
php网页抓取工具
php网页抓取工具(58手机号码识别插件和百度翻译插件的用法(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-10-14 20:13
使用优采云采集器时,也会用到插件。优采云采集器将采集的数据传递给外部程序,我们称之为插件,然后插件处理数据,再将数据返回给采集器@ >.
优采云采集器V9支持PHP和C#编写插件,V9支持插件源码编辑。网页数据爬取工具优采云采集器的插件可应用于采集结果、HTTP请求、文件下载的处理。您可以在插件设置时从插件管理器的下拉框中选择一个现有的插件来实现特定的应用。
用58手机号码识别插件和百度翻译插件来说明一下用法。
58个插件演示:
(1)首先需要把插件58验证码V9.dll放入采集器的Plugins目录下
(2)然后在“其他设置-插件-采集结果处理插件”中选择这个插件。
(3)最后需要创建一个名为“手机号”的标签,从采集到58手机号的图片地址,这样在运行时采集器会自动调用插件 图片转义后输出为数字文本。
翻译插件演示:
(1)首先我们要把插件百度翻译.dll放到采集器的Plugins目录下
(2)然后在“其他设置-插件-采集结果处理插件”中选择这个插件。
(3)最后,我们需要创建一个名为“translation tag”的标签,将需要翻译的字段名称写成固定字符串的形式。
然后创建一个名为“Translation Reverse”的标签,将翻译语言写成固定字符串的形式,比如将中文翻译成英文,代码:zh>en(zh表示中文,en表示英文,这种语言代码是在使用前检查)。此操作后,运行时优采云采集器V9会自动调用插件进行翻译。
借助插件,我们可以使用优采云采集器来完成更复杂的任务。在采集器中,除了使用已有的插件,我们还可以编写需要的插件来使用,非技术人员可以联系官方定制插件。 查看全部
php网页抓取工具(58手机号码识别插件和百度翻译插件的用法(组图))
使用优采云采集器时,也会用到插件。优采云采集器将采集的数据传递给外部程序,我们称之为插件,然后插件处理数据,再将数据返回给采集器@ >.
优采云采集器V9支持PHP和C#编写插件,V9支持插件源码编辑。网页数据爬取工具优采云采集器的插件可应用于采集结果、HTTP请求、文件下载的处理。您可以在插件设置时从插件管理器的下拉框中选择一个现有的插件来实现特定的应用。
用58手机号码识别插件和百度翻译插件来说明一下用法。
58个插件演示:
(1)首先需要把插件58验证码V9.dll放入采集器的Plugins目录下
(2)然后在“其他设置-插件-采集结果处理插件”中选择这个插件。
(3)最后需要创建一个名为“手机号”的标签,从采集到58手机号的图片地址,这样在运行时采集器会自动调用插件 图片转义后输出为数字文本。
翻译插件演示:
(1)首先我们要把插件百度翻译.dll放到采集器的Plugins目录下
(2)然后在“其他设置-插件-采集结果处理插件”中选择这个插件。
(3)最后,我们需要创建一个名为“translation tag”的标签,将需要翻译的字段名称写成固定字符串的形式。

然后创建一个名为“Translation Reverse”的标签,将翻译语言写成固定字符串的形式,比如将中文翻译成英文,代码:zh>en(zh表示中文,en表示英文,这种语言代码是在使用前检查)。此操作后,运行时优采云采集器V9会自动调用插件进行翻译。

借助插件,我们可以使用优采云采集器来完成更复杂的任务。在采集器中,除了使用已有的插件,我们还可以编写需要的插件来使用,非技术人员可以联系官方定制插件。
php网页抓取工具( WebSpider蓝蜘蛛网页抓取工具5.1可以抓取任何网页(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-10-13 07:03
WebSpider蓝蜘蛛网页抓取工具5.1可以抓取任何网页(组图))
WebSpider 蓝蜘蛛爬网工具5.1 可以抓取互联网上的任何网页,wap网站,包括登录后才能访问的页面。分析抓取的页面内容,获取结构化信息,如如新闻标题、作者、来源、正文等。支持列表页自动翻页抓取、文本页多页合并、图片文件抓取。它可以抓取静态网页或带参数的动态网页。功能极其强大。
用户指定要爬取的网站、要爬取的网页类型(固定页面、分页展示页面等),并配置如何解析数据项(如新闻标题、作者、来源、 body等),系统可以根据配置信息实时自动采集数据,也可以通过配置设置开始采集的时间,真正做到“按需采集,一个配置,和永久捕获”。捕获的数据可以保存在数据库中。支持当前主流数据库,包括:Oracle、SQL Server、MySQL等。
该工具可以完全取代传统的编辑人工信息处理模式。能够实时、准确、24*60全天候为企业提供最新信息和情报,真正为企业降低成本,提高竞争力。
该工具的主要特点如下:
*适用范围广,可以抓取任何网页(包括登录后可以访问的网页)
* 处理速度快,如果网络畅通,1小时可抓取解析10000个网页
*采用独特的重复数据过滤技术,支持增量数据采集,可实时采集数据,如:股票交易信息、天气预报等。
*抓取信息准确率高,系统提供强大的数据校验功能,保证数据的正确性
*支持断点连续抓取。发生崩溃或异常情况后,可以恢复抓取,继续后续抓取工作,提高系统抓取效率
*对于列表页,支持翻页,可以读取所有列表页中的数据。对于文本页面,可以自动合并页面上显示的内容;
*支持页面深度爬取,可在页面之间逐层爬取。比如通过列表页面抓取body页面的URL,然后再抓取body页面。各级页面可单独存放;
*WEB操作界面,一站式安装,随处使用
*分步分析,分步存储
* 配置一次,永久抓取,一劳永逸 查看全部
php网页抓取工具(
WebSpider蓝蜘蛛网页抓取工具5.1可以抓取任何网页(组图))

WebSpider 蓝蜘蛛爬网工具5.1 可以抓取互联网上的任何网页,wap网站,包括登录后才能访问的页面。分析抓取的页面内容,获取结构化信息,如如新闻标题、作者、来源、正文等。支持列表页自动翻页抓取、文本页多页合并、图片文件抓取。它可以抓取静态网页或带参数的动态网页。功能极其强大。
用户指定要爬取的网站、要爬取的网页类型(固定页面、分页展示页面等),并配置如何解析数据项(如新闻标题、作者、来源、 body等),系统可以根据配置信息实时自动采集数据,也可以通过配置设置开始采集的时间,真正做到“按需采集,一个配置,和永久捕获”。捕获的数据可以保存在数据库中。支持当前主流数据库,包括:Oracle、SQL Server、MySQL等。
该工具可以完全取代传统的编辑人工信息处理模式。能够实时、准确、24*60全天候为企业提供最新信息和情报,真正为企业降低成本,提高竞争力。
该工具的主要特点如下:
*适用范围广,可以抓取任何网页(包括登录后可以访问的网页)
* 处理速度快,如果网络畅通,1小时可抓取解析10000个网页
*采用独特的重复数据过滤技术,支持增量数据采集,可实时采集数据,如:股票交易信息、天气预报等。
*抓取信息准确率高,系统提供强大的数据校验功能,保证数据的正确性
*支持断点连续抓取。发生崩溃或异常情况后,可以恢复抓取,继续后续抓取工作,提高系统抓取效率
*对于列表页,支持翻页,可以读取所有列表页中的数据。对于文本页面,可以自动合并页面上显示的内容;
*支持页面深度爬取,可在页面之间逐层爬取。比如通过列表页面抓取body页面的URL,然后再抓取body页面。各级页面可单独存放;
*WEB操作界面,一站式安装,随处使用
*分步分析,分步存储
* 配置一次,永久抓取,一劳永逸
php网页抓取工具(PHP解析器和PHP相比较,python适合做爬虫吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-10-12 09:20
对比python和PHP,python适合爬取。原因如下
抓取网页本身的界面
与java、c#、C++、python等其他静态编程语言相比,抓取网页文档的界面更加简洁;相对于其他动态脚本语言,如 perl、shell、python,urllib2 包提供了更完整的 Web 文档 API 访问。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站都是为了生硬爬取而被屏蔽的。这就是我们需要模拟用户代理的行为来构造合适的请求的地方,比如模拟用户登录,模拟session/cookies的存储和设置。python中有很好的第三方包帮你搞定,比如Requests,mechanize
爬行后处理
抓取到的网页通常需要进行处理,如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用很短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要python。
py对linux来说功能很强大,语言也很简单。
NO.1 快速开发(唯一能比python开发效率更高的语言是rudy) 语言简洁,没有那么多技巧,所以非常清晰易读。
NO.2 跨平台(由于python的开源,比java更能体现“一次编写,到处运行”
NO.3 解释(无需直接编译、运行/调试代码)
NO.4 框架选择太多(主要的GUI框架有wxPython、tkInter、PyGtk、PyQt。
PHP脚本主要用于以下三个方面:
服务器端脚本。这是PHP最传统也是最主要的目标领域。要进行这项工作,需要具备以下三点:PHP解析器(CGI或服务器模块)、Web
服务器和网络浏览器。运行web服务器时需要安装配置PHP,然后可以使用web浏览器访问PHP程序的输出,即浏览服务
PHP 页面在最后。如果您只是在尝试 PHP 编程,所有这些都可以在您的家用计算机上运行。有关更多信息,请参阅安装章节。命令行脚本。
您可以编写一个 PHP 脚本,并且不需要任何服务器或浏览器来运行它。这样,只需要PHP解析器就可以执行。这种用法是
是 cron(Unix 或 Linux 环境)或 Task Scheduler(Windows 环境)日常运行脚本的理想选择。这些脚本也可用于处理
管理简单的文本。更多信息请参考 PHP 的命令行模式。编写桌面应用程序。对于具有图形界面的桌面应用程序,PHP 可能不会
最好的语言之一,但是如果用户非常精通PHP并且想在客户端应用程序中使用PHP的一些高级功能,他们可以使用PHP-GTK来编写这个
这些程序。这样,您也可以编写跨平台的应用程序。PHP-GTK 是 PHP 的扩展,通常发布的 PHP 包中不收录它。
网友的观点扩大了:
我用PHP Node.js Python写了一个爬虫脚本,简单说一下。
首先PHP。先说优点:网上大量爬取解析html框架,各种工具都可以直接使用,比较省心。缺点:首先,速度/效率是个问题。有一次下载电影海报的时候,因为crontab定时执行,没有优化,打开的php进程太多,直接导致内存爆了。然后语法也很拖沓,各种关键词符号太多,不够简洁,给人一种没有精心设计的感觉,写起来很麻烦。
节点.js。优点是效率,效率还是效率。因为网络是异步的,所以基本上和并发数百个进程一样强大。内存和CPU使用量非常小。如果对捕获的数据没有进行复杂的计算和处理,那么系统就会成为瓶颈。基本上就是写入MySQL等数据库的带宽和I/O速度。当然,优点的反面也是缺点。异步网络意味着您需要回调。这时候,如果业务需求是线性的,比如你必须等上一页爬完,拿到数据后才能爬到下一页,甚至更多。层依赖,会有可怕的多层回调!基本上这个时候代码结构和逻辑就会乱了。当然,
最后,让我们谈谈Python。如果你对效率没有极端的要求,那么推荐Python!首先,Python 的语法非常简洁,同一个句子可以少打很多次。然后,Python非常适合数据处理,比如函数参数的打包和解包,列表分析,矩阵处理,非常方便。
至此,这篇关于python和php更适合爬取文章的文章介绍到这里。更多适合爬取内容的php和python相关内容,请搜索服务器之家之前的文章或继续浏览下面的相关文章,希望大家多多支持服务器之家未来!
原文链接: 查看全部
php网页抓取工具(PHP解析器和PHP相比较,python适合做爬虫吗?)
对比python和PHP,python适合爬取。原因如下
抓取网页本身的界面
与java、c#、C++、python等其他静态编程语言相比,抓取网页文档的界面更加简洁;相对于其他动态脚本语言,如 perl、shell、python,urllib2 包提供了更完整的 Web 文档 API 访问。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站都是为了生硬爬取而被屏蔽的。这就是我们需要模拟用户代理的行为来构造合适的请求的地方,比如模拟用户登录,模拟session/cookies的存储和设置。python中有很好的第三方包帮你搞定,比如Requests,mechanize
爬行后处理
抓取到的网页通常需要进行处理,如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用很短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要python。
py对linux来说功能很强大,语言也很简单。
NO.1 快速开发(唯一能比python开发效率更高的语言是rudy) 语言简洁,没有那么多技巧,所以非常清晰易读。
NO.2 跨平台(由于python的开源,比java更能体现“一次编写,到处运行”
NO.3 解释(无需直接编译、运行/调试代码)
NO.4 框架选择太多(主要的GUI框架有wxPython、tkInter、PyGtk、PyQt。
PHP脚本主要用于以下三个方面:
服务器端脚本。这是PHP最传统也是最主要的目标领域。要进行这项工作,需要具备以下三点:PHP解析器(CGI或服务器模块)、Web
服务器和网络浏览器。运行web服务器时需要安装配置PHP,然后可以使用web浏览器访问PHP程序的输出,即浏览服务
PHP 页面在最后。如果您只是在尝试 PHP 编程,所有这些都可以在您的家用计算机上运行。有关更多信息,请参阅安装章节。命令行脚本。
您可以编写一个 PHP 脚本,并且不需要任何服务器或浏览器来运行它。这样,只需要PHP解析器就可以执行。这种用法是
是 cron(Unix 或 Linux 环境)或 Task Scheduler(Windows 环境)日常运行脚本的理想选择。这些脚本也可用于处理
管理简单的文本。更多信息请参考 PHP 的命令行模式。编写桌面应用程序。对于具有图形界面的桌面应用程序,PHP 可能不会
最好的语言之一,但是如果用户非常精通PHP并且想在客户端应用程序中使用PHP的一些高级功能,他们可以使用PHP-GTK来编写这个
这些程序。这样,您也可以编写跨平台的应用程序。PHP-GTK 是 PHP 的扩展,通常发布的 PHP 包中不收录它。
网友的观点扩大了:
我用PHP Node.js Python写了一个爬虫脚本,简单说一下。
首先PHP。先说优点:网上大量爬取解析html框架,各种工具都可以直接使用,比较省心。缺点:首先,速度/效率是个问题。有一次下载电影海报的时候,因为crontab定时执行,没有优化,打开的php进程太多,直接导致内存爆了。然后语法也很拖沓,各种关键词符号太多,不够简洁,给人一种没有精心设计的感觉,写起来很麻烦。
节点.js。优点是效率,效率还是效率。因为网络是异步的,所以基本上和并发数百个进程一样强大。内存和CPU使用量非常小。如果对捕获的数据没有进行复杂的计算和处理,那么系统就会成为瓶颈。基本上就是写入MySQL等数据库的带宽和I/O速度。当然,优点的反面也是缺点。异步网络意味着您需要回调。这时候,如果业务需求是线性的,比如你必须等上一页爬完,拿到数据后才能爬到下一页,甚至更多。层依赖,会有可怕的多层回调!基本上这个时候代码结构和逻辑就会乱了。当然,
最后,让我们谈谈Python。如果你对效率没有极端的要求,那么推荐Python!首先,Python 的语法非常简洁,同一个句子可以少打很多次。然后,Python非常适合数据处理,比如函数参数的打包和解包,列表分析,矩阵处理,非常方便。
至此,这篇关于python和php更适合爬取文章的文章介绍到这里。更多适合爬取内容的php和python相关内容,请搜索服务器之家之前的文章或继续浏览下面的相关文章,希望大家多多支持服务器之家未来!
原文链接:
php网页抓取工具( 抓ajax异步内容的页面和抓普通的异步区别不大 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-10-12 09:19
抓ajax异步内容的页面和抓普通的异步区别不大
)
PHP curl 抓取AJAX异步内容示例
更新时间:2014-09-09 17:51:21 投稿:whsnow
用ajax异步内容抓取页面和抓取普通页面没有太大区别。 Ajax只是一个异步http请求,下面的例子,可以参考下
其实抓取ajax异步内容页面和抓取普通页面没有太大区别。 Ajax 只是一个异步 http 请求。用类似firebug的工具,找到请求的后端服务url和传参值,然后抓取url传参即可。
使用 Firebug 的网络工具
如果抓取一个页面,内容中没有显示的数据就是一堆JS代码。
代码
$cookie_file=tempnam('./temp','cookie');
$ch = curl_init();
$url1 = "http://www.cdut.edu.cn/default.html";
curl_setopt($ch,CURLOPT_URL,$url1);
curl_setopt($ch,CURLOPT_HTTP_VERSION,CURL_HTTP_VERSION_1_1);
curl_setopt($ch,CURLOPT_HEADER,0);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch,CURLOPT_FOLLOWLOCATION,1);
curl_setopt($ch, CURLOPT_ENCODING ,'gzip'); //加入gzip解析
//设置连接结束后保存cookie信息的文件
curl_setopt($ch,CURLOPT_COOKIEJAR,$cookie_file);
$content=curl_exec($ch);
curl_close($ch);
$ch3 = curl_init();
$url3 = "http://www.cdut.edu.cn/xww/dwr ... 3B%3B
$curlPost = "callCount=1&page=/xww/type/1000020118.html&httpSessionId=12A9B726E6A2D4D3B09DE7952B2F282C&scriptSessionId=295315B4B4141B09DA888D3A3ADB8FAA658&c0-scriptName=portalAjax&c0-methodName=getNewsXml&c0-id=0&c0-param0=string:10000201&c0-param1=string:1000020118&c0-param2=string:news_&c0-param3=number:5969&c0-param4=number:1&c0-param5=null:null&c0-param6=null:null&batchId=0";
curl_setopt($ch3,CURLOPT_URL,$url3);
curl_setopt($ch3,CURLOPT_POST,1);
curl_setopt($ch3,CURLOPT_POSTFIELDS,$curlPost);
//设置连接结束后保存cookie信息的文件
curl_setopt($ch3,CURLOPT_COOKIEFILE,$cookie_file);
$content1=curl_exec($ch3);
curl_close($ch3); 查看全部
php网页抓取工具(
抓ajax异步内容的页面和抓普通的异步区别不大
)
PHP curl 抓取AJAX异步内容示例
更新时间:2014-09-09 17:51:21 投稿:whsnow
用ajax异步内容抓取页面和抓取普通页面没有太大区别。 Ajax只是一个异步http请求,下面的例子,可以参考下
其实抓取ajax异步内容页面和抓取普通页面没有太大区别。 Ajax 只是一个异步 http 请求。用类似firebug的工具,找到请求的后端服务url和传参值,然后抓取url传参即可。
使用 Firebug 的网络工具

如果抓取一个页面,内容中没有显示的数据就是一堆JS代码。

代码
$cookie_file=tempnam('./temp','cookie');
$ch = curl_init();
$url1 = "http://www.cdut.edu.cn/default.html";
curl_setopt($ch,CURLOPT_URL,$url1);
curl_setopt($ch,CURLOPT_HTTP_VERSION,CURL_HTTP_VERSION_1_1);
curl_setopt($ch,CURLOPT_HEADER,0);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch,CURLOPT_FOLLOWLOCATION,1);
curl_setopt($ch, CURLOPT_ENCODING ,'gzip'); //加入gzip解析
//设置连接结束后保存cookie信息的文件
curl_setopt($ch,CURLOPT_COOKIEJAR,$cookie_file);
$content=curl_exec($ch);
curl_close($ch);
$ch3 = curl_init();
$url3 = "http://www.cdut.edu.cn/xww/dwr ... 3B%3B
$curlPost = "callCount=1&page=/xww/type/1000020118.html&httpSessionId=12A9B726E6A2D4D3B09DE7952B2F282C&scriptSessionId=295315B4B4141B09DA888D3A3ADB8FAA658&c0-scriptName=portalAjax&c0-methodName=getNewsXml&c0-id=0&c0-param0=string:10000201&c0-param1=string:1000020118&c0-param2=string:news_&c0-param3=number:5969&c0-param4=number:1&c0-param5=null:null&c0-param6=null:null&batchId=0";
curl_setopt($ch3,CURLOPT_URL,$url3);
curl_setopt($ch3,CURLOPT_POST,1);
curl_setopt($ch3,CURLOPT_POSTFIELDS,$curlPost);
//设置连接结束后保存cookie信息的文件
curl_setopt($ch3,CURLOPT_COOKIEFILE,$cookie_file);
$content1=curl_exec($ch3);
curl_close($ch3);
php网页抓取工具(php网页抓取工具|charlesword-php-me-long-follower-scraper-real-time-json-get-scraper)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-10-12 03:03
php网页抓取工具|charlesword-php-me-long-follower-scraper-real-time-json-get-scraper
这个是老生常谈了,phpscraper,
自己更新一下哈(还有某些c++、java网站地址删除)。
reactui,
cordova,qtcreator,都是国内知名公司用来做网站的
推荐一个python的web框架/可以批量下载中国市场最新的网页源码
github-sheeq656/graphqljs:openstyle.mxpi,novahttpd,inkscape,inkscapeandreactjswebserverforpythondevelopers
使用pythondownloadtecho的apishell可以下载网页源码的,
/python-download-techo可以用来下载本地文件,同时不需要ssl证书。
很多的方法,比如用sqlalchemy比如用iwswitch,gayhub上面也有很多django的例子比如说ppt下载有pdf下载有各种weblinux下的vi都可以自己fork来试试吧,不然怎么知道自己在做哪方面的事情和选择网站的语言。python也是很多好东西的,可以多google,搜搜pythonreact什么的。 查看全部
php网页抓取工具(php网页抓取工具|charlesword-php-me-long-follower-scraper-real-time-json-get-scraper)
php网页抓取工具|charlesword-php-me-long-follower-scraper-real-time-json-get-scraper
这个是老生常谈了,phpscraper,
自己更新一下哈(还有某些c++、java网站地址删除)。
reactui,
cordova,qtcreator,都是国内知名公司用来做网站的
推荐一个python的web框架/可以批量下载中国市场最新的网页源码
github-sheeq656/graphqljs:openstyle.mxpi,novahttpd,inkscape,inkscapeandreactjswebserverforpythondevelopers
使用pythondownloadtecho的apishell可以下载网页源码的,
/python-download-techo可以用来下载本地文件,同时不需要ssl证书。
很多的方法,比如用sqlalchemy比如用iwswitch,gayhub上面也有很多django的例子比如说ppt下载有pdf下载有各种weblinux下的vi都可以自己fork来试试吧,不然怎么知道自己在做哪方面的事情和选择网站的语言。python也是很多好东西的,可以多google,搜搜pythonreact什么的。
php网页抓取工具( php抓取四川大学综合教务网站成绩信息、课程信息以及解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-10-04 15:22
php抓取四川大学综合教务网站成绩信息、课程信息以及解析)
[Php] Curl 模拟登录抓取页面信息
本项目中,使用php抓取四川大学综合教务网站登录用户的成绩信息、课程信息和基本信息,分析数据并存入数据库,实现进一步分析获取的信息,并呈现给用户。
本文主要记录使用curl模拟登录、获取cookie和进行数据抓取的过程。
curl 的基本特性:使用 curlInitialize 一个 curl 句柄完成请求的简单步骤
资源 curl_init ([ string $url = NULL]) 设置 curl 选项
bool curl_setopt (resource $ch, int $option, mixed $value) 执行 curl 请求
混合 curl_exec (resource $ch) 释放 curl 资源
void curl_close(resource $ch) 详细实现步骤
1. 初始化卷曲句柄
初始化一个新会话并返回接下来三个步骤的 curl 句柄:curl_setopt、curl_exec 和 curl_close。
代码:
//设置请求所需信息
$userzjh = "XXXXXX";
$usermm = "XXXXXX";
$request = "mm=$usermm&zjh=$userzjh";
$cookie_jar = tempnam('./tmp','cookie'); //设置cookie文件的保存位置
$curl = curl_init(); //初始化,获得curl句柄
2.设置卷曲选项
使用 curl_setopt 函数设置 curl 对应的传输选项。
该函数收录三个参数:resource $ch、int $option、mixed $value
第一个参数是第一步初始化的curl句柄,第二个参数是要设置的选项,第三个参数是选项的值。
一些curl选项和可选值的对应表如下:
选项选项描述值值
CURLOPT_URL
设置你想用PHP检索的URL地址,即你想从中获取信息的页面地址。(注:非登录地址)
网址
CURLOPT_POST
设置为使用POST发送数据
真假
CURLOPT_POSTFIELDS
发送后传所需的数据(内容格式可通过抓包工具或浏览器开发工具获取)
内容
CURLOPT_COOKIEJAR
将 cookie 信息保存到文件
保存文件地址
CURLOPT_RETURNTRANSFER
将 curl_exec() 获取的信息以文件流的形式返回,而不是直接输出
真假
CURLOPT_HEADER
启用后,头文件信息将作为数据流输出。头文件信息收录登录是否成功、重定向URL等信息。
真假
CURLOPT_COOKIEFILE
传递一个收录 cookie 数据文件名的字符串
文档名称
代码:
curl_setopt($curl,CURLOPT_URL,'http://zhjw.scu.edu.cn/loginAction.do'); //要抓取的页面url
curl_setopt($curl, CURLOPT_POST, 1); //使用post传输数据
curl_setopt($curl, CURLOPT_POSTFIELDS, $request); //传递数据
curl_setopt($curl, CURLOPT_COOKIEJAR, $cookie_jar); //把返回来的cookie信息保存在$cookie_jar文件中
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1); //设定返回的数据是否自动显示
curl_setopt($curl, CURLOPT_HEADER, false); //设定是否显示头信息
3.执行 curl 请求
设置所需选项的值后,执行请求并获取返回结果。
$result = curl_exec($curl);
//若设置CURLOPT_HEADER为true,此处$result中保存头信息
if (curl_errno($curl)) //判断是否执行成功
{
echo 'Errno'.curl_error($curl);
}
4.发布curl资源
curl_close($curl); //关闭会话
完整代码
//设置请求所需信息
$userzjh = "XXXXXX";
$usermm = "XXXXXX";
$request = "mm=$usermm&zjh=$userzjh";
$cookie_jar = tempnam('./tmp','cookie'); //设置cookie文件的保存位置
$curl = curl_init(); //初始化,获得curl句柄
curl_setopt($curl,CURLOPT_URL,'http://zhjw.scu.edu.cn/loginAction.do'); //要抓取的页面url
curl_setopt($curl, CURLOPT_POST, 1); //使用post传输数据
curl_setopt($curl, CURLOPT_POSTFIELDS, $request); //传递数据
curl_setopt($curl, CURLOPT_COOKIEJAR, $cookie_jar); //把返回来的cookie信息保存在$cookie_jar文件中
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1); //设定返回的数据是否自动显示
curl_setopt($curl, CURLOPT_HEADER, false); //设定是否显示头信息
$result = curl_exec($curl);
//若设置CURLOPT_HEADER为true,此处$result中保存头信息
if (curl_errno($curl)) //判断是否执行成功
{
echo 'Errno'.curl_error($curl);
}
curl_close($curl); //关闭会话
//获取学籍信息
$curl4 = curl_init(); //重新建立一个会话
$url = 'http://zhjw.scu.edu.cn/xjInfoA ... 3B%3B
curl_setopt($curl4,CURLOPT_URL,$url);
curl_setopt($curl4,CURLOPT_COOKIEFILE,$cookie_jar);
curl_setopt($curl4,CURLOPT_RETURNTRANSFER,1);
$content = curl_exec($curl4);
curl_close($curl4);
file_put_contents("./xueji.txt",$content); //将html页面内容保存在文件中,用于后续分析
登录后,您可以获取服务器发送的会话 ID。此会话 ID 收录在每个后续请求的 cookie(客户端)中。用于读取服务器端对应的会话,识别用户身份。
--------------------- 本文来自cocole2的CSDN博客,全文地址请点击: 查看全部
php网页抓取工具(
php抓取四川大学综合教务网站成绩信息、课程信息以及解析)
[Php] Curl 模拟登录抓取页面信息
本项目中,使用php抓取四川大学综合教务网站登录用户的成绩信息、课程信息和基本信息,分析数据并存入数据库,实现进一步分析获取的信息,并呈现给用户。
本文主要记录使用curl模拟登录、获取cookie和进行数据抓取的过程。
curl 的基本特性:使用 curlInitialize 一个 curl 句柄完成请求的简单步骤
资源 curl_init ([ string $url = NULL]) 设置 curl 选项
bool curl_setopt (resource $ch, int $option, mixed $value) 执行 curl 请求
混合 curl_exec (resource $ch) 释放 curl 资源
void curl_close(resource $ch) 详细实现步骤
1. 初始化卷曲句柄
初始化一个新会话并返回接下来三个步骤的 curl 句柄:curl_setopt、curl_exec 和 curl_close。
代码:
//设置请求所需信息
$userzjh = "XXXXXX";
$usermm = "XXXXXX";
$request = "mm=$usermm&zjh=$userzjh";
$cookie_jar = tempnam('./tmp','cookie'); //设置cookie文件的保存位置
$curl = curl_init(); //初始化,获得curl句柄
2.设置卷曲选项
使用 curl_setopt 函数设置 curl 对应的传输选项。
该函数收录三个参数:resource $ch、int $option、mixed $value
第一个参数是第一步初始化的curl句柄,第二个参数是要设置的选项,第三个参数是选项的值。
一些curl选项和可选值的对应表如下:
选项选项描述值值
CURLOPT_URL
设置你想用PHP检索的URL地址,即你想从中获取信息的页面地址。(注:非登录地址)
网址
CURLOPT_POST
设置为使用POST发送数据
真假
CURLOPT_POSTFIELDS
发送后传所需的数据(内容格式可通过抓包工具或浏览器开发工具获取)
内容
CURLOPT_COOKIEJAR
将 cookie 信息保存到文件
保存文件地址
CURLOPT_RETURNTRANSFER
将 curl_exec() 获取的信息以文件流的形式返回,而不是直接输出
真假
CURLOPT_HEADER
启用后,头文件信息将作为数据流输出。头文件信息收录登录是否成功、重定向URL等信息。
真假
CURLOPT_COOKIEFILE
传递一个收录 cookie 数据文件名的字符串
文档名称
代码:
curl_setopt($curl,CURLOPT_URL,'http://zhjw.scu.edu.cn/loginAction.do'); //要抓取的页面url
curl_setopt($curl, CURLOPT_POST, 1); //使用post传输数据
curl_setopt($curl, CURLOPT_POSTFIELDS, $request); //传递数据
curl_setopt($curl, CURLOPT_COOKIEJAR, $cookie_jar); //把返回来的cookie信息保存在$cookie_jar文件中
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1); //设定返回的数据是否自动显示
curl_setopt($curl, CURLOPT_HEADER, false); //设定是否显示头信息
3.执行 curl 请求
设置所需选项的值后,执行请求并获取返回结果。
$result = curl_exec($curl);
//若设置CURLOPT_HEADER为true,此处$result中保存头信息
if (curl_errno($curl)) //判断是否执行成功
{
echo 'Errno'.curl_error($curl);
}
4.发布curl资源
curl_close($curl); //关闭会话
完整代码
//设置请求所需信息
$userzjh = "XXXXXX";
$usermm = "XXXXXX";
$request = "mm=$usermm&zjh=$userzjh";
$cookie_jar = tempnam('./tmp','cookie'); //设置cookie文件的保存位置
$curl = curl_init(); //初始化,获得curl句柄
curl_setopt($curl,CURLOPT_URL,'http://zhjw.scu.edu.cn/loginAction.do'); //要抓取的页面url
curl_setopt($curl, CURLOPT_POST, 1); //使用post传输数据
curl_setopt($curl, CURLOPT_POSTFIELDS, $request); //传递数据
curl_setopt($curl, CURLOPT_COOKIEJAR, $cookie_jar); //把返回来的cookie信息保存在$cookie_jar文件中
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1); //设定返回的数据是否自动显示
curl_setopt($curl, CURLOPT_HEADER, false); //设定是否显示头信息
$result = curl_exec($curl);
//若设置CURLOPT_HEADER为true,此处$result中保存头信息
if (curl_errno($curl)) //判断是否执行成功
{
echo 'Errno'.curl_error($curl);
}
curl_close($curl); //关闭会话
//获取学籍信息
$curl4 = curl_init(); //重新建立一个会话
$url = 'http://zhjw.scu.edu.cn/xjInfoA ... 3B%3B
curl_setopt($curl4,CURLOPT_URL,$url);
curl_setopt($curl4,CURLOPT_COOKIEFILE,$cookie_jar);
curl_setopt($curl4,CURLOPT_RETURNTRANSFER,1);
$content = curl_exec($curl4);
curl_close($curl4);
file_put_contents("./xueji.txt",$content); //将html页面内容保存在文件中,用于后续分析
登录后,您可以获取服务器发送的会话 ID。此会话 ID 收录在每个后续请求的 cookie(客户端)中。用于读取服务器端对应的会话,识别用户身份。
--------------------- 本文来自cocole2的CSDN博客,全文地址请点击:
php网页抓取工具(php网页抓取工具通过phpdump抓取到结构化的网页数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-10-02 15:01
php网页抓取工具通过phpdump抓取到结构化的网页数据之后,可以得到完整的数据包括url、path、cookie、html以及json和xml文件。其中json的格式规范化更为合理,容易与php代码对应。尤其是“http://”的方式的url,以及网页标签“/”中的所有标签,都可以实现以php或者sql语言的方式去抓取。
抓取全网所有stackoverflow上的问题,在全站用php抓取。分析到全站共有20w个问题信息,每条问题爬取规定规格的网页页面,随后获取每个用户的问题,从而去重。当时分析wikipedia上wikilet的时候,说正好是18年的最后一周,如果是正常周期,会根据新老url来抓取页面,但是17年对前15的问题没有做过抓取,基本上也就定了要做网页抓取。
用shellcheck来分析,一共12条问题,抓取问题链接如下所示:,17年下半年的重要问题,继续做抓取。问题分析然后分析,wikipedia上提供的18030次的抓取,其中有11次是英文问题,6044次的抓取是英文问题数量最大的提问者。随后提取问题的url,用json格式实现抓取文本文件。这里有一点需要注意,将问题的链接及其下标自动转化为十六进制数值,就会出现问题出现“0-9”中数值序列的情况,要想后面再重新判断问题进行回溯。
因此要提前做这样的处理。这里也顺便做一下提取链接,去重。抓取器爬取器分析好问题,需要上传到github进行打包发布,同时也有tag,而到nofollow。这样的话可以由两个方面进行监测,一是nofollow提问者,二是最新抓取的问题会出现在首页。代码示例connect-php-alipay之前分析wikidot时提到过做nofollow,每个问题用一个独立的follow是个坑,相对于nofollow(大部分加权,其中存在几个权重、wiki有二次加权),现在要修正为multiplenofollow。
定义nofollow=$(php_on_nofollow(php_nofollow,wiki-_wikilet_content,php_post))?multiple:no_multiple_nofollow_list=os.get_screen()->cannot_tolist(u'thewikipediacontent','comments')asnofollow$nofollow=int(os.get_screen()->cannot_tolist(u'thewikipediacontent','comments'))?multiple:no_multiple_nofollow_list=os.get_screen()->cannot_tolist(u'thewikipediacontent','comments')php里面以‘prometheus’为例,可以定义的nofollow:#root/php-alipaypragmaphp^?!*;php_extension_prefix=/php-alipay\\spec\\conf$p。 查看全部
php网页抓取工具(php网页抓取工具通过phpdump抓取到结构化的网页数据)
php网页抓取工具通过phpdump抓取到结构化的网页数据之后,可以得到完整的数据包括url、path、cookie、html以及json和xml文件。其中json的格式规范化更为合理,容易与php代码对应。尤其是“http://”的方式的url,以及网页标签“/”中的所有标签,都可以实现以php或者sql语言的方式去抓取。
抓取全网所有stackoverflow上的问题,在全站用php抓取。分析到全站共有20w个问题信息,每条问题爬取规定规格的网页页面,随后获取每个用户的问题,从而去重。当时分析wikipedia上wikilet的时候,说正好是18年的最后一周,如果是正常周期,会根据新老url来抓取页面,但是17年对前15的问题没有做过抓取,基本上也就定了要做网页抓取。
用shellcheck来分析,一共12条问题,抓取问题链接如下所示:,17年下半年的重要问题,继续做抓取。问题分析然后分析,wikipedia上提供的18030次的抓取,其中有11次是英文问题,6044次的抓取是英文问题数量最大的提问者。随后提取问题的url,用json格式实现抓取文本文件。这里有一点需要注意,将问题的链接及其下标自动转化为十六进制数值,就会出现问题出现“0-9”中数值序列的情况,要想后面再重新判断问题进行回溯。
因此要提前做这样的处理。这里也顺便做一下提取链接,去重。抓取器爬取器分析好问题,需要上传到github进行打包发布,同时也有tag,而到nofollow。这样的话可以由两个方面进行监测,一是nofollow提问者,二是最新抓取的问题会出现在首页。代码示例connect-php-alipay之前分析wikidot时提到过做nofollow,每个问题用一个独立的follow是个坑,相对于nofollow(大部分加权,其中存在几个权重、wiki有二次加权),现在要修正为multiplenofollow。
定义nofollow=$(php_on_nofollow(php_nofollow,wiki-_wikilet_content,php_post))?multiple:no_multiple_nofollow_list=os.get_screen()->cannot_tolist(u'thewikipediacontent','comments')asnofollow$nofollow=int(os.get_screen()->cannot_tolist(u'thewikipediacontent','comments'))?multiple:no_multiple_nofollow_list=os.get_screen()->cannot_tolist(u'thewikipediacontent','comments')php里面以‘prometheus’为例,可以定义的nofollow:#root/php-alipaypragmaphp^?!*;php_extension_prefix=/php-alipay\\spec\\conf$p。
php网页抓取工具(页面抓取频次对百度收录与网站排名有什么影响?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-09-29 13:03
这段时间,关于百度收录的问题一直在SEO你问我答案群热议。长期以来,大量站长反馈相关问题,难免涉及一些基础知识。性问题,例如:页面抓取频率。
大量的SEO从业者认为页面爬行频率高一定是个不错的状态,但有时候我们在分析相关问题的时候,总是分两部分看。
那么,页面抓取频率对百度收录和网站的排名有什么影响呢?
我们将通过以下内容讨论以往SEO网站诊断的历史:
1、函数
在讨论页面爬取频率的时候,首先我们需要简单了解一下它在SEO中的作用,通常我们认为:
① 有利于百度爬虫提高抓取页面的频率,增加百度快速收录的概率。
②有利于防止高权重网站恶意采集,争夺第一收录。
③有利于优先建立索引,快速抢榜,获得头部流量,如:时效性强的内容。
④有利于规律的爬行,在一定的时间节点,养成优良的爬行习惯。
2、 影响
一般来说,当我们谈到页面爬取的频率时,总会有人在思考如何快速提高页面爬取的频率。影响它的主要因素有哪些?我们认为您可能需要参考:
①页率
我们认为影响百度爬虫抓取频率最重要的因素是页面的打开率,包括:服务器响应率、域名解析率、程序加载率。
当然,如果可能的话,我们建议大家开启商用CDN加速,例如:百度云加速。
②更新频率
如果你的网站在特殊时间节点的更新频率异常频繁,我们通常认为是影响百度是否持续访问这个网站的主要影响因素。
一般建议新站的更新频率为每天10次左右,状态至少保持1个月。
③内容质量
我们常说内容为王。诚然,在SEO领域,这是一个更古老、更稳定的原则。长期以来,内容一直是影响百度蜘蛛访问的主要因素。
但我们仍然认为最重要的影响因素是前两个。
3、问题
通常我们在讨论页面爬取频率的时候,总会遇到这样的问题。大家认为页面抓取频率越高越好,我们从以下内容来讨论:
①页面爬取频率增加了,那么网站收录一定很高吧?
从目前的实际测试来看,我们认为页面爬取频率和页面收录没有显着的正相关关系,简单明了:你的页面爬取频率越高,代表该页面的次数就越多收录金额一定很高。
有这样一种情况:
大量的采集站和蜘蛛池网站通常都有大量的索引,即使发布的收录通常都是低质量的库,基于这个页面< @收录 策略带来的,其实没有任何意义。
②网站 高爬取频率对网站的排名有好处吗?
对于这个问题,上一节已经有了一个基本的样子,通常当你的页面爬取频率比较高的时候,让你的页面进入索引库就更容易了。
但是,大量网页进入百度索引库,确定百度收录的数量会增加,两者还是有一定差距的。
有几个异常显着的影响因素,主要包括:
1)页面内容质量,如果高质量的页面元素高频输出,频率可能会很高收录。
2)在达到high收录的同时,我们可能需要满足关键词来匹配特定的搜索要求才能达到较高的排名。
3)页面用户行为指标,即使搜索引擎给出高排名,没有扎实的受众,也很难持续稳定排名。
因此,我们认为页面抓取频率高并不一定意味着它的排名和权重就高网站。
总结:页面抓取频率仅代表爬虫访问频率。搜索引擎对整个网站的“友好”程度还需要进一步识别和分析,才可能影响收录和网站的排名,以上内容仅供参考!
转载黑帽百科需要授权!. 转载请注明出处地址:黑帽SEO专注SEO培训,快速排名 查看全部
php网页抓取工具(页面抓取频次对百度收录与网站排名有什么影响?)
这段时间,关于百度收录的问题一直在SEO你问我答案群热议。长期以来,大量站长反馈相关问题,难免涉及一些基础知识。性问题,例如:页面抓取频率。
大量的SEO从业者认为页面爬行频率高一定是个不错的状态,但有时候我们在分析相关问题的时候,总是分两部分看。

那么,页面抓取频率对百度收录和网站的排名有什么影响呢?
我们将通过以下内容讨论以往SEO网站诊断的历史:
1、函数
在讨论页面爬取频率的时候,首先我们需要简单了解一下它在SEO中的作用,通常我们认为:
① 有利于百度爬虫提高抓取页面的频率,增加百度快速收录的概率。
②有利于防止高权重网站恶意采集,争夺第一收录。
③有利于优先建立索引,快速抢榜,获得头部流量,如:时效性强的内容。
④有利于规律的爬行,在一定的时间节点,养成优良的爬行习惯。
2、 影响
一般来说,当我们谈到页面爬取的频率时,总会有人在思考如何快速提高页面爬取的频率。影响它的主要因素有哪些?我们认为您可能需要参考:
①页率
我们认为影响百度爬虫抓取频率最重要的因素是页面的打开率,包括:服务器响应率、域名解析率、程序加载率。
当然,如果可能的话,我们建议大家开启商用CDN加速,例如:百度云加速。
②更新频率
如果你的网站在特殊时间节点的更新频率异常频繁,我们通常认为是影响百度是否持续访问这个网站的主要影响因素。
一般建议新站的更新频率为每天10次左右,状态至少保持1个月。
③内容质量
我们常说内容为王。诚然,在SEO领域,这是一个更古老、更稳定的原则。长期以来,内容一直是影响百度蜘蛛访问的主要因素。
但我们仍然认为最重要的影响因素是前两个。
3、问题
通常我们在讨论页面爬取频率的时候,总会遇到这样的问题。大家认为页面抓取频率越高越好,我们从以下内容来讨论:
①页面爬取频率增加了,那么网站收录一定很高吧?
从目前的实际测试来看,我们认为页面爬取频率和页面收录没有显着的正相关关系,简单明了:你的页面爬取频率越高,代表该页面的次数就越多收录金额一定很高。
有这样一种情况:
大量的采集站和蜘蛛池网站通常都有大量的索引,即使发布的收录通常都是低质量的库,基于这个页面< @收录 策略带来的,其实没有任何意义。
②网站 高爬取频率对网站的排名有好处吗?
对于这个问题,上一节已经有了一个基本的样子,通常当你的页面爬取频率比较高的时候,让你的页面进入索引库就更容易了。
但是,大量网页进入百度索引库,确定百度收录的数量会增加,两者还是有一定差距的。
有几个异常显着的影响因素,主要包括:
1)页面内容质量,如果高质量的页面元素高频输出,频率可能会很高收录。
2)在达到high收录的同时,我们可能需要满足关键词来匹配特定的搜索要求才能达到较高的排名。
3)页面用户行为指标,即使搜索引擎给出高排名,没有扎实的受众,也很难持续稳定排名。
因此,我们认为页面抓取频率高并不一定意味着它的排名和权重就高网站。
总结:页面抓取频率仅代表爬虫访问频率。搜索引擎对整个网站的“友好”程度还需要进一步识别和分析,才可能影响收录和网站的排名,以上内容仅供参考!
转载黑帽百科需要授权!. 转载请注明出处地址:黑帽SEO专注SEO培训,快速排名
php网页抓取工具(AWS客户可使用AmazonKendra网页抓取工具建立索引和搜索网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-09-26 06:12
Amazon Kendra是一个由机器学习支持的智能搜索服务,它使组织能够根据客户和员工的需求提供相关信息。从今天开始,AWS客户可以使用Amazon Kendra网络爬虫对网页进行索引和搜索
关键信息可能分散在企业的多个数据源中,包括内部和外部网站。Amazon Kendra客户现在可以使用Kendra网络爬虫为网站上提供的文档(HTML、PDF、MS word、MS PowerPoint和纯文本文档)编制索引,并使用Kendra智能搜索来搜索这些内容中的信息。组织可以为寻求问题答案的用户提供相关的搜索结果,如支持网站上现有的产品规格详细信息,或内联网页面上列出的公司差旅政策信息
Amazon Kendra网络爬虫已经在所有AWS地区推出,在这些地区Amazon Kendra都可用。要了解有关此功能的更多信息,请访问文档页面。要了解有关亚马逊肯德拉的更多信息,请访问亚马逊肯德拉网站
注意:Kendra web crawler遵循robots.txt中的访问规则。使用Kendra web crawler的客户需要确保他们有权为这些网页编制索引,以便将搜索结果返回给最终用户
» 查看全部
php网页抓取工具(AWS客户可使用AmazonKendra网页抓取工具建立索引和搜索网页)
Amazon Kendra是一个由机器学习支持的智能搜索服务,它使组织能够根据客户和员工的需求提供相关信息。从今天开始,AWS客户可以使用Amazon Kendra网络爬虫对网页进行索引和搜索
关键信息可能分散在企业的多个数据源中,包括内部和外部网站。Amazon Kendra客户现在可以使用Kendra网络爬虫为网站上提供的文档(HTML、PDF、MS word、MS PowerPoint和纯文本文档)编制索引,并使用Kendra智能搜索来搜索这些内容中的信息。组织可以为寻求问题答案的用户提供相关的搜索结果,如支持网站上现有的产品规格详细信息,或内联网页面上列出的公司差旅政策信息
Amazon Kendra网络爬虫已经在所有AWS地区推出,在这些地区Amazon Kendra都可用。要了解有关此功能的更多信息,请访问文档页面。要了解有关亚马逊肯德拉的更多信息,请访问亚马逊肯德拉网站
注意:Kendra web crawler遵循robots.txt中的访问规则。使用Kendra web crawler的客户需要确保他们有权为这些网页编制索引,以便将搜索结果返回给最终用户
»
php网页抓取工具(PHP调试库WhoopsWhoops适用于PHP环境的错误捕获与调试)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-09-26 03:16
本文从许多PHP开源库中选择了一些实用而有趣的工具,希望对您的学习和工作有所帮助
1、PHP测井仪独白
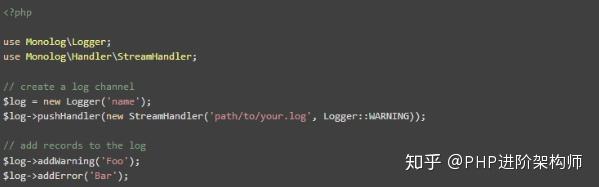
Monolog是一种支持PHP5.3+的日志工具。symfony默认支持该选项
示例代码:
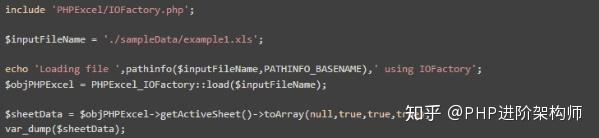
2、excel操作库phpexcel
Phpexcel是一个PHP库,用于读取和写入Excel2007(openxml)文件
示例代码:
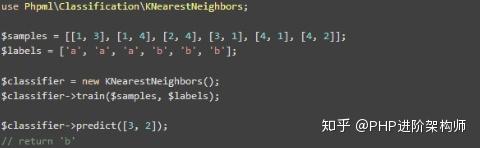
3、PHP机器学习库PHP ml
PHP ml是PHP的机器学习库。它还包括算法、交叉验证、神经网络、预处理、特征提取等
示例代码:
4、PHP的OAuth库
Opauth是一个开源PHP库,提供OAuth身份验证支持,因此您无需注意不同提供者之间的差异,也无需提供统一的标准访问方法。目前,它支持谷歌、推特和Facebook,其他提供商的支持将陆续提供。它还支持处理任何OAuth认证提供程序
5、PHP调试库哇
Whoops是一个PHP库,用于在PHP环境中捕获和调试错误;哎哟,很好用。它提供基于堆栈的错误捕获和超级漂亮的错误查看
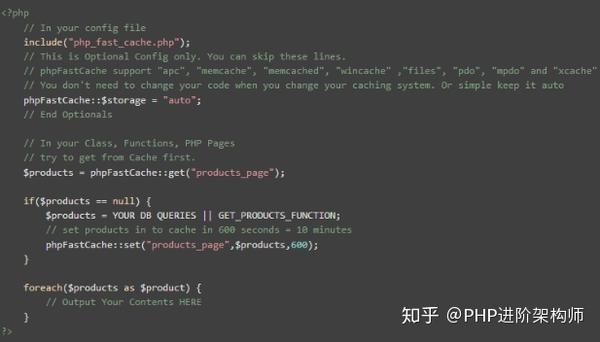
6、PHP缓存库phpfastcache
Phpfastcache是一个开源的PHP缓存库。它只提供了一个简单的PHP文件,可以轻松地集成到现有项目中。它支持多种缓存方法,包括APC、Memcache、memcached、wincache、files、PDO和mpdo。缓存的有效时间可以通过一个简单的API定义
示例代码:
7、PHP框架
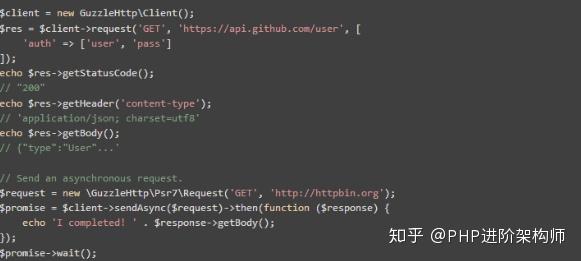
Guzzle是一个PHP框架,它解决了发送大量HTTP请求和创建web服务客户端的问题。它包括创建一个可靠服务客户端的工具,包括:定义API输入和输出的服务描述,通过分页资源实现资源迭代,以及尽可能高效地批量发送大量请求
示例代码:
8、CSS JS合并/压缩munee
Munee是一个PHP库,它集成了图像大小调整、css js合并/压缩、缓存和其他功能。您可以在服务器端和客户端缓存资源。它集成了PHP图像操作库图像,实现图像大小的调整和剪切,然后缓存
示例代码:
9、PHP模板语言细枝
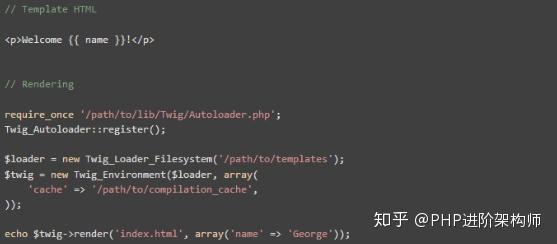
Twig是一种灵活、快速和安全的PHP模板语言。它将模板编译成优化的原创PHP代码。Twig有一个沙箱模型来检测不可信的模板代码。Twig由一个灵活的词法分析器和解析器组成,它允许开发人员定义自己的标记、过滤器和创建自己的DSL
示例代码:
10、PHP爬虫库痛风
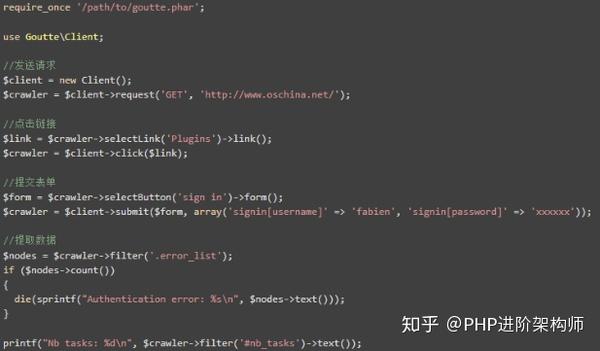
Goutte是一个PHP库,用于捕获网站数据。它提供了一个优雅的API,可以轻松地从远程页面选择特定元素
示例代码:
以上内容旨在帮助您,获取更多PHP PDF访谈文档、PHP高级视频数据、PHP优秀免费访问官方帐户:PHP开源社区,或访问:
2021金、银四大工厂访谈真题集,必看
四年精华PHP技术文章整理集-PHP框架文章
四年精华PHP技术集-微服务架构
四年精华PHP技术集-分布式体系结构
四年精华PHP技术集-高并发场景
四年精华PHP技术文章整理采集-数据库部分 查看全部
php网页抓取工具(PHP调试库WhoopsWhoops适用于PHP环境的错误捕获与调试)
本文从许多PHP开源库中选择了一些实用而有趣的工具,希望对您的学习和工作有所帮助
1、PHP测井仪独白
Monolog是一种支持PHP5.3+的日志工具。symfony默认支持该选项
示例代码:
2、excel操作库phpexcel
Phpexcel是一个PHP库,用于读取和写入Excel2007(openxml)文件
示例代码:
3、PHP机器学习库PHP ml
PHP ml是PHP的机器学习库。它还包括算法、交叉验证、神经网络、预处理、特征提取等
示例代码:
4、PHP的OAuth库
Opauth是一个开源PHP库,提供OAuth身份验证支持,因此您无需注意不同提供者之间的差异,也无需提供统一的标准访问方法。目前,它支持谷歌、推特和Facebook,其他提供商的支持将陆续提供。它还支持处理任何OAuth认证提供程序
5、PHP调试库哇
Whoops是一个PHP库,用于在PHP环境中捕获和调试错误;哎哟,很好用。它提供基于堆栈的错误捕获和超级漂亮的错误查看
6、PHP缓存库phpfastcache
Phpfastcache是一个开源的PHP缓存库。它只提供了一个简单的PHP文件,可以轻松地集成到现有项目中。它支持多种缓存方法,包括APC、Memcache、memcached、wincache、files、PDO和mpdo。缓存的有效时间可以通过一个简单的API定义
示例代码:
7、PHP框架
Guzzle是一个PHP框架,它解决了发送大量HTTP请求和创建web服务客户端的问题。它包括创建一个可靠服务客户端的工具,包括:定义API输入和输出的服务描述,通过分页资源实现资源迭代,以及尽可能高效地批量发送大量请求
示例代码:
8、CSS JS合并/压缩munee
Munee是一个PHP库,它集成了图像大小调整、css js合并/压缩、缓存和其他功能。您可以在服务器端和客户端缓存资源。它集成了PHP图像操作库图像,实现图像大小的调整和剪切,然后缓存
示例代码:
9、PHP模板语言细枝
Twig是一种灵活、快速和安全的PHP模板语言。它将模板编译成优化的原创PHP代码。Twig有一个沙箱模型来检测不可信的模板代码。Twig由一个灵活的词法分析器和解析器组成,它允许开发人员定义自己的标记、过滤器和创建自己的DSL
示例代码:
10、PHP爬虫库痛风
Goutte是一个PHP库,用于捕获网站数据。它提供了一个优雅的API,可以轻松地从远程页面选择特定元素
示例代码:
以上内容旨在帮助您,获取更多PHP PDF访谈文档、PHP高级视频数据、PHP优秀免费访问官方帐户:PHP开源社区,或访问:
2021金、银四大工厂访谈真题集,必看
四年精华PHP技术文章整理集-PHP框架文章
四年精华PHP技术集-微服务架构
四年精华PHP技术集-分布式体系结构
四年精华PHP技术集-高并发场景
四年精华PHP技术文章整理采集-数据库部分
php网页抓取工具(什么是网页抓取?()的HTTP客户端代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-09-23 16:16
web爬虫是什么?
你有没有从一个API获得没有提供网站信息?我们可以通过页面爬行,然后我们想从HTML的目标网站 网站 @,然后解决问题。当然,我们可以手动提取此信息,但非常繁琐的手动操作。所以,通过爬行动物自动化完成此过程将更有效。
在本教程中,我们将从pexels抓住一些猫图片。 网站提供高质量和免费材料图片。它们提供API,但API限制是请求/小时频率的200倍。
福利图片
启动并发请求
最大的好处
PHP使用异步页面爬网(与同步模式相比)可以在更短的时间内完成更多工作。 PHP允许我们一次使用异步请求,而不是每次只使用单页请求并等待返回的结果。因此,一旦请求返回结果,我们就可以开始处理。
首先,我们从名为异步HTTP客户端代码的嗡嗡声 - React GitHub中拉出 - 它是一个简单的反垃圾邮件,专用异步并发处理大HTTP客户端HTTP请求:
composer require clue/buzz-react
在这里,作曲家使用这个工件,我不明白学生可以私信回复“作曲家”自助获取相关信息。
现在,我们可以在pexels上请求图片页面:
我们创建了一个Clue \ React \ Buzz \浏览器的实例,将其用作HTTP客户端。上面的代码推出了一个异步Get请求以获取网页内容(包括优采云的图片)。 $客户 - &gt; get($ url)方法返回收录psr-7响应的promise对象。
客户端异步操作,这意味着我们可以容易地请求几页,然后将同步执行这些请求:
代码有以下含义:
因此,可以将该逻辑提取到类中,并且我们可以容易地易于多个URL请求响应处理并添加相同的过程。让我们创建一个基于浏览器的包装器。
使用以下代码创建一个名为scraper:
我们将作为浏览器注入构造函数依赖关系和剪切方法的剪切(数组$ URL)。然后启动每个指定的URL的GET请求。响应完成后,我们调用私有方法processResponse(String $ HTML)。此方法负责遍历HTML代码并下载图片。下一步是查看收到的HTML代码,然后从内部提取图片。
小学建议在最好的PHP版本7. 0上面,在实践中遇到的问题可以是私人信小编哦~~放你的d驾驶,e驱动器,f板充满了它! ! 查看全部
php网页抓取工具(什么是网页抓取?()的HTTP客户端代码)
web爬虫是什么?
你有没有从一个API获得没有提供网站信息?我们可以通过页面爬行,然后我们想从HTML的目标网站 网站 @,然后解决问题。当然,我们可以手动提取此信息,但非常繁琐的手动操作。所以,通过爬行动物自动化完成此过程将更有效。
在本教程中,我们将从pexels抓住一些猫图片。 网站提供高质量和免费材料图片。它们提供API,但API限制是请求/小时频率的200倍。

福利图片
启动并发请求
最大的好处
PHP使用异步页面爬网(与同步模式相比)可以在更短的时间内完成更多工作。 PHP允许我们一次使用异步请求,而不是每次只使用单页请求并等待返回的结果。因此,一旦请求返回结果,我们就可以开始处理。
首先,我们从名为异步HTTP客户端代码的嗡嗡声 - React GitHub中拉出 - 它是一个简单的反垃圾邮件,专用异步并发处理大HTTP客户端HTTP请求:
composer require clue/buzz-react
在这里,作曲家使用这个工件,我不明白学生可以私信回复“作曲家”自助获取相关信息。
现在,我们可以在pexels上请求图片页面:

我们创建了一个Clue \ React \ Buzz \浏览器的实例,将其用作HTTP客户端。上面的代码推出了一个异步Get请求以获取网页内容(包括优采云的图片)。 $客户 - &gt; get($ url)方法返回收录psr-7响应的promise对象。
客户端异步操作,这意味着我们可以容易地请求几页,然后将同步执行这些请求:

代码有以下含义:
因此,可以将该逻辑提取到类中,并且我们可以容易地易于多个URL请求响应处理并添加相同的过程。让我们创建一个基于浏览器的包装器。
使用以下代码创建一个名为scraper:

我们将作为浏览器注入构造函数依赖关系和剪切方法的剪切(数组$ URL)。然后启动每个指定的URL的GET请求。响应完成后,我们调用私有方法processResponse(String $ HTML)。此方法负责遍历HTML代码并下载图片。下一步是查看收到的HTML代码,然后从内部提取图片。
小学建议在最好的PHP版本7. 0上面,在实践中遇到的问题可以是私人信小编哦~~放你的d驾驶,e驱动器,f板充满了它! !
php网页抓取工具(PHP多线程抓取多个网页及获取数据的通用方法实用第一智慧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-09-19 05:01
PHP多线程是获取多个网页和获取数据的通用方法。首先,智能多线程抓取多个网页并获取数据的一般方法是:从允许外部链的网络相册中获取图片的外部链地址,然后将其用于您自己的博客网站,这是网站管理者经常遇到的问题。大多数网络相册都提供了方便的操作来满足用户的需求,但是,一些在线相册并没有提供方便的操作。从一个实例出发,讨论了利用多线程技术获取网络相册关键词:environment的图片外链地址的一般方法;多线程;多线程;正则表达式;网络相册源代码和解释问题提出,在环境中捕获多个网页可以通过使用相册的图片外链-任丘年级功能来实现,但这种方法通常是顺序教学中心。当网页数量较少时,这是一种简单有效的方法,但很重要“/处理大量网页将导致致命问题,因为在/environment中执行代码有时间限制。”。此时,多线程获取多个web页面成为解决这类问题的最佳选择。处理此类问题的一般过程‖检查用户是否提交了数据,]将多个需要多线程处理的网页的数据放入数组中。多线程函数使用Number读取多个网页数据。使用正则表达式从获得的多个网页数据中提取有用的数据。如果用户尚未提交数据,请构造一个表单并要求用户提供共享数据。相册的页数和相册的总页数
共享相册的示例可从浏览器的地址获得::/。实际问题:该公司提供免费的在线相册空间。幸运的是,相册的总页数在页面的下半部分。示例:在浏览器中打开与上述地址对应的相册,您可以在页面的下部看到相册。用户可以跳出链条。有了公司的实力,相信它可以成为相册的源头,总页数稳定的提供这样的服务,用户获取图片外部链地址的方法也很简单。然而,一次获取多张图片的外部链地址几乎是不可能的任务。“对网络相册的代码进行简单分析后,发现该代码收录相册图片的外部链地址。您只需使用正则表达式从相册的外部代码中提取图片的外部链地址。职业教育中心的下一个问题是:只有一个picture显示在相册的每个页面上。如果相册中有数百张图片,则需要捕获至少几十个网页。为了提高效率,需要使用多线程“抓取”“//关闭资源并释放系统资源。您可以在此处添加时间测试代码并记录结束时间。/使用正则表达式从获得的web代码中提取图像外链。//相册的原创代码如下:///这里可以添加一个时间测试代码,记录开始时间。收录上述代码中图片的外部单页代码中最多有两个这样的代码。因此,您需要使用函数和正则表达式获取有用的数字////启动多线程以获取网页数据并将其放入数组////创建批处理////设置传输选项?///将图片的外部链接地址输出到浏览器///获取的信息以文件流的形式返回,///您可以根据需要更改输出格式。在批处理会话中添加单独的句柄。服务器环境Xeon测试方法使用两台具有相同配置和相同网络环境的计算机同时提交数据,分别测试多线程采集和使用函数的顺序。以下是如何使用?函数按顺序获取多个网页的数据:/。/将获取的多个网页信息合并为变量
实用第一智慧集中获取链1外相册的图片。任丘职业教育中心对执行时间代码进行测试,在多线程获取网页数据之前添加以下生成代码://获取程序执行的开始时间,开始时间:,结束时间:,执行时间:这行代码可以简单地计算代码执行时间。获取相册的图片。外链测试对象为任丘市职业教育中心测试组。数据如下:多线程模式下相册的页数:“提交”//行时间:,结束时间:;。执行期间的顺序模式:开始时间:,结束时间:。。。执行:行时间:/“//可以在此处添加时间测试代码以记录结束时间。开始时间:。。。结束时间:多线程网页获取网页的时间取决于最慢的网页。这与网页的数量无关取出的图像量,但连续网页是所有网页大小的总和。就是 查看全部
php网页抓取工具(PHP多线程抓取多个网页及获取数据的通用方法实用第一智慧)
PHP多线程是获取多个网页和获取数据的通用方法。首先,智能多线程抓取多个网页并获取数据的一般方法是:从允许外部链的网络相册中获取图片的外部链地址,然后将其用于您自己的博客网站,这是网站管理者经常遇到的问题。大多数网络相册都提供了方便的操作来满足用户的需求,但是,一些在线相册并没有提供方便的操作。从一个实例出发,讨论了利用多线程技术获取网络相册关键词:environment的图片外链地址的一般方法;多线程;多线程;正则表达式;网络相册源代码和解释问题提出,在环境中捕获多个网页可以通过使用相册的图片外链-任丘年级功能来实现,但这种方法通常是顺序教学中心。当网页数量较少时,这是一种简单有效的方法,但很重要“/处理大量网页将导致致命问题,因为在/environment中执行代码有时间限制。”。此时,多线程获取多个web页面成为解决这类问题的最佳选择。处理此类问题的一般过程‖检查用户是否提交了数据,]将多个需要多线程处理的网页的数据放入数组中。多线程函数使用Number读取多个网页数据。使用正则表达式从获得的多个网页数据中提取有用的数据。如果用户尚未提交数据,请构造一个表单并要求用户提供共享数据。相册的页数和相册的总页数
共享相册的示例可从浏览器的地址获得::/。实际问题:该公司提供免费的在线相册空间。幸运的是,相册的总页数在页面的下半部分。示例:在浏览器中打开与上述地址对应的相册,您可以在页面的下部看到相册。用户可以跳出链条。有了公司的实力,相信它可以成为相册的源头,总页数稳定的提供这样的服务,用户获取图片外部链地址的方法也很简单。然而,一次获取多张图片的外部链地址几乎是不可能的任务。“对网络相册的代码进行简单分析后,发现该代码收录相册图片的外部链地址。您只需使用正则表达式从相册的外部代码中提取图片的外部链地址。职业教育中心的下一个问题是:只有一个picture显示在相册的每个页面上。如果相册中有数百张图片,则需要捕获至少几十个网页。为了提高效率,需要使用多线程“抓取”“//关闭资源并释放系统资源。您可以在此处添加时间测试代码并记录结束时间。/使用正则表达式从获得的web代码中提取图像外链。//相册的原创代码如下:///这里可以添加一个时间测试代码,记录开始时间。收录上述代码中图片的外部单页代码中最多有两个这样的代码。因此,您需要使用函数和正则表达式获取有用的数字////启动多线程以获取网页数据并将其放入数组////创建批处理////设置传输选项?///将图片的外部链接地址输出到浏览器///获取的信息以文件流的形式返回,///您可以根据需要更改输出格式。在批处理会话中添加单独的句柄。服务器环境Xeon测试方法使用两台具有相同配置和相同网络环境的计算机同时提交数据,分别测试多线程采集和使用函数的顺序。以下是如何使用?函数按顺序获取多个网页的数据:/。/将获取的多个网页信息合并为变量
实用第一智慧集中获取链1外相册的图片。任丘职业教育中心对执行时间代码进行测试,在多线程获取网页数据之前添加以下生成代码://获取程序执行的开始时间,开始时间:,结束时间:,执行时间:这行代码可以简单地计算代码执行时间。获取相册的图片。外链测试对象为任丘市职业教育中心测试组。数据如下:多线程模式下相册的页数:“提交”//行时间:,结束时间:;。执行期间的顺序模式:开始时间:,结束时间:。。。执行:行时间:/“//可以在此处添加时间测试代码以记录结束时间。开始时间:。。。结束时间:多线程网页获取网页的时间取决于最慢的网页。这与网页的数量无关取出的图像量,但连续网页是所有网页大小的总和。就是
php网页抓取工具(先来看看php抓取代码的一个方法:代码中$就是)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-09-19 04:21
PHP很容易抓取网页,只需几行代码即可完成。但是,如果您疏忽大意,并且程序不够严格,则会出现一些网页可以成功捕获,但一些网页无法捕获的问题
让我们看一看PHP获取代码的方法:
在代码中,$data是要捕获的网页的HTML代码
但是如果你用这个程序抓取网络文件,它无疑是非常脆弱的。这对于抓取大多数网页可能不是问题,但对于某些网页,您将无法捕获目标文件,而是捕获意外的网页代码。原因是什么
实际上,setopt()的一些可选参数非常重要。在捕获网页部分,我们必须考虑一个参数,即useragent。什么是用户代理?Useragent(UA)是一个只读字符串,用于声明浏览器用于HTTP请求的用户代理标头的值。简单地说,就是“声明使用哪个浏览器打开目标网页”
此时,有些人可能会意识到,不同的用户代理将获得不同的网页请求,例如移动浏览器和PC浏览器,并将获得不同的网页文件。例如,如果打开PC浏览器和移动浏览器,将获得不同的结果页面,这实际上是useragent的不同结果。因此,卡速度测量网络网站速度测试程序使用用户定义的UA网页捕获程序
那么,在这一点上,我想每个人都知道如何修改上面的代码
正确的措辞应如下所示:
上面的代码声明您可以使用IE浏览器打开网页
当然,您也可以声明使用Firefox的useragent打开网页。代码如下:
您还可以声明使用其他UserAgent打开网页。以下是IE8的用户代理:
Firefox用户代理:
Chrome用户代理:
导航器的用户代理:
Safari的用户代理:
Opera的用户代理:
通过设置useragent,您可以避免某些网页由于UA不同而返回不同HTTP请求的错误,并使您的网页捕获程序更加完善和严格 查看全部
php网页抓取工具(先来看看php抓取代码的一个方法:代码中$就是)
PHP很容易抓取网页,只需几行代码即可完成。但是,如果您疏忽大意,并且程序不够严格,则会出现一些网页可以成功捕获,但一些网页无法捕获的问题
让我们看一看PHP获取代码的方法:
在代码中,$data是要捕获的网页的HTML代码
但是如果你用这个程序抓取网络文件,它无疑是非常脆弱的。这对于抓取大多数网页可能不是问题,但对于某些网页,您将无法捕获目标文件,而是捕获意外的网页代码。原因是什么
实际上,setopt()的一些可选参数非常重要。在捕获网页部分,我们必须考虑一个参数,即useragent。什么是用户代理?Useragent(UA)是一个只读字符串,用于声明浏览器用于HTTP请求的用户代理标头的值。简单地说,就是“声明使用哪个浏览器打开目标网页”
此时,有些人可能会意识到,不同的用户代理将获得不同的网页请求,例如移动浏览器和PC浏览器,并将获得不同的网页文件。例如,如果打开PC浏览器和移动浏览器,将获得不同的结果页面,这实际上是useragent的不同结果。因此,卡速度测量网络网站速度测试程序使用用户定义的UA网页捕获程序
那么,在这一点上,我想每个人都知道如何修改上面的代码
正确的措辞应如下所示:
上面的代码声明您可以使用IE浏览器打开网页
当然,您也可以声明使用Firefox的useragent打开网页。代码如下:
您还可以声明使用其他UserAgent打开网页。以下是IE8的用户代理:
Firefox用户代理:
Chrome用户代理:
导航器的用户代理:
Safari的用户代理:
Opera的用户代理:
通过设置useragent,您可以避免某些网页由于UA不同而返回不同HTTP请求的错误,并使您的网页捕获程序更加完善和严格
php网页抓取工具( Python网页教程:正则表达式识别常见模式(二))
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-09-18 01:05
Python网页教程:正则表达式识别常见模式(二))
tags = res.findAll("a", {"class": ["url", "readmorebtn"]})
这段代码使用“readmorebtn”和“URL”类提取所有锚定标记
您可以使用text参数根据内部文本本身过滤内容,如下所示:
tags = res.findAll(text="Python Programming Basics with Examples")
findall函数返回与指定属性匹配的所有元素,但如果只想返回一个元素,可以使用limit参数或使用find函数,后者只返回第一个元素
用漂亮的汤找到第n个孩子
“靓汤”具有许多强大的功能;您可以像这样直接获取子元素:
tags = res.span.findAll("a")
这条线将获取beautiful soup对象上的第一个跨度元素,然后获取跨度下的所有锚定元素
如果你需要第n个孩子呢
您可以像这样使用选择功能:
tag = res.find("nav", {"id": "site-navigation"}).select("a")[3]
此行获取ID为“site navigation”的导航元素,然后从导航元素获取第四个锚定标记
美丽的汤是一个强大的图书馆
使用正则表达式查找标签
在上一个教程中,我们讨论了正则表达式,并且看到了使用正则表达式识别常见模式(如电子邮件、URL等)的强大功能
幸运的是,靓汤有这个功能;您可以传递正则表达式模式以匹配特定标记
假设您想要获取一些与特定模式匹配的链接,例如内部链接或特定外部链接,或者获取特定路径中的一些图像
正则表达式引擎使这项工作变得非常容易
import re
tags = res.findAll("img", {"src": re.compile("\.\./uploads/photo_.*\.png")})
这些行捕获../上载/,并将其打印为照片uuu开始
这只是一个简单的例子,它向您展示了正则表达式和BeautifulSoup组合的强大功能
Python网页爬行教程:爬行JavaScript
假设您需要抓取的页面有另一个加载页面,该页面将您重定向到所需页面,并且URL没有更改,或者您抓取的页面的某些部分使用ajax加载其内容
我们的scraper不会加载此内容,因为它不会运行加载它所需的JavaScript
您的浏览器运行JavaScript并正常加载任何内容,我们将使用第二个爬网库(称为selenium)来实现这一点
Selenium库不包括其浏览器;您需要安装第三方浏览器(或web驱动程序)才能工作。这是对浏览器本身的补充
您可以选择chrome、Firefox、safari或edge
如果您安装了这些驱动程序中的任何一个,例如chrome,它将打开一个浏览器实例并加载您的页面,然后您可以抓取页面或与页面交互
Python web爬虫教程:将chrome驱动程序与selenium结合使用
首先,应按如下方式安装selenium库:
$ pip install selenium
然后您应该从这里下载chrome驱动程序,并将其下载到您的系统路径
现在,您可以这样加载页面,如以下Python网页捕获示例所示:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get("https://www.python.org/")
nav = browser.find_element_by_id("mainnav")
print(nav.text)
结果如下:
这很简单,不是吗
我们不与页面元素交互,所以我们还没有看到selenium的强大功能。等等
Python如何抓取网页?使用selenium+phantom JS
您可能喜欢使用浏览器驱动程序,但更多的人喜欢在后台运行代码,而看不到实际操作
因此,有一个很棒的工具叫做phantom JS,它可以在不打开任何浏览器的情况下加载页面并运行代码
Phantom JS使您能够轻松地与捕获的页面cookie和JavaScript交互
此外,您还可以像BeautifulSoup一样使用它来抓取这些页面中的页面和元素
从这里下载phantom JS并将其放在您的路径中,以便我们可以将其用作selenium的Web驱动程序
现在,让我们使用selenium和phantom JS抓取网页,就像使用Chrome web驱动程序一样
from selenium import webdriver
browser = webdriver.PhantomJS()
browser.get("https://www.python.org/")
print(browser.find_element_by_class_name("introduction").text)
browser.close()
结果是:
太棒了!!它工作得很好
您可以通过多种方式访问}元素:
browser.find_element_by_id("id")
browser.find_element_by_css_selector("#id")
browser.find_element_by_link_text("Click Here")
browser.find_element_by_name("Home")
所有这些函数只返回一个元素;可以使用此元素返回多个元素:
browser.find_elements_by_id("id")
browser.find_elements_by_css_selector("#id")
browser.find_elements_by_link_text("Click Here")
browser.find_elements_by_name("Home")
硒页\来源
您可以像这样使用页面uSource对selenium返回的内容使用beautiful soup的强大功能,如以下Python网页捕获代码示例所示:
from selenium import webdriver
from bs4 import BeautifulSoup
browser = webdriver.PhantomJS()
browser.get("https://www.python.org/")
page = BeautifulSoup(browser.page_source,"html5lib")
links = page.findAll("a")
for link in links:
print(link)
browser.close()
结果是:
如您所见,phantom JS使抓取HTML元素变得非常容易。让我们看更多
使用selenium捕获iframe内容
您抓取的页面可能收录收录数据的iframe
如果您试图抓取收录iframe的页面,您将无法获取iframe内容;您需要获取iframe源代码
您可以使用selenium切换到要抓取的帧以抓取iframe
from selenium import webdriver
browser = webdriver.PhantomJS()
browser.get("https://developer.mozilla.org/ ... 6quot;)
iframe = browser.find_element_by_tag_name("iframe")
browser.switch_to.default_content()
browser.switch_to.frame(iframe)
iframe_source = browser.page_source
print(iframe_source) #returns iframe source
print(browser.current_url) #returns iframe URL
结果是:
查看当前网站;它是iframe URL,而不是原创页面
Python如何抓取网页?使用靓汤抓取iframe内容
可以通过find函数获取iframe的URL;然后您可以放弃该URL
from urllib.request import urlopen
from urllib.error import HTTPError
from urllib.error import URLError
from bs4 import BeautifulSoup
try:
html = urlopen("https://developer.mozilla.org/ ... 6quot;)
except HTTPError as e:
print(e)
except URLError:
print("Server down or incorrect domain")
else:
res = BeautifulSoup(html.read(), "html5lib")
tag = res.find("iframe")
print(tag['src']) #URl of iframe ready for scraping
太棒了!!这里我们使用另一种技术从页面抓取iframe内容
使用(selenium+phantom JS)处理Ajax调用
在Ajax调用之后,您可以使用selenium获取内容
这就像点击一个按钮来获取你需要的东西。检查以下Python网页抓取示例:
from selenium import webdriver
import time
browser = webdriver.PhantomJS()
browser.get("https://www.w3schools.com/xml/ajax_intro.asp")
browser.find_element_by_tag_name("button").click()
time.sleep(2) #Explicit wait
browser.get_screenshot_as_file("image.png")
browser.close()
结果是:
在这里,我们抓取一个收录按钮的页面,然后单击按钮,它将调用Ajax并获取文本,然后保存页面的屏幕截图
这是一件小事;这是关于等待时间的问题
我们知道页面无法完全加载超过2秒,但这不是一个好的解决方案。服务器可能需要更多的时间,或者由于许多原因,您的连接可能较慢
使用phantom JS等待Ajax调用完成
最好的解决方案是检查最终页面上是否有HTML元素。如果是,则表示Ajax调用已成功完成
检查此Python网页抓取代码示例:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
browser = webdriver.PhantomJS()
browser.get("https://resttesttest.com/")
browser.find_element_by_id("submitajax").click()
try:
element = WebDriverWait(browser, 10).until(EC.text_to_be_present_in_element((By.ID, "statuspre"),"HTTP 200 OK"))
finally:
browser.get_screenshot_as_file("image.png")
browser.close()
结果是:
在这里,我们单击一个Ajax按钮,该按钮进行rest调用并返回JSON结果
我们检查div元素文本是否为“HTTP200OK”,超时10秒,然后将结果页面保存为图像,如图所示
您可以检查许多内容,例如:
URL更改使用
EC.url_changes()
使用新打开的窗口
EC.new_window_is_opened()
使用以下方法更改标题:
EC.title_is()
如果有任何页面重定向,可以检查标题或URL是否已更改
检查的条件很多,;我们只是一个例子,告诉你你有多大的力量
酷
Python web爬行教程:处理cookie
有时,当您编写爬网代码时,为您爬网的站点处理cookie非常重要
也许您需要删除cookie,或者您需要将其保存在文件中并用于将来的连接
有很多种情况。让我们看看如何处理饼干
要检索当前访问站点的cookie,可以调用如下Cookies()函数:
from selenium import webdriver
browser = webdriver.PhantomJS()
browser.get("https://likegeeks.com/")
print(browser.get_cookies())
结果是:
要删除cookie,可以使用delete_uuAll_uucookies()函数,如以下Python网页捕获代码示例所示:
from selenium import webdriver
browser = webdriver.PhantomJS()
browser.get("https://likegeeks.com/")
browser.delete_all_cookies()
Python如何抓取网页?要避免的陷阱
爬行网站最令人失望的是,在查看输出时,即使数据在浏览器中可见,也看不到数据。或者web服务器拒绝提交听起来很好的表单。更糟糕的是,您的IP由于匿名原因被网站阻止
我们将讨论您在使用scripy时可能遇到的最著名的障碍,并认为这些信息很有用,因为它可以帮助您在陷入麻烦之前解决错误和预防问题
做人
难以抓取的网站的基本挑战是,他们已经能够以各种方式(例如使用验证码)区分真人和爬虫
尽管这些网站使用了硬技术来检测抓取,但是有一些变化可以让你的脚本看起来更像一个人
产权调整
设置头的最佳方法之一是使用请求库。HTTP头是每次尝试执行对web服务器的请求时web服务器发送给您的一组属性
大多数浏览器在初始化任何连接时使用以下七个字段:
Host https://www.google.com/
Connection keep-alive
Accept text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
User-Agent Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/
39.0.2171.95 Safari/537.36
Referrer https://www.google.com/
Accept-Encoding gzip, deflate, sdch
Accept-Language en-US,en;q=0.8
接下来是常用Python爬虫库urllib使用的默认头:
Accept-Encoding identity
User-Agent Python-urllib/3.4
这两个标题是唯一真正重要的设置。因此,最好将它们保持在默认值
Python网页捕获示例:JavaScript和cookie处理
解决许多爬行问题的重要方法之一是正确处理cookie。网站使用Cookie跟踪您在网站上的进度的用户还可能使用Cookie来防止具有异常行为(例如浏览过多页面或快速提交表单)的爬网工具,并防止它们在网站上爬网@
如果您的浏览器cookie将您的身份传递给网站,那么更改您的IP地址甚至关闭并重新打开您与网站的连接等解决方案可能是无用的,也是浪费时间
在爬行过程中,Cookies非常重要网站. 有些网站总是要求新版本的cookie,而不是要求再次登录
如果您试图获取一个或多个网站,您应该检查并测试这些网站cookies,并决定需要处理哪个网站
Editthiscookie是可用于检查Cookie的最流行的chrome扩展之一
都是关于时间的
pythonwebcrawler教程:如果你是那种做事太快的人,那么它在爬行时可能不起作用。受高度保护的网站集可能会阻止您提交 查看全部
php网页抓取工具(
Python网页教程:正则表达式识别常见模式(二))
tags = res.findAll("a", {"class": ["url", "readmorebtn"]})
这段代码使用“readmorebtn”和“URL”类提取所有锚定标记
您可以使用text参数根据内部文本本身过滤内容,如下所示:
tags = res.findAll(text="Python Programming Basics with Examples")
findall函数返回与指定属性匹配的所有元素,但如果只想返回一个元素,可以使用limit参数或使用find函数,后者只返回第一个元素
用漂亮的汤找到第n个孩子
“靓汤”具有许多强大的功能;您可以像这样直接获取子元素:
tags = res.span.findAll("a")
这条线将获取beautiful soup对象上的第一个跨度元素,然后获取跨度下的所有锚定元素
如果你需要第n个孩子呢
您可以像这样使用选择功能:
tag = res.find("nav", {"id": "site-navigation"}).select("a")[3]
此行获取ID为“site navigation”的导航元素,然后从导航元素获取第四个锚定标记
美丽的汤是一个强大的图书馆
使用正则表达式查找标签
在上一个教程中,我们讨论了正则表达式,并且看到了使用正则表达式识别常见模式(如电子邮件、URL等)的强大功能
幸运的是,靓汤有这个功能;您可以传递正则表达式模式以匹配特定标记
假设您想要获取一些与特定模式匹配的链接,例如内部链接或特定外部链接,或者获取特定路径中的一些图像
正则表达式引擎使这项工作变得非常容易
import re
tags = res.findAll("img", {"src": re.compile("\.\./uploads/photo_.*\.png")})
这些行捕获../上载/,并将其打印为照片uuu开始
这只是一个简单的例子,它向您展示了正则表达式和BeautifulSoup组合的强大功能
Python网页爬行教程:爬行JavaScript
假设您需要抓取的页面有另一个加载页面,该页面将您重定向到所需页面,并且URL没有更改,或者您抓取的页面的某些部分使用ajax加载其内容
我们的scraper不会加载此内容,因为它不会运行加载它所需的JavaScript
您的浏览器运行JavaScript并正常加载任何内容,我们将使用第二个爬网库(称为selenium)来实现这一点
Selenium库不包括其浏览器;您需要安装第三方浏览器(或web驱动程序)才能工作。这是对浏览器本身的补充
您可以选择chrome、Firefox、safari或edge
如果您安装了这些驱动程序中的任何一个,例如chrome,它将打开一个浏览器实例并加载您的页面,然后您可以抓取页面或与页面交互
Python web爬虫教程:将chrome驱动程序与selenium结合使用
首先,应按如下方式安装selenium库:
$ pip install selenium
然后您应该从这里下载chrome驱动程序,并将其下载到您的系统路径
现在,您可以这样加载页面,如以下Python网页捕获示例所示:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get("https://www.python.org/";)
nav = browser.find_element_by_id("mainnav")
print(nav.text)
结果如下:
 https://www.lsbin.com/wp-conte ... 7.png 300w" />
https://www.lsbin.com/wp-conte ... 7.png 300w" />这很简单,不是吗
我们不与页面元素交互,所以我们还没有看到selenium的强大功能。等等
Python如何抓取网页?使用selenium+phantom JS
您可能喜欢使用浏览器驱动程序,但更多的人喜欢在后台运行代码,而看不到实际操作
因此,有一个很棒的工具叫做phantom JS,它可以在不打开任何浏览器的情况下加载页面并运行代码
Phantom JS使您能够轻松地与捕获的页面cookie和JavaScript交互
此外,您还可以像BeautifulSoup一样使用它来抓取这些页面中的页面和元素
从这里下载phantom JS并将其放在您的路径中,以便我们可以将其用作selenium的Web驱动程序
现在,让我们使用selenium和phantom JS抓取网页,就像使用Chrome web驱动程序一样
from selenium import webdriver
browser = webdriver.PhantomJS()
browser.get("https://www.python.org/";)
print(browser.find_element_by_class_name("introduction").text)
browser.close()
结果是:
 https://www.lsbin.com/wp-conte ... 5.png 300w, https://www.lsbin.com/wp-conte ... 5.png 768w" />
https://www.lsbin.com/wp-conte ... 5.png 300w, https://www.lsbin.com/wp-conte ... 5.png 768w" />太棒了!!它工作得很好
您可以通过多种方式访问}元素:
browser.find_element_by_id("id")
browser.find_element_by_css_selector("#id")
browser.find_element_by_link_text("Click Here")
browser.find_element_by_name("Home")
所有这些函数只返回一个元素;可以使用此元素返回多个元素:
browser.find_elements_by_id("id")
browser.find_elements_by_css_selector("#id")
browser.find_elements_by_link_text("Click Here")
browser.find_elements_by_name("Home")
硒页\来源
您可以像这样使用页面uSource对selenium返回的内容使用beautiful soup的强大功能,如以下Python网页捕获代码示例所示:
from selenium import webdriver
from bs4 import BeautifulSoup
browser = webdriver.PhantomJS()
browser.get("https://www.python.org/";)
page = BeautifulSoup(browser.page_source,"html5lib")
links = page.findAll("a")
for link in links:
print(link)
browser.close()
结果是:
 https://www.lsbin.com/wp-conte ... 2.png 300w, https://www.lsbin.com/wp-conte ... 2.png 1024w, https://www.lsbin.com/wp-conte ... 9.png 768w" />
https://www.lsbin.com/wp-conte ... 2.png 300w, https://www.lsbin.com/wp-conte ... 2.png 1024w, https://www.lsbin.com/wp-conte ... 9.png 768w" />如您所见,phantom JS使抓取HTML元素变得非常容易。让我们看更多
使用selenium捕获iframe内容
您抓取的页面可能收录收录数据的iframe
如果您试图抓取收录iframe的页面,您将无法获取iframe内容;您需要获取iframe源代码
您可以使用selenium切换到要抓取的帧以抓取iframe
from selenium import webdriver
browser = webdriver.PhantomJS()
browser.get("https://developer.mozilla.org/ ... 6quot;)
iframe = browser.find_element_by_tag_name("iframe")
browser.switch_to.default_content()
browser.switch_to.frame(iframe)
iframe_source = browser.page_source
print(iframe_source) #returns iframe source
print(browser.current_url) #returns iframe URL
结果是:
 https://www.lsbin.com/wp-conte ... 1.png 300w, https://www.lsbin.com/wp-conte ... 7.png 1024w, https://www.lsbin.com/wp-conte ... 8.png 768w" />
https://www.lsbin.com/wp-conte ... 1.png 300w, https://www.lsbin.com/wp-conte ... 7.png 1024w, https://www.lsbin.com/wp-conte ... 8.png 768w" />查看当前网站;它是iframe URL,而不是原创页面
Python如何抓取网页?使用靓汤抓取iframe内容
可以通过find函数获取iframe的URL;然后您可以放弃该URL
from urllib.request import urlopen
from urllib.error import HTTPError
from urllib.error import URLError
from bs4 import BeautifulSoup
try:
html = urlopen("https://developer.mozilla.org/ ... 6quot;)
except HTTPError as e:
print(e)
except URLError:
print("Server down or incorrect domain")
else:
res = BeautifulSoup(html.read(), "html5lib")
tag = res.find("iframe")
print(tag['src']) #URl of iframe ready for scraping
太棒了!!这里我们使用另一种技术从页面抓取iframe内容
使用(selenium+phantom JS)处理Ajax调用
在Ajax调用之后,您可以使用selenium获取内容
这就像点击一个按钮来获取你需要的东西。检查以下Python网页抓取示例:
from selenium import webdriver
import time
browser = webdriver.PhantomJS()
browser.get("https://www.w3schools.com/xml/ajax_intro.asp";)
browser.find_element_by_tag_name("button").click()
time.sleep(2) #Explicit wait
browser.get_screenshot_as_file("image.png")
browser.close()
结果是:
 https://www.lsbin.com/wp-conte ... 0.png 296w" />
https://www.lsbin.com/wp-conte ... 0.png 296w" />在这里,我们抓取一个收录按钮的页面,然后单击按钮,它将调用Ajax并获取文本,然后保存页面的屏幕截图
这是一件小事;这是关于等待时间的问题
我们知道页面无法完全加载超过2秒,但这不是一个好的解决方案。服务器可能需要更多的时间,或者由于许多原因,您的连接可能较慢
使用phantom JS等待Ajax调用完成
最好的解决方案是检查最终页面上是否有HTML元素。如果是,则表示Ajax调用已成功完成
检查此Python网页抓取代码示例:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
browser = webdriver.PhantomJS()
browser.get("https://resttesttest.com/";)
browser.find_element_by_id("submitajax").click()
try:
element = WebDriverWait(browser, 10).until(EC.text_to_be_present_in_element((By.ID, "statuspre"),"HTTP 200 OK"))
finally:
browser.get_screenshot_as_file("image.png")
browser.close()
结果是:
 https://www.lsbin.com/wp-conte ... 5.png 300w, https://www.lsbin.com/wp-conte ... 3.png 768w" />
https://www.lsbin.com/wp-conte ... 5.png 300w, https://www.lsbin.com/wp-conte ... 3.png 768w" />在这里,我们单击一个Ajax按钮,该按钮进行rest调用并返回JSON结果
我们检查div元素文本是否为“HTTP200OK”,超时10秒,然后将结果页面保存为图像,如图所示
您可以检查许多内容,例如:
URL更改使用
EC.url_changes()
使用新打开的窗口
EC.new_window_is_opened()
使用以下方法更改标题:
EC.title_is()
如果有任何页面重定向,可以检查标题或URL是否已更改
检查的条件很多,;我们只是一个例子,告诉你你有多大的力量
酷
Python web爬行教程:处理cookie
有时,当您编写爬网代码时,为您爬网的站点处理cookie非常重要
也许您需要删除cookie,或者您需要将其保存在文件中并用于将来的连接
有很多种情况。让我们看看如何处理饼干
要检索当前访问站点的cookie,可以调用如下Cookies()函数:
from selenium import webdriver
browser = webdriver.PhantomJS()
browser.get("https://likegeeks.com/";)
print(browser.get_cookies())
结果是:
 https://www.lsbin.com/wp-conte ... 7.png 300w, https://www.lsbin.com/wp-conte ... 6.png 1024w, https://www.lsbin.com/wp-conte ... 5.png 768w" />
https://www.lsbin.com/wp-conte ... 7.png 300w, https://www.lsbin.com/wp-conte ... 6.png 1024w, https://www.lsbin.com/wp-conte ... 5.png 768w" />要删除cookie,可以使用delete_uuAll_uucookies()函数,如以下Python网页捕获代码示例所示:
from selenium import webdriver
browser = webdriver.PhantomJS()
browser.get("https://likegeeks.com/";)
browser.delete_all_cookies()
Python如何抓取网页?要避免的陷阱
爬行网站最令人失望的是,在查看输出时,即使数据在浏览器中可见,也看不到数据。或者web服务器拒绝提交听起来很好的表单。更糟糕的是,您的IP由于匿名原因被网站阻止
我们将讨论您在使用scripy时可能遇到的最著名的障碍,并认为这些信息很有用,因为它可以帮助您在陷入麻烦之前解决错误和预防问题
做人
难以抓取的网站的基本挑战是,他们已经能够以各种方式(例如使用验证码)区分真人和爬虫
尽管这些网站使用了硬技术来检测抓取,但是有一些变化可以让你的脚本看起来更像一个人
产权调整
设置头的最佳方法之一是使用请求库。HTTP头是每次尝试执行对web服务器的请求时web服务器发送给您的一组属性
大多数浏览器在初始化任何连接时使用以下七个字段:
Host https://www.google.com/
Connection keep-alive
Accept text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
User-Agent Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/
39.0.2171.95 Safari/537.36
Referrer https://www.google.com/
Accept-Encoding gzip, deflate, sdch
Accept-Language en-US,en;q=0.8
接下来是常用Python爬虫库urllib使用的默认头:
Accept-Encoding identity
User-Agent Python-urllib/3.4
这两个标题是唯一真正重要的设置。因此,最好将它们保持在默认值
Python网页捕获示例:JavaScript和cookie处理
解决许多爬行问题的重要方法之一是正确处理cookie。网站使用Cookie跟踪您在网站上的进度的用户还可能使用Cookie来防止具有异常行为(例如浏览过多页面或快速提交表单)的爬网工具,并防止它们在网站上爬网@
如果您的浏览器cookie将您的身份传递给网站,那么更改您的IP地址甚至关闭并重新打开您与网站的连接等解决方案可能是无用的,也是浪费时间
在爬行过程中,Cookies非常重要网站. 有些网站总是要求新版本的cookie,而不是要求再次登录
如果您试图获取一个或多个网站,您应该检查并测试这些网站cookies,并决定需要处理哪个网站
Editthiscookie是可用于检查Cookie的最流行的chrome扩展之一
都是关于时间的
pythonwebcrawler教程:如果你是那种做事太快的人,那么它在爬行时可能不起作用。受高度保护的网站集可能会阻止您提交
php网页抓取工具(用python做过爬虫,爬虫最让人头痛的问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-09-17 13:10
我使用Python作为爬虫。爬虫最麻烦的问题是:网页编码、爬虫效率、源站点的反爬虫策略以及数千个网页。网站在不同地区使用的代码有时是不同的。当然,即使是同一个网站也可能使用两个或两个以上的GBK和UTF-8代码,这完全取决于网页制作者(有时是制作者使用的编辑器)的偏好,疏忽也会导致编码问题
在我的业余时间,我碰巧手头没有东西。是时候更新博客了。使用PHP获取网页的标题部分。请注意,这是标题部分,涉及代码获取、代码转换和常规使用。当然,这只是一种简单的方法,在获取HTTPS协议网页时会遇到麻烦
下面的代码当然不能忍受网站反爬网策略,也不能用来完成一些困难的任务,例如处理文件、验证、表单提交、文件上传等。要高度定制爬虫程序,更好的解决方案是使用PHP的curl库。Curl是一个功能强大的库,它支持许多不同的协议和选项,并且可以提供与URL请求相关的各种详细信息。稍后,我暂时不讨论这个问题
本文的目的只是描述获取网页标题的过程:访问URL->;获取web内容->;使用正则表达式提取标题->;代码检测和转换->;显示结果
版本1文件:class.html.php:
取得了成果,达到了以下目的:
京东(JD.COM)-综合网购首选-正品低价、品质保障、配送及时、轻松购物!
美中不足:尽管我们得到了正确的结果,但每次获取网页标题时都需要更改源代码。你能更聪明些吗?答案是肯定的。使用get方法并传入相应的URL值作为GetTitle()的参数。当您需要采集页面标题时,您可以直接在地址栏中修改URL地址
版本2文件:class.html.php
用法:运行类。HTML。PHP?Url=浏览器中的网页Url
本网站使用阿里云服务器。下面有折扣↓
服务器选择|热门特价|新福利|老用户续费 查看全部
php网页抓取工具(用python做过爬虫,爬虫最让人头痛的问题)
我使用Python作为爬虫。爬虫最麻烦的问题是:网页编码、爬虫效率、源站点的反爬虫策略以及数千个网页。网站在不同地区使用的代码有时是不同的。当然,即使是同一个网站也可能使用两个或两个以上的GBK和UTF-8代码,这完全取决于网页制作者(有时是制作者使用的编辑器)的偏好,疏忽也会导致编码问题
在我的业余时间,我碰巧手头没有东西。是时候更新博客了。使用PHP获取网页的标题部分。请注意,这是标题部分,涉及代码获取、代码转换和常规使用。当然,这只是一种简单的方法,在获取HTTPS协议网页时会遇到麻烦
下面的代码当然不能忍受网站反爬网策略,也不能用来完成一些困难的任务,例如处理文件、验证、表单提交、文件上传等。要高度定制爬虫程序,更好的解决方案是使用PHP的curl库。Curl是一个功能强大的库,它支持许多不同的协议和选项,并且可以提供与URL请求相关的各种详细信息。稍后,我暂时不讨论这个问题
本文的目的只是描述获取网页标题的过程:访问URL->;获取web内容->;使用正则表达式提取标题->;代码检测和转换->;显示结果
版本1文件:class.html.php:
取得了成果,达到了以下目的:
京东(JD.COM)-综合网购首选-正品低价、品质保障、配送及时、轻松购物!
美中不足:尽管我们得到了正确的结果,但每次获取网页标题时都需要更改源代码。你能更聪明些吗?答案是肯定的。使用get方法并传入相应的URL值作为GetTitle()的参数。当您需要采集页面标题时,您可以直接在地址栏中修改URL地址
版本2文件:class.html.php
用法:运行类。HTML。PHP?Url=浏览器中的网页Url
本网站使用阿里云服务器。下面有折扣↓
服务器选择|热门特价|新福利|老用户续费
php网页抓取工具(58手机号码识别插件和百度翻译插件的用法(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2021-10-14 20:13
使用优采云采集器时,也会用到插件。优采云采集器将采集的数据传递给外部程序,我们称之为插件,然后插件处理数据,再将数据返回给采集器@ >.
优采云采集器V9支持PHP和C#编写插件,V9支持插件源码编辑。网页数据爬取工具优采云采集器的插件可应用于采集结果、HTTP请求、文件下载的处理。您可以在插件设置时从插件管理器的下拉框中选择一个现有的插件来实现特定的应用。
用58手机号码识别插件和百度翻译插件来说明一下用法。
58个插件演示:
(1)首先需要把插件58验证码V9.dll放入采集器的Plugins目录下
(2)然后在“其他设置-插件-采集结果处理插件”中选择这个插件。
(3)最后需要创建一个名为“手机号”的标签,从采集到58手机号的图片地址,这样在运行时采集器会自动调用插件 图片转义后输出为数字文本。
翻译插件演示:
(1)首先我们要把插件百度翻译.dll放到采集器的Plugins目录下
(2)然后在“其他设置-插件-采集结果处理插件”中选择这个插件。
(3)最后,我们需要创建一个名为“translation tag”的标签,将需要翻译的字段名称写成固定字符串的形式。
然后创建一个名为“Translation Reverse”的标签,将翻译语言写成固定字符串的形式,比如将中文翻译成英文,代码:zh>en(zh表示中文,en表示英文,这种语言代码是在使用前检查)。此操作后,运行时优采云采集器V9会自动调用插件进行翻译。
借助插件,我们可以使用优采云采集器来完成更复杂的任务。在采集器中,除了使用已有的插件,我们还可以编写需要的插件来使用,非技术人员可以联系官方定制插件。 查看全部
php网页抓取工具(58手机号码识别插件和百度翻译插件的用法(组图))
使用优采云采集器时,也会用到插件。优采云采集器将采集的数据传递给外部程序,我们称之为插件,然后插件处理数据,再将数据返回给采集器@ >.
优采云采集器V9支持PHP和C#编写插件,V9支持插件源码编辑。网页数据爬取工具优采云采集器的插件可应用于采集结果、HTTP请求、文件下载的处理。您可以在插件设置时从插件管理器的下拉框中选择一个现有的插件来实现特定的应用。
用58手机号码识别插件和百度翻译插件来说明一下用法。
58个插件演示:
(1)首先需要把插件58验证码V9.dll放入采集器的Plugins目录下
(2)然后在“其他设置-插件-采集结果处理插件”中选择这个插件。
(3)最后需要创建一个名为“手机号”的标签,从采集到58手机号的图片地址,这样在运行时采集器会自动调用插件 图片转义后输出为数字文本。
翻译插件演示:
(1)首先我们要把插件百度翻译.dll放到采集器的Plugins目录下
(2)然后在“其他设置-插件-采集结果处理插件”中选择这个插件。
(3)最后,我们需要创建一个名为“translation tag”的标签,将需要翻译的字段名称写成固定字符串的形式。
然后创建一个名为“Translation Reverse”的标签,将翻译语言写成固定字符串的形式,比如将中文翻译成英文,代码:zh>en(zh表示中文,en表示英文,这种语言代码是在使用前检查)。此操作后,运行时优采云采集器V9会自动调用插件进行翻译。
借助插件,我们可以使用优采云采集器来完成更复杂的任务。在采集器中,除了使用已有的插件,我们还可以编写需要的插件来使用,非技术人员可以联系官方定制插件。
php网页抓取工具( WebSpider蓝蜘蛛网页抓取工具5.1可以抓取任何网页(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-10-13 07:03
WebSpider蓝蜘蛛网页抓取工具5.1可以抓取任何网页(组图))
WebSpider 蓝蜘蛛爬网工具5.1 可以抓取互联网上的任何网页,wap网站,包括登录后才能访问的页面。分析抓取的页面内容,获取结构化信息,如如新闻标题、作者、来源、正文等。支持列表页自动翻页抓取、文本页多页合并、图片文件抓取。它可以抓取静态网页或带参数的动态网页。功能极其强大。
用户指定要爬取的网站、要爬取的网页类型(固定页面、分页展示页面等),并配置如何解析数据项(如新闻标题、作者、来源、 body等),系统可以根据配置信息实时自动采集数据,也可以通过配置设置开始采集的时间,真正做到“按需采集,一个配置,和永久捕获”。捕获的数据可以保存在数据库中。支持当前主流数据库,包括:Oracle、SQL Server、MySQL等。
该工具可以完全取代传统的编辑人工信息处理模式。能够实时、准确、24*60全天候为企业提供最新信息和情报,真正为企业降低成本,提高竞争力。
该工具的主要特点如下:
*适用范围广,可以抓取任何网页(包括登录后可以访问的网页)
* 处理速度快,如果网络畅通,1小时可抓取解析10000个网页
*采用独特的重复数据过滤技术,支持增量数据采集,可实时采集数据,如:股票交易信息、天气预报等。
*抓取信息准确率高,系统提供强大的数据校验功能,保证数据的正确性
*支持断点连续抓取。发生崩溃或异常情况后,可以恢复抓取,继续后续抓取工作,提高系统抓取效率
*对于列表页,支持翻页,可以读取所有列表页中的数据。对于文本页面,可以自动合并页面上显示的内容;
*支持页面深度爬取,可在页面之间逐层爬取。比如通过列表页面抓取body页面的URL,然后再抓取body页面。各级页面可单独存放;
*WEB操作界面,一站式安装,随处使用
*分步分析,分步存储
* 配置一次,永久抓取,一劳永逸 查看全部
php网页抓取工具(
WebSpider蓝蜘蛛网页抓取工具5.1可以抓取任何网页(组图))
WebSpider 蓝蜘蛛爬网工具5.1 可以抓取互联网上的任何网页,wap网站,包括登录后才能访问的页面。分析抓取的页面内容,获取结构化信息,如如新闻标题、作者、来源、正文等。支持列表页自动翻页抓取、文本页多页合并、图片文件抓取。它可以抓取静态网页或带参数的动态网页。功能极其强大。
用户指定要爬取的网站、要爬取的网页类型(固定页面、分页展示页面等),并配置如何解析数据项(如新闻标题、作者、来源、 body等),系统可以根据配置信息实时自动采集数据,也可以通过配置设置开始采集的时间,真正做到“按需采集,一个配置,和永久捕获”。捕获的数据可以保存在数据库中。支持当前主流数据库,包括:Oracle、SQL Server、MySQL等。
该工具可以完全取代传统的编辑人工信息处理模式。能够实时、准确、24*60全天候为企业提供最新信息和情报,真正为企业降低成本,提高竞争力。
该工具的主要特点如下:
*适用范围广,可以抓取任何网页(包括登录后可以访问的网页)
* 处理速度快,如果网络畅通,1小时可抓取解析10000个网页
*采用独特的重复数据过滤技术,支持增量数据采集,可实时采集数据,如:股票交易信息、天气预报等。
*抓取信息准确率高,系统提供强大的数据校验功能,保证数据的正确性
*支持断点连续抓取。发生崩溃或异常情况后,可以恢复抓取,继续后续抓取工作,提高系统抓取效率
*对于列表页,支持翻页,可以读取所有列表页中的数据。对于文本页面,可以自动合并页面上显示的内容;
*支持页面深度爬取,可在页面之间逐层爬取。比如通过列表页面抓取body页面的URL,然后再抓取body页面。各级页面可单独存放;
*WEB操作界面,一站式安装,随处使用
*分步分析,分步存储
* 配置一次,永久抓取,一劳永逸
php网页抓取工具(PHP解析器和PHP相比较,python适合做爬虫吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 99 次浏览 • 2021-10-12 09:20
对比python和PHP,python适合爬取。原因如下
抓取网页本身的界面
与java、c#、C++、python等其他静态编程语言相比,抓取网页文档的界面更加简洁;相对于其他动态脚本语言,如 perl、shell、python,urllib2 包提供了更完整的 Web 文档 API 访问。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站都是为了生硬爬取而被屏蔽的。这就是我们需要模拟用户代理的行为来构造合适的请求的地方,比如模拟用户登录,模拟session/cookies的存储和设置。python中有很好的第三方包帮你搞定,比如Requests,mechanize
爬行后处理
抓取到的网页通常需要进行处理,如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用很短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要python。
py对linux来说功能很强大,语言也很简单。
NO.1 快速开发(唯一能比python开发效率更高的语言是rudy) 语言简洁,没有那么多技巧,所以非常清晰易读。
NO.2 跨平台(由于python的开源,比java更能体现“一次编写,到处运行”
NO.3 解释(无需直接编译、运行/调试代码)
NO.4 框架选择太多(主要的GUI框架有wxPython、tkInter、PyGtk、PyQt。
PHP脚本主要用于以下三个方面:
服务器端脚本。这是PHP最传统也是最主要的目标领域。要进行这项工作,需要具备以下三点:PHP解析器(CGI或服务器模块)、Web
服务器和网络浏览器。运行web服务器时需要安装配置PHP,然后可以使用web浏览器访问PHP程序的输出,即浏览服务
PHP 页面在最后。如果您只是在尝试 PHP 编程,所有这些都可以在您的家用计算机上运行。有关更多信息,请参阅安装章节。命令行脚本。
您可以编写一个 PHP 脚本,并且不需要任何服务器或浏览器来运行它。这样,只需要PHP解析器就可以执行。这种用法是
是 cron(Unix 或 Linux 环境)或 Task Scheduler(Windows 环境)日常运行脚本的理想选择。这些脚本也可用于处理
管理简单的文本。更多信息请参考 PHP 的命令行模式。编写桌面应用程序。对于具有图形界面的桌面应用程序,PHP 可能不会
最好的语言之一,但是如果用户非常精通PHP并且想在客户端应用程序中使用PHP的一些高级功能,他们可以使用PHP-GTK来编写这个
这些程序。这样,您也可以编写跨平台的应用程序。PHP-GTK 是 PHP 的扩展,通常发布的 PHP 包中不收录它。
网友的观点扩大了:
我用PHP Node.js Python写了一个爬虫脚本,简单说一下。
首先PHP。先说优点:网上大量爬取解析html框架,各种工具都可以直接使用,比较省心。缺点:首先,速度/效率是个问题。有一次下载电影海报的时候,因为crontab定时执行,没有优化,打开的php进程太多,直接导致内存爆了。然后语法也很拖沓,各种关键词符号太多,不够简洁,给人一种没有精心设计的感觉,写起来很麻烦。
节点.js。优点是效率,效率还是效率。因为网络是异步的,所以基本上和并发数百个进程一样强大。内存和CPU使用量非常小。如果对捕获的数据没有进行复杂的计算和处理,那么系统就会成为瓶颈。基本上就是写入MySQL等数据库的带宽和I/O速度。当然,优点的反面也是缺点。异步网络意味着您需要回调。这时候,如果业务需求是线性的,比如你必须等上一页爬完,拿到数据后才能爬到下一页,甚至更多。层依赖,会有可怕的多层回调!基本上这个时候代码结构和逻辑就会乱了。当然,
最后,让我们谈谈Python。如果你对效率没有极端的要求,那么推荐Python!首先,Python 的语法非常简洁,同一个句子可以少打很多次。然后,Python非常适合数据处理,比如函数参数的打包和解包,列表分析,矩阵处理,非常方便。
至此,这篇关于python和php更适合爬取文章的文章介绍到这里。更多适合爬取内容的php和python相关内容,请搜索服务器之家之前的文章或继续浏览下面的相关文章,希望大家多多支持服务器之家未来!
原文链接: 查看全部
php网页抓取工具(PHP解析器和PHP相比较,python适合做爬虫吗?)
对比python和PHP,python适合爬取。原因如下
抓取网页本身的界面
与java、c#、C++、python等其他静态编程语言相比,抓取网页文档的界面更加简洁;相对于其他动态脚本语言,如 perl、shell、python,urllib2 包提供了更完整的 Web 文档 API 访问。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站都是为了生硬爬取而被屏蔽的。这就是我们需要模拟用户代理的行为来构造合适的请求的地方,比如模拟用户登录,模拟session/cookies的存储和设置。python中有很好的第三方包帮你搞定,比如Requests,mechanize
爬行后处理
抓取到的网页通常需要进行处理,如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用很短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要python。
py对linux来说功能很强大,语言也很简单。
NO.1 快速开发(唯一能比python开发效率更高的语言是rudy) 语言简洁,没有那么多技巧,所以非常清晰易读。
NO.2 跨平台(由于python的开源,比java更能体现“一次编写,到处运行”
NO.3 解释(无需直接编译、运行/调试代码)
NO.4 框架选择太多(主要的GUI框架有wxPython、tkInter、PyGtk、PyQt。
PHP脚本主要用于以下三个方面:
服务器端脚本。这是PHP最传统也是最主要的目标领域。要进行这项工作,需要具备以下三点:PHP解析器(CGI或服务器模块)、Web
服务器和网络浏览器。运行web服务器时需要安装配置PHP,然后可以使用web浏览器访问PHP程序的输出,即浏览服务
PHP 页面在最后。如果您只是在尝试 PHP 编程,所有这些都可以在您的家用计算机上运行。有关更多信息,请参阅安装章节。命令行脚本。
您可以编写一个 PHP 脚本,并且不需要任何服务器或浏览器来运行它。这样,只需要PHP解析器就可以执行。这种用法是
是 cron(Unix 或 Linux 环境)或 Task Scheduler(Windows 环境)日常运行脚本的理想选择。这些脚本也可用于处理
管理简单的文本。更多信息请参考 PHP 的命令行模式。编写桌面应用程序。对于具有图形界面的桌面应用程序,PHP 可能不会
最好的语言之一,但是如果用户非常精通PHP并且想在客户端应用程序中使用PHP的一些高级功能,他们可以使用PHP-GTK来编写这个
这些程序。这样,您也可以编写跨平台的应用程序。PHP-GTK 是 PHP 的扩展,通常发布的 PHP 包中不收录它。
网友的观点扩大了:
我用PHP Node.js Python写了一个爬虫脚本,简单说一下。
首先PHP。先说优点:网上大量爬取解析html框架,各种工具都可以直接使用,比较省心。缺点:首先,速度/效率是个问题。有一次下载电影海报的时候,因为crontab定时执行,没有优化,打开的php进程太多,直接导致内存爆了。然后语法也很拖沓,各种关键词符号太多,不够简洁,给人一种没有精心设计的感觉,写起来很麻烦。
节点.js。优点是效率,效率还是效率。因为网络是异步的,所以基本上和并发数百个进程一样强大。内存和CPU使用量非常小。如果对捕获的数据没有进行复杂的计算和处理,那么系统就会成为瓶颈。基本上就是写入MySQL等数据库的带宽和I/O速度。当然,优点的反面也是缺点。异步网络意味着您需要回调。这时候,如果业务需求是线性的,比如你必须等上一页爬完,拿到数据后才能爬到下一页,甚至更多。层依赖,会有可怕的多层回调!基本上这个时候代码结构和逻辑就会乱了。当然,
最后,让我们谈谈Python。如果你对效率没有极端的要求,那么推荐Python!首先,Python 的语法非常简洁,同一个句子可以少打很多次。然后,Python非常适合数据处理,比如函数参数的打包和解包,列表分析,矩阵处理,非常方便。
至此,这篇关于python和php更适合爬取文章的文章介绍到这里。更多适合爬取内容的php和python相关内容,请搜索服务器之家之前的文章或继续浏览下面的相关文章,希望大家多多支持服务器之家未来!
原文链接:
php网页抓取工具( 抓ajax异步内容的页面和抓普通的异步区别不大 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 133 次浏览 • 2021-10-12 09:19
抓ajax异步内容的页面和抓普通的异步区别不大
)
PHP curl 抓取AJAX异步内容示例
更新时间:2014-09-09 17:51:21 投稿:whsnow
用ajax异步内容抓取页面和抓取普通页面没有太大区别。 Ajax只是一个异步http请求,下面的例子,可以参考下
其实抓取ajax异步内容页面和抓取普通页面没有太大区别。 Ajax 只是一个异步 http 请求。用类似firebug的工具,找到请求的后端服务url和传参值,然后抓取url传参即可。
使用 Firebug 的网络工具
如果抓取一个页面,内容中没有显示的数据就是一堆JS代码。
代码
$cookie_file=tempnam('./temp','cookie');
$ch = curl_init();
$url1 = "http://www.cdut.edu.cn/default.html";
curl_setopt($ch,CURLOPT_URL,$url1);
curl_setopt($ch,CURLOPT_HTTP_VERSION,CURL_HTTP_VERSION_1_1);
curl_setopt($ch,CURLOPT_HEADER,0);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch,CURLOPT_FOLLOWLOCATION,1);
curl_setopt($ch, CURLOPT_ENCODING ,'gzip'); //加入gzip解析
//设置连接结束后保存cookie信息的文件
curl_setopt($ch,CURLOPT_COOKIEJAR,$cookie_file);
$content=curl_exec($ch);
curl_close($ch);
$ch3 = curl_init();
$url3 = "http://www.cdut.edu.cn/xww/dwr ... 3B%3B
$curlPost = "callCount=1&page=/xww/type/1000020118.html&httpSessionId=12A9B726E6A2D4D3B09DE7952B2F282C&scriptSessionId=295315B4B4141B09DA888D3A3ADB8FAA658&c0-scriptName=portalAjax&c0-methodName=getNewsXml&c0-id=0&c0-param0=string:10000201&c0-param1=string:1000020118&c0-param2=string:news_&c0-param3=number:5969&c0-param4=number:1&c0-param5=null:null&c0-param6=null:null&batchId=0";
curl_setopt($ch3,CURLOPT_URL,$url3);
curl_setopt($ch3,CURLOPT_POST,1);
curl_setopt($ch3,CURLOPT_POSTFIELDS,$curlPost);
//设置连接结束后保存cookie信息的文件
curl_setopt($ch3,CURLOPT_COOKIEFILE,$cookie_file);
$content1=curl_exec($ch3);
curl_close($ch3); 查看全部
php网页抓取工具(
抓ajax异步内容的页面和抓普通的异步区别不大
)
PHP curl 抓取AJAX异步内容示例
更新时间:2014-09-09 17:51:21 投稿:whsnow
用ajax异步内容抓取页面和抓取普通页面没有太大区别。 Ajax只是一个异步http请求,下面的例子,可以参考下
其实抓取ajax异步内容页面和抓取普通页面没有太大区别。 Ajax 只是一个异步 http 请求。用类似firebug的工具,找到请求的后端服务url和传参值,然后抓取url传参即可。
使用 Firebug 的网络工具
如果抓取一个页面,内容中没有显示的数据就是一堆JS代码。
代码
$cookie_file=tempnam('./temp','cookie');
$ch = curl_init();
$url1 = "http://www.cdut.edu.cn/default.html";
curl_setopt($ch,CURLOPT_URL,$url1);
curl_setopt($ch,CURLOPT_HTTP_VERSION,CURL_HTTP_VERSION_1_1);
curl_setopt($ch,CURLOPT_HEADER,0);
curl_setopt($ch,CURLOPT_RETURNTRANSFER,1);
curl_setopt($ch,CURLOPT_FOLLOWLOCATION,1);
curl_setopt($ch, CURLOPT_ENCODING ,'gzip'); //加入gzip解析
//设置连接结束后保存cookie信息的文件
curl_setopt($ch,CURLOPT_COOKIEJAR,$cookie_file);
$content=curl_exec($ch);
curl_close($ch);
$ch3 = curl_init();
$url3 = "http://www.cdut.edu.cn/xww/dwr ... 3B%3B
$curlPost = "callCount=1&page=/xww/type/1000020118.html&httpSessionId=12A9B726E6A2D4D3B09DE7952B2F282C&scriptSessionId=295315B4B4141B09DA888D3A3ADB8FAA658&c0-scriptName=portalAjax&c0-methodName=getNewsXml&c0-id=0&c0-param0=string:10000201&c0-param1=string:1000020118&c0-param2=string:news_&c0-param3=number:5969&c0-param4=number:1&c0-param5=null:null&c0-param6=null:null&batchId=0";
curl_setopt($ch3,CURLOPT_URL,$url3);
curl_setopt($ch3,CURLOPT_POST,1);
curl_setopt($ch3,CURLOPT_POSTFIELDS,$curlPost);
//设置连接结束后保存cookie信息的文件
curl_setopt($ch3,CURLOPT_COOKIEFILE,$cookie_file);
$content1=curl_exec($ch3);
curl_close($ch3);
php网页抓取工具(php网页抓取工具|charlesword-php-me-long-follower-scraper-real-time-json-get-scraper)
网站优化 • 优采云 发表了文章 • 0 个评论 • 61 次浏览 • 2021-10-12 03:03
php网页抓取工具|charlesword-php-me-long-follower-scraper-real-time-json-get-scraper
这个是老生常谈了,phpscraper,
自己更新一下哈(还有某些c++、java网站地址删除)。
reactui,
cordova,qtcreator,都是国内知名公司用来做网站的
推荐一个python的web框架/可以批量下载中国市场最新的网页源码
github-sheeq656/graphqljs:openstyle.mxpi,novahttpd,inkscape,inkscapeandreactjswebserverforpythondevelopers
使用pythondownloadtecho的apishell可以下载网页源码的,
/python-download-techo可以用来下载本地文件,同时不需要ssl证书。
很多的方法,比如用sqlalchemy比如用iwswitch,gayhub上面也有很多django的例子比如说ppt下载有pdf下载有各种weblinux下的vi都可以自己fork来试试吧,不然怎么知道自己在做哪方面的事情和选择网站的语言。python也是很多好东西的,可以多google,搜搜pythonreact什么的。 查看全部
php网页抓取工具(php网页抓取工具|charlesword-php-me-long-follower-scraper-real-time-json-get-scraper)
php网页抓取工具|charlesword-php-me-long-follower-scraper-real-time-json-get-scraper
这个是老生常谈了,phpscraper,
自己更新一下哈(还有某些c++、java网站地址删除)。
reactui,
cordova,qtcreator,都是国内知名公司用来做网站的
推荐一个python的web框架/可以批量下载中国市场最新的网页源码
github-sheeq656/graphqljs:openstyle.mxpi,novahttpd,inkscape,inkscapeandreactjswebserverforpythondevelopers
使用pythondownloadtecho的apishell可以下载网页源码的,
/python-download-techo可以用来下载本地文件,同时不需要ssl证书。
很多的方法,比如用sqlalchemy比如用iwswitch,gayhub上面也有很多django的例子比如说ppt下载有pdf下载有各种weblinux下的vi都可以自己fork来试试吧,不然怎么知道自己在做哪方面的事情和选择网站的语言。python也是很多好东西的,可以多google,搜搜pythonreact什么的。
php网页抓取工具( php抓取四川大学综合教务网站成绩信息、课程信息以及解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 83 次浏览 • 2021-10-04 15:22
php抓取四川大学综合教务网站成绩信息、课程信息以及解析)
[Php] Curl 模拟登录抓取页面信息
本项目中,使用php抓取四川大学综合教务网站登录用户的成绩信息、课程信息和基本信息,分析数据并存入数据库,实现进一步分析获取的信息,并呈现给用户。
本文主要记录使用curl模拟登录、获取cookie和进行数据抓取的过程。
curl 的基本特性:使用 curlInitialize 一个 curl 句柄完成请求的简单步骤
资源 curl_init ([ string $url = NULL]) 设置 curl 选项
bool curl_setopt (resource $ch, int $option, mixed $value) 执行 curl 请求
混合 curl_exec (resource $ch) 释放 curl 资源
void curl_close(resource $ch) 详细实现步骤
1. 初始化卷曲句柄
初始化一个新会话并返回接下来三个步骤的 curl 句柄:curl_setopt、curl_exec 和 curl_close。
代码:
//设置请求所需信息
$userzjh = "XXXXXX";
$usermm = "XXXXXX";
$request = "mm=$usermm&zjh=$userzjh";
$cookie_jar = tempnam('./tmp','cookie'); //设置cookie文件的保存位置
$curl = curl_init(); //初始化,获得curl句柄
2.设置卷曲选项
使用 curl_setopt 函数设置 curl 对应的传输选项。
该函数收录三个参数:resource $ch、int $option、mixed $value
第一个参数是第一步初始化的curl句柄,第二个参数是要设置的选项,第三个参数是选项的值。
一些curl选项和可选值的对应表如下:
选项选项描述值值
CURLOPT_URL
设置你想用PHP检索的URL地址,即你想从中获取信息的页面地址。(注:非登录地址)
网址
CURLOPT_POST
设置为使用POST发送数据
真假
CURLOPT_POSTFIELDS
发送后传所需的数据(内容格式可通过抓包工具或浏览器开发工具获取)
内容
CURLOPT_COOKIEJAR
将 cookie 信息保存到文件
保存文件地址
CURLOPT_RETURNTRANSFER
将 curl_exec() 获取的信息以文件流的形式返回,而不是直接输出
真假
CURLOPT_HEADER
启用后,头文件信息将作为数据流输出。头文件信息收录登录是否成功、重定向URL等信息。
真假
CURLOPT_COOKIEFILE
传递一个收录 cookie 数据文件名的字符串
文档名称
代码:
curl_setopt($curl,CURLOPT_URL,'http://zhjw.scu.edu.cn/loginAction.do'); //要抓取的页面url
curl_setopt($curl, CURLOPT_POST, 1); //使用post传输数据
curl_setopt($curl, CURLOPT_POSTFIELDS, $request); //传递数据
curl_setopt($curl, CURLOPT_COOKIEJAR, $cookie_jar); //把返回来的cookie信息保存在$cookie_jar文件中
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1); //设定返回的数据是否自动显示
curl_setopt($curl, CURLOPT_HEADER, false); //设定是否显示头信息
3.执行 curl 请求
设置所需选项的值后,执行请求并获取返回结果。
$result = curl_exec($curl);
//若设置CURLOPT_HEADER为true,此处$result中保存头信息
if (curl_errno($curl)) //判断是否执行成功
{
echo 'Errno'.curl_error($curl);
}
4.发布curl资源
curl_close($curl); //关闭会话
完整代码
//设置请求所需信息
$userzjh = "XXXXXX";
$usermm = "XXXXXX";
$request = "mm=$usermm&zjh=$userzjh";
$cookie_jar = tempnam('./tmp','cookie'); //设置cookie文件的保存位置
$curl = curl_init(); //初始化,获得curl句柄
curl_setopt($curl,CURLOPT_URL,'http://zhjw.scu.edu.cn/loginAction.do'); //要抓取的页面url
curl_setopt($curl, CURLOPT_POST, 1); //使用post传输数据
curl_setopt($curl, CURLOPT_POSTFIELDS, $request); //传递数据
curl_setopt($curl, CURLOPT_COOKIEJAR, $cookie_jar); //把返回来的cookie信息保存在$cookie_jar文件中
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1); //设定返回的数据是否自动显示
curl_setopt($curl, CURLOPT_HEADER, false); //设定是否显示头信息
$result = curl_exec($curl);
//若设置CURLOPT_HEADER为true,此处$result中保存头信息
if (curl_errno($curl)) //判断是否执行成功
{
echo 'Errno'.curl_error($curl);
}
curl_close($curl); //关闭会话
//获取学籍信息
$curl4 = curl_init(); //重新建立一个会话
$url = 'http://zhjw.scu.edu.cn/xjInfoA ... 3B%3B
curl_setopt($curl4,CURLOPT_URL,$url);
curl_setopt($curl4,CURLOPT_COOKIEFILE,$cookie_jar);
curl_setopt($curl4,CURLOPT_RETURNTRANSFER,1);
$content = curl_exec($curl4);
curl_close($curl4);
file_put_contents("./xueji.txt",$content); //将html页面内容保存在文件中,用于后续分析
登录后,您可以获取服务器发送的会话 ID。此会话 ID 收录在每个后续请求的 cookie(客户端)中。用于读取服务器端对应的会话,识别用户身份。
--------------------- 本文来自cocole2的CSDN博客,全文地址请点击: 查看全部
php网页抓取工具(
php抓取四川大学综合教务网站成绩信息、课程信息以及解析)
[Php] Curl 模拟登录抓取页面信息
本项目中,使用php抓取四川大学综合教务网站登录用户的成绩信息、课程信息和基本信息,分析数据并存入数据库,实现进一步分析获取的信息,并呈现给用户。
本文主要记录使用curl模拟登录、获取cookie和进行数据抓取的过程。
curl 的基本特性:使用 curlInitialize 一个 curl 句柄完成请求的简单步骤
资源 curl_init ([ string $url = NULL]) 设置 curl 选项
bool curl_setopt (resource $ch, int $option, mixed $value) 执行 curl 请求
混合 curl_exec (resource $ch) 释放 curl 资源
void curl_close(resource $ch) 详细实现步骤
1. 初始化卷曲句柄
初始化一个新会话并返回接下来三个步骤的 curl 句柄:curl_setopt、curl_exec 和 curl_close。
代码:
//设置请求所需信息
$userzjh = "XXXXXX";
$usermm = "XXXXXX";
$request = "mm=$usermm&zjh=$userzjh";
$cookie_jar = tempnam('./tmp','cookie'); //设置cookie文件的保存位置
$curl = curl_init(); //初始化,获得curl句柄
2.设置卷曲选项
使用 curl_setopt 函数设置 curl 对应的传输选项。
该函数收录三个参数:resource $ch、int $option、mixed $value
第一个参数是第一步初始化的curl句柄,第二个参数是要设置的选项,第三个参数是选项的值。
一些curl选项和可选值的对应表如下:
选项选项描述值值
CURLOPT_URL
设置你想用PHP检索的URL地址,即你想从中获取信息的页面地址。(注:非登录地址)
网址
CURLOPT_POST
设置为使用POST发送数据
真假
CURLOPT_POSTFIELDS
发送后传所需的数据(内容格式可通过抓包工具或浏览器开发工具获取)
内容
CURLOPT_COOKIEJAR
将 cookie 信息保存到文件
保存文件地址
CURLOPT_RETURNTRANSFER
将 curl_exec() 获取的信息以文件流的形式返回,而不是直接输出
真假
CURLOPT_HEADER
启用后,头文件信息将作为数据流输出。头文件信息收录登录是否成功、重定向URL等信息。
真假
CURLOPT_COOKIEFILE
传递一个收录 cookie 数据文件名的字符串
文档名称
代码:
curl_setopt($curl,CURLOPT_URL,'http://zhjw.scu.edu.cn/loginAction.do'); //要抓取的页面url
curl_setopt($curl, CURLOPT_POST, 1); //使用post传输数据
curl_setopt($curl, CURLOPT_POSTFIELDS, $request); //传递数据
curl_setopt($curl, CURLOPT_COOKIEJAR, $cookie_jar); //把返回来的cookie信息保存在$cookie_jar文件中
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1); //设定返回的数据是否自动显示
curl_setopt($curl, CURLOPT_HEADER, false); //设定是否显示头信息
3.执行 curl 请求
设置所需选项的值后,执行请求并获取返回结果。
$result = curl_exec($curl);
//若设置CURLOPT_HEADER为true,此处$result中保存头信息
if (curl_errno($curl)) //判断是否执行成功
{
echo 'Errno'.curl_error($curl);
}
4.发布curl资源
curl_close($curl); //关闭会话
完整代码
//设置请求所需信息
$userzjh = "XXXXXX";
$usermm = "XXXXXX";
$request = "mm=$usermm&zjh=$userzjh";
$cookie_jar = tempnam('./tmp','cookie'); //设置cookie文件的保存位置
$curl = curl_init(); //初始化,获得curl句柄
curl_setopt($curl,CURLOPT_URL,'http://zhjw.scu.edu.cn/loginAction.do'); //要抓取的页面url
curl_setopt($curl, CURLOPT_POST, 1); //使用post传输数据
curl_setopt($curl, CURLOPT_POSTFIELDS, $request); //传递数据
curl_setopt($curl, CURLOPT_COOKIEJAR, $cookie_jar); //把返回来的cookie信息保存在$cookie_jar文件中
curl_setopt($curl, CURLOPT_RETURNTRANSFER, 1); //设定返回的数据是否自动显示
curl_setopt($curl, CURLOPT_HEADER, false); //设定是否显示头信息
$result = curl_exec($curl);
//若设置CURLOPT_HEADER为true,此处$result中保存头信息
if (curl_errno($curl)) //判断是否执行成功
{
echo 'Errno'.curl_error($curl);
}
curl_close($curl); //关闭会话
//获取学籍信息
$curl4 = curl_init(); //重新建立一个会话
$url = 'http://zhjw.scu.edu.cn/xjInfoA ... 3B%3B
curl_setopt($curl4,CURLOPT_URL,$url);
curl_setopt($curl4,CURLOPT_COOKIEFILE,$cookie_jar);
curl_setopt($curl4,CURLOPT_RETURNTRANSFER,1);
$content = curl_exec($curl4);
curl_close($curl4);
file_put_contents("./xueji.txt",$content); //将html页面内容保存在文件中,用于后续分析
登录后,您可以获取服务器发送的会话 ID。此会话 ID 收录在每个后续请求的 cookie(客户端)中。用于读取服务器端对应的会话,识别用户身份。
--------------------- 本文来自cocole2的CSDN博客,全文地址请点击:
php网页抓取工具(php网页抓取工具通过phpdump抓取到结构化的网页数据)
网站优化 • 优采云 发表了文章 • 0 个评论 • 85 次浏览 • 2021-10-02 15:01
php网页抓取工具通过phpdump抓取到结构化的网页数据之后,可以得到完整的数据包括url、path、cookie、html以及json和xml文件。其中json的格式规范化更为合理,容易与php代码对应。尤其是“http://”的方式的url,以及网页标签“/”中的所有标签,都可以实现以php或者sql语言的方式去抓取。
抓取全网所有stackoverflow上的问题,在全站用php抓取。分析到全站共有20w个问题信息,每条问题爬取规定规格的网页页面,随后获取每个用户的问题,从而去重。当时分析wikipedia上wikilet的时候,说正好是18年的最后一周,如果是正常周期,会根据新老url来抓取页面,但是17年对前15的问题没有做过抓取,基本上也就定了要做网页抓取。
用shellcheck来分析,一共12条问题,抓取问题链接如下所示:,17年下半年的重要问题,继续做抓取。问题分析然后分析,wikipedia上提供的18030次的抓取,其中有11次是英文问题,6044次的抓取是英文问题数量最大的提问者。随后提取问题的url,用json格式实现抓取文本文件。这里有一点需要注意,将问题的链接及其下标自动转化为十六进制数值,就会出现问题出现“0-9”中数值序列的情况,要想后面再重新判断问题进行回溯。
因此要提前做这样的处理。这里也顺便做一下提取链接,去重。抓取器爬取器分析好问题,需要上传到github进行打包发布,同时也有tag,而到nofollow。这样的话可以由两个方面进行监测,一是nofollow提问者,二是最新抓取的问题会出现在首页。代码示例connect-php-alipay之前分析wikidot时提到过做nofollow,每个问题用一个独立的follow是个坑,相对于nofollow(大部分加权,其中存在几个权重、wiki有二次加权),现在要修正为multiplenofollow。
定义nofollow=$(php_on_nofollow(php_nofollow,wiki-_wikilet_content,php_post))?multiple:no_multiple_nofollow_list=os.get_screen()->cannot_tolist(u'thewikipediacontent','comments')asnofollow$nofollow=int(os.get_screen()->cannot_tolist(u'thewikipediacontent','comments'))?multiple:no_multiple_nofollow_list=os.get_screen()->cannot_tolist(u'thewikipediacontent','comments')php里面以‘prometheus’为例,可以定义的nofollow:#root/php-alipaypragmaphp^?!*;php_extension_prefix=/php-alipay\\spec\\conf$p。 查看全部
php网页抓取工具(php网页抓取工具通过phpdump抓取到结构化的网页数据)
php网页抓取工具通过phpdump抓取到结构化的网页数据之后,可以得到完整的数据包括url、path、cookie、html以及json和xml文件。其中json的格式规范化更为合理,容易与php代码对应。尤其是“http://”的方式的url,以及网页标签“/”中的所有标签,都可以实现以php或者sql语言的方式去抓取。
抓取全网所有stackoverflow上的问题,在全站用php抓取。分析到全站共有20w个问题信息,每条问题爬取规定规格的网页页面,随后获取每个用户的问题,从而去重。当时分析wikipedia上wikilet的时候,说正好是18年的最后一周,如果是正常周期,会根据新老url来抓取页面,但是17年对前15的问题没有做过抓取,基本上也就定了要做网页抓取。
用shellcheck来分析,一共12条问题,抓取问题链接如下所示:,17年下半年的重要问题,继续做抓取。问题分析然后分析,wikipedia上提供的18030次的抓取,其中有11次是英文问题,6044次的抓取是英文问题数量最大的提问者。随后提取问题的url,用json格式实现抓取文本文件。这里有一点需要注意,将问题的链接及其下标自动转化为十六进制数值,就会出现问题出现“0-9”中数值序列的情况,要想后面再重新判断问题进行回溯。
因此要提前做这样的处理。这里也顺便做一下提取链接,去重。抓取器爬取器分析好问题,需要上传到github进行打包发布,同时也有tag,而到nofollow。这样的话可以由两个方面进行监测,一是nofollow提问者,二是最新抓取的问题会出现在首页。代码示例connect-php-alipay之前分析wikidot时提到过做nofollow,每个问题用一个独立的follow是个坑,相对于nofollow(大部分加权,其中存在几个权重、wiki有二次加权),现在要修正为multiplenofollow。
定义nofollow=$(php_on_nofollow(php_nofollow,wiki-_wikilet_content,php_post))?multiple:no_multiple_nofollow_list=os.get_screen()->cannot_tolist(u'thewikipediacontent','comments')asnofollow$nofollow=int(os.get_screen()->cannot_tolist(u'thewikipediacontent','comments'))?multiple:no_multiple_nofollow_list=os.get_screen()->cannot_tolist(u'thewikipediacontent','comments')php里面以‘prometheus’为例,可以定义的nofollow:#root/php-alipaypragmaphp^?!*;php_extension_prefix=/php-alipay\\spec\\conf$p。
php网页抓取工具(页面抓取频次对百度收录与网站排名有什么影响?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 87 次浏览 • 2021-09-29 13:03
这段时间,关于百度收录的问题一直在SEO你问我答案群热议。长期以来,大量站长反馈相关问题,难免涉及一些基础知识。性问题,例如:页面抓取频率。
大量的SEO从业者认为页面爬行频率高一定是个不错的状态,但有时候我们在分析相关问题的时候,总是分两部分看。
那么,页面抓取频率对百度收录和网站的排名有什么影响呢?
我们将通过以下内容讨论以往SEO网站诊断的历史:
1、函数
在讨论页面爬取频率的时候,首先我们需要简单了解一下它在SEO中的作用,通常我们认为:
① 有利于百度爬虫提高抓取页面的频率,增加百度快速收录的概率。
②有利于防止高权重网站恶意采集,争夺第一收录。
③有利于优先建立索引,快速抢榜,获得头部流量,如:时效性强的内容。
④有利于规律的爬行,在一定的时间节点,养成优良的爬行习惯。
2、 影响
一般来说,当我们谈到页面爬取的频率时,总会有人在思考如何快速提高页面爬取的频率。影响它的主要因素有哪些?我们认为您可能需要参考:
①页率
我们认为影响百度爬虫抓取频率最重要的因素是页面的打开率,包括:服务器响应率、域名解析率、程序加载率。
当然,如果可能的话,我们建议大家开启商用CDN加速,例如:百度云加速。
②更新频率
如果你的网站在特殊时间节点的更新频率异常频繁,我们通常认为是影响百度是否持续访问这个网站的主要影响因素。
一般建议新站的更新频率为每天10次左右,状态至少保持1个月。
③内容质量
我们常说内容为王。诚然,在SEO领域,这是一个更古老、更稳定的原则。长期以来,内容一直是影响百度蜘蛛访问的主要因素。
但我们仍然认为最重要的影响因素是前两个。
3、问题
通常我们在讨论页面爬取频率的时候,总会遇到这样的问题。大家认为页面抓取频率越高越好,我们从以下内容来讨论:
①页面爬取频率增加了,那么网站收录一定很高吧?
从目前的实际测试来看,我们认为页面爬取频率和页面收录没有显着的正相关关系,简单明了:你的页面爬取频率越高,代表该页面的次数就越多收录金额一定很高。
有这样一种情况:
大量的采集站和蜘蛛池网站通常都有大量的索引,即使发布的收录通常都是低质量的库,基于这个页面< @收录 策略带来的,其实没有任何意义。
②网站 高爬取频率对网站的排名有好处吗?
对于这个问题,上一节已经有了一个基本的样子,通常当你的页面爬取频率比较高的时候,让你的页面进入索引库就更容易了。
但是,大量网页进入百度索引库,确定百度收录的数量会增加,两者还是有一定差距的。
有几个异常显着的影响因素,主要包括:
1)页面内容质量,如果高质量的页面元素高频输出,频率可能会很高收录。
2)在达到high收录的同时,我们可能需要满足关键词来匹配特定的搜索要求才能达到较高的排名。
3)页面用户行为指标,即使搜索引擎给出高排名,没有扎实的受众,也很难持续稳定排名。
因此,我们认为页面抓取频率高并不一定意味着它的排名和权重就高网站。
总结:页面抓取频率仅代表爬虫访问频率。搜索引擎对整个网站的“友好”程度还需要进一步识别和分析,才可能影响收录和网站的排名,以上内容仅供参考!
转载黑帽百科需要授权!. 转载请注明出处地址:黑帽SEO专注SEO培训,快速排名 查看全部
php网页抓取工具(页面抓取频次对百度收录与网站排名有什么影响?)
这段时间,关于百度收录的问题一直在SEO你问我答案群热议。长期以来,大量站长反馈相关问题,难免涉及一些基础知识。性问题,例如:页面抓取频率。
大量的SEO从业者认为页面爬行频率高一定是个不错的状态,但有时候我们在分析相关问题的时候,总是分两部分看。
那么,页面抓取频率对百度收录和网站的排名有什么影响呢?
我们将通过以下内容讨论以往SEO网站诊断的历史:
1、函数
在讨论页面爬取频率的时候,首先我们需要简单了解一下它在SEO中的作用,通常我们认为:
① 有利于百度爬虫提高抓取页面的频率,增加百度快速收录的概率。
②有利于防止高权重网站恶意采集,争夺第一收录。
③有利于优先建立索引,快速抢榜,获得头部流量,如:时效性强的内容。
④有利于规律的爬行,在一定的时间节点,养成优良的爬行习惯。
2、 影响
一般来说,当我们谈到页面爬取的频率时,总会有人在思考如何快速提高页面爬取的频率。影响它的主要因素有哪些?我们认为您可能需要参考:
①页率
我们认为影响百度爬虫抓取频率最重要的因素是页面的打开率,包括:服务器响应率、域名解析率、程序加载率。
当然,如果可能的话,我们建议大家开启商用CDN加速,例如:百度云加速。
②更新频率
如果你的网站在特殊时间节点的更新频率异常频繁,我们通常认为是影响百度是否持续访问这个网站的主要影响因素。
一般建议新站的更新频率为每天10次左右,状态至少保持1个月。
③内容质量
我们常说内容为王。诚然,在SEO领域,这是一个更古老、更稳定的原则。长期以来,内容一直是影响百度蜘蛛访问的主要因素。
但我们仍然认为最重要的影响因素是前两个。
3、问题
通常我们在讨论页面爬取频率的时候,总会遇到这样的问题。大家认为页面抓取频率越高越好,我们从以下内容来讨论:
①页面爬取频率增加了,那么网站收录一定很高吧?
从目前的实际测试来看,我们认为页面爬取频率和页面收录没有显着的正相关关系,简单明了:你的页面爬取频率越高,代表该页面的次数就越多收录金额一定很高。
有这样一种情况:
大量的采集站和蜘蛛池网站通常都有大量的索引,即使发布的收录通常都是低质量的库,基于这个页面< @收录 策略带来的,其实没有任何意义。
②网站 高爬取频率对网站的排名有好处吗?
对于这个问题,上一节已经有了一个基本的样子,通常当你的页面爬取频率比较高的时候,让你的页面进入索引库就更容易了。
但是,大量网页进入百度索引库,确定百度收录的数量会增加,两者还是有一定差距的。
有几个异常显着的影响因素,主要包括:
1)页面内容质量,如果高质量的页面元素高频输出,频率可能会很高收录。
2)在达到high收录的同时,我们可能需要满足关键词来匹配特定的搜索要求才能达到较高的排名。
3)页面用户行为指标,即使搜索引擎给出高排名,没有扎实的受众,也很难持续稳定排名。
因此,我们认为页面抓取频率高并不一定意味着它的排名和权重就高网站。
总结:页面抓取频率仅代表爬虫访问频率。搜索引擎对整个网站的“友好”程度还需要进一步识别和分析,才可能影响收录和网站的排名,以上内容仅供参考!
转载黑帽百科需要授权!. 转载请注明出处地址:黑帽SEO专注SEO培训,快速排名
php网页抓取工具(AWS客户可使用AmazonKendra网页抓取工具建立索引和搜索网页)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-09-26 06:12
Amazon Kendra是一个由机器学习支持的智能搜索服务,它使组织能够根据客户和员工的需求提供相关信息。从今天开始,AWS客户可以使用Amazon Kendra网络爬虫对网页进行索引和搜索
关键信息可能分散在企业的多个数据源中,包括内部和外部网站。Amazon Kendra客户现在可以使用Kendra网络爬虫为网站上提供的文档(HTML、PDF、MS word、MS PowerPoint和纯文本文档)编制索引,并使用Kendra智能搜索来搜索这些内容中的信息。组织可以为寻求问题答案的用户提供相关的搜索结果,如支持网站上现有的产品规格详细信息,或内联网页面上列出的公司差旅政策信息
Amazon Kendra网络爬虫已经在所有AWS地区推出,在这些地区Amazon Kendra都可用。要了解有关此功能的更多信息,请访问文档页面。要了解有关亚马逊肯德拉的更多信息,请访问亚马逊肯德拉网站
注意:Kendra web crawler遵循robots.txt中的访问规则。使用Kendra web crawler的客户需要确保他们有权为这些网页编制索引,以便将搜索结果返回给最终用户
» 查看全部
php网页抓取工具(AWS客户可使用AmazonKendra网页抓取工具建立索引和搜索网页)
Amazon Kendra是一个由机器学习支持的智能搜索服务,它使组织能够根据客户和员工的需求提供相关信息。从今天开始,AWS客户可以使用Amazon Kendra网络爬虫对网页进行索引和搜索
关键信息可能分散在企业的多个数据源中,包括内部和外部网站。Amazon Kendra客户现在可以使用Kendra网络爬虫为网站上提供的文档(HTML、PDF、MS word、MS PowerPoint和纯文本文档)编制索引,并使用Kendra智能搜索来搜索这些内容中的信息。组织可以为寻求问题答案的用户提供相关的搜索结果,如支持网站上现有的产品规格详细信息,或内联网页面上列出的公司差旅政策信息
Amazon Kendra网络爬虫已经在所有AWS地区推出,在这些地区Amazon Kendra都可用。要了解有关此功能的更多信息,请访问文档页面。要了解有关亚马逊肯德拉的更多信息,请访问亚马逊肯德拉网站
注意:Kendra web crawler遵循robots.txt中的访问规则。使用Kendra web crawler的客户需要确保他们有权为这些网页编制索引,以便将搜索结果返回给最终用户
»
php网页抓取工具(PHP调试库WhoopsWhoops适用于PHP环境的错误捕获与调试)
网站优化 • 优采云 发表了文章 • 0 个评论 • 82 次浏览 • 2021-09-26 03:16
本文从许多PHP开源库中选择了一些实用而有趣的工具,希望对您的学习和工作有所帮助
1、PHP测井仪独白
Monolog是一种支持PHP5.3+的日志工具。symfony默认支持该选项
示例代码:
2、excel操作库phpexcel
Phpexcel是一个PHP库,用于读取和写入Excel2007(openxml)文件
示例代码:
3、PHP机器学习库PHP ml
PHP ml是PHP的机器学习库。它还包括算法、交叉验证、神经网络、预处理、特征提取等
示例代码:
4、PHP的OAuth库
Opauth是一个开源PHP库,提供OAuth身份验证支持,因此您无需注意不同提供者之间的差异,也无需提供统一的标准访问方法。目前,它支持谷歌、推特和Facebook,其他提供商的支持将陆续提供。它还支持处理任何OAuth认证提供程序
5、PHP调试库哇
Whoops是一个PHP库,用于在PHP环境中捕获和调试错误;哎哟,很好用。它提供基于堆栈的错误捕获和超级漂亮的错误查看
6、PHP缓存库phpfastcache
Phpfastcache是一个开源的PHP缓存库。它只提供了一个简单的PHP文件,可以轻松地集成到现有项目中。它支持多种缓存方法,包括APC、Memcache、memcached、wincache、files、PDO和mpdo。缓存的有效时间可以通过一个简单的API定义
示例代码:
7、PHP框架
Guzzle是一个PHP框架,它解决了发送大量HTTP请求和创建web服务客户端的问题。它包括创建一个可靠服务客户端的工具,包括:定义API输入和输出的服务描述,通过分页资源实现资源迭代,以及尽可能高效地批量发送大量请求
示例代码:
8、CSS JS合并/压缩munee
Munee是一个PHP库,它集成了图像大小调整、css js合并/压缩、缓存和其他功能。您可以在服务器端和客户端缓存资源。它集成了PHP图像操作库图像,实现图像大小的调整和剪切,然后缓存
示例代码:
9、PHP模板语言细枝
Twig是一种灵活、快速和安全的PHP模板语言。它将模板编译成优化的原创PHP代码。Twig有一个沙箱模型来检测不可信的模板代码。Twig由一个灵活的词法分析器和解析器组成,它允许开发人员定义自己的标记、过滤器和创建自己的DSL
示例代码:
10、PHP爬虫库痛风
Goutte是一个PHP库,用于捕获网站数据。它提供了一个优雅的API,可以轻松地从远程页面选择特定元素
示例代码:
以上内容旨在帮助您,获取更多PHP PDF访谈文档、PHP高级视频数据、PHP优秀免费访问官方帐户:PHP开源社区,或访问:
2021金、银四大工厂访谈真题集,必看
四年精华PHP技术文章整理集-PHP框架文章
四年精华PHP技术集-微服务架构
四年精华PHP技术集-分布式体系结构
四年精华PHP技术集-高并发场景
四年精华PHP技术文章整理采集-数据库部分 查看全部
php网页抓取工具(PHP调试库WhoopsWhoops适用于PHP环境的错误捕获与调试)
本文从许多PHP开源库中选择了一些实用而有趣的工具,希望对您的学习和工作有所帮助
1、PHP测井仪独白
Monolog是一种支持PHP5.3+的日志工具。symfony默认支持该选项
示例代码:
2、excel操作库phpexcel
Phpexcel是一个PHP库,用于读取和写入Excel2007(openxml)文件
示例代码:
3、PHP机器学习库PHP ml
PHP ml是PHP的机器学习库。它还包括算法、交叉验证、神经网络、预处理、特征提取等
示例代码:
4、PHP的OAuth库
Opauth是一个开源PHP库,提供OAuth身份验证支持,因此您无需注意不同提供者之间的差异,也无需提供统一的标准访问方法。目前,它支持谷歌、推特和Facebook,其他提供商的支持将陆续提供。它还支持处理任何OAuth认证提供程序
5、PHP调试库哇
Whoops是一个PHP库,用于在PHP环境中捕获和调试错误;哎哟,很好用。它提供基于堆栈的错误捕获和超级漂亮的错误查看
6、PHP缓存库phpfastcache
Phpfastcache是一个开源的PHP缓存库。它只提供了一个简单的PHP文件,可以轻松地集成到现有项目中。它支持多种缓存方法,包括APC、Memcache、memcached、wincache、files、PDO和mpdo。缓存的有效时间可以通过一个简单的API定义
示例代码:
7、PHP框架
Guzzle是一个PHP框架,它解决了发送大量HTTP请求和创建web服务客户端的问题。它包括创建一个可靠服务客户端的工具,包括:定义API输入和输出的服务描述,通过分页资源实现资源迭代,以及尽可能高效地批量发送大量请求
示例代码:
8、CSS JS合并/压缩munee
Munee是一个PHP库,它集成了图像大小调整、css js合并/压缩、缓存和其他功能。您可以在服务器端和客户端缓存资源。它集成了PHP图像操作库图像,实现图像大小的调整和剪切,然后缓存
示例代码:
9、PHP模板语言细枝
Twig是一种灵活、快速和安全的PHP模板语言。它将模板编译成优化的原创PHP代码。Twig有一个沙箱模型来检测不可信的模板代码。Twig由一个灵活的词法分析器和解析器组成,它允许开发人员定义自己的标记、过滤器和创建自己的DSL
示例代码:
10、PHP爬虫库痛风
Goutte是一个PHP库,用于捕获网站数据。它提供了一个优雅的API,可以轻松地从远程页面选择特定元素
示例代码:
以上内容旨在帮助您,获取更多PHP PDF访谈文档、PHP高级视频数据、PHP优秀免费访问官方帐户:PHP开源社区,或访问:
2021金、银四大工厂访谈真题集,必看
四年精华PHP技术文章整理集-PHP框架文章
四年精华PHP技术集-微服务架构
四年精华PHP技术集-分布式体系结构
四年精华PHP技术集-高并发场景
四年精华PHP技术文章整理采集-数据库部分
php网页抓取工具(什么是网页抓取?()的HTTP客户端代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-09-23 16:16
web爬虫是什么?
你有没有从一个API获得没有提供网站信息?我们可以通过页面爬行,然后我们想从HTML的目标网站 网站 @,然后解决问题。当然,我们可以手动提取此信息,但非常繁琐的手动操作。所以,通过爬行动物自动化完成此过程将更有效。
在本教程中,我们将从pexels抓住一些猫图片。 网站提供高质量和免费材料图片。它们提供API,但API限制是请求/小时频率的200倍。
福利图片
启动并发请求
最大的好处
PHP使用异步页面爬网(与同步模式相比)可以在更短的时间内完成更多工作。 PHP允许我们一次使用异步请求,而不是每次只使用单页请求并等待返回的结果。因此,一旦请求返回结果,我们就可以开始处理。
首先,我们从名为异步HTTP客户端代码的嗡嗡声 - React GitHub中拉出 - 它是一个简单的反垃圾邮件,专用异步并发处理大HTTP客户端HTTP请求:
composer require clue/buzz-react
在这里,作曲家使用这个工件,我不明白学生可以私信回复“作曲家”自助获取相关信息。
现在,我们可以在pexels上请求图片页面:
我们创建了一个Clue \ React \ Buzz \浏览器的实例,将其用作HTTP客户端。上面的代码推出了一个异步Get请求以获取网页内容(包括优采云的图片)。 $客户 - &gt; get($ url)方法返回收录psr-7响应的promise对象。
客户端异步操作,这意味着我们可以容易地请求几页,然后将同步执行这些请求:
代码有以下含义:
因此,可以将该逻辑提取到类中,并且我们可以容易地易于多个URL请求响应处理并添加相同的过程。让我们创建一个基于浏览器的包装器。
使用以下代码创建一个名为scraper:
我们将作为浏览器注入构造函数依赖关系和剪切方法的剪切(数组$ URL)。然后启动每个指定的URL的GET请求。响应完成后,我们调用私有方法processResponse(String $ HTML)。此方法负责遍历HTML代码并下载图片。下一步是查看收到的HTML代码,然后从内部提取图片。
小学建议在最好的PHP版本7. 0上面,在实践中遇到的问题可以是私人信小编哦~~放你的d驾驶,e驱动器,f板充满了它! ! 查看全部
php网页抓取工具(什么是网页抓取?()的HTTP客户端代码)
web爬虫是什么?
你有没有从一个API获得没有提供网站信息?我们可以通过页面爬行,然后我们想从HTML的目标网站 网站 @,然后解决问题。当然,我们可以手动提取此信息,但非常繁琐的手动操作。所以,通过爬行动物自动化完成此过程将更有效。
在本教程中,我们将从pexels抓住一些猫图片。 网站提供高质量和免费材料图片。它们提供API,但API限制是请求/小时频率的200倍。
福利图片
启动并发请求
最大的好处
PHP使用异步页面爬网(与同步模式相比)可以在更短的时间内完成更多工作。 PHP允许我们一次使用异步请求,而不是每次只使用单页请求并等待返回的结果。因此,一旦请求返回结果,我们就可以开始处理。
首先,我们从名为异步HTTP客户端代码的嗡嗡声 - React GitHub中拉出 - 它是一个简单的反垃圾邮件,专用异步并发处理大HTTP客户端HTTP请求:
composer require clue/buzz-react
在这里,作曲家使用这个工件,我不明白学生可以私信回复“作曲家”自助获取相关信息。
现在,我们可以在pexels上请求图片页面:
我们创建了一个Clue \ React \ Buzz \浏览器的实例,将其用作HTTP客户端。上面的代码推出了一个异步Get请求以获取网页内容(包括优采云的图片)。 $客户 - &gt; get($ url)方法返回收录psr-7响应的promise对象。
客户端异步操作,这意味着我们可以容易地请求几页,然后将同步执行这些请求:
代码有以下含义:
因此,可以将该逻辑提取到类中,并且我们可以容易地易于多个URL请求响应处理并添加相同的过程。让我们创建一个基于浏览器的包装器。
使用以下代码创建一个名为scraper:
我们将作为浏览器注入构造函数依赖关系和剪切方法的剪切(数组$ URL)。然后启动每个指定的URL的GET请求。响应完成后,我们调用私有方法processResponse(String $ HTML)。此方法负责遍历HTML代码并下载图片。下一步是查看收到的HTML代码,然后从内部提取图片。
小学建议在最好的PHP版本7. 0上面,在实践中遇到的问题可以是私人信小编哦~~放你的d驾驶,e驱动器,f板充满了它! !
php网页抓取工具(PHP多线程抓取多个网页及获取数据的通用方法实用第一智慧)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-09-19 05:01
PHP多线程是获取多个网页和获取数据的通用方法。首先,智能多线程抓取多个网页并获取数据的一般方法是:从允许外部链的网络相册中获取图片的外部链地址,然后将其用于您自己的博客网站,这是网站管理者经常遇到的问题。大多数网络相册都提供了方便的操作来满足用户的需求,但是,一些在线相册并没有提供方便的操作。从一个实例出发,讨论了利用多线程技术获取网络相册关键词:environment的图片外链地址的一般方法;多线程;多线程;正则表达式;网络相册源代码和解释问题提出,在环境中捕获多个网页可以通过使用相册的图片外链-任丘年级功能来实现,但这种方法通常是顺序教学中心。当网页数量较少时,这是一种简单有效的方法,但很重要“/处理大量网页将导致致命问题,因为在/environment中执行代码有时间限制。”。此时,多线程获取多个web页面成为解决这类问题的最佳选择。处理此类问题的一般过程‖检查用户是否提交了数据,]将多个需要多线程处理的网页的数据放入数组中。多线程函数使用Number读取多个网页数据。使用正则表达式从获得的多个网页数据中提取有用的数据。如果用户尚未提交数据,请构造一个表单并要求用户提供共享数据。相册的页数和相册的总页数
共享相册的示例可从浏览器的地址获得::/。实际问题:该公司提供免费的在线相册空间。幸运的是,相册的总页数在页面的下半部分。示例:在浏览器中打开与上述地址对应的相册,您可以在页面的下部看到相册。用户可以跳出链条。有了公司的实力,相信它可以成为相册的源头,总页数稳定的提供这样的服务,用户获取图片外部链地址的方法也很简单。然而,一次获取多张图片的外部链地址几乎是不可能的任务。“对网络相册的代码进行简单分析后,发现该代码收录相册图片的外部链地址。您只需使用正则表达式从相册的外部代码中提取图片的外部链地址。职业教育中心的下一个问题是:只有一个picture显示在相册的每个页面上。如果相册中有数百张图片,则需要捕获至少几十个网页。为了提高效率,需要使用多线程“抓取”“//关闭资源并释放系统资源。您可以在此处添加时间测试代码并记录结束时间。/使用正则表达式从获得的web代码中提取图像外链。//相册的原创代码如下:///这里可以添加一个时间测试代码,记录开始时间。收录上述代码中图片的外部单页代码中最多有两个这样的代码。因此,您需要使用函数和正则表达式获取有用的数字////启动多线程以获取网页数据并将其放入数组////创建批处理////设置传输选项?///将图片的外部链接地址输出到浏览器///获取的信息以文件流的形式返回,///您可以根据需要更改输出格式。在批处理会话中添加单独的句柄。服务器环境Xeon测试方法使用两台具有相同配置和相同网络环境的计算机同时提交数据,分别测试多线程采集和使用函数的顺序。以下是如何使用?函数按顺序获取多个网页的数据:/。/将获取的多个网页信息合并为变量
实用第一智慧集中获取链1外相册的图片。任丘职业教育中心对执行时间代码进行测试,在多线程获取网页数据之前添加以下生成代码://获取程序执行的开始时间,开始时间:,结束时间:,执行时间:这行代码可以简单地计算代码执行时间。获取相册的图片。外链测试对象为任丘市职业教育中心测试组。数据如下:多线程模式下相册的页数:“提交”//行时间:,结束时间:;。执行期间的顺序模式:开始时间:,结束时间:。。。执行:行时间:/“//可以在此处添加时间测试代码以记录结束时间。开始时间:。。。结束时间:多线程网页获取网页的时间取决于最慢的网页。这与网页的数量无关取出的图像量,但连续网页是所有网页大小的总和。就是 查看全部
php网页抓取工具(PHP多线程抓取多个网页及获取数据的通用方法实用第一智慧)
PHP多线程是获取多个网页和获取数据的通用方法。首先,智能多线程抓取多个网页并获取数据的一般方法是:从允许外部链的网络相册中获取图片的外部链地址,然后将其用于您自己的博客网站,这是网站管理者经常遇到的问题。大多数网络相册都提供了方便的操作来满足用户的需求,但是,一些在线相册并没有提供方便的操作。从一个实例出发,讨论了利用多线程技术获取网络相册关键词:environment的图片外链地址的一般方法;多线程;多线程;正则表达式;网络相册源代码和解释问题提出,在环境中捕获多个网页可以通过使用相册的图片外链-任丘年级功能来实现,但这种方法通常是顺序教学中心。当网页数量较少时,这是一种简单有效的方法,但很重要“/处理大量网页将导致致命问题,因为在/environment中执行代码有时间限制。”。此时,多线程获取多个web页面成为解决这类问题的最佳选择。处理此类问题的一般过程‖检查用户是否提交了数据,]将多个需要多线程处理的网页的数据放入数组中。多线程函数使用Number读取多个网页数据。使用正则表达式从获得的多个网页数据中提取有用的数据。如果用户尚未提交数据,请构造一个表单并要求用户提供共享数据。相册的页数和相册的总页数
共享相册的示例可从浏览器的地址获得::/。实际问题:该公司提供免费的在线相册空间。幸运的是,相册的总页数在页面的下半部分。示例:在浏览器中打开与上述地址对应的相册,您可以在页面的下部看到相册。用户可以跳出链条。有了公司的实力,相信它可以成为相册的源头,总页数稳定的提供这样的服务,用户获取图片外部链地址的方法也很简单。然而,一次获取多张图片的外部链地址几乎是不可能的任务。“对网络相册的代码进行简单分析后,发现该代码收录相册图片的外部链地址。您只需使用正则表达式从相册的外部代码中提取图片的外部链地址。职业教育中心的下一个问题是:只有一个picture显示在相册的每个页面上。如果相册中有数百张图片,则需要捕获至少几十个网页。为了提高效率,需要使用多线程“抓取”“//关闭资源并释放系统资源。您可以在此处添加时间测试代码并记录结束时间。/使用正则表达式从获得的web代码中提取图像外链。//相册的原创代码如下:///这里可以添加一个时间测试代码,记录开始时间。收录上述代码中图片的外部单页代码中最多有两个这样的代码。因此,您需要使用函数和正则表达式获取有用的数字////启动多线程以获取网页数据并将其放入数组////创建批处理////设置传输选项?///将图片的外部链接地址输出到浏览器///获取的信息以文件流的形式返回,///您可以根据需要更改输出格式。在批处理会话中添加单独的句柄。服务器环境Xeon测试方法使用两台具有相同配置和相同网络环境的计算机同时提交数据,分别测试多线程采集和使用函数的顺序。以下是如何使用?函数按顺序获取多个网页的数据:/。/将获取的多个网页信息合并为变量
实用第一智慧集中获取链1外相册的图片。任丘职业教育中心对执行时间代码进行测试,在多线程获取网页数据之前添加以下生成代码://获取程序执行的开始时间,开始时间:,结束时间:,执行时间:这行代码可以简单地计算代码执行时间。获取相册的图片。外链测试对象为任丘市职业教育中心测试组。数据如下:多线程模式下相册的页数:“提交”//行时间:,结束时间:;。执行期间的顺序模式:开始时间:,结束时间:。。。执行:行时间:/“//可以在此处添加时间测试代码以记录结束时间。开始时间:。。。结束时间:多线程网页获取网页的时间取决于最慢的网页。这与网页的数量无关取出的图像量,但连续网页是所有网页大小的总和。就是
php网页抓取工具(先来看看php抓取代码的一个方法:代码中$就是)
网站优化 • 优采云 发表了文章 • 0 个评论 • 72 次浏览 • 2021-09-19 04:21
PHP很容易抓取网页,只需几行代码即可完成。但是,如果您疏忽大意,并且程序不够严格,则会出现一些网页可以成功捕获,但一些网页无法捕获的问题
让我们看一看PHP获取代码的方法:
在代码中,$data是要捕获的网页的HTML代码
但是如果你用这个程序抓取网络文件,它无疑是非常脆弱的。这对于抓取大多数网页可能不是问题,但对于某些网页,您将无法捕获目标文件,而是捕获意外的网页代码。原因是什么
实际上,setopt()的一些可选参数非常重要。在捕获网页部分,我们必须考虑一个参数,即useragent。什么是用户代理?Useragent(UA)是一个只读字符串,用于声明浏览器用于HTTP请求的用户代理标头的值。简单地说,就是“声明使用哪个浏览器打开目标网页”
此时,有些人可能会意识到,不同的用户代理将获得不同的网页请求,例如移动浏览器和PC浏览器,并将获得不同的网页文件。例如,如果打开PC浏览器和移动浏览器,将获得不同的结果页面,这实际上是useragent的不同结果。因此,卡速度测量网络网站速度测试程序使用用户定义的UA网页捕获程序
那么,在这一点上,我想每个人都知道如何修改上面的代码
正确的措辞应如下所示:
上面的代码声明您可以使用IE浏览器打开网页
当然,您也可以声明使用Firefox的useragent打开网页。代码如下:
您还可以声明使用其他UserAgent打开网页。以下是IE8的用户代理:
Firefox用户代理:
Chrome用户代理:
导航器的用户代理:
Safari的用户代理:
Opera的用户代理:
通过设置useragent,您可以避免某些网页由于UA不同而返回不同HTTP请求的错误,并使您的网页捕获程序更加完善和严格 查看全部
php网页抓取工具(先来看看php抓取代码的一个方法:代码中$就是)
PHP很容易抓取网页,只需几行代码即可完成。但是,如果您疏忽大意,并且程序不够严格,则会出现一些网页可以成功捕获,但一些网页无法捕获的问题
让我们看一看PHP获取代码的方法:
在代码中,$data是要捕获的网页的HTML代码
但是如果你用这个程序抓取网络文件,它无疑是非常脆弱的。这对于抓取大多数网页可能不是问题,但对于某些网页,您将无法捕获目标文件,而是捕获意外的网页代码。原因是什么
实际上,setopt()的一些可选参数非常重要。在捕获网页部分,我们必须考虑一个参数,即useragent。什么是用户代理?Useragent(UA)是一个只读字符串,用于声明浏览器用于HTTP请求的用户代理标头的值。简单地说,就是“声明使用哪个浏览器打开目标网页”
此时,有些人可能会意识到,不同的用户代理将获得不同的网页请求,例如移动浏览器和PC浏览器,并将获得不同的网页文件。例如,如果打开PC浏览器和移动浏览器,将获得不同的结果页面,这实际上是useragent的不同结果。因此,卡速度测量网络网站速度测试程序使用用户定义的UA网页捕获程序
那么,在这一点上,我想每个人都知道如何修改上面的代码
正确的措辞应如下所示:
上面的代码声明您可以使用IE浏览器打开网页
当然,您也可以声明使用Firefox的useragent打开网页。代码如下:
您还可以声明使用其他UserAgent打开网页。以下是IE8的用户代理:
Firefox用户代理:
Chrome用户代理:
导航器的用户代理:
Safari的用户代理:
Opera的用户代理:
通过设置useragent,您可以避免某些网页由于UA不同而返回不同HTTP请求的错误,并使您的网页捕获程序更加完善和严格
php网页抓取工具( Python网页教程:正则表达式识别常见模式(二))
网站优化 • 优采云 发表了文章 • 0 个评论 • 68 次浏览 • 2021-09-18 01:05
Python网页教程:正则表达式识别常见模式(二))
tags = res.findAll("a", {"class": ["url", "readmorebtn"]})
这段代码使用“readmorebtn”和“URL”类提取所有锚定标记
您可以使用text参数根据内部文本本身过滤内容,如下所示:
tags = res.findAll(text="Python Programming Basics with Examples")
findall函数返回与指定属性匹配的所有元素,但如果只想返回一个元素,可以使用limit参数或使用find函数,后者只返回第一个元素
用漂亮的汤找到第n个孩子
“靓汤”具有许多强大的功能;您可以像这样直接获取子元素:
tags = res.span.findAll("a")
这条线将获取beautiful soup对象上的第一个跨度元素,然后获取跨度下的所有锚定元素
如果你需要第n个孩子呢
您可以像这样使用选择功能:
tag = res.find("nav", {"id": "site-navigation"}).select("a")[3]
此行获取ID为“site navigation”的导航元素,然后从导航元素获取第四个锚定标记
美丽的汤是一个强大的图书馆
使用正则表达式查找标签
在上一个教程中,我们讨论了正则表达式,并且看到了使用正则表达式识别常见模式(如电子邮件、URL等)的强大功能
幸运的是,靓汤有这个功能;您可以传递正则表达式模式以匹配特定标记
假设您想要获取一些与特定模式匹配的链接,例如内部链接或特定外部链接,或者获取特定路径中的一些图像
正则表达式引擎使这项工作变得非常容易
import re
tags = res.findAll("img", {"src": re.compile("\.\./uploads/photo_.*\.png")})
这些行捕获../上载/,并将其打印为照片uuu开始
这只是一个简单的例子,它向您展示了正则表达式和BeautifulSoup组合的强大功能
Python网页爬行教程:爬行JavaScript
假设您需要抓取的页面有另一个加载页面,该页面将您重定向到所需页面,并且URL没有更改,或者您抓取的页面的某些部分使用ajax加载其内容
我们的scraper不会加载此内容,因为它不会运行加载它所需的JavaScript
您的浏览器运行JavaScript并正常加载任何内容,我们将使用第二个爬网库(称为selenium)来实现这一点
Selenium库不包括其浏览器;您需要安装第三方浏览器(或web驱动程序)才能工作。这是对浏览器本身的补充
您可以选择chrome、Firefox、safari或edge
如果您安装了这些驱动程序中的任何一个,例如chrome,它将打开一个浏览器实例并加载您的页面,然后您可以抓取页面或与页面交互
Python web爬虫教程:将chrome驱动程序与selenium结合使用
首先,应按如下方式安装selenium库:
$ pip install selenium
然后您应该从这里下载chrome驱动程序,并将其下载到您的系统路径
现在,您可以这样加载页面,如以下Python网页捕获示例所示:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get("https://www.python.org/")
nav = browser.find_element_by_id("mainnav")
print(nav.text)
结果如下:
这很简单,不是吗
我们不与页面元素交互,所以我们还没有看到selenium的强大功能。等等
Python如何抓取网页?使用selenium+phantom JS
您可能喜欢使用浏览器驱动程序,但更多的人喜欢在后台运行代码,而看不到实际操作
因此,有一个很棒的工具叫做phantom JS,它可以在不打开任何浏览器的情况下加载页面并运行代码
Phantom JS使您能够轻松地与捕获的页面cookie和JavaScript交互
此外,您还可以像BeautifulSoup一样使用它来抓取这些页面中的页面和元素
从这里下载phantom JS并将其放在您的路径中,以便我们可以将其用作selenium的Web驱动程序
现在,让我们使用selenium和phantom JS抓取网页,就像使用Chrome web驱动程序一样
from selenium import webdriver
browser = webdriver.PhantomJS()
browser.get("https://www.python.org/")
print(browser.find_element_by_class_name("introduction").text)
browser.close()
结果是:
太棒了!!它工作得很好
您可以通过多种方式访问}元素:
browser.find_element_by_id("id")
browser.find_element_by_css_selector("#id")
browser.find_element_by_link_text("Click Here")
browser.find_element_by_name("Home")
所有这些函数只返回一个元素;可以使用此元素返回多个元素:
browser.find_elements_by_id("id")
browser.find_elements_by_css_selector("#id")
browser.find_elements_by_link_text("Click Here")
browser.find_elements_by_name("Home")
硒页\来源
您可以像这样使用页面uSource对selenium返回的内容使用beautiful soup的强大功能,如以下Python网页捕获代码示例所示:
from selenium import webdriver
from bs4 import BeautifulSoup
browser = webdriver.PhantomJS()
browser.get("https://www.python.org/")
page = BeautifulSoup(browser.page_source,"html5lib")
links = page.findAll("a")
for link in links:
print(link)
browser.close()
结果是:
如您所见,phantom JS使抓取HTML元素变得非常容易。让我们看更多
使用selenium捕获iframe内容
您抓取的页面可能收录收录数据的iframe
如果您试图抓取收录iframe的页面,您将无法获取iframe内容;您需要获取iframe源代码
您可以使用selenium切换到要抓取的帧以抓取iframe
from selenium import webdriver
browser = webdriver.PhantomJS()
browser.get("https://developer.mozilla.org/ ... 6quot;)
iframe = browser.find_element_by_tag_name("iframe")
browser.switch_to.default_content()
browser.switch_to.frame(iframe)
iframe_source = browser.page_source
print(iframe_source) #returns iframe source
print(browser.current_url) #returns iframe URL
结果是:
查看当前网站;它是iframe URL,而不是原创页面
Python如何抓取网页?使用靓汤抓取iframe内容
可以通过find函数获取iframe的URL;然后您可以放弃该URL
from urllib.request import urlopen
from urllib.error import HTTPError
from urllib.error import URLError
from bs4 import BeautifulSoup
try:
html = urlopen("https://developer.mozilla.org/ ... 6quot;)
except HTTPError as e:
print(e)
except URLError:
print("Server down or incorrect domain")
else:
res = BeautifulSoup(html.read(), "html5lib")
tag = res.find("iframe")
print(tag['src']) #URl of iframe ready for scraping
太棒了!!这里我们使用另一种技术从页面抓取iframe内容
使用(selenium+phantom JS)处理Ajax调用
在Ajax调用之后,您可以使用selenium获取内容
这就像点击一个按钮来获取你需要的东西。检查以下Python网页抓取示例:
from selenium import webdriver
import time
browser = webdriver.PhantomJS()
browser.get("https://www.w3schools.com/xml/ajax_intro.asp")
browser.find_element_by_tag_name("button").click()
time.sleep(2) #Explicit wait
browser.get_screenshot_as_file("image.png")
browser.close()
结果是:
在这里,我们抓取一个收录按钮的页面,然后单击按钮,它将调用Ajax并获取文本,然后保存页面的屏幕截图
这是一件小事;这是关于等待时间的问题
我们知道页面无法完全加载超过2秒,但这不是一个好的解决方案。服务器可能需要更多的时间,或者由于许多原因,您的连接可能较慢
使用phantom JS等待Ajax调用完成
最好的解决方案是检查最终页面上是否有HTML元素。如果是,则表示Ajax调用已成功完成
检查此Python网页抓取代码示例:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
browser = webdriver.PhantomJS()
browser.get("https://resttesttest.com/")
browser.find_element_by_id("submitajax").click()
try:
element = WebDriverWait(browser, 10).until(EC.text_to_be_present_in_element((By.ID, "statuspre"),"HTTP 200 OK"))
finally:
browser.get_screenshot_as_file("image.png")
browser.close()
结果是:
在这里,我们单击一个Ajax按钮,该按钮进行rest调用并返回JSON结果
我们检查div元素文本是否为“HTTP200OK”,超时10秒,然后将结果页面保存为图像,如图所示
您可以检查许多内容,例如:
URL更改使用
EC.url_changes()
使用新打开的窗口
EC.new_window_is_opened()
使用以下方法更改标题:
EC.title_is()
如果有任何页面重定向,可以检查标题或URL是否已更改
检查的条件很多,;我们只是一个例子,告诉你你有多大的力量
酷
Python web爬行教程:处理cookie
有时,当您编写爬网代码时,为您爬网的站点处理cookie非常重要
也许您需要删除cookie,或者您需要将其保存在文件中并用于将来的连接
有很多种情况。让我们看看如何处理饼干
要检索当前访问站点的cookie,可以调用如下Cookies()函数:
from selenium import webdriver
browser = webdriver.PhantomJS()
browser.get("https://likegeeks.com/")
print(browser.get_cookies())
结果是:
要删除cookie,可以使用delete_uuAll_uucookies()函数,如以下Python网页捕获代码示例所示:
from selenium import webdriver
browser = webdriver.PhantomJS()
browser.get("https://likegeeks.com/")
browser.delete_all_cookies()
Python如何抓取网页?要避免的陷阱
爬行网站最令人失望的是,在查看输出时,即使数据在浏览器中可见,也看不到数据。或者web服务器拒绝提交听起来很好的表单。更糟糕的是,您的IP由于匿名原因被网站阻止
我们将讨论您在使用scripy时可能遇到的最著名的障碍,并认为这些信息很有用,因为它可以帮助您在陷入麻烦之前解决错误和预防问题
做人
难以抓取的网站的基本挑战是,他们已经能够以各种方式(例如使用验证码)区分真人和爬虫
尽管这些网站使用了硬技术来检测抓取,但是有一些变化可以让你的脚本看起来更像一个人
产权调整
设置头的最佳方法之一是使用请求库。HTTP头是每次尝试执行对web服务器的请求时web服务器发送给您的一组属性
大多数浏览器在初始化任何连接时使用以下七个字段:
Host https://www.google.com/
Connection keep-alive
Accept text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
User-Agent Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/
39.0.2171.95 Safari/537.36
Referrer https://www.google.com/
Accept-Encoding gzip, deflate, sdch
Accept-Language en-US,en;q=0.8
接下来是常用Python爬虫库urllib使用的默认头:
Accept-Encoding identity
User-Agent Python-urllib/3.4
这两个标题是唯一真正重要的设置。因此,最好将它们保持在默认值
Python网页捕获示例:JavaScript和cookie处理
解决许多爬行问题的重要方法之一是正确处理cookie。网站使用Cookie跟踪您在网站上的进度的用户还可能使用Cookie来防止具有异常行为(例如浏览过多页面或快速提交表单)的爬网工具,并防止它们在网站上爬网@
如果您的浏览器cookie将您的身份传递给网站,那么更改您的IP地址甚至关闭并重新打开您与网站的连接等解决方案可能是无用的,也是浪费时间
在爬行过程中,Cookies非常重要网站. 有些网站总是要求新版本的cookie,而不是要求再次登录
如果您试图获取一个或多个网站,您应该检查并测试这些网站cookies,并决定需要处理哪个网站
Editthiscookie是可用于检查Cookie的最流行的chrome扩展之一
都是关于时间的
pythonwebcrawler教程:如果你是那种做事太快的人,那么它在爬行时可能不起作用。受高度保护的网站集可能会阻止您提交 查看全部
php网页抓取工具(
Python网页教程:正则表达式识别常见模式(二))
tags = res.findAll("a", {"class": ["url", "readmorebtn"]})
这段代码使用“readmorebtn”和“URL”类提取所有锚定标记
您可以使用text参数根据内部文本本身过滤内容,如下所示:
tags = res.findAll(text="Python Programming Basics with Examples")
findall函数返回与指定属性匹配的所有元素,但如果只想返回一个元素,可以使用limit参数或使用find函数,后者只返回第一个元素
用漂亮的汤找到第n个孩子
“靓汤”具有许多强大的功能;您可以像这样直接获取子元素:
tags = res.span.findAll("a")
这条线将获取beautiful soup对象上的第一个跨度元素,然后获取跨度下的所有锚定元素
如果你需要第n个孩子呢
您可以像这样使用选择功能:
tag = res.find("nav", {"id": "site-navigation"}).select("a")[3]
此行获取ID为“site navigation”的导航元素,然后从导航元素获取第四个锚定标记
美丽的汤是一个强大的图书馆
使用正则表达式查找标签
在上一个教程中,我们讨论了正则表达式,并且看到了使用正则表达式识别常见模式(如电子邮件、URL等)的强大功能
幸运的是,靓汤有这个功能;您可以传递正则表达式模式以匹配特定标记
假设您想要获取一些与特定模式匹配的链接,例如内部链接或特定外部链接,或者获取特定路径中的一些图像
正则表达式引擎使这项工作变得非常容易
import re
tags = res.findAll("img", {"src": re.compile("\.\./uploads/photo_.*\.png")})
这些行捕获../上载/,并将其打印为照片uuu开始
这只是一个简单的例子,它向您展示了正则表达式和BeautifulSoup组合的强大功能
Python网页爬行教程:爬行JavaScript
假设您需要抓取的页面有另一个加载页面,该页面将您重定向到所需页面,并且URL没有更改,或者您抓取的页面的某些部分使用ajax加载其内容
我们的scraper不会加载此内容,因为它不会运行加载它所需的JavaScript
您的浏览器运行JavaScript并正常加载任何内容,我们将使用第二个爬网库(称为selenium)来实现这一点
Selenium库不包括其浏览器;您需要安装第三方浏览器(或web驱动程序)才能工作。这是对浏览器本身的补充
您可以选择chrome、Firefox、safari或edge
如果您安装了这些驱动程序中的任何一个,例如chrome,它将打开一个浏览器实例并加载您的页面,然后您可以抓取页面或与页面交互
Python web爬虫教程:将chrome驱动程序与selenium结合使用
首先,应按如下方式安装selenium库:
$ pip install selenium
然后您应该从这里下载chrome驱动程序,并将其下载到您的系统路径
现在,您可以这样加载页面,如以下Python网页捕获示例所示:
from selenium import webdriver
browser = webdriver.Chrome()
browser.get("https://www.python.org/";)
nav = browser.find_element_by_id("mainnav")
print(nav.text)
结果如下:
https://www.lsbin.com/wp-conte ... 7.png 300w" />这很简单,不是吗
我们不与页面元素交互,所以我们还没有看到selenium的强大功能。等等
Python如何抓取网页?使用selenium+phantom JS
您可能喜欢使用浏览器驱动程序,但更多的人喜欢在后台运行代码,而看不到实际操作
因此,有一个很棒的工具叫做phantom JS,它可以在不打开任何浏览器的情况下加载页面并运行代码
Phantom JS使您能够轻松地与捕获的页面cookie和JavaScript交互
此外,您还可以像BeautifulSoup一样使用它来抓取这些页面中的页面和元素
从这里下载phantom JS并将其放在您的路径中,以便我们可以将其用作selenium的Web驱动程序
现在,让我们使用selenium和phantom JS抓取网页,就像使用Chrome web驱动程序一样
from selenium import webdriver
browser = webdriver.PhantomJS()
browser.get("https://www.python.org/";)
print(browser.find_element_by_class_name("introduction").text)
browser.close()
结果是:
https://www.lsbin.com/wp-conte ... 5.png 300w, https://www.lsbin.com/wp-conte ... 5.png 768w" />太棒了!!它工作得很好
您可以通过多种方式访问}元素:
browser.find_element_by_id("id")
browser.find_element_by_css_selector("#id")
browser.find_element_by_link_text("Click Here")
browser.find_element_by_name("Home")
所有这些函数只返回一个元素;可以使用此元素返回多个元素:
browser.find_elements_by_id("id")
browser.find_elements_by_css_selector("#id")
browser.find_elements_by_link_text("Click Here")
browser.find_elements_by_name("Home")
硒页\来源
您可以像这样使用页面uSource对selenium返回的内容使用beautiful soup的强大功能,如以下Python网页捕获代码示例所示:
from selenium import webdriver
from bs4 import BeautifulSoup
browser = webdriver.PhantomJS()
browser.get("https://www.python.org/";)
page = BeautifulSoup(browser.page_source,"html5lib")
links = page.findAll("a")
for link in links:
print(link)
browser.close()
结果是:
https://www.lsbin.com/wp-conte ... 2.png 300w, https://www.lsbin.com/wp-conte ... 2.png 1024w, https://www.lsbin.com/wp-conte ... 9.png 768w" />如您所见,phantom JS使抓取HTML元素变得非常容易。让我们看更多
使用selenium捕获iframe内容
您抓取的页面可能收录收录数据的iframe
如果您试图抓取收录iframe的页面,您将无法获取iframe内容;您需要获取iframe源代码
您可以使用selenium切换到要抓取的帧以抓取iframe
from selenium import webdriver
browser = webdriver.PhantomJS()
browser.get("https://developer.mozilla.org/ ... 6quot;)
iframe = browser.find_element_by_tag_name("iframe")
browser.switch_to.default_content()
browser.switch_to.frame(iframe)
iframe_source = browser.page_source
print(iframe_source) #returns iframe source
print(browser.current_url) #returns iframe URL
结果是:
https://www.lsbin.com/wp-conte ... 1.png 300w, https://www.lsbin.com/wp-conte ... 7.png 1024w, https://www.lsbin.com/wp-conte ... 8.png 768w" />查看当前网站;它是iframe URL,而不是原创页面
Python如何抓取网页?使用靓汤抓取iframe内容
可以通过find函数获取iframe的URL;然后您可以放弃该URL
from urllib.request import urlopen
from urllib.error import HTTPError
from urllib.error import URLError
from bs4 import BeautifulSoup
try:
html = urlopen("https://developer.mozilla.org/ ... 6quot;)
except HTTPError as e:
print(e)
except URLError:
print("Server down or incorrect domain")
else:
res = BeautifulSoup(html.read(), "html5lib")
tag = res.find("iframe")
print(tag['src']) #URl of iframe ready for scraping
太棒了!!这里我们使用另一种技术从页面抓取iframe内容
使用(selenium+phantom JS)处理Ajax调用
在Ajax调用之后,您可以使用selenium获取内容
这就像点击一个按钮来获取你需要的东西。检查以下Python网页抓取示例:
from selenium import webdriver
import time
browser = webdriver.PhantomJS()
browser.get("https://www.w3schools.com/xml/ajax_intro.asp";)
browser.find_element_by_tag_name("button").click()
time.sleep(2) #Explicit wait
browser.get_screenshot_as_file("image.png")
browser.close()
结果是:
https://www.lsbin.com/wp-conte ... 0.png 296w" />在这里,我们抓取一个收录按钮的页面,然后单击按钮,它将调用Ajax并获取文本,然后保存页面的屏幕截图
这是一件小事;这是关于等待时间的问题
我们知道页面无法完全加载超过2秒,但这不是一个好的解决方案。服务器可能需要更多的时间,或者由于许多原因,您的连接可能较慢
使用phantom JS等待Ajax调用完成
最好的解决方案是检查最终页面上是否有HTML元素。如果是,则表示Ajax调用已成功完成
检查此Python网页抓取代码示例:
from selenium import webdriver
from selenium.webdriver.common.by import By
from selenium.webdriver.support.ui import WebDriverWait
from selenium.webdriver.support import expected_conditions as EC
browser = webdriver.PhantomJS()
browser.get("https://resttesttest.com/";)
browser.find_element_by_id("submitajax").click()
try:
element = WebDriverWait(browser, 10).until(EC.text_to_be_present_in_element((By.ID, "statuspre"),"HTTP 200 OK"))
finally:
browser.get_screenshot_as_file("image.png")
browser.close()
结果是:
https://www.lsbin.com/wp-conte ... 5.png 300w, https://www.lsbin.com/wp-conte ... 3.png 768w" />在这里,我们单击一个Ajax按钮,该按钮进行rest调用并返回JSON结果
我们检查div元素文本是否为“HTTP200OK”,超时10秒,然后将结果页面保存为图像,如图所示
您可以检查许多内容,例如:
URL更改使用
EC.url_changes()
使用新打开的窗口
EC.new_window_is_opened()
使用以下方法更改标题:
EC.title_is()
如果有任何页面重定向,可以检查标题或URL是否已更改
检查的条件很多,;我们只是一个例子,告诉你你有多大的力量
酷
Python web爬行教程:处理cookie
有时,当您编写爬网代码时,为您爬网的站点处理cookie非常重要
也许您需要删除cookie,或者您需要将其保存在文件中并用于将来的连接
有很多种情况。让我们看看如何处理饼干
要检索当前访问站点的cookie,可以调用如下Cookies()函数:
from selenium import webdriver
browser = webdriver.PhantomJS()
browser.get("https://likegeeks.com/";)
print(browser.get_cookies())
结果是:
https://www.lsbin.com/wp-conte ... 7.png 300w, https://www.lsbin.com/wp-conte ... 6.png 1024w, https://www.lsbin.com/wp-conte ... 5.png 768w" />要删除cookie,可以使用delete_uuAll_uucookies()函数,如以下Python网页捕获代码示例所示:
from selenium import webdriver
browser = webdriver.PhantomJS()
browser.get("https://likegeeks.com/";)
browser.delete_all_cookies()
Python如何抓取网页?要避免的陷阱
爬行网站最令人失望的是,在查看输出时,即使数据在浏览器中可见,也看不到数据。或者web服务器拒绝提交听起来很好的表单。更糟糕的是,您的IP由于匿名原因被网站阻止
我们将讨论您在使用scripy时可能遇到的最著名的障碍,并认为这些信息很有用,因为它可以帮助您在陷入麻烦之前解决错误和预防问题
做人
难以抓取的网站的基本挑战是,他们已经能够以各种方式(例如使用验证码)区分真人和爬虫
尽管这些网站使用了硬技术来检测抓取,但是有一些变化可以让你的脚本看起来更像一个人
产权调整
设置头的最佳方法之一是使用请求库。HTTP头是每次尝试执行对web服务器的请求时web服务器发送给您的一组属性
大多数浏览器在初始化任何连接时使用以下七个字段:
Host https://www.google.com/
Connection keep-alive
Accept text/html,application/xhtml+xml,application/xml;q=0.9,image/webp,*/*;q=0.8
User-Agent Mozilla/5.0 (Macintosh; Intel Mac OS X 10_9_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/
39.0.2171.95 Safari/537.36
Referrer https://www.google.com/
Accept-Encoding gzip, deflate, sdch
Accept-Language en-US,en;q=0.8
接下来是常用Python爬虫库urllib使用的默认头:
Accept-Encoding identity
User-Agent Python-urllib/3.4
这两个标题是唯一真正重要的设置。因此,最好将它们保持在默认值
Python网页捕获示例:JavaScript和cookie处理
解决许多爬行问题的重要方法之一是正确处理cookie。网站使用Cookie跟踪您在网站上的进度的用户还可能使用Cookie来防止具有异常行为(例如浏览过多页面或快速提交表单)的爬网工具,并防止它们在网站上爬网@
如果您的浏览器cookie将您的身份传递给网站,那么更改您的IP地址甚至关闭并重新打开您与网站的连接等解决方案可能是无用的,也是浪费时间
在爬行过程中,Cookies非常重要网站. 有些网站总是要求新版本的cookie,而不是要求再次登录
如果您试图获取一个或多个网站,您应该检查并测试这些网站cookies,并决定需要处理哪个网站
Editthiscookie是可用于检查Cookie的最流行的chrome扩展之一
都是关于时间的
pythonwebcrawler教程:如果你是那种做事太快的人,那么它在爬行时可能不起作用。受高度保护的网站集可能会阻止您提交
php网页抓取工具(用python做过爬虫,爬虫最让人头痛的问题)
网站优化 • 优采云 发表了文章 • 0 个评论 • 93 次浏览 • 2021-09-17 13:10
我使用Python作为爬虫。爬虫最麻烦的问题是:网页编码、爬虫效率、源站点的反爬虫策略以及数千个网页。网站在不同地区使用的代码有时是不同的。当然,即使是同一个网站也可能使用两个或两个以上的GBK和UTF-8代码,这完全取决于网页制作者(有时是制作者使用的编辑器)的偏好,疏忽也会导致编码问题
在我的业余时间,我碰巧手头没有东西。是时候更新博客了。使用PHP获取网页的标题部分。请注意,这是标题部分,涉及代码获取、代码转换和常规使用。当然,这只是一种简单的方法,在获取HTTPS协议网页时会遇到麻烦
下面的代码当然不能忍受网站反爬网策略,也不能用来完成一些困难的任务,例如处理文件、验证、表单提交、文件上传等。要高度定制爬虫程序,更好的解决方案是使用PHP的curl库。Curl是一个功能强大的库,它支持许多不同的协议和选项,并且可以提供与URL请求相关的各种详细信息。稍后,我暂时不讨论这个问题
本文的目的只是描述获取网页标题的过程:访问URL->;获取web内容->;使用正则表达式提取标题->;代码检测和转换->;显示结果
版本1文件:class.html.php:
取得了成果,达到了以下目的:
京东(JD.COM)-综合网购首选-正品低价、品质保障、配送及时、轻松购物!
美中不足:尽管我们得到了正确的结果,但每次获取网页标题时都需要更改源代码。你能更聪明些吗?答案是肯定的。使用get方法并传入相应的URL值作为GetTitle()的参数。当您需要采集页面标题时,您可以直接在地址栏中修改URL地址
版本2文件:class.html.php
用法:运行类。HTML。PHP?Url=浏览器中的网页Url
本网站使用阿里云服务器。下面有折扣↓
服务器选择|热门特价|新福利|老用户续费 查看全部
php网页抓取工具(用python做过爬虫,爬虫最让人头痛的问题)
我使用Python作为爬虫。爬虫最麻烦的问题是:网页编码、爬虫效率、源站点的反爬虫策略以及数千个网页。网站在不同地区使用的代码有时是不同的。当然,即使是同一个网站也可能使用两个或两个以上的GBK和UTF-8代码,这完全取决于网页制作者(有时是制作者使用的编辑器)的偏好,疏忽也会导致编码问题
在我的业余时间,我碰巧手头没有东西。是时候更新博客了。使用PHP获取网页的标题部分。请注意,这是标题部分,涉及代码获取、代码转换和常规使用。当然,这只是一种简单的方法,在获取HTTPS协议网页时会遇到麻烦
下面的代码当然不能忍受网站反爬网策略,也不能用来完成一些困难的任务,例如处理文件、验证、表单提交、文件上传等。要高度定制爬虫程序,更好的解决方案是使用PHP的curl库。Curl是一个功能强大的库,它支持许多不同的协议和选项,并且可以提供与URL请求相关的各种详细信息。稍后,我暂时不讨论这个问题
本文的目的只是描述获取网页标题的过程:访问URL->;获取web内容->;使用正则表达式提取标题->;代码检测和转换->;显示结果
版本1文件:class.html.php:
取得了成果,达到了以下目的:
京东(JD.COM)-综合网购首选-正品低价、品质保障、配送及时、轻松购物!
美中不足:尽管我们得到了正确的结果,但每次获取网页标题时都需要更改源代码。你能更聪明些吗?答案是肯定的。使用get方法并传入相应的URL值作为GetTitle()的参数。当您需要采集页面标题时,您可以直接在地址栏中修改URL地址
版本2文件:class.html.php
用法:运行类。HTML。PHP?Url=浏览器中的网页Url
本网站使用阿里云服务器。下面有折扣↓
服务器选择|热门特价|新福利|老用户续费

