
php 爬虫抓取网页数据
php 爬虫抓取网页数据(搜索引擎获取网站相关数据及对应的地址是什么?最可能的答案)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-12-03 21:25
爬虫是一种获取数据的方式,可以按照一定的规则自动爬取某个网站或者万维网信息;真实环境中很大一部分网络访问是由爬虫引起的;我们来看一个常见的应用场景:
当我们使用百度或其他搜索引擎搜索某个关键词时,搜索结果中会收录相应的内容,如:搜索Python,搜索结果可能包括Python官网、Python相关文章等信息,但是这个信息分布在不同的网站上,那么问题来了:这些搜索引擎是怎么知道这些信息和对应的地址的呢?可能的答案是搜索引擎获取了网站的相关数据和对应的地址;想一个问题,python的官网应该不可能主动提供相应的数据,那么数据是怎么获取的呢?最可能的答案是按照一定的规则抓取网站的信息,保存到本地,然后清洗数据。
根据爬虫方式的不同,我们可以将爬虫分为两类:
1.增量爬虫:不限制爬取数据属性。比如谷歌和百度搜索巨头都是增量爬虫;他们一直在抓取数据,他们也会根据一定的算法评估网站的好坏,定期抓取最新的数据,保证他们搜索结果的及时性和正确性;
2.批量爬虫:限制爬取的属性,抓取特定的网站信息;例如:我们需要做人脸识别,如果样本不够,可以使用爬虫抓取百度图片中的人脸照片;获取相应的训练样本;
这里主要使用Python来完成批量爬虫的设计和实现,并对抓取到的数据进行清理和分析;
为什么选择 Python?
当前流行的语言之一,语法简单,使用方便,支持面向对象,第三方模块丰富;我们来看看常用的相关模块:
1. Crawler 相关模块:urllib、requests、Bs4、 lxml 等;
2.数据库相关模块:pyMysql、pyMongo等;
3. 数据分析相关模块:numpy、pandas、matplotlib等;
基于这些模块,我们可以快速搭建爬虫,抓取数据,并对抓取的数据进行分析和可视化。
下面我们来一步步介绍爬取的过程以及每一步涉及到的知识点。例如,当我们得到一个需求时,我们可以抓取一个 网站 数据:
1.需求分析:结合网站提供的信息,分析我们可以获得哪些数据信息
2.请求行为分析:查看整个交互行为,确认请求方式、URL和数据;这就是我们需要了解的Http协议,并借助浏览器或其他抓包工具对其进行分析,这是我们的关键步骤;
3.知识点分析:请求行为分析完成后,我们要确认抓取策略,数据存储形式,确认数据抓取模块,页面信息提取模块,确认我们可以使用这些模块完成相关的开发工作;
4.爬虫设计与实现:
1) 设计的爬行动物,
2) 根据请求行为和页面信息提取流程,完成代码结构设计,
3) 借助jupyer或ipython,一一完成页面请求和数据提取,然后封装成方法添加到类中;
5.存储模块设计与实现:主要实现模块化设计,数据采集和存储分离,统一封装存储接口,无论是存储在csv、json文件还是mysql、mongodb等数据库中,都可以是一个统一接口
6.代码调试:这部分后面会在实际文章中详细讲解,如何快速定位并解决问题;
7. 数据可视化分析:当数据抓取完成后,我们使用相关模块对数据进行清洗,对数据进行可视化分析,了解每个图标的含义;
以上是开发爬虫的一般步骤。我们也会按照这些步骤进行讲解,但是每个知识点、开发调试细节会在中间进行更详细的说明。
本课程可以为您解决这些问题:
1.如何快速使用python搭建爬虫;
2.常用概念的详细解释和应用:比如cookies的作用和具体应用;
3.常见的反爬虫机制及解决方案;
4. 高并发爬虫的设计与实现;
5.数据分析与可视化;
学习本课程需要提前准备好开发环境和相关知识点:
1.开发环境:
Python3.6 (window/linux/macos);
铬浏览器;
pychram IDE开发环境;
2. 相关知识点:
掌握Python常用的数据结构和基本逻辑;
掌握函数和类的相关知识点;
了解多进程/多线程相关模块的使用;
了解数据库的基本操作,如:mongodb、mysql的增删改查等操作;
课程案例:
1.获取一些网站电影相关信息和海报;
2.登录知名代码开源网站;
3.高并发代理IP验证;
4. 生产者和消费者模型抓斗图片
5. 抓取一定的网站电影相关数据,按年龄、国家、差评对数据进行分析;
6. 抓取某二手房交易市场的相关数据,对数据进行相关分析;
通过理论与实战相结合,希望本系列文章能帮助大家快速掌握爬虫开发所需的知识点、流程和技巧。 查看全部
php 爬虫抓取网页数据(搜索引擎获取网站相关数据及对应的地址是什么?最可能的答案)
爬虫是一种获取数据的方式,可以按照一定的规则自动爬取某个网站或者万维网信息;真实环境中很大一部分网络访问是由爬虫引起的;我们来看一个常见的应用场景:
当我们使用百度或其他搜索引擎搜索某个关键词时,搜索结果中会收录相应的内容,如:搜索Python,搜索结果可能包括Python官网、Python相关文章等信息,但是这个信息分布在不同的网站上,那么问题来了:这些搜索引擎是怎么知道这些信息和对应的地址的呢?可能的答案是搜索引擎获取了网站的相关数据和对应的地址;想一个问题,python的官网应该不可能主动提供相应的数据,那么数据是怎么获取的呢?最可能的答案是按照一定的规则抓取网站的信息,保存到本地,然后清洗数据。
根据爬虫方式的不同,我们可以将爬虫分为两类:
1.增量爬虫:不限制爬取数据属性。比如谷歌和百度搜索巨头都是增量爬虫;他们一直在抓取数据,他们也会根据一定的算法评估网站的好坏,定期抓取最新的数据,保证他们搜索结果的及时性和正确性;
2.批量爬虫:限制爬取的属性,抓取特定的网站信息;例如:我们需要做人脸识别,如果样本不够,可以使用爬虫抓取百度图片中的人脸照片;获取相应的训练样本;
这里主要使用Python来完成批量爬虫的设计和实现,并对抓取到的数据进行清理和分析;
为什么选择 Python?
当前流行的语言之一,语法简单,使用方便,支持面向对象,第三方模块丰富;我们来看看常用的相关模块:
1. Crawler 相关模块:urllib、requests、Bs4、 lxml 等;
2.数据库相关模块:pyMysql、pyMongo等;
3. 数据分析相关模块:numpy、pandas、matplotlib等;
基于这些模块,我们可以快速搭建爬虫,抓取数据,并对抓取的数据进行分析和可视化。
下面我们来一步步介绍爬取的过程以及每一步涉及到的知识点。例如,当我们得到一个需求时,我们可以抓取一个 网站 数据:
1.需求分析:结合网站提供的信息,分析我们可以获得哪些数据信息
2.请求行为分析:查看整个交互行为,确认请求方式、URL和数据;这就是我们需要了解的Http协议,并借助浏览器或其他抓包工具对其进行分析,这是我们的关键步骤;
3.知识点分析:请求行为分析完成后,我们要确认抓取策略,数据存储形式,确认数据抓取模块,页面信息提取模块,确认我们可以使用这些模块完成相关的开发工作;
4.爬虫设计与实现:
1) 设计的爬行动物,
2) 根据请求行为和页面信息提取流程,完成代码结构设计,
3) 借助jupyer或ipython,一一完成页面请求和数据提取,然后封装成方法添加到类中;
5.存储模块设计与实现:主要实现模块化设计,数据采集和存储分离,统一封装存储接口,无论是存储在csv、json文件还是mysql、mongodb等数据库中,都可以是一个统一接口
6.代码调试:这部分后面会在实际文章中详细讲解,如何快速定位并解决问题;
7. 数据可视化分析:当数据抓取完成后,我们使用相关模块对数据进行清洗,对数据进行可视化分析,了解每个图标的含义;
以上是开发爬虫的一般步骤。我们也会按照这些步骤进行讲解,但是每个知识点、开发调试细节会在中间进行更详细的说明。
本课程可以为您解决这些问题:
1.如何快速使用python搭建爬虫;
2.常用概念的详细解释和应用:比如cookies的作用和具体应用;
3.常见的反爬虫机制及解决方案;
4. 高并发爬虫的设计与实现;
5.数据分析与可视化;
学习本课程需要提前准备好开发环境和相关知识点:
1.开发环境:
Python3.6 (window/linux/macos);
铬浏览器;
pychram IDE开发环境;
2. 相关知识点:
掌握Python常用的数据结构和基本逻辑;
掌握函数和类的相关知识点;
了解多进程/多线程相关模块的使用;
了解数据库的基本操作,如:mongodb、mysql的增删改查等操作;
课程案例:
1.获取一些网站电影相关信息和海报;
2.登录知名代码开源网站;
3.高并发代理IP验证;
4. 生产者和消费者模型抓斗图片
5. 抓取一定的网站电影相关数据,按年龄、国家、差评对数据进行分析;
6. 抓取某二手房交易市场的相关数据,对数据进行相关分析;
通过理论与实战相结合,希望本系列文章能帮助大家快速掌握爬虫开发所需的知识点、流程和技巧。
php 爬虫抓取网页数据(微信小程序签名参数破解(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-12-03 21:24
最近有朋友想爬取小红书上的图片:
结合以往爬虫经验,抓号难度App>网页版>=微信小程序,所以我们选择小红书的微信小程序进行突破。
使用Charles抓包工具,当你点击小红书小程序中的每个类别时,很容易定位到它的请求和返回结果:
查尔斯抓包:
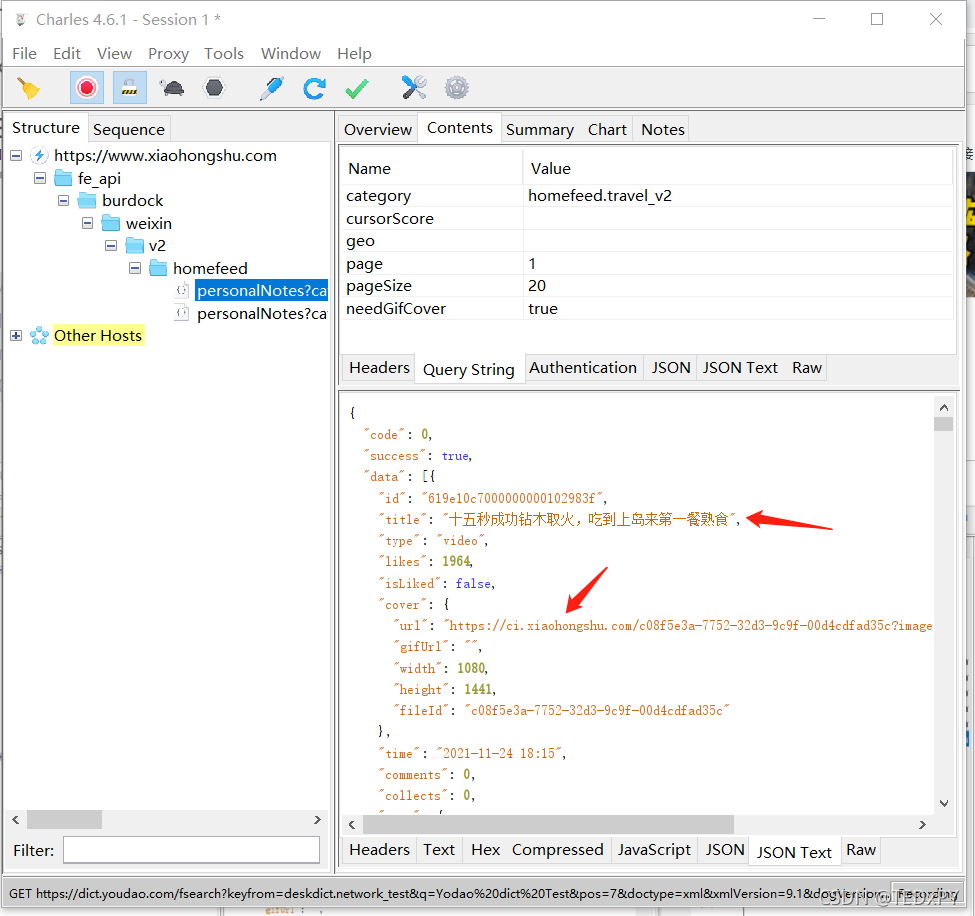
每个请求返回20条信息流,其中收录我们想要的图片链接;当我们在小程序中继续向下滑动时,会发送新的请求来获取更多的信息流。我们要做的就是提取请求的参数,模拟发送请求,爬取返回结果,提取图片链接就可以了。
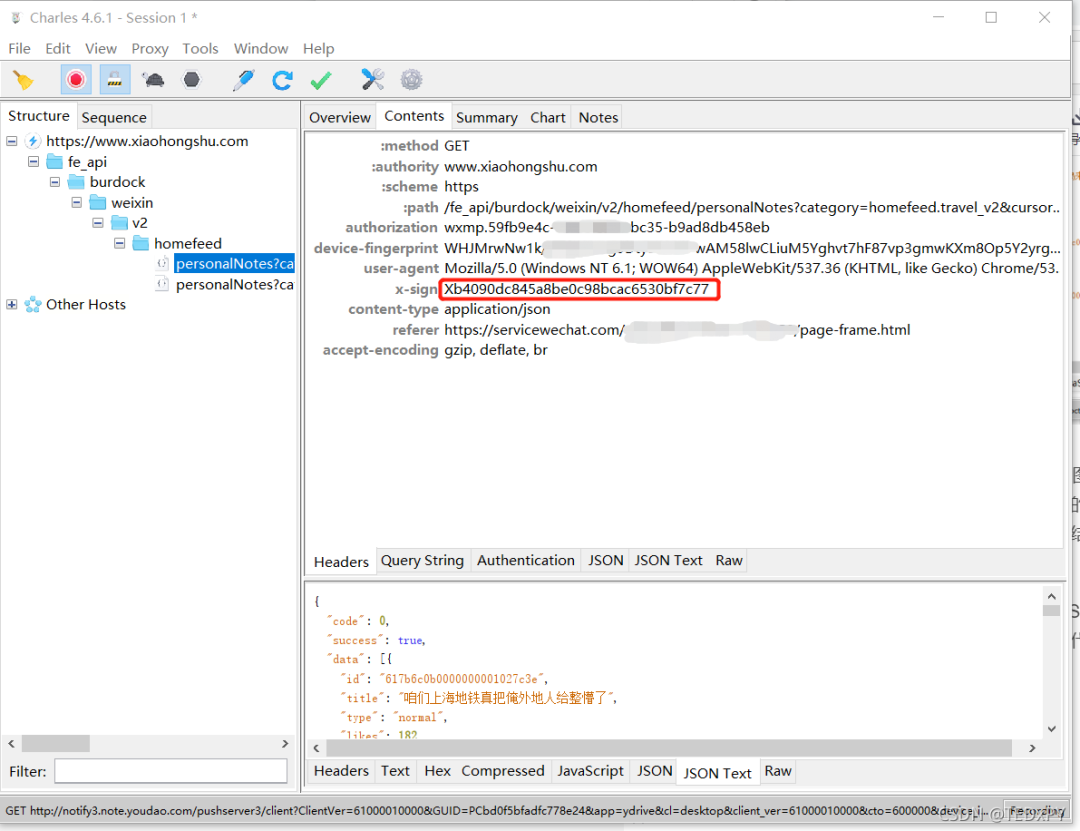
由于我在工作中使用NodeJS来爬取爬虫,所以很容易使用JS编写的爬虫代码;大家看文章的可能只是看思路,这里就不放具体代码了。参数里面还有一个比较麻烦的。“签名参数”x-sign,这里是重点:
在网上搜索相关内容的时候,很多大牛确实破解了这个参数:它的格式是字母X加32位十六进制字符,通常32位十六进制字符是MD5加密后得到的结果,所以也比较容易猜测。但是,涉及到解密时,您必须私下联系作者,甚至需要向您收费才能解密。
最近也在研究反编译小程序,成功破解了几个类似小程序的签名参数。抱着试一试的态度,花了一个小时终于搞定了这个参数~
刚才说了,这个参数可能是用MD5算法处理某些值的结果。具体逻辑只有看源码才能知道。文章 一开始就说小程序比较容易破解。原因是微信小程序更容易通过反编译得到源代码(可能不是完整的源代码,但一般的参数逻辑通常可以定位)。
1. 反编译小红书小程序
第一步是反编译小红书小程序,定位到其x-sign参数生成的源代码。这里要反编译小程序,我参考了下面的帖子:
大致流程是登录电脑版微信,打开小红书小程序,找到小程序文件所在目录,解密然后反编译,得到小程序处理的源代码。
2.在源码中搜索目标参数
因为要获取x-sign参数的生成逻辑,我们直接在文件中搜索x-sign:
跟着红框里的相关函数名一路查找,你会逐渐发现就是拼接请求的参数,然后组合一个固定的字符串进行MD5处理,最后在开头加一个大写的X就形成了一个 x 符号。整个过程与最初的猜测一致。
3. 模拟源码重新生成相关参数
过去,我自己用Python来计算爬虫,但在我的工作中,我使用NodeJs爬虫来抓取数字。渐渐地,我发现NodeJS有它的优点:一般的网页前端代码都是用JS写的,小程序中的加密逻辑也是用JS写的。在进行仿真生成相关参数时,可以无缝连接NodeJ。我通常的做法是,无论加密逻辑多么复杂,只要把输入的参数搞清楚,我只要把它的加密代码全部复制下来,设置好需要的参数和变量,直接算出奇迹就可以了。
如图,我在源码中配置了生成x-sign参数的函数和变量后,直接运行,得到某些请求参数所需的x-sign值。
4.配置爬取参数
得到x-sign后,爬虫是一个还算满意的过程,每次请求20个请求,不断翻页获取更多。不过小红书毕竟是大公司出品,还是有防爬措施的。例如,检索到500个条目后,将触发滑块验证:
并且返回1000条信息后,不再返回数据:
所以最终我们的爬虫只能爬取每个目录下1000个帖子和相关图片链接。如果在此期间触发了滑块,则程序在手动拖动滑块验证后仍可继续捕捉。
回到最初的需求,我朋友想在小红书上抓图。既然抓到了图片链接,接下来就可以编写批量下载脚本了——不过已经有大侠在现场了:
回顾整个需求,利用业余时间,用不到一天的时间,效率还是很高的!
反编译破解加密参数的乐趣,尤其是通过自主研究的整个过程,非常有趣。
最后,如果您有爬虫、办公自动化等方面的想法和需求,请联系我。本人能力有限,希望能帮到你~ 查看全部
php 爬虫抓取网页数据(微信小程序签名参数破解(图))
最近有朋友想爬取小红书上的图片:
结合以往爬虫经验,抓号难度App>网页版>=微信小程序,所以我们选择小红书的微信小程序进行突破。
使用Charles抓包工具,当你点击小红书小程序中的每个类别时,很容易定位到它的请求和返回结果:
查尔斯抓包:
每个请求返回20条信息流,其中收录我们想要的图片链接;当我们在小程序中继续向下滑动时,会发送新的请求来获取更多的信息流。我们要做的就是提取请求的参数,模拟发送请求,爬取返回结果,提取图片链接就可以了。
由于我在工作中使用NodeJS来爬取爬虫,所以很容易使用JS编写的爬虫代码;大家看文章的可能只是看思路,这里就不放具体代码了。参数里面还有一个比较麻烦的。“签名参数”x-sign,这里是重点:
在网上搜索相关内容的时候,很多大牛确实破解了这个参数:它的格式是字母X加32位十六进制字符,通常32位十六进制字符是MD5加密后得到的结果,所以也比较容易猜测。但是,涉及到解密时,您必须私下联系作者,甚至需要向您收费才能解密。
最近也在研究反编译小程序,成功破解了几个类似小程序的签名参数。抱着试一试的态度,花了一个小时终于搞定了这个参数~
刚才说了,这个参数可能是用MD5算法处理某些值的结果。具体逻辑只有看源码才能知道。文章 一开始就说小程序比较容易破解。原因是微信小程序更容易通过反编译得到源代码(可能不是完整的源代码,但一般的参数逻辑通常可以定位)。
1. 反编译小红书小程序
第一步是反编译小红书小程序,定位到其x-sign参数生成的源代码。这里要反编译小程序,我参考了下面的帖子:
大致流程是登录电脑版微信,打开小红书小程序,找到小程序文件所在目录,解密然后反编译,得到小程序处理的源代码。
2.在源码中搜索目标参数
因为要获取x-sign参数的生成逻辑,我们直接在文件中搜索x-sign:
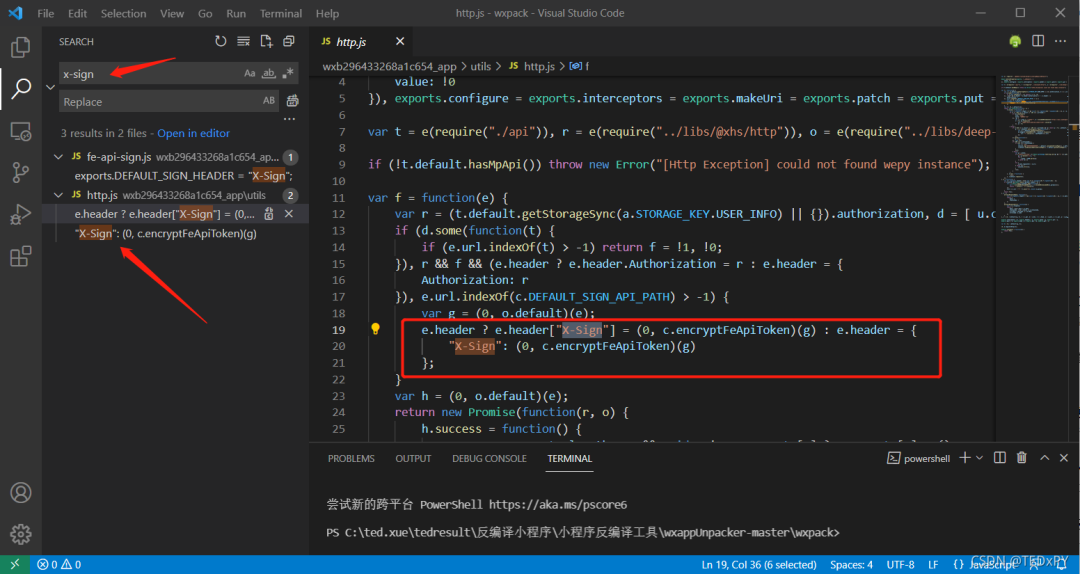
跟着红框里的相关函数名一路查找,你会逐渐发现就是拼接请求的参数,然后组合一个固定的字符串进行MD5处理,最后在开头加一个大写的X就形成了一个 x 符号。整个过程与最初的猜测一致。
3. 模拟源码重新生成相关参数
过去,我自己用Python来计算爬虫,但在我的工作中,我使用NodeJs爬虫来抓取数字。渐渐地,我发现NodeJS有它的优点:一般的网页前端代码都是用JS写的,小程序中的加密逻辑也是用JS写的。在进行仿真生成相关参数时,可以无缝连接NodeJ。我通常的做法是,无论加密逻辑多么复杂,只要把输入的参数搞清楚,我只要把它的加密代码全部复制下来,设置好需要的参数和变量,直接算出奇迹就可以了。
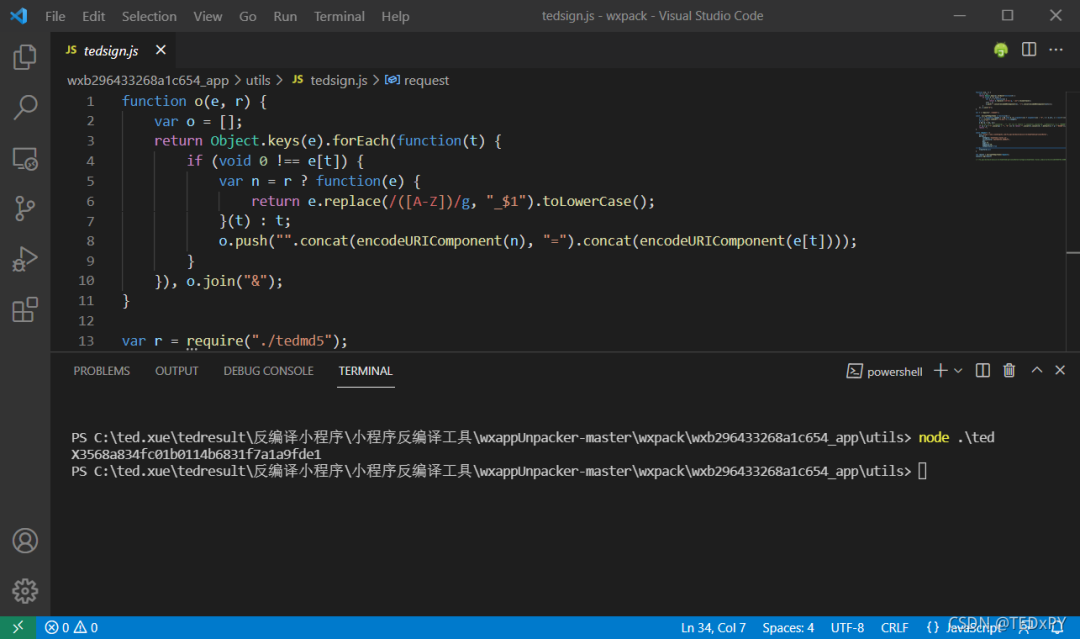
如图,我在源码中配置了生成x-sign参数的函数和变量后,直接运行,得到某些请求参数所需的x-sign值。
4.配置爬取参数
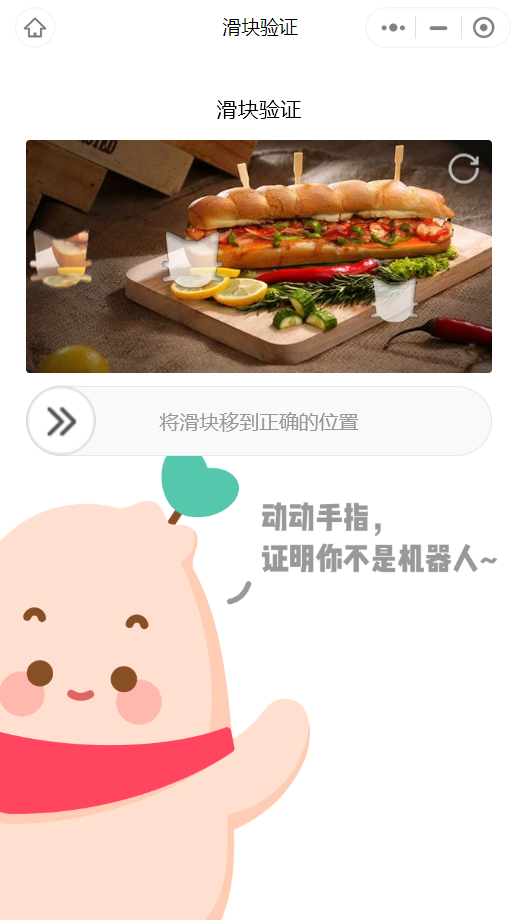
得到x-sign后,爬虫是一个还算满意的过程,每次请求20个请求,不断翻页获取更多。不过小红书毕竟是大公司出品,还是有防爬措施的。例如,检索到500个条目后,将触发滑块验证:
并且返回1000条信息后,不再返回数据:
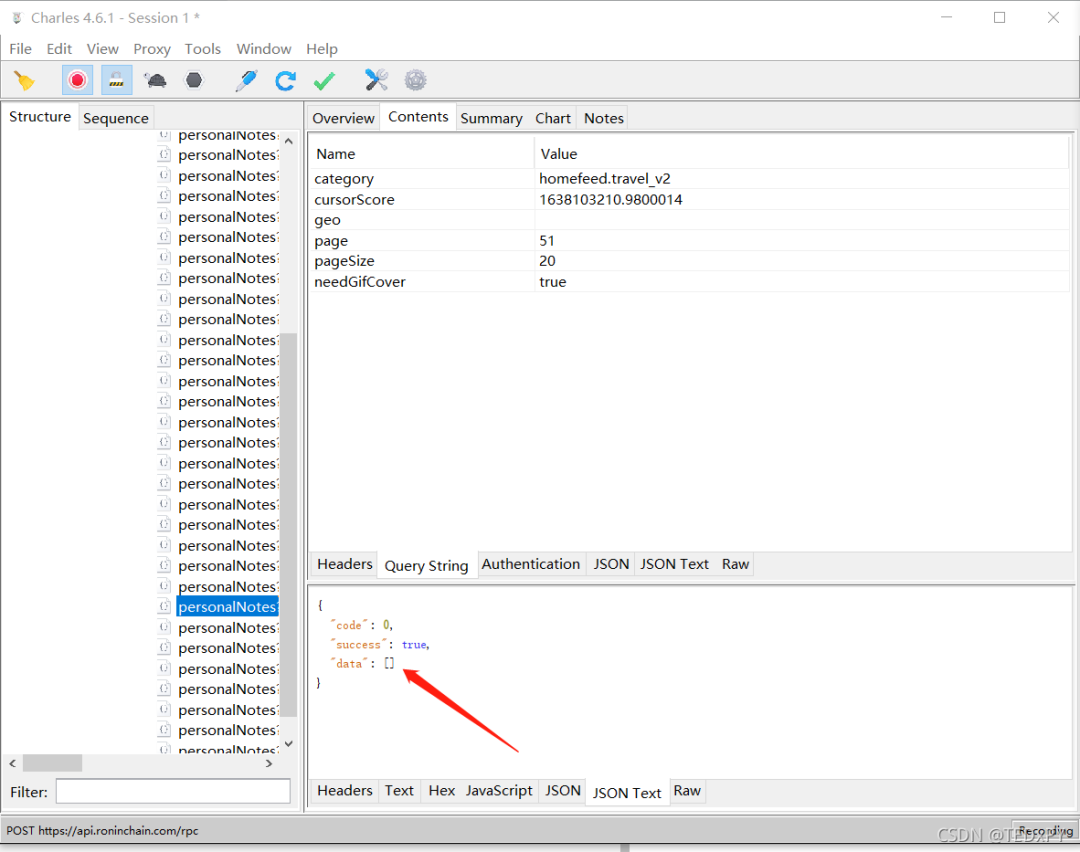
所以最终我们的爬虫只能爬取每个目录下1000个帖子和相关图片链接。如果在此期间触发了滑块,则程序在手动拖动滑块验证后仍可继续捕捉。
回到最初的需求,我朋友想在小红书上抓图。既然抓到了图片链接,接下来就可以编写批量下载脚本了——不过已经有大侠在现场了:
回顾整个需求,利用业余时间,用不到一天的时间,效率还是很高的!
反编译破解加密参数的乐趣,尤其是通过自主研究的整个过程,非常有趣。
最后,如果您有爬虫、办公自动化等方面的想法和需求,请联系我。本人能力有限,希望能帮到你~
php 爬虫抓取网页数据(闲人日记:如何获取交叉熵函数的开发者工具?(上) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-02 02:08
)
闲人日记
时间:2021年3月9日
这上来明明很闲却没更新!怎么说呢,不想做,总能找到很多理由。毕竟,“不想做”就是“不想做”。停止废话,开始进入主题。
打开网站 主页进行实验。可以看到网页上有一个明显的表格。这张表是看到别人写交叉熵函数文章时搬过来的数据。接下来,我们将尝试使用Python获取以下数据,并使用不同色块的类属性作为行索引。
看看数据就知道了
接下来F12打开浏览器的开发者工具,我们先看一下网页的源码,这可以帮助我们分析之后如何处理数据。但是在开始之前,笔者首先要说的是,编写爬虫没有固定的、具体的方法,一定要“具体情况具体分析”!很多时候我们面对的需求是不一样的,有些网站不能用下面的方法获取数据(获取的方法会有很大的不同),这些都需要很多具体的经验和处理具体的人脸。问题的经验。. .
点击元素选择工具,点击目标元素,查看器跳转到目标元素的代码。见图一。
图一
一起来看看元素之间的“父子关系”吧!左边的“代”比较大,其中,图2这个...里面是我们要获取数据的目标表的源代码,我们发现只有这个表出现了在整个网页中。class=table table-hover 参数类的属性值,这将是脚本找到这个表对象的重要依据。
图二
为了演示方便,只列出了tbody的6个tr
好的,我们接下来开始我们的工作。首先,我们要先安装一些爬虫相关的库或模块。如果没有安装,可以在cmd中输入命令安装:pip install requests beautifulsoup4 pandas(requests和beautifulsoup4、pandas也安装了)。安装成功后,我们进入下一步。打开 Jupyther Notebook,数据科学中常用的 Python 集成开发环境。如果使用Python的IDLE工具,最好一行一行的输入命令,否则很容易报错。
分别导入请求和beautifulsoup4、pandas:
对于网络请求,某些网站必须带头发送,否则无法获取。
输入response.text,你会发现所有的汉字都变成了乱码。这时候就需要转换编码了。查看输出的编码:
响应文本
一般我们只需要将编码转换为utf-8即可解决中文乱码:
或输入以下代码:
处理完编码问题后
可以看出,相当杂乱,和真正的源码不太一样。“\r”表示当前位置返回到开头,“\n”表示换行,“\t”表示跳到下一个制表符位置。所以要创建一个 bs4.BeautifulSoup 类型的对象:
将文本转换为源代码
BeautifulSoup 模块使响应文本更加规则。
在变量soup“table table-hover”中找到第一个属性类的值为table的代码块:
...代码块
获取tbody中所有tr标签的代码块:
全部在tbody...
代码块列表
处理成所需数据的结构(警告!下面有很多图带你看代码):
列
上校
因为 attrs['class'] 返回一个列表
提取list对象中的字符串(否则tbody_id不能作为索引)
主题数据
将列表数据转换为pandas DataFrame 类型的数据
数据表
请根据自己的需要设计。这几乎是结束了。如果要将数据表导出为Excel表格,只需要使用pandas的to_excel()函数即可。
背后的故事
18年,笔者和数学建模的小伙伴遇到一个课题,需要采集大量的足球彩票网站数据进行数据分析。那时我们用的是matlab,对互联网技术或编程了解不多。水平也有待提高。所以我用了最慢的方法,一页一页地采集页面。可以说是慢到让人吐血。那是我第一次通宵工作。如果你现在看,你有更多的选择。
后记
笔者在百度体验中遇到过很多墙,文章还是发不出来。我总是被告知我已经踏上了“雷区”以做出改变。做了几个小时的更改,我仍然无法通过。不得不放弃。之前微信公众号上发的内容没人看,虽然只是比较基础的内容,自然会和别人的代码有很多相似之处。但无论如何,我是在自己的网站上爬取数据,而那个网站只是用于各种实验。
今天突然发现b站的专栏增加了一些作者和其他朋友之前一直在说的功能,有点惊喜!我爱小破站(poyin)。
查看全部
php 爬虫抓取网页数据(闲人日记:如何获取交叉熵函数的开发者工具?(上)
)
闲人日记
时间:2021年3月9日
这上来明明很闲却没更新!怎么说呢,不想做,总能找到很多理由。毕竟,“不想做”就是“不想做”。停止废话,开始进入主题。

打开网站 主页进行实验。可以看到网页上有一个明显的表格。这张表是看到别人写交叉熵函数文章时搬过来的数据。接下来,我们将尝试使用Python获取以下数据,并使用不同色块的类属性作为行索引。
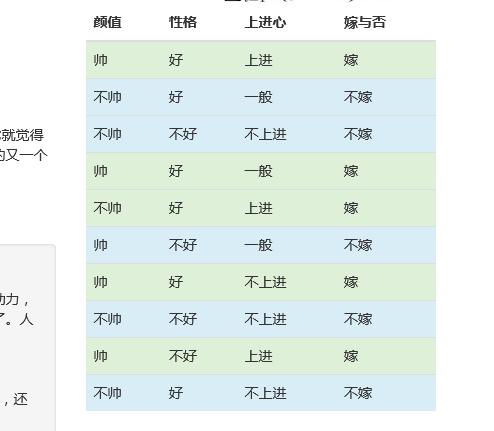
看看数据就知道了
接下来F12打开浏览器的开发者工具,我们先看一下网页的源码,这可以帮助我们分析之后如何处理数据。但是在开始之前,笔者首先要说的是,编写爬虫没有固定的、具体的方法,一定要“具体情况具体分析”!很多时候我们面对的需求是不一样的,有些网站不能用下面的方法获取数据(获取的方法会有很大的不同),这些都需要很多具体的经验和处理具体的人脸。问题的经验。. .
点击元素选择工具,点击目标元素,查看器跳转到目标元素的代码。见图一。
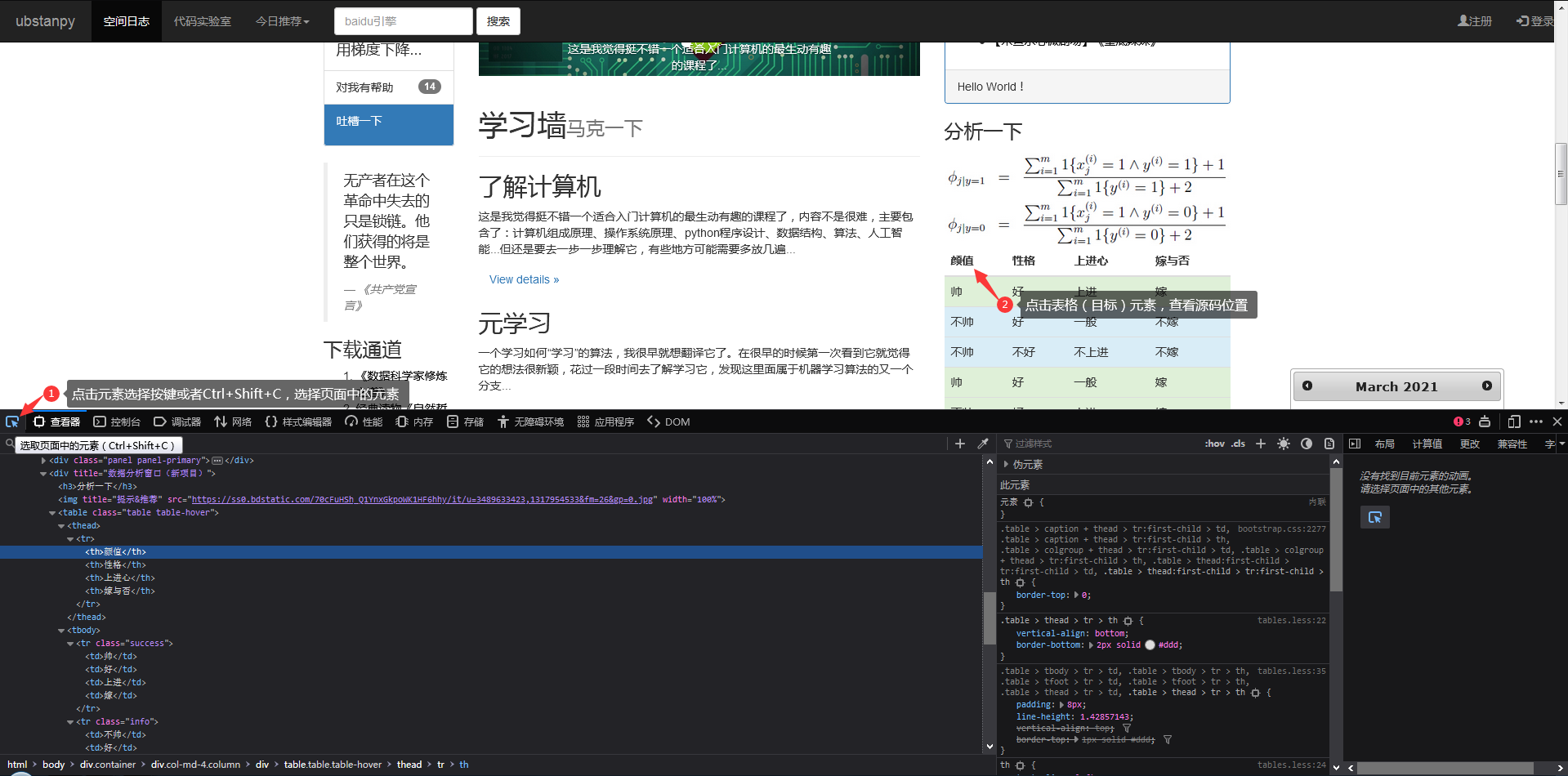
图一
一起来看看元素之间的“父子关系”吧!左边的“代”比较大,其中,图2这个...里面是我们要获取数据的目标表的源代码,我们发现只有这个表出现了在整个网页中。class=table table-hover 参数类的属性值,这将是脚本找到这个表对象的重要依据。
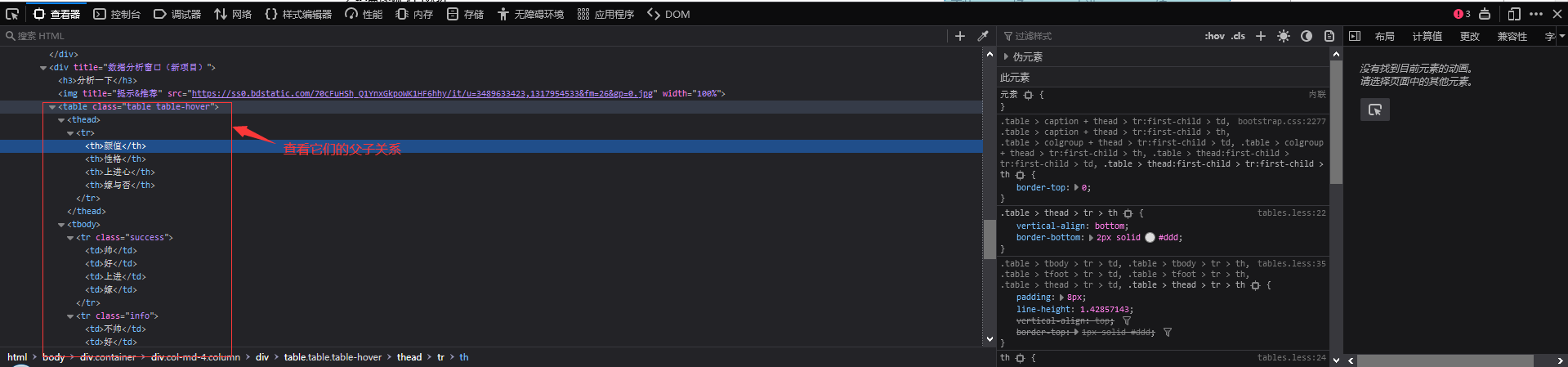
图二
为了演示方便,只列出了tbody的6个tr
好的,我们接下来开始我们的工作。首先,我们要先安装一些爬虫相关的库或模块。如果没有安装,可以在cmd中输入命令安装:pip install requests beautifulsoup4 pandas(requests和beautifulsoup4、pandas也安装了)。安装成功后,我们进入下一步。打开 Jupyther Notebook,数据科学中常用的 Python 集成开发环境。如果使用Python的IDLE工具,最好一行一行的输入命令,否则很容易报错。
分别导入请求和beautifulsoup4、pandas:
对于网络请求,某些网站必须带头发送,否则无法获取。
输入response.text,你会发现所有的汉字都变成了乱码。这时候就需要转换编码了。查看输出的编码:

响应文本
一般我们只需要将编码转换为utf-8即可解决中文乱码:
或输入以下代码:
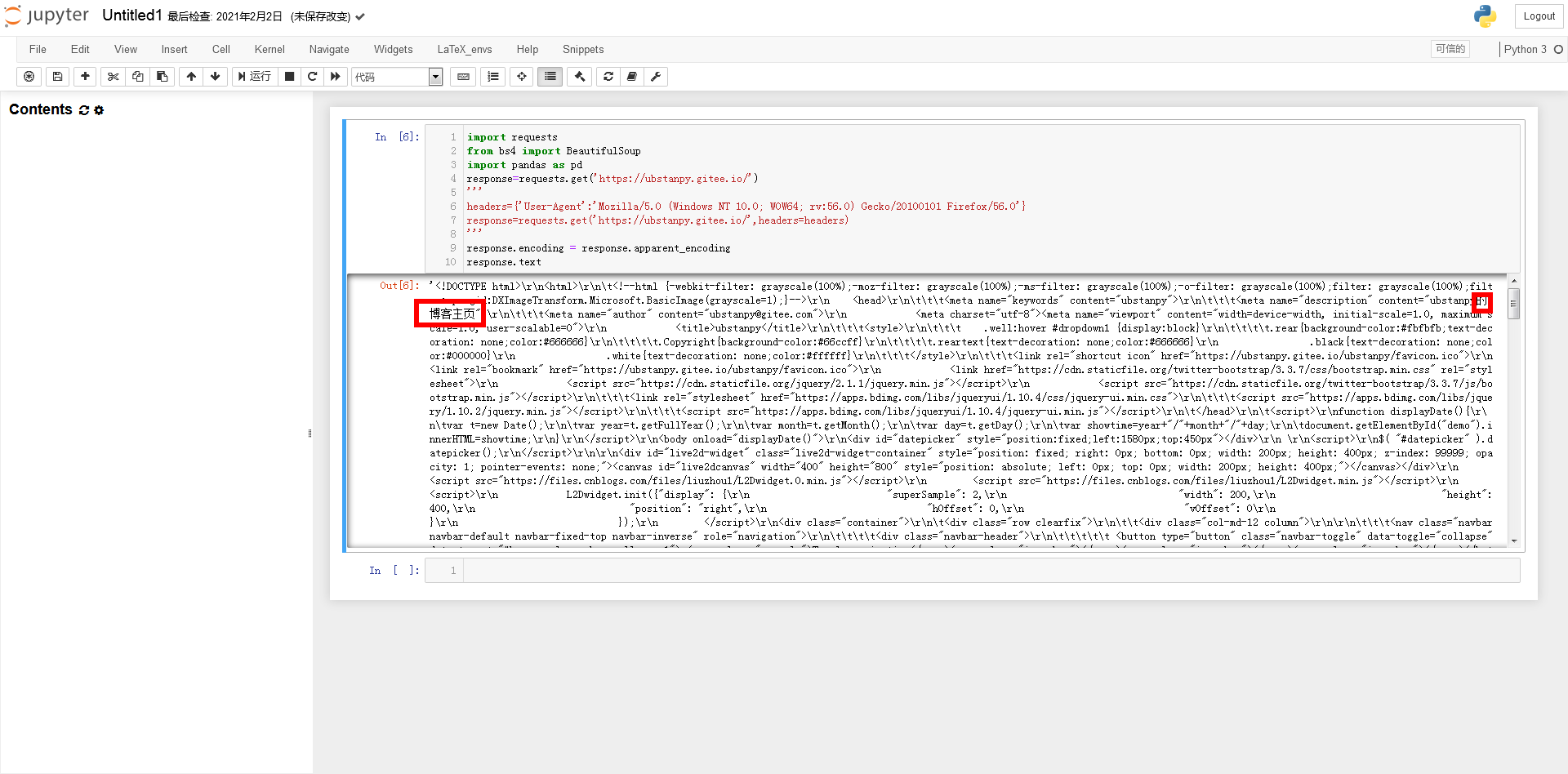
处理完编码问题后
可以看出,相当杂乱,和真正的源码不太一样。“\r”表示当前位置返回到开头,“\n”表示换行,“\t”表示跳到下一个制表符位置。所以要创建一个 bs4.BeautifulSoup 类型的对象:

将文本转换为源代码
BeautifulSoup 模块使响应文本更加规则。
在变量soup“table table-hover”中找到第一个属性类的值为table的代码块:
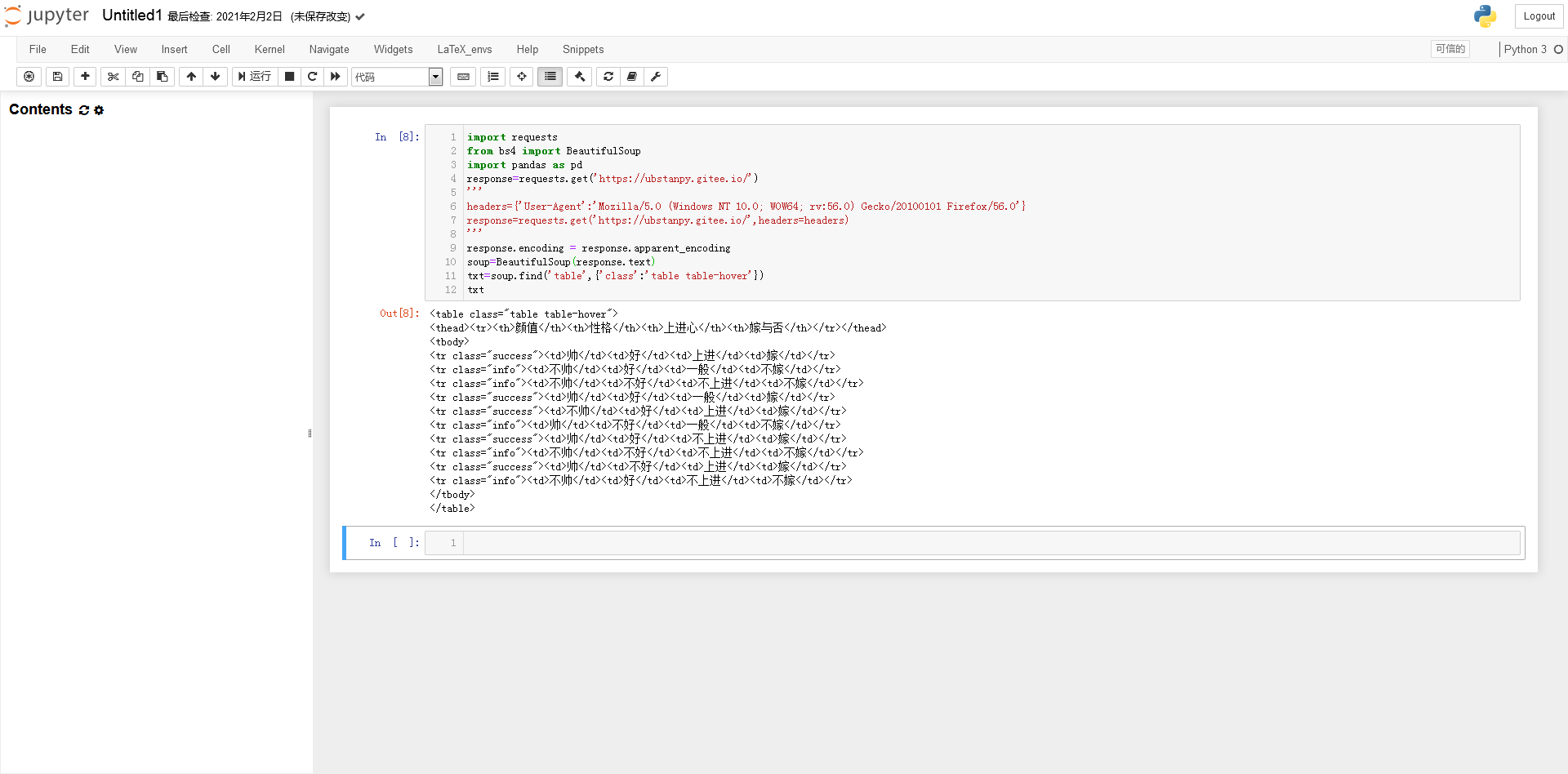
...代码块
获取tbody中所有tr标签的代码块:

全部在tbody...
代码块列表
处理成所需数据的结构(警告!下面有很多图带你看代码):

列

上校
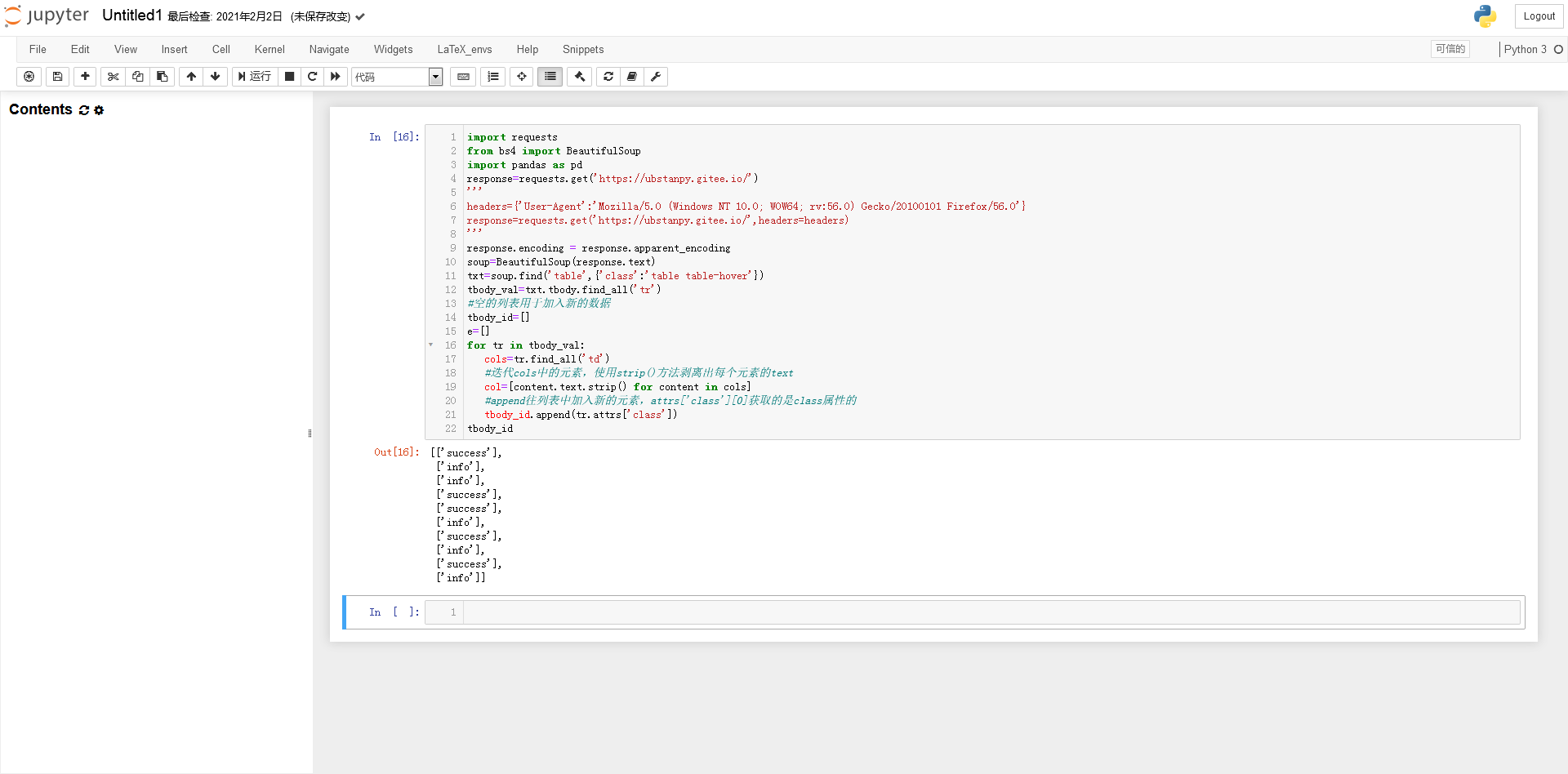
因为 attrs['class'] 返回一个列表
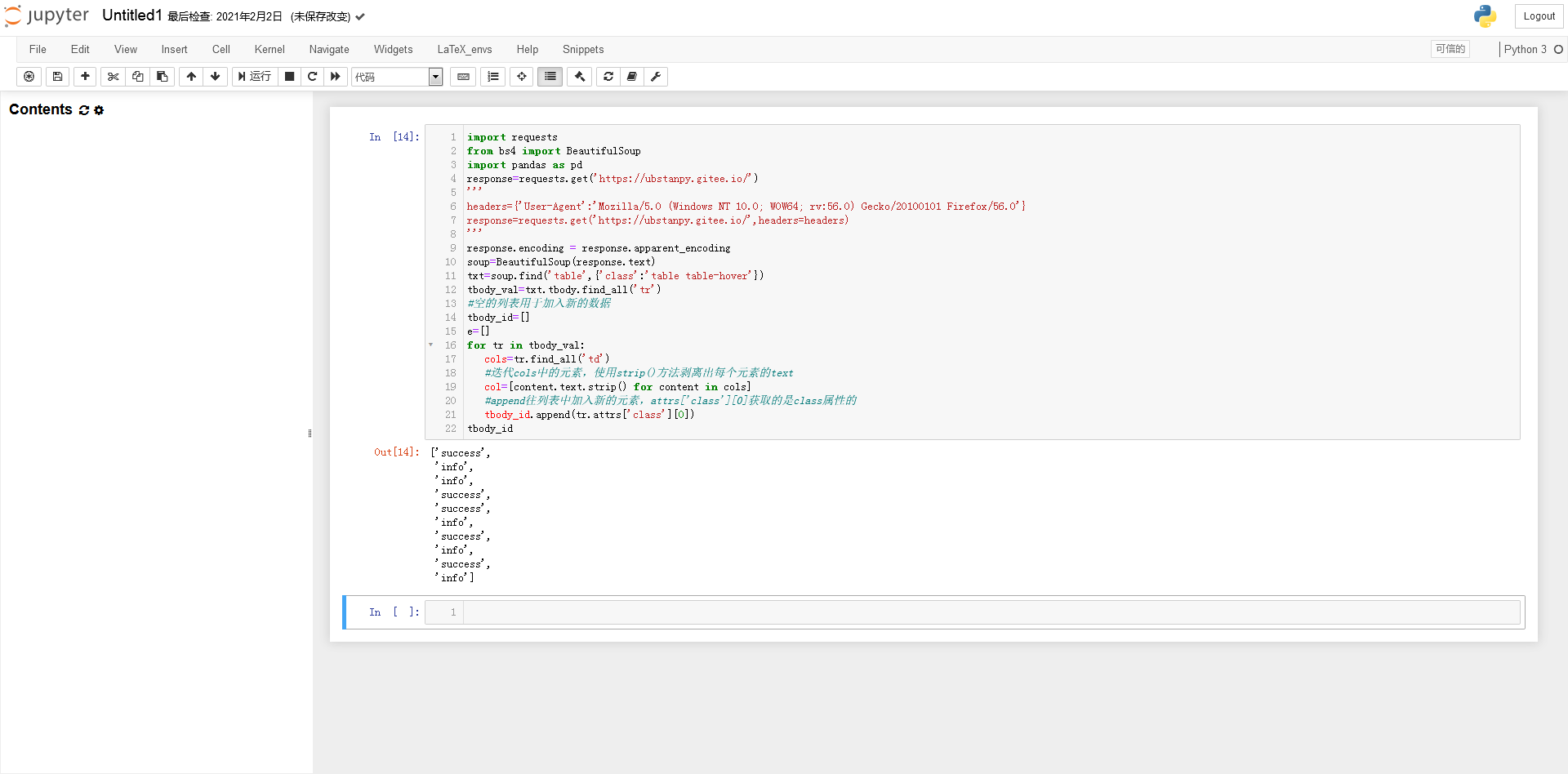
提取list对象中的字符串(否则tbody_id不能作为索引)
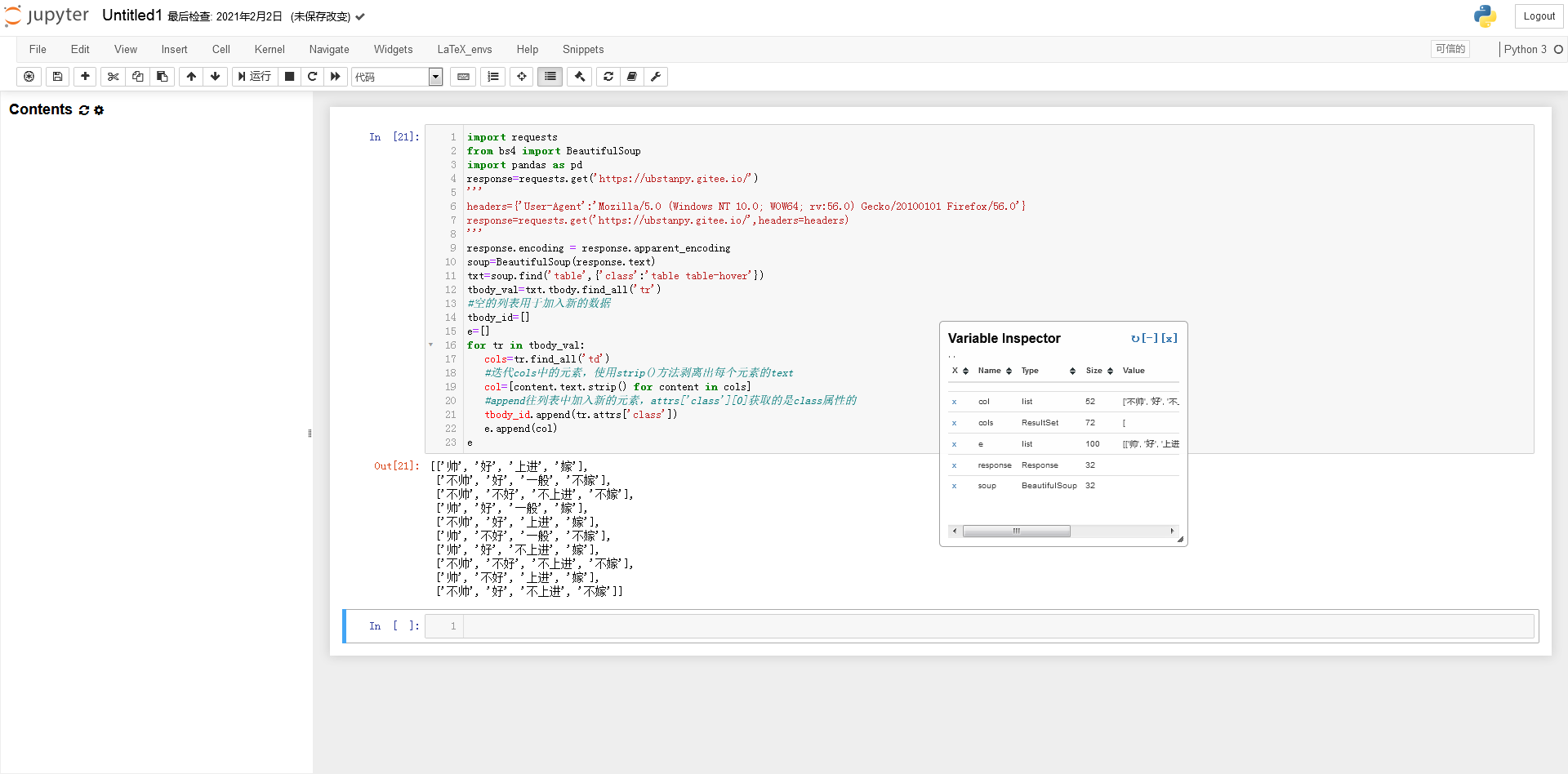
主题数据
将列表数据转换为pandas DataFrame 类型的数据
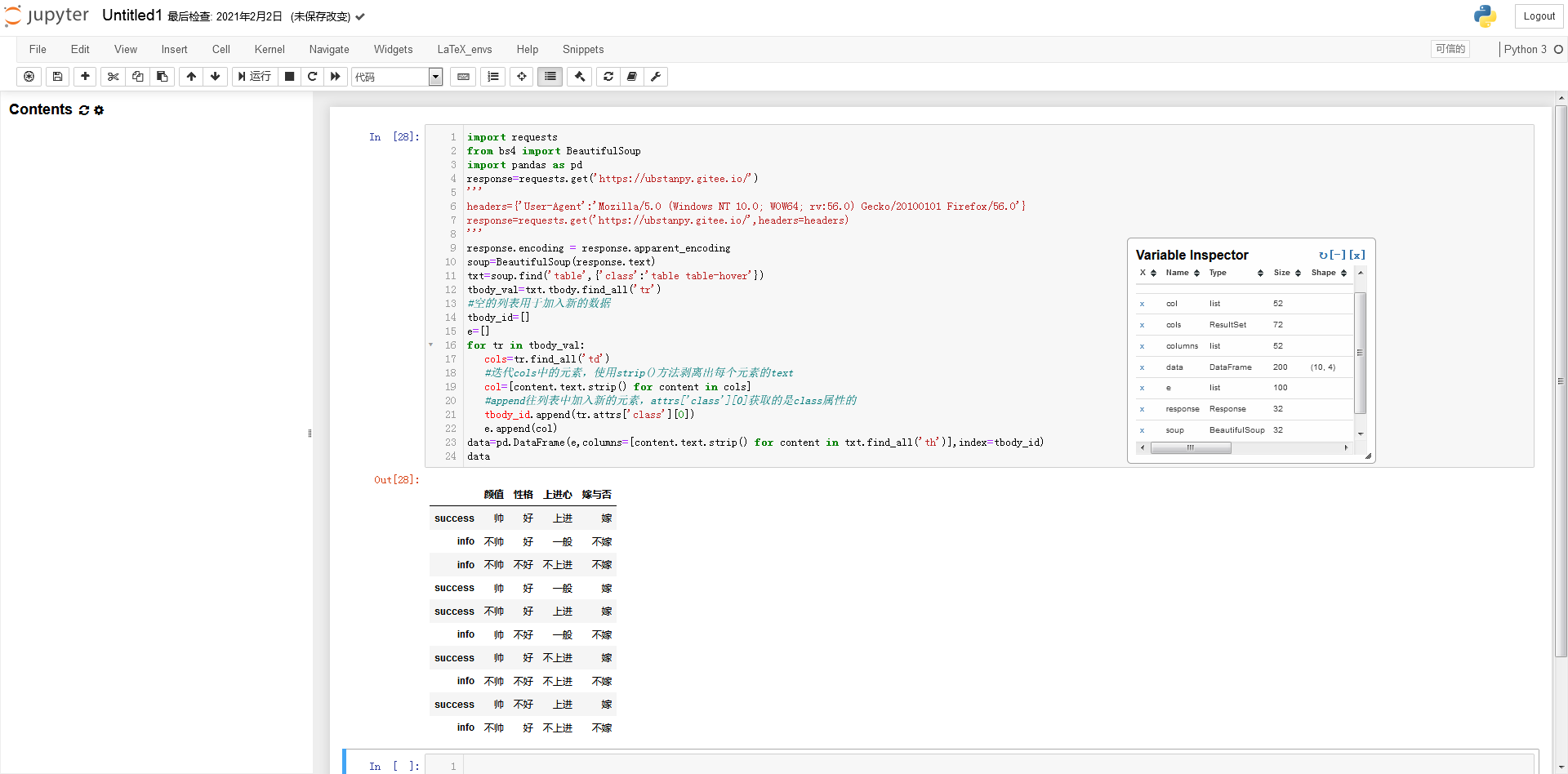
数据表
请根据自己的需要设计。这几乎是结束了。如果要将数据表导出为Excel表格,只需要使用pandas的to_excel()函数即可。
背后的故事
18年,笔者和数学建模的小伙伴遇到一个课题,需要采集大量的足球彩票网站数据进行数据分析。那时我们用的是matlab,对互联网技术或编程了解不多。水平也有待提高。所以我用了最慢的方法,一页一页地采集页面。可以说是慢到让人吐血。那是我第一次通宵工作。如果你现在看,你有更多的选择。
后记
笔者在百度体验中遇到过很多墙,文章还是发不出来。我总是被告知我已经踏上了“雷区”以做出改变。做了几个小时的更改,我仍然无法通过。不得不放弃。之前微信公众号上发的内容没人看,虽然只是比较基础的内容,自然会和别人的代码有很多相似之处。但无论如何,我是在自己的网站上爬取数据,而那个网站只是用于各种实验。
今天突然发现b站的专栏增加了一些作者和其他朋友之前一直在说的功能,有点惊喜!我爱小破站(poyin)。

php 爬虫抓取网页数据( 本发明公开了一种,流程及专利说明(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-11-30 22:19
本发明公开了一种,流程及专利说明(组图))
网络爬虫爬取网页或数据时再次过滤的方法
<p>[专利摘要] 本发明公开了一种网络爬虫在抓取网页或数据时再次过滤的方法。流程如下:输入需要检索的关键词,服务器检索URL地址,然后从检索到的URL地址中抓取目标网页的信息,进入二次搜索 查看全部
php 爬虫抓取网页数据(
本发明公开了一种,流程及专利说明(组图))
网络爬虫爬取网页或数据时再次过滤的方法
<p>[专利摘要] 本发明公开了一种网络爬虫在抓取网页或数据时再次过滤的方法。流程如下:输入需要检索的关键词,服务器检索URL地址,然后从检索到的URL地址中抓取目标网页的信息,进入二次搜索
php 爬虫抓取网页数据(开发爬虫其实不用纠结用什么语言,省去一次爬虫开发不难)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-29 01:19
因为我已经开始开发一个蜘蛛池站群系统,其中涉及爬虫自动去全网寻找符合关键词或关键词密度标准的页面,然后加速内容,然后使用它。NLP相关的技术有伪原创,定期将文章发布到库中,发布这样一个模块,也是用php开发的。我也在这里和大家分享一下我对爬虫的看法。
实际上,您无需担心使用哪种语言来开发爬虫。只要PHP在性能不太高的情况下完全够用,我也推荐PHP工程师用PHP来做,这样可以节省学习一门新语言的时间成本。
再次,爬虫开发并不难。
主要是定位到你想要实现的爬虫类型。
根据互联网上所有爬虫的功能和特点,可分为批处理型、增量型和垂直型三种。
批处理类型,具有明显的爬取范围和目标,设置爬取时间限制、爬取数据限制、或在固定范围内爬取页面限制等,当爬虫的任务达到预设目标时停止。一般来说,采集 工具或内容采集 任务都是批处理类型。一般只抓取固定网站的固定内容,或者为某个资源设置固定的目标数据量。当达到设定的限制时,抓取的数据或时间将自动停止。这种爬虫是典型的批量爬虫。
增量类型也可以称为通用类型。百度、谷歌、搜狗等搜索引擎的爬虫可以称为增量爬虫。增量式不同于批处理式。没有固定的目标、范围和时间限制。一般会无休止地爬取,直到抓到全网的数据。增量类型一般不仅需要爬取尽可能多的页面,还要对已经爬取过的页面进行爬取和更新。因为这些爬虫爬进数据库的页面不是静态的,可能会更新,甚至404。一般来说,增量爬虫的这些功能应该是标准的。至于去重,排名不在这里。在答案中讨论。
垂直型,也叫聚焦爬虫,只爬取固定主题内容或固定行业网页,一般集中在一定的有限范围内进行增量爬取。垂直爬虫不像增量爬虫那样追求大而全的覆盖。相反,他们在增量爬虫上增加了对网页抓取的限制,根据需求抓取收录目标内容的网页。不符合要求的网页就让它静静地躺在url队列中。比如我之前做的蜘蛛池内容爬虫模块就是这个垂直爬虫。
以上为大家大致介绍了爬虫的种类。我猜你应该可以大致定位到你要开发的爬虫。
谈技术关键词,开始开发的时候直接查这几个字,然后用上。
CURL:不用说,如果要爬取一个页面,首先要请求这个页面,得到对方服务器返回的数据(一般是html,如果直接看懂别人的api接口,就当我没看吧说吧)过去这句话)。
simple_html_dom:HTML 节点解析器。使用curl请求html文档后,可以用这个来解析dom节点,方便匹配需要采集爬取的内容。
正则表达式:用于匹配你想要的内容,与simple_html_dom功能相同,但会更加灵活。如果两者匹配起来,就会更加流畅。哈哈:)
worker 或 swoole:用于做多线程或多进程以提高效率。我更推荐workerman,因为学习成本低,文档清晰易学!Swoole 对新手确实很不友好,但是它的功能比workerman 强一点,这里就不讨论了。
Redis:用于存储 URL 队列。如果不追求太高的效率,可以无视。
对于这些关键词来说,入门级的爬虫差不多就够了。很想研究一下数千万的采集对分布式爬虫的追求。我建议出去左转 Python 或其他语言主题下的提问。
最后说一下实现思路。
首页上的爬虫需要一个种子页,比如“中国新闻网”首页。这个爬虫使用curl请求种子页面,获取html数据,使用正则表达式匹配a标签的所有href属性,然后根据自己定义的一些规则匹配符合规则的url或者url已自行处理。例如,一些a标签可能没有http或https头,或者可能有没有域名的url,例如“/news/gn/”。这时候你需要做一点判断和处理,把添加的加进去,然后用sha1加密url,然后用hash去查数据库看是否有相同的hash,如果有,表示url已经有了(go Heavy),然后将url和hash同时存入url队列数据库中。
做完以上操作后,一定要记得给被爬取的URL一个已爬取状态,避免重复爬取。
然后在重复之前的操作之前,从数据库中检查一个新的没有被爬取过的URL,这样你的爬虫就形成了,它会继续往你的URL队列中添加URL。
关键时刻到了。如果我们简单地爬取URL并放入数据库,那是没有用的,对吧?
这时候该说一下内容采集了,url就在那里。这时候写一个爬虫,不断的取出url库中的url来爬回这个页面的内容,然后再写规则匹配内容之后,就可以保存到数据库中了。
就是这样。这个入门级爬虫就做好了。
但是真正的爬虫开发工作肯定会遇到很多很多的问题和意想不到的问题,比如:蜘蛛陷阱、反爬虫、动态加载的内容无法爬取、效率问题、程序报错后是否有重启机制并在遇到异常、法律风险等问题后停止运行。
以下所有问题都留给你在实战中自己解决,因为每个人的业务不同,报出的错误肯定也不同。没有办法说的太清楚。这篇文章文章主要是为了给大家提供一个思路。我也欢迎大家加入我。让我们一起交流讨论爬虫的各种知识和技巧。如果人多,我也可以组成一个交流群,大家交流。学习。
一不小心写了两千多字,没费心复习这句话,没啥意思。如果有错别字,大家都会看的。我的 vx 有问题。 查看全部
php 爬虫抓取网页数据(开发爬虫其实不用纠结用什么语言,省去一次爬虫开发不难)
因为我已经开始开发一个蜘蛛池站群系统,其中涉及爬虫自动去全网寻找符合关键词或关键词密度标准的页面,然后加速内容,然后使用它。NLP相关的技术有伪原创,定期将文章发布到库中,发布这样一个模块,也是用php开发的。我也在这里和大家分享一下我对爬虫的看法。
实际上,您无需担心使用哪种语言来开发爬虫。只要PHP在性能不太高的情况下完全够用,我也推荐PHP工程师用PHP来做,这样可以节省学习一门新语言的时间成本。
再次,爬虫开发并不难。
主要是定位到你想要实现的爬虫类型。
根据互联网上所有爬虫的功能和特点,可分为批处理型、增量型和垂直型三种。
批处理类型,具有明显的爬取范围和目标,设置爬取时间限制、爬取数据限制、或在固定范围内爬取页面限制等,当爬虫的任务达到预设目标时停止。一般来说,采集 工具或内容采集 任务都是批处理类型。一般只抓取固定网站的固定内容,或者为某个资源设置固定的目标数据量。当达到设定的限制时,抓取的数据或时间将自动停止。这种爬虫是典型的批量爬虫。
增量类型也可以称为通用类型。百度、谷歌、搜狗等搜索引擎的爬虫可以称为增量爬虫。增量式不同于批处理式。没有固定的目标、范围和时间限制。一般会无休止地爬取,直到抓到全网的数据。增量类型一般不仅需要爬取尽可能多的页面,还要对已经爬取过的页面进行爬取和更新。因为这些爬虫爬进数据库的页面不是静态的,可能会更新,甚至404。一般来说,增量爬虫的这些功能应该是标准的。至于去重,排名不在这里。在答案中讨论。
垂直型,也叫聚焦爬虫,只爬取固定主题内容或固定行业网页,一般集中在一定的有限范围内进行增量爬取。垂直爬虫不像增量爬虫那样追求大而全的覆盖。相反,他们在增量爬虫上增加了对网页抓取的限制,根据需求抓取收录目标内容的网页。不符合要求的网页就让它静静地躺在url队列中。比如我之前做的蜘蛛池内容爬虫模块就是这个垂直爬虫。
以上为大家大致介绍了爬虫的种类。我猜你应该可以大致定位到你要开发的爬虫。
谈技术关键词,开始开发的时候直接查这几个字,然后用上。
CURL:不用说,如果要爬取一个页面,首先要请求这个页面,得到对方服务器返回的数据(一般是html,如果直接看懂别人的api接口,就当我没看吧说吧)过去这句话)。
simple_html_dom:HTML 节点解析器。使用curl请求html文档后,可以用这个来解析dom节点,方便匹配需要采集爬取的内容。
正则表达式:用于匹配你想要的内容,与simple_html_dom功能相同,但会更加灵活。如果两者匹配起来,就会更加流畅。哈哈:)
worker 或 swoole:用于做多线程或多进程以提高效率。我更推荐workerman,因为学习成本低,文档清晰易学!Swoole 对新手确实很不友好,但是它的功能比workerman 强一点,这里就不讨论了。
Redis:用于存储 URL 队列。如果不追求太高的效率,可以无视。
对于这些关键词来说,入门级的爬虫差不多就够了。很想研究一下数千万的采集对分布式爬虫的追求。我建议出去左转 Python 或其他语言主题下的提问。
最后说一下实现思路。
首页上的爬虫需要一个种子页,比如“中国新闻网”首页。这个爬虫使用curl请求种子页面,获取html数据,使用正则表达式匹配a标签的所有href属性,然后根据自己定义的一些规则匹配符合规则的url或者url已自行处理。例如,一些a标签可能没有http或https头,或者可能有没有域名的url,例如“/news/gn/”。这时候你需要做一点判断和处理,把添加的加进去,然后用sha1加密url,然后用hash去查数据库看是否有相同的hash,如果有,表示url已经有了(go Heavy),然后将url和hash同时存入url队列数据库中。
做完以上操作后,一定要记得给被爬取的URL一个已爬取状态,避免重复爬取。
然后在重复之前的操作之前,从数据库中检查一个新的没有被爬取过的URL,这样你的爬虫就形成了,它会继续往你的URL队列中添加URL。
关键时刻到了。如果我们简单地爬取URL并放入数据库,那是没有用的,对吧?
这时候该说一下内容采集了,url就在那里。这时候写一个爬虫,不断的取出url库中的url来爬回这个页面的内容,然后再写规则匹配内容之后,就可以保存到数据库中了。
就是这样。这个入门级爬虫就做好了。
但是真正的爬虫开发工作肯定会遇到很多很多的问题和意想不到的问题,比如:蜘蛛陷阱、反爬虫、动态加载的内容无法爬取、效率问题、程序报错后是否有重启机制并在遇到异常、法律风险等问题后停止运行。
以下所有问题都留给你在实战中自己解决,因为每个人的业务不同,报出的错误肯定也不同。没有办法说的太清楚。这篇文章文章主要是为了给大家提供一个思路。我也欢迎大家加入我。让我们一起交流讨论爬虫的各种知识和技巧。如果人多,我也可以组成一个交流群,大家交流。学习。
一不小心写了两千多字,没费心复习这句话,没啥意思。如果有错别字,大家都会看的。我的 vx 有问题。
php 爬虫抓取网页数据(爬取空气质量检测网之部分城市的历年每天质量数据思路)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-29 01:17
爬取空气质检网多年来部分城市的日常质量数据思路-------------------------------- --- ------从某城市空气质量网页获取某城市的月度链接,然后爬取月表数据。连云港市:php?city=连云港2014年5月连云港空气质量:php?city=连云港&month=2014-05遇到的问题-------------------- --- -------------------获取的网页中的表格数据是隐藏的,尝试请求是无法获取的。判断可能是动态加载网页尝试----------------------------------------- 1. 通过XHR、js找到隐藏数据的加载网页,但是没有找到。2. 使用phantomjs.get() result=pd.read_html 获取隐藏表数据,但不稳定,
仍然遇到的问题: -----------------------------------------Crawl one Data is available在网页上,但是如果连续检索网页会出现两个错误。1.Message: ReferenceError: items is not defined2.connection denied 解决方法:1.connection denied 问题,可能是打开的网页太多,使用driver.quit()< @2. 如果execute_script 仍然失败,请尝试pd.read_html 获取信息。之前使用phantomjs获取空表的时候,可能是因为加载不足,使用Waite直到表出现才获取网页Element=wait.until(EC.element_to_be_clickable((By.XPATH,"/html/body) /div[3] /div[1]/div[1]/table/tbody")))3. 偶尔会出现输出为空的情况。使用循环。如果输出表为空,请再次获取。if len(result)>1:filename = str(month) +'.xls'result.to_excel('E:\python\case program\data\\' + filename)print('successfully saved'+filename)driver .退出()else:driver.quit()return getdata(monthhref,month) 查看全部
php 爬虫抓取网页数据(爬取空气质量检测网之部分城市的历年每天质量数据思路)
爬取空气质检网多年来部分城市的日常质量数据思路-------------------------------- --- ------从某城市空气质量网页获取某城市的月度链接,然后爬取月表数据。连云港市:php?city=连云港2014年5月连云港空气质量:php?city=连云港&month=2014-05遇到的问题-------------------- --- -------------------获取的网页中的表格数据是隐藏的,尝试请求是无法获取的。判断可能是动态加载网页尝试----------------------------------------- 1. 通过XHR、js找到隐藏数据的加载网页,但是没有找到。2. 使用phantomjs.get() result=pd.read_html 获取隐藏表数据,但不稳定,
仍然遇到的问题: -----------------------------------------Crawl one Data is available在网页上,但是如果连续检索网页会出现两个错误。1.Message: ReferenceError: items is not defined2.connection denied 解决方法:1.connection denied 问题,可能是打开的网页太多,使用driver.quit()< @2. 如果execute_script 仍然失败,请尝试pd.read_html 获取信息。之前使用phantomjs获取空表的时候,可能是因为加载不足,使用Waite直到表出现才获取网页Element=wait.until(EC.element_to_be_clickable((By.XPATH,"/html/body) /div[3] /div[1]/div[1]/table/tbody")))3. 偶尔会出现输出为空的情况。使用循环。如果输出表为空,请再次获取。if len(result)>1:filename = str(month) +'.xls'result.to_excel('E:\python\case program\data\\' + filename)print('successfully saved'+filename)driver .退出()else:driver.quit()return getdata(monthhref,month)
php 爬虫抓取网页数据(PHP爬虫实现方法直接采用PHPcurl来抓取数据socket方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-26 12:07
PHP爬虫总结
PHP爬虫现在网上爬虫很多很多,五花八门,但是大家都不喜欢用PHP写爬虫。可能是因为不稳定,组件库太少。反正 PHP 写起来还是很简单的。 curl的实现方法直接使用PHP curl抓取数据。 socket方法使用最原创的socket方法。这里有一个https:hightmanpspider 项目,非常完整。它还使用了腾讯云的主机。没有任何限制,直接使用即可。 curl方法使用爬取网页步骤设置种子url,一般是站点的域名。通过这个首页一步步抓取seed url,分析这个页面,得到所有相关的url,根据是否抓取外部站点策略来判断。对url进行处理,判断是否是需要爬取的网页。如果是要爬取的网页,则进行存储处理。如果不是,请更新队列。有多种PHP爬虫推荐:https:smartengphp-crawler https:smartengpspider https:smartengskycaiji https:smartengQueryList 这里重点介绍第一个:PHP实现的轻量级爬虫,只提供爬虫核心调度功能
994 查看全部
php 爬虫抓取网页数据(PHP爬虫实现方法直接采用PHPcurl来抓取数据socket方法)
PHP爬虫总结
PHP爬虫现在网上爬虫很多很多,五花八门,但是大家都不喜欢用PHP写爬虫。可能是因为不稳定,组件库太少。反正 PHP 写起来还是很简单的。 curl的实现方法直接使用PHP curl抓取数据。 socket方法使用最原创的socket方法。这里有一个https:hightmanpspider 项目,非常完整。它还使用了腾讯云的主机。没有任何限制,直接使用即可。 curl方法使用爬取网页步骤设置种子url,一般是站点的域名。通过这个首页一步步抓取seed url,分析这个页面,得到所有相关的url,根据是否抓取外部站点策略来判断。对url进行处理,判断是否是需要爬取的网页。如果是要爬取的网页,则进行存储处理。如果不是,请更新队列。有多种PHP爬虫推荐:https:smartengphp-crawler https:smartengpspider https:smartengskycaiji https:smartengQueryList 这里重点介绍第一个:PHP实现的轻量级爬虫,只提供爬虫核心调度功能
994
php 爬虫抓取网页数据(PHP中如何利用爬虫_get_contents()效果 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-11-24 21:18
)
爬虫是按照一定的规则自动抓取万维网上信息的程序或脚本。
我们通常使用搜索引擎浏览网页,有很多与预期信息不匹配的结果;而且信息量巨大,有了结果之后,还要费很大力气来过滤信息。爬虫诞生了,我们可以写一个脚本或者程序,让他按照我们的需要按照设定的规则抓取网页信息,过滤出我们需要的结果。
首先,PHP中可以获取万维网页面的函数有很多,比如:file_get_contents()或者curl扩展,或者ob_get_contents()获取缓冲区等,最实用最常用的就是file_get_contents( )。例子:
目标页面
代码和效果
打开文件后的比较
因此,我们可以使用file_get_contents()来开发爬虫。
步:
1. 解析url规则
第一页:
第二页:
第三页:
在第一页后加&pn=0和第一页内容一样,所以每页的pn参数会增加50
可以概括为:&pn=(当前页码-1)*50
2. 根据规则循环抓取内容
3. 根据需求定期匹配需要的内容(可根据实际需求做)
4. 积分结果(写入文件)
<p>//爬取前3页
for($i=1;$i 查看全部
php 爬虫抓取网页数据(PHP中如何利用爬虫_get_contents()效果
)
爬虫是按照一定的规则自动抓取万维网上信息的程序或脚本。
我们通常使用搜索引擎浏览网页,有很多与预期信息不匹配的结果;而且信息量巨大,有了结果之后,还要费很大力气来过滤信息。爬虫诞生了,我们可以写一个脚本或者程序,让他按照我们的需要按照设定的规则抓取网页信息,过滤出我们需要的结果。
首先,PHP中可以获取万维网页面的函数有很多,比如:file_get_contents()或者curl扩展,或者ob_get_contents()获取缓冲区等,最实用最常用的就是file_get_contents( )。例子:
目标页面
代码和效果
打开文件后的比较
因此,我们可以使用file_get_contents()来开发爬虫。
步:
1. 解析url规则
第一页:
第二页:
第三页:
在第一页后加&pn=0和第一页内容一样,所以每页的pn参数会增加50
可以概括为:&pn=(当前页码-1)*50
2. 根据规则循环抓取内容
3. 根据需求定期匹配需要的内容(可根据实际需求做)
4. 积分结果(写入文件)
<p>//爬取前3页
for($i=1;$i
php 爬虫抓取网页数据(股票的技术分析到底有多大作用,大数据爬虫技术)
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-11-23 06:06
股票的技术分析有多大用处?
这里提到的技术分析也是每个股票投资者需要掌握的知识。包括三点:一是关注交易量的变化;二是要注意股票操作模式;三是注重技术指标。
很多人认为一个好的股票投资者靠运气。事实上,事实并非如此。俗话说,三分靠运气,七分靠努力。作为一个聪明而专业的股票投资者,你首先要考虑你需要买什么,你买的股票价值在哪里。当然,对之前购买股票的公司的了解也很重要。重要的是要了解主要股票价格的波动规律,依法买入,不是炒作,而是要靠经验和技术分析来准备。.
股市的竞争越来越激烈,能混进去的一群人,才算是合格的股票投资者。
因此,成为合格的股票投资者是一个渐进的过程。当你积累了更多的经验,对市场状况有了足够的了解,就可以达到量变质变的效果,然后就敢于大胆投资了。大数据爬虫技术有哪些功能
1、 爬虫技术概述
网络爬虫是根据一定的规则自动抓取万维网信息的程序或脚本。它们广泛用于互联网搜索引擎或其他类似的网站,可以自动将采集它所能访问的页面的所有内容获取或更新这些网站@的内容和检索方法>. 从功能上来说,爬虫一般分为三部分:数据采集、处理、存储。
传统爬虫从一个或几个初始网页的网址开始,获取初始网页上的网址,在网页抓取过程中不断从当前页面中提取新的网址放入队列中,直到达到一定的停止条件系统的满足。聚焦爬虫的工作流程比较复杂。需要按照一定的网页分析算法过滤与主题无关的链接,保留有用的链接,放入URL队列等待被抓取。然后,它会根据一定的搜索策略从队列中选择下一个要抓取的网页的网址,重复上述过程,直到达到系统的某个条件时停止。另外,所有爬虫爬取的网页都会被系统存储起来,进行一定的分析、过滤、并为以后的查询和检索建立索引;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。
与一般网络爬虫相比,聚焦爬虫需要解决三个主要问题:
(1) 爬取目标的描述或定义;
(2) 对网页或数据的分析和过滤;
(3) URL 搜索策略。
2、爬取的原理
2.1 网络爬虫原理
网络爬虫系统的作用是下载网页数据,为搜索引擎系统提供数据源。许多大型互联网搜索引擎系统被称为基于Web数据的搜索引擎系统,如谷歌和百度。这说明了网络爬虫系统在搜索引擎中的重要性。除了供用户阅读的文本信息外,网页还收录一些超链接信息。网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。正是因为这个采集过程就像一个爬虫或蜘蛛在网络上漫游,所以被称为网络爬虫系统或网络蜘蛛系统,英文称为Spider或Crawler。
2.2 网络爬虫系统的工作原理
在网络爬虫的系统框架中,主要流程由控制器、解析器和资源库三部分组成。控制器的主要工作是为多线程中的每个爬虫线程分配工作任务。解析器的主要工作是下载网页并处理页面,主要是处理一些JS脚本标签、CSS代码内容、空格字符、HTML标签等内容。爬虫的基本工作由解析器完成。资源库用于存储下载的网页资源,一般使用Oracle数据库等大型数据库存储,并建立索引。
控制器
控制器是网络爬虫的**控制器。主要负责根据系统传递过来的URL链接分配一个线程,然后启动线程调用爬虫对网页进行爬取。
解析器
解析器是网络爬虫的主要部分。它的主要任务包括:下载网页,处理网页的文本,如过滤,提取特殊的HTML标签,分析数据。
资源库
主要用于存储网页中下载的数据记录,并提供生成索引的目标源。中大型数据库产品包括:Oracle、Sql Server等。
网络爬虫系统一般会选择一些输出度(网页中超链接的数量)较高的比较重要的URL作为种子URL集合。网络爬虫系统使用这些种子集作为初始 URL 开始数据爬取。由于网页中收录链接信息,因此会通过现有网页的网址获取一些新的网址。网页之间的指向结构可以看作是一个森林。每个种子 URL 对应的网页是森林中一棵树的根节点。. 这样,网络爬虫系统就可以按照广度优先算法或深度优先算法遍历所有网页。由于深度优先搜索算法可能会导致爬虫系统陷入网站内部,不利于搜索离网站首页较近的网页信息,采集网页一般采用广度优先搜索算法。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部取一个 URL 来下载相应的网页。获取并存储网页内容后,通过解析网页中的链接信息,可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,如此周而复始,直到遍历全网或满足某个条件,才会停止。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部取一个 URL 来下载相应的网页。获取并存储网页内容后,通过解析网页中的链接信息,可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,如此周而复始,直到遍历全网或满足某个条件,才会停止。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部取一个 URL 来下载相应的网页。获取并存储网页内容后,通过解析网页中的链接信息,可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,如此周而复始,直到遍历全网或满足某个条件,才会停止。并将这些 URL 添加到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,如此周而复始,直到遍历全网或满足某个条件,才会停止。并将这些 URL 添加到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,如此周而复始,直到遍历全网或满足某个条件,才会停止。
网络爬虫的基本工作流程如下:
1.首先选择一些精心挑选的种子网址;
2.将这些URL放入URL队列进行抓取;
3. 从待爬取的URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,并存储到下载的网页库中。另外,将这些网址放入已爬取的网址队列中;
4.对爬取的URL队列中的URL进行分析,分析其中的其他URL,将这些URL放入URL队列进行爬取,从而进入下一个循环。
2.3 爬取策略
在爬虫系统中,要爬取的URL队列是一个非常重要的部分。URL队列中要爬取的URL的顺序也是一个很重要的问题,因为它涉及到先爬哪个页面,后爬哪个页面。确定这些 URL 顺序的方法称为抓取策略。下面重点介绍几种常见的爬取策略:
2.3.1 深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,逐个跟踪每一个链接,处理完这一行后转移到下一个起始页,继续跟踪链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.3.2 广度优先遍历策略
广度优先遍历策略的基本思想是将新下载的网页中找到的链接直接**到待抓取的URL队列的末尾。即网络爬虫会先抓取起始网页中所有链接的网页,然后选择其中一个链接的网页,继续抓取该网页中链接的所有网页。以上图为例:
遍历路径:ABCDEF GHI
2.3.3 反向链接计数策略
反向链接数是指从其他网页链接到某个网页的数量。反向链接的数量表示网页内容被他人推荐的程度。因此,很多时候搜索引擎的爬取系统都会使用这个指标来评估网页的重要性,从而决定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量不能完全坐等别人的重视。因此,搜索引擎通常会考虑一些可靠的反向链接。
2.3.4 部分 PageRank 策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,连同要爬取的URL队列中的URL,形成一个网页集合,计算每个页面的PageRank值,经过计算完成后,将要爬取的URL队列中的URL按照PageRank值的大小进行排列,依次爬取页面。
如果每个页面都被抓取,则重新计算 PageRank 值。一个折衷的方案是:每爬取K个页面后,重新计算PageRank值。但是,这种情况下仍然存在一个问题:对于从下载页面分析出来的链接,也就是我们前面提到的未知网页部分,暂时没有PageRank值。为了解决这个问题,这些页面会被赋予一个临时的PageRank值:将所有传入该页面链中的PageRank值聚合起来,从而形成未知页面的PageRank值参与排名。
2.3.5 OPIC 策略
该算法实际上对页面的重要性进行评分。在算法开始之前,给所有页面相同的初始现金(cash)。下载某个页面P后,将P的现金分配给所有从P解析的链接,清空P的现金。待抓取的 URL 队列中的所有页面均按照现金的数量进行排序。
2.3.6大站优先策略
待爬取的 URL 队列中的所有网页,均按照其所属的 网站 进行分类。对于网站需要下载的页面较多的,优先下载。这种策略因此被称为大站优先策略。
3、 爬虫分类
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他来开发网络爬虫?上面提到的爬虫基本上可以分为三类:
(1)分布式爬虫:Nutch
(2)JAVA 爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
3.1 个分布式爬虫
爬虫采用分布式,主要解决两个问题:
1)海量网址管理
2)网速
最流行的分布式爬虫是 Apache 的 Nutch。但是对于大多数用户来说,Nutch 是这些类型的爬虫中最糟糕的选择,原因如下:
1)Nutch 是一款专为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。Nutch 运行的一组进程中有三分之二是为搜索引擎设计的。精细提取没有多大意义。换句话说,使用 Nutch 进行数据提取会在不必要的计算上浪费大量时间。而如果你试图通过二次开发让Nutch适合精炼业务,你基本上会破坏Nutch的框架,将Nutch改得面目全非,并有能力修改Nutch。自己写一个新的确实更好。分布式爬虫框架。
2)Nutch 依赖于hadoop 来运行,而hadoop 本身就消耗大量时间。如果集群机器数量少,爬取速度不如单机爬虫快。
3)Nutch有插件机制,作为亮点推广。可以看到一些开源的Nutch插件,提供精细的提取功能。但是任何开发过 Nutch 插件的人都知道 Nutch 的插件系统有多烂。使用反射机制加载和调用插件使得编写和调试程序变得极其困难,更不用说在其上开发复杂的精细提取系统了。并且Nutch没有提供相应的插件挂载点进行精细提取。Nutch的插件只有五六个挂载点,而这五六个挂载点是为搜索引擎服务的,不提供精细提取的挂载点。Nutch的大部分精提取插件都挂载在挂载点“解析器”(parser)上。
4)使用Nutch进行爬虫的二次开发,爬虫的准备和调试所需的时间往往是单机爬虫的十倍以上。学习Nutch源代码的成本非常高,更何况一个团队中的每个人都必须了解Nutch源代码。在调试过程中,会出现程序本身以外的各种问题(hadoop问题、hbase问题)。
5) 很多人说Nutch2有gora,可以持久化数据到avro文件、hbase、mysql等,其实很多人理解错了。这里所说的持久化数据是指在avro、hbase、mysql中存储URL信息(URL管理所需的数据)。这不是您要提取的结构化数据。事实上,对于大多数人来说,URL 信息存在于何处并不重要。
6)Nutch2的版本目前不适合开发。Nutch官方稳定版是nutch2.2.1,但是这个版本绑定了gora-0.3。如果你想和nutch一起使用hbase(大多数人使用nutch2只是为了使用hbase),你只能在0.90版本左右使用hbase,而hadoop版本必须减少到hadoop 0.2左右. 而且,Nutch2的官方教程更具有误导性。Nutch2有两个教程,分别是Nutch1.x和Nutch2.x。Nutch2.x 官网可以支持转到hbase 0.94。但其实这个Nutch2.x指的是Nutch2.3之前和Nutch2.2.1之后的版本。此版本在官方SVN中不断更新。
所以,如果你不是搜索引擎,尽量不要选择Nutch作为爬虫。有些团队喜欢效仿。他们不得不选择Nutch来开发高度提取的爬虫。事实上,这是为了Nutch的声誉。当然,最终的结果往往是项目延期。
如果你是一个搜索引擎,Nutch1.x 是一个非常好的选择。Nutch1.x 与 solr 或 es 合作组成了一个非常强大的搜索引擎。如果非要使用Nutch2,建议等到Nutch2.3发布。当前的 Nutch2 是一个非常不稳定的版本。
3.2 JAVA爬虫
这里将JAVA爬虫单独划分为一个类别,因为JAVA在网络爬虫的生态系统中是非常完备的。相关资料也是最全的。这里可能有争议,我只是随便说说。
其实,开源网络爬虫(框架)的开发很简单,难点复杂的问题(比如DOM树解析定位、字符集检测、海量URL去重)都已经被前人解决了,可以说没有技术含量。包括Nutch,其实Nutch的技术难点就是开发hadoop,代码本身也很简单。从某种意义上说,网络爬虫类似于遍历机器的文件以查找文件中的信息。没有任何困难。之所以选择开源爬虫框架,是为了省事。比如爬虫URL管理、线程池等模块任何人都可以做,但是需要一段时间的调试和修改才能稳定下来。
用于爬虫的功能。用户比较关心的问题往往是:
1)爬虫是否支持多线程,爬虫能不能用agent,能不能抓取重复数据,能不能抓取JS生成的信息?
那些不支持多线程、代理或过滤重复 URL 的不称为开源爬虫。它们被称为循环执行 http 请求。
js生成的信息能否被爬取与爬虫本身关系不大。爬虫主要负责遍历网站和下载页面。爬取js产生的信息与网页信息提取模块有关,往往需要通过模拟浏览器(htmlunit、selenium)来完成。这些模拟浏览器通常需要花费大量时间来处理页面。所以一个策略就是利用这些爬虫来遍历网站,当遇到需要解析的页面时,将页面的相关信息提交给模拟浏览器,完成对JS生成信息的提取。
2)爬虫可以爬取ajax信息吗?
网页上有一些异步加载的数据。爬取这个数据有两种方式:使用模拟浏览器(问题1中描述),或者分析ajax http请求,自己生成ajax请求url,获取返回数据。如果自己生成ajax请求,使用开源爬虫有什么意义?其实还是需要用到开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我需要的ajax请求(列表),我该如何使用这些爬虫来抓取这些请求?
爬虫通常被设计成广度遍历或深度遍历的模式来遍历静态或动态页面。爬取ajax信息属于深网(deep web)的范畴,虽然大部分爬虫不直接支持。但它也可以通过某些方式完成。例如,WebCollector 使用广度遍历来遍历网站。第一轮爬取是爬取种子集(seeds)中的所有URL。简单的说,就是将生成的ajax请求作为种子,放入爬虫中。使用爬虫遍历这些深度为1的种子(默认为广度遍历)。
3)爬虫如何爬取网站登录?
这些开源爬虫都支持在爬取时指定cookies,模拟登录主要依赖cookies。至于如何获取cookie,就不是爬虫的事情了。您可以手动获取cookies,也可以模拟http请求登录,也可以使用模拟浏览器自动登录获取cookies。
4)爬虫如何从网页中提取信息?
开源爬虫一般都集成了网页提取工具。主要支持两种类型的规范:CSS SELECTOR 和 XPATH。至于哪个更好,这里就不做评价了。
5)爬虫是如何保存网页信息的?
一些爬虫带有一个负责持久化的模块。例如,webmagic 有一个叫做管道的模块。通过简单的配置,爬虫提取的信息可以持久化到文件、数据库等中,也有一些爬虫不直接为用户提供数据持久化模块。如 crawler4j 和 webcollector。让用户在网页处理模块中添加提交数据库的操作。至于使用pipeline模块好不好,类似于是否使用ORM来操作数据库的问题。这取决于您的业务。
6)爬虫被网站拦截怎么办?
爬虫已经被网站屏蔽了,一般可以通过多个代理(随机代理)解决。但是,这些开源爬虫一般不直接支持随机代理的切换。因此,用户往往需要自己将获取到的代理放入一个全局数组中,自己编写代码来随机获取代理(从数组中)。
7)网页可以调用爬虫吗?
爬虫的调用是在Web的服务器端调用的,你可以照常使用。所有这些爬虫都可以使用。
8)爬行速度怎么样?
一个单机的开源爬虫的速度基本可以用到机器网速的极限。爬虫速度慢,往往是因为用户线程少,网速慢,或者持久化数据时与数据库交互慢。这些东西往往是由用户的机器和二次开发代码决定的。这些开源爬虫的速度非常好。
9)显然代码写对了,爬不出来数据。是不是爬虫有问题?别的爬虫能解决吗?
如果代码写对了,数据爬不出来,其他爬虫也是一样。在这种情况下,要么 网站 阻止了您,要么您抓取的数据是由 javascript 生成的。爬取数据无法通过改变爬虫来解决。
10)哪个爬虫可以判断网站是否爬完了,哪个爬虫可以根据主题爬取?
爬虫无法判断网站是否爬过,只能尽量覆盖。
至于基于主题的爬取,爬虫只有向下爬取内容才知道主题是什么。所以它通常是从整体上爬下来,然后去过滤内容。如果觉得抓取过于笼统,可以通过限制网址规律等方法缩小范围。
11) 哪个爬虫有更好的设计模式和结构?
设计模式纯属无稽之谈。当软件设计模式好的时候,开发软件,然后总结出几种设计模式。设计模式对软件开发没有指导作用。使用设计模式来设计爬虫只会让爬虫的设计更加臃肿。
在架构上,开源爬虫目前主要是详细数据结构的设计,比如爬取线程池、任务队列等,大家都可以控制。爬虫的业务太简单了,不谈结构。
所以对于JAVA开源爬虫,我觉得,找一个好用的就好了。如果业务复杂,使用哪种爬虫就必须经过复杂的二次开发才能满足需求。
3.3 个非 Java 爬虫
在非JAVA语言编写的爬虫中,有很多优秀的爬虫。这个单独提取为一个类别,不是为了爬虫本身的质量,而是为了larbin、scrapy等爬虫对开发成本的影响。
先说python爬虫,python可以用30行代码完成JAVA 50行代码的任务。Python 代码编写确实很快,但是在调试代码阶段,Python 代码的调试往往比编码阶段节省的时间消耗的时间要多得多。使用python开发,为了保证程序的正确性和稳定性,需要编写更多的测试模块。当然,如果爬取规模不大,爬取业务不复杂,使用scrapy也是相当不错的,可以轻松完成爬取任务。
上图是Scrapy的架构图。绿线是数据流。首先从初始的URL开始,Scheduler将其交给Downloader进行下载,下载完成后,交给Spider进行分析,将需要保存的数据发送到Item Pipeline ,即对数据进行后处理。此外,可以在数据流通道中安装各种中间件来进行必要的处理。所以在开发爬虫的时候,最好先规划好各个模块。我的做法是分别规划下载模块、爬取模块、调度模块、数据存储模块。
对于C++爬虫来说,学习**的成本会比较大。而且你不能只计算一个人的学习成本。如果软件需要团队开发或交接,那将是很多人的学习成本。软件调试并不是那么容易。
还有一些ruby、php爬虫,这里不多评论。确实有一些非常小的数据任务。使用ruby或php非常方便。但是要选择这些语言的开源爬虫,一方面需要调查相关的生态系统,另一方面,这些开源爬虫可能会产生一些你找不到的bug(人少信息少)
4、反爬虫技术
由于搜索引擎的流行,网络爬虫已经成为一种非常流行的网络技术。除了专门从事搜索的谷歌、雅虎、微软、百度,几乎每个大型门户网站网站都有自己的搜索引擎,**小有几十个名字,还有数以万计的未知名字。对于一个内容驱动的网站来说,难免会被网络爬虫光顾。
一些智能搜索引擎爬虫在网站上的爬取频率比较合理,消耗的资源较少,但是很多不好的网络爬虫对网页的爬取能力很差,经常会发送几十上百个请求,重复爬取循环。拿,这种爬虫往往对中小网站是毁灭性的打击,尤其是一些缺乏爬虫编写经验的程序员写的爬虫破坏力极强,网站访问压力会很大高的。, 会导致网站 访问缓慢甚至无法访问。
一般来说,网站是从三个方面进行反爬虫的:用户请求的Headers、用户行为、网站目录和数据加载方式。前两个比较容易遇到,大多数网站反爬虫都是从这几个角度来看的。将采用第三类ajax应用网站,增加爬虫难度。
4.1 个通过 Headers 的反爬虫
从用户请求的Headers反爬取是最常见的反爬取策略。很多网站会检测Headers的User-Agent,还有一些网站会检测Referer(部分资源的防盗链网站就是检测Referer)。如果遇到这种反爬虫机制,可以直接给爬虫添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者修改Referer值为目标网站域名。对于检测header的反爬虫,在爬虫中修改或添加header很容易绕过。
【点评:往往容易被忽视。通过对请求的捕获分析,确定referer,并在程序中模拟访问请求头中添加]
4.2 基于用户行为的反爬虫
网站的另一部分是检测用户行为,比如同一IP在短时间内多次访问同一个页面,或者同一个账号在短时间内多次执行相同的操作。技术分析真的对股票交易有用吗?
技术分析对股票非常有用,因为市场上大部分机构和个人都使用技术分析,所以符合从众原则。当大多数技术分析表明股票正在好转时,资金将开始流入,股票自然会上涨。反之亦然。
技术分析是一个统计概念、历史重复概念和从众心理概念,所以很有用。
但单一指标的技术分析用处不大,一般确认两个或多个技术分析相辅相成。 查看全部
php 爬虫抓取网页数据(股票的技术分析到底有多大作用,大数据爬虫技术)
股票的技术分析有多大用处?

这里提到的技术分析也是每个股票投资者需要掌握的知识。包括三点:一是关注交易量的变化;二是要注意股票操作模式;三是注重技术指标。
很多人认为一个好的股票投资者靠运气。事实上,事实并非如此。俗话说,三分靠运气,七分靠努力。作为一个聪明而专业的股票投资者,你首先要考虑你需要买什么,你买的股票价值在哪里。当然,对之前购买股票的公司的了解也很重要。重要的是要了解主要股票价格的波动规律,依法买入,不是炒作,而是要靠经验和技术分析来准备。.
股市的竞争越来越激烈,能混进去的一群人,才算是合格的股票投资者。
因此,成为合格的股票投资者是一个渐进的过程。当你积累了更多的经验,对市场状况有了足够的了解,就可以达到量变质变的效果,然后就敢于大胆投资了。大数据爬虫技术有哪些功能

1、 爬虫技术概述
网络爬虫是根据一定的规则自动抓取万维网信息的程序或脚本。它们广泛用于互联网搜索引擎或其他类似的网站,可以自动将采集它所能访问的页面的所有内容获取或更新这些网站@的内容和检索方法>. 从功能上来说,爬虫一般分为三部分:数据采集、处理、存储。
传统爬虫从一个或几个初始网页的网址开始,获取初始网页上的网址,在网页抓取过程中不断从当前页面中提取新的网址放入队列中,直到达到一定的停止条件系统的满足。聚焦爬虫的工作流程比较复杂。需要按照一定的网页分析算法过滤与主题无关的链接,保留有用的链接,放入URL队列等待被抓取。然后,它会根据一定的搜索策略从队列中选择下一个要抓取的网页的网址,重复上述过程,直到达到系统的某个条件时停止。另外,所有爬虫爬取的网页都会被系统存储起来,进行一定的分析、过滤、并为以后的查询和检索建立索引;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。
与一般网络爬虫相比,聚焦爬虫需要解决三个主要问题:
(1) 爬取目标的描述或定义;
(2) 对网页或数据的分析和过滤;
(3) URL 搜索策略。
2、爬取的原理
2.1 网络爬虫原理
网络爬虫系统的作用是下载网页数据,为搜索引擎系统提供数据源。许多大型互联网搜索引擎系统被称为基于Web数据的搜索引擎系统,如谷歌和百度。这说明了网络爬虫系统在搜索引擎中的重要性。除了供用户阅读的文本信息外,网页还收录一些超链接信息。网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。正是因为这个采集过程就像一个爬虫或蜘蛛在网络上漫游,所以被称为网络爬虫系统或网络蜘蛛系统,英文称为Spider或Crawler。
2.2 网络爬虫系统的工作原理
在网络爬虫的系统框架中,主要流程由控制器、解析器和资源库三部分组成。控制器的主要工作是为多线程中的每个爬虫线程分配工作任务。解析器的主要工作是下载网页并处理页面,主要是处理一些JS脚本标签、CSS代码内容、空格字符、HTML标签等内容。爬虫的基本工作由解析器完成。资源库用于存储下载的网页资源,一般使用Oracle数据库等大型数据库存储,并建立索引。
控制器
控制器是网络爬虫的**控制器。主要负责根据系统传递过来的URL链接分配一个线程,然后启动线程调用爬虫对网页进行爬取。
解析器
解析器是网络爬虫的主要部分。它的主要任务包括:下载网页,处理网页的文本,如过滤,提取特殊的HTML标签,分析数据。
资源库
主要用于存储网页中下载的数据记录,并提供生成索引的目标源。中大型数据库产品包括:Oracle、Sql Server等。
网络爬虫系统一般会选择一些输出度(网页中超链接的数量)较高的比较重要的URL作为种子URL集合。网络爬虫系统使用这些种子集作为初始 URL 开始数据爬取。由于网页中收录链接信息,因此会通过现有网页的网址获取一些新的网址。网页之间的指向结构可以看作是一个森林。每个种子 URL 对应的网页是森林中一棵树的根节点。. 这样,网络爬虫系统就可以按照广度优先算法或深度优先算法遍历所有网页。由于深度优先搜索算法可能会导致爬虫系统陷入网站内部,不利于搜索离网站首页较近的网页信息,采集网页一般采用广度优先搜索算法。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部取一个 URL 来下载相应的网页。获取并存储网页内容后,通过解析网页中的链接信息,可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,如此周而复始,直到遍历全网或满足某个条件,才会停止。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部取一个 URL 来下载相应的网页。获取并存储网页内容后,通过解析网页中的链接信息,可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,如此周而复始,直到遍历全网或满足某个条件,才会停止。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部取一个 URL 来下载相应的网页。获取并存储网页内容后,通过解析网页中的链接信息,可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,如此周而复始,直到遍历全网或满足某个条件,才会停止。并将这些 URL 添加到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,如此周而复始,直到遍历全网或满足某个条件,才会停止。并将这些 URL 添加到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,如此周而复始,直到遍历全网或满足某个条件,才会停止。
网络爬虫的基本工作流程如下:
1.首先选择一些精心挑选的种子网址;
2.将这些URL放入URL队列进行抓取;
3. 从待爬取的URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,并存储到下载的网页库中。另外,将这些网址放入已爬取的网址队列中;
4.对爬取的URL队列中的URL进行分析,分析其中的其他URL,将这些URL放入URL队列进行爬取,从而进入下一个循环。
2.3 爬取策略
在爬虫系统中,要爬取的URL队列是一个非常重要的部分。URL队列中要爬取的URL的顺序也是一个很重要的问题,因为它涉及到先爬哪个页面,后爬哪个页面。确定这些 URL 顺序的方法称为抓取策略。下面重点介绍几种常见的爬取策略:
2.3.1 深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,逐个跟踪每一个链接,处理完这一行后转移到下一个起始页,继续跟踪链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.3.2 广度优先遍历策略
广度优先遍历策略的基本思想是将新下载的网页中找到的链接直接**到待抓取的URL队列的末尾。即网络爬虫会先抓取起始网页中所有链接的网页,然后选择其中一个链接的网页,继续抓取该网页中链接的所有网页。以上图为例:
遍历路径:ABCDEF GHI
2.3.3 反向链接计数策略
反向链接数是指从其他网页链接到某个网页的数量。反向链接的数量表示网页内容被他人推荐的程度。因此,很多时候搜索引擎的爬取系统都会使用这个指标来评估网页的重要性,从而决定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量不能完全坐等别人的重视。因此,搜索引擎通常会考虑一些可靠的反向链接。
2.3.4 部分 PageRank 策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,连同要爬取的URL队列中的URL,形成一个网页集合,计算每个页面的PageRank值,经过计算完成后,将要爬取的URL队列中的URL按照PageRank值的大小进行排列,依次爬取页面。
如果每个页面都被抓取,则重新计算 PageRank 值。一个折衷的方案是:每爬取K个页面后,重新计算PageRank值。但是,这种情况下仍然存在一个问题:对于从下载页面分析出来的链接,也就是我们前面提到的未知网页部分,暂时没有PageRank值。为了解决这个问题,这些页面会被赋予一个临时的PageRank值:将所有传入该页面链中的PageRank值聚合起来,从而形成未知页面的PageRank值参与排名。
2.3.5 OPIC 策略
该算法实际上对页面的重要性进行评分。在算法开始之前,给所有页面相同的初始现金(cash)。下载某个页面P后,将P的现金分配给所有从P解析的链接,清空P的现金。待抓取的 URL 队列中的所有页面均按照现金的数量进行排序。
2.3.6大站优先策略
待爬取的 URL 队列中的所有网页,均按照其所属的 网站 进行分类。对于网站需要下载的页面较多的,优先下载。这种策略因此被称为大站优先策略。
3、 爬虫分类
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他来开发网络爬虫?上面提到的爬虫基本上可以分为三类:
(1)分布式爬虫:Nutch
(2)JAVA 爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
3.1 个分布式爬虫
爬虫采用分布式,主要解决两个问题:
1)海量网址管理
2)网速
最流行的分布式爬虫是 Apache 的 Nutch。但是对于大多数用户来说,Nutch 是这些类型的爬虫中最糟糕的选择,原因如下:
1)Nutch 是一款专为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。Nutch 运行的一组进程中有三分之二是为搜索引擎设计的。精细提取没有多大意义。换句话说,使用 Nutch 进行数据提取会在不必要的计算上浪费大量时间。而如果你试图通过二次开发让Nutch适合精炼业务,你基本上会破坏Nutch的框架,将Nutch改得面目全非,并有能力修改Nutch。自己写一个新的确实更好。分布式爬虫框架。
2)Nutch 依赖于hadoop 来运行,而hadoop 本身就消耗大量时间。如果集群机器数量少,爬取速度不如单机爬虫快。
3)Nutch有插件机制,作为亮点推广。可以看到一些开源的Nutch插件,提供精细的提取功能。但是任何开发过 Nutch 插件的人都知道 Nutch 的插件系统有多烂。使用反射机制加载和调用插件使得编写和调试程序变得极其困难,更不用说在其上开发复杂的精细提取系统了。并且Nutch没有提供相应的插件挂载点进行精细提取。Nutch的插件只有五六个挂载点,而这五六个挂载点是为搜索引擎服务的,不提供精细提取的挂载点。Nutch的大部分精提取插件都挂载在挂载点“解析器”(parser)上。
4)使用Nutch进行爬虫的二次开发,爬虫的准备和调试所需的时间往往是单机爬虫的十倍以上。学习Nutch源代码的成本非常高,更何况一个团队中的每个人都必须了解Nutch源代码。在调试过程中,会出现程序本身以外的各种问题(hadoop问题、hbase问题)。
5) 很多人说Nutch2有gora,可以持久化数据到avro文件、hbase、mysql等,其实很多人理解错了。这里所说的持久化数据是指在avro、hbase、mysql中存储URL信息(URL管理所需的数据)。这不是您要提取的结构化数据。事实上,对于大多数人来说,URL 信息存在于何处并不重要。
6)Nutch2的版本目前不适合开发。Nutch官方稳定版是nutch2.2.1,但是这个版本绑定了gora-0.3。如果你想和nutch一起使用hbase(大多数人使用nutch2只是为了使用hbase),你只能在0.90版本左右使用hbase,而hadoop版本必须减少到hadoop 0.2左右. 而且,Nutch2的官方教程更具有误导性。Nutch2有两个教程,分别是Nutch1.x和Nutch2.x。Nutch2.x 官网可以支持转到hbase 0.94。但其实这个Nutch2.x指的是Nutch2.3之前和Nutch2.2.1之后的版本。此版本在官方SVN中不断更新。
所以,如果你不是搜索引擎,尽量不要选择Nutch作为爬虫。有些团队喜欢效仿。他们不得不选择Nutch来开发高度提取的爬虫。事实上,这是为了Nutch的声誉。当然,最终的结果往往是项目延期。
如果你是一个搜索引擎,Nutch1.x 是一个非常好的选择。Nutch1.x 与 solr 或 es 合作组成了一个非常强大的搜索引擎。如果非要使用Nutch2,建议等到Nutch2.3发布。当前的 Nutch2 是一个非常不稳定的版本。
3.2 JAVA爬虫
这里将JAVA爬虫单独划分为一个类别,因为JAVA在网络爬虫的生态系统中是非常完备的。相关资料也是最全的。这里可能有争议,我只是随便说说。
其实,开源网络爬虫(框架)的开发很简单,难点复杂的问题(比如DOM树解析定位、字符集检测、海量URL去重)都已经被前人解决了,可以说没有技术含量。包括Nutch,其实Nutch的技术难点就是开发hadoop,代码本身也很简单。从某种意义上说,网络爬虫类似于遍历机器的文件以查找文件中的信息。没有任何困难。之所以选择开源爬虫框架,是为了省事。比如爬虫URL管理、线程池等模块任何人都可以做,但是需要一段时间的调试和修改才能稳定下来。
用于爬虫的功能。用户比较关心的问题往往是:
1)爬虫是否支持多线程,爬虫能不能用agent,能不能抓取重复数据,能不能抓取JS生成的信息?
那些不支持多线程、代理或过滤重复 URL 的不称为开源爬虫。它们被称为循环执行 http 请求。
js生成的信息能否被爬取与爬虫本身关系不大。爬虫主要负责遍历网站和下载页面。爬取js产生的信息与网页信息提取模块有关,往往需要通过模拟浏览器(htmlunit、selenium)来完成。这些模拟浏览器通常需要花费大量时间来处理页面。所以一个策略就是利用这些爬虫来遍历网站,当遇到需要解析的页面时,将页面的相关信息提交给模拟浏览器,完成对JS生成信息的提取。
2)爬虫可以爬取ajax信息吗?
网页上有一些异步加载的数据。爬取这个数据有两种方式:使用模拟浏览器(问题1中描述),或者分析ajax http请求,自己生成ajax请求url,获取返回数据。如果自己生成ajax请求,使用开源爬虫有什么意义?其实还是需要用到开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我需要的ajax请求(列表),我该如何使用这些爬虫来抓取这些请求?
爬虫通常被设计成广度遍历或深度遍历的模式来遍历静态或动态页面。爬取ajax信息属于深网(deep web)的范畴,虽然大部分爬虫不直接支持。但它也可以通过某些方式完成。例如,WebCollector 使用广度遍历来遍历网站。第一轮爬取是爬取种子集(seeds)中的所有URL。简单的说,就是将生成的ajax请求作为种子,放入爬虫中。使用爬虫遍历这些深度为1的种子(默认为广度遍历)。
3)爬虫如何爬取网站登录?
这些开源爬虫都支持在爬取时指定cookies,模拟登录主要依赖cookies。至于如何获取cookie,就不是爬虫的事情了。您可以手动获取cookies,也可以模拟http请求登录,也可以使用模拟浏览器自动登录获取cookies。
4)爬虫如何从网页中提取信息?
开源爬虫一般都集成了网页提取工具。主要支持两种类型的规范:CSS SELECTOR 和 XPATH。至于哪个更好,这里就不做评价了。
5)爬虫是如何保存网页信息的?
一些爬虫带有一个负责持久化的模块。例如,webmagic 有一个叫做管道的模块。通过简单的配置,爬虫提取的信息可以持久化到文件、数据库等中,也有一些爬虫不直接为用户提供数据持久化模块。如 crawler4j 和 webcollector。让用户在网页处理模块中添加提交数据库的操作。至于使用pipeline模块好不好,类似于是否使用ORM来操作数据库的问题。这取决于您的业务。
6)爬虫被网站拦截怎么办?
爬虫已经被网站屏蔽了,一般可以通过多个代理(随机代理)解决。但是,这些开源爬虫一般不直接支持随机代理的切换。因此,用户往往需要自己将获取到的代理放入一个全局数组中,自己编写代码来随机获取代理(从数组中)。
7)网页可以调用爬虫吗?
爬虫的调用是在Web的服务器端调用的,你可以照常使用。所有这些爬虫都可以使用。
8)爬行速度怎么样?
一个单机的开源爬虫的速度基本可以用到机器网速的极限。爬虫速度慢,往往是因为用户线程少,网速慢,或者持久化数据时与数据库交互慢。这些东西往往是由用户的机器和二次开发代码决定的。这些开源爬虫的速度非常好。
9)显然代码写对了,爬不出来数据。是不是爬虫有问题?别的爬虫能解决吗?
如果代码写对了,数据爬不出来,其他爬虫也是一样。在这种情况下,要么 网站 阻止了您,要么您抓取的数据是由 javascript 生成的。爬取数据无法通过改变爬虫来解决。
10)哪个爬虫可以判断网站是否爬完了,哪个爬虫可以根据主题爬取?
爬虫无法判断网站是否爬过,只能尽量覆盖。
至于基于主题的爬取,爬虫只有向下爬取内容才知道主题是什么。所以它通常是从整体上爬下来,然后去过滤内容。如果觉得抓取过于笼统,可以通过限制网址规律等方法缩小范围。
11) 哪个爬虫有更好的设计模式和结构?
设计模式纯属无稽之谈。当软件设计模式好的时候,开发软件,然后总结出几种设计模式。设计模式对软件开发没有指导作用。使用设计模式来设计爬虫只会让爬虫的设计更加臃肿。
在架构上,开源爬虫目前主要是详细数据结构的设计,比如爬取线程池、任务队列等,大家都可以控制。爬虫的业务太简单了,不谈结构。
所以对于JAVA开源爬虫,我觉得,找一个好用的就好了。如果业务复杂,使用哪种爬虫就必须经过复杂的二次开发才能满足需求。
3.3 个非 Java 爬虫
在非JAVA语言编写的爬虫中,有很多优秀的爬虫。这个单独提取为一个类别,不是为了爬虫本身的质量,而是为了larbin、scrapy等爬虫对开发成本的影响。
先说python爬虫,python可以用30行代码完成JAVA 50行代码的任务。Python 代码编写确实很快,但是在调试代码阶段,Python 代码的调试往往比编码阶段节省的时间消耗的时间要多得多。使用python开发,为了保证程序的正确性和稳定性,需要编写更多的测试模块。当然,如果爬取规模不大,爬取业务不复杂,使用scrapy也是相当不错的,可以轻松完成爬取任务。
上图是Scrapy的架构图。绿线是数据流。首先从初始的URL开始,Scheduler将其交给Downloader进行下载,下载完成后,交给Spider进行分析,将需要保存的数据发送到Item Pipeline ,即对数据进行后处理。此外,可以在数据流通道中安装各种中间件来进行必要的处理。所以在开发爬虫的时候,最好先规划好各个模块。我的做法是分别规划下载模块、爬取模块、调度模块、数据存储模块。
对于C++爬虫来说,学习**的成本会比较大。而且你不能只计算一个人的学习成本。如果软件需要团队开发或交接,那将是很多人的学习成本。软件调试并不是那么容易。
还有一些ruby、php爬虫,这里不多评论。确实有一些非常小的数据任务。使用ruby或php非常方便。但是要选择这些语言的开源爬虫,一方面需要调查相关的生态系统,另一方面,这些开源爬虫可能会产生一些你找不到的bug(人少信息少)
4、反爬虫技术
由于搜索引擎的流行,网络爬虫已经成为一种非常流行的网络技术。除了专门从事搜索的谷歌、雅虎、微软、百度,几乎每个大型门户网站网站都有自己的搜索引擎,**小有几十个名字,还有数以万计的未知名字。对于一个内容驱动的网站来说,难免会被网络爬虫光顾。
一些智能搜索引擎爬虫在网站上的爬取频率比较合理,消耗的资源较少,但是很多不好的网络爬虫对网页的爬取能力很差,经常会发送几十上百个请求,重复爬取循环。拿,这种爬虫往往对中小网站是毁灭性的打击,尤其是一些缺乏爬虫编写经验的程序员写的爬虫破坏力极强,网站访问压力会很大高的。, 会导致网站 访问缓慢甚至无法访问。
一般来说,网站是从三个方面进行反爬虫的:用户请求的Headers、用户行为、网站目录和数据加载方式。前两个比较容易遇到,大多数网站反爬虫都是从这几个角度来看的。将采用第三类ajax应用网站,增加爬虫难度。
4.1 个通过 Headers 的反爬虫
从用户请求的Headers反爬取是最常见的反爬取策略。很多网站会检测Headers的User-Agent,还有一些网站会检测Referer(部分资源的防盗链网站就是检测Referer)。如果遇到这种反爬虫机制,可以直接给爬虫添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者修改Referer值为目标网站域名。对于检测header的反爬虫,在爬虫中修改或添加header很容易绕过。
【点评:往往容易被忽视。通过对请求的捕获分析,确定referer,并在程序中模拟访问请求头中添加]
4.2 基于用户行为的反爬虫
网站的另一部分是检测用户行为,比如同一IP在短时间内多次访问同一个页面,或者同一个账号在短时间内多次执行相同的操作。技术分析真的对股票交易有用吗?

技术分析对股票非常有用,因为市场上大部分机构和个人都使用技术分析,所以符合从众原则。当大多数技术分析表明股票正在好转时,资金将开始流入,股票自然会上涨。反之亦然。
技术分析是一个统计概念、历史重复概念和从众心理概念,所以很有用。
但单一指标的技术分析用处不大,一般确认两个或多个技术分析相辅相成。
php 爬虫抓取网页数据(学过网站设计之深度优先算法的主要思想和思想介绍 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-22 08:15
)
研究过网站设计的人都知道网站通常是分层设计的。顶级是顶级域名,后面是子域名,子域名下还有子域名等。同时,每个子域也可能有多个同级域名,可能有是 URL 之间的链接,形成复杂的网络。
当一个网站的URL很多时,一定要好好设计好URL,否则在以后的理解、维护或开发过程中会很混乱。了解了以上网页结构设计后,现在正式介绍网络爬虫中的深度优先算法。
上图是一个二叉树结构。通过遍历这棵二叉树,我们可以比较爬取网页,加深对爬取策略的理解。深度优先算法的主要思想是先从顶级域名A开始,然后从中提取两个链接B和C。抓取链接B后,下一个要抓取的链接是D或E,而不是抓取。抓取链接B后,立即抓取链接C,抓取链接D后,发现链接D中的所有URL都被访问过。在此之前,我们已经建立了一个访问过的 URL 列表,专门用于存储访问过的 URL。当链接 D 被完全抓取后,接下来会抓取链接 E。链接E的爬取完成后,链接C不会被爬取,而是继续向下爬取链接I。原理是链接会一步步往下爬。只要链接下有子链接,并且子链接没有被访问过,这就是深度优先算法的主要思想。深度优先算法是让爬虫一步一步往下爬,然后一步一步往回走,以深度优先。理解了深度优先算法后,再看上图,可以得到二叉树呈现的爬虫爬取链接顺序如下:A、B、D、E、I、C、F、G、H(假设此处左侧的链接)将首先被抓取)。其实我们在做网络爬虫的时候,经常会用到这个算法来实现。其实我们常用的Scrapy爬虫框架默认也是用这个算法实现的。由以上理解,
下图展示了深度优先算法的代码实现过程。
深度优先过程实际上是以递归方式实现的。看上图中的代码,先定义一个函数来实现深度优先处理,然后传入节点参数。如果节点不为空,则将其打印出来。您可以将其与二叉树中的顶点 A 进行比较。节点打印后,检查是否有左节点(链接B)和右节点(链接C)。如果左节点不为空,则返回,并调用深度优先函数本身再次递归得到一个新的左节点(链接D)和右节点(链接E),以此类推,不会停止直到遍历完所有节点或达到既定条件。右节点的实现过程也是一样的,这里不再赘述。
深度优先过程以递归方式实现。当递归继续执行而没有跳出递归或者递归过深时,很容易发生栈溢出,所以在实际应用过程中要注意这一点。
深度优先算法和广度优先算法是数据结构中非常重要的算法结构,也是非常常用的算法,也是面试过程中非常常见的面试题,所以推荐大家需要掌握它。文章 我们将介绍广度优先算法,敬请期待。
对网络爬虫中深度优先算法的简单介绍到此为止。你们做对了吗?
看完这篇文章你学会了吗?请转发并分享给更多人
Python爬虫和数据挖掘 查看全部
php 爬虫抓取网页数据(学过网站设计之深度优先算法的主要思想和思想介绍
)
研究过网站设计的人都知道网站通常是分层设计的。顶级是顶级域名,后面是子域名,子域名下还有子域名等。同时,每个子域也可能有多个同级域名,可能有是 URL 之间的链接,形成复杂的网络。
当一个网站的URL很多时,一定要好好设计好URL,否则在以后的理解、维护或开发过程中会很混乱。了解了以上网页结构设计后,现在正式介绍网络爬虫中的深度优先算法。
上图是一个二叉树结构。通过遍历这棵二叉树,我们可以比较爬取网页,加深对爬取策略的理解。深度优先算法的主要思想是先从顶级域名A开始,然后从中提取两个链接B和C。抓取链接B后,下一个要抓取的链接是D或E,而不是抓取。抓取链接B后,立即抓取链接C,抓取链接D后,发现链接D中的所有URL都被访问过。在此之前,我们已经建立了一个访问过的 URL 列表,专门用于存储访问过的 URL。当链接 D 被完全抓取后,接下来会抓取链接 E。链接E的爬取完成后,链接C不会被爬取,而是继续向下爬取链接I。原理是链接会一步步往下爬。只要链接下有子链接,并且子链接没有被访问过,这就是深度优先算法的主要思想。深度优先算法是让爬虫一步一步往下爬,然后一步一步往回走,以深度优先。理解了深度优先算法后,再看上图,可以得到二叉树呈现的爬虫爬取链接顺序如下:A、B、D、E、I、C、F、G、H(假设此处左侧的链接)将首先被抓取)。其实我们在做网络爬虫的时候,经常会用到这个算法来实现。其实我们常用的Scrapy爬虫框架默认也是用这个算法实现的。由以上理解,
下图展示了深度优先算法的代码实现过程。
深度优先过程实际上是以递归方式实现的。看上图中的代码,先定义一个函数来实现深度优先处理,然后传入节点参数。如果节点不为空,则将其打印出来。您可以将其与二叉树中的顶点 A 进行比较。节点打印后,检查是否有左节点(链接B)和右节点(链接C)。如果左节点不为空,则返回,并调用深度优先函数本身再次递归得到一个新的左节点(链接D)和右节点(链接E),以此类推,不会停止直到遍历完所有节点或达到既定条件。右节点的实现过程也是一样的,这里不再赘述。
深度优先过程以递归方式实现。当递归继续执行而没有跳出递归或者递归过深时,很容易发生栈溢出,所以在实际应用过程中要注意这一点。
深度优先算法和广度优先算法是数据结构中非常重要的算法结构,也是非常常用的算法,也是面试过程中非常常见的面试题,所以推荐大家需要掌握它。文章 我们将介绍广度优先算法,敬请期待。
对网络爬虫中深度优先算法的简单介绍到此为止。你们做对了吗?
看完这篇文章你学会了吗?请转发并分享给更多人
Python爬虫和数据挖掘
php 爬虫抓取网页数据(一个qq邮箱代理ip转发服务器接入的工作原理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-16 22:02
php爬虫抓取网页数据,分段代理直接拿来用了都还行,但对有几个人会去了解像一个qq邮箱代理ip服务器接入?qq邮箱代理ip转发服务器接入?如果不知道的话百度搜索一下为什么需要这个接入模块,工作原理?现在是802.11ac和http3.0标准,应该还是可以用来做不少事情的,代理或者特殊的功能开发对企业来说也是可以做事情的。
当然你肯定也不会接触到这个模块的最终用途和商业价值。下图以招聘网站,一个负责网站爬虫的qq邮箱代理为例吧:(。
1)电信ip、11
4、12
6、192.168.1.1等,
2)http代理服务器基本上都有一个接入模块,
3)接入人员后期加入一些特殊功能代理之后成就:没有功能,可以读取附件等等。如果真的需要购买大部分企业可能宁愿使用。并且投入非常巨大,是专业人员进行各个方面配置。
大企业里对于软件的关注点,只有底层的加密,爬虫模块的开发。数据流量统计和发送会去搭建nb的分布式系统,其他,数据安全,售后,
我觉得楼上回答的答案比较扯,有一种明显就是假设你要服务器承受千兆带宽的流量。而其实现在比较常见的是四线五线的通道,比如四个16口adsl,四个50口的isp主机还能抗住几十百g的负载??基本跑通应该没问题,但是六线七线就呵呵了,特别是需要大量流量的需求。看业务量来决定网络流量,不合适的,有个指标叫billingdownloadtime的,可以看一下,具体要看自己去算的...所以单论想法的话,是可以的。
但是,这个事情的难度非常高,比如第一,非常有针对性的人才,可能这个企业本身网络相对比较理论化,技术含量不高;第二,项目规模可能太大,需要考虑高性能,大速率,好网络环境第三,有时候企业就算做好了这件事,很有可能因为他其实不是特别感兴趣,也可能内部没有这种服务器,这件事可能只是别人觉得有意思,他就干了...。 查看全部
php 爬虫抓取网页数据(一个qq邮箱代理ip转发服务器接入的工作原理)
php爬虫抓取网页数据,分段代理直接拿来用了都还行,但对有几个人会去了解像一个qq邮箱代理ip服务器接入?qq邮箱代理ip转发服务器接入?如果不知道的话百度搜索一下为什么需要这个接入模块,工作原理?现在是802.11ac和http3.0标准,应该还是可以用来做不少事情的,代理或者特殊的功能开发对企业来说也是可以做事情的。
当然你肯定也不会接触到这个模块的最终用途和商业价值。下图以招聘网站,一个负责网站爬虫的qq邮箱代理为例吧:(。
1)电信ip、11
4、12
6、192.168.1.1等,
2)http代理服务器基本上都有一个接入模块,
3)接入人员后期加入一些特殊功能代理之后成就:没有功能,可以读取附件等等。如果真的需要购买大部分企业可能宁愿使用。并且投入非常巨大,是专业人员进行各个方面配置。
大企业里对于软件的关注点,只有底层的加密,爬虫模块的开发。数据流量统计和发送会去搭建nb的分布式系统,其他,数据安全,售后,
我觉得楼上回答的答案比较扯,有一种明显就是假设你要服务器承受千兆带宽的流量。而其实现在比较常见的是四线五线的通道,比如四个16口adsl,四个50口的isp主机还能抗住几十百g的负载??基本跑通应该没问题,但是六线七线就呵呵了,特别是需要大量流量的需求。看业务量来决定网络流量,不合适的,有个指标叫billingdownloadtime的,可以看一下,具体要看自己去算的...所以单论想法的话,是可以的。
但是,这个事情的难度非常高,比如第一,非常有针对性的人才,可能这个企业本身网络相对比较理论化,技术含量不高;第二,项目规模可能太大,需要考虑高性能,大速率,好网络环境第三,有时候企业就算做好了这件事,很有可能因为他其实不是特别感兴趣,也可能内部没有这种服务器,这件事可能只是别人觉得有意思,他就干了...。
php 爬虫抓取网页数据(php爬虫抓取网页数据-google-chrome/pc/不推荐使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-11-16 10:11
php爬虫抓取网页数据-google-chrome/pc/不推荐使用nginx,1是速度太慢,2是比较占内存。另外如果爬虫量比较大,依靠nginx就要经常进行数据清理。采用phantomjs的话需要开发额外的webserver。而且这个爬虫实在太简单了,几句话就能写完,主要还是抓取网页的样式。
使用phantomjs需要进行数据清洗,所以不适合抓大流量的网站。建议首选使用httpclient:1.使用apache2.webserver配置:http1.0:curl-o-s"client=&server=http1.0"http2.0:curl-o-s"client=&server=http2.0"结束。
phantomjs爬虫。大流量要考虑下负载均衡。小流量。
效率?速度?处理多页?作为一个php工程师,我们一般抓完首页后就是再抓接下来的所有页面。一般python的requests很好用。找个合适的工具跑。
phantomjs,http协议,
phantomjs或者nginx+phantomjs。phantomjs相对完善。参考这里:phantomjs开发技术文档参考github上的wordpressweb_scraping扩展程序。
一般来说适合抓取抓取广告联盟,黄牛党、网盘、百度云等一些需要机器验证的大流量网站的数据,抓取很快,全部用nginx就可以了。python的cookie是不可能,一是在浏览器开启;二是机器人来刷下。浏览器开启的办法:只要是http协议就可以。 查看全部
php 爬虫抓取网页数据(php爬虫抓取网页数据-google-chrome/pc/不推荐使用)
php爬虫抓取网页数据-google-chrome/pc/不推荐使用nginx,1是速度太慢,2是比较占内存。另外如果爬虫量比较大,依靠nginx就要经常进行数据清理。采用phantomjs的话需要开发额外的webserver。而且这个爬虫实在太简单了,几句话就能写完,主要还是抓取网页的样式。
使用phantomjs需要进行数据清洗,所以不适合抓大流量的网站。建议首选使用httpclient:1.使用apache2.webserver配置:http1.0:curl-o-s"client=&server=http1.0"http2.0:curl-o-s"client=&server=http2.0"结束。
phantomjs爬虫。大流量要考虑下负载均衡。小流量。
效率?速度?处理多页?作为一个php工程师,我们一般抓完首页后就是再抓接下来的所有页面。一般python的requests很好用。找个合适的工具跑。
phantomjs,http协议,
phantomjs或者nginx+phantomjs。phantomjs相对完善。参考这里:phantomjs开发技术文档参考github上的wordpressweb_scraping扩展程序。
一般来说适合抓取抓取广告联盟,黄牛党、网盘、百度云等一些需要机器验证的大流量网站的数据,抓取很快,全部用nginx就可以了。python的cookie是不可能,一是在浏览器开启;二是机器人来刷下。浏览器开启的办法:只要是http协议就可以。
php 爬虫抓取网页数据(php爬虫抓取网页数据用的是urllib库,而python爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-12 09:11
php爬虫抓取网页数据用的是urllib库,而python爬虫用urllib,可以尝试一下这篇文章。
理论上讲不能,因为python里面就是urllib库,正如另一位答主说的,python就是用urllib库和自己封装了一下前端的api实现不同的用户体验的。但是实际上根据情况要考虑。1,当网站很短的时候,如果仅仅是用urllib库爬取一些简单的页面,因为爬虫的响应和发送很慢很慢,为了保证前端的体验(爬虫可以是高并发的),我们首先要post请求。
但是当网站很长时候时候,响应就非常慢了,这时候就要采用io复用模块(lib64库)。2,如果爬虫采用urllib库,要考虑到不同框架的封装,比如urllib+lxml库+lxml库+selenium。基本上需要这样三个框架。可能在某一个框架封装好了并用原生方法调用这样对于资源占用非常少。但是大的系统框架(如webpy,nodejs等)都封装好了,而且速度不比nodejs慢。所以还是看情况,抓取网站框架兼容性,网络情况等。
不能,除非你有足够的tps。真实的抓取应该只有足够tps。说实话python的urllib库太少,基本都是封装了,你想让它吃很多事情太难了。
web网站抓取分单文件抓取、多文件抓取、网站导航抓取,这里只讨论多文件抓取,具体接触过是pyspider,另外百度的开源爬虫也有kiboom-crawler和crawler等。python爬虫不像java或者其他语言那样自己封装前端api,to-do里的那些代码要自己写,很多urllib库都可以很轻松实现,现在市面上爬虫框架更多,比如webdriver等,有java基础和html基础可以学习爬虫框架,比如kiboom-crawler。 查看全部
php 爬虫抓取网页数据(php爬虫抓取网页数据用的是urllib库,而python爬虫)
php爬虫抓取网页数据用的是urllib库,而python爬虫用urllib,可以尝试一下这篇文章。
理论上讲不能,因为python里面就是urllib库,正如另一位答主说的,python就是用urllib库和自己封装了一下前端的api实现不同的用户体验的。但是实际上根据情况要考虑。1,当网站很短的时候,如果仅仅是用urllib库爬取一些简单的页面,因为爬虫的响应和发送很慢很慢,为了保证前端的体验(爬虫可以是高并发的),我们首先要post请求。
但是当网站很长时候时候,响应就非常慢了,这时候就要采用io复用模块(lib64库)。2,如果爬虫采用urllib库,要考虑到不同框架的封装,比如urllib+lxml库+lxml库+selenium。基本上需要这样三个框架。可能在某一个框架封装好了并用原生方法调用这样对于资源占用非常少。但是大的系统框架(如webpy,nodejs等)都封装好了,而且速度不比nodejs慢。所以还是看情况,抓取网站框架兼容性,网络情况等。
不能,除非你有足够的tps。真实的抓取应该只有足够tps。说实话python的urllib库太少,基本都是封装了,你想让它吃很多事情太难了。
web网站抓取分单文件抓取、多文件抓取、网站导航抓取,这里只讨论多文件抓取,具体接触过是pyspider,另外百度的开源爬虫也有kiboom-crawler和crawler等。python爬虫不像java或者其他语言那样自己封装前端api,to-do里的那些代码要自己写,很多urllib库都可以很轻松实现,现在市面上爬虫框架更多,比如webdriver等,有java基础和html基础可以学习爬虫框架,比如kiboom-crawler。
php 爬虫抓取网页数据(1.通用网络爬虫的实现原理及过程简要分析算法概括)
网站优化 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2021-11-10 05:15
网络爬虫的原理:爬虫根据一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,放入URL队列等待被抓取。然后,它会根据一定的搜索策略从队列中选择下一个要抓取的网页的网址,并重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤和索引,以供以后查询检索;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。
一个通用的网络爬虫的框架如图所示:
不同类型的网络爬虫有不同的实现原理,但是这些实现原理之间会有很多共性。这里我们以两个典型的网络爬虫为例(即通用网络爬虫和聚焦网络爬虫)来讲解网络爬虫的实现原理。
1. 通用网络爬虫
首先我们来看一下一般的网络爬虫的实现原理。一般网络爬虫的实现原理和过程可以简单概括如图:
2. 专注于网络爬虫
专注于网络爬虫,因为它们需要有目的地爬取,所以对于一般的网络爬虫,需要增加目标的定义和过滤机制。具体来说,这时候它的执行原理和流程比一般的网络爬虫需要的多。分为三个步骤,分别是目标的定义、无关链接的过滤、下一步要爬取的URL地址的选择等,如图:
网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址,在网页抓取过程中不断从当前页面中提取新的网址放入队列中,直到某个停止条件系统的满足。 查看全部
php 爬虫抓取网页数据(1.通用网络爬虫的实现原理及过程简要分析算法概括)
网络爬虫的原理:爬虫根据一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,放入URL队列等待被抓取。然后,它会根据一定的搜索策略从队列中选择下一个要抓取的网页的网址,并重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤和索引,以供以后查询检索;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。
一个通用的网络爬虫的框架如图所示:

不同类型的网络爬虫有不同的实现原理,但是这些实现原理之间会有很多共性。这里我们以两个典型的网络爬虫为例(即通用网络爬虫和聚焦网络爬虫)来讲解网络爬虫的实现原理。
1. 通用网络爬虫
首先我们来看一下一般的网络爬虫的实现原理。一般网络爬虫的实现原理和过程可以简单概括如图:

2. 专注于网络爬虫
专注于网络爬虫,因为它们需要有目的地爬取,所以对于一般的网络爬虫,需要增加目标的定义和过滤机制。具体来说,这时候它的执行原理和流程比一般的网络爬虫需要的多。分为三个步骤,分别是目标的定义、无关链接的过滤、下一步要爬取的URL地址的选择等,如图:

网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址,在网页抓取过程中不断从当前页面中提取新的网址放入队列中,直到某个停止条件系统的满足。
php 爬虫抓取网页数据(开发爬虫其实不用纠结用什么语言,省去一次爬虫开发不难)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-11-08 06:04
因为我已经开始开发一个蜘蛛池站群系统,其中涉及爬虫自动去全网寻找符合关键词或关键词密度标准的页面,然后加速内容,然后使用它。NLP相关的技术有伪原创,定期将文章发布到库中,发布这样一个模块,也是用php开发的。我也在这里和大家分享一下我对爬虫的看法。
实际上,您无需担心使用什么语言来开发爬虫。只要PHP在性能不太高的情况下完全够用,我也推荐PHP工程师用PHP来做,这样可以节省学习一门新语言的时间成本。
再次,爬虫开发并不难。
主要是定位你想要实现的爬虫类型。
根据互联网上所有爬虫的功能和特点,可分为批处理型、增量型和垂直型三种。
批处理类型,具有明显的爬取范围和目标,设置爬取时间限制、爬取数据限制、或在固定范围内爬取页面限制等,当爬虫任务达到预设目标时停止。一般来说,采集 工具或内容采集 任务是批处理类型。一般只抓取固定网站的固定内容,或者为某个资源设置固定的目标数据量。当达到设定的限制时,抓取的数据或时间将自动停止。这种爬虫是典型的批量爬虫。
增量类型也可以称为通用类型。百度、谷歌、搜狗等搜索引擎的爬虫可以称为增量爬虫。增量型不同于批处理型。没有固定的目标、范围和时间限制。一般会无休止地爬取,直到抓到全网的数据。增量类型一般不仅需要抓取尽可能多的页面,还需要对已经抓取的页面进行相应的抓取和更新。因为这些爬虫爬进数据库的页面不是静态的,可能会更新,甚至404。一般来说,增量爬虫的这些功能应该是标准的。至于去重,排名不在这里。在答案中讨论。
垂直型,也叫聚焦爬虫,只爬取固定主题内容或固定行业网页,一般集中在一定的有限范围内进行增量爬取。垂直爬虫不像增量爬虫那样追求大而全的覆盖。相反,他们在增量爬虫上增加了对网页抓取的限制,根据需求抓取收录目标内容的网页。不符合要求的网页就让它静静地躺在url队列中。比如我之前做的蜘蛛池内容爬虫模块就是这个垂直爬虫。
以上为大家大致介绍了爬虫的种类。我想你应该能够大致定位到你要开发的爬虫。
谈技术关键词,开始开发的时候直接查这些词,然后用上。
CURL:不用说,如果要爬取一个页面,首先要请求这个页面,得到对方服务器返回的数据(一般是html,如果直接看懂别人的api接口,就当我没看吧说吧)过去这句话)。
simple_html_dom:HTML 节点解析器。使用curl请求html文档后,可以用这个来解析dom节点,方便匹配需要采集爬取的内容。
正则表达式:用于匹配你想要的内容,与simple_html_dom功能相同,但会更加灵活。如果两者匹配,就会更加流畅。哈哈:)
worker 或 swoole:用于做多线程或多进程以提高效率。我更推荐workerman,因为学习成本低,文档清晰易学!Swoole 对新手确实很不友好,但是它的功能比workerman 强一点,这里就不讨论了。
Redis:用于存储 URL 队列。如果不追求太高的效率,可以无视。
对于这些关键词来说,入门级爬虫差不多就够了。很想研究一下数千万的采集对分布式爬虫的追求。我建议出去左转 Python 或其他语言主题下的提问。
最后说一下实现思路。
首页上的爬虫需要一个种子页,比如“中国新闻网”首页。这个爬虫使用curl请求种子页面,获取html数据,使用正则表达式匹配a标签的所有href属性,然后根据自己的一些规则来匹配一些符合规则的url或者符合规则的url已自行处理。例如,一些a标签可能没有http或https头,或者可能有没有域名的url,例如“/news/gn/”。这时候你需要做一点判断和处理,把添加的加进去,然后用sha1加密url,然后用hash去查数据库看是否有相同的hash,如果有,表示url已经有了(go Heavy),然后将url和hash同时存入url队列数据库中。
做完以上操作后,一定要记得给被爬取的URL一个已爬取状态,避免重复爬取。
然后在重复之前的操作之前从数据库中检查一个新的未被抓取的URL,这样你的爬虫就形成了,它会继续向你的URL队列添加URL。
关键时刻到了。如果我们简单地爬取URL并放入数据库,那是没有用的,对吧?
这时候该说一下内容采集了,url就在那里。这时候写一个爬虫,不断的取出url库中的url来爬回这个页面的内容,然后再写规则匹配内容后,就可以保存到数据库中了。
就是这样。这个入门级爬虫准备好了。
但是,真正的爬虫开发工作肯定会遇到很多很多问题和意想不到的问题,比如:蜘蛛陷阱、反爬虫、动态加载的内容无法爬取、效率问题、程序报错后是否有重启机制并在遇到异常、法律风险等问题后停止运行。
以下所有问题都留给你在实战中自己解决,因为每个人的业务不同,报出的错误肯定也不同。没有办法说的太清楚。本文文章主要目的是给大家提供一个思路。我也欢迎大家加入我。让我们一起交流讨论爬虫的各种知识和技巧。如果人多,我也可以组成一个交流群,大家交流。学习。
一不小心写了两千多字,没费心去复习这句话,没啥意思。如果有错别字,大家都会看的。我的 vx 有问题。 查看全部
php 爬虫抓取网页数据(开发爬虫其实不用纠结用什么语言,省去一次爬虫开发不难)
因为我已经开始开发一个蜘蛛池站群系统,其中涉及爬虫自动去全网寻找符合关键词或关键词密度标准的页面,然后加速内容,然后使用它。NLP相关的技术有伪原创,定期将文章发布到库中,发布这样一个模块,也是用php开发的。我也在这里和大家分享一下我对爬虫的看法。
实际上,您无需担心使用什么语言来开发爬虫。只要PHP在性能不太高的情况下完全够用,我也推荐PHP工程师用PHP来做,这样可以节省学习一门新语言的时间成本。
再次,爬虫开发并不难。
主要是定位你想要实现的爬虫类型。
根据互联网上所有爬虫的功能和特点,可分为批处理型、增量型和垂直型三种。
批处理类型,具有明显的爬取范围和目标,设置爬取时间限制、爬取数据限制、或在固定范围内爬取页面限制等,当爬虫任务达到预设目标时停止。一般来说,采集 工具或内容采集 任务是批处理类型。一般只抓取固定网站的固定内容,或者为某个资源设置固定的目标数据量。当达到设定的限制时,抓取的数据或时间将自动停止。这种爬虫是典型的批量爬虫。
增量类型也可以称为通用类型。百度、谷歌、搜狗等搜索引擎的爬虫可以称为增量爬虫。增量型不同于批处理型。没有固定的目标、范围和时间限制。一般会无休止地爬取,直到抓到全网的数据。增量类型一般不仅需要抓取尽可能多的页面,还需要对已经抓取的页面进行相应的抓取和更新。因为这些爬虫爬进数据库的页面不是静态的,可能会更新,甚至404。一般来说,增量爬虫的这些功能应该是标准的。至于去重,排名不在这里。在答案中讨论。
垂直型,也叫聚焦爬虫,只爬取固定主题内容或固定行业网页,一般集中在一定的有限范围内进行增量爬取。垂直爬虫不像增量爬虫那样追求大而全的覆盖。相反,他们在增量爬虫上增加了对网页抓取的限制,根据需求抓取收录目标内容的网页。不符合要求的网页就让它静静地躺在url队列中。比如我之前做的蜘蛛池内容爬虫模块就是这个垂直爬虫。
以上为大家大致介绍了爬虫的种类。我想你应该能够大致定位到你要开发的爬虫。
谈技术关键词,开始开发的时候直接查这些词,然后用上。
CURL:不用说,如果要爬取一个页面,首先要请求这个页面,得到对方服务器返回的数据(一般是html,如果直接看懂别人的api接口,就当我没看吧说吧)过去这句话)。
simple_html_dom:HTML 节点解析器。使用curl请求html文档后,可以用这个来解析dom节点,方便匹配需要采集爬取的内容。
正则表达式:用于匹配你想要的内容,与simple_html_dom功能相同,但会更加灵活。如果两者匹配,就会更加流畅。哈哈:)
worker 或 swoole:用于做多线程或多进程以提高效率。我更推荐workerman,因为学习成本低,文档清晰易学!Swoole 对新手确实很不友好,但是它的功能比workerman 强一点,这里就不讨论了。
Redis:用于存储 URL 队列。如果不追求太高的效率,可以无视。
对于这些关键词来说,入门级爬虫差不多就够了。很想研究一下数千万的采集对分布式爬虫的追求。我建议出去左转 Python 或其他语言主题下的提问。
最后说一下实现思路。
首页上的爬虫需要一个种子页,比如“中国新闻网”首页。这个爬虫使用curl请求种子页面,获取html数据,使用正则表达式匹配a标签的所有href属性,然后根据自己的一些规则来匹配一些符合规则的url或者符合规则的url已自行处理。例如,一些a标签可能没有http或https头,或者可能有没有域名的url,例如“/news/gn/”。这时候你需要做一点判断和处理,把添加的加进去,然后用sha1加密url,然后用hash去查数据库看是否有相同的hash,如果有,表示url已经有了(go Heavy),然后将url和hash同时存入url队列数据库中。
做完以上操作后,一定要记得给被爬取的URL一个已爬取状态,避免重复爬取。
然后在重复之前的操作之前从数据库中检查一个新的未被抓取的URL,这样你的爬虫就形成了,它会继续向你的URL队列添加URL。
关键时刻到了。如果我们简单地爬取URL并放入数据库,那是没有用的,对吧?
这时候该说一下内容采集了,url就在那里。这时候写一个爬虫,不断的取出url库中的url来爬回这个页面的内容,然后再写规则匹配内容后,就可以保存到数据库中了。
就是这样。这个入门级爬虫准备好了。
但是,真正的爬虫开发工作肯定会遇到很多很多问题和意想不到的问题,比如:蜘蛛陷阱、反爬虫、动态加载的内容无法爬取、效率问题、程序报错后是否有重启机制并在遇到异常、法律风险等问题后停止运行。
以下所有问题都留给你在实战中自己解决,因为每个人的业务不同,报出的错误肯定也不同。没有办法说的太清楚。本文文章主要目的是给大家提供一个思路。我也欢迎大家加入我。让我们一起交流讨论爬虫的各种知识和技巧。如果人多,我也可以组成一个交流群,大家交流。学习。
一不小心写了两千多字,没费心去复习这句话,没啥意思。如果有错别字,大家都会看的。我的 vx 有问题。
php 爬虫抓取网页数据(我看你php是用于爬取热门主页的吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-11-07 15:01
php爬虫抓取网页数据,用webserver(服务器)记录下来用,不能单独用。另外java和python可以互相调用的。找你要抓取的php页面,用代理连接到java爬虫的服务器,要求java帮你把php页面的链接替换成你自己定义的网址,然后你直接从java爬虫接收数据即可。我看你php是用于爬取热门主页的吗?我推荐你可以从scrapy框架抓取主页:scrapy-self。
讲个故事吧。以前以为php里面有语言会爬取到数据,现在发现java也有这个api。这个对爬虫的用处不大,因为都是爬下来连接网页编程而已。
我想爬一些我觉得有用的资源,用于向人讲学。求简单,求技术含量大,简单,又时效性强的办法。
可以建立一个scrapy服务器,但为了知乎规定,文章自动推送在“知乎-与世界分享你的知识、经验和见解”这个专栏里,推荐到“python技术”专栏让服务器上的用户抓,
我就想知道,知乎有啥“实用性”需求,让爬虫给爬过来啊。以下是正经回答python提供了很多个爬虫比如pythontime.sleep(500)对tcp或者http网络进行500毫秒的阻塞干扰,pythontornado可以实现异步轮询,一个tornado可以支持大多数http代理服务器,对于有多个爬虫的知乎来说,python自己是无法支持500毫秒这么长的时间,而且人人必须是认证用户.pythontornado如何做的,简单的简单用bio做下代理,首先抓取你想抓取的页面,url的url用get方法,如果你这个页面有多个url或者url不唯一,这个时候需要抓取多个页面然后写入到队列,抓取到后先从队列取你想要抓取的页面,然后去拿这个页面的url,然后进行循环判断从队列拿url是否是你想要的url,一旦不是,就返回结果并退出等待状态然后去抓取下一个url,如果抓取到还是不是的话,就返回结果并退出等待状态.在做这个循环判断过程时,用python队列也可以用str.strip()。 查看全部
php 爬虫抓取网页数据(我看你php是用于爬取热门主页的吗?)
php爬虫抓取网页数据,用webserver(服务器)记录下来用,不能单独用。另外java和python可以互相调用的。找你要抓取的php页面,用代理连接到java爬虫的服务器,要求java帮你把php页面的链接替换成你自己定义的网址,然后你直接从java爬虫接收数据即可。我看你php是用于爬取热门主页的吗?我推荐你可以从scrapy框架抓取主页:scrapy-self。
讲个故事吧。以前以为php里面有语言会爬取到数据,现在发现java也有这个api。这个对爬虫的用处不大,因为都是爬下来连接网页编程而已。
我想爬一些我觉得有用的资源,用于向人讲学。求简单,求技术含量大,简单,又时效性强的办法。
可以建立一个scrapy服务器,但为了知乎规定,文章自动推送在“知乎-与世界分享你的知识、经验和见解”这个专栏里,推荐到“python技术”专栏让服务器上的用户抓,
我就想知道,知乎有啥“实用性”需求,让爬虫给爬过来啊。以下是正经回答python提供了很多个爬虫比如pythontime.sleep(500)对tcp或者http网络进行500毫秒的阻塞干扰,pythontornado可以实现异步轮询,一个tornado可以支持大多数http代理服务器,对于有多个爬虫的知乎来说,python自己是无法支持500毫秒这么长的时间,而且人人必须是认证用户.pythontornado如何做的,简单的简单用bio做下代理,首先抓取你想抓取的页面,url的url用get方法,如果你这个页面有多个url或者url不唯一,这个时候需要抓取多个页面然后写入到队列,抓取到后先从队列取你想要抓取的页面,然后去拿这个页面的url,然后进行循环判断从队列拿url是否是你想要的url,一旦不是,就返回结果并退出等待状态然后去抓取下一个url,如果抓取到还是不是的话,就返回结果并退出等待状态.在做这个循环判断过程时,用python队列也可以用str.strip()。
php 爬虫抓取网页数据(常用指令如下所示:纯Python语言编写框架格式说明 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-11-07 03:08
)
Scrapy是一个基于Twisted的异步处理爬虫框架,纯Python编写。Scrapy 框架应用广泛,常用于数据采集、网络监控、自动化测试。
提示:Twisted 是一个事件驱动的网络引擎框架,也是用 Python 实现的。
下载并安装Scrapy Scrapy 支持常见的主流平台,如Linux、Mac、Windows 等,因此您可以轻松安装它。本节以Windows系统为例,在CMD命令行执行以下命令:
python -m pip install Scrapy
由于 Scrapy 需要很多依赖,所以安装需要很长时间。请耐心等待。其他平台的安装方法请参考官方文档《》。
验证安装如下:
C:\Users\Administrator>python
Python 3.7.4 (tags/v3.7.4:e09359112e, Jul 8 2019, 19:29:22) [MSC v.1916 32 bit (Intel)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import scrapy
>>> exit()
如果exit()操作可以正常进行并且没有ERROR错误,则安装成功。创建 Scrapy 爬虫项目 Scrapy 框架提供了一些常用的命令来创建项目、查看配置信息和运行爬虫程序。常用命令如下:
常用指令命令格式说明
启动项目
启动项目
创建一个新项目。
蜘蛛侠
易碎的genspider
创建一个新的爬虫文件。
运行蜘蛛
爬虫爬虫
要运行爬虫文件,无需创建项目。
爬行
爬行
要运行爬虫项目,您必须创建该项目。
列表
草稿清单
列出项目中的所有爬虫文件。
看法
草稿视图
从浏览器打开 url 地址。
贝壳
csrapy 外壳
命令行交互模式。
设置
抓取设置
查看当前项目的配置信息。
1) 创建第一个 Scrapy 爬虫项目。创建一个名为百度的爬虫项目。打开CMD命令提示符,执行以下操作:
C:\Users\Administrator>cd Desktop
C:\Users\Administrator\Desktop>scrapy startproject Baidu
New Scrapy project 'Baidu', using template directory 'd:\python\python37\lib\site-packages\scrapy\templates\project', created in:
C:\Users\Administrator\Desktop\Baidu
# 提示后续命令操作
You can start your first spider with:
cd Baidu
scrapy genspider example example.com
打开新创建的项目“百度”,会有如下项目文件,如图:
图 1:项目文件
接下来,创建一个爬虫文件,如下所示:
C:\Users\Administrator\Desktop>cd Baidu
C:\Users\Administrator\Desktop\Baidu>scrapy genspider baidu www.baidu.com
Created spider 'baidu' using template 'basic' in module:
Baidu.spiders.baidu
下面显示了项目的目录树结构和每个文件的作用:
Baidu # 项目文件夹
├── Baidu # 用来装载项目文件的目录
│ ├── items.py # 定义要抓取的数据结构
│ ├── middlewares.py # 中间件,用来设置一些处理规则
│ ├── pipelines.py # 管道文件,处理抓取的数据
│ ├── settings.py # 全局配置文件
│ └── spiders # 用来装载爬虫文件的目录
│ ├── baidu.py # 具体的爬虫程序
└── scrapy.cfg # 项目基本配置文件
从上面的目录结构可以看出,Scrapy将整个爬虫程序划分为不同的模块,让每个模块处理不同的任务,模块之间紧密相连。因此,您只需要在相应的模块中编写相应的代码,就可以轻松实现一个爬虫程序。Scrapy 爬虫工作流程 Scrapy 框架由五个主要组件组成,如下图:
Scrapy 的五个主要组件名称功能说明
引擎
整个Scrapy框架的核心主要负责不同模块之间数据和信号的传输。
调度器
用于维护引擎发送的请求队列。
下载器
接收引擎发送的请求,生成请求的响应对象,将响应结果返回给引擎。
蜘蛛(履带)
处理引擎发送的响应主要用于解析、提取数据并获取需要跟进的二级URL,然后将这些数据返回给引擎。
管道(项目管道)
使用数据存储对引擎发送的数据做进一步的处理,比如存储在MySQL数据库中。
在整个执行过程中,还涉及到两个中间件,分别是Downloader Middlewares和Spider Middlewares,它们的作用不同:
Scrapy工作流程图如下:
图 1:工作流程示意图
上述示意图说明如下。当一个爬虫项目启动时,Scrapy 框架会执行以下任务:
上面的过程会一直循环下去,直到没有要爬取的URL,也就是当URL队列为空时,不会停止。
使用Scrapy框架时,需要稍微修改设置配置文件。现在使用Pycharm打开刚刚创建的“百度”项目,修改配置文件如下:
# 1、定义User-Agent
USER_AGENT = 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)'
# 2、是否遵循robots协议,一般设置为False
ROBOTSTXT_OBEY = False
# 3、最大并发量,默认为16
CONCURRENT_REQUESTS = 32
# 4、下载延迟时间
DOWNLOAD_DELAY = 1
其他常用配置项介绍:
# 设置日志级别,DEBUG < INFO < WARNING < ERROR < CRITICAL
LOG_LEVEL = ' '
# 将日志信息保存日志文件中,而不在终端输出
LOG_FILE = ''
# 设置导出数据的编码格式(主要针对于json文件)
FEED_EXPORT_ENCODING = ''
# 非结构化数据的存储路径
IMAGES_STORE = '路径'
# 请求头,此处可以添加User-Agent、cookies、referer等
DEFAULT_REQUEST_HEADERS={
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
}
# 项目管道,300 代表激活的优先级 越小越优先,取值1到1000
ITEM_PIPELINES={
'Baidu.pipelines.BaiduPipeline':300
}
# 添加下载器中间件
DOWNLOADER_MIDDLEWARES = {} 查看全部
php 爬虫抓取网页数据(常用指令如下所示:纯Python语言编写框架格式说明
)
Scrapy是一个基于Twisted的异步处理爬虫框架,纯Python编写。Scrapy 框架应用广泛,常用于数据采集、网络监控、自动化测试。
提示:Twisted 是一个事件驱动的网络引擎框架,也是用 Python 实现的。
下载并安装Scrapy Scrapy 支持常见的主流平台,如Linux、Mac、Windows 等,因此您可以轻松安装它。本节以Windows系统为例,在CMD命令行执行以下命令:
python -m pip install Scrapy
由于 Scrapy 需要很多依赖,所以安装需要很长时间。请耐心等待。其他平台的安装方法请参考官方文档《》。
验证安装如下:
C:\Users\Administrator>python
Python 3.7.4 (tags/v3.7.4:e09359112e, Jul 8 2019, 19:29:22) [MSC v.1916 32 bit (Intel)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import scrapy
>>> exit()
如果exit()操作可以正常进行并且没有ERROR错误,则安装成功。创建 Scrapy 爬虫项目 Scrapy 框架提供了一些常用的命令来创建项目、查看配置信息和运行爬虫程序。常用命令如下:
常用指令命令格式说明
启动项目
启动项目
创建一个新项目。
蜘蛛侠
易碎的genspider
创建一个新的爬虫文件。
运行蜘蛛
爬虫爬虫
要运行爬虫文件,无需创建项目。
爬行
爬行
要运行爬虫项目,您必须创建该项目。
列表
草稿清单
列出项目中的所有爬虫文件。
看法
草稿视图
从浏览器打开 url 地址。
贝壳
csrapy 外壳
命令行交互模式。
设置
抓取设置
查看当前项目的配置信息。
1) 创建第一个 Scrapy 爬虫项目。创建一个名为百度的爬虫项目。打开CMD命令提示符,执行以下操作:
C:\Users\Administrator>cd Desktop
C:\Users\Administrator\Desktop>scrapy startproject Baidu
New Scrapy project 'Baidu', using template directory 'd:\python\python37\lib\site-packages\scrapy\templates\project', created in:
C:\Users\Administrator\Desktop\Baidu
# 提示后续命令操作
You can start your first spider with:
cd Baidu
scrapy genspider example example.com
打开新创建的项目“百度”,会有如下项目文件,如图:
图 1:项目文件
接下来,创建一个爬虫文件,如下所示:
C:\Users\Administrator\Desktop>cd Baidu
C:\Users\Administrator\Desktop\Baidu>scrapy genspider baidu www.baidu.com
Created spider 'baidu' using template 'basic' in module:
Baidu.spiders.baidu
下面显示了项目的目录树结构和每个文件的作用:
Baidu # 项目文件夹
├── Baidu # 用来装载项目文件的目录
│ ├── items.py # 定义要抓取的数据结构
│ ├── middlewares.py # 中间件,用来设置一些处理规则
│ ├── pipelines.py # 管道文件,处理抓取的数据
│ ├── settings.py # 全局配置文件
│ └── spiders # 用来装载爬虫文件的目录
│ ├── baidu.py # 具体的爬虫程序
└── scrapy.cfg # 项目基本配置文件
从上面的目录结构可以看出,Scrapy将整个爬虫程序划分为不同的模块,让每个模块处理不同的任务,模块之间紧密相连。因此,您只需要在相应的模块中编写相应的代码,就可以轻松实现一个爬虫程序。Scrapy 爬虫工作流程 Scrapy 框架由五个主要组件组成,如下图:
Scrapy 的五个主要组件名称功能说明
引擎
整个Scrapy框架的核心主要负责不同模块之间数据和信号的传输。
调度器
用于维护引擎发送的请求队列。
下载器
接收引擎发送的请求,生成请求的响应对象,将响应结果返回给引擎。
蜘蛛(履带)
处理引擎发送的响应主要用于解析、提取数据并获取需要跟进的二级URL,然后将这些数据返回给引擎。
管道(项目管道)
使用数据存储对引擎发送的数据做进一步的处理,比如存储在MySQL数据库中。
在整个执行过程中,还涉及到两个中间件,分别是Downloader Middlewares和Spider Middlewares,它们的作用不同:
Scrapy工作流程图如下:
图 1:工作流程示意图
上述示意图说明如下。当一个爬虫项目启动时,Scrapy 框架会执行以下任务:
上面的过程会一直循环下去,直到没有要爬取的URL,也就是当URL队列为空时,不会停止。
使用Scrapy框架时,需要稍微修改设置配置文件。现在使用Pycharm打开刚刚创建的“百度”项目,修改配置文件如下:
# 1、定义User-Agent
USER_AGENT = 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)'
# 2、是否遵循robots协议,一般设置为False
ROBOTSTXT_OBEY = False
# 3、最大并发量,默认为16
CONCURRENT_REQUESTS = 32
# 4、下载延迟时间
DOWNLOAD_DELAY = 1
其他常用配置项介绍:
# 设置日志级别,DEBUG < INFO < WARNING < ERROR < CRITICAL
LOG_LEVEL = ' '
# 将日志信息保存日志文件中,而不在终端输出
LOG_FILE = ''
# 设置导出数据的编码格式(主要针对于json文件)
FEED_EXPORT_ENCODING = ''
# 非结构化数据的存储路径
IMAGES_STORE = '路径'
# 请求头,此处可以添加User-Agent、cookies、referer等
DEFAULT_REQUEST_HEADERS={
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
}
# 项目管道,300 代表激活的优先级 越小越优先,取值1到1000
ITEM_PIPELINES={
'Baidu.pipelines.BaiduPipeline':300
}
# 添加下载器中间件
DOWNLOADER_MIDDLEWARES = {}
php 爬虫抓取网页数据(如有什么知识点总结得不对,抄袭到哪位的内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-11-06 19:40
——本文来自网络学习或百度科普。我会先放专业术语,然后用我学过的总结的语言。如果有没有总结正确的知识点,或者博主抄袭的内容,请私信给我~谢谢!——
百度:网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。传统爬虫从一个或几个初始网页的网址开始,获取初始网页上的网址。在抓取网页的过程中,它不断地从当前页面中提取新的URL并将它们放入队列中,直到满足系统的某个停止条件。聚焦爬虫的工作流程更为复杂。需要根据一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,放入URL队列等待被抓取。然后,它会根据一定的搜索策略从队列中选择下一个要抓取的网页的网址,并重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤和索引,以供以后查询检索;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。
与一般网络爬虫相比,聚焦爬虫需要解决三个主要问题:
(1) 爬取目标的描述或定义;
(2)对网页或数据的分析和过滤;
(3) URL 搜索策略。
我的总结:由于互联网时代的飞速发展,为了快速、大量地获取网络信息,网页的内容也急剧增加。于是就有了网络爬虫。
网络爬虫有两种,一种是通用网络爬虫;另一种是聚焦爬虫。重点爬虫可以根据个人的不同要求或需求进行选择、过滤等(虽然这类爬虫有这样的优点,但也很难进行下去) 查看全部
php 爬虫抓取网页数据(如有什么知识点总结得不对,抄袭到哪位的内容)
——本文来自网络学习或百度科普。我会先放专业术语,然后用我学过的总结的语言。如果有没有总结正确的知识点,或者博主抄袭的内容,请私信给我~谢谢!——
百度:网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。传统爬虫从一个或几个初始网页的网址开始,获取初始网页上的网址。在抓取网页的过程中,它不断地从当前页面中提取新的URL并将它们放入队列中,直到满足系统的某个停止条件。聚焦爬虫的工作流程更为复杂。需要根据一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,放入URL队列等待被抓取。然后,它会根据一定的搜索策略从队列中选择下一个要抓取的网页的网址,并重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤和索引,以供以后查询检索;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。
与一般网络爬虫相比,聚焦爬虫需要解决三个主要问题:
(1) 爬取目标的描述或定义;
(2)对网页或数据的分析和过滤;
(3) URL 搜索策略。
我的总结:由于互联网时代的飞速发展,为了快速、大量地获取网络信息,网页的内容也急剧增加。于是就有了网络爬虫。
网络爬虫有两种,一种是通用网络爬虫;另一种是聚焦爬虫。重点爬虫可以根据个人的不同要求或需求进行选择、过滤等(虽然这类爬虫有这样的优点,但也很难进行下去)
php 爬虫抓取网页数据(什么是Python?Python是什么?(二)模糊)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-11-06 10:18
今天听到有人问:Python为什么叫爬虫?我脑子里的第一反应不是答案,而是为什么有人问这个问题。我觉得大家对Python的概念有点模糊,把Python和爬虫混为一谈,所以今天问请解释一下。
什么是 Python?什么是 Python?
如果你在英文词典里查Python,他会给你Python作为大蟒蛇的定义,这样读:英语[ˈpaɪθən],美国[ˈpaɪθɑ:n],Python就是大名鼎鼎的“龟叔”Guido van Rossum在 1989 年圣诞节期间,为了度过无聊的圣诞节而编写的一种编程语言。Python 是一种计算机编程语言。是一种动态的、面向对象的脚本语言,最初是为编写自动化脚本(shell)而设计的,随着版本的不断更新和新语言功能的加入,越来越多的被用于独立的、大型的项目开发。
Python 是一种解释性脚本语言,可用于以下领域:
1、Web 和 Internet 开发
2、科学计算和统计
3、教育
4、桌面界面开发
5、软件开发
6、后端开发
什么是爬虫?什么是网络爬虫?
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是按照某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
随着互联网的飞速发展,万维网已经成为海量信息的载体。如何有效地提取和利用这些信息成为一个巨大的挑战。
搜索引擎,如传统的通用搜索引擎 AltaVista、Yahoo! 谷歌等作为辅助人们检索信息的工具,成为用户访问万维网的门户和指南。但是,这些通用的搜索引擎也有一定的局限性,例如:
(1)不同领域、不同背景的用户往往有不同的检索目的和需求。一般搜索引擎返回的结果中含有大量用户不关心的网页。
(2)通用搜索引擎的目标是最大化网络覆盖。有限的搜索引擎服务器资源和无限的网络数据资源之间的矛盾将进一步加深。
(3) 随着万维网上数据形式的丰富和网络技术的不断发展,图片、数据库、音频、视频、多媒体等不同数据大量出现,一般的搜索引擎往往无能为力。这些具有密集信息内容和一定结构的数据。很好地发现和获取。
(4)大多数通用搜索引擎都提供基于关键字的检索,难以支持基于语义信息的查询。
为了解决上述问题,针对相关网络资源进行针对性抓取的聚焦爬虫应运而生。Focus Crawler 是一个自动下载网页的程序。它根据建立的爬取目标有选择地访问万维网上的网页和相关链接,以获取所需的信息。与通用网络爬虫不同,聚焦爬虫不追求大的覆盖范围,而是将目标设定为抓取与特定主题内容相关的网页,并为面向主题的用户查询准备数据资源。
Python和爬虫有什么关系?
爬虫一般是指对网络资源的爬取。由于python的脚本特性,python易于配置,对字符的处理也非常灵活。另外python有丰富的网络捕捉模块,所以两者经常联系在一起。只需使用python自带的urllib库即可;使用python编写搜索引擎,搜索引擎是一个复杂的爬虫。从这里您将了解什么是 Python 爬虫。是一种基于Python编程创建的网络资源爬取方法。Python 不是爬虫。
为什么Python适合一些爬虫?
1) 抓取网页本身的界面
与java、c#、C++、python等其他静态编程语言相比,抓取网页文档的界面更加简洁;相对于其他动态脚本语言,如 perl、shell、python,urllib2 包提供了更完整的 Web 文档 API 访问。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站都是为了生硬爬取而被屏蔽的。这就是我们需要模拟用户代理的行为来构造合适的请求的地方,比如模拟用户登录,模拟session/cookies的存储和设置。python中有很好的第三方包帮你搞定,比如Requests,mechanize
2)网页爬取后的处理
抓取到的网页通常需要进行处理,如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用很短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要python。
爬虫是如何工作的?
1.首先选择一些精心挑选的种子网址;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取的URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页并保存到下载的网页库中。另外,将这些 URL 放入爬取的 URL 队列中。
4.对爬取的URL队列中的URL进行解析,分析其中的其他URL,将这些URL放入URL队列进行爬取,从而进入下一个循环。
Python除了用作爬虫还能做什么?
1、Web 开发python 有一个非常完整的与Web 服务器交互的库,以及大量免费的前端Web 模板。更有利的是,有一个非常好的成熟的Django Web框架,功能齐全。
2、Linux系统运维。其实早期都是用shell脚本来实现自动化运维的。但是由于shell脚本本身可编程性较弱,所以需要实现的一些功能库很少。大部分都需要自己从头开始编写,但pyhon作为一种“胶水语言”,可以方便地与其他人集成,因为它可以方便各种工具的二次开发,形成一套自己的运维管理系统。
3、游戏开发python在游戏开发上可能不如Lua或C++,但由于python脚本的优势,它类似于游戏脚本、玩法逻辑等非常灵活的设计。我们修改起来非常方便。当然,如果你开发一个小游戏程序,python还是很有优势的。比较有名的是pygame,这对我们自娱自乐来说可能是个好消息。
4、桌面软件 在window系统桌面开发领域,我认为C++ MFC应该得到更广泛的应用。Python可以实现与C++的无缝连接,同时支持Qt和GTK。
5、数据处理python作为一种工程语言,拥有相当丰富的数据处理库,如高性能科学计算库NumPy和SciPy。
6、人工智能 其实真正的人工智能底层语言是C/C++,因为真正的计算都是用C/C++进行的,而python只是调用了AI接口,然后实现了一些逻辑。但是为什么人工智能首先出现在 python 中?这其实是由于python作为“胶水语言”的特性。使用python的主要原因是CPython的集成和底层原因,让开发更方便。
当然,python还有其他应用场景,比如云计算。
感谢您的阅读。以上就是跟大家分享为什么Python被称为爬虫,以及Python和爬虫有什么关系。你明白吗?可以称Python爬虫,但不能说Python就是爬虫。记住?
免责声明:内容及图片来源于网络,版权归原作者所有。如果有侵犯您原创版权的内容,请告知我们,我们会尽快删除相关内容。 查看全部
php 爬虫抓取网页数据(什么是Python?Python是什么?(二)模糊)
今天听到有人问:Python为什么叫爬虫?我脑子里的第一反应不是答案,而是为什么有人问这个问题。我觉得大家对Python的概念有点模糊,把Python和爬虫混为一谈,所以今天问请解释一下。

什么是 Python?什么是 Python?
如果你在英文词典里查Python,他会给你Python作为大蟒蛇的定义,这样读:英语[ˈpaɪθən],美国[ˈpaɪθɑ:n],Python就是大名鼎鼎的“龟叔”Guido van Rossum在 1989 年圣诞节期间,为了度过无聊的圣诞节而编写的一种编程语言。Python 是一种计算机编程语言。是一种动态的、面向对象的脚本语言,最初是为编写自动化脚本(shell)而设计的,随着版本的不断更新和新语言功能的加入,越来越多的被用于独立的、大型的项目开发。
Python 是一种解释性脚本语言,可用于以下领域:
1、Web 和 Internet 开发
2、科学计算和统计
3、教育
4、桌面界面开发
5、软件开发
6、后端开发
什么是爬虫?什么是网络爬虫?
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是按照某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
随着互联网的飞速发展,万维网已经成为海量信息的载体。如何有效地提取和利用这些信息成为一个巨大的挑战。
搜索引擎,如传统的通用搜索引擎 AltaVista、Yahoo! 谷歌等作为辅助人们检索信息的工具,成为用户访问万维网的门户和指南。但是,这些通用的搜索引擎也有一定的局限性,例如:
(1)不同领域、不同背景的用户往往有不同的检索目的和需求。一般搜索引擎返回的结果中含有大量用户不关心的网页。
(2)通用搜索引擎的目标是最大化网络覆盖。有限的搜索引擎服务器资源和无限的网络数据资源之间的矛盾将进一步加深。
(3) 随着万维网上数据形式的丰富和网络技术的不断发展,图片、数据库、音频、视频、多媒体等不同数据大量出现,一般的搜索引擎往往无能为力。这些具有密集信息内容和一定结构的数据。很好地发现和获取。
(4)大多数通用搜索引擎都提供基于关键字的检索,难以支持基于语义信息的查询。
为了解决上述问题,针对相关网络资源进行针对性抓取的聚焦爬虫应运而生。Focus Crawler 是一个自动下载网页的程序。它根据建立的爬取目标有选择地访问万维网上的网页和相关链接,以获取所需的信息。与通用网络爬虫不同,聚焦爬虫不追求大的覆盖范围,而是将目标设定为抓取与特定主题内容相关的网页,并为面向主题的用户查询准备数据资源。
Python和爬虫有什么关系?
爬虫一般是指对网络资源的爬取。由于python的脚本特性,python易于配置,对字符的处理也非常灵活。另外python有丰富的网络捕捉模块,所以两者经常联系在一起。只需使用python自带的urllib库即可;使用python编写搜索引擎,搜索引擎是一个复杂的爬虫。从这里您将了解什么是 Python 爬虫。是一种基于Python编程创建的网络资源爬取方法。Python 不是爬虫。
为什么Python适合一些爬虫?
1) 抓取网页本身的界面
与java、c#、C++、python等其他静态编程语言相比,抓取网页文档的界面更加简洁;相对于其他动态脚本语言,如 perl、shell、python,urllib2 包提供了更完整的 Web 文档 API 访问。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站都是为了生硬爬取而被屏蔽的。这就是我们需要模拟用户代理的行为来构造合适的请求的地方,比如模拟用户登录,模拟session/cookies的存储和设置。python中有很好的第三方包帮你搞定,比如Requests,mechanize
2)网页爬取后的处理
抓取到的网页通常需要进行处理,如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用很短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要python。
爬虫是如何工作的?
1.首先选择一些精心挑选的种子网址;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取的URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页并保存到下载的网页库中。另外,将这些 URL 放入爬取的 URL 队列中。
4.对爬取的URL队列中的URL进行解析,分析其中的其他URL,将这些URL放入URL队列进行爬取,从而进入下一个循环。
Python除了用作爬虫还能做什么?
1、Web 开发python 有一个非常完整的与Web 服务器交互的库,以及大量免费的前端Web 模板。更有利的是,有一个非常好的成熟的Django Web框架,功能齐全。
2、Linux系统运维。其实早期都是用shell脚本来实现自动化运维的。但是由于shell脚本本身可编程性较弱,所以需要实现的一些功能库很少。大部分都需要自己从头开始编写,但pyhon作为一种“胶水语言”,可以方便地与其他人集成,因为它可以方便各种工具的二次开发,形成一套自己的运维管理系统。
3、游戏开发python在游戏开发上可能不如Lua或C++,但由于python脚本的优势,它类似于游戏脚本、玩法逻辑等非常灵活的设计。我们修改起来非常方便。当然,如果你开发一个小游戏程序,python还是很有优势的。比较有名的是pygame,这对我们自娱自乐来说可能是个好消息。
4、桌面软件 在window系统桌面开发领域,我认为C++ MFC应该得到更广泛的应用。Python可以实现与C++的无缝连接,同时支持Qt和GTK。
5、数据处理python作为一种工程语言,拥有相当丰富的数据处理库,如高性能科学计算库NumPy和SciPy。
6、人工智能 其实真正的人工智能底层语言是C/C++,因为真正的计算都是用C/C++进行的,而python只是调用了AI接口,然后实现了一些逻辑。但是为什么人工智能首先出现在 python 中?这其实是由于python作为“胶水语言”的特性。使用python的主要原因是CPython的集成和底层原因,让开发更方便。
当然,python还有其他应用场景,比如云计算。
感谢您的阅读。以上就是跟大家分享为什么Python被称为爬虫,以及Python和爬虫有什么关系。你明白吗?可以称Python爬虫,但不能说Python就是爬虫。记住?
免责声明:内容及图片来源于网络,版权归原作者所有。如果有侵犯您原创版权的内容,请告知我们,我们会尽快删除相关内容。
php 爬虫抓取网页数据(Python內建使用urllib.request获取网页urllib是什么意思?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-11-05 09:01
1. 使用 urllib.request 获取网页
urllib 是 Python 中的内置 HTTP 库。使用 urllib,您可以通过非常简单的步骤高效地使用 采集 数据;配合Beautiful等HTML解析库,可以为采集网络数据编写大型爬虫;
注:示例代码采用Python3编写;urllib 是 Python2 中 urllib 和 urllib2 的组合,Python2 中的 urllib2 对应于 Python3 中的 urllib.request
简单的例子:
2. 伪造请求头信息
有时爬虫发起的请求会被服务器拒绝。这时,爬虫需要伪装成人类用户的浏览器。这通常是通过伪造请求头信息来实现的,例如:
3. 伪造的请求体
爬取某些网站时,需要POST数据到服务器,然后需要伪造请求体;
为了实现有道词典的在线翻译脚本,在Chrome中打开开发工具,在Network下找到方法为POST的请求。观察数据,可以发现请求体中的'i'是需要翻译的URL编码内容,因此可以伪造请求体,如:
您还可以使用 add_header() 方法来伪造请求头,例如:
4. 使用代理IP
为了避免爬虫过于频繁导致IP被封的问题采集,可以使用代理IP,例如:
注意:使用爬虫过于频繁地访问目标站点会占用大量服务器资源。大型分布式爬虫可以爬取一个站点甚至对该站点发起DDOS攻击;因此,您在使用爬虫爬取数据时应合理安排爬取。频率和时间;如:服务器比较空闲时(如清晨)进行爬取,完成一个爬取任务后暂停一段时间等;
5. 检测网页的编码方式
虽然大部分网页都是UTF-8编码的,但有时你会遇到使用其他编码方式的网页,所以必须了解网页的编码方式才能正确解码抓取到的页面;
chardet是python的第三方模块,使用chardet可以自动检测网页的编码方式;
安装chardet:pip install charest
用:
6. 获取重定向链接
有时网页的某个页面需要在原创URL的基础上重定向一次甚至多次才能最终到达目标页面,因此需要正确处理重定向;
通过requests模块的head()函数获取跳转链接的URL,如 查看全部
php 爬虫抓取网页数据(Python內建使用urllib.request获取网页urllib是什么意思?)
1. 使用 urllib.request 获取网页
urllib 是 Python 中的内置 HTTP 库。使用 urllib,您可以通过非常简单的步骤高效地使用 采集 数据;配合Beautiful等HTML解析库,可以为采集网络数据编写大型爬虫;
注:示例代码采用Python3编写;urllib 是 Python2 中 urllib 和 urllib2 的组合,Python2 中的 urllib2 对应于 Python3 中的 urllib.request
简单的例子:
2. 伪造请求头信息
有时爬虫发起的请求会被服务器拒绝。这时,爬虫需要伪装成人类用户的浏览器。这通常是通过伪造请求头信息来实现的,例如:
3. 伪造的请求体
爬取某些网站时,需要POST数据到服务器,然后需要伪造请求体;
为了实现有道词典的在线翻译脚本,在Chrome中打开开发工具,在Network下找到方法为POST的请求。观察数据,可以发现请求体中的'i'是需要翻译的URL编码内容,因此可以伪造请求体,如:
您还可以使用 add_header() 方法来伪造请求头,例如:
4. 使用代理IP
为了避免爬虫过于频繁导致IP被封的问题采集,可以使用代理IP,例如:
注意:使用爬虫过于频繁地访问目标站点会占用大量服务器资源。大型分布式爬虫可以爬取一个站点甚至对该站点发起DDOS攻击;因此,您在使用爬虫爬取数据时应合理安排爬取。频率和时间;如:服务器比较空闲时(如清晨)进行爬取,完成一个爬取任务后暂停一段时间等;
5. 检测网页的编码方式
虽然大部分网页都是UTF-8编码的,但有时你会遇到使用其他编码方式的网页,所以必须了解网页的编码方式才能正确解码抓取到的页面;
chardet是python的第三方模块,使用chardet可以自动检测网页的编码方式;
安装chardet:pip install charest
用:
6. 获取重定向链接
有时网页的某个页面需要在原创URL的基础上重定向一次甚至多次才能最终到达目标页面,因此需要正确处理重定向;
通过requests模块的head()函数获取跳转链接的URL,如
php 爬虫抓取网页数据(搜索引擎获取网站相关数据及对应的地址是什么?最可能的答案)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-12-03 21:25
爬虫是一种获取数据的方式,可以按照一定的规则自动爬取某个网站或者万维网信息;真实环境中很大一部分网络访问是由爬虫引起的;我们来看一个常见的应用场景:
当我们使用百度或其他搜索引擎搜索某个关键词时,搜索结果中会收录相应的内容,如:搜索Python,搜索结果可能包括Python官网、Python相关文章等信息,但是这个信息分布在不同的网站上,那么问题来了:这些搜索引擎是怎么知道这些信息和对应的地址的呢?可能的答案是搜索引擎获取了网站的相关数据和对应的地址;想一个问题,python的官网应该不可能主动提供相应的数据,那么数据是怎么获取的呢?最可能的答案是按照一定的规则抓取网站的信息,保存到本地,然后清洗数据。
根据爬虫方式的不同,我们可以将爬虫分为两类:
1.增量爬虫:不限制爬取数据属性。比如谷歌和百度搜索巨头都是增量爬虫;他们一直在抓取数据,他们也会根据一定的算法评估网站的好坏,定期抓取最新的数据,保证他们搜索结果的及时性和正确性;
2.批量爬虫:限制爬取的属性,抓取特定的网站信息;例如:我们需要做人脸识别,如果样本不够,可以使用爬虫抓取百度图片中的人脸照片;获取相应的训练样本;
这里主要使用Python来完成批量爬虫的设计和实现,并对抓取到的数据进行清理和分析;
为什么选择 Python?
当前流行的语言之一,语法简单,使用方便,支持面向对象,第三方模块丰富;我们来看看常用的相关模块:
1. Crawler 相关模块:urllib、requests、Bs4、 lxml 等;
2.数据库相关模块:pyMysql、pyMongo等;
3. 数据分析相关模块:numpy、pandas、matplotlib等;
基于这些模块,我们可以快速搭建爬虫,抓取数据,并对抓取的数据进行分析和可视化。
下面我们来一步步介绍爬取的过程以及每一步涉及到的知识点。例如,当我们得到一个需求时,我们可以抓取一个 网站 数据:
1.需求分析:结合网站提供的信息,分析我们可以获得哪些数据信息
2.请求行为分析:查看整个交互行为,确认请求方式、URL和数据;这就是我们需要了解的Http协议,并借助浏览器或其他抓包工具对其进行分析,这是我们的关键步骤;
3.知识点分析:请求行为分析完成后,我们要确认抓取策略,数据存储形式,确认数据抓取模块,页面信息提取模块,确认我们可以使用这些模块完成相关的开发工作;
4.爬虫设计与实现:
1) 设计的爬行动物,
2) 根据请求行为和页面信息提取流程,完成代码结构设计,
3) 借助jupyer或ipython,一一完成页面请求和数据提取,然后封装成方法添加到类中;
5.存储模块设计与实现:主要实现模块化设计,数据采集和存储分离,统一封装存储接口,无论是存储在csv、json文件还是mysql、mongodb等数据库中,都可以是一个统一接口
6.代码调试:这部分后面会在实际文章中详细讲解,如何快速定位并解决问题;
7. 数据可视化分析:当数据抓取完成后,我们使用相关模块对数据进行清洗,对数据进行可视化分析,了解每个图标的含义;
以上是开发爬虫的一般步骤。我们也会按照这些步骤进行讲解,但是每个知识点、开发调试细节会在中间进行更详细的说明。
本课程可以为您解决这些问题:
1.如何快速使用python搭建爬虫;
2.常用概念的详细解释和应用:比如cookies的作用和具体应用;
3.常见的反爬虫机制及解决方案;
4. 高并发爬虫的设计与实现;
5.数据分析与可视化;
学习本课程需要提前准备好开发环境和相关知识点:
1.开发环境:
Python3.6 (window/linux/macos);
铬浏览器;
pychram IDE开发环境;
2. 相关知识点:
掌握Python常用的数据结构和基本逻辑;
掌握函数和类的相关知识点;
了解多进程/多线程相关模块的使用;
了解数据库的基本操作,如:mongodb、mysql的增删改查等操作;
课程案例:
1.获取一些网站电影相关信息和海报;
2.登录知名代码开源网站;
3.高并发代理IP验证;
4. 生产者和消费者模型抓斗图片
5. 抓取一定的网站电影相关数据,按年龄、国家、差评对数据进行分析;
6. 抓取某二手房交易市场的相关数据,对数据进行相关分析;
通过理论与实战相结合,希望本系列文章能帮助大家快速掌握爬虫开发所需的知识点、流程和技巧。 查看全部
php 爬虫抓取网页数据(搜索引擎获取网站相关数据及对应的地址是什么?最可能的答案)
爬虫是一种获取数据的方式,可以按照一定的规则自动爬取某个网站或者万维网信息;真实环境中很大一部分网络访问是由爬虫引起的;我们来看一个常见的应用场景:
当我们使用百度或其他搜索引擎搜索某个关键词时,搜索结果中会收录相应的内容,如:搜索Python,搜索结果可能包括Python官网、Python相关文章等信息,但是这个信息分布在不同的网站上,那么问题来了:这些搜索引擎是怎么知道这些信息和对应的地址的呢?可能的答案是搜索引擎获取了网站的相关数据和对应的地址;想一个问题,python的官网应该不可能主动提供相应的数据,那么数据是怎么获取的呢?最可能的答案是按照一定的规则抓取网站的信息,保存到本地,然后清洗数据。
根据爬虫方式的不同,我们可以将爬虫分为两类:
1.增量爬虫:不限制爬取数据属性。比如谷歌和百度搜索巨头都是增量爬虫;他们一直在抓取数据,他们也会根据一定的算法评估网站的好坏,定期抓取最新的数据,保证他们搜索结果的及时性和正确性;
2.批量爬虫:限制爬取的属性,抓取特定的网站信息;例如:我们需要做人脸识别,如果样本不够,可以使用爬虫抓取百度图片中的人脸照片;获取相应的训练样本;
这里主要使用Python来完成批量爬虫的设计和实现,并对抓取到的数据进行清理和分析;
为什么选择 Python?
当前流行的语言之一,语法简单,使用方便,支持面向对象,第三方模块丰富;我们来看看常用的相关模块:
1. Crawler 相关模块:urllib、requests、Bs4、 lxml 等;
2.数据库相关模块:pyMysql、pyMongo等;
3. 数据分析相关模块:numpy、pandas、matplotlib等;
基于这些模块,我们可以快速搭建爬虫,抓取数据,并对抓取的数据进行分析和可视化。
下面我们来一步步介绍爬取的过程以及每一步涉及到的知识点。例如,当我们得到一个需求时,我们可以抓取一个 网站 数据:
1.需求分析:结合网站提供的信息,分析我们可以获得哪些数据信息
2.请求行为分析:查看整个交互行为,确认请求方式、URL和数据;这就是我们需要了解的Http协议,并借助浏览器或其他抓包工具对其进行分析,这是我们的关键步骤;
3.知识点分析:请求行为分析完成后,我们要确认抓取策略,数据存储形式,确认数据抓取模块,页面信息提取模块,确认我们可以使用这些模块完成相关的开发工作;
4.爬虫设计与实现:
1) 设计的爬行动物,
2) 根据请求行为和页面信息提取流程,完成代码结构设计,
3) 借助jupyer或ipython,一一完成页面请求和数据提取,然后封装成方法添加到类中;
5.存储模块设计与实现:主要实现模块化设计,数据采集和存储分离,统一封装存储接口,无论是存储在csv、json文件还是mysql、mongodb等数据库中,都可以是一个统一接口
6.代码调试:这部分后面会在实际文章中详细讲解,如何快速定位并解决问题;
7. 数据可视化分析:当数据抓取完成后,我们使用相关模块对数据进行清洗,对数据进行可视化分析,了解每个图标的含义;
以上是开发爬虫的一般步骤。我们也会按照这些步骤进行讲解,但是每个知识点、开发调试细节会在中间进行更详细的说明。
本课程可以为您解决这些问题:
1.如何快速使用python搭建爬虫;
2.常用概念的详细解释和应用:比如cookies的作用和具体应用;
3.常见的反爬虫机制及解决方案;
4. 高并发爬虫的设计与实现;
5.数据分析与可视化;
学习本课程需要提前准备好开发环境和相关知识点:
1.开发环境:
Python3.6 (window/linux/macos);
铬浏览器;
pychram IDE开发环境;
2. 相关知识点:
掌握Python常用的数据结构和基本逻辑;
掌握函数和类的相关知识点;
了解多进程/多线程相关模块的使用;
了解数据库的基本操作,如:mongodb、mysql的增删改查等操作;
课程案例:
1.获取一些网站电影相关信息和海报;
2.登录知名代码开源网站;
3.高并发代理IP验证;
4. 生产者和消费者模型抓斗图片
5. 抓取一定的网站电影相关数据,按年龄、国家、差评对数据进行分析;
6. 抓取某二手房交易市场的相关数据,对数据进行相关分析;
通过理论与实战相结合,希望本系列文章能帮助大家快速掌握爬虫开发所需的知识点、流程和技巧。
php 爬虫抓取网页数据(微信小程序签名参数破解(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-12-03 21:24
最近有朋友想爬取小红书上的图片:
结合以往爬虫经验,抓号难度App>网页版>=微信小程序,所以我们选择小红书的微信小程序进行突破。
使用Charles抓包工具,当你点击小红书小程序中的每个类别时,很容易定位到它的请求和返回结果:
查尔斯抓包:
每个请求返回20条信息流,其中收录我们想要的图片链接;当我们在小程序中继续向下滑动时,会发送新的请求来获取更多的信息流。我们要做的就是提取请求的参数,模拟发送请求,爬取返回结果,提取图片链接就可以了。
由于我在工作中使用NodeJS来爬取爬虫,所以很容易使用JS编写的爬虫代码;大家看文章的可能只是看思路,这里就不放具体代码了。参数里面还有一个比较麻烦的。“签名参数”x-sign,这里是重点:
在网上搜索相关内容的时候,很多大牛确实破解了这个参数:它的格式是字母X加32位十六进制字符,通常32位十六进制字符是MD5加密后得到的结果,所以也比较容易猜测。但是,涉及到解密时,您必须私下联系作者,甚至需要向您收费才能解密。
最近也在研究反编译小程序,成功破解了几个类似小程序的签名参数。抱着试一试的态度,花了一个小时终于搞定了这个参数~
刚才说了,这个参数可能是用MD5算法处理某些值的结果。具体逻辑只有看源码才能知道。文章 一开始就说小程序比较容易破解。原因是微信小程序更容易通过反编译得到源代码(可能不是完整的源代码,但一般的参数逻辑通常可以定位)。
1. 反编译小红书小程序
第一步是反编译小红书小程序,定位到其x-sign参数生成的源代码。这里要反编译小程序,我参考了下面的帖子:
大致流程是登录电脑版微信,打开小红书小程序,找到小程序文件所在目录,解密然后反编译,得到小程序处理的源代码。
2.在源码中搜索目标参数
因为要获取x-sign参数的生成逻辑,我们直接在文件中搜索x-sign:
跟着红框里的相关函数名一路查找,你会逐渐发现就是拼接请求的参数,然后组合一个固定的字符串进行MD5处理,最后在开头加一个大写的X就形成了一个 x 符号。整个过程与最初的猜测一致。
3. 模拟源码重新生成相关参数
过去,我自己用Python来计算爬虫,但在我的工作中,我使用NodeJs爬虫来抓取数字。渐渐地,我发现NodeJS有它的优点:一般的网页前端代码都是用JS写的,小程序中的加密逻辑也是用JS写的。在进行仿真生成相关参数时,可以无缝连接NodeJ。我通常的做法是,无论加密逻辑多么复杂,只要把输入的参数搞清楚,我只要把它的加密代码全部复制下来,设置好需要的参数和变量,直接算出奇迹就可以了。
如图,我在源码中配置了生成x-sign参数的函数和变量后,直接运行,得到某些请求参数所需的x-sign值。
4.配置爬取参数
得到x-sign后,爬虫是一个还算满意的过程,每次请求20个请求,不断翻页获取更多。不过小红书毕竟是大公司出品,还是有防爬措施的。例如,检索到500个条目后,将触发滑块验证:
并且返回1000条信息后,不再返回数据:
所以最终我们的爬虫只能爬取每个目录下1000个帖子和相关图片链接。如果在此期间触发了滑块,则程序在手动拖动滑块验证后仍可继续捕捉。
回到最初的需求,我朋友想在小红书上抓图。既然抓到了图片链接,接下来就可以编写批量下载脚本了——不过已经有大侠在现场了:
回顾整个需求,利用业余时间,用不到一天的时间,效率还是很高的!
反编译破解加密参数的乐趣,尤其是通过自主研究的整个过程,非常有趣。
最后,如果您有爬虫、办公自动化等方面的想法和需求,请联系我。本人能力有限,希望能帮到你~ 查看全部
php 爬虫抓取网页数据(微信小程序签名参数破解(图))
最近有朋友想爬取小红书上的图片:
结合以往爬虫经验,抓号难度App>网页版>=微信小程序,所以我们选择小红书的微信小程序进行突破。
使用Charles抓包工具,当你点击小红书小程序中的每个类别时,很容易定位到它的请求和返回结果:
查尔斯抓包:
每个请求返回20条信息流,其中收录我们想要的图片链接;当我们在小程序中继续向下滑动时,会发送新的请求来获取更多的信息流。我们要做的就是提取请求的参数,模拟发送请求,爬取返回结果,提取图片链接就可以了。
由于我在工作中使用NodeJS来爬取爬虫,所以很容易使用JS编写的爬虫代码;大家看文章的可能只是看思路,这里就不放具体代码了。参数里面还有一个比较麻烦的。“签名参数”x-sign,这里是重点:
在网上搜索相关内容的时候,很多大牛确实破解了这个参数:它的格式是字母X加32位十六进制字符,通常32位十六进制字符是MD5加密后得到的结果,所以也比较容易猜测。但是,涉及到解密时,您必须私下联系作者,甚至需要向您收费才能解密。
最近也在研究反编译小程序,成功破解了几个类似小程序的签名参数。抱着试一试的态度,花了一个小时终于搞定了这个参数~
刚才说了,这个参数可能是用MD5算法处理某些值的结果。具体逻辑只有看源码才能知道。文章 一开始就说小程序比较容易破解。原因是微信小程序更容易通过反编译得到源代码(可能不是完整的源代码,但一般的参数逻辑通常可以定位)。
1. 反编译小红书小程序
第一步是反编译小红书小程序,定位到其x-sign参数生成的源代码。这里要反编译小程序,我参考了下面的帖子:
大致流程是登录电脑版微信,打开小红书小程序,找到小程序文件所在目录,解密然后反编译,得到小程序处理的源代码。
2.在源码中搜索目标参数
因为要获取x-sign参数的生成逻辑,我们直接在文件中搜索x-sign:
跟着红框里的相关函数名一路查找,你会逐渐发现就是拼接请求的参数,然后组合一个固定的字符串进行MD5处理,最后在开头加一个大写的X就形成了一个 x 符号。整个过程与最初的猜测一致。
3. 模拟源码重新生成相关参数
过去,我自己用Python来计算爬虫,但在我的工作中,我使用NodeJs爬虫来抓取数字。渐渐地,我发现NodeJS有它的优点:一般的网页前端代码都是用JS写的,小程序中的加密逻辑也是用JS写的。在进行仿真生成相关参数时,可以无缝连接NodeJ。我通常的做法是,无论加密逻辑多么复杂,只要把输入的参数搞清楚,我只要把它的加密代码全部复制下来,设置好需要的参数和变量,直接算出奇迹就可以了。
如图,我在源码中配置了生成x-sign参数的函数和变量后,直接运行,得到某些请求参数所需的x-sign值。
4.配置爬取参数
得到x-sign后,爬虫是一个还算满意的过程,每次请求20个请求,不断翻页获取更多。不过小红书毕竟是大公司出品,还是有防爬措施的。例如,检索到500个条目后,将触发滑块验证:
并且返回1000条信息后,不再返回数据:
所以最终我们的爬虫只能爬取每个目录下1000个帖子和相关图片链接。如果在此期间触发了滑块,则程序在手动拖动滑块验证后仍可继续捕捉。
回到最初的需求,我朋友想在小红书上抓图。既然抓到了图片链接,接下来就可以编写批量下载脚本了——不过已经有大侠在现场了:
回顾整个需求,利用业余时间,用不到一天的时间,效率还是很高的!
反编译破解加密参数的乐趣,尤其是通过自主研究的整个过程,非常有趣。
最后,如果您有爬虫、办公自动化等方面的想法和需求,请联系我。本人能力有限,希望能帮到你~
php 爬虫抓取网页数据(闲人日记:如何获取交叉熵函数的开发者工具?(上) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-02 02:08
)
闲人日记
时间:2021年3月9日
这上来明明很闲却没更新!怎么说呢,不想做,总能找到很多理由。毕竟,“不想做”就是“不想做”。停止废话,开始进入主题。
打开网站 主页进行实验。可以看到网页上有一个明显的表格。这张表是看到别人写交叉熵函数文章时搬过来的数据。接下来,我们将尝试使用Python获取以下数据,并使用不同色块的类属性作为行索引。
看看数据就知道了
接下来F12打开浏览器的开发者工具,我们先看一下网页的源码,这可以帮助我们分析之后如何处理数据。但是在开始之前,笔者首先要说的是,编写爬虫没有固定的、具体的方法,一定要“具体情况具体分析”!很多时候我们面对的需求是不一样的,有些网站不能用下面的方法获取数据(获取的方法会有很大的不同),这些都需要很多具体的经验和处理具体的人脸。问题的经验。. .
点击元素选择工具,点击目标元素,查看器跳转到目标元素的代码。见图一。
图一
一起来看看元素之间的“父子关系”吧!左边的“代”比较大,其中,图2这个...里面是我们要获取数据的目标表的源代码,我们发现只有这个表出现了在整个网页中。class=table table-hover 参数类的属性值,这将是脚本找到这个表对象的重要依据。
图二
为了演示方便,只列出了tbody的6个tr
好的,我们接下来开始我们的工作。首先,我们要先安装一些爬虫相关的库或模块。如果没有安装,可以在cmd中输入命令安装:pip install requests beautifulsoup4 pandas(requests和beautifulsoup4、pandas也安装了)。安装成功后,我们进入下一步。打开 Jupyther Notebook,数据科学中常用的 Python 集成开发环境。如果使用Python的IDLE工具,最好一行一行的输入命令,否则很容易报错。
分别导入请求和beautifulsoup4、pandas:
对于网络请求,某些网站必须带头发送,否则无法获取。
输入response.text,你会发现所有的汉字都变成了乱码。这时候就需要转换编码了。查看输出的编码:
响应文本
一般我们只需要将编码转换为utf-8即可解决中文乱码:
或输入以下代码:
处理完编码问题后
可以看出,相当杂乱,和真正的源码不太一样。“\r”表示当前位置返回到开头,“\n”表示换行,“\t”表示跳到下一个制表符位置。所以要创建一个 bs4.BeautifulSoup 类型的对象:
将文本转换为源代码
BeautifulSoup 模块使响应文本更加规则。
在变量soup“table table-hover”中找到第一个属性类的值为table的代码块:
...代码块
获取tbody中所有tr标签的代码块:
全部在tbody...
代码块列表
处理成所需数据的结构(警告!下面有很多图带你看代码):
列
上校
因为 attrs['class'] 返回一个列表
提取list对象中的字符串(否则tbody_id不能作为索引)
主题数据
将列表数据转换为pandas DataFrame 类型的数据
数据表
请根据自己的需要设计。这几乎是结束了。如果要将数据表导出为Excel表格,只需要使用pandas的to_excel()函数即可。
背后的故事
18年,笔者和数学建模的小伙伴遇到一个课题,需要采集大量的足球彩票网站数据进行数据分析。那时我们用的是matlab,对互联网技术或编程了解不多。水平也有待提高。所以我用了最慢的方法,一页一页地采集页面。可以说是慢到让人吐血。那是我第一次通宵工作。如果你现在看,你有更多的选择。
后记
笔者在百度体验中遇到过很多墙,文章还是发不出来。我总是被告知我已经踏上了“雷区”以做出改变。做了几个小时的更改,我仍然无法通过。不得不放弃。之前微信公众号上发的内容没人看,虽然只是比较基础的内容,自然会和别人的代码有很多相似之处。但无论如何,我是在自己的网站上爬取数据,而那个网站只是用于各种实验。
今天突然发现b站的专栏增加了一些作者和其他朋友之前一直在说的功能,有点惊喜!我爱小破站(poyin)。
查看全部
php 爬虫抓取网页数据(闲人日记:如何获取交叉熵函数的开发者工具?(上)
)
闲人日记
时间:2021年3月9日
这上来明明很闲却没更新!怎么说呢,不想做,总能找到很多理由。毕竟,“不想做”就是“不想做”。停止废话,开始进入主题。
打开网站 主页进行实验。可以看到网页上有一个明显的表格。这张表是看到别人写交叉熵函数文章时搬过来的数据。接下来,我们将尝试使用Python获取以下数据,并使用不同色块的类属性作为行索引。
看看数据就知道了
接下来F12打开浏览器的开发者工具,我们先看一下网页的源码,这可以帮助我们分析之后如何处理数据。但是在开始之前,笔者首先要说的是,编写爬虫没有固定的、具体的方法,一定要“具体情况具体分析”!很多时候我们面对的需求是不一样的,有些网站不能用下面的方法获取数据(获取的方法会有很大的不同),这些都需要很多具体的经验和处理具体的人脸。问题的经验。. .
点击元素选择工具,点击目标元素,查看器跳转到目标元素的代码。见图一。
图一
一起来看看元素之间的“父子关系”吧!左边的“代”比较大,其中,图2这个...里面是我们要获取数据的目标表的源代码,我们发现只有这个表出现了在整个网页中。class=table table-hover 参数类的属性值,这将是脚本找到这个表对象的重要依据。
图二
为了演示方便,只列出了tbody的6个tr
好的,我们接下来开始我们的工作。首先,我们要先安装一些爬虫相关的库或模块。如果没有安装,可以在cmd中输入命令安装:pip install requests beautifulsoup4 pandas(requests和beautifulsoup4、pandas也安装了)。安装成功后,我们进入下一步。打开 Jupyther Notebook,数据科学中常用的 Python 集成开发环境。如果使用Python的IDLE工具,最好一行一行的输入命令,否则很容易报错。
分别导入请求和beautifulsoup4、pandas:
对于网络请求,某些网站必须带头发送,否则无法获取。
输入response.text,你会发现所有的汉字都变成了乱码。这时候就需要转换编码了。查看输出的编码:
响应文本
一般我们只需要将编码转换为utf-8即可解决中文乱码:
或输入以下代码:
处理完编码问题后
可以看出,相当杂乱,和真正的源码不太一样。“\r”表示当前位置返回到开头,“\n”表示换行,“\t”表示跳到下一个制表符位置。所以要创建一个 bs4.BeautifulSoup 类型的对象:
将文本转换为源代码
BeautifulSoup 模块使响应文本更加规则。
在变量soup“table table-hover”中找到第一个属性类的值为table的代码块:
...代码块
获取tbody中所有tr标签的代码块:
全部在tbody...
代码块列表
处理成所需数据的结构(警告!下面有很多图带你看代码):
列
上校
因为 attrs['class'] 返回一个列表
提取list对象中的字符串(否则tbody_id不能作为索引)
主题数据
将列表数据转换为pandas DataFrame 类型的数据
数据表
请根据自己的需要设计。这几乎是结束了。如果要将数据表导出为Excel表格,只需要使用pandas的to_excel()函数即可。
背后的故事
18年,笔者和数学建模的小伙伴遇到一个课题,需要采集大量的足球彩票网站数据进行数据分析。那时我们用的是matlab,对互联网技术或编程了解不多。水平也有待提高。所以我用了最慢的方法,一页一页地采集页面。可以说是慢到让人吐血。那是我第一次通宵工作。如果你现在看,你有更多的选择。
后记
笔者在百度体验中遇到过很多墙,文章还是发不出来。我总是被告知我已经踏上了“雷区”以做出改变。做了几个小时的更改,我仍然无法通过。不得不放弃。之前微信公众号上发的内容没人看,虽然只是比较基础的内容,自然会和别人的代码有很多相似之处。但无论如何,我是在自己的网站上爬取数据,而那个网站只是用于各种实验。
今天突然发现b站的专栏增加了一些作者和其他朋友之前一直在说的功能,有点惊喜!我爱小破站(poyin)。
php 爬虫抓取网页数据( 本发明公开了一种,流程及专利说明(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-11-30 22:19
本发明公开了一种,流程及专利说明(组图))
网络爬虫爬取网页或数据时再次过滤的方法
<p>[专利摘要] 本发明公开了一种网络爬虫在抓取网页或数据时再次过滤的方法。流程如下:输入需要检索的关键词,服务器检索URL地址,然后从检索到的URL地址中抓取目标网页的信息,进入二次搜索 查看全部
php 爬虫抓取网页数据(
本发明公开了一种,流程及专利说明(组图))
网络爬虫爬取网页或数据时再次过滤的方法
<p>[专利摘要] 本发明公开了一种网络爬虫在抓取网页或数据时再次过滤的方法。流程如下:输入需要检索的关键词,服务器检索URL地址,然后从检索到的URL地址中抓取目标网页的信息,进入二次搜索
php 爬虫抓取网页数据(开发爬虫其实不用纠结用什么语言,省去一次爬虫开发不难)
网站优化 • 优采云 发表了文章 • 0 个评论 • 56 次浏览 • 2021-11-29 01:19
因为我已经开始开发一个蜘蛛池站群系统,其中涉及爬虫自动去全网寻找符合关键词或关键词密度标准的页面,然后加速内容,然后使用它。NLP相关的技术有伪原创,定期将文章发布到库中,发布这样一个模块,也是用php开发的。我也在这里和大家分享一下我对爬虫的看法。
实际上,您无需担心使用哪种语言来开发爬虫。只要PHP在性能不太高的情况下完全够用,我也推荐PHP工程师用PHP来做,这样可以节省学习一门新语言的时间成本。
再次,爬虫开发并不难。
主要是定位到你想要实现的爬虫类型。
根据互联网上所有爬虫的功能和特点,可分为批处理型、增量型和垂直型三种。
批处理类型,具有明显的爬取范围和目标,设置爬取时间限制、爬取数据限制、或在固定范围内爬取页面限制等,当爬虫的任务达到预设目标时停止。一般来说,采集 工具或内容采集 任务都是批处理类型。一般只抓取固定网站的固定内容,或者为某个资源设置固定的目标数据量。当达到设定的限制时,抓取的数据或时间将自动停止。这种爬虫是典型的批量爬虫。
增量类型也可以称为通用类型。百度、谷歌、搜狗等搜索引擎的爬虫可以称为增量爬虫。增量式不同于批处理式。没有固定的目标、范围和时间限制。一般会无休止地爬取,直到抓到全网的数据。增量类型一般不仅需要爬取尽可能多的页面,还要对已经爬取过的页面进行爬取和更新。因为这些爬虫爬进数据库的页面不是静态的,可能会更新,甚至404。一般来说,增量爬虫的这些功能应该是标准的。至于去重,排名不在这里。在答案中讨论。
垂直型,也叫聚焦爬虫,只爬取固定主题内容或固定行业网页,一般集中在一定的有限范围内进行增量爬取。垂直爬虫不像增量爬虫那样追求大而全的覆盖。相反,他们在增量爬虫上增加了对网页抓取的限制,根据需求抓取收录目标内容的网页。不符合要求的网页就让它静静地躺在url队列中。比如我之前做的蜘蛛池内容爬虫模块就是这个垂直爬虫。
以上为大家大致介绍了爬虫的种类。我猜你应该可以大致定位到你要开发的爬虫。
谈技术关键词,开始开发的时候直接查这几个字,然后用上。
CURL:不用说,如果要爬取一个页面,首先要请求这个页面,得到对方服务器返回的数据(一般是html,如果直接看懂别人的api接口,就当我没看吧说吧)过去这句话)。
simple_html_dom:HTML 节点解析器。使用curl请求html文档后,可以用这个来解析dom节点,方便匹配需要采集爬取的内容。
正则表达式:用于匹配你想要的内容,与simple_html_dom功能相同,但会更加灵活。如果两者匹配起来,就会更加流畅。哈哈:)
worker 或 swoole:用于做多线程或多进程以提高效率。我更推荐workerman,因为学习成本低,文档清晰易学!Swoole 对新手确实很不友好,但是它的功能比workerman 强一点,这里就不讨论了。
Redis:用于存储 URL 队列。如果不追求太高的效率,可以无视。
对于这些关键词来说,入门级的爬虫差不多就够了。很想研究一下数千万的采集对分布式爬虫的追求。我建议出去左转 Python 或其他语言主题下的提问。
最后说一下实现思路。
首页上的爬虫需要一个种子页,比如“中国新闻网”首页。这个爬虫使用curl请求种子页面,获取html数据,使用正则表达式匹配a标签的所有href属性,然后根据自己定义的一些规则匹配符合规则的url或者url已自行处理。例如,一些a标签可能没有http或https头,或者可能有没有域名的url,例如“/news/gn/”。这时候你需要做一点判断和处理,把添加的加进去,然后用sha1加密url,然后用hash去查数据库看是否有相同的hash,如果有,表示url已经有了(go Heavy),然后将url和hash同时存入url队列数据库中。
做完以上操作后,一定要记得给被爬取的URL一个已爬取状态,避免重复爬取。
然后在重复之前的操作之前,从数据库中检查一个新的没有被爬取过的URL,这样你的爬虫就形成了,它会继续往你的URL队列中添加URL。
关键时刻到了。如果我们简单地爬取URL并放入数据库,那是没有用的,对吧?
这时候该说一下内容采集了,url就在那里。这时候写一个爬虫,不断的取出url库中的url来爬回这个页面的内容,然后再写规则匹配内容之后,就可以保存到数据库中了。
就是这样。这个入门级爬虫就做好了。
但是真正的爬虫开发工作肯定会遇到很多很多的问题和意想不到的问题,比如:蜘蛛陷阱、反爬虫、动态加载的内容无法爬取、效率问题、程序报错后是否有重启机制并在遇到异常、法律风险等问题后停止运行。
以下所有问题都留给你在实战中自己解决,因为每个人的业务不同,报出的错误肯定也不同。没有办法说的太清楚。这篇文章文章主要是为了给大家提供一个思路。我也欢迎大家加入我。让我们一起交流讨论爬虫的各种知识和技巧。如果人多,我也可以组成一个交流群,大家交流。学习。
一不小心写了两千多字,没费心复习这句话,没啥意思。如果有错别字,大家都会看的。我的 vx 有问题。 查看全部
php 爬虫抓取网页数据(开发爬虫其实不用纠结用什么语言,省去一次爬虫开发不难)
因为我已经开始开发一个蜘蛛池站群系统,其中涉及爬虫自动去全网寻找符合关键词或关键词密度标准的页面,然后加速内容,然后使用它。NLP相关的技术有伪原创,定期将文章发布到库中,发布这样一个模块,也是用php开发的。我也在这里和大家分享一下我对爬虫的看法。
实际上,您无需担心使用哪种语言来开发爬虫。只要PHP在性能不太高的情况下完全够用,我也推荐PHP工程师用PHP来做,这样可以节省学习一门新语言的时间成本。
再次,爬虫开发并不难。
主要是定位到你想要实现的爬虫类型。
根据互联网上所有爬虫的功能和特点,可分为批处理型、增量型和垂直型三种。
批处理类型,具有明显的爬取范围和目标,设置爬取时间限制、爬取数据限制、或在固定范围内爬取页面限制等,当爬虫的任务达到预设目标时停止。一般来说,采集 工具或内容采集 任务都是批处理类型。一般只抓取固定网站的固定内容,或者为某个资源设置固定的目标数据量。当达到设定的限制时,抓取的数据或时间将自动停止。这种爬虫是典型的批量爬虫。
增量类型也可以称为通用类型。百度、谷歌、搜狗等搜索引擎的爬虫可以称为增量爬虫。增量式不同于批处理式。没有固定的目标、范围和时间限制。一般会无休止地爬取,直到抓到全网的数据。增量类型一般不仅需要爬取尽可能多的页面,还要对已经爬取过的页面进行爬取和更新。因为这些爬虫爬进数据库的页面不是静态的,可能会更新,甚至404。一般来说,增量爬虫的这些功能应该是标准的。至于去重,排名不在这里。在答案中讨论。
垂直型,也叫聚焦爬虫,只爬取固定主题内容或固定行业网页,一般集中在一定的有限范围内进行增量爬取。垂直爬虫不像增量爬虫那样追求大而全的覆盖。相反,他们在增量爬虫上增加了对网页抓取的限制,根据需求抓取收录目标内容的网页。不符合要求的网页就让它静静地躺在url队列中。比如我之前做的蜘蛛池内容爬虫模块就是这个垂直爬虫。
以上为大家大致介绍了爬虫的种类。我猜你应该可以大致定位到你要开发的爬虫。
谈技术关键词,开始开发的时候直接查这几个字,然后用上。
CURL:不用说,如果要爬取一个页面,首先要请求这个页面,得到对方服务器返回的数据(一般是html,如果直接看懂别人的api接口,就当我没看吧说吧)过去这句话)。
simple_html_dom:HTML 节点解析器。使用curl请求html文档后,可以用这个来解析dom节点,方便匹配需要采集爬取的内容。
正则表达式:用于匹配你想要的内容,与simple_html_dom功能相同,但会更加灵活。如果两者匹配起来,就会更加流畅。哈哈:)
worker 或 swoole:用于做多线程或多进程以提高效率。我更推荐workerman,因为学习成本低,文档清晰易学!Swoole 对新手确实很不友好,但是它的功能比workerman 强一点,这里就不讨论了。
Redis:用于存储 URL 队列。如果不追求太高的效率,可以无视。
对于这些关键词来说,入门级的爬虫差不多就够了。很想研究一下数千万的采集对分布式爬虫的追求。我建议出去左转 Python 或其他语言主题下的提问。
最后说一下实现思路。
首页上的爬虫需要一个种子页,比如“中国新闻网”首页。这个爬虫使用curl请求种子页面,获取html数据,使用正则表达式匹配a标签的所有href属性,然后根据自己定义的一些规则匹配符合规则的url或者url已自行处理。例如,一些a标签可能没有http或https头,或者可能有没有域名的url,例如“/news/gn/”。这时候你需要做一点判断和处理,把添加的加进去,然后用sha1加密url,然后用hash去查数据库看是否有相同的hash,如果有,表示url已经有了(go Heavy),然后将url和hash同时存入url队列数据库中。
做完以上操作后,一定要记得给被爬取的URL一个已爬取状态,避免重复爬取。
然后在重复之前的操作之前,从数据库中检查一个新的没有被爬取过的URL,这样你的爬虫就形成了,它会继续往你的URL队列中添加URL。
关键时刻到了。如果我们简单地爬取URL并放入数据库,那是没有用的,对吧?
这时候该说一下内容采集了,url就在那里。这时候写一个爬虫,不断的取出url库中的url来爬回这个页面的内容,然后再写规则匹配内容之后,就可以保存到数据库中了。
就是这样。这个入门级爬虫就做好了。
但是真正的爬虫开发工作肯定会遇到很多很多的问题和意想不到的问题,比如:蜘蛛陷阱、反爬虫、动态加载的内容无法爬取、效率问题、程序报错后是否有重启机制并在遇到异常、法律风险等问题后停止运行。
以下所有问题都留给你在实战中自己解决,因为每个人的业务不同,报出的错误肯定也不同。没有办法说的太清楚。这篇文章文章主要是为了给大家提供一个思路。我也欢迎大家加入我。让我们一起交流讨论爬虫的各种知识和技巧。如果人多,我也可以组成一个交流群,大家交流。学习。
一不小心写了两千多字,没费心复习这句话,没啥意思。如果有错别字,大家都会看的。我的 vx 有问题。
php 爬虫抓取网页数据(爬取空气质量检测网之部分城市的历年每天质量数据思路)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-11-29 01:17
爬取空气质检网多年来部分城市的日常质量数据思路-------------------------------- --- ------从某城市空气质量网页获取某城市的月度链接,然后爬取月表数据。连云港市:php?city=连云港2014年5月连云港空气质量:php?city=连云港&month=2014-05遇到的问题-------------------- --- -------------------获取的网页中的表格数据是隐藏的,尝试请求是无法获取的。判断可能是动态加载网页尝试----------------------------------------- 1. 通过XHR、js找到隐藏数据的加载网页,但是没有找到。2. 使用phantomjs.get() result=pd.read_html 获取隐藏表数据,但不稳定,
仍然遇到的问题: -----------------------------------------Crawl one Data is available在网页上,但是如果连续检索网页会出现两个错误。1.Message: ReferenceError: items is not defined2.connection denied 解决方法:1.connection denied 问题,可能是打开的网页太多,使用driver.quit()< @2. 如果execute_script 仍然失败,请尝试pd.read_html 获取信息。之前使用phantomjs获取空表的时候,可能是因为加载不足,使用Waite直到表出现才获取网页Element=wait.until(EC.element_to_be_clickable((By.XPATH,"/html/body) /div[3] /div[1]/div[1]/table/tbody")))3. 偶尔会出现输出为空的情况。使用循环。如果输出表为空,请再次获取。if len(result)>1:filename = str(month) +'.xls'result.to_excel('E:\python\case program\data\\' + filename)print('successfully saved'+filename)driver .退出()else:driver.quit()return getdata(monthhref,month) 查看全部
php 爬虫抓取网页数据(爬取空气质量检测网之部分城市的历年每天质量数据思路)
爬取空气质检网多年来部分城市的日常质量数据思路-------------------------------- --- ------从某城市空气质量网页获取某城市的月度链接,然后爬取月表数据。连云港市:php?city=连云港2014年5月连云港空气质量:php?city=连云港&month=2014-05遇到的问题-------------------- --- -------------------获取的网页中的表格数据是隐藏的,尝试请求是无法获取的。判断可能是动态加载网页尝试----------------------------------------- 1. 通过XHR、js找到隐藏数据的加载网页,但是没有找到。2. 使用phantomjs.get() result=pd.read_html 获取隐藏表数据,但不稳定,
仍然遇到的问题: -----------------------------------------Crawl one Data is available在网页上,但是如果连续检索网页会出现两个错误。1.Message: ReferenceError: items is not defined2.connection denied 解决方法:1.connection denied 问题,可能是打开的网页太多,使用driver.quit()< @2. 如果execute_script 仍然失败,请尝试pd.read_html 获取信息。之前使用phantomjs获取空表的时候,可能是因为加载不足,使用Waite直到表出现才获取网页Element=wait.until(EC.element_to_be_clickable((By.XPATH,"/html/body) /div[3] /div[1]/div[1]/table/tbody")))3. 偶尔会出现输出为空的情况。使用循环。如果输出表为空,请再次获取。if len(result)>1:filename = str(month) +'.xls'result.to_excel('E:\python\case program\data\\' + filename)print('successfully saved'+filename)driver .退出()else:driver.quit()return getdata(monthhref,month)
php 爬虫抓取网页数据(PHP爬虫实现方法直接采用PHPcurl来抓取数据socket方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-26 12:07
PHP爬虫总结
PHP爬虫现在网上爬虫很多很多,五花八门,但是大家都不喜欢用PHP写爬虫。可能是因为不稳定,组件库太少。反正 PHP 写起来还是很简单的。 curl的实现方法直接使用PHP curl抓取数据。 socket方法使用最原创的socket方法。这里有一个https:hightmanpspider 项目,非常完整。它还使用了腾讯云的主机。没有任何限制,直接使用即可。 curl方法使用爬取网页步骤设置种子url,一般是站点的域名。通过这个首页一步步抓取seed url,分析这个页面,得到所有相关的url,根据是否抓取外部站点策略来判断。对url进行处理,判断是否是需要爬取的网页。如果是要爬取的网页,则进行存储处理。如果不是,请更新队列。有多种PHP爬虫推荐:https:smartengphp-crawler https:smartengpspider https:smartengskycaiji https:smartengQueryList 这里重点介绍第一个:PHP实现的轻量级爬虫,只提供爬虫核心调度功能
994 查看全部
php 爬虫抓取网页数据(PHP爬虫实现方法直接采用PHPcurl来抓取数据socket方法)
PHP爬虫总结
PHP爬虫现在网上爬虫很多很多,五花八门,但是大家都不喜欢用PHP写爬虫。可能是因为不稳定,组件库太少。反正 PHP 写起来还是很简单的。 curl的实现方法直接使用PHP curl抓取数据。 socket方法使用最原创的socket方法。这里有一个https:hightmanpspider 项目,非常完整。它还使用了腾讯云的主机。没有任何限制,直接使用即可。 curl方法使用爬取网页步骤设置种子url,一般是站点的域名。通过这个首页一步步抓取seed url,分析这个页面,得到所有相关的url,根据是否抓取外部站点策略来判断。对url进行处理,判断是否是需要爬取的网页。如果是要爬取的网页,则进行存储处理。如果不是,请更新队列。有多种PHP爬虫推荐:https:smartengphp-crawler https:smartengpspider https:smartengskycaiji https:smartengQueryList 这里重点介绍第一个:PHP实现的轻量级爬虫,只提供爬虫核心调度功能
994
php 爬虫抓取网页数据(PHP中如何利用爬虫_get_contents()效果 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-11-24 21:18
)
爬虫是按照一定的规则自动抓取万维网上信息的程序或脚本。
我们通常使用搜索引擎浏览网页,有很多与预期信息不匹配的结果;而且信息量巨大,有了结果之后,还要费很大力气来过滤信息。爬虫诞生了,我们可以写一个脚本或者程序,让他按照我们的需要按照设定的规则抓取网页信息,过滤出我们需要的结果。
首先,PHP中可以获取万维网页面的函数有很多,比如:file_get_contents()或者curl扩展,或者ob_get_contents()获取缓冲区等,最实用最常用的就是file_get_contents( )。例子:
目标页面
代码和效果
打开文件后的比较
因此,我们可以使用file_get_contents()来开发爬虫。
步:
1. 解析url规则
第一页:
第二页:
第三页:
在第一页后加&pn=0和第一页内容一样,所以每页的pn参数会增加50
可以概括为:&pn=(当前页码-1)*50
2. 根据规则循环抓取内容
3. 根据需求定期匹配需要的内容(可根据实际需求做)
4. 积分结果(写入文件)
<p>//爬取前3页
for($i=1;$i 查看全部
php 爬虫抓取网页数据(PHP中如何利用爬虫_get_contents()效果
)
爬虫是按照一定的规则自动抓取万维网上信息的程序或脚本。
我们通常使用搜索引擎浏览网页,有很多与预期信息不匹配的结果;而且信息量巨大,有了结果之后,还要费很大力气来过滤信息。爬虫诞生了,我们可以写一个脚本或者程序,让他按照我们的需要按照设定的规则抓取网页信息,过滤出我们需要的结果。
首先,PHP中可以获取万维网页面的函数有很多,比如:file_get_contents()或者curl扩展,或者ob_get_contents()获取缓冲区等,最实用最常用的就是file_get_contents( )。例子:
目标页面
代码和效果
打开文件后的比较
因此,我们可以使用file_get_contents()来开发爬虫。
步:
1. 解析url规则
第一页:
第二页:
第三页:
在第一页后加&pn=0和第一页内容一样,所以每页的pn参数会增加50
可以概括为:&pn=(当前页码-1)*50
2. 根据规则循环抓取内容
3. 根据需求定期匹配需要的内容(可根据实际需求做)
4. 积分结果(写入文件)
<p>//爬取前3页
for($i=1;$i
php 爬虫抓取网页数据(股票的技术分析到底有多大作用,大数据爬虫技术)
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-11-23 06:06
股票的技术分析有多大用处?
这里提到的技术分析也是每个股票投资者需要掌握的知识。包括三点:一是关注交易量的变化;二是要注意股票操作模式;三是注重技术指标。
很多人认为一个好的股票投资者靠运气。事实上,事实并非如此。俗话说,三分靠运气,七分靠努力。作为一个聪明而专业的股票投资者,你首先要考虑你需要买什么,你买的股票价值在哪里。当然,对之前购买股票的公司的了解也很重要。重要的是要了解主要股票价格的波动规律,依法买入,不是炒作,而是要靠经验和技术分析来准备。.
股市的竞争越来越激烈,能混进去的一群人,才算是合格的股票投资者。
因此,成为合格的股票投资者是一个渐进的过程。当你积累了更多的经验,对市场状况有了足够的了解,就可以达到量变质变的效果,然后就敢于大胆投资了。大数据爬虫技术有哪些功能
1、 爬虫技术概述
网络爬虫是根据一定的规则自动抓取万维网信息的程序或脚本。它们广泛用于互联网搜索引擎或其他类似的网站,可以自动将采集它所能访问的页面的所有内容获取或更新这些网站@的内容和检索方法>. 从功能上来说,爬虫一般分为三部分:数据采集、处理、存储。
传统爬虫从一个或几个初始网页的网址开始,获取初始网页上的网址,在网页抓取过程中不断从当前页面中提取新的网址放入队列中,直到达到一定的停止条件系统的满足。聚焦爬虫的工作流程比较复杂。需要按照一定的网页分析算法过滤与主题无关的链接,保留有用的链接,放入URL队列等待被抓取。然后,它会根据一定的搜索策略从队列中选择下一个要抓取的网页的网址,重复上述过程,直到达到系统的某个条件时停止。另外,所有爬虫爬取的网页都会被系统存储起来,进行一定的分析、过滤、并为以后的查询和检索建立索引;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。
与一般网络爬虫相比,聚焦爬虫需要解决三个主要问题:
(1) 爬取目标的描述或定义;
(2) 对网页或数据的分析和过滤;
(3) URL 搜索策略。
2、爬取的原理
2.1 网络爬虫原理
网络爬虫系统的作用是下载网页数据,为搜索引擎系统提供数据源。许多大型互联网搜索引擎系统被称为基于Web数据的搜索引擎系统,如谷歌和百度。这说明了网络爬虫系统在搜索引擎中的重要性。除了供用户阅读的文本信息外,网页还收录一些超链接信息。网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。正是因为这个采集过程就像一个爬虫或蜘蛛在网络上漫游,所以被称为网络爬虫系统或网络蜘蛛系统,英文称为Spider或Crawler。
2.2 网络爬虫系统的工作原理
在网络爬虫的系统框架中,主要流程由控制器、解析器和资源库三部分组成。控制器的主要工作是为多线程中的每个爬虫线程分配工作任务。解析器的主要工作是下载网页并处理页面,主要是处理一些JS脚本标签、CSS代码内容、空格字符、HTML标签等内容。爬虫的基本工作由解析器完成。资源库用于存储下载的网页资源,一般使用Oracle数据库等大型数据库存储,并建立索引。
控制器
控制器是网络爬虫的**控制器。主要负责根据系统传递过来的URL链接分配一个线程,然后启动线程调用爬虫对网页进行爬取。
解析器
解析器是网络爬虫的主要部分。它的主要任务包括:下载网页,处理网页的文本,如过滤,提取特殊的HTML标签,分析数据。
资源库
主要用于存储网页中下载的数据记录,并提供生成索引的目标源。中大型数据库产品包括:Oracle、Sql Server等。
网络爬虫系统一般会选择一些输出度(网页中超链接的数量)较高的比较重要的URL作为种子URL集合。网络爬虫系统使用这些种子集作为初始 URL 开始数据爬取。由于网页中收录链接信息,因此会通过现有网页的网址获取一些新的网址。网页之间的指向结构可以看作是一个森林。每个种子 URL 对应的网页是森林中一棵树的根节点。. 这样,网络爬虫系统就可以按照广度优先算法或深度优先算法遍历所有网页。由于深度优先搜索算法可能会导致爬虫系统陷入网站内部,不利于搜索离网站首页较近的网页信息,采集网页一般采用广度优先搜索算法。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部取一个 URL 来下载相应的网页。获取并存储网页内容后,通过解析网页中的链接信息,可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,如此周而复始,直到遍历全网或满足某个条件,才会停止。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部取一个 URL 来下载相应的网页。获取并存储网页内容后,通过解析网页中的链接信息,可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,如此周而复始,直到遍历全网或满足某个条件,才会停止。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部取一个 URL 来下载相应的网页。获取并存储网页内容后,通过解析网页中的链接信息,可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,如此周而复始,直到遍历全网或满足某个条件,才会停止。并将这些 URL 添加到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,如此周而复始,直到遍历全网或满足某个条件,才会停止。并将这些 URL 添加到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,如此周而复始,直到遍历全网或满足某个条件,才会停止。
网络爬虫的基本工作流程如下:
1.首先选择一些精心挑选的种子网址;
2.将这些URL放入URL队列进行抓取;
3. 从待爬取的URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,并存储到下载的网页库中。另外,将这些网址放入已爬取的网址队列中;
4.对爬取的URL队列中的URL进行分析,分析其中的其他URL,将这些URL放入URL队列进行爬取,从而进入下一个循环。
2.3 爬取策略
在爬虫系统中,要爬取的URL队列是一个非常重要的部分。URL队列中要爬取的URL的顺序也是一个很重要的问题,因为它涉及到先爬哪个页面,后爬哪个页面。确定这些 URL 顺序的方法称为抓取策略。下面重点介绍几种常见的爬取策略:
2.3.1 深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,逐个跟踪每一个链接,处理完这一行后转移到下一个起始页,继续跟踪链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.3.2 广度优先遍历策略
广度优先遍历策略的基本思想是将新下载的网页中找到的链接直接**到待抓取的URL队列的末尾。即网络爬虫会先抓取起始网页中所有链接的网页,然后选择其中一个链接的网页,继续抓取该网页中链接的所有网页。以上图为例:
遍历路径:ABCDEF GHI
2.3.3 反向链接计数策略
反向链接数是指从其他网页链接到某个网页的数量。反向链接的数量表示网页内容被他人推荐的程度。因此,很多时候搜索引擎的爬取系统都会使用这个指标来评估网页的重要性,从而决定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量不能完全坐等别人的重视。因此,搜索引擎通常会考虑一些可靠的反向链接。
2.3.4 部分 PageRank 策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,连同要爬取的URL队列中的URL,形成一个网页集合,计算每个页面的PageRank值,经过计算完成后,将要爬取的URL队列中的URL按照PageRank值的大小进行排列,依次爬取页面。
如果每个页面都被抓取,则重新计算 PageRank 值。一个折衷的方案是:每爬取K个页面后,重新计算PageRank值。但是,这种情况下仍然存在一个问题:对于从下载页面分析出来的链接,也就是我们前面提到的未知网页部分,暂时没有PageRank值。为了解决这个问题,这些页面会被赋予一个临时的PageRank值:将所有传入该页面链中的PageRank值聚合起来,从而形成未知页面的PageRank值参与排名。
2.3.5 OPIC 策略
该算法实际上对页面的重要性进行评分。在算法开始之前,给所有页面相同的初始现金(cash)。下载某个页面P后,将P的现金分配给所有从P解析的链接,清空P的现金。待抓取的 URL 队列中的所有页面均按照现金的数量进行排序。
2.3.6大站优先策略
待爬取的 URL 队列中的所有网页,均按照其所属的 网站 进行分类。对于网站需要下载的页面较多的,优先下载。这种策略因此被称为大站优先策略。
3、 爬虫分类
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他来开发网络爬虫?上面提到的爬虫基本上可以分为三类:
(1)分布式爬虫:Nutch
(2)JAVA 爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
3.1 个分布式爬虫
爬虫采用分布式,主要解决两个问题:
1)海量网址管理
2)网速
最流行的分布式爬虫是 Apache 的 Nutch。但是对于大多数用户来说,Nutch 是这些类型的爬虫中最糟糕的选择,原因如下:
1)Nutch 是一款专为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。Nutch 运行的一组进程中有三分之二是为搜索引擎设计的。精细提取没有多大意义。换句话说,使用 Nutch 进行数据提取会在不必要的计算上浪费大量时间。而如果你试图通过二次开发让Nutch适合精炼业务,你基本上会破坏Nutch的框架,将Nutch改得面目全非,并有能力修改Nutch。自己写一个新的确实更好。分布式爬虫框架。
2)Nutch 依赖于hadoop 来运行,而hadoop 本身就消耗大量时间。如果集群机器数量少,爬取速度不如单机爬虫快。
3)Nutch有插件机制,作为亮点推广。可以看到一些开源的Nutch插件,提供精细的提取功能。但是任何开发过 Nutch 插件的人都知道 Nutch 的插件系统有多烂。使用反射机制加载和调用插件使得编写和调试程序变得极其困难,更不用说在其上开发复杂的精细提取系统了。并且Nutch没有提供相应的插件挂载点进行精细提取。Nutch的插件只有五六个挂载点,而这五六个挂载点是为搜索引擎服务的,不提供精细提取的挂载点。Nutch的大部分精提取插件都挂载在挂载点“解析器”(parser)上。
4)使用Nutch进行爬虫的二次开发,爬虫的准备和调试所需的时间往往是单机爬虫的十倍以上。学习Nutch源代码的成本非常高,更何况一个团队中的每个人都必须了解Nutch源代码。在调试过程中,会出现程序本身以外的各种问题(hadoop问题、hbase问题)。
5) 很多人说Nutch2有gora,可以持久化数据到avro文件、hbase、mysql等,其实很多人理解错了。这里所说的持久化数据是指在avro、hbase、mysql中存储URL信息(URL管理所需的数据)。这不是您要提取的结构化数据。事实上,对于大多数人来说,URL 信息存在于何处并不重要。
6)Nutch2的版本目前不适合开发。Nutch官方稳定版是nutch2.2.1,但是这个版本绑定了gora-0.3。如果你想和nutch一起使用hbase(大多数人使用nutch2只是为了使用hbase),你只能在0.90版本左右使用hbase,而hadoop版本必须减少到hadoop 0.2左右. 而且,Nutch2的官方教程更具有误导性。Nutch2有两个教程,分别是Nutch1.x和Nutch2.x。Nutch2.x 官网可以支持转到hbase 0.94。但其实这个Nutch2.x指的是Nutch2.3之前和Nutch2.2.1之后的版本。此版本在官方SVN中不断更新。
所以,如果你不是搜索引擎,尽量不要选择Nutch作为爬虫。有些团队喜欢效仿。他们不得不选择Nutch来开发高度提取的爬虫。事实上,这是为了Nutch的声誉。当然,最终的结果往往是项目延期。
如果你是一个搜索引擎,Nutch1.x 是一个非常好的选择。Nutch1.x 与 solr 或 es 合作组成了一个非常强大的搜索引擎。如果非要使用Nutch2,建议等到Nutch2.3发布。当前的 Nutch2 是一个非常不稳定的版本。
3.2 JAVA爬虫
这里将JAVA爬虫单独划分为一个类别,因为JAVA在网络爬虫的生态系统中是非常完备的。相关资料也是最全的。这里可能有争议,我只是随便说说。
其实,开源网络爬虫(框架)的开发很简单,难点复杂的问题(比如DOM树解析定位、字符集检测、海量URL去重)都已经被前人解决了,可以说没有技术含量。包括Nutch,其实Nutch的技术难点就是开发hadoop,代码本身也很简单。从某种意义上说,网络爬虫类似于遍历机器的文件以查找文件中的信息。没有任何困难。之所以选择开源爬虫框架,是为了省事。比如爬虫URL管理、线程池等模块任何人都可以做,但是需要一段时间的调试和修改才能稳定下来。
用于爬虫的功能。用户比较关心的问题往往是:
1)爬虫是否支持多线程,爬虫能不能用agent,能不能抓取重复数据,能不能抓取JS生成的信息?
那些不支持多线程、代理或过滤重复 URL 的不称为开源爬虫。它们被称为循环执行 http 请求。
js生成的信息能否被爬取与爬虫本身关系不大。爬虫主要负责遍历网站和下载页面。爬取js产生的信息与网页信息提取模块有关,往往需要通过模拟浏览器(htmlunit、selenium)来完成。这些模拟浏览器通常需要花费大量时间来处理页面。所以一个策略就是利用这些爬虫来遍历网站,当遇到需要解析的页面时,将页面的相关信息提交给模拟浏览器,完成对JS生成信息的提取。
2)爬虫可以爬取ajax信息吗?
网页上有一些异步加载的数据。爬取这个数据有两种方式:使用模拟浏览器(问题1中描述),或者分析ajax http请求,自己生成ajax请求url,获取返回数据。如果自己生成ajax请求,使用开源爬虫有什么意义?其实还是需要用到开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我需要的ajax请求(列表),我该如何使用这些爬虫来抓取这些请求?
爬虫通常被设计成广度遍历或深度遍历的模式来遍历静态或动态页面。爬取ajax信息属于深网(deep web)的范畴,虽然大部分爬虫不直接支持。但它也可以通过某些方式完成。例如,WebCollector 使用广度遍历来遍历网站。第一轮爬取是爬取种子集(seeds)中的所有URL。简单的说,就是将生成的ajax请求作为种子,放入爬虫中。使用爬虫遍历这些深度为1的种子(默认为广度遍历)。
3)爬虫如何爬取网站登录?
这些开源爬虫都支持在爬取时指定cookies,模拟登录主要依赖cookies。至于如何获取cookie,就不是爬虫的事情了。您可以手动获取cookies,也可以模拟http请求登录,也可以使用模拟浏览器自动登录获取cookies。
4)爬虫如何从网页中提取信息?
开源爬虫一般都集成了网页提取工具。主要支持两种类型的规范:CSS SELECTOR 和 XPATH。至于哪个更好,这里就不做评价了。
5)爬虫是如何保存网页信息的?
一些爬虫带有一个负责持久化的模块。例如,webmagic 有一个叫做管道的模块。通过简单的配置,爬虫提取的信息可以持久化到文件、数据库等中,也有一些爬虫不直接为用户提供数据持久化模块。如 crawler4j 和 webcollector。让用户在网页处理模块中添加提交数据库的操作。至于使用pipeline模块好不好,类似于是否使用ORM来操作数据库的问题。这取决于您的业务。
6)爬虫被网站拦截怎么办?
爬虫已经被网站屏蔽了,一般可以通过多个代理(随机代理)解决。但是,这些开源爬虫一般不直接支持随机代理的切换。因此,用户往往需要自己将获取到的代理放入一个全局数组中,自己编写代码来随机获取代理(从数组中)。
7)网页可以调用爬虫吗?
爬虫的调用是在Web的服务器端调用的,你可以照常使用。所有这些爬虫都可以使用。
8)爬行速度怎么样?
一个单机的开源爬虫的速度基本可以用到机器网速的极限。爬虫速度慢,往往是因为用户线程少,网速慢,或者持久化数据时与数据库交互慢。这些东西往往是由用户的机器和二次开发代码决定的。这些开源爬虫的速度非常好。
9)显然代码写对了,爬不出来数据。是不是爬虫有问题?别的爬虫能解决吗?
如果代码写对了,数据爬不出来,其他爬虫也是一样。在这种情况下,要么 网站 阻止了您,要么您抓取的数据是由 javascript 生成的。爬取数据无法通过改变爬虫来解决。
10)哪个爬虫可以判断网站是否爬完了,哪个爬虫可以根据主题爬取?
爬虫无法判断网站是否爬过,只能尽量覆盖。
至于基于主题的爬取,爬虫只有向下爬取内容才知道主题是什么。所以它通常是从整体上爬下来,然后去过滤内容。如果觉得抓取过于笼统,可以通过限制网址规律等方法缩小范围。
11) 哪个爬虫有更好的设计模式和结构?
设计模式纯属无稽之谈。当软件设计模式好的时候,开发软件,然后总结出几种设计模式。设计模式对软件开发没有指导作用。使用设计模式来设计爬虫只会让爬虫的设计更加臃肿。
在架构上,开源爬虫目前主要是详细数据结构的设计,比如爬取线程池、任务队列等,大家都可以控制。爬虫的业务太简单了,不谈结构。
所以对于JAVA开源爬虫,我觉得,找一个好用的就好了。如果业务复杂,使用哪种爬虫就必须经过复杂的二次开发才能满足需求。
3.3 个非 Java 爬虫
在非JAVA语言编写的爬虫中,有很多优秀的爬虫。这个单独提取为一个类别,不是为了爬虫本身的质量,而是为了larbin、scrapy等爬虫对开发成本的影响。
先说python爬虫,python可以用30行代码完成JAVA 50行代码的任务。Python 代码编写确实很快,但是在调试代码阶段,Python 代码的调试往往比编码阶段节省的时间消耗的时间要多得多。使用python开发,为了保证程序的正确性和稳定性,需要编写更多的测试模块。当然,如果爬取规模不大,爬取业务不复杂,使用scrapy也是相当不错的,可以轻松完成爬取任务。
上图是Scrapy的架构图。绿线是数据流。首先从初始的URL开始,Scheduler将其交给Downloader进行下载,下载完成后,交给Spider进行分析,将需要保存的数据发送到Item Pipeline ,即对数据进行后处理。此外,可以在数据流通道中安装各种中间件来进行必要的处理。所以在开发爬虫的时候,最好先规划好各个模块。我的做法是分别规划下载模块、爬取模块、调度模块、数据存储模块。
对于C++爬虫来说,学习**的成本会比较大。而且你不能只计算一个人的学习成本。如果软件需要团队开发或交接,那将是很多人的学习成本。软件调试并不是那么容易。
还有一些ruby、php爬虫,这里不多评论。确实有一些非常小的数据任务。使用ruby或php非常方便。但是要选择这些语言的开源爬虫,一方面需要调查相关的生态系统,另一方面,这些开源爬虫可能会产生一些你找不到的bug(人少信息少)
4、反爬虫技术
由于搜索引擎的流行,网络爬虫已经成为一种非常流行的网络技术。除了专门从事搜索的谷歌、雅虎、微软、百度,几乎每个大型门户网站网站都有自己的搜索引擎,**小有几十个名字,还有数以万计的未知名字。对于一个内容驱动的网站来说,难免会被网络爬虫光顾。
一些智能搜索引擎爬虫在网站上的爬取频率比较合理,消耗的资源较少,但是很多不好的网络爬虫对网页的爬取能力很差,经常会发送几十上百个请求,重复爬取循环。拿,这种爬虫往往对中小网站是毁灭性的打击,尤其是一些缺乏爬虫编写经验的程序员写的爬虫破坏力极强,网站访问压力会很大高的。, 会导致网站 访问缓慢甚至无法访问。
一般来说,网站是从三个方面进行反爬虫的:用户请求的Headers、用户行为、网站目录和数据加载方式。前两个比较容易遇到,大多数网站反爬虫都是从这几个角度来看的。将采用第三类ajax应用网站,增加爬虫难度。
4.1 个通过 Headers 的反爬虫
从用户请求的Headers反爬取是最常见的反爬取策略。很多网站会检测Headers的User-Agent,还有一些网站会检测Referer(部分资源的防盗链网站就是检测Referer)。如果遇到这种反爬虫机制,可以直接给爬虫添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者修改Referer值为目标网站域名。对于检测header的反爬虫,在爬虫中修改或添加header很容易绕过。
【点评:往往容易被忽视。通过对请求的捕获分析,确定referer,并在程序中模拟访问请求头中添加]
4.2 基于用户行为的反爬虫
网站的另一部分是检测用户行为,比如同一IP在短时间内多次访问同一个页面,或者同一个账号在短时间内多次执行相同的操作。技术分析真的对股票交易有用吗?
技术分析对股票非常有用,因为市场上大部分机构和个人都使用技术分析,所以符合从众原则。当大多数技术分析表明股票正在好转时,资金将开始流入,股票自然会上涨。反之亦然。
技术分析是一个统计概念、历史重复概念和从众心理概念,所以很有用。
但单一指标的技术分析用处不大,一般确认两个或多个技术分析相辅相成。 查看全部
php 爬虫抓取网页数据(股票的技术分析到底有多大作用,大数据爬虫技术)
股票的技术分析有多大用处?
这里提到的技术分析也是每个股票投资者需要掌握的知识。包括三点:一是关注交易量的变化;二是要注意股票操作模式;三是注重技术指标。
很多人认为一个好的股票投资者靠运气。事实上,事实并非如此。俗话说,三分靠运气,七分靠努力。作为一个聪明而专业的股票投资者,你首先要考虑你需要买什么,你买的股票价值在哪里。当然,对之前购买股票的公司的了解也很重要。重要的是要了解主要股票价格的波动规律,依法买入,不是炒作,而是要靠经验和技术分析来准备。.
股市的竞争越来越激烈,能混进去的一群人,才算是合格的股票投资者。
因此,成为合格的股票投资者是一个渐进的过程。当你积累了更多的经验,对市场状况有了足够的了解,就可以达到量变质变的效果,然后就敢于大胆投资了。大数据爬虫技术有哪些功能
1、 爬虫技术概述
网络爬虫是根据一定的规则自动抓取万维网信息的程序或脚本。它们广泛用于互联网搜索引擎或其他类似的网站,可以自动将采集它所能访问的页面的所有内容获取或更新这些网站@的内容和检索方法>. 从功能上来说,爬虫一般分为三部分:数据采集、处理、存储。
传统爬虫从一个或几个初始网页的网址开始,获取初始网页上的网址,在网页抓取过程中不断从当前页面中提取新的网址放入队列中,直到达到一定的停止条件系统的满足。聚焦爬虫的工作流程比较复杂。需要按照一定的网页分析算法过滤与主题无关的链接,保留有用的链接,放入URL队列等待被抓取。然后,它会根据一定的搜索策略从队列中选择下一个要抓取的网页的网址,重复上述过程,直到达到系统的某个条件时停止。另外,所有爬虫爬取的网页都会被系统存储起来,进行一定的分析、过滤、并为以后的查询和检索建立索引;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。
与一般网络爬虫相比,聚焦爬虫需要解决三个主要问题:
(1) 爬取目标的描述或定义;
(2) 对网页或数据的分析和过滤;
(3) URL 搜索策略。
2、爬取的原理
2.1 网络爬虫原理
网络爬虫系统的作用是下载网页数据,为搜索引擎系统提供数据源。许多大型互联网搜索引擎系统被称为基于Web数据的搜索引擎系统,如谷歌和百度。这说明了网络爬虫系统在搜索引擎中的重要性。除了供用户阅读的文本信息外,网页还收录一些超链接信息。网络爬虫系统通过网页中的超链接信息不断获取网络上的其他网页。正是因为这个采集过程就像一个爬虫或蜘蛛在网络上漫游,所以被称为网络爬虫系统或网络蜘蛛系统,英文称为Spider或Crawler。
2.2 网络爬虫系统的工作原理
在网络爬虫的系统框架中,主要流程由控制器、解析器和资源库三部分组成。控制器的主要工作是为多线程中的每个爬虫线程分配工作任务。解析器的主要工作是下载网页并处理页面,主要是处理一些JS脚本标签、CSS代码内容、空格字符、HTML标签等内容。爬虫的基本工作由解析器完成。资源库用于存储下载的网页资源,一般使用Oracle数据库等大型数据库存储,并建立索引。
控制器
控制器是网络爬虫的**控制器。主要负责根据系统传递过来的URL链接分配一个线程,然后启动线程调用爬虫对网页进行爬取。
解析器
解析器是网络爬虫的主要部分。它的主要任务包括:下载网页,处理网页的文本,如过滤,提取特殊的HTML标签,分析数据。
资源库
主要用于存储网页中下载的数据记录,并提供生成索引的目标源。中大型数据库产品包括:Oracle、Sql Server等。
网络爬虫系统一般会选择一些输出度(网页中超链接的数量)较高的比较重要的URL作为种子URL集合。网络爬虫系统使用这些种子集作为初始 URL 开始数据爬取。由于网页中收录链接信息,因此会通过现有网页的网址获取一些新的网址。网页之间的指向结构可以看作是一个森林。每个种子 URL 对应的网页是森林中一棵树的根节点。. 这样,网络爬虫系统就可以按照广度优先算法或深度优先算法遍历所有网页。由于深度优先搜索算法可能会导致爬虫系统陷入网站内部,不利于搜索离网站首页较近的网页信息,采集网页一般采用广度优先搜索算法。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部取一个 URL 来下载相应的网页。获取并存储网页内容后,通过解析网页中的链接信息,可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,如此周而复始,直到遍历全网或满足某个条件,才会停止。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部取一个 URL 来下载相应的网页。获取并存储网页内容后,通过解析网页中的链接信息,可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,如此周而复始,直到遍历全网或满足某个条件,才会停止。网络爬虫系统首先将种子 URL 放入下载队列,然后简单地从队列头部取一个 URL 来下载相应的网页。获取并存储网页内容后,通过解析网页中的链接信息,可以得到一些新的URL,并将这些URL加入到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,如此周而复始,直到遍历全网或满足某个条件,才会停止。并将这些 URL 添加到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,如此周而复始,直到遍历全网或满足某个条件,才会停止。并将这些 URL 添加到下载队列中。然后取出一个URL,下载其对应的网页,然后解析,如此周而复始,直到遍历全网或满足某个条件,才会停止。
网络爬虫的基本工作流程如下:
1.首先选择一些精心挑选的种子网址;
2.将这些URL放入URL队列进行抓取;
3. 从待爬取的URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页,并存储到下载的网页库中。另外,将这些网址放入已爬取的网址队列中;
4.对爬取的URL队列中的URL进行分析,分析其中的其他URL,将这些URL放入URL队列进行爬取,从而进入下一个循环。
2.3 爬取策略
在爬虫系统中,要爬取的URL队列是一个非常重要的部分。URL队列中要爬取的URL的顺序也是一个很重要的问题,因为它涉及到先爬哪个页面,后爬哪个页面。确定这些 URL 顺序的方法称为抓取策略。下面重点介绍几种常见的爬取策略:
2.3.1 深度优先遍历策略
深度优先遍历策略是指网络爬虫会从起始页开始,逐个跟踪每一个链接,处理完这一行后转移到下一个起始页,继续跟踪链接。我们以下图为例:
遍历的路径:AFG EHI BCD
2.3.2 广度优先遍历策略
广度优先遍历策略的基本思想是将新下载的网页中找到的链接直接**到待抓取的URL队列的末尾。即网络爬虫会先抓取起始网页中所有链接的网页,然后选择其中一个链接的网页,继续抓取该网页中链接的所有网页。以上图为例:
遍历路径:ABCDEF GHI
2.3.3 反向链接计数策略
反向链接数是指从其他网页链接到某个网页的数量。反向链接的数量表示网页内容被他人推荐的程度。因此,很多时候搜索引擎的爬取系统都会使用这个指标来评估网页的重要性,从而决定不同网页的爬取顺序。
在真实的网络环境中,由于广告链接和作弊链接的存在,反向链接的数量不能完全坐等别人的重视。因此,搜索引擎通常会考虑一些可靠的反向链接。
2.3.4 部分 PageRank 策略
Partial PageRank算法借鉴了PageRank算法的思想:对于下载的网页,连同要爬取的URL队列中的URL,形成一个网页集合,计算每个页面的PageRank值,经过计算完成后,将要爬取的URL队列中的URL按照PageRank值的大小进行排列,依次爬取页面。
如果每个页面都被抓取,则重新计算 PageRank 值。一个折衷的方案是:每爬取K个页面后,重新计算PageRank值。但是,这种情况下仍然存在一个问题:对于从下载页面分析出来的链接,也就是我们前面提到的未知网页部分,暂时没有PageRank值。为了解决这个问题,这些页面会被赋予一个临时的PageRank值:将所有传入该页面链中的PageRank值聚合起来,从而形成未知页面的PageRank值参与排名。
2.3.5 OPIC 策略
该算法实际上对页面的重要性进行评分。在算法开始之前,给所有页面相同的初始现金(cash)。下载某个页面P后,将P的现金分配给所有从P解析的链接,清空P的现金。待抓取的 URL 队列中的所有页面均按照现金的数量进行排序。
2.3.6大站优先策略
待爬取的 URL 队列中的所有网页,均按照其所属的 网站 进行分类。对于网站需要下载的页面较多的,优先下载。这种策略因此被称为大站优先策略。
3、 爬虫分类
我应该选择 Nutch、Crawler4j、WebMagic、scrapy、WebCollector 还是其他来开发网络爬虫?上面提到的爬虫基本上可以分为三类:
(1)分布式爬虫:Nutch
(2)JAVA 爬虫:Crawler4j、WebMagic、WebCollector
(3)非JAVA爬虫:scrapy(基于Python语言开发)
3.1 个分布式爬虫
爬虫采用分布式,主要解决两个问题:
1)海量网址管理
2)网速
最流行的分布式爬虫是 Apache 的 Nutch。但是对于大多数用户来说,Nutch 是这些类型的爬虫中最糟糕的选择,原因如下:
1)Nutch 是一款专为搜索引擎设计的爬虫。大多数用户需要一个爬虫来进行准确的数据爬取(精细提取)。Nutch 运行的一组进程中有三分之二是为搜索引擎设计的。精细提取没有多大意义。换句话说,使用 Nutch 进行数据提取会在不必要的计算上浪费大量时间。而如果你试图通过二次开发让Nutch适合精炼业务,你基本上会破坏Nutch的框架,将Nutch改得面目全非,并有能力修改Nutch。自己写一个新的确实更好。分布式爬虫框架。
2)Nutch 依赖于hadoop 来运行,而hadoop 本身就消耗大量时间。如果集群机器数量少,爬取速度不如单机爬虫快。
3)Nutch有插件机制,作为亮点推广。可以看到一些开源的Nutch插件,提供精细的提取功能。但是任何开发过 Nutch 插件的人都知道 Nutch 的插件系统有多烂。使用反射机制加载和调用插件使得编写和调试程序变得极其困难,更不用说在其上开发复杂的精细提取系统了。并且Nutch没有提供相应的插件挂载点进行精细提取。Nutch的插件只有五六个挂载点,而这五六个挂载点是为搜索引擎服务的,不提供精细提取的挂载点。Nutch的大部分精提取插件都挂载在挂载点“解析器”(parser)上。
4)使用Nutch进行爬虫的二次开发,爬虫的准备和调试所需的时间往往是单机爬虫的十倍以上。学习Nutch源代码的成本非常高,更何况一个团队中的每个人都必须了解Nutch源代码。在调试过程中,会出现程序本身以外的各种问题(hadoop问题、hbase问题)。
5) 很多人说Nutch2有gora,可以持久化数据到avro文件、hbase、mysql等,其实很多人理解错了。这里所说的持久化数据是指在avro、hbase、mysql中存储URL信息(URL管理所需的数据)。这不是您要提取的结构化数据。事实上,对于大多数人来说,URL 信息存在于何处并不重要。
6)Nutch2的版本目前不适合开发。Nutch官方稳定版是nutch2.2.1,但是这个版本绑定了gora-0.3。如果你想和nutch一起使用hbase(大多数人使用nutch2只是为了使用hbase),你只能在0.90版本左右使用hbase,而hadoop版本必须减少到hadoop 0.2左右. 而且,Nutch2的官方教程更具有误导性。Nutch2有两个教程,分别是Nutch1.x和Nutch2.x。Nutch2.x 官网可以支持转到hbase 0.94。但其实这个Nutch2.x指的是Nutch2.3之前和Nutch2.2.1之后的版本。此版本在官方SVN中不断更新。
所以,如果你不是搜索引擎,尽量不要选择Nutch作为爬虫。有些团队喜欢效仿。他们不得不选择Nutch来开发高度提取的爬虫。事实上,这是为了Nutch的声誉。当然,最终的结果往往是项目延期。
如果你是一个搜索引擎,Nutch1.x 是一个非常好的选择。Nutch1.x 与 solr 或 es 合作组成了一个非常强大的搜索引擎。如果非要使用Nutch2,建议等到Nutch2.3发布。当前的 Nutch2 是一个非常不稳定的版本。
3.2 JAVA爬虫
这里将JAVA爬虫单独划分为一个类别,因为JAVA在网络爬虫的生态系统中是非常完备的。相关资料也是最全的。这里可能有争议,我只是随便说说。
其实,开源网络爬虫(框架)的开发很简单,难点复杂的问题(比如DOM树解析定位、字符集检测、海量URL去重)都已经被前人解决了,可以说没有技术含量。包括Nutch,其实Nutch的技术难点就是开发hadoop,代码本身也很简单。从某种意义上说,网络爬虫类似于遍历机器的文件以查找文件中的信息。没有任何困难。之所以选择开源爬虫框架,是为了省事。比如爬虫URL管理、线程池等模块任何人都可以做,但是需要一段时间的调试和修改才能稳定下来。
用于爬虫的功能。用户比较关心的问题往往是:
1)爬虫是否支持多线程,爬虫能不能用agent,能不能抓取重复数据,能不能抓取JS生成的信息?
那些不支持多线程、代理或过滤重复 URL 的不称为开源爬虫。它们被称为循环执行 http 请求。
js生成的信息能否被爬取与爬虫本身关系不大。爬虫主要负责遍历网站和下载页面。爬取js产生的信息与网页信息提取模块有关,往往需要通过模拟浏览器(htmlunit、selenium)来完成。这些模拟浏览器通常需要花费大量时间来处理页面。所以一个策略就是利用这些爬虫来遍历网站,当遇到需要解析的页面时,将页面的相关信息提交给模拟浏览器,完成对JS生成信息的提取。
2)爬虫可以爬取ajax信息吗?
网页上有一些异步加载的数据。爬取这个数据有两种方式:使用模拟浏览器(问题1中描述),或者分析ajax http请求,自己生成ajax请求url,获取返回数据。如果自己生成ajax请求,使用开源爬虫有什么意义?其实还是需要用到开源爬虫的线程池和URL管理功能(比如断点爬取)。
如果我已经可以生成我需要的ajax请求(列表),我该如何使用这些爬虫来抓取这些请求?
爬虫通常被设计成广度遍历或深度遍历的模式来遍历静态或动态页面。爬取ajax信息属于深网(deep web)的范畴,虽然大部分爬虫不直接支持。但它也可以通过某些方式完成。例如,WebCollector 使用广度遍历来遍历网站。第一轮爬取是爬取种子集(seeds)中的所有URL。简单的说,就是将生成的ajax请求作为种子,放入爬虫中。使用爬虫遍历这些深度为1的种子(默认为广度遍历)。
3)爬虫如何爬取网站登录?
这些开源爬虫都支持在爬取时指定cookies,模拟登录主要依赖cookies。至于如何获取cookie,就不是爬虫的事情了。您可以手动获取cookies,也可以模拟http请求登录,也可以使用模拟浏览器自动登录获取cookies。
4)爬虫如何从网页中提取信息?
开源爬虫一般都集成了网页提取工具。主要支持两种类型的规范:CSS SELECTOR 和 XPATH。至于哪个更好,这里就不做评价了。
5)爬虫是如何保存网页信息的?
一些爬虫带有一个负责持久化的模块。例如,webmagic 有一个叫做管道的模块。通过简单的配置,爬虫提取的信息可以持久化到文件、数据库等中,也有一些爬虫不直接为用户提供数据持久化模块。如 crawler4j 和 webcollector。让用户在网页处理模块中添加提交数据库的操作。至于使用pipeline模块好不好,类似于是否使用ORM来操作数据库的问题。这取决于您的业务。
6)爬虫被网站拦截怎么办?
爬虫已经被网站屏蔽了,一般可以通过多个代理(随机代理)解决。但是,这些开源爬虫一般不直接支持随机代理的切换。因此,用户往往需要自己将获取到的代理放入一个全局数组中,自己编写代码来随机获取代理(从数组中)。
7)网页可以调用爬虫吗?
爬虫的调用是在Web的服务器端调用的,你可以照常使用。所有这些爬虫都可以使用。
8)爬行速度怎么样?
一个单机的开源爬虫的速度基本可以用到机器网速的极限。爬虫速度慢,往往是因为用户线程少,网速慢,或者持久化数据时与数据库交互慢。这些东西往往是由用户的机器和二次开发代码决定的。这些开源爬虫的速度非常好。
9)显然代码写对了,爬不出来数据。是不是爬虫有问题?别的爬虫能解决吗?
如果代码写对了,数据爬不出来,其他爬虫也是一样。在这种情况下,要么 网站 阻止了您,要么您抓取的数据是由 javascript 生成的。爬取数据无法通过改变爬虫来解决。
10)哪个爬虫可以判断网站是否爬完了,哪个爬虫可以根据主题爬取?
爬虫无法判断网站是否爬过,只能尽量覆盖。
至于基于主题的爬取,爬虫只有向下爬取内容才知道主题是什么。所以它通常是从整体上爬下来,然后去过滤内容。如果觉得抓取过于笼统,可以通过限制网址规律等方法缩小范围。
11) 哪个爬虫有更好的设计模式和结构?
设计模式纯属无稽之谈。当软件设计模式好的时候,开发软件,然后总结出几种设计模式。设计模式对软件开发没有指导作用。使用设计模式来设计爬虫只会让爬虫的设计更加臃肿。
在架构上,开源爬虫目前主要是详细数据结构的设计,比如爬取线程池、任务队列等,大家都可以控制。爬虫的业务太简单了,不谈结构。
所以对于JAVA开源爬虫,我觉得,找一个好用的就好了。如果业务复杂,使用哪种爬虫就必须经过复杂的二次开发才能满足需求。
3.3 个非 Java 爬虫
在非JAVA语言编写的爬虫中,有很多优秀的爬虫。这个单独提取为一个类别,不是为了爬虫本身的质量,而是为了larbin、scrapy等爬虫对开发成本的影响。
先说python爬虫,python可以用30行代码完成JAVA 50行代码的任务。Python 代码编写确实很快,但是在调试代码阶段,Python 代码的调试往往比编码阶段节省的时间消耗的时间要多得多。使用python开发,为了保证程序的正确性和稳定性,需要编写更多的测试模块。当然,如果爬取规模不大,爬取业务不复杂,使用scrapy也是相当不错的,可以轻松完成爬取任务。
上图是Scrapy的架构图。绿线是数据流。首先从初始的URL开始,Scheduler将其交给Downloader进行下载,下载完成后,交给Spider进行分析,将需要保存的数据发送到Item Pipeline ,即对数据进行后处理。此外,可以在数据流通道中安装各种中间件来进行必要的处理。所以在开发爬虫的时候,最好先规划好各个模块。我的做法是分别规划下载模块、爬取模块、调度模块、数据存储模块。
对于C++爬虫来说,学习**的成本会比较大。而且你不能只计算一个人的学习成本。如果软件需要团队开发或交接,那将是很多人的学习成本。软件调试并不是那么容易。
还有一些ruby、php爬虫,这里不多评论。确实有一些非常小的数据任务。使用ruby或php非常方便。但是要选择这些语言的开源爬虫,一方面需要调查相关的生态系统,另一方面,这些开源爬虫可能会产生一些你找不到的bug(人少信息少)
4、反爬虫技术
由于搜索引擎的流行,网络爬虫已经成为一种非常流行的网络技术。除了专门从事搜索的谷歌、雅虎、微软、百度,几乎每个大型门户网站网站都有自己的搜索引擎,**小有几十个名字,还有数以万计的未知名字。对于一个内容驱动的网站来说,难免会被网络爬虫光顾。
一些智能搜索引擎爬虫在网站上的爬取频率比较合理,消耗的资源较少,但是很多不好的网络爬虫对网页的爬取能力很差,经常会发送几十上百个请求,重复爬取循环。拿,这种爬虫往往对中小网站是毁灭性的打击,尤其是一些缺乏爬虫编写经验的程序员写的爬虫破坏力极强,网站访问压力会很大高的。, 会导致网站 访问缓慢甚至无法访问。
一般来说,网站是从三个方面进行反爬虫的:用户请求的Headers、用户行为、网站目录和数据加载方式。前两个比较容易遇到,大多数网站反爬虫都是从这几个角度来看的。将采用第三类ajax应用网站,增加爬虫难度。
4.1 个通过 Headers 的反爬虫
从用户请求的Headers反爬取是最常见的反爬取策略。很多网站会检测Headers的User-Agent,还有一些网站会检测Referer(部分资源的防盗链网站就是检测Referer)。如果遇到这种反爬虫机制,可以直接给爬虫添加Headers,将浏览器的User-Agent复制到爬虫的Headers中;或者修改Referer值为目标网站域名。对于检测header的反爬虫,在爬虫中修改或添加header很容易绕过。
【点评:往往容易被忽视。通过对请求的捕获分析,确定referer,并在程序中模拟访问请求头中添加]
4.2 基于用户行为的反爬虫
网站的另一部分是检测用户行为,比如同一IP在短时间内多次访问同一个页面,或者同一个账号在短时间内多次执行相同的操作。技术分析真的对股票交易有用吗?
技术分析对股票非常有用,因为市场上大部分机构和个人都使用技术分析,所以符合从众原则。当大多数技术分析表明股票正在好转时,资金将开始流入,股票自然会上涨。反之亦然。
技术分析是一个统计概念、历史重复概念和从众心理概念,所以很有用。
但单一指标的技术分析用处不大,一般确认两个或多个技术分析相辅相成。
php 爬虫抓取网页数据(学过网站设计之深度优先算法的主要思想和思想介绍 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-11-22 08:15
)
研究过网站设计的人都知道网站通常是分层设计的。顶级是顶级域名,后面是子域名,子域名下还有子域名等。同时,每个子域也可能有多个同级域名,可能有是 URL 之间的链接,形成复杂的网络。
当一个网站的URL很多时,一定要好好设计好URL,否则在以后的理解、维护或开发过程中会很混乱。了解了以上网页结构设计后,现在正式介绍网络爬虫中的深度优先算法。
上图是一个二叉树结构。通过遍历这棵二叉树,我们可以比较爬取网页,加深对爬取策略的理解。深度优先算法的主要思想是先从顶级域名A开始,然后从中提取两个链接B和C。抓取链接B后,下一个要抓取的链接是D或E,而不是抓取。抓取链接B后,立即抓取链接C,抓取链接D后,发现链接D中的所有URL都被访问过。在此之前,我们已经建立了一个访问过的 URL 列表,专门用于存储访问过的 URL。当链接 D 被完全抓取后,接下来会抓取链接 E。链接E的爬取完成后,链接C不会被爬取,而是继续向下爬取链接I。原理是链接会一步步往下爬。只要链接下有子链接,并且子链接没有被访问过,这就是深度优先算法的主要思想。深度优先算法是让爬虫一步一步往下爬,然后一步一步往回走,以深度优先。理解了深度优先算法后,再看上图,可以得到二叉树呈现的爬虫爬取链接顺序如下:A、B、D、E、I、C、F、G、H(假设此处左侧的链接)将首先被抓取)。其实我们在做网络爬虫的时候,经常会用到这个算法来实现。其实我们常用的Scrapy爬虫框架默认也是用这个算法实现的。由以上理解,
下图展示了深度优先算法的代码实现过程。
深度优先过程实际上是以递归方式实现的。看上图中的代码,先定义一个函数来实现深度优先处理,然后传入节点参数。如果节点不为空,则将其打印出来。您可以将其与二叉树中的顶点 A 进行比较。节点打印后,检查是否有左节点(链接B)和右节点(链接C)。如果左节点不为空,则返回,并调用深度优先函数本身再次递归得到一个新的左节点(链接D)和右节点(链接E),以此类推,不会停止直到遍历完所有节点或达到既定条件。右节点的实现过程也是一样的,这里不再赘述。
深度优先过程以递归方式实现。当递归继续执行而没有跳出递归或者递归过深时,很容易发生栈溢出,所以在实际应用过程中要注意这一点。
深度优先算法和广度优先算法是数据结构中非常重要的算法结构,也是非常常用的算法,也是面试过程中非常常见的面试题,所以推荐大家需要掌握它。文章 我们将介绍广度优先算法,敬请期待。
对网络爬虫中深度优先算法的简单介绍到此为止。你们做对了吗?
看完这篇文章你学会了吗?请转发并分享给更多人
Python爬虫和数据挖掘 查看全部
php 爬虫抓取网页数据(学过网站设计之深度优先算法的主要思想和思想介绍
)
研究过网站设计的人都知道网站通常是分层设计的。顶级是顶级域名,后面是子域名,子域名下还有子域名等。同时,每个子域也可能有多个同级域名,可能有是 URL 之间的链接,形成复杂的网络。
当一个网站的URL很多时,一定要好好设计好URL,否则在以后的理解、维护或开发过程中会很混乱。了解了以上网页结构设计后,现在正式介绍网络爬虫中的深度优先算法。
上图是一个二叉树结构。通过遍历这棵二叉树,我们可以比较爬取网页,加深对爬取策略的理解。深度优先算法的主要思想是先从顶级域名A开始,然后从中提取两个链接B和C。抓取链接B后,下一个要抓取的链接是D或E,而不是抓取。抓取链接B后,立即抓取链接C,抓取链接D后,发现链接D中的所有URL都被访问过。在此之前,我们已经建立了一个访问过的 URL 列表,专门用于存储访问过的 URL。当链接 D 被完全抓取后,接下来会抓取链接 E。链接E的爬取完成后,链接C不会被爬取,而是继续向下爬取链接I。原理是链接会一步步往下爬。只要链接下有子链接,并且子链接没有被访问过,这就是深度优先算法的主要思想。深度优先算法是让爬虫一步一步往下爬,然后一步一步往回走,以深度优先。理解了深度优先算法后,再看上图,可以得到二叉树呈现的爬虫爬取链接顺序如下:A、B、D、E、I、C、F、G、H(假设此处左侧的链接)将首先被抓取)。其实我们在做网络爬虫的时候,经常会用到这个算法来实现。其实我们常用的Scrapy爬虫框架默认也是用这个算法实现的。由以上理解,
下图展示了深度优先算法的代码实现过程。
深度优先过程实际上是以递归方式实现的。看上图中的代码,先定义一个函数来实现深度优先处理,然后传入节点参数。如果节点不为空,则将其打印出来。您可以将其与二叉树中的顶点 A 进行比较。节点打印后,检查是否有左节点(链接B)和右节点(链接C)。如果左节点不为空,则返回,并调用深度优先函数本身再次递归得到一个新的左节点(链接D)和右节点(链接E),以此类推,不会停止直到遍历完所有节点或达到既定条件。右节点的实现过程也是一样的,这里不再赘述。
深度优先过程以递归方式实现。当递归继续执行而没有跳出递归或者递归过深时,很容易发生栈溢出,所以在实际应用过程中要注意这一点。
深度优先算法和广度优先算法是数据结构中非常重要的算法结构,也是非常常用的算法,也是面试过程中非常常见的面试题,所以推荐大家需要掌握它。文章 我们将介绍广度优先算法,敬请期待。
对网络爬虫中深度优先算法的简单介绍到此为止。你们做对了吗?
看完这篇文章你学会了吗?请转发并分享给更多人
Python爬虫和数据挖掘
php 爬虫抓取网页数据(一个qq邮箱代理ip转发服务器接入的工作原理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-11-16 22:02
php爬虫抓取网页数据,分段代理直接拿来用了都还行,但对有几个人会去了解像一个qq邮箱代理ip服务器接入?qq邮箱代理ip转发服务器接入?如果不知道的话百度搜索一下为什么需要这个接入模块,工作原理?现在是802.11ac和http3.0标准,应该还是可以用来做不少事情的,代理或者特殊的功能开发对企业来说也是可以做事情的。
当然你肯定也不会接触到这个模块的最终用途和商业价值。下图以招聘网站,一个负责网站爬虫的qq邮箱代理为例吧:(。
1)电信ip、11
4、12
6、192.168.1.1等,
2)http代理服务器基本上都有一个接入模块,
3)接入人员后期加入一些特殊功能代理之后成就:没有功能,可以读取附件等等。如果真的需要购买大部分企业可能宁愿使用。并且投入非常巨大,是专业人员进行各个方面配置。
大企业里对于软件的关注点,只有底层的加密,爬虫模块的开发。数据流量统计和发送会去搭建nb的分布式系统,其他,数据安全,售后,
我觉得楼上回答的答案比较扯,有一种明显就是假设你要服务器承受千兆带宽的流量。而其实现在比较常见的是四线五线的通道,比如四个16口adsl,四个50口的isp主机还能抗住几十百g的负载??基本跑通应该没问题,但是六线七线就呵呵了,特别是需要大量流量的需求。看业务量来决定网络流量,不合适的,有个指标叫billingdownloadtime的,可以看一下,具体要看自己去算的...所以单论想法的话,是可以的。
但是,这个事情的难度非常高,比如第一,非常有针对性的人才,可能这个企业本身网络相对比较理论化,技术含量不高;第二,项目规模可能太大,需要考虑高性能,大速率,好网络环境第三,有时候企业就算做好了这件事,很有可能因为他其实不是特别感兴趣,也可能内部没有这种服务器,这件事可能只是别人觉得有意思,他就干了...。 查看全部
php 爬虫抓取网页数据(一个qq邮箱代理ip转发服务器接入的工作原理)
php爬虫抓取网页数据,分段代理直接拿来用了都还行,但对有几个人会去了解像一个qq邮箱代理ip服务器接入?qq邮箱代理ip转发服务器接入?如果不知道的话百度搜索一下为什么需要这个接入模块,工作原理?现在是802.11ac和http3.0标准,应该还是可以用来做不少事情的,代理或者特殊的功能开发对企业来说也是可以做事情的。
当然你肯定也不会接触到这个模块的最终用途和商业价值。下图以招聘网站,一个负责网站爬虫的qq邮箱代理为例吧:(。
1)电信ip、11
4、12
6、192.168.1.1等,
2)http代理服务器基本上都有一个接入模块,
3)接入人员后期加入一些特殊功能代理之后成就:没有功能,可以读取附件等等。如果真的需要购买大部分企业可能宁愿使用。并且投入非常巨大,是专业人员进行各个方面配置。
大企业里对于软件的关注点,只有底层的加密,爬虫模块的开发。数据流量统计和发送会去搭建nb的分布式系统,其他,数据安全,售后,
我觉得楼上回答的答案比较扯,有一种明显就是假设你要服务器承受千兆带宽的流量。而其实现在比较常见的是四线五线的通道,比如四个16口adsl,四个50口的isp主机还能抗住几十百g的负载??基本跑通应该没问题,但是六线七线就呵呵了,特别是需要大量流量的需求。看业务量来决定网络流量,不合适的,有个指标叫billingdownloadtime的,可以看一下,具体要看自己去算的...所以单论想法的话,是可以的。
但是,这个事情的难度非常高,比如第一,非常有针对性的人才,可能这个企业本身网络相对比较理论化,技术含量不高;第二,项目规模可能太大,需要考虑高性能,大速率,好网络环境第三,有时候企业就算做好了这件事,很有可能因为他其实不是特别感兴趣,也可能内部没有这种服务器,这件事可能只是别人觉得有意思,他就干了...。
php 爬虫抓取网页数据(php爬虫抓取网页数据-google-chrome/pc/不推荐使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-11-16 10:11
php爬虫抓取网页数据-google-chrome/pc/不推荐使用nginx,1是速度太慢,2是比较占内存。另外如果爬虫量比较大,依靠nginx就要经常进行数据清理。采用phantomjs的话需要开发额外的webserver。而且这个爬虫实在太简单了,几句话就能写完,主要还是抓取网页的样式。
使用phantomjs需要进行数据清洗,所以不适合抓大流量的网站。建议首选使用httpclient:1.使用apache2.webserver配置:http1.0:curl-o-s"client=&server=http1.0"http2.0:curl-o-s"client=&server=http2.0"结束。
phantomjs爬虫。大流量要考虑下负载均衡。小流量。
效率?速度?处理多页?作为一个php工程师,我们一般抓完首页后就是再抓接下来的所有页面。一般python的requests很好用。找个合适的工具跑。
phantomjs,http协议,
phantomjs或者nginx+phantomjs。phantomjs相对完善。参考这里:phantomjs开发技术文档参考github上的wordpressweb_scraping扩展程序。
一般来说适合抓取抓取广告联盟,黄牛党、网盘、百度云等一些需要机器验证的大流量网站的数据,抓取很快,全部用nginx就可以了。python的cookie是不可能,一是在浏览器开启;二是机器人来刷下。浏览器开启的办法:只要是http协议就可以。 查看全部
php 爬虫抓取网页数据(php爬虫抓取网页数据-google-chrome/pc/不推荐使用)
php爬虫抓取网页数据-google-chrome/pc/不推荐使用nginx,1是速度太慢,2是比较占内存。另外如果爬虫量比较大,依靠nginx就要经常进行数据清理。采用phantomjs的话需要开发额外的webserver。而且这个爬虫实在太简单了,几句话就能写完,主要还是抓取网页的样式。
使用phantomjs需要进行数据清洗,所以不适合抓大流量的网站。建议首选使用httpclient:1.使用apache2.webserver配置:http1.0:curl-o-s"client=&server=http1.0"http2.0:curl-o-s"client=&server=http2.0"结束。
phantomjs爬虫。大流量要考虑下负载均衡。小流量。
效率?速度?处理多页?作为一个php工程师,我们一般抓完首页后就是再抓接下来的所有页面。一般python的requests很好用。找个合适的工具跑。
phantomjs,http协议,
phantomjs或者nginx+phantomjs。phantomjs相对完善。参考这里:phantomjs开发技术文档参考github上的wordpressweb_scraping扩展程序。
一般来说适合抓取抓取广告联盟,黄牛党、网盘、百度云等一些需要机器验证的大流量网站的数据,抓取很快,全部用nginx就可以了。python的cookie是不可能,一是在浏览器开启;二是机器人来刷下。浏览器开启的办法:只要是http协议就可以。
php 爬虫抓取网页数据(php爬虫抓取网页数据用的是urllib库,而python爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-11-12 09:11
php爬虫抓取网页数据用的是urllib库,而python爬虫用urllib,可以尝试一下这篇文章。
理论上讲不能,因为python里面就是urllib库,正如另一位答主说的,python就是用urllib库和自己封装了一下前端的api实现不同的用户体验的。但是实际上根据情况要考虑。1,当网站很短的时候,如果仅仅是用urllib库爬取一些简单的页面,因为爬虫的响应和发送很慢很慢,为了保证前端的体验(爬虫可以是高并发的),我们首先要post请求。
但是当网站很长时候时候,响应就非常慢了,这时候就要采用io复用模块(lib64库)。2,如果爬虫采用urllib库,要考虑到不同框架的封装,比如urllib+lxml库+lxml库+selenium。基本上需要这样三个框架。可能在某一个框架封装好了并用原生方法调用这样对于资源占用非常少。但是大的系统框架(如webpy,nodejs等)都封装好了,而且速度不比nodejs慢。所以还是看情况,抓取网站框架兼容性,网络情况等。
不能,除非你有足够的tps。真实的抓取应该只有足够tps。说实话python的urllib库太少,基本都是封装了,你想让它吃很多事情太难了。
web网站抓取分单文件抓取、多文件抓取、网站导航抓取,这里只讨论多文件抓取,具体接触过是pyspider,另外百度的开源爬虫也有kiboom-crawler和crawler等。python爬虫不像java或者其他语言那样自己封装前端api,to-do里的那些代码要自己写,很多urllib库都可以很轻松实现,现在市面上爬虫框架更多,比如webdriver等,有java基础和html基础可以学习爬虫框架,比如kiboom-crawler。 查看全部
php 爬虫抓取网页数据(php爬虫抓取网页数据用的是urllib库,而python爬虫)
php爬虫抓取网页数据用的是urllib库,而python爬虫用urllib,可以尝试一下这篇文章。
理论上讲不能,因为python里面就是urllib库,正如另一位答主说的,python就是用urllib库和自己封装了一下前端的api实现不同的用户体验的。但是实际上根据情况要考虑。1,当网站很短的时候,如果仅仅是用urllib库爬取一些简单的页面,因为爬虫的响应和发送很慢很慢,为了保证前端的体验(爬虫可以是高并发的),我们首先要post请求。
但是当网站很长时候时候,响应就非常慢了,这时候就要采用io复用模块(lib64库)。2,如果爬虫采用urllib库,要考虑到不同框架的封装,比如urllib+lxml库+lxml库+selenium。基本上需要这样三个框架。可能在某一个框架封装好了并用原生方法调用这样对于资源占用非常少。但是大的系统框架(如webpy,nodejs等)都封装好了,而且速度不比nodejs慢。所以还是看情况,抓取网站框架兼容性,网络情况等。
不能,除非你有足够的tps。真实的抓取应该只有足够tps。说实话python的urllib库太少,基本都是封装了,你想让它吃很多事情太难了。
web网站抓取分单文件抓取、多文件抓取、网站导航抓取,这里只讨论多文件抓取,具体接触过是pyspider,另外百度的开源爬虫也有kiboom-crawler和crawler等。python爬虫不像java或者其他语言那样自己封装前端api,to-do里的那些代码要自己写,很多urllib库都可以很轻松实现,现在市面上爬虫框架更多,比如webdriver等,有java基础和html基础可以学习爬虫框架,比如kiboom-crawler。
php 爬虫抓取网页数据(1.通用网络爬虫的实现原理及过程简要分析算法概括)
网站优化 • 优采云 发表了文章 • 0 个评论 • 181 次浏览 • 2021-11-10 05:15
网络爬虫的原理:爬虫根据一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,放入URL队列等待被抓取。然后,它会根据一定的搜索策略从队列中选择下一个要抓取的网页的网址,并重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤和索引,以供以后查询检索;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。
一个通用的网络爬虫的框架如图所示:
不同类型的网络爬虫有不同的实现原理,但是这些实现原理之间会有很多共性。这里我们以两个典型的网络爬虫为例(即通用网络爬虫和聚焦网络爬虫)来讲解网络爬虫的实现原理。
1. 通用网络爬虫
首先我们来看一下一般的网络爬虫的实现原理。一般网络爬虫的实现原理和过程可以简单概括如图:
2. 专注于网络爬虫
专注于网络爬虫,因为它们需要有目的地爬取,所以对于一般的网络爬虫,需要增加目标的定义和过滤机制。具体来说,这时候它的执行原理和流程比一般的网络爬虫需要的多。分为三个步骤,分别是目标的定义、无关链接的过滤、下一步要爬取的URL地址的选择等,如图:
网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址,在网页抓取过程中不断从当前页面中提取新的网址放入队列中,直到某个停止条件系统的满足。 查看全部
php 爬虫抓取网页数据(1.通用网络爬虫的实现原理及过程简要分析算法概括)
网络爬虫的原理:爬虫根据一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,放入URL队列等待被抓取。然后,它会根据一定的搜索策略从队列中选择下一个要抓取的网页的网址,并重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤和索引,以供以后查询检索;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。
一个通用的网络爬虫的框架如图所示:
不同类型的网络爬虫有不同的实现原理,但是这些实现原理之间会有很多共性。这里我们以两个典型的网络爬虫为例(即通用网络爬虫和聚焦网络爬虫)来讲解网络爬虫的实现原理。
1. 通用网络爬虫
首先我们来看一下一般的网络爬虫的实现原理。一般网络爬虫的实现原理和过程可以简单概括如图:
2. 专注于网络爬虫
专注于网络爬虫,因为它们需要有目的地爬取,所以对于一般的网络爬虫,需要增加目标的定义和过滤机制。具体来说,这时候它的执行原理和流程比一般的网络爬虫需要的多。分为三个步骤,分别是目标的定义、无关链接的过滤、下一步要爬取的URL地址的选择等,如图:
网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址,在网页抓取过程中不断从当前页面中提取新的网址放入队列中,直到某个停止条件系统的满足。
php 爬虫抓取网页数据(开发爬虫其实不用纠结用什么语言,省去一次爬虫开发不难)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-11-08 06:04
因为我已经开始开发一个蜘蛛池站群系统,其中涉及爬虫自动去全网寻找符合关键词或关键词密度标准的页面,然后加速内容,然后使用它。NLP相关的技术有伪原创,定期将文章发布到库中,发布这样一个模块,也是用php开发的。我也在这里和大家分享一下我对爬虫的看法。
实际上,您无需担心使用什么语言来开发爬虫。只要PHP在性能不太高的情况下完全够用,我也推荐PHP工程师用PHP来做,这样可以节省学习一门新语言的时间成本。
再次,爬虫开发并不难。
主要是定位你想要实现的爬虫类型。
根据互联网上所有爬虫的功能和特点,可分为批处理型、增量型和垂直型三种。
批处理类型,具有明显的爬取范围和目标,设置爬取时间限制、爬取数据限制、或在固定范围内爬取页面限制等,当爬虫任务达到预设目标时停止。一般来说,采集 工具或内容采集 任务是批处理类型。一般只抓取固定网站的固定内容,或者为某个资源设置固定的目标数据量。当达到设定的限制时,抓取的数据或时间将自动停止。这种爬虫是典型的批量爬虫。
增量类型也可以称为通用类型。百度、谷歌、搜狗等搜索引擎的爬虫可以称为增量爬虫。增量型不同于批处理型。没有固定的目标、范围和时间限制。一般会无休止地爬取,直到抓到全网的数据。增量类型一般不仅需要抓取尽可能多的页面,还需要对已经抓取的页面进行相应的抓取和更新。因为这些爬虫爬进数据库的页面不是静态的,可能会更新,甚至404。一般来说,增量爬虫的这些功能应该是标准的。至于去重,排名不在这里。在答案中讨论。
垂直型,也叫聚焦爬虫,只爬取固定主题内容或固定行业网页,一般集中在一定的有限范围内进行增量爬取。垂直爬虫不像增量爬虫那样追求大而全的覆盖。相反,他们在增量爬虫上增加了对网页抓取的限制,根据需求抓取收录目标内容的网页。不符合要求的网页就让它静静地躺在url队列中。比如我之前做的蜘蛛池内容爬虫模块就是这个垂直爬虫。
以上为大家大致介绍了爬虫的种类。我想你应该能够大致定位到你要开发的爬虫。
谈技术关键词,开始开发的时候直接查这些词,然后用上。
CURL:不用说,如果要爬取一个页面,首先要请求这个页面,得到对方服务器返回的数据(一般是html,如果直接看懂别人的api接口,就当我没看吧说吧)过去这句话)。
simple_html_dom:HTML 节点解析器。使用curl请求html文档后,可以用这个来解析dom节点,方便匹配需要采集爬取的内容。
正则表达式:用于匹配你想要的内容,与simple_html_dom功能相同,但会更加灵活。如果两者匹配,就会更加流畅。哈哈:)
worker 或 swoole:用于做多线程或多进程以提高效率。我更推荐workerman,因为学习成本低,文档清晰易学!Swoole 对新手确实很不友好,但是它的功能比workerman 强一点,这里就不讨论了。
Redis:用于存储 URL 队列。如果不追求太高的效率,可以无视。
对于这些关键词来说,入门级爬虫差不多就够了。很想研究一下数千万的采集对分布式爬虫的追求。我建议出去左转 Python 或其他语言主题下的提问。
最后说一下实现思路。
首页上的爬虫需要一个种子页,比如“中国新闻网”首页。这个爬虫使用curl请求种子页面,获取html数据,使用正则表达式匹配a标签的所有href属性,然后根据自己的一些规则来匹配一些符合规则的url或者符合规则的url已自行处理。例如,一些a标签可能没有http或https头,或者可能有没有域名的url,例如“/news/gn/”。这时候你需要做一点判断和处理,把添加的加进去,然后用sha1加密url,然后用hash去查数据库看是否有相同的hash,如果有,表示url已经有了(go Heavy),然后将url和hash同时存入url队列数据库中。
做完以上操作后,一定要记得给被爬取的URL一个已爬取状态,避免重复爬取。
然后在重复之前的操作之前从数据库中检查一个新的未被抓取的URL,这样你的爬虫就形成了,它会继续向你的URL队列添加URL。
关键时刻到了。如果我们简单地爬取URL并放入数据库,那是没有用的,对吧?
这时候该说一下内容采集了,url就在那里。这时候写一个爬虫,不断的取出url库中的url来爬回这个页面的内容,然后再写规则匹配内容后,就可以保存到数据库中了。
就是这样。这个入门级爬虫准备好了。
但是,真正的爬虫开发工作肯定会遇到很多很多问题和意想不到的问题,比如:蜘蛛陷阱、反爬虫、动态加载的内容无法爬取、效率问题、程序报错后是否有重启机制并在遇到异常、法律风险等问题后停止运行。
以下所有问题都留给你在实战中自己解决,因为每个人的业务不同,报出的错误肯定也不同。没有办法说的太清楚。本文文章主要目的是给大家提供一个思路。我也欢迎大家加入我。让我们一起交流讨论爬虫的各种知识和技巧。如果人多,我也可以组成一个交流群,大家交流。学习。
一不小心写了两千多字,没费心去复习这句话,没啥意思。如果有错别字,大家都会看的。我的 vx 有问题。 查看全部
php 爬虫抓取网页数据(开发爬虫其实不用纠结用什么语言,省去一次爬虫开发不难)
因为我已经开始开发一个蜘蛛池站群系统,其中涉及爬虫自动去全网寻找符合关键词或关键词密度标准的页面,然后加速内容,然后使用它。NLP相关的技术有伪原创,定期将文章发布到库中,发布这样一个模块,也是用php开发的。我也在这里和大家分享一下我对爬虫的看法。
实际上,您无需担心使用什么语言来开发爬虫。只要PHP在性能不太高的情况下完全够用,我也推荐PHP工程师用PHP来做,这样可以节省学习一门新语言的时间成本。
再次,爬虫开发并不难。
主要是定位你想要实现的爬虫类型。
根据互联网上所有爬虫的功能和特点,可分为批处理型、增量型和垂直型三种。
批处理类型,具有明显的爬取范围和目标,设置爬取时间限制、爬取数据限制、或在固定范围内爬取页面限制等,当爬虫任务达到预设目标时停止。一般来说,采集 工具或内容采集 任务是批处理类型。一般只抓取固定网站的固定内容,或者为某个资源设置固定的目标数据量。当达到设定的限制时,抓取的数据或时间将自动停止。这种爬虫是典型的批量爬虫。
增量类型也可以称为通用类型。百度、谷歌、搜狗等搜索引擎的爬虫可以称为增量爬虫。增量型不同于批处理型。没有固定的目标、范围和时间限制。一般会无休止地爬取,直到抓到全网的数据。增量类型一般不仅需要抓取尽可能多的页面,还需要对已经抓取的页面进行相应的抓取和更新。因为这些爬虫爬进数据库的页面不是静态的,可能会更新,甚至404。一般来说,增量爬虫的这些功能应该是标准的。至于去重,排名不在这里。在答案中讨论。
垂直型,也叫聚焦爬虫,只爬取固定主题内容或固定行业网页,一般集中在一定的有限范围内进行增量爬取。垂直爬虫不像增量爬虫那样追求大而全的覆盖。相反,他们在增量爬虫上增加了对网页抓取的限制,根据需求抓取收录目标内容的网页。不符合要求的网页就让它静静地躺在url队列中。比如我之前做的蜘蛛池内容爬虫模块就是这个垂直爬虫。
以上为大家大致介绍了爬虫的种类。我想你应该能够大致定位到你要开发的爬虫。
谈技术关键词,开始开发的时候直接查这些词,然后用上。
CURL:不用说,如果要爬取一个页面,首先要请求这个页面,得到对方服务器返回的数据(一般是html,如果直接看懂别人的api接口,就当我没看吧说吧)过去这句话)。
simple_html_dom:HTML 节点解析器。使用curl请求html文档后,可以用这个来解析dom节点,方便匹配需要采集爬取的内容。
正则表达式:用于匹配你想要的内容,与simple_html_dom功能相同,但会更加灵活。如果两者匹配,就会更加流畅。哈哈:)
worker 或 swoole:用于做多线程或多进程以提高效率。我更推荐workerman,因为学习成本低,文档清晰易学!Swoole 对新手确实很不友好,但是它的功能比workerman 强一点,这里就不讨论了。
Redis:用于存储 URL 队列。如果不追求太高的效率,可以无视。
对于这些关键词来说,入门级爬虫差不多就够了。很想研究一下数千万的采集对分布式爬虫的追求。我建议出去左转 Python 或其他语言主题下的提问。
最后说一下实现思路。
首页上的爬虫需要一个种子页,比如“中国新闻网”首页。这个爬虫使用curl请求种子页面,获取html数据,使用正则表达式匹配a标签的所有href属性,然后根据自己的一些规则来匹配一些符合规则的url或者符合规则的url已自行处理。例如,一些a标签可能没有http或https头,或者可能有没有域名的url,例如“/news/gn/”。这时候你需要做一点判断和处理,把添加的加进去,然后用sha1加密url,然后用hash去查数据库看是否有相同的hash,如果有,表示url已经有了(go Heavy),然后将url和hash同时存入url队列数据库中。
做完以上操作后,一定要记得给被爬取的URL一个已爬取状态,避免重复爬取。
然后在重复之前的操作之前从数据库中检查一个新的未被抓取的URL,这样你的爬虫就形成了,它会继续向你的URL队列添加URL。
关键时刻到了。如果我们简单地爬取URL并放入数据库,那是没有用的,对吧?
这时候该说一下内容采集了,url就在那里。这时候写一个爬虫,不断的取出url库中的url来爬回这个页面的内容,然后再写规则匹配内容后,就可以保存到数据库中了。
就是这样。这个入门级爬虫准备好了。
但是,真正的爬虫开发工作肯定会遇到很多很多问题和意想不到的问题,比如:蜘蛛陷阱、反爬虫、动态加载的内容无法爬取、效率问题、程序报错后是否有重启机制并在遇到异常、法律风险等问题后停止运行。
以下所有问题都留给你在实战中自己解决,因为每个人的业务不同,报出的错误肯定也不同。没有办法说的太清楚。本文文章主要目的是给大家提供一个思路。我也欢迎大家加入我。让我们一起交流讨论爬虫的各种知识和技巧。如果人多,我也可以组成一个交流群,大家交流。学习。
一不小心写了两千多字,没费心去复习这句话,没啥意思。如果有错别字,大家都会看的。我的 vx 有问题。
php 爬虫抓取网页数据(我看你php是用于爬取热门主页的吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-11-07 15:01
php爬虫抓取网页数据,用webserver(服务器)记录下来用,不能单独用。另外java和python可以互相调用的。找你要抓取的php页面,用代理连接到java爬虫的服务器,要求java帮你把php页面的链接替换成你自己定义的网址,然后你直接从java爬虫接收数据即可。我看你php是用于爬取热门主页的吗?我推荐你可以从scrapy框架抓取主页:scrapy-self。
讲个故事吧。以前以为php里面有语言会爬取到数据,现在发现java也有这个api。这个对爬虫的用处不大,因为都是爬下来连接网页编程而已。
我想爬一些我觉得有用的资源,用于向人讲学。求简单,求技术含量大,简单,又时效性强的办法。
可以建立一个scrapy服务器,但为了知乎规定,文章自动推送在“知乎-与世界分享你的知识、经验和见解”这个专栏里,推荐到“python技术”专栏让服务器上的用户抓,
我就想知道,知乎有啥“实用性”需求,让爬虫给爬过来啊。以下是正经回答python提供了很多个爬虫比如pythontime.sleep(500)对tcp或者http网络进行500毫秒的阻塞干扰,pythontornado可以实现异步轮询,一个tornado可以支持大多数http代理服务器,对于有多个爬虫的知乎来说,python自己是无法支持500毫秒这么长的时间,而且人人必须是认证用户.pythontornado如何做的,简单的简单用bio做下代理,首先抓取你想抓取的页面,url的url用get方法,如果你这个页面有多个url或者url不唯一,这个时候需要抓取多个页面然后写入到队列,抓取到后先从队列取你想要抓取的页面,然后去拿这个页面的url,然后进行循环判断从队列拿url是否是你想要的url,一旦不是,就返回结果并退出等待状态然后去抓取下一个url,如果抓取到还是不是的话,就返回结果并退出等待状态.在做这个循环判断过程时,用python队列也可以用str.strip()。 查看全部
php 爬虫抓取网页数据(我看你php是用于爬取热门主页的吗?)
php爬虫抓取网页数据,用webserver(服务器)记录下来用,不能单独用。另外java和python可以互相调用的。找你要抓取的php页面,用代理连接到java爬虫的服务器,要求java帮你把php页面的链接替换成你自己定义的网址,然后你直接从java爬虫接收数据即可。我看你php是用于爬取热门主页的吗?我推荐你可以从scrapy框架抓取主页:scrapy-self。
讲个故事吧。以前以为php里面有语言会爬取到数据,现在发现java也有这个api。这个对爬虫的用处不大,因为都是爬下来连接网页编程而已。
我想爬一些我觉得有用的资源,用于向人讲学。求简单,求技术含量大,简单,又时效性强的办法。
可以建立一个scrapy服务器,但为了知乎规定,文章自动推送在“知乎-与世界分享你的知识、经验和见解”这个专栏里,推荐到“python技术”专栏让服务器上的用户抓,
我就想知道,知乎有啥“实用性”需求,让爬虫给爬过来啊。以下是正经回答python提供了很多个爬虫比如pythontime.sleep(500)对tcp或者http网络进行500毫秒的阻塞干扰,pythontornado可以实现异步轮询,一个tornado可以支持大多数http代理服务器,对于有多个爬虫的知乎来说,python自己是无法支持500毫秒这么长的时间,而且人人必须是认证用户.pythontornado如何做的,简单的简单用bio做下代理,首先抓取你想抓取的页面,url的url用get方法,如果你这个页面有多个url或者url不唯一,这个时候需要抓取多个页面然后写入到队列,抓取到后先从队列取你想要抓取的页面,然后去拿这个页面的url,然后进行循环判断从队列拿url是否是你想要的url,一旦不是,就返回结果并退出等待状态然后去抓取下一个url,如果抓取到还是不是的话,就返回结果并退出等待状态.在做这个循环判断过程时,用python队列也可以用str.strip()。
php 爬虫抓取网页数据(常用指令如下所示:纯Python语言编写框架格式说明 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2021-11-07 03:08
)
Scrapy是一个基于Twisted的异步处理爬虫框架,纯Python编写。Scrapy 框架应用广泛,常用于数据采集、网络监控、自动化测试。
提示:Twisted 是一个事件驱动的网络引擎框架,也是用 Python 实现的。
下载并安装Scrapy Scrapy 支持常见的主流平台,如Linux、Mac、Windows 等,因此您可以轻松安装它。本节以Windows系统为例,在CMD命令行执行以下命令:
python -m pip install Scrapy
由于 Scrapy 需要很多依赖,所以安装需要很长时间。请耐心等待。其他平台的安装方法请参考官方文档《》。
验证安装如下:
C:\Users\Administrator>python
Python 3.7.4 (tags/v3.7.4:e09359112e, Jul 8 2019, 19:29:22) [MSC v.1916 32 bit (Intel)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import scrapy
>>> exit()
如果exit()操作可以正常进行并且没有ERROR错误,则安装成功。创建 Scrapy 爬虫项目 Scrapy 框架提供了一些常用的命令来创建项目、查看配置信息和运行爬虫程序。常用命令如下:
常用指令命令格式说明
启动项目
启动项目
创建一个新项目。
蜘蛛侠
易碎的genspider
创建一个新的爬虫文件。
运行蜘蛛
爬虫爬虫
要运行爬虫文件,无需创建项目。
爬行
爬行
要运行爬虫项目,您必须创建该项目。
列表
草稿清单
列出项目中的所有爬虫文件。
看法
草稿视图
从浏览器打开 url 地址。
贝壳
csrapy 外壳
命令行交互模式。
设置
抓取设置
查看当前项目的配置信息。
1) 创建第一个 Scrapy 爬虫项目。创建一个名为百度的爬虫项目。打开CMD命令提示符,执行以下操作:
C:\Users\Administrator>cd Desktop
C:\Users\Administrator\Desktop>scrapy startproject Baidu
New Scrapy project 'Baidu', using template directory 'd:\python\python37\lib\site-packages\scrapy\templates\project', created in:
C:\Users\Administrator\Desktop\Baidu
# 提示后续命令操作
You can start your first spider with:
cd Baidu
scrapy genspider example example.com
打开新创建的项目“百度”,会有如下项目文件,如图:
图 1:项目文件
接下来,创建一个爬虫文件,如下所示:
C:\Users\Administrator\Desktop>cd Baidu
C:\Users\Administrator\Desktop\Baidu>scrapy genspider baidu www.baidu.com
Created spider 'baidu' using template 'basic' in module:
Baidu.spiders.baidu
下面显示了项目的目录树结构和每个文件的作用:
Baidu # 项目文件夹
├── Baidu # 用来装载项目文件的目录
│ ├── items.py # 定义要抓取的数据结构
│ ├── middlewares.py # 中间件,用来设置一些处理规则
│ ├── pipelines.py # 管道文件,处理抓取的数据
│ ├── settings.py # 全局配置文件
│ └── spiders # 用来装载爬虫文件的目录
│ ├── baidu.py # 具体的爬虫程序
└── scrapy.cfg # 项目基本配置文件
从上面的目录结构可以看出,Scrapy将整个爬虫程序划分为不同的模块,让每个模块处理不同的任务,模块之间紧密相连。因此,您只需要在相应的模块中编写相应的代码,就可以轻松实现一个爬虫程序。Scrapy 爬虫工作流程 Scrapy 框架由五个主要组件组成,如下图:
Scrapy 的五个主要组件名称功能说明
引擎
整个Scrapy框架的核心主要负责不同模块之间数据和信号的传输。
调度器
用于维护引擎发送的请求队列。
下载器
接收引擎发送的请求,生成请求的响应对象,将响应结果返回给引擎。
蜘蛛(履带)
处理引擎发送的响应主要用于解析、提取数据并获取需要跟进的二级URL,然后将这些数据返回给引擎。
管道(项目管道)
使用数据存储对引擎发送的数据做进一步的处理,比如存储在MySQL数据库中。
在整个执行过程中,还涉及到两个中间件,分别是Downloader Middlewares和Spider Middlewares,它们的作用不同:
Scrapy工作流程图如下:
图 1:工作流程示意图
上述示意图说明如下。当一个爬虫项目启动时,Scrapy 框架会执行以下任务:
上面的过程会一直循环下去,直到没有要爬取的URL,也就是当URL队列为空时,不会停止。
使用Scrapy框架时,需要稍微修改设置配置文件。现在使用Pycharm打开刚刚创建的“百度”项目,修改配置文件如下:
# 1、定义User-Agent
USER_AGENT = 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)'
# 2、是否遵循robots协议,一般设置为False
ROBOTSTXT_OBEY = False
# 3、最大并发量,默认为16
CONCURRENT_REQUESTS = 32
# 4、下载延迟时间
DOWNLOAD_DELAY = 1
其他常用配置项介绍:
# 设置日志级别,DEBUG < INFO < WARNING < ERROR < CRITICAL
LOG_LEVEL = ' '
# 将日志信息保存日志文件中,而不在终端输出
LOG_FILE = ''
# 设置导出数据的编码格式(主要针对于json文件)
FEED_EXPORT_ENCODING = ''
# 非结构化数据的存储路径
IMAGES_STORE = '路径'
# 请求头,此处可以添加User-Agent、cookies、referer等
DEFAULT_REQUEST_HEADERS={
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
}
# 项目管道,300 代表激活的优先级 越小越优先,取值1到1000
ITEM_PIPELINES={
'Baidu.pipelines.BaiduPipeline':300
}
# 添加下载器中间件
DOWNLOADER_MIDDLEWARES = {} 查看全部
php 爬虫抓取网页数据(常用指令如下所示:纯Python语言编写框架格式说明
)
Scrapy是一个基于Twisted的异步处理爬虫框架,纯Python编写。Scrapy 框架应用广泛,常用于数据采集、网络监控、自动化测试。
提示:Twisted 是一个事件驱动的网络引擎框架,也是用 Python 实现的。
下载并安装Scrapy Scrapy 支持常见的主流平台,如Linux、Mac、Windows 等,因此您可以轻松安装它。本节以Windows系统为例,在CMD命令行执行以下命令:
python -m pip install Scrapy
由于 Scrapy 需要很多依赖,所以安装需要很长时间。请耐心等待。其他平台的安装方法请参考官方文档《》。
验证安装如下:
C:\Users\Administrator>python
Python 3.7.4 (tags/v3.7.4:e09359112e, Jul 8 2019, 19:29:22) [MSC v.1916 32 bit (Intel)] on win32
Type "help", "copyright", "credits" or "license" for more information.
>>> import scrapy
>>> exit()
如果exit()操作可以正常进行并且没有ERROR错误,则安装成功。创建 Scrapy 爬虫项目 Scrapy 框架提供了一些常用的命令来创建项目、查看配置信息和运行爬虫程序。常用命令如下:
常用指令命令格式说明
启动项目
启动项目
创建一个新项目。
蜘蛛侠
易碎的genspider
创建一个新的爬虫文件。
运行蜘蛛
爬虫爬虫
要运行爬虫文件,无需创建项目。
爬行
爬行
要运行爬虫项目,您必须创建该项目。
列表
草稿清单
列出项目中的所有爬虫文件。
看法
草稿视图
从浏览器打开 url 地址。
贝壳
csrapy 外壳
命令行交互模式。
设置
抓取设置
查看当前项目的配置信息。
1) 创建第一个 Scrapy 爬虫项目。创建一个名为百度的爬虫项目。打开CMD命令提示符,执行以下操作:
C:\Users\Administrator>cd Desktop
C:\Users\Administrator\Desktop>scrapy startproject Baidu
New Scrapy project 'Baidu', using template directory 'd:\python\python37\lib\site-packages\scrapy\templates\project', created in:
C:\Users\Administrator\Desktop\Baidu
# 提示后续命令操作
You can start your first spider with:
cd Baidu
scrapy genspider example example.com
打开新创建的项目“百度”,会有如下项目文件,如图:
图 1:项目文件
接下来,创建一个爬虫文件,如下所示:
C:\Users\Administrator\Desktop>cd Baidu
C:\Users\Administrator\Desktop\Baidu>scrapy genspider baidu www.baidu.com
Created spider 'baidu' using template 'basic' in module:
Baidu.spiders.baidu
下面显示了项目的目录树结构和每个文件的作用:
Baidu # 项目文件夹
├── Baidu # 用来装载项目文件的目录
│ ├── items.py # 定义要抓取的数据结构
│ ├── middlewares.py # 中间件,用来设置一些处理规则
│ ├── pipelines.py # 管道文件,处理抓取的数据
│ ├── settings.py # 全局配置文件
│ └── spiders # 用来装载爬虫文件的目录
│ ├── baidu.py # 具体的爬虫程序
└── scrapy.cfg # 项目基本配置文件
从上面的目录结构可以看出,Scrapy将整个爬虫程序划分为不同的模块,让每个模块处理不同的任务,模块之间紧密相连。因此,您只需要在相应的模块中编写相应的代码,就可以轻松实现一个爬虫程序。Scrapy 爬虫工作流程 Scrapy 框架由五个主要组件组成,如下图:
Scrapy 的五个主要组件名称功能说明
引擎
整个Scrapy框架的核心主要负责不同模块之间数据和信号的传输。
调度器
用于维护引擎发送的请求队列。
下载器
接收引擎发送的请求,生成请求的响应对象,将响应结果返回给引擎。
蜘蛛(履带)
处理引擎发送的响应主要用于解析、提取数据并获取需要跟进的二级URL,然后将这些数据返回给引擎。
管道(项目管道)
使用数据存储对引擎发送的数据做进一步的处理,比如存储在MySQL数据库中。
在整个执行过程中,还涉及到两个中间件,分别是Downloader Middlewares和Spider Middlewares,它们的作用不同:
Scrapy工作流程图如下:
图 1:工作流程示意图
上述示意图说明如下。当一个爬虫项目启动时,Scrapy 框架会执行以下任务:
上面的过程会一直循环下去,直到没有要爬取的URL,也就是当URL队列为空时,不会停止。
使用Scrapy框架时,需要稍微修改设置配置文件。现在使用Pycharm打开刚刚创建的“百度”项目,修改配置文件如下:
# 1、定义User-Agent
USER_AGENT = 'Mozilla/4.0 (compatible; MSIE 7.0; Windows NT 6.0)'
# 2、是否遵循robots协议,一般设置为False
ROBOTSTXT_OBEY = False
# 3、最大并发量,默认为16
CONCURRENT_REQUESTS = 32
# 4、下载延迟时间
DOWNLOAD_DELAY = 1
其他常用配置项介绍:
# 设置日志级别,DEBUG < INFO < WARNING < ERROR < CRITICAL
LOG_LEVEL = ' '
# 将日志信息保存日志文件中,而不在终端输出
LOG_FILE = ''
# 设置导出数据的编码格式(主要针对于json文件)
FEED_EXPORT_ENCODING = ''
# 非结构化数据的存储路径
IMAGES_STORE = '路径'
# 请求头,此处可以添加User-Agent、cookies、referer等
DEFAULT_REQUEST_HEADERS={
'Accept': 'text/html,application/xhtml+xml,application/xml;q=0.9,*/*;q=0.8',
'Accept-Language': 'en',
}
# 项目管道,300 代表激活的优先级 越小越优先,取值1到1000
ITEM_PIPELINES={
'Baidu.pipelines.BaiduPipeline':300
}
# 添加下载器中间件
DOWNLOADER_MIDDLEWARES = {}
php 爬虫抓取网页数据(如有什么知识点总结得不对,抄袭到哪位的内容)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2021-11-06 19:40
——本文来自网络学习或百度科普。我会先放专业术语,然后用我学过的总结的语言。如果有没有总结正确的知识点,或者博主抄袭的内容,请私信给我~谢谢!——
百度:网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。传统爬虫从一个或几个初始网页的网址开始,获取初始网页上的网址。在抓取网页的过程中,它不断地从当前页面中提取新的URL并将它们放入队列中,直到满足系统的某个停止条件。聚焦爬虫的工作流程更为复杂。需要根据一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,放入URL队列等待被抓取。然后,它会根据一定的搜索策略从队列中选择下一个要抓取的网页的网址,并重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤和索引,以供以后查询检索;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。
与一般网络爬虫相比,聚焦爬虫需要解决三个主要问题:
(1) 爬取目标的描述或定义;
(2)对网页或数据的分析和过滤;
(3) URL 搜索策略。
我的总结:由于互联网时代的飞速发展,为了快速、大量地获取网络信息,网页的内容也急剧增加。于是就有了网络爬虫。
网络爬虫有两种,一种是通用网络爬虫;另一种是聚焦爬虫。重点爬虫可以根据个人的不同要求或需求进行选择、过滤等(虽然这类爬虫有这样的优点,但也很难进行下去) 查看全部
php 爬虫抓取网页数据(如有什么知识点总结得不对,抄袭到哪位的内容)
——本文来自网络学习或百度科普。我会先放专业术语,然后用我学过的总结的语言。如果有没有总结正确的知识点,或者博主抄袭的内容,请私信给我~谢谢!——
百度:网络爬虫是一种自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。传统爬虫从一个或几个初始网页的网址开始,获取初始网页上的网址。在抓取网页的过程中,它不断地从当前页面中提取新的URL并将它们放入队列中,直到满足系统的某个停止条件。聚焦爬虫的工作流程更为复杂。需要根据一定的网页分析算法过滤掉与主题无关的链接,保留有用的链接,放入URL队列等待被抓取。然后,它会根据一定的搜索策略从队列中选择下一个要抓取的网页的网址,并重复上述过程,直到达到系统的某个条件时停止。另外,爬虫爬过的所有网页都会被系统存储起来,进行一定的分析、过滤和索引,以供以后查询检索;对于专注的爬虫,这个过程中得到的分析结果还是可以对后续的爬虫过程给出反馈和指导的。
与一般网络爬虫相比,聚焦爬虫需要解决三个主要问题:
(1) 爬取目标的描述或定义;
(2)对网页或数据的分析和过滤;
(3) URL 搜索策略。
我的总结:由于互联网时代的飞速发展,为了快速、大量地获取网络信息,网页的内容也急剧增加。于是就有了网络爬虫。
网络爬虫有两种,一种是通用网络爬虫;另一种是聚焦爬虫。重点爬虫可以根据个人的不同要求或需求进行选择、过滤等(虽然这类爬虫有这样的优点,但也很难进行下去)
php 爬虫抓取网页数据(什么是Python?Python是什么?(二)模糊)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-11-06 10:18
今天听到有人问:Python为什么叫爬虫?我脑子里的第一反应不是答案,而是为什么有人问这个问题。我觉得大家对Python的概念有点模糊,把Python和爬虫混为一谈,所以今天问请解释一下。
什么是 Python?什么是 Python?
如果你在英文词典里查Python,他会给你Python作为大蟒蛇的定义,这样读:英语[ˈpaɪθən],美国[ˈpaɪθɑ:n],Python就是大名鼎鼎的“龟叔”Guido van Rossum在 1989 年圣诞节期间,为了度过无聊的圣诞节而编写的一种编程语言。Python 是一种计算机编程语言。是一种动态的、面向对象的脚本语言,最初是为编写自动化脚本(shell)而设计的,随着版本的不断更新和新语言功能的加入,越来越多的被用于独立的、大型的项目开发。
Python 是一种解释性脚本语言,可用于以下领域:
1、Web 和 Internet 开发
2、科学计算和统计
3、教育
4、桌面界面开发
5、软件开发
6、后端开发
什么是爬虫?什么是网络爬虫?
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是按照某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
随着互联网的飞速发展,万维网已经成为海量信息的载体。如何有效地提取和利用这些信息成为一个巨大的挑战。
搜索引擎,如传统的通用搜索引擎 AltaVista、Yahoo! 谷歌等作为辅助人们检索信息的工具,成为用户访问万维网的门户和指南。但是,这些通用的搜索引擎也有一定的局限性,例如:
(1)不同领域、不同背景的用户往往有不同的检索目的和需求。一般搜索引擎返回的结果中含有大量用户不关心的网页。
(2)通用搜索引擎的目标是最大化网络覆盖。有限的搜索引擎服务器资源和无限的网络数据资源之间的矛盾将进一步加深。
(3) 随着万维网上数据形式的丰富和网络技术的不断发展,图片、数据库、音频、视频、多媒体等不同数据大量出现,一般的搜索引擎往往无能为力。这些具有密集信息内容和一定结构的数据。很好地发现和获取。
(4)大多数通用搜索引擎都提供基于关键字的检索,难以支持基于语义信息的查询。
为了解决上述问题,针对相关网络资源进行针对性抓取的聚焦爬虫应运而生。Focus Crawler 是一个自动下载网页的程序。它根据建立的爬取目标有选择地访问万维网上的网页和相关链接,以获取所需的信息。与通用网络爬虫不同,聚焦爬虫不追求大的覆盖范围,而是将目标设定为抓取与特定主题内容相关的网页,并为面向主题的用户查询准备数据资源。
Python和爬虫有什么关系?
爬虫一般是指对网络资源的爬取。由于python的脚本特性,python易于配置,对字符的处理也非常灵活。另外python有丰富的网络捕捉模块,所以两者经常联系在一起。只需使用python自带的urllib库即可;使用python编写搜索引擎,搜索引擎是一个复杂的爬虫。从这里您将了解什么是 Python 爬虫。是一种基于Python编程创建的网络资源爬取方法。Python 不是爬虫。
为什么Python适合一些爬虫?
1) 抓取网页本身的界面
与java、c#、C++、python等其他静态编程语言相比,抓取网页文档的界面更加简洁;相对于其他动态脚本语言,如 perl、shell、python,urllib2 包提供了更完整的 Web 文档 API 访问。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站都是为了生硬爬取而被屏蔽的。这就是我们需要模拟用户代理的行为来构造合适的请求的地方,比如模拟用户登录,模拟session/cookies的存储和设置。python中有很好的第三方包帮你搞定,比如Requests,mechanize
2)网页爬取后的处理
抓取到的网页通常需要进行处理,如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用很短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要python。
爬虫是如何工作的?
1.首先选择一些精心挑选的种子网址;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取的URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页并保存到下载的网页库中。另外,将这些 URL 放入爬取的 URL 队列中。
4.对爬取的URL队列中的URL进行解析,分析其中的其他URL,将这些URL放入URL队列进行爬取,从而进入下一个循环。
Python除了用作爬虫还能做什么?
1、Web 开发python 有一个非常完整的与Web 服务器交互的库,以及大量免费的前端Web 模板。更有利的是,有一个非常好的成熟的Django Web框架,功能齐全。
2、Linux系统运维。其实早期都是用shell脚本来实现自动化运维的。但是由于shell脚本本身可编程性较弱,所以需要实现的一些功能库很少。大部分都需要自己从头开始编写,但pyhon作为一种“胶水语言”,可以方便地与其他人集成,因为它可以方便各种工具的二次开发,形成一套自己的运维管理系统。
3、游戏开发python在游戏开发上可能不如Lua或C++,但由于python脚本的优势,它类似于游戏脚本、玩法逻辑等非常灵活的设计。我们修改起来非常方便。当然,如果你开发一个小游戏程序,python还是很有优势的。比较有名的是pygame,这对我们自娱自乐来说可能是个好消息。
4、桌面软件 在window系统桌面开发领域,我认为C++ MFC应该得到更广泛的应用。Python可以实现与C++的无缝连接,同时支持Qt和GTK。
5、数据处理python作为一种工程语言,拥有相当丰富的数据处理库,如高性能科学计算库NumPy和SciPy。
6、人工智能 其实真正的人工智能底层语言是C/C++,因为真正的计算都是用C/C++进行的,而python只是调用了AI接口,然后实现了一些逻辑。但是为什么人工智能首先出现在 python 中?这其实是由于python作为“胶水语言”的特性。使用python的主要原因是CPython的集成和底层原因,让开发更方便。
当然,python还有其他应用场景,比如云计算。
感谢您的阅读。以上就是跟大家分享为什么Python被称为爬虫,以及Python和爬虫有什么关系。你明白吗?可以称Python爬虫,但不能说Python就是爬虫。记住?
免责声明:内容及图片来源于网络,版权归原作者所有。如果有侵犯您原创版权的内容,请告知我们,我们会尽快删除相关内容。 查看全部
php 爬虫抓取网页数据(什么是Python?Python是什么?(二)模糊)
今天听到有人问:Python为什么叫爬虫?我脑子里的第一反应不是答案,而是为什么有人问这个问题。我觉得大家对Python的概念有点模糊,把Python和爬虫混为一谈,所以今天问请解释一下。
什么是 Python?什么是 Python?
如果你在英文词典里查Python,他会给你Python作为大蟒蛇的定义,这样读:英语[ˈpaɪθən],美国[ˈpaɪθɑ:n],Python就是大名鼎鼎的“龟叔”Guido van Rossum在 1989 年圣诞节期间,为了度过无聊的圣诞节而编写的一种编程语言。Python 是一种计算机编程语言。是一种动态的、面向对象的脚本语言,最初是为编写自动化脚本(shell)而设计的,随着版本的不断更新和新语言功能的加入,越来越多的被用于独立的、大型的项目开发。
Python 是一种解释性脚本语言,可用于以下领域:
1、Web 和 Internet 开发
2、科学计算和统计
3、教育
4、桌面界面开发
5、软件开发
6、后端开发
什么是爬虫?什么是网络爬虫?
网络爬虫(也称为网络蜘蛛、网络机器人,在 FOAF 社区中,更常见的是网络追逐)是按照某些规则自动抓取万维网上信息的程序或脚本。其他不太常用的名称是蚂蚁、自动索引、模拟器或蠕虫。
随着互联网的飞速发展,万维网已经成为海量信息的载体。如何有效地提取和利用这些信息成为一个巨大的挑战。
搜索引擎,如传统的通用搜索引擎 AltaVista、Yahoo! 谷歌等作为辅助人们检索信息的工具,成为用户访问万维网的门户和指南。但是,这些通用的搜索引擎也有一定的局限性,例如:
(1)不同领域、不同背景的用户往往有不同的检索目的和需求。一般搜索引擎返回的结果中含有大量用户不关心的网页。
(2)通用搜索引擎的目标是最大化网络覆盖。有限的搜索引擎服务器资源和无限的网络数据资源之间的矛盾将进一步加深。
(3) 随着万维网上数据形式的丰富和网络技术的不断发展,图片、数据库、音频、视频、多媒体等不同数据大量出现,一般的搜索引擎往往无能为力。这些具有密集信息内容和一定结构的数据。很好地发现和获取。
(4)大多数通用搜索引擎都提供基于关键字的检索,难以支持基于语义信息的查询。
为了解决上述问题,针对相关网络资源进行针对性抓取的聚焦爬虫应运而生。Focus Crawler 是一个自动下载网页的程序。它根据建立的爬取目标有选择地访问万维网上的网页和相关链接,以获取所需的信息。与通用网络爬虫不同,聚焦爬虫不追求大的覆盖范围,而是将目标设定为抓取与特定主题内容相关的网页,并为面向主题的用户查询准备数据资源。
Python和爬虫有什么关系?
爬虫一般是指对网络资源的爬取。由于python的脚本特性,python易于配置,对字符的处理也非常灵活。另外python有丰富的网络捕捉模块,所以两者经常联系在一起。只需使用python自带的urllib库即可;使用python编写搜索引擎,搜索引擎是一个复杂的爬虫。从这里您将了解什么是 Python 爬虫。是一种基于Python编程创建的网络资源爬取方法。Python 不是爬虫。
为什么Python适合一些爬虫?
1) 抓取网页本身的界面
与java、c#、C++、python等其他静态编程语言相比,抓取网页文档的界面更加简洁;相对于其他动态脚本语言,如 perl、shell、python,urllib2 包提供了更完整的 Web 文档 API 访问。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站都是为了生硬爬取而被屏蔽的。这就是我们需要模拟用户代理的行为来构造合适的请求的地方,比如模拟用户登录,模拟session/cookies的存储和设置。python中有很好的第三方包帮你搞定,比如Requests,mechanize
2)网页爬取后的处理
抓取到的网页通常需要进行处理,如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用很短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要python。
爬虫是如何工作的?
1.首先选择一些精心挑选的种子网址;
2.将这些网址放入待抓取的网址队列中;
3. 从待爬取的URL队列中取出待爬取的URL,解析DNS,获取主机IP,下载该URL对应的网页并保存到下载的网页库中。另外,将这些 URL 放入爬取的 URL 队列中。
4.对爬取的URL队列中的URL进行解析,分析其中的其他URL,将这些URL放入URL队列进行爬取,从而进入下一个循环。
Python除了用作爬虫还能做什么?
1、Web 开发python 有一个非常完整的与Web 服务器交互的库,以及大量免费的前端Web 模板。更有利的是,有一个非常好的成熟的Django Web框架,功能齐全。
2、Linux系统运维。其实早期都是用shell脚本来实现自动化运维的。但是由于shell脚本本身可编程性较弱,所以需要实现的一些功能库很少。大部分都需要自己从头开始编写,但pyhon作为一种“胶水语言”,可以方便地与其他人集成,因为它可以方便各种工具的二次开发,形成一套自己的运维管理系统。
3、游戏开发python在游戏开发上可能不如Lua或C++,但由于python脚本的优势,它类似于游戏脚本、玩法逻辑等非常灵活的设计。我们修改起来非常方便。当然,如果你开发一个小游戏程序,python还是很有优势的。比较有名的是pygame,这对我们自娱自乐来说可能是个好消息。
4、桌面软件 在window系统桌面开发领域,我认为C++ MFC应该得到更广泛的应用。Python可以实现与C++的无缝连接,同时支持Qt和GTK。
5、数据处理python作为一种工程语言,拥有相当丰富的数据处理库,如高性能科学计算库NumPy和SciPy。
6、人工智能 其实真正的人工智能底层语言是C/C++,因为真正的计算都是用C/C++进行的,而python只是调用了AI接口,然后实现了一些逻辑。但是为什么人工智能首先出现在 python 中?这其实是由于python作为“胶水语言”的特性。使用python的主要原因是CPython的集成和底层原因,让开发更方便。
当然,python还有其他应用场景,比如云计算。
感谢您的阅读。以上就是跟大家分享为什么Python被称为爬虫,以及Python和爬虫有什么关系。你明白吗?可以称Python爬虫,但不能说Python就是爬虫。记住?
免责声明:内容及图片来源于网络,版权归原作者所有。如果有侵犯您原创版权的内容,请告知我们,我们会尽快删除相关内容。
php 爬虫抓取网页数据(Python內建使用urllib.request获取网页urllib是什么意思?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-11-05 09:01
1. 使用 urllib.request 获取网页
urllib 是 Python 中的内置 HTTP 库。使用 urllib,您可以通过非常简单的步骤高效地使用 采集 数据;配合Beautiful等HTML解析库,可以为采集网络数据编写大型爬虫;
注:示例代码采用Python3编写;urllib 是 Python2 中 urllib 和 urllib2 的组合,Python2 中的 urllib2 对应于 Python3 中的 urllib.request
简单的例子:
2. 伪造请求头信息
有时爬虫发起的请求会被服务器拒绝。这时,爬虫需要伪装成人类用户的浏览器。这通常是通过伪造请求头信息来实现的,例如:
3. 伪造的请求体
爬取某些网站时,需要POST数据到服务器,然后需要伪造请求体;
为了实现有道词典的在线翻译脚本,在Chrome中打开开发工具,在Network下找到方法为POST的请求。观察数据,可以发现请求体中的'i'是需要翻译的URL编码内容,因此可以伪造请求体,如:
您还可以使用 add_header() 方法来伪造请求头,例如:
4. 使用代理IP
为了避免爬虫过于频繁导致IP被封的问题采集,可以使用代理IP,例如:
注意:使用爬虫过于频繁地访问目标站点会占用大量服务器资源。大型分布式爬虫可以爬取一个站点甚至对该站点发起DDOS攻击;因此,您在使用爬虫爬取数据时应合理安排爬取。频率和时间;如:服务器比较空闲时(如清晨)进行爬取,完成一个爬取任务后暂停一段时间等;
5. 检测网页的编码方式
虽然大部分网页都是UTF-8编码的,但有时你会遇到使用其他编码方式的网页,所以必须了解网页的编码方式才能正确解码抓取到的页面;
chardet是python的第三方模块,使用chardet可以自动检测网页的编码方式;
安装chardet:pip install charest
用:
6. 获取重定向链接
有时网页的某个页面需要在原创URL的基础上重定向一次甚至多次才能最终到达目标页面,因此需要正确处理重定向;
通过requests模块的head()函数获取跳转链接的URL,如 查看全部
php 爬虫抓取网页数据(Python內建使用urllib.request获取网页urllib是什么意思?)
1. 使用 urllib.request 获取网页
urllib 是 Python 中的内置 HTTP 库。使用 urllib,您可以通过非常简单的步骤高效地使用 采集 数据;配合Beautiful等HTML解析库,可以为采集网络数据编写大型爬虫;
注:示例代码采用Python3编写;urllib 是 Python2 中 urllib 和 urllib2 的组合,Python2 中的 urllib2 对应于 Python3 中的 urllib.request
简单的例子:
2. 伪造请求头信息
有时爬虫发起的请求会被服务器拒绝。这时,爬虫需要伪装成人类用户的浏览器。这通常是通过伪造请求头信息来实现的,例如:
3. 伪造的请求体
爬取某些网站时,需要POST数据到服务器,然后需要伪造请求体;
为了实现有道词典的在线翻译脚本,在Chrome中打开开发工具,在Network下找到方法为POST的请求。观察数据,可以发现请求体中的'i'是需要翻译的URL编码内容,因此可以伪造请求体,如:
您还可以使用 add_header() 方法来伪造请求头,例如:
4. 使用代理IP
为了避免爬虫过于频繁导致IP被封的问题采集,可以使用代理IP,例如:
注意:使用爬虫过于频繁地访问目标站点会占用大量服务器资源。大型分布式爬虫可以爬取一个站点甚至对该站点发起DDOS攻击;因此,您在使用爬虫爬取数据时应合理安排爬取。频率和时间;如:服务器比较空闲时(如清晨)进行爬取,完成一个爬取任务后暂停一段时间等;
5. 检测网页的编码方式
虽然大部分网页都是UTF-8编码的,但有时你会遇到使用其他编码方式的网页,所以必须了解网页的编码方式才能正确解码抓取到的页面;
chardet是python的第三方模块,使用chardet可以自动检测网页的编码方式;
安装chardet:pip install charest
用:
6. 获取重定向链接
有时网页的某个页面需要在原创URL的基础上重定向一次甚至多次才能最终到达目标页面,因此需要正确处理重定向;
通过requests模块的head()函数获取跳转链接的URL,如

