
python
使用Python编撰多线程爬虫抓取百度贴吧邮箱与手机号
采集交流 • 优采云 发表了文章 • 0 个评论 • 484 次浏览 • 2020-07-05 08:00
本爬虫主要是对百度贴吧中各类贴子的内容进行抓取,并且剖析贴子内容将其中的手机号和邮箱地址抓取下来。主要流程在代码注释中有详尽解释。
代码在Windows7 64bit,python 2.7 64bit(安装mysqldb扩充)以及centos 6.5,python 2.7(带mysqldb扩充)环境下测试通过
工欲善其事必先利其器,大家可以从截图看出我的环境是Windows 7 + PyCharm。我的Python环境是Python 2.7 64bit。这是比较适宜菜鸟使用的开发环境。然后我再建议你们安装一个easy_install,听名子就晓得这是一个安装器,它是拿来安装一些扩充包的,比如说在python中假如我们要操作mysql数据库的话,python原生是不支持的,我们必须安装mysqldb包来让python可以操作mysql数据库,如果有easy_install的话我们只须要一行命令就可以快速安装号mysqldb扩充包,他如同php中的composer,centos中的yum,Ubuntu中的apt-get一样便捷。
相关工具可在我的github中找到:cw1997/python-tools,其中easy_install的安装只须要在python命令行下运行哪个py脚本之后稍等片刻即可邮箱爬虫软件,他会手动加入Windows的环境变量,在Windows命令行下假如输入easy_install有回显说明安装成功。
至于电脑硬件其实是越快越好,内存至少8G起步,因为爬虫本身须要大量储存和解析中间数据,尤其是多线程爬虫,在遇到抓取带有分页的列表和详情页,并且抓取数据量很大的情况下使用queue队列分配抓取任务会特别占显存。包括有的时候我们抓取的数据是使用json,如果使用mongodb等nosql数据库储存,也会太占显存。
网络联接建议使用有线网,因为市面上一些劣质的无线路由器和普通的民用无线网卡在线程开的比较大的情况下会出现间歇性断网或则数据遗失,掉包等情况,这个我亲有感受。
至于操作系统和python其实肯定是选择64位。如果你使用的是32位的操作系统,那么难以使用大显存。如果你使用的是32位的python,可能在小规模抓取数据的时侯觉得不出有哪些问题,但是当数据量变大的时侯,比如说某个列表,队列,字典上面储存了大量数据,导致python的显存占用超过2g的时侯会报显存溢出错误。原因在我以前segmentfault上提过的问题中依云的回答有解释(java – python只要占用显存达到1.9G以后httplib模块就开始报内存溢出错误 – SegmentFault)
如果你打算使用mysql储存数据,建议使用mysql5.5之后的版本,因为mysql5.5版本支持json数据类型,这样的话可以抛弃mongodb了。(有人说mysql会比mongodb稳定一点,这个我不确定。)
至于现今python都早已出了3.x版本了,为什么我这儿还使用的是python2.7?我个人选择2.7版本的缘由是自己当年很早曾经买的python核心编程这本书是第二版的,仍然以2.7为示例版本。并且目前网上一直有大量的教程资料是以2.7为版本讲解,2.7在个别方面与3.x还是有很大差异,如果我们没有学过2.7,可能对于一些细微的句型差异不是太懂会导致我们理解上出现误差,或者看不懂demo代码。而且如今还是有部份依赖包只兼容2.7版本。我的建议是假如你是打算急着学python之后去公司工作,并且公司没有老代码须要维护,那么可以考虑直接上手3.x,如果你有比较充沛的时间,并且没有太系统的大牛带,只能借助网上零零散散的博客文章来学习,那么还是先学2.7在学3.x,毕竟学会了2.7以后3.x上手也很快。
其实对于任何软件项目而言,我们但凡想知道编撰这个项目须要哪些知识点,我们都可以观察一下这个项目的主要入口文件都导出了什么包。
现在来看一下我们这个项目,作为一个刚接触python的人,可能有一些包几乎都没有用过,那么我们在本小节就来简单的谈谈这种包起哪些作用,要把握她们分别会涉及到哪些知识点,这些知识点的关键词是哪些。这篇文章并不会耗费长篇大论来从基础讲起,因此我们要学会善用百度,搜索那些知识点的关键词来自学。下面就来一一剖析一下这种知识点。
我们的爬虫抓取数据本质上就是不停的发起http请求,获取http响应,将其存入我们的笔记本中。了解http协议有助于我们在抓取数据的时侯对一些才能加速抓取速率的参数才能精准的控制,比如说keep-alive等。
我们平常编撰的程序都是单线程程序,我们写的代码都在主线程上面运行,这个主线程又运行在python进程中。关于线程和进程的解释可以参考阮一峰的博客:进程与线程的一个简单解释 – 阮一峰的网路日志
在python中实现多线程是通过一个名子称作threading的模块来实现。之前还有thread模块,但是threading对于线程的控制更强,因此我们后来都改用threading来实现多线程编程了。
关于threading多线程的一些用法,我认为这篇文章不错:[python] 专题八.多线程编程之thread和threading 大家可以参考参考。
简单来说,使用threading模块编撰多线程程序,就是先自己定义一个类,然后这个类要承继threading.Thread,并且把每位线程要做的工作代码讲到一个类的run方式中,当然若果线程本身在创建的时侯假如要做一些初始化工作,那么就要在他的__init__方法中编撰好初始化工作所要执行的代码,这个方式如同php,java中的构造方式一样。
这里还要额外讲的一点就是线程安全这个概念。通常情况下我们单线程情况下每位时刻只有一个线程在对资源(文件,变量)操作,所以不可能会出现冲突。但是当多线程的情况下,可能会出现同一个时刻两个线程在操作同一个资源,导致资源受损,所以我们须要一种机制来解决这些冲突带来的破坏,通常有加锁等操作,比如说mysql数据库的innodb表引擎有行级锁等,文件操作有读取锁等等,这些都是她们的程序底层帮我们完成了。所以我们一般只要晓得这些操作,或者这些程序对于线程安全问题做了处理,然后就可以在多线程编程中去使用它们了。而这些考虑到线程安全问题的程序通常就叫做“线程安全版本”,比如说php就有TS版本,这个TS就是Thread Safety线程安全的意思。下面我们要提到的Queue模块就是一种线程安全的队列数据结构,所以我们可以放心的在多线程编程中使用它。
***我们就要来讲讲至关重要的线程阻塞这个概念了。当我们详尽学习完threading模块以后,大概就晓得怎样创建和启动线程了。但是假如我们把线程创建好了,然后调用了start方式,那么我们会发觉似乎整个程序立刻就结束了,这是如何回事呢?其实这是因为我们在主线程中只有负责启动子线程的代码,也就意味着主线程只有启动子线程的功能,至于子线程执行的这些代码,他们本质上只是写在类上面的一个方式,并没在主线程上面真正去执行他,所以主线程启动完子线程以后他的本职工作就早已全部完成了,已经光荣离场了。既然主线程都离场了,那么python进程就跟随结束了,那么其他线程也就没有显存空间继续执行了。所以我们应当是要使主线程大婶等到所有的子线程鄙人全部执行完毕再光荣离场,那么在线程对象中有哪些方式才能把主线程卡住呢?thread.sleep嘛?这确实是个办法,但是到底应当使主线程sleep多久呢?我们并不能确切晓得执行完一个任务要多久时间,肯定不能用这个办法。所以我们这个时侯应当上网查询一下有哪些办法才能使子线程“卡住”主线程呢?“卡住”这个词似乎很粗俗了,其实说专业一点,应该称作“阻塞”,所以我们可以查询“python 子线程阻塞主线程”,如果我们会正确使用搜索引擎的话,应该会查到一个方式称作join(),没错,这个join()方法就是子线程用于阻塞主线程的方式,当子线程还未执行完毕的时侯,主线程运行到富含join()方法的这一行都会卡在那里,直到所有线程都执行完毕才能执行join()方法前面的代码。
假设有一个这样的场景,我们须要抓取一个人的博客,我们晓得这个人的博客有两个页面,一个list.php页面显示的是此博客的所有文章链接,还有一个view.php页面显示的是一篇文章的具体内容。
如果我们要把这个人的博客上面所有文章内容抓取出来,编写单线程爬虫的思路是:先用正则表达式把这个list.php页面的所有链接a标签的href属性抓取出来,存入一个名子称作article_list的链表(在python中不叫链表,叫做list,中文名列表),然后再用一个for循环遍历这个article_list链表,用各类抓取网页内容的函数把内容抓取出来之后存入数据库。
如果我们要编撰一个多线程爬虫来完成这个任务的话,就假定我们的程序用10个线程把,那么我们就要想办法把之前抓取的article_list平均分成10份,分别把每一份分配给其中一个子线程。
但是问题来了,如果我们的article_list链表宽度不是10的倍数,也就是文章数量并不是10的整数倍,那么***一个线程都会比别的线程少分配到一些任务,那么它将会更快的结束。
如果仅仅是抓取这些只有几千字的博客文章这看似没哪些问题,但是假如我们一个任务(不一定是抓取网页的任务,有可能是物理估算,或者图形渲染等等历时任务)的运行时间太长,那么这将导致极大地资源和时间浪费。我们多线程的目的就是尽可能的借助一切估算资源而且估算时间,所以我们要想办法使任务才能愈发科学合理的分配。
并且我还要考虑一种情况,就是文章数量很大的情况下,我们要既能快速抓取到文章内容,又能尽早的看见我们早已抓取到的内容,这种需求在好多CMS采集站上常常会彰显下来。
比如说我们如今要抓取的目标博客,有几千万篇文章,通常这些情况下博客还会做分页处理,那么我们若果根据前面的传统思路先抓取完list.php的所有页面至少就要几个小时甚至几天,老板假如希望你还能早日显示出抓取内容,并且尽早将早已抓取到的内容诠释到我们的CMS采集站上,那么我们就要实现一边抓取list.php而且把早已抓取到的数据丢入一个article_list链表,一边用另一个线程从article_list链表中提取早已抓取到的文章URL地址,然后这个线程再去对应的URL地址中用正则表达式取到博客文章内容。如何实现这个功能呢?
我们就须要同时开启两类线程,一类线程专门负责抓取list.php中的url之后丢入article_list链表,另外一类线程专门负责从article_list中提取出url之后从对应的view.php页面中抓取出对应的博客内容。
但是我们是否还记得上面提及过线程安全这个概念?前一类线程一边往article_list字段中写入数据,另外那一类的线程从article_list中读取数据但是删掉早已读取完毕的数据。但是python中list并不是线程安全版本的数据结构,因此这样操作会导致不可预想的错误。所以我们可以尝试使用一个愈发便捷且线程安全的数据结构,这就是我们的子标题中所提及的Queue队列数据结构。
同样Queue也有一个join()方法,这个join()方法虽然和上一个小节所提到的threading中join()方法差不多,只不过在Queue中,join()的阻塞条件是当队列不为空空的时侯才阻塞,否则继续执行join()后面的代码。在这个爬虫中我便使用了这些技巧来阻塞主线程而不是直接通过线程的join方法来阻塞主线程,这样的用处是可以不用写一个死循环来判定当前任务队列中是否还有未执行完的任务,让程序运行愈发高效,也使代码愈发柔美。
还有一个细节就是在python2.7中队列模块的名子是Queue,而在python3.x中早已更名为queue,就是首字母大小写的区别,大家假如是复制网上的代码,要记得这个小区别。
如果你们学过c语言的话,对这个模块应当会太熟悉,他就是一个负责从命令行中的命令上面提取出附送参数的模块。比如说我们一般在命令行中操作mysql数据库,就是输入mysql -h127.0.0.1 -uroot -p,其中mysql前面的“-h127.0.0.1 -uroot -p”就是可以获取的参数部份。
我们平常在编撰爬虫的时侯,有一些参数是须要用户自己自动输入的,比如说mysql的主机IP,用户名密码等等。为了使我们的程序愈加友好通用,有一些配置项是不需要硬编码在代码上面,而是在执行他的时侯我们动态传入,结合getopt模块我们就可以实现这个功能。
哈希本质上就是一类物理算法的集合,这种物理算法有个特点就是你给定一个参数,他就能输出另外一个结果,虽然这个结果太短,但是他可以近似觉得是***的。比如说我们平常听过的md5,sha-1等等,他们都属于哈希算法。他们可以把一些文件,文字经过一系列的物理运算然后弄成短短不到一百位的一段数字中文混和的字符串。
python中的hashlib模块就为我们封装好了这种物理运算函数,我们只须要简单的调用它就可以完成哈希运算。
为什么在我这个爬虫中用到了这个包呢?因为在一些插口恳求中,服务器须要带上一些校验码,保证插口恳求的数据没有被篡改或则遗失,这些校验码通常都是hash算法,所以我们须要用到这个模块来完成这些运算。
很多时侯我们抓取到的数据不是html,而是一些json数据,json本质上只是一段富含通配符对的字符串,如果我们须要提取出其中特定的字符串,那么我们须要json这个模块来将这个json字符串转换为dict类型便捷我们操作。
有的时侯我们抓取到了一些网页内容,但是我们须要将网页中的一些特定格式的内容提取下来,比如说电子邮箱的格式通常都是上面几位英语数字字母加一个@符号加的域名,而要象计算机语言描述这些格式,我们可以使用一种称作正则表达式的表达式来抒发出这些格式,并且使计算机手动从一大段字符串上将符合这些特定格式的文字匹配下来。
这个模块主要用于处理一些系统方面的事情,在这个爬虫中我用他来解决输出编码问题。
稍微学过一点法语的人都还能猜下来这个模块用于处理时间,在这个爬虫中我用它来获取当前时间戳,然后通过在主线程末尾用当前时间戳除以程序开始运行时的时间戳,得到程序的运行时间。
如图所示,开50个线程抓取100页(每页30个贴子,相当于抓取了3000个贴子)贴吧贴子内容而且从中提取出手机邮箱这个步骤共历时330秒。
这两个模块都是用于处理一些http请求,以及url低格方面的事情。我的爬虫http请求部份的核心代码就是使用这个模块完成的。
这是一个第三方模块,用于在python中操作mysql数据库。
这里我们要注意一个细节问题:mysqldb模块并不是线程安全版本,意味着我们不能在多线程中共享同一个mysql联接句柄。所以你们可以在我的代码中听到,我在每位线程的构造函数中都传入了一个新的mysql联接句柄。因此每位子线程只会用自己独立的mysql联接句柄。
这也是一个第三方模块,网上还能找到相关代码,这个模块主要用于向命令行中输出彩色字符串。比如说我们一般爬虫出现错误,要输出黄色的字体会比较醒目,就要使用到这个模块。
如果你们在网路质量不是挺好的环境下使用该爬虫,会发觉有的时侯会报如图所示的异常,这是我为了偷懒并没有写各类异常处理的逻辑。
通常情况下我们假如要编撰高度自动化的爬虫,那么就须要意料到我们的爬虫可能会遇见的所有异常情况邮箱爬虫软件,针对这种异常情况做处理。
比如说如图所示的错误,我们就应当把当时正在处理的任务重新伸入任务队列,否则我们还会出现遗漏信息的情况。这也是爬虫编撰的一个复杂点。
其实多线程爬虫的编撰也不复杂,多看示例代码,多自己动手尝试,多去社区,论坛交流,很多精典的书上对多线程编程也有特别详尽的解释。这篇文章本质上主要还是一篇科普文章,内容讲解的都不是太深入,大家还须要课外自己多结合网上各类资料自己学习。
【编辑推荐】
Python程序员都该用的一个库Python正则表达式re模块简明笔记这种方式推动Python开发者提升效率Python并发编程之线程池/进程池Python黑魔法之描述符 查看全部
不知道你们春节都是如何过的,反正栏主是在家睡了三天,醒来的时侯登QQ发觉有人找我要一份帖吧爬虫的源代码,想起之前练手的时侯写过一个抓取百度贴吧发贴记录中的邮箱与手机号的爬虫,于是开源分享给你们学习与参考。
本爬虫主要是对百度贴吧中各类贴子的内容进行抓取,并且剖析贴子内容将其中的手机号和邮箱地址抓取下来。主要流程在代码注释中有详尽解释。
代码在Windows7 64bit,python 2.7 64bit(安装mysqldb扩充)以及centos 6.5,python 2.7(带mysqldb扩充)环境下测试通过


工欲善其事必先利其器,大家可以从截图看出我的环境是Windows 7 + PyCharm。我的Python环境是Python 2.7 64bit。这是比较适宜菜鸟使用的开发环境。然后我再建议你们安装一个easy_install,听名子就晓得这是一个安装器,它是拿来安装一些扩充包的,比如说在python中假如我们要操作mysql数据库的话,python原生是不支持的,我们必须安装mysqldb包来让python可以操作mysql数据库,如果有easy_install的话我们只须要一行命令就可以快速安装号mysqldb扩充包,他如同php中的composer,centos中的yum,Ubuntu中的apt-get一样便捷。
相关工具可在我的github中找到:cw1997/python-tools,其中easy_install的安装只须要在python命令行下运行哪个py脚本之后稍等片刻即可邮箱爬虫软件,他会手动加入Windows的环境变量,在Windows命令行下假如输入easy_install有回显说明安装成功。
至于电脑硬件其实是越快越好,内存至少8G起步,因为爬虫本身须要大量储存和解析中间数据,尤其是多线程爬虫,在遇到抓取带有分页的列表和详情页,并且抓取数据量很大的情况下使用queue队列分配抓取任务会特别占显存。包括有的时候我们抓取的数据是使用json,如果使用mongodb等nosql数据库储存,也会太占显存。
网络联接建议使用有线网,因为市面上一些劣质的无线路由器和普通的民用无线网卡在线程开的比较大的情况下会出现间歇性断网或则数据遗失,掉包等情况,这个我亲有感受。
至于操作系统和python其实肯定是选择64位。如果你使用的是32位的操作系统,那么难以使用大显存。如果你使用的是32位的python,可能在小规模抓取数据的时侯觉得不出有哪些问题,但是当数据量变大的时侯,比如说某个列表,队列,字典上面储存了大量数据,导致python的显存占用超过2g的时侯会报显存溢出错误。原因在我以前segmentfault上提过的问题中依云的回答有解释(java – python只要占用显存达到1.9G以后httplib模块就开始报内存溢出错误 – SegmentFault)
如果你打算使用mysql储存数据,建议使用mysql5.5之后的版本,因为mysql5.5版本支持json数据类型,这样的话可以抛弃mongodb了。(有人说mysql会比mongodb稳定一点,这个我不确定。)
至于现今python都早已出了3.x版本了,为什么我这儿还使用的是python2.7?我个人选择2.7版本的缘由是自己当年很早曾经买的python核心编程这本书是第二版的,仍然以2.7为示例版本。并且目前网上一直有大量的教程资料是以2.7为版本讲解,2.7在个别方面与3.x还是有很大差异,如果我们没有学过2.7,可能对于一些细微的句型差异不是太懂会导致我们理解上出现误差,或者看不懂demo代码。而且如今还是有部份依赖包只兼容2.7版本。我的建议是假如你是打算急着学python之后去公司工作,并且公司没有老代码须要维护,那么可以考虑直接上手3.x,如果你有比较充沛的时间,并且没有太系统的大牛带,只能借助网上零零散散的博客文章来学习,那么还是先学2.7在学3.x,毕竟学会了2.7以后3.x上手也很快。
其实对于任何软件项目而言,我们但凡想知道编撰这个项目须要哪些知识点,我们都可以观察一下这个项目的主要入口文件都导出了什么包。

现在来看一下我们这个项目,作为一个刚接触python的人,可能有一些包几乎都没有用过,那么我们在本小节就来简单的谈谈这种包起哪些作用,要把握她们分别会涉及到哪些知识点,这些知识点的关键词是哪些。这篇文章并不会耗费长篇大论来从基础讲起,因此我们要学会善用百度,搜索那些知识点的关键词来自学。下面就来一一剖析一下这种知识点。
我们的爬虫抓取数据本质上就是不停的发起http请求,获取http响应,将其存入我们的笔记本中。了解http协议有助于我们在抓取数据的时侯对一些才能加速抓取速率的参数才能精准的控制,比如说keep-alive等。
我们平常编撰的程序都是单线程程序,我们写的代码都在主线程上面运行,这个主线程又运行在python进程中。关于线程和进程的解释可以参考阮一峰的博客:进程与线程的一个简单解释 – 阮一峰的网路日志
在python中实现多线程是通过一个名子称作threading的模块来实现。之前还有thread模块,但是threading对于线程的控制更强,因此我们后来都改用threading来实现多线程编程了。
关于threading多线程的一些用法,我认为这篇文章不错:[python] 专题八.多线程编程之thread和threading 大家可以参考参考。
简单来说,使用threading模块编撰多线程程序,就是先自己定义一个类,然后这个类要承继threading.Thread,并且把每位线程要做的工作代码讲到一个类的run方式中,当然若果线程本身在创建的时侯假如要做一些初始化工作,那么就要在他的__init__方法中编撰好初始化工作所要执行的代码,这个方式如同php,java中的构造方式一样。
这里还要额外讲的一点就是线程安全这个概念。通常情况下我们单线程情况下每位时刻只有一个线程在对资源(文件,变量)操作,所以不可能会出现冲突。但是当多线程的情况下,可能会出现同一个时刻两个线程在操作同一个资源,导致资源受损,所以我们须要一种机制来解决这些冲突带来的破坏,通常有加锁等操作,比如说mysql数据库的innodb表引擎有行级锁等,文件操作有读取锁等等,这些都是她们的程序底层帮我们完成了。所以我们一般只要晓得这些操作,或者这些程序对于线程安全问题做了处理,然后就可以在多线程编程中去使用它们了。而这些考虑到线程安全问题的程序通常就叫做“线程安全版本”,比如说php就有TS版本,这个TS就是Thread Safety线程安全的意思。下面我们要提到的Queue模块就是一种线程安全的队列数据结构,所以我们可以放心的在多线程编程中使用它。
***我们就要来讲讲至关重要的线程阻塞这个概念了。当我们详尽学习完threading模块以后,大概就晓得怎样创建和启动线程了。但是假如我们把线程创建好了,然后调用了start方式,那么我们会发觉似乎整个程序立刻就结束了,这是如何回事呢?其实这是因为我们在主线程中只有负责启动子线程的代码,也就意味着主线程只有启动子线程的功能,至于子线程执行的这些代码,他们本质上只是写在类上面的一个方式,并没在主线程上面真正去执行他,所以主线程启动完子线程以后他的本职工作就早已全部完成了,已经光荣离场了。既然主线程都离场了,那么python进程就跟随结束了,那么其他线程也就没有显存空间继续执行了。所以我们应当是要使主线程大婶等到所有的子线程鄙人全部执行完毕再光荣离场,那么在线程对象中有哪些方式才能把主线程卡住呢?thread.sleep嘛?这确实是个办法,但是到底应当使主线程sleep多久呢?我们并不能确切晓得执行完一个任务要多久时间,肯定不能用这个办法。所以我们这个时侯应当上网查询一下有哪些办法才能使子线程“卡住”主线程呢?“卡住”这个词似乎很粗俗了,其实说专业一点,应该称作“阻塞”,所以我们可以查询“python 子线程阻塞主线程”,如果我们会正确使用搜索引擎的话,应该会查到一个方式称作join(),没错,这个join()方法就是子线程用于阻塞主线程的方式,当子线程还未执行完毕的时侯,主线程运行到富含join()方法的这一行都会卡在那里,直到所有线程都执行完毕才能执行join()方法前面的代码。
假设有一个这样的场景,我们须要抓取一个人的博客,我们晓得这个人的博客有两个页面,一个list.php页面显示的是此博客的所有文章链接,还有一个view.php页面显示的是一篇文章的具体内容。
如果我们要把这个人的博客上面所有文章内容抓取出来,编写单线程爬虫的思路是:先用正则表达式把这个list.php页面的所有链接a标签的href属性抓取出来,存入一个名子称作article_list的链表(在python中不叫链表,叫做list,中文名列表),然后再用一个for循环遍历这个article_list链表,用各类抓取网页内容的函数把内容抓取出来之后存入数据库。
如果我们要编撰一个多线程爬虫来完成这个任务的话,就假定我们的程序用10个线程把,那么我们就要想办法把之前抓取的article_list平均分成10份,分别把每一份分配给其中一个子线程。
但是问题来了,如果我们的article_list链表宽度不是10的倍数,也就是文章数量并不是10的整数倍,那么***一个线程都会比别的线程少分配到一些任务,那么它将会更快的结束。
如果仅仅是抓取这些只有几千字的博客文章这看似没哪些问题,但是假如我们一个任务(不一定是抓取网页的任务,有可能是物理估算,或者图形渲染等等历时任务)的运行时间太长,那么这将导致极大地资源和时间浪费。我们多线程的目的就是尽可能的借助一切估算资源而且估算时间,所以我们要想办法使任务才能愈发科学合理的分配。
并且我还要考虑一种情况,就是文章数量很大的情况下,我们要既能快速抓取到文章内容,又能尽早的看见我们早已抓取到的内容,这种需求在好多CMS采集站上常常会彰显下来。
比如说我们如今要抓取的目标博客,有几千万篇文章,通常这些情况下博客还会做分页处理,那么我们若果根据前面的传统思路先抓取完list.php的所有页面至少就要几个小时甚至几天,老板假如希望你还能早日显示出抓取内容,并且尽早将早已抓取到的内容诠释到我们的CMS采集站上,那么我们就要实现一边抓取list.php而且把早已抓取到的数据丢入一个article_list链表,一边用另一个线程从article_list链表中提取早已抓取到的文章URL地址,然后这个线程再去对应的URL地址中用正则表达式取到博客文章内容。如何实现这个功能呢?
我们就须要同时开启两类线程,一类线程专门负责抓取list.php中的url之后丢入article_list链表,另外一类线程专门负责从article_list中提取出url之后从对应的view.php页面中抓取出对应的博客内容。
但是我们是否还记得上面提及过线程安全这个概念?前一类线程一边往article_list字段中写入数据,另外那一类的线程从article_list中读取数据但是删掉早已读取完毕的数据。但是python中list并不是线程安全版本的数据结构,因此这样操作会导致不可预想的错误。所以我们可以尝试使用一个愈发便捷且线程安全的数据结构,这就是我们的子标题中所提及的Queue队列数据结构。
同样Queue也有一个join()方法,这个join()方法虽然和上一个小节所提到的threading中join()方法差不多,只不过在Queue中,join()的阻塞条件是当队列不为空空的时侯才阻塞,否则继续执行join()后面的代码。在这个爬虫中我便使用了这些技巧来阻塞主线程而不是直接通过线程的join方法来阻塞主线程,这样的用处是可以不用写一个死循环来判定当前任务队列中是否还有未执行完的任务,让程序运行愈发高效,也使代码愈发柔美。
还有一个细节就是在python2.7中队列模块的名子是Queue,而在python3.x中早已更名为queue,就是首字母大小写的区别,大家假如是复制网上的代码,要记得这个小区别。
如果你们学过c语言的话,对这个模块应当会太熟悉,他就是一个负责从命令行中的命令上面提取出附送参数的模块。比如说我们一般在命令行中操作mysql数据库,就是输入mysql -h127.0.0.1 -uroot -p,其中mysql前面的“-h127.0.0.1 -uroot -p”就是可以获取的参数部份。
我们平常在编撰爬虫的时侯,有一些参数是须要用户自己自动输入的,比如说mysql的主机IP,用户名密码等等。为了使我们的程序愈加友好通用,有一些配置项是不需要硬编码在代码上面,而是在执行他的时侯我们动态传入,结合getopt模块我们就可以实现这个功能。
哈希本质上就是一类物理算法的集合,这种物理算法有个特点就是你给定一个参数,他就能输出另外一个结果,虽然这个结果太短,但是他可以近似觉得是***的。比如说我们平常听过的md5,sha-1等等,他们都属于哈希算法。他们可以把一些文件,文字经过一系列的物理运算然后弄成短短不到一百位的一段数字中文混和的字符串。
python中的hashlib模块就为我们封装好了这种物理运算函数,我们只须要简单的调用它就可以完成哈希运算。
为什么在我这个爬虫中用到了这个包呢?因为在一些插口恳求中,服务器须要带上一些校验码,保证插口恳求的数据没有被篡改或则遗失,这些校验码通常都是hash算法,所以我们须要用到这个模块来完成这些运算。
很多时侯我们抓取到的数据不是html,而是一些json数据,json本质上只是一段富含通配符对的字符串,如果我们须要提取出其中特定的字符串,那么我们须要json这个模块来将这个json字符串转换为dict类型便捷我们操作。
有的时侯我们抓取到了一些网页内容,但是我们须要将网页中的一些特定格式的内容提取下来,比如说电子邮箱的格式通常都是上面几位英语数字字母加一个@符号加的域名,而要象计算机语言描述这些格式,我们可以使用一种称作正则表达式的表达式来抒发出这些格式,并且使计算机手动从一大段字符串上将符合这些特定格式的文字匹配下来。
这个模块主要用于处理一些系统方面的事情,在这个爬虫中我用他来解决输出编码问题。
稍微学过一点法语的人都还能猜下来这个模块用于处理时间,在这个爬虫中我用它来获取当前时间戳,然后通过在主线程末尾用当前时间戳除以程序开始运行时的时间戳,得到程序的运行时间。

如图所示,开50个线程抓取100页(每页30个贴子,相当于抓取了3000个贴子)贴吧贴子内容而且从中提取出手机邮箱这个步骤共历时330秒。
这两个模块都是用于处理一些http请求,以及url低格方面的事情。我的爬虫http请求部份的核心代码就是使用这个模块完成的。
这是一个第三方模块,用于在python中操作mysql数据库。
这里我们要注意一个细节问题:mysqldb模块并不是线程安全版本,意味着我们不能在多线程中共享同一个mysql联接句柄。所以你们可以在我的代码中听到,我在每位线程的构造函数中都传入了一个新的mysql联接句柄。因此每位子线程只会用自己独立的mysql联接句柄。
这也是一个第三方模块,网上还能找到相关代码,这个模块主要用于向命令行中输出彩色字符串。比如说我们一般爬虫出现错误,要输出黄色的字体会比较醒目,就要使用到这个模块。

如果你们在网路质量不是挺好的环境下使用该爬虫,会发觉有的时侯会报如图所示的异常,这是我为了偷懒并没有写各类异常处理的逻辑。
通常情况下我们假如要编撰高度自动化的爬虫,那么就须要意料到我们的爬虫可能会遇见的所有异常情况邮箱爬虫软件,针对这种异常情况做处理。
比如说如图所示的错误,我们就应当把当时正在处理的任务重新伸入任务队列,否则我们还会出现遗漏信息的情况。这也是爬虫编撰的一个复杂点。
其实多线程爬虫的编撰也不复杂,多看示例代码,多自己动手尝试,多去社区,论坛交流,很多精典的书上对多线程编程也有特别详尽的解释。这篇文章本质上主要还是一篇科普文章,内容讲解的都不是太深入,大家还须要课外自己多结合网上各类资料自己学习。
【编辑推荐】
Python程序员都该用的一个库Python正则表达式re模块简明笔记这种方式推动Python开发者提升效率Python并发编程之线程池/进程池Python黑魔法之描述符
Python爬虫借助cookie实现模拟登录实例解读
采集交流 • 优采云 发表了文章 • 0 个评论 • 454 次浏览 • 2020-07-05 08:00
举个事例,某些网站是须要登陆后就能得到你想要的信息的,不登录只能是旅客模式,那么我们可以借助Urllib2库保存我们曾经登陆过的Cookie,之后载入cookie获取我们想要的页面,然后再进行抓取。理解cookie主要是为我们快捷模拟登陆抓取目标网页作出打算。
我之前的贴子中使用过urlopen()这个函数来打开网页进行抓取,这仅仅只是一个简单的Python网页打开器,其参数也仅有urlopen(url,data,timeout),这三个参数对于我们获取目标网页的cookie是远远不够的。这时候我们就要借助到另外一种Opener——CookieJar。
cookielib也是Python进行爬虫的一个重要模块python爬虫模拟登录python爬虫模拟登录,他能与urllib2互相结合一起爬取想要的内容。该模块的CookieJar类的对象可以捕获cookie并在后续联接恳求时重新发送,这样就可以实现我们所须要的模拟登陆功能。
这里非常说明一下,cookielib是在py2.7中自带的模块,无需重新安装,想要查看其自带模块可以查看Python目录下的Lib文件夹,里面有所有安装的模块。我一开始没想起来,在pycharm中居然没有搜到cookielib,使用了快捷安装也报错:Couldn't find index page for 'Cookielib' (maybe misspelled?)
之后才想起来是不是自带的就有,没想到去lib文件夹一看还真有,白白浪费半个小时各类瞎折腾~~
下面我们就来介绍一下这个模块,该模块主要的对象有CookieJar、FileCookieJar、MozillaCookieJar、LWPCookieJar。
它们的关系:CookieJar —-派生—->FileCookieJar —-派生—–>MozillaCookieJar和LWPCookieJar 主要用法,我们下边也会提到。urllib2.urlopen()函数不支持验证、cookie或则其它HTTP中级功能。要支持这种功能,必须使用build_opener()(可以用于使python程序模拟浏览器进行访问,作用你懂得~)函数创建自定义Opener对象。
1、首先我们就来获取一下网站的cookie
例子:
#coding=utf-8
import cookielib
import urllib2
mycookie = cookielib.CookieJar() #声明一个CookieJar的类对象保存cookie(注意CookieJar的大小写问题)
handler = urllib2.HTTPCookieProcessor(mycookie) #利用urllib2库中的HTTPCookieProcessor来声明一个处理cookie的处理器
opener = urllib2.build_opener(handler) #利用handler来构造opener,opener的用法和urlopen()类似
response = opener.open("http://www.baidu.com") #opener返回的一个应答对象response
for item in my.cookie:
print"name="+item.name
print"value="+item.value
结果:
name=BAIDUID
value=73BD718962A6EA0DAD4CB9578A08FDD0:FG=1
name=BIDUPSID
value=73BD718962A6EA0DAD4CB9578A08FDD0
name=H_PS_PSSID
value=1450_19035_21122_17001_21454_21409_21394_21377_21526_21189_21398
name=PSTM
value=1478834132
name=BDSVRTM
value=0
name=BD_HOME
value=0
这样我们就得到了一个最简单的cookie。
2、将cookie保存到文件
上面我们得到了cookie,下面我们学习怎么保存cookie。在这里我们使用它的泛型MozillaCookieJar来实现Cookie的保存
例子:
#coding=utf-8
import cookielib
import urllib2
mycookie = cookielib.MozillaCookieJar() #声明一个MozillaCookieJar的类对象保存cookie(注意MozillaCookieJar的大小写问题)
handler = urllib2.HTTPCookieProcessor(mycookie) #利用urllib2库中的HTTPCookieProcessor来声明一个处理cookie的处理器
opener = urllib2.build_opener(handler) #利用handler来构造opener,opener的用法和urlopen()类似
response = opener.open("http://www.baidu.com") #opener返回的一个应答对象response
for item in mycookie:
print"name="+item.name
print"value="+item.value
filename='mycookie.txt'#设定保存的文件名
mycookie.save(filename,ignore_discard=True, ignore_expires=True)
将里面的事例简单变型就可以得到本例,使用了CookieJar的泛型MozillaCookiJar,为什么呢?我们将MozillaCookiJar换成CookieJar试试,下面一张图你能够明白:
CookieJar是没有保存save属性的~
save()这个方式中:ignore_discard的意思是虽然cookies将被遗弃也将它保存出来,ignore_expires的意思是假如在该文件中cookies早已存在,则覆盖原文件写入,在这里,我们将这两个全部设置为True。运行以后,cookies将被保存到cookie.txt文件中,我们查看一下内容:
这样我们就成功保存了我们想要的cookie
3、从文件中获取cookie并访问 查看全部
Cookie,指个别网站为了分辨用户身分、进行session跟踪而存储在用户本地终端上的数据(通常经过加密)。
举个事例,某些网站是须要登陆后就能得到你想要的信息的,不登录只能是旅客模式,那么我们可以借助Urllib2库保存我们曾经登陆过的Cookie,之后载入cookie获取我们想要的页面,然后再进行抓取。理解cookie主要是为我们快捷模拟登陆抓取目标网页作出打算。
我之前的贴子中使用过urlopen()这个函数来打开网页进行抓取,这仅仅只是一个简单的Python网页打开器,其参数也仅有urlopen(url,data,timeout),这三个参数对于我们获取目标网页的cookie是远远不够的。这时候我们就要借助到另外一种Opener——CookieJar。
cookielib也是Python进行爬虫的一个重要模块python爬虫模拟登录python爬虫模拟登录,他能与urllib2互相结合一起爬取想要的内容。该模块的CookieJar类的对象可以捕获cookie并在后续联接恳求时重新发送,这样就可以实现我们所须要的模拟登陆功能。
这里非常说明一下,cookielib是在py2.7中自带的模块,无需重新安装,想要查看其自带模块可以查看Python目录下的Lib文件夹,里面有所有安装的模块。我一开始没想起来,在pycharm中居然没有搜到cookielib,使用了快捷安装也报错:Couldn't find index page for 'Cookielib' (maybe misspelled?)

之后才想起来是不是自带的就有,没想到去lib文件夹一看还真有,白白浪费半个小时各类瞎折腾~~
下面我们就来介绍一下这个模块,该模块主要的对象有CookieJar、FileCookieJar、MozillaCookieJar、LWPCookieJar。
它们的关系:CookieJar —-派生—->FileCookieJar —-派生—–>MozillaCookieJar和LWPCookieJar 主要用法,我们下边也会提到。urllib2.urlopen()函数不支持验证、cookie或则其它HTTP中级功能。要支持这种功能,必须使用build_opener()(可以用于使python程序模拟浏览器进行访问,作用你懂得~)函数创建自定义Opener对象。
1、首先我们就来获取一下网站的cookie
例子:
#coding=utf-8
import cookielib
import urllib2
mycookie = cookielib.CookieJar() #声明一个CookieJar的类对象保存cookie(注意CookieJar的大小写问题)
handler = urllib2.HTTPCookieProcessor(mycookie) #利用urllib2库中的HTTPCookieProcessor来声明一个处理cookie的处理器
opener = urllib2.build_opener(handler) #利用handler来构造opener,opener的用法和urlopen()类似
response = opener.open("http://www.baidu.com";) #opener返回的一个应答对象response
for item in my.cookie:
print"name="+item.name
print"value="+item.value
结果:
name=BAIDUID
value=73BD718962A6EA0DAD4CB9578A08FDD0:FG=1
name=BIDUPSID
value=73BD718962A6EA0DAD4CB9578A08FDD0
name=H_PS_PSSID
value=1450_19035_21122_17001_21454_21409_21394_21377_21526_21189_21398
name=PSTM
value=1478834132
name=BDSVRTM
value=0
name=BD_HOME
value=0
这样我们就得到了一个最简单的cookie。
2、将cookie保存到文件
上面我们得到了cookie,下面我们学习怎么保存cookie。在这里我们使用它的泛型MozillaCookieJar来实现Cookie的保存
例子:
#coding=utf-8
import cookielib
import urllib2
mycookie = cookielib.MozillaCookieJar() #声明一个MozillaCookieJar的类对象保存cookie(注意MozillaCookieJar的大小写问题)
handler = urllib2.HTTPCookieProcessor(mycookie) #利用urllib2库中的HTTPCookieProcessor来声明一个处理cookie的处理器
opener = urllib2.build_opener(handler) #利用handler来构造opener,opener的用法和urlopen()类似
response = opener.open("http://www.baidu.com";) #opener返回的一个应答对象response
for item in mycookie:
print"name="+item.name
print"value="+item.value
filename='mycookie.txt'#设定保存的文件名
mycookie.save(filename,ignore_discard=True, ignore_expires=True)
将里面的事例简单变型就可以得到本例,使用了CookieJar的泛型MozillaCookiJar,为什么呢?我们将MozillaCookiJar换成CookieJar试试,下面一张图你能够明白:

CookieJar是没有保存save属性的~
save()这个方式中:ignore_discard的意思是虽然cookies将被遗弃也将它保存出来,ignore_expires的意思是假如在该文件中cookies早已存在,则覆盖原文件写入,在这里,我们将这两个全部设置为True。运行以后,cookies将被保存到cookie.txt文件中,我们查看一下内容:

这样我们就成功保存了我们想要的cookie
3、从文件中获取cookie并访问
从python基础到爬虫的书有哪些值得推荐
采集交流 • 优采云 发表了文章 • 0 个评论 • 483 次浏览 • 2020-07-04 08:00
第一个
个人觉得《Python学习手册:第3版》是学习语言基础比较好的书了.
《Python学习手册(第3版)》讲述了:Python可移植、功能强悍、易于使用,是编撰独立应用程序和脚本应用程序的理想选择。无论你是刚接触编程或则刚接触Python,通过学习《Python学习手册(第3版)》,你可以迅速高效地精通核心Python语言基础。读完《Python学习手册(第3版)》,你会对这门语言有足够的了解,从而可以在你所从事的任何应用领域中使用它。
《Python学习手册(第3版)》是作者依据过去10年用于教学而广为人知的培训课程的材料编撰而成的。除了有许多详尽说明和每章小结之外,每章还包括一个头脑风暴:这是《Python学习手册(第3版)》独特的一部分,配合以实用的练习题和复习题,让读者练习新学的方法并测试自己的理解程度。
《Python学习手册(第3版)》包括:
类型和操作——深入讨论Python主要的外置对象类型:数字、列表和字典等。
语句和句型——在Python中输入代码来构建并处理对象,以及Python通常的句型模型。
函数——Python基本的面向过程工具,用于组织代码和重用。
模块——封装句子、函数以及其他工具,从而可以组织成较大的组件。
类和OOP——Python可选的面向对象编程工具,可用于组织程序代码因而实现订制和重用。
异常和工具——异常处理模型和句子,并介绍编撰更大程序的开发工具。
讨论Python 3.0。
《Python学习手册(第3版)》让你对Python语言有深入而完整的了解,从而帮助你理解今后碰到的任何Python应用程序实例。如果你打算探求Google和YouTube为何选中了Python,《Python学习手册(第3版)》就是你入门的最佳手册。
第二个
《Python基础教程(第2版·修订版)》也是精典的Python入门教程,层次鲜明,结构严谨,内容详实,特别是最后几章,作者将上面述说的内容应用到10个引人入胜的项目中,并以模板的方式介绍了项目的开发过程,手把手院长Python开发,让读者从项目中展现Python的真正魅力。这本书既适宜初学者筑牢基础,又能帮助Python程序员提高技能,即使是Python方面的技术专家,也能从书里找到耳目一新的内容。
第三个
《“笨办法”学Python(第3版)》是一本Python入门书籍,适合对计算机了解不多,没有学过编程,但对编程感兴趣的初学者使用。这本书结构十分简单,其中覆盖了输入/输出、变量和函数三个主题,以及一些比较中级的话题,如条件判定、循环、类和对象、代码测试及项目的实现等。每一章的格式基本相同,以代码习题开始,按照说明编撰代码,运行并检测结果,然后再做附加练习。这本书以习题的方法引导读者一步一步学习编程,从简单的复印仍然讲授到完整项目的实现,让初学者从基础的编程技术入手,最终体验到软件开发的基本过程。
【大牛评价】hardway(笨办法)比较适宜起步编程,作为Python的入门挺不错。
第四个
在这里给你们推荐最后一本《集体智慧编程》
本书以机器学习与估算统计为主题背景,专门述说怎么挖掘和剖析Web上的数据和资源,如何剖析用户体验、市场营销、个人品位等众多信息,并得出有用的推论python爬虫数据书籍,通过复杂的算法来从Web网站获取、收集并剖析用户的数据和反馈信息,以便创造新的用户价值和商业价值。
全书内容详实,包括协作过滤技术(实现关联产品推荐功能)、集群数据剖析(在大规模数据集中开掘相像的数据子集)、搜索引擎核心技术(爬虫、索引、查询引擎、PageRank算法等)、搜索海量信息并进行剖析统计得出结论的优化算法、贝叶斯过滤技术(垃圾邮件过滤、文本过滤)、用决策树技术实现预测和决策建模功能、社交网络的信息匹配技术、机器学习和人工智能应用等。
本书是Web开发者、架构师、应用工程师等的极佳选择。
“太棒了!对于初学这种算法的开发者而言,我想不出有比这本书更好的选择了,而对于象我这样学过Al的道友而言,我也想不出还有什么更好的办法才能使自己重温这种知识的细节。”
——Dan Russell,资深技术总监,Google
“Toby的这本书十分成功地将机器学习算法这一复杂的议程分拆成了一个个既实用又易懂的事例,我们可以直接借助那些反例来剖析当前网路上的社会化交互作用。假如我早三年读过这本书,就会省去许多宝贵的时间python爬虫数据书籍,也不至于走那么多的弯路了。”
——Tim Wolters,CTO,Collective Intellect
第五个
其实我认为很多人也在看《Python核心编程:第2版》.在我自己看来,我并不喜欢这本书.
这本书的原书的勘误表就有够长的,翻译时却几乎没有参考勘误表,把原书的所有低级错误都搬进去了。这本书的原书质量也并不好,书的结构组织并不合理,不适宜初学者阅读。有人说,这本书适宜进阶阅读,我认为也不尽然。这本书好多地方都写的欲言又止的,看得人很郁闷。 查看全部
于我个人而言,我很喜欢2113Python,当然我也5261有很多的理由推荐你去学python.我只4102说两点.一是简单,二是写python工资高1653.我感觉这俩理由就够了,对不对.买本书,装上pycharm,把书里面的事例习题都敲一遍.再用flask,web.py等框架搭个小网站.. 完美...(小伙伴们有问到该学python2.7还是3.X,那我的答案是:目前大多数实际开发,都是用2.7的,因为实际项目开发有很多依赖的包,都只支持到2.7,你用3.X干不了活.那你能怎样办.所以不需要苦恼.等3.X普及,你写的2.7代码,都可以无痛移植,妥妥的不用害怕.)
第一个
个人觉得《Python学习手册:第3版》是学习语言基础比较好的书了.
《Python学习手册(第3版)》讲述了:Python可移植、功能强悍、易于使用,是编撰独立应用程序和脚本应用程序的理想选择。无论你是刚接触编程或则刚接触Python,通过学习《Python学习手册(第3版)》,你可以迅速高效地精通核心Python语言基础。读完《Python学习手册(第3版)》,你会对这门语言有足够的了解,从而可以在你所从事的任何应用领域中使用它。
《Python学习手册(第3版)》是作者依据过去10年用于教学而广为人知的培训课程的材料编撰而成的。除了有许多详尽说明和每章小结之外,每章还包括一个头脑风暴:这是《Python学习手册(第3版)》独特的一部分,配合以实用的练习题和复习题,让读者练习新学的方法并测试自己的理解程度。
《Python学习手册(第3版)》包括:
类型和操作——深入讨论Python主要的外置对象类型:数字、列表和字典等。
语句和句型——在Python中输入代码来构建并处理对象,以及Python通常的句型模型。
函数——Python基本的面向过程工具,用于组织代码和重用。
模块——封装句子、函数以及其他工具,从而可以组织成较大的组件。
类和OOP——Python可选的面向对象编程工具,可用于组织程序代码因而实现订制和重用。
异常和工具——异常处理模型和句子,并介绍编撰更大程序的开发工具。
讨论Python 3.0。
《Python学习手册(第3版)》让你对Python语言有深入而完整的了解,从而帮助你理解今后碰到的任何Python应用程序实例。如果你打算探求Google和YouTube为何选中了Python,《Python学习手册(第3版)》就是你入门的最佳手册。
第二个
《Python基础教程(第2版·修订版)》也是精典的Python入门教程,层次鲜明,结构严谨,内容详实,特别是最后几章,作者将上面述说的内容应用到10个引人入胜的项目中,并以模板的方式介绍了项目的开发过程,手把手院长Python开发,让读者从项目中展现Python的真正魅力。这本书既适宜初学者筑牢基础,又能帮助Python程序员提高技能,即使是Python方面的技术专家,也能从书里找到耳目一新的内容。
第三个
《“笨办法”学Python(第3版)》是一本Python入门书籍,适合对计算机了解不多,没有学过编程,但对编程感兴趣的初学者使用。这本书结构十分简单,其中覆盖了输入/输出、变量和函数三个主题,以及一些比较中级的话题,如条件判定、循环、类和对象、代码测试及项目的实现等。每一章的格式基本相同,以代码习题开始,按照说明编撰代码,运行并检测结果,然后再做附加练习。这本书以习题的方法引导读者一步一步学习编程,从简单的复印仍然讲授到完整项目的实现,让初学者从基础的编程技术入手,最终体验到软件开发的基本过程。
【大牛评价】hardway(笨办法)比较适宜起步编程,作为Python的入门挺不错。
第四个
在这里给你们推荐最后一本《集体智慧编程》
本书以机器学习与估算统计为主题背景,专门述说怎么挖掘和剖析Web上的数据和资源,如何剖析用户体验、市场营销、个人品位等众多信息,并得出有用的推论python爬虫数据书籍,通过复杂的算法来从Web网站获取、收集并剖析用户的数据和反馈信息,以便创造新的用户价值和商业价值。
全书内容详实,包括协作过滤技术(实现关联产品推荐功能)、集群数据剖析(在大规模数据集中开掘相像的数据子集)、搜索引擎核心技术(爬虫、索引、查询引擎、PageRank算法等)、搜索海量信息并进行剖析统计得出结论的优化算法、贝叶斯过滤技术(垃圾邮件过滤、文本过滤)、用决策树技术实现预测和决策建模功能、社交网络的信息匹配技术、机器学习和人工智能应用等。
本书是Web开发者、架构师、应用工程师等的极佳选择。
“太棒了!对于初学这种算法的开发者而言,我想不出有比这本书更好的选择了,而对于象我这样学过Al的道友而言,我也想不出还有什么更好的办法才能使自己重温这种知识的细节。”
——Dan Russell,资深技术总监,Google
“Toby的这本书十分成功地将机器学习算法这一复杂的议程分拆成了一个个既实用又易懂的事例,我们可以直接借助那些反例来剖析当前网路上的社会化交互作用。假如我早三年读过这本书,就会省去许多宝贵的时间python爬虫数据书籍,也不至于走那么多的弯路了。”
——Tim Wolters,CTO,Collective Intellect
第五个
其实我认为很多人也在看《Python核心编程:第2版》.在我自己看来,我并不喜欢这本书.
这本书的原书的勘误表就有够长的,翻译时却几乎没有参考勘误表,把原书的所有低级错误都搬进去了。这本书的原书质量也并不好,书的结构组织并不合理,不适宜初学者阅读。有人说,这本书适宜进阶阅读,我认为也不尽然。这本书好多地方都写的欲言又止的,看得人很郁闷。
Python爬虫的用途
采集交流 • 优采云 发表了文章 • 0 个评论 • 361 次浏览 • 2020-06-30 08:01
Python 爬虫的用途 Python 爬虫是用 Python 编程语言实现的网路爬虫,主要用于网路数据的抓取和处理,相比于其他语言,Python 是一门特别适宜开发网路爬虫的编程语言,大量外置包,可以轻松实现网路爬虫功能。 Python 爬虫可以做的事情好多,如搜索引擎、采集数据、广告过滤等,Python爬虫还可以用于数据剖析,在数据的抓取方面可以作用巨大! n Python 爬虫构架组成 1. URL 管理器:管理待爬取的 url 集合和已爬取的 url 集合,传送待爬取的 url 给网页下载器; 2. 网页下载器:爬取 url 对应的网页,存储成字符串,传送给网页解析器; 3. 网页解析器:解析出有价值的数据,存储出来,同时补充 url 到 URL 管理器。 n Python 爬虫工作原理 Python 爬虫通过 URL 管理器,判断是否有待爬 URL,如果有待爬 URL,通过调度器进行传递给下载器网络爬虫 作用,下载 URL 内容,并通过调度器传送给解析器,解析URL 内容,并将价值数据和新 URL 列表通过调度器传递给应用程序,并输出价值信息的过程。 n Python 爬虫常用框架有: grab:网络爬虫框架(基于 pycurl/multicur); scrapy:网络爬虫框架(基于 twisted),不支持 Python3; pyspider:一个强悍的爬虫系统;cola:一个分布式爬虫框架; portia:基于 Scrapy 的可视化爬虫; restkit:Python 的 HTTP 资源工具包。它可以使你轻松地访问 HTTP 资源,并围绕它完善的对象; demiurge:基于 PyQuery 的爬虫微框架。 Python 爬虫应用领域广泛,在网络爬虫领域处于霸主位置,Scrapy、Request、BeautifuSoap、urlib 等框架的应用,可以实现爬行自如的功能,只要您数据抓取看法网络爬虫 作用,Python 爬虫均可实现!
Python爬虫实现百度图片手动下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 343 次浏览 • 2020-06-29 08:01
分析需求剖析网页源代码,配合开发者工具编撰正则表达式或则XPath表达式即将编撰 python 爬虫代码 效果预览
运行疗效如下:
存放图片的文件夹:
我们的爬虫起码要实现两个功能:一是搜索图片,二是手动下载。
搜索图片:最容易想到的是爬百度图片的结果,我们就上百度图片瞧瞧:
随便搜索几个关键字,可以看见早已搜索下来好多张图片:
我们点击右键,查看源代码:
打开源代码以后,发现一堆源代码比较难找出我们想要的资源。
这个时侯,就要用开发者工具!我们回到上一页面,调出开发者工具,我们须要用的是左上角那种东西:(鼠标追随)。
然后选择你想看源代码的地方,就可以发觉,下面的代码市手动定位到了相应的位置。如下图:
我们复制这个地址,然后到昨天的一堆源代码里搜索一下百度图片 爬虫,发现了它的位置,但是这儿我们又困惑了,这个图片有这么多地址,到底用那个呢?我们可以看见有thumbURL,middleURL,hoverURL,objURL
通过剖析可以晓得,前面两个是缩小的版本,hoverURL 是键盘联通之后显示的版本,objURL 应该是我们须要的,可以分别打开这几个网址瞧瞧,发现 objURL 的那种最大最清晰。
找到了图片地址,接下来我们剖析源代码。看看是不是所有的 objURL 都是图片。
发现都是以.jpg格式结尾的图片。
pic_url = re.findall('"objURL":"(.*?)",',html,re.S)
这里我们用了2个包百度图片 爬虫,一个是正则,一个是 requests 包
#-*- coding:utf-8 -*-
import re
import requests
复制百度图片搜索的链接,传入 requests ,然后把正则表达式写好
url = 'https://image.baidu.com/search/index?tn=baiduimage&ie=utf-8&word=%E6%A0%97%E5%B1%B1%E6%9C%AA%E6%9D%A5%E5%A4%B4%E5%83%8F&ct=201326592&ic=0&lm=-1&width=&height=&v=index' html = requests.get(url).text pic_url = re.findall('"objURL":"(.*?)",',html,re.S)
因为有很多张图片,所以要循环,我们复印出结果来瞧瞧,然后用 requests 获取网址,由于有些图片可能存在网址打不开的情况,所以加了10秒超时控制。
pic_url = re.findall('"objURL":"(.*?)",',html,re.S) i = 1 for each in pic_url:
print each
try:
pic= requests.get(each, timeout=10)
except requests.exceptions.ConnectionError: print('【错误】当前图片无法下载')
continue
接着就是把图片保存出来,我们事先构建好一个 images 目录,把图片都放进去,命名的时侯,以数字命名。
dir = '../images/' + keyword + '_' + str(i) + '.jpg'
fp = open(dir, 'wb')
fp.write(pic.content)
fp.close()
i += 1
完整的代码
# -*- coding:utf-8 -*-
import re
import requests
def dowmloadPic(html, keyword):
pic_url = re.findall('"objURL":"(.*?)",', html, re.S)
i = 1
print('找到关键词:' + keyword + '的图片,现在开始下载图片...')
for each in pic_url:
print('正在下载第' + str(i) + '张图片,图片地址:' + str(each))
try:
pic = requests.get(each, timeout=10)
except requests.exceptions.ConnectionError:
print('【错误】当前图片无法下载')
continue
dir = '../images/' + keyword + '_' + str(i) + '.jpg'
fp = open(dir, 'wb')
fp.write(pic.content)
fp.close()
i += 1
if __name__ == '__main__':
word = input("Input key word: ")
url = 'http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=' + word + '&ct=201326592&v=flip'
result = requests.get(url)
dowmloadPic(result.text, word)
我们听到有的图片没显示下来,打开网址看,发现确实没了。
因为百度有些图片它缓存到百度的服务器上,所以我们在百度上能够看到它,但它的实际链接早已失效了。
enjoy 我们的第一个图片下载爬虫吧!当然它除了能下载百度的图片,依葫芦画瓢,你如今应当能做好多事情了,比如爬取头像,爬天猫展示图等等。
完整代码已然放在Githut上 查看全部
制作一个爬虫通常分以下几个步骤:
分析需求剖析网页源代码,配合开发者工具编撰正则表达式或则XPath表达式即将编撰 python 爬虫代码 效果预览
运行疗效如下:

存放图片的文件夹:

我们的爬虫起码要实现两个功能:一是搜索图片,二是手动下载。
搜索图片:最容易想到的是爬百度图片的结果,我们就上百度图片瞧瞧:

随便搜索几个关键字,可以看见早已搜索下来好多张图片:

我们点击右键,查看源代码:
打开源代码以后,发现一堆源代码比较难找出我们想要的资源。
这个时侯,就要用开发者工具!我们回到上一页面,调出开发者工具,我们须要用的是左上角那种东西:(鼠标追随)。
然后选择你想看源代码的地方,就可以发觉,下面的代码市手动定位到了相应的位置。如下图:


我们复制这个地址,然后到昨天的一堆源代码里搜索一下百度图片 爬虫,发现了它的位置,但是这儿我们又困惑了,这个图片有这么多地址,到底用那个呢?我们可以看见有thumbURL,middleURL,hoverURL,objURL

通过剖析可以晓得,前面两个是缩小的版本,hoverURL 是键盘联通之后显示的版本,objURL 应该是我们须要的,可以分别打开这几个网址瞧瞧,发现 objURL 的那种最大最清晰。
找到了图片地址,接下来我们剖析源代码。看看是不是所有的 objURL 都是图片。

发现都是以.jpg格式结尾的图片。
pic_url = re.findall('"objURL":"(.*?)",',html,re.S)
这里我们用了2个包百度图片 爬虫,一个是正则,一个是 requests 包
#-*- coding:utf-8 -*-
import re
import requests
复制百度图片搜索的链接,传入 requests ,然后把正则表达式写好

url = 'https://image.baidu.com/search/index?tn=baiduimage&ie=utf-8&word=%E6%A0%97%E5%B1%B1%E6%9C%AA%E6%9D%A5%E5%A4%B4%E5%83%8F&ct=201326592&ic=0&lm=-1&width=&height=&v=index' html = requests.get(url).text pic_url = re.findall('"objURL":"(.*?)",',html,re.S)
因为有很多张图片,所以要循环,我们复印出结果来瞧瞧,然后用 requests 获取网址,由于有些图片可能存在网址打不开的情况,所以加了10秒超时控制。
pic_url = re.findall('"objURL":"(.*?)",',html,re.S) i = 1 for each in pic_url:
print each
try:
pic= requests.get(each, timeout=10)
except requests.exceptions.ConnectionError: print('【错误】当前图片无法下载')
continue
接着就是把图片保存出来,我们事先构建好一个 images 目录,把图片都放进去,命名的时侯,以数字命名。
dir = '../images/' + keyword + '_' + str(i) + '.jpg'
fp = open(dir, 'wb')
fp.write(pic.content)
fp.close()
i += 1
完整的代码
# -*- coding:utf-8 -*-
import re
import requests
def dowmloadPic(html, keyword):
pic_url = re.findall('"objURL":"(.*?)",', html, re.S)
i = 1
print('找到关键词:' + keyword + '的图片,现在开始下载图片...')
for each in pic_url:
print('正在下载第' + str(i) + '张图片,图片地址:' + str(each))
try:
pic = requests.get(each, timeout=10)
except requests.exceptions.ConnectionError:
print('【错误】当前图片无法下载')
continue
dir = '../images/' + keyword + '_' + str(i) + '.jpg'
fp = open(dir, 'wb')
fp.write(pic.content)
fp.close()
i += 1
if __name__ == '__main__':
word = input("Input key word: ")
url = 'http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=' + word + '&ct=201326592&v=flip'
result = requests.get(url)
dowmloadPic(result.text, word)


我们听到有的图片没显示下来,打开网址看,发现确实没了。

因为百度有些图片它缓存到百度的服务器上,所以我们在百度上能够看到它,但它的实际链接早已失效了。
enjoy 我们的第一个图片下载爬虫吧!当然它除了能下载百度的图片,依葫芦画瓢,你如今应当能做好多事情了,比如爬取头像,爬天猫展示图等等。
完整代码已然放在Githut上
2019最新30个小时搞定Python网络爬虫(全套详尽版) 零基础入门 视频教
采集交流 • 优采云 发表了文章 • 0 个评论 • 369 次浏览 • 2020-06-26 08:01
1、零基础对Python网络爬虫感兴趣的开发者
2、想从事Python网路爬虫工程师相关工作的开发者
3、想学习Python网路爬虫作为技术储备的开发者
1、本课程的目标是将你们培养成Python网路爬虫工程师。薪资基本在13k-36k左右;
2、学完才能从零开始把握Python爬虫项目的编撰,学会独立开发常见的爬虫项目;
3、学完能把握常见的反爬处理手段爬虫入门书籍,比如验证码处理、浏览器伪装、代理IP池技术和用户代理池技术等;
4、学完才能熟练使用正则表达式和XPath表达式进行信息提取;
5、学完把握抓包技术,掌握屏蔽的数据信息怎样进行提取,学会手动模拟加载行为、进行网址构造和手动模拟Ajax异步恳求数据;
6、熟练把握urllib模块,熟练使用Scrapy框架进行爬虫项目开发。
第一章节:Python 网络爬虫之基础
第二章节:Python网路爬虫之工作原理
第三章节:Python网路爬虫之正则表达式
第五章节:Python网路爬虫之用户和IP代理池
第六章节 :Python网路爬虫之腾讯陌陌和视频实战
第七章节:Python网路爬虫之Scrapy框架
第八章节:Python网路爬虫之Scrapy与Urllib的整合
第九章节:Python网路爬虫之扩充学习
第十章节:Python网路爬虫之分布式爬虫 查看全部
这是一套完整的网路爬虫课程,通过该课程把握网路爬虫的相关知识,以便把握网路爬虫方方面面的知识,学完后胜任网路爬虫相关工作。 1、体系完整科学,可以系统化学习; 2、课程通俗易懂爬虫入门书籍,可以使学员真正学会; 3、从零开始教学直至深入,零基础的朋友亦可以学习!
1、零基础对Python网络爬虫感兴趣的开发者
2、想从事Python网路爬虫工程师相关工作的开发者
3、想学习Python网路爬虫作为技术储备的开发者
1、本课程的目标是将你们培养成Python网路爬虫工程师。薪资基本在13k-36k左右;
2、学完才能从零开始把握Python爬虫项目的编撰,学会独立开发常见的爬虫项目;
3、学完能把握常见的反爬处理手段爬虫入门书籍,比如验证码处理、浏览器伪装、代理IP池技术和用户代理池技术等;
4、学完才能熟练使用正则表达式和XPath表达式进行信息提取;
5、学完把握抓包技术,掌握屏蔽的数据信息怎样进行提取,学会手动模拟加载行为、进行网址构造和手动模拟Ajax异步恳求数据;
6、熟练把握urllib模块,熟练使用Scrapy框架进行爬虫项目开发。
第一章节:Python 网络爬虫之基础
第二章节:Python网路爬虫之工作原理
第三章节:Python网路爬虫之正则表达式
第五章节:Python网路爬虫之用户和IP代理池
第六章节 :Python网路爬虫之腾讯陌陌和视频实战
第七章节:Python网路爬虫之Scrapy框架
第八章节:Python网路爬虫之Scrapy与Urllib的整合
第九章节:Python网路爬虫之扩充学习
第十章节:Python网路爬虫之分布式爬虫
求大神们推荐python入门书籍(爬虫方面)?
采集交流 • 优采云 发表了文章 • 0 个评论 • 316 次浏览 • 2020-06-25 08:03
题主的要求是Python入门,而且是和爬虫相关的书籍,那么有一本书简直很适宜了,那就是《 Python for Informatics 》(中文翻译叫《信息管理专业Python教程》),这本书除了是一本挺好的Python爬虫方面的入门书,而且还有以这本书为教材的配套的Coursera课程。
这本书是美国密西根大学信息学院院长为他的课程编撰的,是一本开源书,有人将他翻译成了中文版爬虫入门书籍,书上有配套的习题和代码,而且这种习题代码都可以在网上获取到,书本身并不厚,前面十章将的都是Python的基础用法,后面几张就是讲解和Python爬虫有关的,像正则表达式,网络编程(HTTP 协议), Web Service,数据库与SQL句子,数据可视化,书中还仔细讲解了用Python爬取Twiter上的用户信息,和各类解析html会用到的工具,如BeautifulSoup等,学完本书,爬取个知乎哪些的都是小意思!本书中文版下载地址地址。
说完了书在来说说配套的Coursera课程,是Coursera上太火的零基础 Python 入门 专项课程,内容大致和书上的内容差不多,分成了6门课程,前三门课程讲解Python句型,后面讲Python爬虫的数据采集数据处理等爬虫入门书籍,并且有不少的习题,老师也十分特别有趣,,知乎上很早之前就有人介绍这门课程coursera上有什么值得学习的Python,数据剖析的课程? - 程刚的回答,本课的课程地址,并且这门课正好就是今天开课(7月25号),学习课程假如不要证书的话也不用花钱,貌似大部分配有英文字幕。 查看全部

题主的要求是Python入门,而且是和爬虫相关的书籍,那么有一本书简直很适宜了,那就是《 Python for Informatics 》(中文翻译叫《信息管理专业Python教程》),这本书除了是一本挺好的Python爬虫方面的入门书,而且还有以这本书为教材的配套的Coursera课程。
这本书是美国密西根大学信息学院院长为他的课程编撰的,是一本开源书,有人将他翻译成了中文版爬虫入门书籍,书上有配套的习题和代码,而且这种习题代码都可以在网上获取到,书本身并不厚,前面十章将的都是Python的基础用法,后面几张就是讲解和Python爬虫有关的,像正则表达式,网络编程(HTTP 协议), Web Service,数据库与SQL句子,数据可视化,书中还仔细讲解了用Python爬取Twiter上的用户信息,和各类解析html会用到的工具,如BeautifulSoup等,学完本书,爬取个知乎哪些的都是小意思!本书中文版下载地址地址。
说完了书在来说说配套的Coursera课程,是Coursera上太火的零基础 Python 入门 专项课程,内容大致和书上的内容差不多,分成了6门课程,前三门课程讲解Python句型,后面讲Python爬虫的数据采集数据处理等爬虫入门书籍,并且有不少的习题,老师也十分特别有趣,,知乎上很早之前就有人介绍这门课程coursera上有什么值得学习的Python,数据剖析的课程? - 程刚的回答,本课的课程地址,并且这门课正好就是今天开课(7月25号),学习课程假如不要证书的话也不用花钱,貌似大部分配有英文字幕。
Python借助requests进行模拟登陆
采集交流 • 优采云 发表了文章 • 0 个评论 • 669 次浏览 • 2020-06-25 08:00
Python3 模拟登陆并爬取表格数据!
本节主要内容有:通过requests库模拟表单递交通过pandas库提取网页表格上周五,大师兄发给我一个网址,哭哭啼啼地求我:“去!把这个网页上所有年所有市所有小麦的数据全爬出来,存到Access里!”我看他可怜,勉为其难地挥挥手说:“好嘞,马上就开始!”目标剖析Python学习交流群:1004391443大师兄给我的网址是这个:
使用python模拟登陆
使用python模拟登陆Windows + Linux 均成功
Python模拟一个用户登入系统
题目:模拟一个用户登入系统,用户输入用户名和密码,输入正确即可步入系统直接上代码:#模拟一个用户登入系统,用户输入用户名和密码,输入正确即可步入系统d=['yao','123456']while 1:name =input("请输入用户名:")if name in d:breakelse:print("你输入的用户名不存在,请...
使用python模拟浏览器实现登录
让我们通过命令行模拟浏览器实现登录操作,看看一个简单的登录操作,具体是怎样实现的
Python爬虫入门-表单递交与模拟登陆
前言明天主要讲两个方面:利用Request库进行POST恳求表单交互cookie实现模拟登陆网站Requests实现POST恳求今requests可以以多种形式进行post恳求,比如form表单方式、json方式等。今天主要以表单方式举例:Reqeusts支持以form表单方式发送post恳求,只须要将恳求的参数构造成一个字典,然后传给requests.post()...
Python模拟百度登陆
注:本文转载,如有侵权,请告知将给以删掉原文章链接:本来写这个玩意是想拿来手动登入百度,然后按照帖吧内的的排行抓取会员头像的,比如生成一个帖吧万人头像图或千人头像图。也算是练练手。完成后才发觉抓那种帖吧排行完全不需要登陆…也好,以后拿来做手动一键签到(经常忘打卡),抢二楼哪些的,也...
任务自动化_request 模拟登陆实战
知识点:request 带密码登入、selenium+headless Chrome、pandas、思路:request 爬虫模拟登陆,下载文档,再用 pandas 进行数据剖析
python实现模拟登陆
本文主要用python实现了对网站的模拟登陆。通过自己构造post数据来用Python实现登陆过程。当你要模拟登陆一个网站时,首先要搞清楚网站的登陆处理细节(发了什么样的数据,给谁发等...)。我是通过HTTPfox来抓取http数据包来剖析该网站的登陆流程。同时,我们还要剖析抓到的post包的数据结构和header,要按照递交的数据结构和heander来构造自己的pos...
请问写python爬虫怎样用urllib或则requests模拟用户登入
比如我在百度文库下个教案,,我用urllib2或则request,我可以用urllib2.open(url)或者requests.get(url)来打开页面,但是不知道怎么写cookie的,就是使浏览器觉得你早已登陆了,请问怎么写urllib或则requests.get呢?谢谢
requests 实现模拟登陆,获取cookie
有个需求须要模拟登陆csdn获取cookie,对csdn进行后续系列操作,刚开始使用的selenium,功能可以实现,但是效率有点低,后来改用的requests,遇到不少坑,今天来总结一下。首先找到csdn登陆的url,在故意输错密码的情况下点击登陆,检查会发觉network中有一个dologin的响应,这就是要递交到服务器的帐号密码信息。点开会发觉下图所示:请求的url,请求方法p...
Python模拟登录
最近想做一个可以模拟人工,对网站的内容进行操作,比如手动购物,自动支付。朋友向我推荐用Python去写python爬虫模拟登录,我也就开始用Python。看了一些大约,用Python3 的requests去弄,感觉逻辑很简单。最主要的问题是怎样去剖析网站的逻辑,这很难。用了chrome f12 记录网页的操作,但是一点是,chrome不能全文查找,没办法搜索到诸如帐号密码的传送,cookie等问题,手动查找好烦。
Python模拟登陆的几种方式
目录方式一:直接使用已知的cookie访问技巧二:模拟登陆后再携带得到的cookie访问方式三:模拟登陆后用session保持登入状态方式四:使用无头浏览器访问正文方式一:直接使用已知的cookie访问特征:简单,但须要先在浏览器登陆原理:简单地说,cookie保存在发起恳求的客户端中,服务器借助cookie来分辨不同的客户端。因为htt...
用Python模拟登陆中学教务系统抢课
-- Illustrations by Vladislav Solovjov --作者:小苏打博客地址:地址:github....
Python爬虫之模拟登陆总结
备注:python 2.7.9,32位有些网站需要登入后才会爬取所须要的信息python爬虫模拟登录,此时可以设计爬虫进行模拟登陆,原理是借助浏览器cookie。一、浏览器访问服务器的过程: (1)浏览器(客户端)向Web服务器发出一个HTTP请求(Http request); (2)Web服务器收到恳求,发回响应信息(Http Response); (3)浏览器解析内容呈现
python模拟浏览器登陆
转自:
python3下使用requests实现模拟用户登入 —— 基础篇(马蜂窝)
python3下使用requests实现模拟用户登入 —— 基础篇(马蜂窝)1. 了解cookie和session首先一定要先了解到cookie和session是哪些,这是前面理解网站交互,模拟用户登入的基础。1.1. 无状态合同:Http如上图所示,HTTP合同 是无状态的合同,用户浏览服务器上的内容,只须要发送页面恳求,服务器返回内容。对于服务器来说,并不关心,也...
Visual C++技术内幕(第四版).part4.rar下载
一个十分清淅的PDF版的Visual C++技术黑幕(第四版),至于这本书究竟有多强就不用我介绍了吧!本书共分part1、part2、part3、part4 四部份相关下载链接:
sap施行顾问宝典2下载
sap施行顾问宝典一共3个压缩包挺好的东西。相关下载链接:
Xilinx_ise使用教程(配合Modelsim使用)下载
这是我搜集的一个Xilinx_ISE6.1的教程,结合了MODELSIM的仿真功能,自己觉得讲解的还可以,适合初学者入门使用,对其他人员也有一定的参考价值。相关下载链接:
相关热词c# 程序跳转c#索引器定义、c#扫描软件c# 文字复印左右反转c#byte转换成数字c# 音量调节组件c# wpf 界面c# 读取证书文件的内容c# dgv 树结构c#承继 反序列化
我们是太有底线的 查看全部

Python3 模拟登陆并爬取表格数据!
本节主要内容有:通过requests库模拟表单递交通过pandas库提取网页表格上周五,大师兄发给我一个网址,哭哭啼啼地求我:“去!把这个网页上所有年所有市所有小麦的数据全爬出来,存到Access里!”我看他可怜,勉为其难地挥挥手说:“好嘞,马上就开始!”目标剖析Python学习交流群:1004391443大师兄给我的网址是这个:
使用python模拟登陆
使用python模拟登陆Windows + Linux 均成功
Python模拟一个用户登入系统
题目:模拟一个用户登入系统,用户输入用户名和密码,输入正确即可步入系统直接上代码:#模拟一个用户登入系统,用户输入用户名和密码,输入正确即可步入系统d=['yao','123456']while 1:name =input("请输入用户名:")if name in d:breakelse:print("你输入的用户名不存在,请...

使用python模拟浏览器实现登录
让我们通过命令行模拟浏览器实现登录操作,看看一个简单的登录操作,具体是怎样实现的
Python爬虫入门-表单递交与模拟登陆
前言明天主要讲两个方面:利用Request库进行POST恳求表单交互cookie实现模拟登陆网站Requests实现POST恳求今requests可以以多种形式进行post恳求,比如form表单方式、json方式等。今天主要以表单方式举例:Reqeusts支持以form表单方式发送post恳求,只须要将恳求的参数构造成一个字典,然后传给requests.post()...
Python模拟百度登陆
注:本文转载,如有侵权,请告知将给以删掉原文章链接:本来写这个玩意是想拿来手动登入百度,然后按照帖吧内的的排行抓取会员头像的,比如生成一个帖吧万人头像图或千人头像图。也算是练练手。完成后才发觉抓那种帖吧排行完全不需要登陆…也好,以后拿来做手动一键签到(经常忘打卡),抢二楼哪些的,也...
任务自动化_request 模拟登陆实战
知识点:request 带密码登入、selenium+headless Chrome、pandas、思路:request 爬虫模拟登陆,下载文档,再用 pandas 进行数据剖析
python实现模拟登陆
本文主要用python实现了对网站的模拟登陆。通过自己构造post数据来用Python实现登陆过程。当你要模拟登陆一个网站时,首先要搞清楚网站的登陆处理细节(发了什么样的数据,给谁发等...)。我是通过HTTPfox来抓取http数据包来剖析该网站的登陆流程。同时,我们还要剖析抓到的post包的数据结构和header,要按照递交的数据结构和heander来构造自己的pos...

请问写python爬虫怎样用urllib或则requests模拟用户登入
比如我在百度文库下个教案,,我用urllib2或则request,我可以用urllib2.open(url)或者requests.get(url)来打开页面,但是不知道怎么写cookie的,就是使浏览器觉得你早已登陆了,请问怎么写urllib或则requests.get呢?谢谢
requests 实现模拟登陆,获取cookie
有个需求须要模拟登陆csdn获取cookie,对csdn进行后续系列操作,刚开始使用的selenium,功能可以实现,但是效率有点低,后来改用的requests,遇到不少坑,今天来总结一下。首先找到csdn登陆的url,在故意输错密码的情况下点击登陆,检查会发觉network中有一个dologin的响应,这就是要递交到服务器的帐号密码信息。点开会发觉下图所示:请求的url,请求方法p...
Python模拟登录
最近想做一个可以模拟人工,对网站的内容进行操作,比如手动购物,自动支付。朋友向我推荐用Python去写python爬虫模拟登录,我也就开始用Python。看了一些大约,用Python3 的requests去弄,感觉逻辑很简单。最主要的问题是怎样去剖析网站的逻辑,这很难。用了chrome f12 记录网页的操作,但是一点是,chrome不能全文查找,没办法搜索到诸如帐号密码的传送,cookie等问题,手动查找好烦。
Python模拟登陆的几种方式
目录方式一:直接使用已知的cookie访问技巧二:模拟登陆后再携带得到的cookie访问方式三:模拟登陆后用session保持登入状态方式四:使用无头浏览器访问正文方式一:直接使用已知的cookie访问特征:简单,但须要先在浏览器登陆原理:简单地说,cookie保存在发起恳求的客户端中,服务器借助cookie来分辨不同的客户端。因为htt...
用Python模拟登陆中学教务系统抢课
-- Illustrations by Vladislav Solovjov --作者:小苏打博客地址:地址:github....
Python爬虫之模拟登陆总结
备注:python 2.7.9,32位有些网站需要登入后才会爬取所须要的信息python爬虫模拟登录,此时可以设计爬虫进行模拟登陆,原理是借助浏览器cookie。一、浏览器访问服务器的过程: (1)浏览器(客户端)向Web服务器发出一个HTTP请求(Http request); (2)Web服务器收到恳求,发回响应信息(Http Response); (3)浏览器解析内容呈现
python模拟浏览器登陆
转自:
python3下使用requests实现模拟用户登入 —— 基础篇(马蜂窝)
python3下使用requests实现模拟用户登入 —— 基础篇(马蜂窝)1. 了解cookie和session首先一定要先了解到cookie和session是哪些,这是前面理解网站交互,模拟用户登入的基础。1.1. 无状态合同:Http如上图所示,HTTP合同 是无状态的合同,用户浏览服务器上的内容,只须要发送页面恳求,服务器返回内容。对于服务器来说,并不关心,也...
Visual C++技术内幕(第四版).part4.rar下载
一个十分清淅的PDF版的Visual C++技术黑幕(第四版),至于这本书究竟有多强就不用我介绍了吧!本书共分part1、part2、part3、part4 四部份相关下载链接:
sap施行顾问宝典2下载
sap施行顾问宝典一共3个压缩包挺好的东西。相关下载链接:
Xilinx_ise使用教程(配合Modelsim使用)下载
这是我搜集的一个Xilinx_ISE6.1的教程,结合了MODELSIM的仿真功能,自己觉得讲解的还可以,适合初学者入门使用,对其他人员也有一定的参考价值。相关下载链接:
相关热词c# 程序跳转c#索引器定义、c#扫描软件c# 文字复印左右反转c#byte转换成数字c# 音量调节组件c# wpf 界面c# 读取证书文件的内容c# dgv 树结构c#承继 反序列化
我们是太有底线的
Python代理IP爬虫的菜鸟使用教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 373 次浏览 • 2020-06-24 08:01
Python爬虫要经历爬虫、爬虫被限制、爬虫反限制的过程。当然后续还要网页爬虫限制优化爬虫代理,爬虫再反限制的一系列道高一尺魔高一丈的过程。爬虫的中级阶段,添加headers和ip代理可以解决好多问题。
本人自己在爬取豆瓣读书的时侯,就以为爬取次数过多,直接被封了IP.后来就研究了代理IP的问题.
(当时不知道哪些情况,差点态度就崩了...),下面给你们介绍一下我自己代理IP爬取数据的问题,请你们强调不足之处.
问题
这是我的IP被封了,一开始好好的,我还以为是我的代码问题了
思路:
从网上查找了一些关于爬虫代理IP的资料,得到下边的思路
爬取一些IP,过滤掉不可用. 在requests的恳求的proxies参数加入对应的IP. 继续爬取. 收工 好吧,都是屁话,理论你们都懂,上面直接上代码...
思路有了,动手上去.
运行环境
Python 3.7, Pycharm
这些须要你们直接去搭建好环境...
准备工作
爬取IP地址的网站(国内高匿代理) 校准IP地址的网站 你之前被封IP的py爬虫脚本...
上面的网址看个人的情况来选定
爬取IP的完整代码
PS:简单的使用bs4获取IP和端口号,没有啥难度,里面降低了一个过滤不可用IP的逻辑
关键地方都有注释了
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# @Time : 2018/11/22
# @Author : liangk
# @Site :
# @File : auto_archive_ios.py
# @Software: PyCharm
import requests
from bs4 import BeautifulSoup
import json
class GetIp(object):
"""抓取代理IP"""
def __init__(self):
"""初始化变量"""
self.url = 'http://www.xicidaili.com/nn/'
self.check_url = 'https://www.ip.cn/'
self.ip_list = []
@staticmethod
def get_html(url):
"""请求html页面信息"""
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'
}
try:
request = requests.get(url=url, headers=header)
request.encoding = 'utf-8'
html = request.text
return html
except Exception as e:
return ''
def get_available_ip(self, ip_address, ip_port):
"""检测IP地址是否可用"""
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'
}
ip_url_next = '://' + ip_address + ':' + ip_port
proxies = {'http': 'http' + ip_url_next, 'https': 'https' + ip_url_next}
try:
r = requests.get(self.check_url, headers=header, proxies=proxies, timeout=3)
html = r.text
except:
print('fail-%s' % ip_address)
else:
print('success-%s' % ip_address)
soup = BeautifulSoup(html, 'lxml')
div = soup.find(class_='well')
if div:
print(div.text)
ip_info = {'address': ip_address, 'port': ip_port}
self.ip_list.append(ip_info)
def main(self):
"""主方法"""
web_html = self.get_html(self.url)
soup = BeautifulSoup(web_html, 'lxml')
ip_list = soup.find(id='ip_list').find_all('tr')
for ip_info in ip_list:
td_list = ip_info.find_all('td')
if len(td_list) > 0:
ip_address = td_list[1].text
ip_port = td_list[2].text
# 检测IP地址是否有效
self.get_available_ip(ip_address, ip_port)
# 写入有效文件
with open('ip.txt', 'w') as file:
json.dump(self.ip_list, file)
print(self.ip_list)
# 程序主入口
if __name__ == '__main__':
get_ip = GetIp()
get_ip.main()
使用方式完整代码
PS: 主要是通过使用随机的IP来爬取,根据request_status来判定这个IP是否可以用.
为什么要这样判定?
主要是即使前面经过了过滤,但是不代表在你爬取的时侯是可以用的,所以还是得多做一个判定.
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# @Time : 2018/11/22
# @Author : liangk
# @Site :
# @File : get_douban_books.py
# @Software: PyCharm
from bs4 import BeautifulSoup
import datetime
import requests
import json
import random
ip_random = -1
article_tag_list = []
article_type_list = []
def get_html(url):
header = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36'
}
global ip_random
ip_rand, proxies = get_proxie(ip_random)
print(proxies)
try:
request = requests.get(url=url, headers=header, proxies=proxies, timeout=3)
except:
request_status = 500
else:
request_status = request.status_code
print(request_status)
while request_status != 200:
ip_random = -1
ip_rand, proxies = get_proxie(ip_random)
print(proxies)
try:
request = requests.get(url=url, headers=header, proxies=proxies, timeout=3)
except:
request_status = 500
else:
request_status = request.status_code
print(request_status)
ip_random = ip_rand
request.encoding = 'gbk'
html = request.content
print(html)
return html
def get_proxie(random_number):
with open('ip.txt', 'r') as file:
ip_list = json.load(file)
if random_number == -1:
random_number = random.randint(0, len(ip_list) - 1)
ip_info = ip_list[random_number]
ip_url_next = '://' + ip_info['address'] + ':' + ip_info['port']
proxies = {'http': 'http' + ip_url_next, 'https': 'https' + ip_url_next}
return random_number, proxies
# 程序主入口
if __name__ == '__main__':
"""只是爬取了书籍的第一页,按照评价排序"""
start_time = datetime.datetime.now()
url = 'https://book.douban.com/tag/?view=type&icn=index-sorttags-all'
base_url = 'https://book.douban.com/tag/'
html = get_html(url)
soup = BeautifulSoup(html, 'lxml')
article_tag_list = soup.find_all(class_='tag-content-wrapper')
tagCol_list = soup.find_all(class_='tagCol')
for table in tagCol_list:
""" 整理分析数据 """
sub_type_list = []
a = table.find_all('a')
for book_type in a:
sub_type_list.append(book_type.text)
article_type_list.append(sub_type_list)
for sub in article_type_list:
for sub1 in sub:
title = '==============' + sub1 + '=============='
print(title)
print(base_url + sub1 + '?start=0' + '&type=S')
with open('book.text', 'a', encoding='utf-8') as f:
f.write('\n' + title + '\n')
f.write(url + '\n')
for start in range(0, 2):
# (start * 20) 分页是0 20 40 这样的
# type=S是按评价排序
url = base_url + sub1 + '?start=%s' % (start * 20) + '&type=S'
html = get_html(url)
soup = BeautifulSoup(html, 'lxml')
li = soup.find_all(class_='subject-item')
for div in li:
info = div.find(class_='info').find('a')
img = div.find(class_='pic').find('img')
content = '书名:<%s>' % info['title'] + ' 书本图片:' + img['src'] + '\n'
print(content)
with open('book.text', 'a', encoding='utf-8') as f:
f.write(content)
end_time = datetime.datetime.now()
print('耗时: ', (end_time - start_time).seconds)
为什么选择国外高匿代理!
总结
使用这样简单的代理IP,基本上就可以应付在爬爬爬着被封IP的情况了.而且没有使用自己的IP,间接的保护?!?!
大家有其他的愈发快捷的方式,欢迎你们可以拿出来交流和讨论爬虫代理,谢谢。 查看全部
前言
Python爬虫要经历爬虫、爬虫被限制、爬虫反限制的过程。当然后续还要网页爬虫限制优化爬虫代理,爬虫再反限制的一系列道高一尺魔高一丈的过程。爬虫的中级阶段,添加headers和ip代理可以解决好多问题。
本人自己在爬取豆瓣读书的时侯,就以为爬取次数过多,直接被封了IP.后来就研究了代理IP的问题.
(当时不知道哪些情况,差点态度就崩了...),下面给你们介绍一下我自己代理IP爬取数据的问题,请你们强调不足之处.
问题
这是我的IP被封了,一开始好好的,我还以为是我的代码问题了

思路:
从网上查找了一些关于爬虫代理IP的资料,得到下边的思路
爬取一些IP,过滤掉不可用. 在requests的恳求的proxies参数加入对应的IP. 继续爬取. 收工 好吧,都是屁话,理论你们都懂,上面直接上代码...
思路有了,动手上去.
运行环境
Python 3.7, Pycharm
这些须要你们直接去搭建好环境...
准备工作
爬取IP地址的网站(国内高匿代理) 校准IP地址的网站 你之前被封IP的py爬虫脚本...
上面的网址看个人的情况来选定
爬取IP的完整代码
PS:简单的使用bs4获取IP和端口号,没有啥难度,里面降低了一个过滤不可用IP的逻辑
关键地方都有注释了
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# @Time : 2018/11/22
# @Author : liangk
# @Site :
# @File : auto_archive_ios.py
# @Software: PyCharm
import requests
from bs4 import BeautifulSoup
import json
class GetIp(object):
"""抓取代理IP"""
def __init__(self):
"""初始化变量"""
self.url = 'http://www.xicidaili.com/nn/'
self.check_url = 'https://www.ip.cn/'
self.ip_list = []
@staticmethod
def get_html(url):
"""请求html页面信息"""
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'
}
try:
request = requests.get(url=url, headers=header)
request.encoding = 'utf-8'
html = request.text
return html
except Exception as e:
return ''
def get_available_ip(self, ip_address, ip_port):
"""检测IP地址是否可用"""
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'
}
ip_url_next = '://' + ip_address + ':' + ip_port
proxies = {'http': 'http' + ip_url_next, 'https': 'https' + ip_url_next}
try:
r = requests.get(self.check_url, headers=header, proxies=proxies, timeout=3)
html = r.text
except:
print('fail-%s' % ip_address)
else:
print('success-%s' % ip_address)
soup = BeautifulSoup(html, 'lxml')
div = soup.find(class_='well')
if div:
print(div.text)
ip_info = {'address': ip_address, 'port': ip_port}
self.ip_list.append(ip_info)
def main(self):
"""主方法"""
web_html = self.get_html(self.url)
soup = BeautifulSoup(web_html, 'lxml')
ip_list = soup.find(id='ip_list').find_all('tr')
for ip_info in ip_list:
td_list = ip_info.find_all('td')
if len(td_list) > 0:
ip_address = td_list[1].text
ip_port = td_list[2].text
# 检测IP地址是否有效
self.get_available_ip(ip_address, ip_port)
# 写入有效文件
with open('ip.txt', 'w') as file:
json.dump(self.ip_list, file)
print(self.ip_list)
# 程序主入口
if __name__ == '__main__':
get_ip = GetIp()
get_ip.main()
使用方式完整代码
PS: 主要是通过使用随机的IP来爬取,根据request_status来判定这个IP是否可以用.
为什么要这样判定?
主要是即使前面经过了过滤,但是不代表在你爬取的时侯是可以用的,所以还是得多做一个判定.
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# @Time : 2018/11/22
# @Author : liangk
# @Site :
# @File : get_douban_books.py
# @Software: PyCharm
from bs4 import BeautifulSoup
import datetime
import requests
import json
import random
ip_random = -1
article_tag_list = []
article_type_list = []
def get_html(url):
header = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36'
}
global ip_random
ip_rand, proxies = get_proxie(ip_random)
print(proxies)
try:
request = requests.get(url=url, headers=header, proxies=proxies, timeout=3)
except:
request_status = 500
else:
request_status = request.status_code
print(request_status)
while request_status != 200:
ip_random = -1
ip_rand, proxies = get_proxie(ip_random)
print(proxies)
try:
request = requests.get(url=url, headers=header, proxies=proxies, timeout=3)
except:
request_status = 500
else:
request_status = request.status_code
print(request_status)
ip_random = ip_rand
request.encoding = 'gbk'
html = request.content
print(html)
return html
def get_proxie(random_number):
with open('ip.txt', 'r') as file:
ip_list = json.load(file)
if random_number == -1:
random_number = random.randint(0, len(ip_list) - 1)
ip_info = ip_list[random_number]
ip_url_next = '://' + ip_info['address'] + ':' + ip_info['port']
proxies = {'http': 'http' + ip_url_next, 'https': 'https' + ip_url_next}
return random_number, proxies
# 程序主入口
if __name__ == '__main__':
"""只是爬取了书籍的第一页,按照评价排序"""
start_time = datetime.datetime.now()
url = 'https://book.douban.com/tag/?view=type&icn=index-sorttags-all'
base_url = 'https://book.douban.com/tag/'
html = get_html(url)
soup = BeautifulSoup(html, 'lxml')
article_tag_list = soup.find_all(class_='tag-content-wrapper')
tagCol_list = soup.find_all(class_='tagCol')
for table in tagCol_list:
""" 整理分析数据 """
sub_type_list = []
a = table.find_all('a')
for book_type in a:
sub_type_list.append(book_type.text)
article_type_list.append(sub_type_list)
for sub in article_type_list:
for sub1 in sub:
title = '==============' + sub1 + '=============='
print(title)
print(base_url + sub1 + '?start=0' + '&type=S')
with open('book.text', 'a', encoding='utf-8') as f:
f.write('\n' + title + '\n')
f.write(url + '\n')
for start in range(0, 2):
# (start * 20) 分页是0 20 40 这样的
# type=S是按评价排序
url = base_url + sub1 + '?start=%s' % (start * 20) + '&type=S'
html = get_html(url)
soup = BeautifulSoup(html, 'lxml')
li = soup.find_all(class_='subject-item')
for div in li:
info = div.find(class_='info').find('a')
img = div.find(class_='pic').find('img')
content = '书名:<%s>' % info['title'] + ' 书本图片:' + img['src'] + '\n'
print(content)
with open('book.text', 'a', encoding='utf-8') as f:
f.write(content)
end_time = datetime.datetime.now()
print('耗时: ', (end_time - start_time).seconds)
为什么选择国外高匿代理!

总结
使用这样简单的代理IP,基本上就可以应付在爬爬爬着被封IP的情况了.而且没有使用自己的IP,间接的保护?!?!
大家有其他的愈发快捷的方式,欢迎你们可以拿出来交流和讨论爬虫代理,谢谢。
写爬虫,用哪些编程语言好,python好吗
采集交流 • 优采云 发表了文章 • 0 个评论 • 423 次浏览 • 2020-06-23 08:01
之前换了份工作,不再是单纯的Web开发了,要学习的东西真的很多的。入职的第1天,就让我入手写个爬虫,只是这个爬虫没有采集几个亿数据量的业务场景。
于是,整理了下需求,简单的设计了下方案就草草开始了。小B是我学院时侯的同事,那天这哥们约我喝水,想看下能够顺带介绍几个姑娘。酒过三巡,不胜酒力,于是便聊起了近来的工作。
当他知晓我居然在写爬虫,便起了同情之心,觉得我怀才不遇。仿佛写爬虫是件太低级太low的技术活。在他那家公司,招进来的实习生就多多少少会点爬虫,什么nodejs、golang,哪个不是爬虫的好手。没想到我结业多年,竟然沦落到做实习生的工作,可悲可泣。
接着建议我转入Java阵营,如果到他公司去,多多少少也能混个主任的职位。搞得自己只能一番苦笑。
不知道从何时起,程序员的世界流行起了鄙视链这玩意。什么写C语言的厌恶写C++,写C++的厌恶写Java的,最后鄙视链最高端是PHP。具体是如何的关系,就不再揣测了。
写爬虫,用哪些编程语言好,python好吗
然而,纵观整个行业,都说Python火。具体有多火,看培训机构的广告就晓得了。在16年之前,Python还是1个若不见经传的词组,之后各家培训机构铺天盖地的广告,什么大数据、自动化运维全都跟Python扯上了关系。毕业学生工资更是达到了50-100W,还老是招不到人。
更有意思的是,学Python最容易上手的过程就是写爬虫。什么Scrapy、Pysider是必学,HTML、Javascript是重点,外带几个豆瓣、花瓣网的实战案例,让你一下子才能解决企业的刚需。
这样说来,难怪连实习生也能跟你抢饭碗了,技术发展的很快,各种框架构建的结果是释放人力,降低成本。
据我了解,Python的优势集中于数据剖析、信息安全那些领域。你可能听说过Hadoop、Spark、Tensorflow这种高大上的名词,但是对于数据取证、DLL注入等内容可能从无听闻。举个简单的事例,在数据取证中,由于犯罪人员不配合检测机关的工作,通过数据取证技术我们可以进行一些信息的提取,从而辅助否认其犯罪记录,如获取系统密码、浏览器中帐号及密码。
听起来觉得很高大上的,但是假如我跟你说其过程就是对sqlite3文件数据库查询一下SQL,不知道你会不会认为上述取证的事例顿时很low的。但是,当你不留神把陌陌消息的图片删除想寻回的时侯,或许你能在Python中找到对应的方案,而其他的语言还真没发觉有合适的。
于是,我开导他说,搞完这波爬虫骚操作,下一次就是数据剖析了,你看不有前进了一步?
还数据剖析,你似乎想的很远的。小B打断了我的话,你认为人家会使你搞数据剖析,没有数据何来的剖析。况且,没有哪家公司会笨到把所有数据都曝露在互联网上。你能看到的只是那冰山的一角。即使你想深入进去,没有分布式技术支撑和几十个亿的数据业务,你简历上也不会有亮点。
然后,又聊到他公司近日招了个大数据的开发,薪资比他还要高出一大截,但是技术却不咋地。我从小B的话里听出了一丝揶揄了。于是,又教唆我不要再搞哪些爬虫了,还是搞Spark才有未来。既不用害怕大深夜服务挂了,又不用害怕完不成采集数量。完全是实打实的数据,何乐而不为呢?
这话听得我都有点动心了,没有攀比就没有伤害。但是一想到Java是加班加点工作,我还是打消了这个念头。
我不知道该说些哪些,只是认为时间过得太慢,是种熬煎。于是只能扯开了话题,免得喝顿饭都艰难。
结语
技术没有low不low,没有烂的技术,只有不会用的人。重要的是人家能给你多少钱,你能弄成如何的结果。
这年头会有多少公司乐意给实习生税后1W+的起薪,而这一切都只是份养活自己的技能而已,别把面子很当回事。
写爬虫,用哪些编程语言好,python好吗,其实编程的路上只在于擅长,没有所谓的行不行,如果不擅长,就是给您好用的编程语言也没有疗效,如果想要学编程,那就关注IT培训网网络爬虫用什么语言写,让我们一起走入编程的世界! 查看全部
用Python写爬虫就太low?你赞成嘛?为何不建议使用python写爬虫呢网络爬虫用什么语言写,是有哪些诱因吗,难道用python写爬虫不好吗?
之前换了份工作,不再是单纯的Web开发了,要学习的东西真的很多的。入职的第1天,就让我入手写个爬虫,只是这个爬虫没有采集几个亿数据量的业务场景。
于是,整理了下需求,简单的设计了下方案就草草开始了。小B是我学院时侯的同事,那天这哥们约我喝水,想看下能够顺带介绍几个姑娘。酒过三巡,不胜酒力,于是便聊起了近来的工作。
当他知晓我居然在写爬虫,便起了同情之心,觉得我怀才不遇。仿佛写爬虫是件太低级太low的技术活。在他那家公司,招进来的实习生就多多少少会点爬虫,什么nodejs、golang,哪个不是爬虫的好手。没想到我结业多年,竟然沦落到做实习生的工作,可悲可泣。
接着建议我转入Java阵营,如果到他公司去,多多少少也能混个主任的职位。搞得自己只能一番苦笑。
不知道从何时起,程序员的世界流行起了鄙视链这玩意。什么写C语言的厌恶写C++,写C++的厌恶写Java的,最后鄙视链最高端是PHP。具体是如何的关系,就不再揣测了。

写爬虫,用哪些编程语言好,python好吗
然而,纵观整个行业,都说Python火。具体有多火,看培训机构的广告就晓得了。在16年之前,Python还是1个若不见经传的词组,之后各家培训机构铺天盖地的广告,什么大数据、自动化运维全都跟Python扯上了关系。毕业学生工资更是达到了50-100W,还老是招不到人。
更有意思的是,学Python最容易上手的过程就是写爬虫。什么Scrapy、Pysider是必学,HTML、Javascript是重点,外带几个豆瓣、花瓣网的实战案例,让你一下子才能解决企业的刚需。
这样说来,难怪连实习生也能跟你抢饭碗了,技术发展的很快,各种框架构建的结果是释放人力,降低成本。
据我了解,Python的优势集中于数据剖析、信息安全那些领域。你可能听说过Hadoop、Spark、Tensorflow这种高大上的名词,但是对于数据取证、DLL注入等内容可能从无听闻。举个简单的事例,在数据取证中,由于犯罪人员不配合检测机关的工作,通过数据取证技术我们可以进行一些信息的提取,从而辅助否认其犯罪记录,如获取系统密码、浏览器中帐号及密码。
听起来觉得很高大上的,但是假如我跟你说其过程就是对sqlite3文件数据库查询一下SQL,不知道你会不会认为上述取证的事例顿时很low的。但是,当你不留神把陌陌消息的图片删除想寻回的时侯,或许你能在Python中找到对应的方案,而其他的语言还真没发觉有合适的。
于是,我开导他说,搞完这波爬虫骚操作,下一次就是数据剖析了,你看不有前进了一步?
还数据剖析,你似乎想的很远的。小B打断了我的话,你认为人家会使你搞数据剖析,没有数据何来的剖析。况且,没有哪家公司会笨到把所有数据都曝露在互联网上。你能看到的只是那冰山的一角。即使你想深入进去,没有分布式技术支撑和几十个亿的数据业务,你简历上也不会有亮点。
然后,又聊到他公司近日招了个大数据的开发,薪资比他还要高出一大截,但是技术却不咋地。我从小B的话里听出了一丝揶揄了。于是,又教唆我不要再搞哪些爬虫了,还是搞Spark才有未来。既不用害怕大深夜服务挂了,又不用害怕完不成采集数量。完全是实打实的数据,何乐而不为呢?
这话听得我都有点动心了,没有攀比就没有伤害。但是一想到Java是加班加点工作,我还是打消了这个念头。
我不知道该说些哪些,只是认为时间过得太慢,是种熬煎。于是只能扯开了话题,免得喝顿饭都艰难。
结语
技术没有low不low,没有烂的技术,只有不会用的人。重要的是人家能给你多少钱,你能弄成如何的结果。
这年头会有多少公司乐意给实习生税后1W+的起薪,而这一切都只是份养活自己的技能而已,别把面子很当回事。
写爬虫,用哪些编程语言好,python好吗,其实编程的路上只在于擅长,没有所谓的行不行,如果不擅长,就是给您好用的编程语言也没有疗效,如果想要学编程,那就关注IT培训网网络爬虫用什么语言写,让我们一起走入编程的世界!
三种 Python 网络内容抓取工具与爬虫
采集交流 • 优采云 发表了文章 • 0 个评论 • 437 次浏览 • 2020-06-23 08:01
在一个理想的世界里,你须要的所有数据都将以公开而文档完备的格式清晰地诠释,你可以轻松地下载并在任何你须要的地方使用。
然而,在真实世界里,数据是零乱的,极少被打包成你须要的样子,要么常常是过期的。
你所须要的信息常常是埋藏在一个网站里。相比一些清晰地、有调养地呈现数据的网站,更多的网站则不是这样的。爬取数据crawling、挖掘数据scraping、加工数据、整理数据那些是获取整个网站结构来勾画网站拓扑来搜集数据所必须的活动,这些可以是以网站的格式存储的或则是存放在一个专有数据库中。
也许在不久的将来,你须要通过爬取和挖掘来获得一些你须要的数据,当然你几乎肯定须要进行一点点的编程来正确的获取。你要如何做取决于你自己,但是我发觉 Python 社区是一个挺好的提供者,它提供了工具、框架以及文档来帮助你从网站上获取数据。
在我们进行之前,这里有一个小小的恳求:在你做事情之前请思索,以及请耐心。抓取这件事情并不简单。不要把网站爬出来只是复制一遍,并其它人的工作当作是你自己的东西(当然,没有许可)。要注意版权和许可,以及你所爬行的内容应用哪一个标准。尊重 robots.txt 文件。不要频繁的针对一个网站,这将造成真实的访问者会碰到访问困难的问题。
在知晓那些警告过后,这里有一些太棒的 Python 网站爬虫工具,你可以拿来获得你须要的数据。
让我们先从 pyspider 开始介绍。这是一个带有 web 界面的网路爬虫,让与让之容易跟踪多个爬虫。其具有扩展性,支持多个前端数据库和消息队列。它还具有一些便捷的特点,从优先级到再度访问抓取失败的页面linux 爬虫软件,此外还有通过时间次序来爬取和其他的一些特点。Pyspider 同时支持 Python 2 和 Python 3。为了实现一个更快的爬取,你可以在分布式的环境下一次使用多个爬虫进行爬取。
Pyspyder 的基本用法都有良好的 文档说明 ,包括简单的代码片断。你能通过查看一个 在线的样例 来体验用户界面。它在 Apache 2 许可证下开源,Pyspyder 仍然在 GitHub 上积极地开发。
MechanicalSoup 是一个基于非常流行而异常多能的 HTML 解析库 Beautiful Soup 建立的爬虫库。如果你的爬虫须要相当的简单,但是又要求检测一些选择框或则输入一些文字,而你又不想为这个任务单独写一个爬虫,那么这会是一个值得考虑的选择。
MechanicalSoup 在 MIT 许可证下开源。查看 GitHub 上该项目的 example.py 样例文件来获得更多的用法。不幸的是,到目前为止,这个项目还没有一个挺好的文档。
Scrapy 是一个有着活跃社区支持的抓取框架,在那里你可以建造自己的抓取工具。除了爬取和解析工具,它能够将它搜集的数据以 JSON 或者 CSV 之类的格式轻松输出,并储存在一个你选择的前端数据库。它还有许多外置的任务扩充linux 爬虫软件,例如 cookie 处理、代理误导、限制爬取深度等等,同时还可以构建你自己附加的 API。
要了解 Scrapy,你可以查看网上的文档或则是访问它众多的社区资源,包括一个 IRC 频道、Reddit 子版块以及关注她们的 StackOverflow 标签。Scrapy 的代码在 3 句版 BSD 许可证下开源,你可以在 GitHub 上找到它们。
如果你完全不熟悉编程,Portia 提供了一个易用的可视化的界面。 则提供一个托管的版本。
这远不是一个完整的列表,当然,如果你是一个编程专家,你可以选择采取你自己的方式而不是使用这种框架中的一个。或者你发觉一个用其他语言编撰的替代品。例如 Python 编程者可能更喜欢 Python 附带的Selenium,它可以在不使用实际浏览器的情况下进行爬取。如果你有喜欢的爬取和挖掘工具,请在下边评论使我们晓得。
(题图:You as a Machine. Modified by Rikki Endsley. CC BY-SA 2.0)
via: /resources/python/web-scraper-crawler 查看全部
运用这种太棒的 Python 爬虫工具来获取你须要的数据。
在一个理想的世界里,你须要的所有数据都将以公开而文档完备的格式清晰地诠释,你可以轻松地下载并在任何你须要的地方使用。
然而,在真实世界里,数据是零乱的,极少被打包成你须要的样子,要么常常是过期的。
你所须要的信息常常是埋藏在一个网站里。相比一些清晰地、有调养地呈现数据的网站,更多的网站则不是这样的。爬取数据crawling、挖掘数据scraping、加工数据、整理数据那些是获取整个网站结构来勾画网站拓扑来搜集数据所必须的活动,这些可以是以网站的格式存储的或则是存放在一个专有数据库中。
也许在不久的将来,你须要通过爬取和挖掘来获得一些你须要的数据,当然你几乎肯定须要进行一点点的编程来正确的获取。你要如何做取决于你自己,但是我发觉 Python 社区是一个挺好的提供者,它提供了工具、框架以及文档来帮助你从网站上获取数据。
在我们进行之前,这里有一个小小的恳求:在你做事情之前请思索,以及请耐心。抓取这件事情并不简单。不要把网站爬出来只是复制一遍,并其它人的工作当作是你自己的东西(当然,没有许可)。要注意版权和许可,以及你所爬行的内容应用哪一个标准。尊重 robots.txt 文件。不要频繁的针对一个网站,这将造成真实的访问者会碰到访问困难的问题。
在知晓那些警告过后,这里有一些太棒的 Python 网站爬虫工具,你可以拿来获得你须要的数据。
让我们先从 pyspider 开始介绍。这是一个带有 web 界面的网路爬虫,让与让之容易跟踪多个爬虫。其具有扩展性,支持多个前端数据库和消息队列。它还具有一些便捷的特点,从优先级到再度访问抓取失败的页面linux 爬虫软件,此外还有通过时间次序来爬取和其他的一些特点。Pyspider 同时支持 Python 2 和 Python 3。为了实现一个更快的爬取,你可以在分布式的环境下一次使用多个爬虫进行爬取。
Pyspyder 的基本用法都有良好的 文档说明 ,包括简单的代码片断。你能通过查看一个 在线的样例 来体验用户界面。它在 Apache 2 许可证下开源,Pyspyder 仍然在 GitHub 上积极地开发。
MechanicalSoup 是一个基于非常流行而异常多能的 HTML 解析库 Beautiful Soup 建立的爬虫库。如果你的爬虫须要相当的简单,但是又要求检测一些选择框或则输入一些文字,而你又不想为这个任务单独写一个爬虫,那么这会是一个值得考虑的选择。
MechanicalSoup 在 MIT 许可证下开源。查看 GitHub 上该项目的 example.py 样例文件来获得更多的用法。不幸的是,到目前为止,这个项目还没有一个挺好的文档。
Scrapy 是一个有着活跃社区支持的抓取框架,在那里你可以建造自己的抓取工具。除了爬取和解析工具,它能够将它搜集的数据以 JSON 或者 CSV 之类的格式轻松输出,并储存在一个你选择的前端数据库。它还有许多外置的任务扩充linux 爬虫软件,例如 cookie 处理、代理误导、限制爬取深度等等,同时还可以构建你自己附加的 API。
要了解 Scrapy,你可以查看网上的文档或则是访问它众多的社区资源,包括一个 IRC 频道、Reddit 子版块以及关注她们的 StackOverflow 标签。Scrapy 的代码在 3 句版 BSD 许可证下开源,你可以在 GitHub 上找到它们。
如果你完全不熟悉编程,Portia 提供了一个易用的可视化的界面。 则提供一个托管的版本。
这远不是一个完整的列表,当然,如果你是一个编程专家,你可以选择采取你自己的方式而不是使用这种框架中的一个。或者你发觉一个用其他语言编撰的替代品。例如 Python 编程者可能更喜欢 Python 附带的Selenium,它可以在不使用实际浏览器的情况下进行爬取。如果你有喜欢的爬取和挖掘工具,请在下边评论使我们晓得。
(题图:You as a Machine. Modified by Rikki Endsley. CC BY-SA 2.0)
via: /resources/python/web-scraper-crawler
手把手教你写网络爬虫(2):迷你爬虫构架-通用网路爬虫
采集交流 • 优采云 发表了文章 • 0 个评论 • 355 次浏览 • 2020-06-20 08:00
介绍
大家好!回顾上一期,我们在介绍了爬虫的基本概念以后,就借助各类工具横冲直撞的完成了一个小爬虫,目的就是猛、糙、快,方便初学者上手,建立信心。对于有一定基础的读者,请不要着急,以后我们会学习主流的开源框架,打造出一个强悍专业的爬虫系统!不过在此之前,要继续打好基础,本期我们先介绍爬虫的种类,然后选定最典型的通用网路爬虫,为其设计一个迷你框架。有了自己对框架的思索后爬虫结构,再学习复杂的开源框架就有头绪了。
今天我们会把更多的时间用在思索上,而不是一根筋的coding。用80%的时间思索,20%的时间敲按键,这样更有利于进步。
语言&环境
语言:带足弹药,继续用Python开路!
一个迷你框架
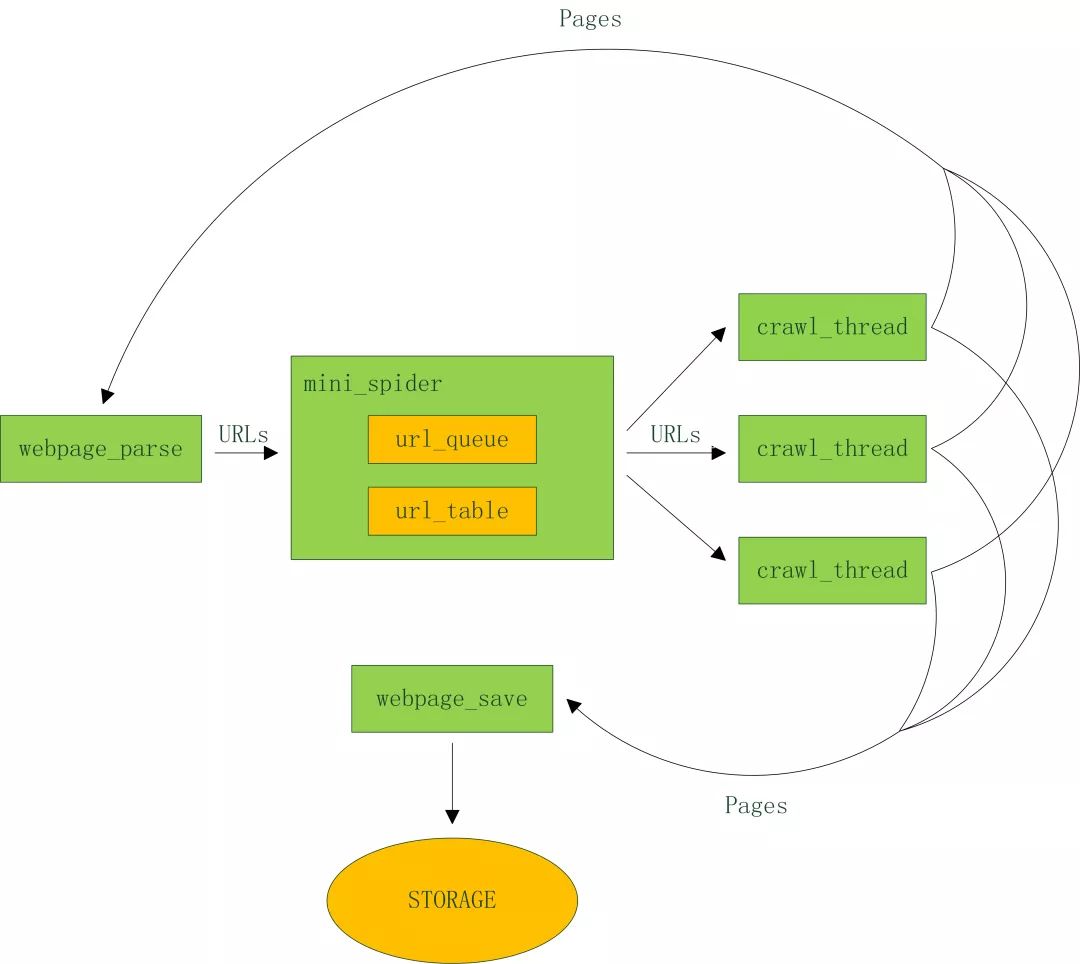
下面以比较典型的通用爬虫为例爬虫结构,分析其工程要点,设计并实现一个迷你框架。架构图如下:
代码结构:
config_load.py 配置文件加载
crawl_thread.py 爬取线程
mini_spider.py 主线程
spider.conf 配置文件
url_table.py url队列、url表
urls.txt 种子url集合
webpage_parse.py 网页剖析
webpage_save.py 网页储存
看看配置文件里有哪些内容:
spider.conf
url_table.py
Step 3. 记录什么网页早已下载过的小笔记本——URL表。
在互联网上,一个网页可能被多个网页中的超链接所指向。这样在遍历互联网这张图的时侯,这个网页可能被多次访问到。为了避免一个网页被下载和解析多次,需要一个URL表记录什么网页早已下载过。再碰到这个网页的时侯,我们就可以跳过它。
crawl_thread.py
Step 5. 页面剖析模块
从网页中解析出URLs或则其他有用的数据。这个是下期重点介绍的,可以参考之前的代码。
Step 6. 页面储存模块
保存页面的模块,目前将文件保存为文件,以后可以扩充出多种储存方法,如mysql,mongodb,hbase等等。
webpage_save.py
写到这儿,整个框架早已清晰的呈如今大伙眼前了,千万不要小看它,不管多么复杂的框架都是在这种基本要素上扩充下来的。
下一步
基础知识的学习暂时告一段落,希望还能帮助你们打下一定的基础。下期开始为你们介绍强悍成熟的爬虫框架Scrapy,它提供了好多强悍的特点来促使爬取更为简单高效,更多精彩,敬请期盼!
【编辑推荐】
如何用Python来找你喜欢的女生?初识Python:全局、局部和非局部变量(带示例)教你用Python解决非平衡数据问题(附代码)调查显示:你是否是一个合格的Python开发者?手把手教你写网络爬虫(1):网易云音乐歌单 查看全部

介绍
大家好!回顾上一期,我们在介绍了爬虫的基本概念以后,就借助各类工具横冲直撞的完成了一个小爬虫,目的就是猛、糙、快,方便初学者上手,建立信心。对于有一定基础的读者,请不要着急,以后我们会学习主流的开源框架,打造出一个强悍专业的爬虫系统!不过在此之前,要继续打好基础,本期我们先介绍爬虫的种类,然后选定最典型的通用网路爬虫,为其设计一个迷你框架。有了自己对框架的思索后爬虫结构,再学习复杂的开源框架就有头绪了。
今天我们会把更多的时间用在思索上,而不是一根筋的coding。用80%的时间思索,20%的时间敲按键,这样更有利于进步。

语言&环境
语言:带足弹药,继续用Python开路!






一个迷你框架
下面以比较典型的通用爬虫为例爬虫结构,分析其工程要点,设计并实现一个迷你框架。架构图如下:
代码结构:

config_load.py 配置文件加载
crawl_thread.py 爬取线程
mini_spider.py 主线程
spider.conf 配置文件
url_table.py url队列、url表
urls.txt 种子url集合
webpage_parse.py 网页剖析
webpage_save.py 网页储存
看看配置文件里有哪些内容:
spider.conf





url_table.py

Step 3. 记录什么网页早已下载过的小笔记本——URL表。
在互联网上,一个网页可能被多个网页中的超链接所指向。这样在遍历互联网这张图的时侯,这个网页可能被多次访问到。为了避免一个网页被下载和解析多次,需要一个URL表记录什么网页早已下载过。再碰到这个网页的时侯,我们就可以跳过它。
crawl_thread.py



Step 5. 页面剖析模块
从网页中解析出URLs或则其他有用的数据。这个是下期重点介绍的,可以参考之前的代码。
Step 6. 页面储存模块
保存页面的模块,目前将文件保存为文件,以后可以扩充出多种储存方法,如mysql,mongodb,hbase等等。
webpage_save.py

写到这儿,整个框架早已清晰的呈如今大伙眼前了,千万不要小看它,不管多么复杂的框架都是在这种基本要素上扩充下来的。
下一步
基础知识的学习暂时告一段落,希望还能帮助你们打下一定的基础。下期开始为你们介绍强悍成熟的爬虫框架Scrapy,它提供了好多强悍的特点来促使爬取更为简单高效,更多精彩,敬请期盼!
【编辑推荐】
如何用Python来找你喜欢的女生?初识Python:全局、局部和非局部变量(带示例)教你用Python解决非平衡数据问题(附代码)调查显示:你是否是一个合格的Python开发者?手把手教你写网络爬虫(1):网易云音乐歌单
一份Python爬虫电子书
采集交流 • 优采云 发表了文章 • 0 个评论 • 283 次浏览 • 2020-06-19 08:01
Python爬虫现如今早已越来越吃香了,随意打开一个急聘网站从工资水平来看,入门的爬虫工程师都能领到15k以上,爬虫构架相关的都能领到30k以上,我们还有什么理由去拒绝爬虫呢?当然,除非你跟钱过意不去。
所以秉承使更多想改行学习Python爬虫的的朋友快速学习、让更多的小伙伴领到高薪我整理了一份十分健全的Python爬虫的电子书。
之前在知乎写分享早已有一年多,一直有同学说我的回答和文章能整理成书籍了仍然偷懒没做,也有出版社的小伙伴找我把这种内容弄成书都被我拒绝了。所以也是借着这个机会仔细整理了知乎上的回答和文章另外也添加了一些新的内容,完成了几本小小的电子书,这一本比较小一部分是有关于Python方面的,主要内容还是Python爬虫。
这本书主要内容是Python入门爬虫饲养书,以及Python爬虫入门和Python爬虫进阶,以下这是这本电子书的一个主要的目录:
这本书不仅一些自己的学习、面试感受之外,还有好多包括书籍方面的资源、教程方面的学习资源,为了克服选择困难症,我在选择教程或则书籍的时侯尽量保证了资源少而且精准,能用最少最精华的教程使你们快速入门Python以及比较熟悉的使用Python爬虫。
如果你能用心用2-3个月的时间认真通读这本电子书爬虫饲养书,并且学习这本书上推荐的一些教程和书籍,相信你一定能找到一份不错的Python爬虫工作。 查看全部

Python爬虫现如今早已越来越吃香了,随意打开一个急聘网站从工资水平来看,入门的爬虫工程师都能领到15k以上,爬虫构架相关的都能领到30k以上,我们还有什么理由去拒绝爬虫呢?当然,除非你跟钱过意不去。
所以秉承使更多想改行学习Python爬虫的的朋友快速学习、让更多的小伙伴领到高薪我整理了一份十分健全的Python爬虫的电子书。
之前在知乎写分享早已有一年多,一直有同学说我的回答和文章能整理成书籍了仍然偷懒没做,也有出版社的小伙伴找我把这种内容弄成书都被我拒绝了。所以也是借着这个机会仔细整理了知乎上的回答和文章另外也添加了一些新的内容,完成了几本小小的电子书,这一本比较小一部分是有关于Python方面的,主要内容还是Python爬虫。
这本书主要内容是Python入门爬虫饲养书,以及Python爬虫入门和Python爬虫进阶,以下这是这本电子书的一个主要的目录:
这本书不仅一些自己的学习、面试感受之外,还有好多包括书籍方面的资源、教程方面的学习资源,为了克服选择困难症,我在选择教程或则书籍的时侯尽量保证了资源少而且精准,能用最少最精华的教程使你们快速入门Python以及比较熟悉的使用Python爬虫。
如果你能用心用2-3个月的时间认真通读这本电子书爬虫饲养书,并且学习这本书上推荐的一些教程和书籍,相信你一定能找到一份不错的Python爬虫工作。
Python网络爬虫实战项目代码大全(长期更新,欢迎补充)
采集交流 • 优采云 发表了文章 • 0 个评论 • 825 次浏览 • 2020-06-14 08:02
WechatSogou[1]- 微信公众号爬虫。基于搜狗微信搜索的微信公众号爬虫插口,可以扩充成基于搜狗搜索的爬虫,返回结果是列表,每一项均是公众号具体信息字典。[1]:
DouBanSpider[2]- 豆瓣读书爬虫。可以爬下豆瓣读书标签下的所有图书,按评分排行依次储存,存储到Excel中,可便捷你们筛选搜罗,比如筛选评价人数>1000的高分书籍;可根据不同的主题储存到Excel不同的Sheet ,采用User Agent伪装为浏览器进行爬取,并加入随机延时来更好的模仿浏览器行为,避免爬虫被封。[2]:
zhihu_spider[3]- 知乎爬虫。此项目的功能是爬取知乎用户信息以及人际拓扑关系,爬虫框架使用scrapy,数据储存使用mongodb。[3]:
bilibili-user[4]- Bilibili用户爬虫。总数据数:20119918,抓取数组:用户id,昵称,性别,头像,等级,经验值,粉丝数,生日,地址,注册时间,签名,等级与经验值等。抓取然后生成B站用户数据报告。[4]:
SinaSpider[5]- 新浪微博爬虫。主要爬取新浪微博用户的个人信息、微博信息、粉丝和关注。代码获取新浪微博Cookie进行登陆,可通过多帐号登入来避免新浪的反扒。主要使用 scrapy 爬虫框架。[5]:
distribute_crawler[6]- 小说下载分布式爬虫。使用scrapy,redis, mongodb,graphite实现的一个分布式网路爬虫,底层储存mongodb集群,分布式使用redis实现,爬虫状态显示使用graphite实现网络爬虫 代码,主要针对一个小说站点。[6]:
CnkiSpider[7]- 中国知网爬虫。设置检索条件后,执行src/CnkiSpider.py抓取数据,抓取数据储存在/data目录下,每个数据文件的第一行为数组名称。[7]:
LianJiaSpider[8]- 链家网爬虫。爬取北京地区链家历年二手房成交记录。涵盖链家爬虫一文的全部代码,包括链家模拟登陆代码。[8]:
scrapy_jingdong[9]- 京东爬虫。基于scrapy的易迅网站爬虫,保存格式为csv。[9]:
QQ-Groups-Spider[10]- QQ 群爬虫。批量抓取 QQ 群信息,包括群名称、群号、群人数、群主、群简介等内容,最终生成 XLS(X) / CSV 结果文件。[10]:
wooyun_public[11]-乌云爬虫。 乌云公开漏洞、知识库爬虫和搜索。全部公开漏洞的列表和每位漏洞的文本内容存在mongodb中,大概约2G内容;如果整站爬全部文本和图片作为离线查询,大概须要10G空间、2小时(10M联通带宽);爬取全部知识库网络爬虫 代码,总共约500M空间。漏洞搜索使用了Flask作为web server,bootstrap作为后端。[11]:
2016.9.11补充:
QunarSpider[12]- 去哪儿网爬虫。 网络爬虫之Selenium使用代理登录:爬取去哪儿网站,使用selenium模拟浏览器登录,获取翻页操作。代理可以存入一个文件,程序读取并使用。支持多进程抓取。[12]:
findtrip[13]- 机票爬虫(去哪儿和携程网)。Findtrip是一个基于Scrapy的机票爬虫,目前整合了国外两大机票网站(去哪儿 + 携程)。[13]:
163spider[14] - 基于requests、MySQLdb、torndb的网易客户端内容爬虫。[14]:
doubanspiders[15]- 豆瓣影片、书籍、小组、相册、东西等爬虫集。[15]:
QQSpider[16]- QQ空间爬虫,包括日志、说说、个人信息等,一天可抓取 400 万条数据。[16]:
baidu-music-spider[17]- 百度mp3全站爬虫,使用redis支持断点续传。[17]:
tbcrawler[18]- 淘宝和淘宝的爬虫,可以按照搜索关键词,物品id来抓去页面的信息,数据储存在mongodb。[18]:
stockholm[19]- 一个股票数据(沪深)爬虫和选股策略测试框架。根据选取的日期范围抓取所有沪深两县股票的行情数据。支持使用表达式定义选股策略。支持多线程处理。保存数据到JSON文件、CSV文件。[19]
--------------------------
本项目收录各类Python网路爬虫实战开源代码,并常年更新,欢迎补充。
更多Python干货欢迎扫码关注:
微信公众号:Python英文社区
知乎专栏:Python英文社区 <;
Python QQ交流群 :273186166
--------------------------
微信公众号:Python英文社区
Python英文社区 QQ交流群:
--------------------------
Python开发基础教学视频百度网盘下载地址: 查看全部
WechatSogou[1]- 微信公众号爬虫。基于搜狗微信搜索的微信公众号爬虫插口,可以扩充成基于搜狗搜索的爬虫,返回结果是列表,每一项均是公众号具体信息字典。[1]:
DouBanSpider[2]- 豆瓣读书爬虫。可以爬下豆瓣读书标签下的所有图书,按评分排行依次储存,存储到Excel中,可便捷你们筛选搜罗,比如筛选评价人数>1000的高分书籍;可根据不同的主题储存到Excel不同的Sheet ,采用User Agent伪装为浏览器进行爬取,并加入随机延时来更好的模仿浏览器行为,避免爬虫被封。[2]:
zhihu_spider[3]- 知乎爬虫。此项目的功能是爬取知乎用户信息以及人际拓扑关系,爬虫框架使用scrapy,数据储存使用mongodb。[3]:
bilibili-user[4]- Bilibili用户爬虫。总数据数:20119918,抓取数组:用户id,昵称,性别,头像,等级,经验值,粉丝数,生日,地址,注册时间,签名,等级与经验值等。抓取然后生成B站用户数据报告。[4]:
SinaSpider[5]- 新浪微博爬虫。主要爬取新浪微博用户的个人信息、微博信息、粉丝和关注。代码获取新浪微博Cookie进行登陆,可通过多帐号登入来避免新浪的反扒。主要使用 scrapy 爬虫框架。[5]:
distribute_crawler[6]- 小说下载分布式爬虫。使用scrapy,redis, mongodb,graphite实现的一个分布式网路爬虫,底层储存mongodb集群,分布式使用redis实现,爬虫状态显示使用graphite实现网络爬虫 代码,主要针对一个小说站点。[6]:
CnkiSpider[7]- 中国知网爬虫。设置检索条件后,执行src/CnkiSpider.py抓取数据,抓取数据储存在/data目录下,每个数据文件的第一行为数组名称。[7]:
LianJiaSpider[8]- 链家网爬虫。爬取北京地区链家历年二手房成交记录。涵盖链家爬虫一文的全部代码,包括链家模拟登陆代码。[8]:
scrapy_jingdong[9]- 京东爬虫。基于scrapy的易迅网站爬虫,保存格式为csv。[9]:
QQ-Groups-Spider[10]- QQ 群爬虫。批量抓取 QQ 群信息,包括群名称、群号、群人数、群主、群简介等内容,最终生成 XLS(X) / CSV 结果文件。[10]:
wooyun_public[11]-乌云爬虫。 乌云公开漏洞、知识库爬虫和搜索。全部公开漏洞的列表和每位漏洞的文本内容存在mongodb中,大概约2G内容;如果整站爬全部文本和图片作为离线查询,大概须要10G空间、2小时(10M联通带宽);爬取全部知识库网络爬虫 代码,总共约500M空间。漏洞搜索使用了Flask作为web server,bootstrap作为后端。[11]:
2016.9.11补充:
QunarSpider[12]- 去哪儿网爬虫。 网络爬虫之Selenium使用代理登录:爬取去哪儿网站,使用selenium模拟浏览器登录,获取翻页操作。代理可以存入一个文件,程序读取并使用。支持多进程抓取。[12]:
findtrip[13]- 机票爬虫(去哪儿和携程网)。Findtrip是一个基于Scrapy的机票爬虫,目前整合了国外两大机票网站(去哪儿 + 携程)。[13]:
163spider[14] - 基于requests、MySQLdb、torndb的网易客户端内容爬虫。[14]:
doubanspiders[15]- 豆瓣影片、书籍、小组、相册、东西等爬虫集。[15]:
QQSpider[16]- QQ空间爬虫,包括日志、说说、个人信息等,一天可抓取 400 万条数据。[16]:
baidu-music-spider[17]- 百度mp3全站爬虫,使用redis支持断点续传。[17]:
tbcrawler[18]- 淘宝和淘宝的爬虫,可以按照搜索关键词,物品id来抓去页面的信息,数据储存在mongodb。[18]:
stockholm[19]- 一个股票数据(沪深)爬虫和选股策略测试框架。根据选取的日期范围抓取所有沪深两县股票的行情数据。支持使用表达式定义选股策略。支持多线程处理。保存数据到JSON文件、CSV文件。[19]
--------------------------
本项目收录各类Python网路爬虫实战开源代码,并常年更新,欢迎补充。
更多Python干货欢迎扫码关注:
微信公众号:Python英文社区
知乎专栏:Python英文社区 <;
Python QQ交流群 :273186166
--------------------------
微信公众号:Python英文社区
Python英文社区 QQ交流群:
--------------------------
Python开发基础教学视频百度网盘下载地址:
python爬虫入门教程(一)
采集交流 • 优采云 发表了文章 • 0 个评论 • 246 次浏览 • 2020-06-12 08:01
1、Python能做哪些
2、网络爬虫简介
3、网络爬虫能做哪些
4、开发爬虫的打算工作
5、推荐的python爬虫学习书籍
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Python能做哪些
网络爬虫简介
网络爬虫,也叫网路蜘蛛(Web Spider)。爬虫是依照网页地址(URL)爬取网页上的内容,这里说的网页地址(URL)就是我们在浏览器中输入的网站链接。例如:/,这就是一个URL。
爬虫是在某个URL页面入手,抓取到这个页面的内容网络爬虫 教程,从当前的页面中找到其他的链接地址,然后从这地址再度爬到下一个网站页面,这样仍然不停的抓取到有用的信息,所以可以说网络爬虫是不停的抓取获得页面上想要的信息的程序。
网络爬虫能做哪些
例如:我关注的找工作的网站会不定期的发布急聘信息,我不信每晚都耗费自己的精力去点击网站查看信息,但是我又想在有新的通知时,能够及时晓得信息并看见这个信息。
此时,我就须要爬虫来帮助我,这个爬虫程序会手动在一定的时间模拟人去访问官网,检查是否有新的通知发布,如果没有就不进行任何操作,如果有通知,那么就将通知从网页中提取下来,保存到指定的位置,然后发送邮件或则电邮告知我即可。
开发爬虫的打算工作
编程语言:Python
IDE的话,推荐使用Pycharm。windows、linux、macos多平台支持网络爬虫 教程,非常好用。
开发环境:Win7+Python 2.7 64bit+PyCharm :环境配置方式自行百度
推荐的python爬虫学习书籍
1.米切尔 (Ryan Mitchell) (作者), 陶俊杰 (译者), 陈小莉 (译者)的Python网路数据采集
2.范传辉 (作者)的Python爬虫开发与项目实战 查看全部
目录:
1、Python能做哪些
2、网络爬虫简介
3、网络爬虫能做哪些
4、开发爬虫的打算工作
5、推荐的python爬虫学习书籍
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Python能做哪些
网络爬虫简介
网络爬虫,也叫网路蜘蛛(Web Spider)。爬虫是依照网页地址(URL)爬取网页上的内容,这里说的网页地址(URL)就是我们在浏览器中输入的网站链接。例如:/,这就是一个URL。
爬虫是在某个URL页面入手,抓取到这个页面的内容网络爬虫 教程,从当前的页面中找到其他的链接地址,然后从这地址再度爬到下一个网站页面,这样仍然不停的抓取到有用的信息,所以可以说网络爬虫是不停的抓取获得页面上想要的信息的程序。
网络爬虫能做哪些
例如:我关注的找工作的网站会不定期的发布急聘信息,我不信每晚都耗费自己的精力去点击网站查看信息,但是我又想在有新的通知时,能够及时晓得信息并看见这个信息。
此时,我就须要爬虫来帮助我,这个爬虫程序会手动在一定的时间模拟人去访问官网,检查是否有新的通知发布,如果没有就不进行任何操作,如果有通知,那么就将通知从网页中提取下来,保存到指定的位置,然后发送邮件或则电邮告知我即可。
开发爬虫的打算工作
编程语言:Python
IDE的话,推荐使用Pycharm。windows、linux、macos多平台支持网络爬虫 教程,非常好用。
开发环境:Win7+Python 2.7 64bit+PyCharm :环境配置方式自行百度
推荐的python爬虫学习书籍
1.米切尔 (Ryan Mitchell) (作者), 陶俊杰 (译者), 陈小莉 (译者)的Python网路数据采集
2.范传辉 (作者)的Python爬虫开发与项目实战
python爬虫入门到精通必备的书籍
采集交流 • 优采云 发表了文章 • 0 个评论 • 357 次浏览 • 2020-06-09 10:25
3、《笨办法学 Python》这并不是关于亲子关系的编程书, 而是一本正儿八经 Python 编程入 门书,只是以这些寓教于乐的方式阐释编程,显得更轻松愉快一些。4、《深入浅出 Python》Head First 系列的书籍仍然遭受称赞,这本也不例外。Head First Python 主要述说了 Python 3 的基础句型知识以及怎样使用 Python八爪鱼·云采集网络爬虫软件 快速地进行 Web、手机上的开发。5、《像计算机科学家一样思索 python》内容讲解清楚明白python爬虫经典书籍,非常适宜 python 入门用,但对于学习过其他编 程语言的读者来说可能会认为进度比较慢, 但作者的思路和看法确实 给人好多启发,对于新手来说利润颇丰,书中好多反例还是有一定难 度的python爬虫经典书籍,完全吃透也不容易。6、《Python 编程:入门到实践》厚厚的一本书,本书的内容基础并且全面,适合纯小白看。Python 学习进阶书籍1、《Python 学习指南》 本书解释详尽,例子丰富;关于 Python 语言本身的讲解全面详细而八爪鱼·云采集网络爬虫软件 又循序渐进不断重复,同时阐述语言现象背后的机制和原理;除语言 本身,还包含编程实践和设计以及中级主题。
2、《Python 核心编程第 3 版》 本书的内容实际上就是大致介绍了一下部份 python 标准库里的模块 和一些第三方模块,并且主要是网路方向。适合学习完 python 语法 知识后进阶阅读,简单但又囊括了开发所用到的一些基本的库,引起 你继续学习的兴趣。3、《编写高质量 Python 代码的 59 个有效方式》关于库,引用,生产环境这种知识倘若只是埋头写代码,很多时侯都 不会涉及到, 但是这本书里关于这种东西的条目比较简约的把前因后 果理清楚了,感觉太有帮助。4、《Python CookBook》这本书不太适宜从头到尾阅读,适合当一本参考书或是字典书,遇到八爪鱼·云采集网络爬虫软件 了总是上来查查,看看有没有取巧的办法。书中把一些小技巧按章节 集合上去,可以节约不少 google 的时间。5、《流畅的 Python》 本书是极好的 Python 进阶书籍,详细解释了魔术技巧、生成器、协 程、元编程等概念,值得反复阅读。以上是进阶书籍最终要的还是要多动手,找项目实践,从实际应用场 景出发,用程序解决手头的一些冗长复杂问题。二、HTTP 入门书籍 1、《图解 HTTP》本书详尽介绍了 HTTP 的常用的知识,大部分内容以图文的形式展 示,易于读者理解,避免了去啃厚厚的《HTTP 权威指南》和 RFC 文档。
同时作者逻辑清晰,没有介绍过分深奥的知识,满足了读者对 HTTP 基础的需求。八爪鱼·云采集网络爬虫软件 三、数据库入门书籍 1、《MySQL 必知必会》 对入门者太照料的一本书,与其说是一本书不如说是一本小册子,不 到 250 页的小册子,实践性太强,基本没有哪些理论的拼凑,完完 全全就是一本实践手册, 教会你如何用 SQL 语句操作 MySQL。看完 这本书基本就可以说是入门了。 四、正则表达式入门书籍 1、《精通正则表达式》 本书面向的读者是:1) 会用正则表达式;2) 愿意从一个代码工人向 专家进化的;3) 对技术有狂热的追求的;本书注重讲解关于正则表 达式匹配原理、优化方式和使用方法,读完以后你会感觉豁然开朗, 没想到正则表达式还有这样一片天空。 五、爬虫相关书籍 1、《用 Python 写网络爬虫》 本书适宜早已熟悉 python 且熟悉大多数模块的人。 作者对爬虫的编 写考虑较为全面,且有相关练习网页可以实操。八爪鱼·云采集网络爬虫软件 2、《Python 爬虫开发与项目实战》这本书从爬虫会涉及的多线程,多进程讲起,然后介绍 web 前端的 基础知识,然后是数据储存,网络合同,再就是综合的爬虫项目。
这本书不适宜没有任何 Python 基础的人阅读, 因为这本书根本没有 提到任何 Python 的基础知识。但是对于想要进阶 Python 爬虫的人 来说是非常好的。相关阅读:百度地图数据采集: 58 同城信息采集: 黄页 88 企业名录数据采集: 天猫买家秀图片采集详细教程:八爪鱼·云采集网络爬虫软件 八爪鱼采集原理(7.0 版本): 微信公众号文章正文采集: 八爪鱼——90 万用户选择的网页数据采集器。 1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。 查看全部
八爪鱼·云采集网络爬虫软件 python 爬虫入门到精通必备的书籍python 是一种常见的网路爬虫语言,学习 python 爬虫,需要理论 与实践相结合,Python 生态中的爬虫库多如牛毛,urllib、urllib2、 requests、beautifulsoup、scrapy、pyspider 都是爬虫相关的库, 但是假如没有理论知识, 纯粹地学习怎么使用这种 API 如何调用是不 会有提高的。所以,在学习这种库的同时,需要去系统的学习爬虫的 相关原理。你须要懂的技术包括 Python 编程语言、HTTP 协议、数 据库、 Linux 等知识。 这样能够做到真正从入门 python 爬虫到精通, 下面推荐几本精典的书籍。1、Python 语言入门的书籍:适合没有编程基础的,入门 Python 的书籍1、《简明 Python 教程》本书采用知识共享合同免费分发,意味着任何人都可以免费获取,这八爪鱼·云采集网络爬虫软件 本书走过了 11 个年头,最新版以 Python3 为基础同时也会兼具到 Python2 的一些东西,内容十分精简。2、《父与子的编程之旅》一本正儿八经 Python 编程入门书,以寓教于乐的方式阐释编程,显 得更轻松愉快一些。
3、《笨办法学 Python》这并不是关于亲子关系的编程书, 而是一本正儿八经 Python 编程入 门书,只是以这些寓教于乐的方式阐释编程,显得更轻松愉快一些。4、《深入浅出 Python》Head First 系列的书籍仍然遭受称赞,这本也不例外。Head First Python 主要述说了 Python 3 的基础句型知识以及怎样使用 Python八爪鱼·云采集网络爬虫软件 快速地进行 Web、手机上的开发。5、《像计算机科学家一样思索 python》内容讲解清楚明白python爬虫经典书籍,非常适宜 python 入门用,但对于学习过其他编 程语言的读者来说可能会认为进度比较慢, 但作者的思路和看法确实 给人好多启发,对于新手来说利润颇丰,书中好多反例还是有一定难 度的python爬虫经典书籍,完全吃透也不容易。6、《Python 编程:入门到实践》厚厚的一本书,本书的内容基础并且全面,适合纯小白看。Python 学习进阶书籍1、《Python 学习指南》 本书解释详尽,例子丰富;关于 Python 语言本身的讲解全面详细而八爪鱼·云采集网络爬虫软件 又循序渐进不断重复,同时阐述语言现象背后的机制和原理;除语言 本身,还包含编程实践和设计以及中级主题。
2、《Python 核心编程第 3 版》 本书的内容实际上就是大致介绍了一下部份 python 标准库里的模块 和一些第三方模块,并且主要是网路方向。适合学习完 python 语法 知识后进阶阅读,简单但又囊括了开发所用到的一些基本的库,引起 你继续学习的兴趣。3、《编写高质量 Python 代码的 59 个有效方式》关于库,引用,生产环境这种知识倘若只是埋头写代码,很多时侯都 不会涉及到, 但是这本书里关于这种东西的条目比较简约的把前因后 果理清楚了,感觉太有帮助。4、《Python CookBook》这本书不太适宜从头到尾阅读,适合当一本参考书或是字典书,遇到八爪鱼·云采集网络爬虫软件 了总是上来查查,看看有没有取巧的办法。书中把一些小技巧按章节 集合上去,可以节约不少 google 的时间。5、《流畅的 Python》 本书是极好的 Python 进阶书籍,详细解释了魔术技巧、生成器、协 程、元编程等概念,值得反复阅读。以上是进阶书籍最终要的还是要多动手,找项目实践,从实际应用场 景出发,用程序解决手头的一些冗长复杂问题。二、HTTP 入门书籍 1、《图解 HTTP》本书详尽介绍了 HTTP 的常用的知识,大部分内容以图文的形式展 示,易于读者理解,避免了去啃厚厚的《HTTP 权威指南》和 RFC 文档。
同时作者逻辑清晰,没有介绍过分深奥的知识,满足了读者对 HTTP 基础的需求。八爪鱼·云采集网络爬虫软件 三、数据库入门书籍 1、《MySQL 必知必会》 对入门者太照料的一本书,与其说是一本书不如说是一本小册子,不 到 250 页的小册子,实践性太强,基本没有哪些理论的拼凑,完完 全全就是一本实践手册, 教会你如何用 SQL 语句操作 MySQL。看完 这本书基本就可以说是入门了。 四、正则表达式入门书籍 1、《精通正则表达式》 本书面向的读者是:1) 会用正则表达式;2) 愿意从一个代码工人向 专家进化的;3) 对技术有狂热的追求的;本书注重讲解关于正则表 达式匹配原理、优化方式和使用方法,读完以后你会感觉豁然开朗, 没想到正则表达式还有这样一片天空。 五、爬虫相关书籍 1、《用 Python 写网络爬虫》 本书适宜早已熟悉 python 且熟悉大多数模块的人。 作者对爬虫的编 写考虑较为全面,且有相关练习网页可以实操。八爪鱼·云采集网络爬虫软件 2、《Python 爬虫开发与项目实战》这本书从爬虫会涉及的多线程,多进程讲起,然后介绍 web 前端的 基础知识,然后是数据储存,网络合同,再就是综合的爬虫项目。
这本书不适宜没有任何 Python 基础的人阅读, 因为这本书根本没有 提到任何 Python 的基础知识。但是对于想要进阶 Python 爬虫的人 来说是非常好的。相关阅读:百度地图数据采集: 58 同城信息采集: 黄页 88 企业名录数据采集: 天猫买家秀图片采集详细教程:八爪鱼·云采集网络爬虫软件 八爪鱼采集原理(7.0 版本): 微信公众号文章正文采集: 八爪鱼——90 万用户选择的网页数据采集器。 1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。
Python爬虫实战(1):爬取Drupal峰会贴子列表
采集交流 • 优采云 发表了文章 • 0 个评论 • 349 次浏览 • 2020-06-09 10:24
在《Python即时网路爬虫项目: 内容提取器的定义》一文我们定义了一个通用的python网路爬虫类,期望通过这个项目节约程序员一半以上的时间。本文将用一个实例讲解如何使用这个爬虫类。我们将爬集搜客老版峰会,是一个用Drupal做的峰会。
我们在多个文章都在说:节省程序员的时间。关键是市去编撰提取规则的时间,尤其是调试规则的正确性太花时间。在《1分钟快速生成用于网页内容提取的xslt》演示了如何快速生成提取规则网络爬虫论坛,接下来我们再通过GooSeeker的api插口实时获得提取规则,对网页进行抓取。本示例主要有如下两个技术要点:
通过GooSeeker API实时获取用于页面提取的xslt
使用GooSeeker提取器gsExtractor从网页上一次提取多个数组内容。
# _*_coding:utf8_*_
# crawler_gooseeker_bbs.py
# 版本: V1.0
from urllib import request
from lxml import etree
from gooseeker import GsExtractor
# 访问并读取网页内容
url = ""
conn = request.urlopen(url)
doc = etree.HTML(conn.read())
bbsExtra = GsExtractor()
bbsExtra.setXsltFromAPI("31d24931e043e2d5364d03b8ff9cc77e" , "gooseeker_bbs_xslt") # 设置xslt抓取规则,第一个参数是app key,请到会员中心申请
result = bbsExtra.extract(doc) # 调用extract方法提取所需内容
print(str(result))
源代码下载位置请看文章末尾的GitHub源。
运行上节的代码,即可在控制台复印出提取结果,是一个xml文件,如果加上换行缩进,内容如下图:
/img/bVwAyA
1网络爬虫论坛, Python即时网路爬虫项目: 内容提取器的定义
1, GooSeeker开源Python网络爬虫GitHub源 查看全部
/img/bVxTdG
在《Python即时网路爬虫项目: 内容提取器的定义》一文我们定义了一个通用的python网路爬虫类,期望通过这个项目节约程序员一半以上的时间。本文将用一个实例讲解如何使用这个爬虫类。我们将爬集搜客老版峰会,是一个用Drupal做的峰会。
我们在多个文章都在说:节省程序员的时间。关键是市去编撰提取规则的时间,尤其是调试规则的正确性太花时间。在《1分钟快速生成用于网页内容提取的xslt》演示了如何快速生成提取规则网络爬虫论坛,接下来我们再通过GooSeeker的api插口实时获得提取规则,对网页进行抓取。本示例主要有如下两个技术要点:
通过GooSeeker API实时获取用于页面提取的xslt
使用GooSeeker提取器gsExtractor从网页上一次提取多个数组内容。
# _*_coding:utf8_*_
# crawler_gooseeker_bbs.py
# 版本: V1.0
from urllib import request
from lxml import etree
from gooseeker import GsExtractor
# 访问并读取网页内容
url = ""
conn = request.urlopen(url)
doc = etree.HTML(conn.read())
bbsExtra = GsExtractor()
bbsExtra.setXsltFromAPI("31d24931e043e2d5364d03b8ff9cc77e" , "gooseeker_bbs_xslt") # 设置xslt抓取规则,第一个参数是app key,请到会员中心申请
result = bbsExtra.extract(doc) # 调用extract方法提取所需内容
print(str(result))
源代码下载位置请看文章末尾的GitHub源。
运行上节的代码,即可在控制台复印出提取结果,是一个xml文件,如果加上换行缩进,内容如下图:
/img/bVwAyA
1网络爬虫论坛, Python即时网路爬虫项目: 内容提取器的定义
1, GooSeeker开源Python网络爬虫GitHub源
让你从零开始学会写爬虫的5个教程(Python)
采集交流 • 优采云 发表了文章 • 0 个评论 • 264 次浏览 • 2020-06-09 08:02
其实懂了以后,写个爬虫脚本是很简单的,但是对于菜鸟来说却并不是这么容易。实验楼就给这些想学写爬虫,却苦于没有详尽教程的小伙伴推荐5个爬虫教程,都是基于Python语言开发的,因此可能更适宜有一定Python基础的人进行学习。
首先介绍这个教程,比较简单,也容易上手,只要有Python基础的人都可以跟随教程去写天气数据爬虫。先跟随教程动手敲一遍再说,毕竟先讲一大堆理论知识,是太枯燥无味的。
学完第一个教程以后,就可以学习这个教程了,因为有第一个教程的基础python爬虫教程,对爬虫有了一个大约的认知,但对其中的一些原理还不太清楚,那么学习这个教程就太必要啦,这个教程十分详尽的介绍了爬虫的原理等一些基础知识,最后教你用爬虫爬名模相片。
前面写了两个爬虫脚本,理论和实践都有了,这个时侯可以再找个项目练练手,熟悉一下,这个项目就是教你一步步实现一个天猫女郎图片搜集爬虫。
当然爬虫也是有很多种的,这个教程就介绍几种实现爬虫的方式,从传统的线程池到使用解释器,每节课实现一个小爬虫。另外学习解释器的时侯,会从原理入手,以ayncio协程库为原型,实现一个简单的异步编程模型。
课程注重爬虫原理的讲解以及python爬虫代码的实现。
当然,爬虫的应用地方好多,而不只是便捷自己,比如可以写一个聊天机器人,用爬虫爬网路上的笑话,然后按照用户的问题回复相应的笑话内容,是一个很实用和常见的一个功能,学会将爬虫应用到实际的项目中是十分便捷的。 查看全部
写爬虫总是十分吸引IT学习者,毕竟光听上去就太拉风极客,我也晓得很多人学完基础知识以后python爬虫教程,第一个项目开发就是自己写一个爬虫玩儿。
其实懂了以后,写个爬虫脚本是很简单的,但是对于菜鸟来说却并不是这么容易。实验楼就给这些想学写爬虫,却苦于没有详尽教程的小伙伴推荐5个爬虫教程,都是基于Python语言开发的,因此可能更适宜有一定Python基础的人进行学习。
首先介绍这个教程,比较简单,也容易上手,只要有Python基础的人都可以跟随教程去写天气数据爬虫。先跟随教程动手敲一遍再说,毕竟先讲一大堆理论知识,是太枯燥无味的。
学完第一个教程以后,就可以学习这个教程了,因为有第一个教程的基础python爬虫教程,对爬虫有了一个大约的认知,但对其中的一些原理还不太清楚,那么学习这个教程就太必要啦,这个教程十分详尽的介绍了爬虫的原理等一些基础知识,最后教你用爬虫爬名模相片。
前面写了两个爬虫脚本,理论和实践都有了,这个时侯可以再找个项目练练手,熟悉一下,这个项目就是教你一步步实现一个天猫女郎图片搜集爬虫。
当然爬虫也是有很多种的,这个教程就介绍几种实现爬虫的方式,从传统的线程池到使用解释器,每节课实现一个小爬虫。另外学习解释器的时侯,会从原理入手,以ayncio协程库为原型,实现一个简单的异步编程模型。
课程注重爬虫原理的讲解以及python爬虫代码的实现。
当然,爬虫的应用地方好多,而不只是便捷自己,比如可以写一个聊天机器人,用爬虫爬网路上的笑话,然后按照用户的问题回复相应的笑话内容,是一个很实用和常见的一个功能,学会将爬虫应用到实际的项目中是十分便捷的。
【苹果IP代理】 8大高效的Python爬虫框架,你用过几个?
采集交流 • 优采云 发表了文章 • 0 个评论 • 269 次浏览 • 2020-06-09 08:01
4.Portia Portia 是一个开源可视化爬虫工具,可使您在不需要任何编程知识的情况下爬取网站!简单地注释您感兴趣的页面爬虫代理软件爬虫代理软件,Portia 将创建一个蜘蛛来从类似的页面提取数据。5.Newspaper Newspaper 可以拿来提取新闻、文章和内容剖析。使用多线 程,支持 10 多种语言等。 6.Beautiful Soup Beautiful Soup 是一个可以从 HTML 或 XML 文件中提取数据 的 Python 库.它还能通过你喜欢的转换器实现惯用的文档导航, 查找,修改文档的方法.Beautiful Soup 会帮你节约数小时甚至数天 的工作时间。 7.Grab Grab 是一个用于建立 Web 刮板的 Python 框架。借助 Grab, 您可以建立各类复杂的网页抓取工具,从简单的 5 行脚本到处理 数百万个网页的复杂异步网站抓取工具。Grab 提供一个 API 用于 执行网路恳求和处理接收到的内容,例如与 HTML 文档的 DOM 树进行交互。 8.Cola Cola 是一个分布式的爬虫框架,对于用户来说,只需编撰几 个特定的函数,而无需关注分布式运行的细节。任务会手动分配 到多台机器上,整个过程对用户是透明的。 查看全部
【苹果 IP 代理】8 大高效的 Python 爬虫框架,你用过几个? 【苹果 IP 代理】大数据时代下,数据采集推动着数据剖析, 数据剖析加快发展。但是在这个过程中会出现好多问题。拿最简 单最基础的爬虫采集数据为例,过程中还会面临,IP 被封,爬取 受限、违法操作等多种问题,所以在爬取数据之前,一定要了解 好预爬网站是否涉及违规操作,找到合适的代理 IP 访问网站等 一系列问题。今天我们就来讲讲这些高效的爬虫框架。 1.Scrapy Scrapy 是一个为了爬取网站数据,提取结构性数据而编撰的 应用框架。 可以应用在包括数据挖掘,信息处理或储存历史数 据等一系列的程序中。。用这个框架可以轻松爬出来如亚马逊商 品信息之类的数据。 2.PySpider pyspider 是一个用 python 实现的功能强悍的网路爬虫系统, 能在浏览器界面上进行脚本的编撰,功能的调度和爬取结果的实 时查看,后端使用常用的数据库进行爬取结果的储存,还能定时 设置任务与任务优先级等。 3.Crawley Crawley 可以高速爬取对应网站的内容,支持关系和非关系 数据库,数据可以导入为 JSON、XML 等。
4.Portia Portia 是一个开源可视化爬虫工具,可使您在不需要任何编程知识的情况下爬取网站!简单地注释您感兴趣的页面爬虫代理软件爬虫代理软件,Portia 将创建一个蜘蛛来从类似的页面提取数据。5.Newspaper Newspaper 可以拿来提取新闻、文章和内容剖析。使用多线 程,支持 10 多种语言等。 6.Beautiful Soup Beautiful Soup 是一个可以从 HTML 或 XML 文件中提取数据 的 Python 库.它还能通过你喜欢的转换器实现惯用的文档导航, 查找,修改文档的方法.Beautiful Soup 会帮你节约数小时甚至数天 的工作时间。 7.Grab Grab 是一个用于建立 Web 刮板的 Python 框架。借助 Grab, 您可以建立各类复杂的网页抓取工具,从简单的 5 行脚本到处理 数百万个网页的复杂异步网站抓取工具。Grab 提供一个 API 用于 执行网路恳求和处理接收到的内容,例如与 HTML 文档的 DOM 树进行交互。 8.Cola Cola 是一个分布式的爬虫框架,对于用户来说,只需编撰几 个特定的函数,而无需关注分布式运行的细节。任务会手动分配 到多台机器上,整个过程对用户是透明的。
终于知晓python网路爬虫的作用
采集交流 • 优采云 发表了文章 • 0 个评论 • 266 次浏览 • 2020-06-08 08:00
python网路爬虫的作用
1.做为通用搜索引擎网页收集器。
2.做垂直搜索引擎.
3.科学研究:在线人类行为,在线社群演变,人类动力学研究,计量社会学,复杂网路,数据挖掘,等领域的实证研究都须要大量数据,网络爬虫是搜集相关数据的神器。
4.偷窥,hacking,发垃圾邮件……
request恳求包含哪些
当我们通过浏览器向服务器发送request恳求时,这个request包含了一些哪些信息呢?我们可以通过chrome的开发者工具进行说明(如果不知道怎样使用看本篇备注)。
请求方法:最常用的恳求方法包括get恳求和post恳求。post恳求在开发中最常见的是通过表单进行递交,从用户角度来讲网络爬虫 作用,最常见的就是登入验证。当你须要输入一些信息进行登陆的时侯,这次恳求即为post恳求。
url统一资源定位符:一个网址,一张图片,一个视频等都可以用url去定义。当我们恳求一个网页时,我们可以查看network标签网络爬虫 作用,第一个一般是一个document,也就是说这个document是一个未加外部图片、css、js等渲染的html代码,在这个document的下边我们会听到一系列的jpg,js等,这是浏览器按照html代码发起的一次又一次的恳求,而恳求的地址,即为html文档中图片、js等的url地址
request headers:请求头,包括此次恳求的恳求类型,cookie信息以及浏览器类型等。 这个恳求头在我们进行网页抓取的时侯还是有些作用的,服务器会通过解析恳求头来进行信息的初审,判断此次恳求是一次合法的恳求。所以当我们通过程序伪装浏览器进行恳求的时侯,就可以设置一下恳求头的信息。
请求体:post恳求会把用户信息包装在form-data上面进行递交,因此相比于get恳求,post恳求的Headers标签的内容会多出Form Data这个信息包。get恳求可以简单的理解为普通的搜索回车,信息将会以?间隔添加在url的旁边。
为什么python适宜写爬虫
1)抓取网页本身的插口
相比与其他静态编程语言,如java,c#,C++,python抓取网页文档的插口更简约;相比其他动态脚本语言,如perl,shell,python的urllib2包提供了较为完整的访问网页文档的API。(当然ruby也是挺好的选择)
此外,抓取网页有时候须要模拟浏览器的行为,很多网站对于死板的爬虫抓取都是封杀的。这是我们须要模拟user agent的行为构造合适的恳求,譬如模拟用户登录、模拟session/cookie的储存和设置。在python里都有特别优秀的第三方包帮你搞定,如Requests,mechanize
2)网页抓取后的处理
抓取的网页一般须要处理,比如过滤html标签,提取文本等。python的beautifulsoap提供了简约的文档处理功能,能用极短的代码完成大部分文档的处理。
其实以上功能好多语言和工具都能做,但是用python才能干得最快,最干净。Life is short, u need python.
聚焦爬虫过滤方式
1.浅聚焦爬虫
选取符合目标主题的种子URL,例如我们定义抓取的信息为急聘信息,我们便可将急聘网站的URL(拉勾网、大街网等)作为种子URL,这样便保证了抓取内容与我们定义的主题的一致性。
2.深聚焦爬虫
一般有两种,一是针对内容二是针对URL。其中针对内容的如页面中绝大部分超链接都是带有锚文本的,我们可以依据锚文本进行筛选。 查看全部
python网路爬虫的作用
1.做为通用搜索引擎网页收集器。
2.做垂直搜索引擎.
3.科学研究:在线人类行为,在线社群演变,人类动力学研究,计量社会学,复杂网路,数据挖掘,等领域的实证研究都须要大量数据,网络爬虫是搜集相关数据的神器。
4.偷窥,hacking,发垃圾邮件……
request恳求包含哪些
当我们通过浏览器向服务器发送request恳求时,这个request包含了一些哪些信息呢?我们可以通过chrome的开发者工具进行说明(如果不知道怎样使用看本篇备注)。
请求方法:最常用的恳求方法包括get恳求和post恳求。post恳求在开发中最常见的是通过表单进行递交,从用户角度来讲网络爬虫 作用,最常见的就是登入验证。当你须要输入一些信息进行登陆的时侯,这次恳求即为post恳求。
url统一资源定位符:一个网址,一张图片,一个视频等都可以用url去定义。当我们恳求一个网页时,我们可以查看network标签网络爬虫 作用,第一个一般是一个document,也就是说这个document是一个未加外部图片、css、js等渲染的html代码,在这个document的下边我们会听到一系列的jpg,js等,这是浏览器按照html代码发起的一次又一次的恳求,而恳求的地址,即为html文档中图片、js等的url地址
request headers:请求头,包括此次恳求的恳求类型,cookie信息以及浏览器类型等。 这个恳求头在我们进行网页抓取的时侯还是有些作用的,服务器会通过解析恳求头来进行信息的初审,判断此次恳求是一次合法的恳求。所以当我们通过程序伪装浏览器进行恳求的时侯,就可以设置一下恳求头的信息。
请求体:post恳求会把用户信息包装在form-data上面进行递交,因此相比于get恳求,post恳求的Headers标签的内容会多出Form Data这个信息包。get恳求可以简单的理解为普通的搜索回车,信息将会以?间隔添加在url的旁边。
为什么python适宜写爬虫
1)抓取网页本身的插口
相比与其他静态编程语言,如java,c#,C++,python抓取网页文档的插口更简约;相比其他动态脚本语言,如perl,shell,python的urllib2包提供了较为完整的访问网页文档的API。(当然ruby也是挺好的选择)
此外,抓取网页有时候须要模拟浏览器的行为,很多网站对于死板的爬虫抓取都是封杀的。这是我们须要模拟user agent的行为构造合适的恳求,譬如模拟用户登录、模拟session/cookie的储存和设置。在python里都有特别优秀的第三方包帮你搞定,如Requests,mechanize
2)网页抓取后的处理
抓取的网页一般须要处理,比如过滤html标签,提取文本等。python的beautifulsoap提供了简约的文档处理功能,能用极短的代码完成大部分文档的处理。
其实以上功能好多语言和工具都能做,但是用python才能干得最快,最干净。Life is short, u need python.
聚焦爬虫过滤方式
1.浅聚焦爬虫
选取符合目标主题的种子URL,例如我们定义抓取的信息为急聘信息,我们便可将急聘网站的URL(拉勾网、大街网等)作为种子URL,这样便保证了抓取内容与我们定义的主题的一致性。
2.深聚焦爬虫
一般有两种,一是针对内容二是针对URL。其中针对内容的如页面中绝大部分超链接都是带有锚文本的,我们可以依据锚文本进行筛选。
使用Python编撰多线程爬虫抓取百度贴吧邮箱与手机号
采集交流 • 优采云 发表了文章 • 0 个评论 • 484 次浏览 • 2020-07-05 08:00
本爬虫主要是对百度贴吧中各类贴子的内容进行抓取,并且剖析贴子内容将其中的手机号和邮箱地址抓取下来。主要流程在代码注释中有详尽解释。
代码在Windows7 64bit,python 2.7 64bit(安装mysqldb扩充)以及centos 6.5,python 2.7(带mysqldb扩充)环境下测试通过
工欲善其事必先利其器,大家可以从截图看出我的环境是Windows 7 + PyCharm。我的Python环境是Python 2.7 64bit。这是比较适宜菜鸟使用的开发环境。然后我再建议你们安装一个easy_install,听名子就晓得这是一个安装器,它是拿来安装一些扩充包的,比如说在python中假如我们要操作mysql数据库的话,python原生是不支持的,我们必须安装mysqldb包来让python可以操作mysql数据库,如果有easy_install的话我们只须要一行命令就可以快速安装号mysqldb扩充包,他如同php中的composer,centos中的yum,Ubuntu中的apt-get一样便捷。
相关工具可在我的github中找到:cw1997/python-tools,其中easy_install的安装只须要在python命令行下运行哪个py脚本之后稍等片刻即可邮箱爬虫软件,他会手动加入Windows的环境变量,在Windows命令行下假如输入easy_install有回显说明安装成功。
至于电脑硬件其实是越快越好,内存至少8G起步,因为爬虫本身须要大量储存和解析中间数据,尤其是多线程爬虫,在遇到抓取带有分页的列表和详情页,并且抓取数据量很大的情况下使用queue队列分配抓取任务会特别占显存。包括有的时候我们抓取的数据是使用json,如果使用mongodb等nosql数据库储存,也会太占显存。
网络联接建议使用有线网,因为市面上一些劣质的无线路由器和普通的民用无线网卡在线程开的比较大的情况下会出现间歇性断网或则数据遗失,掉包等情况,这个我亲有感受。
至于操作系统和python其实肯定是选择64位。如果你使用的是32位的操作系统,那么难以使用大显存。如果你使用的是32位的python,可能在小规模抓取数据的时侯觉得不出有哪些问题,但是当数据量变大的时侯,比如说某个列表,队列,字典上面储存了大量数据,导致python的显存占用超过2g的时侯会报显存溢出错误。原因在我以前segmentfault上提过的问题中依云的回答有解释(java – python只要占用显存达到1.9G以后httplib模块就开始报内存溢出错误 – SegmentFault)
如果你打算使用mysql储存数据,建议使用mysql5.5之后的版本,因为mysql5.5版本支持json数据类型,这样的话可以抛弃mongodb了。(有人说mysql会比mongodb稳定一点,这个我不确定。)
至于现今python都早已出了3.x版本了,为什么我这儿还使用的是python2.7?我个人选择2.7版本的缘由是自己当年很早曾经买的python核心编程这本书是第二版的,仍然以2.7为示例版本。并且目前网上一直有大量的教程资料是以2.7为版本讲解,2.7在个别方面与3.x还是有很大差异,如果我们没有学过2.7,可能对于一些细微的句型差异不是太懂会导致我们理解上出现误差,或者看不懂demo代码。而且如今还是有部份依赖包只兼容2.7版本。我的建议是假如你是打算急着学python之后去公司工作,并且公司没有老代码须要维护,那么可以考虑直接上手3.x,如果你有比较充沛的时间,并且没有太系统的大牛带,只能借助网上零零散散的博客文章来学习,那么还是先学2.7在学3.x,毕竟学会了2.7以后3.x上手也很快。
其实对于任何软件项目而言,我们但凡想知道编撰这个项目须要哪些知识点,我们都可以观察一下这个项目的主要入口文件都导出了什么包。
现在来看一下我们这个项目,作为一个刚接触python的人,可能有一些包几乎都没有用过,那么我们在本小节就来简单的谈谈这种包起哪些作用,要把握她们分别会涉及到哪些知识点,这些知识点的关键词是哪些。这篇文章并不会耗费长篇大论来从基础讲起,因此我们要学会善用百度,搜索那些知识点的关键词来自学。下面就来一一剖析一下这种知识点。
我们的爬虫抓取数据本质上就是不停的发起http请求,获取http响应,将其存入我们的笔记本中。了解http协议有助于我们在抓取数据的时侯对一些才能加速抓取速率的参数才能精准的控制,比如说keep-alive等。
我们平常编撰的程序都是单线程程序,我们写的代码都在主线程上面运行,这个主线程又运行在python进程中。关于线程和进程的解释可以参考阮一峰的博客:进程与线程的一个简单解释 – 阮一峰的网路日志
在python中实现多线程是通过一个名子称作threading的模块来实现。之前还有thread模块,但是threading对于线程的控制更强,因此我们后来都改用threading来实现多线程编程了。
关于threading多线程的一些用法,我认为这篇文章不错:[python] 专题八.多线程编程之thread和threading 大家可以参考参考。
简单来说,使用threading模块编撰多线程程序,就是先自己定义一个类,然后这个类要承继threading.Thread,并且把每位线程要做的工作代码讲到一个类的run方式中,当然若果线程本身在创建的时侯假如要做一些初始化工作,那么就要在他的__init__方法中编撰好初始化工作所要执行的代码,这个方式如同php,java中的构造方式一样。
这里还要额外讲的一点就是线程安全这个概念。通常情况下我们单线程情况下每位时刻只有一个线程在对资源(文件,变量)操作,所以不可能会出现冲突。但是当多线程的情况下,可能会出现同一个时刻两个线程在操作同一个资源,导致资源受损,所以我们须要一种机制来解决这些冲突带来的破坏,通常有加锁等操作,比如说mysql数据库的innodb表引擎有行级锁等,文件操作有读取锁等等,这些都是她们的程序底层帮我们完成了。所以我们一般只要晓得这些操作,或者这些程序对于线程安全问题做了处理,然后就可以在多线程编程中去使用它们了。而这些考虑到线程安全问题的程序通常就叫做“线程安全版本”,比如说php就有TS版本,这个TS就是Thread Safety线程安全的意思。下面我们要提到的Queue模块就是一种线程安全的队列数据结构,所以我们可以放心的在多线程编程中使用它。
***我们就要来讲讲至关重要的线程阻塞这个概念了。当我们详尽学习完threading模块以后,大概就晓得怎样创建和启动线程了。但是假如我们把线程创建好了,然后调用了start方式,那么我们会发觉似乎整个程序立刻就结束了,这是如何回事呢?其实这是因为我们在主线程中只有负责启动子线程的代码,也就意味着主线程只有启动子线程的功能,至于子线程执行的这些代码,他们本质上只是写在类上面的一个方式,并没在主线程上面真正去执行他,所以主线程启动完子线程以后他的本职工作就早已全部完成了,已经光荣离场了。既然主线程都离场了,那么python进程就跟随结束了,那么其他线程也就没有显存空间继续执行了。所以我们应当是要使主线程大婶等到所有的子线程鄙人全部执行完毕再光荣离场,那么在线程对象中有哪些方式才能把主线程卡住呢?thread.sleep嘛?这确实是个办法,但是到底应当使主线程sleep多久呢?我们并不能确切晓得执行完一个任务要多久时间,肯定不能用这个办法。所以我们这个时侯应当上网查询一下有哪些办法才能使子线程“卡住”主线程呢?“卡住”这个词似乎很粗俗了,其实说专业一点,应该称作“阻塞”,所以我们可以查询“python 子线程阻塞主线程”,如果我们会正确使用搜索引擎的话,应该会查到一个方式称作join(),没错,这个join()方法就是子线程用于阻塞主线程的方式,当子线程还未执行完毕的时侯,主线程运行到富含join()方法的这一行都会卡在那里,直到所有线程都执行完毕才能执行join()方法前面的代码。
假设有一个这样的场景,我们须要抓取一个人的博客,我们晓得这个人的博客有两个页面,一个list.php页面显示的是此博客的所有文章链接,还有一个view.php页面显示的是一篇文章的具体内容。
如果我们要把这个人的博客上面所有文章内容抓取出来,编写单线程爬虫的思路是:先用正则表达式把这个list.php页面的所有链接a标签的href属性抓取出来,存入一个名子称作article_list的链表(在python中不叫链表,叫做list,中文名列表),然后再用一个for循环遍历这个article_list链表,用各类抓取网页内容的函数把内容抓取出来之后存入数据库。
如果我们要编撰一个多线程爬虫来完成这个任务的话,就假定我们的程序用10个线程把,那么我们就要想办法把之前抓取的article_list平均分成10份,分别把每一份分配给其中一个子线程。
但是问题来了,如果我们的article_list链表宽度不是10的倍数,也就是文章数量并不是10的整数倍,那么***一个线程都会比别的线程少分配到一些任务,那么它将会更快的结束。
如果仅仅是抓取这些只有几千字的博客文章这看似没哪些问题,但是假如我们一个任务(不一定是抓取网页的任务,有可能是物理估算,或者图形渲染等等历时任务)的运行时间太长,那么这将导致极大地资源和时间浪费。我们多线程的目的就是尽可能的借助一切估算资源而且估算时间,所以我们要想办法使任务才能愈发科学合理的分配。
并且我还要考虑一种情况,就是文章数量很大的情况下,我们要既能快速抓取到文章内容,又能尽早的看见我们早已抓取到的内容,这种需求在好多CMS采集站上常常会彰显下来。
比如说我们如今要抓取的目标博客,有几千万篇文章,通常这些情况下博客还会做分页处理,那么我们若果根据前面的传统思路先抓取完list.php的所有页面至少就要几个小时甚至几天,老板假如希望你还能早日显示出抓取内容,并且尽早将早已抓取到的内容诠释到我们的CMS采集站上,那么我们就要实现一边抓取list.php而且把早已抓取到的数据丢入一个article_list链表,一边用另一个线程从article_list链表中提取早已抓取到的文章URL地址,然后这个线程再去对应的URL地址中用正则表达式取到博客文章内容。如何实现这个功能呢?
我们就须要同时开启两类线程,一类线程专门负责抓取list.php中的url之后丢入article_list链表,另外一类线程专门负责从article_list中提取出url之后从对应的view.php页面中抓取出对应的博客内容。
但是我们是否还记得上面提及过线程安全这个概念?前一类线程一边往article_list字段中写入数据,另外那一类的线程从article_list中读取数据但是删掉早已读取完毕的数据。但是python中list并不是线程安全版本的数据结构,因此这样操作会导致不可预想的错误。所以我们可以尝试使用一个愈发便捷且线程安全的数据结构,这就是我们的子标题中所提及的Queue队列数据结构。
同样Queue也有一个join()方法,这个join()方法虽然和上一个小节所提到的threading中join()方法差不多,只不过在Queue中,join()的阻塞条件是当队列不为空空的时侯才阻塞,否则继续执行join()后面的代码。在这个爬虫中我便使用了这些技巧来阻塞主线程而不是直接通过线程的join方法来阻塞主线程,这样的用处是可以不用写一个死循环来判定当前任务队列中是否还有未执行完的任务,让程序运行愈发高效,也使代码愈发柔美。
还有一个细节就是在python2.7中队列模块的名子是Queue,而在python3.x中早已更名为queue,就是首字母大小写的区别,大家假如是复制网上的代码,要记得这个小区别。
如果你们学过c语言的话,对这个模块应当会太熟悉,他就是一个负责从命令行中的命令上面提取出附送参数的模块。比如说我们一般在命令行中操作mysql数据库,就是输入mysql -h127.0.0.1 -uroot -p,其中mysql前面的“-h127.0.0.1 -uroot -p”就是可以获取的参数部份。
我们平常在编撰爬虫的时侯,有一些参数是须要用户自己自动输入的,比如说mysql的主机IP,用户名密码等等。为了使我们的程序愈加友好通用,有一些配置项是不需要硬编码在代码上面,而是在执行他的时侯我们动态传入,结合getopt模块我们就可以实现这个功能。
哈希本质上就是一类物理算法的集合,这种物理算法有个特点就是你给定一个参数,他就能输出另外一个结果,虽然这个结果太短,但是他可以近似觉得是***的。比如说我们平常听过的md5,sha-1等等,他们都属于哈希算法。他们可以把一些文件,文字经过一系列的物理运算然后弄成短短不到一百位的一段数字中文混和的字符串。
python中的hashlib模块就为我们封装好了这种物理运算函数,我们只须要简单的调用它就可以完成哈希运算。
为什么在我这个爬虫中用到了这个包呢?因为在一些插口恳求中,服务器须要带上一些校验码,保证插口恳求的数据没有被篡改或则遗失,这些校验码通常都是hash算法,所以我们须要用到这个模块来完成这些运算。
很多时侯我们抓取到的数据不是html,而是一些json数据,json本质上只是一段富含通配符对的字符串,如果我们须要提取出其中特定的字符串,那么我们须要json这个模块来将这个json字符串转换为dict类型便捷我们操作。
有的时侯我们抓取到了一些网页内容,但是我们须要将网页中的一些特定格式的内容提取下来,比如说电子邮箱的格式通常都是上面几位英语数字字母加一个@符号加的域名,而要象计算机语言描述这些格式,我们可以使用一种称作正则表达式的表达式来抒发出这些格式,并且使计算机手动从一大段字符串上将符合这些特定格式的文字匹配下来。
这个模块主要用于处理一些系统方面的事情,在这个爬虫中我用他来解决输出编码问题。
稍微学过一点法语的人都还能猜下来这个模块用于处理时间,在这个爬虫中我用它来获取当前时间戳,然后通过在主线程末尾用当前时间戳除以程序开始运行时的时间戳,得到程序的运行时间。
如图所示,开50个线程抓取100页(每页30个贴子,相当于抓取了3000个贴子)贴吧贴子内容而且从中提取出手机邮箱这个步骤共历时330秒。
这两个模块都是用于处理一些http请求,以及url低格方面的事情。我的爬虫http请求部份的核心代码就是使用这个模块完成的。
这是一个第三方模块,用于在python中操作mysql数据库。
这里我们要注意一个细节问题:mysqldb模块并不是线程安全版本,意味着我们不能在多线程中共享同一个mysql联接句柄。所以你们可以在我的代码中听到,我在每位线程的构造函数中都传入了一个新的mysql联接句柄。因此每位子线程只会用自己独立的mysql联接句柄。
这也是一个第三方模块,网上还能找到相关代码,这个模块主要用于向命令行中输出彩色字符串。比如说我们一般爬虫出现错误,要输出黄色的字体会比较醒目,就要使用到这个模块。
如果你们在网路质量不是挺好的环境下使用该爬虫,会发觉有的时侯会报如图所示的异常,这是我为了偷懒并没有写各类异常处理的逻辑。
通常情况下我们假如要编撰高度自动化的爬虫,那么就须要意料到我们的爬虫可能会遇见的所有异常情况邮箱爬虫软件,针对这种异常情况做处理。
比如说如图所示的错误,我们就应当把当时正在处理的任务重新伸入任务队列,否则我们还会出现遗漏信息的情况。这也是爬虫编撰的一个复杂点。
其实多线程爬虫的编撰也不复杂,多看示例代码,多自己动手尝试,多去社区,论坛交流,很多精典的书上对多线程编程也有特别详尽的解释。这篇文章本质上主要还是一篇科普文章,内容讲解的都不是太深入,大家还须要课外自己多结合网上各类资料自己学习。
【编辑推荐】
Python程序员都该用的一个库Python正则表达式re模块简明笔记这种方式推动Python开发者提升效率Python并发编程之线程池/进程池Python黑魔法之描述符 查看全部
不知道你们春节都是如何过的,反正栏主是在家睡了三天,醒来的时侯登QQ发觉有人找我要一份帖吧爬虫的源代码,想起之前练手的时侯写过一个抓取百度贴吧发贴记录中的邮箱与手机号的爬虫,于是开源分享给你们学习与参考。
本爬虫主要是对百度贴吧中各类贴子的内容进行抓取,并且剖析贴子内容将其中的手机号和邮箱地址抓取下来。主要流程在代码注释中有详尽解释。
代码在Windows7 64bit,python 2.7 64bit(安装mysqldb扩充)以及centos 6.5,python 2.7(带mysqldb扩充)环境下测试通过
工欲善其事必先利其器,大家可以从截图看出我的环境是Windows 7 + PyCharm。我的Python环境是Python 2.7 64bit。这是比较适宜菜鸟使用的开发环境。然后我再建议你们安装一个easy_install,听名子就晓得这是一个安装器,它是拿来安装一些扩充包的,比如说在python中假如我们要操作mysql数据库的话,python原生是不支持的,我们必须安装mysqldb包来让python可以操作mysql数据库,如果有easy_install的话我们只须要一行命令就可以快速安装号mysqldb扩充包,他如同php中的composer,centos中的yum,Ubuntu中的apt-get一样便捷。
相关工具可在我的github中找到:cw1997/python-tools,其中easy_install的安装只须要在python命令行下运行哪个py脚本之后稍等片刻即可邮箱爬虫软件,他会手动加入Windows的环境变量,在Windows命令行下假如输入easy_install有回显说明安装成功。
至于电脑硬件其实是越快越好,内存至少8G起步,因为爬虫本身须要大量储存和解析中间数据,尤其是多线程爬虫,在遇到抓取带有分页的列表和详情页,并且抓取数据量很大的情况下使用queue队列分配抓取任务会特别占显存。包括有的时候我们抓取的数据是使用json,如果使用mongodb等nosql数据库储存,也会太占显存。
网络联接建议使用有线网,因为市面上一些劣质的无线路由器和普通的民用无线网卡在线程开的比较大的情况下会出现间歇性断网或则数据遗失,掉包等情况,这个我亲有感受。
至于操作系统和python其实肯定是选择64位。如果你使用的是32位的操作系统,那么难以使用大显存。如果你使用的是32位的python,可能在小规模抓取数据的时侯觉得不出有哪些问题,但是当数据量变大的时侯,比如说某个列表,队列,字典上面储存了大量数据,导致python的显存占用超过2g的时侯会报显存溢出错误。原因在我以前segmentfault上提过的问题中依云的回答有解释(java – python只要占用显存达到1.9G以后httplib模块就开始报内存溢出错误 – SegmentFault)
如果你打算使用mysql储存数据,建议使用mysql5.5之后的版本,因为mysql5.5版本支持json数据类型,这样的话可以抛弃mongodb了。(有人说mysql会比mongodb稳定一点,这个我不确定。)
至于现今python都早已出了3.x版本了,为什么我这儿还使用的是python2.7?我个人选择2.7版本的缘由是自己当年很早曾经买的python核心编程这本书是第二版的,仍然以2.7为示例版本。并且目前网上一直有大量的教程资料是以2.7为版本讲解,2.7在个别方面与3.x还是有很大差异,如果我们没有学过2.7,可能对于一些细微的句型差异不是太懂会导致我们理解上出现误差,或者看不懂demo代码。而且如今还是有部份依赖包只兼容2.7版本。我的建议是假如你是打算急着学python之后去公司工作,并且公司没有老代码须要维护,那么可以考虑直接上手3.x,如果你有比较充沛的时间,并且没有太系统的大牛带,只能借助网上零零散散的博客文章来学习,那么还是先学2.7在学3.x,毕竟学会了2.7以后3.x上手也很快。
其实对于任何软件项目而言,我们但凡想知道编撰这个项目须要哪些知识点,我们都可以观察一下这个项目的主要入口文件都导出了什么包。
现在来看一下我们这个项目,作为一个刚接触python的人,可能有一些包几乎都没有用过,那么我们在本小节就来简单的谈谈这种包起哪些作用,要把握她们分别会涉及到哪些知识点,这些知识点的关键词是哪些。这篇文章并不会耗费长篇大论来从基础讲起,因此我们要学会善用百度,搜索那些知识点的关键词来自学。下面就来一一剖析一下这种知识点。
我们的爬虫抓取数据本质上就是不停的发起http请求,获取http响应,将其存入我们的笔记本中。了解http协议有助于我们在抓取数据的时侯对一些才能加速抓取速率的参数才能精准的控制,比如说keep-alive等。
我们平常编撰的程序都是单线程程序,我们写的代码都在主线程上面运行,这个主线程又运行在python进程中。关于线程和进程的解释可以参考阮一峰的博客:进程与线程的一个简单解释 – 阮一峰的网路日志
在python中实现多线程是通过一个名子称作threading的模块来实现。之前还有thread模块,但是threading对于线程的控制更强,因此我们后来都改用threading来实现多线程编程了。
关于threading多线程的一些用法,我认为这篇文章不错:[python] 专题八.多线程编程之thread和threading 大家可以参考参考。
简单来说,使用threading模块编撰多线程程序,就是先自己定义一个类,然后这个类要承继threading.Thread,并且把每位线程要做的工作代码讲到一个类的run方式中,当然若果线程本身在创建的时侯假如要做一些初始化工作,那么就要在他的__init__方法中编撰好初始化工作所要执行的代码,这个方式如同php,java中的构造方式一样。
这里还要额外讲的一点就是线程安全这个概念。通常情况下我们单线程情况下每位时刻只有一个线程在对资源(文件,变量)操作,所以不可能会出现冲突。但是当多线程的情况下,可能会出现同一个时刻两个线程在操作同一个资源,导致资源受损,所以我们须要一种机制来解决这些冲突带来的破坏,通常有加锁等操作,比如说mysql数据库的innodb表引擎有行级锁等,文件操作有读取锁等等,这些都是她们的程序底层帮我们完成了。所以我们一般只要晓得这些操作,或者这些程序对于线程安全问题做了处理,然后就可以在多线程编程中去使用它们了。而这些考虑到线程安全问题的程序通常就叫做“线程安全版本”,比如说php就有TS版本,这个TS就是Thread Safety线程安全的意思。下面我们要提到的Queue模块就是一种线程安全的队列数据结构,所以我们可以放心的在多线程编程中使用它。
***我们就要来讲讲至关重要的线程阻塞这个概念了。当我们详尽学习完threading模块以后,大概就晓得怎样创建和启动线程了。但是假如我们把线程创建好了,然后调用了start方式,那么我们会发觉似乎整个程序立刻就结束了,这是如何回事呢?其实这是因为我们在主线程中只有负责启动子线程的代码,也就意味着主线程只有启动子线程的功能,至于子线程执行的这些代码,他们本质上只是写在类上面的一个方式,并没在主线程上面真正去执行他,所以主线程启动完子线程以后他的本职工作就早已全部完成了,已经光荣离场了。既然主线程都离场了,那么python进程就跟随结束了,那么其他线程也就没有显存空间继续执行了。所以我们应当是要使主线程大婶等到所有的子线程鄙人全部执行完毕再光荣离场,那么在线程对象中有哪些方式才能把主线程卡住呢?thread.sleep嘛?这确实是个办法,但是到底应当使主线程sleep多久呢?我们并不能确切晓得执行完一个任务要多久时间,肯定不能用这个办法。所以我们这个时侯应当上网查询一下有哪些办法才能使子线程“卡住”主线程呢?“卡住”这个词似乎很粗俗了,其实说专业一点,应该称作“阻塞”,所以我们可以查询“python 子线程阻塞主线程”,如果我们会正确使用搜索引擎的话,应该会查到一个方式称作join(),没错,这个join()方法就是子线程用于阻塞主线程的方式,当子线程还未执行完毕的时侯,主线程运行到富含join()方法的这一行都会卡在那里,直到所有线程都执行完毕才能执行join()方法前面的代码。
假设有一个这样的场景,我们须要抓取一个人的博客,我们晓得这个人的博客有两个页面,一个list.php页面显示的是此博客的所有文章链接,还有一个view.php页面显示的是一篇文章的具体内容。
如果我们要把这个人的博客上面所有文章内容抓取出来,编写单线程爬虫的思路是:先用正则表达式把这个list.php页面的所有链接a标签的href属性抓取出来,存入一个名子称作article_list的链表(在python中不叫链表,叫做list,中文名列表),然后再用一个for循环遍历这个article_list链表,用各类抓取网页内容的函数把内容抓取出来之后存入数据库。
如果我们要编撰一个多线程爬虫来完成这个任务的话,就假定我们的程序用10个线程把,那么我们就要想办法把之前抓取的article_list平均分成10份,分别把每一份分配给其中一个子线程。
但是问题来了,如果我们的article_list链表宽度不是10的倍数,也就是文章数量并不是10的整数倍,那么***一个线程都会比别的线程少分配到一些任务,那么它将会更快的结束。
如果仅仅是抓取这些只有几千字的博客文章这看似没哪些问题,但是假如我们一个任务(不一定是抓取网页的任务,有可能是物理估算,或者图形渲染等等历时任务)的运行时间太长,那么这将导致极大地资源和时间浪费。我们多线程的目的就是尽可能的借助一切估算资源而且估算时间,所以我们要想办法使任务才能愈发科学合理的分配。
并且我还要考虑一种情况,就是文章数量很大的情况下,我们要既能快速抓取到文章内容,又能尽早的看见我们早已抓取到的内容,这种需求在好多CMS采集站上常常会彰显下来。
比如说我们如今要抓取的目标博客,有几千万篇文章,通常这些情况下博客还会做分页处理,那么我们若果根据前面的传统思路先抓取完list.php的所有页面至少就要几个小时甚至几天,老板假如希望你还能早日显示出抓取内容,并且尽早将早已抓取到的内容诠释到我们的CMS采集站上,那么我们就要实现一边抓取list.php而且把早已抓取到的数据丢入一个article_list链表,一边用另一个线程从article_list链表中提取早已抓取到的文章URL地址,然后这个线程再去对应的URL地址中用正则表达式取到博客文章内容。如何实现这个功能呢?
我们就须要同时开启两类线程,一类线程专门负责抓取list.php中的url之后丢入article_list链表,另外一类线程专门负责从article_list中提取出url之后从对应的view.php页面中抓取出对应的博客内容。
但是我们是否还记得上面提及过线程安全这个概念?前一类线程一边往article_list字段中写入数据,另外那一类的线程从article_list中读取数据但是删掉早已读取完毕的数据。但是python中list并不是线程安全版本的数据结构,因此这样操作会导致不可预想的错误。所以我们可以尝试使用一个愈发便捷且线程安全的数据结构,这就是我们的子标题中所提及的Queue队列数据结构。
同样Queue也有一个join()方法,这个join()方法虽然和上一个小节所提到的threading中join()方法差不多,只不过在Queue中,join()的阻塞条件是当队列不为空空的时侯才阻塞,否则继续执行join()后面的代码。在这个爬虫中我便使用了这些技巧来阻塞主线程而不是直接通过线程的join方法来阻塞主线程,这样的用处是可以不用写一个死循环来判定当前任务队列中是否还有未执行完的任务,让程序运行愈发高效,也使代码愈发柔美。
还有一个细节就是在python2.7中队列模块的名子是Queue,而在python3.x中早已更名为queue,就是首字母大小写的区别,大家假如是复制网上的代码,要记得这个小区别。
如果你们学过c语言的话,对这个模块应当会太熟悉,他就是一个负责从命令行中的命令上面提取出附送参数的模块。比如说我们一般在命令行中操作mysql数据库,就是输入mysql -h127.0.0.1 -uroot -p,其中mysql前面的“-h127.0.0.1 -uroot -p”就是可以获取的参数部份。
我们平常在编撰爬虫的时侯,有一些参数是须要用户自己自动输入的,比如说mysql的主机IP,用户名密码等等。为了使我们的程序愈加友好通用,有一些配置项是不需要硬编码在代码上面,而是在执行他的时侯我们动态传入,结合getopt模块我们就可以实现这个功能。
哈希本质上就是一类物理算法的集合,这种物理算法有个特点就是你给定一个参数,他就能输出另外一个结果,虽然这个结果太短,但是他可以近似觉得是***的。比如说我们平常听过的md5,sha-1等等,他们都属于哈希算法。他们可以把一些文件,文字经过一系列的物理运算然后弄成短短不到一百位的一段数字中文混和的字符串。
python中的hashlib模块就为我们封装好了这种物理运算函数,我们只须要简单的调用它就可以完成哈希运算。
为什么在我这个爬虫中用到了这个包呢?因为在一些插口恳求中,服务器须要带上一些校验码,保证插口恳求的数据没有被篡改或则遗失,这些校验码通常都是hash算法,所以我们须要用到这个模块来完成这些运算。
很多时侯我们抓取到的数据不是html,而是一些json数据,json本质上只是一段富含通配符对的字符串,如果我们须要提取出其中特定的字符串,那么我们须要json这个模块来将这个json字符串转换为dict类型便捷我们操作。
有的时侯我们抓取到了一些网页内容,但是我们须要将网页中的一些特定格式的内容提取下来,比如说电子邮箱的格式通常都是上面几位英语数字字母加一个@符号加的域名,而要象计算机语言描述这些格式,我们可以使用一种称作正则表达式的表达式来抒发出这些格式,并且使计算机手动从一大段字符串上将符合这些特定格式的文字匹配下来。
这个模块主要用于处理一些系统方面的事情,在这个爬虫中我用他来解决输出编码问题。
稍微学过一点法语的人都还能猜下来这个模块用于处理时间,在这个爬虫中我用它来获取当前时间戳,然后通过在主线程末尾用当前时间戳除以程序开始运行时的时间戳,得到程序的运行时间。
如图所示,开50个线程抓取100页(每页30个贴子,相当于抓取了3000个贴子)贴吧贴子内容而且从中提取出手机邮箱这个步骤共历时330秒。
这两个模块都是用于处理一些http请求,以及url低格方面的事情。我的爬虫http请求部份的核心代码就是使用这个模块完成的。
这是一个第三方模块,用于在python中操作mysql数据库。
这里我们要注意一个细节问题:mysqldb模块并不是线程安全版本,意味着我们不能在多线程中共享同一个mysql联接句柄。所以你们可以在我的代码中听到,我在每位线程的构造函数中都传入了一个新的mysql联接句柄。因此每位子线程只会用自己独立的mysql联接句柄。
这也是一个第三方模块,网上还能找到相关代码,这个模块主要用于向命令行中输出彩色字符串。比如说我们一般爬虫出现错误,要输出黄色的字体会比较醒目,就要使用到这个模块。
如果你们在网路质量不是挺好的环境下使用该爬虫,会发觉有的时侯会报如图所示的异常,这是我为了偷懒并没有写各类异常处理的逻辑。
通常情况下我们假如要编撰高度自动化的爬虫,那么就须要意料到我们的爬虫可能会遇见的所有异常情况邮箱爬虫软件,针对这种异常情况做处理。
比如说如图所示的错误,我们就应当把当时正在处理的任务重新伸入任务队列,否则我们还会出现遗漏信息的情况。这也是爬虫编撰的一个复杂点。
其实多线程爬虫的编撰也不复杂,多看示例代码,多自己动手尝试,多去社区,论坛交流,很多精典的书上对多线程编程也有特别详尽的解释。这篇文章本质上主要还是一篇科普文章,内容讲解的都不是太深入,大家还须要课外自己多结合网上各类资料自己学习。
【编辑推荐】
Python程序员都该用的一个库Python正则表达式re模块简明笔记这种方式推动Python开发者提升效率Python并发编程之线程池/进程池Python黑魔法之描述符
Python爬虫借助cookie实现模拟登录实例解读
采集交流 • 优采云 发表了文章 • 0 个评论 • 454 次浏览 • 2020-07-05 08:00
举个事例,某些网站是须要登陆后就能得到你想要的信息的,不登录只能是旅客模式,那么我们可以借助Urllib2库保存我们曾经登陆过的Cookie,之后载入cookie获取我们想要的页面,然后再进行抓取。理解cookie主要是为我们快捷模拟登陆抓取目标网页作出打算。
我之前的贴子中使用过urlopen()这个函数来打开网页进行抓取,这仅仅只是一个简单的Python网页打开器,其参数也仅有urlopen(url,data,timeout),这三个参数对于我们获取目标网页的cookie是远远不够的。这时候我们就要借助到另外一种Opener——CookieJar。
cookielib也是Python进行爬虫的一个重要模块python爬虫模拟登录python爬虫模拟登录,他能与urllib2互相结合一起爬取想要的内容。该模块的CookieJar类的对象可以捕获cookie并在后续联接恳求时重新发送,这样就可以实现我们所须要的模拟登陆功能。
这里非常说明一下,cookielib是在py2.7中自带的模块,无需重新安装,想要查看其自带模块可以查看Python目录下的Lib文件夹,里面有所有安装的模块。我一开始没想起来,在pycharm中居然没有搜到cookielib,使用了快捷安装也报错:Couldn't find index page for 'Cookielib' (maybe misspelled?)
之后才想起来是不是自带的就有,没想到去lib文件夹一看还真有,白白浪费半个小时各类瞎折腾~~
下面我们就来介绍一下这个模块,该模块主要的对象有CookieJar、FileCookieJar、MozillaCookieJar、LWPCookieJar。
它们的关系:CookieJar —-派生—->FileCookieJar —-派生—–>MozillaCookieJar和LWPCookieJar 主要用法,我们下边也会提到。urllib2.urlopen()函数不支持验证、cookie或则其它HTTP中级功能。要支持这种功能,必须使用build_opener()(可以用于使python程序模拟浏览器进行访问,作用你懂得~)函数创建自定义Opener对象。
1、首先我们就来获取一下网站的cookie
例子:
#coding=utf-8
import cookielib
import urllib2
mycookie = cookielib.CookieJar() #声明一个CookieJar的类对象保存cookie(注意CookieJar的大小写问题)
handler = urllib2.HTTPCookieProcessor(mycookie) #利用urllib2库中的HTTPCookieProcessor来声明一个处理cookie的处理器
opener = urllib2.build_opener(handler) #利用handler来构造opener,opener的用法和urlopen()类似
response = opener.open("http://www.baidu.com") #opener返回的一个应答对象response
for item in my.cookie:
print"name="+item.name
print"value="+item.value
结果:
name=BAIDUID
value=73BD718962A6EA0DAD4CB9578A08FDD0:FG=1
name=BIDUPSID
value=73BD718962A6EA0DAD4CB9578A08FDD0
name=H_PS_PSSID
value=1450_19035_21122_17001_21454_21409_21394_21377_21526_21189_21398
name=PSTM
value=1478834132
name=BDSVRTM
value=0
name=BD_HOME
value=0
这样我们就得到了一个最简单的cookie。
2、将cookie保存到文件
上面我们得到了cookie,下面我们学习怎么保存cookie。在这里我们使用它的泛型MozillaCookieJar来实现Cookie的保存
例子:
#coding=utf-8
import cookielib
import urllib2
mycookie = cookielib.MozillaCookieJar() #声明一个MozillaCookieJar的类对象保存cookie(注意MozillaCookieJar的大小写问题)
handler = urllib2.HTTPCookieProcessor(mycookie) #利用urllib2库中的HTTPCookieProcessor来声明一个处理cookie的处理器
opener = urllib2.build_opener(handler) #利用handler来构造opener,opener的用法和urlopen()类似
response = opener.open("http://www.baidu.com") #opener返回的一个应答对象response
for item in mycookie:
print"name="+item.name
print"value="+item.value
filename='mycookie.txt'#设定保存的文件名
mycookie.save(filename,ignore_discard=True, ignore_expires=True)
将里面的事例简单变型就可以得到本例,使用了CookieJar的泛型MozillaCookiJar,为什么呢?我们将MozillaCookiJar换成CookieJar试试,下面一张图你能够明白:
CookieJar是没有保存save属性的~
save()这个方式中:ignore_discard的意思是虽然cookies将被遗弃也将它保存出来,ignore_expires的意思是假如在该文件中cookies早已存在,则覆盖原文件写入,在这里,我们将这两个全部设置为True。运行以后,cookies将被保存到cookie.txt文件中,我们查看一下内容:
这样我们就成功保存了我们想要的cookie
3、从文件中获取cookie并访问 查看全部
Cookie,指个别网站为了分辨用户身分、进行session跟踪而存储在用户本地终端上的数据(通常经过加密)。
举个事例,某些网站是须要登陆后就能得到你想要的信息的,不登录只能是旅客模式,那么我们可以借助Urllib2库保存我们曾经登陆过的Cookie,之后载入cookie获取我们想要的页面,然后再进行抓取。理解cookie主要是为我们快捷模拟登陆抓取目标网页作出打算。
我之前的贴子中使用过urlopen()这个函数来打开网页进行抓取,这仅仅只是一个简单的Python网页打开器,其参数也仅有urlopen(url,data,timeout),这三个参数对于我们获取目标网页的cookie是远远不够的。这时候我们就要借助到另外一种Opener——CookieJar。
cookielib也是Python进行爬虫的一个重要模块python爬虫模拟登录python爬虫模拟登录,他能与urllib2互相结合一起爬取想要的内容。该模块的CookieJar类的对象可以捕获cookie并在后续联接恳求时重新发送,这样就可以实现我们所须要的模拟登陆功能。
这里非常说明一下,cookielib是在py2.7中自带的模块,无需重新安装,想要查看其自带模块可以查看Python目录下的Lib文件夹,里面有所有安装的模块。我一开始没想起来,在pycharm中居然没有搜到cookielib,使用了快捷安装也报错:Couldn't find index page for 'Cookielib' (maybe misspelled?)
之后才想起来是不是自带的就有,没想到去lib文件夹一看还真有,白白浪费半个小时各类瞎折腾~~
下面我们就来介绍一下这个模块,该模块主要的对象有CookieJar、FileCookieJar、MozillaCookieJar、LWPCookieJar。
它们的关系:CookieJar —-派生—->FileCookieJar —-派生—–>MozillaCookieJar和LWPCookieJar 主要用法,我们下边也会提到。urllib2.urlopen()函数不支持验证、cookie或则其它HTTP中级功能。要支持这种功能,必须使用build_opener()(可以用于使python程序模拟浏览器进行访问,作用你懂得~)函数创建自定义Opener对象。
1、首先我们就来获取一下网站的cookie
例子:
#coding=utf-8
import cookielib
import urllib2
mycookie = cookielib.CookieJar() #声明一个CookieJar的类对象保存cookie(注意CookieJar的大小写问题)
handler = urllib2.HTTPCookieProcessor(mycookie) #利用urllib2库中的HTTPCookieProcessor来声明一个处理cookie的处理器
opener = urllib2.build_opener(handler) #利用handler来构造opener,opener的用法和urlopen()类似
response = opener.open("http://www.baidu.com";) #opener返回的一个应答对象response
for item in my.cookie:
print"name="+item.name
print"value="+item.value
结果:
name=BAIDUID
value=73BD718962A6EA0DAD4CB9578A08FDD0:FG=1
name=BIDUPSID
value=73BD718962A6EA0DAD4CB9578A08FDD0
name=H_PS_PSSID
value=1450_19035_21122_17001_21454_21409_21394_21377_21526_21189_21398
name=PSTM
value=1478834132
name=BDSVRTM
value=0
name=BD_HOME
value=0
这样我们就得到了一个最简单的cookie。
2、将cookie保存到文件
上面我们得到了cookie,下面我们学习怎么保存cookie。在这里我们使用它的泛型MozillaCookieJar来实现Cookie的保存
例子:
#coding=utf-8
import cookielib
import urllib2
mycookie = cookielib.MozillaCookieJar() #声明一个MozillaCookieJar的类对象保存cookie(注意MozillaCookieJar的大小写问题)
handler = urllib2.HTTPCookieProcessor(mycookie) #利用urllib2库中的HTTPCookieProcessor来声明一个处理cookie的处理器
opener = urllib2.build_opener(handler) #利用handler来构造opener,opener的用法和urlopen()类似
response = opener.open("http://www.baidu.com";) #opener返回的一个应答对象response
for item in mycookie:
print"name="+item.name
print"value="+item.value
filename='mycookie.txt'#设定保存的文件名
mycookie.save(filename,ignore_discard=True, ignore_expires=True)
将里面的事例简单变型就可以得到本例,使用了CookieJar的泛型MozillaCookiJar,为什么呢?我们将MozillaCookiJar换成CookieJar试试,下面一张图你能够明白:
CookieJar是没有保存save属性的~
save()这个方式中:ignore_discard的意思是虽然cookies将被遗弃也将它保存出来,ignore_expires的意思是假如在该文件中cookies早已存在,则覆盖原文件写入,在这里,我们将这两个全部设置为True。运行以后,cookies将被保存到cookie.txt文件中,我们查看一下内容:
这样我们就成功保存了我们想要的cookie
3、从文件中获取cookie并访问
从python基础到爬虫的书有哪些值得推荐
采集交流 • 优采云 发表了文章 • 0 个评论 • 483 次浏览 • 2020-07-04 08:00
第一个
个人觉得《Python学习手册:第3版》是学习语言基础比较好的书了.
《Python学习手册(第3版)》讲述了:Python可移植、功能强悍、易于使用,是编撰独立应用程序和脚本应用程序的理想选择。无论你是刚接触编程或则刚接触Python,通过学习《Python学习手册(第3版)》,你可以迅速高效地精通核心Python语言基础。读完《Python学习手册(第3版)》,你会对这门语言有足够的了解,从而可以在你所从事的任何应用领域中使用它。
《Python学习手册(第3版)》是作者依据过去10年用于教学而广为人知的培训课程的材料编撰而成的。除了有许多详尽说明和每章小结之外,每章还包括一个头脑风暴:这是《Python学习手册(第3版)》独特的一部分,配合以实用的练习题和复习题,让读者练习新学的方法并测试自己的理解程度。
《Python学习手册(第3版)》包括:
类型和操作——深入讨论Python主要的外置对象类型:数字、列表和字典等。
语句和句型——在Python中输入代码来构建并处理对象,以及Python通常的句型模型。
函数——Python基本的面向过程工具,用于组织代码和重用。
模块——封装句子、函数以及其他工具,从而可以组织成较大的组件。
类和OOP——Python可选的面向对象编程工具,可用于组织程序代码因而实现订制和重用。
异常和工具——异常处理模型和句子,并介绍编撰更大程序的开发工具。
讨论Python 3.0。
《Python学习手册(第3版)》让你对Python语言有深入而完整的了解,从而帮助你理解今后碰到的任何Python应用程序实例。如果你打算探求Google和YouTube为何选中了Python,《Python学习手册(第3版)》就是你入门的最佳手册。
第二个
《Python基础教程(第2版·修订版)》也是精典的Python入门教程,层次鲜明,结构严谨,内容详实,特别是最后几章,作者将上面述说的内容应用到10个引人入胜的项目中,并以模板的方式介绍了项目的开发过程,手把手院长Python开发,让读者从项目中展现Python的真正魅力。这本书既适宜初学者筑牢基础,又能帮助Python程序员提高技能,即使是Python方面的技术专家,也能从书里找到耳目一新的内容。
第三个
《“笨办法”学Python(第3版)》是一本Python入门书籍,适合对计算机了解不多,没有学过编程,但对编程感兴趣的初学者使用。这本书结构十分简单,其中覆盖了输入/输出、变量和函数三个主题,以及一些比较中级的话题,如条件判定、循环、类和对象、代码测试及项目的实现等。每一章的格式基本相同,以代码习题开始,按照说明编撰代码,运行并检测结果,然后再做附加练习。这本书以习题的方法引导读者一步一步学习编程,从简单的复印仍然讲授到完整项目的实现,让初学者从基础的编程技术入手,最终体验到软件开发的基本过程。
【大牛评价】hardway(笨办法)比较适宜起步编程,作为Python的入门挺不错。
第四个
在这里给你们推荐最后一本《集体智慧编程》
本书以机器学习与估算统计为主题背景,专门述说怎么挖掘和剖析Web上的数据和资源,如何剖析用户体验、市场营销、个人品位等众多信息,并得出有用的推论python爬虫数据书籍,通过复杂的算法来从Web网站获取、收集并剖析用户的数据和反馈信息,以便创造新的用户价值和商业价值。
全书内容详实,包括协作过滤技术(实现关联产品推荐功能)、集群数据剖析(在大规模数据集中开掘相像的数据子集)、搜索引擎核心技术(爬虫、索引、查询引擎、PageRank算法等)、搜索海量信息并进行剖析统计得出结论的优化算法、贝叶斯过滤技术(垃圾邮件过滤、文本过滤)、用决策树技术实现预测和决策建模功能、社交网络的信息匹配技术、机器学习和人工智能应用等。
本书是Web开发者、架构师、应用工程师等的极佳选择。
“太棒了!对于初学这种算法的开发者而言,我想不出有比这本书更好的选择了,而对于象我这样学过Al的道友而言,我也想不出还有什么更好的办法才能使自己重温这种知识的细节。”
——Dan Russell,资深技术总监,Google
“Toby的这本书十分成功地将机器学习算法这一复杂的议程分拆成了一个个既实用又易懂的事例,我们可以直接借助那些反例来剖析当前网路上的社会化交互作用。假如我早三年读过这本书,就会省去许多宝贵的时间python爬虫数据书籍,也不至于走那么多的弯路了。”
——Tim Wolters,CTO,Collective Intellect
第五个
其实我认为很多人也在看《Python核心编程:第2版》.在我自己看来,我并不喜欢这本书.
这本书的原书的勘误表就有够长的,翻译时却几乎没有参考勘误表,把原书的所有低级错误都搬进去了。这本书的原书质量也并不好,书的结构组织并不合理,不适宜初学者阅读。有人说,这本书适宜进阶阅读,我认为也不尽然。这本书好多地方都写的欲言又止的,看得人很郁闷。 查看全部
于我个人而言,我很喜欢2113Python,当然我也5261有很多的理由推荐你去学python.我只4102说两点.一是简单,二是写python工资高1653.我感觉这俩理由就够了,对不对.买本书,装上pycharm,把书里面的事例习题都敲一遍.再用flask,web.py等框架搭个小网站.. 完美...(小伙伴们有问到该学python2.7还是3.X,那我的答案是:目前大多数实际开发,都是用2.7的,因为实际项目开发有很多依赖的包,都只支持到2.7,你用3.X干不了活.那你能怎样办.所以不需要苦恼.等3.X普及,你写的2.7代码,都可以无痛移植,妥妥的不用害怕.)
第一个
个人觉得《Python学习手册:第3版》是学习语言基础比较好的书了.
《Python学习手册(第3版)》讲述了:Python可移植、功能强悍、易于使用,是编撰独立应用程序和脚本应用程序的理想选择。无论你是刚接触编程或则刚接触Python,通过学习《Python学习手册(第3版)》,你可以迅速高效地精通核心Python语言基础。读完《Python学习手册(第3版)》,你会对这门语言有足够的了解,从而可以在你所从事的任何应用领域中使用它。
《Python学习手册(第3版)》是作者依据过去10年用于教学而广为人知的培训课程的材料编撰而成的。除了有许多详尽说明和每章小结之外,每章还包括一个头脑风暴:这是《Python学习手册(第3版)》独特的一部分,配合以实用的练习题和复习题,让读者练习新学的方法并测试自己的理解程度。
《Python学习手册(第3版)》包括:
类型和操作——深入讨论Python主要的外置对象类型:数字、列表和字典等。
语句和句型——在Python中输入代码来构建并处理对象,以及Python通常的句型模型。
函数——Python基本的面向过程工具,用于组织代码和重用。
模块——封装句子、函数以及其他工具,从而可以组织成较大的组件。
类和OOP——Python可选的面向对象编程工具,可用于组织程序代码因而实现订制和重用。
异常和工具——异常处理模型和句子,并介绍编撰更大程序的开发工具。
讨论Python 3.0。
《Python学习手册(第3版)》让你对Python语言有深入而完整的了解,从而帮助你理解今后碰到的任何Python应用程序实例。如果你打算探求Google和YouTube为何选中了Python,《Python学习手册(第3版)》就是你入门的最佳手册。
第二个
《Python基础教程(第2版·修订版)》也是精典的Python入门教程,层次鲜明,结构严谨,内容详实,特别是最后几章,作者将上面述说的内容应用到10个引人入胜的项目中,并以模板的方式介绍了项目的开发过程,手把手院长Python开发,让读者从项目中展现Python的真正魅力。这本书既适宜初学者筑牢基础,又能帮助Python程序员提高技能,即使是Python方面的技术专家,也能从书里找到耳目一新的内容。
第三个
《“笨办法”学Python(第3版)》是一本Python入门书籍,适合对计算机了解不多,没有学过编程,但对编程感兴趣的初学者使用。这本书结构十分简单,其中覆盖了输入/输出、变量和函数三个主题,以及一些比较中级的话题,如条件判定、循环、类和对象、代码测试及项目的实现等。每一章的格式基本相同,以代码习题开始,按照说明编撰代码,运行并检测结果,然后再做附加练习。这本书以习题的方法引导读者一步一步学习编程,从简单的复印仍然讲授到完整项目的实现,让初学者从基础的编程技术入手,最终体验到软件开发的基本过程。
【大牛评价】hardway(笨办法)比较适宜起步编程,作为Python的入门挺不错。
第四个
在这里给你们推荐最后一本《集体智慧编程》
本书以机器学习与估算统计为主题背景,专门述说怎么挖掘和剖析Web上的数据和资源,如何剖析用户体验、市场营销、个人品位等众多信息,并得出有用的推论python爬虫数据书籍,通过复杂的算法来从Web网站获取、收集并剖析用户的数据和反馈信息,以便创造新的用户价值和商业价值。
全书内容详实,包括协作过滤技术(实现关联产品推荐功能)、集群数据剖析(在大规模数据集中开掘相像的数据子集)、搜索引擎核心技术(爬虫、索引、查询引擎、PageRank算法等)、搜索海量信息并进行剖析统计得出结论的优化算法、贝叶斯过滤技术(垃圾邮件过滤、文本过滤)、用决策树技术实现预测和决策建模功能、社交网络的信息匹配技术、机器学习和人工智能应用等。
本书是Web开发者、架构师、应用工程师等的极佳选择。
“太棒了!对于初学这种算法的开发者而言,我想不出有比这本书更好的选择了,而对于象我这样学过Al的道友而言,我也想不出还有什么更好的办法才能使自己重温这种知识的细节。”
——Dan Russell,资深技术总监,Google
“Toby的这本书十分成功地将机器学习算法这一复杂的议程分拆成了一个个既实用又易懂的事例,我们可以直接借助那些反例来剖析当前网路上的社会化交互作用。假如我早三年读过这本书,就会省去许多宝贵的时间python爬虫数据书籍,也不至于走那么多的弯路了。”
——Tim Wolters,CTO,Collective Intellect
第五个
其实我认为很多人也在看《Python核心编程:第2版》.在我自己看来,我并不喜欢这本书.
这本书的原书的勘误表就有够长的,翻译时却几乎没有参考勘误表,把原书的所有低级错误都搬进去了。这本书的原书质量也并不好,书的结构组织并不合理,不适宜初学者阅读。有人说,这本书适宜进阶阅读,我认为也不尽然。这本书好多地方都写的欲言又止的,看得人很郁闷。
Python爬虫的用途
采集交流 • 优采云 发表了文章 • 0 个评论 • 361 次浏览 • 2020-06-30 08:01
Python 爬虫的用途 Python 爬虫是用 Python 编程语言实现的网路爬虫,主要用于网路数据的抓取和处理,相比于其他语言,Python 是一门特别适宜开发网路爬虫的编程语言,大量外置包,可以轻松实现网路爬虫功能。 Python 爬虫可以做的事情好多,如搜索引擎、采集数据、广告过滤等,Python爬虫还可以用于数据剖析,在数据的抓取方面可以作用巨大! n Python 爬虫构架组成 1. URL 管理器:管理待爬取的 url 集合和已爬取的 url 集合,传送待爬取的 url 给网页下载器; 2. 网页下载器:爬取 url 对应的网页,存储成字符串,传送给网页解析器; 3. 网页解析器:解析出有价值的数据,存储出来,同时补充 url 到 URL 管理器。 n Python 爬虫工作原理 Python 爬虫通过 URL 管理器,判断是否有待爬 URL,如果有待爬 URL,通过调度器进行传递给下载器网络爬虫 作用,下载 URL 内容,并通过调度器传送给解析器,解析URL 内容,并将价值数据和新 URL 列表通过调度器传递给应用程序,并输出价值信息的过程。 n Python 爬虫常用框架有: grab:网络爬虫框架(基于 pycurl/multicur); scrapy:网络爬虫框架(基于 twisted),不支持 Python3; pyspider:一个强悍的爬虫系统;cola:一个分布式爬虫框架; portia:基于 Scrapy 的可视化爬虫; restkit:Python 的 HTTP 资源工具包。它可以使你轻松地访问 HTTP 资源,并围绕它完善的对象; demiurge:基于 PyQuery 的爬虫微框架。 Python 爬虫应用领域广泛,在网络爬虫领域处于霸主位置,Scrapy、Request、BeautifuSoap、urlib 等框架的应用,可以实现爬行自如的功能,只要您数据抓取看法网络爬虫 作用,Python 爬虫均可实现!
Python爬虫实现百度图片手动下载
采集交流 • 优采云 发表了文章 • 0 个评论 • 343 次浏览 • 2020-06-29 08:01
分析需求剖析网页源代码,配合开发者工具编撰正则表达式或则XPath表达式即将编撰 python 爬虫代码 效果预览
运行疗效如下:
存放图片的文件夹:
我们的爬虫起码要实现两个功能:一是搜索图片,二是手动下载。
搜索图片:最容易想到的是爬百度图片的结果,我们就上百度图片瞧瞧:
随便搜索几个关键字,可以看见早已搜索下来好多张图片:
我们点击右键,查看源代码:
打开源代码以后,发现一堆源代码比较难找出我们想要的资源。
这个时侯,就要用开发者工具!我们回到上一页面,调出开发者工具,我们须要用的是左上角那种东西:(鼠标追随)。
然后选择你想看源代码的地方,就可以发觉,下面的代码市手动定位到了相应的位置。如下图:
我们复制这个地址,然后到昨天的一堆源代码里搜索一下百度图片 爬虫,发现了它的位置,但是这儿我们又困惑了,这个图片有这么多地址,到底用那个呢?我们可以看见有thumbURL,middleURL,hoverURL,objURL
通过剖析可以晓得,前面两个是缩小的版本,hoverURL 是键盘联通之后显示的版本,objURL 应该是我们须要的,可以分别打开这几个网址瞧瞧,发现 objURL 的那种最大最清晰。
找到了图片地址,接下来我们剖析源代码。看看是不是所有的 objURL 都是图片。
发现都是以.jpg格式结尾的图片。
pic_url = re.findall('"objURL":"(.*?)",',html,re.S)
这里我们用了2个包百度图片 爬虫,一个是正则,一个是 requests 包
#-*- coding:utf-8 -*-
import re
import requests
复制百度图片搜索的链接,传入 requests ,然后把正则表达式写好
url = 'https://image.baidu.com/search/index?tn=baiduimage&ie=utf-8&word=%E6%A0%97%E5%B1%B1%E6%9C%AA%E6%9D%A5%E5%A4%B4%E5%83%8F&ct=201326592&ic=0&lm=-1&width=&height=&v=index' html = requests.get(url).text pic_url = re.findall('"objURL":"(.*?)",',html,re.S)
因为有很多张图片,所以要循环,我们复印出结果来瞧瞧,然后用 requests 获取网址,由于有些图片可能存在网址打不开的情况,所以加了10秒超时控制。
pic_url = re.findall('"objURL":"(.*?)",',html,re.S) i = 1 for each in pic_url:
print each
try:
pic= requests.get(each, timeout=10)
except requests.exceptions.ConnectionError: print('【错误】当前图片无法下载')
continue
接着就是把图片保存出来,我们事先构建好一个 images 目录,把图片都放进去,命名的时侯,以数字命名。
dir = '../images/' + keyword + '_' + str(i) + '.jpg'
fp = open(dir, 'wb')
fp.write(pic.content)
fp.close()
i += 1
完整的代码
# -*- coding:utf-8 -*-
import re
import requests
def dowmloadPic(html, keyword):
pic_url = re.findall('"objURL":"(.*?)",', html, re.S)
i = 1
print('找到关键词:' + keyword + '的图片,现在开始下载图片...')
for each in pic_url:
print('正在下载第' + str(i) + '张图片,图片地址:' + str(each))
try:
pic = requests.get(each, timeout=10)
except requests.exceptions.ConnectionError:
print('【错误】当前图片无法下载')
continue
dir = '../images/' + keyword + '_' + str(i) + '.jpg'
fp = open(dir, 'wb')
fp.write(pic.content)
fp.close()
i += 1
if __name__ == '__main__':
word = input("Input key word: ")
url = 'http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=' + word + '&ct=201326592&v=flip'
result = requests.get(url)
dowmloadPic(result.text, word)
我们听到有的图片没显示下来,打开网址看,发现确实没了。
因为百度有些图片它缓存到百度的服务器上,所以我们在百度上能够看到它,但它的实际链接早已失效了。
enjoy 我们的第一个图片下载爬虫吧!当然它除了能下载百度的图片,依葫芦画瓢,你如今应当能做好多事情了,比如爬取头像,爬天猫展示图等等。
完整代码已然放在Githut上 查看全部
制作一个爬虫通常分以下几个步骤:
分析需求剖析网页源代码,配合开发者工具编撰正则表达式或则XPath表达式即将编撰 python 爬虫代码 效果预览
运行疗效如下:
存放图片的文件夹:
我们的爬虫起码要实现两个功能:一是搜索图片,二是手动下载。
搜索图片:最容易想到的是爬百度图片的结果,我们就上百度图片瞧瞧:
随便搜索几个关键字,可以看见早已搜索下来好多张图片:
我们点击右键,查看源代码:
打开源代码以后,发现一堆源代码比较难找出我们想要的资源。
这个时侯,就要用开发者工具!我们回到上一页面,调出开发者工具,我们须要用的是左上角那种东西:(鼠标追随)。
然后选择你想看源代码的地方,就可以发觉,下面的代码市手动定位到了相应的位置。如下图:
我们复制这个地址,然后到昨天的一堆源代码里搜索一下百度图片 爬虫,发现了它的位置,但是这儿我们又困惑了,这个图片有这么多地址,到底用那个呢?我们可以看见有thumbURL,middleURL,hoverURL,objURL
通过剖析可以晓得,前面两个是缩小的版本,hoverURL 是键盘联通之后显示的版本,objURL 应该是我们须要的,可以分别打开这几个网址瞧瞧,发现 objURL 的那种最大最清晰。
找到了图片地址,接下来我们剖析源代码。看看是不是所有的 objURL 都是图片。
发现都是以.jpg格式结尾的图片。
pic_url = re.findall('"objURL":"(.*?)",',html,re.S)
这里我们用了2个包百度图片 爬虫,一个是正则,一个是 requests 包
#-*- coding:utf-8 -*-
import re
import requests
复制百度图片搜索的链接,传入 requests ,然后把正则表达式写好
url = 'https://image.baidu.com/search/index?tn=baiduimage&ie=utf-8&word=%E6%A0%97%E5%B1%B1%E6%9C%AA%E6%9D%A5%E5%A4%B4%E5%83%8F&ct=201326592&ic=0&lm=-1&width=&height=&v=index' html = requests.get(url).text pic_url = re.findall('"objURL":"(.*?)",',html,re.S)
因为有很多张图片,所以要循环,我们复印出结果来瞧瞧,然后用 requests 获取网址,由于有些图片可能存在网址打不开的情况,所以加了10秒超时控制。
pic_url = re.findall('"objURL":"(.*?)",',html,re.S) i = 1 for each in pic_url:
print each
try:
pic= requests.get(each, timeout=10)
except requests.exceptions.ConnectionError: print('【错误】当前图片无法下载')
continue
接着就是把图片保存出来,我们事先构建好一个 images 目录,把图片都放进去,命名的时侯,以数字命名。
dir = '../images/' + keyword + '_' + str(i) + '.jpg'
fp = open(dir, 'wb')
fp.write(pic.content)
fp.close()
i += 1
完整的代码
# -*- coding:utf-8 -*-
import re
import requests
def dowmloadPic(html, keyword):
pic_url = re.findall('"objURL":"(.*?)",', html, re.S)
i = 1
print('找到关键词:' + keyword + '的图片,现在开始下载图片...')
for each in pic_url:
print('正在下载第' + str(i) + '张图片,图片地址:' + str(each))
try:
pic = requests.get(each, timeout=10)
except requests.exceptions.ConnectionError:
print('【错误】当前图片无法下载')
continue
dir = '../images/' + keyword + '_' + str(i) + '.jpg'
fp = open(dir, 'wb')
fp.write(pic.content)
fp.close()
i += 1
if __name__ == '__main__':
word = input("Input key word: ")
url = 'http://image.baidu.com/search/flip?tn=baiduimage&ie=utf-8&word=' + word + '&ct=201326592&v=flip'
result = requests.get(url)
dowmloadPic(result.text, word)
我们听到有的图片没显示下来,打开网址看,发现确实没了。
因为百度有些图片它缓存到百度的服务器上,所以我们在百度上能够看到它,但它的实际链接早已失效了。
enjoy 我们的第一个图片下载爬虫吧!当然它除了能下载百度的图片,依葫芦画瓢,你如今应当能做好多事情了,比如爬取头像,爬天猫展示图等等。
完整代码已然放在Githut上
2019最新30个小时搞定Python网络爬虫(全套详尽版) 零基础入门 视频教
采集交流 • 优采云 发表了文章 • 0 个评论 • 369 次浏览 • 2020-06-26 08:01
1、零基础对Python网络爬虫感兴趣的开发者
2、想从事Python网路爬虫工程师相关工作的开发者
3、想学习Python网路爬虫作为技术储备的开发者
1、本课程的目标是将你们培养成Python网路爬虫工程师。薪资基本在13k-36k左右;
2、学完才能从零开始把握Python爬虫项目的编撰,学会独立开发常见的爬虫项目;
3、学完能把握常见的反爬处理手段爬虫入门书籍,比如验证码处理、浏览器伪装、代理IP池技术和用户代理池技术等;
4、学完才能熟练使用正则表达式和XPath表达式进行信息提取;
5、学完把握抓包技术,掌握屏蔽的数据信息怎样进行提取,学会手动模拟加载行为、进行网址构造和手动模拟Ajax异步恳求数据;
6、熟练把握urllib模块,熟练使用Scrapy框架进行爬虫项目开发。
第一章节:Python 网络爬虫之基础
第二章节:Python网路爬虫之工作原理
第三章节:Python网路爬虫之正则表达式
第五章节:Python网路爬虫之用户和IP代理池
第六章节 :Python网路爬虫之腾讯陌陌和视频实战
第七章节:Python网路爬虫之Scrapy框架
第八章节:Python网路爬虫之Scrapy与Urllib的整合
第九章节:Python网路爬虫之扩充学习
第十章节:Python网路爬虫之分布式爬虫 查看全部
这是一套完整的网路爬虫课程,通过该课程把握网路爬虫的相关知识,以便把握网路爬虫方方面面的知识,学完后胜任网路爬虫相关工作。 1、体系完整科学,可以系统化学习; 2、课程通俗易懂爬虫入门书籍,可以使学员真正学会; 3、从零开始教学直至深入,零基础的朋友亦可以学习!
1、零基础对Python网络爬虫感兴趣的开发者
2、想从事Python网路爬虫工程师相关工作的开发者
3、想学习Python网路爬虫作为技术储备的开发者
1、本课程的目标是将你们培养成Python网路爬虫工程师。薪资基本在13k-36k左右;
2、学完才能从零开始把握Python爬虫项目的编撰,学会独立开发常见的爬虫项目;
3、学完能把握常见的反爬处理手段爬虫入门书籍,比如验证码处理、浏览器伪装、代理IP池技术和用户代理池技术等;
4、学完才能熟练使用正则表达式和XPath表达式进行信息提取;
5、学完把握抓包技术,掌握屏蔽的数据信息怎样进行提取,学会手动模拟加载行为、进行网址构造和手动模拟Ajax异步恳求数据;
6、熟练把握urllib模块,熟练使用Scrapy框架进行爬虫项目开发。
第一章节:Python 网络爬虫之基础
第二章节:Python网路爬虫之工作原理
第三章节:Python网路爬虫之正则表达式
第五章节:Python网路爬虫之用户和IP代理池
第六章节 :Python网路爬虫之腾讯陌陌和视频实战
第七章节:Python网路爬虫之Scrapy框架
第八章节:Python网路爬虫之Scrapy与Urllib的整合
第九章节:Python网路爬虫之扩充学习
第十章节:Python网路爬虫之分布式爬虫
求大神们推荐python入门书籍(爬虫方面)?
采集交流 • 优采云 发表了文章 • 0 个评论 • 316 次浏览 • 2020-06-25 08:03
题主的要求是Python入门,而且是和爬虫相关的书籍,那么有一本书简直很适宜了,那就是《 Python for Informatics 》(中文翻译叫《信息管理专业Python教程》),这本书除了是一本挺好的Python爬虫方面的入门书,而且还有以这本书为教材的配套的Coursera课程。
这本书是美国密西根大学信息学院院长为他的课程编撰的,是一本开源书,有人将他翻译成了中文版爬虫入门书籍,书上有配套的习题和代码,而且这种习题代码都可以在网上获取到,书本身并不厚,前面十章将的都是Python的基础用法,后面几张就是讲解和Python爬虫有关的,像正则表达式,网络编程(HTTP 协议), Web Service,数据库与SQL句子,数据可视化,书中还仔细讲解了用Python爬取Twiter上的用户信息,和各类解析html会用到的工具,如BeautifulSoup等,学完本书,爬取个知乎哪些的都是小意思!本书中文版下载地址地址。
说完了书在来说说配套的Coursera课程,是Coursera上太火的零基础 Python 入门 专项课程,内容大致和书上的内容差不多,分成了6门课程,前三门课程讲解Python句型,后面讲Python爬虫的数据采集数据处理等爬虫入门书籍,并且有不少的习题,老师也十分特别有趣,,知乎上很早之前就有人介绍这门课程coursera上有什么值得学习的Python,数据剖析的课程? - 程刚的回答,本课的课程地址,并且这门课正好就是今天开课(7月25号),学习课程假如不要证书的话也不用花钱,貌似大部分配有英文字幕。 查看全部
题主的要求是Python入门,而且是和爬虫相关的书籍,那么有一本书简直很适宜了,那就是《 Python for Informatics 》(中文翻译叫《信息管理专业Python教程》),这本书除了是一本挺好的Python爬虫方面的入门书,而且还有以这本书为教材的配套的Coursera课程。
这本书是美国密西根大学信息学院院长为他的课程编撰的,是一本开源书,有人将他翻译成了中文版爬虫入门书籍,书上有配套的习题和代码,而且这种习题代码都可以在网上获取到,书本身并不厚,前面十章将的都是Python的基础用法,后面几张就是讲解和Python爬虫有关的,像正则表达式,网络编程(HTTP 协议), Web Service,数据库与SQL句子,数据可视化,书中还仔细讲解了用Python爬取Twiter上的用户信息,和各类解析html会用到的工具,如BeautifulSoup等,学完本书,爬取个知乎哪些的都是小意思!本书中文版下载地址地址。
说完了书在来说说配套的Coursera课程,是Coursera上太火的零基础 Python 入门 专项课程,内容大致和书上的内容差不多,分成了6门课程,前三门课程讲解Python句型,后面讲Python爬虫的数据采集数据处理等爬虫入门书籍,并且有不少的习题,老师也十分特别有趣,,知乎上很早之前就有人介绍这门课程coursera上有什么值得学习的Python,数据剖析的课程? - 程刚的回答,本课的课程地址,并且这门课正好就是今天开课(7月25号),学习课程假如不要证书的话也不用花钱,貌似大部分配有英文字幕。
Python借助requests进行模拟登陆
采集交流 • 优采云 发表了文章 • 0 个评论 • 669 次浏览 • 2020-06-25 08:00
Python3 模拟登陆并爬取表格数据!
本节主要内容有:通过requests库模拟表单递交通过pandas库提取网页表格上周五,大师兄发给我一个网址,哭哭啼啼地求我:“去!把这个网页上所有年所有市所有小麦的数据全爬出来,存到Access里!”我看他可怜,勉为其难地挥挥手说:“好嘞,马上就开始!”目标剖析Python学习交流群:1004391443大师兄给我的网址是这个:
使用python模拟登陆
使用python模拟登陆Windows + Linux 均成功
Python模拟一个用户登入系统
题目:模拟一个用户登入系统,用户输入用户名和密码,输入正确即可步入系统直接上代码:#模拟一个用户登入系统,用户输入用户名和密码,输入正确即可步入系统d=['yao','123456']while 1:name =input("请输入用户名:")if name in d:breakelse:print("你输入的用户名不存在,请...
使用python模拟浏览器实现登录
让我们通过命令行模拟浏览器实现登录操作,看看一个简单的登录操作,具体是怎样实现的
Python爬虫入门-表单递交与模拟登陆
前言明天主要讲两个方面:利用Request库进行POST恳求表单交互cookie实现模拟登陆网站Requests实现POST恳求今requests可以以多种形式进行post恳求,比如form表单方式、json方式等。今天主要以表单方式举例:Reqeusts支持以form表单方式发送post恳求,只须要将恳求的参数构造成一个字典,然后传给requests.post()...
Python模拟百度登陆
注:本文转载,如有侵权,请告知将给以删掉原文章链接:本来写这个玩意是想拿来手动登入百度,然后按照帖吧内的的排行抓取会员头像的,比如生成一个帖吧万人头像图或千人头像图。也算是练练手。完成后才发觉抓那种帖吧排行完全不需要登陆…也好,以后拿来做手动一键签到(经常忘打卡),抢二楼哪些的,也...
任务自动化_request 模拟登陆实战
知识点:request 带密码登入、selenium+headless Chrome、pandas、思路:request 爬虫模拟登陆,下载文档,再用 pandas 进行数据剖析
python实现模拟登陆
本文主要用python实现了对网站的模拟登陆。通过自己构造post数据来用Python实现登陆过程。当你要模拟登陆一个网站时,首先要搞清楚网站的登陆处理细节(发了什么样的数据,给谁发等...)。我是通过HTTPfox来抓取http数据包来剖析该网站的登陆流程。同时,我们还要剖析抓到的post包的数据结构和header,要按照递交的数据结构和heander来构造自己的pos...
请问写python爬虫怎样用urllib或则requests模拟用户登入
比如我在百度文库下个教案,,我用urllib2或则request,我可以用urllib2.open(url)或者requests.get(url)来打开页面,但是不知道怎么写cookie的,就是使浏览器觉得你早已登陆了,请问怎么写urllib或则requests.get呢?谢谢
requests 实现模拟登陆,获取cookie
有个需求须要模拟登陆csdn获取cookie,对csdn进行后续系列操作,刚开始使用的selenium,功能可以实现,但是效率有点低,后来改用的requests,遇到不少坑,今天来总结一下。首先找到csdn登陆的url,在故意输错密码的情况下点击登陆,检查会发觉network中有一个dologin的响应,这就是要递交到服务器的帐号密码信息。点开会发觉下图所示:请求的url,请求方法p...
Python模拟登录
最近想做一个可以模拟人工,对网站的内容进行操作,比如手动购物,自动支付。朋友向我推荐用Python去写python爬虫模拟登录,我也就开始用Python。看了一些大约,用Python3 的requests去弄,感觉逻辑很简单。最主要的问题是怎样去剖析网站的逻辑,这很难。用了chrome f12 记录网页的操作,但是一点是,chrome不能全文查找,没办法搜索到诸如帐号密码的传送,cookie等问题,手动查找好烦。
Python模拟登陆的几种方式
目录方式一:直接使用已知的cookie访问技巧二:模拟登陆后再携带得到的cookie访问方式三:模拟登陆后用session保持登入状态方式四:使用无头浏览器访问正文方式一:直接使用已知的cookie访问特征:简单,但须要先在浏览器登陆原理:简单地说,cookie保存在发起恳求的客户端中,服务器借助cookie来分辨不同的客户端。因为htt...
用Python模拟登陆中学教务系统抢课
-- Illustrations by Vladislav Solovjov --作者:小苏打博客地址:地址:github....
Python爬虫之模拟登陆总结
备注:python 2.7.9,32位有些网站需要登入后才会爬取所须要的信息python爬虫模拟登录,此时可以设计爬虫进行模拟登陆,原理是借助浏览器cookie。一、浏览器访问服务器的过程: (1)浏览器(客户端)向Web服务器发出一个HTTP请求(Http request); (2)Web服务器收到恳求,发回响应信息(Http Response); (3)浏览器解析内容呈现
python模拟浏览器登陆
转自:
python3下使用requests实现模拟用户登入 —— 基础篇(马蜂窝)
python3下使用requests实现模拟用户登入 —— 基础篇(马蜂窝)1. 了解cookie和session首先一定要先了解到cookie和session是哪些,这是前面理解网站交互,模拟用户登入的基础。1.1. 无状态合同:Http如上图所示,HTTP合同 是无状态的合同,用户浏览服务器上的内容,只须要发送页面恳求,服务器返回内容。对于服务器来说,并不关心,也...
Visual C++技术内幕(第四版).part4.rar下载
一个十分清淅的PDF版的Visual C++技术黑幕(第四版),至于这本书究竟有多强就不用我介绍了吧!本书共分part1、part2、part3、part4 四部份相关下载链接:
sap施行顾问宝典2下载
sap施行顾问宝典一共3个压缩包挺好的东西。相关下载链接:
Xilinx_ise使用教程(配合Modelsim使用)下载
这是我搜集的一个Xilinx_ISE6.1的教程,结合了MODELSIM的仿真功能,自己觉得讲解的还可以,适合初学者入门使用,对其他人员也有一定的参考价值。相关下载链接:
相关热词c# 程序跳转c#索引器定义、c#扫描软件c# 文字复印左右反转c#byte转换成数字c# 音量调节组件c# wpf 界面c# 读取证书文件的内容c# dgv 树结构c#承继 反序列化
我们是太有底线的 查看全部
Python3 模拟登陆并爬取表格数据!
本节主要内容有:通过requests库模拟表单递交通过pandas库提取网页表格上周五,大师兄发给我一个网址,哭哭啼啼地求我:“去!把这个网页上所有年所有市所有小麦的数据全爬出来,存到Access里!”我看他可怜,勉为其难地挥挥手说:“好嘞,马上就开始!”目标剖析Python学习交流群:1004391443大师兄给我的网址是这个:
使用python模拟登陆
使用python模拟登陆Windows + Linux 均成功
Python模拟一个用户登入系统
题目:模拟一个用户登入系统,用户输入用户名和密码,输入正确即可步入系统直接上代码:#模拟一个用户登入系统,用户输入用户名和密码,输入正确即可步入系统d=['yao','123456']while 1:name =input("请输入用户名:")if name in d:breakelse:print("你输入的用户名不存在,请...
使用python模拟浏览器实现登录
让我们通过命令行模拟浏览器实现登录操作,看看一个简单的登录操作,具体是怎样实现的
Python爬虫入门-表单递交与模拟登陆
前言明天主要讲两个方面:利用Request库进行POST恳求表单交互cookie实现模拟登陆网站Requests实现POST恳求今requests可以以多种形式进行post恳求,比如form表单方式、json方式等。今天主要以表单方式举例:Reqeusts支持以form表单方式发送post恳求,只须要将恳求的参数构造成一个字典,然后传给requests.post()...
Python模拟百度登陆
注:本文转载,如有侵权,请告知将给以删掉原文章链接:本来写这个玩意是想拿来手动登入百度,然后按照帖吧内的的排行抓取会员头像的,比如生成一个帖吧万人头像图或千人头像图。也算是练练手。完成后才发觉抓那种帖吧排行完全不需要登陆…也好,以后拿来做手动一键签到(经常忘打卡),抢二楼哪些的,也...
任务自动化_request 模拟登陆实战
知识点:request 带密码登入、selenium+headless Chrome、pandas、思路:request 爬虫模拟登陆,下载文档,再用 pandas 进行数据剖析
python实现模拟登陆
本文主要用python实现了对网站的模拟登陆。通过自己构造post数据来用Python实现登陆过程。当你要模拟登陆一个网站时,首先要搞清楚网站的登陆处理细节(发了什么样的数据,给谁发等...)。我是通过HTTPfox来抓取http数据包来剖析该网站的登陆流程。同时,我们还要剖析抓到的post包的数据结构和header,要按照递交的数据结构和heander来构造自己的pos...
请问写python爬虫怎样用urllib或则requests模拟用户登入
比如我在百度文库下个教案,,我用urllib2或则request,我可以用urllib2.open(url)或者requests.get(url)来打开页面,但是不知道怎么写cookie的,就是使浏览器觉得你早已登陆了,请问怎么写urllib或则requests.get呢?谢谢
requests 实现模拟登陆,获取cookie
有个需求须要模拟登陆csdn获取cookie,对csdn进行后续系列操作,刚开始使用的selenium,功能可以实现,但是效率有点低,后来改用的requests,遇到不少坑,今天来总结一下。首先找到csdn登陆的url,在故意输错密码的情况下点击登陆,检查会发觉network中有一个dologin的响应,这就是要递交到服务器的帐号密码信息。点开会发觉下图所示:请求的url,请求方法p...
Python模拟登录
最近想做一个可以模拟人工,对网站的内容进行操作,比如手动购物,自动支付。朋友向我推荐用Python去写python爬虫模拟登录,我也就开始用Python。看了一些大约,用Python3 的requests去弄,感觉逻辑很简单。最主要的问题是怎样去剖析网站的逻辑,这很难。用了chrome f12 记录网页的操作,但是一点是,chrome不能全文查找,没办法搜索到诸如帐号密码的传送,cookie等问题,手动查找好烦。
Python模拟登陆的几种方式
目录方式一:直接使用已知的cookie访问技巧二:模拟登陆后再携带得到的cookie访问方式三:模拟登陆后用session保持登入状态方式四:使用无头浏览器访问正文方式一:直接使用已知的cookie访问特征:简单,但须要先在浏览器登陆原理:简单地说,cookie保存在发起恳求的客户端中,服务器借助cookie来分辨不同的客户端。因为htt...
用Python模拟登陆中学教务系统抢课
-- Illustrations by Vladislav Solovjov --作者:小苏打博客地址:地址:github....
Python爬虫之模拟登陆总结
备注:python 2.7.9,32位有些网站需要登入后才会爬取所须要的信息python爬虫模拟登录,此时可以设计爬虫进行模拟登陆,原理是借助浏览器cookie。一、浏览器访问服务器的过程: (1)浏览器(客户端)向Web服务器发出一个HTTP请求(Http request); (2)Web服务器收到恳求,发回响应信息(Http Response); (3)浏览器解析内容呈现
python模拟浏览器登陆
转自:
python3下使用requests实现模拟用户登入 —— 基础篇(马蜂窝)
python3下使用requests实现模拟用户登入 —— 基础篇(马蜂窝)1. 了解cookie和session首先一定要先了解到cookie和session是哪些,这是前面理解网站交互,模拟用户登入的基础。1.1. 无状态合同:Http如上图所示,HTTP合同 是无状态的合同,用户浏览服务器上的内容,只须要发送页面恳求,服务器返回内容。对于服务器来说,并不关心,也...
Visual C++技术内幕(第四版).part4.rar下载
一个十分清淅的PDF版的Visual C++技术黑幕(第四版),至于这本书究竟有多强就不用我介绍了吧!本书共分part1、part2、part3、part4 四部份相关下载链接:
sap施行顾问宝典2下载
sap施行顾问宝典一共3个压缩包挺好的东西。相关下载链接:
Xilinx_ise使用教程(配合Modelsim使用)下载
这是我搜集的一个Xilinx_ISE6.1的教程,结合了MODELSIM的仿真功能,自己觉得讲解的还可以,适合初学者入门使用,对其他人员也有一定的参考价值。相关下载链接:
相关热词c# 程序跳转c#索引器定义、c#扫描软件c# 文字复印左右反转c#byte转换成数字c# 音量调节组件c# wpf 界面c# 读取证书文件的内容c# dgv 树结构c#承继 反序列化
我们是太有底线的
Python代理IP爬虫的菜鸟使用教程
采集交流 • 优采云 发表了文章 • 0 个评论 • 373 次浏览 • 2020-06-24 08:01
Python爬虫要经历爬虫、爬虫被限制、爬虫反限制的过程。当然后续还要网页爬虫限制优化爬虫代理,爬虫再反限制的一系列道高一尺魔高一丈的过程。爬虫的中级阶段,添加headers和ip代理可以解决好多问题。
本人自己在爬取豆瓣读书的时侯,就以为爬取次数过多,直接被封了IP.后来就研究了代理IP的问题.
(当时不知道哪些情况,差点态度就崩了...),下面给你们介绍一下我自己代理IP爬取数据的问题,请你们强调不足之处.
问题
这是我的IP被封了,一开始好好的,我还以为是我的代码问题了
思路:
从网上查找了一些关于爬虫代理IP的资料,得到下边的思路
爬取一些IP,过滤掉不可用. 在requests的恳求的proxies参数加入对应的IP. 继续爬取. 收工 好吧,都是屁话,理论你们都懂,上面直接上代码...
思路有了,动手上去.
运行环境
Python 3.7, Pycharm
这些须要你们直接去搭建好环境...
准备工作
爬取IP地址的网站(国内高匿代理) 校准IP地址的网站 你之前被封IP的py爬虫脚本...
上面的网址看个人的情况来选定
爬取IP的完整代码
PS:简单的使用bs4获取IP和端口号,没有啥难度,里面降低了一个过滤不可用IP的逻辑
关键地方都有注释了
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# @Time : 2018/11/22
# @Author : liangk
# @Site :
# @File : auto_archive_ios.py
# @Software: PyCharm
import requests
from bs4 import BeautifulSoup
import json
class GetIp(object):
"""抓取代理IP"""
def __init__(self):
"""初始化变量"""
self.url = 'http://www.xicidaili.com/nn/'
self.check_url = 'https://www.ip.cn/'
self.ip_list = []
@staticmethod
def get_html(url):
"""请求html页面信息"""
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'
}
try:
request = requests.get(url=url, headers=header)
request.encoding = 'utf-8'
html = request.text
return html
except Exception as e:
return ''
def get_available_ip(self, ip_address, ip_port):
"""检测IP地址是否可用"""
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'
}
ip_url_next = '://' + ip_address + ':' + ip_port
proxies = {'http': 'http' + ip_url_next, 'https': 'https' + ip_url_next}
try:
r = requests.get(self.check_url, headers=header, proxies=proxies, timeout=3)
html = r.text
except:
print('fail-%s' % ip_address)
else:
print('success-%s' % ip_address)
soup = BeautifulSoup(html, 'lxml')
div = soup.find(class_='well')
if div:
print(div.text)
ip_info = {'address': ip_address, 'port': ip_port}
self.ip_list.append(ip_info)
def main(self):
"""主方法"""
web_html = self.get_html(self.url)
soup = BeautifulSoup(web_html, 'lxml')
ip_list = soup.find(id='ip_list').find_all('tr')
for ip_info in ip_list:
td_list = ip_info.find_all('td')
if len(td_list) > 0:
ip_address = td_list[1].text
ip_port = td_list[2].text
# 检测IP地址是否有效
self.get_available_ip(ip_address, ip_port)
# 写入有效文件
with open('ip.txt', 'w') as file:
json.dump(self.ip_list, file)
print(self.ip_list)
# 程序主入口
if __name__ == '__main__':
get_ip = GetIp()
get_ip.main()
使用方式完整代码
PS: 主要是通过使用随机的IP来爬取,根据request_status来判定这个IP是否可以用.
为什么要这样判定?
主要是即使前面经过了过滤,但是不代表在你爬取的时侯是可以用的,所以还是得多做一个判定.
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# @Time : 2018/11/22
# @Author : liangk
# @Site :
# @File : get_douban_books.py
# @Software: PyCharm
from bs4 import BeautifulSoup
import datetime
import requests
import json
import random
ip_random = -1
article_tag_list = []
article_type_list = []
def get_html(url):
header = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36'
}
global ip_random
ip_rand, proxies = get_proxie(ip_random)
print(proxies)
try:
request = requests.get(url=url, headers=header, proxies=proxies, timeout=3)
except:
request_status = 500
else:
request_status = request.status_code
print(request_status)
while request_status != 200:
ip_random = -1
ip_rand, proxies = get_proxie(ip_random)
print(proxies)
try:
request = requests.get(url=url, headers=header, proxies=proxies, timeout=3)
except:
request_status = 500
else:
request_status = request.status_code
print(request_status)
ip_random = ip_rand
request.encoding = 'gbk'
html = request.content
print(html)
return html
def get_proxie(random_number):
with open('ip.txt', 'r') as file:
ip_list = json.load(file)
if random_number == -1:
random_number = random.randint(0, len(ip_list) - 1)
ip_info = ip_list[random_number]
ip_url_next = '://' + ip_info['address'] + ':' + ip_info['port']
proxies = {'http': 'http' + ip_url_next, 'https': 'https' + ip_url_next}
return random_number, proxies
# 程序主入口
if __name__ == '__main__':
"""只是爬取了书籍的第一页,按照评价排序"""
start_time = datetime.datetime.now()
url = 'https://book.douban.com/tag/?view=type&icn=index-sorttags-all'
base_url = 'https://book.douban.com/tag/'
html = get_html(url)
soup = BeautifulSoup(html, 'lxml')
article_tag_list = soup.find_all(class_='tag-content-wrapper')
tagCol_list = soup.find_all(class_='tagCol')
for table in tagCol_list:
""" 整理分析数据 """
sub_type_list = []
a = table.find_all('a')
for book_type in a:
sub_type_list.append(book_type.text)
article_type_list.append(sub_type_list)
for sub in article_type_list:
for sub1 in sub:
title = '==============' + sub1 + '=============='
print(title)
print(base_url + sub1 + '?start=0' + '&type=S')
with open('book.text', 'a', encoding='utf-8') as f:
f.write('\n' + title + '\n')
f.write(url + '\n')
for start in range(0, 2):
# (start * 20) 分页是0 20 40 这样的
# type=S是按评价排序
url = base_url + sub1 + '?start=%s' % (start * 20) + '&type=S'
html = get_html(url)
soup = BeautifulSoup(html, 'lxml')
li = soup.find_all(class_='subject-item')
for div in li:
info = div.find(class_='info').find('a')
img = div.find(class_='pic').find('img')
content = '书名:<%s>' % info['title'] + ' 书本图片:' + img['src'] + '\n'
print(content)
with open('book.text', 'a', encoding='utf-8') as f:
f.write(content)
end_time = datetime.datetime.now()
print('耗时: ', (end_time - start_time).seconds)
为什么选择国外高匿代理!
总结
使用这样简单的代理IP,基本上就可以应付在爬爬爬着被封IP的情况了.而且没有使用自己的IP,间接的保护?!?!
大家有其他的愈发快捷的方式,欢迎你们可以拿出来交流和讨论爬虫代理,谢谢。 查看全部
前言
Python爬虫要经历爬虫、爬虫被限制、爬虫反限制的过程。当然后续还要网页爬虫限制优化爬虫代理,爬虫再反限制的一系列道高一尺魔高一丈的过程。爬虫的中级阶段,添加headers和ip代理可以解决好多问题。
本人自己在爬取豆瓣读书的时侯,就以为爬取次数过多,直接被封了IP.后来就研究了代理IP的问题.
(当时不知道哪些情况,差点态度就崩了...),下面给你们介绍一下我自己代理IP爬取数据的问题,请你们强调不足之处.
问题
这是我的IP被封了,一开始好好的,我还以为是我的代码问题了
思路:
从网上查找了一些关于爬虫代理IP的资料,得到下边的思路
爬取一些IP,过滤掉不可用. 在requests的恳求的proxies参数加入对应的IP. 继续爬取. 收工 好吧,都是屁话,理论你们都懂,上面直接上代码...
思路有了,动手上去.
运行环境
Python 3.7, Pycharm
这些须要你们直接去搭建好环境...
准备工作
爬取IP地址的网站(国内高匿代理) 校准IP地址的网站 你之前被封IP的py爬虫脚本...
上面的网址看个人的情况来选定
爬取IP的完整代码
PS:简单的使用bs4获取IP和端口号,没有啥难度,里面降低了一个过滤不可用IP的逻辑
关键地方都有注释了
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# @Time : 2018/11/22
# @Author : liangk
# @Site :
# @File : auto_archive_ios.py
# @Software: PyCharm
import requests
from bs4 import BeautifulSoup
import json
class GetIp(object):
"""抓取代理IP"""
def __init__(self):
"""初始化变量"""
self.url = 'http://www.xicidaili.com/nn/'
self.check_url = 'https://www.ip.cn/'
self.ip_list = []
@staticmethod
def get_html(url):
"""请求html页面信息"""
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'
}
try:
request = requests.get(url=url, headers=header)
request.encoding = 'utf-8'
html = request.text
return html
except Exception as e:
return ''
def get_available_ip(self, ip_address, ip_port):
"""检测IP地址是否可用"""
header = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.77 Safari/537.36'
}
ip_url_next = '://' + ip_address + ':' + ip_port
proxies = {'http': 'http' + ip_url_next, 'https': 'https' + ip_url_next}
try:
r = requests.get(self.check_url, headers=header, proxies=proxies, timeout=3)
html = r.text
except:
print('fail-%s' % ip_address)
else:
print('success-%s' % ip_address)
soup = BeautifulSoup(html, 'lxml')
div = soup.find(class_='well')
if div:
print(div.text)
ip_info = {'address': ip_address, 'port': ip_port}
self.ip_list.append(ip_info)
def main(self):
"""主方法"""
web_html = self.get_html(self.url)
soup = BeautifulSoup(web_html, 'lxml')
ip_list = soup.find(id='ip_list').find_all('tr')
for ip_info in ip_list:
td_list = ip_info.find_all('td')
if len(td_list) > 0:
ip_address = td_list[1].text
ip_port = td_list[2].text
# 检测IP地址是否有效
self.get_available_ip(ip_address, ip_port)
# 写入有效文件
with open('ip.txt', 'w') as file:
json.dump(self.ip_list, file)
print(self.ip_list)
# 程序主入口
if __name__ == '__main__':
get_ip = GetIp()
get_ip.main()
使用方式完整代码
PS: 主要是通过使用随机的IP来爬取,根据request_status来判定这个IP是否可以用.
为什么要这样判定?
主要是即使前面经过了过滤,但是不代表在你爬取的时侯是可以用的,所以还是得多做一个判定.
#!/usr/bin/env python3
# -*- coding: utf-8 -*-
# @Time : 2018/11/22
# @Author : liangk
# @Site :
# @File : get_douban_books.py
# @Software: PyCharm
from bs4 import BeautifulSoup
import datetime
import requests
import json
import random
ip_random = -1
article_tag_list = []
article_type_list = []
def get_html(url):
header = {
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_14_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/70.0.3538.102 Safari/537.36'
}
global ip_random
ip_rand, proxies = get_proxie(ip_random)
print(proxies)
try:
request = requests.get(url=url, headers=header, proxies=proxies, timeout=3)
except:
request_status = 500
else:
request_status = request.status_code
print(request_status)
while request_status != 200:
ip_random = -1
ip_rand, proxies = get_proxie(ip_random)
print(proxies)
try:
request = requests.get(url=url, headers=header, proxies=proxies, timeout=3)
except:
request_status = 500
else:
request_status = request.status_code
print(request_status)
ip_random = ip_rand
request.encoding = 'gbk'
html = request.content
print(html)
return html
def get_proxie(random_number):
with open('ip.txt', 'r') as file:
ip_list = json.load(file)
if random_number == -1:
random_number = random.randint(0, len(ip_list) - 1)
ip_info = ip_list[random_number]
ip_url_next = '://' + ip_info['address'] + ':' + ip_info['port']
proxies = {'http': 'http' + ip_url_next, 'https': 'https' + ip_url_next}
return random_number, proxies
# 程序主入口
if __name__ == '__main__':
"""只是爬取了书籍的第一页,按照评价排序"""
start_time = datetime.datetime.now()
url = 'https://book.douban.com/tag/?view=type&icn=index-sorttags-all'
base_url = 'https://book.douban.com/tag/'
html = get_html(url)
soup = BeautifulSoup(html, 'lxml')
article_tag_list = soup.find_all(class_='tag-content-wrapper')
tagCol_list = soup.find_all(class_='tagCol')
for table in tagCol_list:
""" 整理分析数据 """
sub_type_list = []
a = table.find_all('a')
for book_type in a:
sub_type_list.append(book_type.text)
article_type_list.append(sub_type_list)
for sub in article_type_list:
for sub1 in sub:
title = '==============' + sub1 + '=============='
print(title)
print(base_url + sub1 + '?start=0' + '&type=S')
with open('book.text', 'a', encoding='utf-8') as f:
f.write('\n' + title + '\n')
f.write(url + '\n')
for start in range(0, 2):
# (start * 20) 分页是0 20 40 这样的
# type=S是按评价排序
url = base_url + sub1 + '?start=%s' % (start * 20) + '&type=S'
html = get_html(url)
soup = BeautifulSoup(html, 'lxml')
li = soup.find_all(class_='subject-item')
for div in li:
info = div.find(class_='info').find('a')
img = div.find(class_='pic').find('img')
content = '书名:<%s>' % info['title'] + ' 书本图片:' + img['src'] + '\n'
print(content)
with open('book.text', 'a', encoding='utf-8') as f:
f.write(content)
end_time = datetime.datetime.now()
print('耗时: ', (end_time - start_time).seconds)
为什么选择国外高匿代理!
总结
使用这样简单的代理IP,基本上就可以应付在爬爬爬着被封IP的情况了.而且没有使用自己的IP,间接的保护?!?!
大家有其他的愈发快捷的方式,欢迎你们可以拿出来交流和讨论爬虫代理,谢谢。
写爬虫,用哪些编程语言好,python好吗
采集交流 • 优采云 发表了文章 • 0 个评论 • 423 次浏览 • 2020-06-23 08:01
之前换了份工作,不再是单纯的Web开发了,要学习的东西真的很多的。入职的第1天,就让我入手写个爬虫,只是这个爬虫没有采集几个亿数据量的业务场景。
于是,整理了下需求,简单的设计了下方案就草草开始了。小B是我学院时侯的同事,那天这哥们约我喝水,想看下能够顺带介绍几个姑娘。酒过三巡,不胜酒力,于是便聊起了近来的工作。
当他知晓我居然在写爬虫,便起了同情之心,觉得我怀才不遇。仿佛写爬虫是件太低级太low的技术活。在他那家公司,招进来的实习生就多多少少会点爬虫,什么nodejs、golang,哪个不是爬虫的好手。没想到我结业多年,竟然沦落到做实习生的工作,可悲可泣。
接着建议我转入Java阵营,如果到他公司去,多多少少也能混个主任的职位。搞得自己只能一番苦笑。
不知道从何时起,程序员的世界流行起了鄙视链这玩意。什么写C语言的厌恶写C++,写C++的厌恶写Java的,最后鄙视链最高端是PHP。具体是如何的关系,就不再揣测了。
写爬虫,用哪些编程语言好,python好吗
然而,纵观整个行业,都说Python火。具体有多火,看培训机构的广告就晓得了。在16年之前,Python还是1个若不见经传的词组,之后各家培训机构铺天盖地的广告,什么大数据、自动化运维全都跟Python扯上了关系。毕业学生工资更是达到了50-100W,还老是招不到人。
更有意思的是,学Python最容易上手的过程就是写爬虫。什么Scrapy、Pysider是必学,HTML、Javascript是重点,外带几个豆瓣、花瓣网的实战案例,让你一下子才能解决企业的刚需。
这样说来,难怪连实习生也能跟你抢饭碗了,技术发展的很快,各种框架构建的结果是释放人力,降低成本。
据我了解,Python的优势集中于数据剖析、信息安全那些领域。你可能听说过Hadoop、Spark、Tensorflow这种高大上的名词,但是对于数据取证、DLL注入等内容可能从无听闻。举个简单的事例,在数据取证中,由于犯罪人员不配合检测机关的工作,通过数据取证技术我们可以进行一些信息的提取,从而辅助否认其犯罪记录,如获取系统密码、浏览器中帐号及密码。
听起来觉得很高大上的,但是假如我跟你说其过程就是对sqlite3文件数据库查询一下SQL,不知道你会不会认为上述取证的事例顿时很low的。但是,当你不留神把陌陌消息的图片删除想寻回的时侯,或许你能在Python中找到对应的方案,而其他的语言还真没发觉有合适的。
于是,我开导他说,搞完这波爬虫骚操作,下一次就是数据剖析了,你看不有前进了一步?
还数据剖析,你似乎想的很远的。小B打断了我的话,你认为人家会使你搞数据剖析,没有数据何来的剖析。况且,没有哪家公司会笨到把所有数据都曝露在互联网上。你能看到的只是那冰山的一角。即使你想深入进去,没有分布式技术支撑和几十个亿的数据业务,你简历上也不会有亮点。
然后,又聊到他公司近日招了个大数据的开发,薪资比他还要高出一大截,但是技术却不咋地。我从小B的话里听出了一丝揶揄了。于是,又教唆我不要再搞哪些爬虫了,还是搞Spark才有未来。既不用害怕大深夜服务挂了,又不用害怕完不成采集数量。完全是实打实的数据,何乐而不为呢?
这话听得我都有点动心了,没有攀比就没有伤害。但是一想到Java是加班加点工作,我还是打消了这个念头。
我不知道该说些哪些,只是认为时间过得太慢,是种熬煎。于是只能扯开了话题,免得喝顿饭都艰难。
结语
技术没有low不low,没有烂的技术,只有不会用的人。重要的是人家能给你多少钱,你能弄成如何的结果。
这年头会有多少公司乐意给实习生税后1W+的起薪,而这一切都只是份养活自己的技能而已,别把面子很当回事。
写爬虫,用哪些编程语言好,python好吗,其实编程的路上只在于擅长,没有所谓的行不行,如果不擅长,就是给您好用的编程语言也没有疗效,如果想要学编程,那就关注IT培训网网络爬虫用什么语言写,让我们一起走入编程的世界! 查看全部
用Python写爬虫就太low?你赞成嘛?为何不建议使用python写爬虫呢网络爬虫用什么语言写,是有哪些诱因吗,难道用python写爬虫不好吗?
之前换了份工作,不再是单纯的Web开发了,要学习的东西真的很多的。入职的第1天,就让我入手写个爬虫,只是这个爬虫没有采集几个亿数据量的业务场景。
于是,整理了下需求,简单的设计了下方案就草草开始了。小B是我学院时侯的同事,那天这哥们约我喝水,想看下能够顺带介绍几个姑娘。酒过三巡,不胜酒力,于是便聊起了近来的工作。
当他知晓我居然在写爬虫,便起了同情之心,觉得我怀才不遇。仿佛写爬虫是件太低级太low的技术活。在他那家公司,招进来的实习生就多多少少会点爬虫,什么nodejs、golang,哪个不是爬虫的好手。没想到我结业多年,竟然沦落到做实习生的工作,可悲可泣。
接着建议我转入Java阵营,如果到他公司去,多多少少也能混个主任的职位。搞得自己只能一番苦笑。
不知道从何时起,程序员的世界流行起了鄙视链这玩意。什么写C语言的厌恶写C++,写C++的厌恶写Java的,最后鄙视链最高端是PHP。具体是如何的关系,就不再揣测了。
写爬虫,用哪些编程语言好,python好吗
然而,纵观整个行业,都说Python火。具体有多火,看培训机构的广告就晓得了。在16年之前,Python还是1个若不见经传的词组,之后各家培训机构铺天盖地的广告,什么大数据、自动化运维全都跟Python扯上了关系。毕业学生工资更是达到了50-100W,还老是招不到人。
更有意思的是,学Python最容易上手的过程就是写爬虫。什么Scrapy、Pysider是必学,HTML、Javascript是重点,外带几个豆瓣、花瓣网的实战案例,让你一下子才能解决企业的刚需。
这样说来,难怪连实习生也能跟你抢饭碗了,技术发展的很快,各种框架构建的结果是释放人力,降低成本。
据我了解,Python的优势集中于数据剖析、信息安全那些领域。你可能听说过Hadoop、Spark、Tensorflow这种高大上的名词,但是对于数据取证、DLL注入等内容可能从无听闻。举个简单的事例,在数据取证中,由于犯罪人员不配合检测机关的工作,通过数据取证技术我们可以进行一些信息的提取,从而辅助否认其犯罪记录,如获取系统密码、浏览器中帐号及密码。
听起来觉得很高大上的,但是假如我跟你说其过程就是对sqlite3文件数据库查询一下SQL,不知道你会不会认为上述取证的事例顿时很low的。但是,当你不留神把陌陌消息的图片删除想寻回的时侯,或许你能在Python中找到对应的方案,而其他的语言还真没发觉有合适的。
于是,我开导他说,搞完这波爬虫骚操作,下一次就是数据剖析了,你看不有前进了一步?
还数据剖析,你似乎想的很远的。小B打断了我的话,你认为人家会使你搞数据剖析,没有数据何来的剖析。况且,没有哪家公司会笨到把所有数据都曝露在互联网上。你能看到的只是那冰山的一角。即使你想深入进去,没有分布式技术支撑和几十个亿的数据业务,你简历上也不会有亮点。
然后,又聊到他公司近日招了个大数据的开发,薪资比他还要高出一大截,但是技术却不咋地。我从小B的话里听出了一丝揶揄了。于是,又教唆我不要再搞哪些爬虫了,还是搞Spark才有未来。既不用害怕大深夜服务挂了,又不用害怕完不成采集数量。完全是实打实的数据,何乐而不为呢?
这话听得我都有点动心了,没有攀比就没有伤害。但是一想到Java是加班加点工作,我还是打消了这个念头。
我不知道该说些哪些,只是认为时间过得太慢,是种熬煎。于是只能扯开了话题,免得喝顿饭都艰难。
结语
技术没有low不low,没有烂的技术,只有不会用的人。重要的是人家能给你多少钱,你能弄成如何的结果。
这年头会有多少公司乐意给实习生税后1W+的起薪,而这一切都只是份养活自己的技能而已,别把面子很当回事。
写爬虫,用哪些编程语言好,python好吗,其实编程的路上只在于擅长,没有所谓的行不行,如果不擅长,就是给您好用的编程语言也没有疗效,如果想要学编程,那就关注IT培训网网络爬虫用什么语言写,让我们一起走入编程的世界!
三种 Python 网络内容抓取工具与爬虫
采集交流 • 优采云 发表了文章 • 0 个评论 • 437 次浏览 • 2020-06-23 08:01
在一个理想的世界里,你须要的所有数据都将以公开而文档完备的格式清晰地诠释,你可以轻松地下载并在任何你须要的地方使用。
然而,在真实世界里,数据是零乱的,极少被打包成你须要的样子,要么常常是过期的。
你所须要的信息常常是埋藏在一个网站里。相比一些清晰地、有调养地呈现数据的网站,更多的网站则不是这样的。爬取数据crawling、挖掘数据scraping、加工数据、整理数据那些是获取整个网站结构来勾画网站拓扑来搜集数据所必须的活动,这些可以是以网站的格式存储的或则是存放在一个专有数据库中。
也许在不久的将来,你须要通过爬取和挖掘来获得一些你须要的数据,当然你几乎肯定须要进行一点点的编程来正确的获取。你要如何做取决于你自己,但是我发觉 Python 社区是一个挺好的提供者,它提供了工具、框架以及文档来帮助你从网站上获取数据。
在我们进行之前,这里有一个小小的恳求:在你做事情之前请思索,以及请耐心。抓取这件事情并不简单。不要把网站爬出来只是复制一遍,并其它人的工作当作是你自己的东西(当然,没有许可)。要注意版权和许可,以及你所爬行的内容应用哪一个标准。尊重 robots.txt 文件。不要频繁的针对一个网站,这将造成真实的访问者会碰到访问困难的问题。
在知晓那些警告过后,这里有一些太棒的 Python 网站爬虫工具,你可以拿来获得你须要的数据。
让我们先从 pyspider 开始介绍。这是一个带有 web 界面的网路爬虫,让与让之容易跟踪多个爬虫。其具有扩展性,支持多个前端数据库和消息队列。它还具有一些便捷的特点,从优先级到再度访问抓取失败的页面linux 爬虫软件,此外还有通过时间次序来爬取和其他的一些特点。Pyspider 同时支持 Python 2 和 Python 3。为了实现一个更快的爬取,你可以在分布式的环境下一次使用多个爬虫进行爬取。
Pyspyder 的基本用法都有良好的 文档说明 ,包括简单的代码片断。你能通过查看一个 在线的样例 来体验用户界面。它在 Apache 2 许可证下开源,Pyspyder 仍然在 GitHub 上积极地开发。
MechanicalSoup 是一个基于非常流行而异常多能的 HTML 解析库 Beautiful Soup 建立的爬虫库。如果你的爬虫须要相当的简单,但是又要求检测一些选择框或则输入一些文字,而你又不想为这个任务单独写一个爬虫,那么这会是一个值得考虑的选择。
MechanicalSoup 在 MIT 许可证下开源。查看 GitHub 上该项目的 example.py 样例文件来获得更多的用法。不幸的是,到目前为止,这个项目还没有一个挺好的文档。
Scrapy 是一个有着活跃社区支持的抓取框架,在那里你可以建造自己的抓取工具。除了爬取和解析工具,它能够将它搜集的数据以 JSON 或者 CSV 之类的格式轻松输出,并储存在一个你选择的前端数据库。它还有许多外置的任务扩充linux 爬虫软件,例如 cookie 处理、代理误导、限制爬取深度等等,同时还可以构建你自己附加的 API。
要了解 Scrapy,你可以查看网上的文档或则是访问它众多的社区资源,包括一个 IRC 频道、Reddit 子版块以及关注她们的 StackOverflow 标签。Scrapy 的代码在 3 句版 BSD 许可证下开源,你可以在 GitHub 上找到它们。
如果你完全不熟悉编程,Portia 提供了一个易用的可视化的界面。 则提供一个托管的版本。
这远不是一个完整的列表,当然,如果你是一个编程专家,你可以选择采取你自己的方式而不是使用这种框架中的一个。或者你发觉一个用其他语言编撰的替代品。例如 Python 编程者可能更喜欢 Python 附带的Selenium,它可以在不使用实际浏览器的情况下进行爬取。如果你有喜欢的爬取和挖掘工具,请在下边评论使我们晓得。
(题图:You as a Machine. Modified by Rikki Endsley. CC BY-SA 2.0)
via: /resources/python/web-scraper-crawler 查看全部
运用这种太棒的 Python 爬虫工具来获取你须要的数据。
在一个理想的世界里,你须要的所有数据都将以公开而文档完备的格式清晰地诠释,你可以轻松地下载并在任何你须要的地方使用。
然而,在真实世界里,数据是零乱的,极少被打包成你须要的样子,要么常常是过期的。
你所须要的信息常常是埋藏在一个网站里。相比一些清晰地、有调养地呈现数据的网站,更多的网站则不是这样的。爬取数据crawling、挖掘数据scraping、加工数据、整理数据那些是获取整个网站结构来勾画网站拓扑来搜集数据所必须的活动,这些可以是以网站的格式存储的或则是存放在一个专有数据库中。
也许在不久的将来,你须要通过爬取和挖掘来获得一些你须要的数据,当然你几乎肯定须要进行一点点的编程来正确的获取。你要如何做取决于你自己,但是我发觉 Python 社区是一个挺好的提供者,它提供了工具、框架以及文档来帮助你从网站上获取数据。
在我们进行之前,这里有一个小小的恳求:在你做事情之前请思索,以及请耐心。抓取这件事情并不简单。不要把网站爬出来只是复制一遍,并其它人的工作当作是你自己的东西(当然,没有许可)。要注意版权和许可,以及你所爬行的内容应用哪一个标准。尊重 robots.txt 文件。不要频繁的针对一个网站,这将造成真实的访问者会碰到访问困难的问题。
在知晓那些警告过后,这里有一些太棒的 Python 网站爬虫工具,你可以拿来获得你须要的数据。
让我们先从 pyspider 开始介绍。这是一个带有 web 界面的网路爬虫,让与让之容易跟踪多个爬虫。其具有扩展性,支持多个前端数据库和消息队列。它还具有一些便捷的特点,从优先级到再度访问抓取失败的页面linux 爬虫软件,此外还有通过时间次序来爬取和其他的一些特点。Pyspider 同时支持 Python 2 和 Python 3。为了实现一个更快的爬取,你可以在分布式的环境下一次使用多个爬虫进行爬取。
Pyspyder 的基本用法都有良好的 文档说明 ,包括简单的代码片断。你能通过查看一个 在线的样例 来体验用户界面。它在 Apache 2 许可证下开源,Pyspyder 仍然在 GitHub 上积极地开发。
MechanicalSoup 是一个基于非常流行而异常多能的 HTML 解析库 Beautiful Soup 建立的爬虫库。如果你的爬虫须要相当的简单,但是又要求检测一些选择框或则输入一些文字,而你又不想为这个任务单独写一个爬虫,那么这会是一个值得考虑的选择。
MechanicalSoup 在 MIT 许可证下开源。查看 GitHub 上该项目的 example.py 样例文件来获得更多的用法。不幸的是,到目前为止,这个项目还没有一个挺好的文档。
Scrapy 是一个有着活跃社区支持的抓取框架,在那里你可以建造自己的抓取工具。除了爬取和解析工具,它能够将它搜集的数据以 JSON 或者 CSV 之类的格式轻松输出,并储存在一个你选择的前端数据库。它还有许多外置的任务扩充linux 爬虫软件,例如 cookie 处理、代理误导、限制爬取深度等等,同时还可以构建你自己附加的 API。
要了解 Scrapy,你可以查看网上的文档或则是访问它众多的社区资源,包括一个 IRC 频道、Reddit 子版块以及关注她们的 StackOverflow 标签。Scrapy 的代码在 3 句版 BSD 许可证下开源,你可以在 GitHub 上找到它们。
如果你完全不熟悉编程,Portia 提供了一个易用的可视化的界面。 则提供一个托管的版本。
这远不是一个完整的列表,当然,如果你是一个编程专家,你可以选择采取你自己的方式而不是使用这种框架中的一个。或者你发觉一个用其他语言编撰的替代品。例如 Python 编程者可能更喜欢 Python 附带的Selenium,它可以在不使用实际浏览器的情况下进行爬取。如果你有喜欢的爬取和挖掘工具,请在下边评论使我们晓得。
(题图:You as a Machine. Modified by Rikki Endsley. CC BY-SA 2.0)
via: /resources/python/web-scraper-crawler
手把手教你写网络爬虫(2):迷你爬虫构架-通用网路爬虫
采集交流 • 优采云 发表了文章 • 0 个评论 • 355 次浏览 • 2020-06-20 08:00
介绍
大家好!回顾上一期,我们在介绍了爬虫的基本概念以后,就借助各类工具横冲直撞的完成了一个小爬虫,目的就是猛、糙、快,方便初学者上手,建立信心。对于有一定基础的读者,请不要着急,以后我们会学习主流的开源框架,打造出一个强悍专业的爬虫系统!不过在此之前,要继续打好基础,本期我们先介绍爬虫的种类,然后选定最典型的通用网路爬虫,为其设计一个迷你框架。有了自己对框架的思索后爬虫结构,再学习复杂的开源框架就有头绪了。
今天我们会把更多的时间用在思索上,而不是一根筋的coding。用80%的时间思索,20%的时间敲按键,这样更有利于进步。
语言&环境
语言:带足弹药,继续用Python开路!
一个迷你框架
下面以比较典型的通用爬虫为例爬虫结构,分析其工程要点,设计并实现一个迷你框架。架构图如下:
代码结构:
config_load.py 配置文件加载
crawl_thread.py 爬取线程
mini_spider.py 主线程
spider.conf 配置文件
url_table.py url队列、url表
urls.txt 种子url集合
webpage_parse.py 网页剖析
webpage_save.py 网页储存
看看配置文件里有哪些内容:
spider.conf
url_table.py
Step 3. 记录什么网页早已下载过的小笔记本——URL表。
在互联网上,一个网页可能被多个网页中的超链接所指向。这样在遍历互联网这张图的时侯,这个网页可能被多次访问到。为了避免一个网页被下载和解析多次,需要一个URL表记录什么网页早已下载过。再碰到这个网页的时侯,我们就可以跳过它。
crawl_thread.py
Step 5. 页面剖析模块
从网页中解析出URLs或则其他有用的数据。这个是下期重点介绍的,可以参考之前的代码。
Step 6. 页面储存模块
保存页面的模块,目前将文件保存为文件,以后可以扩充出多种储存方法,如mysql,mongodb,hbase等等。
webpage_save.py
写到这儿,整个框架早已清晰的呈如今大伙眼前了,千万不要小看它,不管多么复杂的框架都是在这种基本要素上扩充下来的。
下一步
基础知识的学习暂时告一段落,希望还能帮助你们打下一定的基础。下期开始为你们介绍强悍成熟的爬虫框架Scrapy,它提供了好多强悍的特点来促使爬取更为简单高效,更多精彩,敬请期盼!
【编辑推荐】
如何用Python来找你喜欢的女生?初识Python:全局、局部和非局部变量(带示例)教你用Python解决非平衡数据问题(附代码)调查显示:你是否是一个合格的Python开发者?手把手教你写网络爬虫(1):网易云音乐歌单 查看全部
介绍
大家好!回顾上一期,我们在介绍了爬虫的基本概念以后,就借助各类工具横冲直撞的完成了一个小爬虫,目的就是猛、糙、快,方便初学者上手,建立信心。对于有一定基础的读者,请不要着急,以后我们会学习主流的开源框架,打造出一个强悍专业的爬虫系统!不过在此之前,要继续打好基础,本期我们先介绍爬虫的种类,然后选定最典型的通用网路爬虫,为其设计一个迷你框架。有了自己对框架的思索后爬虫结构,再学习复杂的开源框架就有头绪了。
今天我们会把更多的时间用在思索上,而不是一根筋的coding。用80%的时间思索,20%的时间敲按键,这样更有利于进步。
语言&环境
语言:带足弹药,继续用Python开路!
一个迷你框架
下面以比较典型的通用爬虫为例爬虫结构,分析其工程要点,设计并实现一个迷你框架。架构图如下:
代码结构:
config_load.py 配置文件加载
crawl_thread.py 爬取线程
mini_spider.py 主线程
spider.conf 配置文件
url_table.py url队列、url表
urls.txt 种子url集合
webpage_parse.py 网页剖析
webpage_save.py 网页储存
看看配置文件里有哪些内容:
spider.conf
url_table.py
Step 3. 记录什么网页早已下载过的小笔记本——URL表。
在互联网上,一个网页可能被多个网页中的超链接所指向。这样在遍历互联网这张图的时侯,这个网页可能被多次访问到。为了避免一个网页被下载和解析多次,需要一个URL表记录什么网页早已下载过。再碰到这个网页的时侯,我们就可以跳过它。
crawl_thread.py
Step 5. 页面剖析模块
从网页中解析出URLs或则其他有用的数据。这个是下期重点介绍的,可以参考之前的代码。
Step 6. 页面储存模块
保存页面的模块,目前将文件保存为文件,以后可以扩充出多种储存方法,如mysql,mongodb,hbase等等。
webpage_save.py
写到这儿,整个框架早已清晰的呈如今大伙眼前了,千万不要小看它,不管多么复杂的框架都是在这种基本要素上扩充下来的。
下一步
基础知识的学习暂时告一段落,希望还能帮助你们打下一定的基础。下期开始为你们介绍强悍成熟的爬虫框架Scrapy,它提供了好多强悍的特点来促使爬取更为简单高效,更多精彩,敬请期盼!
【编辑推荐】
如何用Python来找你喜欢的女生?初识Python:全局、局部和非局部变量(带示例)教你用Python解决非平衡数据问题(附代码)调查显示:你是否是一个合格的Python开发者?手把手教你写网络爬虫(1):网易云音乐歌单
一份Python爬虫电子书
采集交流 • 优采云 发表了文章 • 0 个评论 • 283 次浏览 • 2020-06-19 08:01
Python爬虫现如今早已越来越吃香了,随意打开一个急聘网站从工资水平来看,入门的爬虫工程师都能领到15k以上,爬虫构架相关的都能领到30k以上,我们还有什么理由去拒绝爬虫呢?当然,除非你跟钱过意不去。
所以秉承使更多想改行学习Python爬虫的的朋友快速学习、让更多的小伙伴领到高薪我整理了一份十分健全的Python爬虫的电子书。
之前在知乎写分享早已有一年多,一直有同学说我的回答和文章能整理成书籍了仍然偷懒没做,也有出版社的小伙伴找我把这种内容弄成书都被我拒绝了。所以也是借着这个机会仔细整理了知乎上的回答和文章另外也添加了一些新的内容,完成了几本小小的电子书,这一本比较小一部分是有关于Python方面的,主要内容还是Python爬虫。
这本书主要内容是Python入门爬虫饲养书,以及Python爬虫入门和Python爬虫进阶,以下这是这本电子书的一个主要的目录:
这本书不仅一些自己的学习、面试感受之外,还有好多包括书籍方面的资源、教程方面的学习资源,为了克服选择困难症,我在选择教程或则书籍的时侯尽量保证了资源少而且精准,能用最少最精华的教程使你们快速入门Python以及比较熟悉的使用Python爬虫。
如果你能用心用2-3个月的时间认真通读这本电子书爬虫饲养书,并且学习这本书上推荐的一些教程和书籍,相信你一定能找到一份不错的Python爬虫工作。 查看全部
Python爬虫现如今早已越来越吃香了,随意打开一个急聘网站从工资水平来看,入门的爬虫工程师都能领到15k以上,爬虫构架相关的都能领到30k以上,我们还有什么理由去拒绝爬虫呢?当然,除非你跟钱过意不去。
所以秉承使更多想改行学习Python爬虫的的朋友快速学习、让更多的小伙伴领到高薪我整理了一份十分健全的Python爬虫的电子书。
之前在知乎写分享早已有一年多,一直有同学说我的回答和文章能整理成书籍了仍然偷懒没做,也有出版社的小伙伴找我把这种内容弄成书都被我拒绝了。所以也是借着这个机会仔细整理了知乎上的回答和文章另外也添加了一些新的内容,完成了几本小小的电子书,这一本比较小一部分是有关于Python方面的,主要内容还是Python爬虫。
这本书主要内容是Python入门爬虫饲养书,以及Python爬虫入门和Python爬虫进阶,以下这是这本电子书的一个主要的目录:
这本书不仅一些自己的学习、面试感受之外,还有好多包括书籍方面的资源、教程方面的学习资源,为了克服选择困难症,我在选择教程或则书籍的时侯尽量保证了资源少而且精准,能用最少最精华的教程使你们快速入门Python以及比较熟悉的使用Python爬虫。
如果你能用心用2-3个月的时间认真通读这本电子书爬虫饲养书,并且学习这本书上推荐的一些教程和书籍,相信你一定能找到一份不错的Python爬虫工作。
Python网络爬虫实战项目代码大全(长期更新,欢迎补充)
采集交流 • 优采云 发表了文章 • 0 个评论 • 825 次浏览 • 2020-06-14 08:02
WechatSogou[1]- 微信公众号爬虫。基于搜狗微信搜索的微信公众号爬虫插口,可以扩充成基于搜狗搜索的爬虫,返回结果是列表,每一项均是公众号具体信息字典。[1]:
DouBanSpider[2]- 豆瓣读书爬虫。可以爬下豆瓣读书标签下的所有图书,按评分排行依次储存,存储到Excel中,可便捷你们筛选搜罗,比如筛选评价人数>1000的高分书籍;可根据不同的主题储存到Excel不同的Sheet ,采用User Agent伪装为浏览器进行爬取,并加入随机延时来更好的模仿浏览器行为,避免爬虫被封。[2]:
zhihu_spider[3]- 知乎爬虫。此项目的功能是爬取知乎用户信息以及人际拓扑关系,爬虫框架使用scrapy,数据储存使用mongodb。[3]:
bilibili-user[4]- Bilibili用户爬虫。总数据数:20119918,抓取数组:用户id,昵称,性别,头像,等级,经验值,粉丝数,生日,地址,注册时间,签名,等级与经验值等。抓取然后生成B站用户数据报告。[4]:
SinaSpider[5]- 新浪微博爬虫。主要爬取新浪微博用户的个人信息、微博信息、粉丝和关注。代码获取新浪微博Cookie进行登陆,可通过多帐号登入来避免新浪的反扒。主要使用 scrapy 爬虫框架。[5]:
distribute_crawler[6]- 小说下载分布式爬虫。使用scrapy,redis, mongodb,graphite实现的一个分布式网路爬虫,底层储存mongodb集群,分布式使用redis实现,爬虫状态显示使用graphite实现网络爬虫 代码,主要针对一个小说站点。[6]:
CnkiSpider[7]- 中国知网爬虫。设置检索条件后,执行src/CnkiSpider.py抓取数据,抓取数据储存在/data目录下,每个数据文件的第一行为数组名称。[7]:
LianJiaSpider[8]- 链家网爬虫。爬取北京地区链家历年二手房成交记录。涵盖链家爬虫一文的全部代码,包括链家模拟登陆代码。[8]:
scrapy_jingdong[9]- 京东爬虫。基于scrapy的易迅网站爬虫,保存格式为csv。[9]:
QQ-Groups-Spider[10]- QQ 群爬虫。批量抓取 QQ 群信息,包括群名称、群号、群人数、群主、群简介等内容,最终生成 XLS(X) / CSV 结果文件。[10]:
wooyun_public[11]-乌云爬虫。 乌云公开漏洞、知识库爬虫和搜索。全部公开漏洞的列表和每位漏洞的文本内容存在mongodb中,大概约2G内容;如果整站爬全部文本和图片作为离线查询,大概须要10G空间、2小时(10M联通带宽);爬取全部知识库网络爬虫 代码,总共约500M空间。漏洞搜索使用了Flask作为web server,bootstrap作为后端。[11]:
2016.9.11补充:
QunarSpider[12]- 去哪儿网爬虫。 网络爬虫之Selenium使用代理登录:爬取去哪儿网站,使用selenium模拟浏览器登录,获取翻页操作。代理可以存入一个文件,程序读取并使用。支持多进程抓取。[12]:
findtrip[13]- 机票爬虫(去哪儿和携程网)。Findtrip是一个基于Scrapy的机票爬虫,目前整合了国外两大机票网站(去哪儿 + 携程)。[13]:
163spider[14] - 基于requests、MySQLdb、torndb的网易客户端内容爬虫。[14]:
doubanspiders[15]- 豆瓣影片、书籍、小组、相册、东西等爬虫集。[15]:
QQSpider[16]- QQ空间爬虫,包括日志、说说、个人信息等,一天可抓取 400 万条数据。[16]:
baidu-music-spider[17]- 百度mp3全站爬虫,使用redis支持断点续传。[17]:
tbcrawler[18]- 淘宝和淘宝的爬虫,可以按照搜索关键词,物品id来抓去页面的信息,数据储存在mongodb。[18]:
stockholm[19]- 一个股票数据(沪深)爬虫和选股策略测试框架。根据选取的日期范围抓取所有沪深两县股票的行情数据。支持使用表达式定义选股策略。支持多线程处理。保存数据到JSON文件、CSV文件。[19]
--------------------------
本项目收录各类Python网路爬虫实战开源代码,并常年更新,欢迎补充。
更多Python干货欢迎扫码关注:
微信公众号:Python英文社区
知乎专栏:Python英文社区 <;
Python QQ交流群 :273186166
--------------------------
微信公众号:Python英文社区
Python英文社区 QQ交流群:
--------------------------
Python开发基础教学视频百度网盘下载地址: 查看全部
WechatSogou[1]- 微信公众号爬虫。基于搜狗微信搜索的微信公众号爬虫插口,可以扩充成基于搜狗搜索的爬虫,返回结果是列表,每一项均是公众号具体信息字典。[1]:
DouBanSpider[2]- 豆瓣读书爬虫。可以爬下豆瓣读书标签下的所有图书,按评分排行依次储存,存储到Excel中,可便捷你们筛选搜罗,比如筛选评价人数>1000的高分书籍;可根据不同的主题储存到Excel不同的Sheet ,采用User Agent伪装为浏览器进行爬取,并加入随机延时来更好的模仿浏览器行为,避免爬虫被封。[2]:
zhihu_spider[3]- 知乎爬虫。此项目的功能是爬取知乎用户信息以及人际拓扑关系,爬虫框架使用scrapy,数据储存使用mongodb。[3]:
bilibili-user[4]- Bilibili用户爬虫。总数据数:20119918,抓取数组:用户id,昵称,性别,头像,等级,经验值,粉丝数,生日,地址,注册时间,签名,等级与经验值等。抓取然后生成B站用户数据报告。[4]:
SinaSpider[5]- 新浪微博爬虫。主要爬取新浪微博用户的个人信息、微博信息、粉丝和关注。代码获取新浪微博Cookie进行登陆,可通过多帐号登入来避免新浪的反扒。主要使用 scrapy 爬虫框架。[5]:
distribute_crawler[6]- 小说下载分布式爬虫。使用scrapy,redis, mongodb,graphite实现的一个分布式网路爬虫,底层储存mongodb集群,分布式使用redis实现,爬虫状态显示使用graphite实现网络爬虫 代码,主要针对一个小说站点。[6]:
CnkiSpider[7]- 中国知网爬虫。设置检索条件后,执行src/CnkiSpider.py抓取数据,抓取数据储存在/data目录下,每个数据文件的第一行为数组名称。[7]:
LianJiaSpider[8]- 链家网爬虫。爬取北京地区链家历年二手房成交记录。涵盖链家爬虫一文的全部代码,包括链家模拟登陆代码。[8]:
scrapy_jingdong[9]- 京东爬虫。基于scrapy的易迅网站爬虫,保存格式为csv。[9]:
QQ-Groups-Spider[10]- QQ 群爬虫。批量抓取 QQ 群信息,包括群名称、群号、群人数、群主、群简介等内容,最终生成 XLS(X) / CSV 结果文件。[10]:
wooyun_public[11]-乌云爬虫。 乌云公开漏洞、知识库爬虫和搜索。全部公开漏洞的列表和每位漏洞的文本内容存在mongodb中,大概约2G内容;如果整站爬全部文本和图片作为离线查询,大概须要10G空间、2小时(10M联通带宽);爬取全部知识库网络爬虫 代码,总共约500M空间。漏洞搜索使用了Flask作为web server,bootstrap作为后端。[11]:
2016.9.11补充:
QunarSpider[12]- 去哪儿网爬虫。 网络爬虫之Selenium使用代理登录:爬取去哪儿网站,使用selenium模拟浏览器登录,获取翻页操作。代理可以存入一个文件,程序读取并使用。支持多进程抓取。[12]:
findtrip[13]- 机票爬虫(去哪儿和携程网)。Findtrip是一个基于Scrapy的机票爬虫,目前整合了国外两大机票网站(去哪儿 + 携程)。[13]:
163spider[14] - 基于requests、MySQLdb、torndb的网易客户端内容爬虫。[14]:
doubanspiders[15]- 豆瓣影片、书籍、小组、相册、东西等爬虫集。[15]:
QQSpider[16]- QQ空间爬虫,包括日志、说说、个人信息等,一天可抓取 400 万条数据。[16]:
baidu-music-spider[17]- 百度mp3全站爬虫,使用redis支持断点续传。[17]:
tbcrawler[18]- 淘宝和淘宝的爬虫,可以按照搜索关键词,物品id来抓去页面的信息,数据储存在mongodb。[18]:
stockholm[19]- 一个股票数据(沪深)爬虫和选股策略测试框架。根据选取的日期范围抓取所有沪深两县股票的行情数据。支持使用表达式定义选股策略。支持多线程处理。保存数据到JSON文件、CSV文件。[19]
--------------------------
本项目收录各类Python网路爬虫实战开源代码,并常年更新,欢迎补充。
更多Python干货欢迎扫码关注:
微信公众号:Python英文社区
知乎专栏:Python英文社区 <;
Python QQ交流群 :273186166
--------------------------
微信公众号:Python英文社区
Python英文社区 QQ交流群:
--------------------------
Python开发基础教学视频百度网盘下载地址:
python爬虫入门教程(一)
采集交流 • 优采云 发表了文章 • 0 个评论 • 246 次浏览 • 2020-06-12 08:01
1、Python能做哪些
2、网络爬虫简介
3、网络爬虫能做哪些
4、开发爬虫的打算工作
5、推荐的python爬虫学习书籍
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Python能做哪些
网络爬虫简介
网络爬虫,也叫网路蜘蛛(Web Spider)。爬虫是依照网页地址(URL)爬取网页上的内容,这里说的网页地址(URL)就是我们在浏览器中输入的网站链接。例如:/,这就是一个URL。
爬虫是在某个URL页面入手,抓取到这个页面的内容网络爬虫 教程,从当前的页面中找到其他的链接地址,然后从这地址再度爬到下一个网站页面,这样仍然不停的抓取到有用的信息,所以可以说网络爬虫是不停的抓取获得页面上想要的信息的程序。
网络爬虫能做哪些
例如:我关注的找工作的网站会不定期的发布急聘信息,我不信每晚都耗费自己的精力去点击网站查看信息,但是我又想在有新的通知时,能够及时晓得信息并看见这个信息。
此时,我就须要爬虫来帮助我,这个爬虫程序会手动在一定的时间模拟人去访问官网,检查是否有新的通知发布,如果没有就不进行任何操作,如果有通知,那么就将通知从网页中提取下来,保存到指定的位置,然后发送邮件或则电邮告知我即可。
开发爬虫的打算工作
编程语言:Python
IDE的话,推荐使用Pycharm。windows、linux、macos多平台支持网络爬虫 教程,非常好用。
开发环境:Win7+Python 2.7 64bit+PyCharm :环境配置方式自行百度
推荐的python爬虫学习书籍
1.米切尔 (Ryan Mitchell) (作者), 陶俊杰 (译者), 陈小莉 (译者)的Python网路数据采集
2.范传辉 (作者)的Python爬虫开发与项目实战 查看全部
目录:
1、Python能做哪些
2、网络爬虫简介
3、网络爬虫能做哪些
4、开发爬虫的打算工作
5、推荐的python爬虫学习书籍
--------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
Python能做哪些
网络爬虫简介
网络爬虫,也叫网路蜘蛛(Web Spider)。爬虫是依照网页地址(URL)爬取网页上的内容,这里说的网页地址(URL)就是我们在浏览器中输入的网站链接。例如:/,这就是一个URL。
爬虫是在某个URL页面入手,抓取到这个页面的内容网络爬虫 教程,从当前的页面中找到其他的链接地址,然后从这地址再度爬到下一个网站页面,这样仍然不停的抓取到有用的信息,所以可以说网络爬虫是不停的抓取获得页面上想要的信息的程序。
网络爬虫能做哪些
例如:我关注的找工作的网站会不定期的发布急聘信息,我不信每晚都耗费自己的精力去点击网站查看信息,但是我又想在有新的通知时,能够及时晓得信息并看见这个信息。
此时,我就须要爬虫来帮助我,这个爬虫程序会手动在一定的时间模拟人去访问官网,检查是否有新的通知发布,如果没有就不进行任何操作,如果有通知,那么就将通知从网页中提取下来,保存到指定的位置,然后发送邮件或则电邮告知我即可。
开发爬虫的打算工作
编程语言:Python
IDE的话,推荐使用Pycharm。windows、linux、macos多平台支持网络爬虫 教程,非常好用。
开发环境:Win7+Python 2.7 64bit+PyCharm :环境配置方式自行百度
推荐的python爬虫学习书籍
1.米切尔 (Ryan Mitchell) (作者), 陶俊杰 (译者), 陈小莉 (译者)的Python网路数据采集
2.范传辉 (作者)的Python爬虫开发与项目实战
python爬虫入门到精通必备的书籍
采集交流 • 优采云 发表了文章 • 0 个评论 • 357 次浏览 • 2020-06-09 10:25
3、《笨办法学 Python》这并不是关于亲子关系的编程书, 而是一本正儿八经 Python 编程入 门书,只是以这些寓教于乐的方式阐释编程,显得更轻松愉快一些。4、《深入浅出 Python》Head First 系列的书籍仍然遭受称赞,这本也不例外。Head First Python 主要述说了 Python 3 的基础句型知识以及怎样使用 Python八爪鱼·云采集网络爬虫软件 快速地进行 Web、手机上的开发。5、《像计算机科学家一样思索 python》内容讲解清楚明白python爬虫经典书籍,非常适宜 python 入门用,但对于学习过其他编 程语言的读者来说可能会认为进度比较慢, 但作者的思路和看法确实 给人好多启发,对于新手来说利润颇丰,书中好多反例还是有一定难 度的python爬虫经典书籍,完全吃透也不容易。6、《Python 编程:入门到实践》厚厚的一本书,本书的内容基础并且全面,适合纯小白看。Python 学习进阶书籍1、《Python 学习指南》 本书解释详尽,例子丰富;关于 Python 语言本身的讲解全面详细而八爪鱼·云采集网络爬虫软件 又循序渐进不断重复,同时阐述语言现象背后的机制和原理;除语言 本身,还包含编程实践和设计以及中级主题。
2、《Python 核心编程第 3 版》 本书的内容实际上就是大致介绍了一下部份 python 标准库里的模块 和一些第三方模块,并且主要是网路方向。适合学习完 python 语法 知识后进阶阅读,简单但又囊括了开发所用到的一些基本的库,引起 你继续学习的兴趣。3、《编写高质量 Python 代码的 59 个有效方式》关于库,引用,生产环境这种知识倘若只是埋头写代码,很多时侯都 不会涉及到, 但是这本书里关于这种东西的条目比较简约的把前因后 果理清楚了,感觉太有帮助。4、《Python CookBook》这本书不太适宜从头到尾阅读,适合当一本参考书或是字典书,遇到八爪鱼·云采集网络爬虫软件 了总是上来查查,看看有没有取巧的办法。书中把一些小技巧按章节 集合上去,可以节约不少 google 的时间。5、《流畅的 Python》 本书是极好的 Python 进阶书籍,详细解释了魔术技巧、生成器、协 程、元编程等概念,值得反复阅读。以上是进阶书籍最终要的还是要多动手,找项目实践,从实际应用场 景出发,用程序解决手头的一些冗长复杂问题。二、HTTP 入门书籍 1、《图解 HTTP》本书详尽介绍了 HTTP 的常用的知识,大部分内容以图文的形式展 示,易于读者理解,避免了去啃厚厚的《HTTP 权威指南》和 RFC 文档。
同时作者逻辑清晰,没有介绍过分深奥的知识,满足了读者对 HTTP 基础的需求。八爪鱼·云采集网络爬虫软件 三、数据库入门书籍 1、《MySQL 必知必会》 对入门者太照料的一本书,与其说是一本书不如说是一本小册子,不 到 250 页的小册子,实践性太强,基本没有哪些理论的拼凑,完完 全全就是一本实践手册, 教会你如何用 SQL 语句操作 MySQL。看完 这本书基本就可以说是入门了。 四、正则表达式入门书籍 1、《精通正则表达式》 本书面向的读者是:1) 会用正则表达式;2) 愿意从一个代码工人向 专家进化的;3) 对技术有狂热的追求的;本书注重讲解关于正则表 达式匹配原理、优化方式和使用方法,读完以后你会感觉豁然开朗, 没想到正则表达式还有这样一片天空。 五、爬虫相关书籍 1、《用 Python 写网络爬虫》 本书适宜早已熟悉 python 且熟悉大多数模块的人。 作者对爬虫的编 写考虑较为全面,且有相关练习网页可以实操。八爪鱼·云采集网络爬虫软件 2、《Python 爬虫开发与项目实战》这本书从爬虫会涉及的多线程,多进程讲起,然后介绍 web 前端的 基础知识,然后是数据储存,网络合同,再就是综合的爬虫项目。
这本书不适宜没有任何 Python 基础的人阅读, 因为这本书根本没有 提到任何 Python 的基础知识。但是对于想要进阶 Python 爬虫的人 来说是非常好的。相关阅读:百度地图数据采集: 58 同城信息采集: 黄页 88 企业名录数据采集: 天猫买家秀图片采集详细教程:八爪鱼·云采集网络爬虫软件 八爪鱼采集原理(7.0 版本): 微信公众号文章正文采集: 八爪鱼——90 万用户选择的网页数据采集器。 1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。 查看全部
八爪鱼·云采集网络爬虫软件 python 爬虫入门到精通必备的书籍python 是一种常见的网路爬虫语言,学习 python 爬虫,需要理论 与实践相结合,Python 生态中的爬虫库多如牛毛,urllib、urllib2、 requests、beautifulsoup、scrapy、pyspider 都是爬虫相关的库, 但是假如没有理论知识, 纯粹地学习怎么使用这种 API 如何调用是不 会有提高的。所以,在学习这种库的同时,需要去系统的学习爬虫的 相关原理。你须要懂的技术包括 Python 编程语言、HTTP 协议、数 据库、 Linux 等知识。 这样能够做到真正从入门 python 爬虫到精通, 下面推荐几本精典的书籍。1、Python 语言入门的书籍:适合没有编程基础的,入门 Python 的书籍1、《简明 Python 教程》本书采用知识共享合同免费分发,意味着任何人都可以免费获取,这八爪鱼·云采集网络爬虫软件 本书走过了 11 个年头,最新版以 Python3 为基础同时也会兼具到 Python2 的一些东西,内容十分精简。2、《父与子的编程之旅》一本正儿八经 Python 编程入门书,以寓教于乐的方式阐释编程,显 得更轻松愉快一些。
3、《笨办法学 Python》这并不是关于亲子关系的编程书, 而是一本正儿八经 Python 编程入 门书,只是以这些寓教于乐的方式阐释编程,显得更轻松愉快一些。4、《深入浅出 Python》Head First 系列的书籍仍然遭受称赞,这本也不例外。Head First Python 主要述说了 Python 3 的基础句型知识以及怎样使用 Python八爪鱼·云采集网络爬虫软件 快速地进行 Web、手机上的开发。5、《像计算机科学家一样思索 python》内容讲解清楚明白python爬虫经典书籍,非常适宜 python 入门用,但对于学习过其他编 程语言的读者来说可能会认为进度比较慢, 但作者的思路和看法确实 给人好多启发,对于新手来说利润颇丰,书中好多反例还是有一定难 度的python爬虫经典书籍,完全吃透也不容易。6、《Python 编程:入门到实践》厚厚的一本书,本书的内容基础并且全面,适合纯小白看。Python 学习进阶书籍1、《Python 学习指南》 本书解释详尽,例子丰富;关于 Python 语言本身的讲解全面详细而八爪鱼·云采集网络爬虫软件 又循序渐进不断重复,同时阐述语言现象背后的机制和原理;除语言 本身,还包含编程实践和设计以及中级主题。
2、《Python 核心编程第 3 版》 本书的内容实际上就是大致介绍了一下部份 python 标准库里的模块 和一些第三方模块,并且主要是网路方向。适合学习完 python 语法 知识后进阶阅读,简单但又囊括了开发所用到的一些基本的库,引起 你继续学习的兴趣。3、《编写高质量 Python 代码的 59 个有效方式》关于库,引用,生产环境这种知识倘若只是埋头写代码,很多时侯都 不会涉及到, 但是这本书里关于这种东西的条目比较简约的把前因后 果理清楚了,感觉太有帮助。4、《Python CookBook》这本书不太适宜从头到尾阅读,适合当一本参考书或是字典书,遇到八爪鱼·云采集网络爬虫软件 了总是上来查查,看看有没有取巧的办法。书中把一些小技巧按章节 集合上去,可以节约不少 google 的时间。5、《流畅的 Python》 本书是极好的 Python 进阶书籍,详细解释了魔术技巧、生成器、协 程、元编程等概念,值得反复阅读。以上是进阶书籍最终要的还是要多动手,找项目实践,从实际应用场 景出发,用程序解决手头的一些冗长复杂问题。二、HTTP 入门书籍 1、《图解 HTTP》本书详尽介绍了 HTTP 的常用的知识,大部分内容以图文的形式展 示,易于读者理解,避免了去啃厚厚的《HTTP 权威指南》和 RFC 文档。
同时作者逻辑清晰,没有介绍过分深奥的知识,满足了读者对 HTTP 基础的需求。八爪鱼·云采集网络爬虫软件 三、数据库入门书籍 1、《MySQL 必知必会》 对入门者太照料的一本书,与其说是一本书不如说是一本小册子,不 到 250 页的小册子,实践性太强,基本没有哪些理论的拼凑,完完 全全就是一本实践手册, 教会你如何用 SQL 语句操作 MySQL。看完 这本书基本就可以说是入门了。 四、正则表达式入门书籍 1、《精通正则表达式》 本书面向的读者是:1) 会用正则表达式;2) 愿意从一个代码工人向 专家进化的;3) 对技术有狂热的追求的;本书注重讲解关于正则表 达式匹配原理、优化方式和使用方法,读完以后你会感觉豁然开朗, 没想到正则表达式还有这样一片天空。 五、爬虫相关书籍 1、《用 Python 写网络爬虫》 本书适宜早已熟悉 python 且熟悉大多数模块的人。 作者对爬虫的编 写考虑较为全面,且有相关练习网页可以实操。八爪鱼·云采集网络爬虫软件 2、《Python 爬虫开发与项目实战》这本书从爬虫会涉及的多线程,多进程讲起,然后介绍 web 前端的 基础知识,然后是数据储存,网络合同,再就是综合的爬虫项目。
这本书不适宜没有任何 Python 基础的人阅读, 因为这本书根本没有 提到任何 Python 的基础知识。但是对于想要进阶 Python 爬虫的人 来说是非常好的。相关阅读:百度地图数据采集: 58 同城信息采集: 黄页 88 企业名录数据采集: 天猫买家秀图片采集详细教程:八爪鱼·云采集网络爬虫软件 八爪鱼采集原理(7.0 版本): 微信公众号文章正文采集: 八爪鱼——90 万用户选择的网页数据采集器。 1、操作简单,任何人都可以用:无需技术背景,会上网才能采集。完全可视化 流程,点击滑鼠完成操作,2 分钟即可快速入门。 2、功能强悍,任何网站都可以采:对于点击、登陆、翻页、识别验证码、瀑布 流、Ajax 脚本异步加载数据的网页,均可经过简单设置进行采集。 3、云采集,关机也可以。配置好采集任务后可死机,任务可在云端执行。庞大 云采集集群 24*7 不间断运行,不用害怕 IP 被封,网络中断。 4、功能免费+增值服务,可按需选择。免费版具备所有功能,能够满足用户的 基本采集需求。同时设置了一些增值服务(如私有云),满足低端付费企业用户 的须要。
Python爬虫实战(1):爬取Drupal峰会贴子列表
采集交流 • 优采云 发表了文章 • 0 个评论 • 349 次浏览 • 2020-06-09 10:24
在《Python即时网路爬虫项目: 内容提取器的定义》一文我们定义了一个通用的python网路爬虫类,期望通过这个项目节约程序员一半以上的时间。本文将用一个实例讲解如何使用这个爬虫类。我们将爬集搜客老版峰会,是一个用Drupal做的峰会。
我们在多个文章都在说:节省程序员的时间。关键是市去编撰提取规则的时间,尤其是调试规则的正确性太花时间。在《1分钟快速生成用于网页内容提取的xslt》演示了如何快速生成提取规则网络爬虫论坛,接下来我们再通过GooSeeker的api插口实时获得提取规则,对网页进行抓取。本示例主要有如下两个技术要点:
通过GooSeeker API实时获取用于页面提取的xslt
使用GooSeeker提取器gsExtractor从网页上一次提取多个数组内容。
# _*_coding:utf8_*_
# crawler_gooseeker_bbs.py
# 版本: V1.0
from urllib import request
from lxml import etree
from gooseeker import GsExtractor
# 访问并读取网页内容
url = ""
conn = request.urlopen(url)
doc = etree.HTML(conn.read())
bbsExtra = GsExtractor()
bbsExtra.setXsltFromAPI("31d24931e043e2d5364d03b8ff9cc77e" , "gooseeker_bbs_xslt") # 设置xslt抓取规则,第一个参数是app key,请到会员中心申请
result = bbsExtra.extract(doc) # 调用extract方法提取所需内容
print(str(result))
源代码下载位置请看文章末尾的GitHub源。
运行上节的代码,即可在控制台复印出提取结果,是一个xml文件,如果加上换行缩进,内容如下图:
/img/bVwAyA
1网络爬虫论坛, Python即时网路爬虫项目: 内容提取器的定义
1, GooSeeker开源Python网络爬虫GitHub源 查看全部
/img/bVxTdG
在《Python即时网路爬虫项目: 内容提取器的定义》一文我们定义了一个通用的python网路爬虫类,期望通过这个项目节约程序员一半以上的时间。本文将用一个实例讲解如何使用这个爬虫类。我们将爬集搜客老版峰会,是一个用Drupal做的峰会。
我们在多个文章都在说:节省程序员的时间。关键是市去编撰提取规则的时间,尤其是调试规则的正确性太花时间。在《1分钟快速生成用于网页内容提取的xslt》演示了如何快速生成提取规则网络爬虫论坛,接下来我们再通过GooSeeker的api插口实时获得提取规则,对网页进行抓取。本示例主要有如下两个技术要点:
通过GooSeeker API实时获取用于页面提取的xslt
使用GooSeeker提取器gsExtractor从网页上一次提取多个数组内容。
# _*_coding:utf8_*_
# crawler_gooseeker_bbs.py
# 版本: V1.0
from urllib import request
from lxml import etree
from gooseeker import GsExtractor
# 访问并读取网页内容
url = ""
conn = request.urlopen(url)
doc = etree.HTML(conn.read())
bbsExtra = GsExtractor()
bbsExtra.setXsltFromAPI("31d24931e043e2d5364d03b8ff9cc77e" , "gooseeker_bbs_xslt") # 设置xslt抓取规则,第一个参数是app key,请到会员中心申请
result = bbsExtra.extract(doc) # 调用extract方法提取所需内容
print(str(result))
源代码下载位置请看文章末尾的GitHub源。
运行上节的代码,即可在控制台复印出提取结果,是一个xml文件,如果加上换行缩进,内容如下图:
/img/bVwAyA
1网络爬虫论坛, Python即时网路爬虫项目: 内容提取器的定义
1, GooSeeker开源Python网络爬虫GitHub源
让你从零开始学会写爬虫的5个教程(Python)
采集交流 • 优采云 发表了文章 • 0 个评论 • 264 次浏览 • 2020-06-09 08:02
其实懂了以后,写个爬虫脚本是很简单的,但是对于菜鸟来说却并不是这么容易。实验楼就给这些想学写爬虫,却苦于没有详尽教程的小伙伴推荐5个爬虫教程,都是基于Python语言开发的,因此可能更适宜有一定Python基础的人进行学习。
首先介绍这个教程,比较简单,也容易上手,只要有Python基础的人都可以跟随教程去写天气数据爬虫。先跟随教程动手敲一遍再说,毕竟先讲一大堆理论知识,是太枯燥无味的。
学完第一个教程以后,就可以学习这个教程了,因为有第一个教程的基础python爬虫教程,对爬虫有了一个大约的认知,但对其中的一些原理还不太清楚,那么学习这个教程就太必要啦,这个教程十分详尽的介绍了爬虫的原理等一些基础知识,最后教你用爬虫爬名模相片。
前面写了两个爬虫脚本,理论和实践都有了,这个时侯可以再找个项目练练手,熟悉一下,这个项目就是教你一步步实现一个天猫女郎图片搜集爬虫。
当然爬虫也是有很多种的,这个教程就介绍几种实现爬虫的方式,从传统的线程池到使用解释器,每节课实现一个小爬虫。另外学习解释器的时侯,会从原理入手,以ayncio协程库为原型,实现一个简单的异步编程模型。
课程注重爬虫原理的讲解以及python爬虫代码的实现。
当然,爬虫的应用地方好多,而不只是便捷自己,比如可以写一个聊天机器人,用爬虫爬网路上的笑话,然后按照用户的问题回复相应的笑话内容,是一个很实用和常见的一个功能,学会将爬虫应用到实际的项目中是十分便捷的。 查看全部
写爬虫总是十分吸引IT学习者,毕竟光听上去就太拉风极客,我也晓得很多人学完基础知识以后python爬虫教程,第一个项目开发就是自己写一个爬虫玩儿。
其实懂了以后,写个爬虫脚本是很简单的,但是对于菜鸟来说却并不是这么容易。实验楼就给这些想学写爬虫,却苦于没有详尽教程的小伙伴推荐5个爬虫教程,都是基于Python语言开发的,因此可能更适宜有一定Python基础的人进行学习。
首先介绍这个教程,比较简单,也容易上手,只要有Python基础的人都可以跟随教程去写天气数据爬虫。先跟随教程动手敲一遍再说,毕竟先讲一大堆理论知识,是太枯燥无味的。
学完第一个教程以后,就可以学习这个教程了,因为有第一个教程的基础python爬虫教程,对爬虫有了一个大约的认知,但对其中的一些原理还不太清楚,那么学习这个教程就太必要啦,这个教程十分详尽的介绍了爬虫的原理等一些基础知识,最后教你用爬虫爬名模相片。
前面写了两个爬虫脚本,理论和实践都有了,这个时侯可以再找个项目练练手,熟悉一下,这个项目就是教你一步步实现一个天猫女郎图片搜集爬虫。
当然爬虫也是有很多种的,这个教程就介绍几种实现爬虫的方式,从传统的线程池到使用解释器,每节课实现一个小爬虫。另外学习解释器的时侯,会从原理入手,以ayncio协程库为原型,实现一个简单的异步编程模型。
课程注重爬虫原理的讲解以及python爬虫代码的实现。
当然,爬虫的应用地方好多,而不只是便捷自己,比如可以写一个聊天机器人,用爬虫爬网路上的笑话,然后按照用户的问题回复相应的笑话内容,是一个很实用和常见的一个功能,学会将爬虫应用到实际的项目中是十分便捷的。
【苹果IP代理】 8大高效的Python爬虫框架,你用过几个?
采集交流 • 优采云 发表了文章 • 0 个评论 • 269 次浏览 • 2020-06-09 08:01
4.Portia Portia 是一个开源可视化爬虫工具,可使您在不需要任何编程知识的情况下爬取网站!简单地注释您感兴趣的页面爬虫代理软件爬虫代理软件,Portia 将创建一个蜘蛛来从类似的页面提取数据。5.Newspaper Newspaper 可以拿来提取新闻、文章和内容剖析。使用多线 程,支持 10 多种语言等。 6.Beautiful Soup Beautiful Soup 是一个可以从 HTML 或 XML 文件中提取数据 的 Python 库.它还能通过你喜欢的转换器实现惯用的文档导航, 查找,修改文档的方法.Beautiful Soup 会帮你节约数小时甚至数天 的工作时间。 7.Grab Grab 是一个用于建立 Web 刮板的 Python 框架。借助 Grab, 您可以建立各类复杂的网页抓取工具,从简单的 5 行脚本到处理 数百万个网页的复杂异步网站抓取工具。Grab 提供一个 API 用于 执行网路恳求和处理接收到的内容,例如与 HTML 文档的 DOM 树进行交互。 8.Cola Cola 是一个分布式的爬虫框架,对于用户来说,只需编撰几 个特定的函数,而无需关注分布式运行的细节。任务会手动分配 到多台机器上,整个过程对用户是透明的。 查看全部
【苹果 IP 代理】8 大高效的 Python 爬虫框架,你用过几个? 【苹果 IP 代理】大数据时代下,数据采集推动着数据剖析, 数据剖析加快发展。但是在这个过程中会出现好多问题。拿最简 单最基础的爬虫采集数据为例,过程中还会面临,IP 被封,爬取 受限、违法操作等多种问题,所以在爬取数据之前,一定要了解 好预爬网站是否涉及违规操作,找到合适的代理 IP 访问网站等 一系列问题。今天我们就来讲讲这些高效的爬虫框架。 1.Scrapy Scrapy 是一个为了爬取网站数据,提取结构性数据而编撰的 应用框架。 可以应用在包括数据挖掘,信息处理或储存历史数 据等一系列的程序中。。用这个框架可以轻松爬出来如亚马逊商 品信息之类的数据。 2.PySpider pyspider 是一个用 python 实现的功能强悍的网路爬虫系统, 能在浏览器界面上进行脚本的编撰,功能的调度和爬取结果的实 时查看,后端使用常用的数据库进行爬取结果的储存,还能定时 设置任务与任务优先级等。 3.Crawley Crawley 可以高速爬取对应网站的内容,支持关系和非关系 数据库,数据可以导入为 JSON、XML 等。
4.Portia Portia 是一个开源可视化爬虫工具,可使您在不需要任何编程知识的情况下爬取网站!简单地注释您感兴趣的页面爬虫代理软件爬虫代理软件,Portia 将创建一个蜘蛛来从类似的页面提取数据。5.Newspaper Newspaper 可以拿来提取新闻、文章和内容剖析。使用多线 程,支持 10 多种语言等。 6.Beautiful Soup Beautiful Soup 是一个可以从 HTML 或 XML 文件中提取数据 的 Python 库.它还能通过你喜欢的转换器实现惯用的文档导航, 查找,修改文档的方法.Beautiful Soup 会帮你节约数小时甚至数天 的工作时间。 7.Grab Grab 是一个用于建立 Web 刮板的 Python 框架。借助 Grab, 您可以建立各类复杂的网页抓取工具,从简单的 5 行脚本到处理 数百万个网页的复杂异步网站抓取工具。Grab 提供一个 API 用于 执行网路恳求和处理接收到的内容,例如与 HTML 文档的 DOM 树进行交互。 8.Cola Cola 是一个分布式的爬虫框架,对于用户来说,只需编撰几 个特定的函数,而无需关注分布式运行的细节。任务会手动分配 到多台机器上,整个过程对用户是透明的。
终于知晓python网路爬虫的作用
采集交流 • 优采云 发表了文章 • 0 个评论 • 266 次浏览 • 2020-06-08 08:00
python网路爬虫的作用
1.做为通用搜索引擎网页收集器。
2.做垂直搜索引擎.
3.科学研究:在线人类行为,在线社群演变,人类动力学研究,计量社会学,复杂网路,数据挖掘,等领域的实证研究都须要大量数据,网络爬虫是搜集相关数据的神器。
4.偷窥,hacking,发垃圾邮件……
request恳求包含哪些
当我们通过浏览器向服务器发送request恳求时,这个request包含了一些哪些信息呢?我们可以通过chrome的开发者工具进行说明(如果不知道怎样使用看本篇备注)。
请求方法:最常用的恳求方法包括get恳求和post恳求。post恳求在开发中最常见的是通过表单进行递交,从用户角度来讲网络爬虫 作用,最常见的就是登入验证。当你须要输入一些信息进行登陆的时侯,这次恳求即为post恳求。
url统一资源定位符:一个网址,一张图片,一个视频等都可以用url去定义。当我们恳求一个网页时,我们可以查看network标签网络爬虫 作用,第一个一般是一个document,也就是说这个document是一个未加外部图片、css、js等渲染的html代码,在这个document的下边我们会听到一系列的jpg,js等,这是浏览器按照html代码发起的一次又一次的恳求,而恳求的地址,即为html文档中图片、js等的url地址
request headers:请求头,包括此次恳求的恳求类型,cookie信息以及浏览器类型等。 这个恳求头在我们进行网页抓取的时侯还是有些作用的,服务器会通过解析恳求头来进行信息的初审,判断此次恳求是一次合法的恳求。所以当我们通过程序伪装浏览器进行恳求的时侯,就可以设置一下恳求头的信息。
请求体:post恳求会把用户信息包装在form-data上面进行递交,因此相比于get恳求,post恳求的Headers标签的内容会多出Form Data这个信息包。get恳求可以简单的理解为普通的搜索回车,信息将会以?间隔添加在url的旁边。
为什么python适宜写爬虫
1)抓取网页本身的插口
相比与其他静态编程语言,如java,c#,C++,python抓取网页文档的插口更简约;相比其他动态脚本语言,如perl,shell,python的urllib2包提供了较为完整的访问网页文档的API。(当然ruby也是挺好的选择)
此外,抓取网页有时候须要模拟浏览器的行为,很多网站对于死板的爬虫抓取都是封杀的。这是我们须要模拟user agent的行为构造合适的恳求,譬如模拟用户登录、模拟session/cookie的储存和设置。在python里都有特别优秀的第三方包帮你搞定,如Requests,mechanize
2)网页抓取后的处理
抓取的网页一般须要处理,比如过滤html标签,提取文本等。python的beautifulsoap提供了简约的文档处理功能,能用极短的代码完成大部分文档的处理。
其实以上功能好多语言和工具都能做,但是用python才能干得最快,最干净。Life is short, u need python.
聚焦爬虫过滤方式
1.浅聚焦爬虫
选取符合目标主题的种子URL,例如我们定义抓取的信息为急聘信息,我们便可将急聘网站的URL(拉勾网、大街网等)作为种子URL,这样便保证了抓取内容与我们定义的主题的一致性。
2.深聚焦爬虫
一般有两种,一是针对内容二是针对URL。其中针对内容的如页面中绝大部分超链接都是带有锚文本的,我们可以依据锚文本进行筛选。 查看全部
python网路爬虫的作用
1.做为通用搜索引擎网页收集器。
2.做垂直搜索引擎.
3.科学研究:在线人类行为,在线社群演变,人类动力学研究,计量社会学,复杂网路,数据挖掘,等领域的实证研究都须要大量数据,网络爬虫是搜集相关数据的神器。
4.偷窥,hacking,发垃圾邮件……
request恳求包含哪些
当我们通过浏览器向服务器发送request恳求时,这个request包含了一些哪些信息呢?我们可以通过chrome的开发者工具进行说明(如果不知道怎样使用看本篇备注)。
请求方法:最常用的恳求方法包括get恳求和post恳求。post恳求在开发中最常见的是通过表单进行递交,从用户角度来讲网络爬虫 作用,最常见的就是登入验证。当你须要输入一些信息进行登陆的时侯,这次恳求即为post恳求。
url统一资源定位符:一个网址,一张图片,一个视频等都可以用url去定义。当我们恳求一个网页时,我们可以查看network标签网络爬虫 作用,第一个一般是一个document,也就是说这个document是一个未加外部图片、css、js等渲染的html代码,在这个document的下边我们会听到一系列的jpg,js等,这是浏览器按照html代码发起的一次又一次的恳求,而恳求的地址,即为html文档中图片、js等的url地址
request headers:请求头,包括此次恳求的恳求类型,cookie信息以及浏览器类型等。 这个恳求头在我们进行网页抓取的时侯还是有些作用的,服务器会通过解析恳求头来进行信息的初审,判断此次恳求是一次合法的恳求。所以当我们通过程序伪装浏览器进行恳求的时侯,就可以设置一下恳求头的信息。
请求体:post恳求会把用户信息包装在form-data上面进行递交,因此相比于get恳求,post恳求的Headers标签的内容会多出Form Data这个信息包。get恳求可以简单的理解为普通的搜索回车,信息将会以?间隔添加在url的旁边。
为什么python适宜写爬虫
1)抓取网页本身的插口
相比与其他静态编程语言,如java,c#,C++,python抓取网页文档的插口更简约;相比其他动态脚本语言,如perl,shell,python的urllib2包提供了较为完整的访问网页文档的API。(当然ruby也是挺好的选择)
此外,抓取网页有时候须要模拟浏览器的行为,很多网站对于死板的爬虫抓取都是封杀的。这是我们须要模拟user agent的行为构造合适的恳求,譬如模拟用户登录、模拟session/cookie的储存和设置。在python里都有特别优秀的第三方包帮你搞定,如Requests,mechanize
2)网页抓取后的处理
抓取的网页一般须要处理,比如过滤html标签,提取文本等。python的beautifulsoap提供了简约的文档处理功能,能用极短的代码完成大部分文档的处理。
其实以上功能好多语言和工具都能做,但是用python才能干得最快,最干净。Life is short, u need python.
聚焦爬虫过滤方式
1.浅聚焦爬虫
选取符合目标主题的种子URL,例如我们定义抓取的信息为急聘信息,我们便可将急聘网站的URL(拉勾网、大街网等)作为种子URL,这样便保证了抓取内容与我们定义的主题的一致性。
2.深聚焦爬虫
一般有两种,一是针对内容二是针对URL。其中针对内容的如页面中绝大部分超链接都是带有锚文本的,我们可以依据锚文本进行筛选。

