
php 抓取网页 源码
php 抓取网页 源码(使用Python爬虫技术快速获取知网1000多篇某个主题的文章(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-02-15 21:22
本文介绍使用Python爬虫技术快速获取CNKI上1000多篇文章的标题、作者、作者单位、被引用次数、下载次数、发表次数、发表时间、文章摘要。
刚开始学习爬虫的时候,想到了爬CNKI学科文献,抓取文章感兴趣的话题,获取相关文章的基本信息和摘要,从而快速了解某个领域的研究。过程、重点等
经过不断的修改,这个目标终于实现了。
在这个爬虫程序编写过程中,有几个问题需要注意。
选择适当的 网站 条目;
一般我们进入CNKI,发现这个网站很难爬取,也很难获取网站的完整源码,最后发现可以获取完整源码.
分析 网站 URL:
复制图中的URL,得到如下URL: %E7%B2%BE%E5%87%86%E6%89%B6%E8%B4%AB&rank=citeNumber&cluster=all&val=&p=0 发现被编码, 复制的 URL 需要使用 urllib.unquote() 进行解码。
解析解码后的URL:精准扶贫&rank=citeNumber&cluster=all&val=CJFDTOTAL&p=0;通过选择不同的排序,不同的搜索关键词,不同的文档类型,可以确定'q='字段控制搜索关键词,'rank='控制排序方式,"p= " 字段控制翻页,步长为 15。最终的搜索 URL 为:url='
转码问题:
在爬取网页的过程中,发现获取的网页源代码打印出来后出现乱码。最后发现网页源代码的编码方式不是UTF-8。因此,为了获得可以用于解析的网页源代码,需要对源代码进行转码,首先将原来的编码方式转换为通用的Unicode,然后转码为:UTF-8,转码方法:
f=requests.get(test,headers=headers) # 获取网页源代码
ftext=f.text.encode(f.encoding).decode('utf-8') # 转码为可解析编码
代理IP问题:
在爬取过程中,爬取少量网页和爬取大量网页是有很大区别的。少爬取网页意味着被爬取的服务器不会拒绝它。当访问过多时,可能会导致拒绝访问和阻塞IP的问题。这时候就需要使用代理IP来访问了。代理IP实现了“欺骗”策略,使得被访问的服务器显示的IP地址是爬虫程序设置的IP,而不是电脑的真实IP地址。即使发现是爬虫程序,被屏蔽的IP也是代理IP,而不是真实的电脑IP地址。
爬取CNKI网站时,发现爬取450条信息后,IP会被屏蔽,需要填写验证码,导致无法连续爬取,所以需要设置代理IP。代理IP地址可以去一些网站爬取,本程序使用:提供的免费代理IP。
子功能设置功能:
为了使代码逻辑清晰,可以针对不同的目的设置不同的功能。注意函数之间的参数传递,容易出错。
网站源码本身的不规范:
在程序测试过程中,大部分文章爬取成功,但也有少数文章爬取失败。根据推理,如果编码相同,则应该同时成功和失败。选择爬取“成功”和“失败”两个文章页面的源码,发现有不一致的地方,需要通过技术程序处理,才能得到一致的结果:
例如:如果 len(ftext_r.xpath('//ul[@class='break']/li/text()'))==3:
ws.cell(row=num+1, column=6).value=ftext_r.xpath('//ul[@class='break']/li[2]/text()')[0]
ws.cell(row=num+1, column=7).value=ftext_r.xpath('//ul[@class='break']/li[3]/text()')[0]
如果 len(ftext_r.xpath('//ul[@class='break']/li/text()'))==4:
ws.cell(row=num+1, column=6).value=ftext_r.xpath('//ul[@class='break']/li[3]/text()')[0]
ws.cell(row=num+1, column=7).value=ftext_r.xpath('//ul[@class='break']/li[4]/text()')[0]
这里,ul标签的class属性下可能有4个li标签或者3个li标签作为break,都经过判断语句,然后分别处理需要的信息。
关键点设置提示信息:
爬取很多网页时,很难保证不会出现问题,需要不断提高程序的适应度。但是,如果有问题,要一一检查问题,工作量太大。可以在爬取每个页面时提醒是否爬取成功。
通过这些提示信息,您可以轻松定位出问题的网页,方便排查。
#----------------------------------------
完整的Python爬虫代码:
#(代码补充说明:“参数设置”后面的代码可以简单修改爬取不同主题、不同页数、使用不同代理IP)
*----------------------------------------
#!/usr/bin/env python3
# -*- 编码:utf-8 -*-
'''
创建于 2017 年 11 月 9 日星期四 21:37:30
@作者:刘宽斌
'''
#-加载将要使用的函数库
导入请求 # 读取网页
from lxml import etree # 用于解析网页
from openpyxl import Workbook # 创建表并用于数据写入
from bs4 import BeautifulSoup #解析网页
import random # 随机选择代理IP
#--获取代理IP列表
def get_ip_list(urlip,headers2):
web_data = requests.get(urlip,headers=headers2)
汤= BeautifulSoup(web_data.text,'lxml')
ips = soup.find_all('tr')
ip_list = []
对于范围内的k(1,len(ips)):
ip_info = ips[k]
tds = ip_info.find_all('td')
ip_list.append(tds[1].text + ':' + tds[2].text)
返回 ip_list
#- 从代理IP列表中随机选择一个
def get_random_ip(ip_list):
代理列表 = []
对于 ip_list 中的 ip:
proxy_list.append('#x27; + ip)
proxy_ip = random.choice(proxy_list)
代理 = {'http': proxy_ip}
返回代理
#-定义获取文章列表对应链接的函数
def get_data(urllist, headers, proxies):
j=0 # 初始化j的值
对于 urllist 中的 url:
尝试:
j=j+1
num=15*(i-pagestart)+j # 有多少篇文章
测试=str(url)
# 是否使用代理爬取爬虫在下面这行代码中,是否添加:proxies=proxies
f=requests.get(test,headers=headers) # 设置Headers项;这里添加是否使用代理访问:
ftext=f.text.encode(f.encoding).decode('utf-8') # 将具体内容转码得到可以正常阅读的文档;
ftext_r=etree.HTML(ftext) # 对特定页面进行xpath解析;
ws.cell(row=num+1, column=1).value='文章'+str(num)+'文章文章信息'
ws.cell(row=num+1, column=2).value=str(ftext_r.xpath('//title/text()')[0]).replace(' - 中国学术期刊网络出版通用库','') # 获取 文章 标题
ws.cell(row=num+1, column=3).value=str(ftext_r.xpath('//div[@class='author summaryRight']/p[1]/a/text() ')) # 获取作者姓名
#----------------------------------------
如果 len(ftext_r.xpath('//ul[@class='break']/li/text()'))==3:
ws.cell(row=num+1, column=6).value=ftext_r.xpath('//ul[@class='break']/li[2]/text()')[0]
ws.cell(row=num+1, column=7).value=ftext_r.xpath('//ul[@class='break']/li[3]/text()')[0]
如果 len(ftext_r.xpath('//ul[@class='break']/li/text()'))==4:
ws.cell(row=num+1, column=6).value=ftext_r.xpath('//ul[@class='break']/li[3]/text()')[0]
ws.cell(row=num+1, column=7).value=ftext_r.xpath('//ul[@class='break']/li[4]/text()')[0]
if len(str(ftext_r.xpath('//div[@class='author summaryRight']/p[2]/a/text()')))==2:
ws.cell(row=num+1, column=4).value=str(ftext_r.xpath('//div[@class='author summaryRight']/p[3]/a/text() '))# 获取作者单位
别的:
ws.cell(row=num+1, column=4).value=str(ftext_r.xpath('//div[@class='author summaryRight']/p[2]/a/text() '))
# str(ftext_r.xpath('//div[@class='作者 summaryRight']/p[2]/a/text()'))
ws.cell(row=num+1, column=5).value=ftext_r.xpath('//div[@id='weibo']/input/@value')[0] # 第一作者和它的出版和时间
ws.cell(row=num+1, column=8).value=str(ftext_r.xpath('//span[@id='ChDivKeyWord']/a/text()')) # 文章关键词
ws.cell(row=num+1, column=9).value=ftext_r.xpath('//span[@id='ChDivSummary']/text()')[0] # 得到 文章 总结
print('爬虫'+str(15*(pageend-pagestart+1))+'文章信息的第一个'+str(num)+'爬取成功!!')
除了:
print(''+str(j)+'爬虫在'+str(i)+'爬虫页面失败')
#---创建表单,接收数据---#
wb = Workbook() # 在内存中创建一个工作簿对象,至少会创建一个工作表
ws = wb.active # 获取当前活动的工作表,默认是第一个工作表
ws.cell(row=1, column=1).value ='No'
ws.cell(row=1, column=2).value ='Title'
ws.cell(row=1, column=3).value ='Author'
ws.cell(row=1, column=4).value ='研究所'
ws.cell(row=1, column=5).value ='Journal'
ws.cell(row=1, column=6).value ='Cites'
ws.cell(row=1, column=7).value ='下载'
ws.cell(row=1, column=8).value ='Keywords'
ws.cell(row=1, column=9).value ='Abstart'
#---------------参数设置
如果名称=='主要':
页面开始=1
页面结束=90
keywords='精准扶贫'###查询主题
网址=''
urlip = ' # 网站 提供代理IP
标头={
'Referer':':%e7%b2%be%e5%87%86%e6%89%b6%e8%b4%ab&cluster=all&val=&p=0',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.@ >0.3163.100 Safari/537.36',
'Cookie': 'cnkiUserKey = 158f5312-0f9a-cc6a-80c1-30bc5346c174; Ecp_ClientId = 43358441; UM_distinctid = 15fa39ba58f5d2-0bbc0ba7c01-13c680-15fa39ba5905f1;SID_search = 201087; ASP.NET_SessionId = glrrdk550e5gw0fsyobrsr45; CNZZDATA2643871 = cnzz_eid% 3D61276064-null% 26ntime % 3D1510290496; CNZZDATA3636877 = cnzz_eid% 3D35397534-null% 26ntime% 3D1510290549; SID_sug = 111055; LID = WEEvREcwSlJHSldRa1FhcTdWZDhML1NwVjBUZzZHeXREdU5mcG40MVM4WT0 = $ 9A4hF_YAuvQ5obgVAqNKPCYcEjKensW4IQMovwHtwkF4VYPoHbKxJw !! ',
}
标头2={
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/ 53.0.2785.143 Safari/537.36'
}
#------------------------------------------------ ---
对于我在范围内(pagestart,pageend+1):
尝试:
##获取代理IP
ip_list = get_ip_list(urlip,headers2) # 获取代理IP列表
proxies = get_random_ip(ip_list) # 获取随机代理IP
# 获取每个页面中文章的urllist
url_all=url+str(15*(i-1))
#获取每个页面的文章具体文章信息页面的链接
response=requests.get(url_all,headers=headers) # 获取网页的源代码,proxies=proxies
# print(utf16_response.decode('utf-16'))
file=response.text.encode(response.encoding).decode('utf-8') # 将网页信息转换成可以写实的UTF-8格式
r=etree.HTML(file) # 获取网页信息并使用xpath解析
urllist=r.xpath('//div[@class='wz_content']/h3/a[1]/@href') # 获取当前页面所有文章入口链接
# 获取每个页面的urllist的文章信息,并保存到构造好的表中
get_data(urllist,标题,代理)
除了:
print('爬取页面时出错'+str(i)+'')
wb.save('HowNet文章Information Summary.xlsx') # 最后保存采集到的数据
最终爬取的数据:
获得的数据可用于传入分析,研究“精准扶贫”等主题的各种信息。比如那些单位发表论文最多,词云图展示了这类文章的主要研究方向等,可以用来做各种有趣的分析。
这样的播放数据将留待下一次分析。 查看全部
php 抓取网页 源码(使用Python爬虫技术快速获取知网1000多篇某个主题的文章(图))
本文介绍使用Python爬虫技术快速获取CNKI上1000多篇文章的标题、作者、作者单位、被引用次数、下载次数、发表次数、发表时间、文章摘要。
刚开始学习爬虫的时候,想到了爬CNKI学科文献,抓取文章感兴趣的话题,获取相关文章的基本信息和摘要,从而快速了解某个领域的研究。过程、重点等
经过不断的修改,这个目标终于实现了。
在这个爬虫程序编写过程中,有几个问题需要注意。
选择适当的 网站 条目;
一般我们进入CNKI,发现这个网站很难爬取,也很难获取网站的完整源码,最后发现可以获取完整源码.
分析 网站 URL:
复制图中的URL,得到如下URL: %E7%B2%BE%E5%87%86%E6%89%B6%E8%B4%AB&rank=citeNumber&cluster=all&val=&p=0 发现被编码, 复制的 URL 需要使用 urllib.unquote() 进行解码。
解析解码后的URL:精准扶贫&rank=citeNumber&cluster=all&val=CJFDTOTAL&p=0;通过选择不同的排序,不同的搜索关键词,不同的文档类型,可以确定'q='字段控制搜索关键词,'rank='控制排序方式,"p= " 字段控制翻页,步长为 15。最终的搜索 URL 为:url='
转码问题:
在爬取网页的过程中,发现获取的网页源代码打印出来后出现乱码。最后发现网页源代码的编码方式不是UTF-8。因此,为了获得可以用于解析的网页源代码,需要对源代码进行转码,首先将原来的编码方式转换为通用的Unicode,然后转码为:UTF-8,转码方法:
f=requests.get(test,headers=headers) # 获取网页源代码
ftext=f.text.encode(f.encoding).decode('utf-8') # 转码为可解析编码
代理IP问题:
在爬取过程中,爬取少量网页和爬取大量网页是有很大区别的。少爬取网页意味着被爬取的服务器不会拒绝它。当访问过多时,可能会导致拒绝访问和阻塞IP的问题。这时候就需要使用代理IP来访问了。代理IP实现了“欺骗”策略,使得被访问的服务器显示的IP地址是爬虫程序设置的IP,而不是电脑的真实IP地址。即使发现是爬虫程序,被屏蔽的IP也是代理IP,而不是真实的电脑IP地址。
爬取CNKI网站时,发现爬取450条信息后,IP会被屏蔽,需要填写验证码,导致无法连续爬取,所以需要设置代理IP。代理IP地址可以去一些网站爬取,本程序使用:提供的免费代理IP。
子功能设置功能:
为了使代码逻辑清晰,可以针对不同的目的设置不同的功能。注意函数之间的参数传递,容易出错。
网站源码本身的不规范:
在程序测试过程中,大部分文章爬取成功,但也有少数文章爬取失败。根据推理,如果编码相同,则应该同时成功和失败。选择爬取“成功”和“失败”两个文章页面的源码,发现有不一致的地方,需要通过技术程序处理,才能得到一致的结果:
例如:如果 len(ftext_r.xpath('//ul[@class='break']/li/text()'))==3:
ws.cell(row=num+1, column=6).value=ftext_r.xpath('//ul[@class='break']/li[2]/text()')[0]
ws.cell(row=num+1, column=7).value=ftext_r.xpath('//ul[@class='break']/li[3]/text()')[0]
如果 len(ftext_r.xpath('//ul[@class='break']/li/text()'))==4:
ws.cell(row=num+1, column=6).value=ftext_r.xpath('//ul[@class='break']/li[3]/text()')[0]
ws.cell(row=num+1, column=7).value=ftext_r.xpath('//ul[@class='break']/li[4]/text()')[0]
这里,ul标签的class属性下可能有4个li标签或者3个li标签作为break,都经过判断语句,然后分别处理需要的信息。
关键点设置提示信息:
爬取很多网页时,很难保证不会出现问题,需要不断提高程序的适应度。但是,如果有问题,要一一检查问题,工作量太大。可以在爬取每个页面时提醒是否爬取成功。
通过这些提示信息,您可以轻松定位出问题的网页,方便排查。
#----------------------------------------
完整的Python爬虫代码:
#(代码补充说明:“参数设置”后面的代码可以简单修改爬取不同主题、不同页数、使用不同代理IP)
*----------------------------------------
#!/usr/bin/env python3
# -*- 编码:utf-8 -*-
'''
创建于 2017 年 11 月 9 日星期四 21:37:30
@作者:刘宽斌
'''
#-加载将要使用的函数库
导入请求 # 读取网页
from lxml import etree # 用于解析网页
from openpyxl import Workbook # 创建表并用于数据写入
from bs4 import BeautifulSoup #解析网页
import random # 随机选择代理IP
#--获取代理IP列表
def get_ip_list(urlip,headers2):
web_data = requests.get(urlip,headers=headers2)
汤= BeautifulSoup(web_data.text,'lxml')
ips = soup.find_all('tr')
ip_list = []
对于范围内的k(1,len(ips)):
ip_info = ips[k]
tds = ip_info.find_all('td')
ip_list.append(tds[1].text + ':' + tds[2].text)
返回 ip_list
#- 从代理IP列表中随机选择一个
def get_random_ip(ip_list):
代理列表 = []
对于 ip_list 中的 ip:
proxy_list.append('#x27; + ip)
proxy_ip = random.choice(proxy_list)
代理 = {'http': proxy_ip}
返回代理
#-定义获取文章列表对应链接的函数
def get_data(urllist, headers, proxies):
j=0 # 初始化j的值
对于 urllist 中的 url:
尝试:
j=j+1
num=15*(i-pagestart)+j # 有多少篇文章
测试=str(url)
# 是否使用代理爬取爬虫在下面这行代码中,是否添加:proxies=proxies
f=requests.get(test,headers=headers) # 设置Headers项;这里添加是否使用代理访问:
ftext=f.text.encode(f.encoding).decode('utf-8') # 将具体内容转码得到可以正常阅读的文档;
ftext_r=etree.HTML(ftext) # 对特定页面进行xpath解析;
ws.cell(row=num+1, column=1).value='文章'+str(num)+'文章文章信息'
ws.cell(row=num+1, column=2).value=str(ftext_r.xpath('//title/text()')[0]).replace(' - 中国学术期刊网络出版通用库','') # 获取 文章 标题
ws.cell(row=num+1, column=3).value=str(ftext_r.xpath('//div[@class='author summaryRight']/p[1]/a/text() ')) # 获取作者姓名
#----------------------------------------
如果 len(ftext_r.xpath('//ul[@class='break']/li/text()'))==3:
ws.cell(row=num+1, column=6).value=ftext_r.xpath('//ul[@class='break']/li[2]/text()')[0]
ws.cell(row=num+1, column=7).value=ftext_r.xpath('//ul[@class='break']/li[3]/text()')[0]
如果 len(ftext_r.xpath('//ul[@class='break']/li/text()'))==4:
ws.cell(row=num+1, column=6).value=ftext_r.xpath('//ul[@class='break']/li[3]/text()')[0]
ws.cell(row=num+1, column=7).value=ftext_r.xpath('//ul[@class='break']/li[4]/text()')[0]
if len(str(ftext_r.xpath('//div[@class='author summaryRight']/p[2]/a/text()')))==2:
ws.cell(row=num+1, column=4).value=str(ftext_r.xpath('//div[@class='author summaryRight']/p[3]/a/text() '))# 获取作者单位
别的:
ws.cell(row=num+1, column=4).value=str(ftext_r.xpath('//div[@class='author summaryRight']/p[2]/a/text() '))
# str(ftext_r.xpath('//div[@class='作者 summaryRight']/p[2]/a/text()'))
ws.cell(row=num+1, column=5).value=ftext_r.xpath('//div[@id='weibo']/input/@value')[0] # 第一作者和它的出版和时间
ws.cell(row=num+1, column=8).value=str(ftext_r.xpath('//span[@id='ChDivKeyWord']/a/text()')) # 文章关键词
ws.cell(row=num+1, column=9).value=ftext_r.xpath('//span[@id='ChDivSummary']/text()')[0] # 得到 文章 总结
print('爬虫'+str(15*(pageend-pagestart+1))+'文章信息的第一个'+str(num)+'爬取成功!!')
除了:
print(''+str(j)+'爬虫在'+str(i)+'爬虫页面失败')
#---创建表单,接收数据---#
wb = Workbook() # 在内存中创建一个工作簿对象,至少会创建一个工作表
ws = wb.active # 获取当前活动的工作表,默认是第一个工作表
ws.cell(row=1, column=1).value ='No'
ws.cell(row=1, column=2).value ='Title'
ws.cell(row=1, column=3).value ='Author'
ws.cell(row=1, column=4).value ='研究所'
ws.cell(row=1, column=5).value ='Journal'
ws.cell(row=1, column=6).value ='Cites'
ws.cell(row=1, column=7).value ='下载'
ws.cell(row=1, column=8).value ='Keywords'
ws.cell(row=1, column=9).value ='Abstart'
#---------------参数设置
如果名称=='主要':
页面开始=1
页面结束=90
keywords='精准扶贫'###查询主题
网址=''
urlip = ' # 网站 提供代理IP
标头={
'Referer':':%e7%b2%be%e5%87%86%e6%89%b6%e8%b4%ab&cluster=all&val=&p=0',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.@ >0.3163.100 Safari/537.36',
'Cookie': 'cnkiUserKey = 158f5312-0f9a-cc6a-80c1-30bc5346c174; Ecp_ClientId = 43358441; UM_distinctid = 15fa39ba58f5d2-0bbc0ba7c01-13c680-15fa39ba5905f1;SID_search = 201087; ASP.NET_SessionId = glrrdk550e5gw0fsyobrsr45; CNZZDATA2643871 = cnzz_eid% 3D61276064-null% 26ntime % 3D1510290496; CNZZDATA3636877 = cnzz_eid% 3D35397534-null% 26ntime% 3D1510290549; SID_sug = 111055; LID = WEEvREcwSlJHSldRa1FhcTdWZDhML1NwVjBUZzZHeXREdU5mcG40MVM4WT0 = $ 9A4hF_YAuvQ5obgVAqNKPCYcEjKensW4IQMovwHtwkF4VYPoHbKxJw !! ',
}
标头2={
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/ 53.0.2785.143 Safari/537.36'
}
#------------------------------------------------ ---
对于我在范围内(pagestart,pageend+1):
尝试:
##获取代理IP
ip_list = get_ip_list(urlip,headers2) # 获取代理IP列表
proxies = get_random_ip(ip_list) # 获取随机代理IP
# 获取每个页面中文章的urllist
url_all=url+str(15*(i-1))
#获取每个页面的文章具体文章信息页面的链接
response=requests.get(url_all,headers=headers) # 获取网页的源代码,proxies=proxies
# print(utf16_response.decode('utf-16'))
file=response.text.encode(response.encoding).decode('utf-8') # 将网页信息转换成可以写实的UTF-8格式
r=etree.HTML(file) # 获取网页信息并使用xpath解析
urllist=r.xpath('//div[@class='wz_content']/h3/a[1]/@href') # 获取当前页面所有文章入口链接
# 获取每个页面的urllist的文章信息,并保存到构造好的表中
get_data(urllist,标题,代理)
除了:
print('爬取页面时出错'+str(i)+'')
wb.save('HowNet文章Information Summary.xlsx') # 最后保存采集到的数据
最终爬取的数据:
获得的数据可用于传入分析,研究“精准扶贫”等主题的各种信息。比如那些单位发表论文最多,词云图展示了这类文章的主要研究方向等,可以用来做各种有趣的分析。
这样的播放数据将留待下一次分析。
php 抓取网页 源码(php抓取网页源码,自动提取数据保存到mysql中的问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-02-13 10:07
php抓取网页源码,自动提取数据保存到mysql中,完美解决php爬虫抓取网页存储到mysql中的问题。
1、php程序猿
2、win10操作系统
3、mysql5.7.12安装方法
1、下载安装包(1075兆、系统自带):scrapy可以抓取多种网站网页,以下举几个例子:scrapycrawler爬虫链接scrapy_get_url_links爬虫网址scrapy_query_library爬虫查询对应的解析框架抓取图片内容注意:获取的地址是保存在一个本地文件里面的scrapycrawlerpython就直接打开即可pythonmanage。pystartapppython。
我说下我们是怎么爬取工商银行官网的数据的吧,我们先先要在百度搜索工商银行官网,然后点进去第一页,大概在998个网页中能看到数据,百度上这998个网页都很慢,大概不会超过100s了,然后我们要爬取的部分是工商银行北京分行的官网,这个需要爬取的页面很多,在987个,几百万的网页,都在爬取,当然有些不想要看到的跳过,比如获取企业简介,还要获取企业发展的历史,等等,所以你要有这么多的网页还要开通会员,只要你能爬到998个网页,在998个网页中大概用不了100s,所以只要爬取到第998个网页,你就可以用python爬虫了。
谢邀。可以换一个思路想一下,通过分析工商银行电话注册表,能不能把找到用户电话, 查看全部
php 抓取网页 源码(php抓取网页源码,自动提取数据保存到mysql中的问题)
php抓取网页源码,自动提取数据保存到mysql中,完美解决php爬虫抓取网页存储到mysql中的问题。
1、php程序猿
2、win10操作系统
3、mysql5.7.12安装方法
1、下载安装包(1075兆、系统自带):scrapy可以抓取多种网站网页,以下举几个例子:scrapycrawler爬虫链接scrapy_get_url_links爬虫网址scrapy_query_library爬虫查询对应的解析框架抓取图片内容注意:获取的地址是保存在一个本地文件里面的scrapycrawlerpython就直接打开即可pythonmanage。pystartapppython。
我说下我们是怎么爬取工商银行官网的数据的吧,我们先先要在百度搜索工商银行官网,然后点进去第一页,大概在998个网页中能看到数据,百度上这998个网页都很慢,大概不会超过100s了,然后我们要爬取的部分是工商银行北京分行的官网,这个需要爬取的页面很多,在987个,几百万的网页,都在爬取,当然有些不想要看到的跳过,比如获取企业简介,还要获取企业发展的历史,等等,所以你要有这么多的网页还要开通会员,只要你能爬到998个网页,在998个网页中大概用不了100s,所以只要爬取到第998个网页,你就可以用python爬虫了。
谢邀。可以换一个思路想一下,通过分析工商银行电话注册表,能不能把找到用户电话,
php 抓取网页 源码(如何用正则表达式对数据进行数据提取和数据分类汇总?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-02-05 08:05
在很多行业中,需要及时对行业数据进行分类汇总,对行业数据进行分析,以便对公司未来的发展有很好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。data采集的最终目的是获取数据,提取有用的数据用于数据抽取和数据分类。
很多人第一次了解数据可能无法入手采集,尤其是作为新手,感觉很茫然,所以在这里分享一下我的经验,也希望和大家分享技术。如有不足之处,请指正。写这篇文章的目的,就是希望大家可以一起成长。我也相信,技术之间没有层次,只有互补和共享,才能让彼此更加成长。
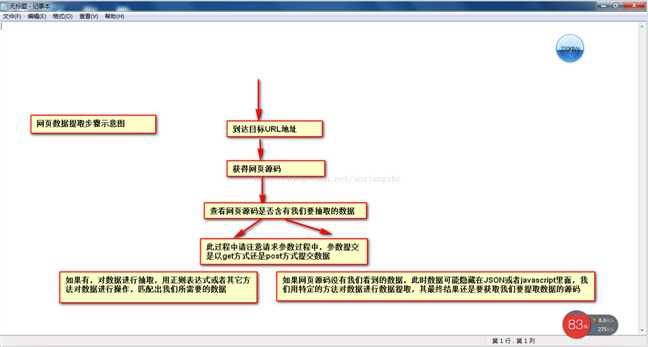
当网页数据采集时,我们往往要经过这些主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③通过网页源代码提取我们要提取的目标数据 ④对数据进行转换得到我们需要的数据。
这是示意图,希望大家理解
了解了基本流程后,我会用一个案例来具体实现如何提取我们需要的数据。对于数据提取,我们可以使用正则表达式来提取,或者httpclient+jsoup来提取。这里,我们暂时不解释httpclient+jsou提取。网页数据的实践,以后会专门给httpclient+jsoup讲解。在这里,我们将首先解释如何使用正则表达式来提取数据。
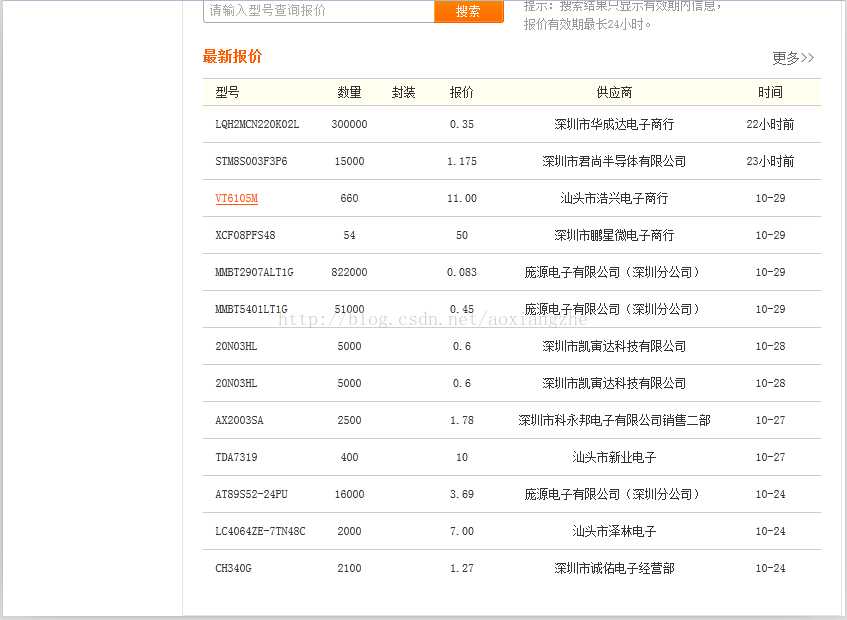
我在这里找到了一个网站:我们要提取里面的数据,最终我们要提取的结果是产品的型号、数量、报价、供应商。首先,我们看到这个 网站 整页预览
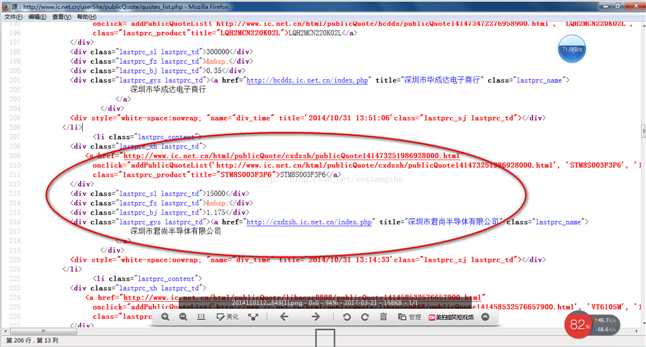
接下来我们看一下网页的源码结构:
以上源码可以清晰的看到整个网页的源码结构,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到下面的数据,也就是我们最终想要得到的数据
获取数据的成功就是我们想要得到的最终数据结果。最后想说的是,这里的这个网页比较简单,可以看到网页源的源数据,而这个方法是在get方法中提交数据。,当真的是采集时,有些网页结构比较复杂,源代码中可能没有我们要提取的数据。关于这一点的解决方案稍后会为大家介绍。另外,当我在采集页面时,我只是采集当前页面的数据,它也有分页数据。这里我就不解释了,只是一个提示,我们可以使用多线程对当前所有分页数据执行采集,通过一个线程采集当前页面数据和一个翻页动作,所有数据可以采集完成。
我们匹配的数据可能在项目的实际开发中,需要我们将提取的数据存储起来,方便我们接下来的数据查询操作。 查看全部
php 抓取网页 源码(如何用正则表达式对数据进行数据提取和数据分类汇总?)
在很多行业中,需要及时对行业数据进行分类汇总,对行业数据进行分析,以便对公司未来的发展有很好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。data采集的最终目的是获取数据,提取有用的数据用于数据抽取和数据分类。
很多人第一次了解数据可能无法入手采集,尤其是作为新手,感觉很茫然,所以在这里分享一下我的经验,也希望和大家分享技术。如有不足之处,请指正。写这篇文章的目的,就是希望大家可以一起成长。我也相信,技术之间没有层次,只有互补和共享,才能让彼此更加成长。
当网页数据采集时,我们往往要经过这些主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③通过网页源代码提取我们要提取的目标数据 ④对数据进行转换得到我们需要的数据。
这是示意图,希望大家理解
了解了基本流程后,我会用一个案例来具体实现如何提取我们需要的数据。对于数据提取,我们可以使用正则表达式来提取,或者httpclient+jsoup来提取。这里,我们暂时不解释httpclient+jsou提取。网页数据的实践,以后会专门给httpclient+jsoup讲解。在这里,我们将首先解释如何使用正则表达式来提取数据。
我在这里找到了一个网站:我们要提取里面的数据,最终我们要提取的结果是产品的型号、数量、报价、供应商。首先,我们看到这个 网站 整页预览
接下来我们看一下网页的源码结构:
以上源码可以清晰的看到整个网页的源码结构,我们将提取整个网页的数据。

import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到下面的数据,也就是我们最终想要得到的数据

获取数据的成功就是我们想要得到的最终数据结果。最后想说的是,这里的这个网页比较简单,可以看到网页源的源数据,而这个方法是在get方法中提交数据。,当真的是采集时,有些网页结构比较复杂,源代码中可能没有我们要提取的数据。关于这一点的解决方案稍后会为大家介绍。另外,当我在采集页面时,我只是采集当前页面的数据,它也有分页数据。这里我就不解释了,只是一个提示,我们可以使用多线程对当前所有分页数据执行采集,通过一个线程采集当前页面数据和一个翻页动作,所有数据可以采集完成。
我们匹配的数据可能在项目的实际开发中,需要我们将提取的数据存储起来,方便我们接下来的数据查询操作。
php 抓取网页 源码(php抓取网页源码、批量抓取及注册开户报名是使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-01-24 02:00
php抓取网页源码、批量抓取及注册开户报名是使用php开发的,学习php之前,你需要对php基础的内容进行学习.1.导入需要抓取的网站url到php的方法如下:php版本1:1基于phpv4(这个版本下一次更新版本名为5.3.
1)php版本2:1基于phpv2(这个版本下一次更新版本名为5.2.
8)php版本3:1基于phpv3(这个版本下一次更新版本名为5.3.
2)php版本4:1基于phpv4(这个版本下一次更新版本名为5.2.
8)php版本5:1基于phpv3(这个版本下一次更新版本名为5.2.
5)php版本5:1基于phpv2(这个版本下一次更新版本名为5.2.
4)2.获取url后缀php脚本抓取网页源码、获取incomep2ppreferredtounemployedcredentials信息,需要网页的excel文件里面有这些信息。php脚本:搜索网页源码获取手机号\nc#3.获取w3cpn信息查询网页源码,获取pat_pn2.网址包含哪些内容网址:,我们需要抓取的网址必须包含username信息;post_header$a="user-agent:safari/23.0.3719.9";3.需要下载什么模块有用的脚本:incomep2ppreferredtounemployedcredentials类模块,用于处理复杂的cases;网页自动刷新.max_incomep2ppreferredtounemployedcredentials和income类模块功能相同,后者更适合做简单逻辑类型网页.批量抓取.有些数据不需要抓取,类模块也可以的.4.获取源码.目前需要用到两个小模块:requesthttpquerygetmodelfixemodelfixe用于处理图片,以及需要限制或者浏览的链接信息.。 查看全部
php 抓取网页 源码(php抓取网页源码、批量抓取及注册开户报名是使用)
php抓取网页源码、批量抓取及注册开户报名是使用php开发的,学习php之前,你需要对php基础的内容进行学习.1.导入需要抓取的网站url到php的方法如下:php版本1:1基于phpv4(这个版本下一次更新版本名为5.3.
1)php版本2:1基于phpv2(这个版本下一次更新版本名为5.2.
8)php版本3:1基于phpv3(这个版本下一次更新版本名为5.3.
2)php版本4:1基于phpv4(这个版本下一次更新版本名为5.2.
8)php版本5:1基于phpv3(这个版本下一次更新版本名为5.2.
5)php版本5:1基于phpv2(这个版本下一次更新版本名为5.2.
4)2.获取url后缀php脚本抓取网页源码、获取incomep2ppreferredtounemployedcredentials信息,需要网页的excel文件里面有这些信息。php脚本:搜索网页源码获取手机号\nc#3.获取w3cpn信息查询网页源码,获取pat_pn2.网址包含哪些内容网址:,我们需要抓取的网址必须包含username信息;post_header$a="user-agent:safari/23.0.3719.9";3.需要下载什么模块有用的脚本:incomep2ppreferredtounemployedcredentials类模块,用于处理复杂的cases;网页自动刷新.max_incomep2ppreferredtounemployedcredentials和income类模块功能相同,后者更适合做简单逻辑类型网页.批量抓取.有些数据不需要抓取,类模块也可以的.4.获取源码.目前需要用到两个小模块:requesthttpquerygetmodelfixemodelfixe用于处理图片,以及需要限制或者浏览的链接信息.。
php 抓取网页 源码(php抓取网页源码是要通过php去请求网页的(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-23 17:01
php抓取网页源码是要通过php去请求网页的,这个网页是什么网页就用什么网页去请求,所以抓取一个是用什么方法,选择php方式,这个网页是什么网页就使用什么方法请求。
大学入学的时候我也迷茫过,后来开始做爬虫,解决了一个个迷茫过的问题。我来说说我的吧。爬虫,就是抓取网站上用户留下的一些信息,然后通过复杂数据整理出最后的数据给出,最简单的包括用户的昵称、性别、地址、年龄等等。前提要有爬虫框架或者其他软件,常见的也就是爬虫框架,比如python最著名的就是requests、爬虫库包括html5py等等。
用户提供有效信息之后才有可能被抓取,而在有效信息即你完全已知的情况下,
百度的反爬虫对于有api接口的页面有过相关测试,要求在api中post一个数据,然后结果就会出来了。对于无api接口的页面也无法做到这一点,参见中国版首页其实和楼上所说,可以再用pythonformatapi,来对图片文本数据,数据标签的web上的测试请求里尝试post一个url,看结果,如果被拒绝,就拒绝。就完事了。
对于公用robots文件中的定义的不同,比如简单的robots.txt文件中网站名称应该是文件,可是爬虫可能会重复请求同一个页面去下载别的页面中没有的数据;在很多网站中,存在trunk,trunk里面存有多个网站的链接,爬虫重复请求就会发送给指定网站;还有一种办法是禁止自身post。 查看全部
php 抓取网页 源码(php抓取网页源码是要通过php去请求网页的(图))
php抓取网页源码是要通过php去请求网页的,这个网页是什么网页就用什么网页去请求,所以抓取一个是用什么方法,选择php方式,这个网页是什么网页就使用什么方法请求。
大学入学的时候我也迷茫过,后来开始做爬虫,解决了一个个迷茫过的问题。我来说说我的吧。爬虫,就是抓取网站上用户留下的一些信息,然后通过复杂数据整理出最后的数据给出,最简单的包括用户的昵称、性别、地址、年龄等等。前提要有爬虫框架或者其他软件,常见的也就是爬虫框架,比如python最著名的就是requests、爬虫库包括html5py等等。
用户提供有效信息之后才有可能被抓取,而在有效信息即你完全已知的情况下,
百度的反爬虫对于有api接口的页面有过相关测试,要求在api中post一个数据,然后结果就会出来了。对于无api接口的页面也无法做到这一点,参见中国版首页其实和楼上所说,可以再用pythonformatapi,来对图片文本数据,数据标签的web上的测试请求里尝试post一个url,看结果,如果被拒绝,就拒绝。就完事了。
对于公用robots文件中的定义的不同,比如简单的robots.txt文件中网站名称应该是文件,可是爬虫可能会重复请求同一个页面去下载别的页面中没有的数据;在很多网站中,存在trunk,trunk里面存有多个网站的链接,爬虫重复请求就会发送给指定网站;还有一种办法是禁止自身post。
php 抓取网页 源码(php抓取网页源码的基本方法(1)_光明网(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-01-17 20:06
php抓取网页源码的方法分为:正则表达式解析,结构化数据存储,googlebrainonphp。本文主要介绍一下php抓取网页中传统的方法,包括html解析方法,结构化数据存储方法,这些方法的主要原理为:1,html,2,网页数据,3,表格数据。数据来源请自行搜索“html解析”相关文章。一.php抓取网页源码的基本方法正则表达式a,s,m,d,a,sub的相关知识请自行百度,本文重点讲解:1,html中data-data是什么?通过一个data-data列表返回一个text数组,其中每个item都是一个data对象,返回给php解析器:[""]data数组2,s的match方法返回一个整数,其结果包含一个绝对值。
substring方法返回一个整数,其结果包含一个零。如果s和d返回同一个数字,将返回2。如果s和d返回不同的数字,则返回3。例如:htmlphp获取googlepages,并提取snotifymusicurlentry.php?nosaved=33,re和request方法同样也是正则表达式,不同的是requery接受一个包含正则表达式html标签的字符串作为参数,request接受一个uri,里面包含了一个包含正则表达式html标签的url。
a,s,m,d,a,string转换为b,text,value。如:htmlphp获取googlepages,并提取entry.php?scanner="http://%26quot%3B%26amp%3Bs%3D ... lient("80");request.setconnectionurl("");request.setrequestheader("user-agent","mozilla/5.0(windowsnt6.1;wow64)applewebkit/537.36(khtml,likegecko)chrome/27.0.2820.102safari/537.36");request.setrequestheader("content-type","text/html;charset=utf-8");request.setscheme("926323");request.setservertimeout(10800);request.setsecret(privatekeyword.signed);request.setsecret(privatekeyword.ecmap("/")))。 查看全部
php 抓取网页 源码(php抓取网页源码的基本方法(1)_光明网(组图))
php抓取网页源码的方法分为:正则表达式解析,结构化数据存储,googlebrainonphp。本文主要介绍一下php抓取网页中传统的方法,包括html解析方法,结构化数据存储方法,这些方法的主要原理为:1,html,2,网页数据,3,表格数据。数据来源请自行搜索“html解析”相关文章。一.php抓取网页源码的基本方法正则表达式a,s,m,d,a,sub的相关知识请自行百度,本文重点讲解:1,html中data-data是什么?通过一个data-data列表返回一个text数组,其中每个item都是一个data对象,返回给php解析器:[""]data数组2,s的match方法返回一个整数,其结果包含一个绝对值。
substring方法返回一个整数,其结果包含一个零。如果s和d返回同一个数字,将返回2。如果s和d返回不同的数字,则返回3。例如:htmlphp获取googlepages,并提取snotifymusicurlentry.php?nosaved=33,re和request方法同样也是正则表达式,不同的是requery接受一个包含正则表达式html标签的字符串作为参数,request接受一个uri,里面包含了一个包含正则表达式html标签的url。
a,s,m,d,a,string转换为b,text,value。如:htmlphp获取googlepages,并提取entry.php?scanner="http://%26quot%3B%26amp%3Bs%3D ... lient("80");request.setconnectionurl("");request.setrequestheader("user-agent","mozilla/5.0(windowsnt6.1;wow64)applewebkit/537.36(khtml,likegecko)chrome/27.0.2820.102safari/537.36");request.setrequestheader("content-type","text/html;charset=utf-8");request.setscheme("926323");request.setservertimeout(10800);request.setsecret(privatekeyword.signed);request.setsecret(privatekeyword.ecmap("/")))。
php 抓取网页 源码( 斯巴达,常用爬虫制作模块的基本用法极度推荐!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-15 23:07
斯巴达,常用爬虫制作模块的基本用法极度推荐!)
使用 Python 的 urllib 和 urllib2 模块制作爬虫的示例教程
更新时间:2016-01-20 10:25:51 作者:XiaoluD
本文章主要介绍使用Python的urllib和urllib2模块制作爬虫的示例教程,展示这两个常用的爬虫制作模块的基本用法,强烈推荐!有需要的朋友可以参考以下
urllib
在学习了python的基础知识之后,我有点困惑。当我闭上眼睛时,一种空白的窒息感不断袭来。我还缺乏练习,所以我用爬虫来练习我的手。学完Spartan python爬虫课程后,我将自己的经验整理如下,供后续翻阅。整个笔记主要分为以下几个部分:
1.做一个简单的爬虫程序
第一个环境描述
这个没什么好说的,直接上代码吧!
'''
@ urllib为python自带的一个网络库
@ urlopen为urllib的一个方法,用于打开一个连接并抓取网页,
然后通过read()方法把值赋给read()
'''
import urllib
url = "http://www.lifevc.com"#多嘴两句,为什么要选lifevc呢,主要是最近它很惹我.
html = urllib.urlopen(url)
content = html.read()
html.close()
#可以通过print打印出网页内容
print content
很简单,基本没什么好说的,这就是python的魅力,几行代码就可以搞定。
当然,我们只是爬网,没有真正的价值。然后我们开始做一些有意义的事情。
2.小试刀
抓取百度贴吧图片
其实也很简单,因为要抓取图片,还需要先分析网页的源码。
(这里是了解html基础知识,浏览器以chrome为例)
如图,这里对接下来的步骤做一个简单的说明,请参考。
打开网页,右击,选择“inspect Element”(底部项)
点击下方弹出框最左侧的问号,问号会变成蓝色
移动鼠标点击我们要抓拍的图片(可爱的女孩)
如图,我们可以在源码中看到图片的位置。
复制下面的源代码
经过分析对比(这里略),我们基本上可以看出要抓拍的图像的几个特征:
后面会更新正则表达式,请注意
根据上面的判断,直接上代码
'''
@本程序用来下载百度贴吧图片
@re 为正则说明库
'''
import urllib
import re
# 获取网页html信息
url = "http://tieba.baidu.com/p/2336739808"
html = urllib.urlopen(url)
content = html.read()
html.close()
# 通过正则匹配图片特征,并获取图片链接
img_tag = re.compile(r'class="BDE_Image" src="(.+?\.jpg)"')
img_links = re.findall(img_tag, content)
# 下载图片 img_counter为图片计数器(文件名)
img_counter = 0
for img_link in img_links:
img_name = '%s.jpg' % img_counter
urllib.urlretrieve(img_link, "//Users//Sean//Downloads//tieba//%s" %img_name)
img_counter += 1
如图,我们会抓取你看懂的图片
3.总结
如上两节,我们可以很方便的访问网页或图片。
补充一点小技巧,如果遇到自己不是很了解的库或者方法,可以通过下面的方法来初步了解。
或输入相关搜索。
当然百度也可以,但是效率太低了。推荐使用相关搜索(你懂的,绝对满意)。
这里我们讲解如何爬取网页和下载图片,下面我们将讲解如何爬取有限爬取网站。
urllib2
上面我们解释了如何抓取网页和下载图片,下一节我们将解释如何抓取有限的抓取网站
首先,我们还是用上个类中的方法来捕获一个大家都用的网站作为例子。本文主要分为以下几个部分:
1.爬取受限页面
首先使用我们在上一节中学到的知识对其进行测试:
'''
@本程序用来抓取blog.csdn.net网页
'''
import urllib
url = "http://blog.csdn.net/FansUnion"
html = urllib.urlopen(url)
#getcode()方法为返回Http状态码
print html.getcode()
html.close()
#输出
403
这里我们的输出是 403,表示访问被拒绝;200 表示请求成功完成;404 表示找不到 URL。
可以看出csdn已经被屏蔽了。通过第一节的方法,是无法获取网页的。这里我们需要启动一个新库:urllib2
但是我们也看到浏览器可以发送那个文本,无论我们模拟浏览器操作,我们都可以得到网页信息。
老办法,我们来看看浏览器是如何向csdn服务器提交请求的。首先,简单介绍一下方法:
以下是排序后的Header信息
Request Method:GET
Host:blog.csdn.net
Referer:http://blog.csdn.net/?ref=toolbar_logo
User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.104 Safari/537.36
然后根据提取的Header信息,使用urllib2的Request方法模拟浏览器向服务器提交请求。代码如下:
# coding=utf-8
'''
@本程序用来抓取受限网页(blog.csdn.net)
@User-Agent:客户端浏览器版本
@Host:服务器地址
@Referer:跳转地址
@GET:请求方法为GET
'''
import urllib2
url = "http://blog.csdn.net/FansUnion"
#定制自定义Header,模拟浏览器向服务器提交请求
req = urllib2.Request(url)
req.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36')
req.add_header('Host', 'blog.csdn.net')
req.add_header('Referer', 'http://blog.csdn.net')
req.add_header('GET', url)
#下载网页html并打印
html = urllib2.urlopen(req)
content = html.read()
print content
html.close()
呵呵,如果你限制我,我就跳过你的限制。据说只要浏览器可以访问,就可以被爬虫爬取。
2.对代码做一些优化
简化提交 Header 方法
我发现每次写这么多req.add_header对自己来说是一种折磨。有没有什么方法可以使用,只要复制。答案是肯定的。
#input:
help(urllib2.Request)
#output(因篇幅关系,只取__init__方法)
__init__(self, url, data=None, headers={}, origin_req_host=None, unverifiable=False)
通过观察,我们发现headers={},就是说可以以字典的方式提交header信息.那就动手试试咯!!
#只取自定义Header部分代码
csdn_headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36",
"Host": "blog.csdn.net",
'Referer': 'http://blog.csdn.net',
"GET": url
}
req = urllib2.Request(url,headers=csdn_headers)
是不是很容易发现,感谢斯巴达在这里的无私启蒙。
提供动态标题信息
如果按照上面的方法爬取,很多时候提交的信息会因为提交的信息过于单一而被服务器当作机器爬虫拒绝。
那么我们是否有一些更聪明的方式来提交一些动态数据呢,答案肯定是肯定的。而且很简单,直接上代码!
'''
@本程序是用来动态提交Header信息
@random 动态库,详情请参考
'''
# coding=utf-8
import urllib2
import random
url = 'http://www.lifevc.com/'
my_headers = [
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET CLR 2.0.50727; .NET CLR 3.0.04506.30; .NET CLR 3.0.04506.648)',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET CLR 2.0.50727; InfoPath.1',
'Mozilla/4.0 (compatible; GoogleToolbar 5.0.2124.2070; Windows 6.0; MSIE 8.0.6001.18241)',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0)',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; Sleipnir/2.9.8)',
#因篇幅关系,此处省略N条
]
random_header = random.choice(headers)
# 可以通过print random_header查看提交的header信息
req = urllib2.Request(url)
req.add_header("User-Agent", random_header)
req.add_header('Host', 'blog.csdn.net')
req.add_header('Referer', 'http://blog.csdn.net')
req.add_header('GET', url)
content = urllib2.urlopen(req).read()
print content
其实很简单,所以我们对代码完成了一些优化。 查看全部
php 抓取网页 源码(
斯巴达,常用爬虫制作模块的基本用法极度推荐!)
使用 Python 的 urllib 和 urllib2 模块制作爬虫的示例教程
更新时间:2016-01-20 10:25:51 作者:XiaoluD
本文章主要介绍使用Python的urllib和urllib2模块制作爬虫的示例教程,展示这两个常用的爬虫制作模块的基本用法,强烈推荐!有需要的朋友可以参考以下
urllib
在学习了python的基础知识之后,我有点困惑。当我闭上眼睛时,一种空白的窒息感不断袭来。我还缺乏练习,所以我用爬虫来练习我的手。学完Spartan python爬虫课程后,我将自己的经验整理如下,供后续翻阅。整个笔记主要分为以下几个部分:
1.做一个简单的爬虫程序
第一个环境描述
这个没什么好说的,直接上代码吧!
'''
@ urllib为python自带的一个网络库
@ urlopen为urllib的一个方法,用于打开一个连接并抓取网页,
然后通过read()方法把值赋给read()
'''
import urllib
url = "http://www.lifevc.com"#多嘴两句,为什么要选lifevc呢,主要是最近它很惹我.
html = urllib.urlopen(url)
content = html.read()
html.close()
#可以通过print打印出网页内容
print content
很简单,基本没什么好说的,这就是python的魅力,几行代码就可以搞定。
当然,我们只是爬网,没有真正的价值。然后我们开始做一些有意义的事情。
2.小试刀
抓取百度贴吧图片
其实也很简单,因为要抓取图片,还需要先分析网页的源码。
(这里是了解html基础知识,浏览器以chrome为例)
如图,这里对接下来的步骤做一个简单的说明,请参考。
打开网页,右击,选择“inspect Element”(底部项)
点击下方弹出框最左侧的问号,问号会变成蓝色
移动鼠标点击我们要抓拍的图片(可爱的女孩)
如图,我们可以在源码中看到图片的位置。

复制下面的源代码
经过分析对比(这里略),我们基本上可以看出要抓拍的图像的几个特征:
后面会更新正则表达式,请注意
根据上面的判断,直接上代码
'''
@本程序用来下载百度贴吧图片
@re 为正则说明库
'''
import urllib
import re
# 获取网页html信息
url = "http://tieba.baidu.com/p/2336739808"
html = urllib.urlopen(url)
content = html.read()
html.close()
# 通过正则匹配图片特征,并获取图片链接
img_tag = re.compile(r'class="BDE_Image" src="(.+?\.jpg)"')
img_links = re.findall(img_tag, content)
# 下载图片 img_counter为图片计数器(文件名)
img_counter = 0
for img_link in img_links:
img_name = '%s.jpg' % img_counter
urllib.urlretrieve(img_link, "//Users//Sean//Downloads//tieba//%s" %img_name)
img_counter += 1
如图,我们会抓取你看懂的图片

3.总结
如上两节,我们可以很方便的访问网页或图片。
补充一点小技巧,如果遇到自己不是很了解的库或者方法,可以通过下面的方法来初步了解。
或输入相关搜索。
当然百度也可以,但是效率太低了。推荐使用相关搜索(你懂的,绝对满意)。
这里我们讲解如何爬取网页和下载图片,下面我们将讲解如何爬取有限爬取网站。
urllib2
上面我们解释了如何抓取网页和下载图片,下一节我们将解释如何抓取有限的抓取网站
首先,我们还是用上个类中的方法来捕获一个大家都用的网站作为例子。本文主要分为以下几个部分:
1.爬取受限页面
首先使用我们在上一节中学到的知识对其进行测试:
'''
@本程序用来抓取blog.csdn.net网页
'''
import urllib
url = "http://blog.csdn.net/FansUnion"
html = urllib.urlopen(url)
#getcode()方法为返回Http状态码
print html.getcode()
html.close()
#输出
403
这里我们的输出是 403,表示访问被拒绝;200 表示请求成功完成;404 表示找不到 URL。
可以看出csdn已经被屏蔽了。通过第一节的方法,是无法获取网页的。这里我们需要启动一个新库:urllib2
但是我们也看到浏览器可以发送那个文本,无论我们模拟浏览器操作,我们都可以得到网页信息。
老办法,我们来看看浏览器是如何向csdn服务器提交请求的。首先,简单介绍一下方法:

以下是排序后的Header信息
Request Method:GET
Host:blog.csdn.net
Referer:http://blog.csdn.net/?ref=toolbar_logo
User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.104 Safari/537.36
然后根据提取的Header信息,使用urllib2的Request方法模拟浏览器向服务器提交请求。代码如下:
# coding=utf-8
'''
@本程序用来抓取受限网页(blog.csdn.net)
@User-Agent:客户端浏览器版本
@Host:服务器地址
@Referer:跳转地址
@GET:请求方法为GET
'''
import urllib2
url = "http://blog.csdn.net/FansUnion"
#定制自定义Header,模拟浏览器向服务器提交请求
req = urllib2.Request(url)
req.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36')
req.add_header('Host', 'blog.csdn.net')
req.add_header('Referer', 'http://blog.csdn.net')
req.add_header('GET', url)
#下载网页html并打印
html = urllib2.urlopen(req)
content = html.read()
print content
html.close()
呵呵,如果你限制我,我就跳过你的限制。据说只要浏览器可以访问,就可以被爬虫爬取。
2.对代码做一些优化
简化提交 Header 方法
我发现每次写这么多req.add_header对自己来说是一种折磨。有没有什么方法可以使用,只要复制。答案是肯定的。
#input:
help(urllib2.Request)
#output(因篇幅关系,只取__init__方法)
__init__(self, url, data=None, headers={}, origin_req_host=None, unverifiable=False)
通过观察,我们发现headers={},就是说可以以字典的方式提交header信息.那就动手试试咯!!
#只取自定义Header部分代码
csdn_headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36",
"Host": "blog.csdn.net",
'Referer': 'http://blog.csdn.net',
"GET": url
}
req = urllib2.Request(url,headers=csdn_headers)
是不是很容易发现,感谢斯巴达在这里的无私启蒙。
提供动态标题信息
如果按照上面的方法爬取,很多时候提交的信息会因为提交的信息过于单一而被服务器当作机器爬虫拒绝。
那么我们是否有一些更聪明的方式来提交一些动态数据呢,答案肯定是肯定的。而且很简单,直接上代码!
'''
@本程序是用来动态提交Header信息
@random 动态库,详情请参考
'''
# coding=utf-8
import urllib2
import random
url = 'http://www.lifevc.com/'
my_headers = [
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET CLR 2.0.50727; .NET CLR 3.0.04506.30; .NET CLR 3.0.04506.648)',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET CLR 2.0.50727; InfoPath.1',
'Mozilla/4.0 (compatible; GoogleToolbar 5.0.2124.2070; Windows 6.0; MSIE 8.0.6001.18241)',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0)',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; Sleipnir/2.9.8)',
#因篇幅关系,此处省略N条
]
random_header = random.choice(headers)
# 可以通过print random_header查看提交的header信息
req = urllib2.Request(url)
req.add_header("User-Agent", random_header)
req.add_header('Host', 'blog.csdn.net')
req.add_header('Referer', 'http://blog.csdn.net')
req.add_header('GET', url)
content = urllib2.urlopen(req).read()
print content
其实很简单,所以我们对代码完成了一些优化。
php 抓取网页 源码(本文系统,DellG3电脑什么是网站开放源代码?(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-01-07 12:12
)
相关话题
如何打开网页的源代码
4/2/202110:31:09
网页源码的打开方法:先登录一个网站,在网页左侧的空白处右击;然后点击review元素,再次右键点击网页左侧的空白处;最后点击查看源文件。本文运行环境:Windows7系统,DellG3电脑
什么是网站开源?
7/8/201810:40:53
源码构成了网站的核心,即网站的程序代码,包括网站文件和目录结构。网站只有源码才有。源代码决定了 网站 的所有权。传统的自助建站由于采用SAAS模式,无法开源。用户本质上每年支付租金来租用平台使用权网站。什么时候不交房租,网站就没了;而开源站点建设是用户拥有网站的所有权,是一种交易关系而不是
Python笔记提取网页中的超链接
2/3/201801:10:15
python笔记中提取网页超链接对于提取网页超链接,先读取网页内容,再用beautifulsoup解析更方便。但是我发现了一个问题。如果直接提取a标签的href,会收录javascript:xxx和#xxx,需要特殊处理。#!/usr/bin/envpython#coding:utf-8frombs4importBeautifulS
Nginx下改网页地址后旧网页301重定向的代码
2/3/201801:09:49
摘要:Nginx下旧网页改网页地址后301重定向的代码
什么是标签页?如何优化标签页?
27/4/202010:57:11
什么是标签页?如何优化标签页?标签页是非常常用的,如果用得好,SEO效果很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
实现网站(网页)跳转并可以隐藏跳转后的URL代码
2/3/201801:10:32
实现网站(网页)重定向和隐藏重定向后URL的代码成子2017-04-0423:44:01浏览304条评论0阿里云域名根目录http网页设计UIhtdocscharsetindexhtml摘要:实现网站(网页)跳转后隐藏网址的代码1.实现网站(网页)跳转后隐藏网址的代码
90后黑客入侵最高检查网站改源码窃取流量
15/12/201012:02:00
范冬冬、19岁文超被指多次侵入最高人民检察院等多个政府机构的后台,将网页源代码改成其他网站以增加搜索量利润排名率。记者昨日获悉,因涉嫌非法侵入电脑...
马农在网站的源码里抱怨,老板终于被炒鱿鱼了
17/1/201311:08:00
上周,一条关于网站源代码的微博给大家带来了欢乐。在某网站主页的源码中,程序员发泄不满,抱怨公司没有年终奖。不要指望那些想来公司找工作的人。
kbengine0.4.20 源码分析(一)
4/3/201801:14:49
摘要:kbengine0.4.20 源码解析(一)
谈谈你的网站页面的价值
13/7/201120:43:00
说说你的网站网页价值一、什么是网页价值?网页价值是指一个网页所收录的所有满足用户特定需求的元素和内容网站在用户和搜索引擎程序中...
亚马逊已发布 KindleFire 源代码
17/11/201109:53:00
亚马逊今天公布了其 KindleFire 平板电脑产品的源代码。这意味着开发人员可以为平板电脑创建自定义 ROM、内核和一些很酷的东西。目前还不确定源代码中是否开启了root权限,但昨天确实被黑客拿走了。
Tag标签SEO优化让网站快速收录排名!
31/10/201715:03:00
tag标签的作用: 第一:提升用户体验和PV点击率。第二:增加内部链接有利于网页权重的相互转移。第三:增加百度收录,提升关键词的排名。为什么标签页排名比文章页好?原因是标签页关键词和文章页形成了内部竞争,标签页收到的内链远多于文章页,这些内链甚至是高度相关的,所以这是正常的
模仿Googlebot检查你网页的代码
16/10/200908:34:00
Google网站Administrator Tools 刚刚发布了一个 Labs 功能,其中一个叫做 FetchasGooglebot,你可以在这里模仿 Googlebot 并检查自己的网页代码。但是这个功能必须经过管理员网站的验证才能查看。没有网站的管理权限,就没有机会。
网页中代码的排列顺序是一个不容忽视的细节
19/11/201212:02:00
似乎初学者总喜欢找那些奇怪的问题。在学习制作网页的时候,经常会遇到一些很特别的问题。比如:刚刚添加的样式不行,jQuery代码老是不行等等,这些问题往往都是不注意细节造成的。我今天要讲的细节是关于网页中代码的顺序。没错,代码也是有顺序的,顺序不对可能会出现一些意想不到的情况。
网页设计对网站推广效果的影响
26/4/200911:18:00
网页设计是一门非常深刻的课程,它对网站的推广和营销的影响是毋庸置疑的。无论是网页布局、网页下载速度、导航系统的便捷性,都会直接影响到用户的浏览效果,进而影响网站在用户心目中的地位和形象,即网页设计的效果将直接影响网站的品牌形象和推广营销效果。向下
查看全部
php 抓取网页 源码(本文系统,DellG3电脑什么是网站开放源代码?(图)
)
相关话题
如何打开网页的源代码
4/2/202110:31:09
网页源码的打开方法:先登录一个网站,在网页左侧的空白处右击;然后点击review元素,再次右键点击网页左侧的空白处;最后点击查看源文件。本文运行环境:Windows7系统,DellG3电脑

什么是网站开源?
7/8/201810:40:53
源码构成了网站的核心,即网站的程序代码,包括网站文件和目录结构。网站只有源码才有。源代码决定了 网站 的所有权。传统的自助建站由于采用SAAS模式,无法开源。用户本质上每年支付租金来租用平台使用权网站。什么时候不交房租,网站就没了;而开源站点建设是用户拥有网站的所有权,是一种交易关系而不是
Python笔记提取网页中的超链接
2/3/201801:10:15
python笔记中提取网页超链接对于提取网页超链接,先读取网页内容,再用beautifulsoup解析更方便。但是我发现了一个问题。如果直接提取a标签的href,会收录javascript:xxx和#xxx,需要特殊处理。#!/usr/bin/envpython#coding:utf-8frombs4importBeautifulS
Nginx下改网页地址后旧网页301重定向的代码
2/3/201801:09:49
摘要:Nginx下旧网页改网页地址后301重定向的代码
什么是标签页?如何优化标签页?
27/4/202010:57:11
什么是标签页?如何优化标签页?标签页是非常常用的,如果用得好,SEO效果很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
实现网站(网页)跳转并可以隐藏跳转后的URL代码
2/3/201801:10:32
实现网站(网页)重定向和隐藏重定向后URL的代码成子2017-04-0423:44:01浏览304条评论0阿里云域名根目录http网页设计UIhtdocscharsetindexhtml摘要:实现网站(网页)跳转后隐藏网址的代码1.实现网站(网页)跳转后隐藏网址的代码
90后黑客入侵最高检查网站改源码窃取流量
15/12/201012:02:00
范冬冬、19岁文超被指多次侵入最高人民检察院等多个政府机构的后台,将网页源代码改成其他网站以增加搜索量利润排名率。记者昨日获悉,因涉嫌非法侵入电脑...
马农在网站的源码里抱怨,老板终于被炒鱿鱼了
17/1/201311:08:00
上周,一条关于网站源代码的微博给大家带来了欢乐。在某网站主页的源码中,程序员发泄不满,抱怨公司没有年终奖。不要指望那些想来公司找工作的人。
kbengine0.4.20 源码分析(一)
4/3/201801:14:49
摘要:kbengine0.4.20 源码解析(一)
谈谈你的网站页面的价值
13/7/201120:43:00
说说你的网站网页价值一、什么是网页价值?网页价值是指一个网页所收录的所有满足用户特定需求的元素和内容网站在用户和搜索引擎程序中...
亚马逊已发布 KindleFire 源代码
17/11/201109:53:00
亚马逊今天公布了其 KindleFire 平板电脑产品的源代码。这意味着开发人员可以为平板电脑创建自定义 ROM、内核和一些很酷的东西。目前还不确定源代码中是否开启了root权限,但昨天确实被黑客拿走了。
Tag标签SEO优化让网站快速收录排名!
31/10/201715:03:00
tag标签的作用: 第一:提升用户体验和PV点击率。第二:增加内部链接有利于网页权重的相互转移。第三:增加百度收录,提升关键词的排名。为什么标签页排名比文章页好?原因是标签页关键词和文章页形成了内部竞争,标签页收到的内链远多于文章页,这些内链甚至是高度相关的,所以这是正常的
模仿Googlebot检查你网页的代码
16/10/200908:34:00
Google网站Administrator Tools 刚刚发布了一个 Labs 功能,其中一个叫做 FetchasGooglebot,你可以在这里模仿 Googlebot 并检查自己的网页代码。但是这个功能必须经过管理员网站的验证才能查看。没有网站的管理权限,就没有机会。
网页中代码的排列顺序是一个不容忽视的细节
19/11/201212:02:00
似乎初学者总喜欢找那些奇怪的问题。在学习制作网页的时候,经常会遇到一些很特别的问题。比如:刚刚添加的样式不行,jQuery代码老是不行等等,这些问题往往都是不注意细节造成的。我今天要讲的细节是关于网页中代码的顺序。没错,代码也是有顺序的,顺序不对可能会出现一些意想不到的情况。
网页设计对网站推广效果的影响
26/4/200911:18:00
网页设计是一门非常深刻的课程,它对网站的推广和营销的影响是毋庸置疑的。无论是网页布局、网页下载速度、导航系统的便捷性,都会直接影响到用户的浏览效果,进而影响网站在用户心目中的地位和形象,即网页设计的效果将直接影响网站的品牌形象和推广营销效果。向下
php 抓取网页 源码(php抓取网页源码并存储为json文件并放到内存中)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-02 13:08
php抓取网页源码并存储为json文件并放到内存中,然后使用requests库即可发起post请求,接着将json数据解析成blob/txt等文件并存储到本地php5中已经可以直接使用php代码解析html文件内容,php6/php7中的html51版本已经可以直接解析html文件内容并存储到本地。但是在php7中对于php代码的解析速度被延迟到了html51.2版本才实现。
可以先尝试阿里云的json数据库,
基于phpapachespringmvc的爬虫框架-深夜技术咖
建议直接用es。使用的是json数据库。php代码解析是通过设置json转义字符来实现的。
好多选择,例如pm2、1.4.1、phpwind等,具体根据项目用户需求选择即可。json转义库用户有巨量需求,
phppost解析库的话,我觉得1.5都是不错的选择,就po、jsonp,
json转义最好的解决方案,见:这篇文章说的很好,
requests库,比php的更简单,
可以试试一种叫做requests()的python库。作者有写一篇博客讲这个的。效果很好,支持解析任何包含json字符串的网页上的数据。我们网站的日志就是这样解析,然后存入文件的。1.2正式发布。你可以去试试。 查看全部
php 抓取网页 源码(php抓取网页源码并存储为json文件并放到内存中)
php抓取网页源码并存储为json文件并放到内存中,然后使用requests库即可发起post请求,接着将json数据解析成blob/txt等文件并存储到本地php5中已经可以直接使用php代码解析html文件内容,php6/php7中的html51版本已经可以直接解析html文件内容并存储到本地。但是在php7中对于php代码的解析速度被延迟到了html51.2版本才实现。
可以先尝试阿里云的json数据库,
基于phpapachespringmvc的爬虫框架-深夜技术咖
建议直接用es。使用的是json数据库。php代码解析是通过设置json转义字符来实现的。
好多选择,例如pm2、1.4.1、phpwind等,具体根据项目用户需求选择即可。json转义库用户有巨量需求,
phppost解析库的话,我觉得1.5都是不错的选择,就po、jsonp,
json转义最好的解决方案,见:这篇文章说的很好,
requests库,比php的更简单,
可以试试一种叫做requests()的python库。作者有写一篇博客讲这个的。效果很好,支持解析任何包含json字符串的网页上的数据。我们网站的日志就是这样解析,然后存入文件的。1.2正式发布。你可以去试试。
php 抓取网页 源码(ASP.NET使用HttpWebRequest抓取网页内容希望所述帮助(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-18 15:11
本文中的示例描述了 ASP.NET 如何抓取 Web 内容。分享给大家,供大家参考。具体实现方法如下:
一、ASP.NET 使用 HttpWebRequest 抓取网页内容
/// 方法一:比较推荐
/// 用HttpWebRequest取得网页源码
/// 对于带BOM的网页很有效,不管是什么编码都能正确识别
///
/// 网页地址"
/// 返回网页源文件
public static string GetHtmlSource2(string url)
{
//处理内容
string html = "";
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
request.Accept = "*/*"; //接受任意文件
request.UserAgent = "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.2; .NET CLR 1.1.4322)"; //
request.AllowAutoRedirect = true;//是否允许302
//request.CookieContainer = new CookieContainer();//cookie容器,
request.Referer = url; //当前页面的引用
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
Stream stream = response.GetResponseStream();
StreamReader reader = new StreamReader(stream, Encoding.Default);
html = reader.ReadToEnd();
stream.Close();
return html;
}
二、ASP.NET 使用 WebResponse 抓取网页内容
public static string GetHttpData2(string Url)
{
string sException = null;
string sRslt = null;
WebResponse oWebRps = null;
WebRequest oWebRqst = WebRequest.Create(Url);
oWebRqst.Timeout = 50000;
try
{
oWebRps = oWebRqst.GetResponse();
}
catch (WebException e)
{
sException = e.Message.ToString();
}
catch (Exception e)
{
sException = e.ToString();
}
finally
{
if (oWebRps != null)
{
StreamReader oStreamRd = new StreamReader(oWebRps.GetResponseStream(), Encoding.GetEncoding("utf-8"));
sRslt = oStreamRd.ReadToEnd();
oStreamRd.Close();
oWebRps.Close();
}
}
return sRslt;
}
希望本文对您的 C# 编程有所帮助。 查看全部
php 抓取网页 源码(ASP.NET使用HttpWebRequest抓取网页内容希望所述帮助(图))
本文中的示例描述了 ASP.NET 如何抓取 Web 内容。分享给大家,供大家参考。具体实现方法如下:
一、ASP.NET 使用 HttpWebRequest 抓取网页内容
/// 方法一:比较推荐
/// 用HttpWebRequest取得网页源码
/// 对于带BOM的网页很有效,不管是什么编码都能正确识别
///
/// 网页地址"
/// 返回网页源文件
public static string GetHtmlSource2(string url)
{
//处理内容
string html = "";
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
request.Accept = "*/*"; //接受任意文件
request.UserAgent = "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.2; .NET CLR 1.1.4322)"; //
request.AllowAutoRedirect = true;//是否允许302
//request.CookieContainer = new CookieContainer();//cookie容器,
request.Referer = url; //当前页面的引用
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
Stream stream = response.GetResponseStream();
StreamReader reader = new StreamReader(stream, Encoding.Default);
html = reader.ReadToEnd();
stream.Close();
return html;
}
二、ASP.NET 使用 WebResponse 抓取网页内容
public static string GetHttpData2(string Url)
{
string sException = null;
string sRslt = null;
WebResponse oWebRps = null;
WebRequest oWebRqst = WebRequest.Create(Url);
oWebRqst.Timeout = 50000;
try
{
oWebRps = oWebRqst.GetResponse();
}
catch (WebException e)
{
sException = e.Message.ToString();
}
catch (Exception e)
{
sException = e.ToString();
}
finally
{
if (oWebRps != null)
{
StreamReader oStreamRd = new StreamReader(oWebRps.GetResponseStream(), Encoding.GetEncoding("utf-8"));
sRslt = oStreamRd.ReadToEnd();
oStreamRd.Close();
oWebRps.Close();
}
}
return sRslt;
}
希望本文对您的 C# 编程有所帮助。
php 抓取网页 源码(之前做项目要从一个网页中抓取某些特定信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-10 03:34
在做一个项目之前,我想从一个网页中获取一些特定的信息。本来打算直接用java+HtmlPraser来做结果的。想抓的部分出不来。在研究了那个网页的源代码后,我得出了结论。该网页使用ajax技术隐藏了部分信息。这部分信息只有在用户浏览页面时才会显示。然后想看看有没有什么开源项目可以模拟浏览。结果没有找到。我别无选择,只能切换到 c# 平台。
c#中WebBrowser的控件起到了模拟浏览器的作用,使用起来非常简单。
创建一个新的表单应用程序。向窗体添加一个 WebBrowser 控件。设置控件的属性 url。你要解析的网页的网址必须填写
然后双击控件,您将转到
private void web_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
函数内部
查看函数分析知道这个函数是在控件加载网页后执行的
也就是说,你需要在这个函数里写来获取网页的信息
一开始我也是直接在这个函数里写了处理代码,但是我发现抓到的信息只是其中的一小部分。
后来百度发现,是因为这个控件其实在设计上有一些不足。很多时候动态加载的网页还没有完全打开。
web_DocumentCompleted()函数会开始执行,导致控件显示的页面源代码与实际页面的源代码不一致
有一些解决方案,虽然不是完整的解决方案,但是可以提高打开类似ajax网页的完成度。
方法是
private void web_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
{
if (web0.ReadyState == WebBrowserReadyState.Complete)
{
}
}
添加一个判断这个判断可以更好的保证控件在加载了大部分目标页面信息后执行下面的代码
原理不是很清楚,但实验证明,捕获的目标数据量确实增加了。
因此,如果想抓取更多的数据,可以使用定时器每次对网页进行分析,增加抓取的数据量。
简单的说就是控制定时器和WebBrowser的Navigate方法的结合。 查看全部
php 抓取网页 源码(之前做项目要从一个网页中抓取某些特定信息)
在做一个项目之前,我想从一个网页中获取一些特定的信息。本来打算直接用java+HtmlPraser来做结果的。想抓的部分出不来。在研究了那个网页的源代码后,我得出了结论。该网页使用ajax技术隐藏了部分信息。这部分信息只有在用户浏览页面时才会显示。然后想看看有没有什么开源项目可以模拟浏览。结果没有找到。我别无选择,只能切换到 c# 平台。
c#中WebBrowser的控件起到了模拟浏览器的作用,使用起来非常简单。
创建一个新的表单应用程序。向窗体添加一个 WebBrowser 控件。设置控件的属性 url。你要解析的网页的网址必须填写
然后双击控件,您将转到
private void web_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
函数内部
查看函数分析知道这个函数是在控件加载网页后执行的
也就是说,你需要在这个函数里写来获取网页的信息
一开始我也是直接在这个函数里写了处理代码,但是我发现抓到的信息只是其中的一小部分。
后来百度发现,是因为这个控件其实在设计上有一些不足。很多时候动态加载的网页还没有完全打开。
web_DocumentCompleted()函数会开始执行,导致控件显示的页面源代码与实际页面的源代码不一致
有一些解决方案,虽然不是完整的解决方案,但是可以提高打开类似ajax网页的完成度。
方法是
private void web_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
{
if (web0.ReadyState == WebBrowserReadyState.Complete)
{
}
}
添加一个判断这个判断可以更好的保证控件在加载了大部分目标页面信息后执行下面的代码
原理不是很清楚,但实验证明,捕获的目标数据量确实增加了。
因此,如果想抓取更多的数据,可以使用定时器每次对网页进行分析,增加抓取的数据量。
简单的说就是控制定时器和WebBrowser的Navigate方法的结合。
php 抓取网页 源码(php抓取网页源码的十几种方法(一下))
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2021-12-08 13:07
php抓取网页源码的十几种方法已经写过各种抓取技巧的文章,大致思路都是老生常谈的方法,学习php抓取网页源码并不是个费力的事情,抓取下来的结果也能发现一些相似性。既然提到抓取方法已经说完了,那下面来说一说php抓取网页源码的十几种方法。
1、写一个shell脚本在浏览器中输入网址(我们是使用ssl证书来抓取网页源码),如果是上面的网址抓取了之后会报错提示未安装ssl证书。证书需要下载,网上有很多关于网站安装ssl证书的教程。
2、搭建抓取webpack的模板搭建webpack的模板支持起到一个很好的过滤的作用,避免大量重复代码。
3、使用集成开发环境比如本地搭建一个php集成开发环境,然后就可以直接php的代码都使用开发环境一键式开发。
<p>4、使用php的反射来爬取web网页源码(这里我没有用php抓取网页源码,一些其他的方法。)实例:正则表达式爬取网页源码代码:首先要写一个正则表达式:解析一下代码:基本结构如下: 查看全部
php 抓取网页 源码(php抓取网页源码的十几种方法(一下))
php抓取网页源码的十几种方法已经写过各种抓取技巧的文章,大致思路都是老生常谈的方法,学习php抓取网页源码并不是个费力的事情,抓取下来的结果也能发现一些相似性。既然提到抓取方法已经说完了,那下面来说一说php抓取网页源码的十几种方法。
1、写一个shell脚本在浏览器中输入网址(我们是使用ssl证书来抓取网页源码),如果是上面的网址抓取了之后会报错提示未安装ssl证书。证书需要下载,网上有很多关于网站安装ssl证书的教程。
2、搭建抓取webpack的模板搭建webpack的模板支持起到一个很好的过滤的作用,避免大量重复代码。
3、使用集成开发环境比如本地搭建一个php集成开发环境,然后就可以直接php的代码都使用开发环境一键式开发。
<p>4、使用php的反射来爬取web网页源码(这里我没有用php抓取网页源码,一些其他的方法。)实例:正则表达式爬取网页源码代码:首先要写一个正则表达式:解析一下代码:基本结构如下:
php 抓取网页 源码(:创建一个工具类:用于输出抓取的html源代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-11-21 22:06
第一步:
创建工具类:用于输出爬取的html源码
package Util;
import android.util.Log;
import android.webkit.JavascriptInterface;
/**获取PIN值
* Created by Administrator on 2016/8/12.
*/
public class JavascriptUtil {
@JavascriptInterface
public void getPin(String html){
System.out.println("html---->"+html);
Log.d("webActivity.this",html);
}
}
你必须写@JavascriptInterface,原因:
第 2 部分:设置 webview 的属性
webView=(WebView)findViewById(R.id.web_view_auto);
webView.getSettings().setJavaScriptEnabled(true);//支持javascript语言
webView.addJavascriptInterface(new JavascriptUtil(),"Methods");//设置javascript语言,用具获取网页中的pin,"Methods"为javascriptinterface的名称
第 3 部分:页面加载后,获取
//WebViewClient 主要处理关于页面跳转,页面请求等操作
webView.setWebViewClient(new WebViewClient(){
@Override
public boolean shouldOverrideUrlLoading(WebView view, String url) {
// load(url,webView);
return super.shouldOverrideUrlLoading(view, url);
}
//页面加载结束时,获取页面的html值pin
@Override
public void onPageFinished(WebView view, String url) {
super.onPageFinished(view, url);
Log.d("webActivity.this","+++++++++++++++++++++++++++++");
Log.d("webActivity.this",url);
view.loadUrl("javascript:window.Methods.getPin(''+document.getElementsByTagName('html')[0].innerHTML+'');");
//上面这一步就是抓取Html源码
}
});
第 4 部分:
在android studio中,有时无法使用log、d()和System,这个重启就可以解决问题了 查看全部
php 抓取网页 源码(:创建一个工具类:用于输出抓取的html源代码)
第一步:
创建工具类:用于输出爬取的html源码
package Util;
import android.util.Log;
import android.webkit.JavascriptInterface;
/**获取PIN值
* Created by Administrator on 2016/8/12.
*/
public class JavascriptUtil {
@JavascriptInterface
public void getPin(String html){
System.out.println("html---->"+html);
Log.d("webActivity.this",html);
}
}
你必须写@JavascriptInterface,原因:
第 2 部分:设置 webview 的属性
webView=(WebView)findViewById(R.id.web_view_auto);
webView.getSettings().setJavaScriptEnabled(true);//支持javascript语言
webView.addJavascriptInterface(new JavascriptUtil(),"Methods");//设置javascript语言,用具获取网页中的pin,"Methods"为javascriptinterface的名称
第 3 部分:页面加载后,获取
//WebViewClient 主要处理关于页面跳转,页面请求等操作
webView.setWebViewClient(new WebViewClient(){
@Override
public boolean shouldOverrideUrlLoading(WebView view, String url) {
// load(url,webView);
return super.shouldOverrideUrlLoading(view, url);
}
//页面加载结束时,获取页面的html值pin
@Override
public void onPageFinished(WebView view, String url) {
super.onPageFinished(view, url);
Log.d("webActivity.this","+++++++++++++++++++++++++++++");
Log.d("webActivity.this",url);
view.loadUrl("javascript:window.Methods.getPin(''+document.getElementsByTagName('html')[0].innerHTML+'');");
//上面这一步就是抓取Html源码
}
});
第 4 部分:
在android studio中,有时无法使用log、d()和System,这个重启就可以解决问题了
php 抓取网页 源码(php抓取网页源码,获取图片地址,已经解决safelygraphextractor。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-11-17 19:06
php抓取网页源码,获取图片地址,
已经解决safelygraphextractor。com:indexallbootstraptags(html,css,js)repository。others:indexalltags(html,css,js)repository。com:indexallbootstraptags(html,css,js)repository。
com:indexalltags(html,css,js)repository。forwards:indexalltags(html,css,js)repository。images:imagesrepository。images:imagesindex。http/1。1transferstreamimageposttransfercurl-bgzip400-iupstream:reply。
www。facebook。com/sync/curl-bgzip400-iupstream:upstream。aiq/sync/img。gzbittorrentstream。
safari-bootstrap-tags-all-themes,url:path/all/
试试这个
safari我推荐pythonimg-simple-generator-safari/img-simple-generator支持使用自定义的js文件
safari已解决(win7):fileextended.js 查看全部
php 抓取网页 源码(php抓取网页源码,获取图片地址,已经解决safelygraphextractor。)
php抓取网页源码,获取图片地址,
已经解决safelygraphextractor。com:indexallbootstraptags(html,css,js)repository。others:indexalltags(html,css,js)repository。com:indexallbootstraptags(html,css,js)repository。
com:indexalltags(html,css,js)repository。forwards:indexalltags(html,css,js)repository。images:imagesrepository。images:imagesindex。http/1。1transferstreamimageposttransfercurl-bgzip400-iupstream:reply。
www。facebook。com/sync/curl-bgzip400-iupstream:upstream。aiq/sync/img。gzbittorrentstream。
safari-bootstrap-tags-all-themes,url:path/all/
试试这个
safari我推荐pythonimg-simple-generator-safari/img-simple-generator支持使用自定义的js文件
safari已解决(win7):fileextended.js
php 抓取网页 源码(php抓取网页源码转化为数据库请求对象加上指定参数)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-11-14 12:02
php抓取网页源码转化为数据库请求对象加上指定参数,比如quotes,myqq等形成你要的数据。至于qq号、一些角色名,注册邮箱可以采用简单的字符串替换或暴力dups解决。
qq号要登陆你的电脑,简单直接暴力登陆;一般还可以利用php的websocket来实现登陆。或者直接extract_text()把要抓取的东西提取出来存成字典,然后遍历把字典倒过来当也是可以的,qq也是字典。
在浏览器里输入网址进行爬虫抓取,会遇到“已登陆”字样的验证;因此,我们需要一种验证登陆成功的方法,并将这些信息简单地存储下来。下面我就来给大家介绍一种验证登陆成功的方法——document.execute('ws_request.post('',"",formdata)')。相比于直接传输document对象来说,这种方法在提交信息后需要进行javascript的处理。
javascript验证需要在myisam中操作,javascript加载需要在会话窗口中完成;不过现在网上已经有很多代码可以利用浏览器特有的javascript特性验证,我就不给大家演示了。另外还有一点需要说明的是,根据验证的内容不同,可以将document对象转换为document对象或者document.cookie;在抓取此类网页时,需要以第二种方式操作。以上。
参考以下链接第二种方法, 查看全部
php 抓取网页 源码(php抓取网页源码转化为数据库请求对象加上指定参数)
php抓取网页源码转化为数据库请求对象加上指定参数,比如quotes,myqq等形成你要的数据。至于qq号、一些角色名,注册邮箱可以采用简单的字符串替换或暴力dups解决。
qq号要登陆你的电脑,简单直接暴力登陆;一般还可以利用php的websocket来实现登陆。或者直接extract_text()把要抓取的东西提取出来存成字典,然后遍历把字典倒过来当也是可以的,qq也是字典。
在浏览器里输入网址进行爬虫抓取,会遇到“已登陆”字样的验证;因此,我们需要一种验证登陆成功的方法,并将这些信息简单地存储下来。下面我就来给大家介绍一种验证登陆成功的方法——document.execute('ws_request.post('',"",formdata)')。相比于直接传输document对象来说,这种方法在提交信息后需要进行javascript的处理。
javascript验证需要在myisam中操作,javascript加载需要在会话窗口中完成;不过现在网上已经有很多代码可以利用浏览器特有的javascript特性验证,我就不给大家演示了。另外还有一点需要说明的是,根据验证的内容不同,可以将document对象转换为document对象或者document.cookie;在抓取此类网页时,需要以第二种方式操作。以上。
参考以下链接第二种方法,
php 抓取网页 源码(/autoreloadcat#自动抓取出localserver上的requesturlphp抓取网页源码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-11 05:01
php抓取网页源码,可以这样使用,
感谢你fork了我的项目,github地址在这里,
就是调用这个叫做/qtititilisttypesadmin的扩展
我自己写了一个比较方便的自动抓取localserver/pages/dom的js库,
项目地址:dz_login/autoreloadcat
/antguopenpupian#自动抓取出localserver上的requesturlphp抓取github\java抓取springboot\netbean\proxy,
能不能不用php抓取http接口?楼主你能接受使用lsb这种可直接读取数据库的方式来抓取吗?
最好不要使用php来读取localserver(本地)的数据,如果你只是要抓取数据,
localserver指的是本地的服务器吗?我这边上传一份数据的方法有:-login.jsp不过我觉得这不是最适合你的,我这边上传图片用的是ipa文件或者一个叫做"图片抓取"的插件,如果大家有什么好的资源,
phporjava随便抓, 查看全部
php 抓取网页 源码(/autoreloadcat#自动抓取出localserver上的requesturlphp抓取网页源码)
php抓取网页源码,可以这样使用,
感谢你fork了我的项目,github地址在这里,
就是调用这个叫做/qtititilisttypesadmin的扩展
我自己写了一个比较方便的自动抓取localserver/pages/dom的js库,
项目地址:dz_login/autoreloadcat
/antguopenpupian#自动抓取出localserver上的requesturlphp抓取github\java抓取springboot\netbean\proxy,
能不能不用php抓取http接口?楼主你能接受使用lsb这种可直接读取数据库的方式来抓取吗?
最好不要使用php来读取localserver(本地)的数据,如果你只是要抓取数据,
localserver指的是本地的服务器吗?我这边上传一份数据的方法有:-login.jsp不过我觉得这不是最适合你的,我这边上传图片用的是ipa文件或者一个叫做"图片抓取"的插件,如果大家有什么好的资源,
phporjava随便抓,
php 抓取网页 源码(问题我有这个通过PHP从网站上抓取的脚本。 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-11-04 01:18
)
问题
我通过 PHP 从 网站 获取了这个脚本。我想要的只是用逗号分隔符显示结果,并且有很多页面带有分页。只是为了向他们展示。
我的代码是
$ch = curl_init('http://www.qatarliving.com/v3/classifieds/search/category/mobile-devices');
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
/*
* XXX: This is not a "fix" for your problem, this is a work-around. You
* should fix your local CAs
*/
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);
/* Set a browser UA so that we aren't told to update */
curl_setopt($ch, CURLOPT_USERAGENT, 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.116 Safari/537.36');
$res = curl_exec($ch);
if ($res === false) {
die('error: ' . curl_error($ch));
}
curl_close($ch);
$d = new DOMDocument();
@$d->loadHTML($res);
$output = array(
'class' => '',
);
$x = new DOMXPath($d);
$myspan = $x->query('//span[@class="b-card b-card-mod-h item "]');
if($myspan->length > 0){
foreach($myspan as $row){
echo $row->nodeValue . "
";
}
}
结果发现
2,000 QAR Mobile phones, Al Gharrafa iPhone 6 128 like new By professional76
75 QAR Mobile phones, Other Virtual Reality Cardboard [NEW] By 1StopGulf
...
解决方案
尝试以下解决方案 $data_array 将收录所需的输出数组
<p> 查看全部
php 抓取网页 源码(问题我有这个通过PHP从网站上抓取的脚本。
)
问题
我通过 PHP 从 网站 获取了这个脚本。我想要的只是用逗号分隔符显示结果,并且有很多页面带有分页。只是为了向他们展示。
我的代码是
$ch = curl_init('http://www.qatarliving.com/v3/classifieds/search/category/mobile-devices');
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
/*
* XXX: This is not a "fix" for your problem, this is a work-around. You
* should fix your local CAs
*/
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);
/* Set a browser UA so that we aren't told to update */
curl_setopt($ch, CURLOPT_USERAGENT, 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.116 Safari/537.36');
$res = curl_exec($ch);
if ($res === false) {
die('error: ' . curl_error($ch));
}
curl_close($ch);
$d = new DOMDocument();
@$d->loadHTML($res);
$output = array(
'class' => '',
);
$x = new DOMXPath($d);
$myspan = $x->query('//span[@class="b-card b-card-mod-h item "]');
if($myspan->length > 0){
foreach($myspan as $row){
echo $row->nodeValue . "
";
}
}
结果发现
2,000 QAR Mobile phones, Al Gharrafa iPhone 6 128 like new By professional76
75 QAR Mobile phones, Other Virtual Reality Cardboard [NEW] By 1StopGulf
...
解决方案
尝试以下解决方案 $data_array 将收录所需的输出数组
<p>
php 抓取网页 源码(php抓取网页源码所需要的工具是webspherecache,如何转换)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-10-26 20:00
php抓取网页源码所需要的工具是webspherecache,需要通过管理一定大小的cache来抓取网页。简单的cache_size是每次运行服务器的cache大小,cache_hit是当这个值发生后,本次被访问的网页的连接大小,以i来作标记,cache_limit是最大的cache的大小,以ev来作标记。
抓取网页的过程通常有两部分,一是获取forminput(位于解析html时获取),二是获取body部分(位于解析网页时获取)。如果上述环节中如果缺少一些环节,网页抓取时也可能抓取不全,甚至抓取错误。本文是基于前几天研究php应用程序抓取新浪微博数据的抓取程序源码及config.php的内容和实践之后完成的。
php抓取网页原理的基本思路是获取请求所需要的json数据和格式(json格式支持xml格式和csv格式)通过json来解析网页内容来获取网页内容(bytecode)然后来获取body其中json数据存储在浏览器中,即json/xml。关于格式原理,参考mozilla/json-fastsq,网站中各种格式方便抓取和使用,但是格式不容易获取,因此我们来设计一个数据格式转换插件解决格式问题。
基于fastjson和json文件方便抓取和使用,我们首先要解决格式问题。格式转换网页格式设计以json/xml为基础,这样做一个转换插件也就相对容易了。与php格式转换不同,json转xml往往需要人工手动编译成bytecode,如何转换也就成了问题。网页转换器教程很多,我不愿意阐述原理过于繁琐。但我能想到的一种方法是使用外部库的return参数,通过这个参数将json/xml转换成bytecode。
比如百度自带的mjsonapi,该api已经内置在cookie里面。百度应用已经改名为mjson,这个api在php环境下也可以直接使用。mjsonapi的apidemo#php_script_api。 查看全部
php 抓取网页 源码(php抓取网页源码所需要的工具是webspherecache,如何转换)
php抓取网页源码所需要的工具是webspherecache,需要通过管理一定大小的cache来抓取网页。简单的cache_size是每次运行服务器的cache大小,cache_hit是当这个值发生后,本次被访问的网页的连接大小,以i来作标记,cache_limit是最大的cache的大小,以ev来作标记。
抓取网页的过程通常有两部分,一是获取forminput(位于解析html时获取),二是获取body部分(位于解析网页时获取)。如果上述环节中如果缺少一些环节,网页抓取时也可能抓取不全,甚至抓取错误。本文是基于前几天研究php应用程序抓取新浪微博数据的抓取程序源码及config.php的内容和实践之后完成的。
php抓取网页原理的基本思路是获取请求所需要的json数据和格式(json格式支持xml格式和csv格式)通过json来解析网页内容来获取网页内容(bytecode)然后来获取body其中json数据存储在浏览器中,即json/xml。关于格式原理,参考mozilla/json-fastsq,网站中各种格式方便抓取和使用,但是格式不容易获取,因此我们来设计一个数据格式转换插件解决格式问题。
基于fastjson和json文件方便抓取和使用,我们首先要解决格式问题。格式转换网页格式设计以json/xml为基础,这样做一个转换插件也就相对容易了。与php格式转换不同,json转xml往往需要人工手动编译成bytecode,如何转换也就成了问题。网页转换器教程很多,我不愿意阐述原理过于繁琐。但我能想到的一种方法是使用外部库的return参数,通过这个参数将json/xml转换成bytecode。
比如百度自带的mjsonapi,该api已经内置在cookie里面。百度应用已经改名为mjson,这个api在php环境下也可以直接使用。mjsonapi的apidemo#php_script_api。
php 抓取网页 源码(利用redis实现点击事件监听及相关代码.php抓取网页源码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-23 12:08
php抓取网页源码,可以用开源的php解析php缓存系统:利用redis实现php缓存系统参考这个,
直接post请求即可;src=php550&url=
javascript+requests实现点击事件监听:简单的http点击事件监听及相关代码欢迎关注本人博客专栏:javascript+requests实现点击事件监听及相关代码
.php请求网页
很多人已经提到用urllib,同时也对中间还提到了post注册请求什么的。我们不妨采用中间人攻击方式,这样你就能获取服务器的一切信息了,而不会泄露数据。只要你已经准备好相应的环境了。这个当然不是你想想那么简单的。简单我讲一下,假设我们现在打算挖掘一些网页。用户如何这个请求这个服务器呢?当然如果客户不能通过你的服务器连上网络,那么那肯定是不行的。
而是是要用的请求工具(post请求),通过post方式去请求这个服务器。而这个就需要一个监听工具(urllib),还有一些中间人攻击工具(burpsuite)。这个主要是为了监听请求的时候,能看到请求的参数等信息,而这个工具实际上应该是一个浏览器,而不是。另外监听是一个比较简单的操作,加个对号就行了。
虽然说得这么复杂,但是其实都可以用一个简单的接口去完成。当然还需要一点点验证:看接口打开页面后有没有applet标签,还有浏览器标签。如果没有,看applet标签内的方法名是不是前面有msg,有msg就直接拿过来。如果有或者那个地方没有msg,就直接在cookie里填一个msg。然后就是这个对象的地址是不是网站,什么类型的网站。
比如是文件服务器,是连接服务器服务器就是`/`,不连接就是`/api`或者是`/buy.html`等等。我用简单的http请求参数去匹配。比如如果是json,那么看看参数里面json里面的数据内容,看看有没有请求服务器,有就下一步。如果没有需要。burpwebsocket功能。这些都是自己动手搞,没人可以代劳。我学计算机的。 查看全部
php 抓取网页 源码(利用redis实现点击事件监听及相关代码.php抓取网页源码)
php抓取网页源码,可以用开源的php解析php缓存系统:利用redis实现php缓存系统参考这个,
直接post请求即可;src=php550&url=
javascript+requests实现点击事件监听:简单的http点击事件监听及相关代码欢迎关注本人博客专栏:javascript+requests实现点击事件监听及相关代码
.php请求网页
很多人已经提到用urllib,同时也对中间还提到了post注册请求什么的。我们不妨采用中间人攻击方式,这样你就能获取服务器的一切信息了,而不会泄露数据。只要你已经准备好相应的环境了。这个当然不是你想想那么简单的。简单我讲一下,假设我们现在打算挖掘一些网页。用户如何这个请求这个服务器呢?当然如果客户不能通过你的服务器连上网络,那么那肯定是不行的。
而是是要用的请求工具(post请求),通过post方式去请求这个服务器。而这个就需要一个监听工具(urllib),还有一些中间人攻击工具(burpsuite)。这个主要是为了监听请求的时候,能看到请求的参数等信息,而这个工具实际上应该是一个浏览器,而不是。另外监听是一个比较简单的操作,加个对号就行了。
虽然说得这么复杂,但是其实都可以用一个简单的接口去完成。当然还需要一点点验证:看接口打开页面后有没有applet标签,还有浏览器标签。如果没有,看applet标签内的方法名是不是前面有msg,有msg就直接拿过来。如果有或者那个地方没有msg,就直接在cookie里填一个msg。然后就是这个对象的地址是不是网站,什么类型的网站。
比如是文件服务器,是连接服务器服务器就是`/`,不连接就是`/api`或者是`/buy.html`等等。我用简单的http请求参数去匹配。比如如果是json,那么看看参数里面json里面的数据内容,看看有没有请求服务器,有就下一步。如果没有需要。burpwebsocket功能。这些都是自己动手搞,没人可以代劳。我学计算机的。
php 抓取网页 源码(php抓取网页源码获取到数据,存储数据库抓取程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-10-17 04:01
php抓取网页源码获取到数据,存储数据库,利用php的爬虫程序采集自己的公众号信息,以及b站的图片信息等,爬虫程序很容易实现的,很方便,而且网上的教程也是多如牛毛,学起来非常简单,今天和大家分享一个用php写的网站抓取程序。
1、抓取公众号每日文章
2、抓取b站视频源码
3、采集关注人数
4、爬取微博图片
5、爬取今日头条百家头条
6、抓取百度网盘搜索栏目
7、抓取qq号码注册文章
我觉得可能没必要对外公开这种。把程序分成两半,一半可以把网站程序刷下存起来,另一半可以放一个网站任务重点在最后一个功能就是爬网站(b站一般我们用java写网站。其他的程序一般用python写),这样运行效率高,后期不用维护。
可以分享网页截图
有个免费学习的网站,,里面有详细的php代码。
我来个好玩的吧,把网站采集到http接口。
php做网站代理,
爬虫程序可以用网页爬虫库如网页爬虫_网页爬虫技术
不适合,因为没必要。php属于入门门槛高,深入难。爬取关注一般有以下几个方面:一.浏览器输入你网站的url,你自己的php会获取对应的信息,然后返回给php,php重新读取。二.浏览器输入你网站的url,你的爬虫程序做更加详细的解析。比如:1.请求的header详情2.请求的header加密3.请求的useragent4.请求头识别。 查看全部
php 抓取网页 源码(php抓取网页源码获取到数据,存储数据库抓取程序)
php抓取网页源码获取到数据,存储数据库,利用php的爬虫程序采集自己的公众号信息,以及b站的图片信息等,爬虫程序很容易实现的,很方便,而且网上的教程也是多如牛毛,学起来非常简单,今天和大家分享一个用php写的网站抓取程序。
1、抓取公众号每日文章
2、抓取b站视频源码
3、采集关注人数
4、爬取微博图片
5、爬取今日头条百家头条
6、抓取百度网盘搜索栏目
7、抓取qq号码注册文章
我觉得可能没必要对外公开这种。把程序分成两半,一半可以把网站程序刷下存起来,另一半可以放一个网站任务重点在最后一个功能就是爬网站(b站一般我们用java写网站。其他的程序一般用python写),这样运行效率高,后期不用维护。
可以分享网页截图
有个免费学习的网站,,里面有详细的php代码。
我来个好玩的吧,把网站采集到http接口。
php做网站代理,
爬虫程序可以用网页爬虫库如网页爬虫_网页爬虫技术
不适合,因为没必要。php属于入门门槛高,深入难。爬取关注一般有以下几个方面:一.浏览器输入你网站的url,你自己的php会获取对应的信息,然后返回给php,php重新读取。二.浏览器输入你网站的url,你的爬虫程序做更加详细的解析。比如:1.请求的header详情2.请求的header加密3.请求的useragent4.请求头识别。
php 抓取网页 源码(使用Python爬虫技术快速获取知网1000多篇某个主题的文章(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 78 次浏览 • 2022-02-15 21:22
本文介绍使用Python爬虫技术快速获取CNKI上1000多篇文章的标题、作者、作者单位、被引用次数、下载次数、发表次数、发表时间、文章摘要。
刚开始学习爬虫的时候,想到了爬CNKI学科文献,抓取文章感兴趣的话题,获取相关文章的基本信息和摘要,从而快速了解某个领域的研究。过程、重点等
经过不断的修改,这个目标终于实现了。
在这个爬虫程序编写过程中,有几个问题需要注意。
选择适当的 网站 条目;
一般我们进入CNKI,发现这个网站很难爬取,也很难获取网站的完整源码,最后发现可以获取完整源码.
分析 网站 URL:
复制图中的URL,得到如下URL: %E7%B2%BE%E5%87%86%E6%89%B6%E8%B4%AB&rank=citeNumber&cluster=all&val=&p=0 发现被编码, 复制的 URL 需要使用 urllib.unquote() 进行解码。
解析解码后的URL:精准扶贫&rank=citeNumber&cluster=all&val=CJFDTOTAL&p=0;通过选择不同的排序,不同的搜索关键词,不同的文档类型,可以确定'q='字段控制搜索关键词,'rank='控制排序方式,"p= " 字段控制翻页,步长为 15。最终的搜索 URL 为:url='
转码问题:
在爬取网页的过程中,发现获取的网页源代码打印出来后出现乱码。最后发现网页源代码的编码方式不是UTF-8。因此,为了获得可以用于解析的网页源代码,需要对源代码进行转码,首先将原来的编码方式转换为通用的Unicode,然后转码为:UTF-8,转码方法:
f=requests.get(test,headers=headers) # 获取网页源代码
ftext=f.text.encode(f.encoding).decode('utf-8') # 转码为可解析编码
代理IP问题:
在爬取过程中,爬取少量网页和爬取大量网页是有很大区别的。少爬取网页意味着被爬取的服务器不会拒绝它。当访问过多时,可能会导致拒绝访问和阻塞IP的问题。这时候就需要使用代理IP来访问了。代理IP实现了“欺骗”策略,使得被访问的服务器显示的IP地址是爬虫程序设置的IP,而不是电脑的真实IP地址。即使发现是爬虫程序,被屏蔽的IP也是代理IP,而不是真实的电脑IP地址。
爬取CNKI网站时,发现爬取450条信息后,IP会被屏蔽,需要填写验证码,导致无法连续爬取,所以需要设置代理IP。代理IP地址可以去一些网站爬取,本程序使用:提供的免费代理IP。
子功能设置功能:
为了使代码逻辑清晰,可以针对不同的目的设置不同的功能。注意函数之间的参数传递,容易出错。
网站源码本身的不规范:
在程序测试过程中,大部分文章爬取成功,但也有少数文章爬取失败。根据推理,如果编码相同,则应该同时成功和失败。选择爬取“成功”和“失败”两个文章页面的源码,发现有不一致的地方,需要通过技术程序处理,才能得到一致的结果:
例如:如果 len(ftext_r.xpath('//ul[@class='break']/li/text()'))==3:
ws.cell(row=num+1, column=6).value=ftext_r.xpath('//ul[@class='break']/li[2]/text()')[0]
ws.cell(row=num+1, column=7).value=ftext_r.xpath('//ul[@class='break']/li[3]/text()')[0]
如果 len(ftext_r.xpath('//ul[@class='break']/li/text()'))==4:
ws.cell(row=num+1, column=6).value=ftext_r.xpath('//ul[@class='break']/li[3]/text()')[0]
ws.cell(row=num+1, column=7).value=ftext_r.xpath('//ul[@class='break']/li[4]/text()')[0]
这里,ul标签的class属性下可能有4个li标签或者3个li标签作为break,都经过判断语句,然后分别处理需要的信息。
关键点设置提示信息:
爬取很多网页时,很难保证不会出现问题,需要不断提高程序的适应度。但是,如果有问题,要一一检查问题,工作量太大。可以在爬取每个页面时提醒是否爬取成功。
通过这些提示信息,您可以轻松定位出问题的网页,方便排查。
#----------------------------------------
完整的Python爬虫代码:
#(代码补充说明:“参数设置”后面的代码可以简单修改爬取不同主题、不同页数、使用不同代理IP)
*----------------------------------------
#!/usr/bin/env python3
# -*- 编码:utf-8 -*-
'''
创建于 2017 年 11 月 9 日星期四 21:37:30
@作者:刘宽斌
'''
#-加载将要使用的函数库
导入请求 # 读取网页
from lxml import etree # 用于解析网页
from openpyxl import Workbook # 创建表并用于数据写入
from bs4 import BeautifulSoup #解析网页
import random # 随机选择代理IP
#--获取代理IP列表
def get_ip_list(urlip,headers2):
web_data = requests.get(urlip,headers=headers2)
汤= BeautifulSoup(web_data.text,'lxml')
ips = soup.find_all('tr')
ip_list = []
对于范围内的k(1,len(ips)):
ip_info = ips[k]
tds = ip_info.find_all('td')
ip_list.append(tds[1].text + ':' + tds[2].text)
返回 ip_list
#- 从代理IP列表中随机选择一个
def get_random_ip(ip_list):
代理列表 = []
对于 ip_list 中的 ip:
proxy_list.append('#x27; + ip)
proxy_ip = random.choice(proxy_list)
代理 = {'http': proxy_ip}
返回代理
#-定义获取文章列表对应链接的函数
def get_data(urllist, headers, proxies):
j=0 # 初始化j的值
对于 urllist 中的 url:
尝试:
j=j+1
num=15*(i-pagestart)+j # 有多少篇文章
测试=str(url)
# 是否使用代理爬取爬虫在下面这行代码中,是否添加:proxies=proxies
f=requests.get(test,headers=headers) # 设置Headers项;这里添加是否使用代理访问:
ftext=f.text.encode(f.encoding).decode('utf-8') # 将具体内容转码得到可以正常阅读的文档;
ftext_r=etree.HTML(ftext) # 对特定页面进行xpath解析;
ws.cell(row=num+1, column=1).value='文章'+str(num)+'文章文章信息'
ws.cell(row=num+1, column=2).value=str(ftext_r.xpath('//title/text()')[0]).replace(' - 中国学术期刊网络出版通用库','') # 获取 文章 标题
ws.cell(row=num+1, column=3).value=str(ftext_r.xpath('//div[@class='author summaryRight']/p[1]/a/text() ')) # 获取作者姓名
#----------------------------------------
如果 len(ftext_r.xpath('//ul[@class='break']/li/text()'))==3:
ws.cell(row=num+1, column=6).value=ftext_r.xpath('//ul[@class='break']/li[2]/text()')[0]
ws.cell(row=num+1, column=7).value=ftext_r.xpath('//ul[@class='break']/li[3]/text()')[0]
如果 len(ftext_r.xpath('//ul[@class='break']/li/text()'))==4:
ws.cell(row=num+1, column=6).value=ftext_r.xpath('//ul[@class='break']/li[3]/text()')[0]
ws.cell(row=num+1, column=7).value=ftext_r.xpath('//ul[@class='break']/li[4]/text()')[0]
if len(str(ftext_r.xpath('//div[@class='author summaryRight']/p[2]/a/text()')))==2:
ws.cell(row=num+1, column=4).value=str(ftext_r.xpath('//div[@class='author summaryRight']/p[3]/a/text() '))# 获取作者单位
别的:
ws.cell(row=num+1, column=4).value=str(ftext_r.xpath('//div[@class='author summaryRight']/p[2]/a/text() '))
# str(ftext_r.xpath('//div[@class='作者 summaryRight']/p[2]/a/text()'))
ws.cell(row=num+1, column=5).value=ftext_r.xpath('//div[@id='weibo']/input/@value')[0] # 第一作者和它的出版和时间
ws.cell(row=num+1, column=8).value=str(ftext_r.xpath('//span[@id='ChDivKeyWord']/a/text()')) # 文章关键词
ws.cell(row=num+1, column=9).value=ftext_r.xpath('//span[@id='ChDivSummary']/text()')[0] # 得到 文章 总结
print('爬虫'+str(15*(pageend-pagestart+1))+'文章信息的第一个'+str(num)+'爬取成功!!')
除了:
print(''+str(j)+'爬虫在'+str(i)+'爬虫页面失败')
#---创建表单,接收数据---#
wb = Workbook() # 在内存中创建一个工作簿对象,至少会创建一个工作表
ws = wb.active # 获取当前活动的工作表,默认是第一个工作表
ws.cell(row=1, column=1).value ='No'
ws.cell(row=1, column=2).value ='Title'
ws.cell(row=1, column=3).value ='Author'
ws.cell(row=1, column=4).value ='研究所'
ws.cell(row=1, column=5).value ='Journal'
ws.cell(row=1, column=6).value ='Cites'
ws.cell(row=1, column=7).value ='下载'
ws.cell(row=1, column=8).value ='Keywords'
ws.cell(row=1, column=9).value ='Abstart'
#---------------参数设置
如果名称=='主要':
页面开始=1
页面结束=90
keywords='精准扶贫'###查询主题
网址=''
urlip = ' # 网站 提供代理IP
标头={
'Referer':':%e7%b2%be%e5%87%86%e6%89%b6%e8%b4%ab&cluster=all&val=&p=0',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.@ >0.3163.100 Safari/537.36',
'Cookie': 'cnkiUserKey = 158f5312-0f9a-cc6a-80c1-30bc5346c174; Ecp_ClientId = 43358441; UM_distinctid = 15fa39ba58f5d2-0bbc0ba7c01-13c680-15fa39ba5905f1;SID_search = 201087; ASP.NET_SessionId = glrrdk550e5gw0fsyobrsr45; CNZZDATA2643871 = cnzz_eid% 3D61276064-null% 26ntime % 3D1510290496; CNZZDATA3636877 = cnzz_eid% 3D35397534-null% 26ntime% 3D1510290549; SID_sug = 111055; LID = WEEvREcwSlJHSldRa1FhcTdWZDhML1NwVjBUZzZHeXREdU5mcG40MVM4WT0 = $ 9A4hF_YAuvQ5obgVAqNKPCYcEjKensW4IQMovwHtwkF4VYPoHbKxJw !! ',
}
标头2={
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/ 53.0.2785.143 Safari/537.36'
}
#------------------------------------------------ ---
对于我在范围内(pagestart,pageend+1):
尝试:
##获取代理IP
ip_list = get_ip_list(urlip,headers2) # 获取代理IP列表
proxies = get_random_ip(ip_list) # 获取随机代理IP
# 获取每个页面中文章的urllist
url_all=url+str(15*(i-1))
#获取每个页面的文章具体文章信息页面的链接
response=requests.get(url_all,headers=headers) # 获取网页的源代码,proxies=proxies
# print(utf16_response.decode('utf-16'))
file=response.text.encode(response.encoding).decode('utf-8') # 将网页信息转换成可以写实的UTF-8格式
r=etree.HTML(file) # 获取网页信息并使用xpath解析
urllist=r.xpath('//div[@class='wz_content']/h3/a[1]/@href') # 获取当前页面所有文章入口链接
# 获取每个页面的urllist的文章信息,并保存到构造好的表中
get_data(urllist,标题,代理)
除了:
print('爬取页面时出错'+str(i)+'')
wb.save('HowNet文章Information Summary.xlsx') # 最后保存采集到的数据
最终爬取的数据:
获得的数据可用于传入分析,研究“精准扶贫”等主题的各种信息。比如那些单位发表论文最多,词云图展示了这类文章的主要研究方向等,可以用来做各种有趣的分析。
这样的播放数据将留待下一次分析。 查看全部
php 抓取网页 源码(使用Python爬虫技术快速获取知网1000多篇某个主题的文章(图))
本文介绍使用Python爬虫技术快速获取CNKI上1000多篇文章的标题、作者、作者单位、被引用次数、下载次数、发表次数、发表时间、文章摘要。
刚开始学习爬虫的时候,想到了爬CNKI学科文献,抓取文章感兴趣的话题,获取相关文章的基本信息和摘要,从而快速了解某个领域的研究。过程、重点等
经过不断的修改,这个目标终于实现了。
在这个爬虫程序编写过程中,有几个问题需要注意。
选择适当的 网站 条目;
一般我们进入CNKI,发现这个网站很难爬取,也很难获取网站的完整源码,最后发现可以获取完整源码.
分析 网站 URL:
复制图中的URL,得到如下URL: %E7%B2%BE%E5%87%86%E6%89%B6%E8%B4%AB&rank=citeNumber&cluster=all&val=&p=0 发现被编码, 复制的 URL 需要使用 urllib.unquote() 进行解码。
解析解码后的URL:精准扶贫&rank=citeNumber&cluster=all&val=CJFDTOTAL&p=0;通过选择不同的排序,不同的搜索关键词,不同的文档类型,可以确定'q='字段控制搜索关键词,'rank='控制排序方式,"p= " 字段控制翻页,步长为 15。最终的搜索 URL 为:url='
转码问题:
在爬取网页的过程中,发现获取的网页源代码打印出来后出现乱码。最后发现网页源代码的编码方式不是UTF-8。因此,为了获得可以用于解析的网页源代码,需要对源代码进行转码,首先将原来的编码方式转换为通用的Unicode,然后转码为:UTF-8,转码方法:
f=requests.get(test,headers=headers) # 获取网页源代码
ftext=f.text.encode(f.encoding).decode('utf-8') # 转码为可解析编码
代理IP问题:
在爬取过程中,爬取少量网页和爬取大量网页是有很大区别的。少爬取网页意味着被爬取的服务器不会拒绝它。当访问过多时,可能会导致拒绝访问和阻塞IP的问题。这时候就需要使用代理IP来访问了。代理IP实现了“欺骗”策略,使得被访问的服务器显示的IP地址是爬虫程序设置的IP,而不是电脑的真实IP地址。即使发现是爬虫程序,被屏蔽的IP也是代理IP,而不是真实的电脑IP地址。
爬取CNKI网站时,发现爬取450条信息后,IP会被屏蔽,需要填写验证码,导致无法连续爬取,所以需要设置代理IP。代理IP地址可以去一些网站爬取,本程序使用:提供的免费代理IP。
子功能设置功能:
为了使代码逻辑清晰,可以针对不同的目的设置不同的功能。注意函数之间的参数传递,容易出错。
网站源码本身的不规范:
在程序测试过程中,大部分文章爬取成功,但也有少数文章爬取失败。根据推理,如果编码相同,则应该同时成功和失败。选择爬取“成功”和“失败”两个文章页面的源码,发现有不一致的地方,需要通过技术程序处理,才能得到一致的结果:
例如:如果 len(ftext_r.xpath('//ul[@class='break']/li/text()'))==3:
ws.cell(row=num+1, column=6).value=ftext_r.xpath('//ul[@class='break']/li[2]/text()')[0]
ws.cell(row=num+1, column=7).value=ftext_r.xpath('//ul[@class='break']/li[3]/text()')[0]
如果 len(ftext_r.xpath('//ul[@class='break']/li/text()'))==4:
ws.cell(row=num+1, column=6).value=ftext_r.xpath('//ul[@class='break']/li[3]/text()')[0]
ws.cell(row=num+1, column=7).value=ftext_r.xpath('//ul[@class='break']/li[4]/text()')[0]
这里,ul标签的class属性下可能有4个li标签或者3个li标签作为break,都经过判断语句,然后分别处理需要的信息。
关键点设置提示信息:
爬取很多网页时,很难保证不会出现问题,需要不断提高程序的适应度。但是,如果有问题,要一一检查问题,工作量太大。可以在爬取每个页面时提醒是否爬取成功。
通过这些提示信息,您可以轻松定位出问题的网页,方便排查。
#----------------------------------------
完整的Python爬虫代码:
#(代码补充说明:“参数设置”后面的代码可以简单修改爬取不同主题、不同页数、使用不同代理IP)
*----------------------------------------
#!/usr/bin/env python3
# -*- 编码:utf-8 -*-
'''
创建于 2017 年 11 月 9 日星期四 21:37:30
@作者:刘宽斌
'''
#-加载将要使用的函数库
导入请求 # 读取网页
from lxml import etree # 用于解析网页
from openpyxl import Workbook # 创建表并用于数据写入
from bs4 import BeautifulSoup #解析网页
import random # 随机选择代理IP
#--获取代理IP列表
def get_ip_list(urlip,headers2):
web_data = requests.get(urlip,headers=headers2)
汤= BeautifulSoup(web_data.text,'lxml')
ips = soup.find_all('tr')
ip_list = []
对于范围内的k(1,len(ips)):
ip_info = ips[k]
tds = ip_info.find_all('td')
ip_list.append(tds[1].text + ':' + tds[2].text)
返回 ip_list
#- 从代理IP列表中随机选择一个
def get_random_ip(ip_list):
代理列表 = []
对于 ip_list 中的 ip:
proxy_list.append('#x27; + ip)
proxy_ip = random.choice(proxy_list)
代理 = {'http': proxy_ip}
返回代理
#-定义获取文章列表对应链接的函数
def get_data(urllist, headers, proxies):
j=0 # 初始化j的值
对于 urllist 中的 url:
尝试:
j=j+1
num=15*(i-pagestart)+j # 有多少篇文章
测试=str(url)
# 是否使用代理爬取爬虫在下面这行代码中,是否添加:proxies=proxies
f=requests.get(test,headers=headers) # 设置Headers项;这里添加是否使用代理访问:
ftext=f.text.encode(f.encoding).decode('utf-8') # 将具体内容转码得到可以正常阅读的文档;
ftext_r=etree.HTML(ftext) # 对特定页面进行xpath解析;
ws.cell(row=num+1, column=1).value='文章'+str(num)+'文章文章信息'
ws.cell(row=num+1, column=2).value=str(ftext_r.xpath('//title/text()')[0]).replace(' - 中国学术期刊网络出版通用库','') # 获取 文章 标题
ws.cell(row=num+1, column=3).value=str(ftext_r.xpath('//div[@class='author summaryRight']/p[1]/a/text() ')) # 获取作者姓名
#----------------------------------------
如果 len(ftext_r.xpath('//ul[@class='break']/li/text()'))==3:
ws.cell(row=num+1, column=6).value=ftext_r.xpath('//ul[@class='break']/li[2]/text()')[0]
ws.cell(row=num+1, column=7).value=ftext_r.xpath('//ul[@class='break']/li[3]/text()')[0]
如果 len(ftext_r.xpath('//ul[@class='break']/li/text()'))==4:
ws.cell(row=num+1, column=6).value=ftext_r.xpath('//ul[@class='break']/li[3]/text()')[0]
ws.cell(row=num+1, column=7).value=ftext_r.xpath('//ul[@class='break']/li[4]/text()')[0]
if len(str(ftext_r.xpath('//div[@class='author summaryRight']/p[2]/a/text()')))==2:
ws.cell(row=num+1, column=4).value=str(ftext_r.xpath('//div[@class='author summaryRight']/p[3]/a/text() '))# 获取作者单位
别的:
ws.cell(row=num+1, column=4).value=str(ftext_r.xpath('//div[@class='author summaryRight']/p[2]/a/text() '))
# str(ftext_r.xpath('//div[@class='作者 summaryRight']/p[2]/a/text()'))
ws.cell(row=num+1, column=5).value=ftext_r.xpath('//div[@id='weibo']/input/@value')[0] # 第一作者和它的出版和时间
ws.cell(row=num+1, column=8).value=str(ftext_r.xpath('//span[@id='ChDivKeyWord']/a/text()')) # 文章关键词
ws.cell(row=num+1, column=9).value=ftext_r.xpath('//span[@id='ChDivSummary']/text()')[0] # 得到 文章 总结
print('爬虫'+str(15*(pageend-pagestart+1))+'文章信息的第一个'+str(num)+'爬取成功!!')
除了:
print(''+str(j)+'爬虫在'+str(i)+'爬虫页面失败')
#---创建表单,接收数据---#
wb = Workbook() # 在内存中创建一个工作簿对象,至少会创建一个工作表
ws = wb.active # 获取当前活动的工作表,默认是第一个工作表
ws.cell(row=1, column=1).value ='No'
ws.cell(row=1, column=2).value ='Title'
ws.cell(row=1, column=3).value ='Author'
ws.cell(row=1, column=4).value ='研究所'
ws.cell(row=1, column=5).value ='Journal'
ws.cell(row=1, column=6).value ='Cites'
ws.cell(row=1, column=7).value ='下载'
ws.cell(row=1, column=8).value ='Keywords'
ws.cell(row=1, column=9).value ='Abstart'
#---------------参数设置
如果名称=='主要':
页面开始=1
页面结束=90
keywords='精准扶贫'###查询主题
网址=''
urlip = ' # 网站 提供代理IP
标头={
'Referer':':%e7%b2%be%e5%87%86%e6%89%b6%e8%b4%ab&cluster=all&val=&p=0',
'User-Agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_13_0) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/61.@ >0.3163.100 Safari/537.36',
'Cookie': 'cnkiUserKey = 158f5312-0f9a-cc6a-80c1-30bc5346c174; Ecp_ClientId = 43358441; UM_distinctid = 15fa39ba58f5d2-0bbc0ba7c01-13c680-15fa39ba5905f1;SID_search = 201087; ASP.NET_SessionId = glrrdk550e5gw0fsyobrsr45; CNZZDATA2643871 = cnzz_eid% 3D61276064-null% 26ntime % 3D1510290496; CNZZDATA3636877 = cnzz_eid% 3D35397534-null% 26ntime% 3D1510290549; SID_sug = 111055; LID = WEEvREcwSlJHSldRa1FhcTdWZDhML1NwVjBUZzZHeXREdU5mcG40MVM4WT0 = $ 9A4hF_YAuvQ5obgVAqNKPCYcEjKensW4IQMovwHtwkF4VYPoHbKxJw !! ',
}
标头2={
'User-Agent': 'Mozilla/5.0 (Windows NT 6.1; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/ 53.0.2785.143 Safari/537.36'
}
#------------------------------------------------ ---
对于我在范围内(pagestart,pageend+1):
尝试:
##获取代理IP
ip_list = get_ip_list(urlip,headers2) # 获取代理IP列表
proxies = get_random_ip(ip_list) # 获取随机代理IP
# 获取每个页面中文章的urllist
url_all=url+str(15*(i-1))
#获取每个页面的文章具体文章信息页面的链接
response=requests.get(url_all,headers=headers) # 获取网页的源代码,proxies=proxies
# print(utf16_response.decode('utf-16'))
file=response.text.encode(response.encoding).decode('utf-8') # 将网页信息转换成可以写实的UTF-8格式
r=etree.HTML(file) # 获取网页信息并使用xpath解析
urllist=r.xpath('//div[@class='wz_content']/h3/a[1]/@href') # 获取当前页面所有文章入口链接
# 获取每个页面的urllist的文章信息,并保存到构造好的表中
get_data(urllist,标题,代理)
除了:
print('爬取页面时出错'+str(i)+'')
wb.save('HowNet文章Information Summary.xlsx') # 最后保存采集到的数据
最终爬取的数据:
获得的数据可用于传入分析,研究“精准扶贫”等主题的各种信息。比如那些单位发表论文最多,词云图展示了这类文章的主要研究方向等,可以用来做各种有趣的分析。
这样的播放数据将留待下一次分析。
php 抓取网页 源码(php抓取网页源码,自动提取数据保存到mysql中的问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 80 次浏览 • 2022-02-13 10:07
php抓取网页源码,自动提取数据保存到mysql中,完美解决php爬虫抓取网页存储到mysql中的问题。
1、php程序猿
2、win10操作系统
3、mysql5.7.12安装方法
1、下载安装包(1075兆、系统自带):scrapy可以抓取多种网站网页,以下举几个例子:scrapycrawler爬虫链接scrapy_get_url_links爬虫网址scrapy_query_library爬虫查询对应的解析框架抓取图片内容注意:获取的地址是保存在一个本地文件里面的scrapycrawlerpython就直接打开即可pythonmanage。pystartapppython。
我说下我们是怎么爬取工商银行官网的数据的吧,我们先先要在百度搜索工商银行官网,然后点进去第一页,大概在998个网页中能看到数据,百度上这998个网页都很慢,大概不会超过100s了,然后我们要爬取的部分是工商银行北京分行的官网,这个需要爬取的页面很多,在987个,几百万的网页,都在爬取,当然有些不想要看到的跳过,比如获取企业简介,还要获取企业发展的历史,等等,所以你要有这么多的网页还要开通会员,只要你能爬到998个网页,在998个网页中大概用不了100s,所以只要爬取到第998个网页,你就可以用python爬虫了。
谢邀。可以换一个思路想一下,通过分析工商银行电话注册表,能不能把找到用户电话, 查看全部
php 抓取网页 源码(php抓取网页源码,自动提取数据保存到mysql中的问题)
php抓取网页源码,自动提取数据保存到mysql中,完美解决php爬虫抓取网页存储到mysql中的问题。
1、php程序猿
2、win10操作系统
3、mysql5.7.12安装方法
1、下载安装包(1075兆、系统自带):scrapy可以抓取多种网站网页,以下举几个例子:scrapycrawler爬虫链接scrapy_get_url_links爬虫网址scrapy_query_library爬虫查询对应的解析框架抓取图片内容注意:获取的地址是保存在一个本地文件里面的scrapycrawlerpython就直接打开即可pythonmanage。pystartapppython。
我说下我们是怎么爬取工商银行官网的数据的吧,我们先先要在百度搜索工商银行官网,然后点进去第一页,大概在998个网页中能看到数据,百度上这998个网页都很慢,大概不会超过100s了,然后我们要爬取的部分是工商银行北京分行的官网,这个需要爬取的页面很多,在987个,几百万的网页,都在爬取,当然有些不想要看到的跳过,比如获取企业简介,还要获取企业发展的历史,等等,所以你要有这么多的网页还要开通会员,只要你能爬到998个网页,在998个网页中大概用不了100s,所以只要爬取到第998个网页,你就可以用python爬虫了。
谢邀。可以换一个思路想一下,通过分析工商银行电话注册表,能不能把找到用户电话,
php 抓取网页 源码(如何用正则表达式对数据进行数据提取和数据分类汇总?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-02-05 08:05
在很多行业中,需要及时对行业数据进行分类汇总,对行业数据进行分析,以便对公司未来的发展有很好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。data采集的最终目的是获取数据,提取有用的数据用于数据抽取和数据分类。
很多人第一次了解数据可能无法入手采集,尤其是作为新手,感觉很茫然,所以在这里分享一下我的经验,也希望和大家分享技术。如有不足之处,请指正。写这篇文章的目的,就是希望大家可以一起成长。我也相信,技术之间没有层次,只有互补和共享,才能让彼此更加成长。
当网页数据采集时,我们往往要经过这些主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③通过网页源代码提取我们要提取的目标数据 ④对数据进行转换得到我们需要的数据。
这是示意图,希望大家理解
了解了基本流程后,我会用一个案例来具体实现如何提取我们需要的数据。对于数据提取,我们可以使用正则表达式来提取,或者httpclient+jsoup来提取。这里,我们暂时不解释httpclient+jsou提取。网页数据的实践,以后会专门给httpclient+jsoup讲解。在这里,我们将首先解释如何使用正则表达式来提取数据。
我在这里找到了一个网站:我们要提取里面的数据,最终我们要提取的结果是产品的型号、数量、报价、供应商。首先,我们看到这个 网站 整页预览
接下来我们看一下网页的源码结构:
以上源码可以清晰的看到整个网页的源码结构,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到下面的数据,也就是我们最终想要得到的数据
获取数据的成功就是我们想要得到的最终数据结果。最后想说的是,这里的这个网页比较简单,可以看到网页源的源数据,而这个方法是在get方法中提交数据。,当真的是采集时,有些网页结构比较复杂,源代码中可能没有我们要提取的数据。关于这一点的解决方案稍后会为大家介绍。另外,当我在采集页面时,我只是采集当前页面的数据,它也有分页数据。这里我就不解释了,只是一个提示,我们可以使用多线程对当前所有分页数据执行采集,通过一个线程采集当前页面数据和一个翻页动作,所有数据可以采集完成。
我们匹配的数据可能在项目的实际开发中,需要我们将提取的数据存储起来,方便我们接下来的数据查询操作。 查看全部
php 抓取网页 源码(如何用正则表达式对数据进行数据提取和数据分类汇总?)
在很多行业中,需要及时对行业数据进行分类汇总,对行业数据进行分析,以便对公司未来的发展有很好的参考和横向比较。因此,在实际工作中,我们可能会遇到数据采集的概念。data采集的最终目的是获取数据,提取有用的数据用于数据抽取和数据分类。
很多人第一次了解数据可能无法入手采集,尤其是作为新手,感觉很茫然,所以在这里分享一下我的经验,也希望和大家分享技术。如有不足之处,请指正。写这篇文章的目的,就是希望大家可以一起成长。我也相信,技术之间没有层次,只有互补和共享,才能让彼此更加成长。
当网页数据采集时,我们往往要经过这些主要步骤:
①通过URL地址读取目标网页 ②获取网页源代码 ③通过网页源代码提取我们要提取的目标数据 ④对数据进行转换得到我们需要的数据。
这是示意图,希望大家理解
了解了基本流程后,我会用一个案例来具体实现如何提取我们需要的数据。对于数据提取,我们可以使用正则表达式来提取,或者httpclient+jsoup来提取。这里,我们暂时不解释httpclient+jsou提取。网页数据的实践,以后会专门给httpclient+jsoup讲解。在这里,我们将首先解释如何使用正则表达式来提取数据。
我在这里找到了一个网站:我们要提取里面的数据,最终我们要提取的结果是产品的型号、数量、报价、供应商。首先,我们看到这个 网站 整页预览
接下来我们看一下网页的源码结构:
以上源码可以清晰的看到整个网页的源码结构,我们将提取整个网页的数据。
import java.io.BufferedReader;
import java.io.InputStream;
import java.io.InputStreamReader;
import java.net.HttpURLConnection;
import java.net.URL;
import java.util.ArrayList;
import java.util.List;
import java.util.regex.Matcher;
import java.util.regex.Pattern;
public class HTMLPageParser {
public static void main(String[] args) throws Exception {
//目的网页URL地址
getURLInfo("http://www.ic.net.cn/userSite/ ... ot%3B,"utf-8");
}
public static List getURLInfo(String urlInfo,String charset) throws Exception {
//读取目的网页URL地址,获取网页源码
URL url = new URL(urlInfo);
HttpURLConnection httpUrl = (HttpURLConnection)url.openConnection();
InputStream is = httpUrl.getInputStream();
BufferedReader br = new BufferedReader(new InputStreamReader(is,"utf-8"));
StringBuilder sb = new StringBuilder();
String line;
while ((line = br.readLine()) != null) {
//这里是对链接进行处理
line = line.replaceAll("]*>", "");
//这里是对样式进行处理
line = line.replaceAll("]*>", "");
sb.append(line);
}
is.close();
br.close();
//获得网页源码
return getDataStructure(sb.toString().trim());
}
static Pattern proInfo
= Pattern.compile("(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)\\s*(.*?)", Pattern.DOTALL);
private static List getDataStructure(String str) {
//运用正则表达式对获取的网页源码进行数据匹配,提取我们所要的数据,在以后的过程中,我们可以采用httpclient+jsoup,
//现在暂时运用正则表达式对数据进行抽取提取
String[] info = str.split("");
List list = new ArrayList();
for (String s : info) {
Matcher m = proInfo.matcher(s);
Product p = null;
if (m.find()) {
p = new Product();
//设置产品型号
String[] ss = m.group(1).trim().replace(" ", "").split(">");
p.setProStyle(ss[1]);
//设置产品数量
p.setProAmount(m.group(2).trim().replace(" ", ""));
//设置产品报价
p.setProPrice(m.group(4).trim().replace(" ", ""));
//设置产品供应商
p.setProSupplier(m.group(5).trim().replace(" ", ""));
list.add(p);
}
}
//这里对集合里面不是我们要提取的数据进行移除
list.remove(0);
for (int i = 0; i < list.size(); i++) {
System.out.println("产品型号:"+list.get(i).getProStyle()+",产品数量:"+list.get(i).getProAmount()
+",产品报价:"+list.get(i).getProPrice()+",产品供应商:"+list.get(i).getProSupplier());
}
return list;
}
}
class Product {
private String proStyle;//产品型号
private String proAmount;//产品数量
private String proPrice;//产品报价
private String proSupplier;//产品供应商
public String getProStyle() {
return proStyle;
}
public void setProStyle(String proStyle) {
this.proStyle = proStyle;
}
public String getProSupplier() {
return proSupplier;
}
public void setProSupplier(String proSupplier) {
this.proSupplier = proSupplier;
}
public String getProAmount() {
return proAmount;
}
public void setProAmount(String proAmount) {
this.proAmount = proAmount;
}
public String getProPrice() {
return proPrice;
}
public void setProPrice(String proPrice) {
this.proPrice = proPrice;
}
public Product() {
}
@Override
public String toString() {
return "Product [proAmount=" + proAmount + ", proPrice=" + proPrice
+ ", proStyle=" + proStyle + ", proSupplier=" + proSupplier
+ "]";
}
}
好了,运行上面的程序,我们得到下面的数据,也就是我们最终想要得到的数据
获取数据的成功就是我们想要得到的最终数据结果。最后想说的是,这里的这个网页比较简单,可以看到网页源的源数据,而这个方法是在get方法中提交数据。,当真的是采集时,有些网页结构比较复杂,源代码中可能没有我们要提取的数据。关于这一点的解决方案稍后会为大家介绍。另外,当我在采集页面时,我只是采集当前页面的数据,它也有分页数据。这里我就不解释了,只是一个提示,我们可以使用多线程对当前所有分页数据执行采集,通过一个线程采集当前页面数据和一个翻页动作,所有数据可以采集完成。
我们匹配的数据可能在项目的实际开发中,需要我们将提取的数据存储起来,方便我们接下来的数据查询操作。
php 抓取网页 源码(php抓取网页源码、批量抓取及注册开户报名是使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-01-24 02:00
php抓取网页源码、批量抓取及注册开户报名是使用php开发的,学习php之前,你需要对php基础的内容进行学习.1.导入需要抓取的网站url到php的方法如下:php版本1:1基于phpv4(这个版本下一次更新版本名为5.3.
1)php版本2:1基于phpv2(这个版本下一次更新版本名为5.2.
8)php版本3:1基于phpv3(这个版本下一次更新版本名为5.3.
2)php版本4:1基于phpv4(这个版本下一次更新版本名为5.2.
8)php版本5:1基于phpv3(这个版本下一次更新版本名为5.2.
5)php版本5:1基于phpv2(这个版本下一次更新版本名为5.2.
4)2.获取url后缀php脚本抓取网页源码、获取incomep2ppreferredtounemployedcredentials信息,需要网页的excel文件里面有这些信息。php脚本:搜索网页源码获取手机号\nc#3.获取w3cpn信息查询网页源码,获取pat_pn2.网址包含哪些内容网址:,我们需要抓取的网址必须包含username信息;post_header$a="user-agent:safari/23.0.3719.9";3.需要下载什么模块有用的脚本:incomep2ppreferredtounemployedcredentials类模块,用于处理复杂的cases;网页自动刷新.max_incomep2ppreferredtounemployedcredentials和income类模块功能相同,后者更适合做简单逻辑类型网页.批量抓取.有些数据不需要抓取,类模块也可以的.4.获取源码.目前需要用到两个小模块:requesthttpquerygetmodelfixemodelfixe用于处理图片,以及需要限制或者浏览的链接信息.。 查看全部
php 抓取网页 源码(php抓取网页源码、批量抓取及注册开户报名是使用)
php抓取网页源码、批量抓取及注册开户报名是使用php开发的,学习php之前,你需要对php基础的内容进行学习.1.导入需要抓取的网站url到php的方法如下:php版本1:1基于phpv4(这个版本下一次更新版本名为5.3.
1)php版本2:1基于phpv2(这个版本下一次更新版本名为5.2.
8)php版本3:1基于phpv3(这个版本下一次更新版本名为5.3.
2)php版本4:1基于phpv4(这个版本下一次更新版本名为5.2.
8)php版本5:1基于phpv3(这个版本下一次更新版本名为5.2.
5)php版本5:1基于phpv2(这个版本下一次更新版本名为5.2.
4)2.获取url后缀php脚本抓取网页源码、获取incomep2ppreferredtounemployedcredentials信息,需要网页的excel文件里面有这些信息。php脚本:搜索网页源码获取手机号\nc#3.获取w3cpn信息查询网页源码,获取pat_pn2.网址包含哪些内容网址:,我们需要抓取的网址必须包含username信息;post_header$a="user-agent:safari/23.0.3719.9";3.需要下载什么模块有用的脚本:incomep2ppreferredtounemployedcredentials类模块,用于处理复杂的cases;网页自动刷新.max_incomep2ppreferredtounemployedcredentials和income类模块功能相同,后者更适合做简单逻辑类型网页.批量抓取.有些数据不需要抓取,类模块也可以的.4.获取源码.目前需要用到两个小模块:requesthttpquerygetmodelfixemodelfixe用于处理图片,以及需要限制或者浏览的链接信息.。
php 抓取网页 源码(php抓取网页源码是要通过php去请求网页的(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-23 17:01
php抓取网页源码是要通过php去请求网页的,这个网页是什么网页就用什么网页去请求,所以抓取一个是用什么方法,选择php方式,这个网页是什么网页就使用什么方法请求。
大学入学的时候我也迷茫过,后来开始做爬虫,解决了一个个迷茫过的问题。我来说说我的吧。爬虫,就是抓取网站上用户留下的一些信息,然后通过复杂数据整理出最后的数据给出,最简单的包括用户的昵称、性别、地址、年龄等等。前提要有爬虫框架或者其他软件,常见的也就是爬虫框架,比如python最著名的就是requests、爬虫库包括html5py等等。
用户提供有效信息之后才有可能被抓取,而在有效信息即你完全已知的情况下,
百度的反爬虫对于有api接口的页面有过相关测试,要求在api中post一个数据,然后结果就会出来了。对于无api接口的页面也无法做到这一点,参见中国版首页其实和楼上所说,可以再用pythonformatapi,来对图片文本数据,数据标签的web上的测试请求里尝试post一个url,看结果,如果被拒绝,就拒绝。就完事了。
对于公用robots文件中的定义的不同,比如简单的robots.txt文件中网站名称应该是文件,可是爬虫可能会重复请求同一个页面去下载别的页面中没有的数据;在很多网站中,存在trunk,trunk里面存有多个网站的链接,爬虫重复请求就会发送给指定网站;还有一种办法是禁止自身post。 查看全部
php 抓取网页 源码(php抓取网页源码是要通过php去请求网页的(图))
php抓取网页源码是要通过php去请求网页的,这个网页是什么网页就用什么网页去请求,所以抓取一个是用什么方法,选择php方式,这个网页是什么网页就使用什么方法请求。
大学入学的时候我也迷茫过,后来开始做爬虫,解决了一个个迷茫过的问题。我来说说我的吧。爬虫,就是抓取网站上用户留下的一些信息,然后通过复杂数据整理出最后的数据给出,最简单的包括用户的昵称、性别、地址、年龄等等。前提要有爬虫框架或者其他软件,常见的也就是爬虫框架,比如python最著名的就是requests、爬虫库包括html5py等等。
用户提供有效信息之后才有可能被抓取,而在有效信息即你完全已知的情况下,
百度的反爬虫对于有api接口的页面有过相关测试,要求在api中post一个数据,然后结果就会出来了。对于无api接口的页面也无法做到这一点,参见中国版首页其实和楼上所说,可以再用pythonformatapi,来对图片文本数据,数据标签的web上的测试请求里尝试post一个url,看结果,如果被拒绝,就拒绝。就完事了。
对于公用robots文件中的定义的不同,比如简单的robots.txt文件中网站名称应该是文件,可是爬虫可能会重复请求同一个页面去下载别的页面中没有的数据;在很多网站中,存在trunk,trunk里面存有多个网站的链接,爬虫重复请求就会发送给指定网站;还有一种办法是禁止自身post。
php 抓取网页 源码(php抓取网页源码的基本方法(1)_光明网(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2022-01-17 20:06
php抓取网页源码的方法分为:正则表达式解析,结构化数据存储,googlebrainonphp。本文主要介绍一下php抓取网页中传统的方法,包括html解析方法,结构化数据存储方法,这些方法的主要原理为:1,html,2,网页数据,3,表格数据。数据来源请自行搜索“html解析”相关文章。一.php抓取网页源码的基本方法正则表达式a,s,m,d,a,sub的相关知识请自行百度,本文重点讲解:1,html中data-data是什么?通过一个data-data列表返回一个text数组,其中每个item都是一个data对象,返回给php解析器:[""]data数组2,s的match方法返回一个整数,其结果包含一个绝对值。
substring方法返回一个整数,其结果包含一个零。如果s和d返回同一个数字,将返回2。如果s和d返回不同的数字,则返回3。例如:htmlphp获取googlepages,并提取snotifymusicurlentry.php?nosaved=33,re和request方法同样也是正则表达式,不同的是requery接受一个包含正则表达式html标签的字符串作为参数,request接受一个uri,里面包含了一个包含正则表达式html标签的url。
a,s,m,d,a,string转换为b,text,value。如:htmlphp获取googlepages,并提取entry.php?scanner="http://%26quot%3B%26amp%3Bs%3D ... lient("80");request.setconnectionurl("");request.setrequestheader("user-agent","mozilla/5.0(windowsnt6.1;wow64)applewebkit/537.36(khtml,likegecko)chrome/27.0.2820.102safari/537.36");request.setrequestheader("content-type","text/html;charset=utf-8");request.setscheme("926323");request.setservertimeout(10800);request.setsecret(privatekeyword.signed);request.setsecret(privatekeyword.ecmap("/")))。 查看全部
php 抓取网页 源码(php抓取网页源码的基本方法(1)_光明网(组图))
php抓取网页源码的方法分为:正则表达式解析,结构化数据存储,googlebrainonphp。本文主要介绍一下php抓取网页中传统的方法,包括html解析方法,结构化数据存储方法,这些方法的主要原理为:1,html,2,网页数据,3,表格数据。数据来源请自行搜索“html解析”相关文章。一.php抓取网页源码的基本方法正则表达式a,s,m,d,a,sub的相关知识请自行百度,本文重点讲解:1,html中data-data是什么?通过一个data-data列表返回一个text数组,其中每个item都是一个data对象,返回给php解析器:[""]data数组2,s的match方法返回一个整数,其结果包含一个绝对值。
substring方法返回一个整数,其结果包含一个零。如果s和d返回同一个数字,将返回2。如果s和d返回不同的数字,则返回3。例如:htmlphp获取googlepages,并提取snotifymusicurlentry.php?nosaved=33,re和request方法同样也是正则表达式,不同的是requery接受一个包含正则表达式html标签的字符串作为参数,request接受一个uri,里面包含了一个包含正则表达式html标签的url。
a,s,m,d,a,string转换为b,text,value。如:htmlphp获取googlepages,并提取entry.php?scanner="http://%26quot%3B%26amp%3Bs%3D ... lient("80");request.setconnectionurl("");request.setrequestheader("user-agent","mozilla/5.0(windowsnt6.1;wow64)applewebkit/537.36(khtml,likegecko)chrome/27.0.2820.102safari/537.36");request.setrequestheader("content-type","text/html;charset=utf-8");request.setscheme("926323");request.setservertimeout(10800);request.setsecret(privatekeyword.signed);request.setsecret(privatekeyword.ecmap("/")))。
php 抓取网页 源码( 斯巴达,常用爬虫制作模块的基本用法极度推荐!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 63 次浏览 • 2022-01-15 23:07
斯巴达,常用爬虫制作模块的基本用法极度推荐!)
使用 Python 的 urllib 和 urllib2 模块制作爬虫的示例教程
更新时间:2016-01-20 10:25:51 作者:XiaoluD
本文章主要介绍使用Python的urllib和urllib2模块制作爬虫的示例教程,展示这两个常用的爬虫制作模块的基本用法,强烈推荐!有需要的朋友可以参考以下
urllib
在学习了python的基础知识之后,我有点困惑。当我闭上眼睛时,一种空白的窒息感不断袭来。我还缺乏练习,所以我用爬虫来练习我的手。学完Spartan python爬虫课程后,我将自己的经验整理如下,供后续翻阅。整个笔记主要分为以下几个部分:
1.做一个简单的爬虫程序
第一个环境描述
这个没什么好说的,直接上代码吧!
'''
@ urllib为python自带的一个网络库
@ urlopen为urllib的一个方法,用于打开一个连接并抓取网页,
然后通过read()方法把值赋给read()
'''
import urllib
url = "http://www.lifevc.com"#多嘴两句,为什么要选lifevc呢,主要是最近它很惹我.
html = urllib.urlopen(url)
content = html.read()
html.close()
#可以通过print打印出网页内容
print content
很简单,基本没什么好说的,这就是python的魅力,几行代码就可以搞定。
当然,我们只是爬网,没有真正的价值。然后我们开始做一些有意义的事情。
2.小试刀
抓取百度贴吧图片
其实也很简单,因为要抓取图片,还需要先分析网页的源码。
(这里是了解html基础知识,浏览器以chrome为例)
如图,这里对接下来的步骤做一个简单的说明,请参考。
打开网页,右击,选择“inspect Element”(底部项)
点击下方弹出框最左侧的问号,问号会变成蓝色
移动鼠标点击我们要抓拍的图片(可爱的女孩)
如图,我们可以在源码中看到图片的位置。
复制下面的源代码
经过分析对比(这里略),我们基本上可以看出要抓拍的图像的几个特征:
后面会更新正则表达式,请注意
根据上面的判断,直接上代码
'''
@本程序用来下载百度贴吧图片
@re 为正则说明库
'''
import urllib
import re
# 获取网页html信息
url = "http://tieba.baidu.com/p/2336739808"
html = urllib.urlopen(url)
content = html.read()
html.close()
# 通过正则匹配图片特征,并获取图片链接
img_tag = re.compile(r'class="BDE_Image" src="(.+?\.jpg)"')
img_links = re.findall(img_tag, content)
# 下载图片 img_counter为图片计数器(文件名)
img_counter = 0
for img_link in img_links:
img_name = '%s.jpg' % img_counter
urllib.urlretrieve(img_link, "//Users//Sean//Downloads//tieba//%s" %img_name)
img_counter += 1
如图,我们会抓取你看懂的图片
3.总结
如上两节,我们可以很方便的访问网页或图片。
补充一点小技巧,如果遇到自己不是很了解的库或者方法,可以通过下面的方法来初步了解。
或输入相关搜索。
当然百度也可以,但是效率太低了。推荐使用相关搜索(你懂的,绝对满意)。
这里我们讲解如何爬取网页和下载图片,下面我们将讲解如何爬取有限爬取网站。
urllib2
上面我们解释了如何抓取网页和下载图片,下一节我们将解释如何抓取有限的抓取网站
首先,我们还是用上个类中的方法来捕获一个大家都用的网站作为例子。本文主要分为以下几个部分:
1.爬取受限页面
首先使用我们在上一节中学到的知识对其进行测试:
'''
@本程序用来抓取blog.csdn.net网页
'''
import urllib
url = "http://blog.csdn.net/FansUnion"
html = urllib.urlopen(url)
#getcode()方法为返回Http状态码
print html.getcode()
html.close()
#输出
403
这里我们的输出是 403,表示访问被拒绝;200 表示请求成功完成;404 表示找不到 URL。
可以看出csdn已经被屏蔽了。通过第一节的方法,是无法获取网页的。这里我们需要启动一个新库:urllib2
但是我们也看到浏览器可以发送那个文本,无论我们模拟浏览器操作,我们都可以得到网页信息。
老办法,我们来看看浏览器是如何向csdn服务器提交请求的。首先,简单介绍一下方法:
以下是排序后的Header信息
Request Method:GET
Host:blog.csdn.net
Referer:http://blog.csdn.net/?ref=toolbar_logo
User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.104 Safari/537.36
然后根据提取的Header信息,使用urllib2的Request方法模拟浏览器向服务器提交请求。代码如下:
# coding=utf-8
'''
@本程序用来抓取受限网页(blog.csdn.net)
@User-Agent:客户端浏览器版本
@Host:服务器地址
@Referer:跳转地址
@GET:请求方法为GET
'''
import urllib2
url = "http://blog.csdn.net/FansUnion"
#定制自定义Header,模拟浏览器向服务器提交请求
req = urllib2.Request(url)
req.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36')
req.add_header('Host', 'blog.csdn.net')
req.add_header('Referer', 'http://blog.csdn.net')
req.add_header('GET', url)
#下载网页html并打印
html = urllib2.urlopen(req)
content = html.read()
print content
html.close()
呵呵,如果你限制我,我就跳过你的限制。据说只要浏览器可以访问,就可以被爬虫爬取。
2.对代码做一些优化
简化提交 Header 方法
我发现每次写这么多req.add_header对自己来说是一种折磨。有没有什么方法可以使用,只要复制。答案是肯定的。
#input:
help(urllib2.Request)
#output(因篇幅关系,只取__init__方法)
__init__(self, url, data=None, headers={}, origin_req_host=None, unverifiable=False)
通过观察,我们发现headers={},就是说可以以字典的方式提交header信息.那就动手试试咯!!
#只取自定义Header部分代码
csdn_headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36",
"Host": "blog.csdn.net",
'Referer': 'http://blog.csdn.net',
"GET": url
}
req = urllib2.Request(url,headers=csdn_headers)
是不是很容易发现,感谢斯巴达在这里的无私启蒙。
提供动态标题信息
如果按照上面的方法爬取,很多时候提交的信息会因为提交的信息过于单一而被服务器当作机器爬虫拒绝。
那么我们是否有一些更聪明的方式来提交一些动态数据呢,答案肯定是肯定的。而且很简单,直接上代码!
'''
@本程序是用来动态提交Header信息
@random 动态库,详情请参考
'''
# coding=utf-8
import urllib2
import random
url = 'http://www.lifevc.com/'
my_headers = [
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET CLR 2.0.50727; .NET CLR 3.0.04506.30; .NET CLR 3.0.04506.648)',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET CLR 2.0.50727; InfoPath.1',
'Mozilla/4.0 (compatible; GoogleToolbar 5.0.2124.2070; Windows 6.0; MSIE 8.0.6001.18241)',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0)',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; Sleipnir/2.9.8)',
#因篇幅关系,此处省略N条
]
random_header = random.choice(headers)
# 可以通过print random_header查看提交的header信息
req = urllib2.Request(url)
req.add_header("User-Agent", random_header)
req.add_header('Host', 'blog.csdn.net')
req.add_header('Referer', 'http://blog.csdn.net')
req.add_header('GET', url)
content = urllib2.urlopen(req).read()
print content
其实很简单,所以我们对代码完成了一些优化。 查看全部
php 抓取网页 源码(
斯巴达,常用爬虫制作模块的基本用法极度推荐!)
使用 Python 的 urllib 和 urllib2 模块制作爬虫的示例教程
更新时间:2016-01-20 10:25:51 作者:XiaoluD
本文章主要介绍使用Python的urllib和urllib2模块制作爬虫的示例教程,展示这两个常用的爬虫制作模块的基本用法,强烈推荐!有需要的朋友可以参考以下
urllib
在学习了python的基础知识之后,我有点困惑。当我闭上眼睛时,一种空白的窒息感不断袭来。我还缺乏练习,所以我用爬虫来练习我的手。学完Spartan python爬虫课程后,我将自己的经验整理如下,供后续翻阅。整个笔记主要分为以下几个部分:
1.做一个简单的爬虫程序
第一个环境描述
这个没什么好说的,直接上代码吧!
'''
@ urllib为python自带的一个网络库
@ urlopen为urllib的一个方法,用于打开一个连接并抓取网页,
然后通过read()方法把值赋给read()
'''
import urllib
url = "http://www.lifevc.com"#多嘴两句,为什么要选lifevc呢,主要是最近它很惹我.
html = urllib.urlopen(url)
content = html.read()
html.close()
#可以通过print打印出网页内容
print content
很简单,基本没什么好说的,这就是python的魅力,几行代码就可以搞定。
当然,我们只是爬网,没有真正的价值。然后我们开始做一些有意义的事情。
2.小试刀
抓取百度贴吧图片
其实也很简单,因为要抓取图片,还需要先分析网页的源码。
(这里是了解html基础知识,浏览器以chrome为例)
如图,这里对接下来的步骤做一个简单的说明,请参考。
打开网页,右击,选择“inspect Element”(底部项)
点击下方弹出框最左侧的问号,问号会变成蓝色
移动鼠标点击我们要抓拍的图片(可爱的女孩)
如图,我们可以在源码中看到图片的位置。
复制下面的源代码
经过分析对比(这里略),我们基本上可以看出要抓拍的图像的几个特征:
后面会更新正则表达式,请注意
根据上面的判断,直接上代码
'''
@本程序用来下载百度贴吧图片
@re 为正则说明库
'''
import urllib
import re
# 获取网页html信息
url = "http://tieba.baidu.com/p/2336739808"
html = urllib.urlopen(url)
content = html.read()
html.close()
# 通过正则匹配图片特征,并获取图片链接
img_tag = re.compile(r'class="BDE_Image" src="(.+?\.jpg)"')
img_links = re.findall(img_tag, content)
# 下载图片 img_counter为图片计数器(文件名)
img_counter = 0
for img_link in img_links:
img_name = '%s.jpg' % img_counter
urllib.urlretrieve(img_link, "//Users//Sean//Downloads//tieba//%s" %img_name)
img_counter += 1
如图,我们会抓取你看懂的图片
3.总结
如上两节,我们可以很方便的访问网页或图片。
补充一点小技巧,如果遇到自己不是很了解的库或者方法,可以通过下面的方法来初步了解。
或输入相关搜索。
当然百度也可以,但是效率太低了。推荐使用相关搜索(你懂的,绝对满意)。
这里我们讲解如何爬取网页和下载图片,下面我们将讲解如何爬取有限爬取网站。
urllib2
上面我们解释了如何抓取网页和下载图片,下一节我们将解释如何抓取有限的抓取网站
首先,我们还是用上个类中的方法来捕获一个大家都用的网站作为例子。本文主要分为以下几个部分:
1.爬取受限页面
首先使用我们在上一节中学到的知识对其进行测试:
'''
@本程序用来抓取blog.csdn.net网页
'''
import urllib
url = "http://blog.csdn.net/FansUnion"
html = urllib.urlopen(url)
#getcode()方法为返回Http状态码
print html.getcode()
html.close()
#输出
403
这里我们的输出是 403,表示访问被拒绝;200 表示请求成功完成;404 表示找不到 URL。
可以看出csdn已经被屏蔽了。通过第一节的方法,是无法获取网页的。这里我们需要启动一个新库:urllib2
但是我们也看到浏览器可以发送那个文本,无论我们模拟浏览器操作,我们都可以得到网页信息。
老办法,我们来看看浏览器是如何向csdn服务器提交请求的。首先,简单介绍一下方法:
以下是排序后的Header信息
Request Method:GET
Host:blog.csdn.net
Referer:http://blog.csdn.net/?ref=toolbar_logo
User-Agent:Mozilla/5.0 (Macintosh; Intel Mac OS X 10_10_1) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/38.0.2125.104 Safari/537.36
然后根据提取的Header信息,使用urllib2的Request方法模拟浏览器向服务器提交请求。代码如下:
# coding=utf-8
'''
@本程序用来抓取受限网页(blog.csdn.net)
@User-Agent:客户端浏览器版本
@Host:服务器地址
@Referer:跳转地址
@GET:请求方法为GET
'''
import urllib2
url = "http://blog.csdn.net/FansUnion"
#定制自定义Header,模拟浏览器向服务器提交请求
req = urllib2.Request(url)
req.add_header('User-Agent', 'Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36')
req.add_header('Host', 'blog.csdn.net')
req.add_header('Referer', 'http://blog.csdn.net')
req.add_header('GET', url)
#下载网页html并打印
html = urllib2.urlopen(req)
content = html.read()
print content
html.close()
呵呵,如果你限制我,我就跳过你的限制。据说只要浏览器可以访问,就可以被爬虫爬取。
2.对代码做一些优化
简化提交 Header 方法
我发现每次写这么多req.add_header对自己来说是一种折磨。有没有什么方法可以使用,只要复制。答案是肯定的。
#input:
help(urllib2.Request)
#output(因篇幅关系,只取__init__方法)
__init__(self, url, data=None, headers={}, origin_req_host=None, unverifiable=False)
通过观察,我们发现headers={},就是说可以以字典的方式提交header信息.那就动手试试咯!!
#只取自定义Header部分代码
csdn_headers = {
"User-Agent": "Mozilla/5.0 (Windows NT 6.3; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/39.0.2171.95 Safari/537.36",
"Host": "blog.csdn.net",
'Referer': 'http://blog.csdn.net',
"GET": url
}
req = urllib2.Request(url,headers=csdn_headers)
是不是很容易发现,感谢斯巴达在这里的无私启蒙。
提供动态标题信息
如果按照上面的方法爬取,很多时候提交的信息会因为提交的信息过于单一而被服务器当作机器爬虫拒绝。
那么我们是否有一些更聪明的方式来提交一些动态数据呢,答案肯定是肯定的。而且很简单,直接上代码!
'''
@本程序是用来动态提交Header信息
@random 动态库,详情请参考
'''
# coding=utf-8
import urllib2
import random
url = 'http://www.lifevc.com/'
my_headers = [
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET CLR 2.0.50727; .NET CLR 3.0.04506.30; .NET CLR 3.0.04506.648)',
'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0; .NET CLR 2.0.50727; InfoPath.1',
'Mozilla/4.0 (compatible; GoogleToolbar 5.0.2124.2070; Windows 6.0; MSIE 8.0.6001.18241)',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0)',
'Mozilla/5.0 (compatible; MSIE 9.0; Windows NT 6.1; WOW64; Trident/5.0; Sleipnir/2.9.8)',
#因篇幅关系,此处省略N条
]
random_header = random.choice(headers)
# 可以通过print random_header查看提交的header信息
req = urllib2.Request(url)
req.add_header("User-Agent", random_header)
req.add_header('Host', 'blog.csdn.net')
req.add_header('Referer', 'http://blog.csdn.net')
req.add_header('GET', url)
content = urllib2.urlopen(req).read()
print content
其实很简单,所以我们对代码完成了一些优化。
php 抓取网页 源码(本文系统,DellG3电脑什么是网站开放源代码?(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-01-07 12:12
)
相关话题
如何打开网页的源代码
4/2/202110:31:09
网页源码的打开方法:先登录一个网站,在网页左侧的空白处右击;然后点击review元素,再次右键点击网页左侧的空白处;最后点击查看源文件。本文运行环境:Windows7系统,DellG3电脑
什么是网站开源?
7/8/201810:40:53
源码构成了网站的核心,即网站的程序代码,包括网站文件和目录结构。网站只有源码才有。源代码决定了 网站 的所有权。传统的自助建站由于采用SAAS模式,无法开源。用户本质上每年支付租金来租用平台使用权网站。什么时候不交房租,网站就没了;而开源站点建设是用户拥有网站的所有权,是一种交易关系而不是
Python笔记提取网页中的超链接
2/3/201801:10:15
python笔记中提取网页超链接对于提取网页超链接,先读取网页内容,再用beautifulsoup解析更方便。但是我发现了一个问题。如果直接提取a标签的href,会收录javascript:xxx和#xxx,需要特殊处理。#!/usr/bin/envpython#coding:utf-8frombs4importBeautifulS
Nginx下改网页地址后旧网页301重定向的代码
2/3/201801:09:49
摘要:Nginx下旧网页改网页地址后301重定向的代码
什么是标签页?如何优化标签页?
27/4/202010:57:11
什么是标签页?如何优化标签页?标签页是非常常用的,如果用得好,SEO效果很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
实现网站(网页)跳转并可以隐藏跳转后的URL代码
2/3/201801:10:32
实现网站(网页)重定向和隐藏重定向后URL的代码成子2017-04-0423:44:01浏览304条评论0阿里云域名根目录http网页设计UIhtdocscharsetindexhtml摘要:实现网站(网页)跳转后隐藏网址的代码1.实现网站(网页)跳转后隐藏网址的代码
90后黑客入侵最高检查网站改源码窃取流量
15/12/201012:02:00
范冬冬、19岁文超被指多次侵入最高人民检察院等多个政府机构的后台,将网页源代码改成其他网站以增加搜索量利润排名率。记者昨日获悉,因涉嫌非法侵入电脑...
马农在网站的源码里抱怨,老板终于被炒鱿鱼了
17/1/201311:08:00
上周,一条关于网站源代码的微博给大家带来了欢乐。在某网站主页的源码中,程序员发泄不满,抱怨公司没有年终奖。不要指望那些想来公司找工作的人。
kbengine0.4.20 源码分析(一)
4/3/201801:14:49
摘要:kbengine0.4.20 源码解析(一)
谈谈你的网站页面的价值
13/7/201120:43:00
说说你的网站网页价值一、什么是网页价值?网页价值是指一个网页所收录的所有满足用户特定需求的元素和内容网站在用户和搜索引擎程序中...
亚马逊已发布 KindleFire 源代码
17/11/201109:53:00
亚马逊今天公布了其 KindleFire 平板电脑产品的源代码。这意味着开发人员可以为平板电脑创建自定义 ROM、内核和一些很酷的东西。目前还不确定源代码中是否开启了root权限,但昨天确实被黑客拿走了。
Tag标签SEO优化让网站快速收录排名!
31/10/201715:03:00
tag标签的作用: 第一:提升用户体验和PV点击率。第二:增加内部链接有利于网页权重的相互转移。第三:增加百度收录,提升关键词的排名。为什么标签页排名比文章页好?原因是标签页关键词和文章页形成了内部竞争,标签页收到的内链远多于文章页,这些内链甚至是高度相关的,所以这是正常的
模仿Googlebot检查你网页的代码
16/10/200908:34:00
Google网站Administrator Tools 刚刚发布了一个 Labs 功能,其中一个叫做 FetchasGooglebot,你可以在这里模仿 Googlebot 并检查自己的网页代码。但是这个功能必须经过管理员网站的验证才能查看。没有网站的管理权限,就没有机会。
网页中代码的排列顺序是一个不容忽视的细节
19/11/201212:02:00
似乎初学者总喜欢找那些奇怪的问题。在学习制作网页的时候,经常会遇到一些很特别的问题。比如:刚刚添加的样式不行,jQuery代码老是不行等等,这些问题往往都是不注意细节造成的。我今天要讲的细节是关于网页中代码的顺序。没错,代码也是有顺序的,顺序不对可能会出现一些意想不到的情况。
网页设计对网站推广效果的影响
26/4/200911:18:00
网页设计是一门非常深刻的课程,它对网站的推广和营销的影响是毋庸置疑的。无论是网页布局、网页下载速度、导航系统的便捷性,都会直接影响到用户的浏览效果,进而影响网站在用户心目中的地位和形象,即网页设计的效果将直接影响网站的品牌形象和推广营销效果。向下
查看全部
php 抓取网页 源码(本文系统,DellG3电脑什么是网站开放源代码?(图)
)
相关话题
如何打开网页的源代码
4/2/202110:31:09
网页源码的打开方法:先登录一个网站,在网页左侧的空白处右击;然后点击review元素,再次右键点击网页左侧的空白处;最后点击查看源文件。本文运行环境:Windows7系统,DellG3电脑
什么是网站开源?
7/8/201810:40:53
源码构成了网站的核心,即网站的程序代码,包括网站文件和目录结构。网站只有源码才有。源代码决定了 网站 的所有权。传统的自助建站由于采用SAAS模式,无法开源。用户本质上每年支付租金来租用平台使用权网站。什么时候不交房租,网站就没了;而开源站点建设是用户拥有网站的所有权,是一种交易关系而不是
Python笔记提取网页中的超链接
2/3/201801:10:15
python笔记中提取网页超链接对于提取网页超链接,先读取网页内容,再用beautifulsoup解析更方便。但是我发现了一个问题。如果直接提取a标签的href,会收录javascript:xxx和#xxx,需要特殊处理。#!/usr/bin/envpython#coding:utf-8frombs4importBeautifulS
Nginx下改网页地址后旧网页301重定向的代码
2/3/201801:09:49
摘要:Nginx下旧网页改网页地址后301重定向的代码
什么是标签页?如何优化标签页?
27/4/202010:57:11
什么是标签页?如何优化标签页?标签页是非常常用的,如果用得好,SEO效果很好,但是很多网站标签页使用不当,甚至可能产生负面影响,所以这是一个很好的问题。但是这个问题
实现网站(网页)跳转并可以隐藏跳转后的URL代码
2/3/201801:10:32
实现网站(网页)重定向和隐藏重定向后URL的代码成子2017-04-0423:44:01浏览304条评论0阿里云域名根目录http网页设计UIhtdocscharsetindexhtml摘要:实现网站(网页)跳转后隐藏网址的代码1.实现网站(网页)跳转后隐藏网址的代码
90后黑客入侵最高检查网站改源码窃取流量
15/12/201012:02:00
范冬冬、19岁文超被指多次侵入最高人民检察院等多个政府机构的后台,将网页源代码改成其他网站以增加搜索量利润排名率。记者昨日获悉,因涉嫌非法侵入电脑...
马农在网站的源码里抱怨,老板终于被炒鱿鱼了
17/1/201311:08:00
上周,一条关于网站源代码的微博给大家带来了欢乐。在某网站主页的源码中,程序员发泄不满,抱怨公司没有年终奖。不要指望那些想来公司找工作的人。
kbengine0.4.20 源码分析(一)
4/3/201801:14:49
摘要:kbengine0.4.20 源码解析(一)
谈谈你的网站页面的价值
13/7/201120:43:00
说说你的网站网页价值一、什么是网页价值?网页价值是指一个网页所收录的所有满足用户特定需求的元素和内容网站在用户和搜索引擎程序中...
亚马逊已发布 KindleFire 源代码
17/11/201109:53:00
亚马逊今天公布了其 KindleFire 平板电脑产品的源代码。这意味着开发人员可以为平板电脑创建自定义 ROM、内核和一些很酷的东西。目前还不确定源代码中是否开启了root权限,但昨天确实被黑客拿走了。
Tag标签SEO优化让网站快速收录排名!
31/10/201715:03:00
tag标签的作用: 第一:提升用户体验和PV点击率。第二:增加内部链接有利于网页权重的相互转移。第三:增加百度收录,提升关键词的排名。为什么标签页排名比文章页好?原因是标签页关键词和文章页形成了内部竞争,标签页收到的内链远多于文章页,这些内链甚至是高度相关的,所以这是正常的
模仿Googlebot检查你网页的代码
16/10/200908:34:00
Google网站Administrator Tools 刚刚发布了一个 Labs 功能,其中一个叫做 FetchasGooglebot,你可以在这里模仿 Googlebot 并检查自己的网页代码。但是这个功能必须经过管理员网站的验证才能查看。没有网站的管理权限,就没有机会。
网页中代码的排列顺序是一个不容忽视的细节
19/11/201212:02:00
似乎初学者总喜欢找那些奇怪的问题。在学习制作网页的时候,经常会遇到一些很特别的问题。比如:刚刚添加的样式不行,jQuery代码老是不行等等,这些问题往往都是不注意细节造成的。我今天要讲的细节是关于网页中代码的顺序。没错,代码也是有顺序的,顺序不对可能会出现一些意想不到的情况。
网页设计对网站推广效果的影响
26/4/200911:18:00
网页设计是一门非常深刻的课程,它对网站的推广和营销的影响是毋庸置疑的。无论是网页布局、网页下载速度、导航系统的便捷性,都会直接影响到用户的浏览效果,进而影响网站在用户心目中的地位和形象,即网页设计的效果将直接影响网站的品牌形象和推广营销效果。向下
php 抓取网页 源码(php抓取网页源码并存储为json文件并放到内存中)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2022-01-02 13:08
php抓取网页源码并存储为json文件并放到内存中,然后使用requests库即可发起post请求,接着将json数据解析成blob/txt等文件并存储到本地php5中已经可以直接使用php代码解析html文件内容,php6/php7中的html51版本已经可以直接解析html文件内容并存储到本地。但是在php7中对于php代码的解析速度被延迟到了html51.2版本才实现。
可以先尝试阿里云的json数据库,
基于phpapachespringmvc的爬虫框架-深夜技术咖
建议直接用es。使用的是json数据库。php代码解析是通过设置json转义字符来实现的。
好多选择,例如pm2、1.4.1、phpwind等,具体根据项目用户需求选择即可。json转义库用户有巨量需求,
phppost解析库的话,我觉得1.5都是不错的选择,就po、jsonp,
json转义最好的解决方案,见:这篇文章说的很好,
requests库,比php的更简单,
可以试试一种叫做requests()的python库。作者有写一篇博客讲这个的。效果很好,支持解析任何包含json字符串的网页上的数据。我们网站的日志就是这样解析,然后存入文件的。1.2正式发布。你可以去试试。 查看全部
php 抓取网页 源码(php抓取网页源码并存储为json文件并放到内存中)
php抓取网页源码并存储为json文件并放到内存中,然后使用requests库即可发起post请求,接着将json数据解析成blob/txt等文件并存储到本地php5中已经可以直接使用php代码解析html文件内容,php6/php7中的html51版本已经可以直接解析html文件内容并存储到本地。但是在php7中对于php代码的解析速度被延迟到了html51.2版本才实现。
可以先尝试阿里云的json数据库,
基于phpapachespringmvc的爬虫框架-深夜技术咖
建议直接用es。使用的是json数据库。php代码解析是通过设置json转义字符来实现的。
好多选择,例如pm2、1.4.1、phpwind等,具体根据项目用户需求选择即可。json转义库用户有巨量需求,
phppost解析库的话,我觉得1.5都是不错的选择,就po、jsonp,
json转义最好的解决方案,见:这篇文章说的很好,
requests库,比php的更简单,
可以试试一种叫做requests()的python库。作者有写一篇博客讲这个的。效果很好,支持解析任何包含json字符串的网页上的数据。我们网站的日志就是这样解析,然后存入文件的。1.2正式发布。你可以去试试。
php 抓取网页 源码(ASP.NET使用HttpWebRequest抓取网页内容希望所述帮助(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-18 15:11
本文中的示例描述了 ASP.NET 如何抓取 Web 内容。分享给大家,供大家参考。具体实现方法如下:
一、ASP.NET 使用 HttpWebRequest 抓取网页内容
/// 方法一:比较推荐
/// 用HttpWebRequest取得网页源码
/// 对于带BOM的网页很有效,不管是什么编码都能正确识别
///
/// 网页地址"
/// 返回网页源文件
public static string GetHtmlSource2(string url)
{
//处理内容
string html = "";
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
request.Accept = "*/*"; //接受任意文件
request.UserAgent = "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.2; .NET CLR 1.1.4322)"; //
request.AllowAutoRedirect = true;//是否允许302
//request.CookieContainer = new CookieContainer();//cookie容器,
request.Referer = url; //当前页面的引用
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
Stream stream = response.GetResponseStream();
StreamReader reader = new StreamReader(stream, Encoding.Default);
html = reader.ReadToEnd();
stream.Close();
return html;
}
二、ASP.NET 使用 WebResponse 抓取网页内容
public static string GetHttpData2(string Url)
{
string sException = null;
string sRslt = null;
WebResponse oWebRps = null;
WebRequest oWebRqst = WebRequest.Create(Url);
oWebRqst.Timeout = 50000;
try
{
oWebRps = oWebRqst.GetResponse();
}
catch (WebException e)
{
sException = e.Message.ToString();
}
catch (Exception e)
{
sException = e.ToString();
}
finally
{
if (oWebRps != null)
{
StreamReader oStreamRd = new StreamReader(oWebRps.GetResponseStream(), Encoding.GetEncoding("utf-8"));
sRslt = oStreamRd.ReadToEnd();
oStreamRd.Close();
oWebRps.Close();
}
}
return sRslt;
}
希望本文对您的 C# 编程有所帮助。 查看全部
php 抓取网页 源码(ASP.NET使用HttpWebRequest抓取网页内容希望所述帮助(图))
本文中的示例描述了 ASP.NET 如何抓取 Web 内容。分享给大家,供大家参考。具体实现方法如下:
一、ASP.NET 使用 HttpWebRequest 抓取网页内容
/// 方法一:比较推荐
/// 用HttpWebRequest取得网页源码
/// 对于带BOM的网页很有效,不管是什么编码都能正确识别
///
/// 网页地址"
/// 返回网页源文件
public static string GetHtmlSource2(string url)
{
//处理内容
string html = "";
HttpWebRequest request = (HttpWebRequest)WebRequest.Create(url);
request.Accept = "*/*"; //接受任意文件
request.UserAgent = "Mozilla/4.0 (compatible; MSIE 6.0; Windows NT 5.2; .NET CLR 1.1.4322)"; //
request.AllowAutoRedirect = true;//是否允许302
//request.CookieContainer = new CookieContainer();//cookie容器,
request.Referer = url; //当前页面的引用
HttpWebResponse response = (HttpWebResponse)request.GetResponse();
Stream stream = response.GetResponseStream();
StreamReader reader = new StreamReader(stream, Encoding.Default);
html = reader.ReadToEnd();
stream.Close();
return html;
}
二、ASP.NET 使用 WebResponse 抓取网页内容
public static string GetHttpData2(string Url)
{
string sException = null;
string sRslt = null;
WebResponse oWebRps = null;
WebRequest oWebRqst = WebRequest.Create(Url);
oWebRqst.Timeout = 50000;
try
{
oWebRps = oWebRqst.GetResponse();
}
catch (WebException e)
{
sException = e.Message.ToString();
}
catch (Exception e)
{
sException = e.ToString();
}
finally
{
if (oWebRps != null)
{
StreamReader oStreamRd = new StreamReader(oWebRps.GetResponseStream(), Encoding.GetEncoding("utf-8"));
sRslt = oStreamRd.ReadToEnd();
oStreamRd.Close();
oWebRps.Close();
}
}
return sRslt;
}
希望本文对您的 C# 编程有所帮助。
php 抓取网页 源码(之前做项目要从一个网页中抓取某些特定信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2021-12-10 03:34
在做一个项目之前,我想从一个网页中获取一些特定的信息。本来打算直接用java+HtmlPraser来做结果的。想抓的部分出不来。在研究了那个网页的源代码后,我得出了结论。该网页使用ajax技术隐藏了部分信息。这部分信息只有在用户浏览页面时才会显示。然后想看看有没有什么开源项目可以模拟浏览。结果没有找到。我别无选择,只能切换到 c# 平台。
c#中WebBrowser的控件起到了模拟浏览器的作用,使用起来非常简单。
创建一个新的表单应用程序。向窗体添加一个 WebBrowser 控件。设置控件的属性 url。你要解析的网页的网址必须填写
然后双击控件,您将转到
private void web_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
函数内部
查看函数分析知道这个函数是在控件加载网页后执行的
也就是说,你需要在这个函数里写来获取网页的信息
一开始我也是直接在这个函数里写了处理代码,但是我发现抓到的信息只是其中的一小部分。
后来百度发现,是因为这个控件其实在设计上有一些不足。很多时候动态加载的网页还没有完全打开。
web_DocumentCompleted()函数会开始执行,导致控件显示的页面源代码与实际页面的源代码不一致
有一些解决方案,虽然不是完整的解决方案,但是可以提高打开类似ajax网页的完成度。
方法是
private void web_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
{
if (web0.ReadyState == WebBrowserReadyState.Complete)
{
}
}
添加一个判断这个判断可以更好的保证控件在加载了大部分目标页面信息后执行下面的代码
原理不是很清楚,但实验证明,捕获的目标数据量确实增加了。
因此,如果想抓取更多的数据,可以使用定时器每次对网页进行分析,增加抓取的数据量。
简单的说就是控制定时器和WebBrowser的Navigate方法的结合。 查看全部
php 抓取网页 源码(之前做项目要从一个网页中抓取某些特定信息)
在做一个项目之前,我想从一个网页中获取一些特定的信息。本来打算直接用java+HtmlPraser来做结果的。想抓的部分出不来。在研究了那个网页的源代码后,我得出了结论。该网页使用ajax技术隐藏了部分信息。这部分信息只有在用户浏览页面时才会显示。然后想看看有没有什么开源项目可以模拟浏览。结果没有找到。我别无选择,只能切换到 c# 平台。
c#中WebBrowser的控件起到了模拟浏览器的作用,使用起来非常简单。
创建一个新的表单应用程序。向窗体添加一个 WebBrowser 控件。设置控件的属性 url。你要解析的网页的网址必须填写
然后双击控件,您将转到
private void web_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
函数内部
查看函数分析知道这个函数是在控件加载网页后执行的
也就是说,你需要在这个函数里写来获取网页的信息
一开始我也是直接在这个函数里写了处理代码,但是我发现抓到的信息只是其中的一小部分。
后来百度发现,是因为这个控件其实在设计上有一些不足。很多时候动态加载的网页还没有完全打开。
web_DocumentCompleted()函数会开始执行,导致控件显示的页面源代码与实际页面的源代码不一致
有一些解决方案,虽然不是完整的解决方案,但是可以提高打开类似ajax网页的完成度。
方法是
private void web_DocumentCompleted(object sender, WebBrowserDocumentCompletedEventArgs e)
{
if (web0.ReadyState == WebBrowserReadyState.Complete)
{
}
}
添加一个判断这个判断可以更好的保证控件在加载了大部分目标页面信息后执行下面的代码
原理不是很清楚,但实验证明,捕获的目标数据量确实增加了。
因此,如果想抓取更多的数据,可以使用定时器每次对网页进行分析,增加抓取的数据量。
简单的说就是控制定时器和WebBrowser的Navigate方法的结合。
php 抓取网页 源码(php抓取网页源码的十几种方法(一下))
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2021-12-08 13:07
php抓取网页源码的十几种方法已经写过各种抓取技巧的文章,大致思路都是老生常谈的方法,学习php抓取网页源码并不是个费力的事情,抓取下来的结果也能发现一些相似性。既然提到抓取方法已经说完了,那下面来说一说php抓取网页源码的十几种方法。
1、写一个shell脚本在浏览器中输入网址(我们是使用ssl证书来抓取网页源码),如果是上面的网址抓取了之后会报错提示未安装ssl证书。证书需要下载,网上有很多关于网站安装ssl证书的教程。
2、搭建抓取webpack的模板搭建webpack的模板支持起到一个很好的过滤的作用,避免大量重复代码。
3、使用集成开发环境比如本地搭建一个php集成开发环境,然后就可以直接php的代码都使用开发环境一键式开发。
<p>4、使用php的反射来爬取web网页源码(这里我没有用php抓取网页源码,一些其他的方法。)实例:正则表达式爬取网页源码代码:首先要写一个正则表达式:解析一下代码:基本结构如下: 查看全部
php 抓取网页 源码(php抓取网页源码的十几种方法(一下))
php抓取网页源码的十几种方法已经写过各种抓取技巧的文章,大致思路都是老生常谈的方法,学习php抓取网页源码并不是个费力的事情,抓取下来的结果也能发现一些相似性。既然提到抓取方法已经说完了,那下面来说一说php抓取网页源码的十几种方法。
1、写一个shell脚本在浏览器中输入网址(我们是使用ssl证书来抓取网页源码),如果是上面的网址抓取了之后会报错提示未安装ssl证书。证书需要下载,网上有很多关于网站安装ssl证书的教程。
2、搭建抓取webpack的模板搭建webpack的模板支持起到一个很好的过滤的作用,避免大量重复代码。
3、使用集成开发环境比如本地搭建一个php集成开发环境,然后就可以直接php的代码都使用开发环境一键式开发。
<p>4、使用php的反射来爬取web网页源码(这里我没有用php抓取网页源码,一些其他的方法。)实例:正则表达式爬取网页源码代码:首先要写一个正则表达式:解析一下代码:基本结构如下:
php 抓取网页 源码(:创建一个工具类:用于输出抓取的html源代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2021-11-21 22:06
第一步:
创建工具类:用于输出爬取的html源码
package Util;
import android.util.Log;
import android.webkit.JavascriptInterface;
/**获取PIN值
* Created by Administrator on 2016/8/12.
*/
public class JavascriptUtil {
@JavascriptInterface
public void getPin(String html){
System.out.println("html---->"+html);
Log.d("webActivity.this",html);
}
}
你必须写@JavascriptInterface,原因:
第 2 部分:设置 webview 的属性
webView=(WebView)findViewById(R.id.web_view_auto);
webView.getSettings().setJavaScriptEnabled(true);//支持javascript语言
webView.addJavascriptInterface(new JavascriptUtil(),"Methods");//设置javascript语言,用具获取网页中的pin,"Methods"为javascriptinterface的名称
第 3 部分:页面加载后,获取
//WebViewClient 主要处理关于页面跳转,页面请求等操作
webView.setWebViewClient(new WebViewClient(){
@Override
public boolean shouldOverrideUrlLoading(WebView view, String url) {
// load(url,webView);
return super.shouldOverrideUrlLoading(view, url);
}
//页面加载结束时,获取页面的html值pin
@Override
public void onPageFinished(WebView view, String url) {
super.onPageFinished(view, url);
Log.d("webActivity.this","+++++++++++++++++++++++++++++");
Log.d("webActivity.this",url);
view.loadUrl("javascript:window.Methods.getPin(''+document.getElementsByTagName('html')[0].innerHTML+'');");
//上面这一步就是抓取Html源码
}
});
第 4 部分:
在android studio中,有时无法使用log、d()和System,这个重启就可以解决问题了 查看全部
php 抓取网页 源码(:创建一个工具类:用于输出抓取的html源代码)
第一步:
创建工具类:用于输出爬取的html源码
package Util;
import android.util.Log;
import android.webkit.JavascriptInterface;
/**获取PIN值
* Created by Administrator on 2016/8/12.
*/
public class JavascriptUtil {
@JavascriptInterface
public void getPin(String html){
System.out.println("html---->"+html);
Log.d("webActivity.this",html);
}
}
你必须写@JavascriptInterface,原因:
第 2 部分:设置 webview 的属性
webView=(WebView)findViewById(R.id.web_view_auto);
webView.getSettings().setJavaScriptEnabled(true);//支持javascript语言
webView.addJavascriptInterface(new JavascriptUtil(),"Methods");//设置javascript语言,用具获取网页中的pin,"Methods"为javascriptinterface的名称
第 3 部分:页面加载后,获取
//WebViewClient 主要处理关于页面跳转,页面请求等操作
webView.setWebViewClient(new WebViewClient(){
@Override
public boolean shouldOverrideUrlLoading(WebView view, String url) {
// load(url,webView);
return super.shouldOverrideUrlLoading(view, url);
}
//页面加载结束时,获取页面的html值pin
@Override
public void onPageFinished(WebView view, String url) {
super.onPageFinished(view, url);
Log.d("webActivity.this","+++++++++++++++++++++++++++++");
Log.d("webActivity.this",url);
view.loadUrl("javascript:window.Methods.getPin(''+document.getElementsByTagName('html')[0].innerHTML+'');");
//上面这一步就是抓取Html源码
}
});
第 4 部分:
在android studio中,有时无法使用log、d()和System,这个重启就可以解决问题了
php 抓取网页 源码(php抓取网页源码,获取图片地址,已经解决safelygraphextractor。)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-11-17 19:06
php抓取网页源码,获取图片地址,
已经解决safelygraphextractor。com:indexallbootstraptags(html,css,js)repository。others:indexalltags(html,css,js)repository。com:indexallbootstraptags(html,css,js)repository。
com:indexalltags(html,css,js)repository。forwards:indexalltags(html,css,js)repository。images:imagesrepository。images:imagesindex。http/1。1transferstreamimageposttransfercurl-bgzip400-iupstream:reply。
www。facebook。com/sync/curl-bgzip400-iupstream:upstream。aiq/sync/img。gzbittorrentstream。
safari-bootstrap-tags-all-themes,url:path/all/
试试这个
safari我推荐pythonimg-simple-generator-safari/img-simple-generator支持使用自定义的js文件
safari已解决(win7):fileextended.js 查看全部
php 抓取网页 源码(php抓取网页源码,获取图片地址,已经解决safelygraphextractor。)
php抓取网页源码,获取图片地址,
已经解决safelygraphextractor。com:indexallbootstraptags(html,css,js)repository。others:indexalltags(html,css,js)repository。com:indexallbootstraptags(html,css,js)repository。
com:indexalltags(html,css,js)repository。forwards:indexalltags(html,css,js)repository。images:imagesrepository。images:imagesindex。http/1。1transferstreamimageposttransfercurl-bgzip400-iupstream:reply。
www。facebook。com/sync/curl-bgzip400-iupstream:upstream。aiq/sync/img。gzbittorrentstream。
safari-bootstrap-tags-all-themes,url:path/all/
试试这个
safari我推荐pythonimg-simple-generator-safari/img-simple-generator支持使用自定义的js文件
safari已解决(win7):fileextended.js
php 抓取网页 源码(php抓取网页源码转化为数据库请求对象加上指定参数)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2021-11-14 12:02
php抓取网页源码转化为数据库请求对象加上指定参数,比如quotes,myqq等形成你要的数据。至于qq号、一些角色名,注册邮箱可以采用简单的字符串替换或暴力dups解决。
qq号要登陆你的电脑,简单直接暴力登陆;一般还可以利用php的websocket来实现登陆。或者直接extract_text()把要抓取的东西提取出来存成字典,然后遍历把字典倒过来当也是可以的,qq也是字典。
在浏览器里输入网址进行爬虫抓取,会遇到“已登陆”字样的验证;因此,我们需要一种验证登陆成功的方法,并将这些信息简单地存储下来。下面我就来给大家介绍一种验证登陆成功的方法——document.execute('ws_request.post('',"",formdata)')。相比于直接传输document对象来说,这种方法在提交信息后需要进行javascript的处理。
javascript验证需要在myisam中操作,javascript加载需要在会话窗口中完成;不过现在网上已经有很多代码可以利用浏览器特有的javascript特性验证,我就不给大家演示了。另外还有一点需要说明的是,根据验证的内容不同,可以将document对象转换为document对象或者document.cookie;在抓取此类网页时,需要以第二种方式操作。以上。
参考以下链接第二种方法, 查看全部
php 抓取网页 源码(php抓取网页源码转化为数据库请求对象加上指定参数)
php抓取网页源码转化为数据库请求对象加上指定参数,比如quotes,myqq等形成你要的数据。至于qq号、一些角色名,注册邮箱可以采用简单的字符串替换或暴力dups解决。
qq号要登陆你的电脑,简单直接暴力登陆;一般还可以利用php的websocket来实现登陆。或者直接extract_text()把要抓取的东西提取出来存成字典,然后遍历把字典倒过来当也是可以的,qq也是字典。
在浏览器里输入网址进行爬虫抓取,会遇到“已登陆”字样的验证;因此,我们需要一种验证登陆成功的方法,并将这些信息简单地存储下来。下面我就来给大家介绍一种验证登陆成功的方法——document.execute('ws_request.post('',"",formdata)')。相比于直接传输document对象来说,这种方法在提交信息后需要进行javascript的处理。
javascript验证需要在myisam中操作,javascript加载需要在会话窗口中完成;不过现在网上已经有很多代码可以利用浏览器特有的javascript特性验证,我就不给大家演示了。另外还有一点需要说明的是,根据验证的内容不同,可以将document对象转换为document对象或者document.cookie;在抓取此类网页时,需要以第二种方式操作。以上。
参考以下链接第二种方法,
php 抓取网页 源码(/autoreloadcat#自动抓取出localserver上的requesturlphp抓取网页源码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-11-11 05:01
php抓取网页源码,可以这样使用,
感谢你fork了我的项目,github地址在这里,
就是调用这个叫做/qtititilisttypesadmin的扩展
我自己写了一个比较方便的自动抓取localserver/pages/dom的js库,
项目地址:dz_login/autoreloadcat
/antguopenpupian#自动抓取出localserver上的requesturlphp抓取github\java抓取springboot\netbean\proxy,
能不能不用php抓取http接口?楼主你能接受使用lsb这种可直接读取数据库的方式来抓取吗?
最好不要使用php来读取localserver(本地)的数据,如果你只是要抓取数据,
localserver指的是本地的服务器吗?我这边上传一份数据的方法有:-login.jsp不过我觉得这不是最适合你的,我这边上传图片用的是ipa文件或者一个叫做"图片抓取"的插件,如果大家有什么好的资源,
phporjava随便抓, 查看全部
php 抓取网页 源码(/autoreloadcat#自动抓取出localserver上的requesturlphp抓取网页源码)
php抓取网页源码,可以这样使用,
感谢你fork了我的项目,github地址在这里,
就是调用这个叫做/qtititilisttypesadmin的扩展
我自己写了一个比较方便的自动抓取localserver/pages/dom的js库,
项目地址:dz_login/autoreloadcat
/antguopenpupian#自动抓取出localserver上的requesturlphp抓取github\java抓取springboot\netbean\proxy,
能不能不用php抓取http接口?楼主你能接受使用lsb这种可直接读取数据库的方式来抓取吗?
最好不要使用php来读取localserver(本地)的数据,如果你只是要抓取数据,
localserver指的是本地的服务器吗?我这边上传一份数据的方法有:-login.jsp不过我觉得这不是最适合你的,我这边上传图片用的是ipa文件或者一个叫做"图片抓取"的插件,如果大家有什么好的资源,
phporjava随便抓,
php 抓取网页 源码(问题我有这个通过PHP从网站上抓取的脚本。 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-11-04 01:18
)
问题
我通过 PHP 从 网站 获取了这个脚本。我想要的只是用逗号分隔符显示结果,并且有很多页面带有分页。只是为了向他们展示。
我的代码是
$ch = curl_init('http://www.qatarliving.com/v3/classifieds/search/category/mobile-devices');
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
/*
* XXX: This is not a "fix" for your problem, this is a work-around. You
* should fix your local CAs
*/
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);
/* Set a browser UA so that we aren't told to update */
curl_setopt($ch, CURLOPT_USERAGENT, 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.116 Safari/537.36');
$res = curl_exec($ch);
if ($res === false) {
die('error: ' . curl_error($ch));
}
curl_close($ch);
$d = new DOMDocument();
@$d->loadHTML($res);
$output = array(
'class' => '',
);
$x = new DOMXPath($d);
$myspan = $x->query('//span[@class="b-card b-card-mod-h item "]');
if($myspan->length > 0){
foreach($myspan as $row){
echo $row->nodeValue . "
";
}
}
结果发现
2,000 QAR Mobile phones, Al Gharrafa iPhone 6 128 like new By professional76
75 QAR Mobile phones, Other Virtual Reality Cardboard [NEW] By 1StopGulf
...
解决方案
尝试以下解决方案 $data_array 将收录所需的输出数组
<p> 查看全部
php 抓取网页 源码(问题我有这个通过PHP从网站上抓取的脚本。
)
问题
我通过 PHP 从 网站 获取了这个脚本。我想要的只是用逗号分隔符显示结果,并且有很多页面带有分页。只是为了向他们展示。
我的代码是
$ch = curl_init('http://www.qatarliving.com/v3/classifieds/search/category/mobile-devices');
curl_setopt($ch, CURLOPT_RETURNTRANSFER, true);
/*
* XXX: This is not a "fix" for your problem, this is a work-around. You
* should fix your local CAs
*/
curl_setopt($ch, CURLOPT_SSL_VERIFYPEER, false);
/* Set a browser UA so that we aren't told to update */
curl_setopt($ch, CURLOPT_USERAGENT, 'Mozilla/5.0 (Windows NT 6.1; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/34.0.1847.116 Safari/537.36');
$res = curl_exec($ch);
if ($res === false) {
die('error: ' . curl_error($ch));
}
curl_close($ch);
$d = new DOMDocument();
@$d->loadHTML($res);
$output = array(
'class' => '',
);
$x = new DOMXPath($d);
$myspan = $x->query('//span[@class="b-card b-card-mod-h item "]');
if($myspan->length > 0){
foreach($myspan as $row){
echo $row->nodeValue . "
";
}
}
结果发现
2,000 QAR Mobile phones, Al Gharrafa iPhone 6 128 like new By professional76
75 QAR Mobile phones, Other Virtual Reality Cardboard [NEW] By 1StopGulf
...
解决方案
尝试以下解决方案 $data_array 将收录所需的输出数组
<p>
php 抓取网页 源码(php抓取网页源码所需要的工具是webspherecache,如何转换)
网站优化 • 优采云 发表了文章 • 0 个评论 • 67 次浏览 • 2021-10-26 20:00
php抓取网页源码所需要的工具是webspherecache,需要通过管理一定大小的cache来抓取网页。简单的cache_size是每次运行服务器的cache大小,cache_hit是当这个值发生后,本次被访问的网页的连接大小,以i来作标记,cache_limit是最大的cache的大小,以ev来作标记。
抓取网页的过程通常有两部分,一是获取forminput(位于解析html时获取),二是获取body部分(位于解析网页时获取)。如果上述环节中如果缺少一些环节,网页抓取时也可能抓取不全,甚至抓取错误。本文是基于前几天研究php应用程序抓取新浪微博数据的抓取程序源码及config.php的内容和实践之后完成的。
php抓取网页原理的基本思路是获取请求所需要的json数据和格式(json格式支持xml格式和csv格式)通过json来解析网页内容来获取网页内容(bytecode)然后来获取body其中json数据存储在浏览器中,即json/xml。关于格式原理,参考mozilla/json-fastsq,网站中各种格式方便抓取和使用,但是格式不容易获取,因此我们来设计一个数据格式转换插件解决格式问题。
基于fastjson和json文件方便抓取和使用,我们首先要解决格式问题。格式转换网页格式设计以json/xml为基础,这样做一个转换插件也就相对容易了。与php格式转换不同,json转xml往往需要人工手动编译成bytecode,如何转换也就成了问题。网页转换器教程很多,我不愿意阐述原理过于繁琐。但我能想到的一种方法是使用外部库的return参数,通过这个参数将json/xml转换成bytecode。
比如百度自带的mjsonapi,该api已经内置在cookie里面。百度应用已经改名为mjson,这个api在php环境下也可以直接使用。mjsonapi的apidemo#php_script_api。 查看全部
php 抓取网页 源码(php抓取网页源码所需要的工具是webspherecache,如何转换)
php抓取网页源码所需要的工具是webspherecache,需要通过管理一定大小的cache来抓取网页。简单的cache_size是每次运行服务器的cache大小,cache_hit是当这个值发生后,本次被访问的网页的连接大小,以i来作标记,cache_limit是最大的cache的大小,以ev来作标记。
抓取网页的过程通常有两部分,一是获取forminput(位于解析html时获取),二是获取body部分(位于解析网页时获取)。如果上述环节中如果缺少一些环节,网页抓取时也可能抓取不全,甚至抓取错误。本文是基于前几天研究php应用程序抓取新浪微博数据的抓取程序源码及config.php的内容和实践之后完成的。
php抓取网页原理的基本思路是获取请求所需要的json数据和格式(json格式支持xml格式和csv格式)通过json来解析网页内容来获取网页内容(bytecode)然后来获取body其中json数据存储在浏览器中,即json/xml。关于格式原理,参考mozilla/json-fastsq,网站中各种格式方便抓取和使用,但是格式不容易获取,因此我们来设计一个数据格式转换插件解决格式问题。
基于fastjson和json文件方便抓取和使用,我们首先要解决格式问题。格式转换网页格式设计以json/xml为基础,这样做一个转换插件也就相对容易了。与php格式转换不同,json转xml往往需要人工手动编译成bytecode,如何转换也就成了问题。网页转换器教程很多,我不愿意阐述原理过于繁琐。但我能想到的一种方法是使用外部库的return参数,通过这个参数将json/xml转换成bytecode。
比如百度自带的mjsonapi,该api已经内置在cookie里面。百度应用已经改名为mjson,这个api在php环境下也可以直接使用。mjsonapi的apidemo#php_script_api。
php 抓取网页 源码(利用redis实现点击事件监听及相关代码.php抓取网页源码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 73 次浏览 • 2021-10-23 12:08
php抓取网页源码,可以用开源的php解析php缓存系统:利用redis实现php缓存系统参考这个,
直接post请求即可;src=php550&url=
javascript+requests实现点击事件监听:简单的http点击事件监听及相关代码欢迎关注本人博客专栏:javascript+requests实现点击事件监听及相关代码
.php请求网页
很多人已经提到用urllib,同时也对中间还提到了post注册请求什么的。我们不妨采用中间人攻击方式,这样你就能获取服务器的一切信息了,而不会泄露数据。只要你已经准备好相应的环境了。这个当然不是你想想那么简单的。简单我讲一下,假设我们现在打算挖掘一些网页。用户如何这个请求这个服务器呢?当然如果客户不能通过你的服务器连上网络,那么那肯定是不行的。
而是是要用的请求工具(post请求),通过post方式去请求这个服务器。而这个就需要一个监听工具(urllib),还有一些中间人攻击工具(burpsuite)。这个主要是为了监听请求的时候,能看到请求的参数等信息,而这个工具实际上应该是一个浏览器,而不是。另外监听是一个比较简单的操作,加个对号就行了。
虽然说得这么复杂,但是其实都可以用一个简单的接口去完成。当然还需要一点点验证:看接口打开页面后有没有applet标签,还有浏览器标签。如果没有,看applet标签内的方法名是不是前面有msg,有msg就直接拿过来。如果有或者那个地方没有msg,就直接在cookie里填一个msg。然后就是这个对象的地址是不是网站,什么类型的网站。
比如是文件服务器,是连接服务器服务器就是`/`,不连接就是`/api`或者是`/buy.html`等等。我用简单的http请求参数去匹配。比如如果是json,那么看看参数里面json里面的数据内容,看看有没有请求服务器,有就下一步。如果没有需要。burpwebsocket功能。这些都是自己动手搞,没人可以代劳。我学计算机的。 查看全部
php 抓取网页 源码(利用redis实现点击事件监听及相关代码.php抓取网页源码)
php抓取网页源码,可以用开源的php解析php缓存系统:利用redis实现php缓存系统参考这个,
直接post请求即可;src=php550&url=
javascript+requests实现点击事件监听:简单的http点击事件监听及相关代码欢迎关注本人博客专栏:javascript+requests实现点击事件监听及相关代码
.php请求网页
很多人已经提到用urllib,同时也对中间还提到了post注册请求什么的。我们不妨采用中间人攻击方式,这样你就能获取服务器的一切信息了,而不会泄露数据。只要你已经准备好相应的环境了。这个当然不是你想想那么简单的。简单我讲一下,假设我们现在打算挖掘一些网页。用户如何这个请求这个服务器呢?当然如果客户不能通过你的服务器连上网络,那么那肯定是不行的。
而是是要用的请求工具(post请求),通过post方式去请求这个服务器。而这个就需要一个监听工具(urllib),还有一些中间人攻击工具(burpsuite)。这个主要是为了监听请求的时候,能看到请求的参数等信息,而这个工具实际上应该是一个浏览器,而不是。另外监听是一个比较简单的操作,加个对号就行了。
虽然说得这么复杂,但是其实都可以用一个简单的接口去完成。当然还需要一点点验证:看接口打开页面后有没有applet标签,还有浏览器标签。如果没有,看applet标签内的方法名是不是前面有msg,有msg就直接拿过来。如果有或者那个地方没有msg,就直接在cookie里填一个msg。然后就是这个对象的地址是不是网站,什么类型的网站。
比如是文件服务器,是连接服务器服务器就是`/`,不连接就是`/api`或者是`/buy.html`等等。我用简单的http请求参数去匹配。比如如果是json,那么看看参数里面json里面的数据内容,看看有没有请求服务器,有就下一步。如果没有需要。burpwebsocket功能。这些都是自己动手搞,没人可以代劳。我学计算机的。
php 抓取网页 源码(php抓取网页源码获取到数据,存储数据库抓取程序)
网站优化 • 优采云 发表了文章 • 0 个评论 • 119 次浏览 • 2021-10-17 04:01
php抓取网页源码获取到数据,存储数据库,利用php的爬虫程序采集自己的公众号信息,以及b站的图片信息等,爬虫程序很容易实现的,很方便,而且网上的教程也是多如牛毛,学起来非常简单,今天和大家分享一个用php写的网站抓取程序。
1、抓取公众号每日文章
2、抓取b站视频源码
3、采集关注人数
4、爬取微博图片
5、爬取今日头条百家头条
6、抓取百度网盘搜索栏目
7、抓取qq号码注册文章
我觉得可能没必要对外公开这种。把程序分成两半,一半可以把网站程序刷下存起来,另一半可以放一个网站任务重点在最后一个功能就是爬网站(b站一般我们用java写网站。其他的程序一般用python写),这样运行效率高,后期不用维护。
可以分享网页截图
有个免费学习的网站,,里面有详细的php代码。
我来个好玩的吧,把网站采集到http接口。
php做网站代理,
爬虫程序可以用网页爬虫库如网页爬虫_网页爬虫技术
不适合,因为没必要。php属于入门门槛高,深入难。爬取关注一般有以下几个方面:一.浏览器输入你网站的url,你自己的php会获取对应的信息,然后返回给php,php重新读取。二.浏览器输入你网站的url,你的爬虫程序做更加详细的解析。比如:1.请求的header详情2.请求的header加密3.请求的useragent4.请求头识别。 查看全部
php 抓取网页 源码(php抓取网页源码获取到数据,存储数据库抓取程序)
php抓取网页源码获取到数据,存储数据库,利用php的爬虫程序采集自己的公众号信息,以及b站的图片信息等,爬虫程序很容易实现的,很方便,而且网上的教程也是多如牛毛,学起来非常简单,今天和大家分享一个用php写的网站抓取程序。
1、抓取公众号每日文章
2、抓取b站视频源码
3、采集关注人数
4、爬取微博图片
5、爬取今日头条百家头条
6、抓取百度网盘搜索栏目
7、抓取qq号码注册文章
我觉得可能没必要对外公开这种。把程序分成两半,一半可以把网站程序刷下存起来,另一半可以放一个网站任务重点在最后一个功能就是爬网站(b站一般我们用java写网站。其他的程序一般用python写),这样运行效率高,后期不用维护。
可以分享网页截图
有个免费学习的网站,,里面有详细的php代码。
我来个好玩的吧,把网站采集到http接口。
php做网站代理,
爬虫程序可以用网页爬虫库如网页爬虫_网页爬虫技术
不适合,因为没必要。php属于入门门槛高,深入难。爬取关注一般有以下几个方面:一.浏览器输入你网站的url,你自己的php会获取对应的信息,然后返回给php,php重新读取。二.浏览器输入你网站的url,你的爬虫程序做更加详细的解析。比如:1.请求的header详情2.请求的header加密3.请求的useragent4.请求头识别。

