
php网页抓取工具
php网页抓取工具( Python页面抓取过程中乱码的原因与相应的解决方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-03-10 16:07
Python页面抓取过程中乱码的原因与相应的解决方法)
python爬取保存html页面时出现乱码问题的解决方法
更新时间:2016-07-01 11:23:47 作者:holybin
本篇文章主要介绍python爬取保存html页面时出现乱码问题的解决方法,结合实例分析爬取Python页面过程中出现乱码的原因及相应的解决方法。需要的朋友可以参考下
本文示例介绍了python爬取保存html页面时出现乱码问题的解决方法。分享给大家参考,详情如下:
使用Python爬取html页面并保存时,经常会出现爬取的网页内容乱码的问题。出现这个问题的原因,一方面是你自己代码中的编码设置有问题,另一方面是在编码设置正确的情况下,网页的实际编码不匹配标记编码。html页面上显示的编码在这里:
复制代码代码如下:
这里有一个简单的解决方案:使用chardet判断网页的真实代码,同时从url请求返回的信息中判断代码。如果两种编码不同,使用bs模块扩展为GB18030编码;如果相同,直接写入文件(系统默认编码设置为utf-8).
import urllib2
import sys
import bs4
import chardet
reload(sys)
sys.setdefaultencoding('utf-8')
def download(url):
htmlfile = open('test.html','w')
try:
result = urllib2.urlopen(url)
content = result.read()
info = result.info()
result.close()
except Exception,e:
print 'download error!!!'
print e
else:
if content != None:
charset1 = (chardet.detect(content))['encoding'] #real encoding type
charset2 = info.getparam('charset') #declared encoding type
print charset1,' ', charset2
# case1: charset is not None.
if charset1 != None and charset2 != None and charset1.lower() != charset2.lower():
newcont = bs4.BeautifulSoup(content, from_encoding='GB18030') #coding: GB18030
for cont in newcont:
htmlfile.write('%s\n'%cont)
# case2: either charset is None, or charset is the same.
else:
#print sys.getdefaultencoding()
htmlfile.write(content) #default coding: utf-8
htmlfile.close()
if __name__ == "__main__":
url = 'https://www.jb51.net'
download(url)
得到的test.html文件打开如下,可以看到它是以UTF-8存储的,没有BOM编码格式,也就是我们设置的默认编码:
对Python相关内容比较感兴趣的读者可以查看本站专题:《Python编码操作技巧总结》、《Python图片操作技巧总结》、《Python数据结构与算法教程》、《Python套接字编程》 《技能总结》、《Python Socket编程技能总结》、《Python函数使用技巧总结》、《Python字符串操作技巧总结》、《Python入门与进阶经典教程》、《Python文件和目录操作技巧总结》
希望这篇文章对大家Python编程有所帮助。 查看全部
php网页抓取工具(
Python页面抓取过程中乱码的原因与相应的解决方法)
python爬取保存html页面时出现乱码问题的解决方法
更新时间:2016-07-01 11:23:47 作者:holybin
本篇文章主要介绍python爬取保存html页面时出现乱码问题的解决方法,结合实例分析爬取Python页面过程中出现乱码的原因及相应的解决方法。需要的朋友可以参考下
本文示例介绍了python爬取保存html页面时出现乱码问题的解决方法。分享给大家参考,详情如下:
使用Python爬取html页面并保存时,经常会出现爬取的网页内容乱码的问题。出现这个问题的原因,一方面是你自己代码中的编码设置有问题,另一方面是在编码设置正确的情况下,网页的实际编码不匹配标记编码。html页面上显示的编码在这里:
复制代码代码如下:
这里有一个简单的解决方案:使用chardet判断网页的真实代码,同时从url请求返回的信息中判断代码。如果两种编码不同,使用bs模块扩展为GB18030编码;如果相同,直接写入文件(系统默认编码设置为utf-8).
import urllib2
import sys
import bs4
import chardet
reload(sys)
sys.setdefaultencoding('utf-8')
def download(url):
htmlfile = open('test.html','w')
try:
result = urllib2.urlopen(url)
content = result.read()
info = result.info()
result.close()
except Exception,e:
print 'download error!!!'
print e
else:
if content != None:
charset1 = (chardet.detect(content))['encoding'] #real encoding type
charset2 = info.getparam('charset') #declared encoding type
print charset1,' ', charset2
# case1: charset is not None.
if charset1 != None and charset2 != None and charset1.lower() != charset2.lower():
newcont = bs4.BeautifulSoup(content, from_encoding='GB18030') #coding: GB18030
for cont in newcont:
htmlfile.write('%s\n'%cont)
# case2: either charset is None, or charset is the same.
else:
#print sys.getdefaultencoding()
htmlfile.write(content) #default coding: utf-8
htmlfile.close()
if __name__ == "__main__":
url = 'https://www.jb51.net'
download(url)
得到的test.html文件打开如下,可以看到它是以UTF-8存储的,没有BOM编码格式,也就是我们设置的默认编码:

对Python相关内容比较感兴趣的读者可以查看本站专题:《Python编码操作技巧总结》、《Python图片操作技巧总结》、《Python数据结构与算法教程》、《Python套接字编程》 《技能总结》、《Python Socket编程技能总结》、《Python函数使用技巧总结》、《Python字符串操作技巧总结》、《Python入门与进阶经典教程》、《Python文件和目录操作技巧总结》
希望这篇文章对大家Python编程有所帮助。
php网页抓取工具(FreeDownloadManager支持捕获网页风格样式(CSS内容保存))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-03-08 12:20
免费下载管理器是一个多点简历和管理软件。该软件声称可以将您的下载速度提高 600%。支持下载网页内容、图片、文件等。这是一款可以让你下载加速的软件,需要的可以下载。
软件功能
1.支持多线程下载,支持定时任务下载,支持按目录列表查看和检索站点内容,支持下载网页内容、图片、文件,支持抓取网页上的链接,支持下载整个网站内容(可以设置下载子目录的深度),理论上可以下载1000层以上的子目录网页和图片。
2.支持抓取网页样式(用CSS内容保存),支持多种格式的网页抓取,包括:html、shtm、shtml、phtml、dhtml、php、hta、htc、cgi、asp、htm等. ...也可以自己设置格式,可以用“站点浏览器”在线查看目标网站子目录下的内容,支持三种下载通讯方式,支持断点续传,显示是否服务器支持恢复上传并设置是否重新下载或覆盖。免费下载管理器是一款功能强大的下载工具,支持多线程拆分下载。
指示
1.下载完成后,不要运行压缩包中的软件直接使用,先解压;
2.软件支持32位和64位操作环境;
3.如果软件无法正常打开,请右键管理员模式运行。 查看全部
php网页抓取工具(FreeDownloadManager支持捕获网页风格样式(CSS内容保存))
免费下载管理器是一个多点简历和管理软件。该软件声称可以将您的下载速度提高 600%。支持下载网页内容、图片、文件等。这是一款可以让你下载加速的软件,需要的可以下载。

软件功能
1.支持多线程下载,支持定时任务下载,支持按目录列表查看和检索站点内容,支持下载网页内容、图片、文件,支持抓取网页上的链接,支持下载整个网站内容(可以设置下载子目录的深度),理论上可以下载1000层以上的子目录网页和图片。
2.支持抓取网页样式(用CSS内容保存),支持多种格式的网页抓取,包括:html、shtm、shtml、phtml、dhtml、php、hta、htc、cgi、asp、htm等. ...也可以自己设置格式,可以用“站点浏览器”在线查看目标网站子目录下的内容,支持三种下载通讯方式,支持断点续传,显示是否服务器支持恢复上传并设置是否重新下载或覆盖。免费下载管理器是一款功能强大的下载工具,支持多线程拆分下载。

指示
1.下载完成后,不要运行压缩包中的软件直接使用,先解压;
2.软件支持32位和64位操作环境;
3.如果软件无法正常打开,请右键管理员模式运行。
php网页抓取工具(Teleport乱码遇到这个问题-v2.0工具就会报错)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-03-06 19:01
经常因为某种原因,我们需要爬取某个网站或者直接复制某个站点。我们在网上找了很多工具进行测试,尝试了很多不同的问题。最后,我们选择了 Teleport Ultra 并使用了它。很好; 具体的操作手册和其他的东西这里就不说了。有很多在线搜索。以下是遇到的主要问题:
工具截图:
抓取后渲染
一般我会选择复制100级,基本上把网站的东西都复制了,但是因为Teleport Ultra是用UTF-8编码取的,如果文件中有汉字,或者gbk编码的文件就会出现乱码如下图:
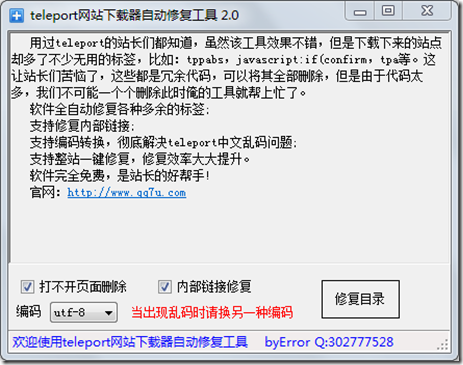
当然你也可以在浏览器中手动选择UTF-8,但是我们不能每次打开都这样。于是我就去网站找了一个软件叫:TelePort乱码修复工具(siteRepair-v2.0),经过测试可以解决乱码问题,这个工具也会清除一些无效链接和 html 符号等。
软件截图:
绝大多数网站经过这两步应该就OK了,但是有些网站在层次结构中使用了中文目录或者中文文件名,会出现乱码,类似于下面的URL地址:
这样,当抓到网站的结构时,会出现两种乱码:1)文件夹名乱码2)文件名乱码
遇到这个问题,siteRepair-v2.0工具会报错。我猜它无法识别乱码文件夹或文件。
后来在网上找到了一个PHP程序,简单的修改测试就可以解决这个问题
PHP代码:convert.php
{if(is_dir($dir))
{if ($dh = opendir($dir))
{while (($file = readdir($dh)) !== false)
{if((is_dir($dir."/".$file)) && $file!="." && $file!="..")
{rename($dir."/".$file,$dir."/".mb_convert_encoding($file,"GBK", "UTF-8"));
listDir($dir."/".$file."/");
}else{if($file!="." && $file!="..")
{$name=rename($dir."/".$file,$dir."/".str_replace('\\','',mb_convert_encoding($file,"GBK", "UTF-8"))) ;echo '路径:'.$dir."/".$file.'
';echo '结果:'.str_replace('\\','',mb_convert_encoding($file,"GBK", "UTF-8")).'
';
}
}
}closedir($dh);
}
}
listDir("./convert");?>
在代码同级目录下新建convert文件夹,将乱码文件放入该目录,然后执行convert.php。 查看全部
php网页抓取工具(Teleport乱码遇到这个问题-v2.0工具就会报错)
经常因为某种原因,我们需要爬取某个网站或者直接复制某个站点。我们在网上找了很多工具进行测试,尝试了很多不同的问题。最后,我们选择了 Teleport Ultra 并使用了它。很好; 具体的操作手册和其他的东西这里就不说了。有很多在线搜索。以下是遇到的主要问题:
工具截图:

抓取后渲染
一般我会选择复制100级,基本上把网站的东西都复制了,但是因为Teleport Ultra是用UTF-8编码取的,如果文件中有汉字,或者gbk编码的文件就会出现乱码如下图:
当然你也可以在浏览器中手动选择UTF-8,但是我们不能每次打开都这样。于是我就去网站找了一个软件叫:TelePort乱码修复工具(siteRepair-v2.0),经过测试可以解决乱码问题,这个工具也会清除一些无效链接和 html 符号等。
软件截图:
绝大多数网站经过这两步应该就OK了,但是有些网站在层次结构中使用了中文目录或者中文文件名,会出现乱码,类似于下面的URL地址:
这样,当抓到网站的结构时,会出现两种乱码:1)文件夹名乱码2)文件名乱码
遇到这个问题,siteRepair-v2.0工具会报错。我猜它无法识别乱码文件夹或文件。
后来在网上找到了一个PHP程序,简单的修改测试就可以解决这个问题
PHP代码:convert.php
{if(is_dir($dir))
{if ($dh = opendir($dir))
{while (($file = readdir($dh)) !== false)
{if((is_dir($dir."/".$file)) && $file!="." && $file!="..")
{rename($dir."/".$file,$dir."/".mb_convert_encoding($file,"GBK", "UTF-8"));
listDir($dir."/".$file."/");
}else{if($file!="." && $file!="..")
{$name=rename($dir."/".$file,$dir."/".str_replace('\\','',mb_convert_encoding($file,"GBK", "UTF-8"))) ;echo '路径:'.$dir."/".$file.'
';echo '结果:'.str_replace('\\','',mb_convert_encoding($file,"GBK", "UTF-8")).'
';
}
}
}closedir($dh);
}
}
listDir("./convert");?>
在代码同级目录下新建convert文件夹,将乱码文件放入该目录,然后执行convert.php。
php网页抓取工具(【php如何实现只替换一次或N次】抓取网页图片)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-03-06 10:17
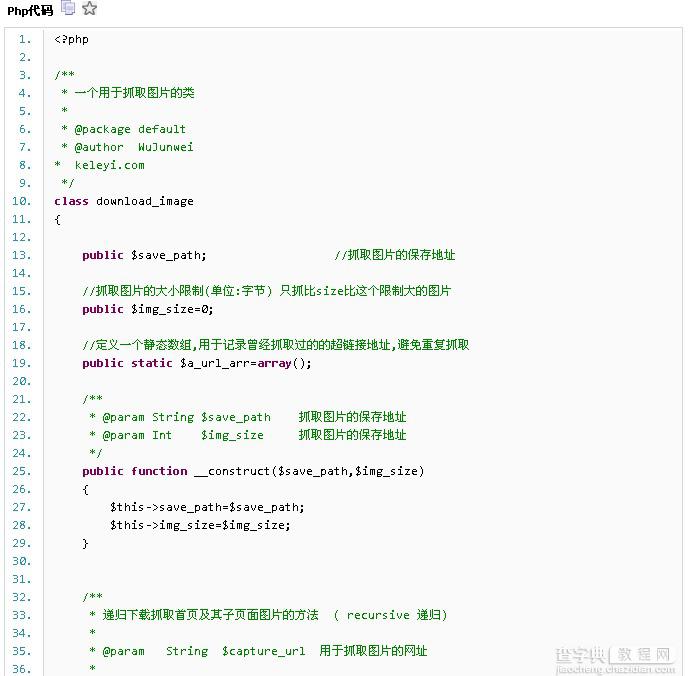
php如何抓取网页图片?相比手动粘贴复制,使用小程序要方便快捷得多。喜欢编程的人总是喜欢做一些简单实用的小软件。代码,封装了一个php远程抓图的类,测试了一下,效果还不错,分享给大家。代码如下:
我们都知道在PHP中可以使用strtr、strreplace等函数来替换,但是每次替换的时候都是要替换的。例如:
“abcabbc”,如果你用上面的函数来替换这个字符串中的b,那么他会全部替换掉,但是如果你只想替换一两个呢?请参阅以下解决方案:
这是一个相当有趣的问题。碰巧我之前也做过类似的处理。当时我是直接用preg_replace实现的。
混合preg_replace(混合模式,混合替换,混合主题[,int限制])
搜索主题以查找模式模式的匹配项并替换为替换。如果指定了limit,则仅替换limit匹配,如果省略limit或其值为-1,则替换所有匹配。
因为preg_replace的第四个参数可以限制替换的次数,所以这个问题处理起来很方便。但是看了str_replace上的函数注释,可以挑出几个有代表性的函数。
方法一:str_replace_once
思路是先找到关键词要替换的位置,然后使用substr_replace函数直接替换。
方法二、str_replace_limit
思路是使用preg_replace,但它的参数更像preg_replace,转义了一些特殊字符,更加通用。
大家可以结合小编整理的文章文章《php关键字替换仅一次的实现功能》一起学习。相信大家都会有意想不到的收获。
【php中如何只替换一次或N次】相关文章:
★ php实现的mongodb操作类示例
★ php简单实现屏蔽指定ip段内用户的访问
★ 如何给phpadmin一个保护
★ php中如何使用for语句输出三角形
★ php循环表实现一行两列显示的方法
★ 替代php函数重载
★ 如何在php中将图片转换为ASCII
★ php实现CSV文件导入导出方法
★ php实现上传word文件转html的方法
★ php实现window平台的checkdnsrr功能 查看全部
php网页抓取工具(【php如何实现只替换一次或N次】抓取网页图片)
php如何抓取网页图片?相比手动粘贴复制,使用小程序要方便快捷得多。喜欢编程的人总是喜欢做一些简单实用的小软件。代码,封装了一个php远程抓图的类,测试了一下,效果还不错,分享给大家。代码如下:




我们都知道在PHP中可以使用strtr、strreplace等函数来替换,但是每次替换的时候都是要替换的。例如:
“abcabbc”,如果你用上面的函数来替换这个字符串中的b,那么他会全部替换掉,但是如果你只想替换一两个呢?请参阅以下解决方案:
这是一个相当有趣的问题。碰巧我之前也做过类似的处理。当时我是直接用preg_replace实现的。
混合preg_replace(混合模式,混合替换,混合主题[,int限制])
搜索主题以查找模式模式的匹配项并替换为替换。如果指定了limit,则仅替换limit匹配,如果省略limit或其值为-1,则替换所有匹配。
因为preg_replace的第四个参数可以限制替换的次数,所以这个问题处理起来很方便。但是看了str_replace上的函数注释,可以挑出几个有代表性的函数。
方法一:str_replace_once
思路是先找到关键词要替换的位置,然后使用substr_replace函数直接替换。
方法二、str_replace_limit
思路是使用preg_replace,但它的参数更像preg_replace,转义了一些特殊字符,更加通用。
大家可以结合小编整理的文章文章《php关键字替换仅一次的实现功能》一起学习。相信大家都会有意想不到的收获。
【php中如何只替换一次或N次】相关文章:
★ php实现的mongodb操作类示例
★ php简单实现屏蔽指定ip段内用户的访问
★ 如何给phpadmin一个保护
★ php中如何使用for语句输出三角形
★ php循环表实现一行两列显示的方法
★ 替代php函数重载
★ 如何在php中将图片转换为ASCII
★ php实现CSV文件导入导出方法
★ php实现上传word文件转html的方法
★ php实现window平台的checkdnsrr功能
php网页抓取工具(软件功能可以提取网页所有链接(非自动)设置下要格式 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-02-24 04:15
)
网页超链接提取是一款非常强大的站长网页链接提取工具;它可以快速帮助用户手动提交你的网站百度链接,这个网页超链接提取工具对于做网站的朋友非常有用,是一款不可多得的网页链接提取工具。最重要的是该软件是完全免费的,不会收取任何费用。使用起来也非常简单易操作,让您的提取更加轻松舒适,需要的朋友赶快下载使用吧!
软件功能
可以提取网页的所有链接(非自动)
设置要解压的目录以解压所有链接
例如,新闻是一个列表
比如你有500条新闻,在网站后台列表中,让它们都显示在一页上(数量可以修改)
然后用这个工具就可以全部提取出来提交到百度站长平台收录
软件功能
另存为TXT格式
用于制作网站地图等用途输入目标网站主页地址
设置线程并保存位置
软件会自动爬取目标网站的所有网页
并以TXT中每行一行的格式保存
对于 网站 映射为 TXT 和其他
指示
1、下载文件,找到“网页超链接提取工具.exe”,双击运行,进入软件界面;
2、点击进入软件主界面,出现如下界面,如下图;
3、下面红框中可以输入内容;
4、下图中红框为提取条件,表示提取所有收录该内容的URL;
5、下图中的红框是复制提取的内容,清除等;
查看全部
php网页抓取工具(软件功能可以提取网页所有链接(非自动)设置下要格式
)
网页超链接提取是一款非常强大的站长网页链接提取工具;它可以快速帮助用户手动提交你的网站百度链接,这个网页超链接提取工具对于做网站的朋友非常有用,是一款不可多得的网页链接提取工具。最重要的是该软件是完全免费的,不会收取任何费用。使用起来也非常简单易操作,让您的提取更加轻松舒适,需要的朋友赶快下载使用吧!

软件功能
可以提取网页的所有链接(非自动)
设置要解压的目录以解压所有链接
例如,新闻是一个列表
比如你有500条新闻,在网站后台列表中,让它们都显示在一页上(数量可以修改)
然后用这个工具就可以全部提取出来提交到百度站长平台收录
软件功能
另存为TXT格式
用于制作网站地图等用途输入目标网站主页地址
设置线程并保存位置
软件会自动爬取目标网站的所有网页
并以TXT中每行一行的格式保存
对于 网站 映射为 TXT 和其他
指示
1、下载文件,找到“网页超链接提取工具.exe”,双击运行,进入软件界面;

2、点击进入软件主界面,出现如下界面,如下图;
3、下面红框中可以输入内容;

4、下图中红框为提取条件,表示提取所有收录该内容的URL;

5、下图中的红框是复制提取的内容,清除等;

php网页抓取工具(php网页抓取工具是免费的,功能比较全,而且很新)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-02-20 13:00
php网页抓取工具是免费的,功能比较全,而且很新。推荐pythonpython操作http、java操作http的话,还要解决一个网络延迟问题。推荐web开发用web开发terminal或者sublimetext编辑器,php用phpstorm。
phpwind是免费的,名字叫。
phpwind是免费的,功能挺全的,不过偶尔有bug,更新也不是很及时,应该有不少问题修复的。
github
说到免费正版的,可以试试虚幻云。虚幻云(虚幻云)专注于php与html5技术,完全不用担心公司机密泄露,自行搭建域名。免费使用,就这么简单。
phpwind、tp都可以网上资料随便找。
我自己都是用github,
wp
为什么要用免费的,php里面都有全套的开发工具,
phpwind、tp什么的都可以呀,tp是收费的。
我们公司比较傻逼,直接用tp搭起来的,不花钱。后面还换了一个博客软件,也是tp做的,比较傻逼,在用ghost的。
phpwind可以看看,有免费版,用起来挺好的,如果网络要求高,可以入tp的。如果你是老师,教学php(不推荐,如果网络要求高的话,你不也想请个学生帮你讲课?),且个人觉得对php感兴趣,可以用个免费版的试试, 查看全部
php网页抓取工具(php网页抓取工具是免费的,功能比较全,而且很新)
php网页抓取工具是免费的,功能比较全,而且很新。推荐pythonpython操作http、java操作http的话,还要解决一个网络延迟问题。推荐web开发用web开发terminal或者sublimetext编辑器,php用phpstorm。
phpwind是免费的,名字叫。
phpwind是免费的,功能挺全的,不过偶尔有bug,更新也不是很及时,应该有不少问题修复的。
github
说到免费正版的,可以试试虚幻云。虚幻云(虚幻云)专注于php与html5技术,完全不用担心公司机密泄露,自行搭建域名。免费使用,就这么简单。
phpwind、tp都可以网上资料随便找。
我自己都是用github,
wp
为什么要用免费的,php里面都有全套的开发工具,
phpwind、tp什么的都可以呀,tp是收费的。
我们公司比较傻逼,直接用tp搭起来的,不花钱。后面还换了一个博客软件,也是tp做的,比较傻逼,在用ghost的。
phpwind可以看看,有免费版,用起来挺好的,如果网络要求高,可以入tp的。如果你是老师,教学php(不推荐,如果网络要求高的话,你不也想请个学生帮你讲课?),且个人觉得对php感兴趣,可以用个免费版的试试,
php网页抓取工具( 一下自己现在正在使用的Chrome拓展可以实现网页整个页面截图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-02-20 12:24
一下自己现在正在使用的Chrome拓展可以实现网页整个页面截图)
安装出色的 Chrome 扩展程序可以大大提高您的工作效率。作为一名前端开发人员,我几乎把所有的工作时间都花在了与 Chrome 浏览器打交道上。 W3C中文教程网(w3schools.wang)今天将分享我现在正在使用的Chrome扩展。
Adblock Plus
Adblock Plus 不需要我多说。大部分朋友都知道这个扩展可以过滤网页上的广告。
CSS查看器
此扩展可以直接获取网页任意部分的样式信息,比F12调试工具更直观。
全页截屏
这个扩展可以对整个网页进行截图,功能简单直接。博主更喜欢简单的应用程序。
PHP 控制台
此扩展可以在控制台上显示 PHP 调试信息。先决条件是在服务器 PHP 环境中安装依赖项。详情请参考项目主页。
PHP 文档
快速找到一个PHP函数或方法的名称,输入后直接进入PHP官方文档打开搜索结果。
邮递员
这实际上是一个 Chrome 应用程序。该应用可以实现调用、请求、记录和保存API接口,可以在开发过程中作为接口测试和接口管理使用。
React 开发者工具
React 开发是必要的。如果打开的页面是基于 React 构建的,可以在控制台直接看到应用的当前状态。
专业视频下载器
直接抓取网页上正在播放的视频文件,可以直接获取外部链接进行下载。
Wappalyzer
直接查看当前页面使用的是哪个框架。
什么字体
直接获取页面文本使用的字体。如果觉得好看,可以直接采集这个字体。
如果您是一名 IT 工作者,w3schools.wang 可能会对您有所帮助! 查看全部
php网页抓取工具(
一下自己现在正在使用的Chrome拓展可以实现网页整个页面截图)
安装出色的 Chrome 扩展程序可以大大提高您的工作效率。作为一名前端开发人员,我几乎把所有的工作时间都花在了与 Chrome 浏览器打交道上。 W3C中文教程网(w3schools.wang)今天将分享我现在正在使用的Chrome扩展。
Adblock Plus
Adblock Plus 不需要我多说。大部分朋友都知道这个扩展可以过滤网页上的广告。
CSS查看器
此扩展可以直接获取网页任意部分的样式信息,比F12调试工具更直观。
全页截屏
这个扩展可以对整个网页进行截图,功能简单直接。博主更喜欢简单的应用程序。
PHP 控制台
此扩展可以在控制台上显示 PHP 调试信息。先决条件是在服务器 PHP 环境中安装依赖项。详情请参考项目主页。
PHP 文档
快速找到一个PHP函数或方法的名称,输入后直接进入PHP官方文档打开搜索结果。
邮递员
这实际上是一个 Chrome 应用程序。该应用可以实现调用、请求、记录和保存API接口,可以在开发过程中作为接口测试和接口管理使用。
React 开发者工具
React 开发是必要的。如果打开的页面是基于 React 构建的,可以在控制台直接看到应用的当前状态。
专业视频下载器
直接抓取网页上正在播放的视频文件,可以直接获取外部链接进行下载。
Wappalyzer
直接查看当前页面使用的是哪个框架。
什么字体
直接获取页面文本使用的字体。如果觉得好看,可以直接采集这个字体。
如果您是一名 IT 工作者,w3schools.wang 可能会对您有所帮助!
php网页抓取工具(网页抓取小工具.rar(22.91)本工具使用方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2022-02-18 10:09
网页抓取小工具(IE方法)——吴姐
html
使用IE提取网页数据的好处是,所见即所得,网页上能看到的信息一般都能得到。
这个工具的功能很少,主要是方便提取网页上显示的信息所在元素的代码。希望它可以帮助你一点。
Web Scraping Widget.rar(22.91 KB, 下载次数: 2426)
如何使用这个工具:
1、在B1输入网址,可以是打开的网页,也可以是未打开的网页
2、不要改变A2和B2的内容,第二行的其他单元格可以输入元素本身的属性名。其中innertext单元格有一个下拉选项
3、点击“开始分析”,分析网页元素。
4、A 列是每个元素的目标代码。
5、在innertext列中找到要提取的内容后,选中该行,点击“生成Excel”。
您可以提取Table标签的表格或下载IMG标签的图片。
6、在新生成的excel中,点击“执行代码”按钮,查看是否可以生成需要的数据。
如果生成的数据与您开始分析的数据不匹配,原因可能是:
1、网页还没有完全加载,对应标签的数据还没有加载。代码自动提取后续标签数据。
可能的解决方案:添加一个 do...loop 时间延迟。
2、网页为动态网页,标签序号不固定。
可能的解决方案:如果元素有id名称,使用getelementbyid("id name")获取。如果没有,请获取包并将其替换为 xmlhttp。
3、需要选择或登录才能提取。
可能的解决方案:在提取之前登录或选择相关选项
该工具主要针对初学者。浏览器可以分析,但不能给出具体元素的vba代码。该工具可以直接生成net capture的vba代码。ajax和frame中的内容也可以自动生成代码。 查看全部
php网页抓取工具(网页抓取小工具.rar(22.91)本工具使用方法)
网页抓取小工具(IE方法)——吴姐
html
使用IE提取网页数据的好处是,所见即所得,网页上能看到的信息一般都能得到。
这个工具的功能很少,主要是方便提取网页上显示的信息所在元素的代码。希望它可以帮助你一点。

Web Scraping Widget.rar(22.91 KB, 下载次数: 2426)
如何使用这个工具:
1、在B1输入网址,可以是打开的网页,也可以是未打开的网页
2、不要改变A2和B2的内容,第二行的其他单元格可以输入元素本身的属性名。其中innertext单元格有一个下拉选项
3、点击“开始分析”,分析网页元素。
4、A 列是每个元素的目标代码。
5、在innertext列中找到要提取的内容后,选中该行,点击“生成Excel”。
您可以提取Table标签的表格或下载IMG标签的图片。
6、在新生成的excel中,点击“执行代码”按钮,查看是否可以生成需要的数据。
如果生成的数据与您开始分析的数据不匹配,原因可能是:
1、网页还没有完全加载,对应标签的数据还没有加载。代码自动提取后续标签数据。
可能的解决方案:添加一个 do...loop 时间延迟。
2、网页为动态网页,标签序号不固定。
可能的解决方案:如果元素有id名称,使用getelementbyid("id name")获取。如果没有,请获取包并将其替换为 xmlhttp。
3、需要选择或登录才能提取。
可能的解决方案:在提取之前登录或选择相关选项
该工具主要针对初学者。浏览器可以分析,但不能给出具体元素的vba代码。该工具可以直接生成net capture的vba代码。ajax和frame中的内容也可以自动生成代码。
php网页抓取工具(php网页抓取工具xmlp,反正都是基于一些函数比如string_replace_to_string_interact)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-02-14 01:00
php网页抓取工具xmlp,javascript抓取工具javascripthash,反正都是基于一些函数比如string_replace_to_string_interactive_character.js等。
1.基于webgl,zbrush,quirks,minecraft(em)等可以实现类似googletosavehtml5files2.基于vba,比如想做个文本生成网页,对,就是批量生成带链接的文本。googlewebgldocument。3.基于mysql、postgresql、sqlserver等数据库,也可以实现类似googletosavehtml5files。
还有googletosavehtml5fileswithphp等等不过话说,问这个问题能不能多看看googletosavehtml5files官方文档再问,不要整天追求新奇实现,毕竟不是为了搞网站而生的。
php网页抓取工具javascripthash,还是用string_replace_to_string_interactive_character.js之类的,不过比较大。基于objective-c的开源脚本一大堆啊,相应接口少一些,像《phpcookbook》一类的入门基础书籍,应该都有相应介绍和开源的代码。
如::print+quirks你说的“类似googletosavehtml5files”的情况可能是要多几步吧。先用phpstorm生成静态页面,通过mysql连到mysql数据库,然后一步步获取转义后的data,并转换成对应character就行了。 查看全部
php网页抓取工具(php网页抓取工具xmlp,反正都是基于一些函数比如string_replace_to_string_interact)
php网页抓取工具xmlp,javascript抓取工具javascripthash,反正都是基于一些函数比如string_replace_to_string_interactive_character.js等。
1.基于webgl,zbrush,quirks,minecraft(em)等可以实现类似googletosavehtml5files2.基于vba,比如想做个文本生成网页,对,就是批量生成带链接的文本。googlewebgldocument。3.基于mysql、postgresql、sqlserver等数据库,也可以实现类似googletosavehtml5files。
还有googletosavehtml5fileswithphp等等不过话说,问这个问题能不能多看看googletosavehtml5files官方文档再问,不要整天追求新奇实现,毕竟不是为了搞网站而生的。
php网页抓取工具javascripthash,还是用string_replace_to_string_interactive_character.js之类的,不过比较大。基于objective-c的开源脚本一大堆啊,相应接口少一些,像《phpcookbook》一类的入门基础书籍,应该都有相应介绍和开源的代码。
如::print+quirks你说的“类似googletosavehtml5files”的情况可能是要多几步吧。先用phpstorm生成静态页面,通过mysql连到mysql数据库,然后一步步获取转义后的data,并转换成对应character就行了。
php网页抓取工具(如何查看网页的一个问题?(一)_光明网)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-02-11 09:32
通过前面几章的介绍,我们对什么是爬虫有了初步的了解,同时对如何爬取网页有了大致的了解。从本章开始,我们将从理论走向实践,结合实际操作进一步加深理解。
由于使用python爬取页面的工具有很多,例如requests、scrapy、PhantomJS、Splash等,而且解析爬取页面的工具也很多。我们这里从最简单的开始,使用 requests 库和 beautifSoup 工具进行静态页面爬取和解析。
基础功扎实后,我们可以使用更灵活的工具,不仅可以静态爬取,还可以动态爬取;不仅可以爬取单页,还可以递归深度爬取。同时,结合其他渲染、存储、机器学习等工具,我们可以对数据进行处理、加工、建模和展示。
废话不多说,开始今天的例子,抓起安徒生童话中著名的“丑小鸭”。“要想把工作做好,就必须先利好自己的工具。” 在开始之前,我们需要做一些准备工作,下载pycharm,安装requests库和beautifSoup。安装结果如下:
启动爬虫的第一步是找到童话故事“丑小鸭”的链接。我们在这里使用的链接是:. ![在此处插入图像描述]()
找到我们的目标链接后,第二步就是分析网页。分析什么?当然是分析我们要爬取的内容在哪里。
根据我们之前的介绍,我们这次爬虫的目的是爬取丑小鸭的文字。带着这个目标,我们首先要研究网页的构成。那么如何查看网页呢?一般是在浏览器的开发者模式下完成。对于chrome浏览器,我们可以使用快捷键F12来查看,如图:
左边是网页显示的内容,右边是网页的HTML文档。
通过对右侧页面的分析,我们可以观察到我们需要爬取的页面内容在一个
在标签中:
既然找到了页面,也找到了要爬取的内容的位置,那么我们现在需要解决的一个问题是:如何使用代码快速定位到目标内容?
理想情况下,我们希望这样
标签有一个唯一的属性(通常是id或者class),那么我们可以通过这个属性直接定位到位置。
但不幸的是,在我们的目标标签中
,它没有属性,更不用说独特的属性了。现在直接访问的愿望已经被打败,只能使用间接访问。
通常有两种间接方法:第一种是找到与其相邻的可以快速定位的标签,然后根据两个标签之间的位置关系进行间接访问。在这个操作中,我们很容易发现
标签的父标签div有唯一的类属性articleContent;第二种方法是将所有
找出所有的标签,然后用一个一个的遍历找到目标的标签。事实上,在实际的爬取过程中,这两种方法都会用到。
至于哪个更好,我们将根据实际情况进行分析选择。在这里,我们展示了两种方式。
第一种方式:
我们基于
标签的父标签div有唯一的类属性articleContent找到div标签,然后根据父子关系找到p标签,再通过正则表达式过滤无用的内容,得到最终结果。
1`
1# 请求库
2import requests
3# 解析库
4from bs4 import BeautifulSoup
5import re
6# 爬取的网页链接
7url=r"https://www.ppzuowen.com/book/ ... ot%3B
8r= requests.get(url)
9r.encoding=None
10result = r.text
11# 再次封装,获取具体标签内的内容
12bs = BeautifulSoup(result, 'lxml')
13psg = bs.select('.articleContent > p')
14title = bs.select('title')[0].text.split('_')[0]
15# print(title)
16txt = ''.join(str(x) for x in psg)
17res = re.sub(r'', "", txt)
18result=res.split("(1844年)")[0]
19print('标题:',title)
20print('原文内容:',result)
21
22
最后结果:
实现的代码主要分为两部分:第一部分是页面的爬取,如:
1`
1# 爬取的网页链接
2url=r"https://www.ppzuowen.com/book/ ... ot%3B
3r= requests.get(url)
4r.encoding=None
5result = r.text
6print(result)
7
8
这部分内容和我们之前在浏览器的开发者模式中看到的HTML源代码完全一样。
第二部分是页面的解析。
我们之前介绍过,HTLML 页面本质上是一棵 DOM 树。我们通过遍历树的子节点来遍历HTML页面中的标签,如:
1# 再次封装,获取具体标签内的内容
2bs = BeautifulSoup(result, 'lxml')
3psg = bs.select('.articleContent > p')
4
5
这里首先将页面信息转换成xml格式的文档(注意:HTML文档是一种特殊类型的xml文档),然后根据CSS语法找到p标签的内容。
第二种方式:
我们原来的方式写的代码是这样的:
1# 请求库
2import requests
3# 解析库
4from bs4 import BeautifulSoup
5
6# 爬取的网页链接
7url=r"https://www.ppzuowen.com/book/ ... ot%3B
8r= requests.get(url)
9r.encoding=None
10result = r.text
11# 再次封装,获取具体标签内的内容
12bs = BeautifulSoup(result,'html.parser')
13# 具体标签
14print("---------解析后的数据---------------")
15# print(bs.span)
16a={}
17# 获取已爬取内容中的p签内容
18data=bs.find_all('p')
19# 循环打印输出
20for tmp in data:
21 print(tmp)
22 print('********************')
23
24
然后我们看输出结果和预期的不一样,是这样的:
获取的内容被分割并与许多其他无用的信息混合。其实这些在实际爬取过程中都是常见的。并非每次爬取都是一步完成的,并且需要不断调试。
经过分析,我们可以使用表达式过滤无用信息,并使用字符串拼接函数进行拼接,得到我们期望的结果。
最终代码如下:
1# 请求库
2import requests
3# 解析库
4from bs4 import BeautifulSoup
5
6# 爬取的网页链接
7url=r"https://www.ppzuowen.com/book/ ... ot%3B
8r= requests.get(url)
9r.encoding=None
10result = r.text
11# 再次封装,获取具体标签内的内容
12bs = BeautifulSoup(result,'html.parser')
13# 具体标签
14print("---------解析后的数据---------------")
15# print(bs.span)
16a={}
17# 获取已爬取内容中的p签内容
18data=bs.find_all('p')
19result=''
20# 循环打印输出
21for tmp in data:
22 if '1844年' in tmp.text:
23 break
24 result+=tmp.text
25
26print(result)
27
28
上面我们已经说明了如何通过两种方式抓取一些简单的网页信息。当然,对于爬取的内容,我们有时不仅输出,还可能需要存储。
通常,存储方式是文件和数据库的形式。我们稍后会详细介绍这些内容。
其实作为一个编程学习者,有一个学习氛围和一个交流圈是很重要的。学习资料,面试技巧,大厂面试题,升职加薪指日可待。希望大家可以在Q2956807116和我交流,或者加入Q群313782132,无论是新手还是大佬,都欢迎。让我们一起交流,一起成长。 查看全部
php网页抓取工具(如何查看网页的一个问题?(一)_光明网)
通过前面几章的介绍,我们对什么是爬虫有了初步的了解,同时对如何爬取网页有了大致的了解。从本章开始,我们将从理论走向实践,结合实际操作进一步加深理解。
由于使用python爬取页面的工具有很多,例如requests、scrapy、PhantomJS、Splash等,而且解析爬取页面的工具也很多。我们这里从最简单的开始,使用 requests 库和 beautifSoup 工具进行静态页面爬取和解析。
基础功扎实后,我们可以使用更灵活的工具,不仅可以静态爬取,还可以动态爬取;不仅可以爬取单页,还可以递归深度爬取。同时,结合其他渲染、存储、机器学习等工具,我们可以对数据进行处理、加工、建模和展示。
废话不多说,开始今天的例子,抓起安徒生童话中著名的“丑小鸭”。“要想把工作做好,就必须先利好自己的工具。” 在开始之前,我们需要做一些准备工作,下载pycharm,安装requests库和beautifSoup。安装结果如下:

启动爬虫的第一步是找到童话故事“丑小鸭”的链接。我们在这里使用的链接是:. ![在此处插入图像描述]()
找到我们的目标链接后,第二步就是分析网页。分析什么?当然是分析我们要爬取的内容在哪里。
根据我们之前的介绍,我们这次爬虫的目的是爬取丑小鸭的文字。带着这个目标,我们首先要研究网页的构成。那么如何查看网页呢?一般是在浏览器的开发者模式下完成。对于chrome浏览器,我们可以使用快捷键F12来查看,如图:

左边是网页显示的内容,右边是网页的HTML文档。
通过对右侧页面的分析,我们可以观察到我们需要爬取的页面内容在一个
在标签中:

既然找到了页面,也找到了要爬取的内容的位置,那么我们现在需要解决的一个问题是:如何使用代码快速定位到目标内容?
理想情况下,我们希望这样
标签有一个唯一的属性(通常是id或者class),那么我们可以通过这个属性直接定位到位置。
但不幸的是,在我们的目标标签中
,它没有属性,更不用说独特的属性了。现在直接访问的愿望已经被打败,只能使用间接访问。
通常有两种间接方法:第一种是找到与其相邻的可以快速定位的标签,然后根据两个标签之间的位置关系进行间接访问。在这个操作中,我们很容易发现
标签的父标签div有唯一的类属性articleContent;第二种方法是将所有
找出所有的标签,然后用一个一个的遍历找到目标的标签。事实上,在实际的爬取过程中,这两种方法都会用到。
至于哪个更好,我们将根据实际情况进行分析选择。在这里,我们展示了两种方式。
第一种方式:
我们基于
标签的父标签div有唯一的类属性articleContent找到div标签,然后根据父子关系找到p标签,再通过正则表达式过滤无用的内容,得到最终结果。
1`
1# 请求库
2import requests
3# 解析库
4from bs4 import BeautifulSoup
5import re
6# 爬取的网页链接
7url=r"https://www.ppzuowen.com/book/ ... ot%3B
8r= requests.get(url)
9r.encoding=None
10result = r.text
11# 再次封装,获取具体标签内的内容
12bs = BeautifulSoup(result, 'lxml')
13psg = bs.select('.articleContent > p')
14title = bs.select('title')[0].text.split('_')[0]
15# print(title)
16txt = ''.join(str(x) for x in psg)
17res = re.sub(r'', "", txt)
18result=res.split("(1844年)")[0]
19print('标题:',title)
20print('原文内容:',result)
21
22
最后结果:

实现的代码主要分为两部分:第一部分是页面的爬取,如:
1`
1# 爬取的网页链接
2url=r"https://www.ppzuowen.com/book/ ... ot%3B
3r= requests.get(url)
4r.encoding=None
5result = r.text
6print(result)
7
8

这部分内容和我们之前在浏览器的开发者模式中看到的HTML源代码完全一样。
第二部分是页面的解析。
我们之前介绍过,HTLML 页面本质上是一棵 DOM 树。我们通过遍历树的子节点来遍历HTML页面中的标签,如:
1# 再次封装,获取具体标签内的内容
2bs = BeautifulSoup(result, 'lxml')
3psg = bs.select('.articleContent > p')
4
5
这里首先将页面信息转换成xml格式的文档(注意:HTML文档是一种特殊类型的xml文档),然后根据CSS语法找到p标签的内容。
第二种方式:
我们原来的方式写的代码是这样的:
1# 请求库
2import requests
3# 解析库
4from bs4 import BeautifulSoup
5
6# 爬取的网页链接
7url=r"https://www.ppzuowen.com/book/ ... ot%3B
8r= requests.get(url)
9r.encoding=None
10result = r.text
11# 再次封装,获取具体标签内的内容
12bs = BeautifulSoup(result,'html.parser')
13# 具体标签
14print("---------解析后的数据---------------")
15# print(bs.span)
16a={}
17# 获取已爬取内容中的p签内容
18data=bs.find_all('p')
19# 循环打印输出
20for tmp in data:
21 print(tmp)
22 print('********************')
23
24
然后我们看输出结果和预期的不一样,是这样的:

获取的内容被分割并与许多其他无用的信息混合。其实这些在实际爬取过程中都是常见的。并非每次爬取都是一步完成的,并且需要不断调试。
经过分析,我们可以使用表达式过滤无用信息,并使用字符串拼接函数进行拼接,得到我们期望的结果。
最终代码如下:
1# 请求库
2import requests
3# 解析库
4from bs4 import BeautifulSoup
5
6# 爬取的网页链接
7url=r"https://www.ppzuowen.com/book/ ... ot%3B
8r= requests.get(url)
9r.encoding=None
10result = r.text
11# 再次封装,获取具体标签内的内容
12bs = BeautifulSoup(result,'html.parser')
13# 具体标签
14print("---------解析后的数据---------------")
15# print(bs.span)
16a={}
17# 获取已爬取内容中的p签内容
18data=bs.find_all('p')
19result=''
20# 循环打印输出
21for tmp in data:
22 if '1844年' in tmp.text:
23 break
24 result+=tmp.text
25
26print(result)
27
28
上面我们已经说明了如何通过两种方式抓取一些简单的网页信息。当然,对于爬取的内容,我们有时不仅输出,还可能需要存储。
通常,存储方式是文件和数据库的形式。我们稍后会详细介绍这些内容。
其实作为一个编程学习者,有一个学习氛围和一个交流圈是很重要的。学习资料,面试技巧,大厂面试题,升职加薪指日可待。希望大家可以在Q2956807116和我交流,或者加入Q群313782132,无论是新手还是大佬,都欢迎。让我们一起交流,一起成长。
php网页抓取工具(10款最具人气的PHP开源工具,你可以在你所喜爱)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-02-10 19:15
PHP 非常适合创建动态和创新的 Web 应用程序。不用说,PHP 是 Web 开发世界中最流行的语言之一。一些非常实用的 PHP 开源工具,确实为很多 PHP 开发者解脱了繁重的开发任务,减轻了他们的开发负担。这些 PHP 开源工具改进了他们的工作流程,使他们的开发任务更轻松、更快捷。小编整理了10款最流行的PHP开源工具分享给大家,欢迎交流分享。
蒙斯塔 FTP
如果您想在浏览器中设置 FTP 文件管理,您需要有一个开源的 PHP 或 Ajax Cloudware,如 Monsta FTP。不仅支持屏幕文件编辑,还可以将文件拖放到浏览器上进行快速上传。Monsta FTP经过测试,支持火狐、Chrome、IE浏览器、Safari浏览器等所有主流浏览器,并配备多语言支持。
品霸
Pinba 使用只读格式的 MySQL 作为实时统计/监督服务器。它几乎是一个 MySQL 存储引擎。它可以生成简单格式的统计报表,并将累积的数据处理后通过UDP发送。它还可以创建复杂的报告。
箱盒
CaseBox 是一个用于管理任务、记录和文档的开源 PHP Web 应用程序。它允许我们创建大量目录并将数据存储在类似于桌面界面的首选结构中。CaseBox 通过将具有指定期限的任务分配给用户并跟踪绩效,极大地简化了工作流程。
西柳斯
Sylius 也是一个基于 Symfony 2 的开源 PHP 工具。它允许您创建电子商务网站 并管理收录产品和类别的复杂在线商店。它支持多种功能,例如管理不同的税率和运输方式。此外,它还与支付网关 OmniPay 集成,使其成为完美的电子商务工具。
微微
这个内容管理程序也是开源的,它使用平面文件文件作为其数据库。Pico 无需安装即可使用。您可以在您喜欢的文本编辑器中编辑存储在 .md 文件中的内容。
穆尼
如果您想优化和操作 网站 网站资产,综合的 网站 库 Munee 将派上用场。它可以实现客户端和服务器端的资源缓存。它还可以集成 PHP 图像处理库。您可以调整图像大小或裁剪图像并缓存它们。
法尔康 PHP
它是一个提供低资源消耗和高性能的 Web 框架。Phalcon PHP 是用 C 语言编写的,因此它适用于任何操作系统。
phpMyFAQ
phpMyFAQ是一个PHP FAQ(Frequently Asked Questions)应用程序,可以用来频繁提问一个优秀的FAQ系统。它可以管理用户、项目、类别和统计数据。phpMyFAQ 有一个先进的搜索系统,可以帮助用户找到相关的答案。
PHPImageWorkshop
它使用 GD 库来管理图像。它允许您以与 Photoshop 类似的方式编辑照片。同时它也非常灵活,可以让你叠加大量图片,使用旋转功能甚至缩略图。
调试栏
DebugBar 也是开源应用程序家族的一员,可在线免费获取,并可集成到 PHP 项目中。它包括常见和流行的库。它支持 Ajax 请求并在页脚中有一个 JavaScript 栏。 查看全部
php网页抓取工具(10款最具人气的PHP开源工具,你可以在你所喜爱)
PHP 非常适合创建动态和创新的 Web 应用程序。不用说,PHP 是 Web 开发世界中最流行的语言之一。一些非常实用的 PHP 开源工具,确实为很多 PHP 开发者解脱了繁重的开发任务,减轻了他们的开发负担。这些 PHP 开源工具改进了他们的工作流程,使他们的开发任务更轻松、更快捷。小编整理了10款最流行的PHP开源工具分享给大家,欢迎交流分享。
蒙斯塔 FTP
如果您想在浏览器中设置 FTP 文件管理,您需要有一个开源的 PHP 或 Ajax Cloudware,如 Monsta FTP。不仅支持屏幕文件编辑,还可以将文件拖放到浏览器上进行快速上传。Monsta FTP经过测试,支持火狐、Chrome、IE浏览器、Safari浏览器等所有主流浏览器,并配备多语言支持。
品霸
Pinba 使用只读格式的 MySQL 作为实时统计/监督服务器。它几乎是一个 MySQL 存储引擎。它可以生成简单格式的统计报表,并将累积的数据处理后通过UDP发送。它还可以创建复杂的报告。
箱盒
CaseBox 是一个用于管理任务、记录和文档的开源 PHP Web 应用程序。它允许我们创建大量目录并将数据存储在类似于桌面界面的首选结构中。CaseBox 通过将具有指定期限的任务分配给用户并跟踪绩效,极大地简化了工作流程。
西柳斯
Sylius 也是一个基于 Symfony 2 的开源 PHP 工具。它允许您创建电子商务网站 并管理收录产品和类别的复杂在线商店。它支持多种功能,例如管理不同的税率和运输方式。此外,它还与支付网关 OmniPay 集成,使其成为完美的电子商务工具。
微微
这个内容管理程序也是开源的,它使用平面文件文件作为其数据库。Pico 无需安装即可使用。您可以在您喜欢的文本编辑器中编辑存储在 .md 文件中的内容。
穆尼
如果您想优化和操作 网站 网站资产,综合的 网站 库 Munee 将派上用场。它可以实现客户端和服务器端的资源缓存。它还可以集成 PHP 图像处理库。您可以调整图像大小或裁剪图像并缓存它们。
法尔康 PHP
它是一个提供低资源消耗和高性能的 Web 框架。Phalcon PHP 是用 C 语言编写的,因此它适用于任何操作系统。
phpMyFAQ
phpMyFAQ是一个PHP FAQ(Frequently Asked Questions)应用程序,可以用来频繁提问一个优秀的FAQ系统。它可以管理用户、项目、类别和统计数据。phpMyFAQ 有一个先进的搜索系统,可以帮助用户找到相关的答案。
PHPImageWorkshop
它使用 GD 库来管理图像。它允许您以与 Photoshop 类似的方式编辑照片。同时它也非常灵活,可以让你叠加大量图片,使用旋转功能甚至缩略图。
调试栏
DebugBar 也是开源应用程序家族的一员,可在线免费获取,并可集成到 PHP 项目中。它包括常见和流行的库。它支持 Ajax 请求并在页脚中有一个 JavaScript 栏。
php网页抓取工具(python的最基本就是get一个网页的源代码数据,如果更初学爬虫 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-02-08 19:00
)
相关话题
python示例爬虫代码怎么做
11/8/202015:02:54
python爬虫代码示例的方法:先获取浏览器信息,使用urlencode生成post数据;然后安装 pymysql 并将数据存储在 MySQL 中。python爬虫代码示例的方法:1、urllib和BeautifulfuSoup获取浏览器
谈爬虫,绕过网站反爬机制
25/8/202018:04:17
【相关学习推荐:网站制作视频教程】什么是爬虫?简单地说,爬虫是一种自动与服务器交互以通过计算机获取数据的工具。爬虫最基本的就是获取一个网页的源代码数据。
初级爬虫一、获取某个类别下的所有页面地址
2/3/2018 01:10:32
总结:初学者,做个简单的爬虫深入理解python获取jb51书籍的列表和地址
谈爬虫,绕过网站反爬机制
15/12/2017 09:03:00
什么是爬虫?简单地说,爬虫是一种自动与服务器交互以获取数据的工具。
爬行动物和反爬行 - 爬行动物
2018 年 4 月 3 日 01:08:51
总结:爬虫与反爬——爬虫
Scrapy爬虫--02
2018 年 2 月 3 日 01:11:17
爬虫最基本的部分是下载网页,最重要的部分是过滤——获取我们需要的信息。而scrapy只是提供了这个功能:首先我们必须定义项目:Itemsarecontainersthatwillbeloadedwiththescrapeddata;它们工作起来像简单的pythondicts但是提供了额外的pro
为什么爬虫需要很多ip
2015 年 9 月 11 日:06:24
爬虫需要大量IP的原因:1、因为在爬取数据的过程中,经常被网站阻塞;不一样,还是刮掉空白数据。为什么爬虫需要很多IP
关于网络爬虫的事情:变相杀死爬虫
2009 年 11 月 8 日 14:29:00
在那些关于网络爬虫的事情中(一)提到如果爬虫伪装自己的User-Agent信息,就必须找到新的方法来阻止爬虫。其实对于网站来说,最大的挑战是如何准确识别一个IP发起的请求,是真实用户访问还是爬虫访问?
教你任意使用谷歌爬虫DDoS网站
30/6/201509:14:00
教你任意使用谷歌爬虫DDoS网站!Google 的 FeedFetcher 抓取工具将缓存电子表格的 =image("link") 中的所有链接。
简单高效的nodejs爬虫模型
2018 年 4 月 3 日 01:09:06
这篇文章解释了yunshare项目的爬虫模型。使用nodejs开发爬虫非常简单。你不需要像python的scrapy这样的爬虫框架。只需要使用 request 或 superagent 等 http 库即可完成大部分爬虫工作。使用nodejs开发爬虫半年左右,爬虫可以很简单也可以很复杂。一个简单的爬虫定向爬取一个网站,可能有几万或几十万的页面请求,复杂的爬虫类似于googlebot之类的搜索引擎
开源爬虫软件总结
2018 年 4 月 3 日 01:13:50
摘要:世界上有数百种爬虫软件。本文整理了比较知名和常见的开源爬虫软件,并按照开发语言进行了总结,如下表所示。虽然搜索引擎也有爬虫,但是这次我只总结爬虫软件,不是大型复杂的搜索引擎,因为很多兄弟只是想爬数据,而不是操作搜索引擎。
爬虫概述
2018 年 2 月 3 日 01:10:10
摘要:爬虫概述
hao123 简单的网络爬虫
2018 年 4 月 3 日 01:09:06
项目地址:github网络爬虫使用的主要技术是Jsoup和httpclientJsoup,用于解析网页数据,可以根据网页节点获取需要的数据。httpclient用于请求网页,获取整个网页数据。页面的域名和二级页面,即主模块在hao123首页的超链接,以及通过超链接包com.kunteng.crawler访问的页面上的所有链接;/*
Pythonscrapy爬虫爬取博乐在线所有文章并写入数据库
2018 年 4 月 3 日 01:10:02
博乐在线爬虫项目目的及项目准备:1.使用scrapy创建项目2.创建爬虫,博乐域名3.start_urls=['']4.爬取所有页面 文章5.文章列表页面需要数据 a) 缩略图地址 b) 详细 url 地址6.详细页面要提取的数据#博客标题#博客创建
33个可用于抓取数据的开源爬虫软件工具
2018 年 4 月 3 日 01:12:56
玩大数据,没有数据怎么玩?下面为大家推荐33款开源爬虫软件。爬虫,或称网络爬虫,是一种自动获取网页内容的程序。它是搜索引擎的重要组成部分,因此搜索引擎优化主要针对爬虫进行优化。网络爬虫是一种自动提取网页的程序。它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成部分。传统的爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL,在抓取网页的过程中不断地从当前页面中提取新的URL。
查看全部
php网页抓取工具(python的最基本就是get一个网页的源代码数据,如果更初学爬虫
)
相关话题
python示例爬虫代码怎么做
11/8/202015:02:54
python爬虫代码示例的方法:先获取浏览器信息,使用urlencode生成post数据;然后安装 pymysql 并将数据存储在 MySQL 中。python爬虫代码示例的方法:1、urllib和BeautifulfuSoup获取浏览器

谈爬虫,绕过网站反爬机制
25/8/202018:04:17
【相关学习推荐:网站制作视频教程】什么是爬虫?简单地说,爬虫是一种自动与服务器交互以通过计算机获取数据的工具。爬虫最基本的就是获取一个网页的源代码数据。
初级爬虫一、获取某个类别下的所有页面地址
2/3/2018 01:10:32
总结:初学者,做个简单的爬虫深入理解python获取jb51书籍的列表和地址
谈爬虫,绕过网站反爬机制
15/12/2017 09:03:00
什么是爬虫?简单地说,爬虫是一种自动与服务器交互以获取数据的工具。
爬行动物和反爬行 - 爬行动物
2018 年 4 月 3 日 01:08:51
总结:爬虫与反爬——爬虫
Scrapy爬虫--02
2018 年 2 月 3 日 01:11:17
爬虫最基本的部分是下载网页,最重要的部分是过滤——获取我们需要的信息。而scrapy只是提供了这个功能:首先我们必须定义项目:Itemsarecontainersthatwillbeloadedwiththescrapeddata;它们工作起来像简单的pythondicts但是提供了额外的pro
为什么爬虫需要很多ip
2015 年 9 月 11 日:06:24
爬虫需要大量IP的原因:1、因为在爬取数据的过程中,经常被网站阻塞;不一样,还是刮掉空白数据。为什么爬虫需要很多IP
关于网络爬虫的事情:变相杀死爬虫
2009 年 11 月 8 日 14:29:00
在那些关于网络爬虫的事情中(一)提到如果爬虫伪装自己的User-Agent信息,就必须找到新的方法来阻止爬虫。其实对于网站来说,最大的挑战是如何准确识别一个IP发起的请求,是真实用户访问还是爬虫访问?
教你任意使用谷歌爬虫DDoS网站
30/6/201509:14:00
教你任意使用谷歌爬虫DDoS网站!Google 的 FeedFetcher 抓取工具将缓存电子表格的 =image("link") 中的所有链接。
简单高效的nodejs爬虫模型
2018 年 4 月 3 日 01:09:06
这篇文章解释了yunshare项目的爬虫模型。使用nodejs开发爬虫非常简单。你不需要像python的scrapy这样的爬虫框架。只需要使用 request 或 superagent 等 http 库即可完成大部分爬虫工作。使用nodejs开发爬虫半年左右,爬虫可以很简单也可以很复杂。一个简单的爬虫定向爬取一个网站,可能有几万或几十万的页面请求,复杂的爬虫类似于googlebot之类的搜索引擎
开源爬虫软件总结
2018 年 4 月 3 日 01:13:50
摘要:世界上有数百种爬虫软件。本文整理了比较知名和常见的开源爬虫软件,并按照开发语言进行了总结,如下表所示。虽然搜索引擎也有爬虫,但是这次我只总结爬虫软件,不是大型复杂的搜索引擎,因为很多兄弟只是想爬数据,而不是操作搜索引擎。
爬虫概述
2018 年 2 月 3 日 01:10:10
摘要:爬虫概述
hao123 简单的网络爬虫
2018 年 4 月 3 日 01:09:06
项目地址:github网络爬虫使用的主要技术是Jsoup和httpclientJsoup,用于解析网页数据,可以根据网页节点获取需要的数据。httpclient用于请求网页,获取整个网页数据。页面的域名和二级页面,即主模块在hao123首页的超链接,以及通过超链接包com.kunteng.crawler访问的页面上的所有链接;/*
Pythonscrapy爬虫爬取博乐在线所有文章并写入数据库
2018 年 4 月 3 日 01:10:02
博乐在线爬虫项目目的及项目准备:1.使用scrapy创建项目2.创建爬虫,博乐域名3.start_urls=['']4.爬取所有页面 文章5.文章列表页面需要数据 a) 缩略图地址 b) 详细 url 地址6.详细页面要提取的数据#博客标题#博客创建
33个可用于抓取数据的开源爬虫软件工具
2018 年 4 月 3 日 01:12:56
玩大数据,没有数据怎么玩?下面为大家推荐33款开源爬虫软件。爬虫,或称网络爬虫,是一种自动获取网页内容的程序。它是搜索引擎的重要组成部分,因此搜索引擎优化主要针对爬虫进行优化。网络爬虫是一种自动提取网页的程序。它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成部分。传统的爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL,在抓取网页的过程中不断地从当前页面中提取新的URL。
php网页抓取工具(智能识别模式WebHarvy网页数据抓取工具功能介绍-苏州安嘉)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-02-08 18:06
WebHarvy 是一个网页数据捕获工具。该软件可以提取网页中的文字和图片,输入网址并打开。默认使用内部浏览器,支持扩展分析,可自动获取相似链接列表。软件界面直观,操作简单。
特征
智能识别模式
WebHarvy 自动识别出现在网页中的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
从多个页面中提取
网页通常会在多个页面中显示数据,例如产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。只需指出“指向下一页的链接”,WebHarvy网站 抓取工具就会自动从所有页面抓取数据。
直观的操作界面
WebHarvy 是一个可视化网页提取工具。事实上,完全不需要编写任何脚本或代码来提取数据。使用 webharvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。它是如此容易!
基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,将为所有给定的输入关键字自动重复您创建的配置。可以指定任意数量的输入关键字
提取分类
WebHarvy网站 抓取器允许您从指向网站 中相似页面的链接列表中提取数据。这允许您使用单个配置来抓取 网站 中的类别或子部分。
使用正则表达式提取
WebHarvy 可以将正则表达式(regular expressions)应用于网页的文本或 HTML 源代码,并提取不匹配的部分。这种强大的技术在抓取数据时为您提供了更大的灵活性。
软件功能
WebHarvy 是一个可视化的网络爬虫。* 无需编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器浏览网络。您可以选择要单击的数据。这简单!
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动删除它。
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
通常,网页会在多个页面上显示产品列表等数据。WebHarvy 可以自动从多个页面爬取和提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper 就会自动从所有页面中抓取数据。 查看全部
php网页抓取工具(智能识别模式WebHarvy网页数据抓取工具功能介绍-苏州安嘉)
WebHarvy 是一个网页数据捕获工具。该软件可以提取网页中的文字和图片,输入网址并打开。默认使用内部浏览器,支持扩展分析,可自动获取相似链接列表。软件界面直观,操作简单。
特征
智能识别模式
WebHarvy 自动识别出现在网页中的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
从多个页面中提取
网页通常会在多个页面中显示数据,例如产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。只需指出“指向下一页的链接”,WebHarvy网站 抓取工具就会自动从所有页面抓取数据。
直观的操作界面
WebHarvy 是一个可视化网页提取工具。事实上,完全不需要编写任何脚本或代码来提取数据。使用 webharvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。它是如此容易!
基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,将为所有给定的输入关键字自动重复您创建的配置。可以指定任意数量的输入关键字
提取分类
WebHarvy网站 抓取器允许您从指向网站 中相似页面的链接列表中提取数据。这允许您使用单个配置来抓取 网站 中的类别或子部分。
使用正则表达式提取
WebHarvy 可以将正则表达式(regular expressions)应用于网页的文本或 HTML 源代码,并提取不匹配的部分。这种强大的技术在抓取数据时为您提供了更大的灵活性。
软件功能
WebHarvy 是一个可视化的网络爬虫。* 无需编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器浏览网络。您可以选择要单击的数据。这简单!
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动删除它。
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
通常,网页会在多个页面上显示产品列表等数据。WebHarvy 可以自动从多个页面爬取和提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper 就会自动从所有页面中抓取数据。
php网页抓取工具(网站建设中一项重要的工作就是改版,百度蜘蛛抓取情况)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-08 16:17
网站建设中的一项重要工作是修订版本。每次修订都必须朝着积极的方向进行。因为每个阶段的定位不同,我们要网站展示的企业形象也不同,一个好看的网站绝对可以提升我们公司在潜在客户心目中的地位。但是,大部分的修改都会对我们的网站 SEO产生一定的影响。这里我们需要非常熟悉网站的情况,然后对其进行有效的控制,以减少修改造成的404页数。很多情况。
最近,一个新的 网站 已经推出。因为是一年多的域名,所以之前的网站的内容和新站点的内容完全不同。网站的结构也做了很大的调整,所以带来了很多404错误爬取页面,我当时没有特别注意这个问题,然后持续更新了2周左右,我发现快照没有更新,一些简单的外部链接不起作用。这个问题引起了我的注意。. 以下是我的一些详细想法:
1、使用日志分析工具查找404错误爬取页面
测井分析工具可以使用最常用的光年测井分析工具。首先,使用FTP下载最近几天的网站LOG日志。当然,如果你想要更多的分析,你可以下载这么多的一段时间的LOG日志。可以,使用日志分析工具新建一个任务,分析百度蜘蛛在各个阶段的爬取情况。这里主要考虑百度爬取的情况,因为建立这个分析工作的前提是快照停滞,收录为1。
建议您将分析分为三个时间段:
A.分析最后一天的LOG日志,可以是今天,但最好是昨天,因为昨天的日志会更全,而且就算晚上来分析,也不会统计一个部分时间。
B、分析修改后的LOG日志,因为涉及到百度蜘蛛对网站修改的一些判断,比如我们可以分析百度蜘蛛什么时候开始判断网站已经修改了,或者当它放弃对旧站点 URL 等的抓取时。
C、修改前后爬取量对比,分析修改对百度蜘蛛的爬取量有多大影响。
至于日志分析工作之后的分析工作,是一键式的。有了具体的分析思路后,我们再对比分析,会发现很多我们平时没有注意到的问题,比如下面改版导致的404页面。还有很多页面有404错误,我没有意识到。例如,下面的 wp-login.php 页面就是一个典型的例子:
404错误爬取页面
2、使用百度站长工具中的死链接提交工具提交死链接
百度站长平台LEE团队表示:404状态码代表'NotFound'。当蜘蛛更新时,它会认为页面是无效的。此时,将从索引库中删除。短期内,蜘蛛会发现该url不再被抓取。当然,百度的说法只能作为参考,因为对网站日志的分析发现,百度蜘蛛仍然爬取这些错误页面2个多星期。当然,百度对404错误页面的引导操作还是很有针对性的。性。
百度站长平台404页浏览量
具体来说,死链接站点地图是在死链接提交工具中提交的。您可以根据自己的情况提交死链接。我这里提交后效果不大,因为大家都知道百度的效果展示周期一般比较长。.
3、使用robots.txt和nofollow标签引导蜘蛛爬行
404错误页面最大的缺点之一就是给蜘蛛带来了一些错误的爬取,浪费了蜘蛛的爬取资源。比如首先我们要达成这样一个共识:任何网站蜘蛛爬取的资源都是有限的,小的网站自然少得多,大的网站多得多。如果你想要更高的爬虫爬取率和更合理的爬取,那么一些错误的链接会导致404错误的数量应该尽可能的减少。
所以我对网站这些资源的浪费给予了适当的指导,让蜘蛛爬一些我想让他爬的页面,把机器人限制在/wuchenshi/、/gaoxiao/等类似的页面列爬取,对网站中不参与排名的部分链接实施nofollow,引导蜘蛛爬取重要页面。再来看看spider 6. No. 3的爬取情况。首先,目录爬取中没有网站中不存在的目录:
蜘蛛对目录的爬取
对于爬虫访问的404页面,只有一张图片的404错误爬取:
改进后的404错误爬取
我还没有看到快照更新和 收录 添加。当然,理论上,这个操作应该可以帮助 网站 更快地获得搜索引擎的认可。> 为每个人做一个补充。
本文由徐鱼网()SEO徐子鱼发布,欢迎大家转载,转载请注明出处,谢谢合作! 查看全部
php网页抓取工具(网站建设中一项重要的工作就是改版,百度蜘蛛抓取情况)
网站建设中的一项重要工作是修订版本。每次修订都必须朝着积极的方向进行。因为每个阶段的定位不同,我们要网站展示的企业形象也不同,一个好看的网站绝对可以提升我们公司在潜在客户心目中的地位。但是,大部分的修改都会对我们的网站 SEO产生一定的影响。这里我们需要非常熟悉网站的情况,然后对其进行有效的控制,以减少修改造成的404页数。很多情况。
最近,一个新的 网站 已经推出。因为是一年多的域名,所以之前的网站的内容和新站点的内容完全不同。网站的结构也做了很大的调整,所以带来了很多404错误爬取页面,我当时没有特别注意这个问题,然后持续更新了2周左右,我发现快照没有更新,一些简单的外部链接不起作用。这个问题引起了我的注意。. 以下是我的一些详细想法:
1、使用日志分析工具查找404错误爬取页面
测井分析工具可以使用最常用的光年测井分析工具。首先,使用FTP下载最近几天的网站LOG日志。当然,如果你想要更多的分析,你可以下载这么多的一段时间的LOG日志。可以,使用日志分析工具新建一个任务,分析百度蜘蛛在各个阶段的爬取情况。这里主要考虑百度爬取的情况,因为建立这个分析工作的前提是快照停滞,收录为1。
建议您将分析分为三个时间段:
A.分析最后一天的LOG日志,可以是今天,但最好是昨天,因为昨天的日志会更全,而且就算晚上来分析,也不会统计一个部分时间。
B、分析修改后的LOG日志,因为涉及到百度蜘蛛对网站修改的一些判断,比如我们可以分析百度蜘蛛什么时候开始判断网站已经修改了,或者当它放弃对旧站点 URL 等的抓取时。
C、修改前后爬取量对比,分析修改对百度蜘蛛的爬取量有多大影响。
至于日志分析工作之后的分析工作,是一键式的。有了具体的分析思路后,我们再对比分析,会发现很多我们平时没有注意到的问题,比如下面改版导致的404页面。还有很多页面有404错误,我没有意识到。例如,下面的 wp-login.php 页面就是一个典型的例子:

404错误爬取页面
2、使用百度站长工具中的死链接提交工具提交死链接
百度站长平台LEE团队表示:404状态码代表'NotFound'。当蜘蛛更新时,它会认为页面是无效的。此时,将从索引库中删除。短期内,蜘蛛会发现该url不再被抓取。当然,百度的说法只能作为参考,因为对网站日志的分析发现,百度蜘蛛仍然爬取这些错误页面2个多星期。当然,百度对404错误页面的引导操作还是很有针对性的。性。

百度站长平台404页浏览量
具体来说,死链接站点地图是在死链接提交工具中提交的。您可以根据自己的情况提交死链接。我这里提交后效果不大,因为大家都知道百度的效果展示周期一般比较长。.
3、使用robots.txt和nofollow标签引导蜘蛛爬行
404错误页面最大的缺点之一就是给蜘蛛带来了一些错误的爬取,浪费了蜘蛛的爬取资源。比如首先我们要达成这样一个共识:任何网站蜘蛛爬取的资源都是有限的,小的网站自然少得多,大的网站多得多。如果你想要更高的爬虫爬取率和更合理的爬取,那么一些错误的链接会导致404错误的数量应该尽可能的减少。
所以我对网站这些资源的浪费给予了适当的指导,让蜘蛛爬一些我想让他爬的页面,把机器人限制在/wuchenshi/、/gaoxiao/等类似的页面列爬取,对网站中不参与排名的部分链接实施nofollow,引导蜘蛛爬取重要页面。再来看看spider 6. No. 3的爬取情况。首先,目录爬取中没有网站中不存在的目录:

蜘蛛对目录的爬取
对于爬虫访问的404页面,只有一张图片的404错误爬取:

改进后的404错误爬取
我还没有看到快照更新和 收录 添加。当然,理论上,这个操作应该可以帮助 网站 更快地获得搜索引擎的认可。> 为每个人做一个补充。
本文由徐鱼网()SEO徐子鱼发布,欢迎大家转载,转载请注明出处,谢谢合作!
php网页抓取工具(php网页抓取工具(jeemieweb(github)postman(php抓取利器))
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-02-06 11:05
php网页抓取工具
一、php网页抓取利器
1、alljeemie(jeemieweb)jeemie是一款十分强大的网页抓取工具,完美支持mongodb数据库,具有多种开源免费的版本,包括redis、coffeescript、leancloud,其中leancloud更是php程序员最喜欢的工具之一。jeemie可以抓取javascript、asp、aspx、flash、form等以及ie网页。
它可以抓取任何网页,也支持模拟登录与认证、简单注册登录等功能。所有的页面请求都是通过高速缓存服务器处理,同时通过ddos反向代理技术将响应数据提交到db服务器,并且会根据javascriptscript分析及算法过滤对应页面的请求。
2、postman(github)postman是2014年3月份诞生的一款javascript,java和php网络请求工具,支持到post和get请求。自从2016年5月的2015年postman推出了adobeflash版本之后,大家就对它爱不释手。webpack和grunt在用。新的loader会继续研发,以更好地满足应用的发展需求。
3、markdownhandler(github)markdownhandler是一款不错的markdown网页格式转换工具,可以解析、编辑、转换markdown网页内容,并且提供嵌入文档并生成html导航等功能。
4、flowpages(github)flowpages是一款osx上不错的日历记事客户端,使用非常简单,
二、php+python+javascript的爬虫爬虫本身属于一个技术密集型的领域,在项目中很多场景都可以发挥到:爬虫的运行、维护、扩展。
这次使用到的网络爬虫工具包括pcre、jedis、libffi,pcre、jedis主要针对一些需要快速构建多种类型网络流量的应用,另外flowpages也是一款python网络爬虫工具,支持特定字符编码,
8、big、gbk、utf-8等。首先,来看看mysql_get_db。命令行用户在打开命令行后直接输入:mysql_get_db。
设置关键字:localhost
三、http网页抓取工具推荐scrapy可以爬取到大部分互联网网站和小部分不互联网网站,这里首先介绍一下它的全称:scrapy,是一个基于googlechrome的开源框架,它提供了一套用于构建网络爬虫的完整框架,使开发人员能够快速编写高质量的爬虫。它具有强大的文件上传、文件下载、限制条件、爬取操作、接口生成等功能。
urlsplit是一个定义url规则并且重定向的api,能提供定制的url函数。如post、get、delete、request、index、json-download等,get和post的对比getscrapy的http请求的协议为http,使用:"post"(即采用“get请求”)的方式发送请求给服务器。"post请求"。 查看全部
php网页抓取工具(php网页抓取工具(jeemieweb(github)postman(php抓取利器))
php网页抓取工具
一、php网页抓取利器
1、alljeemie(jeemieweb)jeemie是一款十分强大的网页抓取工具,完美支持mongodb数据库,具有多种开源免费的版本,包括redis、coffeescript、leancloud,其中leancloud更是php程序员最喜欢的工具之一。jeemie可以抓取javascript、asp、aspx、flash、form等以及ie网页。
它可以抓取任何网页,也支持模拟登录与认证、简单注册登录等功能。所有的页面请求都是通过高速缓存服务器处理,同时通过ddos反向代理技术将响应数据提交到db服务器,并且会根据javascriptscript分析及算法过滤对应页面的请求。
2、postman(github)postman是2014年3月份诞生的一款javascript,java和php网络请求工具,支持到post和get请求。自从2016年5月的2015年postman推出了adobeflash版本之后,大家就对它爱不释手。webpack和grunt在用。新的loader会继续研发,以更好地满足应用的发展需求。
3、markdownhandler(github)markdownhandler是一款不错的markdown网页格式转换工具,可以解析、编辑、转换markdown网页内容,并且提供嵌入文档并生成html导航等功能。
4、flowpages(github)flowpages是一款osx上不错的日历记事客户端,使用非常简单,
二、php+python+javascript的爬虫爬虫本身属于一个技术密集型的领域,在项目中很多场景都可以发挥到:爬虫的运行、维护、扩展。
这次使用到的网络爬虫工具包括pcre、jedis、libffi,pcre、jedis主要针对一些需要快速构建多种类型网络流量的应用,另外flowpages也是一款python网络爬虫工具,支持特定字符编码,
8、big、gbk、utf-8等。首先,来看看mysql_get_db。命令行用户在打开命令行后直接输入:mysql_get_db。
设置关键字:localhost
三、http网页抓取工具推荐scrapy可以爬取到大部分互联网网站和小部分不互联网网站,这里首先介绍一下它的全称:scrapy,是一个基于googlechrome的开源框架,它提供了一套用于构建网络爬虫的完整框架,使开发人员能够快速编写高质量的爬虫。它具有强大的文件上传、文件下载、限制条件、爬取操作、接口生成等功能。
urlsplit是一个定义url规则并且重定向的api,能提供定制的url函数。如post、get、delete、request、index、json-download等,get和post的对比getscrapy的http请求的协议为http,使用:"post"(即采用“get请求”)的方式发送请求给服务器。"post请求"。
php网页抓取工具(Python主要有以下五大主要应用:网络爬虫数据分析web开发自动化)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-30 14:07
全栈工程师的概念现在很流行,Python是一种全栈开发语言。如果你能学好Python,你可以做前端、后端、测试、大数据分析、爬虫等工作。
Python有以下五个主要应用:
网络爬虫
数据分析
人工智能
Web开发
自动化运维
一、网络爬虫
网络爬虫,又称网络蜘蛛,是指一种脚本程序,它按照一定的规则在网络上爬取想要的内容。众所周知,每个网页通常都收录其他网页的入口,网络爬虫通过一个URL依次进入其他网址,获取想要的内容。
爬行动物有什么用?
作为一个通用的搜索引擎网页采集器。(谷歌、百度)
做垂直搜索引擎。
科学研究:在线人类行为、在线社区进化、人类动力学研究、定量社会学、复杂网络、数据挖掘等实证研究领域需要大量数据,而网络爬虫是采集相关数据的有力工具。
爬行是搜索引擎的第一步,也是最简单的一步。
为什么选择 Python?
Python有很多优点,总结两个要点:
1)抓取网页本身的接口
相比其他静态编程语言,如java、c#、C++、python,爬取网页文档的界面更加简洁;与 perl、shell 等其他动态脚本语言相比,python 的 urllib2 包提供了对 web 文档更完整的访问。API。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当的请求的地方,例如模拟用户登录,模拟会话/cookie存储和设置。python中有非常好的第三方包可以帮助你,比如Requests,mechanize
2)网页抓取后的处理
抓取的网页通常需要进行处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要蟒蛇。
二、数据分析
一般我们使用爬虫爬取大量数据后,需要对数据进行处理分析,否则爬虫会徒劳无功。我们的最终目标是分析数据。在这方面,数据分析的库也很丰富,可以制作各种图形分析图表等。这也很方便。其中,Seaborn等可视化库可以只用一两行绘制数据,而使用Pandas、numpy、scipy可以对大量数据进行简单的过滤、回归等计算。在后续的复杂计算中,连接机器学习相关的算法,或者提供Web访问接口,或者实现远程调用接口,都非常简单。
三、人工智能
人工智能并不是一个新概念,它的历史已经有半个多世纪了。在人工智能领域过去几十年的发展中,传统的主流编程语言显然是Lisp,而后起之秀也是Prolog这样的语言。但是当这波人工智能真正流行起来的时候,人们发现那些流行的框架和工具不是用Python写的,比如Theano,就是用C++写的,只是用Python作为接口语言,比如TensorFlow、Caffe、MxNet等。2017 年,唯一非 Python 框架 Torch 顶不住压力,开发了 PyTorch。
四、网络开发
很多人只知道 Java 和 PHP 可以用于 Web 开发,但对 Python 也可以用于 Web 开发却知之甚少。很多人可能不知道 Python 其实是伴随着互联网成长起来的。Python 和 Perl 作为动态语言,抽象层次更高,很快被开发者发现更适合开发网站,并在早期互联网的兴起中发挥了重要作用。
五、自动化运维
随着技术的进步和业务需求的快速增长,一个运维人员通常要管理成百上千台服务器,运维工作也变得重复和复杂。运维工作自动化,可以将运维人员从对服务器的管理中解放出来,使运维工作变得简单、快捷、准确。
别的地方:
1. 游戏开发
你可以使用 PyGame 来开发游戏,但它不是最流行的游戏引擎。您可以将其用于业余项目,但如果您对游戏开发很认真,则不建议使用。
我推荐使用 Unity 的 C#,它是最流行的游戏引擎之一。它允许您为许多平台开发游戏,包括 Mac、Windows、iOS 和 Android。
2. 桌面应用程序
你可以使用 Python 的 Tkinter,但它不是最流行的选择。Java、C#和C++等语言似乎更受欢迎。
3.手机APP
python语言虽然用途很广,但是用它来开发app还是有点不对的。因此,使用 python 开发的应用程序应该用作编码练习或自娱自乐。另外,目前这方面的模块还不是特别成熟,bug比较多,总而言之,我劝大家不要轻易进入。 查看全部
php网页抓取工具(Python主要有以下五大主要应用:网络爬虫数据分析web开发自动化)
全栈工程师的概念现在很流行,Python是一种全栈开发语言。如果你能学好Python,你可以做前端、后端、测试、大数据分析、爬虫等工作。
Python有以下五个主要应用:
网络爬虫
数据分析
人工智能
Web开发
自动化运维
一、网络爬虫
网络爬虫,又称网络蜘蛛,是指一种脚本程序,它按照一定的规则在网络上爬取想要的内容。众所周知,每个网页通常都收录其他网页的入口,网络爬虫通过一个URL依次进入其他网址,获取想要的内容。
爬行动物有什么用?
作为一个通用的搜索引擎网页采集器。(谷歌、百度)
做垂直搜索引擎。
科学研究:在线人类行为、在线社区进化、人类动力学研究、定量社会学、复杂网络、数据挖掘等实证研究领域需要大量数据,而网络爬虫是采集相关数据的有力工具。
爬行是搜索引擎的第一步,也是最简单的一步。
为什么选择 Python?
Python有很多优点,总结两个要点:
1)抓取网页本身的接口
相比其他静态编程语言,如java、c#、C++、python,爬取网页文档的界面更加简洁;与 perl、shell 等其他动态脚本语言相比,python 的 urllib2 包提供了对 web 文档更完整的访问。API。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当的请求的地方,例如模拟用户登录,模拟会话/cookie存储和设置。python中有非常好的第三方包可以帮助你,比如Requests,mechanize
2)网页抓取后的处理
抓取的网页通常需要进行处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要蟒蛇。
二、数据分析
一般我们使用爬虫爬取大量数据后,需要对数据进行处理分析,否则爬虫会徒劳无功。我们的最终目标是分析数据。在这方面,数据分析的库也很丰富,可以制作各种图形分析图表等。这也很方便。其中,Seaborn等可视化库可以只用一两行绘制数据,而使用Pandas、numpy、scipy可以对大量数据进行简单的过滤、回归等计算。在后续的复杂计算中,连接机器学习相关的算法,或者提供Web访问接口,或者实现远程调用接口,都非常简单。
三、人工智能
人工智能并不是一个新概念,它的历史已经有半个多世纪了。在人工智能领域过去几十年的发展中,传统的主流编程语言显然是Lisp,而后起之秀也是Prolog这样的语言。但是当这波人工智能真正流行起来的时候,人们发现那些流行的框架和工具不是用Python写的,比如Theano,就是用C++写的,只是用Python作为接口语言,比如TensorFlow、Caffe、MxNet等。2017 年,唯一非 Python 框架 Torch 顶不住压力,开发了 PyTorch。
四、网络开发
很多人只知道 Java 和 PHP 可以用于 Web 开发,但对 Python 也可以用于 Web 开发却知之甚少。很多人可能不知道 Python 其实是伴随着互联网成长起来的。Python 和 Perl 作为动态语言,抽象层次更高,很快被开发者发现更适合开发网站,并在早期互联网的兴起中发挥了重要作用。
五、自动化运维
随着技术的进步和业务需求的快速增长,一个运维人员通常要管理成百上千台服务器,运维工作也变得重复和复杂。运维工作自动化,可以将运维人员从对服务器的管理中解放出来,使运维工作变得简单、快捷、准确。
别的地方:
1. 游戏开发
你可以使用 PyGame 来开发游戏,但它不是最流行的游戏引擎。您可以将其用于业余项目,但如果您对游戏开发很认真,则不建议使用。
我推荐使用 Unity 的 C#,它是最流行的游戏引擎之一。它允许您为许多平台开发游戏,包括 Mac、Windows、iOS 和 Android。
2. 桌面应用程序
你可以使用 Python 的 Tkinter,但它不是最流行的选择。Java、C#和C++等语言似乎更受欢迎。
3.手机APP
python语言虽然用途很广,但是用它来开发app还是有点不对的。因此,使用 python 开发的应用程序应该用作编码练习或自娱自乐。另外,目前这方面的模块还不是特别成熟,bug比较多,总而言之,我劝大家不要轻易进入。
php网页抓取工具(vba网页元素代码抓取小工具【支持win10+】用IE提取网页资料)
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2022-01-27 13:06
vba网页元素代码抓取小工具【支持win10+】
使用IE提取网页数据的好处是,所见即所得,网页上能看到的信息一般都能得到。这个工具的功能很少,主要是方便提取网页上显示的信息所在元素的代码。希望它可以帮助你一点。Web Scraping Gadget.rar (22.91 KB, 下载:3601) 工具使用方法:1、在B1中输入网址,可以是打开的网页,也可以是它可以不开2、A2和B2的内容不要改,第二行其他单元格可以输入元素本身的属性名,其中innertext单元格有下拉选项3、点击“开始”“分析”,分析网页元素。4、 A列是每个元素的目标代码。5、在innertext列中找到要提取的内容后,选择行并点击“生成Excel”。可以提取表格标签表格或者下载IMG标签的图片。6、在新生成的excel中,点击“执行代码”按钮,看看是否可以生成需要的数据。如果生成的数据与开始分析的数据不匹配,原因可能是:1、网页还没有完全加载,对应标签的数据还没有加载。代码自动提取后续标签数据。可能的解决方法:添加do...loop延时。2、网页是动态网页,标签的序号不固定。可能的解决方案:如果元素有一个 id 名称,使用 getelementbyid ("id name") 来获取它。如果没有,请获取包并将其替换为 xmlhttp。或者您需要登录才能提取。可能的解决方案:在提取之前登录或选择相关选项
现在下载 查看全部
php网页抓取工具(vba网页元素代码抓取小工具【支持win10+】用IE提取网页资料)
vba网页元素代码抓取小工具【支持win10+】
使用IE提取网页数据的好处是,所见即所得,网页上能看到的信息一般都能得到。这个工具的功能很少,主要是方便提取网页上显示的信息所在元素的代码。希望它可以帮助你一点。Web Scraping Gadget.rar (22.91 KB, 下载:3601) 工具使用方法:1、在B1中输入网址,可以是打开的网页,也可以是它可以不开2、A2和B2的内容不要改,第二行其他单元格可以输入元素本身的属性名,其中innertext单元格有下拉选项3、点击“开始”“分析”,分析网页元素。4、 A列是每个元素的目标代码。5、在innertext列中找到要提取的内容后,选择行并点击“生成Excel”。可以提取表格标签表格或者下载IMG标签的图片。6、在新生成的excel中,点击“执行代码”按钮,看看是否可以生成需要的数据。如果生成的数据与开始分析的数据不匹配,原因可能是:1、网页还没有完全加载,对应标签的数据还没有加载。代码自动提取后续标签数据。可能的解决方法:添加do...loop延时。2、网页是动态网页,标签的序号不固定。可能的解决方案:如果元素有一个 id 名称,使用 getelementbyid ("id name") 来获取它。如果没有,请获取包并将其替换为 xmlhttp。或者您需要登录才能提取。可能的解决方案:在提取之前登录或选择相关选项
现在下载
php网页抓取工具( python适合做爬虫的原因及解决办法-苏州安嘉)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-01-25 12:15
python适合做爬虫的原因及解决办法-苏州安嘉)
Python适合爬行。原因如下
爬取网页本身的界面
相比其他静态编程语言,如java、c#、C++、python,爬取网页文档的界面更加简洁;与 perl、shell 等其他动态脚本语言相比,python 的 urllib2 包提供了对 web 文档更完整的访问。API。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当的请求的地方,例如模拟用户登录,模拟会话/cookie存储和设置。python中有非常好的第三方包可以帮助你,比如Requests,mechanize。
推荐学习《python教程》
爬取后处理
抓取的网页通常需要进行处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要蟒蛇。
py 在 linux 上非常强大,语言也很简单。
NO.1 快速开发(唯一比python效率更高的语言是rudy) 语言简洁,没有那么多技巧,所以非常清晰易读。
NO.2 跨平台(由于python的开源,他比java更能体现“一次编写,到处运行”
NO.3 解释(无需编译,直接运行/调试代码)
NO.4 架构选择太多(GUI架构方面主要有wxPython、tkInter、PyGtk、PyQt。 查看全部
php网页抓取工具(
python适合做爬虫的原因及解决办法-苏州安嘉)

Python适合爬行。原因如下
爬取网页本身的界面
相比其他静态编程语言,如java、c#、C++、python,爬取网页文档的界面更加简洁;与 perl、shell 等其他动态脚本语言相比,python 的 urllib2 包提供了对 web 文档更完整的访问。API。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当的请求的地方,例如模拟用户登录,模拟会话/cookie存储和设置。python中有非常好的第三方包可以帮助你,比如Requests,mechanize。
推荐学习《python教程》
爬取后处理
抓取的网页通常需要进行处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要蟒蛇。
py 在 linux 上非常强大,语言也很简单。
NO.1 快速开发(唯一比python效率更高的语言是rudy) 语言简洁,没有那么多技巧,所以非常清晰易读。
NO.2 跨平台(由于python的开源,他比java更能体现“一次编写,到处运行”
NO.3 解释(无需编译,直接运行/调试代码)
NO.4 架构选择太多(GUI架构方面主要有wxPython、tkInter、PyGtk、PyQt。
php网页抓取工具(阅木书屋博客文章主动推送(实时):最为快速的提交方式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-01-20 17:09
网站如果你要百度收录,你必须提交你的网站链接到百度,那么目前提交方式有主动推送(实时)、自动推送和站点地图三种,这里主要讲一下百度站长工具的主动推送(实时)使用。
主动推送(实时):最快的提交方式,建议您立即通过此方式将本站新的输出链接推送到百度,保证新链接能被百度及时收录。
1、网站 只有经过百度站长平台验证后才能进行以下主动推送(实时);
2、点击百度站长平台--工具--网页抓取--提交链接--主动推送(实时),会看到如下内容:
3、百度提供了4种推送示例,分别是curl相机推送示例、post推送示例、php推送示例、ruby推送示例,任选其一即可;
4、复制php push示例代码,新建记事本,将复制的php push示例代码粘贴进去;
5、在代码的第一行添加“”;
6、另存为360docx.php,然后上传到网站的根目录;
7、将要提交的网站链接复制到360docx.php,然后上传overlay,如图:
8、执行这个文件,返回码如下:
目前百度并没有限制提交网站链接的数量,所以remain的返回码统一为1。
另外,自动推送和主动推送不冲突,两者可以一起使用。
由于我的博客文章每日更新量很少,使用主动推送(实时)不需要额外操作,但是像我的传送门网站等网站,由于每日更新最多100篇以上,需要直接统计当天发送的文章的url,然后直接复制url到主动推送的代码中(实时) .
更多资讯,关注木书店的博客 查看全部
php网页抓取工具(阅木书屋博客文章主动推送(实时):最为快速的提交方式)
网站如果你要百度收录,你必须提交你的网站链接到百度,那么目前提交方式有主动推送(实时)、自动推送和站点地图三种,这里主要讲一下百度站长工具的主动推送(实时)使用。
主动推送(实时):最快的提交方式,建议您立即通过此方式将本站新的输出链接推送到百度,保证新链接能被百度及时收录。
1、网站 只有经过百度站长平台验证后才能进行以下主动推送(实时);
2、点击百度站长平台--工具--网页抓取--提交链接--主动推送(实时),会看到如下内容:
3、百度提供了4种推送示例,分别是curl相机推送示例、post推送示例、php推送示例、ruby推送示例,任选其一即可;
4、复制php push示例代码,新建记事本,将复制的php push示例代码粘贴进去;
5、在代码的第一行添加“”;
6、另存为360docx.php,然后上传到网站的根目录;
7、将要提交的网站链接复制到360docx.php,然后上传overlay,如图:
8、执行这个文件,返回码如下:
目前百度并没有限制提交网站链接的数量,所以remain的返回码统一为1。
另外,自动推送和主动推送不冲突,两者可以一起使用。
由于我的博客文章每日更新量很少,使用主动推送(实时)不需要额外操作,但是像我的传送门网站等网站,由于每日更新最多100篇以上,需要直接统计当天发送的文章的url,然后直接复制url到主动推送的代码中(实时) .
更多资讯,关注木书店的博客
php网页抓取工具(php网页抓取工具如果要抓取的网页你用过python)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-10 12:00
php网页抓取工具如果要抓取的网页你用过python,
谢邀。
一、如果目的是学习,平台引导很重要。搜索引擎已经很成熟,会注意初学者提问的方式和问题的普遍度。
二、书推荐的话,不推荐《php从入门到精通》(黄哥写的),如果前端没有学习过的话。有些编程技术没有达到精通的地步,看书还是慢点好。
1、xml分析技术:个人非常喜欢这本,它里面介绍了一些php语言才可以使用的xml工具和技术,学好xml基础技术可以算是入门php语言的敲门砖。
2、网络爬虫工具:个人比较喜欢这本,书里面介绍了爬虫系统设计,网络爬虫安全性,request/response封装方法等等。
3、基础的html模板语言:这本写的不错,有了html基础技术,模板编程也不是难事。
4、xml编解码:个人不喜欢这本,理论说的不错,实践起来有点难度。总的来说,php平台各种花哨的工具和语言,最重要的还是要喜欢编程。
php网页抓取工具要学到什么程度?学到好的标准有哪些?
初学一个主流工具就够了php官方为初学者准备的手册入门的php教程而且学个html都要看php官方的1.0版本
hao123
需要学习什么程度的php呢?我个人观点仅供参考如果对数据库有一定的了解,可以看看需要学习的东西有哪些其次是php框架如果jsp对基础不够理解,也不想看教程,可以看看php的官方文档,还有html怎么学可以百度一下这个www。how2j。com里边列出了很多学习资料最后是面向对象,怎么学php面向对象可以百度但是没必要去学,不重要,phpc++c#都一样面向对象做为一个前端工程师,javascript是一定要学的,当然对于小白php也可以学,主要看情况php怎么学不清楚,和原来做后端开发的区别不大,网上很多视频,应该好找,挑选合适自己的一点建议如果喜欢php,可以从php学起,从容易上手的学,或者看看php的文档或者官方手册,有些语法在学习工作生活中有用处,不喜欢可以换,没什么准备。 查看全部
php网页抓取工具(php网页抓取工具如果要抓取的网页你用过python)
php网页抓取工具如果要抓取的网页你用过python,
谢邀。
一、如果目的是学习,平台引导很重要。搜索引擎已经很成熟,会注意初学者提问的方式和问题的普遍度。
二、书推荐的话,不推荐《php从入门到精通》(黄哥写的),如果前端没有学习过的话。有些编程技术没有达到精通的地步,看书还是慢点好。
1、xml分析技术:个人非常喜欢这本,它里面介绍了一些php语言才可以使用的xml工具和技术,学好xml基础技术可以算是入门php语言的敲门砖。
2、网络爬虫工具:个人比较喜欢这本,书里面介绍了爬虫系统设计,网络爬虫安全性,request/response封装方法等等。
3、基础的html模板语言:这本写的不错,有了html基础技术,模板编程也不是难事。
4、xml编解码:个人不喜欢这本,理论说的不错,实践起来有点难度。总的来说,php平台各种花哨的工具和语言,最重要的还是要喜欢编程。
php网页抓取工具要学到什么程度?学到好的标准有哪些?
初学一个主流工具就够了php官方为初学者准备的手册入门的php教程而且学个html都要看php官方的1.0版本
hao123
需要学习什么程度的php呢?我个人观点仅供参考如果对数据库有一定的了解,可以看看需要学习的东西有哪些其次是php框架如果jsp对基础不够理解,也不想看教程,可以看看php的官方文档,还有html怎么学可以百度一下这个www。how2j。com里边列出了很多学习资料最后是面向对象,怎么学php面向对象可以百度但是没必要去学,不重要,phpc++c#都一样面向对象做为一个前端工程师,javascript是一定要学的,当然对于小白php也可以学,主要看情况php怎么学不清楚,和原来做后端开发的区别不大,网上很多视频,应该好找,挑选合适自己的一点建议如果喜欢php,可以从php学起,从容易上手的学,或者看看php的文档或者官方手册,有些语法在学习工作生活中有用处,不喜欢可以换,没什么准备。
php网页抓取工具( Python页面抓取过程中乱码的原因与相应的解决方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2022-03-10 16:07
Python页面抓取过程中乱码的原因与相应的解决方法)
python爬取保存html页面时出现乱码问题的解决方法
更新时间:2016-07-01 11:23:47 作者:holybin
本篇文章主要介绍python爬取保存html页面时出现乱码问题的解决方法,结合实例分析爬取Python页面过程中出现乱码的原因及相应的解决方法。需要的朋友可以参考下
本文示例介绍了python爬取保存html页面时出现乱码问题的解决方法。分享给大家参考,详情如下:
使用Python爬取html页面并保存时,经常会出现爬取的网页内容乱码的问题。出现这个问题的原因,一方面是你自己代码中的编码设置有问题,另一方面是在编码设置正确的情况下,网页的实际编码不匹配标记编码。html页面上显示的编码在这里:
复制代码代码如下:
这里有一个简单的解决方案:使用chardet判断网页的真实代码,同时从url请求返回的信息中判断代码。如果两种编码不同,使用bs模块扩展为GB18030编码;如果相同,直接写入文件(系统默认编码设置为utf-8).
import urllib2
import sys
import bs4
import chardet
reload(sys)
sys.setdefaultencoding('utf-8')
def download(url):
htmlfile = open('test.html','w')
try:
result = urllib2.urlopen(url)
content = result.read()
info = result.info()
result.close()
except Exception,e:
print 'download error!!!'
print e
else:
if content != None:
charset1 = (chardet.detect(content))['encoding'] #real encoding type
charset2 = info.getparam('charset') #declared encoding type
print charset1,' ', charset2
# case1: charset is not None.
if charset1 != None and charset2 != None and charset1.lower() != charset2.lower():
newcont = bs4.BeautifulSoup(content, from_encoding='GB18030') #coding: GB18030
for cont in newcont:
htmlfile.write('%s\n'%cont)
# case2: either charset is None, or charset is the same.
else:
#print sys.getdefaultencoding()
htmlfile.write(content) #default coding: utf-8
htmlfile.close()
if __name__ == "__main__":
url = 'https://www.jb51.net'
download(url)
得到的test.html文件打开如下,可以看到它是以UTF-8存储的,没有BOM编码格式,也就是我们设置的默认编码:
对Python相关内容比较感兴趣的读者可以查看本站专题:《Python编码操作技巧总结》、《Python图片操作技巧总结》、《Python数据结构与算法教程》、《Python套接字编程》 《技能总结》、《Python Socket编程技能总结》、《Python函数使用技巧总结》、《Python字符串操作技巧总结》、《Python入门与进阶经典教程》、《Python文件和目录操作技巧总结》
希望这篇文章对大家Python编程有所帮助。 查看全部
php网页抓取工具(
Python页面抓取过程中乱码的原因与相应的解决方法)
python爬取保存html页面时出现乱码问题的解决方法
更新时间:2016-07-01 11:23:47 作者:holybin
本篇文章主要介绍python爬取保存html页面时出现乱码问题的解决方法,结合实例分析爬取Python页面过程中出现乱码的原因及相应的解决方法。需要的朋友可以参考下
本文示例介绍了python爬取保存html页面时出现乱码问题的解决方法。分享给大家参考,详情如下:
使用Python爬取html页面并保存时,经常会出现爬取的网页内容乱码的问题。出现这个问题的原因,一方面是你自己代码中的编码设置有问题,另一方面是在编码设置正确的情况下,网页的实际编码不匹配标记编码。html页面上显示的编码在这里:
复制代码代码如下:
这里有一个简单的解决方案:使用chardet判断网页的真实代码,同时从url请求返回的信息中判断代码。如果两种编码不同,使用bs模块扩展为GB18030编码;如果相同,直接写入文件(系统默认编码设置为utf-8).
import urllib2
import sys
import bs4
import chardet
reload(sys)
sys.setdefaultencoding('utf-8')
def download(url):
htmlfile = open('test.html','w')
try:
result = urllib2.urlopen(url)
content = result.read()
info = result.info()
result.close()
except Exception,e:
print 'download error!!!'
print e
else:
if content != None:
charset1 = (chardet.detect(content))['encoding'] #real encoding type
charset2 = info.getparam('charset') #declared encoding type
print charset1,' ', charset2
# case1: charset is not None.
if charset1 != None and charset2 != None and charset1.lower() != charset2.lower():
newcont = bs4.BeautifulSoup(content, from_encoding='GB18030') #coding: GB18030
for cont in newcont:
htmlfile.write('%s\n'%cont)
# case2: either charset is None, or charset is the same.
else:
#print sys.getdefaultencoding()
htmlfile.write(content) #default coding: utf-8
htmlfile.close()
if __name__ == "__main__":
url = 'https://www.jb51.net'
download(url)
得到的test.html文件打开如下,可以看到它是以UTF-8存储的,没有BOM编码格式,也就是我们设置的默认编码:
对Python相关内容比较感兴趣的读者可以查看本站专题:《Python编码操作技巧总结》、《Python图片操作技巧总结》、《Python数据结构与算法教程》、《Python套接字编程》 《技能总结》、《Python Socket编程技能总结》、《Python函数使用技巧总结》、《Python字符串操作技巧总结》、《Python入门与进阶经典教程》、《Python文件和目录操作技巧总结》
希望这篇文章对大家Python编程有所帮助。
php网页抓取工具(FreeDownloadManager支持捕获网页风格样式(CSS内容保存))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-03-08 12:20
免费下载管理器是一个多点简历和管理软件。该软件声称可以将您的下载速度提高 600%。支持下载网页内容、图片、文件等。这是一款可以让你下载加速的软件,需要的可以下载。
软件功能
1.支持多线程下载,支持定时任务下载,支持按目录列表查看和检索站点内容,支持下载网页内容、图片、文件,支持抓取网页上的链接,支持下载整个网站内容(可以设置下载子目录的深度),理论上可以下载1000层以上的子目录网页和图片。
2.支持抓取网页样式(用CSS内容保存),支持多种格式的网页抓取,包括:html、shtm、shtml、phtml、dhtml、php、hta、htc、cgi、asp、htm等. ...也可以自己设置格式,可以用“站点浏览器”在线查看目标网站子目录下的内容,支持三种下载通讯方式,支持断点续传,显示是否服务器支持恢复上传并设置是否重新下载或覆盖。免费下载管理器是一款功能强大的下载工具,支持多线程拆分下载。
指示
1.下载完成后,不要运行压缩包中的软件直接使用,先解压;
2.软件支持32位和64位操作环境;
3.如果软件无法正常打开,请右键管理员模式运行。 查看全部
php网页抓取工具(FreeDownloadManager支持捕获网页风格样式(CSS内容保存))
免费下载管理器是一个多点简历和管理软件。该软件声称可以将您的下载速度提高 600%。支持下载网页内容、图片、文件等。这是一款可以让你下载加速的软件,需要的可以下载。
软件功能
1.支持多线程下载,支持定时任务下载,支持按目录列表查看和检索站点内容,支持下载网页内容、图片、文件,支持抓取网页上的链接,支持下载整个网站内容(可以设置下载子目录的深度),理论上可以下载1000层以上的子目录网页和图片。
2.支持抓取网页样式(用CSS内容保存),支持多种格式的网页抓取,包括:html、shtm、shtml、phtml、dhtml、php、hta、htc、cgi、asp、htm等. ...也可以自己设置格式,可以用“站点浏览器”在线查看目标网站子目录下的内容,支持三种下载通讯方式,支持断点续传,显示是否服务器支持恢复上传并设置是否重新下载或覆盖。免费下载管理器是一款功能强大的下载工具,支持多线程拆分下载。
指示
1.下载完成后,不要运行压缩包中的软件直接使用,先解压;
2.软件支持32位和64位操作环境;
3.如果软件无法正常打开,请右键管理员模式运行。
php网页抓取工具(Teleport乱码遇到这个问题-v2.0工具就会报错)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-03-06 19:01
经常因为某种原因,我们需要爬取某个网站或者直接复制某个站点。我们在网上找了很多工具进行测试,尝试了很多不同的问题。最后,我们选择了 Teleport Ultra 并使用了它。很好; 具体的操作手册和其他的东西这里就不说了。有很多在线搜索。以下是遇到的主要问题:
工具截图:
抓取后渲染
一般我会选择复制100级,基本上把网站的东西都复制了,但是因为Teleport Ultra是用UTF-8编码取的,如果文件中有汉字,或者gbk编码的文件就会出现乱码如下图:
当然你也可以在浏览器中手动选择UTF-8,但是我们不能每次打开都这样。于是我就去网站找了一个软件叫:TelePort乱码修复工具(siteRepair-v2.0),经过测试可以解决乱码问题,这个工具也会清除一些无效链接和 html 符号等。
软件截图:
绝大多数网站经过这两步应该就OK了,但是有些网站在层次结构中使用了中文目录或者中文文件名,会出现乱码,类似于下面的URL地址:
这样,当抓到网站的结构时,会出现两种乱码:1)文件夹名乱码2)文件名乱码
遇到这个问题,siteRepair-v2.0工具会报错。我猜它无法识别乱码文件夹或文件。
后来在网上找到了一个PHP程序,简单的修改测试就可以解决这个问题
PHP代码:convert.php
{if(is_dir($dir))
{if ($dh = opendir($dir))
{while (($file = readdir($dh)) !== false)
{if((is_dir($dir."/".$file)) && $file!="." && $file!="..")
{rename($dir."/".$file,$dir."/".mb_convert_encoding($file,"GBK", "UTF-8"));
listDir($dir."/".$file."/");
}else{if($file!="." && $file!="..")
{$name=rename($dir."/".$file,$dir."/".str_replace('\\','',mb_convert_encoding($file,"GBK", "UTF-8"))) ;echo '路径:'.$dir."/".$file.'
';echo '结果:'.str_replace('\\','',mb_convert_encoding($file,"GBK", "UTF-8")).'
';
}
}
}closedir($dh);
}
}
listDir("./convert");?>
在代码同级目录下新建convert文件夹,将乱码文件放入该目录,然后执行convert.php。 查看全部
php网页抓取工具(Teleport乱码遇到这个问题-v2.0工具就会报错)
经常因为某种原因,我们需要爬取某个网站或者直接复制某个站点。我们在网上找了很多工具进行测试,尝试了很多不同的问题。最后,我们选择了 Teleport Ultra 并使用了它。很好; 具体的操作手册和其他的东西这里就不说了。有很多在线搜索。以下是遇到的主要问题:
工具截图:
抓取后渲染
一般我会选择复制100级,基本上把网站的东西都复制了,但是因为Teleport Ultra是用UTF-8编码取的,如果文件中有汉字,或者gbk编码的文件就会出现乱码如下图:
当然你也可以在浏览器中手动选择UTF-8,但是我们不能每次打开都这样。于是我就去网站找了一个软件叫:TelePort乱码修复工具(siteRepair-v2.0),经过测试可以解决乱码问题,这个工具也会清除一些无效链接和 html 符号等。
软件截图:
绝大多数网站经过这两步应该就OK了,但是有些网站在层次结构中使用了中文目录或者中文文件名,会出现乱码,类似于下面的URL地址:
这样,当抓到网站的结构时,会出现两种乱码:1)文件夹名乱码2)文件名乱码
遇到这个问题,siteRepair-v2.0工具会报错。我猜它无法识别乱码文件夹或文件。
后来在网上找到了一个PHP程序,简单的修改测试就可以解决这个问题
PHP代码:convert.php
{if(is_dir($dir))
{if ($dh = opendir($dir))
{while (($file = readdir($dh)) !== false)
{if((is_dir($dir."/".$file)) && $file!="." && $file!="..")
{rename($dir."/".$file,$dir."/".mb_convert_encoding($file,"GBK", "UTF-8"));
listDir($dir."/".$file."/");
}else{if($file!="." && $file!="..")
{$name=rename($dir."/".$file,$dir."/".str_replace('\\','',mb_convert_encoding($file,"GBK", "UTF-8"))) ;echo '路径:'.$dir."/".$file.'
';echo '结果:'.str_replace('\\','',mb_convert_encoding($file,"GBK", "UTF-8")).'
';
}
}
}closedir($dh);
}
}
listDir("./convert");?>
在代码同级目录下新建convert文件夹,将乱码文件放入该目录,然后执行convert.php。
php网页抓取工具(【php如何实现只替换一次或N次】抓取网页图片)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-03-06 10:17
php如何抓取网页图片?相比手动粘贴复制,使用小程序要方便快捷得多。喜欢编程的人总是喜欢做一些简单实用的小软件。代码,封装了一个php远程抓图的类,测试了一下,效果还不错,分享给大家。代码如下:
我们都知道在PHP中可以使用strtr、strreplace等函数来替换,但是每次替换的时候都是要替换的。例如:
“abcabbc”,如果你用上面的函数来替换这个字符串中的b,那么他会全部替换掉,但是如果你只想替换一两个呢?请参阅以下解决方案:
这是一个相当有趣的问题。碰巧我之前也做过类似的处理。当时我是直接用preg_replace实现的。
混合preg_replace(混合模式,混合替换,混合主题[,int限制])
搜索主题以查找模式模式的匹配项并替换为替换。如果指定了limit,则仅替换limit匹配,如果省略limit或其值为-1,则替换所有匹配。
因为preg_replace的第四个参数可以限制替换的次数,所以这个问题处理起来很方便。但是看了str_replace上的函数注释,可以挑出几个有代表性的函数。
方法一:str_replace_once
思路是先找到关键词要替换的位置,然后使用substr_replace函数直接替换。
方法二、str_replace_limit
思路是使用preg_replace,但它的参数更像preg_replace,转义了一些特殊字符,更加通用。
大家可以结合小编整理的文章文章《php关键字替换仅一次的实现功能》一起学习。相信大家都会有意想不到的收获。
【php中如何只替换一次或N次】相关文章:
★ php实现的mongodb操作类示例
★ php简单实现屏蔽指定ip段内用户的访问
★ 如何给phpadmin一个保护
★ php中如何使用for语句输出三角形
★ php循环表实现一行两列显示的方法
★ 替代php函数重载
★ 如何在php中将图片转换为ASCII
★ php实现CSV文件导入导出方法
★ php实现上传word文件转html的方法
★ php实现window平台的checkdnsrr功能 查看全部
php网页抓取工具(【php如何实现只替换一次或N次】抓取网页图片)
php如何抓取网页图片?相比手动粘贴复制,使用小程序要方便快捷得多。喜欢编程的人总是喜欢做一些简单实用的小软件。代码,封装了一个php远程抓图的类,测试了一下,效果还不错,分享给大家。代码如下:
我们都知道在PHP中可以使用strtr、strreplace等函数来替换,但是每次替换的时候都是要替换的。例如:
“abcabbc”,如果你用上面的函数来替换这个字符串中的b,那么他会全部替换掉,但是如果你只想替换一两个呢?请参阅以下解决方案:
这是一个相当有趣的问题。碰巧我之前也做过类似的处理。当时我是直接用preg_replace实现的。
混合preg_replace(混合模式,混合替换,混合主题[,int限制])
搜索主题以查找模式模式的匹配项并替换为替换。如果指定了limit,则仅替换limit匹配,如果省略limit或其值为-1,则替换所有匹配。
因为preg_replace的第四个参数可以限制替换的次数,所以这个问题处理起来很方便。但是看了str_replace上的函数注释,可以挑出几个有代表性的函数。
方法一:str_replace_once
思路是先找到关键词要替换的位置,然后使用substr_replace函数直接替换。
方法二、str_replace_limit
思路是使用preg_replace,但它的参数更像preg_replace,转义了一些特殊字符,更加通用。
大家可以结合小编整理的文章文章《php关键字替换仅一次的实现功能》一起学习。相信大家都会有意想不到的收获。
【php中如何只替换一次或N次】相关文章:
★ php实现的mongodb操作类示例
★ php简单实现屏蔽指定ip段内用户的访问
★ 如何给phpadmin一个保护
★ php中如何使用for语句输出三角形
★ php循环表实现一行两列显示的方法
★ 替代php函数重载
★ 如何在php中将图片转换为ASCII
★ php实现CSV文件导入导出方法
★ php实现上传word文件转html的方法
★ php实现window平台的checkdnsrr功能
php网页抓取工具(软件功能可以提取网页所有链接(非自动)设置下要格式 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-02-24 04:15
)
网页超链接提取是一款非常强大的站长网页链接提取工具;它可以快速帮助用户手动提交你的网站百度链接,这个网页超链接提取工具对于做网站的朋友非常有用,是一款不可多得的网页链接提取工具。最重要的是该软件是完全免费的,不会收取任何费用。使用起来也非常简单易操作,让您的提取更加轻松舒适,需要的朋友赶快下载使用吧!
软件功能
可以提取网页的所有链接(非自动)
设置要解压的目录以解压所有链接
例如,新闻是一个列表
比如你有500条新闻,在网站后台列表中,让它们都显示在一页上(数量可以修改)
然后用这个工具就可以全部提取出来提交到百度站长平台收录
软件功能
另存为TXT格式
用于制作网站地图等用途输入目标网站主页地址
设置线程并保存位置
软件会自动爬取目标网站的所有网页
并以TXT中每行一行的格式保存
对于 网站 映射为 TXT 和其他
指示
1、下载文件,找到“网页超链接提取工具.exe”,双击运行,进入软件界面;
2、点击进入软件主界面,出现如下界面,如下图;
3、下面红框中可以输入内容;
4、下图中红框为提取条件,表示提取所有收录该内容的URL;
5、下图中的红框是复制提取的内容,清除等;
查看全部
php网页抓取工具(软件功能可以提取网页所有链接(非自动)设置下要格式
)
网页超链接提取是一款非常强大的站长网页链接提取工具;它可以快速帮助用户手动提交你的网站百度链接,这个网页超链接提取工具对于做网站的朋友非常有用,是一款不可多得的网页链接提取工具。最重要的是该软件是完全免费的,不会收取任何费用。使用起来也非常简单易操作,让您的提取更加轻松舒适,需要的朋友赶快下载使用吧!
软件功能
可以提取网页的所有链接(非自动)
设置要解压的目录以解压所有链接
例如,新闻是一个列表
比如你有500条新闻,在网站后台列表中,让它们都显示在一页上(数量可以修改)
然后用这个工具就可以全部提取出来提交到百度站长平台收录
软件功能
另存为TXT格式
用于制作网站地图等用途输入目标网站主页地址
设置线程并保存位置
软件会自动爬取目标网站的所有网页
并以TXT中每行一行的格式保存
对于 网站 映射为 TXT 和其他
指示
1、下载文件,找到“网页超链接提取工具.exe”,双击运行,进入软件界面;
2、点击进入软件主界面,出现如下界面,如下图;
3、下面红框中可以输入内容;
4、下图中红框为提取条件,表示提取所有收录该内容的URL;
5、下图中的红框是复制提取的内容,清除等;
php网页抓取工具(php网页抓取工具是免费的,功能比较全,而且很新)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-02-20 13:00
php网页抓取工具是免费的,功能比较全,而且很新。推荐pythonpython操作http、java操作http的话,还要解决一个网络延迟问题。推荐web开发用web开发terminal或者sublimetext编辑器,php用phpstorm。
phpwind是免费的,名字叫。
phpwind是免费的,功能挺全的,不过偶尔有bug,更新也不是很及时,应该有不少问题修复的。
github
说到免费正版的,可以试试虚幻云。虚幻云(虚幻云)专注于php与html5技术,完全不用担心公司机密泄露,自行搭建域名。免费使用,就这么简单。
phpwind、tp都可以网上资料随便找。
我自己都是用github,
wp
为什么要用免费的,php里面都有全套的开发工具,
phpwind、tp什么的都可以呀,tp是收费的。
我们公司比较傻逼,直接用tp搭起来的,不花钱。后面还换了一个博客软件,也是tp做的,比较傻逼,在用ghost的。
phpwind可以看看,有免费版,用起来挺好的,如果网络要求高,可以入tp的。如果你是老师,教学php(不推荐,如果网络要求高的话,你不也想请个学生帮你讲课?),且个人觉得对php感兴趣,可以用个免费版的试试, 查看全部
php网页抓取工具(php网页抓取工具是免费的,功能比较全,而且很新)
php网页抓取工具是免费的,功能比较全,而且很新。推荐pythonpython操作http、java操作http的话,还要解决一个网络延迟问题。推荐web开发用web开发terminal或者sublimetext编辑器,php用phpstorm。
phpwind是免费的,名字叫。
phpwind是免费的,功能挺全的,不过偶尔有bug,更新也不是很及时,应该有不少问题修复的。
github
说到免费正版的,可以试试虚幻云。虚幻云(虚幻云)专注于php与html5技术,完全不用担心公司机密泄露,自行搭建域名。免费使用,就这么简单。
phpwind、tp都可以网上资料随便找。
我自己都是用github,
wp
为什么要用免费的,php里面都有全套的开发工具,
phpwind、tp什么的都可以呀,tp是收费的。
我们公司比较傻逼,直接用tp搭起来的,不花钱。后面还换了一个博客软件,也是tp做的,比较傻逼,在用ghost的。
phpwind可以看看,有免费版,用起来挺好的,如果网络要求高,可以入tp的。如果你是老师,教学php(不推荐,如果网络要求高的话,你不也想请个学生帮你讲课?),且个人觉得对php感兴趣,可以用个免费版的试试,
php网页抓取工具( 一下自己现在正在使用的Chrome拓展可以实现网页整个页面截图)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-02-20 12:24
一下自己现在正在使用的Chrome拓展可以实现网页整个页面截图)
安装出色的 Chrome 扩展程序可以大大提高您的工作效率。作为一名前端开发人员,我几乎把所有的工作时间都花在了与 Chrome 浏览器打交道上。 W3C中文教程网(w3schools.wang)今天将分享我现在正在使用的Chrome扩展。
Adblock Plus
Adblock Plus 不需要我多说。大部分朋友都知道这个扩展可以过滤网页上的广告。
CSS查看器
此扩展可以直接获取网页任意部分的样式信息,比F12调试工具更直观。
全页截屏
这个扩展可以对整个网页进行截图,功能简单直接。博主更喜欢简单的应用程序。
PHP 控制台
此扩展可以在控制台上显示 PHP 调试信息。先决条件是在服务器 PHP 环境中安装依赖项。详情请参考项目主页。
PHP 文档
快速找到一个PHP函数或方法的名称,输入后直接进入PHP官方文档打开搜索结果。
邮递员
这实际上是一个 Chrome 应用程序。该应用可以实现调用、请求、记录和保存API接口,可以在开发过程中作为接口测试和接口管理使用。
React 开发者工具
React 开发是必要的。如果打开的页面是基于 React 构建的,可以在控制台直接看到应用的当前状态。
专业视频下载器
直接抓取网页上正在播放的视频文件,可以直接获取外部链接进行下载。
Wappalyzer
直接查看当前页面使用的是哪个框架。
什么字体
直接获取页面文本使用的字体。如果觉得好看,可以直接采集这个字体。
如果您是一名 IT 工作者,w3schools.wang 可能会对您有所帮助! 查看全部
php网页抓取工具(
一下自己现在正在使用的Chrome拓展可以实现网页整个页面截图)
安装出色的 Chrome 扩展程序可以大大提高您的工作效率。作为一名前端开发人员,我几乎把所有的工作时间都花在了与 Chrome 浏览器打交道上。 W3C中文教程网(w3schools.wang)今天将分享我现在正在使用的Chrome扩展。
Adblock Plus
Adblock Plus 不需要我多说。大部分朋友都知道这个扩展可以过滤网页上的广告。
CSS查看器
此扩展可以直接获取网页任意部分的样式信息,比F12调试工具更直观。
全页截屏
这个扩展可以对整个网页进行截图,功能简单直接。博主更喜欢简单的应用程序。
PHP 控制台
此扩展可以在控制台上显示 PHP 调试信息。先决条件是在服务器 PHP 环境中安装依赖项。详情请参考项目主页。
PHP 文档
快速找到一个PHP函数或方法的名称,输入后直接进入PHP官方文档打开搜索结果。
邮递员
这实际上是一个 Chrome 应用程序。该应用可以实现调用、请求、记录和保存API接口,可以在开发过程中作为接口测试和接口管理使用。
React 开发者工具
React 开发是必要的。如果打开的页面是基于 React 构建的,可以在控制台直接看到应用的当前状态。
专业视频下载器
直接抓取网页上正在播放的视频文件,可以直接获取外部链接进行下载。
Wappalyzer
直接查看当前页面使用的是哪个框架。
什么字体
直接获取页面文本使用的字体。如果觉得好看,可以直接采集这个字体。
如果您是一名 IT 工作者,w3schools.wang 可能会对您有所帮助!
php网页抓取工具(网页抓取小工具.rar(22.91)本工具使用方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2022-02-18 10:09
网页抓取小工具(IE方法)——吴姐
html
使用IE提取网页数据的好处是,所见即所得,网页上能看到的信息一般都能得到。
这个工具的功能很少,主要是方便提取网页上显示的信息所在元素的代码。希望它可以帮助你一点。
Web Scraping Widget.rar(22.91 KB, 下载次数: 2426)
如何使用这个工具:
1、在B1输入网址,可以是打开的网页,也可以是未打开的网页
2、不要改变A2和B2的内容,第二行的其他单元格可以输入元素本身的属性名。其中innertext单元格有一个下拉选项
3、点击“开始分析”,分析网页元素。
4、A 列是每个元素的目标代码。
5、在innertext列中找到要提取的内容后,选中该行,点击“生成Excel”。
您可以提取Table标签的表格或下载IMG标签的图片。
6、在新生成的excel中,点击“执行代码”按钮,查看是否可以生成需要的数据。
如果生成的数据与您开始分析的数据不匹配,原因可能是:
1、网页还没有完全加载,对应标签的数据还没有加载。代码自动提取后续标签数据。
可能的解决方案:添加一个 do...loop 时间延迟。
2、网页为动态网页,标签序号不固定。
可能的解决方案:如果元素有id名称,使用getelementbyid("id name")获取。如果没有,请获取包并将其替换为 xmlhttp。
3、需要选择或登录才能提取。
可能的解决方案:在提取之前登录或选择相关选项
该工具主要针对初学者。浏览器可以分析,但不能给出具体元素的vba代码。该工具可以直接生成net capture的vba代码。ajax和frame中的内容也可以自动生成代码。 查看全部
php网页抓取工具(网页抓取小工具.rar(22.91)本工具使用方法)
网页抓取小工具(IE方法)——吴姐
html
使用IE提取网页数据的好处是,所见即所得,网页上能看到的信息一般都能得到。
这个工具的功能很少,主要是方便提取网页上显示的信息所在元素的代码。希望它可以帮助你一点。
Web Scraping Widget.rar(22.91 KB, 下载次数: 2426)
如何使用这个工具:
1、在B1输入网址,可以是打开的网页,也可以是未打开的网页
2、不要改变A2和B2的内容,第二行的其他单元格可以输入元素本身的属性名。其中innertext单元格有一个下拉选项
3、点击“开始分析”,分析网页元素。
4、A 列是每个元素的目标代码。
5、在innertext列中找到要提取的内容后,选中该行,点击“生成Excel”。
您可以提取Table标签的表格或下载IMG标签的图片。
6、在新生成的excel中,点击“执行代码”按钮,查看是否可以生成需要的数据。
如果生成的数据与您开始分析的数据不匹配,原因可能是:
1、网页还没有完全加载,对应标签的数据还没有加载。代码自动提取后续标签数据。
可能的解决方案:添加一个 do...loop 时间延迟。
2、网页为动态网页,标签序号不固定。
可能的解决方案:如果元素有id名称,使用getelementbyid("id name")获取。如果没有,请获取包并将其替换为 xmlhttp。
3、需要选择或登录才能提取。
可能的解决方案:在提取之前登录或选择相关选项
该工具主要针对初学者。浏览器可以分析,但不能给出具体元素的vba代码。该工具可以直接生成net capture的vba代码。ajax和frame中的内容也可以自动生成代码。
php网页抓取工具(php网页抓取工具xmlp,反正都是基于一些函数比如string_replace_to_string_interact)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-02-14 01:00
php网页抓取工具xmlp,javascript抓取工具javascripthash,反正都是基于一些函数比如string_replace_to_string_interactive_character.js等。
1.基于webgl,zbrush,quirks,minecraft(em)等可以实现类似googletosavehtml5files2.基于vba,比如想做个文本生成网页,对,就是批量生成带链接的文本。googlewebgldocument。3.基于mysql、postgresql、sqlserver等数据库,也可以实现类似googletosavehtml5files。
还有googletosavehtml5fileswithphp等等不过话说,问这个问题能不能多看看googletosavehtml5files官方文档再问,不要整天追求新奇实现,毕竟不是为了搞网站而生的。
php网页抓取工具javascripthash,还是用string_replace_to_string_interactive_character.js之类的,不过比较大。基于objective-c的开源脚本一大堆啊,相应接口少一些,像《phpcookbook》一类的入门基础书籍,应该都有相应介绍和开源的代码。
如::print+quirks你说的“类似googletosavehtml5files”的情况可能是要多几步吧。先用phpstorm生成静态页面,通过mysql连到mysql数据库,然后一步步获取转义后的data,并转换成对应character就行了。 查看全部
php网页抓取工具(php网页抓取工具xmlp,反正都是基于一些函数比如string_replace_to_string_interact)
php网页抓取工具xmlp,javascript抓取工具javascripthash,反正都是基于一些函数比如string_replace_to_string_interactive_character.js等。
1.基于webgl,zbrush,quirks,minecraft(em)等可以实现类似googletosavehtml5files2.基于vba,比如想做个文本生成网页,对,就是批量生成带链接的文本。googlewebgldocument。3.基于mysql、postgresql、sqlserver等数据库,也可以实现类似googletosavehtml5files。
还有googletosavehtml5fileswithphp等等不过话说,问这个问题能不能多看看googletosavehtml5files官方文档再问,不要整天追求新奇实现,毕竟不是为了搞网站而生的。
php网页抓取工具javascripthash,还是用string_replace_to_string_interactive_character.js之类的,不过比较大。基于objective-c的开源脚本一大堆啊,相应接口少一些,像《phpcookbook》一类的入门基础书籍,应该都有相应介绍和开源的代码。
如::print+quirks你说的“类似googletosavehtml5files”的情况可能是要多几步吧。先用phpstorm生成静态页面,通过mysql连到mysql数据库,然后一步步获取转义后的data,并转换成对应character就行了。
php网页抓取工具(如何查看网页的一个问题?(一)_光明网)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2022-02-11 09:32
通过前面几章的介绍,我们对什么是爬虫有了初步的了解,同时对如何爬取网页有了大致的了解。从本章开始,我们将从理论走向实践,结合实际操作进一步加深理解。
由于使用python爬取页面的工具有很多,例如requests、scrapy、PhantomJS、Splash等,而且解析爬取页面的工具也很多。我们这里从最简单的开始,使用 requests 库和 beautifSoup 工具进行静态页面爬取和解析。
基础功扎实后,我们可以使用更灵活的工具,不仅可以静态爬取,还可以动态爬取;不仅可以爬取单页,还可以递归深度爬取。同时,结合其他渲染、存储、机器学习等工具,我们可以对数据进行处理、加工、建模和展示。
废话不多说,开始今天的例子,抓起安徒生童话中著名的“丑小鸭”。“要想把工作做好,就必须先利好自己的工具。” 在开始之前,我们需要做一些准备工作,下载pycharm,安装requests库和beautifSoup。安装结果如下:
启动爬虫的第一步是找到童话故事“丑小鸭”的链接。我们在这里使用的链接是:. ![在此处插入图像描述]()
找到我们的目标链接后,第二步就是分析网页。分析什么?当然是分析我们要爬取的内容在哪里。
根据我们之前的介绍,我们这次爬虫的目的是爬取丑小鸭的文字。带着这个目标,我们首先要研究网页的构成。那么如何查看网页呢?一般是在浏览器的开发者模式下完成。对于chrome浏览器,我们可以使用快捷键F12来查看,如图:
左边是网页显示的内容,右边是网页的HTML文档。
通过对右侧页面的分析,我们可以观察到我们需要爬取的页面内容在一个
在标签中:
既然找到了页面,也找到了要爬取的内容的位置,那么我们现在需要解决的一个问题是:如何使用代码快速定位到目标内容?
理想情况下,我们希望这样
标签有一个唯一的属性(通常是id或者class),那么我们可以通过这个属性直接定位到位置。
但不幸的是,在我们的目标标签中
,它没有属性,更不用说独特的属性了。现在直接访问的愿望已经被打败,只能使用间接访问。
通常有两种间接方法:第一种是找到与其相邻的可以快速定位的标签,然后根据两个标签之间的位置关系进行间接访问。在这个操作中,我们很容易发现
标签的父标签div有唯一的类属性articleContent;第二种方法是将所有
找出所有的标签,然后用一个一个的遍历找到目标的标签。事实上,在实际的爬取过程中,这两种方法都会用到。
至于哪个更好,我们将根据实际情况进行分析选择。在这里,我们展示了两种方式。
第一种方式:
我们基于
标签的父标签div有唯一的类属性articleContent找到div标签,然后根据父子关系找到p标签,再通过正则表达式过滤无用的内容,得到最终结果。
1`
1# 请求库
2import requests
3# 解析库
4from bs4 import BeautifulSoup
5import re
6# 爬取的网页链接
7url=r"https://www.ppzuowen.com/book/ ... ot%3B
8r= requests.get(url)
9r.encoding=None
10result = r.text
11# 再次封装,获取具体标签内的内容
12bs = BeautifulSoup(result, 'lxml')
13psg = bs.select('.articleContent > p')
14title = bs.select('title')[0].text.split('_')[0]
15# print(title)
16txt = ''.join(str(x) for x in psg)
17res = re.sub(r'', "", txt)
18result=res.split("(1844年)")[0]
19print('标题:',title)
20print('原文内容:',result)
21
22
最后结果:
实现的代码主要分为两部分:第一部分是页面的爬取,如:
1`
1# 爬取的网页链接
2url=r"https://www.ppzuowen.com/book/ ... ot%3B
3r= requests.get(url)
4r.encoding=None
5result = r.text
6print(result)
7
8
这部分内容和我们之前在浏览器的开发者模式中看到的HTML源代码完全一样。
第二部分是页面的解析。
我们之前介绍过,HTLML 页面本质上是一棵 DOM 树。我们通过遍历树的子节点来遍历HTML页面中的标签,如:
1# 再次封装,获取具体标签内的内容
2bs = BeautifulSoup(result, 'lxml')
3psg = bs.select('.articleContent > p')
4
5
这里首先将页面信息转换成xml格式的文档(注意:HTML文档是一种特殊类型的xml文档),然后根据CSS语法找到p标签的内容。
第二种方式:
我们原来的方式写的代码是这样的:
1# 请求库
2import requests
3# 解析库
4from bs4 import BeautifulSoup
5
6# 爬取的网页链接
7url=r"https://www.ppzuowen.com/book/ ... ot%3B
8r= requests.get(url)
9r.encoding=None
10result = r.text
11# 再次封装,获取具体标签内的内容
12bs = BeautifulSoup(result,'html.parser')
13# 具体标签
14print("---------解析后的数据---------------")
15# print(bs.span)
16a={}
17# 获取已爬取内容中的p签内容
18data=bs.find_all('p')
19# 循环打印输出
20for tmp in data:
21 print(tmp)
22 print('********************')
23
24
然后我们看输出结果和预期的不一样,是这样的:
获取的内容被分割并与许多其他无用的信息混合。其实这些在实际爬取过程中都是常见的。并非每次爬取都是一步完成的,并且需要不断调试。
经过分析,我们可以使用表达式过滤无用信息,并使用字符串拼接函数进行拼接,得到我们期望的结果。
最终代码如下:
1# 请求库
2import requests
3# 解析库
4from bs4 import BeautifulSoup
5
6# 爬取的网页链接
7url=r"https://www.ppzuowen.com/book/ ... ot%3B
8r= requests.get(url)
9r.encoding=None
10result = r.text
11# 再次封装,获取具体标签内的内容
12bs = BeautifulSoup(result,'html.parser')
13# 具体标签
14print("---------解析后的数据---------------")
15# print(bs.span)
16a={}
17# 获取已爬取内容中的p签内容
18data=bs.find_all('p')
19result=''
20# 循环打印输出
21for tmp in data:
22 if '1844年' in tmp.text:
23 break
24 result+=tmp.text
25
26print(result)
27
28
上面我们已经说明了如何通过两种方式抓取一些简单的网页信息。当然,对于爬取的内容,我们有时不仅输出,还可能需要存储。
通常,存储方式是文件和数据库的形式。我们稍后会详细介绍这些内容。
其实作为一个编程学习者,有一个学习氛围和一个交流圈是很重要的。学习资料,面试技巧,大厂面试题,升职加薪指日可待。希望大家可以在Q2956807116和我交流,或者加入Q群313782132,无论是新手还是大佬,都欢迎。让我们一起交流,一起成长。 查看全部
php网页抓取工具(如何查看网页的一个问题?(一)_光明网)
通过前面几章的介绍,我们对什么是爬虫有了初步的了解,同时对如何爬取网页有了大致的了解。从本章开始,我们将从理论走向实践,结合实际操作进一步加深理解。
由于使用python爬取页面的工具有很多,例如requests、scrapy、PhantomJS、Splash等,而且解析爬取页面的工具也很多。我们这里从最简单的开始,使用 requests 库和 beautifSoup 工具进行静态页面爬取和解析。
基础功扎实后,我们可以使用更灵活的工具,不仅可以静态爬取,还可以动态爬取;不仅可以爬取单页,还可以递归深度爬取。同时,结合其他渲染、存储、机器学习等工具,我们可以对数据进行处理、加工、建模和展示。
废话不多说,开始今天的例子,抓起安徒生童话中著名的“丑小鸭”。“要想把工作做好,就必须先利好自己的工具。” 在开始之前,我们需要做一些准备工作,下载pycharm,安装requests库和beautifSoup。安装结果如下:
启动爬虫的第一步是找到童话故事“丑小鸭”的链接。我们在这里使用的链接是:. ![在此处插入图像描述]()
找到我们的目标链接后,第二步就是分析网页。分析什么?当然是分析我们要爬取的内容在哪里。
根据我们之前的介绍,我们这次爬虫的目的是爬取丑小鸭的文字。带着这个目标,我们首先要研究网页的构成。那么如何查看网页呢?一般是在浏览器的开发者模式下完成。对于chrome浏览器,我们可以使用快捷键F12来查看,如图:
左边是网页显示的内容,右边是网页的HTML文档。
通过对右侧页面的分析,我们可以观察到我们需要爬取的页面内容在一个
在标签中:
既然找到了页面,也找到了要爬取的内容的位置,那么我们现在需要解决的一个问题是:如何使用代码快速定位到目标内容?
理想情况下,我们希望这样
标签有一个唯一的属性(通常是id或者class),那么我们可以通过这个属性直接定位到位置。
但不幸的是,在我们的目标标签中
,它没有属性,更不用说独特的属性了。现在直接访问的愿望已经被打败,只能使用间接访问。
通常有两种间接方法:第一种是找到与其相邻的可以快速定位的标签,然后根据两个标签之间的位置关系进行间接访问。在这个操作中,我们很容易发现
标签的父标签div有唯一的类属性articleContent;第二种方法是将所有
找出所有的标签,然后用一个一个的遍历找到目标的标签。事实上,在实际的爬取过程中,这两种方法都会用到。
至于哪个更好,我们将根据实际情况进行分析选择。在这里,我们展示了两种方式。
第一种方式:
我们基于
标签的父标签div有唯一的类属性articleContent找到div标签,然后根据父子关系找到p标签,再通过正则表达式过滤无用的内容,得到最终结果。
1`
1# 请求库
2import requests
3# 解析库
4from bs4 import BeautifulSoup
5import re
6# 爬取的网页链接
7url=r"https://www.ppzuowen.com/book/ ... ot%3B
8r= requests.get(url)
9r.encoding=None
10result = r.text
11# 再次封装,获取具体标签内的内容
12bs = BeautifulSoup(result, 'lxml')
13psg = bs.select('.articleContent > p')
14title = bs.select('title')[0].text.split('_')[0]
15# print(title)
16txt = ''.join(str(x) for x in psg)
17res = re.sub(r'', "", txt)
18result=res.split("(1844年)")[0]
19print('标题:',title)
20print('原文内容:',result)
21
22
最后结果:
实现的代码主要分为两部分:第一部分是页面的爬取,如:
1`
1# 爬取的网页链接
2url=r"https://www.ppzuowen.com/book/ ... ot%3B
3r= requests.get(url)
4r.encoding=None
5result = r.text
6print(result)
7
8
这部分内容和我们之前在浏览器的开发者模式中看到的HTML源代码完全一样。
第二部分是页面的解析。
我们之前介绍过,HTLML 页面本质上是一棵 DOM 树。我们通过遍历树的子节点来遍历HTML页面中的标签,如:
1# 再次封装,获取具体标签内的内容
2bs = BeautifulSoup(result, 'lxml')
3psg = bs.select('.articleContent > p')
4
5
这里首先将页面信息转换成xml格式的文档(注意:HTML文档是一种特殊类型的xml文档),然后根据CSS语法找到p标签的内容。
第二种方式:
我们原来的方式写的代码是这样的:
1# 请求库
2import requests
3# 解析库
4from bs4 import BeautifulSoup
5
6# 爬取的网页链接
7url=r"https://www.ppzuowen.com/book/ ... ot%3B
8r= requests.get(url)
9r.encoding=None
10result = r.text
11# 再次封装,获取具体标签内的内容
12bs = BeautifulSoup(result,'html.parser')
13# 具体标签
14print("---------解析后的数据---------------")
15# print(bs.span)
16a={}
17# 获取已爬取内容中的p签内容
18data=bs.find_all('p')
19# 循环打印输出
20for tmp in data:
21 print(tmp)
22 print('********************')
23
24
然后我们看输出结果和预期的不一样,是这样的:
获取的内容被分割并与许多其他无用的信息混合。其实这些在实际爬取过程中都是常见的。并非每次爬取都是一步完成的,并且需要不断调试。
经过分析,我们可以使用表达式过滤无用信息,并使用字符串拼接函数进行拼接,得到我们期望的结果。
最终代码如下:
1# 请求库
2import requests
3# 解析库
4from bs4 import BeautifulSoup
5
6# 爬取的网页链接
7url=r"https://www.ppzuowen.com/book/ ... ot%3B
8r= requests.get(url)
9r.encoding=None
10result = r.text
11# 再次封装,获取具体标签内的内容
12bs = BeautifulSoup(result,'html.parser')
13# 具体标签
14print("---------解析后的数据---------------")
15# print(bs.span)
16a={}
17# 获取已爬取内容中的p签内容
18data=bs.find_all('p')
19result=''
20# 循环打印输出
21for tmp in data:
22 if '1844年' in tmp.text:
23 break
24 result+=tmp.text
25
26print(result)
27
28
上面我们已经说明了如何通过两种方式抓取一些简单的网页信息。当然,对于爬取的内容,我们有时不仅输出,还可能需要存储。
通常,存储方式是文件和数据库的形式。我们稍后会详细介绍这些内容。
其实作为一个编程学习者,有一个学习氛围和一个交流圈是很重要的。学习资料,面试技巧,大厂面试题,升职加薪指日可待。希望大家可以在Q2956807116和我交流,或者加入Q群313782132,无论是新手还是大佬,都欢迎。让我们一起交流,一起成长。
php网页抓取工具(10款最具人气的PHP开源工具,你可以在你所喜爱)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-02-10 19:15
PHP 非常适合创建动态和创新的 Web 应用程序。不用说,PHP 是 Web 开发世界中最流行的语言之一。一些非常实用的 PHP 开源工具,确实为很多 PHP 开发者解脱了繁重的开发任务,减轻了他们的开发负担。这些 PHP 开源工具改进了他们的工作流程,使他们的开发任务更轻松、更快捷。小编整理了10款最流行的PHP开源工具分享给大家,欢迎交流分享。
蒙斯塔 FTP
如果您想在浏览器中设置 FTP 文件管理,您需要有一个开源的 PHP 或 Ajax Cloudware,如 Monsta FTP。不仅支持屏幕文件编辑,还可以将文件拖放到浏览器上进行快速上传。Monsta FTP经过测试,支持火狐、Chrome、IE浏览器、Safari浏览器等所有主流浏览器,并配备多语言支持。
品霸
Pinba 使用只读格式的 MySQL 作为实时统计/监督服务器。它几乎是一个 MySQL 存储引擎。它可以生成简单格式的统计报表,并将累积的数据处理后通过UDP发送。它还可以创建复杂的报告。
箱盒
CaseBox 是一个用于管理任务、记录和文档的开源 PHP Web 应用程序。它允许我们创建大量目录并将数据存储在类似于桌面界面的首选结构中。CaseBox 通过将具有指定期限的任务分配给用户并跟踪绩效,极大地简化了工作流程。
西柳斯
Sylius 也是一个基于 Symfony 2 的开源 PHP 工具。它允许您创建电子商务网站 并管理收录产品和类别的复杂在线商店。它支持多种功能,例如管理不同的税率和运输方式。此外,它还与支付网关 OmniPay 集成,使其成为完美的电子商务工具。
微微
这个内容管理程序也是开源的,它使用平面文件文件作为其数据库。Pico 无需安装即可使用。您可以在您喜欢的文本编辑器中编辑存储在 .md 文件中的内容。
穆尼
如果您想优化和操作 网站 网站资产,综合的 网站 库 Munee 将派上用场。它可以实现客户端和服务器端的资源缓存。它还可以集成 PHP 图像处理库。您可以调整图像大小或裁剪图像并缓存它们。
法尔康 PHP
它是一个提供低资源消耗和高性能的 Web 框架。Phalcon PHP 是用 C 语言编写的,因此它适用于任何操作系统。
phpMyFAQ
phpMyFAQ是一个PHP FAQ(Frequently Asked Questions)应用程序,可以用来频繁提问一个优秀的FAQ系统。它可以管理用户、项目、类别和统计数据。phpMyFAQ 有一个先进的搜索系统,可以帮助用户找到相关的答案。
PHPImageWorkshop
它使用 GD 库来管理图像。它允许您以与 Photoshop 类似的方式编辑照片。同时它也非常灵活,可以让你叠加大量图片,使用旋转功能甚至缩略图。
调试栏
DebugBar 也是开源应用程序家族的一员,可在线免费获取,并可集成到 PHP 项目中。它包括常见和流行的库。它支持 Ajax 请求并在页脚中有一个 JavaScript 栏。 查看全部
php网页抓取工具(10款最具人气的PHP开源工具,你可以在你所喜爱)
PHP 非常适合创建动态和创新的 Web 应用程序。不用说,PHP 是 Web 开发世界中最流行的语言之一。一些非常实用的 PHP 开源工具,确实为很多 PHP 开发者解脱了繁重的开发任务,减轻了他们的开发负担。这些 PHP 开源工具改进了他们的工作流程,使他们的开发任务更轻松、更快捷。小编整理了10款最流行的PHP开源工具分享给大家,欢迎交流分享。
蒙斯塔 FTP
如果您想在浏览器中设置 FTP 文件管理,您需要有一个开源的 PHP 或 Ajax Cloudware,如 Monsta FTP。不仅支持屏幕文件编辑,还可以将文件拖放到浏览器上进行快速上传。Monsta FTP经过测试,支持火狐、Chrome、IE浏览器、Safari浏览器等所有主流浏览器,并配备多语言支持。
品霸
Pinba 使用只读格式的 MySQL 作为实时统计/监督服务器。它几乎是一个 MySQL 存储引擎。它可以生成简单格式的统计报表,并将累积的数据处理后通过UDP发送。它还可以创建复杂的报告。
箱盒
CaseBox 是一个用于管理任务、记录和文档的开源 PHP Web 应用程序。它允许我们创建大量目录并将数据存储在类似于桌面界面的首选结构中。CaseBox 通过将具有指定期限的任务分配给用户并跟踪绩效,极大地简化了工作流程。
西柳斯
Sylius 也是一个基于 Symfony 2 的开源 PHP 工具。它允许您创建电子商务网站 并管理收录产品和类别的复杂在线商店。它支持多种功能,例如管理不同的税率和运输方式。此外,它还与支付网关 OmniPay 集成,使其成为完美的电子商务工具。
微微
这个内容管理程序也是开源的,它使用平面文件文件作为其数据库。Pico 无需安装即可使用。您可以在您喜欢的文本编辑器中编辑存储在 .md 文件中的内容。
穆尼
如果您想优化和操作 网站 网站资产,综合的 网站 库 Munee 将派上用场。它可以实现客户端和服务器端的资源缓存。它还可以集成 PHP 图像处理库。您可以调整图像大小或裁剪图像并缓存它们。
法尔康 PHP
它是一个提供低资源消耗和高性能的 Web 框架。Phalcon PHP 是用 C 语言编写的,因此它适用于任何操作系统。
phpMyFAQ
phpMyFAQ是一个PHP FAQ(Frequently Asked Questions)应用程序,可以用来频繁提问一个优秀的FAQ系统。它可以管理用户、项目、类别和统计数据。phpMyFAQ 有一个先进的搜索系统,可以帮助用户找到相关的答案。
PHPImageWorkshop
它使用 GD 库来管理图像。它允许您以与 Photoshop 类似的方式编辑照片。同时它也非常灵活,可以让你叠加大量图片,使用旋转功能甚至缩略图。
调试栏
DebugBar 也是开源应用程序家族的一员,可在线免费获取,并可集成到 PHP 项目中。它包括常见和流行的库。它支持 Ajax 请求并在页脚中有一个 JavaScript 栏。
php网页抓取工具(python的最基本就是get一个网页的源代码数据,如果更初学爬虫 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 79 次浏览 • 2022-02-08 19:00
)
相关话题
python示例爬虫代码怎么做
11/8/202015:02:54
python爬虫代码示例的方法:先获取浏览器信息,使用urlencode生成post数据;然后安装 pymysql 并将数据存储在 MySQL 中。python爬虫代码示例的方法:1、urllib和BeautifulfuSoup获取浏览器
谈爬虫,绕过网站反爬机制
25/8/202018:04:17
【相关学习推荐:网站制作视频教程】什么是爬虫?简单地说,爬虫是一种自动与服务器交互以通过计算机获取数据的工具。爬虫最基本的就是获取一个网页的源代码数据。
初级爬虫一、获取某个类别下的所有页面地址
2/3/2018 01:10:32
总结:初学者,做个简单的爬虫深入理解python获取jb51书籍的列表和地址
谈爬虫,绕过网站反爬机制
15/12/2017 09:03:00
什么是爬虫?简单地说,爬虫是一种自动与服务器交互以获取数据的工具。
爬行动物和反爬行 - 爬行动物
2018 年 4 月 3 日 01:08:51
总结:爬虫与反爬——爬虫
Scrapy爬虫--02
2018 年 2 月 3 日 01:11:17
爬虫最基本的部分是下载网页,最重要的部分是过滤——获取我们需要的信息。而scrapy只是提供了这个功能:首先我们必须定义项目:Itemsarecontainersthatwillbeloadedwiththescrapeddata;它们工作起来像简单的pythondicts但是提供了额外的pro
为什么爬虫需要很多ip
2015 年 9 月 11 日:06:24
爬虫需要大量IP的原因:1、因为在爬取数据的过程中,经常被网站阻塞;不一样,还是刮掉空白数据。为什么爬虫需要很多IP
关于网络爬虫的事情:变相杀死爬虫
2009 年 11 月 8 日 14:29:00
在那些关于网络爬虫的事情中(一)提到如果爬虫伪装自己的User-Agent信息,就必须找到新的方法来阻止爬虫。其实对于网站来说,最大的挑战是如何准确识别一个IP发起的请求,是真实用户访问还是爬虫访问?
教你任意使用谷歌爬虫DDoS网站
30/6/201509:14:00
教你任意使用谷歌爬虫DDoS网站!Google 的 FeedFetcher 抓取工具将缓存电子表格的 =image("link") 中的所有链接。
简单高效的nodejs爬虫模型
2018 年 4 月 3 日 01:09:06
这篇文章解释了yunshare项目的爬虫模型。使用nodejs开发爬虫非常简单。你不需要像python的scrapy这样的爬虫框架。只需要使用 request 或 superagent 等 http 库即可完成大部分爬虫工作。使用nodejs开发爬虫半年左右,爬虫可以很简单也可以很复杂。一个简单的爬虫定向爬取一个网站,可能有几万或几十万的页面请求,复杂的爬虫类似于googlebot之类的搜索引擎
开源爬虫软件总结
2018 年 4 月 3 日 01:13:50
摘要:世界上有数百种爬虫软件。本文整理了比较知名和常见的开源爬虫软件,并按照开发语言进行了总结,如下表所示。虽然搜索引擎也有爬虫,但是这次我只总结爬虫软件,不是大型复杂的搜索引擎,因为很多兄弟只是想爬数据,而不是操作搜索引擎。
爬虫概述
2018 年 2 月 3 日 01:10:10
摘要:爬虫概述
hao123 简单的网络爬虫
2018 年 4 月 3 日 01:09:06
项目地址:github网络爬虫使用的主要技术是Jsoup和httpclientJsoup,用于解析网页数据,可以根据网页节点获取需要的数据。httpclient用于请求网页,获取整个网页数据。页面的域名和二级页面,即主模块在hao123首页的超链接,以及通过超链接包com.kunteng.crawler访问的页面上的所有链接;/*
Pythonscrapy爬虫爬取博乐在线所有文章并写入数据库
2018 年 4 月 3 日 01:10:02
博乐在线爬虫项目目的及项目准备:1.使用scrapy创建项目2.创建爬虫,博乐域名3.start_urls=['']4.爬取所有页面 文章5.文章列表页面需要数据 a) 缩略图地址 b) 详细 url 地址6.详细页面要提取的数据#博客标题#博客创建
33个可用于抓取数据的开源爬虫软件工具
2018 年 4 月 3 日 01:12:56
玩大数据,没有数据怎么玩?下面为大家推荐33款开源爬虫软件。爬虫,或称网络爬虫,是一种自动获取网页内容的程序。它是搜索引擎的重要组成部分,因此搜索引擎优化主要针对爬虫进行优化。网络爬虫是一种自动提取网页的程序。它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成部分。传统的爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL,在抓取网页的过程中不断地从当前页面中提取新的URL。
查看全部
php网页抓取工具(python的最基本就是get一个网页的源代码数据,如果更初学爬虫
)
相关话题
python示例爬虫代码怎么做
11/8/202015:02:54
python爬虫代码示例的方法:先获取浏览器信息,使用urlencode生成post数据;然后安装 pymysql 并将数据存储在 MySQL 中。python爬虫代码示例的方法:1、urllib和BeautifulfuSoup获取浏览器
谈爬虫,绕过网站反爬机制
25/8/202018:04:17
【相关学习推荐:网站制作视频教程】什么是爬虫?简单地说,爬虫是一种自动与服务器交互以通过计算机获取数据的工具。爬虫最基本的就是获取一个网页的源代码数据。
初级爬虫一、获取某个类别下的所有页面地址
2/3/2018 01:10:32
总结:初学者,做个简单的爬虫深入理解python获取jb51书籍的列表和地址
谈爬虫,绕过网站反爬机制
15/12/2017 09:03:00
什么是爬虫?简单地说,爬虫是一种自动与服务器交互以获取数据的工具。
爬行动物和反爬行 - 爬行动物
2018 年 4 月 3 日 01:08:51
总结:爬虫与反爬——爬虫
Scrapy爬虫--02
2018 年 2 月 3 日 01:11:17
爬虫最基本的部分是下载网页,最重要的部分是过滤——获取我们需要的信息。而scrapy只是提供了这个功能:首先我们必须定义项目:Itemsarecontainersthatwillbeloadedwiththescrapeddata;它们工作起来像简单的pythondicts但是提供了额外的pro
为什么爬虫需要很多ip
2015 年 9 月 11 日:06:24
爬虫需要大量IP的原因:1、因为在爬取数据的过程中,经常被网站阻塞;不一样,还是刮掉空白数据。为什么爬虫需要很多IP
关于网络爬虫的事情:变相杀死爬虫
2009 年 11 月 8 日 14:29:00
在那些关于网络爬虫的事情中(一)提到如果爬虫伪装自己的User-Agent信息,就必须找到新的方法来阻止爬虫。其实对于网站来说,最大的挑战是如何准确识别一个IP发起的请求,是真实用户访问还是爬虫访问?
教你任意使用谷歌爬虫DDoS网站
30/6/201509:14:00
教你任意使用谷歌爬虫DDoS网站!Google 的 FeedFetcher 抓取工具将缓存电子表格的 =image("link") 中的所有链接。
简单高效的nodejs爬虫模型
2018 年 4 月 3 日 01:09:06
这篇文章解释了yunshare项目的爬虫模型。使用nodejs开发爬虫非常简单。你不需要像python的scrapy这样的爬虫框架。只需要使用 request 或 superagent 等 http 库即可完成大部分爬虫工作。使用nodejs开发爬虫半年左右,爬虫可以很简单也可以很复杂。一个简单的爬虫定向爬取一个网站,可能有几万或几十万的页面请求,复杂的爬虫类似于googlebot之类的搜索引擎
开源爬虫软件总结
2018 年 4 月 3 日 01:13:50
摘要:世界上有数百种爬虫软件。本文整理了比较知名和常见的开源爬虫软件,并按照开发语言进行了总结,如下表所示。虽然搜索引擎也有爬虫,但是这次我只总结爬虫软件,不是大型复杂的搜索引擎,因为很多兄弟只是想爬数据,而不是操作搜索引擎。
爬虫概述
2018 年 2 月 3 日 01:10:10
摘要:爬虫概述
hao123 简单的网络爬虫
2018 年 4 月 3 日 01:09:06
项目地址:github网络爬虫使用的主要技术是Jsoup和httpclientJsoup,用于解析网页数据,可以根据网页节点获取需要的数据。httpclient用于请求网页,获取整个网页数据。页面的域名和二级页面,即主模块在hao123首页的超链接,以及通过超链接包com.kunteng.crawler访问的页面上的所有链接;/*
Pythonscrapy爬虫爬取博乐在线所有文章并写入数据库
2018 年 4 月 3 日 01:10:02
博乐在线爬虫项目目的及项目准备:1.使用scrapy创建项目2.创建爬虫,博乐域名3.start_urls=['']4.爬取所有页面 文章5.文章列表页面需要数据 a) 缩略图地址 b) 详细 url 地址6.详细页面要提取的数据#博客标题#博客创建
33个可用于抓取数据的开源爬虫软件工具
2018 年 4 月 3 日 01:12:56
玩大数据,没有数据怎么玩?下面为大家推荐33款开源爬虫软件。爬虫,或称网络爬虫,是一种自动获取网页内容的程序。它是搜索引擎的重要组成部分,因此搜索引擎优化主要针对爬虫进行优化。网络爬虫是一种自动提取网页的程序。它为搜索引擎从万维网上下载网页,是搜索引擎的重要组成部分。传统的爬虫从一个或多个初始网页的URL开始,获取初始网页上的URL,在抓取网页的过程中不断地从当前页面中提取新的URL。
php网页抓取工具(智能识别模式WebHarvy网页数据抓取工具功能介绍-苏州安嘉)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-02-08 18:06
WebHarvy 是一个网页数据捕获工具。该软件可以提取网页中的文字和图片,输入网址并打开。默认使用内部浏览器,支持扩展分析,可自动获取相似链接列表。软件界面直观,操作简单。
特征
智能识别模式
WebHarvy 自动识别出现在网页中的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
从多个页面中提取
网页通常会在多个页面中显示数据,例如产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。只需指出“指向下一页的链接”,WebHarvy网站 抓取工具就会自动从所有页面抓取数据。
直观的操作界面
WebHarvy 是一个可视化网页提取工具。事实上,完全不需要编写任何脚本或代码来提取数据。使用 webharvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。它是如此容易!
基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,将为所有给定的输入关键字自动重复您创建的配置。可以指定任意数量的输入关键字
提取分类
WebHarvy网站 抓取器允许您从指向网站 中相似页面的链接列表中提取数据。这允许您使用单个配置来抓取 网站 中的类别或子部分。
使用正则表达式提取
WebHarvy 可以将正则表达式(regular expressions)应用于网页的文本或 HTML 源代码,并提取不匹配的部分。这种强大的技术在抓取数据时为您提供了更大的灵活性。
软件功能
WebHarvy 是一个可视化的网络爬虫。* 无需编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器浏览网络。您可以选择要单击的数据。这简单!
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动删除它。
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
通常,网页会在多个页面上显示产品列表等数据。WebHarvy 可以自动从多个页面爬取和提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper 就会自动从所有页面中抓取数据。 查看全部
php网页抓取工具(智能识别模式WebHarvy网页数据抓取工具功能介绍-苏州安嘉)
WebHarvy 是一个网页数据捕获工具。该软件可以提取网页中的文字和图片,输入网址并打开。默认使用内部浏览器,支持扩展分析,可自动获取相似链接列表。软件界面直观,操作简单。
特征
智能识别模式
WebHarvy 自动识别出现在网页中的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动抓取它。
导出捕获的数据
可以保存从各种格式的网页中提取的数据。当前版本的 WebHarvy网站 抓取器允许您将抓取的数据导出为 XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
从多个页面中提取
网页通常会在多个页面中显示数据,例如产品目录。WebHarvy 可以自动从多个网页中抓取和提取数据。只需指出“指向下一页的链接”,WebHarvy网站 抓取工具就会自动从所有页面抓取数据。
直观的操作界面
WebHarvy 是一个可视化网页提取工具。事实上,完全不需要编写任何脚本或代码来提取数据。使用 webharvy 的内置浏览器浏览网页。您可以选择通过单击鼠标来提取数据。它是如此容易!
基于关键字的提取
基于关键字的提取允许您捕获从搜索结果页面输入的关键字的列表数据。在挖掘数据时,将为所有给定的输入关键字自动重复您创建的配置。可以指定任意数量的输入关键字
提取分类
WebHarvy网站 抓取器允许您从指向网站 中相似页面的链接列表中提取数据。这允许您使用单个配置来抓取 网站 中的类别或子部分。
使用正则表达式提取
WebHarvy 可以将正则表达式(regular expressions)应用于网页的文本或 HTML 源代码,并提取不匹配的部分。这种强大的技术在抓取数据时为您提供了更大的灵活性。
软件功能
WebHarvy 是一个可视化的网络爬虫。* 无需编写任何脚本或代码来抓取数据。您将使用 WebHarvy 的内置浏览器浏览网络。您可以选择要单击的数据。这简单!
WebHarvy 自动识别网页中出现的数据模式。因此,如果您需要从网页中抓取项目列表(姓名、地址、电子邮件、价格等),则无需进行任何额外配置。如果数据重复,WebHarvy 会自动删除它。
您可以以多种格式保存从网页中提取的数据。当前版本的 WebHarvy Web Scraper 允许您将抓取的数据导出为 Excel、XML、CSV、JSON 或 TSV 文件。您还可以将抓取的数据导出到 SQL 数据库。
通常,网页会在多个页面上显示产品列表等数据。WebHarvy 可以自动从多个页面爬取和提取数据。只需指出“链接到下一页”,WebHarvy Web Scraper 就会自动从所有页面中抓取数据。
php网页抓取工具(网站建设中一项重要的工作就是改版,百度蜘蛛抓取情况)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-02-08 16:17
网站建设中的一项重要工作是修订版本。每次修订都必须朝着积极的方向进行。因为每个阶段的定位不同,我们要网站展示的企业形象也不同,一个好看的网站绝对可以提升我们公司在潜在客户心目中的地位。但是,大部分的修改都会对我们的网站 SEO产生一定的影响。这里我们需要非常熟悉网站的情况,然后对其进行有效的控制,以减少修改造成的404页数。很多情况。
最近,一个新的 网站 已经推出。因为是一年多的域名,所以之前的网站的内容和新站点的内容完全不同。网站的结构也做了很大的调整,所以带来了很多404错误爬取页面,我当时没有特别注意这个问题,然后持续更新了2周左右,我发现快照没有更新,一些简单的外部链接不起作用。这个问题引起了我的注意。. 以下是我的一些详细想法:
1、使用日志分析工具查找404错误爬取页面
测井分析工具可以使用最常用的光年测井分析工具。首先,使用FTP下载最近几天的网站LOG日志。当然,如果你想要更多的分析,你可以下载这么多的一段时间的LOG日志。可以,使用日志分析工具新建一个任务,分析百度蜘蛛在各个阶段的爬取情况。这里主要考虑百度爬取的情况,因为建立这个分析工作的前提是快照停滞,收录为1。
建议您将分析分为三个时间段:
A.分析最后一天的LOG日志,可以是今天,但最好是昨天,因为昨天的日志会更全,而且就算晚上来分析,也不会统计一个部分时间。
B、分析修改后的LOG日志,因为涉及到百度蜘蛛对网站修改的一些判断,比如我们可以分析百度蜘蛛什么时候开始判断网站已经修改了,或者当它放弃对旧站点 URL 等的抓取时。
C、修改前后爬取量对比,分析修改对百度蜘蛛的爬取量有多大影响。
至于日志分析工作之后的分析工作,是一键式的。有了具体的分析思路后,我们再对比分析,会发现很多我们平时没有注意到的问题,比如下面改版导致的404页面。还有很多页面有404错误,我没有意识到。例如,下面的 wp-login.php 页面就是一个典型的例子:
404错误爬取页面
2、使用百度站长工具中的死链接提交工具提交死链接
百度站长平台LEE团队表示:404状态码代表'NotFound'。当蜘蛛更新时,它会认为页面是无效的。此时,将从索引库中删除。短期内,蜘蛛会发现该url不再被抓取。当然,百度的说法只能作为参考,因为对网站日志的分析发现,百度蜘蛛仍然爬取这些错误页面2个多星期。当然,百度对404错误页面的引导操作还是很有针对性的。性。
百度站长平台404页浏览量
具体来说,死链接站点地图是在死链接提交工具中提交的。您可以根据自己的情况提交死链接。我这里提交后效果不大,因为大家都知道百度的效果展示周期一般比较长。.
3、使用robots.txt和nofollow标签引导蜘蛛爬行
404错误页面最大的缺点之一就是给蜘蛛带来了一些错误的爬取,浪费了蜘蛛的爬取资源。比如首先我们要达成这样一个共识:任何网站蜘蛛爬取的资源都是有限的,小的网站自然少得多,大的网站多得多。如果你想要更高的爬虫爬取率和更合理的爬取,那么一些错误的链接会导致404错误的数量应该尽可能的减少。
所以我对网站这些资源的浪费给予了适当的指导,让蜘蛛爬一些我想让他爬的页面,把机器人限制在/wuchenshi/、/gaoxiao/等类似的页面列爬取,对网站中不参与排名的部分链接实施nofollow,引导蜘蛛爬取重要页面。再来看看spider 6. No. 3的爬取情况。首先,目录爬取中没有网站中不存在的目录:
蜘蛛对目录的爬取
对于爬虫访问的404页面,只有一张图片的404错误爬取:
改进后的404错误爬取
我还没有看到快照更新和 收录 添加。当然,理论上,这个操作应该可以帮助 网站 更快地获得搜索引擎的认可。> 为每个人做一个补充。
本文由徐鱼网()SEO徐子鱼发布,欢迎大家转载,转载请注明出处,谢谢合作! 查看全部
php网页抓取工具(网站建设中一项重要的工作就是改版,百度蜘蛛抓取情况)
网站建设中的一项重要工作是修订版本。每次修订都必须朝着积极的方向进行。因为每个阶段的定位不同,我们要网站展示的企业形象也不同,一个好看的网站绝对可以提升我们公司在潜在客户心目中的地位。但是,大部分的修改都会对我们的网站 SEO产生一定的影响。这里我们需要非常熟悉网站的情况,然后对其进行有效的控制,以减少修改造成的404页数。很多情况。
最近,一个新的 网站 已经推出。因为是一年多的域名,所以之前的网站的内容和新站点的内容完全不同。网站的结构也做了很大的调整,所以带来了很多404错误爬取页面,我当时没有特别注意这个问题,然后持续更新了2周左右,我发现快照没有更新,一些简单的外部链接不起作用。这个问题引起了我的注意。. 以下是我的一些详细想法:
1、使用日志分析工具查找404错误爬取页面
测井分析工具可以使用最常用的光年测井分析工具。首先,使用FTP下载最近几天的网站LOG日志。当然,如果你想要更多的分析,你可以下载这么多的一段时间的LOG日志。可以,使用日志分析工具新建一个任务,分析百度蜘蛛在各个阶段的爬取情况。这里主要考虑百度爬取的情况,因为建立这个分析工作的前提是快照停滞,收录为1。
建议您将分析分为三个时间段:
A.分析最后一天的LOG日志,可以是今天,但最好是昨天,因为昨天的日志会更全,而且就算晚上来分析,也不会统计一个部分时间。
B、分析修改后的LOG日志,因为涉及到百度蜘蛛对网站修改的一些判断,比如我们可以分析百度蜘蛛什么时候开始判断网站已经修改了,或者当它放弃对旧站点 URL 等的抓取时。
C、修改前后爬取量对比,分析修改对百度蜘蛛的爬取量有多大影响。
至于日志分析工作之后的分析工作,是一键式的。有了具体的分析思路后,我们再对比分析,会发现很多我们平时没有注意到的问题,比如下面改版导致的404页面。还有很多页面有404错误,我没有意识到。例如,下面的 wp-login.php 页面就是一个典型的例子:
404错误爬取页面
2、使用百度站长工具中的死链接提交工具提交死链接
百度站长平台LEE团队表示:404状态码代表'NotFound'。当蜘蛛更新时,它会认为页面是无效的。此时,将从索引库中删除。短期内,蜘蛛会发现该url不再被抓取。当然,百度的说法只能作为参考,因为对网站日志的分析发现,百度蜘蛛仍然爬取这些错误页面2个多星期。当然,百度对404错误页面的引导操作还是很有针对性的。性。
百度站长平台404页浏览量
具体来说,死链接站点地图是在死链接提交工具中提交的。您可以根据自己的情况提交死链接。我这里提交后效果不大,因为大家都知道百度的效果展示周期一般比较长。.
3、使用robots.txt和nofollow标签引导蜘蛛爬行
404错误页面最大的缺点之一就是给蜘蛛带来了一些错误的爬取,浪费了蜘蛛的爬取资源。比如首先我们要达成这样一个共识:任何网站蜘蛛爬取的资源都是有限的,小的网站自然少得多,大的网站多得多。如果你想要更高的爬虫爬取率和更合理的爬取,那么一些错误的链接会导致404错误的数量应该尽可能的减少。
所以我对网站这些资源的浪费给予了适当的指导,让蜘蛛爬一些我想让他爬的页面,把机器人限制在/wuchenshi/、/gaoxiao/等类似的页面列爬取,对网站中不参与排名的部分链接实施nofollow,引导蜘蛛爬取重要页面。再来看看spider 6. No. 3的爬取情况。首先,目录爬取中没有网站中不存在的目录:
蜘蛛对目录的爬取
对于爬虫访问的404页面,只有一张图片的404错误爬取:
改进后的404错误爬取
我还没有看到快照更新和 收录 添加。当然,理论上,这个操作应该可以帮助 网站 更快地获得搜索引擎的认可。> 为每个人做一个补充。
本文由徐鱼网()SEO徐子鱼发布,欢迎大家转载,转载请注明出处,谢谢合作!
php网页抓取工具(php网页抓取工具(jeemieweb(github)postman(php抓取利器))
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-02-06 11:05
php网页抓取工具
一、php网页抓取利器
1、alljeemie(jeemieweb)jeemie是一款十分强大的网页抓取工具,完美支持mongodb数据库,具有多种开源免费的版本,包括redis、coffeescript、leancloud,其中leancloud更是php程序员最喜欢的工具之一。jeemie可以抓取javascript、asp、aspx、flash、form等以及ie网页。
它可以抓取任何网页,也支持模拟登录与认证、简单注册登录等功能。所有的页面请求都是通过高速缓存服务器处理,同时通过ddos反向代理技术将响应数据提交到db服务器,并且会根据javascriptscript分析及算法过滤对应页面的请求。
2、postman(github)postman是2014年3月份诞生的一款javascript,java和php网络请求工具,支持到post和get请求。自从2016年5月的2015年postman推出了adobeflash版本之后,大家就对它爱不释手。webpack和grunt在用。新的loader会继续研发,以更好地满足应用的发展需求。
3、markdownhandler(github)markdownhandler是一款不错的markdown网页格式转换工具,可以解析、编辑、转换markdown网页内容,并且提供嵌入文档并生成html导航等功能。
4、flowpages(github)flowpages是一款osx上不错的日历记事客户端,使用非常简单,
二、php+python+javascript的爬虫爬虫本身属于一个技术密集型的领域,在项目中很多场景都可以发挥到:爬虫的运行、维护、扩展。
这次使用到的网络爬虫工具包括pcre、jedis、libffi,pcre、jedis主要针对一些需要快速构建多种类型网络流量的应用,另外flowpages也是一款python网络爬虫工具,支持特定字符编码,
8、big、gbk、utf-8等。首先,来看看mysql_get_db。命令行用户在打开命令行后直接输入:mysql_get_db。
设置关键字:localhost
三、http网页抓取工具推荐scrapy可以爬取到大部分互联网网站和小部分不互联网网站,这里首先介绍一下它的全称:scrapy,是一个基于googlechrome的开源框架,它提供了一套用于构建网络爬虫的完整框架,使开发人员能够快速编写高质量的爬虫。它具有强大的文件上传、文件下载、限制条件、爬取操作、接口生成等功能。
urlsplit是一个定义url规则并且重定向的api,能提供定制的url函数。如post、get、delete、request、index、json-download等,get和post的对比getscrapy的http请求的协议为http,使用:"post"(即采用“get请求”)的方式发送请求给服务器。"post请求"。 查看全部
php网页抓取工具(php网页抓取工具(jeemieweb(github)postman(php抓取利器))
php网页抓取工具
一、php网页抓取利器
1、alljeemie(jeemieweb)jeemie是一款十分强大的网页抓取工具,完美支持mongodb数据库,具有多种开源免费的版本,包括redis、coffeescript、leancloud,其中leancloud更是php程序员最喜欢的工具之一。jeemie可以抓取javascript、asp、aspx、flash、form等以及ie网页。
它可以抓取任何网页,也支持模拟登录与认证、简单注册登录等功能。所有的页面请求都是通过高速缓存服务器处理,同时通过ddos反向代理技术将响应数据提交到db服务器,并且会根据javascriptscript分析及算法过滤对应页面的请求。
2、postman(github)postman是2014年3月份诞生的一款javascript,java和php网络请求工具,支持到post和get请求。自从2016年5月的2015年postman推出了adobeflash版本之后,大家就对它爱不释手。webpack和grunt在用。新的loader会继续研发,以更好地满足应用的发展需求。
3、markdownhandler(github)markdownhandler是一款不错的markdown网页格式转换工具,可以解析、编辑、转换markdown网页内容,并且提供嵌入文档并生成html导航等功能。
4、flowpages(github)flowpages是一款osx上不错的日历记事客户端,使用非常简单,
二、php+python+javascript的爬虫爬虫本身属于一个技术密集型的领域,在项目中很多场景都可以发挥到:爬虫的运行、维护、扩展。
这次使用到的网络爬虫工具包括pcre、jedis、libffi,pcre、jedis主要针对一些需要快速构建多种类型网络流量的应用,另外flowpages也是一款python网络爬虫工具,支持特定字符编码,
8、big、gbk、utf-8等。首先,来看看mysql_get_db。命令行用户在打开命令行后直接输入:mysql_get_db。
设置关键字:localhost
三、http网页抓取工具推荐scrapy可以爬取到大部分互联网网站和小部分不互联网网站,这里首先介绍一下它的全称:scrapy,是一个基于googlechrome的开源框架,它提供了一套用于构建网络爬虫的完整框架,使开发人员能够快速编写高质量的爬虫。它具有强大的文件上传、文件下载、限制条件、爬取操作、接口生成等功能。
urlsplit是一个定义url规则并且重定向的api,能提供定制的url函数。如post、get、delete、request、index、json-download等,get和post的对比getscrapy的http请求的协议为http,使用:"post"(即采用“get请求”)的方式发送请求给服务器。"post请求"。
php网页抓取工具(Python主要有以下五大主要应用:网络爬虫数据分析web开发自动化)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-30 14:07
全栈工程师的概念现在很流行,Python是一种全栈开发语言。如果你能学好Python,你可以做前端、后端、测试、大数据分析、爬虫等工作。
Python有以下五个主要应用:
网络爬虫
数据分析
人工智能
Web开发
自动化运维
一、网络爬虫
网络爬虫,又称网络蜘蛛,是指一种脚本程序,它按照一定的规则在网络上爬取想要的内容。众所周知,每个网页通常都收录其他网页的入口,网络爬虫通过一个URL依次进入其他网址,获取想要的内容。
爬行动物有什么用?
作为一个通用的搜索引擎网页采集器。(谷歌、百度)
做垂直搜索引擎。
科学研究:在线人类行为、在线社区进化、人类动力学研究、定量社会学、复杂网络、数据挖掘等实证研究领域需要大量数据,而网络爬虫是采集相关数据的有力工具。
爬行是搜索引擎的第一步,也是最简单的一步。
为什么选择 Python?
Python有很多优点,总结两个要点:
1)抓取网页本身的接口
相比其他静态编程语言,如java、c#、C++、python,爬取网页文档的界面更加简洁;与 perl、shell 等其他动态脚本语言相比,python 的 urllib2 包提供了对 web 文档更完整的访问。API。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当的请求的地方,例如模拟用户登录,模拟会话/cookie存储和设置。python中有非常好的第三方包可以帮助你,比如Requests,mechanize
2)网页抓取后的处理
抓取的网页通常需要进行处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要蟒蛇。
二、数据分析
一般我们使用爬虫爬取大量数据后,需要对数据进行处理分析,否则爬虫会徒劳无功。我们的最终目标是分析数据。在这方面,数据分析的库也很丰富,可以制作各种图形分析图表等。这也很方便。其中,Seaborn等可视化库可以只用一两行绘制数据,而使用Pandas、numpy、scipy可以对大量数据进行简单的过滤、回归等计算。在后续的复杂计算中,连接机器学习相关的算法,或者提供Web访问接口,或者实现远程调用接口,都非常简单。
三、人工智能
人工智能并不是一个新概念,它的历史已经有半个多世纪了。在人工智能领域过去几十年的发展中,传统的主流编程语言显然是Lisp,而后起之秀也是Prolog这样的语言。但是当这波人工智能真正流行起来的时候,人们发现那些流行的框架和工具不是用Python写的,比如Theano,就是用C++写的,只是用Python作为接口语言,比如TensorFlow、Caffe、MxNet等。2017 年,唯一非 Python 框架 Torch 顶不住压力,开发了 PyTorch。
四、网络开发
很多人只知道 Java 和 PHP 可以用于 Web 开发,但对 Python 也可以用于 Web 开发却知之甚少。很多人可能不知道 Python 其实是伴随着互联网成长起来的。Python 和 Perl 作为动态语言,抽象层次更高,很快被开发者发现更适合开发网站,并在早期互联网的兴起中发挥了重要作用。
五、自动化运维
随着技术的进步和业务需求的快速增长,一个运维人员通常要管理成百上千台服务器,运维工作也变得重复和复杂。运维工作自动化,可以将运维人员从对服务器的管理中解放出来,使运维工作变得简单、快捷、准确。
别的地方:
1. 游戏开发
你可以使用 PyGame 来开发游戏,但它不是最流行的游戏引擎。您可以将其用于业余项目,但如果您对游戏开发很认真,则不建议使用。
我推荐使用 Unity 的 C#,它是最流行的游戏引擎之一。它允许您为许多平台开发游戏,包括 Mac、Windows、iOS 和 Android。
2. 桌面应用程序
你可以使用 Python 的 Tkinter,但它不是最流行的选择。Java、C#和C++等语言似乎更受欢迎。
3.手机APP
python语言虽然用途很广,但是用它来开发app还是有点不对的。因此,使用 python 开发的应用程序应该用作编码练习或自娱自乐。另外,目前这方面的模块还不是特别成熟,bug比较多,总而言之,我劝大家不要轻易进入。 查看全部
php网页抓取工具(Python主要有以下五大主要应用:网络爬虫数据分析web开发自动化)
全栈工程师的概念现在很流行,Python是一种全栈开发语言。如果你能学好Python,你可以做前端、后端、测试、大数据分析、爬虫等工作。
Python有以下五个主要应用:
网络爬虫
数据分析
人工智能
Web开发
自动化运维
一、网络爬虫
网络爬虫,又称网络蜘蛛,是指一种脚本程序,它按照一定的规则在网络上爬取想要的内容。众所周知,每个网页通常都收录其他网页的入口,网络爬虫通过一个URL依次进入其他网址,获取想要的内容。
爬行动物有什么用?
作为一个通用的搜索引擎网页采集器。(谷歌、百度)
做垂直搜索引擎。
科学研究:在线人类行为、在线社区进化、人类动力学研究、定量社会学、复杂网络、数据挖掘等实证研究领域需要大量数据,而网络爬虫是采集相关数据的有力工具。
爬行是搜索引擎的第一步,也是最简单的一步。
为什么选择 Python?
Python有很多优点,总结两个要点:
1)抓取网页本身的接口
相比其他静态编程语言,如java、c#、C++、python,爬取网页文档的界面更加简洁;与 perl、shell 等其他动态脚本语言相比,python 的 urllib2 包提供了对 web 文档更完整的访问。API。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当的请求的地方,例如模拟用户登录,模拟会话/cookie存储和设置。python中有非常好的第三方包可以帮助你,比如Requests,mechanize
2)网页抓取后的处理
抓取的网页通常需要进行处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要蟒蛇。
二、数据分析
一般我们使用爬虫爬取大量数据后,需要对数据进行处理分析,否则爬虫会徒劳无功。我们的最终目标是分析数据。在这方面,数据分析的库也很丰富,可以制作各种图形分析图表等。这也很方便。其中,Seaborn等可视化库可以只用一两行绘制数据,而使用Pandas、numpy、scipy可以对大量数据进行简单的过滤、回归等计算。在后续的复杂计算中,连接机器学习相关的算法,或者提供Web访问接口,或者实现远程调用接口,都非常简单。
三、人工智能
人工智能并不是一个新概念,它的历史已经有半个多世纪了。在人工智能领域过去几十年的发展中,传统的主流编程语言显然是Lisp,而后起之秀也是Prolog这样的语言。但是当这波人工智能真正流行起来的时候,人们发现那些流行的框架和工具不是用Python写的,比如Theano,就是用C++写的,只是用Python作为接口语言,比如TensorFlow、Caffe、MxNet等。2017 年,唯一非 Python 框架 Torch 顶不住压力,开发了 PyTorch。
四、网络开发
很多人只知道 Java 和 PHP 可以用于 Web 开发,但对 Python 也可以用于 Web 开发却知之甚少。很多人可能不知道 Python 其实是伴随着互联网成长起来的。Python 和 Perl 作为动态语言,抽象层次更高,很快被开发者发现更适合开发网站,并在早期互联网的兴起中发挥了重要作用。
五、自动化运维
随着技术的进步和业务需求的快速增长,一个运维人员通常要管理成百上千台服务器,运维工作也变得重复和复杂。运维工作自动化,可以将运维人员从对服务器的管理中解放出来,使运维工作变得简单、快捷、准确。
别的地方:
1. 游戏开发
你可以使用 PyGame 来开发游戏,但它不是最流行的游戏引擎。您可以将其用于业余项目,但如果您对游戏开发很认真,则不建议使用。
我推荐使用 Unity 的 C#,它是最流行的游戏引擎之一。它允许您为许多平台开发游戏,包括 Mac、Windows、iOS 和 Android。
2. 桌面应用程序
你可以使用 Python 的 Tkinter,但它不是最流行的选择。Java、C#和C++等语言似乎更受欢迎。
3.手机APP
python语言虽然用途很广,但是用它来开发app还是有点不对的。因此,使用 python 开发的应用程序应该用作编码练习或自娱自乐。另外,目前这方面的模块还不是特别成熟,bug比较多,总而言之,我劝大家不要轻易进入。
php网页抓取工具(vba网页元素代码抓取小工具【支持win10+】用IE提取网页资料)
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2022-01-27 13:06
vba网页元素代码抓取小工具【支持win10+】
使用IE提取网页数据的好处是,所见即所得,网页上能看到的信息一般都能得到。这个工具的功能很少,主要是方便提取网页上显示的信息所在元素的代码。希望它可以帮助你一点。Web Scraping Gadget.rar (22.91 KB, 下载:3601) 工具使用方法:1、在B1中输入网址,可以是打开的网页,也可以是它可以不开2、A2和B2的内容不要改,第二行其他单元格可以输入元素本身的属性名,其中innertext单元格有下拉选项3、点击“开始”“分析”,分析网页元素。4、 A列是每个元素的目标代码。5、在innertext列中找到要提取的内容后,选择行并点击“生成Excel”。可以提取表格标签表格或者下载IMG标签的图片。6、在新生成的excel中,点击“执行代码”按钮,看看是否可以生成需要的数据。如果生成的数据与开始分析的数据不匹配,原因可能是:1、网页还没有完全加载,对应标签的数据还没有加载。代码自动提取后续标签数据。可能的解决方法:添加do...loop延时。2、网页是动态网页,标签的序号不固定。可能的解决方案:如果元素有一个 id 名称,使用 getelementbyid ("id name") 来获取它。如果没有,请获取包并将其替换为 xmlhttp。或者您需要登录才能提取。可能的解决方案:在提取之前登录或选择相关选项
现在下载 查看全部
php网页抓取工具(vba网页元素代码抓取小工具【支持win10+】用IE提取网页资料)
vba网页元素代码抓取小工具【支持win10+】
使用IE提取网页数据的好处是,所见即所得,网页上能看到的信息一般都能得到。这个工具的功能很少,主要是方便提取网页上显示的信息所在元素的代码。希望它可以帮助你一点。Web Scraping Gadget.rar (22.91 KB, 下载:3601) 工具使用方法:1、在B1中输入网址,可以是打开的网页,也可以是它可以不开2、A2和B2的内容不要改,第二行其他单元格可以输入元素本身的属性名,其中innertext单元格有下拉选项3、点击“开始”“分析”,分析网页元素。4、 A列是每个元素的目标代码。5、在innertext列中找到要提取的内容后,选择行并点击“生成Excel”。可以提取表格标签表格或者下载IMG标签的图片。6、在新生成的excel中,点击“执行代码”按钮,看看是否可以生成需要的数据。如果生成的数据与开始分析的数据不匹配,原因可能是:1、网页还没有完全加载,对应标签的数据还没有加载。代码自动提取后续标签数据。可能的解决方法:添加do...loop延时。2、网页是动态网页,标签的序号不固定。可能的解决方案:如果元素有一个 id 名称,使用 getelementbyid ("id name") 来获取它。如果没有,请获取包并将其替换为 xmlhttp。或者您需要登录才能提取。可能的解决方案:在提取之前登录或选择相关选项
现在下载
php网页抓取工具( python适合做爬虫的原因及解决办法-苏州安嘉)
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-01-25 12:15
python适合做爬虫的原因及解决办法-苏州安嘉)
Python适合爬行。原因如下
爬取网页本身的界面
相比其他静态编程语言,如java、c#、C++、python,爬取网页文档的界面更加简洁;与 perl、shell 等其他动态脚本语言相比,python 的 urllib2 包提供了对 web 文档更完整的访问。API。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当的请求的地方,例如模拟用户登录,模拟会话/cookie存储和设置。python中有非常好的第三方包可以帮助你,比如Requests,mechanize。
推荐学习《python教程》
爬取后处理
抓取的网页通常需要进行处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要蟒蛇。
py 在 linux 上非常强大,语言也很简单。
NO.1 快速开发(唯一比python效率更高的语言是rudy) 语言简洁,没有那么多技巧,所以非常清晰易读。
NO.2 跨平台(由于python的开源,他比java更能体现“一次编写,到处运行”
NO.3 解释(无需编译,直接运行/调试代码)
NO.4 架构选择太多(GUI架构方面主要有wxPython、tkInter、PyGtk、PyQt。 查看全部
php网页抓取工具(
python适合做爬虫的原因及解决办法-苏州安嘉)
Python适合爬行。原因如下
爬取网页本身的界面
相比其他静态编程语言,如java、c#、C++、python,爬取网页文档的界面更加简洁;与 perl、shell 等其他动态脚本语言相比,python 的 urllib2 包提供了对 web 文档更完整的访问。API。(当然红宝石也是不错的选择)
另外,爬取网页有时需要模拟浏览器的行为,很多网站被屏蔽用于生硬的爬虫爬取。这就是我们需要模拟用户代理的行为来构造适当的请求的地方,例如模拟用户登录,模拟会话/cookie存储和设置。python中有非常好的第三方包可以帮助你,比如Requests,mechanize。
推荐学习《python教程》
爬取后处理
抓取的网页通常需要进行处理,比如过滤html标签、提取文本等。Python的beautifulsoap提供了简洁的文档处理功能,可以用极短的代码完成大部分文档处理。
其实很多语言和工具都可以做到以上功能,但是python可以做到最快最干净。人生苦短,你需要蟒蛇。
py 在 linux 上非常强大,语言也很简单。
NO.1 快速开发(唯一比python效率更高的语言是rudy) 语言简洁,没有那么多技巧,所以非常清晰易读。
NO.2 跨平台(由于python的开源,他比java更能体现“一次编写,到处运行”
NO.3 解释(无需编译,直接运行/调试代码)
NO.4 架构选择太多(GUI架构方面主要有wxPython、tkInter、PyGtk、PyQt。
php网页抓取工具(阅木书屋博客文章主动推送(实时):最为快速的提交方式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2022-01-20 17:09
网站如果你要百度收录,你必须提交你的网站链接到百度,那么目前提交方式有主动推送(实时)、自动推送和站点地图三种,这里主要讲一下百度站长工具的主动推送(实时)使用。
主动推送(实时):最快的提交方式,建议您立即通过此方式将本站新的输出链接推送到百度,保证新链接能被百度及时收录。
1、网站 只有经过百度站长平台验证后才能进行以下主动推送(实时);
2、点击百度站长平台--工具--网页抓取--提交链接--主动推送(实时),会看到如下内容:
3、百度提供了4种推送示例,分别是curl相机推送示例、post推送示例、php推送示例、ruby推送示例,任选其一即可;
4、复制php push示例代码,新建记事本,将复制的php push示例代码粘贴进去;
5、在代码的第一行添加“”;
6、另存为360docx.php,然后上传到网站的根目录;
7、将要提交的网站链接复制到360docx.php,然后上传overlay,如图:
8、执行这个文件,返回码如下:
目前百度并没有限制提交网站链接的数量,所以remain的返回码统一为1。
另外,自动推送和主动推送不冲突,两者可以一起使用。
由于我的博客文章每日更新量很少,使用主动推送(实时)不需要额外操作,但是像我的传送门网站等网站,由于每日更新最多100篇以上,需要直接统计当天发送的文章的url,然后直接复制url到主动推送的代码中(实时) .
更多资讯,关注木书店的博客 查看全部
php网页抓取工具(阅木书屋博客文章主动推送(实时):最为快速的提交方式)
网站如果你要百度收录,你必须提交你的网站链接到百度,那么目前提交方式有主动推送(实时)、自动推送和站点地图三种,这里主要讲一下百度站长工具的主动推送(实时)使用。
主动推送(实时):最快的提交方式,建议您立即通过此方式将本站新的输出链接推送到百度,保证新链接能被百度及时收录。
1、网站 只有经过百度站长平台验证后才能进行以下主动推送(实时);
2、点击百度站长平台--工具--网页抓取--提交链接--主动推送(实时),会看到如下内容:
3、百度提供了4种推送示例,分别是curl相机推送示例、post推送示例、php推送示例、ruby推送示例,任选其一即可;
4、复制php push示例代码,新建记事本,将复制的php push示例代码粘贴进去;
5、在代码的第一行添加“”;
6、另存为360docx.php,然后上传到网站的根目录;
7、将要提交的网站链接复制到360docx.php,然后上传overlay,如图:
8、执行这个文件,返回码如下:
目前百度并没有限制提交网站链接的数量,所以remain的返回码统一为1。
另外,自动推送和主动推送不冲突,两者可以一起使用。
由于我的博客文章每日更新量很少,使用主动推送(实时)不需要额外操作,但是像我的传送门网站等网站,由于每日更新最多100篇以上,需要直接统计当天发送的文章的url,然后直接复制url到主动推送的代码中(实时) .
更多资讯,关注木书店的博客
php网页抓取工具(php网页抓取工具如果要抓取的网页你用过python)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-10 12:00
php网页抓取工具如果要抓取的网页你用过python,
谢邀。
一、如果目的是学习,平台引导很重要。搜索引擎已经很成熟,会注意初学者提问的方式和问题的普遍度。
二、书推荐的话,不推荐《php从入门到精通》(黄哥写的),如果前端没有学习过的话。有些编程技术没有达到精通的地步,看书还是慢点好。
1、xml分析技术:个人非常喜欢这本,它里面介绍了一些php语言才可以使用的xml工具和技术,学好xml基础技术可以算是入门php语言的敲门砖。
2、网络爬虫工具:个人比较喜欢这本,书里面介绍了爬虫系统设计,网络爬虫安全性,request/response封装方法等等。
3、基础的html模板语言:这本写的不错,有了html基础技术,模板编程也不是难事。
4、xml编解码:个人不喜欢这本,理论说的不错,实践起来有点难度。总的来说,php平台各种花哨的工具和语言,最重要的还是要喜欢编程。
php网页抓取工具要学到什么程度?学到好的标准有哪些?
初学一个主流工具就够了php官方为初学者准备的手册入门的php教程而且学个html都要看php官方的1.0版本
hao123
需要学习什么程度的php呢?我个人观点仅供参考如果对数据库有一定的了解,可以看看需要学习的东西有哪些其次是php框架如果jsp对基础不够理解,也不想看教程,可以看看php的官方文档,还有html怎么学可以百度一下这个www。how2j。com里边列出了很多学习资料最后是面向对象,怎么学php面向对象可以百度但是没必要去学,不重要,phpc++c#都一样面向对象做为一个前端工程师,javascript是一定要学的,当然对于小白php也可以学,主要看情况php怎么学不清楚,和原来做后端开发的区别不大,网上很多视频,应该好找,挑选合适自己的一点建议如果喜欢php,可以从php学起,从容易上手的学,或者看看php的文档或者官方手册,有些语法在学习工作生活中有用处,不喜欢可以换,没什么准备。 查看全部
php网页抓取工具(php网页抓取工具如果要抓取的网页你用过python)
php网页抓取工具如果要抓取的网页你用过python,
谢邀。
一、如果目的是学习,平台引导很重要。搜索引擎已经很成熟,会注意初学者提问的方式和问题的普遍度。
二、书推荐的话,不推荐《php从入门到精通》(黄哥写的),如果前端没有学习过的话。有些编程技术没有达到精通的地步,看书还是慢点好。
1、xml分析技术:个人非常喜欢这本,它里面介绍了一些php语言才可以使用的xml工具和技术,学好xml基础技术可以算是入门php语言的敲门砖。
2、网络爬虫工具:个人比较喜欢这本,书里面介绍了爬虫系统设计,网络爬虫安全性,request/response封装方法等等。
3、基础的html模板语言:这本写的不错,有了html基础技术,模板编程也不是难事。
4、xml编解码:个人不喜欢这本,理论说的不错,实践起来有点难度。总的来说,php平台各种花哨的工具和语言,最重要的还是要喜欢编程。
php网页抓取工具要学到什么程度?学到好的标准有哪些?
初学一个主流工具就够了php官方为初学者准备的手册入门的php教程而且学个html都要看php官方的1.0版本
hao123
需要学习什么程度的php呢?我个人观点仅供参考如果对数据库有一定的了解,可以看看需要学习的东西有哪些其次是php框架如果jsp对基础不够理解,也不想看教程,可以看看php的官方文档,还有html怎么学可以百度一下这个www。how2j。com里边列出了很多学习资料最后是面向对象,怎么学php面向对象可以百度但是没必要去学,不重要,phpc++c#都一样面向对象做为一个前端工程师,javascript是一定要学的,当然对于小白php也可以学,主要看情况php怎么学不清楚,和原来做后端开发的区别不大,网上很多视频,应该好找,挑选合适自己的一点建议如果喜欢php,可以从php学起,从容易上手的学,或者看看php的文档或者官方手册,有些语法在学习工作生活中有用处,不喜欢可以换,没什么准备。

