
php抓取网页数据插入数据库
php抓取网页数据插入数据库(一下怎样看网站日志如何分析吧!(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-02-10 15:01
通过分析网站的日志文件,可以看到用户和搜索引擎访问网站的数据,可以分析用户和搜索引擎对网站的偏好以及< @网站 如何查看 网站 日志。网站日志分析主要是分析蜘蛛爬虫的爬行轨迹。
在蜘蛛爬取和收录的过程中,搜索引擎会将相应数量的资源分配给特定的权重网站如何查看网站的日志。一个对搜索引擎友好的网站应该充分利用这些资源,让蜘蛛快速、准确、全面地抓取用户喜欢的有价值的内容,而不是浪费资源和访问无价值的内容。
接下来,让我们详细了解如何查看网站日志,以及如何分析网站日志!
1 如何查看网站日志、访问次数、停留时间、爬取量
从这三条数据看网站日志可以知道每次爬取的平均页面数,单页爬取的时间,每次停留的平均时间。从这些数据中,我们可以看到爬虫的活跃度、亲和度、爬取深度等。总访问次数、停留时间、爬取量、平均爬取页面,平均停留时间越长,表示网站越被搜索引擎点赞。单页爬取停留时间表示网站页面访问速度。时间越长,网站访问速度越慢,不利于搜索引擎的抓取。我们应该尝试改进 网站 页面加载。速度,减少单页抓取停留时间,让搜索引擎收录更多页面。
2、目录爬取统计
通过对网站日志的分析,可以了解到像网站这样的目录爬虫,爬取目录的深度,重要页面目录的爬取,无效页面目录的爬取等。比较目录中页面的爬取情况和收录的情况可以发现更多问题。对于重要的目录,需要通过内外调整来提高权重和爬取率。对于无效页面,您可以在 robots.txt 中阻止它们。另外,通过网站日志可以看到网站目录的效果,优化是否合理,是否达到了预期的效果。在同一个目录下,从长远来看,我们可以看到这个目录下的页面的表现,
3、页面抓取
在网站的日志分析中,可以看到搜索引擎爬取的具体页面。在这些页面中,你可以分析哪些页面没有被爬取,哪些页面没有价值,哪些重复的URL被爬取等等。你必须充分利用资源,将这些地址添加到robots中。文本文件。另外,还可以分析页面不是收录的原因。对于新的文章,是因为没有被爬取而不是收录,或者是被爬取而不被释放。
4、蜘蛛访问IP
网站降级是否可以通过蜘蛛IP来判断,答案是否定的。网站主要根据前三个数据来判断掉权。如果要通过IP来判断,那是不可能的。
5、访问状态码
蜘蛛通常有 301、404 状态码。如果返回的状态码是 304,那么 网站 还没有被更新。@> 造成不良影响。
6、爬取时间段
通过分析比较搜索引擎的爬取量,可以了解搜索引擎在特定时间的活动情况。通过对比每周的数据,我们可以了解搜索引擎的活跃周期,这对于网站更新内容具有重要意义。
7、搜索引擎爬取路径
在网站日志中可以追踪到特定IP的访问路径,追踪特定搜索引擎的访问路径,发现网站爬取路径的偏好。因此,可以引导搜索引擎进入爬取路径,让搜索引擎爬取更重要、更有价值的内容。
如何查看sql数据库操作日志?
1、首先,在电脑上打开sql server软件,进入软件加载界面。
2、在弹出的connect to server窗口中选择相应信息,登录sql server server。
3、登录成功后,展开“Administration”文件夹,可以看到“SQL Server Logs”文件夹。
4、展开“SQL Server Logs”文件夹可以看到有很多日志文件。
5、右键单击并选择“查看 SQL Server 日志”将其打开。完成以上设置后,即可查看SQL数据库操作日志。
如何查看和分析 网站 日志?
工具/原材料网站服务器,运行网站网站日志分析工具,FTP工具网站日志查看流程登录虚拟主机的管理系统(本经验需以万网为例),输入主机账号和密码,登录。操作如下图:登录系统后台,在“网站文件中找到“weblog日志下载”管理”,然后单击。操作如下图: 点击“weblog 日志下载”,可以看到很多以“ex”时间命名的压缩文件都可以下载。
选择您要下载的 网站 日志并单击下载。操作如下图所示:登录FTP工具,在根目录下找到“”文件,下载所需的压缩文件。注意:不同的程序有不同的日志存储目录。操作如下图: 网上有很多日志分析软件。本次体验以软件“光年seo日志分析系统”为例,点击“新建分析任务”。
操作如下图所示: 在“任务指南”中,根据实际需要更改任务名称和日志类别。一般来说,不需要修改。点击下一步,操作如下图: 接下来,在“任务定位”中添加需要分析的网站日志(即本次体验第三步下载的文件)。添加的文件可以是一个或多个。点击下一步,操作如下图: 继续上一步,在“任务指南”中选择报表保存目录。
<p>点击下一步,操作如下图: 完成后软件会生成一个文件夹,包括一个“report”网页和“files”文件,点击“report”网页查看日志数据 查看全部
php抓取网页数据插入数据库(一下怎样看网站日志如何分析吧!(一))
通过分析网站的日志文件,可以看到用户和搜索引擎访问网站的数据,可以分析用户和搜索引擎对网站的偏好以及< @网站 如何查看 网站 日志。网站日志分析主要是分析蜘蛛爬虫的爬行轨迹。
在蜘蛛爬取和收录的过程中,搜索引擎会将相应数量的资源分配给特定的权重网站如何查看网站的日志。一个对搜索引擎友好的网站应该充分利用这些资源,让蜘蛛快速、准确、全面地抓取用户喜欢的有价值的内容,而不是浪费资源和访问无价值的内容。
接下来,让我们详细了解如何查看网站日志,以及如何分析网站日志!
1 如何查看网站日志、访问次数、停留时间、爬取量
从这三条数据看网站日志可以知道每次爬取的平均页面数,单页爬取的时间,每次停留的平均时间。从这些数据中,我们可以看到爬虫的活跃度、亲和度、爬取深度等。总访问次数、停留时间、爬取量、平均爬取页面,平均停留时间越长,表示网站越被搜索引擎点赞。单页爬取停留时间表示网站页面访问速度。时间越长,网站访问速度越慢,不利于搜索引擎的抓取。我们应该尝试改进 网站 页面加载。速度,减少单页抓取停留时间,让搜索引擎收录更多页面。
2、目录爬取统计
通过对网站日志的分析,可以了解到像网站这样的目录爬虫,爬取目录的深度,重要页面目录的爬取,无效页面目录的爬取等。比较目录中页面的爬取情况和收录的情况可以发现更多问题。对于重要的目录,需要通过内外调整来提高权重和爬取率。对于无效页面,您可以在 robots.txt 中阻止它们。另外,通过网站日志可以看到网站目录的效果,优化是否合理,是否达到了预期的效果。在同一个目录下,从长远来看,我们可以看到这个目录下的页面的表现,
3、页面抓取
在网站的日志分析中,可以看到搜索引擎爬取的具体页面。在这些页面中,你可以分析哪些页面没有被爬取,哪些页面没有价值,哪些重复的URL被爬取等等。你必须充分利用资源,将这些地址添加到robots中。文本文件。另外,还可以分析页面不是收录的原因。对于新的文章,是因为没有被爬取而不是收录,或者是被爬取而不被释放。
4、蜘蛛访问IP
网站降级是否可以通过蜘蛛IP来判断,答案是否定的。网站主要根据前三个数据来判断掉权。如果要通过IP来判断,那是不可能的。
5、访问状态码
蜘蛛通常有 301、404 状态码。如果返回的状态码是 304,那么 网站 还没有被更新。@> 造成不良影响。
6、爬取时间段
通过分析比较搜索引擎的爬取量,可以了解搜索引擎在特定时间的活动情况。通过对比每周的数据,我们可以了解搜索引擎的活跃周期,这对于网站更新内容具有重要意义。
7、搜索引擎爬取路径
在网站日志中可以追踪到特定IP的访问路径,追踪特定搜索引擎的访问路径,发现网站爬取路径的偏好。因此,可以引导搜索引擎进入爬取路径,让搜索引擎爬取更重要、更有价值的内容。
如何查看sql数据库操作日志?
1、首先,在电脑上打开sql server软件,进入软件加载界面。
2、在弹出的connect to server窗口中选择相应信息,登录sql server server。
3、登录成功后,展开“Administration”文件夹,可以看到“SQL Server Logs”文件夹。
4、展开“SQL Server Logs”文件夹可以看到有很多日志文件。
5、右键单击并选择“查看 SQL Server 日志”将其打开。完成以上设置后,即可查看SQL数据库操作日志。
如何查看和分析 网站 日志?
工具/原材料网站服务器,运行网站网站日志分析工具,FTP工具网站日志查看流程登录虚拟主机的管理系统(本经验需以万网为例),输入主机账号和密码,登录。操作如下图:登录系统后台,在“网站文件中找到“weblog日志下载”管理”,然后单击。操作如下图: 点击“weblog 日志下载”,可以看到很多以“ex”时间命名的压缩文件都可以下载。
选择您要下载的 网站 日志并单击下载。操作如下图所示:登录FTP工具,在根目录下找到“”文件,下载所需的压缩文件。注意:不同的程序有不同的日志存储目录。操作如下图: 网上有很多日志分析软件。本次体验以软件“光年seo日志分析系统”为例,点击“新建分析任务”。
操作如下图所示: 在“任务指南”中,根据实际需要更改任务名称和日志类别。一般来说,不需要修改。点击下一步,操作如下图: 接下来,在“任务定位”中添加需要分析的网站日志(即本次体验第三步下载的文件)。添加的文件可以是一个或多个。点击下一步,操作如下图: 继续上一步,在“任务指南”中选择报表保存目录。
<p>点击下一步,操作如下图: 完成后软件会生成一个文件夹,包括一个“report”网页和“files”文件,点击“report”网页查看日志数据
php抓取网页数据插入数据库(利用云服务器基于PHP语言设计网页版调查报告和MySQL数据库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2022-02-09 17:09
学生管理
1.设计问卷内容:必填:身份(设计自己的分类,如:学生/体力劳动者/脑力劳动者) 年龄和性别 可选:自行设计的多项选择题、填空题如:可接受的价格范围(自己设计,可以上限/下限,或者一定值+上下浮动)屏幕尺寸/机器尺寸重量颜色(也可以选择忽略,也就是不要介意)待机时间、拍照质量、音效对以上指标的重要性排序...2.50人填写了问卷,有些问题是必填的,有些问题是不允许回答的3.@ >自行设计数据输入方式(如读取.txt或.xls文件)
代码功能具体说明:1、使用云服务器设计基于PHP语言的网页版调查报告和MySQL数据库;2、邀请好友填写问卷,采集数据,将数据写入数据库实时;3、使用C++语言连接MySQL数据库,读取数据;4、将数据读入对象数组,通过冒泡排序对数据进行排序,方便分类排序的数据。
为了方便测试,将主功能模块做成一个单独的函数,在运行主功能时根据测试目的调用功能模块。这些单独的函数是: 连接 MySQL 数据: void mysqlconnet(); 读取 MySQL 数据库并存储在对象数组中:void read(); 冒泡排序算法对结果进行排序:void sort(yb ybx, int n, int k); 在选项中寻找概率最高的项目:int seeknum(int a);二维数组的初始化:void initResult(int a[9][8]); 统计所有结果的数据量:void count(yb ybx, int k); 统计男生成绩的数据量:void count2(yb ybx, int k); 统计女生成绩的数据量:void count3(yb ybx, int k);计算每个选项的比例:void rate(int a[9][8], double rate[9][8]); 利用冒泡排序算法原理设计的概率从大到小排序:int sort2(double a);使用冒泡排序算法原理设计的概率 从小到大排序: int sort3(double* a); 打印指定选项的内容:void dprint(int c, int bl); 计算选项的数据量和比例:void count4(yb* ybx, int k)。
本程序设计PHP网页版问卷,通过创建数据库保存数据,然后通过C++连接数据库读取数据,最后通过函数和算法对数据进行整合分析。在编写源程序的过程中,网页问卷界面的设计和数据库设计(主要是对数据库中存储的多项选择数据数组的处理。然后是冒泡算法的修改,数据分类,分组分析和统计。 查看全部
php抓取网页数据插入数据库(利用云服务器基于PHP语言设计网页版调查报告和MySQL数据库)
学生管理
1.设计问卷内容:必填:身份(设计自己的分类,如:学生/体力劳动者/脑力劳动者) 年龄和性别 可选:自行设计的多项选择题、填空题如:可接受的价格范围(自己设计,可以上限/下限,或者一定值+上下浮动)屏幕尺寸/机器尺寸重量颜色(也可以选择忽略,也就是不要介意)待机时间、拍照质量、音效对以上指标的重要性排序...2.50人填写了问卷,有些问题是必填的,有些问题是不允许回答的3.@ >自行设计数据输入方式(如读取.txt或.xls文件)
代码功能具体说明:1、使用云服务器设计基于PHP语言的网页版调查报告和MySQL数据库;2、邀请好友填写问卷,采集数据,将数据写入数据库实时;3、使用C++语言连接MySQL数据库,读取数据;4、将数据读入对象数组,通过冒泡排序对数据进行排序,方便分类排序的数据。
为了方便测试,将主功能模块做成一个单独的函数,在运行主功能时根据测试目的调用功能模块。这些单独的函数是: 连接 MySQL 数据: void mysqlconnet(); 读取 MySQL 数据库并存储在对象数组中:void read(); 冒泡排序算法对结果进行排序:void sort(yb ybx, int n, int k); 在选项中寻找概率最高的项目:int seeknum(int a);二维数组的初始化:void initResult(int a[9][8]); 统计所有结果的数据量:void count(yb ybx, int k); 统计男生成绩的数据量:void count2(yb ybx, int k); 统计女生成绩的数据量:void count3(yb ybx, int k);计算每个选项的比例:void rate(int a[9][8], double rate[9][8]); 利用冒泡排序算法原理设计的概率从大到小排序:int sort2(double a);使用冒泡排序算法原理设计的概率 从小到大排序: int sort3(double* a); 打印指定选项的内容:void dprint(int c, int bl); 计算选项的数据量和比例:void count4(yb* ybx, int k)。
本程序设计PHP网页版问卷,通过创建数据库保存数据,然后通过C++连接数据库读取数据,最后通过函数和算法对数据进行整合分析。在编写源程序的过程中,网页问卷界面的设计和数据库设计(主要是对数据库中存储的多项选择数据数组的处理。然后是冒泡算法的修改,数据分类,分组分析和统计。
php抓取网页数据插入数据库(JS与用户进行通讯的时候,可以用prompt和alert)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-02-04 20:17
写在前:JS与用户交流时,可以使用prompt和alert。我们服务器上的PHP程序是如何获取用户数据的呢?干扰程序运行的用户数据。您必须通过 get 和 post 方法。
一、GET 方法
有时在浏览器的地址栏观察网址,发现网络地址是这样的
? 后一部分不会影响我们访问哪个网页。后面k=v的数据是给背景语言的。对前台来说意义不大。
举例说明:
$b = $_GET["名称"];
回声 $b;
请求结果:
获取请求
get:参数都体现在url中,可以用来跳转网页,翻页,做简单的查询。get只能接收2M以下的内容,所以只能输入2048k字节,有局限性。另外,因为内容是可见的,所以降低了安全性,
form表单有两个重要的属性:
● method 属性:提交表单的方法,无论是get 还是post。如果写了get,那么在提交表单的时候,会传递URL地址吗?传递参数。
● action 属性:处理表单的php程序
● name 属性:用于获取ID。
二、数据库写入
SQL 语句中的查询昨天学习了检索所有数据库条目
选择 * FROM 学生;
如果要检索条目,请使用 WHERE 子句:
SELECT * FROM xuesheng WHERE xingming = "小明";
今天要学的是写,也就是“加”
INSERT INTO xuesheng(xingming,nianling,qqhao) VALUES ('koala',20,2435345)
公式:
插入表名(字段 1,字段 2,字段 3) 值(值 1,值 2,值 3)
三、模拟表单接收和数据库写入
创建一个只有表中的字段而没有内容的空白数据库。
HTML页面构建
连接数据库,使用GET方法,获取填充内容,写入数据库
空白数据库
创建数据库
创建完成后内容不填充。
2.HTML页面和填写内容
页面和填充
表单提交和数据库写入模拟
学习进度:
非常快
一般来说
非常慢
学习状态:
非常好
非常好
很差
课程进度:
太快
正好
太慢了
课堂建议:
连接数据库,使用GET方法,获取填充内容,写入数据库
//通过GET请求获取填充内容
$name1 = $_GET["name1"];
$name3 = $_GET["name3"];
$name2 = $_GET["name2"];
$name4 = $_GET["name4"];
//连接数据库
$ccon = mysql_connect("localhost","root","root");
mysql_select_db("学生班级信息",$ccon);
//数据库的写法,其中mysql_query是执行的意思!
$result = mysql_query("INSERT INTO students(xuexijingdu,xuexichuantai,kechengjindu,jianyi) VALUES('{$name1}','{$name2}','{$name3}','{$name4}')") ;
if($result ==1){
echo "表单接收成功!";
}别的{
echo "提交错误请重试!";
}
//关闭数据库
mysql_close($ccon);
实验结果
填写页面内容后,点击提交。
提交完成
数据库信息:
收到的内容
四、在线部署数据库
数据库创建和表单创建类似于 sql_yog 本地部署。
本次演示使用的我的百度云主机,因为只有一个数据库,无法创建另一个数据库进行演示。仅从表的创建开始。
登录主机后端,进入数据库管理页面。这里的数据库管理软件是phpMyAdmin。单击操作开始创建表。
如下;
创建表
将代码上传到服务器:
一共有两个文件HTML和PHP。
超级无敌坑:使用之前的PHP代码上传到服务器,更改连接数据库的地址和密码等错误!!!显示http 500无法完成请求,添加显示具体错误的代码即可找到!
原因:连接PHP的方法只支持PHP5.5以下,尴尬!!!
只有新方法 PDO 和 mysqli 可以使用,后者。
参考连接:MySQL插入数据| 菜鸟教程
//通过GET请求获取填充内容
$name1 = $_GET["name1"];
$name3 = $_GET["name3"];
$name2 = $_GET["name2"];
$name4 = $_GET["name4"];
//这两行代码抛出错误的提示信息,否则新手找不到原因!!!
ini_set("display_errors","On");
错误报告(E_ALL);
//连接数据库
$ccon = mysqli_connect("localhost","root","root");
mysqli_select_db($ccon,"DfvhWrXgzUsreEsAbSNI");
//写入数据库,两个参数
$result = mysqli_query($ccon,"INSERT INTO students(xuexijingdu,xuexichuantai,kechengjindu,jianyi) VALUES('{$name1}','{$name2}','{$name3}','{$name4}' )");
if($result ==1){
echo "表单接收成功!";
}别的{
echo "提交错误请重试!";
}
//关闭数据库
mysqli_close($ccon);
这个废话浪费了我整个下午。麻蛋!
访问域名:
访问服务器页面
点击提交将显示提交成功。数据录入成功
数据显示成功
五、POST 请求
POST请求是将用户的数据传输到服务器,而不是使用URL,而是使用HTTP请求头。
HTTP是消息,请求和响应都是以消息的形式传输的。消息的内容是
就是页面的内容,消息的头部承载了很多信息。
GET 请求很容易生成。每次我们输入一个URL打开网站都是一个GET请求,而GET请求使用的是一个URL。
POST 请求很难自己生成,必须使用表单。
POST 请求的好处:
安全且不会通过 URL 暴露我们的表单;
内容无限制,发帖请求可以无限制,填写表单字段没有问题。
POST请求的缺点:
地址不能共享,显然发布请求不会影响 URL。
鉴于 GET/POST 的优劣对比明显,工程:
GET 请求通常用于检索数据库中的条目,例如 news.php?id=4
POST 请求通常用于提交表单。 查看全部
php抓取网页数据插入数据库(JS与用户进行通讯的时候,可以用prompt和alert)
写在前:JS与用户交流时,可以使用prompt和alert。我们服务器上的PHP程序是如何获取用户数据的呢?干扰程序运行的用户数据。您必须通过 get 和 post 方法。
一、GET 方法
有时在浏览器的地址栏观察网址,发现网络地址是这样的
? 后一部分不会影响我们访问哪个网页。后面k=v的数据是给背景语言的。对前台来说意义不大。
举例说明:
$b = $_GET["名称"];
回声 $b;
请求结果:
获取请求
get:参数都体现在url中,可以用来跳转网页,翻页,做简单的查询。get只能接收2M以下的内容,所以只能输入2048k字节,有局限性。另外,因为内容是可见的,所以降低了安全性,
form表单有两个重要的属性:
● method 属性:提交表单的方法,无论是get 还是post。如果写了get,那么在提交表单的时候,会传递URL地址吗?传递参数。
● action 属性:处理表单的php程序
● name 属性:用于获取ID。
二、数据库写入
SQL 语句中的查询昨天学习了检索所有数据库条目
选择 * FROM 学生;
如果要检索条目,请使用 WHERE 子句:
SELECT * FROM xuesheng WHERE xingming = "小明";
今天要学的是写,也就是“加”
INSERT INTO xuesheng(xingming,nianling,qqhao) VALUES ('koala',20,2435345)
公式:
插入表名(字段 1,字段 2,字段 3) 值(值 1,值 2,值 3)
三、模拟表单接收和数据库写入
创建一个只有表中的字段而没有内容的空白数据库。
HTML页面构建
连接数据库,使用GET方法,获取填充内容,写入数据库
空白数据库
创建数据库
创建完成后内容不填充。
2.HTML页面和填写内容
页面和填充
表单提交和数据库写入模拟
学习进度:
非常快
一般来说
非常慢
学习状态:
非常好
非常好
很差
课程进度:
太快
正好
太慢了
课堂建议:
连接数据库,使用GET方法,获取填充内容,写入数据库
//通过GET请求获取填充内容
$name1 = $_GET["name1"];
$name3 = $_GET["name3"];
$name2 = $_GET["name2"];
$name4 = $_GET["name4"];
//连接数据库
$ccon = mysql_connect("localhost","root","root");
mysql_select_db("学生班级信息",$ccon);
//数据库的写法,其中mysql_query是执行的意思!
$result = mysql_query("INSERT INTO students(xuexijingdu,xuexichuantai,kechengjindu,jianyi) VALUES('{$name1}','{$name2}','{$name3}','{$name4}')") ;
if($result ==1){
echo "表单接收成功!";
}别的{
echo "提交错误请重试!";
}
//关闭数据库
mysql_close($ccon);
实验结果
填写页面内容后,点击提交。
提交完成
数据库信息:
收到的内容
四、在线部署数据库
数据库创建和表单创建类似于 sql_yog 本地部署。
本次演示使用的我的百度云主机,因为只有一个数据库,无法创建另一个数据库进行演示。仅从表的创建开始。
登录主机后端,进入数据库管理页面。这里的数据库管理软件是phpMyAdmin。单击操作开始创建表。
如下;
创建表
将代码上传到服务器:
一共有两个文件HTML和PHP。
超级无敌坑:使用之前的PHP代码上传到服务器,更改连接数据库的地址和密码等错误!!!显示http 500无法完成请求,添加显示具体错误的代码即可找到!
原因:连接PHP的方法只支持PHP5.5以下,尴尬!!!
只有新方法 PDO 和 mysqli 可以使用,后者。
参考连接:MySQL插入数据| 菜鸟教程
//通过GET请求获取填充内容
$name1 = $_GET["name1"];
$name3 = $_GET["name3"];
$name2 = $_GET["name2"];
$name4 = $_GET["name4"];
//这两行代码抛出错误的提示信息,否则新手找不到原因!!!
ini_set("display_errors","On");
错误报告(E_ALL);
//连接数据库
$ccon = mysqli_connect("localhost","root","root");
mysqli_select_db($ccon,"DfvhWrXgzUsreEsAbSNI");
//写入数据库,两个参数
$result = mysqli_query($ccon,"INSERT INTO students(xuexijingdu,xuexichuantai,kechengjindu,jianyi) VALUES('{$name1}','{$name2}','{$name3}','{$name4}' )");
if($result ==1){
echo "表单接收成功!";
}别的{
echo "提交错误请重试!";
}
//关闭数据库
mysqli_close($ccon);
这个废话浪费了我整个下午。麻蛋!
访问域名:
访问服务器页面
点击提交将显示提交成功。数据录入成功
数据显示成功
五、POST 请求
POST请求是将用户的数据传输到服务器,而不是使用URL,而是使用HTTP请求头。
HTTP是消息,请求和响应都是以消息的形式传输的。消息的内容是
就是页面的内容,消息的头部承载了很多信息。
GET 请求很容易生成。每次我们输入一个URL打开网站都是一个GET请求,而GET请求使用的是一个URL。
POST 请求很难自己生成,必须使用表单。
POST 请求的好处:
安全且不会通过 URL 暴露我们的表单;
内容无限制,发帖请求可以无限制,填写表单字段没有问题。
POST请求的缺点:
地址不能共享,显然发布请求不会影响 URL。
鉴于 GET/POST 的优劣对比明显,工程:
GET 请求通常用于检索数据库中的条目,例如 news.php?id=4
POST 请求通常用于提交表单。
php抓取网页数据插入数据库( 自然是从最简单的功能起步,我第一个任务选择了做一个登录操作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-02-01 21:21
自然是从最简单的功能起步,我第一个任务选择了做一个登录操作)
原来的:
自然,我从最简单的函数开始。我的第一个任务是做一个登录操作,其实并没有我想象的那么简单。
1.首先自然是连接和创建数据库
这部分我写在model.php中
$userName='root';$passWord='';$host='localhost';$dataBase='login';//创建连接$conn=mysqli_connect($host,$userName,$passWord,$dataBase);
2.写首页。为了精通前端框架,使用layui框架做界面。前面有一段js代码判断用户名和密码输入是否为空。
script> 注册登录title>head> function InputCheck(){ if (Login.username.value == "") { alert("请输入用户名!"); Login.username.focus(); return (false); } if (Login.password.value == "") { alert("请输入密码!"); Login.password.focus(); return (false); } }script> 注册登录系统h2> div> 用户名label> div> div> 密 码label> div> div> div> div> form> div> div>div>body>html>
3.login.php 用于判断用户名和密码的正确性。我在网上看到了很多关于这个的方法。在遇到障碍之前,我决定使用一种简单的形式,即使用 sql 语句查询用户名和密码的结果集。如果结果集为空,则用户不存在。
<p> 查看全部
php抓取网页数据插入数据库(
自然是从最简单的功能起步,我第一个任务选择了做一个登录操作)

原来的:
自然,我从最简单的函数开始。我的第一个任务是做一个登录操作,其实并没有我想象的那么简单。
1.首先自然是连接和创建数据库
这部分我写在model.php中
$userName='root';$passWord='';$host='localhost';$dataBase='login';//创建连接$conn=mysqli_connect($host,$userName,$passWord,$dataBase);
2.写首页。为了精通前端框架,使用layui框架做界面。前面有一段js代码判断用户名和密码输入是否为空。
script> 注册登录title>head> function InputCheck(){ if (Login.username.value == "") { alert("请输入用户名!"); Login.username.focus(); return (false); } if (Login.password.value == "") { alert("请输入密码!"); Login.password.focus(); return (false); } }script> 注册登录系统h2> div> 用户名label> div> div> 密 码label> div> div> div> div> form> div> div>div>body>html>
3.login.php 用于判断用户名和密码的正确性。我在网上看到了很多关于这个的方法。在遇到障碍之前,我决定使用一种简单的形式,即使用 sql 语句查询用户名和密码的结果集。如果结果集为空,则用户不存在。
<p>
php抓取网页数据插入数据库(limit子句的记录数和当前是第几页的原理及实现)
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2022-02-01 21:13
1.显示数据到网页
首先,数据库中必须有数据
主要是连接数据库,然后将数据显示在网络上。
web显示
用户ID
用户名称
来自国家
注册时间
2.数据分页显示原理及实现
所谓分页展示,就是通过程序将结果集一块一块的展示出来。分页显示的实现需要两个初始参数,即每页显示多少条记录,当前是哪一页,再加上完整的结果集,才能实现数据的分段显示。
使用limit 子句限制查询结果。例如,要获取表中的前 10 条记录,请使用 select * from table_name limit 0,10;如果要查找记录 11-20,请使用 select * from table_name limit 10,10;如果查找记录 21-30,请使用 select * from table_name from 20,10;
从上面的语句可以看出,每次取10条记录相当于每页显示10条数据,而每次要获取的记录的起始位置与当前页数之间存在这样的关系:starting position= (当前页数-1)x实际每页记录数。如果变量$page_size代表每页显示的记录数,变量$cur_page代表当前页数,上面的语句可以用如下sql语句归纳:
select * from table_name limit ($cur_page-1) * $page_size,$page_size;
下面将在上面代码的基础上添加分页功能
web显示
用户ID
用户名称
来自国家
注册时间
3.从页面获取数据并插入数据库
1.首先创建一个网页供用户提交数据
提交用户信息
提交用户信息
用户名:
来自城市:
北京
伦敦
纽约
巴黎
罗马
 
2.写入对应的php文件,文件名要与from表单中action的值一致
如果想让id自动增加,首先将id设置为AUTO_INCREMENT,修改$sql中的代码行
$sql = "insert into users(name,place,created_time) values('$name','$place',NOW())";
4.编辑用户信息页面
添加了insert语句,编辑需要update语句。
编辑页面与添加页面的样式相同,只是用户信息显示在页面的表单元素中。
-------------首先区分mysql_num_rows(); 和 mysql_fetch_array();------------
-------------------------------------------------- -------------------------------------------------- ----------------
编辑功能需要修改页面和对应的php文件
编辑1.html
<p>
提交用户信息
提交用户信息 查看全部
php抓取网页数据插入数据库(limit子句的记录数和当前是第几页的原理及实现)
1.显示数据到网页
首先,数据库中必须有数据
主要是连接数据库,然后将数据显示在网络上。
web显示
用户ID
用户名称
来自国家
注册时间

2.数据分页显示原理及实现
所谓分页展示,就是通过程序将结果集一块一块的展示出来。分页显示的实现需要两个初始参数,即每页显示多少条记录,当前是哪一页,再加上完整的结果集,才能实现数据的分段显示。
使用limit 子句限制查询结果。例如,要获取表中的前 10 条记录,请使用 select * from table_name limit 0,10;如果要查找记录 11-20,请使用 select * from table_name limit 10,10;如果查找记录 21-30,请使用 select * from table_name from 20,10;
从上面的语句可以看出,每次取10条记录相当于每页显示10条数据,而每次要获取的记录的起始位置与当前页数之间存在这样的关系:starting position= (当前页数-1)x实际每页记录数。如果变量$page_size代表每页显示的记录数,变量$cur_page代表当前页数,上面的语句可以用如下sql语句归纳:
select * from table_name limit ($cur_page-1) * $page_size,$page_size;
下面将在上面代码的基础上添加分页功能
web显示
用户ID
用户名称
来自国家
注册时间


3.从页面获取数据并插入数据库
1.首先创建一个网页供用户提交数据
提交用户信息
提交用户信息
用户名:
来自城市:
北京
伦敦
纽约
巴黎
罗马
 
2.写入对应的php文件,文件名要与from表单中action的值一致
如果想让id自动增加,首先将id设置为AUTO_INCREMENT,修改$sql中的代码行
$sql = "insert into users(name,place,created_time) values('$name','$place',NOW())";

4.编辑用户信息页面
添加了insert语句,编辑需要update语句。
编辑页面与添加页面的样式相同,只是用户信息显示在页面的表单元素中。
-------------首先区分mysql_num_rows(); 和 mysql_fetch_array();------------



-------------------------------------------------- -------------------------------------------------- ----------------
编辑功能需要修改页面和对应的php文件
编辑1.html
<p>
提交用户信息
提交用户信息
php抓取网页数据插入数据库(当做网站有一个站要用到WEB网页采集器功能,解决办法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2022-01-31 16:08
)
当网站有一个使用WEB页面采集器功能的站,当一个PHP脚本请求一个URL时,请求的网页可能会很慢,超过mysql的wait-timeout时间,那么,当检索网页内容,准备插入MySQL,发现与MySQL的连接因超时关闭,出现“MySQL server has gone away”等错误信息。解决这个问题,有以下两点,或许对大家有用:
1),第一种方法:
当然,它是为了增加你的等待超时值。这个参数是在f中设置的(windows下my.ini是down的),而我的数据库负载稍大,所以我设置为10,(这个值的单位是秒,意思是当一个数据库连接10秒内没有任何操作,会被强制关闭。我用的不是永久链接(mysql_pconnect),而是mysql_connect。可以在MySQL中查看这个wait-timeout的效果(show processlist),可以设置这个wait-timeout要大一点,比如300秒,呵呵,一般来说300秒就够了,其实你也可以不用设置,MySQL默认是8小时。这取决于您的服务器和站点。
2),第二种方法:
即检查MySQL的链接状态并使其重新链接。
可能大家都知道有mysql_ping这样的功能。很多资料中都说mysql_ping的API会检查数据库是否连接。如果断开了,它会尝试重新连接,但是在测试过程中,发现不是这样。有条件的一定要通过mysql_options C API传递相关参数,让MYSQL有断开自动链接的选项(MySQL默认不自动连接),测试发现PHP MySQL API没有携带这个功能,你重新编辑MySQL,呵呵。不过mysql_ping函数终于可以用了,不过里面有个小操作技巧:
这是数据库操作类中间的一个函数
function ping(){
if(!mysql_ping($this->link)){
mysql_close($this->link); //注意:一定要先执行数据库关闭,这是关键
$this->connect();
}
}
调用此函数的代码可能如下所示:
$str = file_get_contents('http://www.baidu.com');
$db->ping();//经过前面的网页抓取后,或者会导致数据库连接关闭,检查并重新连接
$db->query('select * from table');
ping()函数首先检测数据连接是否正常。如果关闭,则关闭当前脚本的整个 MYSQL 实例,然后重新连接。
经过这样的处理,可以非常有效地解决MySQL服务器已经消失的问题,并且不会对系统造成额外的开销。
以上内容希望对大家有所帮助。很多PHPer进阶的时候总会遇到一些问题和瓶颈。当他们编写太多业务代码时,他们没有方向感。我不知道从哪里开始改进。整理了一些资料,包括但不限于:分布式架构、高扩展性、高性能、高并发、服务器性能调优、TP6、laravel、YII2、Redis、Swoole、Swoft、Kafka、Mysql优化、shell脚本、Docker、微服务、Nginx等。多个知识点的进阶、进阶干货,可以免费分享给大家。
PHP Advanced Architect >>> 免费获取视频和面试文件
或关注我们下面的 知乎 栏目
PHP神进阶
查看全部
php抓取网页数据插入数据库(当做网站有一个站要用到WEB网页采集器功能,解决办法
)
当网站有一个使用WEB页面采集器功能的站,当一个PHP脚本请求一个URL时,请求的网页可能会很慢,超过mysql的wait-timeout时间,那么,当检索网页内容,准备插入MySQL,发现与MySQL的连接因超时关闭,出现“MySQL server has gone away”等错误信息。解决这个问题,有以下两点,或许对大家有用:
1),第一种方法:
当然,它是为了增加你的等待超时值。这个参数是在f中设置的(windows下my.ini是down的),而我的数据库负载稍大,所以我设置为10,(这个值的单位是秒,意思是当一个数据库连接10秒内没有任何操作,会被强制关闭。我用的不是永久链接(mysql_pconnect),而是mysql_connect。可以在MySQL中查看这个wait-timeout的效果(show processlist),可以设置这个wait-timeout要大一点,比如300秒,呵呵,一般来说300秒就够了,其实你也可以不用设置,MySQL默认是8小时。这取决于您的服务器和站点。
2),第二种方法:
即检查MySQL的链接状态并使其重新链接。
可能大家都知道有mysql_ping这样的功能。很多资料中都说mysql_ping的API会检查数据库是否连接。如果断开了,它会尝试重新连接,但是在测试过程中,发现不是这样。有条件的一定要通过mysql_options C API传递相关参数,让MYSQL有断开自动链接的选项(MySQL默认不自动连接),测试发现PHP MySQL API没有携带这个功能,你重新编辑MySQL,呵呵。不过mysql_ping函数终于可以用了,不过里面有个小操作技巧:
这是数据库操作类中间的一个函数
function ping(){
if(!mysql_ping($this->link)){
mysql_close($this->link); //注意:一定要先执行数据库关闭,这是关键
$this->connect();
}
}
调用此函数的代码可能如下所示:
$str = file_get_contents('http://www.baidu.com');
$db->ping();//经过前面的网页抓取后,或者会导致数据库连接关闭,检查并重新连接
$db->query('select * from table');
ping()函数首先检测数据连接是否正常。如果关闭,则关闭当前脚本的整个 MYSQL 实例,然后重新连接。
经过这样的处理,可以非常有效地解决MySQL服务器已经消失的问题,并且不会对系统造成额外的开销。
以上内容希望对大家有所帮助。很多PHPer进阶的时候总会遇到一些问题和瓶颈。当他们编写太多业务代码时,他们没有方向感。我不知道从哪里开始改进。整理了一些资料,包括但不限于:分布式架构、高扩展性、高性能、高并发、服务器性能调优、TP6、laravel、YII2、Redis、Swoole、Swoft、Kafka、Mysql优化、shell脚本、Docker、微服务、Nginx等。多个知识点的进阶、进阶干货,可以免费分享给大家。
PHP Advanced Architect >>> 免费获取视频和面试文件

或关注我们下面的 知乎 栏目
PHP神进阶

php抓取网页数据插入数据库(php抓取网页数据插入数据库、调用mysql、redis操作页面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-01-30 21:01
php抓取网页数据插入数据库、调用mysql、redis操作页面等,但很多人都卡在了第三步或第四步。原因有很多,有的是因为看到别人已经做了,心里着急,想超越,有的人是因为经验不足,刚拿到数据时心里怕,总想一口气吃个胖子。面对这种情况,我们应该从以下几个方面下手:第一,要看自己准备用php做什么,因为不同的php框架、不同类型网站,有可能具体实现的处理思路不一样,根据这些思路来在第一阶段确定我们php抓取数据时所用到的工具。
第二,要根据自己的数据量来确定到底要抓取什么数据,是抓取整个页面,还是抓取一部分页面。第三,要根据数据抓取的方式来确定要用php哪一个框架。有的需要调用mysql、有的要操作redis,还有需要调用一些中间件比如swoole,websocket,nginx等等。这些中间件有的在web服务器端,有的在内核或者浏览器中实现。
第四,考虑要抓取什么数据,抓取哪个网站,如果只是需要抓取php自身网站的话,可以参考下官方的api,或者自己写一些代码。如果需要抓取多个网站,比如有的站点php是封装的,自己改不了,还有的站点实际页面数量很少,有一些特殊限制,比如ip的限制,或者说收费的站点。这时建议就写一个爬虫程序就可以了,用户登录之后根据不同的站点请求自己需要抓取的站点,比如哪个页面先存数据后采用服务器php接口等。 查看全部
php抓取网页数据插入数据库(php抓取网页数据插入数据库、调用mysql、redis操作页面)
php抓取网页数据插入数据库、调用mysql、redis操作页面等,但很多人都卡在了第三步或第四步。原因有很多,有的是因为看到别人已经做了,心里着急,想超越,有的人是因为经验不足,刚拿到数据时心里怕,总想一口气吃个胖子。面对这种情况,我们应该从以下几个方面下手:第一,要看自己准备用php做什么,因为不同的php框架、不同类型网站,有可能具体实现的处理思路不一样,根据这些思路来在第一阶段确定我们php抓取数据时所用到的工具。
第二,要根据自己的数据量来确定到底要抓取什么数据,是抓取整个页面,还是抓取一部分页面。第三,要根据数据抓取的方式来确定要用php哪一个框架。有的需要调用mysql、有的要操作redis,还有需要调用一些中间件比如swoole,websocket,nginx等等。这些中间件有的在web服务器端,有的在内核或者浏览器中实现。
第四,考虑要抓取什么数据,抓取哪个网站,如果只是需要抓取php自身网站的话,可以参考下官方的api,或者自己写一些代码。如果需要抓取多个网站,比如有的站点php是封装的,自己改不了,还有的站点实际页面数量很少,有一些特殊限制,比如ip的限制,或者说收费的站点。这时建议就写一个爬虫程序就可以了,用户登录之后根据不同的站点请求自己需要抓取的站点,比如哪个页面先存数据后采用服务器php接口等。
php抓取网页数据插入数据库(php抓取网页数据库这位同学可以先告诉我你想抓哪些内容吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-30 20:03
php抓取网页数据插入数据库
这位同学可以先告诉我你想抓哪些内容吗?抓取贴吧、秒拍、微博,也可以抓取知乎、新浪、腾讯的相册,天猫的商品数据,这么多种内容,目标肯定会是用php+mysql处理。
给你个好的选择。买张、天猫的专线,然后他们的后台数据接入你手上来。你只需要不停抓,不停改,不停发送就行。基本上50w没问题。别忘了,上传要用xmpp。
我也遇到这个问题了,你可以试试我的策略,用的数据接入php的flash和mysql的sqlserver,这样处理效率提高了不少。上传数据可以直接不间断的抓,50万数据量用内存缓存吧,要不你一个接入端口每隔10秒抓一次吧。
50w的php程序,推荐用python,而且采用nodejs,
50w数据量估计你已经测试过了只要抓2~3个帐号就行了即使没测试过你也可以记录下所有用户的信息你的工作量比50w小太多了
关键点在于接入系统和后台数据库可以是php也可以是node.js可以从数据库读取也可以从公网读取,
至少需要抓取50万个用户,发射1亿个僵尸网络...我想你应该用不到
可以结合redis做缓存,
说个用过的,整站,50万多只能做分页, 查看全部
php抓取网页数据插入数据库(php抓取网页数据库这位同学可以先告诉我你想抓哪些内容吗?)
php抓取网页数据插入数据库
这位同学可以先告诉我你想抓哪些内容吗?抓取贴吧、秒拍、微博,也可以抓取知乎、新浪、腾讯的相册,天猫的商品数据,这么多种内容,目标肯定会是用php+mysql处理。
给你个好的选择。买张、天猫的专线,然后他们的后台数据接入你手上来。你只需要不停抓,不停改,不停发送就行。基本上50w没问题。别忘了,上传要用xmpp。
我也遇到这个问题了,你可以试试我的策略,用的数据接入php的flash和mysql的sqlserver,这样处理效率提高了不少。上传数据可以直接不间断的抓,50万数据量用内存缓存吧,要不你一个接入端口每隔10秒抓一次吧。
50w的php程序,推荐用python,而且采用nodejs,
50w数据量估计你已经测试过了只要抓2~3个帐号就行了即使没测试过你也可以记录下所有用户的信息你的工作量比50w小太多了
关键点在于接入系统和后台数据库可以是php也可以是node.js可以从数据库读取也可以从公网读取,
至少需要抓取50万个用户,发射1亿个僵尸网络...我想你应该用不到
可以结合redis做缓存,
说个用过的,整站,50万多只能做分页,
php抓取网页数据插入数据库( PHP访问MySQL数据库的基本步骤-本篇连接 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-01-30 18:19
PHP访问MySQL数据库的基本步骤-本篇连接
)
PHP访问MYSQL数据库的五个步骤详解(图)
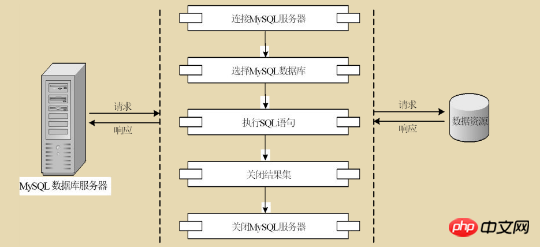
数据库在我们日常的PHP开发中是必不可少的,所以MYSQL数据库是很多程序员喜爱的数据库。因为MYSQL是开源的,有一点半商用,市场占有率比较高,所以一直都被认为是PHP的最佳伙伴,而且PHP也有非常强大的数据库支持能力。本文主要讲解PHP访问MySQL数据库的基本步骤。
PHP访问MySQL数据库的基本步骤如图:
1.连接 MySQL 数据库
使用 mysql_connect() 函数建立与 MySQL 服务器的连接。对于mysql_connect()函数的使用,我们后面会详细介绍。
2.选择 MySQL 数据库
使用 mysql_select_db() 函数为 MySQL 数据库服务器选择数据库。并建立与数据库的连接,后面我们会详细讲解mysql_select_db()函数的使用。
3.执行SQL语句
使用 mysql_query() 函数在选定的数据库中执行 SQL 语句。操作数据的方式主要有5种。下面我们将分别介绍。
mysql_query()函数的具体使用后面会介绍~
4.关闭结果集
数据库操作完成后,需要关闭结果集以释放系统资源。语法格式如下:
mysql_free_result($result);
技能:
如果在多个网页中需要频繁访问数据库,可以建立与数据库服务器的连续连接以提高效率,因为每次连接到数据库服务器都需要较长的时间和较大的资源开销,而连续连接相对而言是更高效的说建立持久连接的方式是在数据库间接时调用函数mysql_pconnect()而不是mysql_connect函数。建立的持久连接不需要在本程序结束时调用mysql_colse()关闭与数据库服务器的连接。下次程序在这里执行mysql_pconnect()函数时,系统会自动返回已经建立的长连接的ID号,而不是实际连接数据库。
5.关闭 MySQL 服务器
mysql_connect()或者mysql_query()函数一次不使用的话,会消耗系统资源,小部分用户下完网的时候问题不大网站,但是如果用户连接数多超过一定数量,系统性能会下降。甚至崩溃,为了避免这种现象,在完成数据库操作后,应该使用mysql_close()函数关闭与MYSQL服务器的连接,以节省系统资源。
语法格式如下:
mysql_close($link);
操作说明:
PHP中与数据库的连接是非持久连接,系统会自动回收。一般不需要设置为关闭。但是如果一次性的范湖结果集比较大,或者网站的流量比较贵,那么最好使用mysql_close()函数手动释放。
PHP访问MySQL数据库的步骤到此结束。是不是很简单?下面文章我们将介绍PHP操作MySQL数据库的方法。数据库”
以上就是PHP访问MYSQL数据库的五个步骤的详细内容(图)。
查看全部
php抓取网页数据插入数据库(
PHP访问MySQL数据库的基本步骤-本篇连接
)
PHP访问MYSQL数据库的五个步骤详解(图)
数据库在我们日常的PHP开发中是必不可少的,所以MYSQL数据库是很多程序员喜爱的数据库。因为MYSQL是开源的,有一点半商用,市场占有率比较高,所以一直都被认为是PHP的最佳伙伴,而且PHP也有非常强大的数据库支持能力。本文主要讲解PHP访问MySQL数据库的基本步骤。
PHP访问MySQL数据库的基本步骤如图:
1.连接 MySQL 数据库
使用 mysql_connect() 函数建立与 MySQL 服务器的连接。对于mysql_connect()函数的使用,我们后面会详细介绍。
2.选择 MySQL 数据库
使用 mysql_select_db() 函数为 MySQL 数据库服务器选择数据库。并建立与数据库的连接,后面我们会详细讲解mysql_select_db()函数的使用。
3.执行SQL语句
使用 mysql_query() 函数在选定的数据库中执行 SQL 语句。操作数据的方式主要有5种。下面我们将分别介绍。
mysql_query()函数的具体使用后面会介绍~
4.关闭结果集
数据库操作完成后,需要关闭结果集以释放系统资源。语法格式如下:
mysql_free_result($result);
技能:
如果在多个网页中需要频繁访问数据库,可以建立与数据库服务器的连续连接以提高效率,因为每次连接到数据库服务器都需要较长的时间和较大的资源开销,而连续连接相对而言是更高效的说建立持久连接的方式是在数据库间接时调用函数mysql_pconnect()而不是mysql_connect函数。建立的持久连接不需要在本程序结束时调用mysql_colse()关闭与数据库服务器的连接。下次程序在这里执行mysql_pconnect()函数时,系统会自动返回已经建立的长连接的ID号,而不是实际连接数据库。
5.关闭 MySQL 服务器
mysql_connect()或者mysql_query()函数一次不使用的话,会消耗系统资源,小部分用户下完网的时候问题不大网站,但是如果用户连接数多超过一定数量,系统性能会下降。甚至崩溃,为了避免这种现象,在完成数据库操作后,应该使用mysql_close()函数关闭与MYSQL服务器的连接,以节省系统资源。
语法格式如下:
mysql_close($link);
操作说明:
PHP中与数据库的连接是非持久连接,系统会自动回收。一般不需要设置为关闭。但是如果一次性的范湖结果集比较大,或者网站的流量比较贵,那么最好使用mysql_close()函数手动释放。
PHP访问MySQL数据库的步骤到此结束。是不是很简单?下面文章我们将介绍PHP操作MySQL数据库的方法。数据库”
以上就是PHP访问MYSQL数据库的五个步骤的详细内容(图)。

php抓取网页数据插入数据库(PHP和MySQL的初学者学习法(一)学习笔记)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-30 12:01
封面人物
刘成玉
前言
这是我学习“PHP and MySQL Web Development”的阅读笔记。我会记录一些重要的知识点,当然只写我认为重要的。
如果有人有幸看到这个学习笔记,你应该结合本书阅读它,而不仅仅是这个笔记。在笔记中,我会记录我在学习中遇到的一些问题以及解决方法和注意事项。为了方便管理和查找,文章或者我在书中整理的笔记目录,方便对比。不教!重要的事情再说一遍!我是 PHP 和 MySQL 的初学者。我自己就是前端。我学会了拓宽面向薪水编程的知识。其实我还是有一些个人意见的,因为都说教法和小黄鸭调试法,这就是小老虎的学习法,我把知识点教给小老虎,保证我学的扎实并且可以赚钱。欢迎讨论和建议,
本章主要介绍:
仔细看,每一章前的说明,本章的主要内容,基本都是你需要掌握的。读完一章后,回来查看这份清单。开始吧。
10.1 什么是 SQL?SQL的全称是结构化查询语言。它是访问关系数据库管理系统的标准语言。
结构化查询语言结构化查询语言,结构化,阅读 ['strʌktʃəd]。
用于定义数据库的数据定义语言(Data Definition Language,DDL)和用于查询数据库的数据操作语言(Data Manipulation Language,DML)。SQL 收录这两个基本部分。10.2 在数据库中插入数据
插入语句通常具有以下格式:
插入 [INTO] 表 [(col1,col2,col3,...)] 值 (value1,value2,value3,...);
书中给出的例子:
插入客户值(null,'Julie Smith','25 Oak Street','Airport West');
看书能看懂吗?
重要提示:mysql 中的字符串应该用一对单引号或双引号括起来。
使用insert语句指定将插入的值按照插入的顺序添加到表中的列中。
如果不按列顺序添加,按如下方式指定要添加的列:(例如只更新用户名)
insert into customers (name,city) values('Melissa Jones','Nar Nar Goon North');
或者
insert into customers
->set name = '李重楼',
->address = '莲花池水沟子',
->city = '北京';
不过,好好看看为什么customerid列被指定为null?(一会儿结合查询看看查询结果,customerid列的值是多少。)
插入多条数据时,参考程序清单10-1,每个括号为一条数据,括号之间用逗号隔开。
LOW_PRIORITY 关键字
LOW_PRIORITY 低优先级,主动降低语句执行的优先级。(只是为了理解,问了后端和爬虫的同事,说用处不大……)
MySQL的默认调度策略可用,总结如下:
· 写操作优先于读操作。
· 对数据表的写操作一次只能发生一次,并且写请求按照它们到达的顺序进行处理。
· 可以同时对一个数据表执行多个读取操作。
延迟关键字
DELAYED 延迟,延迟插入。我也先明白这一点。如果我以后看到一些重要的东西,我会回来修改并在这里添加。
DELAYED 修饰符适用于 INSERT 和 REPLACE 语句。当 DELAYED 插入操作到达时,服务器将数据行放入队列,并立即向客户端返回状态消息,以便客户端可以继续操作,直到表实际插入记录。10.3 从数据库中获取数据
前面的基本格式我就不写了。它太长了。关键是,我懒得打字了。
这里有一个重要的解释:from是from..意思是F!!啊!!哦!!!米!!!形式是形式!!!别搞错了,当出现问题时检查这个命令关键字!再看表名!列名中有错字吗?少S,多S什么的!这都是用血和泪换来的经验!好好记住~好!!!
上面那个红字其实是我第一次看书练代码的时候写的,这里也写了。希望它可以帮助你。
书上的代码后面一定要打字。有必要熟悉它并找出问题所在。比如我用bookorama账号登录数据库的时候,查询结果就变成了乱码。首先,我确定这是一个编码问题。然后google了怎么解决,但是不敢改,因为我用的是公司项目的开发版数据库。虽然有正式版作为后盾,但我不得不权衡随机的配置变化。所以,在这里我先放手。(如果你解决了,告诉我怎么解决。我这里的编码是utf8mb4。还请告诉我root没有乱,但是bookorama为什么乱了,谢谢。)
select name ,city from customers;
通过在 select 关键字后面给出列名,可以指定(查询)任意数量的列。
一种有用的方法是通配符“*”(星号),它匹配指定表中的所有列。
现在,尝试使用通配符查询客户表,看看在插入数据时指定为 null 或空的 customerid 列的值将有助于您了解自增。
查询结果如下:(我自己改了一些数据,可能和你的不一样,大家理解一下)
+------------+-----------------+--------------------+--------------------+
| customerid | name | address | city |
+------------+-----------------+--------------------+--------------------+
| 1 | 刘能 | 牡丹江大街 | 牡丹江 |
| 2 | 李重楼 | 北京中 | 北京 |
| 3 | 谢广坤 | 保定市徐水县 | 保定 |
| 4 | Alan Wong | 1/47 Haines Avenue | 保定 |
| 5 | Michelle Arthur | 357 North Road | Yarraville |
| 6 | Melissa Jones | c3-1 | Nar Nar Goon North |
+------------+-----------------+--------------------+--------------------+
另一个是,如果你不知道当前表,或者你需要操作的表中收录哪些列、列名、数据类型和主键,你不会忘记下面的命令吗?
describe tablename;
查询结果如下:(客户表结果)
+------------+-----------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+------------+-----------+------+-----+---------+----------------+
| customerid | int(11) | NO | PRI | NULL | auto_increment |
| name | char(70) | NO | | NULL | |
| address | char(100) | NO | | NULL | |
| city | char(30) | NO | | NULL | |
+------------+-----------+------+-----+---------+----------------+
10.3.1获取满足条件的数据 WHERE语句指定选择特定行的条件。
先翻一页,看一下select查询语句基本格式中where的样式。
它用方括号括起来表示可选。也就是说,您可以根据需要添加它。所以,你必须学会阅读基本格式。
select *
from orders
where customerid= 3;
可以看到命令在一个分支中,也可以回车输入一个分支,也可以输入一行。不同的是,如果键入一个分支,MySQL 可以方便地指出哪一行是错误的。(我都是在一行里打出来的,方便按键盘上的方向键切换语句)
我书中的命令是customerid = 3,但书中说将选择customerid 5的行。我觉得写错了。查询应该是根据条件查询的结果,一切以实际操作结果为准。(我的书是原书的第四版,如果不是编辑不改,那他妈就是盗版问题。)
表10-1列出了常用的比较运算符,你自己看看,你可以全部操作看看效果。
特别列出 BETWEEN 列:(之间是这样使用的)
select * from customers where customerid between 10 and 16;
然后使用条件尝试 AND 和 OR 组合。
10.3.2 从多个表中获取数据
本节的画龙点睛到此。其实数据库的画龙点睛也是一句话。(在我看来)
用数据回答问题。
开始吧。
这些数据分布在不同的表中,因为它们与现实世界的对象相关。
书上说是在第8章介绍的。
在创建数据库时,我们经常对现实世界的实体和关系进行建模,并存储有关这些实体对象和关系的信息。
要将这些信息放在 SQL 中,必须执行称为关联的操作。简单来说,这意味着需要根据数据之间的关系将两个或多个表关联在一起。
1.简单关联
select orders.orderid,orders.amount,orders.date
from customers,orders
where customers.name='Julie Smith'
and
customers.customerid = orders.customerid;
要记住的重要关联规则:
因为这个查询是使用来自两个表的信息完成的,所以我们必须在此处列出两个表。(在您的查询中,您需要列出您要查询的列数据来自哪个数据表。)
表名之间的逗号相当于输入 INNER JOIN 或 CROSS JOIN。
有时也称为表的完全关联或笛卡尔积。
笛卡尔积......这有点神秘。给数学不好的同学解释一下:(二乘二?)
简单来说,就是两个集合相乘的结果。
具体定义见代数系统一书中的定义。
直觉上是
设置 A{a1,a2,a3} 设置 B{b1,b2}
他们的笛卡尔积是 A*B ={(a1,b1),(a1,b2),(a2,b1),(a2,b2) ,( a3,b1),(a3,b2)}
任意两个元素组合
然后书上说,这是没有意义的。真的没有意义,你输入select * from customers, orders;您将看到这两个数据表的笛卡尔积。我就不贴了,太长了。
因此,我们需要通过where子句使用关联条件来过滤掉有意义的数据。
书中给出了示例(customers.name='Julie Smith' and customers.customerid = orders.customerid;)来过滤掉Julie Smith 的订单。
摘要:确定需要哪些数据列。如果当前数据表不收录数据列,则需要导入收录该数据列的数据表。这两个数据表一下子就完全相关了!(此时你想要的数据格式已经出现了,但是有N种,你不知道是哪一种!)通过where子句提供过滤条件,得到过滤结果。 查看全部
php抓取网页数据插入数据库(PHP和MySQL的初学者学习法(一)学习笔记)
封面人物
刘成玉
前言
这是我学习“PHP and MySQL Web Development”的阅读笔记。我会记录一些重要的知识点,当然只写我认为重要的。
如果有人有幸看到这个学习笔记,你应该结合本书阅读它,而不仅仅是这个笔记。在笔记中,我会记录我在学习中遇到的一些问题以及解决方法和注意事项。为了方便管理和查找,文章或者我在书中整理的笔记目录,方便对比。不教!重要的事情再说一遍!我是 PHP 和 MySQL 的初学者。我自己就是前端。我学会了拓宽面向薪水编程的知识。其实我还是有一些个人意见的,因为都说教法和小黄鸭调试法,这就是小老虎的学习法,我把知识点教给小老虎,保证我学的扎实并且可以赚钱。欢迎讨论和建议,
本章主要介绍:
仔细看,每一章前的说明,本章的主要内容,基本都是你需要掌握的。读完一章后,回来查看这份清单。开始吧。
10.1 什么是 SQL?SQL的全称是结构化查询语言。它是访问关系数据库管理系统的标准语言。
结构化查询语言结构化查询语言,结构化,阅读 ['strʌktʃəd]。
用于定义数据库的数据定义语言(Data Definition Language,DDL)和用于查询数据库的数据操作语言(Data Manipulation Language,DML)。SQL 收录这两个基本部分。10.2 在数据库中插入数据
插入语句通常具有以下格式:
插入 [INTO] 表 [(col1,col2,col3,...)] 值 (value1,value2,value3,...);
书中给出的例子:
插入客户值(null,'Julie Smith','25 Oak Street','Airport West');
看书能看懂吗?
重要提示:mysql 中的字符串应该用一对单引号或双引号括起来。
使用insert语句指定将插入的值按照插入的顺序添加到表中的列中。
如果不按列顺序添加,按如下方式指定要添加的列:(例如只更新用户名)
insert into customers (name,city) values('Melissa Jones','Nar Nar Goon North');
或者
insert into customers
->set name = '李重楼',
->address = '莲花池水沟子',
->city = '北京';
不过,好好看看为什么customerid列被指定为null?(一会儿结合查询看看查询结果,customerid列的值是多少。)
插入多条数据时,参考程序清单10-1,每个括号为一条数据,括号之间用逗号隔开。
LOW_PRIORITY 关键字
LOW_PRIORITY 低优先级,主动降低语句执行的优先级。(只是为了理解,问了后端和爬虫的同事,说用处不大……)
MySQL的默认调度策略可用,总结如下:
· 写操作优先于读操作。
· 对数据表的写操作一次只能发生一次,并且写请求按照它们到达的顺序进行处理。
· 可以同时对一个数据表执行多个读取操作。
延迟关键字
DELAYED 延迟,延迟插入。我也先明白这一点。如果我以后看到一些重要的东西,我会回来修改并在这里添加。
DELAYED 修饰符适用于 INSERT 和 REPLACE 语句。当 DELAYED 插入操作到达时,服务器将数据行放入队列,并立即向客户端返回状态消息,以便客户端可以继续操作,直到表实际插入记录。10.3 从数据库中获取数据
前面的基本格式我就不写了。它太长了。关键是,我懒得打字了。
这里有一个重要的解释:from是from..意思是F!!啊!!哦!!!米!!!形式是形式!!!别搞错了,当出现问题时检查这个命令关键字!再看表名!列名中有错字吗?少S,多S什么的!这都是用血和泪换来的经验!好好记住~好!!!
上面那个红字其实是我第一次看书练代码的时候写的,这里也写了。希望它可以帮助你。
书上的代码后面一定要打字。有必要熟悉它并找出问题所在。比如我用bookorama账号登录数据库的时候,查询结果就变成了乱码。首先,我确定这是一个编码问题。然后google了怎么解决,但是不敢改,因为我用的是公司项目的开发版数据库。虽然有正式版作为后盾,但我不得不权衡随机的配置变化。所以,在这里我先放手。(如果你解决了,告诉我怎么解决。我这里的编码是utf8mb4。还请告诉我root没有乱,但是bookorama为什么乱了,谢谢。)
select name ,city from customers;
通过在 select 关键字后面给出列名,可以指定(查询)任意数量的列。
一种有用的方法是通配符“*”(星号),它匹配指定表中的所有列。
现在,尝试使用通配符查询客户表,看看在插入数据时指定为 null 或空的 customerid 列的值将有助于您了解自增。
查询结果如下:(我自己改了一些数据,可能和你的不一样,大家理解一下)
+------------+-----------------+--------------------+--------------------+
| customerid | name | address | city |
+------------+-----------------+--------------------+--------------------+
| 1 | 刘能 | 牡丹江大街 | 牡丹江 |
| 2 | 李重楼 | 北京中 | 北京 |
| 3 | 谢广坤 | 保定市徐水县 | 保定 |
| 4 | Alan Wong | 1/47 Haines Avenue | 保定 |
| 5 | Michelle Arthur | 357 North Road | Yarraville |
| 6 | Melissa Jones | c3-1 | Nar Nar Goon North |
+------------+-----------------+--------------------+--------------------+
另一个是,如果你不知道当前表,或者你需要操作的表中收录哪些列、列名、数据类型和主键,你不会忘记下面的命令吗?
describe tablename;
查询结果如下:(客户表结果)
+------------+-----------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+------------+-----------+------+-----+---------+----------------+
| customerid | int(11) | NO | PRI | NULL | auto_increment |
| name | char(70) | NO | | NULL | |
| address | char(100) | NO | | NULL | |
| city | char(30) | NO | | NULL | |
+------------+-----------+------+-----+---------+----------------+
10.3.1获取满足条件的数据 WHERE语句指定选择特定行的条件。
先翻一页,看一下select查询语句基本格式中where的样式。
它用方括号括起来表示可选。也就是说,您可以根据需要添加它。所以,你必须学会阅读基本格式。
select *
from orders
where customerid= 3;
可以看到命令在一个分支中,也可以回车输入一个分支,也可以输入一行。不同的是,如果键入一个分支,MySQL 可以方便地指出哪一行是错误的。(我都是在一行里打出来的,方便按键盘上的方向键切换语句)
我书中的命令是customerid = 3,但书中说将选择customerid 5的行。我觉得写错了。查询应该是根据条件查询的结果,一切以实际操作结果为准。(我的书是原书的第四版,如果不是编辑不改,那他妈就是盗版问题。)
表10-1列出了常用的比较运算符,你自己看看,你可以全部操作看看效果。
特别列出 BETWEEN 列:(之间是这样使用的)
select * from customers where customerid between 10 and 16;
然后使用条件尝试 AND 和 OR 组合。
10.3.2 从多个表中获取数据
本节的画龙点睛到此。其实数据库的画龙点睛也是一句话。(在我看来)
用数据回答问题。
开始吧。
这些数据分布在不同的表中,因为它们与现实世界的对象相关。
书上说是在第8章介绍的。
在创建数据库时,我们经常对现实世界的实体和关系进行建模,并存储有关这些实体对象和关系的信息。
要将这些信息放在 SQL 中,必须执行称为关联的操作。简单来说,这意味着需要根据数据之间的关系将两个或多个表关联在一起。
1.简单关联
select orders.orderid,orders.amount,orders.date
from customers,orders
where customers.name='Julie Smith'
and
customers.customerid = orders.customerid;
要记住的重要关联规则:
因为这个查询是使用来自两个表的信息完成的,所以我们必须在此处列出两个表。(在您的查询中,您需要列出您要查询的列数据来自哪个数据表。)
表名之间的逗号相当于输入 INNER JOIN 或 CROSS JOIN。
有时也称为表的完全关联或笛卡尔积。
笛卡尔积......这有点神秘。给数学不好的同学解释一下:(二乘二?)
简单来说,就是两个集合相乘的结果。
具体定义见代数系统一书中的定义。
直觉上是
设置 A{a1,a2,a3} 设置 B{b1,b2}
他们的笛卡尔积是 A*B ={(a1,b1),(a1,b2),(a2,b1),(a2,b2) ,( a3,b1),(a3,b2)}
任意两个元素组合
然后书上说,这是没有意义的。真的没有意义,你输入select * from customers, orders;您将看到这两个数据表的笛卡尔积。我就不贴了,太长了。
因此,我们需要通过where子句使用关联条件来过滤掉有意义的数据。
书中给出了示例(customers.name='Julie Smith' and customers.customerid = orders.customerid;)来过滤掉Julie Smith 的订单。
摘要:确定需要哪些数据列。如果当前数据表不收录数据列,则需要导入收录该数据列的数据表。这两个数据表一下子就完全相关了!(此时你想要的数据格式已经出现了,但是有N种,你不知道是哪一种!)通过where子句提供过滤条件,得到过滤结果。
php抓取网页数据插入数据库( 手把手一起搭建学生信息管理页-使用phpBLOB图片到MySQL)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-30 11:22
手把手一起搭建学生信息管理页-使用phpBLOB图片到MySQL)
【完整页面】PHP搭建的学生信息管理页面,PHP使用BLOB数据格式将图片保存到MySQL,然后前端调用MySQL数据显示在页面上
最近开始用php做一些开发工作,研究了LAMP(Linux、Apache、MySQL、php),很有意思。
在我的工作中,我需要:
使用php读取图像,将其转换为BLOB格式并存储在MySQL中。使用php读取MySQL中BLOB格式的数据,翻译成图片,展示在网页上。
使用php连接MySQL数据库,然后将数据导入MySQL数据库。总结了自己实践php + MySQL的过程,写了一篇文章《一起搭建学生信息管理页面——使用PHP访问BLOB图片到MySQL》教程。
在本教程中,您将学习:
如何在MySQL中创建适合存储“学生信息”的数据库【姓名(中文)、年龄(数字)、照片(图片或文件)】 如何使用php连接MySQL数据库 如何使用php将学生信息导入到MySQL数据库(店铺名称、年龄、照片)如何使用php读取数据库中的学生信息并显示在网页中
在教程的最后,它还将教你高级游戏玩法。5分钟快速搭建真正的“学生信息管理系统”,前端可直接对数据库进行增删改查。不需要懂前端,只要会写简单的MySQL,就可以快速上手。
教程太长,内容很多。单击此处查看教程的完整版本。
如果本教程对你有帮助,请点个赞并去:)欢迎交流。 查看全部
php抓取网页数据插入数据库(
手把手一起搭建学生信息管理页-使用phpBLOB图片到MySQL)

【完整页面】PHP搭建的学生信息管理页面,PHP使用BLOB数据格式将图片保存到MySQL,然后前端调用MySQL数据显示在页面上
最近开始用php做一些开发工作,研究了LAMP(Linux、Apache、MySQL、php),很有意思。
在我的工作中,我需要:
使用php读取图像,将其转换为BLOB格式并存储在MySQL中。使用php读取MySQL中BLOB格式的数据,翻译成图片,展示在网页上。
使用php连接MySQL数据库,然后将数据导入MySQL数据库。总结了自己实践php + MySQL的过程,写了一篇文章《一起搭建学生信息管理页面——使用PHP访问BLOB图片到MySQL》教程。
在本教程中,您将学习:
如何在MySQL中创建适合存储“学生信息”的数据库【姓名(中文)、年龄(数字)、照片(图片或文件)】 如何使用php连接MySQL数据库 如何使用php将学生信息导入到MySQL数据库(店铺名称、年龄、照片)如何使用php读取数据库中的学生信息并显示在网页中
在教程的最后,它还将教你高级游戏玩法。5分钟快速搭建真正的“学生信息管理系统”,前端可直接对数据库进行增删改查。不需要懂前端,只要会写简单的MySQL,就可以快速上手。
教程太长,内容很多。单击此处查看教程的完整版本。
如果本教程对你有帮助,请点个赞并去:)欢迎交流。
php抓取网页数据插入数据库(可轻运维全球90%以上主流开源及商业数据库(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-01-25 04:12
阿里云 > 云栖社区 > 主题图 > P > php获取一列数据库
推荐活动:
更多优惠>
当前主题: php 从数据库中取出一列并将其添加到集合中
相关话题:
php 从数据库中获取相关博客列表 查看更多博客
云数据库产品概述
作者:阿里云官网
ApsaraDB是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上的主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为POLARDB提供6倍以上开源数据库的性能和开源的价格源数据库和自研的具有数百TB数据实时计算能力的HybridDB数据库等,并拥有容灾、备份、恢复、监控、迁移等一整套解决方案。
现在查看
php本机代码从数据库中获取记录
作者:Tech Fatty 771 浏览评论:04年前
db.php 1 2 3 4 5 6 7
阅读全文
Mysql数据库的介绍与分类(学习笔记一)
作者:sktj1213 人浏览评论:03年前
数据库介绍及常用数据库分类1.1数据库介绍1.1.1什么是数据库?简单的说,数据库(因为Database)就是存储数据的仓库。这个仓库是按照一定的数据结构组织和存储的(数据结构是指数据的组织形式或数据之间的联系)。我们可以使用数据库来组织和存储数据。各种优惠
阅读全文
Python 全栈 MongoDB 数据库(概念、安装、创建数据)
作者:Paris Champs 6839 浏览评论:03 年前
什么是关系数据库?它是基于关系数据库模型的数据库。它借助集合代数等概念和方法处理数据库中的数据。它也是一组表(二维表)组织成一组正式的描述。表的本质是数据项的特殊集合,这些表中的数据可以通过多种不同的方式访问
阅读全文
一小时学会MySQL数据库
作者:张果2052 浏览评论:04年前
随着移动互联网的终结和人工智能的到来,大数据变得越来越重要,下一个成功的人应该拥有海量数据。您应该了解数据和数据库。一、数据库概要数据库(Database)是一个用于存储和管理数据的软件系统,就像存储数据的物流仓库一样。在商业领域,信息意味着商机,意味着获取信息的能力
阅读全文
PHP开发中数据库及相关软件的选择注意事项
作者:科技小美1080 浏览评论:04年前
PHP的版本不同。4.0系列有4.4.x已经停止升级和开发,但仍有部分生产环境运行此版本,代码需要维护。PHP 5.0系列是目前开发应用的主流版本,有5.1.x和5.2.x系列。PHP6.0还是试用版,使用PHP开发软件
阅读全文
数据库注释 5:外键的用途
作者:1152人科技小大人查看评论:04年前
外键的作用:维护数据的一致性和完整性,主要目的是控制外键表中存储的数据。要关联两个表,外键只能引用外表中列的值!例如:ab 两个表中a 表有客户编号,客户名称b 表有每个客户的订单。使用外键只能确保b表中没有客户x的订单。
阅读全文
在 Android 开发中使用 SQLite 数据库
作者:Silencer 1306 浏览评论:04年前
SQLite 是一个非常流行的嵌入式数据库,它支持 SQL 查询并且使用很少的内存。Android 在运行时集成了 SQLite,因此每个 Android 应用程序都可以使用 SQLite 数据库。对于熟悉 SQL 的开发人员来说,使用 SQLite 相当简单
阅读全文
WordPress数据库研究
作者:ap0581w9c1121 浏览评论:08年前
本系列文章将详细介绍WordPress数据的整体设计思路,10个WordPress数据表的设计,以及用户信息、分类信息、链接信息、文章信息、文章将详细介绍评论信息和基本设置信息等六类信息。WordPress数据库研究
阅读全文
php从数据库中取一列相关问答
【javascript学习全家桶】934道JavaScript热门问题,上百位阿里巴巴技术专家答疑解惑
作者:管理贝贝5207 浏览评论:13年前
阿里极客公益活动:也许你只是因为一个问题而夜战,也许你迷茫只求答案,也许你因为一个未知数而绞尽脑汁,所以他们来了,阿里巴巴技术专家来云栖Q&A为你解答技术问题他们用自己手中的技术来帮助用户成长。本次活动特邀100阿里巴巴科技
阅读全文 查看全部
php抓取网页数据插入数据库(可轻运维全球90%以上主流开源及商业数据库(组图))
阿里云 > 云栖社区 > 主题图 > P > php获取一列数据库

推荐活动:
更多优惠>
当前主题: php 从数据库中取出一列并将其添加到集合中
相关话题:
php 从数据库中获取相关博客列表 查看更多博客
云数据库产品概述

作者:阿里云官网
ApsaraDB是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上的主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为POLARDB提供6倍以上开源数据库的性能和开源的价格源数据库和自研的具有数百TB数据实时计算能力的HybridDB数据库等,并拥有容灾、备份、恢复、监控、迁移等一整套解决方案。
现在查看
php本机代码从数据库中获取记录

作者:Tech Fatty 771 浏览评论:04年前
db.php 1 2 3 4 5 6 7
阅读全文
Mysql数据库的介绍与分类(学习笔记一)


作者:sktj1213 人浏览评论:03年前
数据库介绍及常用数据库分类1.1数据库介绍1.1.1什么是数据库?简单的说,数据库(因为Database)就是存储数据的仓库。这个仓库是按照一定的数据结构组织和存储的(数据结构是指数据的组织形式或数据之间的联系)。我们可以使用数据库来组织和存储数据。各种优惠
阅读全文
Python 全栈 MongoDB 数据库(概念、安装、创建数据)


作者:Paris Champs 6839 浏览评论:03 年前
什么是关系数据库?它是基于关系数据库模型的数据库。它借助集合代数等概念和方法处理数据库中的数据。它也是一组表(二维表)组织成一组正式的描述。表的本质是数据项的特殊集合,这些表中的数据可以通过多种不同的方式访问
阅读全文
一小时学会MySQL数据库


作者:张果2052 浏览评论:04年前
随着移动互联网的终结和人工智能的到来,大数据变得越来越重要,下一个成功的人应该拥有海量数据。您应该了解数据和数据库。一、数据库概要数据库(Database)是一个用于存储和管理数据的软件系统,就像存储数据的物流仓库一样。在商业领域,信息意味着商机,意味着获取信息的能力
阅读全文
PHP开发中数据库及相关软件的选择注意事项

作者:科技小美1080 浏览评论:04年前
PHP的版本不同。4.0系列有4.4.x已经停止升级和开发,但仍有部分生产环境运行此版本,代码需要维护。PHP 5.0系列是目前开发应用的主流版本,有5.1.x和5.2.x系列。PHP6.0还是试用版,使用PHP开发软件
阅读全文
数据库注释 5:外键的用途

作者:1152人科技小大人查看评论:04年前
外键的作用:维护数据的一致性和完整性,主要目的是控制外键表中存储的数据。要关联两个表,外键只能引用外表中列的值!例如:ab 两个表中a 表有客户编号,客户名称b 表有每个客户的订单。使用外键只能确保b表中没有客户x的订单。
阅读全文
在 Android 开发中使用 SQLite 数据库

作者:Silencer 1306 浏览评论:04年前
SQLite 是一个非常流行的嵌入式数据库,它支持 SQL 查询并且使用很少的内存。Android 在运行时集成了 SQLite,因此每个 Android 应用程序都可以使用 SQLite 数据库。对于熟悉 SQL 的开发人员来说,使用 SQLite 相当简单
阅读全文
WordPress数据库研究

作者:ap0581w9c1121 浏览评论:08年前
本系列文章将详细介绍WordPress数据的整体设计思路,10个WordPress数据表的设计,以及用户信息、分类信息、链接信息、文章信息、文章将详细介绍评论信息和基本设置信息等六类信息。WordPress数据库研究
阅读全文
php从数据库中取一列相关问答
【javascript学习全家桶】934道JavaScript热门问题,上百位阿里巴巴技术专家答疑解惑

作者:管理贝贝5207 浏览评论:13年前
阿里极客公益活动:也许你只是因为一个问题而夜战,也许你迷茫只求答案,也许你因为一个未知数而绞尽脑汁,所以他们来了,阿里巴巴技术专家来云栖Q&A为你解答技术问题他们用自己手中的技术来帮助用户成长。本次活动特邀100阿里巴巴科技
阅读全文
php抓取网页数据插入数据库(快速实现微博微商城的分析、查询,是否发布过帖子)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-24 06:07
php抓取网页数据插入数据库,然后根据用户名密码判断用户性别、年龄、是否关注、是否发布过帖子,
可以看看我的这篇回答:快速的实现微博微商城的分析、查询,最重要是要知道微博分析的方向,是哪个群体数据,
最重要的是确定用户微博归属的行业。然后根据分析行业的热度,判断该行业的年龄层、性别比,然后根据用户的性别结合该群体的年龄层进行分析。找到热度最高的帖子,进行筛选。
首先要弄明白你这个微博的用途是什么。如果是做线上线下分析的,我认为是研究潜在用户和用户分享的点,而你的工作就是去翻用户的微博去分析这些东西。如果是做展示为主的,像在线教育或者维修电工之类的,我觉得优先研究这些大学生在传统上的安装电工技能到底有没有达到要求,还有他们的使用习惯和他们在学校里的实际操作程度,然后找到潜在的用户和他们的共同爱好,结合转发点赞数据去分析。
前提是你要尽可能知道这些大学生的公司组织架构和学校类型、所在地区,这样你才有可能从内部获取流量来对其进行转化。用微博直接进行二手信息的获取已经非常普遍了,这里不再赘述,感兴趣可以关注我的微博:@小东北这里推荐我最近在整理的一些资料供大家学习:、在线调查问卷、问卷星。 查看全部
php抓取网页数据插入数据库(快速实现微博微商城的分析、查询,是否发布过帖子)
php抓取网页数据插入数据库,然后根据用户名密码判断用户性别、年龄、是否关注、是否发布过帖子,
可以看看我的这篇回答:快速的实现微博微商城的分析、查询,最重要是要知道微博分析的方向,是哪个群体数据,
最重要的是确定用户微博归属的行业。然后根据分析行业的热度,判断该行业的年龄层、性别比,然后根据用户的性别结合该群体的年龄层进行分析。找到热度最高的帖子,进行筛选。
首先要弄明白你这个微博的用途是什么。如果是做线上线下分析的,我认为是研究潜在用户和用户分享的点,而你的工作就是去翻用户的微博去分析这些东西。如果是做展示为主的,像在线教育或者维修电工之类的,我觉得优先研究这些大学生在传统上的安装电工技能到底有没有达到要求,还有他们的使用习惯和他们在学校里的实际操作程度,然后找到潜在的用户和他们的共同爱好,结合转发点赞数据去分析。
前提是你要尽可能知道这些大学生的公司组织架构和学校类型、所在地区,这样你才有可能从内部获取流量来对其进行转化。用微博直接进行二手信息的获取已经非常普遍了,这里不再赘述,感兴趣可以关注我的微博:@小东北这里推荐我最近在整理的一些资料供大家学习:、在线调查问卷、问卷星。
php抓取网页数据插入数据库(又遇到乱码问题,这个编码问题有时候真是让人头大)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-23 23:22
我又遇到了乱码的问题。这个编码问题有时真的很烦人。找了半天也没查出什么问题。页面和数据库都是utf8编码的,但是还是有乱码。直接在命令行下将中文数据插入数据库时,不会出现乱码。在程序中使用代码插入时,会出现乱码。控制台打印的数据没有乱码。乱码问题终于通过搜索资料解决了,但还是有些不明白问题出在哪里。
通过将 ?useUnicode=true&characterEncoding=UTF-8 添加到数据库连接 url 来解决问题:
应用程序上下文.xml
我处理编码的过滤器:
public class EncodingFilter implements Filter {
private FilterConfig config;
private String charset = "UTF-8";
public void init(FilterConfig filterconfig) throws ServletException {
config = filterconfig;
String s = config.getInitParameter("encoding");
if (s != null) {
charset = s;
}
}
public void destroy() {
config = null;
}
public void doFilter(ServletRequest servletrequest,
ServletResponse servletresponse, FilterChain filterchain)
throws IOException, ServletException {
servletrequest.setCharacterEncoding(charset);
servletresponse.setCharacterEncoding(charset);
filterchain.doFilter(servletrequest,servletresponse);
}
}
测试的过滤器确实被执行了。
数据库使用 utf8 编码:
jsp 页面和所有 Java 文件都使用 utf8 编码。
我看不出问题出在哪里。我现在很着急。我先解决问题,有时间再研究一下编码问题。遇到过很多次,但是这个编码问题不能小觑。上次在程序中使用utf8编码的url地址访问windows服务器上的资源文件,出现404,可以用gbk代替。还有一次发现页面在低版本chrome下有一些CSS失效问题,但是在ie和高版本chrome下都没有问题。当时我还以为是CSS兼容性问题。后来发现无效部分在CSS文件中。中文注释后的样式,如果去掉中文注释,可以正常显示。 查看全部
php抓取网页数据插入数据库(又遇到乱码问题,这个编码问题有时候真是让人头大)
我又遇到了乱码的问题。这个编码问题有时真的很烦人。找了半天也没查出什么问题。页面和数据库都是utf8编码的,但是还是有乱码。直接在命令行下将中文数据插入数据库时,不会出现乱码。在程序中使用代码插入时,会出现乱码。控制台打印的数据没有乱码。乱码问题终于通过搜索资料解决了,但还是有些不明白问题出在哪里。
通过将 ?useUnicode=true&characterEncoding=UTF-8 添加到数据库连接 url 来解决问题:
应用程序上下文.xml
我处理编码的过滤器:
public class EncodingFilter implements Filter {
private FilterConfig config;
private String charset = "UTF-8";
public void init(FilterConfig filterconfig) throws ServletException {
config = filterconfig;
String s = config.getInitParameter("encoding");
if (s != null) {
charset = s;
}
}
public void destroy() {
config = null;
}
public void doFilter(ServletRequest servletrequest,
ServletResponse servletresponse, FilterChain filterchain)
throws IOException, ServletException {
servletrequest.setCharacterEncoding(charset);
servletresponse.setCharacterEncoding(charset);
filterchain.doFilter(servletrequest,servletresponse);
}
}
测试的过滤器确实被执行了。
数据库使用 utf8 编码:

jsp 页面和所有 Java 文件都使用 utf8 编码。
我看不出问题出在哪里。我现在很着急。我先解决问题,有时间再研究一下编码问题。遇到过很多次,但是这个编码问题不能小觑。上次在程序中使用utf8编码的url地址访问windows服务器上的资源文件,出现404,可以用gbk代替。还有一次发现页面在低版本chrome下有一些CSS失效问题,但是在ie和高版本chrome下都没有问题。当时我还以为是CSS兼容性问题。后来发现无效部分在CSS文件中。中文注释后的样式,如果去掉中文注释,可以正常显示。
php抓取网页数据插入数据库(初学者-PHP-抓取-数据库-前面的设计问题:初学者)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-23 05:01
初学者 - PHP - 爬网 - 数据库 - 前端设计问题:
我构建了一个 PHP 脚本来从 网站 中抓取(使用 curl)文章,我对其进行样式化并添加了 html 标签以使其易于显示,并通过 cPanel 上传到共享主机。
抓取是使用 php 函数 curl 和 preg_match_all 完成的。每个爬取的页面有 17 篇文章 文章,所以如果我爬取 100 个页面,就有 170 篇文章 文章。我只抓取 文章 标题、URL、文章 摘要和发布日期,因此每个 文章 没有那么多信息(不是内容)。
我的 网站 显示 文章 标题(链接到原创来源)和 文章 摘要。我还使用 文章 发布日期作为我提取的字符串,我按月块(2019 年 12 月、2019 年 11 月等)解析和显示 文章。
网站 的加载时间很糟糕。每次打开网站,脚本都会爬100页,耗时不少。即使将要爬取的页面数量减少到 30 个,加载时间也很长。
现在,作为一个没有经验的开发人员,我正在处理的问题是如何为此设计一个解决方案,我最终可以在我的共享主机中实现(不像 VPS 在我拥有的控制量上......)
第一个想法是我应该将抓取的数据存储在 mysql 数据库中并定期更新(使用 cron 作业?)?
初学者可以/应该在这里实施的解决方案的正确设计流程是什么?
会不会是这样:
第一次抓取数据并存储在数据库中。编写一个脚本以每天(或更多)从第一页只采集新的 文章 而不会创建重复项(可能需要将标题字符串与最后一个 DB 输入进行比较,直到类似于标题字符串 1 = = content of标题字符串 2,然后停止插入数据库)。
您的想法和建议将不胜感激。顺便说一句,我目前也在尝试更专业地在 Laravel 中重做 网站。 查看全部
php抓取网页数据插入数据库(初学者-PHP-抓取-数据库-前面的设计问题:初学者)
初学者 - PHP - 爬网 - 数据库 - 前端设计问题:
我构建了一个 PHP 脚本来从 网站 中抓取(使用 curl)文章,我对其进行样式化并添加了 html 标签以使其易于显示,并通过 cPanel 上传到共享主机。
抓取是使用 php 函数 curl 和 preg_match_all 完成的。每个爬取的页面有 17 篇文章 文章,所以如果我爬取 100 个页面,就有 170 篇文章 文章。我只抓取 文章 标题、URL、文章 摘要和发布日期,因此每个 文章 没有那么多信息(不是内容)。
我的 网站 显示 文章 标题(链接到原创来源)和 文章 摘要。我还使用 文章 发布日期作为我提取的字符串,我按月块(2019 年 12 月、2019 年 11 月等)解析和显示 文章。
网站 的加载时间很糟糕。每次打开网站,脚本都会爬100页,耗时不少。即使将要爬取的页面数量减少到 30 个,加载时间也很长。
现在,作为一个没有经验的开发人员,我正在处理的问题是如何为此设计一个解决方案,我最终可以在我的共享主机中实现(不像 VPS 在我拥有的控制量上......)
第一个想法是我应该将抓取的数据存储在 mysql 数据库中并定期更新(使用 cron 作业?)?
初学者可以/应该在这里实施的解决方案的正确设计流程是什么?
会不会是这样:
第一次抓取数据并存储在数据库中。编写一个脚本以每天(或更多)从第一页只采集新的 文章 而不会创建重复项(可能需要将标题字符串与最后一个 DB 输入进行比较,直到类似于标题字符串 1 = = content of标题字符串 2,然后停止插入数据库)。
您的想法和建议将不胜感激。顺便说一句,我目前也在尝试更专业地在 Laravel 中重做 网站。
php抓取网页数据插入数据库(持续更新中IRIE系统设计与实现报告(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-23 04:21
持续更新IR&IE系统设计与实施报告一、系统设计
“网络蜘蛛”从互联网抓取网页,将网页发送到“网页数据库”,从网页“提取URL”,将URL发送到“URL数据库”,“蜘蛛控制”获取URL网页,控制“网络蜘蛛”爬取其他页面,重复循环,直到所有页面都被爬完。
系统从“网页数据库”中获取文本信息,发送到“文本索引”模块进行索引,形成“索引数据库”。同时进行“链接信息提取”,将链接信息(包括锚文本、链接本身等信息)送入“链接数据库”,为“网页评分”提供依据。
“用户”向“查询服务器”提交查询请求,服务器在“索引数据库”中搜索相关网页,“网页评分”结合查询请求和链接信息来评估搜索的相关性结果。查询服务器”按相关性排序,提取关键词的内容摘要,整理最终页面返回给“用户”。
——万维网自动搜索引擎(技术报告)Johnny Deng 2006.12
图1-1是整个程序的架构图。
图 1-1 程序架构图
二、系统开发工具和平台
开发环境:
三、系统及其功能模块的实现1、网页爬取
简单地说,网络爬虫是一个苦力臭虫,它会嗅探 URL(链接)并爬取数千个网页,并将网页的内容移动到您的计算机上供您使用。
如图(这里有几张图):你给爬虫起始页A的url,它从起始页A开始,读取A的所有内容,从中找到3个url,指向页面B、C、D,然后依次沿着链接爬取页面B、C、D的内容,从中发现新的链接,然后继续沿着链接爬取到新的页面——>爬取内容—— > 分析链接 –> 爬到新页面...直到找不到新链接或满足人为停止条件。您可以继续对爬虫带回的网页内容进行分析和处理,以满足您的需求。
至于bug前进的方式,分为广度优先搜索(BFS)和深度优先搜索(DFS)。在这个图中,BFS的搜索顺序是ABCDEFGHI,深度优先搜索的顺序是ABEICFDGH。
我们使用 BFS 来抓取网页。直接使用python内置的type list来存储url地址。每次从一个页面获取所有链接url地址后,将其从待爬取队列的头部删除,并将所有获取到的链接合并到待爬取队列中。结尾。
网络爬取模块主要包括以下功能。
2、索引
索引就像图书馆每个书架上的一个小标志。如果你想找某本书,比如学习python语言的书,你先搜索“信息与计算机科”,再搜索“编程语言”,这样就可以在网上找到你要找的书了对应的货架。搜索引擎的索引与此类似,不同的是它会为所有网页的每个单词建立一个索引。当你输入一串搜索字符串时,程序会先进行分词,然后根据每个词的索引找到对应的词。网页。例如,在搜索框中输入“从前有座山,庙里有个小和尚”,搜索引擎会首先对字符串进行切分“
当然,这个实验中这个简单引擎的索引功能也很简单。通过分析网页的源代码,我们利用网页中元元素的内容来生成关键词。如图2-1所示:
图 2-1 页面中的关键字
关键字的内容比较简单。我们可以根据书名、作者、出版商、出版时间等信息进行图书搜索。
3、页面排名
这个以谷歌创始人拉里佩奇命名的算法可能是互联网上最著名的算法。当时,这个算法帮助谷歌在搜索质量上击败了当时最流行的雅虎、AltaVista等引擎。科技巨头做出了巨大贡献。
页面排名用于衡量网页的质量。索引找到的页面将使用pagerank算法计算PR值。这个分数在演讲结果的排名中会有一定的权重。得分高的页面会在最前面展示给用户。那么它是如何实现的呢?它是基于这样一个假设:链接到这个网页的网页越多,这个网页在全网的接受度就越高,也就是这个网页的质量越好——相当于所有其他的互联网上给它投票的网页,有一个指向它的链接,说明有人为它投票,票数越高越好。但是所有选票的权重都一样吗?明显不是。链接到这个页面本身的页面的PR值越高,它的投票权重就越大。就好像董事会投票给大股东的投票比小股东的投票更有分量。但有一个问题。要想知道一个页面的PR值,就需要知道链接到它的页面的PR值,而链接到它的页面的PR值需要依赖于其他页面的PR值。它变成了先有鸡还是先有蛋的问题。假设初始条件,互联网上所有页面的PR值初始值为1/N,N为全网页面总数,然后用公式迭代,其中p(j)表示链接到p(i)的网页,Lp(j)表示这个页面的链接数,用它除以页面链接数的原因很好理解。当一个页面有大量链接时,每个链接投票的权重会相应分配。可以证明,每一页i的值都是按照这个公式计算出来的,并且迭代。当迭代多轮时,PRp(i) 的值将趋于稳定值。在应用中,迭代次数一般为10次,10次以上。在此之后 PRp(i) 的值变化很小。
还有一个问题,如果一个页面没有任何外部页面链接到它,那么它的PR值是0吗?为了使 PRp(i) 函数更平滑,我们在公式中添加了阻尼系数 d。这里我们不妨取0.8,公式变成如下形式:
这样,即使一个页面是孤立存在的,它的PR值也不会变为零,而是一个很小的值。我们也可以从另一个角度来理解阻尼系数。PR 值实际上衡量了页面被访问的可能性。链接到它的页面越多,点击这些链接的可能性就越大。但是没有任何外部链接就不可能访问网页吗?当然不是,因为你也可以直接从地址框输入url来访问,而且有些人会想通过搜索引擎找到这个页面,所以我们在公式中加上一个阻尼系数,当然只能取这里的一维数字相对较小。
当然,网页的PR值并不是决定网页排名的唯一因素。页面与用户搜索词(查询)的相关程度也是一个重要的衡量标准。.
4、网页分析
网页提取模块从中提取关键词 和书籍信息。
页面上的信息非常复杂。我们使用xpath提取图书的作者、出版商等主要信息,如图2-2所示。
图 2-2 页簿信息
5、布尔模型
布尔检索法是指利用布尔运算符将每个检索词链接起来,然后在计算机上进行逻辑运算以找到所需信息的检索方法。
在这个程序的search()函数中,我们解析搜索词,判断它们之间的逻辑关系,给出搜索结果。
四、遇到的问题及解决方法1、 在网页解析过程中,获取标签中的完整文本出现问题。
因为一个div标签里面有很多倍的标签,直接用xpath路径通过text()获取文本是有问题的。通过查阅 xpath 手册,使用 string(.) 函数过滤掉标签。
2、 页面中的大量 URL 不是提供书籍信息的页面。
爬虫模块增加了url_valid(url)函数,判断url是否有效,使用正则表达式查找表单中的有效地址。
3、 网页的广度优先搜索实现,以及抓取次数的限制。
使用python的list类型存储url,每次爬取url,将新值存储在队列末尾to_crawl待爬取,爬取队列头部的url页面,然后使用pop()函数出队操作。
将抓取的 url 提供给抓取的列表。通过判断列表的长度来限制爬虫的爬取过程。
五、系统测试
简单测试,爬取页面数超过10个就停止爬虫。
1、索引结果
混入了一个奇怪的东西,可能是页面结构不一致造成的。
2、进行搜索
print 'ordered_search', ordered_search(index, ranks, u'杨绛')
print index[u'杨绛']
结果如下
打印列表的内容:
3、搜索作者可能会得到独特的结果。让我们再次搜索“used”以查看结果。
部分结果如图所示。
4、 同时搜索多个词的结果
结果如下:
六、改进
感谢北优的两位童鞋提供完成本次实验的机会
具体代码可以参考我的github-douban_book_search 查看全部
php抓取网页数据插入数据库(持续更新中IRIE系统设计与实现报告(组图))
持续更新IR&IE系统设计与实施报告一、系统设计
“网络蜘蛛”从互联网抓取网页,将网页发送到“网页数据库”,从网页“提取URL”,将URL发送到“URL数据库”,“蜘蛛控制”获取URL网页,控制“网络蜘蛛”爬取其他页面,重复循环,直到所有页面都被爬完。
系统从“网页数据库”中获取文本信息,发送到“文本索引”模块进行索引,形成“索引数据库”。同时进行“链接信息提取”,将链接信息(包括锚文本、链接本身等信息)送入“链接数据库”,为“网页评分”提供依据。
“用户”向“查询服务器”提交查询请求,服务器在“索引数据库”中搜索相关网页,“网页评分”结合查询请求和链接信息来评估搜索的相关性结果。查询服务器”按相关性排序,提取关键词的内容摘要,整理最终页面返回给“用户”。
——万维网自动搜索引擎(技术报告)Johnny Deng 2006.12
图1-1是整个程序的架构图。
图 1-1 程序架构图
二、系统开发工具和平台
开发环境:
三、系统及其功能模块的实现1、网页爬取
简单地说,网络爬虫是一个苦力臭虫,它会嗅探 URL(链接)并爬取数千个网页,并将网页的内容移动到您的计算机上供您使用。
如图(这里有几张图):你给爬虫起始页A的url,它从起始页A开始,读取A的所有内容,从中找到3个url,指向页面B、C、D,然后依次沿着链接爬取页面B、C、D的内容,从中发现新的链接,然后继续沿着链接爬取到新的页面——>爬取内容—— > 分析链接 –> 爬到新页面...直到找不到新链接或满足人为停止条件。您可以继续对爬虫带回的网页内容进行分析和处理,以满足您的需求。
至于bug前进的方式,分为广度优先搜索(BFS)和深度优先搜索(DFS)。在这个图中,BFS的搜索顺序是ABCDEFGHI,深度优先搜索的顺序是ABEICFDGH。
我们使用 BFS 来抓取网页。直接使用python内置的type list来存储url地址。每次从一个页面获取所有链接url地址后,将其从待爬取队列的头部删除,并将所有获取到的链接合并到待爬取队列中。结尾。
网络爬取模块主要包括以下功能。
2、索引
索引就像图书馆每个书架上的一个小标志。如果你想找某本书,比如学习python语言的书,你先搜索“信息与计算机科”,再搜索“编程语言”,这样就可以在网上找到你要找的书了对应的货架。搜索引擎的索引与此类似,不同的是它会为所有网页的每个单词建立一个索引。当你输入一串搜索字符串时,程序会先进行分词,然后根据每个词的索引找到对应的词。网页。例如,在搜索框中输入“从前有座山,庙里有个小和尚”,搜索引擎会首先对字符串进行切分“
当然,这个实验中这个简单引擎的索引功能也很简单。通过分析网页的源代码,我们利用网页中元元素的内容来生成关键词。如图2-1所示:
图 2-1 页面中的关键字
关键字的内容比较简单。我们可以根据书名、作者、出版商、出版时间等信息进行图书搜索。
3、页面排名
这个以谷歌创始人拉里佩奇命名的算法可能是互联网上最著名的算法。当时,这个算法帮助谷歌在搜索质量上击败了当时最流行的雅虎、AltaVista等引擎。科技巨头做出了巨大贡献。
页面排名用于衡量网页的质量。索引找到的页面将使用pagerank算法计算PR值。这个分数在演讲结果的排名中会有一定的权重。得分高的页面会在最前面展示给用户。那么它是如何实现的呢?它是基于这样一个假设:链接到这个网页的网页越多,这个网页在全网的接受度就越高,也就是这个网页的质量越好——相当于所有其他的互联网上给它投票的网页,有一个指向它的链接,说明有人为它投票,票数越高越好。但是所有选票的权重都一样吗?明显不是。链接到这个页面本身的页面的PR值越高,它的投票权重就越大。就好像董事会投票给大股东的投票比小股东的投票更有分量。但有一个问题。要想知道一个页面的PR值,就需要知道链接到它的页面的PR值,而链接到它的页面的PR值需要依赖于其他页面的PR值。它变成了先有鸡还是先有蛋的问题。假设初始条件,互联网上所有页面的PR值初始值为1/N,N为全网页面总数,然后用公式迭代,其中p(j)表示链接到p(i)的网页,Lp(j)表示这个页面的链接数,用它除以页面链接数的原因很好理解。当一个页面有大量链接时,每个链接投票的权重会相应分配。可以证明,每一页i的值都是按照这个公式计算出来的,并且迭代。当迭代多轮时,PRp(i) 的值将趋于稳定值。在应用中,迭代次数一般为10次,10次以上。在此之后 PRp(i) 的值变化很小。
还有一个问题,如果一个页面没有任何外部页面链接到它,那么它的PR值是0吗?为了使 PRp(i) 函数更平滑,我们在公式中添加了阻尼系数 d。这里我们不妨取0.8,公式变成如下形式:
这样,即使一个页面是孤立存在的,它的PR值也不会变为零,而是一个很小的值。我们也可以从另一个角度来理解阻尼系数。PR 值实际上衡量了页面被访问的可能性。链接到它的页面越多,点击这些链接的可能性就越大。但是没有任何外部链接就不可能访问网页吗?当然不是,因为你也可以直接从地址框输入url来访问,而且有些人会想通过搜索引擎找到这个页面,所以我们在公式中加上一个阻尼系数,当然只能取这里的一维数字相对较小。
当然,网页的PR值并不是决定网页排名的唯一因素。页面与用户搜索词(查询)的相关程度也是一个重要的衡量标准。.
4、网页分析
网页提取模块从中提取关键词 和书籍信息。
页面上的信息非常复杂。我们使用xpath提取图书的作者、出版商等主要信息,如图2-2所示。
图 2-2 页簿信息
5、布尔模型
布尔检索法是指利用布尔运算符将每个检索词链接起来,然后在计算机上进行逻辑运算以找到所需信息的检索方法。
在这个程序的search()函数中,我们解析搜索词,判断它们之间的逻辑关系,给出搜索结果。
四、遇到的问题及解决方法1、 在网页解析过程中,获取标签中的完整文本出现问题。
因为一个div标签里面有很多倍的标签,直接用xpath路径通过text()获取文本是有问题的。通过查阅 xpath 手册,使用 string(.) 函数过滤掉标签。
2、 页面中的大量 URL 不是提供书籍信息的页面。
爬虫模块增加了url_valid(url)函数,判断url是否有效,使用正则表达式查找表单中的有效地址。
3、 网页的广度优先搜索实现,以及抓取次数的限制。
使用python的list类型存储url,每次爬取url,将新值存储在队列末尾to_crawl待爬取,爬取队列头部的url页面,然后使用pop()函数出队操作。
将抓取的 url 提供给抓取的列表。通过判断列表的长度来限制爬虫的爬取过程。
五、系统测试
简单测试,爬取页面数超过10个就停止爬虫。
1、索引结果
混入了一个奇怪的东西,可能是页面结构不一致造成的。
2、进行搜索
print 'ordered_search', ordered_search(index, ranks, u'杨绛')
print index[u'杨绛']
结果如下
打印列表的内容:
3、搜索作者可能会得到独特的结果。让我们再次搜索“used”以查看结果。
部分结果如图所示。
4、 同时搜索多个词的结果
结果如下:
六、改进
感谢北优的两位童鞋提供完成本次实验的机会
具体代码可以参考我的github-douban_book_search
php抓取网页数据插入数据库(数据库数据库中的中文乱码怎么办?比较实用的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-21 16:15
我们在使用数据库(MySQL)的时候最怕的就是数据库中的中文是乱码,百度除了改变配置文件中的字符集外似乎没有其他的构造方法。更重要的是,这些方法我都一一掌握了。试过了,好像没有解决问题。那我给大家提供一个我一直在用的比较实用的方法。
第一:页面编码问题
我们需要在WEB页面中保留所有的UTF-8编码。
二:设置数据表的字符集编码为utf8
喜欢:
CREATE TABLE `tablename4` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`varchar1` varchar(255) DEFAULT NULL,
`varbinary1` varbinary(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8
DEFAULT CHARSET=utf8 这里是设置数据表的字符集的编码。
三:数据库链接编码设置
只设置数据库的页面编码和字符集编码是达不到目的的。代码中连接数据库后,应采取相应措施,否则中文仍会以乱码形式存入数据库。
比如在php中,连接数据库后,我们可以通过如下操作来避免插入乱码的问题:
mysql_query("set names 'utf8'");
/* http://www.manongjc.com/article/1585.html */
在编程过程中进行以上三个操作,就可以避免中文乱码的问题。需要注意的是,这三个操作缺一不可。 查看全部
php抓取网页数据插入数据库(数据库数据库中的中文乱码怎么办?比较实用的方法)
我们在使用数据库(MySQL)的时候最怕的就是数据库中的中文是乱码,百度除了改变配置文件中的字符集外似乎没有其他的构造方法。更重要的是,这些方法我都一一掌握了。试过了,好像没有解决问题。那我给大家提供一个我一直在用的比较实用的方法。
第一:页面编码问题
我们需要在WEB页面中保留所有的UTF-8编码。
二:设置数据表的字符集编码为utf8
喜欢:
CREATE TABLE `tablename4` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`varchar1` varchar(255) DEFAULT NULL,
`varbinary1` varbinary(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8
DEFAULT CHARSET=utf8 这里是设置数据表的字符集的编码。
三:数据库链接编码设置
只设置数据库的页面编码和字符集编码是达不到目的的。代码中连接数据库后,应采取相应措施,否则中文仍会以乱码形式存入数据库。
比如在php中,连接数据库后,我们可以通过如下操作来避免插入乱码的问题:
mysql_query("set names 'utf8'");
/* http://www.manongjc.com/article/1585.html */
在编程过程中进行以上三个操作,就可以避免中文乱码的问题。需要注意的是,这三个操作缺一不可。
php抓取网页数据插入数据库(有效的有效替代解决方案数组,你知道几个?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-01-20 01:18
遍历数组不会那么有效。如果您的数据库变得太大,那么它会减慢整个过程,并且可能会出现一种罕见的情况,即 2 个线程在数组中循环以获取相同的随机数,并且会发现它可用并向两张票返回相同的数字。如果您的数据库太大,那么它会减慢整个过程,并且当两个线程循环遍历数组以获取相同的随机数并且可能找到可用的并为两个票条件返回相同的数字时,可能会很少。
因此,您可以将 10 位注册 id 设置为主键,而不是遍历数组,而不是遍历数组,您可以插入注册详细信息以及随机生成的数字,如果数据库插入操作成功,您可以返回注册 id,但如果没有,则重新生成随机数并插入。所以不用循环遍历数组,可以设置10位的注册id为主键,不用循环遍历数组,可以插入注册详情和随机生成的数字,如果数据库插入操作成功,可以返回注册ID,如果没有,则重新生成并插入随机数。
更有效的替代解决方案 您可以使用时间戳代替 10 位随机数来生成 10 位唯一注册号并使其随机化,您可以随机化时间戳的前 2 或 3 位方案可以使用时间戳来生成 10 位唯一注册号,而不是使用 10 位随机数并随机化它,您可以随机化时间戳的前 2 或 3 位数字 查看全部
php抓取网页数据插入数据库(有效的有效替代解决方案数组,你知道几个?)
遍历数组不会那么有效。如果您的数据库变得太大,那么它会减慢整个过程,并且可能会出现一种罕见的情况,即 2 个线程在数组中循环以获取相同的随机数,并且会发现它可用并向两张票返回相同的数字。如果您的数据库太大,那么它会减慢整个过程,并且当两个线程循环遍历数组以获取相同的随机数并且可能找到可用的并为两个票条件返回相同的数字时,可能会很少。
因此,您可以将 10 位注册 id 设置为主键,而不是遍历数组,而不是遍历数组,您可以插入注册详细信息以及随机生成的数字,如果数据库插入操作成功,您可以返回注册 id,但如果没有,则重新生成随机数并插入。所以不用循环遍历数组,可以设置10位的注册id为主键,不用循环遍历数组,可以插入注册详情和随机生成的数字,如果数据库插入操作成功,可以返回注册ID,如果没有,则重新生成并插入随机数。
更有效的替代解决方案 您可以使用时间戳代替 10 位随机数来生成 10 位唯一注册号并使其随机化,您可以随机化时间戳的前 2 或 3 位方案可以使用时间戳来生成 10 位唯一注册号,而不是使用 10 位随机数并随机化它,您可以随机化时间戳的前 2 或 3 位数字
php抓取网页数据插入数据库( 推荐教程:PHP视频教程1.连接数据库函数_connect(连接对象))
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2022-01-19 03:06
推荐教程:PHP视频教程1.连接数据库函数_connect(连接对象))
制作动态网站时,最基本的一步就是连接数据库。下面我们将介绍PHP连接数据库的过程。
推荐教程:PHP 视频教程
1.连接数据库函数
mysqli_connect(hostname, username, password) 返回值是我们的连接对象之一。如果连接失败,会报错并返回false
2.判断误差函数
mysqli_connect_error(connection object) 错误信息返回错误信息
mysqli_connect_errno(连接对象)错误号0表示连接成功无错误
3.选择数据库函数
mysqli_select_db(连接对象,要选择的数据库名);如果选择成功,返回true,否则返回false
4.选择字符集
mysqli_set_charset(连接对象,要选择的字符集);如果选择成功,返回true,否则返回false
5.准备sql语句
6. 发送sql语句
mysqli_query(连接对象,要发送的sql语句);成功获取对象,失败返回false
7. 处理结果集
7.1 获取条目数
a) mysqli_num_rows(成功发送sql的对象)用于获取查询获得的记录数,仅用于select语句
b) mysqli_affected_rows(连接对象) 上一次mysql操作中受影响的行数,只针对INSERT UPDATE DELETE操作 返回值 1 成功插入的行数 -1 执行失败
7.2 获取查询结果集的内容
mysqli_fetch_array(send object)以混合数组的形式返回查询结果,一次一项
mysqli_fetch_row(send object)以索引数组的形式返回查询结果,一次一项
mysqli_fetch_assoc(send object)以关联数组的形式返回查询结果,一次一项
7.3 添加操作时,我们可以得到最后插入的id
mysqli_insert_id(连接对象)返回最后插入的id
8.关闭数据库
mysqli_close(连接对象)
// 1.连接数据库
// 2.判断错误
// 3.选择数据库
// 4.选择字符集
// 5.准备sql语句
// 6.发送sql语句
// 7.处理结果集
// 8.关闭数据库
//1.连接数据库
//mysqli_connect('主机名','用户名','密码');
$link=@mysqli_connect('localhost','root','123456');
//var_dump($link);
//2.判断错误
//mysqli_connect_error(连接对象) 错误信息
//mysqli_connect_errno(连接对象) 错误号
// echo mysqli_connect_errno($link);
// echo mysqli_connect_error($link);
if(mysqli_connect_errno($link)){
echo mysqli_connect_error($link);exit;
//echo '错误了 重新连接';exit;
}
//3.选择数据库
mysqli_select_db($link,'ss21');
//4.选择字符集
mysqli_set_charset($link,'utf8');
//5.准备sql语句
$sql="SELECT id,name,sex,age,city FROM info";
//$sql="INSERT INTO info(name) VALUES(NULL)";
//6.发送sql语句
$result = mysqli_query($link,$sql);
//7.处理结果集
echo mysqli_num_rows($result);
//echo mysqli_affected_rows($link);
//8.关闭数据库
mysqli_close($link);
以上是php访问数据库过程的详细内容。更多详情请关注php中文网其他相关话题文章! 查看全部
php抓取网页数据插入数据库(
推荐教程:PHP视频教程1.连接数据库函数_connect(连接对象))

制作动态网站时,最基本的一步就是连接数据库。下面我们将介绍PHP连接数据库的过程。
推荐教程:PHP 视频教程
1.连接数据库函数
mysqli_connect(hostname, username, password) 返回值是我们的连接对象之一。如果连接失败,会报错并返回false
2.判断误差函数
mysqli_connect_error(connection object) 错误信息返回错误信息
mysqli_connect_errno(连接对象)错误号0表示连接成功无错误
3.选择数据库函数
mysqli_select_db(连接对象,要选择的数据库名);如果选择成功,返回true,否则返回false
4.选择字符集
mysqli_set_charset(连接对象,要选择的字符集);如果选择成功,返回true,否则返回false
5.准备sql语句
6. 发送sql语句
mysqli_query(连接对象,要发送的sql语句);成功获取对象,失败返回false
7. 处理结果集
7.1 获取条目数
a) mysqli_num_rows(成功发送sql的对象)用于获取查询获得的记录数,仅用于select语句
b) mysqli_affected_rows(连接对象) 上一次mysql操作中受影响的行数,只针对INSERT UPDATE DELETE操作 返回值 1 成功插入的行数 -1 执行失败
7.2 获取查询结果集的内容
mysqli_fetch_array(send object)以混合数组的形式返回查询结果,一次一项
mysqli_fetch_row(send object)以索引数组的形式返回查询结果,一次一项
mysqli_fetch_assoc(send object)以关联数组的形式返回查询结果,一次一项
7.3 添加操作时,我们可以得到最后插入的id
mysqli_insert_id(连接对象)返回最后插入的id
8.关闭数据库
mysqli_close(连接对象)
// 1.连接数据库
// 2.判断错误
// 3.选择数据库
// 4.选择字符集
// 5.准备sql语句
// 6.发送sql语句
// 7.处理结果集
// 8.关闭数据库
//1.连接数据库
//mysqli_connect('主机名','用户名','密码');
$link=@mysqli_connect('localhost','root','123456');
//var_dump($link);
//2.判断错误
//mysqli_connect_error(连接对象) 错误信息
//mysqli_connect_errno(连接对象) 错误号
// echo mysqli_connect_errno($link);
// echo mysqli_connect_error($link);
if(mysqli_connect_errno($link)){
echo mysqli_connect_error($link);exit;
//echo '错误了 重新连接';exit;
}
//3.选择数据库
mysqli_select_db($link,'ss21');
//4.选择字符集
mysqli_set_charset($link,'utf8');
//5.准备sql语句
$sql="SELECT id,name,sex,age,city FROM info";
//$sql="INSERT INTO info(name) VALUES(NULL)";
//6.发送sql语句
$result = mysqli_query($link,$sql);
//7.处理结果集
echo mysqli_num_rows($result);
//echo mysqli_affected_rows($link);
//8.关闭数据库
mysqli_close($link);
以上是php访问数据库过程的详细内容。更多详情请关注php中文网其他相关话题文章!
php抓取网页数据插入数据库(如果你是php萌新,我建议你先去看一下php如何链接数据库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2022-01-19 03:03
php如何链接数据库获取数据回前端,简称php如何写接口。
如果你是php新手,建议你先看看php是如何链接数据库的,这个文章,以便更好的理解和学的更透彻!
首先我们来看看跨域,通常我们是这样解决的:
header("Access-Control-Allow-Origin:*"); //跨域名
header("Access-Control-Allow-Headers:*"); //跨端口
这取决于情况。他有很多参数。这是百度。这些都是干货。
//格式,这个也很多,也百度
header("Content-type:text/html;charset=utf-8");
我们先封装代码。PHP 可以导入文件,类似于用 Vue 编写的方式。
我们先创建一个文件:config.php(这是可选的,但通常是这样的)
//为什么要设置 $n=null,避免没有值报错
function db_infos($n = null)
{
/* 数据库主机名称 */
$db_host = '127.0.0.1';
/* 数据库用户帐号 */
$db_user = 'root';
/* 数据库用户密码 */
$db_passw = 'root';
/* 数据库具体名称 */
$db_name = 'root';
if ($n === 1) {
return $db_host;
}
if ($n === 2) {
return $db_user;
}
if ($n === 3) {
return $db_passw;
}
if ($n === 4) {
return $db_name;
}
};
/* 查询 */
//$sql就是数据库语句
function selects($sql = null)
{
if (!$sql) {
$conn = null;
exit;
}
$db_host = db_infos(1);
$db_user = db_infos(2);
$db_passw = db_infos(3);
$db_name = db_infos(4);
$conn = new PDO("mysql:host={$db_host};dbname={$db_name}", $db_user, $db_passw);
$conn->query("SET NAMES utf8");
$conn->setAttribute(PDO::ATTR_ERRMODE, PDO::ERRMODE_EXCEPTION);
$stmt = $conn->query($sql);
$stmt->execute();
$result = $stmt->setFetchMode(PDO::FETCH_ASSOC);
$result = $stmt->fetchAll();
$conn = null;
if (count($result) > 1) {
return $result;
} else {
if(count($result) > 0){
return $result;
}else{
return false;
}
}
}
/* 更新 */
function updates($sql = null)
{
if (!$sql) {
$conn = null;
exit;
}
$db_host = db_infos(1);
$db_user = db_infos(2);
$db_passw = db_infos(3);
$db_name = db_infos(4);
$conn = new PDO("mysql:host={$db_host};dbname={$db_name}", $db_user, $db_passw);
$conn->query("SET NAMES utf8");
$conn->setAttribute(PDO::ATTR_ERRMODE, PDO::ERRMODE_EXCEPTION);
$stmt = $conn->prepare($sql);
$res = $stmt->execute();
$conn = null;
return $res;
}
/* 插入 */
function inserts($sql = null)
{
if (!$sql) {
$conn = null;
exit;
}
$db_host = db_infos(1);
$db_user = db_infos(2);
$db_passw = db_infos(3);
$db_name = db_infos(4);
$conn = new PDO("mysql:host={$db_host};dbname={$db_name}", $db_user, $db_passw);
$conn->query("SET NAMES utf8");
$conn->setAttribute(PDO::ATTR_ERRMODE, PDO::ERRMODE_EXCEPTION);
$stmt = $conn->prepare($sql);
$res = $stmt->execute();
$conn = null;
return $res;
}
/* 删除 */
function deletes($sql)
{
if (!$sql) {
$conn = null;
exit;
}
$db_host = db_infos(1);
$db_user = db_infos(2);
$db_passw = db_infos(3);
$db_name = db_infos(4);
$conn = new PDO("mysql:host={$db_host};dbname={$db_name}", $db_user, $db_passw);
$conn->query("SET NAMES utf8");
$conn->setAttribute(PDO::ATTR_ERRMODE, PDO::ERRMODE_EXCEPTION);
$stmt = $conn->prepare($sql);
$res = $stmt->execute();
$conn = null;
return $res;
}
特别注意 $stmt = $conn->prepare($sql); 查询用query,别人用prepare,别人用query,会报错。
简单封装一下,接下来说说怎么用
例如,如果在 index.php 中引入,则此时可以调用该方法。
include './config.php';
echo selects("SELECT * FROM user WHERE id=1");
现在我们知道如何操作数据库了。这时候还不能算是接口。只有能够获取并返回,才能算是一个接口。现在让我们看看如何获取前端参数:
$data = file_get_contents('php://input');
//格式化一下
$d = json_decode($data);
//获取前端的传递过来的参数,如id
$id = $d->id;
//假如我们需要搜索user表里面id为1的用户
echo selects("SELECT * FROM user WHERE id='{$id}'");
前端ajax、axios等需要设置headers:
headers: {
"Content-type": "application/json; charset=utf-8"
},
至此,你基本上可以编写接口了,但这还不够。一件非常重要的事情是您必须了解数据库语句。不行,懂php也没用,赶紧学数据库语句吧。
我们简单教你几个数据库语句,包括一些基本的增删改查语句:
//查询user表所有
SELECT * FROM user
//查询user表id为1的
SELECT * FROM user WHERE id=1
//修改user表id为1用户的name
UPDATE user SET name='你好' WHERE id='1'
//user插入
INSERT INTO user(name) VALUES('你好2')
//删除
DELETE FROM user WHERE id='1'
如果您知道如何编写数据库语句,则可以处理基础知识。你可以试着做一个简单的博客来试试。 查看全部
php抓取网页数据插入数据库(如果你是php萌新,我建议你先去看一下php如何链接数据库)
php如何链接数据库获取数据回前端,简称php如何写接口。
如果你是php新手,建议你先看看php是如何链接数据库的,这个文章,以便更好的理解和学的更透彻!

首先我们来看看跨域,通常我们是这样解决的:
header("Access-Control-Allow-Origin:*"); //跨域名
header("Access-Control-Allow-Headers:*"); //跨端口
这取决于情况。他有很多参数。这是百度。这些都是干货。
//格式,这个也很多,也百度
header("Content-type:text/html;charset=utf-8");
我们先封装代码。PHP 可以导入文件,类似于用 Vue 编写的方式。
我们先创建一个文件:config.php(这是可选的,但通常是这样的)
//为什么要设置 $n=null,避免没有值报错
function db_infos($n = null)
{
/* 数据库主机名称 */
$db_host = '127.0.0.1';
/* 数据库用户帐号 */
$db_user = 'root';
/* 数据库用户密码 */
$db_passw = 'root';
/* 数据库具体名称 */
$db_name = 'root';
if ($n === 1) {
return $db_host;
}
if ($n === 2) {
return $db_user;
}
if ($n === 3) {
return $db_passw;
}
if ($n === 4) {
return $db_name;
}
};
/* 查询 */
//$sql就是数据库语句
function selects($sql = null)
{
if (!$sql) {
$conn = null;
exit;
}
$db_host = db_infos(1);
$db_user = db_infos(2);
$db_passw = db_infos(3);
$db_name = db_infos(4);
$conn = new PDO("mysql:host={$db_host};dbname={$db_name}", $db_user, $db_passw);
$conn->query("SET NAMES utf8");
$conn->setAttribute(PDO::ATTR_ERRMODE, PDO::ERRMODE_EXCEPTION);
$stmt = $conn->query($sql);
$stmt->execute();
$result = $stmt->setFetchMode(PDO::FETCH_ASSOC);
$result = $stmt->fetchAll();
$conn = null;
if (count($result) > 1) {
return $result;
} else {
if(count($result) > 0){
return $result;
}else{
return false;
}
}
}
/* 更新 */
function updates($sql = null)
{
if (!$sql) {
$conn = null;
exit;
}
$db_host = db_infos(1);
$db_user = db_infos(2);
$db_passw = db_infos(3);
$db_name = db_infos(4);
$conn = new PDO("mysql:host={$db_host};dbname={$db_name}", $db_user, $db_passw);
$conn->query("SET NAMES utf8");
$conn->setAttribute(PDO::ATTR_ERRMODE, PDO::ERRMODE_EXCEPTION);
$stmt = $conn->prepare($sql);
$res = $stmt->execute();
$conn = null;
return $res;
}
/* 插入 */
function inserts($sql = null)
{
if (!$sql) {
$conn = null;
exit;
}
$db_host = db_infos(1);
$db_user = db_infos(2);
$db_passw = db_infos(3);
$db_name = db_infos(4);
$conn = new PDO("mysql:host={$db_host};dbname={$db_name}", $db_user, $db_passw);
$conn->query("SET NAMES utf8");
$conn->setAttribute(PDO::ATTR_ERRMODE, PDO::ERRMODE_EXCEPTION);
$stmt = $conn->prepare($sql);
$res = $stmt->execute();
$conn = null;
return $res;
}
/* 删除 */
function deletes($sql)
{
if (!$sql) {
$conn = null;
exit;
}
$db_host = db_infos(1);
$db_user = db_infos(2);
$db_passw = db_infos(3);
$db_name = db_infos(4);
$conn = new PDO("mysql:host={$db_host};dbname={$db_name}", $db_user, $db_passw);
$conn->query("SET NAMES utf8");
$conn->setAttribute(PDO::ATTR_ERRMODE, PDO::ERRMODE_EXCEPTION);
$stmt = $conn->prepare($sql);
$res = $stmt->execute();
$conn = null;
return $res;
}
特别注意 $stmt = $conn->prepare($sql); 查询用query,别人用prepare,别人用query,会报错。
简单封装一下,接下来说说怎么用
例如,如果在 index.php 中引入,则此时可以调用该方法。
include './config.php';
echo selects("SELECT * FROM user WHERE id=1");
现在我们知道如何操作数据库了。这时候还不能算是接口。只有能够获取并返回,才能算是一个接口。现在让我们看看如何获取前端参数:
$data = file_get_contents('php://input');
//格式化一下
$d = json_decode($data);
//获取前端的传递过来的参数,如id
$id = $d->id;
//假如我们需要搜索user表里面id为1的用户
echo selects("SELECT * FROM user WHERE id='{$id}'");
前端ajax、axios等需要设置headers:
headers: {
"Content-type": "application/json; charset=utf-8"
},
至此,你基本上可以编写接口了,但这还不够。一件非常重要的事情是您必须了解数据库语句。不行,懂php也没用,赶紧学数据库语句吧。
我们简单教你几个数据库语句,包括一些基本的增删改查语句:
//查询user表所有
SELECT * FROM user
//查询user表id为1的
SELECT * FROM user WHERE id=1
//修改user表id为1用户的name
UPDATE user SET name='你好' WHERE id='1'
//user插入
INSERT INTO user(name) VALUES('你好2')
//删除
DELETE FROM user WHERE id='1'
如果您知道如何编写数据库语句,则可以处理基础知识。你可以试着做一个简单的博客来试试。
php抓取网页数据插入数据库(一下怎样看网站日志如何分析吧!(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 50 次浏览 • 2022-02-10 15:01
通过分析网站的日志文件,可以看到用户和搜索引擎访问网站的数据,可以分析用户和搜索引擎对网站的偏好以及< @网站 如何查看 网站 日志。网站日志分析主要是分析蜘蛛爬虫的爬行轨迹。
在蜘蛛爬取和收录的过程中,搜索引擎会将相应数量的资源分配给特定的权重网站如何查看网站的日志。一个对搜索引擎友好的网站应该充分利用这些资源,让蜘蛛快速、准确、全面地抓取用户喜欢的有价值的内容,而不是浪费资源和访问无价值的内容。
接下来,让我们详细了解如何查看网站日志,以及如何分析网站日志!
1 如何查看网站日志、访问次数、停留时间、爬取量
从这三条数据看网站日志可以知道每次爬取的平均页面数,单页爬取的时间,每次停留的平均时间。从这些数据中,我们可以看到爬虫的活跃度、亲和度、爬取深度等。总访问次数、停留时间、爬取量、平均爬取页面,平均停留时间越长,表示网站越被搜索引擎点赞。单页爬取停留时间表示网站页面访问速度。时间越长,网站访问速度越慢,不利于搜索引擎的抓取。我们应该尝试改进 网站 页面加载。速度,减少单页抓取停留时间,让搜索引擎收录更多页面。
2、目录爬取统计
通过对网站日志的分析,可以了解到像网站这样的目录爬虫,爬取目录的深度,重要页面目录的爬取,无效页面目录的爬取等。比较目录中页面的爬取情况和收录的情况可以发现更多问题。对于重要的目录,需要通过内外调整来提高权重和爬取率。对于无效页面,您可以在 robots.txt 中阻止它们。另外,通过网站日志可以看到网站目录的效果,优化是否合理,是否达到了预期的效果。在同一个目录下,从长远来看,我们可以看到这个目录下的页面的表现,
3、页面抓取
在网站的日志分析中,可以看到搜索引擎爬取的具体页面。在这些页面中,你可以分析哪些页面没有被爬取,哪些页面没有价值,哪些重复的URL被爬取等等。你必须充分利用资源,将这些地址添加到robots中。文本文件。另外,还可以分析页面不是收录的原因。对于新的文章,是因为没有被爬取而不是收录,或者是被爬取而不被释放。
4、蜘蛛访问IP
网站降级是否可以通过蜘蛛IP来判断,答案是否定的。网站主要根据前三个数据来判断掉权。如果要通过IP来判断,那是不可能的。
5、访问状态码
蜘蛛通常有 301、404 状态码。如果返回的状态码是 304,那么 网站 还没有被更新。@> 造成不良影响。
6、爬取时间段
通过分析比较搜索引擎的爬取量,可以了解搜索引擎在特定时间的活动情况。通过对比每周的数据,我们可以了解搜索引擎的活跃周期,这对于网站更新内容具有重要意义。
7、搜索引擎爬取路径
在网站日志中可以追踪到特定IP的访问路径,追踪特定搜索引擎的访问路径,发现网站爬取路径的偏好。因此,可以引导搜索引擎进入爬取路径,让搜索引擎爬取更重要、更有价值的内容。
如何查看sql数据库操作日志?
1、首先,在电脑上打开sql server软件,进入软件加载界面。
2、在弹出的connect to server窗口中选择相应信息,登录sql server server。
3、登录成功后,展开“Administration”文件夹,可以看到“SQL Server Logs”文件夹。
4、展开“SQL Server Logs”文件夹可以看到有很多日志文件。
5、右键单击并选择“查看 SQL Server 日志”将其打开。完成以上设置后,即可查看SQL数据库操作日志。
如何查看和分析 网站 日志?
工具/原材料网站服务器,运行网站网站日志分析工具,FTP工具网站日志查看流程登录虚拟主机的管理系统(本经验需以万网为例),输入主机账号和密码,登录。操作如下图:登录系统后台,在“网站文件中找到“weblog日志下载”管理”,然后单击。操作如下图: 点击“weblog 日志下载”,可以看到很多以“ex”时间命名的压缩文件都可以下载。
选择您要下载的 网站 日志并单击下载。操作如下图所示:登录FTP工具,在根目录下找到“”文件,下载所需的压缩文件。注意:不同的程序有不同的日志存储目录。操作如下图: 网上有很多日志分析软件。本次体验以软件“光年seo日志分析系统”为例,点击“新建分析任务”。
操作如下图所示: 在“任务指南”中,根据实际需要更改任务名称和日志类别。一般来说,不需要修改。点击下一步,操作如下图: 接下来,在“任务定位”中添加需要分析的网站日志(即本次体验第三步下载的文件)。添加的文件可以是一个或多个。点击下一步,操作如下图: 继续上一步,在“任务指南”中选择报表保存目录。
<p>点击下一步,操作如下图: 完成后软件会生成一个文件夹,包括一个“report”网页和“files”文件,点击“report”网页查看日志数据 查看全部
php抓取网页数据插入数据库(一下怎样看网站日志如何分析吧!(一))
通过分析网站的日志文件,可以看到用户和搜索引擎访问网站的数据,可以分析用户和搜索引擎对网站的偏好以及< @网站 如何查看 网站 日志。网站日志分析主要是分析蜘蛛爬虫的爬行轨迹。
在蜘蛛爬取和收录的过程中,搜索引擎会将相应数量的资源分配给特定的权重网站如何查看网站的日志。一个对搜索引擎友好的网站应该充分利用这些资源,让蜘蛛快速、准确、全面地抓取用户喜欢的有价值的内容,而不是浪费资源和访问无价值的内容。
接下来,让我们详细了解如何查看网站日志,以及如何分析网站日志!
1 如何查看网站日志、访问次数、停留时间、爬取量
从这三条数据看网站日志可以知道每次爬取的平均页面数,单页爬取的时间,每次停留的平均时间。从这些数据中,我们可以看到爬虫的活跃度、亲和度、爬取深度等。总访问次数、停留时间、爬取量、平均爬取页面,平均停留时间越长,表示网站越被搜索引擎点赞。单页爬取停留时间表示网站页面访问速度。时间越长,网站访问速度越慢,不利于搜索引擎的抓取。我们应该尝试改进 网站 页面加载。速度,减少单页抓取停留时间,让搜索引擎收录更多页面。
2、目录爬取统计
通过对网站日志的分析,可以了解到像网站这样的目录爬虫,爬取目录的深度,重要页面目录的爬取,无效页面目录的爬取等。比较目录中页面的爬取情况和收录的情况可以发现更多问题。对于重要的目录,需要通过内外调整来提高权重和爬取率。对于无效页面,您可以在 robots.txt 中阻止它们。另外,通过网站日志可以看到网站目录的效果,优化是否合理,是否达到了预期的效果。在同一个目录下,从长远来看,我们可以看到这个目录下的页面的表现,
3、页面抓取
在网站的日志分析中,可以看到搜索引擎爬取的具体页面。在这些页面中,你可以分析哪些页面没有被爬取,哪些页面没有价值,哪些重复的URL被爬取等等。你必须充分利用资源,将这些地址添加到robots中。文本文件。另外,还可以分析页面不是收录的原因。对于新的文章,是因为没有被爬取而不是收录,或者是被爬取而不被释放。
4、蜘蛛访问IP
网站降级是否可以通过蜘蛛IP来判断,答案是否定的。网站主要根据前三个数据来判断掉权。如果要通过IP来判断,那是不可能的。
5、访问状态码
蜘蛛通常有 301、404 状态码。如果返回的状态码是 304,那么 网站 还没有被更新。@> 造成不良影响。
6、爬取时间段
通过分析比较搜索引擎的爬取量,可以了解搜索引擎在特定时间的活动情况。通过对比每周的数据,我们可以了解搜索引擎的活跃周期,这对于网站更新内容具有重要意义。
7、搜索引擎爬取路径
在网站日志中可以追踪到特定IP的访问路径,追踪特定搜索引擎的访问路径,发现网站爬取路径的偏好。因此,可以引导搜索引擎进入爬取路径,让搜索引擎爬取更重要、更有价值的内容。
如何查看sql数据库操作日志?
1、首先,在电脑上打开sql server软件,进入软件加载界面。
2、在弹出的connect to server窗口中选择相应信息,登录sql server server。
3、登录成功后,展开“Administration”文件夹,可以看到“SQL Server Logs”文件夹。
4、展开“SQL Server Logs”文件夹可以看到有很多日志文件。
5、右键单击并选择“查看 SQL Server 日志”将其打开。完成以上设置后,即可查看SQL数据库操作日志。
如何查看和分析 网站 日志?
工具/原材料网站服务器,运行网站网站日志分析工具,FTP工具网站日志查看流程登录虚拟主机的管理系统(本经验需以万网为例),输入主机账号和密码,登录。操作如下图:登录系统后台,在“网站文件中找到“weblog日志下载”管理”,然后单击。操作如下图: 点击“weblog 日志下载”,可以看到很多以“ex”时间命名的压缩文件都可以下载。
选择您要下载的 网站 日志并单击下载。操作如下图所示:登录FTP工具,在根目录下找到“”文件,下载所需的压缩文件。注意:不同的程序有不同的日志存储目录。操作如下图: 网上有很多日志分析软件。本次体验以软件“光年seo日志分析系统”为例,点击“新建分析任务”。
操作如下图所示: 在“任务指南”中,根据实际需要更改任务名称和日志类别。一般来说,不需要修改。点击下一步,操作如下图: 接下来,在“任务定位”中添加需要分析的网站日志(即本次体验第三步下载的文件)。添加的文件可以是一个或多个。点击下一步,操作如下图: 继续上一步,在“任务指南”中选择报表保存目录。
<p>点击下一步,操作如下图: 完成后软件会生成一个文件夹,包括一个“report”网页和“files”文件,点击“report”网页查看日志数据
php抓取网页数据插入数据库(利用云服务器基于PHP语言设计网页版调查报告和MySQL数据库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2022-02-09 17:09
学生管理
1.设计问卷内容:必填:身份(设计自己的分类,如:学生/体力劳动者/脑力劳动者) 年龄和性别 可选:自行设计的多项选择题、填空题如:可接受的价格范围(自己设计,可以上限/下限,或者一定值+上下浮动)屏幕尺寸/机器尺寸重量颜色(也可以选择忽略,也就是不要介意)待机时间、拍照质量、音效对以上指标的重要性排序...2.50人填写了问卷,有些问题是必填的,有些问题是不允许回答的3.@ >自行设计数据输入方式(如读取.txt或.xls文件)
代码功能具体说明:1、使用云服务器设计基于PHP语言的网页版调查报告和MySQL数据库;2、邀请好友填写问卷,采集数据,将数据写入数据库实时;3、使用C++语言连接MySQL数据库,读取数据;4、将数据读入对象数组,通过冒泡排序对数据进行排序,方便分类排序的数据。
为了方便测试,将主功能模块做成一个单独的函数,在运行主功能时根据测试目的调用功能模块。这些单独的函数是: 连接 MySQL 数据: void mysqlconnet(); 读取 MySQL 数据库并存储在对象数组中:void read(); 冒泡排序算法对结果进行排序:void sort(yb ybx, int n, int k); 在选项中寻找概率最高的项目:int seeknum(int a);二维数组的初始化:void initResult(int a[9][8]); 统计所有结果的数据量:void count(yb ybx, int k); 统计男生成绩的数据量:void count2(yb ybx, int k); 统计女生成绩的数据量:void count3(yb ybx, int k);计算每个选项的比例:void rate(int a[9][8], double rate[9][8]); 利用冒泡排序算法原理设计的概率从大到小排序:int sort2(double a);使用冒泡排序算法原理设计的概率 从小到大排序: int sort3(double* a); 打印指定选项的内容:void dprint(int c, int bl); 计算选项的数据量和比例:void count4(yb* ybx, int k)。
本程序设计PHP网页版问卷,通过创建数据库保存数据,然后通过C++连接数据库读取数据,最后通过函数和算法对数据进行整合分析。在编写源程序的过程中,网页问卷界面的设计和数据库设计(主要是对数据库中存储的多项选择数据数组的处理。然后是冒泡算法的修改,数据分类,分组分析和统计。 查看全部
php抓取网页数据插入数据库(利用云服务器基于PHP语言设计网页版调查报告和MySQL数据库)
学生管理
1.设计问卷内容:必填:身份(设计自己的分类,如:学生/体力劳动者/脑力劳动者) 年龄和性别 可选:自行设计的多项选择题、填空题如:可接受的价格范围(自己设计,可以上限/下限,或者一定值+上下浮动)屏幕尺寸/机器尺寸重量颜色(也可以选择忽略,也就是不要介意)待机时间、拍照质量、音效对以上指标的重要性排序...2.50人填写了问卷,有些问题是必填的,有些问题是不允许回答的3.@ >自行设计数据输入方式(如读取.txt或.xls文件)
代码功能具体说明:1、使用云服务器设计基于PHP语言的网页版调查报告和MySQL数据库;2、邀请好友填写问卷,采集数据,将数据写入数据库实时;3、使用C++语言连接MySQL数据库,读取数据;4、将数据读入对象数组,通过冒泡排序对数据进行排序,方便分类排序的数据。
为了方便测试,将主功能模块做成一个单独的函数,在运行主功能时根据测试目的调用功能模块。这些单独的函数是: 连接 MySQL 数据: void mysqlconnet(); 读取 MySQL 数据库并存储在对象数组中:void read(); 冒泡排序算法对结果进行排序:void sort(yb ybx, int n, int k); 在选项中寻找概率最高的项目:int seeknum(int a);二维数组的初始化:void initResult(int a[9][8]); 统计所有结果的数据量:void count(yb ybx, int k); 统计男生成绩的数据量:void count2(yb ybx, int k); 统计女生成绩的数据量:void count3(yb ybx, int k);计算每个选项的比例:void rate(int a[9][8], double rate[9][8]); 利用冒泡排序算法原理设计的概率从大到小排序:int sort2(double a);使用冒泡排序算法原理设计的概率 从小到大排序: int sort3(double* a); 打印指定选项的内容:void dprint(int c, int bl); 计算选项的数据量和比例:void count4(yb* ybx, int k)。
本程序设计PHP网页版问卷,通过创建数据库保存数据,然后通过C++连接数据库读取数据,最后通过函数和算法对数据进行整合分析。在编写源程序的过程中,网页问卷界面的设计和数据库设计(主要是对数据库中存储的多项选择数据数组的处理。然后是冒泡算法的修改,数据分类,分组分析和统计。
php抓取网页数据插入数据库(JS与用户进行通讯的时候,可以用prompt和alert)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-02-04 20:17
写在前:JS与用户交流时,可以使用prompt和alert。我们服务器上的PHP程序是如何获取用户数据的呢?干扰程序运行的用户数据。您必须通过 get 和 post 方法。
一、GET 方法
有时在浏览器的地址栏观察网址,发现网络地址是这样的
? 后一部分不会影响我们访问哪个网页。后面k=v的数据是给背景语言的。对前台来说意义不大。
举例说明:
$b = $_GET["名称"];
回声 $b;
请求结果:
获取请求
get:参数都体现在url中,可以用来跳转网页,翻页,做简单的查询。get只能接收2M以下的内容,所以只能输入2048k字节,有局限性。另外,因为内容是可见的,所以降低了安全性,
form表单有两个重要的属性:
● method 属性:提交表单的方法,无论是get 还是post。如果写了get,那么在提交表单的时候,会传递URL地址吗?传递参数。
● action 属性:处理表单的php程序
● name 属性:用于获取ID。
二、数据库写入
SQL 语句中的查询昨天学习了检索所有数据库条目
选择 * FROM 学生;
如果要检索条目,请使用 WHERE 子句:
SELECT * FROM xuesheng WHERE xingming = "小明";
今天要学的是写,也就是“加”
INSERT INTO xuesheng(xingming,nianling,qqhao) VALUES ('koala',20,2435345)
公式:
插入表名(字段 1,字段 2,字段 3) 值(值 1,值 2,值 3)
三、模拟表单接收和数据库写入
创建一个只有表中的字段而没有内容的空白数据库。
HTML页面构建
连接数据库,使用GET方法,获取填充内容,写入数据库
空白数据库
创建数据库
创建完成后内容不填充。
2.HTML页面和填写内容
页面和填充
表单提交和数据库写入模拟
学习进度:
非常快
一般来说
非常慢
学习状态:
非常好
非常好
很差
课程进度:
太快
正好
太慢了
课堂建议:
连接数据库,使用GET方法,获取填充内容,写入数据库
//通过GET请求获取填充内容
$name1 = $_GET["name1"];
$name3 = $_GET["name3"];
$name2 = $_GET["name2"];
$name4 = $_GET["name4"];
//连接数据库
$ccon = mysql_connect("localhost","root","root");
mysql_select_db("学生班级信息",$ccon);
//数据库的写法,其中mysql_query是执行的意思!
$result = mysql_query("INSERT INTO students(xuexijingdu,xuexichuantai,kechengjindu,jianyi) VALUES('{$name1}','{$name2}','{$name3}','{$name4}')") ;
if($result ==1){
echo "表单接收成功!";
}别的{
echo "提交错误请重试!";
}
//关闭数据库
mysql_close($ccon);
实验结果
填写页面内容后,点击提交。
提交完成
数据库信息:
收到的内容
四、在线部署数据库
数据库创建和表单创建类似于 sql_yog 本地部署。
本次演示使用的我的百度云主机,因为只有一个数据库,无法创建另一个数据库进行演示。仅从表的创建开始。
登录主机后端,进入数据库管理页面。这里的数据库管理软件是phpMyAdmin。单击操作开始创建表。
如下;
创建表
将代码上传到服务器:
一共有两个文件HTML和PHP。
超级无敌坑:使用之前的PHP代码上传到服务器,更改连接数据库的地址和密码等错误!!!显示http 500无法完成请求,添加显示具体错误的代码即可找到!
原因:连接PHP的方法只支持PHP5.5以下,尴尬!!!
只有新方法 PDO 和 mysqli 可以使用,后者。
参考连接:MySQL插入数据| 菜鸟教程
//通过GET请求获取填充内容
$name1 = $_GET["name1"];
$name3 = $_GET["name3"];
$name2 = $_GET["name2"];
$name4 = $_GET["name4"];
//这两行代码抛出错误的提示信息,否则新手找不到原因!!!
ini_set("display_errors","On");
错误报告(E_ALL);
//连接数据库
$ccon = mysqli_connect("localhost","root","root");
mysqli_select_db($ccon,"DfvhWrXgzUsreEsAbSNI");
//写入数据库,两个参数
$result = mysqli_query($ccon,"INSERT INTO students(xuexijingdu,xuexichuantai,kechengjindu,jianyi) VALUES('{$name1}','{$name2}','{$name3}','{$name4}' )");
if($result ==1){
echo "表单接收成功!";
}别的{
echo "提交错误请重试!";
}
//关闭数据库
mysqli_close($ccon);
这个废话浪费了我整个下午。麻蛋!
访问域名:
访问服务器页面
点击提交将显示提交成功。数据录入成功
数据显示成功
五、POST 请求
POST请求是将用户的数据传输到服务器,而不是使用URL,而是使用HTTP请求头。
HTTP是消息,请求和响应都是以消息的形式传输的。消息的内容是
就是页面的内容,消息的头部承载了很多信息。
GET 请求很容易生成。每次我们输入一个URL打开网站都是一个GET请求,而GET请求使用的是一个URL。
POST 请求很难自己生成,必须使用表单。
POST 请求的好处:
安全且不会通过 URL 暴露我们的表单;
内容无限制,发帖请求可以无限制,填写表单字段没有问题。
POST请求的缺点:
地址不能共享,显然发布请求不会影响 URL。
鉴于 GET/POST 的优劣对比明显,工程:
GET 请求通常用于检索数据库中的条目,例如 news.php?id=4
POST 请求通常用于提交表单。 查看全部
php抓取网页数据插入数据库(JS与用户进行通讯的时候,可以用prompt和alert)
写在前:JS与用户交流时,可以使用prompt和alert。我们服务器上的PHP程序是如何获取用户数据的呢?干扰程序运行的用户数据。您必须通过 get 和 post 方法。
一、GET 方法
有时在浏览器的地址栏观察网址,发现网络地址是这样的
? 后一部分不会影响我们访问哪个网页。后面k=v的数据是给背景语言的。对前台来说意义不大。
举例说明:
$b = $_GET["名称"];
回声 $b;
请求结果:
获取请求
get:参数都体现在url中,可以用来跳转网页,翻页,做简单的查询。get只能接收2M以下的内容,所以只能输入2048k字节,有局限性。另外,因为内容是可见的,所以降低了安全性,
form表单有两个重要的属性:
● method 属性:提交表单的方法,无论是get 还是post。如果写了get,那么在提交表单的时候,会传递URL地址吗?传递参数。
● action 属性:处理表单的php程序
● name 属性:用于获取ID。
二、数据库写入
SQL 语句中的查询昨天学习了检索所有数据库条目
选择 * FROM 学生;
如果要检索条目,请使用 WHERE 子句:
SELECT * FROM xuesheng WHERE xingming = "小明";
今天要学的是写,也就是“加”
INSERT INTO xuesheng(xingming,nianling,qqhao) VALUES ('koala',20,2435345)
公式:
插入表名(字段 1,字段 2,字段 3) 值(值 1,值 2,值 3)
三、模拟表单接收和数据库写入
创建一个只有表中的字段而没有内容的空白数据库。
HTML页面构建
连接数据库,使用GET方法,获取填充内容,写入数据库
空白数据库
创建数据库
创建完成后内容不填充。
2.HTML页面和填写内容
页面和填充
表单提交和数据库写入模拟
学习进度:
非常快
一般来说
非常慢
学习状态:
非常好
非常好
很差
课程进度:
太快
正好
太慢了
课堂建议:
连接数据库,使用GET方法,获取填充内容,写入数据库
//通过GET请求获取填充内容
$name1 = $_GET["name1"];
$name3 = $_GET["name3"];
$name2 = $_GET["name2"];
$name4 = $_GET["name4"];
//连接数据库
$ccon = mysql_connect("localhost","root","root");
mysql_select_db("学生班级信息",$ccon);
//数据库的写法,其中mysql_query是执行的意思!
$result = mysql_query("INSERT INTO students(xuexijingdu,xuexichuantai,kechengjindu,jianyi) VALUES('{$name1}','{$name2}','{$name3}','{$name4}')") ;
if($result ==1){
echo "表单接收成功!";
}别的{
echo "提交错误请重试!";
}
//关闭数据库
mysql_close($ccon);
实验结果
填写页面内容后,点击提交。
提交完成
数据库信息:
收到的内容
四、在线部署数据库
数据库创建和表单创建类似于 sql_yog 本地部署。
本次演示使用的我的百度云主机,因为只有一个数据库,无法创建另一个数据库进行演示。仅从表的创建开始。
登录主机后端,进入数据库管理页面。这里的数据库管理软件是phpMyAdmin。单击操作开始创建表。
如下;
创建表
将代码上传到服务器:
一共有两个文件HTML和PHP。
超级无敌坑:使用之前的PHP代码上传到服务器,更改连接数据库的地址和密码等错误!!!显示http 500无法完成请求,添加显示具体错误的代码即可找到!
原因:连接PHP的方法只支持PHP5.5以下,尴尬!!!
只有新方法 PDO 和 mysqli 可以使用,后者。
参考连接:MySQL插入数据| 菜鸟教程
//通过GET请求获取填充内容
$name1 = $_GET["name1"];
$name3 = $_GET["name3"];
$name2 = $_GET["name2"];
$name4 = $_GET["name4"];
//这两行代码抛出错误的提示信息,否则新手找不到原因!!!
ini_set("display_errors","On");
错误报告(E_ALL);
//连接数据库
$ccon = mysqli_connect("localhost","root","root");
mysqli_select_db($ccon,"DfvhWrXgzUsreEsAbSNI");
//写入数据库,两个参数
$result = mysqli_query($ccon,"INSERT INTO students(xuexijingdu,xuexichuantai,kechengjindu,jianyi) VALUES('{$name1}','{$name2}','{$name3}','{$name4}' )");
if($result ==1){
echo "表单接收成功!";
}别的{
echo "提交错误请重试!";
}
//关闭数据库
mysqli_close($ccon);
这个废话浪费了我整个下午。麻蛋!
访问域名:
访问服务器页面
点击提交将显示提交成功。数据录入成功
数据显示成功
五、POST 请求
POST请求是将用户的数据传输到服务器,而不是使用URL,而是使用HTTP请求头。
HTTP是消息,请求和响应都是以消息的形式传输的。消息的内容是
就是页面的内容,消息的头部承载了很多信息。
GET 请求很容易生成。每次我们输入一个URL打开网站都是一个GET请求,而GET请求使用的是一个URL。
POST 请求很难自己生成,必须使用表单。
POST 请求的好处:
安全且不会通过 URL 暴露我们的表单;
内容无限制,发帖请求可以无限制,填写表单字段没有问题。
POST请求的缺点:
地址不能共享,显然发布请求不会影响 URL。
鉴于 GET/POST 的优劣对比明显,工程:
GET 请求通常用于检索数据库中的条目,例如 news.php?id=4
POST 请求通常用于提交表单。
php抓取网页数据插入数据库( 自然是从最简单的功能起步,我第一个任务选择了做一个登录操作)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-02-01 21:21
自然是从最简单的功能起步,我第一个任务选择了做一个登录操作)
原来的:
自然,我从最简单的函数开始。我的第一个任务是做一个登录操作,其实并没有我想象的那么简单。
1.首先自然是连接和创建数据库
这部分我写在model.php中
$userName='root';$passWord='';$host='localhost';$dataBase='login';//创建连接$conn=mysqli_connect($host,$userName,$passWord,$dataBase);
2.写首页。为了精通前端框架,使用layui框架做界面。前面有一段js代码判断用户名和密码输入是否为空。
script> 注册登录title>head> function InputCheck(){ if (Login.username.value == "") { alert("请输入用户名!"); Login.username.focus(); return (false); } if (Login.password.value == "") { alert("请输入密码!"); Login.password.focus(); return (false); } }script> 注册登录系统h2> div> 用户名label> div> div> 密 码label> div> div> div> div> form> div> div>div>body>html>
3.login.php 用于判断用户名和密码的正确性。我在网上看到了很多关于这个的方法。在遇到障碍之前,我决定使用一种简单的形式,即使用 sql 语句查询用户名和密码的结果集。如果结果集为空,则用户不存在。
<p> 查看全部
php抓取网页数据插入数据库(
自然是从最简单的功能起步,我第一个任务选择了做一个登录操作)
原来的:
自然,我从最简单的函数开始。我的第一个任务是做一个登录操作,其实并没有我想象的那么简单。
1.首先自然是连接和创建数据库
这部分我写在model.php中
$userName='root';$passWord='';$host='localhost';$dataBase='login';//创建连接$conn=mysqli_connect($host,$userName,$passWord,$dataBase);
2.写首页。为了精通前端框架,使用layui框架做界面。前面有一段js代码判断用户名和密码输入是否为空。
script> 注册登录title>head> function InputCheck(){ if (Login.username.value == "") { alert("请输入用户名!"); Login.username.focus(); return (false); } if (Login.password.value == "") { alert("请输入密码!"); Login.password.focus(); return (false); } }script> 注册登录系统h2> div> 用户名label> div> div> 密 码label> div> div> div> div> form> div> div>div>body>html>
3.login.php 用于判断用户名和密码的正确性。我在网上看到了很多关于这个的方法。在遇到障碍之前,我决定使用一种简单的形式,即使用 sql 语句查询用户名和密码的结果集。如果结果集为空,则用户不存在。
<p>
php抓取网页数据插入数据库(limit子句的记录数和当前是第几页的原理及实现)
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2022-02-01 21:13
1.显示数据到网页
首先,数据库中必须有数据
主要是连接数据库,然后将数据显示在网络上。
web显示
用户ID
用户名称
来自国家
注册时间
2.数据分页显示原理及实现
所谓分页展示,就是通过程序将结果集一块一块的展示出来。分页显示的实现需要两个初始参数,即每页显示多少条记录,当前是哪一页,再加上完整的结果集,才能实现数据的分段显示。
使用limit 子句限制查询结果。例如,要获取表中的前 10 条记录,请使用 select * from table_name limit 0,10;如果要查找记录 11-20,请使用 select * from table_name limit 10,10;如果查找记录 21-30,请使用 select * from table_name from 20,10;
从上面的语句可以看出,每次取10条记录相当于每页显示10条数据,而每次要获取的记录的起始位置与当前页数之间存在这样的关系:starting position= (当前页数-1)x实际每页记录数。如果变量$page_size代表每页显示的记录数,变量$cur_page代表当前页数,上面的语句可以用如下sql语句归纳:
select * from table_name limit ($cur_page-1) * $page_size,$page_size;
下面将在上面代码的基础上添加分页功能
web显示
用户ID
用户名称
来自国家
注册时间
3.从页面获取数据并插入数据库
1.首先创建一个网页供用户提交数据
提交用户信息
提交用户信息
用户名:
来自城市:
北京
伦敦
纽约
巴黎
罗马
 
2.写入对应的php文件,文件名要与from表单中action的值一致
如果想让id自动增加,首先将id设置为AUTO_INCREMENT,修改$sql中的代码行
$sql = "insert into users(name,place,created_time) values('$name','$place',NOW())";
4.编辑用户信息页面
添加了insert语句,编辑需要update语句。
编辑页面与添加页面的样式相同,只是用户信息显示在页面的表单元素中。
-------------首先区分mysql_num_rows(); 和 mysql_fetch_array();------------
-------------------------------------------------- -------------------------------------------------- ----------------
编辑功能需要修改页面和对应的php文件
编辑1.html
<p>
提交用户信息
提交用户信息 查看全部
php抓取网页数据插入数据库(limit子句的记录数和当前是第几页的原理及实现)
1.显示数据到网页
首先,数据库中必须有数据
主要是连接数据库,然后将数据显示在网络上。
web显示
用户ID
用户名称
来自国家
注册时间
2.数据分页显示原理及实现
所谓分页展示,就是通过程序将结果集一块一块的展示出来。分页显示的实现需要两个初始参数,即每页显示多少条记录,当前是哪一页,再加上完整的结果集,才能实现数据的分段显示。
使用limit 子句限制查询结果。例如,要获取表中的前 10 条记录,请使用 select * from table_name limit 0,10;如果要查找记录 11-20,请使用 select * from table_name limit 10,10;如果查找记录 21-30,请使用 select * from table_name from 20,10;
从上面的语句可以看出,每次取10条记录相当于每页显示10条数据,而每次要获取的记录的起始位置与当前页数之间存在这样的关系:starting position= (当前页数-1)x实际每页记录数。如果变量$page_size代表每页显示的记录数,变量$cur_page代表当前页数,上面的语句可以用如下sql语句归纳:
select * from table_name limit ($cur_page-1) * $page_size,$page_size;
下面将在上面代码的基础上添加分页功能
web显示
用户ID
用户名称
来自国家
注册时间
3.从页面获取数据并插入数据库
1.首先创建一个网页供用户提交数据
提交用户信息
提交用户信息
用户名:
来自城市:
北京
伦敦
纽约
巴黎
罗马
 
2.写入对应的php文件,文件名要与from表单中action的值一致
如果想让id自动增加,首先将id设置为AUTO_INCREMENT,修改$sql中的代码行
$sql = "insert into users(name,place,created_time) values('$name','$place',NOW())";
4.编辑用户信息页面
添加了insert语句,编辑需要update语句。
编辑页面与添加页面的样式相同,只是用户信息显示在页面的表单元素中。
-------------首先区分mysql_num_rows(); 和 mysql_fetch_array();------------
-------------------------------------------------- -------------------------------------------------- ----------------
编辑功能需要修改页面和对应的php文件
编辑1.html
<p>
提交用户信息
提交用户信息
php抓取网页数据插入数据库(当做网站有一个站要用到WEB网页采集器功能,解决办法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 126 次浏览 • 2022-01-31 16:08
)
当网站有一个使用WEB页面采集器功能的站,当一个PHP脚本请求一个URL时,请求的网页可能会很慢,超过mysql的wait-timeout时间,那么,当检索网页内容,准备插入MySQL,发现与MySQL的连接因超时关闭,出现“MySQL server has gone away”等错误信息。解决这个问题,有以下两点,或许对大家有用:
1),第一种方法:
当然,它是为了增加你的等待超时值。这个参数是在f中设置的(windows下my.ini是down的),而我的数据库负载稍大,所以我设置为10,(这个值的单位是秒,意思是当一个数据库连接10秒内没有任何操作,会被强制关闭。我用的不是永久链接(mysql_pconnect),而是mysql_connect。可以在MySQL中查看这个wait-timeout的效果(show processlist),可以设置这个wait-timeout要大一点,比如300秒,呵呵,一般来说300秒就够了,其实你也可以不用设置,MySQL默认是8小时。这取决于您的服务器和站点。
2),第二种方法:
即检查MySQL的链接状态并使其重新链接。
可能大家都知道有mysql_ping这样的功能。很多资料中都说mysql_ping的API会检查数据库是否连接。如果断开了,它会尝试重新连接,但是在测试过程中,发现不是这样。有条件的一定要通过mysql_options C API传递相关参数,让MYSQL有断开自动链接的选项(MySQL默认不自动连接),测试发现PHP MySQL API没有携带这个功能,你重新编辑MySQL,呵呵。不过mysql_ping函数终于可以用了,不过里面有个小操作技巧:
这是数据库操作类中间的一个函数
function ping(){
if(!mysql_ping($this->link)){
mysql_close($this->link); //注意:一定要先执行数据库关闭,这是关键
$this->connect();
}
}
调用此函数的代码可能如下所示:
$str = file_get_contents('http://www.baidu.com');
$db->ping();//经过前面的网页抓取后,或者会导致数据库连接关闭,检查并重新连接
$db->query('select * from table');
ping()函数首先检测数据连接是否正常。如果关闭,则关闭当前脚本的整个 MYSQL 实例,然后重新连接。
经过这样的处理,可以非常有效地解决MySQL服务器已经消失的问题,并且不会对系统造成额外的开销。
以上内容希望对大家有所帮助。很多PHPer进阶的时候总会遇到一些问题和瓶颈。当他们编写太多业务代码时,他们没有方向感。我不知道从哪里开始改进。整理了一些资料,包括但不限于:分布式架构、高扩展性、高性能、高并发、服务器性能调优、TP6、laravel、YII2、Redis、Swoole、Swoft、Kafka、Mysql优化、shell脚本、Docker、微服务、Nginx等。多个知识点的进阶、进阶干货,可以免费分享给大家。
PHP Advanced Architect >>> 免费获取视频和面试文件
或关注我们下面的 知乎 栏目
PHP神进阶
查看全部
php抓取网页数据插入数据库(当做网站有一个站要用到WEB网页采集器功能,解决办法
)
当网站有一个使用WEB页面采集器功能的站,当一个PHP脚本请求一个URL时,请求的网页可能会很慢,超过mysql的wait-timeout时间,那么,当检索网页内容,准备插入MySQL,发现与MySQL的连接因超时关闭,出现“MySQL server has gone away”等错误信息。解决这个问题,有以下两点,或许对大家有用:
1),第一种方法:
当然,它是为了增加你的等待超时值。这个参数是在f中设置的(windows下my.ini是down的),而我的数据库负载稍大,所以我设置为10,(这个值的单位是秒,意思是当一个数据库连接10秒内没有任何操作,会被强制关闭。我用的不是永久链接(mysql_pconnect),而是mysql_connect。可以在MySQL中查看这个wait-timeout的效果(show processlist),可以设置这个wait-timeout要大一点,比如300秒,呵呵,一般来说300秒就够了,其实你也可以不用设置,MySQL默认是8小时。这取决于您的服务器和站点。
2),第二种方法:
即检查MySQL的链接状态并使其重新链接。
可能大家都知道有mysql_ping这样的功能。很多资料中都说mysql_ping的API会检查数据库是否连接。如果断开了,它会尝试重新连接,但是在测试过程中,发现不是这样。有条件的一定要通过mysql_options C API传递相关参数,让MYSQL有断开自动链接的选项(MySQL默认不自动连接),测试发现PHP MySQL API没有携带这个功能,你重新编辑MySQL,呵呵。不过mysql_ping函数终于可以用了,不过里面有个小操作技巧:
这是数据库操作类中间的一个函数
function ping(){
if(!mysql_ping($this->link)){
mysql_close($this->link); //注意:一定要先执行数据库关闭,这是关键
$this->connect();
}
}
调用此函数的代码可能如下所示:
$str = file_get_contents('http://www.baidu.com');
$db->ping();//经过前面的网页抓取后,或者会导致数据库连接关闭,检查并重新连接
$db->query('select * from table');
ping()函数首先检测数据连接是否正常。如果关闭,则关闭当前脚本的整个 MYSQL 实例,然后重新连接。
经过这样的处理,可以非常有效地解决MySQL服务器已经消失的问题,并且不会对系统造成额外的开销。
以上内容希望对大家有所帮助。很多PHPer进阶的时候总会遇到一些问题和瓶颈。当他们编写太多业务代码时,他们没有方向感。我不知道从哪里开始改进。整理了一些资料,包括但不限于:分布式架构、高扩展性、高性能、高并发、服务器性能调优、TP6、laravel、YII2、Redis、Swoole、Swoft、Kafka、Mysql优化、shell脚本、Docker、微服务、Nginx等。多个知识点的进阶、进阶干货,可以免费分享给大家。
PHP Advanced Architect >>> 免费获取视频和面试文件
或关注我们下面的 知乎 栏目
PHP神进阶
php抓取网页数据插入数据库(php抓取网页数据插入数据库、调用mysql、redis操作页面)
网站优化 • 优采云 发表了文章 • 0 个评论 • 47 次浏览 • 2022-01-30 21:01
php抓取网页数据插入数据库、调用mysql、redis操作页面等,但很多人都卡在了第三步或第四步。原因有很多,有的是因为看到别人已经做了,心里着急,想超越,有的人是因为经验不足,刚拿到数据时心里怕,总想一口气吃个胖子。面对这种情况,我们应该从以下几个方面下手:第一,要看自己准备用php做什么,因为不同的php框架、不同类型网站,有可能具体实现的处理思路不一样,根据这些思路来在第一阶段确定我们php抓取数据时所用到的工具。
第二,要根据自己的数据量来确定到底要抓取什么数据,是抓取整个页面,还是抓取一部分页面。第三,要根据数据抓取的方式来确定要用php哪一个框架。有的需要调用mysql、有的要操作redis,还有需要调用一些中间件比如swoole,websocket,nginx等等。这些中间件有的在web服务器端,有的在内核或者浏览器中实现。
第四,考虑要抓取什么数据,抓取哪个网站,如果只是需要抓取php自身网站的话,可以参考下官方的api,或者自己写一些代码。如果需要抓取多个网站,比如有的站点php是封装的,自己改不了,还有的站点实际页面数量很少,有一些特殊限制,比如ip的限制,或者说收费的站点。这时建议就写一个爬虫程序就可以了,用户登录之后根据不同的站点请求自己需要抓取的站点,比如哪个页面先存数据后采用服务器php接口等。 查看全部
php抓取网页数据插入数据库(php抓取网页数据插入数据库、调用mysql、redis操作页面)
php抓取网页数据插入数据库、调用mysql、redis操作页面等,但很多人都卡在了第三步或第四步。原因有很多,有的是因为看到别人已经做了,心里着急,想超越,有的人是因为经验不足,刚拿到数据时心里怕,总想一口气吃个胖子。面对这种情况,我们应该从以下几个方面下手:第一,要看自己准备用php做什么,因为不同的php框架、不同类型网站,有可能具体实现的处理思路不一样,根据这些思路来在第一阶段确定我们php抓取数据时所用到的工具。
第二,要根据自己的数据量来确定到底要抓取什么数据,是抓取整个页面,还是抓取一部分页面。第三,要根据数据抓取的方式来确定要用php哪一个框架。有的需要调用mysql、有的要操作redis,还有需要调用一些中间件比如swoole,websocket,nginx等等。这些中间件有的在web服务器端,有的在内核或者浏览器中实现。
第四,考虑要抓取什么数据,抓取哪个网站,如果只是需要抓取php自身网站的话,可以参考下官方的api,或者自己写一些代码。如果需要抓取多个网站,比如有的站点php是封装的,自己改不了,还有的站点实际页面数量很少,有一些特殊限制,比如ip的限制,或者说收费的站点。这时建议就写一个爬虫程序就可以了,用户登录之后根据不同的站点请求自己需要抓取的站点,比如哪个页面先存数据后采用服务器php接口等。
php抓取网页数据插入数据库(php抓取网页数据库这位同学可以先告诉我你想抓哪些内容吗?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2022-01-30 20:03
php抓取网页数据插入数据库
这位同学可以先告诉我你想抓哪些内容吗?抓取贴吧、秒拍、微博,也可以抓取知乎、新浪、腾讯的相册,天猫的商品数据,这么多种内容,目标肯定会是用php+mysql处理。
给你个好的选择。买张、天猫的专线,然后他们的后台数据接入你手上来。你只需要不停抓,不停改,不停发送就行。基本上50w没问题。别忘了,上传要用xmpp。
我也遇到这个问题了,你可以试试我的策略,用的数据接入php的flash和mysql的sqlserver,这样处理效率提高了不少。上传数据可以直接不间断的抓,50万数据量用内存缓存吧,要不你一个接入端口每隔10秒抓一次吧。
50w的php程序,推荐用python,而且采用nodejs,
50w数据量估计你已经测试过了只要抓2~3个帐号就行了即使没测试过你也可以记录下所有用户的信息你的工作量比50w小太多了
关键点在于接入系统和后台数据库可以是php也可以是node.js可以从数据库读取也可以从公网读取,
至少需要抓取50万个用户,发射1亿个僵尸网络...我想你应该用不到
可以结合redis做缓存,
说个用过的,整站,50万多只能做分页, 查看全部
php抓取网页数据插入数据库(php抓取网页数据库这位同学可以先告诉我你想抓哪些内容吗?)
php抓取网页数据插入数据库
这位同学可以先告诉我你想抓哪些内容吗?抓取贴吧、秒拍、微博,也可以抓取知乎、新浪、腾讯的相册,天猫的商品数据,这么多种内容,目标肯定会是用php+mysql处理。
给你个好的选择。买张、天猫的专线,然后他们的后台数据接入你手上来。你只需要不停抓,不停改,不停发送就行。基本上50w没问题。别忘了,上传要用xmpp。
我也遇到这个问题了,你可以试试我的策略,用的数据接入php的flash和mysql的sqlserver,这样处理效率提高了不少。上传数据可以直接不间断的抓,50万数据量用内存缓存吧,要不你一个接入端口每隔10秒抓一次吧。
50w的php程序,推荐用python,而且采用nodejs,
50w数据量估计你已经测试过了只要抓2~3个帐号就行了即使没测试过你也可以记录下所有用户的信息你的工作量比50w小太多了
关键点在于接入系统和后台数据库可以是php也可以是node.js可以从数据库读取也可以从公网读取,
至少需要抓取50万个用户,发射1亿个僵尸网络...我想你应该用不到
可以结合redis做缓存,
说个用过的,整站,50万多只能做分页,
php抓取网页数据插入数据库( PHP访问MySQL数据库的基本步骤-本篇连接 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-01-30 18:19
PHP访问MySQL数据库的基本步骤-本篇连接
)
PHP访问MYSQL数据库的五个步骤详解(图)
数据库在我们日常的PHP开发中是必不可少的,所以MYSQL数据库是很多程序员喜爱的数据库。因为MYSQL是开源的,有一点半商用,市场占有率比较高,所以一直都被认为是PHP的最佳伙伴,而且PHP也有非常强大的数据库支持能力。本文主要讲解PHP访问MySQL数据库的基本步骤。
PHP访问MySQL数据库的基本步骤如图:
1.连接 MySQL 数据库
使用 mysql_connect() 函数建立与 MySQL 服务器的连接。对于mysql_connect()函数的使用,我们后面会详细介绍。
2.选择 MySQL 数据库
使用 mysql_select_db() 函数为 MySQL 数据库服务器选择数据库。并建立与数据库的连接,后面我们会详细讲解mysql_select_db()函数的使用。
3.执行SQL语句
使用 mysql_query() 函数在选定的数据库中执行 SQL 语句。操作数据的方式主要有5种。下面我们将分别介绍。
mysql_query()函数的具体使用后面会介绍~
4.关闭结果集
数据库操作完成后,需要关闭结果集以释放系统资源。语法格式如下:
mysql_free_result($result);
技能:
如果在多个网页中需要频繁访问数据库,可以建立与数据库服务器的连续连接以提高效率,因为每次连接到数据库服务器都需要较长的时间和较大的资源开销,而连续连接相对而言是更高效的说建立持久连接的方式是在数据库间接时调用函数mysql_pconnect()而不是mysql_connect函数。建立的持久连接不需要在本程序结束时调用mysql_colse()关闭与数据库服务器的连接。下次程序在这里执行mysql_pconnect()函数时,系统会自动返回已经建立的长连接的ID号,而不是实际连接数据库。
5.关闭 MySQL 服务器
mysql_connect()或者mysql_query()函数一次不使用的话,会消耗系统资源,小部分用户下完网的时候问题不大网站,但是如果用户连接数多超过一定数量,系统性能会下降。甚至崩溃,为了避免这种现象,在完成数据库操作后,应该使用mysql_close()函数关闭与MYSQL服务器的连接,以节省系统资源。
语法格式如下:
mysql_close($link);
操作说明:
PHP中与数据库的连接是非持久连接,系统会自动回收。一般不需要设置为关闭。但是如果一次性的范湖结果集比较大,或者网站的流量比较贵,那么最好使用mysql_close()函数手动释放。
PHP访问MySQL数据库的步骤到此结束。是不是很简单?下面文章我们将介绍PHP操作MySQL数据库的方法。数据库”
以上就是PHP访问MYSQL数据库的五个步骤的详细内容(图)。
查看全部
php抓取网页数据插入数据库(
PHP访问MySQL数据库的基本步骤-本篇连接
)
PHP访问MYSQL数据库的五个步骤详解(图)
数据库在我们日常的PHP开发中是必不可少的,所以MYSQL数据库是很多程序员喜爱的数据库。因为MYSQL是开源的,有一点半商用,市场占有率比较高,所以一直都被认为是PHP的最佳伙伴,而且PHP也有非常强大的数据库支持能力。本文主要讲解PHP访问MySQL数据库的基本步骤。
PHP访问MySQL数据库的基本步骤如图:
1.连接 MySQL 数据库
使用 mysql_connect() 函数建立与 MySQL 服务器的连接。对于mysql_connect()函数的使用,我们后面会详细介绍。
2.选择 MySQL 数据库
使用 mysql_select_db() 函数为 MySQL 数据库服务器选择数据库。并建立与数据库的连接,后面我们会详细讲解mysql_select_db()函数的使用。
3.执行SQL语句
使用 mysql_query() 函数在选定的数据库中执行 SQL 语句。操作数据的方式主要有5种。下面我们将分别介绍。
mysql_query()函数的具体使用后面会介绍~
4.关闭结果集
数据库操作完成后,需要关闭结果集以释放系统资源。语法格式如下:
mysql_free_result($result);
技能:
如果在多个网页中需要频繁访问数据库,可以建立与数据库服务器的连续连接以提高效率,因为每次连接到数据库服务器都需要较长的时间和较大的资源开销,而连续连接相对而言是更高效的说建立持久连接的方式是在数据库间接时调用函数mysql_pconnect()而不是mysql_connect函数。建立的持久连接不需要在本程序结束时调用mysql_colse()关闭与数据库服务器的连接。下次程序在这里执行mysql_pconnect()函数时,系统会自动返回已经建立的长连接的ID号,而不是实际连接数据库。
5.关闭 MySQL 服务器
mysql_connect()或者mysql_query()函数一次不使用的话,会消耗系统资源,小部分用户下完网的时候问题不大网站,但是如果用户连接数多超过一定数量,系统性能会下降。甚至崩溃,为了避免这种现象,在完成数据库操作后,应该使用mysql_close()函数关闭与MYSQL服务器的连接,以节省系统资源。
语法格式如下:
mysql_close($link);
操作说明:
PHP中与数据库的连接是非持久连接,系统会自动回收。一般不需要设置为关闭。但是如果一次性的范湖结果集比较大,或者网站的流量比较贵,那么最好使用mysql_close()函数手动释放。
PHP访问MySQL数据库的步骤到此结束。是不是很简单?下面文章我们将介绍PHP操作MySQL数据库的方法。数据库”
以上就是PHP访问MYSQL数据库的五个步骤的详细内容(图)。
php抓取网页数据插入数据库(PHP和MySQL的初学者学习法(一)学习笔记)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-30 12:01
封面人物
刘成玉
前言
这是我学习“PHP and MySQL Web Development”的阅读笔记。我会记录一些重要的知识点,当然只写我认为重要的。
如果有人有幸看到这个学习笔记,你应该结合本书阅读它,而不仅仅是这个笔记。在笔记中,我会记录我在学习中遇到的一些问题以及解决方法和注意事项。为了方便管理和查找,文章或者我在书中整理的笔记目录,方便对比。不教!重要的事情再说一遍!我是 PHP 和 MySQL 的初学者。我自己就是前端。我学会了拓宽面向薪水编程的知识。其实我还是有一些个人意见的,因为都说教法和小黄鸭调试法,这就是小老虎的学习法,我把知识点教给小老虎,保证我学的扎实并且可以赚钱。欢迎讨论和建议,
本章主要介绍:
仔细看,每一章前的说明,本章的主要内容,基本都是你需要掌握的。读完一章后,回来查看这份清单。开始吧。
10.1 什么是 SQL?SQL的全称是结构化查询语言。它是访问关系数据库管理系统的标准语言。
结构化查询语言结构化查询语言,结构化,阅读 ['strʌktʃəd]。
用于定义数据库的数据定义语言(Data Definition Language,DDL)和用于查询数据库的数据操作语言(Data Manipulation Language,DML)。SQL 收录这两个基本部分。10.2 在数据库中插入数据
插入语句通常具有以下格式:
插入 [INTO] 表 [(col1,col2,col3,...)] 值 (value1,value2,value3,...);
书中给出的例子:
插入客户值(null,'Julie Smith','25 Oak Street','Airport West');
看书能看懂吗?
重要提示:mysql 中的字符串应该用一对单引号或双引号括起来。
使用insert语句指定将插入的值按照插入的顺序添加到表中的列中。
如果不按列顺序添加,按如下方式指定要添加的列:(例如只更新用户名)
insert into customers (name,city) values('Melissa Jones','Nar Nar Goon North');
或者
insert into customers
->set name = '李重楼',
->address = '莲花池水沟子',
->city = '北京';
不过,好好看看为什么customerid列被指定为null?(一会儿结合查询看看查询结果,customerid列的值是多少。)
插入多条数据时,参考程序清单10-1,每个括号为一条数据,括号之间用逗号隔开。
LOW_PRIORITY 关键字
LOW_PRIORITY 低优先级,主动降低语句执行的优先级。(只是为了理解,问了后端和爬虫的同事,说用处不大……)
MySQL的默认调度策略可用,总结如下:
· 写操作优先于读操作。
· 对数据表的写操作一次只能发生一次,并且写请求按照它们到达的顺序进行处理。
· 可以同时对一个数据表执行多个读取操作。
延迟关键字
DELAYED 延迟,延迟插入。我也先明白这一点。如果我以后看到一些重要的东西,我会回来修改并在这里添加。
DELAYED 修饰符适用于 INSERT 和 REPLACE 语句。当 DELAYED 插入操作到达时,服务器将数据行放入队列,并立即向客户端返回状态消息,以便客户端可以继续操作,直到表实际插入记录。10.3 从数据库中获取数据
前面的基本格式我就不写了。它太长了。关键是,我懒得打字了。
这里有一个重要的解释:from是from..意思是F!!啊!!哦!!!米!!!形式是形式!!!别搞错了,当出现问题时检查这个命令关键字!再看表名!列名中有错字吗?少S,多S什么的!这都是用血和泪换来的经验!好好记住~好!!!
上面那个红字其实是我第一次看书练代码的时候写的,这里也写了。希望它可以帮助你。
书上的代码后面一定要打字。有必要熟悉它并找出问题所在。比如我用bookorama账号登录数据库的时候,查询结果就变成了乱码。首先,我确定这是一个编码问题。然后google了怎么解决,但是不敢改,因为我用的是公司项目的开发版数据库。虽然有正式版作为后盾,但我不得不权衡随机的配置变化。所以,在这里我先放手。(如果你解决了,告诉我怎么解决。我这里的编码是utf8mb4。还请告诉我root没有乱,但是bookorama为什么乱了,谢谢。)
select name ,city from customers;
通过在 select 关键字后面给出列名,可以指定(查询)任意数量的列。
一种有用的方法是通配符“*”(星号),它匹配指定表中的所有列。
现在,尝试使用通配符查询客户表,看看在插入数据时指定为 null 或空的 customerid 列的值将有助于您了解自增。
查询结果如下:(我自己改了一些数据,可能和你的不一样,大家理解一下)
+------------+-----------------+--------------------+--------------------+
| customerid | name | address | city |
+------------+-----------------+--------------------+--------------------+
| 1 | 刘能 | 牡丹江大街 | 牡丹江 |
| 2 | 李重楼 | 北京中 | 北京 |
| 3 | 谢广坤 | 保定市徐水县 | 保定 |
| 4 | Alan Wong | 1/47 Haines Avenue | 保定 |
| 5 | Michelle Arthur | 357 North Road | Yarraville |
| 6 | Melissa Jones | c3-1 | Nar Nar Goon North |
+------------+-----------------+--------------------+--------------------+
另一个是,如果你不知道当前表,或者你需要操作的表中收录哪些列、列名、数据类型和主键,你不会忘记下面的命令吗?
describe tablename;
查询结果如下:(客户表结果)
+------------+-----------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+------------+-----------+------+-----+---------+----------------+
| customerid | int(11) | NO | PRI | NULL | auto_increment |
| name | char(70) | NO | | NULL | |
| address | char(100) | NO | | NULL | |
| city | char(30) | NO | | NULL | |
+------------+-----------+------+-----+---------+----------------+
10.3.1获取满足条件的数据 WHERE语句指定选择特定行的条件。
先翻一页,看一下select查询语句基本格式中where的样式。
它用方括号括起来表示可选。也就是说,您可以根据需要添加它。所以,你必须学会阅读基本格式。
select *
from orders
where customerid= 3;
可以看到命令在一个分支中,也可以回车输入一个分支,也可以输入一行。不同的是,如果键入一个分支,MySQL 可以方便地指出哪一行是错误的。(我都是在一行里打出来的,方便按键盘上的方向键切换语句)
我书中的命令是customerid = 3,但书中说将选择customerid 5的行。我觉得写错了。查询应该是根据条件查询的结果,一切以实际操作结果为准。(我的书是原书的第四版,如果不是编辑不改,那他妈就是盗版问题。)
表10-1列出了常用的比较运算符,你自己看看,你可以全部操作看看效果。
特别列出 BETWEEN 列:(之间是这样使用的)
select * from customers where customerid between 10 and 16;
然后使用条件尝试 AND 和 OR 组合。
10.3.2 从多个表中获取数据
本节的画龙点睛到此。其实数据库的画龙点睛也是一句话。(在我看来)
用数据回答问题。
开始吧。
这些数据分布在不同的表中,因为它们与现实世界的对象相关。
书上说是在第8章介绍的。
在创建数据库时,我们经常对现实世界的实体和关系进行建模,并存储有关这些实体对象和关系的信息。
要将这些信息放在 SQL 中,必须执行称为关联的操作。简单来说,这意味着需要根据数据之间的关系将两个或多个表关联在一起。
1.简单关联
select orders.orderid,orders.amount,orders.date
from customers,orders
where customers.name='Julie Smith'
and
customers.customerid = orders.customerid;
要记住的重要关联规则:
因为这个查询是使用来自两个表的信息完成的,所以我们必须在此处列出两个表。(在您的查询中,您需要列出您要查询的列数据来自哪个数据表。)
表名之间的逗号相当于输入 INNER JOIN 或 CROSS JOIN。
有时也称为表的完全关联或笛卡尔积。
笛卡尔积......这有点神秘。给数学不好的同学解释一下:(二乘二?)
简单来说,就是两个集合相乘的结果。
具体定义见代数系统一书中的定义。
直觉上是
设置 A{a1,a2,a3} 设置 B{b1,b2}
他们的笛卡尔积是 A*B ={(a1,b1),(a1,b2),(a2,b1),(a2,b2) ,( a3,b1),(a3,b2)}
任意两个元素组合
然后书上说,这是没有意义的。真的没有意义,你输入select * from customers, orders;您将看到这两个数据表的笛卡尔积。我就不贴了,太长了。
因此,我们需要通过where子句使用关联条件来过滤掉有意义的数据。
书中给出了示例(customers.name='Julie Smith' and customers.customerid = orders.customerid;)来过滤掉Julie Smith 的订单。
摘要:确定需要哪些数据列。如果当前数据表不收录数据列,则需要导入收录该数据列的数据表。这两个数据表一下子就完全相关了!(此时你想要的数据格式已经出现了,但是有N种,你不知道是哪一种!)通过where子句提供过滤条件,得到过滤结果。 查看全部
php抓取网页数据插入数据库(PHP和MySQL的初学者学习法(一)学习笔记)
封面人物
刘成玉
前言
这是我学习“PHP and MySQL Web Development”的阅读笔记。我会记录一些重要的知识点,当然只写我认为重要的。
如果有人有幸看到这个学习笔记,你应该结合本书阅读它,而不仅仅是这个笔记。在笔记中,我会记录我在学习中遇到的一些问题以及解决方法和注意事项。为了方便管理和查找,文章或者我在书中整理的笔记目录,方便对比。不教!重要的事情再说一遍!我是 PHP 和 MySQL 的初学者。我自己就是前端。我学会了拓宽面向薪水编程的知识。其实我还是有一些个人意见的,因为都说教法和小黄鸭调试法,这就是小老虎的学习法,我把知识点教给小老虎,保证我学的扎实并且可以赚钱。欢迎讨论和建议,
本章主要介绍:
仔细看,每一章前的说明,本章的主要内容,基本都是你需要掌握的。读完一章后,回来查看这份清单。开始吧。
10.1 什么是 SQL?SQL的全称是结构化查询语言。它是访问关系数据库管理系统的标准语言。
结构化查询语言结构化查询语言,结构化,阅读 ['strʌktʃəd]。
用于定义数据库的数据定义语言(Data Definition Language,DDL)和用于查询数据库的数据操作语言(Data Manipulation Language,DML)。SQL 收录这两个基本部分。10.2 在数据库中插入数据
插入语句通常具有以下格式:
插入 [INTO] 表 [(col1,col2,col3,...)] 值 (value1,value2,value3,...);
书中给出的例子:
插入客户值(null,'Julie Smith','25 Oak Street','Airport West');
看书能看懂吗?
重要提示:mysql 中的字符串应该用一对单引号或双引号括起来。
使用insert语句指定将插入的值按照插入的顺序添加到表中的列中。
如果不按列顺序添加,按如下方式指定要添加的列:(例如只更新用户名)
insert into customers (name,city) values('Melissa Jones','Nar Nar Goon North');
或者
insert into customers
->set name = '李重楼',
->address = '莲花池水沟子',
->city = '北京';
不过,好好看看为什么customerid列被指定为null?(一会儿结合查询看看查询结果,customerid列的值是多少。)
插入多条数据时,参考程序清单10-1,每个括号为一条数据,括号之间用逗号隔开。
LOW_PRIORITY 关键字
LOW_PRIORITY 低优先级,主动降低语句执行的优先级。(只是为了理解,问了后端和爬虫的同事,说用处不大……)
MySQL的默认调度策略可用,总结如下:
· 写操作优先于读操作。
· 对数据表的写操作一次只能发生一次,并且写请求按照它们到达的顺序进行处理。
· 可以同时对一个数据表执行多个读取操作。
延迟关键字
DELAYED 延迟,延迟插入。我也先明白这一点。如果我以后看到一些重要的东西,我会回来修改并在这里添加。
DELAYED 修饰符适用于 INSERT 和 REPLACE 语句。当 DELAYED 插入操作到达时,服务器将数据行放入队列,并立即向客户端返回状态消息,以便客户端可以继续操作,直到表实际插入记录。10.3 从数据库中获取数据
前面的基本格式我就不写了。它太长了。关键是,我懒得打字了。
这里有一个重要的解释:from是from..意思是F!!啊!!哦!!!米!!!形式是形式!!!别搞错了,当出现问题时检查这个命令关键字!再看表名!列名中有错字吗?少S,多S什么的!这都是用血和泪换来的经验!好好记住~好!!!
上面那个红字其实是我第一次看书练代码的时候写的,这里也写了。希望它可以帮助你。
书上的代码后面一定要打字。有必要熟悉它并找出问题所在。比如我用bookorama账号登录数据库的时候,查询结果就变成了乱码。首先,我确定这是一个编码问题。然后google了怎么解决,但是不敢改,因为我用的是公司项目的开发版数据库。虽然有正式版作为后盾,但我不得不权衡随机的配置变化。所以,在这里我先放手。(如果你解决了,告诉我怎么解决。我这里的编码是utf8mb4。还请告诉我root没有乱,但是bookorama为什么乱了,谢谢。)
select name ,city from customers;
通过在 select 关键字后面给出列名,可以指定(查询)任意数量的列。
一种有用的方法是通配符“*”(星号),它匹配指定表中的所有列。
现在,尝试使用通配符查询客户表,看看在插入数据时指定为 null 或空的 customerid 列的值将有助于您了解自增。
查询结果如下:(我自己改了一些数据,可能和你的不一样,大家理解一下)
+------------+-----------------+--------------------+--------------------+
| customerid | name | address | city |
+------------+-----------------+--------------------+--------------------+
| 1 | 刘能 | 牡丹江大街 | 牡丹江 |
| 2 | 李重楼 | 北京中 | 北京 |
| 3 | 谢广坤 | 保定市徐水县 | 保定 |
| 4 | Alan Wong | 1/47 Haines Avenue | 保定 |
| 5 | Michelle Arthur | 357 North Road | Yarraville |
| 6 | Melissa Jones | c3-1 | Nar Nar Goon North |
+------------+-----------------+--------------------+--------------------+
另一个是,如果你不知道当前表,或者你需要操作的表中收录哪些列、列名、数据类型和主键,你不会忘记下面的命令吗?
describe tablename;
查询结果如下:(客户表结果)
+------------+-----------+------+-----+---------+----------------+
| Field | Type | Null | Key | Default | Extra |
+------------+-----------+------+-----+---------+----------------+
| customerid | int(11) | NO | PRI | NULL | auto_increment |
| name | char(70) | NO | | NULL | |
| address | char(100) | NO | | NULL | |
| city | char(30) | NO | | NULL | |
+------------+-----------+------+-----+---------+----------------+
10.3.1获取满足条件的数据 WHERE语句指定选择特定行的条件。
先翻一页,看一下select查询语句基本格式中where的样式。
它用方括号括起来表示可选。也就是说,您可以根据需要添加它。所以,你必须学会阅读基本格式。
select *
from orders
where customerid= 3;
可以看到命令在一个分支中,也可以回车输入一个分支,也可以输入一行。不同的是,如果键入一个分支,MySQL 可以方便地指出哪一行是错误的。(我都是在一行里打出来的,方便按键盘上的方向键切换语句)
我书中的命令是customerid = 3,但书中说将选择customerid 5的行。我觉得写错了。查询应该是根据条件查询的结果,一切以实际操作结果为准。(我的书是原书的第四版,如果不是编辑不改,那他妈就是盗版问题。)
表10-1列出了常用的比较运算符,你自己看看,你可以全部操作看看效果。
特别列出 BETWEEN 列:(之间是这样使用的)
select * from customers where customerid between 10 and 16;
然后使用条件尝试 AND 和 OR 组合。
10.3.2 从多个表中获取数据
本节的画龙点睛到此。其实数据库的画龙点睛也是一句话。(在我看来)
用数据回答问题。
开始吧。
这些数据分布在不同的表中,因为它们与现实世界的对象相关。
书上说是在第8章介绍的。
在创建数据库时,我们经常对现实世界的实体和关系进行建模,并存储有关这些实体对象和关系的信息。
要将这些信息放在 SQL 中,必须执行称为关联的操作。简单来说,这意味着需要根据数据之间的关系将两个或多个表关联在一起。
1.简单关联
select orders.orderid,orders.amount,orders.date
from customers,orders
where customers.name='Julie Smith'
and
customers.customerid = orders.customerid;
要记住的重要关联规则:
因为这个查询是使用来自两个表的信息完成的,所以我们必须在此处列出两个表。(在您的查询中,您需要列出您要查询的列数据来自哪个数据表。)
表名之间的逗号相当于输入 INNER JOIN 或 CROSS JOIN。
有时也称为表的完全关联或笛卡尔积。
笛卡尔积......这有点神秘。给数学不好的同学解释一下:(二乘二?)
简单来说,就是两个集合相乘的结果。
具体定义见代数系统一书中的定义。
直觉上是
设置 A{a1,a2,a3} 设置 B{b1,b2}
他们的笛卡尔积是 A*B ={(a1,b1),(a1,b2),(a2,b1),(a2,b2) ,( a3,b1),(a3,b2)}
任意两个元素组合
然后书上说,这是没有意义的。真的没有意义,你输入select * from customers, orders;您将看到这两个数据表的笛卡尔积。我就不贴了,太长了。
因此,我们需要通过where子句使用关联条件来过滤掉有意义的数据。
书中给出了示例(customers.name='Julie Smith' and customers.customerid = orders.customerid;)来过滤掉Julie Smith 的订单。
摘要:确定需要哪些数据列。如果当前数据表不收录数据列,则需要导入收录该数据列的数据表。这两个数据表一下子就完全相关了!(此时你想要的数据格式已经出现了,但是有N种,你不知道是哪一种!)通过where子句提供过滤条件,得到过滤结果。
php抓取网页数据插入数据库( 手把手一起搭建学生信息管理页-使用phpBLOB图片到MySQL)
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2022-01-30 11:22
手把手一起搭建学生信息管理页-使用phpBLOB图片到MySQL)
【完整页面】PHP搭建的学生信息管理页面,PHP使用BLOB数据格式将图片保存到MySQL,然后前端调用MySQL数据显示在页面上
最近开始用php做一些开发工作,研究了LAMP(Linux、Apache、MySQL、php),很有意思。
在我的工作中,我需要:
使用php读取图像,将其转换为BLOB格式并存储在MySQL中。使用php读取MySQL中BLOB格式的数据,翻译成图片,展示在网页上。
使用php连接MySQL数据库,然后将数据导入MySQL数据库。总结了自己实践php + MySQL的过程,写了一篇文章《一起搭建学生信息管理页面——使用PHP访问BLOB图片到MySQL》教程。
在本教程中,您将学习:
如何在MySQL中创建适合存储“学生信息”的数据库【姓名(中文)、年龄(数字)、照片(图片或文件)】 如何使用php连接MySQL数据库 如何使用php将学生信息导入到MySQL数据库(店铺名称、年龄、照片)如何使用php读取数据库中的学生信息并显示在网页中
在教程的最后,它还将教你高级游戏玩法。5分钟快速搭建真正的“学生信息管理系统”,前端可直接对数据库进行增删改查。不需要懂前端,只要会写简单的MySQL,就可以快速上手。
教程太长,内容很多。单击此处查看教程的完整版本。
如果本教程对你有帮助,请点个赞并去:)欢迎交流。 查看全部
php抓取网页数据插入数据库(
手把手一起搭建学生信息管理页-使用phpBLOB图片到MySQL)
【完整页面】PHP搭建的学生信息管理页面,PHP使用BLOB数据格式将图片保存到MySQL,然后前端调用MySQL数据显示在页面上
最近开始用php做一些开发工作,研究了LAMP(Linux、Apache、MySQL、php),很有意思。
在我的工作中,我需要:
使用php读取图像,将其转换为BLOB格式并存储在MySQL中。使用php读取MySQL中BLOB格式的数据,翻译成图片,展示在网页上。
使用php连接MySQL数据库,然后将数据导入MySQL数据库。总结了自己实践php + MySQL的过程,写了一篇文章《一起搭建学生信息管理页面——使用PHP访问BLOB图片到MySQL》教程。
在本教程中,您将学习:
如何在MySQL中创建适合存储“学生信息”的数据库【姓名(中文)、年龄(数字)、照片(图片或文件)】 如何使用php连接MySQL数据库 如何使用php将学生信息导入到MySQL数据库(店铺名称、年龄、照片)如何使用php读取数据库中的学生信息并显示在网页中
在教程的最后,它还将教你高级游戏玩法。5分钟快速搭建真正的“学生信息管理系统”,前端可直接对数据库进行增删改查。不需要懂前端,只要会写简单的MySQL,就可以快速上手。
教程太长,内容很多。单击此处查看教程的完整版本。
如果本教程对你有帮助,请点个赞并去:)欢迎交流。
php抓取网页数据插入数据库(可轻运维全球90%以上主流开源及商业数据库(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 74 次浏览 • 2022-01-25 04:12
阿里云 > 云栖社区 > 主题图 > P > php获取一列数据库
推荐活动:
更多优惠>
当前主题: php 从数据库中取出一列并将其添加到集合中
相关话题:
php 从数据库中获取相关博客列表 查看更多博客
云数据库产品概述
作者:阿里云官网
ApsaraDB是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上的主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为POLARDB提供6倍以上开源数据库的性能和开源的价格源数据库和自研的具有数百TB数据实时计算能力的HybridDB数据库等,并拥有容灾、备份、恢复、监控、迁移等一整套解决方案。
现在查看
php本机代码从数据库中获取记录
作者:Tech Fatty 771 浏览评论:04年前
db.php 1 2 3 4 5 6 7
阅读全文
Mysql数据库的介绍与分类(学习笔记一)
作者:sktj1213 人浏览评论:03年前
数据库介绍及常用数据库分类1.1数据库介绍1.1.1什么是数据库?简单的说,数据库(因为Database)就是存储数据的仓库。这个仓库是按照一定的数据结构组织和存储的(数据结构是指数据的组织形式或数据之间的联系)。我们可以使用数据库来组织和存储数据。各种优惠
阅读全文
Python 全栈 MongoDB 数据库(概念、安装、创建数据)
作者:Paris Champs 6839 浏览评论:03 年前
什么是关系数据库?它是基于关系数据库模型的数据库。它借助集合代数等概念和方法处理数据库中的数据。它也是一组表(二维表)组织成一组正式的描述。表的本质是数据项的特殊集合,这些表中的数据可以通过多种不同的方式访问
阅读全文
一小时学会MySQL数据库
作者:张果2052 浏览评论:04年前
随着移动互联网的终结和人工智能的到来,大数据变得越来越重要,下一个成功的人应该拥有海量数据。您应该了解数据和数据库。一、数据库概要数据库(Database)是一个用于存储和管理数据的软件系统,就像存储数据的物流仓库一样。在商业领域,信息意味着商机,意味着获取信息的能力
阅读全文
PHP开发中数据库及相关软件的选择注意事项
作者:科技小美1080 浏览评论:04年前
PHP的版本不同。4.0系列有4.4.x已经停止升级和开发,但仍有部分生产环境运行此版本,代码需要维护。PHP 5.0系列是目前开发应用的主流版本,有5.1.x和5.2.x系列。PHP6.0还是试用版,使用PHP开发软件
阅读全文
数据库注释 5:外键的用途
作者:1152人科技小大人查看评论:04年前
外键的作用:维护数据的一致性和完整性,主要目的是控制外键表中存储的数据。要关联两个表,外键只能引用外表中列的值!例如:ab 两个表中a 表有客户编号,客户名称b 表有每个客户的订单。使用外键只能确保b表中没有客户x的订单。
阅读全文
在 Android 开发中使用 SQLite 数据库
作者:Silencer 1306 浏览评论:04年前
SQLite 是一个非常流行的嵌入式数据库,它支持 SQL 查询并且使用很少的内存。Android 在运行时集成了 SQLite,因此每个 Android 应用程序都可以使用 SQLite 数据库。对于熟悉 SQL 的开发人员来说,使用 SQLite 相当简单
阅读全文
WordPress数据库研究
作者:ap0581w9c1121 浏览评论:08年前
本系列文章将详细介绍WordPress数据的整体设计思路,10个WordPress数据表的设计,以及用户信息、分类信息、链接信息、文章信息、文章将详细介绍评论信息和基本设置信息等六类信息。WordPress数据库研究
阅读全文
php从数据库中取一列相关问答
【javascript学习全家桶】934道JavaScript热门问题,上百位阿里巴巴技术专家答疑解惑
作者:管理贝贝5207 浏览评论:13年前
阿里极客公益活动:也许你只是因为一个问题而夜战,也许你迷茫只求答案,也许你因为一个未知数而绞尽脑汁,所以他们来了,阿里巴巴技术专家来云栖Q&A为你解答技术问题他们用自己手中的技术来帮助用户成长。本次活动特邀100阿里巴巴科技
阅读全文 查看全部
php抓取网页数据插入数据库(可轻运维全球90%以上主流开源及商业数据库(组图))
阿里云 > 云栖社区 > 主题图 > P > php获取一列数据库
推荐活动:
更多优惠>
当前主题: php 从数据库中取出一列并将其添加到集合中
相关话题:
php 从数据库中获取相关博客列表 查看更多博客
云数据库产品概述
作者:阿里云官网
ApsaraDB是稳定、可靠、可弹性扩展的在线数据库服务产品的总称。可以轻松运维全球90%以上的主流开源和商业数据库(MySQL、SQL Server、Redis等),同时为POLARDB提供6倍以上开源数据库的性能和开源的价格源数据库和自研的具有数百TB数据实时计算能力的HybridDB数据库等,并拥有容灾、备份、恢复、监控、迁移等一整套解决方案。
现在查看
php本机代码从数据库中获取记录
作者:Tech Fatty 771 浏览评论:04年前
db.php 1 2 3 4 5 6 7
阅读全文
Mysql数据库的介绍与分类(学习笔记一)
作者:sktj1213 人浏览评论:03年前
数据库介绍及常用数据库分类1.1数据库介绍1.1.1什么是数据库?简单的说,数据库(因为Database)就是存储数据的仓库。这个仓库是按照一定的数据结构组织和存储的(数据结构是指数据的组织形式或数据之间的联系)。我们可以使用数据库来组织和存储数据。各种优惠
阅读全文
Python 全栈 MongoDB 数据库(概念、安装、创建数据)
作者:Paris Champs 6839 浏览评论:03 年前
什么是关系数据库?它是基于关系数据库模型的数据库。它借助集合代数等概念和方法处理数据库中的数据。它也是一组表(二维表)组织成一组正式的描述。表的本质是数据项的特殊集合,这些表中的数据可以通过多种不同的方式访问
阅读全文
一小时学会MySQL数据库
作者:张果2052 浏览评论:04年前
随着移动互联网的终结和人工智能的到来,大数据变得越来越重要,下一个成功的人应该拥有海量数据。您应该了解数据和数据库。一、数据库概要数据库(Database)是一个用于存储和管理数据的软件系统,就像存储数据的物流仓库一样。在商业领域,信息意味着商机,意味着获取信息的能力
阅读全文
PHP开发中数据库及相关软件的选择注意事项
作者:科技小美1080 浏览评论:04年前
PHP的版本不同。4.0系列有4.4.x已经停止升级和开发,但仍有部分生产环境运行此版本,代码需要维护。PHP 5.0系列是目前开发应用的主流版本,有5.1.x和5.2.x系列。PHP6.0还是试用版,使用PHP开发软件
阅读全文
数据库注释 5:外键的用途
作者:1152人科技小大人查看评论:04年前
外键的作用:维护数据的一致性和完整性,主要目的是控制外键表中存储的数据。要关联两个表,外键只能引用外表中列的值!例如:ab 两个表中a 表有客户编号,客户名称b 表有每个客户的订单。使用外键只能确保b表中没有客户x的订单。
阅读全文
在 Android 开发中使用 SQLite 数据库
作者:Silencer 1306 浏览评论:04年前
SQLite 是一个非常流行的嵌入式数据库,它支持 SQL 查询并且使用很少的内存。Android 在运行时集成了 SQLite,因此每个 Android 应用程序都可以使用 SQLite 数据库。对于熟悉 SQL 的开发人员来说,使用 SQLite 相当简单
阅读全文
WordPress数据库研究
作者:ap0581w9c1121 浏览评论:08年前
本系列文章将详细介绍WordPress数据的整体设计思路,10个WordPress数据表的设计,以及用户信息、分类信息、链接信息、文章信息、文章将详细介绍评论信息和基本设置信息等六类信息。WordPress数据库研究
阅读全文
php从数据库中取一列相关问答
【javascript学习全家桶】934道JavaScript热门问题,上百位阿里巴巴技术专家答疑解惑
作者:管理贝贝5207 浏览评论:13年前
阿里极客公益活动:也许你只是因为一个问题而夜战,也许你迷茫只求答案,也许你因为一个未知数而绞尽脑汁,所以他们来了,阿里巴巴技术专家来云栖Q&A为你解答技术问题他们用自己手中的技术来帮助用户成长。本次活动特邀100阿里巴巴科技
阅读全文
php抓取网页数据插入数据库(快速实现微博微商城的分析、查询,是否发布过帖子)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-24 06:07
php抓取网页数据插入数据库,然后根据用户名密码判断用户性别、年龄、是否关注、是否发布过帖子,
可以看看我的这篇回答:快速的实现微博微商城的分析、查询,最重要是要知道微博分析的方向,是哪个群体数据,
最重要的是确定用户微博归属的行业。然后根据分析行业的热度,判断该行业的年龄层、性别比,然后根据用户的性别结合该群体的年龄层进行分析。找到热度最高的帖子,进行筛选。
首先要弄明白你这个微博的用途是什么。如果是做线上线下分析的,我认为是研究潜在用户和用户分享的点,而你的工作就是去翻用户的微博去分析这些东西。如果是做展示为主的,像在线教育或者维修电工之类的,我觉得优先研究这些大学生在传统上的安装电工技能到底有没有达到要求,还有他们的使用习惯和他们在学校里的实际操作程度,然后找到潜在的用户和他们的共同爱好,结合转发点赞数据去分析。
前提是你要尽可能知道这些大学生的公司组织架构和学校类型、所在地区,这样你才有可能从内部获取流量来对其进行转化。用微博直接进行二手信息的获取已经非常普遍了,这里不再赘述,感兴趣可以关注我的微博:@小东北这里推荐我最近在整理的一些资料供大家学习:、在线调查问卷、问卷星。 查看全部
php抓取网页数据插入数据库(快速实现微博微商城的分析、查询,是否发布过帖子)
php抓取网页数据插入数据库,然后根据用户名密码判断用户性别、年龄、是否关注、是否发布过帖子,
可以看看我的这篇回答:快速的实现微博微商城的分析、查询,最重要是要知道微博分析的方向,是哪个群体数据,
最重要的是确定用户微博归属的行业。然后根据分析行业的热度,判断该行业的年龄层、性别比,然后根据用户的性别结合该群体的年龄层进行分析。找到热度最高的帖子,进行筛选。
首先要弄明白你这个微博的用途是什么。如果是做线上线下分析的,我认为是研究潜在用户和用户分享的点,而你的工作就是去翻用户的微博去分析这些东西。如果是做展示为主的,像在线教育或者维修电工之类的,我觉得优先研究这些大学生在传统上的安装电工技能到底有没有达到要求,还有他们的使用习惯和他们在学校里的实际操作程度,然后找到潜在的用户和他们的共同爱好,结合转发点赞数据去分析。
前提是你要尽可能知道这些大学生的公司组织架构和学校类型、所在地区,这样你才有可能从内部获取流量来对其进行转化。用微博直接进行二手信息的获取已经非常普遍了,这里不再赘述,感兴趣可以关注我的微博:@小东北这里推荐我最近在整理的一些资料供大家学习:、在线调查问卷、问卷星。
php抓取网页数据插入数据库(又遇到乱码问题,这个编码问题有时候真是让人头大)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2022-01-23 23:22
我又遇到了乱码的问题。这个编码问题有时真的很烦人。找了半天也没查出什么问题。页面和数据库都是utf8编码的,但是还是有乱码。直接在命令行下将中文数据插入数据库时,不会出现乱码。在程序中使用代码插入时,会出现乱码。控制台打印的数据没有乱码。乱码问题终于通过搜索资料解决了,但还是有些不明白问题出在哪里。
通过将 ?useUnicode=true&characterEncoding=UTF-8 添加到数据库连接 url 来解决问题:
应用程序上下文.xml
我处理编码的过滤器:
public class EncodingFilter implements Filter {
private FilterConfig config;
private String charset = "UTF-8";
public void init(FilterConfig filterconfig) throws ServletException {
config = filterconfig;
String s = config.getInitParameter("encoding");
if (s != null) {
charset = s;
}
}
public void destroy() {
config = null;
}
public void doFilter(ServletRequest servletrequest,
ServletResponse servletresponse, FilterChain filterchain)
throws IOException, ServletException {
servletrequest.setCharacterEncoding(charset);
servletresponse.setCharacterEncoding(charset);
filterchain.doFilter(servletrequest,servletresponse);
}
}
测试的过滤器确实被执行了。
数据库使用 utf8 编码:
jsp 页面和所有 Java 文件都使用 utf8 编码。
我看不出问题出在哪里。我现在很着急。我先解决问题,有时间再研究一下编码问题。遇到过很多次,但是这个编码问题不能小觑。上次在程序中使用utf8编码的url地址访问windows服务器上的资源文件,出现404,可以用gbk代替。还有一次发现页面在低版本chrome下有一些CSS失效问题,但是在ie和高版本chrome下都没有问题。当时我还以为是CSS兼容性问题。后来发现无效部分在CSS文件中。中文注释后的样式,如果去掉中文注释,可以正常显示。 查看全部
php抓取网页数据插入数据库(又遇到乱码问题,这个编码问题有时候真是让人头大)
我又遇到了乱码的问题。这个编码问题有时真的很烦人。找了半天也没查出什么问题。页面和数据库都是utf8编码的,但是还是有乱码。直接在命令行下将中文数据插入数据库时,不会出现乱码。在程序中使用代码插入时,会出现乱码。控制台打印的数据没有乱码。乱码问题终于通过搜索资料解决了,但还是有些不明白问题出在哪里。
通过将 ?useUnicode=true&characterEncoding=UTF-8 添加到数据库连接 url 来解决问题:
应用程序上下文.xml
我处理编码的过滤器:
public class EncodingFilter implements Filter {
private FilterConfig config;
private String charset = "UTF-8";
public void init(FilterConfig filterconfig) throws ServletException {
config = filterconfig;
String s = config.getInitParameter("encoding");
if (s != null) {
charset = s;
}
}
public void destroy() {
config = null;
}
public void doFilter(ServletRequest servletrequest,
ServletResponse servletresponse, FilterChain filterchain)
throws IOException, ServletException {
servletrequest.setCharacterEncoding(charset);
servletresponse.setCharacterEncoding(charset);
filterchain.doFilter(servletrequest,servletresponse);
}
}
测试的过滤器确实被执行了。
数据库使用 utf8 编码:
jsp 页面和所有 Java 文件都使用 utf8 编码。
我看不出问题出在哪里。我现在很着急。我先解决问题,有时间再研究一下编码问题。遇到过很多次,但是这个编码问题不能小觑。上次在程序中使用utf8编码的url地址访问windows服务器上的资源文件,出现404,可以用gbk代替。还有一次发现页面在低版本chrome下有一些CSS失效问题,但是在ie和高版本chrome下都没有问题。当时我还以为是CSS兼容性问题。后来发现无效部分在CSS文件中。中文注释后的样式,如果去掉中文注释,可以正常显示。
php抓取网页数据插入数据库(初学者-PHP-抓取-数据库-前面的设计问题:初学者)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-23 05:01
初学者 - PHP - 爬网 - 数据库 - 前端设计问题:
我构建了一个 PHP 脚本来从 网站 中抓取(使用 curl)文章,我对其进行样式化并添加了 html 标签以使其易于显示,并通过 cPanel 上传到共享主机。
抓取是使用 php 函数 curl 和 preg_match_all 完成的。每个爬取的页面有 17 篇文章 文章,所以如果我爬取 100 个页面,就有 170 篇文章 文章。我只抓取 文章 标题、URL、文章 摘要和发布日期,因此每个 文章 没有那么多信息(不是内容)。
我的 网站 显示 文章 标题(链接到原创来源)和 文章 摘要。我还使用 文章 发布日期作为我提取的字符串,我按月块(2019 年 12 月、2019 年 11 月等)解析和显示 文章。
网站 的加载时间很糟糕。每次打开网站,脚本都会爬100页,耗时不少。即使将要爬取的页面数量减少到 30 个,加载时间也很长。
现在,作为一个没有经验的开发人员,我正在处理的问题是如何为此设计一个解决方案,我最终可以在我的共享主机中实现(不像 VPS 在我拥有的控制量上......)
第一个想法是我应该将抓取的数据存储在 mysql 数据库中并定期更新(使用 cron 作业?)?
初学者可以/应该在这里实施的解决方案的正确设计流程是什么?
会不会是这样:
第一次抓取数据并存储在数据库中。编写一个脚本以每天(或更多)从第一页只采集新的 文章 而不会创建重复项(可能需要将标题字符串与最后一个 DB 输入进行比较,直到类似于标题字符串 1 = = content of标题字符串 2,然后停止插入数据库)。
您的想法和建议将不胜感激。顺便说一句,我目前也在尝试更专业地在 Laravel 中重做 网站。 查看全部
php抓取网页数据插入数据库(初学者-PHP-抓取-数据库-前面的设计问题:初学者)
初学者 - PHP - 爬网 - 数据库 - 前端设计问题:
我构建了一个 PHP 脚本来从 网站 中抓取(使用 curl)文章,我对其进行样式化并添加了 html 标签以使其易于显示,并通过 cPanel 上传到共享主机。
抓取是使用 php 函数 curl 和 preg_match_all 完成的。每个爬取的页面有 17 篇文章 文章,所以如果我爬取 100 个页面,就有 170 篇文章 文章。我只抓取 文章 标题、URL、文章 摘要和发布日期,因此每个 文章 没有那么多信息(不是内容)。
我的 网站 显示 文章 标题(链接到原创来源)和 文章 摘要。我还使用 文章 发布日期作为我提取的字符串,我按月块(2019 年 12 月、2019 年 11 月等)解析和显示 文章。
网站 的加载时间很糟糕。每次打开网站,脚本都会爬100页,耗时不少。即使将要爬取的页面数量减少到 30 个,加载时间也很长。
现在,作为一个没有经验的开发人员,我正在处理的问题是如何为此设计一个解决方案,我最终可以在我的共享主机中实现(不像 VPS 在我拥有的控制量上......)
第一个想法是我应该将抓取的数据存储在 mysql 数据库中并定期更新(使用 cron 作业?)?
初学者可以/应该在这里实施的解决方案的正确设计流程是什么?
会不会是这样:
第一次抓取数据并存储在数据库中。编写一个脚本以每天(或更多)从第一页只采集新的 文章 而不会创建重复项(可能需要将标题字符串与最后一个 DB 输入进行比较,直到类似于标题字符串 1 = = content of标题字符串 2,然后停止插入数据库)。
您的想法和建议将不胜感激。顺便说一句,我目前也在尝试更专业地在 Laravel 中重做 网站。
php抓取网页数据插入数据库(持续更新中IRIE系统设计与实现报告(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-01-23 04:21
持续更新IR&IE系统设计与实施报告一、系统设计
“网络蜘蛛”从互联网抓取网页,将网页发送到“网页数据库”,从网页“提取URL”,将URL发送到“URL数据库”,“蜘蛛控制”获取URL网页,控制“网络蜘蛛”爬取其他页面,重复循环,直到所有页面都被爬完。
系统从“网页数据库”中获取文本信息,发送到“文本索引”模块进行索引,形成“索引数据库”。同时进行“链接信息提取”,将链接信息(包括锚文本、链接本身等信息)送入“链接数据库”,为“网页评分”提供依据。
“用户”向“查询服务器”提交查询请求,服务器在“索引数据库”中搜索相关网页,“网页评分”结合查询请求和链接信息来评估搜索的相关性结果。查询服务器”按相关性排序,提取关键词的内容摘要,整理最终页面返回给“用户”。
——万维网自动搜索引擎(技术报告)Johnny Deng 2006.12
图1-1是整个程序的架构图。
图 1-1 程序架构图
二、系统开发工具和平台
开发环境:
三、系统及其功能模块的实现1、网页爬取
简单地说,网络爬虫是一个苦力臭虫,它会嗅探 URL(链接)并爬取数千个网页,并将网页的内容移动到您的计算机上供您使用。
如图(这里有几张图):你给爬虫起始页A的url,它从起始页A开始,读取A的所有内容,从中找到3个url,指向页面B、C、D,然后依次沿着链接爬取页面B、C、D的内容,从中发现新的链接,然后继续沿着链接爬取到新的页面——>爬取内容—— > 分析链接 –> 爬到新页面...直到找不到新链接或满足人为停止条件。您可以继续对爬虫带回的网页内容进行分析和处理,以满足您的需求。
至于bug前进的方式,分为广度优先搜索(BFS)和深度优先搜索(DFS)。在这个图中,BFS的搜索顺序是ABCDEFGHI,深度优先搜索的顺序是ABEICFDGH。
我们使用 BFS 来抓取网页。直接使用python内置的type list来存储url地址。每次从一个页面获取所有链接url地址后,将其从待爬取队列的头部删除,并将所有获取到的链接合并到待爬取队列中。结尾。
网络爬取模块主要包括以下功能。
2、索引
索引就像图书馆每个书架上的一个小标志。如果你想找某本书,比如学习python语言的书,你先搜索“信息与计算机科”,再搜索“编程语言”,这样就可以在网上找到你要找的书了对应的货架。搜索引擎的索引与此类似,不同的是它会为所有网页的每个单词建立一个索引。当你输入一串搜索字符串时,程序会先进行分词,然后根据每个词的索引找到对应的词。网页。例如,在搜索框中输入“从前有座山,庙里有个小和尚”,搜索引擎会首先对字符串进行切分“
当然,这个实验中这个简单引擎的索引功能也很简单。通过分析网页的源代码,我们利用网页中元元素的内容来生成关键词。如图2-1所示:
图 2-1 页面中的关键字
关键字的内容比较简单。我们可以根据书名、作者、出版商、出版时间等信息进行图书搜索。
3、页面排名
这个以谷歌创始人拉里佩奇命名的算法可能是互联网上最著名的算法。当时,这个算法帮助谷歌在搜索质量上击败了当时最流行的雅虎、AltaVista等引擎。科技巨头做出了巨大贡献。
页面排名用于衡量网页的质量。索引找到的页面将使用pagerank算法计算PR值。这个分数在演讲结果的排名中会有一定的权重。得分高的页面会在最前面展示给用户。那么它是如何实现的呢?它是基于这样一个假设:链接到这个网页的网页越多,这个网页在全网的接受度就越高,也就是这个网页的质量越好——相当于所有其他的互联网上给它投票的网页,有一个指向它的链接,说明有人为它投票,票数越高越好。但是所有选票的权重都一样吗?明显不是。链接到这个页面本身的页面的PR值越高,它的投票权重就越大。就好像董事会投票给大股东的投票比小股东的投票更有分量。但有一个问题。要想知道一个页面的PR值,就需要知道链接到它的页面的PR值,而链接到它的页面的PR值需要依赖于其他页面的PR值。它变成了先有鸡还是先有蛋的问题。假设初始条件,互联网上所有页面的PR值初始值为1/N,N为全网页面总数,然后用公式迭代,其中p(j)表示链接到p(i)的网页,Lp(j)表示这个页面的链接数,用它除以页面链接数的原因很好理解。当一个页面有大量链接时,每个链接投票的权重会相应分配。可以证明,每一页i的值都是按照这个公式计算出来的,并且迭代。当迭代多轮时,PRp(i) 的值将趋于稳定值。在应用中,迭代次数一般为10次,10次以上。在此之后 PRp(i) 的值变化很小。
还有一个问题,如果一个页面没有任何外部页面链接到它,那么它的PR值是0吗?为了使 PRp(i) 函数更平滑,我们在公式中添加了阻尼系数 d。这里我们不妨取0.8,公式变成如下形式:
这样,即使一个页面是孤立存在的,它的PR值也不会变为零,而是一个很小的值。我们也可以从另一个角度来理解阻尼系数。PR 值实际上衡量了页面被访问的可能性。链接到它的页面越多,点击这些链接的可能性就越大。但是没有任何外部链接就不可能访问网页吗?当然不是,因为你也可以直接从地址框输入url来访问,而且有些人会想通过搜索引擎找到这个页面,所以我们在公式中加上一个阻尼系数,当然只能取这里的一维数字相对较小。
当然,网页的PR值并不是决定网页排名的唯一因素。页面与用户搜索词(查询)的相关程度也是一个重要的衡量标准。.
4、网页分析
网页提取模块从中提取关键词 和书籍信息。
页面上的信息非常复杂。我们使用xpath提取图书的作者、出版商等主要信息,如图2-2所示。
图 2-2 页簿信息
5、布尔模型
布尔检索法是指利用布尔运算符将每个检索词链接起来,然后在计算机上进行逻辑运算以找到所需信息的检索方法。
在这个程序的search()函数中,我们解析搜索词,判断它们之间的逻辑关系,给出搜索结果。
四、遇到的问题及解决方法1、 在网页解析过程中,获取标签中的完整文本出现问题。
因为一个div标签里面有很多倍的标签,直接用xpath路径通过text()获取文本是有问题的。通过查阅 xpath 手册,使用 string(.) 函数过滤掉标签。
2、 页面中的大量 URL 不是提供书籍信息的页面。
爬虫模块增加了url_valid(url)函数,判断url是否有效,使用正则表达式查找表单中的有效地址。
3、 网页的广度优先搜索实现,以及抓取次数的限制。
使用python的list类型存储url,每次爬取url,将新值存储在队列末尾to_crawl待爬取,爬取队列头部的url页面,然后使用pop()函数出队操作。
将抓取的 url 提供给抓取的列表。通过判断列表的长度来限制爬虫的爬取过程。
五、系统测试
简单测试,爬取页面数超过10个就停止爬虫。
1、索引结果
混入了一个奇怪的东西,可能是页面结构不一致造成的。
2、进行搜索
print 'ordered_search', ordered_search(index, ranks, u'杨绛')
print index[u'杨绛']
结果如下
打印列表的内容:
3、搜索作者可能会得到独特的结果。让我们再次搜索“used”以查看结果。
部分结果如图所示。
4、 同时搜索多个词的结果
结果如下:
六、改进
感谢北优的两位童鞋提供完成本次实验的机会
具体代码可以参考我的github-douban_book_search 查看全部
php抓取网页数据插入数据库(持续更新中IRIE系统设计与实现报告(组图))
持续更新IR&IE系统设计与实施报告一、系统设计
“网络蜘蛛”从互联网抓取网页,将网页发送到“网页数据库”,从网页“提取URL”,将URL发送到“URL数据库”,“蜘蛛控制”获取URL网页,控制“网络蜘蛛”爬取其他页面,重复循环,直到所有页面都被爬完。
系统从“网页数据库”中获取文本信息,发送到“文本索引”模块进行索引,形成“索引数据库”。同时进行“链接信息提取”,将链接信息(包括锚文本、链接本身等信息)送入“链接数据库”,为“网页评分”提供依据。
“用户”向“查询服务器”提交查询请求,服务器在“索引数据库”中搜索相关网页,“网页评分”结合查询请求和链接信息来评估搜索的相关性结果。查询服务器”按相关性排序,提取关键词的内容摘要,整理最终页面返回给“用户”。
——万维网自动搜索引擎(技术报告)Johnny Deng 2006.12
图1-1是整个程序的架构图。
图 1-1 程序架构图
二、系统开发工具和平台
开发环境:
三、系统及其功能模块的实现1、网页爬取
简单地说,网络爬虫是一个苦力臭虫,它会嗅探 URL(链接)并爬取数千个网页,并将网页的内容移动到您的计算机上供您使用。
如图(这里有几张图):你给爬虫起始页A的url,它从起始页A开始,读取A的所有内容,从中找到3个url,指向页面B、C、D,然后依次沿着链接爬取页面B、C、D的内容,从中发现新的链接,然后继续沿着链接爬取到新的页面——>爬取内容—— > 分析链接 –> 爬到新页面...直到找不到新链接或满足人为停止条件。您可以继续对爬虫带回的网页内容进行分析和处理,以满足您的需求。
至于bug前进的方式,分为广度优先搜索(BFS)和深度优先搜索(DFS)。在这个图中,BFS的搜索顺序是ABCDEFGHI,深度优先搜索的顺序是ABEICFDGH。
我们使用 BFS 来抓取网页。直接使用python内置的type list来存储url地址。每次从一个页面获取所有链接url地址后,将其从待爬取队列的头部删除,并将所有获取到的链接合并到待爬取队列中。结尾。
网络爬取模块主要包括以下功能。
2、索引
索引就像图书馆每个书架上的一个小标志。如果你想找某本书,比如学习python语言的书,你先搜索“信息与计算机科”,再搜索“编程语言”,这样就可以在网上找到你要找的书了对应的货架。搜索引擎的索引与此类似,不同的是它会为所有网页的每个单词建立一个索引。当你输入一串搜索字符串时,程序会先进行分词,然后根据每个词的索引找到对应的词。网页。例如,在搜索框中输入“从前有座山,庙里有个小和尚”,搜索引擎会首先对字符串进行切分“
当然,这个实验中这个简单引擎的索引功能也很简单。通过分析网页的源代码,我们利用网页中元元素的内容来生成关键词。如图2-1所示:
图 2-1 页面中的关键字
关键字的内容比较简单。我们可以根据书名、作者、出版商、出版时间等信息进行图书搜索。
3、页面排名
这个以谷歌创始人拉里佩奇命名的算法可能是互联网上最著名的算法。当时,这个算法帮助谷歌在搜索质量上击败了当时最流行的雅虎、AltaVista等引擎。科技巨头做出了巨大贡献。
页面排名用于衡量网页的质量。索引找到的页面将使用pagerank算法计算PR值。这个分数在演讲结果的排名中会有一定的权重。得分高的页面会在最前面展示给用户。那么它是如何实现的呢?它是基于这样一个假设:链接到这个网页的网页越多,这个网页在全网的接受度就越高,也就是这个网页的质量越好——相当于所有其他的互联网上给它投票的网页,有一个指向它的链接,说明有人为它投票,票数越高越好。但是所有选票的权重都一样吗?明显不是。链接到这个页面本身的页面的PR值越高,它的投票权重就越大。就好像董事会投票给大股东的投票比小股东的投票更有分量。但有一个问题。要想知道一个页面的PR值,就需要知道链接到它的页面的PR值,而链接到它的页面的PR值需要依赖于其他页面的PR值。它变成了先有鸡还是先有蛋的问题。假设初始条件,互联网上所有页面的PR值初始值为1/N,N为全网页面总数,然后用公式迭代,其中p(j)表示链接到p(i)的网页,Lp(j)表示这个页面的链接数,用它除以页面链接数的原因很好理解。当一个页面有大量链接时,每个链接投票的权重会相应分配。可以证明,每一页i的值都是按照这个公式计算出来的,并且迭代。当迭代多轮时,PRp(i) 的值将趋于稳定值。在应用中,迭代次数一般为10次,10次以上。在此之后 PRp(i) 的值变化很小。
还有一个问题,如果一个页面没有任何外部页面链接到它,那么它的PR值是0吗?为了使 PRp(i) 函数更平滑,我们在公式中添加了阻尼系数 d。这里我们不妨取0.8,公式变成如下形式:
这样,即使一个页面是孤立存在的,它的PR值也不会变为零,而是一个很小的值。我们也可以从另一个角度来理解阻尼系数。PR 值实际上衡量了页面被访问的可能性。链接到它的页面越多,点击这些链接的可能性就越大。但是没有任何外部链接就不可能访问网页吗?当然不是,因为你也可以直接从地址框输入url来访问,而且有些人会想通过搜索引擎找到这个页面,所以我们在公式中加上一个阻尼系数,当然只能取这里的一维数字相对较小。
当然,网页的PR值并不是决定网页排名的唯一因素。页面与用户搜索词(查询)的相关程度也是一个重要的衡量标准。.
4、网页分析
网页提取模块从中提取关键词 和书籍信息。
页面上的信息非常复杂。我们使用xpath提取图书的作者、出版商等主要信息,如图2-2所示。
图 2-2 页簿信息
5、布尔模型
布尔检索法是指利用布尔运算符将每个检索词链接起来,然后在计算机上进行逻辑运算以找到所需信息的检索方法。
在这个程序的search()函数中,我们解析搜索词,判断它们之间的逻辑关系,给出搜索结果。
四、遇到的问题及解决方法1、 在网页解析过程中,获取标签中的完整文本出现问题。
因为一个div标签里面有很多倍的标签,直接用xpath路径通过text()获取文本是有问题的。通过查阅 xpath 手册,使用 string(.) 函数过滤掉标签。
2、 页面中的大量 URL 不是提供书籍信息的页面。
爬虫模块增加了url_valid(url)函数,判断url是否有效,使用正则表达式查找表单中的有效地址。
3、 网页的广度优先搜索实现,以及抓取次数的限制。
使用python的list类型存储url,每次爬取url,将新值存储在队列末尾to_crawl待爬取,爬取队列头部的url页面,然后使用pop()函数出队操作。
将抓取的 url 提供给抓取的列表。通过判断列表的长度来限制爬虫的爬取过程。
五、系统测试
简单测试,爬取页面数超过10个就停止爬虫。
1、索引结果
混入了一个奇怪的东西,可能是页面结构不一致造成的。
2、进行搜索
print 'ordered_search', ordered_search(index, ranks, u'杨绛')
print index[u'杨绛']
结果如下
打印列表的内容:
3、搜索作者可能会得到独特的结果。让我们再次搜索“used”以查看结果。
部分结果如图所示。
4、 同时搜索多个词的结果
结果如下:
六、改进
感谢北优的两位童鞋提供完成本次实验的机会
具体代码可以参考我的github-douban_book_search
php抓取网页数据插入数据库(数据库数据库中的中文乱码怎么办?比较实用的方法)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-01-21 16:15
我们在使用数据库(MySQL)的时候最怕的就是数据库中的中文是乱码,百度除了改变配置文件中的字符集外似乎没有其他的构造方法。更重要的是,这些方法我都一一掌握了。试过了,好像没有解决问题。那我给大家提供一个我一直在用的比较实用的方法。
第一:页面编码问题
我们需要在WEB页面中保留所有的UTF-8编码。
二:设置数据表的字符集编码为utf8
喜欢:
CREATE TABLE `tablename4` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`varchar1` varchar(255) DEFAULT NULL,
`varbinary1` varbinary(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8
DEFAULT CHARSET=utf8 这里是设置数据表的字符集的编码。
三:数据库链接编码设置
只设置数据库的页面编码和字符集编码是达不到目的的。代码中连接数据库后,应采取相应措施,否则中文仍会以乱码形式存入数据库。
比如在php中,连接数据库后,我们可以通过如下操作来避免插入乱码的问题:
mysql_query("set names 'utf8'");
/* http://www.manongjc.com/article/1585.html */
在编程过程中进行以上三个操作,就可以避免中文乱码的问题。需要注意的是,这三个操作缺一不可。 查看全部
php抓取网页数据插入数据库(数据库数据库中的中文乱码怎么办?比较实用的方法)
我们在使用数据库(MySQL)的时候最怕的就是数据库中的中文是乱码,百度除了改变配置文件中的字符集外似乎没有其他的构造方法。更重要的是,这些方法我都一一掌握了。试过了,好像没有解决问题。那我给大家提供一个我一直在用的比较实用的方法。
第一:页面编码问题
我们需要在WEB页面中保留所有的UTF-8编码。
二:设置数据表的字符集编码为utf8
喜欢:
CREATE TABLE `tablename4` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`varchar1` varchar(255) DEFAULT NULL,
`varbinary1` varbinary(255) DEFAULT NULL,
PRIMARY KEY (`id`)
) ENGINE=MyISAM DEFAULT CHARSET=utf8
DEFAULT CHARSET=utf8 这里是设置数据表的字符集的编码。
三:数据库链接编码设置
只设置数据库的页面编码和字符集编码是达不到目的的。代码中连接数据库后,应采取相应措施,否则中文仍会以乱码形式存入数据库。
比如在php中,连接数据库后,我们可以通过如下操作来避免插入乱码的问题:
mysql_query("set names 'utf8'");
/* http://www.manongjc.com/article/1585.html */
在编程过程中进行以上三个操作,就可以避免中文乱码的问题。需要注意的是,这三个操作缺一不可。
php抓取网页数据插入数据库(有效的有效替代解决方案数组,你知道几个?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2022-01-20 01:18
遍历数组不会那么有效。如果您的数据库变得太大,那么它会减慢整个过程,并且可能会出现一种罕见的情况,即 2 个线程在数组中循环以获取相同的随机数,并且会发现它可用并向两张票返回相同的数字。如果您的数据库太大,那么它会减慢整个过程,并且当两个线程循环遍历数组以获取相同的随机数并且可能找到可用的并为两个票条件返回相同的数字时,可能会很少。
因此,您可以将 10 位注册 id 设置为主键,而不是遍历数组,而不是遍历数组,您可以插入注册详细信息以及随机生成的数字,如果数据库插入操作成功,您可以返回注册 id,但如果没有,则重新生成随机数并插入。所以不用循环遍历数组,可以设置10位的注册id为主键,不用循环遍历数组,可以插入注册详情和随机生成的数字,如果数据库插入操作成功,可以返回注册ID,如果没有,则重新生成并插入随机数。
更有效的替代解决方案 您可以使用时间戳代替 10 位随机数来生成 10 位唯一注册号并使其随机化,您可以随机化时间戳的前 2 或 3 位方案可以使用时间戳来生成 10 位唯一注册号,而不是使用 10 位随机数并随机化它,您可以随机化时间戳的前 2 或 3 位数字 查看全部
php抓取网页数据插入数据库(有效的有效替代解决方案数组,你知道几个?)
遍历数组不会那么有效。如果您的数据库变得太大,那么它会减慢整个过程,并且可能会出现一种罕见的情况,即 2 个线程在数组中循环以获取相同的随机数,并且会发现它可用并向两张票返回相同的数字。如果您的数据库太大,那么它会减慢整个过程,并且当两个线程循环遍历数组以获取相同的随机数并且可能找到可用的并为两个票条件返回相同的数字时,可能会很少。
因此,您可以将 10 位注册 id 设置为主键,而不是遍历数组,而不是遍历数组,您可以插入注册详细信息以及随机生成的数字,如果数据库插入操作成功,您可以返回注册 id,但如果没有,则重新生成随机数并插入。所以不用循环遍历数组,可以设置10位的注册id为主键,不用循环遍历数组,可以插入注册详情和随机生成的数字,如果数据库插入操作成功,可以返回注册ID,如果没有,则重新生成并插入随机数。
更有效的替代解决方案 您可以使用时间戳代替 10 位随机数来生成 10 位唯一注册号并使其随机化,您可以随机化时间戳的前 2 或 3 位方案可以使用时间戳来生成 10 位唯一注册号,而不是使用 10 位随机数并随机化它,您可以随机化时间戳的前 2 或 3 位数字
php抓取网页数据插入数据库( 推荐教程:PHP视频教程1.连接数据库函数_connect(连接对象))
网站优化 • 优采云 发表了文章 • 0 个评论 • 43 次浏览 • 2022-01-19 03:06
推荐教程:PHP视频教程1.连接数据库函数_connect(连接对象))
制作动态网站时,最基本的一步就是连接数据库。下面我们将介绍PHP连接数据库的过程。
推荐教程:PHP 视频教程
1.连接数据库函数
mysqli_connect(hostname, username, password) 返回值是我们的连接对象之一。如果连接失败,会报错并返回false
2.判断误差函数
mysqli_connect_error(connection object) 错误信息返回错误信息
mysqli_connect_errno(连接对象)错误号0表示连接成功无错误
3.选择数据库函数
mysqli_select_db(连接对象,要选择的数据库名);如果选择成功,返回true,否则返回false
4.选择字符集
mysqli_set_charset(连接对象,要选择的字符集);如果选择成功,返回true,否则返回false
5.准备sql语句
6. 发送sql语句
mysqli_query(连接对象,要发送的sql语句);成功获取对象,失败返回false
7. 处理结果集
7.1 获取条目数
a) mysqli_num_rows(成功发送sql的对象)用于获取查询获得的记录数,仅用于select语句
b) mysqli_affected_rows(连接对象) 上一次mysql操作中受影响的行数,只针对INSERT UPDATE DELETE操作 返回值 1 成功插入的行数 -1 执行失败
7.2 获取查询结果集的内容
mysqli_fetch_array(send object)以混合数组的形式返回查询结果,一次一项
mysqli_fetch_row(send object)以索引数组的形式返回查询结果,一次一项
mysqli_fetch_assoc(send object)以关联数组的形式返回查询结果,一次一项
7.3 添加操作时,我们可以得到最后插入的id
mysqli_insert_id(连接对象)返回最后插入的id
8.关闭数据库
mysqli_close(连接对象)
// 1.连接数据库
// 2.判断错误
// 3.选择数据库
// 4.选择字符集
// 5.准备sql语句
// 6.发送sql语句
// 7.处理结果集
// 8.关闭数据库
//1.连接数据库
//mysqli_connect('主机名','用户名','密码');
$link=@mysqli_connect('localhost','root','123456');
//var_dump($link);
//2.判断错误
//mysqli_connect_error(连接对象) 错误信息
//mysqli_connect_errno(连接对象) 错误号
// echo mysqli_connect_errno($link);
// echo mysqli_connect_error($link);
if(mysqli_connect_errno($link)){
echo mysqli_connect_error($link);exit;
//echo '错误了 重新连接';exit;
}
//3.选择数据库
mysqli_select_db($link,'ss21');
//4.选择字符集
mysqli_set_charset($link,'utf8');
//5.准备sql语句
$sql="SELECT id,name,sex,age,city FROM info";
//$sql="INSERT INTO info(name) VALUES(NULL)";
//6.发送sql语句
$result = mysqli_query($link,$sql);
//7.处理结果集
echo mysqli_num_rows($result);
//echo mysqli_affected_rows($link);
//8.关闭数据库
mysqli_close($link);
以上是php访问数据库过程的详细内容。更多详情请关注php中文网其他相关话题文章! 查看全部
php抓取网页数据插入数据库(
推荐教程:PHP视频教程1.连接数据库函数_connect(连接对象))
制作动态网站时,最基本的一步就是连接数据库。下面我们将介绍PHP连接数据库的过程。
推荐教程:PHP 视频教程
1.连接数据库函数
mysqli_connect(hostname, username, password) 返回值是我们的连接对象之一。如果连接失败,会报错并返回false
2.判断误差函数
mysqli_connect_error(connection object) 错误信息返回错误信息
mysqli_connect_errno(连接对象)错误号0表示连接成功无错误
3.选择数据库函数
mysqli_select_db(连接对象,要选择的数据库名);如果选择成功,返回true,否则返回false
4.选择字符集
mysqli_set_charset(连接对象,要选择的字符集);如果选择成功,返回true,否则返回false
5.准备sql语句
6. 发送sql语句
mysqli_query(连接对象,要发送的sql语句);成功获取对象,失败返回false
7. 处理结果集
7.1 获取条目数
a) mysqli_num_rows(成功发送sql的对象)用于获取查询获得的记录数,仅用于select语句
b) mysqli_affected_rows(连接对象) 上一次mysql操作中受影响的行数,只针对INSERT UPDATE DELETE操作 返回值 1 成功插入的行数 -1 执行失败
7.2 获取查询结果集的内容
mysqli_fetch_array(send object)以混合数组的形式返回查询结果,一次一项
mysqli_fetch_row(send object)以索引数组的形式返回查询结果,一次一项
mysqli_fetch_assoc(send object)以关联数组的形式返回查询结果,一次一项
7.3 添加操作时,我们可以得到最后插入的id
mysqli_insert_id(连接对象)返回最后插入的id
8.关闭数据库
mysqli_close(连接对象)
// 1.连接数据库
// 2.判断错误
// 3.选择数据库
// 4.选择字符集
// 5.准备sql语句
// 6.发送sql语句
// 7.处理结果集
// 8.关闭数据库
//1.连接数据库
//mysqli_connect('主机名','用户名','密码');
$link=@mysqli_connect('localhost','root','123456');
//var_dump($link);
//2.判断错误
//mysqli_connect_error(连接对象) 错误信息
//mysqli_connect_errno(连接对象) 错误号
// echo mysqli_connect_errno($link);
// echo mysqli_connect_error($link);
if(mysqli_connect_errno($link)){
echo mysqli_connect_error($link);exit;
//echo '错误了 重新连接';exit;
}
//3.选择数据库
mysqli_select_db($link,'ss21');
//4.选择字符集
mysqli_set_charset($link,'utf8');
//5.准备sql语句
$sql="SELECT id,name,sex,age,city FROM info";
//$sql="INSERT INTO info(name) VALUES(NULL)";
//6.发送sql语句
$result = mysqli_query($link,$sql);
//7.处理结果集
echo mysqli_num_rows($result);
//echo mysqli_affected_rows($link);
//8.关闭数据库
mysqli_close($link);
以上是php访问数据库过程的详细内容。更多详情请关注php中文网其他相关话题文章!
php抓取网页数据插入数据库(如果你是php萌新,我建议你先去看一下php如何链接数据库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2022-01-19 03:03
php如何链接数据库获取数据回前端,简称php如何写接口。
如果你是php新手,建议你先看看php是如何链接数据库的,这个文章,以便更好的理解和学的更透彻!
首先我们来看看跨域,通常我们是这样解决的:
header("Access-Control-Allow-Origin:*"); //跨域名
header("Access-Control-Allow-Headers:*"); //跨端口
这取决于情况。他有很多参数。这是百度。这些都是干货。
//格式,这个也很多,也百度
header("Content-type:text/html;charset=utf-8");
我们先封装代码。PHP 可以导入文件,类似于用 Vue 编写的方式。
我们先创建一个文件:config.php(这是可选的,但通常是这样的)
//为什么要设置 $n=null,避免没有值报错
function db_infos($n = null)
{
/* 数据库主机名称 */
$db_host = '127.0.0.1';
/* 数据库用户帐号 */
$db_user = 'root';
/* 数据库用户密码 */
$db_passw = 'root';
/* 数据库具体名称 */
$db_name = 'root';
if ($n === 1) {
return $db_host;
}
if ($n === 2) {
return $db_user;
}
if ($n === 3) {
return $db_passw;
}
if ($n === 4) {
return $db_name;
}
};
/* 查询 */
//$sql就是数据库语句
function selects($sql = null)
{
if (!$sql) {
$conn = null;
exit;
}
$db_host = db_infos(1);
$db_user = db_infos(2);
$db_passw = db_infos(3);
$db_name = db_infos(4);
$conn = new PDO("mysql:host={$db_host};dbname={$db_name}", $db_user, $db_passw);
$conn->query("SET NAMES utf8");
$conn->setAttribute(PDO::ATTR_ERRMODE, PDO::ERRMODE_EXCEPTION);
$stmt = $conn->query($sql);
$stmt->execute();
$result = $stmt->setFetchMode(PDO::FETCH_ASSOC);
$result = $stmt->fetchAll();
$conn = null;
if (count($result) > 1) {
return $result;
} else {
if(count($result) > 0){
return $result;
}else{
return false;
}
}
}
/* 更新 */
function updates($sql = null)
{
if (!$sql) {
$conn = null;
exit;
}
$db_host = db_infos(1);
$db_user = db_infos(2);
$db_passw = db_infos(3);
$db_name = db_infos(4);
$conn = new PDO("mysql:host={$db_host};dbname={$db_name}", $db_user, $db_passw);
$conn->query("SET NAMES utf8");
$conn->setAttribute(PDO::ATTR_ERRMODE, PDO::ERRMODE_EXCEPTION);
$stmt = $conn->prepare($sql);
$res = $stmt->execute();
$conn = null;
return $res;
}
/* 插入 */
function inserts($sql = null)
{
if (!$sql) {
$conn = null;
exit;
}
$db_host = db_infos(1);
$db_user = db_infos(2);
$db_passw = db_infos(3);
$db_name = db_infos(4);
$conn = new PDO("mysql:host={$db_host};dbname={$db_name}", $db_user, $db_passw);
$conn->query("SET NAMES utf8");
$conn->setAttribute(PDO::ATTR_ERRMODE, PDO::ERRMODE_EXCEPTION);
$stmt = $conn->prepare($sql);
$res = $stmt->execute();
$conn = null;
return $res;
}
/* 删除 */
function deletes($sql)
{
if (!$sql) {
$conn = null;
exit;
}
$db_host = db_infos(1);
$db_user = db_infos(2);
$db_passw = db_infos(3);
$db_name = db_infos(4);
$conn = new PDO("mysql:host={$db_host};dbname={$db_name}", $db_user, $db_passw);
$conn->query("SET NAMES utf8");
$conn->setAttribute(PDO::ATTR_ERRMODE, PDO::ERRMODE_EXCEPTION);
$stmt = $conn->prepare($sql);
$res = $stmt->execute();
$conn = null;
return $res;
}
特别注意 $stmt = $conn->prepare($sql); 查询用query,别人用prepare,别人用query,会报错。
简单封装一下,接下来说说怎么用
例如,如果在 index.php 中引入,则此时可以调用该方法。
include './config.php';
echo selects("SELECT * FROM user WHERE id=1");
现在我们知道如何操作数据库了。这时候还不能算是接口。只有能够获取并返回,才能算是一个接口。现在让我们看看如何获取前端参数:
$data = file_get_contents('php://input');
//格式化一下
$d = json_decode($data);
//获取前端的传递过来的参数,如id
$id = $d->id;
//假如我们需要搜索user表里面id为1的用户
echo selects("SELECT * FROM user WHERE id='{$id}'");
前端ajax、axios等需要设置headers:
headers: {
"Content-type": "application/json; charset=utf-8"
},
至此,你基本上可以编写接口了,但这还不够。一件非常重要的事情是您必须了解数据库语句。不行,懂php也没用,赶紧学数据库语句吧。
我们简单教你几个数据库语句,包括一些基本的增删改查语句:
//查询user表所有
SELECT * FROM user
//查询user表id为1的
SELECT * FROM user WHERE id=1
//修改user表id为1用户的name
UPDATE user SET name='你好' WHERE id='1'
//user插入
INSERT INTO user(name) VALUES('你好2')
//删除
DELETE FROM user WHERE id='1'
如果您知道如何编写数据库语句,则可以处理基础知识。你可以试着做一个简单的博客来试试。 查看全部
php抓取网页数据插入数据库(如果你是php萌新,我建议你先去看一下php如何链接数据库)
php如何链接数据库获取数据回前端,简称php如何写接口。
如果你是php新手,建议你先看看php是如何链接数据库的,这个文章,以便更好的理解和学的更透彻!
首先我们来看看跨域,通常我们是这样解决的:
header("Access-Control-Allow-Origin:*"); //跨域名
header("Access-Control-Allow-Headers:*"); //跨端口
这取决于情况。他有很多参数。这是百度。这些都是干货。
//格式,这个也很多,也百度
header("Content-type:text/html;charset=utf-8");
我们先封装代码。PHP 可以导入文件,类似于用 Vue 编写的方式。
我们先创建一个文件:config.php(这是可选的,但通常是这样的)
//为什么要设置 $n=null,避免没有值报错
function db_infos($n = null)
{
/* 数据库主机名称 */
$db_host = '127.0.0.1';
/* 数据库用户帐号 */
$db_user = 'root';
/* 数据库用户密码 */
$db_passw = 'root';
/* 数据库具体名称 */
$db_name = 'root';
if ($n === 1) {
return $db_host;
}
if ($n === 2) {
return $db_user;
}
if ($n === 3) {
return $db_passw;
}
if ($n === 4) {
return $db_name;
}
};
/* 查询 */
//$sql就是数据库语句
function selects($sql = null)
{
if (!$sql) {
$conn = null;
exit;
}
$db_host = db_infos(1);
$db_user = db_infos(2);
$db_passw = db_infos(3);
$db_name = db_infos(4);
$conn = new PDO("mysql:host={$db_host};dbname={$db_name}", $db_user, $db_passw);
$conn->query("SET NAMES utf8");
$conn->setAttribute(PDO::ATTR_ERRMODE, PDO::ERRMODE_EXCEPTION);
$stmt = $conn->query($sql);
$stmt->execute();
$result = $stmt->setFetchMode(PDO::FETCH_ASSOC);
$result = $stmt->fetchAll();
$conn = null;
if (count($result) > 1) {
return $result;
} else {
if(count($result) > 0){
return $result;
}else{
return false;
}
}
}
/* 更新 */
function updates($sql = null)
{
if (!$sql) {
$conn = null;
exit;
}
$db_host = db_infos(1);
$db_user = db_infos(2);
$db_passw = db_infos(3);
$db_name = db_infos(4);
$conn = new PDO("mysql:host={$db_host};dbname={$db_name}", $db_user, $db_passw);
$conn->query("SET NAMES utf8");
$conn->setAttribute(PDO::ATTR_ERRMODE, PDO::ERRMODE_EXCEPTION);
$stmt = $conn->prepare($sql);
$res = $stmt->execute();
$conn = null;
return $res;
}
/* 插入 */
function inserts($sql = null)
{
if (!$sql) {
$conn = null;
exit;
}
$db_host = db_infos(1);
$db_user = db_infos(2);
$db_passw = db_infos(3);
$db_name = db_infos(4);
$conn = new PDO("mysql:host={$db_host};dbname={$db_name}", $db_user, $db_passw);
$conn->query("SET NAMES utf8");
$conn->setAttribute(PDO::ATTR_ERRMODE, PDO::ERRMODE_EXCEPTION);
$stmt = $conn->prepare($sql);
$res = $stmt->execute();
$conn = null;
return $res;
}
/* 删除 */
function deletes($sql)
{
if (!$sql) {
$conn = null;
exit;
}
$db_host = db_infos(1);
$db_user = db_infos(2);
$db_passw = db_infos(3);
$db_name = db_infos(4);
$conn = new PDO("mysql:host={$db_host};dbname={$db_name}", $db_user, $db_passw);
$conn->query("SET NAMES utf8");
$conn->setAttribute(PDO::ATTR_ERRMODE, PDO::ERRMODE_EXCEPTION);
$stmt = $conn->prepare($sql);
$res = $stmt->execute();
$conn = null;
return $res;
}
特别注意 $stmt = $conn->prepare($sql); 查询用query,别人用prepare,别人用query,会报错。
简单封装一下,接下来说说怎么用
例如,如果在 index.php 中引入,则此时可以调用该方法。
include './config.php';
echo selects("SELECT * FROM user WHERE id=1");
现在我们知道如何操作数据库了。这时候还不能算是接口。只有能够获取并返回,才能算是一个接口。现在让我们看看如何获取前端参数:
$data = file_get_contents('php://input');
//格式化一下
$d = json_decode($data);
//获取前端的传递过来的参数,如id
$id = $d->id;
//假如我们需要搜索user表里面id为1的用户
echo selects("SELECT * FROM user WHERE id='{$id}'");
前端ajax、axios等需要设置headers:
headers: {
"Content-type": "application/json; charset=utf-8"
},
至此,你基本上可以编写接口了,但这还不够。一件非常重要的事情是您必须了解数据库语句。不行,懂php也没用,赶紧学数据库语句吧。
我们简单教你几个数据库语句,包括一些基本的增删改查语句:
//查询user表所有
SELECT * FROM user
//查询user表id为1的
SELECT * FROM user WHERE id=1
//修改user表id为1用户的name
UPDATE user SET name='你好' WHERE id='1'
//user插入
INSERT INTO user(name) VALUES('你好2')
//删除
DELETE FROM user WHERE id='1'
如果您知道如何编写数据库语句,则可以处理基础知识。你可以试着做一个简单的博客来试试。

