
python
【Scrapy】走进成熟的爬虫框架
采集交流 • 优采云 发表了文章 • 0 个评论 • 313 次浏览 • 2020-05-10 08:02
今天简单说说Scrapy的安装。
前几天有小伙伴留言说能不能介绍推荐一下爬虫框架,我给他推荐了Scrapy,本来想偷个懒,推荐他去看官方文档,里面有一些demo代码可供学习测试。结果收到回复说文档中演示用到的网站已经难以访问了。所以只能自己来简单写一下了,也算是自己一个学习记录。
Scrapy是哪些?
定义介绍我也不复制粘贴了。简单来说,Scrapy是一个中小型的爬虫框架,框架的意义就在于帮你预设好了好多可以用的东西,让你可以从复杂的数据流和底层控制中抽离下来,专心于页面的解析即可完成中大项目爬虫,甚至是分布式爬虫。
但是爬虫入门是不推荐直接从框架入手的,直接从框架入手会使你头晕目眩,觉得哪里哪里都看不懂,有点类似于还没学会基础的措词造句就直接套用模板写成文章,自然是非常费力的。所以还是推荐你们有一定的手写爬虫基础再深入了解框架。(当然还没有入门爬虫的朋友…可以催更我的爬虫入门文章…)
那么首先是安装。
Python的版本选择之前提过,推荐你们全面拥抱Python 3.x。
很久以前,大概是我刚入门学习Scrapy时爬虫框架,Scrapy还没有支持Python 3.x,那时一部分爬虫工程师把Scrapy不支持Python 3.x作为不进行迁移的理由。当然了,那时更具体的缘由是Scrapy所依赖的twisted和mitmproxy不支持Python 3.x。
现在我仍然推荐你们全面拥抱Python 3.x。
先安装Python
这次我们以本地环境来进行安装(Windows+Anaconda),由于Python的跨平台特点爬虫框架,我们本地写的代码可以很容易迁移到别的笔记本或服务器使用。(当然了,从规范使用的角度上推荐你们使用单独的env,或者直接使用docker或则vagrant,不过那就说来话长了…以后可以考虑单独介绍)
按照惯例,我们直接使用 pip install scrapy 进行安装。
那么,你大几率会碰到这样的错误:
具体的错误缘由…缺少Microsoft Visual C++ 14.0…你也可以自己通过其他渠道解决,当然我们最推荐的做法是直接使用 conda install scrapy 命令(前提是你安装了Anaconda而非普通Python)。
如果碰到写入权限错误,请用管理员模式运行cmd。
之后我们可以写一个太小的demo,依然是官方案例中的DMOZ,DMOZ网站是一个知名的开放式分类目录(Open DirectoryProject),原版的DMOZ已于今年的3月17日停止了营运,目前网站处于403状态。但是网上大量过去的教程都是以DMOZ为案例的。我为你们找到了原DMOZ网站的静态镜像站,大家可以直接访问
大家根据官方文档的步骤继续做就可以了,后续的问题不大。
()
需要注意的就是工作目录问题。
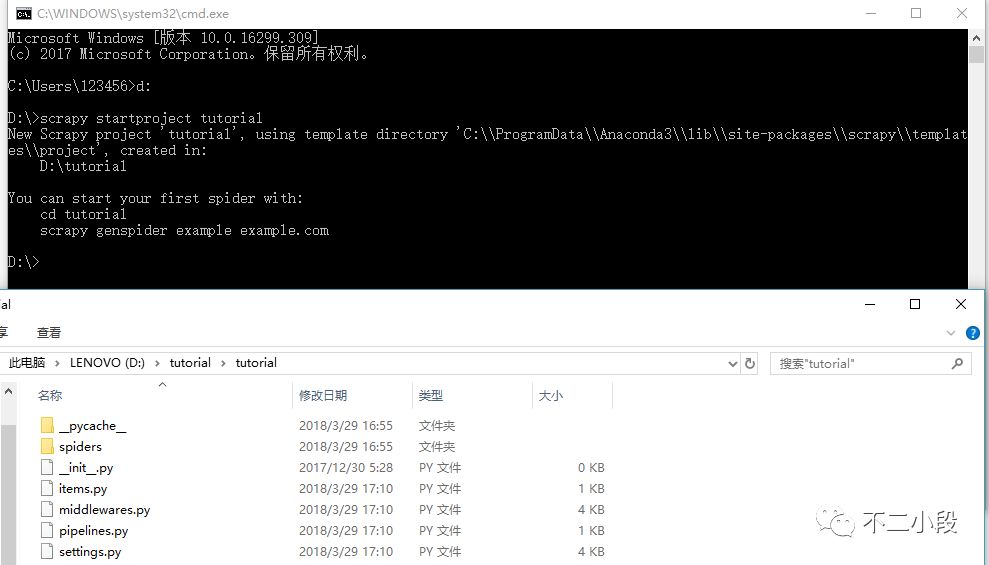
启动Scrapy项目。
scrapy startproject tutorial
进入目录,我们可以看见手动生成的一些文件,这些文件就是scrapy框架所须要的最基础的组织结构。
scrapy.cfg: 项目的配置文件
tutorial/: 该项目的python模块。之后您将在此加入代码。
tutorial/items.py: 项目中的item文件.
tutorial/pipelines.py: 项目中的pipelines文件.
tutorial/settings.py: 项目的设置文件.
tutorial/spiders/: 放置spider代码的目录. 查看全部
今天简单说说Scrapy的安装。
前几天有小伙伴留言说能不能介绍推荐一下爬虫框架,我给他推荐了Scrapy,本来想偷个懒,推荐他去看官方文档,里面有一些demo代码可供学习测试。结果收到回复说文档中演示用到的网站已经难以访问了。所以只能自己来简单写一下了,也算是自己一个学习记录。
Scrapy是哪些?
定义介绍我也不复制粘贴了。简单来说,Scrapy是一个中小型的爬虫框架,框架的意义就在于帮你预设好了好多可以用的东西,让你可以从复杂的数据流和底层控制中抽离下来,专心于页面的解析即可完成中大项目爬虫,甚至是分布式爬虫。
但是爬虫入门是不推荐直接从框架入手的,直接从框架入手会使你头晕目眩,觉得哪里哪里都看不懂,有点类似于还没学会基础的措词造句就直接套用模板写成文章,自然是非常费力的。所以还是推荐你们有一定的手写爬虫基础再深入了解框架。(当然还没有入门爬虫的朋友…可以催更我的爬虫入门文章…)
那么首先是安装。
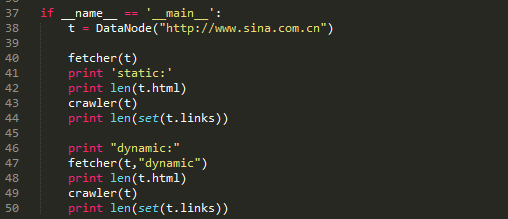
Python的版本选择之前提过,推荐你们全面拥抱Python 3.x。
很久以前,大概是我刚入门学习Scrapy时爬虫框架,Scrapy还没有支持Python 3.x,那时一部分爬虫工程师把Scrapy不支持Python 3.x作为不进行迁移的理由。当然了,那时更具体的缘由是Scrapy所依赖的twisted和mitmproxy不支持Python 3.x。
现在我仍然推荐你们全面拥抱Python 3.x。
先安装Python
这次我们以本地环境来进行安装(Windows+Anaconda),由于Python的跨平台特点爬虫框架,我们本地写的代码可以很容易迁移到别的笔记本或服务器使用。(当然了,从规范使用的角度上推荐你们使用单独的env,或者直接使用docker或则vagrant,不过那就说来话长了…以后可以考虑单独介绍)
按照惯例,我们直接使用 pip install scrapy 进行安装。
那么,你大几率会碰到这样的错误:

具体的错误缘由…缺少Microsoft Visual C++ 14.0…你也可以自己通过其他渠道解决,当然我们最推荐的做法是直接使用 conda install scrapy 命令(前提是你安装了Anaconda而非普通Python)。
如果碰到写入权限错误,请用管理员模式运行cmd。
之后我们可以写一个太小的demo,依然是官方案例中的DMOZ,DMOZ网站是一个知名的开放式分类目录(Open DirectoryProject),原版的DMOZ已于今年的3月17日停止了营运,目前网站处于403状态。但是网上大量过去的教程都是以DMOZ为案例的。我为你们找到了原DMOZ网站的静态镜像站,大家可以直接访问
大家根据官方文档的步骤继续做就可以了,后续的问题不大。
()
需要注意的就是工作目录问题。
启动Scrapy项目。
scrapy startproject tutorial
进入目录,我们可以看见手动生成的一些文件,这些文件就是scrapy框架所须要的最基础的组织结构。
scrapy.cfg: 项目的配置文件
tutorial/: 该项目的python模块。之后您将在此加入代码。
tutorial/items.py: 项目中的item文件.
tutorial/pipelines.py: 项目中的pipelines文件.
tutorial/settings.py: 项目的设置文件.
tutorial/spiders/: 放置spider代码的目录.
爬虫常用库的安装(二)
采集交流 • 优采云 发表了文章 • 0 个评论 • 261 次浏览 • 2020-05-09 08:02
那么首先,我们先安装一下python自带的模块,request模块,这里给对编程完全陌生的菜鸟来简单介绍一下,request可以取得客户端发送给服务器的恳求信息。
言归正传,我们如今来安装request模块,同样的,我们先打开命令执行程序cmd。
然后输入pip install requests,我们可以看见系统会手动完成这个安装过程。
随后我们来测量一下,第一步,运行python,如果看了今天文章的小伙伴,应该不会再出现其他问题了爬虫软件安装,这里假如有朋友未能正常运行python的话,建议回头看一下今天的《爬虫常用库的安装(一)》。
随后,我们来测量一下python自带的urllib以及re库是否可以正常运行。
那哪些是urllib呢?urllib是可以处理url的组件集合,url就是网上每位文件特有的惟一的强调文件位置以及浏览器如何处理的信息。
在步入python后,输入importurllib,然后import urllib.request;如果没有任何报错的话,说明urllib的安装正常。然后,我们使用urlopen命令来打开一下网址,例如百度,如果运行后显示如右图信息,那么说明url的使用也是没有问题的。
好,我们检查完urllib以后,再来看一下re模块是否正常,re就是python语言中拿来实现正则匹配,通俗的说就是检索、替换这些符合规则的文本。那么我们再度使用import re的命令,如果没有报错,则说明re模块的安装也是没有问题的,因为这两个模块一般问题不大爬虫软件安装,这里就不做截图说明了。
那么虽然其他的模块下载也都是类似的情况,为防止赘言,这里就不花大篇幅讲解了,我们可以通过pip install requests selenium beautifulsoup4 pyquery pymysql pymongoredis flask django jupyter的命令来完成统一下载。为了不给你们添加很大负担,就不一一赘言每位模块的功能了,这些就会在日后的文章中为你们述说,这里还请对python感兴趣的同学们加一下启蒙君的公众号——人工智能python启蒙,今后会为你们带来更多有关于人工智能、大数据剖析以及区块链的学习信息~
下载完成后,python的各大模块应当都可以正常使用了,大家也晓得爬虫的主要功能就是获取数据,当然须要一些储存的数据处理的工具,那么今天启蒙君会给你们带来诸如mongodb、mysql等常用数据库的下载、安装教程。祝你们假期愉快! 查看全部
那么首先,我们先安装一下python自带的模块,request模块,这里给对编程完全陌生的菜鸟来简单介绍一下,request可以取得客户端发送给服务器的恳求信息。
言归正传,我们如今来安装request模块,同样的,我们先打开命令执行程序cmd。
然后输入pip install requests,我们可以看见系统会手动完成这个安装过程。
随后我们来测量一下,第一步,运行python,如果看了今天文章的小伙伴,应该不会再出现其他问题了爬虫软件安装,这里假如有朋友未能正常运行python的话,建议回头看一下今天的《爬虫常用库的安装(一)》。
随后,我们来测量一下python自带的urllib以及re库是否可以正常运行。
那哪些是urllib呢?urllib是可以处理url的组件集合,url就是网上每位文件特有的惟一的强调文件位置以及浏览器如何处理的信息。
在步入python后,输入importurllib,然后import urllib.request;如果没有任何报错的话,说明urllib的安装正常。然后,我们使用urlopen命令来打开一下网址,例如百度,如果运行后显示如右图信息,那么说明url的使用也是没有问题的。
好,我们检查完urllib以后,再来看一下re模块是否正常,re就是python语言中拿来实现正则匹配,通俗的说就是检索、替换这些符合规则的文本。那么我们再度使用import re的命令,如果没有报错,则说明re模块的安装也是没有问题的,因为这两个模块一般问题不大爬虫软件安装,这里就不做截图说明了。
那么虽然其他的模块下载也都是类似的情况,为防止赘言,这里就不花大篇幅讲解了,我们可以通过pip install requests selenium beautifulsoup4 pyquery pymysql pymongoredis flask django jupyter的命令来完成统一下载。为了不给你们添加很大负担,就不一一赘言每位模块的功能了,这些就会在日后的文章中为你们述说,这里还请对python感兴趣的同学们加一下启蒙君的公众号——人工智能python启蒙,今后会为你们带来更多有关于人工智能、大数据剖析以及区块链的学习信息~
下载完成后,python的各大模块应当都可以正常使用了,大家也晓得爬虫的主要功能就是获取数据,当然须要一些储存的数据处理的工具,那么今天启蒙君会给你们带来诸如mongodb、mysql等常用数据库的下载、安装教程。祝你们假期愉快!
Python和数据剖析
采集交流 • 优采云 发表了文章 • 0 个评论 • 265 次浏览 • 2020-05-08 08:03
缺点:有点奇特。? Python:相对年青一点的语言。对于爬虫来说各 方面能力挺好,并且还在建立中,没有Perl那样有 专门的爬虫书籍,不过网上能搜到一些文章。为什么最终选择Python?? 跨平台,对Linux和windows都有不错的支持。 ? 科学估算,数值拟合:Numpy,Scipy ? 可视化:2d:Matplotlib(做图很漂亮), 3d: Mayavi2 ? 复杂网路:Networkx ? 统计:与R语言插口:Rpy ? 交互式终端 ? 网站的快速开发?从一个简单的Python爬虫开始说明:加说明句子时要注意#需要英语编码里的,而不能是英文输入法中的#号,所 以添加英文说明时先在英语输入法下攻入#号后再切换到英文输入瀚海星云Pie 版的网页部份代码………Pie版的Html树部份结构借助BeautifulSoup分析树FindAll()是最方便最好用的函数通用搜索策略? 页面中的link? 深度优先? 广度优先现实中的策略是多种多样的? 因为瀚海星云link有很简单的规律,每页递减20,所以借助这个规 律设置每次赋入的URL,这样爬完了PIE版所有贴子运行结果? 有乱 码!!爬取英文网页常有的问题:不规 格的编码模式? 解决方式:编码转换最后的结果? Perfect!请温柔的对待瀚海星云!!? 设置延后时间(对于一个峰会,如果假定一 个真实的浏览者每10秒掀开一个新的网页的 话,一个不延时的爬虫每秒可以抓10个网页, 这样一个爬虫相当于占用了100个人的带 宽!)? 在午夜爬取可以适当推进速率道上的规矩:用Mysql储存数据? 先要在自己数据库里构建一个空的表,这里, 这里我早已构建了一个名为lilybbs的数据库, 表名为hunan_a? 导入相应的模块? 与相应的数据库联接? 写入数据库里的结果统计和做图? 这部份主要用于科研方 面,利用爬取到的数据 做一些简单的统计工作? 右图是某峰会的回复网 络,使用python的 networkx包做的。
? Pylab 是 matplotlib作 图包的一部 分? 左图是某 blog四年间 每天发表文 章的数目? 左一是某blog网站每个blog 评论数的统计,x是blog评 论数目,y是有这样数目的 blog的数目。可以看见是标 准的“power-law”分布,幂 指数为-1.2左右,拟合使用 了Scipy包的optimize.leastsq, 函数,具体可见scipy cookbook页面的fitting data 一栏? 左二是blog的comment networks 的入度与出度的散 点图,也就是每位点的坐 标x,y分别代表某个人获 得的评论和发出的评论数。 颜色代表这样点的数目。 本图使用了matplotlib中的 hexbin函数中级主题(一):编写更强壮的爬虫? 伪装成浏 览器? 容错中级主题(二):由内嵌脚本形成 的动态网页的爬取? 如何爬取 像左图这 样的网页 呢?? 它显示的 内容并不 会呈现在 html文件 里。高级主题(三):SQLAlchemyMysql这样关系型数据库的缺点:在表 示复杂网路这样一对多,和多对多 的关系时,非常冗余;一旦须要做 比较复杂的统计,sql句子会显得异 常复杂。
? 当你越关注性能,就会发觉 SQL 数据库距对象集合越来越远;当你越关 注具象,就会发觉对象集合距表和行这种概念越来越远。SQLAlchemy 将 致力于尽量宽容这两个世界。? SQLAlchemy 并不把数据库简单地视为数据表的集合;它把它们看作是关 系代数引擎。它的关系对象映射才能使类以不同的形式映射到数据库。 SQL 工具包也不光才能对数据表进行 select 操作——你能够对联接、子查 询和联合进行 select。这样数据库关系和领域对象模型之间的耦合从一开 始就得以挺好地解开,使得两个领域都得以发挥其各自的极至。? 我写过的某个冗长的调用? 号称能更简约明了的SQLAlchemy会成为 mysql的替代品么?高级主题(四):统计神器R语言? 求残差,聚类,判 别,拟合,团簇探 测,时间序列剖析, 生存剖析,甚至复 杂网路,这些R语言 里都有挺好的函数? 可以直接使用R语言, 也可以借助Rpy在 python上面调用R的 函数,不过Rpy一直 开发中,还不是太 成熟以前我们获取数据的手段: 我们用望远镜来洞察宇宙高昂的实验 只是为了获取大自然的数据Internet 带给我们了海量的数据 善用数据,了解我们自己广袤的比特海是另一片未知的星空感谢你们! 查看全部
网络爬虫, Python和数据 分析王澎 中国科技大学哪些是网络爬虫?? 网络爬虫是一个手动提取网页的程序,它为搜索 引擎从万维网上下载网页,是搜索引擎的重要组 成。传统爬虫从一个或若干初始网页的URL开始, 获得初始网页上的URL,在抓取网页的过程中, 不断从当前页面上抽取新的URL装入队列,直到满 足系统的一定停止条件爬虫有哪些用?? 做为通用搜索引擎网页收集器。(google,baidu) ? 做垂直搜索引擎.(找工作的搜索引擎:,数据来源于: , , 等等) ? 科学研究:在线人类行为,在线社群演变,人类 动力学研究数据挖掘与网络爬虫,计量社会学,复杂网路,数据挖掘, 等领域的实证研究都须要大量数据,网络爬虫是 收集相关数据的神器。 ? 偷窥,hacking数据挖掘与网络爬虫,发垃圾邮件……(《google hack》….)爬虫是搜索引擎的第一步 也是最容易的一步? 网页收集 ? 建立索引 ? 查询排序用哪些语言写爬虫?? C,C++。高效率,快速,适合通用搜索引 擎做全网爬取。缺点,开发慢,写上去又 臭又长,例如:天网搜索源代码。? 脚本语言:Perl, Python, Java, Ruby。简单, 易学,良好的文本处理能便捷网页内容的 细致提取,但效率常常不高,适合对少量 网站的聚焦爬取? C#?(貌似信息管理的人比较喜欢的语言)我当初拿来写过爬虫的语言? Perl: 古老的脚本语言,hack 语言,被拿来写爬虫 有着悠久的历史,因此,书本支持相当丰富: 《spidering hacks》,《Perl & LWP》;强大的文 本处理能力,数据库支持能力。
缺点:有点奇特。? Python:相对年青一点的语言。对于爬虫来说各 方面能力挺好,并且还在建立中,没有Perl那样有 专门的爬虫书籍,不过网上能搜到一些文章。为什么最终选择Python?? 跨平台,对Linux和windows都有不错的支持。 ? 科学估算,数值拟合:Numpy,Scipy ? 可视化:2d:Matplotlib(做图很漂亮), 3d: Mayavi2 ? 复杂网路:Networkx ? 统计:与R语言插口:Rpy ? 交互式终端 ? 网站的快速开发?从一个简单的Python爬虫开始说明:加说明句子时要注意#需要英语编码里的,而不能是英文输入法中的#号,所 以添加英文说明时先在英语输入法下攻入#号后再切换到英文输入瀚海星云Pie 版的网页部份代码………Pie版的Html树部份结构借助BeautifulSoup分析树FindAll()是最方便最好用的函数通用搜索策略? 页面中的link? 深度优先? 广度优先现实中的策略是多种多样的? 因为瀚海星云link有很简单的规律,每页递减20,所以借助这个规 律设置每次赋入的URL,这样爬完了PIE版所有贴子运行结果? 有乱 码!!爬取英文网页常有的问题:不规 格的编码模式? 解决方式:编码转换最后的结果? Perfect!请温柔的对待瀚海星云!!? 设置延后时间(对于一个峰会,如果假定一 个真实的浏览者每10秒掀开一个新的网页的 话,一个不延时的爬虫每秒可以抓10个网页, 这样一个爬虫相当于占用了100个人的带 宽!)? 在午夜爬取可以适当推进速率道上的规矩:用Mysql储存数据? 先要在自己数据库里构建一个空的表,这里, 这里我早已构建了一个名为lilybbs的数据库, 表名为hunan_a? 导入相应的模块? 与相应的数据库联接? 写入数据库里的结果统计和做图? 这部份主要用于科研方 面,利用爬取到的数据 做一些简单的统计工作? 右图是某峰会的回复网 络,使用python的 networkx包做的。
? Pylab 是 matplotlib作 图包的一部 分? 左图是某 blog四年间 每天发表文 章的数目? 左一是某blog网站每个blog 评论数的统计,x是blog评 论数目,y是有这样数目的 blog的数目。可以看见是标 准的“power-law”分布,幂 指数为-1.2左右,拟合使用 了Scipy包的optimize.leastsq, 函数,具体可见scipy cookbook页面的fitting data 一栏? 左二是blog的comment networks 的入度与出度的散 点图,也就是每位点的坐 标x,y分别代表某个人获 得的评论和发出的评论数。 颜色代表这样点的数目。 本图使用了matplotlib中的 hexbin函数中级主题(一):编写更强壮的爬虫? 伪装成浏 览器? 容错中级主题(二):由内嵌脚本形成 的动态网页的爬取? 如何爬取 像左图这 样的网页 呢?? 它显示的 内容并不 会呈现在 html文件 里。高级主题(三):SQLAlchemyMysql这样关系型数据库的缺点:在表 示复杂网路这样一对多,和多对多 的关系时,非常冗余;一旦须要做 比较复杂的统计,sql句子会显得异 常复杂。
? 当你越关注性能,就会发觉 SQL 数据库距对象集合越来越远;当你越关 注具象,就会发觉对象集合距表和行这种概念越来越远。SQLAlchemy 将 致力于尽量宽容这两个世界。? SQLAlchemy 并不把数据库简单地视为数据表的集合;它把它们看作是关 系代数引擎。它的关系对象映射才能使类以不同的形式映射到数据库。 SQL 工具包也不光才能对数据表进行 select 操作——你能够对联接、子查 询和联合进行 select。这样数据库关系和领域对象模型之间的耦合从一开 始就得以挺好地解开,使得两个领域都得以发挥其各自的极至。? 我写过的某个冗长的调用? 号称能更简约明了的SQLAlchemy会成为 mysql的替代品么?高级主题(四):统计神器R语言? 求残差,聚类,判 别,拟合,团簇探 测,时间序列剖析, 生存剖析,甚至复 杂网路,这些R语言 里都有挺好的函数? 可以直接使用R语言, 也可以借助Rpy在 python上面调用R的 函数,不过Rpy一直 开发中,还不是太 成熟以前我们获取数据的手段: 我们用望远镜来洞察宇宙高昂的实验 只是为了获取大自然的数据Internet 带给我们了海量的数据 善用数据,了解我们自己广袤的比特海是另一片未知的星空感谢你们!
网络爬虫技术,为什么说使用Python最合适?请听四星教育讲解
采集交流 • 优采云 发表了文章 • 0 个评论 • 326 次浏览 • 2020-05-07 08:00
但是你晓得Python与其他编程语言最主要的区别吗?
网络爬虫技术人才,一直是被各企业争相抢劫。而网路爬虫主要是用Python来编撰,所以缔造了Python与之不同的地位。
也许会有人指责,难道就不能用其他语言来编撰么?
答案是可以的,像java、c、c++、php都可以做爬虫。但是,我们运用一种语言常常并不是说这个会不会做就可以了,还取决于过程中的运行速率、开发效率、人力成本等不同诱因,最后互相比较一下,Python是最合适的。就好象一份工作,大家都可以去做,但是老总肯定会选择更适宜更经济更有能力的人去做。
在写爬虫的过程中,往往是一边写,一边测试爬虫技术用什么语言,测试不过再改改。这个过程用 python 写上去最方便。并且python 相关的库也是最方便,有 request, jieba, redis,gevent,NLTK, lxml,pyquery爬虫技术用什么语言,BeautifulSoup,Pillow,不论是简单的爬虫还是复杂的爬虫都轻松搞定。
这也是Python的又一大特点,与其他编程语言显著不同。
网络爬虫常常被称为网页追逐者,是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。另外一些不常使用的名子还有蚂蚁、自动索引、模拟程序或则蠕虫。
网络爬虫根据系统结构和实现技术,大致可以分为以下几种类型:通用网路爬虫、聚焦网路爬虫、增量式网路爬虫、深层网路爬虫。
通用网路爬虫又称全网爬虫,爬行对象从一些种子 URL 扩充到整个 Web,主要为门户站点搜索引擎和小型 Web 服务提供商采集数据。
聚焦网路爬虫,是指选择性地爬行这些与预先定义好的主题相关页面的网路爬虫。只须要爬行与主题相关的页面,极大地节约了硬件和网路资源,保存的页面也因为数目少而更新快,还可以挺好地满足一些特定人群对特定领域信息的需求。
增量式网路爬虫,是指对已下载网页采取增量式更新和只爬行新形成的或则早已发生变化网页的爬虫,它还能在一定程度上保证所爬行的页面是尽可能新的页面。
随着互联网的发展,网络爬虫技术在未来10年里,都不会有衰落的现象。人生苦短,我学Python,如果听到此文的你正好不知道学哪些语言,六星教育诚挚推荐Python。
六星教育Python全栈VIP课程,囊括了Python各个方面的知识点,内含基础、高级、进阶、商业项目实战等内容,一站式提供从小白到大鳄课程。 查看全部

但是你晓得Python与其他编程语言最主要的区别吗?
网络爬虫技术人才,一直是被各企业争相抢劫。而网路爬虫主要是用Python来编撰,所以缔造了Python与之不同的地位。
也许会有人指责,难道就不能用其他语言来编撰么?
答案是可以的,像java、c、c++、php都可以做爬虫。但是,我们运用一种语言常常并不是说这个会不会做就可以了,还取决于过程中的运行速率、开发效率、人力成本等不同诱因,最后互相比较一下,Python是最合适的。就好象一份工作,大家都可以去做,但是老总肯定会选择更适宜更经济更有能力的人去做。
在写爬虫的过程中,往往是一边写,一边测试爬虫技术用什么语言,测试不过再改改。这个过程用 python 写上去最方便。并且python 相关的库也是最方便,有 request, jieba, redis,gevent,NLTK, lxml,pyquery爬虫技术用什么语言,BeautifulSoup,Pillow,不论是简单的爬虫还是复杂的爬虫都轻松搞定。
这也是Python的又一大特点,与其他编程语言显著不同。

网络爬虫常常被称为网页追逐者,是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。另外一些不常使用的名子还有蚂蚁、自动索引、模拟程序或则蠕虫。
网络爬虫根据系统结构和实现技术,大致可以分为以下几种类型:通用网路爬虫、聚焦网路爬虫、增量式网路爬虫、深层网路爬虫。
通用网路爬虫又称全网爬虫,爬行对象从一些种子 URL 扩充到整个 Web,主要为门户站点搜索引擎和小型 Web 服务提供商采集数据。
聚焦网路爬虫,是指选择性地爬行这些与预先定义好的主题相关页面的网路爬虫。只须要爬行与主题相关的页面,极大地节约了硬件和网路资源,保存的页面也因为数目少而更新快,还可以挺好地满足一些特定人群对特定领域信息的需求。
增量式网路爬虫,是指对已下载网页采取增量式更新和只爬行新形成的或则早已发生变化网页的爬虫,它还能在一定程度上保证所爬行的页面是尽可能新的页面。
随着互联网的发展,网络爬虫技术在未来10年里,都不会有衰落的现象。人生苦短,我学Python,如果听到此文的你正好不知道学哪些语言,六星教育诚挚推荐Python。
六星教育Python全栈VIP课程,囊括了Python各个方面的知识点,内含基础、高级、进阶、商业项目实战等内容,一站式提供从小白到大鳄课程。
python采集微信公众号文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 745 次浏览 • 2020-05-06 08:04
在python一个子目录里存2个文件,分别是:采集公众号文章.py和config.py。 代码如下:
1.采集公众号文章.py
from urllib.parse import urlencode
import pymongo
import requests
from lxml.etree import XMLSyntaxError
from requests.exceptions import ConnectionError
from pyquery import PyQuery as pq
from config import *
#配置MongoDB
client = pymongo.MongoClient(MONGO_URI)
db = client[MONGO_DB]
base_url = 'http://weixin.sogou.com/weixin?'
#添加头文件
headers = {
'Cookie': 'usid=S-pkM6vW_ac4ktr1; SUV=00A75E9078EFD9F75A6573ECAD0EC883; wuid=AAGCxerSHQAAAAqRGn4SoAgAAAA=; IPLOC=CN4414; SUID=767BEAB73220910A000000005AA9E2AA; pgv_pvi=159197184; pgv_si=s8252565504; ABTEST=0|1521083055|v1; weixinIndexVisited=1; sct=1; JSESSIONID=aaalXqKRP6JjS8ac4Hwhw; ppinf=5|1521083238|1522292838|dHJ1c3Q6MToxfGNsaWVudGlkOjQ6MjAxN3x1bmlxbmFtZTo2OiUzQSUyOXxjcnQ6MTA6MTUyMTA4MzIzOHxyZWZuaWNrOjY6JTNBJTI5fHVzZXJpZDo0NDpvOXQybHVOaExNcS1vLW1zbjMxMmNMSkp4OGpZQHdlaXhpbi5zb2h1LmNvbXw; pprdig=tbVf7qLZdDMjpCn4jTf3dg8C8NeRX-YgDi8KUcezn0rteWuhkgU4xMNaxZbakVQuswboIGl_rD-34abU6VY9Jkv7me3BypigyDnIv2lJUchGCo7Gk58m9Qhrm3Aa7NHLHjFVYoaQkQgBSYKpatxMNPe3Tm57ZDlzdPg_8mBmBNQ; sgid=23-30671195-AVqp42ZctqiaCybbDvvfWno4; PHPSESSID=4jjk2a9rv6kq7m50f42r92u3r3; SUIR=D2DF4E12A5A1C3CE1A8AD7F2A5FE18FE; ppmdig=1521087492000000855f9824f94abe82b25d2839135ad3a8; SNUID=FEF36D3F8882EFEC4FCF61E68801DA49; seccodeRight=success; successCount=1|Thu, 15 Mar 2018 04:23:23 GMT',
'Host': 'weixin.sogou.com',
'Referer': 'http://weixin.sogou.com/antispider/?from=%2fweixin%3Fquery%3d%E9%A3%8E%E6%99%AF%26type%3d2%26page%3d95%26ie%3dutf8',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36'
}
#初始化代理为本地IP
proxy = None
#定义获取代理函数
def get_proxy():
try:
response = requests.get(PROXY_POOL_URL)
if response.status_code == 200:
return response.text
return None
except ConnectionError:
return None
#添加代理获取网页内容
def get_html(url, count=1):
print('Crawling', url)
print('Trying Count', count)
global proxy
if count >= MAX_COUNT:
print('Tried Too Many Counts')
return None
try:
if proxy:
proxies = {
'http': 'http://' + proxy
}
response = requests.get(url, allow_redirects=False, headers=headers, proxies=proxies)
else:
response = requests.get(url, allow_redirects=False, headers=headers)
if response.status_code == 200:
return response.text
if response.status_code == 302:
# Need Proxy
print('302')
proxy = get_proxy()
if proxy:
print('Using Proxy', proxy)
return get_html(url)
else:
print('Get Proxy Failed')
return None
except ConnectionError as e:
print('Error Occurred', e.args)
proxy = get_proxy()
count += 1
return get_html(url, count)
#获取索引页内容
def get_index(keyword, page):
data = {
'query': keyword,
'type': 2,
'page': page
}
queries = urlencode(data)
url = base_url + queries
html = get_html(url)
return html
#解析索引页,提取详情页网址
def parse_index(html):
doc = pq(html)
items = doc('.news-box .news-list li .txt-box h3 a').items()
for item in items:
yield item.attr('href')
#获取详情页
def get_detail(url):
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
return None
except ConnectionError:
return None
#解析索引页,返回微信文章标题、内容、日期、公众号名称等
def parse_detail(html):
try:
doc = pq(html)
title = doc('.rich_media_title').text()
content = doc('.rich_media_content').text()
date = doc('#post-date').text()
nickname = doc('#js_profile_qrcode > div > strong').text()
wechat = doc('#js_profile_qrcode > div > p:nth-child(3) > span').text()
return {
'title': title,
'content': content,
'date': date,
'nickname': nickname,
'wechat': wechat
}
except XMLSyntaxError:
return None
#存储到MongoDB,去重操作
def save_to_mongo(data):
if db['articles'].update({'title': data['title']}, {'$set': data}, True):
print('Saved to Mongo', data['title'])
else:
print('Saved to Mongo Failed', data['title'])
#主函数
def main():
for page in range(1, 101):
html = get_index(KEYWORD, page)
if html:
article_urls = parse_index(html)
for article_url in article_urls:
article_html = get_detail(article_url)
if article_html:
article_data = parse_detail(article_html)
print(article_data)
if __name__ == '__main__':
main()
2.config.py代码:
#爬取公众号文章
PROXY_POOL_URL = 'http://127.0.0.1:5000/get'
KEYWORD ='计算机等级二级' # 输入关键词
MONGO_URI = 'localhost'
MONGO_DB = 'data'
MAX_COUNT = 5
其中,config.py中KEYWORD为查找关键词采集微信文章,可以按照须要修改。经实测,运行"采集公众号文章.py"成功!若因受限不成功,可多运行几次。
以上就是本文的全部内容,希望对你们的学习有所帮助,也希望你们多多支持优采云。 查看全部
在python一个子目录里存2个文件,分别是:采集公众号文章.py和config.py。 代码如下:
1.采集公众号文章.py
from urllib.parse import urlencode
import pymongo
import requests
from lxml.etree import XMLSyntaxError
from requests.exceptions import ConnectionError
from pyquery import PyQuery as pq
from config import *
#配置MongoDB
client = pymongo.MongoClient(MONGO_URI)
db = client[MONGO_DB]
base_url = 'http://weixin.sogou.com/weixin?'
#添加头文件
headers = {
'Cookie': 'usid=S-pkM6vW_ac4ktr1; SUV=00A75E9078EFD9F75A6573ECAD0EC883; wuid=AAGCxerSHQAAAAqRGn4SoAgAAAA=; IPLOC=CN4414; SUID=767BEAB73220910A000000005AA9E2AA; pgv_pvi=159197184; pgv_si=s8252565504; ABTEST=0|1521083055|v1; weixinIndexVisited=1; sct=1; JSESSIONID=aaalXqKRP6JjS8ac4Hwhw; ppinf=5|1521083238|1522292838|dHJ1c3Q6MToxfGNsaWVudGlkOjQ6MjAxN3x1bmlxbmFtZTo2OiUzQSUyOXxjcnQ6MTA6MTUyMTA4MzIzOHxyZWZuaWNrOjY6JTNBJTI5fHVzZXJpZDo0NDpvOXQybHVOaExNcS1vLW1zbjMxMmNMSkp4OGpZQHdlaXhpbi5zb2h1LmNvbXw; pprdig=tbVf7qLZdDMjpCn4jTf3dg8C8NeRX-YgDi8KUcezn0rteWuhkgU4xMNaxZbakVQuswboIGl_rD-34abU6VY9Jkv7me3BypigyDnIv2lJUchGCo7Gk58m9Qhrm3Aa7NHLHjFVYoaQkQgBSYKpatxMNPe3Tm57ZDlzdPg_8mBmBNQ; sgid=23-30671195-AVqp42ZctqiaCybbDvvfWno4; PHPSESSID=4jjk2a9rv6kq7m50f42r92u3r3; SUIR=D2DF4E12A5A1C3CE1A8AD7F2A5FE18FE; ppmdig=1521087492000000855f9824f94abe82b25d2839135ad3a8; SNUID=FEF36D3F8882EFEC4FCF61E68801DA49; seccodeRight=success; successCount=1|Thu, 15 Mar 2018 04:23:23 GMT',
'Host': 'weixin.sogou.com',
'Referer': 'http://weixin.sogou.com/antispider/?from=%2fweixin%3Fquery%3d%E9%A3%8E%E6%99%AF%26type%3d2%26page%3d95%26ie%3dutf8',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36'
}
#初始化代理为本地IP
proxy = None
#定义获取代理函数
def get_proxy():
try:
response = requests.get(PROXY_POOL_URL)
if response.status_code == 200:
return response.text
return None
except ConnectionError:
return None
#添加代理获取网页内容
def get_html(url, count=1):
print('Crawling', url)
print('Trying Count', count)
global proxy
if count >= MAX_COUNT:
print('Tried Too Many Counts')
return None
try:
if proxy:
proxies = {
'http': 'http://' + proxy
}
response = requests.get(url, allow_redirects=False, headers=headers, proxies=proxies)
else:
response = requests.get(url, allow_redirects=False, headers=headers)
if response.status_code == 200:
return response.text
if response.status_code == 302:
# Need Proxy
print('302')
proxy = get_proxy()
if proxy:
print('Using Proxy', proxy)
return get_html(url)
else:
print('Get Proxy Failed')
return None
except ConnectionError as e:
print('Error Occurred', e.args)
proxy = get_proxy()
count += 1
return get_html(url, count)
#获取索引页内容
def get_index(keyword, page):
data = {
'query': keyword,
'type': 2,
'page': page
}
queries = urlencode(data)
url = base_url + queries
html = get_html(url)
return html
#解析索引页,提取详情页网址
def parse_index(html):
doc = pq(html)
items = doc('.news-box .news-list li .txt-box h3 a').items()
for item in items:
yield item.attr('href')
#获取详情页
def get_detail(url):
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
return None
except ConnectionError:
return None
#解析索引页,返回微信文章标题、内容、日期、公众号名称等
def parse_detail(html):
try:
doc = pq(html)
title = doc('.rich_media_title').text()
content = doc('.rich_media_content').text()
date = doc('#post-date').text()
nickname = doc('#js_profile_qrcode > div > strong').text()
wechat = doc('#js_profile_qrcode > div > p:nth-child(3) > span').text()
return {
'title': title,
'content': content,
'date': date,
'nickname': nickname,
'wechat': wechat
}
except XMLSyntaxError:
return None
#存储到MongoDB,去重操作
def save_to_mongo(data):
if db['articles'].update({'title': data['title']}, {'$set': data}, True):
print('Saved to Mongo', data['title'])
else:
print('Saved to Mongo Failed', data['title'])
#主函数
def main():
for page in range(1, 101):
html = get_index(KEYWORD, page)
if html:
article_urls = parse_index(html)
for article_url in article_urls:
article_html = get_detail(article_url)
if article_html:
article_data = parse_detail(article_html)
print(article_data)
if __name__ == '__main__':
main()
2.config.py代码:
#爬取公众号文章
PROXY_POOL_URL = 'http://127.0.0.1:5000/get'
KEYWORD ='计算机等级二级' # 输入关键词
MONGO_URI = 'localhost'
MONGO_DB = 'data'
MAX_COUNT = 5
其中,config.py中KEYWORD为查找关键词采集微信文章,可以按照须要修改。经实测,运行"采集公众号文章.py"成功!若因受限不成功,可多运行几次。

以上就是本文的全部内容,希望对你们的学习有所帮助,也希望你们多多支持优采云。
从零开始学Python网络爬虫中文pdf完整版[144MB]
采集交流 • 优采云 发表了文章 • 0 个评论 • 307 次浏览 • 2020-05-06 08:02
本书共分12章,核心主题包括Python零基础句型入门、爬虫原理和网页构造、我的第一个爬虫程序、正则表达式、Lxml库与Xpath句型、使用API、数据库储存、多进程爬虫、异步加载、表单交互与模拟登陆、Selenium模拟浏览器、Scrapy爬虫框架。此外,书中通过一些典型爬虫案例数据挖掘爬虫书籍,讲解了有经纬信息的地图图表和词云的制做方式,让读者体验数据背后的乐趣。
本书适宜爬虫技术初学者、爱好者及高等院校的相关中学生,也适宜数据爬虫工程师作为参考读物,同时也适宜各大Python数据剖析的培训机构作为教材使用
第1章 Python零基础句型入门 1
第2章 爬虫原理和网页构造 17
第3章 我的第一个爬虫程序 26
第4章 正则表达式 45
第5章 Lxml库与Xpath句型 63
第6章 使用API 88
第7章 数据库储存 109
第8章 多进程爬虫 139
第9章 异步加载 159
第10章 表单交互与模拟登陆 182
第11章 Selenium模拟浏览器 209
第12章 Scrapy爬虫框架 229 查看全部
本书共分12章,核心主题包括Python零基础句型入门、爬虫原理和网页构造、我的第一个爬虫程序、正则表达式、Lxml库与Xpath句型、使用API、数据库储存、多进程爬虫、异步加载、表单交互与模拟登陆、Selenium模拟浏览器、Scrapy爬虫框架。此外,书中通过一些典型爬虫案例数据挖掘爬虫书籍,讲解了有经纬信息的地图图表和词云的制做方式,让读者体验数据背后的乐趣。
本书适宜爬虫技术初学者、爱好者及高等院校的相关中学生,也适宜数据爬虫工程师作为参考读物,同时也适宜各大Python数据剖析的培训机构作为教材使用
第1章 Python零基础句型入门 1
第2章 爬虫原理和网页构造 17
第3章 我的第一个爬虫程序 26
第4章 正则表达式 45
第5章 Lxml库与Xpath句型 63
第6章 使用API 88
第7章 数据库储存 109
第8章 多进程爬虫 139
第9章 异步加载 159
第10章 表单交互与模拟登陆 182
第11章 Selenium模拟浏览器 209
第12章 Scrapy爬虫框架 229
老司机带你学爬虫——Python爬虫技术分享
采集交流 • 优采云 发表了文章 • 0 个评论 • 310 次浏览 • 2020-05-06 08:01
简单来说,写一个从web上获取须要数据并按规定格式储存的程序就叫爬虫;
爬虫理论上步骤很简单,第一步获取html源码,第二步剖析html并领到数据。但实际操作,老麻烦了~
用Python写“爬虫”有什么便捷的库
常用网路恳求库:requests、urllib、urllib2、
urllib和urllib2是Python自带模块,requests是第三方库
常用解析库和爬虫框架:BeautifulSoup、lxml、HTMLParser、selenium、Scrapy
HTMLParser是Python自带模块;
BeautifulSoup可以将html解析成Python句型对象,直接操作对象会十分便捷;
lxml可以解析xml和html标签语言,优点是速度快;
selenium调用浏览器的driver,通过这个库你可以直接调用浏览器完成个别操作,比如输入验证码;
Scrapy太强悍且有名的爬虫框架,可以轻松满足简单网站的爬取;这个python学习(q-u-n):二二七,四三五,四五零 期待你们一起交流讨论,讲实话还是一个特别适宜学习的地方的。软件各类入门资料
“爬虫”需要把握什么知识
1)超文本传输协议HTTP:HTTP合同定义了浏览器如何向万维网服务器恳求万维网文档,以及服务器如何把文档传送给浏览器。常用的HTTP方式有GET、POST、PUT、DELETE。
【插曲:某站长做了一个网站,奇葩的他把删掉的操作绑定在GET恳求上。百度或则微软爬虫爬取网站链接,都是用的GET恳求,而且通常用浏览器访问网页都是GET恳求。在微软爬虫爬取他网站的信息时,该网站自动删掉了数据库的全部数据】
2)统一资源定位符URL: URL是拿来表示从因特网上得到的资源位置和访问那些资源的方式。URL给资源的位置提供一种具象的辨识方式,并用这些方式给资源定位。只要才能对资源定位,系统就可以对资源进行各类操作,如存取、更新、替换和查找其属性。URL相当于一个文件名在网路范围的扩充。
3)超文本标记语言HTTP:HTML指的是超文本标记语言,是使用标记标签来描述网页的。HTML文档包含HTML标签和纯文本,也称为网页。Web 浏览器的作用是读取 HTML 文档,并以网页的方式显示出它们。浏览器不会显示 HTML 标签,而是使用标签来解释页面的内容。简而言之就是你要懂点后端语言,这样描述更直观贴切。
4)浏览器调试功能:学爬虫就是抓包,对恳求和响应进行剖析,用代码来模拟
进阶爬虫
熟练了基本爬虫以后,你会想着获取更多的数据,抓取更难的网站,然后你才会发觉获取数据并不简单,而且现今反爬机制也十分的多。
a.爬取知乎、简书,需要登入并将上次的恳求时将sessions带上,保持登入姿态;
b.爬取亚马逊、京东、天猫等商品信息,由于信息量大、反爬机制建立,需要分布式【这里就难了】爬取,以及不断切换USER_AGENT和代理IP;
c.滑动或下拉加载和同一url加载不同数据时,涉及ajax的异步加载。这里可以有简单的返回html代码、或者json数据,也可能有更变态的返回js代码之后用浏览器执行,逻辑上很简单、但是写代码那叫一个苦哇;
d.还有点是须要面对的,验证码识别。这个有专门解析验证码的平台.....不属于爬虫范畴了,自己处理须要更多的数据剖析知识。
e.数据存储,关系数据库和非关系数据库的选择和使用,设计防冗余数据库表格,去重。大量数据储存数据库,会显得太难受,
f.编码解码问题,数据的储存涉及一个格式的问题,python2或则3也就会涉及编码问题。另外网页结构的不规范性,编码格式的不同很容易触发编码异常问题。下图一个简单的转码规则
一些常见的限制形式
a.Basic Auth:一般会有用户授权的限制,会在headers的Autheration数组里要求加入;
b.Referer:通常是在访问链接时,必须要带上Referer数组,服务器会进行验证,例如抓取易迅的评论;
c.User-Agent:会要求真是的设备,如果不加会用编程语言包里自有User-Agent,可以被辨认下来;
d.Cookie:一般在用户登入或则个别操作后,服务端会在返回包中包含Cookie信息要求浏览器设置Cookie,没有Cookie会很容易被辨认下来是伪造恳求;也有本地通过JS,根据服务端返回的某个信息进行处理生成的加密信息,设置在Cookie上面;
e.Gzip:请求headers上面带了gzip,返回有时候会是gzip压缩,需要解压;
f.JavaScript加密操作:一般都是在恳求的数据包内容上面会包含一些被javascript进行加密限制的信息,例如新浪微博会进行SHA1和RSA加密,之前是两次SHA1加密,然后发送的密码和用户名就会被加密;
g.网站自定义其他数组:因为http的headers可以自定义地段,所以第三方可能会加入了一些自定义的数组名称或则数组值,这也是须要注意的。
真实的恳求过程中爬虫技术,其实不止里面某一种限制,可能是几种限制组合在一次,比如假如是类似RSA加密的话,可能先恳求服务器得到Cookie,然后再带着Cookie去恳求服务器领到私钥,然后再用js进行加密,再发送数据到服务器。所以弄清楚这其中的原理爬虫技术,并且耐心剖析很重要。
总结
爬虫入门不难,但是须要知识面更广和更多的耐心 查看全部
什么是“爬虫”?
简单来说,写一个从web上获取须要数据并按规定格式储存的程序就叫爬虫;
爬虫理论上步骤很简单,第一步获取html源码,第二步剖析html并领到数据。但实际操作,老麻烦了~
用Python写“爬虫”有什么便捷的库
常用网路恳求库:requests、urllib、urllib2、
urllib和urllib2是Python自带模块,requests是第三方库
常用解析库和爬虫框架:BeautifulSoup、lxml、HTMLParser、selenium、Scrapy
HTMLParser是Python自带模块;
BeautifulSoup可以将html解析成Python句型对象,直接操作对象会十分便捷;
lxml可以解析xml和html标签语言,优点是速度快;
selenium调用浏览器的driver,通过这个库你可以直接调用浏览器完成个别操作,比如输入验证码;
Scrapy太强悍且有名的爬虫框架,可以轻松满足简单网站的爬取;这个python学习(q-u-n):二二七,四三五,四五零 期待你们一起交流讨论,讲实话还是一个特别适宜学习的地方的。软件各类入门资料
“爬虫”需要把握什么知识
1)超文本传输协议HTTP:HTTP合同定义了浏览器如何向万维网服务器恳求万维网文档,以及服务器如何把文档传送给浏览器。常用的HTTP方式有GET、POST、PUT、DELETE。
【插曲:某站长做了一个网站,奇葩的他把删掉的操作绑定在GET恳求上。百度或则微软爬虫爬取网站链接,都是用的GET恳求,而且通常用浏览器访问网页都是GET恳求。在微软爬虫爬取他网站的信息时,该网站自动删掉了数据库的全部数据】
2)统一资源定位符URL: URL是拿来表示从因特网上得到的资源位置和访问那些资源的方式。URL给资源的位置提供一种具象的辨识方式,并用这些方式给资源定位。只要才能对资源定位,系统就可以对资源进行各类操作,如存取、更新、替换和查找其属性。URL相当于一个文件名在网路范围的扩充。
3)超文本标记语言HTTP:HTML指的是超文本标记语言,是使用标记标签来描述网页的。HTML文档包含HTML标签和纯文本,也称为网页。Web 浏览器的作用是读取 HTML 文档,并以网页的方式显示出它们。浏览器不会显示 HTML 标签,而是使用标签来解释页面的内容。简而言之就是你要懂点后端语言,这样描述更直观贴切。
4)浏览器调试功能:学爬虫就是抓包,对恳求和响应进行剖析,用代码来模拟
进阶爬虫
熟练了基本爬虫以后,你会想着获取更多的数据,抓取更难的网站,然后你才会发觉获取数据并不简单,而且现今反爬机制也十分的多。
a.爬取知乎、简书,需要登入并将上次的恳求时将sessions带上,保持登入姿态;
b.爬取亚马逊、京东、天猫等商品信息,由于信息量大、反爬机制建立,需要分布式【这里就难了】爬取,以及不断切换USER_AGENT和代理IP;
c.滑动或下拉加载和同一url加载不同数据时,涉及ajax的异步加载。这里可以有简单的返回html代码、或者json数据,也可能有更变态的返回js代码之后用浏览器执行,逻辑上很简单、但是写代码那叫一个苦哇;
d.还有点是须要面对的,验证码识别。这个有专门解析验证码的平台.....不属于爬虫范畴了,自己处理须要更多的数据剖析知识。
e.数据存储,关系数据库和非关系数据库的选择和使用,设计防冗余数据库表格,去重。大量数据储存数据库,会显得太难受,
f.编码解码问题,数据的储存涉及一个格式的问题,python2或则3也就会涉及编码问题。另外网页结构的不规范性,编码格式的不同很容易触发编码异常问题。下图一个简单的转码规则
一些常见的限制形式
a.Basic Auth:一般会有用户授权的限制,会在headers的Autheration数组里要求加入;
b.Referer:通常是在访问链接时,必须要带上Referer数组,服务器会进行验证,例如抓取易迅的评论;
c.User-Agent:会要求真是的设备,如果不加会用编程语言包里自有User-Agent,可以被辨认下来;
d.Cookie:一般在用户登入或则个别操作后,服务端会在返回包中包含Cookie信息要求浏览器设置Cookie,没有Cookie会很容易被辨认下来是伪造恳求;也有本地通过JS,根据服务端返回的某个信息进行处理生成的加密信息,设置在Cookie上面;
e.Gzip:请求headers上面带了gzip,返回有时候会是gzip压缩,需要解压;
f.JavaScript加密操作:一般都是在恳求的数据包内容上面会包含一些被javascript进行加密限制的信息,例如新浪微博会进行SHA1和RSA加密,之前是两次SHA1加密,然后发送的密码和用户名就会被加密;
g.网站自定义其他数组:因为http的headers可以自定义地段,所以第三方可能会加入了一些自定义的数组名称或则数组值,这也是须要注意的。
真实的恳求过程中爬虫技术,其实不止里面某一种限制,可能是几种限制组合在一次,比如假如是类似RSA加密的话,可能先恳求服务器得到Cookie,然后再带着Cookie去恳求服务器领到私钥,然后再用js进行加密,再发送数据到服务器。所以弄清楚这其中的原理爬虫技术,并且耐心剖析很重要。
总结
爬虫入门不难,但是须要知识面更广和更多的耐心
[ Python爬虫实战 ] 爬虫简介与作用
采集交流 • 优采云 发表了文章 • 0 个评论 • 588 次浏览 • 2020-05-03 08:02
网络爬虫(又被称为网页蜘蛛,网络机器人),是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。我们可以使用爬虫手动抓取互联网信息的程序,从互联网上抓取对于我们有价值的信息。但是须要注意网络爬虫 作用,爬虫不会创造数据,也不会生产数据。他只能爬取网路上输出的信息。
目前好多语言都支持爬虫,除了我们这儿介绍Python爬虫,还有php,javascript,java,php,go等等都可以实现爬虫,但是Python爬虫由于使用发布并且有很多好用的拓展包,让python爬虫十分有效并且受欢迎。
在我们浏览网页,浏览器会渲染输出HTML、JS、CSS等信息;通过这种元素,我们就可以看见我们想要查看的新闻,图片,电影,评论,商品等等。一般情况下我们看见自己须要的内容,图片可能会复制文字而且下载图片保存,但是假如面对大量的文字和图片,我们人工是处理不过来的,同时例如类似百度须要每晚定时获取大量网站最新文章并且收录网络爬虫 作用,这些大量数据与每晚的定时的工作我们是难以通过人工去处理的,这时候爬虫的作用就彰显下来了。
爬虫可以抓取网页信息,APP以及客户端信息;我们可以访问保存新闻,图片,电影,评论,商品等等。理论上来说,只要我们可以访问到的数据,我们能够通过爬虫抓取到,同时若果你了解编程基础,你也可以抓取到你在网页中看不到的数据。 查看全部
网络爬虫(又被称为网页蜘蛛,网络机器人),是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。我们可以使用爬虫手动抓取互联网信息的程序,从互联网上抓取对于我们有价值的信息。但是须要注意网络爬虫 作用,爬虫不会创造数据,也不会生产数据。他只能爬取网路上输出的信息。
目前好多语言都支持爬虫,除了我们这儿介绍Python爬虫,还有php,javascript,java,php,go等等都可以实现爬虫,但是Python爬虫由于使用发布并且有很多好用的拓展包,让python爬虫十分有效并且受欢迎。
在我们浏览网页,浏览器会渲染输出HTML、JS、CSS等信息;通过这种元素,我们就可以看见我们想要查看的新闻,图片,电影,评论,商品等等。一般情况下我们看见自己须要的内容,图片可能会复制文字而且下载图片保存,但是假如面对大量的文字和图片,我们人工是处理不过来的,同时例如类似百度须要每晚定时获取大量网站最新文章并且收录网络爬虫 作用,这些大量数据与每晚的定时的工作我们是难以通过人工去处理的,这时候爬虫的作用就彰显下来了。
爬虫可以抓取网页信息,APP以及客户端信息;我们可以访问保存新闻,图片,电影,评论,商品等等。理论上来说,只要我们可以访问到的数据,我们能够通过爬虫抓取到,同时若果你了解编程基础,你也可以抓取到你在网页中看不到的数据。
Python网路爬虫之必备工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 342 次浏览 • 2020-05-03 08:01
1 Python基础知识
Python作为现今最流行的编程语言之一爬虫工具,其强悍之处也是毋庸置疑的,利用Python写网路爬虫是最好不过的选择啦,所以万丈高楼平地起,学习网路爬虫最最基本的就是要把握Python编程的基础知识,了解以下几点即可:
基本数据结构数据类型控制流函数的使用模块的使用Python学习教程推荐:
(1)廖雪峰之Python教程。具体学习网址百度一下就可以,其讲解堪称通俗易懂,学习上去特别快。
(2)Python简明教程
2 开发环境
操作系统:Windows7及以上
Python版本:Python3.x
代码开发环境:个人比较推荐PyCharm作为自己的IDE,当然你也可以按照自己的使用习惯选择代码编辑器,如Notepad++等
3 Python库
一般网路爬虫所需根据的库有:
urllib和urllib2库
这两个库是学习爬虫最基本的库,其才能将URL所指定的网路资源(HTML)获得,并可用正则表达式对其内容进行提取爬虫工具,进而得到我们想要的结果。
Pythonre模块
re模块是Python提供的用于字符串匹配非常好用的工具,其设计思想就是借助一种描述性语言来定义字符串的规则,凡是符合这一规则的字符串,则表明就匹配成功,这就是我们熟悉的正则表达式。利用re模块提供的抒发功能,我们可以很方便从爬取到的网页内容中匹配出须要的内容数据。
BeautifulSoup库
此库是一个强悍的解析文档工具箱,其才能将我们爬取的到HTML页面内容解析成一个复杂的树状结构,每一个节点都是一个Python对象,具体讲在前面给你们详尽讲解。
以上介绍都是一些基本爬取所需的库,当然假如你想做一个有深度的爬虫,还须要把握如requests库、pymongo库、selenium库等,等把握的差不多了,还可以学习一下爬虫框架Scrapy。 查看全部
网络爬虫(又被称为网页蜘蛛,网络机器人),是一种根据一定的规则,自动的抓取万维网信息的程序或则脚本。那么要学会并精通Python网络爬虫,我们须要打算什么知识和工具那?

1 Python基础知识
Python作为现今最流行的编程语言之一爬虫工具,其强悍之处也是毋庸置疑的,利用Python写网路爬虫是最好不过的选择啦,所以万丈高楼平地起,学习网路爬虫最最基本的就是要把握Python编程的基础知识,了解以下几点即可:
基本数据结构数据类型控制流函数的使用模块的使用Python学习教程推荐:
(1)廖雪峰之Python教程。具体学习网址百度一下就可以,其讲解堪称通俗易懂,学习上去特别快。
(2)Python简明教程
2 开发环境
操作系统:Windows7及以上
Python版本:Python3.x
代码开发环境:个人比较推荐PyCharm作为自己的IDE,当然你也可以按照自己的使用习惯选择代码编辑器,如Notepad++等
3 Python库
一般网路爬虫所需根据的库有:
urllib和urllib2库
这两个库是学习爬虫最基本的库,其才能将URL所指定的网路资源(HTML)获得,并可用正则表达式对其内容进行提取爬虫工具,进而得到我们想要的结果。
Pythonre模块
re模块是Python提供的用于字符串匹配非常好用的工具,其设计思想就是借助一种描述性语言来定义字符串的规则,凡是符合这一规则的字符串,则表明就匹配成功,这就是我们熟悉的正则表达式。利用re模块提供的抒发功能,我们可以很方便从爬取到的网页内容中匹配出须要的内容数据。
BeautifulSoup库
此库是一个强悍的解析文档工具箱,其才能将我们爬取的到HTML页面内容解析成一个复杂的树状结构,每一个节点都是一个Python对象,具体讲在前面给你们详尽讲解。
以上介绍都是一些基本爬取所需的库,当然假如你想做一个有深度的爬虫,还须要把握如requests库、pymongo库、selenium库等,等把握的差不多了,还可以学习一下爬虫框架Scrapy。
爬虫技术浅析
采集交流 • 优采云 发表了文章 • 0 个评论 • 351 次浏览 • 2020-05-02 08:09
上图是Scrapy的构架图,绿线是数据流向,首先从初始URL 开始,Scheduler 会将其交给 Downloader 进行下载,下载以后会交给 Spider 进行剖析,需要保存的数据则会被送到Item Pipeline,那是对数据进行后期处理。另外,在数据流动的通道里还可以安装各类中间件,进行必要的处理。 因此在开发爬虫的时侯,最好也先规划好各类模块。我的做法是单独规划下载模块,爬行模块,调度模块,数据储存模块。
页面下载分为静态和动态两种下载形式。
传统爬虫借助的是静态下载形式,静态下载的优势是下载过程快,但是页面只是一个无趣的html,因此页面链接剖析中获取的只是< a >标签的href属性或则大神可以自己剖析js,form之类的标签捕获一些链接。在python中可以借助urllib2模块或requests模块实现功能。 动态爬虫在web2.0时代则有特殊的优势,由于网页会使用javascript处理,网页内容通过Ajax异步获取。所以,动态爬虫须要剖析经过javascript处理和ajax获取内容后的页面。目前简单的解决方式是通过基于webkit的模块直接处理。PYQT4、Splinter和Selenium这三个模块都可以达到目的。对于爬虫而言,浏览器界面是不需要的,因此使用一个headless browser是十分实惠的,HtmlUnit和phantomjs都是可以使用的headless browser。
以上这段代码是访问新浪网主站。通过对比静态抓取页面和动态抓取页面的厚度和对比静态抓取页面和动态抓取页面内抓取的链接个数。
在静态抓取中,页面的宽度是563838,页面内抓取的链接数目只有166个。而在动态抓取中,页面的宽度下降到了695991,而链接数达到了1422,有了逾10倍的提高。
抓链接表达式
正则:re.compile("href=\"([^\"]*)\"")
Xpath:xpath('//*[@href]')
页面解析是实现抓取页面内链接和抓取特定数据的模块,页面解析主要是对字符串的处理,而html是一种特殊的字符串,在Python中re、beautifulsoup、HTMLParser、lxml等模块都可以解决问题。对于链接,主要抓取a标签下的href属性,还有其他一些标签的src属性。
URL去重是爬虫运行中一项关键的步骤,由于运行中的爬虫主要阻塞在网路交互中,因此防止重复的网路交互至关重要。爬虫通常会将待抓取的URL置于一个队列中,从抓取后的网页中提取到新的URL,在她们被装入队列之前,首先要确定这种新的URL没有被抓取过,如果之前早已抓取过了,就不再装入队列了。
Hash表
利用hash表做去重操作通常是最容易想到的方式,因为hash表查询的时间复杂度是O(1),而且在hash表足够大的情况下,hash冲突的机率就显得太小,因此URL是否重复的判定准确性就十分高。利用hash表去重的这个做法是一个比较简单的解决方式。但是普通hash表也有显著的缺陷爬虫技术,在考虑显存的情况下,使用一张大的hash表是不妥的。Python中可以使用字典这一数据结构。
URL压缩
如果hash表中,当每位节点存储的是一个str方式的具体URL,是十分占用显存的,如果把这个URL进行压缩成一个int型变量,内存占用程度上便有了3倍以上的缩小。因此可以借助Python的hashlib模块来进行URL压缩。 思路:把hash表的节点的数据结构设置为集合,集合内贮存压缩后的URL。
Bloom Filter
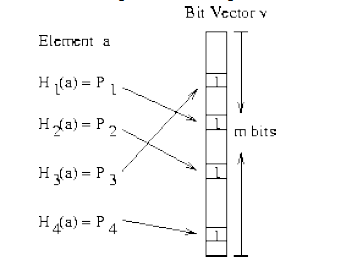
Bloom Filter是通过很少的错误换取了储存空间的极大节约。Bloom Filter 是通过一组k 个定义在n 个输入key 上的Hash Function,将上述n 个key 映射到m 位上的数据容器。
上图太清楚的说明了Bloom Filter的优势,在可控的容器宽度内,所有hash函数对同一个元素估算的hash值都为1时,就判定这个元素存在。 Python中hashlib,自带多种hash函数,有MD5,sha1,sha224,sha256,sha384,sha512。代码中还可以进行加水处理,还是很方便的。 Bloom Filter也会形成冲突的情况,具体内容查看文章结尾的参考文章。
在Python编程过程中,可以使用jaybaird提供的BloomFilter插口,或者自己造轮子。
小细节
有个小细节,在构建hash表的时侯选择容器很重要。hash表占用空间很大是个太不爽的问题,因此针对爬虫去重,下列方式可以解决一些问题。
上面这段代码简单验证了生成容器的运行时间。
由上图可以看出,建立一个宽度为1亿的容器时,选择list容器程序的运行时间耗费了7.2s,而选择字符串作为容器时,才耗费了0.2s的运行时间。
接下来瞧瞧显存的占用情况。
如果构建1亿的列表占用了794660k显存。
而构建1亿宽度的字符串却占用了109720k显存,空间占用大概降低了700000k。
初级算法
对于URL相似性,我只是实践一个十分简单的技巧。
在保证不进行重复爬去的情况下,还须要对类似的URL进行判定。我采用的是sponge和ly5066113提供的思路。具体资料在参考文章里。
下列是一组可以判定为相像的URL组
按照预期,以上URL归并后应当为
思路如下,需要提取如下特点
1,host字符串
2,目录深度(以’/’分割)
3,尾页特点
具体算法
算法本身太菜,各位一看才能懂。
实际疗效:
上图显示了把8个不一样的url,算出了2个值。通过实践,在一张千万级的hash表中,冲突的情况是可以接受的。
Python中的并发操作主要涉及的模型有:多线程模型、多进程模型、协程模型。Elias专门写了一篇文章爬虫技术,来比较常用的几种模型并发方案的性能。对于爬虫本身来说,限制爬虫速率主要来自目标服务器的响应速率,因此选择一个控制上去顺手的模块才是对的。
多线程模型,是最容易上手的,Python中自带的threading模块能挺好的实现并发需求,配合Queue模块来实现共享数据。
多进程模型和多线程模型类似,multiprocessing模块中也有类似的Queue模块来实现数据共享。在linux中,用户态的进程可以借助多核心的优势,因此在多核背景下,能解决爬虫的并发问题。
协程模型,在Elias的文章中,基于greenlet实现的解释器程序的性能仅次于Stackless Python,大致比Stackless Python慢一倍,比其他方案快接近一个数量级。因此基于gevent(封装了greenlet)的并发程序会有挺好的性能优势。
具体说明下gevent(非阻塞异步IO)。,“Gevent是一种基于解释器的Python网络库,它用到Greenlet提供的,封装了libevent风波循环的高层同步API。”
从实际的编程疗效来看,协程模型确实表现非常好,运行结果的可控性显著强了不少, gevent库的封装易用性极强。
数据储存本身设计的技术就十分多,作为小菜不敢乱说,但是工作还是有一些小经验是可以分享的。
前提:使用关系数据库,测试中选择的是mysql,其他类似sqlite,SqlServer思路上没有区别。
当我们进行数据储存时,目的就是降低与数据库的交互操作,这样可以增强性能。通常情况下,每当一个URL节点被读取,就进行一次数据储存,对于这样的逻辑进行无限循环。其实这样的性能体验是十分差的,存储速率特别慢。
进阶做法,为了减轻与数据库的交互次数,每次与数据库交互从之前传送1个节点弄成传送10个节点,到传送100个节点内容,这样效率变有了10倍至100倍的提高,在实际应用中,效果是非常好的。:D
爬虫模型
目前这个爬虫模型如上图,调度模块是核心模块。调度模块分别与下载模块,析取模块,存储模块共享三个队列,下载模块与析取模块共享一个队列。数据传递方向如图示。 查看全部
 谈到爬虫构架,不得不提的是Scrapy的爬虫构架。Scrapy,是Python开发的一个快速,高层次的爬虫框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。Scrapy吸引人的地方在于它是一个框架,任何人都可以依照需求便捷的更改。它也提供了多种类型爬虫的子类,如BaseSpider、sitemap爬虫等。
谈到爬虫构架,不得不提的是Scrapy的爬虫构架。Scrapy,是Python开发的一个快速,高层次的爬虫框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。Scrapy吸引人的地方在于它是一个框架,任何人都可以依照需求便捷的更改。它也提供了多种类型爬虫的子类,如BaseSpider、sitemap爬虫等。上图是Scrapy的构架图,绿线是数据流向,首先从初始URL 开始,Scheduler 会将其交给 Downloader 进行下载,下载以后会交给 Spider 进行剖析,需要保存的数据则会被送到Item Pipeline,那是对数据进行后期处理。另外,在数据流动的通道里还可以安装各类中间件,进行必要的处理。 因此在开发爬虫的时侯,最好也先规划好各类模块。我的做法是单独规划下载模块,爬行模块,调度模块,数据储存模块。
页面下载分为静态和动态两种下载形式。
传统爬虫借助的是静态下载形式,静态下载的优势是下载过程快,但是页面只是一个无趣的html,因此页面链接剖析中获取的只是< a >标签的href属性或则大神可以自己剖析js,form之类的标签捕获一些链接。在python中可以借助urllib2模块或requests模块实现功能。 动态爬虫在web2.0时代则有特殊的优势,由于网页会使用javascript处理,网页内容通过Ajax异步获取。所以,动态爬虫须要剖析经过javascript处理和ajax获取内容后的页面。目前简单的解决方式是通过基于webkit的模块直接处理。PYQT4、Splinter和Selenium这三个模块都可以达到目的。对于爬虫而言,浏览器界面是不需要的,因此使用一个headless browser是十分实惠的,HtmlUnit和phantomjs都是可以使用的headless browser。
以上这段代码是访问新浪网主站。通过对比静态抓取页面和动态抓取页面的厚度和对比静态抓取页面和动态抓取页面内抓取的链接个数。

在静态抓取中,页面的宽度是563838,页面内抓取的链接数目只有166个。而在动态抓取中,页面的宽度下降到了695991,而链接数达到了1422,有了逾10倍的提高。
抓链接表达式
正则:re.compile("href=\"([^\"]*)\"")
Xpath:xpath('//*[@href]')
页面解析是实现抓取页面内链接和抓取特定数据的模块,页面解析主要是对字符串的处理,而html是一种特殊的字符串,在Python中re、beautifulsoup、HTMLParser、lxml等模块都可以解决问题。对于链接,主要抓取a标签下的href属性,还有其他一些标签的src属性。
URL去重是爬虫运行中一项关键的步骤,由于运行中的爬虫主要阻塞在网路交互中,因此防止重复的网路交互至关重要。爬虫通常会将待抓取的URL置于一个队列中,从抓取后的网页中提取到新的URL,在她们被装入队列之前,首先要确定这种新的URL没有被抓取过,如果之前早已抓取过了,就不再装入队列了。
Hash表
利用hash表做去重操作通常是最容易想到的方式,因为hash表查询的时间复杂度是O(1),而且在hash表足够大的情况下,hash冲突的机率就显得太小,因此URL是否重复的判定准确性就十分高。利用hash表去重的这个做法是一个比较简单的解决方式。但是普通hash表也有显著的缺陷爬虫技术,在考虑显存的情况下,使用一张大的hash表是不妥的。Python中可以使用字典这一数据结构。
URL压缩
如果hash表中,当每位节点存储的是一个str方式的具体URL,是十分占用显存的,如果把这个URL进行压缩成一个int型变量,内存占用程度上便有了3倍以上的缩小。因此可以借助Python的hashlib模块来进行URL压缩。 思路:把hash表的节点的数据结构设置为集合,集合内贮存压缩后的URL。
Bloom Filter
Bloom Filter是通过很少的错误换取了储存空间的极大节约。Bloom Filter 是通过一组k 个定义在n 个输入key 上的Hash Function,将上述n 个key 映射到m 位上的数据容器。
上图太清楚的说明了Bloom Filter的优势,在可控的容器宽度内,所有hash函数对同一个元素估算的hash值都为1时,就判定这个元素存在。 Python中hashlib,自带多种hash函数,有MD5,sha1,sha224,sha256,sha384,sha512。代码中还可以进行加水处理,还是很方便的。 Bloom Filter也会形成冲突的情况,具体内容查看文章结尾的参考文章。
在Python编程过程中,可以使用jaybaird提供的BloomFilter插口,或者自己造轮子。
小细节
有个小细节,在构建hash表的时侯选择容器很重要。hash表占用空间很大是个太不爽的问题,因此针对爬虫去重,下列方式可以解决一些问题。
上面这段代码简单验证了生成容器的运行时间。
由上图可以看出,建立一个宽度为1亿的容器时,选择list容器程序的运行时间耗费了7.2s,而选择字符串作为容器时,才耗费了0.2s的运行时间。
接下来瞧瞧显存的占用情况。
如果构建1亿的列表占用了794660k显存。
而构建1亿宽度的字符串却占用了109720k显存,空间占用大概降低了700000k。
初级算法
对于URL相似性,我只是实践一个十分简单的技巧。
在保证不进行重复爬去的情况下,还须要对类似的URL进行判定。我采用的是sponge和ly5066113提供的思路。具体资料在参考文章里。
下列是一组可以判定为相像的URL组
按照预期,以上URL归并后应当为
思路如下,需要提取如下特点
1,host字符串
2,目录深度(以’/’分割)
3,尾页特点
具体算法
算法本身太菜,各位一看才能懂。
实际疗效:
上图显示了把8个不一样的url,算出了2个值。通过实践,在一张千万级的hash表中,冲突的情况是可以接受的。
Python中的并发操作主要涉及的模型有:多线程模型、多进程模型、协程模型。Elias专门写了一篇文章爬虫技术,来比较常用的几种模型并发方案的性能。对于爬虫本身来说,限制爬虫速率主要来自目标服务器的响应速率,因此选择一个控制上去顺手的模块才是对的。
多线程模型,是最容易上手的,Python中自带的threading模块能挺好的实现并发需求,配合Queue模块来实现共享数据。
多进程模型和多线程模型类似,multiprocessing模块中也有类似的Queue模块来实现数据共享。在linux中,用户态的进程可以借助多核心的优势,因此在多核背景下,能解决爬虫的并发问题。
协程模型,在Elias的文章中,基于greenlet实现的解释器程序的性能仅次于Stackless Python,大致比Stackless Python慢一倍,比其他方案快接近一个数量级。因此基于gevent(封装了greenlet)的并发程序会有挺好的性能优势。
具体说明下gevent(非阻塞异步IO)。,“Gevent是一种基于解释器的Python网络库,它用到Greenlet提供的,封装了libevent风波循环的高层同步API。”
从实际的编程疗效来看,协程模型确实表现非常好,运行结果的可控性显著强了不少, gevent库的封装易用性极强。
数据储存本身设计的技术就十分多,作为小菜不敢乱说,但是工作还是有一些小经验是可以分享的。
前提:使用关系数据库,测试中选择的是mysql,其他类似sqlite,SqlServer思路上没有区别。
当我们进行数据储存时,目的就是降低与数据库的交互操作,这样可以增强性能。通常情况下,每当一个URL节点被读取,就进行一次数据储存,对于这样的逻辑进行无限循环。其实这样的性能体验是十分差的,存储速率特别慢。
进阶做法,为了减轻与数据库的交互次数,每次与数据库交互从之前传送1个节点弄成传送10个节点,到传送100个节点内容,这样效率变有了10倍至100倍的提高,在实际应用中,效果是非常好的。:D
爬虫模型

目前这个爬虫模型如上图,调度模块是核心模块。调度模块分别与下载模块,析取模块,存储模块共享三个队列,下载模块与析取模块共享一个队列。数据传递方向如图示。
爬虫框架是哪些?常见的Python爬虫框架有什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 294 次浏览 • 2020-05-02 08:09
爬虫框架是哪些?常见的 Python 爬虫框架有什么?学习爬虫的人对爬虫框架并不陌生,在爬虫渐渐入门以后,可以有两个选择。 一个是深入学习, 比如设计模式相关的一些知识, 强化 Python 相关知识,自己动手造轮子爬虫框架, 继续为自己的爬虫降低分布式,多线程等功能扩充。另一条路便是学习一些优秀的框架, 先把这种框架用熟, 可以确保才能应付一些基本的爬虫 任务,也就是可以解决基本的爬虫问题,然后再深入学习它的源码等知识,进一步加强。所以,爬虫框架就是前人积累出来的,可以满足自己爬虫需求,又可以以此提高自己的爬虫 水平。那么,爬虫框架都有什么呢?常见 python 爬虫框架(1)Scrapy:很强悍的爬虫框架,可以满足简单的页面爬取(比如可以明晰得知 url pattern 的 情况) 。用这个框架可以轻松爬出来如亚马逊商品信息之类的数据。但是对于稍稍复杂一点 的页面爬虫框架,如 weibo 的页面信息,这个框架就满足不了需求了。(2)Crawley: 高速爬取对应网站的内容, 支持关系和非关系数据库, 数据可以导入为 JSON、 XML 等(3)Portia:可视化爬取网页内容(4)newspaper:提取新闻、文章以及内容剖析(5)python-goose:java 写的文章提取工具(6)Beautiful Soup:名气大,整合了一些常用爬虫需求。缺点:不能加载 JS。(7)mechanize:优点:可以加载 JS。缺点:文档严重缺位。不过通过官方的 example 以及 人肉尝试的方式,还是勉强能用的。(8)selenium:这是一个调用浏览器的 driver, 通过这个库你可以直接调用浏览器完成个别操 作,比如输入验证码。(9)cola:一个分布式爬虫框架。项目整体设计有点糟,模块间耦合度较高。
Python库大全
采集交流 • 优采云 发表了文章 • 0 个评论 • 319 次浏览 • 2020-04-05 11:09
urlib -网络库(stdlib)。requests -网络库。
grab -网络库(基于pycurl)。pycurl -网络库(绑定libcurl)
ullib3 - Python HTTP库,安全连接池、支持文件post、可用性高。httplib2一网络库。
RoboBrowser -一个简单的、极具Python风格的Python库,无需独立的浏览器即可浏览网页。
MechanicalSoup一个与网站自动交互Python库。
mechanize -有状态、可编程的Web浏览库。socket -底层网路插口(stdlib)。
Unirest for Python - Unirest是一套可用于 多种语言的轻量级的HTTP库。
hyper - Python的HTTP/2客户端。
PySocks - SocksiPy更新并积极维护的版本,包括错误修补和一些其他的特点。作为socket模块的直接替换。
网络爬虫框架
grab -网络爬虫框架(基 于pycur/multicur)。
scrapy -网络爬虫框架(基 于twisted), 不支持Python3。
pyspider -一个强悍的爬虫系统。cola-一个分布式爬虫框架。其他
portia -基于Scrapy的可视化爬虫。
restkit - Python的HTTP资源工具包。它可以使你轻松地访问HTTP资源,并围绕它完善的对象。
demiurge -基于PyQuery的爬虫微框架。HTML/XML解析器
lxml - C语言编撰高效HTML/ XML处理库。支持XPath。
cssselect -解析DOM树和CSS选择器。pyquery -解析DOM树和jQuery选择器。
BeautIFulSoup -低效HTML/ XML处理库,纯Python实现。
html5lib -根据WHATWG规范生成HTML/ XML文档的DOM。该规范被用在现今所有的浏览器上。
feedparser一解析RSS/ATOM feeds。
MarkupSafe -为XML/HTML/XHTML提供了安全通配符的字符串。
xmltodict-一个可以使你在处理XML时觉得象在处理JSON一样的Python模块。
xhtml2pdf -将HTML/CSS转换为PDF。
untangle -轻松实现将XML文件转换为Python对象。清理
Bleach -清理HTML (需要html5lib)。sanitize -为混乱的数据世界带来端午。文本处理
用于解析和操作简单文本的库。
difflib - (Python标准库) 帮助进行差异化比较。
Levenshtein一快速估算L evenshtein距离和字符串相似度。
fuzzywuzzy -模糊字符串匹配。esmre -正则表达式加速器。
ftfy-自动整理Unicode文本,减少碎片化。.自然语言处理
处理人类语言问题的库。
NLTK -编写Python程序来处理人类语言数据的最好平台。
Pattern一Python的网路挖掘模块。他有自然语言处理工具,机器学习以及其它。
TextBlob -为深入自然语言处理任务提供了一致的API。是基于NLTK以及Pattern的巨人之肩上发展的。
jieba-中文动词工具。
SnowNLP -中文文本处理库。
loso-另一个英文分词库。浏览器自动化与仿真
selenium一自动化真正的浏览器(Chrome浏览器,火狐浏览器,Opera浏览器, IE浏览器)。
Ghost.py -对PyQt的webkit的封装(需 要PyQT)。
Spynner -对PyQt的webkit的封装(需要PyQT),
Splinter -通用API浏览器模拟器(seleniumweb驱动,Django顾客 端,Zope) 。多重处理
threading - Python标准库的线程运行。对于I/0密集型任务太有效。对于CPU绑定的任务没用,因为python GIL。
multiprocessing -标准的Python库运行多进程。
celery -基于分布式消息传递的异步任务队列/作业队列。;
concurrent-futures一concurrent-futures模块为调用异步执行提供了一个高层次的插口。
异步网路编程库
asyncio- (在Python 3.4 +版本以上的Python标准库)异步I/O, 时间循环,协同程序和任务。
Twisted一基于风波驱动的网路引|擎框架。Tornado -一个网路框架和异步网路库。pulsar - Python风波驱动的并发框架。
diesel - Python的基于红色风波的I/O框架。gevent -一个使用greenlet的基于解释器的Python网路库。
eventlet -有WSGI支持的异步框架。
Tomorrow -异步代码的奇妙的修饰句型。队列
celery -基于分布式消息传递的异步任务队列/作业队列。
huey -小型多线程任务队列。
mrq - Mr. Queue -使用redis & Gevent的Python分布式工作任务队列。
RQ -基于Redis的轻量级任务队列管理器。simpleq--个简单的,可无限扩充,基于Amazon SQS的队列。
python-geARMan一Gearman的Python API。
云计算
picloud -云端执行Python代码。
dominoup.com -云端执行R,Python和matlab代码网页内容提取
提取网页内容的库。
HTML页面的文本和元数据
newspaper -用Python进行新闻提取、文章提I取和内容策展。
html2text -将HTML转为Markdown格式文本。
python-goose一HTML内容/文章提取器。lassie -人性化的网页内容检索工具WebSocket
用于WebSocket的库。
Crossbar -开源的应用消息传递路由器
(Python实现的用于Autobahn的WebSocket和WAMP)。
AutobahnPython -提供了WebSocket合同和WAMP合同的Python实现而且开源。
WebSocket-for-Python - Python 2和3以及PyPy的WebSocket客户端和服务器库。DNS解析
dnsyo -在全球超过1 500个的DNS服务器.上检测你的DNS。
pycares - c-ares的插口。c-ares是 进行DNS恳求和异步名称决议的C语言库。
计算机视觉
SimpleCV -用于照相机、图像处理、特征提取、格式转换的简介,可读性强的插口(基于OpenCV)。
Flask是一个轻量级的Web应用框架,使用Python编撰。基于WerkzeugWSGI工具箱和Jinja2模板引擎。使用BSD授权。
Flask也被称为"microframework" ,因为它使用简单的核心,用extension降低其他功能。Flask没有默认使用的数据库、窗体验证工具。然而,Flask保留了扩增的弹性,可以用Flask-extension加入这种功能: ORM、窗体验证工具、文件上传、各种开放式身分验证技术。
Web2py是一个用Python语言 编写的免费的开源Web框架,旨在敏捷快速的开发Web应用,具有快速、可扩充、安全以及可移植的数据库驱动的应用,遵循LGPLv3开 源合同。
Web2py提供一站式的解决方案,整个开发过程都可以在浏览器上进行,提供了Web版的在线开发,HTML模版编撰,静态文件的上传,数据库的编撰的功能。其它的还有日志功能,以及一个自动化的admin插口。
4.Tornado
Tornado即是一.个Web server(对此本文不作阐述)python分布式爬虫框架,同时又是一个类web.py的micro-framework,作为框架Tornado的思想主要来源于Web.py,大家在Web.py的网站首页也可以见到Tornado的大鳄Bret Taylor的那么一段话(他这儿说的FriendFeed用的框架跟Tornado可以看作是一个东西) :
"[web.pyinspired the] Web framework we useat FriendFeed [and] the webapp frameworkthat ships with App Engin...”
因为有这层关系,后面不再单独讨论Tornado。
5.CherryPy
CherryPy是一种用于Python的、简单而特别有用的Web框架,其主要作用是以尽可能少的操作将Web服务器与Python代码联接,其功能包括外置的剖析功能、灵活的插件系统以及一次运行多个HTTP服务器的功能python分布式爬虫框架,可与运行在最新版本的Python、Jython、 Android上。 查看全部

urlib -网络库(stdlib)。requests -网络库。
grab -网络库(基于pycurl)。pycurl -网络库(绑定libcurl)
ullib3 - Python HTTP库,安全连接池、支持文件post、可用性高。httplib2一网络库。
RoboBrowser -一个简单的、极具Python风格的Python库,无需独立的浏览器即可浏览网页。
MechanicalSoup一个与网站自动交互Python库。
mechanize -有状态、可编程的Web浏览库。socket -底层网路插口(stdlib)。
Unirest for Python - Unirest是一套可用于 多种语言的轻量级的HTTP库。
hyper - Python的HTTP/2客户端。
PySocks - SocksiPy更新并积极维护的版本,包括错误修补和一些其他的特点。作为socket模块的直接替换。
网络爬虫框架
grab -网络爬虫框架(基 于pycur/multicur)。
scrapy -网络爬虫框架(基 于twisted), 不支持Python3。
pyspider -一个强悍的爬虫系统。cola-一个分布式爬虫框架。其他
portia -基于Scrapy的可视化爬虫。
restkit - Python的HTTP资源工具包。它可以使你轻松地访问HTTP资源,并围绕它完善的对象。
demiurge -基于PyQuery的爬虫微框架。HTML/XML解析器
lxml - C语言编撰高效HTML/ XML处理库。支持XPath。
cssselect -解析DOM树和CSS选择器。pyquery -解析DOM树和jQuery选择器。
BeautIFulSoup -低效HTML/ XML处理库,纯Python实现。
html5lib -根据WHATWG规范生成HTML/ XML文档的DOM。该规范被用在现今所有的浏览器上。
feedparser一解析RSS/ATOM feeds。
MarkupSafe -为XML/HTML/XHTML提供了安全通配符的字符串。
xmltodict-一个可以使你在处理XML时觉得象在处理JSON一样的Python模块。
xhtml2pdf -将HTML/CSS转换为PDF。
untangle -轻松实现将XML文件转换为Python对象。清理
Bleach -清理HTML (需要html5lib)。sanitize -为混乱的数据世界带来端午。文本处理
用于解析和操作简单文本的库。
difflib - (Python标准库) 帮助进行差异化比较。
Levenshtein一快速估算L evenshtein距离和字符串相似度。
fuzzywuzzy -模糊字符串匹配。esmre -正则表达式加速器。
ftfy-自动整理Unicode文本,减少碎片化。.自然语言处理
处理人类语言问题的库。
NLTK -编写Python程序来处理人类语言数据的最好平台。
Pattern一Python的网路挖掘模块。他有自然语言处理工具,机器学习以及其它。
TextBlob -为深入自然语言处理任务提供了一致的API。是基于NLTK以及Pattern的巨人之肩上发展的。
jieba-中文动词工具。
SnowNLP -中文文本处理库。
loso-另一个英文分词库。浏览器自动化与仿真
selenium一自动化真正的浏览器(Chrome浏览器,火狐浏览器,Opera浏览器, IE浏览器)。
Ghost.py -对PyQt的webkit的封装(需 要PyQT)。
Spynner -对PyQt的webkit的封装(需要PyQT),
Splinter -通用API浏览器模拟器(seleniumweb驱动,Django顾客 端,Zope) 。多重处理
threading - Python标准库的线程运行。对于I/0密集型任务太有效。对于CPU绑定的任务没用,因为python GIL。
multiprocessing -标准的Python库运行多进程。
celery -基于分布式消息传递的异步任务队列/作业队列。;
concurrent-futures一concurrent-futures模块为调用异步执行提供了一个高层次的插口。
异步网路编程库
asyncio- (在Python 3.4 +版本以上的Python标准库)异步I/O, 时间循环,协同程序和任务。
Twisted一基于风波驱动的网路引|擎框架。Tornado -一个网路框架和异步网路库。pulsar - Python风波驱动的并发框架。
diesel - Python的基于红色风波的I/O框架。gevent -一个使用greenlet的基于解释器的Python网路库。
eventlet -有WSGI支持的异步框架。
Tomorrow -异步代码的奇妙的修饰句型。队列
celery -基于分布式消息传递的异步任务队列/作业队列。
huey -小型多线程任务队列。
mrq - Mr. Queue -使用redis & Gevent的Python分布式工作任务队列。
RQ -基于Redis的轻量级任务队列管理器。simpleq--个简单的,可无限扩充,基于Amazon SQS的队列。
python-geARMan一Gearman的Python API。
云计算
picloud -云端执行Python代码。
dominoup.com -云端执行R,Python和matlab代码网页内容提取
提取网页内容的库。
HTML页面的文本和元数据
newspaper -用Python进行新闻提取、文章提I取和内容策展。
html2text -将HTML转为Markdown格式文本。
python-goose一HTML内容/文章提取器。lassie -人性化的网页内容检索工具WebSocket
用于WebSocket的库。
Crossbar -开源的应用消息传递路由器
(Python实现的用于Autobahn的WebSocket和WAMP)。
AutobahnPython -提供了WebSocket合同和WAMP合同的Python实现而且开源。
WebSocket-for-Python - Python 2和3以及PyPy的WebSocket客户端和服务器库。DNS解析
dnsyo -在全球超过1 500个的DNS服务器.上检测你的DNS。
pycares - c-ares的插口。c-ares是 进行DNS恳求和异步名称决议的C语言库。
计算机视觉
SimpleCV -用于照相机、图像处理、特征提取、格式转换的简介,可读性强的插口(基于OpenCV)。
Flask是一个轻量级的Web应用框架,使用Python编撰。基于WerkzeugWSGI工具箱和Jinja2模板引擎。使用BSD授权。
Flask也被称为"microframework" ,因为它使用简单的核心,用extension降低其他功能。Flask没有默认使用的数据库、窗体验证工具。然而,Flask保留了扩增的弹性,可以用Flask-extension加入这种功能: ORM、窗体验证工具、文件上传、各种开放式身分验证技术。
Web2py是一个用Python语言 编写的免费的开源Web框架,旨在敏捷快速的开发Web应用,具有快速、可扩充、安全以及可移植的数据库驱动的应用,遵循LGPLv3开 源合同。
Web2py提供一站式的解决方案,整个开发过程都可以在浏览器上进行,提供了Web版的在线开发,HTML模版编撰,静态文件的上传,数据库的编撰的功能。其它的还有日志功能,以及一个自动化的admin插口。
4.Tornado
Tornado即是一.个Web server(对此本文不作阐述)python分布式爬虫框架,同时又是一个类web.py的micro-framework,作为框架Tornado的思想主要来源于Web.py,大家在Web.py的网站首页也可以见到Tornado的大鳄Bret Taylor的那么一段话(他这儿说的FriendFeed用的框架跟Tornado可以看作是一个东西) :
"[web.pyinspired the] Web framework we useat FriendFeed [and] the webapp frameworkthat ships with App Engin...”
因为有这层关系,后面不再单独讨论Tornado。
5.CherryPy
CherryPy是一种用于Python的、简单而特别有用的Web框架,其主要作用是以尽可能少的操作将Web服务器与Python代码联接,其功能包括外置的剖析功能、灵活的插件系统以及一次运行多个HTTP服务器的功能python分布式爬虫框架,可与运行在最新版本的Python、Jython、 Android上。
【Scrapy】走进成熟的爬虫框架
采集交流 • 优采云 发表了文章 • 0 个评论 • 313 次浏览 • 2020-05-10 08:02
今天简单说说Scrapy的安装。
前几天有小伙伴留言说能不能介绍推荐一下爬虫框架,我给他推荐了Scrapy,本来想偷个懒,推荐他去看官方文档,里面有一些demo代码可供学习测试。结果收到回复说文档中演示用到的网站已经难以访问了。所以只能自己来简单写一下了,也算是自己一个学习记录。
Scrapy是哪些?
定义介绍我也不复制粘贴了。简单来说,Scrapy是一个中小型的爬虫框架,框架的意义就在于帮你预设好了好多可以用的东西,让你可以从复杂的数据流和底层控制中抽离下来,专心于页面的解析即可完成中大项目爬虫,甚至是分布式爬虫。
但是爬虫入门是不推荐直接从框架入手的,直接从框架入手会使你头晕目眩,觉得哪里哪里都看不懂,有点类似于还没学会基础的措词造句就直接套用模板写成文章,自然是非常费力的。所以还是推荐你们有一定的手写爬虫基础再深入了解框架。(当然还没有入门爬虫的朋友…可以催更我的爬虫入门文章…)
那么首先是安装。
Python的版本选择之前提过,推荐你们全面拥抱Python 3.x。
很久以前,大概是我刚入门学习Scrapy时爬虫框架,Scrapy还没有支持Python 3.x,那时一部分爬虫工程师把Scrapy不支持Python 3.x作为不进行迁移的理由。当然了,那时更具体的缘由是Scrapy所依赖的twisted和mitmproxy不支持Python 3.x。
现在我仍然推荐你们全面拥抱Python 3.x。
先安装Python
这次我们以本地环境来进行安装(Windows+Anaconda),由于Python的跨平台特点爬虫框架,我们本地写的代码可以很容易迁移到别的笔记本或服务器使用。(当然了,从规范使用的角度上推荐你们使用单独的env,或者直接使用docker或则vagrant,不过那就说来话长了…以后可以考虑单独介绍)
按照惯例,我们直接使用 pip install scrapy 进行安装。
那么,你大几率会碰到这样的错误:
具体的错误缘由…缺少Microsoft Visual C++ 14.0…你也可以自己通过其他渠道解决,当然我们最推荐的做法是直接使用 conda install scrapy 命令(前提是你安装了Anaconda而非普通Python)。
如果碰到写入权限错误,请用管理员模式运行cmd。
之后我们可以写一个太小的demo,依然是官方案例中的DMOZ,DMOZ网站是一个知名的开放式分类目录(Open DirectoryProject),原版的DMOZ已于今年的3月17日停止了营运,目前网站处于403状态。但是网上大量过去的教程都是以DMOZ为案例的。我为你们找到了原DMOZ网站的静态镜像站,大家可以直接访问
大家根据官方文档的步骤继续做就可以了,后续的问题不大。
()
需要注意的就是工作目录问题。
启动Scrapy项目。
scrapy startproject tutorial
进入目录,我们可以看见手动生成的一些文件,这些文件就是scrapy框架所须要的最基础的组织结构。
scrapy.cfg: 项目的配置文件
tutorial/: 该项目的python模块。之后您将在此加入代码。
tutorial/items.py: 项目中的item文件.
tutorial/pipelines.py: 项目中的pipelines文件.
tutorial/settings.py: 项目的设置文件.
tutorial/spiders/: 放置spider代码的目录. 查看全部
今天简单说说Scrapy的安装。
前几天有小伙伴留言说能不能介绍推荐一下爬虫框架,我给他推荐了Scrapy,本来想偷个懒,推荐他去看官方文档,里面有一些demo代码可供学习测试。结果收到回复说文档中演示用到的网站已经难以访问了。所以只能自己来简单写一下了,也算是自己一个学习记录。
Scrapy是哪些?
定义介绍我也不复制粘贴了。简单来说,Scrapy是一个中小型的爬虫框架,框架的意义就在于帮你预设好了好多可以用的东西,让你可以从复杂的数据流和底层控制中抽离下来,专心于页面的解析即可完成中大项目爬虫,甚至是分布式爬虫。
但是爬虫入门是不推荐直接从框架入手的,直接从框架入手会使你头晕目眩,觉得哪里哪里都看不懂,有点类似于还没学会基础的措词造句就直接套用模板写成文章,自然是非常费力的。所以还是推荐你们有一定的手写爬虫基础再深入了解框架。(当然还没有入门爬虫的朋友…可以催更我的爬虫入门文章…)
那么首先是安装。
Python的版本选择之前提过,推荐你们全面拥抱Python 3.x。
很久以前,大概是我刚入门学习Scrapy时爬虫框架,Scrapy还没有支持Python 3.x,那时一部分爬虫工程师把Scrapy不支持Python 3.x作为不进行迁移的理由。当然了,那时更具体的缘由是Scrapy所依赖的twisted和mitmproxy不支持Python 3.x。
现在我仍然推荐你们全面拥抱Python 3.x。
先安装Python
这次我们以本地环境来进行安装(Windows+Anaconda),由于Python的跨平台特点爬虫框架,我们本地写的代码可以很容易迁移到别的笔记本或服务器使用。(当然了,从规范使用的角度上推荐你们使用单独的env,或者直接使用docker或则vagrant,不过那就说来话长了…以后可以考虑单独介绍)
按照惯例,我们直接使用 pip install scrapy 进行安装。
那么,你大几率会碰到这样的错误:
具体的错误缘由…缺少Microsoft Visual C++ 14.0…你也可以自己通过其他渠道解决,当然我们最推荐的做法是直接使用 conda install scrapy 命令(前提是你安装了Anaconda而非普通Python)。
如果碰到写入权限错误,请用管理员模式运行cmd。
之后我们可以写一个太小的demo,依然是官方案例中的DMOZ,DMOZ网站是一个知名的开放式分类目录(Open DirectoryProject),原版的DMOZ已于今年的3月17日停止了营运,目前网站处于403状态。但是网上大量过去的教程都是以DMOZ为案例的。我为你们找到了原DMOZ网站的静态镜像站,大家可以直接访问
大家根据官方文档的步骤继续做就可以了,后续的问题不大。
()
需要注意的就是工作目录问题。
启动Scrapy项目。
scrapy startproject tutorial
进入目录,我们可以看见手动生成的一些文件,这些文件就是scrapy框架所须要的最基础的组织结构。
scrapy.cfg: 项目的配置文件
tutorial/: 该项目的python模块。之后您将在此加入代码。
tutorial/items.py: 项目中的item文件.
tutorial/pipelines.py: 项目中的pipelines文件.
tutorial/settings.py: 项目的设置文件.
tutorial/spiders/: 放置spider代码的目录.
爬虫常用库的安装(二)
采集交流 • 优采云 发表了文章 • 0 个评论 • 261 次浏览 • 2020-05-09 08:02
那么首先,我们先安装一下python自带的模块,request模块,这里给对编程完全陌生的菜鸟来简单介绍一下,request可以取得客户端发送给服务器的恳求信息。
言归正传,我们如今来安装request模块,同样的,我们先打开命令执行程序cmd。
然后输入pip install requests,我们可以看见系统会手动完成这个安装过程。
随后我们来测量一下,第一步,运行python,如果看了今天文章的小伙伴,应该不会再出现其他问题了爬虫软件安装,这里假如有朋友未能正常运行python的话,建议回头看一下今天的《爬虫常用库的安装(一)》。
随后,我们来测量一下python自带的urllib以及re库是否可以正常运行。
那哪些是urllib呢?urllib是可以处理url的组件集合,url就是网上每位文件特有的惟一的强调文件位置以及浏览器如何处理的信息。
在步入python后,输入importurllib,然后import urllib.request;如果没有任何报错的话,说明urllib的安装正常。然后,我们使用urlopen命令来打开一下网址,例如百度,如果运行后显示如右图信息,那么说明url的使用也是没有问题的。
好,我们检查完urllib以后,再来看一下re模块是否正常,re就是python语言中拿来实现正则匹配,通俗的说就是检索、替换这些符合规则的文本。那么我们再度使用import re的命令,如果没有报错,则说明re模块的安装也是没有问题的,因为这两个模块一般问题不大爬虫软件安装,这里就不做截图说明了。
那么虽然其他的模块下载也都是类似的情况,为防止赘言,这里就不花大篇幅讲解了,我们可以通过pip install requests selenium beautifulsoup4 pyquery pymysql pymongoredis flask django jupyter的命令来完成统一下载。为了不给你们添加很大负担,就不一一赘言每位模块的功能了,这些就会在日后的文章中为你们述说,这里还请对python感兴趣的同学们加一下启蒙君的公众号——人工智能python启蒙,今后会为你们带来更多有关于人工智能、大数据剖析以及区块链的学习信息~
下载完成后,python的各大模块应当都可以正常使用了,大家也晓得爬虫的主要功能就是获取数据,当然须要一些储存的数据处理的工具,那么今天启蒙君会给你们带来诸如mongodb、mysql等常用数据库的下载、安装教程。祝你们假期愉快! 查看全部
那么首先,我们先安装一下python自带的模块,request模块,这里给对编程完全陌生的菜鸟来简单介绍一下,request可以取得客户端发送给服务器的恳求信息。
言归正传,我们如今来安装request模块,同样的,我们先打开命令执行程序cmd。
然后输入pip install requests,我们可以看见系统会手动完成这个安装过程。
随后我们来测量一下,第一步,运行python,如果看了今天文章的小伙伴,应该不会再出现其他问题了爬虫软件安装,这里假如有朋友未能正常运行python的话,建议回头看一下今天的《爬虫常用库的安装(一)》。
随后,我们来测量一下python自带的urllib以及re库是否可以正常运行。
那哪些是urllib呢?urllib是可以处理url的组件集合,url就是网上每位文件特有的惟一的强调文件位置以及浏览器如何处理的信息。
在步入python后,输入importurllib,然后import urllib.request;如果没有任何报错的话,说明urllib的安装正常。然后,我们使用urlopen命令来打开一下网址,例如百度,如果运行后显示如右图信息,那么说明url的使用也是没有问题的。
好,我们检查完urllib以后,再来看一下re模块是否正常,re就是python语言中拿来实现正则匹配,通俗的说就是检索、替换这些符合规则的文本。那么我们再度使用import re的命令,如果没有报错,则说明re模块的安装也是没有问题的,因为这两个模块一般问题不大爬虫软件安装,这里就不做截图说明了。
那么虽然其他的模块下载也都是类似的情况,为防止赘言,这里就不花大篇幅讲解了,我们可以通过pip install requests selenium beautifulsoup4 pyquery pymysql pymongoredis flask django jupyter的命令来完成统一下载。为了不给你们添加很大负担,就不一一赘言每位模块的功能了,这些就会在日后的文章中为你们述说,这里还请对python感兴趣的同学们加一下启蒙君的公众号——人工智能python启蒙,今后会为你们带来更多有关于人工智能、大数据剖析以及区块链的学习信息~
下载完成后,python的各大模块应当都可以正常使用了,大家也晓得爬虫的主要功能就是获取数据,当然须要一些储存的数据处理的工具,那么今天启蒙君会给你们带来诸如mongodb、mysql等常用数据库的下载、安装教程。祝你们假期愉快!
Python和数据剖析
采集交流 • 优采云 发表了文章 • 0 个评论 • 265 次浏览 • 2020-05-08 08:03
缺点:有点奇特。? Python:相对年青一点的语言。对于爬虫来说各 方面能力挺好,并且还在建立中,没有Perl那样有 专门的爬虫书籍,不过网上能搜到一些文章。为什么最终选择Python?? 跨平台,对Linux和windows都有不错的支持。 ? 科学估算,数值拟合:Numpy,Scipy ? 可视化:2d:Matplotlib(做图很漂亮), 3d: Mayavi2 ? 复杂网路:Networkx ? 统计:与R语言插口:Rpy ? 交互式终端 ? 网站的快速开发?从一个简单的Python爬虫开始说明:加说明句子时要注意#需要英语编码里的,而不能是英文输入法中的#号,所 以添加英文说明时先在英语输入法下攻入#号后再切换到英文输入瀚海星云Pie 版的网页部份代码………Pie版的Html树部份结构借助BeautifulSoup分析树FindAll()是最方便最好用的函数通用搜索策略? 页面中的link? 深度优先? 广度优先现实中的策略是多种多样的? 因为瀚海星云link有很简单的规律,每页递减20,所以借助这个规 律设置每次赋入的URL,这样爬完了PIE版所有贴子运行结果? 有乱 码!!爬取英文网页常有的问题:不规 格的编码模式? 解决方式:编码转换最后的结果? Perfect!请温柔的对待瀚海星云!!? 设置延后时间(对于一个峰会,如果假定一 个真实的浏览者每10秒掀开一个新的网页的 话,一个不延时的爬虫每秒可以抓10个网页, 这样一个爬虫相当于占用了100个人的带 宽!)? 在午夜爬取可以适当推进速率道上的规矩:用Mysql储存数据? 先要在自己数据库里构建一个空的表,这里, 这里我早已构建了一个名为lilybbs的数据库, 表名为hunan_a? 导入相应的模块? 与相应的数据库联接? 写入数据库里的结果统计和做图? 这部份主要用于科研方 面,利用爬取到的数据 做一些简单的统计工作? 右图是某峰会的回复网 络,使用python的 networkx包做的。
? Pylab 是 matplotlib作 图包的一部 分? 左图是某 blog四年间 每天发表文 章的数目? 左一是某blog网站每个blog 评论数的统计,x是blog评 论数目,y是有这样数目的 blog的数目。可以看见是标 准的“power-law”分布,幂 指数为-1.2左右,拟合使用 了Scipy包的optimize.leastsq, 函数,具体可见scipy cookbook页面的fitting data 一栏? 左二是blog的comment networks 的入度与出度的散 点图,也就是每位点的坐 标x,y分别代表某个人获 得的评论和发出的评论数。 颜色代表这样点的数目。 本图使用了matplotlib中的 hexbin函数中级主题(一):编写更强壮的爬虫? 伪装成浏 览器? 容错中级主题(二):由内嵌脚本形成 的动态网页的爬取? 如何爬取 像左图这 样的网页 呢?? 它显示的 内容并不 会呈现在 html文件 里。高级主题(三):SQLAlchemyMysql这样关系型数据库的缺点:在表 示复杂网路这样一对多,和多对多 的关系时,非常冗余;一旦须要做 比较复杂的统计,sql句子会显得异 常复杂。
? 当你越关注性能,就会发觉 SQL 数据库距对象集合越来越远;当你越关 注具象,就会发觉对象集合距表和行这种概念越来越远。SQLAlchemy 将 致力于尽量宽容这两个世界。? SQLAlchemy 并不把数据库简单地视为数据表的集合;它把它们看作是关 系代数引擎。它的关系对象映射才能使类以不同的形式映射到数据库。 SQL 工具包也不光才能对数据表进行 select 操作——你能够对联接、子查 询和联合进行 select。这样数据库关系和领域对象模型之间的耦合从一开 始就得以挺好地解开,使得两个领域都得以发挥其各自的极至。? 我写过的某个冗长的调用? 号称能更简约明了的SQLAlchemy会成为 mysql的替代品么?高级主题(四):统计神器R语言? 求残差,聚类,判 别,拟合,团簇探 测,时间序列剖析, 生存剖析,甚至复 杂网路,这些R语言 里都有挺好的函数? 可以直接使用R语言, 也可以借助Rpy在 python上面调用R的 函数,不过Rpy一直 开发中,还不是太 成熟以前我们获取数据的手段: 我们用望远镜来洞察宇宙高昂的实验 只是为了获取大自然的数据Internet 带给我们了海量的数据 善用数据,了解我们自己广袤的比特海是另一片未知的星空感谢你们! 查看全部
网络爬虫, Python和数据 分析王澎 中国科技大学哪些是网络爬虫?? 网络爬虫是一个手动提取网页的程序,它为搜索 引擎从万维网上下载网页,是搜索引擎的重要组 成。传统爬虫从一个或若干初始网页的URL开始, 获得初始网页上的URL,在抓取网页的过程中, 不断从当前页面上抽取新的URL装入队列,直到满 足系统的一定停止条件爬虫有哪些用?? 做为通用搜索引擎网页收集器。(google,baidu) ? 做垂直搜索引擎.(找工作的搜索引擎:,数据来源于: , , 等等) ? 科学研究:在线人类行为,在线社群演变,人类 动力学研究数据挖掘与网络爬虫,计量社会学,复杂网路,数据挖掘, 等领域的实证研究都须要大量数据,网络爬虫是 收集相关数据的神器。 ? 偷窥,hacking数据挖掘与网络爬虫,发垃圾邮件……(《google hack》….)爬虫是搜索引擎的第一步 也是最容易的一步? 网页收集 ? 建立索引 ? 查询排序用哪些语言写爬虫?? C,C++。高效率,快速,适合通用搜索引 擎做全网爬取。缺点,开发慢,写上去又 臭又长,例如:天网搜索源代码。? 脚本语言:Perl, Python, Java, Ruby。简单, 易学,良好的文本处理能便捷网页内容的 细致提取,但效率常常不高,适合对少量 网站的聚焦爬取? C#?(貌似信息管理的人比较喜欢的语言)我当初拿来写过爬虫的语言? Perl: 古老的脚本语言,hack 语言,被拿来写爬虫 有着悠久的历史,因此,书本支持相当丰富: 《spidering hacks》,《Perl & LWP》;强大的文 本处理能力,数据库支持能力。
缺点:有点奇特。? Python:相对年青一点的语言。对于爬虫来说各 方面能力挺好,并且还在建立中,没有Perl那样有 专门的爬虫书籍,不过网上能搜到一些文章。为什么最终选择Python?? 跨平台,对Linux和windows都有不错的支持。 ? 科学估算,数值拟合:Numpy,Scipy ? 可视化:2d:Matplotlib(做图很漂亮), 3d: Mayavi2 ? 复杂网路:Networkx ? 统计:与R语言插口:Rpy ? 交互式终端 ? 网站的快速开发?从一个简单的Python爬虫开始说明:加说明句子时要注意#需要英语编码里的,而不能是英文输入法中的#号,所 以添加英文说明时先在英语输入法下攻入#号后再切换到英文输入瀚海星云Pie 版的网页部份代码………Pie版的Html树部份结构借助BeautifulSoup分析树FindAll()是最方便最好用的函数通用搜索策略? 页面中的link? 深度优先? 广度优先现实中的策略是多种多样的? 因为瀚海星云link有很简单的规律,每页递减20,所以借助这个规 律设置每次赋入的URL,这样爬完了PIE版所有贴子运行结果? 有乱 码!!爬取英文网页常有的问题:不规 格的编码模式? 解决方式:编码转换最后的结果? Perfect!请温柔的对待瀚海星云!!? 设置延后时间(对于一个峰会,如果假定一 个真实的浏览者每10秒掀开一个新的网页的 话,一个不延时的爬虫每秒可以抓10个网页, 这样一个爬虫相当于占用了100个人的带 宽!)? 在午夜爬取可以适当推进速率道上的规矩:用Mysql储存数据? 先要在自己数据库里构建一个空的表,这里, 这里我早已构建了一个名为lilybbs的数据库, 表名为hunan_a? 导入相应的模块? 与相应的数据库联接? 写入数据库里的结果统计和做图? 这部份主要用于科研方 面,利用爬取到的数据 做一些简单的统计工作? 右图是某峰会的回复网 络,使用python的 networkx包做的。
? Pylab 是 matplotlib作 图包的一部 分? 左图是某 blog四年间 每天发表文 章的数目? 左一是某blog网站每个blog 评论数的统计,x是blog评 论数目,y是有这样数目的 blog的数目。可以看见是标 准的“power-law”分布,幂 指数为-1.2左右,拟合使用 了Scipy包的optimize.leastsq, 函数,具体可见scipy cookbook页面的fitting data 一栏? 左二是blog的comment networks 的入度与出度的散 点图,也就是每位点的坐 标x,y分别代表某个人获 得的评论和发出的评论数。 颜色代表这样点的数目。 本图使用了matplotlib中的 hexbin函数中级主题(一):编写更强壮的爬虫? 伪装成浏 览器? 容错中级主题(二):由内嵌脚本形成 的动态网页的爬取? 如何爬取 像左图这 样的网页 呢?? 它显示的 内容并不 会呈现在 html文件 里。高级主题(三):SQLAlchemyMysql这样关系型数据库的缺点:在表 示复杂网路这样一对多,和多对多 的关系时,非常冗余;一旦须要做 比较复杂的统计,sql句子会显得异 常复杂。
? 当你越关注性能,就会发觉 SQL 数据库距对象集合越来越远;当你越关 注具象,就会发觉对象集合距表和行这种概念越来越远。SQLAlchemy 将 致力于尽量宽容这两个世界。? SQLAlchemy 并不把数据库简单地视为数据表的集合;它把它们看作是关 系代数引擎。它的关系对象映射才能使类以不同的形式映射到数据库。 SQL 工具包也不光才能对数据表进行 select 操作——你能够对联接、子查 询和联合进行 select。这样数据库关系和领域对象模型之间的耦合从一开 始就得以挺好地解开,使得两个领域都得以发挥其各自的极至。? 我写过的某个冗长的调用? 号称能更简约明了的SQLAlchemy会成为 mysql的替代品么?高级主题(四):统计神器R语言? 求残差,聚类,判 别,拟合,团簇探 测,时间序列剖析, 生存剖析,甚至复 杂网路,这些R语言 里都有挺好的函数? 可以直接使用R语言, 也可以借助Rpy在 python上面调用R的 函数,不过Rpy一直 开发中,还不是太 成熟以前我们获取数据的手段: 我们用望远镜来洞察宇宙高昂的实验 只是为了获取大自然的数据Internet 带给我们了海量的数据 善用数据,了解我们自己广袤的比特海是另一片未知的星空感谢你们!
网络爬虫技术,为什么说使用Python最合适?请听四星教育讲解
采集交流 • 优采云 发表了文章 • 0 个评论 • 326 次浏览 • 2020-05-07 08:00
但是你晓得Python与其他编程语言最主要的区别吗?
网络爬虫技术人才,一直是被各企业争相抢劫。而网路爬虫主要是用Python来编撰,所以缔造了Python与之不同的地位。
也许会有人指责,难道就不能用其他语言来编撰么?
答案是可以的,像java、c、c++、php都可以做爬虫。但是,我们运用一种语言常常并不是说这个会不会做就可以了,还取决于过程中的运行速率、开发效率、人力成本等不同诱因,最后互相比较一下,Python是最合适的。就好象一份工作,大家都可以去做,但是老总肯定会选择更适宜更经济更有能力的人去做。
在写爬虫的过程中,往往是一边写,一边测试爬虫技术用什么语言,测试不过再改改。这个过程用 python 写上去最方便。并且python 相关的库也是最方便,有 request, jieba, redis,gevent,NLTK, lxml,pyquery爬虫技术用什么语言,BeautifulSoup,Pillow,不论是简单的爬虫还是复杂的爬虫都轻松搞定。
这也是Python的又一大特点,与其他编程语言显著不同。
网络爬虫常常被称为网页追逐者,是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。另外一些不常使用的名子还有蚂蚁、自动索引、模拟程序或则蠕虫。
网络爬虫根据系统结构和实现技术,大致可以分为以下几种类型:通用网路爬虫、聚焦网路爬虫、增量式网路爬虫、深层网路爬虫。
通用网路爬虫又称全网爬虫,爬行对象从一些种子 URL 扩充到整个 Web,主要为门户站点搜索引擎和小型 Web 服务提供商采集数据。
聚焦网路爬虫,是指选择性地爬行这些与预先定义好的主题相关页面的网路爬虫。只须要爬行与主题相关的页面,极大地节约了硬件和网路资源,保存的页面也因为数目少而更新快,还可以挺好地满足一些特定人群对特定领域信息的需求。
增量式网路爬虫,是指对已下载网页采取增量式更新和只爬行新形成的或则早已发生变化网页的爬虫,它还能在一定程度上保证所爬行的页面是尽可能新的页面。
随着互联网的发展,网络爬虫技术在未来10年里,都不会有衰落的现象。人生苦短,我学Python,如果听到此文的你正好不知道学哪些语言,六星教育诚挚推荐Python。
六星教育Python全栈VIP课程,囊括了Python各个方面的知识点,内含基础、高级、进阶、商业项目实战等内容,一站式提供从小白到大鳄课程。 查看全部
但是你晓得Python与其他编程语言最主要的区别吗?
网络爬虫技术人才,一直是被各企业争相抢劫。而网路爬虫主要是用Python来编撰,所以缔造了Python与之不同的地位。
也许会有人指责,难道就不能用其他语言来编撰么?
答案是可以的,像java、c、c++、php都可以做爬虫。但是,我们运用一种语言常常并不是说这个会不会做就可以了,还取决于过程中的运行速率、开发效率、人力成本等不同诱因,最后互相比较一下,Python是最合适的。就好象一份工作,大家都可以去做,但是老总肯定会选择更适宜更经济更有能力的人去做。
在写爬虫的过程中,往往是一边写,一边测试爬虫技术用什么语言,测试不过再改改。这个过程用 python 写上去最方便。并且python 相关的库也是最方便,有 request, jieba, redis,gevent,NLTK, lxml,pyquery爬虫技术用什么语言,BeautifulSoup,Pillow,不论是简单的爬虫还是复杂的爬虫都轻松搞定。
这也是Python的又一大特点,与其他编程语言显著不同。
网络爬虫常常被称为网页追逐者,是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。另外一些不常使用的名子还有蚂蚁、自动索引、模拟程序或则蠕虫。
网络爬虫根据系统结构和实现技术,大致可以分为以下几种类型:通用网路爬虫、聚焦网路爬虫、增量式网路爬虫、深层网路爬虫。
通用网路爬虫又称全网爬虫,爬行对象从一些种子 URL 扩充到整个 Web,主要为门户站点搜索引擎和小型 Web 服务提供商采集数据。
聚焦网路爬虫,是指选择性地爬行这些与预先定义好的主题相关页面的网路爬虫。只须要爬行与主题相关的页面,极大地节约了硬件和网路资源,保存的页面也因为数目少而更新快,还可以挺好地满足一些特定人群对特定领域信息的需求。
增量式网路爬虫,是指对已下载网页采取增量式更新和只爬行新形成的或则早已发生变化网页的爬虫,它还能在一定程度上保证所爬行的页面是尽可能新的页面。
随着互联网的发展,网络爬虫技术在未来10年里,都不会有衰落的现象。人生苦短,我学Python,如果听到此文的你正好不知道学哪些语言,六星教育诚挚推荐Python。
六星教育Python全栈VIP课程,囊括了Python各个方面的知识点,内含基础、高级、进阶、商业项目实战等内容,一站式提供从小白到大鳄课程。
python采集微信公众号文章
采集交流 • 优采云 发表了文章 • 0 个评论 • 745 次浏览 • 2020-05-06 08:04
在python一个子目录里存2个文件,分别是:采集公众号文章.py和config.py。 代码如下:
1.采集公众号文章.py
from urllib.parse import urlencode
import pymongo
import requests
from lxml.etree import XMLSyntaxError
from requests.exceptions import ConnectionError
from pyquery import PyQuery as pq
from config import *
#配置MongoDB
client = pymongo.MongoClient(MONGO_URI)
db = client[MONGO_DB]
base_url = 'http://weixin.sogou.com/weixin?'
#添加头文件
headers = {
'Cookie': 'usid=S-pkM6vW_ac4ktr1; SUV=00A75E9078EFD9F75A6573ECAD0EC883; wuid=AAGCxerSHQAAAAqRGn4SoAgAAAA=; IPLOC=CN4414; SUID=767BEAB73220910A000000005AA9E2AA; pgv_pvi=159197184; pgv_si=s8252565504; ABTEST=0|1521083055|v1; weixinIndexVisited=1; sct=1; JSESSIONID=aaalXqKRP6JjS8ac4Hwhw; ppinf=5|1521083238|1522292838|dHJ1c3Q6MToxfGNsaWVudGlkOjQ6MjAxN3x1bmlxbmFtZTo2OiUzQSUyOXxjcnQ6MTA6MTUyMTA4MzIzOHxyZWZuaWNrOjY6JTNBJTI5fHVzZXJpZDo0NDpvOXQybHVOaExNcS1vLW1zbjMxMmNMSkp4OGpZQHdlaXhpbi5zb2h1LmNvbXw; pprdig=tbVf7qLZdDMjpCn4jTf3dg8C8NeRX-YgDi8KUcezn0rteWuhkgU4xMNaxZbakVQuswboIGl_rD-34abU6VY9Jkv7me3BypigyDnIv2lJUchGCo7Gk58m9Qhrm3Aa7NHLHjFVYoaQkQgBSYKpatxMNPe3Tm57ZDlzdPg_8mBmBNQ; sgid=23-30671195-AVqp42ZctqiaCybbDvvfWno4; PHPSESSID=4jjk2a9rv6kq7m50f42r92u3r3; SUIR=D2DF4E12A5A1C3CE1A8AD7F2A5FE18FE; ppmdig=1521087492000000855f9824f94abe82b25d2839135ad3a8; SNUID=FEF36D3F8882EFEC4FCF61E68801DA49; seccodeRight=success; successCount=1|Thu, 15 Mar 2018 04:23:23 GMT',
'Host': 'weixin.sogou.com',
'Referer': 'http://weixin.sogou.com/antispider/?from=%2fweixin%3Fquery%3d%E9%A3%8E%E6%99%AF%26type%3d2%26page%3d95%26ie%3dutf8',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36'
}
#初始化代理为本地IP
proxy = None
#定义获取代理函数
def get_proxy():
try:
response = requests.get(PROXY_POOL_URL)
if response.status_code == 200:
return response.text
return None
except ConnectionError:
return None
#添加代理获取网页内容
def get_html(url, count=1):
print('Crawling', url)
print('Trying Count', count)
global proxy
if count >= MAX_COUNT:
print('Tried Too Many Counts')
return None
try:
if proxy:
proxies = {
'http': 'http://' + proxy
}
response = requests.get(url, allow_redirects=False, headers=headers, proxies=proxies)
else:
response = requests.get(url, allow_redirects=False, headers=headers)
if response.status_code == 200:
return response.text
if response.status_code == 302:
# Need Proxy
print('302')
proxy = get_proxy()
if proxy:
print('Using Proxy', proxy)
return get_html(url)
else:
print('Get Proxy Failed')
return None
except ConnectionError as e:
print('Error Occurred', e.args)
proxy = get_proxy()
count += 1
return get_html(url, count)
#获取索引页内容
def get_index(keyword, page):
data = {
'query': keyword,
'type': 2,
'page': page
}
queries = urlencode(data)
url = base_url + queries
html = get_html(url)
return html
#解析索引页,提取详情页网址
def parse_index(html):
doc = pq(html)
items = doc('.news-box .news-list li .txt-box h3 a').items()
for item in items:
yield item.attr('href')
#获取详情页
def get_detail(url):
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
return None
except ConnectionError:
return None
#解析索引页,返回微信文章标题、内容、日期、公众号名称等
def parse_detail(html):
try:
doc = pq(html)
title = doc('.rich_media_title').text()
content = doc('.rich_media_content').text()
date = doc('#post-date').text()
nickname = doc('#js_profile_qrcode > div > strong').text()
wechat = doc('#js_profile_qrcode > div > p:nth-child(3) > span').text()
return {
'title': title,
'content': content,
'date': date,
'nickname': nickname,
'wechat': wechat
}
except XMLSyntaxError:
return None
#存储到MongoDB,去重操作
def save_to_mongo(data):
if db['articles'].update({'title': data['title']}, {'$set': data}, True):
print('Saved to Mongo', data['title'])
else:
print('Saved to Mongo Failed', data['title'])
#主函数
def main():
for page in range(1, 101):
html = get_index(KEYWORD, page)
if html:
article_urls = parse_index(html)
for article_url in article_urls:
article_html = get_detail(article_url)
if article_html:
article_data = parse_detail(article_html)
print(article_data)
if __name__ == '__main__':
main()
2.config.py代码:
#爬取公众号文章
PROXY_POOL_URL = 'http://127.0.0.1:5000/get'
KEYWORD ='计算机等级二级' # 输入关键词
MONGO_URI = 'localhost'
MONGO_DB = 'data'
MAX_COUNT = 5
其中,config.py中KEYWORD为查找关键词采集微信文章,可以按照须要修改。经实测,运行"采集公众号文章.py"成功!若因受限不成功,可多运行几次。
以上就是本文的全部内容,希望对你们的学习有所帮助,也希望你们多多支持优采云。 查看全部
在python一个子目录里存2个文件,分别是:采集公众号文章.py和config.py。 代码如下:
1.采集公众号文章.py
from urllib.parse import urlencode
import pymongo
import requests
from lxml.etree import XMLSyntaxError
from requests.exceptions import ConnectionError
from pyquery import PyQuery as pq
from config import *
#配置MongoDB
client = pymongo.MongoClient(MONGO_URI)
db = client[MONGO_DB]
base_url = 'http://weixin.sogou.com/weixin?'
#添加头文件
headers = {
'Cookie': 'usid=S-pkM6vW_ac4ktr1; SUV=00A75E9078EFD9F75A6573ECAD0EC883; wuid=AAGCxerSHQAAAAqRGn4SoAgAAAA=; IPLOC=CN4414; SUID=767BEAB73220910A000000005AA9E2AA; pgv_pvi=159197184; pgv_si=s8252565504; ABTEST=0|1521083055|v1; weixinIndexVisited=1; sct=1; JSESSIONID=aaalXqKRP6JjS8ac4Hwhw; ppinf=5|1521083238|1522292838|dHJ1c3Q6MToxfGNsaWVudGlkOjQ6MjAxN3x1bmlxbmFtZTo2OiUzQSUyOXxjcnQ6MTA6MTUyMTA4MzIzOHxyZWZuaWNrOjY6JTNBJTI5fHVzZXJpZDo0NDpvOXQybHVOaExNcS1vLW1zbjMxMmNMSkp4OGpZQHdlaXhpbi5zb2h1LmNvbXw; pprdig=tbVf7qLZdDMjpCn4jTf3dg8C8NeRX-YgDi8KUcezn0rteWuhkgU4xMNaxZbakVQuswboIGl_rD-34abU6VY9Jkv7me3BypigyDnIv2lJUchGCo7Gk58m9Qhrm3Aa7NHLHjFVYoaQkQgBSYKpatxMNPe3Tm57ZDlzdPg_8mBmBNQ; sgid=23-30671195-AVqp42ZctqiaCybbDvvfWno4; PHPSESSID=4jjk2a9rv6kq7m50f42r92u3r3; SUIR=D2DF4E12A5A1C3CE1A8AD7F2A5FE18FE; ppmdig=1521087492000000855f9824f94abe82b25d2839135ad3a8; SNUID=FEF36D3F8882EFEC4FCF61E68801DA49; seccodeRight=success; successCount=1|Thu, 15 Mar 2018 04:23:23 GMT',
'Host': 'weixin.sogou.com',
'Referer': 'http://weixin.sogou.com/antispider/?from=%2fweixin%3Fquery%3d%E9%A3%8E%E6%99%AF%26type%3d2%26page%3d95%26ie%3dutf8',
'Upgrade-Insecure-Requests': '1',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_6) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/65.0.3325.146 Safari/537.36'
}
#初始化代理为本地IP
proxy = None
#定义获取代理函数
def get_proxy():
try:
response = requests.get(PROXY_POOL_URL)
if response.status_code == 200:
return response.text
return None
except ConnectionError:
return None
#添加代理获取网页内容
def get_html(url, count=1):
print('Crawling', url)
print('Trying Count', count)
global proxy
if count >= MAX_COUNT:
print('Tried Too Many Counts')
return None
try:
if proxy:
proxies = {
'http': 'http://' + proxy
}
response = requests.get(url, allow_redirects=False, headers=headers, proxies=proxies)
else:
response = requests.get(url, allow_redirects=False, headers=headers)
if response.status_code == 200:
return response.text
if response.status_code == 302:
# Need Proxy
print('302')
proxy = get_proxy()
if proxy:
print('Using Proxy', proxy)
return get_html(url)
else:
print('Get Proxy Failed')
return None
except ConnectionError as e:
print('Error Occurred', e.args)
proxy = get_proxy()
count += 1
return get_html(url, count)
#获取索引页内容
def get_index(keyword, page):
data = {
'query': keyword,
'type': 2,
'page': page
}
queries = urlencode(data)
url = base_url + queries
html = get_html(url)
return html
#解析索引页,提取详情页网址
def parse_index(html):
doc = pq(html)
items = doc('.news-box .news-list li .txt-box h3 a').items()
for item in items:
yield item.attr('href')
#获取详情页
def get_detail(url):
try:
response = requests.get(url)
if response.status_code == 200:
return response.text
return None
except ConnectionError:
return None
#解析索引页,返回微信文章标题、内容、日期、公众号名称等
def parse_detail(html):
try:
doc = pq(html)
title = doc('.rich_media_title').text()
content = doc('.rich_media_content').text()
date = doc('#post-date').text()
nickname = doc('#js_profile_qrcode > div > strong').text()
wechat = doc('#js_profile_qrcode > div > p:nth-child(3) > span').text()
return {
'title': title,
'content': content,
'date': date,
'nickname': nickname,
'wechat': wechat
}
except XMLSyntaxError:
return None
#存储到MongoDB,去重操作
def save_to_mongo(data):
if db['articles'].update({'title': data['title']}, {'$set': data}, True):
print('Saved to Mongo', data['title'])
else:
print('Saved to Mongo Failed', data['title'])
#主函数
def main():
for page in range(1, 101):
html = get_index(KEYWORD, page)
if html:
article_urls = parse_index(html)
for article_url in article_urls:
article_html = get_detail(article_url)
if article_html:
article_data = parse_detail(article_html)
print(article_data)
if __name__ == '__main__':
main()
2.config.py代码:
#爬取公众号文章
PROXY_POOL_URL = 'http://127.0.0.1:5000/get'
KEYWORD ='计算机等级二级' # 输入关键词
MONGO_URI = 'localhost'
MONGO_DB = 'data'
MAX_COUNT = 5
其中,config.py中KEYWORD为查找关键词采集微信文章,可以按照须要修改。经实测,运行"采集公众号文章.py"成功!若因受限不成功,可多运行几次。
以上就是本文的全部内容,希望对你们的学习有所帮助,也希望你们多多支持优采云。
从零开始学Python网络爬虫中文pdf完整版[144MB]
采集交流 • 优采云 发表了文章 • 0 个评论 • 307 次浏览 • 2020-05-06 08:02
本书共分12章,核心主题包括Python零基础句型入门、爬虫原理和网页构造、我的第一个爬虫程序、正则表达式、Lxml库与Xpath句型、使用API、数据库储存、多进程爬虫、异步加载、表单交互与模拟登陆、Selenium模拟浏览器、Scrapy爬虫框架。此外,书中通过一些典型爬虫案例数据挖掘爬虫书籍,讲解了有经纬信息的地图图表和词云的制做方式,让读者体验数据背后的乐趣。
本书适宜爬虫技术初学者、爱好者及高等院校的相关中学生,也适宜数据爬虫工程师作为参考读物,同时也适宜各大Python数据剖析的培训机构作为教材使用
第1章 Python零基础句型入门 1
第2章 爬虫原理和网页构造 17
第3章 我的第一个爬虫程序 26
第4章 正则表达式 45
第5章 Lxml库与Xpath句型 63
第6章 使用API 88
第7章 数据库储存 109
第8章 多进程爬虫 139
第9章 异步加载 159
第10章 表单交互与模拟登陆 182
第11章 Selenium模拟浏览器 209
第12章 Scrapy爬虫框架 229 查看全部
本书共分12章,核心主题包括Python零基础句型入门、爬虫原理和网页构造、我的第一个爬虫程序、正则表达式、Lxml库与Xpath句型、使用API、数据库储存、多进程爬虫、异步加载、表单交互与模拟登陆、Selenium模拟浏览器、Scrapy爬虫框架。此外,书中通过一些典型爬虫案例数据挖掘爬虫书籍,讲解了有经纬信息的地图图表和词云的制做方式,让读者体验数据背后的乐趣。
本书适宜爬虫技术初学者、爱好者及高等院校的相关中学生,也适宜数据爬虫工程师作为参考读物,同时也适宜各大Python数据剖析的培训机构作为教材使用
第1章 Python零基础句型入门 1
第2章 爬虫原理和网页构造 17
第3章 我的第一个爬虫程序 26
第4章 正则表达式 45
第5章 Lxml库与Xpath句型 63
第6章 使用API 88
第7章 数据库储存 109
第8章 多进程爬虫 139
第9章 异步加载 159
第10章 表单交互与模拟登陆 182
第11章 Selenium模拟浏览器 209
第12章 Scrapy爬虫框架 229
老司机带你学爬虫——Python爬虫技术分享
采集交流 • 优采云 发表了文章 • 0 个评论 • 310 次浏览 • 2020-05-06 08:01
简单来说,写一个从web上获取须要数据并按规定格式储存的程序就叫爬虫;
爬虫理论上步骤很简单,第一步获取html源码,第二步剖析html并领到数据。但实际操作,老麻烦了~
用Python写“爬虫”有什么便捷的库
常用网路恳求库:requests、urllib、urllib2、
urllib和urllib2是Python自带模块,requests是第三方库
常用解析库和爬虫框架:BeautifulSoup、lxml、HTMLParser、selenium、Scrapy
HTMLParser是Python自带模块;
BeautifulSoup可以将html解析成Python句型对象,直接操作对象会十分便捷;
lxml可以解析xml和html标签语言,优点是速度快;
selenium调用浏览器的driver,通过这个库你可以直接调用浏览器完成个别操作,比如输入验证码;
Scrapy太强悍且有名的爬虫框架,可以轻松满足简单网站的爬取;这个python学习(q-u-n):二二七,四三五,四五零 期待你们一起交流讨论,讲实话还是一个特别适宜学习的地方的。软件各类入门资料
“爬虫”需要把握什么知识
1)超文本传输协议HTTP:HTTP合同定义了浏览器如何向万维网服务器恳求万维网文档,以及服务器如何把文档传送给浏览器。常用的HTTP方式有GET、POST、PUT、DELETE。
【插曲:某站长做了一个网站,奇葩的他把删掉的操作绑定在GET恳求上。百度或则微软爬虫爬取网站链接,都是用的GET恳求,而且通常用浏览器访问网页都是GET恳求。在微软爬虫爬取他网站的信息时,该网站自动删掉了数据库的全部数据】
2)统一资源定位符URL: URL是拿来表示从因特网上得到的资源位置和访问那些资源的方式。URL给资源的位置提供一种具象的辨识方式,并用这些方式给资源定位。只要才能对资源定位,系统就可以对资源进行各类操作,如存取、更新、替换和查找其属性。URL相当于一个文件名在网路范围的扩充。
3)超文本标记语言HTTP:HTML指的是超文本标记语言,是使用标记标签来描述网页的。HTML文档包含HTML标签和纯文本,也称为网页。Web 浏览器的作用是读取 HTML 文档,并以网页的方式显示出它们。浏览器不会显示 HTML 标签,而是使用标签来解释页面的内容。简而言之就是你要懂点后端语言,这样描述更直观贴切。
4)浏览器调试功能:学爬虫就是抓包,对恳求和响应进行剖析,用代码来模拟
进阶爬虫
熟练了基本爬虫以后,你会想着获取更多的数据,抓取更难的网站,然后你才会发觉获取数据并不简单,而且现今反爬机制也十分的多。
a.爬取知乎、简书,需要登入并将上次的恳求时将sessions带上,保持登入姿态;
b.爬取亚马逊、京东、天猫等商品信息,由于信息量大、反爬机制建立,需要分布式【这里就难了】爬取,以及不断切换USER_AGENT和代理IP;
c.滑动或下拉加载和同一url加载不同数据时,涉及ajax的异步加载。这里可以有简单的返回html代码、或者json数据,也可能有更变态的返回js代码之后用浏览器执行,逻辑上很简单、但是写代码那叫一个苦哇;
d.还有点是须要面对的,验证码识别。这个有专门解析验证码的平台.....不属于爬虫范畴了,自己处理须要更多的数据剖析知识。
e.数据存储,关系数据库和非关系数据库的选择和使用,设计防冗余数据库表格,去重。大量数据储存数据库,会显得太难受,
f.编码解码问题,数据的储存涉及一个格式的问题,python2或则3也就会涉及编码问题。另外网页结构的不规范性,编码格式的不同很容易触发编码异常问题。下图一个简单的转码规则
一些常见的限制形式
a.Basic Auth:一般会有用户授权的限制,会在headers的Autheration数组里要求加入;
b.Referer:通常是在访问链接时,必须要带上Referer数组,服务器会进行验证,例如抓取易迅的评论;
c.User-Agent:会要求真是的设备,如果不加会用编程语言包里自有User-Agent,可以被辨认下来;
d.Cookie:一般在用户登入或则个别操作后,服务端会在返回包中包含Cookie信息要求浏览器设置Cookie,没有Cookie会很容易被辨认下来是伪造恳求;也有本地通过JS,根据服务端返回的某个信息进行处理生成的加密信息,设置在Cookie上面;
e.Gzip:请求headers上面带了gzip,返回有时候会是gzip压缩,需要解压;
f.JavaScript加密操作:一般都是在恳求的数据包内容上面会包含一些被javascript进行加密限制的信息,例如新浪微博会进行SHA1和RSA加密,之前是两次SHA1加密,然后发送的密码和用户名就会被加密;
g.网站自定义其他数组:因为http的headers可以自定义地段,所以第三方可能会加入了一些自定义的数组名称或则数组值,这也是须要注意的。
真实的恳求过程中爬虫技术,其实不止里面某一种限制,可能是几种限制组合在一次,比如假如是类似RSA加密的话,可能先恳求服务器得到Cookie,然后再带着Cookie去恳求服务器领到私钥,然后再用js进行加密,再发送数据到服务器。所以弄清楚这其中的原理爬虫技术,并且耐心剖析很重要。
总结
爬虫入门不难,但是须要知识面更广和更多的耐心 查看全部
什么是“爬虫”?
简单来说,写一个从web上获取须要数据并按规定格式储存的程序就叫爬虫;
爬虫理论上步骤很简单,第一步获取html源码,第二步剖析html并领到数据。但实际操作,老麻烦了~
用Python写“爬虫”有什么便捷的库
常用网路恳求库:requests、urllib、urllib2、
urllib和urllib2是Python自带模块,requests是第三方库
常用解析库和爬虫框架:BeautifulSoup、lxml、HTMLParser、selenium、Scrapy
HTMLParser是Python自带模块;
BeautifulSoup可以将html解析成Python句型对象,直接操作对象会十分便捷;
lxml可以解析xml和html标签语言,优点是速度快;
selenium调用浏览器的driver,通过这个库你可以直接调用浏览器完成个别操作,比如输入验证码;
Scrapy太强悍且有名的爬虫框架,可以轻松满足简单网站的爬取;这个python学习(q-u-n):二二七,四三五,四五零 期待你们一起交流讨论,讲实话还是一个特别适宜学习的地方的。软件各类入门资料
“爬虫”需要把握什么知识
1)超文本传输协议HTTP:HTTP合同定义了浏览器如何向万维网服务器恳求万维网文档,以及服务器如何把文档传送给浏览器。常用的HTTP方式有GET、POST、PUT、DELETE。
【插曲:某站长做了一个网站,奇葩的他把删掉的操作绑定在GET恳求上。百度或则微软爬虫爬取网站链接,都是用的GET恳求,而且通常用浏览器访问网页都是GET恳求。在微软爬虫爬取他网站的信息时,该网站自动删掉了数据库的全部数据】
2)统一资源定位符URL: URL是拿来表示从因特网上得到的资源位置和访问那些资源的方式。URL给资源的位置提供一种具象的辨识方式,并用这些方式给资源定位。只要才能对资源定位,系统就可以对资源进行各类操作,如存取、更新、替换和查找其属性。URL相当于一个文件名在网路范围的扩充。
3)超文本标记语言HTTP:HTML指的是超文本标记语言,是使用标记标签来描述网页的。HTML文档包含HTML标签和纯文本,也称为网页。Web 浏览器的作用是读取 HTML 文档,并以网页的方式显示出它们。浏览器不会显示 HTML 标签,而是使用标签来解释页面的内容。简而言之就是你要懂点后端语言,这样描述更直观贴切。
4)浏览器调试功能:学爬虫就是抓包,对恳求和响应进行剖析,用代码来模拟
进阶爬虫
熟练了基本爬虫以后,你会想着获取更多的数据,抓取更难的网站,然后你才会发觉获取数据并不简单,而且现今反爬机制也十分的多。
a.爬取知乎、简书,需要登入并将上次的恳求时将sessions带上,保持登入姿态;
b.爬取亚马逊、京东、天猫等商品信息,由于信息量大、反爬机制建立,需要分布式【这里就难了】爬取,以及不断切换USER_AGENT和代理IP;
c.滑动或下拉加载和同一url加载不同数据时,涉及ajax的异步加载。这里可以有简单的返回html代码、或者json数据,也可能有更变态的返回js代码之后用浏览器执行,逻辑上很简单、但是写代码那叫一个苦哇;
d.还有点是须要面对的,验证码识别。这个有专门解析验证码的平台.....不属于爬虫范畴了,自己处理须要更多的数据剖析知识。
e.数据存储,关系数据库和非关系数据库的选择和使用,设计防冗余数据库表格,去重。大量数据储存数据库,会显得太难受,
f.编码解码问题,数据的储存涉及一个格式的问题,python2或则3也就会涉及编码问题。另外网页结构的不规范性,编码格式的不同很容易触发编码异常问题。下图一个简单的转码规则
一些常见的限制形式
a.Basic Auth:一般会有用户授权的限制,会在headers的Autheration数组里要求加入;
b.Referer:通常是在访问链接时,必须要带上Referer数组,服务器会进行验证,例如抓取易迅的评论;
c.User-Agent:会要求真是的设备,如果不加会用编程语言包里自有User-Agent,可以被辨认下来;
d.Cookie:一般在用户登入或则个别操作后,服务端会在返回包中包含Cookie信息要求浏览器设置Cookie,没有Cookie会很容易被辨认下来是伪造恳求;也有本地通过JS,根据服务端返回的某个信息进行处理生成的加密信息,设置在Cookie上面;
e.Gzip:请求headers上面带了gzip,返回有时候会是gzip压缩,需要解压;
f.JavaScript加密操作:一般都是在恳求的数据包内容上面会包含一些被javascript进行加密限制的信息,例如新浪微博会进行SHA1和RSA加密,之前是两次SHA1加密,然后发送的密码和用户名就会被加密;
g.网站自定义其他数组:因为http的headers可以自定义地段,所以第三方可能会加入了一些自定义的数组名称或则数组值,这也是须要注意的。
真实的恳求过程中爬虫技术,其实不止里面某一种限制,可能是几种限制组合在一次,比如假如是类似RSA加密的话,可能先恳求服务器得到Cookie,然后再带着Cookie去恳求服务器领到私钥,然后再用js进行加密,再发送数据到服务器。所以弄清楚这其中的原理爬虫技术,并且耐心剖析很重要。
总结
爬虫入门不难,但是须要知识面更广和更多的耐心
[ Python爬虫实战 ] 爬虫简介与作用
采集交流 • 优采云 发表了文章 • 0 个评论 • 588 次浏览 • 2020-05-03 08:02
网络爬虫(又被称为网页蜘蛛,网络机器人),是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。我们可以使用爬虫手动抓取互联网信息的程序,从互联网上抓取对于我们有价值的信息。但是须要注意网络爬虫 作用,爬虫不会创造数据,也不会生产数据。他只能爬取网路上输出的信息。
目前好多语言都支持爬虫,除了我们这儿介绍Python爬虫,还有php,javascript,java,php,go等等都可以实现爬虫,但是Python爬虫由于使用发布并且有很多好用的拓展包,让python爬虫十分有效并且受欢迎。
在我们浏览网页,浏览器会渲染输出HTML、JS、CSS等信息;通过这种元素,我们就可以看见我们想要查看的新闻,图片,电影,评论,商品等等。一般情况下我们看见自己须要的内容,图片可能会复制文字而且下载图片保存,但是假如面对大量的文字和图片,我们人工是处理不过来的,同时例如类似百度须要每晚定时获取大量网站最新文章并且收录网络爬虫 作用,这些大量数据与每晚的定时的工作我们是难以通过人工去处理的,这时候爬虫的作用就彰显下来了。
爬虫可以抓取网页信息,APP以及客户端信息;我们可以访问保存新闻,图片,电影,评论,商品等等。理论上来说,只要我们可以访问到的数据,我们能够通过爬虫抓取到,同时若果你了解编程基础,你也可以抓取到你在网页中看不到的数据。 查看全部
网络爬虫(又被称为网页蜘蛛,网络机器人),是一种根据一定的规则,自动地抓取万维网信息的程序或则脚本。我们可以使用爬虫手动抓取互联网信息的程序,从互联网上抓取对于我们有价值的信息。但是须要注意网络爬虫 作用,爬虫不会创造数据,也不会生产数据。他只能爬取网路上输出的信息。
目前好多语言都支持爬虫,除了我们这儿介绍Python爬虫,还有php,javascript,java,php,go等等都可以实现爬虫,但是Python爬虫由于使用发布并且有很多好用的拓展包,让python爬虫十分有效并且受欢迎。
在我们浏览网页,浏览器会渲染输出HTML、JS、CSS等信息;通过这种元素,我们就可以看见我们想要查看的新闻,图片,电影,评论,商品等等。一般情况下我们看见自己须要的内容,图片可能会复制文字而且下载图片保存,但是假如面对大量的文字和图片,我们人工是处理不过来的,同时例如类似百度须要每晚定时获取大量网站最新文章并且收录网络爬虫 作用,这些大量数据与每晚的定时的工作我们是难以通过人工去处理的,这时候爬虫的作用就彰显下来了。
爬虫可以抓取网页信息,APP以及客户端信息;我们可以访问保存新闻,图片,电影,评论,商品等等。理论上来说,只要我们可以访问到的数据,我们能够通过爬虫抓取到,同时若果你了解编程基础,你也可以抓取到你在网页中看不到的数据。
Python网路爬虫之必备工具
采集交流 • 优采云 发表了文章 • 0 个评论 • 342 次浏览 • 2020-05-03 08:01
1 Python基础知识
Python作为现今最流行的编程语言之一爬虫工具,其强悍之处也是毋庸置疑的,利用Python写网路爬虫是最好不过的选择啦,所以万丈高楼平地起,学习网路爬虫最最基本的就是要把握Python编程的基础知识,了解以下几点即可:
基本数据结构数据类型控制流函数的使用模块的使用Python学习教程推荐:
(1)廖雪峰之Python教程。具体学习网址百度一下就可以,其讲解堪称通俗易懂,学习上去特别快。
(2)Python简明教程
2 开发环境
操作系统:Windows7及以上
Python版本:Python3.x
代码开发环境:个人比较推荐PyCharm作为自己的IDE,当然你也可以按照自己的使用习惯选择代码编辑器,如Notepad++等
3 Python库
一般网路爬虫所需根据的库有:
urllib和urllib2库
这两个库是学习爬虫最基本的库,其才能将URL所指定的网路资源(HTML)获得,并可用正则表达式对其内容进行提取爬虫工具,进而得到我们想要的结果。
Pythonre模块
re模块是Python提供的用于字符串匹配非常好用的工具,其设计思想就是借助一种描述性语言来定义字符串的规则,凡是符合这一规则的字符串,则表明就匹配成功,这就是我们熟悉的正则表达式。利用re模块提供的抒发功能,我们可以很方便从爬取到的网页内容中匹配出须要的内容数据。
BeautifulSoup库
此库是一个强悍的解析文档工具箱,其才能将我们爬取的到HTML页面内容解析成一个复杂的树状结构,每一个节点都是一个Python对象,具体讲在前面给你们详尽讲解。
以上介绍都是一些基本爬取所需的库,当然假如你想做一个有深度的爬虫,还须要把握如requests库、pymongo库、selenium库等,等把握的差不多了,还可以学习一下爬虫框架Scrapy。 查看全部
网络爬虫(又被称为网页蜘蛛,网络机器人),是一种根据一定的规则,自动的抓取万维网信息的程序或则脚本。那么要学会并精通Python网络爬虫,我们须要打算什么知识和工具那?
1 Python基础知识
Python作为现今最流行的编程语言之一爬虫工具,其强悍之处也是毋庸置疑的,利用Python写网路爬虫是最好不过的选择啦,所以万丈高楼平地起,学习网路爬虫最最基本的就是要把握Python编程的基础知识,了解以下几点即可:
基本数据结构数据类型控制流函数的使用模块的使用Python学习教程推荐:
(1)廖雪峰之Python教程。具体学习网址百度一下就可以,其讲解堪称通俗易懂,学习上去特别快。
(2)Python简明教程
2 开发环境
操作系统:Windows7及以上
Python版本:Python3.x
代码开发环境:个人比较推荐PyCharm作为自己的IDE,当然你也可以按照自己的使用习惯选择代码编辑器,如Notepad++等
3 Python库
一般网路爬虫所需根据的库有:
urllib和urllib2库
这两个库是学习爬虫最基本的库,其才能将URL所指定的网路资源(HTML)获得,并可用正则表达式对其内容进行提取爬虫工具,进而得到我们想要的结果。
Pythonre模块
re模块是Python提供的用于字符串匹配非常好用的工具,其设计思想就是借助一种描述性语言来定义字符串的规则,凡是符合这一规则的字符串,则表明就匹配成功,这就是我们熟悉的正则表达式。利用re模块提供的抒发功能,我们可以很方便从爬取到的网页内容中匹配出须要的内容数据。
BeautifulSoup库
此库是一个强悍的解析文档工具箱,其才能将我们爬取的到HTML页面内容解析成一个复杂的树状结构,每一个节点都是一个Python对象,具体讲在前面给你们详尽讲解。
以上介绍都是一些基本爬取所需的库,当然假如你想做一个有深度的爬虫,还须要把握如requests库、pymongo库、selenium库等,等把握的差不多了,还可以学习一下爬虫框架Scrapy。
爬虫技术浅析
采集交流 • 优采云 发表了文章 • 0 个评论 • 351 次浏览 • 2020-05-02 08:09
上图是Scrapy的构架图,绿线是数据流向,首先从初始URL 开始,Scheduler 会将其交给 Downloader 进行下载,下载以后会交给 Spider 进行剖析,需要保存的数据则会被送到Item Pipeline,那是对数据进行后期处理。另外,在数据流动的通道里还可以安装各类中间件,进行必要的处理。 因此在开发爬虫的时侯,最好也先规划好各类模块。我的做法是单独规划下载模块,爬行模块,调度模块,数据储存模块。
页面下载分为静态和动态两种下载形式。
传统爬虫借助的是静态下载形式,静态下载的优势是下载过程快,但是页面只是一个无趣的html,因此页面链接剖析中获取的只是< a >标签的href属性或则大神可以自己剖析js,form之类的标签捕获一些链接。在python中可以借助urllib2模块或requests模块实现功能。 动态爬虫在web2.0时代则有特殊的优势,由于网页会使用javascript处理,网页内容通过Ajax异步获取。所以,动态爬虫须要剖析经过javascript处理和ajax获取内容后的页面。目前简单的解决方式是通过基于webkit的模块直接处理。PYQT4、Splinter和Selenium这三个模块都可以达到目的。对于爬虫而言,浏览器界面是不需要的,因此使用一个headless browser是十分实惠的,HtmlUnit和phantomjs都是可以使用的headless browser。
以上这段代码是访问新浪网主站。通过对比静态抓取页面和动态抓取页面的厚度和对比静态抓取页面和动态抓取页面内抓取的链接个数。
在静态抓取中,页面的宽度是563838,页面内抓取的链接数目只有166个。而在动态抓取中,页面的宽度下降到了695991,而链接数达到了1422,有了逾10倍的提高。
抓链接表达式
正则:re.compile("href=\"([^\"]*)\"")
Xpath:xpath('//*[@href]')
页面解析是实现抓取页面内链接和抓取特定数据的模块,页面解析主要是对字符串的处理,而html是一种特殊的字符串,在Python中re、beautifulsoup、HTMLParser、lxml等模块都可以解决问题。对于链接,主要抓取a标签下的href属性,还有其他一些标签的src属性。
URL去重是爬虫运行中一项关键的步骤,由于运行中的爬虫主要阻塞在网路交互中,因此防止重复的网路交互至关重要。爬虫通常会将待抓取的URL置于一个队列中,从抓取后的网页中提取到新的URL,在她们被装入队列之前,首先要确定这种新的URL没有被抓取过,如果之前早已抓取过了,就不再装入队列了。
Hash表
利用hash表做去重操作通常是最容易想到的方式,因为hash表查询的时间复杂度是O(1),而且在hash表足够大的情况下,hash冲突的机率就显得太小,因此URL是否重复的判定准确性就十分高。利用hash表去重的这个做法是一个比较简单的解决方式。但是普通hash表也有显著的缺陷爬虫技术,在考虑显存的情况下,使用一张大的hash表是不妥的。Python中可以使用字典这一数据结构。
URL压缩
如果hash表中,当每位节点存储的是一个str方式的具体URL,是十分占用显存的,如果把这个URL进行压缩成一个int型变量,内存占用程度上便有了3倍以上的缩小。因此可以借助Python的hashlib模块来进行URL压缩。 思路:把hash表的节点的数据结构设置为集合,集合内贮存压缩后的URL。
Bloom Filter
Bloom Filter是通过很少的错误换取了储存空间的极大节约。Bloom Filter 是通过一组k 个定义在n 个输入key 上的Hash Function,将上述n 个key 映射到m 位上的数据容器。
上图太清楚的说明了Bloom Filter的优势,在可控的容器宽度内,所有hash函数对同一个元素估算的hash值都为1时,就判定这个元素存在。 Python中hashlib,自带多种hash函数,有MD5,sha1,sha224,sha256,sha384,sha512。代码中还可以进行加水处理,还是很方便的。 Bloom Filter也会形成冲突的情况,具体内容查看文章结尾的参考文章。
在Python编程过程中,可以使用jaybaird提供的BloomFilter插口,或者自己造轮子。
小细节
有个小细节,在构建hash表的时侯选择容器很重要。hash表占用空间很大是个太不爽的问题,因此针对爬虫去重,下列方式可以解决一些问题。
上面这段代码简单验证了生成容器的运行时间。
由上图可以看出,建立一个宽度为1亿的容器时,选择list容器程序的运行时间耗费了7.2s,而选择字符串作为容器时,才耗费了0.2s的运行时间。
接下来瞧瞧显存的占用情况。
如果构建1亿的列表占用了794660k显存。
而构建1亿宽度的字符串却占用了109720k显存,空间占用大概降低了700000k。
初级算法
对于URL相似性,我只是实践一个十分简单的技巧。
在保证不进行重复爬去的情况下,还须要对类似的URL进行判定。我采用的是sponge和ly5066113提供的思路。具体资料在参考文章里。
下列是一组可以判定为相像的URL组
按照预期,以上URL归并后应当为
思路如下,需要提取如下特点
1,host字符串
2,目录深度(以’/’分割)
3,尾页特点
具体算法
算法本身太菜,各位一看才能懂。
实际疗效:
上图显示了把8个不一样的url,算出了2个值。通过实践,在一张千万级的hash表中,冲突的情况是可以接受的。
Python中的并发操作主要涉及的模型有:多线程模型、多进程模型、协程模型。Elias专门写了一篇文章爬虫技术,来比较常用的几种模型并发方案的性能。对于爬虫本身来说,限制爬虫速率主要来自目标服务器的响应速率,因此选择一个控制上去顺手的模块才是对的。
多线程模型,是最容易上手的,Python中自带的threading模块能挺好的实现并发需求,配合Queue模块来实现共享数据。
多进程模型和多线程模型类似,multiprocessing模块中也有类似的Queue模块来实现数据共享。在linux中,用户态的进程可以借助多核心的优势,因此在多核背景下,能解决爬虫的并发问题。
协程模型,在Elias的文章中,基于greenlet实现的解释器程序的性能仅次于Stackless Python,大致比Stackless Python慢一倍,比其他方案快接近一个数量级。因此基于gevent(封装了greenlet)的并发程序会有挺好的性能优势。
具体说明下gevent(非阻塞异步IO)。,“Gevent是一种基于解释器的Python网络库,它用到Greenlet提供的,封装了libevent风波循环的高层同步API。”
从实际的编程疗效来看,协程模型确实表现非常好,运行结果的可控性显著强了不少, gevent库的封装易用性极强。
数据储存本身设计的技术就十分多,作为小菜不敢乱说,但是工作还是有一些小经验是可以分享的。
前提:使用关系数据库,测试中选择的是mysql,其他类似sqlite,SqlServer思路上没有区别。
当我们进行数据储存时,目的就是降低与数据库的交互操作,这样可以增强性能。通常情况下,每当一个URL节点被读取,就进行一次数据储存,对于这样的逻辑进行无限循环。其实这样的性能体验是十分差的,存储速率特别慢。
进阶做法,为了减轻与数据库的交互次数,每次与数据库交互从之前传送1个节点弄成传送10个节点,到传送100个节点内容,这样效率变有了10倍至100倍的提高,在实际应用中,效果是非常好的。:D
爬虫模型
目前这个爬虫模型如上图,调度模块是核心模块。调度模块分别与下载模块,析取模块,存储模块共享三个队列,下载模块与析取模块共享一个队列。数据传递方向如图示。 查看全部
谈到爬虫构架,不得不提的是Scrapy的爬虫构架。Scrapy,是Python开发的一个快速,高层次的爬虫框架,用于抓取web站点并从页面中提取结构化的数据。Scrapy用途广泛,可以用于数据挖掘、监测和自动化测试。Scrapy吸引人的地方在于它是一个框架,任何人都可以依照需求便捷的更改。它也提供了多种类型爬虫的子类,如BaseSpider、sitemap爬虫等。上图是Scrapy的构架图,绿线是数据流向,首先从初始URL 开始,Scheduler 会将其交给 Downloader 进行下载,下载以后会交给 Spider 进行剖析,需要保存的数据则会被送到Item Pipeline,那是对数据进行后期处理。另外,在数据流动的通道里还可以安装各类中间件,进行必要的处理。 因此在开发爬虫的时侯,最好也先规划好各类模块。我的做法是单独规划下载模块,爬行模块,调度模块,数据储存模块。
页面下载分为静态和动态两种下载形式。
传统爬虫借助的是静态下载形式,静态下载的优势是下载过程快,但是页面只是一个无趣的html,因此页面链接剖析中获取的只是< a >标签的href属性或则大神可以自己剖析js,form之类的标签捕获一些链接。在python中可以借助urllib2模块或requests模块实现功能。 动态爬虫在web2.0时代则有特殊的优势,由于网页会使用javascript处理,网页内容通过Ajax异步获取。所以,动态爬虫须要剖析经过javascript处理和ajax获取内容后的页面。目前简单的解决方式是通过基于webkit的模块直接处理。PYQT4、Splinter和Selenium这三个模块都可以达到目的。对于爬虫而言,浏览器界面是不需要的,因此使用一个headless browser是十分实惠的,HtmlUnit和phantomjs都是可以使用的headless browser。
以上这段代码是访问新浪网主站。通过对比静态抓取页面和动态抓取页面的厚度和对比静态抓取页面和动态抓取页面内抓取的链接个数。
在静态抓取中,页面的宽度是563838,页面内抓取的链接数目只有166个。而在动态抓取中,页面的宽度下降到了695991,而链接数达到了1422,有了逾10倍的提高。
抓链接表达式
正则:re.compile("href=\"([^\"]*)\"")
Xpath:xpath('//*[@href]')
页面解析是实现抓取页面内链接和抓取特定数据的模块,页面解析主要是对字符串的处理,而html是一种特殊的字符串,在Python中re、beautifulsoup、HTMLParser、lxml等模块都可以解决问题。对于链接,主要抓取a标签下的href属性,还有其他一些标签的src属性。
URL去重是爬虫运行中一项关键的步骤,由于运行中的爬虫主要阻塞在网路交互中,因此防止重复的网路交互至关重要。爬虫通常会将待抓取的URL置于一个队列中,从抓取后的网页中提取到新的URL,在她们被装入队列之前,首先要确定这种新的URL没有被抓取过,如果之前早已抓取过了,就不再装入队列了。
Hash表
利用hash表做去重操作通常是最容易想到的方式,因为hash表查询的时间复杂度是O(1),而且在hash表足够大的情况下,hash冲突的机率就显得太小,因此URL是否重复的判定准确性就十分高。利用hash表去重的这个做法是一个比较简单的解决方式。但是普通hash表也有显著的缺陷爬虫技术,在考虑显存的情况下,使用一张大的hash表是不妥的。Python中可以使用字典这一数据结构。
URL压缩
如果hash表中,当每位节点存储的是一个str方式的具体URL,是十分占用显存的,如果把这个URL进行压缩成一个int型变量,内存占用程度上便有了3倍以上的缩小。因此可以借助Python的hashlib模块来进行URL压缩。 思路:把hash表的节点的数据结构设置为集合,集合内贮存压缩后的URL。
Bloom Filter
Bloom Filter是通过很少的错误换取了储存空间的极大节约。Bloom Filter 是通过一组k 个定义在n 个输入key 上的Hash Function,将上述n 个key 映射到m 位上的数据容器。
上图太清楚的说明了Bloom Filter的优势,在可控的容器宽度内,所有hash函数对同一个元素估算的hash值都为1时,就判定这个元素存在。 Python中hashlib,自带多种hash函数,有MD5,sha1,sha224,sha256,sha384,sha512。代码中还可以进行加水处理,还是很方便的。 Bloom Filter也会形成冲突的情况,具体内容查看文章结尾的参考文章。
在Python编程过程中,可以使用jaybaird提供的BloomFilter插口,或者自己造轮子。
小细节
有个小细节,在构建hash表的时侯选择容器很重要。hash表占用空间很大是个太不爽的问题,因此针对爬虫去重,下列方式可以解决一些问题。
上面这段代码简单验证了生成容器的运行时间。
由上图可以看出,建立一个宽度为1亿的容器时,选择list容器程序的运行时间耗费了7.2s,而选择字符串作为容器时,才耗费了0.2s的运行时间。
接下来瞧瞧显存的占用情况。
如果构建1亿的列表占用了794660k显存。
而构建1亿宽度的字符串却占用了109720k显存,空间占用大概降低了700000k。
初级算法
对于URL相似性,我只是实践一个十分简单的技巧。
在保证不进行重复爬去的情况下,还须要对类似的URL进行判定。我采用的是sponge和ly5066113提供的思路。具体资料在参考文章里。
下列是一组可以判定为相像的URL组
按照预期,以上URL归并后应当为
思路如下,需要提取如下特点
1,host字符串
2,目录深度(以’/’分割)
3,尾页特点
具体算法
算法本身太菜,各位一看才能懂。
实际疗效:
上图显示了把8个不一样的url,算出了2个值。通过实践,在一张千万级的hash表中,冲突的情况是可以接受的。
Python中的并发操作主要涉及的模型有:多线程模型、多进程模型、协程模型。Elias专门写了一篇文章爬虫技术,来比较常用的几种模型并发方案的性能。对于爬虫本身来说,限制爬虫速率主要来自目标服务器的响应速率,因此选择一个控制上去顺手的模块才是对的。
多线程模型,是最容易上手的,Python中自带的threading模块能挺好的实现并发需求,配合Queue模块来实现共享数据。
多进程模型和多线程模型类似,multiprocessing模块中也有类似的Queue模块来实现数据共享。在linux中,用户态的进程可以借助多核心的优势,因此在多核背景下,能解决爬虫的并发问题。
协程模型,在Elias的文章中,基于greenlet实现的解释器程序的性能仅次于Stackless Python,大致比Stackless Python慢一倍,比其他方案快接近一个数量级。因此基于gevent(封装了greenlet)的并发程序会有挺好的性能优势。
具体说明下gevent(非阻塞异步IO)。,“Gevent是一种基于解释器的Python网络库,它用到Greenlet提供的,封装了libevent风波循环的高层同步API。”
从实际的编程疗效来看,协程模型确实表现非常好,运行结果的可控性显著强了不少, gevent库的封装易用性极强。
数据储存本身设计的技术就十分多,作为小菜不敢乱说,但是工作还是有一些小经验是可以分享的。
前提:使用关系数据库,测试中选择的是mysql,其他类似sqlite,SqlServer思路上没有区别。
当我们进行数据储存时,目的就是降低与数据库的交互操作,这样可以增强性能。通常情况下,每当一个URL节点被读取,就进行一次数据储存,对于这样的逻辑进行无限循环。其实这样的性能体验是十分差的,存储速率特别慢。
进阶做法,为了减轻与数据库的交互次数,每次与数据库交互从之前传送1个节点弄成传送10个节点,到传送100个节点内容,这样效率变有了10倍至100倍的提高,在实际应用中,效果是非常好的。:D
爬虫模型
目前这个爬虫模型如上图,调度模块是核心模块。调度模块分别与下载模块,析取模块,存储模块共享三个队列,下载模块与析取模块共享一个队列。数据传递方向如图示。
爬虫框架是哪些?常见的Python爬虫框架有什么?
采集交流 • 优采云 发表了文章 • 0 个评论 • 294 次浏览 • 2020-05-02 08:09
爬虫框架是哪些?常见的 Python 爬虫框架有什么?学习爬虫的人对爬虫框架并不陌生,在爬虫渐渐入门以后,可以有两个选择。 一个是深入学习, 比如设计模式相关的一些知识, 强化 Python 相关知识,自己动手造轮子爬虫框架, 继续为自己的爬虫降低分布式,多线程等功能扩充。另一条路便是学习一些优秀的框架, 先把这种框架用熟, 可以确保才能应付一些基本的爬虫 任务,也就是可以解决基本的爬虫问题,然后再深入学习它的源码等知识,进一步加强。所以,爬虫框架就是前人积累出来的,可以满足自己爬虫需求,又可以以此提高自己的爬虫 水平。那么,爬虫框架都有什么呢?常见 python 爬虫框架(1)Scrapy:很强悍的爬虫框架,可以满足简单的页面爬取(比如可以明晰得知 url pattern 的 情况) 。用这个框架可以轻松爬出来如亚马逊商品信息之类的数据。但是对于稍稍复杂一点 的页面爬虫框架,如 weibo 的页面信息,这个框架就满足不了需求了。(2)Crawley: 高速爬取对应网站的内容, 支持关系和非关系数据库, 数据可以导入为 JSON、 XML 等(3)Portia:可视化爬取网页内容(4)newspaper:提取新闻、文章以及内容剖析(5)python-goose:java 写的文章提取工具(6)Beautiful Soup:名气大,整合了一些常用爬虫需求。缺点:不能加载 JS。(7)mechanize:优点:可以加载 JS。缺点:文档严重缺位。不过通过官方的 example 以及 人肉尝试的方式,还是勉强能用的。(8)selenium:这是一个调用浏览器的 driver, 通过这个库你可以直接调用浏览器完成个别操 作,比如输入验证码。(9)cola:一个分布式爬虫框架。项目整体设计有点糟,模块间耦合度较高。
Python库大全
采集交流 • 优采云 发表了文章 • 0 个评论 • 319 次浏览 • 2020-04-05 11:09
urlib -网络库(stdlib)。requests -网络库。
grab -网络库(基于pycurl)。pycurl -网络库(绑定libcurl)
ullib3 - Python HTTP库,安全连接池、支持文件post、可用性高。httplib2一网络库。
RoboBrowser -一个简单的、极具Python风格的Python库,无需独立的浏览器即可浏览网页。
MechanicalSoup一个与网站自动交互Python库。
mechanize -有状态、可编程的Web浏览库。socket -底层网路插口(stdlib)。
Unirest for Python - Unirest是一套可用于 多种语言的轻量级的HTTP库。
hyper - Python的HTTP/2客户端。
PySocks - SocksiPy更新并积极维护的版本,包括错误修补和一些其他的特点。作为socket模块的直接替换。
网络爬虫框架
grab -网络爬虫框架(基 于pycur/multicur)。
scrapy -网络爬虫框架(基 于twisted), 不支持Python3。
pyspider -一个强悍的爬虫系统。cola-一个分布式爬虫框架。其他
portia -基于Scrapy的可视化爬虫。
restkit - Python的HTTP资源工具包。它可以使你轻松地访问HTTP资源,并围绕它完善的对象。
demiurge -基于PyQuery的爬虫微框架。HTML/XML解析器
lxml - C语言编撰高效HTML/ XML处理库。支持XPath。
cssselect -解析DOM树和CSS选择器。pyquery -解析DOM树和jQuery选择器。
BeautIFulSoup -低效HTML/ XML处理库,纯Python实现。
html5lib -根据WHATWG规范生成HTML/ XML文档的DOM。该规范被用在现今所有的浏览器上。
feedparser一解析RSS/ATOM feeds。
MarkupSafe -为XML/HTML/XHTML提供了安全通配符的字符串。
xmltodict-一个可以使你在处理XML时觉得象在处理JSON一样的Python模块。
xhtml2pdf -将HTML/CSS转换为PDF。
untangle -轻松实现将XML文件转换为Python对象。清理
Bleach -清理HTML (需要html5lib)。sanitize -为混乱的数据世界带来端午。文本处理
用于解析和操作简单文本的库。
difflib - (Python标准库) 帮助进行差异化比较。
Levenshtein一快速估算L evenshtein距离和字符串相似度。
fuzzywuzzy -模糊字符串匹配。esmre -正则表达式加速器。
ftfy-自动整理Unicode文本,减少碎片化。.自然语言处理
处理人类语言问题的库。
NLTK -编写Python程序来处理人类语言数据的最好平台。
Pattern一Python的网路挖掘模块。他有自然语言处理工具,机器学习以及其它。
TextBlob -为深入自然语言处理任务提供了一致的API。是基于NLTK以及Pattern的巨人之肩上发展的。
jieba-中文动词工具。
SnowNLP -中文文本处理库。
loso-另一个英文分词库。浏览器自动化与仿真
selenium一自动化真正的浏览器(Chrome浏览器,火狐浏览器,Opera浏览器, IE浏览器)。
Ghost.py -对PyQt的webkit的封装(需 要PyQT)。
Spynner -对PyQt的webkit的封装(需要PyQT),
Splinter -通用API浏览器模拟器(seleniumweb驱动,Django顾客 端,Zope) 。多重处理
threading - Python标准库的线程运行。对于I/0密集型任务太有效。对于CPU绑定的任务没用,因为python GIL。
multiprocessing -标准的Python库运行多进程。
celery -基于分布式消息传递的异步任务队列/作业队列。;
concurrent-futures一concurrent-futures模块为调用异步执行提供了一个高层次的插口。
异步网路编程库
asyncio- (在Python 3.4 +版本以上的Python标准库)异步I/O, 时间循环,协同程序和任务。
Twisted一基于风波驱动的网路引|擎框架。Tornado -一个网路框架和异步网路库。pulsar - Python风波驱动的并发框架。
diesel - Python的基于红色风波的I/O框架。gevent -一个使用greenlet的基于解释器的Python网路库。
eventlet -有WSGI支持的异步框架。
Tomorrow -异步代码的奇妙的修饰句型。队列
celery -基于分布式消息传递的异步任务队列/作业队列。
huey -小型多线程任务队列。
mrq - Mr. Queue -使用redis & Gevent的Python分布式工作任务队列。
RQ -基于Redis的轻量级任务队列管理器。simpleq--个简单的,可无限扩充,基于Amazon SQS的队列。
python-geARMan一Gearman的Python API。
云计算
picloud -云端执行Python代码。
dominoup.com -云端执行R,Python和matlab代码网页内容提取
提取网页内容的库。
HTML页面的文本和元数据
newspaper -用Python进行新闻提取、文章提I取和内容策展。
html2text -将HTML转为Markdown格式文本。
python-goose一HTML内容/文章提取器。lassie -人性化的网页内容检索工具WebSocket
用于WebSocket的库。
Crossbar -开源的应用消息传递路由器
(Python实现的用于Autobahn的WebSocket和WAMP)。
AutobahnPython -提供了WebSocket合同和WAMP合同的Python实现而且开源。
WebSocket-for-Python - Python 2和3以及PyPy的WebSocket客户端和服务器库。DNS解析
dnsyo -在全球超过1 500个的DNS服务器.上检测你的DNS。
pycares - c-ares的插口。c-ares是 进行DNS恳求和异步名称决议的C语言库。
计算机视觉
SimpleCV -用于照相机、图像处理、特征提取、格式转换的简介,可读性强的插口(基于OpenCV)。
Flask是一个轻量级的Web应用框架,使用Python编撰。基于WerkzeugWSGI工具箱和Jinja2模板引擎。使用BSD授权。
Flask也被称为"microframework" ,因为它使用简单的核心,用extension降低其他功能。Flask没有默认使用的数据库、窗体验证工具。然而,Flask保留了扩增的弹性,可以用Flask-extension加入这种功能: ORM、窗体验证工具、文件上传、各种开放式身分验证技术。
Web2py是一个用Python语言 编写的免费的开源Web框架,旨在敏捷快速的开发Web应用,具有快速、可扩充、安全以及可移植的数据库驱动的应用,遵循LGPLv3开 源合同。
Web2py提供一站式的解决方案,整个开发过程都可以在浏览器上进行,提供了Web版的在线开发,HTML模版编撰,静态文件的上传,数据库的编撰的功能。其它的还有日志功能,以及一个自动化的admin插口。
4.Tornado
Tornado即是一.个Web server(对此本文不作阐述)python分布式爬虫框架,同时又是一个类web.py的micro-framework,作为框架Tornado的思想主要来源于Web.py,大家在Web.py的网站首页也可以见到Tornado的大鳄Bret Taylor的那么一段话(他这儿说的FriendFeed用的框架跟Tornado可以看作是一个东西) :
"[web.pyinspired the] Web framework we useat FriendFeed [and] the webapp frameworkthat ships with App Engin...”
因为有这层关系,后面不再单独讨论Tornado。
5.CherryPy
CherryPy是一种用于Python的、简单而特别有用的Web框架,其主要作用是以尽可能少的操作将Web服务器与Python代码联接,其功能包括外置的剖析功能、灵活的插件系统以及一次运行多个HTTP服务器的功能python分布式爬虫框架,可与运行在最新版本的Python、Jython、 Android上。 查看全部
urlib -网络库(stdlib)。requests -网络库。
grab -网络库(基于pycurl)。pycurl -网络库(绑定libcurl)
ullib3 - Python HTTP库,安全连接池、支持文件post、可用性高。httplib2一网络库。
RoboBrowser -一个简单的、极具Python风格的Python库,无需独立的浏览器即可浏览网页。
MechanicalSoup一个与网站自动交互Python库。
mechanize -有状态、可编程的Web浏览库。socket -底层网路插口(stdlib)。
Unirest for Python - Unirest是一套可用于 多种语言的轻量级的HTTP库。
hyper - Python的HTTP/2客户端。
PySocks - SocksiPy更新并积极维护的版本,包括错误修补和一些其他的特点。作为socket模块的直接替换。
网络爬虫框架
grab -网络爬虫框架(基 于pycur/multicur)。
scrapy -网络爬虫框架(基 于twisted), 不支持Python3。
pyspider -一个强悍的爬虫系统。cola-一个分布式爬虫框架。其他
portia -基于Scrapy的可视化爬虫。
restkit - Python的HTTP资源工具包。它可以使你轻松地访问HTTP资源,并围绕它完善的对象。
demiurge -基于PyQuery的爬虫微框架。HTML/XML解析器
lxml - C语言编撰高效HTML/ XML处理库。支持XPath。
cssselect -解析DOM树和CSS选择器。pyquery -解析DOM树和jQuery选择器。
BeautIFulSoup -低效HTML/ XML处理库,纯Python实现。
html5lib -根据WHATWG规范生成HTML/ XML文档的DOM。该规范被用在现今所有的浏览器上。
feedparser一解析RSS/ATOM feeds。
MarkupSafe -为XML/HTML/XHTML提供了安全通配符的字符串。
xmltodict-一个可以使你在处理XML时觉得象在处理JSON一样的Python模块。
xhtml2pdf -将HTML/CSS转换为PDF。
untangle -轻松实现将XML文件转换为Python对象。清理
Bleach -清理HTML (需要html5lib)。sanitize -为混乱的数据世界带来端午。文本处理
用于解析和操作简单文本的库。
difflib - (Python标准库) 帮助进行差异化比较。
Levenshtein一快速估算L evenshtein距离和字符串相似度。
fuzzywuzzy -模糊字符串匹配。esmre -正则表达式加速器。
ftfy-自动整理Unicode文本,减少碎片化。.自然语言处理
处理人类语言问题的库。
NLTK -编写Python程序来处理人类语言数据的最好平台。
Pattern一Python的网路挖掘模块。他有自然语言处理工具,机器学习以及其它。
TextBlob -为深入自然语言处理任务提供了一致的API。是基于NLTK以及Pattern的巨人之肩上发展的。
jieba-中文动词工具。
SnowNLP -中文文本处理库。
loso-另一个英文分词库。浏览器自动化与仿真
selenium一自动化真正的浏览器(Chrome浏览器,火狐浏览器,Opera浏览器, IE浏览器)。
Ghost.py -对PyQt的webkit的封装(需 要PyQT)。
Spynner -对PyQt的webkit的封装(需要PyQT),
Splinter -通用API浏览器模拟器(seleniumweb驱动,Django顾客 端,Zope) 。多重处理
threading - Python标准库的线程运行。对于I/0密集型任务太有效。对于CPU绑定的任务没用,因为python GIL。
multiprocessing -标准的Python库运行多进程。
celery -基于分布式消息传递的异步任务队列/作业队列。;
concurrent-futures一concurrent-futures模块为调用异步执行提供了一个高层次的插口。
异步网路编程库
asyncio- (在Python 3.4 +版本以上的Python标准库)异步I/O, 时间循环,协同程序和任务。
Twisted一基于风波驱动的网路引|擎框架。Tornado -一个网路框架和异步网路库。pulsar - Python风波驱动的并发框架。
diesel - Python的基于红色风波的I/O框架。gevent -一个使用greenlet的基于解释器的Python网路库。
eventlet -有WSGI支持的异步框架。
Tomorrow -异步代码的奇妙的修饰句型。队列
celery -基于分布式消息传递的异步任务队列/作业队列。
huey -小型多线程任务队列。
mrq - Mr. Queue -使用redis & Gevent的Python分布式工作任务队列。
RQ -基于Redis的轻量级任务队列管理器。simpleq--个简单的,可无限扩充,基于Amazon SQS的队列。
python-geARMan一Gearman的Python API。
云计算
picloud -云端执行Python代码。
dominoup.com -云端执行R,Python和matlab代码网页内容提取
提取网页内容的库。
HTML页面的文本和元数据
newspaper -用Python进行新闻提取、文章提I取和内容策展。
html2text -将HTML转为Markdown格式文本。
python-goose一HTML内容/文章提取器。lassie -人性化的网页内容检索工具WebSocket
用于WebSocket的库。
Crossbar -开源的应用消息传递路由器
(Python实现的用于Autobahn的WebSocket和WAMP)。
AutobahnPython -提供了WebSocket合同和WAMP合同的Python实现而且开源。
WebSocket-for-Python - Python 2和3以及PyPy的WebSocket客户端和服务器库。DNS解析
dnsyo -在全球超过1 500个的DNS服务器.上检测你的DNS。
pycares - c-ares的插口。c-ares是 进行DNS恳求和异步名称决议的C语言库。
计算机视觉
SimpleCV -用于照相机、图像处理、特征提取、格式转换的简介,可读性强的插口(基于OpenCV)。
Flask是一个轻量级的Web应用框架,使用Python编撰。基于WerkzeugWSGI工具箱和Jinja2模板引擎。使用BSD授权。
Flask也被称为"microframework" ,因为它使用简单的核心,用extension降低其他功能。Flask没有默认使用的数据库、窗体验证工具。然而,Flask保留了扩增的弹性,可以用Flask-extension加入这种功能: ORM、窗体验证工具、文件上传、各种开放式身分验证技术。
Web2py是一个用Python语言 编写的免费的开源Web框架,旨在敏捷快速的开发Web应用,具有快速、可扩充、安全以及可移植的数据库驱动的应用,遵循LGPLv3开 源合同。
Web2py提供一站式的解决方案,整个开发过程都可以在浏览器上进行,提供了Web版的在线开发,HTML模版编撰,静态文件的上传,数据库的编撰的功能。其它的还有日志功能,以及一个自动化的admin插口。
4.Tornado
Tornado即是一.个Web server(对此本文不作阐述)python分布式爬虫框架,同时又是一个类web.py的micro-framework,作为框架Tornado的思想主要来源于Web.py,大家在Web.py的网站首页也可以见到Tornado的大鳄Bret Taylor的那么一段话(他这儿说的FriendFeed用的框架跟Tornado可以看作是一个东西) :
"[web.pyinspired the] Web framework we useat FriendFeed [and] the webapp frameworkthat ships with App Engin...”
因为有这层关系,后面不再单独讨论Tornado。
5.CherryPy
CherryPy是一种用于Python的、简单而特别有用的Web框架,其主要作用是以尽可能少的操作将Web服务器与Python代码联接,其功能包括外置的剖析功能、灵活的插件系统以及一次运行多个HTTP服务器的功能python分布式爬虫框架,可与运行在最新版本的Python、Jython、 Android上。

