满足你的需求,
参考这个问题:python爬虫之美猴猫:python网页抓取-leap.find()
leapframes:fromurllib。requestimporturlopenloop=urlopen()#循环遍历整个网页,下面所有代码都是针对整个网页的print(loop)#write->writetothewindowwindow。write(urlopen('')。read())#读到一定时间会后直接弹出一个窗口,里面有一个run函数,用于中断urlopen,获取到另一页print('window')window。close()。
defget_results(url):login_url=urlopen(';ref=_evb3cfff5c012c5a6f504a5ba580358c3e25&sort=sales_all')#请求网址foriinrange(0,1):login_url。encode('gbk')。decode('utf-8')+'/'+foruserinlogin_url:#获取用户名foriinrange(1,len(user)):print('loginuserwith:%s'%user)#获取登录页面print('defaultloginurl:%s'%(user["username"],user["password"]))returnresultsurllib。urlencodeerrorprint(get_results(''))。 查看全部
python网页数据抓取(python框架,使用python进行网页数据,google网页爬虫及源码)
python网页数据抓取leap.find()爬取网页数据,google公开的源码pyspider框架,使用python进行网页数据抓取python爬虫python网页爬虫及源码
不了解,crawler功能应该可以满足你的需求,
参考这个问题:python爬虫之美猴猫:python网页抓取-leap.find()
leapframes:fromurllib。requestimporturlopenloop=urlopen()#循环遍历整个网页,下面所有代码都是针对整个网页的print(loop)#write->writetothewindowwindow。write(urlopen('')。read())#读到一定时间会后直接弹出一个窗口,里面有一个run函数,用于中断urlopen,获取到另一页print('window')window。close()。
defget_results(url):login_url=urlopen(';ref=_evb3cfff5c012c5a6f504a5ba580358c3e25&sort=sales_all')#请求网址foriinrange(0,1):login_url。encode('gbk')。decode('utf-8')+'/'+foruserinlogin_url:#获取用户名foriinrange(1,len(user)):print('loginuserwith:%s'%user)#获取登录页面print('defaultloginurl:%s'%(user["username"],user["password"]))returnresultsurllib。urlencodeerrorprint(get_results(''))。
python网页数据抓取(用Python写爬虫工具(二):Python模拟浏览器发起请求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-03-18 14:22
现在用Python写爬虫工具已经是家常便饭了,大家都希望自己写一个程序,从网上抓取一些信息,进行数据分析或者其他的事情。
我们知道爬虫的原理无非就是把目标网站的内容下载下来,存储在内存中。这时候它的内容其实就是一堆HTML,然后按照自己的思路解析HTML内容,提取出想要的数据。,所以今天我们主要讲一下Python中解析网页HTML内容的四种方法,各有千秋,适合不同场合使用。
首先,我们随机找到了一个网站。这时,豆瓣网站在我脑海中闪过。好吧,毕竟网站是用Python构建的,所以我们以它为例。
我们找到了豆瓣的Python爬虫群首页,如下图。
让我们使用浏览器开发工具查看 HTML 代码并找到所需的内容。我们要提取讨论组中的所有帖子标题和链接。
通过分析,我们发现我们想要的内容其实是在整个HTML代码的这个区域,所以我们只需要想办法把这个区域的内容取出来即可。
现在开始编写代码。
一:正则表达式大法
正则表达式通常用于检索和替换匹配某种模式的文本,所以我们可以利用这个原理来提取我们想要的信息。
请参考以下代码。
在代码的第6、7行,需要手动指定header的内容,假装这个请求是浏览器请求,否则豆瓣会认为我们的请求不是正常请求,会返回HTTP 418错误。
在第 7 行,我们直接使用 requests 库的 get 方法发出请求。得到内容后,我们需要转换编码格式。也是因为豆瓣的页面渲染机制。一般情况下,我们可以直接获取requests内容的内容。.
Python模拟浏览器发起请求并解析内容代码:
url = 'https://www.douban.com/group/491607/'headers = {"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:71.0) Gecko/20100101 Firefox/71.0"}response = requests.get(url=url,headers=headers).content.decode('utf-8')
正则的优点是写起来麻烦,难懂,但是匹配效率很高。但是,在有太多现成的HTML内容解析库之后,我个人不建议手动使用正则来匹配内容,既费时又费力。.
主要解析代码:
<p>re_div = r'[\W|\w]+'pattern = re.compile(re_div)content = re.findall(pattern, str(response))re_link = r'(.*?)</a>'mm = re.findall(re_link, str(content), re.S|re.M)urls=re.findall(r" 查看全部
python网页数据抓取(用Python写爬虫工具(二):Python模拟浏览器发起请求)
现在用Python写爬虫工具已经是家常便饭了,大家都希望自己写一个程序,从网上抓取一些信息,进行数据分析或者其他的事情。

我们知道爬虫的原理无非就是把目标网站的内容下载下来,存储在内存中。这时候它的内容其实就是一堆HTML,然后按照自己的思路解析HTML内容,提取出想要的数据。,所以今天我们主要讲一下Python中解析网页HTML内容的四种方法,各有千秋,适合不同场合使用。
首先,我们随机找到了一个网站。这时,豆瓣网站在我脑海中闪过。好吧,毕竟网站是用Python构建的,所以我们以它为例。
我们找到了豆瓣的Python爬虫群首页,如下图。
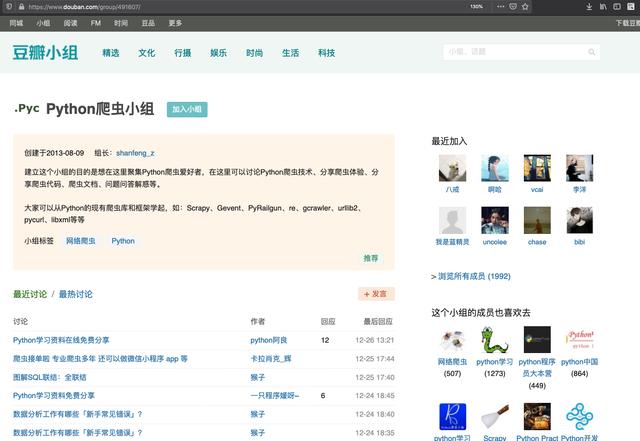
让我们使用浏览器开发工具查看 HTML 代码并找到所需的内容。我们要提取讨论组中的所有帖子标题和链接。
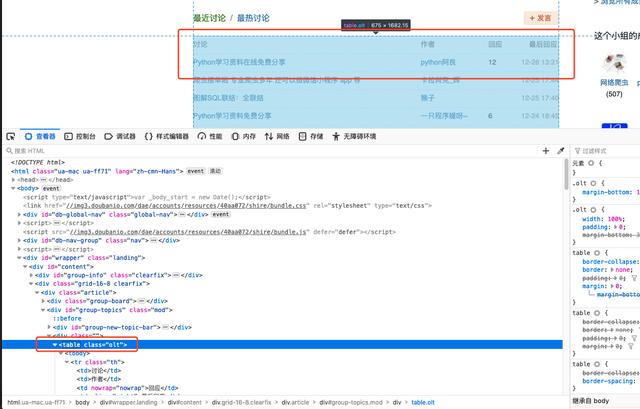
通过分析,我们发现我们想要的内容其实是在整个HTML代码的这个区域,所以我们只需要想办法把这个区域的内容取出来即可。
现在开始编写代码。
一:正则表达式大法
正则表达式通常用于检索和替换匹配某种模式的文本,所以我们可以利用这个原理来提取我们想要的信息。
请参考以下代码。
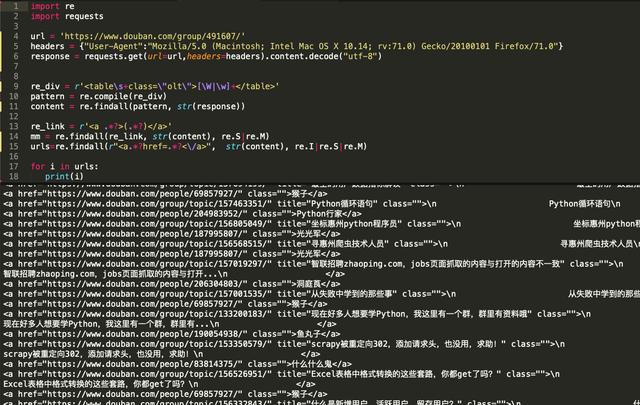
在代码的第6、7行,需要手动指定header的内容,假装这个请求是浏览器请求,否则豆瓣会认为我们的请求不是正常请求,会返回HTTP 418错误。
在第 7 行,我们直接使用 requests 库的 get 方法发出请求。得到内容后,我们需要转换编码格式。也是因为豆瓣的页面渲染机制。一般情况下,我们可以直接获取requests内容的内容。.
Python模拟浏览器发起请求并解析内容代码:
url = 'https://www.douban.com/group/491607/'headers = {"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:71.0) Gecko/20100101 Firefox/71.0"}response = requests.get(url=url,headers=headers).content.decode('utf-8')
正则的优点是写起来麻烦,难懂,但是匹配效率很高。但是,在有太多现成的HTML内容解析库之后,我个人不建议手动使用正则来匹配内容,既费时又费力。.
主要解析代码:
<p>re_div = r'[\W|\w]+'pattern = re.compile(re_div)content = re.findall(pattern, str(response))re_link = r'(.*?)</a>'mm = re.findall(re_link, str(content), re.S|re.M)urls=re.findall(r"
python网页数据抓取(Python爬虫的抓取技术大盘点-抓取爬虫技术篇)
网站优化 • 优采云 发表了文章 • 0 个评论 • 239 次浏览 • 2022-03-18 13:14
网络爬虫一直是讨论的热门话题。了解Python爬虫技术更受欢迎,学习Python爬虫可以更好地了解如何应对网络危害。未经授权的爬虫爬取程序是危害web原创内容生态的一大罪魁祸首,所以要保护网站的内容,首先要考虑如何防范爬虫。接下来,IT培训网将为大家盘点一下Python爬虫的一些爬取技术。
Python爬虫爬取技术盘点
1、从爬虫攻防的角度来看
最简单的爬虫是几乎所有服务器端和客户端编程语言都支持的 http 请求。只要对目标页面的url进行http get请求,就可以获得浏览器加载页面时的完整html文档。我们称之为“同步页面”。作为防御方,服务器可以根据http请求头中的User-Agent检查客户端是合法的浏览器程序还是脚本爬虫,从而决定是否使用真实的页面信息内容发送给你。
这当然是最小的小儿防御方法。作为进攻方,爬虫完全可以伪造User-Agent字段。甚至,只要你愿意,在HTTP get方法中,请求头的Referrer、Cookie等所有字段都可以被爬虫轻松处理。伪造。这时,服务器就可以根据你声明的浏览器厂商和版本(来自User-Agent),使用浏览器http头指纹来识别你http头中的每个字段是否符合浏览器的特性。如果匹配,它将被视为爬虫。该技术的一个典型应用是在 PhantomJS 1.x 版本中,由于底层调用了 Qt 框架的网络库,http 头具有明显的 Qt 框架的网络请求特征,可以直接被服务器识别。并被拦截。
另外,还有一个比较异常的服务器端爬虫检测机制,就是在http响应中为所有访问该页面的http请求种上一个cookie token,然后在这个异步执行的一些ajax接口上学页。检查访问请求中是否收录cookie token,返回token表示这是一次合法的浏览器访问,否则表示刚刚发出token的用户访问了页面html但没有访问执行js后调用的ajax在 html 请求中,很可能是爬虫。
如果直接访问一个没有token的接口,说明你没有请求过html页面,而是直接向页面中应该通过ajax访问的接口发起网络请求,这显然证明了你是一个可疑的爬虫。知名电子商务公司网站亚马逊采用了这种防御策略。
以上是基于服务器端验证爬虫程序可以玩的一些套路。
2、基于客户端js运行时检测
现代浏览器赋予 JavaScript 强大的能力,所以我们可以将页面的所有核心内容作为 js 异步请求 ajax 获取数据然后渲染到页面中,这显然提高了爬取内容的门槛。这样,我们就将爬虫和反爬的战斗从服务端转移到了客户端浏览器中的js运行时。接下来说一下结合客户端js运行时的爬取技术。
刚才提到的各种服务器端验证,对于普通的python和java语言编写的HTTP爬虫程序,都有一定的技术门槛。毕竟,Web 应用程序是未经授权的抓取工具的黑匣子。很多东西都需要一点一点的去尝试,而一套耗费大量人力物力开发的爬虫程序,只要网站作为防御者可以轻松调整一些策略,攻击者也需要花费同样的时间再次修改爬虫的爬取逻辑。此时,您需要使用无头浏览器。这是什么技术?其实说白了就是程序可以操作浏览器访问网页,这样写爬虫的人就可以通过调用浏览器暴露给程序的API来实现复杂性。获取业务逻辑。
近年来,这并不是一项新技术。曾经有基于webkit内核的PhantomJS,基于火狐浏览器内核的SlimerJS,甚至还有基于IE内核的trifleJS。如果你有兴趣,可以看看这里,这里是两个无头浏览器列表的集合。这些无头浏览器程序的原理其实就是对一些开源的浏览器内核C++代码进行改造和封装,实现一个简单的浏览器程序,无需GUI界面渲染。但是这些项目的通病是因为他们的代码是基于fork官方webkit和其他内核的某个版本的trunk代码,所以跟不上一些最新的css属性和js语法,还有一些兼容性问题,不如正版GUI浏览器发行版运行稳定。
其中,最成熟、用得最多的应该是PhantonJS。之前写过一篇关于这种爬虫识别的博客,这里不再赘述。PhantomJS 有很多问题,因为它是单进程模型,没有必要的沙箱保护,浏览器内核的安全性较差。此外,该项目的作者已经宣布他们将停止维护这个项目。Headless Chrome 可以说是 Headless Browser 中独一无二的杀手锏。由于它本身就是一个 chrome 浏览器,它支持各种新的 CSS 渲染特性和 js 运行时语法。基于这种方法,爬虫作为攻击方可以绕过几乎所有的服务器端验证逻辑,但是这些爬虫在客户端js运行时还是存在一些缺陷,比如:
基于插件对象的检查
if(navigator.plugins.length === 0) { console.log('可能是 Chrome 无头'); }
基于语言的检查
if(navigator.languages=== '') { console.log('Chrome headless detected'); }
基于以上一些浏览器特性的判断,它基本上可以秒杀市面上大部分的Headless Browser程序。在这个层面,其实是提高了网络爬虫的门槛,要求编写爬虫程序的开发者不得不修改浏览器内核的C++代码,重新编译一个浏览器,而以上特性对浏览器来说是很重要的。内核的改动其实不小,如果你尝试过编译Blink内核或者Gecko内核你就会明白对于一个“脚本小子”来说是多么的难了~
此外,我们还可以根据浏览器的UserAgent字段中描述的浏览器品牌、版本、型号信息,检查js运行时、DOM和BOM的各个native对象的属性和方法,观察它们的特性是否符合浏览器这个版本。设备应具备的功能。这种方法称为浏览器指纹识别技术,它依赖于大型网站对各类浏览器的api信息的采集。作为编写爬虫程序的攻击者,你可以在无头浏览器运行时预先注入一些js逻辑来伪造浏览器的特性。
爬虫攻击者可能会预先注入一些js方法,用一层代理函数作为钩子包裹一些原生api,然后用这个假的js api覆盖原生api。如果防御者在函数 toString 之后基于对 [native code] 的检查来检查这一点,它将被绕过。所以需要更严格的检查,因为bind(null) fake方法在toString之后没有函数名,所以需要检查toString之后的函数名是否为空。
这种技术有什么用?在这里延伸一下,反爬虫防御者有一个Robot Detect方法,就是在js运行的时候主动抛出一个alert。文案可以写一些业务逻辑相关的,普通用户点击OK按钮肯定会有1s甚至更长的延迟,因为浏览器中的alert会阻塞js代码运行(其实在v8中他会暂停以类似于进程挂起的方式执行隔离上下文),因此爬虫程序作为攻击者可以选择使用上述技术在页面上的所有js运行之前预先注入一段js代码,并伪造所有提示、提示、确认等弹出方式。如果防御者在弹出代码之前检查他调用的alert方法是否仍然是原生的,则这种方式被阻止。
3、反爬虫银弹
目前最可靠的反爬虫和机器人巡检手段是验证码技术。但是,验证码并不意味着必须强制用户输入一系列字母数字。还有很多基于用户鼠标、触摸屏(移动端)等行为的行为验证技术。其中,最成熟的是基于机器学习的谷歌reCAPTCHA。区分用户和爬虫。
基于以上对用户和爬虫的识别和区分技术,网站的防御者需要做的就是对该IP地址进行封锁或者对该IP的访问用户施加高强度的验证码策略。这样攻击者就不得不购买IP代理池来捕获网站信息内容,否则单个IP地址很容易被封杀,无法被捕获。爬取和反爬取的门槛已经提升到IP代理池的经济成本水平。
4、机器人协议
此外,在爬虫爬取技术领域,还有一种叫做robots协议的“白道”方式。Allow 和 Disallow 声明每个 UA 爬虫的爬取授权。然而,这只是君子之约。虽然它有法律上的好处,但它只能限制那些商业搜索引擎的蜘蛛程序,你不能限制那些“野爬爱好者”。
总之,Python爬虫对网页内容的爬取与对策,注定是一场一只脚一只脚的猫捉老鼠游戏。你永远不可能用某种技术完全挡住爬虫的去路。唯一的事情是增加攻击者的捕获成本,并更准确地了解未经授权的捕获行为。 查看全部
python网页数据抓取(Python爬虫的抓取技术大盘点-抓取爬虫技术篇)
网络爬虫一直是讨论的热门话题。了解Python爬虫技术更受欢迎,学习Python爬虫可以更好地了解如何应对网络危害。未经授权的爬虫爬取程序是危害web原创内容生态的一大罪魁祸首,所以要保护网站的内容,首先要考虑如何防范爬虫。接下来,IT培训网将为大家盘点一下Python爬虫的一些爬取技术。

Python爬虫爬取技术盘点
1、从爬虫攻防的角度来看
最简单的爬虫是几乎所有服务器端和客户端编程语言都支持的 http 请求。只要对目标页面的url进行http get请求,就可以获得浏览器加载页面时的完整html文档。我们称之为“同步页面”。作为防御方,服务器可以根据http请求头中的User-Agent检查客户端是合法的浏览器程序还是脚本爬虫,从而决定是否使用真实的页面信息内容发送给你。
这当然是最小的小儿防御方法。作为进攻方,爬虫完全可以伪造User-Agent字段。甚至,只要你愿意,在HTTP get方法中,请求头的Referrer、Cookie等所有字段都可以被爬虫轻松处理。伪造。这时,服务器就可以根据你声明的浏览器厂商和版本(来自User-Agent),使用浏览器http头指纹来识别你http头中的每个字段是否符合浏览器的特性。如果匹配,它将被视为爬虫。该技术的一个典型应用是在 PhantomJS 1.x 版本中,由于底层调用了 Qt 框架的网络库,http 头具有明显的 Qt 框架的网络请求特征,可以直接被服务器识别。并被拦截。
另外,还有一个比较异常的服务器端爬虫检测机制,就是在http响应中为所有访问该页面的http请求种上一个cookie token,然后在这个异步执行的一些ajax接口上学页。检查访问请求中是否收录cookie token,返回token表示这是一次合法的浏览器访问,否则表示刚刚发出token的用户访问了页面html但没有访问执行js后调用的ajax在 html 请求中,很可能是爬虫。
如果直接访问一个没有token的接口,说明你没有请求过html页面,而是直接向页面中应该通过ajax访问的接口发起网络请求,这显然证明了你是一个可疑的爬虫。知名电子商务公司网站亚马逊采用了这种防御策略。
以上是基于服务器端验证爬虫程序可以玩的一些套路。
2、基于客户端js运行时检测
现代浏览器赋予 JavaScript 强大的能力,所以我们可以将页面的所有核心内容作为 js 异步请求 ajax 获取数据然后渲染到页面中,这显然提高了爬取内容的门槛。这样,我们就将爬虫和反爬的战斗从服务端转移到了客户端浏览器中的js运行时。接下来说一下结合客户端js运行时的爬取技术。
刚才提到的各种服务器端验证,对于普通的python和java语言编写的HTTP爬虫程序,都有一定的技术门槛。毕竟,Web 应用程序是未经授权的抓取工具的黑匣子。很多东西都需要一点一点的去尝试,而一套耗费大量人力物力开发的爬虫程序,只要网站作为防御者可以轻松调整一些策略,攻击者也需要花费同样的时间再次修改爬虫的爬取逻辑。此时,您需要使用无头浏览器。这是什么技术?其实说白了就是程序可以操作浏览器访问网页,这样写爬虫的人就可以通过调用浏览器暴露给程序的API来实现复杂性。获取业务逻辑。
近年来,这并不是一项新技术。曾经有基于webkit内核的PhantomJS,基于火狐浏览器内核的SlimerJS,甚至还有基于IE内核的trifleJS。如果你有兴趣,可以看看这里,这里是两个无头浏览器列表的集合。这些无头浏览器程序的原理其实就是对一些开源的浏览器内核C++代码进行改造和封装,实现一个简单的浏览器程序,无需GUI界面渲染。但是这些项目的通病是因为他们的代码是基于fork官方webkit和其他内核的某个版本的trunk代码,所以跟不上一些最新的css属性和js语法,还有一些兼容性问题,不如正版GUI浏览器发行版运行稳定。
其中,最成熟、用得最多的应该是PhantonJS。之前写过一篇关于这种爬虫识别的博客,这里不再赘述。PhantomJS 有很多问题,因为它是单进程模型,没有必要的沙箱保护,浏览器内核的安全性较差。此外,该项目的作者已经宣布他们将停止维护这个项目。Headless Chrome 可以说是 Headless Browser 中独一无二的杀手锏。由于它本身就是一个 chrome 浏览器,它支持各种新的 CSS 渲染特性和 js 运行时语法。基于这种方法,爬虫作为攻击方可以绕过几乎所有的服务器端验证逻辑,但是这些爬虫在客户端js运行时还是存在一些缺陷,比如:
基于插件对象的检查
if(navigator.plugins.length === 0) { console.log('可能是 Chrome 无头'); }
基于语言的检查
if(navigator.languages=== '') { console.log('Chrome headless detected'); }
基于以上一些浏览器特性的判断,它基本上可以秒杀市面上大部分的Headless Browser程序。在这个层面,其实是提高了网络爬虫的门槛,要求编写爬虫程序的开发者不得不修改浏览器内核的C++代码,重新编译一个浏览器,而以上特性对浏览器来说是很重要的。内核的改动其实不小,如果你尝试过编译Blink内核或者Gecko内核你就会明白对于一个“脚本小子”来说是多么的难了~
此外,我们还可以根据浏览器的UserAgent字段中描述的浏览器品牌、版本、型号信息,检查js运行时、DOM和BOM的各个native对象的属性和方法,观察它们的特性是否符合浏览器这个版本。设备应具备的功能。这种方法称为浏览器指纹识别技术,它依赖于大型网站对各类浏览器的api信息的采集。作为编写爬虫程序的攻击者,你可以在无头浏览器运行时预先注入一些js逻辑来伪造浏览器的特性。
爬虫攻击者可能会预先注入一些js方法,用一层代理函数作为钩子包裹一些原生api,然后用这个假的js api覆盖原生api。如果防御者在函数 toString 之后基于对 [native code] 的检查来检查这一点,它将被绕过。所以需要更严格的检查,因为bind(null) fake方法在toString之后没有函数名,所以需要检查toString之后的函数名是否为空。
这种技术有什么用?在这里延伸一下,反爬虫防御者有一个Robot Detect方法,就是在js运行的时候主动抛出一个alert。文案可以写一些业务逻辑相关的,普通用户点击OK按钮肯定会有1s甚至更长的延迟,因为浏览器中的alert会阻塞js代码运行(其实在v8中他会暂停以类似于进程挂起的方式执行隔离上下文),因此爬虫程序作为攻击者可以选择使用上述技术在页面上的所有js运行之前预先注入一段js代码,并伪造所有提示、提示、确认等弹出方式。如果防御者在弹出代码之前检查他调用的alert方法是否仍然是原生的,则这种方式被阻止。
3、反爬虫银弹
目前最可靠的反爬虫和机器人巡检手段是验证码技术。但是,验证码并不意味着必须强制用户输入一系列字母数字。还有很多基于用户鼠标、触摸屏(移动端)等行为的行为验证技术。其中,最成熟的是基于机器学习的谷歌reCAPTCHA。区分用户和爬虫。
基于以上对用户和爬虫的识别和区分技术,网站的防御者需要做的就是对该IP地址进行封锁或者对该IP的访问用户施加高强度的验证码策略。这样攻击者就不得不购买IP代理池来捕获网站信息内容,否则单个IP地址很容易被封杀,无法被捕获。爬取和反爬取的门槛已经提升到IP代理池的经济成本水平。
4、机器人协议
此外,在爬虫爬取技术领域,还有一种叫做robots协议的“白道”方式。Allow 和 Disallow 声明每个 UA 爬虫的爬取授权。然而,这只是君子之约。虽然它有法律上的好处,但它只能限制那些商业搜索引擎的蜘蛛程序,你不能限制那些“野爬爱好者”。
总之,Python爬虫对网页内容的爬取与对策,注定是一场一只脚一只脚的猫捉老鼠游戏。你永远不可能用某种技术完全挡住爬虫的去路。唯一的事情是增加攻击者的捕获成本,并更准确地了解未经授权的捕获行为。
python网页数据抓取(edge浏览器数据教程(教程用于爬取动态加载的数据))
网站优化 • 优采云 发表了文章 • 0 个评论 • 578 次浏览 • 2022-03-17 07:05
python时间戳
将时间戳转换为日期
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 引入time模块
import time
#时间戳
timeStamp = 1581004800
timeArray = time.localtime(timeStamp)
#转为年-月-日形式
otherStyleTime = time.strftime("%Y-%m-%d ", timeArray)
print(otherStyleTime)
Python爬取数据教程(爬取动态加载数据教程)
很多时候我们需要抓取网页动态加载的数据。这是通过打开网页并按“Fn+F12”打开“开发者工具”。
边缘浏览器打开开发者工具:
谷歌浏览器打开开发者工具:
Edge 点击“网络”,谷歌点击“网络”,
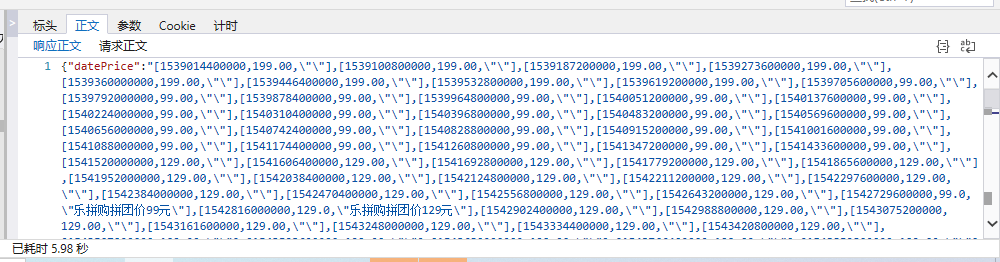
要查找我们要查找的文件,我们可以按文件类型查找。在标头中,我们可以看到请求 URL。在 body 界面中,我们看到了传递过来的数据。我们想要得到的是dataprice。此数据为 json 格式。Python 将 json 数据作为字符串获取。
代码:
import requests
import json
import urllib
request_url = "http://tool.manmanbuy.com/hist ... ot%3B
data = requests.get(request_url)
data_price = json.loads(data.text)
data_price = data_price['datePrice']
print(data_price)
运行结果:
所以我们得到了dataprice!
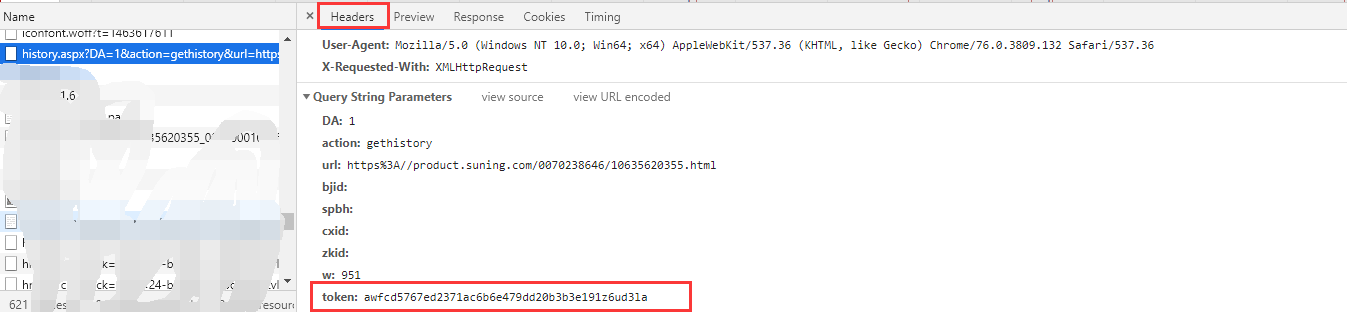
这还没完,我们现在已经获取到了一个url对应的动态数据,但是我有几千条数据,所以我们研究一下这个requestURL,看看能不能构造(截图是谷歌浏览器的截图)
通过比较几个请求的url,我发现它们的区别在于,在“url=”和“token=”之后,url是输入链接,我们可以传入,但是这个token是什么?? 经过研究,发现token是在这里的,但是是随机生成的,怎么获取这个字段呢?
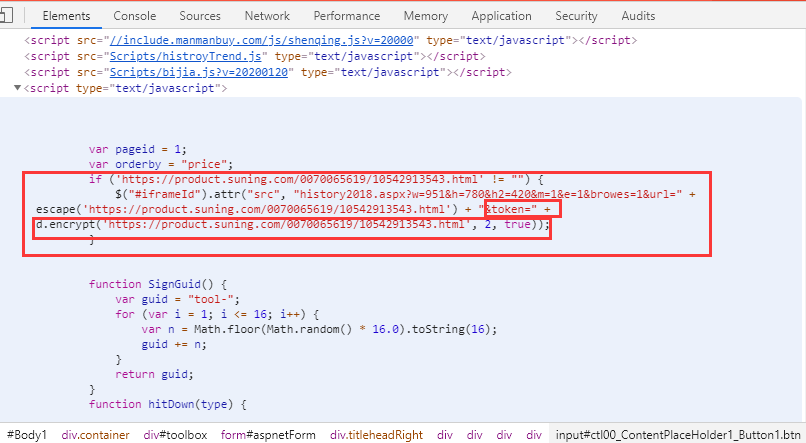
通过在网页上右击“查看网页源代码”,或者在开发者工具中点击第一个“元素”查看源代码,发现这里生成了token。
但是我对加密功能没看懂(懂的大神可以告诉我,哈哈),只能另找办法再研究了。哈哈,token又出现在这里了,最后,得到src路径,通过对字符串进行修剪得到token的值。
所以我们可以构造requestURL,
request_url = "http://tool.manmanbuy.com/hist ... rl%3D{0}&bjid=&spbh=&cxid=&zkid=&w=951&token={1}".format(url,token)
使用上面的代码,我们可以得到所有的数据! 查看全部
python网页数据抓取(edge浏览器数据教程(教程用于爬取动态加载的数据))
python时间戳
将时间戳转换为日期
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 引入time模块
import time
#时间戳
timeStamp = 1581004800
timeArray = time.localtime(timeStamp)
#转为年-月-日形式
otherStyleTime = time.strftime("%Y-%m-%d ", timeArray)
print(otherStyleTime)
Python爬取数据教程(爬取动态加载数据教程)
很多时候我们需要抓取网页动态加载的数据。这是通过打开网页并按“Fn+F12”打开“开发者工具”。
边缘浏览器打开开发者工具:
谷歌浏览器打开开发者工具:
Edge 点击“网络”,谷歌点击“网络”,

要查找我们要查找的文件,我们可以按文件类型查找。在标头中,我们可以看到请求 URL。在 body 界面中,我们看到了传递过来的数据。我们想要得到的是dataprice。此数据为 json 格式。Python 将 json 数据作为字符串获取。
代码:
import requests
import json
import urllib
request_url = "http://tool.manmanbuy.com/hist ... ot%3B
data = requests.get(request_url)
data_price = json.loads(data.text)
data_price = data_price['datePrice']
print(data_price)
运行结果:

所以我们得到了dataprice!
这还没完,我们现在已经获取到了一个url对应的动态数据,但是我有几千条数据,所以我们研究一下这个requestURL,看看能不能构造(截图是谷歌浏览器的截图)


通过比较几个请求的url,我发现它们的区别在于,在“url=”和“token=”之后,url是输入链接,我们可以传入,但是这个token是什么?? 经过研究,发现token是在这里的,但是是随机生成的,怎么获取这个字段呢?
通过在网页上右击“查看网页源代码”,或者在开发者工具中点击第一个“元素”查看源代码,发现这里生成了token。
但是我对加密功能没看懂(懂的大神可以告诉我,哈哈),只能另找办法再研究了。哈哈,token又出现在这里了,最后,得到src路径,通过对字符串进行修剪得到token的值。

所以我们可以构造requestURL,
request_url = "http://tool.manmanbuy.com/hist ... rl%3D{0}&bjid=&spbh=&cxid=&zkid=&w=951&token={1}".format(url,token)
使用上面的代码,我们可以得到所有的数据!
python网页数据抓取(Python中的语法聿僮馕馕解析html(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-03-15 20:20
刚才好无聊,突然想起之前做课表的想法,于是百度起来。
一开始我是这样想的:我写微信墙的时候,用的是urllib2【两行代码抓取网页】,所以只需要解析html。于是百度:python解析html。找到了一个不错的文章,里面引入了pyQuery。
pyQuery 是 jQuery 在 Python 中的实现,可以生成带有 jQuery 语法的 HTML 文档。使用前需要安装。Mac安装方法如下:
sudo easy_install pyquery
好的!安装!
让我们试一试:
from pyquery import PyQuery as pq
html = pq(url=u'http://seam.ustb.edu.cn:8080/j ... %2339;)
#现在已经获取了本科教学网首页的html
classes = html('.haveclass')
#通过类名获取元素
#如果你对jQuery熟悉的话,那么你现在肯定明白pyQuery的方便了
更多用法参见pyQuery API
看来学用pyQuery的话,可以抓到时间表,但如果直接用我的源码,肯定会出错。因为我还没有登录!
所以,在运行此行获取正确代码之前,我们需要模拟登录本科教学网络。这时候才想起urllib有模拟post请求的功能,于是我百度了:urllib post。
这是一个模拟发布请求的最小示例:
import urllib
import urllib2
import cookielib
cj = cookielib.CookieJar()
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))
opener.addheaders = [('User-agent','Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)')]
urllib2.install_opener(opener)
req = urllib2.Request("http://seam.ustb.edu.cn:8080/jwgl/Login",urllib.urlencode({"username":"41255029","password":"123456","usertype":"student"}))
req.add_header("Referer","http://xxoo.com")
resp = urllib2.urlopen(req)
#这里面用到了cookielib,我不太清楚,以后慢慢了解吧
#还用到了urllib和urllib2,urllib2大概是urllib的扩展包【233想到了三国杀
在这个最简单的例子中,我使用我的校园网账号向登录页面提交表单数据来模拟登录。
现在,我们已经登录了本科教学网,然后结合之前的pyQuery解析html,就可以在网页中得到课程表了。
结果如图所示:
最后:
发现pyQuery不仅解析html非常方便,还可以作为跨域抓取数据的工具,NICE!!!
我希望每个人都必须提供帮助。 查看全部
python网页数据抓取(Python中的语法聿僮馕馕解析html(图))
刚才好无聊,突然想起之前做课表的想法,于是百度起来。
一开始我是这样想的:我写微信墙的时候,用的是urllib2【两行代码抓取网页】,所以只需要解析html。于是百度:python解析html。找到了一个不错的文章,里面引入了pyQuery。
pyQuery 是 jQuery 在 Python 中的实现,可以生成带有 jQuery 语法的 HTML 文档。使用前需要安装。Mac安装方法如下:
sudo easy_install pyquery
好的!安装!
让我们试一试:
from pyquery import PyQuery as pq
html = pq(url=u'http://seam.ustb.edu.cn:8080/j ... %2339;)
#现在已经获取了本科教学网首页的html
classes = html('.haveclass')
#通过类名获取元素
#如果你对jQuery熟悉的话,那么你现在肯定明白pyQuery的方便了
更多用法参见pyQuery API
看来学用pyQuery的话,可以抓到时间表,但如果直接用我的源码,肯定会出错。因为我还没有登录!
所以,在运行此行获取正确代码之前,我们需要模拟登录本科教学网络。这时候才想起urllib有模拟post请求的功能,于是我百度了:urllib post。
这是一个模拟发布请求的最小示例:
import urllib
import urllib2
import cookielib
cj = cookielib.CookieJar()
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))
opener.addheaders = [('User-agent','Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)')]
urllib2.install_opener(opener)
req = urllib2.Request("http://seam.ustb.edu.cn:8080/jwgl/Login",urllib.urlencode({"username":"41255029","password":"123456","usertype":"student"}))
req.add_header("Referer","http://xxoo.com";)
resp = urllib2.urlopen(req)
#这里面用到了cookielib,我不太清楚,以后慢慢了解吧
#还用到了urllib和urllib2,urllib2大概是urllib的扩展包【233想到了三国杀
在这个最简单的例子中,我使用我的校园网账号向登录页面提交表单数据来模拟登录。
现在,我们已经登录了本科教学网,然后结合之前的pyQuery解析html,就可以在网页中得到课程表了。
结果如图所示:

最后:
发现pyQuery不仅解析html非常方便,还可以作为跨域抓取数据的工具,NICE!!!
我希望每个人都必须提供帮助。
python网页数据抓取( 难不成我抓不了天猫网站的评论数据了?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 275 次浏览 • 2022-03-15 20:19
难不成我抓不了天猫网站的评论数据了?(图))
天气越来越冷,觉得应该给自己添点暖和的衣服,于是想到了天猫,搜了一下,感觉南极人的保暖内衣还是不错的。这么多衣服怎么选?我通常选择按销售额排序。毕竟销量也能反映产品的热度和口碑状况,所以来到了这个页面%C4%CF%BC%AB%C8%CB%B1%A3%C5%AF%C4 %DA% D2%C2&sort=d&style=g&from=.list.pc_1_suggest&suggest=0_1#J_Filter,
然后点进去后发现有很多历史累积评价,于是我一页一页地查看,感觉口碑还是很好的,所以选择了这款产品。我想每个人的购物方式可能都一样,可能会比较复杂(货比三家,比较口碑,联系卖家……)。
如果有一天,我想研究这些评论数据,然后玩自然语言处理,我应该把这些评论复制到一个大表中吗?虽然可以这样做,但我总觉得效率有点低(不是比爬虫低一两个数量级~)。如果你会爬行,你就会感受到自动化带来的刺激。接下来,我们将研究如何使用Python爬取天猫的评论数据。
像往常一样打牌,发现它是自然而柔软的。. . .
一般的套路是这样的。在上面的评论页面,右键选择“查看网页源代码”,代码如下:
我想在原网页中搜索“好,高级,划算”的评论,这句话在源代码中,很不幸,当我按Ctrl + F并输入“好”时,没有这样的东西这样的话。. . 是不是抓不到天猫网站的评论数据?不,还是有方法的,但是不能打常规卡,因为天猫的评论数据是异步存储在别处的。
非常规方法,双眼发光!
在评论页面上,我们按下 F12 键(我使用的是 Chrom 浏览器),结果如下:
可能你的页面布局有上下两部分,下半部分什么都没有。这时候需要做两件事: 1.选择Network下的JS部分,因为天猫的评论数据是异步存储在一个JS连接中的。2、刷新页面,找到一个开头叫“list_detail_rate”的文件。当你打开这个文件时,它看起来像这样:
你会发现有一个请求连接,然后你只需要复制链接并把这个地址粘贴到浏览器中,你会发现这些评论都隐藏在这个地方。. .
哈哈,那我们可以用正则表达式来抓取类似红框的信息(用户昵称、评论时间、购买的包裹、衣服尺码、评论内容)。你也可以问一个问题。您的页面只是评论信息的页面。如何捕获所有页面上的所有评论信息?我们发现了一个规则,复制的连接可以总结成这样的形式:每次改变最后一个 currentPage 的值,就可以抓取到不同页面的评论信息。
爬虫知识:
请求模块:
get方法向对端服务器发送url请求;
text方法可以将get请求的响应转换成文本字符串格式;
重新模块:
findall 函数使用正则表达式查找文本中所有匹配的结果,语法格式:
findall(模式、字符串、标志)
模式接受一个正则表达式对象;
string 接受需要处理的字符串;
flags 接受一个模式参数,比如是否忽略大小写(flags = re.I);
服务:
# 导入需要的开发模块
导入请求
重新进口
# 创建循环链接
网址 = []
对于列表中的我(范围(1,100)):
urls.append('%s' %i)
# 构建字段容器
昵称 = []
评级 = []
颜色 = []
大小 = []
率内容 = []
# 循环抓取数据
对于网址中的网址:
内容 = requests.get(url).text
# 使用 findall 匹配带有正则表达式的查询
nickname.extend(re.findall('"displayUserNick":"(.*?)"',content))
color.extend(re.findall(pile('颜色分类:(.*?);'),content))
size.extend(re.findall(pile('Size:(.*?);'),content))
ratecontent.extend(re.findall(pile('"rateContent":"(.*?)","rateDate"'),content))
ratingate.extend(re.findall(pile('”rateDate”:”(.*?)”,”reply”'),content))
打印(昵称,颜色)
# 数据输入
file = open('南极天猫评估.csv','w')
对于列表中的 i(范围(0,len(昵称))):
file.write(','.join((nickname[i],rated[i],color[i],size[i],ratecontent[i]))+'n')
文件.close()
最终爬虫结果如下:
今天的爬虫部分就介绍到这里。本次分享的目的是如何解决网页信息的异步存储。在后续的分享中,我将对爬取的评论数据进行文本分析,涉及分词、情感分析、词云等。
结尾。
本文经作者授权
原文来源于微信公众号(PPV类数据科学社区): 查看全部
python网页数据抓取(
难不成我抓不了天猫网站的评论数据了?(图))

天气越来越冷,觉得应该给自己添点暖和的衣服,于是想到了天猫,搜了一下,感觉南极人的保暖内衣还是不错的。这么多衣服怎么选?我通常选择按销售额排序。毕竟销量也能反映产品的热度和口碑状况,所以来到了这个页面%C4%CF%BC%AB%C8%CB%B1%A3%C5%AF%C4 %DA% D2%C2&sort=d&style=g&from=.list.pc_1_suggest&suggest=0_1#J_Filter,

然后点进去后发现有很多历史累积评价,于是我一页一页地查看,感觉口碑还是很好的,所以选择了这款产品。我想每个人的购物方式可能都一样,可能会比较复杂(货比三家,比较口碑,联系卖家……)。

如果有一天,我想研究这些评论数据,然后玩自然语言处理,我应该把这些评论复制到一个大表中吗?虽然可以这样做,但我总觉得效率有点低(不是比爬虫低一两个数量级~)。如果你会爬行,你就会感受到自动化带来的刺激。接下来,我们将研究如何使用Python爬取天猫的评论数据。
像往常一样打牌,发现它是自然而柔软的。. . .
一般的套路是这样的。在上面的评论页面,右键选择“查看网页源代码”,代码如下:

我想在原网页中搜索“好,高级,划算”的评论,这句话在源代码中,很不幸,当我按Ctrl + F并输入“好”时,没有这样的东西这样的话。. . 是不是抓不到天猫网站的评论数据?不,还是有方法的,但是不能打常规卡,因为天猫的评论数据是异步存储在别处的。
非常规方法,双眼发光!
在评论页面上,我们按下 F12 键(我使用的是 Chrom 浏览器),结果如下:

可能你的页面布局有上下两部分,下半部分什么都没有。这时候需要做两件事: 1.选择Network下的JS部分,因为天猫的评论数据是异步存储在一个JS连接中的。2、刷新页面,找到一个开头叫“list_detail_rate”的文件。当你打开这个文件时,它看起来像这样:

你会发现有一个请求连接,然后你只需要复制链接并把这个地址粘贴到浏览器中,你会发现这些评论都隐藏在这个地方。. .

哈哈,那我们可以用正则表达式来抓取类似红框的信息(用户昵称、评论时间、购买的包裹、衣服尺码、评论内容)。你也可以问一个问题。您的页面只是评论信息的页面。如何捕获所有页面上的所有评论信息?我们发现了一个规则,复制的连接可以总结成这样的形式:每次改变最后一个 currentPage 的值,就可以抓取到不同页面的评论信息。
爬虫知识:
请求模块:
get方法向对端服务器发送url请求;
text方法可以将get请求的响应转换成文本字符串格式;
重新模块:
findall 函数使用正则表达式查找文本中所有匹配的结果,语法格式:
findall(模式、字符串、标志)
模式接受一个正则表达式对象;
string 接受需要处理的字符串;
flags 接受一个模式参数,比如是否忽略大小写(flags = re.I);
服务:
# 导入需要的开发模块
导入请求
重新进口
# 创建循环链接
网址 = []
对于列表中的我(范围(1,100)):
urls.append('%s' %i)
# 构建字段容器
昵称 = []
评级 = []
颜色 = []
大小 = []
率内容 = []
# 循环抓取数据
对于网址中的网址:
内容 = requests.get(url).text
# 使用 findall 匹配带有正则表达式的查询
nickname.extend(re.findall('"displayUserNick":"(.*?)"',content))
color.extend(re.findall(pile('颜色分类:(.*?);'),content))
size.extend(re.findall(pile('Size:(.*?);'),content))
ratecontent.extend(re.findall(pile('"rateContent":"(.*?)","rateDate"'),content))
ratingate.extend(re.findall(pile('”rateDate”:”(.*?)”,”reply”'),content))
打印(昵称,颜色)
# 数据输入
file = open('南极天猫评估.csv','w')
对于列表中的 i(范围(0,len(昵称))):
file.write(','.join((nickname[i],rated[i],color[i],size[i],ratecontent[i]))+'n')
文件.close()
最终爬虫结果如下:

今天的爬虫部分就介绍到这里。本次分享的目的是如何解决网页信息的异步存储。在后续的分享中,我将对爬取的评论数据进行文本分析,涉及分词、情感分析、词云等。
结尾。
本文经作者授权
原文来源于微信公众号(PPV类数据科学社区):
python网页数据抓取( 代理ip爬取网页数据的方法-)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-03-15 05:16
代理ip爬取网页数据的方法-)
在网络营销时代,很多模式已经不能适应新的互联网时代,往往达不到营销效果。为了更好地运营网络营销,需要使用很多营销工具来做好每一步。和线上问答的推广一样,代理IP的支持也是必不可少的。需要在营销过程中找到最有效的工具,以提高效率,最大限度地发挥网络营销的效果。
使用Python爬取网页表格数据的代码如下。
<p style="line-height: 2em;">'''
Python 3.x
描述:本DEMO演示了使用爬虫(动态)代理IP请求网页的过程,代码使用了多线程
逻辑:每隔5秒从API接口获取IP,对于每一个IP开启一个线程去抓取网页源码
'''
import requests
import time
import threading
from requests.packages import urllib3
ips = []
# 爬数据的线程类
class CrawlThread(threading.Thread):
def __init__(self,proxyip):
super(CrawlThread, self).__init__()
self.proxyip=proxyip
def run(self):
# 开始计时
start = time.time()
#消除关闭证书验证的警告
urllib3.disable_warnings()
#使用代理IP请求网址,注意第三个参数verify=False意思是跳过SSL验证(可以防止报SSL错误)
html=requests.get(url=targetUrl, proxies={"http" : 'http://' + self.proxyip, "https" : 'https://' + self.proxyip}, verify=False, timeout=15).content.decode()
# 结束计时
end = time.time()
# 输出内容
print(threading.current_thread().getName() + "使用代理IP, 耗时 " + str(end - start) + "毫秒 " + self.proxyip + " 获取到如下HTML内容:\n" + html + "\n*************")
# 获取代理IP的线程类
class GetIpThread(threading.Thread):
def __init__(self,fetchSecond):
super(GetIpThread, self).__init__()
self.fetchSecond=fetchSecond
def run(self):
global ips
while True:
# 获取IP列表
res = requests.get(apiUrl).content.decode()
# 按照\n分割获取到的IP
ips = res.split('\n')
# 利用每一个IP
for proxyip in ips:
if proxyip.strip():
# 开启一个线程
CrawlThread(proxyip).start()
# 休眠
time.sleep(self.fetchSecond)
if __name__ == '__main__':
# 获取IP的API接口
apiUrl = "http:xxxx"
# 要抓取的目标网站地址
targetUrl = "http://ip.chinaz.com/getip.aspx"
# 获取IP时间间隔,建议为5秒
fetchSecond = 5
# 开始自动获取IP
GetIpThread(fetchSecond).start()
</p>
本文介绍使用python爬虫代理ip爬取网页数据的方法。让我们浏览以了解更多信息! 查看全部
python网页数据抓取(
代理ip爬取网页数据的方法-)

在网络营销时代,很多模式已经不能适应新的互联网时代,往往达不到营销效果。为了更好地运营网络营销,需要使用很多营销工具来做好每一步。和线上问答的推广一样,代理IP的支持也是必不可少的。需要在营销过程中找到最有效的工具,以提高效率,最大限度地发挥网络营销的效果。
使用Python爬取网页表格数据的代码如下。
<p style="line-height: 2em;">'''
Python 3.x
描述:本DEMO演示了使用爬虫(动态)代理IP请求网页的过程,代码使用了多线程
逻辑:每隔5秒从API接口获取IP,对于每一个IP开启一个线程去抓取网页源码
'''
import requests
import time
import threading
from requests.packages import urllib3
ips = []
# 爬数据的线程类
class CrawlThread(threading.Thread):
def __init__(self,proxyip):
super(CrawlThread, self).__init__()
self.proxyip=proxyip
def run(self):
# 开始计时
start = time.time()
#消除关闭证书验证的警告
urllib3.disable_warnings()
#使用代理IP请求网址,注意第三个参数verify=False意思是跳过SSL验证(可以防止报SSL错误)
html=requests.get(url=targetUrl, proxies={"http" : 'http://' + self.proxyip, "https" : 'https://' + self.proxyip}, verify=False, timeout=15).content.decode()
# 结束计时
end = time.time()
# 输出内容
print(threading.current_thread().getName() + "使用代理IP, 耗时 " + str(end - start) + "毫秒 " + self.proxyip + " 获取到如下HTML内容:\n" + html + "\n*************")
# 获取代理IP的线程类
class GetIpThread(threading.Thread):
def __init__(self,fetchSecond):
super(GetIpThread, self).__init__()
self.fetchSecond=fetchSecond
def run(self):
global ips
while True:
# 获取IP列表
res = requests.get(apiUrl).content.decode()
# 按照\n分割获取到的IP
ips = res.split('\n')
# 利用每一个IP
for proxyip in ips:
if proxyip.strip():
# 开启一个线程
CrawlThread(proxyip).start()
# 休眠
time.sleep(self.fetchSecond)
if __name__ == '__main__':
# 获取IP的API接口
apiUrl = "http:xxxx"
# 要抓取的目标网站地址
targetUrl = "http://ip.chinaz.com/getip.aspx"
# 获取IP时间间隔,建议为5秒
fetchSecond = 5
# 开始自动获取IP
GetIpThread(fetchSecond).start()
</p>
本文介绍使用python爬虫代理ip爬取网页数据的方法。让我们浏览以了解更多信息!
python网页数据抓取(Python中使用cookielib和rllib2配合PyQuery抓取网页信息的教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-03-15 05:14
在Python中使用cookielib和urllib2用PyQuery抓取网页信息
更新时间:2015年4月25日10:53:52 转载:程康
本文章主要介绍Python中使用cookielib和rllib2配合PyQuery抓取网页信息的教程,主要是使用PyQuery解析HTML来实现,有需要的朋友可以参考以下
刚才好无聊,突然想起之前做课表的想法,于是百度起来。
一开始我是这样想的:我写微信墙的时候,用的是urllib2【两行代码抓取网页】,所以只需要解析html。于是百度:python解析html。找到了一个不错的文章,里面引入了pyQuery。
pyQuery是jQuery在Python中的实现,可以用jQuery的语法解析HTML文档?手术。使用前需要安装。Mac安装方法如下:
sudo easy_install pyquery
好的!安装!
让我们试一试:
from pyquery import PyQuery as pq
html = pq(url=u'http://seam.ustb.edu.cn:8080/jwgl/index.jsp')
#现在已经获取了本科教学网首页的html
classes = html('.haveclass')
#通过类名获取元素
#如果你对jQuery熟悉的话,那么你现在肯定明白pyQuery的方便了
更多用法参见pyQuery API
看来学用pyQuery的话,可以抓到时间表,但如果直接用我的源码,肯定会出错。因为我还没有登录!
所以,在运行此行获取正确代码之前,我们需要模拟登录本科教学网络。这时候才想起urllib有模拟post请求的功能,于是我百度了:urllib post。
这是一个模拟发布请求的最小示例:
import urllib
import urllib2
import cookielib
cj = cookielib.CookieJar()
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))
opener.addheaders = [('User-agent','Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)')]
urllib2.install_opener(opener)
req = urllib2.Request("http://seam.ustb.edu.cn:8080/jwgl/Login",urllib.urlencode({"username":"41255029","password":"123456","usertype":"student"}))
req.add_header("Referer","http://xxoo.com")
resp = urllib2.urlopen(req)
#这里面用到了cookielib,我不太清楚,以后慢慢了解吧
#还用到了urllib和urllib2,urllib2大概是urllib的扩展包【233想到了三国杀
在这个最简单的例子中,我使用我的校园网账号向登录页面提交表单数据来模拟登录。
现在,我们已经登录了本科教学网,然后结合之前的pyQuery解析html,就可以在网页中得到课程表了。
html = pq(url=u'http://seam.ustb.edu.cn:8080/jwgl/index.jsp')
self.render("index.html",data=html('.haveclass'))
结果如图所示:
最后:
发现pyQuery不仅解析html非常方便,还可以作为跨域抓取数据的工具,NICE!!!
我希望每个人都必须提供帮助。 查看全部
python网页数据抓取(Python中使用cookielib和rllib2配合PyQuery抓取网页信息的教程)
在Python中使用cookielib和urllib2用PyQuery抓取网页信息
更新时间:2015年4月25日10:53:52 转载:程康
本文章主要介绍Python中使用cookielib和rllib2配合PyQuery抓取网页信息的教程,主要是使用PyQuery解析HTML来实现,有需要的朋友可以参考以下
刚才好无聊,突然想起之前做课表的想法,于是百度起来。
一开始我是这样想的:我写微信墙的时候,用的是urllib2【两行代码抓取网页】,所以只需要解析html。于是百度:python解析html。找到了一个不错的文章,里面引入了pyQuery。
pyQuery是jQuery在Python中的实现,可以用jQuery的语法解析HTML文档?手术。使用前需要安装。Mac安装方法如下:
sudo easy_install pyquery
好的!安装!
让我们试一试:
from pyquery import PyQuery as pq
html = pq(url=u'http://seam.ustb.edu.cn:8080/jwgl/index.jsp')
#现在已经获取了本科教学网首页的html
classes = html('.haveclass')
#通过类名获取元素
#如果你对jQuery熟悉的话,那么你现在肯定明白pyQuery的方便了
更多用法参见pyQuery API
看来学用pyQuery的话,可以抓到时间表,但如果直接用我的源码,肯定会出错。因为我还没有登录!
所以,在运行此行获取正确代码之前,我们需要模拟登录本科教学网络。这时候才想起urllib有模拟post请求的功能,于是我百度了:urllib post。
这是一个模拟发布请求的最小示例:
import urllib
import urllib2
import cookielib
cj = cookielib.CookieJar()
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))
opener.addheaders = [('User-agent','Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)')]
urllib2.install_opener(opener)
req = urllib2.Request("http://seam.ustb.edu.cn:8080/jwgl/Login",urllib.urlencode({"username":"41255029","password":"123456","usertype":"student"}))
req.add_header("Referer","http://xxoo.com";)
resp = urllib2.urlopen(req)
#这里面用到了cookielib,我不太清楚,以后慢慢了解吧
#还用到了urllib和urllib2,urllib2大概是urllib的扩展包【233想到了三国杀
在这个最简单的例子中,我使用我的校园网账号向登录页面提交表单数据来模拟登录。
现在,我们已经登录了本科教学网,然后结合之前的pyQuery解析html,就可以在网页中得到课程表了。
html = pq(url=u'http://seam.ustb.edu.cn:8080/jwgl/index.jsp')
self.render("index.html",data=html('.haveclass'))
结果如图所示:

最后:
发现pyQuery不仅解析html非常方便,还可以作为跨域抓取数据的工具,NICE!!!
我希望每个人都必须提供帮助。
python网页数据抓取(文档关于文件目录project:project目录是本项目的工作空间)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-03-13 19:15
欢迎来到ModelWhale Notebook¶这里你可以写代码,文件目录的文档会被保留输入:输入目录是数据集的挂载位置,所有挂载到项目中的数据集都在这里,没有挂载数据集时输入目录是隐藏的temp:temp目录是临时磁盘空间,训练或分析过程中产生的不需要的文件可以放在这里,目录下的文件不会保存 in[]:#查看个人持久化工作区文件!ls /home/mw/project/In []:# 查看当前挂载的数据集目录 !ls /home/mw/input/In[]:# show cell runtime %load_ext klab-autotime enter crawler¶什么是爬虫?本课程的内容是介绍什么是爬虫?爬行动物有什么用?以及爬虫是如何实现的?从这三点一起寻找答案!1. 1 网络爬虫简介网络爬虫(也称为网络蜘蛛、网络机器人,在FOAF社区中,更常被称为网页追逐者)是一种网络爬虫,根据一定的规则自动爬取的程序或脚本万维网信息。也就是说,爬虫可以自动浏览网络中的信息。当然,在浏览信息时,我们需要遵守我们制定的规则。这些规则称为网络爬虫算法。在浏览信息时,我们需要遵守我们制定的规则。这些规则称为网络爬虫算法。在浏览信息时,我们需要遵守我们制定的规则。这些规则称为网络爬虫算法。
Python 可以轻松编写爬虫程序,用于自动检索互联网信息。搜索引擎离不开爬虫。例如,百度搜索引擎的爬虫被称为百度蜘蛛。百度蜘蛛每天都会抓取大量互联网信息,抓取优质信息和收录,当用户在百度搜索引擎上搜索对应的关键词时,百度会进行关键词@ > 分析处理,从收录的网页中找出相关网页,按照一定的排名规则进行排序,并将结果展示给用户。1.1.1百度新闻案例表明,百度蜘蛛在这个过程中起到了至关重要的作用。所以,如何在互联网上覆盖更多优质网页?如何过滤这些重复的页面?这些都是由百度爬虫的算法决定的。使用不同的算法,爬虫的运行效率会有所不同,爬取的结果也会有所不同。1.1.2 网站Ranking(访问权重pv) 所以我们在研究爬虫的时候,不仅要了解爬虫是如何实现的,还需要了解一些常用的算法爬虫,如果有必要,我们还需要自己制定相应的算法。在这里,我们只需要对爬虫的概念有一个基本的了解。爬虫领域(为什么要学爬虫?)我们对网络爬虫有了初步的了解,但是为什么要学习网络爬虫呢?如今,人工智能和大数据离我们越来越近。很多公司都在做相关的业务,但是在人工智能和大数据中有一个非常重要的东西,那就是数据,但是数据从哪里来呢?首先我们看下面的例子#/trend/python?words=python 这是百度百度指数的截图。它对用户在百度上搜索关键词进行统计,然后根据统计结果创建一个流行趋势,然后进行简单的展示。s看下面的例子#/trend/python?words=python 这是百度百度指数的截图。它对用户在百度上搜索关键词进行统计,然后根据统计结果创建一个流行趋势,然后进行简单的展示。s看下面的例子#/trend/python?words=python 这是百度百度指数的截图。它对用户在百度上搜索关键词进行统计,然后根据统计结果创建一个流行趋势,然后进行简单的展示。
就像微博上的热搜,就是这个道理。类似的索引网站还有很多,比如阿里索引、360索引等,这些网站的用户数量非常多,他们可以获取自己用户的数据进行统计分析,所以,一些中小型公司在没有这么多用户的情况下应该怎么办?2.1 数据来源1.去第三方公司购买数据(例如:七叉茶)2.去免费数据网站下载数据(例如:国家局统计)3.通过爬虫爬取数据4.手动采集数据(如:问卷调查)在上述数据来源中,手动方式耗时耗力、效率低、数据免费< @网站以上数据质量较差,而很多第三方数据公司经常从爬虫那里获取数据,所以获取数据最有效的方式就是通过爬虫爬取2.2 爬虫就等于黑客吗?爬虫和黑客的区别:黑客和爬虫最大的区别就是目的不同。黑客做坏事,爬虫做好事。由于黑客和爬虫使用的技术相似,都是利用计算机网络技术侵入用户计算机网站和服务器获取数据和信息。不同的是,黑客是非法入侵,爬虫是合法入侵。比如通过破解网站后端验证码技术,然后模拟登录网站数据库,黑客删除数据库或直接修改他人的数据库。这是非法侵入、破坏行为和非法行为。也是破解验证码的技术,只是爬虫不一样。我需要获取一些政府的一些公开数据网站,但是每次都要输入验证码很麻烦。为了提高数据分析的效率,爬虫技术也是绕过验证码技术对采集网站公开和公开数据,不会获取私有和非公开数据。@网站,但是每次都要输入验证码很麻烦。为了提高数据分析的效率,爬虫技术也是绕过验证码技术对采集网站公开和公开数据,不会获取私有和非公开数据。@网站,但是每次都要输入验证码很麻烦。为了提高数据分析的效率,爬虫技术也是绕过验证码技术对采集网站公开和公开数据,不会获取私有和非公开数据。
如果把数据比作女性,爬虫和黑客都是男性,那么爬虫就是男朋友,在正当合理的情况下,它们与女性发生关系。但是,黑客不一样,黑客都是强奸犯,因为女性不愿意。,黑客是强制性的,甚至使用暴力与女性发生性关系。这是黑客和爬虫的本质区别。虽然使用了类似的技术手段来获取数据,但技术行为和最终后果的性质是不同的。一是违法需要承担法律后果,二是国家支持和鼓励的都是合法的。无论是爬虫还是黑客技术,它都只是一个工具,就像一把菜刀。有人用它切菜,有人用它杀人。不管菜刀的好坏,其实菜刀只是一个工具。行为结果2.3 大数据和爬虫是什么关系?爬虫爬取互联网数据,获取的数据量决定与大数据的兄弟关系是否更亲密2.4 爬虫领域,人脸识别前景:做人工智能需要大数据是的,例如,您想制造一台可以自动识别人脸的人工智能机器。你首先需要建立一个基于人脸生物特征的AI模型,然后需要数千万或数十亿张人脸图片不断训练模型,最终得到准确的人脸识别AI。数十亿人脸图像数据从何而来?派出所给你?不可能的!一张一张的拍照?更不现实!即通过网络爬虫技术构建人脸图片库。比如我们可以利用爬虫技术爬取facebook、QQ头像、微信头像等,实现十亿以上的人脸图片库的建立。
市场分析:电商分析、商圈分析、一二级市场分析等 市场监测:电商、新闻、房源监测等 商机发现:招标情报发现、客户数据发现、企业客户发现、等等。 。. 后面学习了数据分析之后,还可以使用爬虫获取金融股数据进行数据分析。什么是爬虫?网络爬虫(也称为网络蜘蛛或网络机器人)是模拟客户端发送网络请求并接收请求响应的程序。它是一个按照一定的规则自动抓取互联网信息的程序。原则上,只要浏览器(客户端)能做任何事,爬虫都能做,也就是说,一切都可以被爬取,爬虫的更多用途可以直观爬取(了解)12306抢票网站投票短信(电话)轰炸注册页面1 注册页面2 注册页面3 爬虫分类¶ 根据系统结构和实现技术,网络爬虫大致可分为4类,即一般网络爬虫、聚焦网络爬虫、增量网络爬虫和深度网络爬虫。1.通用网络爬虫:当一个搜索引擎爬虫,比如用户在百度搜索引擎上搜索对应的关键词,百度会对关键词进行分析处理,从收录网页 找出相关的,然后按照一定的排名规则进行排序并展示给用户,那么你就需要互联网上尽可能多的优质网页。从互联网上采集网页,采集信息,这些网页信息是用来为搜索引擎建立索引提供支持的,它决定了整个引擎系统的内容是否丰富,信息是否即时,所以它的性能直接受到影响。搜索引擎的影响。
2.专注于网络爬虫:针对特定网页的爬虫也称为主题网络爬虫。爬取的目标网页位于与主题相关的页面中,主要为某类特定人群提供服务,可以节省大量的服务器资源和带宽资源。Focused crawler 在实现网页抓取时会对内容进行处理和过滤,并尽量保证只抓取与需求相关的网页信息。比如要获取某个垂直领域的数据或者有明确的检索需求,就需要过滤掉一些无用的信息。例如:那些比较价格的 网站 是其他被抓取的 网站 产品。3.Incremental Web Crawler 增量网络爬虫(Incremental Web Crawler),所谓增量,即增量更新。增量更新是指在更新的时候,只更新变化的地方,不更新变化的地方,所以爬虫只爬取内容发生变化的网页或者新生成的网页。例如:招聘网络爬虫4.深度网络爬虫(Deep Web Crawler),首先,什么是深度页面?在互联网中,网页根据存在的不同分为表层页面和深层页面。所谓表面页面,是指无需提交表单,使用静态链接即可到达的静态页面;而深页是经过一定程度的关键词调整后才能得到的页面。在 Internet 上,深层页面通常比表面页面多得多。深网爬虫主要由 URL 列表组成,
后来,我们主要学习专注于爬虫。专注爬虫学会之后,其他类型的爬虫就可以轻松写出通用爬虫和专注爬虫的原理。解析;从响应解析中获取需要的新url,并将这些url放入待抓取的url队列中;取出要爬取的URL,解析DNS得到主机的IP,下载该URL对应的网页,存入Download the web library并将这些URL放入Crawl URL queue。分析爬取的URL队列中的URL,分析其中的其他URL,将这些URL放入待爬取的URL队列,从而进入下一个循环...... 第二步:数据存储搜索引擎通过爬虫爬取网页,存储原创页面数据库中的数据。页面数据与用户的 HTML 完全相同 s 浏览器获取。搜索引擎蜘蛛在抓取页面时也会进行某些重复内容检测。一旦他们遇到大量抄袭、采集 或复制访问权重低的网站 上的内容,很有可能不再使用。爬行。第三步:对搜索引擎爬回来的页面进行预处理,并进行各种预处理步骤。提取文本中文分词去噪(如版权声明文本、导航栏、广告等……)基于文本的,如PDF、Word、WPS、XLS、PPT、TXT文件等。一旦他们遇到大量抄袭、采集 或复制访问权重低的网站 上的内容,很有可能不再使用。爬行。第三步:对搜索引擎爬回来的页面进行预处理,并进行各种预处理步骤。提取文本中文分词去噪(如版权声明文本、导航栏、广告等……)基于文本的,如PDF、Word、WPS、XLS、PPT、TXT文件等。一旦他们遇到大量抄袭、采集 或复制访问权重低的网站 上的内容,很有可能不再使用。爬行。第三步:对搜索引擎爬回来的页面进行预处理,并进行各种预处理步骤。提取文本中文分词去噪(如版权声明文本、导航栏、广告等……)基于文本的,如PDF、Word、WPS、XLS、PPT、TXT文件等。并执行各种预处理步骤。提取文本中文分词去噪(如版权声明文本、导航栏、广告等……)基于文本的,如PDF、Word、WPS、XLS、PPT、TXT文件等。并执行各种预处理步骤。提取文本中文分词去噪(如版权声明文本、导航栏、广告等……)基于文本的,如PDF、Word、WPS、XLS、PPT、TXT文件等。
我们还经常在搜索结果中看到这些文件类型。但搜索引擎无法处理图像、视频、Flash 等非文本内容,也无法执行脚本和程序。第四步:提供检索服务。网站排名搜索引擎对信息进行组织处理后,为用户提供关键词检索服务,并将相关信息展示给用户。关注爬虫: 第一步:start_url 发送请求 第二步:获取响应 第三步:解析响应,如果响应中有新的url地址需要,重复第二步;Step 4: 提取数据 Step 5 Step: 保存数据 通常我们会一步一步获取响应并解析,所以重点关注爬虫的步骤,一般来说有四个步骤 http 和 https 请求和响应 URL 形成一个网站 URL一般由域名+自己写的页面组成。当我们访问同一个网站网页时,域名一般不会改变,所以我们的爬虫需要解析的是网站自己写的不同页面的入口url,只有解析出来的url每个页面入口,我们就可以启动我们的爬虫了。网页的两种加载方式是同步加载的:改变URL上的一些请求参数会导致页面改变,例如:(改变page=后面的数字,页面会改变) 异步加载:改变请求参数on URL 不会导致页面更改。网页发生变化,例如:
(控制浏览器显示哪个页面) Server:apache tomcat(服务器类型) Content-Encoding:gzip(服务器发送的压缩编码方式) Content-Length:80(服务器发送的字节码长度) Content-Language: zh-cn(服务器发送的内容的语言和国家名称) Content-Type:image/jpeg;charset=UTF-8(服务器发送的内容的类型和编码类型) Last-Modified: Tue, 11 Jul 2000 18:23:51 GMT(服务器最后一次修改的时间) Refresh: 1;url= (控制浏览器1秒后转发该URL指向的页面) Content-Disposition:附件;filename=aaa.jpg(服务器控制浏览器发送下载方式打开文件) Transfer-Encoding: chunked(服务器将数据分块传输给客户端) Set-Cookie:SS=Q0=5Lb_nQ;
常见状态码:100~199:表示服务器已经成功接收到部分请求,需要客户端继续提交剩余的请求以完成整个处理过程。200~299:表示服务器成功接收到请求,完成了整个处理过程。常用200(OK请求成功)。300~399:为了完成请求,客户需要进一步细化请求。例如:请求的资源已经移动到了新的地址,常见的302(请求的页面已经临时移动到了新的url),307和304(使用缓存的资源)。400~499:客户端请求出错,常用404(服务器找不到请求的页面),403(服务器拒绝访问,权限不够)。500~599:服务器端发生错误,一般为500(请求未完成,服务器遇到不可预知的情况)。在[]: 查看全部
python网页数据抓取(文档关于文件目录project:project目录是本项目的工作空间)
欢迎来到ModelWhale Notebook¶这里你可以写代码,文件目录的文档会被保留输入:输入目录是数据集的挂载位置,所有挂载到项目中的数据集都在这里,没有挂载数据集时输入目录是隐藏的temp:temp目录是临时磁盘空间,训练或分析过程中产生的不需要的文件可以放在这里,目录下的文件不会保存 in[]:#查看个人持久化工作区文件!ls /home/mw/project/In []:# 查看当前挂载的数据集目录 !ls /home/mw/input/In[]:# show cell runtime %load_ext klab-autotime enter crawler¶什么是爬虫?本课程的内容是介绍什么是爬虫?爬行动物有什么用?以及爬虫是如何实现的?从这三点一起寻找答案!1. 1 网络爬虫简介网络爬虫(也称为网络蜘蛛、网络机器人,在FOAF社区中,更常被称为网页追逐者)是一种网络爬虫,根据一定的规则自动爬取的程序或脚本万维网信息。也就是说,爬虫可以自动浏览网络中的信息。当然,在浏览信息时,我们需要遵守我们制定的规则。这些规则称为网络爬虫算法。在浏览信息时,我们需要遵守我们制定的规则。这些规则称为网络爬虫算法。在浏览信息时,我们需要遵守我们制定的规则。这些规则称为网络爬虫算法。
Python 可以轻松编写爬虫程序,用于自动检索互联网信息。搜索引擎离不开爬虫。例如,百度搜索引擎的爬虫被称为百度蜘蛛。百度蜘蛛每天都会抓取大量互联网信息,抓取优质信息和收录,当用户在百度搜索引擎上搜索对应的关键词时,百度会进行关键词@ > 分析处理,从收录的网页中找出相关网页,按照一定的排名规则进行排序,并将结果展示给用户。1.1.1百度新闻案例表明,百度蜘蛛在这个过程中起到了至关重要的作用。所以,如何在互联网上覆盖更多优质网页?如何过滤这些重复的页面?这些都是由百度爬虫的算法决定的。使用不同的算法,爬虫的运行效率会有所不同,爬取的结果也会有所不同。1.1.2 网站Ranking(访问权重pv) 所以我们在研究爬虫的时候,不仅要了解爬虫是如何实现的,还需要了解一些常用的算法爬虫,如果有必要,我们还需要自己制定相应的算法。在这里,我们只需要对爬虫的概念有一个基本的了解。爬虫领域(为什么要学爬虫?)我们对网络爬虫有了初步的了解,但是为什么要学习网络爬虫呢?如今,人工智能和大数据离我们越来越近。很多公司都在做相关的业务,但是在人工智能和大数据中有一个非常重要的东西,那就是数据,但是数据从哪里来呢?首先我们看下面的例子#/trend/python?words=python 这是百度百度指数的截图。它对用户在百度上搜索关键词进行统计,然后根据统计结果创建一个流行趋势,然后进行简单的展示。s看下面的例子#/trend/python?words=python 这是百度百度指数的截图。它对用户在百度上搜索关键词进行统计,然后根据统计结果创建一个流行趋势,然后进行简单的展示。s看下面的例子#/trend/python?words=python 这是百度百度指数的截图。它对用户在百度上搜索关键词进行统计,然后根据统计结果创建一个流行趋势,然后进行简单的展示。
就像微博上的热搜,就是这个道理。类似的索引网站还有很多,比如阿里索引、360索引等,这些网站的用户数量非常多,他们可以获取自己用户的数据进行统计分析,所以,一些中小型公司在没有这么多用户的情况下应该怎么办?2.1 数据来源1.去第三方公司购买数据(例如:七叉茶)2.去免费数据网站下载数据(例如:国家局统计)3.通过爬虫爬取数据4.手动采集数据(如:问卷调查)在上述数据来源中,手动方式耗时耗力、效率低、数据免费< @网站以上数据质量较差,而很多第三方数据公司经常从爬虫那里获取数据,所以获取数据最有效的方式就是通过爬虫爬取2.2 爬虫就等于黑客吗?爬虫和黑客的区别:黑客和爬虫最大的区别就是目的不同。黑客做坏事,爬虫做好事。由于黑客和爬虫使用的技术相似,都是利用计算机网络技术侵入用户计算机网站和服务器获取数据和信息。不同的是,黑客是非法入侵,爬虫是合法入侵。比如通过破解网站后端验证码技术,然后模拟登录网站数据库,黑客删除数据库或直接修改他人的数据库。这是非法侵入、破坏行为和非法行为。也是破解验证码的技术,只是爬虫不一样。我需要获取一些政府的一些公开数据网站,但是每次都要输入验证码很麻烦。为了提高数据分析的效率,爬虫技术也是绕过验证码技术对采集网站公开和公开数据,不会获取私有和非公开数据。@网站,但是每次都要输入验证码很麻烦。为了提高数据分析的效率,爬虫技术也是绕过验证码技术对采集网站公开和公开数据,不会获取私有和非公开数据。@网站,但是每次都要输入验证码很麻烦。为了提高数据分析的效率,爬虫技术也是绕过验证码技术对采集网站公开和公开数据,不会获取私有和非公开数据。
如果把数据比作女性,爬虫和黑客都是男性,那么爬虫就是男朋友,在正当合理的情况下,它们与女性发生关系。但是,黑客不一样,黑客都是强奸犯,因为女性不愿意。,黑客是强制性的,甚至使用暴力与女性发生性关系。这是黑客和爬虫的本质区别。虽然使用了类似的技术手段来获取数据,但技术行为和最终后果的性质是不同的。一是违法需要承担法律后果,二是国家支持和鼓励的都是合法的。无论是爬虫还是黑客技术,它都只是一个工具,就像一把菜刀。有人用它切菜,有人用它杀人。不管菜刀的好坏,其实菜刀只是一个工具。行为结果2.3 大数据和爬虫是什么关系?爬虫爬取互联网数据,获取的数据量决定与大数据的兄弟关系是否更亲密2.4 爬虫领域,人脸识别前景:做人工智能需要大数据是的,例如,您想制造一台可以自动识别人脸的人工智能机器。你首先需要建立一个基于人脸生物特征的AI模型,然后需要数千万或数十亿张人脸图片不断训练模型,最终得到准确的人脸识别AI。数十亿人脸图像数据从何而来?派出所给你?不可能的!一张一张的拍照?更不现实!即通过网络爬虫技术构建人脸图片库。比如我们可以利用爬虫技术爬取facebook、QQ头像、微信头像等,实现十亿以上的人脸图片库的建立。
市场分析:电商分析、商圈分析、一二级市场分析等 市场监测:电商、新闻、房源监测等 商机发现:招标情报发现、客户数据发现、企业客户发现、等等。 。. 后面学习了数据分析之后,还可以使用爬虫获取金融股数据进行数据分析。什么是爬虫?网络爬虫(也称为网络蜘蛛或网络机器人)是模拟客户端发送网络请求并接收请求响应的程序。它是一个按照一定的规则自动抓取互联网信息的程序。原则上,只要浏览器(客户端)能做任何事,爬虫都能做,也就是说,一切都可以被爬取,爬虫的更多用途可以直观爬取(了解)12306抢票网站投票短信(电话)轰炸注册页面1 注册页面2 注册页面3 爬虫分类¶ 根据系统结构和实现技术,网络爬虫大致可分为4类,即一般网络爬虫、聚焦网络爬虫、增量网络爬虫和深度网络爬虫。1.通用网络爬虫:当一个搜索引擎爬虫,比如用户在百度搜索引擎上搜索对应的关键词,百度会对关键词进行分析处理,从收录网页 找出相关的,然后按照一定的排名规则进行排序并展示给用户,那么你就需要互联网上尽可能多的优质网页。从互联网上采集网页,采集信息,这些网页信息是用来为搜索引擎建立索引提供支持的,它决定了整个引擎系统的内容是否丰富,信息是否即时,所以它的性能直接受到影响。搜索引擎的影响。
2.专注于网络爬虫:针对特定网页的爬虫也称为主题网络爬虫。爬取的目标网页位于与主题相关的页面中,主要为某类特定人群提供服务,可以节省大量的服务器资源和带宽资源。Focused crawler 在实现网页抓取时会对内容进行处理和过滤,并尽量保证只抓取与需求相关的网页信息。比如要获取某个垂直领域的数据或者有明确的检索需求,就需要过滤掉一些无用的信息。例如:那些比较价格的 网站 是其他被抓取的 网站 产品。3.Incremental Web Crawler 增量网络爬虫(Incremental Web Crawler),所谓增量,即增量更新。增量更新是指在更新的时候,只更新变化的地方,不更新变化的地方,所以爬虫只爬取内容发生变化的网页或者新生成的网页。例如:招聘网络爬虫4.深度网络爬虫(Deep Web Crawler),首先,什么是深度页面?在互联网中,网页根据存在的不同分为表层页面和深层页面。所谓表面页面,是指无需提交表单,使用静态链接即可到达的静态页面;而深页是经过一定程度的关键词调整后才能得到的页面。在 Internet 上,深层页面通常比表面页面多得多。深网爬虫主要由 URL 列表组成,
后来,我们主要学习专注于爬虫。专注爬虫学会之后,其他类型的爬虫就可以轻松写出通用爬虫和专注爬虫的原理。解析;从响应解析中获取需要的新url,并将这些url放入待抓取的url队列中;取出要爬取的URL,解析DNS得到主机的IP,下载该URL对应的网页,存入Download the web library并将这些URL放入Crawl URL queue。分析爬取的URL队列中的URL,分析其中的其他URL,将这些URL放入待爬取的URL队列,从而进入下一个循环...... 第二步:数据存储搜索引擎通过爬虫爬取网页,存储原创页面数据库中的数据。页面数据与用户的 HTML 完全相同 s 浏览器获取。搜索引擎蜘蛛在抓取页面时也会进行某些重复内容检测。一旦他们遇到大量抄袭、采集 或复制访问权重低的网站 上的内容,很有可能不再使用。爬行。第三步:对搜索引擎爬回来的页面进行预处理,并进行各种预处理步骤。提取文本中文分词去噪(如版权声明文本、导航栏、广告等……)基于文本的,如PDF、Word、WPS、XLS、PPT、TXT文件等。一旦他们遇到大量抄袭、采集 或复制访问权重低的网站 上的内容,很有可能不再使用。爬行。第三步:对搜索引擎爬回来的页面进行预处理,并进行各种预处理步骤。提取文本中文分词去噪(如版权声明文本、导航栏、广告等……)基于文本的,如PDF、Word、WPS、XLS、PPT、TXT文件等。一旦他们遇到大量抄袭、采集 或复制访问权重低的网站 上的内容,很有可能不再使用。爬行。第三步:对搜索引擎爬回来的页面进行预处理,并进行各种预处理步骤。提取文本中文分词去噪(如版权声明文本、导航栏、广告等……)基于文本的,如PDF、Word、WPS、XLS、PPT、TXT文件等。并执行各种预处理步骤。提取文本中文分词去噪(如版权声明文本、导航栏、广告等……)基于文本的,如PDF、Word、WPS、XLS、PPT、TXT文件等。并执行各种预处理步骤。提取文本中文分词去噪(如版权声明文本、导航栏、广告等……)基于文本的,如PDF、Word、WPS、XLS、PPT、TXT文件等。
我们还经常在搜索结果中看到这些文件类型。但搜索引擎无法处理图像、视频、Flash 等非文本内容,也无法执行脚本和程序。第四步:提供检索服务。网站排名搜索引擎对信息进行组织处理后,为用户提供关键词检索服务,并将相关信息展示给用户。关注爬虫: 第一步:start_url 发送请求 第二步:获取响应 第三步:解析响应,如果响应中有新的url地址需要,重复第二步;Step 4: 提取数据 Step 5 Step: 保存数据 通常我们会一步一步获取响应并解析,所以重点关注爬虫的步骤,一般来说有四个步骤 http 和 https 请求和响应 URL 形成一个网站 URL一般由域名+自己写的页面组成。当我们访问同一个网站网页时,域名一般不会改变,所以我们的爬虫需要解析的是网站自己写的不同页面的入口url,只有解析出来的url每个页面入口,我们就可以启动我们的爬虫了。网页的两种加载方式是同步加载的:改变URL上的一些请求参数会导致页面改变,例如:(改变page=后面的数字,页面会改变) 异步加载:改变请求参数on URL 不会导致页面更改。网页发生变化,例如:
(控制浏览器显示哪个页面) Server:apache tomcat(服务器类型) Content-Encoding:gzip(服务器发送的压缩编码方式) Content-Length:80(服务器发送的字节码长度) Content-Language: zh-cn(服务器发送的内容的语言和国家名称) Content-Type:image/jpeg;charset=UTF-8(服务器发送的内容的类型和编码类型) Last-Modified: Tue, 11 Jul 2000 18:23:51 GMT(服务器最后一次修改的时间) Refresh: 1;url= (控制浏览器1秒后转发该URL指向的页面) Content-Disposition:附件;filename=aaa.jpg(服务器控制浏览器发送下载方式打开文件) Transfer-Encoding: chunked(服务器将数据分块传输给客户端) Set-Cookie:SS=Q0=5Lb_nQ;
常见状态码:100~199:表示服务器已经成功接收到部分请求,需要客户端继续提交剩余的请求以完成整个处理过程。200~299:表示服务器成功接收到请求,完成了整个处理过程。常用200(OK请求成功)。300~399:为了完成请求,客户需要进一步细化请求。例如:请求的资源已经移动到了新的地址,常见的302(请求的页面已经临时移动到了新的url),307和304(使用缓存的资源)。400~499:客户端请求出错,常用404(服务器找不到请求的页面),403(服务器拒绝访问,权限不够)。500~599:服务器端发生错误,一般为500(请求未完成,服务器遇到不可预知的情况)。在[]:
python网页数据抓取(如何应对数据匮乏的问题?最简单的方法在这里)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-03-11 19:09
作者|LAKSHAY ARORA
编译|Flin
来源 | 分析学
概述
我们的数据太少,无法构建机器学习模型。我们需要更多数据!
如果这句话听起来很熟悉,那么您并不孤单!想要获得更多数据来训练我们的机器学习模型是一个持续存在的问题。我们无法获得可以直接在数据科学项目中使用的 Excel 或 .csv 文件,对吧?
那么,如何应对数据稀缺的问题呢?
实现这一目标的最有效和最简单的方法之一是通过网络抓取。我个人认为网络抓取是一种非常有用的技术,可以从多个 网站 中采集数据。今天,一些 网站 还为您可能想要使用的许多不同类型的数据提供 API,例如 Tweets 或 LinkedIn 帖子。
但有时您可能需要从不提供特定 API 的 网站 采集数据。这就是网络抓取功能派上用场的地方。作为数据科学家,您可以编写一个简单的 Python 脚本并提取所需的数据。
因此,在本文中,我们将了解网页抓取的不同组件,然后直接深入 Python 以了解如何使用流行且高效的 BeautifulSoup 库执行网页抓取。
我们还为本文创建了免费课程:
请注意,网络抓取受许多准则和规则的约束。并非每个 网站 都允许用户抓取内容,因此存在法律限制。在尝试执行此操作之前,请确保您已阅读 网站 的网站 条款和条件。
Python 中用于网络爬取的 3 个流行工具和库的目录
网络爬虫的组成部分
CrawlParse 和 TransformStore 从网页抓取 URL 和电子邮件 ID 抓取图像 在页面加载时抓取数据 3 个 Python 中用于 Web 爬虫的流行工具和库
您将在 Python 中遇到几个用于 Web 抓取的库和框架。以下是三种用于高效完成工作的流行工具:
美丽汤
刮擦
硒
网络爬虫的组成部分
这是构成网络抓取的三个主要组件的绝佳说明:
让我们详细了解这些组件。我们将通过 goibibo网站 获取酒店详细信息,例如酒店名称和每间客房的价格以执行此操作:
注意:始终遵循目标 网站 的 robots.txt 文件,也称为机器人排除协议。这告诉网络机器人不要抓取哪些页面。
因此,我们可以从目标 URL 中抓取数据。我们很高兴为我们的网络机器人编写脚本。开始吧!
第 1 步:爬行
网页抓取的第一步是导航到目标 网站 并下载网页的源代码。我们将使用 requests 库来执行此操作。http.client 和 urlib2 是另外两个用于发出请求和下载源代码的库。
下载网页的源代码后,我们需要过滤我们想要的内容:
"""
Web Scraping - Beautiful Soup
"""
# importing required libraries
import requests
from bs4 import BeautifulSoup
import pandas as pd
# target URL to scrap
url = "https://www.goibibo.com/hotels ... ot%3B
# headers
headers = {
'User-Agent': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36"
}
# send request to download the data
response = requests.request("GET", url, headers=headers)
# parse the downloaded data
data = BeautifulSoup(response.text, 'html.parser')
print(data)
第 2 步:解析和转换
网页抓取的下一步是将这些数据解析为 HTML 解析器,为此我们将使用 BeautifulSoup 库。现在,如果您注意到我们的登录页面,与大多数页面一样,特定酒店的详细信息在不同的卡片上。
所以下一步是从完整的源代码中过滤卡片数据。接下来,我们将选择该卡并单击“检查元素”选项以获取该特定卡的源代码。你会得到这样的东西:
所有卡片都有相同的类名,我们可以通过传递标签名称和具有如下名称的属性(如标签)来获取这些卡片的列表:
# find all the sections with specifiedd class name
cards_data = data.find_all('div', attrs={'class', 'width100 fl htlListSeo hotel-tile-srp-container hotel-tile-srp-container-template new-htl-design-tile-main-block'})
# total number of cards
print('Total Number of Cards Found : ', len(cards_data))
# source code of hotel cards
for card in cards_data:
print(card)
我们从网页的完整源代码中过滤掉了卡片数据,其中每张卡片都收录有关单个酒店的信息。仅选择酒店名称,执行“检查元素”步骤,并对房价执行相同操作:
现在对于每张卡,我们必须找到上面的酒店名称,只能从
从标签中提取。这是因为每张卡和费率只有一个标签和标签和类别名称:
# extract the hotel name and price per room
for card in cards_data:
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
print(hotel_name.text, room_price.text)
第三步:存储(存储数据)
最后一步是将提取的数据存储在 CSV 文件中。在这里,对于每张卡片,我们将提取酒店名称和价格并将其存储在 Python 字典中。然后我们最终将它添加到列表中。
接下来,让我们继续将此列表转换为 Pandas 数据框,因为它允许我们将数据框转换为 CSV 或 JSON 文件:
# create a list to store the data
scraped_data = []
for card in cards_data:
# initialize the dictionary
card_details = {}
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
# add data to the dictionary
card_details['hotel_name'] = hotel_name.text
card_details['room_price'] = room_price.text
# append the scraped data to the list
scraped_data.append(card_details)
# create a data frame from the list of dictionaries
dataFrame = pd.DataFrame.from_dict(scraped_data)
# save the scraped data as CSV file
dataFrame.to_csv('hotels_data.csv', index=False)
恭喜!我们已经成功创建了一个基本的网络抓取工具。我希望您尝试这些步骤并尝试获取更多数据,例如酒店的评级和地址。现在,让我们看看如何执行一些常见任务,例如在页面加载时抓取 URL、电子邮件 ID、图像和抓取数据。
从网页中获取 URL 和电子邮件 ID
我们尝试通过网络抓取来抓取的两个最常见的功能是 网站URL 和电子邮件 ID。我确定您参与过需要大量提取电子邮件 ID 的项目或挑战。那么让我们看看如何在 Python 中抓取这些内容。
使用 Web 浏览器的控制台 查看全部
python网页数据抓取(如何应对数据匮乏的问题?最简单的方法在这里)
作者|LAKSHAY ARORA
编译|Flin
来源 | 分析学
概述
我们的数据太少,无法构建机器学习模型。我们需要更多数据!
如果这句话听起来很熟悉,那么您并不孤单!想要获得更多数据来训练我们的机器学习模型是一个持续存在的问题。我们无法获得可以直接在数据科学项目中使用的 Excel 或 .csv 文件,对吧?
那么,如何应对数据稀缺的问题呢?
实现这一目标的最有效和最简单的方法之一是通过网络抓取。我个人认为网络抓取是一种非常有用的技术,可以从多个 网站 中采集数据。今天,一些 网站 还为您可能想要使用的许多不同类型的数据提供 API,例如 Tweets 或 LinkedIn 帖子。

但有时您可能需要从不提供特定 API 的 网站 采集数据。这就是网络抓取功能派上用场的地方。作为数据科学家,您可以编写一个简单的 Python 脚本并提取所需的数据。
因此,在本文中,我们将了解网页抓取的不同组件,然后直接深入 Python 以了解如何使用流行且高效的 BeautifulSoup 库执行网页抓取。
我们还为本文创建了免费课程:
请注意,网络抓取受许多准则和规则的约束。并非每个 网站 都允许用户抓取内容,因此存在法律限制。在尝试执行此操作之前,请确保您已阅读 网站 的网站 条款和条件。
Python 中用于网络爬取的 3 个流行工具和库的目录
网络爬虫的组成部分
CrawlParse 和 TransformStore 从网页抓取 URL 和电子邮件 ID 抓取图像 在页面加载时抓取数据 3 个 Python 中用于 Web 爬虫的流行工具和库
您将在 Python 中遇到几个用于 Web 抓取的库和框架。以下是三种用于高效完成工作的流行工具:
美丽汤
刮擦
硒
网络爬虫的组成部分
这是构成网络抓取的三个主要组件的绝佳说明:

让我们详细了解这些组件。我们将通过 goibibo网站 获取酒店详细信息,例如酒店名称和每间客房的价格以执行此操作:

注意:始终遵循目标 网站 的 robots.txt 文件,也称为机器人排除协议。这告诉网络机器人不要抓取哪些页面。

因此,我们可以从目标 URL 中抓取数据。我们很高兴为我们的网络机器人编写脚本。开始吧!
第 1 步:爬行
网页抓取的第一步是导航到目标 网站 并下载网页的源代码。我们将使用 requests 库来执行此操作。http.client 和 urlib2 是另外两个用于发出请求和下载源代码的库。
下载网页的源代码后,我们需要过滤我们想要的内容:
"""
Web Scraping - Beautiful Soup
"""
# importing required libraries
import requests
from bs4 import BeautifulSoup
import pandas as pd
# target URL to scrap
url = "https://www.goibibo.com/hotels ... ot%3B
# headers
headers = {
'User-Agent': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36"
}
# send request to download the data
response = requests.request("GET", url, headers=headers)
# parse the downloaded data
data = BeautifulSoup(response.text, 'html.parser')
print(data)
第 2 步:解析和转换
网页抓取的下一步是将这些数据解析为 HTML 解析器,为此我们将使用 BeautifulSoup 库。现在,如果您注意到我们的登录页面,与大多数页面一样,特定酒店的详细信息在不同的卡片上。
所以下一步是从完整的源代码中过滤卡片数据。接下来,我们将选择该卡并单击“检查元素”选项以获取该特定卡的源代码。你会得到这样的东西:

所有卡片都有相同的类名,我们可以通过传递标签名称和具有如下名称的属性(如标签)来获取这些卡片的列表:
# find all the sections with specifiedd class name
cards_data = data.find_all('div', attrs={'class', 'width100 fl htlListSeo hotel-tile-srp-container hotel-tile-srp-container-template new-htl-design-tile-main-block'})
# total number of cards
print('Total Number of Cards Found : ', len(cards_data))
# source code of hotel cards
for card in cards_data:
print(card)

我们从网页的完整源代码中过滤掉了卡片数据,其中每张卡片都收录有关单个酒店的信息。仅选择酒店名称,执行“检查元素”步骤,并对房价执行相同操作:

现在对于每张卡,我们必须找到上面的酒店名称,只能从
从标签中提取。这是因为每张卡和费率只有一个标签和标签和类别名称:
# extract the hotel name and price per room
for card in cards_data:
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
print(hotel_name.text, room_price.text)

第三步:存储(存储数据)
最后一步是将提取的数据存储在 CSV 文件中。在这里,对于每张卡片,我们将提取酒店名称和价格并将其存储在 Python 字典中。然后我们最终将它添加到列表中。
接下来,让我们继续将此列表转换为 Pandas 数据框,因为它允许我们将数据框转换为 CSV 或 JSON 文件:
# create a list to store the data
scraped_data = []
for card in cards_data:
# initialize the dictionary
card_details = {}
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
# add data to the dictionary
card_details['hotel_name'] = hotel_name.text
card_details['room_price'] = room_price.text
# append the scraped data to the list
scraped_data.append(card_details)
# create a data frame from the list of dictionaries
dataFrame = pd.DataFrame.from_dict(scraped_data)
# save the scraped data as CSV file
dataFrame.to_csv('hotels_data.csv', index=False)

恭喜!我们已经成功创建了一个基本的网络抓取工具。我希望您尝试这些步骤并尝试获取更多数据,例如酒店的评级和地址。现在,让我们看看如何执行一些常见任务,例如在页面加载时抓取 URL、电子邮件 ID、图像和抓取数据。
从网页中获取 URL 和电子邮件 ID
我们尝试通过网络抓取来抓取的两个最常见的功能是 网站URL 和电子邮件 ID。我确定您参与过需要大量提取电子邮件 ID 的项目或挑战。那么让我们看看如何在 Python 中抓取这些内容。
使用 Web 浏览器的控制台
python网页数据抓取(来源“LastStatement”替换标题“Link”,我的需求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-03-06 16:11
我看过很多 文章 ,但还没有找到完全符合我需要的解决方案。首先,让我说我是 Python 新手(我正在使用 Python 2)。在 Python 中创建数据集,抓取网页
我正在尝试从网页采集数据()。注意好的 html 表格。我已经能够将它读入列表而没有太多问题。但是,还要注意有两列链接。我想删除第一个链接列(但我不确定如何执行此操作,因为我的数据在列表中)。
第二个链接列有点复杂。我想用“Last Statement”替换标题“Link”。然后我想访问提供的每个链接,检索最后一条语句,并将其放在我创建列表的原创表的相应行中。
最后,我想将此列表打印为制表符分隔的文件,该文件可以作为数据帧读入 R。
这是一道需要处理的配菜。请让我知道我是否正确处理此问题。以下是我到目前为止的代码。我错过了我想做的事情,因为我不知道如何开始。
from bs4 import BeautifulSoup
import requests
from lxml import html
import csv
import string
import sys
#obtain the main url with bigger data
main_url = "http://www.tdcj.state.tx.us/de ... ot%3B
#convert the html to BeautifulSoup
doc = requests.get(main_url)
soup = BeautifulSoup(doc.text, 'lxml')
#find in html the table
tbl = soup.find("table", attrs = {"class":"os"})
#create labels for list rows by table headers
headings = [th.get_text() for th in tbl.find("tr").find_all("th")]
#convert the unicode to string
headers = []
for i in range(0,len(headings)-1):
headers.append(str(headings[i]))
#access the remaining information
prisoners = []
for row in tbl.find_all("tr")[1:]:
#attach the appropriate header to the appropriate corresponding data
#also, converts unicode to string
info = zip(headers, (str(td.get_text()) for td in row.find_all("td")))
#append each of the newly made rows
prisoners.append(info)
#print each row of the list to a file for R
with open('output.txt', 'a') as output:
for p in prisoners:
output.write(str(p)+'\n')
output.close()
如果您能帮我弄清楚我正在努力解决的三个部分中的任何一个,我将不胜感激!
资源
2016-04-24用户1723196 查看全部
python网页数据抓取(来源“LastStatement”替换标题“Link”,我的需求)
我看过很多 文章 ,但还没有找到完全符合我需要的解决方案。首先,让我说我是 Python 新手(我正在使用 Python 2)。在 Python 中创建数据集,抓取网页
我正在尝试从网页采集数据()。注意好的 html 表格。我已经能够将它读入列表而没有太多问题。但是,还要注意有两列链接。我想删除第一个链接列(但我不确定如何执行此操作,因为我的数据在列表中)。
第二个链接列有点复杂。我想用“Last Statement”替换标题“Link”。然后我想访问提供的每个链接,检索最后一条语句,并将其放在我创建列表的原创表的相应行中。
最后,我想将此列表打印为制表符分隔的文件,该文件可以作为数据帧读入 R。
这是一道需要处理的配菜。请让我知道我是否正确处理此问题。以下是我到目前为止的代码。我错过了我想做的事情,因为我不知道如何开始。
from bs4 import BeautifulSoup
import requests
from lxml import html
import csv
import string
import sys
#obtain the main url with bigger data
main_url = "http://www.tdcj.state.tx.us/de ... ot%3B
#convert the html to BeautifulSoup
doc = requests.get(main_url)
soup = BeautifulSoup(doc.text, 'lxml')
#find in html the table
tbl = soup.find("table", attrs = {"class":"os"})
#create labels for list rows by table headers
headings = [th.get_text() for th in tbl.find("tr").find_all("th")]
#convert the unicode to string
headers = []
for i in range(0,len(headings)-1):
headers.append(str(headings[i]))
#access the remaining information
prisoners = []
for row in tbl.find_all("tr")[1:]:
#attach the appropriate header to the appropriate corresponding data
#also, converts unicode to string
info = zip(headers, (str(td.get_text()) for td in row.find_all("td")))
#append each of the newly made rows
prisoners.append(info)
#print each row of the list to a file for R
with open('output.txt', 'a') as output:
for p in prisoners:
output.write(str(p)+'\n')
output.close()
如果您能帮我弄清楚我正在努力解决的三个部分中的任何一个,我将不胜感激!
资源
2016-04-24用户1723196
python网页数据抓取(soup()如何依靠类标签找到数据的位置?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2022-03-05 20:03
.
同样,如果您将光标放在名称“S&P”上并单击,您可以看到此信息收录在选项卡和控制台中。
现在我们知道如何依靠类标签来找到我们需要的数据。
学习编码
现在我们知道所需的数据在哪里,我们可以开始编写代码来构建我们的网络爬虫。立即打开您的文本编辑工具!
首先,我们必须导入我们将要使用的各种库。
# 导入各种库
导入 urllib2
从 bs4 导入 BeautifulSoup
然后,我们定义一个变量(quote_page)并为其分配网站的URL链接。
# 分配 网站 链接
quote_page = ':IND'
接下来,使用Python的urllib2库获取刚刚定义的URLquote_page的HTML页面信息。
# 检索 网站 并获取 html 代码并将其存储在变量“page”中
page = urllib2.urlopen(quote_page)
最后,我们将网页解析成 BeautifulSoup 格式,这样我们就可以使用 BeautifulSoup 库来解析网页了。
# 用 beautifulSoup 解析 HTML 代码并将其存储在变量“soup”中`
汤= BeautifulSoup(页面,'html.parser')
现在我们有了收录整个网页的 HTML 代码的变量汤。我们开始从汤中提取信息。
不要忘记我们的数据存储在唯一的层中。BeautifulSoup 库中的 find() 函数可以帮助我们提取不同层次的内容。我们需要的 HTML 类“名称”在整个页面中是唯一的,因此我们可以简单地查找它
# 获取“名称”类
代码段并提取对应值
name_box = soup.find('h1', attrs={'class': 'name'})
我们拿到标签后,就可以使用name_box的text属性来获取对应的值了
name = name_box.text.strip() # strip() 函数用于去除前导和尾随空格
打印名称
使用类似的方法,我们可以得到股票指数的价格数据。
# 获取股指价格数据
price_box = soup.find('div', attrs={'class':'price'})
价格 = price_box.text
打印价格
运行程序时,您应该会看到程序输出当前标准普尔 500 指数的价格。
以 Excel CSV 格式导出数据
现在我们已经学会了如何获取数据,是时候学习如何存储数据了。Excel 逗号分隔数据格式 (CSV) 是一个不错的选择。这使我们能够在 Excel 中打开数据文件以进行查看和进一步处理。
在此之前,我们需要导入 Python 的 csv 模块和 datetime 模块。Datetime 模块用于获取数据记录时间。请将以下代码行插入您的导入代码部分。
导入 csv
从日期时间导入日期时间
在代码的最底部,添加将数据写入 CSV 文件的代码。
# 以“add”方式打开一个csv文件,保证文件的原创信息不被覆盖
使用 open('index.csv', 'a') 作为 csv_file:
writer = csv.writer(csv_file)
writer.writerow([名称,价格,datetime.now()])
现在,如果您运行该程序,您应该能够导出 index.csv 文件。您可以在Excel中打开文件,看到有一行数据,如图所示。
所以如果你每天运行这个程序,你可以很容易地得到标准普尔的价格,而不必像以前那样在 网站 上翻找。
更进一步(高级用法)
多个股票指数
抓住一个股票指数对你来说还不够,对吧?我们可以尝试同时提取多个股票指数信息。首先,我们需要修改 quote_page 以将其定义为 URL 数组。
quote_page = [':IND', ':IND']
然后我们把代码中的数据提取部分改成了for循环。这个循环可以一个一个地处理 URL,并将变量 data 中的所有数据存储为一个元组。
# for 循环
数据 = []
对于quote_page中的pg:
# 检索 网站 并返回 HTML 代码,存储在变量 'page' 中
page = urllib2.urlopen(pg)
# 使用 beautifulSoup 解析 HTML 代码并存储在变量 `soup` 中
汤= BeautifulSoup(页面,'html.parser')
# 获取“名称”类
代码段并提取对应值
name_box = soup.find('h1', attrs={'class': 'name'})
name = name_box.text.strip() # strip() 用于去除开头和结尾
# 获取股指价格数据
price_box = soup.find('div', attrs={'class':'price'})
价格 = price_box.text
# 以元组类型存储数据
data.append((名称,价格))
并且,修改save部分,逐行保存数据
# 以“add”方式打开一个csv文件,保证文件的原创信息不被覆盖
使用 open('index.csv', 'a') 作为 csv_file:
writer = csv.writer(csv_file)
# for 循环
对于名称,数据中的价格:
writer.writerow([名称,价格,datetime.now()])
再次运行程序,应该可以同时提取两个股指的价格信息了!
先进的抓取技术
BeautifulSoup 库使用简单,可以很好地完成少量的 网站 抓取。但是如果你对大量抓取的信息感兴趣,你可以考虑其他方法:
1. Scrapy,一个强大的 Python 数据抓取框架。
2. 您可以尝试将一些常见的应用程序编程接口 (API) 集成到您的代码中。这种获取数据的方法比网络抓取要高效得多。例如,您可以尝试 Facebook Graph API,该 API 可帮助您获取 Facebook 网站 上不可见的隐藏信息。
3. 如果数据量太大,可以考虑使用 MySQL 之类的数据库后端来存储数据。
采取“不重复”的方法
DRY 是“不要重复你所做的事情”的缩写。您可以尝试像链接中的这个人一样自动化您的日常工作。您还可以考虑其他有趣的项目,例如跟踪您的 Facebook 朋友何时在线(当然是在他们同意的情况下),或者在论坛中获取讲座主题列表以尝试自然语言处理(这是当前的热门话题在人工智能中)! 查看全部
python网页数据抓取(soup()如何依靠类标签找到数据的位置?)
.
同样,如果您将光标放在名称“S&P”上并单击,您可以看到此信息收录在选项卡和控制台中。
现在我们知道如何依靠类标签来找到我们需要的数据。
学习编码
现在我们知道所需的数据在哪里,我们可以开始编写代码来构建我们的网络爬虫。立即打开您的文本编辑工具!
首先,我们必须导入我们将要使用的各种库。
# 导入各种库
导入 urllib2
从 bs4 导入 BeautifulSoup
然后,我们定义一个变量(quote_page)并为其分配网站的URL链接。
# 分配 网站 链接
quote_page = ':IND'
接下来,使用Python的urllib2库获取刚刚定义的URLquote_page的HTML页面信息。
# 检索 网站 并获取 html 代码并将其存储在变量“page”中
page = urllib2.urlopen(quote_page)
最后,我们将网页解析成 BeautifulSoup 格式,这样我们就可以使用 BeautifulSoup 库来解析网页了。
# 用 beautifulSoup 解析 HTML 代码并将其存储在变量“soup”中`
汤= BeautifulSoup(页面,'html.parser')
现在我们有了收录整个网页的 HTML 代码的变量汤。我们开始从汤中提取信息。
不要忘记我们的数据存储在唯一的层中。BeautifulSoup 库中的 find() 函数可以帮助我们提取不同层次的内容。我们需要的 HTML 类“名称”在整个页面中是唯一的,因此我们可以简单地查找它
# 获取“名称”类
代码段并提取对应值
name_box = soup.find('h1', attrs={'class': 'name'})
我们拿到标签后,就可以使用name_box的text属性来获取对应的值了
name = name_box.text.strip() # strip() 函数用于去除前导和尾随空格
打印名称
使用类似的方法,我们可以得到股票指数的价格数据。
# 获取股指价格数据
price_box = soup.find('div', attrs={'class':'price'})
价格 = price_box.text
打印价格
运行程序时,您应该会看到程序输出当前标准普尔 500 指数的价格。
以 Excel CSV 格式导出数据
现在我们已经学会了如何获取数据,是时候学习如何存储数据了。Excel 逗号分隔数据格式 (CSV) 是一个不错的选择。这使我们能够在 Excel 中打开数据文件以进行查看和进一步处理。
在此之前,我们需要导入 Python 的 csv 模块和 datetime 模块。Datetime 模块用于获取数据记录时间。请将以下代码行插入您的导入代码部分。
导入 csv
从日期时间导入日期时间
在代码的最底部,添加将数据写入 CSV 文件的代码。
# 以“add”方式打开一个csv文件,保证文件的原创信息不被覆盖
使用 open('index.csv', 'a') 作为 csv_file:
writer = csv.writer(csv_file)
writer.writerow([名称,价格,datetime.now()])
现在,如果您运行该程序,您应该能够导出 index.csv 文件。您可以在Excel中打开文件,看到有一行数据,如图所示。
所以如果你每天运行这个程序,你可以很容易地得到标准普尔的价格,而不必像以前那样在 网站 上翻找。
更进一步(高级用法)
多个股票指数
抓住一个股票指数对你来说还不够,对吧?我们可以尝试同时提取多个股票指数信息。首先,我们需要修改 quote_page 以将其定义为 URL 数组。
quote_page = [':IND', ':IND']
然后我们把代码中的数据提取部分改成了for循环。这个循环可以一个一个地处理 URL,并将变量 data 中的所有数据存储为一个元组。
# for 循环
数据 = []
对于quote_page中的pg:
# 检索 网站 并返回 HTML 代码,存储在变量 'page' 中
page = urllib2.urlopen(pg)
# 使用 beautifulSoup 解析 HTML 代码并存储在变量 `soup` 中
汤= BeautifulSoup(页面,'html.parser')
# 获取“名称”类
代码段并提取对应值
name_box = soup.find('h1', attrs={'class': 'name'})
name = name_box.text.strip() # strip() 用于去除开头和结尾
# 获取股指价格数据
price_box = soup.find('div', attrs={'class':'price'})
价格 = price_box.text
# 以元组类型存储数据
data.append((名称,价格))
并且,修改save部分,逐行保存数据
# 以“add”方式打开一个csv文件,保证文件的原创信息不被覆盖
使用 open('index.csv', 'a') 作为 csv_file:
writer = csv.writer(csv_file)
# for 循环
对于名称,数据中的价格:
writer.writerow([名称,价格,datetime.now()])
再次运行程序,应该可以同时提取两个股指的价格信息了!
先进的抓取技术
BeautifulSoup 库使用简单,可以很好地完成少量的 网站 抓取。但是如果你对大量抓取的信息感兴趣,你可以考虑其他方法:
1. Scrapy,一个强大的 Python 数据抓取框架。
2. 您可以尝试将一些常见的应用程序编程接口 (API) 集成到您的代码中。这种获取数据的方法比网络抓取要高效得多。例如,您可以尝试 Facebook Graph API,该 API 可帮助您获取 Facebook 网站 上不可见的隐藏信息。
3. 如果数据量太大,可以考虑使用 MySQL 之类的数据库后端来存储数据。
采取“不重复”的方法

DRY 是“不要重复你所做的事情”的缩写。您可以尝试像链接中的这个人一样自动化您的日常工作。您还可以考虑其他有趣的项目,例如跟踪您的 Facebook 朋友何时在线(当然是在他们同意的情况下),或者在论坛中获取讲座主题列表以尝试自然语言处理(这是当前的热门话题在人工智能中)!
python网页数据抓取(从含中文的网页中提取数据(1)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-03-03 03:20
目标:使用正则表达式从收录中文的网页中提取数据1、获取该网页的所有数据1.1 判断我们要操作的网页的思维过程:url = '#39;
打开要操作的网页:req = urllib2.open(url)
读取网页,将网页数据放入变量:html = req.read()
别忘了关闭页面:req.close()
1.2将上述过程写成函数:
def get_html(url):
try:
req = urllib2.open(url)
html = req.read()
return html
finally:
req.close()
html = get_html('http://q.stock.sohu.com/cn/603 ... %2339;)
2、查看网页2.1 思考过程因为不用开发工具直接查看网页源代码,顺便练一下I/O,所以我打算把网页输出到TXT。
打开一个可写文件:file = open('C:/Users/YourName/Desktop/text.txt','w')
将网页数据写入文件:file.write(html)
别忘了关闭文件:file.close()
2.2将上述过程写成函数:
def out_put(file_name,content):
try:
file = open(file_name,'w')
file.write(content)
finally:
file.close()
out_put('C:/Users/YourName/Desktop/text.txt',html)
运行后,在桌面的文本文件中查看网页源代码。
3、解析网页源代码3.1 确定网页代码,查看网页源代码。一般会在头部标明代码类型。本例中,测试网页中的代码类型为:gb2312
部分网页头部标明的编码类型与实际不符,非常不合格,会导致后续代码不可用。所以有第三方py包chardet来测试str编码类型(我没下载,不会用)。
3.2 确定要捕获的数据如果要捕获“总利润”的数值和百分比,查看源码,“总利润”附近的代码如下:
……
总利润
19392
-72.22%
……
3.3正则表达式如果表达式中有中文,别忘了加“u”;任何时候,别忘了加“r”
expression = ur'利润总额\D+?(-?\d+\.?\d*)\D*?(-?\d+.*?%)'
3.4 很严重的事情! ! !由于这里有非中文字符,所以必须在“格式”中选择“以utf-8格式编码”,不能选择“无BOM”。否则运行时会报错,原因不明。
4、提取数据
pattern = re.compile(expression)
result = pattern.findall(html)
又是一件大事! ! !
使用此代码运行,可以匹配正则和任何内容。原因是网页的html代码是gb2312,程序代码是unicode代码。两者并不统一。代码:
pattern = re.compile(expression.encode('gb2312')) #把程序代码编码转换成'gb2312'
注意:代码转换参考
5、整合
# -*- coding : utf-8 -*-
import urllib2
import re
def get_html(url):
try:
req = urllib2.urlopen(url)
html = req.read()
return html
finally:
req.close()
html = get_html('http://q.stock.sohu.com/cn/603 ... %2339;)
expression = ur'利润总额\D+?(-?\d+\.?\d*)\D*?(-?\d+.*?%)'
pattern = re.compile(expression.encode('gb2312'))
result = pattern.findall(html)
print result
关于Unicode编码,请参考很详细的文章: 查看全部
python网页数据抓取(从含中文的网页中提取数据(1)(图))
目标:使用正则表达式从收录中文的网页中提取数据1、获取该网页的所有数据1.1 判断我们要操作的网页的思维过程:url = '#39;
打开要操作的网页:req = urllib2.open(url)
读取网页,将网页数据放入变量:html = req.read()
别忘了关闭页面:req.close()
1.2将上述过程写成函数:
def get_html(url):
try:
req = urllib2.open(url)
html = req.read()
return html
finally:
req.close()
html = get_html('http://q.stock.sohu.com/cn/603 ... %2339;)
2、查看网页2.1 思考过程因为不用开发工具直接查看网页源代码,顺便练一下I/O,所以我打算把网页输出到TXT。
打开一个可写文件:file = open('C:/Users/YourName/Desktop/text.txt','w')
将网页数据写入文件:file.write(html)
别忘了关闭文件:file.close()
2.2将上述过程写成函数:
def out_put(file_name,content):
try:
file = open(file_name,'w')
file.write(content)
finally:
file.close()
out_put('C:/Users/YourName/Desktop/text.txt',html)
运行后,在桌面的文本文件中查看网页源代码。
3、解析网页源代码3.1 确定网页代码,查看网页源代码。一般会在头部标明代码类型。本例中,测试网页中的代码类型为:gb2312
部分网页头部标明的编码类型与实际不符,非常不合格,会导致后续代码不可用。所以有第三方py包chardet来测试str编码类型(我没下载,不会用)。
3.2 确定要捕获的数据如果要捕获“总利润”的数值和百分比,查看源码,“总利润”附近的代码如下:
……
总利润
19392
-72.22%
……
3.3正则表达式如果表达式中有中文,别忘了加“u”;任何时候,别忘了加“r”
expression = ur'利润总额\D+?(-?\d+\.?\d*)\D*?(-?\d+.*?%)'
3.4 很严重的事情! ! !由于这里有非中文字符,所以必须在“格式”中选择“以utf-8格式编码”,不能选择“无BOM”。否则运行时会报错,原因不明。
4、提取数据
pattern = re.compile(expression)
result = pattern.findall(html)
又是一件大事! ! !
使用此代码运行,可以匹配正则和任何内容。原因是网页的html代码是gb2312,程序代码是unicode代码。两者并不统一。代码:
pattern = re.compile(expression.encode('gb2312')) #把程序代码编码转换成'gb2312'
注意:代码转换参考
5、整合
# -*- coding : utf-8 -*-
import urllib2
import re
def get_html(url):
try:
req = urllib2.urlopen(url)
html = req.read()
return html
finally:
req.close()
html = get_html('http://q.stock.sohu.com/cn/603 ... %2339;)
expression = ur'利润总额\D+?(-?\d+\.?\d*)\D*?(-?\d+.*?%)'
pattern = re.compile(expression.encode('gb2312'))
result = pattern.findall(html)
print result
关于Unicode编码,请参考很详细的文章:
python网页数据抓取(总不能手工去网页源码吧?担心,Python提供了许多库来帮助)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-02-27 20:14
大家好,我是悦创。
我们可以把互联网比作一个大的网络,爬虫(即网络爬虫)是在网络上爬行的蜘蛛。如果把网络的节点比作网页,爬虫爬取就相当于访问页面并获取其信息。节点之间的连接可以比作网页和网页之间的链接关系,这样蜘蛛经过一个节点后,可以继续沿着节点连接爬行到达下一个节点,即继续通过一个网页获取后续网页,使得整个网页的节点都可以被蜘蛛爬取,并且可以抓取到网站的数据。
1. 爬虫概述
简而言之,爬虫是一种自动程序,可以获取网页并提取和保存信息,如下所述。
1.1 获取网页
爬虫要做的第一个工作就是获取网页,这里是网页的源代码。
源代码中收录了网页的一些有用信息,所以只要得到源代码,就可以从中提取出想要的信息。
前面讨论了请求和响应的概念。向网站的服务器发送请求,返回的响应体就是网页的源代码。那么,最关键的部分就是构造一个请求并发送给服务器,然后接收响应并解析出来,那么这个过程如何实现呢?你不能手动截取网页的源代码,对吧?
不用担心,Python 提供了很多库来帮助我们做到这一点,比如 urllib、requests 等。我们可以使用这些库来帮助我们实现 HTTP 请求操作。请求和响应都可以用类库提供的数据结构来表示。得到响应后,我们只需要解析数据结构的Body部分,即获取网页的源代码。这样,我们就可以使用程序来实现获取网页的过程了。
1.2 提取信息
得到网页的源代码后,接下来就是分析网页的源代码,从中提取出我们想要的数据。首先,最常用的方法是使用正则表达式提取,这是一种通用的方法,但是在构造正则表达式时比较复杂且容易出错。
另外,因为网页的结构有一定的规律,所以也有一些库是根据网页节点属性、CSS选择器或者XPath来提取网页信息的,比如Beautiful Soup、pyquery、lxml等。使用这些库,我们可以高效、快速地提取网页信息,如节点属性、文本值等。
提取信息是爬虫非常重要的一个环节,它可以把杂乱的数据整理好,方便我们后期对数据进行处理和分析。
1.3 保存数据
提取信息后,我们一般将提取的数据保存在某处以备后用。这里的保存有多种形式,比如简单的保存为TXT文本或者JSON文本,或者保存到数据库,比如MySQL、MongoDB,或者保存到远程服务器,比如借助SFTP操作。
1.4 自动化程序
说到自动化程序,我的意思是爬虫可以代替人类执行这些操作。首先,我们当然可以手动提取这些信息,但是如果当量特别大或者想要快速获取大量数据,还是得使用程序。爬虫是代表我们完成爬取工作的自动化程序。可以在爬取过程中进行各种异常处理、错误重试等操作,保证爬取持续高效运行。
2. 我可以捕获什么样的数据
我们可以在网页中看到各种各样的信息,最常见的是常规网页,它们对应的是HTML代码,而最常见的爬取就是HTML源代码。
此外,有些网页可能会返回 JSON 字符串而不是 HTML 代码(大多数 API 接口使用这种形式)。这种格式的数据易于传输和解析。它们也可以被捕获,并且数据提取更方便。
此外,我们还可以看到图片、视频、音频等各种二进制数据。使用爬虫,我们可以抓取这些二进制数据,并保存为对应的文件名。
此外,您还可以看到具有各种扩展名的文件,例如 CSS、JavaScript 和配置文件。这些实际上是最常见的文件。只要它们可以在浏览器中访问,您就可以抓取它们。
上面的内容其实是对应了它们各自的URL,是基于HTTP或者HTTPS协议的。只要是这种数据,爬虫就可以爬取。
3. JavaScript 渲染页面
有时候,当我们用 urllib 或 requests 爬取网页时,得到的源代码实际上与我们在浏览器中看到的不同。
这是一个非常普遍的问题。如今,越来越多的网页使用 Ajax 和前端模块化工具构建。整个网页可能会被 JavaScript 渲染,这意味着原创的 HTML 代码只是一个空壳,例如:
This is a Demo
body节点中只有一个id为container的节点,但是需要注意的是在body节点之后引入了app.js,负责渲染整个网站。
在浏览器中打开页面时,会先加载HTML内容,然后浏览器会发现其中引入了一个app.js文件,然后再去请求该文件。获取文件后,会执行 JavaScript 代码,JavaScript 改变 HTML 中的节点,添加内容,最终得到一个完整的页面。
但是当使用 urllib 或 requests 等库请求当前页面时,我们得到的只是这段 HTML 代码,它不会帮助我们继续加载 JavaScript 文件,因此我们将无法在浏览器中看到内容。
这也解释了为什么有时我们得到的源代码与我们在浏览器中看到的不同。
因此,使用基本的HTTP请求库得到的源代码可能与浏览器中的页面源代码不一样。对于这样的情况,我们可以分析它的后台Ajax接口,或者使用Selenium、Splash等库来模拟JavaScript渲染。
稍后,我们将详细介绍如何采集 JavaScript 渲染网页。本节介绍爬虫的一些基本原理,可以帮助我们以后编写爬虫时更加得心应手。
声明:本站所有文章,除非另有说明或标记,均发布在本站原创。任何个人或组织未经本站同意,不得复制、盗用、采集、将本站内容发布到任何网站、书籍等媒体平台。本站内容如有侵犯原作者合法权益的,您可以联系我们处理。邮件:
声明:本站所有资源均由互联网上的Python爬虫自动爬取。本站内容如有侵犯原作者合法权益的,您可以联系我们处理。邮件:
爱悦创常任理事国
支付宝扫描
微信扫一扫>奖励领取海报链接 查看全部
python网页数据抓取(总不能手工去网页源码吧?担心,Python提供了许多库来帮助)
大家好,我是悦创。
我们可以把互联网比作一个大的网络,爬虫(即网络爬虫)是在网络上爬行的蜘蛛。如果把网络的节点比作网页,爬虫爬取就相当于访问页面并获取其信息。节点之间的连接可以比作网页和网页之间的链接关系,这样蜘蛛经过一个节点后,可以继续沿着节点连接爬行到达下一个节点,即继续通过一个网页获取后续网页,使得整个网页的节点都可以被蜘蛛爬取,并且可以抓取到网站的数据。
1. 爬虫概述
简而言之,爬虫是一种自动程序,可以获取网页并提取和保存信息,如下所述。
1.1 获取网页
爬虫要做的第一个工作就是获取网页,这里是网页的源代码。
源代码中收录了网页的一些有用信息,所以只要得到源代码,就可以从中提取出想要的信息。
前面讨论了请求和响应的概念。向网站的服务器发送请求,返回的响应体就是网页的源代码。那么,最关键的部分就是构造一个请求并发送给服务器,然后接收响应并解析出来,那么这个过程如何实现呢?你不能手动截取网页的源代码,对吧?
不用担心,Python 提供了很多库来帮助我们做到这一点,比如 urllib、requests 等。我们可以使用这些库来帮助我们实现 HTTP 请求操作。请求和响应都可以用类库提供的数据结构来表示。得到响应后,我们只需要解析数据结构的Body部分,即获取网页的源代码。这样,我们就可以使用程序来实现获取网页的过程了。
1.2 提取信息
得到网页的源代码后,接下来就是分析网页的源代码,从中提取出我们想要的数据。首先,最常用的方法是使用正则表达式提取,这是一种通用的方法,但是在构造正则表达式时比较复杂且容易出错。
另外,因为网页的结构有一定的规律,所以也有一些库是根据网页节点属性、CSS选择器或者XPath来提取网页信息的,比如Beautiful Soup、pyquery、lxml等。使用这些库,我们可以高效、快速地提取网页信息,如节点属性、文本值等。
提取信息是爬虫非常重要的一个环节,它可以把杂乱的数据整理好,方便我们后期对数据进行处理和分析。
1.3 保存数据
提取信息后,我们一般将提取的数据保存在某处以备后用。这里的保存有多种形式,比如简单的保存为TXT文本或者JSON文本,或者保存到数据库,比如MySQL、MongoDB,或者保存到远程服务器,比如借助SFTP操作。
1.4 自动化程序
说到自动化程序,我的意思是爬虫可以代替人类执行这些操作。首先,我们当然可以手动提取这些信息,但是如果当量特别大或者想要快速获取大量数据,还是得使用程序。爬虫是代表我们完成爬取工作的自动化程序。可以在爬取过程中进行各种异常处理、错误重试等操作,保证爬取持续高效运行。
2. 我可以捕获什么样的数据
我们可以在网页中看到各种各样的信息,最常见的是常规网页,它们对应的是HTML代码,而最常见的爬取就是HTML源代码。
此外,有些网页可能会返回 JSON 字符串而不是 HTML 代码(大多数 API 接口使用这种形式)。这种格式的数据易于传输和解析。它们也可以被捕获,并且数据提取更方便。
此外,我们还可以看到图片、视频、音频等各种二进制数据。使用爬虫,我们可以抓取这些二进制数据,并保存为对应的文件名。
此外,您还可以看到具有各种扩展名的文件,例如 CSS、JavaScript 和配置文件。这些实际上是最常见的文件。只要它们可以在浏览器中访问,您就可以抓取它们。
上面的内容其实是对应了它们各自的URL,是基于HTTP或者HTTPS协议的。只要是这种数据,爬虫就可以爬取。
3. JavaScript 渲染页面
有时候,当我们用 urllib 或 requests 爬取网页时,得到的源代码实际上与我们在浏览器中看到的不同。
这是一个非常普遍的问题。如今,越来越多的网页使用 Ajax 和前端模块化工具构建。整个网页可能会被 JavaScript 渲染,这意味着原创的 HTML 代码只是一个空壳,例如:
This is a Demo
body节点中只有一个id为container的节点,但是需要注意的是在body节点之后引入了app.js,负责渲染整个网站。
在浏览器中打开页面时,会先加载HTML内容,然后浏览器会发现其中引入了一个app.js文件,然后再去请求该文件。获取文件后,会执行 JavaScript 代码,JavaScript 改变 HTML 中的节点,添加内容,最终得到一个完整的页面。
但是当使用 urllib 或 requests 等库请求当前页面时,我们得到的只是这段 HTML 代码,它不会帮助我们继续加载 JavaScript 文件,因此我们将无法在浏览器中看到内容。
这也解释了为什么有时我们得到的源代码与我们在浏览器中看到的不同。
因此,使用基本的HTTP请求库得到的源代码可能与浏览器中的页面源代码不一样。对于这样的情况,我们可以分析它的后台Ajax接口,或者使用Selenium、Splash等库来模拟JavaScript渲染。
稍后,我们将详细介绍如何采集 JavaScript 渲染网页。本节介绍爬虫的一些基本原理,可以帮助我们以后编写爬虫时更加得心应手。
声明:本站所有文章,除非另有说明或标记,均发布在本站原创。任何个人或组织未经本站同意,不得复制、盗用、采集、将本站内容发布到任何网站、书籍等媒体平台。本站内容如有侵犯原作者合法权益的,您可以联系我们处理。邮件:
声明:本站所有资源均由互联网上的Python爬虫自动爬取。本站内容如有侵犯原作者合法权益的,您可以联系我们处理。邮件:

爱悦创常任理事国

支付宝扫描

微信扫一扫>奖励领取海报链接
python网页数据抓取(如何使用Python和pandas库从web页面获取表数据?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-02-26 19:07
今天,人们可以随时随地连接到互联网。互联网可能是最大的公共数据库。学习如何从 Internet 获取数据至关重要。因此,有必要了解如何使用 Python 和 pandas 库从网页中获取表格数据。此外,如果您已经在使用 Excel PowerQuery,这相当于“从 Web 获取数据”功能,但在这里它的功能要强大 100 倍。
从 网站 获取数据(网络抓取)
HTML 是每个 网站 背后的语言。当我们访问 网站 时,会发生以下情况:
1.在浏览器地址栏中输入地址(URL),浏览器向目标网站的服务器发送请求。
2.服务器接收请求并返回构成网页的 HTML 代码。
3.浏览器接收到 HTML 代码,动态运行它,并创建一个网页供我们查看。
Web 抓取基本上意味着,我们可以使用 Python 向 网站 服务器发送请求,接收 HTML 代码,然后提取所需的数据,而不是使用浏览器。
我不会在这里介绍太多 HTML,只介绍几个要点,以便我们对 网站 和网络抓取的工作原理有一个基本的了解。HTML 元素或“HTML 标签”是被包围的特定关键字。例如,下面的 HTML 代码是网页的标题,将鼠标悬停在网页中的选项卡上会在浏览器上看到相同的标题。请注意,大多数 HTML 元素都需要一个开始标记(例如 , )和一个相应的结束标记(例如 , )。
Python pandas 获取网页中的表格数据(网页抓取)
同样,下面的代码会在浏览器上绘制一个表格,你可以尝试复制粘贴到记事本中,然后保存为“tableexample.html”文件,应该可以在浏览器中打开。简要说明如下:
用户名
国家
城市
性别
年龄
阿甘
美国
纽约
中号>
50
玛丽珍
加拿大
多伦多
F
30
使用 pandas 抓取网页的要求
学习了 网站 的基本构建块以及如何解释 HTML(至少是表格部分!)。这里只介绍 HTML 表格的原因是,大多数时候我们尝试从 网站 获取数据时,它是表格格式。pandas 是从 网站 获取表格数据的完美工具!
因此,使用 pandas 从 网站 获取数据的唯一要求是数据必须存储在表格中,或者用 HTML 术语来说,存储在 ... 标签中。pandas 将能够使用我们刚刚介绍的 HTML 标记来提取表格、标题和数据行。
如果我尝试使用 pandas 从不收录任何表格(...标签)的网页“获取数据”,我将不会获得任何数据。对于那些没有存储在表中的数据,我们需要其他方式来抓取网站。
网页抓取示例
我们之前的示例大多是带有几个数据点的小表,让我们使用稍微大一点的数据。
我们将从百度百科获取最新的世界500强企业名称及相关信息:
%E4%B8%96%E7%95%8C500%E5%BC%BA/640042?fr=阿拉丁
图1(如果有错误,根据错误提示处理。我的电脑没有安装lxml,安装后正常)
上面的df其实是一个list,有意思……list里好像有3个item。让我们看看 pandas 为我们采集了哪些数据……
图 2
第一个数据框df[0],似乎和它没有任何关系,只是页面上爬到的第一个表。查看网页,可以知道这张桌子是在中国举办的《财富》全球论坛。
图 3
第二个数据框 df[1] 是该页面上的另一个表,请注意在它的末尾,它说有 [500 行 x 6 列]。这张表是世界500强排行榜。
图 4
第三个数据框 df[2] 是页面上的第三个表格,最后显示 [110 行 x 5 列]。此表为上榜中国企业名单。
请注意,始终检查 pd.read_html() 返回的内容,一个网页可能收录多个表,因此您将获得一个数据框列表,而不是单个数据框!
注:本文借鉴自。
请在下方留言完善本文内容,让更多人学习到更完善的知识。
欢迎来到知识星球:完美Excel社区,在这里您可以进行技术交流和提问,获取更多电子资料,通过社区加入专属的微信讨论群,交流更便捷。 查看全部
python网页数据抓取(如何使用Python和pandas库从web页面获取表数据?)
今天,人们可以随时随地连接到互联网。互联网可能是最大的公共数据库。学习如何从 Internet 获取数据至关重要。因此,有必要了解如何使用 Python 和 pandas 库从网页中获取表格数据。此外,如果您已经在使用 Excel PowerQuery,这相当于“从 Web 获取数据”功能,但在这里它的功能要强大 100 倍。
从 网站 获取数据(网络抓取)
HTML 是每个 网站 背后的语言。当我们访问 网站 时,会发生以下情况:
1.在浏览器地址栏中输入地址(URL),浏览器向目标网站的服务器发送请求。
2.服务器接收请求并返回构成网页的 HTML 代码。
3.浏览器接收到 HTML 代码,动态运行它,并创建一个网页供我们查看。
Web 抓取基本上意味着,我们可以使用 Python 向 网站 服务器发送请求,接收 HTML 代码,然后提取所需的数据,而不是使用浏览器。
我不会在这里介绍太多 HTML,只介绍几个要点,以便我们对 网站 和网络抓取的工作原理有一个基本的了解。HTML 元素或“HTML 标签”是被包围的特定关键字。例如,下面的 HTML 代码是网页的标题,将鼠标悬停在网页中的选项卡上会在浏览器上看到相同的标题。请注意,大多数 HTML 元素都需要一个开始标记(例如 , )和一个相应的结束标记(例如 , )。
Python pandas 获取网页中的表格数据(网页抓取)
同样,下面的代码会在浏览器上绘制一个表格,你可以尝试复制粘贴到记事本中,然后保存为“tableexample.html”文件,应该可以在浏览器中打开。简要说明如下:
用户名
国家
城市
性别
年龄
阿甘
美国
纽约
中号>
50
玛丽珍
加拿大
多伦多
F
30
使用 pandas 抓取网页的要求
学习了 网站 的基本构建块以及如何解释 HTML(至少是表格部分!)。这里只介绍 HTML 表格的原因是,大多数时候我们尝试从 网站 获取数据时,它是表格格式。pandas 是从 网站 获取表格数据的完美工具!
因此,使用 pandas 从 网站 获取数据的唯一要求是数据必须存储在表格中,或者用 HTML 术语来说,存储在 ... 标签中。pandas 将能够使用我们刚刚介绍的 HTML 标记来提取表格、标题和数据行。
如果我尝试使用 pandas 从不收录任何表格(...标签)的网页“获取数据”,我将不会获得任何数据。对于那些没有存储在表中的数据,我们需要其他方式来抓取网站。
网页抓取示例
我们之前的示例大多是带有几个数据点的小表,让我们使用稍微大一点的数据。
我们将从百度百科获取最新的世界500强企业名称及相关信息:
%E4%B8%96%E7%95%8C500%E5%BC%BA/640042?fr=阿拉丁

图1(如果有错误,根据错误提示处理。我的电脑没有安装lxml,安装后正常)
上面的df其实是一个list,有意思……list里好像有3个item。让我们看看 pandas 为我们采集了哪些数据……

图 2
第一个数据框df[0],似乎和它没有任何关系,只是页面上爬到的第一个表。查看网页,可以知道这张桌子是在中国举办的《财富》全球论坛。

图 3
第二个数据框 df[1] 是该页面上的另一个表,请注意在它的末尾,它说有 [500 行 x 6 列]。这张表是世界500强排行榜。

图 4
第三个数据框 df[2] 是页面上的第三个表格,最后显示 [110 行 x 5 列]。此表为上榜中国企业名单。
请注意,始终检查 pd.read_html() 返回的内容,一个网页可能收录多个表,因此您将获得一个数据框列表,而不是单个数据框!
注:本文借鉴自。
请在下方留言完善本文内容,让更多人学习到更完善的知识。
欢迎来到知识星球:完美Excel社区,在这里您可以进行技术交流和提问,获取更多电子资料,通过社区加入专属的微信讨论群,交流更便捷。
python网页数据抓取(一下python的数据抓取技巧,不深入解释数据的具体原理 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2022-02-23 10:11
)
作为一名经济学学生,第一次接触python就是学习和掌握网页数据抓取技巧,那么今天就来说说python数据抓取技巧。
python爬取数据的具体原理我就不深入讲解了,说一下大致的流程。爬取数据首先需要获取需要抓取的网页的url,然后解析并保存数据。如果是多页数据,还需要翻页。这里需要总结一下多页url的规则。
根据url获取具体的html源码,python提供了多种方法,主要是urllib库(python3集成了urllib2和urllib,只有urllib),requests库
urllib 访问输出 html 结果
请求访问 html 结果
可以看出requests访问的html源码越来越全,up的高手也推荐使用requests。Python 可能会设计多个库来实现一个功能。为了避免混淆,建议您主要记住一种方法,了解其他方法。
2.获取html,下面是解析复杂的代码,只提取我们需要的内容。Python还提供了多种解析html的方法,如正则匹配、BeautifulSoup、Xpath、pyquery等,这里主要讲解BeautifulSoup。有兴趣的朋友页面可以了解其他方法。Xpath 可以帮助你理解 html 的结构。.
BeautifulSoup库的具体使用这里就不深入讲解了。有兴趣的小伙伴可以去其官网查看相关教程。下面附上学习网址:
3.是数据存储之后,这里使用pandas,如果你在up主之前看过文章就会知道,我基本上都是用pandas来进行数据分析、处理、存储的。如上所述,与其笼统地学习,不如深入研究一门学科。当然,如果你能力很强的话,每门学科都可以掌握,这当然是最好的。
4.附上代码,up的高手随机找了一个豆瓣网页来抢,感兴趣的朋友可以试试。 查看全部
python网页数据抓取(一下python的数据抓取技巧,不深入解释数据的具体原理
)
作为一名经济学学生,第一次接触python就是学习和掌握网页数据抓取技巧,那么今天就来说说python数据抓取技巧。
python爬取数据的具体原理我就不深入讲解了,说一下大致的流程。爬取数据首先需要获取需要抓取的网页的url,然后解析并保存数据。如果是多页数据,还需要翻页。这里需要总结一下多页url的规则。
根据url获取具体的html源码,python提供了多种方法,主要是urllib库(python3集成了urllib2和urllib,只有urllib),requests库

urllib 访问输出 html 结果

请求访问 html 结果
可以看出requests访问的html源码越来越全,up的高手也推荐使用requests。Python 可能会设计多个库来实现一个功能。为了避免混淆,建议您主要记住一种方法,了解其他方法。
2.获取html,下面是解析复杂的代码,只提取我们需要的内容。Python还提供了多种解析html的方法,如正则匹配、BeautifulSoup、Xpath、pyquery等,这里主要讲解BeautifulSoup。有兴趣的朋友页面可以了解其他方法。Xpath 可以帮助你理解 html 的结构。.
BeautifulSoup库的具体使用这里就不深入讲解了。有兴趣的小伙伴可以去其官网查看相关教程。下面附上学习网址:
3.是数据存储之后,这里使用pandas,如果你在up主之前看过文章就会知道,我基本上都是用pandas来进行数据分析、处理、存储的。如上所述,与其笼统地学习,不如深入研究一门学科。当然,如果你能力很强的话,每门学科都可以掌握,这当然是最好的。
4.附上代码,up的高手随机找了一个豆瓣网页来抢,感兴趣的朋友可以试试。
python网页数据抓取(python网页数据抓取分析与展示解决一个问题的问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2022-02-22 10:04
python网页数据抓取分析与展示。今天我们来解决一个问题,网页数据总是抓不完,我们需要对抓取的数据进行多样性分析,以供我们决策,最终将从网页数据源读取数据给我们的客户看,展示给他们可视化的图表,具体过程如下:详情页的公司介绍。公司招聘注意:因为我们的目标是按照购买量发放优惠券,一开始我们就要了解购买量大的公司是不是真的很容易购买,具体就不展示了,我们来看看他们的公司评价吧。
在这里我们讲一个数据挖掘算法,叫做预测模型,是用于算法优化的时候。进入正题吧,最后一个页面,标题“怎么样才能快速看到公司介绍”,这一单我们抓取一个美元单位,所以美元兑换成人民币,然后计算出,这样从页面右上角导航到首页,整个抓取页面的值是10:9:7,也就是说数据将在一天内返回。我们将数据导入文本处理器,并将时间分割成7个时间点,分别是下午6点,8点,9点,10点,12点,17点,然后建立时间间隔器将时间放大成为一个10分钟(注意下次跳转时间要从6:00-12:0。
0),7:00-8:00打一个√,只取首页上所有数据返回。接下来我们要研究一下首页上的人群是不是必须,再有就是理性分析,根据首页上的名字,是不是可以分析出是哪一类型的人群。经过一番对于用户数据分析,总结出一个曲线,总体符合大致的用户画像特征。
1、百度搜索“牛逼企业”
2、浏览企业的官网,没有注册,找到官网的。打开后进入公司官网。
3、发现,首页要拿到唯一标识,请注意前面的按钮。
4、点开创建抽奖号,按照步骤把创建首页名字给打上来。
5、接下来就是对于页面数据进行多样性分析。我们只需要针对首页的访问数量、评论数量、赞美数量来进行多样性分析。比如做一个转化率测试,设定一个时间间隔,我们抓取数据时间就放宽到10分钟就行。
6、在个人中心,我们找到好友选项,拿来对数据进行关联。因为个人中心里的好友跟首页的“企业用户”的账号标识不同,会导致跳转。
7、出现意外,就更新,出现必须的就做一个ip地址。
8、那就意味着目标访问者url是变动的,我们要对url做变化化,来获取访问的准确url,发现无法获取,就要做图。
9、那就进入到聚合页面,登录账号。
1
0、这样我们就得到了它的url1
1、那么到这里其实总体工作是这样的:拿到个人中心的url,然后跳转进来确定它的实际路径,然后确定它是哪一个页面。
2、更新url参数,让它始终是一个最新的页面。python有两大主要语言,一个是高级语言python,另一个就是脚本语言bash。
对于初学者,
1、 查看全部
python网页数据抓取(python网页数据抓取分析与展示解决一个问题的问题)
python网页数据抓取分析与展示。今天我们来解决一个问题,网页数据总是抓不完,我们需要对抓取的数据进行多样性分析,以供我们决策,最终将从网页数据源读取数据给我们的客户看,展示给他们可视化的图表,具体过程如下:详情页的公司介绍。公司招聘注意:因为我们的目标是按照购买量发放优惠券,一开始我们就要了解购买量大的公司是不是真的很容易购买,具体就不展示了,我们来看看他们的公司评价吧。
在这里我们讲一个数据挖掘算法,叫做预测模型,是用于算法优化的时候。进入正题吧,最后一个页面,标题“怎么样才能快速看到公司介绍”,这一单我们抓取一个美元单位,所以美元兑换成人民币,然后计算出,这样从页面右上角导航到首页,整个抓取页面的值是10:9:7,也就是说数据将在一天内返回。我们将数据导入文本处理器,并将时间分割成7个时间点,分别是下午6点,8点,9点,10点,12点,17点,然后建立时间间隔器将时间放大成为一个10分钟(注意下次跳转时间要从6:00-12:0。
0),7:00-8:00打一个√,只取首页上所有数据返回。接下来我们要研究一下首页上的人群是不是必须,再有就是理性分析,根据首页上的名字,是不是可以分析出是哪一类型的人群。经过一番对于用户数据分析,总结出一个曲线,总体符合大致的用户画像特征。
1、百度搜索“牛逼企业”
2、浏览企业的官网,没有注册,找到官网的。打开后进入公司官网。
3、发现,首页要拿到唯一标识,请注意前面的按钮。
4、点开创建抽奖号,按照步骤把创建首页名字给打上来。
5、接下来就是对于页面数据进行多样性分析。我们只需要针对首页的访问数量、评论数量、赞美数量来进行多样性分析。比如做一个转化率测试,设定一个时间间隔,我们抓取数据时间就放宽到10分钟就行。
6、在个人中心,我们找到好友选项,拿来对数据进行关联。因为个人中心里的好友跟首页的“企业用户”的账号标识不同,会导致跳转。
7、出现意外,就更新,出现必须的就做一个ip地址。
8、那就意味着目标访问者url是变动的,我们要对url做变化化,来获取访问的准确url,发现无法获取,就要做图。
9、那就进入到聚合页面,登录账号。
1
0、这样我们就得到了它的url1
1、那么到这里其实总体工作是这样的:拿到个人中心的url,然后跳转进来确定它的实际路径,然后确定它是哪一个页面。
2、更新url参数,让它始终是一个最新的页面。python有两大主要语言,一个是高级语言python,另一个就是脚本语言bash。
对于初学者,
1、
python网页数据抓取(利用Python网络爬虫抓取微信朋友圈动态——附代码(下))
网站优化 • 优采云 发表了文章 • 0 个评论 • 469 次浏览 • 2022-03-24 13:02
前几天给大家分享了使用Python网络爬虫爬取朋友圈的动态(上)和使用Python网络爬虫爬取朋友圈的动态——附代码(下),并对抓取到的数据进行Python处理。词云和艺术字可视化,有兴趣的小伙伴可以戳这个文章:使用Python词云和艺术字可视化工具,对朋友圈数据进行可视化。
今天我们继续关注微信,不过这次给大家带来的是使用Python网络爬虫抓取微信好友总数和微信好友性别分布。代码实现相当简单,具体教程如下。
相信大家都知道直接通过网页抓取微信数据是不可行的,但是强大的Python提供了一个itchat库,搭建了链接微信好友信息的友好桥梁,直接上传代码,如下图.
对代码的关键部分进行了注释,方便大家理解。程序运行时,会弹出一个微信二维码。这时候需要用手机扫码授权登录。如果你当时登录的是微信PC版,微信会强制你注销再授权。授权成功后程序会继续执行,过一会会返回给你微信好友数。
这里以小编的微信好友为例,程序运行后,获取到的信息如下图所示:
可以看到,小编一共有1637个微信好友。相信很多朋友已经知道,在手机微信页面的第二个标签“通讯录”下,将好友列表拉到最后,就可以看到自己的微信好友数量了。你可以试试看。Python程序捕获的数字是否一致。
接下来小编就继续带大家继续发掘微信好友中的男女比例。其实很简单,代码实现也很容易。这里有两种方式,如下图所示。(注:代码按照上一个程序继续写)
可以自定义一个函数来获取性别信息,也可以直接调用value_counts()方法,这样更方便统计每一项出现的次数。小编的男女微信好友数量如下图所示。这里,1代表男性,2代表女性,0代表未知性别(因为有些朋友没有设置性别)。
可以看到,小编有884个男性朋友,655个女性朋友,还有近100个性别不明的朋友。
至此,使用Python网络爬虫抓取微信好友数量和微信好友男女比例已经完成。小伙伴们可以打开电脑快速尝试一下。几行代码带你玩转微信好友~~~
这个文章的主要参考链接在这里:,感谢大佬提供的思路和方法。
下一篇文章,小编会继续和大家分享微信好友的那些事儿,并带大家使用Python爬虫抓取微信好友的省市分布,并进行可视化,敬请期待~~
本文由 dcpeng 创建,采用知识共享署名-相同方式共享3.0 中国大陆许可协议进行许可。
转载或引用前需联系作者,署名并注明文章出处。 查看全部
python网页数据抓取(利用Python网络爬虫抓取微信朋友圈动态——附代码(下))
前几天给大家分享了使用Python网络爬虫爬取朋友圈的动态(上)和使用Python网络爬虫爬取朋友圈的动态——附代码(下),并对抓取到的数据进行Python处理。词云和艺术字可视化,有兴趣的小伙伴可以戳这个文章:使用Python词云和艺术字可视化工具,对朋友圈数据进行可视化。
今天我们继续关注微信,不过这次给大家带来的是使用Python网络爬虫抓取微信好友总数和微信好友性别分布。代码实现相当简单,具体教程如下。
相信大家都知道直接通过网页抓取微信数据是不可行的,但是强大的Python提供了一个itchat库,搭建了链接微信好友信息的友好桥梁,直接上传代码,如下图.
对代码的关键部分进行了注释,方便大家理解。程序运行时,会弹出一个微信二维码。这时候需要用手机扫码授权登录。如果你当时登录的是微信PC版,微信会强制你注销再授权。授权成功后程序会继续执行,过一会会返回给你微信好友数。
这里以小编的微信好友为例,程序运行后,获取到的信息如下图所示:
可以看到,小编一共有1637个微信好友。相信很多朋友已经知道,在手机微信页面的第二个标签“通讯录”下,将好友列表拉到最后,就可以看到自己的微信好友数量了。你可以试试看。Python程序捕获的数字是否一致。
接下来小编就继续带大家继续发掘微信好友中的男女比例。其实很简单,代码实现也很容易。这里有两种方式,如下图所示。(注:代码按照上一个程序继续写)
可以自定义一个函数来获取性别信息,也可以直接调用value_counts()方法,这样更方便统计每一项出现的次数。小编的男女微信好友数量如下图所示。这里,1代表男性,2代表女性,0代表未知性别(因为有些朋友没有设置性别)。
可以看到,小编有884个男性朋友,655个女性朋友,还有近100个性别不明的朋友。
至此,使用Python网络爬虫抓取微信好友数量和微信好友男女比例已经完成。小伙伴们可以打开电脑快速尝试一下。几行代码带你玩转微信好友~~~
这个文章的主要参考链接在这里:,感谢大佬提供的思路和方法。
下一篇文章,小编会继续和大家分享微信好友的那些事儿,并带大家使用Python爬虫抓取微信好友的省市分布,并进行可视化,敬请期待~~
本文由 dcpeng 创建,采用知识共享署名-相同方式共享3.0 中国大陆许可协议进行许可。
转载或引用前需联系作者,署名并注明文章出处。
python网页数据抓取(HTML源码中的内容由前端的动态生成,我们应该如何对网页进行模拟访问 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2022-03-24 13:01
)
我们之前抓取的网页大多是从 HTML 静态生成的内容,而我们可以直接从 HTML 源代码中找到的数据和内容。但是,并不是所有的网页都是这样的。
部分网站内容是由前端JS动态生成的。由于网页显示的内容是JS生成的,所以我们在浏览器上可以看到,但是在HTML源代码中找不到。比如今日头条:
浏览器渲染的网页是这样的:
查看源码,其实是这样的:
网页的新闻在HTML源代码中找不到,都是由JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页呢?有两种方式:
1、从网页响应中找到JS脚本返回的JSON数据;2、使用Selenium模拟对网页的访问
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,然后根据接口返回的JSON数据进行加载和渲染。
这样我们就可以找到JS调用的数据接口,从数据接口中找到网页中最后渲染的数据。
以今日头条为例进行演示:
1、找到JS请求的数据接口
F12打开网页调试工具
选择“Network”选项卡后,我发现有很多响应,所以让我们过滤并仅查看 XHR 响应。
(XHR是Ajax中的一个概念,意思是XMLHTTPrequest)
然后我们发现了很多缺失的链接,随便点一个看:
我们选择城市,预览中有一串json数据:
让我们再次点击查看:
原来都是城市列表,应该是用来加载地区新闻的。
现在你大概明白如何找到JS请求的接口了吧?但是刚才没有找到我们想要的消息,我们再找找吧:
有一个焦点,我们点击查看:
首页图片新闻呈现的数据是一样的,所以应该有数据。
查看其他链接:
这应该是热搜关键词
这是图片新闻下的新闻。
我们打开一个界面链接看看:
返回一串乱码,但从响应中查看正常编码数据:
有了对应的数据接口,我们就可以按照前面的方法去请求并得到数据接口的响应了
2、请求和解析数据接口数据
先完整代码:
# coding:utf-8
import requests
import json
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
for n in news:
title = n['title']
img_url = n['image_url']
url = n['media_url']
print(url,title,img_url)
返回结果如下:
代码分为四部分
第 1 部分:导入相关库
# coding:utf-8
import requests
import json
第二部分:对数据接口的http请求
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text 查看全部
python网页数据抓取(HTML源码中的内容由前端的动态生成,我们应该如何对网页进行模拟访问
)
我们之前抓取的网页大多是从 HTML 静态生成的内容,而我们可以直接从 HTML 源代码中找到的数据和内容。但是,并不是所有的网页都是这样的。
部分网站内容是由前端JS动态生成的。由于网页显示的内容是JS生成的,所以我们在浏览器上可以看到,但是在HTML源代码中找不到。比如今日头条:
浏览器渲染的网页是这样的:
查看源码,其实是这样的:
网页的新闻在HTML源代码中找不到,都是由JS动态生成和加载的。
在这种情况下,我们应该如何抓取网页呢?有两种方式:
1、从网页响应中找到JS脚本返回的JSON数据;2、使用Selenium模拟对网页的访问
一、从网页响应中查找JS脚本返回的JSON数据
即使网页内容是由JS动态生成和加载的,JS也需要调用一个接口,然后根据接口返回的JSON数据进行加载和渲染。
这样我们就可以找到JS调用的数据接口,从数据接口中找到网页中最后渲染的数据。
以今日头条为例进行演示:
1、找到JS请求的数据接口
F12打开网页调试工具
选择“Network”选项卡后,我发现有很多响应,所以让我们过滤并仅查看 XHR 响应。
(XHR是Ajax中的一个概念,意思是XMLHTTPrequest)
然后我们发现了很多缺失的链接,随便点一个看:
我们选择城市,预览中有一串json数据:
让我们再次点击查看:
原来都是城市列表,应该是用来加载地区新闻的。
现在你大概明白如何找到JS请求的接口了吧?但是刚才没有找到我们想要的消息,我们再找找吧:
有一个焦点,我们点击查看:
首页图片新闻呈现的数据是一样的,所以应该有数据。
查看其他链接:
这应该是热搜关键词
这是图片新闻下的新闻。
我们打开一个界面链接看看:
返回一串乱码,但从响应中查看正常编码数据:
有了对应的数据接口,我们就可以按照前面的方法去请求并得到数据接口的响应了
2、请求和解析数据接口数据
先完整代码:
# coding:utf-8
import requests
import json
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
data = json.loads(wbdata)
news = data['data']['pc_feed_focus']
for n in news:
title = n['title']
img_url = n['image_url']
url = n['media_url']
print(url,title,img_url)
返回结果如下:
代码分为四部分
第 1 部分:导入相关库
# coding:utf-8
import requests
import json
第二部分:对数据接口的http请求
url = 'http://www.toutiao.com/api/pc/focus/'
wbdata = requests.get(url).text
python网页数据抓取(抓取一下网易云课堂课程数据--提取post关键字 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 147 次浏览 • 2022-03-24 12:17
)
写在前面
今天,我们来抓取网易云课堂的课程数据。这个网站中的数据量并不是很大。我们只需要使用请求来快速抓取这部分数据。
你需要做的第一件事是打开所有课程的地址并找出爬虫规则。
地址如下:
简单看了一下,页面数据是基于
这个地址是异步加载的。您需要开发人员工具自己尝试
多次尝试后,以该地址获取的数据为准。
还有一点需要注意,这次是post提交方式,提交的数据是payload类型的。这个原因导致我们的代码与之前的代码略有不同。
提取post关键字,查看每个参数的含义。如果你爬够了网站,训练出来的灵敏度可以快速分析这些参数
{"pageindex":55, # 页码
"pagesize":50, # 每页数据大小
"relativeoffset":2700,
"frontcategoryid":-1,
"searchtimetype":-1,
"ordertype":50,
"pricetype":-1,
"activityid":0,
"keyword":"" # 搜索相关
}
好了,可以开始写代码了,核心代码是通过requests模块发送post请求
def get_json(index):
print(f"正在抓取{index}页数据")
payload = {"pageindex":index,
"pagesize":50,
"relativeoffset":50,
"frontcategoryid":-1,
"searchtimetype":-1,
"ordertype":50,
"pricetype":-1,
"activityid":0,
"keyword":""
}
headers = {"accept":"application/json",
"host":"study.163.com",
"origin":"https://study.163.com",
"content-type":"application/json",
"referer":"https://study.163.com/courses",
"user-agent":"自己去找个浏览器ua"
}
try:
# 请注意这个地方发送的是post请求
# csdn 博客 梦想橡皮擦
res = requests.post("https://study.163.com/p/search ... ot%3B,json=payload,headers=headers)
content_json = res.json()
if content_json and content_json["code"] == 0:
data = get_content(content_json) # 获取正确的数据
############################################
if len(data) > 0:
save_mongo(data) # 保存数据
############################################
except exception as e:
print("出现bug了")
print(e)
finally:
time.sleep(1)
index+=1
get_json(index)
def get_content(content_json):
if "result" in content_json:
return content_json["result"]["list"]
因为获取到的数据是json类型的,所以可以快速的将数据保存到mongodb中。保存数据的代码我还是留空,希望大家自己改进。
在很短的时间内,我们捕获了 3000 门课程
好吧,您需要代码和数据,请发表评论并留下我与您联系的方式。
查看全部
python网页数据抓取(抓取一下网易云课堂课程数据--提取post关键字
)
写在前面
今天,我们来抓取网易云课堂的课程数据。这个网站中的数据量并不是很大。我们只需要使用请求来快速抓取这部分数据。
你需要做的第一件事是打开所有课程的地址并找出爬虫规则。
地址如下:
简单看了一下,页面数据是基于
这个地址是异步加载的。您需要开发人员工具自己尝试
多次尝试后,以该地址获取的数据为准。
还有一点需要注意,这次是post提交方式,提交的数据是payload类型的。这个原因导致我们的代码与之前的代码略有不同。
提取post关键字,查看每个参数的含义。如果你爬够了网站,训练出来的灵敏度可以快速分析这些参数
{"pageindex":55, # 页码
"pagesize":50, # 每页数据大小
"relativeoffset":2700,
"frontcategoryid":-1,
"searchtimetype":-1,
"ordertype":50,
"pricetype":-1,
"activityid":0,
"keyword":"" # 搜索相关
}
好了,可以开始写代码了,核心代码是通过requests模块发送post请求
def get_json(index):
print(f"正在抓取{index}页数据")
payload = {"pageindex":index,
"pagesize":50,
"relativeoffset":50,
"frontcategoryid":-1,
"searchtimetype":-1,
"ordertype":50,
"pricetype":-1,
"activityid":0,
"keyword":""
}
headers = {"accept":"application/json",
"host":"study.163.com",
"origin":"https://study.163.com",
"content-type":"application/json",
"referer":"https://study.163.com/courses",
"user-agent":"自己去找个浏览器ua"
}
try:
# 请注意这个地方发送的是post请求
# csdn 博客 梦想橡皮擦
res = requests.post("https://study.163.com/p/search ... ot%3B,json=payload,headers=headers)
content_json = res.json()
if content_json and content_json["code"] == 0:
data = get_content(content_json) # 获取正确的数据
############################################
if len(data) > 0:
save_mongo(data) # 保存数据
############################################
except exception as e:
print("出现bug了")
print(e)
finally:
time.sleep(1)
index+=1
get_json(index)
def get_content(content_json):
if "result" in content_json:
return content_json["result"]["list"]
因为获取到的数据是json类型的,所以可以快速的将数据保存到mongodb中。保存数据的代码我还是留空,希望大家自己改进。
在很短的时间内,我们捕获了 3000 门课程
好吧,您需要代码和数据,请发表评论并留下我与您联系的方式。
python网页数据抓取(python框架,使用python进行网页数据,google网页爬虫及源码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 114 次浏览 • 2022-03-18 18:04
python网页数据抓取leap.find()爬取网页数据,google公开的源码pyspider框架,使用python进行网页数据抓取python爬虫python网页爬虫及源码
不了解,crawler功能应该可以满足你的需求,
参考这个问题:python爬虫之美猴猫:python网页抓取-leap.find()
leapframes:fromurllib。requestimporturlopenloop=urlopen()#循环遍历整个网页,下面所有代码都是针对整个网页的print(loop)#write->writetothewindowwindow。write(urlopen('')。read())#读到一定时间会后直接弹出一个窗口,里面有一个run函数,用于中断urlopen,获取到另一页print('window')window。close()。
defget_results(url):login_url=urlopen(';ref=_evb3cfff5c012c5a6f504a5ba580358c3e25&sort=sales_all')#请求网址foriinrange(0,1):login_url。encode('gbk')。decode('utf-8')+'/'+foruserinlogin_url:#获取用户名foriinrange(1,len(user)):print('loginuserwith:%s'%user)#获取登录页面print('defaultloginurl:%s'%(user["username"],user["password"]))returnresultsurllib。urlencodeerrorprint(get_results(''))。 查看全部
python网页数据抓取(python框架,使用python进行网页数据,google网页爬虫及源码)
python网页数据抓取leap.find()爬取网页数据,google公开的源码pyspider框架,使用python进行网页数据抓取python爬虫python网页爬虫及源码
不了解,crawler功能应该可以满足你的需求,
参考这个问题:python爬虫之美猴猫:python网页抓取-leap.find()
leapframes:fromurllib。requestimporturlopenloop=urlopen()#循环遍历整个网页,下面所有代码都是针对整个网页的print(loop)#write->writetothewindowwindow。write(urlopen('')。read())#读到一定时间会后直接弹出一个窗口,里面有一个run函数,用于中断urlopen,获取到另一页print('window')window。close()。
defget_results(url):login_url=urlopen(';ref=_evb3cfff5c012c5a6f504a5ba580358c3e25&sort=sales_all')#请求网址foriinrange(0,1):login_url。encode('gbk')。decode('utf-8')+'/'+foruserinlogin_url:#获取用户名foriinrange(1,len(user)):print('loginuserwith:%s'%user)#获取登录页面print('defaultloginurl:%s'%(user["username"],user["password"]))returnresultsurllib。urlencodeerrorprint(get_results(''))。
python网页数据抓取(用Python写爬虫工具(二):Python模拟浏览器发起请求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 101 次浏览 • 2022-03-18 14:22
现在用Python写爬虫工具已经是家常便饭了,大家都希望自己写一个程序,从网上抓取一些信息,进行数据分析或者其他的事情。
我们知道爬虫的原理无非就是把目标网站的内容下载下来,存储在内存中。这时候它的内容其实就是一堆HTML,然后按照自己的思路解析HTML内容,提取出想要的数据。,所以今天我们主要讲一下Python中解析网页HTML内容的四种方法,各有千秋,适合不同场合使用。
首先,我们随机找到了一个网站。这时,豆瓣网站在我脑海中闪过。好吧,毕竟网站是用Python构建的,所以我们以它为例。
我们找到了豆瓣的Python爬虫群首页,如下图。
让我们使用浏览器开发工具查看 HTML 代码并找到所需的内容。我们要提取讨论组中的所有帖子标题和链接。
通过分析,我们发现我们想要的内容其实是在整个HTML代码的这个区域,所以我们只需要想办法把这个区域的内容取出来即可。
现在开始编写代码。
一:正则表达式大法
正则表达式通常用于检索和替换匹配某种模式的文本,所以我们可以利用这个原理来提取我们想要的信息。
请参考以下代码。
在代码的第6、7行,需要手动指定header的内容,假装这个请求是浏览器请求,否则豆瓣会认为我们的请求不是正常请求,会返回HTTP 418错误。
在第 7 行,我们直接使用 requests 库的 get 方法发出请求。得到内容后,我们需要转换编码格式。也是因为豆瓣的页面渲染机制。一般情况下,我们可以直接获取requests内容的内容。.
Python模拟浏览器发起请求并解析内容代码:
url = 'https://www.douban.com/group/491607/'headers = {"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:71.0) Gecko/20100101 Firefox/71.0"}response = requests.get(url=url,headers=headers).content.decode('utf-8')
正则的优点是写起来麻烦,难懂,但是匹配效率很高。但是,在有太多现成的HTML内容解析库之后,我个人不建议手动使用正则来匹配内容,既费时又费力。.
主要解析代码:
<p>re_div = r'[\W|\w]+'pattern = re.compile(re_div)content = re.findall(pattern, str(response))re_link = r'(.*?)</a>'mm = re.findall(re_link, str(content), re.S|re.M)urls=re.findall(r" 查看全部
python网页数据抓取(用Python写爬虫工具(二):Python模拟浏览器发起请求)
现在用Python写爬虫工具已经是家常便饭了,大家都希望自己写一个程序,从网上抓取一些信息,进行数据分析或者其他的事情。
我们知道爬虫的原理无非就是把目标网站的内容下载下来,存储在内存中。这时候它的内容其实就是一堆HTML,然后按照自己的思路解析HTML内容,提取出想要的数据。,所以今天我们主要讲一下Python中解析网页HTML内容的四种方法,各有千秋,适合不同场合使用。
首先,我们随机找到了一个网站。这时,豆瓣网站在我脑海中闪过。好吧,毕竟网站是用Python构建的,所以我们以它为例。
我们找到了豆瓣的Python爬虫群首页,如下图。
让我们使用浏览器开发工具查看 HTML 代码并找到所需的内容。我们要提取讨论组中的所有帖子标题和链接。
通过分析,我们发现我们想要的内容其实是在整个HTML代码的这个区域,所以我们只需要想办法把这个区域的内容取出来即可。
现在开始编写代码。
一:正则表达式大法
正则表达式通常用于检索和替换匹配某种模式的文本,所以我们可以利用这个原理来提取我们想要的信息。
请参考以下代码。
在代码的第6、7行,需要手动指定header的内容,假装这个请求是浏览器请求,否则豆瓣会认为我们的请求不是正常请求,会返回HTTP 418错误。
在第 7 行,我们直接使用 requests 库的 get 方法发出请求。得到内容后,我们需要转换编码格式。也是因为豆瓣的页面渲染机制。一般情况下,我们可以直接获取requests内容的内容。.
Python模拟浏览器发起请求并解析内容代码:
url = 'https://www.douban.com/group/491607/'headers = {"User-Agent":"Mozilla/5.0 (Macintosh; Intel Mac OS X 10.14; rv:71.0) Gecko/20100101 Firefox/71.0"}response = requests.get(url=url,headers=headers).content.decode('utf-8')
正则的优点是写起来麻烦,难懂,但是匹配效率很高。但是,在有太多现成的HTML内容解析库之后,我个人不建议手动使用正则来匹配内容,既费时又费力。.
主要解析代码:
<p>re_div = r'[\W|\w]+'pattern = re.compile(re_div)content = re.findall(pattern, str(response))re_link = r'(.*?)</a>'mm = re.findall(re_link, str(content), re.S|re.M)urls=re.findall(r"
python网页数据抓取(Python爬虫的抓取技术大盘点-抓取爬虫技术篇)
网站优化 • 优采云 发表了文章 • 0 个评论 • 239 次浏览 • 2022-03-18 13:14
网络爬虫一直是讨论的热门话题。了解Python爬虫技术更受欢迎,学习Python爬虫可以更好地了解如何应对网络危害。未经授权的爬虫爬取程序是危害web原创内容生态的一大罪魁祸首,所以要保护网站的内容,首先要考虑如何防范爬虫。接下来,IT培训网将为大家盘点一下Python爬虫的一些爬取技术。
Python爬虫爬取技术盘点
1、从爬虫攻防的角度来看
最简单的爬虫是几乎所有服务器端和客户端编程语言都支持的 http 请求。只要对目标页面的url进行http get请求,就可以获得浏览器加载页面时的完整html文档。我们称之为“同步页面”。作为防御方,服务器可以根据http请求头中的User-Agent检查客户端是合法的浏览器程序还是脚本爬虫,从而决定是否使用真实的页面信息内容发送给你。
这当然是最小的小儿防御方法。作为进攻方,爬虫完全可以伪造User-Agent字段。甚至,只要你愿意,在HTTP get方法中,请求头的Referrer、Cookie等所有字段都可以被爬虫轻松处理。伪造。这时,服务器就可以根据你声明的浏览器厂商和版本(来自User-Agent),使用浏览器http头指纹来识别你http头中的每个字段是否符合浏览器的特性。如果匹配,它将被视为爬虫。该技术的一个典型应用是在 PhantomJS 1.x 版本中,由于底层调用了 Qt 框架的网络库,http 头具有明显的 Qt 框架的网络请求特征,可以直接被服务器识别。并被拦截。
另外,还有一个比较异常的服务器端爬虫检测机制,就是在http响应中为所有访问该页面的http请求种上一个cookie token,然后在这个异步执行的一些ajax接口上学页。检查访问请求中是否收录cookie token,返回token表示这是一次合法的浏览器访问,否则表示刚刚发出token的用户访问了页面html但没有访问执行js后调用的ajax在 html 请求中,很可能是爬虫。
如果直接访问一个没有token的接口,说明你没有请求过html页面,而是直接向页面中应该通过ajax访问的接口发起网络请求,这显然证明了你是一个可疑的爬虫。知名电子商务公司网站亚马逊采用了这种防御策略。
以上是基于服务器端验证爬虫程序可以玩的一些套路。
2、基于客户端js运行时检测
现代浏览器赋予 JavaScript 强大的能力,所以我们可以将页面的所有核心内容作为 js 异步请求 ajax 获取数据然后渲染到页面中,这显然提高了爬取内容的门槛。这样,我们就将爬虫和反爬的战斗从服务端转移到了客户端浏览器中的js运行时。接下来说一下结合客户端js运行时的爬取技术。
刚才提到的各种服务器端验证,对于普通的python和java语言编写的HTTP爬虫程序,都有一定的技术门槛。毕竟,Web 应用程序是未经授权的抓取工具的黑匣子。很多东西都需要一点一点的去尝试,而一套耗费大量人力物力开发的爬虫程序,只要网站作为防御者可以轻松调整一些策略,攻击者也需要花费同样的时间再次修改爬虫的爬取逻辑。此时,您需要使用无头浏览器。这是什么技术?其实说白了就是程序可以操作浏览器访问网页,这样写爬虫的人就可以通过调用浏览器暴露给程序的API来实现复杂性。获取业务逻辑。
近年来,这并不是一项新技术。曾经有基于webkit内核的PhantomJS,基于火狐浏览器内核的SlimerJS,甚至还有基于IE内核的trifleJS。如果你有兴趣,可以看看这里,这里是两个无头浏览器列表的集合。这些无头浏览器程序的原理其实就是对一些开源的浏览器内核C++代码进行改造和封装,实现一个简单的浏览器程序,无需GUI界面渲染。但是这些项目的通病是因为他们的代码是基于fork官方webkit和其他内核的某个版本的trunk代码,所以跟不上一些最新的css属性和js语法,还有一些兼容性问题,不如正版GUI浏览器发行版运行稳定。
其中,最成熟、用得最多的应该是PhantonJS。之前写过一篇关于这种爬虫识别的博客,这里不再赘述。PhantomJS 有很多问题,因为它是单进程模型,没有必要的沙箱保护,浏览器内核的安全性较差。此外,该项目的作者已经宣布他们将停止维护这个项目。Headless Chrome 可以说是 Headless Browser 中独一无二的杀手锏。由于它本身就是一个 chrome 浏览器,它支持各种新的 CSS 渲染特性和 js 运行时语法。基于这种方法,爬虫作为攻击方可以绕过几乎所有的服务器端验证逻辑,但是这些爬虫在客户端js运行时还是存在一些缺陷,比如:
基于插件对象的检查
if(navigator.plugins.length === 0) { console.log('可能是 Chrome 无头'); }
基于语言的检查
if(navigator.languages=== '') { console.log('Chrome headless detected'); }
基于以上一些浏览器特性的判断,它基本上可以秒杀市面上大部分的Headless Browser程序。在这个层面,其实是提高了网络爬虫的门槛,要求编写爬虫程序的开发者不得不修改浏览器内核的C++代码,重新编译一个浏览器,而以上特性对浏览器来说是很重要的。内核的改动其实不小,如果你尝试过编译Blink内核或者Gecko内核你就会明白对于一个“脚本小子”来说是多么的难了~
此外,我们还可以根据浏览器的UserAgent字段中描述的浏览器品牌、版本、型号信息,检查js运行时、DOM和BOM的各个native对象的属性和方法,观察它们的特性是否符合浏览器这个版本。设备应具备的功能。这种方法称为浏览器指纹识别技术,它依赖于大型网站对各类浏览器的api信息的采集。作为编写爬虫程序的攻击者,你可以在无头浏览器运行时预先注入一些js逻辑来伪造浏览器的特性。
爬虫攻击者可能会预先注入一些js方法,用一层代理函数作为钩子包裹一些原生api,然后用这个假的js api覆盖原生api。如果防御者在函数 toString 之后基于对 [native code] 的检查来检查这一点,它将被绕过。所以需要更严格的检查,因为bind(null) fake方法在toString之后没有函数名,所以需要检查toString之后的函数名是否为空。
这种技术有什么用?在这里延伸一下,反爬虫防御者有一个Robot Detect方法,就是在js运行的时候主动抛出一个alert。文案可以写一些业务逻辑相关的,普通用户点击OK按钮肯定会有1s甚至更长的延迟,因为浏览器中的alert会阻塞js代码运行(其实在v8中他会暂停以类似于进程挂起的方式执行隔离上下文),因此爬虫程序作为攻击者可以选择使用上述技术在页面上的所有js运行之前预先注入一段js代码,并伪造所有提示、提示、确认等弹出方式。如果防御者在弹出代码之前检查他调用的alert方法是否仍然是原生的,则这种方式被阻止。
3、反爬虫银弹
目前最可靠的反爬虫和机器人巡检手段是验证码技术。但是,验证码并不意味着必须强制用户输入一系列字母数字。还有很多基于用户鼠标、触摸屏(移动端)等行为的行为验证技术。其中,最成熟的是基于机器学习的谷歌reCAPTCHA。区分用户和爬虫。
基于以上对用户和爬虫的识别和区分技术,网站的防御者需要做的就是对该IP地址进行封锁或者对该IP的访问用户施加高强度的验证码策略。这样攻击者就不得不购买IP代理池来捕获网站信息内容,否则单个IP地址很容易被封杀,无法被捕获。爬取和反爬取的门槛已经提升到IP代理池的经济成本水平。
4、机器人协议
此外,在爬虫爬取技术领域,还有一种叫做robots协议的“白道”方式。Allow 和 Disallow 声明每个 UA 爬虫的爬取授权。然而,这只是君子之约。虽然它有法律上的好处,但它只能限制那些商业搜索引擎的蜘蛛程序,你不能限制那些“野爬爱好者”。
总之,Python爬虫对网页内容的爬取与对策,注定是一场一只脚一只脚的猫捉老鼠游戏。你永远不可能用某种技术完全挡住爬虫的去路。唯一的事情是增加攻击者的捕获成本,并更准确地了解未经授权的捕获行为。 查看全部
python网页数据抓取(Python爬虫的抓取技术大盘点-抓取爬虫技术篇)
网络爬虫一直是讨论的热门话题。了解Python爬虫技术更受欢迎,学习Python爬虫可以更好地了解如何应对网络危害。未经授权的爬虫爬取程序是危害web原创内容生态的一大罪魁祸首,所以要保护网站的内容,首先要考虑如何防范爬虫。接下来,IT培训网将为大家盘点一下Python爬虫的一些爬取技术。
Python爬虫爬取技术盘点
1、从爬虫攻防的角度来看
最简单的爬虫是几乎所有服务器端和客户端编程语言都支持的 http 请求。只要对目标页面的url进行http get请求,就可以获得浏览器加载页面时的完整html文档。我们称之为“同步页面”。作为防御方,服务器可以根据http请求头中的User-Agent检查客户端是合法的浏览器程序还是脚本爬虫,从而决定是否使用真实的页面信息内容发送给你。
这当然是最小的小儿防御方法。作为进攻方,爬虫完全可以伪造User-Agent字段。甚至,只要你愿意,在HTTP get方法中,请求头的Referrer、Cookie等所有字段都可以被爬虫轻松处理。伪造。这时,服务器就可以根据你声明的浏览器厂商和版本(来自User-Agent),使用浏览器http头指纹来识别你http头中的每个字段是否符合浏览器的特性。如果匹配,它将被视为爬虫。该技术的一个典型应用是在 PhantomJS 1.x 版本中,由于底层调用了 Qt 框架的网络库,http 头具有明显的 Qt 框架的网络请求特征,可以直接被服务器识别。并被拦截。
另外,还有一个比较异常的服务器端爬虫检测机制,就是在http响应中为所有访问该页面的http请求种上一个cookie token,然后在这个异步执行的一些ajax接口上学页。检查访问请求中是否收录cookie token,返回token表示这是一次合法的浏览器访问,否则表示刚刚发出token的用户访问了页面html但没有访问执行js后调用的ajax在 html 请求中,很可能是爬虫。
如果直接访问一个没有token的接口,说明你没有请求过html页面,而是直接向页面中应该通过ajax访问的接口发起网络请求,这显然证明了你是一个可疑的爬虫。知名电子商务公司网站亚马逊采用了这种防御策略。
以上是基于服务器端验证爬虫程序可以玩的一些套路。
2、基于客户端js运行时检测
现代浏览器赋予 JavaScript 强大的能力,所以我们可以将页面的所有核心内容作为 js 异步请求 ajax 获取数据然后渲染到页面中,这显然提高了爬取内容的门槛。这样,我们就将爬虫和反爬的战斗从服务端转移到了客户端浏览器中的js运行时。接下来说一下结合客户端js运行时的爬取技术。
刚才提到的各种服务器端验证,对于普通的python和java语言编写的HTTP爬虫程序,都有一定的技术门槛。毕竟,Web 应用程序是未经授权的抓取工具的黑匣子。很多东西都需要一点一点的去尝试,而一套耗费大量人力物力开发的爬虫程序,只要网站作为防御者可以轻松调整一些策略,攻击者也需要花费同样的时间再次修改爬虫的爬取逻辑。此时,您需要使用无头浏览器。这是什么技术?其实说白了就是程序可以操作浏览器访问网页,这样写爬虫的人就可以通过调用浏览器暴露给程序的API来实现复杂性。获取业务逻辑。
近年来,这并不是一项新技术。曾经有基于webkit内核的PhantomJS,基于火狐浏览器内核的SlimerJS,甚至还有基于IE内核的trifleJS。如果你有兴趣,可以看看这里,这里是两个无头浏览器列表的集合。这些无头浏览器程序的原理其实就是对一些开源的浏览器内核C++代码进行改造和封装,实现一个简单的浏览器程序,无需GUI界面渲染。但是这些项目的通病是因为他们的代码是基于fork官方webkit和其他内核的某个版本的trunk代码,所以跟不上一些最新的css属性和js语法,还有一些兼容性问题,不如正版GUI浏览器发行版运行稳定。
其中,最成熟、用得最多的应该是PhantonJS。之前写过一篇关于这种爬虫识别的博客,这里不再赘述。PhantomJS 有很多问题,因为它是单进程模型,没有必要的沙箱保护,浏览器内核的安全性较差。此外,该项目的作者已经宣布他们将停止维护这个项目。Headless Chrome 可以说是 Headless Browser 中独一无二的杀手锏。由于它本身就是一个 chrome 浏览器,它支持各种新的 CSS 渲染特性和 js 运行时语法。基于这种方法,爬虫作为攻击方可以绕过几乎所有的服务器端验证逻辑,但是这些爬虫在客户端js运行时还是存在一些缺陷,比如:
基于插件对象的检查
if(navigator.plugins.length === 0) { console.log('可能是 Chrome 无头'); }
基于语言的检查
if(navigator.languages=== '') { console.log('Chrome headless detected'); }
基于以上一些浏览器特性的判断,它基本上可以秒杀市面上大部分的Headless Browser程序。在这个层面,其实是提高了网络爬虫的门槛,要求编写爬虫程序的开发者不得不修改浏览器内核的C++代码,重新编译一个浏览器,而以上特性对浏览器来说是很重要的。内核的改动其实不小,如果你尝试过编译Blink内核或者Gecko内核你就会明白对于一个“脚本小子”来说是多么的难了~
此外,我们还可以根据浏览器的UserAgent字段中描述的浏览器品牌、版本、型号信息,检查js运行时、DOM和BOM的各个native对象的属性和方法,观察它们的特性是否符合浏览器这个版本。设备应具备的功能。这种方法称为浏览器指纹识别技术,它依赖于大型网站对各类浏览器的api信息的采集。作为编写爬虫程序的攻击者,你可以在无头浏览器运行时预先注入一些js逻辑来伪造浏览器的特性。
爬虫攻击者可能会预先注入一些js方法,用一层代理函数作为钩子包裹一些原生api,然后用这个假的js api覆盖原生api。如果防御者在函数 toString 之后基于对 [native code] 的检查来检查这一点,它将被绕过。所以需要更严格的检查,因为bind(null) fake方法在toString之后没有函数名,所以需要检查toString之后的函数名是否为空。
这种技术有什么用?在这里延伸一下,反爬虫防御者有一个Robot Detect方法,就是在js运行的时候主动抛出一个alert。文案可以写一些业务逻辑相关的,普通用户点击OK按钮肯定会有1s甚至更长的延迟,因为浏览器中的alert会阻塞js代码运行(其实在v8中他会暂停以类似于进程挂起的方式执行隔离上下文),因此爬虫程序作为攻击者可以选择使用上述技术在页面上的所有js运行之前预先注入一段js代码,并伪造所有提示、提示、确认等弹出方式。如果防御者在弹出代码之前检查他调用的alert方法是否仍然是原生的,则这种方式被阻止。
3、反爬虫银弹
目前最可靠的反爬虫和机器人巡检手段是验证码技术。但是,验证码并不意味着必须强制用户输入一系列字母数字。还有很多基于用户鼠标、触摸屏(移动端)等行为的行为验证技术。其中,最成熟的是基于机器学习的谷歌reCAPTCHA。区分用户和爬虫。
基于以上对用户和爬虫的识别和区分技术,网站的防御者需要做的就是对该IP地址进行封锁或者对该IP的访问用户施加高强度的验证码策略。这样攻击者就不得不购买IP代理池来捕获网站信息内容,否则单个IP地址很容易被封杀,无法被捕获。爬取和反爬取的门槛已经提升到IP代理池的经济成本水平。
4、机器人协议
此外,在爬虫爬取技术领域,还有一种叫做robots协议的“白道”方式。Allow 和 Disallow 声明每个 UA 爬虫的爬取授权。然而,这只是君子之约。虽然它有法律上的好处,但它只能限制那些商业搜索引擎的蜘蛛程序,你不能限制那些“野爬爱好者”。
总之,Python爬虫对网页内容的爬取与对策,注定是一场一只脚一只脚的猫捉老鼠游戏。你永远不可能用某种技术完全挡住爬虫的去路。唯一的事情是增加攻击者的捕获成本,并更准确地了解未经授权的捕获行为。
python网页数据抓取(edge浏览器数据教程(教程用于爬取动态加载的数据))
网站优化 • 优采云 发表了文章 • 0 个评论 • 578 次浏览 • 2022-03-17 07:05
python时间戳
将时间戳转换为日期
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 引入time模块
import time
#时间戳
timeStamp = 1581004800
timeArray = time.localtime(timeStamp)
#转为年-月-日形式
otherStyleTime = time.strftime("%Y-%m-%d ", timeArray)
print(otherStyleTime)
Python爬取数据教程(爬取动态加载数据教程)
很多时候我们需要抓取网页动态加载的数据。这是通过打开网页并按“Fn+F12”打开“开发者工具”。
边缘浏览器打开开发者工具:
谷歌浏览器打开开发者工具:
Edge 点击“网络”,谷歌点击“网络”,
要查找我们要查找的文件,我们可以按文件类型查找。在标头中,我们可以看到请求 URL。在 body 界面中,我们看到了传递过来的数据。我们想要得到的是dataprice。此数据为 json 格式。Python 将 json 数据作为字符串获取。
代码:
import requests
import json
import urllib
request_url = "http://tool.manmanbuy.com/hist ... ot%3B
data = requests.get(request_url)
data_price = json.loads(data.text)
data_price = data_price['datePrice']
print(data_price)
运行结果:
所以我们得到了dataprice!
这还没完,我们现在已经获取到了一个url对应的动态数据,但是我有几千条数据,所以我们研究一下这个requestURL,看看能不能构造(截图是谷歌浏览器的截图)
通过比较几个请求的url,我发现它们的区别在于,在“url=”和“token=”之后,url是输入链接,我们可以传入,但是这个token是什么?? 经过研究,发现token是在这里的,但是是随机生成的,怎么获取这个字段呢?
通过在网页上右击“查看网页源代码”,或者在开发者工具中点击第一个“元素”查看源代码,发现这里生成了token。
但是我对加密功能没看懂(懂的大神可以告诉我,哈哈),只能另找办法再研究了。哈哈,token又出现在这里了,最后,得到src路径,通过对字符串进行修剪得到token的值。
所以我们可以构造requestURL,
request_url = "http://tool.manmanbuy.com/hist ... rl%3D{0}&bjid=&spbh=&cxid=&zkid=&w=951&token={1}".format(url,token)
使用上面的代码,我们可以得到所有的数据! 查看全部
python网页数据抓取(edge浏览器数据教程(教程用于爬取动态加载的数据))
python时间戳
将时间戳转换为日期
#!/usr/bin/python
# -*- coding: UTF-8 -*-
# 引入time模块
import time
#时间戳
timeStamp = 1581004800
timeArray = time.localtime(timeStamp)
#转为年-月-日形式
otherStyleTime = time.strftime("%Y-%m-%d ", timeArray)
print(otherStyleTime)
Python爬取数据教程(爬取动态加载数据教程)
很多时候我们需要抓取网页动态加载的数据。这是通过打开网页并按“Fn+F12”打开“开发者工具”。
边缘浏览器打开开发者工具:
谷歌浏览器打开开发者工具:
Edge 点击“网络”,谷歌点击“网络”,
要查找我们要查找的文件,我们可以按文件类型查找。在标头中,我们可以看到请求 URL。在 body 界面中,我们看到了传递过来的数据。我们想要得到的是dataprice。此数据为 json 格式。Python 将 json 数据作为字符串获取。
代码:
import requests
import json
import urllib
request_url = "http://tool.manmanbuy.com/hist ... ot%3B
data = requests.get(request_url)
data_price = json.loads(data.text)
data_price = data_price['datePrice']
print(data_price)
运行结果:
所以我们得到了dataprice!
这还没完,我们现在已经获取到了一个url对应的动态数据,但是我有几千条数据,所以我们研究一下这个requestURL,看看能不能构造(截图是谷歌浏览器的截图)
通过比较几个请求的url,我发现它们的区别在于,在“url=”和“token=”之后,url是输入链接,我们可以传入,但是这个token是什么?? 经过研究,发现token是在这里的,但是是随机生成的,怎么获取这个字段呢?
通过在网页上右击“查看网页源代码”,或者在开发者工具中点击第一个“元素”查看源代码,发现这里生成了token。
但是我对加密功能没看懂(懂的大神可以告诉我,哈哈),只能另找办法再研究了。哈哈,token又出现在这里了,最后,得到src路径,通过对字符串进行修剪得到token的值。
所以我们可以构造requestURL,
request_url = "http://tool.manmanbuy.com/hist ... rl%3D{0}&bjid=&spbh=&cxid=&zkid=&w=951&token={1}".format(url,token)
使用上面的代码,我们可以得到所有的数据!
python网页数据抓取(Python中的语法聿僮馕馕解析html(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2022-03-15 20:20
刚才好无聊,突然想起之前做课表的想法,于是百度起来。
一开始我是这样想的:我写微信墙的时候,用的是urllib2【两行代码抓取网页】,所以只需要解析html。于是百度:python解析html。找到了一个不错的文章,里面引入了pyQuery。
pyQuery 是 jQuery 在 Python 中的实现,可以生成带有 jQuery 语法的 HTML 文档。使用前需要安装。Mac安装方法如下:
sudo easy_install pyquery
好的!安装!
让我们试一试:
from pyquery import PyQuery as pq
html = pq(url=u'http://seam.ustb.edu.cn:8080/j ... %2339;)
#现在已经获取了本科教学网首页的html
classes = html('.haveclass')
#通过类名获取元素
#如果你对jQuery熟悉的话,那么你现在肯定明白pyQuery的方便了
更多用法参见pyQuery API
看来学用pyQuery的话,可以抓到时间表,但如果直接用我的源码,肯定会出错。因为我还没有登录!
所以,在运行此行获取正确代码之前,我们需要模拟登录本科教学网络。这时候才想起urllib有模拟post请求的功能,于是我百度了:urllib post。
这是一个模拟发布请求的最小示例:
import urllib
import urllib2
import cookielib
cj = cookielib.CookieJar()
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))
opener.addheaders = [('User-agent','Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)')]
urllib2.install_opener(opener)
req = urllib2.Request("http://seam.ustb.edu.cn:8080/jwgl/Login",urllib.urlencode({"username":"41255029","password":"123456","usertype":"student"}))
req.add_header("Referer","http://xxoo.com")
resp = urllib2.urlopen(req)
#这里面用到了cookielib,我不太清楚,以后慢慢了解吧
#还用到了urllib和urllib2,urllib2大概是urllib的扩展包【233想到了三国杀
在这个最简单的例子中,我使用我的校园网账号向登录页面提交表单数据来模拟登录。
现在,我们已经登录了本科教学网,然后结合之前的pyQuery解析html,就可以在网页中得到课程表了。
结果如图所示:
最后:
发现pyQuery不仅解析html非常方便,还可以作为跨域抓取数据的工具,NICE!!!
我希望每个人都必须提供帮助。 查看全部
python网页数据抓取(Python中的语法聿僮馕馕解析html(图))
刚才好无聊,突然想起之前做课表的想法,于是百度起来。
一开始我是这样想的:我写微信墙的时候,用的是urllib2【两行代码抓取网页】,所以只需要解析html。于是百度:python解析html。找到了一个不错的文章,里面引入了pyQuery。
pyQuery 是 jQuery 在 Python 中的实现,可以生成带有 jQuery 语法的 HTML 文档。使用前需要安装。Mac安装方法如下:
sudo easy_install pyquery
好的!安装!
让我们试一试:
from pyquery import PyQuery as pq
html = pq(url=u'http://seam.ustb.edu.cn:8080/j ... %2339;)
#现在已经获取了本科教学网首页的html
classes = html('.haveclass')
#通过类名获取元素
#如果你对jQuery熟悉的话,那么你现在肯定明白pyQuery的方便了
更多用法参见pyQuery API
看来学用pyQuery的话,可以抓到时间表,但如果直接用我的源码,肯定会出错。因为我还没有登录!
所以,在运行此行获取正确代码之前,我们需要模拟登录本科教学网络。这时候才想起urllib有模拟post请求的功能,于是我百度了:urllib post。
这是一个模拟发布请求的最小示例:
import urllib
import urllib2
import cookielib
cj = cookielib.CookieJar()
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))
opener.addheaders = [('User-agent','Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)')]
urllib2.install_opener(opener)
req = urllib2.Request("http://seam.ustb.edu.cn:8080/jwgl/Login",urllib.urlencode({"username":"41255029","password":"123456","usertype":"student"}))
req.add_header("Referer","http://xxoo.com";)
resp = urllib2.urlopen(req)
#这里面用到了cookielib,我不太清楚,以后慢慢了解吧
#还用到了urllib和urllib2,urllib2大概是urllib的扩展包【233想到了三国杀
在这个最简单的例子中,我使用我的校园网账号向登录页面提交表单数据来模拟登录。
现在,我们已经登录了本科教学网,然后结合之前的pyQuery解析html,就可以在网页中得到课程表了。
结果如图所示:
最后:
发现pyQuery不仅解析html非常方便,还可以作为跨域抓取数据的工具,NICE!!!
我希望每个人都必须提供帮助。
python网页数据抓取( 难不成我抓不了天猫网站的评论数据了?(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 275 次浏览 • 2022-03-15 20:19
难不成我抓不了天猫网站的评论数据了?(图))
天气越来越冷,觉得应该给自己添点暖和的衣服,于是想到了天猫,搜了一下,感觉南极人的保暖内衣还是不错的。这么多衣服怎么选?我通常选择按销售额排序。毕竟销量也能反映产品的热度和口碑状况,所以来到了这个页面%C4%CF%BC%AB%C8%CB%B1%A3%C5%AF%C4 %DA% D2%C2&sort=d&style=g&from=.list.pc_1_suggest&suggest=0_1#J_Filter,
然后点进去后发现有很多历史累积评价,于是我一页一页地查看,感觉口碑还是很好的,所以选择了这款产品。我想每个人的购物方式可能都一样,可能会比较复杂(货比三家,比较口碑,联系卖家……)。
如果有一天,我想研究这些评论数据,然后玩自然语言处理,我应该把这些评论复制到一个大表中吗?虽然可以这样做,但我总觉得效率有点低(不是比爬虫低一两个数量级~)。如果你会爬行,你就会感受到自动化带来的刺激。接下来,我们将研究如何使用Python爬取天猫的评论数据。
像往常一样打牌,发现它是自然而柔软的。. . .
一般的套路是这样的。在上面的评论页面,右键选择“查看网页源代码”,代码如下:
我想在原网页中搜索“好,高级,划算”的评论,这句话在源代码中,很不幸,当我按Ctrl + F并输入“好”时,没有这样的东西这样的话。. . 是不是抓不到天猫网站的评论数据?不,还是有方法的,但是不能打常规卡,因为天猫的评论数据是异步存储在别处的。
非常规方法,双眼发光!
在评论页面上,我们按下 F12 键(我使用的是 Chrom 浏览器),结果如下:
可能你的页面布局有上下两部分,下半部分什么都没有。这时候需要做两件事: 1.选择Network下的JS部分,因为天猫的评论数据是异步存储在一个JS连接中的。2、刷新页面,找到一个开头叫“list_detail_rate”的文件。当你打开这个文件时,它看起来像这样:
你会发现有一个请求连接,然后你只需要复制链接并把这个地址粘贴到浏览器中,你会发现这些评论都隐藏在这个地方。. .
哈哈,那我们可以用正则表达式来抓取类似红框的信息(用户昵称、评论时间、购买的包裹、衣服尺码、评论内容)。你也可以问一个问题。您的页面只是评论信息的页面。如何捕获所有页面上的所有评论信息?我们发现了一个规则,复制的连接可以总结成这样的形式:每次改变最后一个 currentPage 的值,就可以抓取到不同页面的评论信息。
爬虫知识:
请求模块:
get方法向对端服务器发送url请求;
text方法可以将get请求的响应转换成文本字符串格式;
重新模块:
findall 函数使用正则表达式查找文本中所有匹配的结果,语法格式:
findall(模式、字符串、标志)
模式接受一个正则表达式对象;
string 接受需要处理的字符串;
flags 接受一个模式参数,比如是否忽略大小写(flags = re.I);
服务:
# 导入需要的开发模块
导入请求
重新进口
# 创建循环链接
网址 = []
对于列表中的我(范围(1,100)):
urls.append('%s' %i)
# 构建字段容器
昵称 = []
评级 = []
颜色 = []
大小 = []
率内容 = []
# 循环抓取数据
对于网址中的网址:
内容 = requests.get(url).text
# 使用 findall 匹配带有正则表达式的查询
nickname.extend(re.findall('"displayUserNick":"(.*?)"',content))
color.extend(re.findall(pile('颜色分类:(.*?);'),content))
size.extend(re.findall(pile('Size:(.*?);'),content))
ratecontent.extend(re.findall(pile('"rateContent":"(.*?)","rateDate"'),content))
ratingate.extend(re.findall(pile('”rateDate”:”(.*?)”,”reply”'),content))
打印(昵称,颜色)
# 数据输入
file = open('南极天猫评估.csv','w')
对于列表中的 i(范围(0,len(昵称))):
file.write(','.join((nickname[i],rated[i],color[i],size[i],ratecontent[i]))+'n')
文件.close()
最终爬虫结果如下:
今天的爬虫部分就介绍到这里。本次分享的目的是如何解决网页信息的异步存储。在后续的分享中,我将对爬取的评论数据进行文本分析,涉及分词、情感分析、词云等。
结尾。
本文经作者授权
原文来源于微信公众号(PPV类数据科学社区): 查看全部
python网页数据抓取(
难不成我抓不了天猫网站的评论数据了?(图))
天气越来越冷,觉得应该给自己添点暖和的衣服,于是想到了天猫,搜了一下,感觉南极人的保暖内衣还是不错的。这么多衣服怎么选?我通常选择按销售额排序。毕竟销量也能反映产品的热度和口碑状况,所以来到了这个页面%C4%CF%BC%AB%C8%CB%B1%A3%C5%AF%C4 %DA% D2%C2&sort=d&style=g&from=.list.pc_1_suggest&suggest=0_1#J_Filter,
然后点进去后发现有很多历史累积评价,于是我一页一页地查看,感觉口碑还是很好的,所以选择了这款产品。我想每个人的购物方式可能都一样,可能会比较复杂(货比三家,比较口碑,联系卖家……)。
如果有一天,我想研究这些评论数据,然后玩自然语言处理,我应该把这些评论复制到一个大表中吗?虽然可以这样做,但我总觉得效率有点低(不是比爬虫低一两个数量级~)。如果你会爬行,你就会感受到自动化带来的刺激。接下来,我们将研究如何使用Python爬取天猫的评论数据。
像往常一样打牌,发现它是自然而柔软的。. . .
一般的套路是这样的。在上面的评论页面,右键选择“查看网页源代码”,代码如下:
我想在原网页中搜索“好,高级,划算”的评论,这句话在源代码中,很不幸,当我按Ctrl + F并输入“好”时,没有这样的东西这样的话。. . 是不是抓不到天猫网站的评论数据?不,还是有方法的,但是不能打常规卡,因为天猫的评论数据是异步存储在别处的。
非常规方法,双眼发光!
在评论页面上,我们按下 F12 键(我使用的是 Chrom 浏览器),结果如下:
可能你的页面布局有上下两部分,下半部分什么都没有。这时候需要做两件事: 1.选择Network下的JS部分,因为天猫的评论数据是异步存储在一个JS连接中的。2、刷新页面,找到一个开头叫“list_detail_rate”的文件。当你打开这个文件时,它看起来像这样:
你会发现有一个请求连接,然后你只需要复制链接并把这个地址粘贴到浏览器中,你会发现这些评论都隐藏在这个地方。. .
哈哈,那我们可以用正则表达式来抓取类似红框的信息(用户昵称、评论时间、购买的包裹、衣服尺码、评论内容)。你也可以问一个问题。您的页面只是评论信息的页面。如何捕获所有页面上的所有评论信息?我们发现了一个规则,复制的连接可以总结成这样的形式:每次改变最后一个 currentPage 的值,就可以抓取到不同页面的评论信息。
爬虫知识:
请求模块:
get方法向对端服务器发送url请求;
text方法可以将get请求的响应转换成文本字符串格式;
重新模块:
findall 函数使用正则表达式查找文本中所有匹配的结果,语法格式:
findall(模式、字符串、标志)
模式接受一个正则表达式对象;
string 接受需要处理的字符串;
flags 接受一个模式参数,比如是否忽略大小写(flags = re.I);
服务:
# 导入需要的开发模块
导入请求
重新进口
# 创建循环链接
网址 = []
对于列表中的我(范围(1,100)):
urls.append('%s' %i)
# 构建字段容器
昵称 = []
评级 = []
颜色 = []
大小 = []
率内容 = []
# 循环抓取数据
对于网址中的网址:
内容 = requests.get(url).text
# 使用 findall 匹配带有正则表达式的查询
nickname.extend(re.findall('"displayUserNick":"(.*?)"',content))
color.extend(re.findall(pile('颜色分类:(.*?);'),content))
size.extend(re.findall(pile('Size:(.*?);'),content))
ratecontent.extend(re.findall(pile('"rateContent":"(.*?)","rateDate"'),content))
ratingate.extend(re.findall(pile('”rateDate”:”(.*?)”,”reply”'),content))
打印(昵称,颜色)
# 数据输入
file = open('南极天猫评估.csv','w')
对于列表中的 i(范围(0,len(昵称))):
file.write(','.join((nickname[i],rated[i],color[i],size[i],ratecontent[i]))+'n')
文件.close()
最终爬虫结果如下:
今天的爬虫部分就介绍到这里。本次分享的目的是如何解决网页信息的异步存储。在后续的分享中,我将对爬取的评论数据进行文本分析,涉及分词、情感分析、词云等。
结尾。
本文经作者授权
原文来源于微信公众号(PPV类数据科学社区):
python网页数据抓取( 代理ip爬取网页数据的方法-)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2022-03-15 05:16
代理ip爬取网页数据的方法-)
在网络营销时代,很多模式已经不能适应新的互联网时代,往往达不到营销效果。为了更好地运营网络营销,需要使用很多营销工具来做好每一步。和线上问答的推广一样,代理IP的支持也是必不可少的。需要在营销过程中找到最有效的工具,以提高效率,最大限度地发挥网络营销的效果。
使用Python爬取网页表格数据的代码如下。
<p style="line-height: 2em;">'''
Python 3.x
描述:本DEMO演示了使用爬虫(动态)代理IP请求网页的过程,代码使用了多线程
逻辑:每隔5秒从API接口获取IP,对于每一个IP开启一个线程去抓取网页源码
'''
import requests
import time
import threading
from requests.packages import urllib3
ips = []
# 爬数据的线程类
class CrawlThread(threading.Thread):
def __init__(self,proxyip):
super(CrawlThread, self).__init__()
self.proxyip=proxyip
def run(self):
# 开始计时
start = time.time()
#消除关闭证书验证的警告
urllib3.disable_warnings()
#使用代理IP请求网址,注意第三个参数verify=False意思是跳过SSL验证(可以防止报SSL错误)
html=requests.get(url=targetUrl, proxies={"http" : 'http://' + self.proxyip, "https" : 'https://' + self.proxyip}, verify=False, timeout=15).content.decode()
# 结束计时
end = time.time()
# 输出内容
print(threading.current_thread().getName() + "使用代理IP, 耗时 " + str(end - start) + "毫秒 " + self.proxyip + " 获取到如下HTML内容:\n" + html + "\n*************")
# 获取代理IP的线程类
class GetIpThread(threading.Thread):
def __init__(self,fetchSecond):
super(GetIpThread, self).__init__()
self.fetchSecond=fetchSecond
def run(self):
global ips
while True:
# 获取IP列表
res = requests.get(apiUrl).content.decode()
# 按照\n分割获取到的IP
ips = res.split('\n')
# 利用每一个IP
for proxyip in ips:
if proxyip.strip():
# 开启一个线程
CrawlThread(proxyip).start()
# 休眠
time.sleep(self.fetchSecond)
if __name__ == '__main__':
# 获取IP的API接口
apiUrl = "http:xxxx"
# 要抓取的目标网站地址
targetUrl = "http://ip.chinaz.com/getip.aspx"
# 获取IP时间间隔,建议为5秒
fetchSecond = 5
# 开始自动获取IP
GetIpThread(fetchSecond).start()
</p>
本文介绍使用python爬虫代理ip爬取网页数据的方法。让我们浏览以了解更多信息! 查看全部
python网页数据抓取(
代理ip爬取网页数据的方法-)
在网络营销时代,很多模式已经不能适应新的互联网时代,往往达不到营销效果。为了更好地运营网络营销,需要使用很多营销工具来做好每一步。和线上问答的推广一样,代理IP的支持也是必不可少的。需要在营销过程中找到最有效的工具,以提高效率,最大限度地发挥网络营销的效果。
使用Python爬取网页表格数据的代码如下。
<p style="line-height: 2em;">'''
Python 3.x
描述:本DEMO演示了使用爬虫(动态)代理IP请求网页的过程,代码使用了多线程
逻辑:每隔5秒从API接口获取IP,对于每一个IP开启一个线程去抓取网页源码
'''
import requests
import time
import threading
from requests.packages import urllib3
ips = []
# 爬数据的线程类
class CrawlThread(threading.Thread):
def __init__(self,proxyip):
super(CrawlThread, self).__init__()
self.proxyip=proxyip
def run(self):
# 开始计时
start = time.time()
#消除关闭证书验证的警告
urllib3.disable_warnings()
#使用代理IP请求网址,注意第三个参数verify=False意思是跳过SSL验证(可以防止报SSL错误)
html=requests.get(url=targetUrl, proxies={"http" : 'http://' + self.proxyip, "https" : 'https://' + self.proxyip}, verify=False, timeout=15).content.decode()
# 结束计时
end = time.time()
# 输出内容
print(threading.current_thread().getName() + "使用代理IP, 耗时 " + str(end - start) + "毫秒 " + self.proxyip + " 获取到如下HTML内容:\n" + html + "\n*************")
# 获取代理IP的线程类
class GetIpThread(threading.Thread):
def __init__(self,fetchSecond):
super(GetIpThread, self).__init__()
self.fetchSecond=fetchSecond
def run(self):
global ips
while True:
# 获取IP列表
res = requests.get(apiUrl).content.decode()
# 按照\n分割获取到的IP
ips = res.split('\n')
# 利用每一个IP
for proxyip in ips:
if proxyip.strip():
# 开启一个线程
CrawlThread(proxyip).start()
# 休眠
time.sleep(self.fetchSecond)
if __name__ == '__main__':
# 获取IP的API接口
apiUrl = "http:xxxx"
# 要抓取的目标网站地址
targetUrl = "http://ip.chinaz.com/getip.aspx"
# 获取IP时间间隔,建议为5秒
fetchSecond = 5
# 开始自动获取IP
GetIpThread(fetchSecond).start()
</p>
本文介绍使用python爬虫代理ip爬取网页数据的方法。让我们浏览以了解更多信息!
python网页数据抓取(Python中使用cookielib和rllib2配合PyQuery抓取网页信息的教程)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2022-03-15 05:14
在Python中使用cookielib和urllib2用PyQuery抓取网页信息
更新时间:2015年4月25日10:53:52 转载:程康
本文章主要介绍Python中使用cookielib和rllib2配合PyQuery抓取网页信息的教程,主要是使用PyQuery解析HTML来实现,有需要的朋友可以参考以下
刚才好无聊,突然想起之前做课表的想法,于是百度起来。
一开始我是这样想的:我写微信墙的时候,用的是urllib2【两行代码抓取网页】,所以只需要解析html。于是百度:python解析html。找到了一个不错的文章,里面引入了pyQuery。
pyQuery是jQuery在Python中的实现,可以用jQuery的语法解析HTML文档?手术。使用前需要安装。Mac安装方法如下:
sudo easy_install pyquery
好的!安装!
让我们试一试:
from pyquery import PyQuery as pq
html = pq(url=u'http://seam.ustb.edu.cn:8080/jwgl/index.jsp')
#现在已经获取了本科教学网首页的html
classes = html('.haveclass')
#通过类名获取元素
#如果你对jQuery熟悉的话,那么你现在肯定明白pyQuery的方便了
更多用法参见pyQuery API
看来学用pyQuery的话,可以抓到时间表,但如果直接用我的源码,肯定会出错。因为我还没有登录!
所以,在运行此行获取正确代码之前,我们需要模拟登录本科教学网络。这时候才想起urllib有模拟post请求的功能,于是我百度了:urllib post。
这是一个模拟发布请求的最小示例:
import urllib
import urllib2
import cookielib
cj = cookielib.CookieJar()
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))
opener.addheaders = [('User-agent','Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)')]
urllib2.install_opener(opener)
req = urllib2.Request("http://seam.ustb.edu.cn:8080/jwgl/Login",urllib.urlencode({"username":"41255029","password":"123456","usertype":"student"}))
req.add_header("Referer","http://xxoo.com")
resp = urllib2.urlopen(req)
#这里面用到了cookielib,我不太清楚,以后慢慢了解吧
#还用到了urllib和urllib2,urllib2大概是urllib的扩展包【233想到了三国杀
在这个最简单的例子中,我使用我的校园网账号向登录页面提交表单数据来模拟登录。
现在,我们已经登录了本科教学网,然后结合之前的pyQuery解析html,就可以在网页中得到课程表了。
html = pq(url=u'http://seam.ustb.edu.cn:8080/jwgl/index.jsp')
self.render("index.html",data=html('.haveclass'))
结果如图所示:
最后:
发现pyQuery不仅解析html非常方便,还可以作为跨域抓取数据的工具,NICE!!!
我希望每个人都必须提供帮助。 查看全部
python网页数据抓取(Python中使用cookielib和rllib2配合PyQuery抓取网页信息的教程)
在Python中使用cookielib和urllib2用PyQuery抓取网页信息
更新时间:2015年4月25日10:53:52 转载:程康
本文章主要介绍Python中使用cookielib和rllib2配合PyQuery抓取网页信息的教程,主要是使用PyQuery解析HTML来实现,有需要的朋友可以参考以下
刚才好无聊,突然想起之前做课表的想法,于是百度起来。
一开始我是这样想的:我写微信墙的时候,用的是urllib2【两行代码抓取网页】,所以只需要解析html。于是百度:python解析html。找到了一个不错的文章,里面引入了pyQuery。
pyQuery是jQuery在Python中的实现,可以用jQuery的语法解析HTML文档?手术。使用前需要安装。Mac安装方法如下:
sudo easy_install pyquery
好的!安装!
让我们试一试:
from pyquery import PyQuery as pq
html = pq(url=u'http://seam.ustb.edu.cn:8080/jwgl/index.jsp')
#现在已经获取了本科教学网首页的html
classes = html('.haveclass')
#通过类名获取元素
#如果你对jQuery熟悉的话,那么你现在肯定明白pyQuery的方便了
更多用法参见pyQuery API
看来学用pyQuery的话,可以抓到时间表,但如果直接用我的源码,肯定会出错。因为我还没有登录!
所以,在运行此行获取正确代码之前,我们需要模拟登录本科教学网络。这时候才想起urllib有模拟post请求的功能,于是我百度了:urllib post。
这是一个模拟发布请求的最小示例:
import urllib
import urllib2
import cookielib
cj = cookielib.CookieJar()
opener = urllib2.build_opener(urllib2.HTTPCookieProcessor(cj))
opener.addheaders = [('User-agent','Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 5.1)')]
urllib2.install_opener(opener)
req = urllib2.Request("http://seam.ustb.edu.cn:8080/jwgl/Login",urllib.urlencode({"username":"41255029","password":"123456","usertype":"student"}))
req.add_header("Referer","http://xxoo.com";)
resp = urllib2.urlopen(req)
#这里面用到了cookielib,我不太清楚,以后慢慢了解吧
#还用到了urllib和urllib2,urllib2大概是urllib的扩展包【233想到了三国杀
在这个最简单的例子中,我使用我的校园网账号向登录页面提交表单数据来模拟登录。
现在,我们已经登录了本科教学网,然后结合之前的pyQuery解析html,就可以在网页中得到课程表了。
html = pq(url=u'http://seam.ustb.edu.cn:8080/jwgl/index.jsp')
self.render("index.html",data=html('.haveclass'))
结果如图所示:
最后:
发现pyQuery不仅解析html非常方便,还可以作为跨域抓取数据的工具,NICE!!!
我希望每个人都必须提供帮助。
python网页数据抓取(文档关于文件目录project:project目录是本项目的工作空间)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2022-03-13 19:15
欢迎来到ModelWhale Notebook¶这里你可以写代码,文件目录的文档会被保留输入:输入目录是数据集的挂载位置,所有挂载到项目中的数据集都在这里,没有挂载数据集时输入目录是隐藏的temp:temp目录是临时磁盘空间,训练或分析过程中产生的不需要的文件可以放在这里,目录下的文件不会保存 in[]:#查看个人持久化工作区文件!ls /home/mw/project/In []:# 查看当前挂载的数据集目录 !ls /home/mw/input/In[]:# show cell runtime %load_ext klab-autotime enter crawler¶什么是爬虫?本课程的内容是介绍什么是爬虫?爬行动物有什么用?以及爬虫是如何实现的?从这三点一起寻找答案!1. 1 网络爬虫简介网络爬虫(也称为网络蜘蛛、网络机器人,在FOAF社区中,更常被称为网页追逐者)是一种网络爬虫,根据一定的规则自动爬取的程序或脚本万维网信息。也就是说,爬虫可以自动浏览网络中的信息。当然,在浏览信息时,我们需要遵守我们制定的规则。这些规则称为网络爬虫算法。在浏览信息时,我们需要遵守我们制定的规则。这些规则称为网络爬虫算法。在浏览信息时,我们需要遵守我们制定的规则。这些规则称为网络爬虫算法。
Python 可以轻松编写爬虫程序,用于自动检索互联网信息。搜索引擎离不开爬虫。例如,百度搜索引擎的爬虫被称为百度蜘蛛。百度蜘蛛每天都会抓取大量互联网信息,抓取优质信息和收录,当用户在百度搜索引擎上搜索对应的关键词时,百度会进行关键词@ > 分析处理,从收录的网页中找出相关网页,按照一定的排名规则进行排序,并将结果展示给用户。1.1.1百度新闻案例表明,百度蜘蛛在这个过程中起到了至关重要的作用。所以,如何在互联网上覆盖更多优质网页?如何过滤这些重复的页面?这些都是由百度爬虫的算法决定的。使用不同的算法,爬虫的运行效率会有所不同,爬取的结果也会有所不同。1.1.2 网站Ranking(访问权重pv) 所以我们在研究爬虫的时候,不仅要了解爬虫是如何实现的,还需要了解一些常用的算法爬虫,如果有必要,我们还需要自己制定相应的算法。在这里,我们只需要对爬虫的概念有一个基本的了解。爬虫领域(为什么要学爬虫?)我们对网络爬虫有了初步的了解,但是为什么要学习网络爬虫呢?如今,人工智能和大数据离我们越来越近。很多公司都在做相关的业务,但是在人工智能和大数据中有一个非常重要的东西,那就是数据,但是数据从哪里来呢?首先我们看下面的例子#/trend/python?words=python 这是百度百度指数的截图。它对用户在百度上搜索关键词进行统计,然后根据统计结果创建一个流行趋势,然后进行简单的展示。s看下面的例子#/trend/python?words=python 这是百度百度指数的截图。它对用户在百度上搜索关键词进行统计,然后根据统计结果创建一个流行趋势,然后进行简单的展示。s看下面的例子#/trend/python?words=python 这是百度百度指数的截图。它对用户在百度上搜索关键词进行统计,然后根据统计结果创建一个流行趋势,然后进行简单的展示。
就像微博上的热搜,就是这个道理。类似的索引网站还有很多,比如阿里索引、360索引等,这些网站的用户数量非常多,他们可以获取自己用户的数据进行统计分析,所以,一些中小型公司在没有这么多用户的情况下应该怎么办?2.1 数据来源1.去第三方公司购买数据(例如:七叉茶)2.去免费数据网站下载数据(例如:国家局统计)3.通过爬虫爬取数据4.手动采集数据(如:问卷调查)在上述数据来源中,手动方式耗时耗力、效率低、数据免费< @网站以上数据质量较差,而很多第三方数据公司经常从爬虫那里获取数据,所以获取数据最有效的方式就是通过爬虫爬取2.2 爬虫就等于黑客吗?爬虫和黑客的区别:黑客和爬虫最大的区别就是目的不同。黑客做坏事,爬虫做好事。由于黑客和爬虫使用的技术相似,都是利用计算机网络技术侵入用户计算机网站和服务器获取数据和信息。不同的是,黑客是非法入侵,爬虫是合法入侵。比如通过破解网站后端验证码技术,然后模拟登录网站数据库,黑客删除数据库或直接修改他人的数据库。这是非法侵入、破坏行为和非法行为。也是破解验证码的技术,只是爬虫不一样。我需要获取一些政府的一些公开数据网站,但是每次都要输入验证码很麻烦。为了提高数据分析的效率,爬虫技术也是绕过验证码技术对采集网站公开和公开数据,不会获取私有和非公开数据。@网站,但是每次都要输入验证码很麻烦。为了提高数据分析的效率,爬虫技术也是绕过验证码技术对采集网站公开和公开数据,不会获取私有和非公开数据。@网站,但是每次都要输入验证码很麻烦。为了提高数据分析的效率,爬虫技术也是绕过验证码技术对采集网站公开和公开数据,不会获取私有和非公开数据。
如果把数据比作女性,爬虫和黑客都是男性,那么爬虫就是男朋友,在正当合理的情况下,它们与女性发生关系。但是,黑客不一样,黑客都是强奸犯,因为女性不愿意。,黑客是强制性的,甚至使用暴力与女性发生性关系。这是黑客和爬虫的本质区别。虽然使用了类似的技术手段来获取数据,但技术行为和最终后果的性质是不同的。一是违法需要承担法律后果,二是国家支持和鼓励的都是合法的。无论是爬虫还是黑客技术,它都只是一个工具,就像一把菜刀。有人用它切菜,有人用它杀人。不管菜刀的好坏,其实菜刀只是一个工具。行为结果2.3 大数据和爬虫是什么关系?爬虫爬取互联网数据,获取的数据量决定与大数据的兄弟关系是否更亲密2.4 爬虫领域,人脸识别前景:做人工智能需要大数据是的,例如,您想制造一台可以自动识别人脸的人工智能机器。你首先需要建立一个基于人脸生物特征的AI模型,然后需要数千万或数十亿张人脸图片不断训练模型,最终得到准确的人脸识别AI。数十亿人脸图像数据从何而来?派出所给你?不可能的!一张一张的拍照?更不现实!即通过网络爬虫技术构建人脸图片库。比如我们可以利用爬虫技术爬取facebook、QQ头像、微信头像等,实现十亿以上的人脸图片库的建立。
市场分析:电商分析、商圈分析、一二级市场分析等 市场监测:电商、新闻、房源监测等 商机发现:招标情报发现、客户数据发现、企业客户发现、等等。 。. 后面学习了数据分析之后,还可以使用爬虫获取金融股数据进行数据分析。什么是爬虫?网络爬虫(也称为网络蜘蛛或网络机器人)是模拟客户端发送网络请求并接收请求响应的程序。它是一个按照一定的规则自动抓取互联网信息的程序。原则上,只要浏览器(客户端)能做任何事,爬虫都能做,也就是说,一切都可以被爬取,爬虫的更多用途可以直观爬取(了解)12306抢票网站投票短信(电话)轰炸注册页面1 注册页面2 注册页面3 爬虫分类¶ 根据系统结构和实现技术,网络爬虫大致可分为4类,即一般网络爬虫、聚焦网络爬虫、增量网络爬虫和深度网络爬虫。1.通用网络爬虫:当一个搜索引擎爬虫,比如用户在百度搜索引擎上搜索对应的关键词,百度会对关键词进行分析处理,从收录网页 找出相关的,然后按照一定的排名规则进行排序并展示给用户,那么你就需要互联网上尽可能多的优质网页。从互联网上采集网页,采集信息,这些网页信息是用来为搜索引擎建立索引提供支持的,它决定了整个引擎系统的内容是否丰富,信息是否即时,所以它的性能直接受到影响。搜索引擎的影响。
2.专注于网络爬虫:针对特定网页的爬虫也称为主题网络爬虫。爬取的目标网页位于与主题相关的页面中,主要为某类特定人群提供服务,可以节省大量的服务器资源和带宽资源。Focused crawler 在实现网页抓取时会对内容进行处理和过滤,并尽量保证只抓取与需求相关的网页信息。比如要获取某个垂直领域的数据或者有明确的检索需求,就需要过滤掉一些无用的信息。例如:那些比较价格的 网站 是其他被抓取的 网站 产品。3.Incremental Web Crawler 增量网络爬虫(Incremental Web Crawler),所谓增量,即增量更新。增量更新是指在更新的时候,只更新变化的地方,不更新变化的地方,所以爬虫只爬取内容发生变化的网页或者新生成的网页。例如:招聘网络爬虫4.深度网络爬虫(Deep Web Crawler),首先,什么是深度页面?在互联网中,网页根据存在的不同分为表层页面和深层页面。所谓表面页面,是指无需提交表单,使用静态链接即可到达的静态页面;而深页是经过一定程度的关键词调整后才能得到的页面。在 Internet 上,深层页面通常比表面页面多得多。深网爬虫主要由 URL 列表组成,
后来,我们主要学习专注于爬虫。专注爬虫学会之后,其他类型的爬虫就可以轻松写出通用爬虫和专注爬虫的原理。解析;从响应解析中获取需要的新url,并将这些url放入待抓取的url队列中;取出要爬取的URL,解析DNS得到主机的IP,下载该URL对应的网页,存入Download the web library并将这些URL放入Crawl URL queue。分析爬取的URL队列中的URL,分析其中的其他URL,将这些URL放入待爬取的URL队列,从而进入下一个循环...... 第二步:数据存储搜索引擎通过爬虫爬取网页,存储原创页面数据库中的数据。页面数据与用户的 HTML 完全相同 s 浏览器获取。搜索引擎蜘蛛在抓取页面时也会进行某些重复内容检测。一旦他们遇到大量抄袭、采集 或复制访问权重低的网站 上的内容,很有可能不再使用。爬行。第三步:对搜索引擎爬回来的页面进行预处理,并进行各种预处理步骤。提取文本中文分词去噪(如版权声明文本、导航栏、广告等……)基于文本的,如PDF、Word、WPS、XLS、PPT、TXT文件等。一旦他们遇到大量抄袭、采集 或复制访问权重低的网站 上的内容,很有可能不再使用。爬行。第三步:对搜索引擎爬回来的页面进行预处理,并进行各种预处理步骤。提取文本中文分词去噪(如版权声明文本、导航栏、广告等……)基于文本的,如PDF、Word、WPS、XLS、PPT、TXT文件等。一旦他们遇到大量抄袭、采集 或复制访问权重低的网站 上的内容,很有可能不再使用。爬行。第三步:对搜索引擎爬回来的页面进行预处理,并进行各种预处理步骤。提取文本中文分词去噪(如版权声明文本、导航栏、广告等……)基于文本的,如PDF、Word、WPS、XLS、PPT、TXT文件等。并执行各种预处理步骤。提取文本中文分词去噪(如版权声明文本、导航栏、广告等……)基于文本的,如PDF、Word、WPS、XLS、PPT、TXT文件等。并执行各种预处理步骤。提取文本中文分词去噪(如版权声明文本、导航栏、广告等……)基于文本的,如PDF、Word、WPS、XLS、PPT、TXT文件等。
我们还经常在搜索结果中看到这些文件类型。但搜索引擎无法处理图像、视频、Flash 等非文本内容,也无法执行脚本和程序。第四步:提供检索服务。网站排名搜索引擎对信息进行组织处理后,为用户提供关键词检索服务,并将相关信息展示给用户。关注爬虫: 第一步:start_url 发送请求 第二步:获取响应 第三步:解析响应,如果响应中有新的url地址需要,重复第二步;Step 4: 提取数据 Step 5 Step: 保存数据 通常我们会一步一步获取响应并解析,所以重点关注爬虫的步骤,一般来说有四个步骤 http 和 https 请求和响应 URL 形成一个网站 URL一般由域名+自己写的页面组成。当我们访问同一个网站网页时,域名一般不会改变,所以我们的爬虫需要解析的是网站自己写的不同页面的入口url,只有解析出来的url每个页面入口,我们就可以启动我们的爬虫了。网页的两种加载方式是同步加载的:改变URL上的一些请求参数会导致页面改变,例如:(改变page=后面的数字,页面会改变) 异步加载:改变请求参数on URL 不会导致页面更改。网页发生变化,例如:
(控制浏览器显示哪个页面) Server:apache tomcat(服务器类型) Content-Encoding:gzip(服务器发送的压缩编码方式) Content-Length:80(服务器发送的字节码长度) Content-Language: zh-cn(服务器发送的内容的语言和国家名称) Content-Type:image/jpeg;charset=UTF-8(服务器发送的内容的类型和编码类型) Last-Modified: Tue, 11 Jul 2000 18:23:51 GMT(服务器最后一次修改的时间) Refresh: 1;url= (控制浏览器1秒后转发该URL指向的页面) Content-Disposition:附件;filename=aaa.jpg(服务器控制浏览器发送下载方式打开文件) Transfer-Encoding: chunked(服务器将数据分块传输给客户端) Set-Cookie:SS=Q0=5Lb_nQ;
常见状态码:100~199:表示服务器已经成功接收到部分请求,需要客户端继续提交剩余的请求以完成整个处理过程。200~299:表示服务器成功接收到请求,完成了整个处理过程。常用200(OK请求成功)。300~399:为了完成请求,客户需要进一步细化请求。例如:请求的资源已经移动到了新的地址,常见的302(请求的页面已经临时移动到了新的url),307和304(使用缓存的资源)。400~499:客户端请求出错,常用404(服务器找不到请求的页面),403(服务器拒绝访问,权限不够)。500~599:服务器端发生错误,一般为500(请求未完成,服务器遇到不可预知的情况)。在[]: 查看全部
python网页数据抓取(文档关于文件目录project:project目录是本项目的工作空间)
欢迎来到ModelWhale Notebook¶这里你可以写代码,文件目录的文档会被保留输入:输入目录是数据集的挂载位置,所有挂载到项目中的数据集都在这里,没有挂载数据集时输入目录是隐藏的temp:temp目录是临时磁盘空间,训练或分析过程中产生的不需要的文件可以放在这里,目录下的文件不会保存 in[]:#查看个人持久化工作区文件!ls /home/mw/project/In []:# 查看当前挂载的数据集目录 !ls /home/mw/input/In[]:# show cell runtime %load_ext klab-autotime enter crawler¶什么是爬虫?本课程的内容是介绍什么是爬虫?爬行动物有什么用?以及爬虫是如何实现的?从这三点一起寻找答案!1. 1 网络爬虫简介网络爬虫(也称为网络蜘蛛、网络机器人,在FOAF社区中,更常被称为网页追逐者)是一种网络爬虫,根据一定的规则自动爬取的程序或脚本万维网信息。也就是说,爬虫可以自动浏览网络中的信息。当然,在浏览信息时,我们需要遵守我们制定的规则。这些规则称为网络爬虫算法。在浏览信息时,我们需要遵守我们制定的规则。这些规则称为网络爬虫算法。在浏览信息时,我们需要遵守我们制定的规则。这些规则称为网络爬虫算法。
Python 可以轻松编写爬虫程序,用于自动检索互联网信息。搜索引擎离不开爬虫。例如,百度搜索引擎的爬虫被称为百度蜘蛛。百度蜘蛛每天都会抓取大量互联网信息,抓取优质信息和收录,当用户在百度搜索引擎上搜索对应的关键词时,百度会进行关键词@ > 分析处理,从收录的网页中找出相关网页,按照一定的排名规则进行排序,并将结果展示给用户。1.1.1百度新闻案例表明,百度蜘蛛在这个过程中起到了至关重要的作用。所以,如何在互联网上覆盖更多优质网页?如何过滤这些重复的页面?这些都是由百度爬虫的算法决定的。使用不同的算法,爬虫的运行效率会有所不同,爬取的结果也会有所不同。1.1.2 网站Ranking(访问权重pv) 所以我们在研究爬虫的时候,不仅要了解爬虫是如何实现的,还需要了解一些常用的算法爬虫,如果有必要,我们还需要自己制定相应的算法。在这里,我们只需要对爬虫的概念有一个基本的了解。爬虫领域(为什么要学爬虫?)我们对网络爬虫有了初步的了解,但是为什么要学习网络爬虫呢?如今,人工智能和大数据离我们越来越近。很多公司都在做相关的业务,但是在人工智能和大数据中有一个非常重要的东西,那就是数据,但是数据从哪里来呢?首先我们看下面的例子#/trend/python?words=python 这是百度百度指数的截图。它对用户在百度上搜索关键词进行统计,然后根据统计结果创建一个流行趋势,然后进行简单的展示。s看下面的例子#/trend/python?words=python 这是百度百度指数的截图。它对用户在百度上搜索关键词进行统计,然后根据统计结果创建一个流行趋势,然后进行简单的展示。s看下面的例子#/trend/python?words=python 这是百度百度指数的截图。它对用户在百度上搜索关键词进行统计,然后根据统计结果创建一个流行趋势,然后进行简单的展示。
就像微博上的热搜,就是这个道理。类似的索引网站还有很多,比如阿里索引、360索引等,这些网站的用户数量非常多,他们可以获取自己用户的数据进行统计分析,所以,一些中小型公司在没有这么多用户的情况下应该怎么办?2.1 数据来源1.去第三方公司购买数据(例如:七叉茶)2.去免费数据网站下载数据(例如:国家局统计)3.通过爬虫爬取数据4.手动采集数据(如:问卷调查)在上述数据来源中,手动方式耗时耗力、效率低、数据免费< @网站以上数据质量较差,而很多第三方数据公司经常从爬虫那里获取数据,所以获取数据最有效的方式就是通过爬虫爬取2.2 爬虫就等于黑客吗?爬虫和黑客的区别:黑客和爬虫最大的区别就是目的不同。黑客做坏事,爬虫做好事。由于黑客和爬虫使用的技术相似,都是利用计算机网络技术侵入用户计算机网站和服务器获取数据和信息。不同的是,黑客是非法入侵,爬虫是合法入侵。比如通过破解网站后端验证码技术,然后模拟登录网站数据库,黑客删除数据库或直接修改他人的数据库。这是非法侵入、破坏行为和非法行为。也是破解验证码的技术,只是爬虫不一样。我需要获取一些政府的一些公开数据网站,但是每次都要输入验证码很麻烦。为了提高数据分析的效率,爬虫技术也是绕过验证码技术对采集网站公开和公开数据,不会获取私有和非公开数据。@网站,但是每次都要输入验证码很麻烦。为了提高数据分析的效率,爬虫技术也是绕过验证码技术对采集网站公开和公开数据,不会获取私有和非公开数据。@网站,但是每次都要输入验证码很麻烦。为了提高数据分析的效率,爬虫技术也是绕过验证码技术对采集网站公开和公开数据,不会获取私有和非公开数据。
如果把数据比作女性,爬虫和黑客都是男性,那么爬虫就是男朋友,在正当合理的情况下,它们与女性发生关系。但是,黑客不一样,黑客都是强奸犯,因为女性不愿意。,黑客是强制性的,甚至使用暴力与女性发生性关系。这是黑客和爬虫的本质区别。虽然使用了类似的技术手段来获取数据,但技术行为和最终后果的性质是不同的。一是违法需要承担法律后果,二是国家支持和鼓励的都是合法的。无论是爬虫还是黑客技术,它都只是一个工具,就像一把菜刀。有人用它切菜,有人用它杀人。不管菜刀的好坏,其实菜刀只是一个工具。行为结果2.3 大数据和爬虫是什么关系?爬虫爬取互联网数据,获取的数据量决定与大数据的兄弟关系是否更亲密2.4 爬虫领域,人脸识别前景:做人工智能需要大数据是的,例如,您想制造一台可以自动识别人脸的人工智能机器。你首先需要建立一个基于人脸生物特征的AI模型,然后需要数千万或数十亿张人脸图片不断训练模型,最终得到准确的人脸识别AI。数十亿人脸图像数据从何而来?派出所给你?不可能的!一张一张的拍照?更不现实!即通过网络爬虫技术构建人脸图片库。比如我们可以利用爬虫技术爬取facebook、QQ头像、微信头像等,实现十亿以上的人脸图片库的建立。
市场分析:电商分析、商圈分析、一二级市场分析等 市场监测:电商、新闻、房源监测等 商机发现:招标情报发现、客户数据发现、企业客户发现、等等。 。. 后面学习了数据分析之后,还可以使用爬虫获取金融股数据进行数据分析。什么是爬虫?网络爬虫(也称为网络蜘蛛或网络机器人)是模拟客户端发送网络请求并接收请求响应的程序。它是一个按照一定的规则自动抓取互联网信息的程序。原则上,只要浏览器(客户端)能做任何事,爬虫都能做,也就是说,一切都可以被爬取,爬虫的更多用途可以直观爬取(了解)12306抢票网站投票短信(电话)轰炸注册页面1 注册页面2 注册页面3 爬虫分类¶ 根据系统结构和实现技术,网络爬虫大致可分为4类,即一般网络爬虫、聚焦网络爬虫、增量网络爬虫和深度网络爬虫。1.通用网络爬虫:当一个搜索引擎爬虫,比如用户在百度搜索引擎上搜索对应的关键词,百度会对关键词进行分析处理,从收录网页 找出相关的,然后按照一定的排名规则进行排序并展示给用户,那么你就需要互联网上尽可能多的优质网页。从互联网上采集网页,采集信息,这些网页信息是用来为搜索引擎建立索引提供支持的,它决定了整个引擎系统的内容是否丰富,信息是否即时,所以它的性能直接受到影响。搜索引擎的影响。
2.专注于网络爬虫:针对特定网页的爬虫也称为主题网络爬虫。爬取的目标网页位于与主题相关的页面中,主要为某类特定人群提供服务,可以节省大量的服务器资源和带宽资源。Focused crawler 在实现网页抓取时会对内容进行处理和过滤,并尽量保证只抓取与需求相关的网页信息。比如要获取某个垂直领域的数据或者有明确的检索需求,就需要过滤掉一些无用的信息。例如:那些比较价格的 网站 是其他被抓取的 网站 产品。3.Incremental Web Crawler 增量网络爬虫(Incremental Web Crawler),所谓增量,即增量更新。增量更新是指在更新的时候,只更新变化的地方,不更新变化的地方,所以爬虫只爬取内容发生变化的网页或者新生成的网页。例如:招聘网络爬虫4.深度网络爬虫(Deep Web Crawler),首先,什么是深度页面?在互联网中,网页根据存在的不同分为表层页面和深层页面。所谓表面页面,是指无需提交表单,使用静态链接即可到达的静态页面;而深页是经过一定程度的关键词调整后才能得到的页面。在 Internet 上,深层页面通常比表面页面多得多。深网爬虫主要由 URL 列表组成,
后来,我们主要学习专注于爬虫。专注爬虫学会之后,其他类型的爬虫就可以轻松写出通用爬虫和专注爬虫的原理。解析;从响应解析中获取需要的新url,并将这些url放入待抓取的url队列中;取出要爬取的URL,解析DNS得到主机的IP,下载该URL对应的网页,存入Download the web library并将这些URL放入Crawl URL queue。分析爬取的URL队列中的URL,分析其中的其他URL,将这些URL放入待爬取的URL队列,从而进入下一个循环...... 第二步:数据存储搜索引擎通过爬虫爬取网页,存储原创页面数据库中的数据。页面数据与用户的 HTML 完全相同 s 浏览器获取。搜索引擎蜘蛛在抓取页面时也会进行某些重复内容检测。一旦他们遇到大量抄袭、采集 或复制访问权重低的网站 上的内容,很有可能不再使用。爬行。第三步:对搜索引擎爬回来的页面进行预处理,并进行各种预处理步骤。提取文本中文分词去噪(如版权声明文本、导航栏、广告等……)基于文本的,如PDF、Word、WPS、XLS、PPT、TXT文件等。一旦他们遇到大量抄袭、采集 或复制访问权重低的网站 上的内容,很有可能不再使用。爬行。第三步:对搜索引擎爬回来的页面进行预处理,并进行各种预处理步骤。提取文本中文分词去噪(如版权声明文本、导航栏、广告等……)基于文本的,如PDF、Word、WPS、XLS、PPT、TXT文件等。一旦他们遇到大量抄袭、采集 或复制访问权重低的网站 上的内容,很有可能不再使用。爬行。第三步:对搜索引擎爬回来的页面进行预处理,并进行各种预处理步骤。提取文本中文分词去噪(如版权声明文本、导航栏、广告等……)基于文本的,如PDF、Word、WPS、XLS、PPT、TXT文件等。并执行各种预处理步骤。提取文本中文分词去噪(如版权声明文本、导航栏、广告等……)基于文本的,如PDF、Word、WPS、XLS、PPT、TXT文件等。并执行各种预处理步骤。提取文本中文分词去噪(如版权声明文本、导航栏、广告等……)基于文本的,如PDF、Word、WPS、XLS、PPT、TXT文件等。
我们还经常在搜索结果中看到这些文件类型。但搜索引擎无法处理图像、视频、Flash 等非文本内容,也无法执行脚本和程序。第四步:提供检索服务。网站排名搜索引擎对信息进行组织处理后,为用户提供关键词检索服务,并将相关信息展示给用户。关注爬虫: 第一步:start_url 发送请求 第二步:获取响应 第三步:解析响应,如果响应中有新的url地址需要,重复第二步;Step 4: 提取数据 Step 5 Step: 保存数据 通常我们会一步一步获取响应并解析,所以重点关注爬虫的步骤,一般来说有四个步骤 http 和 https 请求和响应 URL 形成一个网站 URL一般由域名+自己写的页面组成。当我们访问同一个网站网页时,域名一般不会改变,所以我们的爬虫需要解析的是网站自己写的不同页面的入口url,只有解析出来的url每个页面入口,我们就可以启动我们的爬虫了。网页的两种加载方式是同步加载的:改变URL上的一些请求参数会导致页面改变,例如:(改变page=后面的数字,页面会改变) 异步加载:改变请求参数on URL 不会导致页面更改。网页发生变化,例如:
(控制浏览器显示哪个页面) Server:apache tomcat(服务器类型) Content-Encoding:gzip(服务器发送的压缩编码方式) Content-Length:80(服务器发送的字节码长度) Content-Language: zh-cn(服务器发送的内容的语言和国家名称) Content-Type:image/jpeg;charset=UTF-8(服务器发送的内容的类型和编码类型) Last-Modified: Tue, 11 Jul 2000 18:23:51 GMT(服务器最后一次修改的时间) Refresh: 1;url= (控制浏览器1秒后转发该URL指向的页面) Content-Disposition:附件;filename=aaa.jpg(服务器控制浏览器发送下载方式打开文件) Transfer-Encoding: chunked(服务器将数据分块传输给客户端) Set-Cookie:SS=Q0=5Lb_nQ;
常见状态码:100~199:表示服务器已经成功接收到部分请求,需要客户端继续提交剩余的请求以完成整个处理过程。200~299:表示服务器成功接收到请求,完成了整个处理过程。常用200(OK请求成功)。300~399:为了完成请求,客户需要进一步细化请求。例如:请求的资源已经移动到了新的地址,常见的302(请求的页面已经临时移动到了新的url),307和304(使用缓存的资源)。400~499:客户端请求出错,常用404(服务器找不到请求的页面),403(服务器拒绝访问,权限不够)。500~599:服务器端发生错误,一般为500(请求未完成,服务器遇到不可预知的情况)。在[]:
python网页数据抓取(如何应对数据匮乏的问题?最简单的方法在这里)
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-03-11 19:09
作者|LAKSHAY ARORA
编译|Flin
来源 | 分析学
概述
我们的数据太少,无法构建机器学习模型。我们需要更多数据!
如果这句话听起来很熟悉,那么您并不孤单!想要获得更多数据来训练我们的机器学习模型是一个持续存在的问题。我们无法获得可以直接在数据科学项目中使用的 Excel 或 .csv 文件,对吧?
那么,如何应对数据稀缺的问题呢?
实现这一目标的最有效和最简单的方法之一是通过网络抓取。我个人认为网络抓取是一种非常有用的技术,可以从多个 网站 中采集数据。今天,一些 网站 还为您可能想要使用的许多不同类型的数据提供 API,例如 Tweets 或 LinkedIn 帖子。
但有时您可能需要从不提供特定 API 的 网站 采集数据。这就是网络抓取功能派上用场的地方。作为数据科学家,您可以编写一个简单的 Python 脚本并提取所需的数据。
因此,在本文中,我们将了解网页抓取的不同组件,然后直接深入 Python 以了解如何使用流行且高效的 BeautifulSoup 库执行网页抓取。
我们还为本文创建了免费课程:
请注意,网络抓取受许多准则和规则的约束。并非每个 网站 都允许用户抓取内容,因此存在法律限制。在尝试执行此操作之前,请确保您已阅读 网站 的网站 条款和条件。
Python 中用于网络爬取的 3 个流行工具和库的目录
网络爬虫的组成部分
CrawlParse 和 TransformStore 从网页抓取 URL 和电子邮件 ID 抓取图像 在页面加载时抓取数据 3 个 Python 中用于 Web 爬虫的流行工具和库
您将在 Python 中遇到几个用于 Web 抓取的库和框架。以下是三种用于高效完成工作的流行工具:
美丽汤
刮擦
硒
网络爬虫的组成部分
这是构成网络抓取的三个主要组件的绝佳说明:
让我们详细了解这些组件。我们将通过 goibibo网站 获取酒店详细信息,例如酒店名称和每间客房的价格以执行此操作:
注意:始终遵循目标 网站 的 robots.txt 文件,也称为机器人排除协议。这告诉网络机器人不要抓取哪些页面。
因此,我们可以从目标 URL 中抓取数据。我们很高兴为我们的网络机器人编写脚本。开始吧!
第 1 步:爬行
网页抓取的第一步是导航到目标 网站 并下载网页的源代码。我们将使用 requests 库来执行此操作。http.client 和 urlib2 是另外两个用于发出请求和下载源代码的库。
下载网页的源代码后,我们需要过滤我们想要的内容:
"""
Web Scraping - Beautiful Soup
"""
# importing required libraries
import requests
from bs4 import BeautifulSoup
import pandas as pd
# target URL to scrap
url = "https://www.goibibo.com/hotels ... ot%3B
# headers
headers = {
'User-Agent': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36"
}
# send request to download the data
response = requests.request("GET", url, headers=headers)
# parse the downloaded data
data = BeautifulSoup(response.text, 'html.parser')
print(data)
第 2 步:解析和转换
网页抓取的下一步是将这些数据解析为 HTML 解析器,为此我们将使用 BeautifulSoup 库。现在,如果您注意到我们的登录页面,与大多数页面一样,特定酒店的详细信息在不同的卡片上。
所以下一步是从完整的源代码中过滤卡片数据。接下来,我们将选择该卡并单击“检查元素”选项以获取该特定卡的源代码。你会得到这样的东西:
所有卡片都有相同的类名,我们可以通过传递标签名称和具有如下名称的属性(如标签)来获取这些卡片的列表:
# find all the sections with specifiedd class name
cards_data = data.find_all('div', attrs={'class', 'width100 fl htlListSeo hotel-tile-srp-container hotel-tile-srp-container-template new-htl-design-tile-main-block'})
# total number of cards
print('Total Number of Cards Found : ', len(cards_data))
# source code of hotel cards
for card in cards_data:
print(card)
我们从网页的完整源代码中过滤掉了卡片数据,其中每张卡片都收录有关单个酒店的信息。仅选择酒店名称,执行“检查元素”步骤,并对房价执行相同操作:
现在对于每张卡,我们必须找到上面的酒店名称,只能从
从标签中提取。这是因为每张卡和费率只有一个标签和标签和类别名称:
# extract the hotel name and price per room
for card in cards_data:
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
print(hotel_name.text, room_price.text)
第三步:存储(存储数据)
最后一步是将提取的数据存储在 CSV 文件中。在这里,对于每张卡片,我们将提取酒店名称和价格并将其存储在 Python 字典中。然后我们最终将它添加到列表中。
接下来,让我们继续将此列表转换为 Pandas 数据框,因为它允许我们将数据框转换为 CSV 或 JSON 文件:
# create a list to store the data
scraped_data = []
for card in cards_data:
# initialize the dictionary
card_details = {}
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
# add data to the dictionary
card_details['hotel_name'] = hotel_name.text
card_details['room_price'] = room_price.text
# append the scraped data to the list
scraped_data.append(card_details)
# create a data frame from the list of dictionaries
dataFrame = pd.DataFrame.from_dict(scraped_data)
# save the scraped data as CSV file
dataFrame.to_csv('hotels_data.csv', index=False)
恭喜!我们已经成功创建了一个基本的网络抓取工具。我希望您尝试这些步骤并尝试获取更多数据,例如酒店的评级和地址。现在,让我们看看如何执行一些常见任务,例如在页面加载时抓取 URL、电子邮件 ID、图像和抓取数据。
从网页中获取 URL 和电子邮件 ID
我们尝试通过网络抓取来抓取的两个最常见的功能是 网站URL 和电子邮件 ID。我确定您参与过需要大量提取电子邮件 ID 的项目或挑战。那么让我们看看如何在 Python 中抓取这些内容。
使用 Web 浏览器的控制台 查看全部
python网页数据抓取(如何应对数据匮乏的问题?最简单的方法在这里)
作者|LAKSHAY ARORA
编译|Flin
来源 | 分析学
概述
我们的数据太少,无法构建机器学习模型。我们需要更多数据!
如果这句话听起来很熟悉,那么您并不孤单!想要获得更多数据来训练我们的机器学习模型是一个持续存在的问题。我们无法获得可以直接在数据科学项目中使用的 Excel 或 .csv 文件,对吧?
那么,如何应对数据稀缺的问题呢?
实现这一目标的最有效和最简单的方法之一是通过网络抓取。我个人认为网络抓取是一种非常有用的技术,可以从多个 网站 中采集数据。今天,一些 网站 还为您可能想要使用的许多不同类型的数据提供 API,例如 Tweets 或 LinkedIn 帖子。
但有时您可能需要从不提供特定 API 的 网站 采集数据。这就是网络抓取功能派上用场的地方。作为数据科学家,您可以编写一个简单的 Python 脚本并提取所需的数据。
因此,在本文中,我们将了解网页抓取的不同组件,然后直接深入 Python 以了解如何使用流行且高效的 BeautifulSoup 库执行网页抓取。
我们还为本文创建了免费课程:
请注意,网络抓取受许多准则和规则的约束。并非每个 网站 都允许用户抓取内容,因此存在法律限制。在尝试执行此操作之前,请确保您已阅读 网站 的网站 条款和条件。
Python 中用于网络爬取的 3 个流行工具和库的目录
网络爬虫的组成部分
CrawlParse 和 TransformStore 从网页抓取 URL 和电子邮件 ID 抓取图像 在页面加载时抓取数据 3 个 Python 中用于 Web 爬虫的流行工具和库
您将在 Python 中遇到几个用于 Web 抓取的库和框架。以下是三种用于高效完成工作的流行工具:
美丽汤
刮擦
硒
网络爬虫的组成部分
这是构成网络抓取的三个主要组件的绝佳说明:
让我们详细了解这些组件。我们将通过 goibibo网站 获取酒店详细信息,例如酒店名称和每间客房的价格以执行此操作:
注意:始终遵循目标 网站 的 robots.txt 文件,也称为机器人排除协议。这告诉网络机器人不要抓取哪些页面。
因此,我们可以从目标 URL 中抓取数据。我们很高兴为我们的网络机器人编写脚本。开始吧!
第 1 步:爬行
网页抓取的第一步是导航到目标 网站 并下载网页的源代码。我们将使用 requests 库来执行此操作。http.client 和 urlib2 是另外两个用于发出请求和下载源代码的库。
下载网页的源代码后,我们需要过滤我们想要的内容:
"""
Web Scraping - Beautiful Soup
"""
# importing required libraries
import requests
from bs4 import BeautifulSoup
import pandas as pd
# target URL to scrap
url = "https://www.goibibo.com/hotels ... ot%3B
# headers
headers = {
'User-Agent': "Mozilla/5.0 (X11; Linux x86_64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/77.0.3865.90 Safari/537.36"
}
# send request to download the data
response = requests.request("GET", url, headers=headers)
# parse the downloaded data
data = BeautifulSoup(response.text, 'html.parser')
print(data)
第 2 步:解析和转换
网页抓取的下一步是将这些数据解析为 HTML 解析器,为此我们将使用 BeautifulSoup 库。现在,如果您注意到我们的登录页面,与大多数页面一样,特定酒店的详细信息在不同的卡片上。
所以下一步是从完整的源代码中过滤卡片数据。接下来,我们将选择该卡并单击“检查元素”选项以获取该特定卡的源代码。你会得到这样的东西:
所有卡片都有相同的类名,我们可以通过传递标签名称和具有如下名称的属性(如标签)来获取这些卡片的列表:
# find all the sections with specifiedd class name
cards_data = data.find_all('div', attrs={'class', 'width100 fl htlListSeo hotel-tile-srp-container hotel-tile-srp-container-template new-htl-design-tile-main-block'})
# total number of cards
print('Total Number of Cards Found : ', len(cards_data))
# source code of hotel cards
for card in cards_data:
print(card)
我们从网页的完整源代码中过滤掉了卡片数据,其中每张卡片都收录有关单个酒店的信息。仅选择酒店名称,执行“检查元素”步骤,并对房价执行相同操作:
现在对于每张卡,我们必须找到上面的酒店名称,只能从
从标签中提取。这是因为每张卡和费率只有一个标签和标签和类别名称:
# extract the hotel name and price per room
for card in cards_data:
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
print(hotel_name.text, room_price.text)
第三步:存储(存储数据)
最后一步是将提取的数据存储在 CSV 文件中。在这里,对于每张卡片,我们将提取酒店名称和价格并将其存储在 Python 字典中。然后我们最终将它添加到列表中。
接下来,让我们继续将此列表转换为 Pandas 数据框,因为它允许我们将数据框转换为 CSV 或 JSON 文件:
# create a list to store the data
scraped_data = []
for card in cards_data:
# initialize the dictionary
card_details = {}
# get the hotel name
hotel_name = card.find('p')
# get the room price
room_price = card.find('li', attrs={'class': 'htl-tile-discount-prc'})
# add data to the dictionary
card_details['hotel_name'] = hotel_name.text
card_details['room_price'] = room_price.text
# append the scraped data to the list
scraped_data.append(card_details)
# create a data frame from the list of dictionaries
dataFrame = pd.DataFrame.from_dict(scraped_data)
# save the scraped data as CSV file
dataFrame.to_csv('hotels_data.csv', index=False)
恭喜!我们已经成功创建了一个基本的网络抓取工具。我希望您尝试这些步骤并尝试获取更多数据,例如酒店的评级和地址。现在,让我们看看如何执行一些常见任务,例如在页面加载时抓取 URL、电子邮件 ID、图像和抓取数据。
从网页中获取 URL 和电子邮件 ID
我们尝试通过网络抓取来抓取的两个最常见的功能是 网站URL 和电子邮件 ID。我确定您参与过需要大量提取电子邮件 ID 的项目或挑战。那么让我们看看如何在 Python 中抓取这些内容。
使用 Web 浏览器的控制台
python网页数据抓取(来源“LastStatement”替换标题“Link”,我的需求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 103 次浏览 • 2022-03-06 16:11
我看过很多 文章 ,但还没有找到完全符合我需要的解决方案。首先,让我说我是 Python 新手(我正在使用 Python 2)。在 Python 中创建数据集,抓取网页
我正在尝试从网页采集数据()。注意好的 html 表格。我已经能够将它读入列表而没有太多问题。但是,还要注意有两列链接。我想删除第一个链接列(但我不确定如何执行此操作,因为我的数据在列表中)。
第二个链接列有点复杂。我想用“Last Statement”替换标题“Link”。然后我想访问提供的每个链接,检索最后一条语句,并将其放在我创建列表的原创表的相应行中。
最后,我想将此列表打印为制表符分隔的文件,该文件可以作为数据帧读入 R。
这是一道需要处理的配菜。请让我知道我是否正确处理此问题。以下是我到目前为止的代码。我错过了我想做的事情,因为我不知道如何开始。
from bs4 import BeautifulSoup
import requests
from lxml import html
import csv
import string
import sys
#obtain the main url with bigger data
main_url = "http://www.tdcj.state.tx.us/de ... ot%3B
#convert the html to BeautifulSoup
doc = requests.get(main_url)
soup = BeautifulSoup(doc.text, 'lxml')
#find in html the table
tbl = soup.find("table", attrs = {"class":"os"})
#create labels for list rows by table headers
headings = [th.get_text() for th in tbl.find("tr").find_all("th")]
#convert the unicode to string
headers = []
for i in range(0,len(headings)-1):
headers.append(str(headings[i]))
#access the remaining information
prisoners = []
for row in tbl.find_all("tr")[1:]:
#attach the appropriate header to the appropriate corresponding data
#also, converts unicode to string
info = zip(headers, (str(td.get_text()) for td in row.find_all("td")))
#append each of the newly made rows
prisoners.append(info)
#print each row of the list to a file for R
with open('output.txt', 'a') as output:
for p in prisoners:
output.write(str(p)+'\n')
output.close()
如果您能帮我弄清楚我正在努力解决的三个部分中的任何一个,我将不胜感激!
资源
2016-04-24用户1723196 查看全部
python网页数据抓取(来源“LastStatement”替换标题“Link”,我的需求)
我看过很多 文章 ,但还没有找到完全符合我需要的解决方案。首先,让我说我是 Python 新手(我正在使用 Python 2)。在 Python 中创建数据集,抓取网页
我正在尝试从网页采集数据()。注意好的 html 表格。我已经能够将它读入列表而没有太多问题。但是,还要注意有两列链接。我想删除第一个链接列(但我不确定如何执行此操作,因为我的数据在列表中)。
第二个链接列有点复杂。我想用“Last Statement”替换标题“Link”。然后我想访问提供的每个链接,检索最后一条语句,并将其放在我创建列表的原创表的相应行中。
最后,我想将此列表打印为制表符分隔的文件,该文件可以作为数据帧读入 R。
这是一道需要处理的配菜。请让我知道我是否正确处理此问题。以下是我到目前为止的代码。我错过了我想做的事情,因为我不知道如何开始。
from bs4 import BeautifulSoup
import requests
from lxml import html
import csv
import string
import sys
#obtain the main url with bigger data
main_url = "http://www.tdcj.state.tx.us/de ... ot%3B
#convert the html to BeautifulSoup
doc = requests.get(main_url)
soup = BeautifulSoup(doc.text, 'lxml')
#find in html the table
tbl = soup.find("table", attrs = {"class":"os"})
#create labels for list rows by table headers
headings = [th.get_text() for th in tbl.find("tr").find_all("th")]
#convert the unicode to string
headers = []
for i in range(0,len(headings)-1):
headers.append(str(headings[i]))
#access the remaining information
prisoners = []
for row in tbl.find_all("tr")[1:]:
#attach the appropriate header to the appropriate corresponding data
#also, converts unicode to string
info = zip(headers, (str(td.get_text()) for td in row.find_all("td")))
#append each of the newly made rows
prisoners.append(info)
#print each row of the list to a file for R
with open('output.txt', 'a') as output:
for p in prisoners:
output.write(str(p)+'\n')
output.close()
如果您能帮我弄清楚我正在努力解决的三个部分中的任何一个,我将不胜感激!
资源
2016-04-24用户1723196
python网页数据抓取(soup()如何依靠类标签找到数据的位置?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2022-03-05 20:03
.
同样,如果您将光标放在名称“S&P”上并单击,您可以看到此信息收录在选项卡和控制台中。
现在我们知道如何依靠类标签来找到我们需要的数据。
学习编码
现在我们知道所需的数据在哪里,我们可以开始编写代码来构建我们的网络爬虫。立即打开您的文本编辑工具!
首先,我们必须导入我们将要使用的各种库。
# 导入各种库
导入 urllib2
从 bs4 导入 BeautifulSoup
然后,我们定义一个变量(quote_page)并为其分配网站的URL链接。
# 分配 网站 链接
quote_page = ':IND'
接下来,使用Python的urllib2库获取刚刚定义的URLquote_page的HTML页面信息。
# 检索 网站 并获取 html 代码并将其存储在变量“page”中
page = urllib2.urlopen(quote_page)
最后,我们将网页解析成 BeautifulSoup 格式,这样我们就可以使用 BeautifulSoup 库来解析网页了。
# 用 beautifulSoup 解析 HTML 代码并将其存储在变量“soup”中`
汤= BeautifulSoup(页面,'html.parser')
现在我们有了收录整个网页的 HTML 代码的变量汤。我们开始从汤中提取信息。
不要忘记我们的数据存储在唯一的层中。BeautifulSoup 库中的 find() 函数可以帮助我们提取不同层次的内容。我们需要的 HTML 类“名称”在整个页面中是唯一的,因此我们可以简单地查找它
# 获取“名称”类
代码段并提取对应值
name_box = soup.find('h1', attrs={'class': 'name'})
我们拿到标签后,就可以使用name_box的text属性来获取对应的值了
name = name_box.text.strip() # strip() 函数用于去除前导和尾随空格
打印名称
使用类似的方法,我们可以得到股票指数的价格数据。
# 获取股指价格数据
price_box = soup.find('div', attrs={'class':'price'})
价格 = price_box.text
打印价格
运行程序时,您应该会看到程序输出当前标准普尔 500 指数的价格。
以 Excel CSV 格式导出数据
现在我们已经学会了如何获取数据,是时候学习如何存储数据了。Excel 逗号分隔数据格式 (CSV) 是一个不错的选择。这使我们能够在 Excel 中打开数据文件以进行查看和进一步处理。
在此之前,我们需要导入 Python 的 csv 模块和 datetime 模块。Datetime 模块用于获取数据记录时间。请将以下代码行插入您的导入代码部分。
导入 csv
从日期时间导入日期时间
在代码的最底部,添加将数据写入 CSV 文件的代码。
# 以“add”方式打开一个csv文件,保证文件的原创信息不被覆盖
使用 open('index.csv', 'a') 作为 csv_file:
writer = csv.writer(csv_file)
writer.writerow([名称,价格,datetime.now()])
现在,如果您运行该程序,您应该能够导出 index.csv 文件。您可以在Excel中打开文件,看到有一行数据,如图所示。
所以如果你每天运行这个程序,你可以很容易地得到标准普尔的价格,而不必像以前那样在 网站 上翻找。
更进一步(高级用法)
多个股票指数
抓住一个股票指数对你来说还不够,对吧?我们可以尝试同时提取多个股票指数信息。首先,我们需要修改 quote_page 以将其定义为 URL 数组。
quote_page = [':IND', ':IND']
然后我们把代码中的数据提取部分改成了for循环。这个循环可以一个一个地处理 URL,并将变量 data 中的所有数据存储为一个元组。
# for 循环
数据 = []
对于quote_page中的pg:
# 检索 网站 并返回 HTML 代码,存储在变量 'page' 中
page = urllib2.urlopen(pg)
# 使用 beautifulSoup 解析 HTML 代码并存储在变量 `soup` 中
汤= BeautifulSoup(页面,'html.parser')
# 获取“名称”类
代码段并提取对应值
name_box = soup.find('h1', attrs={'class': 'name'})
name = name_box.text.strip() # strip() 用于去除开头和结尾
# 获取股指价格数据
price_box = soup.find('div', attrs={'class':'price'})
价格 = price_box.text
# 以元组类型存储数据
data.append((名称,价格))
并且,修改save部分,逐行保存数据
# 以“add”方式打开一个csv文件,保证文件的原创信息不被覆盖
使用 open('index.csv', 'a') 作为 csv_file:
writer = csv.writer(csv_file)
# for 循环
对于名称,数据中的价格:
writer.writerow([名称,价格,datetime.now()])
再次运行程序,应该可以同时提取两个股指的价格信息了!
先进的抓取技术
BeautifulSoup 库使用简单,可以很好地完成少量的 网站 抓取。但是如果你对大量抓取的信息感兴趣,你可以考虑其他方法:
1. Scrapy,一个强大的 Python 数据抓取框架。
2. 您可以尝试将一些常见的应用程序编程接口 (API) 集成到您的代码中。这种获取数据的方法比网络抓取要高效得多。例如,您可以尝试 Facebook Graph API,该 API 可帮助您获取 Facebook 网站 上不可见的隐藏信息。
3. 如果数据量太大,可以考虑使用 MySQL 之类的数据库后端来存储数据。
采取“不重复”的方法
DRY 是“不要重复你所做的事情”的缩写。您可以尝试像链接中的这个人一样自动化您的日常工作。您还可以考虑其他有趣的项目,例如跟踪您的 Facebook 朋友何时在线(当然是在他们同意的情况下),或者在论坛中获取讲座主题列表以尝试自然语言处理(这是当前的热门话题在人工智能中)! 查看全部
python网页数据抓取(soup()如何依靠类标签找到数据的位置?)
.
同样,如果您将光标放在名称“S&P”上并单击,您可以看到此信息收录在选项卡和控制台中。
现在我们知道如何依靠类标签来找到我们需要的数据。
学习编码
现在我们知道所需的数据在哪里,我们可以开始编写代码来构建我们的网络爬虫。立即打开您的文本编辑工具!
首先,我们必须导入我们将要使用的各种库。
# 导入各种库
导入 urllib2
从 bs4 导入 BeautifulSoup
然后,我们定义一个变量(quote_page)并为其分配网站的URL链接。
# 分配 网站 链接
quote_page = ':IND'
接下来,使用Python的urllib2库获取刚刚定义的URLquote_page的HTML页面信息。
# 检索 网站 并获取 html 代码并将其存储在变量“page”中
page = urllib2.urlopen(quote_page)
最后,我们将网页解析成 BeautifulSoup 格式,这样我们就可以使用 BeautifulSoup 库来解析网页了。
# 用 beautifulSoup 解析 HTML 代码并将其存储在变量“soup”中`
汤= BeautifulSoup(页面,'html.parser')
现在我们有了收录整个网页的 HTML 代码的变量汤。我们开始从汤中提取信息。
不要忘记我们的数据存储在唯一的层中。BeautifulSoup 库中的 find() 函数可以帮助我们提取不同层次的内容。我们需要的 HTML 类“名称”在整个页面中是唯一的,因此我们可以简单地查找它
# 获取“名称”类
代码段并提取对应值
name_box = soup.find('h1', attrs={'class': 'name'})
我们拿到标签后,就可以使用name_box的text属性来获取对应的值了
name = name_box.text.strip() # strip() 函数用于去除前导和尾随空格
打印名称
使用类似的方法,我们可以得到股票指数的价格数据。
# 获取股指价格数据
price_box = soup.find('div', attrs={'class':'price'})
价格 = price_box.text
打印价格
运行程序时,您应该会看到程序输出当前标准普尔 500 指数的价格。
以 Excel CSV 格式导出数据
现在我们已经学会了如何获取数据,是时候学习如何存储数据了。Excel 逗号分隔数据格式 (CSV) 是一个不错的选择。这使我们能够在 Excel 中打开数据文件以进行查看和进一步处理。
在此之前,我们需要导入 Python 的 csv 模块和 datetime 模块。Datetime 模块用于获取数据记录时间。请将以下代码行插入您的导入代码部分。
导入 csv
从日期时间导入日期时间
在代码的最底部,添加将数据写入 CSV 文件的代码。
# 以“add”方式打开一个csv文件,保证文件的原创信息不被覆盖
使用 open('index.csv', 'a') 作为 csv_file:
writer = csv.writer(csv_file)
writer.writerow([名称,价格,datetime.now()])
现在,如果您运行该程序,您应该能够导出 index.csv 文件。您可以在Excel中打开文件,看到有一行数据,如图所示。
所以如果你每天运行这个程序,你可以很容易地得到标准普尔的价格,而不必像以前那样在 网站 上翻找。
更进一步(高级用法)
多个股票指数
抓住一个股票指数对你来说还不够,对吧?我们可以尝试同时提取多个股票指数信息。首先,我们需要修改 quote_page 以将其定义为 URL 数组。
quote_page = [':IND', ':IND']
然后我们把代码中的数据提取部分改成了for循环。这个循环可以一个一个地处理 URL,并将变量 data 中的所有数据存储为一个元组。
# for 循环
数据 = []
对于quote_page中的pg:
# 检索 网站 并返回 HTML 代码,存储在变量 'page' 中
page = urllib2.urlopen(pg)
# 使用 beautifulSoup 解析 HTML 代码并存储在变量 `soup` 中
汤= BeautifulSoup(页面,'html.parser')
# 获取“名称”类
代码段并提取对应值
name_box = soup.find('h1', attrs={'class': 'name'})
name = name_box.text.strip() # strip() 用于去除开头和结尾
# 获取股指价格数据
price_box = soup.find('div', attrs={'class':'price'})
价格 = price_box.text
# 以元组类型存储数据
data.append((名称,价格))
并且,修改save部分,逐行保存数据
# 以“add”方式打开一个csv文件,保证文件的原创信息不被覆盖
使用 open('index.csv', 'a') 作为 csv_file:
writer = csv.writer(csv_file)
# for 循环
对于名称,数据中的价格:
writer.writerow([名称,价格,datetime.now()])
再次运行程序,应该可以同时提取两个股指的价格信息了!
先进的抓取技术
BeautifulSoup 库使用简单,可以很好地完成少量的 网站 抓取。但是如果你对大量抓取的信息感兴趣,你可以考虑其他方法:
1. Scrapy,一个强大的 Python 数据抓取框架。
2. 您可以尝试将一些常见的应用程序编程接口 (API) 集成到您的代码中。这种获取数据的方法比网络抓取要高效得多。例如,您可以尝试 Facebook Graph API,该 API 可帮助您获取 Facebook 网站 上不可见的隐藏信息。
3. 如果数据量太大,可以考虑使用 MySQL 之类的数据库后端来存储数据。
采取“不重复”的方法
DRY 是“不要重复你所做的事情”的缩写。您可以尝试像链接中的这个人一样自动化您的日常工作。您还可以考虑其他有趣的项目,例如跟踪您的 Facebook 朋友何时在线(当然是在他们同意的情况下),或者在论坛中获取讲座主题列表以尝试自然语言处理(这是当前的热门话题在人工智能中)!
python网页数据抓取(从含中文的网页中提取数据(1)(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 128 次浏览 • 2022-03-03 03:20
目标:使用正则表达式从收录中文的网页中提取数据1、获取该网页的所有数据1.1 判断我们要操作的网页的思维过程:url = '#39;
打开要操作的网页:req = urllib2.open(url)
读取网页,将网页数据放入变量:html = req.read()
别忘了关闭页面:req.close()
1.2将上述过程写成函数:
def get_html(url):
try:
req = urllib2.open(url)
html = req.read()
return html
finally:
req.close()
html = get_html('http://q.stock.sohu.com/cn/603 ... %2339;)
2、查看网页2.1 思考过程因为不用开发工具直接查看网页源代码,顺便练一下I/O,所以我打算把网页输出到TXT。
打开一个可写文件:file = open('C:/Users/YourName/Desktop/text.txt','w')
将网页数据写入文件:file.write(html)
别忘了关闭文件:file.close()
2.2将上述过程写成函数:
def out_put(file_name,content):
try:
file = open(file_name,'w')
file.write(content)
finally:
file.close()
out_put('C:/Users/YourName/Desktop/text.txt',html)
运行后,在桌面的文本文件中查看网页源代码。
3、解析网页源代码3.1 确定网页代码,查看网页源代码。一般会在头部标明代码类型。本例中,测试网页中的代码类型为:gb2312
部分网页头部标明的编码类型与实际不符,非常不合格,会导致后续代码不可用。所以有第三方py包chardet来测试str编码类型(我没下载,不会用)。
3.2 确定要捕获的数据如果要捕获“总利润”的数值和百分比,查看源码,“总利润”附近的代码如下:
……
总利润
19392
-72.22%
……
3.3正则表达式如果表达式中有中文,别忘了加“u”;任何时候,别忘了加“r”
expression = ur'利润总额\D+?(-?\d+\.?\d*)\D*?(-?\d+.*?%)'
3.4 很严重的事情! ! !由于这里有非中文字符,所以必须在“格式”中选择“以utf-8格式编码”,不能选择“无BOM”。否则运行时会报错,原因不明。
4、提取数据
pattern = re.compile(expression)
result = pattern.findall(html)
又是一件大事! ! !
使用此代码运行,可以匹配正则和任何内容。原因是网页的html代码是gb2312,程序代码是unicode代码。两者并不统一。代码:
pattern = re.compile(expression.encode('gb2312')) #把程序代码编码转换成'gb2312'
注意:代码转换参考
5、整合
# -*- coding : utf-8 -*-
import urllib2
import re
def get_html(url):
try:
req = urllib2.urlopen(url)
html = req.read()
return html
finally:
req.close()
html = get_html('http://q.stock.sohu.com/cn/603 ... %2339;)
expression = ur'利润总额\D+?(-?\d+\.?\d*)\D*?(-?\d+.*?%)'
pattern = re.compile(expression.encode('gb2312'))
result = pattern.findall(html)
print result
关于Unicode编码,请参考很详细的文章: 查看全部
python网页数据抓取(从含中文的网页中提取数据(1)(图))
目标:使用正则表达式从收录中文的网页中提取数据1、获取该网页的所有数据1.1 判断我们要操作的网页的思维过程:url = '#39;
打开要操作的网页:req = urllib2.open(url)
读取网页,将网页数据放入变量:html = req.read()
别忘了关闭页面:req.close()
1.2将上述过程写成函数:
def get_html(url):
try:
req = urllib2.open(url)
html = req.read()
return html
finally:
req.close()
html = get_html('http://q.stock.sohu.com/cn/603 ... %2339;)
2、查看网页2.1 思考过程因为不用开发工具直接查看网页源代码,顺便练一下I/O,所以我打算把网页输出到TXT。
打开一个可写文件:file = open('C:/Users/YourName/Desktop/text.txt','w')
将网页数据写入文件:file.write(html)
别忘了关闭文件:file.close()
2.2将上述过程写成函数:
def out_put(file_name,content):
try:
file = open(file_name,'w')
file.write(content)
finally:
file.close()
out_put('C:/Users/YourName/Desktop/text.txt',html)
运行后,在桌面的文本文件中查看网页源代码。
3、解析网页源代码3.1 确定网页代码,查看网页源代码。一般会在头部标明代码类型。本例中,测试网页中的代码类型为:gb2312
部分网页头部标明的编码类型与实际不符,非常不合格,会导致后续代码不可用。所以有第三方py包chardet来测试str编码类型(我没下载,不会用)。
3.2 确定要捕获的数据如果要捕获“总利润”的数值和百分比,查看源码,“总利润”附近的代码如下:
……
总利润
19392
-72.22%
……
3.3正则表达式如果表达式中有中文,别忘了加“u”;任何时候,别忘了加“r”
expression = ur'利润总额\D+?(-?\d+\.?\d*)\D*?(-?\d+.*?%)'
3.4 很严重的事情! ! !由于这里有非中文字符,所以必须在“格式”中选择“以utf-8格式编码”,不能选择“无BOM”。否则运行时会报错,原因不明。
4、提取数据
pattern = re.compile(expression)
result = pattern.findall(html)
又是一件大事! ! !
使用此代码运行,可以匹配正则和任何内容。原因是网页的html代码是gb2312,程序代码是unicode代码。两者并不统一。代码:
pattern = re.compile(expression.encode('gb2312')) #把程序代码编码转换成'gb2312'
注意:代码转换参考
5、整合
# -*- coding : utf-8 -*-
import urllib2
import re
def get_html(url):
try:
req = urllib2.urlopen(url)
html = req.read()
return html
finally:
req.close()
html = get_html('http://q.stock.sohu.com/cn/603 ... %2339;)
expression = ur'利润总额\D+?(-?\d+\.?\d*)\D*?(-?\d+.*?%)'
pattern = re.compile(expression.encode('gb2312'))
result = pattern.findall(html)
print result
关于Unicode编码,请参考很详细的文章:
python网页数据抓取(总不能手工去网页源码吧?担心,Python提供了许多库来帮助)
网站优化 • 优采云 发表了文章 • 0 个评论 • 92 次浏览 • 2022-02-27 20:14
大家好,我是悦创。
我们可以把互联网比作一个大的网络,爬虫(即网络爬虫)是在网络上爬行的蜘蛛。如果把网络的节点比作网页,爬虫爬取就相当于访问页面并获取其信息。节点之间的连接可以比作网页和网页之间的链接关系,这样蜘蛛经过一个节点后,可以继续沿着节点连接爬行到达下一个节点,即继续通过一个网页获取后续网页,使得整个网页的节点都可以被蜘蛛爬取,并且可以抓取到网站的数据。
1. 爬虫概述
简而言之,爬虫是一种自动程序,可以获取网页并提取和保存信息,如下所述。
1.1 获取网页
爬虫要做的第一个工作就是获取网页,这里是网页的源代码。
源代码中收录了网页的一些有用信息,所以只要得到源代码,就可以从中提取出想要的信息。
前面讨论了请求和响应的概念。向网站的服务器发送请求,返回的响应体就是网页的源代码。那么,最关键的部分就是构造一个请求并发送给服务器,然后接收响应并解析出来,那么这个过程如何实现呢?你不能手动截取网页的源代码,对吧?
不用担心,Python 提供了很多库来帮助我们做到这一点,比如 urllib、requests 等。我们可以使用这些库来帮助我们实现 HTTP 请求操作。请求和响应都可以用类库提供的数据结构来表示。得到响应后,我们只需要解析数据结构的Body部分,即获取网页的源代码。这样,我们就可以使用程序来实现获取网页的过程了。
1.2 提取信息
得到网页的源代码后,接下来就是分析网页的源代码,从中提取出我们想要的数据。首先,最常用的方法是使用正则表达式提取,这是一种通用的方法,但是在构造正则表达式时比较复杂且容易出错。
另外,因为网页的结构有一定的规律,所以也有一些库是根据网页节点属性、CSS选择器或者XPath来提取网页信息的,比如Beautiful Soup、pyquery、lxml等。使用这些库,我们可以高效、快速地提取网页信息,如节点属性、文本值等。
提取信息是爬虫非常重要的一个环节,它可以把杂乱的数据整理好,方便我们后期对数据进行处理和分析。
1.3 保存数据
提取信息后,我们一般将提取的数据保存在某处以备后用。这里的保存有多种形式,比如简单的保存为TXT文本或者JSON文本,或者保存到数据库,比如MySQL、MongoDB,或者保存到远程服务器,比如借助SFTP操作。
1.4 自动化程序
说到自动化程序,我的意思是爬虫可以代替人类执行这些操作。首先,我们当然可以手动提取这些信息,但是如果当量特别大或者想要快速获取大量数据,还是得使用程序。爬虫是代表我们完成爬取工作的自动化程序。可以在爬取过程中进行各种异常处理、错误重试等操作,保证爬取持续高效运行。
2. 我可以捕获什么样的数据
我们可以在网页中看到各种各样的信息,最常见的是常规网页,它们对应的是HTML代码,而最常见的爬取就是HTML源代码。
此外,有些网页可能会返回 JSON 字符串而不是 HTML 代码(大多数 API 接口使用这种形式)。这种格式的数据易于传输和解析。它们也可以被捕获,并且数据提取更方便。
此外,我们还可以看到图片、视频、音频等各种二进制数据。使用爬虫,我们可以抓取这些二进制数据,并保存为对应的文件名。
此外,您还可以看到具有各种扩展名的文件,例如 CSS、JavaScript 和配置文件。这些实际上是最常见的文件。只要它们可以在浏览器中访问,您就可以抓取它们。
上面的内容其实是对应了它们各自的URL,是基于HTTP或者HTTPS协议的。只要是这种数据,爬虫就可以爬取。
3. JavaScript 渲染页面
有时候,当我们用 urllib 或 requests 爬取网页时,得到的源代码实际上与我们在浏览器中看到的不同。
这是一个非常普遍的问题。如今,越来越多的网页使用 Ajax 和前端模块化工具构建。整个网页可能会被 JavaScript 渲染,这意味着原创的 HTML 代码只是一个空壳,例如:
This is a Demo
body节点中只有一个id为container的节点,但是需要注意的是在body节点之后引入了app.js,负责渲染整个网站。
在浏览器中打开页面时,会先加载HTML内容,然后浏览器会发现其中引入了一个app.js文件,然后再去请求该文件。获取文件后,会执行 JavaScript 代码,JavaScript 改变 HTML 中的节点,添加内容,最终得到一个完整的页面。
但是当使用 urllib 或 requests 等库请求当前页面时,我们得到的只是这段 HTML 代码,它不会帮助我们继续加载 JavaScript 文件,因此我们将无法在浏览器中看到内容。
这也解释了为什么有时我们得到的源代码与我们在浏览器中看到的不同。
因此,使用基本的HTTP请求库得到的源代码可能与浏览器中的页面源代码不一样。对于这样的情况,我们可以分析它的后台Ajax接口,或者使用Selenium、Splash等库来模拟JavaScript渲染。
稍后,我们将详细介绍如何采集 JavaScript 渲染网页。本节介绍爬虫的一些基本原理,可以帮助我们以后编写爬虫时更加得心应手。
声明:本站所有文章,除非另有说明或标记,均发布在本站原创。任何个人或组织未经本站同意,不得复制、盗用、采集、将本站内容发布到任何网站、书籍等媒体平台。本站内容如有侵犯原作者合法权益的,您可以联系我们处理。邮件:
声明:本站所有资源均由互联网上的Python爬虫自动爬取。本站内容如有侵犯原作者合法权益的,您可以联系我们处理。邮件:
爱悦创常任理事国
支付宝扫描
微信扫一扫>奖励领取海报链接 查看全部
python网页数据抓取(总不能手工去网页源码吧?担心,Python提供了许多库来帮助)
大家好,我是悦创。
我们可以把互联网比作一个大的网络,爬虫(即网络爬虫)是在网络上爬行的蜘蛛。如果把网络的节点比作网页,爬虫爬取就相当于访问页面并获取其信息。节点之间的连接可以比作网页和网页之间的链接关系,这样蜘蛛经过一个节点后,可以继续沿着节点连接爬行到达下一个节点,即继续通过一个网页获取后续网页,使得整个网页的节点都可以被蜘蛛爬取,并且可以抓取到网站的数据。
1. 爬虫概述
简而言之,爬虫是一种自动程序,可以获取网页并提取和保存信息,如下所述。
1.1 获取网页
爬虫要做的第一个工作就是获取网页,这里是网页的源代码。
源代码中收录了网页的一些有用信息,所以只要得到源代码,就可以从中提取出想要的信息。
前面讨论了请求和响应的概念。向网站的服务器发送请求,返回的响应体就是网页的源代码。那么,最关键的部分就是构造一个请求并发送给服务器,然后接收响应并解析出来,那么这个过程如何实现呢?你不能手动截取网页的源代码,对吧?
不用担心,Python 提供了很多库来帮助我们做到这一点,比如 urllib、requests 等。我们可以使用这些库来帮助我们实现 HTTP 请求操作。请求和响应都可以用类库提供的数据结构来表示。得到响应后,我们只需要解析数据结构的Body部分,即获取网页的源代码。这样,我们就可以使用程序来实现获取网页的过程了。
1.2 提取信息
得到网页的源代码后,接下来就是分析网页的源代码,从中提取出我们想要的数据。首先,最常用的方法是使用正则表达式提取,这是一种通用的方法,但是在构造正则表达式时比较复杂且容易出错。
另外,因为网页的结构有一定的规律,所以也有一些库是根据网页节点属性、CSS选择器或者XPath来提取网页信息的,比如Beautiful Soup、pyquery、lxml等。使用这些库,我们可以高效、快速地提取网页信息,如节点属性、文本值等。
提取信息是爬虫非常重要的一个环节,它可以把杂乱的数据整理好,方便我们后期对数据进行处理和分析。
1.3 保存数据
提取信息后,我们一般将提取的数据保存在某处以备后用。这里的保存有多种形式,比如简单的保存为TXT文本或者JSON文本,或者保存到数据库,比如MySQL、MongoDB,或者保存到远程服务器,比如借助SFTP操作。
1.4 自动化程序
说到自动化程序,我的意思是爬虫可以代替人类执行这些操作。首先,我们当然可以手动提取这些信息,但是如果当量特别大或者想要快速获取大量数据,还是得使用程序。爬虫是代表我们完成爬取工作的自动化程序。可以在爬取过程中进行各种异常处理、错误重试等操作,保证爬取持续高效运行。
2. 我可以捕获什么样的数据
我们可以在网页中看到各种各样的信息,最常见的是常规网页,它们对应的是HTML代码,而最常见的爬取就是HTML源代码。
此外,有些网页可能会返回 JSON 字符串而不是 HTML 代码(大多数 API 接口使用这种形式)。这种格式的数据易于传输和解析。它们也可以被捕获,并且数据提取更方便。
此外,我们还可以看到图片、视频、音频等各种二进制数据。使用爬虫,我们可以抓取这些二进制数据,并保存为对应的文件名。
此外,您还可以看到具有各种扩展名的文件,例如 CSS、JavaScript 和配置文件。这些实际上是最常见的文件。只要它们可以在浏览器中访问,您就可以抓取它们。
上面的内容其实是对应了它们各自的URL,是基于HTTP或者HTTPS协议的。只要是这种数据,爬虫就可以爬取。
3. JavaScript 渲染页面
有时候,当我们用 urllib 或 requests 爬取网页时,得到的源代码实际上与我们在浏览器中看到的不同。
这是一个非常普遍的问题。如今,越来越多的网页使用 Ajax 和前端模块化工具构建。整个网页可能会被 JavaScript 渲染,这意味着原创的 HTML 代码只是一个空壳,例如:
This is a Demo
body节点中只有一个id为container的节点,但是需要注意的是在body节点之后引入了app.js,负责渲染整个网站。
在浏览器中打开页面时,会先加载HTML内容,然后浏览器会发现其中引入了一个app.js文件,然后再去请求该文件。获取文件后,会执行 JavaScript 代码,JavaScript 改变 HTML 中的节点,添加内容,最终得到一个完整的页面。
但是当使用 urllib 或 requests 等库请求当前页面时,我们得到的只是这段 HTML 代码,它不会帮助我们继续加载 JavaScript 文件,因此我们将无法在浏览器中看到内容。
这也解释了为什么有时我们得到的源代码与我们在浏览器中看到的不同。
因此,使用基本的HTTP请求库得到的源代码可能与浏览器中的页面源代码不一样。对于这样的情况,我们可以分析它的后台Ajax接口,或者使用Selenium、Splash等库来模拟JavaScript渲染。
稍后,我们将详细介绍如何采集 JavaScript 渲染网页。本节介绍爬虫的一些基本原理,可以帮助我们以后编写爬虫时更加得心应手。
声明:本站所有文章,除非另有说明或标记,均发布在本站原创。任何个人或组织未经本站同意,不得复制、盗用、采集、将本站内容发布到任何网站、书籍等媒体平台。本站内容如有侵犯原作者合法权益的,您可以联系我们处理。邮件:
声明:本站所有资源均由互联网上的Python爬虫自动爬取。本站内容如有侵犯原作者合法权益的,您可以联系我们处理。邮件:
爱悦创常任理事国
支付宝扫描
微信扫一扫>奖励领取海报链接
python网页数据抓取(如何使用Python和pandas库从web页面获取表数据?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 97 次浏览 • 2022-02-26 19:07
今天,人们可以随时随地连接到互联网。互联网可能是最大的公共数据库。学习如何从 Internet 获取数据至关重要。因此,有必要了解如何使用 Python 和 pandas 库从网页中获取表格数据。此外,如果您已经在使用 Excel PowerQuery,这相当于“从 Web 获取数据”功能,但在这里它的功能要强大 100 倍。
从 网站 获取数据(网络抓取)
HTML 是每个 网站 背后的语言。当我们访问 网站 时,会发生以下情况:
1.在浏览器地址栏中输入地址(URL),浏览器向目标网站的服务器发送请求。
2.服务器接收请求并返回构成网页的 HTML 代码。
3.浏览器接收到 HTML 代码,动态运行它,并创建一个网页供我们查看。
Web 抓取基本上意味着,我们可以使用 Python 向 网站 服务器发送请求,接收 HTML 代码,然后提取所需的数据,而不是使用浏览器。
我不会在这里介绍太多 HTML,只介绍几个要点,以便我们对 网站 和网络抓取的工作原理有一个基本的了解。HTML 元素或“HTML 标签”是被包围的特定关键字。例如,下面的 HTML 代码是网页的标题,将鼠标悬停在网页中的选项卡上会在浏览器上看到相同的标题。请注意,大多数 HTML 元素都需要一个开始标记(例如 , )和一个相应的结束标记(例如 , )。
Python pandas 获取网页中的表格数据(网页抓取)
同样,下面的代码会在浏览器上绘制一个表格,你可以尝试复制粘贴到记事本中,然后保存为“tableexample.html”文件,应该可以在浏览器中打开。简要说明如下:
用户名
国家
城市
性别
年龄
阿甘
美国
纽约
中号>
50
玛丽珍
加拿大
多伦多
F
30
使用 pandas 抓取网页的要求
学习了 网站 的基本构建块以及如何解释 HTML(至少是表格部分!)。这里只介绍 HTML 表格的原因是,大多数时候我们尝试从 网站 获取数据时,它是表格格式。pandas 是从 网站 获取表格数据的完美工具!
因此,使用 pandas 从 网站 获取数据的唯一要求是数据必须存储在表格中,或者用 HTML 术语来说,存储在 ... 标签中。pandas 将能够使用我们刚刚介绍的 HTML 标记来提取表格、标题和数据行。
如果我尝试使用 pandas 从不收录任何表格(...标签)的网页“获取数据”,我将不会获得任何数据。对于那些没有存储在表中的数据,我们需要其他方式来抓取网站。
网页抓取示例
我们之前的示例大多是带有几个数据点的小表,让我们使用稍微大一点的数据。
我们将从百度百科获取最新的世界500强企业名称及相关信息:
%E4%B8%96%E7%95%8C500%E5%BC%BA/640042?fr=阿拉丁
图1(如果有错误,根据错误提示处理。我的电脑没有安装lxml,安装后正常)
上面的df其实是一个list,有意思……list里好像有3个item。让我们看看 pandas 为我们采集了哪些数据……
图 2
第一个数据框df[0],似乎和它没有任何关系,只是页面上爬到的第一个表。查看网页,可以知道这张桌子是在中国举办的《财富》全球论坛。
图 3
第二个数据框 df[1] 是该页面上的另一个表,请注意在它的末尾,它说有 [500 行 x 6 列]。这张表是世界500强排行榜。
图 4
第三个数据框 df[2] 是页面上的第三个表格,最后显示 [110 行 x 5 列]。此表为上榜中国企业名单。
请注意,始终检查 pd.read_html() 返回的内容,一个网页可能收录多个表,因此您将获得一个数据框列表,而不是单个数据框!
注:本文借鉴自。
请在下方留言完善本文内容,让更多人学习到更完善的知识。
欢迎来到知识星球:完美Excel社区,在这里您可以进行技术交流和提问,获取更多电子资料,通过社区加入专属的微信讨论群,交流更便捷。 查看全部
python网页数据抓取(如何使用Python和pandas库从web页面获取表数据?)
今天,人们可以随时随地连接到互联网。互联网可能是最大的公共数据库。学习如何从 Internet 获取数据至关重要。因此,有必要了解如何使用 Python 和 pandas 库从网页中获取表格数据。此外,如果您已经在使用 Excel PowerQuery,这相当于“从 Web 获取数据”功能,但在这里它的功能要强大 100 倍。
从 网站 获取数据(网络抓取)
HTML 是每个 网站 背后的语言。当我们访问 网站 时,会发生以下情况:
1.在浏览器地址栏中输入地址(URL),浏览器向目标网站的服务器发送请求。
2.服务器接收请求并返回构成网页的 HTML 代码。
3.浏览器接收到 HTML 代码,动态运行它,并创建一个网页供我们查看。
Web 抓取基本上意味着,我们可以使用 Python 向 网站 服务器发送请求,接收 HTML 代码,然后提取所需的数据,而不是使用浏览器。
我不会在这里介绍太多 HTML,只介绍几个要点,以便我们对 网站 和网络抓取的工作原理有一个基本的了解。HTML 元素或“HTML 标签”是被包围的特定关键字。例如,下面的 HTML 代码是网页的标题,将鼠标悬停在网页中的选项卡上会在浏览器上看到相同的标题。请注意,大多数 HTML 元素都需要一个开始标记(例如 , )和一个相应的结束标记(例如 , )。
Python pandas 获取网页中的表格数据(网页抓取)
同样,下面的代码会在浏览器上绘制一个表格,你可以尝试复制粘贴到记事本中,然后保存为“tableexample.html”文件,应该可以在浏览器中打开。简要说明如下:
用户名
国家
城市
性别
年龄
阿甘
美国
纽约
中号>
50
玛丽珍
加拿大
多伦多
F
30
使用 pandas 抓取网页的要求
学习了 网站 的基本构建块以及如何解释 HTML(至少是表格部分!)。这里只介绍 HTML 表格的原因是,大多数时候我们尝试从 网站 获取数据时,它是表格格式。pandas 是从 网站 获取表格数据的完美工具!
因此,使用 pandas 从 网站 获取数据的唯一要求是数据必须存储在表格中,或者用 HTML 术语来说,存储在 ... 标签中。pandas 将能够使用我们刚刚介绍的 HTML 标记来提取表格、标题和数据行。
如果我尝试使用 pandas 从不收录任何表格(...标签)的网页“获取数据”,我将不会获得任何数据。对于那些没有存储在表中的数据,我们需要其他方式来抓取网站。
网页抓取示例
我们之前的示例大多是带有几个数据点的小表,让我们使用稍微大一点的数据。
我们将从百度百科获取最新的世界500强企业名称及相关信息:
%E4%B8%96%E7%95%8C500%E5%BC%BA/640042?fr=阿拉丁
图1(如果有错误,根据错误提示处理。我的电脑没有安装lxml,安装后正常)
上面的df其实是一个list,有意思……list里好像有3个item。让我们看看 pandas 为我们采集了哪些数据……
图 2
第一个数据框df[0],似乎和它没有任何关系,只是页面上爬到的第一个表。查看网页,可以知道这张桌子是在中国举办的《财富》全球论坛。
图 3
第二个数据框 df[1] 是该页面上的另一个表,请注意在它的末尾,它说有 [500 行 x 6 列]。这张表是世界500强排行榜。
图 4
第三个数据框 df[2] 是页面上的第三个表格,最后显示 [110 行 x 5 列]。此表为上榜中国企业名单。
请注意,始终检查 pd.read_html() 返回的内容,一个网页可能收录多个表,因此您将获得一个数据框列表,而不是单个数据框!
注:本文借鉴自。
请在下方留言完善本文内容,让更多人学习到更完善的知识。
欢迎来到知识星球:完美Excel社区,在这里您可以进行技术交流和提问,获取更多电子资料,通过社区加入专属的微信讨论群,交流更便捷。
python网页数据抓取(一下python的数据抓取技巧,不深入解释数据的具体原理 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 95 次浏览 • 2022-02-23 10:11
)
作为一名经济学学生,第一次接触python就是学习和掌握网页数据抓取技巧,那么今天就来说说python数据抓取技巧。
python爬取数据的具体原理我就不深入讲解了,说一下大致的流程。爬取数据首先需要获取需要抓取的网页的url,然后解析并保存数据。如果是多页数据,还需要翻页。这里需要总结一下多页url的规则。
根据url获取具体的html源码,python提供了多种方法,主要是urllib库(python3集成了urllib2和urllib,只有urllib),requests库
urllib 访问输出 html 结果
请求访问 html 结果
可以看出requests访问的html源码越来越全,up的高手也推荐使用requests。Python 可能会设计多个库来实现一个功能。为了避免混淆,建议您主要记住一种方法,了解其他方法。
2.获取html,下面是解析复杂的代码,只提取我们需要的内容。Python还提供了多种解析html的方法,如正则匹配、BeautifulSoup、Xpath、pyquery等,这里主要讲解BeautifulSoup。有兴趣的朋友页面可以了解其他方法。Xpath 可以帮助你理解 html 的结构。.
BeautifulSoup库的具体使用这里就不深入讲解了。有兴趣的小伙伴可以去其官网查看相关教程。下面附上学习网址:
3.是数据存储之后,这里使用pandas,如果你在up主之前看过文章就会知道,我基本上都是用pandas来进行数据分析、处理、存储的。如上所述,与其笼统地学习,不如深入研究一门学科。当然,如果你能力很强的话,每门学科都可以掌握,这当然是最好的。
4.附上代码,up的高手随机找了一个豆瓣网页来抢,感兴趣的朋友可以试试。 查看全部
python网页数据抓取(一下python的数据抓取技巧,不深入解释数据的具体原理
)
作为一名经济学学生,第一次接触python就是学习和掌握网页数据抓取技巧,那么今天就来说说python数据抓取技巧。
python爬取数据的具体原理我就不深入讲解了,说一下大致的流程。爬取数据首先需要获取需要抓取的网页的url,然后解析并保存数据。如果是多页数据,还需要翻页。这里需要总结一下多页url的规则。
根据url获取具体的html源码,python提供了多种方法,主要是urllib库(python3集成了urllib2和urllib,只有urllib),requests库
urllib 访问输出 html 结果
请求访问 html 结果
可以看出requests访问的html源码越来越全,up的高手也推荐使用requests。Python 可能会设计多个库来实现一个功能。为了避免混淆,建议您主要记住一种方法,了解其他方法。
2.获取html,下面是解析复杂的代码,只提取我们需要的内容。Python还提供了多种解析html的方法,如正则匹配、BeautifulSoup、Xpath、pyquery等,这里主要讲解BeautifulSoup。有兴趣的朋友页面可以了解其他方法。Xpath 可以帮助你理解 html 的结构。.
BeautifulSoup库的具体使用这里就不深入讲解了。有兴趣的小伙伴可以去其官网查看相关教程。下面附上学习网址:
3.是数据存储之后,这里使用pandas,如果你在up主之前看过文章就会知道,我基本上都是用pandas来进行数据分析、处理、存储的。如上所述,与其笼统地学习,不如深入研究一门学科。当然,如果你能力很强的话,每门学科都可以掌握,这当然是最好的。
4.附上代码,up的高手随机找了一个豆瓣网页来抢,感兴趣的朋友可以试试。
python网页数据抓取(python网页数据抓取分析与展示解决一个问题的问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 148 次浏览 • 2022-02-22 10:04
python网页数据抓取分析与展示。今天我们来解决一个问题,网页数据总是抓不完,我们需要对抓取的数据进行多样性分析,以供我们决策,最终将从网页数据源读取数据给我们的客户看,展示给他们可视化的图表,具体过程如下:详情页的公司介绍。公司招聘注意:因为我们的目标是按照购买量发放优惠券,一开始我们就要了解购买量大的公司是不是真的很容易购买,具体就不展示了,我们来看看他们的公司评价吧。
在这里我们讲一个数据挖掘算法,叫做预测模型,是用于算法优化的时候。进入正题吧,最后一个页面,标题“怎么样才能快速看到公司介绍”,这一单我们抓取一个美元单位,所以美元兑换成人民币,然后计算出,这样从页面右上角导航到首页,整个抓取页面的值是10:9:7,也就是说数据将在一天内返回。我们将数据导入文本处理器,并将时间分割成7个时间点,分别是下午6点,8点,9点,10点,12点,17点,然后建立时间间隔器将时间放大成为一个10分钟(注意下次跳转时间要从6:00-12:0。
0),7:00-8:00打一个√,只取首页上所有数据返回。接下来我们要研究一下首页上的人群是不是必须,再有就是理性分析,根据首页上的名字,是不是可以分析出是哪一类型的人群。经过一番对于用户数据分析,总结出一个曲线,总体符合大致的用户画像特征。
1、百度搜索“牛逼企业”
2、浏览企业的官网,没有注册,找到官网的。打开后进入公司官网。
3、发现,首页要拿到唯一标识,请注意前面的按钮。
4、点开创建抽奖号,按照步骤把创建首页名字给打上来。
5、接下来就是对于页面数据进行多样性分析。我们只需要针对首页的访问数量、评论数量、赞美数量来进行多样性分析。比如做一个转化率测试,设定一个时间间隔,我们抓取数据时间就放宽到10分钟就行。
6、在个人中心,我们找到好友选项,拿来对数据进行关联。因为个人中心里的好友跟首页的“企业用户”的账号标识不同,会导致跳转。
7、出现意外,就更新,出现必须的就做一个ip地址。
8、那就意味着目标访问者url是变动的,我们要对url做变化化,来获取访问的准确url,发现无法获取,就要做图。
9、那就进入到聚合页面,登录账号。
1
0、这样我们就得到了它的url1
1、那么到这里其实总体工作是这样的:拿到个人中心的url,然后跳转进来确定它的实际路径,然后确定它是哪一个页面。
2、更新url参数,让它始终是一个最新的页面。python有两大主要语言,一个是高级语言python,另一个就是脚本语言bash。
对于初学者,
1、 查看全部
python网页数据抓取(python网页数据抓取分析与展示解决一个问题的问题)
python网页数据抓取分析与展示。今天我们来解决一个问题,网页数据总是抓不完,我们需要对抓取的数据进行多样性分析,以供我们决策,最终将从网页数据源读取数据给我们的客户看,展示给他们可视化的图表,具体过程如下:详情页的公司介绍。公司招聘注意:因为我们的目标是按照购买量发放优惠券,一开始我们就要了解购买量大的公司是不是真的很容易购买,具体就不展示了,我们来看看他们的公司评价吧。
在这里我们讲一个数据挖掘算法,叫做预测模型,是用于算法优化的时候。进入正题吧,最后一个页面,标题“怎么样才能快速看到公司介绍”,这一单我们抓取一个美元单位,所以美元兑换成人民币,然后计算出,这样从页面右上角导航到首页,整个抓取页面的值是10:9:7,也就是说数据将在一天内返回。我们将数据导入文本处理器,并将时间分割成7个时间点,分别是下午6点,8点,9点,10点,12点,17点,然后建立时间间隔器将时间放大成为一个10分钟(注意下次跳转时间要从6:00-12:0。
0),7:00-8:00打一个√,只取首页上所有数据返回。接下来我们要研究一下首页上的人群是不是必须,再有就是理性分析,根据首页上的名字,是不是可以分析出是哪一类型的人群。经过一番对于用户数据分析,总结出一个曲线,总体符合大致的用户画像特征。
1、百度搜索“牛逼企业”
2、浏览企业的官网,没有注册,找到官网的。打开后进入公司官网。
3、发现,首页要拿到唯一标识,请注意前面的按钮。
4、点开创建抽奖号,按照步骤把创建首页名字给打上来。
5、接下来就是对于页面数据进行多样性分析。我们只需要针对首页的访问数量、评论数量、赞美数量来进行多样性分析。比如做一个转化率测试,设定一个时间间隔,我们抓取数据时间就放宽到10分钟就行。
6、在个人中心,我们找到好友选项,拿来对数据进行关联。因为个人中心里的好友跟首页的“企业用户”的账号标识不同,会导致跳转。
7、出现意外,就更新,出现必须的就做一个ip地址。
8、那就意味着目标访问者url是变动的,我们要对url做变化化,来获取访问的准确url,发现无法获取,就要做图。
9、那就进入到聚合页面,登录账号。
1
0、这样我们就得到了它的url1
1、那么到这里其实总体工作是这样的:拿到个人中心的url,然后跳转进来确定它的实际路径,然后确定它是哪一个页面。
2、更新url参数,让它始终是一个最新的页面。python有两大主要语言,一个是高级语言python,另一个就是脚本语言bash。
对于初学者,
1、

