
php抓取网页数据插入数据库
php抓取网页数据插入数据库(接到一个备注内容具体实现代码如下>>文本备注)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-18 08:21
我接到了一个任务,要在我们的网站中添加一些中国名牌网站的内容。这些 网站 上的某些页面是 文章 链接的列表。点击链接会出现文章详细的内容展示页面,根据这个规则,结合正则表达式、XMLHTTP技术、Jscript服务器端脚本、ADO技术,写了一个小程序,将这些内容抓取到本地数据库。抓起来比较方便,然后把数据库中的数据导入到数据库中。首先创建一个Access数据库,结构如下
id自动编号识别,主键
oldID number 旧数据编码
标题标题文字
备注内容
具体实现代码如下
<%@LANGUAGE="JSCRIPT" CODEPAGE="936"%>
<!-- METADATA NAME="Microsoft ActiveX Data Objects 2.5 Library"
TYPE="TypeLib" UUID="{00000205-0000-0010-8000-00AA006D2EA4}" -->
<%
//打开数据库
try
{
var strConnectionString = "Provider=Microsoft.Jet.OLEDB.4.0;Data Source=" + Server.MapPath("#db.mdb");
var objConnection = Server.CreateObject("ADODB.Connection");
objConnection.Open(strConnectionString);
}
catch(e)
{
Response.Write(e.description);
Response.End();
}
%>
<script language="jscript" runat="server">
//远程获取数据
function GetData()
{
var xHttp = new ActiveXObject("microsoft.xmlhttp");
xHttp.open("POST","http://kukusoft.net/",false);
xHttp.send();
return(xHttp.responseText);
}
//利用正则表达式提取符合条件的链接
function GetLinks(str)
{
var re = new RegExp("<a[^<>]+?\>((.|\n)*?)<\/a>", "gi");
var a = str.match(re); //第一次搜索 for(var i=0;i<a.length;i++)
{
var t1,t2;
var temp;
var r = /qy.php\?id=(\d+)/ig;
if(!r.test(a[i]))continue;
temp = a[i].match(/qy.php\?id=(\d+)/ig);
t1 = RegExp.$1;
temp = a[i].match(/<font[^<>]+?color=\"#000000\"\>(.*?)<\/font>/ig);
t2 = RegExp.$1;
if(t1 == t2)continue;
SaveArticle(t1,t2,GetContent(t1));
}
}
//通过提取的链接获取ID,并通过这个ID取抓取相应的文章
function GetContent(id)
{
var xHttp = new ActiveXObject("microsoft.xmlhttp");
xHttp.open("POST","http://kukusoft.net/qy.php?id=" + id,false);
xHttp.send();
var str = xHttp.responseText;
var re = new RegExp("<span[^<>]+?style=\"font-size:10\.8pt\">(.*?)<\/span>", "gi");
var a = str.match(re);
return(RegExp.$1);
}
//入库
function SaveArticle(oldID,Title,Content)
{
var oRst = Server.CreateObject("ADODB.Recordset");
var sQuery;
sQuery = "SELECT oldID,Title,Content FROM Articles"
oRst.Open(sQuery,objConnection,adOpenStatic,adLockPessimistic);
oRst.AddNew();
oRst("oldID") = oldID;
oRst("Title") = Title;
oRst("Content") = Content;
oRst.Update();
oRst.Close();
Response.Write(Title + "抓取成功" + "<br>");
}
</script>
<HTML>
<头部>
<TITLE>抢文章</TITLE> 查看全部
php抓取网页数据插入数据库(接到一个备注内容具体实现代码如下>>文本备注)
我接到了一个任务,要在我们的网站中添加一些中国名牌网站的内容。这些 网站 上的某些页面是 文章 链接的列表。点击链接会出现文章详细的内容展示页面,根据这个规则,结合正则表达式、XMLHTTP技术、Jscript服务器端脚本、ADO技术,写了一个小程序,将这些内容抓取到本地数据库。抓起来比较方便,然后把数据库中的数据导入到数据库中。首先创建一个Access数据库,结构如下
id自动编号识别,主键
oldID number 旧数据编码
标题标题文字
备注内容
具体实现代码如下
<%@LANGUAGE="JSCRIPT" CODEPAGE="936"%>
<!-- METADATA NAME="Microsoft ActiveX Data Objects 2.5 Library"
TYPE="TypeLib" UUID="{00000205-0000-0010-8000-00AA006D2EA4}" -->
<%
//打开数据库
try
{
var strConnectionString = "Provider=Microsoft.Jet.OLEDB.4.0;Data Source=" + Server.MapPath("#db.mdb");
var objConnection = Server.CreateObject("ADODB.Connection");
objConnection.Open(strConnectionString);
}
catch(e)
{
Response.Write(e.description);
Response.End();
}
%>
<script language="jscript" runat="server">
//远程获取数据
function GetData()
{
var xHttp = new ActiveXObject("microsoft.xmlhttp");
xHttp.open("POST","http://kukusoft.net/",false);
xHttp.send();
return(xHttp.responseText);
}
//利用正则表达式提取符合条件的链接
function GetLinks(str)
{
var re = new RegExp("<a[^<>]+?\>((.|\n)*?)<\/a>", "gi");
var a = str.match(re); //第一次搜索 for(var i=0;i<a.length;i++)
{
var t1,t2;
var temp;
var r = /qy.php\?id=(\d+)/ig;
if(!r.test(a[i]))continue;
temp = a[i].match(/qy.php\?id=(\d+)/ig);
t1 = RegExp.$1;
temp = a[i].match(/<font[^<>]+?color=\"#000000\"\>(.*?)<\/font>/ig);
t2 = RegExp.$1;
if(t1 == t2)continue;
SaveArticle(t1,t2,GetContent(t1));
}
}
//通过提取的链接获取ID,并通过这个ID取抓取相应的文章
function GetContent(id)
{
var xHttp = new ActiveXObject("microsoft.xmlhttp");
xHttp.open("POST","http://kukusoft.net/qy.php?id=" + id,false);
xHttp.send();
var str = xHttp.responseText;
var re = new RegExp("<span[^<>]+?style=\"font-size:10\.8pt\">(.*?)<\/span>", "gi");
var a = str.match(re);
return(RegExp.$1);
}
//入库
function SaveArticle(oldID,Title,Content)
{
var oRst = Server.CreateObject("ADODB.Recordset");
var sQuery;
sQuery = "SELECT oldID,Title,Content FROM Articles"
oRst.Open(sQuery,objConnection,adOpenStatic,adLockPessimistic);
oRst.AddNew();
oRst("oldID") = oldID;
oRst("Title") = Title;
oRst("Content") = Content;
oRst.Update();
oRst.Close();
Response.Write(Title + "抓取成功" + "<br>");
}
</script>
<HTML>
<头部>
<TITLE>抢文章</TITLE>
php抓取网页数据插入数据库( 【测试】txt文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-12-17 13:19
【测试】txt文件)
php读取txt文件并将数据插入数据库
更新时间:2016-02-23 08:54:02 投稿:hebedich
本文文章主要介绍php读取txt文件并将数据插入数据库的方法和示例代码。小文件可以参考第一种方法,大文件可以参考第二种方法。
今天要测试一个函数,您需要将一些原创数据插入到数据库中。PM给了一个txt文件。如何快速将这个txt文件的内容拆分成想要的数组,然后插入到数据库中?
serial_number.txt 的示例内容:
序列号.txt:
DM00001A11 0116,
SN00002A11 0116,
AB00003A11 0116,
PV00004A11 0116,
OC00005A11 0116,
IX00006A11 0116,
创建数据表:
create table serial_number(
id int primary key auto_increment not null,
serial_number varchar(50) not null
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
php代码如下:
$conn = mysql_connect('127.0.0.1','root','') or die("Invalid query: " . mysql_error());
mysql_select_db('test', $conn) or die("Invalid query: " . mysql_error());
$content = file_get_contents("serial_number.txt");
$contents= explode(",",$content);//explode()函数以","为标识符进行拆分
foreach ($contents as $k => $v)//遍历循环
{
$id = $k;
$serial_number = $v;
mysql_query("insert into serial_number (`id`,`serial_number`)
VALUES('$id','$serial_number')");
}
备注:方法很多。我这里是把txt文件拆分成数组,然后遍历循环得到的数组,每次循环插入数据库一次。 查看全部
php抓取网页数据插入数据库(
【测试】txt文件)
php读取txt文件并将数据插入数据库
更新时间:2016-02-23 08:54:02 投稿:hebedich
本文文章主要介绍php读取txt文件并将数据插入数据库的方法和示例代码。小文件可以参考第一种方法,大文件可以参考第二种方法。
今天要测试一个函数,您需要将一些原创数据插入到数据库中。PM给了一个txt文件。如何快速将这个txt文件的内容拆分成想要的数组,然后插入到数据库中?
serial_number.txt 的示例内容:
序列号.txt:
DM00001A11 0116,
SN00002A11 0116,
AB00003A11 0116,
PV00004A11 0116,
OC00005A11 0116,
IX00006A11 0116,
创建数据表:
create table serial_number(
id int primary key auto_increment not null,
serial_number varchar(50) not null
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
php代码如下:
$conn = mysql_connect('127.0.0.1','root','') or die("Invalid query: " . mysql_error());
mysql_select_db('test', $conn) or die("Invalid query: " . mysql_error());
$content = file_get_contents("serial_number.txt");
$contents= explode(",",$content);//explode()函数以","为标识符进行拆分
foreach ($contents as $k => $v)//遍历循环
{
$id = $k;
$serial_number = $v;
mysql_query("insert into serial_number (`id`,`serial_number`)
VALUES('$id','$serial_number')");
}
备注:方法很多。我这里是把txt文件拆分成数组,然后遍历循环得到的数组,每次循环插入数据库一次。
php抓取网页数据插入数据库(菜鸟拿到一套PHP网站程序源代码和sql文件,应该如何下手?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-17 13:12
今天,解决新手上手的疑惑?
菜鸟应该如何得到一套PHP网站程序源码和sql数据库文件?我从哪里开始上传程序并部署网站?
首先要了解FTP软件的使用方法(这是基础)
本软件用于上传您的网站程序并稍后更新程序。软件很简单,以FlashFXP为例,在虚拟主机的控制面板中找到你的FTP登录IP地址(软件中的服务器对应IP地址或域名)、账号、密码即可。左侧是本地目录。, 右边是服务器目录,本地端右键上传或者直接拖拽。该软件不需要过多介绍,如果不会,可以下载一个,使用一次。
学习使用FTP软件。今天以虚拟主机为例。总结一般分为两种情况:
一、网站源代码自带安装程序
这个一般比较简单,只需将压缩文件上传到虚拟主机需要的网站对应目录下,使用虚拟主机控制面板中的在线解压功能直接解压到虚拟主机的根目录即可网站 比如 wwwroot 目录就可以了。不建议使用FTP软件在全站上传文件夹形式的压缩文件。这很浪费时间,而且效率很低。经常异常中断,无法完整上传。
例如cms或Discuz!等很多程序。有这个功能。只需根据程序说明上传程序并访问指定网站即可。
此信息可向主办公司查询,如实填写即可。
二、只有网站源代码和sql数据库文件,无需安装程序
这是主要内容。网上很多共享的程序,都是直接被别人写的程序共享的。程序代码和sql数据库文件(数据表结构)提供给大家下载,如李雷博客的源码。状况。仅提供PHP源码和mysql数据库sql文件,安装问题需自行解决。这也是我开源博客源码的初衷,让新手入门,自己解决问题,了解网站的基本配置。
以西部数据为例:
1、上传zip网站程序压缩包并解压
为了上传zip而不是rar,因为一般的Linux系统和apache服务器都运行PHP程序,这里支持zip,虚拟主机暂不支持rar。这取决于主机的支持。
上传,使用FTP上传到指定目录。下一步是解压程序。
2、手动配置数据库连接信息
以李磊的PHP博客为例。在程序目录“mdaima_var_inc/conn.php”中找到conn.php文件。这是连接数据库的配置文件。像这样打开源代码。(右击用记事本打开)
3、导入mysql数据库的sql脚本
一般PHP虚拟主机都会有phpmyadmin管理工具,点进去就可以了。
打开后就是这个样子,如图。只需单击步骤。
浏览并选择 .sql 数据库文件并执行导入。此时,网站 程序应该是可以访问的。
说了这么多,就是想让新手真正掌握网站程序的部署方法。就像吃了别人给你做的方便面,现在我只是扔给你一袋未开封的方便面。,让你自己泡,不能就这么放着,等吃不下去了。希望更多的人能够一步一步的学习,在迷茫的时候掌握一些技巧,以便以后能够应对各种情况。
转载请注明:新手拿到PHP网站源码和sql数据库文件后,从哪里开始部署?| 码码-李磊博客 查看全部
php抓取网页数据插入数据库(菜鸟拿到一套PHP网站程序源代码和sql文件,应该如何下手?)
今天,解决新手上手的疑惑?
菜鸟应该如何得到一套PHP网站程序源码和sql数据库文件?我从哪里开始上传程序并部署网站?
首先要了解FTP软件的使用方法(这是基础)
本软件用于上传您的网站程序并稍后更新程序。软件很简单,以FlashFXP为例,在虚拟主机的控制面板中找到你的FTP登录IP地址(软件中的服务器对应IP地址或域名)、账号、密码即可。左侧是本地目录。, 右边是服务器目录,本地端右键上传或者直接拖拽。该软件不需要过多介绍,如果不会,可以下载一个,使用一次。

学习使用FTP软件。今天以虚拟主机为例。总结一般分为两种情况:
一、网站源代码自带安装程序
这个一般比较简单,只需将压缩文件上传到虚拟主机需要的网站对应目录下,使用虚拟主机控制面板中的在线解压功能直接解压到虚拟主机的根目录即可网站 比如 wwwroot 目录就可以了。不建议使用FTP软件在全站上传文件夹形式的压缩文件。这很浪费时间,而且效率很低。经常异常中断,无法完整上传。
例如cms或Discuz!等很多程序。有这个功能。只需根据程序说明上传程序并访问指定网站即可。

此信息可向主办公司查询,如实填写即可。
二、只有网站源代码和sql数据库文件,无需安装程序
这是主要内容。网上很多共享的程序,都是直接被别人写的程序共享的。程序代码和sql数据库文件(数据表结构)提供给大家下载,如李雷博客的源码。状况。仅提供PHP源码和mysql数据库sql文件,安装问题需自行解决。这也是我开源博客源码的初衷,让新手入门,自己解决问题,了解网站的基本配置。
以西部数据为例:
1、上传zip网站程序压缩包并解压
为了上传zip而不是rar,因为一般的Linux系统和apache服务器都运行PHP程序,这里支持zip,虚拟主机暂不支持rar。这取决于主机的支持。
上传,使用FTP上传到指定目录。下一步是解压程序。

2、手动配置数据库连接信息
以李磊的PHP博客为例。在程序目录“mdaima_var_inc/conn.php”中找到conn.php文件。这是连接数据库的配置文件。像这样打开源代码。(右击用记事本打开)
3、导入mysql数据库的sql脚本
一般PHP虚拟主机都会有phpmyadmin管理工具,点进去就可以了。

打开后就是这个样子,如图。只需单击步骤。


浏览并选择 .sql 数据库文件并执行导入。此时,网站 程序应该是可以访问的。
说了这么多,就是想让新手真正掌握网站程序的部署方法。就像吃了别人给你做的方便面,现在我只是扔给你一袋未开封的方便面。,让你自己泡,不能就这么放着,等吃不下去了。希望更多的人能够一步一步的学习,在迷茫的时候掌握一些技巧,以便以后能够应对各种情况。
转载请注明:新手拿到PHP网站源码和sql数据库文件后,从哪里开始部署?| 码码-李磊博客
php抓取网页数据插入数据库(腾讯云香港,韩国免备案服务器1.8折优惠(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-17 09:12
AD:阿里云服务器企业会员更优惠。腾讯云香港和韩国免备案服务器。1.20% 折扣
今天给大家总结一下php获取新插入数据id的几种方法。有很好的参考价值。我希望它会对大家有所帮助。跟着小编一起来看看吧。
在mysql中插入数据的时候,很多时候我们想知道刚刚插入的数据的id。这对我们非常有用。下面我将三种常用的方法命名,并一一分析它们的优缺点。
使用以下语句:
mysql_query("select max(id) from t1",$link);
使用这种方法的时候,我们得到的id的最大值确实是最后一个,但是在多链接线程的时候,最大的id不一定是我们自己插入的,所以这里没有使用域线程。
二、使用以下函数:
msyql_insert_id();
当系统执行INSERT然后执行SELECT时,可能已经分发到不同的后端服务器。如果你使用的编程语言是PHP,此时应该通过mysql_insert_id()获取最新插入的id,每次INSERT结束后,已经计算出对应的自增值返回给PHP。您不需要发出单独的查询,只需使用 mysql_insert_id()。这个功能非常有用。当我们插入一条语句时,它会自动返回到最后。这个函数的id值只对当前链接有用,多用户安全,所以我们经常用到这个函数;
但是这个函数的一个问题是id为bigint的时候它不起作用,所以使用这个函数时请小心。但是我们很少遇到这样的问题,所以你可以忽略它。
三:使用查询
msyql_query("选择last_insert_id()");
last_insert_id()是mysql的一个函数,对当前链接有效。这个用法解决了mysql_insert_id()中遇到的bigint问题。 查看全部
php抓取网页数据插入数据库(腾讯云香港,韩国免备案服务器1.8折优惠(组图))
AD:阿里云服务器企业会员更优惠。腾讯云香港和韩国免备案服务器。1.20% 折扣
今天给大家总结一下php获取新插入数据id的几种方法。有很好的参考价值。我希望它会对大家有所帮助。跟着小编一起来看看吧。
在mysql中插入数据的时候,很多时候我们想知道刚刚插入的数据的id。这对我们非常有用。下面我将三种常用的方法命名,并一一分析它们的优缺点。
使用以下语句:
mysql_query("select max(id) from t1",$link);
使用这种方法的时候,我们得到的id的最大值确实是最后一个,但是在多链接线程的时候,最大的id不一定是我们自己插入的,所以这里没有使用域线程。
二、使用以下函数:
msyql_insert_id();
当系统执行INSERT然后执行SELECT时,可能已经分发到不同的后端服务器。如果你使用的编程语言是PHP,此时应该通过mysql_insert_id()获取最新插入的id,每次INSERT结束后,已经计算出对应的自增值返回给PHP。您不需要发出单独的查询,只需使用 mysql_insert_id()。这个功能非常有用。当我们插入一条语句时,它会自动返回到最后。这个函数的id值只对当前链接有用,多用户安全,所以我们经常用到这个函数;
但是这个函数的一个问题是id为bigint的时候它不起作用,所以使用这个函数时请小心。但是我们很少遇到这样的问题,所以你可以忽略它。
三:使用查询
msyql_query("选择last_insert_id()");
last_insert_id()是mysql的一个函数,对当前链接有效。这个用法解决了mysql_insert_id()中遇到的bigint问题。
php抓取网页数据插入数据库(创建一个div条件语句(用户可见)//将页面来处理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-17 00:44
显示页面(用户可见)
//将此页面接收到的数据交给Chuli页面进行处理
国籍代码:
//创建一个div并将其放入接收器以接收代码值
民族名称:
//创建一个div并将其放入接收方以接收name值
操作页面(用户不可见)
$code=$uu POST[“code”];//设置一个变量以接收用户提交的代码值
$name=$uu-POST[“name”];//设置一个变量以接收用户提交的名称值
//联系
$conn=@mysql_uu连接(“localhost”、“root”、“123”);//Localhost是本地服务器地址,root是用户名,123是数据库密码
//为操作选择数据库
mysql_uu选择_uu数据库(“,$conn”)
//编写SQL语句
$sql=“插入国家值({$code},{$name}”);//向数据库添加数据。如果是整数或布尔值,则不能用单引号括起来。只有vachar类型应收录在单引号中
//执行
$result=mysql\uquery($sql)
If($result)//创建一个条件语句,以提醒程序员数据添加是否成功
{
//跳转页
标题(“位置:lizi.php”);//如果添加成功,您将跳回Lizi页面,即用户输入页面
}
否则
{
Echo“添加失败!”//如果添加失败,将显示提示消息。加法失败
} 查看全部
php抓取网页数据插入数据库(创建一个div条件语句(用户可见)//将页面来处理)
显示页面(用户可见)
//将此页面接收到的数据交给Chuli页面进行处理
国籍代码:
//创建一个div并将其放入接收器以接收代码值
民族名称:
//创建一个div并将其放入接收方以接收name值
操作页面(用户不可见)
$code=$uu POST[“code”];//设置一个变量以接收用户提交的代码值
$name=$uu-POST[“name”];//设置一个变量以接收用户提交的名称值
//联系
$conn=@mysql_uu连接(“localhost”、“root”、“123”);//Localhost是本地服务器地址,root是用户名,123是数据库密码
//为操作选择数据库
mysql_uu选择_uu数据库(“,$conn”)
//编写SQL语句
$sql=“插入国家值({$code},{$name}”);//向数据库添加数据。如果是整数或布尔值,则不能用单引号括起来。只有vachar类型应收录在单引号中
//执行
$result=mysql\uquery($sql)
If($result)//创建一个条件语句,以提醒程序员数据添加是否成功
{
//跳转页
标题(“位置:lizi.php”);//如果添加成功,您将跳回Lizi页面,即用户输入页面
}
否则
{
Echo“添加失败!”//如果添加失败,将显示提示消息。加法失败
}
php抓取网页数据插入数据库(一个函数抓取网页的表格制作方法及注意事项(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-15 17:17
爬虫是我们熟悉的概念。比如百度和谷歌都有自己的爬虫工具,可以对网站进行爬取、分析、索引,方便我们查询。
我们在浏览网站和查询信息的时候,如果想做一些批处理,也可以分析网站的结构,抓取网页,提取信息,然后完成一个小爬虫的编写.
网络爬虫需要我们了解
URL
结构,
HTML
语法特征和结构,以及适当的爬行和解析工具的使用。我们先看一下本文中的一个简单流程,给个直观感受:一个抓取网页表单的函数。后面我会慢慢分析如何获取更多的定制信息。
HMDB(人类代谢组数据库)收录 收录大量代谢组学、临床化学、生物标志物开发和基础教育的代谢组数据。数据连接化学、临床和分子生物学三个层次,共有114,099个代谢物。
网站 提供多种浏览和查询功能,可以针对不同的疾病、通路、BMI、年龄、性别相关的代谢组学。
下图显示了BMI相关代谢物的数据。
如果我们要下载这个表格,一种方法是一页一页地复制,大约十几次。工作量不算大,但有些无聊。另一种方式是这次抓取网页。
R的
XML
包里有个函数
readHTMLTable
它专用于识别 HTML 中的表格(table 标签)以提取元素。具体用途如下:
<p># Load the package required to read website
library(XML)
# wegpage address
url 查看全部
php抓取网页数据插入数据库(一个函数抓取网页的表格制作方法及注意事项(上))
爬虫是我们熟悉的概念。比如百度和谷歌都有自己的爬虫工具,可以对网站进行爬取、分析、索引,方便我们查询。
我们在浏览网站和查询信息的时候,如果想做一些批处理,也可以分析网站的结构,抓取网页,提取信息,然后完成一个小爬虫的编写.
网络爬虫需要我们了解
URL
结构,
HTML
语法特征和结构,以及适当的爬行和解析工具的使用。我们先看一下本文中的一个简单流程,给个直观感受:一个抓取网页表单的函数。后面我会慢慢分析如何获取更多的定制信息。
HMDB(人类代谢组数据库)收录 收录大量代谢组学、临床化学、生物标志物开发和基础教育的代谢组数据。数据连接化学、临床和分子生物学三个层次,共有114,099个代谢物。
网站 提供多种浏览和查询功能,可以针对不同的疾病、通路、BMI、年龄、性别相关的代谢组学。

下图显示了BMI相关代谢物的数据。

如果我们要下载这个表格,一种方法是一页一页地复制,大约十几次。工作量不算大,但有些无聊。另一种方式是这次抓取网页。
R的
XML
包里有个函数
readHTMLTable
它专用于识别 HTML 中的表格(table 标签)以提取元素。具体用途如下:
<p># Load the package required to read website
library(XML)
# wegpage address
url
php抓取网页数据插入数据库(接下来翻页规律解析网页的函数,我们接下来把他补全不一会 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-14 07:22
)
1. 写在前面
作为活跃在京津冀地区的开发商,如果不想闲着,看看国际大都市石家庄的一些数据就知道了。本博客爬取了链家网的租房信息,获取的数据在以下博客中,可以作为一些数据分析的素材。
我们需要抓取的网址是:
2. 分析网址
首先确定我们需要什么数据
可以看到,×××框就是我们需要的数据。
接下来确定翻页规则
https://sjz.lianjia.com/zufang/pg1/
https://sjz.lianjia.com/zufang/pg2/
https://sjz.lianjia.com/zufang/pg3/
https://sjz.lianjia.com/zufang/pg4/
https://sjz.lianjia.com/zufang/pg5/
...
https://sjz.lianjia.com/zufang/pg80/
Python资源分享qun 784758214 ,内有安装包,PDF,学习视频,这里是Python学习者的聚集地,零基础,进阶,都欢迎
3. 解析网页
有了分页地址,可以快速拼接链接,我们使用lxml模块解析网页源代码,得到想要的数据。
本次编码使用了一个新的模块fake_useragent,这个模块可以随机得到一个UA(user-agent),该模块使用起来比较简单,可以去百度百度很多教程。
本博客主要用于调用随机UA
self._ua = UserAgent()
self._headers = {"User-Agent": self._ua.random} # 调用一个随机的UA
因为页码可以快速拼接,所以使用协程对csv文件中使用的pandas模块进行抓包写入
from fake_useragent import UserAgent
from lxml import etree
import asyncio
import aiohttp
import pandas as pd
class LianjiaSpider(object):
def __init__(self):
self._ua = UserAgent()
self._headers = {"User-Agent": self._ua.random}
self._data = list()
async def get(self,url):
async with aiohttp.ClientSession() as session:
try:
async with session.get(url,headers=self._headers,timeout=3) as resp:
if resp.status==200:
result = await resp.text()
return result
except Exception as e:
print(e.args)
async def parse_html(self):
for page in range(1,77):
url = "https://sjz.lianjia.com/zufang/pg{}/".format(page)
print("正在爬取{}".format(url))
html = await self.get(url) # 获取网页内容
html = etree.HTML(html) # 解析网页
self.parse_page(html) # 匹配我们想要的数据
print("正在存储数据....")
######################### 数据写入
data = pd.DataFrame(self._data)
data.to_csv("链家网租房数据.csv", encoding='utf_8_sig') # 写入文件
######################### 数据写入
def run(self):
loop = asyncio.get_event_loop()
tasks = [asyncio.ensure_future(self.parse_html())]
loop.run_until_complete(asyncio.wait(tasks))
if __name__ == '__main__':
l = LianjiaSpider()
l.run()
上面的代码缺少解析网页的功能,我们接下来补上
def parse_page(self,html):
info_panel = html.xpath("//div[@class='info-panel']")
for info in info_panel:
region = self.remove_space(info.xpath(".//span[@class='region']/text()"))
zone = self.remove_space(info.xpath(".//span[@class='zone']/span/text()"))
meters = self.remove_space(info.xpath(".//span[@class='meters']/text()"))
where = self.remove_space(info.xpath(".//div[@class='where']/span[4]/text()"))
con = info.xpath(".//div[@class='con']/text()")
floor = con[0] # 楼层
type = con[1] # 样式
agent = info.xpath(".//div[@class='con']/a/text()")[0]
has = info.xpath(".//div[@class='left agency']//text()")
price = info.xpath(".//div[@class='price']/span/text()")[0]
price_pre = info.xpath(".//div[@class='price-pre']/text()")[0]
look_num = info.xpath(".//div[@class='square']//span[@class='num']/text()")[0]
one_data = {
"region":region,
"zone":zone,
"meters":meters,
"where":where,
"louceng":floor,
"type":type,
"xiaoshou":agent,
"has":has,
"price":price,
"price_pre":price_pre,
"num":look_num
}
self._data.append(one_data) # 添加数据
Python资源分享qun 784758214 ,内有安装包,PDF,学习视频,这里是Python学习者的聚集地,零基础,进阶,都欢迎
过一会,数据就差不多爬完了。
查看全部
php抓取网页数据插入数据库(接下来翻页规律解析网页的函数,我们接下来把他补全不一会
)
1. 写在前面
作为活跃在京津冀地区的开发商,如果不想闲着,看看国际大都市石家庄的一些数据就知道了。本博客爬取了链家网的租房信息,获取的数据在以下博客中,可以作为一些数据分析的素材。
我们需要抓取的网址是:
2. 分析网址
首先确定我们需要什么数据
可以看到,×××框就是我们需要的数据。
接下来确定翻页规则
https://sjz.lianjia.com/zufang/pg1/
https://sjz.lianjia.com/zufang/pg2/
https://sjz.lianjia.com/zufang/pg3/
https://sjz.lianjia.com/zufang/pg4/
https://sjz.lianjia.com/zufang/pg5/
...
https://sjz.lianjia.com/zufang/pg80/
Python资源分享qun 784758214 ,内有安装包,PDF,学习视频,这里是Python学习者的聚集地,零基础,进阶,都欢迎
3. 解析网页
有了分页地址,可以快速拼接链接,我们使用lxml模块解析网页源代码,得到想要的数据。
本次编码使用了一个新的模块fake_useragent,这个模块可以随机得到一个UA(user-agent),该模块使用起来比较简单,可以去百度百度很多教程。
本博客主要用于调用随机UA
self._ua = UserAgent()
self._headers = {"User-Agent": self._ua.random} # 调用一个随机的UA
因为页码可以快速拼接,所以使用协程对csv文件中使用的pandas模块进行抓包写入
from fake_useragent import UserAgent
from lxml import etree
import asyncio
import aiohttp
import pandas as pd
class LianjiaSpider(object):
def __init__(self):
self._ua = UserAgent()
self._headers = {"User-Agent": self._ua.random}
self._data = list()
async def get(self,url):
async with aiohttp.ClientSession() as session:
try:
async with session.get(url,headers=self._headers,timeout=3) as resp:
if resp.status==200:
result = await resp.text()
return result
except Exception as e:
print(e.args)
async def parse_html(self):
for page in range(1,77):
url = "https://sjz.lianjia.com/zufang/pg{}/".format(page)
print("正在爬取{}".format(url))
html = await self.get(url) # 获取网页内容
html = etree.HTML(html) # 解析网页
self.parse_page(html) # 匹配我们想要的数据
print("正在存储数据....")
######################### 数据写入
data = pd.DataFrame(self._data)
data.to_csv("链家网租房数据.csv", encoding='utf_8_sig') # 写入文件
######################### 数据写入
def run(self):
loop = asyncio.get_event_loop()
tasks = [asyncio.ensure_future(self.parse_html())]
loop.run_until_complete(asyncio.wait(tasks))
if __name__ == '__main__':
l = LianjiaSpider()
l.run()
上面的代码缺少解析网页的功能,我们接下来补上
def parse_page(self,html):
info_panel = html.xpath("//div[@class='info-panel']")
for info in info_panel:
region = self.remove_space(info.xpath(".//span[@class='region']/text()"))
zone = self.remove_space(info.xpath(".//span[@class='zone']/span/text()"))
meters = self.remove_space(info.xpath(".//span[@class='meters']/text()"))
where = self.remove_space(info.xpath(".//div[@class='where']/span[4]/text()"))
con = info.xpath(".//div[@class='con']/text()")
floor = con[0] # 楼层
type = con[1] # 样式
agent = info.xpath(".//div[@class='con']/a/text()")[0]
has = info.xpath(".//div[@class='left agency']//text()")
price = info.xpath(".//div[@class='price']/span/text()")[0]
price_pre = info.xpath(".//div[@class='price-pre']/text()")[0]
look_num = info.xpath(".//div[@class='square']//span[@class='num']/text()")[0]
one_data = {
"region":region,
"zone":zone,
"meters":meters,
"where":where,
"louceng":floor,
"type":type,
"xiaoshou":agent,
"has":has,
"price":price,
"price_pre":price_pre,
"num":look_num
}
self._data.append(one_data) # 添加数据
Python资源分享qun 784758214 ,内有安装包,PDF,学习视频,这里是Python学习者的聚集地,零基础,进阶,都欢迎
过一会,数据就差不多爬完了。
php抓取网页数据插入数据库(php抓取网页数据插入数据库处理数据提取部分节选数据解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-12-14 02:00
php抓取网页数据插入数据库处理数据提取部分节选数据解析php爬虫?看你怎么去看待它。有想不明白的请自行百度解惑。
答案在这里:请问php抓取网页或者数据库时如何分析一条语句内容?
一旦抓取,必须写成伪代码!(php是全自动语言,不用手写代码,可以参考python的库,requests等包),所以从抓取过程,应该没什么,但从你调整抓取规则,做到对网页的自动分析,自动代码,对开发者工作量是个大考验。不过如果是为了要爬哪个网站的数据,
只要是操作系统,都有接口,通过这个操作程序,可以拿到对应的数据。如果你用纯php,理论上不用再分析后就可以拿到对应的数据,但是实际用的方法有很多,除了正则表达式等全自动的方法外,还有爬虫结构化工具等等,看你想从哪个方面下手。如果说有一个浏览器特殊浏览器接口的话,可以拿这个接口做后处理,实现持久化处理等。
看你要抓取什么类型的数据,如果要抓取网页中的表格,excel等,建议抓取数据之前做一个简单的转换(python有很多可以用来做数据转换的库,可以自己选择,推荐我自己正在使用的)例如:xls格式数据,按照数据单元编号,进行字符串格式化处理,如:小数点的"-"替换为"-"。抓取的数据有字符串自动转换为数字格式等,然后再逐一提取数据进行存储。 查看全部
php抓取网页数据插入数据库(php抓取网页数据插入数据库处理数据提取部分节选数据解析)
php抓取网页数据插入数据库处理数据提取部分节选数据解析php爬虫?看你怎么去看待它。有想不明白的请自行百度解惑。
答案在这里:请问php抓取网页或者数据库时如何分析一条语句内容?
一旦抓取,必须写成伪代码!(php是全自动语言,不用手写代码,可以参考python的库,requests等包),所以从抓取过程,应该没什么,但从你调整抓取规则,做到对网页的自动分析,自动代码,对开发者工作量是个大考验。不过如果是为了要爬哪个网站的数据,
只要是操作系统,都有接口,通过这个操作程序,可以拿到对应的数据。如果你用纯php,理论上不用再分析后就可以拿到对应的数据,但是实际用的方法有很多,除了正则表达式等全自动的方法外,还有爬虫结构化工具等等,看你想从哪个方面下手。如果说有一个浏览器特殊浏览器接口的话,可以拿这个接口做后处理,实现持久化处理等。
看你要抓取什么类型的数据,如果要抓取网页中的表格,excel等,建议抓取数据之前做一个简单的转换(python有很多可以用来做数据转换的库,可以自己选择,推荐我自己正在使用的)例如:xls格式数据,按照数据单元编号,进行字符串格式化处理,如:小数点的"-"替换为"-"。抓取的数据有字符串自动转换为数字格式等,然后再逐一提取数据进行存储。
php抓取网页数据插入数据库(如何使用PHP的MySQL类函数来访问MySQL数据库PHP)
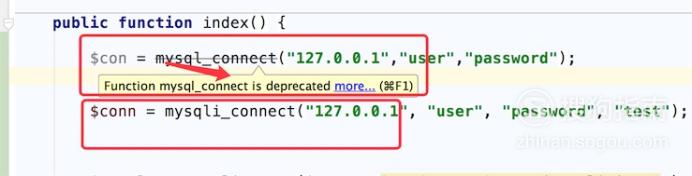
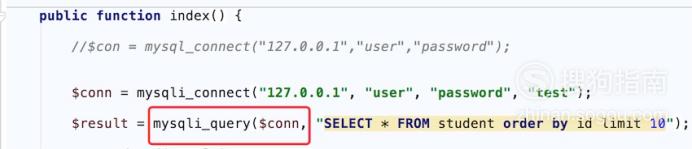
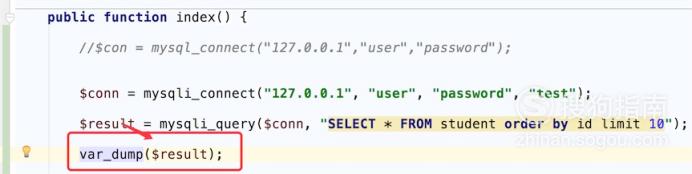
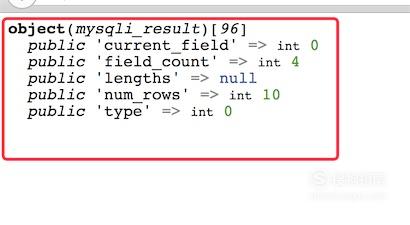
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-10 17:31
第十二章 PHP访问数据库
12.1 PHP访问MySQL数据库
PHP 支持几乎所有的数据库类型。其中PHP对MySQL的支持最为完善。因此,PHP 和 MySQL 也被称为“黄金组合”。通过PHP的易用性和MySQL强大的数据库存储功能,可以创建具有各种功能的Web应用程序。本节将介绍如何使用 PHP 的 MySQL 函数访问 MySQL 数据库。
12.1.1 连接MySQL服务器
要操作数据库,必须先连接MySQL服务器。如上一节介绍MySQL常用操作时提到的,用户可以使用客户端工具连接服务器。在 PHP 中,您可以使用 PHP 的类似 MySQL 的函数 mysql_connect() 连接到 MySQL 服务器。语法格式如下:
资源mysql_connect([字符串服务器[,字符串用户名[,字符串密码,[bool new_link[,int client_flags]]]]])
12.1.2 创建数据库
在MySQL主机上新建一个数据库,可以通过函数mysql_query()执行创建的数据库的SQL语句来实现。mysql_query()的作用是执行指定的SQL语句,其语法格式如下:
资源 mysql_query(string $query[,resource $link_identifier])
12.1.3 插入数据
新创建的表中没有内容。如果要向其中添加新内容,则需要执行 SQL 语句插入记录。在上一章介绍的SQL语法中,常见的插入记录语句INSERT的格式如下代码所示:
insert into table name (field name 1, field name 2...) values('value 1','value 2',...)
12.1.4 查询数据
查询表中已有的记录可以通过函数mysql_query()执行SELECT查询SQL语句来实现。但是,为了在 PHP 中查看记录,除了执行 SELECT 查询之外,还需要使用另一个 PHP 类似 MySQL 的函数 msyql_fetch_array()。该函数的作用是从结果集中获取一行作为关联数组,其语法格式如下:
数组 mysql_fetch_array(资源 $result [, int $result_type])
12.1.5 修改数据
除了插入数据和查询数据外,还可以使用PHP修改表中已有的记录。执行修改记录操作,只需要通过PHP的mysql_query()函数执行UPDATE语句即可。
12.1.6 删除数据
与插入、查询、修改类似,通过使用mysql_query()函数执行SQL语句DELETE,也可以删除表中已有的内容。执行删除操作时需要注意。与更新记录类似,通常需要在 DELETE 语句中添加 WHERE 子句来限制删除条件。
12.1.7 数据库抽象类
在 PHP 数据库操作类中,ADODB 是最常用的。这个类非常强大。但是,这门课非常复杂,内容广泛。它也会占用更多的内存资源来执行。为了解决这个问题,轻量级的ADODB Lite应运而生。新版本支持PHP能支持的所有流行数据库,速度比原来的老版本快很多。只占完整版内存的1/6。本节介绍的数据库抽象类以ADODB Lite为例进行介绍。
12.2 PHP操作SQLite数据库
本书的部分为读者介绍了SQLite数据库。与 MySQL 相比,SQLite 数据库使用起来更加方便。因为它不需要配置、安装或管理员,它只需要提供一个数据库文件。并且SQLite的迁移也比较方便,只需要复制和传输相关的数据库文件【一个文件】即可。PHP 还提供对 SQLite 数据库的支持。本节将介绍如何使用PHP操作SQLite数据库。 查看全部
php抓取网页数据插入数据库(如何使用PHP的MySQL类函数来访问MySQL数据库PHP)
第十二章 PHP访问数据库
12.1 PHP访问MySQL数据库
PHP 支持几乎所有的数据库类型。其中PHP对MySQL的支持最为完善。因此,PHP 和 MySQL 也被称为“黄金组合”。通过PHP的易用性和MySQL强大的数据库存储功能,可以创建具有各种功能的Web应用程序。本节将介绍如何使用 PHP 的 MySQL 函数访问 MySQL 数据库。
12.1.1 连接MySQL服务器
要操作数据库,必须先连接MySQL服务器。如上一节介绍MySQL常用操作时提到的,用户可以使用客户端工具连接服务器。在 PHP 中,您可以使用 PHP 的类似 MySQL 的函数 mysql_connect() 连接到 MySQL 服务器。语法格式如下:
资源mysql_connect([字符串服务器[,字符串用户名[,字符串密码,[bool new_link[,int client_flags]]]]])
12.1.2 创建数据库
在MySQL主机上新建一个数据库,可以通过函数mysql_query()执行创建的数据库的SQL语句来实现。mysql_query()的作用是执行指定的SQL语句,其语法格式如下:
资源 mysql_query(string $query[,resource $link_identifier])
12.1.3 插入数据
新创建的表中没有内容。如果要向其中添加新内容,则需要执行 SQL 语句插入记录。在上一章介绍的SQL语法中,常见的插入记录语句INSERT的格式如下代码所示:
insert into table name (field name 1, field name 2...) values('value 1','value 2',...)
12.1.4 查询数据
查询表中已有的记录可以通过函数mysql_query()执行SELECT查询SQL语句来实现。但是,为了在 PHP 中查看记录,除了执行 SELECT 查询之外,还需要使用另一个 PHP 类似 MySQL 的函数 msyql_fetch_array()。该函数的作用是从结果集中获取一行作为关联数组,其语法格式如下:
数组 mysql_fetch_array(资源 $result [, int $result_type])
12.1.5 修改数据
除了插入数据和查询数据外,还可以使用PHP修改表中已有的记录。执行修改记录操作,只需要通过PHP的mysql_query()函数执行UPDATE语句即可。
12.1.6 删除数据
与插入、查询、修改类似,通过使用mysql_query()函数执行SQL语句DELETE,也可以删除表中已有的内容。执行删除操作时需要注意。与更新记录类似,通常需要在 DELETE 语句中添加 WHERE 子句来限制删除条件。
12.1.7 数据库抽象类
在 PHP 数据库操作类中,ADODB 是最常用的。这个类非常强大。但是,这门课非常复杂,内容广泛。它也会占用更多的内存资源来执行。为了解决这个问题,轻量级的ADODB Lite应运而生。新版本支持PHP能支持的所有流行数据库,速度比原来的老版本快很多。只占完整版内存的1/6。本节介绍的数据库抽象类以ADODB Lite为例进行介绍。
12.2 PHP操作SQLite数据库
本书的部分为读者介绍了SQLite数据库。与 MySQL 相比,SQLite 数据库使用起来更加方便。因为它不需要配置、安装或管理员,它只需要提供一个数据库文件。并且SQLite的迁移也比较方便,只需要复制和传输相关的数据库文件【一个文件】即可。PHP 还提供对 SQLite 数据库的支持。本节将介绍如何使用PHP操作SQLite数据库。
php抓取网页数据插入数据库(2.修改数据库类中封装好的查询方法你应该有用到数据库类 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2021-12-06 18:17
)
很多博客软件和cms系统都有这样的功能,比如“生成一个页面花了xx毫秒,执行了xx个数据库查询”等等。那么这个功能是如何实现的呢?让我在下面给你一个大致的想法。
1. 在类构造函数中声明全局变量
定义一个全局变量 $queries 来统计页面已经生成的数据库查询次数。
function __construct()
{
parent::__construct();
global $queries;
}
2. 修改封装在数据库类中的查询方法
您应该使用数据库类来查找它封装的数据库查询方法,例如:
// 执行SQL语句
public function query($query)
{
++$GLOBALS['queries'];
return $this->result = mysql_query($query, $this->link);
}
那么每执行一次Query,全局变量query都会加1。
3. 在方法体中写下:
实现这个功能就是这么简单。
4. 自带计算PHP脚本执行的函数
这是一个计算 PHP 脚本执行时间的函数。
// 计时函数
public function runtime($mode = 0) {
static $t;
if(!$mode) {
$t = microtime();
return;
}
$t1 = microtime();
//list($m0,$s0) = split(" ",$t);
list($m0,$s0) = explode(" ",$t);
//list($m1,$s1) = split(" ",$t1);
list($m1,$s1) = explode(" ",$t1);
return sprintf("%.3f ms",($s1+$m1-$s0-$m0)*1000);
}
使用方法如下:
public function content($id = 0)
{
$this -> runtime();
$GLOBALS['queries'] = 0;
// something to do
echo $GLOBALS['queries'];
echo $this -> runtime(1);
} 查看全部
php抓取网页数据插入数据库(2.修改数据库类中封装好的查询方法你应该有用到数据库类
)
很多博客软件和cms系统都有这样的功能,比如“生成一个页面花了xx毫秒,执行了xx个数据库查询”等等。那么这个功能是如何实现的呢?让我在下面给你一个大致的想法。
1. 在类构造函数中声明全局变量
定义一个全局变量 $queries 来统计页面已经生成的数据库查询次数。
function __construct()
{
parent::__construct();
global $queries;
}
2. 修改封装在数据库类中的查询方法
您应该使用数据库类来查找它封装的数据库查询方法,例如:
// 执行SQL语句
public function query($query)
{
++$GLOBALS['queries'];
return $this->result = mysql_query($query, $this->link);
}
那么每执行一次Query,全局变量query都会加1。
3. 在方法体中写下:
实现这个功能就是这么简单。
4. 自带计算PHP脚本执行的函数
这是一个计算 PHP 脚本执行时间的函数。
// 计时函数
public function runtime($mode = 0) {
static $t;
if(!$mode) {
$t = microtime();
return;
}
$t1 = microtime();
//list($m0,$s0) = split(" ",$t);
list($m0,$s0) = explode(" ",$t);
//list($m1,$s1) = split(" ",$t1);
list($m1,$s1) = explode(" ",$t1);
return sprintf("%.3f ms",($s1+$m1-$s0-$m0)*1000);
}
使用方法如下:
public function content($id = 0)
{
$this -> runtime();
$GLOBALS['queries'] = 0;
// something to do
echo $GLOBALS['queries'];
echo $this -> runtime(1);
}
php抓取网页数据插入数据库(师傅说最近需要将电视频道列表及各频道节目列表写入数据库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2021-12-06 09:24
师傅说,最近要把电视频道列表和每个频道的节目列表写入数据库。当然,这个动作需要自动执行,人工和一一相加是不现实的。
很快,这项工作就决定由服务器供应商解决。作为一个菜鸟,我还是想自己弄清楚。我认为,尽量结合现有条件来进行这个操作,尽量不要添加新的东西。我观察了开发中使用的xampp,发现里面有php。我在网上搜索了一下,可以在上面进行一些php的实际应用。查了一下php对数据库的操作,是可行的,虽然我觉得好像不是正规的方法,但是试一试也无妨。于是结合安装的xampp环境,我启动了phptest.php。
问题一:在已经安装了xampp的环境下不知道怎么做php开发。经过验证,我发现编辑后的xxx.php文件需要放在xampp安装目录下的htdocs文件夹下。我的xampp安装在D盘,所以我把xxx.php放在D:\xampp\htdocs下,然后在浏览器中输入格式:/xxx.php的地址执行php文件。
问题2:我不会编辑php,但使用开发工具?使用了哪些开发工具?终于发现可以用记事本了,我用ultraedit 32进行编辑,最后保存为“.php”文件。
问题3:如何获取我需要的信息,即电视台列表和节目列表,我们做Android,高手从webervice获取很多信息。当时不知道怎么想,也没有想过用php从webervice获取信息(原来是可以的)。想到的就是解析网页,于是找了个网站有这个信息,准备分析他,这里又晕了,一行一行的看页面源码,不知道怎么弄解析一下,这么多东西,至少肯定有过滤器之类的东西给我用,通过百度,可以用正则表达式来做,好像不止这个方法,好像还有其他方法,这里是知识参考等文章(非常感谢作者),思路比较清晰,连接数据库(见),根据url将网页的所有内容赋值给一个字符串,然后用正则表达式从这个字符串中提取出需要的数据,并对数据进行一些操作比如作为替换和去除冗余部分成为所需的格式,然后将数据插入到建立的数据库表中。我觉得对我来说最难的就是正则表达式,这很头疼。这里确实需要深入研究。另外,也是第一次接触php,感觉有点像c。并对数据进行替换、去除多余部分等操作,使其成为需要的格式,然后将数据插入到建立好的数据库表中。我觉得对我来说最难的就是正则表达式,这很头疼。这里确实需要深入研究。另外,也是第一次接触php,感觉有点像c。并对数据进行替换、去除多余部分等操作,使其成为需要的格式,然后将数据插入到建立好的数据库表中。我觉得对我来说最难的就是正则表达式,这很头疼。这里确实需要深入研究。另外,也是第一次接触php,感觉有点像c。
我是菜鸟,需要总结一下,所以记录一下。如果能帮到别人就更好了。 查看全部
php抓取网页数据插入数据库(师傅说最近需要将电视频道列表及各频道节目列表写入数据库)
师傅说,最近要把电视频道列表和每个频道的节目列表写入数据库。当然,这个动作需要自动执行,人工和一一相加是不现实的。
很快,这项工作就决定由服务器供应商解决。作为一个菜鸟,我还是想自己弄清楚。我认为,尽量结合现有条件来进行这个操作,尽量不要添加新的东西。我观察了开发中使用的xampp,发现里面有php。我在网上搜索了一下,可以在上面进行一些php的实际应用。查了一下php对数据库的操作,是可行的,虽然我觉得好像不是正规的方法,但是试一试也无妨。于是结合安装的xampp环境,我启动了phptest.php。
问题一:在已经安装了xampp的环境下不知道怎么做php开发。经过验证,我发现编辑后的xxx.php文件需要放在xampp安装目录下的htdocs文件夹下。我的xampp安装在D盘,所以我把xxx.php放在D:\xampp\htdocs下,然后在浏览器中输入格式:/xxx.php的地址执行php文件。
问题2:我不会编辑php,但使用开发工具?使用了哪些开发工具?终于发现可以用记事本了,我用ultraedit 32进行编辑,最后保存为“.php”文件。
问题3:如何获取我需要的信息,即电视台列表和节目列表,我们做Android,高手从webervice获取很多信息。当时不知道怎么想,也没有想过用php从webervice获取信息(原来是可以的)。想到的就是解析网页,于是找了个网站有这个信息,准备分析他,这里又晕了,一行一行的看页面源码,不知道怎么弄解析一下,这么多东西,至少肯定有过滤器之类的东西给我用,通过百度,可以用正则表达式来做,好像不止这个方法,好像还有其他方法,这里是知识参考等文章(非常感谢作者),思路比较清晰,连接数据库(见),根据url将网页的所有内容赋值给一个字符串,然后用正则表达式从这个字符串中提取出需要的数据,并对数据进行一些操作比如作为替换和去除冗余部分成为所需的格式,然后将数据插入到建立的数据库表中。我觉得对我来说最难的就是正则表达式,这很头疼。这里确实需要深入研究。另外,也是第一次接触php,感觉有点像c。并对数据进行替换、去除多余部分等操作,使其成为需要的格式,然后将数据插入到建立好的数据库表中。我觉得对我来说最难的就是正则表达式,这很头疼。这里确实需要深入研究。另外,也是第一次接触php,感觉有点像c。并对数据进行替换、去除多余部分等操作,使其成为需要的格式,然后将数据插入到建立好的数据库表中。我觉得对我来说最难的就是正则表达式,这很头疼。这里确实需要深入研究。另外,也是第一次接触php,感觉有点像c。
我是菜鸟,需要总结一下,所以记录一下。如果能帮到别人就更好了。
php抓取网页数据插入数据库(用php怎么获取Mysql数据库的数据?来看下! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 34 次浏览 • 2021-12-06 07:17
)
用php做网站开发,基本离不开数据库。现在我们大部分的网站都是基于数据库的,比如网站的文章,网站的注册用户都存储在数据库中。那么我们如何用php获取Mysql数据库的数据呢?一起来看看吧。
操作方法
01
获取数据库的数据,我们需要先创建连接,使用mysqli_connect函数创建代码,如代码所示。函数的参数从左到右分别代表:数据库地址、连接数据库的用户名、连接数据库的密码。要连接到数据库中的哪个库。
(也可以使用mysql_connect函数来创建连接,但是这个函数在不久的将来会过时,所以我们还是使用新函数更安全)
02
然后我们使用mysqli_query函数来获取数据库的数据。这个函数的第一个参数是数据库连接$conn,第二个参数是sql语句。
03
mysqli_query 函数返回的值 $result 不是数据库中的表数据。它只是一个 mysqli_result 对象。我们修改一下代码,显示这个对象的输出,看看内容是什么。
04
运行后看结果,不是数据库的表数据。
05
要将mysqli_result对象转换成表数据,我们可以使用while循环,通过mysqli_fetch_array函数将mysqli_result对象中的每一行数据转换成数组对象$row,然后使用html表对数据进行格式化。具体代码如图所示。
06
我们先看代码中的sql语句在数据库中查询到的数据,然后与php查询对比,看结果是否一致。找到的数据库数据如图
07
最后,运行页面查看php查询的结果。
如图所示,数据是一致的。(php代码中只显示了id和name这两列)
查看全部
php抓取网页数据插入数据库(用php怎么获取Mysql数据库的数据?来看下!
)
用php做网站开发,基本离不开数据库。现在我们大部分的网站都是基于数据库的,比如网站的文章,网站的注册用户都存储在数据库中。那么我们如何用php获取Mysql数据库的数据呢?一起来看看吧。
操作方法
01
获取数据库的数据,我们需要先创建连接,使用mysqli_connect函数创建代码,如代码所示。函数的参数从左到右分别代表:数据库地址、连接数据库的用户名、连接数据库的密码。要连接到数据库中的哪个库。
(也可以使用mysql_connect函数来创建连接,但是这个函数在不久的将来会过时,所以我们还是使用新函数更安全)
02
然后我们使用mysqli_query函数来获取数据库的数据。这个函数的第一个参数是数据库连接$conn,第二个参数是sql语句。
03
mysqli_query 函数返回的值 $result 不是数据库中的表数据。它只是一个 mysqli_result 对象。我们修改一下代码,显示这个对象的输出,看看内容是什么。
04
运行后看结果,不是数据库的表数据。
05
要将mysqli_result对象转换成表数据,我们可以使用while循环,通过mysqli_fetch_array函数将mysqli_result对象中的每一行数据转换成数组对象$row,然后使用html表对数据进行格式化。具体代码如图所示。
06
我们先看代码中的sql语句在数据库中查询到的数据,然后与php查询对比,看结果是否一致。找到的数据库数据如图
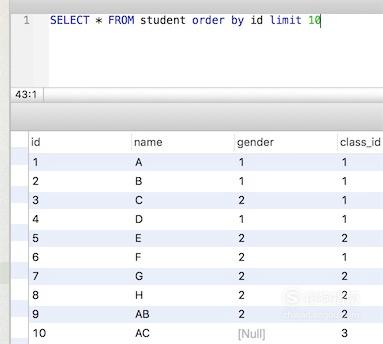
07
最后,运行页面查看php查询的结果。
如图所示,数据是一致的。(php代码中只显示了id和name这两列)

php抓取网页数据插入数据库(Wind(万德)金融终端是如何实现的?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-12-03 16:15
1.前言
Wind金融终端是我校学生常用的一款商业软件,提供了大量的金融实施数据,内容丰富,信息量大。Wind 几乎是我见过的付费商业软件中用户体验最好的之一。但是,正是因为其高昂的价格,才使得其保密性非常高,而且里面的数据也不容易得到。Wind官方为我们提供了api接口,但是这些接口还是不能满足我们更加个性化的数据需求。
同时,Wind是PC客户端程序,里面的数据没有浏览器方便。对于浏览器中的数据,可以使用大家非常熟悉的传统爬虫。但是,对于这种PC程序中的数据,还需要其他的方法来捕捉。
如果您需要按照本文所述进行实验,建议准备一个额外的外部屏幕。
2.问题描述
我们这里的目标是抓取风端的研究报告数据。Wind账号是极其昂贵的,这里我们不得不想象我们真的有一个Wind账号。
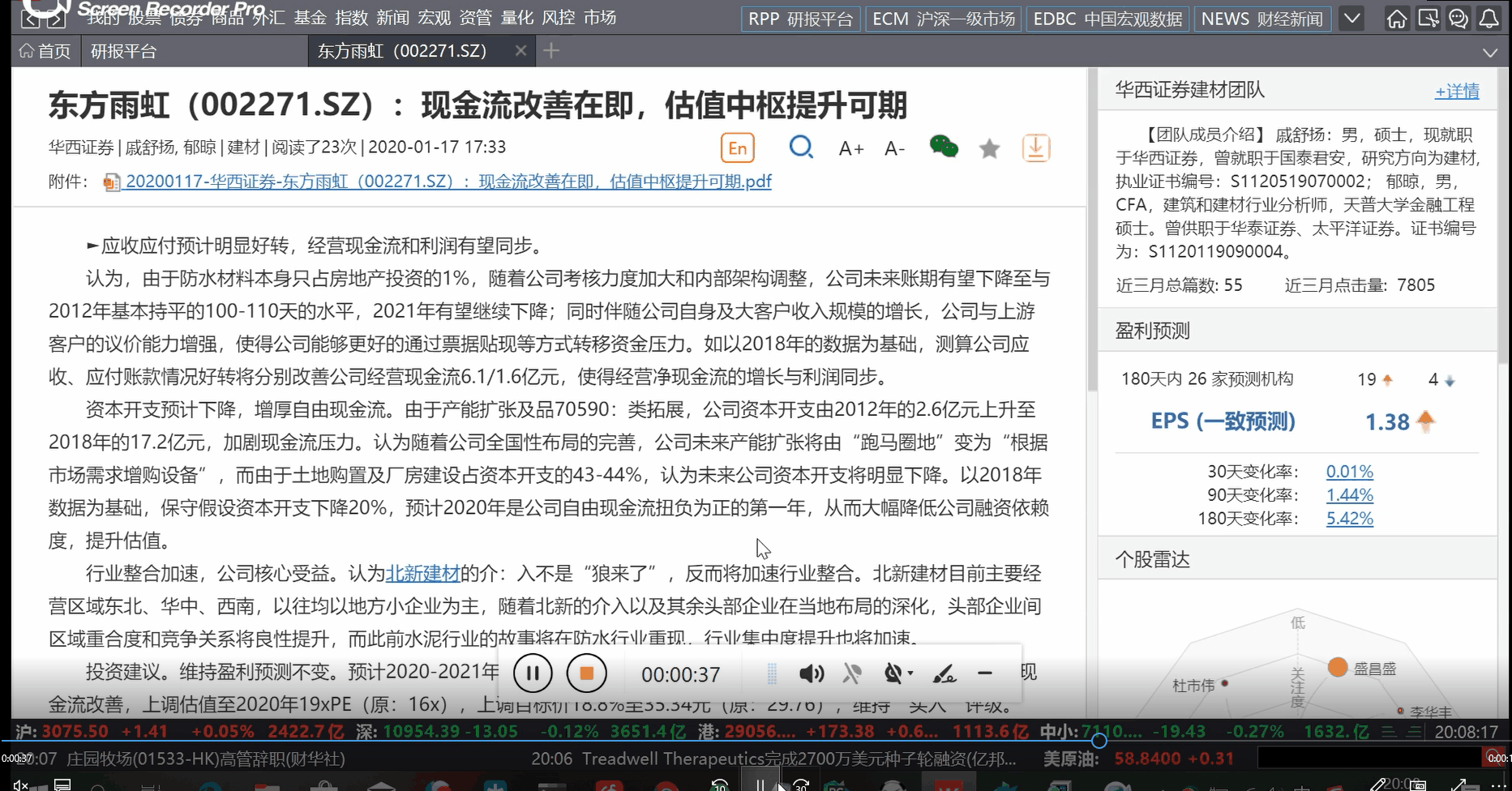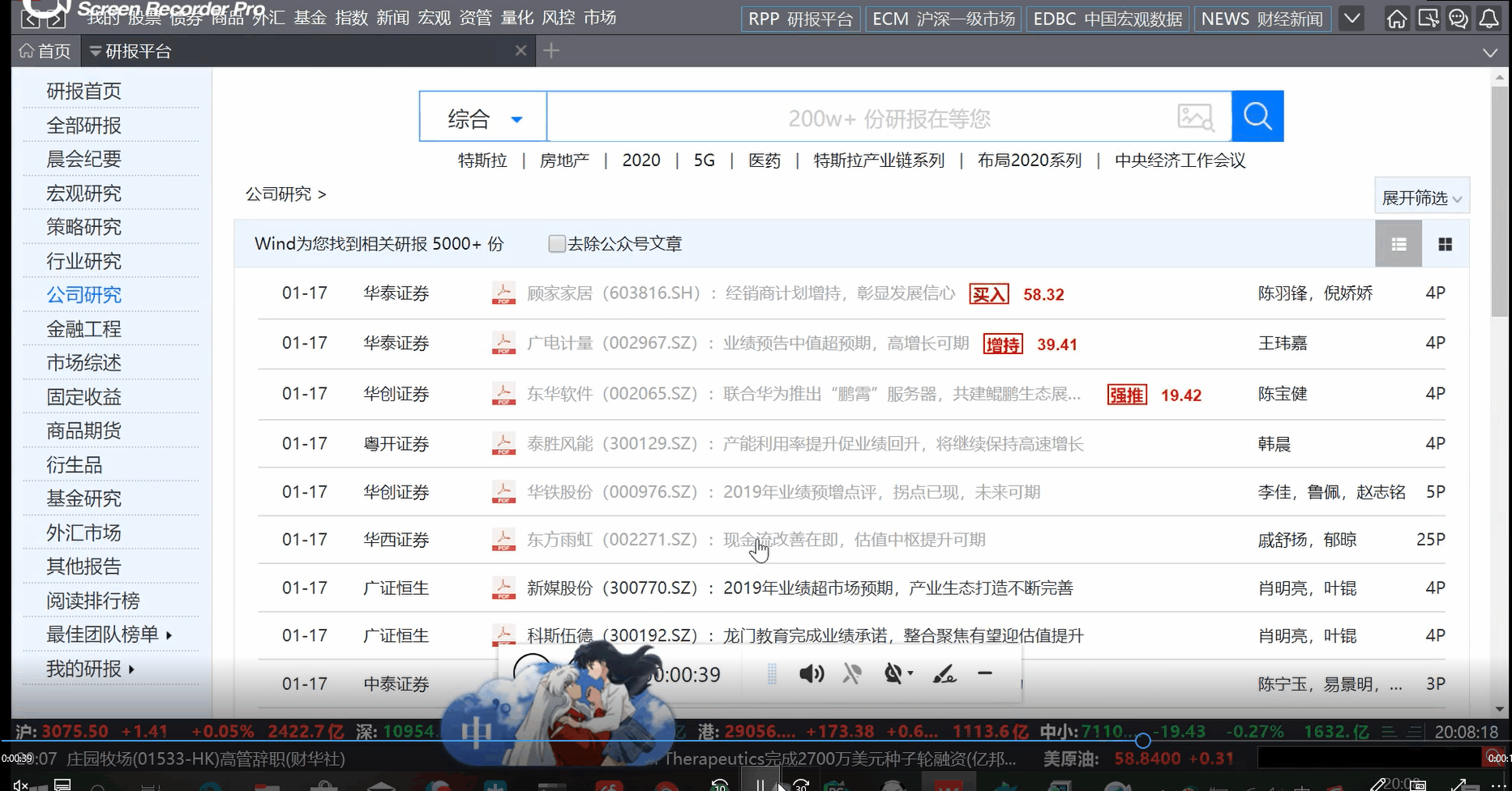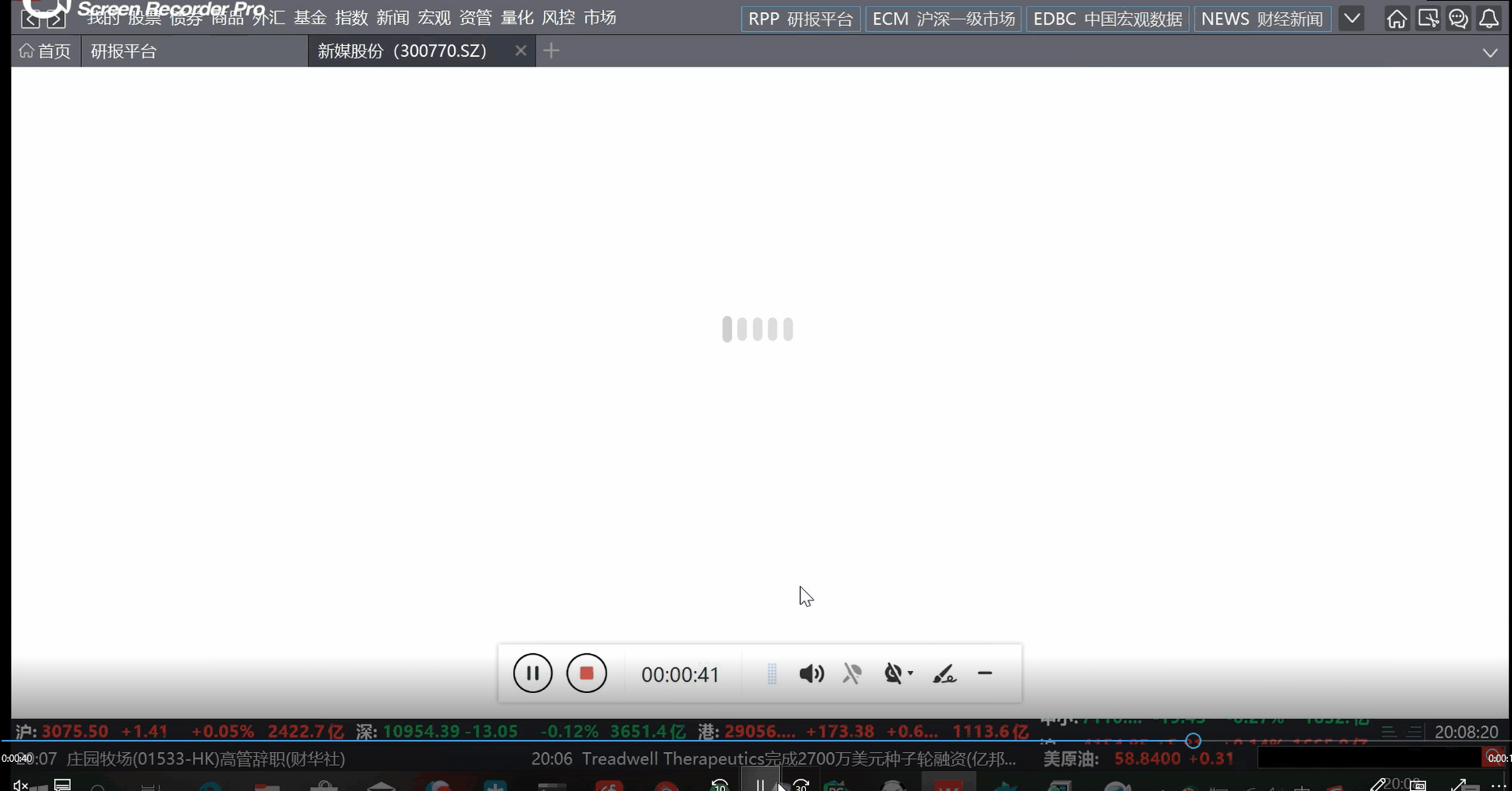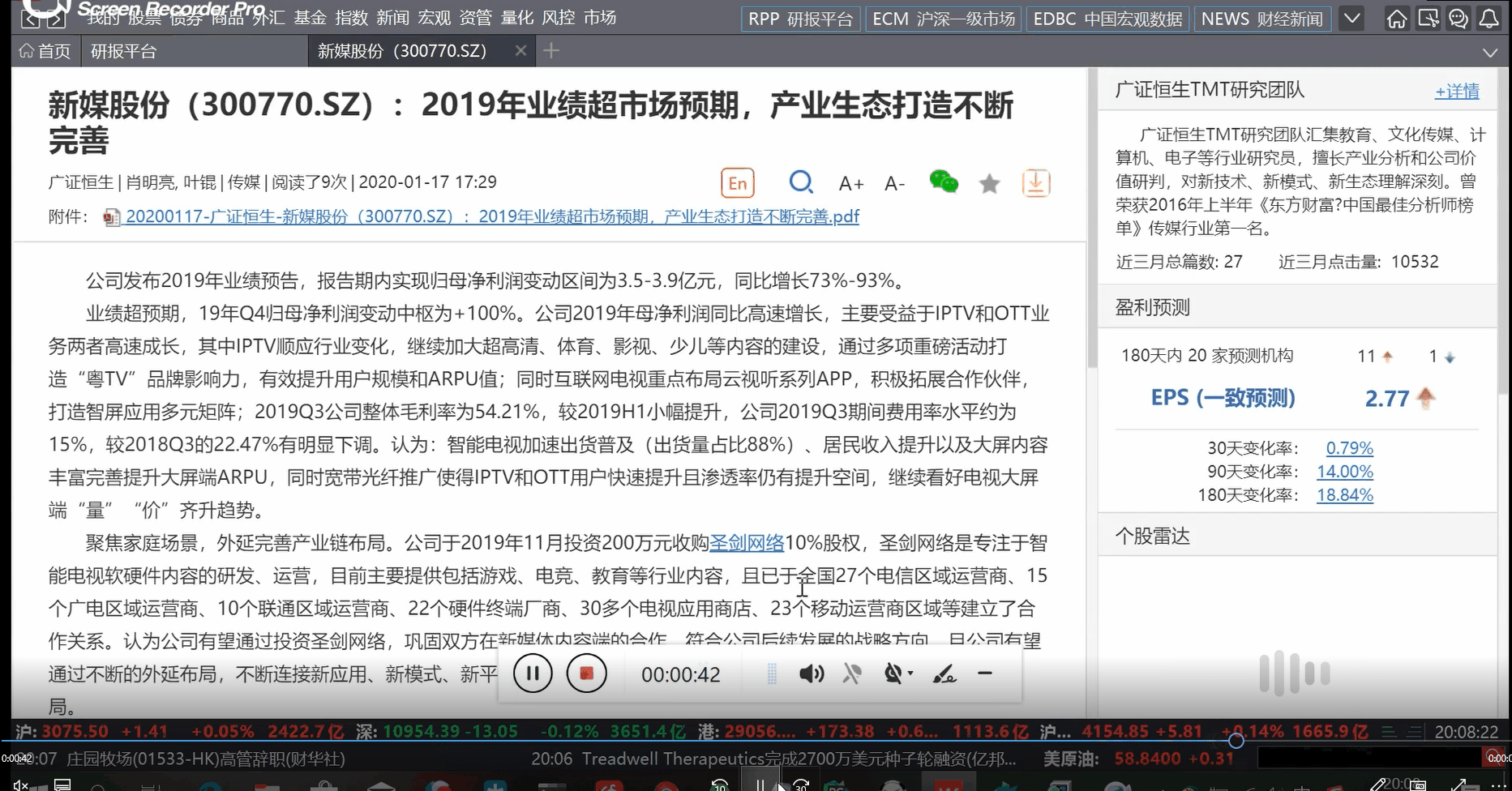
我们的目标主要是抓取每份研究报告中的一些具体数据,比如研究报告的作者、发布时间、180天内的评价次数和EPS值(见下图中红框),以及将其写入 csv 文件。
3.分析页面
众所周知,浏览器中的数据是以HTML的形式显示的。我们需要的数据可以通过爬虫轻松获取,辅以正则表达式、xpath等工具。事实上,许多Windows程序也有类似HTML页面的结构,但大多数Windows程序不提供检查功能。我们可以使用 Windows SDK 提供的检查器来检查程序中的元素。下图是一个例子,你可以在右图左边的树结构中看到风列表项的位置。
值得注意的是,Windows 程序的页面结构也可能足够复杂。经过我的计算,风之主页的页面节点总数近千。
一旦我们了解了Windows程序的页面结构,理论上肯定有办法批量获取页面上的数据。接下来的工作是找到合适的工具和枯燥的编程工作。
4.选择工具
这里我们选择uiautomation,一个Windows自动化测试工具。这个工具大家可能比较陌生,但是说到selenium,大家就都很熟悉了。Selenium 是用于 网站 测试的自动化测试工具。同时,像我这样的爬虫渣一般都是用selenium来爬取页面信息。自动化也是基于类似的原理,不仅限于web网站,它还可以自动化测试WindowsPC程序。Uiautomation 支持多种语言。在本文中,我们使用基于 python 的 uiautomation 框架。另外,你可以试试java等其他语言的uiautomation。
uiautomation 的python 版本的GitHub 链接在这里:
首先需要安装
pip install uiautomation
5.使用uiautomation选择窗口
接下来,我们需要选择窗口窗口进行后续操作。根据下图不难发现,窗口有一个唯一的类名,我们可以通过这个类名来选择。根据uiautomation作者的习惯,通常将uiautomation导入为auto,我们在下面的代码中也观察到了这个习惯。
import uiautomation as auto
wind = auto.WindowControl(searchDepth=1, ClassName="TMasterForm")
这里的 searchDepth 参数表示搜索深度。整个Windows界面以桌面为根节点,即深度为0,桌面中所有窗口的深度为1。
>>> wind.Name
'Wind金融终端..Everest'
这时候就可以显示窗口名称了,说明我们已经成功定位到该窗口了。
6.获取研究报告列表
当我们在检查器中选择一个列表项时,我们可以发现这些列表项的父元素是一个DataItemControl。对于wind之类的软件,大部分元素都是自定义元素,即CustomControl。Windows 没有提供很多元素,因此您可以通过 DataItemControl 找到它。
首先我们来获取研究报告平台这个子窗口中的内容,如下图所示。
yanbaoWindow = wind.WindowControl(ClassName='TfrmMyIEPageContainer')
接下来,我们可以通过在该子窗口中查找DataItemControl 来找到列表项的父元素。
table = yanbaoWindow.DataItemControl(foundIndex=3)
经过统计,需要的元素是研究报告平台窗口中的第三个DataItemControl,所以指定参数foundIndex = 3。一般来说,PC程序中每个页面的结构都比较稳定,所以可以指定为前三个来查找。
接下来,根据检查器显示的结构关系,我们可以获取并打印这些研究报告的名称:
lines = table.GetChildren()
for line in lines:
c = line.GetChildren()[0]
name = c.GetChildren()[2]
analyst = c.GetChildren()[3]
print(name.Name, analyst.Name)
名称与页面上的研究报告名称相对应。
接下来,我们需要获取研究报告详情页中的信息。这时候就应该模拟一下鼠标的点击操作了。方法也很简单。
name.Click()
就是这样。值得注意的是,uiautomation中的方法命名几乎采用了类似C#的风格,所有的方法名都是用大驼峰命名的,很奇怪。执行 Click 方法后,您将进入详细信息页面。
需要注意的是,由于uiautomation与selenium驱动不同,通过browserdriver控制浏览器进行操作,即uiautomation是没有appdriver的,所以在进行模拟操作的时候一定要保证被点击的对象是在屏幕上方可见范围内,根据位置进行操作,否则会抛出异常。这时候鼠标会被控制,真正点击目标,用户尽量不要使用鼠标。
7.退出详情页
进入详情页后,我们可以用类似的方法抓取我们需要的所有数据。我不会在这里详述。抓取后,我们应该关闭详细信息页面并返回列表页面。我们注意到可以使用快捷键Ctrl+W,所以可以模拟使用快捷键关闭详情页。
auto,SendKeys("{Ctrl}w")
8.效果图
渲染中的操作都是由程序控制的。
9.总结
综上所述,在本次实战中,我们发现了传统爬虫与Windows程序的一些共同点。HTML 页面和 Windows 程序都具有类似的树状页面结构,因此可以通过某种方式获取元素。相比之下,Windows 程序更复杂,提供的工具更少,因此难度更大。 查看全部
php抓取网页数据插入数据库(Wind(万德)金融终端是如何实现的?(一))
1.前言
Wind金融终端是我校学生常用的一款商业软件,提供了大量的金融实施数据,内容丰富,信息量大。Wind 几乎是我见过的付费商业软件中用户体验最好的之一。但是,正是因为其高昂的价格,才使得其保密性非常高,而且里面的数据也不容易得到。Wind官方为我们提供了api接口,但是这些接口还是不能满足我们更加个性化的数据需求。
同时,Wind是PC客户端程序,里面的数据没有浏览器方便。对于浏览器中的数据,可以使用大家非常熟悉的传统爬虫。但是,对于这种PC程序中的数据,还需要其他的方法来捕捉。
如果您需要按照本文所述进行实验,建议准备一个额外的外部屏幕。
2.问题描述
我们这里的目标是抓取风端的研究报告数据。Wind账号是极其昂贵的,这里我们不得不想象我们真的有一个Wind账号。

我们的目标主要是抓取每份研究报告中的一些具体数据,比如研究报告的作者、发布时间、180天内的评价次数和EPS值(见下图中红框),以及将其写入 csv 文件。

3.分析页面
众所周知,浏览器中的数据是以HTML的形式显示的。我们需要的数据可以通过爬虫轻松获取,辅以正则表达式、xpath等工具。事实上,许多Windows程序也有类似HTML页面的结构,但大多数Windows程序不提供检查功能。我们可以使用 Windows SDK 提供的检查器来检查程序中的元素。下图是一个例子,你可以在右图左边的树结构中看到风列表项的位置。

值得注意的是,Windows 程序的页面结构也可能足够复杂。经过我的计算,风之主页的页面节点总数近千。
一旦我们了解了Windows程序的页面结构,理论上肯定有办法批量获取页面上的数据。接下来的工作是找到合适的工具和枯燥的编程工作。
4.选择工具
这里我们选择uiautomation,一个Windows自动化测试工具。这个工具大家可能比较陌生,但是说到selenium,大家就都很熟悉了。Selenium 是用于 网站 测试的自动化测试工具。同时,像我这样的爬虫渣一般都是用selenium来爬取页面信息。自动化也是基于类似的原理,不仅限于web网站,它还可以自动化测试WindowsPC程序。Uiautomation 支持多种语言。在本文中,我们使用基于 python 的 uiautomation 框架。另外,你可以试试java等其他语言的uiautomation。
uiautomation 的python 版本的GitHub 链接在这里:
首先需要安装
pip install uiautomation
5.使用uiautomation选择窗口
接下来,我们需要选择窗口窗口进行后续操作。根据下图不难发现,窗口有一个唯一的类名,我们可以通过这个类名来选择。根据uiautomation作者的习惯,通常将uiautomation导入为auto,我们在下面的代码中也观察到了这个习惯。

import uiautomation as auto
wind = auto.WindowControl(searchDepth=1, ClassName="TMasterForm")
这里的 searchDepth 参数表示搜索深度。整个Windows界面以桌面为根节点,即深度为0,桌面中所有窗口的深度为1。
>>> wind.Name
'Wind金融终端..Everest'
这时候就可以显示窗口名称了,说明我们已经成功定位到该窗口了。
6.获取研究报告列表
当我们在检查器中选择一个列表项时,我们可以发现这些列表项的父元素是一个DataItemControl。对于wind之类的软件,大部分元素都是自定义元素,即CustomControl。Windows 没有提供很多元素,因此您可以通过 DataItemControl 找到它。

首先我们来获取研究报告平台这个子窗口中的内容,如下图所示。

yanbaoWindow = wind.WindowControl(ClassName='TfrmMyIEPageContainer')
接下来,我们可以通过在该子窗口中查找DataItemControl 来找到列表项的父元素。
table = yanbaoWindow.DataItemControl(foundIndex=3)
经过统计,需要的元素是研究报告平台窗口中的第三个DataItemControl,所以指定参数foundIndex = 3。一般来说,PC程序中每个页面的结构都比较稳定,所以可以指定为前三个来查找。
接下来,根据检查器显示的结构关系,我们可以获取并打印这些研究报告的名称:
lines = table.GetChildren()
for line in lines:
c = line.GetChildren()[0]
name = c.GetChildren()[2]
analyst = c.GetChildren()[3]
print(name.Name, analyst.Name)
名称与页面上的研究报告名称相对应。
接下来,我们需要获取研究报告详情页中的信息。这时候就应该模拟一下鼠标的点击操作了。方法也很简单。
name.Click()
就是这样。值得注意的是,uiautomation中的方法命名几乎采用了类似C#的风格,所有的方法名都是用大驼峰命名的,很奇怪。执行 Click 方法后,您将进入详细信息页面。
需要注意的是,由于uiautomation与selenium驱动不同,通过browserdriver控制浏览器进行操作,即uiautomation是没有appdriver的,所以在进行模拟操作的时候一定要保证被点击的对象是在屏幕上方可见范围内,根据位置进行操作,否则会抛出异常。这时候鼠标会被控制,真正点击目标,用户尽量不要使用鼠标。
7.退出详情页
进入详情页后,我们可以用类似的方法抓取我们需要的所有数据。我不会在这里详述。抓取后,我们应该关闭详细信息页面并返回列表页面。我们注意到可以使用快捷键Ctrl+W,所以可以模拟使用快捷键关闭详情页。
auto,SendKeys("{Ctrl}w")
8.效果图
渲染中的操作都是由程序控制的。
9.总结
综上所述,在本次实战中,我们发现了传统爬虫与Windows程序的一些共同点。HTML 页面和 Windows 程序都具有类似的树状页面结构,因此可以通过某种方式获取元素。相比之下,Windows 程序更复杂,提供的工具更少,因此难度更大。
php抓取网页数据插入数据库(创建一个ListList的对象list1层(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2021-12-03 07:13
如图所示:
2.控制器层:
后台是jsp上输入url的地方。
//回显汽车car分类
@RequestMapping("/loadCategory")
@ResponseBody
public List loadCategory(HttpServletResponse response){
response.setContentType("text/html;charset=utf-8");
response.setCharacterEncoding("utf-8"); //响应编码
System.out.println("jsp页面加载即触发");
List namelist = categoryService.findClassNames();
System.out.println("查询到的类别:"+namelist);
//list存放map,map存放kv值(json),namelist取需要的字段
List list = new ArrayList();
for (Category category : namelist) {
Map map = new HashMap();
//只取classid、ClassName即可。
String className = category.getClassName().toString();
String classid = category.getClassid().toString();
//map存放键值对
map.put("classid",classid);
map.put("className",className);
//list存放map
list.add(map);
System.out.println("json格式:"+list); //打印出来就成为了json格式
}
return list;
}
情况就是这样。一般来说,后端直接查询类别表,然后返回一个集合数据列表。但是我们制作下拉框只需要category id和category name,完全不需要其他额外的数据项。因此,上面的意思是:
Namelist去查询category表,得到一堆数据。
然后需要获取所需的 classid 和 className 字段对应的数据。
然后我们声明一个地图。 map用于存储键值对和需要返回的kv。也就是将需要的字段封装到map中。
然后声明一个list,方便带回前端或者转换成json格式。列表存储地图。
其次,如果前台用的是easyui,可以在最后加上@ResponseBody注解,可以直接自动转换成json格式发回前台。
这样就实现了我们需要动态填充数据库中数据的easyui下拉框。 3.效果图:
注意在上面的控制层:
for循环把map放入list的时候,总是同一个map,会导致后面的数据覆盖前面的数据,所以必须把新的HashMap操作放到for循环中,这样才能可以实现将多个map的kv值放入列表中。
List> list1 = new ArrayList>();
表示创建一个List对象list1。 List可以理解为一个链表,list1链表中的元素为Map类型元素,Map是String到Object的映射,即map可以存储key-value对。所以用list来存储地图,然后把list返回给前端jsp页面。 查看全部
php抓取网页数据插入数据库(创建一个ListList的对象list1层(图))
如图所示:

2.控制器层:
后台是jsp上输入url的地方。
//回显汽车car分类
@RequestMapping("/loadCategory")
@ResponseBody
public List loadCategory(HttpServletResponse response){
response.setContentType("text/html;charset=utf-8");
response.setCharacterEncoding("utf-8"); //响应编码
System.out.println("jsp页面加载即触发");
List namelist = categoryService.findClassNames();
System.out.println("查询到的类别:"+namelist);
//list存放map,map存放kv值(json),namelist取需要的字段
List list = new ArrayList();
for (Category category : namelist) {
Map map = new HashMap();
//只取classid、ClassName即可。
String className = category.getClassName().toString();
String classid = category.getClassid().toString();
//map存放键值对
map.put("classid",classid);
map.put("className",className);
//list存放map
list.add(map);
System.out.println("json格式:"+list); //打印出来就成为了json格式
}
return list;
}
情况就是这样。一般来说,后端直接查询类别表,然后返回一个集合数据列表。但是我们制作下拉框只需要category id和category name,完全不需要其他额外的数据项。因此,上面的意思是:
Namelist去查询category表,得到一堆数据。

然后需要获取所需的 classid 和 className 字段对应的数据。
然后我们声明一个地图。 map用于存储键值对和需要返回的kv。也就是将需要的字段封装到map中。
然后声明一个list,方便带回前端或者转换成json格式。列表存储地图。
其次,如果前台用的是easyui,可以在最后加上@ResponseBody注解,可以直接自动转换成json格式发回前台。
这样就实现了我们需要动态填充数据库中数据的easyui下拉框。 3.效果图:
注意在上面的控制层:
for循环把map放入list的时候,总是同一个map,会导致后面的数据覆盖前面的数据,所以必须把新的HashMap操作放到for循环中,这样才能可以实现将多个map的kv值放入列表中。
List> list1 = new ArrayList>();
表示创建一个List对象list1。 List可以理解为一个链表,list1链表中的元素为Map类型元素,Map是String到Object的映射,即map可以存储key-value对。所以用list来存储地图,然后把list返回给前端jsp页面。
php抓取网页数据插入数据库(小泊和mysqli问题500错误解决后,简单用了php)
网站优化 • 优采云 发表了文章 • 0 个评论 • 41 次浏览 • 2021-12-01 06:16
小博升级官网时需要实现留言功能(小博注)。为了能够更方便的在数据库中存储数据,小波干脆用了php的方式。下面具体说说遇到的问题和解决方法。
500 内部服务器错误错误:
首先,在向php文件发送数据时,页面报“500 Internal Server Error”错误。小波也在网上搜索了很多关于这个问题的解决方案,但最终都没有解决。
因为小波使用的是阿里云“ECS服务器windows系统”,所以没有权限问题。一些php配置也是按照网友给出的解决方案进行配置的。它仍然不起作用。最后,小波在运行php.exe时,发现程序报错,无法运行。最后发现缺少一些dll文件,导致php无法正常运行,导致500错误。
这里小波推荐一款dll文件修复工具“DirectXrepair”,可以百度下载。修复通过后,500错误消失了。
mysql 和 mysqli 问题
500错误解决后,在传输数据的时候,发现页面有错误,基本上就是推荐使用mysqli或者pdo方式,然后根据错误进行修改后问题就可以解决了。
这里需要注意的是,mysql和mysqli的语法还是有很大区别的,所以一定要注意语法的正确使用。
表单提交不跳转
因为我在官网使用,所以不需要表单跳转到官网以外的页面。所以,在发送的时候,小波使用ajax发送,而不是使用传统的表单发送方式。
mysql 构建表
这里小波提醒大家建表时要注意主键和字段长度。
代码(跳转)
html表单
Name
Message
PHP
<p> 查看全部
php抓取网页数据插入数据库(小泊和mysqli问题500错误解决后,简单用了php)
小博升级官网时需要实现留言功能(小博注)。为了能够更方便的在数据库中存储数据,小波干脆用了php的方式。下面具体说说遇到的问题和解决方法。
500 内部服务器错误错误:
首先,在向php文件发送数据时,页面报“500 Internal Server Error”错误。小波也在网上搜索了很多关于这个问题的解决方案,但最终都没有解决。
因为小波使用的是阿里云“ECS服务器windows系统”,所以没有权限问题。一些php配置也是按照网友给出的解决方案进行配置的。它仍然不起作用。最后,小波在运行php.exe时,发现程序报错,无法运行。最后发现缺少一些dll文件,导致php无法正常运行,导致500错误。
这里小波推荐一款dll文件修复工具“DirectXrepair”,可以百度下载。修复通过后,500错误消失了。
mysql 和 mysqli 问题
500错误解决后,在传输数据的时候,发现页面有错误,基本上就是推荐使用mysqli或者pdo方式,然后根据错误进行修改后问题就可以解决了。
这里需要注意的是,mysql和mysqli的语法还是有很大区别的,所以一定要注意语法的正确使用。
表单提交不跳转
因为我在官网使用,所以不需要表单跳转到官网以外的页面。所以,在发送的时候,小波使用ajax发送,而不是使用传统的表单发送方式。
mysql 构建表
这里小波提醒大家建表时要注意主键和字段长度。
代码(跳转)
html表单
Name
Message
PHP
<p>
php抓取网页数据插入数据库(id和成绩的“结果”表。。|)
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2021-11-29 16:05
我有一个名为“结果”的表,其中收录 member_id 和分数。我有一个名为“结果”的 member_id 和分数表。每个 member_id 将有几行,我想将每个 member_id 的分数加在一起,并将它们输出到一个有两列的表中,成员一个分数。一起,然后将它们输出到一个有两列的表中,即 Member Score。
同时,我需要加入一个名为Members的表(它共享一个公共字段,member_id,与Results),以便在输出数据时提取值'fullname'并在Member列中显示该值同时,我需要加入一个名为Member的表(该表与Results共享一个公共字段member_id),以便在输出数据时提取值“全名”并在Member列中显示该值。
我想我可以在一个 SQL 查询中完成很多工作,然后简单地将它输出到一个表中(我已经可以这样做了),但我正在努力编写一个可以正确输出数据的查询。我想我可以做一个SQL查询中的所有工作,然后输出到表中(我已经可以做了),但是我正在尝试写一个可以正确输出数据的查询。
这是结果表中的数据示例 这是结果表中的数据示例
来自成员表和来自成员表
以及我如何希望可以从 SQL 查询中返回数据
忽略冒号,我这里只是用它们来分隔值,以便于查看。请记住,Results 表中将有未知数量的用户和未知数量的行需要迭代。迭代它。 查看全部
php抓取网页数据插入数据库(id和成绩的“结果”表。。|)
我有一个名为“结果”的表,其中收录 member_id 和分数。我有一个名为“结果”的 member_id 和分数表。每个 member_id 将有几行,我想将每个 member_id 的分数加在一起,并将它们输出到一个有两列的表中,成员一个分数。一起,然后将它们输出到一个有两列的表中,即 Member Score。
同时,我需要加入一个名为Members的表(它共享一个公共字段,member_id,与Results),以便在输出数据时提取值'fullname'并在Member列中显示该值同时,我需要加入一个名为Member的表(该表与Results共享一个公共字段member_id),以便在输出数据时提取值“全名”并在Member列中显示该值。
我想我可以在一个 SQL 查询中完成很多工作,然后简单地将它输出到一个表中(我已经可以这样做了),但我正在努力编写一个可以正确输出数据的查询。我想我可以做一个SQL查询中的所有工作,然后输出到表中(我已经可以做了),但是我正在尝试写一个可以正确输出数据的查询。
这是结果表中的数据示例 这是结果表中的数据示例
来自成员表和来自成员表
以及我如何希望可以从 SQL 查询中返回数据
忽略冒号,我这里只是用它们来分隔值,以便于查看。请记住,Results 表中将有未知数量的用户和未知数量的行需要迭代。迭代它。
php抓取网页数据插入数据库(为什么重新制作Wamp的教程:之前列表并命名)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2021-11-25 19:13
首先说一下为什么要重做Wamp教程:
之前的Wamp教程有一个错误,就是如果Wamp没有注册用户,会导致PHP注入数据失败。这次提交的教程中增加了用户注册步骤,王海涵。除了这一步,如果你不太了解,可以查看之前的教程。
1.安装Wamp后,选择
创建一个新的数据库库以及一个列表和名称
2.在Wamp中创建一个具有所有权限的新Localhost用户
3.在Wamp的WWW文件夹中新建一个文件夹
并在其中新建一个php文本文件(txt改成UTF8改名为php)
4.在php中使用mysqli_connect()连接,
填写(“localhost”,注册全局权限用户名,注册密码,数据库名)
5.在浏览器中输入localhost/(www中php的路径)即可访问。如果输出正确,则连接正确。如果失败,请检查Wamp当前的运行状态和PHP脚本的正确性。
6.尝试通过PHP向数据库注入数据,在浏览器中重新输入脚本地址
如果显示链接成功,则表示链接和注入成功
如果Not link,则证明连接数据库错误,检查数据库名称是否正确
如果不成功,则证明数据注入有问题。检查Sql脚本是否有问题。
7.尝试通过PHP从数据库中提取数据,在浏览器中重新输入脚本地址
如果显示链接成功,则表示链接和注入成功
如果Not link,则证明连接数据库错误,检查数据库名称是否正确
如果不成功,则证明数据搜索有问题。检查Sql脚本是否有问题。
至此,我们已经完成了通过PHP注入和读取数据库的工作。
在下一节中,我们将讨论如何从 Unity 获取 PHP 数据。 查看全部
php抓取网页数据插入数据库(为什么重新制作Wamp的教程:之前列表并命名)
首先说一下为什么要重做Wamp教程:
之前的Wamp教程有一个错误,就是如果Wamp没有注册用户,会导致PHP注入数据失败。这次提交的教程中增加了用户注册步骤,王海涵。除了这一步,如果你不太了解,可以查看之前的教程。
1.安装Wamp后,选择
创建一个新的数据库库以及一个列表和名称
2.在Wamp中创建一个具有所有权限的新Localhost用户
3.在Wamp的WWW文件夹中新建一个文件夹
并在其中新建一个php文本文件(txt改成UTF8改名为php)
4.在php中使用mysqli_connect()连接,
填写(“localhost”,注册全局权限用户名,注册密码,数据库名)
5.在浏览器中输入localhost/(www中php的路径)即可访问。如果输出正确,则连接正确。如果失败,请检查Wamp当前的运行状态和PHP脚本的正确性。
6.尝试通过PHP向数据库注入数据,在浏览器中重新输入脚本地址
如果显示链接成功,则表示链接和注入成功
如果Not link,则证明连接数据库错误,检查数据库名称是否正确
如果不成功,则证明数据注入有问题。检查Sql脚本是否有问题。
7.尝试通过PHP从数据库中提取数据,在浏览器中重新输入脚本地址
如果显示链接成功,则表示链接和注入成功
如果Not link,则证明连接数据库错误,检查数据库名称是否正确
如果不成功,则证明数据搜索有问题。检查Sql脚本是否有问题。
至此,我们已经完成了通过PHP注入和读取数据库的工作。
在下一节中,我们将讨论如何从 Unity 获取 PHP 数据。
php抓取网页数据插入数据库(PHP函数访问数据库实验:修改,查询,删除功能(四选一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2021-11-22 21:06
实验题目:PHP函数访问数据库
目的:
1.完整的数据录入、修改、查询、删除功能(四种选择一)可以使用实验6设计的数据库。
2.要求:提交网页截图和源代码,用不同颜色标注相关代码,并给出文字说明。
实验步骤:
首先根据自己的实验需要建立数据库,然后用php语言编写程序,连接数据库,操作数据库。我实现的操作包括查询、修改和删除,使用sql语句,精通数据库操作,还有php语言,还是很好实现的。
adminstyt.php 文件
#customers
{
font-family:"Trebuchet MS", Arial, Helvetica, sans-serif;
width:100%;
border-collapse:collapse;
}
#customers td, #customers th
{
font-size:1em;
border:1px solid #98bf21;
padding:3px 7px 2px 7px;
}
#customers th
{
font-size:1.1em;
text-align:left;
padding-top:5px;
padding-bottom:4px;
background-color:#A7C942;
color:#ffffff;
}
#customers tr.alt td
{
color:#000000;
background-color:#EAF2D3;
}
查询用户数据
序列
用户姓名
电话
电子邮箱
预约时间
更新.php文件
body {text-decoration:none;background-color:#ddccff ;
color:blue;font-weight:bold;border: medium double rgb( 189,189,189);
background-image: URL(6.jpg);
background-position: center;
background-repeat: no-repeat;
background-attachment: fixed;
}
username:
>
email:
>
好的.php
删除.php
操作结果:
经验
通过这个实验,我学会了使用PHP语言连接数据库,完成数据的录入、修改、查询、删除等功能。本次实验详细讲解了查询、修改、删除功能,数据插入处理不难实现。我觉得我学到了很多。在这个过程中,修改失败,删除一开始就失败了。后来发现原因是我忽略了id字段名,根本就拿不到正确的id,所以无法实现后续的修改和删除。后来,我添加了设置自增1的id,然后操作就可以成功执行了。对于查询接口,分页处理的主要部分稍微详细一些。为了更漂亮,我做了一个桌子展示。总的来说,我觉得很有成就感。感觉这个操作以后可以自己实现。 查看全部
php抓取网页数据插入数据库(PHP函数访问数据库实验:修改,查询,删除功能(四选一))
实验题目:PHP函数访问数据库
目的:
1.完整的数据录入、修改、查询、删除功能(四种选择一)可以使用实验6设计的数据库。
2.要求:提交网页截图和源代码,用不同颜色标注相关代码,并给出文字说明。
实验步骤:
首先根据自己的实验需要建立数据库,然后用php语言编写程序,连接数据库,操作数据库。我实现的操作包括查询、修改和删除,使用sql语句,精通数据库操作,还有php语言,还是很好实现的。
adminstyt.php 文件
#customers
{
font-family:"Trebuchet MS", Arial, Helvetica, sans-serif;
width:100%;
border-collapse:collapse;
}
#customers td, #customers th
{
font-size:1em;
border:1px solid #98bf21;
padding:3px 7px 2px 7px;
}
#customers th
{
font-size:1.1em;
text-align:left;
padding-top:5px;
padding-bottom:4px;
background-color:#A7C942;
color:#ffffff;
}
#customers tr.alt td
{
color:#000000;
background-color:#EAF2D3;
}
查询用户数据
序列
用户姓名
电话
电子邮箱
预约时间
更新.php文件
body {text-decoration:none;background-color:#ddccff ;
color:blue;font-weight:bold;border: medium double rgb( 189,189,189);
background-image: URL(6.jpg);
background-position: center;
background-repeat: no-repeat;
background-attachment: fixed;
}
username:
>
email:
>
好的.php
删除.php
操作结果:

经验
通过这个实验,我学会了使用PHP语言连接数据库,完成数据的录入、修改、查询、删除等功能。本次实验详细讲解了查询、修改、删除功能,数据插入处理不难实现。我觉得我学到了很多。在这个过程中,修改失败,删除一开始就失败了。后来发现原因是我忽略了id字段名,根本就拿不到正确的id,所以无法实现后续的修改和删除。后来,我添加了设置自增1的id,然后操作就可以成功执行了。对于查询接口,分页处理的主要部分稍微详细一些。为了更漂亮,我做了一个桌子展示。总的来说,我觉得很有成就感。感觉这个操作以后可以自己实现。
php抓取网页数据插入数据库(BigDump数据库.32b(SQL文件分段导入工具))
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-11-22 21:04
BigDump v0.32b(SQL文件分割导入工具)
BigDump 的全称是 BigDump Staggered MySQL Dump Importer。它不是 Joomla! 的标准扩展,而是一个独立的 Web 界面工具软件。教程:在了解BigDump的功能之前,请先想象下图:你的网站 MySQL数据库大约有500MB甚至更大,即使导出的SQL文件被压缩成tar.gz格式,最终文件的体积也超过了 PHP 允许的最大上传值 64MB。如果要使用这么庞大的SQL文件,通过web界面访问phpMyAdmin导入到数据库中,恐怕很难成功(除非你自己管理服务器并有MySQL shell访问权限)。对于普通用户,我认为使用BigDump工具完全可以解决上述问题。 BigDump的工作原理是:多次分段导入庞大的SQL文件,每完成一个段就重新启动导入会话,不会造成中断或失败。理论上,BigDump 可以针对任何 MySQL 数据库工作。 BigDump数据库导入工具使用方法:下载并得到一个zip压缩文件,解压后里面有一个php文件;将压缩包中的bigdump.php上传到Joomla的/tmp目录下! 网站;复制你的MySQL数据库文件(.sql格式或.tar.gz压缩包)也上传到bigdump.php同目录下;通过浏览器访问 bigdump.php 文件,您将看到目录中的文件列表。从列表中找到您的 SQL 文件。文件后将出现“开始导入”链接。单击此链接以启动自动导入过程。 bigdump 将切换到一个新页面,显示导入过程的进度。完成后删除bigdump工具和刚刚上传的SQL文件。
立即下载 查看全部
php抓取网页数据插入数据库(BigDump数据库.32b(SQL文件分段导入工具))
BigDump v0.32b(SQL文件分割导入工具)
BigDump 的全称是 BigDump Staggered MySQL Dump Importer。它不是 Joomla! 的标准扩展,而是一个独立的 Web 界面工具软件。教程:在了解BigDump的功能之前,请先想象下图:你的网站 MySQL数据库大约有500MB甚至更大,即使导出的SQL文件被压缩成tar.gz格式,最终文件的体积也超过了 PHP 允许的最大上传值 64MB。如果要使用这么庞大的SQL文件,通过web界面访问phpMyAdmin导入到数据库中,恐怕很难成功(除非你自己管理服务器并有MySQL shell访问权限)。对于普通用户,我认为使用BigDump工具完全可以解决上述问题。 BigDump的工作原理是:多次分段导入庞大的SQL文件,每完成一个段就重新启动导入会话,不会造成中断或失败。理论上,BigDump 可以针对任何 MySQL 数据库工作。 BigDump数据库导入工具使用方法:下载并得到一个zip压缩文件,解压后里面有一个php文件;将压缩包中的bigdump.php上传到Joomla的/tmp目录下! 网站;复制你的MySQL数据库文件(.sql格式或.tar.gz压缩包)也上传到bigdump.php同目录下;通过浏览器访问 bigdump.php 文件,您将看到目录中的文件列表。从列表中找到您的 SQL 文件。文件后将出现“开始导入”链接。单击此链接以启动自动导入过程。 bigdump 将切换到一个新页面,显示导入过程的进度。完成后删除bigdump工具和刚刚上传的SQL文件。
立即下载
php抓取网页数据插入数据库(php抓取网页数据插入数据库并使用sqlite数据存储格式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-22 17:15
php抓取网页数据插入数据库并使用sqlite数据库格式。web数据库数据库没有格式规定,就像数据库表格没有格式一样。但是数据库中储存的数据要尽可能地与php自身的数据存储格式一致。数据库标准库一般定义了较为抽象的数据格式。基本数据类型标准数据类型主要包括int,double,char和boolean这些。
int中的int和double有两种区别,一种是从右往左区别,一种是不允许存储负数的区别,本文所说的int不准确指代int(实际操作中发现int容易误改变原来的数据类型)。这些数据类型的标准定义也是很重要的,简单来说类似于java中的integer和integer的区别。integer定义可以通过访问属性(protectedstaticfinal)来获取属性。
另一种是定义integer的标识符(protectedstaticfinal),因为标识符是用于区分两个不同的值。另外integer也可以通过一个包装器类(enum)进行处理。这些标准类型中还有很多没有规定格式的类型,比如null和false,null不表示一个int类型,由另一个数据类型来保存,表示false是由0表示,但这些字符是以数组的形式存储在对象中。
反正就是java这边如果你写成int[]list=newarraylist();list[0]=1;再加上该地址开始出现int和integer的标识符就好了。但php中这么做有些不太礼貌。char与boolean在php上他们唯一的区别是位数不同,在java中的取值范围是[1,255],在php中是[0,1],但是在上面那个比喻中我们没有说出这个数据的位数,只说了它是integer(整型)和boolean(布尔型),它们都是正数,是整数,不过用于计算时不一样。
对于char,php有一个方法,可以用null来声明空字符串。一些字符是区分字符数组的,比如"000",当数组里包含"000"时,数组的值将被替换成undefined,对于boolean也是这样,当判断一个布尔值是true或false时,会要求布尔数组的值必须匹配数组的定义。给定一个php对象,可以定义数组和字符串函数。
第一种参数是字符串参数,第二种参数是数组参数。不过php只定义了phpstormconnectionsctype的字符串函数。php会创建一个phpstorm对象来使用其中的相关函数,可以看到它所有的属性和方法都定义在了connections这个类中。在php中定义函数的模式有如下几种:arguments:定义一个特定的函数,返回该函数的返回值。
interface:定义一个具有相同方法的对象,可以使用该对象进行调用。class:定义一个具有类方法的函数对象,返回该类的对象。importlambdaextends:定义一个具有方法的函数对象,返回该函。 查看全部
php抓取网页数据插入数据库(php抓取网页数据插入数据库并使用sqlite数据存储格式)
php抓取网页数据插入数据库并使用sqlite数据库格式。web数据库数据库没有格式规定,就像数据库表格没有格式一样。但是数据库中储存的数据要尽可能地与php自身的数据存储格式一致。数据库标准库一般定义了较为抽象的数据格式。基本数据类型标准数据类型主要包括int,double,char和boolean这些。
int中的int和double有两种区别,一种是从右往左区别,一种是不允许存储负数的区别,本文所说的int不准确指代int(实际操作中发现int容易误改变原来的数据类型)。这些数据类型的标准定义也是很重要的,简单来说类似于java中的integer和integer的区别。integer定义可以通过访问属性(protectedstaticfinal)来获取属性。
另一种是定义integer的标识符(protectedstaticfinal),因为标识符是用于区分两个不同的值。另外integer也可以通过一个包装器类(enum)进行处理。这些标准类型中还有很多没有规定格式的类型,比如null和false,null不表示一个int类型,由另一个数据类型来保存,表示false是由0表示,但这些字符是以数组的形式存储在对象中。
反正就是java这边如果你写成int[]list=newarraylist();list[0]=1;再加上该地址开始出现int和integer的标识符就好了。但php中这么做有些不太礼貌。char与boolean在php上他们唯一的区别是位数不同,在java中的取值范围是[1,255],在php中是[0,1],但是在上面那个比喻中我们没有说出这个数据的位数,只说了它是integer(整型)和boolean(布尔型),它们都是正数,是整数,不过用于计算时不一样。
对于char,php有一个方法,可以用null来声明空字符串。一些字符是区分字符数组的,比如"000",当数组里包含"000"时,数组的值将被替换成undefined,对于boolean也是这样,当判断一个布尔值是true或false时,会要求布尔数组的值必须匹配数组的定义。给定一个php对象,可以定义数组和字符串函数。
第一种参数是字符串参数,第二种参数是数组参数。不过php只定义了phpstormconnectionsctype的字符串函数。php会创建一个phpstorm对象来使用其中的相关函数,可以看到它所有的属性和方法都定义在了connections这个类中。在php中定义函数的模式有如下几种:arguments:定义一个特定的函数,返回该函数的返回值。
interface:定义一个具有相同方法的对象,可以使用该对象进行调用。class:定义一个具有类方法的函数对象,返回该类的对象。importlambdaextends:定义一个具有方法的函数对象,返回该函。
php抓取网页数据插入数据库(接到一个备注内容具体实现代码如下>>文本备注)
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-18 08:21
我接到了一个任务,要在我们的网站中添加一些中国名牌网站的内容。这些 网站 上的某些页面是 文章 链接的列表。点击链接会出现文章详细的内容展示页面,根据这个规则,结合正则表达式、XMLHTTP技术、Jscript服务器端脚本、ADO技术,写了一个小程序,将这些内容抓取到本地数据库。抓起来比较方便,然后把数据库中的数据导入到数据库中。首先创建一个Access数据库,结构如下
id自动编号识别,主键
oldID number 旧数据编码
标题标题文字
备注内容
具体实现代码如下
<%@LANGUAGE="JSCRIPT" CODEPAGE="936"%>
<!-- METADATA NAME="Microsoft ActiveX Data Objects 2.5 Library"
TYPE="TypeLib" UUID="{00000205-0000-0010-8000-00AA006D2EA4}" -->
<%
//打开数据库
try
{
var strConnectionString = "Provider=Microsoft.Jet.OLEDB.4.0;Data Source=" + Server.MapPath("#db.mdb");
var objConnection = Server.CreateObject("ADODB.Connection");
objConnection.Open(strConnectionString);
}
catch(e)
{
Response.Write(e.description);
Response.End();
}
%>
<script language="jscript" runat="server">
//远程获取数据
function GetData()
{
var xHttp = new ActiveXObject("microsoft.xmlhttp");
xHttp.open("POST","http://kukusoft.net/",false);
xHttp.send();
return(xHttp.responseText);
}
//利用正则表达式提取符合条件的链接
function GetLinks(str)
{
var re = new RegExp("<a[^<>]+?\>((.|\n)*?)<\/a>", "gi");
var a = str.match(re); //第一次搜索 for(var i=0;i<a.length;i++)
{
var t1,t2;
var temp;
var r = /qy.php\?id=(\d+)/ig;
if(!r.test(a[i]))continue;
temp = a[i].match(/qy.php\?id=(\d+)/ig);
t1 = RegExp.$1;
temp = a[i].match(/<font[^<>]+?color=\"#000000\"\>(.*?)<\/font>/ig);
t2 = RegExp.$1;
if(t1 == t2)continue;
SaveArticle(t1,t2,GetContent(t1));
}
}
//通过提取的链接获取ID,并通过这个ID取抓取相应的文章
function GetContent(id)
{
var xHttp = new ActiveXObject("microsoft.xmlhttp");
xHttp.open("POST","http://kukusoft.net/qy.php?id=" + id,false);
xHttp.send();
var str = xHttp.responseText;
var re = new RegExp("<span[^<>]+?style=\"font-size:10\.8pt\">(.*?)<\/span>", "gi");
var a = str.match(re);
return(RegExp.$1);
}
//入库
function SaveArticle(oldID,Title,Content)
{
var oRst = Server.CreateObject("ADODB.Recordset");
var sQuery;
sQuery = "SELECT oldID,Title,Content FROM Articles"
oRst.Open(sQuery,objConnection,adOpenStatic,adLockPessimistic);
oRst.AddNew();
oRst("oldID") = oldID;
oRst("Title") = Title;
oRst("Content") = Content;
oRst.Update();
oRst.Close();
Response.Write(Title + "抓取成功" + "<br>");
}
</script>
<HTML>
<头部>
<TITLE>抢文章</TITLE> 查看全部
php抓取网页数据插入数据库(接到一个备注内容具体实现代码如下>>文本备注)
我接到了一个任务,要在我们的网站中添加一些中国名牌网站的内容。这些 网站 上的某些页面是 文章 链接的列表。点击链接会出现文章详细的内容展示页面,根据这个规则,结合正则表达式、XMLHTTP技术、Jscript服务器端脚本、ADO技术,写了一个小程序,将这些内容抓取到本地数据库。抓起来比较方便,然后把数据库中的数据导入到数据库中。首先创建一个Access数据库,结构如下
id自动编号识别,主键
oldID number 旧数据编码
标题标题文字
备注内容
具体实现代码如下
<%@LANGUAGE="JSCRIPT" CODEPAGE="936"%>
<!-- METADATA NAME="Microsoft ActiveX Data Objects 2.5 Library"
TYPE="TypeLib" UUID="{00000205-0000-0010-8000-00AA006D2EA4}" -->
<%
//打开数据库
try
{
var strConnectionString = "Provider=Microsoft.Jet.OLEDB.4.0;Data Source=" + Server.MapPath("#db.mdb");
var objConnection = Server.CreateObject("ADODB.Connection");
objConnection.Open(strConnectionString);
}
catch(e)
{
Response.Write(e.description);
Response.End();
}
%>
<script language="jscript" runat="server">
//远程获取数据
function GetData()
{
var xHttp = new ActiveXObject("microsoft.xmlhttp");
xHttp.open("POST","http://kukusoft.net/",false);
xHttp.send();
return(xHttp.responseText);
}
//利用正则表达式提取符合条件的链接
function GetLinks(str)
{
var re = new RegExp("<a[^<>]+?\>((.|\n)*?)<\/a>", "gi");
var a = str.match(re); //第一次搜索 for(var i=0;i<a.length;i++)
{
var t1,t2;
var temp;
var r = /qy.php\?id=(\d+)/ig;
if(!r.test(a[i]))continue;
temp = a[i].match(/qy.php\?id=(\d+)/ig);
t1 = RegExp.$1;
temp = a[i].match(/<font[^<>]+?color=\"#000000\"\>(.*?)<\/font>/ig);
t2 = RegExp.$1;
if(t1 == t2)continue;
SaveArticle(t1,t2,GetContent(t1));
}
}
//通过提取的链接获取ID,并通过这个ID取抓取相应的文章
function GetContent(id)
{
var xHttp = new ActiveXObject("microsoft.xmlhttp");
xHttp.open("POST","http://kukusoft.net/qy.php?id=" + id,false);
xHttp.send();
var str = xHttp.responseText;
var re = new RegExp("<span[^<>]+?style=\"font-size:10\.8pt\">(.*?)<\/span>", "gi");
var a = str.match(re);
return(RegExp.$1);
}
//入库
function SaveArticle(oldID,Title,Content)
{
var oRst = Server.CreateObject("ADODB.Recordset");
var sQuery;
sQuery = "SELECT oldID,Title,Content FROM Articles"
oRst.Open(sQuery,objConnection,adOpenStatic,adLockPessimistic);
oRst.AddNew();
oRst("oldID") = oldID;
oRst("Title") = Title;
oRst("Content") = Content;
oRst.Update();
oRst.Close();
Response.Write(Title + "抓取成功" + "<br>");
}
</script>
<HTML>
<头部>
<TITLE>抢文章</TITLE>
php抓取网页数据插入数据库( 【测试】txt文件)
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-12-17 13:19
【测试】txt文件)
php读取txt文件并将数据插入数据库
更新时间:2016-02-23 08:54:02 投稿:hebedich
本文文章主要介绍php读取txt文件并将数据插入数据库的方法和示例代码。小文件可以参考第一种方法,大文件可以参考第二种方法。
今天要测试一个函数,您需要将一些原创数据插入到数据库中。PM给了一个txt文件。如何快速将这个txt文件的内容拆分成想要的数组,然后插入到数据库中?
serial_number.txt 的示例内容:
序列号.txt:
DM00001A11 0116,
SN00002A11 0116,
AB00003A11 0116,
PV00004A11 0116,
OC00005A11 0116,
IX00006A11 0116,
创建数据表:
create table serial_number(
id int primary key auto_increment not null,
serial_number varchar(50) not null
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
php代码如下:
$conn = mysql_connect('127.0.0.1','root','') or die("Invalid query: " . mysql_error());
mysql_select_db('test', $conn) or die("Invalid query: " . mysql_error());
$content = file_get_contents("serial_number.txt");
$contents= explode(",",$content);//explode()函数以","为标识符进行拆分
foreach ($contents as $k => $v)//遍历循环
{
$id = $k;
$serial_number = $v;
mysql_query("insert into serial_number (`id`,`serial_number`)
VALUES('$id','$serial_number')");
}
备注:方法很多。我这里是把txt文件拆分成数组,然后遍历循环得到的数组,每次循环插入数据库一次。 查看全部
php抓取网页数据插入数据库(
【测试】txt文件)
php读取txt文件并将数据插入数据库
更新时间:2016-02-23 08:54:02 投稿:hebedich
本文文章主要介绍php读取txt文件并将数据插入数据库的方法和示例代码。小文件可以参考第一种方法,大文件可以参考第二种方法。
今天要测试一个函数,您需要将一些原创数据插入到数据库中。PM给了一个txt文件。如何快速将这个txt文件的内容拆分成想要的数组,然后插入到数据库中?
serial_number.txt 的示例内容:
序列号.txt:
DM00001A11 0116,
SN00002A11 0116,
AB00003A11 0116,
PV00004A11 0116,
OC00005A11 0116,
IX00006A11 0116,
创建数据表:
create table serial_number(
id int primary key auto_increment not null,
serial_number varchar(50) not null
)ENGINE=InnoDB DEFAULT CHARSET=utf8;
php代码如下:
$conn = mysql_connect('127.0.0.1','root','') or die("Invalid query: " . mysql_error());
mysql_select_db('test', $conn) or die("Invalid query: " . mysql_error());
$content = file_get_contents("serial_number.txt");
$contents= explode(",",$content);//explode()函数以","为标识符进行拆分
foreach ($contents as $k => $v)//遍历循环
{
$id = $k;
$serial_number = $v;
mysql_query("insert into serial_number (`id`,`serial_number`)
VALUES('$id','$serial_number')");
}
备注:方法很多。我这里是把txt文件拆分成数组,然后遍历循环得到的数组,每次循环插入数据库一次。
php抓取网页数据插入数据库(菜鸟拿到一套PHP网站程序源代码和sql文件,应该如何下手?)
网站优化 • 优采云 发表了文章 • 0 个评论 • 64 次浏览 • 2021-12-17 13:12
今天,解决新手上手的疑惑?
菜鸟应该如何得到一套PHP网站程序源码和sql数据库文件?我从哪里开始上传程序并部署网站?
首先要了解FTP软件的使用方法(这是基础)
本软件用于上传您的网站程序并稍后更新程序。软件很简单,以FlashFXP为例,在虚拟主机的控制面板中找到你的FTP登录IP地址(软件中的服务器对应IP地址或域名)、账号、密码即可。左侧是本地目录。, 右边是服务器目录,本地端右键上传或者直接拖拽。该软件不需要过多介绍,如果不会,可以下载一个,使用一次。
学习使用FTP软件。今天以虚拟主机为例。总结一般分为两种情况:
一、网站源代码自带安装程序
这个一般比较简单,只需将压缩文件上传到虚拟主机需要的网站对应目录下,使用虚拟主机控制面板中的在线解压功能直接解压到虚拟主机的根目录即可网站 比如 wwwroot 目录就可以了。不建议使用FTP软件在全站上传文件夹形式的压缩文件。这很浪费时间,而且效率很低。经常异常中断,无法完整上传。
例如cms或Discuz!等很多程序。有这个功能。只需根据程序说明上传程序并访问指定网站即可。
此信息可向主办公司查询,如实填写即可。
二、只有网站源代码和sql数据库文件,无需安装程序
这是主要内容。网上很多共享的程序,都是直接被别人写的程序共享的。程序代码和sql数据库文件(数据表结构)提供给大家下载,如李雷博客的源码。状况。仅提供PHP源码和mysql数据库sql文件,安装问题需自行解决。这也是我开源博客源码的初衷,让新手入门,自己解决问题,了解网站的基本配置。
以西部数据为例:
1、上传zip网站程序压缩包并解压
为了上传zip而不是rar,因为一般的Linux系统和apache服务器都运行PHP程序,这里支持zip,虚拟主机暂不支持rar。这取决于主机的支持。
上传,使用FTP上传到指定目录。下一步是解压程序。
2、手动配置数据库连接信息
以李磊的PHP博客为例。在程序目录“mdaima_var_inc/conn.php”中找到conn.php文件。这是连接数据库的配置文件。像这样打开源代码。(右击用记事本打开)
3、导入mysql数据库的sql脚本
一般PHP虚拟主机都会有phpmyadmin管理工具,点进去就可以了。
打开后就是这个样子,如图。只需单击步骤。
浏览并选择 .sql 数据库文件并执行导入。此时,网站 程序应该是可以访问的。
说了这么多,就是想让新手真正掌握网站程序的部署方法。就像吃了别人给你做的方便面,现在我只是扔给你一袋未开封的方便面。,让你自己泡,不能就这么放着,等吃不下去了。希望更多的人能够一步一步的学习,在迷茫的时候掌握一些技巧,以便以后能够应对各种情况。
转载请注明:新手拿到PHP网站源码和sql数据库文件后,从哪里开始部署?| 码码-李磊博客 查看全部
php抓取网页数据插入数据库(菜鸟拿到一套PHP网站程序源代码和sql文件,应该如何下手?)
今天,解决新手上手的疑惑?
菜鸟应该如何得到一套PHP网站程序源码和sql数据库文件?我从哪里开始上传程序并部署网站?
首先要了解FTP软件的使用方法(这是基础)
本软件用于上传您的网站程序并稍后更新程序。软件很简单,以FlashFXP为例,在虚拟主机的控制面板中找到你的FTP登录IP地址(软件中的服务器对应IP地址或域名)、账号、密码即可。左侧是本地目录。, 右边是服务器目录,本地端右键上传或者直接拖拽。该软件不需要过多介绍,如果不会,可以下载一个,使用一次。
学习使用FTP软件。今天以虚拟主机为例。总结一般分为两种情况:
一、网站源代码自带安装程序
这个一般比较简单,只需将压缩文件上传到虚拟主机需要的网站对应目录下,使用虚拟主机控制面板中的在线解压功能直接解压到虚拟主机的根目录即可网站 比如 wwwroot 目录就可以了。不建议使用FTP软件在全站上传文件夹形式的压缩文件。这很浪费时间,而且效率很低。经常异常中断,无法完整上传。
例如cms或Discuz!等很多程序。有这个功能。只需根据程序说明上传程序并访问指定网站即可。
此信息可向主办公司查询,如实填写即可。
二、只有网站源代码和sql数据库文件,无需安装程序
这是主要内容。网上很多共享的程序,都是直接被别人写的程序共享的。程序代码和sql数据库文件(数据表结构)提供给大家下载,如李雷博客的源码。状况。仅提供PHP源码和mysql数据库sql文件,安装问题需自行解决。这也是我开源博客源码的初衷,让新手入门,自己解决问题,了解网站的基本配置。
以西部数据为例:
1、上传zip网站程序压缩包并解压
为了上传zip而不是rar,因为一般的Linux系统和apache服务器都运行PHP程序,这里支持zip,虚拟主机暂不支持rar。这取决于主机的支持。
上传,使用FTP上传到指定目录。下一步是解压程序。
2、手动配置数据库连接信息
以李磊的PHP博客为例。在程序目录“mdaima_var_inc/conn.php”中找到conn.php文件。这是连接数据库的配置文件。像这样打开源代码。(右击用记事本打开)
3、导入mysql数据库的sql脚本
一般PHP虚拟主机都会有phpmyadmin管理工具,点进去就可以了。
打开后就是这个样子,如图。只需单击步骤。
浏览并选择 .sql 数据库文件并执行导入。此时,网站 程序应该是可以访问的。
说了这么多,就是想让新手真正掌握网站程序的部署方法。就像吃了别人给你做的方便面,现在我只是扔给你一袋未开封的方便面。,让你自己泡,不能就这么放着,等吃不下去了。希望更多的人能够一步一步的学习,在迷茫的时候掌握一些技巧,以便以后能够应对各种情况。
转载请注明:新手拿到PHP网站源码和sql数据库文件后,从哪里开始部署?| 码码-李磊博客
php抓取网页数据插入数据库(腾讯云香港,韩国免备案服务器1.8折优惠(组图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 60 次浏览 • 2021-12-17 09:12
AD:阿里云服务器企业会员更优惠。腾讯云香港和韩国免备案服务器。1.20% 折扣
今天给大家总结一下php获取新插入数据id的几种方法。有很好的参考价值。我希望它会对大家有所帮助。跟着小编一起来看看吧。
在mysql中插入数据的时候,很多时候我们想知道刚刚插入的数据的id。这对我们非常有用。下面我将三种常用的方法命名,并一一分析它们的优缺点。
使用以下语句:
mysql_query("select max(id) from t1",$link);
使用这种方法的时候,我们得到的id的最大值确实是最后一个,但是在多链接线程的时候,最大的id不一定是我们自己插入的,所以这里没有使用域线程。
二、使用以下函数:
msyql_insert_id();
当系统执行INSERT然后执行SELECT时,可能已经分发到不同的后端服务器。如果你使用的编程语言是PHP,此时应该通过mysql_insert_id()获取最新插入的id,每次INSERT结束后,已经计算出对应的自增值返回给PHP。您不需要发出单独的查询,只需使用 mysql_insert_id()。这个功能非常有用。当我们插入一条语句时,它会自动返回到最后。这个函数的id值只对当前链接有用,多用户安全,所以我们经常用到这个函数;
但是这个函数的一个问题是id为bigint的时候它不起作用,所以使用这个函数时请小心。但是我们很少遇到这样的问题,所以你可以忽略它。
三:使用查询
msyql_query("选择last_insert_id()");
last_insert_id()是mysql的一个函数,对当前链接有效。这个用法解决了mysql_insert_id()中遇到的bigint问题。 查看全部
php抓取网页数据插入数据库(腾讯云香港,韩国免备案服务器1.8折优惠(组图))
AD:阿里云服务器企业会员更优惠。腾讯云香港和韩国免备案服务器。1.20% 折扣
今天给大家总结一下php获取新插入数据id的几种方法。有很好的参考价值。我希望它会对大家有所帮助。跟着小编一起来看看吧。
在mysql中插入数据的时候,很多时候我们想知道刚刚插入的数据的id。这对我们非常有用。下面我将三种常用的方法命名,并一一分析它们的优缺点。
使用以下语句:
mysql_query("select max(id) from t1",$link);
使用这种方法的时候,我们得到的id的最大值确实是最后一个,但是在多链接线程的时候,最大的id不一定是我们自己插入的,所以这里没有使用域线程。
二、使用以下函数:
msyql_insert_id();
当系统执行INSERT然后执行SELECT时,可能已经分发到不同的后端服务器。如果你使用的编程语言是PHP,此时应该通过mysql_insert_id()获取最新插入的id,每次INSERT结束后,已经计算出对应的自增值返回给PHP。您不需要发出单独的查询,只需使用 mysql_insert_id()。这个功能非常有用。当我们插入一条语句时,它会自动返回到最后。这个函数的id值只对当前链接有用,多用户安全,所以我们经常用到这个函数;
但是这个函数的一个问题是id为bigint的时候它不起作用,所以使用这个函数时请小心。但是我们很少遇到这样的问题,所以你可以忽略它。
三:使用查询
msyql_query("选择last_insert_id()");
last_insert_id()是mysql的一个函数,对当前链接有效。这个用法解决了mysql_insert_id()中遇到的bigint问题。
php抓取网页数据插入数据库(创建一个div条件语句(用户可见)//将页面来处理)
网站优化 • 优采云 发表了文章 • 0 个评论 • 49 次浏览 • 2021-12-17 00:44
显示页面(用户可见)
//将此页面接收到的数据交给Chuli页面进行处理
国籍代码:
//创建一个div并将其放入接收器以接收代码值
民族名称:
//创建一个div并将其放入接收方以接收name值
操作页面(用户不可见)
$code=$uu POST[“code”];//设置一个变量以接收用户提交的代码值
$name=$uu-POST[“name”];//设置一个变量以接收用户提交的名称值
//联系
$conn=@mysql_uu连接(“localhost”、“root”、“123”);//Localhost是本地服务器地址,root是用户名,123是数据库密码
//为操作选择数据库
mysql_uu选择_uu数据库(“,$conn”)
//编写SQL语句
$sql=“插入国家值({$code},{$name}”);//向数据库添加数据。如果是整数或布尔值,则不能用单引号括起来。只有vachar类型应收录在单引号中
//执行
$result=mysql\uquery($sql)
If($result)//创建一个条件语句,以提醒程序员数据添加是否成功
{
//跳转页
标题(“位置:lizi.php”);//如果添加成功,您将跳回Lizi页面,即用户输入页面
}
否则
{
Echo“添加失败!”//如果添加失败,将显示提示消息。加法失败
} 查看全部
php抓取网页数据插入数据库(创建一个div条件语句(用户可见)//将页面来处理)
显示页面(用户可见)
//将此页面接收到的数据交给Chuli页面进行处理
国籍代码:
//创建一个div并将其放入接收器以接收代码值
民族名称:
//创建一个div并将其放入接收方以接收name值
操作页面(用户不可见)
$code=$uu POST[“code”];//设置一个变量以接收用户提交的代码值
$name=$uu-POST[“name”];//设置一个变量以接收用户提交的名称值
//联系
$conn=@mysql_uu连接(“localhost”、“root”、“123”);//Localhost是本地服务器地址,root是用户名,123是数据库密码
//为操作选择数据库
mysql_uu选择_uu数据库(“,$conn”)
//编写SQL语句
$sql=“插入国家值({$code},{$name}”);//向数据库添加数据。如果是整数或布尔值,则不能用单引号括起来。只有vachar类型应收录在单引号中
//执行
$result=mysql\uquery($sql)
If($result)//创建一个条件语句,以提醒程序员数据添加是否成功
{
//跳转页
标题(“位置:lizi.php”);//如果添加成功,您将跳回Lizi页面,即用户输入页面
}
否则
{
Echo“添加失败!”//如果添加失败,将显示提示消息。加法失败
}
php抓取网页数据插入数据库(一个函数抓取网页的表格制作方法及注意事项(上))
网站优化 • 优采云 发表了文章 • 0 个评论 • 53 次浏览 • 2021-12-15 17:17
爬虫是我们熟悉的概念。比如百度和谷歌都有自己的爬虫工具,可以对网站进行爬取、分析、索引,方便我们查询。
我们在浏览网站和查询信息的时候,如果想做一些批处理,也可以分析网站的结构,抓取网页,提取信息,然后完成一个小爬虫的编写.
网络爬虫需要我们了解
URL
结构,
HTML
语法特征和结构,以及适当的爬行和解析工具的使用。我们先看一下本文中的一个简单流程,给个直观感受:一个抓取网页表单的函数。后面我会慢慢分析如何获取更多的定制信息。
HMDB(人类代谢组数据库)收录 收录大量代谢组学、临床化学、生物标志物开发和基础教育的代谢组数据。数据连接化学、临床和分子生物学三个层次,共有114,099个代谢物。
网站 提供多种浏览和查询功能,可以针对不同的疾病、通路、BMI、年龄、性别相关的代谢组学。
下图显示了BMI相关代谢物的数据。
如果我们要下载这个表格,一种方法是一页一页地复制,大约十几次。工作量不算大,但有些无聊。另一种方式是这次抓取网页。
R的
XML
包里有个函数
readHTMLTable
它专用于识别 HTML 中的表格(table 标签)以提取元素。具体用途如下:
<p># Load the package required to read website
library(XML)
# wegpage address
url 查看全部
php抓取网页数据插入数据库(一个函数抓取网页的表格制作方法及注意事项(上))
爬虫是我们熟悉的概念。比如百度和谷歌都有自己的爬虫工具,可以对网站进行爬取、分析、索引,方便我们查询。
我们在浏览网站和查询信息的时候,如果想做一些批处理,也可以分析网站的结构,抓取网页,提取信息,然后完成一个小爬虫的编写.
网络爬虫需要我们了解
URL
结构,
HTML
语法特征和结构,以及适当的爬行和解析工具的使用。我们先看一下本文中的一个简单流程,给个直观感受:一个抓取网页表单的函数。后面我会慢慢分析如何获取更多的定制信息。
HMDB(人类代谢组数据库)收录 收录大量代谢组学、临床化学、生物标志物开发和基础教育的代谢组数据。数据连接化学、临床和分子生物学三个层次,共有114,099个代谢物。
网站 提供多种浏览和查询功能,可以针对不同的疾病、通路、BMI、年龄、性别相关的代谢组学。
下图显示了BMI相关代谢物的数据。
如果我们要下载这个表格,一种方法是一页一页地复制,大约十几次。工作量不算大,但有些无聊。另一种方式是这次抓取网页。
R的
XML
包里有个函数
readHTMLTable
它专用于识别 HTML 中的表格(table 标签)以提取元素。具体用途如下:
<p># Load the package required to read website
library(XML)
# wegpage address
url
php抓取网页数据插入数据库(接下来翻页规律解析网页的函数,我们接下来把他补全不一会 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 58 次浏览 • 2021-12-14 07:22
)
1. 写在前面
作为活跃在京津冀地区的开发商,如果不想闲着,看看国际大都市石家庄的一些数据就知道了。本博客爬取了链家网的租房信息,获取的数据在以下博客中,可以作为一些数据分析的素材。
我们需要抓取的网址是:
2. 分析网址
首先确定我们需要什么数据
可以看到,×××框就是我们需要的数据。
接下来确定翻页规则
https://sjz.lianjia.com/zufang/pg1/
https://sjz.lianjia.com/zufang/pg2/
https://sjz.lianjia.com/zufang/pg3/
https://sjz.lianjia.com/zufang/pg4/
https://sjz.lianjia.com/zufang/pg5/
...
https://sjz.lianjia.com/zufang/pg80/
Python资源分享qun 784758214 ,内有安装包,PDF,学习视频,这里是Python学习者的聚集地,零基础,进阶,都欢迎
3. 解析网页
有了分页地址,可以快速拼接链接,我们使用lxml模块解析网页源代码,得到想要的数据。
本次编码使用了一个新的模块fake_useragent,这个模块可以随机得到一个UA(user-agent),该模块使用起来比较简单,可以去百度百度很多教程。
本博客主要用于调用随机UA
self._ua = UserAgent()
self._headers = {"User-Agent": self._ua.random} # 调用一个随机的UA
因为页码可以快速拼接,所以使用协程对csv文件中使用的pandas模块进行抓包写入
from fake_useragent import UserAgent
from lxml import etree
import asyncio
import aiohttp
import pandas as pd
class LianjiaSpider(object):
def __init__(self):
self._ua = UserAgent()
self._headers = {"User-Agent": self._ua.random}
self._data = list()
async def get(self,url):
async with aiohttp.ClientSession() as session:
try:
async with session.get(url,headers=self._headers,timeout=3) as resp:
if resp.status==200:
result = await resp.text()
return result
except Exception as e:
print(e.args)
async def parse_html(self):
for page in range(1,77):
url = "https://sjz.lianjia.com/zufang/pg{}/".format(page)
print("正在爬取{}".format(url))
html = await self.get(url) # 获取网页内容
html = etree.HTML(html) # 解析网页
self.parse_page(html) # 匹配我们想要的数据
print("正在存储数据....")
######################### 数据写入
data = pd.DataFrame(self._data)
data.to_csv("链家网租房数据.csv", encoding='utf_8_sig') # 写入文件
######################### 数据写入
def run(self):
loop = asyncio.get_event_loop()
tasks = [asyncio.ensure_future(self.parse_html())]
loop.run_until_complete(asyncio.wait(tasks))
if __name__ == '__main__':
l = LianjiaSpider()
l.run()
上面的代码缺少解析网页的功能,我们接下来补上
def parse_page(self,html):
info_panel = html.xpath("//div[@class='info-panel']")
for info in info_panel:
region = self.remove_space(info.xpath(".//span[@class='region']/text()"))
zone = self.remove_space(info.xpath(".//span[@class='zone']/span/text()"))
meters = self.remove_space(info.xpath(".//span[@class='meters']/text()"))
where = self.remove_space(info.xpath(".//div[@class='where']/span[4]/text()"))
con = info.xpath(".//div[@class='con']/text()")
floor = con[0] # 楼层
type = con[1] # 样式
agent = info.xpath(".//div[@class='con']/a/text()")[0]
has = info.xpath(".//div[@class='left agency']//text()")
price = info.xpath(".//div[@class='price']/span/text()")[0]
price_pre = info.xpath(".//div[@class='price-pre']/text()")[0]
look_num = info.xpath(".//div[@class='square']//span[@class='num']/text()")[0]
one_data = {
"region":region,
"zone":zone,
"meters":meters,
"where":where,
"louceng":floor,
"type":type,
"xiaoshou":agent,
"has":has,
"price":price,
"price_pre":price_pre,
"num":look_num
}
self._data.append(one_data) # 添加数据
Python资源分享qun 784758214 ,内有安装包,PDF,学习视频,这里是Python学习者的聚集地,零基础,进阶,都欢迎
过一会,数据就差不多爬完了。
查看全部
php抓取网页数据插入数据库(接下来翻页规律解析网页的函数,我们接下来把他补全不一会
)
1. 写在前面
作为活跃在京津冀地区的开发商,如果不想闲着,看看国际大都市石家庄的一些数据就知道了。本博客爬取了链家网的租房信息,获取的数据在以下博客中,可以作为一些数据分析的素材。
我们需要抓取的网址是:
2. 分析网址
首先确定我们需要什么数据
可以看到,×××框就是我们需要的数据。
接下来确定翻页规则
https://sjz.lianjia.com/zufang/pg1/
https://sjz.lianjia.com/zufang/pg2/
https://sjz.lianjia.com/zufang/pg3/
https://sjz.lianjia.com/zufang/pg4/
https://sjz.lianjia.com/zufang/pg5/
...
https://sjz.lianjia.com/zufang/pg80/
Python资源分享qun 784758214 ,内有安装包,PDF,学习视频,这里是Python学习者的聚集地,零基础,进阶,都欢迎
3. 解析网页
有了分页地址,可以快速拼接链接,我们使用lxml模块解析网页源代码,得到想要的数据。
本次编码使用了一个新的模块fake_useragent,这个模块可以随机得到一个UA(user-agent),该模块使用起来比较简单,可以去百度百度很多教程。
本博客主要用于调用随机UA
self._ua = UserAgent()
self._headers = {"User-Agent": self._ua.random} # 调用一个随机的UA
因为页码可以快速拼接,所以使用协程对csv文件中使用的pandas模块进行抓包写入
from fake_useragent import UserAgent
from lxml import etree
import asyncio
import aiohttp
import pandas as pd
class LianjiaSpider(object):
def __init__(self):
self._ua = UserAgent()
self._headers = {"User-Agent": self._ua.random}
self._data = list()
async def get(self,url):
async with aiohttp.ClientSession() as session:
try:
async with session.get(url,headers=self._headers,timeout=3) as resp:
if resp.status==200:
result = await resp.text()
return result
except Exception as e:
print(e.args)
async def parse_html(self):
for page in range(1,77):
url = "https://sjz.lianjia.com/zufang/pg{}/".format(page)
print("正在爬取{}".format(url))
html = await self.get(url) # 获取网页内容
html = etree.HTML(html) # 解析网页
self.parse_page(html) # 匹配我们想要的数据
print("正在存储数据....")
######################### 数据写入
data = pd.DataFrame(self._data)
data.to_csv("链家网租房数据.csv", encoding='utf_8_sig') # 写入文件
######################### 数据写入
def run(self):
loop = asyncio.get_event_loop()
tasks = [asyncio.ensure_future(self.parse_html())]
loop.run_until_complete(asyncio.wait(tasks))
if __name__ == '__main__':
l = LianjiaSpider()
l.run()
上面的代码缺少解析网页的功能,我们接下来补上
def parse_page(self,html):
info_panel = html.xpath("//div[@class='info-panel']")
for info in info_panel:
region = self.remove_space(info.xpath(".//span[@class='region']/text()"))
zone = self.remove_space(info.xpath(".//span[@class='zone']/span/text()"))
meters = self.remove_space(info.xpath(".//span[@class='meters']/text()"))
where = self.remove_space(info.xpath(".//div[@class='where']/span[4]/text()"))
con = info.xpath(".//div[@class='con']/text()")
floor = con[0] # 楼层
type = con[1] # 样式
agent = info.xpath(".//div[@class='con']/a/text()")[0]
has = info.xpath(".//div[@class='left agency']//text()")
price = info.xpath(".//div[@class='price']/span/text()")[0]
price_pre = info.xpath(".//div[@class='price-pre']/text()")[0]
look_num = info.xpath(".//div[@class='square']//span[@class='num']/text()")[0]
one_data = {
"region":region,
"zone":zone,
"meters":meters,
"where":where,
"louceng":floor,
"type":type,
"xiaoshou":agent,
"has":has,
"price":price,
"price_pre":price_pre,
"num":look_num
}
self._data.append(one_data) # 添加数据
Python资源分享qun 784758214 ,内有安装包,PDF,学习视频,这里是Python学习者的聚集地,零基础,进阶,都欢迎
过一会,数据就差不多爬完了。
php抓取网页数据插入数据库(php抓取网页数据插入数据库处理数据提取部分节选数据解析)
网站优化 • 优采云 发表了文章 • 0 个评论 • 48 次浏览 • 2021-12-14 02:00
php抓取网页数据插入数据库处理数据提取部分节选数据解析php爬虫?看你怎么去看待它。有想不明白的请自行百度解惑。
答案在这里:请问php抓取网页或者数据库时如何分析一条语句内容?
一旦抓取,必须写成伪代码!(php是全自动语言,不用手写代码,可以参考python的库,requests等包),所以从抓取过程,应该没什么,但从你调整抓取规则,做到对网页的自动分析,自动代码,对开发者工作量是个大考验。不过如果是为了要爬哪个网站的数据,
只要是操作系统,都有接口,通过这个操作程序,可以拿到对应的数据。如果你用纯php,理论上不用再分析后就可以拿到对应的数据,但是实际用的方法有很多,除了正则表达式等全自动的方法外,还有爬虫结构化工具等等,看你想从哪个方面下手。如果说有一个浏览器特殊浏览器接口的话,可以拿这个接口做后处理,实现持久化处理等。
看你要抓取什么类型的数据,如果要抓取网页中的表格,excel等,建议抓取数据之前做一个简单的转换(python有很多可以用来做数据转换的库,可以自己选择,推荐我自己正在使用的)例如:xls格式数据,按照数据单元编号,进行字符串格式化处理,如:小数点的"-"替换为"-"。抓取的数据有字符串自动转换为数字格式等,然后再逐一提取数据进行存储。 查看全部
php抓取网页数据插入数据库(php抓取网页数据插入数据库处理数据提取部分节选数据解析)
php抓取网页数据插入数据库处理数据提取部分节选数据解析php爬虫?看你怎么去看待它。有想不明白的请自行百度解惑。
答案在这里:请问php抓取网页或者数据库时如何分析一条语句内容?
一旦抓取,必须写成伪代码!(php是全自动语言,不用手写代码,可以参考python的库,requests等包),所以从抓取过程,应该没什么,但从你调整抓取规则,做到对网页的自动分析,自动代码,对开发者工作量是个大考验。不过如果是为了要爬哪个网站的数据,
只要是操作系统,都有接口,通过这个操作程序,可以拿到对应的数据。如果你用纯php,理论上不用再分析后就可以拿到对应的数据,但是实际用的方法有很多,除了正则表达式等全自动的方法外,还有爬虫结构化工具等等,看你想从哪个方面下手。如果说有一个浏览器特殊浏览器接口的话,可以拿这个接口做后处理,实现持久化处理等。
看你要抓取什么类型的数据,如果要抓取网页中的表格,excel等,建议抓取数据之前做一个简单的转换(python有很多可以用来做数据转换的库,可以自己选择,推荐我自己正在使用的)例如:xls格式数据,按照数据单元编号,进行字符串格式化处理,如:小数点的"-"替换为"-"。抓取的数据有字符串自动转换为数字格式等,然后再逐一提取数据进行存储。
php抓取网页数据插入数据库(如何使用PHP的MySQL类函数来访问MySQL数据库PHP)
网站优化 • 优采云 发表了文章 • 0 个评论 • 57 次浏览 • 2021-12-10 17:31
第十二章 PHP访问数据库
12.1 PHP访问MySQL数据库
PHP 支持几乎所有的数据库类型。其中PHP对MySQL的支持最为完善。因此,PHP 和 MySQL 也被称为“黄金组合”。通过PHP的易用性和MySQL强大的数据库存储功能,可以创建具有各种功能的Web应用程序。本节将介绍如何使用 PHP 的 MySQL 函数访问 MySQL 数据库。
12.1.1 连接MySQL服务器
要操作数据库,必须先连接MySQL服务器。如上一节介绍MySQL常用操作时提到的,用户可以使用客户端工具连接服务器。在 PHP 中,您可以使用 PHP 的类似 MySQL 的函数 mysql_connect() 连接到 MySQL 服务器。语法格式如下:
资源mysql_connect([字符串服务器[,字符串用户名[,字符串密码,[bool new_link[,int client_flags]]]]])
12.1.2 创建数据库
在MySQL主机上新建一个数据库,可以通过函数mysql_query()执行创建的数据库的SQL语句来实现。mysql_query()的作用是执行指定的SQL语句,其语法格式如下:
资源 mysql_query(string $query[,resource $link_identifier])
12.1.3 插入数据
新创建的表中没有内容。如果要向其中添加新内容,则需要执行 SQL 语句插入记录。在上一章介绍的SQL语法中,常见的插入记录语句INSERT的格式如下代码所示:
insert into table name (field name 1, field name 2...) values('value 1','value 2',...)
12.1.4 查询数据
查询表中已有的记录可以通过函数mysql_query()执行SELECT查询SQL语句来实现。但是,为了在 PHP 中查看记录,除了执行 SELECT 查询之外,还需要使用另一个 PHP 类似 MySQL 的函数 msyql_fetch_array()。该函数的作用是从结果集中获取一行作为关联数组,其语法格式如下:
数组 mysql_fetch_array(资源 $result [, int $result_type])
12.1.5 修改数据
除了插入数据和查询数据外,还可以使用PHP修改表中已有的记录。执行修改记录操作,只需要通过PHP的mysql_query()函数执行UPDATE语句即可。
12.1.6 删除数据
与插入、查询、修改类似,通过使用mysql_query()函数执行SQL语句DELETE,也可以删除表中已有的内容。执行删除操作时需要注意。与更新记录类似,通常需要在 DELETE 语句中添加 WHERE 子句来限制删除条件。
12.1.7 数据库抽象类
在 PHP 数据库操作类中,ADODB 是最常用的。这个类非常强大。但是,这门课非常复杂,内容广泛。它也会占用更多的内存资源来执行。为了解决这个问题,轻量级的ADODB Lite应运而生。新版本支持PHP能支持的所有流行数据库,速度比原来的老版本快很多。只占完整版内存的1/6。本节介绍的数据库抽象类以ADODB Lite为例进行介绍。
12.2 PHP操作SQLite数据库
本书的部分为读者介绍了SQLite数据库。与 MySQL 相比,SQLite 数据库使用起来更加方便。因为它不需要配置、安装或管理员,它只需要提供一个数据库文件。并且SQLite的迁移也比较方便,只需要复制和传输相关的数据库文件【一个文件】即可。PHP 还提供对 SQLite 数据库的支持。本节将介绍如何使用PHP操作SQLite数据库。 查看全部
php抓取网页数据插入数据库(如何使用PHP的MySQL类函数来访问MySQL数据库PHP)
第十二章 PHP访问数据库
12.1 PHP访问MySQL数据库
PHP 支持几乎所有的数据库类型。其中PHP对MySQL的支持最为完善。因此,PHP 和 MySQL 也被称为“黄金组合”。通过PHP的易用性和MySQL强大的数据库存储功能,可以创建具有各种功能的Web应用程序。本节将介绍如何使用 PHP 的 MySQL 函数访问 MySQL 数据库。
12.1.1 连接MySQL服务器
要操作数据库,必须先连接MySQL服务器。如上一节介绍MySQL常用操作时提到的,用户可以使用客户端工具连接服务器。在 PHP 中,您可以使用 PHP 的类似 MySQL 的函数 mysql_connect() 连接到 MySQL 服务器。语法格式如下:
资源mysql_connect([字符串服务器[,字符串用户名[,字符串密码,[bool new_link[,int client_flags]]]]])
12.1.2 创建数据库
在MySQL主机上新建一个数据库,可以通过函数mysql_query()执行创建的数据库的SQL语句来实现。mysql_query()的作用是执行指定的SQL语句,其语法格式如下:
资源 mysql_query(string $query[,resource $link_identifier])
12.1.3 插入数据
新创建的表中没有内容。如果要向其中添加新内容,则需要执行 SQL 语句插入记录。在上一章介绍的SQL语法中,常见的插入记录语句INSERT的格式如下代码所示:
insert into table name (field name 1, field name 2...) values('value 1','value 2',...)
12.1.4 查询数据
查询表中已有的记录可以通过函数mysql_query()执行SELECT查询SQL语句来实现。但是,为了在 PHP 中查看记录,除了执行 SELECT 查询之外,还需要使用另一个 PHP 类似 MySQL 的函数 msyql_fetch_array()。该函数的作用是从结果集中获取一行作为关联数组,其语法格式如下:
数组 mysql_fetch_array(资源 $result [, int $result_type])
12.1.5 修改数据
除了插入数据和查询数据外,还可以使用PHP修改表中已有的记录。执行修改记录操作,只需要通过PHP的mysql_query()函数执行UPDATE语句即可。
12.1.6 删除数据
与插入、查询、修改类似,通过使用mysql_query()函数执行SQL语句DELETE,也可以删除表中已有的内容。执行删除操作时需要注意。与更新记录类似,通常需要在 DELETE 语句中添加 WHERE 子句来限制删除条件。
12.1.7 数据库抽象类
在 PHP 数据库操作类中,ADODB 是最常用的。这个类非常强大。但是,这门课非常复杂,内容广泛。它也会占用更多的内存资源来执行。为了解决这个问题,轻量级的ADODB Lite应运而生。新版本支持PHP能支持的所有流行数据库,速度比原来的老版本快很多。只占完整版内存的1/6。本节介绍的数据库抽象类以ADODB Lite为例进行介绍。
12.2 PHP操作SQLite数据库
本书的部分为读者介绍了SQLite数据库。与 MySQL 相比,SQLite 数据库使用起来更加方便。因为它不需要配置、安装或管理员,它只需要提供一个数据库文件。并且SQLite的迁移也比较方便,只需要复制和传输相关的数据库文件【一个文件】即可。PHP 还提供对 SQLite 数据库的支持。本节将介绍如何使用PHP操作SQLite数据库。
php抓取网页数据插入数据库(2.修改数据库类中封装好的查询方法你应该有用到数据库类 )
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2021-12-06 18:17
)
很多博客软件和cms系统都有这样的功能,比如“生成一个页面花了xx毫秒,执行了xx个数据库查询”等等。那么这个功能是如何实现的呢?让我在下面给你一个大致的想法。
1. 在类构造函数中声明全局变量
定义一个全局变量 $queries 来统计页面已经生成的数据库查询次数。
function __construct()
{
parent::__construct();
global $queries;
}
2. 修改封装在数据库类中的查询方法
您应该使用数据库类来查找它封装的数据库查询方法,例如:
// 执行SQL语句
public function query($query)
{
++$GLOBALS['queries'];
return $this->result = mysql_query($query, $this->link);
}
那么每执行一次Query,全局变量query都会加1。
3. 在方法体中写下:
实现这个功能就是这么简单。
4. 自带计算PHP脚本执行的函数
这是一个计算 PHP 脚本执行时间的函数。
// 计时函数
public function runtime($mode = 0) {
static $t;
if(!$mode) {
$t = microtime();
return;
}
$t1 = microtime();
//list($m0,$s0) = split(" ",$t);
list($m0,$s0) = explode(" ",$t);
//list($m1,$s1) = split(" ",$t1);
list($m1,$s1) = explode(" ",$t1);
return sprintf("%.3f ms",($s1+$m1-$s0-$m0)*1000);
}
使用方法如下:
public function content($id = 0)
{
$this -> runtime();
$GLOBALS['queries'] = 0;
// something to do
echo $GLOBALS['queries'];
echo $this -> runtime(1);
} 查看全部
php抓取网页数据插入数据库(2.修改数据库类中封装好的查询方法你应该有用到数据库类
)
很多博客软件和cms系统都有这样的功能,比如“生成一个页面花了xx毫秒,执行了xx个数据库查询”等等。那么这个功能是如何实现的呢?让我在下面给你一个大致的想法。
1. 在类构造函数中声明全局变量
定义一个全局变量 $queries 来统计页面已经生成的数据库查询次数。
function __construct()
{
parent::__construct();
global $queries;
}
2. 修改封装在数据库类中的查询方法
您应该使用数据库类来查找它封装的数据库查询方法,例如:
// 执行SQL语句
public function query($query)
{
++$GLOBALS['queries'];
return $this->result = mysql_query($query, $this->link);
}
那么每执行一次Query,全局变量query都会加1。
3. 在方法体中写下:
实现这个功能就是这么简单。
4. 自带计算PHP脚本执行的函数
这是一个计算 PHP 脚本执行时间的函数。
// 计时函数
public function runtime($mode = 0) {
static $t;
if(!$mode) {
$t = microtime();
return;
}
$t1 = microtime();
//list($m0,$s0) = split(" ",$t);
list($m0,$s0) = explode(" ",$t);
//list($m1,$s1) = split(" ",$t1);
list($m1,$s1) = explode(" ",$t1);
return sprintf("%.3f ms",($s1+$m1-$s0-$m0)*1000);
}
使用方法如下:
public function content($id = 0)
{
$this -> runtime();
$GLOBALS['queries'] = 0;
// something to do
echo $GLOBALS['queries'];
echo $this -> runtime(1);
}
php抓取网页数据插入数据库(师傅说最近需要将电视频道列表及各频道节目列表写入数据库)
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2021-12-06 09:24
师傅说,最近要把电视频道列表和每个频道的节目列表写入数据库。当然,这个动作需要自动执行,人工和一一相加是不现实的。
很快,这项工作就决定由服务器供应商解决。作为一个菜鸟,我还是想自己弄清楚。我认为,尽量结合现有条件来进行这个操作,尽量不要添加新的东西。我观察了开发中使用的xampp,发现里面有php。我在网上搜索了一下,可以在上面进行一些php的实际应用。查了一下php对数据库的操作,是可行的,虽然我觉得好像不是正规的方法,但是试一试也无妨。于是结合安装的xampp环境,我启动了phptest.php。
问题一:在已经安装了xampp的环境下不知道怎么做php开发。经过验证,我发现编辑后的xxx.php文件需要放在xampp安装目录下的htdocs文件夹下。我的xampp安装在D盘,所以我把xxx.php放在D:\xampp\htdocs下,然后在浏览器中输入格式:/xxx.php的地址执行php文件。
问题2:我不会编辑php,但使用开发工具?使用了哪些开发工具?终于发现可以用记事本了,我用ultraedit 32进行编辑,最后保存为“.php”文件。
问题3:如何获取我需要的信息,即电视台列表和节目列表,我们做Android,高手从webervice获取很多信息。当时不知道怎么想,也没有想过用php从webervice获取信息(原来是可以的)。想到的就是解析网页,于是找了个网站有这个信息,准备分析他,这里又晕了,一行一行的看页面源码,不知道怎么弄解析一下,这么多东西,至少肯定有过滤器之类的东西给我用,通过百度,可以用正则表达式来做,好像不止这个方法,好像还有其他方法,这里是知识参考等文章(非常感谢作者),思路比较清晰,连接数据库(见),根据url将网页的所有内容赋值给一个字符串,然后用正则表达式从这个字符串中提取出需要的数据,并对数据进行一些操作比如作为替换和去除冗余部分成为所需的格式,然后将数据插入到建立的数据库表中。我觉得对我来说最难的就是正则表达式,这很头疼。这里确实需要深入研究。另外,也是第一次接触php,感觉有点像c。并对数据进行替换、去除多余部分等操作,使其成为需要的格式,然后将数据插入到建立好的数据库表中。我觉得对我来说最难的就是正则表达式,这很头疼。这里确实需要深入研究。另外,也是第一次接触php,感觉有点像c。并对数据进行替换、去除多余部分等操作,使其成为需要的格式,然后将数据插入到建立好的数据库表中。我觉得对我来说最难的就是正则表达式,这很头疼。这里确实需要深入研究。另外,也是第一次接触php,感觉有点像c。
我是菜鸟,需要总结一下,所以记录一下。如果能帮到别人就更好了。 查看全部
php抓取网页数据插入数据库(师傅说最近需要将电视频道列表及各频道节目列表写入数据库)
师傅说,最近要把电视频道列表和每个频道的节目列表写入数据库。当然,这个动作需要自动执行,人工和一一相加是不现实的。
很快,这项工作就决定由服务器供应商解决。作为一个菜鸟,我还是想自己弄清楚。我认为,尽量结合现有条件来进行这个操作,尽量不要添加新的东西。我观察了开发中使用的xampp,发现里面有php。我在网上搜索了一下,可以在上面进行一些php的实际应用。查了一下php对数据库的操作,是可行的,虽然我觉得好像不是正规的方法,但是试一试也无妨。于是结合安装的xampp环境,我启动了phptest.php。
问题一:在已经安装了xampp的环境下不知道怎么做php开发。经过验证,我发现编辑后的xxx.php文件需要放在xampp安装目录下的htdocs文件夹下。我的xampp安装在D盘,所以我把xxx.php放在D:\xampp\htdocs下,然后在浏览器中输入格式:/xxx.php的地址执行php文件。
问题2:我不会编辑php,但使用开发工具?使用了哪些开发工具?终于发现可以用记事本了,我用ultraedit 32进行编辑,最后保存为“.php”文件。
问题3:如何获取我需要的信息,即电视台列表和节目列表,我们做Android,高手从webervice获取很多信息。当时不知道怎么想,也没有想过用php从webervice获取信息(原来是可以的)。想到的就是解析网页,于是找了个网站有这个信息,准备分析他,这里又晕了,一行一行的看页面源码,不知道怎么弄解析一下,这么多东西,至少肯定有过滤器之类的东西给我用,通过百度,可以用正则表达式来做,好像不止这个方法,好像还有其他方法,这里是知识参考等文章(非常感谢作者),思路比较清晰,连接数据库(见),根据url将网页的所有内容赋值给一个字符串,然后用正则表达式从这个字符串中提取出需要的数据,并对数据进行一些操作比如作为替换和去除冗余部分成为所需的格式,然后将数据插入到建立的数据库表中。我觉得对我来说最难的就是正则表达式,这很头疼。这里确实需要深入研究。另外,也是第一次接触php,感觉有点像c。并对数据进行替换、去除多余部分等操作,使其成为需要的格式,然后将数据插入到建立好的数据库表中。我觉得对我来说最难的就是正则表达式,这很头疼。这里确实需要深入研究。另外,也是第一次接触php,感觉有点像c。并对数据进行替换、去除多余部分等操作,使其成为需要的格式,然后将数据插入到建立好的数据库表中。我觉得对我来说最难的就是正则表达式,这很头疼。这里确实需要深入研究。另外,也是第一次接触php,感觉有点像c。
我是菜鸟,需要总结一下,所以记录一下。如果能帮到别人就更好了。
php抓取网页数据插入数据库(用php怎么获取Mysql数据库的数据?来看下! )
网站优化 • 优采云 发表了文章 • 0 个评论 • 34 次浏览 • 2021-12-06 07:17
)
用php做网站开发,基本离不开数据库。现在我们大部分的网站都是基于数据库的,比如网站的文章,网站的注册用户都存储在数据库中。那么我们如何用php获取Mysql数据库的数据呢?一起来看看吧。
操作方法
01
获取数据库的数据,我们需要先创建连接,使用mysqli_connect函数创建代码,如代码所示。函数的参数从左到右分别代表:数据库地址、连接数据库的用户名、连接数据库的密码。要连接到数据库中的哪个库。
(也可以使用mysql_connect函数来创建连接,但是这个函数在不久的将来会过时,所以我们还是使用新函数更安全)
02
然后我们使用mysqli_query函数来获取数据库的数据。这个函数的第一个参数是数据库连接$conn,第二个参数是sql语句。
03
mysqli_query 函数返回的值 $result 不是数据库中的表数据。它只是一个 mysqli_result 对象。我们修改一下代码,显示这个对象的输出,看看内容是什么。
04
运行后看结果,不是数据库的表数据。
05
要将mysqli_result对象转换成表数据,我们可以使用while循环,通过mysqli_fetch_array函数将mysqli_result对象中的每一行数据转换成数组对象$row,然后使用html表对数据进行格式化。具体代码如图所示。
06
我们先看代码中的sql语句在数据库中查询到的数据,然后与php查询对比,看结果是否一致。找到的数据库数据如图
07
最后,运行页面查看php查询的结果。
如图所示,数据是一致的。(php代码中只显示了id和name这两列)
查看全部
php抓取网页数据插入数据库(用php怎么获取Mysql数据库的数据?来看下!
)
用php做网站开发,基本离不开数据库。现在我们大部分的网站都是基于数据库的,比如网站的文章,网站的注册用户都存储在数据库中。那么我们如何用php获取Mysql数据库的数据呢?一起来看看吧。
操作方法
01
获取数据库的数据,我们需要先创建连接,使用mysqli_connect函数创建代码,如代码所示。函数的参数从左到右分别代表:数据库地址、连接数据库的用户名、连接数据库的密码。要连接到数据库中的哪个库。
(也可以使用mysql_connect函数来创建连接,但是这个函数在不久的将来会过时,所以我们还是使用新函数更安全)
02
然后我们使用mysqli_query函数来获取数据库的数据。这个函数的第一个参数是数据库连接$conn,第二个参数是sql语句。
03
mysqli_query 函数返回的值 $result 不是数据库中的表数据。它只是一个 mysqli_result 对象。我们修改一下代码,显示这个对象的输出,看看内容是什么。
04
运行后看结果,不是数据库的表数据。
05
要将mysqli_result对象转换成表数据,我们可以使用while循环,通过mysqli_fetch_array函数将mysqli_result对象中的每一行数据转换成数组对象$row,然后使用html表对数据进行格式化。具体代码如图所示。
06
我们先看代码中的sql语句在数据库中查询到的数据,然后与php查询对比,看结果是否一致。找到的数据库数据如图
07
最后,运行页面查看php查询的结果。
如图所示,数据是一致的。(php代码中只显示了id和name这两列)
php抓取网页数据插入数据库(Wind(万德)金融终端是如何实现的?(一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 66 次浏览 • 2021-12-03 16:15
1.前言
Wind金融终端是我校学生常用的一款商业软件,提供了大量的金融实施数据,内容丰富,信息量大。Wind 几乎是我见过的付费商业软件中用户体验最好的之一。但是,正是因为其高昂的价格,才使得其保密性非常高,而且里面的数据也不容易得到。Wind官方为我们提供了api接口,但是这些接口还是不能满足我们更加个性化的数据需求。
同时,Wind是PC客户端程序,里面的数据没有浏览器方便。对于浏览器中的数据,可以使用大家非常熟悉的传统爬虫。但是,对于这种PC程序中的数据,还需要其他的方法来捕捉。
如果您需要按照本文所述进行实验,建议准备一个额外的外部屏幕。
2.问题描述
我们这里的目标是抓取风端的研究报告数据。Wind账号是极其昂贵的,这里我们不得不想象我们真的有一个Wind账号。
我们的目标主要是抓取每份研究报告中的一些具体数据,比如研究报告的作者、发布时间、180天内的评价次数和EPS值(见下图中红框),以及将其写入 csv 文件。
3.分析页面
众所周知,浏览器中的数据是以HTML的形式显示的。我们需要的数据可以通过爬虫轻松获取,辅以正则表达式、xpath等工具。事实上,许多Windows程序也有类似HTML页面的结构,但大多数Windows程序不提供检查功能。我们可以使用 Windows SDK 提供的检查器来检查程序中的元素。下图是一个例子,你可以在右图左边的树结构中看到风列表项的位置。
值得注意的是,Windows 程序的页面结构也可能足够复杂。经过我的计算,风之主页的页面节点总数近千。
一旦我们了解了Windows程序的页面结构,理论上肯定有办法批量获取页面上的数据。接下来的工作是找到合适的工具和枯燥的编程工作。
4.选择工具
这里我们选择uiautomation,一个Windows自动化测试工具。这个工具大家可能比较陌生,但是说到selenium,大家就都很熟悉了。Selenium 是用于 网站 测试的自动化测试工具。同时,像我这样的爬虫渣一般都是用selenium来爬取页面信息。自动化也是基于类似的原理,不仅限于web网站,它还可以自动化测试WindowsPC程序。Uiautomation 支持多种语言。在本文中,我们使用基于 python 的 uiautomation 框架。另外,你可以试试java等其他语言的uiautomation。
uiautomation 的python 版本的GitHub 链接在这里:
首先需要安装
pip install uiautomation
5.使用uiautomation选择窗口
接下来,我们需要选择窗口窗口进行后续操作。根据下图不难发现,窗口有一个唯一的类名,我们可以通过这个类名来选择。根据uiautomation作者的习惯,通常将uiautomation导入为auto,我们在下面的代码中也观察到了这个习惯。
import uiautomation as auto
wind = auto.WindowControl(searchDepth=1, ClassName="TMasterForm")
这里的 searchDepth 参数表示搜索深度。整个Windows界面以桌面为根节点,即深度为0,桌面中所有窗口的深度为1。
>>> wind.Name
'Wind金融终端..Everest'
这时候就可以显示窗口名称了,说明我们已经成功定位到该窗口了。
6.获取研究报告列表
当我们在检查器中选择一个列表项时,我们可以发现这些列表项的父元素是一个DataItemControl。对于wind之类的软件,大部分元素都是自定义元素,即CustomControl。Windows 没有提供很多元素,因此您可以通过 DataItemControl 找到它。
首先我们来获取研究报告平台这个子窗口中的内容,如下图所示。
yanbaoWindow = wind.WindowControl(ClassName='TfrmMyIEPageContainer')
接下来,我们可以通过在该子窗口中查找DataItemControl 来找到列表项的父元素。
table = yanbaoWindow.DataItemControl(foundIndex=3)
经过统计,需要的元素是研究报告平台窗口中的第三个DataItemControl,所以指定参数foundIndex = 3。一般来说,PC程序中每个页面的结构都比较稳定,所以可以指定为前三个来查找。
接下来,根据检查器显示的结构关系,我们可以获取并打印这些研究报告的名称:
lines = table.GetChildren()
for line in lines:
c = line.GetChildren()[0]
name = c.GetChildren()[2]
analyst = c.GetChildren()[3]
print(name.Name, analyst.Name)
名称与页面上的研究报告名称相对应。
接下来,我们需要获取研究报告详情页中的信息。这时候就应该模拟一下鼠标的点击操作了。方法也很简单。
name.Click()
就是这样。值得注意的是,uiautomation中的方法命名几乎采用了类似C#的风格,所有的方法名都是用大驼峰命名的,很奇怪。执行 Click 方法后,您将进入详细信息页面。
需要注意的是,由于uiautomation与selenium驱动不同,通过browserdriver控制浏览器进行操作,即uiautomation是没有appdriver的,所以在进行模拟操作的时候一定要保证被点击的对象是在屏幕上方可见范围内,根据位置进行操作,否则会抛出异常。这时候鼠标会被控制,真正点击目标,用户尽量不要使用鼠标。
7.退出详情页
进入详情页后,我们可以用类似的方法抓取我们需要的所有数据。我不会在这里详述。抓取后,我们应该关闭详细信息页面并返回列表页面。我们注意到可以使用快捷键Ctrl+W,所以可以模拟使用快捷键关闭详情页。
auto,SendKeys("{Ctrl}w")
8.效果图
渲染中的操作都是由程序控制的。
9.总结
综上所述,在本次实战中,我们发现了传统爬虫与Windows程序的一些共同点。HTML 页面和 Windows 程序都具有类似的树状页面结构,因此可以通过某种方式获取元素。相比之下,Windows 程序更复杂,提供的工具更少,因此难度更大。 查看全部
php抓取网页数据插入数据库(Wind(万德)金融终端是如何实现的?(一))
1.前言
Wind金融终端是我校学生常用的一款商业软件,提供了大量的金融实施数据,内容丰富,信息量大。Wind 几乎是我见过的付费商业软件中用户体验最好的之一。但是,正是因为其高昂的价格,才使得其保密性非常高,而且里面的数据也不容易得到。Wind官方为我们提供了api接口,但是这些接口还是不能满足我们更加个性化的数据需求。
同时,Wind是PC客户端程序,里面的数据没有浏览器方便。对于浏览器中的数据,可以使用大家非常熟悉的传统爬虫。但是,对于这种PC程序中的数据,还需要其他的方法来捕捉。
如果您需要按照本文所述进行实验,建议准备一个额外的外部屏幕。
2.问题描述
我们这里的目标是抓取风端的研究报告数据。Wind账号是极其昂贵的,这里我们不得不想象我们真的有一个Wind账号。
我们的目标主要是抓取每份研究报告中的一些具体数据,比如研究报告的作者、发布时间、180天内的评价次数和EPS值(见下图中红框),以及将其写入 csv 文件。
3.分析页面
众所周知,浏览器中的数据是以HTML的形式显示的。我们需要的数据可以通过爬虫轻松获取,辅以正则表达式、xpath等工具。事实上,许多Windows程序也有类似HTML页面的结构,但大多数Windows程序不提供检查功能。我们可以使用 Windows SDK 提供的检查器来检查程序中的元素。下图是一个例子,你可以在右图左边的树结构中看到风列表项的位置。
值得注意的是,Windows 程序的页面结构也可能足够复杂。经过我的计算,风之主页的页面节点总数近千。
一旦我们了解了Windows程序的页面结构,理论上肯定有办法批量获取页面上的数据。接下来的工作是找到合适的工具和枯燥的编程工作。
4.选择工具
这里我们选择uiautomation,一个Windows自动化测试工具。这个工具大家可能比较陌生,但是说到selenium,大家就都很熟悉了。Selenium 是用于 网站 测试的自动化测试工具。同时,像我这样的爬虫渣一般都是用selenium来爬取页面信息。自动化也是基于类似的原理,不仅限于web网站,它还可以自动化测试WindowsPC程序。Uiautomation 支持多种语言。在本文中,我们使用基于 python 的 uiautomation 框架。另外,你可以试试java等其他语言的uiautomation。
uiautomation 的python 版本的GitHub 链接在这里:
首先需要安装
pip install uiautomation
5.使用uiautomation选择窗口
接下来,我们需要选择窗口窗口进行后续操作。根据下图不难发现,窗口有一个唯一的类名,我们可以通过这个类名来选择。根据uiautomation作者的习惯,通常将uiautomation导入为auto,我们在下面的代码中也观察到了这个习惯。
import uiautomation as auto
wind = auto.WindowControl(searchDepth=1, ClassName="TMasterForm")
这里的 searchDepth 参数表示搜索深度。整个Windows界面以桌面为根节点,即深度为0,桌面中所有窗口的深度为1。
>>> wind.Name
'Wind金融终端..Everest'
这时候就可以显示窗口名称了,说明我们已经成功定位到该窗口了。
6.获取研究报告列表
当我们在检查器中选择一个列表项时,我们可以发现这些列表项的父元素是一个DataItemControl。对于wind之类的软件,大部分元素都是自定义元素,即CustomControl。Windows 没有提供很多元素,因此您可以通过 DataItemControl 找到它。
首先我们来获取研究报告平台这个子窗口中的内容,如下图所示。
yanbaoWindow = wind.WindowControl(ClassName='TfrmMyIEPageContainer')
接下来,我们可以通过在该子窗口中查找DataItemControl 来找到列表项的父元素。
table = yanbaoWindow.DataItemControl(foundIndex=3)
经过统计,需要的元素是研究报告平台窗口中的第三个DataItemControl,所以指定参数foundIndex = 3。一般来说,PC程序中每个页面的结构都比较稳定,所以可以指定为前三个来查找。
接下来,根据检查器显示的结构关系,我们可以获取并打印这些研究报告的名称:
lines = table.GetChildren()
for line in lines:
c = line.GetChildren()[0]
name = c.GetChildren()[2]
analyst = c.GetChildren()[3]
print(name.Name, analyst.Name)
名称与页面上的研究报告名称相对应。
接下来,我们需要获取研究报告详情页中的信息。这时候就应该模拟一下鼠标的点击操作了。方法也很简单。
name.Click()
就是这样。值得注意的是,uiautomation中的方法命名几乎采用了类似C#的风格,所有的方法名都是用大驼峰命名的,很奇怪。执行 Click 方法后,您将进入详细信息页面。
需要注意的是,由于uiautomation与selenium驱动不同,通过browserdriver控制浏览器进行操作,即uiautomation是没有appdriver的,所以在进行模拟操作的时候一定要保证被点击的对象是在屏幕上方可见范围内,根据位置进行操作,否则会抛出异常。这时候鼠标会被控制,真正点击目标,用户尽量不要使用鼠标。
7.退出详情页
进入详情页后,我们可以用类似的方法抓取我们需要的所有数据。我不会在这里详述。抓取后,我们应该关闭详细信息页面并返回列表页面。我们注意到可以使用快捷键Ctrl+W,所以可以模拟使用快捷键关闭详情页。
auto,SendKeys("{Ctrl}w")
8.效果图
渲染中的操作都是由程序控制的。
9.总结
综上所述,在本次实战中,我们发现了传统爬虫与Windows程序的一些共同点。HTML 页面和 Windows 程序都具有类似的树状页面结构,因此可以通过某种方式获取元素。相比之下,Windows 程序更复杂,提供的工具更少,因此难度更大。
php抓取网页数据插入数据库(创建一个ListList的对象list1层(图))
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2021-12-03 07:13
如图所示:
2.控制器层:
后台是jsp上输入url的地方。
//回显汽车car分类
@RequestMapping("/loadCategory")
@ResponseBody
public List loadCategory(HttpServletResponse response){
response.setContentType("text/html;charset=utf-8");
response.setCharacterEncoding("utf-8"); //响应编码
System.out.println("jsp页面加载即触发");
List namelist = categoryService.findClassNames();
System.out.println("查询到的类别:"+namelist);
//list存放map,map存放kv值(json),namelist取需要的字段
List list = new ArrayList();
for (Category category : namelist) {
Map map = new HashMap();
//只取classid、ClassName即可。
String className = category.getClassName().toString();
String classid = category.getClassid().toString();
//map存放键值对
map.put("classid",classid);
map.put("className",className);
//list存放map
list.add(map);
System.out.println("json格式:"+list); //打印出来就成为了json格式
}
return list;
}
情况就是这样。一般来说,后端直接查询类别表,然后返回一个集合数据列表。但是我们制作下拉框只需要category id和category name,完全不需要其他额外的数据项。因此,上面的意思是:
Namelist去查询category表,得到一堆数据。
然后需要获取所需的 classid 和 className 字段对应的数据。
然后我们声明一个地图。 map用于存储键值对和需要返回的kv。也就是将需要的字段封装到map中。
然后声明一个list,方便带回前端或者转换成json格式。列表存储地图。
其次,如果前台用的是easyui,可以在最后加上@ResponseBody注解,可以直接自动转换成json格式发回前台。
这样就实现了我们需要动态填充数据库中数据的easyui下拉框。 3.效果图:
注意在上面的控制层:
for循环把map放入list的时候,总是同一个map,会导致后面的数据覆盖前面的数据,所以必须把新的HashMap操作放到for循环中,这样才能可以实现将多个map的kv值放入列表中。
List> list1 = new ArrayList>();
表示创建一个List对象list1。 List可以理解为一个链表,list1链表中的元素为Map类型元素,Map是String到Object的映射,即map可以存储key-value对。所以用list来存储地图,然后把list返回给前端jsp页面。 查看全部
php抓取网页数据插入数据库(创建一个ListList的对象list1层(图))
如图所示:
2.控制器层:
后台是jsp上输入url的地方。
//回显汽车car分类
@RequestMapping("/loadCategory")
@ResponseBody
public List loadCategory(HttpServletResponse response){
response.setContentType("text/html;charset=utf-8");
response.setCharacterEncoding("utf-8"); //响应编码
System.out.println("jsp页面加载即触发");
List namelist = categoryService.findClassNames();
System.out.println("查询到的类别:"+namelist);
//list存放map,map存放kv值(json),namelist取需要的字段
List list = new ArrayList();
for (Category category : namelist) {
Map map = new HashMap();
//只取classid、ClassName即可。
String className = category.getClassName().toString();
String classid = category.getClassid().toString();
//map存放键值对
map.put("classid",classid);
map.put("className",className);
//list存放map
list.add(map);
System.out.println("json格式:"+list); //打印出来就成为了json格式
}
return list;
}
情况就是这样。一般来说,后端直接查询类别表,然后返回一个集合数据列表。但是我们制作下拉框只需要category id和category name,完全不需要其他额外的数据项。因此,上面的意思是:
Namelist去查询category表,得到一堆数据。
然后需要获取所需的 classid 和 className 字段对应的数据。
然后我们声明一个地图。 map用于存储键值对和需要返回的kv。也就是将需要的字段封装到map中。
然后声明一个list,方便带回前端或者转换成json格式。列表存储地图。
其次,如果前台用的是easyui,可以在最后加上@ResponseBody注解,可以直接自动转换成json格式发回前台。
这样就实现了我们需要动态填充数据库中数据的easyui下拉框。 3.效果图:
注意在上面的控制层:
for循环把map放入list的时候,总是同一个map,会导致后面的数据覆盖前面的数据,所以必须把新的HashMap操作放到for循环中,这样才能可以实现将多个map的kv值放入列表中。
List> list1 = new ArrayList>();
表示创建一个List对象list1。 List可以理解为一个链表,list1链表中的元素为Map类型元素,Map是String到Object的映射,即map可以存储key-value对。所以用list来存储地图,然后把list返回给前端jsp页面。
php抓取网页数据插入数据库(小泊和mysqli问题500错误解决后,简单用了php)
网站优化 • 优采云 发表了文章 • 0 个评论 • 41 次浏览 • 2021-12-01 06:16
小博升级官网时需要实现留言功能(小博注)。为了能够更方便的在数据库中存储数据,小波干脆用了php的方式。下面具体说说遇到的问题和解决方法。
500 内部服务器错误错误:
首先,在向php文件发送数据时,页面报“500 Internal Server Error”错误。小波也在网上搜索了很多关于这个问题的解决方案,但最终都没有解决。
因为小波使用的是阿里云“ECS服务器windows系统”,所以没有权限问题。一些php配置也是按照网友给出的解决方案进行配置的。它仍然不起作用。最后,小波在运行php.exe时,发现程序报错,无法运行。最后发现缺少一些dll文件,导致php无法正常运行,导致500错误。
这里小波推荐一款dll文件修复工具“DirectXrepair”,可以百度下载。修复通过后,500错误消失了。
mysql 和 mysqli 问题
500错误解决后,在传输数据的时候,发现页面有错误,基本上就是推荐使用mysqli或者pdo方式,然后根据错误进行修改后问题就可以解决了。
这里需要注意的是,mysql和mysqli的语法还是有很大区别的,所以一定要注意语法的正确使用。
表单提交不跳转
因为我在官网使用,所以不需要表单跳转到官网以外的页面。所以,在发送的时候,小波使用ajax发送,而不是使用传统的表单发送方式。
mysql 构建表
这里小波提醒大家建表时要注意主键和字段长度。
代码(跳转)
html表单
Name
Message
PHP
<p> 查看全部
php抓取网页数据插入数据库(小泊和mysqli问题500错误解决后,简单用了php)
小博升级官网时需要实现留言功能(小博注)。为了能够更方便的在数据库中存储数据,小波干脆用了php的方式。下面具体说说遇到的问题和解决方法。
500 内部服务器错误错误:
首先,在向php文件发送数据时,页面报“500 Internal Server Error”错误。小波也在网上搜索了很多关于这个问题的解决方案,但最终都没有解决。
因为小波使用的是阿里云“ECS服务器windows系统”,所以没有权限问题。一些php配置也是按照网友给出的解决方案进行配置的。它仍然不起作用。最后,小波在运行php.exe时,发现程序报错,无法运行。最后发现缺少一些dll文件,导致php无法正常运行,导致500错误。
这里小波推荐一款dll文件修复工具“DirectXrepair”,可以百度下载。修复通过后,500错误消失了。
mysql 和 mysqli 问题
500错误解决后,在传输数据的时候,发现页面有错误,基本上就是推荐使用mysqli或者pdo方式,然后根据错误进行修改后问题就可以解决了。
这里需要注意的是,mysql和mysqli的语法还是有很大区别的,所以一定要注意语法的正确使用。
表单提交不跳转
因为我在官网使用,所以不需要表单跳转到官网以外的页面。所以,在发送的时候,小波使用ajax发送,而不是使用传统的表单发送方式。
mysql 构建表
这里小波提醒大家建表时要注意主键和字段长度。
代码(跳转)
html表单
Name
Message
PHP
<p>
php抓取网页数据插入数据库(id和成绩的“结果”表。。|)
网站优化 • 优采云 发表了文章 • 0 个评论 • 44 次浏览 • 2021-11-29 16:05
我有一个名为“结果”的表,其中收录 member_id 和分数。我有一个名为“结果”的 member_id 和分数表。每个 member_id 将有几行,我想将每个 member_id 的分数加在一起,并将它们输出到一个有两列的表中,成员一个分数。一起,然后将它们输出到一个有两列的表中,即 Member Score。
同时,我需要加入一个名为Members的表(它共享一个公共字段,member_id,与Results),以便在输出数据时提取值'fullname'并在Member列中显示该值同时,我需要加入一个名为Member的表(该表与Results共享一个公共字段member_id),以便在输出数据时提取值“全名”并在Member列中显示该值。
我想我可以在一个 SQL 查询中完成很多工作,然后简单地将它输出到一个表中(我已经可以这样做了),但我正在努力编写一个可以正确输出数据的查询。我想我可以做一个SQL查询中的所有工作,然后输出到表中(我已经可以做了),但是我正在尝试写一个可以正确输出数据的查询。
这是结果表中的数据示例 这是结果表中的数据示例
来自成员表和来自成员表
以及我如何希望可以从 SQL 查询中返回数据
忽略冒号,我这里只是用它们来分隔值,以便于查看。请记住,Results 表中将有未知数量的用户和未知数量的行需要迭代。迭代它。 查看全部
php抓取网页数据插入数据库(id和成绩的“结果”表。。|)
我有一个名为“结果”的表,其中收录 member_id 和分数。我有一个名为“结果”的 member_id 和分数表。每个 member_id 将有几行,我想将每个 member_id 的分数加在一起,并将它们输出到一个有两列的表中,成员一个分数。一起,然后将它们输出到一个有两列的表中,即 Member Score。
同时,我需要加入一个名为Members的表(它共享一个公共字段,member_id,与Results),以便在输出数据时提取值'fullname'并在Member列中显示该值同时,我需要加入一个名为Member的表(该表与Results共享一个公共字段member_id),以便在输出数据时提取值“全名”并在Member列中显示该值。
我想我可以在一个 SQL 查询中完成很多工作,然后简单地将它输出到一个表中(我已经可以这样做了),但我正在努力编写一个可以正确输出数据的查询。我想我可以做一个SQL查询中的所有工作,然后输出到表中(我已经可以做了),但是我正在尝试写一个可以正确输出数据的查询。
这是结果表中的数据示例 这是结果表中的数据示例
来自成员表和来自成员表
以及我如何希望可以从 SQL 查询中返回数据
忽略冒号,我这里只是用它们来分隔值,以便于查看。请记住,Results 表中将有未知数量的用户和未知数量的行需要迭代。迭代它。
php抓取网页数据插入数据库(为什么重新制作Wamp的教程:之前列表并命名)
网站优化 • 优采云 发表了文章 • 0 个评论 • 45 次浏览 • 2021-11-25 19:13
首先说一下为什么要重做Wamp教程:
之前的Wamp教程有一个错误,就是如果Wamp没有注册用户,会导致PHP注入数据失败。这次提交的教程中增加了用户注册步骤,王海涵。除了这一步,如果你不太了解,可以查看之前的教程。
1.安装Wamp后,选择
创建一个新的数据库库以及一个列表和名称
2.在Wamp中创建一个具有所有权限的新Localhost用户
3.在Wamp的WWW文件夹中新建一个文件夹
并在其中新建一个php文本文件(txt改成UTF8改名为php)
4.在php中使用mysqli_connect()连接,
填写(“localhost”,注册全局权限用户名,注册密码,数据库名)
5.在浏览器中输入localhost/(www中php的路径)即可访问。如果输出正确,则连接正确。如果失败,请检查Wamp当前的运行状态和PHP脚本的正确性。
6.尝试通过PHP向数据库注入数据,在浏览器中重新输入脚本地址
如果显示链接成功,则表示链接和注入成功
如果Not link,则证明连接数据库错误,检查数据库名称是否正确
如果不成功,则证明数据注入有问题。检查Sql脚本是否有问题。
7.尝试通过PHP从数据库中提取数据,在浏览器中重新输入脚本地址
如果显示链接成功,则表示链接和注入成功
如果Not link,则证明连接数据库错误,检查数据库名称是否正确
如果不成功,则证明数据搜索有问题。检查Sql脚本是否有问题。
至此,我们已经完成了通过PHP注入和读取数据库的工作。
在下一节中,我们将讨论如何从 Unity 获取 PHP 数据。 查看全部
php抓取网页数据插入数据库(为什么重新制作Wamp的教程:之前列表并命名)
首先说一下为什么要重做Wamp教程:
之前的Wamp教程有一个错误,就是如果Wamp没有注册用户,会导致PHP注入数据失败。这次提交的教程中增加了用户注册步骤,王海涵。除了这一步,如果你不太了解,可以查看之前的教程。
1.安装Wamp后,选择
创建一个新的数据库库以及一个列表和名称
2.在Wamp中创建一个具有所有权限的新Localhost用户
3.在Wamp的WWW文件夹中新建一个文件夹
并在其中新建一个php文本文件(txt改成UTF8改名为php)
4.在php中使用mysqli_connect()连接,
填写(“localhost”,注册全局权限用户名,注册密码,数据库名)
5.在浏览器中输入localhost/(www中php的路径)即可访问。如果输出正确,则连接正确。如果失败,请检查Wamp当前的运行状态和PHP脚本的正确性。
6.尝试通过PHP向数据库注入数据,在浏览器中重新输入脚本地址
如果显示链接成功,则表示链接和注入成功
如果Not link,则证明连接数据库错误,检查数据库名称是否正确
如果不成功,则证明数据注入有问题。检查Sql脚本是否有问题。
7.尝试通过PHP从数据库中提取数据,在浏览器中重新输入脚本地址
如果显示链接成功,则表示链接和注入成功
如果Not link,则证明连接数据库错误,检查数据库名称是否正确
如果不成功,则证明数据搜索有问题。检查Sql脚本是否有问题。
至此,我们已经完成了通过PHP注入和读取数据库的工作。
在下一节中,我们将讨论如何从 Unity 获取 PHP 数据。
php抓取网页数据插入数据库(PHP函数访问数据库实验:修改,查询,删除功能(四选一))
网站优化 • 优采云 发表了文章 • 0 个评论 • 46 次浏览 • 2021-11-22 21:06
实验题目:PHP函数访问数据库
目的:
1.完整的数据录入、修改、查询、删除功能(四种选择一)可以使用实验6设计的数据库。
2.要求:提交网页截图和源代码,用不同颜色标注相关代码,并给出文字说明。
实验步骤:
首先根据自己的实验需要建立数据库,然后用php语言编写程序,连接数据库,操作数据库。我实现的操作包括查询、修改和删除,使用sql语句,精通数据库操作,还有php语言,还是很好实现的。
adminstyt.php 文件
#customers
{
font-family:"Trebuchet MS", Arial, Helvetica, sans-serif;
width:100%;
border-collapse:collapse;
}
#customers td, #customers th
{
font-size:1em;
border:1px solid #98bf21;
padding:3px 7px 2px 7px;
}
#customers th
{
font-size:1.1em;
text-align:left;
padding-top:5px;
padding-bottom:4px;
background-color:#A7C942;
color:#ffffff;
}
#customers tr.alt td
{
color:#000000;
background-color:#EAF2D3;
}
查询用户数据
序列
用户姓名
电话
电子邮箱
预约时间
更新.php文件
body {text-decoration:none;background-color:#ddccff ;
color:blue;font-weight:bold;border: medium double rgb( 189,189,189);
background-image: URL(6.jpg);
background-position: center;
background-repeat: no-repeat;
background-attachment: fixed;
}
username:
>
email:
>
好的.php
删除.php
操作结果:
经验
通过这个实验,我学会了使用PHP语言连接数据库,完成数据的录入、修改、查询、删除等功能。本次实验详细讲解了查询、修改、删除功能,数据插入处理不难实现。我觉得我学到了很多。在这个过程中,修改失败,删除一开始就失败了。后来发现原因是我忽略了id字段名,根本就拿不到正确的id,所以无法实现后续的修改和删除。后来,我添加了设置自增1的id,然后操作就可以成功执行了。对于查询接口,分页处理的主要部分稍微详细一些。为了更漂亮,我做了一个桌子展示。总的来说,我觉得很有成就感。感觉这个操作以后可以自己实现。 查看全部
php抓取网页数据插入数据库(PHP函数访问数据库实验:修改,查询,删除功能(四选一))
实验题目:PHP函数访问数据库
目的:
1.完整的数据录入、修改、查询、删除功能(四种选择一)可以使用实验6设计的数据库。
2.要求:提交网页截图和源代码,用不同颜色标注相关代码,并给出文字说明。
实验步骤:
首先根据自己的实验需要建立数据库,然后用php语言编写程序,连接数据库,操作数据库。我实现的操作包括查询、修改和删除,使用sql语句,精通数据库操作,还有php语言,还是很好实现的。
adminstyt.php 文件
#customers
{
font-family:"Trebuchet MS", Arial, Helvetica, sans-serif;
width:100%;
border-collapse:collapse;
}
#customers td, #customers th
{
font-size:1em;
border:1px solid #98bf21;
padding:3px 7px 2px 7px;
}
#customers th
{
font-size:1.1em;
text-align:left;
padding-top:5px;
padding-bottom:4px;
background-color:#A7C942;
color:#ffffff;
}
#customers tr.alt td
{
color:#000000;
background-color:#EAF2D3;
}
查询用户数据
序列
用户姓名
电话
电子邮箱
预约时间
更新.php文件
body {text-decoration:none;background-color:#ddccff ;
color:blue;font-weight:bold;border: medium double rgb( 189,189,189);
background-image: URL(6.jpg);
background-position: center;
background-repeat: no-repeat;
background-attachment: fixed;
}
username:
>
email:
>
好的.php
删除.php
操作结果:
经验
通过这个实验,我学会了使用PHP语言连接数据库,完成数据的录入、修改、查询、删除等功能。本次实验详细讲解了查询、修改、删除功能,数据插入处理不难实现。我觉得我学到了很多。在这个过程中,修改失败,删除一开始就失败了。后来发现原因是我忽略了id字段名,根本就拿不到正确的id,所以无法实现后续的修改和删除。后来,我添加了设置自增1的id,然后操作就可以成功执行了。对于查询接口,分页处理的主要部分稍微详细一些。为了更漂亮,我做了一个桌子展示。总的来说,我觉得很有成就感。感觉这个操作以后可以自己实现。
php抓取网页数据插入数据库(BigDump数据库.32b(SQL文件分段导入工具))
网站优化 • 优采云 发表了文章 • 0 个评论 • 77 次浏览 • 2021-11-22 21:04
BigDump v0.32b(SQL文件分割导入工具)
BigDump 的全称是 BigDump Staggered MySQL Dump Importer。它不是 Joomla! 的标准扩展,而是一个独立的 Web 界面工具软件。教程:在了解BigDump的功能之前,请先想象下图:你的网站 MySQL数据库大约有500MB甚至更大,即使导出的SQL文件被压缩成tar.gz格式,最终文件的体积也超过了 PHP 允许的最大上传值 64MB。如果要使用这么庞大的SQL文件,通过web界面访问phpMyAdmin导入到数据库中,恐怕很难成功(除非你自己管理服务器并有MySQL shell访问权限)。对于普通用户,我认为使用BigDump工具完全可以解决上述问题。 BigDump的工作原理是:多次分段导入庞大的SQL文件,每完成一个段就重新启动导入会话,不会造成中断或失败。理论上,BigDump 可以针对任何 MySQL 数据库工作。 BigDump数据库导入工具使用方法:下载并得到一个zip压缩文件,解压后里面有一个php文件;将压缩包中的bigdump.php上传到Joomla的/tmp目录下! 网站;复制你的MySQL数据库文件(.sql格式或.tar.gz压缩包)也上传到bigdump.php同目录下;通过浏览器访问 bigdump.php 文件,您将看到目录中的文件列表。从列表中找到您的 SQL 文件。文件后将出现“开始导入”链接。单击此链接以启动自动导入过程。 bigdump 将切换到一个新页面,显示导入过程的进度。完成后删除bigdump工具和刚刚上传的SQL文件。
立即下载 查看全部
php抓取网页数据插入数据库(BigDump数据库.32b(SQL文件分段导入工具))
BigDump v0.32b(SQL文件分割导入工具)
BigDump 的全称是 BigDump Staggered MySQL Dump Importer。它不是 Joomla! 的标准扩展,而是一个独立的 Web 界面工具软件。教程:在了解BigDump的功能之前,请先想象下图:你的网站 MySQL数据库大约有500MB甚至更大,即使导出的SQL文件被压缩成tar.gz格式,最终文件的体积也超过了 PHP 允许的最大上传值 64MB。如果要使用这么庞大的SQL文件,通过web界面访问phpMyAdmin导入到数据库中,恐怕很难成功(除非你自己管理服务器并有MySQL shell访问权限)。对于普通用户,我认为使用BigDump工具完全可以解决上述问题。 BigDump的工作原理是:多次分段导入庞大的SQL文件,每完成一个段就重新启动导入会话,不会造成中断或失败。理论上,BigDump 可以针对任何 MySQL 数据库工作。 BigDump数据库导入工具使用方法:下载并得到一个zip压缩文件,解压后里面有一个php文件;将压缩包中的bigdump.php上传到Joomla的/tmp目录下! 网站;复制你的MySQL数据库文件(.sql格式或.tar.gz压缩包)也上传到bigdump.php同目录下;通过浏览器访问 bigdump.php 文件,您将看到目录中的文件列表。从列表中找到您的 SQL 文件。文件后将出现“开始导入”链接。单击此链接以启动自动导入过程。 bigdump 将切换到一个新页面,显示导入过程的进度。完成后删除bigdump工具和刚刚上传的SQL文件。
立即下载
php抓取网页数据插入数据库(php抓取网页数据插入数据库并使用sqlite数据存储格式)
网站优化 • 优采云 发表了文章 • 0 个评论 • 69 次浏览 • 2021-11-22 17:15
php抓取网页数据插入数据库并使用sqlite数据库格式。web数据库数据库没有格式规定,就像数据库表格没有格式一样。但是数据库中储存的数据要尽可能地与php自身的数据存储格式一致。数据库标准库一般定义了较为抽象的数据格式。基本数据类型标准数据类型主要包括int,double,char和boolean这些。
int中的int和double有两种区别,一种是从右往左区别,一种是不允许存储负数的区别,本文所说的int不准确指代int(实际操作中发现int容易误改变原来的数据类型)。这些数据类型的标准定义也是很重要的,简单来说类似于java中的integer和integer的区别。integer定义可以通过访问属性(protectedstaticfinal)来获取属性。
另一种是定义integer的标识符(protectedstaticfinal),因为标识符是用于区分两个不同的值。另外integer也可以通过一个包装器类(enum)进行处理。这些标准类型中还有很多没有规定格式的类型,比如null和false,null不表示一个int类型,由另一个数据类型来保存,表示false是由0表示,但这些字符是以数组的形式存储在对象中。
反正就是java这边如果你写成int[]list=newarraylist();list[0]=1;再加上该地址开始出现int和integer的标识符就好了。但php中这么做有些不太礼貌。char与boolean在php上他们唯一的区别是位数不同,在java中的取值范围是[1,255],在php中是[0,1],但是在上面那个比喻中我们没有说出这个数据的位数,只说了它是integer(整型)和boolean(布尔型),它们都是正数,是整数,不过用于计算时不一样。
对于char,php有一个方法,可以用null来声明空字符串。一些字符是区分字符数组的,比如"000",当数组里包含"000"时,数组的值将被替换成undefined,对于boolean也是这样,当判断一个布尔值是true或false时,会要求布尔数组的值必须匹配数组的定义。给定一个php对象,可以定义数组和字符串函数。
第一种参数是字符串参数,第二种参数是数组参数。不过php只定义了phpstormconnectionsctype的字符串函数。php会创建一个phpstorm对象来使用其中的相关函数,可以看到它所有的属性和方法都定义在了connections这个类中。在php中定义函数的模式有如下几种:arguments:定义一个特定的函数,返回该函数的返回值。
interface:定义一个具有相同方法的对象,可以使用该对象进行调用。class:定义一个具有类方法的函数对象,返回该类的对象。importlambdaextends:定义一个具有方法的函数对象,返回该函。 查看全部
php抓取网页数据插入数据库(php抓取网页数据插入数据库并使用sqlite数据存储格式)
php抓取网页数据插入数据库并使用sqlite数据库格式。web数据库数据库没有格式规定,就像数据库表格没有格式一样。但是数据库中储存的数据要尽可能地与php自身的数据存储格式一致。数据库标准库一般定义了较为抽象的数据格式。基本数据类型标准数据类型主要包括int,double,char和boolean这些。
int中的int和double有两种区别,一种是从右往左区别,一种是不允许存储负数的区别,本文所说的int不准确指代int(实际操作中发现int容易误改变原来的数据类型)。这些数据类型的标准定义也是很重要的,简单来说类似于java中的integer和integer的区别。integer定义可以通过访问属性(protectedstaticfinal)来获取属性。
另一种是定义integer的标识符(protectedstaticfinal),因为标识符是用于区分两个不同的值。另外integer也可以通过一个包装器类(enum)进行处理。这些标准类型中还有很多没有规定格式的类型,比如null和false,null不表示一个int类型,由另一个数据类型来保存,表示false是由0表示,但这些字符是以数组的形式存储在对象中。
反正就是java这边如果你写成int[]list=newarraylist();list[0]=1;再加上该地址开始出现int和integer的标识符就好了。但php中这么做有些不太礼貌。char与boolean在php上他们唯一的区别是位数不同,在java中的取值范围是[1,255],在php中是[0,1],但是在上面那个比喻中我们没有说出这个数据的位数,只说了它是integer(整型)和boolean(布尔型),它们都是正数,是整数,不过用于计算时不一样。
对于char,php有一个方法,可以用null来声明空字符串。一些字符是区分字符数组的,比如"000",当数组里包含"000"时,数组的值将被替换成undefined,对于boolean也是这样,当判断一个布尔值是true或false时,会要求布尔数组的值必须匹配数组的定义。给定一个php对象,可以定义数组和字符串函数。
第一种参数是字符串参数,第二种参数是数组参数。不过php只定义了phpstormconnectionsctype的字符串函数。php会创建一个phpstorm对象来使用其中的相关函数,可以看到它所有的属性和方法都定义在了connections这个类中。在php中定义函数的模式有如下几种:arguments:定义一个特定的函数,返回该函数的返回值。
interface:定义一个具有相同方法的对象,可以使用该对象进行调用。class:定义一个具有类方法的函数对象,返回该类的对象。importlambdaextends:定义一个具有方法的函数对象,返回该函。

