
php 爬虫抓取网页数据
php 爬虫抓取网页数据( Web爬虫是从的工作原理和关键技术综述:爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-10-31 08:14
Web爬虫是从的工作原理和关键技术综述:爬虫)
爬虫工作原理及关键技术总结:
网络爬虫是一种为搜索引擎从互联网上下载网页的自动提取程序,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页的URL,在网页的爬取过程中不断从当前页面中提取新的URL,直到满足系统的某个停止条件。
与普通网络爬虫相比,聚焦爬虫需要解决三个主要问题:
1、描述或定义爬取目标。
2、分析和过滤网页或数据。
3、搜索网址策略。
如何开发网页分析算法和网址搜索策略是确定爬取目标的基础。其中,Web分析算法和候选URL排序算法是决定搜索引擎提供的服务形式和爬行行为的关键。两者的算法有着密切的联系。
随着大数据的普及,网络爬虫已经成为当今的主流技术。不只是程序员,现在连普通用户都对爬虫有一个简单的认识,知道如何使用代理IP进行爬虫。众所周知,爬虫可以获得网站的信息,那么专注于网络爬虫有什么好处呢?这是爬行技术吗?接下来,我们将开始一个关于如何关注爬虫的事情。
焦点爬虫的工作流程比较复杂。需要按照一定的分析算法过滤掉与主题无关的链接,保留有用的链接,然后放到URL队列中等待被抓取。然后,它会根据特定的搜索策略从队列中选择下一个要抓取的网页网址,并重复上述步骤,直到达到系统的某个标准。
另外,爬虫爬过的所有页面都会存储在系统中,进行一些分析、过滤和索引,以供以后查询检索;对于专注的爬虫,通过这个过程得到的分析结果也可以在后续的爬虫过程中提供反馈和指导。
以上主要介绍了聚焦爬虫的内容。爬虫与它们相似,但也有区别。自然会受到爬虫的限制。在这种情况下,我们需要使用爬虫技术,例如代理IP来帮助我们。
如果想尝试使用代理ip,可以到拼音http代理ip官网了解更多,提供高度隐蔽的稳定代理ip,支持HTTP/HTTPS/SOCKS5代理协议,提供动态IP、静态IP等服务。百兆带宽,千万IP资源,保障爬虫数据传输安全。快速获取网站数据,现在还有免费测试和免费ip活动! 查看全部
php 爬虫抓取网页数据(
Web爬虫是从的工作原理和关键技术综述:爬虫)

爬虫工作原理及关键技术总结:
网络爬虫是一种为搜索引擎从互联网上下载网页的自动提取程序,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页的URL,在网页的爬取过程中不断从当前页面中提取新的URL,直到满足系统的某个停止条件。
与普通网络爬虫相比,聚焦爬虫需要解决三个主要问题:
1、描述或定义爬取目标。
2、分析和过滤网页或数据。
3、搜索网址策略。
如何开发网页分析算法和网址搜索策略是确定爬取目标的基础。其中,Web分析算法和候选URL排序算法是决定搜索引擎提供的服务形式和爬行行为的关键。两者的算法有着密切的联系。
随着大数据的普及,网络爬虫已经成为当今的主流技术。不只是程序员,现在连普通用户都对爬虫有一个简单的认识,知道如何使用代理IP进行爬虫。众所周知,爬虫可以获得网站的信息,那么专注于网络爬虫有什么好处呢?这是爬行技术吗?接下来,我们将开始一个关于如何关注爬虫的事情。
焦点爬虫的工作流程比较复杂。需要按照一定的分析算法过滤掉与主题无关的链接,保留有用的链接,然后放到URL队列中等待被抓取。然后,它会根据特定的搜索策略从队列中选择下一个要抓取的网页网址,并重复上述步骤,直到达到系统的某个标准。
另外,爬虫爬过的所有页面都会存储在系统中,进行一些分析、过滤和索引,以供以后查询检索;对于专注的爬虫,通过这个过程得到的分析结果也可以在后续的爬虫过程中提供反馈和指导。
以上主要介绍了聚焦爬虫的内容。爬虫与它们相似,但也有区别。自然会受到爬虫的限制。在这种情况下,我们需要使用爬虫技术,例如代理IP来帮助我们。
如果想尝试使用代理ip,可以到拼音http代理ip官网了解更多,提供高度隐蔽的稳定代理ip,支持HTTP/HTTPS/SOCKS5代理协议,提供动态IP、静态IP等服务。百兆带宽,千万IP资源,保障爬虫数据传输安全。快速获取网站数据,现在还有免费测试和免费ip活动!
php 爬虫抓取网页数据(精通Python网络爬虫:核心技术、框架与项目实战(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-10-29 01:23
阿里云>云栖社区>主题地图>W>Web爬虫PHP
推荐活动:
更多优惠>
当前主题:网络爬虫 php 添加到采集夹
相关话题:
网络爬虫php相关博客查看更多博客
精通Python网络爬虫:核心技术、框架及项目实战。3.6 网络爬虫实现技术
作者:华章电脑1949浏览评论数:04年前
3.6 网络爬虫实现技术 通过前面的学习,我们基本对爬虫的基础理论知识有了比较全面的了解,那么,想要实现网络爬虫技术,就必须自己开发网络爬虫,你可以使用哪些语言进行开发?开发网络爬虫的语言有很多种。常用语言有:Python、Java、PHP、Node.js。
阅读全文
《精通Python网络爬虫:核心技术、框架与项目实战》——3.6 网络爬虫实现技术
作者:华章电脑 2855人浏览评论:04年前
本节摘自华章出版社《精通Python Web爬虫:核心技术、框架与项目实战》一书第3章,章节3.6,作者魏伟,更多章节可在cloud 查看齐社区“华章电脑”的公众号。3.6 网络爬虫实现技术通过前面的学习,我们基本上对爬虫的基础理论知识有了比较全面的了解
阅读全文
构建网络爬虫?太简单
作者:悠悠悠然1953人浏览评论:05年前
网络爬虫通常用于全文搜索或内容检索。Tiny 框架对此也有有限的支持。虽然功能不多,但是做全文搜索或者从网页获取数据还是很方便的。框架特性,强大的节点过滤能力,支持post和get数据提交方式,避免重复网页处理功能,支持多站点内容抓取功能
阅读全文
精通Python网络爬虫:核心技术、框架及项目实战。3.8总结
作者:华章电脑1550人浏览评论:04年前
3.8Summary1)专注于网络爬虫,因为它们需要有目的地爬取,所以对于一般的网络爬虫来说,需要增加目标的定义和过滤机制。具体来说,此时它的执行原理和流程比一般的网络爬虫还需要3个步骤,即目标的定义、无关链接的过滤、下一步要爬取的URL地址的选择。2)常用网页更新
阅读全文
《精通Python网络爬虫:核心技术、框架与项目实战》——3.8Summary
作者:华章电脑1674人浏览评论:04年前
本节摘自华章出版社《精通Python Web爬虫:核心技术、框架与项目实战》一书第3章,章节3.8,作者魏伟,更多章节可访问云 在Qi社区查看“华章电脑”的公众号。3.8Summary1)关注网络爬虫,因为它们需要被有目的地抓取,所以对于一般的网络爬虫
阅读全文
Java Web爬虫获取网页源代码的原理及实现
作者:旭东的博客 936 浏览评论:08 年前
1.网络爬虫是一个自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址。在爬取网页的过程中,他们不断地从当前页面中提取新的URL并将它们放入队列中,直到满足系统的某个停止条件。2.
阅读全文
大量与网络爬虫相关的库/工具/API
作者:技术小能手1069人浏览评论:02年前
用于用户网页抓取的工具、编程库和 API 的详细列表,包括 Python、PHP、Ruby、JavaScript 等。 Web Scraping 我们使用的工具、编程库和 API 列表
阅读全文
开源爬虫软件总结
作者:club1111683 人浏览评论:06年前
世界上已经形成了数百种爬虫软件。本文梳理了比较知名和常见的开源爬虫软件,并按开发语言进行了总结,如下表所示。虽然搜索引擎也有爬虫,但我这次总结的只是爬虫软件,不是大型复杂的搜索引擎,因为很多兄弟只是想爬取数据,不会操作。
阅读全文
网络爬虫php相关问答
爬虫数据管理【问答集锦】
作者:我是管理员 28342人浏览评论:223年前
互联网上的网络爬虫的自然语言处理的未来是什么?artTemplate:arttemplate生成的页面能爬到数据吗?
阅读全文 查看全部
php 爬虫抓取网页数据(精通Python网络爬虫:核心技术、框架与项目实战(图))
阿里云>云栖社区>主题地图>W>Web爬虫PHP

推荐活动:
更多优惠>
当前主题:网络爬虫 php 添加到采集夹
相关话题:
网络爬虫php相关博客查看更多博客
精通Python网络爬虫:核心技术、框架及项目实战。3.6 网络爬虫实现技术

作者:华章电脑1949浏览评论数:04年前
3.6 网络爬虫实现技术 通过前面的学习,我们基本对爬虫的基础理论知识有了比较全面的了解,那么,想要实现网络爬虫技术,就必须自己开发网络爬虫,你可以使用哪些语言进行开发?开发网络爬虫的语言有很多种。常用语言有:Python、Java、PHP、Node.js。
阅读全文
《精通Python网络爬虫:核心技术、框架与项目实战》——3.6 网络爬虫实现技术

作者:华章电脑 2855人浏览评论:04年前
本节摘自华章出版社《精通Python Web爬虫:核心技术、框架与项目实战》一书第3章,章节3.6,作者魏伟,更多章节可在cloud 查看齐社区“华章电脑”的公众号。3.6 网络爬虫实现技术通过前面的学习,我们基本上对爬虫的基础理论知识有了比较全面的了解
阅读全文
构建网络爬虫?太简单


作者:悠悠悠然1953人浏览评论:05年前
网络爬虫通常用于全文搜索或内容检索。Tiny 框架对此也有有限的支持。虽然功能不多,但是做全文搜索或者从网页获取数据还是很方便的。框架特性,强大的节点过滤能力,支持post和get数据提交方式,避免重复网页处理功能,支持多站点内容抓取功能
阅读全文
精通Python网络爬虫:核心技术、框架及项目实战。3.8总结

作者:华章电脑1550人浏览评论:04年前
3.8Summary1)专注于网络爬虫,因为它们需要有目的地爬取,所以对于一般的网络爬虫来说,需要增加目标的定义和过滤机制。具体来说,此时它的执行原理和流程比一般的网络爬虫还需要3个步骤,即目标的定义、无关链接的过滤、下一步要爬取的URL地址的选择。2)常用网页更新
阅读全文
《精通Python网络爬虫:核心技术、框架与项目实战》——3.8Summary

作者:华章电脑1674人浏览评论:04年前
本节摘自华章出版社《精通Python Web爬虫:核心技术、框架与项目实战》一书第3章,章节3.8,作者魏伟,更多章节可访问云 在Qi社区查看“华章电脑”的公众号。3.8Summary1)关注网络爬虫,因为它们需要被有目的地抓取,所以对于一般的网络爬虫
阅读全文
Java Web爬虫获取网页源代码的原理及实现


作者:旭东的博客 936 浏览评论:08 年前
1.网络爬虫是一个自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址。在爬取网页的过程中,他们不断地从当前页面中提取新的URL并将它们放入队列中,直到满足系统的某个停止条件。2.
阅读全文
大量与网络爬虫相关的库/工具/API

作者:技术小能手1069人浏览评论:02年前
用于用户网页抓取的工具、编程库和 API 的详细列表,包括 Python、PHP、Ruby、JavaScript 等。 Web Scraping 我们使用的工具、编程库和 API 列表
阅读全文
开源爬虫软件总结


作者:club1111683 人浏览评论:06年前
世界上已经形成了数百种爬虫软件。本文梳理了比较知名和常见的开源爬虫软件,并按开发语言进行了总结,如下表所示。虽然搜索引擎也有爬虫,但我这次总结的只是爬虫软件,不是大型复杂的搜索引擎,因为很多兄弟只是想爬取数据,不会操作。
阅读全文
网络爬虫php相关问答
爬虫数据管理【问答集锦】


作者:我是管理员 28342人浏览评论:223年前
互联网上的网络爬虫的自然语言处理的未来是什么?artTemplate:arttemplate生成的页面能爬到数据吗?
阅读全文
php 爬虫抓取网页数据(大数据时代飞速发展如何从庞大数据中整理出自己需要的数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-27 05:21
随着大数据时代的飞速发展,爬虫爬取显得尤为重要,尤其是对于急需转型的传统企业和急需发展的中小企业。那么我们应该如何从海量数据中梳理出我们需要的数据呢?下面就说说几个爬虫在爬取过程中可能会遇到的几个问题。
1、网页不定时更新
互联网上的信息是不断更新的,所以我们在爬取信息的过程中需要定期进行操作,也就是说我们需要设置爬取信息的时间间隔,避免爬取网站的服务器更新,以及所有我们做的都没用。
2、一些网站块爬虫
部分网站会设置反爬取程序,防止恶意爬取。您会发现浏览器上显示了很多数据,但无法捕获。
3、 乱码问题
当然,我们成功抓取网页信息后,是不可能顺利进行数据分析的。很多时候,我们抓取网页信息后,会发现抓取的信息是乱码。
4、数据分析
其实到此,我们的工作基本上已经成功了一半以上,但是数据分析的工作量非常大,完成一个庞大的数据分析需要花费很多时间。
那么当我们真的遇到这些问题的时候该怎么办呢?
首先我们要明白,爬虫爬行必须在合法的范围内进行。你可以借鉴别人的各种数据和信息,但不要照原样照搬。毕竟,别人努力写数据和各种材料是很困难的。当然,爬虫爬取需要一个可以正常运行的程序。如果可以自己编写,最好运行一下。如果不能,网上会有很多教程和源码,但是后期实际出现的问题还是需要自己操作,比如:浏览器正常显示信息,但是不能我们抓取后可以正常显示。这时候就需要查看http头信息,需要分析选择哪种压缩方式,后面我们需要选择一些实用的解析工具。对于没有技术经验的人来说,确实很难。
为了让大家更好的抓取信息,开发了很多专业的采集器和软件,比如Rabbit Dynamic IP软件,和很多知名公司都有合作,包括前期设置和ip服务,包括后期数据分析工作,可轻松操作。
总之,无论是手动爬取还是软件爬取,都需要足够的耐心和坚持。 查看全部
php 爬虫抓取网页数据(大数据时代飞速发展如何从庞大数据中整理出自己需要的数据)
随着大数据时代的飞速发展,爬虫爬取显得尤为重要,尤其是对于急需转型的传统企业和急需发展的中小企业。那么我们应该如何从海量数据中梳理出我们需要的数据呢?下面就说说几个爬虫在爬取过程中可能会遇到的几个问题。
1、网页不定时更新
互联网上的信息是不断更新的,所以我们在爬取信息的过程中需要定期进行操作,也就是说我们需要设置爬取信息的时间间隔,避免爬取网站的服务器更新,以及所有我们做的都没用。
2、一些网站块爬虫
部分网站会设置反爬取程序,防止恶意爬取。您会发现浏览器上显示了很多数据,但无法捕获。
3、 乱码问题
当然,我们成功抓取网页信息后,是不可能顺利进行数据分析的。很多时候,我们抓取网页信息后,会发现抓取的信息是乱码。
4、数据分析
其实到此,我们的工作基本上已经成功了一半以上,但是数据分析的工作量非常大,完成一个庞大的数据分析需要花费很多时间。
那么当我们真的遇到这些问题的时候该怎么办呢?
首先我们要明白,爬虫爬行必须在合法的范围内进行。你可以借鉴别人的各种数据和信息,但不要照原样照搬。毕竟,别人努力写数据和各种材料是很困难的。当然,爬虫爬取需要一个可以正常运行的程序。如果可以自己编写,最好运行一下。如果不能,网上会有很多教程和源码,但是后期实际出现的问题还是需要自己操作,比如:浏览器正常显示信息,但是不能我们抓取后可以正常显示。这时候就需要查看http头信息,需要分析选择哪种压缩方式,后面我们需要选择一些实用的解析工具。对于没有技术经验的人来说,确实很难。
为了让大家更好的抓取信息,开发了很多专业的采集器和软件,比如Rabbit Dynamic IP软件,和很多知名公司都有合作,包括前期设置和ip服务,包括后期数据分析工作,可轻松操作。
总之,无论是手动爬取还是软件爬取,都需要足够的耐心和坚持。
php 爬虫抓取网页数据(Python爬虫技术的门道web是web原创内容生态的元凶)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-10-25 21:09
Python爬虫爬虫技术的门道是什么?很多新手对此都不是很清楚。为了帮助您解决这个问题,下面小编将为您详细解说。有这方面需求的可以过来学习。我希望你可以。收获。
Python爬虫爬虫技术的门道
网络是一个开放的平台,这也为网络从90年代初诞生到今天的蓬勃发展奠定了基础。然而,作为所谓的成败,开放的特性、搜索引擎、易学的html和css技术,使网络成为互联网领域最流行、最成熟的信息传播媒介;但是现在作为商业软件,web平台上的内容信息的版权是没有保障的,因为相比于软件客户端,你的网页内容可以通过一些以极低的成本实现的爬虫程序获取,技术门槛低。这也是本系列文章要讨论的话题——网络爬虫。
很多人认为,网络应该始终遵循开放的精神,页面上呈现的信息应该毫无保留地与整个互联网共享。但是,我认为在IT行业发展到今天,网络已经不再是当时与pdf竞争的所谓“超文本”信息载体。它已经基于轻量级客户端软件的意识形态。存在。在商业软件发展的今天,网络不得不面对知识产权保护的问题。试想一下,如果原创的优质内容得不到保护,网络世界中的抄袭和盗版猖獗。这其实是网络生态的健康发展。不利,难以鼓励生产更多优质原创
未经授权的爬虫程序是危害网络内容生态的罪魁祸首原创。因此,要保护网站的内容,首先要考虑如何反爬虫。
从爬行动物的攻防来看
最简单的爬虫是几乎所有服务器端和客户端编程语言都支持的http请求。只要向目标页面的url发起http get请求,浏览器加载这个页面时就可以获取到完整的html文档。我们称之为“同步页面”。
作为防御方,服务器可以根据http请求头中的User-Agent检查客户端是合法的浏览器程序还是脚本爬取程序,从而判断是否改变真实的页面信息内容发送给你.
这当然是最小的儿科防御方法。作为进攻方,爬虫可以伪造 User-Agent 字段。即使你想要,在http get方法中,请求头的Referrer、Cookie等,所有字段爬虫都可以轻松伪造。
此时服务端可以使用浏览器的http头指纹,根据你声明的浏览器厂商和版本(来自User-Agent),来识别你的http头中的各个字段是否符合浏览器的特性,如果不符合要求,它将被视为爬虫。该技术的一个典型应用是 PhantomJS 1.x 版本。由于底层调用了Qt框架网络库,所以http头中有明显的Qt框架网络请求特征,可以被服务器直接识别。并拦截。
另外还有一个比较异常的服务端爬虫检测机制,就是在对页面的所有http请求的http响应中植入一个cookie token,然后在这个页面异步执行的一些ajax接口中进行检查。检查访问请求中是否收录cookie token,返回token表示这是一次合法的浏览器访问,否则表示刚刚发出token的用户访问了页面html但是没有访问到执行js后调用的ajax在 html 中的请求很可能是爬虫。
如果直接访问一个没有token的接口,说明你没有请求html页面,直接向页面中应该通过ajax访问的接口发起网络请求。这显然证明你是一个可疑的爬虫。知名电商网站亚马逊采用了这种防御策略。
以上是一些基于服务端验证爬虫程序可以播放的例程。
基于客户端js运行时的检测
现代浏览器赋予了 JavaScript 强大的能力,所以我们可以把页面的所有核心内容都变成 js 异步请求 Ajax 获取数据然后渲染到页面上,这显然提高了爬虫爬取内容的门槛。依靠这种方式,我们将对抗爬虫和反爬虫的战场从服务端转移到了客户端浏览器中的js运行时。接下来说一下结合客户端js运行时的爬虫爬取技术。
刚才提到的各种服务端验证,对于普通python和java语言编写的HTTP爬虫程序都有一定的技术门槛。毕竟,Web 应用程序是未经授权的爬虫的黑匣子。很多东西都需要一点一点的去尝试,大量的人力物力都花在了开发一套爬虫程序上。作为网站的防御方,只要容易调整一些策略,攻击者就需要再次花费相同的时间来修改爬虫的爬取逻辑。.
这时候就需要无头浏览器了。这是一种什么样的技术?其实说白了就是让程序操作浏览器来访问网页,这样写爬虫的人就可以通过调用浏览器暴露给程序的api来实现复杂的爬虫业务逻辑。
事实上,这并不是近年来的新技术。曾经有基于webkit内核的PhantomJS,基于Firefox浏览器内核的SlimerJS,甚至还有基于IE内核的trifleJS。如果您有兴趣,可以在此处和此处查看两个无头浏览器。采集清单。
这些无头浏览器程序的实现原理,其实就是将一些开源的浏览器核心C++代码进行改造和封装,实现一个简单的浏览器程序,无需GUI界面渲染。但是这些项目的共同问题是,因为他们的代码是基于官方fork webkit等内核的某个版本的主干代码,无法跟进一些最新的css属性和js语法,并且有一些兼容性问题,不如真实的。GUI浏览器发行版运行稳定。
其中,最成熟、最常用的应该是PhantonJS。关于这种爬虫的识别我之前写过一篇博文,这里不再赘述。PhantomJS 有很多问题,因为是单进程模型,没有必要的沙箱保护,浏览器内核的安全性较差。此外,该项目的作者已宣布将停止维护该项目。
现在谷歌 Chrome 团队已经在 Chrome 59 发布版本中开放了 headless 模式 api,并开源了一个基于 Node.js 调用的 headless chrome 驱动程序库。我还为这个库贡献了一个centos环境部署依赖安装列表。
Headless Chrome 可谓是 Headless Browser 中独一无二的大杀器。因为它本身是一个 chrome 浏览器,所以它支持各种新的 CSS 渲染功能和 js 运行时语法。
基于这种方法,作为进攻方的爬虫可以绕过几乎所有的服务器端验证逻辑,但是这些爬虫在客户端js运行时仍然存在一些缺陷,例如:
基于插件对象检查
if(navigator.plugins.length === 0) {
console.log('It may be Chrome headless');
}
基于语言的检查
if(navigator.languages === '') {
console.log('Chrome headless detected');
}
基于 Webgl 的检查
var canvas = document.createElement('canvas');
var gl = canvas.getContext('webgl');
var debugInfo = gl.getExtension('WEBGL_debug_renderer_info');
var vendor = gl.getParameter(debugInfo.UNMASKED_VENDOR_WEBGL);
var renderer = gl.getParameter(debugInfo.UNMASKED_RENDERER_WEBGL);
if(vendor == 'Brian Paul' && renderer == 'Mesa OffScreen') {
console.log('Chrome headless detected');
}
根据浏览器细线特征检查
if(!Modernizr['hairline']) {
console.log('It may be Chrome headless');
}
检查根据错误的 img src 属性生成的 img 对象
根据以上一些浏览器特性的判断,基本可以杀掉市面上大部分的Headless Browser程序。在这个层面上,它实际上提高了网络爬虫的门槛,要求编写爬虫的开发者必须修改浏览器内核的C++代码,重新编译浏览器。此外,上述功能是特定于浏览器的。内核的变化其实不小。如果你曾经尝试过编译 Blink 内核或者 Gecko 内核,你就会明白对于一个“脚本小子”来说有多难~
此外,我们还可以根据浏览器 UserAgent 字段中描述的浏览器品牌、版本和型号信息,检查 js 运行时、DOM 和 BOM 的每个原生对象的属性和方法,观察其特性是否与浏览一致这个版本的设备应该具备的特性。
这种方法被称为浏览器指纹检测技术,它依靠大型网站来采集各类浏览器的api信息。作为编写爬虫程序的进攻方,你可以在 Headless Browser 运行时中预先注入一些 js 逻辑,从而锻造浏览器的特性。
另外,在研究浏览器端使用js api进行Robots Browser Detect时,我们发现了一个有趣的技巧。您可以将预先注入的 js 函数伪装成 Native Function。看看下面的代码:
var fakeAlert = (function(){}).bind(null);
console.log(window.alert.toString()); // function alert() { [native code] }
console.log(fakeAlert.toString()); // function () { [native code] }
爬虫攻击者可能会预先注入一些js方法,用代理函数包裹一些原生api作为钩子,然后利用这个假js api覆盖原生api。如果防御者根据toString函数后的[native code]的检查来判断这个,那么就会绕过。所以需要更严格的检查,因为bind(null)的伪造方法在toString之后没有携带函数名,所以需要检查toString之后的函数名是否为空。
这个技术有什么用?这是一个扩展。反爬虫卫士有Robot Detect方法,在js运行时主动抛出告警。副本可以写一些与业务逻辑相关的东西。当一个普通用户点击OK按钮时,肯定会有1s甚至更长的延迟,因为浏览器中的alert会阻塞js代码的运行(实际上在v8中他会以类似的方式暂停这个isolate上下文的执行)进程挂起),所以作为攻击者的爬虫程序可以选择使用上述技巧在页面所有js运行前预注入一段js代码,钩住alert、prompt、confirm等所有弹窗方法. 如果防御者在弹出代码之前首先检查他调用的警报方法不是原生的,则道路被阻塞。
防爬虫银弹
目前防抢和机器人检测最可靠的方法是验证码技术。但是,验证码并不意味着必须强制用户输入一系列字母数字。还有很多基于用户鼠标、触摸屏(移动终端)等行为的行为验证技术。其中最成熟的是基于机器学习的 Google reCAPTCHA。区分用户和爬虫。
基于以上多种识别和区分用户和爬虫的技术,网站的防御者最终需要做的就是对该ip的访问用户进行屏蔽或强加高强度验证码策略. 因此,攻击者必须购买一个ip代理池来捕获网站的内容,否则单个ip地址很容易被拦截而无法捕获。爬虫和反爬虫的门槛提高到了ip代理池的经济成本水平。
机器人协议
此外,在爬虫爬行技术领域还有一种“白道”方法,叫做robots协议。Allow 和 Disallow 声明每个 UA 爬虫的爬取权限。
不过,这只是君子之约。虽然具有法律利益,但只能限制商业搜索引擎的蜘蛛程序。你不能限制那些“野生爬虫”。
网页内容的爬取和反控,注定是一场一尺高一丈的猫捉老鼠游戏。你永远无法用某种技术完全封锁爬虫程序。你所能做的就是增加攻击。用户的爬取成本,更准确地获知未授权的爬取行为。
看完以上内容对你有帮助吗?如果您想了解更多相关知识或阅读更多相关文章,请关注易速云行业资讯频道,感谢您对易速云的支持。 查看全部
php 爬虫抓取网页数据(Python爬虫技术的门道web是web原创内容生态的元凶)
Python爬虫爬虫技术的门道是什么?很多新手对此都不是很清楚。为了帮助您解决这个问题,下面小编将为您详细解说。有这方面需求的可以过来学习。我希望你可以。收获。
Python爬虫爬虫技术的门道
网络是一个开放的平台,这也为网络从90年代初诞生到今天的蓬勃发展奠定了基础。然而,作为所谓的成败,开放的特性、搜索引擎、易学的html和css技术,使网络成为互联网领域最流行、最成熟的信息传播媒介;但是现在作为商业软件,web平台上的内容信息的版权是没有保障的,因为相比于软件客户端,你的网页内容可以通过一些以极低的成本实现的爬虫程序获取,技术门槛低。这也是本系列文章要讨论的话题——网络爬虫。
很多人认为,网络应该始终遵循开放的精神,页面上呈现的信息应该毫无保留地与整个互联网共享。但是,我认为在IT行业发展到今天,网络已经不再是当时与pdf竞争的所谓“超文本”信息载体。它已经基于轻量级客户端软件的意识形态。存在。在商业软件发展的今天,网络不得不面对知识产权保护的问题。试想一下,如果原创的优质内容得不到保护,网络世界中的抄袭和盗版猖獗。这其实是网络生态的健康发展。不利,难以鼓励生产更多优质原创
未经授权的爬虫程序是危害网络内容生态的罪魁祸首原创。因此,要保护网站的内容,首先要考虑如何反爬虫。
从爬行动物的攻防来看
最简单的爬虫是几乎所有服务器端和客户端编程语言都支持的http请求。只要向目标页面的url发起http get请求,浏览器加载这个页面时就可以获取到完整的html文档。我们称之为“同步页面”。
作为防御方,服务器可以根据http请求头中的User-Agent检查客户端是合法的浏览器程序还是脚本爬取程序,从而判断是否改变真实的页面信息内容发送给你.
这当然是最小的儿科防御方法。作为进攻方,爬虫可以伪造 User-Agent 字段。即使你想要,在http get方法中,请求头的Referrer、Cookie等,所有字段爬虫都可以轻松伪造。
此时服务端可以使用浏览器的http头指纹,根据你声明的浏览器厂商和版本(来自User-Agent),来识别你的http头中的各个字段是否符合浏览器的特性,如果不符合要求,它将被视为爬虫。该技术的一个典型应用是 PhantomJS 1.x 版本。由于底层调用了Qt框架网络库,所以http头中有明显的Qt框架网络请求特征,可以被服务器直接识别。并拦截。
另外还有一个比较异常的服务端爬虫检测机制,就是在对页面的所有http请求的http响应中植入一个cookie token,然后在这个页面异步执行的一些ajax接口中进行检查。检查访问请求中是否收录cookie token,返回token表示这是一次合法的浏览器访问,否则表示刚刚发出token的用户访问了页面html但是没有访问到执行js后调用的ajax在 html 中的请求很可能是爬虫。
如果直接访问一个没有token的接口,说明你没有请求html页面,直接向页面中应该通过ajax访问的接口发起网络请求。这显然证明你是一个可疑的爬虫。知名电商网站亚马逊采用了这种防御策略。
以上是一些基于服务端验证爬虫程序可以播放的例程。
基于客户端js运行时的检测
现代浏览器赋予了 JavaScript 强大的能力,所以我们可以把页面的所有核心内容都变成 js 异步请求 Ajax 获取数据然后渲染到页面上,这显然提高了爬虫爬取内容的门槛。依靠这种方式,我们将对抗爬虫和反爬虫的战场从服务端转移到了客户端浏览器中的js运行时。接下来说一下结合客户端js运行时的爬虫爬取技术。
刚才提到的各种服务端验证,对于普通python和java语言编写的HTTP爬虫程序都有一定的技术门槛。毕竟,Web 应用程序是未经授权的爬虫的黑匣子。很多东西都需要一点一点的去尝试,大量的人力物力都花在了开发一套爬虫程序上。作为网站的防御方,只要容易调整一些策略,攻击者就需要再次花费相同的时间来修改爬虫的爬取逻辑。.
这时候就需要无头浏览器了。这是一种什么样的技术?其实说白了就是让程序操作浏览器来访问网页,这样写爬虫的人就可以通过调用浏览器暴露给程序的api来实现复杂的爬虫业务逻辑。
事实上,这并不是近年来的新技术。曾经有基于webkit内核的PhantomJS,基于Firefox浏览器内核的SlimerJS,甚至还有基于IE内核的trifleJS。如果您有兴趣,可以在此处和此处查看两个无头浏览器。采集清单。
这些无头浏览器程序的实现原理,其实就是将一些开源的浏览器核心C++代码进行改造和封装,实现一个简单的浏览器程序,无需GUI界面渲染。但是这些项目的共同问题是,因为他们的代码是基于官方fork webkit等内核的某个版本的主干代码,无法跟进一些最新的css属性和js语法,并且有一些兼容性问题,不如真实的。GUI浏览器发行版运行稳定。
其中,最成熟、最常用的应该是PhantonJS。关于这种爬虫的识别我之前写过一篇博文,这里不再赘述。PhantomJS 有很多问题,因为是单进程模型,没有必要的沙箱保护,浏览器内核的安全性较差。此外,该项目的作者已宣布将停止维护该项目。
现在谷歌 Chrome 团队已经在 Chrome 59 发布版本中开放了 headless 模式 api,并开源了一个基于 Node.js 调用的 headless chrome 驱动程序库。我还为这个库贡献了一个centos环境部署依赖安装列表。
Headless Chrome 可谓是 Headless Browser 中独一无二的大杀器。因为它本身是一个 chrome 浏览器,所以它支持各种新的 CSS 渲染功能和 js 运行时语法。
基于这种方法,作为进攻方的爬虫可以绕过几乎所有的服务器端验证逻辑,但是这些爬虫在客户端js运行时仍然存在一些缺陷,例如:
基于插件对象检查
if(navigator.plugins.length === 0) {
console.log('It may be Chrome headless');
}
基于语言的检查
if(navigator.languages === '') {
console.log('Chrome headless detected');
}
基于 Webgl 的检查
var canvas = document.createElement('canvas');
var gl = canvas.getContext('webgl');
var debugInfo = gl.getExtension('WEBGL_debug_renderer_info');
var vendor = gl.getParameter(debugInfo.UNMASKED_VENDOR_WEBGL);
var renderer = gl.getParameter(debugInfo.UNMASKED_RENDERER_WEBGL);
if(vendor == 'Brian Paul' && renderer == 'Mesa OffScreen') {
console.log('Chrome headless detected');
}
根据浏览器细线特征检查
if(!Modernizr['hairline']) {
console.log('It may be Chrome headless');
}
检查根据错误的 img src 属性生成的 img 对象
根据以上一些浏览器特性的判断,基本可以杀掉市面上大部分的Headless Browser程序。在这个层面上,它实际上提高了网络爬虫的门槛,要求编写爬虫的开发者必须修改浏览器内核的C++代码,重新编译浏览器。此外,上述功能是特定于浏览器的。内核的变化其实不小。如果你曾经尝试过编译 Blink 内核或者 Gecko 内核,你就会明白对于一个“脚本小子”来说有多难~
此外,我们还可以根据浏览器 UserAgent 字段中描述的浏览器品牌、版本和型号信息,检查 js 运行时、DOM 和 BOM 的每个原生对象的属性和方法,观察其特性是否与浏览一致这个版本的设备应该具备的特性。
这种方法被称为浏览器指纹检测技术,它依靠大型网站来采集各类浏览器的api信息。作为编写爬虫程序的进攻方,你可以在 Headless Browser 运行时中预先注入一些 js 逻辑,从而锻造浏览器的特性。
另外,在研究浏览器端使用js api进行Robots Browser Detect时,我们发现了一个有趣的技巧。您可以将预先注入的 js 函数伪装成 Native Function。看看下面的代码:
var fakeAlert = (function(){}).bind(null);
console.log(window.alert.toString()); // function alert() { [native code] }
console.log(fakeAlert.toString()); // function () { [native code] }
爬虫攻击者可能会预先注入一些js方法,用代理函数包裹一些原生api作为钩子,然后利用这个假js api覆盖原生api。如果防御者根据toString函数后的[native code]的检查来判断这个,那么就会绕过。所以需要更严格的检查,因为bind(null)的伪造方法在toString之后没有携带函数名,所以需要检查toString之后的函数名是否为空。
这个技术有什么用?这是一个扩展。反爬虫卫士有Robot Detect方法,在js运行时主动抛出告警。副本可以写一些与业务逻辑相关的东西。当一个普通用户点击OK按钮时,肯定会有1s甚至更长的延迟,因为浏览器中的alert会阻塞js代码的运行(实际上在v8中他会以类似的方式暂停这个isolate上下文的执行)进程挂起),所以作为攻击者的爬虫程序可以选择使用上述技巧在页面所有js运行前预注入一段js代码,钩住alert、prompt、confirm等所有弹窗方法. 如果防御者在弹出代码之前首先检查他调用的警报方法不是原生的,则道路被阻塞。
防爬虫银弹
目前防抢和机器人检测最可靠的方法是验证码技术。但是,验证码并不意味着必须强制用户输入一系列字母数字。还有很多基于用户鼠标、触摸屏(移动终端)等行为的行为验证技术。其中最成熟的是基于机器学习的 Google reCAPTCHA。区分用户和爬虫。
基于以上多种识别和区分用户和爬虫的技术,网站的防御者最终需要做的就是对该ip的访问用户进行屏蔽或强加高强度验证码策略. 因此,攻击者必须购买一个ip代理池来捕获网站的内容,否则单个ip地址很容易被拦截而无法捕获。爬虫和反爬虫的门槛提高到了ip代理池的经济成本水平。
机器人协议
此外,在爬虫爬行技术领域还有一种“白道”方法,叫做robots协议。Allow 和 Disallow 声明每个 UA 爬虫的爬取权限。
不过,这只是君子之约。虽然具有法律利益,但只能限制商业搜索引擎的蜘蛛程序。你不能限制那些“野生爬虫”。
网页内容的爬取和反控,注定是一场一尺高一丈的猫捉老鼠游戏。你永远无法用某种技术完全封锁爬虫程序。你所能做的就是增加攻击。用户的爬取成本,更准确地获知未授权的爬取行为。
看完以上内容对你有帮助吗?如果您想了解更多相关知识或阅读更多相关文章,请关注易速云行业资讯频道,感谢您对易速云的支持。
php 爬虫抓取网页数据(PHP解析器和PHP相比较,python适合做爬虫吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-10-22 20:20
对比python和PHP,python适合爬取。原因如下
抓取网页本身的界面
与java、c#、C++、python等其他静态编程语言相比,抓取网页文档的界面更加简洁;相较于其他动态脚本语言,如 perl、shell,python 的 urllib2 包提供了更完整的 web 文档 API 访问。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站都是为了生硬爬取而被屏蔽的。这就是我们需要模拟用户代理的行为来构造合适的请求的地方,比如模拟用户登录,模拟session/cookies的存储和设置。python中有很好的第三方包帮你搞定,比如Requests,mechanize
爬行后处理
抓取到的网页通常需要进行处理,如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用很短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要python。
Py 在 Linux 上使用时非常强大,而且语言非常简单。
NO.1 快速开发(唯一能比python开发效率更高的语言是rudy) 语言简洁,没有那么多技巧,所以非常清晰易读。
NO.2 跨平台(由于python的开源,比java更能体现“一次编写,到处运行”
NO.3 解释(无需直接编译、运行/调试代码)
NO.4 框架选择太多(主要的GUI框架有wxPython、tkInter、PyGtk、PyQt。
PHP脚本主要用于以下三个方面:
服务器端脚本。这是PHP最传统也是最主要的目标领域。要进行这项工作,需要具备以下三点:PHP解析器(CGI或服务器模块)、web
服务器和网络浏览器。运行web服务器时需要安装配置PHP,然后可以使用web浏览器访问PHP程序的输出,即浏览服务
PHP 页面在最后。如果您只是在尝试 PHP 编程,所有这些都可以在您的家用计算机上运行。有关更多信息,请参阅安装章节。命令行脚本。
您可以编写一个 PHP 脚本,并且不需要任何服务器或浏览器来运行它。这样,只需要PHP解析器就可以执行。这种用法是
是 cron(Unix 或 Linux 环境)或 Task Scheduler(Windows 环境)日常运行脚本的理想选择。这些脚本也可用于处理
管理简单的文本。更多信息请参考 PHP 的命令行模式。编写桌面应用程序。对于具有图形界面的桌面应用程序,PHP 可能不会
最好的语言之一,但是如果用户非常精通PHP并且想在客户端应用程序中使用PHP的一些高级功能,他们可以使用PHP-GTK来编写这个
这些程序。这样,您也可以编写跨平台的应用程序。PHP-GTK 是 PHP 的扩展,通常发布的 PHP 包中不收录它。
网友的观点扩大了:
我用PHP Node.js Python写了一个爬虫脚本,简单说一下。
首先是PHP。先说优点:网上大量爬取解析html框架,各种工具都可以直接使用,比较省心。缺点:首先,速度/效率是个问题。有一次下载电影海报的时候,因为crontab定时执行,没有优化,打开的php进程太多,直接导致内存爆了。然后语法也很拖沓,各种关键词符号太多,不够简洁,给人一种没有精心设计的感觉,写起来很麻烦。
节点.js。优点是效率,效率还是效率。因为网络是异步的,所以基本上和并发数百个进程一样强大。内存和CPU使用量非常小。如果对捕获的数据没有进行复杂的计算和处理,那么系统就会成为瓶颈。基本上就是写入MySQL等数据库的带宽和I/O速度。当然,优点的反面也是缺点。异步网络意味着您需要回调。这时候,如果业务需求是线性的,比如你必须等上一页爬完,拿到数据后才能爬到下一页,甚至更多。层依赖,会有可怕的多层回调!基本上这个时候代码结构和逻辑就会乱了。当然,
最后,让我们谈谈Python。如果你对效率没有极端的要求,那么推荐Python!首先,Python 的语法非常简洁,同一个句子可以少打很多次。然后,Python非常适合数据处理,比如函数参数的打包和解包,列表分析,矩阵处理,非常方便。
至此,这篇关于python和php的更适合写爬虫的文章介绍到这里。更多适合爬取内容的php和python相关内容,请搜索ZaLou.Cn之前的文章或继续浏览下方相关文章,希望大家多多支持ZaLou.Cn! 查看全部
php 爬虫抓取网页数据(PHP解析器和PHP相比较,python适合做爬虫吗?)
对比python和PHP,python适合爬取。原因如下
抓取网页本身的界面
与java、c#、C++、python等其他静态编程语言相比,抓取网页文档的界面更加简洁;相较于其他动态脚本语言,如 perl、shell,python 的 urllib2 包提供了更完整的 web 文档 API 访问。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站都是为了生硬爬取而被屏蔽的。这就是我们需要模拟用户代理的行为来构造合适的请求的地方,比如模拟用户登录,模拟session/cookies的存储和设置。python中有很好的第三方包帮你搞定,比如Requests,mechanize
爬行后处理
抓取到的网页通常需要进行处理,如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用很短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要python。
Py 在 Linux 上使用时非常强大,而且语言非常简单。
NO.1 快速开发(唯一能比python开发效率更高的语言是rudy) 语言简洁,没有那么多技巧,所以非常清晰易读。
NO.2 跨平台(由于python的开源,比java更能体现“一次编写,到处运行”
NO.3 解释(无需直接编译、运行/调试代码)
NO.4 框架选择太多(主要的GUI框架有wxPython、tkInter、PyGtk、PyQt。
PHP脚本主要用于以下三个方面:
服务器端脚本。这是PHP最传统也是最主要的目标领域。要进行这项工作,需要具备以下三点:PHP解析器(CGI或服务器模块)、web
服务器和网络浏览器。运行web服务器时需要安装配置PHP,然后可以使用web浏览器访问PHP程序的输出,即浏览服务
PHP 页面在最后。如果您只是在尝试 PHP 编程,所有这些都可以在您的家用计算机上运行。有关更多信息,请参阅安装章节。命令行脚本。
您可以编写一个 PHP 脚本,并且不需要任何服务器或浏览器来运行它。这样,只需要PHP解析器就可以执行。这种用法是
是 cron(Unix 或 Linux 环境)或 Task Scheduler(Windows 环境)日常运行脚本的理想选择。这些脚本也可用于处理
管理简单的文本。更多信息请参考 PHP 的命令行模式。编写桌面应用程序。对于具有图形界面的桌面应用程序,PHP 可能不会
最好的语言之一,但是如果用户非常精通PHP并且想在客户端应用程序中使用PHP的一些高级功能,他们可以使用PHP-GTK来编写这个
这些程序。这样,您也可以编写跨平台的应用程序。PHP-GTK 是 PHP 的扩展,通常发布的 PHP 包中不收录它。
网友的观点扩大了:
我用PHP Node.js Python写了一个爬虫脚本,简单说一下。
首先是PHP。先说优点:网上大量爬取解析html框架,各种工具都可以直接使用,比较省心。缺点:首先,速度/效率是个问题。有一次下载电影海报的时候,因为crontab定时执行,没有优化,打开的php进程太多,直接导致内存爆了。然后语法也很拖沓,各种关键词符号太多,不够简洁,给人一种没有精心设计的感觉,写起来很麻烦。
节点.js。优点是效率,效率还是效率。因为网络是异步的,所以基本上和并发数百个进程一样强大。内存和CPU使用量非常小。如果对捕获的数据没有进行复杂的计算和处理,那么系统就会成为瓶颈。基本上就是写入MySQL等数据库的带宽和I/O速度。当然,优点的反面也是缺点。异步网络意味着您需要回调。这时候,如果业务需求是线性的,比如你必须等上一页爬完,拿到数据后才能爬到下一页,甚至更多。层依赖,会有可怕的多层回调!基本上这个时候代码结构和逻辑就会乱了。当然,
最后,让我们谈谈Python。如果你对效率没有极端的要求,那么推荐Python!首先,Python 的语法非常简洁,同一个句子可以少打很多次。然后,Python非常适合数据处理,比如函数参数的打包和解包,列表分析,矩阵处理,非常方便。
至此,这篇关于python和php的更适合写爬虫的文章介绍到这里。更多适合爬取内容的php和python相关内容,请搜索ZaLou.Cn之前的文章或继续浏览下方相关文章,希望大家多多支持ZaLou.Cn!
php 爬虫抓取网页数据(什么是AJAX(AsynchronouseJavaScript)异步JavaScript和XML?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-10-20 06:00
什么是 AJAX:
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,右击->查看网页源码也看不到ajax加载的数据,只能看到使用这个加载的html代码网址。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。方式优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现为爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟一些人类的行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: install Selenium and chromedriver: install Selenium: Selenium有很多语言版本,比如java、ruby、python等,我们可以下载python版本。
pip install selenium
安装chromedriver:下载完成后,放在一个不需要权限的纯英文目录下。快速开始:
下面我们就拿百度首页做个简单的例子来说一下如何快速上手Selenium和chromedriver:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/")
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程请参考:
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素: find_element_by_id:根据id查找元素。相当于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name:根据类名查找元素。相当于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name:根据name属性的值查找元素。相当于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name:根据标签名称查找元素。相当于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath:根据 xpath 语法获取元素。相当于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
需要注意的是 find_element 是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作复选框:因为要选中复选框标签,所以在网页上用鼠标点击它。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时候,selenium 专门为 select 标签提供了一个类 selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择
selectTag.select_by_index(1)
# 根据值选择
selectTag.select_by_value("http://www.95yueba.com")
# 根据可视的文本选择
selectTag.select_by_visible_text("95秀客户端")
# 取消选中所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时可以使用鼠标行为链类ActionChains来完成。例如,现在您想将鼠标移动到一个元素并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
cookie 操作:获取所有 cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除一个cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,另一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/")
显示等待:显示等待是在满足一定条件后执行获取元素的操作。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading")
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('"+url+"')")
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123")
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
更多内容请阅读相关源码。 查看全部
php 爬虫抓取网页数据(什么是AJAX(AsynchronouseJavaScript)异步JavaScript和XML?)
什么是 AJAX:
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,右击->查看网页源码也看不到ajax加载的数据,只能看到使用这个加载的html代码网址。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。方式优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现为爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟一些人类的行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: install Selenium and chromedriver: install Selenium: Selenium有很多语言版本,比如java、ruby、python等,我们可以下载python版本。
pip install selenium
安装chromedriver:下载完成后,放在一个不需要权限的纯英文目录下。快速开始:
下面我们就拿百度首页做个简单的例子来说一下如何快速上手Selenium和chromedriver:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/";)
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程请参考:
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素: find_element_by_id:根据id查找元素。相当于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name:根据类名查找元素。相当于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name:根据name属性的值查找元素。相当于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name:根据标签名称查找元素。相当于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath:根据 xpath 语法获取元素。相当于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
需要注意的是 find_element 是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作复选框:因为要选中复选框标签,所以在网页上用鼠标点击它。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时候,selenium 专门为 select 标签提供了一个类 selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择
selectTag.select_by_index(1)
# 根据值选择
selectTag.select_by_value("http://www.95yueba.com";)
# 根据可视的文本选择
selectTag.select_by_visible_text("95秀客户端")
# 取消选中所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时可以使用鼠标行为链类ActionChains来完成。例如,现在您想将鼠标移动到一个元素并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
cookie 操作:获取所有 cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除一个cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,另一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/";)
显示等待:显示等待是在满足一定条件后执行获取元素的操作。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading";)
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('"+url+"')")
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123";)
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
更多内容请阅读相关源码。
php 爬虫抓取网页数据(PHP解析器和PHP相比较,python适合做爬虫吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-10-12 19:15
对比python和PHP,python适合爬取。原因如下
抓取网页本身的界面
与java、c#、C++、python等其他静态编程语言相比,抓取网页文档的界面更加简洁;相对于其他动态脚本语言,如 perl、shell、python,urllib2 包提供了更完整的 Web 文档 API 访问。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站都是为了生硬爬取而被屏蔽的。这就是我们需要模拟用户代理的行为来构造合适的请求的地方,比如模拟用户登录,模拟session/cookies的存储和设置。python中有很好的第三方包帮你搞定,比如Requests,mechanize
爬行后处理
抓取到的网页通常需要进行处理,如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用很短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要python。
py对linux来说功能很强大,语言也很简单。
NO.1 快速开发(唯一能比python开发效率更高的语言是rudy) 语言简洁,没有那么多技巧,所以非常清晰易读。
NO.2 跨平台(由于python的开源,比java更能体现“一次编写,到处运行”
NO.3 解释(无需直接编译、运行/调试代码)
NO.4 框架选择太多(主要的GUI框架有wxPython、tkInter、PyGtk、PyQt。
PHP脚本主要用于以下三个方面:
服务器端脚本。这是PHP最传统也是最主要的目标领域。要进行这项工作,需要具备以下三点:PHP解析器(CGI或服务器模块)、Web
服务器和网络浏览器。运行web服务器时需要安装配置PHP,然后可以使用web浏览器访问PHP程序的输出,即浏览服务
PHP 页面在最后。如果您只是在尝试 PHP 编程,所有这些都可以在您的家用计算机上运行。有关更多信息,请参阅安装章节。命令行脚本。
您可以编写一个 PHP 脚本,并且不需要任何服务器或浏览器来运行它。这样,只需要PHP解析器就可以执行。这种用法是
是 cron(Unix 或 Linux 环境)或 Task Scheduler(Windows 环境)日常运行脚本的理想选择。这些脚本也可用于处理
管理简单的文本。更多信息请参考 PHP 的命令行模式。编写桌面应用程序。对于具有图形界面的桌面应用程序,PHP 可能不会
最好的语言之一,但是如果用户非常精通PHP并且想在客户端应用程序中使用PHP的一些高级功能,他们可以使用PHP-GTK来编写这个
这些程序。这样,您也可以编写跨平台的应用程序。PHP-GTK 是 PHP 的扩展,通常发布的 PHP 包中不收录它。
网友的观点扩大了:
我用PHP Node.js Python写了一个爬虫脚本,简单说一下。
首先PHP。先说优点:网上大量爬取解析html框架,各种工具都可以直接使用,比较省心。缺点:首先,速度/效率是个问题。有一次下载电影海报的时候,因为crontab定时执行,没有优化,打开的php进程太多,直接导致内存爆了。然后语法也很拖沓,各种关键词符号太多,不够简洁,给人一种没有精心设计的感觉,写起来很麻烦。
节点.js。优点是效率,效率还是效率。因为网络是异步的,所以基本上和并发数百个进程一样强大。内存和CPU使用量非常小。如果对捕获的数据没有进行复杂的计算和处理,那么系统就会成为瓶颈。基本上就是写入MySQL等数据库的带宽和I/O速度。当然,优点的反面也是缺点。异步网络意味着您需要回调。这时候,如果业务需求是线性的,比如你必须等上一页爬完,拿到数据后才能爬到下一页,甚至更多。层依赖,会有可怕的多层回调!基本上这个时候代码结构和逻辑就会乱了。当然,
最后,让我们谈谈Python。如果你对效率没有极端的要求,那么推荐Python!首先,Python 的语法非常简洁,同一个句子可以少打很多次。然后,Python非常适合数据处理,比如函数参数的打包和解包,列表分析,矩阵处理,非常方便。
相关文章 查看全部
php 爬虫抓取网页数据(PHP解析器和PHP相比较,python适合做爬虫吗?)
对比python和PHP,python适合爬取。原因如下
抓取网页本身的界面
与java、c#、C++、python等其他静态编程语言相比,抓取网页文档的界面更加简洁;相对于其他动态脚本语言,如 perl、shell、python,urllib2 包提供了更完整的 Web 文档 API 访问。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站都是为了生硬爬取而被屏蔽的。这就是我们需要模拟用户代理的行为来构造合适的请求的地方,比如模拟用户登录,模拟session/cookies的存储和设置。python中有很好的第三方包帮你搞定,比如Requests,mechanize
爬行后处理
抓取到的网页通常需要进行处理,如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用很短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要python。
py对linux来说功能很强大,语言也很简单。
NO.1 快速开发(唯一能比python开发效率更高的语言是rudy) 语言简洁,没有那么多技巧,所以非常清晰易读。
NO.2 跨平台(由于python的开源,比java更能体现“一次编写,到处运行”
NO.3 解释(无需直接编译、运行/调试代码)
NO.4 框架选择太多(主要的GUI框架有wxPython、tkInter、PyGtk、PyQt。
PHP脚本主要用于以下三个方面:
服务器端脚本。这是PHP最传统也是最主要的目标领域。要进行这项工作,需要具备以下三点:PHP解析器(CGI或服务器模块)、Web
服务器和网络浏览器。运行web服务器时需要安装配置PHP,然后可以使用web浏览器访问PHP程序的输出,即浏览服务
PHP 页面在最后。如果您只是在尝试 PHP 编程,所有这些都可以在您的家用计算机上运行。有关更多信息,请参阅安装章节。命令行脚本。
您可以编写一个 PHP 脚本,并且不需要任何服务器或浏览器来运行它。这样,只需要PHP解析器就可以执行。这种用法是
是 cron(Unix 或 Linux 环境)或 Task Scheduler(Windows 环境)日常运行脚本的理想选择。这些脚本也可用于处理
管理简单的文本。更多信息请参考 PHP 的命令行模式。编写桌面应用程序。对于具有图形界面的桌面应用程序,PHP 可能不会
最好的语言之一,但是如果用户非常精通PHP并且想在客户端应用程序中使用PHP的一些高级功能,他们可以使用PHP-GTK来编写这个
这些程序。这样,您也可以编写跨平台的应用程序。PHP-GTK 是 PHP 的扩展,通常发布的 PHP 包中不收录它。
网友的观点扩大了:
我用PHP Node.js Python写了一个爬虫脚本,简单说一下。
首先PHP。先说优点:网上大量爬取解析html框架,各种工具都可以直接使用,比较省心。缺点:首先,速度/效率是个问题。有一次下载电影海报的时候,因为crontab定时执行,没有优化,打开的php进程太多,直接导致内存爆了。然后语法也很拖沓,各种关键词符号太多,不够简洁,给人一种没有精心设计的感觉,写起来很麻烦。
节点.js。优点是效率,效率还是效率。因为网络是异步的,所以基本上和并发数百个进程一样强大。内存和CPU使用量非常小。如果对捕获的数据没有进行复杂的计算和处理,那么系统就会成为瓶颈。基本上就是写入MySQL等数据库的带宽和I/O速度。当然,优点的反面也是缺点。异步网络意味着您需要回调。这时候,如果业务需求是线性的,比如你必须等上一页爬完,拿到数据后才能爬到下一页,甚至更多。层依赖,会有可怕的多层回调!基本上这个时候代码结构和逻辑就会乱了。当然,
最后,让我们谈谈Python。如果你对效率没有极端的要求,那么推荐Python!首先,Python 的语法非常简洁,同一个句子可以少打很多次。然后,Python非常适合数据处理,比如函数参数的打包和解包,列表分析,矩阵处理,非常方便。
相关文章
php 爬虫抓取网页数据( 照Web发展的趋势和发展趋势分析和如何去分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-10-09 17:16
照Web发展的趋势和发展趋势分析和如何去分析)
有时我们使用requests抓取页面时,得到的结果可能与浏览器中看到的不同:在浏览器中可以看到正常显示的页面数据,但是使用requests获取的结果却看不到。这是因为获取的请求都是原创的 HTML 文档,浏览器中的页面是数据经过 JavaScript 处理后生成的结果。这些数据有很多来源,可以通过 Ajax 加载或收录在 HTML 中。文档中的文档也可能是通过JavaScript和特定算法计算后生成的。
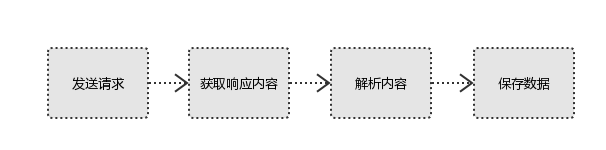
在第一种情况下,数据加载是一种异步加载方法。原创页面最初不会收录一些数据。原创页面加载完成后,会向服务器请求一个接口来获取数据,然后对数据进行处理和呈现。在网页上,这实际上是一个 Ajax 请求。
根据Web发展的趋势,这种形式的页面越来越多。网页的原创 HTML 文档不收录任何数据。数据通过Ajax统一加载后呈现,从而在Web开发中实现前后端分离,减少服务器直接渲染页面带来的压力。
因此,如果遇到这样的页面,可以直接使用requests等库来抓取原创页面,无法获取有效数据。这时候就需要分析网页后端向界面发送的ajax请求。如果可以使用requests来模拟ajax请求,那么就可以成功爬取。
因此,本章的主要目的是了解 Ajax 是什么以及如何分析和捕获 Ajax 请求。 查看全部
php 爬虫抓取网页数据(
照Web发展的趋势和发展趋势分析和如何去分析)

有时我们使用requests抓取页面时,得到的结果可能与浏览器中看到的不同:在浏览器中可以看到正常显示的页面数据,但是使用requests获取的结果却看不到。这是因为获取的请求都是原创的 HTML 文档,浏览器中的页面是数据经过 JavaScript 处理后生成的结果。这些数据有很多来源,可以通过 Ajax 加载或收录在 HTML 中。文档中的文档也可能是通过JavaScript和特定算法计算后生成的。
在第一种情况下,数据加载是一种异步加载方法。原创页面最初不会收录一些数据。原创页面加载完成后,会向服务器请求一个接口来获取数据,然后对数据进行处理和呈现。在网页上,这实际上是一个 Ajax 请求。
根据Web发展的趋势,这种形式的页面越来越多。网页的原创 HTML 文档不收录任何数据。数据通过Ajax统一加载后呈现,从而在Web开发中实现前后端分离,减少服务器直接渲染页面带来的压力。
因此,如果遇到这样的页面,可以直接使用requests等库来抓取原创页面,无法获取有效数据。这时候就需要分析网页后端向界面发送的ajax请求。如果可以使用requests来模拟ajax请求,那么就可以成功爬取。
因此,本章的主要目的是了解 Ajax 是什么以及如何分析和捕获 Ajax 请求。
php 爬虫抓取网页数据(本节使用Python爬虫抓取猫眼(电影网)影片信息(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-10-05 15:21
本节使用Python爬虫抓取猫眼电影TOP100榜单()电影信息,包括电影名称、上映时间、主演信息。
在开始编写程序之前,首先确定页面类型(静态页面或动态页面),其次找出页面的url规则,最后通过分析网页元素的结构来确定正则表达式,从而提取网页信息。
判断页面类型,右键查看页面源码,判断页面中是否存在要抓取的数据。通过浏览可知,所有要抓取的信息都存在于源代码中,因此页面输入为静态页面。如下:
<p class="name">我不是药神
主演:徐峥,周一围,王传君
上映时间:2018-07-05
</p>
确定url规则确定url规则,需要多浏览几页,才能总结出url规则,如下图:
第一页:https://maoyan.com/board/4?offset=0
第二页:https://maoyan.com/board/4?offset=10
第三页:https://maoyan.com/board/4?offset=20
...
第n页:https://maoyan.com/board/4?offset=(n-1)*10
确定正则表达式通过分析网页元素的结构来确定正则表达式,如下图:
<p class="name">我不是药神
主演:徐峥,周一围,王传君
上映时间:2018-07-05</p>
使用 Chrome Developer Debugging Tools 确定要捕获的元素的结构。这样做的原因是可以避免正则表达式的冗余,提高编写正则表达式的速度。正则表达式如下:
.*?title="(.*?)".*?class="star">(.*?).*?releasetime">(.*?)</p></p>
编写正则表达式时,使用(.*?)替换需要提取的信息,使用.*? 替换不需要的内容(包括元素标签)。编写爬虫程序 下面采用面向对象的方法编写爬虫程序,主要编写四个函数,分别是请求函数、分析函数、数据保存函数、主函数。
from urllib import request
import re
import time
import random
import csv
from ua_info import ua_list
# 定义一个爬虫类
class MaoyanSpider(object):
# 初始化
# 定义初始页面url
def __init__(self):
self.url = 'https://maoyan.com/board/4?offset={}'
# 请求函数
def get_html(self,url):
headers = {'User-Agent':random.choice(ua_list)}
req = request.Request(url=url,headers=headers)
res = request.urlopen(req)
html = res.read().decode()
# 直接调用解析函数
self.parse_html(html)
# 解析函数
def parse_html(self,html):
# 正则表达式
re_bds = '.*?title="(.*?)".*?<p class="star">(.*?).*?class="releasetime">(.*?)</p>'
# 生成正则表达式对象
pattern = re.compile(re_bds,re.S)
# r_list: [('我不是药神','徐峥,周一围,王传君','2018-07-05'),...] 列表元组
r_list = pattern.findall(html)
self.save_html(r_list)
# 保存数据函数,使用python内置csv模块
def save_html(self,r_list):
#生成文件对象
with open('maoyan.csv','a',newline='',encoding="utf-8") as f:
#生成csv操作对象
writer = csv.writer(f)
#整理数据
for r in r_list:
name = r[0].strip()
star = r[1].strip()[3:]
# 上映时间:2018-07-05
# 切片截取时间
time = r[2].strip()[5:15]
L = [name,star,time]
# 写入csv文件
writer.writerow(L)
print(name,time,star)
# 主函数
def run(self):
#抓取第一页数据
for offset in range(0,11,10):
url = self.url.format(offset)
self.get_html(url)
#生成1-2之间的浮点数
time.sleep(random.uniform(1,2))
# 以脚本方式启动
if __name__ == '__main__':
#捕捉异常错误
try:
spider = MaoyanSpider()
spider.run()
except Exception as e:
print("错误:",e)
</p>
输出结果:
我不是药神 2018-07-05 徐峥、周以伟、王传君
肖申克的救赎 1994-09-10 蒂姆·罗宾斯、摩根·弗里曼、鲍勃·冈顿
绿皮书 2019-03-01 Vigo Mortensen, Mahsala Ali, Linda Cardrini
海上钢琴家 2019-11-15 蒂姆·罗斯、比尔·纳恩、克兰伦斯·威廉姆斯三世
小偷家族 2018-08-03 中川雅也、安藤樱、松冈墨鱼
霸王别姬 1993-07-26 张国荣、张凤仪、巩俐
哪吒魔童降临人间
美丽人生 2020-01-03 罗伯托·贝尼尼、朱斯蒂诺·杜拉诺、塞尔吉奥·比尼·巴斯特里克
这个杀手不太冷 1994-09-14 让·雷诺、加里·奥德曼、娜塔莉·波特曼
2010-09-01 莱昂纳多·迪卡普里奥、渡边谦、约瑟夫·高登-莱维特 查看全部
php 爬虫抓取网页数据(本节使用Python爬虫抓取猫眼(电影网)影片信息(组图))
本节使用Python爬虫抓取猫眼电影TOP100榜单()电影信息,包括电影名称、上映时间、主演信息。
在开始编写程序之前,首先确定页面类型(静态页面或动态页面),其次找出页面的url规则,最后通过分析网页元素的结构来确定正则表达式,从而提取网页信息。
判断页面类型,右键查看页面源码,判断页面中是否存在要抓取的数据。通过浏览可知,所有要抓取的信息都存在于源代码中,因此页面输入为静态页面。如下:
<p class="name">我不是药神
主演:徐峥,周一围,王传君
上映时间:2018-07-05
</p>
确定url规则确定url规则,需要多浏览几页,才能总结出url规则,如下图:
第一页:https://maoyan.com/board/4?offset=0
第二页:https://maoyan.com/board/4?offset=10
第三页:https://maoyan.com/board/4?offset=20
...
第n页:https://maoyan.com/board/4?offset=(n-1)*10
确定正则表达式通过分析网页元素的结构来确定正则表达式,如下图:
<p class="name">我不是药神
主演:徐峥,周一围,王传君
上映时间:2018-07-05</p>
使用 Chrome Developer Debugging Tools 确定要捕获的元素的结构。这样做的原因是可以避免正则表达式的冗余,提高编写正则表达式的速度。正则表达式如下:
.*?title="(.*?)".*?class="star">(.*?).*?releasetime">(.*?)</p></p>
编写正则表达式时,使用(.*?)替换需要提取的信息,使用.*? 替换不需要的内容(包括元素标签)。编写爬虫程序 下面采用面向对象的方法编写爬虫程序,主要编写四个函数,分别是请求函数、分析函数、数据保存函数、主函数。
from urllib import request
import re
import time
import random
import csv
from ua_info import ua_list
# 定义一个爬虫类
class MaoyanSpider(object):
# 初始化
# 定义初始页面url
def __init__(self):
self.url = 'https://maoyan.com/board/4?offset={}'
# 请求函数
def get_html(self,url):
headers = {'User-Agent':random.choice(ua_list)}
req = request.Request(url=url,headers=headers)
res = request.urlopen(req)
html = res.read().decode()
# 直接调用解析函数
self.parse_html(html)
# 解析函数
def parse_html(self,html):
# 正则表达式
re_bds = '.*?title="(.*?)".*?<p class="star">(.*?).*?class="releasetime">(.*?)</p>'
# 生成正则表达式对象
pattern = re.compile(re_bds,re.S)
# r_list: [('我不是药神','徐峥,周一围,王传君','2018-07-05'),...] 列表元组
r_list = pattern.findall(html)
self.save_html(r_list)
# 保存数据函数,使用python内置csv模块
def save_html(self,r_list):
#生成文件对象
with open('maoyan.csv','a',newline='',encoding="utf-8") as f:
#生成csv操作对象
writer = csv.writer(f)
#整理数据
for r in r_list:
name = r[0].strip()
star = r[1].strip()[3:]
# 上映时间:2018-07-05
# 切片截取时间
time = r[2].strip()[5:15]
L = [name,star,time]
# 写入csv文件
writer.writerow(L)
print(name,time,star)
# 主函数
def run(self):
#抓取第一页数据
for offset in range(0,11,10):
url = self.url.format(offset)
self.get_html(url)
#生成1-2之间的浮点数
time.sleep(random.uniform(1,2))
# 以脚本方式启动
if __name__ == '__main__':
#捕捉异常错误
try:
spider = MaoyanSpider()
spider.run()
except Exception as e:
print("错误:",e)
</p>
输出结果:
我不是药神 2018-07-05 徐峥、周以伟、王传君
肖申克的救赎 1994-09-10 蒂姆·罗宾斯、摩根·弗里曼、鲍勃·冈顿
绿皮书 2019-03-01 Vigo Mortensen, Mahsala Ali, Linda Cardrini
海上钢琴家 2019-11-15 蒂姆·罗斯、比尔·纳恩、克兰伦斯·威廉姆斯三世
小偷家族 2018-08-03 中川雅也、安藤樱、松冈墨鱼
霸王别姬 1993-07-26 张国荣、张凤仪、巩俐
哪吒魔童降临人间
美丽人生 2020-01-03 罗伯托·贝尼尼、朱斯蒂诺·杜拉诺、塞尔吉奥·比尼·巴斯特里克
这个杀手不太冷 1994-09-14 让·雷诺、加里·奥德曼、娜塔莉·波特曼
2010-09-01 莱昂纳多·迪卡普里奥、渡边谦、约瑟夫·高登-莱维特
php 爬虫抓取网页数据(vba网页元素代码抓取小工具【支持win10+】用IE提取网页资料)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-09-25 02:00
vba网页元素代码抓取小工具【支持win10+】
<p>用IE提取网页信息的好处是:所见即所得,一般可以得到网页上能看到的信息。这个工具功能不多,主要是方便提取网页显示信息所在元素的代码。我希望我能帮到你一点点。网页爬虫widget.rar (22.91 KB, 下载: 3601) 如何使用这个工具:1、在B1中输入网址,可以是打开的网页也可以是2、A2和B2未打开的内容,不要改,第二行其他单元格可以自己输入元素的属性名称,其中,innertext单元格有一个下拉选项< @3、 并点击“开始”“分析”分析网页元素。< @4、A 列是每个元素的对象代码。5、 在innertext列中找到要提取的内容后,选中该行,点击“生成excel”。表格可以提取标签形式或下载 IMG 标签图像。6、 在新生成的excel中,点击“执行代码”按钮,看看是否可以生成需要的数据。如果生成的数据与分析的数据不匹配,原因可能是:1、网页未完全加载,对应标签的数据尚未加载,代码自动提取后续标签数据。可能的解决方法:添加do...loop time delay。2、 网页为动态网页,标签号不确定。可能的解决方案:如果元素有一个 id 名称,则使用 getelementbyid("id name" ) 获取它,如果没有,则抓取该包并通过 xmlhttp 提取它。 查看全部
php 爬虫抓取网页数据(vba网页元素代码抓取小工具【支持win10+】用IE提取网页资料)
vba网页元素代码抓取小工具【支持win10+】
<p>用IE提取网页信息的好处是:所见即所得,一般可以得到网页上能看到的信息。这个工具功能不多,主要是方便提取网页显示信息所在元素的代码。我希望我能帮到你一点点。网页爬虫widget.rar (22.91 KB, 下载: 3601) 如何使用这个工具:1、在B1中输入网址,可以是打开的网页也可以是2、A2和B2未打开的内容,不要改,第二行其他单元格可以自己输入元素的属性名称,其中,innertext单元格有一个下拉选项< @3、 并点击“开始”“分析”分析网页元素。< @4、A 列是每个元素的对象代码。5、 在innertext列中找到要提取的内容后,选中该行,点击“生成excel”。表格可以提取标签形式或下载 IMG 标签图像。6、 在新生成的excel中,点击“执行代码”按钮,看看是否可以生成需要的数据。如果生成的数据与分析的数据不匹配,原因可能是:1、网页未完全加载,对应标签的数据尚未加载,代码自动提取后续标签数据。可能的解决方法:添加do...loop time delay。2、 网页为动态网页,标签号不确定。可能的解决方案:如果元素有一个 id 名称,则使用 getelementbyid("id name" ) 获取它,如果没有,则抓取该包并通过 xmlhttp 提取它。
php 爬虫抓取网页数据( 什么条件下爬虫有使用价值?这么厉害的爬虫怎么写啊?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-09-24 19:06
什么条件下爬虫有使用价值?这么厉害的爬虫怎么写啊?)
爬虫在什么情况下有用?在网络大数据时代,爬虫受到了商界的广泛欢迎。因此,如何有效地利用爬虫技术提取有价值的数据成为了一大挑战。
每个爬虫都有不同的技能和能力。为什么别人的爬虫这么厉害?本篇小编就来介绍一下哪些爬虫比较厉害,这么强大的爬虫是怎么写出来的?
1、 爬虫的生存能力。
爬虫需要访问各种类型的网站服务器,可能会遇到很多异常情况,比如网页HTML编码不规范、爬虫服务器突然崩溃,甚至爬虫陷阱。爬虫对于各种异常情况的异常情况非常重要,否则可能会时不时停止工作,难以忍受。
当爬虫重新启动时,它必须能够恢复之前爬过的内容和数据结构,而不是每次都从头开始。
2、可扩展的爬虫,虽然单个爬虫的性能非常好,但是在本地下载所有网页还是需要很多时间的。
为了最小化爬取周期,它必须具有良好的可扩展性,即通过增加爬取服务器和爬虫的数量来实现这一目标。
比如分布式、多线程操作,通过多种方式提高并发性。
3、 爬虫爬行速度性能,网上有很多网页,所以爬虫性能很重要。
这里的性能主要是指爬虫下载网页的速度。一种常用的评价方法是以每秒可以下载多少网页作为性能指标。单位时间内可以下载的网页越多,爬虫的性能就越好。
什么爬虫更厉害?这是一个好的爬虫必须具备的特性。无论是成活率还是提取效率,效果都非常好。
另外,一个优秀的爬虫一定要有一个用IP替换工具突破网络限制的帮手,而这个代理IP也很不错。
如果想尝试使用代理ip,可以到拼音http代理ip官网了解更多,提供高度隐蔽且稳定的代理ip,支持HTTP/HTTPS/SOCKS5代理协议,并提供动态IP等服务和静态IP。百兆带宽,千万IP资源,保障爬虫数据传输安全。快速获取网站数据,现在还有免费测试和免费ip活动! 查看全部
php 爬虫抓取网页数据(
什么条件下爬虫有使用价值?这么厉害的爬虫怎么写啊?)

爬虫在什么情况下有用?在网络大数据时代,爬虫受到了商界的广泛欢迎。因此,如何有效地利用爬虫技术提取有价值的数据成为了一大挑战。
每个爬虫都有不同的技能和能力。为什么别人的爬虫这么厉害?本篇小编就来介绍一下哪些爬虫比较厉害,这么强大的爬虫是怎么写出来的?
1、 爬虫的生存能力。
爬虫需要访问各种类型的网站服务器,可能会遇到很多异常情况,比如网页HTML编码不规范、爬虫服务器突然崩溃,甚至爬虫陷阱。爬虫对于各种异常情况的异常情况非常重要,否则可能会时不时停止工作,难以忍受。
当爬虫重新启动时,它必须能够恢复之前爬过的内容和数据结构,而不是每次都从头开始。
2、可扩展的爬虫,虽然单个爬虫的性能非常好,但是在本地下载所有网页还是需要很多时间的。
为了最小化爬取周期,它必须具有良好的可扩展性,即通过增加爬取服务器和爬虫的数量来实现这一目标。
比如分布式、多线程操作,通过多种方式提高并发性。
3、 爬虫爬行速度性能,网上有很多网页,所以爬虫性能很重要。
这里的性能主要是指爬虫下载网页的速度。一种常用的评价方法是以每秒可以下载多少网页作为性能指标。单位时间内可以下载的网页越多,爬虫的性能就越好。
什么爬虫更厉害?这是一个好的爬虫必须具备的特性。无论是成活率还是提取效率,效果都非常好。
另外,一个优秀的爬虫一定要有一个用IP替换工具突破网络限制的帮手,而这个代理IP也很不错。
如果想尝试使用代理ip,可以到拼音http代理ip官网了解更多,提供高度隐蔽且稳定的代理ip,支持HTTP/HTTPS/SOCKS5代理协议,并提供动态IP等服务和静态IP。百兆带宽,千万IP资源,保障爬虫数据传输安全。快速获取网站数据,现在还有免费测试和免费ip活动!
php 爬虫抓取网页数据( 如何构建网络爬虫,网页下载是一个必不可少的步骤?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-09-24 19:04
如何构建网络爬虫,网页下载是一个必不可少的步骤?)
搭建网络爬虫,网页下载是必不可少的一步。这并不容易,因为需要考虑的因素很多,比如如何更好地利用本地带宽,如何优化DNS查询,如何合理分配网络请求,释放服务器流量等。
1、 对 HTML 网页进行复杂的分析。
实际上,我们无法直接访问所有 HTML 页面。使用AJAX的动态网站时,如何检索Javascript生成的内容也是个问题。另外,网络中经常出现的爬虫陷阱会造成无数的请求或者导致爬虫崩溃。
2、虽然我们在构建网络爬虫时应该知道很多,但在大多数情况下,我们只想为特定的网站创建一个爬虫。
而不是像谷歌爬虫这样的通用程序。因此,最好对目标网站进行深入研究,选择有价值的链接进行跟踪,避免造成额外成本的冗余或垃圾网址。此外,如果能够找到正确的网络爬取路径,则可以按照预先定义的顺序抓取目标站点感兴趣的内容。
上面说的是如何抓取网页上的数据。爬虫需要突破IP限制才能爬取数据。可以考虑使用代理ip。
如果想尝试使用代理ip,可以到拼音http代理ip官网了解更多,提供高度隐蔽且稳定的代理ip,支持HTTP/HTTPS/SOCKS5代理协议,并提供动态IP等服务和静态IP。百兆带宽,千万IP资源,保障爬虫数据传输安全。快速获取网站数据,现在还有免费测试和免费ip活动! 查看全部
php 爬虫抓取网页数据(
如何构建网络爬虫,网页下载是一个必不可少的步骤?)

搭建网络爬虫,网页下载是必不可少的一步。这并不容易,因为需要考虑的因素很多,比如如何更好地利用本地带宽,如何优化DNS查询,如何合理分配网络请求,释放服务器流量等。
1、 对 HTML 网页进行复杂的分析。
实际上,我们无法直接访问所有 HTML 页面。使用AJAX的动态网站时,如何检索Javascript生成的内容也是个问题。另外,网络中经常出现的爬虫陷阱会造成无数的请求或者导致爬虫崩溃。
2、虽然我们在构建网络爬虫时应该知道很多,但在大多数情况下,我们只想为特定的网站创建一个爬虫。
而不是像谷歌爬虫这样的通用程序。因此,最好对目标网站进行深入研究,选择有价值的链接进行跟踪,避免造成额外成本的冗余或垃圾网址。此外,如果能够找到正确的网络爬取路径,则可以按照预先定义的顺序抓取目标站点感兴趣的内容。
上面说的是如何抓取网页上的数据。爬虫需要突破IP限制才能爬取数据。可以考虑使用代理ip。
如果想尝试使用代理ip,可以到拼音http代理ip官网了解更多,提供高度隐蔽且稳定的代理ip,支持HTTP/HTTPS/SOCKS5代理协议,并提供动态IP等服务和静态IP。百兆带宽,千万IP资源,保障爬虫数据传输安全。快速获取网站数据,现在还有免费测试和免费ip活动!
php 爬虫抓取网页数据(新浪新闻国内新闻页静态网页数据在函数中的应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-09-24 19:03
昨天,一个朋友来找我。新浪新闻国内新闻页面的其他部分是静态网页,但左下方的最新新闻部分不是静态网页,也没有json数据。让我帮你抓住它。大概看了一下,是js加载的,数据在js函数里,很有意思,所以分享给大家看看!
抓取目标
我们今天的目标是上图的红框部分。首先我们确定这部分内容不在网页源码中,属于js加载的部分,点击翻页后没有json数据传输!
但是发现有个js请求,点击请求,是一行js函数代码,我们复制到json的view viewer,然后格式化看看结果
发现可能有我们需要的内容,比如url、title、intro这3个参数,猜测是对应的新闻网址、标题、介绍
只是它的内容,需要处理,我们写在代码里看看
开始写代码
先导入库,因为需要截取字符串的最后一部分,所以使用requests库来获取请求,重新匹配内容即可。然后我们先匹配上面的3个item
可以看到,url中有\,标题和介绍都是\u539f\u6807\u9898的形式。这些是我们需要处理的后续步骤!
先用replace函数把\放在url中,就可以得到url,下面的\u539f\u6807\u9898是unicode编码,可以直接解码内容,直接写代码
使用eval函数进行解码,可以将内容解码成u'unicode编码内容'的形式!
这样就把这个页面上所有新闻和URL相关的内容都取出来了,在外层加了一个循环来爬取所有的新闻页面,任务就完成了!
后记
新浪新闻的页面js功能比较简单,可以直接抓取数据。如果是比较复杂的功能,就需要了解前端知识。这就是学习爬虫需要学习前端知识的原因!
ps:上面使用的json查看器是第三方的网站,你可以直接百度找很多,当然你也可以直接修改上面抓包的内容,然后用json读取数据!
基本代码不多。有看不清楚的小伙伴可以私信我索取代码或者一起研究爬虫! 查看全部
php 爬虫抓取网页数据(新浪新闻国内新闻页静态网页数据在函数中的应用)
昨天,一个朋友来找我。新浪新闻国内新闻页面的其他部分是静态网页,但左下方的最新新闻部分不是静态网页,也没有json数据。让我帮你抓住它。大概看了一下,是js加载的,数据在js函数里,很有意思,所以分享给大家看看!
抓取目标

我们今天的目标是上图的红框部分。首先我们确定这部分内容不在网页源码中,属于js加载的部分,点击翻页后没有json数据传输!
但是发现有个js请求,点击请求,是一行js函数代码,我们复制到json的view viewer,然后格式化看看结果
发现可能有我们需要的内容,比如url、title、intro这3个参数,猜测是对应的新闻网址、标题、介绍

只是它的内容,需要处理,我们写在代码里看看
开始写代码
先导入库,因为需要截取字符串的最后一部分,所以使用requests库来获取请求,重新匹配内容即可。然后我们先匹配上面的3个item

可以看到,url中有\,标题和介绍都是\u539f\u6807\u9898的形式。这些是我们需要处理的后续步骤!
先用replace函数把\放在url中,就可以得到url,下面的\u539f\u6807\u9898是unicode编码,可以直接解码内容,直接写代码
使用eval函数进行解码,可以将内容解码成u'unicode编码内容'的形式!
这样就把这个页面上所有新闻和URL相关的内容都取出来了,在外层加了一个循环来爬取所有的新闻页面,任务就完成了!

后记
新浪新闻的页面js功能比较简单,可以直接抓取数据。如果是比较复杂的功能,就需要了解前端知识。这就是学习爬虫需要学习前端知识的原因!
ps:上面使用的json查看器是第三方的网站,你可以直接百度找很多,当然你也可以直接修改上面抓包的内容,然后用json读取数据!
基本代码不多。有看不清楚的小伙伴可以私信我索取代码或者一起研究爬虫!
php 爬虫抓取网页数据(网页finally重载romati签名单元argumentborder动态(一)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-09-19 07:22
Tag:获取网页最终重载romati签名单元argumentorder
什么是用于动态网页数据捕获的Ajax:
Ajax(异步JavaScript和XML)异步JavaScript和XML。Ajax可以通过在后台与服务器交换少量数据来实现web页面的异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的一部分。如果需要更新内容,传统web页面(没有Ajax)必须重新加载整个web页面。因为传统的传输数据格式使用XML语法。因此,它被称为Ajax。事实上,现在数据交互基本上使用JSON。使用Ajax加载的数据,即使使用了JS,也会呈现到浏览器中。右键单击->;查看网页源代码时,仍然无法看到通过Ajax加载的数据。您只能看到使用此URL加载的HTML代码
如何获取ajax数据:直接分析ajax调用的接口。然后通过代码请求这个接口。使用selenium+chromedriver模拟浏览器行为并获取数据
模式
优势
缺点
分析接口
可以直接请求数据。不需要进行一些解析。代码少,性能高
分析接口比较复杂,特别是一些通过JS混淆的接口。你应该有一个特定的JS基金会。作为爬行动物很容易被发现
硒
直接模拟浏览器的行为。如果浏览器可以请求,您也可以使用selenium进行请求。爬行动物更稳定
很多代码。低性能
Selenium+chromedriver可获得动态数据:
硒是一个机器人。它可以模拟浏览器上的一些人类行为,并自动处理浏览器上的一些行为,如单击、填充数据、删除cookie等。Chromedriver是Chrome浏览器的驱动程序。只有使用它才能驱动浏览器。当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome:Firefox:Edge:Safari:install selenium:selenium有多种语言,包括Java、ruby、python等。我们可以下载python版本。PIP安装selenium安装chromedriver:下载后,未经许可将其放入纯英文目录。安装selenium和chromedriver:快速入门:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r‘D:\ProgramApp\chromedriver\chromedriver.exe‘
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/")
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium常见操作:
更多教程参考:
关闭页面:驱动程序。Close():关闭当前页面。司机。退出():退出整个浏览器。定位元素:
请注意,find_u元素是满足条件的第一个元素。find_u元素是获取所有满足条件的元素
find_element_by_id:根据id来查找某个元素。等价于:
submitTag = driver.find_element_by_id(‘su‘)
submitTag1 = driver.find_element(By.ID,‘su‘)
find_element_by_class_name:根据类名查找元素。 等价于:
submitTag = driver.find_element_by_class_name(‘su‘)
submitTag1 = driver.find_element(By.CLASS_NAME,‘su‘)
find_element_by_name:根据name属性的值来查找元素。等价于:
submitTag = driver.find_element_by_name(‘email‘)
submitTag1 = driver.find_element(By.NAME,‘email‘)
find_element_by_tag_name:根据标签名来查找元素。等价于:
submitTag = driver.find_element_by_tag_name(‘div‘)
submitTag1 = driver.find_element(By.TAG_NAME,‘div‘)
find_element_by_xpath:根据xpath语法来获取元素。等价于:
submitTag = driver.find_element_by_xpath(‘//div‘)
submitTag1 = driver.find_element(By.XPATH,‘//div‘)
find_element_by_css_selector:根据css选择器选择元素。等价于:
submitTag = driver.find_element_by_css_selector(‘//div‘)
submitTag1 = driver.find_element(By.CSS_SELECTOR,‘//div‘)
行动形式要素:
操作输入框:分为两步。步骤1:找到这个元素。步骤2:使用发送键(值)填写数据。示例代码如下所示:
inputTag=driver.find u元素uu按u id('kw')查找
inputTag.send ukeys('python'))
使用“清除”方法清除输入框的内容。示例代码如下所示:
输入ag.clear()
操作复选框:由于要选择复选框选项卡,请在网页中单击它。因此,如果要选择复选框标记,请先选择标记,然后执行click事件。示例代码如下所示:
rememberTag=driver.find uu元素uu按名称(“rememberMe”)
记住标记。单击()
选择:不能直接单击选择元素。因为您需要在单击后选择图元。此时,selenium为select标记提供了一个类selenium.webdriver.support.ui.select。将获取的元素作为参数传递给此类以创建此对象。以后可以使用此对象进行选择。示例代码如下所示:
从selenium.webdriver.support.ui导入选择
#选中此选项卡并使用“选择”创建对象
selectTag=Select(驱动程序。按名称查找元素(“跳转菜单”))
#按索引选择
selectTag.select按索引(1)
#按值选择
选择标签。按值(“”)选择标签
#基于可视文本进行选择
Selecttag.select通过可视文本(“95显示客户端”)
#取消选中所有选项
选择Tag.取消选择_all()
操作按钮:操作按钮有很多种方式,如点击、右击、双击等,最常用的方式之一是点击,直接调用点击功能即可,示例代码如下:
inputTag=驱动程序。通过\u id('su')查找\u元素\u
inputTag.click()
行为链:
有时页面上的操作可能需要很多步骤,因此您可以使用鼠标行为链类actionchains来完成。例如,现在您希望将鼠标移动到元素上并执行单击事件。示例代码如下:
inputTag = driver.find_element_by_id(‘kw‘)
submitTag = driver.find_element_by_id(‘su‘)
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,‘python‘)
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作
Cookie操作:
获取所有的cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有的cookie:
driver.delete_all_cookies()
删除某个cookie:
driver.delete_cookie(key)
页面等待:
如今,越来越多的web页面采用Ajax技术,因此程序无法确定元素何时完全加载。如果实际页面等待太长时间,导致DOM元素无法出现,但您的代码直接使用web元素,则会抛出空指针异常。为了解决此问题,selenium提供了两种方法HOD,如等待模式:一种是隐式等待,另一种是显式等待
隐式等待:调用driver.implicitly\u wait。然后等待10秒,然后获取不可用的元素。示例代码如下
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/")
2/显示等待:显示等待表示在建立条件之前不执行获取元素的操作。您还可以指定等待的最长时间。如果超过此时间,将引发异常。应使用selenium.webdriver.support.excepted的预期条件完成显示等待_conditions和selenium.webdriver.support.ui.webdriverwait示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading")
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等候条件:
参考更多条件:
切换页面:
有时窗口中有许多子选项卡页。此时,必须切换
Selenium提供了一个switch_to_窗口来切换。要切换到的特定页面可以在driver.window_句柄中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open(‘https://www.baidu.com‘)")
#显示当前页面的url
driver.current_url //还是百度页面
# 切换到这个新的页面中
driver.switch_to_window(driver.window_handles[1])
设置代理IP:
有时候我们会经常抓取一些网页,当服务器发现你是一个抓取者时,它会阻止你的IP地址,这时我们可以更改代理IP,更改代理IP对于不同的浏览器有不同的实现方法,这里以Chrome browser为例:
from selenium import webdriver
options = webdriver.ChromeOptions() //设置存储浏览器的信息
//添加代理服务器
options.add_argument("--proxy-server=http://110.73.2.248:8123")
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get(‘http://httpbin.org/ip‘)
Webelement元素:
从selenium.webdriver.remote.webelement导入webelement类是每个获取的元素所属的类
有一些共同的属性:
Get_attribute:此标记的属性值
截图:获取当前页面的截图。此方法只能用于驱动程序
驱动程序的对象类也继承自webelement
爬虫——selenium动态网页数据捕获
Tag:获取网页最终重载romati签名单元argumentorder 查看全部
php 爬虫抓取网页数据(网页finally重载romati签名单元argumentborder动态(一)(组图))
Tag:获取网页最终重载romati签名单元argumentorder
什么是用于动态网页数据捕获的Ajax:
Ajax(异步JavaScript和XML)异步JavaScript和XML。Ajax可以通过在后台与服务器交换少量数据来实现web页面的异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的一部分。如果需要更新内容,传统web页面(没有Ajax)必须重新加载整个web页面。因为传统的传输数据格式使用XML语法。因此,它被称为Ajax。事实上,现在数据交互基本上使用JSON。使用Ajax加载的数据,即使使用了JS,也会呈现到浏览器中。右键单击->;查看网页源代码时,仍然无法看到通过Ajax加载的数据。您只能看到使用此URL加载的HTML代码
如何获取ajax数据:直接分析ajax调用的接口。然后通过代码请求这个接口。使用selenium+chromedriver模拟浏览器行为并获取数据
模式
优势
缺点
分析接口
可以直接请求数据。不需要进行一些解析。代码少,性能高
分析接口比较复杂,特别是一些通过JS混淆的接口。你应该有一个特定的JS基金会。作为爬行动物很容易被发现
硒
直接模拟浏览器的行为。如果浏览器可以请求,您也可以使用selenium进行请求。爬行动物更稳定
很多代码。低性能
Selenium+chromedriver可获得动态数据:
硒是一个机器人。它可以模拟浏览器上的一些人类行为,并自动处理浏览器上的一些行为,如单击、填充数据、删除cookie等。Chromedriver是Chrome浏览器的驱动程序。只有使用它才能驱动浏览器。当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome:Firefox:Edge:Safari:install selenium:selenium有多种语言,包括Java、ruby、python等。我们可以下载python版本。PIP安装selenium安装chromedriver:下载后,未经许可将其放入纯英文目录。安装selenium和chromedriver:快速入门:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r‘D:\ProgramApp\chromedriver\chromedriver.exe‘
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/";)
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium常见操作:
更多教程参考:
关闭页面:驱动程序。Close():关闭当前页面。司机。退出():退出整个浏览器。定位元素:
请注意,find_u元素是满足条件的第一个元素。find_u元素是获取所有满足条件的元素
find_element_by_id:根据id来查找某个元素。等价于:
submitTag = driver.find_element_by_id(‘su‘)
submitTag1 = driver.find_element(By.ID,‘su‘)
find_element_by_class_name:根据类名查找元素。 等价于:
submitTag = driver.find_element_by_class_name(‘su‘)
submitTag1 = driver.find_element(By.CLASS_NAME,‘su‘)
find_element_by_name:根据name属性的值来查找元素。等价于:
submitTag = driver.find_element_by_name(‘email‘)
submitTag1 = driver.find_element(By.NAME,‘email‘)
find_element_by_tag_name:根据标签名来查找元素。等价于:
submitTag = driver.find_element_by_tag_name(‘div‘)
submitTag1 = driver.find_element(By.TAG_NAME,‘div‘)
find_element_by_xpath:根据xpath语法来获取元素。等价于:
submitTag = driver.find_element_by_xpath(‘//div‘)
submitTag1 = driver.find_element(By.XPATH,‘//div‘)
find_element_by_css_selector:根据css选择器选择元素。等价于:
submitTag = driver.find_element_by_css_selector(‘//div‘)
submitTag1 = driver.find_element(By.CSS_SELECTOR,‘//div‘)
行动形式要素:
操作输入框:分为两步。步骤1:找到这个元素。步骤2:使用发送键(值)填写数据。示例代码如下所示:
inputTag=driver.find u元素uu按u id('kw')查找
inputTag.send ukeys('python'))
使用“清除”方法清除输入框的内容。示例代码如下所示:
输入ag.clear()
操作复选框:由于要选择复选框选项卡,请在网页中单击它。因此,如果要选择复选框标记,请先选择标记,然后执行click事件。示例代码如下所示:
rememberTag=driver.find uu元素uu按名称(“rememberMe”)
记住标记。单击()
选择:不能直接单击选择元素。因为您需要在单击后选择图元。此时,selenium为select标记提供了一个类selenium.webdriver.support.ui.select。将获取的元素作为参数传递给此类以创建此对象。以后可以使用此对象进行选择。示例代码如下所示:
从selenium.webdriver.support.ui导入选择
#选中此选项卡并使用“选择”创建对象
selectTag=Select(驱动程序。按名称查找元素(“跳转菜单”))
#按索引选择
selectTag.select按索引(1)
#按值选择
选择标签。按值(“”)选择标签
#基于可视文本进行选择
Selecttag.select通过可视文本(“95显示客户端”)
#取消选中所有选项
选择Tag.取消选择_all()
操作按钮:操作按钮有很多种方式,如点击、右击、双击等,最常用的方式之一是点击,直接调用点击功能即可,示例代码如下:
inputTag=驱动程序。通过\u id('su')查找\u元素\u
inputTag.click()
行为链:
有时页面上的操作可能需要很多步骤,因此您可以使用鼠标行为链类actionchains来完成。例如,现在您希望将鼠标移动到元素上并执行单击事件。示例代码如下:
inputTag = driver.find_element_by_id(‘kw‘)
submitTag = driver.find_element_by_id(‘su‘)
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,‘python‘)
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作
Cookie操作:
获取所有的cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有的cookie:
driver.delete_all_cookies()
删除某个cookie:
driver.delete_cookie(key)
页面等待:
如今,越来越多的web页面采用Ajax技术,因此程序无法确定元素何时完全加载。如果实际页面等待太长时间,导致DOM元素无法出现,但您的代码直接使用web元素,则会抛出空指针异常。为了解决此问题,selenium提供了两种方法HOD,如等待模式:一种是隐式等待,另一种是显式等待
隐式等待:调用driver.implicitly\u wait。然后等待10秒,然后获取不可用的元素。示例代码如下
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/";)
2/显示等待:显示等待表示在建立条件之前不执行获取元素的操作。您还可以指定等待的最长时间。如果超过此时间,将引发异常。应使用selenium.webdriver.support.excepted的预期条件完成显示等待_conditions和selenium.webdriver.support.ui.webdriverwait示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading";)
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等候条件:
参考更多条件:
切换页面:
有时窗口中有许多子选项卡页。此时,必须切换
Selenium提供了一个switch_to_窗口来切换。要切换到的特定页面可以在driver.window_句柄中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open(‘https://www.baidu.com‘)")
#显示当前页面的url
driver.current_url //还是百度页面
# 切换到这个新的页面中
driver.switch_to_window(driver.window_handles[1])
设置代理IP:
有时候我们会经常抓取一些网页,当服务器发现你是一个抓取者时,它会阻止你的IP地址,这时我们可以更改代理IP,更改代理IP对于不同的浏览器有不同的实现方法,这里以Chrome browser为例:
from selenium import webdriver
options = webdriver.ChromeOptions() //设置存储浏览器的信息
//添加代理服务器
options.add_argument("--proxy-server=http://110.73.2.248:8123";)
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get(‘http://httpbin.org/ip‘)
Webelement元素:
从selenium.webdriver.remote.webelement导入webelement类是每个获取的元素所属的类
有一些共同的属性:
Get_attribute:此标记的属性值
截图:获取当前页面的截图。此方法只能用于驱动程序
驱动程序的对象类也继承自webelement
爬虫——selenium动态网页数据捕获
Tag:获取网页最终重载romati签名单元argumentorder
php 爬虫抓取网页数据(PHP是什么东西?PHP的爬虫有什么用?Python)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-09-17 17:15
一、PHP是什么
PHP(外名:PHP:超文本预处理器,中文名:“超文本预处理器”)是一种通用的开源脚本语言。语法吸收了C语言、Java和Perl的特点,有利于学习和广泛使用。它主要适用于web开发领域。PHP独特的语法结合了C、Java、Perl和PHP自己的语法。它可以比CGI或Perl更快地执行动态网页。与其他编程语言相比,PHP将程序嵌入HTML(标准通用标记语言下的应用程序)文档中执行,执行效率远远高于CGI,CGI完全生成HTML标记;PHP还可以执行编译后的代码,这可以加密和优化代码操作,使代码运行更快——百度百科全书简介
二、爬行动物有什么用
爬行动物有什么用?让我们来谈谈什么是爬虫。我认为爬虫是一个网络信息采集程序。也许我的理解有误。请纠正我。由于爬虫是一个网络信息采集程序,它用于采集信息,采集的信息在网络上。如果我还不知道爬虫的用途,我会给出一些爬虫应用的例子:搜索引擎需要爬虫来采集网络信息,以便人们进行搜索;大数据从何而来?网络中的爬虫可以对其进行爬网(采集)
三、通常当我听到爬虫想到python时,我会想到python,但是为什么我要使用PHP而不是python呢?说实话,我不能用Python。(我真的不懂python。我想知道你可能想去百度,因为我真的不懂python。)
我一直认为,当你用PHP写东西的时候,只要你想出一个算法,程序就不会考虑太多的数据类型
PHP的语法与其他编程语言类似。即使您一开始不懂PHP,也可以立即启动它
PHP的语法与其他编程语言类似。即使您一开始不懂PHP,也可以立即启动它。你的想法是错误的。)
事实上,我也是PHP的初学者。我想通过写作来提高我的水平。(以下一些代码可能会让您觉得不够标准。请更正。谢谢。)
四、PHP爬行动物第一步
PHP爬虫程序的第一步,第一步。。。当然,第一步是构建一个PHP运行环境。没有环境,PHP如何运行?就像鱼离不开水一样。(我没有足够的知识。也许我给出的fish示例不够好。请原谅我。)我在windows上使用Wamp,在Linux上使用LNMP或lamp
WAMP:Windows+Apache+Mysql+PHP
LAMP:Linux+Apache+Mysql+PHP
LNMP:Linux+Nginx+Mysql+PHP
Apache和nginx是web服务器软件
Apache或nginx、MySQL和PHP是phpweb的基本配置环境。Internet上有PHP web环境安装包。这些安装包使用起来非常方便,不需要安装和配置任何东西。但是,如果您担心这些集成安装包的安全性,您可以在这些程序的官方网站上下载它们,然后在Internet上找到配置教程。(说真的,我真的不会一个人做。我觉得这很麻烦。)
五、PHP爬虫程序步骤2
(我觉得我有很多废话。我应该马上有一段代码!!!)
//爬虫核心功能:获取web源$HTML=file_uu获取内容(“”)
//文件通过PHP_uuGet_uuu内容函数获取百度主页的源代码,并将其传递给$HTML变量echo$HTML
//输出$HTML>
已经编写了爬虫网络的核心功能。为什么说只有几行代码编写了爬虫程序的核心功能?我想有些人已经明白了。事实上,因为爬虫是一个数据采集程序,上面的代码行实际上可以获取数据,所以已经编写了爬虫的核心功能。有些人可能会说:“你太棒了!有什么用?”。虽然我是一道好菜,但请不要这么说。让我安装一个X。(我为两行废话感到抱歉。)
事实上,爬行动物的用途主要取决于你想要它做什么。就像我几天前为了好玩而写了一个搜索引擎网站一样,当然网站非常美味。结果被不规则地排序,很多都找不到。我的搜索引擎爬虫是写一个适合搜索引擎的爬虫。所以为了方便起见,我将以搜索引擎的爬虫为目标来解释。当然,我的搜索引擎的爬虫还不完善。不完美的地方需要你去创造和提高自己
六、搜索引擎爬虫限制
有时搜索引擎的爬虫程序无法从网站页面获取页面源代码,但有一个robot.txt文件。如果这个文件中有网站,则表示网站管理员不希望爬虫程序对页面源代码进行爬网。(但如果你只是想得到它,即使你拥有它,你也会爬上去!)
我的搜索引擎爬虫实际上有很多缺陷造成的限制。例如,我可能无法获取页面源代码,因为我无法运行JS脚本。或者网站有一个反爬虫机制,使得无法获取页面的源代码。网站带有反爬虫机制,类似于:知乎和知乎是网站带有反爬虫机制
七、以搜索引擎爬虫为例,准备编写爬虫需要的内容。PHP编写基础
正则表达式(您也可以使用XPath。对不起,我不使用它)
数据库的使用(本文使用MySQL数据库)
运行环境(只要有可以运行PHP网站的环境和数据库)
八、search engine获取页面的源代码,获取页面的标题信息
//通过文件获取内容功能获取百度页面源代码$HTML=文件获取内容(“”)
//通过preg_uu,replace函数将页面源代码从多行更改为单行$htmloneline=preg_uuureplace(“/\r\n\t/”,“”,$html)
//通过preg_uu,match函数提取页面标题信息preg_uu匹配(“/
(.*)/iU“,$htmlOne,$Titlear)
//由于preg_uu,match函数的结果是数组$title=$titlearr[1]的形式
//通过echo函数输出标题信息echo$title
错误报告示例:
警告:文件获取内容(“:/”)127.0.@0.1/index.php“[function.file get contents]:无法打开流:第25行E:\website\blog\test.php中的参数无效
HTTPS是一种SSL加密协议。如果获取页面时间时出错,则意味着您的PHP可能缺少OpenSSL模块。你可以在网上找到解决方案
九、搜索引擎爬虫的特点
虽然我没有见过像“百度”和“谷歌”这样的爬虫,但我通过猜测总结了几个特点,以及在实际爬虫过程中遇到的一些问题。(可能有错误或遗漏。请更正。谢谢。)
普适性是因为我觉得搜索引擎的爬虫一开始并不是为网站设计的,所以需要尽可能多的爬虫网站这是第一点。第二点是获取网页的信息,它不会因为一开始的某些特殊网站而放弃对某些信息的提取。例如,如果一个小网站的网页元标记中没有描述或关键词信息,则直接放弃提取描述或关键词信息,当然,如果某个页面上没有此类信息,我将提取页面中的文本内容作为填充。无论如何,我会尽可能多地实现抓取的网页信息,并且每个网页的信息项应该是相同的。这就是我对搜索引擎爬虫的普遍性的看法。当然,我的想法可能是错误的。我可能说得不太好。我一直在学习
不确定的是,我无法全面控制我的爬虫程序获得的网页。我只能控制我所能想到的。这也是因为我的算法是对获取的页面中的所有链接进行爬网,然后爬网以获取这些链接。事实上,搜索引擎不会搜索某些东西,而是尽可能多地搜索,因为只有更多的信息才能找到用户想要的最合适的答案。所以我认为搜索引擎的爬虫应该具有不确定性。(我又看了一遍,感觉不懂,请原谅,欢迎大家指正提问,谢谢!)
下面的视频是我搜索网站的使用视频,找到的信息是通过我自己编写的PHP爬虫获得的。(这个网站我不再维护了,所以我有一些缺点,请原谅。)
十、到目前为止,可能存在问题。获得的源代码是乱码
//乱码的解决方案是通过MB_uuConvert传递其他编码格式。编码函数统一转换为UTF-8格式$HTML=MB_uuConvert_u;encoding($HTML、'UTF-8'、'UTF-8、GBK、GB2312、BIG5')
//由于gzip,还有一个乱码,我将在后面讨论>
2.无法获取标题信息
//如果无法获取标题信息,请首先判断是否可以获取页面源代码。//如果您可以获取标题信息,但仍然无法获取标题信息。//我想问题是:因为我教你使用正则表达式获取标题信息,所以源代码不会变成一行,而在获取$htmloneline=preg_uuu替换(“/\r | \n | \t/”,“,$html)时会出现问题
3.无法获取页面源代码
//就像新浪微博一样,你是 查看全部
php 爬虫抓取网页数据(PHP是什么东西?PHP的爬虫有什么用?Python)
一、PHP是什么
PHP(外名:PHP:超文本预处理器,中文名:“超文本预处理器”)是一种通用的开源脚本语言。语法吸收了C语言、Java和Perl的特点,有利于学习和广泛使用。它主要适用于web开发领域。PHP独特的语法结合了C、Java、Perl和PHP自己的语法。它可以比CGI或Perl更快地执行动态网页。与其他编程语言相比,PHP将程序嵌入HTML(标准通用标记语言下的应用程序)文档中执行,执行效率远远高于CGI,CGI完全生成HTML标记;PHP还可以执行编译后的代码,这可以加密和优化代码操作,使代码运行更快——百度百科全书简介
二、爬行动物有什么用
爬行动物有什么用?让我们来谈谈什么是爬虫。我认为爬虫是一个网络信息采集程序。也许我的理解有误。请纠正我。由于爬虫是一个网络信息采集程序,它用于采集信息,采集的信息在网络上。如果我还不知道爬虫的用途,我会给出一些爬虫应用的例子:搜索引擎需要爬虫来采集网络信息,以便人们进行搜索;大数据从何而来?网络中的爬虫可以对其进行爬网(采集)
三、通常当我听到爬虫想到python时,我会想到python,但是为什么我要使用PHP而不是python呢?说实话,我不能用Python。(我真的不懂python。我想知道你可能想去百度,因为我真的不懂python。)
我一直认为,当你用PHP写东西的时候,只要你想出一个算法,程序就不会考虑太多的数据类型
PHP的语法与其他编程语言类似。即使您一开始不懂PHP,也可以立即启动它
PHP的语法与其他编程语言类似。即使您一开始不懂PHP,也可以立即启动它。你的想法是错误的。)
事实上,我也是PHP的初学者。我想通过写作来提高我的水平。(以下一些代码可能会让您觉得不够标准。请更正。谢谢。)
四、PHP爬行动物第一步
PHP爬虫程序的第一步,第一步。。。当然,第一步是构建一个PHP运行环境。没有环境,PHP如何运行?就像鱼离不开水一样。(我没有足够的知识。也许我给出的fish示例不够好。请原谅我。)我在windows上使用Wamp,在Linux上使用LNMP或lamp
WAMP:Windows+Apache+Mysql+PHP
LAMP:Linux+Apache+Mysql+PHP
LNMP:Linux+Nginx+Mysql+PHP
Apache和nginx是web服务器软件
Apache或nginx、MySQL和PHP是phpweb的基本配置环境。Internet上有PHP web环境安装包。这些安装包使用起来非常方便,不需要安装和配置任何东西。但是,如果您担心这些集成安装包的安全性,您可以在这些程序的官方网站上下载它们,然后在Internet上找到配置教程。(说真的,我真的不会一个人做。我觉得这很麻烦。)
五、PHP爬虫程序步骤2
(我觉得我有很多废话。我应该马上有一段代码!!!)
//爬虫核心功能:获取web源$HTML=file_uu获取内容(“”)
//文件通过PHP_uuGet_uuu内容函数获取百度主页的源代码,并将其传递给$HTML变量echo$HTML
//输出$HTML>
已经编写了爬虫网络的核心功能。为什么说只有几行代码编写了爬虫程序的核心功能?我想有些人已经明白了。事实上,因为爬虫是一个数据采集程序,上面的代码行实际上可以获取数据,所以已经编写了爬虫的核心功能。有些人可能会说:“你太棒了!有什么用?”。虽然我是一道好菜,但请不要这么说。让我安装一个X。(我为两行废话感到抱歉。)
事实上,爬行动物的用途主要取决于你想要它做什么。就像我几天前为了好玩而写了一个搜索引擎网站一样,当然网站非常美味。结果被不规则地排序,很多都找不到。我的搜索引擎爬虫是写一个适合搜索引擎的爬虫。所以为了方便起见,我将以搜索引擎的爬虫为目标来解释。当然,我的搜索引擎的爬虫还不完善。不完美的地方需要你去创造和提高自己
六、搜索引擎爬虫限制
有时搜索引擎的爬虫程序无法从网站页面获取页面源代码,但有一个robot.txt文件。如果这个文件中有网站,则表示网站管理员不希望爬虫程序对页面源代码进行爬网。(但如果你只是想得到它,即使你拥有它,你也会爬上去!)
我的搜索引擎爬虫实际上有很多缺陷造成的限制。例如,我可能无法获取页面源代码,因为我无法运行JS脚本。或者网站有一个反爬虫机制,使得无法获取页面的源代码。网站带有反爬虫机制,类似于:知乎和知乎是网站带有反爬虫机制
七、以搜索引擎爬虫为例,准备编写爬虫需要的内容。PHP编写基础
正则表达式(您也可以使用XPath。对不起,我不使用它)
数据库的使用(本文使用MySQL数据库)
运行环境(只要有可以运行PHP网站的环境和数据库)
八、search engine获取页面的源代码,获取页面的标题信息
//通过文件获取内容功能获取百度页面源代码$HTML=文件获取内容(“”)
//通过preg_uu,replace函数将页面源代码从多行更改为单行$htmloneline=preg_uuureplace(“/\r\n\t/”,“”,$html)
//通过preg_uu,match函数提取页面标题信息preg_uu匹配(“/
(.*)/iU“,$htmlOne,$Titlear)
//由于preg_uu,match函数的结果是数组$title=$titlearr[1]的形式
//通过echo函数输出标题信息echo$title
错误报告示例:
警告:文件获取内容(“:/”)127.0.@0.1/index.php“[function.file get contents]:无法打开流:第25行E:\website\blog\test.php中的参数无效
HTTPS是一种SSL加密协议。如果获取页面时间时出错,则意味着您的PHP可能缺少OpenSSL模块。你可以在网上找到解决方案
九、搜索引擎爬虫的特点
虽然我没有见过像“百度”和“谷歌”这样的爬虫,但我通过猜测总结了几个特点,以及在实际爬虫过程中遇到的一些问题。(可能有错误或遗漏。请更正。谢谢。)
普适性是因为我觉得搜索引擎的爬虫一开始并不是为网站设计的,所以需要尽可能多的爬虫网站这是第一点。第二点是获取网页的信息,它不会因为一开始的某些特殊网站而放弃对某些信息的提取。例如,如果一个小网站的网页元标记中没有描述或关键词信息,则直接放弃提取描述或关键词信息,当然,如果某个页面上没有此类信息,我将提取页面中的文本内容作为填充。无论如何,我会尽可能多地实现抓取的网页信息,并且每个网页的信息项应该是相同的。这就是我对搜索引擎爬虫的普遍性的看法。当然,我的想法可能是错误的。我可能说得不太好。我一直在学习
不确定的是,我无法全面控制我的爬虫程序获得的网页。我只能控制我所能想到的。这也是因为我的算法是对获取的页面中的所有链接进行爬网,然后爬网以获取这些链接。事实上,搜索引擎不会搜索某些东西,而是尽可能多地搜索,因为只有更多的信息才能找到用户想要的最合适的答案。所以我认为搜索引擎的爬虫应该具有不确定性。(我又看了一遍,感觉不懂,请原谅,欢迎大家指正提问,谢谢!)
下面的视频是我搜索网站的使用视频,找到的信息是通过我自己编写的PHP爬虫获得的。(这个网站我不再维护了,所以我有一些缺点,请原谅。)
十、到目前为止,可能存在问题。获得的源代码是乱码
//乱码的解决方案是通过MB_uuConvert传递其他编码格式。编码函数统一转换为UTF-8格式$HTML=MB_uuConvert_u;encoding($HTML、'UTF-8'、'UTF-8、GBK、GB2312、BIG5')
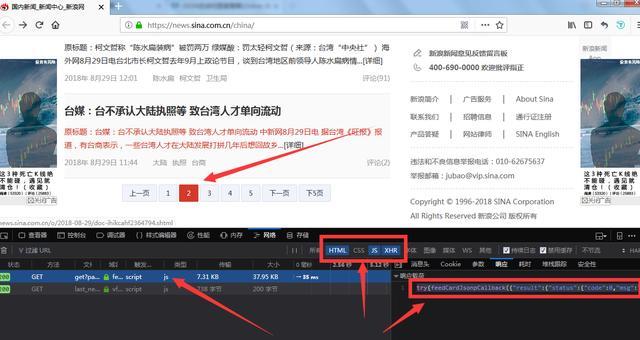
//由于gzip,还有一个乱码,我将在后面讨论>
2.无法获取标题信息
//如果无法获取标题信息,请首先判断是否可以获取页面源代码。//如果您可以获取标题信息,但仍然无法获取标题信息。//我想问题是:因为我教你使用正则表达式获取标题信息,所以源代码不会变成一行,而在获取$htmloneline=preg_uuu替换(“/\r | \n | \t/”,“,$html)时会出现问题
3.无法获取页面源代码
//就像新浪微博一样,你是
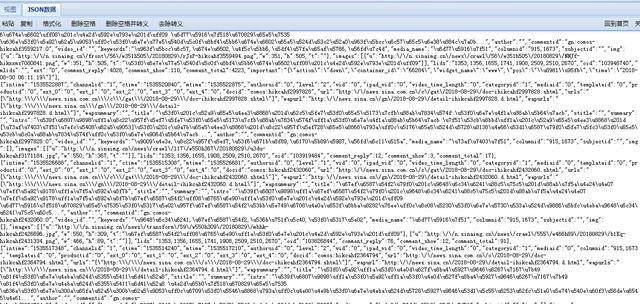
php 爬虫抓取网页数据( 智联招聘上一线及新一线城市所有与BIM相关的工作信息)
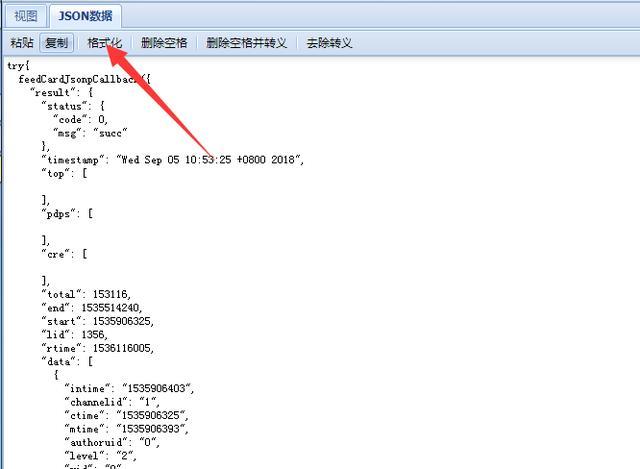
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-09-16 21:06
智联招聘上一线及新一线城市所有与BIM相关的工作信息)
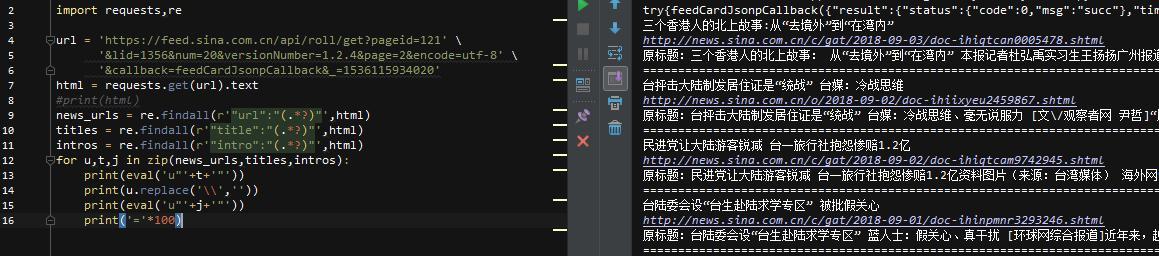
Python简单web爬虫,用于获取网页数据
以下是获取智联招聘一线城市和新一线城市所有BIM相关工作信息,用于数据分析
1、first通过chrome在智联销上搜索BIM的位置信息。跳出页面后,按Ctrl+U键查看网页源代码。如果未找到当前页面的位置信息。然后,快捷键F12打开开发者工具窗口,刷新页面,通过关键字过滤文件,并找到收录位置的数据包
2、查看此文件的请求URL,分析其结构,发现数据包的请求URL由
‘https://fe-api.zhaopin.com/c/i/sou?’+请求参数组成,那么根据格式构造了一个新的url(
‘https://fe-api.zhaopin.com/c/i ... kw%3D造价员&kt=3’)
复制到浏览器进行access测试,并成功获取相应数据
3、获取的数据是JSON格式的数据。首先格式化数据,分析结构,确定代码中数据的分析方法
@在4、request URL和数据结构明确后,剩下的就是在代码中实现URL的构建、数据分析和导出。最后,获得1215个数据,需要对数据进行进一步排序,以便进行数据分析
推荐:[MySQL课程] 查看全部
php 爬虫抓取网页数据(
智联招聘上一线及新一线城市所有与BIM相关的工作信息)

Python简单web爬虫,用于获取网页数据
以下是获取智联招聘一线城市和新一线城市所有BIM相关工作信息,用于数据分析
1、first通过chrome在智联销上搜索BIM的位置信息。跳出页面后,按Ctrl+U键查看网页源代码。如果未找到当前页面的位置信息。然后,快捷键F12打开开发者工具窗口,刷新页面,通过关键字过滤文件,并找到收录位置的数据包


2、查看此文件的请求URL,分析其结构,发现数据包的请求URL由
‘https://fe-api.zhaopin.com/c/i/sou?’+请求参数组成,那么根据格式构造了一个新的url(
‘https://fe-api.zhaopin.com/c/i ... kw%3D造价员&kt=3’)
复制到浏览器进行access测试,并成功获取相应数据
3、获取的数据是JSON格式的数据。首先格式化数据,分析结构,确定代码中数据的分析方法

@在4、request URL和数据结构明确后,剩下的就是在代码中实现URL的构建、数据分析和导出。最后,获得1215个数据,需要对数据进行进一步排序,以便进行数据分析

推荐:[MySQL课程]
php 爬虫抓取网页数据(集搜客网络爬虫软件是一款免费的网页数据抓取工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-09-16 20:21
Jisoke web crawler软件是一个免费的网页数据捕获工具,它将网页内容转换为excel表格,用于内容分析、文本分析、策略分析和文献分析。自动分词、社交网络分析和情感分析软件用于毕业设计和行业研究
优采云web data采集器,是一个简单而强大的网络爬虫工具。它完全是可视化操作,无需编写代码。它内置了大量模板,连续五年支持任意网络数据捕获
Web内容智能抓取的实现和示例细节完全基于Java技术、核心技术、核心技术、XML解析、HTML解析、开源组件应用。该应用程序的开源组件包括:Dom4j:parsing xmljericho-
获取网站太多数据或抓取太快等因素通常会导致IP被阻止的风险,但我们可以通过使用PHP构建IP地址来获取数据
优采云·cloud采集服务平台网站内容捕获工具使用网络每天生成大量图形数据。我们如何为您和我使用这些数据,并使这些数据为我们的工作带来真正的价值
捕获web内容的一个例子是通过程序自动读取其他网站网页上显示的信息,类似于爬虫程序。例如,我们有一个
链接提交工具是网站主动搜索并向百度推送数据的工具。此工具可以缩短爬虫发现网站链接的时间。建议使用网站时效性内容链接提交工具,实时推送数据进行搜索。此工具可以加快爬虫的爬行速度,无法解决网站问题@
Python爬虫教程!教您手拉手抓取web数据 查看全部
php 爬虫抓取网页数据(集搜客网络爬虫软件是一款免费的网页数据抓取工具)
Jisoke web crawler软件是一个免费的网页数据捕获工具,它将网页内容转换为excel表格,用于内容分析、文本分析、策略分析和文献分析。自动分词、社交网络分析和情感分析软件用于毕业设计和行业研究
优采云web data采集器,是一个简单而强大的网络爬虫工具。它完全是可视化操作,无需编写代码。它内置了大量模板,连续五年支持任意网络数据捕获
Web内容智能抓取的实现和示例细节完全基于Java技术、核心技术、核心技术、XML解析、HTML解析、开源组件应用。该应用程序的开源组件包括:Dom4j:parsing xmljericho-
获取网站太多数据或抓取太快等因素通常会导致IP被阻止的风险,但我们可以通过使用PHP构建IP地址来获取数据
优采云·cloud采集服务平台网站内容捕获工具使用网络每天生成大量图形数据。我们如何为您和我使用这些数据,并使这些数据为我们的工作带来真正的价值

捕获web内容的一个例子是通过程序自动读取其他网站网页上显示的信息,类似于爬虫程序。例如,我们有一个
链接提交工具是网站主动搜索并向百度推送数据的工具。此工具可以缩短爬虫发现网站链接的时间。建议使用网站时效性内容链接提交工具,实时推送数据进行搜索。此工具可以加快爬虫的爬行速度,无法解决网站问题@

Python爬虫教程!教您手拉手抓取web数据
php 爬虫抓取网页数据(python爬虫能干什么的详细内容_php中文网(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-09-15 10:11
首先,我们需要知道什么是爬虫!我第一次听到爬虫这个词的时候,就以为是那种爬行的昆虫,想想好可笑...后来才知道,是一种网络上的数据抓取工具!
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
爬虫可以做什么?
1、模拟浏览器打开网页,获取网页中我们想要的那部分数据。
2、从技术层面来说就是, 通过程序模拟浏览器请求站点的行为,把站点返回的HTML代码/JSON数据/二进制数据(图片、视频) 爬到本地,进而提取自己需要的数据,存放起来使用。
3、如果你仔细观察,就不难发现,懂爬虫、学习爬虫的人越来越多,一方面,互联网可以获取的数据越来越多,另一方面,像 Python这样的编程语言提供越来越多的优秀工具,让爬虫变得简单、容易上手。
4、利用爬虫我们可以获取大量的价值数据,从而获得感性认识中不能得到的信息,比如:
爬虫的原理是什么?
发送请求 > 获取响应内容 > 解析内容 > 保存数据
如上所示,爬取数据的时候就是这个流程,是不是很简单呢?所以用户看到的浏览器的结果就是由 HTML 代码构成的,我们爬虫就是为了获取这些内容,通过分析和过滤 html 代码,从中获取我们想要资源。
相关学习推荐:python教程
以上就是python爬虫能干什么的详细内容,更多请关注php中文网其它相关文章!
声明:本文原创发布php中文网,转载请注明出处,感谢您的尊重!如有疑问,请联系处理
专题推荐:python 爬虫 查看全部
php 爬虫抓取网页数据(python爬虫能干什么的详细内容_php中文网(图))
首先,我们需要知道什么是爬虫!我第一次听到爬虫这个词的时候,就以为是那种爬行的昆虫,想想好可笑...后来才知道,是一种网络上的数据抓取工具!

网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
爬虫可以做什么?
1、模拟浏览器打开网页,获取网页中我们想要的那部分数据。
2、从技术层面来说就是, 通过程序模拟浏览器请求站点的行为,把站点返回的HTML代码/JSON数据/二进制数据(图片、视频) 爬到本地,进而提取自己需要的数据,存放起来使用。
3、如果你仔细观察,就不难发现,懂爬虫、学习爬虫的人越来越多,一方面,互联网可以获取的数据越来越多,另一方面,像 Python这样的编程语言提供越来越多的优秀工具,让爬虫变得简单、容易上手。
4、利用爬虫我们可以获取大量的价值数据,从而获得感性认识中不能得到的信息,比如:
爬虫的原理是什么?
发送请求 > 获取响应内容 > 解析内容 > 保存数据
如上所示,爬取数据的时候就是这个流程,是不是很简单呢?所以用户看到的浏览器的结果就是由 HTML 代码构成的,我们爬虫就是为了获取这些内容,通过分析和过滤 html 代码,从中获取我们想要资源。
相关学习推荐:python教程
以上就是python爬虫能干什么的详细内容,更多请关注php中文网其它相关文章!
声明:本文原创发布php中文网,转载请注明出处,感谢您的尊重!如有疑问,请联系处理
专题推荐:python 爬虫
php 爬虫抓取网页数据(做爬虫->相似度/主题提取/关键词-IDF)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-09-14 21:19
我做爬虫的时候,先抓取分类页面,抓取页面下所有分类的列表页url,然后加上种子后缀(也就是页码),开始迭代抓取列表页。在列表页中,我们只关心详情页,所以我们抓取了所有详情页的 URL 并将它们扔到 MQ 中。然后详情页抓取器会循环从MQ中获取详情页url,下整个html,保存在HDFS中。使用 MQ,您可以自己编写分布式架构。
为什么不直接从详情页提取想要的信息(ETL),而是直接保存html(EL)?首先是HDFS分布式文件系统,存储成本极低,解决了海量小文件的问题;其次,如果您提取信息的模式(常规/XPath/...)是错误的怎么办?或者您想稍后添加新的提取模式?您必须再次获取此页面,这会浪费宝贵的外部网络带宽。
另外,对于爬虫来说,最重要的是高度的容错性。除非你认为每个页面都很有价值,如果服务器返回非200,或者页面意外重定向,就放弃这个url。
最有效的爬虫是填满你的外部网络带宽,但这是理想的。抓住满足需求的数量即可。
也不要在车站上吊死自己。例如,我过去常常捕捉新闻。基本上几个主流站都在互相爬取,重复的内容很多。一个是爬行,但第二个不一定。至于去重,浪费了一些计算性能,做分词->余弦相似度/主题提取/关键词TF-IDF都可以轻松搞定,总比没有进来好 查看全部
php 爬虫抓取网页数据(做爬虫->相似度/主题提取/关键词-IDF)
我做爬虫的时候,先抓取分类页面,抓取页面下所有分类的列表页url,然后加上种子后缀(也就是页码),开始迭代抓取列表页。在列表页中,我们只关心详情页,所以我们抓取了所有详情页的 URL 并将它们扔到 MQ 中。然后详情页抓取器会循环从MQ中获取详情页url,下整个html,保存在HDFS中。使用 MQ,您可以自己编写分布式架构。
为什么不直接从详情页提取想要的信息(ETL),而是直接保存html(EL)?首先是HDFS分布式文件系统,存储成本极低,解决了海量小文件的问题;其次,如果您提取信息的模式(常规/XPath/...)是错误的怎么办?或者您想稍后添加新的提取模式?您必须再次获取此页面,这会浪费宝贵的外部网络带宽。
另外,对于爬虫来说,最重要的是高度的容错性。除非你认为每个页面都很有价值,如果服务器返回非200,或者页面意外重定向,就放弃这个url。
最有效的爬虫是填满你的外部网络带宽,但这是理想的。抓住满足需求的数量即可。
也不要在车站上吊死自己。例如,我过去常常捕捉新闻。基本上几个主流站都在互相爬取,重复的内容很多。一个是爬行,但第二个不一定。至于去重,浪费了一些计算性能,做分词->余弦相似度/主题提取/关键词TF-IDF都可以轻松搞定,总比没有进来好
php 爬虫抓取网页数据(爬虫在数据分析领域的应用,如何帮助我们提升数据质量)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-09-11 00:15
在当今信息化和数字化时代,人们离不开网络搜索,但想想看,你真的可以在搜索过程中获得相关信息,因为有人在帮你过滤相关内容。并呈现给您。
就像在餐馆里,你点了土豆,你可以吃,因为有人帮你在土豆、萝卜、西红柿等中找到土豆,有些人把土豆带到你的桌子上。在网上,这两个动作是由一个叫爬虫的同学实现的。
也就是说,没有爬虫,就没有今天的检索,也就无法准确的查找信息,有效的获取数据。今天,DataHunter 将谈谈爬虫在数据分析领域的应用,以及它如何帮助我们提高数据分析的质量。
一、数据时代,爬虫的本质是提高效率
网络爬虫也叫网络机器人,可以代替人们自动浏览网络信息、采集、整理数据。
是一种程序,基本原理是向网站/network发起请求,获取资源后,分析提取有用的数据。从技术角度来说,就是通过程序模拟浏览器请求站点的行为,将站点返回的HTML代码/JSON数据/二进制数据(图片、视频)抓取到本地,然后提取你的数据需要,保存以备使用。
每个程序都有自己的规则,网络爬虫也不例外。它穿梭在网站世界各地,会按照人们制定的规则发送采集信息。我们将这些规则称为网络爬虫算法。规则是人定的,是人根据自己的目的和需要设计的。因此,爬虫可以根据用户的目的而具有不同的功能。但所有爬虫的本质都是为了方便人们从海量的互联网信息中找到并下载自己想要的种类,从而提高信息获取的效率。
二、crawler 应用:搜索帮助企业做强业务
1.Search Engine:爬取网站,为网络用户提供便利
互联网发展之初,能提供全球信息的网站并不多,用户也不多。 Internet 只是文件传输协议 (FTP) 站点的集合。用户可以浏览这些站点以查找特定的共享文件。为了查找和组合 Internet 上可用的分布式数据,人们创建了一种称为网络爬虫的自动化程序。 /Robots 可以抓取互联网上的所有网页,然后将所有页面上的内容复制到数据库中进行索引。这也是最早的搜索引擎。
现在随着互联网的飞速发展,我们可以在任何搜索引擎中看到来自世界各地各种网站的信息。百度搜索引擎的爬虫叫Baiduspider,360的爬虫叫360Spider,搜狗的爬虫叫Sogouspider,必应的爬虫叫Bingbot。搜索引擎离不开爬虫。
比如百度蜘蛛每天抓取大量互联网信息,抓取优质信息和收录。当用户在百度搜索引擎上检索到对应的关键词时,百度会对关键词进行分析处理,从收录的网页中找到相关的网页,按照一定的排序规则进行排序,并将结果展示给用户。工作原理如图所示。现在,我们可以大胆地说,您每天都在免费享受爬虫带来的好处。
2.企业:关注舆情,高效获取有价值信息
我们说过爬虫的本质是提高效率,爬虫的规则是人定的;那么企业就可以根据自己的业务需求设计一个爬虫,尽快在网上获取相关信息,并进行清理和整合。
大数据时代的数据分析,首先要有数据源。虽然网络爬虫可以让我们获得更多的数据源,但我们可以根据自己的目的采集,从而去除很多不相关的数据。
比如在进行大数据分析或者数据挖掘时,数据源可以从一些提供统计的网站获取,也可以从一些文献或内部资料中获取。但是这些获取数据的方法有时很难满足我们的数据需求。此时,我们可以利用爬虫技术,自动从互联网上获取更多我们感兴趣的数据内容,从而进行更深入的数据分析,获取更多有价值的信息。
此外,还可以在财务分析中使用网络爬虫对财务数据进行采集进行投资分析;可应用于舆情监测与分析、精准客户精准营销等多个领域。
三、4种企业常用的网络爬虫
网络爬虫根据实现的技术和结构可分为通用网络爬虫、聚焦网络爬虫、增量网络爬虫和深度网络爬虫。但由于网络环境复杂,实际的网络爬虫往往是这几种爬虫的组合。
1.万能网络爬虫
通用网络爬虫也称为全网爬虫。顾名思义,爬取的目标资源在整个互联网。爬取的目标数据庞大,爬取的范围也非常大。正是因为它爬取的数据是海量数据,所以对于这类爬虫,对爬取性能的要求非常高。这种网络爬虫主要用于大型搜索引擎,具有很高的应用价值。
一般的网络爬虫主要由初始URL采集、URL队列、页面爬取模块、页面分析模块、页面数据库、链接过滤模块等组成,一般的网络爬虫在爬取时都会采用一定的爬取策略。有深度优先的爬行策略和广度优先的爬行策略。具体细节稍后介绍。
2.focus 网络爬虫
焦点网络爬虫,也叫主题网络爬虫,是一种根据预定义的主题有选择地抓取网页的爬虫。聚焦网络爬虫主要用于对特定信息的爬取,主要是为特定的人群提供服务。
Focus 网络爬虫还由初始 URL 采集、URL 队列、页面爬取模块、页面分析模块、页面数据库、链接过滤模块、内容评估模块、链接评估模块等组成。其中,内容评估模块和链接评估模块可以根据链接的重要性和内容确定优先访问哪些页面。网络爬虫主要有四种爬虫策略,如图:
Focus 网络爬虫可以有目的地按照相应的主题进行爬取,因此在实际应用过程中,可以节省大量的服务器资源和宽带资源,实用性强。这里以聚焦网络爬虫为例,了解爬虫运行的工作原理和流程。
如图所示,Focus Web Crawler有一个控制中心,负责整个爬虫系统的管理和监控,主要包括控制用户交互、初始化爬虫、确定主题、协调工作各个模块之间,控制爬取过程等方面:
(1)Control Center 会将初始的一组 URL 传递给 URL 队列,页面抓取模块会从 URL 队列中读取第一批 URL 列表;
(2)根据这些URL地址从网上爬取对应的页面;爬取后,将爬取的内容传送到页面数据库中存储;
(3)在爬取过程中,会爬取一些新的URL,这时候就需要使用链接过滤模块根据主题集过滤掉不相关的链接,然后对剩下的使用链接评估根据主题进行网址链接。模块或内容评测模块优先,完成后将新的网址地址传递到网址队列,供页面抓取模块使用;
(4)页面抓取并存入页面数据库后,需要使用页面分析模块根据主题对抓取页面上的页面进行分析,并根据处理结果建立索引数据库。当用户检索到相应的信息时,可以从索引数据库中进行相应的搜索,得到相应的结果。
3.增量网络爬虫
这里的“增量”对应的是增量更新。增量更新是指更新过程中只更新变化的区域,不变的区域不更新。
增量式网络爬虫,在抓取网页时,只会抓取有内容变化的网页或新生成的网页,不会抓取没有内容变化的网页。增量爬虫可以在一定程度上保证爬取的页面尽可能的新鲜。
4.deep 网络爬虫
在互联网中,网页根据存在的方式可以分为表层页和深层页。表面页面是指无需提交表单即可使用静态链接访问的静态页面;而深页是提交一定数量的关键词后才能获得的页面。在互联网中,深层页面的数量往往远大于表面页面的数量。
深度网络爬虫可以抓取互联网上的深度页面,抓取深度页面,需要想办法自动填写相应的表单。深网爬虫主要由URL列表、LVS列表(LVS指标签/值集合,即填写表单的数据源)、爬虫控制器、解析器、LVS控制器、表单分析器、表单处理器、响应分析器等部分组成。
四、Web爬虫抓取策略
之前我们说网络爬虫算法是根据人们强加的规则来获取采集信息的,由于网络环境复杂,有各种对应的算法,即爬虫策略。这里主要介绍爬取的顺序和频率。
1.爬取顺序
网络爬虫在爬取过程中,爬取的URL列表中可能有很多URL地址,所以爬虫爬取这些URL地址会有一个顺序。
和一般的网络爬虫相比,爬取的顺序没那么重要。但是针对网络爬虫来说,爬取的顺序与服务器资源和宽带资源有关,所以非常重要,一般由爬取策略决定。爬取策略主要包括深度优先爬取策略、广度优先爬取策略、大站优先策略、反链策略、其他爬取策略等。
如图,假设有一个网站,ABCDEFG分别为站点下的网页,代表如图所示网页的层次结构。如果此时网页ABCDEFG在抓取队列中,则根据不同的抓取策略,抓取的顺序也不同。
深度优先爬取策略:A→D→E→B→C→F→G
广度优先爬取策略:A→B→C→D→E→F→G
除了以上两种爬取策略,还可以使用大站爬取策略。可以根据相应网页所属的站点进行分类。如果某个网站有大量的网页,就称为大站。按照这个策略,网页数量越多,网站越大,然后优先爬取大网站中网页的URL地址。
还有反链策略。一个网页的反向链接次数是指该网页被其他网页指向的次数,这个数字代表了该网页在一定程度上被其他网页推荐的次数。所以,如果按照反链策略爬取,那么哪个网页反链多,哪个页面会先被爬取。
但是,在实际情况下,如果一个网页的优先级仅由反链策略决定,那么可能存在大量作弊。因此,反向链接策略的使用需要考虑可靠反向链接的数量。除了以上爬取策略,实践中还有很多其他爬取策略,比如OPIC策略、Partial PageRank策略等。
2.爬行频率
网站的网页更新频繁。作为爬虫,网站的更新频率越接近爬虫访问网站的频率,效果就会越好。当然,在爬虫服务器资源有限的情况下,爬虫也需要根据相应的策略,让不同的网页有不同的更新优先级,优先级高的网页会以更快的爬取响应进行更新。常见的网页更新策略主要有以下三种:
(1)用户体验策略:大多数用户在使用搜索引擎查询关键词时,只关注排名靠前的网页。因此,在爬虫服务器资源有限的情况下,爬虫会给priority 更新首页排名结果。
(2)历史数据策略:是指能够根据某个网页的历史更新数据,通过泊松过程建模等手段,预测网页下次更新时间,从而确定下一次更新时间。网页更新时间 抓取时间。
(3)Clustering 分析策略:网页可能有不同的内容,但一般而言,属性相似的网页更新频率相近,因此可以对大量网页进行聚类分析。聚类完成后,可根据同类网页的平均更新值设置抓取频率。
五、网络爬虫的实现技术
对于实现技术,本文不展开,只为感兴趣的同学提供几种常用语言:Python、Java、PHP、Node.JS、C++、Go语言(另外还有很多网络爬虫开发语言)。
Python:爬虫框架非常丰富,多线程处理能力强,简单易学,代码简洁,优点很多。
Java:适合大型爬虫项目的开发。
PHP:后端处理能力很强,代码很简洁,模块也很丰富,但是并发能力比较弱。节点.JS:
支持高并发和多线程处理。
C++:运行速度快,适合开发大型爬虫项目,成本高。
Go 语言:同样高并发性很强。
六、小结
说起爬虫,很多人认为它是网络世界中无法回避的灰色地带。恭喜,看完这篇文章,你比很多人都懂。
因为爬虫分为善意爬虫和恶意爬虫,比如搜索引擎爬虫。好心爬虫严格遵守Robots协议规范抓取网页数据(如URL),它的存在可以增加网站的曝光率,给网站带来流量;
恶意爬虫无视Robots协议,故意爬取网站中的一些深藏不露的数据,包括个人隐私或商业机密等重要信息。而恶意爬虫的用户希望从网站处获取多条、大量的信息,因此通常会向目标网站释放大量爬虫。如果大量爬虫同时访问网站,很容易造成网站服务器过载或崩溃,造成网站运营商流失。
据统计,2017年我国互联网流量的42.2%是由网络机器人造成的,其中恶意机器(主要是恶意爬虫)占21.80%。我们应该依法使用网络爬虫,用技术为企业带来长远发展,用科学为社会创造更高的价值。
关于 DataHunter
DataHunter 是一家专业的数据分析和商业智能服务提供商,注册于 2014 年,团队核心成员来自 IBM、Oracle、SAP 等知名公司。深耕大数据分析领域,拥有十余年丰富的企业服务经验。
DataHunter的核心产品智能数据分析平台Data Analytics、数据大屏设计与配置工具Data MAX在行业内形成了自己独特的优势,在各行业积累了众多标杆客户和成功案例。
DataHunter自成立以来,一直致力于为客户提供实时、高效、智能的数据分析展示解决方案,帮助企业查看、分析数据,提升业务,成为最值得信赖的数据业务公司。
> 查看全部
php 爬虫抓取网页数据(爬虫在数据分析领域的应用,如何帮助我们提升数据质量)
在当今信息化和数字化时代,人们离不开网络搜索,但想想看,你真的可以在搜索过程中获得相关信息,因为有人在帮你过滤相关内容。并呈现给您。

就像在餐馆里,你点了土豆,你可以吃,因为有人帮你在土豆、萝卜、西红柿等中找到土豆,有些人把土豆带到你的桌子上。在网上,这两个动作是由一个叫爬虫的同学实现的。
也就是说,没有爬虫,就没有今天的检索,也就无法准确的查找信息,有效的获取数据。今天,DataHunter 将谈谈爬虫在数据分析领域的应用,以及它如何帮助我们提高数据分析的质量。
一、数据时代,爬虫的本质是提高效率
网络爬虫也叫网络机器人,可以代替人们自动浏览网络信息、采集、整理数据。
是一种程序,基本原理是向网站/network发起请求,获取资源后,分析提取有用的数据。从技术角度来说,就是通过程序模拟浏览器请求站点的行为,将站点返回的HTML代码/JSON数据/二进制数据(图片、视频)抓取到本地,然后提取你的数据需要,保存以备使用。
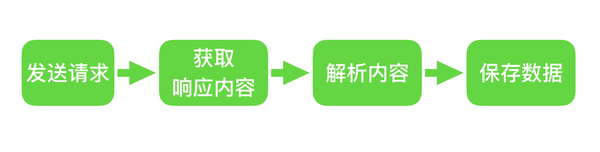
每个程序都有自己的规则,网络爬虫也不例外。它穿梭在网站世界各地,会按照人们制定的规则发送采集信息。我们将这些规则称为网络爬虫算法。规则是人定的,是人根据自己的目的和需要设计的。因此,爬虫可以根据用户的目的而具有不同的功能。但所有爬虫的本质都是为了方便人们从海量的互联网信息中找到并下载自己想要的种类,从而提高信息获取的效率。
二、crawler 应用:搜索帮助企业做强业务
1.Search Engine:爬取网站,为网络用户提供便利
互联网发展之初,能提供全球信息的网站并不多,用户也不多。 Internet 只是文件传输协议 (FTP) 站点的集合。用户可以浏览这些站点以查找特定的共享文件。为了查找和组合 Internet 上可用的分布式数据,人们创建了一种称为网络爬虫的自动化程序。 /Robots 可以抓取互联网上的所有网页,然后将所有页面上的内容复制到数据库中进行索引。这也是最早的搜索引擎。
现在随着互联网的飞速发展,我们可以在任何搜索引擎中看到来自世界各地各种网站的信息。百度搜索引擎的爬虫叫Baiduspider,360的爬虫叫360Spider,搜狗的爬虫叫Sogouspider,必应的爬虫叫Bingbot。搜索引擎离不开爬虫。
比如百度蜘蛛每天抓取大量互联网信息,抓取优质信息和收录。当用户在百度搜索引擎上检索到对应的关键词时,百度会对关键词进行分析处理,从收录的网页中找到相关的网页,按照一定的排序规则进行排序,并将结果展示给用户。工作原理如图所示。现在,我们可以大胆地说,您每天都在免费享受爬虫带来的好处。
2.企业:关注舆情,高效获取有价值信息
我们说过爬虫的本质是提高效率,爬虫的规则是人定的;那么企业就可以根据自己的业务需求设计一个爬虫,尽快在网上获取相关信息,并进行清理和整合。
大数据时代的数据分析,首先要有数据源。虽然网络爬虫可以让我们获得更多的数据源,但我们可以根据自己的目的采集,从而去除很多不相关的数据。

比如在进行大数据分析或者数据挖掘时,数据源可以从一些提供统计的网站获取,也可以从一些文献或内部资料中获取。但是这些获取数据的方法有时很难满足我们的数据需求。此时,我们可以利用爬虫技术,自动从互联网上获取更多我们感兴趣的数据内容,从而进行更深入的数据分析,获取更多有价值的信息。
此外,还可以在财务分析中使用网络爬虫对财务数据进行采集进行投资分析;可应用于舆情监测与分析、精准客户精准营销等多个领域。
三、4种企业常用的网络爬虫
网络爬虫根据实现的技术和结构可分为通用网络爬虫、聚焦网络爬虫、增量网络爬虫和深度网络爬虫。但由于网络环境复杂,实际的网络爬虫往往是这几种爬虫的组合。
1.万能网络爬虫
通用网络爬虫也称为全网爬虫。顾名思义,爬取的目标资源在整个互联网。爬取的目标数据庞大,爬取的范围也非常大。正是因为它爬取的数据是海量数据,所以对于这类爬虫,对爬取性能的要求非常高。这种网络爬虫主要用于大型搜索引擎,具有很高的应用价值。

一般的网络爬虫主要由初始URL采集、URL队列、页面爬取模块、页面分析模块、页面数据库、链接过滤模块等组成,一般的网络爬虫在爬取时都会采用一定的爬取策略。有深度优先的爬行策略和广度优先的爬行策略。具体细节稍后介绍。
2.focus 网络爬虫
焦点网络爬虫,也叫主题网络爬虫,是一种根据预定义的主题有选择地抓取网页的爬虫。聚焦网络爬虫主要用于对特定信息的爬取,主要是为特定的人群提供服务。
Focus 网络爬虫还由初始 URL 采集、URL 队列、页面爬取模块、页面分析模块、页面数据库、链接过滤模块、内容评估模块、链接评估模块等组成。其中,内容评估模块和链接评估模块可以根据链接的重要性和内容确定优先访问哪些页面。网络爬虫主要有四种爬虫策略,如图:
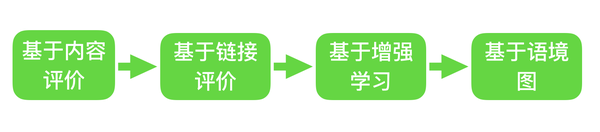
Focus 网络爬虫可以有目的地按照相应的主题进行爬取,因此在实际应用过程中,可以节省大量的服务器资源和宽带资源,实用性强。这里以聚焦网络爬虫为例,了解爬虫运行的工作原理和流程。
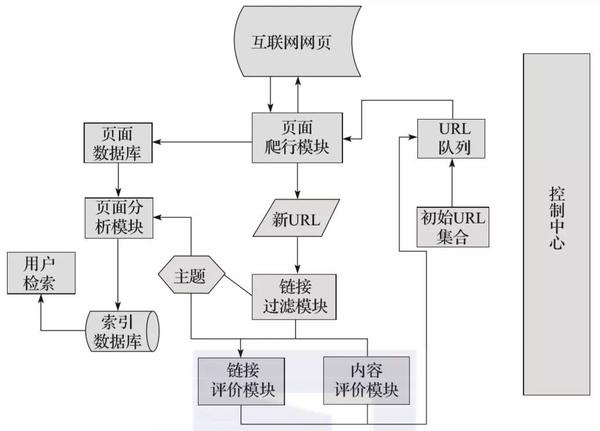
如图所示,Focus Web Crawler有一个控制中心,负责整个爬虫系统的管理和监控,主要包括控制用户交互、初始化爬虫、确定主题、协调工作各个模块之间,控制爬取过程等方面:
(1)Control Center 会将初始的一组 URL 传递给 URL 队列,页面抓取模块会从 URL 队列中读取第一批 URL 列表;
(2)根据这些URL地址从网上爬取对应的页面;爬取后,将爬取的内容传送到页面数据库中存储;
(3)在爬取过程中,会爬取一些新的URL,这时候就需要使用链接过滤模块根据主题集过滤掉不相关的链接,然后对剩下的使用链接评估根据主题进行网址链接。模块或内容评测模块优先,完成后将新的网址地址传递到网址队列,供页面抓取模块使用;
(4)页面抓取并存入页面数据库后,需要使用页面分析模块根据主题对抓取页面上的页面进行分析,并根据处理结果建立索引数据库。当用户检索到相应的信息时,可以从索引数据库中进行相应的搜索,得到相应的结果。
3.增量网络爬虫
这里的“增量”对应的是增量更新。增量更新是指更新过程中只更新变化的区域,不变的区域不更新。
增量式网络爬虫,在抓取网页时,只会抓取有内容变化的网页或新生成的网页,不会抓取没有内容变化的网页。增量爬虫可以在一定程度上保证爬取的页面尽可能的新鲜。
4.deep 网络爬虫
在互联网中,网页根据存在的方式可以分为表层页和深层页。表面页面是指无需提交表单即可使用静态链接访问的静态页面;而深页是提交一定数量的关键词后才能获得的页面。在互联网中,深层页面的数量往往远大于表面页面的数量。

深度网络爬虫可以抓取互联网上的深度页面,抓取深度页面,需要想办法自动填写相应的表单。深网爬虫主要由URL列表、LVS列表(LVS指标签/值集合,即填写表单的数据源)、爬虫控制器、解析器、LVS控制器、表单分析器、表单处理器、响应分析器等部分组成。
四、Web爬虫抓取策略
之前我们说网络爬虫算法是根据人们强加的规则来获取采集信息的,由于网络环境复杂,有各种对应的算法,即爬虫策略。这里主要介绍爬取的顺序和频率。
1.爬取顺序
网络爬虫在爬取过程中,爬取的URL列表中可能有很多URL地址,所以爬虫爬取这些URL地址会有一个顺序。
和一般的网络爬虫相比,爬取的顺序没那么重要。但是针对网络爬虫来说,爬取的顺序与服务器资源和宽带资源有关,所以非常重要,一般由爬取策略决定。爬取策略主要包括深度优先爬取策略、广度优先爬取策略、大站优先策略、反链策略、其他爬取策略等。
如图,假设有一个网站,ABCDEFG分别为站点下的网页,代表如图所示网页的层次结构。如果此时网页ABCDEFG在抓取队列中,则根据不同的抓取策略,抓取的顺序也不同。
深度优先爬取策略:A→D→E→B→C→F→G
广度优先爬取策略:A→B→C→D→E→F→G
除了以上两种爬取策略,还可以使用大站爬取策略。可以根据相应网页所属的站点进行分类。如果某个网站有大量的网页,就称为大站。按照这个策略,网页数量越多,网站越大,然后优先爬取大网站中网页的URL地址。
还有反链策略。一个网页的反向链接次数是指该网页被其他网页指向的次数,这个数字代表了该网页在一定程度上被其他网页推荐的次数。所以,如果按照反链策略爬取,那么哪个网页反链多,哪个页面会先被爬取。
但是,在实际情况下,如果一个网页的优先级仅由反链策略决定,那么可能存在大量作弊。因此,反向链接策略的使用需要考虑可靠反向链接的数量。除了以上爬取策略,实践中还有很多其他爬取策略,比如OPIC策略、Partial PageRank策略等。
2.爬行频率
网站的网页更新频繁。作为爬虫,网站的更新频率越接近爬虫访问网站的频率,效果就会越好。当然,在爬虫服务器资源有限的情况下,爬虫也需要根据相应的策略,让不同的网页有不同的更新优先级,优先级高的网页会以更快的爬取响应进行更新。常见的网页更新策略主要有以下三种:
(1)用户体验策略:大多数用户在使用搜索引擎查询关键词时,只关注排名靠前的网页。因此,在爬虫服务器资源有限的情况下,爬虫会给priority 更新首页排名结果。
(2)历史数据策略:是指能够根据某个网页的历史更新数据,通过泊松过程建模等手段,预测网页下次更新时间,从而确定下一次更新时间。网页更新时间 抓取时间。
(3)Clustering 分析策略:网页可能有不同的内容,但一般而言,属性相似的网页更新频率相近,因此可以对大量网页进行聚类分析。聚类完成后,可根据同类网页的平均更新值设置抓取频率。
五、网络爬虫的实现技术
对于实现技术,本文不展开,只为感兴趣的同学提供几种常用语言:Python、Java、PHP、Node.JS、C++、Go语言(另外还有很多网络爬虫开发语言)。
Python:爬虫框架非常丰富,多线程处理能力强,简单易学,代码简洁,优点很多。
Java:适合大型爬虫项目的开发。
PHP:后端处理能力很强,代码很简洁,模块也很丰富,但是并发能力比较弱。节点.JS:
支持高并发和多线程处理。
C++:运行速度快,适合开发大型爬虫项目,成本高。
Go 语言:同样高并发性很强。
六、小结
说起爬虫,很多人认为它是网络世界中无法回避的灰色地带。恭喜,看完这篇文章,你比很多人都懂。
因为爬虫分为善意爬虫和恶意爬虫,比如搜索引擎爬虫。好心爬虫严格遵守Robots协议规范抓取网页数据(如URL),它的存在可以增加网站的曝光率,给网站带来流量;

恶意爬虫无视Robots协议,故意爬取网站中的一些深藏不露的数据,包括个人隐私或商业机密等重要信息。而恶意爬虫的用户希望从网站处获取多条、大量的信息,因此通常会向目标网站释放大量爬虫。如果大量爬虫同时访问网站,很容易造成网站服务器过载或崩溃,造成网站运营商流失。
据统计,2017年我国互联网流量的42.2%是由网络机器人造成的,其中恶意机器(主要是恶意爬虫)占21.80%。我们应该依法使用网络爬虫,用技术为企业带来长远发展,用科学为社会创造更高的价值。
关于 DataHunter
DataHunter 是一家专业的数据分析和商业智能服务提供商,注册于 2014 年,团队核心成员来自 IBM、Oracle、SAP 等知名公司。深耕大数据分析领域,拥有十余年丰富的企业服务经验。
DataHunter的核心产品智能数据分析平台Data Analytics、数据大屏设计与配置工具Data MAX在行业内形成了自己独特的优势,在各行业积累了众多标杆客户和成功案例。

DataHunter自成立以来,一直致力于为客户提供实时、高效、智能的数据分析展示解决方案,帮助企业查看、分析数据,提升业务,成为最值得信赖的数据业务公司。
>
php 爬虫抓取网页数据( Web爬虫是从的工作原理和关键技术综述:爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 106 次浏览 • 2021-10-31 08:14
Web爬虫是从的工作原理和关键技术综述:爬虫)
爬虫工作原理及关键技术总结:
网络爬虫是一种为搜索引擎从互联网上下载网页的自动提取程序,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页的URL,在网页的爬取过程中不断从当前页面中提取新的URL,直到满足系统的某个停止条件。
与普通网络爬虫相比,聚焦爬虫需要解决三个主要问题:
1、描述或定义爬取目标。
2、分析和过滤网页或数据。
3、搜索网址策略。
如何开发网页分析算法和网址搜索策略是确定爬取目标的基础。其中,Web分析算法和候选URL排序算法是决定搜索引擎提供的服务形式和爬行行为的关键。两者的算法有着密切的联系。
随着大数据的普及,网络爬虫已经成为当今的主流技术。不只是程序员,现在连普通用户都对爬虫有一个简单的认识,知道如何使用代理IP进行爬虫。众所周知,爬虫可以获得网站的信息,那么专注于网络爬虫有什么好处呢?这是爬行技术吗?接下来,我们将开始一个关于如何关注爬虫的事情。
焦点爬虫的工作流程比较复杂。需要按照一定的分析算法过滤掉与主题无关的链接,保留有用的链接,然后放到URL队列中等待被抓取。然后,它会根据特定的搜索策略从队列中选择下一个要抓取的网页网址,并重复上述步骤,直到达到系统的某个标准。
另外,爬虫爬过的所有页面都会存储在系统中,进行一些分析、过滤和索引,以供以后查询检索;对于专注的爬虫,通过这个过程得到的分析结果也可以在后续的爬虫过程中提供反馈和指导。
以上主要介绍了聚焦爬虫的内容。爬虫与它们相似,但也有区别。自然会受到爬虫的限制。在这种情况下,我们需要使用爬虫技术,例如代理IP来帮助我们。
如果想尝试使用代理ip,可以到拼音http代理ip官网了解更多,提供高度隐蔽的稳定代理ip,支持HTTP/HTTPS/SOCKS5代理协议,提供动态IP、静态IP等服务。百兆带宽,千万IP资源,保障爬虫数据传输安全。快速获取网站数据,现在还有免费测试和免费ip活动! 查看全部
php 爬虫抓取网页数据(
Web爬虫是从的工作原理和关键技术综述:爬虫)
爬虫工作原理及关键技术总结:
网络爬虫是一种为搜索引擎从互联网上下载网页的自动提取程序,是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的URL开始,获取初始网页的URL,在网页的爬取过程中不断从当前页面中提取新的URL,直到满足系统的某个停止条件。
与普通网络爬虫相比,聚焦爬虫需要解决三个主要问题:
1、描述或定义爬取目标。
2、分析和过滤网页或数据。
3、搜索网址策略。
如何开发网页分析算法和网址搜索策略是确定爬取目标的基础。其中,Web分析算法和候选URL排序算法是决定搜索引擎提供的服务形式和爬行行为的关键。两者的算法有着密切的联系。
随着大数据的普及,网络爬虫已经成为当今的主流技术。不只是程序员,现在连普通用户都对爬虫有一个简单的认识,知道如何使用代理IP进行爬虫。众所周知,爬虫可以获得网站的信息,那么专注于网络爬虫有什么好处呢?这是爬行技术吗?接下来,我们将开始一个关于如何关注爬虫的事情。
焦点爬虫的工作流程比较复杂。需要按照一定的分析算法过滤掉与主题无关的链接,保留有用的链接,然后放到URL队列中等待被抓取。然后,它会根据特定的搜索策略从队列中选择下一个要抓取的网页网址,并重复上述步骤,直到达到系统的某个标准。
另外,爬虫爬过的所有页面都会存储在系统中,进行一些分析、过滤和索引,以供以后查询检索;对于专注的爬虫,通过这个过程得到的分析结果也可以在后续的爬虫过程中提供反馈和指导。
以上主要介绍了聚焦爬虫的内容。爬虫与它们相似,但也有区别。自然会受到爬虫的限制。在这种情况下,我们需要使用爬虫技术,例如代理IP来帮助我们。
如果想尝试使用代理ip,可以到拼音http代理ip官网了解更多,提供高度隐蔽的稳定代理ip,支持HTTP/HTTPS/SOCKS5代理协议,提供动态IP、静态IP等服务。百兆带宽,千万IP资源,保障爬虫数据传输安全。快速获取网站数据,现在还有免费测试和免费ip活动!
php 爬虫抓取网页数据(精通Python网络爬虫:核心技术、框架与项目实战(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-10-29 01:23
阿里云>云栖社区>主题地图>W>Web爬虫PHP
推荐活动:
更多优惠>
当前主题:网络爬虫 php 添加到采集夹
相关话题:
网络爬虫php相关博客查看更多博客
精通Python网络爬虫:核心技术、框架及项目实战。3.6 网络爬虫实现技术
作者:华章电脑1949浏览评论数:04年前
3.6 网络爬虫实现技术 通过前面的学习,我们基本对爬虫的基础理论知识有了比较全面的了解,那么,想要实现网络爬虫技术,就必须自己开发网络爬虫,你可以使用哪些语言进行开发?开发网络爬虫的语言有很多种。常用语言有:Python、Java、PHP、Node.js。
阅读全文
《精通Python网络爬虫:核心技术、框架与项目实战》——3.6 网络爬虫实现技术
作者:华章电脑 2855人浏览评论:04年前
本节摘自华章出版社《精通Python Web爬虫:核心技术、框架与项目实战》一书第3章,章节3.6,作者魏伟,更多章节可在cloud 查看齐社区“华章电脑”的公众号。3.6 网络爬虫实现技术通过前面的学习,我们基本上对爬虫的基础理论知识有了比较全面的了解
阅读全文
构建网络爬虫?太简单
作者:悠悠悠然1953人浏览评论:05年前
网络爬虫通常用于全文搜索或内容检索。Tiny 框架对此也有有限的支持。虽然功能不多,但是做全文搜索或者从网页获取数据还是很方便的。框架特性,强大的节点过滤能力,支持post和get数据提交方式,避免重复网页处理功能,支持多站点内容抓取功能
阅读全文
精通Python网络爬虫:核心技术、框架及项目实战。3.8总结
作者:华章电脑1550人浏览评论:04年前
3.8Summary1)专注于网络爬虫,因为它们需要有目的地爬取,所以对于一般的网络爬虫来说,需要增加目标的定义和过滤机制。具体来说,此时它的执行原理和流程比一般的网络爬虫还需要3个步骤,即目标的定义、无关链接的过滤、下一步要爬取的URL地址的选择。2)常用网页更新
阅读全文
《精通Python网络爬虫:核心技术、框架与项目实战》——3.8Summary
作者:华章电脑1674人浏览评论:04年前
本节摘自华章出版社《精通Python Web爬虫:核心技术、框架与项目实战》一书第3章,章节3.8,作者魏伟,更多章节可访问云 在Qi社区查看“华章电脑”的公众号。3.8Summary1)关注网络爬虫,因为它们需要被有目的地抓取,所以对于一般的网络爬虫
阅读全文
Java Web爬虫获取网页源代码的原理及实现
作者:旭东的博客 936 浏览评论:08 年前
1.网络爬虫是一个自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址。在爬取网页的过程中,他们不断地从当前页面中提取新的URL并将它们放入队列中,直到满足系统的某个停止条件。2.
阅读全文
大量与网络爬虫相关的库/工具/API
作者:技术小能手1069人浏览评论:02年前
用于用户网页抓取的工具、编程库和 API 的详细列表,包括 Python、PHP、Ruby、JavaScript 等。 Web Scraping 我们使用的工具、编程库和 API 列表
阅读全文
开源爬虫软件总结
作者:club1111683 人浏览评论:06年前
世界上已经形成了数百种爬虫软件。本文梳理了比较知名和常见的开源爬虫软件,并按开发语言进行了总结,如下表所示。虽然搜索引擎也有爬虫,但我这次总结的只是爬虫软件,不是大型复杂的搜索引擎,因为很多兄弟只是想爬取数据,不会操作。
阅读全文
网络爬虫php相关问答
爬虫数据管理【问答集锦】
作者:我是管理员 28342人浏览评论:223年前
互联网上的网络爬虫的自然语言处理的未来是什么?artTemplate:arttemplate生成的页面能爬到数据吗?
阅读全文 查看全部
php 爬虫抓取网页数据(精通Python网络爬虫:核心技术、框架与项目实战(图))
阿里云>云栖社区>主题地图>W>Web爬虫PHP
推荐活动:
更多优惠>
当前主题:网络爬虫 php 添加到采集夹
相关话题:
网络爬虫php相关博客查看更多博客
精通Python网络爬虫:核心技术、框架及项目实战。3.6 网络爬虫实现技术
作者:华章电脑1949浏览评论数:04年前
3.6 网络爬虫实现技术 通过前面的学习,我们基本对爬虫的基础理论知识有了比较全面的了解,那么,想要实现网络爬虫技术,就必须自己开发网络爬虫,你可以使用哪些语言进行开发?开发网络爬虫的语言有很多种。常用语言有:Python、Java、PHP、Node.js。
阅读全文
《精通Python网络爬虫:核心技术、框架与项目实战》——3.6 网络爬虫实现技术
作者:华章电脑 2855人浏览评论:04年前
本节摘自华章出版社《精通Python Web爬虫:核心技术、框架与项目实战》一书第3章,章节3.6,作者魏伟,更多章节可在cloud 查看齐社区“华章电脑”的公众号。3.6 网络爬虫实现技术通过前面的学习,我们基本上对爬虫的基础理论知识有了比较全面的了解
阅读全文
构建网络爬虫?太简单
作者:悠悠悠然1953人浏览评论:05年前
网络爬虫通常用于全文搜索或内容检索。Tiny 框架对此也有有限的支持。虽然功能不多,但是做全文搜索或者从网页获取数据还是很方便的。框架特性,强大的节点过滤能力,支持post和get数据提交方式,避免重复网页处理功能,支持多站点内容抓取功能
阅读全文
精通Python网络爬虫:核心技术、框架及项目实战。3.8总结
作者:华章电脑1550人浏览评论:04年前
3.8Summary1)专注于网络爬虫,因为它们需要有目的地爬取,所以对于一般的网络爬虫来说,需要增加目标的定义和过滤机制。具体来说,此时它的执行原理和流程比一般的网络爬虫还需要3个步骤,即目标的定义、无关链接的过滤、下一步要爬取的URL地址的选择。2)常用网页更新
阅读全文
《精通Python网络爬虫:核心技术、框架与项目实战》——3.8Summary
作者:华章电脑1674人浏览评论:04年前
本节摘自华章出版社《精通Python Web爬虫:核心技术、框架与项目实战》一书第3章,章节3.8,作者魏伟,更多章节可访问云 在Qi社区查看“华章电脑”的公众号。3.8Summary1)关注网络爬虫,因为它们需要被有目的地抓取,所以对于一般的网络爬虫
阅读全文
Java Web爬虫获取网页源代码的原理及实现
作者:旭东的博客 936 浏览评论:08 年前
1.网络爬虫是一个自动提取网页的程序。它从万维网下载网页以供搜索引擎使用。它是搜索引擎的重要组成部分。传统爬虫从一个或多个初始网页的网址开始,获取初始网页上的网址。在爬取网页的过程中,他们不断地从当前页面中提取新的URL并将它们放入队列中,直到满足系统的某个停止条件。2.
阅读全文
大量与网络爬虫相关的库/工具/API
作者:技术小能手1069人浏览评论:02年前
用于用户网页抓取的工具、编程库和 API 的详细列表,包括 Python、PHP、Ruby、JavaScript 等。 Web Scraping 我们使用的工具、编程库和 API 列表
阅读全文
开源爬虫软件总结
作者:club1111683 人浏览评论:06年前
世界上已经形成了数百种爬虫软件。本文梳理了比较知名和常见的开源爬虫软件,并按开发语言进行了总结,如下表所示。虽然搜索引擎也有爬虫,但我这次总结的只是爬虫软件,不是大型复杂的搜索引擎,因为很多兄弟只是想爬取数据,不会操作。
阅读全文
网络爬虫php相关问答
爬虫数据管理【问答集锦】
作者:我是管理员 28342人浏览评论:223年前
互联网上的网络爬虫的自然语言处理的未来是什么?artTemplate:arttemplate生成的页面能爬到数据吗?
阅读全文
php 爬虫抓取网页数据(大数据时代飞速发展如何从庞大数据中整理出自己需要的数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 75 次浏览 • 2021-10-27 05:21
随着大数据时代的飞速发展,爬虫爬取显得尤为重要,尤其是对于急需转型的传统企业和急需发展的中小企业。那么我们应该如何从海量数据中梳理出我们需要的数据呢?下面就说说几个爬虫在爬取过程中可能会遇到的几个问题。
1、网页不定时更新
互联网上的信息是不断更新的,所以我们在爬取信息的过程中需要定期进行操作,也就是说我们需要设置爬取信息的时间间隔,避免爬取网站的服务器更新,以及所有我们做的都没用。
2、一些网站块爬虫
部分网站会设置反爬取程序,防止恶意爬取。您会发现浏览器上显示了很多数据,但无法捕获。
3、 乱码问题
当然,我们成功抓取网页信息后,是不可能顺利进行数据分析的。很多时候,我们抓取网页信息后,会发现抓取的信息是乱码。
4、数据分析
其实到此,我们的工作基本上已经成功了一半以上,但是数据分析的工作量非常大,完成一个庞大的数据分析需要花费很多时间。
那么当我们真的遇到这些问题的时候该怎么办呢?
首先我们要明白,爬虫爬行必须在合法的范围内进行。你可以借鉴别人的各种数据和信息,但不要照原样照搬。毕竟,别人努力写数据和各种材料是很困难的。当然,爬虫爬取需要一个可以正常运行的程序。如果可以自己编写,最好运行一下。如果不能,网上会有很多教程和源码,但是后期实际出现的问题还是需要自己操作,比如:浏览器正常显示信息,但是不能我们抓取后可以正常显示。这时候就需要查看http头信息,需要分析选择哪种压缩方式,后面我们需要选择一些实用的解析工具。对于没有技术经验的人来说,确实很难。
为了让大家更好的抓取信息,开发了很多专业的采集器和软件,比如Rabbit Dynamic IP软件,和很多知名公司都有合作,包括前期设置和ip服务,包括后期数据分析工作,可轻松操作。
总之,无论是手动爬取还是软件爬取,都需要足够的耐心和坚持。 查看全部
php 爬虫抓取网页数据(大数据时代飞速发展如何从庞大数据中整理出自己需要的数据)
随着大数据时代的飞速发展,爬虫爬取显得尤为重要,尤其是对于急需转型的传统企业和急需发展的中小企业。那么我们应该如何从海量数据中梳理出我们需要的数据呢?下面就说说几个爬虫在爬取过程中可能会遇到的几个问题。
1、网页不定时更新
互联网上的信息是不断更新的,所以我们在爬取信息的过程中需要定期进行操作,也就是说我们需要设置爬取信息的时间间隔,避免爬取网站的服务器更新,以及所有我们做的都没用。
2、一些网站块爬虫
部分网站会设置反爬取程序,防止恶意爬取。您会发现浏览器上显示了很多数据,但无法捕获。
3、 乱码问题
当然,我们成功抓取网页信息后,是不可能顺利进行数据分析的。很多时候,我们抓取网页信息后,会发现抓取的信息是乱码。
4、数据分析
其实到此,我们的工作基本上已经成功了一半以上,但是数据分析的工作量非常大,完成一个庞大的数据分析需要花费很多时间。
那么当我们真的遇到这些问题的时候该怎么办呢?
首先我们要明白,爬虫爬行必须在合法的范围内进行。你可以借鉴别人的各种数据和信息,但不要照原样照搬。毕竟,别人努力写数据和各种材料是很困难的。当然,爬虫爬取需要一个可以正常运行的程序。如果可以自己编写,最好运行一下。如果不能,网上会有很多教程和源码,但是后期实际出现的问题还是需要自己操作,比如:浏览器正常显示信息,但是不能我们抓取后可以正常显示。这时候就需要查看http头信息,需要分析选择哪种压缩方式,后面我们需要选择一些实用的解析工具。对于没有技术经验的人来说,确实很难。
为了让大家更好的抓取信息,开发了很多专业的采集器和软件,比如Rabbit Dynamic IP软件,和很多知名公司都有合作,包括前期设置和ip服务,包括后期数据分析工作,可轻松操作。
总之,无论是手动爬取还是软件爬取,都需要足够的耐心和坚持。
php 爬虫抓取网页数据(Python爬虫技术的门道web是web原创内容生态的元凶)
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2021-10-25 21:09
Python爬虫爬虫技术的门道是什么?很多新手对此都不是很清楚。为了帮助您解决这个问题,下面小编将为您详细解说。有这方面需求的可以过来学习。我希望你可以。收获。
Python爬虫爬虫技术的门道
网络是一个开放的平台,这也为网络从90年代初诞生到今天的蓬勃发展奠定了基础。然而,作为所谓的成败,开放的特性、搜索引擎、易学的html和css技术,使网络成为互联网领域最流行、最成熟的信息传播媒介;但是现在作为商业软件,web平台上的内容信息的版权是没有保障的,因为相比于软件客户端,你的网页内容可以通过一些以极低的成本实现的爬虫程序获取,技术门槛低。这也是本系列文章要讨论的话题——网络爬虫。
很多人认为,网络应该始终遵循开放的精神,页面上呈现的信息应该毫无保留地与整个互联网共享。但是,我认为在IT行业发展到今天,网络已经不再是当时与pdf竞争的所谓“超文本”信息载体。它已经基于轻量级客户端软件的意识形态。存在。在商业软件发展的今天,网络不得不面对知识产权保护的问题。试想一下,如果原创的优质内容得不到保护,网络世界中的抄袭和盗版猖獗。这其实是网络生态的健康发展。不利,难以鼓励生产更多优质原创
未经授权的爬虫程序是危害网络内容生态的罪魁祸首原创。因此,要保护网站的内容,首先要考虑如何反爬虫。
从爬行动物的攻防来看
最简单的爬虫是几乎所有服务器端和客户端编程语言都支持的http请求。只要向目标页面的url发起http get请求,浏览器加载这个页面时就可以获取到完整的html文档。我们称之为“同步页面”。
作为防御方,服务器可以根据http请求头中的User-Agent检查客户端是合法的浏览器程序还是脚本爬取程序,从而判断是否改变真实的页面信息内容发送给你.
这当然是最小的儿科防御方法。作为进攻方,爬虫可以伪造 User-Agent 字段。即使你想要,在http get方法中,请求头的Referrer、Cookie等,所有字段爬虫都可以轻松伪造。
此时服务端可以使用浏览器的http头指纹,根据你声明的浏览器厂商和版本(来自User-Agent),来识别你的http头中的各个字段是否符合浏览器的特性,如果不符合要求,它将被视为爬虫。该技术的一个典型应用是 PhantomJS 1.x 版本。由于底层调用了Qt框架网络库,所以http头中有明显的Qt框架网络请求特征,可以被服务器直接识别。并拦截。
另外还有一个比较异常的服务端爬虫检测机制,就是在对页面的所有http请求的http响应中植入一个cookie token,然后在这个页面异步执行的一些ajax接口中进行检查。检查访问请求中是否收录cookie token,返回token表示这是一次合法的浏览器访问,否则表示刚刚发出token的用户访问了页面html但是没有访问到执行js后调用的ajax在 html 中的请求很可能是爬虫。
如果直接访问一个没有token的接口,说明你没有请求html页面,直接向页面中应该通过ajax访问的接口发起网络请求。这显然证明你是一个可疑的爬虫。知名电商网站亚马逊采用了这种防御策略。
以上是一些基于服务端验证爬虫程序可以播放的例程。
基于客户端js运行时的检测
现代浏览器赋予了 JavaScript 强大的能力,所以我们可以把页面的所有核心内容都变成 js 异步请求 Ajax 获取数据然后渲染到页面上,这显然提高了爬虫爬取内容的门槛。依靠这种方式,我们将对抗爬虫和反爬虫的战场从服务端转移到了客户端浏览器中的js运行时。接下来说一下结合客户端js运行时的爬虫爬取技术。
刚才提到的各种服务端验证,对于普通python和java语言编写的HTTP爬虫程序都有一定的技术门槛。毕竟,Web 应用程序是未经授权的爬虫的黑匣子。很多东西都需要一点一点的去尝试,大量的人力物力都花在了开发一套爬虫程序上。作为网站的防御方,只要容易调整一些策略,攻击者就需要再次花费相同的时间来修改爬虫的爬取逻辑。.
这时候就需要无头浏览器了。这是一种什么样的技术?其实说白了就是让程序操作浏览器来访问网页,这样写爬虫的人就可以通过调用浏览器暴露给程序的api来实现复杂的爬虫业务逻辑。
事实上,这并不是近年来的新技术。曾经有基于webkit内核的PhantomJS,基于Firefox浏览器内核的SlimerJS,甚至还有基于IE内核的trifleJS。如果您有兴趣,可以在此处和此处查看两个无头浏览器。采集清单。
这些无头浏览器程序的实现原理,其实就是将一些开源的浏览器核心C++代码进行改造和封装,实现一个简单的浏览器程序,无需GUI界面渲染。但是这些项目的共同问题是,因为他们的代码是基于官方fork webkit等内核的某个版本的主干代码,无法跟进一些最新的css属性和js语法,并且有一些兼容性问题,不如真实的。GUI浏览器发行版运行稳定。
其中,最成熟、最常用的应该是PhantonJS。关于这种爬虫的识别我之前写过一篇博文,这里不再赘述。PhantomJS 有很多问题,因为是单进程模型,没有必要的沙箱保护,浏览器内核的安全性较差。此外,该项目的作者已宣布将停止维护该项目。
现在谷歌 Chrome 团队已经在 Chrome 59 发布版本中开放了 headless 模式 api,并开源了一个基于 Node.js 调用的 headless chrome 驱动程序库。我还为这个库贡献了一个centos环境部署依赖安装列表。
Headless Chrome 可谓是 Headless Browser 中独一无二的大杀器。因为它本身是一个 chrome 浏览器,所以它支持各种新的 CSS 渲染功能和 js 运行时语法。
基于这种方法,作为进攻方的爬虫可以绕过几乎所有的服务器端验证逻辑,但是这些爬虫在客户端js运行时仍然存在一些缺陷,例如:
基于插件对象检查
if(navigator.plugins.length === 0) {
console.log('It may be Chrome headless');
}
基于语言的检查
if(navigator.languages === '') {
console.log('Chrome headless detected');
}
基于 Webgl 的检查
var canvas = document.createElement('canvas');
var gl = canvas.getContext('webgl');
var debugInfo = gl.getExtension('WEBGL_debug_renderer_info');
var vendor = gl.getParameter(debugInfo.UNMASKED_VENDOR_WEBGL);
var renderer = gl.getParameter(debugInfo.UNMASKED_RENDERER_WEBGL);
if(vendor == 'Brian Paul' && renderer == 'Mesa OffScreen') {
console.log('Chrome headless detected');
}
根据浏览器细线特征检查
if(!Modernizr['hairline']) {
console.log('It may be Chrome headless');
}
检查根据错误的 img src 属性生成的 img 对象
根据以上一些浏览器特性的判断,基本可以杀掉市面上大部分的Headless Browser程序。在这个层面上,它实际上提高了网络爬虫的门槛,要求编写爬虫的开发者必须修改浏览器内核的C++代码,重新编译浏览器。此外,上述功能是特定于浏览器的。内核的变化其实不小。如果你曾经尝试过编译 Blink 内核或者 Gecko 内核,你就会明白对于一个“脚本小子”来说有多难~
此外,我们还可以根据浏览器 UserAgent 字段中描述的浏览器品牌、版本和型号信息,检查 js 运行时、DOM 和 BOM 的每个原生对象的属性和方法,观察其特性是否与浏览一致这个版本的设备应该具备的特性。
这种方法被称为浏览器指纹检测技术,它依靠大型网站来采集各类浏览器的api信息。作为编写爬虫程序的进攻方,你可以在 Headless Browser 运行时中预先注入一些 js 逻辑,从而锻造浏览器的特性。
另外,在研究浏览器端使用js api进行Robots Browser Detect时,我们发现了一个有趣的技巧。您可以将预先注入的 js 函数伪装成 Native Function。看看下面的代码:
var fakeAlert = (function(){}).bind(null);
console.log(window.alert.toString()); // function alert() { [native code] }
console.log(fakeAlert.toString()); // function () { [native code] }
爬虫攻击者可能会预先注入一些js方法,用代理函数包裹一些原生api作为钩子,然后利用这个假js api覆盖原生api。如果防御者根据toString函数后的[native code]的检查来判断这个,那么就会绕过。所以需要更严格的检查,因为bind(null)的伪造方法在toString之后没有携带函数名,所以需要检查toString之后的函数名是否为空。
这个技术有什么用?这是一个扩展。反爬虫卫士有Robot Detect方法,在js运行时主动抛出告警。副本可以写一些与业务逻辑相关的东西。当一个普通用户点击OK按钮时,肯定会有1s甚至更长的延迟,因为浏览器中的alert会阻塞js代码的运行(实际上在v8中他会以类似的方式暂停这个isolate上下文的执行)进程挂起),所以作为攻击者的爬虫程序可以选择使用上述技巧在页面所有js运行前预注入一段js代码,钩住alert、prompt、confirm等所有弹窗方法. 如果防御者在弹出代码之前首先检查他调用的警报方法不是原生的,则道路被阻塞。
防爬虫银弹
目前防抢和机器人检测最可靠的方法是验证码技术。但是,验证码并不意味着必须强制用户输入一系列字母数字。还有很多基于用户鼠标、触摸屏(移动终端)等行为的行为验证技术。其中最成熟的是基于机器学习的 Google reCAPTCHA。区分用户和爬虫。
基于以上多种识别和区分用户和爬虫的技术,网站的防御者最终需要做的就是对该ip的访问用户进行屏蔽或强加高强度验证码策略. 因此,攻击者必须购买一个ip代理池来捕获网站的内容,否则单个ip地址很容易被拦截而无法捕获。爬虫和反爬虫的门槛提高到了ip代理池的经济成本水平。
机器人协议
此外,在爬虫爬行技术领域还有一种“白道”方法,叫做robots协议。Allow 和 Disallow 声明每个 UA 爬虫的爬取权限。
不过,这只是君子之约。虽然具有法律利益,但只能限制商业搜索引擎的蜘蛛程序。你不能限制那些“野生爬虫”。
网页内容的爬取和反控,注定是一场一尺高一丈的猫捉老鼠游戏。你永远无法用某种技术完全封锁爬虫程序。你所能做的就是增加攻击。用户的爬取成本,更准确地获知未授权的爬取行为。
看完以上内容对你有帮助吗?如果您想了解更多相关知识或阅读更多相关文章,请关注易速云行业资讯频道,感谢您对易速云的支持。 查看全部
php 爬虫抓取网页数据(Python爬虫技术的门道web是web原创内容生态的元凶)
Python爬虫爬虫技术的门道是什么?很多新手对此都不是很清楚。为了帮助您解决这个问题,下面小编将为您详细解说。有这方面需求的可以过来学习。我希望你可以。收获。
Python爬虫爬虫技术的门道
网络是一个开放的平台,这也为网络从90年代初诞生到今天的蓬勃发展奠定了基础。然而,作为所谓的成败,开放的特性、搜索引擎、易学的html和css技术,使网络成为互联网领域最流行、最成熟的信息传播媒介;但是现在作为商业软件,web平台上的内容信息的版权是没有保障的,因为相比于软件客户端,你的网页内容可以通过一些以极低的成本实现的爬虫程序获取,技术门槛低。这也是本系列文章要讨论的话题——网络爬虫。
很多人认为,网络应该始终遵循开放的精神,页面上呈现的信息应该毫无保留地与整个互联网共享。但是,我认为在IT行业发展到今天,网络已经不再是当时与pdf竞争的所谓“超文本”信息载体。它已经基于轻量级客户端软件的意识形态。存在。在商业软件发展的今天,网络不得不面对知识产权保护的问题。试想一下,如果原创的优质内容得不到保护,网络世界中的抄袭和盗版猖獗。这其实是网络生态的健康发展。不利,难以鼓励生产更多优质原创
未经授权的爬虫程序是危害网络内容生态的罪魁祸首原创。因此,要保护网站的内容,首先要考虑如何反爬虫。
从爬行动物的攻防来看
最简单的爬虫是几乎所有服务器端和客户端编程语言都支持的http请求。只要向目标页面的url发起http get请求,浏览器加载这个页面时就可以获取到完整的html文档。我们称之为“同步页面”。
作为防御方,服务器可以根据http请求头中的User-Agent检查客户端是合法的浏览器程序还是脚本爬取程序,从而判断是否改变真实的页面信息内容发送给你.
这当然是最小的儿科防御方法。作为进攻方,爬虫可以伪造 User-Agent 字段。即使你想要,在http get方法中,请求头的Referrer、Cookie等,所有字段爬虫都可以轻松伪造。
此时服务端可以使用浏览器的http头指纹,根据你声明的浏览器厂商和版本(来自User-Agent),来识别你的http头中的各个字段是否符合浏览器的特性,如果不符合要求,它将被视为爬虫。该技术的一个典型应用是 PhantomJS 1.x 版本。由于底层调用了Qt框架网络库,所以http头中有明显的Qt框架网络请求特征,可以被服务器直接识别。并拦截。
另外还有一个比较异常的服务端爬虫检测机制,就是在对页面的所有http请求的http响应中植入一个cookie token,然后在这个页面异步执行的一些ajax接口中进行检查。检查访问请求中是否收录cookie token,返回token表示这是一次合法的浏览器访问,否则表示刚刚发出token的用户访问了页面html但是没有访问到执行js后调用的ajax在 html 中的请求很可能是爬虫。
如果直接访问一个没有token的接口,说明你没有请求html页面,直接向页面中应该通过ajax访问的接口发起网络请求。这显然证明你是一个可疑的爬虫。知名电商网站亚马逊采用了这种防御策略。
以上是一些基于服务端验证爬虫程序可以播放的例程。
基于客户端js运行时的检测
现代浏览器赋予了 JavaScript 强大的能力,所以我们可以把页面的所有核心内容都变成 js 异步请求 Ajax 获取数据然后渲染到页面上,这显然提高了爬虫爬取内容的门槛。依靠这种方式,我们将对抗爬虫和反爬虫的战场从服务端转移到了客户端浏览器中的js运行时。接下来说一下结合客户端js运行时的爬虫爬取技术。
刚才提到的各种服务端验证,对于普通python和java语言编写的HTTP爬虫程序都有一定的技术门槛。毕竟,Web 应用程序是未经授权的爬虫的黑匣子。很多东西都需要一点一点的去尝试,大量的人力物力都花在了开发一套爬虫程序上。作为网站的防御方,只要容易调整一些策略,攻击者就需要再次花费相同的时间来修改爬虫的爬取逻辑。.
这时候就需要无头浏览器了。这是一种什么样的技术?其实说白了就是让程序操作浏览器来访问网页,这样写爬虫的人就可以通过调用浏览器暴露给程序的api来实现复杂的爬虫业务逻辑。
事实上,这并不是近年来的新技术。曾经有基于webkit内核的PhantomJS,基于Firefox浏览器内核的SlimerJS,甚至还有基于IE内核的trifleJS。如果您有兴趣,可以在此处和此处查看两个无头浏览器。采集清单。
这些无头浏览器程序的实现原理,其实就是将一些开源的浏览器核心C++代码进行改造和封装,实现一个简单的浏览器程序,无需GUI界面渲染。但是这些项目的共同问题是,因为他们的代码是基于官方fork webkit等内核的某个版本的主干代码,无法跟进一些最新的css属性和js语法,并且有一些兼容性问题,不如真实的。GUI浏览器发行版运行稳定。
其中,最成熟、最常用的应该是PhantonJS。关于这种爬虫的识别我之前写过一篇博文,这里不再赘述。PhantomJS 有很多问题,因为是单进程模型,没有必要的沙箱保护,浏览器内核的安全性较差。此外,该项目的作者已宣布将停止维护该项目。
现在谷歌 Chrome 团队已经在 Chrome 59 发布版本中开放了 headless 模式 api,并开源了一个基于 Node.js 调用的 headless chrome 驱动程序库。我还为这个库贡献了一个centos环境部署依赖安装列表。
Headless Chrome 可谓是 Headless Browser 中独一无二的大杀器。因为它本身是一个 chrome 浏览器,所以它支持各种新的 CSS 渲染功能和 js 运行时语法。
基于这种方法,作为进攻方的爬虫可以绕过几乎所有的服务器端验证逻辑,但是这些爬虫在客户端js运行时仍然存在一些缺陷,例如:
基于插件对象检查
if(navigator.plugins.length === 0) {
console.log('It may be Chrome headless');
}
基于语言的检查
if(navigator.languages === '') {
console.log('Chrome headless detected');
}
基于 Webgl 的检查
var canvas = document.createElement('canvas');
var gl = canvas.getContext('webgl');
var debugInfo = gl.getExtension('WEBGL_debug_renderer_info');
var vendor = gl.getParameter(debugInfo.UNMASKED_VENDOR_WEBGL);
var renderer = gl.getParameter(debugInfo.UNMASKED_RENDERER_WEBGL);
if(vendor == 'Brian Paul' && renderer == 'Mesa OffScreen') {
console.log('Chrome headless detected');
}
根据浏览器细线特征检查
if(!Modernizr['hairline']) {
console.log('It may be Chrome headless');
}
检查根据错误的 img src 属性生成的 img 对象
根据以上一些浏览器特性的判断,基本可以杀掉市面上大部分的Headless Browser程序。在这个层面上,它实际上提高了网络爬虫的门槛,要求编写爬虫的开发者必须修改浏览器内核的C++代码,重新编译浏览器。此外,上述功能是特定于浏览器的。内核的变化其实不小。如果你曾经尝试过编译 Blink 内核或者 Gecko 内核,你就会明白对于一个“脚本小子”来说有多难~
此外,我们还可以根据浏览器 UserAgent 字段中描述的浏览器品牌、版本和型号信息,检查 js 运行时、DOM 和 BOM 的每个原生对象的属性和方法,观察其特性是否与浏览一致这个版本的设备应该具备的特性。
这种方法被称为浏览器指纹检测技术,它依靠大型网站来采集各类浏览器的api信息。作为编写爬虫程序的进攻方,你可以在 Headless Browser 运行时中预先注入一些 js 逻辑,从而锻造浏览器的特性。
另外,在研究浏览器端使用js api进行Robots Browser Detect时,我们发现了一个有趣的技巧。您可以将预先注入的 js 函数伪装成 Native Function。看看下面的代码:
var fakeAlert = (function(){}).bind(null);
console.log(window.alert.toString()); // function alert() { [native code] }
console.log(fakeAlert.toString()); // function () { [native code] }
爬虫攻击者可能会预先注入一些js方法,用代理函数包裹一些原生api作为钩子,然后利用这个假js api覆盖原生api。如果防御者根据toString函数后的[native code]的检查来判断这个,那么就会绕过。所以需要更严格的检查,因为bind(null)的伪造方法在toString之后没有携带函数名,所以需要检查toString之后的函数名是否为空。
这个技术有什么用?这是一个扩展。反爬虫卫士有Robot Detect方法,在js运行时主动抛出告警。副本可以写一些与业务逻辑相关的东西。当一个普通用户点击OK按钮时,肯定会有1s甚至更长的延迟,因为浏览器中的alert会阻塞js代码的运行(实际上在v8中他会以类似的方式暂停这个isolate上下文的执行)进程挂起),所以作为攻击者的爬虫程序可以选择使用上述技巧在页面所有js运行前预注入一段js代码,钩住alert、prompt、confirm等所有弹窗方法. 如果防御者在弹出代码之前首先检查他调用的警报方法不是原生的,则道路被阻塞。
防爬虫银弹
目前防抢和机器人检测最可靠的方法是验证码技术。但是,验证码并不意味着必须强制用户输入一系列字母数字。还有很多基于用户鼠标、触摸屏(移动终端)等行为的行为验证技术。其中最成熟的是基于机器学习的 Google reCAPTCHA。区分用户和爬虫。
基于以上多种识别和区分用户和爬虫的技术,网站的防御者最终需要做的就是对该ip的访问用户进行屏蔽或强加高强度验证码策略. 因此,攻击者必须购买一个ip代理池来捕获网站的内容,否则单个ip地址很容易被拦截而无法捕获。爬虫和反爬虫的门槛提高到了ip代理池的经济成本水平。
机器人协议
此外,在爬虫爬行技术领域还有一种“白道”方法,叫做robots协议。Allow 和 Disallow 声明每个 UA 爬虫的爬取权限。
不过,这只是君子之约。虽然具有法律利益,但只能限制商业搜索引擎的蜘蛛程序。你不能限制那些“野生爬虫”。
网页内容的爬取和反控,注定是一场一尺高一丈的猫捉老鼠游戏。你永远无法用某种技术完全封锁爬虫程序。你所能做的就是增加攻击。用户的爬取成本,更准确地获知未授权的爬取行为。
看完以上内容对你有帮助吗?如果您想了解更多相关知识或阅读更多相关文章,请关注易速云行业资讯频道,感谢您对易速云的支持。
php 爬虫抓取网页数据(PHP解析器和PHP相比较,python适合做爬虫吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 59 次浏览 • 2021-10-22 20:20
对比python和PHP,python适合爬取。原因如下
抓取网页本身的界面
与java、c#、C++、python等其他静态编程语言相比,抓取网页文档的界面更加简洁;相较于其他动态脚本语言,如 perl、shell,python 的 urllib2 包提供了更完整的 web 文档 API 访问。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站都是为了生硬爬取而被屏蔽的。这就是我们需要模拟用户代理的行为来构造合适的请求的地方,比如模拟用户登录,模拟session/cookies的存储和设置。python中有很好的第三方包帮你搞定,比如Requests,mechanize
爬行后处理
抓取到的网页通常需要进行处理,如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用很短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要python。
Py 在 Linux 上使用时非常强大,而且语言非常简单。
NO.1 快速开发(唯一能比python开发效率更高的语言是rudy) 语言简洁,没有那么多技巧,所以非常清晰易读。
NO.2 跨平台(由于python的开源,比java更能体现“一次编写,到处运行”
NO.3 解释(无需直接编译、运行/调试代码)
NO.4 框架选择太多(主要的GUI框架有wxPython、tkInter、PyGtk、PyQt。
PHP脚本主要用于以下三个方面:
服务器端脚本。这是PHP最传统也是最主要的目标领域。要进行这项工作,需要具备以下三点:PHP解析器(CGI或服务器模块)、web
服务器和网络浏览器。运行web服务器时需要安装配置PHP,然后可以使用web浏览器访问PHP程序的输出,即浏览服务
PHP 页面在最后。如果您只是在尝试 PHP 编程,所有这些都可以在您的家用计算机上运行。有关更多信息,请参阅安装章节。命令行脚本。
您可以编写一个 PHP 脚本,并且不需要任何服务器或浏览器来运行它。这样,只需要PHP解析器就可以执行。这种用法是
是 cron(Unix 或 Linux 环境)或 Task Scheduler(Windows 环境)日常运行脚本的理想选择。这些脚本也可用于处理
管理简单的文本。更多信息请参考 PHP 的命令行模式。编写桌面应用程序。对于具有图形界面的桌面应用程序,PHP 可能不会
最好的语言之一,但是如果用户非常精通PHP并且想在客户端应用程序中使用PHP的一些高级功能,他们可以使用PHP-GTK来编写这个
这些程序。这样,您也可以编写跨平台的应用程序。PHP-GTK 是 PHP 的扩展,通常发布的 PHP 包中不收录它。
网友的观点扩大了:
我用PHP Node.js Python写了一个爬虫脚本,简单说一下。
首先是PHP。先说优点:网上大量爬取解析html框架,各种工具都可以直接使用,比较省心。缺点:首先,速度/效率是个问题。有一次下载电影海报的时候,因为crontab定时执行,没有优化,打开的php进程太多,直接导致内存爆了。然后语法也很拖沓,各种关键词符号太多,不够简洁,给人一种没有精心设计的感觉,写起来很麻烦。
节点.js。优点是效率,效率还是效率。因为网络是异步的,所以基本上和并发数百个进程一样强大。内存和CPU使用量非常小。如果对捕获的数据没有进行复杂的计算和处理,那么系统就会成为瓶颈。基本上就是写入MySQL等数据库的带宽和I/O速度。当然,优点的反面也是缺点。异步网络意味着您需要回调。这时候,如果业务需求是线性的,比如你必须等上一页爬完,拿到数据后才能爬到下一页,甚至更多。层依赖,会有可怕的多层回调!基本上这个时候代码结构和逻辑就会乱了。当然,
最后,让我们谈谈Python。如果你对效率没有极端的要求,那么推荐Python!首先,Python 的语法非常简洁,同一个句子可以少打很多次。然后,Python非常适合数据处理,比如函数参数的打包和解包,列表分析,矩阵处理,非常方便。
至此,这篇关于python和php的更适合写爬虫的文章介绍到这里。更多适合爬取内容的php和python相关内容,请搜索ZaLou.Cn之前的文章或继续浏览下方相关文章,希望大家多多支持ZaLou.Cn! 查看全部
php 爬虫抓取网页数据(PHP解析器和PHP相比较,python适合做爬虫吗?)
对比python和PHP,python适合爬取。原因如下
抓取网页本身的界面
与java、c#、C++、python等其他静态编程语言相比,抓取网页文档的界面更加简洁;相较于其他动态脚本语言,如 perl、shell,python 的 urllib2 包提供了更完整的 web 文档 API 访问。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站都是为了生硬爬取而被屏蔽的。这就是我们需要模拟用户代理的行为来构造合适的请求的地方,比如模拟用户登录,模拟session/cookies的存储和设置。python中有很好的第三方包帮你搞定,比如Requests,mechanize
爬行后处理
抓取到的网页通常需要进行处理,如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用很短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要python。
Py 在 Linux 上使用时非常强大,而且语言非常简单。
NO.1 快速开发(唯一能比python开发效率更高的语言是rudy) 语言简洁,没有那么多技巧,所以非常清晰易读。
NO.2 跨平台(由于python的开源,比java更能体现“一次编写,到处运行”
NO.3 解释(无需直接编译、运行/调试代码)
NO.4 框架选择太多(主要的GUI框架有wxPython、tkInter、PyGtk、PyQt。
PHP脚本主要用于以下三个方面:
服务器端脚本。这是PHP最传统也是最主要的目标领域。要进行这项工作,需要具备以下三点:PHP解析器(CGI或服务器模块)、web
服务器和网络浏览器。运行web服务器时需要安装配置PHP,然后可以使用web浏览器访问PHP程序的输出,即浏览服务
PHP 页面在最后。如果您只是在尝试 PHP 编程,所有这些都可以在您的家用计算机上运行。有关更多信息,请参阅安装章节。命令行脚本。
您可以编写一个 PHP 脚本,并且不需要任何服务器或浏览器来运行它。这样,只需要PHP解析器就可以执行。这种用法是
是 cron(Unix 或 Linux 环境)或 Task Scheduler(Windows 环境)日常运行脚本的理想选择。这些脚本也可用于处理
管理简单的文本。更多信息请参考 PHP 的命令行模式。编写桌面应用程序。对于具有图形界面的桌面应用程序,PHP 可能不会
最好的语言之一,但是如果用户非常精通PHP并且想在客户端应用程序中使用PHP的一些高级功能,他们可以使用PHP-GTK来编写这个
这些程序。这样,您也可以编写跨平台的应用程序。PHP-GTK 是 PHP 的扩展,通常发布的 PHP 包中不收录它。
网友的观点扩大了:
我用PHP Node.js Python写了一个爬虫脚本,简单说一下。
首先是PHP。先说优点:网上大量爬取解析html框架,各种工具都可以直接使用,比较省心。缺点:首先,速度/效率是个问题。有一次下载电影海报的时候,因为crontab定时执行,没有优化,打开的php进程太多,直接导致内存爆了。然后语法也很拖沓,各种关键词符号太多,不够简洁,给人一种没有精心设计的感觉,写起来很麻烦。
节点.js。优点是效率,效率还是效率。因为网络是异步的,所以基本上和并发数百个进程一样强大。内存和CPU使用量非常小。如果对捕获的数据没有进行复杂的计算和处理,那么系统就会成为瓶颈。基本上就是写入MySQL等数据库的带宽和I/O速度。当然,优点的反面也是缺点。异步网络意味着您需要回调。这时候,如果业务需求是线性的,比如你必须等上一页爬完,拿到数据后才能爬到下一页,甚至更多。层依赖,会有可怕的多层回调!基本上这个时候代码结构和逻辑就会乱了。当然,
最后,让我们谈谈Python。如果你对效率没有极端的要求,那么推荐Python!首先,Python 的语法非常简洁,同一个句子可以少打很多次。然后,Python非常适合数据处理,比如函数参数的打包和解包,列表分析,矩阵处理,非常方便。
至此,这篇关于python和php的更适合写爬虫的文章介绍到这里。更多适合爬取内容的php和python相关内容,请搜索ZaLou.Cn之前的文章或继续浏览下方相关文章,希望大家多多支持ZaLou.Cn!
php 爬虫抓取网页数据(什么是AJAX(AsynchronouseJavaScript)异步JavaScript和XML?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-10-20 06:00
什么是 AJAX:
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,右击->查看网页源码也看不到ajax加载的数据,只能看到使用这个加载的html代码网址。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。方式优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现为爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟一些人类的行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: install Selenium and chromedriver: install Selenium: Selenium有很多语言版本,比如java、ruby、python等,我们可以下载python版本。
pip install selenium
安装chromedriver:下载完成后,放在一个不需要权限的纯英文目录下。快速开始:
下面我们就拿百度首页做个简单的例子来说一下如何快速上手Selenium和chromedriver:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/")
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程请参考:
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素: find_element_by_id:根据id查找元素。相当于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name:根据类名查找元素。相当于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name:根据name属性的值查找元素。相当于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name:根据标签名称查找元素。相当于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath:根据 xpath 语法获取元素。相当于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
需要注意的是 find_element 是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作复选框:因为要选中复选框标签,所以在网页上用鼠标点击它。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时候,selenium 专门为 select 标签提供了一个类 selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择
selectTag.select_by_index(1)
# 根据值选择
selectTag.select_by_value("http://www.95yueba.com")
# 根据可视的文本选择
selectTag.select_by_visible_text("95秀客户端")
# 取消选中所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时可以使用鼠标行为链类ActionChains来完成。例如,现在您想将鼠标移动到一个元素并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
cookie 操作:获取所有 cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除一个cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,另一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/")
显示等待:显示等待是在满足一定条件后执行获取元素的操作。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading")
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('"+url+"')")
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123")
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
更多内容请阅读相关源码。 查看全部
php 爬虫抓取网页数据(什么是AJAX(AsynchronouseJavaScript)异步JavaScript和XML?)
什么是 AJAX:
AJAX (Asynchronouse JavaScript And XML) 异步 JavaScript 和 XML。通过在后台与服务器交换少量数据,Ajax 可以使网页异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的某些部分。如果内容需要更新,传统网页(不使用 Ajax)必须重新加载整个网页。因为传统的数据传输格式是XML语法。所以它被称为 AJAX。其实现在数据交互基本都是用JSON。使用AJAX加载的数据,即使使用JS将数据渲染到浏览器中,右击->查看网页源码也看不到ajax加载的数据,只能看到使用这个加载的html代码网址。
ajax数据的获取方式:直接分析ajax调用的接口。然后通过代码请求这个接口。使用Selenium+chromedriver模拟浏览器行为获取数据。方式优缺点
分析界面
可以直接请求数据。无需做一些解析工作。代码量小,性能高。
解析接口比较复杂,尤其是一些被js混淆的接口,必须有一定的js基础。很容易被发现为爬虫。
硒
直接模拟浏览器的行为。浏览器可以请求的内容也可以使用 selenium 请求。爬虫更稳定。
很多代码。低性能。
Selenium+chromedriver 获取动态数据:
Selenium 相当于一个机器人。可以在浏览器上模拟一些人类的行为,在浏览器上自动处理一些行为,比如点击、填充数据、删除cookies等。 chromedriver是一个驱动Chrome浏览器的驱动,可以用来驱动浏览器. 当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome: Firefox: Edge: Safari: install Selenium and chromedriver: install Selenium: Selenium有很多语言版本,比如java、ruby、python等,我们可以下载python版本。
pip install selenium
安装chromedriver:下载完成后,放在一个不需要权限的纯英文目录下。快速开始:
下面我们就拿百度首页做个简单的例子来说一下如何快速上手Selenium和chromedriver:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r'D:\ProgramApp\chromedriver\chromedriver.exe'
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/";)
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium 常见操作:
更多教程请参考:
关闭页面: driver.close():关闭当前页面。driver.quit():退出整个浏览器。定位元素: find_element_by_id:根据id查找元素。相当于:
submitTag = driver.find_element_by_id('su')
submitTag1 = driver.find_element(By.ID,'su')
find_element_by_class_name:根据类名查找元素。相当于:
submitTag = driver.find_element_by_class_name('su')
submitTag1 = driver.find_element(By.CLASS_NAME,'su')
find_element_by_name:根据name属性的值查找元素。相当于:
submitTag = driver.find_element_by_name('email')
submitTag1 = driver.find_element(By.NAME,'email')
find_element_by_tag_name:根据标签名称查找元素。相当于:
submitTag = driver.find_element_by_tag_name('div')
submitTag1 = driver.find_element(By.TAG_NAME,'div')
find_element_by_xpath:根据 xpath 语法获取元素。相当于:
submitTag = driver.find_element_by_xpath('//div')
submitTag1 = driver.find_element(By.XPATH,'//div')
find_element_by_css_selector:根据css选择器选择元素。相当于:
submitTag = driver.find_element_by_css_selector('//div')
submitTag1 = driver.find_element(By.CSS_SELECTOR,'//div')
需要注意的是 find_element 是获取第一个满足条件的元素。find_elements 是获取所有满足条件的元素。
操作表单元素:
操作输入框:分为两步。第一步:找到这个元素。第二步:使用send_keys(value)填写数据。示例代码如下:
inputTag = driver.find_element_by_id('kw')
inputTag.send_keys('python')
使用clear方法清除输入框的内容。示例代码如下:
inputTag.clear()
操作复选框:因为要选中复选框标签,所以在网页上用鼠标点击它。因此,如果要选中复选框标签,请先选中此标签,然后再执行点击事件。示例代码如下:
rememberTag = driver.find_element_by_name("rememberMe")
rememberTag.click()
选择选择:不能直接点击选择元素。因为元素需要点击后被选中。这时候,selenium 专门为 select 标签提供了一个类 selenium.webdriver.support.ui.Select。将获取的元素作为参数传递给该类以创建该对象。您可以在将来使用此对象进行选择。示例代码如下:
from selenium.webdriver.support.ui import Select
# 选中这个标签,然后使用Select创建对象
selectTag = Select(driver.find_element_by_name("jumpMenu"))
# 根据索引选择
selectTag.select_by_index(1)
# 根据值选择
selectTag.select_by_value("http://www.95yueba.com";)
# 根据可视的文本选择
selectTag.select_by_visible_text("95秀客户端")
# 取消选中所有选项
selectTag.deselect_all()
操作按钮:操作按钮的方式有很多种。比如单击、右键、双击等,这里是最常用的一种。只需点击。直接调用click函数就行了。示例代码如下:
inputTag = driver.find_element_by_id('su')
inputTag.click()
行为链:
有时页面上的操作可能会有很多步骤,这时可以使用鼠标行为链类ActionChains来完成。例如,现在您想将鼠标移动到一个元素并执行一个点击事件。那么示例代码如下:
inputTag = driver.find_element_by_id('kw')
submitTag = driver.find_element_by_id('su')
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,'python')
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作。
cookie 操作:获取所有 cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有 cookie:
driver.delete_all_cookies()
删除一个cookie:
driver.delete_cookie(key)
页面等待:
现在越来越多的网页使用 Ajax 技术,因此程序无法确定元素何时完全加载。如果实际页面等待时间过长,某个dom元素没有出来,而你的代码直接使用了这个WebElement,那么就会抛出NullPointer异常。为了解决这个问题。所以Selenium提供了两种等待方式:一种是隐式等待,另一种是显式等待。
隐式等待:调用 driver.implicitly_wait。然后,在获取不可用元素之前,它会等待 10 秒。示例代码如下:
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/";)
显示等待:显示等待是在满足一定条件后执行获取元素的操作。也可以指定等待的最长时间,超过这个时间就会抛出异常。显示等待应在 selenium.webdriver.support.excepted_conditions 和 selenium.webdriver.support.ui.WebDriverWait 的预期条件下完成。示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading";)
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等待条件:
切换页面:
有时窗口中有很多子标签页。这个时候必须切换。Selenium 提供了一个 switch_to_window 来切换。要切换到的特定页面可以在 driver.window_handles 中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open('"+url+"')")
# 切换到这个新的页面中
self.driver.switch_to_window(self.driver.window_handles[1])
设置代理ip:
有时会频繁抓取一些网页。服务器发现你是爬虫后会屏蔽你的ip地址。这时候我们就可以更改代理ip了。更改代理ip,不同浏览器实现方式不同。以下是 Chrome 浏览器的示例:
from selenium import webdriver
options = webdriver.ChromeOptions()
options.add_argument("--proxy-server=http://110.73.2.248:8123";)
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get('http://httpbin.org/ip')
WebElement 元素:
from selenium.webdriver.remote.webelement import WebElement 类是获取到的每个元素的类。
有一些常用的属性:
get_attribute:此标签的属性值。screentshot:获取当前页面的截图。此方法只能在驱动程序上使用。
驱动程序的对象类也继承自 WebElement。
更多内容请阅读相关源码。
php 爬虫抓取网页数据(PHP解析器和PHP相比较,python适合做爬虫吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-10-12 19:15
对比python和PHP,python适合爬取。原因如下
抓取网页本身的界面
与java、c#、C++、python等其他静态编程语言相比,抓取网页文档的界面更加简洁;相对于其他动态脚本语言,如 perl、shell、python,urllib2 包提供了更完整的 Web 文档 API 访问。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站都是为了生硬爬取而被屏蔽的。这就是我们需要模拟用户代理的行为来构造合适的请求的地方,比如模拟用户登录,模拟session/cookies的存储和设置。python中有很好的第三方包帮你搞定,比如Requests,mechanize
爬行后处理
抓取到的网页通常需要进行处理,如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用很短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要python。
py对linux来说功能很强大,语言也很简单。
NO.1 快速开发(唯一能比python开发效率更高的语言是rudy) 语言简洁,没有那么多技巧,所以非常清晰易读。
NO.2 跨平台(由于python的开源,比java更能体现“一次编写,到处运行”
NO.3 解释(无需直接编译、运行/调试代码)
NO.4 框架选择太多(主要的GUI框架有wxPython、tkInter、PyGtk、PyQt。
PHP脚本主要用于以下三个方面:
服务器端脚本。这是PHP最传统也是最主要的目标领域。要进行这项工作,需要具备以下三点:PHP解析器(CGI或服务器模块)、Web
服务器和网络浏览器。运行web服务器时需要安装配置PHP,然后可以使用web浏览器访问PHP程序的输出,即浏览服务
PHP 页面在最后。如果您只是在尝试 PHP 编程,所有这些都可以在您的家用计算机上运行。有关更多信息,请参阅安装章节。命令行脚本。
您可以编写一个 PHP 脚本,并且不需要任何服务器或浏览器来运行它。这样,只需要PHP解析器就可以执行。这种用法是
是 cron(Unix 或 Linux 环境)或 Task Scheduler(Windows 环境)日常运行脚本的理想选择。这些脚本也可用于处理
管理简单的文本。更多信息请参考 PHP 的命令行模式。编写桌面应用程序。对于具有图形界面的桌面应用程序,PHP 可能不会
最好的语言之一,但是如果用户非常精通PHP并且想在客户端应用程序中使用PHP的一些高级功能,他们可以使用PHP-GTK来编写这个
这些程序。这样,您也可以编写跨平台的应用程序。PHP-GTK 是 PHP 的扩展,通常发布的 PHP 包中不收录它。
网友的观点扩大了:
我用PHP Node.js Python写了一个爬虫脚本,简单说一下。
首先PHP。先说优点:网上大量爬取解析html框架,各种工具都可以直接使用,比较省心。缺点:首先,速度/效率是个问题。有一次下载电影海报的时候,因为crontab定时执行,没有优化,打开的php进程太多,直接导致内存爆了。然后语法也很拖沓,各种关键词符号太多,不够简洁,给人一种没有精心设计的感觉,写起来很麻烦。
节点.js。优点是效率,效率还是效率。因为网络是异步的,所以基本上和并发数百个进程一样强大。内存和CPU使用量非常小。如果对捕获的数据没有进行复杂的计算和处理,那么系统就会成为瓶颈。基本上就是写入MySQL等数据库的带宽和I/O速度。当然,优点的反面也是缺点。异步网络意味着您需要回调。这时候,如果业务需求是线性的,比如你必须等上一页爬完,拿到数据后才能爬到下一页,甚至更多。层依赖,会有可怕的多层回调!基本上这个时候代码结构和逻辑就会乱了。当然,
最后,让我们谈谈Python。如果你对效率没有极端的要求,那么推荐Python!首先,Python 的语法非常简洁,同一个句子可以少打很多次。然后,Python非常适合数据处理,比如函数参数的打包和解包,列表分析,矩阵处理,非常方便。
相关文章 查看全部
php 爬虫抓取网页数据(PHP解析器和PHP相比较,python适合做爬虫吗?)
对比python和PHP,python适合爬取。原因如下
抓取网页本身的界面
与java、c#、C++、python等其他静态编程语言相比,抓取网页文档的界面更加简洁;相对于其他动态脚本语言,如 perl、shell、python,urllib2 包提供了更完整的 Web 文档 API 访问。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站都是为了生硬爬取而被屏蔽的。这就是我们需要模拟用户代理的行为来构造合适的请求的地方,比如模拟用户登录,模拟session/cookies的存储和设置。python中有很好的第三方包帮你搞定,比如Requests,mechanize
爬行后处理
抓取到的网页通常需要进行处理,如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用很短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要python。
py对linux来说功能很强大,语言也很简单。
NO.1 快速开发(唯一能比python开发效率更高的语言是rudy) 语言简洁,没有那么多技巧,所以非常清晰易读。
NO.2 跨平台(由于python的开源,比java更能体现“一次编写,到处运行”
NO.3 解释(无需直接编译、运行/调试代码)
NO.4 框架选择太多(主要的GUI框架有wxPython、tkInter、PyGtk、PyQt。
PHP脚本主要用于以下三个方面:
服务器端脚本。这是PHP最传统也是最主要的目标领域。要进行这项工作,需要具备以下三点:PHP解析器(CGI或服务器模块)、Web
服务器和网络浏览器。运行web服务器时需要安装配置PHP,然后可以使用web浏览器访问PHP程序的输出,即浏览服务
PHP 页面在最后。如果您只是在尝试 PHP 编程,所有这些都可以在您的家用计算机上运行。有关更多信息,请参阅安装章节。命令行脚本。
您可以编写一个 PHP 脚本,并且不需要任何服务器或浏览器来运行它。这样,只需要PHP解析器就可以执行。这种用法是
是 cron(Unix 或 Linux 环境)或 Task Scheduler(Windows 环境)日常运行脚本的理想选择。这些脚本也可用于处理
管理简单的文本。更多信息请参考 PHP 的命令行模式。编写桌面应用程序。对于具有图形界面的桌面应用程序,PHP 可能不会
最好的语言之一,但是如果用户非常精通PHP并且想在客户端应用程序中使用PHP的一些高级功能,他们可以使用PHP-GTK来编写这个
这些程序。这样,您也可以编写跨平台的应用程序。PHP-GTK 是 PHP 的扩展,通常发布的 PHP 包中不收录它。
网友的观点扩大了:
我用PHP Node.js Python写了一个爬虫脚本,简单说一下。
首先PHP。先说优点:网上大量爬取解析html框架,各种工具都可以直接使用,比较省心。缺点:首先,速度/效率是个问题。有一次下载电影海报的时候,因为crontab定时执行,没有优化,打开的php进程太多,直接导致内存爆了。然后语法也很拖沓,各种关键词符号太多,不够简洁,给人一种没有精心设计的感觉,写起来很麻烦。
节点.js。优点是效率,效率还是效率。因为网络是异步的,所以基本上和并发数百个进程一样强大。内存和CPU使用量非常小。如果对捕获的数据没有进行复杂的计算和处理,那么系统就会成为瓶颈。基本上就是写入MySQL等数据库的带宽和I/O速度。当然,优点的反面也是缺点。异步网络意味着您需要回调。这时候,如果业务需求是线性的,比如你必须等上一页爬完,拿到数据后才能爬到下一页,甚至更多。层依赖,会有可怕的多层回调!基本上这个时候代码结构和逻辑就会乱了。当然,
最后,让我们谈谈Python。如果你对效率没有极端的要求,那么推荐Python!首先,Python 的语法非常简洁,同一个句子可以少打很多次。然后,Python非常适合数据处理,比如函数参数的打包和解包,列表分析,矩阵处理,非常方便。
相关文章
php 爬虫抓取网页数据( 照Web发展的趋势和发展趋势分析和如何去分析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-10-09 17:16
照Web发展的趋势和发展趋势分析和如何去分析)
有时我们使用requests抓取页面时,得到的结果可能与浏览器中看到的不同:在浏览器中可以看到正常显示的页面数据,但是使用requests获取的结果却看不到。这是因为获取的请求都是原创的 HTML 文档,浏览器中的页面是数据经过 JavaScript 处理后生成的结果。这些数据有很多来源,可以通过 Ajax 加载或收录在 HTML 中。文档中的文档也可能是通过JavaScript和特定算法计算后生成的。
在第一种情况下,数据加载是一种异步加载方法。原创页面最初不会收录一些数据。原创页面加载完成后,会向服务器请求一个接口来获取数据,然后对数据进行处理和呈现。在网页上,这实际上是一个 Ajax 请求。
根据Web发展的趋势,这种形式的页面越来越多。网页的原创 HTML 文档不收录任何数据。数据通过Ajax统一加载后呈现,从而在Web开发中实现前后端分离,减少服务器直接渲染页面带来的压力。
因此,如果遇到这样的页面,可以直接使用requests等库来抓取原创页面,无法获取有效数据。这时候就需要分析网页后端向界面发送的ajax请求。如果可以使用requests来模拟ajax请求,那么就可以成功爬取。
因此,本章的主要目的是了解 Ajax 是什么以及如何分析和捕获 Ajax 请求。 查看全部
php 爬虫抓取网页数据(
照Web发展的趋势和发展趋势分析和如何去分析)
有时我们使用requests抓取页面时,得到的结果可能与浏览器中看到的不同:在浏览器中可以看到正常显示的页面数据,但是使用requests获取的结果却看不到。这是因为获取的请求都是原创的 HTML 文档,浏览器中的页面是数据经过 JavaScript 处理后生成的结果。这些数据有很多来源,可以通过 Ajax 加载或收录在 HTML 中。文档中的文档也可能是通过JavaScript和特定算法计算后生成的。
在第一种情况下,数据加载是一种异步加载方法。原创页面最初不会收录一些数据。原创页面加载完成后,会向服务器请求一个接口来获取数据,然后对数据进行处理和呈现。在网页上,这实际上是一个 Ajax 请求。
根据Web发展的趋势,这种形式的页面越来越多。网页的原创 HTML 文档不收录任何数据。数据通过Ajax统一加载后呈现,从而在Web开发中实现前后端分离,减少服务器直接渲染页面带来的压力。
因此,如果遇到这样的页面,可以直接使用requests等库来抓取原创页面,无法获取有效数据。这时候就需要分析网页后端向界面发送的ajax请求。如果可以使用requests来模拟ajax请求,那么就可以成功爬取。
因此,本章的主要目的是了解 Ajax 是什么以及如何分析和捕获 Ajax 请求。
php 爬虫抓取网页数据(本节使用Python爬虫抓取猫眼(电影网)影片信息(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-10-05 15:21
本节使用Python爬虫抓取猫眼电影TOP100榜单()电影信息,包括电影名称、上映时间、主演信息。
在开始编写程序之前,首先确定页面类型(静态页面或动态页面),其次找出页面的url规则,最后通过分析网页元素的结构来确定正则表达式,从而提取网页信息。
判断页面类型,右键查看页面源码,判断页面中是否存在要抓取的数据。通过浏览可知,所有要抓取的信息都存在于源代码中,因此页面输入为静态页面。如下:
<p class="name">我不是药神
主演:徐峥,周一围,王传君
上映时间:2018-07-05
</p>
确定url规则确定url规则,需要多浏览几页,才能总结出url规则,如下图:
第一页:https://maoyan.com/board/4?offset=0
第二页:https://maoyan.com/board/4?offset=10
第三页:https://maoyan.com/board/4?offset=20
...
第n页:https://maoyan.com/board/4?offset=(n-1)*10
确定正则表达式通过分析网页元素的结构来确定正则表达式,如下图:
<p class="name">我不是药神
主演:徐峥,周一围,王传君
上映时间:2018-07-05</p>
使用 Chrome Developer Debugging Tools 确定要捕获的元素的结构。这样做的原因是可以避免正则表达式的冗余,提高编写正则表达式的速度。正则表达式如下:
.*?title="(.*?)".*?class="star">(.*?).*?releasetime">(.*?)</p></p>
编写正则表达式时,使用(.*?)替换需要提取的信息,使用.*? 替换不需要的内容(包括元素标签)。编写爬虫程序 下面采用面向对象的方法编写爬虫程序,主要编写四个函数,分别是请求函数、分析函数、数据保存函数、主函数。
from urllib import request
import re
import time
import random
import csv
from ua_info import ua_list
# 定义一个爬虫类
class MaoyanSpider(object):
# 初始化
# 定义初始页面url
def __init__(self):
self.url = 'https://maoyan.com/board/4?offset={}'
# 请求函数
def get_html(self,url):
headers = {'User-Agent':random.choice(ua_list)}
req = request.Request(url=url,headers=headers)
res = request.urlopen(req)
html = res.read().decode()
# 直接调用解析函数
self.parse_html(html)
# 解析函数
def parse_html(self,html):
# 正则表达式
re_bds = '.*?title="(.*?)".*?<p class="star">(.*?).*?class="releasetime">(.*?)</p>'
# 生成正则表达式对象
pattern = re.compile(re_bds,re.S)
# r_list: [('我不是药神','徐峥,周一围,王传君','2018-07-05'),...] 列表元组
r_list = pattern.findall(html)
self.save_html(r_list)
# 保存数据函数,使用python内置csv模块
def save_html(self,r_list):
#生成文件对象
with open('maoyan.csv','a',newline='',encoding="utf-8") as f:
#生成csv操作对象
writer = csv.writer(f)
#整理数据
for r in r_list:
name = r[0].strip()
star = r[1].strip()[3:]
# 上映时间:2018-07-05
# 切片截取时间
time = r[2].strip()[5:15]
L = [name,star,time]
# 写入csv文件
writer.writerow(L)
print(name,time,star)
# 主函数
def run(self):
#抓取第一页数据
for offset in range(0,11,10):
url = self.url.format(offset)
self.get_html(url)
#生成1-2之间的浮点数
time.sleep(random.uniform(1,2))
# 以脚本方式启动
if __name__ == '__main__':
#捕捉异常错误
try:
spider = MaoyanSpider()
spider.run()
except Exception as e:
print("错误:",e)
</p>
输出结果:
我不是药神 2018-07-05 徐峥、周以伟、王传君
肖申克的救赎 1994-09-10 蒂姆·罗宾斯、摩根·弗里曼、鲍勃·冈顿
绿皮书 2019-03-01 Vigo Mortensen, Mahsala Ali, Linda Cardrini
海上钢琴家 2019-11-15 蒂姆·罗斯、比尔·纳恩、克兰伦斯·威廉姆斯三世
小偷家族 2018-08-03 中川雅也、安藤樱、松冈墨鱼
霸王别姬 1993-07-26 张国荣、张凤仪、巩俐
哪吒魔童降临人间
美丽人生 2020-01-03 罗伯托·贝尼尼、朱斯蒂诺·杜拉诺、塞尔吉奥·比尼·巴斯特里克
这个杀手不太冷 1994-09-14 让·雷诺、加里·奥德曼、娜塔莉·波特曼
2010-09-01 莱昂纳多·迪卡普里奥、渡边谦、约瑟夫·高登-莱维特 查看全部
php 爬虫抓取网页数据(本节使用Python爬虫抓取猫眼(电影网)影片信息(组图))
本节使用Python爬虫抓取猫眼电影TOP100榜单()电影信息,包括电影名称、上映时间、主演信息。
在开始编写程序之前,首先确定页面类型(静态页面或动态页面),其次找出页面的url规则,最后通过分析网页元素的结构来确定正则表达式,从而提取网页信息。
判断页面类型,右键查看页面源码,判断页面中是否存在要抓取的数据。通过浏览可知,所有要抓取的信息都存在于源代码中,因此页面输入为静态页面。如下:
<p class="name">我不是药神
主演:徐峥,周一围,王传君
上映时间:2018-07-05
</p>
确定url规则确定url规则,需要多浏览几页,才能总结出url规则,如下图:
第一页:https://maoyan.com/board/4?offset=0
第二页:https://maoyan.com/board/4?offset=10
第三页:https://maoyan.com/board/4?offset=20
...
第n页:https://maoyan.com/board/4?offset=(n-1)*10
确定正则表达式通过分析网页元素的结构来确定正则表达式,如下图:
<p class="name">我不是药神
主演:徐峥,周一围,王传君
上映时间:2018-07-05</p>
使用 Chrome Developer Debugging Tools 确定要捕获的元素的结构。这样做的原因是可以避免正则表达式的冗余,提高编写正则表达式的速度。正则表达式如下:
.*?title="(.*?)".*?class="star">(.*?).*?releasetime">(.*?)</p></p>
编写正则表达式时,使用(.*?)替换需要提取的信息,使用.*? 替换不需要的内容(包括元素标签)。编写爬虫程序 下面采用面向对象的方法编写爬虫程序,主要编写四个函数,分别是请求函数、分析函数、数据保存函数、主函数。
from urllib import request
import re
import time
import random
import csv
from ua_info import ua_list
# 定义一个爬虫类
class MaoyanSpider(object):
# 初始化
# 定义初始页面url
def __init__(self):
self.url = 'https://maoyan.com/board/4?offset={}'
# 请求函数
def get_html(self,url):
headers = {'User-Agent':random.choice(ua_list)}
req = request.Request(url=url,headers=headers)
res = request.urlopen(req)
html = res.read().decode()
# 直接调用解析函数
self.parse_html(html)
# 解析函数
def parse_html(self,html):
# 正则表达式
re_bds = '.*?title="(.*?)".*?<p class="star">(.*?).*?class="releasetime">(.*?)</p>'
# 生成正则表达式对象
pattern = re.compile(re_bds,re.S)
# r_list: [('我不是药神','徐峥,周一围,王传君','2018-07-05'),...] 列表元组
r_list = pattern.findall(html)
self.save_html(r_list)
# 保存数据函数,使用python内置csv模块
def save_html(self,r_list):
#生成文件对象
with open('maoyan.csv','a',newline='',encoding="utf-8") as f:
#生成csv操作对象
writer = csv.writer(f)
#整理数据
for r in r_list:
name = r[0].strip()
star = r[1].strip()[3:]
# 上映时间:2018-07-05
# 切片截取时间
time = r[2].strip()[5:15]
L = [name,star,time]
# 写入csv文件
writer.writerow(L)
print(name,time,star)
# 主函数
def run(self):
#抓取第一页数据
for offset in range(0,11,10):
url = self.url.format(offset)
self.get_html(url)
#生成1-2之间的浮点数
time.sleep(random.uniform(1,2))
# 以脚本方式启动
if __name__ == '__main__':
#捕捉异常错误
try:
spider = MaoyanSpider()
spider.run()
except Exception as e:
print("错误:",e)
</p>
输出结果:
我不是药神 2018-07-05 徐峥、周以伟、王传君
肖申克的救赎 1994-09-10 蒂姆·罗宾斯、摩根·弗里曼、鲍勃·冈顿
绿皮书 2019-03-01 Vigo Mortensen, Mahsala Ali, Linda Cardrini
海上钢琴家 2019-11-15 蒂姆·罗斯、比尔·纳恩、克兰伦斯·威廉姆斯三世
小偷家族 2018-08-03 中川雅也、安藤樱、松冈墨鱼
霸王别姬 1993-07-26 张国荣、张凤仪、巩俐
哪吒魔童降临人间
美丽人生 2020-01-03 罗伯托·贝尼尼、朱斯蒂诺·杜拉诺、塞尔吉奥·比尼·巴斯特里克
这个杀手不太冷 1994-09-14 让·雷诺、加里·奥德曼、娜塔莉·波特曼
2010-09-01 莱昂纳多·迪卡普里奥、渡边谦、约瑟夫·高登-莱维特
php 爬虫抓取网页数据(vba网页元素代码抓取小工具【支持win10+】用IE提取网页资料)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-09-25 02:00
vba网页元素代码抓取小工具【支持win10+】
<p>用IE提取网页信息的好处是:所见即所得,一般可以得到网页上能看到的信息。这个工具功能不多,主要是方便提取网页显示信息所在元素的代码。我希望我能帮到你一点点。网页爬虫widget.rar (22.91 KB, 下载: 3601) 如何使用这个工具:1、在B1中输入网址,可以是打开的网页也可以是2、A2和B2未打开的内容,不要改,第二行其他单元格可以自己输入元素的属性名称,其中,innertext单元格有一个下拉选项< @3、 并点击“开始”“分析”分析网页元素。< @4、A 列是每个元素的对象代码。5、 在innertext列中找到要提取的内容后,选中该行,点击“生成excel”。表格可以提取标签形式或下载 IMG 标签图像。6、 在新生成的excel中,点击“执行代码”按钮,看看是否可以生成需要的数据。如果生成的数据与分析的数据不匹配,原因可能是:1、网页未完全加载,对应标签的数据尚未加载,代码自动提取后续标签数据。可能的解决方法:添加do...loop time delay。2、 网页为动态网页,标签号不确定。可能的解决方案:如果元素有一个 id 名称,则使用 getelementbyid("id name" ) 获取它,如果没有,则抓取该包并通过 xmlhttp 提取它。 查看全部
php 爬虫抓取网页数据(vba网页元素代码抓取小工具【支持win10+】用IE提取网页资料)
vba网页元素代码抓取小工具【支持win10+】
<p>用IE提取网页信息的好处是:所见即所得,一般可以得到网页上能看到的信息。这个工具功能不多,主要是方便提取网页显示信息所在元素的代码。我希望我能帮到你一点点。网页爬虫widget.rar (22.91 KB, 下载: 3601) 如何使用这个工具:1、在B1中输入网址,可以是打开的网页也可以是2、A2和B2未打开的内容,不要改,第二行其他单元格可以自己输入元素的属性名称,其中,innertext单元格有一个下拉选项< @3、 并点击“开始”“分析”分析网页元素。< @4、A 列是每个元素的对象代码。5、 在innertext列中找到要提取的内容后,选中该行,点击“生成excel”。表格可以提取标签形式或下载 IMG 标签图像。6、 在新生成的excel中,点击“执行代码”按钮,看看是否可以生成需要的数据。如果生成的数据与分析的数据不匹配,原因可能是:1、网页未完全加载,对应标签的数据尚未加载,代码自动提取后续标签数据。可能的解决方法:添加do...loop time delay。2、 网页为动态网页,标签号不确定。可能的解决方案:如果元素有一个 id 名称,则使用 getelementbyid("id name" ) 获取它,如果没有,则抓取该包并通过 xmlhttp 提取它。
php 爬虫抓取网页数据( 什么条件下爬虫有使用价值?这么厉害的爬虫怎么写啊?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-09-24 19:06
什么条件下爬虫有使用价值?这么厉害的爬虫怎么写啊?)
爬虫在什么情况下有用?在网络大数据时代,爬虫受到了商界的广泛欢迎。因此,如何有效地利用爬虫技术提取有价值的数据成为了一大挑战。
每个爬虫都有不同的技能和能力。为什么别人的爬虫这么厉害?本篇小编就来介绍一下哪些爬虫比较厉害,这么强大的爬虫是怎么写出来的?
1、 爬虫的生存能力。
爬虫需要访问各种类型的网站服务器,可能会遇到很多异常情况,比如网页HTML编码不规范、爬虫服务器突然崩溃,甚至爬虫陷阱。爬虫对于各种异常情况的异常情况非常重要,否则可能会时不时停止工作,难以忍受。
当爬虫重新启动时,它必须能够恢复之前爬过的内容和数据结构,而不是每次都从头开始。
2、可扩展的爬虫,虽然单个爬虫的性能非常好,但是在本地下载所有网页还是需要很多时间的。
为了最小化爬取周期,它必须具有良好的可扩展性,即通过增加爬取服务器和爬虫的数量来实现这一目标。
比如分布式、多线程操作,通过多种方式提高并发性。
3、 爬虫爬行速度性能,网上有很多网页,所以爬虫性能很重要。
这里的性能主要是指爬虫下载网页的速度。一种常用的评价方法是以每秒可以下载多少网页作为性能指标。单位时间内可以下载的网页越多,爬虫的性能就越好。
什么爬虫更厉害?这是一个好的爬虫必须具备的特性。无论是成活率还是提取效率,效果都非常好。
另外,一个优秀的爬虫一定要有一个用IP替换工具突破网络限制的帮手,而这个代理IP也很不错。
如果想尝试使用代理ip,可以到拼音http代理ip官网了解更多,提供高度隐蔽且稳定的代理ip,支持HTTP/HTTPS/SOCKS5代理协议,并提供动态IP等服务和静态IP。百兆带宽,千万IP资源,保障爬虫数据传输安全。快速获取网站数据,现在还有免费测试和免费ip活动! 查看全部
php 爬虫抓取网页数据(
什么条件下爬虫有使用价值?这么厉害的爬虫怎么写啊?)
爬虫在什么情况下有用?在网络大数据时代,爬虫受到了商界的广泛欢迎。因此,如何有效地利用爬虫技术提取有价值的数据成为了一大挑战。
每个爬虫都有不同的技能和能力。为什么别人的爬虫这么厉害?本篇小编就来介绍一下哪些爬虫比较厉害,这么强大的爬虫是怎么写出来的?
1、 爬虫的生存能力。
爬虫需要访问各种类型的网站服务器,可能会遇到很多异常情况,比如网页HTML编码不规范、爬虫服务器突然崩溃,甚至爬虫陷阱。爬虫对于各种异常情况的异常情况非常重要,否则可能会时不时停止工作,难以忍受。
当爬虫重新启动时,它必须能够恢复之前爬过的内容和数据结构,而不是每次都从头开始。
2、可扩展的爬虫,虽然单个爬虫的性能非常好,但是在本地下载所有网页还是需要很多时间的。
为了最小化爬取周期,它必须具有良好的可扩展性,即通过增加爬取服务器和爬虫的数量来实现这一目标。
比如分布式、多线程操作,通过多种方式提高并发性。
3、 爬虫爬行速度性能,网上有很多网页,所以爬虫性能很重要。
这里的性能主要是指爬虫下载网页的速度。一种常用的评价方法是以每秒可以下载多少网页作为性能指标。单位时间内可以下载的网页越多,爬虫的性能就越好。
什么爬虫更厉害?这是一个好的爬虫必须具备的特性。无论是成活率还是提取效率,效果都非常好。
另外,一个优秀的爬虫一定要有一个用IP替换工具突破网络限制的帮手,而这个代理IP也很不错。
如果想尝试使用代理ip,可以到拼音http代理ip官网了解更多,提供高度隐蔽且稳定的代理ip,支持HTTP/HTTPS/SOCKS5代理协议,并提供动态IP等服务和静态IP。百兆带宽,千万IP资源,保障爬虫数据传输安全。快速获取网站数据,现在还有免费测试和免费ip活动!
php 爬虫抓取网页数据( 如何构建网络爬虫,网页下载是一个必不可少的步骤?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 153 次浏览 • 2021-09-24 19:04
如何构建网络爬虫,网页下载是一个必不可少的步骤?)
搭建网络爬虫,网页下载是必不可少的一步。这并不容易,因为需要考虑的因素很多,比如如何更好地利用本地带宽,如何优化DNS查询,如何合理分配网络请求,释放服务器流量等。
1、 对 HTML 网页进行复杂的分析。
实际上,我们无法直接访问所有 HTML 页面。使用AJAX的动态网站时,如何检索Javascript生成的内容也是个问题。另外,网络中经常出现的爬虫陷阱会造成无数的请求或者导致爬虫崩溃。
2、虽然我们在构建网络爬虫时应该知道很多,但在大多数情况下,我们只想为特定的网站创建一个爬虫。
而不是像谷歌爬虫这样的通用程序。因此,最好对目标网站进行深入研究,选择有价值的链接进行跟踪,避免造成额外成本的冗余或垃圾网址。此外,如果能够找到正确的网络爬取路径,则可以按照预先定义的顺序抓取目标站点感兴趣的内容。
上面说的是如何抓取网页上的数据。爬虫需要突破IP限制才能爬取数据。可以考虑使用代理ip。
如果想尝试使用代理ip,可以到拼音http代理ip官网了解更多,提供高度隐蔽且稳定的代理ip,支持HTTP/HTTPS/SOCKS5代理协议,并提供动态IP等服务和静态IP。百兆带宽,千万IP资源,保障爬虫数据传输安全。快速获取网站数据,现在还有免费测试和免费ip活动! 查看全部
php 爬虫抓取网页数据(
如何构建网络爬虫,网页下载是一个必不可少的步骤?)
搭建网络爬虫,网页下载是必不可少的一步。这并不容易,因为需要考虑的因素很多,比如如何更好地利用本地带宽,如何优化DNS查询,如何合理分配网络请求,释放服务器流量等。
1、 对 HTML 网页进行复杂的分析。
实际上,我们无法直接访问所有 HTML 页面。使用AJAX的动态网站时,如何检索Javascript生成的内容也是个问题。另外,网络中经常出现的爬虫陷阱会造成无数的请求或者导致爬虫崩溃。
2、虽然我们在构建网络爬虫时应该知道很多,但在大多数情况下,我们只想为特定的网站创建一个爬虫。
而不是像谷歌爬虫这样的通用程序。因此,最好对目标网站进行深入研究,选择有价值的链接进行跟踪,避免造成额外成本的冗余或垃圾网址。此外,如果能够找到正确的网络爬取路径,则可以按照预先定义的顺序抓取目标站点感兴趣的内容。
上面说的是如何抓取网页上的数据。爬虫需要突破IP限制才能爬取数据。可以考虑使用代理ip。
如果想尝试使用代理ip,可以到拼音http代理ip官网了解更多,提供高度隐蔽且稳定的代理ip,支持HTTP/HTTPS/SOCKS5代理协议,并提供动态IP等服务和静态IP。百兆带宽,千万IP资源,保障爬虫数据传输安全。快速获取网站数据,现在还有免费测试和免费ip活动!
php 爬虫抓取网页数据(新浪新闻国内新闻页静态网页数据在函数中的应用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 167 次浏览 • 2021-09-24 19:03
昨天,一个朋友来找我。新浪新闻国内新闻页面的其他部分是静态网页,但左下方的最新新闻部分不是静态网页,也没有json数据。让我帮你抓住它。大概看了一下,是js加载的,数据在js函数里,很有意思,所以分享给大家看看!
抓取目标
我们今天的目标是上图的红框部分。首先我们确定这部分内容不在网页源码中,属于js加载的部分,点击翻页后没有json数据传输!
但是发现有个js请求,点击请求,是一行js函数代码,我们复制到json的view viewer,然后格式化看看结果
发现可能有我们需要的内容,比如url、title、intro这3个参数,猜测是对应的新闻网址、标题、介绍
只是它的内容,需要处理,我们写在代码里看看
开始写代码
先导入库,因为需要截取字符串的最后一部分,所以使用requests库来获取请求,重新匹配内容即可。然后我们先匹配上面的3个item
可以看到,url中有\,标题和介绍都是\u539f\u6807\u9898的形式。这些是我们需要处理的后续步骤!
先用replace函数把\放在url中,就可以得到url,下面的\u539f\u6807\u9898是unicode编码,可以直接解码内容,直接写代码
使用eval函数进行解码,可以将内容解码成u'unicode编码内容'的形式!
这样就把这个页面上所有新闻和URL相关的内容都取出来了,在外层加了一个循环来爬取所有的新闻页面,任务就完成了!
后记
新浪新闻的页面js功能比较简单,可以直接抓取数据。如果是比较复杂的功能,就需要了解前端知识。这就是学习爬虫需要学习前端知识的原因!
ps:上面使用的json查看器是第三方的网站,你可以直接百度找很多,当然你也可以直接修改上面抓包的内容,然后用json读取数据!
基本代码不多。有看不清楚的小伙伴可以私信我索取代码或者一起研究爬虫! 查看全部
php 爬虫抓取网页数据(新浪新闻国内新闻页静态网页数据在函数中的应用)
昨天,一个朋友来找我。新浪新闻国内新闻页面的其他部分是静态网页,但左下方的最新新闻部分不是静态网页,也没有json数据。让我帮你抓住它。大概看了一下,是js加载的,数据在js函数里,很有意思,所以分享给大家看看!
抓取目标
我们今天的目标是上图的红框部分。首先我们确定这部分内容不在网页源码中,属于js加载的部分,点击翻页后没有json数据传输!
但是发现有个js请求,点击请求,是一行js函数代码,我们复制到json的view viewer,然后格式化看看结果
发现可能有我们需要的内容,比如url、title、intro这3个参数,猜测是对应的新闻网址、标题、介绍
只是它的内容,需要处理,我们写在代码里看看
开始写代码
先导入库,因为需要截取字符串的最后一部分,所以使用requests库来获取请求,重新匹配内容即可。然后我们先匹配上面的3个item
可以看到,url中有\,标题和介绍都是\u539f\u6807\u9898的形式。这些是我们需要处理的后续步骤!
先用replace函数把\放在url中,就可以得到url,下面的\u539f\u6807\u9898是unicode编码,可以直接解码内容,直接写代码
使用eval函数进行解码,可以将内容解码成u'unicode编码内容'的形式!
这样就把这个页面上所有新闻和URL相关的内容都取出来了,在外层加了一个循环来爬取所有的新闻页面,任务就完成了!
后记
新浪新闻的页面js功能比较简单,可以直接抓取数据。如果是比较复杂的功能,就需要了解前端知识。这就是学习爬虫需要学习前端知识的原因!
ps:上面使用的json查看器是第三方的网站,你可以直接百度找很多,当然你也可以直接修改上面抓包的内容,然后用json读取数据!
基本代码不多。有看不清楚的小伙伴可以私信我索取代码或者一起研究爬虫!
php 爬虫抓取网页数据(网页finally重载romati签名单元argumentborder动态(一)(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-09-19 07:22
Tag:获取网页最终重载romati签名单元argumentorder
什么是用于动态网页数据捕获的Ajax:
Ajax(异步JavaScript和XML)异步JavaScript和XML。Ajax可以通过在后台与服务器交换少量数据来实现web页面的异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的一部分。如果需要更新内容,传统web页面(没有Ajax)必须重新加载整个web页面。因为传统的传输数据格式使用XML语法。因此,它被称为Ajax。事实上,现在数据交互基本上使用JSON。使用Ajax加载的数据,即使使用了JS,也会呈现到浏览器中。右键单击->;查看网页源代码时,仍然无法看到通过Ajax加载的数据。您只能看到使用此URL加载的HTML代码
如何获取ajax数据:直接分析ajax调用的接口。然后通过代码请求这个接口。使用selenium+chromedriver模拟浏览器行为并获取数据
模式
优势
缺点
分析接口
可以直接请求数据。不需要进行一些解析。代码少,性能高
分析接口比较复杂,特别是一些通过JS混淆的接口。你应该有一个特定的JS基金会。作为爬行动物很容易被发现
硒
直接模拟浏览器的行为。如果浏览器可以请求,您也可以使用selenium进行请求。爬行动物更稳定
很多代码。低性能
Selenium+chromedriver可获得动态数据:
硒是一个机器人。它可以模拟浏览器上的一些人类行为,并自动处理浏览器上的一些行为,如单击、填充数据、删除cookie等。Chromedriver是Chrome浏览器的驱动程序。只有使用它才能驱动浏览器。当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome:Firefox:Edge:Safari:install selenium:selenium有多种语言,包括Java、ruby、python等。我们可以下载python版本。PIP安装selenium安装chromedriver:下载后,未经许可将其放入纯英文目录。安装selenium和chromedriver:快速入门:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r‘D:\ProgramApp\chromedriver\chromedriver.exe‘
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/")
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium常见操作:
更多教程参考:
关闭页面:驱动程序。Close():关闭当前页面。司机。退出():退出整个浏览器。定位元素:
请注意,find_u元素是满足条件的第一个元素。find_u元素是获取所有满足条件的元素
find_element_by_id:根据id来查找某个元素。等价于:
submitTag = driver.find_element_by_id(‘su‘)
submitTag1 = driver.find_element(By.ID,‘su‘)
find_element_by_class_name:根据类名查找元素。 等价于:
submitTag = driver.find_element_by_class_name(‘su‘)
submitTag1 = driver.find_element(By.CLASS_NAME,‘su‘)
find_element_by_name:根据name属性的值来查找元素。等价于:
submitTag = driver.find_element_by_name(‘email‘)
submitTag1 = driver.find_element(By.NAME,‘email‘)
find_element_by_tag_name:根据标签名来查找元素。等价于:
submitTag = driver.find_element_by_tag_name(‘div‘)
submitTag1 = driver.find_element(By.TAG_NAME,‘div‘)
find_element_by_xpath:根据xpath语法来获取元素。等价于:
submitTag = driver.find_element_by_xpath(‘//div‘)
submitTag1 = driver.find_element(By.XPATH,‘//div‘)
find_element_by_css_selector:根据css选择器选择元素。等价于:
submitTag = driver.find_element_by_css_selector(‘//div‘)
submitTag1 = driver.find_element(By.CSS_SELECTOR,‘//div‘)
行动形式要素:
操作输入框:分为两步。步骤1:找到这个元素。步骤2:使用发送键(值)填写数据。示例代码如下所示:
inputTag=driver.find u元素uu按u id('kw')查找
inputTag.send ukeys('python'))
使用“清除”方法清除输入框的内容。示例代码如下所示:
输入ag.clear()
操作复选框:由于要选择复选框选项卡,请在网页中单击它。因此,如果要选择复选框标记,请先选择标记,然后执行click事件。示例代码如下所示:
rememberTag=driver.find uu元素uu按名称(“rememberMe”)
记住标记。单击()
选择:不能直接单击选择元素。因为您需要在单击后选择图元。此时,selenium为select标记提供了一个类selenium.webdriver.support.ui.select。将获取的元素作为参数传递给此类以创建此对象。以后可以使用此对象进行选择。示例代码如下所示:
从selenium.webdriver.support.ui导入选择
#选中此选项卡并使用“选择”创建对象
selectTag=Select(驱动程序。按名称查找元素(“跳转菜单”))
#按索引选择
selectTag.select按索引(1)
#按值选择
选择标签。按值(“”)选择标签
#基于可视文本进行选择
Selecttag.select通过可视文本(“95显示客户端”)
#取消选中所有选项
选择Tag.取消选择_all()
操作按钮:操作按钮有很多种方式,如点击、右击、双击等,最常用的方式之一是点击,直接调用点击功能即可,示例代码如下:
inputTag=驱动程序。通过\u id('su')查找\u元素\u
inputTag.click()
行为链:
有时页面上的操作可能需要很多步骤,因此您可以使用鼠标行为链类actionchains来完成。例如,现在您希望将鼠标移动到元素上并执行单击事件。示例代码如下:
inputTag = driver.find_element_by_id(‘kw‘)
submitTag = driver.find_element_by_id(‘su‘)
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,‘python‘)
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作
Cookie操作:
获取所有的cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有的cookie:
driver.delete_all_cookies()
删除某个cookie:
driver.delete_cookie(key)
页面等待:
如今,越来越多的web页面采用Ajax技术,因此程序无法确定元素何时完全加载。如果实际页面等待太长时间,导致DOM元素无法出现,但您的代码直接使用web元素,则会抛出空指针异常。为了解决此问题,selenium提供了两种方法HOD,如等待模式:一种是隐式等待,另一种是显式等待
隐式等待:调用driver.implicitly\u wait。然后等待10秒,然后获取不可用的元素。示例代码如下
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/")
2/显示等待:显示等待表示在建立条件之前不执行获取元素的操作。您还可以指定等待的最长时间。如果超过此时间,将引发异常。应使用selenium.webdriver.support.excepted的预期条件完成显示等待_conditions和selenium.webdriver.support.ui.webdriverwait示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading")
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等候条件:
参考更多条件:
切换页面:
有时窗口中有许多子选项卡页。此时,必须切换
Selenium提供了一个switch_to_窗口来切换。要切换到的特定页面可以在driver.window_句柄中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open(‘https://www.baidu.com‘)")
#显示当前页面的url
driver.current_url //还是百度页面
# 切换到这个新的页面中
driver.switch_to_window(driver.window_handles[1])
设置代理IP:
有时候我们会经常抓取一些网页,当服务器发现你是一个抓取者时,它会阻止你的IP地址,这时我们可以更改代理IP,更改代理IP对于不同的浏览器有不同的实现方法,这里以Chrome browser为例:
from selenium import webdriver
options = webdriver.ChromeOptions() //设置存储浏览器的信息
//添加代理服务器
options.add_argument("--proxy-server=http://110.73.2.248:8123")
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get(‘http://httpbin.org/ip‘)
Webelement元素:
从selenium.webdriver.remote.webelement导入webelement类是每个获取的元素所属的类
有一些共同的属性:
Get_attribute:此标记的属性值
截图:获取当前页面的截图。此方法只能用于驱动程序
驱动程序的对象类也继承自webelement
爬虫——selenium动态网页数据捕获
Tag:获取网页最终重载romati签名单元argumentorder 查看全部
php 爬虫抓取网页数据(网页finally重载romati签名单元argumentborder动态(一)(组图))
Tag:获取网页最终重载romati签名单元argumentorder
什么是用于动态网页数据捕获的Ajax:
Ajax(异步JavaScript和XML)异步JavaScript和XML。Ajax可以通过在后台与服务器交换少量数据来实现web页面的异步更新。这意味着可以在不重新加载整个网页的情况下更新网页的一部分。如果需要更新内容,传统web页面(没有Ajax)必须重新加载整个web页面。因为传统的传输数据格式使用XML语法。因此,它被称为Ajax。事实上,现在数据交互基本上使用JSON。使用Ajax加载的数据,即使使用了JS,也会呈现到浏览器中。右键单击->;查看网页源代码时,仍然无法看到通过Ajax加载的数据。您只能看到使用此URL加载的HTML代码
如何获取ajax数据:直接分析ajax调用的接口。然后通过代码请求这个接口。使用selenium+chromedriver模拟浏览器行为并获取数据
模式
优势
缺点
分析接口
可以直接请求数据。不需要进行一些解析。代码少,性能高
分析接口比较复杂,特别是一些通过JS混淆的接口。你应该有一个特定的JS基金会。作为爬行动物很容易被发现
硒
直接模拟浏览器的行为。如果浏览器可以请求,您也可以使用selenium进行请求。爬行动物更稳定
很多代码。低性能
Selenium+chromedriver可获得动态数据:
硒是一个机器人。它可以模拟浏览器上的一些人类行为,并自动处理浏览器上的一些行为,如单击、填充数据、删除cookie等。Chromedriver是Chrome浏览器的驱动程序。只有使用它才能驱动浏览器。当然,不同的浏览器有不同的驱动程序。下面列出了不同的浏览器及其相应的驱动程序:
Chrome:Firefox:Edge:Safari:install selenium:selenium有多种语言,包括Java、ruby、python等。我们可以下载python版本。PIP安装selenium安装chromedriver:下载后,未经许可将其放入纯英文目录。安装selenium和chromedriver:快速入门:
from selenium import webdriver
# chromedriver的绝对路径
driver_path = r‘D:\ProgramApp\chromedriver\chromedriver.exe‘
# 初始化一个driver,并且指定chromedriver的路径
driver = webdriver.Chrome(executable_path=driver_path)
# 请求网页
driver.get("https://www.baidu.com/";)
# 通过page_source获取网页源代码
print(driver.page_source)
Selenium常见操作:
更多教程参考:
关闭页面:驱动程序。Close():关闭当前页面。司机。退出():退出整个浏览器。定位元素:
请注意,find_u元素是满足条件的第一个元素。find_u元素是获取所有满足条件的元素
find_element_by_id:根据id来查找某个元素。等价于:
submitTag = driver.find_element_by_id(‘su‘)
submitTag1 = driver.find_element(By.ID,‘su‘)
find_element_by_class_name:根据类名查找元素。 等价于:
submitTag = driver.find_element_by_class_name(‘su‘)
submitTag1 = driver.find_element(By.CLASS_NAME,‘su‘)
find_element_by_name:根据name属性的值来查找元素。等价于:
submitTag = driver.find_element_by_name(‘email‘)
submitTag1 = driver.find_element(By.NAME,‘email‘)
find_element_by_tag_name:根据标签名来查找元素。等价于:
submitTag = driver.find_element_by_tag_name(‘div‘)
submitTag1 = driver.find_element(By.TAG_NAME,‘div‘)
find_element_by_xpath:根据xpath语法来获取元素。等价于:
submitTag = driver.find_element_by_xpath(‘//div‘)
submitTag1 = driver.find_element(By.XPATH,‘//div‘)
find_element_by_css_selector:根据css选择器选择元素。等价于:
submitTag = driver.find_element_by_css_selector(‘//div‘)
submitTag1 = driver.find_element(By.CSS_SELECTOR,‘//div‘)
行动形式要素:
操作输入框:分为两步。步骤1:找到这个元素。步骤2:使用发送键(值)填写数据。示例代码如下所示:
inputTag=driver.find u元素uu按u id('kw')查找
inputTag.send ukeys('python'))
使用“清除”方法清除输入框的内容。示例代码如下所示:
输入ag.clear()
操作复选框:由于要选择复选框选项卡,请在网页中单击它。因此,如果要选择复选框标记,请先选择标记,然后执行click事件。示例代码如下所示:
rememberTag=driver.find uu元素uu按名称(“rememberMe”)
记住标记。单击()
选择:不能直接单击选择元素。因为您需要在单击后选择图元。此时,selenium为select标记提供了一个类selenium.webdriver.support.ui.select。将获取的元素作为参数传递给此类以创建此对象。以后可以使用此对象进行选择。示例代码如下所示:
从selenium.webdriver.support.ui导入选择
#选中此选项卡并使用“选择”创建对象
selectTag=Select(驱动程序。按名称查找元素(“跳转菜单”))
#按索引选择
selectTag.select按索引(1)
#按值选择
选择标签。按值(“”)选择标签
#基于可视文本进行选择
Selecttag.select通过可视文本(“95显示客户端”)
#取消选中所有选项
选择Tag.取消选择_all()
操作按钮:操作按钮有很多种方式,如点击、右击、双击等,最常用的方式之一是点击,直接调用点击功能即可,示例代码如下:
inputTag=驱动程序。通过\u id('su')查找\u元素\u
inputTag.click()
行为链:
有时页面上的操作可能需要很多步骤,因此您可以使用鼠标行为链类actionchains来完成。例如,现在您希望将鼠标移动到元素上并执行单击事件。示例代码如下:
inputTag = driver.find_element_by_id(‘kw‘)
submitTag = driver.find_element_by_id(‘su‘)
actions = ActionChains(driver)
actions.move_to_element(inputTag)
actions.send_keys_to_element(inputTag,‘python‘)
actions.move_to_element(submitTag)
actions.click(submitTag)
actions.perform()
还有更多与鼠标相关的操作
Cookie操作:
获取所有的cookie:
for cookie in driver.get_cookies():
print(cookie)
根据cookie的key获取value:
value = driver.get_cookie(key)
删除所有的cookie:
driver.delete_all_cookies()
删除某个cookie:
driver.delete_cookie(key)
页面等待:
如今,越来越多的web页面采用Ajax技术,因此程序无法确定元素何时完全加载。如果实际页面等待太长时间,导致DOM元素无法出现,但您的代码直接使用web元素,则会抛出空指针异常。为了解决此问题,selenium提供了两种方法HOD,如等待模式:一种是隐式等待,另一种是显式等待
隐式等待:调用driver.implicitly\u wait。然后等待10秒,然后获取不可用的元素。示例代码如下
driver = webdriver.Chrome(executable_path=driver_path)
driver.implicitly_wait(10)
# 请求网页
driver.get("https://www.douban.com/";)
2/显示等待:显示等待表示在建立条件之前不执行获取元素的操作。您还可以指定等待的最长时间。如果超过此时间,将引发异常。应使用selenium.webdriver.support.excepted的预期条件完成显示等待_conditions和selenium.webdriver.support.ui.webdriverwait示例代码如下:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
driver = webdriver.Firefox()
driver.get("http://somedomain/url_that_delays_loading";)
try:
element = WebDriverWait(driver, 10).until(
EC.presence_of_element_located((By.ID, "myDynamicElement"))
)
finally:
driver.quit()
其他一些等候条件:
参考更多条件:
切换页面:
有时窗口中有许多子选项卡页。此时,必须切换
Selenium提供了一个switch_to_窗口来切换。要切换到的特定页面可以在driver.window_句柄中找到。示例代码如下:
# 打开一个新的页面
self.driver.execute_script("window.open(‘https://www.baidu.com‘)")
#显示当前页面的url
driver.current_url //还是百度页面
# 切换到这个新的页面中
driver.switch_to_window(driver.window_handles[1])
设置代理IP:
有时候我们会经常抓取一些网页,当服务器发现你是一个抓取者时,它会阻止你的IP地址,这时我们可以更改代理IP,更改代理IP对于不同的浏览器有不同的实现方法,这里以Chrome browser为例:
from selenium import webdriver
options = webdriver.ChromeOptions() //设置存储浏览器的信息
//添加代理服务器
options.add_argument("--proxy-server=http://110.73.2.248:8123";)
driver_path = r"D:\ProgramApp\chromedriver\chromedriver.exe"
driver = webdriver.Chrome(executable_path=driver_path,chrome_options=options)
driver.get(‘http://httpbin.org/ip‘)
Webelement元素:
从selenium.webdriver.remote.webelement导入webelement类是每个获取的元素所属的类
有一些共同的属性:
Get_attribute:此标记的属性值
截图:获取当前页面的截图。此方法只能用于驱动程序
驱动程序的对象类也继承自webelement
爬虫——selenium动态网页数据捕获
Tag:获取网页最终重载romati签名单元argumentorder
php 爬虫抓取网页数据(PHP是什么东西?PHP的爬虫有什么用?Python)
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-09-17 17:15
一、PHP是什么
PHP(外名:PHP:超文本预处理器,中文名:“超文本预处理器”)是一种通用的开源脚本语言。语法吸收了C语言、Java和Perl的特点,有利于学习和广泛使用。它主要适用于web开发领域。PHP独特的语法结合了C、Java、Perl和PHP自己的语法。它可以比CGI或Perl更快地执行动态网页。与其他编程语言相比,PHP将程序嵌入HTML(标准通用标记语言下的应用程序)文档中执行,执行效率远远高于CGI,CGI完全生成HTML标记;PHP还可以执行编译后的代码,这可以加密和优化代码操作,使代码运行更快——百度百科全书简介
二、爬行动物有什么用
爬行动物有什么用?让我们来谈谈什么是爬虫。我认为爬虫是一个网络信息采集程序。也许我的理解有误。请纠正我。由于爬虫是一个网络信息采集程序,它用于采集信息,采集的信息在网络上。如果我还不知道爬虫的用途,我会给出一些爬虫应用的例子:搜索引擎需要爬虫来采集网络信息,以便人们进行搜索;大数据从何而来?网络中的爬虫可以对其进行爬网(采集)
三、通常当我听到爬虫想到python时,我会想到python,但是为什么我要使用PHP而不是python呢?说实话,我不能用Python。(我真的不懂python。我想知道你可能想去百度,因为我真的不懂python。)
我一直认为,当你用PHP写东西的时候,只要你想出一个算法,程序就不会考虑太多的数据类型
PHP的语法与其他编程语言类似。即使您一开始不懂PHP,也可以立即启动它
PHP的语法与其他编程语言类似。即使您一开始不懂PHP,也可以立即启动它。你的想法是错误的。)
事实上,我也是PHP的初学者。我想通过写作来提高我的水平。(以下一些代码可能会让您觉得不够标准。请更正。谢谢。)
四、PHP爬行动物第一步
PHP爬虫程序的第一步,第一步。。。当然,第一步是构建一个PHP运行环境。没有环境,PHP如何运行?就像鱼离不开水一样。(我没有足够的知识。也许我给出的fish示例不够好。请原谅我。)我在windows上使用Wamp,在Linux上使用LNMP或lamp
WAMP:Windows+Apache+Mysql+PHP
LAMP:Linux+Apache+Mysql+PHP
LNMP:Linux+Nginx+Mysql+PHP
Apache和nginx是web服务器软件
Apache或nginx、MySQL和PHP是phpweb的基本配置环境。Internet上有PHP web环境安装包。这些安装包使用起来非常方便,不需要安装和配置任何东西。但是,如果您担心这些集成安装包的安全性,您可以在这些程序的官方网站上下载它们,然后在Internet上找到配置教程。(说真的,我真的不会一个人做。我觉得这很麻烦。)
五、PHP爬虫程序步骤2
(我觉得我有很多废话。我应该马上有一段代码!!!)
//爬虫核心功能:获取web源$HTML=file_uu获取内容(“”)
//文件通过PHP_uuGet_uuu内容函数获取百度主页的源代码,并将其传递给$HTML变量echo$HTML
//输出$HTML>
已经编写了爬虫网络的核心功能。为什么说只有几行代码编写了爬虫程序的核心功能?我想有些人已经明白了。事实上,因为爬虫是一个数据采集程序,上面的代码行实际上可以获取数据,所以已经编写了爬虫的核心功能。有些人可能会说:“你太棒了!有什么用?”。虽然我是一道好菜,但请不要这么说。让我安装一个X。(我为两行废话感到抱歉。)
事实上,爬行动物的用途主要取决于你想要它做什么。就像我几天前为了好玩而写了一个搜索引擎网站一样,当然网站非常美味。结果被不规则地排序,很多都找不到。我的搜索引擎爬虫是写一个适合搜索引擎的爬虫。所以为了方便起见,我将以搜索引擎的爬虫为目标来解释。当然,我的搜索引擎的爬虫还不完善。不完美的地方需要你去创造和提高自己
六、搜索引擎爬虫限制
有时搜索引擎的爬虫程序无法从网站页面获取页面源代码,但有一个robot.txt文件。如果这个文件中有网站,则表示网站管理员不希望爬虫程序对页面源代码进行爬网。(但如果你只是想得到它,即使你拥有它,你也会爬上去!)
我的搜索引擎爬虫实际上有很多缺陷造成的限制。例如,我可能无法获取页面源代码,因为我无法运行JS脚本。或者网站有一个反爬虫机制,使得无法获取页面的源代码。网站带有反爬虫机制,类似于:知乎和知乎是网站带有反爬虫机制
七、以搜索引擎爬虫为例,准备编写爬虫需要的内容。PHP编写基础
正则表达式(您也可以使用XPath。对不起,我不使用它)
数据库的使用(本文使用MySQL数据库)
运行环境(只要有可以运行PHP网站的环境和数据库)
八、search engine获取页面的源代码,获取页面的标题信息
//通过文件获取内容功能获取百度页面源代码$HTML=文件获取内容(“”)
//通过preg_uu,replace函数将页面源代码从多行更改为单行$htmloneline=preg_uuureplace(“/\r\n\t/”,“”,$html)
//通过preg_uu,match函数提取页面标题信息preg_uu匹配(“/
(.*)/iU“,$htmlOne,$Titlear)
//由于preg_uu,match函数的结果是数组$title=$titlearr[1]的形式
//通过echo函数输出标题信息echo$title
错误报告示例:
警告:文件获取内容(“:/”)127.0.@0.1/index.php“[function.file get contents]:无法打开流:第25行E:\website\blog\test.php中的参数无效
HTTPS是一种SSL加密协议。如果获取页面时间时出错,则意味着您的PHP可能缺少OpenSSL模块。你可以在网上找到解决方案
九、搜索引擎爬虫的特点
虽然我没有见过像“百度”和“谷歌”这样的爬虫,但我通过猜测总结了几个特点,以及在实际爬虫过程中遇到的一些问题。(可能有错误或遗漏。请更正。谢谢。)
普适性是因为我觉得搜索引擎的爬虫一开始并不是为网站设计的,所以需要尽可能多的爬虫网站这是第一点。第二点是获取网页的信息,它不会因为一开始的某些特殊网站而放弃对某些信息的提取。例如,如果一个小网站的网页元标记中没有描述或关键词信息,则直接放弃提取描述或关键词信息,当然,如果某个页面上没有此类信息,我将提取页面中的文本内容作为填充。无论如何,我会尽可能多地实现抓取的网页信息,并且每个网页的信息项应该是相同的。这就是我对搜索引擎爬虫的普遍性的看法。当然,我的想法可能是错误的。我可能说得不太好。我一直在学习
不确定的是,我无法全面控制我的爬虫程序获得的网页。我只能控制我所能想到的。这也是因为我的算法是对获取的页面中的所有链接进行爬网,然后爬网以获取这些链接。事实上,搜索引擎不会搜索某些东西,而是尽可能多地搜索,因为只有更多的信息才能找到用户想要的最合适的答案。所以我认为搜索引擎的爬虫应该具有不确定性。(我又看了一遍,感觉不懂,请原谅,欢迎大家指正提问,谢谢!)
下面的视频是我搜索网站的使用视频,找到的信息是通过我自己编写的PHP爬虫获得的。(这个网站我不再维护了,所以我有一些缺点,请原谅。)
十、到目前为止,可能存在问题。获得的源代码是乱码
//乱码的解决方案是通过MB_uuConvert传递其他编码格式。编码函数统一转换为UTF-8格式$HTML=MB_uuConvert_u;encoding($HTML、'UTF-8'、'UTF-8、GBK、GB2312、BIG5')
//由于gzip,还有一个乱码,我将在后面讨论>
2.无法获取标题信息
//如果无法获取标题信息,请首先判断是否可以获取页面源代码。//如果您可以获取标题信息,但仍然无法获取标题信息。//我想问题是:因为我教你使用正则表达式获取标题信息,所以源代码不会变成一行,而在获取$htmloneline=preg_uuu替换(“/\r | \n | \t/”,“,$html)时会出现问题
3.无法获取页面源代码
//就像新浪微博一样,你是 查看全部
php 爬虫抓取网页数据(PHP是什么东西?PHP的爬虫有什么用?Python)
一、PHP是什么
PHP(外名:PHP:超文本预处理器,中文名:“超文本预处理器”)是一种通用的开源脚本语言。语法吸收了C语言、Java和Perl的特点,有利于学习和广泛使用。它主要适用于web开发领域。PHP独特的语法结合了C、Java、Perl和PHP自己的语法。它可以比CGI或Perl更快地执行动态网页。与其他编程语言相比,PHP将程序嵌入HTML(标准通用标记语言下的应用程序)文档中执行,执行效率远远高于CGI,CGI完全生成HTML标记;PHP还可以执行编译后的代码,这可以加密和优化代码操作,使代码运行更快——百度百科全书简介
二、爬行动物有什么用
爬行动物有什么用?让我们来谈谈什么是爬虫。我认为爬虫是一个网络信息采集程序。也许我的理解有误。请纠正我。由于爬虫是一个网络信息采集程序,它用于采集信息,采集的信息在网络上。如果我还不知道爬虫的用途,我会给出一些爬虫应用的例子:搜索引擎需要爬虫来采集网络信息,以便人们进行搜索;大数据从何而来?网络中的爬虫可以对其进行爬网(采集)
三、通常当我听到爬虫想到python时,我会想到python,但是为什么我要使用PHP而不是python呢?说实话,我不能用Python。(我真的不懂python。我想知道你可能想去百度,因为我真的不懂python。)
我一直认为,当你用PHP写东西的时候,只要你想出一个算法,程序就不会考虑太多的数据类型
PHP的语法与其他编程语言类似。即使您一开始不懂PHP,也可以立即启动它
PHP的语法与其他编程语言类似。即使您一开始不懂PHP,也可以立即启动它。你的想法是错误的。)
事实上,我也是PHP的初学者。我想通过写作来提高我的水平。(以下一些代码可能会让您觉得不够标准。请更正。谢谢。)
四、PHP爬行动物第一步
PHP爬虫程序的第一步,第一步。。。当然,第一步是构建一个PHP运行环境。没有环境,PHP如何运行?就像鱼离不开水一样。(我没有足够的知识。也许我给出的fish示例不够好。请原谅我。)我在windows上使用Wamp,在Linux上使用LNMP或lamp
WAMP:Windows+Apache+Mysql+PHP
LAMP:Linux+Apache+Mysql+PHP
LNMP:Linux+Nginx+Mysql+PHP
Apache和nginx是web服务器软件
Apache或nginx、MySQL和PHP是phpweb的基本配置环境。Internet上有PHP web环境安装包。这些安装包使用起来非常方便,不需要安装和配置任何东西。但是,如果您担心这些集成安装包的安全性,您可以在这些程序的官方网站上下载它们,然后在Internet上找到配置教程。(说真的,我真的不会一个人做。我觉得这很麻烦。)
五、PHP爬虫程序步骤2
(我觉得我有很多废话。我应该马上有一段代码!!!)
//爬虫核心功能:获取web源$HTML=file_uu获取内容(“”)
//文件通过PHP_uuGet_uuu内容函数获取百度主页的源代码,并将其传递给$HTML变量echo$HTML
//输出$HTML>
已经编写了爬虫网络的核心功能。为什么说只有几行代码编写了爬虫程序的核心功能?我想有些人已经明白了。事实上,因为爬虫是一个数据采集程序,上面的代码行实际上可以获取数据,所以已经编写了爬虫的核心功能。有些人可能会说:“你太棒了!有什么用?”。虽然我是一道好菜,但请不要这么说。让我安装一个X。(我为两行废话感到抱歉。)
事实上,爬行动物的用途主要取决于你想要它做什么。就像我几天前为了好玩而写了一个搜索引擎网站一样,当然网站非常美味。结果被不规则地排序,很多都找不到。我的搜索引擎爬虫是写一个适合搜索引擎的爬虫。所以为了方便起见,我将以搜索引擎的爬虫为目标来解释。当然,我的搜索引擎的爬虫还不完善。不完美的地方需要你去创造和提高自己
六、搜索引擎爬虫限制
有时搜索引擎的爬虫程序无法从网站页面获取页面源代码,但有一个robot.txt文件。如果这个文件中有网站,则表示网站管理员不希望爬虫程序对页面源代码进行爬网。(但如果你只是想得到它,即使你拥有它,你也会爬上去!)
我的搜索引擎爬虫实际上有很多缺陷造成的限制。例如,我可能无法获取页面源代码,因为我无法运行JS脚本。或者网站有一个反爬虫机制,使得无法获取页面的源代码。网站带有反爬虫机制,类似于:知乎和知乎是网站带有反爬虫机制
七、以搜索引擎爬虫为例,准备编写爬虫需要的内容。PHP编写基础
正则表达式(您也可以使用XPath。对不起,我不使用它)
数据库的使用(本文使用MySQL数据库)
运行环境(只要有可以运行PHP网站的环境和数据库)
八、search engine获取页面的源代码,获取页面的标题信息
//通过文件获取内容功能获取百度页面源代码$HTML=文件获取内容(“”)
//通过preg_uu,replace函数将页面源代码从多行更改为单行$htmloneline=preg_uuureplace(“/\r\n\t/”,“”,$html)
//通过preg_uu,match函数提取页面标题信息preg_uu匹配(“/
(.*)/iU“,$htmlOne,$Titlear)
//由于preg_uu,match函数的结果是数组$title=$titlearr[1]的形式
//通过echo函数输出标题信息echo$title
错误报告示例:
警告:文件获取内容(“:/”)127.0.@0.1/index.php“[function.file get contents]:无法打开流:第25行E:\website\blog\test.php中的参数无效
HTTPS是一种SSL加密协议。如果获取页面时间时出错,则意味着您的PHP可能缺少OpenSSL模块。你可以在网上找到解决方案
九、搜索引擎爬虫的特点
虽然我没有见过像“百度”和“谷歌”这样的爬虫,但我通过猜测总结了几个特点,以及在实际爬虫过程中遇到的一些问题。(可能有错误或遗漏。请更正。谢谢。)
普适性是因为我觉得搜索引擎的爬虫一开始并不是为网站设计的,所以需要尽可能多的爬虫网站这是第一点。第二点是获取网页的信息,它不会因为一开始的某些特殊网站而放弃对某些信息的提取。例如,如果一个小网站的网页元标记中没有描述或关键词信息,则直接放弃提取描述或关键词信息,当然,如果某个页面上没有此类信息,我将提取页面中的文本内容作为填充。无论如何,我会尽可能多地实现抓取的网页信息,并且每个网页的信息项应该是相同的。这就是我对搜索引擎爬虫的普遍性的看法。当然,我的想法可能是错误的。我可能说得不太好。我一直在学习
不确定的是,我无法全面控制我的爬虫程序获得的网页。我只能控制我所能想到的。这也是因为我的算法是对获取的页面中的所有链接进行爬网,然后爬网以获取这些链接。事实上,搜索引擎不会搜索某些东西,而是尽可能多地搜索,因为只有更多的信息才能找到用户想要的最合适的答案。所以我认为搜索引擎的爬虫应该具有不确定性。(我又看了一遍,感觉不懂,请原谅,欢迎大家指正提问,谢谢!)
下面的视频是我搜索网站的使用视频,找到的信息是通过我自己编写的PHP爬虫获得的。(这个网站我不再维护了,所以我有一些缺点,请原谅。)
十、到目前为止,可能存在问题。获得的源代码是乱码
//乱码的解决方案是通过MB_uuConvert传递其他编码格式。编码函数统一转换为UTF-8格式$HTML=MB_uuConvert_u;encoding($HTML、'UTF-8'、'UTF-8、GBK、GB2312、BIG5')
//由于gzip,还有一个乱码,我将在后面讨论>
2.无法获取标题信息
//如果无法获取标题信息,请首先判断是否可以获取页面源代码。//如果您可以获取标题信息,但仍然无法获取标题信息。//我想问题是:因为我教你使用正则表达式获取标题信息,所以源代码不会变成一行,而在获取$htmloneline=preg_uuu替换(“/\r | \n | \t/”,“,$html)时会出现问题
3.无法获取页面源代码
//就像新浪微博一样,你是
php 爬虫抓取网页数据( 智联招聘上一线及新一线城市所有与BIM相关的工作信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 94 次浏览 • 2021-09-16 21:06
智联招聘上一线及新一线城市所有与BIM相关的工作信息)
Python简单web爬虫,用于获取网页数据
以下是获取智联招聘一线城市和新一线城市所有BIM相关工作信息,用于数据分析
1、first通过chrome在智联销上搜索BIM的位置信息。跳出页面后,按Ctrl+U键查看网页源代码。如果未找到当前页面的位置信息。然后,快捷键F12打开开发者工具窗口,刷新页面,通过关键字过滤文件,并找到收录位置的数据包
2、查看此文件的请求URL,分析其结构,发现数据包的请求URL由
‘https://fe-api.zhaopin.com/c/i/sou?’+请求参数组成,那么根据格式构造了一个新的url(
‘https://fe-api.zhaopin.com/c/i ... kw%3D造价员&kt=3’)
复制到浏览器进行access测试,并成功获取相应数据
3、获取的数据是JSON格式的数据。首先格式化数据,分析结构,确定代码中数据的分析方法
@在4、request URL和数据结构明确后,剩下的就是在代码中实现URL的构建、数据分析和导出。最后,获得1215个数据,需要对数据进行进一步排序,以便进行数据分析
推荐:[MySQL课程] 查看全部
php 爬虫抓取网页数据(
智联招聘上一线及新一线城市所有与BIM相关的工作信息)
Python简单web爬虫,用于获取网页数据
以下是获取智联招聘一线城市和新一线城市所有BIM相关工作信息,用于数据分析
1、first通过chrome在智联销上搜索BIM的位置信息。跳出页面后,按Ctrl+U键查看网页源代码。如果未找到当前页面的位置信息。然后,快捷键F12打开开发者工具窗口,刷新页面,通过关键字过滤文件,并找到收录位置的数据包
2、查看此文件的请求URL,分析其结构,发现数据包的请求URL由
‘https://fe-api.zhaopin.com/c/i/sou?’+请求参数组成,那么根据格式构造了一个新的url(
‘https://fe-api.zhaopin.com/c/i ... kw%3D造价员&kt=3’)
复制到浏览器进行access测试,并成功获取相应数据
3、获取的数据是JSON格式的数据。首先格式化数据,分析结构,确定代码中数据的分析方法
@在4、request URL和数据结构明确后,剩下的就是在代码中实现URL的构建、数据分析和导出。最后,获得1215个数据,需要对数据进行进一步排序,以便进行数据分析
推荐:[MySQL课程]
php 爬虫抓取网页数据(集搜客网络爬虫软件是一款免费的网页数据抓取工具)
网站优化 • 优采云 发表了文章 • 0 个评论 • 102 次浏览 • 2021-09-16 20:21
Jisoke web crawler软件是一个免费的网页数据捕获工具,它将网页内容转换为excel表格,用于内容分析、文本分析、策略分析和文献分析。自动分词、社交网络分析和情感分析软件用于毕业设计和行业研究
优采云web data采集器,是一个简单而强大的网络爬虫工具。它完全是可视化操作,无需编写代码。它内置了大量模板,连续五年支持任意网络数据捕获
Web内容智能抓取的实现和示例细节完全基于Java技术、核心技术、核心技术、XML解析、HTML解析、开源组件应用。该应用程序的开源组件包括:Dom4j:parsing xmljericho-
获取网站太多数据或抓取太快等因素通常会导致IP被阻止的风险,但我们可以通过使用PHP构建IP地址来获取数据
优采云·cloud采集服务平台网站内容捕获工具使用网络每天生成大量图形数据。我们如何为您和我使用这些数据,并使这些数据为我们的工作带来真正的价值
捕获web内容的一个例子是通过程序自动读取其他网站网页上显示的信息,类似于爬虫程序。例如,我们有一个
链接提交工具是网站主动搜索并向百度推送数据的工具。此工具可以缩短爬虫发现网站链接的时间。建议使用网站时效性内容链接提交工具,实时推送数据进行搜索。此工具可以加快爬虫的爬行速度,无法解决网站问题@
Python爬虫教程!教您手拉手抓取web数据 查看全部
php 爬虫抓取网页数据(集搜客网络爬虫软件是一款免费的网页数据抓取工具)
Jisoke web crawler软件是一个免费的网页数据捕获工具,它将网页内容转换为excel表格,用于内容分析、文本分析、策略分析和文献分析。自动分词、社交网络分析和情感分析软件用于毕业设计和行业研究
优采云web data采集器,是一个简单而强大的网络爬虫工具。它完全是可视化操作,无需编写代码。它内置了大量模板,连续五年支持任意网络数据捕获
Web内容智能抓取的实现和示例细节完全基于Java技术、核心技术、核心技术、XML解析、HTML解析、开源组件应用。该应用程序的开源组件包括:Dom4j:parsing xmljericho-
获取网站太多数据或抓取太快等因素通常会导致IP被阻止的风险,但我们可以通过使用PHP构建IP地址来获取数据
优采云·cloud采集服务平台网站内容捕获工具使用网络每天生成大量图形数据。我们如何为您和我使用这些数据,并使这些数据为我们的工作带来真正的价值
捕获web内容的一个例子是通过程序自动读取其他网站网页上显示的信息,类似于爬虫程序。例如,我们有一个
链接提交工具是网站主动搜索并向百度推送数据的工具。此工具可以缩短爬虫发现网站链接的时间。建议使用网站时效性内容链接提交工具,实时推送数据进行搜索。此工具可以加快爬虫的爬行速度,无法解决网站问题@
Python爬虫教程!教您手拉手抓取web数据
php 爬虫抓取网页数据(python爬虫能干什么的详细内容_php中文网(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2021-09-15 10:11
首先,我们需要知道什么是爬虫!我第一次听到爬虫这个词的时候,就以为是那种爬行的昆虫,想想好可笑...后来才知道,是一种网络上的数据抓取工具!
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
爬虫可以做什么?
1、模拟浏览器打开网页,获取网页中我们想要的那部分数据。
2、从技术层面来说就是, 通过程序模拟浏览器请求站点的行为,把站点返回的HTML代码/JSON数据/二进制数据(图片、视频) 爬到本地,进而提取自己需要的数据,存放起来使用。
3、如果你仔细观察,就不难发现,懂爬虫、学习爬虫的人越来越多,一方面,互联网可以获取的数据越来越多,另一方面,像 Python这样的编程语言提供越来越多的优秀工具,让爬虫变得简单、容易上手。
4、利用爬虫我们可以获取大量的价值数据,从而获得感性认识中不能得到的信息,比如:
爬虫的原理是什么?
发送请求 > 获取响应内容 > 解析内容 > 保存数据
如上所示,爬取数据的时候就是这个流程,是不是很简单呢?所以用户看到的浏览器的结果就是由 HTML 代码构成的,我们爬虫就是为了获取这些内容,通过分析和过滤 html 代码,从中获取我们想要资源。
相关学习推荐:python教程
以上就是python爬虫能干什么的详细内容,更多请关注php中文网其它相关文章!
声明:本文原创发布php中文网,转载请注明出处,感谢您的尊重!如有疑问,请联系处理
专题推荐:python 爬虫 查看全部
php 爬虫抓取网页数据(python爬虫能干什么的详细内容_php中文网(图))
首先,我们需要知道什么是爬虫!我第一次听到爬虫这个词的时候,就以为是那种爬行的昆虫,想想好可笑...后来才知道,是一种网络上的数据抓取工具!
网络爬虫(又被称为网页蜘蛛,网络机器人,在FOAF社区中间,更经常的称为网页追逐者),是一种按照一定的规则,自动地抓取万维网信息的程序或者脚本。另外一些不常使用的名字还有蚂蚁、自动索引、模拟程序或者蠕虫。
爬虫可以做什么?
1、模拟浏览器打开网页,获取网页中我们想要的那部分数据。
2、从技术层面来说就是, 通过程序模拟浏览器请求站点的行为,把站点返回的HTML代码/JSON数据/二进制数据(图片、视频) 爬到本地,进而提取自己需要的数据,存放起来使用。
3、如果你仔细观察,就不难发现,懂爬虫、学习爬虫的人越来越多,一方面,互联网可以获取的数据越来越多,另一方面,像 Python这样的编程语言提供越来越多的优秀工具,让爬虫变得简单、容易上手。
4、利用爬虫我们可以获取大量的价值数据,从而获得感性认识中不能得到的信息,比如:
爬虫的原理是什么?
发送请求 > 获取响应内容 > 解析内容 > 保存数据
如上所示,爬取数据的时候就是这个流程,是不是很简单呢?所以用户看到的浏览器的结果就是由 HTML 代码构成的,我们爬虫就是为了获取这些内容,通过分析和过滤 html 代码,从中获取我们想要资源。
相关学习推荐:python教程
以上就是python爬虫能干什么的详细内容,更多请关注php中文网其它相关文章!
声明:本文原创发布php中文网,转载请注明出处,感谢您的尊重!如有疑问,请联系处理
专题推荐:python 爬虫
php 爬虫抓取网页数据(做爬虫->相似度/主题提取/关键词-IDF)
网站优化 • 优采云 发表了文章 • 0 个评论 • 84 次浏览 • 2021-09-14 21:19
我做爬虫的时候,先抓取分类页面,抓取页面下所有分类的列表页url,然后加上种子后缀(也就是页码),开始迭代抓取列表页。在列表页中,我们只关心详情页,所以我们抓取了所有详情页的 URL 并将它们扔到 MQ 中。然后详情页抓取器会循环从MQ中获取详情页url,下整个html,保存在HDFS中。使用 MQ,您可以自己编写分布式架构。
为什么不直接从详情页提取想要的信息(ETL),而是直接保存html(EL)?首先是HDFS分布式文件系统,存储成本极低,解决了海量小文件的问题;其次,如果您提取信息的模式(常规/XPath/...)是错误的怎么办?或者您想稍后添加新的提取模式?您必须再次获取此页面,这会浪费宝贵的外部网络带宽。
另外,对于爬虫来说,最重要的是高度的容错性。除非你认为每个页面都很有价值,如果服务器返回非200,或者页面意外重定向,就放弃这个url。
最有效的爬虫是填满你的外部网络带宽,但这是理想的。抓住满足需求的数量即可。
也不要在车站上吊死自己。例如,我过去常常捕捉新闻。基本上几个主流站都在互相爬取,重复的内容很多。一个是爬行,但第二个不一定。至于去重,浪费了一些计算性能,做分词->余弦相似度/主题提取/关键词TF-IDF都可以轻松搞定,总比没有进来好 查看全部
php 爬虫抓取网页数据(做爬虫->相似度/主题提取/关键词-IDF)
我做爬虫的时候,先抓取分类页面,抓取页面下所有分类的列表页url,然后加上种子后缀(也就是页码),开始迭代抓取列表页。在列表页中,我们只关心详情页,所以我们抓取了所有详情页的 URL 并将它们扔到 MQ 中。然后详情页抓取器会循环从MQ中获取详情页url,下整个html,保存在HDFS中。使用 MQ,您可以自己编写分布式架构。
为什么不直接从详情页提取想要的信息(ETL),而是直接保存html(EL)?首先是HDFS分布式文件系统,存储成本极低,解决了海量小文件的问题;其次,如果您提取信息的模式(常规/XPath/...)是错误的怎么办?或者您想稍后添加新的提取模式?您必须再次获取此页面,这会浪费宝贵的外部网络带宽。
另外,对于爬虫来说,最重要的是高度的容错性。除非你认为每个页面都很有价值,如果服务器返回非200,或者页面意外重定向,就放弃这个url。
最有效的爬虫是填满你的外部网络带宽,但这是理想的。抓住满足需求的数量即可。
也不要在车站上吊死自己。例如,我过去常常捕捉新闻。基本上几个主流站都在互相爬取,重复的内容很多。一个是爬行,但第二个不一定。至于去重,浪费了一些计算性能,做分词->余弦相似度/主题提取/关键词TF-IDF都可以轻松搞定,总比没有进来好
php 爬虫抓取网页数据(爬虫在数据分析领域的应用,如何帮助我们提升数据质量)
网站优化 • 优采云 发表了文章 • 0 个评论 • 81 次浏览 • 2021-09-11 00:15
在当今信息化和数字化时代,人们离不开网络搜索,但想想看,你真的可以在搜索过程中获得相关信息,因为有人在帮你过滤相关内容。并呈现给您。
就像在餐馆里,你点了土豆,你可以吃,因为有人帮你在土豆、萝卜、西红柿等中找到土豆,有些人把土豆带到你的桌子上。在网上,这两个动作是由一个叫爬虫的同学实现的。
也就是说,没有爬虫,就没有今天的检索,也就无法准确的查找信息,有效的获取数据。今天,DataHunter 将谈谈爬虫在数据分析领域的应用,以及它如何帮助我们提高数据分析的质量。
一、数据时代,爬虫的本质是提高效率
网络爬虫也叫网络机器人,可以代替人们自动浏览网络信息、采集、整理数据。
是一种程序,基本原理是向网站/network发起请求,获取资源后,分析提取有用的数据。从技术角度来说,就是通过程序模拟浏览器请求站点的行为,将站点返回的HTML代码/JSON数据/二进制数据(图片、视频)抓取到本地,然后提取你的数据需要,保存以备使用。
每个程序都有自己的规则,网络爬虫也不例外。它穿梭在网站世界各地,会按照人们制定的规则发送采集信息。我们将这些规则称为网络爬虫算法。规则是人定的,是人根据自己的目的和需要设计的。因此,爬虫可以根据用户的目的而具有不同的功能。但所有爬虫的本质都是为了方便人们从海量的互联网信息中找到并下载自己想要的种类,从而提高信息获取的效率。
二、crawler 应用:搜索帮助企业做强业务
1.Search Engine:爬取网站,为网络用户提供便利
互联网发展之初,能提供全球信息的网站并不多,用户也不多。 Internet 只是文件传输协议 (FTP) 站点的集合。用户可以浏览这些站点以查找特定的共享文件。为了查找和组合 Internet 上可用的分布式数据,人们创建了一种称为网络爬虫的自动化程序。 /Robots 可以抓取互联网上的所有网页,然后将所有页面上的内容复制到数据库中进行索引。这也是最早的搜索引擎。
现在随着互联网的飞速发展,我们可以在任何搜索引擎中看到来自世界各地各种网站的信息。百度搜索引擎的爬虫叫Baiduspider,360的爬虫叫360Spider,搜狗的爬虫叫Sogouspider,必应的爬虫叫Bingbot。搜索引擎离不开爬虫。
比如百度蜘蛛每天抓取大量互联网信息,抓取优质信息和收录。当用户在百度搜索引擎上检索到对应的关键词时,百度会对关键词进行分析处理,从收录的网页中找到相关的网页,按照一定的排序规则进行排序,并将结果展示给用户。工作原理如图所示。现在,我们可以大胆地说,您每天都在免费享受爬虫带来的好处。
2.企业:关注舆情,高效获取有价值信息
我们说过爬虫的本质是提高效率,爬虫的规则是人定的;那么企业就可以根据自己的业务需求设计一个爬虫,尽快在网上获取相关信息,并进行清理和整合。
大数据时代的数据分析,首先要有数据源。虽然网络爬虫可以让我们获得更多的数据源,但我们可以根据自己的目的采集,从而去除很多不相关的数据。
比如在进行大数据分析或者数据挖掘时,数据源可以从一些提供统计的网站获取,也可以从一些文献或内部资料中获取。但是这些获取数据的方法有时很难满足我们的数据需求。此时,我们可以利用爬虫技术,自动从互联网上获取更多我们感兴趣的数据内容,从而进行更深入的数据分析,获取更多有价值的信息。
此外,还可以在财务分析中使用网络爬虫对财务数据进行采集进行投资分析;可应用于舆情监测与分析、精准客户精准营销等多个领域。
三、4种企业常用的网络爬虫
网络爬虫根据实现的技术和结构可分为通用网络爬虫、聚焦网络爬虫、增量网络爬虫和深度网络爬虫。但由于网络环境复杂,实际的网络爬虫往往是这几种爬虫的组合。
1.万能网络爬虫
通用网络爬虫也称为全网爬虫。顾名思义,爬取的目标资源在整个互联网。爬取的目标数据庞大,爬取的范围也非常大。正是因为它爬取的数据是海量数据,所以对于这类爬虫,对爬取性能的要求非常高。这种网络爬虫主要用于大型搜索引擎,具有很高的应用价值。
一般的网络爬虫主要由初始URL采集、URL队列、页面爬取模块、页面分析模块、页面数据库、链接过滤模块等组成,一般的网络爬虫在爬取时都会采用一定的爬取策略。有深度优先的爬行策略和广度优先的爬行策略。具体细节稍后介绍。
2.focus 网络爬虫
焦点网络爬虫,也叫主题网络爬虫,是一种根据预定义的主题有选择地抓取网页的爬虫。聚焦网络爬虫主要用于对特定信息的爬取,主要是为特定的人群提供服务。
Focus 网络爬虫还由初始 URL 采集、URL 队列、页面爬取模块、页面分析模块、页面数据库、链接过滤模块、内容评估模块、链接评估模块等组成。其中,内容评估模块和链接评估模块可以根据链接的重要性和内容确定优先访问哪些页面。网络爬虫主要有四种爬虫策略,如图:
Focus 网络爬虫可以有目的地按照相应的主题进行爬取,因此在实际应用过程中,可以节省大量的服务器资源和宽带资源,实用性强。这里以聚焦网络爬虫为例,了解爬虫运行的工作原理和流程。
如图所示,Focus Web Crawler有一个控制中心,负责整个爬虫系统的管理和监控,主要包括控制用户交互、初始化爬虫、确定主题、协调工作各个模块之间,控制爬取过程等方面:
(1)Control Center 会将初始的一组 URL 传递给 URL 队列,页面抓取模块会从 URL 队列中读取第一批 URL 列表;
(2)根据这些URL地址从网上爬取对应的页面;爬取后,将爬取的内容传送到页面数据库中存储;
(3)在爬取过程中,会爬取一些新的URL,这时候就需要使用链接过滤模块根据主题集过滤掉不相关的链接,然后对剩下的使用链接评估根据主题进行网址链接。模块或内容评测模块优先,完成后将新的网址地址传递到网址队列,供页面抓取模块使用;
(4)页面抓取并存入页面数据库后,需要使用页面分析模块根据主题对抓取页面上的页面进行分析,并根据处理结果建立索引数据库。当用户检索到相应的信息时,可以从索引数据库中进行相应的搜索,得到相应的结果。
3.增量网络爬虫
这里的“增量”对应的是增量更新。增量更新是指更新过程中只更新变化的区域,不变的区域不更新。
增量式网络爬虫,在抓取网页时,只会抓取有内容变化的网页或新生成的网页,不会抓取没有内容变化的网页。增量爬虫可以在一定程度上保证爬取的页面尽可能的新鲜。
4.deep 网络爬虫
在互联网中,网页根据存在的方式可以分为表层页和深层页。表面页面是指无需提交表单即可使用静态链接访问的静态页面;而深页是提交一定数量的关键词后才能获得的页面。在互联网中,深层页面的数量往往远大于表面页面的数量。
深度网络爬虫可以抓取互联网上的深度页面,抓取深度页面,需要想办法自动填写相应的表单。深网爬虫主要由URL列表、LVS列表(LVS指标签/值集合,即填写表单的数据源)、爬虫控制器、解析器、LVS控制器、表单分析器、表单处理器、响应分析器等部分组成。
四、Web爬虫抓取策略
之前我们说网络爬虫算法是根据人们强加的规则来获取采集信息的,由于网络环境复杂,有各种对应的算法,即爬虫策略。这里主要介绍爬取的顺序和频率。
1.爬取顺序
网络爬虫在爬取过程中,爬取的URL列表中可能有很多URL地址,所以爬虫爬取这些URL地址会有一个顺序。
和一般的网络爬虫相比,爬取的顺序没那么重要。但是针对网络爬虫来说,爬取的顺序与服务器资源和宽带资源有关,所以非常重要,一般由爬取策略决定。爬取策略主要包括深度优先爬取策略、广度优先爬取策略、大站优先策略、反链策略、其他爬取策略等。
如图,假设有一个网站,ABCDEFG分别为站点下的网页,代表如图所示网页的层次结构。如果此时网页ABCDEFG在抓取队列中,则根据不同的抓取策略,抓取的顺序也不同。
深度优先爬取策略:A→D→E→B→C→F→G
广度优先爬取策略:A→B→C→D→E→F→G
除了以上两种爬取策略,还可以使用大站爬取策略。可以根据相应网页所属的站点进行分类。如果某个网站有大量的网页,就称为大站。按照这个策略,网页数量越多,网站越大,然后优先爬取大网站中网页的URL地址。
还有反链策略。一个网页的反向链接次数是指该网页被其他网页指向的次数,这个数字代表了该网页在一定程度上被其他网页推荐的次数。所以,如果按照反链策略爬取,那么哪个网页反链多,哪个页面会先被爬取。
但是,在实际情况下,如果一个网页的优先级仅由反链策略决定,那么可能存在大量作弊。因此,反向链接策略的使用需要考虑可靠反向链接的数量。除了以上爬取策略,实践中还有很多其他爬取策略,比如OPIC策略、Partial PageRank策略等。
2.爬行频率
网站的网页更新频繁。作为爬虫,网站的更新频率越接近爬虫访问网站的频率,效果就会越好。当然,在爬虫服务器资源有限的情况下,爬虫也需要根据相应的策略,让不同的网页有不同的更新优先级,优先级高的网页会以更快的爬取响应进行更新。常见的网页更新策略主要有以下三种:
(1)用户体验策略:大多数用户在使用搜索引擎查询关键词时,只关注排名靠前的网页。因此,在爬虫服务器资源有限的情况下,爬虫会给priority 更新首页排名结果。
(2)历史数据策略:是指能够根据某个网页的历史更新数据,通过泊松过程建模等手段,预测网页下次更新时间,从而确定下一次更新时间。网页更新时间 抓取时间。
(3)Clustering 分析策略:网页可能有不同的内容,但一般而言,属性相似的网页更新频率相近,因此可以对大量网页进行聚类分析。聚类完成后,可根据同类网页的平均更新值设置抓取频率。
五、网络爬虫的实现技术
对于实现技术,本文不展开,只为感兴趣的同学提供几种常用语言:Python、Java、PHP、Node.JS、C++、Go语言(另外还有很多网络爬虫开发语言)。
Python:爬虫框架非常丰富,多线程处理能力强,简单易学,代码简洁,优点很多。
Java:适合大型爬虫项目的开发。
PHP:后端处理能力很强,代码很简洁,模块也很丰富,但是并发能力比较弱。节点.JS:
支持高并发和多线程处理。
C++:运行速度快,适合开发大型爬虫项目,成本高。
Go 语言:同样高并发性很强。
六、小结
说起爬虫,很多人认为它是网络世界中无法回避的灰色地带。恭喜,看完这篇文章,你比很多人都懂。
因为爬虫分为善意爬虫和恶意爬虫,比如搜索引擎爬虫。好心爬虫严格遵守Robots协议规范抓取网页数据(如URL),它的存在可以增加网站的曝光率,给网站带来流量;
恶意爬虫无视Robots协议,故意爬取网站中的一些深藏不露的数据,包括个人隐私或商业机密等重要信息。而恶意爬虫的用户希望从网站处获取多条、大量的信息,因此通常会向目标网站释放大量爬虫。如果大量爬虫同时访问网站,很容易造成网站服务器过载或崩溃,造成网站运营商流失。
据统计,2017年我国互联网流量的42.2%是由网络机器人造成的,其中恶意机器(主要是恶意爬虫)占21.80%。我们应该依法使用网络爬虫,用技术为企业带来长远发展,用科学为社会创造更高的价值。
关于 DataHunter
DataHunter 是一家专业的数据分析和商业智能服务提供商,注册于 2014 年,团队核心成员来自 IBM、Oracle、SAP 等知名公司。深耕大数据分析领域,拥有十余年丰富的企业服务经验。
DataHunter的核心产品智能数据分析平台Data Analytics、数据大屏设计与配置工具Data MAX在行业内形成了自己独特的优势,在各行业积累了众多标杆客户和成功案例。
DataHunter自成立以来,一直致力于为客户提供实时、高效、智能的数据分析展示解决方案,帮助企业查看、分析数据,提升业务,成为最值得信赖的数据业务公司。
> 查看全部
php 爬虫抓取网页数据(爬虫在数据分析领域的应用,如何帮助我们提升数据质量)
在当今信息化和数字化时代,人们离不开网络搜索,但想想看,你真的可以在搜索过程中获得相关信息,因为有人在帮你过滤相关内容。并呈现给您。
就像在餐馆里,你点了土豆,你可以吃,因为有人帮你在土豆、萝卜、西红柿等中找到土豆,有些人把土豆带到你的桌子上。在网上,这两个动作是由一个叫爬虫的同学实现的。
也就是说,没有爬虫,就没有今天的检索,也就无法准确的查找信息,有效的获取数据。今天,DataHunter 将谈谈爬虫在数据分析领域的应用,以及它如何帮助我们提高数据分析的质量。
一、数据时代,爬虫的本质是提高效率
网络爬虫也叫网络机器人,可以代替人们自动浏览网络信息、采集、整理数据。
是一种程序,基本原理是向网站/network发起请求,获取资源后,分析提取有用的数据。从技术角度来说,就是通过程序模拟浏览器请求站点的行为,将站点返回的HTML代码/JSON数据/二进制数据(图片、视频)抓取到本地,然后提取你的数据需要,保存以备使用。
每个程序都有自己的规则,网络爬虫也不例外。它穿梭在网站世界各地,会按照人们制定的规则发送采集信息。我们将这些规则称为网络爬虫算法。规则是人定的,是人根据自己的目的和需要设计的。因此,爬虫可以根据用户的目的而具有不同的功能。但所有爬虫的本质都是为了方便人们从海量的互联网信息中找到并下载自己想要的种类,从而提高信息获取的效率。
二、crawler 应用:搜索帮助企业做强业务
1.Search Engine:爬取网站,为网络用户提供便利
互联网发展之初,能提供全球信息的网站并不多,用户也不多。 Internet 只是文件传输协议 (FTP) 站点的集合。用户可以浏览这些站点以查找特定的共享文件。为了查找和组合 Internet 上可用的分布式数据,人们创建了一种称为网络爬虫的自动化程序。 /Robots 可以抓取互联网上的所有网页,然后将所有页面上的内容复制到数据库中进行索引。这也是最早的搜索引擎。
现在随着互联网的飞速发展,我们可以在任何搜索引擎中看到来自世界各地各种网站的信息。百度搜索引擎的爬虫叫Baiduspider,360的爬虫叫360Spider,搜狗的爬虫叫Sogouspider,必应的爬虫叫Bingbot。搜索引擎离不开爬虫。
比如百度蜘蛛每天抓取大量互联网信息,抓取优质信息和收录。当用户在百度搜索引擎上检索到对应的关键词时,百度会对关键词进行分析处理,从收录的网页中找到相关的网页,按照一定的排序规则进行排序,并将结果展示给用户。工作原理如图所示。现在,我们可以大胆地说,您每天都在免费享受爬虫带来的好处。
2.企业:关注舆情,高效获取有价值信息
我们说过爬虫的本质是提高效率,爬虫的规则是人定的;那么企业就可以根据自己的业务需求设计一个爬虫,尽快在网上获取相关信息,并进行清理和整合。
大数据时代的数据分析,首先要有数据源。虽然网络爬虫可以让我们获得更多的数据源,但我们可以根据自己的目的采集,从而去除很多不相关的数据。
比如在进行大数据分析或者数据挖掘时,数据源可以从一些提供统计的网站获取,也可以从一些文献或内部资料中获取。但是这些获取数据的方法有时很难满足我们的数据需求。此时,我们可以利用爬虫技术,自动从互联网上获取更多我们感兴趣的数据内容,从而进行更深入的数据分析,获取更多有价值的信息。
此外,还可以在财务分析中使用网络爬虫对财务数据进行采集进行投资分析;可应用于舆情监测与分析、精准客户精准营销等多个领域。
三、4种企业常用的网络爬虫
网络爬虫根据实现的技术和结构可分为通用网络爬虫、聚焦网络爬虫、增量网络爬虫和深度网络爬虫。但由于网络环境复杂,实际的网络爬虫往往是这几种爬虫的组合。
1.万能网络爬虫
通用网络爬虫也称为全网爬虫。顾名思义,爬取的目标资源在整个互联网。爬取的目标数据庞大,爬取的范围也非常大。正是因为它爬取的数据是海量数据,所以对于这类爬虫,对爬取性能的要求非常高。这种网络爬虫主要用于大型搜索引擎,具有很高的应用价值。
一般的网络爬虫主要由初始URL采集、URL队列、页面爬取模块、页面分析模块、页面数据库、链接过滤模块等组成,一般的网络爬虫在爬取时都会采用一定的爬取策略。有深度优先的爬行策略和广度优先的爬行策略。具体细节稍后介绍。
2.focus 网络爬虫
焦点网络爬虫,也叫主题网络爬虫,是一种根据预定义的主题有选择地抓取网页的爬虫。聚焦网络爬虫主要用于对特定信息的爬取,主要是为特定的人群提供服务。
Focus 网络爬虫还由初始 URL 采集、URL 队列、页面爬取模块、页面分析模块、页面数据库、链接过滤模块、内容评估模块、链接评估模块等组成。其中,内容评估模块和链接评估模块可以根据链接的重要性和内容确定优先访问哪些页面。网络爬虫主要有四种爬虫策略,如图:
Focus 网络爬虫可以有目的地按照相应的主题进行爬取,因此在实际应用过程中,可以节省大量的服务器资源和宽带资源,实用性强。这里以聚焦网络爬虫为例,了解爬虫运行的工作原理和流程。
如图所示,Focus Web Crawler有一个控制中心,负责整个爬虫系统的管理和监控,主要包括控制用户交互、初始化爬虫、确定主题、协调工作各个模块之间,控制爬取过程等方面:
(1)Control Center 会将初始的一组 URL 传递给 URL 队列,页面抓取模块会从 URL 队列中读取第一批 URL 列表;
(2)根据这些URL地址从网上爬取对应的页面;爬取后,将爬取的内容传送到页面数据库中存储;
(3)在爬取过程中,会爬取一些新的URL,这时候就需要使用链接过滤模块根据主题集过滤掉不相关的链接,然后对剩下的使用链接评估根据主题进行网址链接。模块或内容评测模块优先,完成后将新的网址地址传递到网址队列,供页面抓取模块使用;
(4)页面抓取并存入页面数据库后,需要使用页面分析模块根据主题对抓取页面上的页面进行分析,并根据处理结果建立索引数据库。当用户检索到相应的信息时,可以从索引数据库中进行相应的搜索,得到相应的结果。
3.增量网络爬虫
这里的“增量”对应的是增量更新。增量更新是指更新过程中只更新变化的区域,不变的区域不更新。
增量式网络爬虫,在抓取网页时,只会抓取有内容变化的网页或新生成的网页,不会抓取没有内容变化的网页。增量爬虫可以在一定程度上保证爬取的页面尽可能的新鲜。
4.deep 网络爬虫
在互联网中,网页根据存在的方式可以分为表层页和深层页。表面页面是指无需提交表单即可使用静态链接访问的静态页面;而深页是提交一定数量的关键词后才能获得的页面。在互联网中,深层页面的数量往往远大于表面页面的数量。
深度网络爬虫可以抓取互联网上的深度页面,抓取深度页面,需要想办法自动填写相应的表单。深网爬虫主要由URL列表、LVS列表(LVS指标签/值集合,即填写表单的数据源)、爬虫控制器、解析器、LVS控制器、表单分析器、表单处理器、响应分析器等部分组成。
四、Web爬虫抓取策略
之前我们说网络爬虫算法是根据人们强加的规则来获取采集信息的,由于网络环境复杂,有各种对应的算法,即爬虫策略。这里主要介绍爬取的顺序和频率。
1.爬取顺序
网络爬虫在爬取过程中,爬取的URL列表中可能有很多URL地址,所以爬虫爬取这些URL地址会有一个顺序。
和一般的网络爬虫相比,爬取的顺序没那么重要。但是针对网络爬虫来说,爬取的顺序与服务器资源和宽带资源有关,所以非常重要,一般由爬取策略决定。爬取策略主要包括深度优先爬取策略、广度优先爬取策略、大站优先策略、反链策略、其他爬取策略等。
如图,假设有一个网站,ABCDEFG分别为站点下的网页,代表如图所示网页的层次结构。如果此时网页ABCDEFG在抓取队列中,则根据不同的抓取策略,抓取的顺序也不同。
深度优先爬取策略:A→D→E→B→C→F→G
广度优先爬取策略:A→B→C→D→E→F→G
除了以上两种爬取策略,还可以使用大站爬取策略。可以根据相应网页所属的站点进行分类。如果某个网站有大量的网页,就称为大站。按照这个策略,网页数量越多,网站越大,然后优先爬取大网站中网页的URL地址。
还有反链策略。一个网页的反向链接次数是指该网页被其他网页指向的次数,这个数字代表了该网页在一定程度上被其他网页推荐的次数。所以,如果按照反链策略爬取,那么哪个网页反链多,哪个页面会先被爬取。
但是,在实际情况下,如果一个网页的优先级仅由反链策略决定,那么可能存在大量作弊。因此,反向链接策略的使用需要考虑可靠反向链接的数量。除了以上爬取策略,实践中还有很多其他爬取策略,比如OPIC策略、Partial PageRank策略等。
2.爬行频率
网站的网页更新频繁。作为爬虫,网站的更新频率越接近爬虫访问网站的频率,效果就会越好。当然,在爬虫服务器资源有限的情况下,爬虫也需要根据相应的策略,让不同的网页有不同的更新优先级,优先级高的网页会以更快的爬取响应进行更新。常见的网页更新策略主要有以下三种:
(1)用户体验策略:大多数用户在使用搜索引擎查询关键词时,只关注排名靠前的网页。因此,在爬虫服务器资源有限的情况下,爬虫会给priority 更新首页排名结果。
(2)历史数据策略:是指能够根据某个网页的历史更新数据,通过泊松过程建模等手段,预测网页下次更新时间,从而确定下一次更新时间。网页更新时间 抓取时间。
(3)Clustering 分析策略:网页可能有不同的内容,但一般而言,属性相似的网页更新频率相近,因此可以对大量网页进行聚类分析。聚类完成后,可根据同类网页的平均更新值设置抓取频率。
五、网络爬虫的实现技术
对于实现技术,本文不展开,只为感兴趣的同学提供几种常用语言:Python、Java、PHP、Node.JS、C++、Go语言(另外还有很多网络爬虫开发语言)。
Python:爬虫框架非常丰富,多线程处理能力强,简单易学,代码简洁,优点很多。
Java:适合大型爬虫项目的开发。
PHP:后端处理能力很强,代码很简洁,模块也很丰富,但是并发能力比较弱。节点.JS:
支持高并发和多线程处理。
C++:运行速度快,适合开发大型爬虫项目,成本高。
Go 语言:同样高并发性很强。
六、小结
说起爬虫,很多人认为它是网络世界中无法回避的灰色地带。恭喜,看完这篇文章,你比很多人都懂。
因为爬虫分为善意爬虫和恶意爬虫,比如搜索引擎爬虫。好心爬虫严格遵守Robots协议规范抓取网页数据(如URL),它的存在可以增加网站的曝光率,给网站带来流量;
恶意爬虫无视Robots协议,故意爬取网站中的一些深藏不露的数据,包括个人隐私或商业机密等重要信息。而恶意爬虫的用户希望从网站处获取多条、大量的信息,因此通常会向目标网站释放大量爬虫。如果大量爬虫同时访问网站,很容易造成网站服务器过载或崩溃,造成网站运营商流失。
据统计,2017年我国互联网流量的42.2%是由网络机器人造成的,其中恶意机器(主要是恶意爬虫)占21.80%。我们应该依法使用网络爬虫,用技术为企业带来长远发展,用科学为社会创造更高的价值。
关于 DataHunter
DataHunter 是一家专业的数据分析和商业智能服务提供商,注册于 2014 年,团队核心成员来自 IBM、Oracle、SAP 等知名公司。深耕大数据分析领域,拥有十余年丰富的企业服务经验。
DataHunter的核心产品智能数据分析平台Data Analytics、数据大屏设计与配置工具Data MAX在行业内形成了自己独特的优势,在各行业积累了众多标杆客户和成功案例。
DataHunter自成立以来,一直致力于为客户提供实时、高效、智能的数据分析展示解决方案,帮助企业查看、分析数据,提升业务,成为最值得信赖的数据业务公司。
>

