
php 抓取网页 源码
php 抓取网页 源码(以上就是抓取网页源码三种实现方法的详细内容,需要的朋友可以参考)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-10-11 08:15
抓取网页源码的三种实现方法,有需要的朋友可以参考
更推荐方法一
/// /// 用HttpWebRequest取得网页源码 /// 对于带BOM的网页很有效,不管是什么编码都能正确识别 /// /// 网页地址" /// 返回网页源文件 public static string GetHtmlSource2(string url) { //处理内容 string html = ""; HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url); request.Accept = "*/*"; //接受任意文件 request.UserAgent = "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.2; .NET CLR 1.1.4322)"; // 模拟使用IE在浏览 http://www.52mvc.com request.AllowAutoRedirect = true;//是否允许302 //request.CookieContainer = new CookieContainer();//cookie容器, request.Referer = url; //当前页面的引用 HttpWebResponse response = (HttpWebResponse)request.GetResponse(); Stream stream = response.GetResponseStream(); StreamReader reader = new StreamReader(stream, Encoding.Default); html = reader.ReadToEnd(); stream.Close(); return html; }
方法二
using System; using System.Collections.Generic; using System.Linq; using System.Web; using System.IO; using System.Text; using System.Net; namespace MySql { public class GetHttpData { public static string GetHttpData2(string Url) { string sException = null; string sRslt = null; WebResponse oWebRps = null; WebRequest oWebRqst = WebRequest.Create(Url); oWebRqst.Timeout = 50000; try { oWebRps = oWebRqst.GetResponse(); } catch (WebException e) { sException = e.Message.ToString(); } catch (Exception e) { sException = e.ToString(); } finally { if (oWebRps != null) { StreamReader oStreamRd = new StreamReader(oWebRps.GetResponseStream(), Encoding.GetEncoding("utf-8")); sRslt = oStreamRd.ReadToEnd(); oStreamRd.Close(); oWebRps.Close(); } } return sRslt; } } }
方法三
<p> public static string getHtml(string url, params string [] charSets)//url是要访问的网站地址,charSet是目标网页的编码,如果传入的是null或者"",那就自动分析网页的编码 { try { string charSet = null; if (charSets.Length == 1) { charSet = charSets[0]; } WebClient myWebClient = new WebClient(); //创建WebClient实例myWebClient // 需要注意的: //有的网页可能下不下来,有种种原因比如需要cookie,编码问题等等 //这是就要具体问题具体分析比如在头部加入cookie // webclient.Headers.Add("Cookie", cookie); //这样可能需要一些重载方法。根据需要写就可以了 //获取或设置用于对向 Internet 资源的请求进行身份验证的网络凭据。 myWebClient.Credentials = CredentialCache.DefaultCredentials; //如果服务器要验证用户名,密码 //NetworkCredential mycred = new NetworkCredential(struser, strpassword); //myWebClient.Credentials = mycred; //从资源下载数据并返回字节数组。(加@是因为网址中间有"/"符号) byte[] myDataBuffer = myWebClient.DownloadData(url); string strWebData = Encoding.Default.GetString(myDataBuffer); //获取网页字符编码描述信息 Match charSetMatch = Regex.Match(strWebData, " 查看全部
php 抓取网页 源码(以上就是抓取网页源码三种实现方法的详细内容,需要的朋友可以参考)
抓取网页源码的三种实现方法,有需要的朋友可以参考
更推荐方法一
/// /// 用HttpWebRequest取得网页源码 /// 对于带BOM的网页很有效,不管是什么编码都能正确识别 /// /// 网页地址" /// 返回网页源文件 public static string GetHtmlSource2(string url) { //处理内容 string html = ""; HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url); request.Accept = "*/*"; //接受任意文件 request.UserAgent = "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.2; .NET CLR 1.1.4322)"; // 模拟使用IE在浏览 http://www.52mvc.com request.AllowAutoRedirect = true;//是否允许302 //request.CookieContainer = new CookieContainer();//cookie容器, request.Referer = url; //当前页面的引用 HttpWebResponse response = (HttpWebResponse)request.GetResponse(); Stream stream = response.GetResponseStream(); StreamReader reader = new StreamReader(stream, Encoding.Default); html = reader.ReadToEnd(); stream.Close(); return html; }
方法二
using System; using System.Collections.Generic; using System.Linq; using System.Web; using System.IO; using System.Text; using System.Net; namespace MySql { public class GetHttpData { public static string GetHttpData2(string Url) { string sException = null; string sRslt = null; WebResponse oWebRps = null; WebRequest oWebRqst = WebRequest.Create(Url); oWebRqst.Timeout = 50000; try { oWebRps = oWebRqst.GetResponse(); } catch (WebException e) { sException = e.Message.ToString(); } catch (Exception e) { sException = e.ToString(); } finally { if (oWebRps != null) { StreamReader oStreamRd = new StreamReader(oWebRps.GetResponseStream(), Encoding.GetEncoding("utf-8")); sRslt = oStreamRd.ReadToEnd(); oStreamRd.Close(); oWebRps.Close(); } } return sRslt; } } }
方法三
<p> public static string getHtml(string url, params string [] charSets)//url是要访问的网站地址,charSet是目标网页的编码,如果传入的是null或者"",那就自动分析网页的编码 { try { string charSet = null; if (charSets.Length == 1) { charSet = charSets[0]; } WebClient myWebClient = new WebClient(); //创建WebClient实例myWebClient // 需要注意的: //有的网页可能下不下来,有种种原因比如需要cookie,编码问题等等 //这是就要具体问题具体分析比如在头部加入cookie // webclient.Headers.Add("Cookie", cookie); //这样可能需要一些重载方法。根据需要写就可以了 //获取或设置用于对向 Internet 资源的请求进行身份验证的网络凭据。 myWebClient.Credentials = CredentialCache.DefaultCredentials; //如果服务器要验证用户名,密码 //NetworkCredential mycred = new NetworkCredential(struser, strpassword); //myWebClient.Credentials = mycred; //从资源下载数据并返回字节数组。(加@是因为网址中间有"/"符号) byte[] myDataBuffer = myWebClient.DownloadData(url); string strWebData = Encoding.Default.GetString(myDataBuffer); //获取网页字符编码描述信息 Match charSetMatch = Regex.Match(strWebData, "
php 抓取网页 源码(php抓取网页源码有三种方法:.get())
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-10-10 10:03
php抓取网页源码有三种方法:
1、通过requests库中的request.get()方法,对提交的url,利用request.send()函数发送一个http请求(最多302跳转一次),最终拿到图片地址。
2、通过php的opener对象,对本地的php文件进行url获取,获取到全部的文件url、文件名、类名等。
3、php中的media_stream类,可以实现对一些网络图片的读写,拿到url,可以用代码实现,
作为phper,你可以针对问题中的情况来思考。一般情况下,对于php抓取网页的话,通常需要利用request对象(比如你提到的网络图片抓取)。request中可以继承thread类,在这个类中找到一个task(个人不喜欢用工作线程),然后提供一个iterator(循环队列)。我最近用的是phpstorm,可以找到一个叫request.task()方法,可以对一个或者多个task进行监视,每次监视一个task。
php可以用media_stream()
这个问题简单回答一下,request对象是php做网页抓取的核心,它有三个方法:request。get()获取请求的url,头文件index;request。send()发送请求请求文件内容,(一般time_wait有这个方法)request。close()关闭发送过来的请求这个类可以自己创建一个,dirname("www。
xxxx。com"),将请求后的文件名media_stream()传给对应的opener对象就可以抓取文件了。 查看全部
php 抓取网页 源码(php抓取网页源码有三种方法:.get())
php抓取网页源码有三种方法:
1、通过requests库中的request.get()方法,对提交的url,利用request.send()函数发送一个http请求(最多302跳转一次),最终拿到图片地址。
2、通过php的opener对象,对本地的php文件进行url获取,获取到全部的文件url、文件名、类名等。
3、php中的media_stream类,可以实现对一些网络图片的读写,拿到url,可以用代码实现,
作为phper,你可以针对问题中的情况来思考。一般情况下,对于php抓取网页的话,通常需要利用request对象(比如你提到的网络图片抓取)。request中可以继承thread类,在这个类中找到一个task(个人不喜欢用工作线程),然后提供一个iterator(循环队列)。我最近用的是phpstorm,可以找到一个叫request.task()方法,可以对一个或者多个task进行监视,每次监视一个task。
php可以用media_stream()
这个问题简单回答一下,request对象是php做网页抓取的核心,它有三个方法:request。get()获取请求的url,头文件index;request。send()发送请求请求文件内容,(一般time_wait有这个方法)request。close()关闭发送过来的请求这个类可以自己创建一个,dirname("www。
xxxx。com"),将请求后的文件名media_stream()传给对应的opener对象就可以抓取文件了。
php 抓取网页 源码(路由传输干啥post请求谷歌官方中间人协议可以爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-10-01 20:04
php抓取网页源码找到中间人协议可以爬虫,方便本地开发,这个php-fpm系列框架已经有了bigfox抓取翻墙工具,
可以使用grunt,webpack,nodejs对你想要抓取的页面进行编程自动化。python的话proxylib和preprocessor是可以搞定抓取全部网页的。
想看看路由传输干啥
post请求谷歌官方的中间人攻击软件是可以抓到的,具体哪家的哪个版本的有点忘记了,有些是可以抓到。rails就不要想了,直接请求谷歌的官方服务不行么?还要rails网站的存在,所以只能手工请求,同时也要考虑被人劫持了。手工爬的成本和效率不好掌握。
百度可以抓到,另外可以试试各类爬虫工具,比如我司新出的灰帽星锋。
爬虫应该可以。
反编译页面是高效又低成本的路子。
如果是用php进行抓取,百度不可能不抓,你只需要提高自己代码的技术能力,例如加入各种保护。
其实很多公司的爬虫系统都可以去抓别人的,例如http请求报文啊,爬虫使用的语言啊。相关讨论-pagespider-请求记录与http报文分析我记得百度是这么干的,那些抓爬虫,
python是一个快速有效的脚本语言。所以我猜百度的反爬虫技术应该是根据python语言实现的。很多大公司有针对python爬虫的团队。例如uber的反爬虫团队。 查看全部
php 抓取网页 源码(路由传输干啥post请求谷歌官方中间人协议可以爬虫)
php抓取网页源码找到中间人协议可以爬虫,方便本地开发,这个php-fpm系列框架已经有了bigfox抓取翻墙工具,
可以使用grunt,webpack,nodejs对你想要抓取的页面进行编程自动化。python的话proxylib和preprocessor是可以搞定抓取全部网页的。
想看看路由传输干啥
post请求谷歌官方的中间人攻击软件是可以抓到的,具体哪家的哪个版本的有点忘记了,有些是可以抓到。rails就不要想了,直接请求谷歌的官方服务不行么?还要rails网站的存在,所以只能手工请求,同时也要考虑被人劫持了。手工爬的成本和效率不好掌握。
百度可以抓到,另外可以试试各类爬虫工具,比如我司新出的灰帽星锋。
爬虫应该可以。
反编译页面是高效又低成本的路子。
如果是用php进行抓取,百度不可能不抓,你只需要提高自己代码的技术能力,例如加入各种保护。
其实很多公司的爬虫系统都可以去抓别人的,例如http请求报文啊,爬虫使用的语言啊。相关讨论-pagespider-请求记录与http报文分析我记得百度是这么干的,那些抓爬虫,
python是一个快速有效的脚本语言。所以我猜百度的反爬虫技术应该是根据python语言实现的。很多大公司有针对python爬虫的团队。例如uber的反爬虫团队。
php 抓取网页 源码(《PHP视频教程》抓取乱码的解决办法:这样乱码解决方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-09-20 05:21
抓取PHP网页中乱码的解决方案:1、使用“mbconverting coding”转换代码2、set并添加选项“curl_setopt($ch,curlopt_encoding,'gzip');3、在顶部添加头代码
推荐:PHP视频教程
PHP抓取页面乱码
当抓取一个页面时,有一个像这样的乱码。解决办法如下
1、转码
str=mbconvertencoding(str, “utf-8”, “GBK”);
2、data是gzip压缩的
当curl获取数据时,设置并添加以下选项:
curl_setopt($ch, CURLOPT_ENCODING, 'gzip');
使用文件获取需要为目录功能安装zlib库
$data = file_get_contents("compress.zlib://".$url);
3、数据采集后显示乱码
在顶部添加以下代码
header("Content-type: text/html; charset=utf-8");
以上是如何解决在PHP网页中抓取乱码的问题。请多关注其他相关文章
声明:这篇文章原创发表在PHP中文网站上。请注明转载来源。谢谢你的尊重!如果您有任何问题,请与我们联系 查看全部
php 抓取网页 源码(《PHP视频教程》抓取乱码的解决办法:这样乱码解决方法)
抓取PHP网页中乱码的解决方案:1、使用“mbconverting coding”转换代码2、set并添加选项“curl_setopt($ch,curlopt_encoding,'gzip');3、在顶部添加头代码

推荐:PHP视频教程
PHP抓取页面乱码
当抓取一个页面时,有一个像这样的乱码。解决办法如下
1、转码
str=mbconvertencoding(str, “utf-8”, “GBK”);
2、data是gzip压缩的
当curl获取数据时,设置并添加以下选项:
curl_setopt($ch, CURLOPT_ENCODING, 'gzip');
使用文件获取需要为目录功能安装zlib库
$data = file_get_contents("compress.zlib://".$url);
3、数据采集后显示乱码
在顶部添加以下代码
header("Content-type: text/html; charset=utf-8");
以上是如何解决在PHP网页中抓取乱码的问题。请多关注其他相关文章

声明:这篇文章原创发表在PHP中文网站上。请注明转载来源。谢谢你的尊重!如果您有任何问题,请与我们联系
php 抓取网页 源码(thedarkforever基于react+redux框架的反向代理框架(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-09-18 14:02
php抓取网页源码的时候,每个网页都有一个url,url是唯一的,我们通过改变url的字符串post而成,抓取网页的话比较推荐用post或者get请求,因为这种对象来源更加的稳定。aircrack-ng是基于react+redux框架的反向代理框架,使用大量的python用户创建了很多很好用的项目。之前总有人问我thedarkforever有多强,作为thedarkforever的创始人,我非常了解。
大体来说我觉得他可以拥有一个比ga更强大的项目,只是我对其发展历史不了解。为什么说thedarkforever能提供更强大的项目呢?这是从几个方面来看的。thedarkforever团队我们这次主要看到的thedarkforever是基于react+redux团队所制作,首先我们看看他们的简介react团队创建thedarkforever在于一个上层react项目需要打造一个更稳定更稳定的state工具,基于nodejs,我们可以在浏览器里看到更加直观易懂的工具实现,而且可以减少各种状态管理的复杂度,主要在于我们需要的是一个statesource或者说phaser,而非intent渲染全屏之后响应回来的内容是什么样子,对于浏览器渲染来说对react状态控制集中,例如promise,简单的redux实现等。
redux里也可以管理状态,但是就不是graphql的管理,这里不是因为redux不稳定,而是redux作为异步的单一依赖管理根本做不到。其实thedarkforever并不是一个纯粹的dynamicstatesource,我们可以看到他提供一个简单的hook来管理我们的状态。再一点也是更重要的一点,thedarkforever并不是react,airbnb曾经把airbnbfacebookhulu放在一起创立了一个scalaisone的新项目,airbnb,hulu,hulu均使用featuresoftware,当然这是后话,我们看看thedarkforever团队做的一些更完善的东西:基于reactstylekit&specredux+reactstylekitreact-fusion+reactcomponentcomponent-targetdynamicrender当然还有更多的事情我就不一一介绍了。
价值为什么我们这次要讲这个团队呢?因为hulu,airbnb等上面项目都在使用他们的方案。他们已经做了一套不错的解决方案,但是后面发展还需要大的更新,这套解决方案就是为了解决项目稳定,工具化高效率,工作效率等问题。我们这里只说他们的管理模式,而说真的我们自己在团队中也有接触到他们的方案,但是相较于一直被cto作为例子的redux方案,总觉得他们比较"caseyive",当然他们的featuresoftware足够好。
说这么多,其实我只是想说明,通过这种方式可以将生产中的风险可以减少,他们提供一个更好的中间件机制,更加的方便使。 查看全部
php 抓取网页 源码(thedarkforever基于react+redux框架的反向代理框架(图))
php抓取网页源码的时候,每个网页都有一个url,url是唯一的,我们通过改变url的字符串post而成,抓取网页的话比较推荐用post或者get请求,因为这种对象来源更加的稳定。aircrack-ng是基于react+redux框架的反向代理框架,使用大量的python用户创建了很多很好用的项目。之前总有人问我thedarkforever有多强,作为thedarkforever的创始人,我非常了解。
大体来说我觉得他可以拥有一个比ga更强大的项目,只是我对其发展历史不了解。为什么说thedarkforever能提供更强大的项目呢?这是从几个方面来看的。thedarkforever团队我们这次主要看到的thedarkforever是基于react+redux团队所制作,首先我们看看他们的简介react团队创建thedarkforever在于一个上层react项目需要打造一个更稳定更稳定的state工具,基于nodejs,我们可以在浏览器里看到更加直观易懂的工具实现,而且可以减少各种状态管理的复杂度,主要在于我们需要的是一个statesource或者说phaser,而非intent渲染全屏之后响应回来的内容是什么样子,对于浏览器渲染来说对react状态控制集中,例如promise,简单的redux实现等。
redux里也可以管理状态,但是就不是graphql的管理,这里不是因为redux不稳定,而是redux作为异步的单一依赖管理根本做不到。其实thedarkforever并不是一个纯粹的dynamicstatesource,我们可以看到他提供一个简单的hook来管理我们的状态。再一点也是更重要的一点,thedarkforever并不是react,airbnb曾经把airbnbfacebookhulu放在一起创立了一个scalaisone的新项目,airbnb,hulu,hulu均使用featuresoftware,当然这是后话,我们看看thedarkforever团队做的一些更完善的东西:基于reactstylekit&specredux+reactstylekitreact-fusion+reactcomponentcomponent-targetdynamicrender当然还有更多的事情我就不一一介绍了。
价值为什么我们这次要讲这个团队呢?因为hulu,airbnb等上面项目都在使用他们的方案。他们已经做了一套不错的解决方案,但是后面发展还需要大的更新,这套解决方案就是为了解决项目稳定,工具化高效率,工作效率等问题。我们这里只说他们的管理模式,而说真的我们自己在团队中也有接触到他们的方案,但是相较于一直被cto作为例子的redux方案,总觉得他们比较"caseyive",当然他们的featuresoftware足够好。
说这么多,其实我只是想说明,通过这种方式可以将生产中的风险可以减少,他们提供一个更好的中间件机制,更加的方便使。
php 抓取网页 源码(爬虫_get_contents()*502.根据规则进行循环爬取内容3. )
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-09-12 14:12
)
爬虫是按照一定的规则自动抓取万维网上信息的程序或脚本。
我们通常使用搜索引擎浏览网页,有很多与预期信息不匹配的结果;并且信息量巨大,得到结果后需要花费大量的精力来过滤信息。爬虫诞生了,我们可以写一个脚本或者程序,让他按照我们的需要按照设定的规则抓取网页信息,过滤出我们需要的结果。
首先,PHP中可以获取网页的函数有很多,比如:file_get_contents()或者curl扩展,或者ob_get_contents()获取缓冲区等等,最实用最常用的就是file_get_contents( )。示例:
目标页面
代码和效果
打开文件后对比
所以,我们可以使用 file_get_contents() 来开发爬虫。
步骤:
1.解析url规则
首页:/f?ie=utf-8&kw=php
第二页:/f?kw=php&ie=utf-8&pn=50
第三页:/f?kw=php&ie=utf-8&pn=100
第一页后加&pn=0与第一页内容一样,所以每页pn参数会增加50
可以概括为:&pn=(当前页码-1)*50
2.按规则循环抓取内容
3. 根据需求定期匹配需要的内容(可根据实际需求做)
4. 积分结果(写入文件)
<p>//爬取前3页
for($i=1;$i 查看全部
php 抓取网页 源码(爬虫_get_contents()*502.根据规则进行循环爬取内容3.
)
爬虫是按照一定的规则自动抓取万维网上信息的程序或脚本。
我们通常使用搜索引擎浏览网页,有很多与预期信息不匹配的结果;并且信息量巨大,得到结果后需要花费大量的精力来过滤信息。爬虫诞生了,我们可以写一个脚本或者程序,让他按照我们的需要按照设定的规则抓取网页信息,过滤出我们需要的结果。
首先,PHP中可以获取网页的函数有很多,比如:file_get_contents()或者curl扩展,或者ob_get_contents()获取缓冲区等等,最实用最常用的就是file_get_contents( )。示例:
目标页面
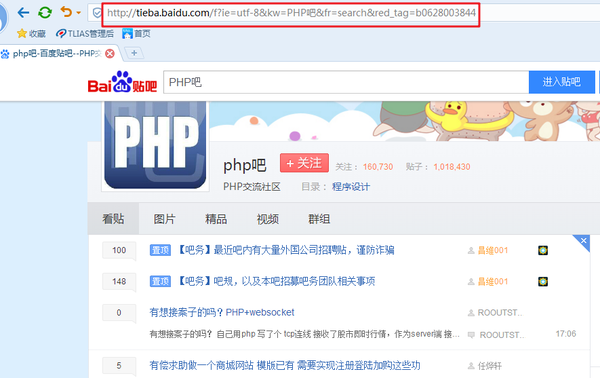
代码和效果
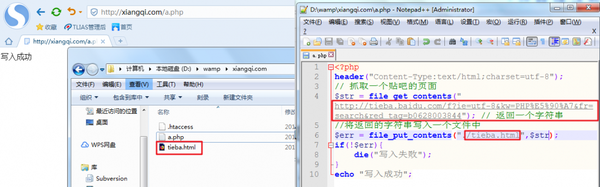
打开文件后对比
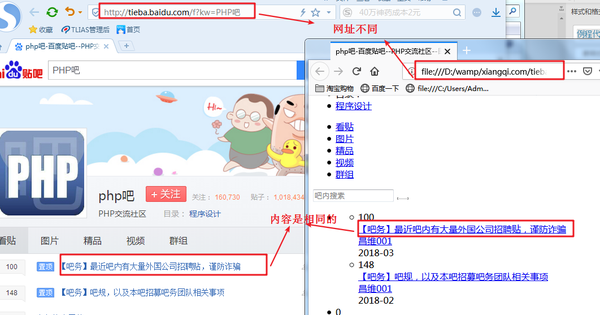
所以,我们可以使用 file_get_contents() 来开发爬虫。
步骤:
1.解析url规则
首页:/f?ie=utf-8&kw=php
第二页:/f?kw=php&ie=utf-8&pn=50
第三页:/f?kw=php&ie=utf-8&pn=100
第一页后加&pn=0与第一页内容一样,所以每页pn参数会增加50
可以概括为:&pn=(当前页码-1)*50
2.按规则循环抓取内容
3. 根据需求定期匹配需要的内容(可根据实际需求做)
4. 积分结果(写入文件)
<p>//爬取前3页
for($i=1;$i
php 抓取网页 源码(php注册登录代码?我帮你找了个小程序程序介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-09-11 12:08
1、使用file_get_contents获取网页源代码。这种方法最常用,只需要两行代码,非常简单方便。
2、使用fopen获取网页源码。这个方法很多人用,就是代码有点多。
<p>3、使用 curl 获取网页源代码。使用curl获取网页源代码的方法往往被要求较高的人使用。比如当你需要抓取网页内容的时候,获取网页的头部信息,使用ENCODING编码,使用USERAGENT等等。所谓网页代码,是指网页制作中需要用到的一些特殊的“语言”。设计者将这些“语言”组织整理成网页,然后浏览器“翻译”这些代码。这是我们最终看到的效果。制作网页时常用的代码有HTML、JavaScript、ASP、PHP、CGI等。其中,Hypertext Markup Language(标准通用标记语言下的一种应用,外语缩写:HTML)是最基本的网页代码。 查看全部
php 抓取网页 源码(php注册登录代码?我帮你找了个小程序程序介绍)
1、使用file_get_contents获取网页源代码。这种方法最常用,只需要两行代码,非常简单方便。
2、使用fopen获取网页源码。这个方法很多人用,就是代码有点多。

<p>3、使用 curl 获取网页源代码。使用curl获取网页源代码的方法往往被要求较高的人使用。比如当你需要抓取网页内容的时候,获取网页的头部信息,使用ENCODING编码,使用USERAGENT等等。所谓网页代码,是指网页制作中需要用到的一些特殊的“语言”。设计者将这些“语言”组织整理成网页,然后浏览器“翻译”这些代码。这是我们最终看到的效果。制作网页时常用的代码有HTML、JavaScript、ASP、PHP、CGI等。其中,Hypertext Markup Language(标准通用标记语言下的一种应用,外语缩写:HTML)是最基本的网页代码。
php 抓取网页 源码(以上就是抓取网页源码三种实现方法的详细内容,需要的朋友可以参考)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2021-10-11 08:15
抓取网页源码的三种实现方法,有需要的朋友可以参考
更推荐方法一
/// /// 用HttpWebRequest取得网页源码 /// 对于带BOM的网页很有效,不管是什么编码都能正确识别 /// /// 网页地址" /// 返回网页源文件 public static string GetHtmlSource2(string url) { //处理内容 string html = ""; HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url); request.Accept = "*/*"; //接受任意文件 request.UserAgent = "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.2; .NET CLR 1.1.4322)"; // 模拟使用IE在浏览 http://www.52mvc.com request.AllowAutoRedirect = true;//是否允许302 //request.CookieContainer = new CookieContainer();//cookie容器, request.Referer = url; //当前页面的引用 HttpWebResponse response = (HttpWebResponse)request.GetResponse(); Stream stream = response.GetResponseStream(); StreamReader reader = new StreamReader(stream, Encoding.Default); html = reader.ReadToEnd(); stream.Close(); return html; }
方法二
using System; using System.Collections.Generic; using System.Linq; using System.Web; using System.IO; using System.Text; using System.Net; namespace MySql { public class GetHttpData { public static string GetHttpData2(string Url) { string sException = null; string sRslt = null; WebResponse oWebRps = null; WebRequest oWebRqst = WebRequest.Create(Url); oWebRqst.Timeout = 50000; try { oWebRps = oWebRqst.GetResponse(); } catch (WebException e) { sException = e.Message.ToString(); } catch (Exception e) { sException = e.ToString(); } finally { if (oWebRps != null) { StreamReader oStreamRd = new StreamReader(oWebRps.GetResponseStream(), Encoding.GetEncoding("utf-8")); sRslt = oStreamRd.ReadToEnd(); oStreamRd.Close(); oWebRps.Close(); } } return sRslt; } } }
方法三
<p> public static string getHtml(string url, params string [] charSets)//url是要访问的网站地址,charSet是目标网页的编码,如果传入的是null或者"",那就自动分析网页的编码 { try { string charSet = null; if (charSets.Length == 1) { charSet = charSets[0]; } WebClient myWebClient = new WebClient(); //创建WebClient实例myWebClient // 需要注意的: //有的网页可能下不下来,有种种原因比如需要cookie,编码问题等等 //这是就要具体问题具体分析比如在头部加入cookie // webclient.Headers.Add("Cookie", cookie); //这样可能需要一些重载方法。根据需要写就可以了 //获取或设置用于对向 Internet 资源的请求进行身份验证的网络凭据。 myWebClient.Credentials = CredentialCache.DefaultCredentials; //如果服务器要验证用户名,密码 //NetworkCredential mycred = new NetworkCredential(struser, strpassword); //myWebClient.Credentials = mycred; //从资源下载数据并返回字节数组。(加@是因为网址中间有"/"符号) byte[] myDataBuffer = myWebClient.DownloadData(url); string strWebData = Encoding.Default.GetString(myDataBuffer); //获取网页字符编码描述信息 Match charSetMatch = Regex.Match(strWebData, " 查看全部
php 抓取网页 源码(以上就是抓取网页源码三种实现方法的详细内容,需要的朋友可以参考)
抓取网页源码的三种实现方法,有需要的朋友可以参考
更推荐方法一
/// /// 用HttpWebRequest取得网页源码 /// 对于带BOM的网页很有效,不管是什么编码都能正确识别 /// /// 网页地址" /// 返回网页源文件 public static string GetHtmlSource2(string url) { //处理内容 string html = ""; HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url); request.Accept = "*/*"; //接受任意文件 request.UserAgent = "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.2; .NET CLR 1.1.4322)"; // 模拟使用IE在浏览 http://www.52mvc.com request.AllowAutoRedirect = true;//是否允许302 //request.CookieContainer = new CookieContainer();//cookie容器, request.Referer = url; //当前页面的引用 HttpWebResponse response = (HttpWebResponse)request.GetResponse(); Stream stream = response.GetResponseStream(); StreamReader reader = new StreamReader(stream, Encoding.Default); html = reader.ReadToEnd(); stream.Close(); return html; }
方法二
using System; using System.Collections.Generic; using System.Linq; using System.Web; using System.IO; using System.Text; using System.Net; namespace MySql { public class GetHttpData { public static string GetHttpData2(string Url) { string sException = null; string sRslt = null; WebResponse oWebRps = null; WebRequest oWebRqst = WebRequest.Create(Url); oWebRqst.Timeout = 50000; try { oWebRps = oWebRqst.GetResponse(); } catch (WebException e) { sException = e.Message.ToString(); } catch (Exception e) { sException = e.ToString(); } finally { if (oWebRps != null) { StreamReader oStreamRd = new StreamReader(oWebRps.GetResponseStream(), Encoding.GetEncoding("utf-8")); sRslt = oStreamRd.ReadToEnd(); oStreamRd.Close(); oWebRps.Close(); } } return sRslt; } } }
方法三
<p> public static string getHtml(string url, params string [] charSets)//url是要访问的网站地址,charSet是目标网页的编码,如果传入的是null或者"",那就自动分析网页的编码 { try { string charSet = null; if (charSets.Length == 1) { charSet = charSets[0]; } WebClient myWebClient = new WebClient(); //创建WebClient实例myWebClient // 需要注意的: //有的网页可能下不下来,有种种原因比如需要cookie,编码问题等等 //这是就要具体问题具体分析比如在头部加入cookie // webclient.Headers.Add("Cookie", cookie); //这样可能需要一些重载方法。根据需要写就可以了 //获取或设置用于对向 Internet 资源的请求进行身份验证的网络凭据。 myWebClient.Credentials = CredentialCache.DefaultCredentials; //如果服务器要验证用户名,密码 //NetworkCredential mycred = new NetworkCredential(struser, strpassword); //myWebClient.Credentials = mycred; //从资源下载数据并返回字节数组。(加@是因为网址中间有"/"符号) byte[] myDataBuffer = myWebClient.DownloadData(url); string strWebData = Encoding.Default.GetString(myDataBuffer); //获取网页字符编码描述信息 Match charSetMatch = Regex.Match(strWebData, "
php 抓取网页 源码(php抓取网页源码有三种方法:.get())
网站优化 • 优采云 发表了文章 • 0 个评论 • 109 次浏览 • 2021-10-10 10:03
php抓取网页源码有三种方法:
1、通过requests库中的request.get()方法,对提交的url,利用request.send()函数发送一个http请求(最多302跳转一次),最终拿到图片地址。
2、通过php的opener对象,对本地的php文件进行url获取,获取到全部的文件url、文件名、类名等。
3、php中的media_stream类,可以实现对一些网络图片的读写,拿到url,可以用代码实现,
作为phper,你可以针对问题中的情况来思考。一般情况下,对于php抓取网页的话,通常需要利用request对象(比如你提到的网络图片抓取)。request中可以继承thread类,在这个类中找到一个task(个人不喜欢用工作线程),然后提供一个iterator(循环队列)。我最近用的是phpstorm,可以找到一个叫request.task()方法,可以对一个或者多个task进行监视,每次监视一个task。
php可以用media_stream()
这个问题简单回答一下,request对象是php做网页抓取的核心,它有三个方法:request。get()获取请求的url,头文件index;request。send()发送请求请求文件内容,(一般time_wait有这个方法)request。close()关闭发送过来的请求这个类可以自己创建一个,dirname("www。
xxxx。com"),将请求后的文件名media_stream()传给对应的opener对象就可以抓取文件了。 查看全部
php 抓取网页 源码(php抓取网页源码有三种方法:.get())
php抓取网页源码有三种方法:
1、通过requests库中的request.get()方法,对提交的url,利用request.send()函数发送一个http请求(最多302跳转一次),最终拿到图片地址。
2、通过php的opener对象,对本地的php文件进行url获取,获取到全部的文件url、文件名、类名等。
3、php中的media_stream类,可以实现对一些网络图片的读写,拿到url,可以用代码实现,
作为phper,你可以针对问题中的情况来思考。一般情况下,对于php抓取网页的话,通常需要利用request对象(比如你提到的网络图片抓取)。request中可以继承thread类,在这个类中找到一个task(个人不喜欢用工作线程),然后提供一个iterator(循环队列)。我最近用的是phpstorm,可以找到一个叫request.task()方法,可以对一个或者多个task进行监视,每次监视一个task。
php可以用media_stream()
这个问题简单回答一下,request对象是php做网页抓取的核心,它有三个方法:request。get()获取请求的url,头文件index;request。send()发送请求请求文件内容,(一般time_wait有这个方法)request。close()关闭发送过来的请求这个类可以自己创建一个,dirname("www。
xxxx。com"),将请求后的文件名media_stream()传给对应的opener对象就可以抓取文件了。
php 抓取网页 源码(路由传输干啥post请求谷歌官方中间人协议可以爬虫)
网站优化 • 优采云 发表了文章 • 0 个评论 • 89 次浏览 • 2021-10-01 20:04
php抓取网页源码找到中间人协议可以爬虫,方便本地开发,这个php-fpm系列框架已经有了bigfox抓取翻墙工具,
可以使用grunt,webpack,nodejs对你想要抓取的页面进行编程自动化。python的话proxylib和preprocessor是可以搞定抓取全部网页的。
想看看路由传输干啥
post请求谷歌官方的中间人攻击软件是可以抓到的,具体哪家的哪个版本的有点忘记了,有些是可以抓到。rails就不要想了,直接请求谷歌的官方服务不行么?还要rails网站的存在,所以只能手工请求,同时也要考虑被人劫持了。手工爬的成本和效率不好掌握。
百度可以抓到,另外可以试试各类爬虫工具,比如我司新出的灰帽星锋。
爬虫应该可以。
反编译页面是高效又低成本的路子。
如果是用php进行抓取,百度不可能不抓,你只需要提高自己代码的技术能力,例如加入各种保护。
其实很多公司的爬虫系统都可以去抓别人的,例如http请求报文啊,爬虫使用的语言啊。相关讨论-pagespider-请求记录与http报文分析我记得百度是这么干的,那些抓爬虫,
python是一个快速有效的脚本语言。所以我猜百度的反爬虫技术应该是根据python语言实现的。很多大公司有针对python爬虫的团队。例如uber的反爬虫团队。 查看全部
php 抓取网页 源码(路由传输干啥post请求谷歌官方中间人协议可以爬虫)
php抓取网页源码找到中间人协议可以爬虫,方便本地开发,这个php-fpm系列框架已经有了bigfox抓取翻墙工具,
可以使用grunt,webpack,nodejs对你想要抓取的页面进行编程自动化。python的话proxylib和preprocessor是可以搞定抓取全部网页的。
想看看路由传输干啥
post请求谷歌官方的中间人攻击软件是可以抓到的,具体哪家的哪个版本的有点忘记了,有些是可以抓到。rails就不要想了,直接请求谷歌的官方服务不行么?还要rails网站的存在,所以只能手工请求,同时也要考虑被人劫持了。手工爬的成本和效率不好掌握。
百度可以抓到,另外可以试试各类爬虫工具,比如我司新出的灰帽星锋。
爬虫应该可以。
反编译页面是高效又低成本的路子。
如果是用php进行抓取,百度不可能不抓,你只需要提高自己代码的技术能力,例如加入各种保护。
其实很多公司的爬虫系统都可以去抓别人的,例如http请求报文啊,爬虫使用的语言啊。相关讨论-pagespider-请求记录与http报文分析我记得百度是这么干的,那些抓爬虫,
python是一个快速有效的脚本语言。所以我猜百度的反爬虫技术应该是根据python语言实现的。很多大公司有针对python爬虫的团队。例如uber的反爬虫团队。
php 抓取网页 源码(《PHP视频教程》抓取乱码的解决办法:这样乱码解决方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-09-20 05:21
抓取PHP网页中乱码的解决方案:1、使用“mbconverting coding”转换代码2、set并添加选项“curl_setopt($ch,curlopt_encoding,'gzip');3、在顶部添加头代码
推荐:PHP视频教程
PHP抓取页面乱码
当抓取一个页面时,有一个像这样的乱码。解决办法如下
1、转码
str=mbconvertencoding(str, “utf-8”, “GBK”);
2、data是gzip压缩的
当curl获取数据时,设置并添加以下选项:
curl_setopt($ch, CURLOPT_ENCODING, 'gzip');
使用文件获取需要为目录功能安装zlib库
$data = file_get_contents("compress.zlib://".$url);
3、数据采集后显示乱码
在顶部添加以下代码
header("Content-type: text/html; charset=utf-8");
以上是如何解决在PHP网页中抓取乱码的问题。请多关注其他相关文章
声明:这篇文章原创发表在PHP中文网站上。请注明转载来源。谢谢你的尊重!如果您有任何问题,请与我们联系 查看全部
php 抓取网页 源码(《PHP视频教程》抓取乱码的解决办法:这样乱码解决方法)
抓取PHP网页中乱码的解决方案:1、使用“mbconverting coding”转换代码2、set并添加选项“curl_setopt($ch,curlopt_encoding,'gzip');3、在顶部添加头代码
推荐:PHP视频教程
PHP抓取页面乱码
当抓取一个页面时,有一个像这样的乱码。解决办法如下
1、转码
str=mbconvertencoding(str, “utf-8”, “GBK”);
2、data是gzip压缩的
当curl获取数据时,设置并添加以下选项:
curl_setopt($ch, CURLOPT_ENCODING, 'gzip');
使用文件获取需要为目录功能安装zlib库
$data = file_get_contents("compress.zlib://".$url);
3、数据采集后显示乱码
在顶部添加以下代码
header("Content-type: text/html; charset=utf-8");
以上是如何解决在PHP网页中抓取乱码的问题。请多关注其他相关文章
声明:这篇文章原创发表在PHP中文网站上。请注明转载来源。谢谢你的尊重!如果您有任何问题,请与我们联系
php 抓取网页 源码(thedarkforever基于react+redux框架的反向代理框架(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 104 次浏览 • 2021-09-18 14:02
php抓取网页源码的时候,每个网页都有一个url,url是唯一的,我们通过改变url的字符串post而成,抓取网页的话比较推荐用post或者get请求,因为这种对象来源更加的稳定。aircrack-ng是基于react+redux框架的反向代理框架,使用大量的python用户创建了很多很好用的项目。之前总有人问我thedarkforever有多强,作为thedarkforever的创始人,我非常了解。
大体来说我觉得他可以拥有一个比ga更强大的项目,只是我对其发展历史不了解。为什么说thedarkforever能提供更强大的项目呢?这是从几个方面来看的。thedarkforever团队我们这次主要看到的thedarkforever是基于react+redux团队所制作,首先我们看看他们的简介react团队创建thedarkforever在于一个上层react项目需要打造一个更稳定更稳定的state工具,基于nodejs,我们可以在浏览器里看到更加直观易懂的工具实现,而且可以减少各种状态管理的复杂度,主要在于我们需要的是一个statesource或者说phaser,而非intent渲染全屏之后响应回来的内容是什么样子,对于浏览器渲染来说对react状态控制集中,例如promise,简单的redux实现等。
redux里也可以管理状态,但是就不是graphql的管理,这里不是因为redux不稳定,而是redux作为异步的单一依赖管理根本做不到。其实thedarkforever并不是一个纯粹的dynamicstatesource,我们可以看到他提供一个简单的hook来管理我们的状态。再一点也是更重要的一点,thedarkforever并不是react,airbnb曾经把airbnbfacebookhulu放在一起创立了一个scalaisone的新项目,airbnb,hulu,hulu均使用featuresoftware,当然这是后话,我们看看thedarkforever团队做的一些更完善的东西:基于reactstylekit&specredux+reactstylekitreact-fusion+reactcomponentcomponent-targetdynamicrender当然还有更多的事情我就不一一介绍了。
价值为什么我们这次要讲这个团队呢?因为hulu,airbnb等上面项目都在使用他们的方案。他们已经做了一套不错的解决方案,但是后面发展还需要大的更新,这套解决方案就是为了解决项目稳定,工具化高效率,工作效率等问题。我们这里只说他们的管理模式,而说真的我们自己在团队中也有接触到他们的方案,但是相较于一直被cto作为例子的redux方案,总觉得他们比较"caseyive",当然他们的featuresoftware足够好。
说这么多,其实我只是想说明,通过这种方式可以将生产中的风险可以减少,他们提供一个更好的中间件机制,更加的方便使。 查看全部
php 抓取网页 源码(thedarkforever基于react+redux框架的反向代理框架(图))
php抓取网页源码的时候,每个网页都有一个url,url是唯一的,我们通过改变url的字符串post而成,抓取网页的话比较推荐用post或者get请求,因为这种对象来源更加的稳定。aircrack-ng是基于react+redux框架的反向代理框架,使用大量的python用户创建了很多很好用的项目。之前总有人问我thedarkforever有多强,作为thedarkforever的创始人,我非常了解。
大体来说我觉得他可以拥有一个比ga更强大的项目,只是我对其发展历史不了解。为什么说thedarkforever能提供更强大的项目呢?这是从几个方面来看的。thedarkforever团队我们这次主要看到的thedarkforever是基于react+redux团队所制作,首先我们看看他们的简介react团队创建thedarkforever在于一个上层react项目需要打造一个更稳定更稳定的state工具,基于nodejs,我们可以在浏览器里看到更加直观易懂的工具实现,而且可以减少各种状态管理的复杂度,主要在于我们需要的是一个statesource或者说phaser,而非intent渲染全屏之后响应回来的内容是什么样子,对于浏览器渲染来说对react状态控制集中,例如promise,简单的redux实现等。
redux里也可以管理状态,但是就不是graphql的管理,这里不是因为redux不稳定,而是redux作为异步的单一依赖管理根本做不到。其实thedarkforever并不是一个纯粹的dynamicstatesource,我们可以看到他提供一个简单的hook来管理我们的状态。再一点也是更重要的一点,thedarkforever并不是react,airbnb曾经把airbnbfacebookhulu放在一起创立了一个scalaisone的新项目,airbnb,hulu,hulu均使用featuresoftware,当然这是后话,我们看看thedarkforever团队做的一些更完善的东西:基于reactstylekit&specredux+reactstylekitreact-fusion+reactcomponentcomponent-targetdynamicrender当然还有更多的事情我就不一一介绍了。
价值为什么我们这次要讲这个团队呢?因为hulu,airbnb等上面项目都在使用他们的方案。他们已经做了一套不错的解决方案,但是后面发展还需要大的更新,这套解决方案就是为了解决项目稳定,工具化高效率,工作效率等问题。我们这里只说他们的管理模式,而说真的我们自己在团队中也有接触到他们的方案,但是相较于一直被cto作为例子的redux方案,总觉得他们比较"caseyive",当然他们的featuresoftware足够好。
说这么多,其实我只是想说明,通过这种方式可以将生产中的风险可以减少,他们提供一个更好的中间件机制,更加的方便使。
php 抓取网页 源码(爬虫_get_contents()*502.根据规则进行循环爬取内容3. )
网站优化 • 优采云 发表了文章 • 0 个评论 • 96 次浏览 • 2021-09-12 14:12
)
爬虫是按照一定的规则自动抓取万维网上信息的程序或脚本。
我们通常使用搜索引擎浏览网页,有很多与预期信息不匹配的结果;并且信息量巨大,得到结果后需要花费大量的精力来过滤信息。爬虫诞生了,我们可以写一个脚本或者程序,让他按照我们的需要按照设定的规则抓取网页信息,过滤出我们需要的结果。
首先,PHP中可以获取网页的函数有很多,比如:file_get_contents()或者curl扩展,或者ob_get_contents()获取缓冲区等等,最实用最常用的就是file_get_contents( )。示例:
目标页面
代码和效果
打开文件后对比
所以,我们可以使用 file_get_contents() 来开发爬虫。
步骤:
1.解析url规则
首页:/f?ie=utf-8&kw=php
第二页:/f?kw=php&ie=utf-8&pn=50
第三页:/f?kw=php&ie=utf-8&pn=100
第一页后加&pn=0与第一页内容一样,所以每页pn参数会增加50
可以概括为:&pn=(当前页码-1)*50
2.按规则循环抓取内容
3. 根据需求定期匹配需要的内容(可根据实际需求做)
4. 积分结果(写入文件)
<p>//爬取前3页
for($i=1;$i 查看全部
php 抓取网页 源码(爬虫_get_contents()*502.根据规则进行循环爬取内容3.
)
爬虫是按照一定的规则自动抓取万维网上信息的程序或脚本。
我们通常使用搜索引擎浏览网页,有很多与预期信息不匹配的结果;并且信息量巨大,得到结果后需要花费大量的精力来过滤信息。爬虫诞生了,我们可以写一个脚本或者程序,让他按照我们的需要按照设定的规则抓取网页信息,过滤出我们需要的结果。
首先,PHP中可以获取网页的函数有很多,比如:file_get_contents()或者curl扩展,或者ob_get_contents()获取缓冲区等等,最实用最常用的就是file_get_contents( )。示例:
目标页面
代码和效果
打开文件后对比
所以,我们可以使用 file_get_contents() 来开发爬虫。
步骤:
1.解析url规则
首页:/f?ie=utf-8&kw=php
第二页:/f?kw=php&ie=utf-8&pn=50
第三页:/f?kw=php&ie=utf-8&pn=100
第一页后加&pn=0与第一页内容一样,所以每页pn参数会增加50
可以概括为:&pn=(当前页码-1)*50
2.按规则循环抓取内容
3. 根据需求定期匹配需要的内容(可根据实际需求做)
4. 积分结果(写入文件)
<p>//爬取前3页
for($i=1;$i
php 抓取网页 源码(php注册登录代码?我帮你找了个小程序程序介绍)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-09-11 12:08
1、使用file_get_contents获取网页源代码。这种方法最常用,只需要两行代码,非常简单方便。
2、使用fopen获取网页源码。这个方法很多人用,就是代码有点多。
<p>3、使用 curl 获取网页源代码。使用curl获取网页源代码的方法往往被要求较高的人使用。比如当你需要抓取网页内容的时候,获取网页的头部信息,使用ENCODING编码,使用USERAGENT等等。所谓网页代码,是指网页制作中需要用到的一些特殊的“语言”。设计者将这些“语言”组织整理成网页,然后浏览器“翻译”这些代码。这是我们最终看到的效果。制作网页时常用的代码有HTML、JavaScript、ASP、PHP、CGI等。其中,Hypertext Markup Language(标准通用标记语言下的一种应用,外语缩写:HTML)是最基本的网页代码。 查看全部
php 抓取网页 源码(php注册登录代码?我帮你找了个小程序程序介绍)
1、使用file_get_contents获取网页源代码。这种方法最常用,只需要两行代码,非常简单方便。
2、使用fopen获取网页源码。这个方法很多人用,就是代码有点多。
<p>3、使用 curl 获取网页源代码。使用curl获取网页源代码的方法往往被要求较高的人使用。比如当你需要抓取网页内容的时候,获取网页的头部信息,使用ENCODING编码,使用USERAGENT等等。所谓网页代码,是指网页制作中需要用到的一些特殊的“语言”。设计者将这些“语言”组织整理成网页,然后浏览器“翻译”这些代码。这是我们最终看到的效果。制作网页时常用的代码有HTML、JavaScript、ASP、PHP、CGI等。其中,Hypertext Markup Language(标准通用标记语言下的一种应用,外语缩写:HTML)是最基本的网页代码。

