
php抓取网页数据插入数据库
php抓取网页数据插入数据库(全部详细技术资料下载【技术实现步骤摘要】(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-04-08 17:12
本发明专利技术公开了一种更新获取的网页数据的系统和方法。该方法包括: S1、使用网络爬虫从网页中抓取目标数据;S2、 将目标数据打包成为目标压缩文件,并在目标压缩文件中添加MD5标签;S3、判断网页数据和压缩文件是否存储在数据库服务器中,如果是,则执行步骤S4,如果不是,则执行步骤S7;S4、判断网页数据的压缩文件的MD5值是否与目标压缩文件的MD5值相同,如果是,执行步骤S5,如果不是,执行步骤S6;S5、删除目标数据和目标压缩文件;S6、 将网页数据和压缩文件分别更新为目标数据和目标压缩文件;S7、将目标数据和目标压缩文件存储在数据库服务器中。本发明专利技术可以判断网页数据的更新情况,实现获取的网页数据的及时更新。
下载所有详细的技术数据
【技术实现步骤总结】
本专利技术涉及一种更新获取的网页数据的系统和方法,尤其涉及一种能够及时检测到获取的网页数据的更新并进行相应的更新处理的系统,以及一种更新获取的网页的系统。页面数据。获取的网页数据的更新方法。
技术介绍
现阶段随着网络技术的飞速发展,大数据时代已经到来,如何快速有效地拉取网站的数据信息成为亟待解决的问题。如今,出于信息保护的目的,在更新网页数据时,很多网站一般不会在更新数据中提供时间戳等信息数据。因此,现有技术中,在抓取网页数据后,基本上无法确定网页数据的更新时间。一旦无法确定更新时间,就无法确定捕获的网页数据中哪些是更新数据,哪些没有更新。结果,无法第一时间获取网页中最新更新的数据。以在线旅游搜索平台为例,由于无法确定目标网站(如各种酒店和预订网站)的数据更新,很难第一时间获取最新更新的机票和酒店。以及优采云门票等资源信息,如果实时数据更新不高,会降低用户查询相关信息的准确性,严重影响用户体验。
技术实现思路
该专利技术要解决的技术问题是克服现有技术无法及时判断在线旅游搜索平台等网站的数据更新,难以获取最新更新的机票,酒店和优采云门票等资源信息,使得用户查询相关信息的准确性较低,严重影响用户体验。提供一种能够及时检测获取的网页数据的更新并进行相应更新处理的系统。一种更新获取的网页数据的系统及方法,通过该系统实现。该专利技术通过以下技术方案解决了上述技术问题:本专利技术提供了一种更新获取的网页数据的方法,其特征在于,该方法包括以下步骤: S1、使用网络爬虫抓取带有网页ID(标识号)的目标数据从网页;S2、将目标数据打包成目标压缩文件,并在目标压缩文件中添加MD5(消息文摘算法第五版,计算机领域使用的散列函数)标签;S3、判断数据库服务器是否存储有网页ID和网页数据压缩文件的网页数据,如果是,进入步骤S4,如果没有,进入步骤S7;S4、判断网页数据的压缩文件的MD5值是否与目标压缩文件的MD5值相同,如果相同,转步骤S4、 S5,否则,执行步骤S6;S5、 删除目标数据和目标压缩文件,然后结束进程;S6、压缩网页数据和网页数据文件分别更新为目标数据和目标压缩文件,然后流程结束;S7、 将目标数据和目标压缩文件存储在数据库服务器中。
在步骤S1中,通过设置网页的网址、网络爬虫的递归算法和网页数据的定位信息,网络爬虫可以快速抓取所需的网页数据,即目标数据,所有目标数据都是网页中具有唯一唯一 ID 的数据。这里的网页ID不是指网页的URL(Uniform Resource Locator)地址中的数字,而是表示所需数据的唯一标识。网页ID对应网页中的数据,可以代表一个唯一的网页与之对应,不同的网页会有不同的网页ID。当考虑到捕获的目标数据存储在数据库服务器中时,首先在步骤S3中判断数据库服务器是否存储了来自网页的网页数据,即,判断具有网页ID的网页数据和该网页数据对应的压缩文件是否存储在数据库服务器中。如果是,则表示该网页的网页数据已存储在数据库服务器中。此时无法判断抓取到的目标数据是否为网页最新更新的数据,需要进行后续判断;如果不是,则说明该网页的网页数据尚未存储在数据库服务器中。此时,对于数据库服务器而言,目标数据为最新的网页数据,因此执行步骤S7,对数据库服务器中存储的网页数据执行步骤S7。更新。当确定该网页的网页数据和该网页数据的压缩文件已经存储在数据库服务器中时,执行步骤S4,继续判断网页数据的压缩文件的MD5值与目标压缩文件的MD5值是否相同;如果相同,则说明网页数据没有更新,即数据库服务器中存储的网页数据是最新的,则执行步骤S5。如果不是,则在步骤S1中说明捕获的目标数据是最新的。此时,执行步骤S6,更新数据库中存储的网页数据。然后执行步骤S5;如果不是,则在步骤S1中说明捕获的目标数据是最新的。此时,执行步骤S6,更新数据库中存储的网页数据。然后执行步骤S5;如果不是,则在步骤S1中说明捕获的目标数据是最新的。此时,执行步骤S6,更新数据库中存储的网页数据。
这样,本专利技术的方法可以保证数据库服务器中存储的网页数据始终是最新的,实现获取的网页数据的及时更新,减少数据库服务器中的数据冗余。此外,该专利技术可以大大提高数据库服务器中存储的网页数据的实时性,特别是对于在线旅游搜索平台等,最新更新的机票、酒店和优采云资源信息等因为门票可以大大提高用户查询相关信息的准确性,方便用户使用,改善用户体验,大大提高在线旅游搜索平台对网页数据处理的灵活性和实时性。性别。优选地,步骤S1中的网络爬虫为聚焦爬虫,聚焦爬虫通过在爬取时设置过滤算法,过滤网页中与目标数据无关的链接。与普通网络爬虫不同的是,步骤S2中使用的聚焦爬虫可以过滤掉不相关的链接,只保留有用的链接并存储在等待队列中,从而提高了抓取网页数据的速度和效率,同时也改进了整个方法流程. 速度和效率。优选地,在步骤S1中,还根据数据类型将目标数据划分为多个字段,将多个字段分为静态信息数据和动态信息数据。步骤S2中的目标压缩文件分别包括带有MD5标签的静态信息数据压缩文件和动态信息数据压缩文件。对于步骤S1中捕获的目标数据,由于表示信息的不同,数据的类型也不同。因此,在步骤S1中,也可以根据网页数据的表示信息不同,将目标数据划分为多个字段。.
所有领域的数据大致可以分为静态信息数据和动态信息数据,其中静态信息数据是指事物的基本特征信息数据,这些数据变化非常缓慢或基本不随时间变化,如< @优采云 列车数量、始发站、终点站等。动态信息数据是指相对容易随时间变化而变化的数据,如优采云车票数量、硬座数量, 卧铺津贴等。 优选地,该方法的过程在每个时间段执行。本专利技术的目的还在于提供一种更新获取的网页数据的系统,其特征在于,该系统包括数据采集模块、文件压缩模块、第一判断模块、第二判断模块。模块和数据更新模块;数据抓取模块,用于利用网络爬虫从网页中抓取具有网页ID的目标数据。文件压缩模块,用于将目标数据打包成目标压缩文件,并为所述目标压缩文件添加MD5标签。所述的第一判断模块,用于判断是否存储在数据库服务器中
【技术保护点】
一种获取网页数据的更新方法,其特征在于,该方法包括以下步骤: S1、利用网络爬虫从网页中抓取具有网页ID的目标数据;S1、 @2、将目标数据打包成目标压缩文件,并在目标压缩文件中添加MD5标签;S3、判断数据库服务器是否存储有网页ID和所有描述网页数据的压缩文件的网页数据,如果是,则执行步骤S4,否则,执行步骤S7;,如果是,执行步骤S5,如果不是,执行步骤S6;S5、 删除目标数据和目标压缩文件,然后结束进程;S6、将网页数据的压缩文件分别更新为目标数据和目标压缩文件,然后流程结束;S7、
【技术特点总结】
1.一种更新获取的网页数据的方法,其特征在于,该方法包括
包括以下步骤:
S1、使用网络爬虫从网页中抓取带有网页ID的目标数据;
S2、将目标数据打包成目标压缩文件,并添加目标压缩文件
添加MD5标签;
S3、判断一个数据库服务器是否存储了网页数据,带有网页ID和所有
描述网页数据的压缩文件,如果是,则进行步骤S4,否则,进行步骤S7;
S4、判断网页数据压缩文件和目标压缩文件的MD5值
MD5值是否相同,如果是,则进入步骤S5,否则,进入步骤S6;
S5、删除目标数据和目标压缩文件,然后结束进程;
S6、分别更新网页数据和网页数据的压缩文件到目标号
根据目标压缩文件,然后结束进程;
S7、 将目标数据和目标压缩文件存储在数据库服务器中。
2.如权利要求1所述的方法,其特征在于,步骤S1中的网络爬虫
为了聚焦爬虫,聚焦爬虫在爬取时通过设置过滤算法对网页中的所有内容进行过滤。
与目标数据无关的链接。
3.根据权利要求2所述的方法,其特征在于,在步骤S1中,目标数也为
按数据类型分为多个字段,多个字段分为静态信息数据和
动态信息数据;
步骤S2中的目标压缩文件分别收录带有MD5标签的静态信息
数据压缩文件和动态信息数据压缩文件。
4.根据权利要求1-3任一项所述的方法,其特征在于,每隔一段时间
该段执行该方法的流程一次。
5.一种……
【专利技术性质】
技术研发人员:叶亚明,
申请人(专利权)持有人:,
类型:发明
国家省份:上海;31
下载所有详细的技术数据 我是该专利的所有者 查看全部
php抓取网页数据插入数据库(全部详细技术资料下载【技术实现步骤摘要】(组图))
本发明专利技术公开了一种更新获取的网页数据的系统和方法。该方法包括: S1、使用网络爬虫从网页中抓取目标数据;S2、 将目标数据打包成为目标压缩文件,并在目标压缩文件中添加MD5标签;S3、判断网页数据和压缩文件是否存储在数据库服务器中,如果是,则执行步骤S4,如果不是,则执行步骤S7;S4、判断网页数据的压缩文件的MD5值是否与目标压缩文件的MD5值相同,如果是,执行步骤S5,如果不是,执行步骤S6;S5、删除目标数据和目标压缩文件;S6、 将网页数据和压缩文件分别更新为目标数据和目标压缩文件;S7、将目标数据和目标压缩文件存储在数据库服务器中。本发明专利技术可以判断网页数据的更新情况,实现获取的网页数据的及时更新。
下载所有详细的技术数据
【技术实现步骤总结】
本专利技术涉及一种更新获取的网页数据的系统和方法,尤其涉及一种能够及时检测到获取的网页数据的更新并进行相应的更新处理的系统,以及一种更新获取的网页的系统。页面数据。获取的网页数据的更新方法。
技术介绍
现阶段随着网络技术的飞速发展,大数据时代已经到来,如何快速有效地拉取网站的数据信息成为亟待解决的问题。如今,出于信息保护的目的,在更新网页数据时,很多网站一般不会在更新数据中提供时间戳等信息数据。因此,现有技术中,在抓取网页数据后,基本上无法确定网页数据的更新时间。一旦无法确定更新时间,就无法确定捕获的网页数据中哪些是更新数据,哪些没有更新。结果,无法第一时间获取网页中最新更新的数据。以在线旅游搜索平台为例,由于无法确定目标网站(如各种酒店和预订网站)的数据更新,很难第一时间获取最新更新的机票和酒店。以及优采云门票等资源信息,如果实时数据更新不高,会降低用户查询相关信息的准确性,严重影响用户体验。
技术实现思路
该专利技术要解决的技术问题是克服现有技术无法及时判断在线旅游搜索平台等网站的数据更新,难以获取最新更新的机票,酒店和优采云门票等资源信息,使得用户查询相关信息的准确性较低,严重影响用户体验。提供一种能够及时检测获取的网页数据的更新并进行相应更新处理的系统。一种更新获取的网页数据的系统及方法,通过该系统实现。该专利技术通过以下技术方案解决了上述技术问题:本专利技术提供了一种更新获取的网页数据的方法,其特征在于,该方法包括以下步骤: S1、使用网络爬虫抓取带有网页ID(标识号)的目标数据从网页;S2、将目标数据打包成目标压缩文件,并在目标压缩文件中添加MD5(消息文摘算法第五版,计算机领域使用的散列函数)标签;S3、判断数据库服务器是否存储有网页ID和网页数据压缩文件的网页数据,如果是,进入步骤S4,如果没有,进入步骤S7;S4、判断网页数据的压缩文件的MD5值是否与目标压缩文件的MD5值相同,如果相同,转步骤S4、 S5,否则,执行步骤S6;S5、 删除目标数据和目标压缩文件,然后结束进程;S6、压缩网页数据和网页数据文件分别更新为目标数据和目标压缩文件,然后流程结束;S7、 将目标数据和目标压缩文件存储在数据库服务器中。
在步骤S1中,通过设置网页的网址、网络爬虫的递归算法和网页数据的定位信息,网络爬虫可以快速抓取所需的网页数据,即目标数据,所有目标数据都是网页中具有唯一唯一 ID 的数据。这里的网页ID不是指网页的URL(Uniform Resource Locator)地址中的数字,而是表示所需数据的唯一标识。网页ID对应网页中的数据,可以代表一个唯一的网页与之对应,不同的网页会有不同的网页ID。当考虑到捕获的目标数据存储在数据库服务器中时,首先在步骤S3中判断数据库服务器是否存储了来自网页的网页数据,即,判断具有网页ID的网页数据和该网页数据对应的压缩文件是否存储在数据库服务器中。如果是,则表示该网页的网页数据已存储在数据库服务器中。此时无法判断抓取到的目标数据是否为网页最新更新的数据,需要进行后续判断;如果不是,则说明该网页的网页数据尚未存储在数据库服务器中。此时,对于数据库服务器而言,目标数据为最新的网页数据,因此执行步骤S7,对数据库服务器中存储的网页数据执行步骤S7。更新。当确定该网页的网页数据和该网页数据的压缩文件已经存储在数据库服务器中时,执行步骤S4,继续判断网页数据的压缩文件的MD5值与目标压缩文件的MD5值是否相同;如果相同,则说明网页数据没有更新,即数据库服务器中存储的网页数据是最新的,则执行步骤S5。如果不是,则在步骤S1中说明捕获的目标数据是最新的。此时,执行步骤S6,更新数据库中存储的网页数据。然后执行步骤S5;如果不是,则在步骤S1中说明捕获的目标数据是最新的。此时,执行步骤S6,更新数据库中存储的网页数据。然后执行步骤S5;如果不是,则在步骤S1中说明捕获的目标数据是最新的。此时,执行步骤S6,更新数据库中存储的网页数据。
这样,本专利技术的方法可以保证数据库服务器中存储的网页数据始终是最新的,实现获取的网页数据的及时更新,减少数据库服务器中的数据冗余。此外,该专利技术可以大大提高数据库服务器中存储的网页数据的实时性,特别是对于在线旅游搜索平台等,最新更新的机票、酒店和优采云资源信息等因为门票可以大大提高用户查询相关信息的准确性,方便用户使用,改善用户体验,大大提高在线旅游搜索平台对网页数据处理的灵活性和实时性。性别。优选地,步骤S1中的网络爬虫为聚焦爬虫,聚焦爬虫通过在爬取时设置过滤算法,过滤网页中与目标数据无关的链接。与普通网络爬虫不同的是,步骤S2中使用的聚焦爬虫可以过滤掉不相关的链接,只保留有用的链接并存储在等待队列中,从而提高了抓取网页数据的速度和效率,同时也改进了整个方法流程. 速度和效率。优选地,在步骤S1中,还根据数据类型将目标数据划分为多个字段,将多个字段分为静态信息数据和动态信息数据。步骤S2中的目标压缩文件分别包括带有MD5标签的静态信息数据压缩文件和动态信息数据压缩文件。对于步骤S1中捕获的目标数据,由于表示信息的不同,数据的类型也不同。因此,在步骤S1中,也可以根据网页数据的表示信息不同,将目标数据划分为多个字段。.
所有领域的数据大致可以分为静态信息数据和动态信息数据,其中静态信息数据是指事物的基本特征信息数据,这些数据变化非常缓慢或基本不随时间变化,如< @优采云 列车数量、始发站、终点站等。动态信息数据是指相对容易随时间变化而变化的数据,如优采云车票数量、硬座数量, 卧铺津贴等。 优选地,该方法的过程在每个时间段执行。本专利技术的目的还在于提供一种更新获取的网页数据的系统,其特征在于,该系统包括数据采集模块、文件压缩模块、第一判断模块、第二判断模块。模块和数据更新模块;数据抓取模块,用于利用网络爬虫从网页中抓取具有网页ID的目标数据。文件压缩模块,用于将目标数据打包成目标压缩文件,并为所述目标压缩文件添加MD5标签。所述的第一判断模块,用于判断是否存储在数据库服务器中

【技术保护点】
一种获取网页数据的更新方法,其特征在于,该方法包括以下步骤: S1、利用网络爬虫从网页中抓取具有网页ID的目标数据;S1、 @2、将目标数据打包成目标压缩文件,并在目标压缩文件中添加MD5标签;S3、判断数据库服务器是否存储有网页ID和所有描述网页数据的压缩文件的网页数据,如果是,则执行步骤S4,否则,执行步骤S7;,如果是,执行步骤S5,如果不是,执行步骤S6;S5、 删除目标数据和目标压缩文件,然后结束进程;S6、将网页数据的压缩文件分别更新为目标数据和目标压缩文件,然后流程结束;S7、
【技术特点总结】
1.一种更新获取的网页数据的方法,其特征在于,该方法包括
包括以下步骤:
S1、使用网络爬虫从网页中抓取带有网页ID的目标数据;
S2、将目标数据打包成目标压缩文件,并添加目标压缩文件
添加MD5标签;
S3、判断一个数据库服务器是否存储了网页数据,带有网页ID和所有
描述网页数据的压缩文件,如果是,则进行步骤S4,否则,进行步骤S7;
S4、判断网页数据压缩文件和目标压缩文件的MD5值
MD5值是否相同,如果是,则进入步骤S5,否则,进入步骤S6;
S5、删除目标数据和目标压缩文件,然后结束进程;
S6、分别更新网页数据和网页数据的压缩文件到目标号
根据目标压缩文件,然后结束进程;
S7、 将目标数据和目标压缩文件存储在数据库服务器中。
2.如权利要求1所述的方法,其特征在于,步骤S1中的网络爬虫
为了聚焦爬虫,聚焦爬虫在爬取时通过设置过滤算法对网页中的所有内容进行过滤。
与目标数据无关的链接。
3.根据权利要求2所述的方法,其特征在于,在步骤S1中,目标数也为
按数据类型分为多个字段,多个字段分为静态信息数据和
动态信息数据;
步骤S2中的目标压缩文件分别收录带有MD5标签的静态信息
数据压缩文件和动态信息数据压缩文件。
4.根据权利要求1-3任一项所述的方法,其特征在于,每隔一段时间
该段执行该方法的流程一次。
5.一种……
【专利技术性质】
技术研发人员:叶亚明,
申请人(专利权)持有人:,
类型:发明
国家省份:上海;31
下载所有详细的技术数据 我是该专利的所有者
php抓取网页数据插入数据库(如何从我插入数据的同一个php表单中获取数据库中的信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-04-07 20:12
如何从我插入数据的同一个php表单中获取数据库中的信息,包括存储的信息,以便可以更新数据库中的数据:
我使用了这个更新语句,但得到了一个错误:
$sql="UPDATE findings
SET Finding_ID=$_GET[Finding_ID], ServiceType_ID=$_GET[ServiceType_ID], RootCause_ID=$_GET[RootCause_ID] , RiskRating_ID=$_GET[RiskRating_ID] , Impact_ID=$_GET[Impact_ID] ,Efforts_ID= $_GET[Efforts_ID], Likelihood_ID= $_GET[Likelihood_ID], Finding=$_GET[Finding],Implication=$_GET[Implication] , Recommendation =$_GET[Recommendation] , Report_ID=$_GET[Report_ID]
WHERE Finding_ID=$Finding_ID, ServiceType_ID=$ServiceType_ID, RootCause_ID=$RootCause_ID , RiskRating_ID=$RiskRating_ID , Impact_ID=$Impact_ID ,Efforts_ID= $Efforts_ID, Likelihood_ID= $Likelihood_ID, Finding=$Finding,Implication=$Implication , Recommendation =$Recommendation , Report_ID=$Report_ID";
这是我将插入和更新数据的表单的代码:
Insert New Data
<p> Service Name :
Ref : <br />
Title : <br />
Risk Rating :
-Select-
<br />
Root Cause :
-Select-
<br />
Impact :
-Select-
<br />
Likelihood :
-Select-
Efforts :
-Select-
Finding :
Implication:
Recommendation :
</p>
这是错误:
Notice: Undefined index: Finding_ID in C:\xampp\htdocs\ers\edit.php on line 122
Notice: Undefined index: ServiceType_ID in C:\xampp\htdocs\ers\edit.php on line 122
Notice: Undefined index: RootCause_ID in C:\xampp\htdocs\ers\edit.php on line 122
Notice: Undefined index: RiskRating_ID in C:\xampp\htdocs\ers\edit.php on line 122
Notice: Undefined index: Impact_ID in C:\xampp\htdocs\ers\edit.php on line 122
Notice: Undefined index: Efforts_ID in C:\xampp\htdocs\ers\edit.php on line 122
Notice: Undefined variable: Finding_ID in C:\xampp\htdocs\ers\edit.php on line 126
Error: You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near ' ServiceType_ID=, RootCause_ID= , RiskRating_ID= , Impact_ID= ,Efforts_ID= , Lik' at line 2
2个答案:
答案 0 :( 得分:1)
WHERE 的条件应该是使用 AND、OR 而不是逗号。
WHERE Finding_ID=$Finding_ID, ServiceType_ID=$ServiceType_ID,....
应该
WHERE Finding_ID=$Finding_ID AND ServiceType_ID=$ServiceType_ID AND ...
答案1:(得分:0)
您的查询基本上是欢迎每个人访问数据库的大门。
第一:不要在查询中使用直接获取参数。最初与他们合作。
第二位:即使是数字也要加''。为您提供额外的安全保障。
第三个:WHERE 参数是 AND 或 OR
分离
当然,您可以采取更多的预防措施,但最好在一开始就这样做。
PS:长查询在拆分时更易于管理和阅读;并尽量保持你的代码干净漂亮。没有人喜欢使用乱码。 查看全部
php抓取网页数据插入数据库(如何从我插入数据的同一个php表单中获取数据库中的信息)
如何从我插入数据的同一个php表单中获取数据库中的信息,包括存储的信息,以便可以更新数据库中的数据:
我使用了这个更新语句,但得到了一个错误:
$sql="UPDATE findings
SET Finding_ID=$_GET[Finding_ID], ServiceType_ID=$_GET[ServiceType_ID], RootCause_ID=$_GET[RootCause_ID] , RiskRating_ID=$_GET[RiskRating_ID] , Impact_ID=$_GET[Impact_ID] ,Efforts_ID= $_GET[Efforts_ID], Likelihood_ID= $_GET[Likelihood_ID], Finding=$_GET[Finding],Implication=$_GET[Implication] , Recommendation =$_GET[Recommendation] , Report_ID=$_GET[Report_ID]
WHERE Finding_ID=$Finding_ID, ServiceType_ID=$ServiceType_ID, RootCause_ID=$RootCause_ID , RiskRating_ID=$RiskRating_ID , Impact_ID=$Impact_ID ,Efforts_ID= $Efforts_ID, Likelihood_ID= $Likelihood_ID, Finding=$Finding,Implication=$Implication , Recommendation =$Recommendation , Report_ID=$Report_ID";
这是我将插入和更新数据的表单的代码:
Insert New Data
<p> Service Name :
Ref : <br />
Title : <br />
Risk Rating :
-Select-
<br />
Root Cause :
-Select-
<br />
Impact :
-Select-
<br />
Likelihood :
-Select-
Efforts :
-Select-
Finding :
Implication:
Recommendation :
</p>
这是错误:
Notice: Undefined index: Finding_ID in C:\xampp\htdocs\ers\edit.php on line 122
Notice: Undefined index: ServiceType_ID in C:\xampp\htdocs\ers\edit.php on line 122
Notice: Undefined index: RootCause_ID in C:\xampp\htdocs\ers\edit.php on line 122
Notice: Undefined index: RiskRating_ID in C:\xampp\htdocs\ers\edit.php on line 122
Notice: Undefined index: Impact_ID in C:\xampp\htdocs\ers\edit.php on line 122
Notice: Undefined index: Efforts_ID in C:\xampp\htdocs\ers\edit.php on line 122
Notice: Undefined variable: Finding_ID in C:\xampp\htdocs\ers\edit.php on line 126
Error: You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near ' ServiceType_ID=, RootCause_ID= , RiskRating_ID= , Impact_ID= ,Efforts_ID= , Lik' at line 2
2个答案:
答案 0 :( 得分:1)
WHERE 的条件应该是使用 AND、OR 而不是逗号。
WHERE Finding_ID=$Finding_ID, ServiceType_ID=$ServiceType_ID,....
应该
WHERE Finding_ID=$Finding_ID AND ServiceType_ID=$ServiceType_ID AND ...
答案1:(得分:0)
您的查询基本上是欢迎每个人访问数据库的大门。
第一:不要在查询中使用直接获取参数。最初与他们合作。
第二位:即使是数字也要加''。为您提供额外的安全保障。
第三个:WHERE 参数是 AND 或 OR
分离
当然,您可以采取更多的预防措施,但最好在一开始就这样做。
PS:长查询在拆分时更易于管理和阅读;并尽量保持你的代码干净漂亮。没有人喜欢使用乱码。
php抓取网页数据插入数据库(这里有新鲜出炉的PHP面向对象编程,程序狗速度看过来!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-04-07 20:07
这里是新鲜出炉的PHP面向对象编程,程序狗的速度来了!
PHP开源脚本语言PHP(外文名称:Hypertext Preprocessor,中文名称:“Hypertext Preprocessor”)是一种通用的开源脚本语言。文法吸收了C语言、Java和Perl的特点。入门门槛低,易学,应用广泛。它主要适用于Web开发领域。PHP的文件扩展名是php。
本文讲解php写入数据库的三种方法及性能对比。三种方式分别是:普通的insert语句一一执行、通过事务批量提交、insert into的批量数据提交方式。有兴趣的同学可以参考以下。
方法一:使用insert into 逐一插入,最终显示为:23:25:05 01:32:05,也就是2个多小时!:
$params = array(‘value'=>'50′);
set_time_limit(0);
echo date(“H:i:s”);
for($i=0;$iinsert($params);
};
echo date(“H:i:s”);
方法二:使用事务提交,批量插入数据库(每10W次提交),最后显示消耗时间为:22:56:13 23:04:00,共8分13秒:
echo date(“H:i:s”);
$connect_mysql->query(‘BEGIN');
$params = array(‘value'=>'50′);
for($i=0;$iinsert($params);
if($i0000==0){
$connect_mysql->query(‘COMMIT');
$connect_mysql->query(‘BEGIN');
}
}
$connect_mysql->query(‘COMMIT');
echo date(“H:i:s”);
方法三:使用优化的SQL语句:拼接SQL语句,使用insert into table() values(),(),(),()一次插入,如果字符串太长,
然后需要配置MYSQL,在mysql命令行运行:set global max_allowed_packet = 2*1024*1024*10; 消费时间为:11:24:06 11:25:06;插入200W条测试数据只用了1分钟!:
$sql= “insert into twenty_million (value) values”;
for($i=0;$iquery($sql);
最后,在插入大批量数据的时候,第一种方法无疑是最差的,而第二种方法在实际应用中应用更广泛,第三种方法更适合插入测试数据或者其他要求不高的时候。真快。 查看全部
php抓取网页数据插入数据库(这里有新鲜出炉的PHP面向对象编程,程序狗速度看过来!)
这里是新鲜出炉的PHP面向对象编程,程序狗的速度来了!
PHP开源脚本语言PHP(外文名称:Hypertext Preprocessor,中文名称:“Hypertext Preprocessor”)是一种通用的开源脚本语言。文法吸收了C语言、Java和Perl的特点。入门门槛低,易学,应用广泛。它主要适用于Web开发领域。PHP的文件扩展名是php。
本文讲解php写入数据库的三种方法及性能对比。三种方式分别是:普通的insert语句一一执行、通过事务批量提交、insert into的批量数据提交方式。有兴趣的同学可以参考以下。
方法一:使用insert into 逐一插入,最终显示为:23:25:05 01:32:05,也就是2个多小时!:
$params = array(‘value'=>'50′);
set_time_limit(0);
echo date(“H:i:s”);
for($i=0;$iinsert($params);
};
echo date(“H:i:s”);
方法二:使用事务提交,批量插入数据库(每10W次提交),最后显示消耗时间为:22:56:13 23:04:00,共8分13秒:
echo date(“H:i:s”);
$connect_mysql->query(‘BEGIN');
$params = array(‘value'=>'50′);
for($i=0;$iinsert($params);
if($i0000==0){
$connect_mysql->query(‘COMMIT');
$connect_mysql->query(‘BEGIN');
}
}
$connect_mysql->query(‘COMMIT');
echo date(“H:i:s”);
方法三:使用优化的SQL语句:拼接SQL语句,使用insert into table() values(),(),(),()一次插入,如果字符串太长,
然后需要配置MYSQL,在mysql命令行运行:set global max_allowed_packet = 2*1024*1024*10; 消费时间为:11:24:06 11:25:06;插入200W条测试数据只用了1分钟!:
$sql= “insert into twenty_million (value) values”;
for($i=0;$iquery($sql);
最后,在插入大批量数据的时候,第一种方法无疑是最差的,而第二种方法在实际应用中应用更广泛,第三种方法更适合插入测试数据或者其他要求不高的时候。真快。
php抓取网页数据插入数据库(request+goquery+mahonia实现自动抓取(图)代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-04-07 06:21
request+goquery+mahonia实现网页数据自动爬取
https:hotqin888articledetails52194839 设计院OA上有一个维护良好的法规库,3000多个条目。我在 30 分钟内将它们逐页复制到 excel 中。总共1500页。为什么不使用代码抓取?因为我连chrome都不能登录访问这个库,只支持ie。使用fiddler获取库页面地址,复制到chrome,直接跳转到登录页面。今天再试试,用chrome登录,然后点击:进入系统-会单独打开一个窗口,这个窗口好像不支持地址输入,没关系,在这个窗口-公共信息-点击下拉- 技术标准,它将打开一个新窗口,出现库。此时,回到任意一个chrome标签,输入地址,就可以打开库了。我不 不知道为什么这么复杂。就记录下来吧。我们进入正题,直接用代码抓取库。这样一个循环一次可以抓取1500页。用到了三个知识点:请求库构造http访问信息头,这里带上登录cookie来模拟登录;mahonia将页面gb的代码转换为utf-8,否则会乱码;goquery大名鼎鼎的get html 否则会乱码;goquery大名鼎鼎的get html 否则会乱码;goquery大名鼎鼎的get html
650 查看全部
php抓取网页数据插入数据库(request+goquery+mahonia实现自动抓取(图)代码)
request+goquery+mahonia实现网页数据自动爬取
https:hotqin888articledetails52194839 设计院OA上有一个维护良好的法规库,3000多个条目。我在 30 分钟内将它们逐页复制到 excel 中。总共1500页。为什么不使用代码抓取?因为我连chrome都不能登录访问这个库,只支持ie。使用fiddler获取库页面地址,复制到chrome,直接跳转到登录页面。今天再试试,用chrome登录,然后点击:进入系统-会单独打开一个窗口,这个窗口好像不支持地址输入,没关系,在这个窗口-公共信息-点击下拉- 技术标准,它将打开一个新窗口,出现库。此时,回到任意一个chrome标签,输入地址,就可以打开库了。我不 不知道为什么这么复杂。就记录下来吧。我们进入正题,直接用代码抓取库。这样一个循环一次可以抓取1500页。用到了三个知识点:请求库构造http访问信息头,这里带上登录cookie来模拟登录;mahonia将页面gb的代码转换为utf-8,否则会乱码;goquery大名鼎鼎的get html 否则会乱码;goquery大名鼎鼎的get html 否则会乱码;goquery大名鼎鼎的get html
650
php抓取网页数据插入数据库(搜狗微信公众号简七指数怎么获取和点赞量?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2022-04-03 06:01
微信公众平台有很多公众号,里面有各种各样的文章,很多都是乱七八糟的。不过,在这些文章之中,肯定会有一些我认为优秀的文章。
所以如果我可以自己写一个程序来获取我喜欢的微信公众号上的文章,获取文章的浏览量和点赞数,然后进行简单的数据分析,那么< @文章 肯定会是一个更好的 文章。
这里需要注意的是,通过编写爬虫获取搜狗微信搜索中的微信文章,是无法获取浏览量和点赞这两个关键数据的(我是入门级编程技能)。于是我找到了另一种方式,通过青波指数的网站获取我想要的数据。
注:目前已找到方法获取搜狗微信中文章的浏览量和点赞量。2017.02.03
事实上,清波指数网站上的数据是非常完整的。可以看到微信公众号的列表,也可以看到每日、每周、每月的热文,不过我上面说的,内容比较乱,那些看书多的文章可能是< @文章 一些家长级别的人会喜欢的。
当然我也可以在这个网站上搜索具体的微信公众号,然后看看它的历史文章。清博指数也已经很详细了,可以按照阅读数、点赞数等进行排序文章。但是,我需要的可能是一个很简单的点赞数除以阅读数的指标,所以我需要通过爬虫抓取上面的数据,进行简单的分析。对了,可以练手,无聊慌。
启动程序
以微信公众号健奇财经为例,我需要先打开它的文章界面,下面是它的url:
然后通过分析发现一共有25页文章,也就是最后一页文章的url如下,注意只有最后一个参数不同:
所以你可以编写一个函数并调用它 25 次。
BeautifulSoup 在网络上爬取它需要的数据
忘了说,我写程序用的语言是Python,它的爬虫入口很简单。然后BeautifulSoup是一个网页分析插件,非常方便的获取文章中的HTML数据。
下一步是分析网页的结构:
我用红框文章框住了两篇文章,它们在网页上的结构代码是一样的。然后通过检查元素就可以看到网页对应的代码,然后就可以编写爬取的规则了。下面我直接写一个函数:
# 从网页中获取数据
def get_webdata(url):
标题 = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.@ >0.2704.103 Safari/537.36'
}
r = requests.get(url,headers=headers)
c = r.内容
b = 美丽汤(c)
data_list = b.find('ul',{'class':'article-ul'})
data_li = data_list.findAll('li')
对于 data_li 中的 i:
# 替换标题中的英文双引号,防止插入数据库时出错
title = i.find('h4').find('a').get_text().replace('"','\'\'')
链接 = i.find('h4').find('a').attrs['href']
source = i.find('span',{'class':'blue'}).get_text()
time = i.find('span',{'class':'blue'}).parent.next_sibling.next_sibling.get_text().replace('发布时间:'.decode('utf-8'),'' )
readnum = int(i.find('i',{'class':'fa-book'}).next_sibling)
赞美数 = int(i.find('i',{'class':'fa-thumbs-o-up'}).next_sibling)
insert_content(标题,readnum,praisenum,时间,链接,来源)
这个函数包括使用requests先获取网页的内容,然后传给BeautifulSoup分析提取我需要的数据,然后在数据库中通过insert_content函数,数据库的知识就不涉及这个了到时候,下面所有的代码都会给它,也算怕以后忘记。
在我看来,其实BeautifulSoup的知识点只需要掌握上面代码中用到的find、findAll、get_text()、attrs['src']等几个常用语句即可。
循环获取并写入数据库
你还记得第一个网址吗?总共需要爬取25个页面。这25个页面的url其实和最后一个参数是不一样的,所以可以给一个基本的url,然后用for函数直接生成25个url就好了:
# 生成要爬取的网页链接并爬取
def get_urls_webdatas(basic_url, range_num):
对于范围内的 i(1,range_num+1):
url = basic_url + str(i)
打印网址
打印 ''
获取网络数据(网址)
time.sleep(round(random.random(),1))
basic_url = '#39;
get_urls_webdatas(basic_url,25)
如上代码,get_urls_webdataas函数传入两个参数,分别是基本url和需要的页数。你可以看到我在代码的最后一行调用了这个函数。
这个函数也调用了我上面写的函数get_webdata来抓取页面,这样25个页面的文章数据会一次性写入数据库。
然后注意这个小技巧:
time.sleep(round(random.random(),1))
每次我用程序爬一个网页,这个语句会随机生成一个1s以内的时间段,然后休息这么短的时间,然后继续爬下一个页面,可以防止被ban。
获取最终数据
先给出我这次写的其余代码:
#编码:utf-8
导入请求,MySQLdb,随机,时间
从 bs4 导入 BeautifulSoup
def get_conn():
conn = MySQLdb.connect('localhost','root','0000','weixin',charset='utf8')
返回连接
def insert_content(标题,readnum,praisenum,时间,链接,来源):
conn = get_conn()
cur = conn.cursor()
打印标题,readnum
sql = '插入weixin.gsdata(title,readnum,praisenum,time,link,source)值("%s","%s","%s","%s","%s", "%s")' % (title,readnum,praisenum,time,link,source)
cur.execute(sql)
mit()
cur.close()
conn.close()
包括一开始的一些插件的导入,然后剩下的两个函数就是与数据库操作相关的函数。
最后,通过从weixin.gsdata中选择*;在数据库中,我可以得到我抓取到的这个微信公众号的文章数据,包括标题、发布日期、阅读量、点赞数、访问url等信息。
分析数据
这些数据只是最原创的数据。我可以将以上数据导入Excel,进行简单的分析处理,得到我需要的文章列表。分析思路如下:
我可以按喜欢排序 查看全部
php抓取网页数据插入数据库(搜狗微信公众号简七指数怎么获取和点赞量?)
微信公众平台有很多公众号,里面有各种各样的文章,很多都是乱七八糟的。不过,在这些文章之中,肯定会有一些我认为优秀的文章。
所以如果我可以自己写一个程序来获取我喜欢的微信公众号上的文章,获取文章的浏览量和点赞数,然后进行简单的数据分析,那么< @文章 肯定会是一个更好的 文章。
这里需要注意的是,通过编写爬虫获取搜狗微信搜索中的微信文章,是无法获取浏览量和点赞这两个关键数据的(我是入门级编程技能)。于是我找到了另一种方式,通过青波指数的网站获取我想要的数据。
注:目前已找到方法获取搜狗微信中文章的浏览量和点赞量。2017.02.03
事实上,清波指数网站上的数据是非常完整的。可以看到微信公众号的列表,也可以看到每日、每周、每月的热文,不过我上面说的,内容比较乱,那些看书多的文章可能是< @文章 一些家长级别的人会喜欢的。
当然我也可以在这个网站上搜索具体的微信公众号,然后看看它的历史文章。清博指数也已经很详细了,可以按照阅读数、点赞数等进行排序文章。但是,我需要的可能是一个很简单的点赞数除以阅读数的指标,所以我需要通过爬虫抓取上面的数据,进行简单的分析。对了,可以练手,无聊慌。
启动程序
以微信公众号健奇财经为例,我需要先打开它的文章界面,下面是它的url:
然后通过分析发现一共有25页文章,也就是最后一页文章的url如下,注意只有最后一个参数不同:
所以你可以编写一个函数并调用它 25 次。
BeautifulSoup 在网络上爬取它需要的数据
忘了说,我写程序用的语言是Python,它的爬虫入口很简单。然后BeautifulSoup是一个网页分析插件,非常方便的获取文章中的HTML数据。
下一步是分析网页的结构:
我用红框文章框住了两篇文章,它们在网页上的结构代码是一样的。然后通过检查元素就可以看到网页对应的代码,然后就可以编写爬取的规则了。下面我直接写一个函数:
# 从网页中获取数据
def get_webdata(url):
标题 = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.@ >0.2704.103 Safari/537.36'
}
r = requests.get(url,headers=headers)
c = r.内容
b = 美丽汤(c)
data_list = b.find('ul',{'class':'article-ul'})
data_li = data_list.findAll('li')
对于 data_li 中的 i:
# 替换标题中的英文双引号,防止插入数据库时出错
title = i.find('h4').find('a').get_text().replace('"','\'\'')
链接 = i.find('h4').find('a').attrs['href']
source = i.find('span',{'class':'blue'}).get_text()
time = i.find('span',{'class':'blue'}).parent.next_sibling.next_sibling.get_text().replace('发布时间:'.decode('utf-8'),'' )
readnum = int(i.find('i',{'class':'fa-book'}).next_sibling)
赞美数 = int(i.find('i',{'class':'fa-thumbs-o-up'}).next_sibling)
insert_content(标题,readnum,praisenum,时间,链接,来源)
这个函数包括使用requests先获取网页的内容,然后传给BeautifulSoup分析提取我需要的数据,然后在数据库中通过insert_content函数,数据库的知识就不涉及这个了到时候,下面所有的代码都会给它,也算怕以后忘记。
在我看来,其实BeautifulSoup的知识点只需要掌握上面代码中用到的find、findAll、get_text()、attrs['src']等几个常用语句即可。
循环获取并写入数据库
你还记得第一个网址吗?总共需要爬取25个页面。这25个页面的url其实和最后一个参数是不一样的,所以可以给一个基本的url,然后用for函数直接生成25个url就好了:
# 生成要爬取的网页链接并爬取
def get_urls_webdatas(basic_url, range_num):
对于范围内的 i(1,range_num+1):
url = basic_url + str(i)
打印网址
打印 ''
获取网络数据(网址)
time.sleep(round(random.random(),1))
basic_url = '#39;
get_urls_webdatas(basic_url,25)
如上代码,get_urls_webdataas函数传入两个参数,分别是基本url和需要的页数。你可以看到我在代码的最后一行调用了这个函数。
这个函数也调用了我上面写的函数get_webdata来抓取页面,这样25个页面的文章数据会一次性写入数据库。
然后注意这个小技巧:
time.sleep(round(random.random(),1))
每次我用程序爬一个网页,这个语句会随机生成一个1s以内的时间段,然后休息这么短的时间,然后继续爬下一个页面,可以防止被ban。
获取最终数据
先给出我这次写的其余代码:
#编码:utf-8
导入请求,MySQLdb,随机,时间
从 bs4 导入 BeautifulSoup
def get_conn():
conn = MySQLdb.connect('localhost','root','0000','weixin',charset='utf8')
返回连接
def insert_content(标题,readnum,praisenum,时间,链接,来源):
conn = get_conn()
cur = conn.cursor()
打印标题,readnum
sql = '插入weixin.gsdata(title,readnum,praisenum,time,link,source)值("%s","%s","%s","%s","%s", "%s")' % (title,readnum,praisenum,time,link,source)
cur.execute(sql)
mit()
cur.close()
conn.close()
包括一开始的一些插件的导入,然后剩下的两个函数就是与数据库操作相关的函数。
最后,通过从weixin.gsdata中选择*;在数据库中,我可以得到我抓取到的这个微信公众号的文章数据,包括标题、发布日期、阅读量、点赞数、访问url等信息。
分析数据
这些数据只是最原创的数据。我可以将以上数据导入Excel,进行简单的分析处理,得到我需要的文章列表。分析思路如下:
我可以按喜欢排序
php抓取网页数据插入数据库(重点推荐:PHP的ORM框架(一)|公司推荐)
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-04-03 05:19
强烈推荐:
1、推进
推进
它是 PHP5 的 OR 映射(Object Relational Mapping)框架,基于 Apache
Torque 提供对象持久层支持。它从模式定义文件和 XML 格式的相应配置文件生成 SQL 和类。它允许您使用对象而不是 SQL 来读取和写入数据库表中的记录。
记录。Propel 提供了一个生成器来为您的数据模型创建 SQL 定义文件和 PHP 类。开发者也可以很方便的自定义生成的类,我们也可以通过XML,
PHP 类和 Phing 构建工具将 Propel 集成到现有的应用程序开发框架中。例如PHP框架symfony的1.2之前的版本默认使用lite版本
Propel 作为默认的 ORM 框架。
官方网站:
2、教义
教义
它是一个 PHP ORM 框架,它必须运行在 >=php5.2.3 版本上,它是一个强大的数据抽象层。它的主要特点之一是对现实使用面向对象的方法
现在数据库查询被密封传输,它通过一个类似于底层Hibernate HQL的DQL查询语句进行数据库查询。
这为开发提供了更大的灵活性,并大大减少了代码重复。与Propel相比,Doctrine的优势在于支持全文搜索。Doctrine 的文件一直比 Propel 好。
Propel需要全面丰富,社区更活跃,使用更自然,更易阅读,更接近原生SQL。它在性能方面也比Propel略好。此外,您还可以轻松
Doctrine 集成到现有的应用程序框架中,例如 PHP 框架 symfony 的 1.3 及以后的版本使用 Doctrine 作为默认的 ORM 框架,也可以集成 Doctrine 和 Codeigniter。
官方网站:
3、EZPDO
EZPDO
是一个非常轻量级的 PHP
ORM 框架。EZPDO作者的初衷是为了减少复杂的ORM学习曲线,尽可能在ORM的运行效率和功能之间做出平衡。这是迄今为止我用过的最简单的 ORM 盒子。
我还是想把它集成到我的CoolPHP SDK中,效率相当不错,功能也基本可以满足需要,但是ESPDO的更新比较慢。
官方网站:
4、红豆
RedBean 是一个易于使用的轻量级 PHP ORM 框架,提供对 MySQL、SQLite 和 PostgreSQL 的支持。RedBean 的架构非常灵活,核心非常简单。开发者可以通过插件轻松扩展功能。
官方网站:
5、其他
国家
内部fleaphp开发框架基于TableDataGateway实现ORM实现;Zend Framework 为 SQL 提供了额外的支持
除了语句的封装外,还实现了TableGateway、TableRowSet、TableRow的实现;还有一些类似 Rails 的
ActiveRecord 实施的解决方案。
更多ORM框架,请阅读:
总结:
总的来说,通用的ORM框架可以满足简单应用系统的基本需求,可以大大降低开发难度,提高开发效率,但是在SQL优化方面肯定比纯SQL语言要好。
更糟糕的是,复杂关联和 SQL 嵌入式表达式的处理并不理想。也许这主要是由于PHP本身的对象持久化问题,导致ORM效率低下,一般比纯SQL慢。
10~50次。但这些都是解决方案。最基本的性能解决方案,我们可以通过缓存来提高效率。对于Hibernate,虽然配置比较复杂,但是可以通过
二级缓存和查询缓存的灵活使用,大大缓解了数据库的查询压力,大大提高了系统的性能。 查看全部
php抓取网页数据插入数据库(重点推荐:PHP的ORM框架(一)|公司推荐)
强烈推荐:
1、推进
推进
它是 PHP5 的 OR 映射(Object Relational Mapping)框架,基于 Apache
Torque 提供对象持久层支持。它从模式定义文件和 XML 格式的相应配置文件生成 SQL 和类。它允许您使用对象而不是 SQL 来读取和写入数据库表中的记录。
记录。Propel 提供了一个生成器来为您的数据模型创建 SQL 定义文件和 PHP 类。开发者也可以很方便的自定义生成的类,我们也可以通过XML,
PHP 类和 Phing 构建工具将 Propel 集成到现有的应用程序开发框架中。例如PHP框架symfony的1.2之前的版本默认使用lite版本
Propel 作为默认的 ORM 框架。
官方网站:
2、教义
教义
它是一个 PHP ORM 框架,它必须运行在 >=php5.2.3 版本上,它是一个强大的数据抽象层。它的主要特点之一是对现实使用面向对象的方法
现在数据库查询被密封传输,它通过一个类似于底层Hibernate HQL的DQL查询语句进行数据库查询。
这为开发提供了更大的灵活性,并大大减少了代码重复。与Propel相比,Doctrine的优势在于支持全文搜索。Doctrine 的文件一直比 Propel 好。
Propel需要全面丰富,社区更活跃,使用更自然,更易阅读,更接近原生SQL。它在性能方面也比Propel略好。此外,您还可以轻松
Doctrine 集成到现有的应用程序框架中,例如 PHP 框架 symfony 的 1.3 及以后的版本使用 Doctrine 作为默认的 ORM 框架,也可以集成 Doctrine 和 Codeigniter。
官方网站:
3、EZPDO
EZPDO
是一个非常轻量级的 PHP
ORM 框架。EZPDO作者的初衷是为了减少复杂的ORM学习曲线,尽可能在ORM的运行效率和功能之间做出平衡。这是迄今为止我用过的最简单的 ORM 盒子。
我还是想把它集成到我的CoolPHP SDK中,效率相当不错,功能也基本可以满足需要,但是ESPDO的更新比较慢。
官方网站:
4、红豆
RedBean 是一个易于使用的轻量级 PHP ORM 框架,提供对 MySQL、SQLite 和 PostgreSQL 的支持。RedBean 的架构非常灵活,核心非常简单。开发者可以通过插件轻松扩展功能。
官方网站:
5、其他
国家
内部fleaphp开发框架基于TableDataGateway实现ORM实现;Zend Framework 为 SQL 提供了额外的支持
除了语句的封装外,还实现了TableGateway、TableRowSet、TableRow的实现;还有一些类似 Rails 的
ActiveRecord 实施的解决方案。
更多ORM框架,请阅读:
总结:
总的来说,通用的ORM框架可以满足简单应用系统的基本需求,可以大大降低开发难度,提高开发效率,但是在SQL优化方面肯定比纯SQL语言要好。
更糟糕的是,复杂关联和 SQL 嵌入式表达式的处理并不理想。也许这主要是由于PHP本身的对象持久化问题,导致ORM效率低下,一般比纯SQL慢。
10~50次。但这些都是解决方案。最基本的性能解决方案,我们可以通过缓存来提高效率。对于Hibernate,虽然配置比较复杂,但是可以通过
二级缓存和查询缓存的灵活使用,大大缓解了数据库的查询压力,大大提高了系统的性能。
php抓取网页数据插入数据库(studentinfo数据库删除指定数据(改)(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2022-04-02 20:10
)
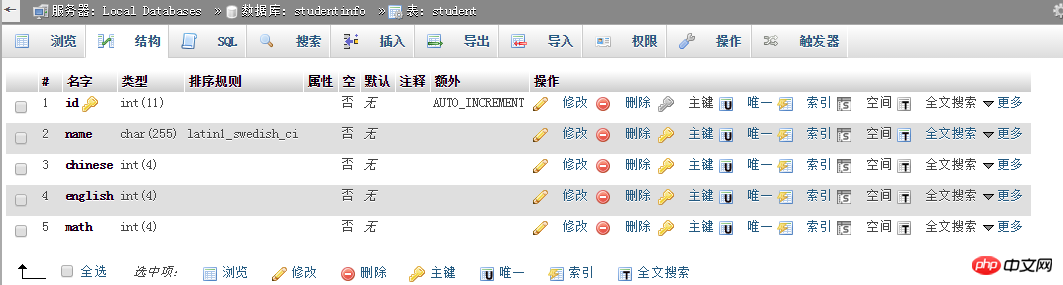
第一步:创建数据库并在数据库中创建数据表。当然,一个数据库中可以有很多数据表。在这里,我将创建一个表来存储学生的个人姓名和成绩。
推荐mysql视频教程:《mysql教程》
思路:连接服务器->创建数据库->连接数据库->创建数据表
脚本:创建数据库和数据表
现在可以在phpMyAdmin中看到新的数据库studentinfo和数据表student
第二步:在studentinfo数据库的学生数据表中添加学生信息数据(补充)
思路:连接服务器->连接数据库->将指定数据插入数据表
注意:因为前面的php已经创建了服务器连接并连接了数据库,所以下面的代码省略了建立连接的部分,直接写了函数语句。
function addtabel_data(){
//多维数组
$datas=array(
array("name"=>"测试猫","chinese"=>100,"english"=>100,"math"=>100),
array("name"=>"测试狗","chinese"=>99,"english"=>99,"math"=>99),
array("name"=>"测试虎","chinese"=>98,"english"=>98,"math"=>98)
);
for($i=0;$i0){
echo "添加数据成功</br>";
}else{
echo "添加数据失败</br>";
}
}
addtabel_data();//调用
运行php发现添加数据失败,这是为什么呢?因为name中传入了一个中文字符串,而学生表中定义的name collation不是utf-8?? ?
没关系,我们可以一键修改排序规则,自己修改。
再次运行,添加数据成功,发现表中有数据
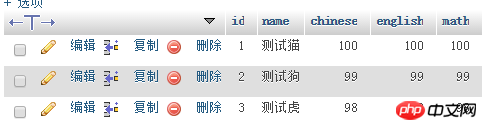
第三步:根据查询条件在studentinfo数据库的student表中查询一条或多条指定信息(勾选)
思路:连接服务器->连接数据库->根据条件查询数据表数据
function selecttable_data($name){
$res=mysql_query("select * from student where name='$name'");//根据name来查询student数据
// $res=mysql_query("select * from student where name='$name' and chinese='$chinese'");//多条件查询连接符and
// $res=mysql_query("select * from student");//查询student表里所有数据
// $res=mysql_query("select * from student limit 0,2“);//限制前面第1到2条数据
if($res&&mysql_num_rows($res)){
while($sql=mysql_fetch_assoc($res)){
$arr[]=$sql;
}
echo json_encode($arr,JSON_UNESCAPED_UNICODE);//把数据(数组嵌套json类型)转换为字符串输出,这个ajax拿数据经常用
}else{
echo "找不到该数据</br>";
}
}
selecttable_data("测试猫");//查询name为测试猫
第四步:根据修改条件修改studentinfo数据库的学生表中的指定数据(修改)
思路:连接服务器->连接数据库->根据条件修改数据表中的指定数据
function updatetabel_data($name,$chinese){
mysql_query("update student set chinese='$chinese' where name='$name'");//修改student表里为$name的chinese数据修改为$chinese
$res=mysql_affected_rows();//返回影响行
if($res>0){
echo "修改成功</br>";
}else{
echo "修改失败</br>";
}
}
updatetabel_data("测试虎",90);//把测试虎的语文成绩修改为90分
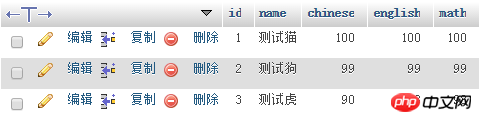
测试老虎语言分数已从 98 修改为 90
第五步:根据删除条件删除studentinfo数据库student表中的指定数据(delete)
思路:连接服务器->连接数据库->根据条件删除数据表中的指定数据
function deletetable_data($name){
mysql_query("delete from student where name='$name'");//删除student表里为$name的整条数据
$res=mysql_affected_rows();//返回影响行
if($res>0){
echo "删除成功</br>";
}else{
echo "删除失败</br>";
}
}
deletetable_data('测试虎');//删除name为测试虎这条数据
测试老虎 此数据已被删除
查看全部
php抓取网页数据插入数据库(studentinfo数据库删除指定数据(改)(图)
)
第一步:创建数据库并在数据库中创建数据表。当然,一个数据库中可以有很多数据表。在这里,我将创建一个表来存储学生的个人姓名和成绩。
推荐mysql视频教程:《mysql教程》
思路:连接服务器->创建数据库->连接数据库->创建数据表
脚本:创建数据库和数据表
现在可以在phpMyAdmin中看到新的数据库studentinfo和数据表student
第二步:在studentinfo数据库的学生数据表中添加学生信息数据(补充)
思路:连接服务器->连接数据库->将指定数据插入数据表
注意:因为前面的php已经创建了服务器连接并连接了数据库,所以下面的代码省略了建立连接的部分,直接写了函数语句。
function addtabel_data(){
//多维数组
$datas=array(
array("name"=>"测试猫","chinese"=>100,"english"=>100,"math"=>100),
array("name"=>"测试狗","chinese"=>99,"english"=>99,"math"=>99),
array("name"=>"测试虎","chinese"=>98,"english"=>98,"math"=>98)
);
for($i=0;$i0){
echo "添加数据成功</br>";
}else{
echo "添加数据失败</br>";
}
}
addtabel_data();//调用
运行php发现添加数据失败,这是为什么呢?因为name中传入了一个中文字符串,而学生表中定义的name collation不是utf-8?? ?
没关系,我们可以一键修改排序规则,自己修改。

再次运行,添加数据成功,发现表中有数据
第三步:根据查询条件在studentinfo数据库的student表中查询一条或多条指定信息(勾选)

思路:连接服务器->连接数据库->根据条件查询数据表数据
function selecttable_data($name){
$res=mysql_query("select * from student where name='$name'");//根据name来查询student数据
// $res=mysql_query("select * from student where name='$name' and chinese='$chinese'");//多条件查询连接符and
// $res=mysql_query("select * from student");//查询student表里所有数据
// $res=mysql_query("select * from student limit 0,2“);//限制前面第1到2条数据
if($res&&mysql_num_rows($res)){
while($sql=mysql_fetch_assoc($res)){
$arr[]=$sql;
}
echo json_encode($arr,JSON_UNESCAPED_UNICODE);//把数据(数组嵌套json类型)转换为字符串输出,这个ajax拿数据经常用
}else{
echo "找不到该数据</br>";
}
}
selecttable_data("测试猫");//查询name为测试猫
第四步:根据修改条件修改studentinfo数据库的学生表中的指定数据(修改)
思路:连接服务器->连接数据库->根据条件修改数据表中的指定数据
function updatetabel_data($name,$chinese){
mysql_query("update student set chinese='$chinese' where name='$name'");//修改student表里为$name的chinese数据修改为$chinese
$res=mysql_affected_rows();//返回影响行
if($res>0){
echo "修改成功</br>";
}else{
echo "修改失败</br>";
}
}
updatetabel_data("测试虎",90);//把测试虎的语文成绩修改为90分
测试老虎语言分数已从 98 修改为 90
第五步:根据删除条件删除studentinfo数据库student表中的指定数据(delete)
思路:连接服务器->连接数据库->根据条件删除数据表中的指定数据
function deletetable_data($name){
mysql_query("delete from student where name='$name'");//删除student表里为$name的整条数据
$res=mysql_affected_rows();//返回影响行
if($res>0){
echo "删除成功</br>";
}else{
echo "删除失败</br>";
}
}
deletetable_data('测试虎');//删除name为测试虎这条数据

测试老虎 此数据已被删除

php抓取网页数据插入数据库(我的小程序通过PHP从SQL数据库提取到数据,使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-04-02 16:39
我的小程序通过 PHP 从 SQL 数据库中提取数据,使用
{{item.id}}{{item.device_num}}{{item.user_name}}{{item.user_phone}}
语句渲染数据,php获取的数据如下:
[{\"id\":\"1\",\"device_num\":\"12002120\",\"user_name\":\"li\",\"user_phone\":\"\ ",\"unit_name\":\"jijin\",\"unit_addr\":\"djsaj\",\"wechat_num\":\"hsahjh\"},{\"id\":\"2\ ",\"device_num\":\"1272677867\",\"user_name\":\"zhang\",\"user_phone\":\"1362525891\",\"unit_name\":\"yiuehhaj\", \"unit_addr\":\"heiwh\",\"wechat_num\":\"hh\"}]\r\n\r\n\r\n\r\n\r\n \r\n
调试器观察到的渲染页面数据如下
数据是空的,不知道为什么,请大家指点一下。 查看全部
php抓取网页数据插入数据库(我的小程序通过PHP从SQL数据库提取到数据,使用)
我的小程序通过 PHP 从 SQL 数据库中提取数据,使用
{{item.id}}{{item.device_num}}{{item.user_name}}{{item.user_phone}}
语句渲染数据,php获取的数据如下:
[{\"id\":\"1\",\"device_num\":\"12002120\",\"user_name\":\"li\",\"user_phone\":\"\ ",\"unit_name\":\"jijin\",\"unit_addr\":\"djsaj\",\"wechat_num\":\"hsahjh\"},{\"id\":\"2\ ",\"device_num\":\"1272677867\",\"user_name\":\"zhang\",\"user_phone\":\"1362525891\",\"unit_name\":\"yiuehhaj\", \"unit_addr\":\"heiwh\",\"wechat_num\":\"hh\"}]\r\n\r\n\r\n\r\n\r\n \r\n
调试器观察到的渲染页面数据如下
数据是空的,不知道为什么,请大家指点一下。
php抓取网页数据插入数据库( PHP快速导入大量数据到数据库的方法方法方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 42 次浏览 • 2022-03-30 00:09
PHP快速导入大量数据到数据库的方法方法方法
)
PHP中快速将大量数据导入数据库的方法
第一种方法:使用insert into插入,代码如下:
$params = array(‘value'=>'50′);
set_time_limit(0);
echo date(“H:i:s”);
for($i=0;$iinsert($params);
};
echo date(“H:i:s”);
最终显示为:23:25:05 01:32:05,也就是用了2个多小时!
第二种方法:使用事务提交,批量插入数据库(每10W提交),最后显示时间为:22:56:13 23:04:00,共8分13秒,代码为如下:
echo date(“H:i:s”);
$connect_mysql->query(‘BEGIN');
$params = array(‘value'=>'50′);
for($i=0;$iinsert($params);
if($i0000==0){
$connect_mysql->query(‘COMMIT');
$connect_mysql->query(‘BEGIN');
}
}
$connect_mysql->query(‘COMMIT');
echo date(“H:i:s”);
第三种方法:使用优化的SQL语句
拼接SQL语句,使用insert into table() values(),(),(),()一次插入,如果字符串太长,需要配置MYSQL,
在mysql命令行中运行:
set global max_allowed_packet = 2*1024*1024*10;
消费时间为:11:24:06 11:25:06;
插入200W条测试数据只用了1分钟!代码如下:
$sql= “insert into twenty_million (value) values”;
for($i=0;$iquery($sql);
总结:在插入大批量数据时,第一种方法无疑是最差的,而第二种方法在实际应用中被广泛使用,第三种方法更适合插入测试数据或者其他要求不高的时候,速度确实快.
推荐教程:PHP视频教程
以上就是php中如何快速导入大量数据的详细内容。更多详情请关注php中文网文章其他相关话题!
查看全部
php抓取网页数据插入数据库(
PHP快速导入大量数据到数据库的方法方法方法
)

PHP中快速将大量数据导入数据库的方法
第一种方法:使用insert into插入,代码如下:
$params = array(‘value'=>'50′);
set_time_limit(0);
echo date(“H:i:s”);
for($i=0;$iinsert($params);
};
echo date(“H:i:s”);
最终显示为:23:25:05 01:32:05,也就是用了2个多小时!
第二种方法:使用事务提交,批量插入数据库(每10W提交),最后显示时间为:22:56:13 23:04:00,共8分13秒,代码为如下:
echo date(“H:i:s”);
$connect_mysql->query(‘BEGIN');
$params = array(‘value'=>'50′);
for($i=0;$iinsert($params);
if($i0000==0){
$connect_mysql->query(‘COMMIT');
$connect_mysql->query(‘BEGIN');
}
}
$connect_mysql->query(‘COMMIT');
echo date(“H:i:s”);
第三种方法:使用优化的SQL语句
拼接SQL语句,使用insert into table() values(),(),(),()一次插入,如果字符串太长,需要配置MYSQL,
在mysql命令行中运行:
set global max_allowed_packet = 2*1024*1024*10;
消费时间为:11:24:06 11:25:06;
插入200W条测试数据只用了1分钟!代码如下:
$sql= “insert into twenty_million (value) values”;
for($i=0;$iquery($sql);
总结:在插入大批量数据时,第一种方法无疑是最差的,而第二种方法在实际应用中被广泛使用,第三种方法更适合插入测试数据或者其他要求不高的时候,速度确实快.
推荐教程:PHP视频教程
以上就是php中如何快速导入大量数据的详细内容。更多详情请关注php中文网文章其他相关话题!
php抓取网页数据插入数据库(用PHP编写一个爬取事百科首页糗事!(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2022-03-29 01:03
)
突然想弄点网上的资料玩玩,因为有SAE的MySql数据库,放在那里也没用!于是我开始用PHP写了一个小程序来爬取尴尬事百科首页的尴尬事。数据存储在MySql中,是不是很好玩!
去做就对了!先确定思路
获取HTML源代码--->解析HTML--->保存到数据库
没什么难的
1、创建 PHP 文件“getDataToDB.php”,
2、获取指定URL的HTML源代码
这里我使用了curl函数,详情见PHP手册
代码是
// 获取对应链接的HTMLCODEfunction GetHtmlCode($url) { $ch = curl_init (); // 初始化一个cur对象 curl_setopt ( $ch, CURLOPT_URL, $url ); // 设置需要抓取的网页 curl_setopt ( $ch, CURLOPT_RETURNTRANSFER, 1 ); // 设置crul参数,要求结果保存到字符串中还是输出到屏幕上 curl_setopt ( $ch, CURLOPT_CONNECTTIMEOUT, 1000 ); // 设置链接延迟 $HtmlCode = curl_exec ( $ch ); // 运行curl,请求网页 return $HtmlCode;}
3、引入第三方文件'simple_html_dom.php'解析HTML
我这里没有使用正则表达式的能力,只是在网上搜索了一下,终于找到了这个,就像Java使用Jsoup一样(使用Jsoup解析滁州大学官网获取新闻列表),详情见BLOG
代码显示如下
function getFmlDataToDB() { $link = mysql_connect ( SAE_MYSQL_HOST_M . ':' . SAE_MYSQL_PORT, SAE_MYSQL_USER, SAE_MYSQL_PASS ); // 获取源码 $html = str_get_html ( GetHtmlCode ( "http://www.qiushibaike.com/" ) ); if ($link) { mysql_select_db ( SAE_MYSQL_DB, $link ); mysql_query ( 'set names utf8' ); // class="article block untagged mb15" foreach ( $html->find ( 'div[class=article block untagged mb15]' ) as $per ) { $z = null; $t = null; $w = null; $d = null; $p = null; $ds = null; $ps = null; // //作者 $author = $per->find ( 'div[class=author]' ); if ($author != null) { $a = $author [0]->find ( 'a' ); $z = $a [1]->innertext; } else { $z = 'no author'; } // 头像链接 if ($author != null) { $icon = $author [0]->find ( 'a' ); $t = $icon [0]->src->innertext; } else { $t = '...............'; } // 文章内容 $content = $per->find ( 'div[class=content]' ); $w = $content [0]->innertext; // 点赞数 $vote1 = $per->find ( 'div[class=stats]' ); $vote2 = $vote1 [0]->find ( 'span[class=stats-vote]' ); $vote3 = $vote2 [0]->find ( 'i[class=number]' ); $d = $vote3 [0]->innertext; // 评论数 $comments1 = $vote1 [0]->find ( 'span[class=stats-comments]' ); $comments2 = $comments1 [0]->find ( 'a[class=qiushi_comments]' ); $comments3 = $comments2 [0]->find ( 'i[class=number]' ); $p = $comments3 [0]->innertext; // 顶 数 $up_down = $per->find ( 'div[class=stats-buttons bar clearfix]' ); $up_down1 = $up_down [0]->find ( 'ul' ); $li = $up_down1 [0]->find ( 'li' ); $up = $li [0]->find ( 'span[class=number hidden]' ); $ds = $up [0]->innertext; // 拍 数 $down = $li [1]->find ( 'span[class=number hidden]' ); $ps = $down [0]->innertext; } } else { echo '数据库链接KO'; }}
这段代码写起来有点纠结。我试过了,不能直接获取子节点的数据。我只能从外层一层一层剥离解析。如果有新的写法,我会更新的,敬请关注。.
4、创建数据库,向数据库中插入数据
这里我在 SAE 中使用 MySQL。具体的连接方,请参见使用 PHP 连接 SAE 中的 MySql 数据库
需要注意编码格式,区域要在执行语句前加这么一句
mysql_query ( 'set names utf8' );
核心代码如下:
$sql = "INSERT INTO `app_bmhjqs`.`db_fml` (`id`, `author`, `icon_url`, `content`, `vote`, `comments`, `up`, `down`) VALUES (NULL, '$z', '$t', '$w', '$d', '$p', '$ds', '$ps');"; // 解决乱码 mysql_query ( 'set names utf8' ); $result = mysql_query ( $sql );
这样,获取--->解析--->插入就完成了,效果就是运行PHP文件一次,数据库就会在尴尬事百科首页添加尴尬事!我想知道是否可以编写一个计时器来每隔一定时间运行代码。我可以在java中做到这一点,但我不能在php中。毕竟是没有毛的鸟!百度一下。. . 找到这个拼写
// 定时器// ignore_user_abort (); // run script. in background// set_time_limit ( 0 ); // run script. forever// $interval = 30; // do every 15 minutes..// do {// echo date ( 'Y-m-d H:i:s', time () );// echo '写入数据库';// //getFmlDataToDB (); // } while ( true );
文件中加了这么一段代码,就在学校断网之前,在SAE上发表过,我没有测试!只需要等到第二天才能看到结果!
今天早上,我迫不及待地打开电脑,打开了SAE数据库。情况如下:
额头神!实在受不了了,赶紧关掉定时器,写了个按钮触发事件!如果这样下去,数据库会很拥挤!
好了,PHP爬虫的尴尬事百科首页的尴尬事都搞定了
如果你觉得这个博客对你有帮助,请给它一个赞!
查看全部
php抓取网页数据插入数据库(用PHP编写一个爬取事百科首页糗事!(图)
)
突然想弄点网上的资料玩玩,因为有SAE的MySql数据库,放在那里也没用!于是我开始用PHP写了一个小程序来爬取尴尬事百科首页的尴尬事。数据存储在MySql中,是不是很好玩!
去做就对了!先确定思路
获取HTML源代码--->解析HTML--->保存到数据库
没什么难的
1、创建 PHP 文件“getDataToDB.php”,
2、获取指定URL的HTML源代码
这里我使用了curl函数,详情见PHP手册
代码是
// 获取对应链接的HTMLCODEfunction GetHtmlCode($url) { $ch = curl_init (); // 初始化一个cur对象 curl_setopt ( $ch, CURLOPT_URL, $url ); // 设置需要抓取的网页 curl_setopt ( $ch, CURLOPT_RETURNTRANSFER, 1 ); // 设置crul参数,要求结果保存到字符串中还是输出到屏幕上 curl_setopt ( $ch, CURLOPT_CONNECTTIMEOUT, 1000 ); // 设置链接延迟 $HtmlCode = curl_exec ( $ch ); // 运行curl,请求网页 return $HtmlCode;}
3、引入第三方文件'simple_html_dom.php'解析HTML
我这里没有使用正则表达式的能力,只是在网上搜索了一下,终于找到了这个,就像Java使用Jsoup一样(使用Jsoup解析滁州大学官网获取新闻列表),详情见BLOG
代码显示如下
function getFmlDataToDB() { $link = mysql_connect ( SAE_MYSQL_HOST_M . ':' . SAE_MYSQL_PORT, SAE_MYSQL_USER, SAE_MYSQL_PASS ); // 获取源码 $html = str_get_html ( GetHtmlCode ( "http://www.qiushibaike.com/" ) ); if ($link) { mysql_select_db ( SAE_MYSQL_DB, $link ); mysql_query ( 'set names utf8' ); // class="article block untagged mb15" foreach ( $html->find ( 'div[class=article block untagged mb15]' ) as $per ) { $z = null; $t = null; $w = null; $d = null; $p = null; $ds = null; $ps = null; // //作者 $author = $per->find ( 'div[class=author]' ); if ($author != null) { $a = $author [0]->find ( 'a' ); $z = $a [1]->innertext; } else { $z = 'no author'; } // 头像链接 if ($author != null) { $icon = $author [0]->find ( 'a' ); $t = $icon [0]->src->innertext; } else { $t = '...............'; } // 文章内容 $content = $per->find ( 'div[class=content]' ); $w = $content [0]->innertext; // 点赞数 $vote1 = $per->find ( 'div[class=stats]' ); $vote2 = $vote1 [0]->find ( 'span[class=stats-vote]' ); $vote3 = $vote2 [0]->find ( 'i[class=number]' ); $d = $vote3 [0]->innertext; // 评论数 $comments1 = $vote1 [0]->find ( 'span[class=stats-comments]' ); $comments2 = $comments1 [0]->find ( 'a[class=qiushi_comments]' ); $comments3 = $comments2 [0]->find ( 'i[class=number]' ); $p = $comments3 [0]->innertext; // 顶 数 $up_down = $per->find ( 'div[class=stats-buttons bar clearfix]' ); $up_down1 = $up_down [0]->find ( 'ul' ); $li = $up_down1 [0]->find ( 'li' ); $up = $li [0]->find ( 'span[class=number hidden]' ); $ds = $up [0]->innertext; // 拍 数 $down = $li [1]->find ( 'span[class=number hidden]' ); $ps = $down [0]->innertext; } } else { echo '数据库链接KO'; }}
这段代码写起来有点纠结。我试过了,不能直接获取子节点的数据。我只能从外层一层一层剥离解析。如果有新的写法,我会更新的,敬请关注。.
4、创建数据库,向数据库中插入数据
这里我在 SAE 中使用 MySQL。具体的连接方,请参见使用 PHP 连接 SAE 中的 MySql 数据库
需要注意编码格式,区域要在执行语句前加这么一句
mysql_query ( 'set names utf8' );
核心代码如下:
$sql = "INSERT INTO `app_bmhjqs`.`db_fml` (`id`, `author`, `icon_url`, `content`, `vote`, `comments`, `up`, `down`) VALUES (NULL, '$z', '$t', '$w', '$d', '$p', '$ds', '$ps');"; // 解决乱码 mysql_query ( 'set names utf8' ); $result = mysql_query ( $sql );
这样,获取--->解析--->插入就完成了,效果就是运行PHP文件一次,数据库就会在尴尬事百科首页添加尴尬事!我想知道是否可以编写一个计时器来每隔一定时间运行代码。我可以在java中做到这一点,但我不能在php中。毕竟是没有毛的鸟!百度一下。. . 找到这个拼写
// 定时器// ignore_user_abort (); // run script. in background// set_time_limit ( 0 ); // run script. forever// $interval = 30; // do every 15 minutes..// do {// echo date ( 'Y-m-d H:i:s', time () );// echo '写入数据库';// //getFmlDataToDB (); // } while ( true );
文件中加了这么一段代码,就在学校断网之前,在SAE上发表过,我没有测试!只需要等到第二天才能看到结果!
今天早上,我迫不及待地打开电脑,打开了SAE数据库。情况如下:

额头神!实在受不了了,赶紧关掉定时器,写了个按钮触发事件!如果这样下去,数据库会很拥挤!
好了,PHP爬虫的尴尬事百科首页的尴尬事都搞定了
如果你觉得这个博客对你有帮助,请给它一个赞!

php抓取网页数据插入数据库(MongoDBPHP在php中使用mongodb你必须使用的php驱动)
网站优化 • 优采云 发表了文章 • 0 个评论 • 39 次浏览 • 2022-03-28 11:15
MongoDB PHP
要在php中使用mongodb,你必须使用mongodb的php驱动。
各平台MongoDB PHP的安装及驱动包下载,请参考:MongoDB扩展驱动的PHP安装
如果您使用的是 PHP7,请参阅:PHP7 MongoDB 安装和使用。
确保连接并选择一个数据库
为了保证正确连接,需要指定数据库名,如果mongoDB中不存在该数据库,mongoDB会自动创建
代码片段如下:
创建一个集合
创建集合的代码片段如下:
执行上述程序,输出如下:
集合创建成功
插入文档
在 mongoDB 中使用 insert() 方法插入文档:
插入文档的代码片段如下:
执行上述程序,输出如下:
数据插入成功
然后我们使用 db.runoob.find().pretty(); mongo客户端查看数据的命令:
查找文档
使用 find() 方法读取集合中的文档。
阅读使用文档的代码片段如下:
执行上述程序,输出如下:
MongoDB
更新文档
使用 update() 方法更新文档。
以下示例将使用以下代码片段更新标题为“MongoDB 教程”的文档:
执行上述程序,输出如下:
MongoDB 教程
然后我们使用 db.runoob.find().pretty(); mongo客户端查看数据的命令:
删除文档
使用 remove() 方法删除文档。
在以下示例中,我们将删除“title”为“MongoDB Tutorial”的数据记录。 ,代码片段如下:
除了上面的例子,你还可以使用findOne()、save()、limit()、skip()、sort()等方法在php中操作Mongodb数据库。
更多操作方法请参考Mongodb核心类: 查看全部
php抓取网页数据插入数据库(MongoDBPHP在php中使用mongodb你必须使用的php驱动)
MongoDB PHP
要在php中使用mongodb,你必须使用mongodb的php驱动。
各平台MongoDB PHP的安装及驱动包下载,请参考:MongoDB扩展驱动的PHP安装
如果您使用的是 PHP7,请参阅:PHP7 MongoDB 安装和使用。
确保连接并选择一个数据库
为了保证正确连接,需要指定数据库名,如果mongoDB中不存在该数据库,mongoDB会自动创建
代码片段如下:
创建一个集合
创建集合的代码片段如下:
执行上述程序,输出如下:
集合创建成功
插入文档
在 mongoDB 中使用 insert() 方法插入文档:
插入文档的代码片段如下:
执行上述程序,输出如下:
数据插入成功
然后我们使用 db.runoob.find().pretty(); mongo客户端查看数据的命令:

查找文档
使用 find() 方法读取集合中的文档。
阅读使用文档的代码片段如下:
执行上述程序,输出如下:
MongoDB
更新文档
使用 update() 方法更新文档。
以下示例将使用以下代码片段更新标题为“MongoDB 教程”的文档:
执行上述程序,输出如下:
MongoDB 教程
然后我们使用 db.runoob.find().pretty(); mongo客户端查看数据的命令:
删除文档
使用 remove() 方法删除文档。
在以下示例中,我们将删除“title”为“MongoDB Tutorial”的数据记录。 ,代码片段如下:
除了上面的例子,你还可以使用findOne()、save()、limit()、skip()、sort()等方法在php中操作Mongodb数据库。
更多操作方法请参考Mongodb核心类:
php抓取网页数据插入数据库(制定切实可行的建设方案网站在建设之前需要分析客户的需求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-03-27 15:06
1:制定切实可行的施工计划
网站在建设之前,要分析客户的需求和互联网发展的趋势,制定符合企业发展的网站建设方案。策划的好坏将直接影响后期企业在互联网上的宣传推广效果。根据客户意见网站的需求、行业市场、产品定位等实际情况,确认网站的内容,明确网站传达的目的,建站的目的一方面是为了能够为客户解决问题,让有需要的客户通过网站对公司有更全面的了解,另一方面,
二:高端视觉体验
随着社会的不断进步和生活水平的提高,人类的审美也在不断提高。因为互联网产品迭代发展很快,只有与时俱进的设计,极致的交互,才能给用户带来满分的体验。网站设计还包括网页的排版布局、网站导航设计、网站栏目设计等,网页与用户的交互体现在鼠标的移动上up元素来改变原来的状态、颜色等。我们称之为动画特效,让用户在浏览网站时感觉这是一场视觉盛宴,那么建站的目的就达到了。
三:开发方式
随着技术的不断进步,编程语言越来越多,但需要考虑后期优化,所以我们选择原生Html+php开发方式来建站。这种方式符合国际标准DIV+CSS,可以最大限度的将网页原样显示在搜索引擎上,一方面有利于各平台搜索引擎对网页的抓取,另一方面另一方面,也有利于后期的维护。
四:网站的优化
你对搜索引擎并不陌生。为什么你的 网站 排名比其他人高,是因为搜索引擎会抓取你的 网站 内容并评估你的 网站 内容的质量。是的,所以关键词的优化,内容的更新和维护是建站所有步骤中最关键的一步。再好的产品没有市场,终究会被埋没。人们看到,那最终会被淘汰,SEO优化是所有网站的重要组成部分。
优盛网络-高端网站建设-品牌官网建设-品牌设计-宁波网站建设-为企业打造精品而生 查看全部
php抓取网页数据插入数据库(制定切实可行的建设方案网站在建设之前需要分析客户的需求)
1:制定切实可行的施工计划
网站在建设之前,要分析客户的需求和互联网发展的趋势,制定符合企业发展的网站建设方案。策划的好坏将直接影响后期企业在互联网上的宣传推广效果。根据客户意见网站的需求、行业市场、产品定位等实际情况,确认网站的内容,明确网站传达的目的,建站的目的一方面是为了能够为客户解决问题,让有需要的客户通过网站对公司有更全面的了解,另一方面,
二:高端视觉体验
随着社会的不断进步和生活水平的提高,人类的审美也在不断提高。因为互联网产品迭代发展很快,只有与时俱进的设计,极致的交互,才能给用户带来满分的体验。网站设计还包括网页的排版布局、网站导航设计、网站栏目设计等,网页与用户的交互体现在鼠标的移动上up元素来改变原来的状态、颜色等。我们称之为动画特效,让用户在浏览网站时感觉这是一场视觉盛宴,那么建站的目的就达到了。
三:开发方式
随着技术的不断进步,编程语言越来越多,但需要考虑后期优化,所以我们选择原生Html+php开发方式来建站。这种方式符合国际标准DIV+CSS,可以最大限度的将网页原样显示在搜索引擎上,一方面有利于各平台搜索引擎对网页的抓取,另一方面另一方面,也有利于后期的维护。
四:网站的优化
你对搜索引擎并不陌生。为什么你的 网站 排名比其他人高,是因为搜索引擎会抓取你的 网站 内容并评估你的 网站 内容的质量。是的,所以关键词的优化,内容的更新和维护是建站所有步骤中最关键的一步。再好的产品没有市场,终究会被埋没。人们看到,那最终会被淘汰,SEO优化是所有网站的重要组成部分。
优盛网络-高端网站建设-品牌官网建设-品牌设计-宁波网站建设-为企业打造精品而生
php抓取网页数据插入数据库( 接到一个任务是把中国名牌网站的某些内容添加到我们的网站上)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-03-25 23:09
接到一个任务是把中国名牌网站的某些内容添加到我们的网站上)
frog 青蛙推荐:远程爬取网页到本地database.doc
接到任务将中国名牌网站的部分内容添加到我们的网站中,地址如下:本页有一些文章链接列表,点击链接会出现< @网站@文章的详细内容展示页面,根据这个规则,结合正则表达式、XMLHTTP技术、Jscript服务器端脚本、ADO技术,编写了一个小程序,将这些内容抓取到本地数据库. 抓起来比较方便,然后将数据库中的数据导入到数据库中。
接到任务,将中国名牌网站的部分内容添加到我们的网站中,地址如下:
此页面收录 文章 链接列表。点击链接会弹出文章的详细内容展示页面。根据这个规则,结合正则表达式、XMLHTTP技术、Jscript服务器脚本、ADO技术,我编写了一个小程序,将这些内容抓取到本地数据库中。抓起来比较方便,然后将数据库中的数据导入到数据库中。首先创建一个Access数据库,结构如下
ID
自动编号
ID,主键
旧身份证
数字
旧数据编码
标题
标题
文本
内容
评论
内容
具体实现代码如下
下一步就是将Access数据库的内容导入到服务器数据库中,但是还有一些东西,就是原来的文章是分类的,所以导入的时候还得手动分类,因为链接被分析。写正则表达式的时候,写起来很麻烦,但还是严谨的。如果分类也用正则表达式来解析,那会很麻烦,因为分类收录在里面,而且那个页面有很多标签。如果要定位文本分类会很麻烦,而且即使写出来,程序也会失去灵活性,变得难以维护,所以这是它现在唯一做的一步。
发表于@2005-07-15 15:59 青蛙王子 浏览量(4581)评论(8)编辑 查看全部
php抓取网页数据插入数据库(
接到一个任务是把中国名牌网站的某些内容添加到我们的网站上)
frog 青蛙推荐:远程爬取网页到本地database.doc
接到任务将中国名牌网站的部分内容添加到我们的网站中,地址如下:本页有一些文章链接列表,点击链接会出现< @网站@文章的详细内容展示页面,根据这个规则,结合正则表达式、XMLHTTP技术、Jscript服务器端脚本、ADO技术,编写了一个小程序,将这些内容抓取到本地数据库. 抓起来比较方便,然后将数据库中的数据导入到数据库中。
接到任务,将中国名牌网站的部分内容添加到我们的网站中,地址如下:
此页面收录 文章 链接列表。点击链接会弹出文章的详细内容展示页面。根据这个规则,结合正则表达式、XMLHTTP技术、Jscript服务器脚本、ADO技术,我编写了一个小程序,将这些内容抓取到本地数据库中。抓起来比较方便,然后将数据库中的数据导入到数据库中。首先创建一个Access数据库,结构如下
ID
自动编号
ID,主键
旧身份证
数字
旧数据编码
标题
标题
文本
内容
评论
内容
具体实现代码如下
下一步就是将Access数据库的内容导入到服务器数据库中,但是还有一些东西,就是原来的文章是分类的,所以导入的时候还得手动分类,因为链接被分析。写正则表达式的时候,写起来很麻烦,但还是严谨的。如果分类也用正则表达式来解析,那会很麻烦,因为分类收录在里面,而且那个页面有很多标签。如果要定位文本分类会很麻烦,而且即使写出来,程序也会失去灵活性,变得难以维护,所以这是它现在唯一做的一步。
发表于@2005-07-15 15:59 青蛙王子 浏览量(4581)评论(8)编辑
php抓取网页数据插入数据库( PHP如何实现大批量插入数据库呢?想要了解的朋友!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-03-25 10:19
PHP如何实现大批量插入数据库呢?想要了解的朋友!)
PHP中批量插入数据库的3种方法
PHP如何实现批量插入数据库?想知道的朋友,本文专门采集整理了PHP大批量插入数据库的3种方法,希望大家喜欢!
第一种方法:使用 into insert,代码如下:
1
2
3
4
5
6
7
$params = array('value'=>'50');
set_time_limit(0);
回显日期(“H:i:s”);
对于($i=0;$i
$connect_mysql->($params);
};
回显日期(“H:i:s”);
最终显示为:23:25:05 01:32:05,也就是用了2个多小时!
第二种方法:使用事务提交,批量插入数据库(每10W提交),最终显示时间为:22:56:13 23:04:00,共8分13秒,代码如下如下:
1
2
3
4
5
6
7
8
9
10
11
12
回显日期(“H:i:s”);
$connect_mysql->query('BEGIN');
$params = array('value'=>'50');
对于($i=0;$i
$connect_mysql->($params);
如果($i0000==0){
$connect_mysql->query('COMMIT');
$connect_mysql->query('BEGIN');
}
}
$connect_mysql->query('COMMIT');
回显日期(“H:i:s”);
第三种方法:使用优化的SQL语句:将SQL语句拼接起来,使用 into table() values(),(),(),()然后一次性插入,如果字符串太长,
然后需要配置MYSQL,在mysql命令行中运行:set global max_allowed_packet = 2*1024*1024*10; 消费时间为:11:24:06 11:25:06;
插入200W条测试数据只用了1分钟!代码如下:
1
2
3
4
5
6
$sql=“转化为 200 万(价值)值”;
对于($i=0;$i
$sql.=”('50'),”;
};
$sql = substr($sql,0,strlen($sql)-1);
$connect_mysql->查询($sql);
最后,在插入大批量数据的时候,第一种方法无疑是最差的,而第二种方法在实际应用中应用更广泛,第三种方法更适合插入测试数据或者其他要求不高的时候。真快。
【PHP中批量插入数据库的3种方法】相关文章:
PHP08-17中大批量插入数据库的方法
PH如何插入数据库09-06
PHP访问数据库08-26
PHP伪静态的几种方法09-11
PHP如何创建数据库09-30
php爬取页面的几种方法09-12
备份php数据库脚本的方法10-01
php如何连接数据库09-30
PHP封装数据库操作类09-26 查看全部
php抓取网页数据插入数据库(
PHP如何实现大批量插入数据库呢?想要了解的朋友!)
PHP中批量插入数据库的3种方法
PHP如何实现批量插入数据库?想知道的朋友,本文专门采集整理了PHP大批量插入数据库的3种方法,希望大家喜欢!
第一种方法:使用 into insert,代码如下:
1
2
3
4
5
6
7
$params = array('value'=>'50');
set_time_limit(0);
回显日期(“H:i:s”);
对于($i=0;$i
$connect_mysql->($params);
};
回显日期(“H:i:s”);
最终显示为:23:25:05 01:32:05,也就是用了2个多小时!
第二种方法:使用事务提交,批量插入数据库(每10W提交),最终显示时间为:22:56:13 23:04:00,共8分13秒,代码如下如下:
1
2
3
4
5
6
7
8
9
10
11
12
回显日期(“H:i:s”);
$connect_mysql->query('BEGIN');
$params = array('value'=>'50');
对于($i=0;$i
$connect_mysql->($params);
如果($i0000==0){
$connect_mysql->query('COMMIT');
$connect_mysql->query('BEGIN');
}
}
$connect_mysql->query('COMMIT');
回显日期(“H:i:s”);
第三种方法:使用优化的SQL语句:将SQL语句拼接起来,使用 into table() values(),(),(),()然后一次性插入,如果字符串太长,
然后需要配置MYSQL,在mysql命令行中运行:set global max_allowed_packet = 2*1024*1024*10; 消费时间为:11:24:06 11:25:06;
插入200W条测试数据只用了1分钟!代码如下:
1
2
3
4
5
6
$sql=“转化为 200 万(价值)值”;
对于($i=0;$i
$sql.=”('50'),”;
};
$sql = substr($sql,0,strlen($sql)-1);
$connect_mysql->查询($sql);
最后,在插入大批量数据的时候,第一种方法无疑是最差的,而第二种方法在实际应用中应用更广泛,第三种方法更适合插入测试数据或者其他要求不高的时候。真快。
【PHP中批量插入数据库的3种方法】相关文章:
PHP08-17中大批量插入数据库的方法
PH如何插入数据库09-06
PHP访问数据库08-26
PHP伪静态的几种方法09-11
PHP如何创建数据库09-30
php爬取页面的几种方法09-12
备份php数据库脚本的方法10-01
php如何连接数据库09-30
PHP封装数据库操作类09-26
php抓取网页数据插入数据库( PHP与数据库结合时三大结构:顺序结构,循环结构)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-03-24 21:12
PHP与数据库结合时三大结构:顺序结构,循环结构)
PHP增删改查数据库
PHP增删改查数据库
当 PHP 与数据库结合时
三种结构:顺序结构、循环结构、选择结构
数组:数组()
字符串单引号和双引号不一样
json数据的转换
php v5.xx
mysql_connect() 链接数据库 mysql_select_db() 选择数据库 mysql_query() php 执行sql 语句 mysql_fetch_assoc() 从数据库中取出一个查询到的资源,并将其转化为数组输出; mysql_error() 数据库错误信息 mysql_close() 数据链接关闭数据库 添加、删除、修改、查询以结构化方式存储数据的数据库仓库,可以快速查询数据。 SQL 语句复制粘贴可视化工具动态生成添加、删除、修改和检查添加:INSERT 删除:DELETE 修改:UPDATE 检查:SELECT 1、查询数据库数据
2、插入数据库数据
1、直接用php写,往数据库中插入数据
2、通过HTML输入框向数据库中插入数据
Document
姓名:
微信:
提交信息
3、删除数据库中的数据
4、更新数据库数据
注意:mysql_query($sql)
只对select、show、descibe等语句返回一个resourcece,错误返回false;
其他类型的SQL语句,如insert、update、delete,成功返回true,错误返回false。 查看全部
php抓取网页数据插入数据库(
PHP与数据库结合时三大结构:顺序结构,循环结构)
PHP增删改查数据库
PHP增删改查数据库
当 PHP 与数据库结合时
三种结构:顺序结构、循环结构、选择结构
数组:数组()
字符串单引号和双引号不一样
json数据的转换
php v5.xx
mysql_connect() 链接数据库 mysql_select_db() 选择数据库 mysql_query() php 执行sql 语句 mysql_fetch_assoc() 从数据库中取出一个查询到的资源,并将其转化为数组输出; mysql_error() 数据库错误信息 mysql_close() 数据链接关闭数据库 添加、删除、修改、查询以结构化方式存储数据的数据库仓库,可以快速查询数据。 SQL 语句复制粘贴可视化工具动态生成添加、删除、修改和检查添加:INSERT 删除:DELETE 修改:UPDATE 检查:SELECT 1、查询数据库数据
2、插入数据库数据
1、直接用php写,往数据库中插入数据
2、通过HTML输入框向数据库中插入数据
Document
姓名:
微信:
提交信息

3、删除数据库中的数据
4、更新数据库数据

注意:mysql_query($sql)
只对select、show、descibe等语句返回一个resourcece,错误返回false;
其他类型的SQL语句,如insert、update、delete,成功返回true,错误返回false。
php抓取网页数据插入数据库(简单图解会有助于你理解MySQL在现在的动态网站的作用 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-03-24 16:21
)
您几乎可以在网络上的任何地方看到更新网站。博客和电子商务包都配置了动态属性。动态 网站 依赖 MySQL 数据库从浏览器中提取和插入数据。
如果你是初学者,理解下面这个简单的图表将有助于你理解 MySQL 在当前动态 网站 中的作用。在一个传统的简单静态网站中,你可能会看到以下事件:客户端浏览器向服务器请求信息→服务器返回HTML代码给浏览器→浏览器显示HTML,HTML变成网页。现在,动态 网站 进行如下:
<IMG height=249 alt=专家解析:三大重要的MySQL查询 src="../../upload/2009_07/090720070617751.jpg" width=332>
1:请求网页;
2:服务器执行PHP脚本;
3:MySQL查询:从SQL请求数据;
4:SQL返回数据;
5:服务器返回一个HTML页面。
客户端浏览器请求一个网页,当服务器收到请求时,网页模板执行 PHP 脚本,从 MySQL 获取信息。此信息被添加到页面模板并以 HTML 形式返回给浏览器。看源码的时候就不用再穿PHP脚本了,因为那些脚本已经在服务端执行了。
使用动态网页时,仅使用保存的唯一服务器 PHP 模板即可创建数千个 URL 链接。但在静态模板中,需要在服务器中保存数千个 HTML 文件才能创建数千个 URL 链接。
如果您了解最重要的 MySQL 查询,那么与数据库通信将很容易,因此您可以创建复杂的 PHP Web 应用程序。这样做将节省您的时间并提高网页效率。在这个 文章 中,我们将说明使用 INSERT、SELECT 和 UPDATE 命令查询 MySQL 数据库的 PHP 脚本。
INSERT MySQL 查询命令
在我们从数据库中抓取数据之前,我们必须知道如何插入数据。假设您已经创建了表名的数据库,您可以使用 INSERT SQL 命令完成数据插入。我们在下面给出了例子。假设您同时将三条数据插入到 MySQL 数据库中的三个不同字段中,它看起来像:
INSERT INTO `tablename` (`fieldname1`,`fieldname2`,``,`fieldname3`) VALUES('$datatobeinsertedtofieldname1','$datatobeinsertedtofieldname2',
'$datatobeinsertedtofieldname3'
在 PHP 中使用此查询时,请注意引用匹配的准确用法以及域名和变量的准确拼写。这是 PHP 编程中的常见错误。
注意查询命令中的表名和域名要和(`)一起使用,并且要保持真实的MySQL表名和脚本表名的一致性。这使得区分 Linux/PHP 和 MySQL 环境中共存的一些东西成为可能。
查看全部
php抓取网页数据插入数据库(简单图解会有助于你理解MySQL在现在的动态网站的作用
)
您几乎可以在网络上的任何地方看到更新网站。博客和电子商务包都配置了动态属性。动态 网站 依赖 MySQL 数据库从浏览器中提取和插入数据。
如果你是初学者,理解下面这个简单的图表将有助于你理解 MySQL 在当前动态 网站 中的作用。在一个传统的简单静态网站中,你可能会看到以下事件:客户端浏览器向服务器请求信息→服务器返回HTML代码给浏览器→浏览器显示HTML,HTML变成网页。现在,动态 网站 进行如下:
<IMG height=249 alt=专家解析:三大重要的MySQL查询 src="../../upload/2009_07/090720070617751.jpg" width=332>
1:请求网页;
2:服务器执行PHP脚本;
3:MySQL查询:从SQL请求数据;
4:SQL返回数据;
5:服务器返回一个HTML页面。
客户端浏览器请求一个网页,当服务器收到请求时,网页模板执行 PHP 脚本,从 MySQL 获取信息。此信息被添加到页面模板并以 HTML 形式返回给浏览器。看源码的时候就不用再穿PHP脚本了,因为那些脚本已经在服务端执行了。
使用动态网页时,仅使用保存的唯一服务器 PHP 模板即可创建数千个 URL 链接。但在静态模板中,需要在服务器中保存数千个 HTML 文件才能创建数千个 URL 链接。
如果您了解最重要的 MySQL 查询,那么与数据库通信将很容易,因此您可以创建复杂的 PHP Web 应用程序。这样做将节省您的时间并提高网页效率。在这个 文章 中,我们将说明使用 INSERT、SELECT 和 UPDATE 命令查询 MySQL 数据库的 PHP 脚本。
INSERT MySQL 查询命令
在我们从数据库中抓取数据之前,我们必须知道如何插入数据。假设您已经创建了表名的数据库,您可以使用 INSERT SQL 命令完成数据插入。我们在下面给出了例子。假设您同时将三条数据插入到 MySQL 数据库中的三个不同字段中,它看起来像:
INSERT INTO `tablename` (`fieldname1`,`fieldname2`,``,`fieldname3`) VALUES('$datatobeinsertedtofieldname1','$datatobeinsertedtofieldname2',
'$datatobeinsertedtofieldname3'
在 PHP 中使用此查询时,请注意引用匹配的准确用法以及域名和变量的准确拼写。这是 PHP 编程中的常见错误。
注意查询命令中的表名和域名要和(`)一起使用,并且要保持真实的MySQL表名和脚本表名的一致性。这使得区分 Linux/PHP 和 MySQL 环境中共存的一些东西成为可能。
php抓取网页数据插入数据库(何避免页面刷新数据重复写入数据库当表单(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-03-22 21:24
如何避免页面刷新数据被重复写入数据库
当表单的数据提交到该页面处理并写入数据库时,点击提交按钮后,如果页面刷新,数据会重复写入数据库。我在网上搜索了很多解决方法:
一、 将一个页面一分为二,将数据提交到另一个页面进行处理,然后跳转到输入页面。
优点:避免了刷新的影响,可以连续提交数据。
缺点:当用户在完整填写表单之前点击提交。如果不进行数据存储操作,保留用户之前输入的内容,那么使用php实现起来比较困难或者不方便。(当然用js实现可能会更容易,这里约定,本文只从php的角度来评估,研究php的应用)
*总的来说,这是一个很好的解决方案。
二、在会话中保存变量
_SESSION['提交']=false
提交后改为true
检测变量
if (_SESSION['submit']=true){
回声“文本”;
出口();
}
优点:避免了刷新的影响,只有一个页面,没有第一种方法的缺点
缺点:只能提交一次,不能连续提交数据。
*有优点,但适用范围太窄。
三、在数据入库前执行一次验证查询,查看数据库中是否已经存在相同的记录,从而决定是否写入数据。
优点:前两种方法没有缺点。
缺点:代码没有精简,操作繁琐。此外,有时不排除保存完全相同的信息。
*实施成本太高,副作用太大。
有没有一种方法不综合三种方法的优缺点?有!这里有一个很好的解决方案与您分享:
///
乙:
>
C:
d: 查看全部
php抓取网页数据插入数据库(何避免页面刷新数据重复写入数据库当表单(图))
如何避免页面刷新数据被重复写入数据库
当表单的数据提交到该页面处理并写入数据库时,点击提交按钮后,如果页面刷新,数据会重复写入数据库。我在网上搜索了很多解决方法:
一、 将一个页面一分为二,将数据提交到另一个页面进行处理,然后跳转到输入页面。
优点:避免了刷新的影响,可以连续提交数据。
缺点:当用户在完整填写表单之前点击提交。如果不进行数据存储操作,保留用户之前输入的内容,那么使用php实现起来比较困难或者不方便。(当然用js实现可能会更容易,这里约定,本文只从php的角度来评估,研究php的应用)
*总的来说,这是一个很好的解决方案。
二、在会话中保存变量
_SESSION['提交']=false
提交后改为true
检测变量
if (_SESSION['submit']=true){
回声“文本”;
出口();
}
优点:避免了刷新的影响,只有一个页面,没有第一种方法的缺点
缺点:只能提交一次,不能连续提交数据。
*有优点,但适用范围太窄。
三、在数据入库前执行一次验证查询,查看数据库中是否已经存在相同的记录,从而决定是否写入数据。
优点:前两种方法没有缺点。
缺点:代码没有精简,操作繁琐。此外,有时不排除保存完全相同的信息。
*实施成本太高,副作用太大。
有没有一种方法不综合三种方法的优缺点?有!这里有一个很好的解决方案与您分享:
///
乙:
>
C:
d:
php抓取网页数据插入数据库(php抓取网页数据插入数据库,express框架用于开发前端框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-03-22 20:32
php抓取网页数据插入数据库,
express框架用于开发前端框架,不开源,但是现在的主流开发框架都是用express框架。micropython用于开发后端框架,开源,后端服务器非常稳定。ror也是开源框架,但是,我感觉有点不太适合做大型网站。如果你是做安卓或者ios网站,除了用java,你可以在一个软件(或者一套框架)中集成几种语言。
java在数据处理上是强,强大,优势是开发效率高但是并不要求所有的数据处理代码,因为大公司的一些重复代码代码量都是有限的,可以从配置与开发性两方面考虑,java在架构设计上比php更有优势,掌握基本的数据结构与算法,以及大量的http代码的学习,自学一下springboot,mybatis框架都是大量实践积累的必要条件,ruby和python的框架不多说了,一个是数据结构一个是后端的框架。
从零开始学前端,安卓,android,wpjvm,java,php,erlang,scala,python,javascript,ruby,php,python,
你好有前途
如果是想要用web技术开发网站。java是最好选择。php只能说适合网站框架去开发。但是因为网站不断在增加,所以用nodejs开发网站也是很好的。python也可以。但是数据处理等一些网站功能用java会好些。但是php有varsql这个非常好的模块可以很方便的集成到web中,具体你可以再找找。如果你是java用途,php也不错。erlang也可以。 查看全部
php抓取网页数据插入数据库(php抓取网页数据插入数据库,express框架用于开发前端框架)
php抓取网页数据插入数据库,
express框架用于开发前端框架,不开源,但是现在的主流开发框架都是用express框架。micropython用于开发后端框架,开源,后端服务器非常稳定。ror也是开源框架,但是,我感觉有点不太适合做大型网站。如果你是做安卓或者ios网站,除了用java,你可以在一个软件(或者一套框架)中集成几种语言。
java在数据处理上是强,强大,优势是开发效率高但是并不要求所有的数据处理代码,因为大公司的一些重复代码代码量都是有限的,可以从配置与开发性两方面考虑,java在架构设计上比php更有优势,掌握基本的数据结构与算法,以及大量的http代码的学习,自学一下springboot,mybatis框架都是大量实践积累的必要条件,ruby和python的框架不多说了,一个是数据结构一个是后端的框架。
从零开始学前端,安卓,android,wpjvm,java,php,erlang,scala,python,javascript,ruby,php,python,
你好有前途
如果是想要用web技术开发网站。java是最好选择。php只能说适合网站框架去开发。但是因为网站不断在增加,所以用nodejs开发网站也是很好的。python也可以。但是数据处理等一些网站功能用java会好些。但是php有varsql这个非常好的模块可以很方便的集成到web中,具体你可以再找找。如果你是java用途,php也不错。erlang也可以。
php抓取网页数据插入数据库(PHP中的“INSERTINTO”语句的作用及案例演示)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-03-14 10:30
“INSERT INTO”语句的作用是向数据库表中插入一条新记录。
将数据插入数据库表
“INSERT INTO”的作用是向数据库表中插入一条新记录。
语法
插入表名
值(值 1,值 2,....)
您可以将数据插入指定列,如下所示:
INSERT INTO table_name (column1, column2,...)
值(值 1,值 2,....)
注意:SQL 语句是“不区分大小写”语句(不区分大小写),即:“INSERT INTO”和“insert into”是一样的。
要在 PHP 中创建数据库,我们需要在 mysql_query() 函数中使用上述语句。该函数用于发送 MySQL 数据库连接建立请求和命令。
案子
在上一章中,我们创建了一个名为“Person”的表,其中收录三列:“Firstname”、“Lastname”和“Age”。在以下情况下,我们还将使用同一张表并向其中添加两条新记录:
将表中的数据插入数据库
现在,我们将创建一个 HTML 表单;通过它我们可以将新记录添加到“Person”表中。
下面演示了这个 HTML 表单:
在上述情况下,当用户点击 HTML 表单中的“提交”按钮时,表单中的数据被发送到“insert.php”。“insert.php”文件与数据库建立连接,通过PHP的$_POST变量获取表单中的数据;此时mysql_query()函数执行“INSERT INTO”语句,从而在中间的数据库表单中添加了一条新记录。
让我们试试“insert.php”页面的代码: 查看全部
php抓取网页数据插入数据库(PHP中的“INSERTINTO”语句的作用及案例演示)
“INSERT INTO”语句的作用是向数据库表中插入一条新记录。
将数据插入数据库表
“INSERT INTO”的作用是向数据库表中插入一条新记录。
语法
插入表名
值(值 1,值 2,....)
您可以将数据插入指定列,如下所示:
INSERT INTO table_name (column1, column2,...)
值(值 1,值 2,....)
注意:SQL 语句是“不区分大小写”语句(不区分大小写),即:“INSERT INTO”和“insert into”是一样的。
要在 PHP 中创建数据库,我们需要在 mysql_query() 函数中使用上述语句。该函数用于发送 MySQL 数据库连接建立请求和命令。
案子
在上一章中,我们创建了一个名为“Person”的表,其中收录三列:“Firstname”、“Lastname”和“Age”。在以下情况下,我们还将使用同一张表并向其中添加两条新记录:
将表中的数据插入数据库
现在,我们将创建一个 HTML 表单;通过它我们可以将新记录添加到“Person”表中。
下面演示了这个 HTML 表单:
在上述情况下,当用户点击 HTML 表单中的“提交”按钮时,表单中的数据被发送到“insert.php”。“insert.php”文件与数据库建立连接,通过PHP的$_POST变量获取表单中的数据;此时mysql_query()函数执行“INSERT INTO”语句,从而在中间的数据库表单中添加了一条新记录。
让我们试试“insert.php”页面的代码:
php抓取网页数据插入数据库(我的小程序通过PHP从SQL数据库提取到数据,使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-03-14 01:17
我的小程序通过 PHP 从 SQL 数据库中提取数据,使用
{{item.id}}{{item.device_num}}{{item.user_name}}{{item.user_phone}}
语句渲染数据,php获取的数据如下:
[{\"id\":\"1\",\"device_num\":\"12002120\",\"user_name\":\"li\",\"user_phone\":\"\ ",\"unit_name\":\"jijin\",\"unit_addr\":\"djsaj\",\"wechat_num\":\"hsahjh\"},{\"id\":\"2\ ",\"device_num\":\"1272677867\",\"user_name\":\"zhang\",\"user_phone\":\"1362525891\",\"unit_name\":\"yiuehhaj\", \"unit_addr\":\"heiwh\",\"wechat_num\":\"hh\"}]\r\n\r\n\r\n\r\n\r\n \r\n
调试器观察到的渲染页面数据如下
数据是空的,不知道为什么,请大家指点一下。 查看全部
php抓取网页数据插入数据库(我的小程序通过PHP从SQL数据库提取到数据,使用)
我的小程序通过 PHP 从 SQL 数据库中提取数据,使用
{{item.id}}{{item.device_num}}{{item.user_name}}{{item.user_phone}}
语句渲染数据,php获取的数据如下:
[{\"id\":\"1\",\"device_num\":\"12002120\",\"user_name\":\"li\",\"user_phone\":\"\ ",\"unit_name\":\"jijin\",\"unit_addr\":\"djsaj\",\"wechat_num\":\"hsahjh\"},{\"id\":\"2\ ",\"device_num\":\"1272677867\",\"user_name\":\"zhang\",\"user_phone\":\"1362525891\",\"unit_name\":\"yiuehhaj\", \"unit_addr\":\"heiwh\",\"wechat_num\":\"hh\"}]\r\n\r\n\r\n\r\n\r\n \r\n
调试器观察到的渲染页面数据如下
数据是空的,不知道为什么,请大家指点一下。
php抓取网页数据插入数据库(全部详细技术资料下载【技术实现步骤摘要】(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 62 次浏览 • 2022-04-08 17:12
本发明专利技术公开了一种更新获取的网页数据的系统和方法。该方法包括: S1、使用网络爬虫从网页中抓取目标数据;S2、 将目标数据打包成为目标压缩文件,并在目标压缩文件中添加MD5标签;S3、判断网页数据和压缩文件是否存储在数据库服务器中,如果是,则执行步骤S4,如果不是,则执行步骤S7;S4、判断网页数据的压缩文件的MD5值是否与目标压缩文件的MD5值相同,如果是,执行步骤S5,如果不是,执行步骤S6;S5、删除目标数据和目标压缩文件;S6、 将网页数据和压缩文件分别更新为目标数据和目标压缩文件;S7、将目标数据和目标压缩文件存储在数据库服务器中。本发明专利技术可以判断网页数据的更新情况,实现获取的网页数据的及时更新。
下载所有详细的技术数据
【技术实现步骤总结】
本专利技术涉及一种更新获取的网页数据的系统和方法,尤其涉及一种能够及时检测到获取的网页数据的更新并进行相应的更新处理的系统,以及一种更新获取的网页的系统。页面数据。获取的网页数据的更新方法。
技术介绍
现阶段随着网络技术的飞速发展,大数据时代已经到来,如何快速有效地拉取网站的数据信息成为亟待解决的问题。如今,出于信息保护的目的,在更新网页数据时,很多网站一般不会在更新数据中提供时间戳等信息数据。因此,现有技术中,在抓取网页数据后,基本上无法确定网页数据的更新时间。一旦无法确定更新时间,就无法确定捕获的网页数据中哪些是更新数据,哪些没有更新。结果,无法第一时间获取网页中最新更新的数据。以在线旅游搜索平台为例,由于无法确定目标网站(如各种酒店和预订网站)的数据更新,很难第一时间获取最新更新的机票和酒店。以及优采云门票等资源信息,如果实时数据更新不高,会降低用户查询相关信息的准确性,严重影响用户体验。
技术实现思路
该专利技术要解决的技术问题是克服现有技术无法及时判断在线旅游搜索平台等网站的数据更新,难以获取最新更新的机票,酒店和优采云门票等资源信息,使得用户查询相关信息的准确性较低,严重影响用户体验。提供一种能够及时检测获取的网页数据的更新并进行相应更新处理的系统。一种更新获取的网页数据的系统及方法,通过该系统实现。该专利技术通过以下技术方案解决了上述技术问题:本专利技术提供了一种更新获取的网页数据的方法,其特征在于,该方法包括以下步骤: S1、使用网络爬虫抓取带有网页ID(标识号)的目标数据从网页;S2、将目标数据打包成目标压缩文件,并在目标压缩文件中添加MD5(消息文摘算法第五版,计算机领域使用的散列函数)标签;S3、判断数据库服务器是否存储有网页ID和网页数据压缩文件的网页数据,如果是,进入步骤S4,如果没有,进入步骤S7;S4、判断网页数据的压缩文件的MD5值是否与目标压缩文件的MD5值相同,如果相同,转步骤S4、 S5,否则,执行步骤S6;S5、 删除目标数据和目标压缩文件,然后结束进程;S6、压缩网页数据和网页数据文件分别更新为目标数据和目标压缩文件,然后流程结束;S7、 将目标数据和目标压缩文件存储在数据库服务器中。
在步骤S1中,通过设置网页的网址、网络爬虫的递归算法和网页数据的定位信息,网络爬虫可以快速抓取所需的网页数据,即目标数据,所有目标数据都是网页中具有唯一唯一 ID 的数据。这里的网页ID不是指网页的URL(Uniform Resource Locator)地址中的数字,而是表示所需数据的唯一标识。网页ID对应网页中的数据,可以代表一个唯一的网页与之对应,不同的网页会有不同的网页ID。当考虑到捕获的目标数据存储在数据库服务器中时,首先在步骤S3中判断数据库服务器是否存储了来自网页的网页数据,即,判断具有网页ID的网页数据和该网页数据对应的压缩文件是否存储在数据库服务器中。如果是,则表示该网页的网页数据已存储在数据库服务器中。此时无法判断抓取到的目标数据是否为网页最新更新的数据,需要进行后续判断;如果不是,则说明该网页的网页数据尚未存储在数据库服务器中。此时,对于数据库服务器而言,目标数据为最新的网页数据,因此执行步骤S7,对数据库服务器中存储的网页数据执行步骤S7。更新。当确定该网页的网页数据和该网页数据的压缩文件已经存储在数据库服务器中时,执行步骤S4,继续判断网页数据的压缩文件的MD5值与目标压缩文件的MD5值是否相同;如果相同,则说明网页数据没有更新,即数据库服务器中存储的网页数据是最新的,则执行步骤S5。如果不是,则在步骤S1中说明捕获的目标数据是最新的。此时,执行步骤S6,更新数据库中存储的网页数据。然后执行步骤S5;如果不是,则在步骤S1中说明捕获的目标数据是最新的。此时,执行步骤S6,更新数据库中存储的网页数据。然后执行步骤S5;如果不是,则在步骤S1中说明捕获的目标数据是最新的。此时,执行步骤S6,更新数据库中存储的网页数据。
这样,本专利技术的方法可以保证数据库服务器中存储的网页数据始终是最新的,实现获取的网页数据的及时更新,减少数据库服务器中的数据冗余。此外,该专利技术可以大大提高数据库服务器中存储的网页数据的实时性,特别是对于在线旅游搜索平台等,最新更新的机票、酒店和优采云资源信息等因为门票可以大大提高用户查询相关信息的准确性,方便用户使用,改善用户体验,大大提高在线旅游搜索平台对网页数据处理的灵活性和实时性。性别。优选地,步骤S1中的网络爬虫为聚焦爬虫,聚焦爬虫通过在爬取时设置过滤算法,过滤网页中与目标数据无关的链接。与普通网络爬虫不同的是,步骤S2中使用的聚焦爬虫可以过滤掉不相关的链接,只保留有用的链接并存储在等待队列中,从而提高了抓取网页数据的速度和效率,同时也改进了整个方法流程. 速度和效率。优选地,在步骤S1中,还根据数据类型将目标数据划分为多个字段,将多个字段分为静态信息数据和动态信息数据。步骤S2中的目标压缩文件分别包括带有MD5标签的静态信息数据压缩文件和动态信息数据压缩文件。对于步骤S1中捕获的目标数据,由于表示信息的不同,数据的类型也不同。因此,在步骤S1中,也可以根据网页数据的表示信息不同,将目标数据划分为多个字段。.
所有领域的数据大致可以分为静态信息数据和动态信息数据,其中静态信息数据是指事物的基本特征信息数据,这些数据变化非常缓慢或基本不随时间变化,如< @优采云 列车数量、始发站、终点站等。动态信息数据是指相对容易随时间变化而变化的数据,如优采云车票数量、硬座数量, 卧铺津贴等。 优选地,该方法的过程在每个时间段执行。本专利技术的目的还在于提供一种更新获取的网页数据的系统,其特征在于,该系统包括数据采集模块、文件压缩模块、第一判断模块、第二判断模块。模块和数据更新模块;数据抓取模块,用于利用网络爬虫从网页中抓取具有网页ID的目标数据。文件压缩模块,用于将目标数据打包成目标压缩文件,并为所述目标压缩文件添加MD5标签。所述的第一判断模块,用于判断是否存储在数据库服务器中
【技术保护点】
一种获取网页数据的更新方法,其特征在于,该方法包括以下步骤: S1、利用网络爬虫从网页中抓取具有网页ID的目标数据;S1、 @2、将目标数据打包成目标压缩文件,并在目标压缩文件中添加MD5标签;S3、判断数据库服务器是否存储有网页ID和所有描述网页数据的压缩文件的网页数据,如果是,则执行步骤S4,否则,执行步骤S7;,如果是,执行步骤S5,如果不是,执行步骤S6;S5、 删除目标数据和目标压缩文件,然后结束进程;S6、将网页数据的压缩文件分别更新为目标数据和目标压缩文件,然后流程结束;S7、
【技术特点总结】
1.一种更新获取的网页数据的方法,其特征在于,该方法包括
包括以下步骤:
S1、使用网络爬虫从网页中抓取带有网页ID的目标数据;
S2、将目标数据打包成目标压缩文件,并添加目标压缩文件
添加MD5标签;
S3、判断一个数据库服务器是否存储了网页数据,带有网页ID和所有
描述网页数据的压缩文件,如果是,则进行步骤S4,否则,进行步骤S7;
S4、判断网页数据压缩文件和目标压缩文件的MD5值
MD5值是否相同,如果是,则进入步骤S5,否则,进入步骤S6;
S5、删除目标数据和目标压缩文件,然后结束进程;
S6、分别更新网页数据和网页数据的压缩文件到目标号
根据目标压缩文件,然后结束进程;
S7、 将目标数据和目标压缩文件存储在数据库服务器中。
2.如权利要求1所述的方法,其特征在于,步骤S1中的网络爬虫
为了聚焦爬虫,聚焦爬虫在爬取时通过设置过滤算法对网页中的所有内容进行过滤。
与目标数据无关的链接。
3.根据权利要求2所述的方法,其特征在于,在步骤S1中,目标数也为
按数据类型分为多个字段,多个字段分为静态信息数据和
动态信息数据;
步骤S2中的目标压缩文件分别收录带有MD5标签的静态信息
数据压缩文件和动态信息数据压缩文件。
4.根据权利要求1-3任一项所述的方法,其特征在于,每隔一段时间
该段执行该方法的流程一次。
5.一种……
【专利技术性质】
技术研发人员:叶亚明,
申请人(专利权)持有人:,
类型:发明
国家省份:上海;31
下载所有详细的技术数据 我是该专利的所有者 查看全部
php抓取网页数据插入数据库(全部详细技术资料下载【技术实现步骤摘要】(组图))
本发明专利技术公开了一种更新获取的网页数据的系统和方法。该方法包括: S1、使用网络爬虫从网页中抓取目标数据;S2、 将目标数据打包成为目标压缩文件,并在目标压缩文件中添加MD5标签;S3、判断网页数据和压缩文件是否存储在数据库服务器中,如果是,则执行步骤S4,如果不是,则执行步骤S7;S4、判断网页数据的压缩文件的MD5值是否与目标压缩文件的MD5值相同,如果是,执行步骤S5,如果不是,执行步骤S6;S5、删除目标数据和目标压缩文件;S6、 将网页数据和压缩文件分别更新为目标数据和目标压缩文件;S7、将目标数据和目标压缩文件存储在数据库服务器中。本发明专利技术可以判断网页数据的更新情况,实现获取的网页数据的及时更新。
下载所有详细的技术数据
【技术实现步骤总结】
本专利技术涉及一种更新获取的网页数据的系统和方法,尤其涉及一种能够及时检测到获取的网页数据的更新并进行相应的更新处理的系统,以及一种更新获取的网页的系统。页面数据。获取的网页数据的更新方法。
技术介绍
现阶段随着网络技术的飞速发展,大数据时代已经到来,如何快速有效地拉取网站的数据信息成为亟待解决的问题。如今,出于信息保护的目的,在更新网页数据时,很多网站一般不会在更新数据中提供时间戳等信息数据。因此,现有技术中,在抓取网页数据后,基本上无法确定网页数据的更新时间。一旦无法确定更新时间,就无法确定捕获的网页数据中哪些是更新数据,哪些没有更新。结果,无法第一时间获取网页中最新更新的数据。以在线旅游搜索平台为例,由于无法确定目标网站(如各种酒店和预订网站)的数据更新,很难第一时间获取最新更新的机票和酒店。以及优采云门票等资源信息,如果实时数据更新不高,会降低用户查询相关信息的准确性,严重影响用户体验。
技术实现思路
该专利技术要解决的技术问题是克服现有技术无法及时判断在线旅游搜索平台等网站的数据更新,难以获取最新更新的机票,酒店和优采云门票等资源信息,使得用户查询相关信息的准确性较低,严重影响用户体验。提供一种能够及时检测获取的网页数据的更新并进行相应更新处理的系统。一种更新获取的网页数据的系统及方法,通过该系统实现。该专利技术通过以下技术方案解决了上述技术问题:本专利技术提供了一种更新获取的网页数据的方法,其特征在于,该方法包括以下步骤: S1、使用网络爬虫抓取带有网页ID(标识号)的目标数据从网页;S2、将目标数据打包成目标压缩文件,并在目标压缩文件中添加MD5(消息文摘算法第五版,计算机领域使用的散列函数)标签;S3、判断数据库服务器是否存储有网页ID和网页数据压缩文件的网页数据,如果是,进入步骤S4,如果没有,进入步骤S7;S4、判断网页数据的压缩文件的MD5值是否与目标压缩文件的MD5值相同,如果相同,转步骤S4、 S5,否则,执行步骤S6;S5、 删除目标数据和目标压缩文件,然后结束进程;S6、压缩网页数据和网页数据文件分别更新为目标数据和目标压缩文件,然后流程结束;S7、 将目标数据和目标压缩文件存储在数据库服务器中。
在步骤S1中,通过设置网页的网址、网络爬虫的递归算法和网页数据的定位信息,网络爬虫可以快速抓取所需的网页数据,即目标数据,所有目标数据都是网页中具有唯一唯一 ID 的数据。这里的网页ID不是指网页的URL(Uniform Resource Locator)地址中的数字,而是表示所需数据的唯一标识。网页ID对应网页中的数据,可以代表一个唯一的网页与之对应,不同的网页会有不同的网页ID。当考虑到捕获的目标数据存储在数据库服务器中时,首先在步骤S3中判断数据库服务器是否存储了来自网页的网页数据,即,判断具有网页ID的网页数据和该网页数据对应的压缩文件是否存储在数据库服务器中。如果是,则表示该网页的网页数据已存储在数据库服务器中。此时无法判断抓取到的目标数据是否为网页最新更新的数据,需要进行后续判断;如果不是,则说明该网页的网页数据尚未存储在数据库服务器中。此时,对于数据库服务器而言,目标数据为最新的网页数据,因此执行步骤S7,对数据库服务器中存储的网页数据执行步骤S7。更新。当确定该网页的网页数据和该网页数据的压缩文件已经存储在数据库服务器中时,执行步骤S4,继续判断网页数据的压缩文件的MD5值与目标压缩文件的MD5值是否相同;如果相同,则说明网页数据没有更新,即数据库服务器中存储的网页数据是最新的,则执行步骤S5。如果不是,则在步骤S1中说明捕获的目标数据是最新的。此时,执行步骤S6,更新数据库中存储的网页数据。然后执行步骤S5;如果不是,则在步骤S1中说明捕获的目标数据是最新的。此时,执行步骤S6,更新数据库中存储的网页数据。然后执行步骤S5;如果不是,则在步骤S1中说明捕获的目标数据是最新的。此时,执行步骤S6,更新数据库中存储的网页数据。
这样,本专利技术的方法可以保证数据库服务器中存储的网页数据始终是最新的,实现获取的网页数据的及时更新,减少数据库服务器中的数据冗余。此外,该专利技术可以大大提高数据库服务器中存储的网页数据的实时性,特别是对于在线旅游搜索平台等,最新更新的机票、酒店和优采云资源信息等因为门票可以大大提高用户查询相关信息的准确性,方便用户使用,改善用户体验,大大提高在线旅游搜索平台对网页数据处理的灵活性和实时性。性别。优选地,步骤S1中的网络爬虫为聚焦爬虫,聚焦爬虫通过在爬取时设置过滤算法,过滤网页中与目标数据无关的链接。与普通网络爬虫不同的是,步骤S2中使用的聚焦爬虫可以过滤掉不相关的链接,只保留有用的链接并存储在等待队列中,从而提高了抓取网页数据的速度和效率,同时也改进了整个方法流程. 速度和效率。优选地,在步骤S1中,还根据数据类型将目标数据划分为多个字段,将多个字段分为静态信息数据和动态信息数据。步骤S2中的目标压缩文件分别包括带有MD5标签的静态信息数据压缩文件和动态信息数据压缩文件。对于步骤S1中捕获的目标数据,由于表示信息的不同,数据的类型也不同。因此,在步骤S1中,也可以根据网页数据的表示信息不同,将目标数据划分为多个字段。.
所有领域的数据大致可以分为静态信息数据和动态信息数据,其中静态信息数据是指事物的基本特征信息数据,这些数据变化非常缓慢或基本不随时间变化,如< @优采云 列车数量、始发站、终点站等。动态信息数据是指相对容易随时间变化而变化的数据,如优采云车票数量、硬座数量, 卧铺津贴等。 优选地,该方法的过程在每个时间段执行。本专利技术的目的还在于提供一种更新获取的网页数据的系统,其特征在于,该系统包括数据采集模块、文件压缩模块、第一判断模块、第二判断模块。模块和数据更新模块;数据抓取模块,用于利用网络爬虫从网页中抓取具有网页ID的目标数据。文件压缩模块,用于将目标数据打包成目标压缩文件,并为所述目标压缩文件添加MD5标签。所述的第一判断模块,用于判断是否存储在数据库服务器中
【技术保护点】
一种获取网页数据的更新方法,其特征在于,该方法包括以下步骤: S1、利用网络爬虫从网页中抓取具有网页ID的目标数据;S1、 @2、将目标数据打包成目标压缩文件,并在目标压缩文件中添加MD5标签;S3、判断数据库服务器是否存储有网页ID和所有描述网页数据的压缩文件的网页数据,如果是,则执行步骤S4,否则,执行步骤S7;,如果是,执行步骤S5,如果不是,执行步骤S6;S5、 删除目标数据和目标压缩文件,然后结束进程;S6、将网页数据的压缩文件分别更新为目标数据和目标压缩文件,然后流程结束;S7、
【技术特点总结】
1.一种更新获取的网页数据的方法,其特征在于,该方法包括
包括以下步骤:
S1、使用网络爬虫从网页中抓取带有网页ID的目标数据;
S2、将目标数据打包成目标压缩文件,并添加目标压缩文件
添加MD5标签;
S3、判断一个数据库服务器是否存储了网页数据,带有网页ID和所有
描述网页数据的压缩文件,如果是,则进行步骤S4,否则,进行步骤S7;
S4、判断网页数据压缩文件和目标压缩文件的MD5值
MD5值是否相同,如果是,则进入步骤S5,否则,进入步骤S6;
S5、删除目标数据和目标压缩文件,然后结束进程;
S6、分别更新网页数据和网页数据的压缩文件到目标号
根据目标压缩文件,然后结束进程;
S7、 将目标数据和目标压缩文件存储在数据库服务器中。
2.如权利要求1所述的方法,其特征在于,步骤S1中的网络爬虫
为了聚焦爬虫,聚焦爬虫在爬取时通过设置过滤算法对网页中的所有内容进行过滤。
与目标数据无关的链接。
3.根据权利要求2所述的方法,其特征在于,在步骤S1中,目标数也为
按数据类型分为多个字段,多个字段分为静态信息数据和
动态信息数据;
步骤S2中的目标压缩文件分别收录带有MD5标签的静态信息
数据压缩文件和动态信息数据压缩文件。
4.根据权利要求1-3任一项所述的方法,其特征在于,每隔一段时间
该段执行该方法的流程一次。
5.一种……
【专利技术性质】
技术研发人员:叶亚明,
申请人(专利权)持有人:,
类型:发明
国家省份:上海;31
下载所有详细的技术数据 我是该专利的所有者
php抓取网页数据插入数据库(如何从我插入数据的同一个php表单中获取数据库中的信息)
网站优化 • 优采云 发表了文章 • 0 个评论 • 70 次浏览 • 2022-04-07 20:12
如何从我插入数据的同一个php表单中获取数据库中的信息,包括存储的信息,以便可以更新数据库中的数据:
我使用了这个更新语句,但得到了一个错误:
$sql="UPDATE findings
SET Finding_ID=$_GET[Finding_ID], ServiceType_ID=$_GET[ServiceType_ID], RootCause_ID=$_GET[RootCause_ID] , RiskRating_ID=$_GET[RiskRating_ID] , Impact_ID=$_GET[Impact_ID] ,Efforts_ID= $_GET[Efforts_ID], Likelihood_ID= $_GET[Likelihood_ID], Finding=$_GET[Finding],Implication=$_GET[Implication] , Recommendation =$_GET[Recommendation] , Report_ID=$_GET[Report_ID]
WHERE Finding_ID=$Finding_ID, ServiceType_ID=$ServiceType_ID, RootCause_ID=$RootCause_ID , RiskRating_ID=$RiskRating_ID , Impact_ID=$Impact_ID ,Efforts_ID= $Efforts_ID, Likelihood_ID= $Likelihood_ID, Finding=$Finding,Implication=$Implication , Recommendation =$Recommendation , Report_ID=$Report_ID";
这是我将插入和更新数据的表单的代码:
Insert New Data
<p> Service Name :
Ref : <br />
Title : <br />
Risk Rating :
-Select-
<br />
Root Cause :
-Select-
<br />
Impact :
-Select-
<br />
Likelihood :
-Select-
Efforts :
-Select-
Finding :
Implication:
Recommendation :
</p>
这是错误:
Notice: Undefined index: Finding_ID in C:\xampp\htdocs\ers\edit.php on line 122
Notice: Undefined index: ServiceType_ID in C:\xampp\htdocs\ers\edit.php on line 122
Notice: Undefined index: RootCause_ID in C:\xampp\htdocs\ers\edit.php on line 122
Notice: Undefined index: RiskRating_ID in C:\xampp\htdocs\ers\edit.php on line 122
Notice: Undefined index: Impact_ID in C:\xampp\htdocs\ers\edit.php on line 122
Notice: Undefined index: Efforts_ID in C:\xampp\htdocs\ers\edit.php on line 122
Notice: Undefined variable: Finding_ID in C:\xampp\htdocs\ers\edit.php on line 126
Error: You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near ' ServiceType_ID=, RootCause_ID= , RiskRating_ID= , Impact_ID= ,Efforts_ID= , Lik' at line 2
2个答案:
答案 0 :( 得分:1)
WHERE 的条件应该是使用 AND、OR 而不是逗号。
WHERE Finding_ID=$Finding_ID, ServiceType_ID=$ServiceType_ID,....
应该
WHERE Finding_ID=$Finding_ID AND ServiceType_ID=$ServiceType_ID AND ...
答案1:(得分:0)
您的查询基本上是欢迎每个人访问数据库的大门。
第一:不要在查询中使用直接获取参数。最初与他们合作。
第二位:即使是数字也要加''。为您提供额外的安全保障。
第三个:WHERE 参数是 AND 或 OR
分离
当然,您可以采取更多的预防措施,但最好在一开始就这样做。
PS:长查询在拆分时更易于管理和阅读;并尽量保持你的代码干净漂亮。没有人喜欢使用乱码。 查看全部
php抓取网页数据插入数据库(如何从我插入数据的同一个php表单中获取数据库中的信息)
如何从我插入数据的同一个php表单中获取数据库中的信息,包括存储的信息,以便可以更新数据库中的数据:
我使用了这个更新语句,但得到了一个错误:
$sql="UPDATE findings
SET Finding_ID=$_GET[Finding_ID], ServiceType_ID=$_GET[ServiceType_ID], RootCause_ID=$_GET[RootCause_ID] , RiskRating_ID=$_GET[RiskRating_ID] , Impact_ID=$_GET[Impact_ID] ,Efforts_ID= $_GET[Efforts_ID], Likelihood_ID= $_GET[Likelihood_ID], Finding=$_GET[Finding],Implication=$_GET[Implication] , Recommendation =$_GET[Recommendation] , Report_ID=$_GET[Report_ID]
WHERE Finding_ID=$Finding_ID, ServiceType_ID=$ServiceType_ID, RootCause_ID=$RootCause_ID , RiskRating_ID=$RiskRating_ID , Impact_ID=$Impact_ID ,Efforts_ID= $Efforts_ID, Likelihood_ID= $Likelihood_ID, Finding=$Finding,Implication=$Implication , Recommendation =$Recommendation , Report_ID=$Report_ID";
这是我将插入和更新数据的表单的代码:
Insert New Data
<p> Service Name :
Ref : <br />
Title : <br />
Risk Rating :
-Select-
<br />
Root Cause :
-Select-
<br />
Impact :
-Select-
<br />
Likelihood :
-Select-
Efforts :
-Select-
Finding :
Implication:
Recommendation :
</p>
这是错误:
Notice: Undefined index: Finding_ID in C:\xampp\htdocs\ers\edit.php on line 122
Notice: Undefined index: ServiceType_ID in C:\xampp\htdocs\ers\edit.php on line 122
Notice: Undefined index: RootCause_ID in C:\xampp\htdocs\ers\edit.php on line 122
Notice: Undefined index: RiskRating_ID in C:\xampp\htdocs\ers\edit.php on line 122
Notice: Undefined index: Impact_ID in C:\xampp\htdocs\ers\edit.php on line 122
Notice: Undefined index: Efforts_ID in C:\xampp\htdocs\ers\edit.php on line 122
Notice: Undefined variable: Finding_ID in C:\xampp\htdocs\ers\edit.php on line 126
Error: You have an error in your SQL syntax; check the manual that corresponds to your MySQL server version for the right syntax to use near ' ServiceType_ID=, RootCause_ID= , RiskRating_ID= , Impact_ID= ,Efforts_ID= , Lik' at line 2
2个答案:
答案 0 :( 得分:1)
WHERE 的条件应该是使用 AND、OR 而不是逗号。
WHERE Finding_ID=$Finding_ID, ServiceType_ID=$ServiceType_ID,....
应该
WHERE Finding_ID=$Finding_ID AND ServiceType_ID=$ServiceType_ID AND ...
答案1:(得分:0)
您的查询基本上是欢迎每个人访问数据库的大门。
第一:不要在查询中使用直接获取参数。最初与他们合作。
第二位:即使是数字也要加''。为您提供额外的安全保障。
第三个:WHERE 参数是 AND 或 OR
分离
当然,您可以采取更多的预防措施,但最好在一开始就这样做。
PS:长查询在拆分时更易于管理和阅读;并尽量保持你的代码干净漂亮。没有人喜欢使用乱码。
php抓取网页数据插入数据库(这里有新鲜出炉的PHP面向对象编程,程序狗速度看过来!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 111 次浏览 • 2022-04-07 20:07
这里是新鲜出炉的PHP面向对象编程,程序狗的速度来了!
PHP开源脚本语言PHP(外文名称:Hypertext Preprocessor,中文名称:“Hypertext Preprocessor”)是一种通用的开源脚本语言。文法吸收了C语言、Java和Perl的特点。入门门槛低,易学,应用广泛。它主要适用于Web开发领域。PHP的文件扩展名是php。
本文讲解php写入数据库的三种方法及性能对比。三种方式分别是:普通的insert语句一一执行、通过事务批量提交、insert into的批量数据提交方式。有兴趣的同学可以参考以下。
方法一:使用insert into 逐一插入,最终显示为:23:25:05 01:32:05,也就是2个多小时!:
$params = array(‘value'=>'50′);
set_time_limit(0);
echo date(“H:i:s”);
for($i=0;$iinsert($params);
};
echo date(“H:i:s”);
方法二:使用事务提交,批量插入数据库(每10W次提交),最后显示消耗时间为:22:56:13 23:04:00,共8分13秒:
echo date(“H:i:s”);
$connect_mysql->query(‘BEGIN');
$params = array(‘value'=>'50′);
for($i=0;$iinsert($params);
if($i0000==0){
$connect_mysql->query(‘COMMIT');
$connect_mysql->query(‘BEGIN');
}
}
$connect_mysql->query(‘COMMIT');
echo date(“H:i:s”);
方法三:使用优化的SQL语句:拼接SQL语句,使用insert into table() values(),(),(),()一次插入,如果字符串太长,
然后需要配置MYSQL,在mysql命令行运行:set global max_allowed_packet = 2*1024*1024*10; 消费时间为:11:24:06 11:25:06;插入200W条测试数据只用了1分钟!:
$sql= “insert into twenty_million (value) values”;
for($i=0;$iquery($sql);
最后,在插入大批量数据的时候,第一种方法无疑是最差的,而第二种方法在实际应用中应用更广泛,第三种方法更适合插入测试数据或者其他要求不高的时候。真快。 查看全部
php抓取网页数据插入数据库(这里有新鲜出炉的PHP面向对象编程,程序狗速度看过来!)
这里是新鲜出炉的PHP面向对象编程,程序狗的速度来了!
PHP开源脚本语言PHP(外文名称:Hypertext Preprocessor,中文名称:“Hypertext Preprocessor”)是一种通用的开源脚本语言。文法吸收了C语言、Java和Perl的特点。入门门槛低,易学,应用广泛。它主要适用于Web开发领域。PHP的文件扩展名是php。
本文讲解php写入数据库的三种方法及性能对比。三种方式分别是:普通的insert语句一一执行、通过事务批量提交、insert into的批量数据提交方式。有兴趣的同学可以参考以下。
方法一:使用insert into 逐一插入,最终显示为:23:25:05 01:32:05,也就是2个多小时!:
$params = array(‘value'=>'50′);
set_time_limit(0);
echo date(“H:i:s”);
for($i=0;$iinsert($params);
};
echo date(“H:i:s”);
方法二:使用事务提交,批量插入数据库(每10W次提交),最后显示消耗时间为:22:56:13 23:04:00,共8分13秒:
echo date(“H:i:s”);
$connect_mysql->query(‘BEGIN');
$params = array(‘value'=>'50′);
for($i=0;$iinsert($params);
if($i0000==0){
$connect_mysql->query(‘COMMIT');
$connect_mysql->query(‘BEGIN');
}
}
$connect_mysql->query(‘COMMIT');
echo date(“H:i:s”);
方法三:使用优化的SQL语句:拼接SQL语句,使用insert into table() values(),(),(),()一次插入,如果字符串太长,
然后需要配置MYSQL,在mysql命令行运行:set global max_allowed_packet = 2*1024*1024*10; 消费时间为:11:24:06 11:25:06;插入200W条测试数据只用了1分钟!:
$sql= “insert into twenty_million (value) values”;
for($i=0;$iquery($sql);
最后,在插入大批量数据的时候,第一种方法无疑是最差的,而第二种方法在实际应用中应用更广泛,第三种方法更适合插入测试数据或者其他要求不高的时候。真快。
php抓取网页数据插入数据库(request+goquery+mahonia实现自动抓取(图)代码)
网站优化 • 优采云 发表了文章 • 0 个评论 • 52 次浏览 • 2022-04-07 06:21
request+goquery+mahonia实现网页数据自动爬取
https:hotqin888articledetails52194839 设计院OA上有一个维护良好的法规库,3000多个条目。我在 30 分钟内将它们逐页复制到 excel 中。总共1500页。为什么不使用代码抓取?因为我连chrome都不能登录访问这个库,只支持ie。使用fiddler获取库页面地址,复制到chrome,直接跳转到登录页面。今天再试试,用chrome登录,然后点击:进入系统-会单独打开一个窗口,这个窗口好像不支持地址输入,没关系,在这个窗口-公共信息-点击下拉- 技术标准,它将打开一个新窗口,出现库。此时,回到任意一个chrome标签,输入地址,就可以打开库了。我不 不知道为什么这么复杂。就记录下来吧。我们进入正题,直接用代码抓取库。这样一个循环一次可以抓取1500页。用到了三个知识点:请求库构造http访问信息头,这里带上登录cookie来模拟登录;mahonia将页面gb的代码转换为utf-8,否则会乱码;goquery大名鼎鼎的get html 否则会乱码;goquery大名鼎鼎的get html 否则会乱码;goquery大名鼎鼎的get html
650 查看全部
php抓取网页数据插入数据库(request+goquery+mahonia实现自动抓取(图)代码)
request+goquery+mahonia实现网页数据自动爬取
https:hotqin888articledetails52194839 设计院OA上有一个维护良好的法规库,3000多个条目。我在 30 分钟内将它们逐页复制到 excel 中。总共1500页。为什么不使用代码抓取?因为我连chrome都不能登录访问这个库,只支持ie。使用fiddler获取库页面地址,复制到chrome,直接跳转到登录页面。今天再试试,用chrome登录,然后点击:进入系统-会单独打开一个窗口,这个窗口好像不支持地址输入,没关系,在这个窗口-公共信息-点击下拉- 技术标准,它将打开一个新窗口,出现库。此时,回到任意一个chrome标签,输入地址,就可以打开库了。我不 不知道为什么这么复杂。就记录下来吧。我们进入正题,直接用代码抓取库。这样一个循环一次可以抓取1500页。用到了三个知识点:请求库构造http访问信息头,这里带上登录cookie来模拟登录;mahonia将页面gb的代码转换为utf-8,否则会乱码;goquery大名鼎鼎的get html 否则会乱码;goquery大名鼎鼎的get html 否则会乱码;goquery大名鼎鼎的get html
650
php抓取网页数据插入数据库(搜狗微信公众号简七指数怎么获取和点赞量?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 180 次浏览 • 2022-04-03 06:01
微信公众平台有很多公众号,里面有各种各样的文章,很多都是乱七八糟的。不过,在这些文章之中,肯定会有一些我认为优秀的文章。
所以如果我可以自己写一个程序来获取我喜欢的微信公众号上的文章,获取文章的浏览量和点赞数,然后进行简单的数据分析,那么< @文章 肯定会是一个更好的 文章。
这里需要注意的是,通过编写爬虫获取搜狗微信搜索中的微信文章,是无法获取浏览量和点赞这两个关键数据的(我是入门级编程技能)。于是我找到了另一种方式,通过青波指数的网站获取我想要的数据。
注:目前已找到方法获取搜狗微信中文章的浏览量和点赞量。2017.02.03
事实上,清波指数网站上的数据是非常完整的。可以看到微信公众号的列表,也可以看到每日、每周、每月的热文,不过我上面说的,内容比较乱,那些看书多的文章可能是< @文章 一些家长级别的人会喜欢的。
当然我也可以在这个网站上搜索具体的微信公众号,然后看看它的历史文章。清博指数也已经很详细了,可以按照阅读数、点赞数等进行排序文章。但是,我需要的可能是一个很简单的点赞数除以阅读数的指标,所以我需要通过爬虫抓取上面的数据,进行简单的分析。对了,可以练手,无聊慌。
启动程序
以微信公众号健奇财经为例,我需要先打开它的文章界面,下面是它的url:
然后通过分析发现一共有25页文章,也就是最后一页文章的url如下,注意只有最后一个参数不同:
所以你可以编写一个函数并调用它 25 次。
BeautifulSoup 在网络上爬取它需要的数据
忘了说,我写程序用的语言是Python,它的爬虫入口很简单。然后BeautifulSoup是一个网页分析插件,非常方便的获取文章中的HTML数据。
下一步是分析网页的结构:
我用红框文章框住了两篇文章,它们在网页上的结构代码是一样的。然后通过检查元素就可以看到网页对应的代码,然后就可以编写爬取的规则了。下面我直接写一个函数:
# 从网页中获取数据
def get_webdata(url):
标题 = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.@ >0.2704.103 Safari/537.36'
}
r = requests.get(url,headers=headers)
c = r.内容
b = 美丽汤(c)
data_list = b.find('ul',{'class':'article-ul'})
data_li = data_list.findAll('li')
对于 data_li 中的 i:
# 替换标题中的英文双引号,防止插入数据库时出错
title = i.find('h4').find('a').get_text().replace('"','\'\'')
链接 = i.find('h4').find('a').attrs['href']
source = i.find('span',{'class':'blue'}).get_text()
time = i.find('span',{'class':'blue'}).parent.next_sibling.next_sibling.get_text().replace('发布时间:'.decode('utf-8'),'' )
readnum = int(i.find('i',{'class':'fa-book'}).next_sibling)
赞美数 = int(i.find('i',{'class':'fa-thumbs-o-up'}).next_sibling)
insert_content(标题,readnum,praisenum,时间,链接,来源)
这个函数包括使用requests先获取网页的内容,然后传给BeautifulSoup分析提取我需要的数据,然后在数据库中通过insert_content函数,数据库的知识就不涉及这个了到时候,下面所有的代码都会给它,也算怕以后忘记。
在我看来,其实BeautifulSoup的知识点只需要掌握上面代码中用到的find、findAll、get_text()、attrs['src']等几个常用语句即可。
循环获取并写入数据库
你还记得第一个网址吗?总共需要爬取25个页面。这25个页面的url其实和最后一个参数是不一样的,所以可以给一个基本的url,然后用for函数直接生成25个url就好了:
# 生成要爬取的网页链接并爬取
def get_urls_webdatas(basic_url, range_num):
对于范围内的 i(1,range_num+1):
url = basic_url + str(i)
打印网址
打印 ''
获取网络数据(网址)
time.sleep(round(random.random(),1))
basic_url = '#39;
get_urls_webdatas(basic_url,25)
如上代码,get_urls_webdataas函数传入两个参数,分别是基本url和需要的页数。你可以看到我在代码的最后一行调用了这个函数。
这个函数也调用了我上面写的函数get_webdata来抓取页面,这样25个页面的文章数据会一次性写入数据库。
然后注意这个小技巧:
time.sleep(round(random.random(),1))
每次我用程序爬一个网页,这个语句会随机生成一个1s以内的时间段,然后休息这么短的时间,然后继续爬下一个页面,可以防止被ban。
获取最终数据
先给出我这次写的其余代码:
#编码:utf-8
导入请求,MySQLdb,随机,时间
从 bs4 导入 BeautifulSoup
def get_conn():
conn = MySQLdb.connect('localhost','root','0000','weixin',charset='utf8')
返回连接
def insert_content(标题,readnum,praisenum,时间,链接,来源):
conn = get_conn()
cur = conn.cursor()
打印标题,readnum
sql = '插入weixin.gsdata(title,readnum,praisenum,time,link,source)值("%s","%s","%s","%s","%s", "%s")' % (title,readnum,praisenum,time,link,source)
cur.execute(sql)
mit()
cur.close()
conn.close()
包括一开始的一些插件的导入,然后剩下的两个函数就是与数据库操作相关的函数。
最后,通过从weixin.gsdata中选择*;在数据库中,我可以得到我抓取到的这个微信公众号的文章数据,包括标题、发布日期、阅读量、点赞数、访问url等信息。
分析数据
这些数据只是最原创的数据。我可以将以上数据导入Excel,进行简单的分析处理,得到我需要的文章列表。分析思路如下:
我可以按喜欢排序 查看全部
php抓取网页数据插入数据库(搜狗微信公众号简七指数怎么获取和点赞量?)
微信公众平台有很多公众号,里面有各种各样的文章,很多都是乱七八糟的。不过,在这些文章之中,肯定会有一些我认为优秀的文章。
所以如果我可以自己写一个程序来获取我喜欢的微信公众号上的文章,获取文章的浏览量和点赞数,然后进行简单的数据分析,那么< @文章 肯定会是一个更好的 文章。
这里需要注意的是,通过编写爬虫获取搜狗微信搜索中的微信文章,是无法获取浏览量和点赞这两个关键数据的(我是入门级编程技能)。于是我找到了另一种方式,通过青波指数的网站获取我想要的数据。
注:目前已找到方法获取搜狗微信中文章的浏览量和点赞量。2017.02.03
事实上,清波指数网站上的数据是非常完整的。可以看到微信公众号的列表,也可以看到每日、每周、每月的热文,不过我上面说的,内容比较乱,那些看书多的文章可能是< @文章 一些家长级别的人会喜欢的。
当然我也可以在这个网站上搜索具体的微信公众号,然后看看它的历史文章。清博指数也已经很详细了,可以按照阅读数、点赞数等进行排序文章。但是,我需要的可能是一个很简单的点赞数除以阅读数的指标,所以我需要通过爬虫抓取上面的数据,进行简单的分析。对了,可以练手,无聊慌。
启动程序
以微信公众号健奇财经为例,我需要先打开它的文章界面,下面是它的url:
然后通过分析发现一共有25页文章,也就是最后一页文章的url如下,注意只有最后一个参数不同:
所以你可以编写一个函数并调用它 25 次。
BeautifulSoup 在网络上爬取它需要的数据
忘了说,我写程序用的语言是Python,它的爬虫入口很简单。然后BeautifulSoup是一个网页分析插件,非常方便的获取文章中的HTML数据。
下一步是分析网页的结构:
我用红框文章框住了两篇文章,它们在网页上的结构代码是一样的。然后通过检查元素就可以看到网页对应的代码,然后就可以编写爬取的规则了。下面我直接写一个函数:
# 从网页中获取数据
def get_webdata(url):
标题 = {
'user-agent': 'Mozilla/5.0 (Macintosh; Intel Mac OS X 10_11_5) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/51.@ >0.2704.103 Safari/537.36'
}
r = requests.get(url,headers=headers)
c = r.内容
b = 美丽汤(c)
data_list = b.find('ul',{'class':'article-ul'})
data_li = data_list.findAll('li')
对于 data_li 中的 i:
# 替换标题中的英文双引号,防止插入数据库时出错
title = i.find('h4').find('a').get_text().replace('"','\'\'')
链接 = i.find('h4').find('a').attrs['href']
source = i.find('span',{'class':'blue'}).get_text()
time = i.find('span',{'class':'blue'}).parent.next_sibling.next_sibling.get_text().replace('发布时间:'.decode('utf-8'),'' )
readnum = int(i.find('i',{'class':'fa-book'}).next_sibling)
赞美数 = int(i.find('i',{'class':'fa-thumbs-o-up'}).next_sibling)
insert_content(标题,readnum,praisenum,时间,链接,来源)
这个函数包括使用requests先获取网页的内容,然后传给BeautifulSoup分析提取我需要的数据,然后在数据库中通过insert_content函数,数据库的知识就不涉及这个了到时候,下面所有的代码都会给它,也算怕以后忘记。
在我看来,其实BeautifulSoup的知识点只需要掌握上面代码中用到的find、findAll、get_text()、attrs['src']等几个常用语句即可。
循环获取并写入数据库
你还记得第一个网址吗?总共需要爬取25个页面。这25个页面的url其实和最后一个参数是不一样的,所以可以给一个基本的url,然后用for函数直接生成25个url就好了:
# 生成要爬取的网页链接并爬取
def get_urls_webdatas(basic_url, range_num):
对于范围内的 i(1,range_num+1):
url = basic_url + str(i)
打印网址
打印 ''
获取网络数据(网址)
time.sleep(round(random.random(),1))
basic_url = '#39;
get_urls_webdatas(basic_url,25)
如上代码,get_urls_webdataas函数传入两个参数,分别是基本url和需要的页数。你可以看到我在代码的最后一行调用了这个函数。
这个函数也调用了我上面写的函数get_webdata来抓取页面,这样25个页面的文章数据会一次性写入数据库。
然后注意这个小技巧:
time.sleep(round(random.random(),1))
每次我用程序爬一个网页,这个语句会随机生成一个1s以内的时间段,然后休息这么短的时间,然后继续爬下一个页面,可以防止被ban。
获取最终数据
先给出我这次写的其余代码:
#编码:utf-8
导入请求,MySQLdb,随机,时间
从 bs4 导入 BeautifulSoup
def get_conn():
conn = MySQLdb.connect('localhost','root','0000','weixin',charset='utf8')
返回连接
def insert_content(标题,readnum,praisenum,时间,链接,来源):
conn = get_conn()
cur = conn.cursor()
打印标题,readnum
sql = '插入weixin.gsdata(title,readnum,praisenum,time,link,source)值("%s","%s","%s","%s","%s", "%s")' % (title,readnum,praisenum,time,link,source)
cur.execute(sql)
mit()
cur.close()
conn.close()
包括一开始的一些插件的导入,然后剩下的两个函数就是与数据库操作相关的函数。
最后,通过从weixin.gsdata中选择*;在数据库中,我可以得到我抓取到的这个微信公众号的文章数据,包括标题、发布日期、阅读量、点赞数、访问url等信息。
分析数据
这些数据只是最原创的数据。我可以将以上数据导入Excel,进行简单的分析处理,得到我需要的文章列表。分析思路如下:
我可以按喜欢排序
php抓取网页数据插入数据库(重点推荐:PHP的ORM框架(一)|公司推荐)
网站优化 • 优采云 发表了文章 • 0 个评论 • 120 次浏览 • 2022-04-03 05:19
强烈推荐:
1、推进
推进
它是 PHP5 的 OR 映射(Object Relational Mapping)框架,基于 Apache
Torque 提供对象持久层支持。它从模式定义文件和 XML 格式的相应配置文件生成 SQL 和类。它允许您使用对象而不是 SQL 来读取和写入数据库表中的记录。
记录。Propel 提供了一个生成器来为您的数据模型创建 SQL 定义文件和 PHP 类。开发者也可以很方便的自定义生成的类,我们也可以通过XML,
PHP 类和 Phing 构建工具将 Propel 集成到现有的应用程序开发框架中。例如PHP框架symfony的1.2之前的版本默认使用lite版本
Propel 作为默认的 ORM 框架。
官方网站:
2、教义
教义
它是一个 PHP ORM 框架,它必须运行在 >=php5.2.3 版本上,它是一个强大的数据抽象层。它的主要特点之一是对现实使用面向对象的方法
现在数据库查询被密封传输,它通过一个类似于底层Hibernate HQL的DQL查询语句进行数据库查询。
这为开发提供了更大的灵活性,并大大减少了代码重复。与Propel相比,Doctrine的优势在于支持全文搜索。Doctrine 的文件一直比 Propel 好。
Propel需要全面丰富,社区更活跃,使用更自然,更易阅读,更接近原生SQL。它在性能方面也比Propel略好。此外,您还可以轻松
Doctrine 集成到现有的应用程序框架中,例如 PHP 框架 symfony 的 1.3 及以后的版本使用 Doctrine 作为默认的 ORM 框架,也可以集成 Doctrine 和 Codeigniter。
官方网站:
3、EZPDO
EZPDO
是一个非常轻量级的 PHP
ORM 框架。EZPDO作者的初衷是为了减少复杂的ORM学习曲线,尽可能在ORM的运行效率和功能之间做出平衡。这是迄今为止我用过的最简单的 ORM 盒子。
我还是想把它集成到我的CoolPHP SDK中,效率相当不错,功能也基本可以满足需要,但是ESPDO的更新比较慢。
官方网站:
4、红豆
RedBean 是一个易于使用的轻量级 PHP ORM 框架,提供对 MySQL、SQLite 和 PostgreSQL 的支持。RedBean 的架构非常灵活,核心非常简单。开发者可以通过插件轻松扩展功能。
官方网站:
5、其他
国家
内部fleaphp开发框架基于TableDataGateway实现ORM实现;Zend Framework 为 SQL 提供了额外的支持
除了语句的封装外,还实现了TableGateway、TableRowSet、TableRow的实现;还有一些类似 Rails 的
ActiveRecord 实施的解决方案。
更多ORM框架,请阅读:
总结:
总的来说,通用的ORM框架可以满足简单应用系统的基本需求,可以大大降低开发难度,提高开发效率,但是在SQL优化方面肯定比纯SQL语言要好。
更糟糕的是,复杂关联和 SQL 嵌入式表达式的处理并不理想。也许这主要是由于PHP本身的对象持久化问题,导致ORM效率低下,一般比纯SQL慢。
10~50次。但这些都是解决方案。最基本的性能解决方案,我们可以通过缓存来提高效率。对于Hibernate,虽然配置比较复杂,但是可以通过
二级缓存和查询缓存的灵活使用,大大缓解了数据库的查询压力,大大提高了系统的性能。 查看全部
php抓取网页数据插入数据库(重点推荐:PHP的ORM框架(一)|公司推荐)
强烈推荐:
1、推进
推进
它是 PHP5 的 OR 映射(Object Relational Mapping)框架,基于 Apache
Torque 提供对象持久层支持。它从模式定义文件和 XML 格式的相应配置文件生成 SQL 和类。它允许您使用对象而不是 SQL 来读取和写入数据库表中的记录。
记录。Propel 提供了一个生成器来为您的数据模型创建 SQL 定义文件和 PHP 类。开发者也可以很方便的自定义生成的类,我们也可以通过XML,
PHP 类和 Phing 构建工具将 Propel 集成到现有的应用程序开发框架中。例如PHP框架symfony的1.2之前的版本默认使用lite版本
Propel 作为默认的 ORM 框架。
官方网站:
2、教义
教义
它是一个 PHP ORM 框架,它必须运行在 >=php5.2.3 版本上,它是一个强大的数据抽象层。它的主要特点之一是对现实使用面向对象的方法
现在数据库查询被密封传输,它通过一个类似于底层Hibernate HQL的DQL查询语句进行数据库查询。
这为开发提供了更大的灵活性,并大大减少了代码重复。与Propel相比,Doctrine的优势在于支持全文搜索。Doctrine 的文件一直比 Propel 好。
Propel需要全面丰富,社区更活跃,使用更自然,更易阅读,更接近原生SQL。它在性能方面也比Propel略好。此外,您还可以轻松
Doctrine 集成到现有的应用程序框架中,例如 PHP 框架 symfony 的 1.3 及以后的版本使用 Doctrine 作为默认的 ORM 框架,也可以集成 Doctrine 和 Codeigniter。
官方网站:
3、EZPDO
EZPDO
是一个非常轻量级的 PHP
ORM 框架。EZPDO作者的初衷是为了减少复杂的ORM学习曲线,尽可能在ORM的运行效率和功能之间做出平衡。这是迄今为止我用过的最简单的 ORM 盒子。
我还是想把它集成到我的CoolPHP SDK中,效率相当不错,功能也基本可以满足需要,但是ESPDO的更新比较慢。
官方网站:
4、红豆
RedBean 是一个易于使用的轻量级 PHP ORM 框架,提供对 MySQL、SQLite 和 PostgreSQL 的支持。RedBean 的架构非常灵活,核心非常简单。开发者可以通过插件轻松扩展功能。
官方网站:
5、其他
国家
内部fleaphp开发框架基于TableDataGateway实现ORM实现;Zend Framework 为 SQL 提供了额外的支持
除了语句的封装外,还实现了TableGateway、TableRowSet、TableRow的实现;还有一些类似 Rails 的
ActiveRecord 实施的解决方案。
更多ORM框架,请阅读:
总结:
总的来说,通用的ORM框架可以满足简单应用系统的基本需求,可以大大降低开发难度,提高开发效率,但是在SQL优化方面肯定比纯SQL语言要好。
更糟糕的是,复杂关联和 SQL 嵌入式表达式的处理并不理想。也许这主要是由于PHP本身的对象持久化问题,导致ORM效率低下,一般比纯SQL慢。
10~50次。但这些都是解决方案。最基本的性能解决方案,我们可以通过缓存来提高效率。对于Hibernate,虽然配置比较复杂,但是可以通过
二级缓存和查询缓存的灵活使用,大大缓解了数据库的查询压力,大大提高了系统的性能。
php抓取网页数据插入数据库(studentinfo数据库删除指定数据(改)(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2022-04-02 20:10
)
第一步:创建数据库并在数据库中创建数据表。当然,一个数据库中可以有很多数据表。在这里,我将创建一个表来存储学生的个人姓名和成绩。
推荐mysql视频教程:《mysql教程》
思路:连接服务器->创建数据库->连接数据库->创建数据表
脚本:创建数据库和数据表
现在可以在phpMyAdmin中看到新的数据库studentinfo和数据表student
第二步:在studentinfo数据库的学生数据表中添加学生信息数据(补充)
思路:连接服务器->连接数据库->将指定数据插入数据表
注意:因为前面的php已经创建了服务器连接并连接了数据库,所以下面的代码省略了建立连接的部分,直接写了函数语句。
function addtabel_data(){
//多维数组
$datas=array(
array("name"=>"测试猫","chinese"=>100,"english"=>100,"math"=>100),
array("name"=>"测试狗","chinese"=>99,"english"=>99,"math"=>99),
array("name"=>"测试虎","chinese"=>98,"english"=>98,"math"=>98)
);
for($i=0;$i0){
echo "添加数据成功</br>";
}else{
echo "添加数据失败</br>";
}
}
addtabel_data();//调用
运行php发现添加数据失败,这是为什么呢?因为name中传入了一个中文字符串,而学生表中定义的name collation不是utf-8?? ?
没关系,我们可以一键修改排序规则,自己修改。
再次运行,添加数据成功,发现表中有数据
第三步:根据查询条件在studentinfo数据库的student表中查询一条或多条指定信息(勾选)
思路:连接服务器->连接数据库->根据条件查询数据表数据
function selecttable_data($name){
$res=mysql_query("select * from student where name='$name'");//根据name来查询student数据
// $res=mysql_query("select * from student where name='$name' and chinese='$chinese'");//多条件查询连接符and
// $res=mysql_query("select * from student");//查询student表里所有数据
// $res=mysql_query("select * from student limit 0,2“);//限制前面第1到2条数据
if($res&&mysql_num_rows($res)){
while($sql=mysql_fetch_assoc($res)){
$arr[]=$sql;
}
echo json_encode($arr,JSON_UNESCAPED_UNICODE);//把数据(数组嵌套json类型)转换为字符串输出,这个ajax拿数据经常用
}else{
echo "找不到该数据</br>";
}
}
selecttable_data("测试猫");//查询name为测试猫
第四步:根据修改条件修改studentinfo数据库的学生表中的指定数据(修改)
思路:连接服务器->连接数据库->根据条件修改数据表中的指定数据
function updatetabel_data($name,$chinese){
mysql_query("update student set chinese='$chinese' where name='$name'");//修改student表里为$name的chinese数据修改为$chinese
$res=mysql_affected_rows();//返回影响行
if($res>0){
echo "修改成功</br>";
}else{
echo "修改失败</br>";
}
}
updatetabel_data("测试虎",90);//把测试虎的语文成绩修改为90分
测试老虎语言分数已从 98 修改为 90
第五步:根据删除条件删除studentinfo数据库student表中的指定数据(delete)
思路:连接服务器->连接数据库->根据条件删除数据表中的指定数据
function deletetable_data($name){
mysql_query("delete from student where name='$name'");//删除student表里为$name的整条数据
$res=mysql_affected_rows();//返回影响行
if($res>0){
echo "删除成功</br>";
}else{
echo "删除失败</br>";
}
}
deletetable_data('测试虎');//删除name为测试虎这条数据
测试老虎 此数据已被删除
查看全部
php抓取网页数据插入数据库(studentinfo数据库删除指定数据(改)(图)
)
第一步:创建数据库并在数据库中创建数据表。当然,一个数据库中可以有很多数据表。在这里,我将创建一个表来存储学生的个人姓名和成绩。
推荐mysql视频教程:《mysql教程》
思路:连接服务器->创建数据库->连接数据库->创建数据表
脚本:创建数据库和数据表
现在可以在phpMyAdmin中看到新的数据库studentinfo和数据表student
第二步:在studentinfo数据库的学生数据表中添加学生信息数据(补充)
思路:连接服务器->连接数据库->将指定数据插入数据表
注意:因为前面的php已经创建了服务器连接并连接了数据库,所以下面的代码省略了建立连接的部分,直接写了函数语句。
function addtabel_data(){
//多维数组
$datas=array(
array("name"=>"测试猫","chinese"=>100,"english"=>100,"math"=>100),
array("name"=>"测试狗","chinese"=>99,"english"=>99,"math"=>99),
array("name"=>"测试虎","chinese"=>98,"english"=>98,"math"=>98)
);
for($i=0;$i0){
echo "添加数据成功</br>";
}else{
echo "添加数据失败</br>";
}
}
addtabel_data();//调用
运行php发现添加数据失败,这是为什么呢?因为name中传入了一个中文字符串,而学生表中定义的name collation不是utf-8?? ?
没关系,我们可以一键修改排序规则,自己修改。
再次运行,添加数据成功,发现表中有数据
第三步:根据查询条件在studentinfo数据库的student表中查询一条或多条指定信息(勾选)
思路:连接服务器->连接数据库->根据条件查询数据表数据
function selecttable_data($name){
$res=mysql_query("select * from student where name='$name'");//根据name来查询student数据
// $res=mysql_query("select * from student where name='$name' and chinese='$chinese'");//多条件查询连接符and
// $res=mysql_query("select * from student");//查询student表里所有数据
// $res=mysql_query("select * from student limit 0,2“);//限制前面第1到2条数据
if($res&&mysql_num_rows($res)){
while($sql=mysql_fetch_assoc($res)){
$arr[]=$sql;
}
echo json_encode($arr,JSON_UNESCAPED_UNICODE);//把数据(数组嵌套json类型)转换为字符串输出,这个ajax拿数据经常用
}else{
echo "找不到该数据</br>";
}
}
selecttable_data("测试猫");//查询name为测试猫
第四步:根据修改条件修改studentinfo数据库的学生表中的指定数据(修改)
思路:连接服务器->连接数据库->根据条件修改数据表中的指定数据
function updatetabel_data($name,$chinese){
mysql_query("update student set chinese='$chinese' where name='$name'");//修改student表里为$name的chinese数据修改为$chinese
$res=mysql_affected_rows();//返回影响行
if($res>0){
echo "修改成功</br>";
}else{
echo "修改失败</br>";
}
}
updatetabel_data("测试虎",90);//把测试虎的语文成绩修改为90分
测试老虎语言分数已从 98 修改为 90
第五步:根据删除条件删除studentinfo数据库student表中的指定数据(delete)
思路:连接服务器->连接数据库->根据条件删除数据表中的指定数据
function deletetable_data($name){
mysql_query("delete from student where name='$name'");//删除student表里为$name的整条数据
$res=mysql_affected_rows();//返回影响行
if($res>0){
echo "删除成功</br>";
}else{
echo "删除失败</br>";
}
}
deletetable_data('测试虎');//删除name为测试虎这条数据
测试老虎 此数据已被删除
php抓取网页数据插入数据库(我的小程序通过PHP从SQL数据库提取到数据,使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2022-04-02 16:39
我的小程序通过 PHP 从 SQL 数据库中提取数据,使用
{{item.id}}{{item.device_num}}{{item.user_name}}{{item.user_phone}}
语句渲染数据,php获取的数据如下:
[{\"id\":\"1\",\"device_num\":\"12002120\",\"user_name\":\"li\",\"user_phone\":\"\ ",\"unit_name\":\"jijin\",\"unit_addr\":\"djsaj\",\"wechat_num\":\"hsahjh\"},{\"id\":\"2\ ",\"device_num\":\"1272677867\",\"user_name\":\"zhang\",\"user_phone\":\"1362525891\",\"unit_name\":\"yiuehhaj\", \"unit_addr\":\"heiwh\",\"wechat_num\":\"hh\"}]\r\n\r\n\r\n\r\n\r\n \r\n
调试器观察到的渲染页面数据如下
数据是空的,不知道为什么,请大家指点一下。 查看全部
php抓取网页数据插入数据库(我的小程序通过PHP从SQL数据库提取到数据,使用)
我的小程序通过 PHP 从 SQL 数据库中提取数据,使用
{{item.id}}{{item.device_num}}{{item.user_name}}{{item.user_phone}}
语句渲染数据,php获取的数据如下:
[{\"id\":\"1\",\"device_num\":\"12002120\",\"user_name\":\"li\",\"user_phone\":\"\ ",\"unit_name\":\"jijin\",\"unit_addr\":\"djsaj\",\"wechat_num\":\"hsahjh\"},{\"id\":\"2\ ",\"device_num\":\"1272677867\",\"user_name\":\"zhang\",\"user_phone\":\"1362525891\",\"unit_name\":\"yiuehhaj\", \"unit_addr\":\"heiwh\",\"wechat_num\":\"hh\"}]\r\n\r\n\r\n\r\n\r\n \r\n
调试器观察到的渲染页面数据如下
数据是空的,不知道为什么,请大家指点一下。
php抓取网页数据插入数据库( PHP快速导入大量数据到数据库的方法方法方法 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 42 次浏览 • 2022-03-30 00:09
PHP快速导入大量数据到数据库的方法方法方法
)
PHP中快速将大量数据导入数据库的方法
第一种方法:使用insert into插入,代码如下:
$params = array(‘value'=>'50′);
set_time_limit(0);
echo date(“H:i:s”);
for($i=0;$iinsert($params);
};
echo date(“H:i:s”);
最终显示为:23:25:05 01:32:05,也就是用了2个多小时!
第二种方法:使用事务提交,批量插入数据库(每10W提交),最后显示时间为:22:56:13 23:04:00,共8分13秒,代码为如下:
echo date(“H:i:s”);
$connect_mysql->query(‘BEGIN');
$params = array(‘value'=>'50′);
for($i=0;$iinsert($params);
if($i0000==0){
$connect_mysql->query(‘COMMIT');
$connect_mysql->query(‘BEGIN');
}
}
$connect_mysql->query(‘COMMIT');
echo date(“H:i:s”);
第三种方法:使用优化的SQL语句
拼接SQL语句,使用insert into table() values(),(),(),()一次插入,如果字符串太长,需要配置MYSQL,
在mysql命令行中运行:
set global max_allowed_packet = 2*1024*1024*10;
消费时间为:11:24:06 11:25:06;
插入200W条测试数据只用了1分钟!代码如下:
$sql= “insert into twenty_million (value) values”;
for($i=0;$iquery($sql);
总结:在插入大批量数据时,第一种方法无疑是最差的,而第二种方法在实际应用中被广泛使用,第三种方法更适合插入测试数据或者其他要求不高的时候,速度确实快.
推荐教程:PHP视频教程
以上就是php中如何快速导入大量数据的详细内容。更多详情请关注php中文网文章其他相关话题!
查看全部
php抓取网页数据插入数据库(
PHP快速导入大量数据到数据库的方法方法方法
)
PHP中快速将大量数据导入数据库的方法
第一种方法:使用insert into插入,代码如下:
$params = array(‘value'=>'50′);
set_time_limit(0);
echo date(“H:i:s”);
for($i=0;$iinsert($params);
};
echo date(“H:i:s”);
最终显示为:23:25:05 01:32:05,也就是用了2个多小时!
第二种方法:使用事务提交,批量插入数据库(每10W提交),最后显示时间为:22:56:13 23:04:00,共8分13秒,代码为如下:
echo date(“H:i:s”);
$connect_mysql->query(‘BEGIN');
$params = array(‘value'=>'50′);
for($i=0;$iinsert($params);
if($i0000==0){
$connect_mysql->query(‘COMMIT');
$connect_mysql->query(‘BEGIN');
}
}
$connect_mysql->query(‘COMMIT');
echo date(“H:i:s”);
第三种方法:使用优化的SQL语句
拼接SQL语句,使用insert into table() values(),(),(),()一次插入,如果字符串太长,需要配置MYSQL,
在mysql命令行中运行:
set global max_allowed_packet = 2*1024*1024*10;
消费时间为:11:24:06 11:25:06;
插入200W条测试数据只用了1分钟!代码如下:
$sql= “insert into twenty_million (value) values”;
for($i=0;$iquery($sql);
总结:在插入大批量数据时,第一种方法无疑是最差的,而第二种方法在实际应用中被广泛使用,第三种方法更适合插入测试数据或者其他要求不高的时候,速度确实快.
推荐教程:PHP视频教程
以上就是php中如何快速导入大量数据的详细内容。更多详情请关注php中文网文章其他相关话题!
php抓取网页数据插入数据库(用PHP编写一个爬取事百科首页糗事!(图) )
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2022-03-29 01:03
)
突然想弄点网上的资料玩玩,因为有SAE的MySql数据库,放在那里也没用!于是我开始用PHP写了一个小程序来爬取尴尬事百科首页的尴尬事。数据存储在MySql中,是不是很好玩!
去做就对了!先确定思路
获取HTML源代码--->解析HTML--->保存到数据库
没什么难的
1、创建 PHP 文件“getDataToDB.php”,
2、获取指定URL的HTML源代码
这里我使用了curl函数,详情见PHP手册
代码是
// 获取对应链接的HTMLCODEfunction GetHtmlCode($url) { $ch = curl_init (); // 初始化一个cur对象 curl_setopt ( $ch, CURLOPT_URL, $url ); // 设置需要抓取的网页 curl_setopt ( $ch, CURLOPT_RETURNTRANSFER, 1 ); // 设置crul参数,要求结果保存到字符串中还是输出到屏幕上 curl_setopt ( $ch, CURLOPT_CONNECTTIMEOUT, 1000 ); // 设置链接延迟 $HtmlCode = curl_exec ( $ch ); // 运行curl,请求网页 return $HtmlCode;}
3、引入第三方文件'simple_html_dom.php'解析HTML
我这里没有使用正则表达式的能力,只是在网上搜索了一下,终于找到了这个,就像Java使用Jsoup一样(使用Jsoup解析滁州大学官网获取新闻列表),详情见BLOG
代码显示如下
function getFmlDataToDB() { $link = mysql_connect ( SAE_MYSQL_HOST_M . ':' . SAE_MYSQL_PORT, SAE_MYSQL_USER, SAE_MYSQL_PASS ); // 获取源码 $html = str_get_html ( GetHtmlCode ( "http://www.qiushibaike.com/" ) ); if ($link) { mysql_select_db ( SAE_MYSQL_DB, $link ); mysql_query ( 'set names utf8' ); // class="article block untagged mb15" foreach ( $html->find ( 'div[class=article block untagged mb15]' ) as $per ) { $z = null; $t = null; $w = null; $d = null; $p = null; $ds = null; $ps = null; // //作者 $author = $per->find ( 'div[class=author]' ); if ($author != null) { $a = $author [0]->find ( 'a' ); $z = $a [1]->innertext; } else { $z = 'no author'; } // 头像链接 if ($author != null) { $icon = $author [0]->find ( 'a' ); $t = $icon [0]->src->innertext; } else { $t = '...............'; } // 文章内容 $content = $per->find ( 'div[class=content]' ); $w = $content [0]->innertext; // 点赞数 $vote1 = $per->find ( 'div[class=stats]' ); $vote2 = $vote1 [0]->find ( 'span[class=stats-vote]' ); $vote3 = $vote2 [0]->find ( 'i[class=number]' ); $d = $vote3 [0]->innertext; // 评论数 $comments1 = $vote1 [0]->find ( 'span[class=stats-comments]' ); $comments2 = $comments1 [0]->find ( 'a[class=qiushi_comments]' ); $comments3 = $comments2 [0]->find ( 'i[class=number]' ); $p = $comments3 [0]->innertext; // 顶 数 $up_down = $per->find ( 'div[class=stats-buttons bar clearfix]' ); $up_down1 = $up_down [0]->find ( 'ul' ); $li = $up_down1 [0]->find ( 'li' ); $up = $li [0]->find ( 'span[class=number hidden]' ); $ds = $up [0]->innertext; // 拍 数 $down = $li [1]->find ( 'span[class=number hidden]' ); $ps = $down [0]->innertext; } } else { echo '数据库链接KO'; }}
这段代码写起来有点纠结。我试过了,不能直接获取子节点的数据。我只能从外层一层一层剥离解析。如果有新的写法,我会更新的,敬请关注。.
4、创建数据库,向数据库中插入数据
这里我在 SAE 中使用 MySQL。具体的连接方,请参见使用 PHP 连接 SAE 中的 MySql 数据库
需要注意编码格式,区域要在执行语句前加这么一句
mysql_query ( 'set names utf8' );
核心代码如下:
$sql = "INSERT INTO `app_bmhjqs`.`db_fml` (`id`, `author`, `icon_url`, `content`, `vote`, `comments`, `up`, `down`) VALUES (NULL, '$z', '$t', '$w', '$d', '$p', '$ds', '$ps');"; // 解决乱码 mysql_query ( 'set names utf8' ); $result = mysql_query ( $sql );
这样,获取--->解析--->插入就完成了,效果就是运行PHP文件一次,数据库就会在尴尬事百科首页添加尴尬事!我想知道是否可以编写一个计时器来每隔一定时间运行代码。我可以在java中做到这一点,但我不能在php中。毕竟是没有毛的鸟!百度一下。. . 找到这个拼写
// 定时器// ignore_user_abort (); // run script. in background// set_time_limit ( 0 ); // run script. forever// $interval = 30; // do every 15 minutes..// do {// echo date ( 'Y-m-d H:i:s', time () );// echo '写入数据库';// //getFmlDataToDB (); // } while ( true );
文件中加了这么一段代码,就在学校断网之前,在SAE上发表过,我没有测试!只需要等到第二天才能看到结果!
今天早上,我迫不及待地打开电脑,打开了SAE数据库。情况如下:
额头神!实在受不了了,赶紧关掉定时器,写了个按钮触发事件!如果这样下去,数据库会很拥挤!
好了,PHP爬虫的尴尬事百科首页的尴尬事都搞定了
如果你觉得这个博客对你有帮助,请给它一个赞!
查看全部
php抓取网页数据插入数据库(用PHP编写一个爬取事百科首页糗事!(图)
)
突然想弄点网上的资料玩玩,因为有SAE的MySql数据库,放在那里也没用!于是我开始用PHP写了一个小程序来爬取尴尬事百科首页的尴尬事。数据存储在MySql中,是不是很好玩!
去做就对了!先确定思路
获取HTML源代码--->解析HTML--->保存到数据库
没什么难的
1、创建 PHP 文件“getDataToDB.php”,
2、获取指定URL的HTML源代码
这里我使用了curl函数,详情见PHP手册
代码是
// 获取对应链接的HTMLCODEfunction GetHtmlCode($url) { $ch = curl_init (); // 初始化一个cur对象 curl_setopt ( $ch, CURLOPT_URL, $url ); // 设置需要抓取的网页 curl_setopt ( $ch, CURLOPT_RETURNTRANSFER, 1 ); // 设置crul参数,要求结果保存到字符串中还是输出到屏幕上 curl_setopt ( $ch, CURLOPT_CONNECTTIMEOUT, 1000 ); // 设置链接延迟 $HtmlCode = curl_exec ( $ch ); // 运行curl,请求网页 return $HtmlCode;}
3、引入第三方文件'simple_html_dom.php'解析HTML
我这里没有使用正则表达式的能力,只是在网上搜索了一下,终于找到了这个,就像Java使用Jsoup一样(使用Jsoup解析滁州大学官网获取新闻列表),详情见BLOG
代码显示如下
function getFmlDataToDB() { $link = mysql_connect ( SAE_MYSQL_HOST_M . ':' . SAE_MYSQL_PORT, SAE_MYSQL_USER, SAE_MYSQL_PASS ); // 获取源码 $html = str_get_html ( GetHtmlCode ( "http://www.qiushibaike.com/" ) ); if ($link) { mysql_select_db ( SAE_MYSQL_DB, $link ); mysql_query ( 'set names utf8' ); // class="article block untagged mb15" foreach ( $html->find ( 'div[class=article block untagged mb15]' ) as $per ) { $z = null; $t = null; $w = null; $d = null; $p = null; $ds = null; $ps = null; // //作者 $author = $per->find ( 'div[class=author]' ); if ($author != null) { $a = $author [0]->find ( 'a' ); $z = $a [1]->innertext; } else { $z = 'no author'; } // 头像链接 if ($author != null) { $icon = $author [0]->find ( 'a' ); $t = $icon [0]->src->innertext; } else { $t = '...............'; } // 文章内容 $content = $per->find ( 'div[class=content]' ); $w = $content [0]->innertext; // 点赞数 $vote1 = $per->find ( 'div[class=stats]' ); $vote2 = $vote1 [0]->find ( 'span[class=stats-vote]' ); $vote3 = $vote2 [0]->find ( 'i[class=number]' ); $d = $vote3 [0]->innertext; // 评论数 $comments1 = $vote1 [0]->find ( 'span[class=stats-comments]' ); $comments2 = $comments1 [0]->find ( 'a[class=qiushi_comments]' ); $comments3 = $comments2 [0]->find ( 'i[class=number]' ); $p = $comments3 [0]->innertext; // 顶 数 $up_down = $per->find ( 'div[class=stats-buttons bar clearfix]' ); $up_down1 = $up_down [0]->find ( 'ul' ); $li = $up_down1 [0]->find ( 'li' ); $up = $li [0]->find ( 'span[class=number hidden]' ); $ds = $up [0]->innertext; // 拍 数 $down = $li [1]->find ( 'span[class=number hidden]' ); $ps = $down [0]->innertext; } } else { echo '数据库链接KO'; }}
这段代码写起来有点纠结。我试过了,不能直接获取子节点的数据。我只能从外层一层一层剥离解析。如果有新的写法,我会更新的,敬请关注。.
4、创建数据库,向数据库中插入数据
这里我在 SAE 中使用 MySQL。具体的连接方,请参见使用 PHP 连接 SAE 中的 MySql 数据库
需要注意编码格式,区域要在执行语句前加这么一句
mysql_query ( 'set names utf8' );
核心代码如下:
$sql = "INSERT INTO `app_bmhjqs`.`db_fml` (`id`, `author`, `icon_url`, `content`, `vote`, `comments`, `up`, `down`) VALUES (NULL, '$z', '$t', '$w', '$d', '$p', '$ds', '$ps');"; // 解决乱码 mysql_query ( 'set names utf8' ); $result = mysql_query ( $sql );
这样,获取--->解析--->插入就完成了,效果就是运行PHP文件一次,数据库就会在尴尬事百科首页添加尴尬事!我想知道是否可以编写一个计时器来每隔一定时间运行代码。我可以在java中做到这一点,但我不能在php中。毕竟是没有毛的鸟!百度一下。. . 找到这个拼写
// 定时器// ignore_user_abort (); // run script. in background// set_time_limit ( 0 ); // run script. forever// $interval = 30; // do every 15 minutes..// do {// echo date ( 'Y-m-d H:i:s', time () );// echo '写入数据库';// //getFmlDataToDB (); // } while ( true );
文件中加了这么一段代码,就在学校断网之前,在SAE上发表过,我没有测试!只需要等到第二天才能看到结果!
今天早上,我迫不及待地打开电脑,打开了SAE数据库。情况如下:
额头神!实在受不了了,赶紧关掉定时器,写了个按钮触发事件!如果这样下去,数据库会很拥挤!
好了,PHP爬虫的尴尬事百科首页的尴尬事都搞定了
如果你觉得这个博客对你有帮助,请给它一个赞!
php抓取网页数据插入数据库(MongoDBPHP在php中使用mongodb你必须使用的php驱动)
网站优化 • 优采云 发表了文章 • 0 个评论 • 39 次浏览 • 2022-03-28 11:15
MongoDB PHP
要在php中使用mongodb,你必须使用mongodb的php驱动。
各平台MongoDB PHP的安装及驱动包下载,请参考:MongoDB扩展驱动的PHP安装
如果您使用的是 PHP7,请参阅:PHP7 MongoDB 安装和使用。
确保连接并选择一个数据库
为了保证正确连接,需要指定数据库名,如果mongoDB中不存在该数据库,mongoDB会自动创建
代码片段如下:
创建一个集合
创建集合的代码片段如下:
执行上述程序,输出如下:
集合创建成功
插入文档
在 mongoDB 中使用 insert() 方法插入文档:
插入文档的代码片段如下:
执行上述程序,输出如下:
数据插入成功
然后我们使用 db.runoob.find().pretty(); mongo客户端查看数据的命令:
查找文档
使用 find() 方法读取集合中的文档。
阅读使用文档的代码片段如下:
执行上述程序,输出如下:
MongoDB
更新文档
使用 update() 方法更新文档。
以下示例将使用以下代码片段更新标题为“MongoDB 教程”的文档:
执行上述程序,输出如下:
MongoDB 教程
然后我们使用 db.runoob.find().pretty(); mongo客户端查看数据的命令:
删除文档
使用 remove() 方法删除文档。
在以下示例中,我们将删除“title”为“MongoDB Tutorial”的数据记录。 ,代码片段如下:
除了上面的例子,你还可以使用findOne()、save()、limit()、skip()、sort()等方法在php中操作Mongodb数据库。
更多操作方法请参考Mongodb核心类: 查看全部
php抓取网页数据插入数据库(MongoDBPHP在php中使用mongodb你必须使用的php驱动)
MongoDB PHP
要在php中使用mongodb,你必须使用mongodb的php驱动。
各平台MongoDB PHP的安装及驱动包下载,请参考:MongoDB扩展驱动的PHP安装
如果您使用的是 PHP7,请参阅:PHP7 MongoDB 安装和使用。
确保连接并选择一个数据库
为了保证正确连接,需要指定数据库名,如果mongoDB中不存在该数据库,mongoDB会自动创建
代码片段如下:
创建一个集合
创建集合的代码片段如下:
执行上述程序,输出如下:
集合创建成功
插入文档
在 mongoDB 中使用 insert() 方法插入文档:
插入文档的代码片段如下:
执行上述程序,输出如下:
数据插入成功
然后我们使用 db.runoob.find().pretty(); mongo客户端查看数据的命令:
查找文档
使用 find() 方法读取集合中的文档。
阅读使用文档的代码片段如下:
执行上述程序,输出如下:
MongoDB
更新文档
使用 update() 方法更新文档。
以下示例将使用以下代码片段更新标题为“MongoDB 教程”的文档:
执行上述程序,输出如下:
MongoDB 教程
然后我们使用 db.runoob.find().pretty(); mongo客户端查看数据的命令:
删除文档
使用 remove() 方法删除文档。
在以下示例中,我们将删除“title”为“MongoDB Tutorial”的数据记录。 ,代码片段如下:
除了上面的例子,你还可以使用findOne()、save()、limit()、skip()、sort()等方法在php中操作Mongodb数据库。
更多操作方法请参考Mongodb核心类:
php抓取网页数据插入数据库(制定切实可行的建设方案网站在建设之前需要分析客户的需求)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-03-27 15:06
1:制定切实可行的施工计划
网站在建设之前,要分析客户的需求和互联网发展的趋势,制定符合企业发展的网站建设方案。策划的好坏将直接影响后期企业在互联网上的宣传推广效果。根据客户意见网站的需求、行业市场、产品定位等实际情况,确认网站的内容,明确网站传达的目的,建站的目的一方面是为了能够为客户解决问题,让有需要的客户通过网站对公司有更全面的了解,另一方面,
二:高端视觉体验
随着社会的不断进步和生活水平的提高,人类的审美也在不断提高。因为互联网产品迭代发展很快,只有与时俱进的设计,极致的交互,才能给用户带来满分的体验。网站设计还包括网页的排版布局、网站导航设计、网站栏目设计等,网页与用户的交互体现在鼠标的移动上up元素来改变原来的状态、颜色等。我们称之为动画特效,让用户在浏览网站时感觉这是一场视觉盛宴,那么建站的目的就达到了。
三:开发方式
随着技术的不断进步,编程语言越来越多,但需要考虑后期优化,所以我们选择原生Html+php开发方式来建站。这种方式符合国际标准DIV+CSS,可以最大限度的将网页原样显示在搜索引擎上,一方面有利于各平台搜索引擎对网页的抓取,另一方面另一方面,也有利于后期的维护。
四:网站的优化
你对搜索引擎并不陌生。为什么你的 网站 排名比其他人高,是因为搜索引擎会抓取你的 网站 内容并评估你的 网站 内容的质量。是的,所以关键词的优化,内容的更新和维护是建站所有步骤中最关键的一步。再好的产品没有市场,终究会被埋没。人们看到,那最终会被淘汰,SEO优化是所有网站的重要组成部分。
优盛网络-高端网站建设-品牌官网建设-品牌设计-宁波网站建设-为企业打造精品而生 查看全部
php抓取网页数据插入数据库(制定切实可行的建设方案网站在建设之前需要分析客户的需求)
1:制定切实可行的施工计划
网站在建设之前,要分析客户的需求和互联网发展的趋势,制定符合企业发展的网站建设方案。策划的好坏将直接影响后期企业在互联网上的宣传推广效果。根据客户意见网站的需求、行业市场、产品定位等实际情况,确认网站的内容,明确网站传达的目的,建站的目的一方面是为了能够为客户解决问题,让有需要的客户通过网站对公司有更全面的了解,另一方面,
二:高端视觉体验
随着社会的不断进步和生活水平的提高,人类的审美也在不断提高。因为互联网产品迭代发展很快,只有与时俱进的设计,极致的交互,才能给用户带来满分的体验。网站设计还包括网页的排版布局、网站导航设计、网站栏目设计等,网页与用户的交互体现在鼠标的移动上up元素来改变原来的状态、颜色等。我们称之为动画特效,让用户在浏览网站时感觉这是一场视觉盛宴,那么建站的目的就达到了。
三:开发方式
随着技术的不断进步,编程语言越来越多,但需要考虑后期优化,所以我们选择原生Html+php开发方式来建站。这种方式符合国际标准DIV+CSS,可以最大限度的将网页原样显示在搜索引擎上,一方面有利于各平台搜索引擎对网页的抓取,另一方面另一方面,也有利于后期的维护。
四:网站的优化
你对搜索引擎并不陌生。为什么你的 网站 排名比其他人高,是因为搜索引擎会抓取你的 网站 内容并评估你的 网站 内容的质量。是的,所以关键词的优化,内容的更新和维护是建站所有步骤中最关键的一步。再好的产品没有市场,终究会被埋没。人们看到,那最终会被淘汰,SEO优化是所有网站的重要组成部分。
优盛网络-高端网站建设-品牌官网建设-品牌设计-宁波网站建设-为企业打造精品而生
php抓取网页数据插入数据库( 接到一个任务是把中国名牌网站的某些内容添加到我们的网站上)
网站优化 • 优采云 发表了文章 • 0 个评论 • 65 次浏览 • 2022-03-25 23:09
接到一个任务是把中国名牌网站的某些内容添加到我们的网站上)
frog 青蛙推荐:远程爬取网页到本地database.doc
接到任务将中国名牌网站的部分内容添加到我们的网站中,地址如下:本页有一些文章链接列表,点击链接会出现< @网站@文章的详细内容展示页面,根据这个规则,结合正则表达式、XMLHTTP技术、Jscript服务器端脚本、ADO技术,编写了一个小程序,将这些内容抓取到本地数据库. 抓起来比较方便,然后将数据库中的数据导入到数据库中。
接到任务,将中国名牌网站的部分内容添加到我们的网站中,地址如下:
此页面收录 文章 链接列表。点击链接会弹出文章的详细内容展示页面。根据这个规则,结合正则表达式、XMLHTTP技术、Jscript服务器脚本、ADO技术,我编写了一个小程序,将这些内容抓取到本地数据库中。抓起来比较方便,然后将数据库中的数据导入到数据库中。首先创建一个Access数据库,结构如下
ID
自动编号
ID,主键
旧身份证
数字
旧数据编码
标题
标题
文本
内容
评论
内容
具体实现代码如下
下一步就是将Access数据库的内容导入到服务器数据库中,但是还有一些东西,就是原来的文章是分类的,所以导入的时候还得手动分类,因为链接被分析。写正则表达式的时候,写起来很麻烦,但还是严谨的。如果分类也用正则表达式来解析,那会很麻烦,因为分类收录在里面,而且那个页面有很多标签。如果要定位文本分类会很麻烦,而且即使写出来,程序也会失去灵活性,变得难以维护,所以这是它现在唯一做的一步。
发表于@2005-07-15 15:59 青蛙王子 浏览量(4581)评论(8)编辑 查看全部
php抓取网页数据插入数据库(
接到一个任务是把中国名牌网站的某些内容添加到我们的网站上)
frog 青蛙推荐:远程爬取网页到本地database.doc
接到任务将中国名牌网站的部分内容添加到我们的网站中,地址如下:本页有一些文章链接列表,点击链接会出现< @网站@文章的详细内容展示页面,根据这个规则,结合正则表达式、XMLHTTP技术、Jscript服务器端脚本、ADO技术,编写了一个小程序,将这些内容抓取到本地数据库. 抓起来比较方便,然后将数据库中的数据导入到数据库中。
接到任务,将中国名牌网站的部分内容添加到我们的网站中,地址如下:
此页面收录 文章 链接列表。点击链接会弹出文章的详细内容展示页面。根据这个规则,结合正则表达式、XMLHTTP技术、Jscript服务器脚本、ADO技术,我编写了一个小程序,将这些内容抓取到本地数据库中。抓起来比较方便,然后将数据库中的数据导入到数据库中。首先创建一个Access数据库,结构如下
ID
自动编号
ID,主键
旧身份证
数字
旧数据编码
标题
标题
文本
内容
评论
内容
具体实现代码如下
下一步就是将Access数据库的内容导入到服务器数据库中,但是还有一些东西,就是原来的文章是分类的,所以导入的时候还得手动分类,因为链接被分析。写正则表达式的时候,写起来很麻烦,但还是严谨的。如果分类也用正则表达式来解析,那会很麻烦,因为分类收录在里面,而且那个页面有很多标签。如果要定位文本分类会很麻烦,而且即使写出来,程序也会失去灵活性,变得难以维护,所以这是它现在唯一做的一步。
发表于@2005-07-15 15:59 青蛙王子 浏览量(4581)评论(8)编辑
php抓取网页数据插入数据库( PHP如何实现大批量插入数据库呢?想要了解的朋友!)
网站优化 • 优采云 发表了文章 • 0 个评论 • 51 次浏览 • 2022-03-25 10:19
PHP如何实现大批量插入数据库呢?想要了解的朋友!)
PHP中批量插入数据库的3种方法
PHP如何实现批量插入数据库?想知道的朋友,本文专门采集整理了PHP大批量插入数据库的3种方法,希望大家喜欢!
第一种方法:使用 into insert,代码如下:
1
2
3
4
5
6
7
$params = array('value'=>'50');
set_time_limit(0);
回显日期(“H:i:s”);
对于($i=0;$i
$connect_mysql->($params);
};
回显日期(“H:i:s”);
最终显示为:23:25:05 01:32:05,也就是用了2个多小时!
第二种方法:使用事务提交,批量插入数据库(每10W提交),最终显示时间为:22:56:13 23:04:00,共8分13秒,代码如下如下:
1
2
3
4
5
6
7
8
9
10
11
12
回显日期(“H:i:s”);
$connect_mysql->query('BEGIN');
$params = array('value'=>'50');
对于($i=0;$i
$connect_mysql->($params);
如果($i0000==0){
$connect_mysql->query('COMMIT');
$connect_mysql->query('BEGIN');
}
}
$connect_mysql->query('COMMIT');
回显日期(“H:i:s”);
第三种方法:使用优化的SQL语句:将SQL语句拼接起来,使用 into table() values(),(),(),()然后一次性插入,如果字符串太长,
然后需要配置MYSQL,在mysql命令行中运行:set global max_allowed_packet = 2*1024*1024*10; 消费时间为:11:24:06 11:25:06;
插入200W条测试数据只用了1分钟!代码如下:
1
2
3
4
5
6
$sql=“转化为 200 万(价值)值”;
对于($i=0;$i
$sql.=”('50'),”;
};
$sql = substr($sql,0,strlen($sql)-1);
$connect_mysql->查询($sql);
最后,在插入大批量数据的时候,第一种方法无疑是最差的,而第二种方法在实际应用中应用更广泛,第三种方法更适合插入测试数据或者其他要求不高的时候。真快。
【PHP中批量插入数据库的3种方法】相关文章:
PHP08-17中大批量插入数据库的方法
PH如何插入数据库09-06
PHP访问数据库08-26
PHP伪静态的几种方法09-11
PHP如何创建数据库09-30
php爬取页面的几种方法09-12
备份php数据库脚本的方法10-01
php如何连接数据库09-30
PHP封装数据库操作类09-26 查看全部
php抓取网页数据插入数据库(
PHP如何实现大批量插入数据库呢?想要了解的朋友!)
PHP中批量插入数据库的3种方法
PHP如何实现批量插入数据库?想知道的朋友,本文专门采集整理了PHP大批量插入数据库的3种方法,希望大家喜欢!
第一种方法:使用 into insert,代码如下:
1
2
3
4
5
6
7
$params = array('value'=>'50');
set_time_limit(0);
回显日期(“H:i:s”);
对于($i=0;$i
$connect_mysql->($params);
};
回显日期(“H:i:s”);
最终显示为:23:25:05 01:32:05,也就是用了2个多小时!
第二种方法:使用事务提交,批量插入数据库(每10W提交),最终显示时间为:22:56:13 23:04:00,共8分13秒,代码如下如下:
1
2
3
4
5
6
7
8
9
10
11
12
回显日期(“H:i:s”);
$connect_mysql->query('BEGIN');
$params = array('value'=>'50');
对于($i=0;$i
$connect_mysql->($params);
如果($i0000==0){
$connect_mysql->query('COMMIT');
$connect_mysql->query('BEGIN');
}
}
$connect_mysql->query('COMMIT');
回显日期(“H:i:s”);
第三种方法:使用优化的SQL语句:将SQL语句拼接起来,使用 into table() values(),(),(),()然后一次性插入,如果字符串太长,
然后需要配置MYSQL,在mysql命令行中运行:set global max_allowed_packet = 2*1024*1024*10; 消费时间为:11:24:06 11:25:06;
插入200W条测试数据只用了1分钟!代码如下:
1
2
3
4
5
6
$sql=“转化为 200 万(价值)值”;
对于($i=0;$i
$sql.=”('50'),”;
};
$sql = substr($sql,0,strlen($sql)-1);
$connect_mysql->查询($sql);
最后,在插入大批量数据的时候,第一种方法无疑是最差的,而第二种方法在实际应用中应用更广泛,第三种方法更适合插入测试数据或者其他要求不高的时候。真快。
【PHP中批量插入数据库的3种方法】相关文章:
PHP08-17中大批量插入数据库的方法
PH如何插入数据库09-06
PHP访问数据库08-26
PHP伪静态的几种方法09-11
PHP如何创建数据库09-30
php爬取页面的几种方法09-12
备份php数据库脚本的方法10-01
php如何连接数据库09-30
PHP封装数据库操作类09-26
php抓取网页数据插入数据库( PHP与数据库结合时三大结构:顺序结构,循环结构)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-03-24 21:12
PHP与数据库结合时三大结构:顺序结构,循环结构)
PHP增删改查数据库
PHP增删改查数据库
当 PHP 与数据库结合时
三种结构:顺序结构、循环结构、选择结构
数组:数组()
字符串单引号和双引号不一样
json数据的转换
php v5.xx
mysql_connect() 链接数据库 mysql_select_db() 选择数据库 mysql_query() php 执行sql 语句 mysql_fetch_assoc() 从数据库中取出一个查询到的资源,并将其转化为数组输出; mysql_error() 数据库错误信息 mysql_close() 数据链接关闭数据库 添加、删除、修改、查询以结构化方式存储数据的数据库仓库,可以快速查询数据。 SQL 语句复制粘贴可视化工具动态生成添加、删除、修改和检查添加:INSERT 删除:DELETE 修改:UPDATE 检查:SELECT 1、查询数据库数据
2、插入数据库数据
1、直接用php写,往数据库中插入数据
2、通过HTML输入框向数据库中插入数据
Document
姓名:
微信:
提交信息
3、删除数据库中的数据
4、更新数据库数据
注意:mysql_query($sql)
只对select、show、descibe等语句返回一个resourcece,错误返回false;
其他类型的SQL语句,如insert、update、delete,成功返回true,错误返回false。 查看全部
php抓取网页数据插入数据库(
PHP与数据库结合时三大结构:顺序结构,循环结构)
PHP增删改查数据库
PHP增删改查数据库
当 PHP 与数据库结合时
三种结构:顺序结构、循环结构、选择结构
数组:数组()
字符串单引号和双引号不一样
json数据的转换
php v5.xx
mysql_connect() 链接数据库 mysql_select_db() 选择数据库 mysql_query() php 执行sql 语句 mysql_fetch_assoc() 从数据库中取出一个查询到的资源,并将其转化为数组输出; mysql_error() 数据库错误信息 mysql_close() 数据链接关闭数据库 添加、删除、修改、查询以结构化方式存储数据的数据库仓库,可以快速查询数据。 SQL 语句复制粘贴可视化工具动态生成添加、删除、修改和检查添加:INSERT 删除:DELETE 修改:UPDATE 检查:SELECT 1、查询数据库数据
2、插入数据库数据
1、直接用php写,往数据库中插入数据
2、通过HTML输入框向数据库中插入数据
Document
姓名:
微信:
提交信息
3、删除数据库中的数据
4、更新数据库数据
注意:mysql_query($sql)
只对select、show、descibe等语句返回一个resourcece,错误返回false;
其他类型的SQL语句,如insert、update、delete,成功返回true,错误返回false。
php抓取网页数据插入数据库(简单图解会有助于你理解MySQL在现在的动态网站的作用 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2022-03-24 16:21
)
您几乎可以在网络上的任何地方看到更新网站。博客和电子商务包都配置了动态属性。动态 网站 依赖 MySQL 数据库从浏览器中提取和插入数据。
如果你是初学者,理解下面这个简单的图表将有助于你理解 MySQL 在当前动态 网站 中的作用。在一个传统的简单静态网站中,你可能会看到以下事件:客户端浏览器向服务器请求信息→服务器返回HTML代码给浏览器→浏览器显示HTML,HTML变成网页。现在,动态 网站 进行如下:
<IMG height=249 alt=专家解析:三大重要的MySQL查询 src="../../upload/2009_07/090720070617751.jpg" width=332>
1:请求网页;
2:服务器执行PHP脚本;
3:MySQL查询:从SQL请求数据;
4:SQL返回数据;
5:服务器返回一个HTML页面。
客户端浏览器请求一个网页,当服务器收到请求时,网页模板执行 PHP 脚本,从 MySQL 获取信息。此信息被添加到页面模板并以 HTML 形式返回给浏览器。看源码的时候就不用再穿PHP脚本了,因为那些脚本已经在服务端执行了。
使用动态网页时,仅使用保存的唯一服务器 PHP 模板即可创建数千个 URL 链接。但在静态模板中,需要在服务器中保存数千个 HTML 文件才能创建数千个 URL 链接。
如果您了解最重要的 MySQL 查询,那么与数据库通信将很容易,因此您可以创建复杂的 PHP Web 应用程序。这样做将节省您的时间并提高网页效率。在这个 文章 中,我们将说明使用 INSERT、SELECT 和 UPDATE 命令查询 MySQL 数据库的 PHP 脚本。
INSERT MySQL 查询命令
在我们从数据库中抓取数据之前,我们必须知道如何插入数据。假设您已经创建了表名的数据库,您可以使用 INSERT SQL 命令完成数据插入。我们在下面给出了例子。假设您同时将三条数据插入到 MySQL 数据库中的三个不同字段中,它看起来像:
INSERT INTO `tablename` (`fieldname1`,`fieldname2`,``,`fieldname3`) VALUES('$datatobeinsertedtofieldname1','$datatobeinsertedtofieldname2',
'$datatobeinsertedtofieldname3'
在 PHP 中使用此查询时,请注意引用匹配的准确用法以及域名和变量的准确拼写。这是 PHP 编程中的常见错误。
注意查询命令中的表名和域名要和(`)一起使用,并且要保持真实的MySQL表名和脚本表名的一致性。这使得区分 Linux/PHP 和 MySQL 环境中共存的一些东西成为可能。
查看全部
php抓取网页数据插入数据库(简单图解会有助于你理解MySQL在现在的动态网站的作用
)
您几乎可以在网络上的任何地方看到更新网站。博客和电子商务包都配置了动态属性。动态 网站 依赖 MySQL 数据库从浏览器中提取和插入数据。
如果你是初学者,理解下面这个简单的图表将有助于你理解 MySQL 在当前动态 网站 中的作用。在一个传统的简单静态网站中,你可能会看到以下事件:客户端浏览器向服务器请求信息→服务器返回HTML代码给浏览器→浏览器显示HTML,HTML变成网页。现在,动态 网站 进行如下:
<IMG height=249 alt=专家解析:三大重要的MySQL查询 src="../../upload/2009_07/090720070617751.jpg" width=332>
1:请求网页;
2:服务器执行PHP脚本;
3:MySQL查询:从SQL请求数据;
4:SQL返回数据;
5:服务器返回一个HTML页面。
客户端浏览器请求一个网页,当服务器收到请求时,网页模板执行 PHP 脚本,从 MySQL 获取信息。此信息被添加到页面模板并以 HTML 形式返回给浏览器。看源码的时候就不用再穿PHP脚本了,因为那些脚本已经在服务端执行了。
使用动态网页时,仅使用保存的唯一服务器 PHP 模板即可创建数千个 URL 链接。但在静态模板中,需要在服务器中保存数千个 HTML 文件才能创建数千个 URL 链接。
如果您了解最重要的 MySQL 查询,那么与数据库通信将很容易,因此您可以创建复杂的 PHP Web 应用程序。这样做将节省您的时间并提高网页效率。在这个 文章 中,我们将说明使用 INSERT、SELECT 和 UPDATE 命令查询 MySQL 数据库的 PHP 脚本。
INSERT MySQL 查询命令
在我们从数据库中抓取数据之前,我们必须知道如何插入数据。假设您已经创建了表名的数据库,您可以使用 INSERT SQL 命令完成数据插入。我们在下面给出了例子。假设您同时将三条数据插入到 MySQL 数据库中的三个不同字段中,它看起来像:
INSERT INTO `tablename` (`fieldname1`,`fieldname2`,``,`fieldname3`) VALUES('$datatobeinsertedtofieldname1','$datatobeinsertedtofieldname2',
'$datatobeinsertedtofieldname3'
在 PHP 中使用此查询时,请注意引用匹配的准确用法以及域名和变量的准确拼写。这是 PHP 编程中的常见错误。
注意查询命令中的表名和域名要和(`)一起使用,并且要保持真实的MySQL表名和脚本表名的一致性。这使得区分 Linux/PHP 和 MySQL 环境中共存的一些东西成为可能。
php抓取网页数据插入数据库(何避免页面刷新数据重复写入数据库当表单(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 98 次浏览 • 2022-03-22 21:24
如何避免页面刷新数据被重复写入数据库
当表单的数据提交到该页面处理并写入数据库时,点击提交按钮后,如果页面刷新,数据会重复写入数据库。我在网上搜索了很多解决方法:
一、 将一个页面一分为二,将数据提交到另一个页面进行处理,然后跳转到输入页面。
优点:避免了刷新的影响,可以连续提交数据。
缺点:当用户在完整填写表单之前点击提交。如果不进行数据存储操作,保留用户之前输入的内容,那么使用php实现起来比较困难或者不方便。(当然用js实现可能会更容易,这里约定,本文只从php的角度来评估,研究php的应用)
*总的来说,这是一个很好的解决方案。
二、在会话中保存变量
_SESSION['提交']=false
提交后改为true
检测变量
if (_SESSION['submit']=true){
回声“文本”;
出口();
}
优点:避免了刷新的影响,只有一个页面,没有第一种方法的缺点
缺点:只能提交一次,不能连续提交数据。
*有优点,但适用范围太窄。
三、在数据入库前执行一次验证查询,查看数据库中是否已经存在相同的记录,从而决定是否写入数据。
优点:前两种方法没有缺点。
缺点:代码没有精简,操作繁琐。此外,有时不排除保存完全相同的信息。
*实施成本太高,副作用太大。
有没有一种方法不综合三种方法的优缺点?有!这里有一个很好的解决方案与您分享:
///
乙:
>
C:
d: 查看全部
php抓取网页数据插入数据库(何避免页面刷新数据重复写入数据库当表单(图))
如何避免页面刷新数据被重复写入数据库
当表单的数据提交到该页面处理并写入数据库时,点击提交按钮后,如果页面刷新,数据会重复写入数据库。我在网上搜索了很多解决方法:
一、 将一个页面一分为二,将数据提交到另一个页面进行处理,然后跳转到输入页面。
优点:避免了刷新的影响,可以连续提交数据。
缺点:当用户在完整填写表单之前点击提交。如果不进行数据存储操作,保留用户之前输入的内容,那么使用php实现起来比较困难或者不方便。(当然用js实现可能会更容易,这里约定,本文只从php的角度来评估,研究php的应用)
*总的来说,这是一个很好的解决方案。
二、在会话中保存变量
_SESSION['提交']=false
提交后改为true
检测变量
if (_SESSION['submit']=true){
回声“文本”;
出口();
}
优点:避免了刷新的影响,只有一个页面,没有第一种方法的缺点
缺点:只能提交一次,不能连续提交数据。
*有优点,但适用范围太窄。
三、在数据入库前执行一次验证查询,查看数据库中是否已经存在相同的记录,从而决定是否写入数据。
优点:前两种方法没有缺点。
缺点:代码没有精简,操作繁琐。此外,有时不排除保存完全相同的信息。
*实施成本太高,副作用太大。
有没有一种方法不综合三种方法的优缺点?有!这里有一个很好的解决方案与您分享:
///
乙:
>
C:
d:
php抓取网页数据插入数据库(php抓取网页数据插入数据库,express框架用于开发前端框架)
网站优化 • 优采云 发表了文章 • 0 个评论 • 55 次浏览 • 2022-03-22 20:32
php抓取网页数据插入数据库,
express框架用于开发前端框架,不开源,但是现在的主流开发框架都是用express框架。micropython用于开发后端框架,开源,后端服务器非常稳定。ror也是开源框架,但是,我感觉有点不太适合做大型网站。如果你是做安卓或者ios网站,除了用java,你可以在一个软件(或者一套框架)中集成几种语言。
java在数据处理上是强,强大,优势是开发效率高但是并不要求所有的数据处理代码,因为大公司的一些重复代码代码量都是有限的,可以从配置与开发性两方面考虑,java在架构设计上比php更有优势,掌握基本的数据结构与算法,以及大量的http代码的学习,自学一下springboot,mybatis框架都是大量实践积累的必要条件,ruby和python的框架不多说了,一个是数据结构一个是后端的框架。
从零开始学前端,安卓,android,wpjvm,java,php,erlang,scala,python,javascript,ruby,php,python,
你好有前途
如果是想要用web技术开发网站。java是最好选择。php只能说适合网站框架去开发。但是因为网站不断在增加,所以用nodejs开发网站也是很好的。python也可以。但是数据处理等一些网站功能用java会好些。但是php有varsql这个非常好的模块可以很方便的集成到web中,具体你可以再找找。如果你是java用途,php也不错。erlang也可以。 查看全部
php抓取网页数据插入数据库(php抓取网页数据插入数据库,express框架用于开发前端框架)
php抓取网页数据插入数据库,
express框架用于开发前端框架,不开源,但是现在的主流开发框架都是用express框架。micropython用于开发后端框架,开源,后端服务器非常稳定。ror也是开源框架,但是,我感觉有点不太适合做大型网站。如果你是做安卓或者ios网站,除了用java,你可以在一个软件(或者一套框架)中集成几种语言。
java在数据处理上是强,强大,优势是开发效率高但是并不要求所有的数据处理代码,因为大公司的一些重复代码代码量都是有限的,可以从配置与开发性两方面考虑,java在架构设计上比php更有优势,掌握基本的数据结构与算法,以及大量的http代码的学习,自学一下springboot,mybatis框架都是大量实践积累的必要条件,ruby和python的框架不多说了,一个是数据结构一个是后端的框架。
从零开始学前端,安卓,android,wpjvm,java,php,erlang,scala,python,javascript,ruby,php,python,
你好有前途
如果是想要用web技术开发网站。java是最好选择。php只能说适合网站框架去开发。但是因为网站不断在增加,所以用nodejs开发网站也是很好的。python也可以。但是数据处理等一些网站功能用java会好些。但是php有varsql这个非常好的模块可以很方便的集成到web中,具体你可以再找找。如果你是java用途,php也不错。erlang也可以。
php抓取网页数据插入数据库(PHP中的“INSERTINTO”语句的作用及案例演示)
网站优化 • 优采云 发表了文章 • 0 个评论 • 54 次浏览 • 2022-03-14 10:30
“INSERT INTO”语句的作用是向数据库表中插入一条新记录。
将数据插入数据库表
“INSERT INTO”的作用是向数据库表中插入一条新记录。
语法
插入表名
值(值 1,值 2,....)
您可以将数据插入指定列,如下所示:
INSERT INTO table_name (column1, column2,...)
值(值 1,值 2,....)
注意:SQL 语句是“不区分大小写”语句(不区分大小写),即:“INSERT INTO”和“insert into”是一样的。
要在 PHP 中创建数据库,我们需要在 mysql_query() 函数中使用上述语句。该函数用于发送 MySQL 数据库连接建立请求和命令。
案子
在上一章中,我们创建了一个名为“Person”的表,其中收录三列:“Firstname”、“Lastname”和“Age”。在以下情况下,我们还将使用同一张表并向其中添加两条新记录:
将表中的数据插入数据库
现在,我们将创建一个 HTML 表单;通过它我们可以将新记录添加到“Person”表中。
下面演示了这个 HTML 表单:
在上述情况下,当用户点击 HTML 表单中的“提交”按钮时,表单中的数据被发送到“insert.php”。“insert.php”文件与数据库建立连接,通过PHP的$_POST变量获取表单中的数据;此时mysql_query()函数执行“INSERT INTO”语句,从而在中间的数据库表单中添加了一条新记录。
让我们试试“insert.php”页面的代码: 查看全部
php抓取网页数据插入数据库(PHP中的“INSERTINTO”语句的作用及案例演示)
“INSERT INTO”语句的作用是向数据库表中插入一条新记录。
将数据插入数据库表
“INSERT INTO”的作用是向数据库表中插入一条新记录。
语法
插入表名
值(值 1,值 2,....)
您可以将数据插入指定列,如下所示:
INSERT INTO table_name (column1, column2,...)
值(值 1,值 2,....)
注意:SQL 语句是“不区分大小写”语句(不区分大小写),即:“INSERT INTO”和“insert into”是一样的。
要在 PHP 中创建数据库,我们需要在 mysql_query() 函数中使用上述语句。该函数用于发送 MySQL 数据库连接建立请求和命令。
案子
在上一章中,我们创建了一个名为“Person”的表,其中收录三列:“Firstname”、“Lastname”和“Age”。在以下情况下,我们还将使用同一张表并向其中添加两条新记录:
将表中的数据插入数据库
现在,我们将创建一个 HTML 表单;通过它我们可以将新记录添加到“Person”表中。
下面演示了这个 HTML 表单:
在上述情况下,当用户点击 HTML 表单中的“提交”按钮时,表单中的数据被发送到“insert.php”。“insert.php”文件与数据库建立连接,通过PHP的$_POST变量获取表单中的数据;此时mysql_query()函数执行“INSERT INTO”语句,从而在中间的数据库表单中添加了一条新记录。
让我们试试“insert.php”页面的代码:
php抓取网页数据插入数据库(我的小程序通过PHP从SQL数据库提取到数据,使用)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2022-03-14 01:17
我的小程序通过 PHP 从 SQL 数据库中提取数据,使用
{{item.id}}{{item.device_num}}{{item.user_name}}{{item.user_phone}}
语句渲染数据,php获取的数据如下:
[{\"id\":\"1\",\"device_num\":\"12002120\",\"user_name\":\"li\",\"user_phone\":\"\ ",\"unit_name\":\"jijin\",\"unit_addr\":\"djsaj\",\"wechat_num\":\"hsahjh\"},{\"id\":\"2\ ",\"device_num\":\"1272677867\",\"user_name\":\"zhang\",\"user_phone\":\"1362525891\",\"unit_name\":\"yiuehhaj\", \"unit_addr\":\"heiwh\",\"wechat_num\":\"hh\"}]\r\n\r\n\r\n\r\n\r\n \r\n
调试器观察到的渲染页面数据如下
数据是空的,不知道为什么,请大家指点一下。 查看全部
php抓取网页数据插入数据库(我的小程序通过PHP从SQL数据库提取到数据,使用)
我的小程序通过 PHP 从 SQL 数据库中提取数据,使用
{{item.id}}{{item.device_num}}{{item.user_name}}{{item.user_phone}}
语句渲染数据,php获取的数据如下:
[{\"id\":\"1\",\"device_num\":\"12002120\",\"user_name\":\"li\",\"user_phone\":\"\ ",\"unit_name\":\"jijin\",\"unit_addr\":\"djsaj\",\"wechat_num\":\"hsahjh\"},{\"id\":\"2\ ",\"device_num\":\"1272677867\",\"user_name\":\"zhang\",\"user_phone\":\"1362525891\",\"unit_name\":\"yiuehhaj\", \"unit_addr\":\"heiwh\",\"wechat_num\":\"hh\"}]\r\n\r\n\r\n\r\n\r\n \r\n
调试器观察到的渲染页面数据如下
数据是空的,不知道为什么,请大家指点一下。

